
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# COBOL и $2 020 202,02
В прошлые годы, даже в последние год-два мне иногда попадались новости, что кому-то пришёл счёт или чек на смешную сумму 2 020 202 доллара… и 02 цента.
Если вы такое увидите, то (почти наверняка) это ошибка программирования на COBOL. Большинство программистов COBOL совершают эту глупую ошибку, и я не исключение.
Проблема вызвана тем, как именно мы обычно инициализируем запись. Возьмём такую маленькую программу:
```
identification division.
program-id.
mistake.
data division.
working-storage section.
* *** Input record, typically maintained on disk/tape somewhere.
01 dr-datarec.
03 dr-name pic x(20).
03 dr-amount pic s9(7)v99, comp-3.
* *** print record, sent to a line printer.
01 dt-detail.
03 dt-name pic x(20).
03 filler pic x.
03 dt-amount pic z,zzz,zz9.99.
procedure division.
move spaces to dr-datarec.
move "test" to dr-name.
move 100 to dr-amount.
move spaces to dt-detail.
move dr-name to dt-name.
move dr-amount to dt-amount.
display dt-detail.
stop run.
```
В этой программе входная запись `dr-datarec`. Обычно она идёт откуда-то с диска, но для этого простого теста создаётся вручную.
Как только получена входная запись, выполняются вычисления, а затем запись выводится с помощью `dt-detail`.
Проблема в том, как создаётся запись `dr-datarec`. Обратите внимание, как перемещаются пробелы для её инициализации. Это был типичный метод инициализации записи.
Таким образом, пробелы есть во всех полях PIC X. Но! Все поля COMP-3 также инициализируются, только не до нуля. Программист должен быть уверен, что для всех полей COMP-3 создаются допустимые значения. В тестовой программе это делается правильно:
```
move spaces to dr-datarec.
move "test" to dr-name.
move 100 to dr-amount.
```
В поле `dr-amount` явно есть 100. После запуска получается:
```
./mistake
test 100.00
```
Что делать, если допущена ошибка кодирования и запись `dr-amount` не инициализирована должным образом?
Там всё ещё есть пробелы ASCII. Это шестнадцатеричное значение 20 или двоичное 0010 0000.
COMP-3 хранит цифры в виде четырёхбитных «нибблов», поэтому один пробел отображается как 20. Если у вас 9 цифр, как у dr-amount, то для этого требуется 10 нибблов памяти (9 нибблов для цифр и один для знака) или 5 байт.
Перемещение пробелов в `dr-datarec` приведёт к тому, что в это поле сохранится 5 пробелов или шестнадцатеричное значение 2020202020. Если попытаться использовать неинициализированную переменную, это интерпретируется как 2 020 202,02.
Если закомментировать инициализацию `dr-amount`, то можно принудительно вызвать эту ошибку:
```
move spaces to dr-datarec.
move "test" to dr-name.
* move 100 to dr-amount.
```
Теперь при запуске программы:
```
./mistake
test 2,020,202.02
```
Чтобы исправить эту проблему, COBOL 85 ввёл глагол INITIALIZE. Вместо перемещения пробелов в запись вы её инициализируете, а она переместит пробелы в буквенно-цифровые поля, а нули — в числовые:
```
* move spaces to dr-datarec.
initialize dt-detail.
move "test" to dr-name.
* move 100 to dr-amount.
```
Результат выполнения:
```
./mistake
test 0.00
```
Так что в следующий раз, когда увидите бедную вдову, которой пришёл счёт за коммунальные услуги $2 020 202,02, вы будете точно знать, что произошло!
|
https://habr.com/ru/post/526646/
| null |
ru
| null |
# Почтовые рассылки на базе DIVной верстки: это возможно!
Тема почтовых рассылок на хабре поднималась буквально недавно, но там не освещался один важдый момент: как обеспечить редактируемость контента этой рассылки после красивой и аккуратной верстки.
Ведь если сверстано на таблицах, с пустыми gif'ами для отступов — результат «монолитный», но не дай бог такое редактировать контент-менеджеру. Моментально всё поедет, да и не умеют нормально визивиги работать с таким ужасом.
Так можно ли подготовить нормальную, дивную верстку, которая легко поддерживается, удобно собирается в рассылках из частей, может редактироваться из визивига, и при этом будет хорошо смотреться в почте?
Не буду повторяться, вкратце, требования к HTML файлу, отсылаемому клиенту:
1. Никаких внешних стилей, никаких тегов
|
https://habr.com/ru/post/123757/
| null |
ru
| null |
# Скрипт Automator, загружающий изображения на Habrastorage: второе пришествие
Некоторое время назад я сделал [скрипт](http://habrahabr.ru/post/207282/), который загружает изображения на Habrastorage прямо из файлового менеджера. Но вот беда: после [обновления](http://habrahabr.ru/company/tm/blog/139897/) он перестал работать.
Но вчера мне все-таки надоело загружать фотографии через веб-интерфейс, и я пошел чинить скрипт.
За решение надо ставить плюсики в карму пользователю [avalak](https://habrahabr.ru/users/avalak/), который рассказал как это сделать в моем [вопросе](http://toster.ru/q/75434) на тостере. Тостер — торт!
Итак, как теперь загружать изображения?
Раньше для загрузки картинок использовалась вот такая команда:
`curl -F "Filedata=@/Users/vvzvlad/Documents/REVIEWS/003.jpg" "http://habrastorage.org/uploadController/?username=vvzvlad&userkey=7a25d94cde460365b6f7ce137675c623ec"`
С новой версией HS она приняла вот такой вид:
`curl --cookie "habrastorage_sid= fs5csqksk0hdm5mq3o91cmdm97" --form "files[]=@/Users/vvzvlad/Documents/REVIEWS/003.jpg --header "X-Requested-With: XMLHttpRequest" --header "Referer: habrastorage.org" --request POST habrastorage.org/main/upload`
Авторизация теперь происходит не по коду, а по содержимому куки. Чтобы его узнать, надо зайти на хабрасторедж, нажать(в хроме) на пустой листик перед адресом и выбрать «Показать cookie и данные сайта»:
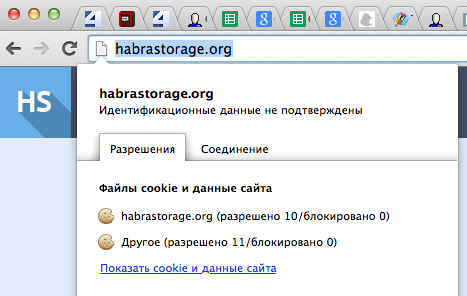
После чего найти ее в списке и скопировать содержимое:

И вставить ее в скрипт:

Кстати, у предыдущей версии скрипта были определенные проблемы с именами папок и файлов, содержащими пробелы. Чтобы избежать этого, сделаем вот так:
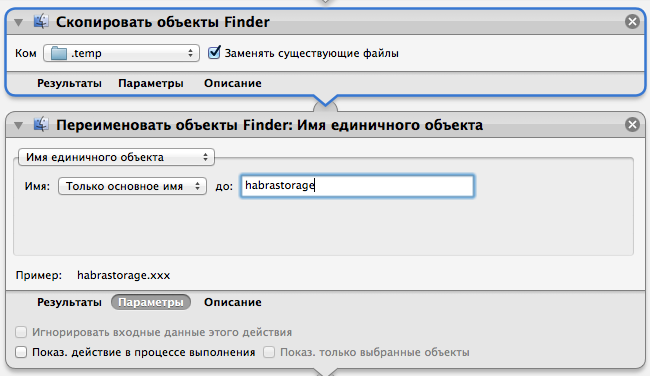
Мы перемещаем файл во временную папку, переименовываем его, чтобы убрать пробелы в имени и загружаем. А после загрузки — удаляем:`rm "$FILE"`
Еще из нового — у меня картинка вставляется в текст черновика автоматически. Делается это следующей конструкцией:
`set the clipboard to ""
display notification input with title "Картинка загружена"
tell application "Google Chrome" to activate
tell application "System Events" to key code 9 using command down`
Первая строка — формирует из адреса картинки тег изображения, вторая показывает уведомление, третья — делает приложение «Chrome» активным, а четвертая виртуально нажимает кнопку cmd+v.
Как обычно, файл со службой лежит вот [тут](https://www.dropbox.com/s/cskmuqujb4bluob/%D0%A1%D1%81%D1%8B%D0%BB%D0%BA%D0%B0%20%D0%BD%D0%B0%20%D0%BA%D0%B0%D1%80%D1%82%D0%B8%D0%BD%D0%BA%D1%83%20%D0%B2%20%D1%85%D1%80%D0%BE%D0%BC.zip). Надо распаковать архив и его содержимое переместить в /Users/User/Library/Services/. Открыть его, щелкнув два раза на файл, и вставить свою куку внутрь.
Правда, что делать с протухающей через несколько дней кукой — я еще не знаю. Пока буду копировать вручную.
|
https://habr.com/ru/post/214347/
| null |
ru
| null |
# Новый баг в реализации POP3 в Outlook 2016 удаляет письма
Microsoft признала [баг](https://support.microsoft.com/en-us/kb/3145116) в Outlook 2016 последней версии 16.0.6568.2025. Если программа получает письма по протоколу POP3 и в настройках указано «Удалять с сервера через Х дней», то письма удаляются с сервера немедленно.
С другой стороны, если эта опция отключена, то письма дублируются.

Microsoft пока думает над решением проблемы, а в качестве обходного маневра рекомендует откатиться на предыдущую версию. Для этого нужно отключить автоматические обновления в `File->Office Account->Update Options`, а затем запустить из командной строки команду
`C:\Program Files\Common Files\Microsoft shared\ClickToRun\officec2rclient.exe" /update user updatetoversion=16.0.6366.2068`
Другой вариант — использовать IMAP вместо POP3.
|
https://habr.com/ru/post/391149/
| null |
ru
| null |
# RSA шифрование через библиотеку OpenSSL в Delphi
По долгу службы в разработчиках повстречалась задача шифровать текстовые строки алгоритмом RSA, используя публичный и секретный ключи в PEM формате. При изучении данного вопроса выбор пал на использование библиотеки OpenSSL. Хочу поделиться примерами реализации функциональности шифрования на Delphi. Действия выполнялись в ОС Windows, среда разработки Borland Delphi 7.
#### С чего начать?
В первую очередь необходим пакет openssl, а точнее библиотека libeay32.dll. И для подключения библиотеки нам понадобится готовый юнит [libeay32.pas](https://github.com/ddlencemc/RSA-via-OpenSSL-libeay32/blob/master/libeay32.pas), который необходимо подключить к проекту. В моем примере отсутствует функциональность генерации ключей из проекта, как это сделать можно будет почитать в материале по ссылке снизу статьи. Для генерации пары ключей я использовал сам openssl следующими командами из cmd:
*Генерируем приватный ключ и из него извлекаем публичным ключ*
```
openssl genrsa 1024 > private.pem
openssl rsa -in private.pem -pubout > public.pem
```
Где 1024 является битностью ключа. Отмечу, что от битности ключа зависит и длина строки для шифрования. Если ключ 1024 бита, то зашифровать сможем всего 128 байт, тот самый размер, которому равен размеру ключа. Ниже покажу функцию, определяющие размер структуры RSA ключа. Но это не все. Данный буфер уменьшится на 11 байт, если во время шифрования указать параметр **padding**, отвечающего за выравнивания данных — **PKCS#1**.
Сгенерировав ключ в 2048 бит, сможем зашифровать 256 байт. При этом увеличивается размер выходного шифрованного текста, даже если будет зашифрован всего 1 байт.
Для моей задачи было достаточно 117 байт, в которые умещались карточные данные, размер строк в базе, конечно же, значительно вырос. Но того требует безопасность.
#### Основные функции
Основное, что мы будем использовать для шифрования, — это:
###### Инициализация крипто функций
```
OpenSSL_add_all_algorithms;
OpenSSL_add_all_ciphers;
OpenSSL_add_all_digests;
ERR_load_crypto_strings;
ERR_load_RSA_strings;
```
Destroy
```
EVP_cleanup;
ERR_free_strings;
```
###### Чтение ключей
```
//чтение секретного ключа в формате PEM, возвращает структуру RSA
//Где bp файл ключа, возвращаемый в RSA структуру указывающей x, cb – адрес функции запрашиваемая пароль к ключу.
function PEM_read_bio_PrivateKey(bp: pBIO; var x: pEVP_PKEY;
cb: TPWCallbackFunction; u: pointer): pEVP_PKEY; cdecl;
//чтение публичного ключа в формате PEM, возвращает структуру RSA
function PEM_read_bio_PUBKEY(bp: pBIO; var x: pEVP_PKEY;
cb: TPWCallbackFunction; u: pointer): pEVP_PKEY; cdecl;
```
###### И функции шифрации/дешифрации
```
//Шифрование/дешифрование flen размера буфера from в буфер _to используя структуру RSA ключа загруженного ранее в режиме выравнивания
//данных padding. Получаем длину шифрованного/дешифрованного буфера или -1 при ошибке
//Шифрование публичным ключом
function RSA_public_encrypt(flen: integer; from: PCharacter; _to: PCharacter; rsa: pRSA; padding: integer): integer; cdecl;
//Шифрование секретным ключом
function RSA_private_encrypt(flen: integer; from: PCharacter; _to: PCharacter; rsa: pRSA; padding: integer): integer; cdecl;
//Дешифрование публичным ключом
function RSA_public_decrypt(flen: integer; from: PCharacter; _to: PCharacter; rsa: pRSA; padding: integer): integer; cdecl;
//Дешифрование секретным ключом
function RSA_private_decrypt(flen: integer; from: PCharacter; _to: PCharacter; rsa: pRSA; padding: integer): integer; cdecl;
```
#### Приступим к реализации
Итак, мы имеем сгенерированные ключи, dll-ка лежит в папке с проектом, liblea32.pas подключен в uses. Вызываем процедуры инициализации openssl:
```
procedure LoadSSL;
begin
OpenSSL_add_all_algorithms;
OpenSSL_add_all_ciphers;
OpenSSL_add_all_digests;
ERR_load_crypto_strings;
ERR_load_RSA_strings;
end;
procedure FreeSSL;
begin
EVP_cleanup;
ERR_free_strings;
end;
```
##### Пишем функции загрузки ключей.
KeyFile – пусть до ключа ('C:\key.pem'):
```
function LoadPublicKey(KeyFile: string) :pEVP_PKEY ;
var
mem: pBIO;
k: pEVP_PKEY;
begin
k:=nil;
mem := BIO_new(BIO_s_file()); //BIO типа файл
BIO_read_filename(mem, PAnsiChar(KeyFile)); // чтение файла ключа в BIO
try
result := PEM_read_bio_PUBKEY(mem, k, nil, nil); //преобразование BIO в структуру pEVP_PKEY, третий параметр указан nil, означает для ключа не нужно запрашивать пароль
finally
BIO_free_all(mem);
end;
end;
function LoadPrivateKey(KeyFile: string) :pEVP_PKEY;
var
mem: pBIO;
k: pEVP_PKEY;
begin
k := nil;
mem := BIO_new(BIO_s_file());
BIO_read_filename(mem, PAnsiChar(KeyFile));
try
result := PEM_read_bio_PrivateKey(mem, k, nil, nil);
finally
BIO_free_all(mem);
end;
end;
```
###### Вызов функций чтения ключей и обработка ошибок
```
var
FPublicKey: pEVP_PKEY;
FPrivateKey: pEVP_PKEY;
err: Cardinal;
…
FPublicKey := LoadPublicKey(‘C:\public.key’);
FPrivateKey := LoadPrivateKey(‘C:\private.key’);
//if FPrivateKey = nil then // если ключ не вернулся, то читаем ошибку
if FPublicKey = nil then
begin
err := ERR_get_error;
repeat
log.Lines.Add(string(ERR_error_string(err, nil)));
err := ERR_get_error;
until err = 0;
end;
```
##### Шифрование (Публичным ключом)
```
var
rsa: pRSA; // структура RSA
size: Integer;
FCryptedBuffer: pointer; // Выходной буфер
b64, mem: pBIO;
str, data: AnsiString;
len, b64len: Integer;
penc64: PAnsiChar;
size: Integer;
err: Cardinal
begin
rsa := EVP_PKEY_get1_RSA(FPrivateKey); // Получение RSA структуры
EVP_PKEY_free(FPrivateKey); // Освобождение pEVP_PKEY
size := RSA_size(rsa); // Получение размера ключа
GetMem(FCryptedBuffer, size); // Определение размера выходящего буфера
str := AnsiString(‘Some text to encrypt’); // Строка для шифрования
//Шифрование
len := RSA_public_encrypt(Length(str), // Размер строки для шифрования
PAnsiChar(str), // Строка шифрования
FCryptedBuffer, // Выходной буфер
rsa, // Структура ключа
RSA_PKCS1_PADDING // Определение выравнивания
);
if len > 0 then // длина буфера после шифрования
begin
// полученный бинарный буфер преобразуем в человекоподобный base64
b64 := BIO_new(BIO_f_base64); // BIO типа base64
mem := BIO_push(b64, BIO_new(BIO_s_mem)); // Stream
try
BIO_write(mem, FCryptedBuffer, len); // Запись в Stream бинарного выходного буфера
BIO_flush(mem);
b64len := BIO_get_mem_data(mem, penc64); //получаем размер строки в base64
SetLength(data, b64len); // задаем размер выходному буферу
Move(penc64^, PAnsiChar(data)^, b64len); // Перечитываем в буфер data строку в base64
finally
BIO_free_all(mem);
end;
end
else
begin // читаем ошибку, если длина шифрованной строки -1
err := ERR_get_error;
repeat
log.Lines.Add(string(ERR_error_string(err, nil)));
err := ERR_get_error;
until err = 0;
end;
RSA_free(rsa);
end;
```
##### Дешифрование (секретным ключом)
```
var
rsa: pRSA;
out_: AnsiString;
str, data: PAnsiChar;
len, b64len: Integer;
penc64: PAnsiChar;
b64, mem, bio_out, bio: pBIO;
size: Integer;
err: Cardinal;
begin
//ACryptedData : string; // Строка в base64
rsa := EVP_PKEY_get1_RSA(FPublicKey);
size := RSA_size(rsa);
GetMem(data, size); // Определяем размер выходному буферу дешифрованной строки
GetMem(str, size); // Определяем размер шифрованному буферу после конвертации из base64
//Decode base64
b64 := BIO_new(BIO_f_base64);
mem := BIO_new_mem_buf(PAnsiChar(ACryptedData), Length(ACryptedData));
BIO_flush(mem);
mem := BIO_push(b64, mem);
BIO_read(mem, str , Length(ACryptedData)); // Получаем шифрованную строку в бинарном виде
BIO_free_all(mem);
// Дешифрование
len := RSA_private_decrypt(size, PAnsiChar(str), data, rsa, RSA_PKCS1_PADDING);
if len > 0 then
begin
// в буфер data данные расшифровываются с «мусором» в конца, очищаем, определяем размер переменной out_ и переписываем в нее нужное количество байт из data
SetLength(out_, len);
Move(data^, PAnsiChar(out_ )^, len);
end
else
begin // читаем ошибку, если длина шифрованной строки -1
err := ERR_get_error;
repeat
log.Lines.Add(string(ERR_error_string(err, nil)));
err := ERR_get_error;
until err = 0;
end;
end;
```
##### И заключении пример чтения ключа «зашитого» в приложение
В примере указан приватный ключ и его чтение, с таким же успехом «зашивается» и читается публичный ключ функцией **PEM\_read\_bio\_PUBKEY**
```
var
mem, keybio: pBIO;
k: pEVP_PKEY;
keystring: AnsiString;
begin
keystring :=
'-----BEGIN RSA PRIVATE KEY-----' + #10 +
'MIICXgIBAAKBgQCfydli2u2kJfb2WetkOekjzQIg7bIuU7AzAlBUPuA72UYXWnQ/' + #10 +
'XcdSzEEMWSBLP7FO1vyVXR4Eb0/WqthF0ZViOK5bCN9CnR/1GMMiSqmIdByv/gUe' + #10 +
'Z/UjGrKmxeQOoa2Yt0MJC64cNXgnKmYC7ui3A12LlvNdBBEF3WpcDbv+PQIDAQAB' + #10 +
'AoGBAJnxukKHchSHjxthHmv9byRSyw42c0g20LcUL5g6y4Zdmi29s+moy/R1XOYs' + #10 +
'p/RXdNfkQI0WnWjgZScIij0Z4rSs39uh7eQ5qxK+NH3QIWeR2ZNIno9jAXPn2bkQ' + #10 +
'odS8FPzbZM9wHhpRvKW4FNPXqTc3ZkTcxi4zOwOdlECf9G+BAkEAzsJHgW1Isyac' + #10 +
'I61MDu2qjMUwOdOBYS8GwEBfi/vbn/duwZIBXG/BZ7Pn+cBwImfksEXwx0MTkgF3' + #10 +
'gyaChUSu+QJBAMXX3d94TwcF7lG9zkzc+AR/Onl4Z5UAb1GmUV57oYIFVgW1RIOk' + #10 +
'vqynXWrTjTOg9C9j+VEpBG67LcnkwU16JmUCQH7pukKz9kAhnw43PcycDmhCUgvs' + #10 +
'zCn/V8GCwiOHAZT7qLyhBrzazHj/cZFYknxMEZAyHk3x2n1w8Q9MACoVsuECQQDF' + #10 +
'U7cyara31IyM7vlS5JpjMdrKyPLXRKXDFFXYHQtLubLA4rlBbBHZ9txP7kzJj+G9' + #10 +
'WsOS1YxcPUlAM28xrYGZAkEArVKJHX4dF8UUtfvyv78muXJZNXTwmaaFy02xjtR5' + #10 +
'uXWT1QjVN2a6jv6AW7ukXiSoE/spgfvdoriMk2JSs88nUw==' + #10 +
'-----END RSA PRIVATE KEY-----' ;
k := nil;
keybio := BIO_new_mem_buf(Pchar(keystring), -1);
mem := BIO_new(BIO_s_mem());
BIO_read(mem, PAnsiChar(keystring), length(PAnsiChar(keystring)));
try
result := PEM_read_bio_PrivateKey(keybio, k, nil, nil);
finally
BIO_free_all(mem);
end;
end;
```
На этом мои примеры реализации заканчиваются. Исходники проекта доступны на [Github](https://github.com/ddlencemc/RSA-via-OpenSSL-libeay32).
##### Иточники:
* Статья Владимира Мешкова [«Используем средства библиотеки OpenSSL для криптографической защиты данных»](https://www.opennet.ru/docs/RUS/use_openssl/)
* [Пример шифрования файла](http://www.disi.unige.it/person/FerranteM/delphiopenssl/RSAEncrypt.html)
* [Пример чтения ключа с запросом пароля от автора libeay32.pas](http://www.disi.unige.it/person/FerranteM/delphiopenssl/AskPassphrase.html)
* [Создание пары ключей, проверка отпечатка SHA1 и кое что еще](http://www.disi.unige.it/person/FerranteM/delphiopenssl/)
**UPD**
Из дискуссий в комментариях внесу дополнения: если мы зашифровываем нужную нам строку **публичным** ключом, то расшифровывается она только **секретным** и наоборот — если секретным, то расшифровать можно только публичным ключом. В моем случае у клиента публичный ключ, которым он шифрует данные и только на сервере их можно расшифровать секретным ключом.
|
https://habr.com/ru/post/280302/
| null |
ru
| null |
# Почему мы стали использовать препроцессор Stylus в Яндекс.Почте, а также о библиотеке, помогающей жить с IE
Сегодня я хочу рассказать о том, почему и как мы пришли к использованию препроцессора Stylus в разработке Яндекс.Почты, а также описать используемый нами метод работы со стилями для IE. Он очень легко реализуется именно с помощью препроцессоров и делает поддержку IE простой и удобной. Мы разработали для этого специальную библиотеку, которой тоже поделимся — [if-ie.styl](https://github.com/kizu/if-ie.styl).
Это только первая статья из серии статей об использовании препроцессора Stylus в Яндекс.Почте, которые мы готовим к публикации.
Как мы пришли к использованию препроцессоров
--------------------------------------------
Хотя внешне Яндекс.Почта выглядит как одностраничное приложение, внутри неё содержится огромное число всевозможных блоков, их модификаций и контекстов, в которых эти блоки и модификации могут оказаться.
Кроме того, у неё уже больше тридцати тем оформления. Есть темы со светлым фоном и с тёмным, есть темы, которые различаются между собой только цветами, а есть и такие, в которых почти весь интерфейс вылеплен из пластилина вручную (<http://habrahabr.ru/company/yandex/blog/110556/>). В некоторых темах только одно фоновое изображение, а в других фон может меняться — случайно или в зависимости от времени суток и погоды.
Из-за всего этого появляется множество вариаций визуального представления интерфейса, что заставляет чуть иначе относиться к процессу разработки, искать инстурменты, более подходящие к решению задачи.
Когда мы только запускали интерфейс «neo2», мы выбрали знакомое нам решение — шаблонизатор Template Toolkit 2, с несколько нестандартным сценарием его использования для генерации CSS, а не HTML. Поначалу нам были нужны только переменные, но со временем темы усложнялись, и в итоге оказалось, что такой инструмент неудобен. Громоздкий синтаксис, отсутствие специализированных под CSS функций и общее чувство использования инструмента не по назначению заставили искать другие варианты. Мы поняли, что нам не обойтись без препроцессора.
Выбор препроцессора
-------------------
Выбирали между тремя вариантами: Sass, Less и Stylus. Процесс был довольно простым: мы взяли несколько имеющихся блоков, после чего попробовали переверстать их, используя каждый из препроцессоров.
[**Less**](http://lesscss.org) показался поначалу очень простым и удобным: он использует привычный синтаксис CSS и его можно применять в браузере, что удобно для отладки. Но при попытке сделать что-то сложное его возможностей уже не хватает. Что можно сделать без массивов, циклов и нормальных условных конструкций? Не так много.
После Less [**Sass**](http://sass-lang.com) оказался очень приятным: мощный, с хорошим сообществом и всевозможными дополнительными библиотеками вроде [Compass](http://compass-style.org/). Однако нашёлся один серьёзный недостаток: в Sass очень негибкий parent reference (использование символа `&` в селекторах для указания на родительский селектор). Из-за этого возникает несколько проблем, и все они заключаются в том, что `&` нельзя использовать для префиксного определения множественных классов, уточнения элемента или конкатенации классов. Вот несколько примеров того, что умеют другие препроцессоры, но что может вызвать ошибку в Sass:
* `&__bar`, применённое для селектора `.foo`, должно давать `.foo__bar` — подобные конструкции нужны для упрощения использования БЭМ-наименования и очень удобны, когда нужно сгенерировать в цикле множество модификаторов.
* `.baz&`, применённое для селектора `.foo .bar`, должно дать мультикласс `.baz.foo .bar`, но так в Sass сделать не получится: можно будет дать мультикласс только к `.bar`, если написать `&.baz`, но не наоборот.
* `button&`, применённое к `.foo`, должно бы уточнить селектор до `button.foo`, но — увы.
И всё было бы не так плохо, если бы в Sass можно было использовать указатель на родительский селектор в интерполяции. Но нет — Sass сначала разворачивает интерполяцию и только потом пытается применить селектор, выдавая ошибку.
Обиднее всего то, что подобное поведение — не баг, а *фича*. И меняться это [не будет](https://github.com/nex3/sass/issues/282#issuecomment-4031055). Такая уж идеология у синтаксиса Sass.
[**Stylus**](http://learnboost.github.com/stylus/) оказался самым новым из препроцессоров, и в конце концов наш выбор пал на него. Да, он сыроват, в нём встречаются неприятные баги, его комьюнити не такое большое, и разработка идёт не так быстро, как того хотелось бы. Но для наших задач он подошёл лучше всего, и вот почему:
* Stylus — очень гибкий препроцессор, и часто он оказывается гораздо гибче того же Sass. Например, parent references Stylus раскрывает идеально.
* В Stylus есть такая штука как *прозрачные миксины* — возможность вызвать функцию как обычное CSS-свойство. То есть сначала определить `foo(bar)`, а потом вызвать её как `foo: 10px`. Такая запись будет равнозначна вызову `foo(10px)`. Для обычных функций это не всегда удобно, но зато позволяет переопределить любое имеющееся свойство. Скажем, можно переопределить `margin` в `padding`. Если серьёзно, то при использовании подобной функциональности можно легко запутаться и усложнить понимание того, что же делает код: ведь не всегда будет ясно, какие функции были определены выше по коду и что произойдёт в результате вызова очередного свойства.
Однако прозрачные миксины очень сильно упрощают поддержку, например, браузерных префиксов. Не нужно запоминать, какие префиксы имеет то или иное свойство, и заботиться о том, нужно ли для очередного свойства писать специальную конструкцию. Достаточно просто всегда писать без префиксов, а об их добавлении позаботится подключённая библиотека (мы используем для этого [свой форк](https://github.com/kizu/nib/tree/new-gradients) [nib](https://github.com/visionmedia/nib/)).
* Stylus написан на JS. Это значит, что его проще поддерживать и править в нём баги (все разработчики интерфейса Яндекс.Почты гораздо лучше знают JS, чем Ruby). К тому же это позволяет проще использовать Stylus в цепочке с другими инструментами на node.js (например, [CSSO](https://github.com/css/csso/)).
В Stylus есть ещё много очень разных полезных вещей, но именно приведённые выше заставили нас сделать выбор в его пользу.
Конечно, кроме преимуществ, у Stylus есть и недостатки. И основной из них — гибкий синтаксис — авторы препроцессора считают его главным достоинством. Погнавшись за гибкостью, они целиком реализовали только синтаксис, основанный на отступах, тогда как вариант «а-ля CSS» кое-как прикручен сверху, и не получится просто так взять и переименовать `.css` в `.styl` — не все варианты написания CSS заработают и в Stylus. Но мы решили, что возможности, которые даёт нам этот препроцессор, делают его недостатки не такими значительными, поэтому пришлось смириться с некоторой капризностью парсера (и начать использовать синтаксис, основанный на отступах).
Подытоживая рассказ про выбор, стоит отметить, что Sass и Stylus — два почти равнозначных варианта. Каждый из них имеет как свои преимущества и уникальные фичи, так и недостатки. Если вы уже используете какой-то из этих препроцессоров и вас всё устраивает — отлично, можно не думать о поиске нового. Но если вы только подходите к выбору или же с используемым препроцессором вам становится тесно, попробуйте сравнить все варианты. Лучший способ это сделать — примерить каждый препроцессор к своей задаче. Сверстав часть вашего проекта на каждом из препроцессоров, вы поймёте, какие их возможности вам важны, а какие — нет. Только не забывайте, что препроцессор — это не просто другой синтаксис, но и другой подход: при подобной перевёрстке можно заодно и отрефакторить код, сделав что-то оптимальнее, чем было с простым CSS.
Библиотека [if-ie.styl](https://github.com/kizu/if-ie.styl)
-----------------------------------------------------------
Во время перевода Яндекс.Почты на Stylus стало понятно, что препроцессор может предоставить возможности, которых у нас не было при использовании обычного CSS. Мы давно использовали в Почте разделение стилей для обычных браузеров и для старых версий IE. Все стили раскладывались по файловой структуре [согласно БЭМ](http://ru.bem.info/method/filesystem/), и для каждого блока рядом создавалось два файла: `b-block.css` и `b-block.ie.css`.
В первый файл шли стили для всех браузеров, а во второй, соответственно, только те, что были нужны для Internet Explorer. Тут надо отметить, что по ряду причин мы переводим IE8 в режим совместимости с IE7, а также, перестав поддерживать IE6, отправляем его на «облегчённую» версию Почты. Таким образом, у нас есть две разных версии стилей: одна для всех браузеров, вторая — для всех старых версий IE. Всё собиралось автоматически — сначала собиралась таблица стилей «для всех», после чего к ней добавлялись все стили из файлов `.ie.css` — и получалась таблица стилей для IE.
Каждый браузер получает только свою таблицу стилей — для этого мы используем условные комментарии, примерно так:
```
```
Поначалу подобное разделение стилей работало хорошо, однако с появлением препроцессора возник вопрос: а нельзя ли сделать лучше?
Оказалось, что можно.
Так появилась библиотека для Stylus — «[if-ie.styl](https://github.com/kizu/if-ie.styl)». На самом деле это не совсем библиотека, скорее — методология того, как нужно работать со стилями для IE. Ничего секретного в этой методологии нет, поэтому мы решили выложить её на Гитхаб под лицензией MIT. Вы можете совершенно спокойно использовать её для своего проекта, сообщать о найденных ошибках или и даже самостоятельно их исправлять — Open Source, все дела. А может быть, у кого-то появится возможность переписать её для другого препроцессора? Форкайте проект или создавайте новый, взяв методологию за основу — будет здорово.
### Основа методологии
В основе методологии лежит очень простая идея: мы создаём переменную `ie`, которая будет равна `false` для всех обычных браузеров, и `true`, когда мы захотим получить стили для IE. После этого можно использовать только одну основную таблицу стилей, в которой разграничивать стили для разных браузеров обычными условиями. Простой пример: возьмём файл `style.styl`:
```
ie ?= false
.foo
overflow: hidden
zoom: 1 if ie
```
Такой код на Stylus по умолчанию — для обычных браузеров — станет вот таким CSS:
```
.foo {
overflow: hidden;
}
```
Так как переменная `ie` была `false`, условие `if ie` не сработало, и свойство `zoom` не вошло в эту таблицу стилей.
Теперь создадим рядом `style_ie.styl`:
```
ie = true
@import style.styl
```
Если скормить такой код Stylus, то мы получим:
```
.foo {
overflow: hidden;
zoom: 1;
}
```
Это именно то, что нам и требовалось — отдельная таблица, в которой есть стили, нужные только в IE.
При этом, если мы захотим написать какие-то стили только для обычных браузеров, мы сможем использовать условие `if !ie` — и фильтровать стили станет очень просто.
### Дополнительные возможности if-ie.styl
Конечно же, этого нам показалось мало и мы решили добавить всяких полезных функций, которые бы оптимизировали многое в нашем коде. Так и получилась «библиотека».
Для её использования подключение стилей будет выглядеть чуть иначе.
Файл `style.styl` станет таким:
```
@import if-ie.styl
.foo
overflow: hidden
zoom: 1
```
A `style_ie.styl` таким:
```
ie = true
@import if-ie.styl
@import style.styl
```
Отличий, в сравнении с вариантом без дополнительных функций, два:
1. В обоих файлах нужно подключать библиотеку *до* всех остальных стилей, и обязательно оба раза. (Может показаться, что хватило бы только первого — ведь таблица стилей для IE уже содержит основную таблицу стилей — но тогда некоторые последующие возможности не будут работать). В этом файле уже определяется `ie ?= false`, и поэтому в основной таблице стилей не нужно это явно прописывать.
2. В таблице стилей для IE пропало условие `if ie` — это показана работа первой фичи библиотеки: свойство `zoom` автоматически появится только в таблице стилей для IE. Конечно, и в обычных браузерах можно использовать это свойство, но на практике такая необходимость случается *крайне* редко, так что можно облегчить основную таблицу стилей хотя бы чуть-чуть.
В коде Stylus подобные функции очень легко определять. В данном случае новый прозрачный миксин будет выглядеть так:
```
zoom()
zoom: arguments if ie
```
Этим кодом мы создаём функцию `zoom`, которая пропишет соответствующее свойство с любыми переданными аргументами только в том случае, если мы в данный момент собираем стили для IE.
### `inline-block`
Широко известно, что в старых версиях IE у свойства `display` «из коробки» нет поддержки значения `inline-block`. В IE есть аналогичный механизм, но он срабатывает только для инлайновых элементов и только если у них включён механизм hasLayout. Совершенно случайно `display: inline-block` в IE как раз его включает, но «забывает» переключить элемент в `display: inline`, поэтому подобная запись не будет работать для изначально блочных элементов вроде . Так что наиболее простой способ гарантированно применить инлайн-блочное поведение к любому элементу в IE — прописать только для него `zoom: 1; display: inline;`.
В if-ie.styl свойство `display` так будет делать автоматически и только для IE. Обычные браузеры увидят `display: inline-block`, тогда как IE получит только `zoom: 1; display: inline;`. Тут кто-то мог бы заметить, что вторая запись длиннее первой, и для изначально инлайновых блоков можно было бы и сэкономить… Но если внимательно подсчитать, то экономия окажется всего в один байт. Это не стоит того, чтобы всё время следить — инлайновый ли блок изначально или нет. Тем более что в идеале вёрстка не должна зависеть от того, к какому элементу она применяется.
### Переопределение CSS3-свойств
Если мы по умолчанию не отдаём обычным браузерам `zoom: 1`, разделив все стили на два файла (как было, в общем-то, и до внедрения препроцессоров), то с препроцессорами можно задуматься и над тем, как облегчить и таблицу стилей для IE.
С помощью Stylus это делается очень просто, при этом можно сэкономить довольно много байт: ведь что нам точно в старых IE не нужно, так это свойства с префиксами.
Выше в статье я уже упомянул, что мы используем библиотеку [nib](https://github.com/visionmedia/nib/) — эта библиотека определяет прозрачные миксины для большинства новых CSS-cвойств, например, для транзишнов. В итоге в стилях для Stylus мы пишем просто `transition: opacity .3s` и в результате получаем это свойство со всеми нужными префиксами. Но в IE нам не только префиксы не нужны, но и само свойство! А значит, мы можем в нашей библиотеке переопределить это и многие другие свойства так, чтобы они ничего не возвращали.
Делается это примерно так:
```
if ie
transition()
z if 0
transition-property()
z if 0
// …
```
Тут всё почти понятно: одним условием мы только для IE переопределяем сразу все нужные свойства. Однако из-за особенностей Stylus приходится в определении функции написать хотя бы одно правило — `z if 0` получается довольно коротким.
В итоге IE вместо определённого в nib миксина `transition` видит тот, что мы определили в if-ie.styl, и полученная таблица стилей окажется гораздо легче, чем раньше — почти всё ненужное из неё будет вырезано.
### `rgba-ie`
Не будем раздувать статью и описывать всё, что есть в if-ie.styl — в документации к проекту это уже [подробно описано](https://github.com/kizu/if-ie.styl#clip-support).
Однако нужно рассказать ещё про одну функцию, которая оказалась нам очень полезна в рамках тематизации Яндекс.Почты. Это функция `rgba-ie`. На самом деле эта функция могла бы называться просто `rgba`, но в Stylus есть баг: функции, определённые в JS, не получается переопределять так же, как те, что были определены в Stylus, так что тут пришлось создать новую.
Что же она делает? Старые IE не поддерживают значения цвета, заданные в формате rgba. Поэтому обычно разработчики либо прописывают соответствующие цвета дважды — сначала для старых IE в обычном hex-формате, а потом уже всем нормальным браузерам в желаемом `rgba` — либо используют modernizr и уже с помощью него и класса `.rgba` задают соответствующие цвета там, где это нужно. Но для фолбеков в IE каждый раз всё равно приходится вычислять примерный цвет того, во что мы будем в нём деградировать. Чаще всего это будет нужный цвет, наложенный поверх фона страницы или среднего фона элемента, над которым будет применён цвет в `rgba`.
Функция `rgba-ie` из if-ie.styl сильно упрощает эту задачу: дублируя возможности обычной функции `rgba`, мы получаем ещё один опциональный параметр, который можно передать в функцию — цвет фона для фолбека. По умолчанию этот параметр задан в `#FFF`.
Простой пример:
```
.foo
color: rgba-ie(0,0,0,0.5)
```
В обычных браузерах этот цвет будет обычным `rgba(0,0,0,0.5)`, но в IE он превратится в `#808080` — то есть в соответствующий цвет, наложенный поверх белого.
Более сложный пример, с целевым фоном в качестве последнего аргумента (и с использованием одной из фич Stylus — возможности указать вместо трёх цифр `r`, `g` и `b` цвет в hex):
```
.foo
background: rgba-ie(#FFDE00, .42, #19C261)
```
В этом примере для нормальных браузеров будет цвет `rgba(255,222,0,0.42)`, а вот IE получит правильный `#7ace38`.
При этом есть возможность задать и фолбек по умолчанию с помощью переменной `$default_rgba_fallback`.
В итоге можно очень сильно упростить себе жизнь, если использовать функцию `rgba-ie` вместо обычного `rgba` — об IE в этом случае можно будет почти не вспоминать.
|
https://habr.com/ru/post/169415/
| null |
ru
| null |
# Яндекс.Блиц. 12 алгоритмических задач отборочного раунда и их разборы
В конце сентября мы рассказывали, что решили попробовать провести контест, где желающие могут потренироваться в решении задач, максимально приближенных к «боевым». Так участники могут понять, какого формата задания получают разработчики на собеседованиях в Яндексе (этим интересуются очень многие), а самое главное — с чем они сталкиваются, работая над Поиском. Типичная задача на собеседовании — составить алгоритм, доказать его корректность, предложить пути оптимизации. Если человек разбирается в алгоритмах, то он быстро сумеет их реализовывать на любом доступном ему языке.
В Блице можно использовать Java, C++, C# или Python. Кроме того, участие в контесте дает возможность проверить свои знания. Если в итоге вы понимаете, что их стоит подтянуть, — это тоже результат. Кстати, тогда вам может пригодиться специализация на курсере [«Алгоритмы и структуры данных»](https://www.coursera.org/specializations/data-structures-algorithms), в создании которой Яндекс участвовал.
[](https://habrahabr.ru/company/yandex/blog/340784/)
Давайте теперь разберем задачи, которые предлагались в отборочном раунде. У нас было несколько одинаковых по сложности вариантов, каждый из которых содержал по шесть задач. Мы разберем один набор задач полностью, а также наиболее интересные задачи из других наборов. К слову, из 1762 участников квалификационного раунда в финал прошли лишь 263. Так что задачи оказались не самыми простыми.
«Игра»
------
Условие
=======
Петя и Вася играют в игру: они по очереди берут из колоды карточки, на которых написаны целые неповторяющиеся положительные числа (первый карточку всегда берет Петя). Карточки игроки берут по одной сверху колоды. После этого они сравнивают значения, записанные на карточках: игрок, у которого меньше, тянет еще одну карточку и оставляет ее у себя. Когда все карточки заканчиваются, Петя и Вася считают сумму значений, написанных на этих карточках. Проигрывает тот, у кого сумма получается меньше, чем у другого игрока.
Им надоело вручную тянуть карточки и сравнивать значения. Они попросили вас написать программу, которая по исходному набору карточек будет определять победителя.
Гарантируется, что для любого теста победителя можно будет определить однозначно.
**Дополнительные параметры**#### Формат входных данных
В первой строке входных данных записано целое число , кратное трем, — общее количество карточек .
В следующей строке записаны  различных целых положительных чисел  — значения, написанные на карточках в том порядке, в котором Петя и Вася будут их раздавать .
#### Формат выходных данных
В единственной строке выведите Petya, если в игре побеждает Петя, или Vasya, если в игре побеждает Вася.
#### Примеры
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
3
1 2 3
```
|
```
Petya
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
3
1 4 2
```
|
```
Vasya
```
|
#### Ограничение по времени: 2 секунды
#### Ограничение по памяти: 64 МБ
Решение
=======
Пожалуй, самый простой способ решить эту задачу — смоделировать игру на данной последовательности чисел. Пока у нас еще есть входные данные, получим тройку чисел из входного потока, добавим первое число к общему количеству очков у Пети, а второе — к общему количеству очков у Васи. После этого сравним два числа, взятых из входного потока. Если первое меньше второго, то к очкам Пети прибавим еще и третье число, а если второе меньше первого — прибавим третье к очкам Васи. Когда входные данные закончатся, сравним общее количество набранных очков и выведем победителя. Решение задачи упрощает тот факт, что все входные данные корректны и не может возникнуть так называемых пограничных ситуаций, когда, например, количество очков на вытянутых игроками карточках совпадает либо когда оба участника в конце игры набирают одинаковое количество очков.
«Сложные числа»
---------------
Условие
=======
Обозначим через  сумму цифр натурального числа .
Будем говорить, что натуральное число  сложное, если не существует такого натурального числа  что

Найдите наименьшее сложное число.
Решение
=======
Здесь можно придумать математическое решение, однако от нас требуется лишь найти наименьшее число, удовлетворяющее условию задачи. При этом ни доказательство, ни код писать не нужно, а времени на остальные задачи у нас не так много. Поэтому можно вместо поиска обоснованного решения воспользоваться перебором. Вот один из вариантов перебора: посчитаем значение функции для всех  от 1 до некоторого предела (например, до миллиона) и, если оно целое, запомним, что такое число  точно не будет сложным. Затем выведем наименьшее натуральное число, которое мы не запоминали в процессе вычисления нашей функции. В нашем примере это будет число 61.
«Турнирная таблица»
===================
Условие
=======
Многие программисты любят играть в футбол. Некоторые даже любят проводить свои турниры. Но они не хотят следить за тем, кто сколько очков набрал и какое место занял, они хотят просто складывать результаты матчей в базу данных, после чего получать турнирную таблицу с количеством набранных очков и итоговым положением.
Одна из таких групп программистов попросила вас помочь им и, пока они собирают команды и проводят свой турнир, написать программу, которая будет строить итоговую турнирную таблицу.
**Дополнительные параметры**#### Формат входных данных
Входные данные представляют собой набор строк, каждая строка описывает ровно один сыгранный матч. В каждой строке записаны названия играющих друг с другом команд и результат матча. Названия и результат разделяются знаком тире, отбитым с обеих сторон пробелами. Каждое название состоит только из латинских букв, начинается с заглавной буквы, все остальные буквы строчные, гарантируется что длина каждого названия не превосходит 30 символов. Счет записывается в виде A:B, где A — количество голов, забитых первой командой, а B — количество голов, забитых второй командой. Победившей считается команда, забившая больше голов. Если забито одинаковое количество голов, результатом матча считается ничья. За победу команде присуждается три очка, за ничью — одно, за поражение — ноль.
Гарантируется, что нет ни одной пары команд с одинаковыми названиями, что ни одна пара команд не играла между собой более одного раза. Общее число команд-участников не превосходит 100. Ни в одном матче не было забито больше ста голов.
#### Формат выходных данных
Вам нужно построить турнирную таблицу с результатами.
Каждая строка таблицы — представление результатов каждой из команд, команды должны быть упорядочены в лексикографическом порядке. В первом столбце содержится порядковый номер команды, во втором — название. Далее следуют  столбцов, в каждом из которых содержится информация об играх с остальными командами: в случае победы в ячейке должна присутствовать буква W, в случае поражения — L, в случае ничьей — D, если участники не играли друг с другом — пробел, если заполняется ячейка матча игрока с самим собой, то туда следует поставить символ X.
В последних двух столбцах должно быть выписано количество набранных командой очков и итоговое место. Команда A занимает более высокое место, чем команда B, если она набрала большее количество очков, или они обе набрали одинаковое количество очков, но команда A одержала больше побед, чем команда B. Если же число очков и число побед у команд одинаковое, они занимают одно и то же место. Для простоты награждения требуется присудить только места с первого по третье.
Все столбцы должны иметь минимально возможную ширину, чтобы вместить данные в каждой строке. Для столбцов, содержащих порядковые номера, количество набранных очков и занятые места, все данные выравниваются по правому краю, все названия выравниваются по левому краю, после каждого названия в таблице должен гарантированно присутствовать пробел.
Оформляя таблицу, ориентируйтесь на примеры.
#### Примеры
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
Linux - Gentoo - 1:0
Gentoo - Windows - 2:1
Linux - Windows - 0:2
```
|
```
+-+--------+-+-+-+-+-+
|1|Gentoo |X|L|W|3|1|
+-+--------+-+-+-+-+-+
|2|Linux |W|X|L|3|1|
+-+--------+-+-+-+-+-+
|3|Windows |L|W|X|3|1|
+-+--------+-+-+-+-+-+
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
Cplusplus - C - 1:0
Cplusplus - Php - 2:0
Java - Php - 1:0
Java - C - 2:2
Java - Perl - 1:1
Java - Haskell - 1:1
```
|
```
+-+----------+-+-+-+-+-+-+-+-+
|1|C |X|L| |D| | |1|3|
+-+----------+-+-+-+-+-+-+-+-+
|2|Cplusplus |W|X| | | |W|6|1|
+-+----------+-+-+-+-+-+-+-+-+
|3|Haskell | | |X|D| | |1|3|
+-+----------+-+-+-+-+-+-+-+-+
|4|Java |D| |D|X|D|W|6|2|
+-+----------+-+-+-+-+-+-+-+-+
|5|Perl | | | |D|X| |1|3|
+-+----------+-+-+-+-+-+-+-+-+
|6|Php | |L| |L| |X|0| |
+-+----------+-+-+-+-+-+-+-+-+
```
|
#### Ограничение по времени: 2 секунды
#### Ограничение по памяти: 64 МБ
Решение
=======
В работе программиста достаточно часто встречаются такие задачи, когда нужно получить данные, имеющие некоторый заранее обговоренный формат, и выдать результат в том виде, в котором его ждет на вход следующий элемент конвейера. Эта задача — именно про правильную обработку данных и их вывод в нужном формате. Основная сложность здесь — написать парсер входных данных и хранилище. Парсер принимает на вход строку и сохраняет результаты игры между двумя командами, а хранилище содержит названия команд и результаты.
Из-за достаточно небольшого объема входных данных можно применять не сложные структуры, а стандартные механизмы любого из доступных языков. Например, при использовании C++ подойдет контейнер `std::map`. Ключом в контейнере будет название команды, а значением — информация о ней: количество набранных очков, число побед и результаты игр с другими командами. Результаты тоже можно хранить в `std::map`, где ключ — название оппонента, а значение — результат матча.
Разобьем на части каждую из строк входного потока и обновим информацию о каждом из участников. `std::map`, выбранный в качестве хранилища, позволяет нам хранить все названия в лексикографическом порядке, поэтому для формирования итоговой таблицы нам нужно всего лишь проитерироваться по элементам хранилища. Когда весь входной поток обработан, посчитаем итоговое место каждого из участников: выберем все пары вида «количество очков — число побед» и упорядочим их в порядке убывания, расставив соответствующие места для первых трех результатов. Кроме того, при пост-обработке мы можем посчитать необходимое количество символов для каждого из столбцов результирующей таблицы, а затем аккуратно реализовать вывод таблицы в выходной поток.
«Кошельки и монеты»
-------------------
Условие
=======
Программист Петя очень любит складывать все имеющиеся у него деньги в кошельки и фиксировать, сколько денег лежит в каждом кошельке. Для этого он сохраняет в файле набор целых положительных чисел — количество денег, которое лежит в каждом из его кошельков (Петя не любит, когда хотя бы один из его кошельков пустует). Петя хранит все деньги в монетах, номинал каждой монеты — 1 условная единица.
Однажды у Пети сломался блок магнитных головок и ему пришлось восстанавливать данные с жесткого диска. Он хочет проверить, корректно ли восстановились данные, и просит вас убедиться, что можно ту сумму денег, которая у него была, разложить во все его кошельки, чтобы получились те же числа, что и в восстановленном файле.
**Дополнительные параметры**#### Формат входных данных
В первой строке выходных данных содержится натуральное число   — количество кошельков у Пети.
Во второй строке через пробел записаны данные из восстановленного файла:  натуральных чисел , каждое из которых означает, сколько денег лежит в -м кошельке у Пети .
В третьей строке записано натуральное число   — общая сумма денег, которая была у Пети до того, как он разложил ее по кошелькам.
#### Формат выходных данных
Если в восстановленном файле нет ошибки, и исходную сумму можно разложить по кошелькам с указанной конфигурацией, выведите Yes. Если такой конфигурации не может существовать, выведите No.
#### Примеры
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
2
2 3
5
```
|
```
Yes
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
2
2 3
4
```
|
```
No
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
2
2 3
3
```
|
```
Yes
```
|
#### Примечания
В первом примере у Пети есть два кошелька, в первом лежат две монеты, во втором — три. Конфигурации, приведенной во втором примере, не может существовать, поэтому файл восстановлен некорректно. В третьем примере предложенная конфигурация возможна: во втором кошельке лежит одна монета и первый кошелек, внутри которого лежат две монеты.
#### Ограничение по времени: 2 секунды
#### Ограничение по памяти: 64 МБ
Решение
=======
Здесь требовалось понять, что в кошельке может лежать несколько других кошельков, где, в свою очередь, лежат монеты. Один из тестовых примеров явно показывал возможность такой ситуации. С учетом этого задача достаточно легко сводится к известной [задаче о рюкзаке](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%B4%D0%B0%D1%87%D0%B0_%D0%BE_%D1%80%D0%B0%D0%BD%D1%86%D0%B5), которая решается методом динамического программирования. Возьмем самый вместительный кошелек и наполним его монетами. Если этого сделать нельзя (то есть количество монет меньше, чем необходимо положить в самый большой кошелек) — способа разложить монеты по кошелькам не существует. Если же у нас получилось наполнить самый большой кошелек — возьмем все оставшиеся монеты и попытаемся найти способ разложить их по оставшимся кошелькам. Здесь мы — прямо как в задаче про рюкзак — делаем выбор. Только там мы бы выбирали, положить ли очередной предмет в рюкзак.
Ограничения позволяют нам выделить память под массив, размер которого равен оставшемуся числу монет. Затем проверим каждый оставшийся кошелек на предмет того, можем ли мы заполнить его оставшимся числом монет. Если существует способ распределить монеты по некоторому подмножеству кошельков, то поместим все неиспользованные кошельки в самый большой, предварительно переложив из него в них нужное количество монет. Если же оставшиеся монеты нельзя распределить между некоторым подмножеством оставшихся кошельков — успешной конфигурации не существует.
«Хорошая последовательность»
----------------------------
Условие
=======
Последовательность точек на плоскости называется тривиальной, если она является строго упорядоченной по возрастанию или по убыванию расстояния до одной из точек этой последовательности.
Последовательность точек в трехмерном пространстве называется хорошей, если ни одна из последовательностей, полученных взятием проекции исходной на одну из базовых плоскостей   и  не является тривиальной.
Дана последовательность из  точек с целочисленными координатами в трехмерном пространстве. Необходимо найти такую нечетную перестановку ее индексов, что после ее применения последовательность становится хорошей.
Гарантируется, что решение существует.
**Дополнительные параметры**#### Формат входных данных
В первой строке входных данных записано целое число  , в следующих  строчках через пробел записаны по три целочисленных координаты   каждой из точек.
Гарантируется, что проекции всех точек на любую из базовых плоскостей различны.
#### Формат выходных данных
Выведите  чисел: искомая перестановка индексов от 1 до . Если существует несколько решений, выведите любое из них. Числа в строке следует разделять пробелами.
#### Примеры
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
4
1 1 1
2 4 16
3 9 81
4 16 256
```
|
```
1 2 4 3
```
|
#### Примечания
Инверсией в перестановке  порядка  называется всякая пара индексов  такая, что  и . Четность числа инверсий в перестановке определяет четность перестановки.
#### Ограничение по времени: 2 секунды
#### Ограничение по памяти: 64 МБ
Решение
=======
Для корректного решения задачи нам вполне достаточно оценить, сколько существует тривиальных перестановок. В каждой из плоскостей их число пропорционально , где  — общее количество точек. Значит, всего в пространстве их будет . При этом общее число перестановок, которое может послужить корректным ответом, равно  (деление происходит из-за того, что нам нужны только нечетные перестановки). Получается, что непригодных ответов гораздо меньше, чем тех, которые нас устраивают. Следовательно, мы можем просто осуществить перебор нечетных перестановок. Ответом будет первая перестановка, которая не является тривиальной при построении ее проекции ни на одну из трех плоскостей.
«Интересное путешествие»
========================
Условие
=======
Не секрет, что некоторые программисты очень любят путешествовать. Хорошо всем известный программист Петя тоже очень любит путешествовать, посещать музеи и осматривать достопримечательности других городов.
Для перемещений из города в город он предпочитает использовать машину. При этом он заправляется только на станциях в городах, но не на станциях по пути. Поэтому он очень аккуратно выбирает маршруты, чтобы машина не заглохла в дороге. А еще Петя очень важный член команды, поэтому он не может себе позволить путешествовать слишком долго. Он решил написать программу, которая поможет ему с выбором очередного путешествия. Но так как сейчас у него слишком много других задач, он попросил вас помочь ему.
Расстояние между двумя городами считается как сумма модулей разности по каждой из координат. Дороги есть между всеми парами городов.
**Дополнительные параметры**#### Формат входных данных
В первой строке входных данных записано количество городов  (). В следующих  строках даны два целых числа: координаты каждого города, не превосходящие по модулю миллиарда. Все города пронумерованы числами от 1 до  в порядке записи во входных данных.
В следующей строке записано целое положительное число , не превосходящее двух миллиардов, — максимальное расстояние между городами, которое Петя может преодолеть без дозаправки машины.
В последней строке записаны два различных числа — номер города, откуда едет Петя, и номер города, куда он едет.
#### Формат выходных данных
Если существуют пути, удовлетворяющие описанным выше условиям, то выведите минимальное количество дорог, которое нужно проехать, чтобы попасть из начальной точки маршрута в конечную. Если пути не существует, выведите -1.
#### Примеры
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
7
0 0
0 2
2 2
0 -2
2 -2
2 -1
2 1
2
1 3
```
|
```
2
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
4
0 0
1 0
0 1
1 1
2
1 4
```
|
```
1
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
4
0 0
2 0
0 2
2 2
1
1 4
```
|
```
-1
```
|
#### Ограничение по времени: 1 секунда
#### Ограничение по памяти: 64 МБ
Решение
=======
Вначале из имеющихся точек нужно построить граф. Для этого переберем все пары точек и, если расстояние между ними меньше заданного ограничения, добавим в граф ребро между вершинами. После построения графа запустим поиск в ширину из города, откуда Петя начинает свое путешествие. Как только он достигнет точки назначения, завершим наш алгоритм и выведем количество пройденных нами ребер. Если алгоритм завершился, а мы так и не достигли пункта назначения, то он недостижим из исходного города, поэтому следует вывести -1. Общая сложность описанного алгоритма — , где  — число городов.
«Разделение числа»
==================
Условие
=======
Дано число . Разбейте десятичную запись числа  на максимальное возможное количество различных чисел.
Использовать числа с незначащими нулями не разрешается.
**Дополнительные параметры**#### Формат входных данных
В единственной строке входных данных задано число  ().
#### Формат выходных данных
Выведите разбиение числа  на различные части. Между частями поставьте знак «-». Если есть несколько возможных разбиений, выведите любое.
#### Примеры
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
0
```
|
```
0
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
101
```
|
```
10-1
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
102
```
|
```
1-0-2
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
11
```
|
```
11
```
|
#### Ограничение по времени: 2 секунды
#### Ограничение по памяти: 64 МБ
Решение
=======
Несмотря на то, что исходное число может быть очень большим, количество способов разбить его на части зависит не от значения, а от количества знаков в числе. В худшем случае число состоит из 18 десятичных знаков (вариант 1019 мы не рассматриваем — там только один вариант разбиения). Значит, знак «-» мы можем поставить только в 17 различных позициях. В каждой из этих позиций мы можем как поставить знак, так и опустить его. Другими словами, существует всего 217 способов выбрать разбиение для самых больших чисел. Это около 105 вариантов. Переберем их все, отсечем те, которые нас не устраивают (то есть при которых получаются одинаковые числа), и выберем вариант, содержащий наибольшее количество частей.
«Максимальный урон»
===================
Условие
=======
Программист Игорь очень любит играть в компьютерные игры. Больше всего Игорю нравятся стратегии, особенно те моменты, когда он отправляет группы своих юнитов атаковать вражеские базы. Игорь довольно давно играет в стратегии, поэтому у него есть четко отработанный план действий при атаке: он разбивает все свои юниты на группы и отправляет их в атаку поочередно. При этом Игорь считает, что общий урон, который будет нанесен в атаке, равен произведению размеров групп. Он пытается разбить свои юниты на группы так, чтобы максимизировать общий урон.
В последнее время Игорь стал часто проигрывать. Он уверен, что проблема в том, что в одной из групп после разбиения получается несчастливое количество юнитов. Он пытается переделать свой алгоритм разбиения и попросил вас посчитать, какой максимальный общий урон смогут нанести его группы, если среди них не будет ни одной, содержащей несчастливое количество юнитов.
**Дополнительные параметры**#### Формат входных данных
В единственной строке входных данных через пробел записаны натуральные числа  и   — количество юнитов, которые есть у Игоря, и число юнитов в группе, которое Игорь считает несчастливым.
#### Формат выходных данных
Выведите максимально возможный общий урон по модулю 109 + 7.
#### Примеры
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
8 2
```
|
```
16
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
9 3
```
|
```
20
```
|
#### Примечания
В первом примере для максимизации общего урона следует разбить юниты на две группы по 4 юнита в каждом, во втором примерe — на две группы: в первой 4 юнита, во второй — 5.
#### Ограничение по времени: 2 секунды
#### Ограничение по памяти: 64 МБ
Решение
=======
Если бы не дополнительный запрет на использование групп определенного размера, который в условии назван несчастливым, то произведение было бы максимальным при разбиении исходного числа на группы по 3 юнита. Если общее число юнитов нацело делится на 3 — просто разбиваем их на группы по 3 юнита. Если остаток от деления на 3 равен 1, то отделяем группу из четырех юнитов (если, конечно, изначально у нас больше одного юнита), а в остальные группы определяем по 3 юнита. И наконец, если остаток от деления на 3 равен 2 — отделяем группу из двух юнитов, а в остальные определяем по 3 юнита.
Докажем, что такое разбиение корректно. Попробуем доказать это методом от противоположного. Предположим сначала, что в нашем разбиении есть числа  ≥ 5. Но тогда мы можем заменить  на два числа: -3 и 3. На общую сумму замена никак не повлияет, а произведение чисел 3 и -3 всегда больше чем  при  ≥ 5. Так что чисел, превосходящих или равных 5 в нашей последовательности существовать не может. Предположим, что в ней есть число 4, но мы можем заменить его на две двойки, никак не повлияв на значения суммы и произведения, поэтому давайте так и поступим. Далее, в нашей последовательности не может быть больше двух двоек, иначе мы могли бы заменить любые три из них на две тройки. Значение суммы от этого бы не поменялось, а значение произведения увеличилось бы (8 = 2⋅2⋅2 < 3⋅3 = 9). Следовательно, трех или большего числа двоек тоже не может быть. Ну и кроме того, у нас не может быть единиц (только если исходная сумма сама не равна единице). Таким образом, наша результирующая последовательность может состоять только из троек и не более чем двух двоек, что мы и показали выше.
Вернемся к ограничению на несчастливый размер группы. Если он превышает значение 3 — наше решение останется точно таким же. Если он равен 3, то, перебрав маленькие размеры групп вручную, будем разбивать последовательность на группы размером 2. Если изначально число юнитов нечетное, то дополнительно возьмем группу, состоящую из 5 юнитов (поскольку одна группа размера 5 обеспечит большее финальное значение, нежели 2 группы по 2 юнита и одна группа из одного юнита). Если же исключены размеры группы, равные 2, то используем алгоритм деления на группы по 3 юнита. Наконец, если их начальное число не делится на 3 нацело, возьмем в качестве размера дополнительных групп не 2, а 4 юнита.
«Красно-черные деревья»
=======================
### Условие
Красно-черным деревом называется дерево, у которого все вершины покрашены в красный или черный цвет и есть еще дополнительные свойства:
* Корень черного цвета.
* Каждая вершина либо имеет два потомка, либо является листом (не имеет потомков).
* Все листья дерева черного цвета.
* У красных вершин оба потомка имеют черный цвет.
* Количество черных вершин на пути от корня до любого листа дерева одинаково.
Найдите число неизоморфных красно-черных деревьев с заданным числом вершин. Два красно-черных дерева  и  являются изоморфными, если существует биекция между вершинами деревьев , удовлетворяющая условиям:
* , т. е. корень переходит в корень.
* Если  и у вершины  есть дети ( и ), то и у вершины  есть дети ( и ), при этом или  и , или  и .
*  сохраняет цвет вершин, то есть .
**Дополнительные параметры**#### Формат входных данных
В первой строке задано число вершин дерева  ().
#### Формат выходных данных
Выведите число неизоморфных красно-черных деревьев с  вершинами по модулю 109 + 7.
#### Примеры
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
5
```
|
```
1
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
7
```
|
```
2
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
6
```
|
```
0
```
|
#### Ограничение по времени: 2 секунды
#### Ограничение по памяти: 256 МБ
Решение
=======
Задачу можно решить методом динамического программирования, однако она немного сложнее, чем те задачи, которые мы решали этим же методом выше.
Обозначим как ![$CountBlack[N][H]$](https://habrastorage.org/getpro/habr/formulas/d1c/184/590/d1c184590a4919622867fb4fd019b595.svg) количество различных с точностью до изоморфизма красно-черных деревьев с черным корнем, которые состоят из  вершин и у которых количество черных вершин от корня до листьев равно . За ![$CountRed[N][H]$](https://habrastorage.org/getpro/habr/formulas/236/df2/717/236df27176c9c2e0e0d22759c64fbb3d.svg) мы обозначим такие же деревья с красным корнем. Это будет нарушать свойство черного корня у красно-черных деревьев, однако такое допущение нужно нам для вычисления результата.
Как вычислить значение ![$CountBlack[N][H]$](https://habrastorage.org/getpro/habr/formulas/d1c/184/590/d1c184590a4919622867fb4fd019b595.svg)? Корнем у него может быть любое число  от 1 до . Тогда в левом поддереве будет содержаться  вершина, а в правом —  вершин. Сколько поддеревьев может получиться в левом поддереве? Если его корень черный, то число поддеревьев равно ![$CountBlack[i-1][H-1]$](https://habrastorage.org/getpro/habr/formulas/e51/476/a2f/e51476a2f9f653c0f99f83fc575ea882.svg), а если красный, то ![$CountRed[i-1][H-1]$](https://habrastorage.org/getpro/habr/formulas/8dc/5be/85a/8dc5be85a9d431d07b89244cdfa5e65c.svg). Аналогично для правого поддерева: ![$CountBlack[j][H-1]$](https://habrastorage.org/getpro/habr/formulas/f32/470/243/f32470243fea8d8d7b46c30278c4d1a9.svg), если корень поддерева черный, и ![$CountRed[j][H-1]$](https://habrastorage.org/getpro/habr/formulas/547/de3/035/547de30358f115e036155ec1c64d9ec1.svg), если корень красный. Просуммируем числа, полученные для левого и правого поддеревьев: ![$CountLeft = CountBlack[i-1][H-1] + CountRed[i-1][H-1]$](https://habrastorage.org/getpro/habr/formulas/5ef/827/939/5ef827939a6aafcf299534ed750f5f7b.svg) и ![$CountRight = CountBlack[j][H-1] + CountRed[j][H-1].$](https://habrastorage.org/getpro/habr/formulas/f03/a4d/3cc/f03a4d3ccb47c18f181f4df72c50501b.svg) Получим общее количество поддеревьев, которые могут быть в нашем дереве с корнем в вершине . Поскольку нам нужно вычислить количество деревьев с точностью до изоморфизма, достаточно посчитать ответ для . Если , то прибавим к ответу ![$CountBlack[N][H]$](https://habrastorage.org/getpro/habr/formulas/d1c/184/590/d1c184590a4919622867fb4fd019b595.svg) произведение числа поддеревьев слева и справа: . Если же мы строим оба поддерева из одинакового числа элементов (), то к результату нужно прибавить  вариантов.
При вычислении значения ![$CountRed[N][H]$](https://habrastorage.org/getpro/habr/formulas/236/df2/717/236df27176c9c2e0e0d22759c64fbb3d.svg) давайте действовать тем же способом, но с двумя замечаниями. Во-первых, число черных вершин во втором индексе не изменяется, поскольку наш корень красный. А во-вторых, раз у красного корня не может быть красных потомков, то слева и справа у нас могут быть только деревья с черными корнями. Следовательно, если мы выбрали число  в качестве нашего красного корня, то количество деревьев слева равно ![$CountBlack[i-1][H]$](https://habrastorage.org/getpro/habr/formulas/5b2/8e7/8b5/5b28e78b57914500f1cbdb3b5957b858.svg), а количество деревьев справа — ![$CountBlack[j][H]$](https://habrastorage.org/getpro/habr/formulas/e29/c9a/5b4/e29c9a5b41db0cd823fd3f6e14289080.svg). Остальные вычисления аналогичны первому случаю.
Чтобы посчитать ответ для исходной задачи, нам нужно вычислить ![$CountBlack[N][H]$](https://habrastorage.org/getpro/habr/formulas/d1c/184/590/d1c184590a4919622867fb4fd019b595.svg) для всех возможных . Количество черных вершин от корня до любого из листьев [пропорционально](https://ru.wikipedia.org/wiki/%D0%9A%D1%80%D0%B0%D1%81%D0%BD%D0%BE-%D1%87%D0%B5%D1%80%D0%BD%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE#.D0.94.D0.BE.D0.BA.D0.B0.D0.B7.D0.B0.D1.82.D0.B5.D0.BB.D1.8C.D1.81.D1.82.D0.B2.D0.BE_.D0.B0.D1.81.D0.B8.D0.BC.D0.BF.D1.82.D0.BE.D1.82.D0.B8.D1.87.D0.B5.D1.81.D0.BA.D0.B8.D1.85_.D0.B3.D1.80.D0.B0.D0.BD.D0.B8.D1.86) логарифму от количества элементов в дереве. Следовательно, достаточно рассмотреть черные высоты, не превосходящие . Переберем все  от 1 до 20 и просуммируем все значения ![$CountBlack[N][H]$](https://habrastorage.org/getpro/habr/formulas/d1c/184/590/d1c184590a4919622867fb4fd019b595.svg). Полученная сумма и будет ответом к задаче.
«Все кроме одной»
=================
### Условие
Даны  перестановок из  элементов, каждая из которых принадлежит к одному из  типов.
Посчитайте позицию первого элемента, если последовательно применить эти  перестановок, убрав одну из них.
**Дополнительные параметры**#### Формат входных данных
В первой строке входных данных заданы числа  и  (, ).
В следующих  строках записано по  чисел. -е число описывает позицию, на которую нужно переставить -й элемент.
В следующей строке записано число  (). В следующей строке записаны  чисел от 1 до  — типы перестановок в начальном наборе.
#### Формат выходных данных
Для каждой из  перестановок выведите в отдельной строке позицию первого элемента, если последовательно применить все остальные перестановки.
#### Примеры
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
3 2
1 3 2
2 3 1
3
1 2 1
```
|
```
3
1
2
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
2 2
1 2
2 1
3
1 2 1
```
|
```
2
1
2
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
1 1
1
1
1
```
|
```
1
```
|
#### Ограничение по времени: 2 секунды
#### Ограничение по памяти: 128 МБ
Решение
=======
Обозначим за ![$prefix[i]$](https://habrastorage.org/getpro/habr/formulas/249/279/8c4/2492798c470212e17796d0549a2b63cc.svg) перестановку, которая получается при последовательном выполнении всех перестановок от первой до -й из нашего набора, содержащего  перестановок. За ![$suffix[i]$](https://habrastorage.org/getpro/habr/formulas/923/2eb/88a/9232eb88a40d138e97f129584b4ac181.svg), в свою очередь, обозначим перестановку, которая получается при последовательном выполнении всех перестановок от -й до -й. Легко увидеть, что, зная ![$prefix[i-1]$](https://habrastorage.org/getpro/habr/formulas/09a/4cc/fb6/09a4ccfb64a0a88d42b5f9188523320d.svg), мы можем получить ![$prefix[i]$](https://habrastorage.org/getpro/habr/formulas/249/279/8c4/2492798c470212e17796d0549a2b63cc.svg), просто применив к ![$prefix[i-1]$](https://habrastorage.org/getpro/habr/formulas/09a/4cc/fb6/09a4ccfb64a0a88d42b5f9188523320d.svg) -ю перестановку из нашего набора. При этом сложность такого вычисления — , где  — количество элементов в перестановке. Значит, мы можем последовательно вычислить все перестановки ![$prefix[i]$](https://habrastorage.org/getpro/habr/formulas/249/279/8c4/2492798c470212e17796d0549a2b63cc.svg) для  от 1 до  за время . Аналогично мы можем вычислить все перестановки ![$suffix[i]$](https://habrastorage.org/getpro/habr/formulas/923/2eb/88a/9232eb88a40d138e97f129584b4ac181.svg), если увидим, что ![$suffix[i]$](https://habrastorage.org/getpro/habr/formulas/923/2eb/88a/9232eb88a40d138e97f129584b4ac181.svg) получается применением ![$suffix[i+1]$](https://habrastorage.org/getpro/habr/formulas/a2a/bd1/d40/a2abd1d40064ea33a9c4518ef49a8bc5.svg) к -й перестановке. Тогда чтобы вычислить, какой элемент будет на первой позиции, если мы исключим некую -ю перестановку из нашего списка, нам достаточно применить к перестановке ![$prefix[j-1]$](https://habrastorage.org/getpro/habr/formulas/468/b27/fd8/468b27fd84a90c7b6bae1a87deb97fd4.svg) перестановку ![$suffix[j+1]$](https://habrastorage.org/getpro/habr/formulas/f51/ff1/aaa/f51ff1aaa6c516c4109d4081db070bc5.svg). Обозначив за ![$prefix[0]$](https://habrastorage.org/getpro/habr/formulas/013/a43/0f6/013a430f6a6a1aba301759a34d37a33f.svg) и ![$suffix[k+1]$](https://habrastorage.org/getpro/habr/formulas/d77/f72/c0a/d77f72c0a91a70c2065f29d0c41984e5.svg) тождественные перестановки и проверив все  от 1 до , мы получим ответ к задаче. Поскольку для каждого  время применения одной перестановки к другой пропорционально , итоговая сложность алгоритма — .
«Вложенные прямоугольники»
==========================
### Условие
На клетчатой плоскости отмечено  клеток.
Для раскрашивания этих клеток проводятся следующие операции. На каждом шаге выбирается прямоугольник минимальной площади, содержащий все отмеченные, но не окрашенные, клетки, и все клетки на его границе перекрашиваются в новый цвет.
Определите, через сколько шагов неокрашенных клеток не останется.
**Дополнительные параметры**#### Формат входных данных
В первой строке входных данных задано число   — количество отмеченных клеток. В следующих  строках заданы целые координаты -й отмеченной клетки  . Все отмеченные клетки различны.
#### Формат выходных данных
Выведите число шагов, после которых не останется неокрашенных клеток.
#### Примеры
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
1
-1 -1
```
|
```
1
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
3
-1 -1
0 0
1 1
```
|
```
2
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
5
0 1
1 0
1 1
2 1
3 2
```
|
```
2
```
|
#### Ограничение по времени: 2 секунды
#### Ограничение по памяти: 64 МБ
Решение
=======
Отсортируем отмеченные клетки по вертикали и горизонтали. Заведем массив флагов, в котором будет отмечено, какие точки уже выброшены. Для нахождения самого внешнего прямоугольника будем поддерживать 4 итератора, которые указывают на невыброшенные клетки — первую и последнюю для горизонтального и вертикального порядка соответственно. На каждом шаге будем вначале сдвигать итераторы до тех пор, пока не найдем невыброшенные клетки. Затем будем сдвигать итераторы до тех пор, пока не изменится соответствующая координата клетки. Отметим все пройденные клетки как выброшенные в массиве флагов.
«Игра с числами»
================
Условие
=======
Дана последовательность  положительных чисел . Пока среди них есть различные, выполняется следующая операция: выбирается некоторое максимальное число и из него вычитается минимальное число.
Через сколько операций числа станут одинаковыми?
**Дополнительные параметры**#### Формат входных данных
В первой строке входных данных задано число  (). В следующей строке заданы  чисел  ().
#### Формат выходных данных
Количество операций, после которых все числа станут одинаковыми.
#### Примеры
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
2
1 1
```
|
```
0
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
3
9 6 3
```
|
```
3
```
|
| | |
| --- | --- |
| **Ввод** | **Вывод** |
|
```
6
1000000000 1000000000 1000000000 1000000000 1000000000 1
```
|
```
4999999995
```
|
#### Ограничение по времени: 2 секунды
#### Ограничение по памяти: 64 МБ
Решение
=======
Пусть  — текущее минимальное число. Заметим, что пока максимальное число больше, чем , минимальное число при наших операциях вычитания не изменяется. Давайте посчитаем, сколько нам понадобится операций до тех пор, пока максимальное число станет меньше, чем . Поскольку при всех таких операциях всегда вычитается число a, то достаточно найти все числа, которые превышают , и с помощью деления вычислить, после какого количества вычитаний эти числа впервые станут меньше, чем . Как только максимум станет меньше, чем , мы просто смоделируем одну операцию вычитания, после которой минимум гарантированно изменится. Затем будем повторять предыдущую процедуру до тех пор, пока максимум не совпадет с минимумом. Оценим число итераций. Обозначим сумму всех чисел за . Тогда , а при каждой итерации сумма чисел уменьшается по крайней мере на . Таким образом, сумма всех чисел уменьшается хотя бы в  раз. Поэтому нам понадобится не больше чем  итераций цикла, где  — максимальное число в исходном наборе.
|
https://habr.com/ru/post/340784/
| null |
ru
| null |
# Разработка приложения для потокового вещания с помощью Node.js и React
Автор материала, перевод которого мы сегодня публикуем, говорит, что работает над приложением, которое позволяет организовывать потоковое вещание (стриминг) того, что происходит на рабочем столе пользователя.
[](https://habr.com/ru/company/ruvds/blog/457860/)
Приложение принимает от стримера поток в формате RTMP и преобразует его в HLS-поток, который может быть воспроизведён в браузерах зрителей. В этой статье будет рассказано о том, как можно создать собственное стриминговое приложение с использованием Node.js и React. Если вы привыкли, увидев заинтересовавшую вас идею, сразу же погружаться в код, можете прямо сейчас заглянуть в [этот](https://github.com/waleedahmad/node-stream) репозиторий.
Разработка веб-сервера с базовой системой аутентификации
--------------------------------------------------------
Давайте создадим простой веб-сервер, основанный на Node.js, в котором, средствами библиотеки passport.js, реализована локальная стратегия аутентификации пользователей. В роли постоянного хранилища информации будем использовать MongoDB. Работать с базой данных будем с помощью ODM-библиотеки Mongoose.
Инициализируем новый проект:
```
$ npm init
```
Установим зависимости:
```
$ npm install axios bcrypt-nodejs body-parser bootstrap config connect-ensure-login connect-flash cookie-parser ejs express express-session mongoose passport passport-local request session-file-store --save-dev
```
В директории проекта создадим две папки — `client` и `server`. Код фронтенда, основанный на React, попадёт в папку `client`, а бэкенд-код будет храниться в папке `server`. Сейчас мы работаем в папке `server`. А именно, для создания системы аутентификации будем использовать passport.js. Мы уже установили модули passport и passport-local. Прежде чем мы опишем локальную стратегию аутентификации пользователей — создадим файл `app.js` и добавим в него код, который нужен для запуска простого сервера. Если вы будете запускать этот код у себя — позаботьтесь о том, чтобы у вас была бы установлена СУБД MongoDB, и чтобы она была бы запущена в виде сервиса.
Вот код файла, который находится в проекте по адресу `server/app.js`:
```
const express = require('express'),
Session = require('express-session'),
bodyParse = require('body-parser'),
mongoose = require('mongoose'),
middleware = require('connect-ensure-login'),
FileStore = require('session-file-store')(Session),
config = require('./config/default'),
flash = require('connect-flash'),
port = 3333,
app = express();
mongoose.connect('mongodb://127.0.0.1/nodeStream' , { useNewUrlParser: true });
app.set('view engine', 'ejs');
app.set('views', path.join(__dirname, './views'));
app.use(express.static('public'));
app.use(flash());
app.use(require('cookie-parser')());
app.use(bodyParse.urlencoded({extended: true}));
app.use(bodyParse.json({extended: true}));
app.use(Session({
store: new FileStore({
path : './server/sessions'
}),
secret: config.server.secret,
maxAge : Date().now + (60 * 1000 * 30)
}));
app.get('*', middleware.ensureLoggedIn(), (req, res) => {
res.render('index');
});
app.listen(port, () => console.log(`App listening on ${port}!`));
```
Мы загрузили всё необходимое для приложения промежуточное ПО, подключились к MongoDB, настроили express-сессию на использование файлового хранилища. Хранение сессий позволит восстанавливать их после перезагрузки сервера.
Теперь опишем стратегии passport.js, предназначенные для организации регистрации и аутентификации пользователей. Создадим в папке `server` папку `auth` и поместим в неё файл `passport.js`. Вот что должно быть в файле `server/auth/passport.js`:
```
const passport = require('passport'),
LocalStrategy = require('passport-local').Strategy,
User = require('../database/Schema').User,
shortid = require('shortid');
passport.serializeUser( (user, cb) => {
cb(null, user);
});
passport.deserializeUser( (obj, cb) => {
cb(null, obj);
});
// Стратегия passport, описывающая регистрацию пользователя
passport.use('localRegister', new LocalStrategy({
usernameField: 'email',
passwordField: 'password',
passReqToCallback: true
},
(req, email, password, done) => {
User.findOne({$or: [{email: email}, {username: req.body.username}]}, (err, user) => {
if (err)
return done(err);
if (user) {
if (user.email === email) {
req.flash('email', 'Email is already taken');
if (user.username === req.body.username) {
req.flash('username', 'Username is already taken');
return done(null, false);
} else {
let user = new User();
user.email = email;
user.password = user.generateHash(password);
user.username = req.body.username;
user.stream_key = shortid.generate();
user.save( (err) => {
if (err)
throw err;
return done(null, user);
});
});
}));
// Стратегия passport, описывающая аутентификацию пользователя
passport.use('localLogin', new LocalStrategy({
usernameField: 'email',
passwordField: 'password',
passReqToCallback: true
},
(req, email, password, done) => {
User.findOne({'email': email}, (err, user) => {
if (err)
return done(err);
if (!user)
return done(null, false, req.flash('email', 'Email doesn\'t exist.'));
if (!user.validPassword(password))
return done(null, false, req.flash('password', 'Oops! Wrong password.'));
return done(null, user);
});
}));
module.exports = passport;
```
Кроме того, нам нужно описать схему для модели пользователя (она будет называться `UserSchema`). Создадим в папке `server` папку `database`, а в ней — файл `UserSchema.js`.
Вот код файла `server/database.UserSchema.js`:
```
let mongoose = require('mongoose'),
bcrypt = require('bcrypt-nodejs'),
shortid = require('shortid'),
Schema = mongoose.Schema;
let UserSchema = new Schema({
username: String,
email : String,
password: String,
stream_key : String,
});
UserSchema.methods.generateHash = (password) => {
return bcrypt.hashSync(password, bcrypt.genSaltSync(8), null);
};
UserSchema.methods.validPassword = function(password){
return bcrypt.compareSync(password, this.password);
};
UserSchema.methods.generateStreamKey = () => {
return shortid.generate();
};
module.exports = UserSchema;
```
В `UserSchema` имеется три метода. Метод `generateHash` предназначен для преобразования пароля, представленного в виде обычного текста, в bcrypt-хэш. Мы используем этот метод в стратегии passport для преобразования паролей, вводимых пользователями, в хэши bcrypt. Полученные хэши паролей потом сохраняются в базе данных. Метод `validPassword` принимает пароль, вводимый пользователем, и проверяет его путём сравнения его хэша с хэшем, хранящимся в базе данных. Метод `generateStreamKey` генерирует уникальные строки, которые мы будем передавать пользователей в качестве их стриминговых ключей (ключей потока) для RTMP-клиентов.
Вот код файла `server/database/Schema.js`:
```
let mongoose = require('mongoose');
exports.User = mongoose.model('User', require('./UserSchema'));
```
Теперь, когда мы определили стратегии passport, описали схему `UserSchema` и создали на её основе модель, давайте инициализируем passport в `app.js`.
Вот код, которым нужно дополнить файл `server/app.js`:
```
// Это нужно добавить в верхнюю часть файла, рядом с командами импорта
const passport = require('./auth/passport');
app.use(passport.initialize());
app.use(passport.session());
```
Кроме того, в `app.js` надо зарегистрировать новые маршруты. Для этого добавим в `server/app.js` следующий код:
```
// Регистрация маршрутов приложения
app.use('/login', require('./routes/login'));
app.use('/register', require('./routes/register'));
```
Создадим файлы `login.js` и `register.js` в папке `routes`, которая находится в папке `server`. В этих файлах определим пару вышеупомянутых маршрутов и воспользуемся промежуточным ПО passport для организации регистрации и аутентификации пользователей.
Вот код файла `server/routes/login.js`:
```
const express = require('express'),
router = express.Router(),
passport = require('passport');
router.get('/',
require('connect-ensure-login').ensureLoggedOut(),
(req, res) => {
res.render('login', {
user : null,
errors : {
email : req.flash('email'),
password : req.flash('password')
});
});
router.post('/', passport.authenticate('localLogin', {
successRedirect : '/',
failureRedirect : '/login',
failureFlash : true
}));
module.exports = router;
```
Вот код файла `server/routes/register.js`:
```
const express = require('express'),
router = express.Router(),
passport = require('passport');
router.get('/',
require('connect-ensure-login').ensureLoggedOut(),
(req, res) => {
res.render('register', {
user : null,
errors : {
username : req.flash('username'),
email : req.flash('email')
});
});
router.post('/',
require('connect-ensure-login').ensureLoggedOut(),
passport.authenticate('localRegister', {
successRedirect : '/',
failureRedirect : '/register',
failureFlash : true
})
);
module.exports = router;
```
Мы используем движок шаблонизации ejs. Добавим файлы шаблонов `login.ejs` и `register.ejs` в папку `views`, которая находится в папке `server`.
Вот содержимое файла `server/views/login.ejs`:
```
<% include header.ejs %>
<% include navbar.ejs %>
#### Login
---
Email address
<% if (errors.email.length) { %>
<%= errors.email %>
<% } %>
Password
<% if (errors.password.length) { %>
<%= errors.password %>
<% } %>
Don't have an account? Register [here](/register).
Login
<% include footer.ejs %>
```
Вот что должно быть в файле `server/views/register.ejs`:
```
<% include header.ejs %>
<% include navbar.ejs %>
#### Register
---
Username
<% if (errors.username.length) { %>
<%= errors.username %>
<% } %>
Email address
<% if (errors.email.length) { %>
<%= errors.email %>
<% } %>
Password
Have an account? Login [here](/login).
Register
<% include footer.ejs %>
```
Мы, можно сказать, закончили работу над системой аутентификации. Теперь приступим к созданию следующей части проекта и настроим RTMP-сервер.
Настройка RTMP-сервера
----------------------
RTMP (Real-Time Messaging Protocol) — это протокол, который был разработан для высокопроизводительной передачи видео, аудио и различных данных между стримером и сервером. Twitch, Facebook, YouTube и многие другие сайты, предлагающие возможность потокового вещания, принимают RTMP-потоки и перекодируют их в HTTP-потоки (формат HLS) перед передачей этих потоков на свои CDN для обеспечения их высокой доступности.
Мы используем модуль node-media-server — Node.js-реализацию медиа-сервера RTMP. Этот медиа-сервер принимает RTMP-потоки и преобразует их в HLS/DASH с использованием мультимедийного фреймворка ffmpeg. Для успешной работы проекта в вашей системе должен быть установлен ffmpeg. Если вы работаете на Linux и у вас уже установлен ffmpeg, вы можете выяснить путь к нему, выполнив следующую команду из терминала:
```
$ which ffmpeg
# /usr/bin/ffmpeg
```
Для работы с пакетом node-media-server рекомендуется ffmpeg версии 4.x. Проверить установленную версию ffmpeg можно так:
```
$ ffmpeg --version
# ffmpeg version 4.1.3-0york1~18.04 Copyright (c) 2000-2019 the
# FFmpeg developers built with gcc 7 (Ubuntu 7.3.0-27ubuntu1~18.04)
```
Если ffmpeg у вас не установлен и вы работаете в Ubuntu, установить этот фреймворк можно, выполнив следующую команду:
```
# Добавьте в систему PPA-репозиторий. Если провести установку без PPA, то установлен будет
# ffmpeg версии 3.x.
$ sudo add-apt-repository ppa:jonathonf/ffmpeg-4
$ sudo apt install ffmpeg
```
Если вы работаете в Windows — можете загрузить [сборки](https://ffmpeg.zeranoe.com/builds/) ffmpeg для Windows.
Добавьте в проект конфигурационный файл `server/config/default.js`:
```
const config = {
server: {
secret: 'kjVkuti2xAyF3JGCzSZTk0YWM5JhI9mgQW4rytXc'
},
rtmp_server: {
rtmp: {
port: 1935,
chunk_size: 60000,
gop_cache: true,
ping: 60,
ping_timeout: 30
},
http: {
port: 8888,
mediaroot: './server/media',
allow_origin: '*'
},
trans: {
ffmpeg: '/usr/bin/ffmpeg',
tasks: [
app: 'live',
hls: true,
hlsFlags: '[hls_time=2:hls_list_size=3:hls_flags=delete_segments]',
dash: true,
dashFlags: '[f=dash:window_size=3:extra_window_size=5]'
};
module.exports = config;
```
Замените значение свойства `ffmpeg` на путь, по которому ffmpeg установлен в вашей системе. Если вы работаете в Windows и загрузили Windows-сборку ffmpeg по вышеприведённой ссылке — не забудьте добавить к имени файла расширение `.exe`. Тогда соответствующий фрагмент вышеприведённого кода будет выглядеть так:
```
const config = {
....
trans: {
ffmpeg: 'D:/ffmpeg/bin/ffmpeg.exe',
...
};
```
Теперь установим node-media-server, выполнив следующую команду:
```
$ npm install node-media-server --save
```
Создайте в папке `server` файл `media_server.js`.
Вот код, который нужно поместить в `server/media_server.js`:
```
const NodeMediaServer = require('node-media-server'),
config = require('./config/default').rtmp_server;
nms = new NodeMediaServer(config);
nms.on('prePublish', async (id, StreamPath, args) => {
let stream_key = getStreamKeyFromStreamPath(StreamPath);
console.log('[NodeEvent on prePublish]', `id=${id} StreamPath=${StreamPath} args=${JSON.stringify(args)}`);
});
const getStreamKeyFromStreamPath = (path) => {
let parts = path.split('/');
return parts[parts.length - 1];
};
module.exports = nms;
```
Пользоваться объектом `NodeMediaService` довольно просто. Он обеспечивает работу RTMP-сервера и позволяет ожидать подключений. Если стриминговый ключ недействителен — входящее подключение можно отклонить. Мы будем обрабатывать событие этого объекта `prePublish`. В следующем разделе мы добавим в замыкание прослушивателя событий `prePublish` дополнительный код. Он позволит отклонять входящие подключения с недействительными стриминговыми ключами. Пока же мы будем принимать все входящие подключения, поступающие на RTMP-порт по умолчанию (1935). Нам нужно лишь импортировать в файле `app.js` объект `node_media_server` и вызвать его метод `run`.
Добавим следующий код в `server/app.js`:
```
// Добавьте это в верхней части app.js,
// туда же, где находятся остальные команды импорта
const node_media_server = require('./media_server');
// Вызовите метод run() в конце файла,
// там, где мы запускаем веб-сервер
node_media_server.run();
```
Загрузите и установите у себя [OBS](https://obsproject.com/) (Open Broadcaster Software). Откройте окно настроек программы и перейдите в раздел `Stream`. Выберите `Custom` в поле `Service` и введите `rtmp://127.0.0.1:1935/live` в поле `Server`. Поле `Stream Key` можно оставить пустым. Если программа не даст сохранить настройки без заполнения этого поля — в него можно ввести произвольный набор символов. Нажмите на кнопку `Apply` и на кнопку `OK`. Щёлкните кнопку `Start Streaming` для того, чтобы начать передачу своего RTMP-потока на собственный локальный сервер.
*Настройка OBS*
Перейдите в терминал и посмотрите на то, что выводит туда медиа-сервер. Вы увидите там сведения о входящем потоке и логи нескольких прослушивателей событий.
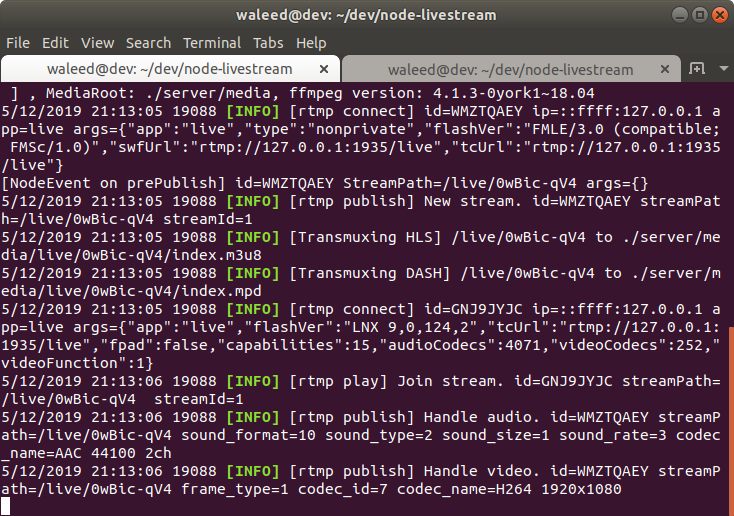
*Данные, которые выводит в терминал медиа-сервер, основанный на Node.js*
Медиа-сервер даёт доступ к API, который позволяет получить список подключённых клиентов. Для того чтобы увидеть этот список — можно перейти в браузере по адресу `http://127.0.0.1:8888/api/streams`. Позже мы воспользуемся этим API в React-приложении для показа списка пользователей, ведущих трансляции. Вот что можно увидеть, обратившись к этому API:
```
{
"live": {
"0wBic-qV4": {
"publisher": {
"app": "live",
"stream": "0wBic-qV4",
"clientId": "WMZTQAEY",
"connectCreated": "2019-05-12T16:13:05.759Z",
"bytes": 33941836,
"ip": "::ffff:127.0.0.1",
"audio": {
"codec": "AAC",
"profile": "LC",
"samplerate": 44100,
"channels": 2
},
"video": {
"codec": "H264",
"width": 1920,
"height": 1080,
"profile": "High",
"level": 4.2,
"fps": 60
},
"subscribers": [
"app": "live",
"stream": "0wBic-qV4",
"clientId": "GNJ9JYJC",
"connectCreated": "2019-05-12T16:13:05.985Z",
"bytes": 33979083,
"ip": "::ffff:127.0.0.1",
"protocol": "rtmp"
}
```
Теперь бэкенд практически готов. Он представляет собой работающий стриминговый сервер, поддерживающий технологии HTTP, RTMP и HLS. Однако мы ещё не создали систему проверки входящих RTMP-подключений. Она должна позволить нам добиться того, чтобы сервер принимал бы потоки только от аутентифицированных пользователей. Добавим следующий код в обработчик события `prePublish` в файле `server/media_server.js`:
```
// Добавьте команду импорта в начало файла
const User = require('./database/Schema').User;
nms.on('prePublish', async (id, StreamPath, args) => {
let stream_key = getStreamKeyFromStreamPath(StreamPath);
console.log('[NodeEvent on prePublish]', `id=${id} StreamPath=${StreamPath} args=${JSON.stringify(args)}`);
User.findOne({stream_key: stream_key}, (err, user) => {
if (!err) {
if (!user) {
let session = nms.getSession(id);
session.reject();
} else {
// что-то делаем
});
});
const getStreamKeyFromStreamPath = (path) => {
let parts = path.split('/');
return parts[parts.length - 1];
};
```
В замыкании мы выполняем запрос к базе данных для нахождения пользователя со стриминговым ключом. Если ключ принадлежит пользователю — мы просто позволяем пользователю подключиться к серверу и опубликовать свою трансляцию. В противном случае мы отклоняем входящее RTMP-соединение.
В следующем разделе мы создадим простую клиентскую часть приложения, основанную на React. Она нужна для того чтобы позволить зрителям просматривать потоковые трансляции, а также для того, чтобы позволить стримерам генерировать и просматривать свои стриминговые ключи.
Показ потоковых трансляций
--------------------------
Теперь переходим в папку `clients`. Так как мы собираемся создать React-приложение, нам понадобится webpack. Нужны нам и загрузчики, которые применяются для транспиляции JSX-кода в JavaScript-код, понятный браузерам. Установим следующие модули:
```
$ npm install @babel/core @babel/preset-env @babel/preset-react babel-loader css-loader file-loader mini-css-extract-plugin node-sass sass-loader style-loader url-loader webpack webpack-cli react react-dom react-router-dom video.js jquery bootstrap history popper.js
```
Добавим в проект, в его корневую директорию, конфигурационный файл для webpack (`webpack.config.js`):
```
const path = require('path');
const MiniCssExtractPlugin = require("mini-css-extract-plugin");
const devMode = process.env.NODE_ENV !== 'production';
const webpack = require('webpack');
module.exports = {
entry : './client/index.js',
output : {
filename : 'bundle.js',
path : path.resolve(__dirname, 'public')
},
module : {
rules : [
test: /\.s?[ac]ss$/,
use: [
MiniCssExtractPlugin.loader,
{ loader: 'css-loader', options: { url: false, sourceMap: true } },
{ loader: 'sass-loader', options: { sourceMap: true } }
],
},
test: /\.js$/,
exclude: /node_modules/,
use: "babel-loader"
},
test: /\.woff($|\?)|\.woff2($|\?)|\.ttf($|\?)|\.eot($|\?)|\.svg($|\?)/,
loader: 'url-loader'
},
test: /\.(png|jpg|gif)$/,
use: [{
loader: 'file-loader',
options: {
outputPath: '/',
},
}],
},
},
devtool: 'source-map',
plugins: [
new MiniCssExtractPlugin({
filename: "style.css"
}),
new webpack.ProvidePlugin({
$: 'jquery',
jQuery: 'jquery'
})
],
mode : devMode ? 'development' : 'production',
watch : devMode,
performance: {
hints: process.env.NODE_ENV === 'production' ? "warning" : false
},
};
```
Добавим в проект файл `client/index.js`:
```
import React from "react";
import ReactDOM from 'react-dom';
import {BrowserRouter} from 'react-router-dom';
import 'bootstrap';
require('./index.scss');
import Root from './components/Root.js';
if(document.getElementById('root')){
ReactDOM.render(
,
document.getElementById('root')
);
}
```
Вот содержимое файла `client/index.scss`:
```
@import '~bootstrap/dist/css/bootstrap.css';
@import '~video.js/dist/video-js.css';
@import url('https://fonts.googleapis.com/css?family=Dosis');
html,body{
font-family: 'Dosis', sans-serif;
}
```
Для маршрутизации используется react-router. Во фронтенде мы также используем bootstrap, и, для показа трансляций — video.js. Теперь добавим в папку `client` папку `components`, а в неё — файл `Root.js`. Вот содержимое файла `client/components/Root.js`:
```
import React from "react";
import {Router, Route} from 'react-router-dom';
import Navbar from './Navbar';
import LiveStreams from './LiveStreams';
import Settings from './Settings';
import VideoPlayer from './VideoPlayer';
const customHistory = require("history").createBrowserHistory();
export default class Root extends React.Component {
constructor(props){
super(props);
render(){
return (
(
)}/>
(
)}/>
(
)}/>
}
```
Компонент рендерит React, содержащий три субкомпонента . Компонент выводит список трансляций. Компонент отвечает за показ проигрывателя video.js. Компонент отвечает за создание интерфейса для работы со стриминговыми ключами.
Создадим компонент `client/components/LiveStreams.js`:
```
import React from 'react';
import axios from 'axios';
import {Link} from 'react-router-dom';
import './LiveStreams.scss';
import config from '../../server/config/default';
export default class Navbar extends React.Component {
constructor(props) {
super(props);
this.state = {
live_streams: []
componentDidMount() {
this.getLiveStreams();
getLiveStreams() {
axios.get('http://127.0.0.1:' + config.rtmp_server.http.port + '/api/streams')
.then(res => {
let streams = res.data;
if (typeof (streams['live'] !== 'undefined')) {
this.getStreamsInfo(streams['live']);
});
getStreamsInfo(live_streams) {
axios.get('/streams/info', {
params: {
streams: live_streams
}).then(res => {
this.setState({
live_streams: res.data
}, () => {
console.log(this.state);
});
});
render() {
let streams = this.state.live_streams.map((stream, index) => {
return (
LIVE

{stream.username}
);
});
return (
#### Live Streams
---
}
```
Вот как выглядит страница приложения.
*Фронтенд стримингового сервиса*
После монтирования компонента выполняется обращение к API NMS для получения списка подключённых к системе клиентов. API NMS выдаёт не особенно много сведений о пользователях. В частности, от него мы можем получить сведения о стриминговых ключах, посредством которых пользователи подключены к RTMP-серверу. Эти ключи мы будем использовать при формировании запросов к базе данных для получения сведений об учётных записях пользователей.
В методе `getStreamsInfo` мы выполняем XHR-запрос к `/streams/info`, но мы пока не создали то, что способно ответить на этот запрос. Создадим файл `server/routes/streams.js` со следующим содержимым:
```
const express = require('express'),
router = express.Router(),
User = require('../database/Schema').User;
router.get('/info',
require('connect-ensure-login').ensureLoggedIn(),
(req, res) => {
if(req.query.streams){
let streams = JSON.parse(req.query.streams);
let query = {$or: []};
for (let stream in streams) {
if (!streams.hasOwnProperty(stream)) continue;
query.$or.push({stream_key : stream});
User.find(query,(err, users) => {
if (err)
return;
if (users) {
res.json(users);
});
});
module.exports = router;
```
Мы передаём сведения о потоках, возвращённые API NMS, бэкенду, делая это для получения информации о подключённых клиентах.
Мы выполняем запрос к базе данных для получения списка пользователей, стриминговые ключи которых совпадают с теми, что мы получили от API NMS. Полученный список мы возвращаем в формате JSON. Зарегистрируем маршрут в файле `server/app.js`:
```
app.use('/streams', require('./routes/streams'));
```
В итоге мы выводим список активных трансляций. В этом списке присутствует имя пользователя и миниатюра. О том, как создавать миниатюры для трансляций, мы поговорим в конце материала. Миниатюры привязаны к конкретным страницам, на которых, с помощью video.js, проигрываются HLS-потоки.
Создадим компонент `client/components/VideoPlayer.js`:
```
import React from 'react';
import videojs from 'video.js'
import axios from 'axios';
import config from '../../server/config/default';
export default class VideoPlayer extends React.Component {
constructor(props) {
super(props);
this.state = {
stream: false,
videoJsOptions: null
componentDidMount() {
axios.get('/user', {
params: {
username: this.props.match.params.username
}).then(res => {
this.setState({
stream: true,
videoJsOptions: {
autoplay: false,
controls: true,
sources: [{
src: 'http://127.0.0.1:' + config.rtmp_server.http.port + '/live/' + res.data.stream_key + '/index.m3u8',
type: 'application/x-mpegURL'
}],
fluid: true,
}, () => {
this.player = videojs(this.videoNode, this.state.videoJsOptions, function onPlayerReady() {
console.log('onPlayerReady', this)
});
});
})
componentWillUnmount() {
if (this.player) {
this.player.dispose()
render() {
return (
{this.state.stream ? (
this.videoNode = node} className="video-js vjs-big-play-centered"/>
) : ' Loading ... '}
}
```
При монтировании компонента мы получаем стриминговый ключ пользователя для инициализации HLS-потока в проигрывателе video.js.
*Проигрыватель*
Выдача стриминговых ключей тем, кто собирается заниматься потоковой трансляцией
-------------------------------------------------------------------------------
Создадим файл компонента `client/components/Settings.js`:
```
import React from 'react';
import axios from 'axios';
export default class Navbar extends React.Component {
constructor(props){
super(props);
this.state = {
stream_key : ''
};
this.generateStreamKey = this.generateStreamKey.bind(this);
componentDidMount() {
this.getStreamKey();
generateStreamKey(e){
axios.post('/settings/stream_key')
.then(res => {
this.setState({
stream_key : res.data.stream_key
});
})
getStreamKey(){
axios.get('/settings/stream_key')
.then(res => {
this.setState({
stream_key : res.data.stream_key
});
})
render() {
return (
#### Streaming Key
---
#### How to Stream
---
You can use [OBS](https://obsproject.com/) or
[XSplit](https://www.xsplit.com/) to Live stream. If you're
using OBS, go to Settings > Stream and select Custom from service dropdown. Enter
**rtmp://127.0.0.1:1935/live** in server input field. Also, add your stream key.
Click apply to save.
}
```
В соответствии с локальной стратегией passport.js, мы, если пользователь успешно зарегистрировался, создаём для него новую учётную запись с уникальным стриминговым ключом. Если пользователь посетит маршрут `/settings` — он сможет увидеть свой ключ. При монтировании компонента мы выполняем XHR-запрос к бэкенду для выяснения существующего стримингового ключа пользователя и выводим его в компоненте .
Пользователь может сгенерировать новый ключ. Для этого нужно нажать на кнопку `Generate a new key`. Это действие вызывает выполнение XHR-запроса к серверу на создание нового ключа. Ключ создаётся, сохраняется и возвращается. Это позволяет показать новый ключ пользователю. Для того чтобы данный механизм заработал — нам нужно определить маршруты `GET` и `POST` для `/settings/stream_key`. Создадим файл `server/routes/settings.js` со следующим кодом:
```
const express = require('express'),
router = express.Router(),
User = require('../database/Schema').User,
shortid = require('shortid');
router.get('/stream_key',
require('connect-ensure-login').ensureLoggedIn(),
(req, res) => {
User.findOne({email: req.user.email}, (err, user) => {
if (!err) {
res.json({
stream_key: user.stream_key
})
});
});
router.post('/stream_key',
require('connect-ensure-login').ensureLoggedIn(),
(req, res) => {
User.findOneAndUpdate({
email: req.user.email
}, {
stream_key: shortid.generate()
}, {
upsert: true,
new: true,
}, (err, user) => {
if (!err) {
res.json({
stream_key: user.stream_key
})
});
});
module.exports = router;
```
Для генерирования уникальных строк мы используем модуль shortid.
Зарегистрируем новые маршруты в `server/app.js`:
```
app.use('/settings', require('./routes/settings'));
```
*Страница, которая позволяет стримерам работать со своими ключами*
Генерирование миниатюр для видеопотоков
---------------------------------------
В компоненте (`client/components/LiveStreams.js`) мы выводим миниатюры для транслируемых стримерами видеопотоков:
```
render() {
let streams = this.state.live_streams.map((stream, index) => {
return (
LIVE

{stream.username}
);
});
return (
#### Live Streams
---
{streams}
}
```
Миниатюры будем генерировать при подключении потока к серверу. Воспользуемся заданием cron, которое, каждые 5 секунд, создаёт новые миниатюры для транслируемых потоков.
Добавим следующий вспомогательный метод в `server/helpers/helpers.js`:
```
const spawn = require('child_process').spawn,
config = require('../config/default'),
cmd = config.rtmp_server.trans.ffmpeg;
const generateStreamThumbnail = (stream_key) => {
const args = [
'-y',
'-i', 'http://127.0.0.1:8888/live/'+stream_key+'/index.m3u8',
'-ss', '00:00:01',
'-vframes', '1',
'-vf', 'scale=-2:300',
'server/thumbnails/'+stream_key+'.png',
];
spawn(cmd, args, {
detached: true,
stdio: 'ignore'
}).unref();
};
module.exports = {
generateStreamThumbnail : generateStreamThumbnail
};
```
Мы передаём стриминговый ключ методу `generateStreamThumbnail`.
Он запускает отдельный ffmpeg-процесс, который создаёт изображение на основе HLS-потока. Этот вспомогательный метод будем вызывать в замыкании `prePublish` после проверки стримингового ключа (`server/media_server.js`):
```
nms.on('prePublish', async (id, StreamPath, args) => {
let stream_key = getStreamKeyFromStreamPath(StreamPath);
console.log('[NodeEvent on prePublish]', `id=${id} StreamPath=${StreamPath} args=${JSON.stringify(args)}`);
User.findOne({stream_key: stream_key}, (err, user) => {
if (!err) {
if (!user) {
let session = nms.getSession(id);
session.reject();
} else {
helpers.generateStreamThumbnail(stream_key);
});
});
```
Для того чтобы сгенерировать свежие миниатюры, мы запускаем задание cron и вызываем из него вышеописанный вспомогательный метод (`server/cron/thumbnails.js`):
```
const CronJob = require('cron').CronJob,
request = require('request'),
helpers = require('../helpers/helpers'),
config = require('../config/default'),
port = config.rtmp_server.http.port;
const job = new CronJob('*/5 * * * * *', function () {
request
.get('http://127.0.0.1:' + port + '/api/streams', function (error, response, body) {
let streams = JSON.parse(body);
if (typeof (streams['live'] !== undefined)) {
let live_streams = streams['live'];
for (let stream in live_streams) {
if (!live_streams.hasOwnProperty(stream)) continue;
helpers.generateStreamThumbnail(stream);
});
}, null, true);
module.exports = job;
```
Это задание будет выполняться каждые 5 секунд. Оно будет получать список активных потоков из API NMS и генерировать для каждого потока миниатюры с использованием стримингового ключа. Задание нужно импортировать в `server/app.js` и вызвать:
```
// Добавьте это в верхней части app.js,
const thumbnail_generator = require('./cron/thumbnails');
// Вызовите метод start() в конце файла
thumbnail_generator.start();
```
Итоги
-----
Только что мы завершили рассказ о разработке приложения, позволяющего организовывать потоковое вещание. Возможно, в ходе разбора кода некоторые фрагменты системы были незаслуженно забыты. Если вы столкнулись с чем-то непонятным — взгляните на [этот](https://github.com/waleedahmad/node-stream) репозиторий. Если вы найдёте в коде какую-нибудь ошибку — автор материала просит вас ему об этом сообщить.
[Вот](https://youtu.be/qY4XCkTqONw) демонстрация работы приложения.
**Уважаемые читатели!** Как вы подошли бы к разработке проекта, подобного тому, о котором шла речь в этом материале?
[](https://ruvds.com/news/read/104)
|
https://habr.com/ru/post/457860/
| null |
ru
| null |
# Почему в Python плохой ООП
В Python ужасный ООП. Кликбейтный тезис, который имеет право на существование. Есть много языков, где ООП представлен не в самом классическом виде, ну или так принято считать. Прототипные JavaScript и Lua, Golang с прикреплением методов и прочие. Но *«не такой как все»* всегда ли синоним слова *«неправильный»*? С чего мы вообще вязли, что ООП в Python не такой каким должен быть ООП? Что вообще является точкой отсчёта *«правильности»* ООП? Smalltalk или *Simula* 67? Вроде бы объектно-ориентированное программирование – это просто парадигма.. или уже догма?
В этом статье мы попробуем понять:
* что не так с ООП в Python;
* чем его ООП отличается от языков с эталонной по мнению многих реализацией ООП: Java, C# и С++;
* почему разработчики языка Python решили сделать всё именно так.
Реализует этот текст автор YouTube-канала [PyLounge](https://www.youtube.com/channel/UCru5FZQN_Xa0tKfrBqUIcng) Макс. Поехали!
> ***Дисклеймер****: В этой статье я хочу высказать свои "рассуждения на тему" и подчёркиваю, что не обладаю монополией на истину. Буду рад осудить альтернативное мнение в комментариях.*
>
>
Для начала необходимо понять. Чем ООП в Python отличается от классической концепции и реализации в других ЯП.
Парадигма ООП появилась ещё 60-70-х годах XX века. **ООП** или **Объектно-ориентированное программирование**— это методология программирования, которая основана представлении программы в виде набора взаимодействующих объектов, каждый из которых является экземпляром класса, а классы образуют иерархию наследования.
Ключевыми особенностями ООП является понятия:
* абстракция;
* инкапсуляция;
* наследование;
* полиморфизм.
Алан Кэй, создателя языка Smalltalk, одним из «отцов-основателей» ООП, говорил, что ООП подход заключается в следующем наборе принципов:
1. Всё является объектом.
2. Вычисления осуществляются путём взаимодействия (обмена данными) между объектами, при котором один объект требует, чтобы другой объект выполнил некоторое действие.
3. Каждый объект имеет независимую память, которая состоит из других объектов.
4. Каждый объект является представителем класса, который выражает общие свойства объектов (таких, как целые числа или списки).
5. В классе задаётся поведение (функциональность) объекта. Тем самым все объекты, которые являются экземплярами одного класса, могут выполнять одни и те же действия.
6. Классы организованы в единую древовидную структуру с общим корнем, называемую иерархией наследования. Память и поведение, связанное с экземплярами определённого класса, автоматически доступны любому классу, расположенному ниже в иерархическом дереве.
> *«ООП для меня означает лишь обмен сообщениями, локальное сохранение, и защита, и скрытие состояния, и крайне позднее связывание». (c) Алан Кэй*
>
>
Другими словами, в соответствии с идеями Алана Кэя, самыми важными ингредиентами ООП является:
1. Передача сообщений (то есть взаимодействие).
2. Инкапсуляция.
3. Динамическое связывание.
Интересно, что указывается именно термин *связывание*, а терминов *наследование* и *полиморфизм* нет. Ведь полиморфизм бывает *статический* (раннее связывание) – это перегрузки и дженерики (шаблоны). То есть Кэй, человек, который считается изобретателем термина *«ООП»* не считал важными частями ООП наследование и полиморфизм. Получается пропорции условны, а границы размыты.
Ключевая идея ООП состоит в том, чтобы *разделить проблему на подзадачи*, которые можно решить с помощью отдельных *объектов*, *взаимодействующих* друг с другом. Это означает, что они сохраняют свой статус внутри, и они связаны с определенным множеством функций (методов) для работы с внутренним статусом и для связи с другими объектами.
Все остальное же было определено, когда появились объектно-ориентированные языки. Языки OO были разработаны, чтобы упростить подход к программированию. И они реализовали инструменты и функции для поддержки ООП — классы были одним из таких инструментов.
Под **инкапсуляцией** стали подразумевать возможность классов содержать данные и методы в себе, которые непосредственно связаны с этим классом по смыслу. При этом одни языки соотносят инкапсуляцию с сокрытием этой информации, а другие (Smalltalk, Eiffel, OCaml) различают эти понятия.
Например, в *Java* можно определить поле как приватное, и тогда оно будет видно только членам этого класса. Также работает и *С++*, однако там есть концепция *друзей (friend)*, которые могут видеть приватные поля других классов, что сильно критикуется.
**Наследование** — свойство системы, позволяющее описать новый класс на основе уже существующего с частично или полностью заимствованной функциональностью.
Полиморфизм — это возможность обработки разных типов данных, т. е. принадлежащих к разным классам, с помощью *"одной и той же"* функции, или метода. На самом деле одинаковым является только имя метода, его исходный код зависит от класса. Поэтому в данном контексте под полиморфизмом понимается множество форм одного и того же слова – имени метода.
**Абстрагирование (абстракция данных)** означает выделение значимой информации и исключение из рассмотрения незначимой. В ООП рассматривают абстракцию данных, подразумевая набор наиболее значимых характеристик объекта, доступных остальной программе.
**Класс** — универсальный, комплексный тип данных, состоящий из тематически единого набора «полей» (переменных более элементарных типов) и «методов» (функций для работы с этими полями), то есть он является моделью информационной сущности с внутренним и внешним интерфейсами для оперирования своим содержимым (значениями полей).
В центре ООП находится понятие *объекта.* **Объект** — это сущность, которой можно посылать сообщения и которая может на них реагировать, используя свои данные. Объект — это экземпляр класса. Данные объекта содержатся в объекте, а не просто лежат внутри программы. Инкапсуляция включает в себя сокрытие (но им не является!).
ООП пытается сделать программное обеспечение похожим на *«реальный мир»*, как его может понять *обычный человек*.
Современная идея ООП — это синтез всех их идей, а также идей Голдберга, Барбары Лисков, Дэвида Парнаса, Бертрана Мейера, Гюля Ага и других. Но никто из них не может утверждать, что же такое *«ООП»*. Термины развиваются, как и задачи, которые изначально эти инструменты должны были решать.
А что же касаемо Python. Python полностью удовлетворяет всем перечисленным выше требования, а значит является *«полностью объектно-ориентированным»*. ООП – просто *стиль*.
Однако дополнительные фишки ООП, которые стали ассоциироваться с ООП за счёт их реализации в других объектных языках, несколько отличаются тем, как они реализованы в Python.
### Отсутствие модификаторов доступа
В Python отсутствует деление на публичные, защищённые, приватные свойства и методы. Многие вещи в Python основаны на соглашениях. Сокрытие данных реализуется чисто конвенционально. За счёт соглашения использовать подчёркивание у свойств и методов (защищённые члены). Да, можно использовать двойное подчёркивание, так называемый *манглинг*. Чисто технически это запрещает прямой доступ к данным и равносильно модификатору приват, но это скорее придуманный адептами классического ООП *«грязный хак»*. Таким образом, в Python нет классического разделения на группы доступа, потому что Python доверяет разработчику. В этом плане Python ближе к С++.

> *«Да, я знаю, что ты можешь выстрелить себе в ногу, но я верю, что ты этого не сделаешь. Ведь не даром ты столько узнал, прежде чем приступить к написанию кода». (с) Python*
>
>
Мне кажется, инкапсуляция не так полезна в языке с динамической типизацией. Выскажу непопулярное мнение – это не добавляет никакой безопасности, она просто дает ощущение безопасности. Если вы грамотный программист, то так или иначе сделаете всё как надо.
Но почему разработчики языка не добавили такой привычный *«предохранитель»*? Ответ кроется в философии Python. Гвидо не любит что-то скрывать. Как он выразился в одном интервью: *«мы все здесь взрослые по обоюдному согласию. Python доверяет вам. Он говорит: «Эй, если хочешь чтобы ковыряться в темных местах, я надеюсь, что у тебя есть уважительная причина, и вы не создаете проблем».* Этого тезиса мы ещё коснёмся ниже. Пока просто запомните.
Вообще инкапсуляция – это не совсем про сокрытие. Инкапсуляция определяется как *«процесс объединения элементов данных и функций в единое целое, называемое классом»* или *«отделение реализации от описания»*. Таким образом, номинально в Python всё соблюдается более чем верно.
### Отсутствие интерфейсов
В языке Python нет как таковой конструкции как интерфейс (*interface*). К слову в С++ их тоже нет. Но что в Python, что в С++, есть механизмы, позволяющие так или иначе использовать интерфейсы. **Абстрактные классы** – это хоть и немного другое, но функционалу отвечает и допускает некоторое упрощение концепции. На мой взгляд, отсутствие интерфейсов *искусственный механизм* избежания неоднозначности. *Вот у тебя есть абстрактные классы, вот их и используй*. С помощью абстрактных классов можно сделать всё тоже что и с интерфейсами, но не надо заморачиваться. Ведь Python идёт по пути простоты и убирает всё лишнее. Создатели языка даже конструкцию `switch case` выкинули, дабы *"место не занимала"*.
### Множественное наследование
Многие современные языки отказываются от множественного наследования, так как оно многое усложняет. Однако Python хоть и идёт по пути упрощения, но старается выкидывать избыточность, а не функциональность, ведь любое упрощение — это потеря гибкости + см. пункт про доверие своему разработчику. Python думает, что разработчик, который его использует достаточно умён, чтобы не плодить гигантскую иерархию и победить *проблему ромба*. Не доверился он разве что, при создании *GIL*. Но спишем это на ошибки молодости. Кстати, С++ также поддерживает множественное наследование. Так что с этим пунктом всё тоже в рамках закона.
### Утиная типизация
Она, конечно, к теме относится косвенно. Но, тем не менее, рядом с Python всегда всплывает понятие утиной типизации.
> *Если что-то выглядит как утка, плавает как утка и крякает как утка, это наверняка и есть утка.*
>
>
Утиная типизация заключается в том, что вместо проверки типа чего-либо в Python мы склонны проверять, какое поведение оно поддерживает, зачастую пытаясь использовать это поведение и перехватывая исключение, если оно не работает.
Тут во всей красе демонстрируется один из главных принципов *Дзена Python* — *«явное лучше, чем неявное*». Если что-то выглядит как утка и крякает, то это утка, к чему погружаться в экзистенциальные копания и вопросы самоопределения? Будь проще и посмотри пример.
Поскольку `Duck` и `Human` это разные классы, Python повторно вызывает функцию `fly_quack()` для экземпляра класса `Human`. И хотя класс `Human` имеет похожие методы `quack` и `fly` , типы объектов были разными и поэтому все работает правильно и вызываются верные методы.
### Константные методы
Нет способов предотвратить изменение состояния класса методами класса (константные методы), снова всё полагается на добрую волю программиста.
Вообще *докопаться* ещё можно много до чего. Например, не совсем стандартное описание *статических* методов и свойств, параметр *self*, *MRO* и многое многое другое.
Но Python отвечает всем требованиям парадигмы ООП. Просто многие моменты выполнены не так как у всех. Но на то есть причины. Гвидо ван Россум при разработке дизайна языка мотивировался выработанным им *Дзеном Python*, где простое лучше, чем сложное, явное лучше не явного и т.д. Через эту философию красной нитью проходит структура всего языка Python.
The Zen of PythonPython задуман как гибрид. Вы можете писать в объектно-ориентированном или функциональном стилях. Отличительными чертами объектной ориентации являются абстракция, инкапсуляция, наследование и полиморфизм. Что из этого отсутствует в Python?
По мнению многих *Smalltalk* — самый *чистый* ООП язык, но что даёт и какова цена этой чистоты? Можно написать очень хороший объектно-ориентированный код как на Smalltalk, так и на Python.
Python прагматичен. Вводятся концепции, представляющие ценность для разработчика, без особого внимания к теологическим концепциям, таким как *«правильный объектно-ориентированный дизайн»* и прочее. Это язык для людей, которые хотят сделать свою работу *быстро* и *просто*, а как там оно *«концептуально»* верно, отходит на второй план.
Есть языки, которые идут по одному из двух векторов развития: доверяют разработчику, дают средства и возможности, за что он может заплатить неправильностью своих решений. И языки, которые по максимуму всё запрещают, чтобы писать было *просто* и *топорно*. Все решения давно приняты за тебя, всем известно как делать правильно, например, *Golang*. С такой точки зрения *«Почти все «фичи» — это сахарная кола, а программирование — это толстяк с диабетом»»*.
Python старается оставаться максимально гибким и давать разработчику свободу действий, сохраняя максимум функционала. Потому Python использует отступы, динамически типизирован и имеет не самые очевидные идеи в дизайне ООП. Но глупо отрицать, что такая стратегия ***может*** привести к ***плохим*** решениям.
Python похож на ту маму, которая позволит вам тусоваться с плохими детьми поздно ночью, *если вы осознаете последствия*.
Он дает вам свободный доступ к свойствам класса, даже если они должны быть частными или константными, потому что вы уже *взрослый*.
Это извечная дилемма: что лучше авторитарная стабильность или нестабильная свобода? Каждый человек отвечает на этот вопрос сам. Так же, как и выбирает подходящий для себя инструмент – *язык программирования*.
ООП в Python не лучше и не хуже, чем в других языка. Он *другой*. Такой каким концептуально его видел главный разработчик языка Гвидо ван Россум. ООП в Python это часть Дзена Python. Философии, для которой язык и был разработан.
Проблема в том, что люди пытаются перенять подходы из других языков, а не учатся использовать уникальные *сильные стороны* Python. У Python довольно надежная объектная модель, но это объектная модель Python, а не C++, Java или…кого-то другого.
Не динамическая типизация, корявый ООП и большое количество библиотек порождают говонокод. Говнокод порождают люди. Люди, которых не интересуют инженерные практики, которые лезут в профессию исключительно за деньгами и не видят в программировании своего ремесла, и, безусловно, те люди, которых привлекает низкий порог вхождения.
А Python просто сейчас очень популярен. Он своего рода фронтмен, а тот кто на передовой, того обычно и критикуют. И да, я понимаю, что Python стремится быть как можно более простым, как завещал Эйнштейн: *«все должно быть настолько простым, насколько это возможно, но не проще»*. Однако иногда Python всё же попадает в это *«проще» чем надо*, что может выливаться в проблемы.
Python получает важные обновления по ходу *игры*, потому что изначально задумывался как простенький язык сценариев (а там чем меньше церемоний, тем лучше).
Дизайн языка потихоньку меняется. Аннотации типов, разного рода оптимизации говорят о том, что язык и сообщество взрослеют и зреют. Python со времён 2 версии уже сильно изменился и будет продолжать меняться. Как молодой бунтарь контркультуртурщик под призмой времени превращается в консерватора и прагматика, также и Python превратится просто в стабильный качественный инструмент. А на смену ему придёт новая рок-звезда, которая будет вертеть устои инженерной культуры и привлекать школьников.
То, что код превращается в беспорядок, — это ваша вина, а не вина языка. И именно таким и должен быть хороший язык: инструментом, помогающим решать ваши проблемы, а не диктатором, который покровительствует вам, что-то запрещает, командует вами.
Если мы напишем язык, который смогут использовать идиоты, в конце концов, только идиоты и будут его использовать. И да, это цена, которую придётся заплатить.
---
Закончу мысль довольно известной фразой: *«Есть всего два типа языков программирования: те, на которые люди всё время ругаются, и те, которые никто не использует»*.
|
https://habr.com/ru/post/698982/
| null |
ru
| null |
# App Engine API под капотом
*Этим топиком я хочу открыть серию переводов [блога Ника Джонсона](http://blog.notdot.net/). Ник публикует крайне полезные статьи по GAE, делится опытом, ставит необычные экспериметы. Надеюсь, эти материалы будут вам полезны.*
Если вы используете App Engine только для простых приложений, то лучше воздержаться от дальнейшего чтения. Если же вам интересны низкоуровневые оптимизации или вы хотите написать библиотеку для работы с самыми сокровенными компонентами App Engine, прошу читать далее!
### Общий API-интерфейс
В конечном счете, каждый API-вызов проходит через один общий интерфейс с 4-я аргументами: имя службы (например, 'datastore\_v3' или 'memcache'), имя метода (например, 'Get' или 'RunQuery'), запрос и ответ. Запрос и ответ являются [буферами протоколов](http://en.wikipedia.org/wiki/Protocol_buffer) — двоичным форматом, широко используемым в Google для обмена структурированными данными между процессами. Конкретный тип запроса и ответа буферов протокола зависит от вызванного метода. Когда происходит вызов API, буфер протокола запроса формируется из данных, отправленных в запросе, а буфер протокола ответа остается пустым и в дальнейшем заполняется данными, возвращенными ответом API-вызова.
Вызовы API осуществляются передачей четырех параметров, описанных выше, функции 'dispatch'. В Питоне эту роль выполняет модуль [apiproxy\_stub\_map](http://code.google.com/p/googleappengine/source/browse/trunk/python/google/appengine/api/apiproxy_stub_map.py). Этот модуль отвечает за поддержку соответствия между именем службы — первым из описанных параметров — и заглушки, ее обрабатывающей. В SDK это соответствие обеспечивается созданием локальных заглушек — модулей, имитирующих поведение API. В продакшене интерфейсы к реальным API передаются этому модулю во время старта приложения, т.е. еще до того, как загрузится код приложения. Программа, которая совершает API-вызовы, никогда не должна заботиться о реализации самих API; она не знает, как обрабатывается вызов: локально или же он был сериализирован и отправлен на другую машину.
Как только функция dispatch нашла соответствующую заглушку для вызванного API, она посылает к ней вызов. То, что происходит в дальнейшем, полностью зависит от API и среды окружения, но в продакшене в целом происходи следующее: запрос буфера протокола сериализируется в двоичные данные, который потом отправляется на сервер(ы), отвечающие за обработку данного API. Наприер, вызовы к хранилищу сериализируются и отправляются к службе хранилища. Эта служба десериализирует запрос, выполняет его, создает объект ответа, сериализирует его и отправляет той заглушке, что совершила вызов. Наконец, заглушка десериализирует ответ в ответ протокола буфера и возвращает значение.
Вы, должно быть, удивлены, почему необходимо обрабатывать ответ протокола буфера в каждом API-вызове. Это потому, что формат буферов протоколов не предоставляет какого-либо способа различить типы передаваемых данных; предполагается, что вы знаете структуру сообщения, которое планируете получить. Поэтому необходимо обеспечить «контейнер», который понимает, как десериализировать полученный ответ.
Рассмотрим на примере, как всё это работает, выполнив низкоуровневый запрос к хранилищу — получние экземпляра сущности по имени ключа:
> `1.
> 2. from google.appengine.datastore import datastore\_pb
> 3. from google.appengine.api import apiproxy\_stub\_map
> 4.
> 5. def do\_get():
> 6. request = datastore\_pb.GetRequest()
> 7. key = request.add\_key()
> 8. key.set\_app(os.environ['APPLICATION\_ID'])
> 9. pathel = key.mutable\_path().add\_element()
> 10. pathel.set\_type('TestKind')
> 11. pathel.set\_name('test')
> 12. response = datastore\_pb.GetResponse()
> 13. apiproxy\_stub\_map.MakeSyncCall('datastore\_v3', 'Get', request, response)
> 14. return str(response)
> 15.`
Очень досконально, не так ли? Особенно в сравнении с аналогичным высокоуровневым методом — TestKind.get\_by\_key\_name('test')! Вы должны понять всю последовательность действий: формирование запроса и ответа буферов протоколов, заполнение запроса соответствующей информацией (в данном случае — именем сущности и именем ключа), затем вызов apiproxy\_stub\_map.MakeSyncCall для создания удаленного объекта (RPC). Когда вызов завершается, заполняется ответ, что можно увидеть по его строковому отображению:
> `1.
> 2. Entity {
> 3. entity <
> 4. key <
> 5. app: "deferredtest"
> 6. path <
> 7. Element {
> 8. type: "TestKind"
> 9. name: "test"
> 10. }
> 11. >
> 12. >
> 13. entity\_group <
> 14. Element {
> 15. type: "TestKind"
> 16. name: "test"
> 17. }
> 18. >
> 19. property <
> 20. name: "test"
> 21. value <
> 22. stringValue: "foo"
> 23. >
> 24. multiple: false
> 25. >
> 26. >
> 27. }
> 28.`
Каждый удаленный вызов для каждого API использует внутри тот же самый паттерн — различаются только набор параметров в объектах запроса и ответа.
### Асинхронные вызовы
Описанный выше процесс относится к синхронному вызову API — то есть мы ждем ответа прежде чем можем делать что-либо дальше. Но платформа App Engine поддерживает асинхронные вызовы API. При асинхронных запросах мы посылаем вызов заглушке, который возвращается мгновенно, без ожидания ответа. Затем мы можем затребовать ответ позже (или подождать его, если нужно) или задать callback-функцию, которая будет автоматически вызвана, когда будет получен ответ.
На момент написания этой статьи только некоторые API поддерживают асинхронные вызовы, в частности, [URL fetch API](http://code.google.com/appengine/docs/python/urlfetch/asynchronousrequests.html), которые крайне полезены для извлечения нескольких веб-ресурсов параллельно. Принцип действия асинхронных API такой же, как и у обычных — он просто зависит от того, реализованы ли асинхронные вызовы в библиотеке. API вроде urlfetch адаптированы для асинхронных операций, но другие, более сложные API гораздо сложнее заставить работать асинхронно.
Рассмотрим на примере, как преобразовать синхронный вызов в асинхронный. Отличия от предыдущено примера выделены жирным:
> `1.
> 2. from google.appengine.datastore import datastore\_pb
> 3. from google.appengine.api import apiproxy\_stub\_map
> 4. **from google.appengine.api import datastore**
> 5.
> 6. def do\_**async**\_get():
> 7. request = datastore\_pb.GetRequest()
> 8. key = request.add\_key()
> 9. key.set\_app(os.environ['APPLICATION\_ID'])
> 10. pathel = key.mutable\_path().add\_element()
> 11. pathel.set\_type('TestKind')
> 12. pathel.set\_name('test')
> 13. response = datastore\_pb.GetResponse()
> 14.
> 15. **rpc = datastore.CreateRPC()**
> 16. **rpc.make\_call('Get', request, response)**
> 17. **return rpc, response**`
Отличия в том, что мы создаем RPC-объект для одного конкретного обращения к хранилищу и вызываем его метод make\_call(), вместо MakeSyncCall(). После чего возвращаем обект и ответ буфера протокола.
Поскольку это асинхронный вызов, он не был завершен, когда мы вернули RPC-объект. Есть несколько способов обработки асинхронного ответа. Например, можно передать callback-функцию в метод CreateRPC() или вызвать метод .check\_success() RPC-объекта, чтобы подождать, пока вызов будет завершен. Продемонстрируем последний вариант, так как его легче реализовать. Вот простой пример нашей функции:
> `1.
> 2. TestKind(key\_name='test', test='foo').put()
> 3. self.response.headers['Content-Type'] = 'text/plain'
> 4. rpc, response = do\_async\_get()
> 5. self.response.out.write("RPC status is %s\n" % rpc.state)
> 6. rpc.check\_success()
> 7. self.response.out.write("RPC status is %s\n" % rpc.state)
> 8. self.response.out.write(str(response))
> 9.`
Выходные данные:
> `1.
> 2. RPC status is 1
> 3. RPC status is 2
> 4. Entity {
> 5. entity <
> 6. key <
> 7. app: "deferredtest"
> 8. path <
> 9. Element {
> 10. type: "TestKind"
> 11. name: "test"
> 12. }
> 13. >
> 14. >
> 15. entity\_group <
> 16. Element {
> 17. type: "TestKind"
> 18. name: "test"
> 19. }
> 20. >
> 21. property <
> 22. name: "test"
> 23. value <
> 24. stringValue: "foo"
> 25. >
> 26. multiple: false
> 27. >
> 28. >
> 29. }
> 30.`
Константы статуса определены в модуле [google.appengine.api.apiproxy\_rpc](http://code.google.com/p/googleappengine/source/browse/trunk/python/google/appengine/api/apiproxy_rpc.py) — в нашем случае, 1 означает «выполняется», 2 — «закончен», из чего следует, что RPC действительно выполнен асинхронно! Фактический результат этого запроса, конечно, такой же, как и у обычного синхронного.
Теперь, когда вы знаете, как работает RPC на низком уровне и как выполнять асинхронные вызовы, ваши возможности как программиста сильно расширились. Кто первым напишет новый асинхронный интерфейс к API App Engine вроде Twisted?
|
https://habr.com/ru/post/110886/
| null |
ru
| null |
# Знакомимся с дата-ориентированным проектированием на примере Rust

### James McMurray
В этом посте мы исследуем основные концепции [«Data-Oriented Design»](https://en.wikipedia.org/wiki/Data-oriented_design) (далее «дата-ориентированное проектирование» на языке Rust.
Весь исходный код для этого поста [выложен на Github.](https://github.com/jamesmcm/data-oriented-example)
### Что такое дата-ориентированное проектирование?
Дата-ориентированное проектирование – это подход к оптимизации программ, предполагающий, что расположение структур данных в памяти должно тщательно оптимизироваться. Также требуется учитывать, как такой подход отражается на автоматической векторизации и использовании кэша ЦП. Настоятельно рекомендую посмотреть лекцию Майка Эктона [«Data-Oriented Design and C++»](https://www.youtube.com/watch?v=rX0ItVEVjHc), если вы ее еще не видели.
В этом посте будет рассмотрено 4 случая, и для бенчмаркинга будет применяться библиотека [criterion](https://docs.rs/criterion/0.3.3/criterion/). Эти случаи таковы:
* Структура массивов и массив структур – в чем разница;
* Цена ветвления внутри горячего цикла;
* Сравнение связного списка и перебора вектора;
* Сравнение цены динамической диспетчеризации и мономорфизации.
### Структура массивов и массив структур
В примере со [структурой массивов и массивом структур](https://en.wikipedia.org/wiki/AoS_and_SoA) мы говорим о двух контрастных способов организации данных объекта, над которыми будут производиться операции.
Представьте, например, что мы пишем видеоигру и хотели бы иметь структуру Player со следующими полями:
```
pub struct Player {
name: String,
health: f64,
location: (f64, f64),
velocity: (f64, f64),
acceleration: (f64, f64),
}
```
Тогда в каждом кадре мы собираемся обновлять положения и скорости каждого из Players. Можно было бы написать нечто подобное:
```
pub fn run_oop(players: &mut Vec) {
for player in players.iter\_mut() {
player.location = (
player.location.0 + player.velocity.0,
player.location.1 + player.velocity.1,
);
player.velocity = (
player.velocity.0 + player.acceleration.0,
player.velocity.1 + player.acceleration.1,
);
}
}
```
Это был бы обычный объектно-ориентированный подход к данной задаче. Проблема в том, что в памяти структуры хранятся следующим образом (предполагается, что не происходит никакого переупорядочивания полей, т. е. #[repr©]), в 64-разрядной архитектуре в каждом поле будет по 64 бита (8 байт, так что у каждого Player 64 байт):
```
-- Vec
name (pointer to heap) -- Player 1
health
location0 (tuple split for clarity)
location1
velocity0
velocity1
acceleration0
acceleration1
name (pointer to heap) -- Player 2
location0
location1
velocity0
velocity1
acceleration0
acceleration1
...
```
Обратите внимание: те части кода, которыми мы собираемся оперировать (позиции, скорости и ускорения) для различных игроков не хранятся одним непрерывным куском. Это не позволяет нам воспользоваться векторными операциями при обращении с несколькими игроками одновременно (поскольку они не могут в одно и то же время быть загружены в одну кэш-линию ЦП, ведь ее обычный размер составляет около 64 байт).
Напротив, дата-ориентированный метод предполагает проектирование в обход данного ограничения и оптимизацию с упором на автовекторизацию. Вместо того, чтобы использовать по структуре на игрока, мы применяем одну структуру на всех игроков, и значения для каждого игрока будут храниться по соответствующему индексу в отдельном атрибуте Vectors:
```
pub struct DOPlayers {
names: Vec,
health: Vec,
locations: Vec<(f64, f64)>,
velocities: Vec<(f64, f64)>,
acceleration: Vec<(f64, f64)>,
}
```
Теперь можно сделать те же вычисления, как и при ООП-подходе, вот так:
```
pub fn run_dop(world: &mut DOPlayers) {
for (pos, (vel, acc)) in world
.locations
.iter_mut()
.zip(world.velocities.iter_mut().zip(world.acceleration.iter()))
{
*pos = (pos.0 + vel.0, pos.1 + vel.1);
*vel = (vel.0 + acc.0, vel.1 + acc.1);
}
}
```
В данном случае имеем такую компоновку в памяти:
```
-- DOPlayers
name1 -- names
name2
...
health1 -- health
health2
...
location1 -- locations
location2
...
```
Теперь все релевантные поля сохранены сплошным куском. Учитывая, что размер каждого кортежа местоположений составит 16 байт, теперь вполне реально загрузить 4 таких кортежа в одну и ту же кэш-линию, чтобы оперировать ими одновременно при помощи ОКМД-команд.
### Бенчмарк
Вот результаты бенчмарка для библиотеки criterion в вышеприведенном коде (полный код и код бенчмарка доступны в [репозитории Github](https://github.com/jamesmcm/data-oriented-example)):

Вообще, как видим, при помощи дата-ориентированного подхода мы смогли управиться за половину времени. Вероятно, дело в том, что в дата-ориентированном случае мы оперируем над двумя игроками одновременно – если хочется в этом убедиться, можно просто посмотреть скомпилированный ассемблерный код.
Просматривая [вывод в Godbolt](https://godbolt.org/z/d8bjMb), видим следующее:
```
// Релевантный цикл в ООП
.LBB0_2:
movupd xmm0, xmmword ptr [rax + rdx + 32]
movupd xmm1, xmmword ptr [rax + rdx + 48]
movupd xmm2, xmmword ptr [rax + rdx + 64]
addpd xmm0, xmm1
movupd xmmword ptr [rax + rdx + 32], xmm0
addpd xmm2, xmm1
movupd xmmword ptr [rax + rdx + 48], xmm2
add rdx, 80
cmp rcx, rdx
jne .LBB0_2
// ...
// Релевантный цикл в ДОП
.LBB1_7:
movupd xmm0, xmmword ptr [rcx + rdx - 16]
movupd xmm1, xmmword ptr [rax + rdx - 16]
addpd xmm1, xmm0
movupd xmmword ptr [rcx + rdx - 16], xmm1
movupd xmm0, xmmword ptr [r9 + rdx - 16]
movupd xmm1, xmmword ptr [rax + rdx - 16]
addpd xmm1, xmm0
movupd xmm0, xmmword ptr [rax + rdx]
movupd xmmword ptr [rax + rdx - 16], xmm1
add rdi, 2
movupd xmm1, xmmword ptr [rcx + rdx]
addpd xmm1, xmm0
movupd xmmword ptr [rcx + rdx], xmm1
movupd xmm0, xmmword ptr [rax + rdx]
movupd xmm1, xmmword ptr [r9 + rdx]
addpd xmm1, xmm0
movupd xmmword ptr [rax + rdx], xmm1
add rdx, 32
cmp rsi, rdi
jne .LBB1_7
test r8, r8
je .LBB1_5
```
Как видим, в дата-ориентированном случае цикл разматывается так, чтобы оперировать двумя элементами одновременно – благодаря чему достигается общее 50%-е ускорение кода!
**Авторское дополнение:** как было отмечено в [/u/five9a2 на Reddit](https://www.reddit.com/r/rust/comments/hxqwom/an_introduction_to_data_oriented_design_with_rust/fz8lxcq/), вышеприведенный вывод специфичен для цели, заданной по умолчанию – и это сбивает, поскольку cargo bench по умолчанию использует нативную цель (т. e., все возможные фичи нашего ЦП), так что в бенчмарках не применяется вышеуказанный ассемблерный код.
Установив флаг компилятора в значение `-C target-cpu=skylake-avx512`, чтобы активировать возможности Skylake, получим [следующий вывод](https://godbolt.org/z/PEPdvn):
```
// ООП-цикл
.LBB0_2:
vmovupd ymm0, ymmword ptr [rax + rdx + 32]
vaddpd ymm0, ymm0, ymmword ptr [rax + rdx + 48]
vmovupd ymmword ptr [rax + rdx + 32], ymm0
add rdx, 80
cmp rcx, rdx
jne .LBB0_2
...
// ДОП-цикл
.LBB1_19:
vmovupd zmm0, zmmword ptr [rsi + 4*rax - 64]
vaddpd zmm0, zmm0, zmmword ptr [rcx + 4*rax - 64]
vmovupd zmmword ptr [rsi + 4*rax - 64], zmm0
vmovupd zmm0, zmmword ptr [rcx + 4*rax - 64]
vaddpd zmm0, zmm0, zmmword ptr [r10 + 4*rax - 64]
vmovupd zmmword ptr [rcx + 4*rax - 64], zmm0
vmovupd zmm0, zmmword ptr [rsi + 4*rax]
vaddpd zmm0, zmm0, zmmword ptr [rcx + 4*rax]
vmovupd zmmword ptr [rsi + 4*rax], zmm0
vmovupd zmm0, zmmword ptr [rcx + 4*rax]
vaddpd zmm0, zmm0, zmmword ptr [r10 + 4*rax]
vmovupd zmmword ptr [rcx + 4*rax], zmm0
add r11, 8
add rax, 32
add rdi, 2
jne .LBB1_19
test r9, r9
je .LBB1_22
```
Здесь видим, что ООП-цикл использует 256-разрядные регистры ymm, в одном из которых размещает кортеж положений и кортеж скорости, а в другом – кортеж скорости и кортеж ускорения. Это возможно сделать, поскольку они смежны в памяти (благодаря тому, как именно упорядочены поля). В ДОП-цикле используется 512-разрядный регистр zmm.
Может показаться, что разница в производительности обусловлена тем, что полоса передачи данных на разных уровнях кэша отличается, ведь для маленьких примеров производительность идентична. Это можно лишний раз продемонстрировать, удалив из структуры лишние поля – в таком случае будем наблюдать разницу производительности лишь 25% ([ссылка на godbolt](https://godbolt.org/z/Th91Wa)), и это означает, что структура Player в данном случае занимает 384 разряда (следовательно, 1/4 из 512 разрядов на чтение/запись остаются неиспользованными).
Здесь стоит акцентировать, насколько важно учитывать, для какой целевой платформы развертывается приложение, и, если развертывается критичный по производительности код – попробовать явно задать target-cpu, чтобы воспользоваться всеми его возможностями.
Также здесь демонстрируется, насколько важным с точки зрения производительности может быть порядок полей. По умолчанию Rust переупорядочивает поля автоматически, но, чтобы этого не происходило, можно установить `#[repr(C)]` (например, это необходимо для интероперабельности с C).
### Итог примера
В этом примере продемонстрировано, насколько важно учитывать компоновку данных в памяти, если требуется высокопроизводительный код и автоматическая векторизация.
Обратите внимание: та же логика применима к работе с массивами структур – если вы уменьшите вашу структуру, то сможете загрузить больше элементов в одну и ту же кэш-линию, что может поспособствовать автовекторизации. [Вот пример](https://github.com/Rene-007/flake_growth/blob/master/src/helpers.rs) контейнера (которым поделились в одном [подреддите по Rust](https://www.reddit.com/r/rust/comments/hmqjvs/growing_gold_with_rust/)), производительность которого удалось повысить на 40%, ограничившись лишь этой операцией.
Данная конкретная реорганизация прямо перекликается с проектированием баз данных. Серьезное отличие между базами данных, приспособленными для транзакционных (OLTP) и аналитических (OLAP) рабочих нагрузок заключается в том, что при вторых данные, как правило, хранятся в колоночном виде. Как и в случае, рассмотренном выше, это означает: при операциях над столбцами можно выгодно пользоваться областями сплошного хранения данных, а также векторными операциями, и такой паттерн доступа является основным для аналитических рабочих нагрузок (например, если нужно рассчитать средний размер покупки по всем строкам, а не обновлять и не извлекать цельные конкретные строки).
На самом деле, в случае с аналитическими базами данных мы здесь выигрываем вдвойне, поскольку такой подход применим и к сериализации данных при записи их на диск. Ведь в данном случае можно осуществлять сжатие данных по столбцам (в одном столбце все данные гарантированно будут относиться к одному и тому же типу), благодаря чему можно добиться гораздо более выгодных коэффициентов сжатия.
Если вы занимаетесь решением задачи, в которой может быть полезен подход со «структурой массивов» – и хотите прогнать быстрый бенчмарк – то вас может заинтересовать контейнер [soa-derive](https://github.com/lumol-org/soa-derive), позволяющий произвести структуру массивов из имеющейся у вас структуры.
### Ветвление в горячем цикле
Другая тактика оптимизации – избегать ветвления в любых «горячих» частях кода (то есть, в участках кода, каждый из которых будет выполняться много-много раз).
Ветвление может возникать довольно неожиданным образом – например, при попытке использовать одну и ту же структуру во множестве разных случаев. Например, можно следующим образом определить некоторый общий тип Node:
```
enum NodeType {
Player,
PhysicsObject,
Script,
}
struct Node {
node_type: NodeType,
position: (f64, f64),
// ...
}
```
А затем выполнить сопоставление по шаблону с `node_type`, когда требуется произвести операцию над Node. Проблемы начинаются, когда у нас возникает Vec с десятками тысяч элементов, и оперировать этими элементами нам требуется в каждом кадре. Задействуя тип `node.node_type`, чтобы решать, какой логикой воспользоваться, необходимо выполнять такую проверку для каждого элемента (поскольку порядок экземпляров `node_type` внутри `Vec` неизвестен).
Это сравнение не только означает, должны проводить дополнительную операцию сравнения для каждого элемента, но и препятствует автовекторизации, поскольку релевантные узлы (относящиеся все к тому же типу `node_type`) могут храниться в памяти не сплошным куском.
При дата-ориентированном подходе требуется разделить эти узлы по `node_type`. В идеале нужно создать отдельную структуру на каждый тип узла, или, как минимум, развести их по отдельным векторам до входа в горячий цикл. Таким образом, нам не потребуется проверять `node_type` в горячем цикле, а также нам на руку может сыграть расположение узлов, которыми мы оперируем: они будут в одном непрерывном блоке памяти.
### Бенчмарк
В рамках данного бенчмарка используется следующий код:
```
#[derive(Copy, Clone)]
pub struct Foo {
x: i32,
calc_type: CalcType,
}
#[derive(Copy, Clone)]
pub enum CalcType {
Identity,
Square,
Cube,
}
// ...
pub fn run_mixed(x: &[Foo]) -> Vec {
x.into\_iter()
.map(|x| match x.calc\_type {
CalcType::Identity => x.x,
CalcType::Square => x.x \* x.x,
CalcType::Cube => x.x \* x.x \* x.x,
})
.collect()
}
pub fn run\_separate(x: &[Foo], y: &[Foo], z: &[Foo]) -> (Vec, Vec, Vec) {
let x = x.into\_iter().map(|x| x.x).collect();
let y = y.into\_iter().map(|x| x.x \* x.x).collect();
let z = z.into\_iter().map(|x| x.x \* x.x \* x.x).collect();
(x, y, z)
}
```
Сравниваем два случая: смешанный вектор Foos и отдельный вектор Foos, разделенный split by `calc_type`.
Результаты бенчмарка таковы:
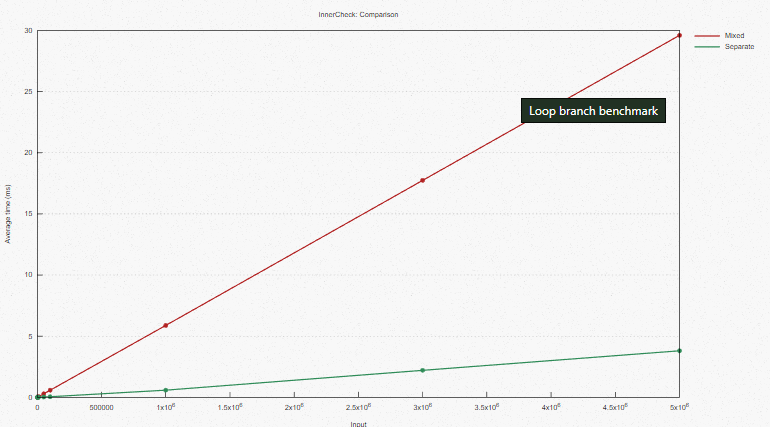
Overall, we see that the data-oriented approach finishes in about a quarter of the time.
На этот раз [вывод в Godbolt](https://godbolt.org/z/6ocTx8) получился не таким ясным, но здесь явно заметна некоторая размотка цикла в случае с отдельными Foo, а в случае со смешанными Foo она невозможна, поскольку в смешанном случае требовалось бы проверять `calc_type`.
### Итог примера
Вам должна быть знакома концепция, при которой из горячих циклов выводятся все инструкции, какие возможно. Но этот пример также демонстрирует, как такой подход может повлиять на векторизацию.
### Косвенность: перебор в связном списке
В данном примере сравнивается перебор (двойного) связного списка и работа с вектором. Этот случай хорошо известен и упоминается, например, [в документации Rust по связным спискам](https://doc.rust-lang.org/beta/std/collections/struct.LinkedList.html), [документации Rust по std::collections](https://doc.rust-lang.org/beta/std/collections/index.html#use-a-linkedlist-when) и в объявлении [Learn Rust With Entirely Too Many Linked Lists’ Public Service Announcement](https://rust-unofficial.github.io/too-many-lists/#an-obligatory-public-service-announcement). В последнем документе освещено множество случаев, в которых принято использовать связные списки, поэтому рекомендую прочитать его, если вы еще не успели. Тем не менее, поверьте моему опыту, лучше посмотреть сам бенчмарк.
В связном списке элементы хранятся *косвенно*. То есть, элемент хранится вместе с указателем на следующий элемент. Таким образом, элементы, последовательно расположенные в связном списке, *не* хранятся в последовательных участках памяти.
Это приводит нас к двум факторам, осложняющим векторизацию:
* Элементы связного списка могут быть сохранены в произвольном порядке, далеко друг от друга. Поэтому мы не сможем просто загрузить в кэш ЦП блок памяти, чтобы оперировать всеми этими элементами одновременно.
* Чтобы получить следующий элемент списка, требуется разыменовать указатель на него.
Например, можно следующим образом сохранить в куче вектор из i32 (удерживая в стеке указатель на начало вектора, емкость вектора и длину вектора):
```
0x00 1
0x01 2
0x02 3
...
```
Значения хранятся сплошным куском, тогда как для (одно)связного списка у нас мог бы сложиться следующий случай.
```
0x00 1
0x01 0x14
0x0C 3
0x0D 0
...
0x14 2
0x15 0x0C
```
Здесь значения не хранятся в непрерывном участке в памяти (более того, их порядок может не совпадать с тем, в котором расположены в списке указатели на них).
### Бенчмарк
В данном случае бенчмарк очень прост: мы просто возводим в квадрат все элементы связного списка и вектора:
```
pub fn run_list(list: &mut LinkedList) {
list.iter\_mut().for\_each(|x| {
\*x = \*x \* \*x;
});
}
pub fn run\_vec(list: &mut Vec) {
list.iter\_mut().for\_each(|x| {
\*x = \*x \* \*x;
});
}
```
Результаты таковы:

В целом видим, что при дата-ориентированном подходе нам требуется вдесятеро меньше времени, чем при объектно-ориентированном.
[Вывод в Godbolt](https://godbolt.org/z/EzznM1) показывает в случае с Vec такую размотку, которая невозможна в случае с LinkedList.
### Итог примера
Этот случай хорошо известен, и в нем наблюдается наибольшая разница между двумя бенчмарками. Обратите внимание: здесь мы оцениваем только перебор, а не другие операции, которые смотрелись бы несколько лучше именно в случае связного списка. Такова, например, вставка, при которой в связном списке избегаются (амортизированные) издержки на изменение размера вектора. Правда, как утверждается в [Learn Rust With Entirely Too Many Linked Lists](https://rust-unofficial.github.io/too-many-lists/#i-cant-afford-amortization), этого можно избежать и при работе с векторами.
Надеюсь, этот момент станет общеизвестным, и на собеседованиях станет поменьше вопросов и практических задач на связные списки и косвенность, ведь они учитывают только сложность задачи по «Big O», а не реальную производительность.
### Косвенность: сравнение динамической диспетчеризации и мономорфизации
Когда мы пишем обобщенные функции (например, для любых типов, реализующих определенные типажи), у нас есть выбор между [динамической диспетчеризацией](https://doc.rust-lang.org/book/ch17-02-trait-objects.html) и мономорфизацией.
Динамическая диспетчеризация позволяет работать со смешанной коллекцией объектов-типажей. То есть, у нас может быть `Vec>`, в котором могут содержаться ссылки на различные типы, и все эти типы реализуют MyTrait. Объект-типаж содержит указатель на экземпляр структуры как таковой (реализующей MyTrait) и указатель на таблицу виртуальных методов структуры (она же vtable, таблица поиска, указывающая на реализацию каждого метода в MyTrait). Затем, когда мы вызываем метод в одном из этих объектов-типажей, во время выполнения выясняется, какую именно реализацию метода мы будем использовать, и эта реализация подыскивается в vtable.
Обратите внимание: это приводит нас к косвенности. Наш вектор должен состоять из указателей на сами экземпляры структуры (поскольку разные структуры, реализующие MyTrait, могут отличаться как по размеру, так и по полям). Также нам приходится разыменовывать указатель в vtable, чтобы выяснить, какую реализацию вызывать.
В свою очередь, мономорфизация – это создание отдельной реализации обобщенной функции на каждый возможный тип. Например, в следующем коде фактически создается две отдельные функции для `run_vecs_square():` для типов `Foo` и `Bar` соответственно:
```
pub struct Foo {
id: usize,
}
pub struct Bar {
id: usize,
}
pub trait MyTrait {
fn square_id(&mut self);
}
impl MyTrait for Foo {
fn square_id(&mut self) {
self.id = self.id * self.id;
}
}
impl MyTrait for Bar {
fn square_id(&mut self) {
self.id = self.id * self.id * self.id;
}
}
pub fn run_vecs_square(x: &mut Vec) {
x.iter\_mut().for\_each(|x| x.square\_id())
}
```
В результате увеличивается размер двоичного файла, зато нам становится просто генерировать множественные реализации функции для разных типов, а также избегать косвенности (например, обратите внимание: можно использовать `Vec и при этом обходиться без `Vec>)`.
А вот в следующем коде используется динамическая диспетчеризация. Там всего одна реализация `run_dyn_square`, но, какую именно реализацию `square_id()` следует вызывать – определяется во время исполнения, по итогам сверки с таблицей vtable объекта-типажа.
```
pub fn run_dyn_square(x: &mut Vec>) {
x.iter\_mut().for\_each(|x| x.square\_id())
}
```
Так может быть удобнее, поскольку мы создаем вектор, содержащий ссылки на различные типы – и можем не беспокоиться, каковы именно конкретные типы (нам важно лишь то, что они реализуют MyTrait), поэтому и двоичный файл у нас не разбухает. Правда, мы вынуждены прибегать к косвенности, поскольку у базовых типов могут быть разные размеры – а, как мы видели в примере с LinkedList, это может существенным образом сказываться на автовекторизации.
### Бенчмарк
При прогоне вышеприведенного примера бенчмарк выглядит так:
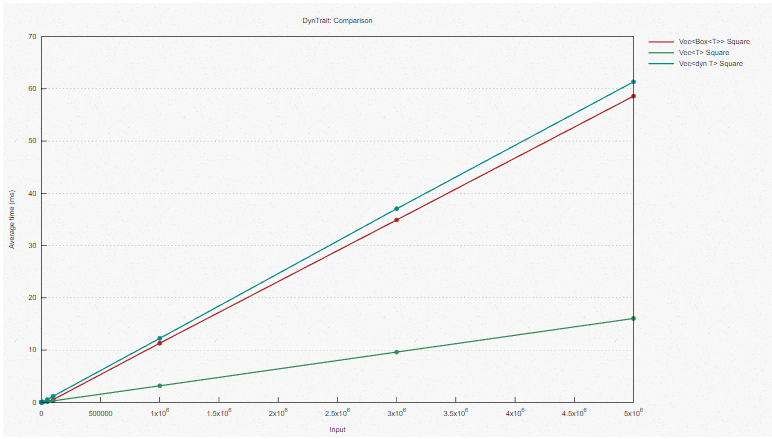
В целом видим, что на выполнение мономорфизированного примера нужно примерно вчетверо меньше времени, чем на вариант с динамической диспетчеризацией. Мономорфизированный случай с применением косвенности (`Vec>`) только чуть-чуть быстрее случая с динамической диспетчеризацией, и именно дополнительной косвенностью обусловлен в основном провал производительности – ведь косвенность мешает векторизации. В свою очередь, при поиске в vtable добавляются лишь небольшие издержки, и они постоянны.
К сожалению, в данном случае [Godbolt](https://godbolt.org/z/46WYaP) не включает в сгенерированный вывод целевые функции.
### Итог примера
Этот бенчмарк показывает, что основные издержки динамической диспетчеризации связаны с осложнением векторизации, так как такой подход обязательно требует косвенности. А издержки на поиск в таблице vtable относительно невелики.
Таким образом, определенно попробуйте проектировать с прицелом на мономорфизацию, если операции ваших методов именно таковы, что им сильно пошла бы на пользу векторизация (как, например, математические операции, показанные выше). С другой стороны, если нужно выполнять операции, которые не векторизуются (например, составлять строки), то издержки на динамическую диспетчеризацию могут в целом оказаться пренебрежимыми.
Как всегда, расставляйте бенчмарки для конкретных практических случаев и паттернов доступа, когда сравниваете различные возможные реализации.
### Заключение
В этой статье было рассмотрено четыре случая, в которых при учете расположения данных в памяти, а также реального состояния и слабых сторон кэша ЦП удалось существенно повысить производительность.
Здесь мы только слегка копнули дата-ориентированное проектирование и оптимизацию. В частности, не были затронуты вопросы [упаковки структур](http://www.catb.org/esr/structure-packing/), [расстановки отступов и выравнивания](https://www.dataorienteddesign.com/dodbook/). Книга Ричарда Фабиана о дата-ориентированном проектировании также освещает некоторые дополнительные темы.
Важно отметить, что во всех рассмотренных здесь примерах мы не дорабатывали алгоритмов, которыми пользовались. У всех реализаций на все случаи была одинаковая алгоритмическая сложность по Big O, но на практике их производительность может быть ускорена в 2-10 раз – благодаря несложной оптимизации, рассчитанной только на векторизацию и другие возможности современных ЦП.
Резюме:
* Предпочитайте структуры данных, в которых косвенности нет или почти нет, а также такие, которые хранят данные в памяти сплошными кусками (также вам будет проще справиться с проверкой заимствования переменных!).
* Избегайте ветвления внутри циклов.
* Расставляйте бенчмарки для конкретных случаев использования и паттернов доступа.
* При развертывании кода, производительность которого критична, старайтесь нацеливаться на сильные стороны именно того ЦП, что установлен на машине назначения (напр. [используйте RUSTFLAGS](https://rust-lang.github.io/packed_simd/perf-guide/target-feature/rustflags.html)).
* [Criterion](https://github.com/bheisler/criterion.rs) – отличный инструмент для бенчмаркинга.
* [cargo-asm](https://github.com/gnzlbg/cargo-asm) и [Godbolt](https://godbolt.org/) отлично подходят для изучения сгенерированного ассемблерного кода (и промежуточного представления LLVM).
* Для профилирования производительности можно воспользоваться [perf](https://rust-lang.github.io/packed_simd/perf-guide/prof/linux.html) и [flamegraph](https://github.com/flamegraph-rs/flamegraph).
[](https://cloud.timeweb.com/vds-vps?utm_source=habr&utm_medium=banner&utm_campaign=vds-promo-6-rub)`
|
https://habr.com/ru/post/683386/
| null |
ru
| null |
# Электронный замок с беспроводным управлением на базе Energia Launchpad

Глядя на множество хабро-статей на базе Arduino мне показалось несколько странным отсутствие интересных беспроводных решений из мира Energia Launchpad. Пора исправить эту вселенскую несправедливость!
Сегодня я познакомлю вас с отладочной платой CC3200-launchpad, расскажу об ее преимуществах перед ESP8266, подключу к ней пару launchpad по радиоканалу и буду щелкать большими советскими релюхами. Поехали!
#### **CC3200-LAUNCHXL Ланчпад с большой буквы**
Сегодняшний рассказ я начну с микроконтроллера CC3200[1] от Texas Instruments.
Этот контроллер представляет собой симбиоз ядра TIVA-C Cortex-M4 и Simplelink Wi-Fi процессора CC3100 в одном корпусе

*Рисунок 1: Структурная схема контроллера*
Немного о приятных и интересных свойствах данного камня, применимо к встраиваемым микромощным решениям[2]:
1. 80МГц ядро Cortex-M4;
2. ОЗУ 256Кбайт;
3. Драйвера периферии в ПЗУ, отсутствует встроенная Flash память программ;
4. Поддержка внешней микросхемы Serial Flash памяти — вешай сколько хочется;
5. Аппаратное шифрование AES, DES, SHA2, MD5, CRC;
6. 2xI2S, 1xSD-card, 2xUART, 1xSPI, 1x2C, 8-разрядный интерфейс камеры;
7. 4 таймера с 16-бит ШИМ;
8. 4 канала 12-разрядного АЦП
9. Сертифицированный 802.11g/b/n Wi-Fi модуль с поддержкой шифрования WEP, WPA2-PSK и WPA-Enterprise. Работа как в режиме устройства, так и в режиме хоста
10. 256-bit AES для SSLv3 и TSLv1. Да-да, он тащит SSL!
11. Микромощное потребление и множество режимов управления питанием
##### **CC3200 vs ESP8266**
С одной стороны ESP8266 обладает следующими преимуществами:
Во-первых, он очень маленький и интегрированный — хренька размером и стоимостью с монетку требует лишь пару батареек питания и ее уже можно втыкать в утюг или чайник.
Во-вторых, у него хорошо проработаны режимы питания — если подойти с умом, то получается диетический продукт.
В-третьих, у него простой старт — достаточно подключить его к компьютеру, открыть среду Arduino и можно работать.
С другой стороны, CC3200 — мощный процессор, способный держать в себе множество активных задач. Кроме того, у него намного более богатая периферия — хочешь — подключай камеру, хочешь аудиоустройства(по I2S) или SD-карту. Хочешь — еще с десяток всякой всячины навешай — выдержит и железо и прошивка. Ну и конечно же SSL. Здесь мой маленький параноик просто ликует от счастья.
Но тут же просыпается жаба и начинает душить вашего покорного слугу — ланчпад у производителя стоит 30 баксов/штука. В РФ есть шанс купить за 40-50 долларов+доставка. Бесплатная доставка у TI кончилась.
В любом случае, у каждого варианта своя ниша использования.
##### **CC3200-LAUNCHXL Быстрый старт[3]**

*Рисунок 2: комплектация*
Как и подобается любому ланчпаду, CC3200 приходит в аккуратной картонной коробке с базовой комплектацией — сама плата, шнур micro-USB, пара джамперов и пара буклетов.
Плата — типичный представитель 40-контактных launchpad, несет на себе сам контроллер CC3200 в 64-ногом корпусе QFN. Не самый страшный корпус для ручной пайки. Также, на плате имеется программатор на базе FT2232 чипа(официальная поддержка openOCD). Микросхема Flash памяти на 8Мбит данных.
Отдельно стоит упомянуть трехосевой +-16G акселерометр BMA222[4] и бесконтактный ИК датчик температуры TMP006[5]

*Рисунок 3: ланчпад в деталях*
Одним словом — все что нужно растущему разработчику IoT.
Подключим плату к питанию изучим имеющуюся на нем демо-прошивку.
Прошивка предлагает немного датащитов, и 4 микродемки. И все это в режиме точки доступа, с http сервером на борту.
Дабы не быть многословным, небольшой видеообзор:
##### **CC3200 SDK[6]**
С помощью CCS UniFlash[7] обновим наш SDK.

*Рисунок 4: CCS UniFlash внешний вид*
Для начала, плату необходимо перевести в режим программирования Flash, для чего замкнуть пины 2 разъема SOP. После этого, подключаемся к UART порту, форматируем Flash память по объем 1Мбайт. После чего указываем путь к нашему ServicePack. на момент написания статьи актуальный Service Pack: 1.0.0.10.0, SDK: 1.1.0.
##### **Программирование в среде Code Composer Studio 6.0.1[8]**
Для больших проектов и нормальной отладки идеальным вариантом является разработка программ в среде Code Composer Studio (хозяйке на заметку — CCS6 бесплатен для любого применения при использовании компилятора GCC). Производитель поддерживает также и IAR.
**Установка и настройка CCS IDE**Первым делом, сконфигурируем джамперы как указано на рисунке:

*Рисунок 5: установка джамперов для программирования в среде CCS*
Кроме того, устанавливая Code Composer Studio не забудем выставить галочку возле соответствующего пакета:
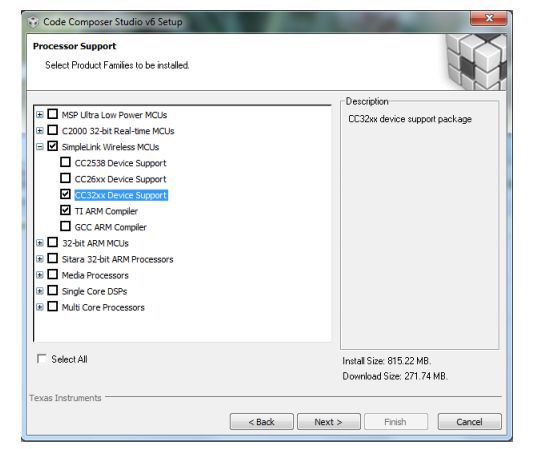
*Рисунок 6: установка CCS с поддержкой CC3200*
Любителям TI-RTOS[9] рекомендую после установки в магазине расширений установить пакет TI-RTOS for SImplelink

*Рисунок 7: установка TI-RTOS для CC3100&CC3200*
Импортируем один из демо-проектов. Я выбрал HTTP server[10].
Наша задача — добавить таргет для подключения к плате. Для этого заходим в пункт меню View->Target Configurations, импортируем файл C:\TI\CC3200SDK\_1.1.0\cc3200-sdk\tools\ccs\_patch\cc3200.ccxml и после этого, в его контекстном меню указываем, что он будет использоваться по умолчанию.
*Рисунок 7: настройка дебаг-интерфейса*
Жмем F11 для запуска Debug-режима, потом F8 для запуска программы и лезем в приложение Wi-Fi Starter для Android[11] или iOS[12]
**Wi-Fi Starter**Указав название точки доступа и пароль к ней, нажимаем кнопку старт

*Рисунок 8: Поиск и настройка устройств*
Как только устройство будет найдено, оно отобразится во вкладке Devices

*Рисунок 9: Список подключенных устройств*
тапаем по нему и попадаем на страничку в браузере, которая говорит о том, что все работает. там же можно перенастроить данные для Wi-Fi подключения и перевести устройство в режим точки доступа.

*Рисунок 10: Демо-приложение*
Дальше мы можем лезть куда нам надо и не надо и писать свои приложения.
#### **Создание электронного замка**
Перейдем уже наконец к практике!
Давайте сделаем электронный замок с датчиком открывания двери и радиобрелком для управления, и чтобы при несанкционированном доступе мне приходила СМС неприличного содержания.
Для этого нам понадобится:
* CC3200 launchpad в роли Wi-Fi шлюза
* TIVA-C launchpad[13] в роли платы управления электронным замком
* MSP430F5529[14] launchpad в роли платы радиобрелока
* и три штуки радиомодулей Anaren CC110L boosterpack в роли радиомодулей[15].
Принцип действия следующий:
Исполнительный механизм снабжен двухпозиционным соленоидом и датчиком периметра. В нашем случае роль соленоида будет исполнять двухпозиционное советское реле РП-12[16], а роль датчика периметра фотореле РФ-8300, столь знакомое сердцу посетителя советского метро (ни один турникет не пострадал). Логика работы следующая: С помощью радиокоманды можно выставить либо дежурный режим, либо режим охраны. В режиме охраны соленоид «запирает» дверь, и срабатывание датчика приведет к тревоге. Переход в дежурный режим отпирает дверь. Статус регулярно передается на Wi-Fi шлюз через радиоканал.
Брелок имеет две кнопки — поставить на охрану/снять с охраны. Передача команд осуществляется непосредственного на исполнительное устройство. тип передачи данных UDP, т.е. без подтверждения приема пакета (губа треснет). Данные передаем без шифрования по той же причине. Исполнительное устройство передает свое состояние на wi-fi шлюз. В случае тревоги Wi-Fi шлюз инициирует передачу SMS.
Зафиксируем команды:
```
enum {IDLE=0x01, ACTIVE, ALERT};
```
##### **Программирование в среде Energia[17]**
Для поклонников Arduino применимо к launchpad существует замечательный форк в виде среды программирования Energia. Он активно поддерживается сообществом:
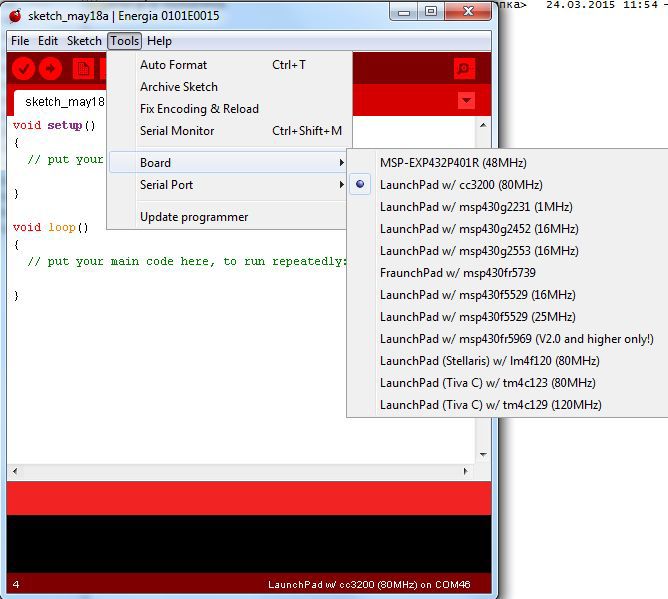
*Рисунок 11: Список плат, поддерживаемых версией Energia-15*
Для того, чтобы CC3200 можно было запрограммировать из Energia, необходимо сделать маленький хак — верхний пин TCK соединить с нижним пином SOP-2:

*Рисунок 12: Подключение режима автопрограммирования*
##### **Брелок**
Здесь все просто. Нажали кнопку 1 — передали на механизм команду «ACTIVE».
нажали кнопку 2 — передали на механизм команду «IDLE».

*Рисунок 13. Составные части брелка*
Накопипастим из примеров простенькую программку:
**Листинг программы для брелка**
```
#include
#include
//define addresses.
#define ADDRESS\_LOCAL 0x02
#define ADDRESS\_REMOTE 0x03
//FSM states. And commands
enum {
IDLE=0x01, ACTIVE, ALERT};
unsigned char txData[60] = {
"\0" };
const int setButton = PUSH1; //set to active mode
const int releaseButton = PUSH2;//set to idle mode
const int ledPin = GREEN\_LED;
const int redPin = RED\_LED;
void setup() {
//define pinouts and add serial outputr
pinMode(ledPin, OUTPUT);
pinMode(redPin, OUTPUT);
Serial.begin(9600);
pinMode(setButton, INPUT\_PULLUP);
pinMode(releaseButton, INPUT\_PULLUP);
Radio.begin(ADDRESS\_LOCAL, CHANNEL\_1, POWER\_MAX);
Serial.println("RF start");
txData[0] = ADDRESS\_LOCAL;//set zer0 byte as our address
}
void loop(){
//check set button
if (digitalRead(setButton) == LOW){
//if button is pressed, send command
Serial.println("Active mode");
digitalWrite(redPin, HIGH);
txData[1] = ACTIVE;//Set command
txData[2] = 0x00;
Radio.transmit(ADDRESS\_REMOTE, (unsigned char\*)&txData, 2);
}
else{
digitalWrite(redPin, LOW);
}
//check release button
if (digitalRead(releaseButton) == LOW){
Serial.println("IDLE mode");
digitalWrite(ledPin, HIGH);
txData[1] = IDLE;//Set command
txData[2] = 0x00;
//send packet
Radio.transmit(ADDRESS\_REMOTE, (unsigned char\*)&txData, 2);
}
else{
digitalWrite(ledPin, LOW);
}
sleepSeconds(1);//Low-power mode delay
delay(50);//to Clock stabilization
}
```
##### **Исполнительный механизм**
Задача исполнительного механизма — управлять двустабильным соленоидом. У такого соленоида имеется две обмотки, подавая напряжение на одну обмотку мы втягиваем сердечник, на другую — отпускаем. Постоянно держать напряжение на обмотках не требуется. Наше реле РП-12 немного не такое — у него обмотка одна, а выбор действия определяется полярностью. Обойдемся парой диодов.

*Рисунок 14: Большое советское реле без купюр. Виден электромагнит и двухпозиционный сердечник. Подавая сигнал разной полярности на сердечник добиваемся переключения реле.*
Подключать будем через симисторы MOC3052 по следующей схеме:

*Рисунок 15: Схема подключения симистора.*
У меня в загашниках нашлась платка с двумя симисторами, так что не пришлось городить макетку.
Датчик контроля периметра на фотореле РФ-8300 работает автономно, группой замыкающих контактов подавая сигнал на актуатор.
**поклонникам Google Cardboard**Линзы эти этих релюх просто созданы для того, чтобы стоять в очках виртуальной реальности.
Получив от брелка команду, выполняем ее, и дублируем на wi-Fi шлюз.
Копипастим программку:
**Листинг программы для актуатора**
```
#include
#include
#define ADDRESS\_LOCAL 0x03
#define ADDRESS\_REMOTE 0x01
unsigned char rxData[60] = {
"\0" };
unsigned char txData[60] = {
"\0" };
/\*
Finite state machine:
1. IDLE mode
2. Action Mode
3. Alert mode
1 -> 2 Received command 0x01
2 -> 1 received command 0x02
2 -> 3 sensor triggered. Send alert
\*/
enum {IDLE=0x01, ACTIVE, ALERT};
unsigned int fsm = IDLE;
static unsigned char sensor = 11;
static unsigned char releopen = 9;
static unsigned char releclose = 10;
static unsigned char releopenled = BLUE\_LED;
static unsigned char relecloseled = GREEN\_LED;
// -----------------------------------------------------------------------------
// Main example
void setup()
{
pinMode(sensor, INPUT\_PULLUP);
pinMode(releopen, OUTPUT);
digitalWrite(releopen, HIGH);
pinMode(releopenled, OUTPUT);
pinMode(relecloseled, OUTPUT);
pinMode(releclose, OUTPUT);
digitalWrite(releclose, HIGH);
pinMode(12, OUTPUT);
pinMode(12, LOW); //return pin for sensor
Radio.begin(ADDRESS\_LOCAL, CHANNEL\_1, POWER\_MAX);
// Setup serial for debug printing.
Serial.begin(9600);
txData[0] = ADDRESS\_LOCAL;//set zer byte as our address
}
uint8\_t length = 0;
void loop()
{
switch (fsm){
case IDLE:
length = Radio.receiverOn(rxData, sizeof(rxData), 1000);
if (length > 0){
if (rxData[1] == ACTIVE){
//change state stage
fsm = ACTIVE;
txData[1] = ACTIVE;//Set command
txData[2] = 0x00;
Radio.transmit(ADDRESS\_REMOTE, (unsigned char\*)&txData, 2);
//send 500ms inpuls to actuator
digitalWrite(releclose, LOW);
digitalWrite(relecloseled, HIGH);
delay(500);
digitalWrite(releclose, HIGH);
digitalWrite(relecloseled, LOW);
}
else{
fsm = IDLE;
}
}
else{
}
break;
case ACTIVE:
length = Radio.receiverOn(rxData, sizeof(rxData), 100);
if (length > 0){
if (rxData[1] == IDLE){
//change state stage
fsm = IDLE;
txData[1] = IDLE;//Set command
txData[2] = 0x00;
Radio.transmit(ADDRESS\_REMOTE, (unsigned char\*)&txData, 2);
//send 500ms inpuls to actuator
digitalWrite(releopen, LOW);
digitalWrite(releopenled, HIGH);
delay(500);
digitalWrite(releopen, HIGH);
digitalWrite(releopenled, LOW);
}
else{
fsm = ACTIVE;
}
}
else{
}
checkperimeter();
break;
case ALERT:
length = Radio.receiverOn(rxData, sizeof(rxData), 1000);
if (length > 0){
if (rxData[1] == IDLE){
//change state stage
fsm = IDLE;
txData[1] = IDLE;//Set command
txData[2] = 0x00;
Radio.transmit(ADDRESS\_REMOTE, (unsigned char\*)&txData, 2);
//send 500ms inpuls to actuator
digitalWrite(releopen, LOW);
digitalWrite(releopenled, HIGH);
delay(500);
digitalWrite(releopen, HIGH);
digitalWrite(releopenled, LOW);
}
else{
fsm = ALERT;
}
}
else{
}
break;
default:
break;
}
}
void checkperimeter(){
uint8\_t sensorstate = digitalRead(sensor);
if (sensorstate == LOW){
Serial.println("Alert!");
//alert!!
fsm = ALERT;
txData[1] = ALERT;//Set command
txData[2] = 0x00;
Radio.transmit(ADDRESS\_REMOTE, (unsigned char\*)&txData, 2);
}
}
```
##### **Шлюз**
Задача шлюза не сложнее — дублировать светодиодами состояние системы (для теста) и в случае тревоги отправить сообщение на телефон.

*Рисунок 15: шлюз в сборе*
###### **Temboo+NEXMO**
Но для начала подготовим API-почву. Для этого регистрируемся на сервисах Temboo[18] и Nexmo[19]. В задачи Nexmo входит подключение к любому мобильному телефону в любой точке мира. При регистрации дают стартовые 2 Евро, которых вполне достаточно, чтобы опробовать этот сервис.
В задачи Temboo будет входить организация связи между нашим устройством и сервисом Nexmo. Здесь для старта дается 250 запросов, которые можно бесплатно расширить на добрый десяток тысяч, приглашая друзей. Что до тарифов — смски мне обошлись в 2 евроцента за штуку.
В списке возможных API выбираем Nexmoo.SMS.TextMessage.
Выбираем нашу плату — CC3200 и указываем параметры Wi-Fi подключения
*Рисунок 16: Настройка Wi-Fi*
Указываем параметры подключения. От нас требуют указать API ключи от нашего аккаунта Nexmoo, номер телефона отправителя, который привязан к нашему аккаунту, номер телефона получателя и текстовое сообщение.

*Рисунок 17: Выбор получателя и настройка сообщения*
Нажатием на кнопку Run можно проверить что все работает.
Копипастим код из блоков и «докопипасчиваем» ему поддержку режимов работы:
**Листинг кода Wi-Fi шлюза**
```
#include
#include
#include
#include
#include
#include "TembooAccount.h" // Contains Temboo account information
WiFiClient client;
#define ADDRESS\_LOCAL 0x01
unsigned char rxData[60] = {
"\0" };
unsigned char txData[60] = {
"\0" };
/\*
Finite state machine:
1. IDLE mode
2. Action Mode
3. Alert mode
1 -> 2 Received command 0x01
2 -> 1 received command 0x02
2 -> 3 sensor triggered. Send alert
\*/
enum {
IDLE=0x01, ACTIVE, ALERT};
unsigned int fsm = IDLE;
// -----------------------------------------------------------------------------
// Main example
void setup()
{
pinMode(GREEN\_LED, OUTPUT);
pinMode(RED\_LED, OUTPUT);
pinMode(YELLOW\_LED, OUTPUT);
digitalWrite(YELLOW\_LED, LOW);
digitalWrite(RED\_LED, LOW);
digitalWrite(GREEN\_LED, LOW);
Radio.begin(ADDRESS\_LOCAL, CHANNEL\_1, POWER\_MAX);
// Setup serial for debug printing.
txData[0] = ADDRESS\_LOCAL;//set zer byte as our address
Serial.begin(9600);
int wifiStatus = WL\_IDLE\_STATUS;
// Determine if the WiFi Shield is present
Serial.print("\n\nShield:");
if (WiFi.status() == WL\_NO\_SHIELD) {
Serial.println("FAIL");
// If there's no WiFi shield, stop here
while(true);
}
Serial.println("OK");
// Try to connect to the local WiFi network
while(wifiStatus != WL\_CONNECTED) {
Serial.print("WiFi:");
wifiStatus = WiFi.begin(WIFI\_SSID, WPA\_PASSWORD);
if (wifiStatus == WL\_CONNECTED) {
Serial.println("OK");
}
else {
Serial.println("FAIL");
}
delay(5000);
}
digitalWrite(YELLOW\_LED, HIGH);
Serial.println("Setup complete.\n");
}
uint8\_t length = 0;
void loop()
{
length = Radio.receiverOn(rxData, sizeof(rxData), 1000);
if (length > 0){
Serial.print("Get state: ");
Serial.println(rxData[1], DEC);
switch (fsm){
case IDLE:
if (rxData[1] == ACTIVE){
fsm = ACTIVE;
digitalWrite(GREEN\_LED, HIGH);
}
break;
case ACTIVE:
if (rxData[1] == IDLE){
fsm = IDLE;
digitalWrite(GREEN\_LED, LOW);
digitalWrite(RED\_LED, LOW);
}
if (rxData[1] == ALERT){
fsm = ALERT;
digitalWrite(RED\_LED, HIGH);
sendmessage();
}
break;
case ALERT:
if (rxData[1] == IDLE){
fsm = IDLE;
digitalWrite(GREEN\_LED, LOW);
digitalWrite(RED\_LED, LOW);
}
break;
}
}
}
void sendmessage(){
Serial.println("Running SendMessage - Run #" + String(numRuns++));
TembooChoreo SendMessageChoreo(client);
// Invoke the Temboo client
SendMessageChoreo.begin();
// Set Temboo account credentials
SendMessageChoreo.setAccountName(TEMBOO\_ACCOUNT);
SendMessageChoreo.setAppKeyName(TEMBOO\_APP\_KEY\_NAME);
SendMessageChoreo.setAppKey(TEMBOO\_APP\_KEY);
// Set Choreo inputs
String TextValue = "Testing! Testing! 1, 2, 3";
SendMessageChoreo.addInput("Text", TextValue);
String APIKeyValue = "000";
SendMessageChoreo.addInput("APIKey", APIKeyValue);
String ToValue = "000";
SendMessageChoreo.addInput("To", ToValue);
String APISecretValue = "000";
SendMessageChoreo.addInput("APISecret", APISecretValue);
String FromValue = "000";
SendMessageChoreo.addInput("From", FromValue);
// Identify the Choreo to run
SendMessageChoreo.setChoreo("/Library/Nexmo/SMS/SendMessage");
// Run the Choreo; when results are available, print them to serial
SendMessageChoreo.run();
while(SendMessageChoreo.available()) {
char c = SendMessageChoreo.read();
Serial.print(c);
}
SendMessageChoreo.close();
}
```
Компилируем, тыкаем кнопочки и убеждаемся, что все работает.
##### **Демонстрация**
Наглядная демонстрация с большими релюшками:
Подведу итоги — отладочная плата CC3200 — весьма приятная железка имеющая свою нишу для применений. Показанное здесь демо сделано по принципу «слепила из того что было» и призвано показать часть возможностей плат Energia lauchpad. В планах — в подробностях рассказать об особенностях подключения датчиков и исполнительных механизмов с учетом надежности и устойчивости к электромагнитным помехам.
Исходный код проекта доступен в репозитории[20].
#### **Полезные ссылки:**
1. CC3200 Product [Brief http://www.ti.com/product/cc3200](http://www.ti.com/product/cc3200)
2. CC3200 Datasheet <http://www.ti.com/lit/ds/symlink/cc3200.pdf>
3. CC3200-LAUNCHXL User Guide <http://www.ti.com/lit/ug/swru372b/swru372b.pdf>
4. BMA222 Accelerometer Datasheet <https://ae-bst.resource.bosch.com/media/products/dokumente/bma222/bst-bma222-ds002-05.pdf>
5. TMP006 IR Thermopile Sensor Datasheet <http://www.ti.com/lit/ds/sbos518e/sbos518e.pdf>
6. CC3200 SDK <http://www.ti.com/tool/cc3200sdk>
7. CCS UniFlash <http://www.ti.com/tool/uniflash>
8. Code Composer Studio 6 IDE <http://www.ti.com/tool/ccstudio>
9. TI-RTOS <http://www.ti.com/tool/TI-RTOS>
10. CC3200 HTTP server User Guide <http://processors.wiki.ti.com/index.php/CC32xx_HTTP_Server>
11. Wi-Fi Starter App for Android <https://play.google.com/store/apps/details?id=com.pandaos.smartconfig>
12. Wi-Fi Starter App for iOS <https://itunes.apple.com/us/app/texas-instruments-simplelink/id884122493?ls=1&mt=8>
13. TIVA-C launchpad <http://www.ti.com/tool/ek-tm4c123gxl>
14. MSP430F5529 launchpad <http://www.ti.com/tool/msp-exp430f5529lp>
15. CC110L Air Module Boosterpack <https://www.anaren.com/air/cc110l-air-module-boosterpack-embedded-antenna-module-anaren>
16, Реле РП-12. Описание: <http://www.cheaz.ru/ru/production/ustroystva-releynoy-zashchity/rele-promezhutochnye-dvukhpozitsionnye-rp-8-9-11-12>
17. Energia IDE <http://energia.nu/>
18. Temboo <https://temboo.com/>
19. Nexmo <https://www.nexmo.com/>
20. Electronic Lock GitHub repo <https://github.com/radiolok/electronic_lock_energia>
|
https://habr.com/ru/post/258155/
| null |
ru
| null |
# Это вам не x86_64. Проблемы сборки Arch Linux под ARM-архитектуру и как мы их решали

Привет, Хабр! Меня зовут Лев Евсеенко, я работаю системным администратором в Selectel, сопровождаю сервисы наших выделенных серверов. В декабре мы пополнили линейку [конфигом Ampere Altra Max M128-30](https://slc.tl/t0pwk) (3 ГГц, 128 ядер) с ARM-процессором внутри.
Перед введением в «эксплуатацию» нужно было разобраться с сетевой загрузкой, модифицировать служебный дистрибутив, адаптировать существующие процессы автоустановки ПО под новую архитектуру. В тексте расскажу, с какими проблемами мы столкнулись и какие решения нашли.
Вы можете подробнее почитать о том, зачем мы добавили ARM-серверы в линейку, а еще посмотреть на результаты бенчмарков тестовой платформы на Ampere Altra Q80-30 в [классной статье от моего коллеги](https://habr.com/ru/company/selectel/blog/707926/).
Если коротко, они хорошо показывают себя в многопоточных задачах и при этом намного энергоэффективнее процессоров от AMD и Intel. Основные задачи, которые решали клиенты во время тестов Ampere Altra, — работа с СУБД, запуск высоконагруженных веб-сервисов, разработка мобильных приложений и embedded-разработка.
[](https://slc.tl/aiqam)
На первый взгляд, новые серверы мало чем отличаются от решений на архитектуре x86\_64. Тем не менее, для их полноценной поддержки нужно было решить несколько проблем:
* разобраться с сетевой загрузкой,
* модифицировать служебный дистрибутив,
* адаптировать существующие процессы автоустановки ОС под новую архитектуру.
Сетевая загрузка, или часть, в которой все идет по плану
--------------------------------------------------------
Это была самая простая часть процесса, где все работало именно так, как ожидалось.
### Автоматизируем сборку и деплой PXE-клиента
Мы используем модифицированный iPXE (небольшие изменения во время сборки, чтобы DHCP-сервер мог опознать PXE-клиент), который уже поддерживает arm64. Единственной проблемой стала сборка бинарного файла для arm64 на x86\_64 GitLab-worker с помощью кросс-компиляции. Для сборки используется стандартный Docker-контейнер linux/amd64 ubuntu:20.04, Dockerfile:
```
FROM ubuntu:20.04
LABEL name="ipxe-builder-aarch64" \
description="Image to build ipxe binary files" \
version="1.0.1"
# Install all necessary packages for compiling the iPXE binary files
RUN apt update && apt install -y git gcc gcc-aarch64-linux-gnu make curl
```
Сборка выполняется из мастера [iPXE GitHub](https://github.com/ipxe/ipxe) следующей командой:
```
make CROSS=aarch64-linux-gnu- ARCH=arm64 bin-aarch64-efi/ipxe.efi EMBED=universal.ipxe
```
, где **universal.ipxe** — встраиваемый скрипт, который обрабатывает проблемы с сетью и работает со ссылками на загрузочные скрипты, которые генерирует наш бэкенд. На выходе получаем готовый arm64-binary, который деплоится на наши TFTP-серверы.
### Убеждаемся, что DHCP-сервер отдаст ссылку на нужную сборку iPXE, в зависимости от архитектуры
Мы определяем архитектуру и/или режим загрузки (Legacy/UEFI) сервера с помощью опции 60 DHCP — Vendor class identifier:

*DHCP DISCOVER от ARM64-EFI сервера.*

*DHCP DISCOVER от x86\_64-EFI сервера.*
Смотрим на часть PXE Client:Arch:000**11**, значения соответствуют [RFC4578](https://www.rfc-editor.org/rfc/rfc4578#section-2.1):
| 0 | Standard PC BIOS |
| --- | --- |
| 6 | 32-bit x86 EFI |
| 7 | 64-bit x86 EFI |
| 9 | 64-bit x86 EFI (obsolete) |
| 10 | 32-bit ARM EFI |
| 11 | 64-bit ARM EFI |
В зависимости от этого значения DHCP-сервер возвращает имя необходимого файла в DHCP Option 67 — Bootfile name.
После iPXE проходит по одноразовой ссылке и получает сгенерированный загрузочный скрипт. В зависимости от содержимого скрипта сервер либо загружается с диска, либо запускает переустановку ОС, либо загружается в дистрибутив для восстановления.
Arch Linux для ARM, или грустный рассказ о неверных эстимейтах
--------------------------------------------------------------
Поскольку мы сдаем выделенные серверы в аренду и стараемся делать это очень быстро, мы автоматизируем многие процессы. Например, запуск операций зачистки дисков при завершении аренды сервера, проведение промежуточных тестов при завершении аренды и приемочных тестов после сборки сервера. Для всего этого мы используем кастомную сборку Arch Linux — внутри компании мы называем этот дистрибутив rescue. Помимо прочего, он используется для диагностики серверов и аварийных работ с ними.
Нам нужно было состыковать Arch Linux с ARM-процессором. Изначально никаких подводных камней не ожидалось: есть проект Arch Linux for ARM, на GitHub есть проект archiso-aarch64 – mkarchiso, адаптированный под aarch64. Казалось бы, собираем все вместе, заменяем архитектуру в существующих пайплайнах по сборке и деплою образа — готово. Мы оценили задачу примерно в 2 недели. Именно в этот момент все пошло не так.

Разумеется, такая потрясающая подготовка не могла не выйти боком: мы столкнулись сразу с пачкой проблем.
### Проблема со сборкой артефактов для загрузки сервера в режиме UEFI
Разработчик archiso-aarch64 просто продублировал большинство классов, поменяв значения переменных на необходимые для архитектуры aarch64. Нам пришлось немного модифицировать сборочные скрипты archiso-aarch64. Модификация только одна: был изменен класс, который используется при сборке образа под legacy-режим загрузки. Дело в том, что тестируемые нами серверы с процессорами ARM работают только в UEFI, но при этом в оригинальных скриптах артефакты загрузки (vmlinuz и initramfs) собираются только в legacy-части скриптов.
В итоге в часть, ответственную за сборку UEFI-артефактов, был импортирован класс, ответственный за упаковку ядра и initramfs. В [строку 622](https://github.com/JackMyers001/archiso-aarch64/blob/aarch64/archiso/mkarchiso%23L622) мы добавили:
```
_run_once _make_boot_on_iso9660
```
Это позволило нам получить необходимые артефакты для сетевой загрузки.
### Не поддерживалась кросс-архитектурная сборка образа
При сборке образа используется chroot, который ломается во время «добавления» пакетов «внутрь» образа.
Тут мы решили попробовать проект archboot, который обещал поддержку кросс-архитектурной сборки, но процесс интеграции наших инструментов сильно затягивался. Кроме того, в образе слишком много лишнего — например, графическая оболочка, доступ через VNC, огромная куча хуков mkinitcpio, с которой было решительно некогда разбираться. Из-за этого вернулись к использованию archiso-aarch64.
Мы пробовали собирать образ в эмулированной через QEMU виртуальной машине, но процесс занимал больше часа. Проблему со сборкой решили заведением GitLab-runners на Raspberry Pi 4. Наши раннеры для сборки x86-образа запущены на хостах облачной платформы Selectel, в то время как раннеры для этого проекта запускаются на физических RPi4, которые находятся в служебной стойке в одном из наших дата-центров.
> Ранее мы писали, как внедряли серверы на «малинках» в дата-центры. Подробно описали каждый этап. Все тексты — в [одной подборке](https://habr.com/ru/company/selectel/news/t/598635/).
В качестве executor в GitLab-runner используется Docker. Это сильно отличается от сборки x86-образа, где используется libvirt и QEMU. Дело в том, что последняя работает пока крайне медленно в режиме эмуляции aarch64, да и использование более простого в настройке исполнителя приветствуется. Dockerfile:
```
FROM agners/archlinuxarm-arm64v8
WORKDIR /archlinux
RUN mkdir -p /archlinux/rootfs
COPY pacstrap-docker /archlinux/
RUN ./pacstrap-docker /archlinux/rootfs \
bash sed gzip pacman
# Remove current pacman database, likely outdated very soon
RUN rm rootfs/var/lib/pacman/sync/*
FROM scratch
COPY --from=0 /archlinux/rootfs/ /
COPY rootfs/ /
ENV LANG=en_US.UTF-8
RUN locale-gen
RUN pacman-key --init
# Currently command crashes. Use key below for package sign
#RUN pacman-key --populate archlinuxarm
RUN pacman-key --recv-keys 68B3537F39A313B3E574D06777193F152BDBE6A6 && pacman-key --lsign-key 68B3537F39A313B3E574D06777193F152BDBE6A6
# Original image outdated, upgrade needed
RUN pacman -Syyu --noconfirm
# mkarchiso dependencies
RUN pacman -Sy --noconfirm arch-install-scripts awk dosfstools e2fsprogs erofs-utils findutils gzip libarchive libisoburn mtools openssl sed squashfs-tools
CMD ["/usr/bin/bash"]
Сборка выполняется стандартной командой ./mkarchiso -v -o $OUTDIR -w $WORKDIR -m $MODE $PROFILE
```
### Недостаток готовых бинарных пакетов в репозиториях
Наш служебный образ достаточно сильно кастомизирован: начиная от вшитых ключей авторизации моих коллег — системных инженеров и сотрудников техподдержки, заканчивая кастомными загрузочными хуками по настройке сети и собственными скриптами и утилитами.
Первым делом нам пришлось сильно переработать список пакетов для установки в дистрибутив. Огромное количество ПО просто не существует в репозиториях, да и сам репозиторий Arch Linux, хоть и поддерживается некоторыми мейнтейнерами, — является скорее неофициальным.
Достаточно много пакетов — stress-ng, утилиты для прошивки материнских плат, SSD и NIC — мы собираем сами. Некоторые из них поставляются в виде бинарных файлов только под архитектуру x86\_64. Из-за этого нам пришлось переписать скрипт автотестов, а также временно отказаться от некоторых используемых фич для архитектуры arm64. Например, автоматической прошивки материнских плат и периферии, а также автоматической настройки BMC.
#### Коротко об автотестах при передаче сервера клиенту
После сборки платформы, а также при передаче сервера новому клиенту мы проводим ряд автотестов.
После сборки сервера он должен пройти **тест комплектующих**. Проверяем, что CPU, RAM, GPU и блочные устройства корректно определяются, их характеристики соответствуют заявленным. Также проверяем SMART-параметры блочных устройств и убеждаемся, что их скорость чтения соответствует классу устройства. Для проверки SMART используем самописную утилиту на Python в сочетании с базой данных граничных значений. Выход за пределы значений вызывает автоматический вывод сервера из эксплуатации и его передачу на диагностику.
Дальше **стресс-тест**. В течение двух часов нагружаем CPU, RAM, GPU и смотрим, чтобы не было ошибок и троттлинга. Для стресс-тестов мы используем утилиту stress-ng.
Завершают цикл **приемочные тесты** (перед передачей сервера новому клиенту). Здесь также проверяем комплектацию сервера и SMART-параметры дисков.
Еще немного граблей, на которые мы наступили
--------------------------------------------
### Отсутствие логов
Эта проблема сильно осложнила дебаг rescue и тесты автоустановки. Вместо логов на экране отображалась очень симпатичная заставка с пингвинами — вроде такой, только пингвинов побольше:

Параметры ядра вроде debug и loglevel=7 не помогали. Через какое-то время мы догадались, в чем проблема, и решили ее добавлением параметра ядра console=tty0.
### Проблема с тестами автоустановки Ubuntu 22.04
Вторая проблема была связана с тестами автоустановки Ubuntu 22.04. Нужно было быстро проверить, что сетевая установка будет работать. Но, поскольку Ubuntu перешел с использования debian-installer к subiquity, legacy-installer больше недоступен.
Мы попытались обмануть систему, вытащив необходимые файлы из установочного образа, и встретились с интересной проблемой — iPXE зависало при попытке загрузить initramfs. Оказалось, что initrd сжат с использованием Zstandart, который iPXE, судя по всему, не поддерживает. Примечательно, что версия для x86\_64 не использует Zstandart.
```
Вывод file для initrd subiquity Ubuntu 22.04 amd64:
initrd: ASCII cpio archive (SVR4 with no CRC)
Вывод file для initrd subiquity Ubuntu 22.04 arm64:
initrd: Zstandard compressed data (v0.8+), Dictionary ID: None
```
Позже мы выяснили несколько вещей:
* установщику в любом случае необходимо выкачивать весь ISO для корректной работы,
* файлы preseed больше не поддерживаются, и необходимо использовать cloud-init/autoinstall.
В общем, без переписывания шаблонов не обойтись. Сейчас мы как раз модернизируем процесс автоустановки ОС, чтобы клиенты могли получить готовый к работе сервер с предустановленной Ubuntu 22.04 в течение нескольких минут.
### Плавающие проблемы с дисками
Эти проблемы всплывали во время динамической разметки дисков, их объединения в программные рейды и добавления в LVM в установщике Ubuntu 20.04. В некоторых случаях установщик пытался создать лишние рейды, либо не мог очистить метаданные LVM. Мы не продолжили анализ проблемы, так как она будет решена вместе с модернизацией системы автоустановки.
Заключение
----------
На первый взгляд, работа с серверами на архитектуре arm64 практически не отличается от x86\_64-аналогов. Но чем глубже погружаешься, тем больше открывается нюансов.
Задача была интересна еще и тем, что из-за небольшого количества информации все решения принимались через практические эксперименты. Мы продолжаем работу над серверами с ARM-архитектурой и обязательно расскажем об этом в следующих материалах.
**Был ли у вас опыт работы с ARM-процессорами? Делитесь в комментариях!**
> **Возможно, эти тексты тоже вас заинтересуют:**
>
>
>
> → [SD – это Linux, а Midjourney – Mac: краткое полное руководство по Stable Diffusion](https://habr.com/ru/company/selectel/blog/712316)
>
> → [Подборка материалов для погружения в Angular: выбор сотрудников Selectel](https://habr.com/ru/company/selectel/blog/713876)
>
> → [Геймерские материнские платы, жесткие диски и раритетный синтезатор: новые находки на испанской барахолке](https://habr.com/ru/company/selectel/blog/712086)
|
https://habr.com/ru/post/714234/
| null |
ru
| null |
# Обновление процесса CI/CD: год спустя
Это четвертая и заключительная часть цикла об обновлении CI/CD процессов. Кстати, вот оглавление:
[Часть 1: что есть, почему оно не нравится, планирование, немного bash.](https://habr.com/ru/post/496204/) Я бы назвал эту часть околотехнической.
[Часть 2: teamcity.](https://habr.com/ru/post/496342)[Часть 3: octopus deploy.](https://habr.com/ru/post/497112/)
[Часть 4: внезапно вполне себе техническая.](https://habr.com/ru/post/550308/) Что произошло за прошедший год.
Сейчас у нас есть рабочая система доставки обновлений, которая прошла испытание временем. О настройке этой системы можно прочесть в первых трёх частях, а сейчас предлагаю вкратце вспомнить что там было.
Осуществлялся переезд CI/CD системы с CruiseControl.NET + git deploy на Teamcity + octopus. Будем честны, CD там и не пахло. Об этом, возможно, будет отдельная статья, но не в этом цикле.
С момента выхода первой статьи цикла прошло чуть больше года, с момента начала работы системы в проде - примерно полтора. Процесс разработки во время внедрения новой системы практически не прерывался. Было два раза, когда делали code freeze: один раз в момент перехода с mercurial репозитория в git (чтобы не потерять коммиты во время конвертации), и второй раз во время перехода билда production окружения с ccnet на teamcity (просто так, на всякий случай).
В результате мы получили систему которая способна наиболее оптимально (с минимальными время- и ресурсозатратами, а также с минимальными рисками) доставлять обновления во все существующие окружения.
С момента выхода 3 части статьи в конфигурации произошли некоторые изменения, о которых, наверное, стоит рассказать.
Что произошло за этот год
-------------------------
1. Мы практически полностью отказались от конфигураций вида “Build + deploy”. Теперь используем отдельно Build и отдельно Deploy. Последние всё также вызываются из teamcity, но это сделано исключительно для упрощения жизни всем менее причастным. На самом деле, для того чтобы обезопасить Octopus от вмешательства любопытных.
2. Полностью перешли на [semver](https://semver.org/). К сожалению, до момента внедрения девопс в проект, ни о каком semver речи не было. Картинка с этой версионностью уже мелькала в [3 части](https://habr.com/ru/post/497112/), останавливаться подробно не будем.
3. Появился опыт настройки деплоя на сервере без каких-либо доступов, только с установленным octopus агентом. Не то, чтобы его не было, просто он был забыт как страшный сон за много лет. А тут пришлось вспоминать. Приятного мало, но на удивление, терпимо.
4. Перешли с Visual studio (sln) раннера на .net msbuild ввиду окончания поддержки первого (Teamcity).
5. Для Special Module (см [часть 1](https://habr.com/ru/post/496204/)) появился интересный вызов билда из деплоя с пробросом параметров через *reverse.dep*…
6. Появился какой-никакой роллбек.
7. Переработали variable set’ы в octopus, используем tenant variables.
8. Практически везде перешли от хранения connection string в репозитории на хранение в Octopus и подстановкой при деплое. К сожалению, раньше хранили именно в репозитории.
9. Для деплоя особо важных модов добавили защиту от тестировщика (подробнее чуть позже).
10. Выросли на 7 новых тенантов (клиентов).
В общем, звучит круто, предлагаю остановиться на некоторых пунктах подробнее.
Build-chain наоборот (пункт 4)
------------------------------
Для Special module, как и для любых других есть несколько окружений. Список всех пайплайнов для этого модуля в teamcity выглядит так:
Build конфигурация используется одна, с вот таким параметром ветки:
Также в данной конфигурации используются две prompted переменные типа Select: env.Environment и env.buildBranch. Выглядят они примерно одинаково, отличаются только Items. Для каждого env ставится в соответствие ветка репозитория.
С учётом всех настроек, перечисленных выше, запуск билда вручную выглядит следующим образом:
В каждой Deploy конфигурации, есть зависимость от актуальности конфигурации build и параметры типа reverse.dep, которые при запуске Build устанавливают для него env.Environment и env.buildBranch. Например, для development это выглядит так:
Как всё это работает вместе: при нажатии кнопки deploy соответствующего окружения проверяется наличие изменений в репозитории. Если изменения есть - запускается конфигурация Build с установленными через reverse.dep переменными. По завершению билда, запускается ожидавший всё это время деплой новой версии пакета.
Rollback (пункт 6)
------------------
Rollback построен на следующем алгоритме:
1. Определить номер текущего и предыдущего релизов в octopus для Core и Module.
2. Откатить Core (задеплоить предыдущий релиз)
3. Откатить Module.
Octopus хранит 3 предыдущих релиза так, на всякий случай. Rollback из teamcity работает только с предыдущим релизом. Откат на более давний релиз надо делать вручную, но такой необходимости ни разу не возникало. Так выглядят определение версий:
```
$packageRelease = ((%env.octoExe% list-deployments --server="%env.octoUrl%" --apikey="%env.octoApiKey%" --project="ProjectName.%env.modName%" --environment="%env.Environment%" --outputFormat=json) | ConvertFrom-Json).Version[0..1]
$coreRelease = (((%env.octoExe% list-deployments --server="%env.octoUrl%" --apikey="%env.octoApiKey%" --project="%env.coreProjectName%" --environment="%env.Environment%" --outputFormat=json) | ConvertFrom-Json).Version | Get-Unique)[0..1]
$OctopusPackageCurrentRelease = $packageRelease[0]
$OctopusPackagePreviousRelease = $packageRelease[1]
$corePreviousVersion = $OctopusPackagePreviousRelease | %{ $_.Split('-')[0]; }
$coreEnv = $OctopusPackagePreviousRelease | %{ $_.Split('-')[1]; } | %{ $_.Split('+')[0]; }
$OctopusCoreCurrentRelease = $coreRelease[0]
$OctopusCorePreviousRelease = "$corePreviousVersion-$coreEnv"
Write-Host "##teamcity[setParameter name='OctopusPackageCurrentRelease' value='$OctopusPackageCurrentRelease']"
Write-Host "##teamcity[setParameter name='OctopusPackagePreviousRelease' value='$OctopusPackagePreviousRelease']"
Write-Host "##teamcity[setParameter name='OctopusCoreCurrentRelease' value='$OctopusCoreCurrentRelease']"
Write-Host "##teamcity[setParameter name='OctopusCorePreviousRelease' value='$OctopusCorePreviousRelease']"
```
Откат является деплоем соответствующей версии, поэтому глобально ничем не отличается от шага Deploy.2 описанного в [части 2](https://habr.com/ru/post/496342/). Меняется только Release Number. Вместо latest используется *%OctopusCorePreviousRelease%* и *%OctopusPackagePreviousRelease%* соответственно.
Переработка variable sets
-------------------------
Раньше все переменные тенантов хранились в конфигурациях проектов и разруливались расстановкой скоупов. Вот хороший пример из [части 3](https://habr.com/ru/post/497112/):
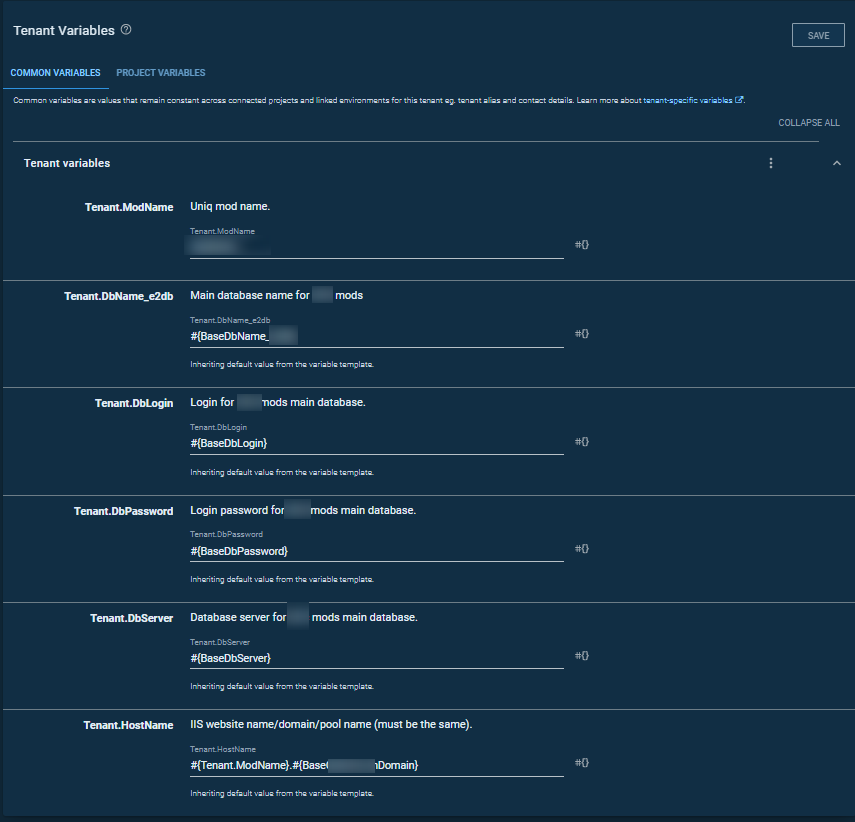При количестве тенантов больше 3 это оказывается неудобно. Поэтому, перешли к хранению переменных клиентов в предназначенном для этого месте - tenant variables - common variables.
Так списки переменных проектов стали чище, и там больше нет каши.
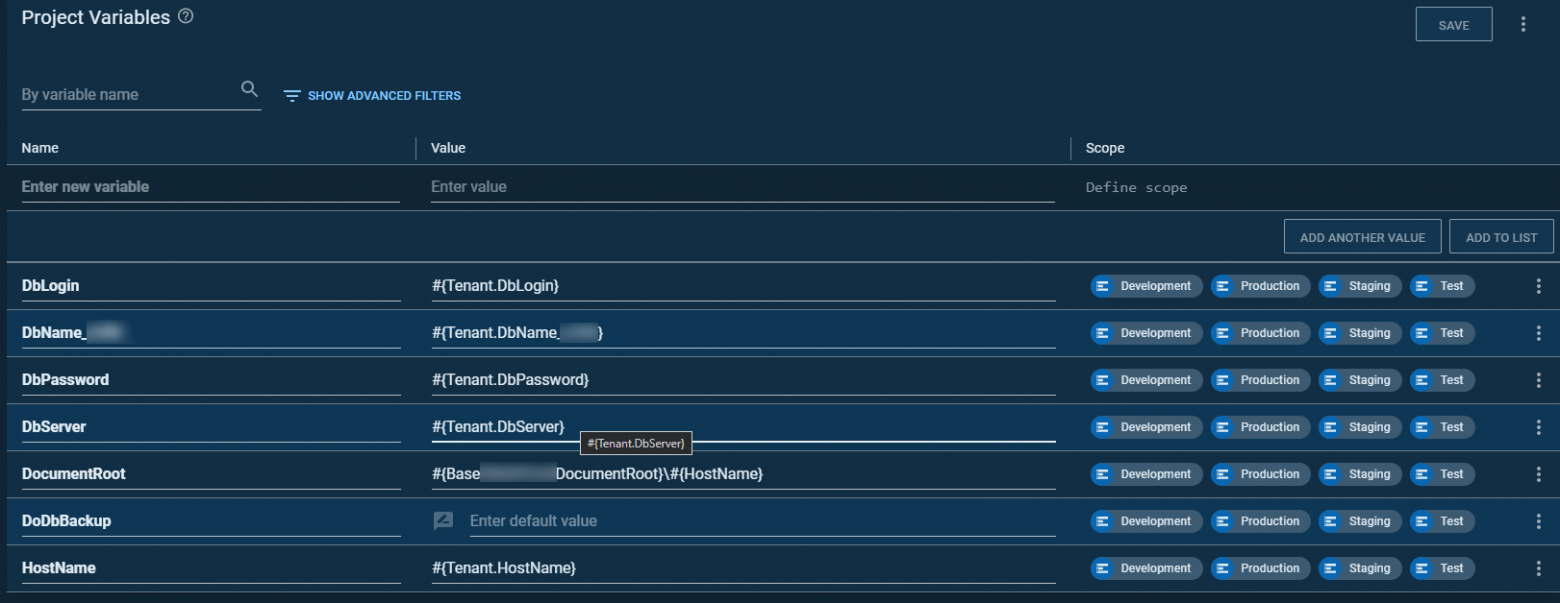Защита от тестировщика (пункт 9)
--------------------------------
В список задач тестировщика входит также деплой на некоторые окружения. Туда, куда деплои не попадают автоматически из за ограничений. Зачастую это выглядит как “клик клик клик клик” по кнопкам Run не задумываясь. Исключение составляет prod окружение, но это не точно. Пару раз были прецеденты деплоя модов, которые помечены как secure. Это особая категория модов, которыми пользуются особые люди. Они очень любят стабильность и все релизы у них планируются, а набор новых фич обсуждается. В общем, для этих модов пришлось добавить элементарную защиту в виде всплывающего “Are you sure” и требованием ввести ответ буквами.
Реализовано это с помощью prompted переменной и regexp.
Заключение
----------
В данный момент я работаю над этим проектом по минимуму. Саппорт практически не требуется, всё работает практически без моего участия. Где-то есть continuous deployment, где-то пришлось ограничиться delivery. Там где надо нажимать кнопки вручную - справляются тестировщик и главный девелопер. Время добавления новых конфигураций (по факту нового клиента) вместе с проверкой работоспособности - час с чайком и без напряга. С CCNet такой результат показался бы фантастикой при условии отcутствия дичайшего оверхеда со стороны ресурсов сервера. Да и удобства никакого. Пропала проблема бесконечной нехватки места, так как на сервере не хранятся лишние копии одного и того же. И даже rollback показал себя с хорошей стороны, и на удивление работает. Всё работает классно шустро, и самое главное - стабильно и прогнозируемо.
Бросать проект в мои планы не входит, но и какие-то крупные изменения в дальнейшем пока не планируются. Так что, я изредка поглядываю в Octopus, радуюсь тому что все работает без моего участия и пилю новые проекты.
Статья получилось вполне технической. На описание неприятных моментов и места то не осталось. Могу сказать, что все неприятные моменты связаны исключительно с впечатлением от windows, а не с проектом. Это всё таки был мой первый проект на оконном стеке. Впечатления непосредственно от проекта только самые лучшие. Хоть это и древнее легаси-зло, проект на самом деле очень крутой и интересный. И опыт поддержки и постановки таких проектов на новые рельсы без преувеличения можно назвать бесценным. В общем, в мире стало на один хороший проект с devops методологией больше.
|
https://habr.com/ru/post/550308/
| null |
ru
| null |
# Перехват вызовов функций в Linux или простейший файрвол своими руками
Вступление
==========
*Нетерпеливым эти лирические отступления можно не читать.*
Некоторое время назад меня посетила мысль: «Как сделать так, чтобы закрыть доступ к интернету (или к какому-то конкретному хосту) какой-нибудь одной программе в Linux?». Эта мысль меня посетила и полетела дальше по своим делам. И вот сегодня я получил в свой RSS-ридер [один вопрос на askdev.ru](http://www.askdev.ru/linux/3776/%D0%9A%D0%B0%D0%BA-%D0%B7%D0%B0%D0%BA%D1%80%D1%8B%D1%82%D1%8C-%D0%BF%D0%BE%D1%80%D1%82-%D1%83-%D0%BE%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%BD%D0%BE%D0%B9-%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D1%8B). Ба! Да это как раз то, о чем я думал! Надо помочь человеку, заодно и самому разобраться в вопросе.
Полез я в гугл смотреть, нету ли каких-нибудь намеков на решение. Оттуда я узнал, что штатным **iptables** это с некоторых пор сделать стало невозможно, а народ рекомендует посмотреть в сторону **AppArmor**. «Горя огромным желанием изучить **AppArmor**», я стал искать дальше и почти случайно наткнулся на [сообщение на ЛОРе](http://www.linux.org.ru/forum/general/3266778#comment-3266795), в котором описывался довольно интересный метод.
Метод
=====
Заключался он в том, чтобы «подменить» функцию соединения на свою, которая решает, разрешить ли соединение и «пропустить» запрос к настоящей функции или нет — вернуть ошибку. В сообщении многоуважаемого Chaoser'а использовалась низкоуровневая блокировка сокетов, которая не давала возможности принимать решение в зависимости от адреса сервера и/или порта. Это меня не устраивало, мне нужно было запретить доступ только для одного порта — 80-го. Запустив **telnet**, под **strace**'ом, я почти сразу увидел подходящую жертву — фунцию **connect**. **strace** ее описал так:
`connect(3, {sa_family=AF_INET, sin_port=htons(80), sin_addr=inet_addr("87.250.251.3")}, 16) = 0`
В этом описании отчетливо видно, что есть все необходимые мне составляющие: и IP-адрес, и порт, и тип подключения (AF\_INET).
Что ж, приступим.
Решение
=======
Для реализации данного метода, мы напишем библиотеку, которая будет загружаться раньше других при запуске приложения, и, таким образом, перехватывать функции, которые в ней определены (и которые предназначены для других библиотек).
Для начала выложу весь код, а затем будем разбирать все по отдельности.
> `1. #define \_GNU\_SOURCE
> 2. #include
> 3. #include
> 4. #include
> 5. #include
> 6. #include in
> .h>
> - #include
>
> - #include
>
> -
>
> - static int (\*real\_connect)(int sockfd, const struct sockaddr \*addr,
>
> - socklen\_t addrlen) = 0;
>
> -
>
> - int connect(int sockfd, const struct sockaddr \*addr,
>
> - socklen\_t addrlen)
>
> - {
>
> - printf("NF\_DEBUG: -----------------------------------------------\n");
>
> - int sa\_family = addr->sa\_family;
>
> - printf("NF\_DEBUG: Address family: %d (AF\_INET = %d)\n", sa\_family, AF\_INET);
>
> -
>
> - if (sa\_family == AF\_INET)
>
> - {
>
> - struct sockaddr\_in \*addr\_in = (struct sockaddr\_in\*)(addr);
>
> -
>
> - struct in\_addr sin\_addr = addr\_in->sin\_addr;
>
> - uint16\_t sin\_port = addr\_in->sin\_port;
>
> - uint16\_t sin\_port\_h = ntohs(sin\_port);
>
> -
>
> - printf("NF\_DEBUG: IP: %s\n", inet\_ntoa(sin\_addr));
>
> - printf("NF\_DEBUG: Port: %d\n", sin\_port\_h);
>
> -
>
> - if (sin\_port\_h == 80)
>
> - {
>
> - printf("NF\_DEBUG: Rejected!\n");
>
> - printf("NF\_DEBUG: -----------------------------------------------\n");
>
> - errno = ENETUNREACH;
>
> - return -1;
>
> - }
>
> - }
>
> -
>
> -
>
> - if(!real\_connect)
>
> - real\_connect = dlsym(RTLD\_NEXT, "connect");
>
> -
>
> - printf("NF\_DEBUG: Accepted\n");
>
> - printf("NF\_DEBUG: -----------------------------------------------\n");
>
> - return real\_connect(sockfd, addr, addrlen);
>
> - }
>
> \* This source code was highlighted with Source Code Highlighter.`
Разбор кода
===========
*Те, кто поняли, как работает вышеприведенная программа, могут этот раздел совершенно спокойно пропустить. В нем будет описано, какая строчка что делает. Это должно быть полезно новичкам. Тем, кто хорошо знает C, из этого, возможно, будут интересны лишь некоторые моменты.*
Строки 1-8 — директивы препроцессора, ничего интересного в них нет. Разве что директива **#define \_GNU\_SOURCE**, которая подключает расширения GNU, необходимые для функции **dlsym**.
В строках 10-11 мы объявляем указатель на «настоящую» функцию connect. У нас она будет называться **real\_connect**. Описание функции взято из **man connect**.
Со строки 13 начинается уже новая функция **connect**, которую будут вызывать приложения и которая будет принимать решение, пропустить это приложение или нет. Ее описание полностью соответствует оригинальной **connect** и взято из того же мануала.
В 17-й строке из структуры, которая содержит все необходимые нам данные (и описание которой я взял [здесь](http://www.retran.com/beej/sockaddr_inman.html)) получаем тип адреса.
Если тип адреса AF\_INET (строка 20), то есть приложение «просится наружу» по протоколу IPv4, то мы применяем фильтрацию (строки 22-37), иначе — сразу пропускаем это соединение к «настоящей» функции **connect**.
Для того, чтобы отфильтровать подключения, необходимо преобразовать структуру **addr** к типу **sockaddr\_in**, который дает возможность доступа к необходимым полям. Это происходит в строке 22.
Далее в строках 24-25 получаем значения адреса и порта, соответственно. В строке 26 мы меняем порядок следования байт в номере порта, тем самым получая обычный формат номера порта (80, 110, 25) из формата, который используется при соединении.
В строке 28 полученный адрес приводим к текстовому виду и выводим его, в 29-й строке выводим номер порта.
Далее в 31-й строке проверяем, соответствует ли номер порта тому, который мы хотим заблокировать, если да, то сообщаем об этом (строки 33-34), устанавливаем номер ошибки (строка 35; в данном случае будет ошибка «Сеть недоступна») и возвращаем ошибку (строка 36).
Если же все в порядке, то есть приложение обратилось, используя либо разрешенный порт, либо разрешенный тип адреса, то получаем адрес (точку входа) «настоящей» функции **connect** (строка 42), если до того мы его не получили (строка 41; не забываем, что **real\_connect** у нас переменная глобальная), пишем, что все хорошо (строки 44-45), и передаем управление «настоящей» функции **connect**.
При получении адреса «настоящей» функции **connect**, мы используем параметр **RTLD\_NEXT** для того, чтобы получить этот адрес из следующей загруженной библиотеки, а не из первой (нашей), иначе получим бесконечную рекурсию.
Использование
=============
Скомпилировать библиотеку:
`gcc -fPIC -shared -Wl,-soname,nonet.so -o nonet.so nonet.c`
и запустить нужное приложение следующим образом:
`LD_PRELOAD=/<полный путь к полученной библиотеке>/nonet.so <приложение>`
Например, если библиотека лежит в **/tmp**, то следующей строкой можно запустить **firefox** без доступа к интернету (естественно, только через 80-й порт):
`LD_PRELOAD=/tmp/nonet.so firefox`
Заключение
==========
Данный метод ни в коем случае не претендует на универсальность и всеприменимость, равно как и статья на Нобелевскую премию. Здесь я всего лишь осветил две темы, которые интересны мне, и, надеюсь, будут интересны еще кому-нибудь: ограничение доступа к сети опредеделенным программам и перехват вызовов функций в Linux.
Спасибо за внимание!
P.S. Чтобы меня не считали бесчестным человеком, укравшим код у digital'а c askdev.ru, думаю следует упомянуть, что digital и я — одно лицо.
**UPD** Большое спасибо за инвайт хабрачеловеку [peter23](https://habrahabr.ru/users/peter23/). Перенес пост в блог «Linux для всех».
|
https://habr.com/ru/post/108622/
| null |
ru
| null |
# Введение в Zend Framework
**Update (2014):** Это статья 2007 года, которая, к моему удивлению, до сих пор пользуется спросом. По этой причине я обновил её в соответствии с новыми правилами оформления постов на Хабре, и добавил подсветку синтаксиса для примеров кода. Если кому-то захочется что-то добавить или исправить, исходник текста с хабра-разметкой выложен в открытый доступ: [gist.github.com/dreikanter/2b4ee996d7a775e707d7](https://gist.github.com/dreikanter/2b4ee996d7a775e707d7)
#### Аннотация от переводчика
PHP — один из самых широко распространенных языков разработки веб-приложений и при этом один из самых спорных. Я очень часто видел негативное отношение к этой технологии, да и недостатки, провоцирующие это отношение — не для кого не являются секретом. Тем не менее, PHP активно эволюционирует и во многих отношениях постепенно становитс лучше. Одним из серьезных шагов его развития, на мой взгляд, является появление MVC-фреймворков, призванных систематизировать процесс разработки веб-приложений и приучить к порядку разработчиков, которым зачастую здорово не хватает силы воли, чтобы при всей предоставляемой языком свободе, сохранить грамотную и красивую инфраструктуру разрабатываемого ПО (сразу уточню, что последнее утверждение субъективно и основано исключительно на виденном мной коде различных программных решений).
В последнее время я активно заинтересовался архитектурой MVC и сделал свою собственную реализацию фреймворка на этой концепции для PHP4. Совсем недавно на глаза попался первый официальный релиз Zend Framework, о котором я давно слышал, но все руки не доходили с ним поиграть. Для PHP существуют и другие подобный библиотеки, но в данном случае привлек бренд.
Вначале я испытал некоторое разочарование в официальной документации, которая оказалась хорошим reference-ом, но просто никаким tutorial-ом и поэтому на роль вводного материала не подошла. Но почти сразу нашлась неплохая статья, в которой автор пошагово разбирает процесс создания веб-приложения. Материала достаточно, чтобы разобравшись в нем можно было начать осмысленно ориентироваться в мане от Zend. Текст ориентирован на программистов, имеющих некоторый опыт в программировании веб-приложений на PHP, но не знакомых с Zend Framework.
Статья довольно объемная, поэтому я решил разделить ее на две части, дабы не перегружать никому мозг. Ниже я привожу первую часть ее перевода, в которой в общих чертах освещена концепция MVC и разобрана структура веб-приложения, реализованного на Zend Framework. Если материал заинтересует хабрачитателей, я опубликую продолжение.
В завершение введения, небольшой дисклаймер. Уважаемые любители Ruby on Rails и Python on Django, я уважаю вашу религию :) Убедительная просьба не развивать в комментариях тему о том, какой фреймворк или язык лучше. Это совсем не относящаяся к топику данного поста тема. Мне и, вероятно, многим сейчас будет гораздо интереснее узнать об опыте реальных разработок ПО на Zend.
**Автор:** Роб Ален, [akrabat.com](http://akrabat.com)
**Оригинал:** [akrabat.com/zend-framework-tutorial](http://akrabat.com/zend-framework-tutorial/)
**Перевод:** Александр Мусаев, [musayev.com](http://musayev.com)
Материал рассчитан на то, чтобы дать общее представление об использовании Zend Framework для создания простейших приложений с использованием баз данных. Приведенные примеры были протестированы на Zend Framework версии 1.0.0. Скорее всего, они будут работать и с более поздними версиями, но не с более ранними.
#### Архитектура Модель-Вид-Контроллер
PHP-приложение, написанное традиционным способом, может представлять собой некое подобие следующего примера:
```
php
include "common-libs.php";
include "config.php";
mysql_connect($hostname, $username, $password);
mysql_select_db($database);
?
php include "header.php"; ?
Home Page
=========
php
$sql = "SELECT * FROM news";
$result = mysql_query($sql);
?
php while ($row = mysql\_fetch\_assoc($result)) { ?| php echo $row['date\_created']; ? | php echo $row['title']; ? |
php } ?
php include "footer.php"; ?
```
В ходе жизненного цикла приложений подобного типа, трудоемкость их поддержки становится крайне высока, т. к. меняющиеся требования заказчика приводят к необходимости вносить большое количество изменений («заплаток») в исходный код. Это делает его плохо структурированным и трудно читаемым. Один из методов для повышения гибкости приложения состоит в разделении кода на три категории:
* **Модель.** Моделью называют ту часть приложения, которая относится к работе с данными. в приведенном выше фрагменте кода, это реализация новостной ленты. Подобные модели широко применимы в управляющей логике приложений, имеющих в своей основе базы данных.
* **Вид.** Под термином «вид» подразумевается пользовательский интерфейс приложения.
* **Контроллер.** Контроллеры реализуют задачи, связанные со взаимодействием между моделью и видом.
Zend Framework основан на программной архитектуре Модель-Вид-Контроллер (Model-View-Controller). Ее суть состоит в разделении приложения на перечисленные выше три отдельные компоненты таким образом, что модификация каждого из них оказывает минимальное воздействие на остальные. Это приводит к существенному облегчению процесса разработки и поддержки.
#### Системные требования
У Zend Framework следующие требования:
* PHP версии 5.1.4 или выше;
* Веб-сервер, поддерживающий mod\_rewrite.
В данной статье используется сервер Apache.
#### Где скачать Zend Framework
Zend Framework доступен для свободного скачивания в виде ZIP или TAR.GZ архивов по адресу [framework.zend.com/download/stable](http://framework.zend.com/download/stable).
#### Структура директорий
На данный момент в Zend Framework жестко не стандартизирована структура директорий приложения, но в официальной документации рекомендуется использовать общепринятую схему. Эта схема основана на том, что пользователь, как предполагается, имеет полный доступ к конфигурированию сервера Apache. Мы же будем использовать немного видоизмененный подход, чтобы смягчить данные требования и сделать Zend Framework более применимым в условиях широко распространенного разделяемого хостинга.
Для начала, создайте директорию `zf-tutorial` в корневом каталоге вашего тестового веб-сайта. Это будет означать, что URL этой директории примет вид `localhost/zf-tutorial` (адрес может варьироваться, в зависимости от настроек вашего сервера).
После этого дополнительно создайте следующую структуру каталогов для хранения файлов веб-приложения:
```
zf-tutorial/
/application
/controllers
/models
/views
/filters
/helpers
/scripts
/library
/public
/images
/scripts
/styles
```
Как можно понять из названий, мы выделили специальные директории для файлов моделей, видов и контроллеров приложения. Графика, скрипты и CSS файлы будут храниться в отдельных подкаталогах, расположенных внутри открытой для публичного доступа директории `public`.
Для начала, разархивируйте скачанный файл `ZendFramework-1.0.0.zip` (или `.tar.gz`) во временную директорию. Все файлы внутри архива находятся в директории `ZendFramework-1.0.0`. Скопируйте содержимое `library/Zend` в `zf-tutorial/library`. Теперь ваша директория `zf-tutorial/library` должна содержать подкаталог `Zend`.
#### Начальная загрузка
Контроллер `Zend_Controller` из библиотеки Zend Framework спроектирован для поддержки сайтов с хорошо читаемыми («чистыми») URL. Для достижения этой цели, все запросы к серверу перенаправляются для обработки на специальный файл `index.php`, именуемый так же файлом начальной загрузки (bootstrapper). Такой подход обеспечивает централизованную организацию инфраструктуры приложения и гарантирует корректную для его функционирования настройку программного окружения. Это достигается благодаря использованию конфигурационного файла `.htaccess`, который находится в директории `zf-tutorial`.
`zf-tutorial/.htaccess:`
```
RewriteEngine on
RewriteRule .* index.php
php_flag magic_quotes_gpc off
php_flag register_globals off
```
Директивой `RewriteRule` задано очень простое правило перенаправления URL, которое может быть переведено на человеческий язык, как «использовать `index.php` вместо любого URL». Для обеспечения безопасности так же откорректированы некоторые настройки интерпретатора PHP. в принципе, они уже должны быть заданы соответствующим образом в конфигурационном файле `php.ini` любого грамотно настроенного сервера, но в нашем примере они дублируются локально для большей надежности. Обратите внимание на то, что директива `php_flag` внутри файла `.htaccess` может применяться только при использовании `mod_php`. Если вы используете PHP через CGI или FastCGI, необходимо удостовериться в правильной настройке `php.ini`.
Вопреки сказанному выше, запросы, относящиеся к графическим файлам, JavaScript и CSS, не должны быть перенаправлены на `index.php`. Учитывая, что все они хранятся в отдельной директории `public`, мы с легкостью можем настроить Apache, чтобы сервер отдавал их напрямую. Для этого необходимо создать еще один файл `.htaccess` в директории `public` и задать в нем соответствующую директиву.
`zf-tutorial/public/.htaccess:`
```
RewriteEngine off
```
Для повышения безопасности, можно создать дополнительные файлы `.htaccess` в директориях `zf-tutorial/application` и `zf-tutorial/library`, с одинаковым содержимым.
`zf-tutorial/application /.htaccess, zf-tutorial/library/.htaccess:`
```
Deny from all
```
Эта директива закроет доступ из web к содержимому указанных директорий. (Прим. переводчика: последние два файла можно не создавать вообще, если все, что находится вне директории `public`, заведомо закрыто глобальными настройками сервера).
Обратите внимание на то, что для использования файлов `.htaccess`, в настройках сервера Apache (`httpd.conf`) должна быть задана директива `AllowOverride` со значением `All`. Приведенная в данной статье идея использования файлов `.htaccess` принадлежит Джейсону Майнарду (Jayson Minard) и опубликована в статье «Схема построения PHP-приложений: начальная загрузка (Часть 2)» (http://devzone.zend.com/node/view/id/119). Начинающим разработчика стоит ознакомиться с обеими ее частями.
#### Файл начальной загрузки index.php
Файл начальной загрузки `zf-tutorial/index.php` содержит следующий код:
```
php
error_reporting(E_ALL|E_STRICT);
date_default_timezone_set('Europe/London');
set_include_path('.'.PATH_SEPARATOR . './library'
.PATH_SEPARATOR.'./application/models/'
.PATH_SEPARATOR.get_include_path());
include "Zend/Loader.php";
Zend_Loader::loadClass('Zend_Controller_Front');
// setup controller
$frontController = Zend_Controller_Front::getInstance();
$frontController-throwExceptions(true);
$frontController->setControllerDirectory('./application/controllers');
// run!
$frontController->dispatch();
```
Заметьте, что в конце файла отсутствует закрытие блока PHP кода `?>`, т. к. в нем нет необходимости. Кроме того, наличие закрывающего тага может привести к появлению сложных для выявления ошибок при редиректе функцией `header()`, если в конце файла по недосмотру останутся лишние пробелы.
Рассмотрим код подробнее.
```
error_reporting(E_ALL|E_STRICT);
date_default_timezone_set('Europe/London');
```
Данные строки обеспечивают вывод интерпретатором всех сообщений о происходящих ошибках (подразумевается, что в конфигурационном файле `php.ini` параметру `display_errors` задано значение `on`). Вторая строка кода задает часовой пояс, согласно стандартному требованию PHP 5.1+. Приведенное в примере значение параметра следует заменить на соответствующее вашему географическому положению.
```
set_include_path('.'.PATH_SEPARATOR.'./library'
.PATH_SEPARATOR.'./application/models/'
.PATH_SEPARATOR.get_include_path());
include "Zend/Loader.php";
```
Zend Framework рассчитан на то, чтобы его файлы находились в `include_path`, поэтому мы добавляем к значению этого параметра путь к нужной директории. Помимо него, в `include_path` добавляется директория моделей, чтобы облегчить подключение файлов и из нее.
Файл `Zend/Loader.php` содержит класс `Zend_Loader` со статическими функциями, позволяющими подключать любой класс из Zend Framework.
```
Zend_Loader::loadClass('');
```
Метод `Zend_Loader::loadClass()` подключает класс с заданным именем. Для этого выполняется преобразование указанного имени в путь к соответствующему файлу: символы «\_» заменяются на «/», а в конце получившейся строки добавляется расширение `.php`. Таким образом, `Zend_Controller_Front` преобразуется в `Zend/Controller/Front.php`. Если следовать аналогичной схеме построения имен для собственных библиотечных классов, то метод `Zend_Loader::loadClass()` можно будет использовать и с ними.
Класс, который понадобится нам прежде всего, — первичный контроллер. При его работе, в свою очередь, используется специальный класс-роутер, чья задача состоит в нахождении по заданному URL функции отображения соответствующей веб страницы. Для этого роутере должен быть определен базовый URL файла `index.php`, относительно которого он сможет выделять URI отдельных страниц.
Базовый URL может автоматически определяется с помощью объекта `Request`, а для того, чтобы применить его в нашем примере следует воспользоваться методом `$frontController->setBaseUrl()`.
Далее нам понадобится сообщить первичному контроллеру о местоположении директории с другими контроллерами:
```
$frontController = Zend_Controller_Front::getInstance();
$frontController->setControllerDirectory('./application/controllers');
$frontController->throwExceptions(true);
```
Учитывая, что наша программа предназначена для образовательных целей и функционирует на тестовой системе, можно разрешить все исключения, которые могут происходить при ее работе. По-умолчанию, первичный контроллер будет перехватывать их все до одного и хранить в свойстве `_exceptions` своего объекта (данному объекту соответствует англоязычный термин Response object). Этот объект используется для хранения всей информации, возвращаемой при обращении к заданному URL, что включает HTTP-заголовок, содержимое веб-страницы и массив произошедших исключений.
Первичный контроллер автоматически выдает заголовок и контент страницы непосредственно перед окончанием своей работы. Тех, кто ранее не встречался с архитектурой веб-приложений, подобной Zend Framework, может привести в некоторое недоумение тот факт, что для отображения сообщений об исключительных ситуациях, их (исключения) необходимо повторно возбуждать. Эта особенность становится актуальной для серверов, работающих в своем штатном режиме, когда вывод сообщений об ошибках на страницах неуместен.
В итоге, после всех выполненных приготовлений, наше приложение может быть запущено:
```
// run!
$frontController->dispatch();
```
Если вы сейчас попытаетесь открыть страницу `localhost/zf-tutorial`, то увидите сообщение о фатальной ошибке, гласящее примерно следующее:
`Fatal error: Uncaught exception 'Zend_Controller_Dispatcher_Exception' with message 'Invalid controller specified (index)' in...`
Это говорит о том, что мы еще не до конца сформировали наше веб-приложение. и прежде чем приступить к делу, стоит уяснить, в чем конкретно состоит задача.
#### Веб-сайт
Предположим, что мы хотим создать простую базу данных для хранения информации о компакт-дисках. На главной странице будет отображен список дисков в нашей коллекции, а так же будет предоставлена возможность добавлять новые CD, редактировать и удалять ненужные записи. Для хранения данных, используем базу со схемой, приведенной ниже:
| Fieldname | Type | Null? | Notes |
| --- | --- | --- | --- |
| id | Integer | No | Primary key, Autoincrement |
| artist | Varchar(100) | No | |
| title | Varchar(100) | No | |
##### Необходимые страницы
Для реализации перечисленных выше функций, нам понадобятся следующие страницы:
* **Начальная («домашняя») страница.** Список альбомов со ссылками для их редактирования и удаления. На странице так же будет присутствовать ссылка для добавления новых дисков.
* **Добавить альбом.** Страница с формой добавления нового диска в базу.
* **Редактировать альбом.** Страница с формой для редактирования записи.
* **Удалить альбом.** Страница для запроса пользовательского подтверждения перед удалением диска.
#### Организация страниц
Прежде чем приступить к созданию файлов, следует понять, как принято организовывать их в Zend Framework. Согласно принятой терминологии, каждая страница веб-приложения определяется термином «действие».
**Примечание переводчика.** Небольшое пояснение терминологии. Англоязычным оригиналом используемого в данной статье термина «действие» является слово action. Приведенный перевод на данный момент еще не является устоявшимся понятием, и в некоторых текстах о модели MVC вместо него попадаются иные определения. Например, так же известна прямая (и режущая слух) транслитерация — «экшен».
Действия, в свою очередь, объединяются в специальные группы — «контроллеры». Например, для URL `localhost/zf-tutorial/news/view` контроллером будет `news`, а действием — `view`. Контроллеры предназначены для объединения родственных действий. Для упомянутого news, могут быть определены действия `current`, `archived` и `view` (соответственно для отображения последней новости, архива записей и новостной ленты).
В Zend Framework так же используются модули для группировки контроллеров, но наше приложение не настолько велико, чтобы имело смысл их применять.
В контроллерах Zend Framework существует понятие действия по-умолчанию, для которого зарезервировано имя `index`. Такие действия исполняются при обращении к URL вида `localhost/zf-tutorial/news` (в данном примере выполняется действие `index` контроллера `news`). Помимо исполняемых по-умолчанию действий, так же предусмотрены выбираемые по-умолчанию контроллеры с аналогичным именем — `index`. Это означает, что URL `localhost/zf-tutorial` будет соответствовать действию `index` контроллера `index`.
Учитывая, что данная статья ориентирована на первое знакомство с Zend Framework, мы не будем пока касаться таких нюансов работы веб-приложения, как авторизация пользователей. Ограничимся реализацией основной функциональности, а именно — набором перечисленных выше страниц. Учитывая, что все они относятся к работе с альбомами, можно отнести их к одному контроллеру. Мы используем стандартный контроллер, а его действия будут выглядеть следующим образом:
| Страница | Контроллер | Действие |
| --- | --- | --- |
| Начальная страница | Index | Index |
| Добавить альбом | Index | Add |
| Редактировать альбом | Index | Edit |
| Удалить альбом | Index | Delete |
#### Настройка контроллера
Приступим к созданию нашего контроллера. в Zend Framework контроллер представляет собой класс с именем типа `{Имя_контроллера}Controller`. Класс должен быть описан внутри файла с именем `{Имя_контроллера}Controller.php`, в общей директории контроллеров. Стоит обратить внимание на важный нюанс: первая буква в имени класса-контроллера и имени его файла должна быть заглавной, а все остальные — строчными. Каждое действие должно быть открытой функцией класса-контроллера с именем типа `{имя_действия}Action`. в данном случае, имена действий должны начинаться со строчной буквы.
Таким образом, наш класс-контроллер будет носить имя `IndexController` и находиться в файле `zf-tutorial/application/controllers/IndexController.php`.
`zf-tutorial/application/controllers/IndexController.php:`
```
php
class IndexController extends Zend_Controller_Action
{
function indexAction()
{
echo "<pin IndexController::indexAction()";
}
function addAction()
{
echo "in IndexController::addAction()
";
}
function editAction()
{
echo "in IndexController::editAction()
";
}
function deleteAction()
{
echo "in IndexController::deleteAction()
";
}
}
```
В данном макете контроллера каждое действие будет выводить свое имя. Это можно протестировать, задавая приведенные ниже URL:
| URL | Displayed text |
| --- | --- |
| `localhost/zf-tutorial` | in `IndexController::indexAction()` |
| `localhost/zf-tutorial/index/add` | in `IndexController::addAction()` |
| `localhost/zf-tutorial/index/edit` | in `IndexController::editAction()` |
| `localhost/zf-tutorial/index/delete` | in `IndexController::deleteAction()` |
Теперь у нас имеется работающий класс-роутер с набором действий, соответствующих каждой странице веб-приложения. При возникновении каких-либо проблем в процессе его создания, обратитесь к разделу «Устранение неполадок» в конце статьи.
А теперь пришло время добавить в наше приложение новый вид.
#### Вид
Класс Zend Framework, на базе которого строится вид, называется просто и бесхитростно — `Zend_View`. Вид позволяет отделить код, отвечающий за отображение страницы, от кода функций-действий.
Простейший вариант использования `Zend_View` выглядит как показано ниже:
```
$view = new Zend_View();
$view->setScriptPath('/path/to/view_files');
echo $view->render('view.php');
```
Легко можно понять, что если бы мы захотели поместить приведенный код в каждую функцию-действие, это привело бы к его многократному дублированию, что не явилось бы красивым решением. Вместо этого, мы выполним инициализацию вида отдельно, а из функций-действий затем будем только обращаться к нему.
Разработчики Zend Framework предусмотрели решение этой задачи и для ее решения создали так называемые «помощники действий» (action helpers). Класс `Zend_Controller_Action_Helper_ViewRenderer` инициализирует свойство `view` для нашего последующего использования (`$this->view`), а так же занимается отображением скриптов вида. Для рендеринга веб-страниц он использует объект `Zend_View`, который в свою очередь находит скрипты видов в файлах `views/scripts/{имя_контроллера}/{имя_действия}.phtml` (по-умолчанию они хранятся именно там, но при необходимости дислокацию скриптов можно менять).
После рендеринга, сгенерированный контент веб-страницы сохраняется в объекте Response, который, как было упомянуто ранее, служит для группировки HTTP заголовков, содержимого страницы и сгенерированных в ходе работы скрипта исключительных ситуаций. в итоге, первичный контроллер автоматически отсылает веб-клиенту заголовок страницы и ее содержательную часть.
Итак, для того, чтобы добавить вид в наше приложение, все, что нам потребуется, — создать несколько файлов с тестовым кодом. Никаких принципиальных изменений внутри контроллера не понадобится, но для большей наглядности мы выполним небольшую корректировку выводимого им текста.
Изменения внутри класса `IndexController` выделены жирным шрифтом.
`zf-tutorial/application/contollers/IndexController.php:`
```
php
class IndexController extends Zend_Controller_Action
{
function indexAction()
{
$this-view->title = "My Albums";
}
function addAction()
{
$this->view->title = "Add New Album";
}
function editAction()
{
$this->view->title = "Edit Album";
}
function deleteAction()
{
$this->view->title = "Delete Album";
}
}
```
Внутри каждой функции мы присваиваем значение переменной `title` свойства `view`. Заметьте, что при этом в действительности не происходит никакого отображения текста — это задача первичного контроллера, которая будет выполнена в самом конце работы системы.
Теперь нам понадобится добавить четыре файла для видов нашего веб-приложения.
`zf-tutorial/application/views/scripts/index/index.phtml:`
```
php echo $this-escape($this->title); ?>
php echo $this-escape($this->title); ?>
=======================================
```
`zf-tutorial/application/views/scripts/index/add.phtml:`
```
php echo $this-escape($this->title); ?>
php echo $this-escape($this->title); ?>
=======================================
```
`zf-tutorial/application/views/scripts/index/edit.phtml:`
```
php echo $this-escape($this->title); ?>
php echo $this-escape($this->title); ?>
=======================================
```
`zf-tutorial/application/views/scripts/index/delete.phtml:`
```
php echo $this-escape($this->title); ?>
php echo $this-escape($this->title); ?>
=======================================
```
При тестирование каждого из действий, должны быть отображены выделенные заголовки каждой из страниц.
##### Общий HTML-код
Уже сейчас становится заметно использование одинаковых фрагментов HTML кода в наших видах. Выделим идентичные для всех файлов части в два отдельных файла: `header.phtml` и `footer.phtml`, созданных внутри все той же директории со скриптами.
`zf-tutorial/application/views/scripts/header.phtml:`
```
php echo $this-escape($this->title); ?>
```
(Обратите внимание на изменения, добавленный в код.)
`zf-tutorial/application/views/scripts/footer.phtml:`
```
```
Файлы видов так же понадобится откорректировать.
`zf-tutorial/application/views/scripts/index/index.phtml:`
```
php echo $this-render('header.phtml'); ?>
php echo $this-escape($this->title); ?>
=======================================
php echo $this-render('footer.phtml'); ?>
```
`zf-tutorial/application/views/scripts/index/add.phtml:`
```
php echo $this-render('header.phtml'); ?>
php echo $this-escape($this->title); ?>
=======================================
php echo $this-render('footer.phtml'); ?>
```
`zf-tutorial/application/views/scripts/index/edit.phtml:`
```
php echo $this-render('header.phtml'); ?>
php echo $this-escape($this->title); ?>
=======================================
php echo $this-render('footer.phtml'); ?>
```
`zf-tutorial/application/views/scripts/index/delete.phtml:`
```
php echo $this-render('header.phtml'); ?>
php echo $this-escape($this->title); ?>
=======================================
php echo $this-render('footer.phtml'); ?>
```
##### Стилевое оформление
Для того, чтобы сделать наше веб-приложение визуально более привлекательным, используем CSS. На этом этапе возникает небольшая проблема, связанная с тем, что заранее неизвестен URL корневой директории, необходимый для ссылки на CSS-файл. Для разрешения этой задачи используется функция `getBaseUrl()` передаваемого в вид объекта `Request`. Она и предоставит нам неизвестный заранее фрагмент URL.
Это свойство становится доступным из любого действия, после выполнения `IndexController::init()`.
`zf-tutorial/application/controllers/IndexController.php:`
```
...
class IndexController extends Zend_Controller_Action
{
function init()
{
$this->view->baseUrl = $this->_request->getBaseUrl();
}
function indexAction()
{
...
```
Ссылку на CSS-фалй понадобится добавить в секцию файла `header.phtml`:
`zf-tutorial/application/views/scripts/header.phtml:`
```
...
php echo $this-escape($this->title); ?>
...
```
В завершении, понадобится создать, собственно, сам стилевой файл.
`zf-tutorial/public/styles/site.css:`
```
body,html {
font-size: 100%;
margin: 0;
font-family: Verdana, Arial, Helvetica, sans-serif;
color: #000;
background-color: #fff;
}
h1 {
font-size:1.4em;
color: #800000;
background-color: transparent;
}
#content {
width: 770px;
margin: 0 auto;
}
label {
width: 100px;
display: block;
float: left;
}
#formbutton {
margin-left: 100px;
}
a {
color: #800000;
}
```
Это заставит страницы выглядеть несколько приятнее.
[Продолжение статьи](http://habrahabr.ru/post/31173/)
|
https://habr.com/ru/post/31168/
| null |
ru
| null |
# Установка vmware tools для debian 8 в виртуальной машине [мануал]
С полноценной установкой debian в VMWare у меня была постоянная морока, т.к. никогда у меня без напильника до конца нормально не устанавливались vmware tools. Может у меня руки не те, спорить не буду — с линуксом я всё же не на ты. Недавно вышла новая версия debian и, на второй день после официального релиза, я принял волевое решение перевести свои виртуалки, организующие серверы FTP/SFTP, с WindowsXP на линукс. Тут как раз подоспела новая версия VMWare 11, новая версия тулзов, debian 8 testing уже давно народом использовалась и я решил что уже всё должно быть гладко и мне надо будет поднапрячься и только разобраться с настройками proftpd. После установки и настройки debian 8 я решил установить vmware tools и завершить, таким образом, начальную фазу — подготовку базовой машины. И что вы думаете? VMware tools встали кривовато…
Этот вопиющий факт не оставил меня равнодушным.Ну сколько уже можно? Например, Gnome3 на debian 7 у меня запускался только в альтернативной режиме и никак не получалось нормально установить драйвера для видео и/или задействовать поддержку 3D. Я помню некоторое время потратил на поиск решения и опробывания предложений по самостоятельной сборке, но успеха мне это не принесло и я забросил это дело, тем более работе оно не мешало. Но оставалось чувство недовыполненности работы.
И тут, опять что-то не то. GUI заработал изначально нормально. Gnome3 после настройки мне даже очень понравился (настройка через gnome-tweak-tool + допрасширения: Lock keys, Remove dropdown arrows). Тулсы ставятся почти нормально. Но в конечном счёте мы не получаем поддержки Shared Folders. Это печально, т.к. такой механизм удобен: подключаем папки в настройках виртуалки, они автоматом монтируются в /mnt/hgfs/. И не надо заморачиваться с расшариванием папок по сети в хостовой машине. Но после установки тулзов мы получаем неработающий модуль vmhgfs. В рунете я решения не нашел, но помню нашёл как решить проблему на каком-то англоязычном форуме. Это всё действо происходило 26-28 апреля. Меня удивило когда вчера ко мне обратился знакомый и посетовал, дескать не могу настроить вмваровскую сеть в виртуалке с новым дебианом. И я решил написать мануал другу, оформив его в виде статьи на хабре — вдруг ещё кому-то пригодится!
Итак, как установить тулзы.
Для начала устанавливаем нужные пакеты для сборки тулзов (это тянется с доисторических времён, иначе есть риск, что нормально ничего не соберётся):
```
sudo apt-get install linux-headers-$(uname -r) make gcc
```
Если далее выполнить установку штатных тулзов из поставки VMWare:
```
mount the VMware tools cdrom and install VMware Tools
sudo mount /dev/cdrom /media/cdrom
tar xvzf /media/cdrom/VMwareTools-9.9.2-2496486.tar.gz
cd vmware-tools-distrib
sudo ./vmware-install.pl -d
```
То после презагрузки получим неработающий модуль vmhgfs. Цитирую конец лога установки:
> /usr/src/linux-headers-3.16.0-4-common/scripts/Makefile.build:262: ошибка выполнения рецепта для цели «/tmp/modconfig-zqp0EX/vmhgfs-only/inode.o»
>
> make[4]: \*\*\* [/tmp/modconfig-zqp0EX/vmhgfs-only/inode.o] Ошибка 1
>
> make[4]: \*\*\* Ожидание завершения заданий…
>
> /usr/src/linux-headers-3.16.0-4-common/Makefile:1350: ошибка выполнения рецепта для цели «\_module\_/tmp/modconfig-zqp0EX/vmhgfs-only»
>
> make[3]: \*\*\* [\_module\_/tmp/modconfig-zqp0EX/vmhgfs-only] Ошибка 2
>
> Makefile:181: ошибка выполнения рецепта для цели «sub-make»
>
> make[2]: \*\*\* [sub-make] Ошибка 2
>
> Makefile:8: ошибка выполнения рецепта для цели «all»
>
> make[1]: \*\*\* [all] Ошибка 2
>
> make[1]: выход из каталога «/usr/src/linux-headers-3.16.0-4-amd64»
>
> Makefile:120: ошибка выполнения рецепта для цели «vmhgfs.ko»
>
> make: \*\*\* [vmhgfs.ko] Ошибка 2
>
> make: выход из каталога «/tmp/modconfig-zqp0EX/vmhgfs-only»
>
>
>
> The filesystem driver (vmhgfs module) is used only for the shared folder
>
> feature. The rest of the software provided by VMware Tools is designed to work
>
> independently of this feature.
>
>
>
> If you wish to have the shared folders feature, you can install the driver by
>
> running vmware-config-tools.pl again after making sure that gcc, binutils, make
>
> and the kernel sources for your running kernel are installed on your machine.
>
> These packages are available on your distribution's installation CD.
Для устранения этой печальной проблемы нужно выполнить ряд действий по замене d\_alias на d\_u.d\_alias в пакете vmhgfs:
```
#!/bin/sh -x
cd /usr/lib/vmware-tools/modules/source
tar xf vmhgfs.tar
grep -q d_u.d_alias vmhgfs-only/inode.c && echo "already patched" && exit 0
sed -i -e s/d_alias/d_u.d_alias/ vmhgfs-only/inode.c
cp -p vmhgfs.tar vmhgfs.tar.orig
tar cf vmhgfs.tar vmhgfs-only
vmware-config-tools.pl -d -m
```
После этого функционал Shared Folders от VMWare начнет нормально работать — в папке /mnt/ngfs появятся подключенные папки в настройках виртуальной машины.
ПРИМЕЧАНИЕ: это метод, несовместим с более ранними версиями ядра (ниже 3.13.0-45)!!!
После этих исправлений я собрал обратно тулзы в архив, из которого теперь можно устанавливать тузлы не заморачиваясь с дополнительными действия по замене d\_alias на d\_u.d\_alias. Если кому-то нужно я могу выложить файл. Подскажите только куда, файл весит 178Мб, хотелось бы выложить его на какой-то файловый хостинг без регистрации и прочей мороки, что бы он там пролежал год-два хотябы.
Справедливости ради, считаю, нужно отметить что не только на тулзах от vmware свет клином сошёлся. Существует замечательный проект [open-vm-tools](https://github.com/vmware/open-vm-tools). Пакет, правда, давно не обновлялся, но в своё время я им вполне успешно обходился и всё там всегда сразу работало. К тому же open.
Так же добрые люди подсказывают, что существует еще удобный набор патчей [vmware-tools-patches](https://github.com/rasa/vmware-tools-patches).
|
https://habr.com/ru/post/259749/
| null |
ru
| null |
# Audio over Bluetooth: most detailed information about profiles, codecs, and devices

[This article is also available in Russian / Эта статья также доступна на русском языке](https://habr.com/ru/post/427997/)
The mass market of smartphones without the 3.5 mm audio jack changed headphones industry, wireless Bluetooth headphones have become the main way to listen to music and communicate in headset mode for many users.
Bluetooth device manufacturers rarely disclose detailed product specifications, and Bluetooth audio articles on the Internet are contradictory and sometimes incorrect. They do not tell about all the features, and often publish the same false information.
Let's try to understand the protocol, the capabilities of Bluetooth stacks, headphones and speakers, Bluetooth codecs for music and speech, find out what affects the quality of the transmitted audio and the delay, learn how to capture and decode information about supported codecs and other device features.
**TL;DR**:
* SBC codec is OK
* Headphones have their own per-codec equalizer and post processing configuration
* aptX is not as good as the advertisements say
* LDAC is a marketing fluff
* Voice audio quality is still low
* Browsers are able to execute audio encoders compiled to WebAssembly from C using emscripten, and they won't even lag.
Music via Bluetooth
===================
The functional components of Bluetooth are defined by profiles—documented features formalized in specifications. Bluetooth music is transmitted using a high-quality audio A2DP transmission profile. The A2DP standard was adopted in 2003, and has not changed drastically since then.
The profile standardize one mandatory codec—SBC, a low computational complexity codec created specifically for Bluetooth, and 3 additional codecs. One can also use vendor-specific codecs of your own implementation, not included into A2DP.
As of June 2019, we live [in XKCD comic](https://xkcd.com/927/) with 14 A2DP codecs:
* **SBC** ← included into A2DP, supported by all devices
* **MPEG-1/2 Layer 1/2/3** ← included into A2DP: widely-known [MP3](https://en.wikipedia.org/wiki/MP3), common in digital TV [MP2](https://en.wikipedia.org/wiki/MPEG-1_Audio_Layer_II), and obsolete [MP1](https://en.wikipedia.org/wiki/MPEG-1_Audio_Layer_I)
* **MPEG-2/4 AAC** ← included into A2DP
* **ATRAC** ← Sony's old codec, included into A2DP
* **LDAC** ← Sony's new codec
* **aptX** ← codec from 1988
* **aptX HD** ← the same as aptX but with different encoding profile
* **aptX Low Latency** ← ~~totally different codec, no software implementation~~ aptX with lower buffer
* **aptX Adaptive** ← another Qualcomm codec
* **FastStream** ← pseudo-codec, SBC bidirectional modification
* **HWA LHDC** ← Huawei’s New Codec
* **Samsung HD** ← supported by 2 devices
* **Samsung Scalable** ← supported by 2 devices
* **Samsung UHQ-BT** ← supported by 3 devices
You may wonder why we need a codec in the first place, if Bluetooth has EDR, which allows you to transfer data at 2 or 3 Mb/s while uncompressed two-channel 16-bit PCM requires only 1.4 Mb/s?
Bluetooth Data Transfer
=======================
There are two types of data transfer in Bluetooth: Asynchronous Connection Less (ACL) for asynchronous transfer without establishing a connection, and Synchronous Connection Oriented (SCO), for synchronous transfer with connection establishment.
Data transmission uses time-division scheme and changes frequency channel for each transmitted data packet (Frequency-Hop/Time-Division-Duplex, FH/TDD). The time is divided into 625 microsecond intervals, called slots. One of the devices transmits in even numbers of slots, the other—in odd numbers. A transmitted packet can occupy 1, 3 or 5 slots, depending on the size of the data and the transmission mode. If the packet is big enough and more than one slot transmission mode is used, the data is carried out in even and odd slots until the end of the transmission. In one second you can receive and send up to 1600 packets if each of them occupies 1 slot and both devices continuously transmit and receive data.
Transfer rates of 2 or 3 Mbps for EDR found in announcements and on Bluetooth website are the maximum channel data transfer rate of all data in total (including the technical headers of all protocols for data to be encapsulated into) in two directions simultaneously. The actual data transfer rate will vary greatly.
Asynchronous method is used for music streaming, almost always using 2-DH5 and 3-DH5 type packets, which carry the maximum amount of data in 2 Mb/s and 3 Mb/s EDR modes respectively and occupy 5 time division slots.
Schematic representation of transmission using 5 slots by one device and 1 slot by another (DH5/DH1):

Due to time sharing principle, we have to wait for a 625 microsecond time slot after transmitting a packet if the second device does not transmit anything to us or transmits a small packet, and more time if the second device performs transmission in large packets. If more than one device is connected to the phone (e. g. headphones, smart watch and a fitness bracelet), then the transmission time is shared between them all.
A2DP audio streaming requires encapsulation in a special transport protocols L2CAP and AVDTP which deduct 16 bytes from the maximum possible amount of audio payload in the packet.
| Packet type | Slot amount | Max bytes per packet | Max A2DP payload bytes | Max A2DP payload bitrate |
| --- | --- | --- | --- | --- |
| 2-DH3 | 3 | 367 | 351 | 936 Kb/s |
| 3-DH3 | 3 | 552 | 536 | 1429 kb/s |
| 2-DH5 | 5 | 679 | 663 | 1414 kb/s |
| 3-DH5 | 5 | 1021 | 1005 | 2143 kb/s |
1414 and 1429 kbps are just not enough to transmit uncompressed audio in real-world conditions, with a noisy 2.4 GHz band and occasional service data. EDR 3 Mbps is demanding of transmit power and signal/noise ratio, so even in 3-DH5 mode no comfortable PCM transmission is possible, as there will always be short-term interruptions and everything will work more or less reliable only at a distance of a couple of meters.
In practice, even 990 kb/s audio stream (LDAC 990 kb/s) is not trivial to transmit reliably.
Let's get back to the codecs.
SBC
---
This codec is mandatory for all devices supporting A2DP standard. The best and the worst codec at the same time.
| Sample rate | Bit depth | Bit rate | Encoding support | Decoding support |
| --- | --- | --- | --- | --- |
| 16, 32, 44.1, 48 kHz | 16 bit | 10-1500 kb/s | All devices | All devices |
SBC is a simple and computationally fast codec with a primitive psychoacoustic model (with simple auditory masking) using adaptive pulse code modulation (APCM).
A2DP specification recommends using two profiles: Middle Quality and High Quality.

The codec has many settings that allow you to control the algorithmic delay, number of samples in the block and bit allocation algorithm, but almost always the parameters used in the specification are used everywhere: Joint Stereo, 8 frequency bands, 16 blocks in the audio frame, Loudness bit allocation method.
SBC can adjust bitpool parameter dynamically, which directly affects the bitrate. If the radio is clogged, packets are lost, or devices are far away, the audio source can reduce bitpool to prevent audio disruptions until the connection is stable again.
Manufacturers of most headphones set the maximum value of bitpool parameter to 53, which limits the bitrate to 328 kilobits per second when using the recommended profile.
Even if the headphone manufacturer has set the maximum bitpool value above 53 (which is true, for instance, for Beats Solo³, JBL Everest Elite 750NC, Apple AirPods, and also for some receivers and car head units), most OS will not allow using higher bit rates due to internal limits in Bluetooth stacks.
In addition, some manufacturers set low maximum bitpool value for some devices. For example, in Bluedio T it equals to 39, in Samsung Gear IconX it is 37, which gives poor sound quality.
The artificial limitations were introduced in Bluetooth stacks probably due to insufficient amount of certification tests and incompatibility of some devices with large Bitpool values or atypical profiles, even if they report to support them. It was easier for the developers to restrict the options to known-good values of a recommended profile, rather than creating database of incompatible devices. Though now they do this for other incorrectly working functions.
SBC dynamically allocates quantization bits for frequency bands, acting from bottom to top, with different weights. If the entire bit rate was used for low and middle frequencies, the upper frequencies will be cut off (replaced by silence).
Example of SBC 328 kbps. Original audio is on the top, SBC-encoded audio is on the bottom. The tracks are switched for comparison. Audio stream in the video file is compressed using FLAC lossless codec. Using FLAC in the mp4 container is not officially standardized, that's why the audio may not play in your browser (should work in the latest versions of desktop Chrome and Firefox). If you do not have sound, you can download the file and open it in any video player.
Your browser does not support HTML5 video.*ZZ Top — Sharp Dressed Man*
The moment of switching is visible on the spectrogram: SBC periodically cuts quiet sounds above 17.5 kHz, and does not allocate bits at all for a band above 20 kHz. The spectrogram is clickable (1.7 MB).
[](https://habrastorage.org/webt/qj/i7/4w/qji74wrphaigw3qtza6nepvur50.png)
I can not hear the difference between the original and the SBC on this track.
Let's take something newer and simulate audio quality of Samsung Gear IconX headphones with Bitpool 37 (top is the original stream, bottom is SBC 239 kbps, FLAC is used for audio).
Your browser does not support HTML5 video.*Mindless Self Indulgence — Witness*
I hear crackle, a smaller stereo effect and an unpleasant «clatter» of vocals at high frequencies.
To sum up, SBC is a very flexible codec: it can be configured for low latency, gives excellent audio quality at high bitrates (452+ kb/s) and is quite good for most people on standard High Quality (328 kb/s). However, there are a few reasons why the codec is infamous for its low sound quality: A2DP standard does not define fixed profiles (it only gives recommendations), Bluetooth stack developers set artificial limits on Bitpool, the parameters of the transmitted audio are not displayed in the user interface, and headphone manufacturers are free to set their settings and never specify the Bitpool value in technical characteristics of the product.
The bitpool parameter directly affects the bitrate only within one profile. The same bitpool value of 53 can produce both the 328 kbps bitrate with the recommended High Quality profile, and 1212 kbps in Dual Channel mode and 4 frequency bands, which is why the OS authors also set limits on bitrate in addition to bitpool. I assume the situation arose due to the flaw in the A2DP standard: it was necessary to negotiate the bitrate, not bitpool.
Table of SBC features supported in different OS:
| OS | Sample rate | Max bitpool limit | Max bitrate limit | Typical bitrate | Dynamic bitpool support |
| --- | --- | --- | --- | --- | --- |
| **Windows 10** | 44.1 kHz | 53 | 512 kb/s | 328 kb/s | ✓\* |
| **Linux (BlueZ + PulseAudio)** | 16, 32, 44.1, 48 kHz | 64 (for incoming connections), 53 (for outgoing connections) | No limit | 328 kb/s | ✓\* |
| **macOS High Sierra** | 44.1 kHz | 64, 53 by default\*\*\* | Unknown | 328 kb/s | ✗ |
| **Android 4.4-9** | 44.1/48 kHz\*\* | 53 | 328 kb/s | 328 kb/s | ✗ |
| **Android 4.1-4.3.1** | 44.1, 48 kHz\*\* | 53 | 229 kb/s | 229 kb/s | ✗ |
| **Blackberry OS 10** | 48 kHz | 53 | No limit | 328 kb/s | ✗ |
***\*** Bitpool decreases, but does not increase automatically in case of varying transmission conditions. To restore bitpool, you need to stop playback, wait a couple of seconds and restart the audio.
**\*\*** The default value depends on the stack settings specified when compiling the firmware. In Android 8/8.1 the frequency is only either 44.1 kHz or 48 kHz, depending on the settings when compiling, other versions support 44.1 kHz and 48 kHz simultaneously.
**\*\*\*** Bitpool value can be adjusted using Bluetooth Explorer software.*
aptX and aptX HD
----------------
aptX is a simple and computationally fast codec, without psychoacoustics, which uses adaptive differential pulse code modulation ([ADPCM](https://en.wikipedia.org/wiki/Adaptive_differential_pulse-code_modulation)). It appeared around 1988 ([patent](https://patents.google.com/patent/EP0398973B1/en) filing date is February 1988). Before Bluetooth, it was used mostly for professional wireless audio equipment. Currently owned by Qualcomm, it requires licensing and license fees. As of 2014: $6,000 one-time payment and ≈ $1 per-device, for batches of up to 10,000 devices ([source](https://www.silabs.com/documents/login/presentations/Developing-Bluetooth-Audio.pdf), page 16).
The codec has only one parameter—sampling rate. Although there's also channel number/mode configuration option, all devices I know only support stereo (70+ models).
| Codec | Sample rate | Bit depth | Bitrate | Encoding support | Decoding support |
| --- | --- | --- | --- | --- | --- |
| **aptX** | 16, 32, 44.1, 48 kHz | 16 bit | 128 / 256 / 352 / 384 kb/s (depending on sample rate) | Windows 10 (desktop and mobile), macOS, Android 4.4+/7\*, Blackberry OS 10 | Wide variety of devices (in hardware) |
***\*** Versions up to 7 require modification of Bluetooth stack. The codec is supported only if the manufacturer of Android device has licensed the codec usage from Qualcomm (if the OS has encoding libraries included).*
aptX splits audio into 4 frequency bands and quantizes them with the same number of bits continuously: 8 bits for 0-5.5 kHz, 4 bits for 5.5-11 kHz, 2 bits for 11-16.5 kHz, 2 bits for 16.5-22 kHz (values for 44.1 kHz sample rate).
aptX audio example (top—original audio, bottom—aptX-encoded audio, spectrograms of left channels only, sound in FLAC):
Your browser does not support HTML5 video.
The upper frequencies are a little redder, but the difference is not audible.
Due to the fixed distribution of quantization bits, the codec cannot “transfer the bits” to frequencies that need them most. Unlike SBC, aptX will not “cut off” frequencies, but will add quantization noise to them, reducing the dynamic range of the audio.
We should not assume that using, for example, 2 bits for a band reduces the dynamic range to 12 dB: ADPCM allows up to 96 dB of dynamic range to be used, even with 2 quantization bits, but only with a certain type of signal.
ADPCM stores the difference between the current and the next value in numerical representation, instead of using the absolute value, as in PCM. This reduces the requirements for the number of bits needed to store the same (without loss) or almost the same (with relatively small rounding error) information. To reduce rounding errors, factor tables are applied.
When creating the codec, the authors calculated ADPCM coefficients on a set of music audio files. The closer audio signal is to the set of music on which the tables were built, the less quantization errors (noise) are generated by aptX.
Because of this, synthetic tests will always produce worse results than music. I made a special synthetic example in which aptX performs badly—a 12.4 kHz sine wave (top—original signal, bottom—aptX. Sound in FLAC. Ear rape, decrease the volume!):
Your browser does not support HTML5 video.
Spectrum Graph:
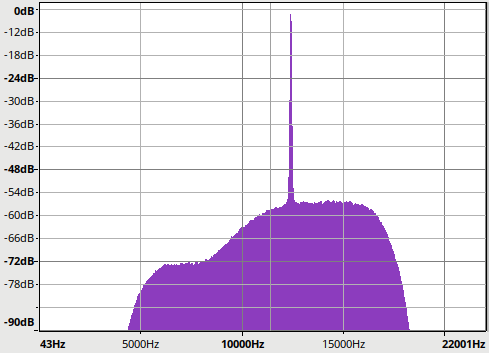
Noise is clearly audible.
However, if you generate a sine wave with a smaller amplitude so that it is quieter, the noise will also become quieter, which indicates a wide dynamic range:
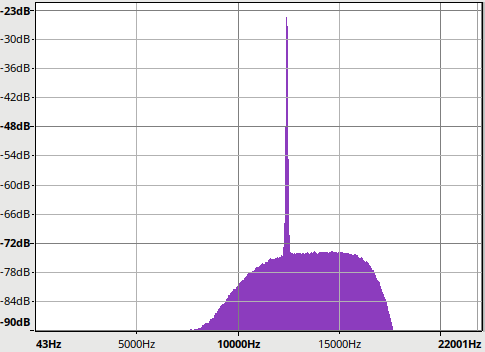
To hear the difference between an original music track and a compressed one, you can invert one of the signals and add tracks to respective channels. This approach is incorrect in general and would not give proper results with more complex codecs, but for ADPCM-class codec usage of this method is reasonable.
[The difference between original and aptX-encoded audio](https://files.catbox.moe/leq24q.flac)
The root mean square difference of the signals is at the level of -37.4 dB, which is not much for such compressed music.
### aptX HD
aptX HD is not a standalone codec—it is an improved aptX encoding profile. The changes affect the number of bits allocated for frequency bands encoding: 10 bits for 0-5.5 kHz, 6 bits for 5.5-11 kHz, 4 bits for 11-16.5 kHz, 4 bits for 16.5-22 kHz (values for 44.1 kHz).
| Codec | Sample rate | Bit depth | Bitrate | Encoding support | Decoding support |
| --- | --- | --- | --- | --- | --- |
| **aptX HD** | 16, 32, 44.1, 48 kHz | 24 bit | 192 / 384 / 529 / 576 kb/s (depending on sample rate) | Android 8+\* | Some audio devices (in hardware) |
***\*** Versions up to 7 require modification of Bluetooth stack. The codec is supported only if the manufacturer of Android device has licensed the codec usage from Qualcomm (if the OS has encoding libraries included).*
This codec is less common than aptX: it seems to require separate licensing from Qualcomm, and separate licensing fees.
Let's repeat the example with a 12.4 kHz sine wave:
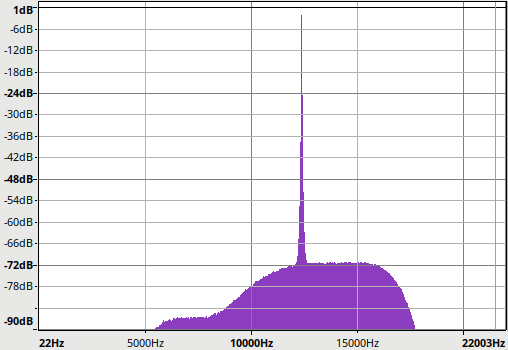
Much better than with aptX, but still noisy.
aptX Low Latency
----------------
Low latency version of aptX is not a stand-alone codec. It differs only in the latency and buffers settings that are applied on the audio unit side. Beside of that, that's a usual aptX.
It was designed for interactive audio transmission with low latency (movies, games), where the sound delay can not be adjusted programmatically. There's [Dell driver software implementation available for Intel Bluetooth chips](http://forum.notebookreview.com/threads/intel-aptx-driver-download.794032/). It is also supported by transmitters, receivers, headphones and speakers, but not smartphones.
| Sample rate | Bitrate | Encoding support | Decoding support |
| --- | --- | --- | --- |
| 44.1 kHz | 352 kb/s | Windows with Dell driver and some transmitters (in hardware) | Some audio devices (in hardware) |
AAC
---
AAC, or Advanced Audio Coding, is a computationally sophisticated codec with a complex psychoacoustic model. It is widely used for audio on the Internet, the second most popular codec after MP3. Requires licensing and license fees: $15,000 one-time payment (or $1000 for companies with less than 15 employees) + $0.98 for the first 500,000 devices ([source](http://www.via-corp.com/us/en/licensing/aac/licensefees.html)).
The codec is standardized within MPEG-2 and MPEG-4 specifications, and, despite frequent misbelief, does not belong to Apple.
| Sample rate | Bitrate | Encoding support | Decoding support |
| --- | --- | --- | --- |
| 8 — 96 kHz | 8 — 576 kb/s (for stereo), 256 — 320 kb/s (typical for Bluetooth) | macOS, Android 7+\*, iOS | Wide variety of devices (in hardware) |
***\*** only on devices whose manufacturers paid royalties*
iOS and macOS contain the best Apple AAC encoder available to date, producing the highest possible audio quality. Android uses the second-best Fraunhofer FDK AAC encoder, but also can use various hardware encoders embedded in the platform (SoC) with an unknown encoding quality. [According to recent tests published on SoundGuys website](https://www.soundguys.com/the-ultimate-guide-to-bluetooth-headphones-aac-20296/), the quality of AAC encoding on different Android phones varies greatly:
[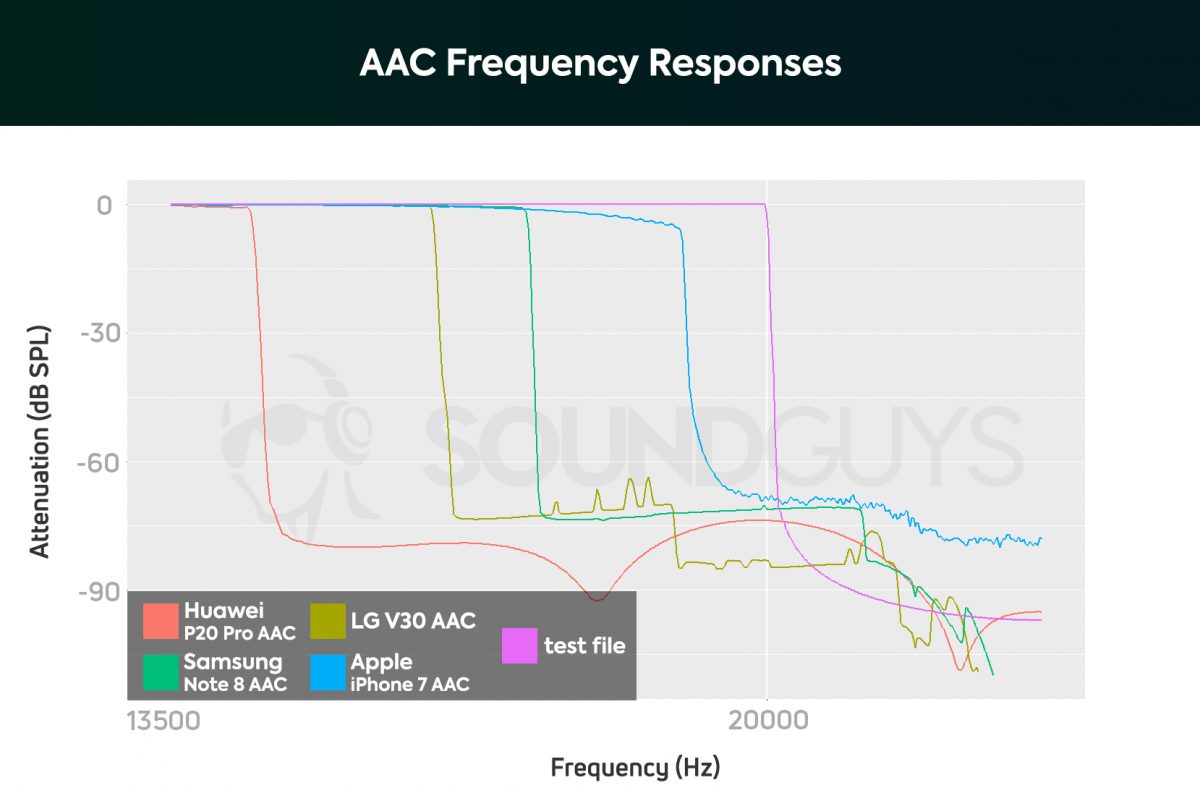](https://www.soundguys.com/wp-content/uploads/2018/10/aac-enhanced-view-fr-1200x788.jpg)
Most wireless audio devices have a maximum bitrate of 320 kbps for AAC, some support only 256 kbps. Other bitrates are extremely rare.
AAC provides excellent quality at 320 and 256 kb/s bit rates, but is prone to [generation loss](https://en.wikipedia.org/wiki/Generation_loss) on already compressed content, however it’s difficult to hear any differences between the original and AAC 256 kb/s on iOS, even with several consecutive encodings. For MP3 320 kbps encoded into AAC 256 kbps the loss can be neglected.
Just as with any other Bluetooth codec, any music is first decoded then encoded with a codec. When listening to music in AAC format, it is first decoded by the OS, then encoded into AAC again, for transmission over Bluetooth. This is necessary to mix several audio streams such as music and new message notifications. iOS is no exception. You can find a lot of statements that iOS does not transcode music in AAC format for transmission via Bluetooth, which is incorrect.
AAC has many extensions to the standard encoding method. One of them—Scalable To Lossless (SLS)—is standardized for Bluetooth and allows you to transfer lossless audio. Unfortunately, no SLS support could be found on existing devices. An extension to reduce transmission delay AAC-LD (Low Delay) is not standardized for Bluetooth.
MP1/2/3
-------
MPEG-1/2 Part 3 codecs consist of well-known and widely used MP3, the less common MP2 (used primarily in digital TV and radio), and the completely unknown MP1.
The old MP1 and MP2 codecs are not supported at all, I could not find any headphones or any Bluetooth stack that would encode or decode them.
MP3 decoding is supported by some headphones, but encoding is not supported on any modern operating system stack. It seems that the third-party BlueSoleil stack for Windows can encode MP3 if you manually edit the configuration file, but on my installation it leads to BSoD on Windows 10. The result: you can’t actually use a codec for Bluetooth audio.
Previously, in 2006-2008, before the A2DP standard was widely used in devices, people listened to MP3 music on the Nokia BH-501 headset through the MSI BluePlayer program, which was available on Symbian and Windows Mobile. At that time, the OS architecture of smartphones allowed access to many low-level functions, it was even possible to install third-party Bluetooth stack on Windows Mobile.
The latest patent of the MP3 codec has expired, the use of the codec does not require license fees since April 23, 2017.
> If the longest-running patent mentioned in the aforementioned references is taken as a measure, then the MP3 technology became patent-free in the United States on 16 April 2017 when U.S. Patent 6,009,399, held by and administered by Technicolor, expired.
*Source: [www.iis.fraunhofer.de/en/ff/amm/prod/audiocodec/audiocodecs/mp3.html](https://www.iis.fraunhofer.de/en/ff/amm/prod/audiocodec/audiocodecs/mp3.html)*
| Sample rate | Bitrate | Encoding support | Decoding support |
| --- | --- | --- | --- |
| 16 — 48 kHz | 8 — 320 kb/s | Not supported anywhere | Some audio devices (in hardware) |
LDAC
----
New and actively promoted «Hi-Res» codec from Sony that supports sampling rates up to 96 kHz and 24-bit depth, with a bitrate up to 990 kbps. It is advertised as an audiophile codec, as a replacement for existing Bluetooth codecs. It has an adaptive bitrate function which tunes bitrate depending on the radio transmission conditions.
The LDAC encoder ([libldac](https://android.googlesource.com/platform/external/libldac/)) is included in the standard Android distribution, encoding is supported on any Android smartphone starting with OS version 8. Software decoders are not freely available and the codec specification is not available to the general public, however, at first glance at the encoder, the internals are similar to Sony's [ATRAC9](https://en.wikipedia.org/wiki/Adaptive_Transform_Acoustic_Coding#ATRAC9) codec used in PlayStation 4 and Vita: both work in the frequency domain, use a modified discrete cosine transform (MDCT) and Huffman compression.
LDAC split audio into 12 or 16 frequency bands: 12 is used for 44.1 and 48 kHz, 16 for 88.2 and 96 kHz.
LDAC is supported almost exclusively only by Sony headphones. LDAC decoding is sometimes found on headphones and DACs from other manufacturers, but very rarely.
| Sample rate | Bitrate | Encoding support | Decoding support |
| --- | --- | --- | --- |
| 44.1 — 96 kHz | 303/606/909 kb/s (for 44.1 and 88.2 kHz), 330/660/990 kb/s (for 48 and 96 kHz) | Android 8+ | Some Sony headphones and selected devices from other manufacturers (in hardware) |
LDAC «Hi-Res codec» marketing harms its technical properties: it’s not wise to spend the bitrate to encode and transmit frequencies that are not audible to the human ear and a higher bit depth when it's still not possible to losslessly compress CD quality audio. Fortunately, the codec has two modes of operation: CD audio transmission and Hi-Res audio transmission. In the first case, only 44.1 kHz / 16 bits are transmitted over the air.
Since the LDAC software decoder is not freely available, it is not possible to test the codec without additional devices that decode LDAC. According to the results of the LDAC test on the DAC with its support, which SoundGuys.com engineers connected via the digital output and recorded the output sound of the test signals, the LDAC 660 and 990 kbit/s in CD quality mode provides a signal-to-noise ratio slightly better than that of aptX HD. This is a good result.
[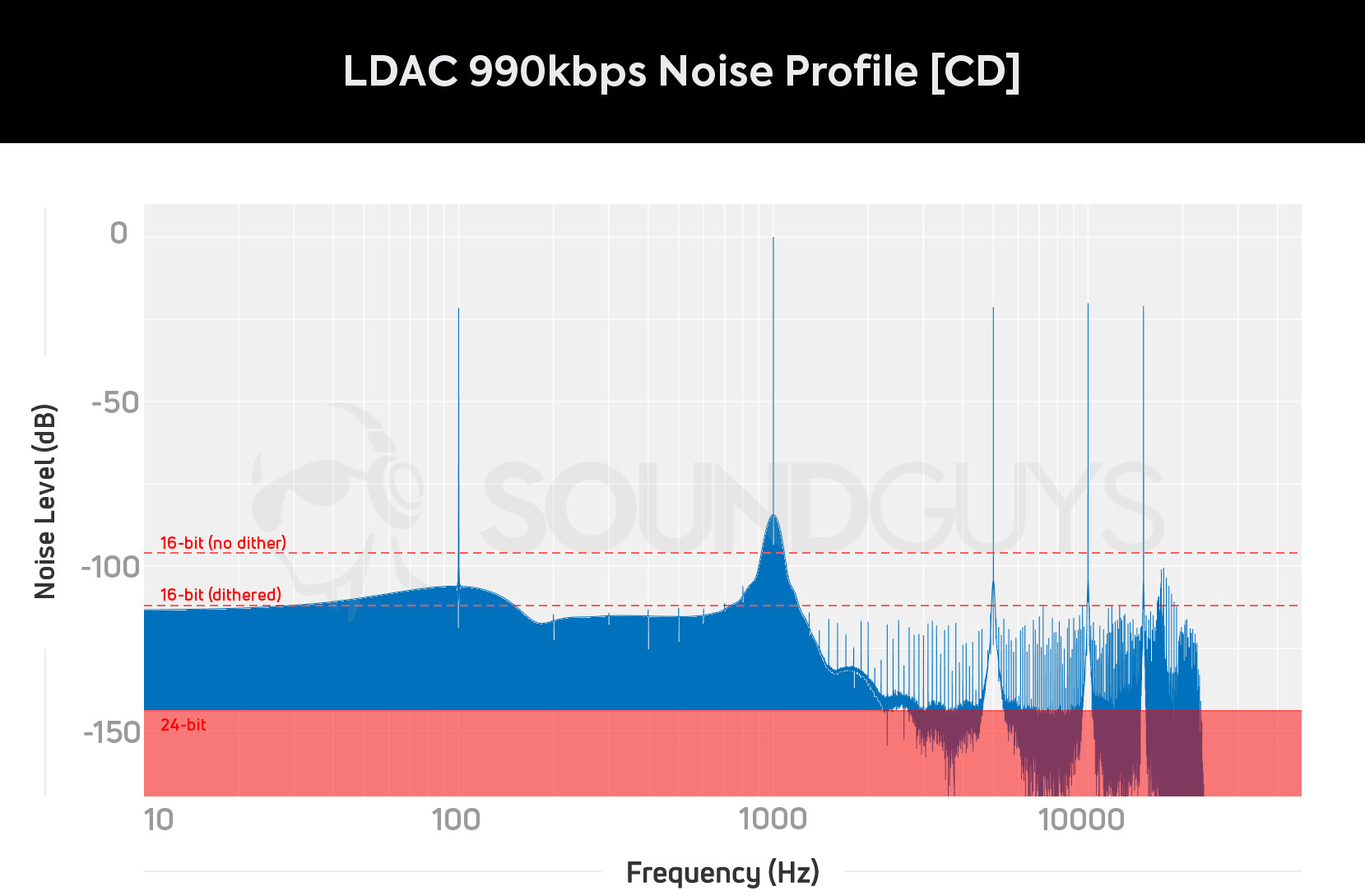](https://www.soundguys.com/wp-content/uploads/2018/10/LDAC-990-CD-Noise-Floor.jpg)
*Source: [www.soundguys.com/ldac-ultimate-bluetooth-guide-20026](https://www.soundguys.com/ldac-ultimate-bluetooth-guide-20026/)*
LDAC also supports dynamic bitrate outside the established profiles — from 138 kbps to 990 kbps, but as far as I can tell, Android only uses standardized profiles of 303/606/909 and 330/660/990 kbps.
Other codecs
------------
Other A2DP codecs are not widely used. Their support is either almost completely absent, or is only available on certain models of headphones and smartphones.
The A2DP-standardized ATRAC codec has never been used as a Bluetooth codec even by Sony. Samsung HD, Samsung Scalable and Samsung UHQ-BT codecs have very limited support from transmitting and receiving devices. HWA LHDC is too new and only supported three (?) devices.
Audio devices' codec support
============================
Not all manufacturers publish accurate information about codecs supported in certain wireless headphones, speakers, receivers or transmitters. Sometimes it happens that certain codec is supported only for transmission but not for reception (relevant for combined transmitter-receivers), although the manufacturer simply declares “support”, without any notes (I assume that separate licensing of encoders and decoders is to blame). In the cheapest devices, you can never find the declared support for aptX.
Unfortunately, supported codecs are not displayed anywhere on most OS interfaces. Information about current used codec is only present in Android, starting with version 8, and macOS. However, even in these operating systems, only those codecs that are supported by both the phone / computer and headphones will be displayed.
How to find out which codecs the device supports? By capturing and analyzing traffic dump with A2DP negotiation options!
This can be done in Linux, macOS and Android. In Linux you can use Wireshark or hcidump, in macOS Bluetooth Explorer could be used, and in Android use Bluetooth HCI dump save feature available in the developers tools. You will get a dump in btsnoop format, which could be opened in Wireshark analyzer.
**NOTE**: you'll need to connect from the smartphone/computer to the headphones to capture correct dump, not vice versa (no matter how silly it sounds)! Headphones can also establish a connection to the smartphone or PC, in which case they will request a list of codecs from the phone, and not disclose their own set of codecs. To ensure that you capture a correct dump, first un-pair the device, and then, while recording the dump, pair the phone with the headphones.
Use the following display filter to hide irrelevant traffic:
```
btavdtp.signal_id
```
As a result, you should see something similar:
[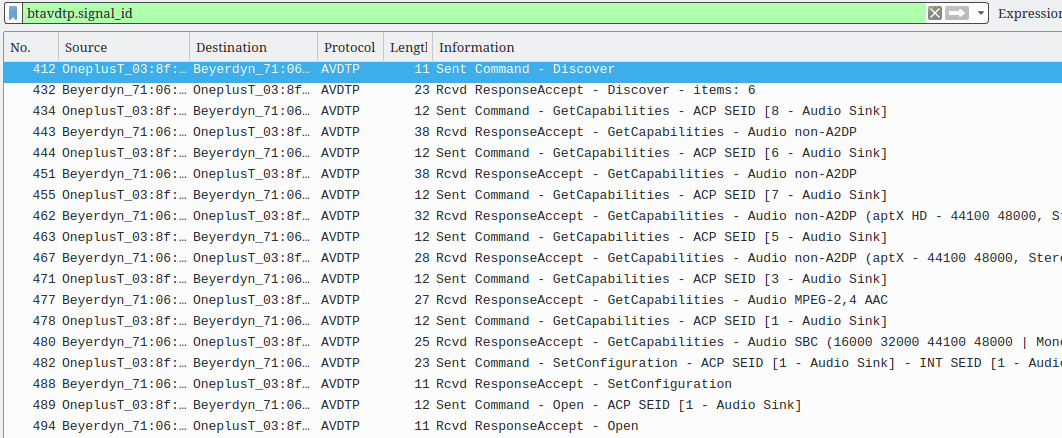](https://habrastorage.org/webt/fv/ku/xs/fvkuxsqcdwtxznupploqmldv9qm.png)
By clicking on GetCapabilities command you can get detailed information of the codec.
[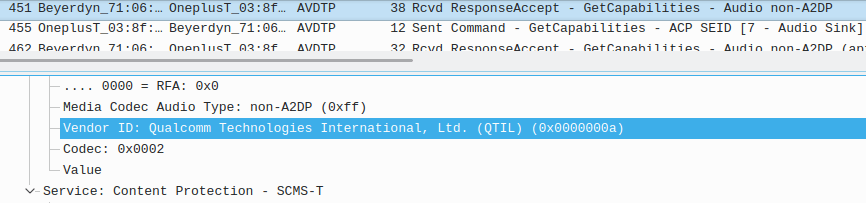](https://habrastorage.org/webt/7s/9a/xa/7s9axaeztya_dr2irptfi68ejxs.png)
Wireshark does not know all codec identifiers, so some of the codecs will have to be decrypted manually, depending on the table of identifiers below:
```
Mandatory:
0x00 - SBC
Optional:
0x01 - MPEG-1,2 (aka MP3)
0x02 - MPEG-2,4 (aka AAC)
0x04 - ATRAC
Vendor specific:
0xFF 0x004F 0x01 - aptX
0xFF 0x00D7 0x24 - aptX HD
0xFF 0x000A 0x02 - aptX Low Latency
0xFF 0x00D7 0x02 - aptX Low Latency
0xFF 0x000A 0x01 - FastStream
0xFF 0x012D 0xAA - LDAC
0xFF 0x0075 0x0102 - Samsung HD
0xFF 0x0075 0x0103 - Samsung Scalable Codec
0xFF 0x053A 0x484C - Savitech LHDC
0xFF 0x000A 0x0104 - The CSR True Wireless Stereo v3 Codec ID for AAC
0xFF 0x000A 0x0105 - The CSR True Wireless Stereo v3 Codec ID for MP3
0xFF 0x000A 0x0106 - The CSR True Wireless Stereo v3 Codec ID for aptX
```
You can find out if your device supports EDR 3 Mbps by using the following filter:
```
bthci_evt.code==0x0b
```
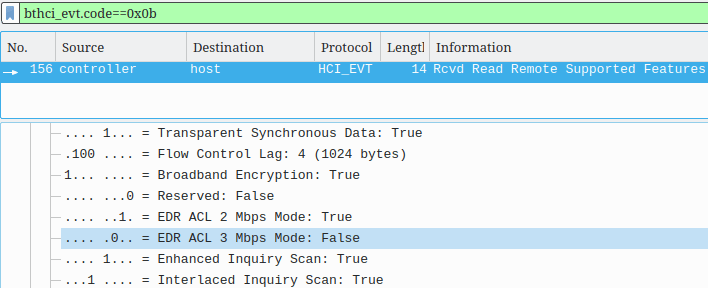
In order to not analyze the dumps manually, I made a service that will analyze everything automatically: [btcodecs.valdikss.org.ru](https://btcodecs.valdikss.org.ru)
Simple but useful Windows [Bluetooth Tweaker](https://www.bluetoothgoodies.com/tweaker/) software shows supported and currently used codecs aside from other functionality.
Linux users can also use avinfo utility from BlueZ package.
Codec comparison. Which codec is better?
========================================
Each codec has its advantages and disadvantages.
aptX and aptX HD use hard-coded profiles that cannot be changed without modifying the encoder and decoder. Neither the smartphone nor the headphone manufacturer can change the bitrate or coding factors of aptX. Qualcomm, the owner of the codec, distributes the reference encoder as a library to the licensees. These facts are aptX's forte—you know in advance what quality of sound you will get, no buts.
SBC, on the contrary, has many adjustable parameters, dynamic bitrate (the encoder can reduce the bitpool parameter if the radio is congested), and does not have hard-coded profiles, but only the recommended «medium quality» and «high quality» that have been added to the A2DP specification in 2003. “High quality” is no longer as high by modern standards, and most Bluetooth stacks do not allow using parameters that are better than in the “high quality” profile, although there are no technical limitations for this.
Bluetooth SIG does not provide SBC reference encoder in the form of a library, and the manufacturers implement it themselves.
These are SBC's weaknesses—it is never clear in advance what sound quality is to be expected from a particular device. SBC can produce both low and very high sound quality, but the latter is unattainable without disabling or circumventing the artificial limitations of Bluetooth stacks.
The situation with AAC is ambiguous: on one hand, theoretically, the codec should produce quality that is indistinguishable from the original, but practice, judging by the tests of the SoundGuys laboratory on different Android devices, is not confirmed. Most likely, the fault is on low-quality hardware audio encoders embedded in various phone chipsets. It makes sense to use AAC only on Apple devices; with Android you'd better stick with aptX/HD and LDAC.
Devices that supports alternative codecs is usually of higher quality, simply because it does not make sense to pay royalties for very cheap, low-quality devices to use these codecs. According to my tests, SBC sounds very good on high-quality hardware.
I made a web service that encodes audio to SBC, aptX and aptX HD in real time, right in your browser. You can use it to test these audio codecs without actually transmitting audio via Bluetooth, on any wired headphones, speakers, and your favorite music, and also change the encoding parameters directly during audio playback:
[btcodecs.valdikss.org.ru/sbc-encoder](https://btcodecs.valdikss.org.ru/sbc-encoder/)
The service uses SBC coding libraries from BlueZ project and libopenaptx from ffmpeg, which are compiled into WebAssembly and JavaScript from C via emscripten, for execution in a browser. Who could have dreamed of such a future!
Here's what it looks like:
Your browser does not support HTML5 video.
Notice how the noise level changes after 20 kHz for different codecs. No frequences above 20 kHz present in the original MP3 file.
Try switching codecs and see if you can hear the difference between the original, SBC 53 Joint Stereo (the standard and most common profile), and aptX / aptX HD.
But I can hear the difference between codecs *in a headphones*!
---------------------------------------------------------------
People who do not hear the difference between codecs while testing via a web service claim they hear it when listening to music with Bluetooth headphones. Unfortunately, that is not a joke or a placebo effect: the difference is really audible, but it is not caused by difference *in codecs*.
The vast majority of Bluetooth audio chipsets used in receiving wireless devices are equipped with a digital signal processor (DSP) that implements an equalizer, compander, stereo extender, and other things designed to improve (or change) the sound. Bluetooth hardware manufacturers can configure the DSP *for each codec separately*, and when switching between codecs, the listener will feel that they can hear the difference in the performance of codecs when in reality they are listening to different DSP settings.
[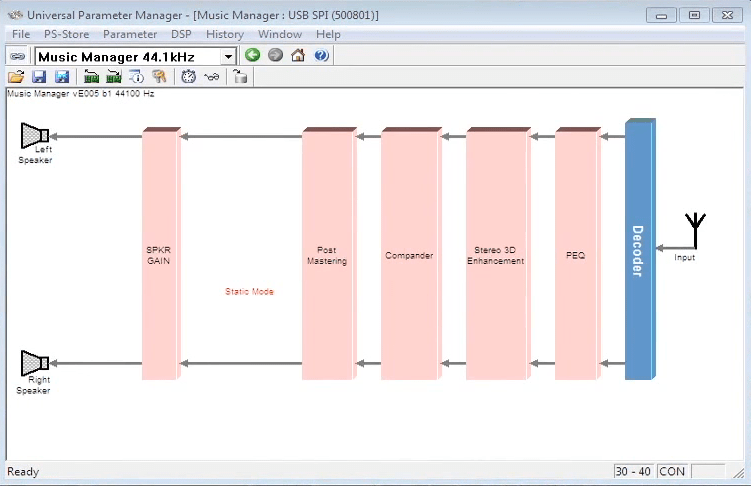](https://habrastorage.org/webt/0j/75/rv/0j75rvrbutguojyxx9yu0s-uang.png)
*Kalimba DSP audio processing pipeline in CSR/Qualcomm SoCs*
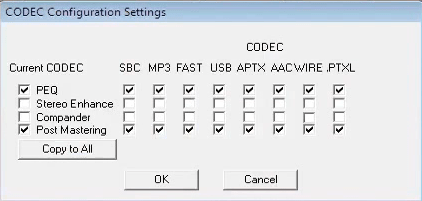
*Activation of various DSP functions for each codec and output separately*
Some premium segment devices are equipped with software that allows you to adjust the DSP parameters, but most of the cheaper headphones do not have this feature, and users cannot turn off the post-processing of sound using standard tools.
Devices' functional features
----------------------------
The current version of the A2DP standard has an **absolute volume control** function allowing to control output gain with special commands by using AVRCP protocol, instead of programmatically reducing the volume of the audio stream itself. If you change the volume on the headphones and the change is not synchronized with the volume on the phone, this means that your headphones or phone do not support this function. In this case, it makes sense to always listen to music at maximum volume on the phone, adjusting the actual volume with the headphone buttons—the signal-to-noise ratio will be better and the audio quality *should be* higher.
In reality, there are sad situations. By RealForce OverDrive D1 headphones use strong compander for SBC and an increase in volume leads to an increase in the level of quiet sounds, and the volume of loud sounds does not change (signal compression occurs). Because of this, it is necessary to set the volume on the computer to about half, in this case there is practically no compression effect.
According to my observations, all headphones with additional codecs support absolute volume control function, which is probably one of the requirements for codec certification.
Some headphones support **connecting two devices at the same time**. This allows, for example, to listen to music from a computer and receive calls from a phone. However, you should be aware that alternative codecs are disabled in this mode, and only SBC is used.
The **AVDTP 1.3 Delay Reporting** feature allows headphones to report a delay to a sending device that actually plays the sound. This helps to adjust the synchronization of audio with video while watching video files: if radio congestion occurs, the audio will not lag behind the video, but on the contrary, the video will be slowed down by the video player until the audio and video are synchronized again.
The feature is supported by many headphones, Android 9+ and Linux with PulseAudio 12.0+. I'm not aware about support in other OS.
Duplex communication over Bluetooth. Voice transmisson.
=======================================================
Synchronous Connection Oriented (SCO) and its enhanced version Enhanced Synchronous Connection Oriented (eSCO) are the modes used for Bluetooth voice transmission. The mode allows you to transmit sound and voice strictly in order, with a symmetrical speed of sending and receiving, without waiting for confirmation of transmission and re-sending packets. This reduces the overall delay in the transmission of audio over the radio channel, but imposes serious restrictions on the amount of data transmitted per unit of time and adversely affects the quality of the audio.
When this mode is used, both the voice from the microphone and the audio are transmitted to the headphones with the same quality.
Transfer of the data itself is standardized by the HSP profile, which also describes additional functions, such as operation of volume control buttons, the pick up of the handset and the hang up.
Unfortunately, as of 2019, the quality of voice transmission via Bluetooth is still poor, and it is not clear why Bluetooth SIG is not doing anything about it.
##### CVSD
The basic speech transfer codec CVSD was standardized in 2002, and is supported by all bidirectional Bluetooth devices. It provides audio transmission with a sampling frequency of 8 kHz, which corresponds to the quality of conventional wired telephony.
[An example of recording in this codec](https://files.catbox.moe/c4h77s.flac).
##### mSBC
Additional mSBC codec was standardized in 2009, and in 2010 there were chips that already used it for voice transmission. mSBC is widely supported by various devices.
This is not a standalone codec, but the usual SBC from the A2DP standard, with a fixed encoding profile: 16 kHz, mono, bitpool 26.
[An example of recording in this codec](https://files.catbox.moe/b09joy.flac).
Not brilliant, but much better than CVSD, though it is still unpleasant to use it to communicate via the Internet, especially when you use headphones for communication in the game — the sound of the game will also be transmitted at a sampling frequency of 16 kHz.
###### FastStream
CSR decided to further develop the idea of re-using SBC. To get around the limitations of the SCO protocol and use higher bit rates, CSR went the other way—they've added support for two-way SBC audio into the one-way audio transmission A2DP standard, and called it «FastStream».
FastStream transmits 44.1 or 48 kHz stereo sound to speakers with a bitrate of 212 kbps. 16 kHz with a bitrate of 72 kbps (slightly better than that of mSBC) is used to transmit audio from a microphone. Such parameters are much better suited for communication in online games—the sound of the game and the teammates will be of high quality.
[An example of recording in this codec](https://files.catbox.moe/4gazzt.flac) (+ [audio from the mic, the same as in mSBC](https://files.catbox.moe/b09joy.flac)).
The company came up with an interesting hack, but due to the fact that it contradicts with A2DP standard, only some of the company's transmitters support it (which work as a USB audio card, and not a Bluetooth device), but it did not receive support in Bluetooth stack. The number of headphones with FastStream support is not so small though.
At the moment, FastStream support is available only [in the form of a patch for Linux PulseAudio](https://lists.freedesktop.org/archives/pulseaudio-discuss/2019-June/031175.html) from Pali Rohár, which is not included in the main program branch.
##### aptX Low Latency
Much to the surprise, aptX Low Latency also supports bidirectional audio, implementing the same principle as FastStream.
There is no way to use this feature of the codec anywhere—there is no support for Low Latency decoding in any OS and in any Bluetooth stack which I'm aware of.
Bluetooth 5, Classic and Low Energy
===================================
There is a lot of confusion around the specifications and versions of Bluetooth due to the presence of two incompatible standards under one brand, both of which are widely used for different purposes.
There are two different, incompatible Bluetooth protocols: Bluetooth Classic and Bluetooth Low Energy (LE, also known as Bluetooth Smart). There is also a third protocol, Bluetooth High Speed, but it is not common, and is not used in home appliances.
Beginning with Bluetooth 4.0, the changes in the specifications focused primarily on Bluetooth Low Energy, while the Classic version received only minor improvements.
List of changes between Bluetooth 4.2 and Bluetooth 5:
> 9 CHANGES FROM v4.2 TO 5.0
>
>
>
> 9.1 NEW FEATURES
>
>
>
> Several new features are introduced in Bluetooth Core Specification 5.0 Release. The major areas of improvement are:
>
> • Slot Availability Mask (SAM)
>
> • 2 Msym/s PHY for LE
>
> • LE Long Range
>
> • High Duty Cycle Non-Connectable Advertising
>
> • LE Advertising Extensions
>
> • LE Channel Selection Algorithm #2
>
> 9.1.1 Features Added in CSA5 — Integrated in v5.0
>
> • Higher Output Power
*Source: [www.bluetooth.org/docman/handlers/DownloadDoc.ashx?doc\_id=421043](https://www.bluetooth.org/docman/handlers/DownloadDoc.ashx?doc_id=421043) (page 291)*
Only one change affected the Classic version within the specification of Bluetooth 5: support for the Slot Availability Mask (SAM) technology, designed to improve radio frequency sharing. All other changes affect only Bluetooth LE (the same applies to Higher Output Power too).
**All** audio devices use only Bluetooth Classic. Headphones and speakers cannot be connected via Bluetooth Low Energy. There is no standard for transmitting audio using LE. The A2DP standard, used to transmit high-quality audio, works only through Bluetooth Classic, and there is no equivalent in LE.
To sum up: buying audio devices with Bluetooth 5 only because of the new version of the protocol is meaningless. Bluetooth 4.0/4.1/4.2 in the context of audio transmission will work the same way.
If the announcement of the new headphone mentions a doubled radius and reduced power consumption thanks to Bluetooth 5, then you should know that they either do not understand themselves or mislead you. No wonder, even the manufacturers of Bluetooth chips confuse the difference in both standards, and some Bluetooth 5 chips support the fifth version only for LE, and use 4.2 for Classic.
Audio transmission latency
==========================
The amount of latency (lag) in the audio depends on many factors: the size of the buffer in the audio library, in Bluetooth stack and in the playback device itself, the algorithmic delay of the codec.
The delay of simple codecs, like SBC, aptX and aptX HD is quite small, about 3-6 ms, which can be neglected, but complex codecs, such as AAC and LDAC can give a noticeable delay. Algorithmic delay AAC for 44.1 kHz is 60 ms. LDAC—about 30 ms (by rough analysis of the source code. I can be wrong, but not much.)
The total delay is highly dependent on the playback device, its chipset and buffer. During the tests, I got a spread of 150 to 250 ms on different devices (with the SBC codec). If we assume that devices with support for aptX, AAC, and LDAC additional codecs use better quality components and a small buffer size, we get the following typical latency values:
SBC: 150-250 ms
aptX: 130-180 ms
AAC: 190-240 ms
LDAC: 160-210 ms
Let me remind you: aptX Low Latency is not supported in operating systems, which is why a lower delay can be obtained only with a transmitter + receiver or transmitter + headphone/speaker bundle, and all devices must support this codec.
The problems with certifications, logos and devices
===================================================
How to distinguish high-quality audio device from cheap crafts? By the appearance, in the first place!
Cheap Chinese headphones, speakers and receivers have:
1. No «Bluetooth» word on the box and the device, most often replaced by «Wireless» and «BT»
2. No Bluetooth logo  on box or device
3. No blue flashing LED
The absence of these elements indicates that the device has not been certified, which means that it is potentially problematic or of poor quality. For example, Bluedio headphones are not certified by Bluetooth, and do not fully comply with the A2DP specification. They would not have passed certification process.
Let's look at several devices and boxes from them:
[](https://habrastorage.org/webt/e4/qa/rr/e4qarrce8fcjv8wwu46aiyib3oa.jpeg)
[](https://habrastorage.org/webt/ba/06/vb/ba06vbcolhpvuie2xlbgnvsycd0.jpeg)
[](https://habrastorage.org/webt/mw/1b/t1/mw1bt1hp0cz11xuilzyz0a70dca.jpeg)
These are all non-certified devices. The instructions may have the logo and «Bluetooth» name, but most importantly—these elements should be present on the device or box itself.
If your headphones or speaker say «Ze bluetooth dewise is connecteda successfulle», this does not say good about quality as well:
Conclusion
==========
Can Bluetooth completely replace wired headphones and headsets? Probably, but at the cost of low quality voice, increased latency in sound transmission, which can be annoying in games, and a multitude of proprietary codecs that require license fees and increase the final cost of both smartphones and headphones.
The marketing of alternative codecs is very strong: aptX and LDAC are presented as a long-awaited replacement of the “outdated and bad” SBC, which is far from as bad as it is commonly thought of.
As it turned out, the artificial limitations of Bluetooth stacks on SBC can be bypassed, so that the SBC will be on par with aptX HD. I took the initiative and made a patch for LineageOS firmware: [Modifying Bluetooth stack to improve the sound on headphones without AAC, aptX and LDAC codecs](https://habr.com/en/post/456476/)
More information about codecs could be found on [SoundGuys](https://www.soundguys.com/) and [SoundExpert](http://soundexpert.org/) websites.
**Bonus:** [SBC reference encoder, A2DP bitstream information and test files](https://files.catbox.moe/29l4kd.zip). This file was previously posted on Bluetooth website publicly, but now it is available only to those who have joined Bluetooth SIG.
**Additional article**: [Bluetooth LC-SBC and SBC-HBR Explained](https://drive.google.com/file/d/1J40QF_gZfW7Lo35lc_pgpGi8MZEeWGVt/view) by Ken Laberteaux.
|
https://habr.com/ru/post/456182/
| null |
en
| null |
# Реализация кэш-компрессии по алгоритму base+delta
### Введение
Существенную часть кристалла современных ЦП занимает кэш-память. Дальнейшее увеличение кэш-памяти без изменения технологических норм приведет к соответствующему увеличению кристалла. Одним из способов увеличения объема хранимой информации в кэше без увеличения объёма самого кэша является использование алгоритмов компрессии. Среди них выделяются алгоритмы Base+Delta и Base-Delta-Immediate. Данная статья посвящена реализации первого алгоритма
### Описание Base+Delta
Кэш-память состоит из кэш-строк фиксированного объема.
Кэш-строку разделяют на несколько сегментов. Нулевой сегмент называют базой. При равенстве старших бит сегментов между собой возможно сжатие с помощью разности сегмента и базы, что и называется дельтой. В зависимости от размеров базы и дельт разделяют несколько режимов
B8-∆1 (Base = 8 Byte, ∆ = 1 Byte)
B8-∆2
B8-∆4
B4-∆1
B4-∆2
B2-∆1
Ниже представлены примеры компрессии 32-ух байтовых кэш-строк
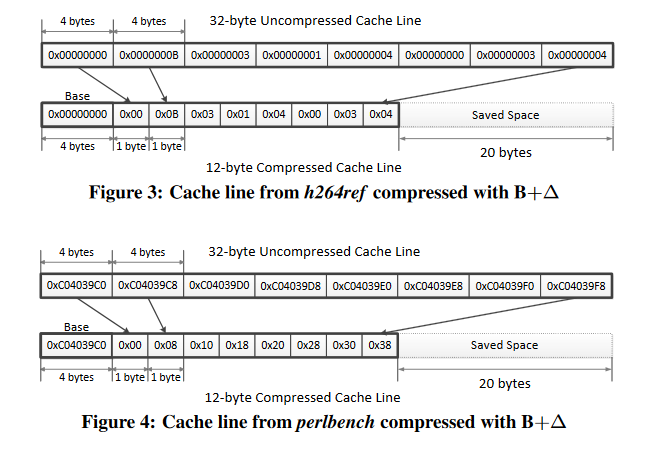Декомпрессия происходит с помощью суммы базы и дельт. В данном примере осуществляется компрессия в режиме B4-∆1. Исходная строка, равная 32-ум байтам, сжимается до 12-ти байт
Данный алгоритм компрессии обоснован, во-первых, регулярностью расположения данных в памяти и, во-вторых, малым динамическим диапазоном значений в кэш-памяти. Объем сегментов отличается в зависимости от типа сжимаемых данных. Он может быть равен 2, 4 и 8 байтам. Использование только одного фиксированного объема сегментов может существенно повлиять на степень компрессии в худшую сторону. Например, для массива указателей объемом 4 байта оптимально использовать 4-ех байтовые сегменты, а для массива 2-ух байтовых целых чисел - сегменты объемом по 2 байта
Значением базы всегда выбирается нулевой сегмент, так как поиск минимального значения базы потребует сложной логики, что существенно скажется на латентности компрессии. Более того, по заявлениям разработчиков алгоритма степень компрессии не увеличится значительно, если реализовать логику поиска базы
### Кэш-память
Кэш-память имеет 16 кэш-строк объемом 64 байта, что позволяет хранить 1КБ данных без компрессии. У каждой кэш-строки помимо данных имеется бит достоверности, определяющий актуальность и достоверность данных, 8-ми байтовое поле тега, хранящий адрес младшего слова в памяти, 8 невидимых байт, о предназначении которых будет упомянуто в последующих разделах, и 3 младших бита, в которых хранится код компрессии
Каждая кэш-строка имеет вход, куда подаются данные, которые можно записать, если активен управляющий сигнал WE (Write Enable). Имеется асинхронный сброс, контролируемый сигналом reset. При сбросе все биты строки заполняются нулями. Выходные данные проходят через буферы трех состояний, контролируемые сигналом OE (Output Enable). На выходе появляются данные только при активности данного сигнала. Описание кэш-строки представлено ниже
```
module cacheline(input tri [643:0] d, input tri clk, reset, we, oe, output tri [643:0] q);
logic [643:0] d1;
always_ff @(posedge clk, posedge reset)
begin
if (reset) d1 <= 644'b0;
else if (we) d1 <= d;
else d1 <= d1;
end
assign q = oe ? d1 : 644'bz;
endmodule
```
Для выбора строки кэш-памяти используется 4-ех битный адрес, который внутренним декодером преобразуется в 16-ти битный one-hot код. Схема декодера описана ниже
```
module decoder4_16(input tri [3:0] a, output logic [15:0] y);
always_comb
case (a)
4'b0000: y = 16'h0001;
4'b0001: y = 16'h0002;
4'b0010: y = 16'h0004;
4'b0011: y = 16'h0008;
4'b0100: y = 16'h0010;
4'b0101: y = 16'h0020;
4'b0110: y = 16'h0040;
4'b0111: y = 16'h0080;
4'b1000: y = 16'h0100;
4'b1001: y = 16'h0200;
4'b1010: y = 16'h0400;
4'b1011: y = 16'h0800;
4'b1100: y = 16'h1000;
4'b1101: y = 16'h2000;
4'b1110: y = 16'h4000;
4'b1111: y = 16'h8000;
default: y = 16'bz;
endcase
endmodule
```
Каждая кэш-строка имеет собственные сигналы WE и OE, что позволяет работать только с одной строкой в данный момент. На вход кэш-памяти подается управляющий сигнал RD (ReaD), указывающий на осуществления операции чтения или записи. В случае его активности значению сигналов OE присваивается значение декодированного адреса, так что выходом кэш-памяти является кэш-строка с активным сигналом OE, это операция чтения. В случае, если RD неактивен, то значению сигналов OE присваиваются нули, а значению WE присваивается one-hot код, так что только одна кэш-строка захватывает данные на входе кэш-памяти, это операция записи. Кэш-память также имеет сигнал асинхронного сброса, который является единым для всех кэш-строк, позволяющий сбросить каждую строку. Схема кэш-памяти представлена ниже
```
module cache(input tri [643:0] d, input tri [3:0] addr, input tri clk, reset, rd, output tri [643:0] q);
tri [15:0] localaddr;
tri [15:0] we, oe;
decoder4_16 decoder(.a(addr), .y(localaddr));
assign we = rd ? 16'b0 : localaddr;
assign oe = rd ? localaddr : 16'b0;
cacheline w0(.d(d[643:0]), .clk(clk), .reset(reset), .we(we[0]), .oe(oe[0]), .q(q[643:0]));
cacheline w1(.d(d[643:0]), .clk(clk), .reset(reset), .we(we[1]), .oe(oe[1]), .q(q[643:0]));
cacheline w2(.d(d[643:0]), .clk(clk), .reset(reset), .we(we[2]), .oe(oe[2]), .q(q[643:0]));
cacheline w3(.d(d[643:0]), .clk(clk), .reset(reset), .we(we[3]), .oe(oe[3]), .q(q[643:0]));
cacheline w4(.d(d[643:0]), .clk(clk), .reset(reset), .we(we[4]), .oe(oe[4]), .q(q[643:0]));
cacheline w5(.d(d[643:0]), .clk(clk), .reset(reset), .we(we[5]), .oe(oe[5]), .q(q[643:0]));
cacheline w6(.d(d[643:0]), .clk(clk), .reset(reset), .we(we[6]), .oe(oe[6]), .q(q[643:0]));
cacheline w7(.d(d[643:0]), .clk(clk), .reset(reset), .we(we[7]), .oe(oe[7]), .q(q[643:0]));
cacheline w8(.d(d[643:0]), .clk(clk), .reset(reset), .we(we[8]), .oe(oe[8]), .q(q[643:0]));
cacheline w9(.d(d[643:0]), .clk(clk), .reset(reset), .we(we[9]), .oe(oe[9]), .q(q[643:0]));
cacheline w10(.d(d[643:0]), .clk(clk), .reset(reset), .we(we[10]), .oe(oe[10]), .q(q[643:0]));
cacheline w11(.d(d[643:0]), .clk(clk), .reset(reset), .we(we[11]), .oe(oe[11]), .q(q[643:0]));
cacheline w12(.d(d[643:0]), .clk(clk), .reset(reset), .we(we[12]), .oe(oe[12]), .q(q[643:0]));
cacheline w13(.d(d[643:0]), .clk(clk), .reset(reset), .we(we[13]), .oe(oe[13]), .q(q[643:0]));
cacheline w14(.d(d[643:0]), .clk(clk), .reset(reset), .we(we[14]), .oe(oe[14]), .q(q[643:0]));
cacheline w15(.d(d[643:0]), .clk(clk), .reset(reset), .we(we[15]), .oe(oe[15]), .q(q[643:0]));
endmodule
```
Бит достоверности может задавать только компрессор при передаче данных и сигнал reset. Отсутствие какой-либо кэш-когерентности связано с отсутствием необходимости при работе над кэш-компрессией
Данный кэш имеет алгоритм прямого отображения. Это связано не с эффективностью, а с удобством реализации, так как для реализации кэш-компрессии не важен алгоритм ассоциативности. Для обращения в кэш следует проверить бит достоверности и сравнить поле тега с полем запроса только в одной кэш-строке, что очень удобно
Мою реализацию отличает то, что кэш-память имеет традиционный вид без использования двух полей тегов, хотя и имеет небольшие модификации в виде хранении кода компресси (их можно хранить и в отдельной таблице, если нужно) и невидимых байт.
### Метод увеличения хранимой информации
Одной из проблем в реализации кэш-компрессии стоит увеличение хранимой информации. Сжимая кэш-строку, мы не можем записать что-либо в свободное пространство. В связи с этим было придумано решение в виде сжатия данных из внешнего источника и записи сжатых данных в кэш-память. Используется специальный буфер чтения, который имеет вдвое больший объём, чем кэш-строка - 128 байт. Значение буфера чтения сжимается по одному из алгоритмов компрессии и записывается в кэш-память
| | | | |
| --- | --- | --- | --- |
| Исходный объём | Режим компрессии | Сжатый объём | Количество сегментов |
| 128 Byte | B8-∆1 | 24 Byte | 16 |
| 128 Byte | B8-∆2 | 40 Byte | 16 |
| 128 Byte | B8-∆4 | 72 Byte | 16 |
| 128 Byte | B4-∆1 | 36 Byte | 32 |
| 128 Byte | B4-∆2 | 68 Byte | 32 |
| 128 Byte | B2-∆1 | 66 Byte | 64 |
Максимальный объем сжатых данных равен 72-ум байтам. В связи с этим были добавлены 8 невидимых байт в каждую кэш-строку, которые будут нужны только при использовании алгоритмов, превышающие порог в 64 байта
Наша система оперирует 64 битными словами, поэтому кэш-строка без компрессии имеет 8 слов. Но с компрессией кэш-строка может хранить в два раза больше слов - 16. Причем режим компрессии не играет роли
Особым случаем является невозможность компрессии. Тогда можно было бы записать данные буфера в две кэш-строки, но это может привести к уничтожению сжатых данных в соседней кэш-строке, поэтому разумнее отбросить некоторые слова буфера чтения и записать оставшиеся в кэш-память. Если степень компрессии в данном приложении будет минимальной, если это может отрицательно повлиять на производительность, можно отключить компрессию с помощью сигнала CON (Compression On). В таком режиме кэш-память ведет себе как обычная.
### Компрессор
На вход компрессора подаются данные из основной оперативной памяти. Эти данные записываются в буфер чтения. Буферов чтения может быть несколько, также может быть несколько компрессоров, если реализовать порядок последовательной записи из компрессоров. Он также имеет асинхронный сбор
Биты буфера чтения проходят через компараторы, которые определяют возможность компрессии по одному из режимов. Одни компараторы сравнивают между собой младшие биты сегментов. Важно, чтобы значение младших бит базы было меньше или равно значениям младших бит сегментов. Достаточно трех таких компараторов для режимов B8-∆4, B4-∆2 и B2-∆1. Чтобы понять, что это так, рассмотрим следующий пример. Предположим, что значение буфера может быть сжато по алгоритму B8-∆1. Тогда значение компараторов для B8-∆4 будет полностью соответствовать значению компараторов для B8-∆1, так как на результат будет влиять только один младший байт, ведь остальные 3 байта равны
```
assign cmpr[0] = ((q[31:0] >= q[991:960]) & (q[95:64] >= q[991:960]) & (q[159:128] >= q[991:960]) & (q[223:192] >= q[991:960]) & (q[287:256] >= q[991:960]) & (q[351:320] >= q[991:960]) & (q[415:384] >= q[991:960]) & (q[479:448] >= q[991:960]) & (q[543:512] >= q[991:960]) & (q[607:576] >= q[991:960]) & (q[671:640] >= q[991:960]) & (q[735:704] >= q[991:960]) & (q[799:768] >= q[991:960]) & (q[863:832] >= q[991:960]) & (q[927:896] >= q[991:960]));
assign cmpr[1] = ((q[15:0] >= q[1007:992]) & (q[47:32] >= q[1007:992]) & (q[79:64] >= q[1007:992]) & (q[111:96] >= q[1007:992]) & (q[143:128] >= q[1007:992]) & (q[175:160] >= q[1007:992]) & (q[207:192] >= q[1007:992]) & (q[239:224] >= q[1007:992]) & (q[271:256] >= q[1007:992]) & (q[303:288] >= q[1007:992]) & (q[335:320] >= q[1007:992]) & (q[367:352] >= q[1007:992]) & (q[399:384] >= q[1007:992]) & (q[431:416] >= q[1007:992]) & (q[463:448]>= q[1007:992]) & (q[495:480] >= q[1007:992]) & (q[527:512] >= q[1007:992]) & (q[559:544] >= q[1007:992]) & (q[591:576] >= q[1007:992]) & (q[623:608] >= q[1007:992]) & (q[655:640] >= q[1007:992]) & (q[687:672] >= q[1007:992]) & (q[719:704] >= q[1007:992]) &(q[751:736] >= q[1007:992]) & (q[783:768] >= q[1007:992]) & (q[815:800] >= q[1007:992]) & (q[847:832] >= q[1007:992]) & (q[879:864] >= q[1007:992]) & (q[911:896] >= q[1007:992]) & (q[943:928] >= q[1007:992]) & (q[975:960] >= q[1007:992]));
assign cmpr[2] = ((q[7:0] >= q[1015:1008]) & (q[23:16] >= q[1015:1008]) & (q[39:32] >= q[1015:1008]) & (q[55:48] >= q[1015:1008]) & (q[71:64] >= q[1015:1008]) &(q[87:80] >= q[1015:1008]) & (q[103:96] >= q[1015:1008]) & (q[119:112] >= q[1015:1008]) & (q[135:128] >= q[1015:1008]) & (q[151:144] >= q[1015:1008]) & (q[167:160] >= q[1015:1008]) & (q[183:176] >= q[1015:1008]) & (q[199:192] >= q[1015:1008]) & (q[215:208] >= q[1015:1008]) & (q[231:224] >= q[1015:1008]) & (q[247:240] >= q[1015:1008]) & (q[263:256] >= q[1015:1008]) & (q[279:272] >= q[1015:1008]) &(q[295:288] >= q[1015:1008]) & (q[311:304] >= q[1015:1008]) & (q[327:320] >= q[1015:1008]) & (q[343:336] >= q[1015:1008]) & (q[359:352] >= q[1015:1008]) & (q[375:368] >= q[1015:1008]) & (q[391:384] >= q[1015:1008]) & (q[407:400] >= q[1015:1008]) & (q[423:416] >= q[1015:1008]) & (q[439:432] >= q[1015:1008]) & (q[455:448] >= q[1015:1008]) & (q[471:464] >= q[1015:1008]) & (q[487:480] >= q[1015:1008]) & (q[503:496] >= q[1015:1008]) & (q[519:512] >= q[1015:1008]) & (q[535:528] >= q[1015:1008]) & (q[551:544] >= q[1015:1008]) & (q[567:560] >= q[1015:1008]) & (q[583:576] >= q[1015:1008]) & (q[599:592] >= q[1015:1008]) & (q[615:608] >= q[1015:1008]) & (q[631:624] >= q[1015:1008]) & (q[647:640] >= q[1015:1008]) & (q[663:656] >= q[1015:1008]) & (q[679:672] >= q[1015:1008]) & (q[695:688] >= q[1015:1008]) & (q[711:704] >= q[1015:1008]) & (q[727:720] >= q[1015:1008]) & (q[743:736]>= q[1015:1008]) & (q[759:752] >= q[1015:1008]) & (q[775:768] >= q[1015:1008]) & (q[791:784] >= q[1015:1008]) & (q[807:800] >= q[1015:1008]) & (q[823:816] >= q[1015:1008]) & (q[839:832] >= q[1015:1008]) & (q[855:848] >= q[1015:1008]) & (q[871:864] >= q[1015:1008]) & (q[887:880] >= q[1015:1008]) & (q[903:896] >= q[1015:1008]) & (q[919:912] >= q[1015:1008]) & (q[935:928] >= q[1015:1008]) & (q[951:944] >= q[1015:1008]) & (q[967:960] >= q[1015:1008]) & (q[983:976] >= q[1015:1008]) & (q[999:992] >= q[1015:1008]));
```
Другие компараторы сравнивают старшие разряды сегментов на равенство. Если старшие разряды сегментов равны, а младшие разряды сегментов больше, либо равны младшим разрядам базы, то возможна компрессия по этому режиму. Так формируется значение сигналов bd
```
assign bd[0] = ((q[63:8] == q[127:72]) & (q[127:72] == q[191:136]) & (q[191:136]== q[255:200]) & (q[388:328] == q[447:392]) & (q[447:392] == q[511:456]) & (q[511:456] == q[575:520]) & (q[575:520] == q[639:584]) & (q[639:584] == q[703:648]) & (q[703:648] == q[767:712]) & (q[767:712] == q[831:776]) & (q[831:776] == q[895:840]) & (q[895:840] == q[959:904]) & (q[959:904] == q[1023:968])) & cmpr[0];
assign bd[1] = ((q[63:16] == q[127:80]) & (q[127:80] == q[191:144]) & (q[191:144] == q[255:208]) & (q[255:208] == q[319:272]) & (q[319:272] == q[383:336]) & (q[383:336] == q[447:400]) & (q[447:400] == q[511:464]) & (q[511:464] == q[575:528]) & (q[575:528] == q[639:592]) & (q[639:592] == q[703:656]) & (q[703:656] == q[767:720]) & (q[767:720] == q[831:784]) & (q[831:784] == q[895:848]) & (q[895:848] == q[959:912]) & (q[959:912] == q[1023:976])) & cmpr[0];
assign bd[2] = ((q[63:32] == q[127:96]) & (q[127:96] == q[191:160]) & (q[191:160] == q[255:224]) & (q[255:224] == q[319:288]) & (q[319:288] == q[383:352]) & (q[383:352] == q[447:416]) & (q[447:416] == q[511:480]) & (q[511:480] == q[575:544]) & (q[575:544] == q[639:608]) & (q[639:608] == q[703:672]) & (q[703:672] == q[767:736]) & (q[767:736] == q[831:800]) & (q[831:800] == q[895:864]) & (q[895:864] == q[959:928]) & (q[959:928] == q[1023:992])) & cmpr[0];
assign bd[3] = ((q[31:8] == q[63:40]) & (q[63:40] == q[95:72]) & (q[95:72] == q[127:104]) & (q[127:104] == q[159:136]) & (q[159:136] == q[191:168]) & (q[191:168] == q[223:200]) & (q[223:200] == q[255:232]) & (q[255:232] == q[287:264]) & (q[287:264] == q[319:296]) & (q[319:296] == q[351:328]) & (q[351:328] == q[383:360]) & (q[383:360] == q[415:392]) & (q[415:392] == q[447:424]) & (q[447:424] == q[479:456]) & (q[479:456] == q[511:488]) & (q[511:488] == q[543:520]) & (q[543:520] == q[575:552]) & (q[575:552] == q[607:584]) & (q[607:584] == q[639:616]) & (q[639:616] == q[671:648]) & (q[671:648] == q[703:680]) & (q[703:680] == q[735:712]) & (q[735:712] == q[767:744]) & (q[767:744] == q[799:776]) & (q[799:776] == q[831:808]) & (q[831:808] == q[863:840]) & (q[863:840] == q[895:872]) & (q[895:872] == q[927:904]) & (q[927:904] == q[959:936]) & (q[959:936] == q[991:968]) & (q[991:968] == q[1023:1000])) & cmpr[1];
assign bd[4] = ((q[31:16] == q[63:48]) & (q[63:48] == q[95:80]) & (q[95:80] == q[127:112]) & (q[127:112] == q[159:144]) & (q[159:144] == q[191:176]) & (q[191:176] == q[223:208]) & (q[223:208] == q[255:240]) & (q[255:240] == q[287:272]) & (q[287:272] == q[319:304]) & (q[319:304] == q[351:336]) & (q[351:336] == q[383:368]) & (q[383:368] == q[415:400]) & (q[415:400] == q[447:432]) & (q[447:432] == q[479:464]) & (q[479:464] == q[511:496]) & (q[511:496] == q[543:528]) & (q[543:528] == q[575:560]) & (q[575:560] == q[607:592]) & (q[607:592] == q[639:624]) & (q[639:624] == q[671:656]) & (q[671:656] == q[703:688]) & (q[703:688] == q[735:720]) & (q[735:720] == q[767:752]) & (q[767:752] == q[799:784]) & (q[799:784] == q[831:816]) & (q[831:816] == q[863:848]) & (q[863:848] == q[895:880]) & (q[895:880]== q[927:912]) & (q[927:912] == q[959:944]) & (q[959:944] == q[991:976]) & (q[991:976] == q[1023:1008])) & cmpr[1];
assign bd[5] = ((q[15:8] == q[31:24]) & (q[31:24] == q[47:40]) & (q[47:40] == q[63:56]) & (q[63:56] == q[79:72]) & (q[79:72] == q[95:88]) & (q[95:88] == q[111:104]) & (q[111:104] == q[127:120]) & (q[127:120] == q[143:136]) & (q[143:136] == q[159:152]) & (q[159:152] == q[175:168]) & (q[175:168] == q[191:184]) & (q[191:184] == q[207:200]) & (q[207:200] == q[223:216]) & (q[223:216] == q[239:232]) & (q[239:232] == q[255:248]) & (q[255:248] == q[271:264]) & (q[271:264] == q[287:280]) & (q[287:280] == q[303:296]) & (q[303:296] == q[319:312]) & (q[319:312] == q[335:328]) & (q[335:328] == q[351:344]) & (q[351:344] == q[367:360]) & (q[367:360] == q[383:376]) & (q[383:376] == q[399:392]) & (q[399:392] == q[415:408]) & (q[415:408] == q[431:424]) & (q[431:424] == q[447:440]) & (q[447:440] == q[463:456]) & (q[463:456] == q[479:472]) & (q[479:472] == q[495:488]) & (q[495:488] == q[511:504]) & (q[511:504] == q[527:520]) & (q[527:520] == q[543:536]) & (q[543:536] == q[559:552]) & (q[559:552] == q[575:568]) & (q[575:568] == q[591:584]) & (q[591:584] == q[607:600]) & (q[607:600] == q[623:616]) & (q[623:616] == q[639:632]) & (q[639:632] == q[655:648]) & (q[655:648] == q[671:664]) & (q[671:664] == q[687:680]) & (q[687:680] == q[703:696]) & (q[703:696] == q[719:712]) & (q[719:712]== q[735:728]) & (q[735:728] == q[751:744]) & (q[751:744] == q[767:760]) & (q[767:760] == q[783:776]) & (q[783:776] == q[799:792]) & (q[799:792] == q[815:808])& (q[815:808] == q[831:824]) & (q[831:824] == q[847:840]) & (q[847:840] == q[863:856]) & (q[863:856] == q[879:872]) & (q[879:872] == q[895:888]) & (q[895:888] == q[911:904]) & (q[911:904] == q[927:920]) & (q[927:920] == q[943:936]) & (q[943:936] == q[959:952]) & (q[959:952] == q[975:968]) & (q[975:968] == q[991:984]) & (q[991:984] == q[1007:1000]) & (q[1007:1000] == q[1023:1016])) & cmpr[2];
assign bd[6] = ~(bd[0] | bd[1] | bd[2] | bd[3] | bd[4] | bd[5]);
```
Сигналы bd подаются на схему приоритета, чтобы не возникал конфликт в случае, когда компрессия может быть осуществлена разными способами. Между собой режимы не имеют приоритетов друг над другом, но они все приоритетнее отсутствия компрессии. Старший бит означает отсутствие компрессии, поэтому приоритет расставлен от младшего разряда к старшему. Ниже представлена схема приоритета.
```
module priority_select(input tri [6:0] a, output logic [6:0] y);
always_comb
casez(a)
7'b1000000: y = 7'b1000000;
7'b?100000: y = 7'b0100000;
7'b??10000: y = 7'b0010000;
7'b???1000: y = 7'b0001000;
7'b????100: y = 7'b0000100;
7'b?????10: y = 7'b0000010;
7'b??????1: y = 7'b0000001;
default: y = 7'b0000000;
endcase
endmodule
```
Данное значение используется при компрессии. В зависимости от установленного режима компрессии вычисляется значение выхода компрессора. В случае удачной компрессии в кэш-строку записываются следующие данные: бит достоверности (равный 1), поле тега (копируется с буфера чтения), сжатые данные, пустое пространство (если есть) и код компрессии
Поле кода компрессии имеет три бита и вычисляется с помощью схемы, обратной схемы декодера, представленной ниже
```
module getcode(input tri [6:0] a, input tri con, output logic [2:0] code);
always_comb
begin
if (con)
begin
case(a)
7'b0000001: code = 3'b000; //b8-1
7'b0000010: code = 3'b001; //b8-2
7'b0000100: code = 3'b010; //b8-4
7'b0001000: code = 3'b011; //b4-1
7'b0010000: code = 3'b100; //b4-2
7'b0100000: code = 3'b101; //b2-1
7'b1000000: code = 3'b110; //No Compression
default: code = 3'bxxx;
endcase
end
else
begin
code = 3'b110;
end
end
endmodule
```
Если компрессия неосуществима, то в кэш-строку записываются старшие 8 слов буфера чтения.
Если сигнал CON равен 0, что свидетельствует об отключенной компрессии, запись в кэш-строку происходит в два цикла. Когда значение T-триггера равно 1, записываются старшие слова буфера чтения. Когда значение T-триггера равно 0, записываются младшие слова буфера чтения по адресу, меньший на 1.
Т-триггер представляет из себя схему, которая за каждый такт инвертирует и выводит внутренний сигнал. При асинхронном сбросе значение внутреннего сигнала становится равным 0. Её описание представлено ниже
```
module ttongle(input tri clk, reset, con, output logic t);
logic a;
always_ff@(posedge clk, posedge reset)
begin
if (reset) a <= 1'b0;
else if(~con)
begin
a <= ~a;
t <= a;
end
else t <= 1'bz;
end
endmodule
```
Вся схема компрессора выглядит следующим образом
```
module compressor(input tri [1087:0] d, input tri con, clk, reset, output logic [643:0] cq, output logic [3:0] way);
tri [6:0] bd, y;
tri [2:0] code, cmpr;
tri [1087:0] q;
tri t;
bufferc bufferc(.d(d), .clk(clk), .reset(reset), .q(q));
assign cmpr[0] = ((q[31:0] >= q[991:960]) & (q[95:64] >= q[991:960]) & (q[159:128] >= q[991:960]) & (q[223:192] >= q[991:960]) & (q[287:256] >= q[991:960]) & (q[351:320] >= q[991:960]) & (q[415:384] >= q[991:960]) & (q[479:448] >= q[991:960]) & (q[543:512] >= q[991:960]) & (q[607:576] >= q[991:960]) & (q[671:640] >= q[991:960]) & (q[735:704] >= q[991:960]) & (q[799:768] >= q[991:960]) & (q[863:832] >= q[991:960]) & (q[927:896] >= q[991:960]));
assign cmpr[1] = ((q[15:0] >= q[1007:992]) & (q[47:32] >= q[1007:992]) & (q[79:64] >= q[1007:992]) & (q[111:96] >= q[1007:992]) & (q[143:128] >= q[1007:992]) & (q[175:160] >= q[1007:992]) & (q[207:192] >= q[1007:992]) & (q[239:224] >= q[1007:992]) & (q[271:256] >= q[1007:992]) & (q[303:288] >= q[1007:992]) & (q[335:320] >= q[1007:992]) & (q[367:352] >= q[1007:992]) & (q[399:384] >= q[1007:992]) & (q[431:416] >= q[1007:992]) & (q[463:448]>= q[1007:992]) & (q[495:480] >= q[1007:992]) & (q[527:512] >= q[1007:992]) & (q[559:544] >= q[1007:992]) & (q[591:576] >= q[1007:992]) & (q[623:608] >= q[1007:992]) & (q[655:640] >= q[1007:992]) & (q[687:672] >= q[1007:992]) & (q[719:704] >= q[1007:992]) &(q[751:736] >= q[1007:992]) & (q[783:768] >= q[1007:992]) & (q[815:800] >= q[1007:992]) & (q[847:832] >= q[1007:992]) & (q[879:864] >= q[1007:992]) & (q[911:896] >= q[1007:992]) & (q[943:928] >= q[1007:992]) & (q[975:960] >= q[1007:992]));
assign cmpr[2] = ((q[7:0] >= q[1015:1008]) & (q[23:16] >= q[1015:1008]) & (q[39:32] >= q[1015:1008]) & (q[55:48] >= q[1015:1008]) & (q[71:64] >= q[1015:1008]) &(q[87:80] >= q[1015:1008]) & (q[103:96] >= q[1015:1008]) & (q[119:112] >= q[1015:1008]) & (q[135:128] >= q[1015:1008]) & (q[151:144] >= q[1015:1008]) & (q[167:160] >= q[1015:1008]) & (q[183:176] >= q[1015:1008]) & (q[199:192] >= q[1015:1008]) & (q[215:208] >= q[1015:1008]) & (q[231:224] >= q[1015:1008]) & (q[247:240] >= q[1015:1008]) & (q[263:256] >= q[1015:1008]) & (q[279:272] >= q[1015:1008]) &(q[295:288] >= q[1015:1008]) & (q[311:304] >= q[1015:1008]) & (q[327:320] >= q[1015:1008]) & (q[343:336] >= q[1015:1008]) & (q[359:352] >= q[1015:1008]) & (q[375:368] >= q[1015:1008]) & (q[391:384] >= q[1015:1008]) & (q[407:400] >= q[1015:1008]) & (q[423:416] >= q[1015:1008]) & (q[439:432] >= q[1015:1008]) & (q[455:448] >= q[1015:1008]) & (q[471:464] >= q[1015:1008]) & (q[487:480] >= q[1015:1008]) & (q[503:496] >= q[1015:1008]) & (q[519:512] >= q[1015:1008]) & (q[535:528] >= q[1015:1008]) & (q[551:544] >= q[1015:1008]) & (q[567:560] >= q[1015:1008]) & (q[583:576] >= q[1015:1008]) & (q[599:592] >= q[1015:1008]) & (q[615:608] >= q[1015:1008]) & (q[631:624] >= q[1015:1008]) & (q[647:640] >= q[1015:1008]) & (q[663:656] >= q[1015:1008]) & (q[679:672] >= q[1015:1008]) & (q[695:688] >= q[1015:1008]) & (q[711:704] >= q[1015:1008]) & (q[727:720] >= q[1015:1008]) & (q[743:736]>= q[1015:1008]) & (q[759:752] >= q[1015:1008]) & (q[775:768] >= q[1015:1008]) & (q[791:784] >= q[1015:1008]) & (q[807:800] >= q[1015:1008]) & (q[823:816] >= q[1015:1008]) & (q[839:832] >= q[1015:1008]) & (q[855:848] >= q[1015:1008]) & (q[871:864] >= q[1015:1008]) & (q[887:880] >= q[1015:1008]) & (q[903:896] >= q[1015:1008]) & (q[919:912] >= q[1015:1008]) & (q[935:928] >= q[1015:1008]) & (q[951:944] >= q[1015:1008]) & (q[967:960] >= q[1015:1008]) & (q[983:976] >= q[1015:1008]) & (q[999:992] >= q[1015:1008]));
assign bd[0] = ((q[63:8] == q[127:72]) & (q[127:72] == q[191:136]) & (q[191:136]== q[255:200]) & (q[388:328] == q[447:392]) & (q[447:392] == q[511:456]) & (q[511:456] == q[575:520]) & (q[575:520] == q[639:584]) & (q[639:584] == q[703:648]) & (q[703:648] == q[767:712]) & (q[767:712] == q[831:776]) & (q[831:776] == q[895:840]) & (q[895:840] == q[959:904]) & (q[959:904] == q[1023:968])) & cmpr[0];
assign bd[1] = ((q[63:16] == q[127:80]) & (q[127:80] == q[191:144]) & (q[191:144] == q[255:208]) & (q[255:208] == q[319:272]) & (q[319:272] == q[383:336]) & (q[383:336] == q[447:400]) & (q[447:400] == q[511:464]) & (q[511:464] == q[575:528]) & (q[575:528] == q[639:592]) & (q[639:592] == q[703:656]) & (q[703:656] == q[767:720]) & (q[767:720] == q[831:784]) & (q[831:784] == q[895:848]) & (q[895:848] == q[959:912]) & (q[959:912] == q[1023:976])) & cmpr[0];
assign bd[2] = ((q[63:32] == q[127:96]) & (q[127:96] == q[191:160]) & (q[191:160] == q[255:224]) & (q[255:224] == q[319:288]) & (q[319:288] == q[383:352]) & (q[383:352] == q[447:416]) & (q[447:416] == q[511:480]) & (q[511:480] == q[575:544]) & (q[575:544] == q[639:608]) & (q[639:608] == q[703:672]) & (q[703:672] == q[767:736]) & (q[767:736] == q[831:800]) & (q[831:800] == q[895:864]) & (q[895:864] == q[959:928]) & (q[959:928] == q[1023:992])) & cmpr[0];
assign bd[3] = ((q[31:8] == q[63:40]) & (q[63:40] == q[95:72]) & (q[95:72] == q[127:104]) & (q[127:104] == q[159:136]) & (q[159:136] == q[191:168]) & (q[191:168] == q[223:200]) & (q[223:200] == q[255:232]) & (q[255:232] == q[287:264]) & (q[287:264] == q[319:296]) & (q[319:296] == q[351:328]) & (q[351:328] == q[383:360]) & (q[383:360] == q[415:392]) & (q[415:392] == q[447:424]) & (q[447:424] == q[479:456]) & (q[479:456] == q[511:488]) & (q[511:488] == q[543:520]) & (q[543:520] == q[575:552]) & (q[575:552] == q[607:584]) & (q[607:584] == q[639:616]) & (q[639:616] == q[671:648]) & (q[671:648] == q[703:680]) & (q[703:680] == q[735:712]) & (q[735:712] == q[767:744]) & (q[767:744] == q[799:776]) & (q[799:776] == q[831:808]) & (q[831:808] == q[863:840]) & (q[863:840] == q[895:872]) & (q[895:872] == q[927:904]) & (q[927:904] == q[959:936]) & (q[959:936] == q[991:968]) & (q[991:968] == q[1023:1000])) & cmpr[1];
assign bd[4] = ((q[31:16] == q[63:48]) & (q[63:48] == q[95:80]) & (q[95:80] == q[127:112]) & (q[127:112] == q[159:144]) & (q[159:144] == q[191:176]) & (q[191:176] == q[223:208]) & (q[223:208] == q[255:240]) & (q[255:240] == q[287:272]) & (q[287:272] == q[319:304]) & (q[319:304] == q[351:336]) & (q[351:336] == q[383:368]) & (q[383:368] == q[415:400]) & (q[415:400] == q[447:432]) & (q[447:432] == q[479:464]) & (q[479:464] == q[511:496]) & (q[511:496] == q[543:528]) & (q[543:528] == q[575:560]) & (q[575:560] == q[607:592]) & (q[607:592] == q[639:624]) & (q[639:624] == q[671:656]) & (q[671:656] == q[703:688]) & (q[703:688] == q[735:720]) & (q[735:720] == q[767:752]) & (q[767:752] == q[799:784]) & (q[799:784] == q[831:816]) & (q[831:816] == q[863:848]) & (q[863:848] == q[895:880]) & (q[895:880]== q[927:912]) & (q[927:912] == q[959:944]) & (q[959:944] == q[991:976]) & (q[991:976] == q[1023:1008])) & cmpr[1];
assign bd[5] = ((q[15:8] == q[31:24]) & (q[31:24] == q[47:40]) & (q[47:40] == q[63:56]) & (q[63:56] == q[79:72]) & (q[79:72] == q[95:88]) & (q[95:88] == q[111:104]) & (q[111:104] == q[127:120]) & (q[127:120] == q[143:136]) & (q[143:136] == q[159:152]) & (q[159:152] == q[175:168]) & (q[175:168] == q[191:184]) & (q[191:184] == q[207:200]) & (q[207:200] == q[223:216]) & (q[223:216] == q[239:232]) & (q[239:232] == q[255:248]) & (q[255:248] == q[271:264]) & (q[271:264] == q[287:280]) & (q[287:280] == q[303:296]) & (q[303:296] == q[319:312]) & (q[319:312] == q[335:328]) & (q[335:328] == q[351:344]) & (q[351:344] == q[367:360]) & (q[367:360] == q[383:376]) & (q[383:376] == q[399:392]) & (q[399:392] == q[415:408]) & (q[415:408] == q[431:424]) & (q[431:424] == q[447:440]) & (q[447:440] == q[463:456]) & (q[463:456] == q[479:472]) & (q[479:472] == q[495:488]) & (q[495:488] == q[511:504]) & (q[511:504] == q[527:520]) & (q[527:520] == q[543:536]) & (q[543:536] == q[559:552]) & (q[559:552] == q[575:568]) & (q[575:568] == q[591:584]) & (q[591:584] == q[607:600]) & (q[607:600] == q[623:616]) & (q[623:616] == q[639:632]) & (q[639:632] == q[655:648]) & (q[655:648] == q[671:664]) & (q[671:664] == q[687:680]) & (q[687:680] == q[703:696]) & (q[703:696] == q[719:712]) & (q[719:712]== q[735:728]) & (q[735:728] == q[751:744]) & (q[751:744] == q[767:760]) & (q[767:760] == q[783:776]) & (q[783:776] == q[799:792]) & (q[799:792] == q[815:808])& (q[815:808] == q[831:824]) & (q[831:824] == q[847:840]) & (q[847:840] == q[863:856]) & (q[863:856] == q[879:872]) & (q[879:872] == q[895:888]) & (q[895:888] == q[911:904]) & (q[911:904] == q[927:920]) & (q[927:920] == q[943:936]) & (q[943:936] == q[959:952]) & (q[959:952] == q[975:968]) & (q[975:968] == q[991:984]) & (q[991:984] == q[1007:1000]) & (q[1007:1000] == q[1023:1016])) & cmpr[2];
assign bd[6] = ~(bd[0] | bd[1] | bd[2] | bd[3] | bd[4] | bd[5]);
priority_select preget(.a(bd), .y(y));
getcode get(.a(y), .code(code), .con(con));
ttongle doubleclockmode(.clk(clk), .reset(reset), .con(con), .t(t));
always_comb
begin
if (con)
begin
case (y)
7'b0000001: cq = {1'b1, q[1087:1024], q[1023:960], 8'b0, (q[903:896] - q[967:960]), (q[839:832] - q[967:960]), (q[775:768] - q[967:960]), (q[711:704] - q[967:960]), (q[647:640] - q[967:960]), (q[583:576] - q[967:960]), (q[519:512] - q[967:960]), (q[455:448] - q[967:960]), (q[391:384] - q[967:960]), (q[327:320] - q[967:960]), (q[263:256] - q[967:960]), (q[199:192] - q[967:960]), (q[135:128] - q[967:960]), (q[71:64] - q[967:960]), (q[7:0] - q[967:960]), 384'b0, code}; //b8-1
7'b0000010: cq = {1'b1, q[1087:1024], q[1023:960], 16'b0, (q[911:896] - q[975:960]), (q[847:832] - q[975:960]), (q[783:768] - q[975:960]), (q[719:704] - q[975:960]), (q[655:640] - q[975:960]), (q[591:576] - q[975:960]), (q[527:512] - q[975:960]), (q[463:448] - q[975:960]), (q[399:384] - q[975:960]), (q[335:320] - q[975:960]), (q[271:256] - q[975:960]), (q[207:192] - q[975:960]), (q[143:128] - q[975:960]), (q[79:64] - q[975:960]), (q[15:0] - q[975:960]), 256'b0, code}; //b8-2
7'b0000100: cq = {1'b1, q[1087:1024], q[1023:960], 32'b0, (q[927:897] - q[991:960]), (q[863:832] - q[991:960]), (q[799:768] - q[991:960]), (q[735:704] - q[991:960]), (q[671:640] - q[991:960]), (q[607:576] - q[991:960]), (q[543:512] - q[991:960]), (q[479:448] - q[991:960]), (q[415:384] - q[991:960]), (q[351:320] - q[991:960]), (q[287:256] - q[991:960]), (q[223:192] - q[991:960]), (q[159:128] - q[991:960]), (q[95:64] - q[991:960]), (q[31:0] - q[991:960]), code}; //b8-4
7'b0001000: cq = {1'b1, q[1087:1024], q[1023:992], 8'b0, (q[967:960] - q[999:992]), (q[935:928] - q[999:992]), (q[903:896] - q[999:992]), (q[871:864] - q[999:992]), (q[839:832] - q[999:992]), (q[807:800] - q[999:992]), (q[775:768] - q[999:992]), (q[743:736] - q[999:992]), (q[711:704] - q[999:992]), (q[679:672] - q[999:992]), (q[647:640] - q[999:992]), (q[615:608] - q[999:992]), (q[583:576] - q[999:992]), (q[551:544] - q[999:992]), (q[519:512] - q[999:992]), (q[487:480] - q[999:992]), (q[455:448] - q[999:992]), (q[423:416] - q[999:992]), (q[391:384] - q[999:992]), (q[359:352] - q[999:992]), (q[327:320] - q[999:992]), (q[295:288] - q[999:992]), (q[263:256] - q[999:992]), (q[231:224] - q[999:992]), (q[199:192] - q[999:992]), (q[167:160] - q[999:992]), (q[135:128] - q[999:992]), (q[103:96] - q[999:992]), (q[71:64] - q[999:992]), (q[39:32] - q[999:992]), (q[7:0] - q[999:992]), 288'b0, code};
7'b0010000: cq = {1'b1, q[1087:1024], q[1023:992], 16'b0, (q[975:960] - q[1007:992]), (q[943:928] - q[1007:992]), (q[911:896] - q[1007:992]), (q[879:864] - q[1007:992]), (q[847:832] - q[1007:992]), (q[815:800] - q[1007:992]), (q[783:768] - q[1007:992]), (q[751:736] - q[1007:992]), (q[719:704] - q[1007:992]), (q[687:672] - q[1007:992]),(q[655:640] - q[1007:992]), (q[623:608] - q[1007:992]), (q[591:576] - q[1007:992]), (q[559:544] - q[1007:992]), (q[527:512] - q[1007:992]), (q[495:480] - q[1007:992]), (q[463:448] - q[1007:992]), (q[431:416] - q[1007:992]), (q[399:384] - q[1007:992]), (q[367:352] - q[1007:992]), (q[335:320] - q[1007:992]), (q[303:288] - q[1007:992]), (q[271:256] - q[1007:992]), (q[239:224] - q[1007:992]), (q[207:192] - q[1007:992]), (q[175:160] - q[1007:992]), (q[143:128] - q[1007:992]), (q[111:96] - q[1007:992]), (q[79:64] - q[1007:992]), (q[47:32] - q[1007:992]), (q[15:0] - q[1007:992]), 32'b0, code};
7'b0100000: cq = {1'b1, q[1087:1024], q[1023:1008], 8'b0, (q[999:992] - q[1015:1008]), (q[983:978] - q[1015:1008]), (q[967:960] - q[1015:1008]), (q[951:944] - q[1015:1008]), (q[935:928] - q[1015:1008]), (q[919:912] - q[1015:1008]), (q[903:896] - q[1015:1008]), (q[887:880] - q[1015:1008]), (q[871:864] - q[1015:1008]), (q[855:848] - q[1015:1008]), (q[839:832] - q[1015:1008]), (q[823:816] - q[1015:1008]), (q[807:800] - q[1015:1008]), (q[791:784] - q[1015:1008]), (q[775:768] - q[1015:1008]), (q[759:752] - q[1015:1008]), (q[743:736] - q[1015:1008]), (q[727:720] - q[1015:1008]), (q[711:704] - q[1015:1008]), (q[695:688] - q[1015:1008]), (q[679:672] - q[1015:1008]), (q[663:656] - q[1015:1008]), (q[647:640] - q[1015:1008]), (q[631:624] - q[1015:1008]), (q[615:608] - q[1015:1008]), (q[599:592] - q[1015:1008]), (q[583:576] - q[1015:1008]), (q[567:560] - q[1015:1008]), (q[551:544] - q[1015:1008]), (q[535:528] - q[1015:1008]), (q[519:512] - q[1015:1008]), (q[503:496] - q[1015:1008]), (q[487:480] - q[1015:1008]), (q[471:464] - q[1015:1008]), (q[455:448] - q[1015:1008]), (q[439:432] - q[1015:1008]), (q[423:416] - q[1015:1008]), (q[407:400] - q[1015:1008]), (q[391:384] - q[1015:1008]), (q[375:368] - q[1015:1008]), (q[359:352] - q[1015:1008]), (q[343:336] - q[1015:1008]), (q[327:320] - q[1015:1008]), (q[311:304] - q[1015:1008]), (q[295:288] - q[1015:1008]), (q[279:272] - q[1015:1008]), (q[263:256] - q[1015:1008]), (q[247:240] - q[1015:1008]), (q[231:224] - q[1015:1008]), (q[215:208] - q[1015:1008]), (q[199:192] - q[1015:1008]), (q[183:176] - q[1015:1008]), (q[167:160] - q[1015:1008]), (q[151:144] - q[1015:1008]), (q[135:128] - q[1015:1008]), (q[119:112] - q[1015:1008]), (q[103:96] - q[1015:1008]), (q[87:80] - q[1015:1008]), (q[71:64] - q[1015:1008]), (q[55:48] - q[1015:1008]), (q[39:32] - q[1015:1008]), (q[23:16] - q[1015:1008]), (q[7:0] - q[1015:1008]), 48'b0, code};
7'b1000000: cq = reset ? 644'b0 : {1'b1, q[1087:512], 64'b0, code};
default: cq = 644'bz;
endcase
way = q[1031:1028];
end
else
begin
if (t)
begin
cq = {1'b1, q[1087:512], 64'b0, code};
way = q[1031:1028];
end
else
begin
cq = {1'b1, q[1087:1024], q[511:0], code};
way = q[1031:1028] - 1'b1;
end
end
end
endmodule
```
### Транзакция с кэш-памятью
С пословной адресацией (64 бит) требуется 8 слов для заполнения кэш-строки объемом 64 байт. Отсюда следует, что 3 младших бита поля тега (адрес младшего слова в памяти) должны быть равны 0. А в теге запроса младшие три бита будут обеспечивать выбор слова в кэш-строке. Для выбора самой кэш-строки (адрес кэш-памяти) нужно считать следующие 4 бита (так как кэш-строк 16 = 2^4) тега запроса (при чтении), либо тега в буфере чтения (при записи)
Когда включена компрессия, каждая кэш-строка может содержать 8, либо 16 слов. Тогда младшие 4 бита поля тега будут равны 0. Младшие 4 бита тега запроса будут обеспечивать выбор слова из кэш-памяти. Следующие 4 бита в теге запроса или в поле тега буфера чтения будут обеспечивать выбор кэш-строки
Запись в кэш-память осуществляется только через компрессор, даже если компрессия отключена.
Операция чтения (RD активен) происходит следующим образом. По тегу запроса известно, в какой кэш-строке находятся данные. Затем поле тега передается и бит достоверности вместе с тегом запроса, а также вместе с сигналом CON передаются в фильтр запросов. Там происходит сравнение старших бит поля тега и старших бит тега запроса. Младшие 3 или 4 бита (в зависимости от сигнала CON) не сравниваются по той причине, что у тега запроса они служат для выбора слова. Если равенство устанавливается, а также бит достоверности равен 1, то сигнал кэш-попадание устанавливается в 0. В противном случае данный сигнал устанавливается в 1.
Когда компрессия включена, но для строки нет режимов компрессии, отсеиваются запросы в первые 4 слова
Схема фильтра запросов описана ниже
```
module requestfilter(input tri [643:0] d, input tri [63:0] tag, input tri con, input tri [3:0] wordaddr, output logic cachemiss);
tri filter;
tri [63:0] tageq;
tri [63:0] deq;
tri code110;
assign tageq = con ? {tag[63:4], 4'b0} : {tag[63:3], 3'b0};
assign deq = con ? {d[642:583], 4'b0} : {d[642:582], 3'b0};
assign code110 = con ? ((d[2:0] == 3'b110) & (wordaddr < 4'b0111)) : 1'b0;
assign filter = code110 ? 1'b1 : 1'b0;
always_comb
begin
if(d[643] & (tageq == deq)) cachemiss = 1'b0 | filter;
else cachemiss = 1'b1;
end
endmodule
```
Данные с кэш-памяти попадают в декомпрессор. Декомпрессия происходит путем сложения базы и дельт. Если компрессия отключена, либо для строки нет режима компрессии, то данные кэш-строки выводятся без декомпрессии. Декомпрессор реализован с помощью сумматоров, работающих параллельно. Декомпрессор представлен ниже
```
module decompressor(input tri [578:0] d, input tri clk, reset, output logic [1023:0] q);
always_comb
begin
case (d[2:0])
3'b000: q = {d[578:515], (d[506:499] + d[578:515]), (d[498:491] + d[578:515]), (d[490:483] + d[578:515]), (d[482:475] + d[578:515]), (d[474:467] + d[578:515]), (d[466:459] + d[578:515]), (d[458:451] + d[578:515]), (d[450:443] + d[578:515]), (d[442:435] + d[578:515]), (d[434:427] + d[578:515]), (d[426:419] + d[578:515]), (d[418:411] + d[578:515]), (d[410:403] + d[578:515]), (d[402:395] + d[578:515]), (d[394:387] + d[578:515])};
3'b001: q = {d[578:515], (d[498:483] + d[578:515]), (d[482:467] + d[578:515]), (d[466:451] + d[578:515]), (d[450:435] + d[578:515]), (d[434:419] + d[578:515]), (d[418:403] + d[578:515]), (d[402:387] + d[578:515]), (d[386:371] + d[578:515]), (d[370:355] + d[578:515]), (d[354:339] + d[578:515]), (d[338:323] + d[578:515]), (d[322:307] + d[578:515]), (d[306:291] + d[578:515]), (d[290:275] + d[578:515]), (d[274:259] + d[578:515])};
3'b010: q = {d[578:515], (d[482:451] + d[578:515]), (d[450:419] + d[578:515]), (d[418:387] + d[578:515]), (d[386:355] + d[578:515]), (d[354:323] + d[578:515]), (d[322:291] + d[578:515]), (d[290:259] + d[578:515]), (d[258:227] + d[578:515]), (d[226:195] + d[578:515]), (d[194:163] + d[578:515]), (d[162:131] + d[578:515]), (d[130:99] + d[578:515]), (d[98:67] + d[578:515]), (d[66:35] + d[578:515]), (d[34:3] + d[578:515])};
3'b011: q = {d[578:547], (d[538:531] + d[578:547]), (d[530:523] + d[578:547]), (d[522:515] + d[578:547]), (d[514:507] + d[578:547]), (d[506:499] + d[578:547]), (d[498:491] + d[578:547]), (d[490:483] + d[578:547]), (d[482:475] + d[578:547]), (d[450:443] + d[578:547]), (d[442:435] + d[578:547]), (d[434:427] + d[578:547]), (d[426:419] + d[578:547]), (d[418:411] + d[578:547]), (d[410:403] + d[578:547]), (d[402:395] + d[578:547]), (d[394:387] + d[578:547]), (d[386:379] + d[578:547]), (d[378:371] + d[578:547]), (d[370:363] + d[578:547]), (d[362:355] +d[578:547]), (d[354:347] + d[578:547]), (d[346:339] + d[578:547]), (d[338:331] +d [578:547]), (d[330:323] + d[578:547]), (d[322:315] + d[578:547]), (d[314:307] + d[578:547]), (d[306:299] + d[578:547]), (d[298:291] + d[578:547])};
3'b100: q = {d[578:547], (d[530:515] + d[578:547]), (d[514:499] + d[578:547]), (d[498:483] + d[578:547]), (d[482:467] + d[578:547]), (d[466:451] + d[578:547]), (d[450:435] + d[578:547]), (d[434:419] + d[578:547]), (d[418:403] + d[578:547]), (d[402:387] + d[578:547]), (d[386:371] + d[578:547]), (d[370:355] + d[578:547]), (d[354:339] + d[578:547]), (d[338:323] + d[578:547]), (d[322:307] + d[578:547]), (d[306:291] + d[578:547]), (d[290:275] + d[578:547]), (d[274:259] + d[578:547]), (d[258:243] + d[578:547]), (d[242:227] + d[578:547]), (d[226:211] + d[578:547]), (d[210:195] + d[578:547]), (d[194:179] + d[578:547]), (d[178:163] + d[578:547]), (d[162:147] + d[578:547]), (d[146:131] + d[578:547]), (d[130:115] + d[578:547]), (d[114:99] + d[578:547]), (d[98:83] + d[578:547]), (d[82:67] + d[578:547]), (d[66:51] + d[578:547]), (d[50:35] + d[578:547])};
3'b101: q = {d[578:563], (d[554:547] + d[578:563]), (d[546:539] + d[578:563]), (d[538:531] + d[578:563]), (d[530:523] + d[578:563]), (d[522:515] + d[578:563]), (d[514:507] + d[578:563]), (d[506:499] + d[578:563]), (d[498:491] + d[578:563]), (d[490:483] + d[578:563]), (d[482:475] + d[578:563]), (d[474:467] + d[578:563]), (d[466:459] + d[578:563]), (d[458:451] + d[578:563]), (d[450:443] + d[578:563]), (d[442:435] + d[578:563]), (d[434:427] + d[578:563]), (d[426:419] + d[578:563]), (d[418:411] + d[578:563]), (d[410:403] + d[578:563]), (d[402:395] + d[578:563]), (d[394:387] + d[578:563]), (d[386:379] + d[578:563]), (d[378:371] +d[578:563]), (d[370:363] + d[578:563]), (d[362:355] + d[578:563]), (d[354:347] +d[578:563]), (d[346:339] + d[578:563]), (d[338:331] + d[578:563]), (d[330:323]+ d[578:563]), (d[322:315] + d[578:563]), (d[314:307] + d[578:563]), (d[306:299]+ d[578:563]), (d[298:291] + d[578:563]), (d[290:283] + d[578:563]), (d[282:275] + d[578:563]), (d[274:267] + d[578:563]), (d[266:259] + d[578:563]), (d[258:251] + d[578:563]), (d[250:243] + d[578:563]), (d[242:235] + d[578:563]), (d[234:227] + d[578:563]), (d[226:219] + d[578:563]), (d[218:211] + d[578:563]), (d[210:203] + d[578:563]), (d[202:195] + d[578:563]), (d[194:187] + d[578:563]), (d[186:179] + d[578:563]), (d[178:171] + d[578:563]), (d[170:163] + d[578:563]), (d[162:155] + d[578:563]), (d[154:147] + d[578:563]), (d[146:139] + d[578:563]), (d[138:131] + d[578:563]), (d[130:123] + d[578:563]), (d[122:115] + d[578:563]), (d[114:107] + d[578:563]), (d[106:99] + d[578:563]), (d[98:91] + d[578:563]), (d[90:83] + d[578:563]), (d[82:75] + d[578:563]), (d[74:67] + d[578:563]), (d[66:59]+ d[578:563]), (d[58:51] + d[578:563])};
3'b110: q = {d[578:3], 448'b0};
default: q = 1024'bz;
endcase
end
endmodule
```
Затем, имея адрес слова, схема WSU (Word Select UnIt) выводит одно из слов памяти на выход. Её описание представлено ниже
```
module wordselectunit(input tri [1023:0] d, input tri [3:0] addr, output logic [63:0] q);
always_comb
begin
case(addr)
4'b1111: q = d[1023:960];
4'b1110: q = d[959:896];
4'b1101: q = d[895:832];
4'b1100: q = d[831:768];
4'b1011: q = d[767:704];
4'b1010: q = d[703:640];
4'b1001: q = d[639:576];
4'b1000: q = d[575:512];
4'b0111: q = d[511:448];
4'b0110: q = d[447:384];
4'b0101: q = d[383:320];
4'b0100: q = d[319:256];
4'b0011: q = d[255:192];
4'b0010: q = d[191:128];
4'b0001: q = d[127:64];
4'b0000: q = d[63:0];
default: q = 64'bz;
endcase
end
endmodule
```
Обращение к кэш-памяти происходит стандартным образом за тем исключением, что есть схема декомпрессии. Со сжатыми кэш-строками мы работаем также, как если бы мы работали с настоящими 128-ми байтовыми кэш-строками. Данная реализация алгоритма Base+Delta не меняет принципов ассоциативности кэш-памяти.
### Конечная схема
Вся система выглядит следующим образом
```
module cachewithcompression(input tri [1087:0] readbuffer, input tri [63:0] tag, input tri con, clk, reset, rd, output tri [63:0] q, output tri cachehit);
tri [643:0] cq;
tri [643:0] cqic;
tri [1023:0] pdq, dq;
tri [3:0] addr;
tri cachemiss;
tri [3:0] wordaddr;
tri [3:0] addrread, addrwrite;
tri [643:0] wsuq;
msbitoutput msbitoutput(.word(tag[3:0]), .s(con), .outputword(wordaddr));
mux2_4 conmux(.a(tag[6:3]), .b(tag[7:4]), .s(con), .c(addrread));
mux2_4 addrselect(.a(addrwrite), .b(addrread), .s(rd), .c(addr));
compressor compressor(.d(readbuffer), .con(con), .clk(clk), .reset(reset), .cq(cq), .way(addrwrite));
cache cache(.d(cq), .addr(addr), .clk(clk), .reset(reset), .rd(rd), .q(cqic));
requestfilter requestfilter(.d(cqic), .tag(tag), .wordaddr(wordaddr), .con(con), .cachemiss(cachemiss));
decompressor decompressor(.d(cqic), .clk(clk), .reset(reset), .q(pdq));
bufferd bufd(.d(pdq), .clk(clk), .reset(reset), .q(dq));
wordselectunit wsu(.d(dq), .addr(wordaddr), .q(wsuq));
assign cachehit = ~cachemiss & rd;
assign q = cachehit ? wsuq : 64'bz;
endmodule
```
Здесь, помимо описанных модулей, есть ещё несколько мультиплексоров, обеспечивающих выбор правильного адреса для кэш-памяти. Стоит ещё отметить, что данные выводятся только при кэш-попадании. Значение кэш-попадания основано на инвертированном значении кэш-промаха и сигнала RD. То есть даже если кэш-попадание есть в принципе есть, считывание не произойдет, если используется операция записи
---
### Полезные ссылки
В статье, как вы увидели, отсутствуют тесты. [Их вы можете посмотреть у авторов-разработчиков](https://users.ece.cmu.edu/~omutlu/pub/bdi-compression_pact12.pdf)
О таких алгоритмах я узнал от других разработчиков, [статью которых прикрепляю](http://www.mcst.ru/files/5a9eb4/a50cd8/500e13/000001/kozhin_a._s._surchenko_a._v._issledovanie_primenimosti_kompressii_dannyh_v_kesh-pamyati.pdf)
[Залил на github](https://github.com/PhenomIIX6/BDcachecompression)
|
https://habr.com/ru/post/686766/
| null |
ru
| null |
# Angular — это паттерн проектирования
Со стремительным приближением Angular 2.0, параллельно существующим с большим количеством других frontend-фреймворков, в воздухе витает множество волнений по поводу предстоящих затрат (как временных, так и денежных), связанных с переводом своих проектов на новую версию. Как вы думаете, есть ли у разработчиков желание изучить еще один новый фреймворк?
Давайте разбираться. Прошу под кат.
Несколько команд разработчиков провели достаточное количество времени с Angular 2.0, примерно столько же, сколько и наша (*Прим. пер.: Ionic team*). Мы вернулись к проектированию [Ionic 2](http://ionic.io/), когда Angular 2 был еще в статусе «пре-альфа», в надежде получить еще более быстрый, более совместимый со стандартами, и перспективный мобильный веб-фреймворк, — еще лучше, чем Angular 1.
Самое главное, что мы поняли, работая над Ionic 2 — это то, как похожи Angular 2 и Angular 1 на высоком уровне, и как понимание этого поможет разработчикам гораздо легче перейти с Angular 1 на Angular 2. Во многих отношениях, Angular 2, на самом деле, не является новым фреймворком как таковым. Это лишь новый стандарт Angular, с которым мы знакомы и который так полюбили.
#### **Один фреймворк, множество стандартов**
Вместе с Angular 1, Angular 2, и Angular Dart, Angular прошел путь от фрейворка, основанного на одном стандарте ES5, до концептуального фреймворка, или паттерна проектирования с множеством стандартов.
Можно спроектировать пользовательский интерфейс и frontend-приложение в стиле Angular, базируясь, по крайней мере, на трех основных языках: ES5, ES6/TypeScript и Dart, хотя ES6/TypeScript становится де-факто стандартом Angular.
Если мы ближе познакомимся с тем, как приложения на Angular работают на каждом из указанных выше языков, мы начнем замечать массу сходтв. Давайте взглянем на примере.
#### **Пример**
Чтобы вывести свойство из нашего скоупа (scope) или контекста, мы можем сделать вот так:
##### Angular 1:
```
Сегодня {{todaysDate | date}}
```
##### Angular Dart:
```
Сегодня {{todaysDate | date}}
```
##### Angular 2:
```
Сегодня {{todaysDate | date}}
```
Заметили что-нибудь? Они абсолютно одинаковые! Давайте попробуем более сложный пример. Представим, что у нас есть список песен:
##### В Angular 1 и Angular Dart это будет выглядеть так:
```
{{song.artist}} - {{song.title}}
```
##### А вот так в Angular 2 (вместе с Ionic 2):
```
{{song.artist}} - {{song.title}}
```
Ну, что ж, здесь мы уже видим больше различий. Но различия эти четко определены: **ng-repeat** теперь превратился в **ngFor**, со звездочкой **\***, которая используется для обозначения данного элемента в качестве шаблона (которй будет повторен N-раз).
В циклах теперь используется "**of**" вместо "**in**", чтобы получить значения списка. Еще ближе к стандарту ES6 и TypeScript. Начиная с Angular 2, мы больше не используем kebab-casing (*Прим. пер.: это когда синткасис написания у нас «вот-такой-вот»*) для написания атрибутов (то есть: ng-repeat, ng-if, ng-show и т.д.). Разработчики решили перейти к более четкому наименованию. ([более подробно об этом (eng)](http://angularjs.blogspot.com/2016/02/angular-2-templates-will-it-parse.html))
Если мы применяем стандарт Angular 1 к синтаксическому преобразованию Angular 2, то мы имеем код, который, концептуально, идентичен Angular 1 и Angular 2. Если предположить, что мы уже знакомы с Angular, то мы можем взглянуть на этот код и сразу понять, что он делает.
#### **Пример компонента**
Большинство пользователей Angular найдут шаблоны прямо в самом Angular 2. Гораздо большие изменения приходят с новой моделью компонента, которая заменяет установку директивы/контроллера из Angular 1.
##### В Angular 1:
```
.controller('HomeCtrl', function($scope) {
// контроллер конкретной страницы
})
.directive('profileImage', [function() {
// ... а здесь директива
}])
```
В Angular 2, учитывая, что все — это компонент, мы можем применить простое преобразование: включить контроллеры в компоненты, а также включить в них и директивы.
Так как Angular 2 живет и дышит стандартами TypeScript и ES6, мы определяем «компоненты» как классы, которые могут содержать внутри себя шаблоны. Аналогом примера выше (Angular 1), код в Angular 2 может выглядеть следующим образом:
```
import {Component} from 'angular2/core';
@Component({
selector: 'home',
template: 'главная страница'
})
export class HomeComponent { }
```
И директива из Angular 1 как компонент Angular 2:
```
@Component({
selector: 'profile-image',
template: 'profile image'
})
export class ProfileImageComponent { }
```
#### **А как же скоуп(scope)?**
В Angular 1 скоуп был на самом деле только «контекстом», доступным в конкретной области пользовательского интерфейса. К примеру, наша директива *profileImage* ссылается на текущего пользователя как часть своего скоупа, или контекста, и рендерит картинку профиля пользователя.
Данная концепция в точности такая же, как в Angular 2, за исключением того, что мы используем естественную концепцию данных экземпляра класса из ES6! Angular прошел путь от обычной контекстной системы до основанного на стандартах подхода. Это благодаря тому, что JavaScript эволюционировал, сделав подобное возможным (с небольшой декоративной магией TypeScript, что делает код еще чище):
```
export class ProfileImageComponent {
@Input() user;
clickFace() {
// теперь мы можем использовать запись this.user, так же, как и $scope.user мы использовали в Angular 1
}
}
```
В Angular 2 нам больше нет необходимости пользоваться привычной $scope системой, чтобы обрабатывать данные для компонента. Теперь мы получаем их свободно\*, благодаря ES6 и TypeScript!
*\*сильно упрощенное понятие, конечно, но для конечного пользователя это действительно свобода действий!*
#### **Снижение порога вхождения**
Наши ветераны Angular 1 имеют тенденцию забывать, как сложно было разобраться с Angular 1. Мне пришлось взять месячный перерыв от большого количества своей остальной работы, чтобы только понять, что это за непонятные термины, как: транклюзии, директивы, связывания, скоупы, и что они на самом деле означают.
Разработчику, который является новичком в Angular и который начинает уже с Angular 2, не понадобится много специальных знаний для его изучения. Он может пропустить все эти эзотерические термины из Angular 1, и сразу с места в карьер прыгнуть в код спецификации ES6/TypeScript.
Плюс, с отсутствием привычной модульной системы, код Angular 2 легко уживается с остальной частью экосистемы ES6, делая его смертельно простым в установке и импорте третьей стороной (*Прим. пер: тут, я полагаю, имеется в виду поддержка кода кем-либо на стороне, сторонними разработчиками*).
#### **Есть ли жизнь после Angular 1?**
После того, как разработчики совершат психологический переход от синтаксиса Angular 1 к синтаксису Angular 2, мы думаем, они обнаружат, что, оказывается, они уже знают Angular 2. Обе концепции практически идентичны, и сходства не ограничиваются лишь шаблонами и компонентами; как только пользователи копнут глубже в [пайпы](https://angular.io/docs/ts/latest/guide/pipes.html), депенденси инджекшен, сервисы, они обнаружат тонну подобных сходств.
Поскольку существует так много совпадений, мы попытались сделать Ionic 2 похожим на Ionic 1, так как в его основе лежит Angular. Но теперь только новая, еще лучшая реализация! До сих пор переход протекает очень хорошо, и я оптимистичен в плане того, что Angular 2 становится хитом, именно сейчас, в тот момент, когда пыль оседает и API Angular 2 становится действительно стабильным.
Angular 2 — это определенно лучший Angular!
|
https://habr.com/ru/post/279671/
| null |
ru
| null |
# Создаём линзы для SnapChat с использованием pix2pix
Почти такой же заголовок носит и моя [предыдущая статья](https://hackernoon.com/how-to-make-snapchat-lenses-f9eae861b5db), с той лишь разницей, что тогда я создавал линзы для SnapChat алгоритмически, используя dlib и openCV, а сегодня хочу показать, как можно добиться результата, используя машинное обучение. Этот подход позволит не заниматься ручным проектированием алгоритма, а получать итоговое изображение прямо из нейронной сети.
Вот что мы получим:

Что такое pix2pix?
------------------
Это способ [преобразования изображения в изображение с помощью состязательных сетей](https://arxiv.org/abs/1611.07004) (широко известный как pix2pix).
Название «pix2pix» означает, что сеть обучена преобразовывать входное изображение в соответствующее ему выходное изображение. Вот примеры таких преобразований:

Самой крутой особенностью pix2pix является **универсальность** подхода. Вместо создания нового алгоритма или новой модели для каждой из задач выше, достаточно просто использовать разные датасеты для тренировки сети.
В отличие от подходов, применявшихся ранее, pix2pix учится решать задачи гораздо быстрее и на меньшей обучающей выборке. Так, например, результаты ниже были получены при обучении с использованием Pascal Titan X GPU на датасете из 400 пар изображений и менее чем за два часа.

Как работает pix2pix?
---------------------
pix2pix использует две нейронные сети, обучающиеся параллельно:
1. Генератор
2. Дискриминатор
Генератор пытается сгенерировать выходное изображение из входных обучающих данных, а дискриминатор пытается определить, является ли результат настоящим или сгенерированным.
Когда у генератора получаются изображения неотличимые (дискриминатором) от настоящих, мы начинаем тренировать дискриминатор на них и на настоящих изображениях. Когда у дискриминатора получается успешно отличать реальные изображения от сгенерированных, мы вновь начинаем тренировать генератор, чтобы тот снова научился обманывать дискриминатор.
Такая «гонка вооружений» приводит к тому, что отличить реальные изображения от сгенерированных становится сложно и человеку.
Практика
--------
Тренировать наш генератор фильтров для SnapChat мы будем на изображениях 256x256 (большие размеры потребуют большего количества видеопамяти). Для создания датасета воспользуемся [кодом из предыдущего туториала](https://github.com/smitshilu/SnapChatFilterExample).
Я скачал множество изображений лиц и применил к каждому фильтр **«Thug Life Glasses»**. Получится что-то типа таких пар:

Для создания модели возьмём [репозиторий](https://github.com/affinelayer/pix2pix-tensorflow) pix2pix на основе TensorFlow. Склонируйте его и [установите](https://www.tensorflow.org/install) Tensorflow.
Команда для запуска обучения будет такой:
```
python pix2pix.py --mode train --output_dir dir_to_save_checkpoint --max_epochs 200 --input_dir dir_with_training_data --which_direction AtoB
```
Параметр **which\_direction**задаёт направление обучения. **AtoB**означает что мы хотим превратить изображение **A** (слева, без очков) в изображение **B** (справа, с очками). Кстати, обратите внимание, что pix2pix может успешно научиться восстанавливать исходное изображение из изображения с фильтром, достаточно лишь поменять направление обучения.
Отслеживать прогресс обучения можно с помощью tensorboard, для чего надо выполнить команду:
```
tensorboard --logdir=dir_to_save_checkpoint
```
Как только вы видите, что результаты на тренировочных данных стали достаточно хорошими, можно остановить обучение и проверить работу модели на произвольных данных. Продолжить тренировку с последней контрольной точки можно так:
```
python pix2pix.py --mode train --output_dir dir_to_save_checkpoint --max_epochs 200 --input_dir dir_with_training_data --which_direction AtoB --checkpoint dir_of_saved_checkpoint
```
Заключение
----------
Появление генеративных сетей типа pix2pix открывает большие перспективы для универсального и простого решения всевозможных задач обработки изображений.
|
https://habr.com/ru/post/483310/
| null |
ru
| null |
# Новые функции внедрения зависимостей в .Net 6
Продолжаем делиться полезными материалами в backend-разработке. Осваивая новые инструменты, специалисты SimbirSoft часто читают материалы зарубежных авторов, чтобы быть в курсе актуальных тенденций. В этот раз наш выбор пал на [серию материалов](https://andrewlock.net/series/exploring-dotnet-6/) британского разработчика Эндрю Лока про новые возможности .NET 6. С разрешения автора мы перевели [статью](https://andrewlock.net/exploring-dotnet-6-part-10-new-dependency-injection-features-in-dotnet-6/), в которой он разбирает функции внедрения зависимостей в .NET 6. Материал будет полезен тем, кто хочет познакомиться с нововведениями в .Net 6 при переходе на эту технологию.
Исследуем .Net 6. Часть 10
--------------------------
В этой серии статей я собираюсь взглянуть на некоторые из новых функций, которые появились в .NET 6. Про .NET 6 уже написано много контента, в том числе множество постов непосредственно от команд .NET и ASP.NET. Я же собираюсь рассмотреть код некоторых из этих новых функций.
Обработка служб IAsyncDisposable с помощью IServiceScope
--------------------------------------------------------
Первая функция, которую мы рассмотрим, устраняет давно существующую проблему. В .NET Core 3.0 и C# 8 добавлена поддержка IAsyncDisposable — асинхронного эквивалента интерфейса IDisposable. Это позволяет запускать асинхронный (async) код при освобождении ресурсов, что в некоторых случаях необходимо для предотвращения взаимоблокировок.
«Проблема» с IAsyncDisposable заключается в том, что везде, где «очищаются» объекты с помощью IDisposable и вызывается Dispose(). Там также требуется поддерживать объекты IAsyncDisposable для очистки объектов. Из-за вирусной природы async/await это означает, что эти пути кода теперь также должны быть асинхронными и так далее.
Одно из очевидных мест, где необходимо поддерживать IAsyncDisposable, — контейнер DI в Microsoft.Extensions.DependencyInjection, используемый ASP.NET Core. [Поддержка этого интерфейса](https://github.com/dotnet/extensions/pull/1005) была добавлена в .NET Core 3.0, но только в IServiceProvider, а для циклов жизни (scopes) поддержки не было.
В [качестве примера, когда это вызывает проблему](https://github.com/dotnet/runtime/issues/43970), представьте, что у вас есть тип, который поддерживает IAsyncDisposable, но не поддерживает IDisposable. Если вы зарегистрируете этот тип с временем существования Scoped и получите его экземпляр из контейнера DI, то при вызове метода Dispose() для него вы получите исключение. Это показано в следующем примере приложения на .NET 5:
```
using System;
using System.Threading.Tasks;
using Microsoft.Extensions.DependencyInjection;
public class Program
{
public static async Task Main()
{
await using var provider = new ServiceCollection()
.AddScoped()
.BuildServiceProvider();
using (var scope = provider.CreateScope())
{
var foo = scope.ServiceProvider.GetRequiredService();
} // Throws System.InvalidOperationException
}
}
class Foo : IAsyncDisposable
{
public ValueTask DisposeAsync() => default;
}
```
Этот пример выдаст исключение при высвобождении неуправляемых ресурсов переменной Scope.
```
Unhandled exception. System.InvalidOperationException: 'Foo' type only implements IAsyncDisposable. Use DisposeAsync to dispose the container.
at Microsoft.Extensions.DependencyInjection.ServiceLookup.ServiceProviderEngineScope.Dispose()
at $.<$>d\_\_0.MoveNext() in C:\src\tmp\asyncdisposablescope\Program.cs:line 12
--- End of stack trace from previous location ---
at $.<$>d\_\_0.MoveNext() in C:\src\tmp\asyncdisposablescope\Program.cs:line 12
--- End of stack trace from previous location ---
at $.(String[] args)
```
Проблема в том, что тип IServiceScope, возвращаемый функцией CreateScope(), реализует IDisposable, а не IAsyncDisposable, поэтому вы не можете вызвать его с помощью await using. Итак, нам просто требуется, чтобы ServiceScope реализовал IAsyncDisposable?
К сожалению, нет, это было бы кардинальным изменением. Кастомные DI-контейнеры (Autofac, Lamar, SimpleInjector и т.д.) должны реализовывать интерфейс IServiceScope, поэтому добавление дополнительных требований к интерфейсу будет серьезным изменением для этих библиотек.
Вместо этого решение, принятое в этом [PR](https://github.com/dotnet/runtime/pull/51840), позволяет реализациям контейнеров медленно подключаться:
1. Добавьте новый метод расширения в IServiceProvider с именем CreateAsyncScope().
2. Создайте оболочку над AsyncServiceScope, реализующую IAsyncDisposable.
Глядя на код ниже, мы видим, как это решает проблему. Во-первых, метод расширения вызывает CreateScope() для получения реализации IServiceScope из контейнера. Это будет зависеть от реализации в зависимости от используемого вами контейнера. Затем из IServiceScope создается и возвращается новый AsyncServiceScope:
```
public static AsyncServiceScope CreateAsyncScope(this IServiceProvider provider)
{
return new AsyncServiceScope(provider.CreateScope());
}
```
AsyncServiceScope реализует как IServiceScope, так и IAsyncDisposable, делегируя первый экземпляру IServiceScope, переданному в конструкторе. В методе DisposeAsync() он проверяет, поддерживает ли реализация IServiceScope DisposeAsync(). Если это так, вызывается DisposeAsync(), и потенциальная причина исключения устраняется. Если реализация не поддерживает IAsyncDisposable, она возвращается к синхронному вызову Dispose().
```
public readonly struct AsyncServiceScope : IServiceScope, IAsyncDisposable
{
private readonly IServiceScope _serviceScope;
public AsyncServiceScope(IServiceScope serviceScope)
{
_serviceScope = serviceScope ?? throw new ArgumentNullException(nameof(serviceScope));
}
public IServiceProvider ServiceProvider => _serviceScope.ServiceProvider;
public void Dispose() => _serviceScope.Dispose();
public ValueTask DisposeAsync()
{
if (_serviceScope is IAsyncDisposable ad)
{
return ad.DisposeAsync();
}
_serviceScope.Dispose();
// ValueTask.CompletedTask доступен только в net5.0 и более поздних версиях.
return default;
}
}
```
Для обернутого таким образом ServiceScope, который теперь поддерживает IAsyncDisposable, проблема решена. В .NET 6 вы можете использовать await using с CreateAsyncScope(), и проблем не возникнет.
```
using Microsoft.Extensions.DependencyInjection;
await using var provider = new ServiceCollection()
.AddScoped()
.BuildServiceProvider();
await using (var scope = provider.CreateAsyncScope())
{
var foo = scope.ServiceProvider.GetRequiredService();
} // не выбрасывается, если контейнер поддерживает DisposeAsync()
class Foo : IAsyncDisposable
{
public ValueTask DisposeAsync() => default;
}
```
Если вы применяете пользовательский контейнер, который не поддерживает IAsyncDisposable, это все равно вызовет исключение. Вам нужно будет либо заставить Foo реализовать IDisposable, либо обновить/изменить собственную реализацию контейнера. Хорошая новость заключается в том, что если сейчас вы не сталкиваетесь с этой проблемой, то все еще можете использовать шаблон CreateAsyncScope(), и когда контейнер будет обновлен, ваш код не нужно будет изменять.
> *В общем, если вы вручную создаете циклы жизни (scopes) в своем приложении (как в приведенном выше примере), мне кажется, что желательно использовать CreateAsyncScope() везде, где это возможно.*
>
>
Использование сторонних DI-контейнеров с WebApplicationBuilder
--------------------------------------------------------------
К слову о кастомных контейнерах. Если вы используете новые минимальные API хостинга .NET 6 с WebApplicationBuilder и WebApplication, то вам может быть интересно, как вы вообще регистрируете свой пользовательский контейнер.
В .NET 5 вам нужно сделать две вещи:
1. Вызвать UseServiceProviderFactory() (или аналогичный метод расширения, например UseLamar()) в IHostBuilder.
2. Реализовать соответствующий метод ConfigureContainer() в своем классе Startup.
Например, для Autofac ваш Program.cs может выглядеть примерно так, как показано ниже, где AutofacServiceProviderFactory создается и передается в UseServiceProviderFactory():
```
public static class Program
{
public static void Main(string[] args)
=> CreateHostBuilder(args).Build().Run();
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.UseServiceProviderFactory(new AutofacServiceProviderFactory()) // <-- добавляем эту строку
.ConfigureWebHostDefaults(webBuilder =>
{
webBuilder.UseStartup();
});
}
```
В Startup вы должны добавить метод ConfigureContainer() (показан ниже) и выполнить регистрацию DI для Autofac:
```
public class Startup
{
public void ConfigureContainer(ContainerBuilder containerBuilder)
{
// Зарегистрируйте напрямую в Autofac здесь
builder.RegisterModule(new MyApplicationModule());
}
}
```
В новом минимальном хостинге .NET 6 приведенные выше шаблоны заменены на WebApplicationBuilder и WebApplication, поэтому класс Startup отсутствует. Итак, как вы должны выполнить приведенную выше конфигурацию?
В .NET 6 вам по-прежнему нужно выполнить те же 2 шага, что и раньше, но в свойстве Host у WebApplicationBuilder. В приведенном ниже примере показано, как вы могли бы перевести пример Autofac на минимальный хостинг:
```
var builder = WebApplication.CreateBuilder(args);
// Вызов UseServiceProviderFactory для подсвойства Host
builder.Host.UseServiceProviderFactory(new AutofacServiceProviderFactory());
// Вызов ConfigureContainer для подсвойства Host
builder.Host.ConfigureContainer(builder =>
{
builder.RegisterModule(new MyApplicationModule());
});
var app = builder.Build();
app.MapGet("/", () => "Hello World!");
app.Run();
```
Как видите, свойство Host имеет тот же метод UseServiceProviderFactory(), что и раньше, поэтому вы можете добавить туда экземпляр AutofacServiceProviderFactory(). Существует также метод ConfigureContainer, который принимает лямбда-метод той же формы, что и метод, который мы использовали ранее в Startup. Обратите внимание, что здесь зависит от контейнера, поэтому это ContainerBuilder для Autofac, ServiceRegistry для Lamar и т. д.
> *Этот пример взят из* [*великолепного руководства Дэвида Фаулера «Миграция на ASP.NET Core в .NET 6»*](https://gist.github.com/davidfowl/0e0372c3c1d895c3ce195ba983b1e03d#migration-to-aspnet-core-in-net-6)*. Если вы застряли, пытаясь понять, как перейти на новые минимальные API-интерфейсы хостинга, обязательно ознакомьтесь с ними, чтобы найти подсказки и ответы на часто задаваемые вопросы.*
>
>
Как определить, зарегистрирована ли служба в контейнере DI
----------------------------------------------------------
Следующая новая функция, которую мы рассмотрим, была введена в .NET 6 для поддержки функций в новых minimal APIs. В частности, minimal APIs позволяют вам запрашивать службы из контейнера DI в обработчиках маршрутов, не помечая их явно с помощью [FromService]. Это отличается от контроллеров MVC API, где вам нужно будет использовать атрибут, чтобы получить эту функцию.
Например, в .NET 6 можно сделать так:
```
var builder = WebApplication.CreateBuilder(args);
// Добавляем сервис в DI
builder.Services.AddSingleton();
var app = builder.Build();
// Добавляем обработчик маршрута, использующий сервис из DI
app.MapGet("/", (IGreeterService service) => service.SayHello());
app.Run();
public class GreeterService: IGreeterService
{
public string SayHello() => "Hellow World!";
}
public interface IGreeterService
{
string SayHello();
}
```
Эквивалентный контроллер API может выглядеть примерно так (обратите внимание на атрибут):
```
public class GreeterApiController : ControllerBase
{
[HttpGet("/")]
public string SayHello([FromService] IGreeterService service)
=> service.SayHello();
}
```
*Очевидно, что обычно для этого используется внедрение конструктора, я просто хочу подчеркнуть!*
Проблема для minimal APIs заключается в том, что теперь нет простого способа узнать назначение данного параметра в обработчике лямбда-маршрута.
— Это модель, которая должна быть привязана к телу запроса?
— Это служба, которую следует извлекать из DI-контейнера?
Одним (плохим) решением было бы то, чтобы API всегда предполагал, что это сервис, и пытался получить его из контейнера DI. Однако при этом будет предпринята попытка создать экземпляр службы, что может иметь непредвиденные последствия. Например, представьте, что контейнер записывает журнал каждый раз, когда вы пытаетесь получить несуществующую службу, чтобы вам было легче обнаруживать неверные настройки. Это может повлиять на производительность, если журнал будет записываться для каждого отдельного запроса!
Вместо этого ASP.NET Core действительно нужен способ проверки регистрации типа без создания его экземпляра, [как описано в этой статье](https://github.com/dotnet/runtime/issues/53919). В .NET 6 [добавлена поддержка этого сценария](https://github.com/dotnet/runtime/pull/54047) с помощью нового интерфейса IServiceProviderIsService в библиотеку абстракций внедрения зависимостей Microsoft.Extensions.DependencyInjection.Abstractions.
```
public partial interface IServiceProviderIsService
{
bool IsService(Type serviceType);
}
```
Эта служба предлагает единственный метод, который можно вызвать, чтобы проверить, зарегистрирован ли данный тип службы в DI контейнере. Саму службу IServiceProviderIsService также можно получить из контейнера. Если вы используете пользовательский контейнер, в котором не добавлена поддержка этой функции, то вызов GetService() вернет значение null.
Обратите внимание, что этот интерфейс предназначен для указания того, может ли вызов IServiceProvider.GetService(serviceType) вернуть допустимую службу. Но нет гарантий, что это действительно сработает, поскольку существует бесконечное количество вещей, которые могут пойти не так при попытке создать службу!
Вы можете увидеть пример того, как мы могли бы использовать новый интерфейс ниже. Это в значительной степени отражает то, как ASP.NET Core использует службу за кулисами при создании минимальных обработчиков маршрутов API:
```
var collection = new ServiceCollection();
collection.AddTransient();
IServiceProvider provider = collection.Build();
// попробуем получить новый интерфейс.
// Это вернет null, если функция еще не поддерживается контейнером
var serviceProviderIsService = provider.GetService();
// IGreeterService регистрируется в контейнере DI
Assert.True(serviceProviderIsService.IsService(typeof(IGreeterService)));
// GreeterService НЕ зарегистрирован непосредственно в контейнере DI.
Assert.False(serviceProviderIsService.IsService(typeof(GreeterService)));
```
Я не планирую использовать эту службу напрямую в своих собственных приложениях, но она может быть полезна для библиотек, ориентированных на .NET 6, а также дает возможность исправить [другие проблемы, связанные с DI](https://github.com/dotnet/runtime/issues/46132).
> *Если вас смущает название IServiceProviderIsService, то не волнуйтесь, как и Дэвид Фаулер, который первоначально предложил эту функцию* [*и реализовал ее*](https://github.com/dotnet/runtime/pull/54047)*:*
>
>
Дополнительная диагностика для DI-контейнера
--------------------------------------------
[dotnet-trace global tool](https://docs.microsoft.com/en-us/dotnet/core/diagnostics/dotnet-trace) — это кроссплатформенный инструмент, который позволяет собирать профили запущенного процесса без использования собственного профилировщика. Он основан на [компоненте .NET Core EventPipe](https://docs.microsoft.com/en-us/dotnet/core/diagnostics/eventpipe), который по сути представляет собой кроссплатформенный эквивалент Event Tracing для Windows (ETW) или LTTng.
В .NET 6 были добавлены [два новых диагностических события](https://github.com/dotnet/runtime/issues/56313):
* ServiceProviderBuilt: показывает, когда создается IServiceProvider и сколько в нем временных, ограниченных и одноэлементных служб. Он также включает [количество зарегистрированных открытых и закрытых дженериков](https://github.com/dotnet/runtime/pull/57753).
* ServiceProviderDescriptors: показывает описание всех служб в контейнере, их время жизни и тип реализации в виде большого двоичного объекта JSON.
Кроме того, хэш-код IServiceProvider включен во все события, поэтому при необходимости вы можете легко сопоставлять различные события. Например, следующий пример устанавливает [global tool dotnet-trac](https://docs.microsoft.com/en-us/dotnet/core/diagnostics/dotnet-trace)e и запускает простое приложение ASP.NET Core .NET 6, собирая события DI:
```
dotnet tool install -g dotnet-trace
dotnet trace collect --providers Microsoft-Extensions-DependencyInjection::Verbose -- name ./aspnettest.exe
```
Полученные логи можно [просмотреть в PerfView](https://github.com/Microsoft/perfview/releases) (в Windows). На приведенном ниже снимке экрана показано, что события были записаны. Вы можете просто увидеть начало дескрипторов для события ServiceProviderDescriptors справа:
Эта функция была частью более масштабной попытки добавить больше диагностических средств в .NET 6, но [большая часть предложенных диагностических средств](https://github.com/dotnet/runtime/issues/56072) не успела появиться в .NET 6 вовремя. Диагностика DI была ошибкой!
Попытка улучшить производительность методов TryAdd\*
----------------------------------------------------
Последняя функция в этом посте касается улучшения, которое не совсем вошло в .NET 6. Тем не менее, я думаю, что это интересно!
[Проблема, о которой идет речь](https://github.com/dotnet/runtime/issues/44728), обнаружилась, когда [фанат производительности Бен Адамс](https://twitter.com/ben_a_adams) [занимался своим делом, сокращая выделение ресурсов в ASP.NET Core.](https://github.com/dotnet/runtime/pull/44696) С относительно небольшим изменением он сократил количество выделений закрытия для Func с 754 объектов до 2 во время запуска приложения ASP.NET MVC.
Проблема связана с тем, что когда большая часть «базовой» платформы ASP.NET Core добавляет службы, она проверяет, не добавляется ли дублирующаяся служба, используя версии метода TryAdd\*. Например, метод расширения ведения журнала AddLogging() содержит такой код:
```
services.TryAdd(ServiceDescriptor.Singleton());
services.TryAdd(ServiceDescriptor.Singleton(typeof(ILogger<>), typeof(Logger<>)));
services.TryAddEnumerable(ServiceDescriptor.Singleton>(
new DefaultLoggerLevelConfigureOptions(LogLevel.Information)));
```
Из-за стиля «Плати за игру» ASP.NET Core метод AddLogging() может вызываться многими различными компонентами. Вы не хотите, чтобы дескриптор службы ILoggerFactory регистрировался несколько раз, поэтому TryAdd\* сначала гарантирует, что служба еще не зарегистрирована, и добавляет регистрацию только в том случае, если это первый вызов.
К сожалению, в настоящее время проверка того, что служба еще не зарегистрирована, требует перечисления всех уже зарегистрированных служб. Если мы будем делать это каждый раз, когда добавляем новый сервис, вы получите поведение O(N²), описанное в приведенной выше проблеме. [Дальнейшее расследование Бена показало, что это так.](https://github.com/dotnet/runtime/issues/44728#issuecomment-803730637)
Итак, как решить эту проблему? Выбранный подход состоял в том, чтобы переместить существующий класс реализации ServiceCollection в пакет Microsoft.Extensions.DependencyInjection.Abstractions (из пакета реализации) и добавить к типу конкретные реализации TryAdd\* (вместо методов расширения IServiceCollection, которые они в настоящее время используют).
Эти дополнительные методы будут использовать Dictionary<> для отслеживания того, какие службы были зарегистрированы, уменьшая стоимость поиска одной службы до O (1) и делая начальную регистрацию N типов O (N) намного лучше, чем существующая О (N²).
ServiceCollection был перемещен, как того требует [этот PR](https://github.com/dotnet/runtime/pull/52284), с перенаправлением типов, чтобы избежать критических изменений в API, но [PR для добавления словаря](https://github.com/dotnet/runtime/pull/52363) в ServiceCollection так и не был объединен 😢 Но почему?
Причина резюмируется в [этом комментарии Эрика Эрхардта](https://github.com/dotnet/runtime/pull/52363):
Как всегда с производительностью, вы должны обязательно ее измерить. В противном случае вы не можете быть уверены, что ваше исправление действительно что-то исправило! В этом случае мы теперь храним дополнительный словарь в ServiceCollection в дополнение к списку дескрипторов.
```
public class ServiceCollection : IServiceCollection
{
private readonly List \_descriptors = new();
private readonly Dictionary> \_serviceTypes = new();
// ...
}
```
Это множество дополнительных объектов, которые хранятся, создаются и управляются, поэтому не ясно, что это определенно улучшит производительность при запуске. К сожалению, тесты производительности не были завершены вовремя для .NET 6, поэтому улучшение так и не было реализовано. Надеюсь, он вернется в будущей версии .NET!
Итого
-----
В этой статье я описал некоторые новые функции, добавленные в библиотеки DI в .NET 6. В IServiceScope была добавлена улучшенная поддержка IAsyncDisposable, появилась возможность запрашивать, зарегистрирована ли служба в DI, а также добавлены новые средства диагностики. Кроме того, я показал, как использовать настраиваемый DI-контейнер с новыми минимальными API-интерфейсами хостинга, и рассказал о функции повышения производительности, которая не вошла в .NET 6.
**Спасибо за внимание! Надеемся, что этот перевод был полезен для вас.**
Авторские материалы для разработчиков мы также публикуем в наших соцсетях – [ВК](https://vk.com/simbirsoft_team) и [Telegram](https://t.me/simbirsoft_dev).
|
https://habr.com/ru/post/690970/
| null |
ru
| null |
# Сделаем защищенный DNS снова быстрым. DNS over QUIC
Протокол DNS (Domain Name System Protocol) является одним из важнейших инфраструктурных протоколов для поддержки сети Интернет и первоначально он разрабатывался для максимальной производительности и возможности распределенного хранения неограниченного числа доменных зон. DNS может функционировать поверх UDP-протокола и это уменьшает накладные расходы на установку соединения и избыточный трафик в сети. Но одной из важнейших проблем стала безопасность обмена данными, поскольку клиент в первоначальном варианте протокола не может проверить достоверность информации и это может приводить к подмене ip-адресов злоумышленниками с переадресацией клиента на фишинговый сайт.
Для решения этой проблемы были введены расширения DNSSEC для генерации цифровой подписи ответа. Но сам запрос и ответ при этом не шифровались, что могло быть использовано для ограничения доступа к определенным доменам или для получения на транзитных узлах статистики доступа к хостам. Частично эту проблему решило использование инкапсуляций DNS-over-TLS (DoT, использует TLS для шифрования UDP-дэйтаграмм) и DNS-over-HTTPS (DoH, передает запросы и ответы поверх HTTPS-подключения), которые функционируют поверх TCP. В первом случае запрос более компактный (но может быть обнаружен по анализу трафика), во втором DNS-диалог неотличим от подключения к сайту или веб-сервисам, но при этом существенно увеличивает избыточной трафик (даже при использовании HTTP/2), а также вынужденно добавляет заголовки (которые могут использоваться для трекинга и перехвата cookies). Но можно ли как-то объединить преимущества UDP и DoH? Встречаем DNS-over-QUIC, который был утвержден в [RFC9250](https://www.rfc-editor.org/info/rfc9250) как Proposed Standard.
Сначала скажем несколько слов о протоколе QUIC (Quick UDP Internet Connections, [RFC9000](https://www.rfc-editor.org/info/rfc9000)). Первоначально он был разработан Google в 2012 году и использует транспортный протокол UDP для передачи потоков данных с обязательным шифрованием. Протокол существенно уменьшает расходы на установку соединения, поддерживает миграцию соединения (возможность замены ip-адреса и порта при переключении сетей, благодаря наличию идентификатора потока), позволяет мультиплексировать несколько потоков данных, допускает возможность переотправки отдельных поврежденных фрагментов (поскольку шифрование выравнивается по границе фрагмента и данные могут быть расшифрованы даже при частичной потере сообщений). Протокол QUIC лежит в основе утвержденного недавно HTTP/3 ([RFC9114](https://www.rfc-editor.org/info/rfc9114)). Все браузеры основанные на Chromium поддерживают QUIC (с установленным флагом enable-quic), также Firefox с версии 80.0 (с конфигурацией network.http.http3.enabled).
Протокол DNS-over-QUIC (далее DoQ) использует TLS 1.3 и может использоваться для отправки запросов от клиентов к DNS-серверам, взаимодействия DNS-серверов (в том числе, передачи обновлений зоны и запросов между рекурсивными и авторитативными серверами). DNS-запросы отображаются поверх потоков QUIC и ответ сервера (независимо от объема) полностью возвращается в том же потоке, что и запрос. При этом запросы могут обрабатываться асинхронно, без необходимости ожидания ответов на ранее полученные запросы. Один клиент может отправить несколько запросов через разные потоки (количество ограничивается через [механизмы управления](https://www.rfc-editor.org/rfc/rfc9000#section-4) соединением со стороны сервера).
Поскольку взаимодействие через QUIC в целом идентично для DNS-запросов и HTTP-сообщений, это позволяет защитить DNS-запросы от возможной пакетной фильтрации на уровне транспортного протокола (дополнительно для этого используется [заполнение](https://www.rfc-editor.org/rfc/rfc9000#section-19.1) QUIC-пакетов, чтобы избежать возможного анализа трафика). Также для исключения атаки DNS amplification (вызванной тем, что в UDP-дэйтаграмме может быть подменен адрес клиента на адрес жертвы, которой и будет отправлен ответ) в QUIC предусмотрен механизм [валидации](https://www.rfc-editor.org/rfc/rfc9000#section-8) адресов. Поскольку в QUIC используется UDP-протокол, то отсутствует фаза установки соединения и ответ может быть получен сразу после согласования протокола (чуть медленнее, чем в случае незащищенного DNS UDP-соединения), но при этом остаются доступными все механизмы защиты и управления сессиями от QUIC (включая возможность продолжения сессии при изменении ip-адреса клиента без прерывания потоков). Сравнение производительности DoQ с другими защищенными типами транспорта можно в [этой](https://essay.utwente.nl/89441/1/Batenburg_BA_eemcs.pdf) работе.
Во время установки соединения через QUIC сервер сообщает о поддержке протокола отправкой ALPN-токена doq. По умолчанию сервер должен отвечать на запросы через UDP-порт 853, но может быть настроен на любой порт (например, 443). DNS-запросы всегда отправляются с Message ID = 0, запрос и ответ не могут превышать 65535 (поскольку длина ограничивается 16-битным полем).
Поддержка DNS-over-QUIC сейчас не представлена в стабильных сборках браузеров, но можно использовать [dnsproxy](https://github.com/AdguardTeam/dnsproxy) для реализации прокси-сервера, который может подключаться с использованием всех протоколов безопасного DNS (DoT, DoH, DoQ и DNSCrypt). Альтернативой DoQ может рассматриваться DoH3 (передача DNS-запросов и ответов поверх HTTP/3 соединения, но она медленнее чем DoQ из-за установки HTTP/3 соединения и имеет недостатки, сходные с DoH — передача заголовков и cookie). При этом нужно отметить, что телефоны на Android 11+ уже [поддерживают](https://security.googleblog.com/2022/07/dns-over-http3-in-android.html) передачу DNS-запросов через http3 с обновлением Google Play System. Для DoH3 можно использовать серверы cloudflare-dns: <https://cloudflare-dns.com/dns-query>. Для настройки DoH3 в Chrome для Android можно перейти в меню, выбрать Settings → Privacy and Security → Use Secure DNS и указать адрес провайдера (например, cloudflare). Проверить используемый протокол для доступа к странице и DNS можно на тестовой странице <https://cloudflare-quic.com> (срабатывает после перезагрузки страницы).
Пока нет официальной поддержки DoQ, можно установить в локальной сети или на своем компьютере проксирующий DNS-сервер, который будет принимать запросы от приложений и ретранслировать их через DoQ на внешний DNS (например, [RouteDNS](https://github.com/folbricht/routedns), [doq-proxy](https://github.com/ns1labs/doq-proxy) или [DNSProxy](https://github.com/AdguardTeam/dnsproxy)). DNSProxy может быть запущен через Docker-контейнер (например, [chenhw2/dnsproxy](https://hub.docker.com/r/chenhw2/dnsproxy)) или установлен через go install. Наиболее важными опциями для нас будут:
* `-u` — указание upstream DNS-серверов (tls://ip для использования DoT, `https://host/path` для DoH, `quic://host` для DoQ), может быть перечислено несколько адресов через запятую. Обратите внимание, что при использовании DNS-имен для подключения к внешнему серверу (например, https или DoQ) для успешного начального подключения (bootstrap) необходимо связать имя хоста с ip-адресом любым доступным способом (например, указанием fallback DNS или использованием --add-host при запуске контейнера);
* `-p` — порт для прослушивания локальных DNS-запросов (также можно разрешить подключения по DoH (-s), DoT (-t), DoQ (-q) и DNSCrypt (-y). В этом случае необходимо передать сертификат и приватный ключ для использования в TLS или шифровании для прикладных протоколов HTTPS/QUIC);
* `--cache` — включить DNS-кэш;
* `--fastest-addr` — возвращать наиболее быстрый адрес (если их несколько).
Запустим DNS-прокси. Мы будем использовать AdguardDNS (но можно установить собственный сервер, например [CoreDNS](https://coredns.io/), [quicdog](https://github.com/private-octopus/quicdoq), [unbound](https://blog.nlnetlabs.nl/newsletter-dns-over-quic/) или [doqd](https://github.com/natesales/doqd)).
```
docker run --restart=always --name dnsproxy -p 53:53/udp -p 53:53 \
--add-host dns.adguard.com:94.140.15.15 -d \
-e "ARGS=-l 0.0.0.0 --cache --fastest-addr -u quic://dns.adguard.com -v" \
chenhw2/dnsproxy
```
Теперь мы можем переключиться на использование локального DNS:
* Windows — `netsh interface ipv4 set dnsservers "Wi-Fi" static 127.0.0.1 primary` или `Set-DnsClientServerAddress -InterfaceAlias "Wi-Fi" -ServerAddresses "127.0.0.1" -Validate` для PowerShell (с правами администратора, название интерфейса может быть другим, список можно получить через `netsh interface show interface`);
* Linux — `sudo systemd-resolve --interface eth0 --set-dns 127.0.0.1` для систем на основе SystemD, либо заменить `nameservers 127.0.0.1` в `/etc/resolv.conf` (название интерфейса может отличаться, можно посмотреть в `ip link show`);
* MacOS — `sudo networksetup -setdnsservers Wi-Fi 127.0.0.1` (название интерфейса может быть другим, можно посмотреть в `sudo networksetup -listallnetworkservices`).
В логе контейнера (`docker logs dnsproxy`) мы можем увидеть запросы и ответы, поступившие от upstream dns-серверов. Попробуем сделать запрос адреса: `nslookup habr.ru` и обнаружим успешное обращение прокси к upstream-серверу:
```
2022/07/24 11:59:59 1#5561 [debug] github.com/AdguardTeam/dnsproxy/proxy.(*Proxy).udpHandlePacket(): Start handling new UDP packet from 172.17.0.1:48889
2022/07/24 11:59:59 1#5561 [debug] github.com/AdguardTeam/dnsproxy/proxy.(*Proxy).logDNSMessage(): IN: ;; opcode: QUERY, status: NOERROR, id: 2
;; flags: rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;habr.ru. IN A
2022/07/24 11:59:59 1#5562 [debug] github.com/AdguardTeam/dnsproxy/upstream.(*bootstrapper).createDialContext.func1(): Dialing to 94.140.15.15:853
2022/07/24 11:59:59 1#5562 [debug] github.com/AdguardTeam/dnsproxy/upstream.(*bootstrapper).createDialContext.func1(): dialer has successfully initialized connection to 94.140.15.15:853 in 51.3µs
2022/07/24 11:59:59 1#5561 [debug] github.com/AdguardTeam/dnsproxy/proxy.(*Proxy).replyFromUpstream(): RTT: 25.3216ms
2022/07/24 11:59:59 1#5561 [debug] github.com/AdguardTeam/dnsproxy/proxy.(*Proxy).logDNSMessage(): OUT: ;; opcode: QUERY, status: NOERROR, id: 2
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;habr.ru. IN A
;; ANSWER SECTION:
habr.ru. 3600 IN A 178.248.233.33
```
Переход на использование DoQ в целом уменьшает время выполнения DNS-запросов, обеспечивает защиту содержания запроса от перехвата и анализа на промежуточном оборудовании и позволяет избежать возможной подмены адресов в ответе. Кроме того, DoQ (и DoH3) успешно функционируют в условиях переключения сетей (например, между различными Wi-Fi сетями или между Wi-Fi и сотовой связью), что особенно важно для мобильных клиентов.
Подробный список публичных серверов с поддержкой DoQ, DoH3, информацию о поддержке протоколов браузерами, клиентских и серверных реализаций защищенного DNS можно найти на [этой странице](https://github.com/curl/curl/wiki/DNS-over-HTTPS).
---
Сегодня вечером в OTUS состоится открытое занятие «IS-IS. Фильтрация LSP-пакетов», на котором участники:
* Сравнят виды и возможности фильтрации в протоколе;
* Настроят фильтрацию как в L1, так и в L2 взаимодействии между устройствами;
* Определят плюсы и минусы каждого из вариантов.
Регистрируйтесь [по ссылке.](https://otus.pw/82ki/)
|
https://habr.com/ru/post/678650/
| null |
ru
| null |
# RE: Идея на тему больших картинок и ограничений хостингов
Этот пост является ответом на идею изложенную в [этом топике](http://alexkuk.habrahabr.ru/blog/47526/)
Суть: вы хозяин сайта и вам нужно ресайзнуть изображение заливаемое юзером, но у вас не достаточно для этого возможностей.
Решение: Мы делаем для вас «проксик» который все делает за вас и отдает вашему скрипту результат.
Как пользоваться:
В форме заливки изображения вы пишете примерно следующее
`Image:`
, где **[sjpg.ru/remoteupload.php](http://sjpg.ru/remoteupload.php)** — это наш прокси;
**destination** — это ваш скрипт которому мы зальем картинку в поле Image, также он получит все поля пост запроса которые нам пришлет юзер(так можно передавать сессии);
**redirecturl** — сюда сервер отправит пользователя после завершения закачки, **но скорее всего до того как картинка попадет к вам на сервер**.
*в этом примере я заливаю картинку на свой же сайт и посылаю юзера в яндекс.*
Вот в общем то и все.
Сервис очень сырой и сейчас захостен на штатовском шаредхостинге. Если будет заинтересованность перенесем в Маскву на вдс например.
Проблема достаточно специфичная и возможно поклонников окажется не так много.
Пробуйте и обязательно пишите отзывы.
**upd**:
Пример кода на php, который загружает картинку для сессии а потом ее выводит для юзера с этой сессией. *Этот код всего лишь демонстрация, не делайте так на продакшне :)*
`php<br/
if(isset($_FILES['Image'])&&isset($_POST['imageId'])){
move_uploaded_file($_FILES['Image']['tmp_name'], "images/".intval($_POST['imageId']).".jpg");
}
else{
session_start();
if(isset($_SESSION['imageId'])) {
echo '';
}
else {
$_SESSION['imageId']= rand();
?>
Image:
php<br/
}
}
?>`
*Попробовать эту штуку, как клиент можно по адресу [c2009.ru/test.php](http://c2009.ru/test.php), там точно такой же код, только домен другой.*
|
https://habr.com/ru/post/47558/
| null |
ru
| null |
# Секционирование таблиц моделей в Django с PostgreSQL
Привет.
Это топик о том, как относительно быстро и безболезненно настроить секционирование (партицирование) таблицы по месяцам, если вы используете Django+PostgreSQL. Многое из описанного подойдёт и для других фреймворков и ORM.
О том, что такое секционирование и зачем оно нужно, можно почитать, например, [здесь](http://habrahabr.ru/company/engineyard/blog/171745/), [здесь](http://habrahabr.ru/post/74984/) и [здесь](http://www.postgresql.org/docs/9.1/static/ddl-partitioning.html).
Итак, есть проект на Django и таблица одной из моделей должна быть очень большой. Если чтение из этой таблицы происходит часто, и всегда известен период времени, в который запись была сделана, секционирование ускорит работу базы данных.
Каждый раз писать запросы для включения секционирования не очень хочется, так что попробуем автоматизировать. Хорошо, если на выходе получится что-то, что может использовать и не сильно знакомый с SQL человек. I've read the docs, so you don't have to.
Сперва я расскажу, как быстро попробовать мои наработки, а потом о том, что под капотом. Действуем так:
1. Ловим `syncdb`, чтобы можно было добавить команды секционирования.
2. Подключаем SQL, который вытащит установленные индексы, создаст секции, активирует индексы на них, добавит функции и триггеры.
3. Активируем секционирование в конечных приложениях и моделях.
Сначала устанавливаем пакет из [репозитория](https://github.com/podshumok/django-post-syncdb-hooks)
```
pip install git+https://github.com/podshumok/django-post-syncdb-hooks
```
и подключаем пару приложений:
```
INSTALLED APPS = (
# ...
'post_syncdb_hooks',
'post_syncdb_hooks.partitioning',
'your.app',
# ...
)
```
Пусть есть модель в `yourapp/models.py`:
```
from django.db import models
class MyModel(models.Model):
date_created = models.DateTimeField()
my_data = models.IntegerField(db_index=True)
```
добавляем файл `yourapp/sql/post_syncdb-hook.postgresql_psycopg2.sql` (можно подредактировать интервалы под нужды):
```
SELECT month_partition_creation(
date_trunc('MONTH', NOW())::date,
date_trunc('MONTH', NOW() + INTERVAL '1 year' )::date,
'yourapp_mymodel', 'date_created');
```
запускаем `syncdb`:
```
./manage.py syncdb
```
… и секции созданы.
Если это первый `syncdb`, то в созданных секциях не будет индексов. Чтобы исправить это, нужно запустить `syncdb` ещё раз.
Что ж, база теперь готова, а вот Django — ещё нет. Дело в том, что, начиная с версии 1.3 Django конструирует для PostgreSQL запросы `INSERT INTO`, добавляя в них `RETURNING...`, чтобы получить `id` вставленной записи. А метод секционирования, который мы используем, не поддерживает этой возможности.
Мы можем грубо заставить Django не использовать `RETURNING` нигде:
```
from django.db import connections, DEFAULT_DB_ALIAS
connections[DEFAULT_DB_ALIAS].features.can_return_id_from_insert = False
```
А можем отредактировать нашу модель так, чтобы `RETURNING` не использовался только с ней:
```
from post_syncdb_hooks.partitioning import to_partition
class MyModel(models.Model):
"..."
#...
@to_partition
def save(self, *args, **kwargs):
return super(MyModel, self).save(*args, **kwargs)
```
Итак, база готова, Django готов, но готовы ли мы? Чтобы запросы на чтение не приводили к опросу базой всех секций, мы должны фильтровать `QuerySet`'ы по полю, для которого реализовано секционирование (в примере — `date_created`):
```
qs = MyModel.objects.filter(date_created__lte=..., date_created__gt=...)
```
Также стоит позаботиться о том, чтобы нигде не происходил, без особой надобности, `count()` всех записей: например, `paginator` в админке любит это делать.
Теперь все готовы. Всё.
##### Подкапотное про `post_syncdb_hooks`
`post_syncdb_hooks` содержит `management.py`, в котором подключается ресивер для сигнала `post_syncdb`. Этот ресивер или хук вызывается для всех установленных приложений. Он просматривает, не лежит ли рядом с файлом `models.py` того или иного приложения папка `sql`, и, если лежит, нет ли там файлов `post_syncdb-hook.sql` или `post_syncdb-hook.(backend).sql`, которые можно запустить.
`post_syncdb_hooks.partitioning` как раз и содержит такой SQL файл. В нём мы создаём SQL-функцию, которая принимает четыре параметра: дату начала, дату конца, имя таблицы и имя поля. При вызове функции, для указанной таблицы создаются секции по выбранному полю, начиная с даты начала до даты конца с шагом в месяц, а также триггер для `INSERT INTO` и индексы таблиц-секций (если индексы заданы для основной таблицы).
##### Подкапотное про индексы
Самым скучным и сложным для меня оказалось создание индексов для секций. Когда есть написанный SQL для создания таблицы и мы переходим к схеме с секционированием, то проблем нет — копипаст. А вот, когда Django создаёт таблицы, не очень понятно как заставить его не создавать индексы для мастер-таблицы, но сохранить соответствующий SQL. В итоге, я решил: пусть Django таки создаст индексы (они всё равно будут пустыми), а я их скопирую в секции.
Осталось решить, как это проделать.
У `psql` есть опция `-E`, которая заставляет его выводить SQL, генерируемый внутренними командами. Так что,
```
sudo -u postgres psql -E db
```
```
db=# \di
********* QUERY **********
SELECT n.nspname as "Schema",
c.relname as "Name",
CASE c.relkind WHEN 'r' THEN 'table' WHEN 'v' THEN 'view' WHEN 'i' THEN 'index' WHEN 'S' THEN 'sequence' WHEN 's' THEN 'special' WHEN 'f' THEN 'foreign table' END as "Type",
pg_catalog.pg_get_userbyid(c.relowner) as "Owner",
c2.relname as "Table"
FROM pg_catalog.pg_class c
LEFT JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace
LEFT JOIN pg_catalog.pg_index i ON i.indexrelid = c.oid
LEFT JOIN pg_catalog.pg_class c2 ON i.indrelid = c2.oid
WHERE c.relkind IN ('i','')
AND n.nspname <> 'pg_catalog'
AND n.nspname <> 'information_schema'
AND n.nspname !~ '^pg_toast'
AND pg_catalog.pg_table_is_visible(c.oid)
ORDER BY 1,2;
**************************
db=#
```
Немного [копипаста](https://github.com/podshumok/django-post-syncdb-hooks/blob/64aa758b22ae935ee673bff4f8f8e97583fbd141/post_syncdb_hooks/partitioning/sql/post_syncdb-hook.postgresql_psycopg2.sql#L30) и у нас есть всё для того, чтобы создать индексы для таблиц-секций.
##### Спасибо!
Представленный здесь пакет используется мною в паре проектов и довольно успешно справляется с поставленными перед ним задачами.
Спасибо всем, кто это прочитал. Надеюсь, сделанное кому-нибудь пригодится.
Также прошу отмечать в комментариях и на [гитхабе](https://github.com/podshumok/django-post-syncdb-hooks/issues/new) найденные недостатки, предлагать улучшения и расширения.
|
https://habr.com/ru/post/179873/
| null |
ru
| null |
# Разбираемся с модулем ШИМ на tms320
Добрый день. Какое-то время назад я прочёл, что какому-то человеку захотелось изучить поглубже вопрос про ePWM модуль на мк tms320f28xxx, поэтому я решил, почему бы и мне не написать статью на эту тему, в которой я постараюсь подробно разжевать этот модуль на примере tms320f28335.
Возможности модуля ePWM
=======================
* Выходы epwmA epwmB могут работать как:
+ single-edge operation
+ dual-edge symmetric operation
+ dual edge asymmetric opperation
* Может быть сконфигурировано мертвое время
* Может быть сконфигурирован TZ эвент и настроено логическое состояние выхода как HI так и LO.
* Может быть настроенно событие прерывания или событие SOC для ADC.
Давайте приблизимся к основным блокам: из чего состоит ePWM модуль и к чему он подключен.
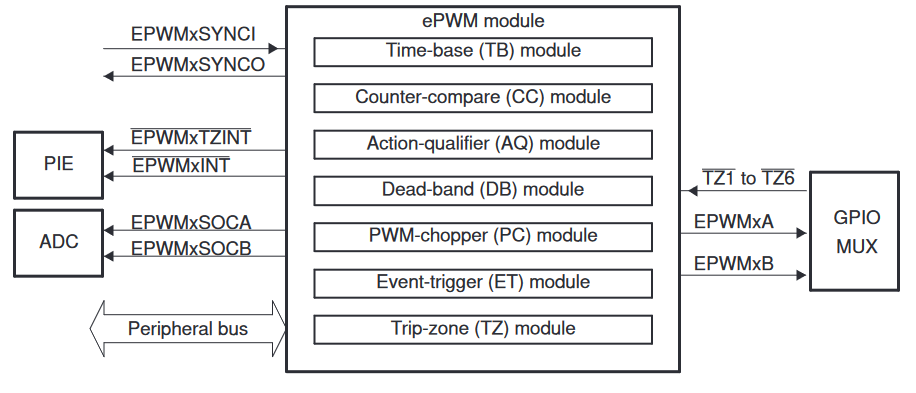
Как видно из рисунка, не так и много блоков находится в модуле ePWM. Поэтому, имеет смысл рассмотреть за что отвечает каждый модуль и начнём с сигналов.
* **EPWMxA и EPWMxB сигналы** — наверное, самый очевидный выходной сигнал. Обычное логическое состояние либо HI, либо LO, в зависимости от того, как сконфигурировано выходное воздействие
* **TZ1 — TZ6 сигналы** — тут уже не совсем очевидные входные сигналы. Для тех, кто обладает около нулевыми знаниями в этой теме, как и я в своё время, подробно опишу это. Эти сигналы обычно используются для генерирования аварийных реакций, а именно вывода EPWMxA и EPWMxB выходов в определённое состояние. Зачастую, у драйверов силовых ключей есть возможность генерировать аварию по ключам, иногда схемотехники делают аппаратную защиту по уровню какого-то значения некой величины, например тока, при достижении которого генерируется некий логический уровень. Это мы сейчас говорили о физической реализации. Кроме физического получения этого сигнала, его можно генерировать и программно.
* **EPWMxSYNCI и EPWMxSYNCO сигналы** — тут мало что можно рассказать, это сигналы сихронизации, которые могут быть входом или выходом.
* **EPWMxSOCA и EPWMxSOCB сигналы** — тут всё более чем понятно из названия. Эти события могут задать события SOC для АЦП.
* **EPWMxTZINT и EPWMxINT сигналы** — тут событие прерываний на TZ и на события связанные с самим ШИМ, например генерирование прерывания по периоду ШИМ.
Теперь перейдём к модулям
**Time base (TB) модуль** — отвечает за время события каждого модуля ePWM. Не будем сильно вдаваться во все настройки этого модуля, думаю достаточно обратить внимание на то, что есть 3 режима работы счётчика:
* Up-Down-Count Mode
* Up-Count Mode
* Down-Count Mode
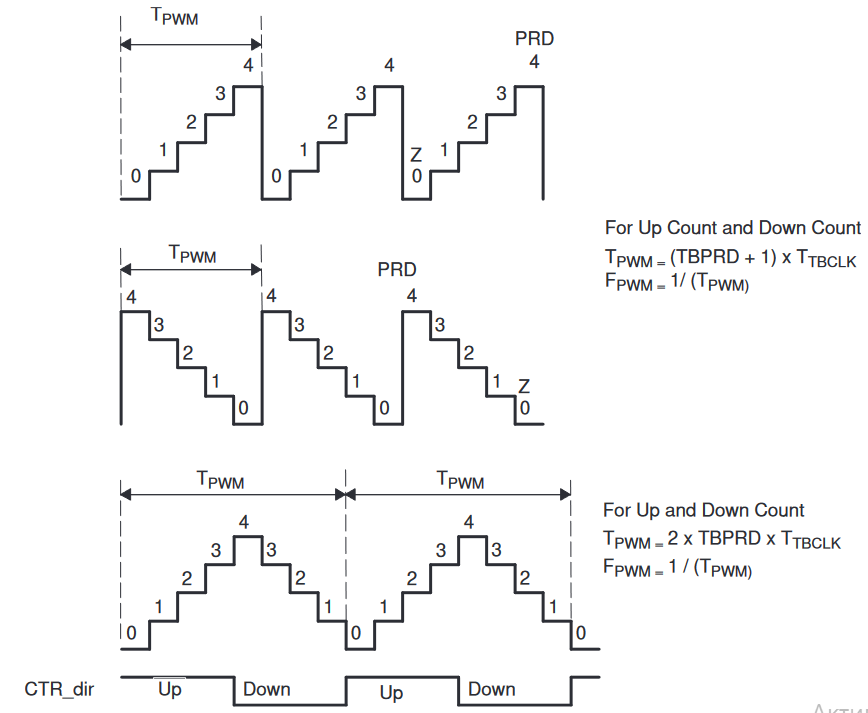
А так же есть настройка синхронности таймера через выставление бита TBCLKSYNC
**Counter compare (CC) модуль** — через него мы как-раз таки и задаём нашу скважность.
**Action-Qualifier (AQ) модуль** — через него можно настроить состояние на событие. А для выходов можно настроить следующие действия:
* Выставить в состояние HI
* Выставить в состояние LO
* Произвести инверсию состояния
* Ничего не делать
**Dead-Band Submodule (DB) модуль** — с помощью этого модуля можно настроить зоны нечувствительности для каналов ШИМа. Ни для кого не будет секретом то, что ключи транзисторов переключаются не мгновенно и для того, чтобы не было ситуации когда верхний ключ полумоста не успел закрыться, а нижний уже открыт, выставляют задержку на переключение в состояние HI и более раннее включение в состояние LO.
**Trip-Zone Submodule (TZ) модуль** — как говорилось выше, этот модуль связан с отработкой аварийных состояний. Тут мы можем выбрать 1 из 4 действий.
* Выставить в состояние HI
* Выставить в состояние LO
* Выставить High-impedance состояние
* Ничего не делать
Событие, вызывающее действие TZ модуля может быть вызвано как программно, так и аппаратно. Кроме этого, предусмотрен вызов прерывания.
### Теперь перейдем от слов к практике
Для начала необходимо настроить GPIO на альтернативную функцию epwm
```
EALLOW;
// Включение pull-up
GpioCtrlRegs.GPAPUD.bit.GPIO0 = 0x000;
GpioCtrlRegs.GPAPUD.bit.GPIO1 = 0x000;
// Настройка GPIO как EPWM1A
GpioCtrlRegs.GPAMUX1.bit.GPIO0 = 0x001;
GpioCtrlRegs.GPAMUX1.bit.GPIO1 = 0x001;
EDIS;
```
Далее, когда мы уже настроили GPIO, мы можем приступать к разным настройкам. Для настройки работы ШИМа надо определиться с тем, что мы хотим получить. Начнём с частоты TBCLK. Она определяется по формуле:

Тут необходимо обратить внимание на то, что CLKDIV по умолчанию равен 1, с HSPCLKDIV всё иначе, по умолчанию он равен 2. Это надо держать в уме, поскольку бывают случаи, когда люди об этом забывают. При загрузке программы в RAM часто HSPCLKDIV = 1, соответственно, эту проблему замечают не сразу.
С частотой тактирования TBCLK мы определились. Но надо бы выбрать, то, как у нас будет работать счётчик. По спаду, по нарастающей, а может и так и эдак, для этого надо настроить соответствующий регистр, например:
```
EPwm1Regs.TBCTL.bit.CTRMODE = TB_COUNT_UP;
```
В дальнейшем, чтобы никто не пугался макросам, определимся откуда они вообще появляются. Эти дефайны определены в файле с названием DSP2833x\_EPwm\_defines.h.
После чего необходимо определиться с тем, как будут реагировать наши GPIO на достижение определённых значений TBCTR. Вариантов действий более чем достаточно. Они приведены в таблице ниже:
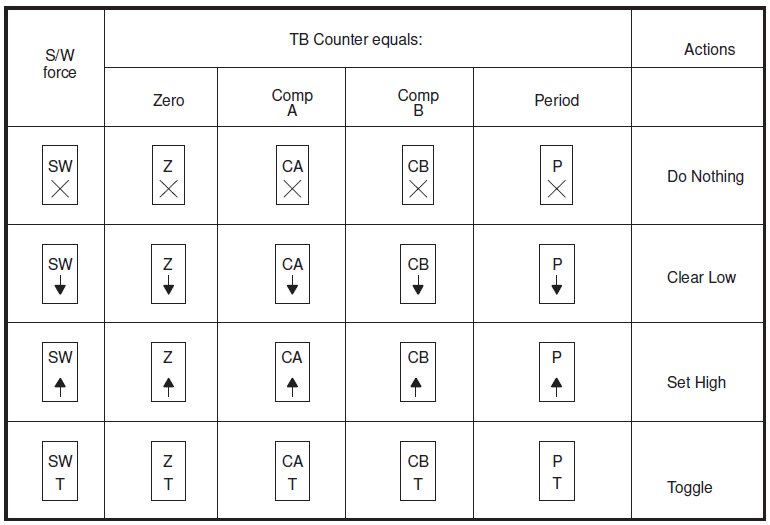
Затем необходимо определиться, какого поведения мы хотим от портов А и В, а именно, мы хотим, чтобы они были связаны друг с другом или же могли работать независимо. Если мы хотим, чтобы порт А был ведущим, то мы просто записываем для него действия, например (случай для отсчёта по нарастающей):
```
EPwm1Regs.AQCTLA.bit.CAU = AQ_SET;
EPwm1Regs.AQCTLA.bit.CAD = AQ_CLEAR;
```
если же хотим независимости и для второго порта, то добавляем:
```
EPwm1Regs.AQCTLA.bit.ZRO = AQ_SET;
EPwm1Regs.AQCTLA.bit.CAU = AQ_CLEAR;
EPwm1Regs.AQCTLB.bit.ZRO = AQ_SET;
EPwm1Regs.AQCTLB.bit.CBU = AQ_CLEAR;
```
По подробнее о настройках необходимо обратиться к изображению выше за одним лишь дополнением, регистров AQCTLA чуть больше, чем изображено на таблице, сильно картину это не меняет, а лишь вносится конкретика касательно того, в каком случае достиг нужного значения счётчик, например, при отсчете в верх или отсчёте в низ. Более кратко с битами можно ознакомиться в вырезке из системного .h файла
```
struct AQCTL_BITS { // bits description
Uint16 ZRO:2; // 1:0 Action Counter = Zero
Uint16 PRD:2; // 3:2 Action Counter = Period
Uint16 CAU:2; // 5:4 Action Counter = Compare A up
Uint16 CAD:2; // 7:6 Action Counter = Compare A down
Uint16 CBU:2; // 9:8 Action Counter = Compare B up
Uint16 CBD:2; // 11:10 Action Counter = Compare B down
Uint16 rsvd:4; // 15:12 reserved
};
```
Если у нас 2 порта ePWM работают зависимо и мы хотим выставить мёртвое время, то необходимо выставить регистр в нужное состояние, например:
```
EPwm1Regs.DBCTL.bit.OUT_MODE = DB_FULL_ENABLE;
```
Теперь, когда с описанием периферии определились, можно перейти к конкретным примерам.
Настройка ePWM в режиме отсчёта по нарастающей
----------------------------------------------
Тут пример без мёртвого времени и порт A, и порт В работают зависимо. Когда A активен, B не активен.
```
EPwm1Regs.TBPRD = 150000 / 5; // т.к частота 150Мгц / 5000 Гц
// Выставляем скважность 50%
EPwm1Regs.CMPA.half.CMPA = EPwm1Regs.TBPRD / 2;
EPwm1Regs.TBPHS.half.TBPHS = 0;
EPwm1Regs.TBCTL.bit.CTRMODE = TB_COUNT_UP;
EPwm1Regs.TBCTL.bit.PHSEN = TB_DISABLE;
EPwm1Regs.TBCTL.bit.PRDLD = TB_SHADOW;
EPwm1Regs.TBCTL.bit.SYNCOSEL = TB_SYNC_DISABLE;
EPwm1Regs.TBCTL.bit.HSPCLKDIV = 0;
EPwm1Regs.CMPCTL.bit.SHDWAMODE = CC_SHADOW;
EPwm1Regs.CMPCTL.bit.SHDWBMODE = CC_SHADOW;
EPwm1Regs.CMPCTL.bit.LOADAMODE = CC_CTR_ZERO;
EPwm1Regs.CMPCTL.bit.LOADBMODE = CC_CTR_ZERO;
EPwm1Regs.AQCTLA.bit.PRD = AQ_CLEAR;
EPwm1Regs.AQCTLA.bit.CAU = AQ_SET;
EPwm1Regs.AQCTLB.bit.PRD = AQ_SET;
EPwm1Regs.AQCTLB.bit.CAU = AQ_CLEAR;
```
На осцилограмме можно увидеть полученный результат:
Теперь можно попробовать добавить мёртвое время, для этого добавляем:
```
EPwm1Regs.DBCTL.bit.OUT_MODE = DB_FULL_ENABLE;
EPwm1Regs.DBCTL.all = BP_ENABLE + POLSEL_ACTIVE_HI_CMP; // Настройка db
EPwm1Regs.DBFED = 300; // Мертвое время = 150Мгц * 2мкс = 300
EPwm1Regs.DBRED = 300;
```
Отсчёт мёртвого времени производится аналогично частоте, по формуле:

А теперь мы получили мёртвое время таким, каким мы и хотели
А что делать, если нам надо развязать порт А и порт В? Такое тоже имеет место быть. Тут всё просто. Возвращаемся к первому примеру и удаляем последние 4 строчки, и записываем каждому скважность в следующие регистры.
```
EPwm1Regs.AQCTLA.bit.ZRO = AQ_SET;
EPwm1Regs.AQCTLA.bit.CAU = AQ_CLEAR;
EPwm1Regs.AQCTLB.bit.ZRO = AQ_SET;
EPwm1Regs.AQCTLB.bit.CBU = AQ_CLEAR;
EPwm1Regs.CMPA.half.CMPA = EPwm1Regs.TBPRD / 2; // Выставляем скважность 50% порта А
EPwm1Regs.CMPB = EPwm1Regs.TBPRD / 3; // Выставляем скважность 33% порта В
```
Теперь мы имеем вот такую вот картину. Можно задавать скважность каждому каналу по отдельности.
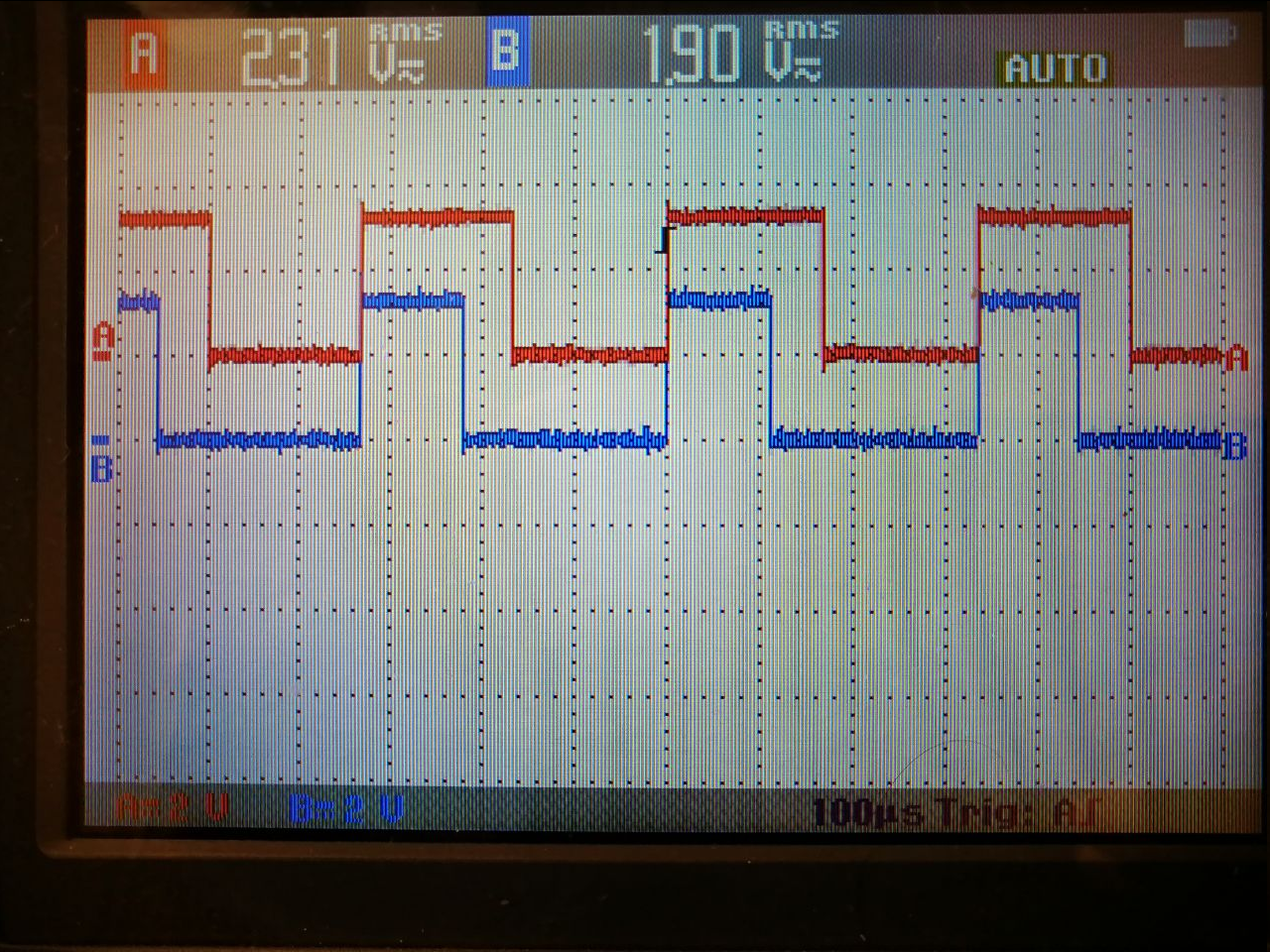
Для режима по спаду всё примерно аналогично. Есть отличие с отсчётом в режиме up-down. Тут частота шима рассчитывается уже по формуле:

Примерно так же и для dead Time.
Наверное, единственно важное, что не было рассмотрено, так это настройка TZ, ну что ж, теперь остановимся на этом модуле чуть чуть по подробнее.
Для программного вызова события аварии достаточно настроить следующие регистры:
```
EPwm1Regs.TZCTL.bit.TZA = TZ_FORCE_LO;
EPwm1Regs.TZCTL.bit.TZB = TZ_FORCE_LO;
```
Вызов и обнуление аварии ШИМа можно осуществить с помощью следующих команд:
```
//Вызов аварии
EALLOW;
EPwm1Regs.TZFRC.bit.OST = 0x001;
EDIS;
//Обнуление сигнала аварии
EALLOW;
EPwm1Regs.TZCLR.bit.OST = 0x0001;
EDIS;
```
Если же мы хотим аппаратно вызвать сигнал TZ, то тут всё ещё проще, через регистр TZSEL выставляем нужный нам TZ, но вдобавок к этому необходимо настроить GPIO на TZ.
#### Заключение
Если кому-то покажется данная статья интересной, то могу в более менее ускоренном порядке написать ещё пару статей. В планах имеется рассмотреть can модуль, хотелось бы dma, а еще может быть напишу небольшую статью по IQMath от ti с их библиотеками.
|
https://habr.com/ru/post/526890/
| null |
ru
| null |
# Вышла Mongodb 3.0 Production Release

Этот релиз знаменует собой начало нового этапа, в котором заложена основа чтобы сделать базу данных мощной, гибкой и легкой в управлении.
Изначально версия данного релиза была 2.8, но из-за важности изменений было принято решение переименовать его в 3.0
Основные нововведения и улучшения:
* **Произвольные механизмы хранения, в том числе WiredTiger.** Теперь api монго отделено от того как база хранит данные. Это позволяет создавать новые способы хранения данных, например InMemory.
* **Высокая производительность и эффективность.** Новый механизм хранения WiredTiger использует блокировку на уровне документа, что позволяет значительно улучшить производительность. Так же он использует алгоритмы сжатия данных и индексов, что значительно уменьшает размеры хранимых данных.
* **Упрощенные операции через Ops Manager.** Он позволяет проводить такие операции, как развертывание, масштабирование, модернизацию и резервное копирование в несколько кликов или вызов API. Улучшена система логирования.
* **Улучшен аудит безопасности.**
* **Улучшен язык запросов и инструменты.** mongoimport, mongoexport, mongodump, mongorestore и mongooplog теперь работают быстрее. Возможность смотреть план выполнения до запроса с помощью explain.
С более подробной информацией вы можете познакомиться здесь:
[Официальный анонс 3.0](http://blog.mongodb.org/post/112603230233/announcing-mongodb-3-0-and-bug-hunt-winners)
[Анонс основных нововведений в Mongodb 3.0](https://www.mongodb.com/blog/post/announcing-mongodb-30)
[Вебинар «Что нового в Mongodb 3.0»](http://www.mongodb.com/presentations/webinar-whats-new-mongodb-30)
[pdf Что нового в Mongodb 3.0](http://info.mongodb.com/rs/mongodb/images/MongoDB-Whats-New-3.0.pdf)
Основные улучшения дает WiredTiger, но в Mongo 3.0 по дефолту основное хранилище еще старое (MMAPv1).
Для использования WT необходимо мигрировать(если есть данные) и запустить mongod со специальным параметром:
```
mongod --storageEngine wiredTiger --dbpath
```
[подробнее](http://docs.mongodb.org/manual/release-notes/3.0-upgrade/)
Старый формат(MMAPv1) и новый(WT) не совместимы, так что необходима ручная миграция с помощью mongodump, mongoexport или с помощью реплики.
|
https://habr.com/ru/post/252129/
| null |
ru
| null |
# Тестирование аннотаций @NonNull/@Nullable
### Вместо «Посвящается ...»
Описанная ниже задача не была новаторской или чертовски полезной, компания в которой я работаю не получит за нее прибыль, а я премию.
Но эта задача была, а значит ее пришлось решить.
### Intro
В статье вы часто будете встречать слово Lombok, прошу хейтеров не торопиться с выводами.
Я не собираюсь «топить» за Lombok или его отсутствие, я как Геральт Сапковского, стараюсь хранить нейтралитет, и могу спокойно и без дрожи в веке читать код как с Lombok, так и без оного.
Но на текущем проекте упомянутая библиотека присутствует, и что-то подсказывает мне, что наш проект такой не единственный.
Так вот.
Последнее время в java безусловно есть тренд к анноташкам. Во славу концепции fast fail часто параметры методов аннотируются аннотацией @NonNull (чтоб если что, как зашло — так и ~~вышло~~ пало).
Вариантов импорта для данной(или похожей по идеологии аннотации) довольно много, мы же, как наверняка уже стало понятно, остановимся на версии
```
import lombok.NonNull;
```
Если вы используете эту(или подобную) аннотацию, то имеете некоторый контракт, который необходимо проверить тестом и любой статический анализатор кода любезно это подскажет(Sonar точно подсказывает).
Протестировать эту аннотацию unit-тестом достаточно просто, проблема в том что такие тесты будут размножаться в вашем проекте со скоростью кроликов по весне, а кролики, как известно, нарушают принцип DRY.
В статье мы напишем небольшой тестовый фреймворк, для тестирования контракта аннотаций @NonNull(и для того чтоб Sonar не светил вам в глаз противным красным светом).
**P.S** На написания названия меня вдохновила песня группы PowerWolf, которая заиграла(ей богу) когда я писал название(в оригинале название звучит более позитивно)
### Основная часть
Изначально мы тестировали аннотацию как-то так:
```
@Test
void methodNameWithNullArgumentThrowException() {
try {
instance.getAnyType(null);
fail("Exception not thrown");
} catch (final NullPointerException e) {
assertNotNull(e);
}
}
```
вызывали метод и подавали null в качестве параметра, аннотированного аннотацией @NonNull.
Получали NPE и оставались довольны(Sonar тоже радовался).
Потом стали делать то же самое, но с более модным assertThrow который работает через Supplier(мы же любим лямбды):
```
@TestUnitRepeatOnce
void methodNameWithNullArgumentThrowException() {
assertThrows(NullPointerException.class, () -> instance.getAnyType(null));
}
```
Стильно. Модно. Молодежно.
Казалось бы можно и закончить, аннотации протестированы, чего же боле?
Проблема (не то чтобы проблема, но все же) данного способа тестирования «всплыла» когда в один прекрасный день я написал тест на метод, он благополучно отработал, а потом я заметил, что аннотации @NonNull на параметре нет.
Оно и понятно: вы вызываете тестовый метод, при этом не описываете поведение моковых классов, через when()/then(). Исполняющий поток благополучно заходит внутрь метода, где то внутри ловит NPE, на незамоканном (или замоканном, но без when()/then()) объекте, и падает, впрочем с NPE, как вы и предупреждали, а значит тест зеленый
Получается что тестируем мы в таком случае уже не аннотацию, а непонятно что. При правильной работе теста мы не должны были вообще зайти вглубь метода(свалившись на пороге).
У @NonNull аннотации Lombok есть одна особенность: если мы падаем с NPE на аннотации, в ошибку записывается имя параметра.
На это мы и завяжемся, после того как упадем с NPE, дополнительно будем проверять текст stacktrace, вот так:
```
exception.getCause().getMessage().equals(parameter.getName())
```
**А если вдруг...**На случай если вдруг Lombok обновится и перестанет писать в stacktrace имя параметра получившего null, то пересмотрим лекцию Андрея Пангина по [JVM TI](https://www.youtube.com/watch?v=aiuKiE5-0g4&t=2267s) и напишем плагинчик для JVM, в котором один фиг-таки передадим имя параметра.
Все бы вроде ничего, сейчас мы действительно проверяем то что надо, но проблема «кроликов» не решена.
Хотелось бы иметь некий инструмент, которому можно было бы сказать, например так:
```
@TestUnitRepeatOnce
@SneakyThrows
void nonNullAnnotationTest() {
assertNonNullAnnotation(YourPerfectClass.class);
}
```
а он бы сам пошел и просканировал все публичные методы указанного класса и проверил все их @NonNull параметры тестом.
Вы скажете, доставай рефлексию, и проверяй, есть ли на методе @NonNull и если есть пуляй в него null.
Все бы ничего, да RetentionPolicy не тот.
У всех аннотаций есть параметр RetentionPolicy, который может быть 3 типов: SOURCE, CLASS и RUNTIME, так вот у Lombok, по умолчанию RetentionPolicy.SOURCE, а это значит что в Runtime этой аннотации не видно и через reflection вы ее не найдете.
В нашем проекте аннотируются все параметры публичных методов(не считая примитивов), если подразумевается что параметр не может быть null, если подразумевается обратное — то параметр аннотируется спринговой @Nullable. На это можно завязаться, мы будем искать все публичные методы, и все параметр в них, не помеченные @Nullable и не являющиеся примитивами.
Подразумеваем, что для всех остальных случаев, на параметрах должна стоять аннотация @NonNull.
Для удобства по возможности будем расскидывать логику по приватным методам, для начала получим все публичные методы:
```
private List getPublicMethods(final Class clazz) {
return Arrays.stream(clazz.getDeclaredMethods())
.filter(METHOD\_FILTER)
.collect(toList());
}
```
где METHOD\_FILTER обычный предикат, в котором мы говорим что:
* Метод должен быть public
* Не должен быть syntetic(а такое случается когда у вас есть метод с raw параметром)
* Не должен быть абстрактный(про абстрактные классы отдельно и ниже)
* Имя метода не должно быть equals(на случай если какой то злой человек решит запулить на вход нашего фреймворка POJO класс с переопределенным equals())
После того как мы получили все нужные нам методы начинаем перебирать их в цикле,
если у метода вообще нет параметров, то это не наш кандидат:
```
if (method.getParameterCount() == 0) {
continue;
}
```
Если параметры есть, нам надо понять, аннотированы ли они @NonNull(точнее должны ли быть, согласно
**логике*** public method
* не @Nullable
* не примитив
Для этого сделаем мапку и положим в нее наши параметры по очередности следования в методе, а напротив них положим флаг, который будет говорить должна быть над параметром аннотация @NonNull или нет:
```
int nonNullAnnotationCount = 0;
int index = 0;
val parameterCurrentMethodArray = method.getParameters();
val notNullAnnotationParameterMap = new HashMap();
for (val parameter : parameterCurrentMethodArray) {
if (isNull(parameter.getAnnotation(Nullable.class)) && isFalse(parameter.getType().isPrimitive())) {
notNullAnnotationParameterMap.put(index++, true);
nonNullAnnotationCount++;
} else {
notNullAnnotationParameterMap.put(index++, false);
}
}
if (nonNullAnnotationCount == 0) {
continue;
}
```
эта мапка пригодится нам чтобы потом вызывать метод и передавать ему null во все параметры с аннотацией @NonNull поочередно, а не только в первый попавшийся.
Параметр nonNullAnnotationCount считает сколько параметров в методе должно быть аннотировано @NonNull, по нему будет определено число интераций вызова каждого метода.
Кстати если аннотаций @NonNull нет(параметры есть, но все примитивные либо @Nullable), то и говорить не о чем:
```
if (nonNullAnnotationCount == 0) {
continue;
}
```
Имеем на руках карту параметров. Знаем, сколько раз вызывать метод и в какие позиции пулять null, дело за малым (как я наивно полагал не разобравшись), нужно создавать instance класса и вызывать у них методы.
Проблемы начинаются когда понимаешь, насколько разные бывают instance: это может быть приватный класс, это может быть класс с одним дефолтным конструктором, с одним конструктором с параметрами, с таким и таким конструктором, абстрактный класс, интерфейс(со своими default методами, которые тоже public и которые тоже надо тестировать).
А когда мы соорудили-таки правдами и неправдами instance, нужно передать в метод invoke параметры и тут тоже раздолье: как создать instance финального класса? а Enum? а примитива? а массива примитивов(который тоже объект и тоже может быть аннотирован).
Ну давайте по порядку.
Первый случай это класс с одним приватным конструктором:
```
if (ONLY_ONE_PRIVATE_CONSTRUCTOR_FILTER.test(clazz)) {
notNullAnnotationParameterMap.put(currentNullableIndex, false);
method.invoke(clazz, invokeMethodParameterArray);
makeErrorMessage(method);
}
```
тут все просто вызываем у нашего метода invoke, передаем ему clazz который пришел из вне в тест и массив параметров, в котором уже заряжен null на первую позицию с флагом на аннотацию @NonNull(помните, выше мы создали карту @NonNull-ов)мы начинаем бежать в цикле и создавать массив параметров, поочередно меняя позицию null параметра, и обнуляя флаг перед вызовом метода, чтобы в следующей интерации другой параметр стал null.
В коде это выглядит так:
```
val invokeMethodParameterArray = new Object[parameterCurrentMethodArray.length];
boolean hasNullParameter = false;
int currentNullableIndex = 0;
for (int i = 0; i < invokeMethodParameterArray.length; i++) {
if (notNullAnnotationParameterMap.get(i) && isFalse(hasNullParameter)) {
currentNullableIndex = i;
invokeMethodParameterArray[i] = null;
hasNullParameter = true;
} else {
mappingParameter(parameterCurrentMethodArray[i], invokeMethodParameterArray, i);
}
}
```
С первым вариантом инстанцирования разобрались.
Дальше интерфейсы, нельзя взять и создать instance интерфейса(у него даже конструктора нет).
Поэтому с интерфейсом это будет так:
```
if (INTERFACE_FILTER.test(clazz)) {
notNullAnnotationParameterMap.put(currentNullableIndex, false);
method.invoke(createInstanceByDynamicProxy(clazz, invokeMethodParameterArray), invokeMethodParameterArray);
makeErrorMessage(method);
}
```
createInstanceByDynamicProxy позволяет нам создать instance на класс, если он реализует хотя бы один интерфейс, либо сам является интерфейсом
**Нюанс**имейте ввиду, что тут принципиально какие именно интерфейсы реализует класс, важен типовой интерфейс(а не какой-нибудь Comparable), в котором есть методы, которые вы реализуете в целевом классе иначе instance удивит вас своим типом
а внутри он какой-то такой:
```
private Object createInstanceByDynamicProxy(final Class clazz, final Object[] invokeMethodParameterArray) {
return newProxyInstance(
currentThread().getContextClassLoader(),
new Class[]{clazz},
(proxy, method1, args) -> {
Constructor constructor = Lookup.class
.getDeclaredConstructor(Class.class);
constructor.setAccessible(true);
constructor.newInstance(clazz)
.in(clazz)
.unreflectSpecial(method1, clazz)
.bindTo(proxy)
.invokeWithArguments(invokeMethodParameterArray);
return null;
}
);
}
```
**Грабли**Кстати тут тоже были какие то грабли, уже не вспомню какие именно, их было много, но создавать проксю надо именно через Lookup.class
Следующий instance(мой любимый) это абстрактный класс. И тут Dynamic proxy нам уже не поможет, так как если абстрактный класс и реализует какой то интерфейс, то это явно не тот тип какой нам бы хотелось. И просто так взять и создать newInstance() у абстрактного класса мы не можем. Тут нам на помощь придет CGLIB, спринговая либа, которая создает прокси на основе наследования, но вот беда, целевой класс должен иметь default (без параметров) конструктор
**Сплетня**Хотя судя по сплетням в интернете начиная со Spring 4 CGLIB умеет работать и без оного, так вот: **Не работает!**
Вариант для инстанцирования абстрактного класса будет такой:
```
if (isAbstract(clazz.getModifiers())) {
createInstanceByCGLIB(clazz, method, invokeMethodParameterArray);
makeErrorMessage();
}
```
makeErrorMessage() который встречался уже в примерах кода, роняет тест, если мы вызывали метод с аннотированным @NonNull параметром передав null и он не упал, значит тест не отработал, надо падать.
Для маппинга параметров у нас один общий метод, который умеет мэппировать и мокировать как параметры конструктора, так и метода, выглядит он так:
```
private void mappingParameter(final Parameter parameter, final Object[] methodParam, final int index)
throws InstantiationException, IllegalAccessException {
if (isFinal(parameter.getType().getModifiers())) {
if (parameter.getType().isEnum()) {
methodParam[index] = Enum.valueOf(
(Class) (parameter.getType()),
parameter.getType().getEnumConstants()[0].toString()
);
} else if (parameter.getType().isPrimitive()) {
mappingPrimitiveName(parameter, methodParam, index);
} else if (parameter.getType().getTypeName().equals("byte[]")) {
methodParam[index] = new byte[0];
} else {
methodParam[index] = parameter.getType().newInstance();
}
} else {
methodParam[index] = mock(parameter.getType());
}
}
```
Обратите внимание на создание Enum(вишенка на торте), вообщем нельзя просто так взять и создать Enum.
Здесь для финальных параметров свой маппинг, для нефинальных свой, а далее просто по тексту (кода).
Ну и после того как мы создали параметры для конструктора и для метода формируем наш instance:
```
val firstFindConstructor = clazz.getConstructors()[0];
val constructorParameterArray = new Object[firstFindConstructor.getParameters().length];
for (int i = 0; i < constructorParameterArray.length; i++) {
mappingParameter(firstFindConstructor.getParameters()[i], constructorParameterArray, i);
}
notNullAnnotationParameterMap.put(currentNullableIndex, false);
createAndInvoke(clazz, method, invokeMethodParameterArray, firstFindConstructor, constructorParameterArray);
makeErrorMessage(method);
```
Мы уже точно знаем, что раз мы дошли до этого этапа кода, значит у нас есть минимум один конструктор, чтобы создать instance мы можем взять любой, поэтому берем первый попавшийся, смотрим, есть ли у него параметры в конструкторе и если нет то вызываем вот так:
```
method.invoke(spy(clazz.getConstructors()[0].newInstance()), invokeMethodParameterArray);
```
ну а если есть то так:
```
method.invoke(spy(clazz.getConstructors()[0].newInstance()), invokeMethodParameterArray);
```
Это та логика которая происходит в методе createAndInvoke() который вы видели чуть выше.
Полная версия тестового класса под спойлером, заливать на git я не стал, так как писал на рабочем проекте, но по сути это всего лишь один класс, который можно отнаследовать в ваших тестах и использовать.
**Исходный код**
```
public class TestUtil {
private static final Predicate METHOD\_FILTER = method ->
isPublic(method.getModifiers())
&& isFalse(method.isSynthetic())
&& isFalse(isAbstract(method.getModifiers()))
&& isFalse(method.getName().equals("equals"));
private static final Predicate ONLY\_ONE\_PRIVATE\_CONSTRUCTOR\_FILTER = clazz ->
clazz.getConstructors().length == 0 && isFalse(clazz.isInterface());
private static final Predicate INTERFACE\_FILTER = clazz ->
clazz.getConstructors().length == 0;
private static final BiPredicate LOMBOK\_ERROR\_FILTER =
(exception, parameter) -> isNull(exception.getCause().getMessage())
|| isFalse(exception.getCause().getMessage().equals(parameter.getName()));
protected void assertNonNullAnnotation(final Class clazz) throws Throwable {
for (val method : getPublicMethods(clazz)) {
if (method.getParameterCount() == 0) {
continue;
}
int nonNullAnnotationCount = 0;
int index = 0;
val parameterCurrentMethodArray = method.getParameters();
val notNullAnnotationParameterMap = new HashMap();
for (val parameter : parameterCurrentMethodArray) {
if (isNull(parameter.getAnnotation(Nullable.class)) && isFalse(parameter.getType().isPrimitive())) {
notNullAnnotationParameterMap.put(index++, true);
nonNullAnnotationCount++;
} else {
notNullAnnotationParameterMap.put(index++, false);
}
}
if (nonNullAnnotationCount == 0) {
continue;
}
for (int j = 0; j < nonNullAnnotationCount; j++) {
val invokeMethodParameterArray = new Object[parameterCurrentMethodArray.length];
boolean hasNullParameter = false;
int currentNullableIndex = 0;
for (int i = 0; i < invokeMethodParameterArray.length; i++) {
if (notNullAnnotationParameterMap.get(i) && isFalse(hasNullParameter)) {
currentNullableIndex = i;
invokeMethodParameterArray[i] = null;
hasNullParameter = true;
} else {
mappingParameter(parameterCurrentMethodArray[i], invokeMethodParameterArray, i);
}
}
try {
if (ONLY\_ONE\_PRIVATE\_CONSTRUCTOR\_FILTER.test(clazz)) {
notNullAnnotationParameterMap.put(currentNullableIndex, false);
method.invoke(clazz, invokeMethodParameterArray);
makeErrorMessage(method);
}
if (INTERFACE\_FILTER.test(clazz)) {
notNullAnnotationParameterMap.put(currentNullableIndex, false);
method.invoke(createInstanceByDynamicProxy(clazz, invokeMethodParameterArray), invokeMethodParameterArray);
makeErrorMessage(method);
}
if (isAbstract(clazz.getModifiers())) {
createInstanceByCGLIB(clazz, method, invokeMethodParameterArray);
makeErrorMessage();
}
val firstFindConstructor = clazz.getConstructors()[0];
val constructorParameterArray = new Object[firstFindConstructor.getParameters().length];
for (int i = 0; i < constructorParameterArray.length; i++) {
mappingParameter(firstFindConstructor.getParameters()[i], constructorParameterArray, i);
}
notNullAnnotationParameterMap.put(currentNullableIndex, false);
createAndInvoke(clazz, method, invokeMethodParameterArray, firstFindConstructor, constructorParameterArray);
makeErrorMessage(method);
} catch (final Exception e) {
if (LOMBOK\_ERROR\_FILTER.test(e, parameterCurrentMethodArray[currentNullableIndex])) {
makeErrorMessage(method);
}
}
}
}
}
@SneakyThrows
private void createAndInvoke(
final Class clazz,
final Method method,
final Object[] invokeMethodParameterArray,
final Constructor firstFindConstructor,
final Object[] constructorParameterArray
) {
if (firstFindConstructor.getParameters().length == 0) {
method.invoke(spy(clazz.getConstructors()[0].newInstance()), invokeMethodParameterArray);
} else {
method.invoke(spy(clazz.getConstructors()[0].newInstance(constructorParameterArray)), invokeMethodParameterArray);
}
}
@SneakyThrows
private void createInstanceByCGLIB(final Class clazz, final Method method, final Object[] invokeMethodParameterArray) {
MethodInterceptor handler =
(obj, method1, args, proxy) -> proxy.invoke(clazz, args);
if (clazz.getConstructors().length > 0) {
val firstFindConstructor = clazz.getConstructors()[0];
val constructorParam = new Object[firstFindConstructor.getParameters().length];
for (int i = 0; i < constructorParam.length; i++) {
mappingParameter(firstFindConstructor.getParameters()[i], constructorParam, i);
}
for (val constructor : clazz.getConstructors()) {
if (constructor.getParameters().length == 0) {
val proxy = Enhancer.create(clazz, handler);
method.invoke(proxy.getClass().newInstance(), invokeMethodParameterArray);
}
}
}
}
private Object createInstanceByDynamicProxy(final Class clazz, final Object[] invokeMethodParameterArray) {
return newProxyInstance(
currentThread().getContextClassLoader(),
new Class[]{clazz},
(proxy, method1, args) -> {
Constructor constructor = Lookup.class
.getDeclaredConstructor(Class.class);
constructor.setAccessible(true);
constructor.newInstance(clazz)
.in(clazz)
.unreflectSpecial(method1, clazz)
.bindTo(proxy)
.invokeWithArguments(invokeMethodParameterArray);
return null;
}
);
}
private void makeErrorMessage() {
fail("Тестирование аннотации @NonNull в Абстрактных классах без DefaultConstructor не поддерживается");
}
private void makeErrorMessage(final Method method) {
fail("Параметр в публичном методе " + method.getName() + " не аннотирован @NonNull");
}
private List getPublicMethods(final Class clazz) {
return Arrays.stream(clazz.getDeclaredMethods())
.filter(METHOD\_FILTER)
.collect(toList());
}
private void mappingParameter(final Parameter parameter, final Object[] methodParam, final int index)
throws InstantiationException, IllegalAccessException {
if (isFinal(parameter.getType().getModifiers())) {
if (parameter.getType().isEnum()) {
methodParam[index] = Enum.valueOf(
(Class) (parameter.getType()),
parameter.getType().getEnumConstants()[0].toString()
);
} else if (parameter.getType().isPrimitive()) {
mappingPrimitiveName(parameter, methodParam, index);
} else if (parameter.getType().getTypeName().equals("byte[]")) {
methodParam[index] = new byte[0];
} else {
methodParam[index] = parameter.getType().newInstance();
}
} else {
methodParam[index] = mock(parameter.getType());
}
}
private void mappingPrimitiveName(final Parameter parameter, final Object[] methodParam, final int index) {
val name = parameter.getType().getName();
if ("long".equals(name)) {
methodParam[index] = 0L;
} else if ("int".equals(name)) {
methodParam[index] = 0;
} else if ("byte".equals(name)) {
methodParam[index] = (byte) 0;
} else if ("short".equals(name)) {
methodParam[index] = (short) 0;
} else if ("double".equals(name)) {
methodParam[index] = 0.0d;
} else if ("float".equals(name)) {
methodParam[index] = 0.0f;
} else if ("boolean".equals(name)) {
methodParam[index] = false;
} else if ("char".equals(name)) {
methodParam[index] = 'A';
}
}
}
```
### Заключение
Данный код работает и тестирует аннотации в реальном проекте, на данный момент возможен только один вариант, когда все сказанное можно заколлапсить.
Объявить в классе ломбоковский setter (если найдется специалист, который ставит сеттер не в Pojo-классе, хотя чего только не бывает) и при этом поле на котором объявят сеттер будет не финальное.
Тогда фреймворк любезно скажет что мол есть публичный метод, а у него есть параметр на котором нет аннотации @NonNull, решение простое: объявить setter явно и аннотировать его параметр, исходя из контекста логики @NonNull/@Nullable.
Учтите, что если вы хотите как я, завязаться на имя параметра метода в своих тестах (или чем то еще), в Runtime по умолчанию недоступны имена переменных в методах, вы найдете там arg[0] и arg[1] и т.д.
Для включения отображения имен методов в Runtime используйте плагин Maven-а:
```
org.apache.maven.plugins
maven-compiler-plugin
${maven.compiler.plugin.version}
${compile.target.source}
${compile.target.source}
${project.build.sourceEncoding}
-parameters
```
и в частности этот ключ:
```
-parameters
```
Надеюсь вам было интересно.
|
https://habr.com/ru/post/464939/
| null |
ru
| null |
# СберТех ♥ Open Source, concurrency и надежные банковские операции — разбор решений задач с Joker 2018
В эти выходные прошел [Joker 2018](https://jokerconf.com/), было интересно! Но не одними выступлениями была богата конференция. Все компании-спонсоры старались выделиться на фоне «конкурентов» и мы — не исключение.
Много интересного было на стенде Сбербанк-Технологий, но я хочу рассказать о том чем выделились именно мы. [Наша команда](https://habr.com/company/sberbank/blog/418997/), занимающаяся развитием [Apache Ignite](https://ignite.apache.org/) в СберТехе, подготовила задачи и провела розыгрыш среди тех, кто отважился их решить.
Под катом вас ожидают задачи, разбор решений и возможность обосновать собственный вариант решения в комментариях.

### Горе-коммитеры
Петя и Коля коммитят в [Apache Ignite](https://ignite.apache.org/) по одной фиче в сутки.
Маша оперативно тестирует каждую фичу и откатывает коммиты, содержащие ошибки.
Каждый третий первоначальный коммит от Пети и пятый от Коли содержат ошибку.
Петя тратит на исправление ошибки дополнительные 2 дня, Коля 3, и они снова делают
коммит.
**Cколько фич будет закоммичено за 86 рабочих дней, если Маше нравится Петя,
и она замечает его ошибку лишь в тот день, когда ошибается только он?**
**Решение**Начиная с 13-го дня, образуется цикличность позволяющая Пете фиксить только каждую вторую свою ошибку.
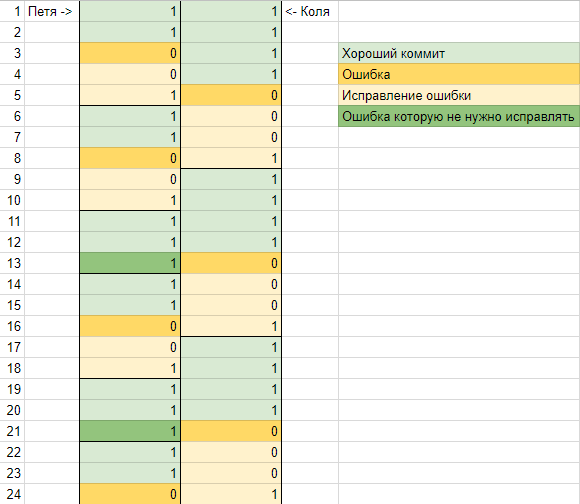
**Ответ**64 + 54 = 118;
### Вилларибо и Виллабаджо
Процессинг ненадежного банка при операциях над группой счетов блокирует ключи
счетов в порядке их объявления в операции, т.е. слева направо.
Каждый дедлок решается специалистами банка вручную и занимает в 10 раз больше
времени, чем обычная операция.
Процессинг надежного банка всегда блокирует ключи по возрастанию, но тратит в 2
раза больше времени, чем на обычную операцию в ненадежном банке.
В обоих банках 10 счетов, ключи счетов — числа от 1 до 10.
Процессингу каждого банка необходимо провести 12 операций.
Операции проводятся параллельно, по две за раз. Каждая операция затрагивает до 3-х
счетов:
— операция №1 (счета: A,B,C), где A=i, B=A+1, C=(A+B)%10,
— операция №2 (счета: D,E,F), где D=11-i, E=D-1, F=(D+E)%10,
i меняется от 1 до 6.
Выполнение последующей пары операций начинается только после полного завершения
предыдущей.
Ключи блокируются согласно политике банка, по одному в каждой из операций, начиная
с операции №1.
Если ключ уже заблокирован в одной из операций, но требуется для выполнения другой,
то сначала полностью завершается первая операция, затем продолжается вторая.
Вынужденное выполнение пары операций в последовательном режиме, ожидаемо, происходит в 2 раза медленнее чем в параллельном.
**Какой банк и во сколько раз быстрее завершит проводить операции?**
**Подсказка**Итого:
— 6 итераций,
— 12 операций,
— во всех операциях, кроме одной, по 3 ключа.
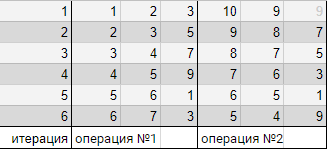
**Решение**Если все ключи разные — параллельное выполнение возможно.
Если нет — то нет, и возможен дедлок.
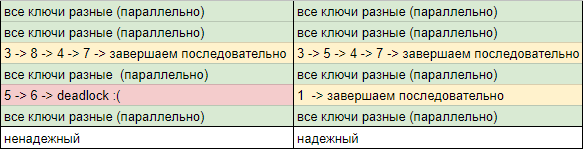
**Рассчеты**Ненадежный банк тратит на операцию 1 «такт», 2 в случае «сложностей» и целых 10 в случае дедлока.
Надежный банк тратит на операцию 2 «такта» и 4 в случае «сложностей». Дедлоков у надежного не бывает.
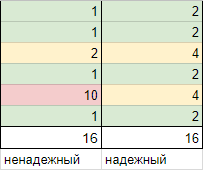
**Ответ**Завершат одновременно.
### Риски публичных репозиториев
Сережа очень опытный программист, крайне азартный и бесконечно жадный.
Однажды он нашел исходный код своего любимого тотализатора на гитхабе.
**Какая минимальная ставка может принести Сереже выигрыш?**
Упрощенный листинг тотализатора прилагается:
```
class Bid { // Ставка
int amount;
boolean checked;
boolean restricted;
Bid(int amount) {this.amount = amount;}
}
~~~
AtomicReference ref = new AtomicReference<>();
volatile boolean winner = false;
~~~
Thread validator = new Thread(() -> { // Запущен заранее!
while (true) {
Bid bid = ref.get();
if (bid == null) continue;
if ((((bid.amount << 5) ^ 1\_000\_000) >>> 6) < (2 << 15))
bid.restricted = true;
bid.checked = true;
}
});
Thread payer = new Thread(() -> { // Запущен заранее!
while (true) {
Bid bid = ref.get();
if (bid == null) continue;
if (bid.checked) {
if (!bid.restricted)
winner = true; // Выигрыш!
ref.set(null);
}
}
});
~~~
synchronized boolean makeMeRich(int amount){ // Какую ставку сделает Сережа?
if (winner) return false; // Сережа должен торопиться - приз всего один
ref.set(new Bid(amount));
while(ref.get() != null) sleep(1);
return winner; // Если вернется "true" - Сережа едет на Бали
}
```
**Подсказка №1** — 131072?
— Нет, вылезай из ловушки :)
**Подсказка №2**Какая минимальная ставка **может** принести Сереже выигрыш?
**Подсказка №3**
```
th1{
bid.restricted = true;
bid.checked = true;
}
...
th2{
while (!bid.checked) {
sleep(1);
}
assert bid.restricted; // 99.999%
}
```
Тут нет интуитивно ожидаемых гарантий видимости.
Добавить их можно следуюшим образом:
```
volatile boolean checked;
```
**Подсказка №4**Какая **минимальная** ставка может принести Сереже выигрыш?
**Решение**
**Ответ**
```
java.lang.Integer#MIN_VALUE
```
Впрочем, «0» и даже «1» расценивались как верное решение.
### Победители
Лучше всех задачи решили
— **Евгений Зубенко**
— **Александр Новиков**
— **Андрей Голиков**
Ребята получили фирменные рюкзаки, футболки и, конечно же, книги.
|
https://habr.com/ru/post/426639/
| null |
ru
| null |
# Погодная станция на Ethernet (HTTP+Modbus) с питанием по POE
Доброго времени суток хабр-сообщество.
С момента моего [последнего поста про умный дом](http://habrahabr.ru/post/187410/) прошло много времени. Я решил его делать начиная с погодной станции.
*Рисунок 1 — Фотография макетного образца*
Несмотря на обилие статей про погодные станции на arduino (http://habrahabr.ru/post/165747/, [habrahabr.ru/post/171525](http://habrahabr.ru/post/171525/), [habrahabr.ru/post/213405](http://habrahabr.ru/post/213405/) ) Я все-таки решил опубликовать своё решение.
##### Функционал
Функции которые она выполняет:
* Измерение температуры
* Измерение влажности
* Измерение давления
* Измерение освещенности
* Индикация измеренных параметров
* Выдача измеренных параметров по интерфейсу HTTP в виде XML документа
* Выдача по протоколу HTTP XSLT процессора для стилизации XML при отображении браузером
* Выдача информации по Modbus (его предполагаю использовать в качестве протокола управления умным домом)
* Питание через Passive POE
Функции которые не удалось реализовать, но хотелось:
* Измерение наличие осадков
* Направление ветра
* Скорость ветра
* DHCP — клиент
Стоимость ~1700руб (по курсу на момент покупки), в него входило:
1. DHT22 Digital Temperature And Humidity Sensor $ 5.13
2. GY-65 BMP085 Atmospheric Pressure Altimeter Module $ 4.09
3. GY-302 BH1750 Chip Light Intensity Light Module $ 2.85
4. IBOARD W5100 Ethernet Module for Arduino Development Board with POE / Xbee and SD Card Slot Expansion $ 18.46
5. MAX7219 Digital Tube Display Module$ 4.74
6. 40pcs 20cm 2.54mm 1p-1p pin Dupont wire cable Line connector $ 2.42
7. FT232RL USB To Serial Line Download Line Downloader USB TO 232 $ 4.47
8. Корпус пластиковый ~100 руб
##### Реализация устройства
Устройство было полностью собрано из покупных компонентов на базе Arduino. Все датчики были соединены проводами и расположены внутри покупного корпуса эля электроустройств. Прозрачные окна в опытном образце сделаны из прозрачной липкой ленты.
В устройстве предусмотрен LED-дисплей, который будет хорошо работать при отрицательных температурах, и позволяет использовать устройство по назначению без компьютера. Для удобства использования в ночное время — в ПО организована обратная связь по освещенности.
В качестве мозгов выбрана плата Iboard w5100, по причине того, что в ней уже присутствует весь функцонал arduino + Ethernet shield + sensor board для размножения питания и земли, при подключении большого количества устройств. Такая высокоинтегрированная плата съэкономит деньги и место. Также эта плата поддерживает работу с Passiv POE.
Передачу данных я решил сделать проводным (в отличие от большинства решений умного дома) по следующим причинам:
1. Провод в любом случае тянуть — будь то питания или передачи данных
2. В случае если решено запитать устройство от химических источников питания — то будет возникать вопрос их замены
3. Проводные коммуникации кажутся более надёжными:
1. К ним не будет претензий со стороны Роскомнадзора, так как ничего не излучают в эфир
2. Не возникнет проблем со взаимным влиянием других приемо-передатчиков в той-же частоты
3. Не возникнет огромного количества проблем связанных с реализацией радиосвязи (временного разделения эфира, затухания сигнала, влиение других таких-же систем при перекрывании зон приёма, и.т.д.)
4. Будут спокойны люди, которым Wifi греет мозг.
Чтобы не плодить интерфейсы, и все сделать единообразно — я решил для передачи данных использовать Ethernet. Питание передавать по этому-же проводу, используя технологию Passiv POE. Достоинства этого способа — если все устройства будут подключены в общую Ethernet сеть — то не возникнет вопроса с протокольными конвекторами/шлюзами.
*Рисунок 2 — Блок схема устройства*
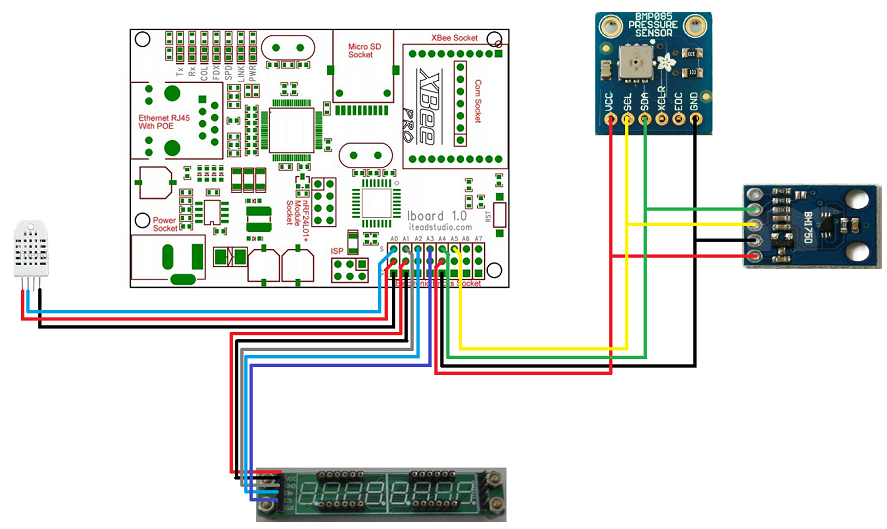
*Рисунок 3 — схема соединения*

*Рисунок 4 — Вид изнутри*
##### Реализация Passiv POE
Passive POE — Это особая реализация модули POE. В оригинальном POE требуется реализация протокола, при этом инжектор при установки связи определяет мощность удаленного оборудования, и если он может его запитать — то записывает. Passive POE придумали хитрые китайцы, которые не хотели делать такую хитрую реализацию, но хотели выйти на рынок POE оборудования, а результате они придумали тупо подать напряжение на неиспользуемые витые пары кабеля категории 5E. Некоторые даже пишут что они якобы придерживаются стандарта IEEE 802.3af в части электрических характеристик, однако даже это не всегда так.
IBOARD W5100 работает, если на выводы 4,5 и 7,8 разъема Ethernet подать напряжение 6-20В. Я подаю 20 В.
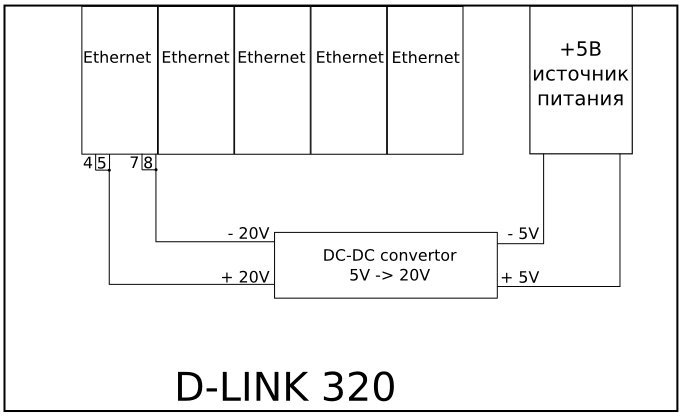
*Рисунок 5 — Схема соединения для инжектирования POE*
Инжектор я вмонтировал в D-LINK 320, установив в него китайский повышающий DC-DC преобразователь.

*Рисунок 6 — Фотография модификации*
После монтажа — все заработало.
Внимание! Перед включением проверьте, что источник питания настроен на выдачу 20В.

*Рисунок 7 — Работы всей конструкции*
##### Реализация WEB-интерфейса
Web-интерфейс был сделан, для наиболее удобного взаимодействия с устройством из сети без дополнительного ПО на стороне клиента. Для возможности автоматизированного доступа к данным было бы удобно выдавать информацию в виде XML файла. В данном проекта было совмещено эти два способа доступа к данным посредством использования XSLT процессора.
Web-браузер посылает запрос на [192.168.0.20](http://192.168.0.20/); Arduino в ответ отправляет XML документ:
```
xml version="1.0" encoding="UTF-8"?
xml-stylesheet type="text/xsl" href="http://192.168.0.20/z1.xsl"?
30.70
32.62
30.70
21.60
99309
745
11
```
Для отображения этой информации в красивом виде браузер загружает XSLT процессор, и с помощью него генерирует HTML документ.
**Исходник**
```
xml version='1.0' encoding='UTF-8'?
Weather station
.z1 {
font-family:Arial, Helvetica, sans-serif;
color:#666; font-size:12px;
text-shadow: 1px 1px 0px #fff;
background:#eaebec;
margin:20px;
border:#ccc 1px solid;
border-collapse:separate;
border-radius:3px;
box-shadow: 0 1px 2px #d1d1d1;
}
.z1 th {
font-weight:bold;
padding:15px;
border-bottom:1px solid #e0e0e0;
background: #ededed;
background: linear-gradient(to top, #ededed, #ebebeb);
}
.z1 td {
padding:10px;
background: #f2f2f2;
background: linear-gradient(to top, #f2f2f2, #f0f0f0);
}
.z1 tr:hover td{
background: #aaaaaa;
background: linear-gradient(to top, #f2f2f2, #e0e0e0);
}
Weather station
---------------
| Property | Value |
| --- | --- |
| Temperature | C |
| Humidity | % |
| Pressure | mm.Hg |
| Illuminance | lx |
Termosensor
-----------
| Sensor | Value |
| --- | --- |
| | |
```
В результате всех этих мероприятий этот XML документ в Web-браузере выглядит вот так:
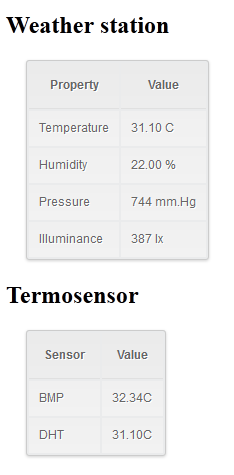
*Рисунок 8 — Внешний вид web-интерфейса в Firefox*
##### Программное обечпечение
В ПО я старался по максимуму использовать готовые библиотеки, чтобы ускорить процесс.
Логика программы достаточно простая — инициализируем все устройства, вызывая соответствующие функции из библиотек.
В цикле считываем все показания датчиков, если необходимо — обновляем данные на 8-разрядном LED-индикаторе и обрабатываем запрос по сети Ethernet.
В проекте были использованы следующие библиотеки:
* [DHTLib](http://playground.arduino.cc/Main/DHTLib) — Библиотека доступа к датчику температуры/влажности
* [Adafruit-BMP085-Library](https://github.com/adafruit/Adafruit-BMP085-Library) — Библиотека доступа к датчику давления/температуры
* [BH1750](https://github.com/claws/BH1750) — Библиотека доступа к датчику освещенности
* [LedControl](http://playground.arduino.cc/Main/LedControl) — Библиотека работы с LED индикатором по птоколу SPI
* [Webduino](https://github.com/sirleech/Webduino/) — Библиотека реализации протокола HTTP
* [Mudbus](http://code.google.com/p/mudbus/) — Библиотека реализации протокола Modbus
Стоит заметить, что для вывода букв — мне пришлось модернизировать таблицу символов в библиотеке LedControl. По умолчанию эта библиотека может отображать только буквы a-f.
**Исходник**
```
#include
#include
#include
#include "DHT.h"
#include "BH1750.h"
#include "Adafruit\_BMP085.h"
#include "LedControl.h"
#include "Mudbus.h"
#include "WebServer.h"
#define WEATHER\_STATION\_Z1 0x20
// ===============================================================
#define DHT\_S1\_PIN A0 // пин для датчика DHT22
// ===============================================================
// assign a MAC address for the ethernet controller.
// fill in your address here:
byte mac[] = {
0xDE, 0xAD, 0xBE, 0xEF, 0xFE, 0xED};
// assign an IP address for the controller:
IPAddress ip(192,168,0,20);
IPAddress gateway(192,168,0,1);
IPAddress subnet(255, 255, 255, 0);
// ===============================================================
float humidity = 0, temp\_dht = 0, temp\_bmp = 0, temp = 0;
uint16\_t light = 0;
int32\_t pressure\_pa = 0, pressure\_mm = 0;
int mode = 0;
dht dht\_s1;
BH1750 lightMeter;
Adafruit\_BMP085 bmp;
/\* This creates an instance of the webserver. By specifying a prefix
\* of "", all pages will be at the root of the server. \*/
#define PREFIX ""
WebServer webserver(PREFIX, 80);
//EthernetServer webserver(80);
#define DEV\_ID Mb.R[0]
#define TEMPERATURE Mb.R[1]
#define TEMPERATURE\_DHT Mb.R[2]
#define TEMPERATURE\_BMP Mb.R[3]
#define HUMIDITY Mb.R[4]
#define PRESSURE\_MM Mb.R[5]
#define LIGHT Mb.R[6]
Mudbus Mb;
// pin A5 is connected to the DataIn
// pin A6 is connected to the CLK
// pin A7 is connected to LOAD
LedControl lc=LedControl(A1,A2,A3,1);
// ======================== Web pages ==========================
void web\_index(WebServer &server, WebServer::ConnectionType type, char \*, bool)
{
/\* this line sends the standard "we're all OK" headers back to the
browser \*/
server.httpSuccess("application/xml; charset=utf-8");
/\* if we're handling a GET or POST, we can output our data here.
For a HEAD request, we just stop after outputting headers. \*/
if (type != WebServer::HEAD)
{
/\* this defines some HTML text in read-only memory aka PROGMEM.
\* This is needed to avoid having the string copied to our limited
\* amount of RAM. \*/
P(index\_p1) =
"xml version=\"1.0\" encoding=\"UTF-8\"?"
"xml-stylesheet type=\"text/xsl\" href=\"http://192.168.0.20/z1.xsl\"?"
""
" "
" ";
P(index\_p2) = ""
" "
" ";
P(index\_p3) = ""
" ";
P(index\_p4) = ""
" "
" "
" "
" ";
P(index\_p5) = ""
" "
" "
" ";
P(index\_p6) = ""
" ";
P(index\_p7) = ""
" "
" "
" ";
P(index\_p8) = ""
" "
"";
/\* this is a special form of print that outputs from PROGMEM \*/
server.printP(index\_p1);
server.print(temp);
server.printP(index\_p2);
server.print(temp\_bmp);
server.printP(index\_p3);
server.print(temp\_dht);
server.printP(index\_p4);
server.print(humidity);
server.printP(index\_p5);
server.print(pressure\_pa);
server.printP(index\_p6);
server.print(pressure\_mm);
server.printP(index\_p7);
server.print(light);
server.printP(index\_p8);
}
}
void web\_z1\_xsl(WebServer &server, WebServer::ConnectionType type, char \*, bool)
{
server.httpSuccess("text/xsl; charset=utf-8");
if (type != WebServer::HEAD)
{
P(z1\_xsl) =
"xml version='1.0' encoding='UTF-8'?"
""
""
" "
" "
" Weather station"
" "
" "
" .z1 {"
" font-family:Arial, Helvetica, sans-serif;"
" color:#666;"
" font-size:12px;"
" text-shadow: 1px 1px 0px #fff;"
" background:#eaebec;"
" margin:20px;"
" border:#ccc 1px solid;"
" border-collapse:separate; "
" border-radius:3px;"
" box-shadow: 0 1px 2px #d1d1d1;"
" }"
" .z1 th {"
" font-weight:bold;"
" padding:15px;"
" border-bottom:1px solid #e0e0e0;"
" background: #ededed;"
" background: linear-gradient(to top, #ededed, #ebebeb);"
" }"
" .z1 td {"
" padding:10px;"
" background: #f2f2f2;"
" background: linear-gradient(to top, #f2f2f2, #f0f0f0); "
" }"
" .z1 tr:hover td{"
" background: #aaaaaa;"
" background: linear-gradient(to top, #f2f2f2, #e0e0e0); "
" }"
" "
" "
" "
" Weather station
---------------
"
"
"
" |"
" Property |"
" Value |"
"
"
" |"
" Temperature |"
" C |"
"
"
" |"
" Humidity |"
" % |"
"
"
" |"
" Pressure |"
" mm.Hg |"
"
"
" |"
" Illuminance |"
" lx |"
"
"
"
"
" Termosensor
-----------
"
"
"
" |"
" Sensor |"
" Value |"
"
"
" "
" |"
" |"
" |"
"
"
" "
"
"
" "
" "
""
"";
/\* this is a special form of print that outputs from PROGMEM \*/
server.printP(z1\_xsl);
}
}
// ========================СТАРТУЕМ=============================
void setup(){
// Init LED display
lc.shutdown(0,false);
lc.setIntensity(0,2);
lc.clearDisplay(0);
lc.setChar(0,7,'L',false);
lc.setChar(0,6,'O',false);
lc.setChar(0,5,'A',false);
lc.setChar(0,4,'d',false);
//запускаем Ethernet
SPI.begin();
Ethernet.begin(mac, ip);
// Init Light sensor
lightMeter.begin();
// Init pressure sensor
if (!bmp.begin()) {
Serial.println("ERROR: BMP085 sensor failed");
}
//enable serial datada print
Serial.begin(9600);
Serial.println("Weather Z1 v 0.1"); // Тестовые строки для отображения в мониторе порта
webserver.setDefaultCommand(&web\_index);
webserver.addCommand("index.html", &web\_index);
webserver.addCommand("z1.xsl", &web\_z1\_xsl);
webserver.begin();
}
void loop(){
char buff[64];
int len = 64;
mode = (mode + 1) % 100;
Z1\_sensors\_update();
Z1\_SerialOutput();
Z1\_ledDisplay();
Z1\_modbus\_tcp\_slave();
// Z1\_http\_server();
webserver.processConnection(buff, &len);
}
void Z1\_sensors\_update() {
if (mode%30==0) {
// BH1750 (light)
light = lightMeter.readLightLevel();
// BMP085 (Temp and Pressure)
temp\_bmp = bmp.readTemperature();
pressure\_pa = bmp.readPressure();
pressure\_mm = pressure\_pa/133.3;
// DHT22 (Temp)
if (dht\_s1.read22(DHT\_S1\_PIN) == DHTLIB\_OK) {
humidity = dht\_s1.humidity;
temp\_dht = dht\_s1.temperature;
temp = temp\_dht;
} else {
temp = temp\_bmp;
}
}
}
void Z1\_SerialOutput() {
Serial.print("T1= ");
Serial.print(temp\_dht);
Serial.print(" \*C \t");
Serial.print("T2= ");
Serial.print(temp\_bmp);
Serial.print(" \*C \t");
Serial.print("Pressure= ");
Serial.print(pressure\_mm);
Serial.print(" mm \t");
Serial.print("Humidity= ");
Serial.print(humidity);
Serial.print(" %\t");
Serial.print("Light= ");
Serial.print(light);
Serial.print(" lx \t");
Serial.print("\n");
}
void Z1\_ledDisplay() {
int v;
if (light<50) {
lc.setIntensity(0,0);
} else if (light>80 && light<200) {
lc.setIntensity(0,2);
} else if (light>250 && light<1000) {
lc.setIntensity(0,5);
} else if (light>1100) {
lc.setIntensity(0,15);
}
if (mode<=25) {
// lc.clearDisplay(0);
lc.setChar(0,7,'t',false);
if (temp>=0) {
lc.setChar(0,6,' ',false);
} else {
lc.setChar(0,6,'-',false);
}
v = (int)( temp / 10 ) % 10;
lc.setDigit(0,5,(byte)v,false);
v = (int)( temp ) % 10;
lc.setDigit(0,4,(byte)v,true);
v = (int)( temp \* 10 ) % 10;
lc.setDigit(0,3,(byte)v,false);
lc.setChar(0,2,' ',false);
lc.setChar(0,1,'\*',false);
lc.setChar(0,0,'C',false);
delay(1);
} else if (mode<=50) {
// lc.clearDisplay(0);
lc.setChar(0,7,'H',false);
lc.setChar(0,6,' ',false);
v = (int)( humidity / 10 ) % 10;
lc.setDigit(0,5,(byte)v,false);
v = (int)( humidity ) % 10;
lc.setDigit(0,4,(byte)v,true);
v = (int)( humidity \* 10 ) % 10;
lc.setDigit(0,3,(byte)v,false);
lc.setChar(0,2,' ',false);
lc.setChar(0,1,'\*',false);
lc.setChar(0,0,'o',false);
delay(1);
} else if (mode<=75) {
// lc.clearDisplay(0);
lc.setChar(0,7,'P',false);
lc.setChar(0,6,' ',false);
v = (int)( pressure\_mm / 100 ) % 10;
lc.setDigit(0,5,(byte)v,false);
v = (int)( pressure\_mm/10 ) % 10;
lc.setDigit(0,4,(byte)v,false);
v = (int)( pressure\_mm ) % 10;
lc.setDigit(0,3,(byte)v,false);
lc.setChar(0,2,' ',false);
lc.setChar(0,1,'n',false);
lc.setChar(0,0,'n',false);
delay(1);
} else {
// lc.clearDisplay(0);
lc.setChar(0,7,'L',false);
lc.setChar(0,6,' ',false);
v = (int)( light / 1000 ) % 10;
lc.setDigit(0,5,(byte)v,false);
v = (int)( light / 100 ) % 10;
lc.setDigit(0,4,(byte)v,false);
v = (int)( light / 10 ) % 10;
lc.setDigit(0,3,(byte)v,false);
v = (int)( light ) % 10;
lc.setDigit(0,2,(byte)v,false);
lc.setChar(0,1,' ',false);
lc.setChar(0,0,' ',false);
delay(1);
}
}
void Z1\_modbus\_tcp\_slave() {
Mb.Run();
DEV\_ID = WEATHER\_STATION\_Z1;
TEMPERATURE = temp\*10;
TEMPERATURE\_DHT = temp\_dht\*10;
TEMPERATURE\_BMP = temp\_bmp\*10;
HUMIDITY = humidity\*10;
PRESSURE\_MM = pressure\_mm;
LIGHT = light;
}
```
Git-репозиторий с ПО контроллера Arduino: [github.com/krotos139/sh1\_arduino\_weather\_station\_v1](https://github.com/krotos139/sh1_arduino_weather_station_v1)
##### Вывод
Умная погодная станция с интерфейсом Ethernet может быть легко реализована на arduino.
Себестоимость устройства при опытном производстве — ~1700 руб
Время на сборку — ~1 день
Функциональность фантастическая — может работать как самостоятельное устройство с питанием от POE и от стандартного arduino-вского источника питания, так и как smart-устройство — позволяя из браузера получать всю необходимую информацию. Для автоматизированной обработки информации устройство предоставляет информацию в виде XML документа и по протоколу modbus.
|
https://habr.com/ru/post/214011/
| null |
ru
| null |
# Spark — Потрясающий веб-микрофреймворк для Java

### Небольшое вступление
**Spark** — это просто чудесный микрофреймворк для создания веб-приложений на джаве без особых усилий. Spark стремится к простоте и обеспечивает только минимальный набор функций. Тем не менее он предоставляет все необходимое для создания веб-приложения, которые поместятся в несколько строк кода. С синтаксисом, вдохновленным Sinatra, код выглядит очень чистым.
Давайте начнем со вездесущого хеллоуворлда.
Создаём новый проект и импортируем Spark. Лично я использую maven для управления зависимостями.
Добавляем в pom.xml.
```
com.sparkjava
spark-core
2.6.0
```
Теперь приступим непосредственно к «хеллоу ворлду».
```
import static spark.Spark.*;
public class Main {
public static void main(String[] args) {
get("/hello", (req, res) -> "Hello, World!");
}
}
```
Вот и всё. Всё настолько просто!
Теперь spark прослушивает GET запросы на /hello. Всякий раз, когда мы переходим на [localhost](http://localhost):4567/hello, вызывается метод *handle()*. Внутри него мы возвращаем объект, который должен быть отправлен клиенту (в этом случае «Hello World»).
Лично мое мнение, что данный код настолько лаконичный, что даже не требует пояснений.
Стоп-стоп. Что насчет запуска/остановки сервера?
1. **Остановка** — надо всего лишь вызвать метод *stop()*.
2. **Запуск** — а вот здесь все интересно. Сервер автоматически запускается, когда вы делаете что-то, что требует запуска сервера (я знаю что звучит действительно странно). Но можно запустить и вручную, вызвав метод *init()*.
### Поддержка шаблонизаторов
Хотел бы затронуть такую тему как шаблонизаторы. Спарк имеет большую нативную поддержку оных. А именно:
* Velocity
* Freemarker
* Mustache
* Handlebars
* Jade
* Thymeleaf
* Pebble
* Water
* jTwig
* Jinjava
* Jetbrick
Для всех них есть «обёртки» от спарка. Для примера давайте рассмотрим мой любимый Freemarker.
Для начала давайте импортируем доп. зависимость.
```
com.sparkjava
spark-template-freemarker
2.5.5
```
Создадим шаблон «hello.ftl» в директории *src/main/resources*.
```
Hello, ${name}!
===============
```
Теперь надо сконфигурировать freemarker дабы он искал шаблоны в ресурсах. Это всего лишь 4 строчки кода.
```
FreeMarkerEngine freeMarkerEngine = new FreeMarkerEngine();
Configuration freeMarkerConfiguration = new Configuration();
freeMarkerConfiguration.setTemplateLoader(new ClassTemplateLoader(Main.class, "/"));
freeMarkerEngine.setConfiguration(freeMarkerConfiguration);
```
Вот и всё, можно спокойно использовать фримаркер.
```
get("/", (request, response) -> {
Map model = new HashMap<>();
model.put("name", "Freemarker");
return freeMarkerEngine.render(new ModelAndView(model, "hello.ftl"));
});
```
#### Почти полноценный проект
Давайте напишем, какой-то лёгкий, но достаточный что бы показать хотя бы малую часть возможностей спарка? Мне из того что можно реально быстро написать, пришел в голову только сокращатель ссылок. Что ж, начнем?
Надо добавить еще одну зависимость Google Guava. В итоге у нас получается 3 зависимости.
```
com.sparkjava
spark-core
2.6.0
com.sparkjava
spark-template-freemarker
2.5.5
com.google.guava
guava
23.0
```
Нам Guava нужна, потому что в ней реализована хэш-функция Murmur3. Весь плюс в том что она достаточно сильна устойчива к коллизиям. Так же что бы не тратить лишнее время, мы будем все данные хранить только в переменных, без всяких бд и т.д.
Сделаем костяк программы.
```
staticFileLocation("/static");
get("/shortener", (request, response) -> {
});
get("/:url", (request, response) -> {
});
```
:url это параметр который можно достать через метод *params()*. К примеру:
```
get("/hello/:name", (request, response) -> {
return "Hello: " + request.params(":name");
});
```
Что-то я отвлекся, продолжим.
Создадим коллекцию(Map) для хранения, настроим шаблонизатор(как я говорил freemarker мой любимый, так что будет именно он) и укажем спарку где у нас будут храниться статистические файлы. *staticFiles.location("/static")* укажет ему что файлы будут лежать в *src/main/resources/static*. К примеру файл /*static/css/style.css* будет доступен по адресу *http://{host}:{port}/css/style.css*. Если же вы хотите хранить файлы предположим в */var/www/public\_html*, тогда используем метод *staticFiles.externalLocation("/var/www/public\_html")*.
```
ConcurrentHashMap urls = new ConcurrentHashMap();
FreeMarkerEngine freeMarkerEngine = new FreeMarkerEngine();
Configuration freemarkerConfiguration = new Configuration();
freemarkerConfiguration.setTemplateLoader(new ClassTemplateLoader(Main.class, "/templates/"));
freeMarkerEngine.setConfiguration(freemarkerConfiguration);
staticFileLocation("/static");
```
Настроим перенаправление.
```
get("/:url", (request, response) -> {
if(urls.containsKey(request.url()))
response.redirect(urls.get(request.url()));
response.redirect("/");
return null;
});
```
Теперь когда пользователь переходит по короткой ссылке, если ссылка есть в коллекции, мы перемещаем его на нужный сайт, если нету, то на главную.
Давайте поработаем с фронтендом, а то мы совсем про него забыли. Начнем с главной.
Здесь мы создадим простую минималистическую форму. И еще запихнем шрифтик Proxima Nova. Заигрался конечно… ну да ладно.
```
```
```
@font-face {
font-family: Proxima Nova;
src: url(pn.otf);
}
* {
font-family: Proxima Nova;
background: #2a2826;
color: #9C9C9C;
margin: 0;
padding: 0;
}
body, html {
height: 100%;
}
#main {
display: flex;
align-items: center;
justify-content: center;
height: 100%;
font-size: 1.5em;
}
#input {
border: none;
outline:none;
font-size: 1.5em;
}
```
В итоге все это добро выглядит так.
Теперь страница на которую будет выводится ссылка «shortener.ftl».
```
${url}
```
Итоговая структура проекта.
Что ж, дописываем последние строки. В итоге Main класс, выглядит так.
```
import com.google.common.hash.Hashing;
import freemarker.cache.ClassTemplateLoader;
import freemarker.template.Configuration;
import spark.ModelAndView;
import spark.Request;
import spark.Response;
import spark.template.freemarker.FreeMarkerEngine;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import static spark.Spark.*;
public class Main {
public static void main(String[] args) {
ConcurrentHashMap urls = new ConcurrentHashMap();
FreeMarkerEngine freeMarkerEngine = new FreeMarkerEngine();
Configuration freemarkerConfiguration = new Configuration();
freemarkerConfiguration.setTemplateLoader(new ClassTemplateLoader(Main.class, "/templates/"));
freeMarkerEngine.setConfiguration(freemarkerConfiguration);
staticFileLocation("/static");
get("/shortener", (request, response) -> {
String shortURL = "http://localhost:4567/" +
Hashing.murmur3\_32().hashString(request.queryParams("url"), StandardCharsets.UTF\_8).toString();
Map model = new HashMap<>();
if(!urls.containsKey(shortURL)) {
model.put("url", shortURL);
urls.put(shortURL, request.queryParams("url"));
return freeMarkerEngine.render(new ModelAndView(model, "shortener.ftl"));
}
model.put("url", shortURL);
return freeMarkerEngine.render(new ModelAndView(model, "shortener.ftl"));
});
get("/:url", (request, response) -> {
if(urls.containsKey(request.url()))
response.redirect(urls.get(request.url()));
response.redirect("/");
return null;
});
}
}
```
Вот и всё. 41 строка кода и мы написали сокращатель ссылок.
#### Заключение
На этом моменте, я закончу эту немного затянувшуюся «Getting started» статью. Мне очень жаль что в рунете этот проект обошли стороной. Если вам понравится, я продолжу писать о Spark`е и раскрою больше его возможностей.
#### Ссылки
→ [Сайт проекта](http://sparkjava.com/)
→ [Исходные коды SparkJava](https://github.com/perwendel/spark)
|
https://habr.com/ru/post/339684/
| null |
ru
| null |
# Размеры CLR-объектов. Точное определение
Думаю, многим разработчикам на управляемом коде всегда интересовало: сколько же байт занимает экземпляр объекта? А каков лимит размера одного объекта в CLR? Существуют ли различия в выделении памяти между 32-битными и 64-битными системами? Если данные вопросы для Вас не пустой звук, тогда прошу под кат.
##### Предисловие
Прежде вспомним, что в .NET существует 2 вида объектов: *value types* и *reference types*, которые создаются, соответственно, в стеке и куче (управляемом сборщиком мусора).
Value types предназначены для хранения простых данных, будь то число, символ. Во время присваивания значения переменной происходит копирование каждого поля объекта. Также время жизни таких объектов зависит от области видимости. Размеры value types определены в Common Type System и составляют:
| | |
| --- | --- |
| CTS-Тип | Количество байт |
| System.Byte | 1 |
| System.SByte | 1 |
| System.Int16 | 2 |
| System.Int32 | 4 |
| System.Int64 | 8 |
| System.UInt16 | 2 |
| System.UInt32 | 4 |
| System.UInt64 | 8 |
| System.Single | 4 |
| System.Double | 8 |
| System.Char | 2 |
| System.Decimal | 16 |
Reference types, наоборот, представляют собой ссылку на область памяти, занимаемой экземпляром объекта в куче.
Ниже приведена внутренняя структура CLR-объектов:
Для переменных ссылочных типов, в стек помещается значение фиксированного размера (4 байта, тип DWORD), содержащее адрес экземпляра объекта, созданного в обычной куче (есть еще Large Object Heap, HighFrequencyHeap и т.п., но на них мы заострять внимание не будем). Например, в C++ это значение называется указателем на объект, а в мире .NET — ссылкой на объект.
Первоначально значение SyncBlock равно нулю. Однако в SyncBlock может хранится хеш-код объекта (при вызове метода *GetHashCode*), или номер записи *syncblk*, который помещает в заголовок объекта среда при синхронизации (использование *lock*, либо напрямую *Monitor.Enter*).
Каждый тип имеет свой MethodTable, и все экземпляры объектов одного и того же типа ссылаются на один и тот же MethodTable. Данная таблица хранит информацию о самом типе (интерфейс, абстрактный класс и т.д.).
Reference type pointer — ссылка на объект, хранящаяся в переменной, размещенной в стеке со смещением 4.
Остальное представляет собой поля класса.
##### SOS
Перейдем от теории к практике. Стандартными средствами CLR невозможно установить размер объекта. Да есть оператор *sizeof* в C#, но предназначен он для установления размера unmanaged-объектов, а также размеров value types. В вопросах ссылочных типов – бесполезен.
Именно для этих целей существует расширение дебаггера Visual Studio – [SOS (Son of Strike)](http://msdn.microsoft.com/en-us/library/bb190764.aspx).
Перед началом использование необходимо разрешить unmanaged code debugging:
Для активации SOS, во время отладки необходимо открыть *VS > Debug > Windows > Immediate Window* и ввести следующее:
`.load sos.dll`
После чего увидим его успешную загрузку:
SOS имеет большое количество команд. В нашем случае необходимы будут лишь следующие:
* !DumpStackObjects (!DSO) – отображает список обнаруженных объектов в пределах текущего стека
* !DumpObj (!DO) – отображает информацию об объекте по заданному адресу
* !ObjSize – возвращает полный размер объекта. Чуть позже мы рассмотрим его предназначение
Остальные команды можно узнать набрав *!Help*.
Для демонстрации создадим простое консольное приложение и напишем класс *MyExampleClass*:
```
class MyExampleClass
{
byte ByteValue = 255; // 1 байт
sbyte SByteValue = 127; // 1 байт
char CharValue = 'a'; // 2 байта
short ShortValue = 128; // 2 байта
ushort UShortValue = 65000; // 2 байта
int Int32Value = 255; // 4 байта
uint UInt32Value = 255; // 4 байта
long LongValue = 512; // 8 байт
ulong ULongValue = 512; // 8 байт
float FloatValue = 128F; // 4 байта
double DoubleValue = 512D; // 8 байт
decimal DecimalValue = 10M; // 16 байт
string StringValue = "String"; // 4 байта
}
```
Возьмем калькулятор и посчитаем предполагаемый размер для экземпляра класса – пока что 64 байт.
Однако помните в начале статьи про структуру объектов? Так вот окончательный размер будет равен:
CLR-объект = SyncBlock (4) + TypeHandle (4) + Fields (64) = 72
Проверим теорию.
Добавим следующий код:
```
class Program
{
static void Main(string[] args)
{
var myObject = new MyExampleClass();
Console.ReadKey(); //Ставим здесь breakpoint
}
}
```
И запустим отладку (F5).
Введем следующие команды в Immediate Window:
`.load sos.dll
!DSO`
На приведенном скриншоте выделен адрес объекта *myObject*, который передадим в качестве параметра команде !DO:
Ну что же, размер *myObject* составляет 72 байта. Не так ли?
Ответ нет. Дело в том, что мы забыли еще добавить размер строки переменной StringValue. Ее 4 байта – это только ссылка. А вот истинный размер мы сейчас и проверим.
Введем команду !ObjSize:

Таким образом, настоящий размер *myObject* составляет 100 байт.
Дополнительные 28 байт занимает переменная StringValue.
Однако проверим это. Для этого используем адрес переменной *StringValue* 01b8c008:
##### Из чего складывается размер System.String?
Во-первых, в CTS символы (тип *System.Char*) представлены в Unicode и занимают 2 байта.
Во-вторых, строка – есть не что иное, как массив символов. Так в StringValue мы записали значение “String”, что равно 12 байт.
В-третьих, System.String – ссылочный тип, а это значит, что располагается он в GC Heap, и будет состоять из SyncBlock, TypeHandle, Reference point + остальные поля класса. Reference point здесь браться в расчет не будет, т.к. уже посчитан в самом классе *MyExampleClass* (ссылка 4 байта).
В-четвертых, структура System.String выглядит следующим образом:
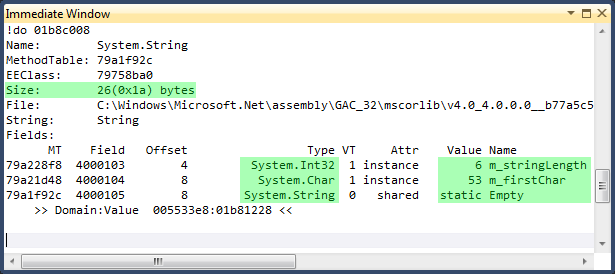
Дополнительные поля класса составляют переменные m\_stringLength типа Int32 (4 байта), m\_firstChar типа Char (2 байта), переменная Empty считаться не будет, т.к. является пустой статичной строкой.
Также обратим внимание на размер – 26 байт вместо 28, посчитанных ранее. Сложим все вместе:
StringValue = SyncBlock (4) + TypeHandle (4) + m\_stringLength (4) + m\_firstChar (2) + “String” (12) = 26
Дополнительные 2 байта образуются из-за выравнивания, производимого менеджером памяти CLR.
##### x86 vs. x64
Основное различие заключается в размере DWORD – указателя памяти. В 32-битных системах он составляет 4 байта, в 64-битных уже 8 байт.
Так, если пустой класс будет равен в x86 лишь 12 байт, то в x64 уже 24 байта.
##### Лимит размеров CLR-объектов
Принято считать, что размер System.String ограничено лишь доступной системной памятью.
Однако любой экземпляр любого типа не может занимать более 2 Gb памяти. И это ограничение распространяется как на x86, так и x64 системы.
Так, List, хотя и имеет метод *LongCount()*, это не означает возможности расположить 2^64 объектов. Решением может быть использование класса BigArray, предназначенного для этих целей.
##### Послесловие
В данной статье захотелось затронуть именно вопрос нахождения размеров CLR-объектов. Конечно, существуют подводные камни, особенно с командой !ObjSize, когда может произойти двойной счет из-за применения intern-строк.
В большинстве своем вопрос размера объектов, их выравнивания в памяти приходят только при сильной необходимости – возможности оптимизации использования ресурсов.
Надеюсь, статья оказалась интересной и полезной. Спасибо за внимание!
##### Полезные ссылки
* [Страница SOS на MSDN](http://msdn.microsoft.com/en-us/library/bb190764.aspx)
* [Internals of .NET Objects and Use of SOS](http://www.abhisheksur.com/2011/09/internals-of-net-objects-and-use-of-sos.html)
* [64-bit Applications (MSDN)](http://msdn.microsoft.com/en-us/library/ms241064(v=vs.90).aspx)
* [BigArray, getting around the 2GB array size limit](http://blogs.msdn.com/b/joshwil/archive/2005/08/10/450202.aspx)
[Внутреннее устройство .NET Framework — как CLR создает объекты периода выполнения](http://msdn.microsoft.com/ru-ru/library/dd335945.aspx)
[Mastering C# structs](http://www.developerfusion.com/article/84519/mastering-structs-in-c/) (перевод на [хабре](http://habrahabr.ru/blogs/net/114953/))
|
https://habr.com/ru/post/136609/
| null |
ru
| null |
# Юнит-тестирование в Qt

*[gollum](http://habrahabr.ru/users/gollum/) подметил что в тексте картинки есть ошибка*
Салют, хабр! ~~Как дела?~~
Хотел немного подучится чему-то. Искал на хабре в хабе «Qt Software» хоть какой-то пост про юнит-тестирование в Qt. Не нашел. Тут я расскажу базовые вещи про юнит-тестирование на Qt (не ожидайте могучего шаманства). На самом деле, юнит-тестить в Qt довольно просто. Что бы узнать как это делать, приглашаю читать дальше.
Я постараюсь разбить все на части. Погрупирую, так сказать. Начнем.
Теория
------
Если вы знаете теорию юнит-тестирования — можете пропустить этот пункт.
У нас есть код. Как бы мы этого не хотели в нем есть баги. Баги — это плохо. Чтобы багов не было, нужно писать очень качественный код (это не в этой статье) и главное, **тестировать** его. Но мы пишем код, дополняем, рефакторим… И каждый раз поддавать каждую версию проекта одному и тому же набору тестов — неприятно. И тут один очень мудрый программист додумался сделать такую программу, которая могла бы тестировать вашу программу этим, заветным набором тестов. И эта модель тестирования называется — юнит-тестинг!
Unit-testing в Qt
-----------------
А теперь конкретнее. В Qt за юнит-тестирование отвечает модуль QTestLib (testlib). Он предоставляет нам набор макросов для тестирования. Но об этом позже. Есть несколько методов проведения тестов:
* Завести тестовый проект в дочерней директории вашего проекта и тестировать в нем.
* Тестировать макросом qExec(..) в основном проекте
Я чаще использую первый метод, второй — уродлив. Но сегодня я вам покажу на примере второго метода, а первый метод распишу сейчас.
Qt использует прикольную модель: один проект — один тест. Поэтому реализовываются тесты созданием проекта tests в дочерней директории tests основного проекта. В tests лежит класс реализующий тест основного класса. Принцип работы его вы узнаете позже, а основное отличие этого подхода лежит в способе запуска теста. Этот подход требует отсутствие main.cpp и наличие макроса Q\_TEST\_MAIN(Test\_ClassName) в конце test\_classname.cpp.
Задача
------
Предлагаю для примера, реализовать класс Smart, который будет работать с сравнением целых чисел. Что он конкретно будет делать? Реализуем метод **int min(int, int)**, который будет возвращать меньшее число и **int max(int, int)**, который вернет большее число.
Ну давайте уже!
---------------
Так. Заходим в Qt Creator. Создаем консольное приложение Qt. Добавляем модуль testlib и gui (надо для тестирования GUI) к .pro-файлу. Теперь можно начинать. Принято начинать с написания тестов, а потом уже самого класса, но я пожалуй отклонюсь от традиций. Будем писать класс Smart. Вам повезло, напишу его я. Вам надо только понять как он работает. Вот этот красавец:
**smart.h**
```
#ifndef SMART_H
#define SMART_H
#include
#include
class Smart : public QObject
{
Q\_OBJECT
public:
explicit Smart(QObject \*parent, const QStringList& list);
public slots:
int max(int a, int b);
int min(int a, int b);
};
#endif // SMART\_H
```
**smart.cpp**
```
#include "smart.h"
Smart::Smart(QObject *parent, const QStringList& list) :
QObject(parent)
{
}
int Smart::max(int a, int b)
{
if(a > b)
return a;
return b;
}
int Smart::min(int a, int b)
{
if(a < b)
return a;
return b;
}
```
Тестирование QObject\* классов
------------------------------
Класс готов. Самое время проверить как он работает! Для этого напишем класс который будет тестировать наш «умный» класс. Он будет называется Test\_Smart.
**test\_smart.h**
```
#ifndef TEST_SMART_H
#define TEST_SMART_H
#include
class Test\_Smart : public QObject
{
Q\_OBJECT
public:
explicit Test\_Smart(QObject \*parent = 0);
private slots: // должны быть приватными
void max(); // int max(int, int)
};
#endif // TEST\_SMART\_H
```
**test\_smart.cpp**
```
#include
#include "test\_smart.h"
#include "smart.h"
Test\_Smart::Test\_Smart(QObject \*parent) :
QObject(parent)
{
}
void Test\_Smart::max()
{
Smart a;
QCOMPARE(a.max(1, 0), 1);
QCOMPARE(a.max(-1, 1), 1);
QCOMPARE(a.max(4, 8), 8);
QCOMPARE(a.max(0, 0), 0);
QCOMPARE(a.max(1, 1), 1);
QCOMPARE(a.max(-10,-5), -5);
}
```
Мы немного не дописали, но это не страшно. Еще успеем. Сейчас надо научится запускать наши тесты.
**main.cpp**
```
#include
#include
#include
#include
#include
#include "test\_smart.h"
using namespace std;
int main(int argc, char \*argv[])
{
freopen("testing.log", "w", stdout);
QApplication a(argc, argv);
QTest::qExec(new Test\_Smart, argc, argv);
return 0;
}
```
Компилируем…
**testing.log**
```
********* Start testing of Test_Smart *********
Config: Using QTest library 4.8.1, Qt 4.8.1
PASS : Test_Smart::initTestCase()
PASS : Test_Smart::max()
PASS : Test_Smart::cleanupTestCase()
Totals: 3 passed, 0 failed, 0 skipped
********* Finished testing of Test_Smart *********
```
Поверьте, это — самый лучший исход тестирования!
Но мы еще не протестировали один метод. Я его оставил, так как хочу показать на нем один прием тестирования. Я называю его просто — "**табличка**". Суть этого метода в том, чтобы не повторять код. Помните наш тестовый метод **void max()**? Там мы много раз повторяли один и тот же самый код (разве что с разными параметрами). Чтобы этого избежать, в Qt реализован метод — «табличка». А как он работает? Создаем метод method\_data(), в нем проводим пару нехитрых операций, а потом загружаем все это макросом QFETCH(). Сейчас как раз время увидеть это все на практике!
Теперь пора добавить в **test\_smart.cpp** реализацию нашей «таблички»:
```
void Test_Smart::min_data()
{
QTest::addColumn("first");
QTest::addColumn("second");
QTest::addColumn("result");
QTest::newRow("min\_data\_1") << 1 << 0 << 0;
QTest::newRow("min\_data\_2") << -1 << 1 << -1;
QTest::newRow("min\_data\_3") << 4 << 8 << 4;
QTest::newRow("min\_data\_4") << 0 << 0 << 0;
QTest::newRow("min\_data\_5") << 1 << 1 << 1;
QTest::newRow("min\_data\_6") << -10 << -5 << -10;
}
void Test\_Smart::min()
{
Smart a;
QFETCH(int, first);
QFETCH(int, second);
QFETCH(int, result);
QCOMPARE(a.min(first, second), result);
}
```
Теперь опять компилируем. Получаем вывод.
**testing.log**
```
********* Start testing of Test_Smart *********
Config: Using QTest library 4.8.1, Qt 4.8.1
PASS : Test_Smart::initTestCase()
PASS : Test_Smart::max()
PASS : Test_Smart::min()
PASS : Test_Smart::cleanupTestCase()
Totals: 4 passed, 0 failed, 0 skipped
********* Finished testing of Test_Smart *********
```
Теперь где-нибудь что-то неправильно сделаем. Например поменяем в Smart::min(..) поменяем < на >.
**testing.log**
```
********* Start testing of Test_Smart *********
Config: Using QTest library 4.8.1, Qt 4.8.1
PASS : Test_Smart::initTestCase()
PASS : Test_Smart::max()
FAIL! : Test_Smart::min(data_1) Compared values are not the same
Actual (a.min(first, second)): 1
Expected (result): 0
Loc: [test_smart.cpp(41)]
FAIL! : Test_Smart::min(data_1) Compared values are not the same
Actual (a.min(first, second)): 1
Expected (result): -1
Loc: [test_smart.cpp(41)]
FAIL! : Test_Smart::min(data_1) Compared values are not the same
Actual (a.min(first, second)): 8
Expected (result): 4
Loc: [test_smart.cpp(41)]
FAIL! : Test_Smart::min(data_1) Compared values are not the same
Actual (a.min(first, second)): -5
Expected (result): -10
Loc: [test_smart.cpp(41)]
PASS : Test_Smart::cleanupTestCase()
Totals: 3 passed, 4 failed, 0 skipped
********* Finished testing of Test_Smart *********
```
Значит все хорошо).
Тестируем GUI
-------------
Иногда, а иногда даже очень часто, нам приходится тестировать графический интерфейс. В QTestLib это тоже реализовано. Давайте протестируем QLineEdit.
Вот как выглядит наш **test\_qlineedit.h**:
```
#ifndef TEST_QLINEEDIT_H
#define TEST_QLINEEDIT_H
#include
class Test\_QLineEdit : public QObject
{
Q\_OBJECT
private slots: // должны быть приватными
void edit();
};
#endif // TEST\_QLINEEDIT\_H
```
А вот как выглядит, тоже наш **test\_qlineedit.cpp**:
```
#include
#include
#include "test\_qlineedit.h"
void Test\_QLineEdit::edit()
{
QLineEdit a;
QTest::keyClicks(&a, "abCDEf123-");
QCOMPARE(a.text(), QString("abCDEf123-"));
QVERIFY(a.isModified());
}
```
Пора поправить **main.cpp**:
```
#include
#include
#include
#include
#include
#include "test\_smart.h"
#include "test\_qlineedit.h"
using namespace std;
int main(int argc, char \*argv[])
{
freopen("testing.log", "w", stdout);
QApplication a(argc, argv);
QTest::qExec(new Test\_Smart, argc, argv);
cout << endl;
QTest::qExec(new Test\_QLineEdit, argc, argv);
return 0;
}
```
Теперь запускаем тестирование:
```
********* Start testing of Test_Smart *********
Config: Using QTest library 4.8.1, Qt 4.8.1
PASS : Test_Smart::initTestCase()
PASS : Test_Smart::max()
PASS : Test_Smart::min()
PASS : Test_Smart::cleanupTestCase()
Totals: 4 passed, 0 failed, 0 skipped
********* Finished testing of Test_Smart *********
********* Start testing of Test_QLineEdit *********
Config: Using QTest library 4.8.1, Qt 4.8.1
PASS : Test_QLineEdit::initTestCase()
PASS : Test_QLineEdit::edit()
PASS : Test_QLineEdit::cleanupTestCase()
Totals: 3 passed, 0 failed, 0 skipped
********* Finished testing of Test_QLineEdit *********
```
Вот мы и научились тестировать GUI. Тест показал что QLineEdit работает корректно)).
Аргументы тестирования
----------------------
| Опция | Объяснение |
| --- | --- |
| **-o filename** | Выведет результаты тестирования в файл filename |
| **-silent** | Ограничить сообщения показом только предупреждений и ошибок |
| **-v1** | Отображать информацию о входе и и выходе тестовых методов |
| **-v2** | Дополняет опцию -v1 тем, что выводит сообщения для макросов QCOMPARE и QVERIFY |
| **-vs** | Отображать каждый высланный сигнал и вызванный слот |
| **-xml** | Осуществлять вывод всей информации в формате XML |
| **-eventdelay ms** | Заставляем тест остановиться и подождать ms миллисекунд. Эта опция полезна для нахождения ошибок в элементах GUI |
Всего того, что я вам сегодня расказал, точно хватит чтобы прямо сейчас начать тестировать свои Qt-приложения. Что я могу вам сказать? Все советы и пожелания для улучшения статьи прошу написать в комментариях — для меня это важно, так как это, надеюсь, не последняя моя статья.
Удачи и хорошого вам кода;)
|
https://habr.com/ru/post/146449/
| null |
ru
| null |
# Прикручиваем Doctrine 2 ORM к Silex
Недавно узнал о великолепном микро-фреймворке [Silex](http://silex.sensiolabs.org/), и примерно столь же недавно о модели [ORM](http://ru.wikipedia.org/wiki/ORM). Туториал будет полезен тем, кто хочет связать одно с другим.
Silex — легкий, расширяемый микро-фреймворк, построен на компонентах [Symfony 2](http://symfony.com/) и [Pimple](http://pimple.sensiolabs.org/).
Doctrine — ORM движок, позволяющий работать с БД не напрямую, а через обычные объекты.
Статья написана по мотивам [этой](http://martinsikora.com/silex-doctrine2-orm), однако не является ее переводом.
Что же, попробуем связать одно с другим. Для установки библиотек будем использовать [Composer](http://getcomposer.org/).
#### Определим зависимости в `composer.json`
```
{
"minimum-stability": "dev",
"require": {
"php": ">=5.3.3",
"silex/silex": "1.*",
"taluu/doctrine-orm-provider": "1.0.*"
},
"config": {
"bin-dir": "bin"
}
}
```
Стоит пояснить поле config. В нем мы указываем место, куда Composer создаст ярлыки (aliases) на файлы, исполняемые в консоли.
Выполним `composer install`
#### Добавим код приложения
В корне проекта создадим папку приложения — `app/src`, или любую другую на выбор. Следуя [шаблону](https://github.com/fabpot/Silex-Skeleton/tree/master/src)(который кстати можно установить, чего я не стал делать) я назвал `src`.
В `index.php` добавим следующий код:
```
// index.php
php
$app = require __DIR__.'/src/app.php';
$app-run();
```
Здесь мы в $app выгружаем приложение и запускаем его.
Что же внутри app.php:
```
// src/app.php
php
require __DIR__.'/../vendor/autoload.php';
$app = new Silex\Application();
$app['debug'] = true;
require __DIR__.'/registers.php';
require __DIR__.'/controllers.php';
return $app;
</code
```
А здесь подключаем автозагрузчик классов, созданный Composer, создаем приложение и настраиваем.
В controllers.php опишем логику контроллеров: $app->get(), $app->error() и тд.
Нас же интересует registers.php:
```
// src/registers.php
php
use Doctrine\Common\Cache\ApcCache;
use Doctrine\Common\Cache\ArrayCache;
$app-register(new Silex\Provider\DoctrineServiceProvider(), array(
'db.options' => array(// Подробнее настройка DBAL тут: http://silex.sensiolabs.org/doc/providers/doctrine.html
'driver' => 'pdo_mysql',
'dbname' => 'silex_test',
'host' => '127.0.0.1',
'user' => 'root',
'password' => 'root',
'charset' => 'utf8'
)
));
$app->register(new Nutwerk\Provider\DoctrineORMServiceProvider(), array(
'db.orm.proxies_dir' => __DIR__.'/../cache/doctrine/proxy',
'db.orm.proxies_namespace' => 'DoctrineProxy',
'db.orm.cache' =>
!$app['debug'] && extension_loaded('apc') ? new ApcCache() : new ArrayCache(),
'db.orm.auto_generate_proxies' => true,
'db.orm.entities' => array(array(
'type' => 'annotation', // как определяем поля в Entity
'path' => __DIR__, // Путь, где храним классы
'namespace' => 'TestApp\Entity', // Пространство имен
)),
));
```
Согласно указанному namespace создадим директории, в данном случае:
`src/TestApp` и `src/TestApp/Entity`
#### Настроим консольное управление Doctrine
Прийдется немного изменить код в консольных инструментов(дальше просто консоль) Doctrine, доступных, благодаря Composer в `bin`.
Чтобы связать консоль и наше приложение настроим `cli-config.php`. Изначально этот файл находится в `vendor/doctrine/orm/tools/sandbox`, скопируем от туда в `bin`. А теперь удалим все, кроме создания `$helpers`.
Весь удаленный код создавал и настраивал то, что мы настроили для нашего приложения. Так почему бы нам это не использовать?
```
// bin/cli-config.php
php
$app = require __DIR__.'/../src/app.php';
$em = $app['db.orm.em'];
$helpers = new Symfony\Component\Console\Helper\HelperSet(array(
'db' = new \Doctrine\DBAL\Tools\Console\Helper\ConnectionHelper($em->getConnection()),
'em' => new \Doctrine\ORM\Tools\Console\Helper\EntityManagerHelper($em)
));
```
Тут стоит добавить, что работая в нашем приложении с Doctine, копию EntityManager мы сможем получить из `$app['db.orm.em']`
##### Варианты подключения этих настроек:
1. Не правильный вариант, так делать не стоит:
Исправим bin/doctrine.php:
```
$configFile = getcwd() . DIRECTORY_SEPARATOR . 'bin/cli-config.php'; // 21 строка
```
Подобное можно было и не делать, поместив cli-config.php в корень проекта. С одной стороны не правильно править код библиотек, с другой — удобно.
2. Можно пойти и иным, более правильным путем — создать свою консоль и подключить свои конфиги самостоятельно:
```
// bin/console
#!/usr/bin/env php
php
require 'cli-config.php';
include('doctrine.php');
</code
```
Теперь надо дать права на исполнение bin/console и для запуска из корня проекта использовать:
```
./bin/console [command_name]
```
Что еще почитать по теме:
[Русская документация по Doctrine](http://odiszapc.ru/doctrine/)
[Английская документация по Doctrine ORM](http://docs.doctrine-project.org/projects/doctrine-orm/en/latest/index.html)
UPD: Добавил на github [репозиторий](https://github.com/hell0w0rd/Silex-skeleton-with-Doctrine-ORM) с каркасом приложения на silex и doctrine orm. Правда используется другой провайдр для ORM
|
https://habr.com/ru/post/173955/
| null |
ru
| null |
# работа с куками из javascript
Всем привет!
Сегодня хочется поделиться с теми кто еще не в теме, теорией о том как работать с cookie из JS
JS не предоставляет удобного API для работы с cookies. И это в принципе не плохо, могло бы быть и хуже (например js вообще не реализовывал бы работы с куками), но все же, лучше, когда можно читать куки с помощью одной инструкции (чего пока нативным js — невозможно).
Существует множество framework'ов и plugin'ов к ним, которые восполняют данный недостаток. Однако бывают проекты где нецелесообразно подключать framework лишь для удобства работы с куками.
Собственно мною была поставлена и реализована задача создания методов по управлению куками, с красивыми аксессорами типа:
`cookie.set('bla', 'blabla');
cookie.get('bla');`
[code.google.com/p/jscookie](http://code.google.com/p/jscookie/) — страничка на гуглокоде
Немножечко теории о механизме предоставляемом js'ом для работы с cookie:
Все что у нас есть — свойство document.cookie, оно не реализует за собой никаких привычных рядовому программисту методов, типа document.cookie.get('bla');
#### Чтение cookie
document.cookie содержит набор значений cookie\_name=cookie\_value; (разделенных между собой "; " (точка с запятой плюс пробел)), отсюда следует, что бы получить значение конкретной куки — необходимо пропарсить всю строку и выдернуть необходимые данные. Что примечательно, в свойстве содержится пары имя=значение, никаких дополнительный данных о куках таких как: expires time, path, domain, secure — не содержит.
#### Создание/обновление cookie
document.cookie ведет себя как строка, но не обычная. представим что у нас есть 2 куки key1 = val1 и key2 = val2.
`alert(document.cookie) //key1=val1; key2=val2;`
Для того что бы добавить новую куку key3 = val3
`document.cookie= 'key3=val3; ';
alert(document.cookie) //key1=val1; key2=val2; key3=val3;`
Для того что бы обновить куку, зададим key2 значение hello world
`document.cookie= 'key2=hello world; ';
alert(document.cookie) //key1=val1; key2=hello world; key3=val3;`
#### Удаление Cookie
Теперь немножечко расскажу о куках как таковых, не претендую на полное и досканальное знание этой тематики, просто чуть чуть расскажу что знаю.
Кука помимо названия и значения имеет в своем арсенале еще несколько важных свойств, а именно:
expires — время, после которого кука удаляется.
domain — домен для которого кука действительна, грубо говоря, если кука была создана на домене js.com, то ни на каком другом домене она не будет видна.
path — множество документов, при запросе на которые браузер будет посылать куку
secure — свойство-флаг разрешающий посылать браузуру куку только при https соединении
вообщем все это записывается в виде document.cookie = 'key4=val4; [expires=Sat, 09 Jan 2010 16:14:53 GMT; ][path=/; ][domain=js.com; ][secure; ]
Фокус с удалением куки состоит в том что бы обновить куку со свойством expires указывающим в прошлое, например:
`document.cookie= 'key2=; expires=Mon, 05 Jul 1982 16:37:55 GMT; ';
alert(document.cookie)//key1=val1; key3=val3;`
Собственно все
UPD: это мой первый пост, прошу сильно не пинать. Надеюсь кому то будет полезно
|
https://habr.com/ru/post/74217/
| null |
ru
| null |
# Обзор php-frontend'а системы мониторинга Zabbix
Здравствуйте, хабраюзеры!
Я думаю, каждый уважающий себя системный администратор локальной сети установит систему мониторинга, чтобы быть в курсе всех изменений и событий. Я хочу рассказать про систему мониторинга Zabbix, а точнее про его php-frontend. Здесь только мой личный опыт полученный на реальной локальной сети.
#### Создание пользователя
Будем считать, что у нас Zabbix-сервер установлен и прикручен php-frontend. Зайдем под логином admin и паролем zabbix (первый вход).

Первым делом предлагаю добавить своего пользователя и удалить дефолтную учетку Admin. Заходим Администрирование-Пользователи, в выпадающем меню в правом верхнем углу выбираем пользователи и жмакаем на кнопку добавить пользователя.

Далее заполняем форму и советую выбрать русский язык. Перезаходим под новой учеткой.
#### Узлы сети
Самое главное меню в заббиксе это Настройка-Узлы сети. Здесь находятся машины(и не только), за которыми мы наблюдаем. У меня эта страница выглядит так.

Для каждого узла сети есть настройки:
* **Группы элементов:** здесь можно собрать в группу несколько элементов данных, например, элементы данных относящиеся к сети, к CPU, к дискам.
* **Элементы данных:** это, проще говоря, источники различных данных от машин, отсюда идет вся информация о состоянии системы.
* **Триггеры:** основываются на элементах данных, они следят за поступающими данными и, в случае отклонения от нормы, оповещают админов
* **Графики:** наглядное изменение данных, поступающие от элементов данных, например скорость исходящих данных интерфейса sk0. Очень удобно разработан выбор интервала просмотра, можно выбирать как и на графике, так и на полосе прокрутки над графиком.
В каждой из 4-х настроек, конечно, можно добавлять свои группы элементов, свои элементы данных, триггеры и графики.
К каждому узлу, желательно, прикрепить шаблон элементов данных, их уже заботливо подготовили разработчики. Есть шаблоны для Windows, Linux, Freebsd и др ОС. Шаблоны различаются разными путями получения данных.
Кроме этих 4-х настроек вы видите справа DNS узла сети, его IP, порт, на котором находится Zabbix Agent, присоединенный шаблон, состояние, наблюдается этот узел или нет, и доступность Zabbix Agent'а.
Добавьте узел сети, за которым вы хотите наблюдать и присоедините шаблон, соответствующий установленной ОС. Если вы хотите наблюдать за, например, Wi-Fi роутером, то вам достаточно его только пинговать. Как это сделать — объясню в следующей статье, если понадобится.
#### Способы оповещений
Итак, теперь у вы наблюдаете за сервером, теперь нужно настроить оповещение админов при отклонении данных от нормы. Для этого идем в Администрирование-Способы оповещений.

У меня настроено оповещение через скрипт, который отправляет письмо через скрипт на ящик админа. Способ оповещения по E-mail, а не через скрипт, требует какой-то дополнительной настройки штатной программы отправки E-mail. Поэтому проще через скрипт. При создании способа оповещения и выборе типа оповещения через скрипт, достаточно написать имя скрипта. Привожу текст скрипта.
`#!/bin/sh
export [email protected] #все, что вы желаете видеть в поле от кого
export smtpdomain=gmail.com #домен smtp сервера
export smtpserver=smtp.gmail.com #адрес smtp сервера
export smtplogin=login #ваш логин
export smtppass=password #ваш пароль
echo "From: \"Zabbix Monitor\" <$smtpemailfrom>" > /usr/home/zabbix/mailz
echo "To: $1" >> /usr/home/zabbix/mailz
echo "Subject: $2" >> /usr/home/zabbix/mailz
echo "" >> /usr/home/zabbix/mailz
echo "$3" >> /usr/home/zabbix/mailz
/usr/local/bin/nbsmtp -d $smtpdomain -f $smtpemailfrom -h $smtpserver -U $smtplogin -D -s -P $smtppass -S < /usr/home/zabbix/mailz
rm /usr/home/zabbix/mailz`
Здесь приведен скрипт отправки на почту gmail. Достаточно установить программу nbsmtp из портов FreeBSD, на Linux, я думаю, такая программа тоже есть. Сам скрипт лежит в /usr/home/zabbix/bin/, т.е. в домашней папке пользователя zabbix, нужно создать в ней папку bin и положить скрипт с именем smtp и выполнить chmod +x smtp.
Также нужно указать в конфиге zabbix\_server.conf параметр, где лежат скрипты способов оповещения.
`...
AlertscriptsPath=/usr/home/zabbix/bin/
....`
Теперь нужно подредактировать своего пользователя в zabbix'е и добавить способы оповещения, если вы этого еще не сделали. У меня настроено отправка на почту и на телефон смс-кой(сервис билайн), такая же фича доступна для абонентов мегафон. У оператора создается e-mail ящик, и входящие письма на этот ящик пересылаются вам смской на телефон. В этом случае вы будете всегда своевременно получать оповещения от заббикса.

При добавления способа оповещения можно указать при какой важности будет использоваться данный способ оповещения, например, на почту могут идти все оповещения, а на телефон только важные и чрезвычайные.
#### Действия
Следующим шагом будет настройка действий. Т.е. что нужно делать и при каких условиях.

В верхнем правом углу можно создать новое действие, рассмотрим что здесь нужно заполнить.

* **Имя** — имя действия
* **Событие** — за чем следит действие, в данном случае за триггерами
* **Тема** — какая будет тема в e-mail сообщении
* **Сообщение** — что будет написано в теле сообщения
* **Условие действия** — это условие, при котором действие будет выполнено. У меня настроено, так что сообщение будет отправлено, если сработает триггер с важностью больше «высокой».
* **Операции действия** — это то что должно выполнится после срабатывания условия. В данном случае у меня настроено отправка е-mail сообщения пользователю Notification.
Теперь мы будем получать своевременно оповещения от заббикса при отклонении триггеров.
#### Комплексные экраны
Следующее меню, что желательно настроить это комплексные экраны.

Комплексный экран это группа однотипных графиков разных машин. Например, загрузки CPU всех машин. Это очень наглядно и приятно :)
Давайте посмотрим как создать комплексный экран. Как всегда в правом верхнем углу щелкнем на кнопку создать комплексный экран, здесь будет предложено ввести лишь имя и размер комплексного экрана. После создания щелкаем по имени комплексного экрана, перед нами появится сетка и в каждой ячейке кнопка изменить. Изменяем каждую ячейку под нужный график и сохраняем. Посмотреть комплексные экраны в действии можно в Мониторинг — Комплексные экраны.

#### Обнаружение
Так же ради любопытства можно настроить обнаружение компьютеров в сети. Делается это с помощью меню Настройка-Обнаружение

В моем случае это пригодится узнать, какие IP никогда не использовались и которые можно удалить из базы DHCP, т.к. пространство IP у нас не резиновое. При создании правила обнаружения достаточно указать диапазон сканируемых IP и что проверить: ping, http, samba и т.д.
Вот все основное в zabbix'е, что я хотел рассказать вам. Если понравилась статья, то могу написать вторую, как добавлять свои элементы данных(это будет интересно, скорее всего только FreeBSD'шникам), как можно контролировать Wi-Fi роутеры и вообще подробней обо всем. За размер изображений не пинайте, наверно, не очень приятно сделал.
|
https://habr.com/ru/post/125340/
| null |
ru
| null |
# Сетевой media сервер для PS3
Давно валялась в черновиках данная заметка, все никак не мог собраться ее оформить и опубликовать. Но как говорят это вечно длится не может, так что приступим к повествовании. Собственно в чем же задача, спросите вы? У кого есть PS3 с установленной CFW, тот знает что записать файл больше 4Гб нельзя на внешний диск, так как это ограничение файловой системы FAT32 (сейчас файловые менеджеры для PS3, такие как Multiman поддерживают возможность чтения с томов NTFS, но эта функциональность появилась довольно недавно). Для решения этой проблемы можно было применить два метода:
* записывать игру на внутренний диск
* использовать специальные программы которые разбивали большие файлы на части, которые понимал файловый менеджер PS3 (в конечном итоге он все равно склеивал эти файлы и копировал на внутренний диск приставки)
Но существовал и еще один метод, это поднять медиа-сервер для «стриминга» контента на PS3. Собственно этим мы займемся :)
У меня на PS3 установлена CFW с функцией **Cobra**, что позволяет использовать ISO образы, и не требует разворачивания образа в отдельный каталог, как того требуется. Дополнительно у меня еще установлен **webMAN** что позволяет мне монтировать образы игр не запуская файловый менеджер и даже управлять образами и самой приставкой из веб-браузера (даже с мобильного). Но не это есть предметом данного сообщения. Кому интересно, может обратиться к документации по этому ПО или мне написать личное сообщение.
Собственно, ничего сложного в сборке этого нет (сложно было найти это все в разных форумах и собрать вместе), скачиваем [подготовленный архив с исходными файлами](https://drive.google.com/file/d/0B4rlEl3jZHocZ1dFMEg4MXZ0dXM/view?usp=sharing). Этот архив предназначен для платформы Linux x86\_64, хотя я его собирал и под FreeBSD и даже для роутера **ASUS RT-N56U**. Я уже не помню всех нюансов сборки под данную платформу, если вас интересует данный вопрос, можете мне написать в личку или почитать **Issue [1106](https://code.google.com/p/rt-n56u/issues/detail?id=1106): compiling ps3netsrv**. В данный архив уже включены измененные файлы «main.cpp» и «netiso.h». Разворачиваем архив и собираем.
```
$ tar -xzvf ps3netsrv.tar.gz
$ make
```
*Примечание.*
*В архиве есть скелет rc-скрипта для автоматического запуска/остановки сервиса, но я пошел другим путем и так его и не закончил.*
Запускаем все это очень просто:
```
$ ./ps3netsrv /mnt/media/ps3netsrv
```
— где **/mnt/media/ps3netsrv** root-директория где будет лежать контент для PS3. Внутри корневой директории создаем папки — **GAMES, PS3ISO**. В первую складываем обычные распакованые образы, а в вторую образы в формате ISO.
Как я и говорил рание, мы не будем использовать rc-скрипты для управление сервисом, а создадим отдельный контейнер для данного сервиса используя возможности Docker.
Создадим отдельную папку для размещения файла конфигурации создания контейнера и скопируем в него скомпилированый файл. Для примера:
```
$ cd ~/docker/ps3netsrv
$ cp ~/source/ps3netsrv/ps3netsrv ./
```
Создадим файл конфигурации:
```
$ vim Dockerfile
```
```
FROM sovicua:jessie
MAINTAINER Viktor M. Sytnyk
ENV DEBIAN\_FRONTEND=noninteractive
RUN apt-get update && apt-get upgrade -y
RUN groupadd -g 1000 ps3netsrv
RUN useradd -u 1000 -g 1000 -m -c "PS3 Media Server" ps3netsrv
VOLUME /home/ps3netsrv/media
RUN chown ps3netsrv:ps3netsrv /home/ps3netsrv/media
COPY ps3netsrv /home/ps3netsrv/
RUN chown ps3netsrv:ps3netsrv /home/ps3netsrv/ps3netsrv
WORKDIR /home/ps3netsrv
CMD ./ps3netsrv ./media
```
Создаем образ для данного сервиса:
```
$ docker build -t sovicua:ps3netsrv .
```
И запускаем контейнер:
```
$ docker run --net=host --name=ps3netsrv --user=ps3netsrv -v /mnt/media/ps3netsrv:/home/ps3netsrv/media -i -t -d sovicua:ps3netsrv
```
— где **/mnt/media/ps3netsrv** — корневой каталог в основной операционной системе, который монтируется в **/home/ps3netsrv/media** в контейнере. Все можно проверять работу нашего медиа-сервера на PS3. Думаю что вы сможете дальше не составить труда вам разобрать что и как.
В дальнейшем я планирую выгрузить данный контейнер в общий пул Docker Hub, что бы каждый мог воспользоваться данным готовым контейнером для создания медиа-сервера.
Хотелось бы услышать ваше мнение по данному вопросу.
*P.S. Изначально я для базового образа забыл установить правильную временную зону, по умолчанию для контейнера была установлена UTC. Процедура изменения временной зоны для базового образа описана в небольшой статье [Установка timezone в базовом образе Docker](http://unixua.blogspot.com/2015/07/timezone-docker.html).*
|
https://habr.com/ru/post/261937/
| null |
ru
| null |
# Простой способ создания и переиспользования модальных диалогов во Vue 3

Модальные диалоги не такая и сложная задача в разработке. Обычно это очень монотонная и неинтересная работа с повторяющейся логикой, которую подчас копируют из компонента в компонент с незначительными изменениями. Часто используется для подтверждения пользователем каких-либо действий. Например удалить какие-либо данные или выполнить авторизацию.
Но что делать, если у вас десятки или даже сотни похожих диалогов на одной странице или даже во всем проекте? Или нужно вызывать диалоги по цепочке в зависимости от выбора пользователя? Как абстрагировать такой функционал и не получить в результате запутанный и плохо поддерживаемый код?
Неплохо было бы создать такую функцию, которая принимала бы компонент диалога и управляла бы его рендерингом в шаблоне, а возвращаемый ею объект содержал бы состояние диалога и методы вызова, чтобы с ним можно было работать как с промисами. Как например в этой библиотеке [vue-modal-dialogs](https://github.com/hjkcai/vue-modal-dialogs). К сожалению она давно не обновлялась и не поддерживает Vue 3.
В этом гайде я представлю вам плагин [vuejs-confirm-dialog](https://github.com/harmyderoman/vuejs-confirm-dialog) и покажу как им пользоваться. Начну с простых примеров и закончу созданием функциии полностью абстрагирующей вызов диалога для подтверждения действия, которую можно применять в любом компоненте вашего проекте. Примеры написаны на `JavaScript` для облегчения восприятия, но сам плагин на `TypeScript`. Плагин полность типизирован и задокументирован, что значительно облегчает работу с ним. В отличие от `vue-modal-dialogs` этот плагин имеет дополнительный функционал. Это особые хуки: `onConfirm` и `onCancel`. Они принимают колбек и срабатывают в зависимости от решения пользователя: `onConfirm` если пользователь согласится и `onCancel` если откажется.
Конечный результат можно посмотреть в [песочнице](https://codesandbox.io/s/vibrant-stonebraker-ml8tms?file=/src/App.vue). Код незначительно отличается от того, что в посте.
Установка
---------
Начнем с создания нового проекта на Vue 3. Введем в консоли:
```
vue create dialogs-guide
// Pick a second option
? Please pick a preset:
Default ([Vue 2] babel, eslint)
> Default (Vue 3) ([Vue 3] babel, eslint)
Manually select features
```
Мы получили стандартный шаблон нового проекта. Далее перейдем в папку проекта и установим плагин согласно документации в [README.md](https://github.com/harmyderoman/vuejs-confirm-dialog/blob/main/README.md).
```
npm i vuejs-confirm-dialog
```
Заменим код в `main.js` на такой:
```
import { createApp } from 'vue'
import App from './App.vue'
import * as ConfirmDialog from 'vuejs-confirm-dialog'
createApp(App).use(ConfirmDialog).mount('#app')
```
Использование
-------------
Теперь перейдем в файл App.vue. Первым делом исправим код шаблона. Для работы библиотеки нам обязательно нужно добавить в него компонент и удалим `HelloWord`:
```

```
Теперь изучим как использовать функцию `createConfirmDialog`. Используем новый синтаксис `setup` для раздела `script`. `createConfirmDialog` первым аргументом принимает компонент, который будет использоваться как модальное окно, а вторым входные данные для него. Функция возвращает обьект с методами для работы с модальным окном, так метод `reveal` вызывает диалог, а хук `onConfirm` принимает код, который выполняется если пользователь нажмет на "согласен". Можно заставить появляться компонент `HelloWord` при нажатии на лого и передать ему значение пропса `msg`:
```
// App.vue

import HelloWorld from './components/HelloWorld.vue'
import { createConfirmDialog } from 'vuejs-confirm-dialog'
const { reveal } = createConfirmDialog(HelloWorld, { msg: 'Hi!'})
```
Никакой дополнительной логики не требуется. Компонент отрисовывается после вызова функции `reveal` и исчезает после того, как пользователь отреагирует на диалог.
Реалистичный пример компонента
------------------------------
Теперь напишем что-то более приближенное к реальному использованию.
Создадим новый компонент `SimpleDialog.vue` в папке `components`:
```
🗙
{{ question }}
--------------
Confirm
Cancel
import { defineProps, defineEmits } from 'vue'
const props = defineProps(['question'])
const emit = defineEmits(['confirm', 'cancel'])
.modal-container {
display: flex;
justify-content: center;
align-items: center;
position: absolute;
top: 0;
left: 0;
right: 0;
width: 100%;
height: 100%;
background-color: #cececeb5;
}
.modal-body {
background-color: #fff;
border: 2px solid #74a2cf;
border-radius: 10px;
text-align: center;
padding: 20px 40px;
min-width: 250px;
display: flex;
flex-direction: column;
}
.modal-action {
display: flex;
flex-direction: row;
gap: 40px;
justify-content: center;
}
.modal-button {
cursor: pointer;
height: 30px;
padding: 0 25px;
border: 2px solid #74a2cf;
border-radius: 5px;
background-color: #80b2e4;
color: #fff;
}
.modal-close {
cursor: pointer;
position: relative;
align-self: end;
right: -33px;
top: -17px;
}
```
Обратите внимание, что для полноценной работы нужно добавить два входящих события в модальный диалог: `['confirm', 'cancel']`.
А теперь используем его для подтверждения какого-либо действия, например, чтобы спрятать лого. Логику кода, который будет исполняться после согласия пользователя, поместим в коллбек хука `onConfirm`.
```

Hide Logo
import SimpleDialog from './components/SimpleDialog.vue'
import { createConfirmDialog } from 'vuejs-confirm-dialog'
import { ref } from 'vue'
const showLogo = ref(true)
const { reveal, onConfirm } = createConfirmDialog(SimpleDialog, { question: 'Are you sure you want to hide the logo?'})
onConfirm(() => {
showLogo.value = false
})
```
Переиспользование
-----------------
Что делать, если у нас есть много случаев, когда требуется подтверждение каких-либо действий? Не писать же каждый раз `createConfirmDialog` заново?
Можно написать функцию, которая автоматизирует этот процесс для нас.
```
// src/composables/useConfirmBeforeAction.js
import SimpleDialog from './../components/SimpleDialog'
import { createConfirmDialog } from 'vuejs-confirm-dialog'
const useConfirmBeforeAction = (action, props) => {
const { reveal, onConfirm } = createConfirmDialog(SimpleDialog, props)
onConfirm(action)
reveal()
}
export default useConfirmBeforeAction
```
Теперь используем ее для подтверждения перехода по внешним ссылкам:
```
// App.vue
* {{ link }}
import useConfirmBeforeAction from './composables/useConfirmBeforeAction'
const LINKS = [
'https://vuejs.org/',
'https://github.com/',
'https://vueuse.org/',
]
const goToLink = (link) => {
useConfirmBeforeAction(
() => {
window.location = link
},
{ question: `Do you want to go to ${link}?` }
)
}
```
Заключение
----------
Функция `createConfirmDialog` позволяет упростить работу с модальными окнами, переиспользование логики и создание цепочек последовательных диалогов. Она берет на себе заботу о рендере модального окна, передачу входящих параметров в компонент и получении данных от него. Она очень гибкая — ее очень легко подстроить под ваши нужды.
Это не все ее возможности. Например, если концеция хуков вам не близка, можно заменить их на работу с промисом, который возвращает `reveal`. И даже использовать её в Options API, если вас не отпускает ностальгия по Vue 2.
|
https://habr.com/ru/post/662652/
| null |
ru
| null |
# Основы CI/CD. Знакомство с Jenkins
В новой статье рассмотрим основы CI/CD и познакомимся Jenkins. Вы узнаете, где применяется Jenkins и какие проблемы помогает решить, поймёте логику архитектурных решений и особенности структуры каталогов. А ещё научитесь устанавливать Jenkins и производить базовую конфигурацию.
*За основу статьи взят первый урок*[***нашего практического курса «CI/CD с Jenkins»***](https://slurm.club/3y9ww9F).
### CI/CD: что это такое и зачем нужно
Скорость разработки продуктов — одно из главных конкурентных преимуществ в разработке ПО. Поэтому на смену старым моделям программирования пришла новая концепция CI/CD.
**CI (Continuous Integration)** — непрерывная интеграция. Разработчики, применяющие данный паттерн, могут проверять основную ветку репозитория каждый раз, когда что-то замержили в неё. Не просто запускать локальные проверки, а в рамках CI-пайплайна выполнять автоматические тесты, unit-тесты и др.
**CD, (Continuous Delivery)** — непрерывная поставка. На этой стадии происходит автоматическое развертывание на стенды и тестовые окружения. Ещё CD расшифровывают как **Continuous Deployment**— непрерывное развёртывание. Это более продвинутый путь, на шаг дольше, чем непрерывная поставка. При таком подходе каждое изменение, которое мы коммитим в основную ветку репозитория, автоматически проходит все этапы CI и CD и затем попадает на продакшн.
Continuous Deployment Pipeline — высший пилотаж, который редко встречается на практике, потому что всегда есть определённые ограничения. Эти ограничения могут быть как в самом пайплайне, так и в бизнес-процессах с точки зрения безопасности. Но, однозначно, Continuous Deployment Pipeline — то, к чему нужно стремиться.
**Цели CI/CD**:
* обеспечение последовательного и автоматизированного способа сборки, упаковки и тестирования;
* автоматизация развёртывания в разных окружениях;
* сведение к минимуму ошибок и проблем.
Добиться этих целей помогают четыре принципа, на которых основана концепция CI/CD. Первый принцип — **разделение активности**. Каждый из участников процесса делит ответственность за жизненные циклы продукта. Проектируется бизнес-логика, выбираются сквозные функции, проводятся тесты, организуется доставка кода из одного окружения в другое.
Второй принцип — **снижение рисков**. Чтобы баги не доходили до продакшена, контролируется корректность бизнес-логики, проверяется пользовательский опыт на стендах, улучшается процесс хранения и обработки данных. Чем раньше мы обнаружим риск, тем быстрее идентифицируем проблему и тем меньше средств потратим на её решение.
Третий принцип — **сокращение цикла обратной связи**. В рамках CI/CD мы стремимся увеличить скорость внесения изменений и согласования правок.
Четвертый принцип — **реализация среды**. У разработчиков должно быть общее пространство для работы с основной веткой или со вспомогательными ветками. Это пространство должно быть отказоустойчивым и удобным для работы.
Основные этапы CI/CD выглядят так:
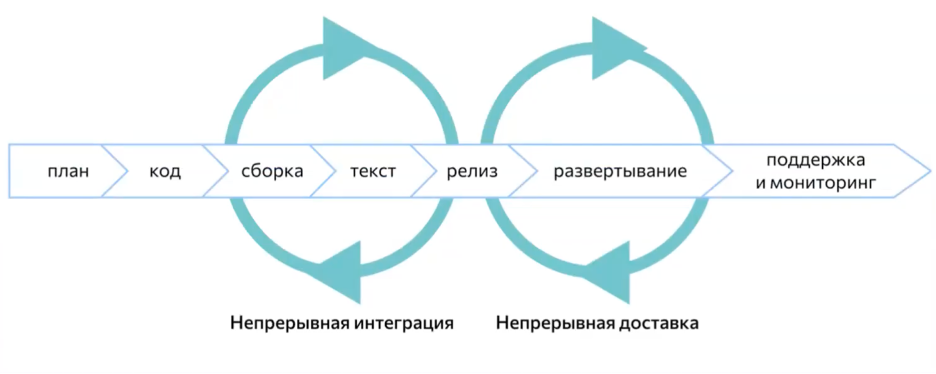Планирование основывается на пользовательском опыте и бизнес-функционале. Обычно за этот этап отвечают люди из анализа: они переводят требования с языка бизнеса на язык, понятный разработчикам и администраторам. Затем начинается этап работы с кодом — разработчики пишут код, проводят тестирования в ручном режиме и добавляют изменения в основную ветку репозитория.
После того, как изменения попадают в репозиторий, система контроля версии инициирует сборку и тестирование проекта. Тестирование может быть как ручным, так и автоматическим — зависит от того, как работает команда. Далее всё уходит сначала на релиз, а затем на развёртывание. На этапе развёртывания уже протестированная версия приложения отправляется на продакшн и становится доступна пользователям.
Когда продукт попадает к пользователям, мы продолжаем следить за ним — этап поддержки и мониторинга. Мы контролируем, как пользователь идёт по бизнес-процессу, корректно ли работают интеграции. Если на стадии мониторинга мы обнаруживаем ошибку, возвращаемся к самому началу — к планированию. Аналитики разбирают, что пошло не так и предлагают новое решение, разработчики пишут код, и снова начинается процесс сборки.
Как и у любой методологии, у CI/CD есть свои плюсы и минусы:
| | |
| --- | --- |
| **Плюсы** | **Минусы** |
| Минимальное время от запроса клиента до запуска в использование — мы быстрее доставляем новые фичи | Сложность обеспечения взаимодействия — и DevOps-инженеры, и разработчики должны понимать, что было сделано и зачем |
| Возможность проверки вариантов — можем моментально проверять изменения и при необходимости откатывать назад | Требования к опыту — нужен опыт настройки CI/CD, который почти всегда добывается с болью |
| Качество результата — можем быстро обнаружить и пофиксить ошибки | |
Реализовать принципы CI/CD, свести к минимуму ошибки интеграции, а также ускорить релизы и повысить их качество помогает Jenkins.
### Что такое Jenkins
Jenkins – не просто инструмент CI/CD. Это Framework, потому что он:
* **Гибок и расширяем**. Jenkins — опенсорсный проект с множеством внешних расширений.
* **Минимален из коробки**. У Jenkins есть контроллер. Вы можете подключить к нему несколько слоев и уже на этом сетапе собрать минимальный пайплайн, который позволит автоматизировать работу по обновлению сервисов.
* **Требует настройки**. Jenkins — один из кубиков, с помощью которого можно построить большую систему автоматизации. Но прежде чем сделать что-то, его придётся настроить.
Jenkins — это Java-приложение. У него есть контроллер или Master Mode — управляющий центр, который занимается планированием задач. Он запускает задачи согласно установленному расписанию на слэйвах, которые вы к нему прикрепили. Помимо этого контроллер хранит логи наших задач. Вся история хранится только на Master Mode, поэтому важно помнить о настройке правильной ротации логов.
Слэйвы или агенты — это то, что непосредственно выполняет сами задания.
Коротко их взаимодействие можно описать так: контроллер запускает задачу и говорит агенту выполнить её, агент выполняет задачу и возвращает результат контроллеру. Контроллер получает результат и сохраняет его в build-логе.
### Установка Jenkins
Разберём, как установить Jenkins, как настроить параметры JVM и почему это важно. Дополнительно познакомимся с Jenkins Home: что это за зверь и с чем его едят. Все действия будем выполнять на Ubuntu.
Перед установкой Jenkins нужно установить Java — без этого никак. Мы проверяем, есть ли на нашем виртуальном энвайронменте Java:
```
root@vs01:~# java --version
```
По умолчанию из коробки Java нет:
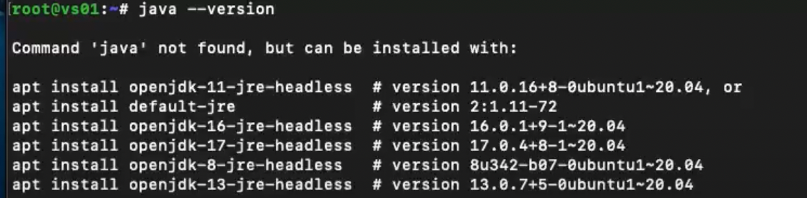Рекомендуется использовать Java 11, потому что у неё более продвинутый Garbage Collector. Поставим её:
```
root@vs01:~# apt install openjdk-11-jre-headless
```
Проверим, что Java установилась:
```
root@vs01:~# java --version
```
Теперь нужно сконфигурировать файл limit.com. Но в Linux всё — файл, поэтому нужно установить фан-лимит, чтобы снять ограничения и позволить Jenkins генерировать файлы, дампы и др. Если не сделать этого, в каких-то случаях мы не сможем получить данные и понять, что же с Jenkins пошло не так.
Редактируем лимиты на Ubuntu:
```
root@vs01:~# vi/etс/security/limits.conf
```
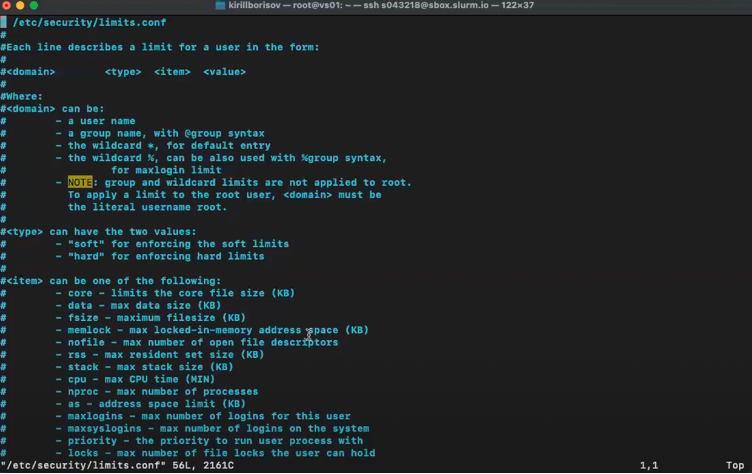И добавляем секцию управления и устанавливаем права на различные лимиты: хардовые, софтовые, size-файлы и др:
Дальше нужно установить фаервол на Ubuntu:
```
root@vs01:~# apt-get install ufw
```
Обязательно разрешаем OpenSSH-порт, потому что больше не сможем подключиться к этой машине:
```
root@vs01:~# ufw allow OpenSSH
```
8080 — порт, по которому работает Jenkins.
```
root@vs01:~# ufw allow 8080
```
Проверяем Jenkins репозиторий, потому что по умолчанию его нет в стоке Ubuntu:
```
root@vs01:~# wget -q -o – http://pkg.jenkins.io/Debian-stable/jenjins.io.key|sudo gpg --dearmor -o /usr/share/keyrings/Jenkins.gpg
```
После того, как скопировали ключи, устанавливаем Jenkins в sources list:
Важно для Ubuntu делать apt-get update:
```
root@vs01:~# apt-get update -y
```
Теперь можем поставить Jenkins:
```
root@vs01:~# apt-get install Jenkins -y
```
Установка проходит довольно быстро. Если посмотреть верхнеуровнево, то Jenkins — это war-файл. И вы можете не устанавливать его в систему через system, а просто скачать war-файл и запускать через war.
Мы можем посмотреть статус Jenkins App:
```
root@vs01:~# systemctl status jenkins
```
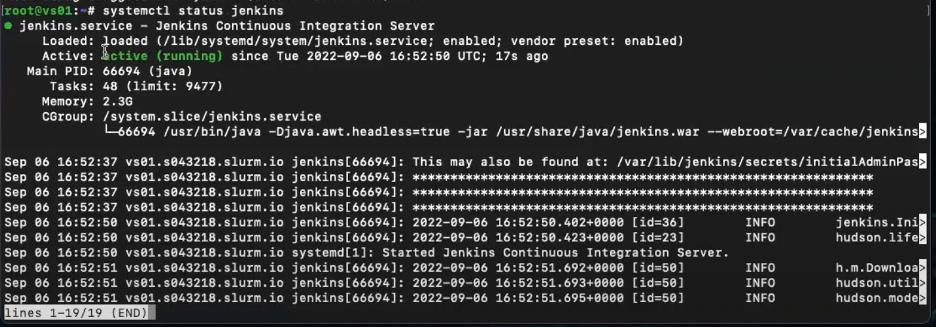Он активный, но нам этого недостаточно. Jenkins — это Java, а Java очень требовательно относится к памяти. Поэтому дальше поговорим про Garbage Collector — службу, которая очищает память от неиспользованных объектов.
Мы немного «подтюним» Java-машину и добавим опции в файл etc systemd/system/jenkins.service:
```
root@vs01:~# vi /lib/systemd/system/Jenkins.service
```
Найдём Java OPTS:
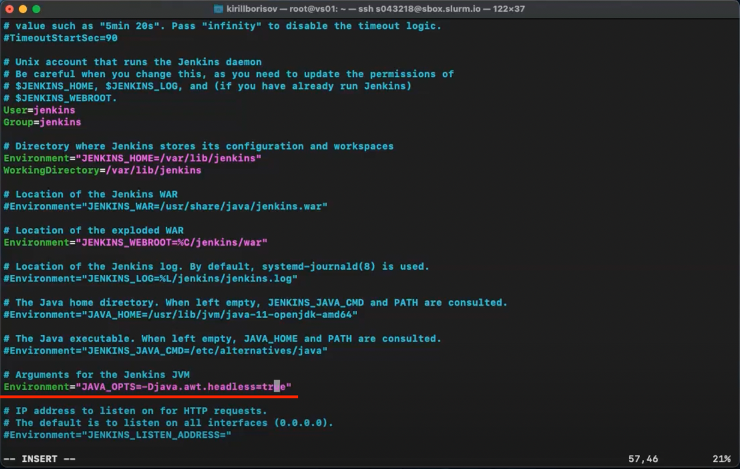Добавим больше опций:
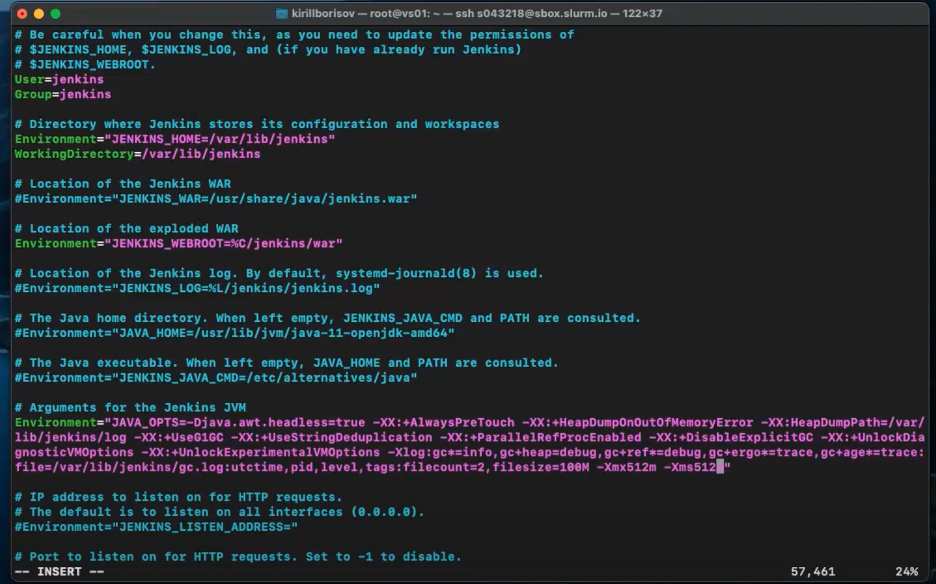Обратите внимание, что в настройках мы указываем Xmx512m и Xms512 — размер оперативной памяти, который выделяем Java-машине для работы. Вообще размер зависит от количества доступной памяти в операционной системе и корректируется в соответствии с ней. По рекомендациям Cloud Business и личному опыту, нужно ставить не больше 16 гигабайт на hip size. Но при этом важно не забывать, что у вас есть Meta Space и система, которые тоже занимают память. Если у вас на машине 20 гигабайт памяти, смело можно ставить 16. Если у вас всего 18 гигабайт памяти, и вы выделяете 16 гигабайт под Jenkins и Java, не удивляйтесь, когда машина начнёт работать плохо, а в какой-то момент просто умрёт.
Здесь выставляем Garbage Collector — UseG1GC:
И добавляем снятие автоматического дампа при out of memory:
Это полезная опция, когда Jenkins падает. Конечно, падения все равно будут случаться — мы не всегда можем рассчитать нагрузку и определить, сколько потребуется памяти для работы. Но параметр поможет понять, что произошло.
Также в Garbage Collector выставляем лог — /var/lib/jenkins/gc.log:
Сохраняем.
Нужно перезагрузить Jenkins, но перед этим сделать daemon-reload:
```
root@vs01:~# systemctl daemon-reload
root@vs01:~# systemctl restart Jenkins
```
Проверим:
```
root@vs01:~# systemctl status Jenkins
```
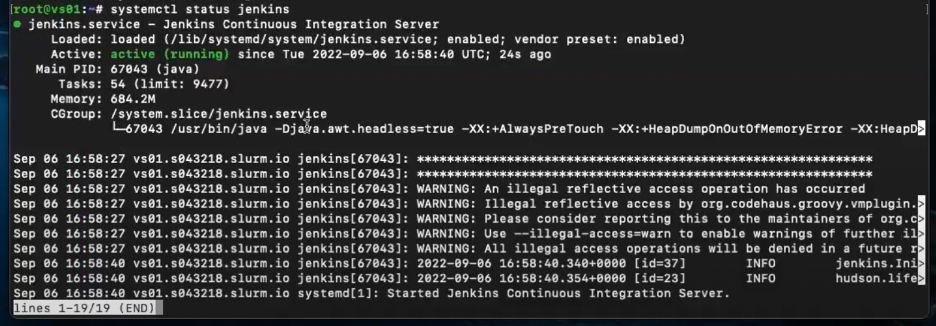
```
oot@vs01:~# cat /proc/http://Jenkins.s043218.edu.slurm.io^C
root@vs01:~# cat /proc/67043/cmdline
```
Видим, что Java настроена как раз под те опции, что мы ей передали, и запускается Jenkins war:
Теперь откроем веб-интерфейс [http://jenkins.s043218.edu.slurm.io](http://jenkins.s043218.edu.slurm.io/). Он предлагает разблокировать Jenkins:
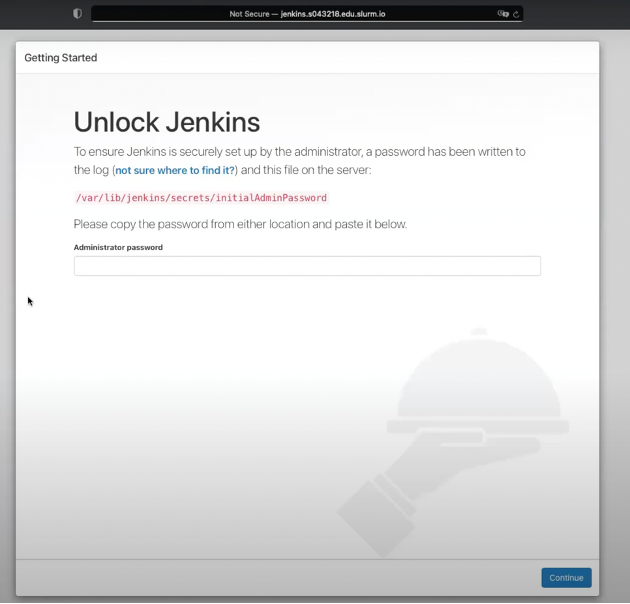То есть первоначальная установка предполагает, что вы введете некий мастер-пароль. Jenkins сам подсказывает, где этот мастер-пароль можно найти — var/lib/jenkins/secret/initialAdminPassword. Давайте пойдём туда и посмотрим:
```
root@vs01:~# cd var/lib/jenkins/
```
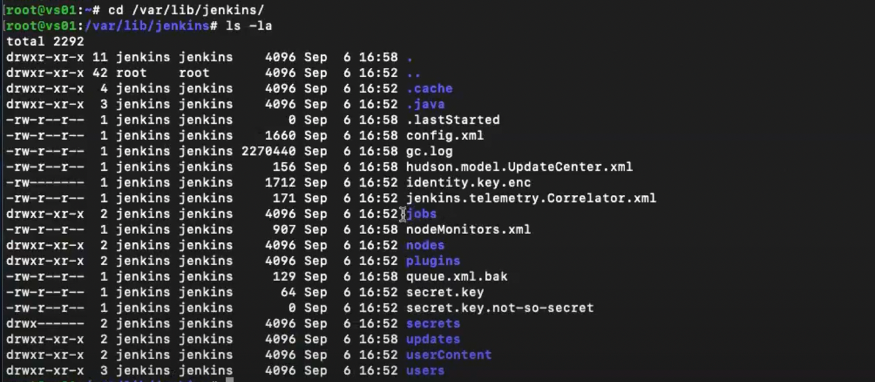
```
root@vs01:/var/lib/jenkins/# cd secrets/
root@vs01:/var/lib/jenkins/secrets# ls -al
```
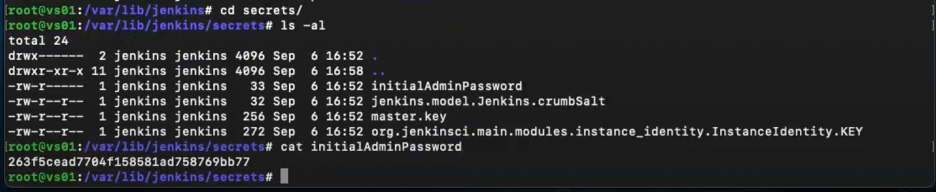Initial password — пароль, который вы можете использовать один раз при первой установке Jenkins. После вы переключитесь на внутреннюю базу авторизации.
Следующий шаг — установить Suggested-плагины или самостоятельно выбрать плагины, которые хотите поставить.
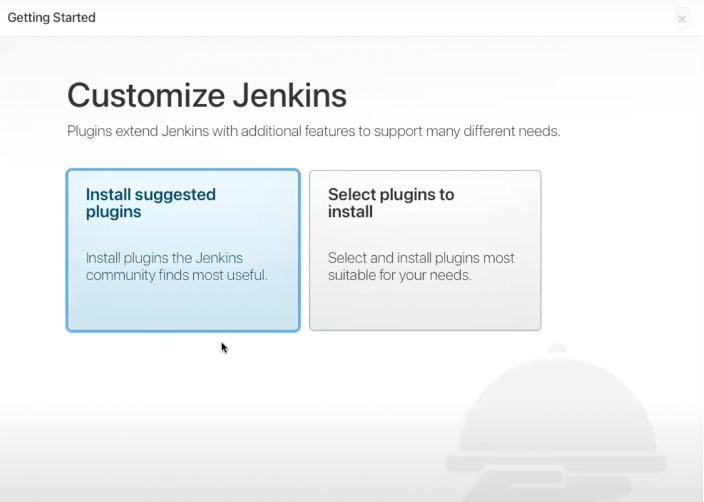Список плагинов, которые используются в Suggested, достаточно правильный, поэтому рекомендуется просто поставить эти плагины автоматом.
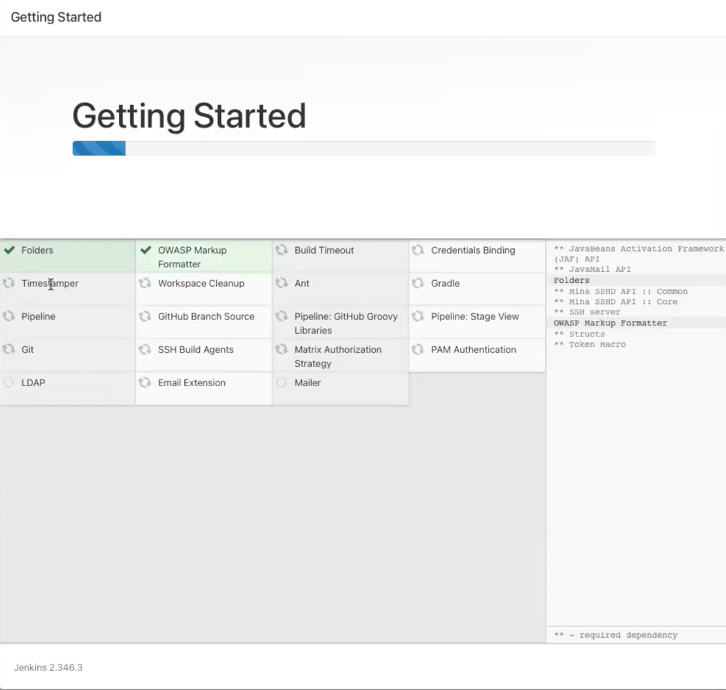А пока Jenkins делает плагины, посмотрим на Home-директорию:
```
root@vs01:/var/lib/jenkins/secrets# cd ..
root@vs01:/var/lib/jenkins# ls -la
```
У Jenkins нет выделенной базы, как у некоторых систем. В качестве базы данных он использует директорию Jenkins Home, которая есть в каталоге файловой системы того сервера, на который выставили контролер. Здесь хранятся: конфиги, плагины, задания, которые мы делаем и всё, что связано с ними и т.д.
Вернёмся к Jenkins — он уже поставил домен и предлагает нам настроить первого пользователя. Заполним поля:
Далее Jenkins предлагает настроить URL:
Этот параметр достаточно важный, потому что его параметр будут использовать различные слэйвы для автоматического коннекта к мастеру.
Итак, мы поставили Jenkins. Пока нет никаких заданий, но мы можем немного пройтись по Manage Jenkins:
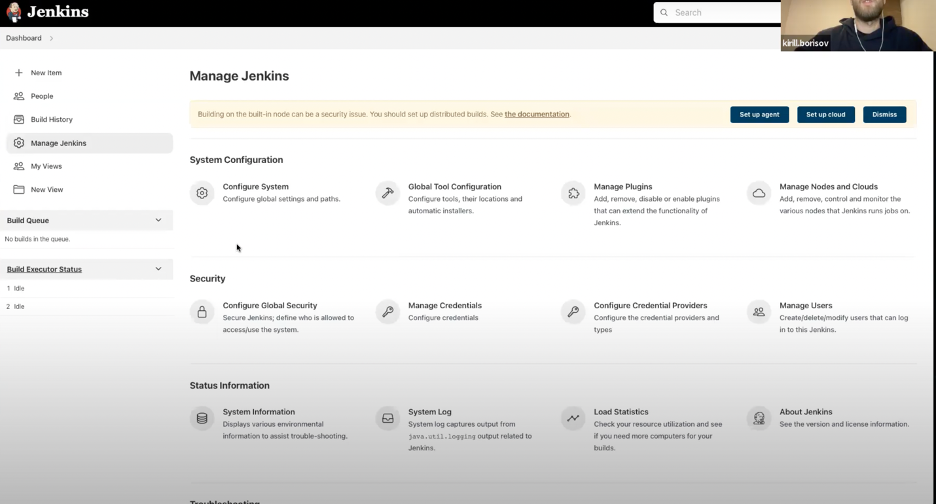Из наиболее интересного здесь:
* System information — хранит всю основную информацию (Java Home, версия Java, версия Ubuntu и т.д.).
* System log — то, куда нужно смотреть, если непонятно, почему не подключается агент или не работает скрип.
* Load statistics — показывает, сколько экзекьюторов всего онлайн.
На этом всё. В рамках первого урока мы повторили цели CI/CD, узнали, что такое Jenkins и рассмотрели область его применения. Ещё попробовали самостоятельно установить Jenkins на Ubuntu-сервер и познакомились с содержимым Jenkins Home. В следующих уроках подробно разберём администрирование Jenkins, научимся настраивать интеграции, создавать конфигурации Jenkins As a Code и многое другое.
|
https://habr.com/ru/post/691876/
| null |
ru
| null |
# IE8b1 — проверка поддержки generated content
Вот результаты проверки поддержки CSS2.1 generated content в IE8b1:
1. если выставить генерируемому содержимому position: relative, у IE8b1 виснет текущий таб (отображается предложение запустить отладку в Visual Studio). Благодаря нововведению в IE8, гарантирующему перезапуск повисшего таба, он запускается заново, снова виснет и снова запускается заново. Бесконечный цикл.
пример кода:
`p:before {content: "test"; position: relative;}`
[testcase](http://sharovatov.ru/testcases/genPosition.html)
p.s. будьте аккуратны с testcase — он реально «вешает» IE8b1.
Если на странице нет хотя бы одного из элементов IMG/OBJECT/IFRAME или не установлена картинка в css-свойстве background-image, то IE8b1 создаёт генерируемое содержимое **после** window.onload!
примеры:
1. [Перечисленных элементов нет](http://sharovatov.ru/testcases/textOnly.html), генерируемое содержимое **не создаётся браузером** до тех пор, пока не нажата кнопка ОК, то есть **после** window.onload
2. Генерируемое содержимое создаётся так, как должно быть — до window.onload в случаях, если:
[у элемента в CSS фоном задана картинка](http://sharovatov.ru/testcases/withCssBg.html), на странице есть элемент [IMG](http://sharovatov.ru/testcases/withImage.html),
[OBJECT](http://sharovatov.ru/testcases/withObject.html) или [IFRAME](http://sharovatov.ru/testcases/withIframe.html)
IE8b1 отображает null вместо значения атрибута class при использовании следующего кода:
`p { content: attr(class); }`
для элемента p, у которого задано значение атрибута class.
Однако если записать правило следующим образом:
`p { content: attr(className); }`
Ie8b1 корректно отобразит значение атрибута class.
[Пример](http://sharovatov.ru/testcases/classNameBug.html)
Я, конечно, могу только догадываться, но эти три бага наводят меня на мысль, что generated content в IE8b1 генерируется javascript'ом, скрытым от пользователя и выполняющимся по определённому событию. Во-первых, предложение отладки в случае зависания от css-правила; во-вторых, то, что generated content создаётся **после** window.onload при отсутствии внешних ресурсов (каким бы то ни было образом обозначенных в коде); в-третьих, то, что значение атрибута class считывается только с помощью его DOM-имени.
Определённо в IE8b1 есть какое-то событие, по которому код поддержки generated content запускается. Мне это показалось из-за бага #2 — ведь в случае, когда страница не ссылается на внешние данные, мы увидели создание генерируемого содержимого **после** window.onload, когда же внешние данные есть, генерируемое содержимое успевает создаться **до** того, как window.onload успевает запуститься.
Вот как было бы хорошо, если бы нам дали это событие в жаваскрипте, чтобы не приходилось для IE огород городить. Получилось бы полноценное DomContentLoaded :)
|
https://habr.com/ru/post/23147/
| null |
ru
| null |
# Пять шагов к спасению Linux-сервера, который рухнул
Мне доводилось видеть множество Linux-серверов, которые, без единой перезагрузки, работали годами, в режиме 24x7. Но ни один компьютер не застрахован от неожиданностей, к которым могут вести «железные», программные и сетевые сбои. Даже самый надёжный сервер может однажды отказать. Что делать? Сегодня вы узнаете о том, что стоит предпринять в первую очередь для того, чтобы выяснить причину проблемы и вернуть машину в строй.
[](https://habrahabr.ru/company/ruvds/blog/330350/)
И, кстати, в самом начале, сразу после сбоя, стоит ответить на весьма важный вопрос: «А сервер ли виноват в том, что случилось?». Вполне возможно, что источник проблемы совсем не в нём. Но, не будем забегать вперёд.
Поиск и устранение неполадок: раньше и теперь
---------------------------------------------
Когда, в 1980-х, я начал работать системным администратором Unix — задолго до того, как Линус Торвальдс загорелся идеей Linux — если с сервером было что-то не так, это была реальная засада. Тогда было сравнительно мало инструментов для поиска проблем, поэтому для того, чтобы сбойный сервер снова заработал, могло понадобиться много времени.
Теперь всё совсем не так, как раньше. Как-то один системный администратор вполне серьёзно сказал мне, говоря о проблемном сервере: «Я его уничтожил и поднял новый».
В былые времена такое звучало бы дико, но сегодня, когда ИТ-инфраструктуры строят на основе виртуальных машин и контейнеров… В конце концов, развёртывание новых серверов по мере необходимости — это обычное дело в любой облачной среде.
Сюда надо добавить инструменты [DevOps](https://insights.hpe.com/articles/why-cloud-makes-agile-and-devops-more-important-1701.html), такие, как [Chef](https://insights.hpe.com/articles/what-is-chef-a-primer-for-devops-newbies-1704.html) и [Puppet](https://insights.hpe.com/articles/what-is-puppet-and-why-should-you-consider-it-for-your-cloud-and-servers-1705.html), используя которые [легче создать новый сервер](http://cloudscaling.com/blog/cloud-computing/the-history-of-pets-vs-cattle/), чем диагностировать и «чинить» старый. А если говорить о таких [высокоуровневых средствах](https://insights.hpe.com/articles/the-basics-explaining-kubernetes-mesosphere-and-docker-swarm-1702.html), как Docker Swarm, Mesosphere и Kubernetes, то благодаря им работоспособность отказавшего сервера будет автоматически восстановлена до того, как администратор узнает о проблеме.
Данная концепция стала настолько распространённой, что ей дали название — [бессерверные вычисления](https://techbeacon.com/aws-lambda-serverless-apps-5-things-you-need-know-about-serverless-computing). Среди платформ, которые предоставляют подобные возможности — [AWS Lambda](http://aws.amazon.com/lambda/), [Iron.io](https://www.iron.io/platform/), [Google Cloud Functions](https://cloud.google.com/functions/docs/).
Благодаря такому подходу облачный сервис отвечает за администрирование серверов, решает вопросы масштабирования и массу других задач для того, чтобы предоставить клиенту вычислительные мощности, необходимые для запуска его приложений.
Бессерверные вычисления, виртуальные машины, контейнеры — все эти уровни абстракции скрывают реальные серверы от пользователей, и, в некоторой степени, от системных администраторов. Однако, в основе всего этого — физическое аппаратное обеспечение и операционные системы. И, если что-то на данном уровне вдруг разладится, кто-то должен привести всё в порядок. Именно поэтому то, о чём мы сегодня говорим, никогда не потеряет актуальности.
Помню разговор с одним системным оператором. Вот что он говорил о том, как надо поступать после сбоя: «Переустановка сервера — это путь вникуда. Так не понять — что стало с машиной, и как не допустить такого в будущем. Ни один сносный администратор так не поступает». Я с этим согласен. До тех пор, пока не обнаружен первоисточник проблемы, её нельзя считать решённой.
Итак, перед нами сервер, который дал сбой, или мы, по крайней мере, подозреваем, что источник неприятностей именно в нём. Предлагаю вместе пройти пять шагов, с которых стоит начинать поиск и решение проблем.
Шаг первый. Проверка аппаратного обеспечения
--------------------------------------------
В первую очередь — проверьте железо. Я знаю, что звучит это тривиально и несовременно, но, всё равно — сделайте это. Встаньте с кресла, подойдите к серверной стойке и удостоверьтесь в том, что сервер правильно подключён ко всему, необходимому для его нормальной работы.
Я и сосчитать не смогу, сколько раз поиски причины проблемы приводили к кабельным соединениям. Один взгляд на светодиоды — и становится ясно, что Ethernet-кабель выдернут, или питание сервера отключено.
Конечно, если всё выглядит более-менее прилично, можно обойтись без визита к серверу и проверить состояние Ethernet-соединения такой командой:
```
$ sudo ethtool eth0
```
Если её ответ можно трактовать, как «да», это значит, что исследуемый интерфейс способен обмениваться данными по сети.
Однако, не пренебрегайте возможностью лично осмотреть устройство. Это поможет, например, узнать, что кто-то выдернул какой-нибудь важный кабель и обесточил таким образом сервер или всю стойку. Да, это до смешного просто, но удивительно — как часто причина отказа системы именно в этом.
Ещё одну распространённую аппаратную проблему невооружённым взглядом не распознать. Так, сбойная память является причиной всевозможных проблем.
Виртуальные машины и контейнеры могут скрывать эти проблемы, но если вы столкнулись с закономерным появлением отказов, связанных с конкретным [физическим выделенным сервером](http://www.internap.com/2015/02/26/bare-metal-vs-hypervisor/), проверьте его память.
Для того, чтобы увидеть, что BIOS/UEFI сообщают об аппаратном обеспечении компьютера, включая память, используйте команду [dmidecode](https://www.howtoforge.com/dmidecode-finding-out-hardware-details-without-opening-the-computer-case):
```
$ sudo dmidecode --type memory
```
Даже если всё тут выглядит нормально, на самом деле это может быть и не так. Дело в том, что данные SMBIOS не всегда точны. Поэтому, если после `dmidecode` память всё ещё остаётся под подозрением — пришло время воспользоваться [Memtest86](http://www.memtest.org/). Это отличная программа для проверки памяти, но работает она медленно. Если вы запустите её на сервере, не рассчитывайте на возможность использовать эту машину для чего-нибудь другого до завершения проверки.
Если вы сталкиваетесь со множеством проблем с памятью — я видел такое в местах, отличающихся нестабильным электропитанием — нужно загрузить модуль ядра Linux [edac\_core](http://buttersideup.com/edacwiki/Main_Page). Этот модуль постоянно проверяет память в поиске [сбойных участков](http://fibrevillage.com/sysadmin/240-how-to-identify-defective-dimm-from-edac-error-on-linux-2). Для того, чтобы загрузить этот модуль, воспользуйтесь такой командой:
```
$ sudo modprobe edac_core
```
Подождите какое-то время и посмотрите, удастся ли что-нибудь увидеть, выполнив такую команду:
```
$ sudo grep "[0-9]" /sys/devices/system/edac/mc/mc*/csrow*/ch*_ce_count
```
Эта команда даст вам сводку о числе ошибок, разбитых по модулям памяти (показатели, название которых начинается с `csrow`). Эти сведения, если сопоставить их с с данными `dmidecode` о каналах памяти, слотах и заводских номерах компонентов, помогут выявить сбойную планку памяти.
Шаг второй. Поиск истинного источника проблемы
----------------------------------------------
Итак, сервер стал странно себя вести, но дым из него ещё пока не идёт. В сервере ли дело? Прежде чем вы попытаетесь решить возникшую проблему, сначала нужно точно определить её источник. Скажем, если пользователи жалуются на странности с серверным приложением, сначала проверьте, что причина проблемы — не в сбоях на клиенте.
Например, друг однажды рассказал мне, как его пользователи сообщили о том, что не могут работать с IBM Tivoli Storage Manager. Сначала, конечно, казалось, что виновен во всём сервер. Но в итоге администратор выяснил, что проблема вообще не была связана с серверной частью. Причиной был неудачный патч Windows-клиента [3076895](https://support.microsoft.com/en-us/help/3092627/september-2015-update-to-fix-windows-or-application-freezes-after-you-install-security-update-3076895). Но то, как сбоило это обновление безопасности, делало происходящее похожим на проблему серверной стороны.
Кроме того, нужно понять, является ли причиной проблемы сам сервер, или серверное приложение. Например, серверная программа может работать кое как, а железо оказывается в полном порядке.
Для начала — самое очевидное. Работает ли приложение? Есть множество способов проверить это. Вот два моих любимых:
```
$ sudo ps -ef | grep apache2
$ sudo netstat -plunt | grep apache2
```
Если оказалось, что, например, веб-сервер Apache не работает, запустить его можно такой командой:
```
$ sudo service apache2 start
```
Если в двух словах, то прежде чем диагностировать сервер и искать причину проблему, узнайте — сервер ли виноват, или что-то другое. Только тогда, когда вы поймёте, где именно находится источник сбоя, вы сможете задавать правильные вопросы и переходить к дальнейшему анализу того, что произошло.
Это можно сравнить с неожиданной остановкой автомобиля. Вы знаете, что машина дальше не едет, но, прежде чем тащить её в сервис, хорошо бы проверить, есть ли бензин в баке.
Шаг третий. Использование команды top
-------------------------------------
Итак, если оказалось, что все пути ведут к серверу, то вот ещё один важный инструмент для проверки системы — команда `top`. Она позволяет узнать среднюю нагрузку на сервер, использование файла подкачки, выяснить, какие ресурсы системы используют процессы. Эта утилита показывает общие сведения о системе и выводит данные по всем выполняющимся процессам на Linux-сервере. [Вот](http://rus-linux.net/MyLDP/consol/komanda-top-v-linux.html) подробное описание данных, которые выводит эта команда. Тут можно найти массу информации, которая способна помочь в поиске проблем с сервером. Вот несколько полезных способов работы с `top`, позволяющих найти проблемные места.
Для того, чтобы обнаружить процесс, потребляющий больше всего памяти, список процессов надо отсортировать в интерактивном режиме, введя с клавиатуры `M`. Для того, чтобы выяснить приложение, потребляющее больше всего ресурсов процессора, отсортируйте список, введя `P`. Для сортировки процессов по времени активности, введите с клавиатуры `T`. Для того, чтобы лучше видеть колонку, по которой производится сортировка, нажмите клавишу `b`.
Кроме того, данные по процессам, выводимые командой в интерактивном режиме, можно отфильтровать, введя `O` или `o`. Появится следующее приглашение, где предлагается добавить фильтр:
```
add filter #1 (ignoring case) as: [!]FLD?VAL
```
Затем можно ввести шаблон, скажем, для фильтрации по конкретному процессу. Например, благодаря фильтру `COMMAND=apache`, программа будет выводить только сведения о процессах Apache.
Ещё одна полезная возможность `top` заключается в выводе полного пути процесса и аргументов запуска. Для того, чтобы просмотреть эти данные, воспользуйтесь клавишей `c`.
Ещё одна похожая возможность `top` активируется вводом символа `V`. Она позволяет переключиться в режим иерархического вывода сведений о процессах.
Кроме того, можно просматривать процессы конкретного пользователя с помощью клавиш `u` или `U`, или скрыть процессы, не потребляющих ресурсы процессора, нажав клавишу `i`.
Хотя `top` долго была самой популярной интерактивной утилитой Linux для просмотра текущей ситуации в системе, у неё есть и альтернативы. Например, существует программа [htop](http://hisham.hm/htop/) обладает расширенным набором возможностей, которая отличается более простым и удобным графическим интерфейсом [Ncurses](https://www.gnu.org/software/ncurses/). Работая с `htop`, можно пользоваться мышью и прокручивать список процессов по вертикали и по горизонтали для того, чтобы просмотреть их полный список и полные командные строки.
Я не жду, что `top` сообщит мне — в чём проблема. Скорее, я использую этот инструмент для того, чтобы найти нечто, что заставит подумать: «А это уже интересно», и вдохновит меня на дальнейшие исследования. Основываясь на данных от `top`, я знаю, например, на какие логи стоит взглянуть в первую очередь. Логи я просматриваю, используя комбинации команд `less`, `grep` и `tail -f`.
Шаг четвёртый. Проверка дискового пространства
----------------------------------------------
Даже сегодня, когда в кармане можно носить терабайты информации, на сервере, совершенно незаметно, может кончиться дисковое пространство. Когда такое происходит — можно увидеть весьма странные вещи.
Разобраться с дисковым пространством нам поможет старая добрая команда [df](http://www.linuxjournal.com/article/2747), имя которой является сокращением от «disk filesystem». С её помощью можно получить сводку по свободному и использованному месту на диске.
Обычно `df` используют двумя способами.
* ```
$ sudo df -h
```
показывает данные о жёстких дисках в удобном для восприятия виде. Например, сведения об объёме накопителя выводятся в гигабайтах, а не в виде точного количества байт.
* ```
$ sudo df -i
```
выводит число использованных [inodes](http://www.grymoire.com/Unix/Inodes.html) и их процент к файловой системе.
Ещё один полезный флаг `df — T`. Он позволяет вывести данные о типах файловых систем хранилищ. Например, команда вида `$ sudo df -hT` показывает и объём занятого пространства диска, и данные о его файловой системе.
Если что-то кажется вам странным, можно копнуть глубже, воспользовавшись командой [Iostat](https://linux.die.net/man/1/iostat). Она является частью [sysstat](http://sebastien.godard.pagesperso-orange.fr/) — продвинутого набора инструментов для мониторинга системы. Она выводит сведения о процессоре, а также данные о подсистеме ввода-вывода для блочных устройств хранения данных, для разделов и сетевых файловых систем.
Вероятно, самый полезный способ вызова этой команды выглядит так:
```
$ iostat -xz 1
```
Такая команда выводит сведения об объёме прочитанных и записанных данных для устройства. Кроме того, она покажет среднее время операций ввода-вывода в миллисекундах. Чем больше это значение — тем вероятнее то, что накопитель перегружен запросами, или перед нами — аппаратная проблема. Что именно? Тут можно воспользоваться утилитой `top` для того, чтобы выяснить, нагружает ли сервер MySQL (или какая-нибудь ещё работающая на нём СУБД). Если подобных приложений найти не удалось, значит есть вероятность, что с диском что-то не так.
Ещё один важный показатель можно найти в разделе `%util`, где выводятся сведения об использовании устройства. Этот показатель указывает на то, как напряжённо работает устройство. Значения, превышающие 60% указывают на низкую производительность дисковой подсистемы. Если значение близко к 100%, это означает, что диск работает на пределе возможностей.
Работая с утилитами для проверки дисков, обращайте внимание, что именно вы анализируете.
Например, нагрузка в 100% на логический диск, который представляет собой несколько физических дисков, может означать лишь то, что система постоянно обрабатывает какие-то операции ввода-вывода. Значение имеет то, что именно происходит на физических дисках. Поэтому, если вы анализируете логический диск, помните, что дисковые утилиты не дадут полезной информации.
Шаг пятый. Проверка логов
-------------------------
Последнее в нашем списке, но лишь по порядку, а не по важности — проверка логов. Обычно их можно найти по адресу `/var/log`, в отдельных папках для различных сервисов.
Для новичков в Linux лог-файлы могут выглядеть как ужасная мешанина. Это — текстовые файлы, в которые записываются сведения о том, чем занимаются операционная система и приложения. Есть два вида записей. Одни записи — это то, что происходит в системе или в программе, например — каждая транзакция или перемещение данных. Вторые — сообщения об ошибках. В лог-файлах может содержаться и то, и другое. Эти файлы могут быть просто огромными.
Данные в файлах журналов обычно выглядят довольно таинственно, но вам всё равно придётся с ними разобраться. [Вот](https://www.digitalocean.com/community/tutorials/how-to-view-and-configure-linux-logs-on-ubuntu-and-centos), например, хорошее введение в эту тему от Digital Ocean.
Есть множество инструментов, которые помогут вам проверить логи. Например — [dmesg](http://www.linfo.org/dmesg.html). Эта утилита выводит сообщения ядра. Обычно их очень и очень много, поэтому используйте следующий простой сценарий командной строки для того, чтобы просмотреть 10 последних записей:
```
$ dmesg | tail
```
Хотите следить за происходящим в реальном времени? Мне, определённо, это нужно, когда я занимаюсь поиском проблем. Для того, чтобы этого добиться, используйте команду `tail` с ключом `-f`. Выглядит это так:
```
$ dmesg | tail -f /var/log/syslog
```
Вышеприведённая команда наблюдает за файлом `syslog`, и когда в него попадают сведения о новых событиях, выводит их на экран.
Вот ещё один удобный сценарий командной строки:
```
$ sudo find /var/log -type f -mtime -1 -exec tail -Fn0 {} +
```
Он сканирует логи и показывает возможные проблемы.
Если в вашей системе применяется [systemd](https://www.freedesktop.org/wiki/Software/systemd/) то, вам нужно будет использовать встроенное средство для работы с журналами — [Journalctl](https://www.freedesktop.org/software/systemd/man/journalctl.html). Systemd централизует управление логированием с помощью демона `journald`. В отличие от других логов Linux, `journald` хранит данные в двоичном, а не в текстовом формате.
Бывает полезно настроить `journald` так, чтобы он сохранял логи после перезагрузки системы. Сделать это можно, воспользовавшись такой командой:
```
$ sudo mkdir -p /var/log/journal
```
Для включения постоянного хранения записей понадобится отредактировать файл `/etc/systemd/journald.conf`, включив в него следующее:
```
[Journal] Storage=persistent
```
Самый распространённый способ работать с этими журналами — такая команда:
```
journalctl -b
```
Она покажет все записи журналов после последней перезагрузки. Если система была перезагружена, посмотреть, что было до этого, можно с помощью такой команды:
```
$ journalctl -b -1
```
Это позволит просмотреть записи журналов, сделанные в предыдущую сессию сервера.
[Вот](https://www.digitalocean.com/community/tutorials/how-to-use-journalctl-to-view-and-manipulate-systemd-logs) полезный материал о том, как пользоваться `journalctl`.
Логи бывают очень большими, с ними сложно работать. Поэтому, хотя разобраться с ними можно с помощью средств командной строки, таких, как `grep`, `awk`, и других, полезно бывает задействовать специальные программы для просмотра логов.
Мне, например, нравится система для управления логами с открытым кодом [Graylog](https://www.graylog.org/). Она собирает, индексирует и анализирует самые разные сведения. В её основе лежат [MongoDB](https://www.mongodb.com/) для работы с данными и [Elasticsearch](https://www.elastic.co/) для поиска по лог-файлам. Graylog упрощает отслеживание состояния сервера. Graylog, если сравнить её со встроенными средствами Linux, проще и удобнее. Кроме того, среди её полезных возможностей можно отметить возможность работы с многими DevOps-системами, такими, как Chef, Puppet и [Ansible](https://www.ansible.com/).
Итоги
-----
Как бы вы ни относились к вашему серверу, возможно, он не попадёт в Книгу Рекордов Гиннеса как тот, который проработал дольше всех. Но стремление сделать сервер как можно более стабильным, добираясь до сути неполадок и исправляя их — достойная цель. Надеемся, то, о чём мы сегодня рассказали, поможет вам достичь этой цели.
Уважаемые читатели! А как вы обычно поступаете с упавшими серверами?
|
https://habr.com/ru/post/330350/
| null |
ru
| null |
# Buzme.buzmob.com — И снова фиды на мобильном
До сегодняшнего дня я читала свои фиды через googlereader (как, наверно, многие из Вас), но все кардинально изменилось в течении 60 секунд.
Встречайте
----------
Все до безобразия просто:
**Шаг 1.**
Заходим на сайт **[Buzme.buzmob.com](http://buzme.buzmob.com/)**.
**Шаг 2.**
Вводим урл сайта. *(я ввела habr.ru)*
Жмем GO.
**Шаг 3.**
С неописуемым удовольствием наблюдаем надпись «Mobilizing feed: **Хабрахабр: Главная / Захабренные**» и вводим свой номер мобильного. *(Система автоматически определила мое местоположение и вежливо предложила код +380 для Украины, на случай ошибки есть опция [Change Country], что значит «Изменить страну»)*
Жмем GO.
**Шаг 4.**
Немного подумав система выдает стандартный текст «О првилах использования» и вполне читабельную капчу. Вводим капчу и, Вы не поверите, но..., жмем GO.
**Шаг 5.** Практически мгновенно получаем на указанный номер SMS с ссылкой на мобильную версию рабочего кабинета и passkey`ем.
**Шаг 6.** Если позволяет телефон, прямо из SMS попадаем в мобильный браузер по умолчанию и читаем.
Как добавлять другие фиды?
--------------------------
Очень просто:
**Шаг 1.**
Снова заходим на сайт **[Buzme.buzmob.com](http://buzme.buzmob.com/)**.
**Шаг 2.**
Снова вводим номер мобильного. (В моем случае он запомнил мой номер, хотя, не спорю, для некоторых это минус.)
Жмем GO.
**Шаг 3.**
Вводим passkey — это три символа (в моем случае три, может и больше бывает), полученные из SMS. В тексте ищем «Your passkey is \*\*\*» — звездочки — это то что нам нужно.
Что внутри?
-----------
1 — 9 Фиды
0 — Параметры.
В Параметрах:
1 — Удалить фиды
2 — Выбор стартовой
0 — Возврат в личный кабинет.
Как выглядит моя ссылка?
------------------------
Так в словах:
`m.buzmob.com/международныйкодбезплюсаномертелефонаpasskey`
А вот так в цифрах:
*`m.buzmob.com/380`\*\*\*\*\*\*\*\*bla*
Я могу так мобилизировать свой ресурс?
--------------------------------------
Да, тут 2 пути:
**Правильный, но не лучший:**
Идем сюда: [Buzmob.com](http://buzmob.com/), и следуем иструкциям, в результате получаем HTML код такого типа:
``
Минус — спаливаем e-mail.
**Неправильный, но лучший (это мое скромное мнение):**
Ссылка на Хабраподписку выглядит так:
`buzme.buzmob.com/?p_feed=http://habrahabr.ru/rss/main/`
После знака "=" вводим урл и все.
Кнопка выглядит (по умолчанию) вот так:
[](http://www.buzmob.com/buzme.php?p_key=c98dd08256f6c6379d2e9d1a44736b67)
Угрюмо как то..., лично я перешла по вот такой кнопочке:

На последок скажу что все бесплатно, поддержка всех и вся RRS, ATOM присутствует, графика «web 0.5», но функционал и юзабилити на высоте.
Вот такой получился обзорчик, спасибо за внимание.
P.S. Интернетные штучки — спасибо за вдохновение, старалсь быть близкой Вашему стилю.
|
https://habr.com/ru/post/24993/
| null |
ru
| null |
# Трансляция рынка — нужны идеи
Мы давно присматриваемся к Китаю
Почему?
По нескольким причинам. Во-первых, это мировой центр производства всего и вся: в частности электроники и коммутации. Во-вторых, цена любой вещи произведенной там является обычно реальной ценой без наценки кучи посредников и таможен, без учета перевозки и складского хранения на многих перегрузочных пунктах. Ну и наконец, если что-то не нравится, можно спокойно попросить сделать по-другому, так как это решается одним звонком на завод.
Китайцы даже, когда спрашивают, где ты работаешь, обычно прямо сразу спрашивают именно про производство — «Что ты производишь?»
Чувствуете разницу с нашей страной?

`Район Hua Qiang Bei. Гигантский рынок электроники. Изображение из wiki-статьи.`
Перейдём к сути.
##### Что имеется?
1. Свой человек в Шеньчжене
2. Доставка 2-3 дня до Москвы на свой склад
##### Что хочется сделать?
Организовать понятный формат трансляции информации с рынка сюда с возможностью заказать любую вещь оттуда за минимально возможные сроки и деньги.
##### Вопрос
Как это грамотно и удобно реализовать?
##### Попытка ответа
Самое простое, что приходит в голову — фотографии. Фотографируешь витрины и прилавки, продукцию, все подряд. Составляешь примерное каткое описание. Выкладываешь все на фотохостинг.
Дальше предоставляешь возможность, указав фотографию сделать запрос по любым вещам. Выставляешь цену и срок.
Фактически, получается некий вариант прямого интернет-рынка.
Минусы понятны: большое количество ручной работы и неудобство пользования. Если на рынке ты можешь взять эту вещь и потрогать (хотя и тут могут не разрешить открыть посмотреть), то тут ты видишь лишь фотографию.
###### Идея!
Сразу возникает идея.
Первому заказавшему вещь привозится по себестоимости. При этом человек пишет обзор по характеристикам и оправданности своих ожиданий. Выставляет какие-то оценки.
Обзор выкладывается в какую-то базу на сайте. Человек впоследствие получает скидки и бонус за свой вклад в проект.
###### Идем дальше
Если посмотреть на это с идеальной точки зрения, то мы увидим… Dealextreme.com!
Там сделали практически тоже самое, но в формате интернет-магазина. Находясь в Гонконге делать этодействительно удобно — покупают у них со всего мира.
Правда, тут доставка долгая — почта до 3х недель.
И точно нельзя подобрать все что угодно, как на рынке, где тебе сделают любую штуку.
##### Реализации
Для реализации нужно несколько вещей:
* Обсуждение идей в комментариях здесь
* Люди, готовые предложить свою ~~без~~возмездную помощь
Кто, что думает?
**UPD**
1. В личку посоветовали пару интересных сервисов по обзорам
[сервис 1](http://ru-sku.livejournal.com/)
[сервис 2](http://www.mysku.ru/)
2. Мы выложили каких-то фоток
[Галерея Flickr](http://www.flickr.com/photos/64416272@N05)
Тут очевидный закос под iPhone, так как был запрос под них недавно. Еще будут адаптеры для ноутов и конвертеры видео.
Завтра попросим пофотать всякого — пишите пожелания! (рынок работает с 5 утра по Москве до 14)
3. Пожелания по фоткам можно писать в личку, на мыло ([email protected]) или в твиттер ответом на последний твит (можно в личку опять же)
[twitter.com/shnurovik](http://twitter.com/shnurovik)
|
https://habr.com/ru/post/122721/
| null |
ru
| null |
# Дайджест интересных материалов из мира веб-разработки и IT за последнюю неделю №70 (11 — 17 августа 2013)
Предлагаем вашему вниманию очередную подборку с ссылками на новости, интересные материалы и полезные ресурсы.

### Горячая семерка
| | |
| --- | --- |
| | [Tessel](http://technical.io/) |
JavaScript уверенно продолжает своё шествие и [теперь настал черёд железа.](http://technical.io/) . Встречаем [Tessel – микроконтроллер, программируемый на JavaScript](http://habrahabr.ru/post/190146/)
| | |
| --- | --- |
| | [Зачем нам нужен HTML5](http://www.computerra.ru/78930/zachem-nam-nuzhen-html5-pyat-prostyih-otvetov/) |
Предлагаем вашему вниманию [обзорную статью](http://www.computerra.ru/78930/zachem-nam-nuzhen-html5-pyat-prostyih-otvetov/), где автор в пяти пунктах пытается рассказать об основных возможностях, которые предоставляет вебу HTML5. Кстати, адрес [www.w3.org/TR/html/](http://www.w3.org/TR/html/) с недавних пор ведет не на XHTML 1.0, как много лет до сих пор, а на HTML5.0
| | |
| --- | --- |
| | [Названия профессий в мире веб разработки](http://css-tricks.com/job-titles-in-the-web-industry/) |
В [этой статье](http://css-tricks.com/job-titles-in-the-web-industry/) автор попытался сопоставить названия веб-профессий с определенным набором навыков разработчика. В мире веб-разработки это довольно актуальный вопрос — обилие похожих айтлов в резюме и сервисах подбора вакансий часто смущает и не всегда отвечает действительности
| | |
| --- | --- |
| | [Абсолютное горизонтальное и вертикальное центрирование](http://habrahabr.ru/post/189696/) |
В то время, когда одни [собираются выпустить часы](http://4pda.ru/2013/08/15/111329/) с 41-мегапиксельной камерой, другие до сих пор изобретают методы центрирования блоков с помощью CSS. [Вот перевод](http://habrahabr.ru/post/189696/) занимательной статьи с самыми свежими техниками
| | |
| --- | --- |
| | Telegram Messenger |
[Telegram Messenger](http://www.cossa.ru/news/237/48075/) — первый проект американской компании Павла Дурова. Приложение является бесплатным и доступно для загрузки в App Store. Еще один небольшой обзор [плюс дайджест мобильных мессенджеров](http://keddr.com/2013/08/durov-pozvonil-telegram-daydzhest-mobilnyih-messendzherov/)
| | |
| --- | --- |
| | [CodePen Demos](http://davidwalsh.name/chris-coyiers-favorite-pens) |
Наверное, все успели оценить функциональность песочницы CodePen. Предлагаем вашему вниманию [подборку любимых демо Криса Койера](http://davidwalsh.name/chris-coyiers-favorite-pens), который и является создателем этого замечательного сервиса
| | |
| --- | --- |
| | Под капотом: [Просмотр улиц](https://www.google.com/maps/about/behind-the-scenes/streetview/) |
У Google появилась [информационная страничка](https://www.google.com/maps/about/behind-the-scenes/streetview/), где подробно рассказано о работе и создании Street View — сервисе, которым периодически пользуется наверное каждый из нас
### Веб-разработка
* [Название профессий в мире веб разработки](http://css-tricks.com/job-titles-in-the-web-industry/) 
* [Зачем нам нужен HTML5](http://www.computerra.ru/78930/zachem-nam-nuzhen-html5-pyat-prostyih-otvetov/): пять простых ответов
* [Чем тестировать адаптивный дизайн?](http://habrahabr.ru/post/189726/)
* [Использование Drag&Drop в HTML 5](http://habrahabr.ru/post/187582/)
* [Вопрос безопасности](http://frontender.info/security-affair/)
* [Проект Mozilla представил FuzzDB](http://www.opennet.ru/opennews/art.shtml?num=37683), базу данных типовых шаблонов атак
* [Игры с SVG и тегом](http://lynn.ru/examples/svg/)
* [Инструкция по созданию Jelly Navigation Menu](http://coding.smashingmagazine.com/2013/08/15/jelly-navigation-menu-canvas-paperjs/) 
* [Создание высокопроизводительных мобильных сайтов](http://mobile.smashingmagazine.com/2013/08/12/creating-high-performance-mobile-websites/) 
* [Создание многоуровнего Push Menu](http://tympanus.net/codrops/2013/08/13/multi-level-push-menu/)
* [Помощник-визард по использованию Github Pages](http://www.thinkful.com/learn/a-guide-to-using-github-pages/start/)
* [О код-редакторе Brackets от Adobe](http://speckyboy.com/2013/08/12/brackets-by-adobe-an-open-source-code-editor-in-the-making/)
* [Как дизайнить текстовые поля под тач клавиатуры (со шпаргалкой)](http://uxdesign.smashingmagazine.com/2013/08/13/guide-to-designing-touch-keyboards-with-cheat-sheet/)
* [Официальное руководство по WebKit-атрибуту srcset в тэге img](https://www.webkit.org/blog/2910/improved-support-for-high-resolution-displays-with-the-srcset-image-attribute/) 
### CSS
* [Переносы слов](http://htmlbook.ru/blog/perenosy-slov)
* [Абсолютное горизонтальное и вертикальное центрирование](http://habrahabr.ru/post/189696/)
* [Круговая навигация с помощью CSS Transforms](http://tympanus.net/codrops/2013/08/09/building-a-circular-navigation-with-css-transforms/) 
* [CSS 3D Image Flip Gallery c динамической тенью](http://demosthenes.info/blog/726/CSS-3D-Image-Flip-Gallery-With-Dynamic-Shadows) 
* [6 методов отключения CSS и подключения своих стилей в Chrome](http://www.youtube.com/watch?v=hftoly8QhEs) 
* [Использование CSS3 для плавного ресайза элементов](http://www.developerdrive.com/2013/08/using-css3-to-provide-smooth-resize-effects/) 
* [uCSS](https://github.com/operasoftware/ucss/) — поиск неиспользуемых и дуплирующихся CSS селекторов по сайту 
* [responsivewebcss](http://www.responsivewebcss.com/) — онлайн-сервис для генерации стилей под адаптивные шаблоны 
* [Скринкаст о том, как использовать Effeckt.css](https://www.youtube.com/watch?v=LgtGNK25UWA) 
* [Начинаем работать с Sass Preprocessor](http://line25.com/tutorials/getting-started-with-the-sass-compass-frameworks) 
* [MetaFizzy Effect with Sass](http://css-tricks.com/metafizzy-effect-with-sass/) 
* [Как создать простую и стильную таблицу цен на CSS](http://desizntech.info/2013/08/pricing-table-using-css/) 
* [CSS Shapes и Float Positioning](http://blogs.adobe.com/webplatform/2013/08/12/css-shapes-and-float-positioning/) 
* [Использование min-width для резиновых изображений](http://www.stucox.com/blog/dont-squash-me-using-min-width-on-fluid-images/) 
* [Пример модульного CSS](http://www.thesassway.com/advanced/modular-css-an-example) 
### JavaScripts
* [JavaScript как новый стандарт корпоративной разработки](http://www.computerra.ru/cio/4883)
* [JavaScript: как правильно курить IE10, или проблемы миграции](http://habrahabr.ru/post/189782/)
* [classList API](https://frontender.info/the-classlist-api/)
* [JS идет в оффлайн](http://technical.io/) , [Tessel – микроконтроллер, программируемый на JavaScript](http://habrahabr.ru/post/190146/)
* [Как использовать drag & drop в HTML5](http://www.webdesignerdepot.com/2013/08/how-to-use-html5s-drag-and-drop/) 
* [К современным веб-приложениям вместе ECMAScript 6](http://www.sencha.com/blog/toward-modern-web-apps-with-ecmascript-6/) 
* [livescript](http://livescript.net/) — язык, компилирующийся в JavaScript
* [Создание графиков с помощью SVG и Angular](http://gaslight.co/blog/angular-backed-svgs) 
* [Как создать город с помощью three.js](http://learningthreejs.com/blog/2013/08/02/how-to-do-a-procedural-city-in-100lines/) 
* [Создание анимациии частиц в 200 строчках кода](http://html5hub.com/build-a-javascript-particle-system/#i.1nzjl4b420fl9w)
* Плагины и библиотеки:
+ [Crossfilter.js, dc.js и D3.js для визуализации Данных](http://habrahabr.ru/post/189838/)
+ [jquery.arbitrary-anchor.js](http://briangonzalez.org/arbitrary-anchor) — jQuery-плагин для расширения навигации по якорям (# хэшам) 
+ [jQuery Flat Shadow](http://thepetedesign.com/demos/jquery_flat_shadow_demo.html) — плагин для добавление длинных теней (тренд плоского дизайна) 
+ [Juicy Slider](http://juicyslider.gopagoda.com/) — Responsive and Lightweight Slider/Slideshow Plugin for JQuery 
+ [Плагин TinyMCE, который позволяет редактировать HTML с возможностями Emmet](https://github.com/e-sites/tinymce-emmet-plugin) 
+ [Tipue Search](http://www.tipue.com/search/) — jQuery-плагин для поиска по сайту 
+ [Iframe Auto Height](http://sly777.github.io/Iframe-Height-Jquery-Plugin/) — плагин недавно обновили 
+ [jQuery плагин для кеширования форм с помощью HTML5 local storage](http://www.developerdrive.com/2013/08/jquery-plugin-for-caching-forms-using-html5-local-storage/) 
### Браузеры
* [The Pirate Bay выпустил пиратский браузер](http://ain.ua/2013/08/12/135695), который [достиг 100к скачиваний за трое суток](http://torrentfreak.com/pirate-bays-anti-clocks-100000-downloads-in-three-days-130813/) 
* [Начало бета-тестирования Firefox 24 и создание aurora-ветки Firefox 25](http://www.opennet.ru/opennews/art.shtml?num=37647)
* [Я люблю Opera 12](http://habrahabr.ru/post/189740/)
* [В Opera 17 Developer появилась панель закладок](http://my-chrome.ru/2013/08/v-opera-17-developer-poyavilas-panel-zakladok-konkurs-ot-opera-software/)
* [На безопасность Chromium потратили уже свыше миллиона долларов](http://my-chrome.ru/2013/08/na-bezopasnost-chromium-potratili-uzhe-svyshe-milliona-dollarov/)
* [Chromium Digest №10](http://my-chrome.ru/2013/08/chromium-digest-10/)
* [chrome.downloads API появится в Google Chrome 30](http://my-chrome.ru/2013/08/chrome-downloads-api-poyavitsya-v-google-chrome-30/)
* [Как улучшить поиск в Firefox с помощью собственных «smart keyword» слов](http://fredericiana.com/2013/08/03/firefox-smart-keywords/) 
* [Firefox developer tools features — Blackboxing](https://www.youtube.com/watch?v=uaFBvItTJrE) 
* [Версии браузеров мертвы](http://html5hub.com/browser-versions-are-dead/#i.1nzjl4b420fl9w) 
* [Firefox остаётся браузером по умолчанию в Ubuntu 13.10](http://www.opennet.ru/opennews/art.shtml?num=37656) 
### Новости
* [Facebook покупает разработчика приложения для распознавания речи Mobile Technologies](http://www.3dnews.ru/660394/)
* [Facebook хочет стать мобильным платежным инструментом](http://www.siliconrus.com/2013/08/facebook-shopping/)
* [Windows 8.1 выйдет 18 октября](http://www.3dnews.ru/660937/), а днём раньше появится в Windows Store, [Skype будет стандартным приложением Windows 8.1](http://microsoftportal.net/windows-blue/2467-skype-budet-standartnym-prilozheniem-windows-81.html)
* [Смартфонов стало больше](http://www.searchengines.ru/blog/archives/011165.html)
* [Запуск первого смартфона на ОС Tizen запланирован на октябрь](http://gagadget.com/other/2013-08-14-zapusk-pervogo-smartfona-na-os-tizen-zaplanirovan-na-oktyabr/)
* [Apple остается передовым производителем мобильных устройств в США](http://ain.ua/2013/08/14/135945)
* [Коротко о новом](http://habrahabr.ru/company/samsung/blog/190350/): Samsung запустила в массовое производство первую в отрасли 3D Vertical NAND флэш-память с вертикальной компоновкой
* [Google окончательно прощается со старым интерфейсом Gmail](http://www.3dnews.ru/660724/)
* [ФСБ готовит закон против Tor и прочих анонимайзеров](http://www.lookatme.ru/mag/industry/industry-news/195449-tor-ban)
* [Новое обновление Win7 случайно ломает пиратские x64 версии](http://www.outsidethebox.ms/15229/)
* [Telegram Messenger](http://www.cossa.ru/news/237/48075/) — первый проект американской компании Павла Дурова, [+дайджест мобильных мессенджеров](http://keddr.com/2013/08/durov-pozvonil-telegram-daydzhest-mobilnyih-messendzherov/)
* [Hyetis собирается выпустить часы с 41-мегапиксельной камерой](http://4pda.ru/2013/08/15/111329/)
### Сервисы
* [Google Maps для Android снова умеет работать в офлайне](http://lifehacker.ru/2013/08/12/google-maps-dlya-android-snova-umeet-rabotat-v-oflajne/)
* [Premailer](http://premailer.dialect.ca/) — сервис для предварительной доработки email-шаблонов 
* Под капотом: [Google Street View](https://www.google.com/maps/about/behind-the-scenes/streetview/)
* [Девелопер ответит](http://devanswers.ru/)
* [Random User Generator](http://randomuser.me/) 
* [В YouTube появился 101 украинский мультфильм](http://ain.ua/2013/08/13/135820)
* [Какой онлайн-кинотеатр выбрать](http://www.lookatme.ru/mag/industry/industry-research/195339-antipirate-questionnaire): 12 российских сервисов
* [Галерея сайтов, отсортированных по цветам](http://www.colorgorize.com/)
### Демо
* [Любимые демо на CodePen Chris Coyier-а](http://davidwalsh.name/chris-coyiers-favorite-pens) 
* [Классная анимация с физическим эффектом упругости на CSS3/JS](http://codepen.io/sol0mka/pen/Jsyxq) 
* [Объемный слайдер на HTML/CSS3/JS](http://codepen.io/Hornebom/pen/ranmi) 
* [Анимированный с помощью CSS3 атом](http://codepen.io/hugo/pen/Dlicg) 
### Сайты с интересным дизайном и функциональностью
* [social-portrait](http://www.teehanlax.com/story/social-portrait/) — нестандартная геометрия плюс параллаксы 
* [letsyep.com/en/](http://letsyep.com/en/) — веселый сайт со стильной графикой и лаконичной анимацией 
* [hydrosys.ca/en/](http://www.hydrosys.ca/en/) — эффектное использование параллакс-эффекта 
* [smiledrive.vw.com](http://smiledrive.vw.com/) — сайт социального приложения для авто от Volkswagen 
* [perspectivewoodworks.com](http://perspectivewoodworks.com/) — сайт с ромбовым дизайном 
* [trask-industries.com](http://www.trask-industries.com/#/home) — сайт с приятными анимационными эффектами и фоновым видео 
* [snipcart.com](https://snipcart.com/) — креативный анимационный слайдер и несколько других занимательных элементов 
* [noiretrenoir.com/parallax](http://www.noiretrenoir.com/parallax/) — одностраничный сайт с параллаксом 
### Дизайн
* [Лебедев нарисовал соцсеть для РЖД — «РЖДшечку»](http://www.artlebedev.ru/everything/rzd/social/)
* [Интервью с иллюстратором Алексеем Байдаковым](http://www.dejurka.ru/articless/%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%B2%D1%8C%D1%8E-%D1%81-%D0%B0%D0%BB%D0%B5%D0%BA%D1%81%D0%B5%D0%B5%D0%BC-%D0%B1%D0%B0%D0%B9%D0%B4%D0%B0%D0%BA%D0%BE%D0%B2%D1%8B%D0%BC/)
* [Разноцветные сайты для вашего вдохновения](http://www.dejurka.ru/web-design/raznotsvetnie_saiti_dlya_vdohnoveniya/)
* [Примеры креативного дизайна упаковки](http://www.dejurka.ru/inspiration/creativ-design-package/)
* [Теория цвета в цифрах](http://habrahabr.ru/post/189766/)
* [Проектирование услуг за пределами экрана](http://frontender.info/designing-for-services-beyond-screen/)
* [История типографики (видео)](https://www.youtube.com/watch?v=wOgIkxAfJsk) 
* [Растровые и векторные логотипы большинства браузеров](https://github.com/paulirish/browser-logos) 
* [Plaid](http://joshondesign.com/2013/08/12/plaid) — следующий шаг после плоского дизайна? 
* [Процесс создания responsive веб-дизайна](http://heliom.ca/blog/posts/a-responsive-web-design-process) 
* [Понимание букв](http://blog.typekit.com/2013/08/14/understanding-letters/) 
* [Вдохновляющие примеры одностраничных веб-дизайнов](http://www.designerledger.com/single-page-website-designs/) 
* [Примеры классных посадочных страниц](http://www.designerledger.com/startup-landing-pages/) 
* [Примеры сайтов с полноэкранными фото](http://www.crazyleafdesign.com/blog/40-examples-of-beautiful-websites-with-full-screen-background/) 
### Подборка бесплатных дизайнерских печенек
* Фоны: [размытые фоны для iOS приложений](http://medialoot.com/item/atmosphere-apps-backgrounds/) 
* [Наборы UI и плоских иконок](http://spyrestudios.com/12-unique-freebie-graphics-designers/) 
* [Четверть сотни исходников PSD визиток](http://www.antsmagazine.com/graphics/25-free-psd-business-card-templates/) 
* UI: [Набор UI](http://www.cssauthor.com/user-interface-design-kit-psd/) в красном и плоском дизайне, [Flattastic UI](http://www.webdesignerdepot.com/2013/08/free-download-flattastic-ui-kit/) — набор с плоским дизайном, [исходники форм авторизации](http://blog.templatemonster.com/2013/08/12/free-psd-login-forms-flat-design/) 
* Иконки: [иконки одежды](http://pixel-fabric.com/24-clothes-icons-20), [почти сотня](http://pepsized.com/90-social-clouds-v2/) социальных иконок, [плоские иконки посвященные покупкам](http://www.webdesignerdepot.com/2013/08/free-download-30-flat-shopping-icons/), в виде шестиугольников, [иконки посвященные SEO](http://www.webresourcesdepot.com/free-and-vector-seo-related-icons/) 
* Шрифты: [Dense](http://www.behance.net/gallery/Dense-typeface/10231891) — шрифт без засечек, [свежие шрифты без засечек](http://webdesignledger.com/freebies/8-fresh-high-quality-free-fonts), от Dense Regular до Kelson Sans, [два десятка свежих шрифтов, от Higher до DK Keswick](http://www.hybridlava.com/free-stuff/20-fresh-downloadable-fonts-for-free/) 
### Занимательное
* [git + webcam = lulz](http://mroth.github.io/lolcommits/) 
* [Samsung не знает что делать с гибкими дисплеями?](http://4pda.ru/2013/08/14/111302/)
* [Рыночная стоимость Google Glass может составить $300](http://www.3dnews.ru/660142/)
* [Разработчики из Азии выдают себя за украинцев и россиян](http://dou.ua/forums/topic/7991/)
* [Очки дополненной реальности SpaceGlasses META.01 — все то, что не умеет Google Glass](http://habrahabr.ru/post/189864/)
* [Занимательная статистика АНБ США: «Мы затрагиваем лишь 1,6% суточного интернет-трафика»](http://itc.ua/news/zanimatelnaya-statistika-anb-ssha-myi-zatragivaem-lish-1-6-sutochnogo-internet-trafika/)
* [Hyperloop — проект высокоскоростной и экономичной транспортной системы](http://itc.ua/news/hyperloop-proekt-vyisokoskorostnoy-i-ekonomichnoy-transportnoy-sistemyi/)
* [Ларри Эллисон: Google творит зло, а Apple деградирует](http://www.3dnews.ru/660602/)
* [Обзор Ouya](http://keddr.com/2013/08/ouya/)
* [Циферкой ошиблись! Как мелкий баг в софте поставил подножку всему миру](http://www.computerra.ru/79247/jbig2/)
* [20 креативных клипов на Vine](http://speckyboy.com/2013/08/13/20-creative-and-inspirational-vine-clips/) 
* [Пользователи Gmail могут не рассчитывать на конфиденциальность и тайну переписки](http://ain.ua/2013/08/14/136038)
* [15 самых дорогих доменов всех времен](http://www.cossa.ru/articles/152/48039/)
* [Заминусованные youtube-видео на одном сайте](http://www.boootube.com/) 
* [Gif Dance Party](http://gifdanceparty.com/) 
[Дайджест за прошлую неделю](http://habrahabr.ru/company/zfort/blog/189670/).
Материал подготовили [dersmoll](http://habrahabr.ru/users/dersmoll/) и [alekskorovin](http://habrahabr.ru/users/alekskorovin/)
|
https://habr.com/ru/post/190436/
| null |
ru
| null |
# А нам все «вертикально» — СУБД Vertica
Привет! Меня зовут Сергей, я работаю главным инженером в Сбертехе. В ИТ-сфере я примерно 10 лет, из которых 6 занимаюсь базами данных, ETL-процессами, DWH и всем, что связано с данными. В этом материале я расскажу о Vertica — аналитической и по-настоящему колоночной СУБД, которая эффективно сжимает, хранит, быстро отдает данные и отлично подходит в качестве big data решения.

Общая информация
----------------
С 2000-х годов начали развиваться большие данные и потребовались движки, которые способны все это переварить. В ответ на это появился ряд предназначенных для этого колоночных СУБД — в том числе и Vertica.
Vertica не просто хранит свои данные в колонках, она делает это рационально, с высокой степенью сжатия, а также эффективно планирует запросы и быстро отдает данные. Информация, которая в классической строчной СУБД занимает около 1 ТБ дискового пространства, на Vertica займет порядка 200-300 Гб, тем самым мы получаем хорошую экономию на дисках.
Vertica изначально проектировалась именно как колоночная СУБД. Другие базы в основном только стараются имитировать различные колоночные механизмы, но у них это не всегда хорошо получается, поскольку движок все равно создан чтобы обрабатывать строки. Как правило, подражатели просто транспонируют таблицу и далее обрабатывают привычным строчным механизмом.
Vertica отказоустойчива, в ней нет управляющей ноды — все ноды равны. Если с одним из серверов в кластере возникают проблемы, то данные мы все равно получим. Очень часто получить данные вовремя бывает критично для бизнес-заказчиков, особенно в период, когда закрывается отчетность и нужно предоставлять информацию в финансовые органы.
Области применения
------------------
Vertica — это в первую очередь аналитическое хранилище данных. В нее не стоит писать мелкими транзакциями, не стоит прикручивать ее к какому-то сайту и т.п. Vertica следует рассматривать как некий batch-слой, куда стоит погружать данные большими пачками. При необходимости Vertica очень быстро готова эти данные отдать — запросы на миллионы строк выполняются за секунды.
Где это может быть полезно? Возьмем для примера телекоммуникационную компанию. Vertica может использоваться в ней для геоаналитики, развития сети, управления качеством, целевого маркетинга, изучения информации с контактных центров, управления оттоком клиентов и антифрод/антиспам-решений.

В других отраслях бизнеса все примерно так же — для получения прибыли важна своевременная и достоверная аналитика. В торговле, например, все пытаются как-то персонализировать клиентов, распространяют для этого дисконтные карты, собирают данные о том, где что и когда человек покупал и т.п. Анализируя массивы информации со всех этих каналов, мы можем ее сопоставлять, строить модели и принимать решения, ведущие к росту прибыли.
Входной порог
-------------
Сегодня любой работодатель требует, чтобы аналитик представлял, что такое SQL. Если вы знаете ANSI SQL, то вас можно назвать уверенным пользователем Vertica. Если вы можете строить модели на Python и R, то вы просто «массажист» данных. Если освоили Linux и имеете базовые знания по администрированию Vertica, то можете работать администратором. В целом, входной порог в Vertica невысокий, но, разумеется, все нюансы можно узнать, только набивая руку в процессе эксплуатации.
Аппаратная архитектура
----------------------
Рассмотрим Vertica на уровне кластера. Эта СУБД обеспечивает массивно-параллельную обработку данных (МРР) в распределенной вычислительной архитектуре — «shared-nothing» — где, в принципе, любая нода готова подхватить функции любой другой ноды. Основные свойства:
* отсутствует единая точка отказа,
* каждый узел независим и самостоятелен,
* отсутствует единая для всей системы точка подключения,
* узлы инфраструктуры дублируются,
* данные на узлах кластера автоматически копируются.
Кластер без проблем линейно масштабируется. Мы просто ставим сервера в полку и подключаем их через графический интерфейс. Помимо серийных серверов, возможно развертывание на виртуальные машины. Что можно добиться с помощью расширения?
* Увеличения объема для новых данных
* Увеличение максимальной рабочей нагрузки
* Повышение отказоустойчивости. Чем больше нод в кластере, тем меньше вероятность выхода кластера из строя из-за отказа, а следовательно, тем ближе мы к обеспечению доступности 24/7.
Но нужно кое-что учесть. Периодически ноды нужно вынимать из кластера для обслуживания. Еще довольно распространенный кейс в крупных организация — сервера сходят с гарантии и переходят из продуктивной в какую-нибудь тестовую среду. На их место встают новые, которые находятся на гарантии производителя. По итогам всех этих операций нужно выполнять ребалансировку. Это процесс, когда данные перераспределяются между нодами — соответственно перераспределяется рабочая нагрузка. Это требовательный к ресурсам процесс, и на кластерах с большим объемом данных он может сильно снизить производительность. Чтобы этого избежать, нужно выбрать сервисное окно — время, когда нагрузка минимальна, и в этом случае пользователи этого не заметят.
Проекции
--------
Для понимания, как хранятся данные в Vertica, требуется разобраться с одним из основных понятий — проекцией.
Логические единицы хранения информации — это схемы, таблицы и представления. Физические единицы — это проекции. Проекции бывают нескольких типов:
* суперпроекции (Superprojection),
* запрос-ориентированные проекции (Query-Specific Projections),
* агрегированные проекции (Aggregate Projections).
При создании любой таблицы автоматически создается *суперпроекция*, которая содержит все колонки нашей таблицы. Если нужно ускорить какой-то из регулярных процессов, мы можем создать специальную *запрос-ориентированную проекцию*, которая будет содержать, допустим, 3 столбца из 10.
Для ускорения предназначен и третий тип — *агрегированные проекции*. Не буду вдаваться в их подклассы — это не очень интересно. Сразу хочу предупредить, что постоянно решать свои проблемы с выполнением запросов через создание новых проекций не стоит. В конечном итоге кластер начнет тормозить.
Создавая проекции, нужно оценивать, хватает ли нашим запросам суперпроекций. Если мы все-таки хотим поэкспериментировать, добавляем строго по одной новой проекции. При возникновении проблем так будет проще найти первопричину. Для больших таблиц следует создавать сегментированную проекцию. Она разбивается на сегменты, которые распределяются по нескольким нодам, что повышает отказоустойчивость и минимизирует нагрузки на одну ноду. Если таблички маленькие, то лучше делать несегментированные проекции. Они полностью копируются на каждую ноду, и производительность таким образом увеличивается. Оговорюсь: в терминах Vertica «маленькая» таблица — это примерно 1 млн строк.
Отказоустойчивость
------------------
Отказоустойчивость в Vertica реализована при помощи механизма K-Safety. Он довольно простой с точки зрения описания, но сложный с точки зрения работы на уровне движка. Им можно управлять с помощью параметра K-Safety — он может иметь значение 0, 1 или 2. Этот параметр задает количество копий сегментированных проекционных данных.
Копии проекций называются buddy projections. Я попытался перевести это словосочетание через Яндекс-переводчик и получилось что-то вроде «проекции-кореша». Гугл предлагал варианты и интересней. Обычно данные проекции называют партнерскими или соседними, по их функциональному назначению. Это проекции, которые просто хранятся на соседних нодах и таким образом резервируются. У несегментированных проекций нет buddy projections — они копируются полностью.
Как это работает? Рассмотрим кластер из пяти машин. Пусть K-safety у нас равен 1.
Ноды пронумерованы, а под ними написаны партнерские проекции, которые хранятся на них. Предположим, у нас отключилась одна нода. Что будет?

Нода 1 содержит дружественную проекцию ноды 2. Поэтому на ноде 1 подрастет нагрузка, но работать кластер не перестанет. А теперь такая ситуация:
Нода 3 содержит проекцию ноды 4, и ноды 1 и 3 будут перегружены.
Усложняем задачу. K-Safety = 2, отключим две соседние ноды.

Здесь будут перегружены ноды 1 и 4 (нода 2 содержит проекцию ноды 1, а нода 3 содержит проекцию ноды 4).
В таких ситуациях движок системы распознает, что одна из нод не отвечает, и нагрузка перекладывается на соседнюю ноду. Она будет использоваться, пока нода снова не восстановится. Как только это происходит, нагрузка и данные перераспределяются обратно. Как только мы теряем больше половины кластера или ноды, содержащие все копии каких-то данных, кластер встает.
Логическое хранение данных
--------------------------
В Vertica есть области хранения данных, оптимизированные для записи, области, оптимизированные для чтения, и механизм Tuple Mover, который обеспечивает перетекание данных из первой области во вторую.
При использовании операции COPY, INSERT, UPDATE мы автоматически попадаем в WOS (Write Optimized Store) — область, где данные не оптимизированы для чтения и сортируются только при запросе, хранятся без сжатия или индексирования. Если объемы данных слишком велики для области WOS, то с помощью дополнительной инструкции DIRECT их стоит писать сразу в ROS. Иначе WOS будет переполнен, и у нас случится сбой.
По истечении заданного в настройках времени данные из WOS перетекают в ROS (Read Optimized Store) — оптимизированную, ориентированную на чтение структуру дискового хранилища. В ROS хранится основная часть данных, здесь она сортируется и сжимается. Данные в ROS разделены на контейнеры хранения. Контейнер представляет собой набор строк, созданных операторами трансляции (COPY DIRECT), и хранится в определенной группе файлов.
Вне зависимости от того, куда записаны данные — в WOS или в ROS — они доступны сразу. Но из WOS чтение идет медленнее, потому что данные там не сгруппированы.

Tuple Mover — это инструмент-уборщик, который выполняет две операции:
* Moveout — сжимает и сортирует данные в WOS, перемещает их в ROS и создает для них в ROS новые контейнеры.
* Mergeout — подметает за нами, когда мы используем DIRECT. Мы не всегда способны грузить столько информации, чтобы получались большие ROS-контейнеры. Поэтому он периодически объединяет небольшие контейнеры ROS в более крупные, очищает данные с пометкой на удаление, работая при этом в фоновом режиме (по времени, заданному в конфигурации).
В чем выгода колоночного хранения?
----------------------------------
Если мы читаем строки, то, например, для выполнения команды
`SELECT 1,11,15 from table1`
нам придется читать всю таблицу. Это огромный объем информации. В данном случае колоночный подход выгоднее. Он позволяет считать только три нужных нам столбца, экономя память и время.
Распределение ресурсов
----------------------
Чтобы в работе не возникало проблем, пользователя нужно немного ограничивать. Всегда есть вероятность, что пользователь напишет тяжелый запрос, который сожрет все ресурсы. По умолчанию в Vertica значительную часть занимает область General, и помимо этого выделяются отдельные области под Tuple Mover, WOS и системные процессы (восстановление и прочее).

Попробуем поделить эти ресурсы. Создаем области для писателей, для читателей и для медленных запросов с низким приоритетом.
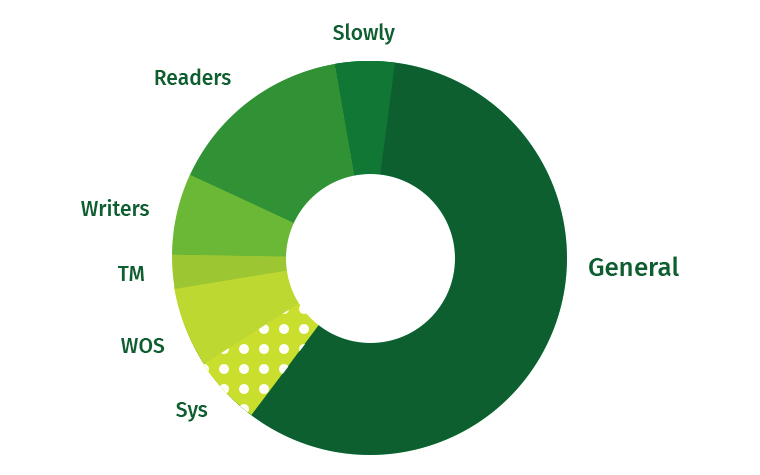
Если посмотреть системные таблицы, в которых хранятся наши ресурсы — ресурсные пулы — то мы увидим множество параметров, с помощью которых можно все отрегулировать более тонко. На старте не стоит в это углубляться, лучше просто ограничиться отсеканием памяти под определенные задачи. Когда наберетесь опыта и будете на 100% уверены, что делаете все правильно, можно будет поэкспериментировать.
К тонким настройкам можно отнести приоритет выполнения, конкурентные сессии, объем выделяемой памяти. И даже с процессорами мы можем кое-что поправить.Для работы с этими настройками нужна полная уверенность в правильности своих действий, так что лучше заручиться поддержкой бизнеса и иметь право на ошибку.
Ниже пример запроса, с помощью которого можно увидеть настройки пула General:
`dbadmin => select * FROM resource_pools WHERE NAME = 'general';
-[ RECORD 1 ]------------+---------------
pool_id | 45035996273721212
name | general
is_internal | t
memorysize |
maxmemorysize | 30G
executionparallelism | AUTO
priority | 0
runtimepriority | MEDIUM
runtimeprioritythreshold | 2
queuetimeout | 0:05
plannedconcurrency | 10
maxconcurrency | 20
runtimecap |
singleinitiator | f
cpuaffinityset |
cpuaffinitymode | ANY
cascadeto |`
ANSI SQL и другие фичи
----------------------
* Vertica позволяет писать на SQL-99 — поддерживается весь функционал.
* Verica имеет большие аналитические возможности — в поставку входят даже инструменты машинного обучения
* Vertica умеет индексировать тексты
* Vertica обрабатывает полуструктурированные данные
Интеграция
----------
Vertica, как и все текущие инструменты, серьезно интегрирована с другими системами. Умеет хорошо работать с HDFS (Hadoop). В ранних версиях Vertica могла только загружать данные с HDFS определенных форматов, а сейчас умеет вообще все, работает со всеми форматами, например, ORC и Parquet. Умеет даже подключать файлы как внешние таблицы (external tables) и хранить свои данные в ROS контейнерах прямо на HDFS. В восьмой версии Vertica была проведена значительная оптимизация скорости работы с HDFS, каталога метаданных и парсинга этих форматов. Можно строить кластер Vertica прямо на Hadoop-кластере.
Начиная с версии 7.2 Vertica умеет работать с Apache Kafka — если кому-то нужен message broker.
В Vertica 8 появилась полная поддержка Spark. Есть возможность копировать данные из Spark в Vertica и обратно.
Вывод
-----
Vertica — хороший вариант для работы с большими данными, не требующий больших знаний на входе. Эта СУБД имеет широкие аналитические возможности. Из минусов — это решение не open source, но можно попробовать развернуть бесплатно с ограничением в 1 ТБ и три ноды — этого вполне хватит, чтобы понять, нужна вам Vertica или нет.
|
https://habr.com/ru/post/414895/
| null |
ru
| null |
# Медиамагия: Настройка
Статья по настройке Медиаджика. Что это такое — можно прочесть [тут](http://habrahabr.ru/blogs/DIY/111954/)
Подробности под катом.
1.Устанавливаем торрент-клиент rtorrent
Устанавливать приложения в Ubuntu можно несколькими способами. Например, можно воспользоваться графическим клиентом Synaptic,, или же запустить процесс установки из консоли. Мы пойдём вторым путём, потому что, во-первых, это проще поддаётся описанию, а во-вторых, всегда бывает полезно уметь пользоваться консолью. Тем более, нам ещё не раз придётся к ней обращаться (мы же в линуксе, как ни крути).
Для начала запустим терминал, если он ещё не запущен. И скопируем туда эту строчку:
```
sudo apt-get install rtorrent
```
Для новичков вкратце объясню что это значит. «sudo» означает, что команду нужно запустить с правами администратора. «apt-get» — это консольный клиент для установки приложений. «install» это команда клиенту «apt-get», сообщающая о необходимости «установить» приложение. rtorrent, соответственно, название приложения, которое мы устанавливаем.
Ещё один маленький совет тем, кто только начинает разбираться с линуксом — в консоли очень удобно использовать кнопку TAB, которая «дописывает» команды/пути/итд и выводит их список, если есть более одного варианта дописывания. Например, можно набрать команду так: sudo apt-g[TAB] i[TAB] rto[TAB]
Ok, набрали команду, ввели пароль, запустилась установка. Apt-get переспросит, уверены ли вы в том, что делаете. Нажмите «Д» (или просто Enter) и установка пойдёт дальше. Ok, мы установили приложение. Для проверки в консоли пишем:`rtorrent`
жмём Enter и перед нами должен появится интерфейс рторрента.
Ok, супер. Всё работает. Жмём Ctrl+q чтобы выйти из приложения.
2.Настраиваем rtorrent
В начале создадим директории, с которыми мы будем работать. В консоли это делается командой mkdir и указанием директории, которую мы хотим создать.
Соответственно пишем в консоли:
```
mkdir ~/torrents
mkdir ~/.rtorrent-session
mkdir /var/lib/mythtv/videos/downloads
```
"~" — это сокращение в линуксе, указывающее путь к вашей домашней директории
Итак мы создали директорию «torrents», в которой у нас будут лежать torrent-файлы, директорию ".rtorrent-session" в которой rtorrent будет хранить свою сессию и директорию «downloads», в которую rtorrent будет скачивать фильмы.
Настройки rtorrent хранятся в файле, который называется .rtorrent.rc и который хранится в вашей домашней директории. Но при установке приложения такой файл не создаётся, поэтому для начала нам придётся его создать. Пишем в консоли:`nano ~/.rtorrent.rc`
откроется консольный текстовый редактор с пустым содержимым.
Вставим туда следующие строки:`download_rate = 1000
upload_rate = 100
directory=/var/lib/mythtv/videos/downloads
session=/home/вашеимя/.rtorrent-session
schedule = u_night_mode,02:00:00,24:00:00,upload_rate=0
schedule = u_day_mode,07:00:00,24:00:00,upload_rate=100
schedule = d_night_mode,02:00:00,24:00:00,download_rate=0
schedule = d_day_mode,07:00:00,24:00:00,download_rate=1000
schedule = low_diskspace,5,60,close_low_diskspace=100M
schedule = watch_directory,10,10,load_start=/home/вашеимя/torrents/*.torrent
schedule = tied_directory,10,10,start_tied=
schedule = untied_directory,10,10,stop_untied=
schedule = ratio,60,60,"stop_on_ratio=200,200M,2000"
# Maximum and minimum number of peers to connect to per torrent
min_peers = 20
max_peers = 40
# Maximum number of simultanious uploads per torrent
max_uploads = 5
encryption = allow_incoming,enable_retry,prefer_plaintext
port_range = 55558-55558
scgi_port = :5000
encoding_list = UTF-8
umask = 0000`
Не забываем в двух местах заменить «вашеимя» на ваше имя в системе (то есть на путь к вашей домашней директории)
Теперь опишу, что значат все эти настройки:
download\_rate, upload\_rate — ограничение по скорости даунлода и аплода соответственно. В килобайтах.
directory — директория для сохранения скачанных файлов
session — директория, необходимая rtorrent'у для сохранения сессий закачки
schedule = u\_night\_mode,02:00:00,24:00:00,upload\_rate=0
schedule = u\_day\_mode,07:00:00,24:00:00,upload\_rate=100
schedule = d\_night\_mode,02:00:00,24:00:00,download\_rate=0
schedule = d\_day\_mode,07:00:00,24:00:00,download\_rate=1000
Эти четыре строчки говорят, что с 7 утра до 2х ночи нужно ограничивать скорость до 1000/100 kbps (down/up), а с 2х ночи до 7 утра работать без ограничений по скорости.
schedule = low\_diskspace,5,60,close\_low\_diskspace=100M
Это означает, что нужно раз в минуту проверять не кончается ли место на винчестере и останавливать все закачки, если осталось менее чем 100 мегабайт.
schedule = watch\_directory,10,10,load\_start=/home/вашеимя/torrents/\*.torrent
каждые 10 секунд проверять, не появились ли новые торрент-файлы в этой директории
schedule = tied\_directory,10,10,start\_tied=
Стартовать закачку, если появился новый торрент файл
schedule = untied\_directory,10,10,stop\_untied=
Останавливать закачку, если торрент файл удалён
schedule = ratio,60,60,«stop\_on\_ratio=200,200M,2000»
Останавливать закачку, если её рейтинг>=2.00, при этом было заапложено более 200Мб ИЛИ рейтинг>=20.00
min\_peers, max\_peers — минимальное и максимальное кол-во пиров на торрент. Если честно, плохо понимаю что значит «min peers»
max\_uploads — максимальное количество аплодов на торрент
encryption — шифрование
port\_range — порт. не забудьте пробросить порт на DSL-модеме/роутере, кстати.
scgi\_port — порт, по которому веб-клиент (который мы потом поставим) будет работать с rtorrent
encoding\_list — кодировка
umask — маска прав по умолчанию
подробнее о тех или иных настройках можно почитать на сайте rtorrent
А мы сохраняем файл (Ctrl+o, Enter) и выходим из редактора (Ctrl+x)
запускаем rtorrent, кидаем в директорию ~/torrents/ какой-нибудь торрент-файл, проверяем что всё работает. Закачка должна стартануть и в директории videos/downloads появится скачиваемый файл. Ура.
3. Учим rtorrent работать в бэкграунде и стартовать автоматически.
Заодно поборем один баг с зависанием рторрента.
В начале ставим screen:
```
sudo apt-get install screen
```
дальше создаём директорию и скрипты для запуска:
```
mkdir ~/bin
nano ~/bin/myrtorrent.sh
```
Внутри пишем
```
#!/bin/bash
PROGRAM="/usr/bin/rtorrent"
GRACE_DELAY=15
while true;
do
"$PROGRAM"
RETURNED=$?
if [ $RETURNED -ne 0 ]
then
echo "$PROGRAM did not exit cleanly with status code $RETURNED"
echo "pausing for $GRACE_DELAY seconds before restarting $PROGRAM"
sleep $GRACE_DELAY;
else
echo "$PROGRAM exited cleanly. It will not be restarted automatically"
exit 0
fi
done
```
сохраняем, выходим (ctrl+o, Enter, ctrl+x)
пишем в консоли
```
>nano ~/bin/checkrtorrent.sh
```
В редакторе пишем:
```
#!/bin/sh
if [ `pgrep myrtorrent|wc -l` -lt 1 ]; then
if [ ! "$(pidof rtorrent)" ]
then
echo "Not running. Starting\n"
/usr/bin/screen -fa -d -m -S rtorrent /home/вашеимя/bin/myrtorrent.sh
fi
fi
```
**не забудьте** сменить «вашеимя» на ваше имя в системе. Сохраняем, выходим.
Таким образом, мы создали несколько скриптов, которые запускают rtorrent в фоновом режиме и следят за тем, что он успешно запустился.
Теперь заставим эти скрипты запускаться. Вначале сделаем их «запускаемыми»
```
chmod +x ~/bin/checkrtorrent.sh
chmod +x ~/bin/myrtorrent.sh
```
ставим скрипты в планировщик задач
```
crontab -e
```
crontab — это приложение, запускающее в определённый момент другие приложения. При первом старте он спросит какой текстовый редактор мы хотим использовать. «3 — nano», конечно же ответим мы. Ок. Видим nano со следующим содержимым:
```
# m h dom mon dow command
```
Очень здорово. Теперь впишем строкой ниже нужный нам текст.
```
*/10 * * * * /home/вашеимя/bin/checkrtorrent.sh
```
только не забудем заменить вашеимя на ваше имя в системе.
Ctrl+o, Enter, Ctrl+x. Можно перегрузить систему, чтобы проверить что всё работает.
для этого после перезагрузки ждём несколько минут (скрипт срабатывает раз в 10 минут) и набираем в консоли
```
screen -r
```
после этого должен показаться интерфейс рторрента. Чтобы выйти из рторрента, но оставить его работать в фоновом режиме НЕ ЖМИТЕ НА Ctrl+q, а вместо этого нажмите «Ctrl+a», а затем «d». программа останется работать.
Вы в любой момент можете посмотреть что у вас происходит, набрав «screen -r» и выйти нажав «ctrl+a, d»
4.Устанавливаем необходимые для работы скриптов Mediagic пакеты.
пишем в консоли
```
sudo apt-get install php5-cli php5-curl php5-gd php5-imap
```
5.Устанавливаем сами скрипты.Правим config.xml
Скачиваем архив со скриптами и разархивируем его на своём компьютере с Виндоус (или что там у вас). Предлагаю править его на своём компьютере, а не на медиацентре, потому что так быстрее
Открываем и видим несколько папок и файлов. Открываем файл config.xml из корня.
Начинаем аккуратно заполнять значения.
Оставляем как есть значения verbose, system\_encoding
Доходим до группы параметров
```
localhost
mythtv
вписасть\_сюда\_пароль
mediagic
```
Открываем консоль на медиацентре. Набираем
```
cat /etc/mythtv/mysql.txt|grep DBPassword
```
эта хитрая команда позволит нам увидеть генерированный пароль от базы данных MythTV. Вписываем этот пароль в поле password.
Следующий интересующий нас параметр называется user\_agent.
Раньше можно было обойтись без этого параметра. user\_agent — это название вашего браузера, в котором вы авторизованы на трекере. Нам понадобится название браузера и cookies. Для того чтобы выдрать значение кукис я рекомендую использовать браузер Opera (наверняка значение cookies можно посмотреть и в других браузеров, но я не знаю как, потому что пользуюсь оперой).
Итак заходим на трекер с оперы, вводим логин-пароль (если ещё не авторизованы), после чего заходим на сайт [whatsmyuseragent.com](http://whatsmyuseragent.com/) (понадобится интернет).
Всё это можно сделать со своего рабочего компа, а не с медиацентра.
Сайт покажет нам какое-то кол-во информации, в самом начале можо прочитать:
Your User Agent is:
Opera/9.80 (Macintosh; Intel Mac OS X; U; en) Presto/2.2.15 Version/10.00
или нечто подобное. Скорее всего у вас будет написано Opera/9.80 (Windows; чтото там)
Копируем содержимое строчки (начиная со слова Opera) в буфер и вставляем в xml-файл заместо указанного там значения.
Следующий интересующий нас параметр называется «coverarts»
Открываем консоль на медиасервере и пишем:
```
mkdir ~/.mythtv/MythVideo/
```
возвращаемся к конфигурационному файлу и пишем:
```
/home/вашеимя/.mythtv/MythVideo/
```
разумеется, **заменив** «вашеимя» на ваше имя в системе.
смотрим дальше. trash. Ок, предлагаю использовать для этого системную корзину, но можно и любую другую папку. Системная корзина лежит тут.
```
/home/вашеимя/.local/share/Trash/files/
```
как всегда, **заменив** «вашеимя» на ваше имя в системе.
Следующая группа значений, которая нас интересует, называется mythtv
Ничего тут не меняем, только пишем тот же пароль, что мы писали в поле mediagic\_db/password выше.
Далее идёт блок настройки email, но я предлагаю его пока не трогать и настроить потом.
6.Правим trackers/tracker.\*название трекера\*.xml
Открываем файл.
Открываем Opera. Открываем в опере любимый трекер. Кликаем правой кнопкой и выбираем «Edit Site Preferences/Настройки для сайта». Выбираем вкладку «Cookies». Внизу будет список переменных и значений. Кликая двойным кликом на каждое из значений, можно будет открыть его в новом окне и скопировать. Аккуратно заполняем все параметры из xml-файла, чтобы получилось что-то вроде
```
1
a3ac2ae1232c43237eac4183726370ac
1234
2abc8bf34fb7b2948dc38749cc2cacbc
b55476116f38bcd5a91e22dc6280e4ee
a3f616f38bcd58ab16f8bcd54916f8bc563
1234\_iUn9kednIu8Jd7wOjw09JHw672lJkwdjhfwJhdeU63Jdg22hsdjciIh7HdgeY7t
1
```
Далее меняем значение minimum\_number\_of\_seeds на интересующее нас.
Ставим в фильтры filters/decline то, что не хотим качать ни при каких обстоятельствах.
Указываем max\_size и min\_size.
Меняем directories/torrents\_dir на необходимое нам значение
```
/home/вашеимя/torrents/
```
**не забываем** заменить «вашеимя», затем меняем значение directories/datafiles\_dir на
```
var/lib/mythtv/videos/downloads/
```
в результате у меня это выглядит так:
```
/home/vadim/torrents/
/var/lib/mythtv/videos/downloads/
```
7.Правим scrubbers/scrubber\*название трекера\*.xml.
копируем весь блок cookies из предыдущего файла и вставляем в соответствующее место сюда.
Несмотря на то, что может показаться глупостью писать 2 раза одно и тоже в разных местах, в этом есть определённый смысл. Позвольте мне вкратце рассказать, как это всё работает и за что отвечают вышеперечисленные файлы.
Файлы, лежащие в trackers/ отвечают за работу с трекерами. Можно создать файл trackers/torrents.ru.xml, прописать туда необходимые значения и Медиаджик будет работать ещё и с torrents.ru.
Файлы, лежащие в scrubbers/ отвечают за скачивание информации о фильме. Так как в случае с локальным трекром мы берём информацию непосредственно с описания торрента, получается, что место откуда мы качаем торрент-файлы и откуда мы берём информацию — это один и тот же сайт. Но может получится, что мы захотим качать фильмы c PirateBay или torrents.ru, а информацию о них брать с кинопоиска или с тех-же локальных торрентов. Или наоборот как-то Получается, что место откуда мы качаем фильмы и место, откуда мы берём информацию, не всегда одно и то же, просто в нашем конкретном случае это один и тот же сайт.
8.Устанавливаем скрипты и разворачиваем базу.
копируем всю папку mediagic со всеми поправленными конфиг-файлами на медиасервер. Рекомендую скопировать их в /var/www. Для этого вначале копируем папку куда угодно, например в домашнюю директорию, а затем из консоли пишем
```
sudo mv ~/mediagic /var/www/
```
набираем пароль и вуяля — скрипты там.
Теперь давайте создадим базу данных.
набираем в консоли
```
mysql -u root -p
```
вводим ваш пароль и попадаем внутрь MySQL.
```
vadim@vadim-vmware:~$ mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 135
Server version: 5.0.75-0ubuntu10.2 (Ubuntu)
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql>
```
Пишем следующее:
```
GRANT ALL ON *.* TO 'mythtv'@'localhost';
```
Возвращаемся в стандартную консоль.
Для дальнейшей работы нам понадобится пароль, который мы выяснили, когда правили config.xml
набираем
```
mysql -u mythtv -p
```
и вводим этот генерированный пароль от базы данных. Попадаем назад в mysql но уже под пользователем «mythtv». Пишем:
```
create database mediagic;
SHOW DATABASES;
```
в результате мы должны увидеть 4 базы данных
```
mysql> create database mediagic;
Query OK, 1 row affected (0.00 sec)
mysql> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mediagic |
| mysql |
| mythconverg |
```
пишем exit и выходим из MySQL.
Пишем в консоли:
```
mysql --user=mythtv --password=пароль mediagic < /var/www/mediagic/mediagic.sql
```
заменив «пароль» на генерированный пароль из config.xml
Ура. База данных создана.
9.Проверяем, что всё работает
набираем в консоли
```
php /var/www/mediagic/autodownload.php
```
И внимательно смотрим на то, что выдаёт скрипт. Если всё сделали правильно, то он не выдаст никаких ошибок, а успешно скачает и запишет в базу данных всё, что надо. По результатам действия скрипта в Mythtv должны появиться несколько новых (но ещё не скачанных) фильмов а в rtorrent новые закачки.
Напоминаю, что rtorrent можно посмотреть в консоли набрав «screen -r» и выйти из него набрав «Ctrl+a, d». Чтобы удалить закачку в rtorrent выберите её кнопками вверх-вниз и нажмите 2 раза Ctrl+d (закачка остановится, но частично скачанный файл останется).
MythTV можно запустить через Applications->Аудио и видео->MythTV Frontend.
10.
пишем в терминале
```
sudo touch /var/log/updatetorrents.log
sudo chmod 777 /var/log/updatetorrents.log
crontab -e
```
и добавляем ещё одну строчку в самый низ
```
0 * * * * /usr/bin/php /var/www/mediagic/autodownload.php > /var/log/updatetorrents.log
```
Теперь раз в час медиаджик будет проверять не появилось ли новых фильмов, качать их и сохранять информацию в базу MythTV.
На сегодня всё. В следующий раз будем бороться с драйверами и кодеками, делать MythTV красивым, работать с rtorrent через красивый веб-интерфейс, прикручивать пульт, учить Mediagic писать и читать почту, а также скачивать интересующие нас сериалы в отдельные директории сразу же после появления хотя-бы одного сида на трекере. Кроме этого, этим же макаром мы будем учить Mediagic скачивать ожидаемые релизы как только они появятся.
Если у вас не получилось что-то — пишите, разберёмся. Если вы делали всё в точности как я описал — то проблем возникнуть не должно, если, конечно, я не описАлся
|
https://habr.com/ru/post/111956/
| null |
ru
| null |
# Vue.js Best Practices For Web Development
I am a full-stack developer at [Syncrasy Tech (IT solutions company)](https://syncrasytech.com/). I love writing React codes. But why I am telling you this as we are here to discuss the Vue.js best practices for web development. I am telling you this so that you can understand my background and why I’m discussing here the Vue.js.
I love working on React codes, but I hate reading them. This is the reason where I fail to code. Even with the best code review practices, I can’t figure out the nesting of React components that simply helps to create more complex UI structures in web apps.
The solution to this problem is Vue that is now not so new in the block of web app development. I have heard a lot about Vue async components, server-side rendering, tools, and libraries. Perhaps you find this myriad of terms to be confusing. Believe me, you’re not alone in that, many developers of all levels feel the same way when they don’t know the Vue best practices.
A few days later, I finally decided to get my codes into it. What I am sharing here are the numerous best practices that I have learned through my experience with Vue. I’m ready to share what I’d find.
#### Let’s Start
Try to learn everything at once on Vue can be overwhelming. Let’s start with the numbers. Today Vue has 147K Github’s stars leaving behind the JS giants like Angular (50.6k stars) and React (135k stars).
**I have split Vue’s best practices into four categories:**
**Vue Functionalities**
Vue’s functionalities have a lot of stuff to discuss under the hood automatically. Vue.js is a simple view-oriented platform that is its first main advantage. All information in coding is valid only if it interacts correctly with the named and nested named views.
Creating a single view is pretty simple in Vue, you only have to load the interface and add JavaScript to start the development of your web app.
```
let vm = new Vue({
el: "#my-webapp",
data: {
firstName: "MyFamous",
lastName: "Magazine",
}
})
```
**Then, a bit of markup to get the final view:**
```
Hello, {{firstName}} {{lastName}}!
==================================
```
**What does the above code reveal?**
The above coding example shows how Vue automatically renders elements without using codes. Simple syntax is used to send the data to view directly. Adding instance properties can be used for Vue elements rendering.
Vue systems such as JQuery keep the information in DOM and for all the additional changes developers need to perform rendering and modification of the related parts. Let’s move onto the other parts of Vue functionalities.
**Components**
For web apps, Vue developers can use components just like other libraries by using Vue.compoment. A component can include a name, configuration or identifier.
```
Vue.component('component-name', {
/* options */
})
```
The single-file components work very well for small to medium-sized web development projects. It is pretty easy to use Vue components in a single file and because of the benefits of JavaScript logic, CSS styling, and HTML code template. Also, see an example:
```
{{ hi }}
export default {
data() {
return {
hi: 'Hi Folks!'
}
}
}
p {
color: yellow;
}
```
Vue single file components use WebPack to provide the ability to use and apply modern web features to your web app. Coders can specify a template built using Pug using preprocessors:
TypeScript
SCSS
Sass
Less
PostCSS
Pug
Vue `v-bind` function allows components to accept data from the parent components (Props) that can be seen in the array of strings:
```
props:{
title: String,
likes: Number,
isPublished: Boolean,
commentIds: Array,
author: Object,
callback: Function,
contactsPromise: Promise // or any other constructor
}
```
This will not only document your components but will also warn you when you pass a wrong code type in the browser’s JavaScript console.
In short, Vue offers great flexibility to web app developers that suits different development strategies and also facilitates the interaction with different Vue libraries.
**Events and Handlers to Handle Errors in Vue**Vue JS is a progressive JS framework that focuses on the view layer and a system of supporting libraries. For all stages of web app development that use Vue, events are created on the directives `v-on` and colons that are used to identify the event type such as `v-on` click.
**A simple example of v-on can be this:**
```
Add 1
The button above has been clicked {{ counter }} times.
```
**Some examples of HTML DOM Events in Vue:**
on change
on click
on hover
on load
on mouse-out
on mouse-over
on load
**Event Handlers in Vue JS**
Handlers are assigned to deal with the errors occur in the Events. It allows a developer to write the code when a specified event is triggered.
**Conditional Rendering and Loops in Vue**
Conditional rendering in Vue means to remove or add some elements from the DOM if a specified value is true. This is the best way for conditional data binding that allows developers to connect information when a particular condition is true. You can use `v-if` directive for conditional rendering.
**See an example:**
```
Hello Vuejs
===========
Click
export default{
data:function(){
return{
isActive:false
}
}
}
```
**You can use v-else to extend the v-if directive:**
```
Hello Vuejs
===========
Hey Vuejs
=========
```
**You can extend it further by using v-else-if block:**
```
Hello Vuejs
===========
You're vuejs
============
Hey Vuejs
=========
```
If the value that a programmer wants to evaluate is true, then run the `v-if` template. For further extensions, `v-else` or `v-if-else` directive is triggered.
Vue JS contains a simple API protocol that allows making space for the v-for directive that renders a list of items into the DOM.
**Example:**
```
* {{user.name}}
export default{
data:function(){
return{
users:[
{id:1,name:"samuel"},
{id:2,name:"queen"},
{id:3,name:"rinha"},
]
}
}
}
```
In the above coding, a loop runs through the code in the form of the array using `v-for` directive. The array refers to objects that allow users to see properties present inside the array.
**Output:**
```
samuel
queen
rinha
```
**Two-way data binding to speed up the development process**
One of the main features of Vue is its reactive two-way binding that keeps your data, arrays, and variables in sync with DOM without requiring you to do anything else. Vue uses `v-model` directive for two-way binding. The `v-model` directive binds the input element to the name property using `v-model` directives that update the input field and also updates the name property field linked to it.
**How does it work?**
```
{{name}}
export default{
data:function(){
return{
name:""
}
}
}
{{name}}
export default{
data:function(){
return{
name:""
}
}
}
```
The `v-model` directive comes with the option of `.lazy` modifier that updates the data property after change event occurs.
You can also use `.trim` function to remove the white space from your code.
The option of `.number` modifier is there if you want to accept numbers to the input field.
Finally, these are key strengths of Vue.js that you can use to code your web apps correctly. So, if you are starting out a new web development project, then Vue.js is your choice. It leads the game with its elegant features, style guidelines, easy coding, and also save your efforts.
|
https://habr.com/ru/post/465409/
| null |
en
| null |
# PPM-to-USB адаптер на STM32F3Discovery, или Подключаем авиамодельный пульт к компьютеру как HID-джойстик с STM32Cube
В этой статье я расскажу, как:
* Создать проект в STM32CubeMX и настроить таймеры для захвата внешних сигналов.
* Декодировать PPM-сигнал с авиамодельного пульта.
* Сделать Human Interface Device на STM32 и написать свой HID Report Descriptor.
* Полетать в симуляторе на гоночном квадрокоптере. :)
### **Предисловие**
В последнее время всё большую популярность набирают FPV-гонки на квадрокоптерах 250-го класса (FPV – First Person View). Число 250 означает расстояние между осями моторов по диагонали, типичное для маленьких манёвренных коптеров. Такие аппараты строят на прочных карбоновых рамах, выдерживающих падения и столкновения. На мощные моторы ставят пропеллеры диаметром 5-6 дюймов с большим шагом (углом наклона лопастей) для максимально динамичного полёта. Изображение с аналоговой курсовой видеокамеры передаётся на частоте 5.8ГГц на монитор или видео-очки пилота. Поскольку цифровая передача через WiFi создаёт большую задержку (200-300 мс), видео всегда транслируется по аналоговому каналу. Для записи эффектных роликов на борт ставят action-камеры (GoPro, Mobius, SJcam, Xiaomi Yi и др.).

**Вот несколько захватывающих видео про FPV-коптеры:**
Перед тем, как строить свой мини-квадрокоптер, мне хотелось полетать в симуляторе и понять, будут ли мне интересны FPV-гонки. Для тренировок хорошо подходит симулятор [FPV FreeRider](http://fpv-freerider.itch.io/fpv-freerider). Он недорогой, имеет бесплатную демо-версию и, по словам опытных пилотов, весьма точно имитирует реальную механику полёта.
Управлять летательным аппаратом в симуляторе можно с клавиатуры или с джойстика. Клавиатура плохо подходит для пилотирования, так как кнопками можно передать лишь дискретное значение (кнопка нажата/не нажата) и нельзя передать плавно изменяющиеся промежуточные значения. Джойстики от игровых консолей с аналоговыми стиками подходят намного лучше, однако у них весьма маленький ход стика, что не позволяет управлять аппаратом достаточно точно. Идеальный вариант для симулятора – это авиамодельный пульт, подключенный к компьютеру через специальный переходник, благодаря которому операционная система видит его как джойстик.
У меня уже был один квадрокоптер, собранный для неспешных полётов и фотосъёмки, но слишком большой и тяжёлый для гонок. Соответственно, был и пульт – Turnigy 9X (на первой иллюстрации). На задней стороне у него есть разъём для подключения адаптера, на который выводится сигнал PPM. Этот сигнал представляет собой короткие импульсы с интервалами от 1 до 2 миллисекунд, длительности которых соответствуют положению органов управления (подробнее о нём в разделе про декодирование).

Надо сказать, что переходники для подключения пульта с PPM к USB уже давно выпускаются и вовсю продаются. Подобный переходник в форм-факторе флешки можно купить за 5 долларов в Китае или немного дороже в российских магазинах. Существуют и [open-source проекты](http://thomaspfeifer.net/ppm2usb_adapter_en.htm) адаптеров на контроллерах AVR.
Но острое желание немедленно полетать пришло ко мне поздно вечером, когда все московские авиамодельные магазины были уже закрыты. Ждать утра не хотелось, травить и паять плату с ATmega было некогда, поэтому я решил сделать адаптер PPM-USB на плате STM32F3Discovery, которая давно лежала без дела и как раз оказалась под рукой.
### **Что потребуется**
Для того, чтобы сделать переходник, понадобятся:
* Плата [STM32F3Discovery](http://www.st.com/web/catalog/tools/FM116/SC959/SS1532/PF254044). Подойдёт любая плата с STM32, у которого есть аппаратный USB, разведённый на плате.
* Двухжильный провод c мини-джеком 3,5 мм с одной стороны (для Turnigy) и двумя BLS-разъёмами, надеваемыми на штыри, с другой (для Discovery).
* Генератор кода [STM32CubeMX](http://www.st.com/stm32cube).
* IDE с компилятором для ARM. Я использую [Keil uVision 5](http://www.keil.com/uvision/). Бесплатная демонстрационная версия поддерживает проекты с исполняемым кодом до 32 кБ, этого хватит для нашей несложной задачи.
* Пульт Turnigy 9X или любой другой с PPM-выходом. Проект был также успешно протестирован с FlySky FS-i6.
Отладочные платы Discovery весьма дорогие. Описываемая F3 стоит около $20 и её возможности избыточны для такого простого проекта. Я использовал её, потому что на момент написания статьи это была единственная плата с аппаратным USB, что нашлась у меня дома. Тем, кто ещё не покупал её, могу посоветовать обратить внимание на миниатюрные платы с контроллером [STM32F103C8T6 с AliExpress за $3](http://ru.aliexpress.com/wholesale?shipCountry=ru&SearchText=stm32f103c8t6+board) и программатор ST-Link оттуда же. Процесс работы не отличается от описанного в статье. Разве что надо будет выбрать в начале другой контроллер, указать наличие кварцевого резонатора и использовать чуть другую распиновку.

### **Создание проекта в STM32CubeMX**
STM32Cube – это комплекс, разработанный STMicroelectronics для того, чтобы облегчить жизнь разработчикам устройств на STM32. Он состоит из графической утилиты CubeMX, HAL-драйверов и Middleware-компонентов.
*CubeMX* – инструмент для создания проектов и инициализации периферии. Чтобы начать работу, достаточно выбрать контроллер, расставить галочки напротив нужных модулей, выбрать в меню требуемые режимы и в нескольких полях ввести желаемые значения. CubeMX сам сгенерирует проект и подключит к нему необходимые библиотеки. Разработчику устройства останется только написать логику работы приложения.
*HAL-драйверы* (Hardware Abstraction Layer) представляют собой API для работы с модулями и периферией микроконтроллера. HAL позволяет отделить верхний слой приложения, которое создаёт разработчик, от работы с регистрами и сделать код программы максимально переносимым между семействами контроллеров STM32.
*Middlewares*, или промежуточные компоненты, включают операционную систему FreeRTOS, библиотеку для работы с файловой системой, библиотеки USB, TCP/IP и т.д.
Казалось бы, теперь можно «программировать мышкой» вместо того, чтобы вручную записывать биты в регистры. Но простота и удобство не отменяют того, что нужно изучать документацию, особенно в случаях, когда надо выжать максимум быстродействия, минимум энергопотребления или использовать периферию в нестандартных режимах. STM32Cube пока ещё не покрывает на 100% всех возможностей микроконтроллера, но приближается к этому. STMicroelectronics время от времени обновляют Cube, расширяют функции и исправляют ошибки. Поэтому, если у вас уже установлен Cube, проверьте, чтоб он был последней версии.
##### **Начальные настройки**
Работа с проектом начинается с выбора контроллера. Запускаем STM32CubeMX, нажимаем *New Project*. На вкладке *MCU Selector* можно по фильтрам подобрать желаемый контроллер. Так как у нас готовая отладочная плата, то на вкладке *Board Selector*, находим *STM32F3Discovery*. После выбора платы появится изображение контроллера с подсвеченными и подписанными пинами.
В верхней части окна четыре больших вкладки:
*Pinout* – для настройки функций пинов и предварительной настройки модулей. На ней мы находимся в данный момент.
*Clock Configuration* – настройка тактирования, PLL, делителей.
*Configuration* – более детальная настройка периферии и middleware.
*Power Consumption Calculator* – расчёт потребляемой микроконтроллером мощности.
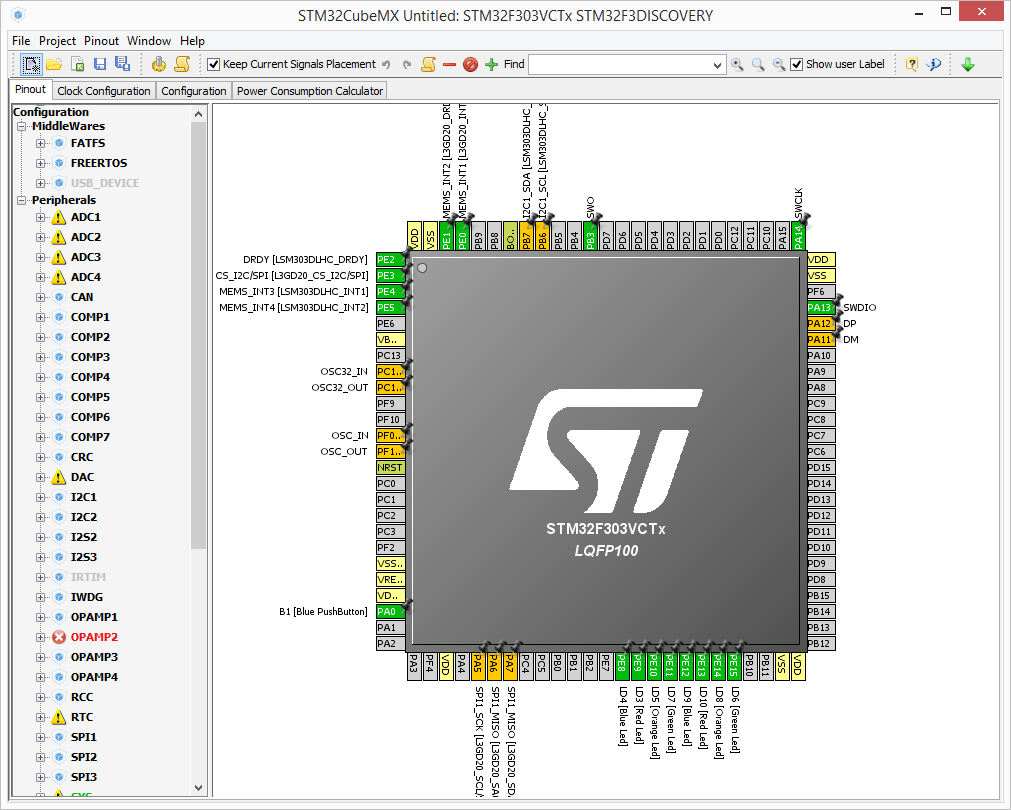
В левом меню на вкладке *Pinout* можно задействовать нужную периферию, а на схеме контроллера выбрать функцию для любого из выводов микроконтроллера. Напротив некоторых пунктов слева стоят значки предупреждений. Это значит, что модули (в данном случае ADC, DAC, OPAMP2, RTC) сейчас можно использовать не полностью, так некоторые их выводы уже заняты другими функциями.
Зелёным на схеме контроллера подсвечены настроенные пины. Поскольку мы выбрали не голый контроллер без обвязки, а готовую отладочную плату F3-Discovery, то некоторые выводы уже сконфигурированы, например, к PA0 подключена синяя кнопка, а к PE8...15 – светодиоды. Оранжевым выделены те пины, к которым на Discovery подключены какие-то внешние устройства, но периферийные модули для них ещё не настроены. Как видим, это пины для USB, кварцевых резонаторов, SPI и I2C для гироскопа и компаса, DP и DM для USB. Серые выводы в данный момент не используются, любые из них мы можем применить для своих целей.
##### **Выбор входа**
Мы собираемся захватывать длительности импульсов, значит вход должен быть подключен к одному из каналов любого таймера. Кроме того, уровень сигнала с Turnigy 9X не 3,3В, как напряжение питания STM32, а 5В. Паять делитель напряжения нам лень, поэтому надо выбрать вход, который выдержит 5В (такие входы называют 5V-tolerant). Подходящие пины можно посмотреть в [datasheet](http://www.st.com/web/en/resource/technical/document/datasheet/DM00058181.pdf) на STM32F303VCT6 в разделе *Pinouts and Pin Description*. Таймеров в STM32F3 много, они разбросаны почти по всем пинам. Удобный вариант – PC6. Он выдерживает 5 Вольт и находится в левом нижнем углу платы, рядом с GND. Назначим на этот пин 1-й канал 3-го таймера TIM3\_CH1.
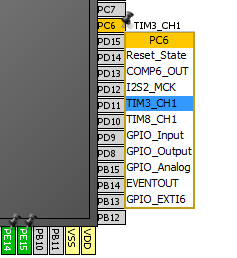
##### **Настройка тактирования**
Для работы USB микроконтроллер должен тактироваться от очень стабильной частоты, именно поэтому почти во всех USB-устройствах установлены кварцевые резонаторы. Стабильности частоты встроенного RC-генератора недостаточно для USB. Но на плате STM32F3 Discovery разработчики по какой-то причине пожадничали и не поставили кварц. Однако, если внимательно изучить [схему](http://www.st.com/st-web-ui/static/active/en/resource/technical/layouts_and_diagrams/schematic_pack/stm32f3discovery_sch.zip), то можно увидеть, что на вход *PF0-OSC\_IN*, куда должен подключаться кварц, подведён сигнал *MCO*. Он поступает от программатора ST-Link на этой же плате, в котором кварц есть. В [User Manual](http://www.st.com/st-web-ui/static/active/en/resource/technical/document/user_manual/DM00063382.pdf) для F3 Discovery (UM1570) в разделе *OSC Clock* сказано, что на эту линию подаются 8 МГц.
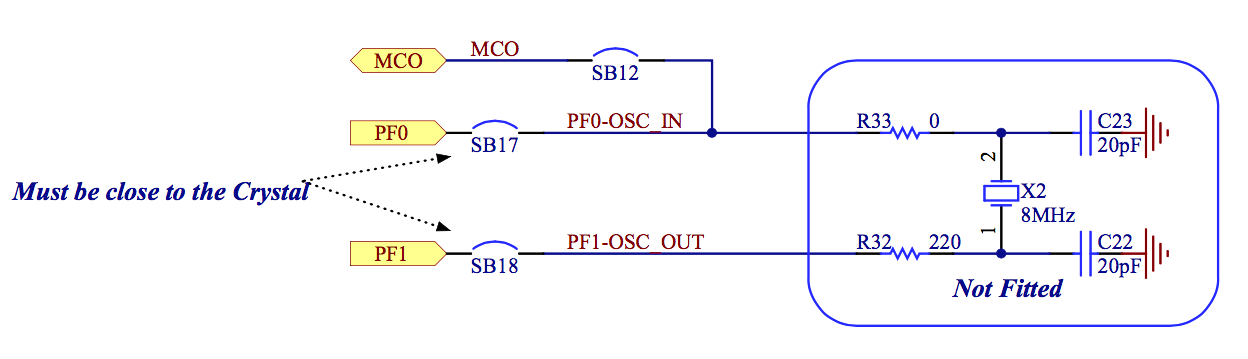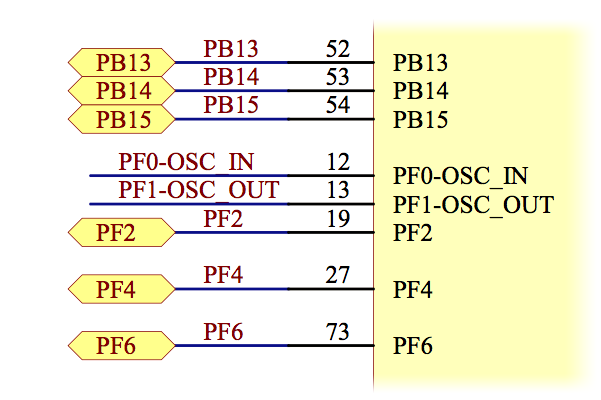
Таким образом, микроконтроллер тактируется от внешнего источника. Этот режим называется Bypass. В меню настройки периферии в разделе *RCC* для тактирования *High Speed Clock* выберем *BYPASS Clock Source*.
Перед тем, как приступить к более детальной настройке тактирования, отметим в меню периферии, что микроконтроллер будет выступать в роли USB-устройства.

Теперь можно перейти к следующей большой вкладке – *Clock Configuration*. Здесь мы увидим огромную схему, на которой показано, какие тактовые сигналы присутствуют в микроконтроллере, откуда они берутся, как они ветвятся, умножаются и делятся. Жёлтым цветом я выделил те параметры, на которые следует обратить внимание.
Проверим, что входная частота *Input Frequency* равна 8 МГц.
Переключатель *PLL Source Mux* ставим в положение *HSE* (High Speed External), чтоб тактироваться от внешнего, а не внутреннего источника.
*PLL* – Phase Lock Loop, или ФАПЧ – фазовая автоподстройка частоты, служит для умножения внешней частоты в несколько раз. Множитель *PLLMul* настроим на 9. Тогда мы достигнем максимальной возможной частоты для STM32F303 – 72 МГц.
*System Clock Mux* должен находиться в положении *PLLCLK*, чтобы для тактирования контроллера использовалась умноженная частота с PLL.
Для модуля USB нужно 48 МГц, поэтому поставим делитель 1,5 перед USB.
Обратим внимание на частоту *APB1 timer clocks* в левой части схемы. Она подаётся на таймеры и пригодится нам в дальнейшем.
Если какая-то частота настроена некорректно, превышает максимально возможное значение или переключатели находятся в недопустимом положении, то CubeMX выделит это место красным.
##### **Настройка таймера**
Для измерения длительности импульсов мы запустим таймер TIM3 в режиме захвата Input Capture. В [Reference Manual](http://www.st.com/web/en/resource/technical/document/reference_manual/DM00043574.pdf) в разделе *General-purpose timers (TIM2/TIM3/TIM4)* есть схема иллюстрирующая работу таймеров. Цветами я выделил сигналы и регистры, используемые в режиме Input Capture.
Сигнал тактирования, выделенный зелёным, непрерывно приходит в регистр счётчика CNT и увеличивает его значение на 1 каждый такт. В делителе *Prescaler PSC* частота тактового сигнала может уменьшаться для более медленного отсчёта.
На вход *TIMx\_CH1* приходит внешний сигнал. *Edge Detector* распознаёт фронты входного сигнала – переходы из 0 в 1 или из 1 в 0. При регистрации фронта он подаёт две команды, выделенные жёлтым:
– команда для записи значения счётчика *CNT* в регистр *Capture/compare 1 register (CCR1)* и вызов прерывания *CC1I*.
– команда для *Slave mode controller*, по которой значение *CNT* сбрасывается в 0 и отсчёт начинается сначала.
Вот иллюстрация процесса на временной диаграмме:
При возниконовении прерывания мы будем совершать действия с захваченным значением. Если входные импульсы приходят слишком часто, а действия, происходящие в обработчике прерывания, слишком долгие, то значение CCR1 может перезаписаться до того, как мы прочитали предыдущее. В этом случае нужно проверять флаг перезаписи (Overcapture) или же применять DMA (Direct Memory Access), когда данные из CCR1 автоматически заполняют заранее подготовленный массив в памяти. В нашем случае самый короткий импульс имеет длительность 1 миллисекунду, а обработчик прерывания будет простым и коротким, поэтому беспокоиться о перезаписи не стоит.
Вернёмся на вкладку *Pinout* и настроим таймер *TIM3* в меню *Peripherals*.
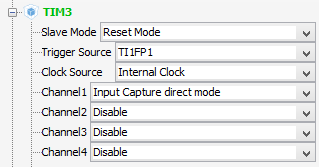
*Slave Mode: Reset Mode* – означает, что при некотором событии таймер будет сбрасываться на 0.
*Trigger Source: TI1FP1* – событие, используемое для сброса и запуска таймера – это фронт сигнала, захваченный со входа TI1.
*ClockSource: Internal Clock* – таймер тактируется от внутреннего генератора микроконтроллера.
*Channel 1: Input Capture direct mode* – захват интервалов с 1-го канала в регистр CCR1.
На следующей большой вкладке *Configuration* сделаем дополнительные настройки таймера.
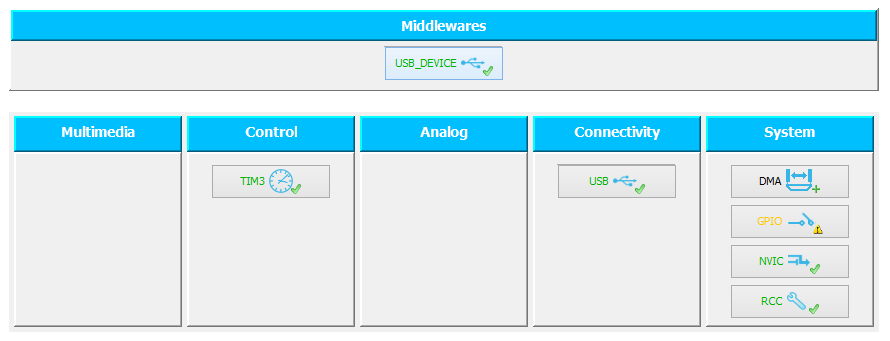
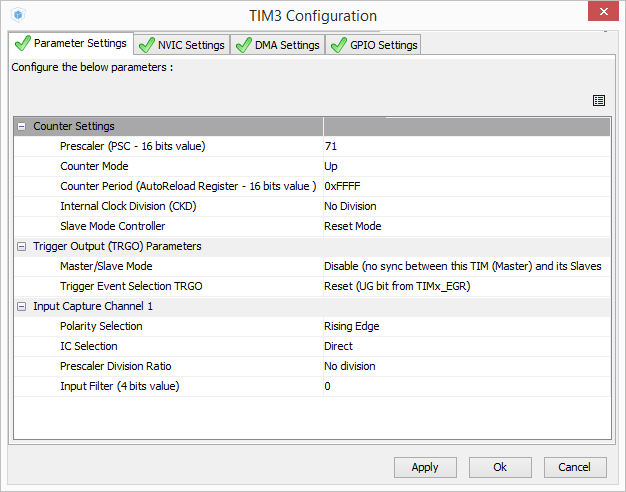
*Prescaler* – делитель таймера. Если он равен 0, частота берётся напрямую с шины тактирования APB clock – 72 МГц. Если prescaler равен 1 – частота делится на 2 и становится равной 36 МГц. Установим делитель на 71, чтобы частота делилась на 72. Тогда частота таймера будет равна 1 МГц и интервалы будут измеряться с разрешением в 1 микросекунду.
*Counter Period* – установим максимально возможное 16-битное значение 0xFFFF. Период важен для генерации временных интервалов, например, для ШИМ. Но для захвата сигналов период не важен, сделаем его заведомо большим любых входных импульсов.
*Polarity Selection: Falling Edge* – значения таймера будут захватываться по заднему фронту сигнала на входе.
На вкладке *NVIC Settings* поставим галку *TIM3 global interrupt*, чтобы при событиях, связанных с 3-м таймером генерировалось прерывание.
##### **Настройка USB-device**
Мы уже отметили, что контроллер будет USB-устройством. Так как джойстик относится к классу HID-устройств, то в меню *Middlewares -> USB\_DEVICE* выберем *Class For FS IP: Human Interface Device Class (HID)*. Тогда CubeMX подключит к проекту библиотеки для HID-устройства.

Зайдём в настройки *USB\_DEVICE* на вкладке *Configuration* в разделе *Middlewares*:
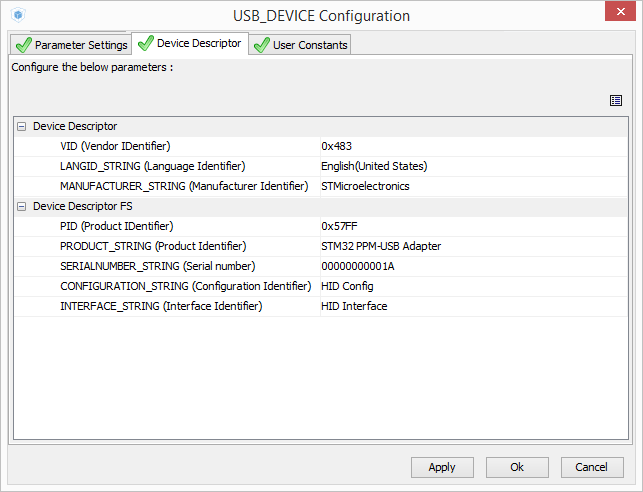
*Vendor ID* и *Product ID* – это два 16-битных идентификатора, уникальных для каждой модели USB-устройств. VID соответствует производителю устройства, а PID каждый производитель присваивает, руководствуясь своими соображениями. Официальный список VID и PID мне найти не удалось, я отыскал лишь [базу идентификаторов](http://www.linux-usb.org/usb.ids), поддерживаемую энтузиастами. Чтобы заиметь собственный Vendor ID, нужно обратиться к USB Implementers Forum на [usb.org](http://www.usb.org/developers/vendor/) и заплатить несколько тысяч долларов. Небольшие компании или open-source разработчики, которым не по карману свой VID, могут обратиться с запросом к производителю USB-микросхем и официально получить для своего проекту пару VID/PID. Такую услугу предлагают, например, FTDI или Silicon Laboratories.
Если подключить к компьютеру два устройства с одинаковыми VID/PID, но разного типа (например, одно – HID-устройство, а другое – Mass Storage), то операционная система попытается установить для них один и тот же драйвер, и как минимум одно из них работать не будет. Именно поэтому пары VID/PID для разных моделей устройств должны быть уникальными.
Поскольку устройство мы делаем для себя, продавать и распространять его не собираемся, то оставим VID 0x0483, соответствующий STMicroelectronics, а PID придумаем свой. По умолчанию CubeMX предлагает PID 0х5710 для HID-устройства. Заменим его, например, на 0x57FF.
Строку *Product string* заменим на *STM32 PPM-USB Adapter*. Это название будет отображаться в списке устройств в панели управления Windows. Серийный номер (S\N) пока менять не будем.
Когда Windows обнаруживает обнаруживает устройство с комбинацией VID, PID и S\N, которая раньше ей не встречалась, система устанавливает для него соответствующий драйвер. Если же комбинация VID, PID и S\N уже использовалась, то Windows автоматически подставляет ранее использованный драйвер. Вы можете это увидеть, например, когда подключаете Flash-накопитель к USB. Первый раз подключение и установка занимает некоторое время. При последующих подключениях накопитель начинает работу почти мгновенно. Однако, если подключить другой экземпляр Flash-накопителя той же модели, но с другим серийным номером, то система будет ставить для него новый драйвер, даже несмотря на то, что VID и PID у него те же самые.
Поясню, почему это важно. Если Вы создали на STM32 USB-мышь со своими VID, PID и S\N, подключили её к компьютеру, а затем сделали USB-джойстик, не изменив VID, PID и S\N, то Windows воспримет новое устройство как мышь, которая уже использовалась в системе, и не будет устанавливать драйвер джойстика. Соответственно, джойстик работать не будет. Поэтому, если хотите изменить тип своего устройства, оставив VID/PID без изменений, то обязательно меняйте его серийный номер.
##### **Генерирование проекта для IDE**
Последние настройки, которые нужно сделать – это настройки генерирования проекта. Это делается через *Project -> Settings*… Там мы зададим имя, папку назначения и желаемую IDE, под которую CubeMX создаст проект. Я выбрал *MDK-ARM V5*, так как пользуюсь Keil uVision 5. На вкладке *Code Generator* можно поставить галку *Copy only the necessary library files*, чтобы не загромождать проект лишними файлами.
Нажимаем кнопку *Project -> Generate code*. CubeMX создаст проект с кодом, который можно открыть в Keil uVision и без дополнительных настроек скомпилировать и прошить. В файле *main.c* в функции *main(void)* уже вставлены функции для инициализации тактирования, портов, таймера и USB. В них модули микроконтроллера настраиваются в соответствии с теми режимами, которые мы задали в CubeMX.
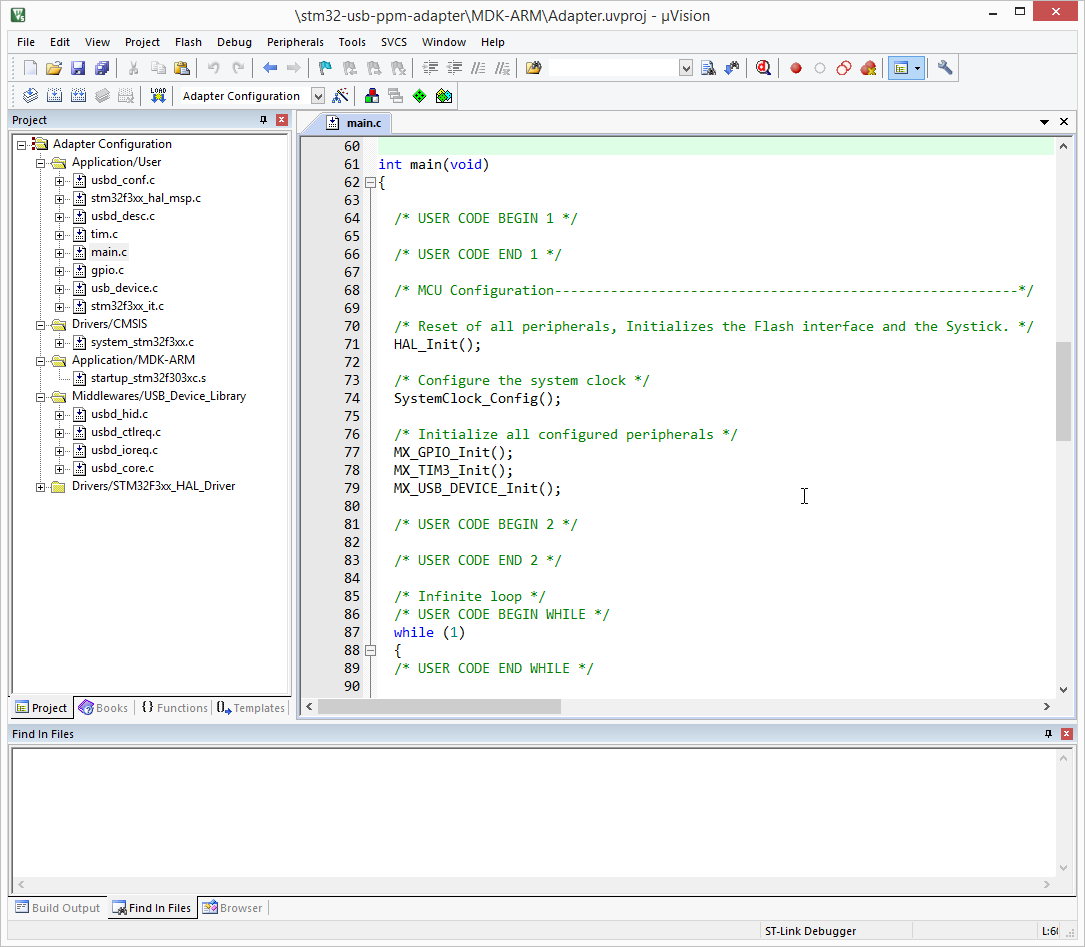
В коде часто встречаются конструкции такого вида:
```
/* USER CODE BEGIN 0 */
(...)
/* USER CODE END 0 */
```
Предполагается, что пользователь будет вставлять свой код в эти секции. Если в настройках проекта CubeMX включена опция *Keep User Code when re-generating*, то при вторичном генерировании уже существующего проекта код, заключённый между этими строками, перезаписываться не будет. К сожалению, сохраняются только секции, созданные CubeMX. Секции */\* USER CODE \*/*, созданные пользователем, будут утеряны. Поэтому, если вы после написания кода в IDE хотите вернуться в CubeMX и сгенерировать проект заново с новыми настройками, рекомендую сделать резервную копию проекта.
В настройках прошивки в uVision (*Flash -> Configure Flash Tools*) советую включить опцию *Reset after flash*, чтобы микроконтроллер стартовал сразу после перепрошивки. По умолчанию она отключена, и после каждой перепрошивки приходится нажимать кнопку Reset на плате.
### **Декодирование PPM-сигнала**
PPM – Pulse Position Modulation – метод кодирования передаваемых сигналов, очень широко распространённый в авиамодельной электронике. Он представляет собой последовательности импульсов, временные интервалы между которыми соответствуют передаваемым числовым значениям.
По этому протоколу пульт посылает информацию передающему радио-модулю, который вставляется в пульт сзади. Многие приёмники, которые ставятся на борт коптера, могут передавать сигналы управления для полётного контроллера посредством PPM. Кроме того, почти в любом пульте есть разъёмы для подключения второго пульта в режиме тренер-ученик и для подключения пульта к симулятору, в которых тоже, как правило, используется PPM.
Запишем логическим анализатором сигнал с симуляторного выхода Turnigy 9X:

Каждая последовательность кодирует текущее состояние органов управления на пульте. Обычно первые четыре значения (их ещё называют каналами) соответствуют положению аналоговых стиков, а последующие – положению тумблеров или потенциометров.
Минимальному положению органа управления соответствует интервал 1000 мкс, максимальному – 2000 мкс, среднему положению – 1500 мкс. Пачки импульсов, или кадры, разделяются существенно бОльшими интервалами и следуют с периодом 20–25 мс.
Рассмотрим сигнал поближе:

Как видим, три стика стоят в нейтральном положении (1, 3, 4), а один находится в крайнем положении (2). Три тумблера выключены (5, 6, 7), а последний включен (8). Микроконтроллер, выступающий в роли адаптера, должен захватить такую последовательность, сложить значения в массив и послать его по USB как команду с джойстика. Напишем декодер последовательности импульсов.
##### **Прерывание по захвату**
После инициализации в *main.c* перед основным циклом *while* запустим таймер TIM3 в режиме захвата Input Capture с 1-го канала, с генерацией прерываний по захвату. Для этого используем соответствующую функцию из HAL:
```
HAL_TIM_IC_Start_IT(&htim3, TIM_CHANNEL_1);
```
Структура *htim3*, объявленная в *main.c* – это handler таймера TIM3, который содержит в себе все структуры и переменные, связанные с таймером: параметры для инициализации, указатели на все регистры таймера (значение счётчика, делителя, все настройки, флаги прерываний), указатель на handler DMA, который работает с этим таймером и т.д. Разработчику не требуется искать, какие биты в каком регистре за что отвечают и вручную их устанавливать и сбрасывать. Достаточно передать handler в функцию HAL. Всё остальное HAL-библиотеки сделают сами.
Про принципы строения HAL более подробно рассказывается в документе [Description of STM32F3xx HAL drivers](http://www.st.com/st-web-ui/static/active/jp/resource/technical/document/user_manual/DM00122016.pdf) (UM1786). Надо отметить, что сами библиотеки HAL хорошо документированы. Чтобы разобраться, как работает HAL для таймером и как им пользоваться, можно почитать комментарии в файлах *stm32f3xx\_hal\_tim.h* и *stm32f3xx\_hal\_tim.c*.
При каждом прерывании, которое генерирует таймер TIM3, вызывается обработчик *TIM3\_IRQHandler*. Он находится в файле *stm32f3xx\_it.c*, в нём в свою очередь вызывается стандартный для всех таймеров обработчик *HAL\_TIM\_IRQHandler*, и в него передаётся указатель на структуру htim3.
```
void TIM3_IRQHandler(void)
{
/* USER CODE BEGIN TIM3_IRQn 0 */
/* USER CODE END TIM3_IRQn 0 */
HAL_TIM_IRQHandler(&htim3);
/* USER CODE BEGIN TIM3_IRQn 1 */
/* USER CODE END TIM3_IRQn 1 */
}
```
Если мы заглянем внутрь *HAL\_TIM\_IRQHandler* в файле *stm32f3xx\_hal\_tim.c*, то увидим огромный обработчик, который проверяет флаги прерываний для таймера, вызывает callback-функции и очищает флаги после выполнения. Если случилось событие захвата, то он вызывает функцию *HAL\_TIM\_IC\_CaptureCallback*. Она выглядит так:
```
__weak void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef *htim)
{
/* NOTE : This function Should not be modified, when the callback is needed, the __HAL_TIM_IC_CaptureCallback could be implemented in the user file
*/
}
```
Это означает, что мы можем переопределить эту функцию в *main.c*. Поэтому вставим перед функцией *int main(void)* этот callback:
```
void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef *htim)
{
};
```
Хотелось бы посмотреть, как выполняется прерывание. Добавим в него быстрое включение-выключение одного из выводов:
```
void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef *htim)
{
HAL_GPIO_WritePin(GPIOE, GPIO_PIN_8, GPIO_PIN_SET);
__nop();__nop();__nop();__nop();__nop();__nop();
HAL_GPIO_WritePin(GPIOE, GPIO_PIN_8, GPIO_PIN_RESET);
};
```
Вывод PE8 уже был инициализирован как выход. Между включением и выключением вставлены инструкции *\_\_nop()*, что формирует задержку на 1 такт. Это сделано, чтобы мой китайский логический анализатор за $8, работающий на частоте 24 МГц не пропустил слишком короткий импульс от микроконтроллера, работающего на 72 МГц. Теперь скомпилируем проект *Project -> Build target* и прошьём контроллер *Flash -> Download*. Подключим PPM от пульта к PC6, и посмотрим анализатором, что происходит на PC6 и PE8.
Callback действительно вызывается в нужные моменты – сразу после того, как произошёл переход входного сигнала из 1 в 0. Значит, всё было сделано правильно.
##### **Сбор и обработка захваченных данных**
Отредактируем callback, чтобы каждое захваченное значение он складывал в буфер *captured\_value* без изменений. Если таймер захватил очень большое значение (больше 5000 мкс), это значит, что была зафиксирована пауза, пакет принят целиком и его можно обрабатывать. Обработанные значения складываются в массив *rc\_data* из 5 элементов. В первые четыре складываются положения стиков, приведённые к диапазону [0; 1000], в пятом выставляются отдельные биты в соответствии с тумблерами, которые будут интерпретироваться как нажатия кнопок на геймпаде.
```
uint16_t captured_value[8] = {0};
uint16_t rc_data[5] = {0};
uint8_t pointer = 0;
uint8_t data_ready = 0;
...
void HAL_TIM_IC_CaptureCallback(TIM_HandleTypeDef *htim)
{
uint8_t i;
uint16_t temp;
// считываем значение из регистра захвата
temp = HAL_TIM_ReadCapturedValue(htim, TIM_CHANNEL_1);
// если интервал слишком длинный, значит, пакет принят
if ((temp > 5000) && (!data_ready))
{
pointer = 0;
// приводим четыре значения со стиков к диапазону [0;1000]
for (i = 0; i < 4; i++)
{
if (captured_value[i] < 1000)
captured_value[i] = 1000;
else if (captured_value[i] > 2000)
captured_value[i] = 2000;
rc_data[i] = captured_value[i]-1000;
};
// записываем положения тумблеров как биты
rc_data[4] = 0;
if (captured_value[4] > 1500)
rc_data[4] |= (1<<4);
if (captured_value[5] > 1500)
rc_data[4] |= (1<<5);
if (captured_value[6] > 1500)
rc_data[4] |= (1<<6);
if (captured_value[7] > 1500)
rc_data[4] |= (1<<7);
data_ready = 1;
}
else // сохраняем одно принятое значение в буфер
{
captured_value[pointer] = temp;
pointer++;
};
if (pointer == 8) // защита от переполнения
pointer = 0;
}
```
Поясню, почему я разместил биты, соответствующие кнопкам, не в младшие 4 бита, а в биты с пятого по восьмой. В симуляторе предполагается подключать геймпад от Xbox, где используются кнопки LB, RB, Start и Back, а они имеют номера с 5 по 8.
В главном цикле будет непрерывно крутиться проверка флага data\_ready, по которому данные будут отправляться на компьютер.
```
while (1)
{
if (data_ready)
{
// здесь будет отправка данных на ПК
data_ready = 0;
}
}
```
Чтобы проверить, как это работает, подключим пульт, снова скомпилируем и прошьём, а потом запустим отладку *Debug -> Start/Stop Debug Session*.
Откроем окно для отслеживания переменных *View -> Watch Windows -> Watch 1* и добавим туда *captured\_value* и *rc\_data*.
Запустим отладку командой *Debug -> Run* и в режиме реального времени, даже не добавляя точек останова, увидим, как вслед за движениями стиков меняются числа.
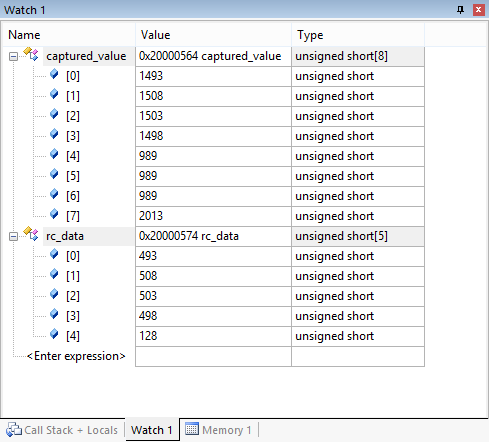
Дальше нужно отправить данные на компьютер в виде команды джойстика.
### **Настройка HID-устройства и создание HID Report Descriptor**
USB HID (Human Interface Device) – это класс устройств для взаимодействия человека с компьютером. К ним относятся клавиатуры, мыши, джойстики, геймпады, сенсорные панели. Главное преимущество HID-устройств в том, что для них не требуется специальных драйверов в любых операционных системах: Windows, OS X, Android и даже iOS (через USB-Lightning adapter). Подробное описание можно прочитать в документе [Device Class Definition for HID](http://www.usb.org/developers/hidpage/HID1_11.pdf). Главное, что нам необходимо знать для создания PPM-USB-адаптера – что такое *HID Report* и *HID Report Descriptor*.
HID-устройство посылает на компьютер пакеты байт в заранее установленном формате. Каждый такой пакет – это HID Report. О формате данных устройство сообщает компьютеру при подключении, отправляя HID Report Descriptor – описание пакета, в котором указывается, сколько байт содержит пакет и назначение каждого байта и бита в пакете. Например, HID Report простой мыши состоит из четырёх байт: в первом байте содержится информацию о нажатых кнопках, во втором и третьем байте – относительное перемещение курсора по X и Y, а четвёртый байт – вращение колеса прокрутки. Report Descriptor хранится в памяти контроллера устройства в виде массива байтов.
Перед тем, как создавать дескриптор, я хотел бы отдельно остановиться на терминологии. В англоязычной среде распространены два термина – *joystick* и *gamepad*. Словом *joystick* принято называть манипулятор, который держат одной рукой и наклоняют в разные стороны, а *gamepad* – устройство с кнопками и стиками, которое держат двумя руками. Русскоязычные пользователи обычно называют джойстиком и то, и другое. В описании HID-устройства между джойстиком и геймпадом есть разница. Авиамодельный пульт больше похож по своему функциональному назначению на геймпад, поэтому в дальнейшем я иногда буду использовать термин «геймпад».
Мы сгенерировали проект, указав, что устройство будет выступать как Human Interface Device. Это значит, что к проекту подключена библиотека USB HID и уже был сформирован Device Descriptor. Он находится в файле *usbd\_hid.c*, описывает репорт мыши и выглядит так:
**HID\_Mouse\_Report\_Descriptor**
```
__ALIGN_BEGIN static uint8_t HID_MOUSE_ReportDesc[HID_MOUSE_REPORT_DESC_SIZE] __ALIGN_END =
{
0x05, 0x01,
0x09, 0x02,
0xA1, 0x01,
0x09, 0x01,
0xA1, 0x00,
0x05, 0x09,
0x19, 0x01,
0x29, 0x03,
0x15, 0x00,
0x25, 0x01,
0x95, 0x03,
0x75, 0x01,
0x81, 0x02,
0x95, 0x01,
0x75, 0x05,
0x81, 0x01,
0x05, 0x01,
0x09, 0x30,
0x09, 0x31,
0x09, 0x38,
0x15, 0x81,
0x25, 0x7F,
0x75, 0x08,
0x95, 0x03,
0x81, 0x06,
0xC0, 0x09,
0x3c, 0x05,
0xff, 0x09,
0x01, 0x15,
0x00, 0x25,
0x01, 0x75,
0x01, 0x95,
0x02, 0xb1,
0x22, 0x75,
0x06, 0x95,
0x01, 0xb1,
0x01, 0xc0
};
```
Создавать HID Report Descriptor вручную – занятие чрезвычайно трудоёмкое. Для облегчения задачи есть инструмент под названием [HID Descriptor Tool](http://www.usb.org/developers/hidpage#HID%20Descriptor%20Tool) (DT). Этой программой можно составить дескриптор для своего устройства. В архиве с ним можно найти несколько примеров дескрипторов для разных устройств.
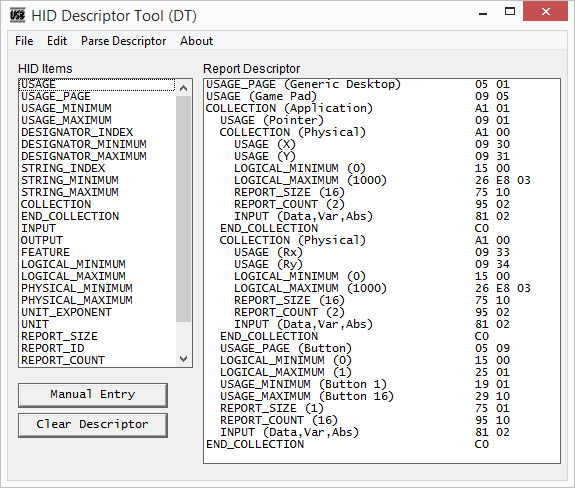
[Здесь](http://eleccelerator.com/tutorial-about-usb-hid-report-descriptors/) очень хорошая статья про создание своего HID-дескриптора для мыши и клавиатуры (на английском). Я расскажу на русском, как сделать дескриптор для геймпада.
HID-Report, отправляемый пультом должен содержать четыре 16-битных значения для двух осей аналоговых стиков и 16 однобитных значений для кнопок. Итого 10 байт. Его дескриптор, созданный в DT, будет выглядеть так:
```
0x05, 0x01, // USAGE_PAGE (Generic Desktop)
0x09, 0x05, // USAGE (Game Pad)
0xa1, 0x01, // COLLECTION (Application)
0x09, 0x01, // USAGE (Pointer)
0xa1, 0x00, // COLLECTION (Physical)
0x09, 0x30, // USAGE (X)
0x09, 0x31, // USAGE (Y)
0x15, 0x00, // LOGICAL_MINIMUM (0)
0x26, 0xe8, 0x03, // LOGICAL_MAXIMUM (1000)
0x75, 0x10, // REPORT_SIZE (16)
0x95, 0x02, // REPORT_COUNT (2)
0x81, 0x02, // INPUT (Data,Var,Abs)
0xc0, // END_COLLECTION
0xa1, 0x00, // COLLECTION (Physical)
0x09, 0x33, // USAGE (Rx)
0x09, 0x34, // USAGE (Ry)
0x15, 0x00, // LOGICAL_MINIMUM (0)
0x26, 0xe8, 0x03, // LOGICAL_MAXIMUM (1000)
0x75, 0x10, // REPORT_SIZE (16)
0x95, 0x02, // REPORT_COUNT (2)
0x81, 0x02, // INPUT (Data,Var,Abs)
0xc0, // END_COLLECTION
0x05, 0x09, // USAGE_PAGE (Button)
0x19, 0x01, // USAGE_MINIMUM (Button 1)
0x29, 0x10, // USAGE_MAXIMUM (Button 16)
0x15, 0x00, // LOGICAL_MINIMUM (0)
0x25, 0x01, // LOGICAL_MAXIMUM (1)
0x75, 0x01, // REPORT_SIZE (1)
0x95, 0x10, // REPORT_COUNT (16)
0x81, 0x02, // INPUT (Data,Var,Abs)
0xc0 // END_COLLECTION
```
Выглядит не менее устрашающе, чем дескриптор мыши. Но если разобраться, что означает каждая строка, всё оказывается вполне понятным и логичным.
USAGE показывает, как система должна интерпретировать данные, которые идут дальше.
Разновидностей Usage бывает очень много, они рассортированы по группам – Usage Pages. Поэтому для того, чтобы выбрать какой-то определённый Usage, надо сначала обратиться к соответствующей USAGE\_PAGE. Про то, какие бывают Usage можно прочитать в документе [Hid Usage Tables](http://www.usb.org/developers/hidpage/Hut1_12v2.pdf). В самом начале дескриптора мы указываем, что будет описываться джойстик:
> USAGE\_PAGE (Generic Desktop)
>
> USAGE (Game Pad)
COLLECTION объединяет в себе несколько связанных друг с другом наборов данных.
Physical Collection используются для данных, относящихся к одной конкретной геометрической точке, например, одному аналоговому стику. Application Collection используется для объединения разных функций в одном устройстве. Например, клавиатура со встроенным трекпадом может иметь две Application Collection. Мы описываем только джойстик, значит, коллекция будет одна:
> COLLECTION (Application)
>
> …
>
> END\_COLLECTION
После этого нужно указать, что будут описываться элементы, передающие координаты. Usage Pointer применяется при описании мыши, джойстиков, геймпадов, дигитайзеров:
> USAGE (Pointer)
Дальше следуют описания аналоговых стиков, объединённых в коллекции:
> COLLECTION (Physical)
>
>
> > USAGE (X)
> >
> > USAGE (Y)
> >
> > LOGICAL\_MINIMUM (0)
> >
> > LOGICAL\_MAXIMUM (1000)
> >
> > REPORT\_SIZE (16)
> >
> > REPORT\_COUNT (2)
> >
> > INPUT (Data,Var,Abs)
>
> END\_COLLECTION
USAGE здесь указывает, что используются значения отклонения по двум осям – X и Y.
LOGICAL\_MINIMUM и LOGICAL\_MAXIMUM задают, в каких пределах может меняться передаваемое значение.
REPORT\_COUNT и REPORT\_SIZE задают, соответственно, сколько чисел и какого размера мы собираемся передать, а именно два 16-битных числа.
INPUT(Data,Var,Abs) означает, что данные поступают от устройства к компьютеру, причём данные эти могут изменяться. Значения в нашем случае абсолютные. От мыши, например, приходят относительные значения для перемещения курсора. Иногда данные описываются как Const, а не Var. Это нужно, чтоб передать не значащие биты. Например, в репорте мыши с тремя кнопками передаются 3 бита Var для кнопок и 5 бит Const, чтобы дополнить размер передачи до одного байта.
Как видим, описания осей X и Y сгруппированы вместе. У них одинаковый размер, одинаковые пределы. Тот же самый аналоговый стик можно было бы описать следующим образом, описывая каждую ось по отдельности. Работать такой дескриптор будет аналогично предыдущему:
> COLLECTION (Physical)
>
>
> > USAGE (X)
> >
> > LOGICAL\_MINIMUM (0)
> >
> > LOGICAL\_MAXIMUM (1000)
> >
> > REPORT\_SIZE (16)
> >
> > REPORT\_COUNT (1)
> >
> > INPUT (Data,Var,Abs)
>
>
> > USAGE (Y)
> >
> > LOGICAL\_MINIMUM (0)
> >
> > LOGICAL\_MAXIMUM (1000)
> >
> > REPORT\_SIZE (16)
> >
> > REPORT\_COUNT (1)
> >
> > INPUT (Data,Var,Abs)
>
> END\_COLLECTION
После первого стика описывается второй аналоговый стик. Его оси имеют другой Usage, чтобы можно было отличить их от первого стика – Rx и Ry:
> COLLECTION (Physical)
>
>
> > USAGE (Rx)
> >
> > USAGE (Ry)
> >
> > LOGICAL\_MINIMUM (0)
> >
> > LOGICAL\_MAXIMUM (1000)
> >
> > REPORT\_SIZE (16)
> >
> > REPORT\_COUNT (2)
> >
> > INPUT (Data,Var,Abs)
>
> END\_COLLECTION
Теперь нужно описать несколько кнопок геймпада. Это можно сделать следующим образом:
> USAGE\_PAGE (Button)
>
> USAGE(Button 1)
>
> USAGE(Button 2)
>
> USAGE(Button 3)
>
> …
>
> USAGE(Button 16)
Громоздкую запись однотипных кнопок можно сократить, использовав диапазон Usage:
> USAGE\_PAGE (Button)
>
> USAGE\_MINIMUM (Button 1)
>
> USAGE\_MAXIMUM (Button 16)
Данные, передаваемые кнопками представляют собой 16 однобитовых значений, изменяющихся от 0 до 1:
> LOGICAL\_MINIMUM (0)
>
> LOGICAL\_MAXIMUM (1)
>
> REPORT\_SIZE (1)
>
> REPORT\_COUNT (16)
>
> INPUT (Data,Var,Abs)
Порядок строк в дескрипторе не строгий. Например, Logical\_Minimum и Logical\_Maximum можно написать перед Usage(Button), или строки Report\_Size и Report\_Count можно поменять местами.
Важно, чтобы перед командой Input располагались все нужные параметры для передачи данных (Usage, Mimimum, Maximum, Size, Count).
Когда дескриптор сформирован, его можно проверить командой *Parse Descriptor* на наличие ошибок.
Если всё в порядке, то экспортируем его с расширением h. В файле *usbd\_hid.c* заменим дескриптор на новый и скорректируем в *usbd\_hid.h* размер дескриптора *HID\_MOUSE\_REPORT\_DESC\_SIZE* с 74 на 61.
Отчёты отправляются по флагу *data\_ready*. Для этого к *main.c* подключим заголовочный файл *usbd\_hid.h* и в главном цикле вызовем функцию отправки отчёта. Массив *rc\_data* имеет тип uint16, поэтому указатель на него надо привести к 8-битному типу и передать размер 10 вместо 5.
```
#include "usbd_hid.h"
...
while (1)
{
if (data_ready)
{
USBD_HID_SendReport(&hUsbDeviceFS, (uint8_t*)rc_data, 10);
data_ready = 0;
};
};
```
Компилируем проект и прошиваем ещё раз.
### **Подключение и использование**
Переподключим кабель USB из разъёма USB ST-LINK в разъём USER USB. Windows обнаружит новое устройство и автоматически установит драйвер. Зайдём в *Панель управления -> Устройства и принтеры* и увидим наше устройство STM32 USB-PPM Adapter со значком геймпада.
В параметрах устройства можно увидеть, как крестик перемещается по полю и столбики шевелятся вслед за перемещением стиков, а обозначения кнопок загораются от переключения тумблеров. Проводить калибровку не обязательно, потому что минимальные и максимальные значения уже были заданы в дескрипторе.
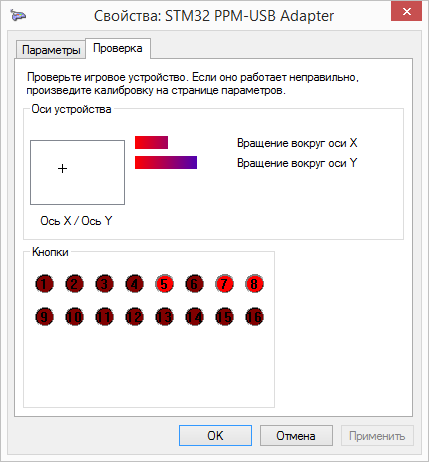
Запустив FPV FreeRider, мы увидим, как на главном экране на нарисованном виртуальном геймпаде стики двигаются в соответствии с нашим пультом. Если оси по какой-то причине назначены неправильно, их можно перенастроить в разделе *Calibrate Controller*.
Тумблеры, соответствующие кнопкам на пульте, служат для переключения полётных режимов (акробатический/стабилизированный), переключения вида камеры (с борта/с земли), запуска полёта с начала или включения гонки на время.
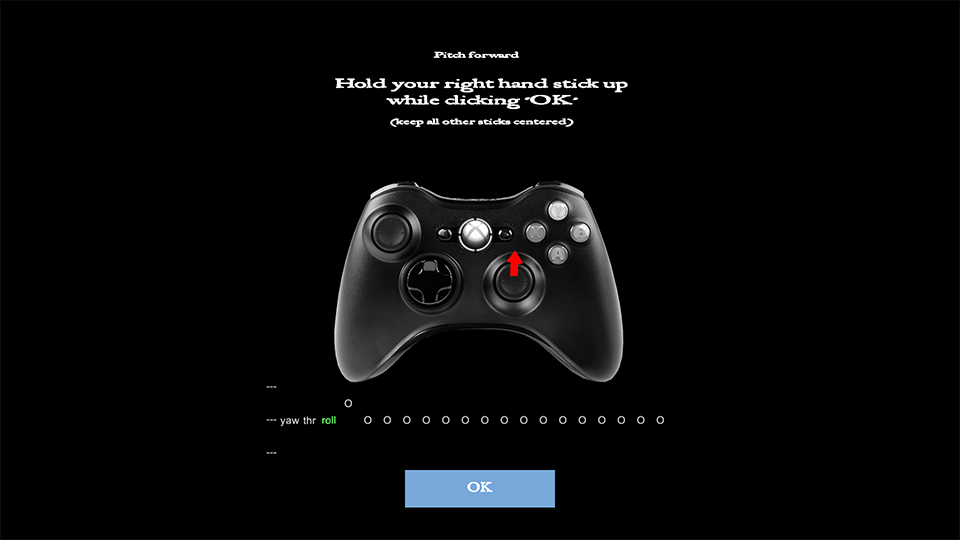
### **Полетели!**
На видео – результат нескольких дней моих тренировок. Пока я летаю с автовыравниванием горизонта, а не в акробатическом режиме, как делают все мастера FPV-гонок. В акро-режиме, если отпустить стики, коптер не возвращается в горизонтальное положение автоматически, а продолжает лететь под тем же углом, как и летел. Управлять в акро-режиме значительно сложнее, но зато можно достичь большей скорости, манёвренности, делать перевороты в воздухе и даже летать вверх-ногами.
До мастеров уровня [Charpu](https://www.youtube.com/user/CharpuFPV) мне пока ещё очень далеко, но я продолжаю тренировки и могу сказать точно, что идея гоночного мини-коптера меня заинтересовала ещё больше. И в скором времени я обязательно займусь его постройкой и полётами уже не в симуляторе, а в суровой реальности, с настоящими падениями, поломанными пропеллерами, разбитыми моторами и сгоревшими аккумуляторами. Но это уже тема для других статей :)
---
Проект для Keil uVision 5 и STM32CubeMX лежит на [GitHub](https://github.com/alexeystn/stm32-ppm-usb-adapter).
|
https://habr.com/ru/post/384813/
| null |
ru
| null |
# Video rip. Часть 1-2. Подготовка DVD. DGMPGDec
#### Содержание
1. Подготовка DVD
1. [vStrip](http://habrahabr.ru/blogs/video_processing/50256/)
2. **DGMPGDec**
2. Обработка видео
1. [Что такое interlace и с чем его едят](http://habrahabr.ru/blogs/video_processing/51201/)
2. [Как определить что у нас: progressive, interlaced или telecined?](http://habrahabr.ru/blogs/video_processing/61826/)
3. [Избавление от обычной чересстрочности (deinterlace)](http://habrahabr.ru/blogs/video_processing/61822/)
4. [IVTC](http://habrahabr.ru/blogs/video_processing/88654/)
3. [Сжимаем и запаковываем](http://habrahabr.ru/blogs/video_processing/88668/)
Эта часть будет короче и проще предыдущей. Я было хотел совместить их, но потом увидел, что скорее всего это будет уже через край, поэтому оформил отдельно. Тем не менее этот этап важен и без него дальше мы не продвинемся.
Так как в дальнейшем работать мы будем с AviSynth, то надо как-то получившиеся VOB файлы им открыть. (если вы не знаете что такое AviSynth, то можете почитать [здесь](http://habrahabr.ru/blogs/video_processing/49735/), например). Проблема в том, что AviSynth сам по себе с MPEG2 не работает и для этого программе нужен плагин который называется DGMPGDec. Скачать его можно, например, [здесь](http://neuron2.net/dgmpgdec/dgmpgdec.html).
#### Этап 1. Создание D2V файла.
D2V это вспомогательный файл, который мы будем использовать для того чтобы AviSynth «увидел» MPEG2. Для его создания воспользуемся утилитой DGIndex которую вы можете найти в скачанном архиве. В нём записаны используемые VOB файлы и прочая служебная информация. После запуска вы должны увидеть вот такое окошко:
[](http://tinypic.com)
Жмите File -> Open или F2 и программа предложит выбрать файлы. Смело выбирайте VOB файл, который получился в предыдущей части. Если же VOB файлов получилось несколько, то можно выбрать и несколько. Правда, если DGMPGDec будет ругаться, то лучше повторите процедуру, которая будет чуть ниже для каждого файла по отдельности. При помощи AviSynth их всё-равно легко склеить воедино.
*Примечание: Ругаться может обычно на некорректный GOP или несовместимость GOP двух кусков. Вообще говоря на это может ругаться даже если вы обрабатываете один файл. :)
GOP – Group of Pictures – дословно «группа изображений». MPEG поток всегда состоит из последовательных GOP. Каждая GOP начинается с опорного, или I-кадра, изображение в котором сжато без учета видеоинформации в соседних кадрах. Все остальные кадры GOP содержат только ту информацию, которой нет в I-кадре. DVD совместимый MPEG должен содержать только GOP с заголовками. В заголовке GOP указываются такие параметры, как скорость потока, размер GOP, соотношение сторон изображения и т.п. (скопипастил [отсюда](http://www.ixbt.com/divideo/skystar.shtml))*
В результате у вас получится примерно такая вот картинка:
[](http://tinypic.com)
Можете поменять порядок файлов и жать OK.
Для начала немного поменяем настройки:
Audio -> Output Method -> Demux All Tracks — этой настройкой мы включаем извлечение всех звуковых дорожек какие есть в VOB файле.
Options -> Use Full Path — здесь мы указываем программе использовать полные пути при составлении D2V файла, чтобы сам файл мы могли поместить куда захочется.
Всё, жмите File -> Save Project или F4 и DGMPGDec начнёт работу. На выходе вы получите D2V файл и звуковую дорожку (или несколько, можете удалить ненужные).
*Примечание: После того, как DGMPGDec отработает и соберётся сохранять файл — может ругаться на неверный порядок появления полей (field order transition). Честно говоря что в такой ситуации делать мне сказать сложно. Здесь надо смотреть глазами. В любом случае соглашайтесь на предложение исправить и получите две копии d2v файла. Исправленную и неисправленную.*
#### Этап 2. AviSynth
Предположим, AviSynth вы поставили. Сперва нам необходимо загрузить плагин отображения MPEG2. Он находится там же где и DGIndex. Имя файла DGDecode.dll. Затем указать какой файл открывать.
Открывайте ваш любимый текстовый редактор и пишите:
`LoadPlugin("путь_к_DGDecode.dll")
mpeg2source("путь_к_d2v_файлу")`
Путь может быть как полный, так и относительный. У меня получилось следующее:
`LoadPlugin("Plugins\DGDecode.dll")
mpeg2source("D2V\e01.d2v")`
Сохраняйте ваш скрипт и попробуйте посмотреть что у вас получилось.
|
https://habr.com/ru/post/50611/
| null |
ru
| null |
# Kubernetes: мониторинг c помощью Prometheus
Привет, Хабр!
Меня зовут Радик, Head of DevOps of AGIMA!
В этой статье я постарался показать, как можно использовать Prometheus в качестве системы мониторинга для микросервисной архитектуры. Подробно рассмотрел архитектуру Prometheus и взаимодействие его компонентов. Обозначил ключевые характеристики благодаря чему эта система получила такое широкое распространение в средах использующих контейнеризацию. Предупреждаю сразу: статья получилась довольно объемной. Эта статься будет полезна для начинающих DevOps специалистов, которые планируют или уже используют в своей работе Docker, Kubernetes. Итак, начнем!
### Что такое Prometheus?
Prometheus — система мониторинга, разработанная специально для динамически изменяющейся среды. Кроме того, она может использоваться для традиционной инфраструктуры, например, на физических серверах с приложениями, развернутыми непосредственно на ОС. На сегодняшний день Prometheus занимает лидирующую позицию среди инструментов, применяемых в мире микросервисов. Чтобы понять, почему Prometheus пользуется такой популярностью, давайте рассмотрим несколько примеров.
В качестве среды для разворачивания системы будем использовать Kubernetes.
Цель — настроить в Prometheus мониторинг для Redis-кластера в Kubernetes. Графический интерфейс — Grafana. Для оповещения задействуем email и Slack.
### Основные компоненты Prometheus
"
В центре Prometheus — сервер, который выполняет работу по мониторингу. Он состоит из следующих частей:
* **Time Series Data Base (TSDB)** — база данных, в которой хранятся метрики, полученные от целевых объектов. Например, CPU usage, Memory utilization или количество запросов к сервису
* **Retrieval worker** отвечает за получение этих метрик с целевых ресурсов и размещение данных в TSDB
* **HTTP server** — API для выполнения запросов к сохраненным в TSDB данным. Используется для отображения данных на дашборде в Prometheus или сторонних системах визуализации — таких, как Grafana.
### От теории к практике
Давайте развернем наш сервер Prometheus с помощью пакетного менеджера Helm.
**Инструкция предназначена для инженеров, которые имеют базовые навыки работы с Kubernetes и может быть использована только в ознакомительных целях. Использование в продакшен данной конфигурации крайне не рекомендуется.**
Для этого потребуются рабочий кластер Kubernetes и настроенный kubectl. Можно попробовать использовать кластер Kubernetes в [MCS](https://mcs.mail.ru/containers/). Сервер Prometheus устанавливается достаточно просто:
```
#Добавляем репозиторий
helm repo add stable https://kubernetes-charts.storage.googleapis.com
#Обновляем
helm repo update
#Создаем namespace
kubectl create namespace monitoring
#Устанавливаем helm c именем my-prometheus
helm install my-prometheus stable/prometheus -n monitoring
```
В результате выполнения мы получаем:
```
The Prometheus PushGateway can be accessed via port 9091 on the following DNS name from within your cluster:
my-prometheus-pushgateway.monitoring.svc.cluster.local
Get the PushGateway URL by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace monitoring -l "app=prometheus,component=pushgateway" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace monitoring port-forward $POD_NAME 9091
For more information on running Prometheus, visit:
https://prometheus.io/
```
Проверяем, все ли поды запущены:
```
kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
my-prometheus-alertmanager-86986878b5-5w2vw 2/2 Running 0 76s
my-prometheus-kube-state-metrics-dc694d6d7-xk85n 1/1 Running 0 76s
my-prometheus-node-exporter-grgqw 1/1 Running 0 76s
my-prometheus-node-exporter-njksq 1/1 Running 0 76s
my-prometheus-node-exporter-pcmgv 1/1 Running 0 76s
my-prometheus-pushgateway-6694855f-n6xwt 1/1 Running 0 76s
my-prometheus-server-77ff45bc6-shrmd 2/2 Running 0 76s
```
При выводе Helm chart предлагает выполнить port-forward для pushgateway, чтобы получить доступ к интерфейсу Prometheus. Меняем component на server и выполняем:
```
#получаем название контейнера и сохраняем его в переменную POD_NAME
export POD_NAME=$(kubectl get pods --namespace monitoring -l "app=prometheus,component=server" -o jsonpath="{.items[0].metadata.name}")
#пробрасываем порт
kubectl --namespace monitoring port-forward $POD_NAME 9090
```
Теперь открываем<http://127.0.0.1:9090/> в браузере — и видим интерфейс Prometheus:

Итак, у нас есть сервер Prometheus, развернутый внутри кластера Kubernetes. Теперь давайте развернем Redis, который впоследствии и поставим на мониторинг в Prometheus. Для этого также используем Helm:
```
#добавляем репозиторий
helm repo add bitnami https://charts.bitnami.com/bitnami
#Обновляем
helm repo update
#Создаем namespace
kubectl create namespace redis
#Устанавливаем helm c именем redis
helm install redis bitnami/redis -n redis --set cluster.enabled=true --set cluster.slaveCount=2 --set master.persistence.enabled=false --set slave.persistence.enabled=false
```
Параметры **cluster.enabled** и **cluster.slaveCount** определяют, что Redis будет развернут в режиме «кластер», и в этом кластере два пода будут работать как slave. В параметрах указываем: не использовать persistent volume для master и slave (persistence.enabled=false). Сейчас это нужно, чтобы продемонстрировать работу Redis. В продакшене будет необходимо сделать настройку persistent volume.
Проверяем, что все поды redis запущены:
```
kubectl get pod -n redis
NAME READY STATUS RESTARTS AGE
redis-master-0 1/1 Running 0 65s
redis-slave-0 1/1 Running 0 65s
redis-slave-1 1/1 Running 0 28s
```
Теперь, когда у нас развернуты Prometheus и Redis, нужно настроить их взаимодействие.
### Targets и metrics
Prometheus-сервер может мониторить самые разные объекты — к примеру, Linux- и Windows-серверы. Это может быть база данных или приложение, которое предоставляет информацию о своем состоянии. Такие объекты в Prometheus называются targets. Каждый объект имеет так называемые единицы мониторинга. Для Linux-сервера это может быть текущая утилизация CPU, использование memory и диска. Для приложения — количество ошибок, количество запросов и время их выполнения. Эти единицы называются metrics и хранятся в TSDB.
### Exporters
Prometheus получает метрики из указанных в его конфигурации источников в блоке targets. Некоторые сервисы самостоятельно предоставляют метрики в формате Prometheus, и для их сбора не нужно ничего дополнительно настраивать. Достаточно подключить Prometheus в конфигурации, как это сделано ниже:
```
scrape_configs:
— job_name: prometheus
static_configs:
— targets:
— localhost:9090
```
Указываем серверу Prometheus забирать метрики из конечной точки: localhost:9090/metrics.
Для сервисов, которые не могут самостоятельно предоставлять метрики в формате Prometheus, нужно установить дополнительный компонент **exporters**. Обычно **exporters** — скрипт или сервис, который получает метрики от цели, конвертирует их формат, который «понимает» Prometheus, и предоставляет эти данные серверу по пути /metrics. Prometheus имеет большой [набор готовых](https://prometheus.io/docs/instrumenting/exporters/) exporters для разных сервисов — эти компоненты можно использовать для HAProxy, Linux system, облачных платформ и др.
### Redis и exporter
Давайте подключим **exporter** для нашего Redis-кластера. Сначала потребуется создать файл values.yaml со следующим содержанием:
```
cluster:
enabled: true
slaveCount: 2
##
## Redis Master parameters
##
master:
persistence:
enabled: false
extraFlags:
— "--maxmemory 256mb"
slave:
persistence:
enabled: false
extraFlags:
— "--maxmemory 256mb"
## Prometheus Exporter / Metrics
##
metrics:
enabled: true
image:
registry: docker.io
repository: bitnami/redis-exporter
tag: 1.4.0-debian-10-r3
pullPolicy: IfNotPresent
## Metrics exporter pod Annotation and Labels
podAnnotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9121"
```
Здесь параметры, которые использовались в командной строке для настройки Redis в режиме cluster, перенесены в yaml-файл. Для сбора метрик добавлено подключение **redis-exporter.**
Обновляем Redis с новыми параметрами:
```
helm upgrade redis -f redis/values.yaml bitnami/redis -n redis
```
Проверяем, что поды Redis запущены:
```
kubectl get pods -n redis
redis-master-0 2/2 Running 0 3m40s
redis-slave-0 2/2 Running 0 2m4s
redis-slave-1 2/2 Running 0 2m16s
```
Теперь к каждому pod «привязан» дополнительный контейнер **redis-exporter**, который предоставляет доступ к метрикам Redis.
Добавлять снятие метрик для развернутых контейнеров redis-exporter в конфигурацию Prometheus не нужно, так как он по умолчанию содержит **kubernetes\_sd\_configs** (листинг представлен ниже). За счёт этого динамически подключается сбор метрик для вновь появившихся подов. Подробнее об этом можно прочитать в [документации](https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config).
```
— job_name: 'kubernetes-pods'
kubernetes_sd_configs:
— role: pod
relabel_configs:
— source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
— source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
— source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
— action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
— source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
— source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
```
Давайте убедимся, что мы получаем данные о состоянии Redis. Для этого можно открыть интерфейс и ввести PromQL-запрос **redis\_up**:
"
В отличие от других систем мониторинга, Prometheus не получает данные от целевых сервисов, а самостоятельно забирает с указанных в конфигурации **endpoints** — это одна из его важнейших характеристик. Когда вы работаете с большим количеством микросервисов, и каждый из них отправляет данные в систему мониторинга, вы можете столкнуться с риском отправки слишком большого количества данных на сервер Prometheus, а это может привести его выходу из строя. Prometheus предоставляет централизованное управление сбором метрик, т.е. вы самостоятельно решаете, откуда и как часто забирать данные. Еще одно преимущество использования Prometheus — возможность динамически получать источники данных с помощью функции **service discovery**, работа которой была продемонстрирована выше на примере Redis-подов.
Но бывает случаи, когда необходимо получать данные от источника временно, и у Prometheus нет необходимости забирать их с сервиса постоянно (например, запланированные задания по крону, снятие бэкапов и т.д.). Для таких случаев Prometheus предлагает **pushgateway**, чтобы сервисы могли отправлять свои метрики в базу данных Prometheus. Использование **pushgateway** — скорее исключение, чем правило, но о его возможности не стоит забывать.
Теперь, для того, чтобы наша система мониторинга стала полноценной, нужно добавить оповещения о выходе значений метрик за допустимые пределы.
### Alertmanager и Alerting rules
За отправку предупреждений в Prometheus отвечает компонент **AlertManager**. В качестве каналов оповещения могут выступать: email, slack и другие клиенты. Для настройки оповещения необходимо обновить конфигурацию файла alertmanager.yml.
Создадим файл prometheus/values.yaml со следующим содержимым:
```
## alertmanager ConfigMap entries
##
alertmanagerFiles:
alertmanager.yml:
global:
slack_api_url:
route:
receiver: slack-alert
group\_by:
— redis\_group
repeat\_interval: 30m
routes:
— match:
severity: critical
receiver: slack-alert
receivers:
— name: slack-alert
slack\_configs:
— channel: 'general'
send\_resolved: true
color: '{{ if eq .Status "firing" }}danger{{ else }}good{{ end }}'
title: '[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing
| len }}{{ end }}] {{ .CommonAnnotations.summary }}'
text: |-
{{ range .Alerts }}
\*Alert:\* {{ .Annotations.summary }} — \*{{ .Labels.severity | toUpper }}\* on {{ .Labels.instance }}
\*Description:\* {{ .Annotations.description }}
\*Details:\*
{{ range .Labels.SortedPairs }} • \*{{ .Name }}:\* `{{ .Value }}`
{{ end }}
{{ end }}
```
**Slack\_api\_url** должен содержать ключ, который можно получить на сайте [Slack](https://slack.com/).
В поле **channel** указывается канал, на который будут приходить оповещения. В нашем случае это general. Остальные параметры отвечают за формат уведомлений.
Конфигурацию, описанную далее, можно найти в [репозитории](https://gitlab.com/radikkit/monitoring).
Обновляем my-prometheus:
```
helm upgrade my-prometheus -f prometheus/values.yaml stable/prometheus -n monitoring
```
Для того, чтобы получить доступ к интерфейсу Alertmanager, выполним следующее:
```
export POD_NAME=$(kubectl get pods --namespace monitoring -l "app=prometheus,component=alertmanager" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace monitoring port-forward $POD_NAME 9093
```
Теперь в интерфейсе **Alertmanager** можно убедиться, что появилась конфигурация для отправки оповещения в канал Slack <http://127.0.0.1:9093/#/status>:

Далее нужно создать правила, по которым нотификация будет отправляться в Slack-канал.
Правила представляют собой значения метрик или их совокупности, объединенные логическим условием. При выходе значения метрики за допустимые пределы Prometheus обращается к Alertmanager, чтобы отправить нотификации по определенным в нем каналам. Например, если метрика redis\_up вернет значение 0, сработает уведомление о недоступности того или иного узла кластера.
Добавляем в файл prometheus/values.yaml стандартные правила для сигнализации о проблемах в Redis:
```
serverFiles:
## Alerts configuration
## Ref: https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
alerting_rules.yml:
groups:
— name: redis_group
rules:
— alert: redis_is_running
expr: redis_up == 0
for: 30s
labels:
severity: critical
annotations:
summary: "Critical: Redis is down on the host {{ $labels.instance }}."
description: "Redis has been down for more than 30 seconds"
— alert: redis_memory_usage
expr: redis_memory_used_bytes / redis_memory_max_bytes * 100 > 40
for: 5m
labels:
severity: warning
annotations:
description: "Warning: Redis high memory(>40%) usage on the host {{ $labels.instance }} for more than 5 minutes"
summary: "Redis memory usage {{ humanize $value}}% of the host memory"
— alert: redis_master
expr: redis_connected_clients{instance!~"server1.mydomain.com.+"} > 50
for: 5m
labels:
severity: warning
annotations:
description: "Warning: Redis has many connections on the host {{ $labels.instance }} for more than 5 minutes"
summary: "Redis number of connections {{ $value }}"
— alert: redis_rejected_connections
expr: increase(redis_rejected_connections_total[1m]) > 0
for: 30s
labels:
severity: critical
annotations:
description: "Critical: Redis rejected connections on the host {{ $labels.instance }}"
summary: "Redis rejected connections are {{ $value }}"
— alert: redis_evicted_keys
expr: increase(redis_evicted_keys_total[1m]) > 0
for: 30s
labels:
severity: critical
annotations:
description: "Critical: Redis evicted keys on the host {{ $labels.instance }}"
summary: "Redis evicted keys are {{ $value }}"
```
Обновляем my-prometheus:
```
helm upgrade my-prometheus -f prometheus/values.yaml stable/prometheus -n monitoring
```
Для проверки работы нотификации в Slack, изменим правило алерта **redis\_memory\_usage**:
```
expr: redis_memory_used_bytes / redis_memory_max_bytes * 100 < 40
```
Снова обновляем my-prometheus:
```
helm upgrade my-prometheus -f prometheus/values.yaml stable/prometheus -n monitoring
```
Переходим на страницу <http://127.0.0.1:9090/alerts>:

Redis\_memory\_usage перешел в статус «pending». Значение выражения для всех трех подов чуть больше 0.72. Далее уведомление проходит в Slack:
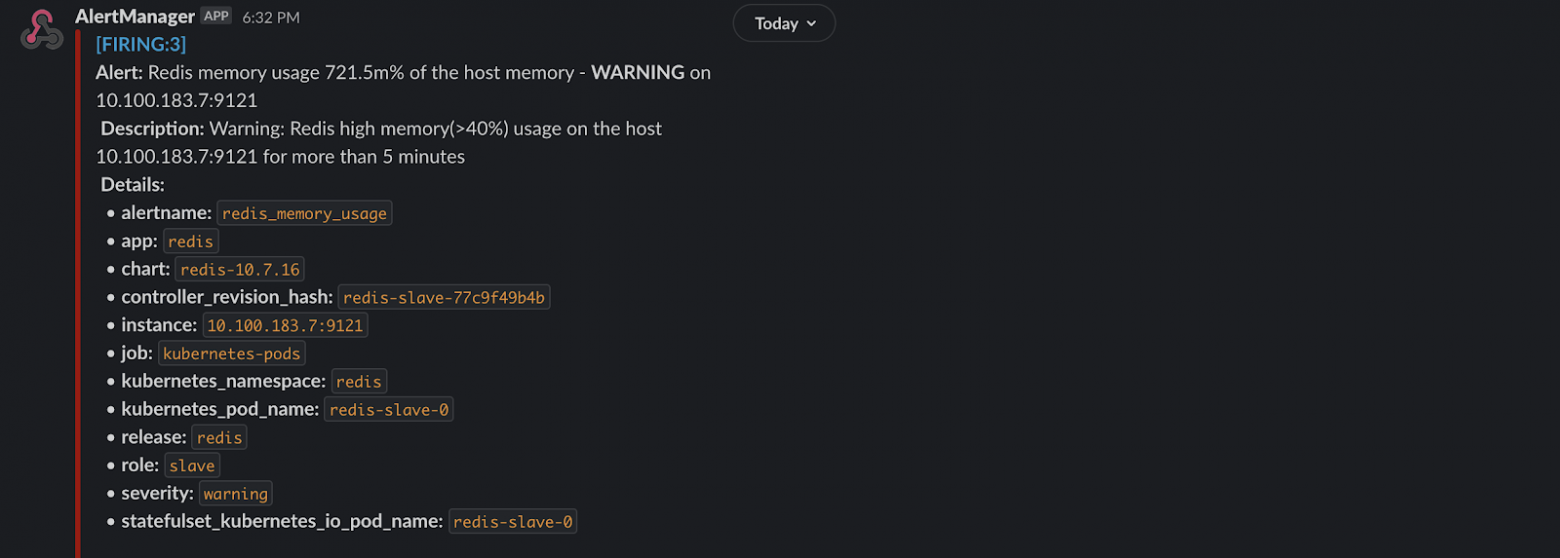
Теперь добавляем нотификацию по email. При этом конфигурация alermanager.yml изменится так:
```
alertmanagerFiles:
alertmanager.yml:
global:
slack_api_url:
route:
receiver: slack-alert
group\_by:
— redis\_group
repeat\_interval: 30m
routes:
— match:
severity: critical
receiver: slack-alert
continue: true
— match:
severity: critical
receiver: email-alert
receivers:
— name: slack-alert
slack\_configs:
— channel: 'general'
send\_resolved: true
color: '{{ if eq .Status "firing" }}danger{{ else }}good{{ end }}'
title: '[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing
| len }}{{ end }}] {{ .CommonAnnotations.summary }}'
text: |-
{{ range .Alerts }}
\*Alert:\* {{ .Annotations.summary }} — \*{{ .Labels.severity | toUpper }}\* on {{ .Labels.instance }}
\*Description:\* {{ .Annotations.description }}
\*Details:\*
{{ range .Labels.SortedPairs }} • \*{{ .Name }}:\* `{{ .Value }}`
{{ end }}
{{ end }}
— name: email-alert
email\_configs:
— to: [email protected]
send\_resolved: true
require\_tls: false
from: [email protected]
smarthost: smtp.agima.ru:465
auth\_username: "[email protected]"
auth\_identity: "[email protected]"
auth\_password:
```
В блок routes добавляем еще один путь для нотификации: **receiver: email-alert.** Ниже описываем параметры для email. В этом случае при том или ином событии мы получим уведомления одновременно в Slack и на email:
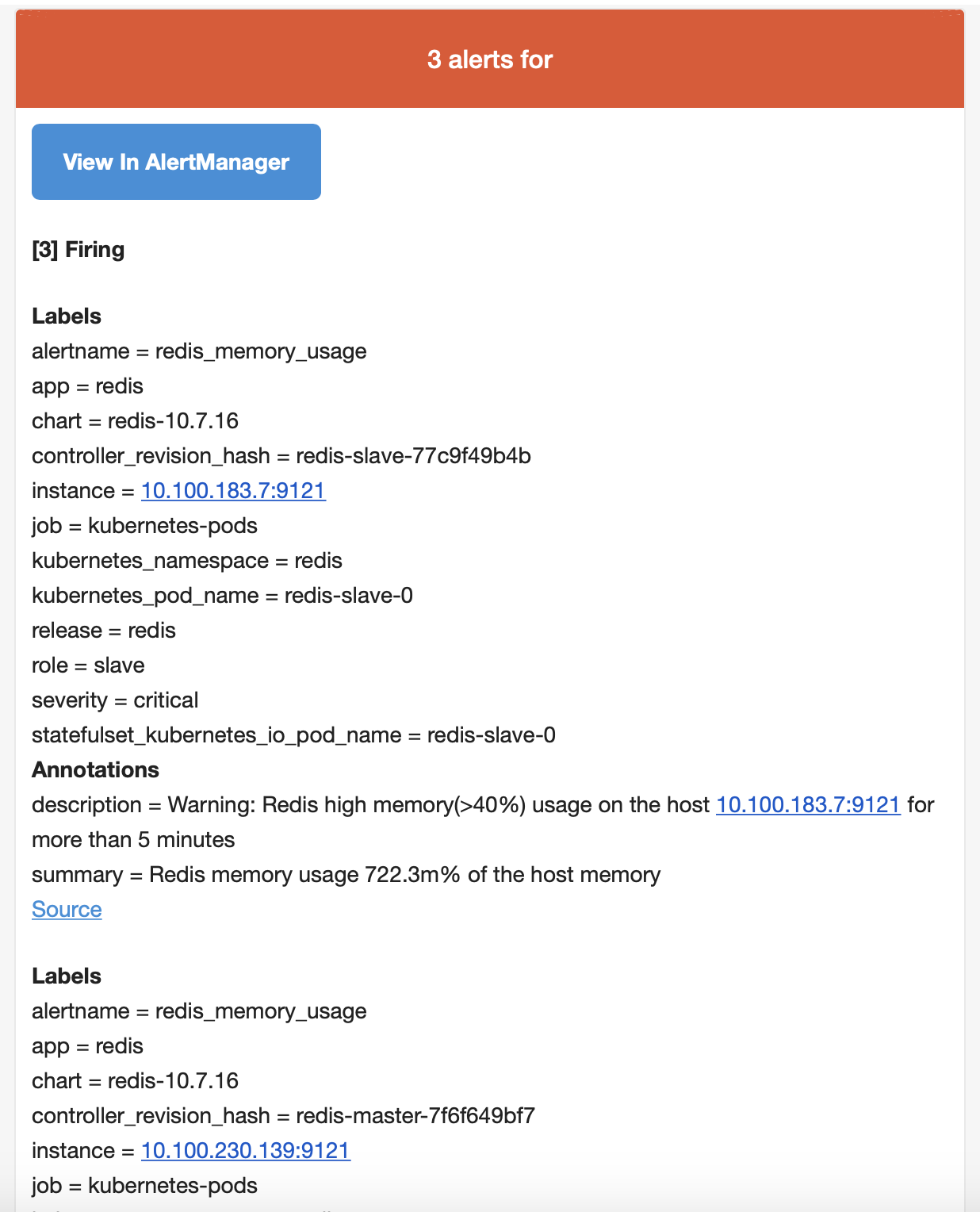
### Blackbox exporter
Теперь рассмотрим, как в Prometheus добавляются **targets** на примере контейнера **blackbox exporter**, который позволяет организовать мониторинг внешних сервисов по протоколам HTTP(s), DNS, TCP, ICMP.
Для установки blackbox exporter используем Helm:
```
helm install blackbox-exporter stable/prometheus-blackbox-exporter --namespace monitoring
```
Проверяем, что поды blackbox exporter запущены:
```
kubectl get pods -n monitoring | grep blackbox
blackbox-exporter-prometheus-blackbox-exporter-df9f6d679-tvhrp 1/1 Running 0 20s
```
Добавляем в файл prometheus/values.yaml следующую конфигурацию:
```
extraScrapeConfigs: |
— job_name: 'prometheus-blackbox-exporter'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
— targets:
— https://example.org
relabel_configs:
— source_labels: [__address__]
target_label: __param_target
— source_labels: [__param_target]
target_label: instance
— target_label: __address__
replacement: blackbox-exporter-prometheus-blackbox-exporter.monitoring.svc.cluster.local:9115
```
Указываем, откуда собирать метрики:
blackbox-exporter-prometheus-blackbox-exporter.monitoring.svc.cluster.local:9115/probe. В качестве targets указываем URL сервиса для мониторинга: <https://example.org>. Для проверки используется модуль http\_2xx, который по умолчанию устанавливается в **blackbox exporter**. Конфигурация проверки:
```
secretConfig: false
config:
modules:
http_2xx:
prober: http
timeout: 5s
http:
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
no_follow_redirects: false
preferred_ip_protocol: "ip4"
```
Обновляем конфигурацию my-prometheus:
```
helm upgrade my-prometheus -f prometheus/values.yaml stable/prometheus -n monitoring
```
В интерфейсе Prometheus <http://127.0.0.1:9090/targets>проверяем, что у нас появилась конечная точка для сбора метрик:

Чтобы расширить область проверки, добавляем http\_2xx\_check-модуль, который, помимо валидации версии и статуса 200 http, будет проверять наличие заданного текста в теле ответа:
```
secretConfig: false
config:
modules:
http_2xx:
prober: http
timeout: 5s
http:
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
no_follow_redirects: false
preferred_ip_protocol: "ip4"
valid_status_codes: [200]
http_2xx_check:
prober: http
timeout: 5s
http:
method: GET
fail_if_body_not_matches_regexp:
— "Example Domain"
fail_if_not_ssl: true
preferred_ip_protocol: ip4
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
valid_status_codes: [200]
```
Обновляем конфигурацию blackbox-exporter/values.yaml:
```
helm upgrade blackbox-exporter -f blackbox-exporter/values.yaml stable/prometheus-blackbox-exporter --namespace monitoring
```
Изменяем в файле prometheus/values.yaml модуль **http\_2xx** на **http\_2xx\_check**:
```
extraScrapeConfigs: |
— job_name: 'prometheus-blackbox-exporter'
metrics_path: /probe
params:
module: [http_2xx]
```
Описания проверок, которые можно делать с blackbox exporter, приведены в [документации](https://github.com/prometheus/blackbox_exporter/blob/master/CONFIGURATION.md).
Теперь добавим правила для сигнализации в Prometheus в файл prometheus/values.yaml:
```
— name: http_probe
rules:
— alert: example.org_down
expr: probe_success{instance="https://example.org",job="prometheus-blackbox-exporter"} == 0
for: 5s
labels:
severity: critical
annotations:
description: '{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes.'
summary: 'Instance {{ $labels.instance }} down'
```
И обновляем конфигурацию my-prometheus:
```
helm upgrade my-prometheus -f prometheus/values.yaml stable/prometheus -n monitoring
```
Для проверки можно изменить в blackbox-exporter/values.yaml значение текста для модуля **http\_2xx\_check**, который ищется в теле ответа, и обновить blackbox exporter. Должна сработать нотификация в Slack и Email.
### Grafana
Настала очередь визуализации. Для отображения графиков будем использовать
**Grafana**.
Устанавливаем его уже привычным для нас образом с помощью пакетного менеджера Helm:
```
helm install my-grafana bitnami/grafana -n monitoring --set=persistence.enabled=false
```
В параметрах указываем «не использовать persistent volume» (--set=persistence.enabled=false), чтобы только продемонстрировать работу grafana. В продакшн- среде нужно настроить хранилище, так как поды по своей природе эфемерны, и есть риск потерять настройки Grafana.
Должен получиться вот такой вывод:
```
2. Get the admin credentials:
echo "User: admin"
echo "Password: $(kubectl get secret my-grafana-admin --namespace monitoring -o jsonpath="{.data.GF_SECURITY_ADMIN_PASSWORD}" | base64 --decode)"
```
Проверяем, что под Grafana запущен:
```
$kubectl get pods -n monitoring | grep grafana
NAME READY STATUS RESTARTS AGE
my-grafana-67c9776d7-nwbqj 1/1 Running 0 55s
```
Перед тем как открыть интерфейс Grafana, нужно получить пароль от пользователя admin, сделать это можно так:
```
$echo "Password: $(kubectl get secret my-grafana-admin --namespace monitoring -o jsonpath="{.data.GF_SECURITY_ADMIN_PASSWORD}" | base64 --decode)"
```
Затем «пробрасываем» порт Grafana:
```
kubectl port-forward -n monitoring svc/my-grafana 8080:3000
```
Открываем <http://127.0.0.1:9090/> в браузере и авторизуемся:
Для того чтобы Grafana могла получать значения метрик, хранящихся в базе данных Prometheus, необходимо подключить его. Переходим на <http://127.0.0.1:8080/datasources>и добавляем **data source.** В качестве TSDB выбираем Prometheus, который доступен в нашем кластере по адресу my-prometheus-server.monitoring.svc.cluster.local.
Должно получиться примерно так:

После добавления **data source** нужно добавить dashboard в Grafana — чтобы состояния показателей Redis-кластера отображались на графиках. Переходим на <http://127.0.0.1:8080/dashboard/import> и добавляем id = [763](https://grafana.com/grafana/dashboards/763). Итог:

После импорта получаем следующий dashboard с виджетами, которые отображают собранные метрики c кластера Redis:

Вы можете собирать такие дашборды самостоятельно или использовать уже [готовые](https://grafana.com/grafana/dashboards).
Вот, в принципе, и всё. Надеюсь, что сумел рассказать вам что-то новое. А главное — убедил, что пользоваться Prometheus просто и удобно!
|
https://habr.com/ru/post/524654/
| null |
ru
| null |
# Coins classifier Neural Network: Head or Tail?
[Home of this article](https://robotics.snowcron.com/coins/02_head_or_tail.htm).
The global objective of these articles is to build a coin classifier, capable of scanning your pocket change and find rare / valuable coins. This is a second article in a series, so let me remind you [what happened earlier](https://habr.com/ru/post/538958/).
During previous step we got a rather large dataset composed of pairs of images, loaded from an online coins site meshok.ru. Those images were uploaded to the Internet by people we do not know, and though they are supposed to contain coin's head in one image and tail in the other, we can not rule out a situation when we have two heads and no tail and vice versa. Also at the moment we have no idea which image contains head and which contains tail: this might be important when we feed data to our final classifier.
So let's write a program to distinguish heads from tails. It is a rather simple task, involving a convolutional neural network that is using transfer learning.
Same way as before, we are going to use Google Colab environment, taking the advantage of a free video card they grant us an access to. We will store data on a Google Drive, so first thing we need is to allow Colab to access the Drive:
```
from google.colab import drive
drive.mount("/content/drive/", force_remount=True)
```
Next step, we are going to install the Efficient Net. This is the pretrained network (remember I spoke about transfer learning?) that we use as a starting point, rather than training a network from scratch.
```
!pip install -q efficientnet
import efficientnet.tfkeras as efn
```
Next, i usually have a large "include" section, please note that some files may be included that are not really used: feel free to delete them:
```
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import sys
import random
import os
from os import listdir
from os.path import isfile, join
from tensorflow.keras import regularizers
from tensorflow.keras.optimizers import Adamax
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.preprocessing.image import array_to_img, img_to_array
from tensorflow.keras import backend as K
from tensorflow.keras.applications.vgg16 import VGG16,preprocess_input
from tensorflow.keras.applications import InceptionResNetV2, Xception, NASNetLarge
from mpl_toolkits.mplot3d import Axes3D
from sklearn.manifold import TSNE
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, Dense, Activation, Dropout, Flatten, Lambda, concatenate, BatchNormalization, GlobalAveragePooling2D
from tensorflow.keras.callbacks import LambdaCallback
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.models import Sequential
from sklearn.neighbors import NearestNeighbors
import seaborn as sns
import cv2
from tensorflow.python.keras.utils.data_utils import Sequence
import re
```
Let's see which version of Tensorflow is used. This step is important, as Google is known for suddenly changing (increasing) versions:
```
import tensorflow as tf
print(tf.__version__)
tf.test.gpu_device_name()
```
The output in my case was:
```
2.4.0
'/device:GPU:0'
```
Then we do some additional initializations. Setting directories where our project is, and some subfolders for weight stored during training:
```
working_path = "/content/drive/My Drive/02_avers_or_revers/"
best_weights_filepath = working_path + "models/01_avers_or_revers.h5"
last_weights_filepath = working_path + "models/01_avers_or_revers.h5"
```
We only train once, why would we do it every time, right? So we are going to use the boolean flag, if false, it means that training was already done, weights are stored in files, and instead of re-training, we can simply load those weights:
```
bDoTraining = True
```
We are going to scale down images to 256x256, use batch size 8 during training, and so on: here are constants we will need. Names are self-explainatory. We are also going to break our data to training images (used to tune network's weights), validation images used to calculate performance on data the net never saw) and the rest (testing data, used to test the result).
```
IMAGE_SIZE = 256
input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3)
BATCH_SIZE = 8
embedding_model = 0
alpha = 0.4
TRAINING_IMAGES_PERCENT = 0.6
VALIDATION_IMAGES_PERCENT = 0.2
IMAGE_ROTATION_ANGLE = 180
```
We have two classes for our classifier to distinguish between:
```
# Class name corresponds to a folder.
# Image path is "images" + class name + image name
arrClasses = ["head", "tail"]
```
Let's load data by reading the "head" and "tail" folders' content:
```
if(bDoTraining):
pdLabels = pd.get_dummies(arrClasses)
arrLabeledData = []
for cls in arrClasses:
arrImageNames = [f for f in listdir(working_path + "images/" + cls) if isfile(join(working_path, "images/", cls, f))]
arrLabeledData.append(
{
'class':cls,
'image_names':arrImageNames
})
```
Function to load images:
```
def loadImage(path):
img=cv2.imread(str(path))
#img = rotate_bound(img, angle)
img = cv2.resize(img, (IMAGE_SIZE, IMAGE_SIZE))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32)/255.
img = img.reshape(input_shape)
return img
```
For an array of image info (file names and so on), get max indexes of training, validation and testing subsets:
```
def getClassMinMax(cls, bIsTrain):
nLen = len(cls['image_names'])
if(bIsTrain):
nMinIdx = 0
nMaxIdx = nLen * TRAINING_IMAGES_PERCENT
else:
nMinIdx = nLen * TRAINING_IMAGES_PERCENT + 1
nMaxIdx = nLen * (TRAINING_IMAGES_PERCENT + VALIDATION_IMAGES_PERCENT)
return int(nMinIdx), int(nMaxIdx)
```
It is always a good idea to make sure everything works as intended, so let's test image loading:
```
if(bDoTraining):
nClassIdx = np.random.randint(len(arrLabeledData))
cls = arrLabeledData[nClassIdx]
nMinIdx, nMaxIdx = getClassMinMax(cls, False)
nImageIdx = random.randint(nMinIdx, nMaxIdx)
arrLabeledData[0]['class']
img = loadImage(join(working_path, "images/", cls['class'], cls['image_names'][nImageIdx]))#, 0)
#img = img.reshape((IMAGE_SIZE, IMAGE_SIZE))
print(cls['class'])
plt.imshow(img)
plt.show()
```
To make our dataset more diverse (augmentation), we might want to add noise to images:
```
def add_noise(img):
'''Add random noise to an image'''
VARIABILITY = 40
deviation = VARIABILITY*random.random() / 255.
noise = np.random.normal(0, deviation, img.shape)
img += noise
np.clip(img, 0., 1.)
return img
```
We will need the ImageDataGenerator to produce augmented images:
```
if(bDoTraining):
datagen = ImageDataGenerator(
samplewise_center=True,
rotation_range=IMAGE_ROTATION_ANGLE,
width_shift_range=0.1,
height_shift_range=0.1,
zoom_range=0.1 #[1, 1.2],
#preprocessing_function=add_noise
)
```
The following function is used to get an image by index from data we loaded earlier, using image data generator we just created:
```
def getImage(cClass, nImageIdx, datagen):
image_name = cClass['image_names'][nImageIdx]
#angle = random.randint(-180, 180)
img = loadImage(join(working_path, "images/", cClass['class'], cClass['image_names'][nImageIdx]))#, angle)
arrImg = img_to_array(img)
arrImg = datagen.random_transform(arrImg) # augmentation
arrImg = add_noise(arrImg)
return np.array(arrImg, dtype="float32")
```
Again, we need to make sure everything works, so let's see what this function returns:
```
if(bDoTraining):
nClassIdx = np.random.randint(len(arrLabeledData))
cls = arrLabeledData[nClassIdx]
img = getImage(cls, 0, datagen)
print(cls['class'])
plt.imshow(img) #, cmap='gray')
plt.show()
```
If we do training and for some reason want to start it over, we need to delete network we saved by that time:
```
def deleteSavedNet(best_weights_filepath):
if(os.path.isfile(best_weights_filepath)):
os.remove(best_weights_filepath)
print("deleteSavedNet():File removed")
else:
print("deleteSavedNet():No file to remove")
```
As we train our network, it accumulates "history". It is a good idea to be able to show it as a chart, this way we can often see if training can be improved:
```
def plotHistory(history, strParam1, strParam2):
plt.plot(history.history[strParam1], label=strParam1)
plt.plot(history.history[strParam2], label=strParam2)
#plt.title('strParam1')
#plt.ylabel('Y')
#plt.xlabel('Epoch')
plt.legend(loc="best")
plt.show()
def plotFullHistory(history):
arrHistory = []
for i,his in enumerate(history.history):
arrHistory.append(his)
plotHistory(history, arrHistory[0], arrHistory[2])
plotHistory(history, arrHistory[1], arrHistory[3])
```
Now a function that creates a model. It loads the EfficientNet, removes its last layers (the classifier) and attaches our own classifier, one we are going to train:
```
def createModel(nL2, optimizer):
global embedding_model
inputs = keras.Input(shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
model_b0 = efn.EfficientNetB0(weights='imagenet', include_top=False)(inputs)
model_b0.trainable = False
model_concat = model_b0 #layers.concatenate([model_b0, model_vgg16]) #, model_x]) #model_b0
model_classifier = layers.Flatten(name="Flatten")(model_concat)
model_classifier = layers.Dense(32, kernel_regularizer=regularizers.l2(nL2), activation='relu', name="Dense128")(model_classifier)
model_classifier = layers.LeakyReLU(alpha=0.1, name="LeakyReLU")(model_classifier)
model_classifier = layers.Dropout(0.4, name="Dropout")(model_classifier)
base_model = layers.Dense(len(arrClasses), activation="softmax", kernel_regularizer=regularizers.l2(nL2), name="DenseEmbedding")(model_classifier)
embedding_model = keras.Model(inputs=inputs, outputs=base_model, name="embedding_model")
embedding_model.compile(loss=keras.losses.CategoricalCrossentropy(), optimizer=optimizer, metrics=["accuracy"])
return embedding_model
```
The following class is used to produce batches of images (and labels) that are used during training. Sequence class that is used as a parent is a new standard of Keras (if you don't want to use tfdata), it is highly paralelizeable and convenient:
```
from skimage.io import imread
from skimage.transform import resize
import numpy as np
# Here, `x_set` is list of path to the images
# and `y_set` are the associated classes.
class MyImageDataGenerator(Sequence):
def __init__(self, bIsTrain):
self.batch_size = BATCH_SIZE
self.bIsTrain = bIsTrain
nNumOfTrainSamples = 10000
for cls in arrLabeledData:
nMin, nMax = getClassMinMax(cls, True)
nNumOfTrainSamples = min(nNumOfTrainSamples, nMax - nMin)
if(self.bIsTrain):
self.STEP_SIZE = nNumOfTrainSamples // BATCH_SIZE
else:
nNumOfValidSamples = int(nNumOfTrainSamples * VALIDATION_IMAGES_PERCENT / TRAINING_IMAGES_PERCENT)
self.STEP_SIZE = nNumOfValidSamples // BATCH_SIZE
if(self.STEP_SIZE < 100):
self.STEP_SIZE = 100
print("STEP_SIZE: ", self.STEP_SIZE, " (bIsTrain: ", bIsTrain, ")")
def __len__(self):
return self.STEP_SIZE
def __getitem__(self, idx):
arrBatchImages = []
arrBatchLabels = []
for i in range(self.batch_size):
arrClassIdx = np.random.randint(len(arrLabeledData))
cls = arrLabeledData[arrClassIdx]
nMinIdx, nMaxIdx = getClassMinMax(cls, self.bIsTrain)
nImageIdx = random.randint(nMinIdx, nMaxIdx)
img = getImage(cls, nImageIdx, datagen)
strLabel = cls['class']
arrBatchImages.append(img)
arrBatchLabels.append(pdLabels[strLabel].to_list())
return np.array(arrBatchImages), np.array(arrBatchLabels)
```
We will need two objects of this class, one for training and one for validation:
```
if(bDoTraining):
gen_train = MyImageDataGenerator(True)
gen_valid = MyImageDataGenerator(False)
```
As usual, we need a function to show image obtained this way:
```
def ShowImg(img, label):
print(label)
fig = plt.figure()
fig.add_subplot(1, 1, 1)
plt.imshow(img) #, cmap='gray')
plt.show()
plt.close()
```
And (again, as usual) we want to test the result:
```
if(bDoTraining):
(images, labels) = gen_valid.__getitem__(0) #next(gen_train)
for i, img in enumerate(images):
ShowImg(img, labels[i])
break
```
We want to be able to stop training any time and later start from where we left, so we need to save weights at the end of each epoch. To do it, we create a list of callbacks and use it during training.
```
def getCallbacks(monitor, mode):
checkpoint = ModelCheckpoint(best_weights_filepath, monitor=monitor, save_best_only=True, save_weights_only=True, mode=mode, verbose=1)
save_model_at_epoch_end_callback = LambdaCallback(on_epoch_end=lambda epoch, logs: embedding_model.save_weights(last_weights_filepath))
callbacks_list = [checkpoint, save_model_at_epoch_end_callback] # , early]
return callbacks_list
```
Also, we need to be able to load the model (to continue training or to do testing):
```
def loadModel(embedding_model, bBest):
if(bBest):
path = best_weights_filepath
strMessage = "load best model"
else:
path = last_weights_filepath
strMessage = "load last model"
if(os.path.isfile(path)):
embedding_model.load_weights(path)
print(strMessage, ": File loaded")
else:
print(strMessage, ": No file to load")
return embedding_model
```
The following function does actual training:
```
def trainNetwork(EPOCHS, nL2, optimizer, bCumulativeLearning = False):
global embedding_model
global history
global arrImages
global arrLabels
if(bCumulativeLearning == False):
deleteSavedNet(best_weights_filepath)
random.seed(7)
embedding_model = createModel(nL2, optimizer)
print("Model created")
callbacks_list = getCallbacks("val_accuracy", 'max')
if(bCumulativeLearning == True):
loadModel(embedding_model, False)
nNumOfTrainSamples = 10000
for cls in arrLabeledData:
nMin, nMax = getClassMinMax(cls, True)
nNumOfTrainSamples = min(nNumOfTrainSamples, nMax - nMin)
STEP_SIZE_TRAIN = nNumOfTrainSamples // BATCH_SIZE
if(STEP_SIZE_TRAIN < 100):
STEP_SIZE_TRAIN = 100
nNumOfValidSamples = int(nNumOfTrainSamples * VALIDATION_IMAGES_PERCENT / TRAINING_IMAGES_PERCENT)
STEP_SIZE_VALID = nNumOfValidSamples // BATCH_SIZE
if(STEP_SIZE_VALID < 100):
STEP_SIZE_VALID = 100
print(STEP_SIZE_TRAIN, STEP_SIZE_VALID)
print("Available metrics: ", embedding_model.metrics_names)
history = embedding_model.fit(gen_train,
validation_data=gen_valid, verbose=0,
epochs=EPOCHS, steps_per_epoch=STEP_SIZE_TRAIN,
validation_steps=STEP_SIZE_VALID, callbacks=callbacks_list)
print(nL2)
plotFullHistory(history)
# TBD: here, return best model, not last one
return embedding_model
```
As you can see, it does some initializations, and then calls Keras's "fit" function.
Another data generator. This one reads images that we use AFTER network was trained. We don't care about labels here, as we deal with test set (or pretend it is test data).
```
def data_generator_simple(arrAllImageNames, arrAllImageClasses):
i = 0
arrImages = []
arrImageLabels = []
arrImageClasses = []
for nImageIdx in range(len(arrAllImageNames)):
if(i == 0):
arrImages = []
arrImageNames = []
arrImageClasses = []
i += 1
strClass = arrAllImageClasses[nImageIdx]
strImageName = arrAllImageNames[nImageIdx]
#angle = random.randint(0, 90)
img = loadImage(join(working_path, "images/", strClass, strImageName)) #, angle)
arrImg = img_to_array(img)
#arrImg = datagen.random_transform(arrImg) #/ 255.
#arrImg = add_noise(arrImg)
arrImg = np.array(arrImg, dtype="float32")
arrImages.append(arrImg)
arrImageNames.append(strImageName)
arrImageClasses.append(strClass)
if i == BATCH_SIZE:
i = 0
yield np.array(arrImages), arrImageNames, arrImageClasses
raise StopIteration()
```
As usual, load image using this generator:
```
def ShowImgSimple(img, label):
print(label)
fig = plt.figure()
fig.add_subplot(1, 1, 1)
plt.imshow(img, cmap='gray')
plt.show()
plt.close()
```
And display it:
Using the generator above, we can load all test images and run prediction on them:
```
def getAllTestImages():
global embedding_model
arrAllImageNames = []
arrAllImageClasses = []
for cClass in arrLabeledData:
for nIdx in range(int(len(cClass['image_names']) * (TRAINING_IMAGES_PERCENT + VALIDATION_IMAGES_PERCENT)), len(cClass['image_names'])):
arrAllImageNames.append(cClass['image_names'][nIdx])
arrAllImageClasses.append(cClass['class'])
test_preds = []
test_file_names = []
test_class_names = []
for imgs, fnames, classes in data_generator_simple(arrAllImageNames, arrAllImageClasses):
predicts = embedding_model.predict(imgs)
predicts = predicts.tolist()
test_preds += predicts
test_file_names += fnames
test_class_names += classes
test_preds = np.array(test_preds)
return test_preds, test_file_names, test_class_names
```
By the way, we can get accuracies for all our predictions:
```
def getAccuracy(test_preds, test_file_names, test_class_names):
nTotalSuccess = 0
for i, arrPredictedProbabilities in enumerate(test_preds):
nPredictedClassIdx = arrPredictedProbabilities.argmax()
gt_class = test_class_names[i]
predicted_class = arrClasses[nPredictedClassIdx]
if(predicted_class == gt_class):
nTotalSuccess += 1
else:
print("GT: ", gt_class, "; Pred: ", predicted_class, "; Probabilitires: ", arrPredictedProbabilities[0], ", ", arrPredictedProbabilities[1])
img = loadImage(join(working_path, "images/", gt_class, test_file_names[i]))#, 0)
plt.imshow(img)
plt.show()
nSuccess = nTotalSuccess / (i+1)
return nSuccess
```
Finally, here is the function that STARTS the training. It has somewhat confusing name "test":
```
def test(EPOCHS, nL2, optimizer, learning_rate, bCumulativeLearning):
global embedding_model
embedding_model = trainNetwork(EPOCHS, nL2, optimizer, bCumulativeLearning)
print("loading best model")
embedding_model = loadModel(embedding_model, True)
test_preds, test_file_names, test_class_names = getAllTestImages()
# print("test_preds[0], test_file_names[0], test_class_names[0]: ", test_preds[0], test_file_names[0], test_class_names[0])
nSuccess = getAccuracy(test_preds, test_file_names, test_class_names)
print(">>> Accuracy on test set:", nSuccess, "<<<")
```
We can now call this function and therefore start training:
```
opt = tf.keras.optimizers.Adam(0.0002) ##Adamax(lr=0.0001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0)
nL2 = 0.4
if(bDoTraining):
EPOCHS = 50
learning_rate=0.001
np.random.seed(7)
test(EPOCHS, nL2, opt, learning_rate, bCumulativeLearning=False)
embedding_model = loadModel(embedding_model, True)
embedding_model.save(best_weights_filepath) # A full model is saved
```
After training is complete, we can run predictions on all test data:
```
if(bDoTraining):
nClassIdx = np.random.randint(len(arrLabeledData))
cls = arrLabeledData[nClassIdx]
nMinIdx, nMaxIdx = getClassMinMax(cls, False)
nImageIdx = random.randint(nMinIdx, nMaxIdx)
for i, nImageIdx in enumerate(range(nMinIdx, nMaxIdx)):
print(i+1, "of", nMaxIdx - nMinIdx)
img = loadImage(join(working_path, "images/", arrLabeledData[nClassIdx]['class'], arrLabeledData[nClassIdx]['image_names'][nImageIdx]))#, 0)
arrImg = img_to_array(img)
arrImg = np.array(arrImg, dtype="float32")
# ---
test_preds = embedding_model.predict(arrImg.reshape(1, IMAGE_SIZE, IMAGE_SIZE, 3))
nIdx = test_preds.argmax()
if(nClassIdx != nIdx):
print("GT: ", arrLabeledData[nClassIdx]['class'], "; Pred: ", arrClasses[nIdx])
plt.imshow(img)
plt.show()
```
Ok, our model is trained and tested on a test data set. Now we can actually USE it: we can load a HUGE set of images and classify them (see comments in code). Note that this code is written to work with image file names convention from [previous step](https://robotics.snowcron.com/coins/01_crop_and_group.htm):
```
# Same as above in "test" section, but this time we process images from output folder
# The "/content/drive/My Drive/01_Output/" is the output of the previous step, remember, we goi pairs of images, and
# now need to figure which ones are avers and which ones are revers?
images_source_path = "/content/drive/My Drive/01_Output/"
# We will save images by new names (with "head" or "tail" suffix) in this folder
images_dest_path = working_path + "images_processed/"
arrSourceImageNames = [f for f in listdir(images_source_path) if isfile(join(images_source_path, f))]
# Create model and load its weights (ones we got during training)
embedding_model = createModel(nL2, opt)
embedding_model = loadModel(embedding_model, True)
# Dictionary will store image names and counter: see below for details
dictNames = {}
nTotal = len(arrSourceImageNames)
for i, file_name in enumerate(arrSourceImageNames):
image_path = join(images_source_path, file_name)
img = loadImage(image_path)
arrImg = img_to_array(img)
arrImg = np.array(arrImg, dtype="float32")
# ---
# For image, predict its class
test_preds = embedding_model.predict(arrImg.reshape(1, IMAGE_SIZE, IMAGE_SIZE, 3))
nIdx = test_preds.argmax()
#print(i+1, "of", nTotal, ": ", arrClasses[nIdx])
#plt.imshow(img)
#plt.show()
# Split image name
word_list = file_name.split(".") # ['0_000_00', 'png']
image_name = word_list[0]
image_ext = word_list[1]
plt.imsave(images_dest_path + image_name + "_" + arrClasses[nIdx] + ".png", img)
# Now we need to move source file to trash, but make it zero size first so it doesn't take space there
open(image_path, 'w').close() #overwrite and make the file blank instead
os.remove(image_path)
if(i%100 == 0):
print(i, " of ", nTotal)
# File names look like 123496110_07_03.
# Here 123496110 is the file root name, 07 is number of a coin in that image (some images contain >1 coins), and 03 is a number of images of that coin
# (Say, we have 169860023_000.jpg, 169860023_001.jpg, 169860023_002.jpg, one coin per image, tail-tail-head. Then at step 1 we will get
# 169860023_00_00, 169860023_00_01, and 169860023_00_02)
# We append _head or _tail: 169860023_00_00_tail(.png)
# In dictNames we keep pairs 169860023_00 + flag. Flag == 0 if no heads, no tails, 1 if heads / no tails, 2 if tails / no heads and 3 if has both
# When scanning is complete, we delete files that have flag != 3
arrImageNameParts = image_name.split("_") # ['169860023', '000', '00']
# We do not need "000" here, as it is just number of an image in a group of images for that coin. We need name (169860023) of course, plus
# number of a coin (00)
coin_name = arrImageNameParts[0] + "_" + arrImageNameParts[2]
if(arrClasses[nIdx] == "head"):
if coin_name in dictNames:
dictNames[coin_name] = dictNames[coin_name] | 1
else:
dictNames[coin_name] = 1
else:
if coin_name in dictNames:
dictNames[coin_name] = dictNames[coin_name] | 2
else:
dictNames[coin_name] = 2
#print(dictNames)
# Now we need to delete all files for which dictNames[coin_name] != 3
print("Deleting files that do not have both head and tail")
nDeleted = 0
for i, file_name in enumerate(arrSourceImageNames):
image_path = join(images_dest_path, file_name)
word_list = file_name.split(".") # ['0_000_00', 'png']
image_name = word_list[0]
image_ext = word_list[1]
arrImageNameParts = image_name.split("_") # ['169860023', '000', '00']
# We do not need "000" here, as it is just number of an image in a group of images for that coin. We need name (169860023) of course, plus
# number of a coin (00)
coin_name = arrImageNameParts[0] + "_" + arrImageNameParts[2]
if (coin_name not in dictNames) or (dictNames[coin_name] != 3):
open(image_path, 'w').close() #overwrite and make the file blank instead
os.remove(image_path)
if(i%100 == 0):
print(i, " of ", nTotal)
print("Deleted", nDeleted)
```
As the result, we have file names with "\_head" or "\_tail" suffix, and coins that have no pair are removed.

|
https://habr.com/ru/post/540324/
| null |
en
| null |
# Улучшение системы комментариев на Хабрахабре (Обновление)
**Обновление см. под кат.**
На хабре (да и не только) сейчас я вижу систему комментариев, где идут ветви, по типу:
`1
|.2
|.|.3
|.|.|.4
|.2
1`
Я вижу проблему веток в том, что при больших ветвях ориентироваться довольно не удобно.
Чтобы найти первоначальный комментарий, нужно представить линию, которая ведёт ровно к нужному комментарию и прокручивать страницу до тех пор, пока не упрёшься в этот самый комментарий. На хабре я вижу, что эту проблему частично решили путём добавления стрелочкек вверх(↑) и вниз(↓), но всё же это не решает проблему полностью.
Если я, например, решил ответить на комментарий, то приходится возвращаться к нему обратно (жать на стрелочку вниз), а мне на самом деле нужно было просто прочитать комментарий, на который отвечают. То есть на глазах потеря времени из-за лишних действий.
В моём же понимании я вижу решение этой проблемы так:
У комментариев есть схемы-линии, если подвести к линии курсором, то появится всплывающая подсказка, внутри которой комментарий, на который собственно идут ответы в этой ветке-уровне.
Короче, по рисунку должно быть понятно (**Новая схема**):
[
Новая схема](http://xs331.xs.to/xs331/08370/habrcomm_ex2268.png)
[Предыдущая схема](http://xs331.xs.to/xs331/08376/habrcomm_ex315.png)
**Обновление:**
Как я уже писал выше, логика простая:
1. Если навести курсор на область реагирования, линия становится чёткой и рядом с курсором вылезает окошечко с комментарием, на который идут ответы в этой ветке.
2. Кроме этого, при наведении по бокам линии появляются стрелочки вверх(↑), которые находятся напротив курсора (ездят за ним) и символизируют — что если нажать в этой области, то можно непосредственно подняться к начальному комментарию в этой ветке.
3. Далее после нажатия эти стрелочки меняют направление вниз(↓) и если ещё раз нажать по этой области, то можно перейти в конец этой ветки — к следующей.
Можно ещё добавить линии, которые примыкают непосредственно к комментариям — для наглядности, но это дополнительные таблицы.
|
https://habr.com/ru/post/39776/
| null |
ru
| null |
# Как объединить несколько JS приложений с .NET Core (Create React APP + Next JS + .NET Core)
Всем привет! Пару месяцев назад у нас возникла задача запилить лендос для нашего онлайн сервиса. Наш стек - Create React App + .Net Core. Погугля немного, мы решили, что хотим запилить лендос на Next JS, но возник вопрос - как это все вместе подружить.
Мы хотели, что бы приложение открывалось по ссылке: `yourdomain.com/app`, а все остальные ссылки вели бы на лендос.
---
Для начала в папке, где у Вас лежит ClientApp нужно создать папку LandingApp куда вы добавите второй проект. (Если что, папки можно назвать, как угодно)
---
После того, как Вы добавите второй проект нужно немного обновить **startup.cs,** чтобы **.Net Core** мог "переключать трафик" с одного проекта на другой.
Отключаем endpoint routing в методе **ConfigureServices**
```
services.AddMvc(options =>
{
options.EnableEndpointRouting = false;
});
```
В метод **Configure** добавляем статичные файлы для **CRA**
```
app.UseSpaStaticFiles(new StaticFileOptions() {
RequestPath = "/app"
});
```
Добавляем **маппер**, который при переходе по ссылке `/app` будет открывать наше приложение
```
app.MapWhen(context => context.Request.Path.Value.StartsWith("/app"), builder =>
{
builder.UseMvc(routes =>
{
routes.MapSpaFallbackRoute(
"app",
new { controller = "", action = "app" }
);
});
builder.UseSpa(spa =>
{
spa.Options.SourcePath = "ClientApp";
if (env.IsDevelopment())
{
spa.UseReactDevelopmentServer(npmScript: "start");
}
});
});
```
После по дефолту открываем наше **Next JS** приложение
```
app.UseSpa(spa =>
{
spa.Options.SourcePath = "LandingApp";
// Для простоты билда, мы забилдили лендос отдельно
// И там скрывается ссылка по типу
// https://yourapp.azurewebsites.net
var url = Configuration.GetSection("urls")["landingUrl"];
if (env.IsDevelopment())
{
url = "http://localhost:3005";
}
spa.UseProxyToSpaDevelopmentServer(url);
if (env.IsDevelopment())
{
spa.UseReactDevelopmentServer(npmScript: "dev");
}
});
```
Весь метод Configure
```
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
_env = env;
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
else
{
app.UseExceptionHandler("/Error");
// The default HSTS value is 30 days. You may want to change this for production scenarios, see https://aka.ms/aspnetcore-hsts.
app.UseHsts();
}
app.Use(async (context, next) =>
{
context.Response.Headers.Add("X-Frame-Options", "SAMEORIGIN");
await next();
});
app.UseHttpsRedirection();
app.UseStaticFiles();
app.UseSpaStaticFiles(new StaticFileOptions() {
RequestPath = "/app"
});
app.UseRouting();
app.UseAuthentication();
app.UseAuthorization();
app.UseEndpoints(endpoints =>
{
endpoints.MapControllerRoute(
name: "default",
pattern: "{controller}/{action=Index}/{id?}");
});
app.MapWhen(context => context.Request.Path.Value.StartsWith("/app"), builder =>
{
builder.UseMvc(routes =>
{
routes.MapSpaFallbackRoute(
"app",
new { controller = "", action = "app" }
);
});
builder.UseSpa(spa =>
{
spa.Options.SourcePath = "ClientApp";
if (env.IsDevelopment())
{
spa.UseReactDevelopmentServer(npmScript: "start");
}
});
});
app.UseSpa(spa =>
{
spa.Options.SourcePath = "LandingApp";
var url = Configuration.GetSection("urls")["landingUrl"];
if (env.IsDevelopment())
{
url = "http://localhost:3005";
}
spa.UseProxyToSpaDevelopmentServer(url);
if (env.IsDevelopment())
{
spa.UseReactDevelopmentServer(npmScript: "dev");
}
});
}
```
---
Далее, нам нужно сказать CRA откуда брать бандл т.к. теперь он находится не в корне, а в `/app`. Для этого, мы в **package.json** указываем свойство `homepage: "/app/"`
Если вы используете библиотеку **history** то нужно указать еще `basename: '/app'`
```
import { connectRouter } from 'connected-react-router';
import { createBrowserHistory } from 'history';
export const history = createBrowserHistory({
basename: '/app',
});
export const routerReducer = connectRouter(history);
```
И на этом вроде все :)
|
https://habr.com/ru/post/583830/
| null |
ru
| null |
# Прогноз погоды по телефону
#### Решил я, что получится весьма полезная возможность собираясь на работу послушать прогноз погоды на громкоговорителе телефона нажав одну запрограммированную кнопку. Как я это сделал смотрите под катом.
###### Первое что нам потребуется это сам прогноз погоды. Я решил его брать с сайта gismeteo.ru.
Как я это сделал:
Зашел на сайт gismeteo.ru нашел свой город.
Нажал в шапке ссылку «Информеры».
На открывшейся странице нашел текст «Данные в формате XML» и взял ссылку с кнопки «получить код».
Таким образом мы теперь знаем как нам получать свежий прогноз в формате XML.
Теперь нужно его сохранить для последующей обработки:
Велосипед изобретать я не стал и написал скрипт на bash из двух строк
> `Copy Source | Copy HTML1. #!/bin/bash
> 2. cd /usr/isp/weather
> 3. /usr/bin/wget 'http://informer.gismeteo.ru/xml/34214\_1.xml' -O ./34214\_1.xml
> 4.`
###### где **[informer.gismeteo.ru/xml/34214\_1.xml](http://informer.gismeteo.ru/xml/34214_1.xml)** и есть ссылка для вашего города. Команда wget скачивает наш XML и записывает его в фаил 34214\_1.xml в текущем каталоге, он нам потребуется далее. Что бы прогноз был всегда свежим необходимо этот скрипт записать на выполнение в cron например вот так:
`*/60 * * * * /usr/isp/weather/weather_up.sh`
###### Алгоритм озвучивающий прогноз я решил сделать на Perl который взаимодействует с Asterisk через [AGI](http://voip.rus.net/tiki-index.php?page=Asterisk+AGI). От нашего алгоритма требуется произвести разбор XML файла и вывести в stdout последовательность строк с командами для Asterisk на воспроизведение звуковых файлов примерно вот так:
> `Copy Source | Copy HTML1. EXEC Playback weather/Po\_dannym\_Gismeteo ""
> 2. EXEC Playback weather/tod/dnem ""
> 3. EXEC Playback weather/m/15ogo ""
> 4. EXEC Playback weather/budet ""
> 5. EXEC Playback weather/cloudiness/pasmurno ""
> 6. EXEC Playback weather/precipitation/dozhd' ""
>
>
> EXECPlayback weather/temp\_vosduha\_sostavit ""
> EXECPlayback weather/digits/20 ""
> EXECPlayback weather/digits/2 ""
> EXECPlayback weather/Do ""
> EXECPlayback weather/digits/20 ""
> EXECPlayback weather/gradusov\_C ""
> EXECPlayback weather/Skorost'\_vetra\_sostavit ""
> 7. EXEC Playback weather/digits/5 ""
> 8. EXEC Playback weather/Do ""
> 9. EXEC Playback weather/digits/3 ""
> 10. EXEC Playback weather/metrov\_v\_sekundu ""
> 11. EXEC Playback weather/Atmosfernoe\_davlenie\_sostavit ""
> 12. EXEC Playback weather/digits/700 ""
> 13. EXEC Playback weather/digits/40 ""
> 14. EXEC Playback weather/digits/7 ""
> 15. EXEC Playback weather/Do ""
> 16. EXEC Playback weather/digits/700 ""
> 17. EXEC Playback weather/digits/40 ""
> 18. EXEC Playback weather/digits/5 ""
> 19. EXEC Playback weather/milimetrov\_rtutnogo\_stolba ""`
###### Как вы заметели звуковых записей придётся подготовить очень много, но ведь это раз и навсегда.
В моём варианте в некоторых записанных фразах присутствует слово «от». Например: Atmosfernoe\_davlenie\_sostavit читать как «Атмосферное давление составит от».
Собственно для разбора XML я использовал модуль **XML::Simple** он мне показался самым простым в использовании. Для замены XML тэгов на необходимые мне строки для озвучивания применил списки:
> `Copy Source | Copy HTML1. my $date\_name = {
> 2. 1 => ["EXEC Playback weather\/m\/1ogo \"\"\n"],
> 3. 2 => ["EXEC Playback weather\/m\/2ogo \"\"\n"],
> 4. 3 => ["EXEC Playback weather\/m\/3ogo \"\"\n"],
> 5. .....
> 6.`
###### С алгоритмом для преобразования чисел в набор команд для воспроизведения цифр решил тоже не изобретать велосипед и взял готовый алгоритм преобразования денег в пропись (к сожалению уже не вспомню чей), заменил в нужных местах строки такие как "**один**" на "**Playback weather\/digits\/1 \"\"\n**" и алгоритм адаптирован (куча времени сэкономлена).
Думаю теперь всё будет понятно, пришло время посмотреть на скрипт:
> `Copy Source | Copy HTML1. #!/usr/bin/perl
> 2.
> 3. use strict;
> 4. use XML::Simple;
> 5. use Data::Dumper;
> 6.
> 7. my $date\_name = {
> 8. 1 => ["EXEC Playback weather\/m\/1ogo \"\"\n"],
> 9. 2 => ["EXEC Playback weather\/m\/2ogo \"\"\n"],
> 10. 3 => ["EXEC Playback weather\/m\/3ogo \"\"\n"],
> 11. 4 => ["EXEC Playback weather\/m\/4ogo \"\"\n"],
> 12. 5 => ["EXEC Playback weather\/m\/5ogo \"\"\n"],
> 13. 6 => ["EXEC Playback weather\/m\/6ogo \"\"\n"],
> 14. 7 => ["EXEC Playback weather\/m\/7ogo \"\"\n"],
> 15. 8 => ["EXEC Playback weather\/m\/8ogo \"\"\n"],
> 16. 9 => ["EXEC Playback weather\/m\/9ogo \"\"\n"],
> 17. 10 => ["EXEC Playback weather\/m\/10ogo \"\"\n"],
> 18. 11 => ["EXEC Playback weather\/m\/11ogo \"\"\n"],
> 19. 12 => ["EXEC Playback weather\/m\/12ogo \"\"\n"],
> 20. 13 => ["EXEC Playback weather\/m\/13ogo \"\"\n"],
> 21. 14 => ["EXEC Playback weather\/m\/14ogo \"\"\n"],
> 22. 15 => ["EXEC Playback weather\/m\/15ogo \"\"\n"],
> 23. 16 => ["EXEC Playback weather\/m\/16ogo \"\"\n"],
> 24. 17 => ["EXEC Playback weather\/m\/17ogo \"\"\n"],
> 25. 18 => ["EXEC Playback weather\/m\/18ogo \"\"\n"],
> 26. 19 => ["EXEC Playback weather\/m\/19ogo \"\"\n"],
> 27. 20 => ["EXEC Playback weather\/m\/10ogo \"\"\n"],
> 28. 21 => ["EXEC Playback weather\/m\/21ogo \"\"\n"],
> 29. 22 => ["EXEC Playback weather\/m\/22ogo \"\"\n"],
> 30. 23 => ["EXEC Playback weather\/m\/23ogo \"\"\n"],
> 31. 24 => ["EXEC Playback weather\/m\/24ogo \"\"\n"],
> 32. 25 => ["EXEC Playback weather\/m\/25ogo \"\"\n"],
> 33. 26 => ["EXEC Playback weather\/m\/26ogo \"\"\n"],
> 34. 27 => ["EXEC Playback weather\/m\/27ogo \"\"\n"],
> 35. 28 => ["EXEC Playback weather\/m\/28ogo \"\"\n"],
> 36. 29 => ["EXEC Playback weather\/m\/29ogo \"\"\n"],
> 37. 30 => ["EXEC Playback weather\/m\/30ogo \"\"\n"],
> 38. 31 => ["EXEC Playback weather\/m\/31ogo \"\"\n"]
> 39. };
> 40.
> 41. my $hour\_name = {
> 42. 0 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 43. 1 => ["EXEC Playback weather\/hour\/chas \"\"\n"],
> 44. 2 => ["EXEC Playback weather\/hour\/chasa \"\"\n"],
> 45. 3 => ["EXEC Playback weather\/hour\/chasa \"\"\n"],
> 46. 4 => ["EXEC Playback weather\/hour\/chasa \"\"\n"],
> 47. 5 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 48. 6 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 49. 7 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 50. 8 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 51. 9 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 52. 10 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 53. 11 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 54. 12 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 55. 13 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 56. 14 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 57. 15 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 58. 16 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 59. 17 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 60. 18 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 61. 19 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 62. 20 => ["EXEC Playback weather\/hour\/chasov \"\"\n"],
> 63. 21 => ["EXEC Playback weather\/hour\/chas \"\"\n"],
> 64. 22 => ["EXEC Playback weather\/hour\/chasa \"\"\n"],
> 65. 23 => ["EXEC Playback weather\/hour\/chasa \"\"\n"],
> 66. };
> 67.
> 68. my $m\_name = {
> 69. 1 => ["EXEC Playback weather\/m\/yanvarya \"\"\n"],
> 70. 2 => ["EXEC Playback weather\/m\/fevralya \"\"\n"],
> 71. 3 => ["EXEC Playback weather\/m\/marta \"\"\n"],
> 72. 4 => ["EXEC Playback weather\/m\/aprelya \"\"\n"],
> 73. 5 => ["EXEC Playback weather\/m\/maya \"\"\n"],
> 74. 6 => ["EXEC Playback weather\/m\/iunya \"\"\n"],
> 75. 7 => ["EXEC Playback weather\/m\/iylya \"\"\n"],
> 76. 8 => ["EXEC Playback weather\/m\/avgusta \"\"\n"],
> 77. 9 => ["EXEC Playback weather\/m\/sentyabrya \"\"\n"],
> 78. 10 => ["EXEC Playback weather\/m\/octyabya \"\"\n"],
> 79. 11 => ["EXEC Playback weather\/m\/noyabrya \"\"\n"],
> 80. 12 => ["EXEC Playback weather\/m\/decabrya \"\"\n"]
> 81. };
> 82.
> 83. my $tod\_name = {
> 84. 0 => ["EXEC Playback weather\/tod\/noch'u \"\"\n"],
> 85. 1 => ["EXEC Playback weather\/tod\/utrom \"\"\n"],
> 86. 2 => ["EXEC Playback weather\/tod\/dnem \"\"\n"],
> 87. 3 => ["EXEC Playback weather\/tod\/vecherom \"\"\n"]
> 88. };
> 89.
> 90. my $cloudiness\_name = {
> 91. 0 => ["EXEC Playback weather\/cloudiness\/yasno \"\"\n"],
> 92. 1 => ["EXEC Playback weather\/cloudiness\/malooblachno \"\"\n"],
> 93. 2 => ["EXEC Playback weather\/cloudiness\/oblachno \"\"\n"],
> 94. 3 => ["EXEC Playback weather\/cloudiness\/pasmurno \"\"\n"]
> 95. };
> 96.
> 97. my $precipitation\_name = {
> 98. 4 => ["EXEC Playback weather\/precipitation\/dozhd' \"\"\n"],
> 99. 5 => ["EXEC Playback weather\/precipitation\/liven' \"\"\n"],
> 100. 6 => ["EXEC Playback weather\/precipitation\/sneg \"\"\n"],
> 101. 7 => ["EXEC Playback weather\/precipitation\/sneg \"\"\n"],
> 102. 8 => ["EXEC Playback weather\/precipitation\/groza \"\"\n"],
> 103. 9 => [""],
> 104. 10 => ["EXEC Playback weather\/precipitation\/bez\_osadkov \"\"\n"]
> 105. };
> 106.
> 107. my $wind\_direction\_name = {
> 108. 0 => ["EXEC Playback weather\/wind\_direction\/severnyi \"\"\n"],
> 109. 1 => ["EXEC Playback weather\/wind\_direction\/severo-vostochnyi \"\"\n"],
> 110. 2 => ["EXEC Playback weather\/wind\_direction\/vostochno-uzhnyi \"\"\n"],
> 111. 3 => ["EXEC Playback weather\/wind\_direction\/ugo-zapadnyi \"\"\n"]
> 112. };
> 113.
> 114.
> 115. my $xmlWeather = new XML::Simple(keeproot => 1,searchpath => ".", forcearray => 1, suppressempty => '');
> 116. my $xmlData1 = $xmlWeather->XMLin('/usr/isp/weather/34214\_1.xml');
> 117. my $xmlData = $xmlData1->{MMWEATHER}[ 0]->{REPORT}[ 0]->{TOWN}[ 0]->{FORECAST};
> 118.
> 119. $| = 1;
> 120. while( ) {
> 121. chomp($\_);
> 122. last if length($\_) == 0;
> 123. }
> 124.
> 125. # "Po dannym Gismeteo"
> 126. print "EXEC Playback weather\/Po\_dannym\_Gismeteo \"\"\n";
> 127. my $i= 0;
> 128. for ($i = 0; $i < 4; $i++)
> 129. {
> 130. print $tod\_name->{$xmlData->[$i]->{tod}}->[ 0];
> 131. print $date\_name->{$xmlData->[$i]->{day}}->[ 0];
> 132. print $m\_name->{$xmlData->[$i]->{month}}->[ 0];
> 133. #
> 134. print "EXEC Playback weather\/budet \"\"\n";
> 135. print $cloudiness\_name->{$xmlData->[$i]->{PHENOMENA}[ 0]->{cloudiness}}->[ 0];
> 136. print $precipitation\_name->{$xmlData->[$i]->{PHENOMENA}[ 0]->{precipitation}}->[ 0];
> 137. # Temp
> 138. print "EXEC Playback weather\/temp\_vosduha\_sostavit \"\"\n";
> 139. print digit\_string( $xmlData->[$i]->{TEMPERATURE}[ 0]->{max} );
> 140. print "EXEC Playback weather\/Do \"\"\n";
> 141. print digit\_string( $xmlData->[$i]->{TEMPERATURE}[ 0]->{min} );
> 142. print "EXEC Playback weather\/gradusov\_C \"\"\n";
> 143. # Veter
> 144. print "EXEC Playback weather\/Skorost'\_vetra\_sostavit \"\"\n";
> 145. print digit\_string( $xmlData->[$i]->{WIND}[ 0]->{max} );
> 146. print "EXEC Playback weather\/Do \"\"\n";
> 147. print digit\_string( $xmlData->[$i]->{WIND}[ 0]->{min} );
> 148. print "EXEC Playback weather\/metrov\_v\_sekundu \"\"\n";
> 149. # Atmosfernoe davlenie
> 150. print "EXEC Playback weather\/Atmosfernoe\_davlenie\_sostavit \"\"\n";
> 151. print digit\_string( $xmlData->[$i]->{PRESSURE}[ 0]->{max} );
> 152. print "EXEC Playback weather\/Do \"\"\n";
> 153. print digit\_string( $xmlData->[$i]->{PRESSURE}[ 0]->{min} );
> 154. print "EXEC Playback weather\/milimetrov\_rtutnogo\_stolba \"\"\n";
> 155.
> 156. }
> 157.
> 158.
> 159. #===================================================================================================
> 160. #===================================================================================================
> 161. #===================================================================================================
> 162. sub digit\_string {
> 163. my $digit = shift;
> 164. local $\_;
> 165.
> 166. my $sign = 1 if $digit =~ s/^-+//;
> 167.
> 168.
> 169. $digit =~ s#^0+##;
> 170. my ( $b\_dig, $s\_dig ) = ( split( m/[,.]/, $digit, 2 ) );
> 171. $s\_dig ="";
> 172. #
> 173. # Очищаем числа от `лишних' символов ( 100\_000,43 )
> 174. #
> 175. if ( defined $b\_dig and length $b\_dig ) {
> 176. # $b\_dig =~ s#[^\d]##sg;
> 177. } else {
> 178. $b\_dig = "";
> 179. }
> 180. if ( defined $s\_dig and length $s\_dig ) {
> 181. # $s\_dig =~ s#[^\d]##sg;
> 182. } else {
> 183. $s\_dig = "";
> 184. }
> 185. #
> 186. # Округляем копейки в большую сторону, если в результате округления
> 187. # получаем рубль, то приплюсовываем его к b\_dig ( рублям )
> 188. #
> 189. # if ( sprintf('%0.2f', "0.$s\_dig" ) == 1 ) {
> 190. # $b\_dig ++;
> 191. # $s\_dig = '00';
> 192. # } else {
> 193. # $s\_dig = substr( sprintf('%0.2f', "0.$s\_dig" ), 2 );
> 194. # }
> 195. #
> 196. my @array = split( //, ( $b\_dig || 0 ) );
> 197.
> 198. #
> 199. # Определяем разрядность числа.
> 200. #
> 201. my $class\_id = int( scalar ( @array ) / 3);
> 202. $class\_id++ if ( scalar ( @array ) % 3 );
> 203. #
> 204. # Неподдерживаемая разрядность.
> 205. #
> 206. return $digit if $class\_id > 5;
> 207.
> 208. my $digits\_name = {
> 209. 0 => ["EXEC Playback weather\/digits\/0 \"\"\n","",""],
> 210. 1 => [["EXEC Playback weather\/digits\/1 \"\"\n","EXEC Playback weather\/digits\/1a \"\"\n"],"EXEC Playback weather\/digits\/10 \"\"\n","EXEC Playback weather\/digits\/100 \"\"\n"],
> 211. 2 => [["EXEC Playback weather\/digits\/2 \"\"\n","EXEC Playback weather\/digits\/2e \"\"\n"],"EXEC Playback weather\/digits\/20 \"\"\n","EXEC Playback weather\/digits\/200 \"\"\n"],
> 212. 3 => ["EXEC Playback weather\/digits\/3 \"\"\n","EXEC Playback weather\/digits\/30 \"\"\n","EXEC Playback weather\/digits\/300 \"\"\n"],
> 213. 4 => ["EXEC Playback weather\/digits\/4 \"\"\n","EXEC Playback weather\/digits\/40 \"\"\n","EXEC Playback weather\/digits\/400 \"\"\n"],
> 214. 5 => ["EXEC Playback weather\/digits\/5 \"\"\n","EXEC Playback weather\/digits\/50 \"\"\n","EXEC Playback weather\/digits\/500 \"\"\n"],
> 215. 6 => ["EXEC Playback weather\/digits\/6 \"\"\n","EXEC Playback weather\/digits\/60 \"\"\n","EXEC Playback weather\/digits\/600 \"\"\n"],
> 216. 7 => ["EXEC Playback weather\/digits\/7 \"\"\n","EXEC Playback weather\/digits\/70 \"\"\n","EXEC Playback weather\/digits\/700 \"\"\n"],
> 217. 8 => ["EXEC Playback weather\/digits\/8 \"\"\n","EXEC Playback weather\/digits\/80 \"\"\n","EXEC Playback weather\/digits\/800 \"\"\n"],
> 218. 9 => ["EXEC Playback weather\/digits\/9 \"\"\n","EXEC Playback weather\/digits\/90 \"\"\n","EXEC Playback weather\/digits\/900 \"\"\n"],
> 219. };
> 220.
> 221. my $dec\_digits = {
> 222. 11 => "EXEC Playback weather\/digits\/11 \"\"\n",
> 223. 12 => "EXEC Playback weather\/digits\/12 \"\"\n",
> 224. 13 => "EXEC Playback weather\/digits\/13 \"\"\n",
> 225. 14 => "EXEC Playback weather\/digits\/14 \"\"\n",
> 226. 15 => "EXEC Playback weather\/digits\/15 \"\"\n",
> 227. 16 => "EXEC Playback weather\/digits\/16 \"\"\n",
> 228. 17 => "EXEC Playback weather\/digits\/17 \"\"\n",
> 229. 18 => "EXEC Playback weather\/digits\/18 \"\"\n",
> 230. 19 => "EXEC Playback weather\/digits\/19 \"\"\n"
> 231. };
> 232.
> 233. my $digits\_class = {
> 234. '-1'=> [ 1,"","",""],
> 235. 0 => [ 0,"","",""],
> 236. 1 => [ 1, "EXEC Playback weather\/digits\/tysiacha \"\"\n","EXEC Playback weather\/digits\/tysiach \"\"\n","EXEC Playback weather\/digits\/tysiachi \"\"\n" ],
> 237. 2 => [ 0, "EXEC Playback weather\/digits\/million \"\"\n","EXEC Playback weather\/digits\/millionov \"\"\n","EXEC Playback weather\/digits\/milliona \"\"\n" ],
> 238. 3 => [ 0, "EXEC Playback weather\/digits\/milliard \"\"\n","EXEC Playback weather\/digits\/milliardov \"\"\n","EXEC Playback weather\/digits\/milliarda \"\"\n" ],
> 239. 4 => [ 0, "EXEC Playback weather\/digits\/trillion \"\"\n","EXEC Playback weather\/digits\/trillionov \"\"\n","EXEC Playback weather\/digits\/trilliona \"\"\n"],
> 240. };
> 241. #
> 242. # Определяем длину левой `тройки'...
> 243. #
> 244. my $id = 0;
> 245. unless ( ( scalar @array ) % 3 ) {
> 246. $id = 2;
> 247. } else {
> 248. $id = ( ( scalar @array ) % 3 ) - 1;
> 249. }
> 250.
> 251. my $str = '';
> 252. my $sub\_str = 0;
> 253. my $tvar = 0;
> 254.
> 255. if ( $array[ 0] == 0 ) {
> 256. #
> 257. # Если рублей таки ноль, то так и пишем 'ноль рублей',
> 258. # если не надо то просто закомнтировать следующую строку...
> 259. #
> 260. $str .= $digits\_name->{'0'}->[ 0] . ' ' . $digits\_class->{'0'}->[2] . ' ';
> 261. } else {
> 262. while ( defined ( $\_ = shift @array ) ) {
> 263. if ( $\_ > 0 ) {
> 264. if ( $\_ == 1 and $id == 1 ) {
> 265. #
> 266. # Считаем сумму для использования в sub num()
> 267. #
> 268. $sub\_str += $\_ \* 10;
> 269. if ( defined ( $tvar = shift @array ) and $tvar > 0 ) {
> 270. $str .= $dec\_digits->{ $\_ . $tvar };
> 271. $sub\_str += $tvar;
> 272. $id--;
> 273. } else {
> 274. unshift @array, $tvar;
> 275. if ( ref $digits\_name->{$\_}->[$id] eq 'ARRAY' ) {
> 276. # $str .= $digits\_name->{$\_}->[$id]->[$digits\_class->{$class\_id-1}->[0]];
> 277. } else {
> 278. $str .= $digits\_name->{$\_}->[$id];
> 279. }
> 280. }
> 281. } else {
> 282. #
> 283. # Считаем сумму для использования в sub num()
> 284. #
> 285. $sub\_str += ( $\_ \* ( 10 \*\* $id ) );
> 286. if ( ref $digits\_name->{$\_}->[$id] eq 'ARRAY' ) {
> 287. $str .= $digits\_name->{$\_}->[$id]->[$digits\_class->{$class\_id-1}->[ 0]];
> 288. } else {
> 289. $str .= $digits\_name->{$\_}->[$id];
> 290. }
> 291. }
> 292. $str .= ' ';
> 293. }
> 294. if ( --$id == -1 ) {
> 295. $id = 2;
> 296. $class\_id--;
> 297. if ( $sub\_str > 0 ) {
> 298. $str .= num( $sub\_str, ( @{ $digits\_class->{$class\_id} } )[ 1 .. 3 ] ) . ' ';
> 299. } elsif ( $class\_id == 0 ) {
> 300. $str .= $digits\_class->{$class\_id}->[2] . ' ';
> 301. }
> 302. $sub\_str = 0;
> 303. }
> 304. }
> 305. }
> 306.
> 307. $str .= $s\_dig . ' ' . num( $s\_dig, ( @{ $digits\_class->{ '-1' } } )[ 1 .. 3 ] );
> 308.
> 309. if ( defined $sign ) {
> 310. $str = "EXEC Playback weather\/digits/minus \"\"\n" . $str;
> 311. }
> 312.
> 313. $s\_dig = substr( $str, 0, 1 );
> 314. #
> 315. # В том случае где оно пользовалось оказалось проще
> 316. # так, чем через use locale & ucfirst...
> 317. #
> 318. if ( $s\_dig =~ tr/абвгдеёжзийклмнопрстуфхцчшщъыьэюя/АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ/ ) {
> 319. substr( $str, 0, 1, $s\_dig );
> 320. }
> 321.
> 322. return $str;
> 323. }
> 324.
> 325. #
> 326. # Используется при переводе денежного числа в строку прописью..
> 327. #
> 328.
> 329. sub num {
> 330. my $d1 = $\_[ 0] % 10;
> 331. my $d2 = int( ( $\_[ 0] % 100 ) / 10 );
> 332. return $\_[2] if ( ( $d2 == 1 ) or ( $d1 =~ /[05-9]/ ) );
> 333. return $\_[1] if ( $d1==1 );
> 334. return $\_[3];
> 335. }
> 336.`
###### Далее нам необходимо научить Asterisk пользваться этим скриптом. Для этого в файле **extensions.conf** в нужном контексте прописываем вот так:
> `Copy Source | Copy HTML1. exten => XXXX,1,Wait(1)
> 2. exten => XXXX,n,Answer()
> 3. exten => XXXX,n,Agi(/usr/isp/weather/weather.pl)
> 4. exten => XXXX,n,Hangup()
> 5.`
###### Где XXXX номер который вы хотите присвоить сервису «Погода». У меня к примеру стоит плата Digium, через которую все желающие могут узнать погоду позвонив с любого телефона.
Вот и всё!
|
https://habr.com/ru/post/70771/
| null |
ru
| null |
# Оценка качества кластеризации: свойства, метрики, код на GitHub
Кластеризация — это такая магическая штука: она превращает большой объём неструктурированных данных в потенциально обозримый набор кластеров, анализ которых позволяет делать выводы о содержании этих данных.
Приложений у методов кластеризации огромное количество. Например, мы кластеризуем поисковые запросы для того, чтобы повышать обобщающую способность алгоритмов ранжирования: любая статистика, вычисленная по группе похожих запросов, надёжнее той же статистики, вычисленной для одного отдельного запроса. Кластеризация позволяет повышать качество на запросах с редко встречающимися формулировками. Другой понятный пример — Яндекс.Новости, которые автоматически формируют сюжеты из новостных сообщений.
В далёком 2013 году мне повезло поучаствовать в разработке очень сложного алгоритма кластеризации. Требовалось с очень высоким качеством кластеризовать сотни тысяч объектов и делать это быстро: за десятки секунд на одной машине. Первым делом нужно было построить систему оценки качества, и в этой статье я расскажу именно о ней.
[](https://habr.com/ru/company/yandex/blog/500742/)
Когда речь заходит об оценке качества, начинать нужно, конечно же, с метрик.
Алгоритм кластеризации можно и нужно оценивать с позиции сервиса, частью которого этот алгоритм является: рост качества кластеризации должен приводить к росту числа пользователей, конверсий, возвращаемости и так далее, так что классическое А/Б-тестирование вполне уместно. Вместе с тем любой большой системе нужны метрики, специфичные для каждого из её компонентов. Кластеризация — не исключение.
### **1. Метрики и их свойства**
Обычно задано *образцовое* разбиение на кластеры и разбиение, построенное *алгоритмически*. Метрика качества должна оценить степень соответствия между ними.
Обсуждение метрик стоит предварить обсуждением принципов, которым эти метрики должны удовлетворять. В статье [Amigo et. al, 2009. A comparison of Extrinsic Clustering Evaluation Metrics based on Formal Constraints](http://nlp.uned.es/docs/amigo2007a.pdf) очень подробно разбирается ряд принципов, их корректность и то, как различные классы метрик удовлетворяют этим принципам.
**1.1. Cluster Homogeneity, однородность кластеров**

Значение метрики качества должно уменьшаться при объединении в один кластер двух эталонных.
**1.2. Cluster Completeness, полнота кластеров**

Это свойство, двойственное свойству однородности. Значение метрики качества должно уменьшаться при разделении эталонного кластера на части.
**1.3. Rag Bag**

Пусть есть два кластера: чистый, содержащий элементы из одного эталонного кластера, и шумный («лоскутный»), где собраны элементы из большого числа различных эталонных кластеров. Тогда значение метрики качества должно быть выше у той версии кластеризации, которая помещает новый нерелевантный обоим кластерам элемент в шумный кластер, по сравнению с версией, которая помещает этот элемент в чистый кластер.
Это свойство может показаться очень естественным, но обязательно нужно принимать во внимание специфику приложения. Скажем, в Яндекс.Новостях большие «лоскутные» кластеры очень вредны: их невозможно адекватно проаннотировать, а благодаря своему размеру и разнообразию источников они могут ранжироваться очень высоко.
**1.4. Size vs Quantity**

Значительное ухудшение кластеризации большого числа небольших кластеров должно обходиться дороже небольшого ухудшения кластеризации в крупном кластере.
### **2. Метрики качества кластеризации**
Теперь обсудим несколько важных классов метрик качества кластеризации.
Будем считать заданным конечное множество объектов . Множеством кластеров будем называть всякую совокупность его непересекающихся непустых подмножеств. Таким образом,  — множество кластеров, если

При этом множество кластеров не обязательно является *покрытием* множества объектов: допускается неполная кластеризация. Впрочем, иногда удобно считать каждый некластеризованный элемент тривиальным одноэлементным кластером.
Будем считать, что определены два множества кластеров: эталонное  и построенное алгоритмом . Через  и  будем обозначать, соответственно, эталонный и алгоритмический кластеры, которым принадлежит объект .
**2.1. Метрики, основанные на подсчёте пар (классификационные)**
В этом подходе задача кластеризации сводится к бинарной классификации на множестве пар объектов. Пара объектов считается относящейся к положительному классу тогда и только тогда, когда оба объекта относятся к одному и тому же эталонному кластеру. Предсказание считается положительным тогда и только тогда, когда эти объекты относятся к одному и тому же алгоритмическому кластеру.
Иллюстрация ниже поясняет это определение. Восемь объектов разбиты на три эталонных кластера размеров 3 («жёлтый»), 3 («фиолетовый») и 2 («синий»). Эти же объекты кластеризованы алгоритмом так: «синий» кластер собран абсолютно верно, а вот один из «фиолетовых» объектов ошибочно отнесён в кластер к «жёлтым».

Тогда здесь суммарно  пар объектов, из них:
—  положительных;
—  отрицательных.
Построенная алгоритмом матрица содержит шесть лишних положительных элементов за счёт создания связей между «жёлтыми» объектами и одним из «фиолетовых» объектов, а также теряет четыре элемента из-за потери связей между «фиолетовыми» элементами.
В терминах качества бинарной классификации получается, что:
—  пар определены как положительные и при этом являются положительными;
—  пар определены как положительные, но ими не являются;
—  пар определены как отрицательные и при этом являются отрицательными;
—  пары определены как отрицательные, но ими не являются.
Теперь можно вычислить точность, полноту и любые другие метрики:



В процессе вычислений можно учитывать тот факт, что матрица симметрична: это вносит изменения в получаемые значения.
Описанный способ интуитивно очень понятен и прост в реализации. Другая его замечательная особенность в том, что получение оценок не требует построения эталонного разбиения на кластеры: достаточно разметить репрезентативное множество *пар объектов*.
Главный недостаток pairwise-метрик — квадратичная зависимость числа порождаемых пар от размера кластера. Из-за этого значение pairwise-метрик может быть обусловлено качеством кластеризации буквально нескольких самых крупных кластеров.
**2.2. Метрики, основанные на сопоставлении множеств**
Для определения метрик этого класса вначале вводятся метрики точности и полноты соответствия между кластером и эталоном:


Пример ниже содержит два эталонных кластера: «жёлтый» (y) и «фиолетовый» (v). Единственный алгоритмический кластер содержит 25 жёлтых точек и 10 фиолетовых. Точность соответствия этого кластера жёлтому кластеру составляет 25/35, а фиолетовому — 10/35. Вне кластера находятся ещё пять жёлтых и две фиолетовых точки. Значит, всего имеется 30 жёлтых и 12 фиолетовых точек, поэтому полнота соответствия жёлтому кластеру равна 25/30, фиолетовому — 10/12.
Физический смысл введённых величин прост: точность равна вероятности выбрать элемент эталонного кластера при выборе случайного элемента из алгоритмического кластера, полнота равна вероятности выбрать элемент алгоритмического кластера при выборе случайного элемента из эталонного кластера. Показатели двойственны:

Далее можно определить и F-меру:

Теперь необходимо определить интегральный показатель. Самый известный способ определить его через показатели отдельных соответствий приводит к метрике «чистоты» кластеров, *Purity*:

Вводится и двойственная метрика, в которой суммирование и нормировка производятся по эталонным кластерам:

Высокое значение  означает, что для кластера найдётся хорошо соответствующий ему эталон. Высокое значение  — что для эталона найдётся хорошо соответствующий ему алгоритмический кластер. Значит ли это, что близость обеих метрик к единице гарантирует очень хорошее качество кластеризации? К сожалению, нет. Рассмотрим следующий пример:


Для примера можно взять , , , . Кластер  полностью находится внутри , поэтому:


Отсюда можно вычислить метрики точности для соответствий:




Из этого уже ясно, что показатели Purity и InversePurity высоки для каждого из алгоритмических и эталонных кластеров соответственно. Аккуратное вычисление даёт:


Обе величины близки к единице, хотя для кластера  в действительности нет ни одного хорошего представителя из числа алгоритмических кластеров. Метрики не заметили этого, т. к. при подсчёте Purity кластеру  соответствовал кластер , а при подсчёте InversePurity — кластер . При вычислении двух различных показателей в качестве оптимальных были выбраны различные соответствия!
Отчасти с этой проблемой помогает справиться F-мера:

Использование такого показателя может быть оправданным в некоторых ситуациях, но стоит иметь в виду, что один и тот же кластер может сопоставиться сразу нескольким эталонам. Кроме того, кластеризация элементов из кластеров, не сопоставленных ни одному из эталонов, не оказывает влияния на значение метрики.
**2.3. BCubed-метрики**
Этот класс метрик предлагает взглянуть на кластеризацию с точки зрения одного отдельного элемента. Предположим, пользователь изучает конкретный документ внутри новостного сюжета. Какова доля документов этого сюжета, относящихся к той же теме, что и изучаемый документ? А какую долю документы по этой теме в сюжете составляют от числа всех документов по теме?
Вполне законные вопросы, и ответ на них приводит к BCubed-метрикам точности и полноты. Они определены для конкретного объекта:


Интегральные показатели определяются усреднением по элементам:


BCubed Precision удовлетворяет свойствам Cluster Homogeneity и Rag Bag, а BCubed Recall — свойствам Cluster Completeness и Size vs Quantity. Сводный показатель — F-мера — удовлетворяет всем четырём свойствам:

### **3. Метрики эталонных кластеров**
В некоторых приложениях полезно оценивать не только интегральные показатели качества, но и качество кластеризации отдельных эталонных кластеров. Поэтому в нашей системе оценки качества все метрики определялись для эталонных кластеров, которые затем агрегировались путём усреднения.
Рассмотрим, как это работает, на следующем примере. Пусть множество объектов  состоит из девяти элементов, образующих два эталонных кластера  и  («зелёный» и «жёлтый» соответственно).
Алгоритмические кластеры не повторяют эталонные в точности: , .

**3.1. BCubed**
Введём BCubed-метрики для отдельных эталонных кластеров:


Для рассмотренного примера получим следующие значения метрики точности кластеризации отдельных элементов:


Отсюда метрики точности эталонных кластеров:


Аналогично для полноты:




Средневзвешенные по всем эталонным кластерам значения BCP и BCR будут такими:


Именно эти характеристики мы и использовали при оценке качества кластеризации.
**3.2. Expected Cluster Completeness**
Разложение качества кластеризации на характеристики точности и полноты бывает очень полезным для анализа и дальнейшего совершенствования алгоритма. Для принятия *решений* о том, какой из алгоритмов лучше, требуется, впрочем, выработать один-единственный показатель.
Стандартный способ — F-мера — подходит лишь в ограниченном смысле. Это действительно один показатель, но является ли его значение подходящим для принятия решений? Вовсе не факт.
В конечном счёте требование к алгоритму заключается в том, чтобы каждому эталонному кластеру сопоставить некоторый уникальный алгоритмический кластер, который служил бы для эталона «представителем». Алгоритмический кластер может представлять только один эталонный кластер. При этом из всех сопоставлений важно лишь одно — самое удачное. Такой ход рассуждений является естественным для многих приложений: например, при анализе поисковых запросов судить о содержании кластера проще всего по тексту типичного представителя, то есть единственного запроса.
Сопоставление — функция из множества алгоритмических кластеров в множество эталонных кластеров:

Тогда для конкретного эталона и сопоставления  можно вычислить характеристику полноты (*cluster completeness*):

Среднее значение полноты:

Теперь возникает вопрос — как именно построить сопоставление, то есть функцию . В действительности никакой конкретный алгоритм не будет работать хорошо: незначительные изменения в кластеризации могут существенно повлиять на сопоставление и сильно изменить значение метрики.
Поэтому придётся ввести на множестве всех возможных сопоставлений вероятностную меру и затем вычислить математическое ожидание. Пусть вероятность того, что , равна

Теперь вероятность выбора функции  определяется через произведение вероятностей выбора всех её значений:

Теперь можно вычислить ожидаемое покрытие для эталонного кластера:

Интегральный показатель можно определить так:

Либо эквивалентно:

Опишу и другой способ понять эту метрику. Пусть с эталоном  пересекаются кластеры , , ..., , пронумерованные в порядке невозрастания размера пересечения:

Кластер  выбирается в соответствие эталону  с вероятностью

При этом покрытие будет равно

Поскольку это максимально возможное покрытие, которое может обеспечить один из кластеров, то выбранные для других кластеров сопоставления не играют роли. Так что в этом случае покрытие окажется равным .
Если же для кластера  выбрано другое сопоставление, то с вероятностью  эталону  будет сопоставлен кластер . Тогда покрытие окажется равным . Это рассуждение можно продолжить, и в конце концов мы получим, что математическое ожидание покрытия равняется

Код для вычисления метрики ECC для конкретного эталонного кластера получается очень простым. Вектор `sortedMatchings` состоит из всех кластеров, которые пересекаются с эталоном, он отсортирован по неубыванию полноты. Точность и полноту каждого соответствия эталону можно вычислить при помощи методов `Precision()` и `Recall()` соответственно. Тогда:
```
double ExpectedClusterCompleteness(const TMatchings& sortedMatchings) {
double expectedClusterCompleteness = 0.;
double probability = 1.;
for (const TMatching& matching : sortedMatchings) {
expectedClusterCompleteness += matching.Recall() * matching.Precision() * probability;
probability *= 1. - matching.Precision();
}
return expectedClusterCompleteness;
}
```
Интересно, что в этой метрике агрегирующей функцией для точности и полноты в итоге оказалась не -мера, а простое произведение!
Вычислим теперь ECC для эталонных кластеров, с которых начался пункт 3. Максимальное покрытие эталону  обеспечивает кластер , а эталону  — . Поэтому:




Интегральное значение вычисляется как среднее значение по всем эталонам, поэтому:

### **4. Реализация**
Метрики, описанные в пункте 3, реализованы на C++ и выложены под лицензией MIT [на GitHub](https://github.com/yandex/cluster_metrics/). Реализация компилируется и запускается как на Linux, так и на Windows.
Программу легко собрать:
```
git clone https://github.com/yandex/cluster_metrics/ .
cmake .
cmake --build .
```
После этого её можно запустить для того же примера, что разбирался в пункте 3. Расчёты из статьи совпадают с показаниями программы!
```
./cluster_metrics samples/sample_markup.tsv samples/sample_clusters.tsv
ECC 0.61250 (0.61250)
BCP 0.65125 (0.65125)
BCR 0.65250 (0.65250)
BCF1 0.65187 (0.65187)
```
В скобках указываются значения метрик для «оптимистичного» сценария, когда все неразмеченные элементы в действительности относятся к тем эталонам, с которыми пересекаются содержащие их кластеры. На практике это даже слишком оптимистичная оценка, так как каждый объект может относиться только к одной конкретной теме, но не ко всем сразу. Тем не менее, эта оценка полезна для случаев, когда алгоритм уж очень сильно меняет множество кластеризованных элементов. Если значение метрики существенно меньше оптимистичной оценки — стоит расширить разметку.
### **5. Как понять, что метрики работают**
После того, как метрики придуманы, нужно аккуратно убедиться в том, что они действительно позволяют принимать правильные решения.
Мы построили систему экспертного сравнения алгоритмов кластеризации. Всякий раз, как алгоритм претерпевал существенные изменения, асессоры размечали изменения. Интерфейс, если изображать схематично, выглядел так:
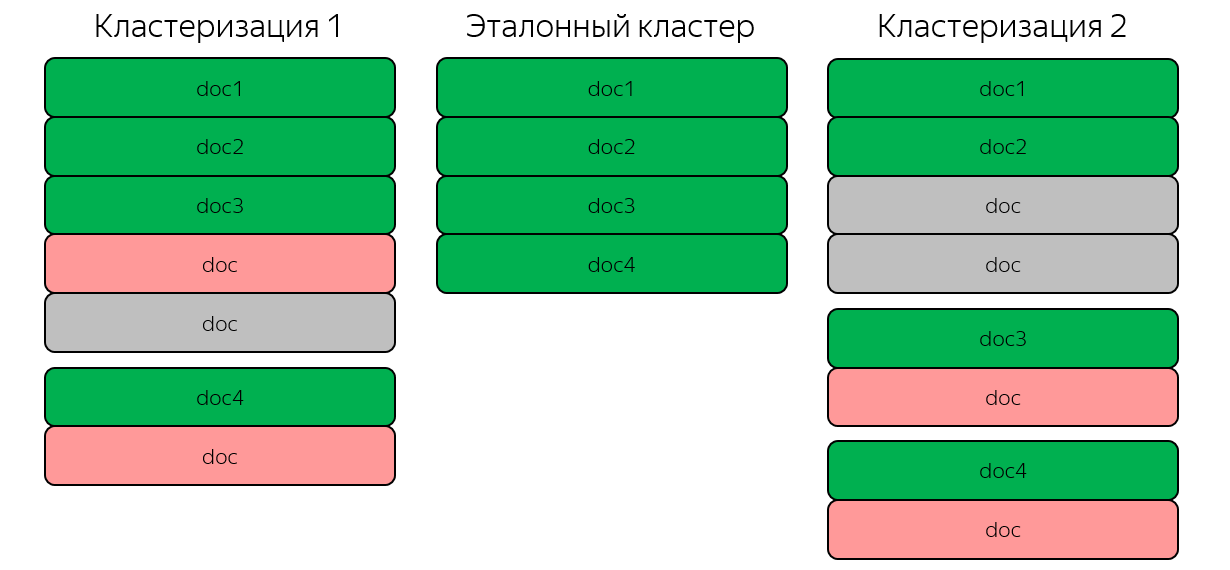
В центре экрана находился эталонный кластер: были перечислены все документы, отнесённые к нему в процессе разметки. С двух сторон от него отображались кластеры, построенные двумя соревнующимися алгоритмами, имеющие непустое пересечение с эталоном. Стороны для алгоритмов выбирались случайным образом, чтобы асессор не знал, с какой стороны находится старый алгоритм, а с какой — новый. Порядок кластеров для каждого алгоритма определялся сортировкой по произведению точности на полноту соответствия — совсем как в метрике ECC!
Зелёным помечались документы, относящиеся к выбранному эталонному кластеру, красным — относящиеся к другому эталонному кластеру. Серым обозначались неразмеченные документы.
Асессор смотрел на этот экран, изучал документы, при необходимости определял правильные эталонные кластеры для неразмеченных документов и в конце концов принимал решение о том, какой из алгоритмов сработал лучше. После разметки нескольких сотен эталонных кластеров можно было получить статистически значимый вывод о превосходстве того или иного алгоритма.
Такую процедуру мы использовали в течение нескольких месяцев, пока не обнаружили, что асессоры всегда выбирают тот алгоритм, для которого выше значение метрики ECC! Если показатели ECC различались хотя бы сколько-то существенно, асессоры всегда выбирали тот же вариант, что и метрика, это происходило буквально в 100% случаев. Поэтому со временем мы отказались от процедуры ручной приёмки и принимали решения просто по метрикам.
Интересно рассказать, что свойства метрик кластеризации из пункта 1 также исследовались на соответствие интуитивным представлениям о качестве кластеризации. В уже цитировавшейся статье описывается следующий эксперимент: для каждого правила формулировался пример — эталонное разбиение некоторого множества объектов и два альтернативных способа кластеризовать эти же объекты.
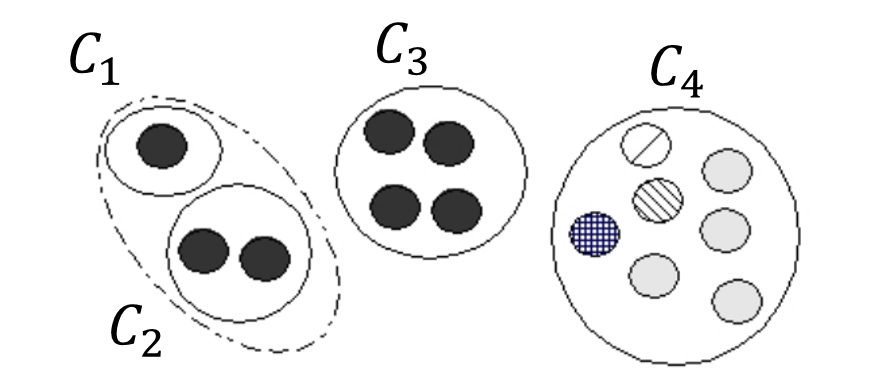
**Пример сравнения двух разбиений на кластеры для свойства Cluster Completeness**
Далее сорок асессоров выносили вердикты о том, какой из двух способов лучше, и их ответы сравнивались с вердиктами правил. Оказалось, что с каждым из правил Cluster Homogeneity, Cluster Completeness, Rag Bag не согласился только один из сорока асессоров, а свойству Size vs Quantity не противоречил никто.
Это очень интересное исследование, хотя оно и обладает очевидными недостатками: пример для каждого правила был только один, а восприятие качества кластеризации, очевидно, сильно связано с геометрической интерпретацией.
Уверенности в метриках, описанных в пункте 3, намного больше, так как мы исследовали их на многих сотнях или даже тысячах примеров.
Закончить, однако, хочу предостережением: в каждой новой задаче применимость тех или иных метрик нужно изучать заново. Мне лишь остаётся надеяться, что статья поможет всем, кто будет заниматься этой нелёгкой работой в будущем.
|
https://habr.com/ru/post/500742/
| null |
ru
| null |
# Электронный «излучатель информации» при минимуме затрат
Когда у нас надёжно заработала непрерывная интеграция на Jenkins и устоялись процессы выпуска релизов продукта, возникла мысль: а почему бы не перенять [передовой опыт](http://panic.com/blog/the-panic-status-board/) и не поставить в офисе свой электронный [излучатель информации](http://whatis.techtarget.com/definition/information-radiatorhttp://whatis.techtarget.com/definition/information-radiator) (information radiator): большой красивый экран, на котором автоматически отображаются происходящие с проектом процессы?

Мысль хорошая, но ведь это стоит денег и времени, т. е. того, чего никогда нет. Особенно сейчас. Особенно у маленьких компаний без бюджетов на всевозможные вспомогательные цели. Сделать всё предстояло за «пять копеек» и за «пять минут» — и вот как я с этим [частично] справился.
### Зачем это нужно
Разумеется, затем, чтобы увеличить производительность труда.
Прежде всего, чтобы облегчить отслеживание «здоровья» непрерывной сборки Jenkins. В том, что проблема с исправлением сборки/модульных тестов решается тем проще, чем раньше её начинают решать, мы давно убедились на собственнном опыте. Пока свежи в памяти все детали того, что ты только что сделал — проще починить «сломанное» в результате твоих действий. А висящий в комнате большой «светофор», переключившийся с зелёного сигнала на красный, оповещает о «развалившейся» сборке всех и сразу, это самый быстрый и заметный способ оповещения. Об этом давно сказано в руководствах по модульному тестированию и непрерывной интеграции, и это — несомненная истина.
Во-вторых, информационный экран должен быть частью комплекса мер по налаживанию коммуникаций в проекте. В разросшемся проекте много параллельно выполняющихся задач, и человек, целиком погруженный в одну изолированную задачу, часто невовремя получает сведения о том, над чем работают разработчики в соседней комнате и удалённо из других городов (а у нас есть и те, и другие). Все подробности разъясняются на семинарах и в рассылках, но ещё прежде них увидеть ключевые слова, мелькающие в задачах системы контроля запросов на изменение и комментариях к коммитам в систему контроля версий, несомненно, полезно всем участникам проекта.
Далее, это повышает качество работы. Осознание того, что комментарий к коммиту в систему контроля версий, который ты сейчас делаешь, будет через секунду у всех на виду на большом экране, невольно заставляет написать эти несколько слов поаккуратнее.
Ну и не в последнюю очередь — это круто выглядит!
### Software-часть
Итак, при минимальном финансовом и временн**о**м бюджете не было никакой возможности вкладываться в то, чтобы разрабатывать что-нибудь уникальное, да ещё и рисовать дизайн. Мне нужно было что-то почти готовое. Поиски привели меня к Ruby-фреймворку [Dashing](http://dashing.io/), как раз предназначенному для конструирования информационных табло на больших экранах.
Архитектурно идея очень проста: формируется «живая», автоматически обновляемая Web-страница, на мониторе открывается веб-браузер во весь экран — и готово. У Dashing оказались следующие достоинства:
1. готовый [пример](http://dashingdemo.herokuapp.com/sampletv) с раскладкой, оптимизированной для телевизора 1080p,
2. возможность при помощи мыши расположить виджеты (aka информеры aka плитки с информацией) по экрану,
3. много стандартных виджетов,
4. ещё больше [дополнительных виджетов](https://github.com/Shopify/dashing/wiki/Additional-Widgets),
5. лёгкость, с которой можно разрабатывать свои собственные виджеты (почитать о технологии Dashing можно [и на Хабре](https://habrahabr.ru/company/xakep/blog/225249/)).
В апреле 2016 года основные разработчики Dashing объявили, что не будут больше развивать его, но, полагаю, это не проблема для востребованного OpenSource проекта.
До этого момента я никогда не работал с Ruby. Однако разобраться в том, как всё установить и сконфигурировать оказалось нетрудно. Немного лишних телодвижений нужно, чтобы установить всё на Windows (с Linux, насколько я понимаю, всё элементарно), **вот какой перечень действий сработал у меня:**1. Установить [node.js.](https://nodejs.org)
2. Установить Ruby с [rubyinstaller.org](http://rubyinstaller.org/).
3. Установить оттуда же RubyDevKit.
4. ```
ruby dk.rb init
ruby dk.rb review
ruby dk.rb install
```
5. ```
gem update system ::если не сделать этого, могут возникнуть проблемы с установкой других пакетов
gem install htmlentities
gem install bundle
gem install nokogiri
gem install dashing
```
Разместить на виджетах я решил следующую информацию:
1. информеры о статусах сборок Jenkins,
2. заголовки свежих сообщений в группу рассылки Google,
3. комментарии к свежим коммитам в репозитории SVN с исходными кодами,
4. информацию об изменении статусов тикетов в Trac.

За основу виджета для Jenkins я взял один из готовых в [богатой библиотеке виджетов](https://github.com/Shopify/dashing/wiki/Additional-Widgets) к Dashing. Т. к. мне хотелось, чтобы отображаемое на мониторе максимально походило на то, что человек видит на странице Jenkins, я усовершенствовал виджет, добавив к нему иконки с «погодными условиями» проекта, используемые в самом Jenkins. При этом фоновый цвет «плитки» соответствует статусу последней сборки: зелёный — последняя сборка успешна, серый — сборка в процессе, красный — сборка неуспешна. Дорабатывать виджеты под Dashing оказалось довольно легко и приятно, и я решил пойти дальше.
Для отображения информации о том, что присходит в системе Trac и в группе рассылки, понадобился виджет, отображающий RSS-ленту. Его пришлось клонировать и отдельно доработать для Trac и для Google-группы в силу местных особенностей RSS-формата. «Украсить» ленту Trac-событий удалось при помощи Trac-овских иконок открытого и закрытого тикета.
Более всего повозиться пришлось с лентой комментариев к коммитам из SVN. У сервера Subversion нет встроенного RSS-сервиса, каких-то готовых решений в библитеке виджетов Dashing также не было. Поизучав вопрос, я понял, что единственным подходящим методом является запуск команды svn log и анализ выводимых ею данных при помощи регулярных выражений. К этому моменту я уже достаточно разобрался и в Ruby, и в создании виджетов, чтобы сделать скрипт, объединяющий в один список комментарии к разным репозитариям и затем сортирующий их в хронологическом порядке.
Напоследок оставалось поэкспериментировать с раскладкой виджетов по экрану с добавлением часов и — сверху — виджета, отображающего имя пользователя, время и характер последнего зафиксированного информационной панелью действия.
Информационное наполнение было готово, и настала пора приобретать и устанавливать большой экран.
### Hardware-часть
Что выбрать в качестве монитора? Я сразу понял, что, с одной стороны, есть такая вещь, как «профессиональные мониторы с широкой диагональю». Их стоимость исчисляется сотнями тысяч рублей и для нас это был абсолютно неприемлемый по бюджету вариант. С другой стороны, современные бытовые телевизоры оснащены HDMI-входами, обладают высоким разрешением и стоят на порядок дешевле. Поэтому я решил брать бытовой телевизор.
Как впоследствии оказалось, всё, конечно, не так просто и бытовой телевизор слабо подходит для такой задачи (о чём ещё будет рассказано). Но и колоссальную разницу в цене это не оправдывает, так что если решитесь на что-то подобное — выбирать вам.
Исходя из размеров нашего помещения и места установки, я решил, что подходящей является диагональ 46''. Мой выбор первоначально пал на бренд Samsung, но в означенный час поставщик сообщил мне, что заказанной и предоплаченной по безналу модели Samsung у них больше нет и они могут предложить похожую, и даже более «продвинутую» модель LG. Так у нас в офисе оказался огромный плоский телевизор LG.
NB: Бухгалтеру нужно дополнительно сообщить, что телевизор приобретён в качестве монитора, т. е. средства производства, чтобы не покупать его из прибыли компании и тем самым уменьшить налог.
Надо сказать, что в гаджетах типа «телевизор» я разбираюсь плохо, ибо своего телевизора в доме, за ненадобностью, не имею. Оказывается, все они теперь хотят по функциональности быть похожими на смартфоны или планшеты. Доставшийся нам LG имеет «систему WebOS», подключение к сети по WiFi и возможность *устанавливать приложения* и вбивать тексты с пульта при помощи T9.
Среди всего этого изобилия возможностей меня интересовали подключение по WiFi (не нужен провод) и веб-браузер. Это позволяло разместить сервер приложения в виртуальной машине в датацентре, открыть браузер в телевизоре, набрать с помощью пульта адрес сервера — и вуаля, на экране засияла информационная панель, дело сделано!
К сожалению, радовался я слишком рано. Ровно через 10 минут картинка погасла и телевизор начал показывать «скринсейвер», исчезавший, только если нажать на пульте любую клавишу. «Не проблема,» — решил я и стал искать в меню опции отключения скринсейвера. Опция не находилась. Я обратился к Google и вместо готового рецепта набрёл на страницу на официальных форумах компании LG, где несколько таких же, как я, бедолаг рассказывали о том, что купили их великолепный большой телевизор для постоянной трансляции на его экране веб-страницы, и сетовали на невозможность отключить скринсейвер. LG на своём официальном форуме не отвечал. Видимо, недаром: что-то такое знает LG про матрицы своих телевизоров, если на них часами показывать статическое изображение, и не желает тратиться на их гарантийную замену.
Так идея использования встроенного в телевизор браузера оказалась провальной и надо было придумывать что-то ещё. Оставалось только задействовать HDMI-вход, а это значит, что рядом с телевизором должен быть размещён источник видеосигнала, т. е. какой-никакой компьютер. Затраты на реализацию проекта увеличивались.
Источник видеосигнала должен был быть простым, дешёвым и надёжным, при этом без особых требований к быстродействию системы. Я остановился на неттопе MSI WindBox DC-111, который подвернулся по выгодной цене. Должен сказать, что эта маленькая машина нас не подвела: работая круглые сутки, она надёжно выполняла (и продолжает выполнять) свою задачу уже почти год. А во время корпоративных вечеринок мы запускаем на ней прокрутку фотографий и видео.

Телевизор же продолжил «проявлять характер». При помощи таймеров он был настроен таким образом, чтобы автоматически включаться в 9:00 и выключаться в 19:00 по рабочим дням. Но почему-то через три часа после автоматического утреннего включения (т. е. ровно в полдень) он, если не понажимать какие угодно кнопки на пульте, гаснет. Если после этого включить его вручную, он работает уже без выключения столько, сколько надо (естественно, всё меню настроек было внимательно изучено, все «энергосберегающие» опции отключены). Так продолжается и поныне.
### Заключение
Наш «излучатель» проработал уже почти год, и по результатам этой истории я могу сделать следующие выводы:
1. Задача требует некоторой смекалки, но ничего невыполнимого для профессиональных программистов.
2. Фреймворк Dashing смело рекомендую в качестве системы быстрой и удобной сборки информационных панелей.
3. Идея использовать в качестве инфопанели бытовой телевизор имеет подводные камни: наш телевизор LG изо всех сил сопротивляется работе в таком режиме. Хотя за год работы с его матрицей вообще ничего не случилось.
Я не привожу здесь исходных кодов своей системы, потому что понимаю, что в каждом конкретном случае требования к наполнению информационной панели очень индивидуальны (но готов поделиться с желающими). Примеры и готовые решения на сайте Dashing имеются в изобилии.
|
https://habr.com/ru/post/301860/
| null |
ru
| null |
# Как я проект с JavaScript на Scala переписывал

*Я никогда не смогу ходить! Потому что я ползаю.*
*—Цитаты великих*
Меня всегда учили прежде всего здороваться, так что — здравствуйте. Сегодня я расскажу про творческие (и не очень) муки, страдания и боль, которые я испытывал на протяжении определенного периода своей жизни, который я обозначу как ПРОЕКТ. Сначала он был на JavaScript (node.js), а теперь он на Scala (Play). Сразу скажу, что я — один из самых субъективных негодяев в обозримой Вселенной, поэтому некоторые обороты, высказывания и иже с ними могут быть восприняты уважаемыми читателями весьма неоднозначно. Короче, я предупредил. И у меня еще одна небольшая просьба — если уж взялись прочитать статью, то не кидайтесь сразу строчить разоблачающие комментарии. Дочитайте. Я не Пастернак, правду говорю. И вообще, почти все спорные моменты так или иначе освещаю, объясняю.
### Пролог
Но для начала я позволю себе небольшое отступление и расскажу, что же я делал, и как давно это началось.
Примерно года полтора назад я как раз стоял перед выбором темы для дипломной работы в моем техническом ВУЗе. Конечно, я мог бы отмазаться каким-то банальным сайтом для автомойки, очередной концепцией нового дизайна для сайта Кофехауза или еще чем-то похожим (кстати, это реальные дипломные проекты, и меня от этого коробит, но опустим). Но мы ведь упертые, да еще и профессионалы в своем деле! Легких путей не ищем и бла бла бла.
Стоит сказать, что к тому времени у меня за плечами было уже порядка 3 лет именно рабочего опыта и ~6-7 лет просто угорания по программированию, а конкретно — по вебу. Поэтому вопросов о реализации передо мной не стояло. Осталась тема, то есть тот самый ПРОЕКТ. Местные ребята должны знать забавную статью про [разработку через страдания](http://habrahabr.ru/post/155959/).
Так вот на тот момент я действительно испытывал страдания при совместной работе или изучении очередного ЯП с товарищами. Мне нужен был инструмент на подобии pastebin, т.е. банальный как квадрат (отправил — копипастнул ссылку — поделился), но все же с фишкой Google Docs, а именно — одновременным редактированием кода. Согласитесь — это круто, когда ты просто видишь, как кто-то поставил курсор на косяк и исправил его в два нажатия по клавишам. Ну всяко быстрее, чем один и тот же код дублировать каждый раз, меняться ссылкам. Боль.
И вот пошарился я по этим вашим интернетам в поисках такого сервиса, и… не нашел. Конечно, я в курсе про плагины к тому же Eclipse, Sublime и т.п., и даже знаю про целые standalone-решения. Но вот что-то простое как pastebin я не нашел. Отсюда и начал свой отсчет мой ПРОЕКТ.
### Глава 1. JavaScript
Из пролога у вас могло уже сформироваться краткое ТЗ, что же из себя представляет нужный сервис, и как его следует исполнить.
Имеем, грубо говоря, некие пользовательские чатики, где вместо чата — код, над которым все и корпеют. Как? Если кратко — не люблю флэш, хочу вебсокеты.
На тот момент я плотно сидел на PHP, но на нем писать WebSocket сервис, где полнодуплексные соединения могут висеть примерно бесконечность — прямая дорога в Ад. Поэтому я обратил свое внимание на node.js как WS-сервис, а статику генерить и отдавать пыхой. И знаете, что? Это было круто. Прототип я накидал буквально за пару дней. Все работало, и это было непередаваемое ощущение. Будто ты только что до конца осознал теорию струн. Или догадался, куда пропадает информация в черной дыре. Ну вы меня поняли, да? А тогда как раз еще вышел релиз nginx'a, который умел в проксирование WebSocket.
**Ляпота**
```
//Кусок кода, который отвечал за прием сообщений и контроль соединения. Довольно кратко и доступно.
var sockjs_im = sockjs.createServer(sockjs_opts);
sockjs_im.on('connection', function(c) {
//устанавливаем таймаут на начало обмена
sender.setValidTimeout(c);
//если пришли данные
c.on('data', function(message) {
sender.process(message,c);
});
c.on('close',function() {
connection.removeConnection(c);
})
});
var server = http.createServer();
server.addListener('upgrade', function(req,res){
res.end();
});
sockjs_im.installHandlers(server, {
prefix: config.get("path")
});
exports.startWSServer = function() {
server.listen(2410, '0.0.0.0',function() {
console.log(' [*] Listening WS on 0.0.0.0:2410' );
});
}
```
Но вернемся к делу. Я схватил этот молоток и начал колотить по всему вокруг, а там уже пусть сам разбираются — кто гвоздь, а кто верблюд. Взял самые хипстерские технологии: SockJS как клиент-сервер под WS-соединения, MongoDB как, вы не поверите, базу данных, Ace Editor как редактор на клиенте, слепил их и начал писать обвязку, логику.
> *Тут я сделаю маленьку пометочку — проект был дипломный, поэтому мне нужно было делать все быстрокачественнодешево и сразу, а ведь еще и работу надо было работать, сдавать что-то.*
Месяц спустя после очередной банки энергетика я, оторвав красные глаза от экрана, понял, что на свет родился монстр, тварь, нечто, что лучше бы исдохло сразу. Не, оно работало, без сбоев, функционал был *почти* весь готов. Но то, как оно работало — внушало священный ужас. Я совершил фатальную ошибку и не переписал прототип. Я его нарастил. Код стал слиииишком сложен и избыточен.
С этого момента работа над проектом превратилась в пытку. Добавление новой функции или фишки требовало немалого усилия. Я чувствовал себя Сизифом, только камень был еще и квадратным. Страдания.
Логичный вопрос — что ж ты такого там наговнокодил? Вот небольшой список:
* Callback hell
* Попытка писать ООП на JS с его prototype
* … отсюда попытка сделать уберабстракцию над абстракцией
* … а пока ты абстрагируешься — уже приходит седьмой, мать его, круг callback-ада и ты здороваешься за руку с богохульниками и содомитами (как же был прав Данте!)
И вот подходит ко мне Минотавр, который охраняет пояса седьмого круга и говорит:
-*Эй, парень. Ну ты же сам дурак. Написал чертовщину, ногу сломишь, сам же сознался. В чем твоя проблема?*
И знаете, что я отвечу? Это все JavaScript. То есть не поймите неправильно, я не имею ввиду, что я такой милый и пушистый с iq >>> бесконечности. Я имею ввиду то, что язык сам подталкивает тебя писать именно так, а не иначе. Эдакий змий, который шепчет:
-*Да ладно, браток, воткни-ссс здесь быстренько третий колбэк в аргументы, ничего не убудет-ccc...*.
И такой длинный красный язык перед глазами.
**Выглядело все это примерно так**
```
/**
* Загрузка сессии. а точнее - передача колбэка в загрузчик сессии...
*/
var loadSession = function(sessid, callback) {
if(typeof sessid != 'string') return;
var sess = sessions.getSession(sessid);
sess.setLoadCallback(callback);
}
...
/**
* Загрузим сессиию, получим пользователя, попробуем получить комнату, потом попробуем туда пихнуть юзера.
* Все в колбэки-колбэки, а там внутри еще колбэки.
*/
loadSession(msgObj["sessid"], function(sess) {
var r = rooms.getRoom(msgObj["room"]);
r.setLoadCallback(function() {
r.addUser(connection, sess, function(newUser) {
if(newUser!==false) {
var outMsg = {
action: "newUser",
data: newUser
}
r.broadcast(connection, outMsg);
r.write(connection,{
action: "join"
});
}else{
error(connection,{
error:true,
errsmg: "something went wrong"
})
}
});
});
});
...
```
Возможно, это все энергетики, и никакой минотавр со змием ко мне и не приходили (приползали), но получилось то, что получилось. Диплом был сдан, но тварь жить осталась, если это можно было назвать жизнью.
После нескольких попыток отрефакторить это чудовище или вообще переписать все на coffeescript, я забросил всю эту чертовщину до лучших времен и уехал кататься по Европе. Дааа, так глубоко я пал и так далеко бежал от кошмаров прошлого!
### Глава 2. Scala
Прошло полгода. Чудище все существовало, а у меня не было никакого желания его добить и выпустить уже в продакшн. Открывая код на JavaScript мне приходилось срочно бежать за металлическим тазиком, который со звоном использовался под рвотные массы.
И тут, заблудившись в интернете, я оказался на сайте Play Framework. Уже не помню, что же меня привлекло и задержало на сайте, да и важно ли? В итоге, через день я уже копался с фреймворком, писал первое приложение и записался на курс Scala на coursera.org.
Не могу сказать, что было просто, особенно по началу. Конечно, питон или пыха попроще, но имея бэкграунд на Qt/C++ и Java я разобрался в скалке довольно быстро, по крайней мере в основных моментах. Чтобы вкурить в неявные преобразования и параметры, ко/контр/инвариантность и иже с ними понадобилось поднапрячь свой гугл-скилл в поисках различных примеров и документации, дабы составить общую картину происходящего где-то там, под капотом. И все же какое-то время я чувствовал себя тупым валенком, хотя есть мнение, что это нормально.
И вот, немного набив руку, я решил посмотреть, как Play умеет в вебсокеты. И вот тут меня словно ушатом с ледяной водой окатили. Первая реакция была простой — *WTF???* Куда делись милые и доступные решения, что это за функционалохардкор с околонизкоуровневыми Iteratee/Enumeratee? Да, ничего общего с той ляпотой на JavaScript. Верните мне мои `push` и `onMessage`!
**Хрен тебе, а не каналы**
```
def index = WebSocket.using[String] { request =>
// Just consume and ignore the input
val in = Iteratee.consume[String]()
// Send a single 'Hello!' message and close
val out = Enumerator("Hello!").andThen(Enumerator.eof)
(in, out)
}
```
Однако, будучи наученным горьким опытом слишком простых решений, я решил не сдаваться и снова взял в руки… Нет, не молоток. Гугл. В итоге нашелся приятный подход через
**Concurrent.unicast**
```
val promiseIn = Promise[Iteratee[String, Unit]]()
val out = Concurrent.unicast[String](
onStart = onStart(promiseIn, r, userSession),
onError = onError
)
(Iteratee flatten (promiseIn.future), out)
...
private def onStart(promiseIn: Promise[Iteratee[String, Unit]], ...): (Channel[String] => Unit) = {
...
(ch: Channel[String]) => {
val channel = new ChannelContainer(ch)
for (optUserConnection <- isConnectedF(r, channel)) yield {
optUserConnection match {
case Some(userConnection) => {
val in = Iteratee.foreach[String] {
MessageController onMessage (r, userConnection, channel) //bind handler for room and this connection
} map {
MessageController onDisconnect (r, userConnection, channel) //handler for disconnect
}
promiseIn success in //success promise and fill it with iteratee
}
case None => channel eofAndEnd //in case of some troubles with new user creation - close connection
}
}
}
}
```
Да, согласен. Смотрится все же это не так мило и весьма громоздко, но позволяет использовать каноничные каналы, создающиеся для обмена сообщениями, запихивать эти каналы в обертки, передавать их сообщениями в акторы… Акторы!
Акторы в Scala. Рахат-лукум моего сердца. BEST PARADIGM EVAH! Ну или уж точно то, что надо для моих целей. Комната — актор, менеджер комнат — актор. И даже клиенты — акторы. Логично вливается в идеологию об обмене сообщениями между пользователями. Кстати, разработчики Play тоже прочухали эту тему, и начиная с недавно вышедей версии 2.3
**WebSocket-соединения теперь тоже акторы**
```
import play.api.mvc._
import play.api.Play.current
def socket = WebSocket.acceptWithActor[String, String] { request => out =>
MyWebSocketActor.props(out)
}
```
```
import akka.actor._
object MyWebSocketActor {
def props(out: ActorRef) = Props(new MyWebSocketActor(out))
}
class MyWebSocketActor(out: ActorRef) extends Actor {
def receive = {
case msg: String =>
out ! ("I received your message: " + msg)
}
```
И это прекрасно, когда Вселенная тебя слышит. Мои сигналы таки отразились от какой-то поверхности в световых годах отсюда, на планете бабочек, какающих радугами, и прилетели обратно. Кванты таки запутались, Алиса и Боб нашли друг друга. А я обрел спокойствие.
А почему? Потому что Scala в большинстве случаев просто смотрит на тебя как на говно, если ты делаешь что-то не по правилам. Она как бы говорит тебе:
*-Парень, я даю тебе нативную поддержку Future в виде монад, JSON сообщения кастую в нужные тебе инстансы case class'ов, предоставляю возможность наследования множества трейтов, я проверяю тебя, слежу за каждым чихом при компиляции, не играй со мной в игры. Делай нормально или возвращайся в свой Ад к Минотаврам.*
Строгий, но справедливый компаньон. Бородатый Хайзенберг программирования. Yea, Scala, biaaatch! А в спину тебя буравит глазами сам Мартин Одерски.
### Эпилог
Итак, что можно сказать после столь сумбурного потока ~~воды~~сознания, каков вывод?
**Первое**. Я не сравниваю языки. Упаси макарон. Сравнивать Scala и JavaScript — это как сравнивать льва и бабушкины пирожки. Да, вы можете съесть бабушкины пирожки и будете сыты. А вот льва — вряд ли. Зато лев может съесть вас. Это разные языки для разных задач. [Кто будет писать на Scala фронтенд](https://github.com/scala-js/scala-js)?
**Второе**. Я сравниваю возможности, даже вернее — подходы, которые предоставляют языки и платформы, используемые в решении конкретных задач. Господа, но колбэки не компонуются! Это гребаный приговор.
Я могу взять и сделать в одну строку из десятка Future один единственный и ждать его исполнения. Просто потому, что Future — это монада, все выглядит просто и естественно, в духе языка. Для колбэков мне придется писать обертку, которая либо будет считать количество окончившихся функций, либо станет полноценным Deferred/Promise. Да, да, я знаю про существование подобных библиотек для JavaScript. Но это же просто раздутые обертки к тем самым колбэкам. Замкнутый ~~ад~~круг.
**Третье**. Написал бы я сейчас на JavaScript лучше, чем тогда? Несомненно. Это, возможно, даже выглядело и работало бы попроще. Опыт в решении задач одного типа — это опыт, его не пропьешь. Вышло бы лучше, чем на Scala? Не факт. Да, на Scala местами приходится писать гораздо больше кода, но я, черт возьми, уверен в нем! Мне не нужно писать сотни тестов на один метод, который принимает объект из JSON'a, чтоб убедиться, что все идет так, как я задумал. Что какой-то скрипт-кидди не подставил строку вместо массива, массив вместо числа и т.п. За меня это сделает язык, платформа, компилятор.
**Четвертое**. [Scala сложна](http://habrahabr.ru/post/134897/), [Scala сложна](http://habrahabr.ru/post/127727/), [Scala сложна](https://groups.google.com/forum/#!topic/scala-debate/XJWh99TfYtc). Тысячи их. Бла бла бла. Знаете, что сложно? Держать в голове контекст this и еще сотни аспектов, которые постоянно мытарствуют по нервным узлам труъ JavaScript-ниндзя. Серьезно, что бы писать большой проект с кучей логики на JSe, нужно быть гораздо большим спецом, чем на Scala. Я это ощутил на своей заднице. Уважения тем, кто каждый день идет в этот неравный бой. Вы круты, без шуток. JavaScript не прост.
Но для себя я решил — не страдать. Зачем?
|
https://habr.com/ru/post/227731/
| null |
ru
| null |
# Уязвимость в Atlassian Confluence Server и Data Center позволяет злоумышленникам удаленно выполнять команды на сервере
Поступают сообщения о массовых атаках на Confluence Server с использованием уязвимости [CVE-2022-26134](https://nvd.nist.gov/vuln/detail/CVE-2022-26134), которая используется хакерами для установки веб-оболочек (например, Behinder).
Согласно [бюллетеню](https://confluence.atlassian.com/doc/confluence-security-advisory-2022-06-02-1130377146.html) Atlassian проблема - не требующая аутентификации уязвимость RCE в Confluence Server и Data Center.
Подверженными к атакам можно считать Confluence Server 7.18.0, Confluence Server и Data Center 7.4.0 и выше. Организации, использующие Atlassian Cloud, не подвержены уязвимости. Максимальное число вторжений сейчас фиксируется на версию 7.18.0.
Компания признала уровень уязвимости критическим. Информация о ней была получена разработчиками еще 31 мая.
В ходе атаки злоумышленники устанавливают свою веб-оболочку Java Server Pages, которая позволяет им выполнять произвольный код на сервере, загружать webshell, а затем получать полный доступ к атакуемому ресурсу.
На данный момент Atlassian выпустила обновления 7.4.17, 7.13.7, 7.14.3, 7.15.2, 7.16.4, 7.17.4 и 7.18.1, которые решают проблему.
Если обновление по тем или иным причинам установить нельзя, компания предлагает временный обходной вариант:
Если система кластерная - выполнять инструкции нужно на каждом сервере в кластере!
**Для версий Confluence 7.15.0 - 7.18.0:**
1. Остановить Confluence
2. Загрузить файл: [xwork-1.0.3-atlassian-10.jar](https://packages.atlassian.com/maven-internal/opensymphony/xwork/1.0.3-atlassian-10/xwork-1.0.3-atlassian-10.jar)
3. Удалить или переместить в другой каталог файл `/confluence/WEB-INF/lib/xwork-1.0.3-atlassian-8.jar`
4. Скопировать файл xwork-1.0.3-atlassian-10.jar в каталог /confluence/WEB-INF/lib/
5. Проверить разрешения и владельца на него
6. Запустить Confluence
**Для версий Confluence 7.0.0 - Confluence 7.14.2:**
1. Остановить Confluence
2. Загрузить следующие три файла: [xwork-1.0.3-atlassian-10.jar](https://packages.atlassian.com/maven-internal/opensymphony/xwork/1.0.3-atlassian-10/xwork-1.0.3-atlassian-10.jar), [webwork-2.1.5-atlassian-4.jar](https://packages.atlassian.com/maven-internal/opensymphony/webwork/2.1.5-atlassian-4/webwork-2.1.5-atlassian-4.jar), [CachedConfigurationProvider.class](https://confluence.atlassian.com/doc/files/1130377146/1137639562/3/1654274890463/CachedConfigurationProvider.class)
3. Удалить или переместить в другой каталог файлы`/confluence/WEB-INF/lib/xwork-1.0.3.6.jar и /confluence/WEB-INF/lib/webwork-2.1.5-atlassian-3.jar`
4. Скопировать файл xwork-1.0.3-atlassian-10.jar в каталог /confluence/WEB-INF/lib/
5. Скопировать файл webwork-2.1.5-atlassian-4.jar into `/confluence/WEB-INF/lib/`
6. Проверить разрешения и владельца этих новых файлов и убедиться, что они совпадают в разрешениями на другие файлы в этой папке
7. Перейти в папку `/confluence/WEB-INF/classes/com/atlassian/confluence/setup`
8. Создать в ней папку webwork
9. Скопировать в нее файл CachedConfigurationProvider.class
10. Проверить разрешения и владельца на файлы `/confluence/WEB-INF/classes/com/atlassian/confluence/setup/webwork и /confluence/WEB-INF/classes/com/atlassian/confluence/setup/webwork/CachedConfigurationProvider.class`
11. Запустить Confluence
|
https://habr.com/ru/post/669592/
| null |
ru
| null |
# Как подключить свой умный дом на базе Home Assistant к Марусе и управлять им голосом
Home Assistant — платформа которая помогает подключать самые разные устройства умного дома, включая малоизвестные и самодельные, а также управлять ими, следить за статусами на удобном [дашборде](https://demo.home-assistant.io/#/lovelace/0) и создавать сложные сценарии. Например, чтобы обеспечить безопасность дома, автоматизировать рутины, развлечь детей и гостей.
Всё это становится в разы удобнее, если добавить голосовое управление — например, с помощью [Маруси](https://marusia.mail.ru/) от VK. В этой статье мы по шагам расскажем, как настроить Home Assistant и «подружить» его с Марусей.
*По аналогии с инструкцией в этой статье Марусю можно подключить и к другим «кастомным» системам умного дома, используя протоколы Яндекса, Google и Tuya.*
Примечание* Все ссылки на программное обеспечение и рекомендации — по выбору версий и другие — актуальны на момент создания статьи, ноябрь 2022.
* Перед установкой Home Assistant ознакомьтесь с [исправлениями](https://github.com/home-assistant/operating-system/releases) в выбранной вами версии HASS OS и более новыми.
* В статье есть ссылки на сторонние репозитории — мы не можем гарантировать, что они не изменятся и в них не появится вредоносный код. Пожалуйста, используйте их ответственно.
### 0. Настройка Home Assistant
Если у вас уже настроен Home Assistant, пропустите этот раздел. А если нет, следуйте пошаговой инструкции.
Инструкция#### Вам понадобятся:
* Одноплатный компьютер Raspberry Pi 4 или 3
* Блок питания 5V / 2A
* Micro SD Card (флешка) не хуже Class 2, рекомендуемый объём — от 32 Гб
* SD Card Reader
* Ethernet-кабель
#### Установка Home Assistant на Raspberry Pi
1. Вставить флешку в компьютер.
2. Скачать и установить приложение для записи образов — например, [Balena Etcher](https://www.balena.io/etcher/).
3. В приложении выбрать **Flash from URL**.
4. Вставить ссылку на нужный образ:
**● Raspberry 4 (64 Bit):** <https://github.com/home-assistant/operating-system/releases/download/9.3/haos_rpi4-64-9.3.img.xz>
● Raspberry 4 (32 Bit): <https://github.com/home-assistant/operating-system/releases/download/9.3/haos_rpi4-9.3.img.xz>
**● Raspberry 3 (64 Bit):** <https://github.com/home-assistant/operating-system/releases/download/9.3/haos_rpi3-64-9.3.img.xz>
● Raspberry 3 (32 Bit): <https://github.com/home-assistant/operating-system/releases/download/9.3/haos_rpi3-9.3.img.xz>
5. После скачивания образа выбрать флешку для установки:
6. Нажать **Flash**, чтобы записать образ на флешку.
#### Запуск Home Assistant на Raspberry Pi
1. Вставить флешку в Raspberry Pi.
2. Соединить с роутером при помощи Ethernet-кабеля.
3. Включить в розетку и подождать пару минут.
4. Открыть в браузере на компьютере ссылку: <http://homeassistant.local:8123>
5. Подождать 5–15 минут, пока Home Assistant загрузится.
После этого в Home Assistant можно добавить умные устройства. Здесь не получится сделать универсальную инструкцию, потому что у разных устройств — свои конфигурации. Примеры можно поискать в статьях других пользователей Хабра — например, в [этой](https://habr.com/ru/company/singularis/blog/546072/).
### 1. Настройка доступа к Home Assistant из внешнего мира
Это нужно, чтобы в дальнейшем вы могли удалённо подключаться к Home Assistant с устройств не в локальной сети, а также чтобы к нему получила доступ Маруся.
1. Установить в Home Assistant аддон SSH & Web Terminal: **Settings → Add-ons → Add-on Store → Home Assistant Community Add-on → SSH & Web Terminal**
2. Открыть настройки аддона и включить параметр **Show in sidebar**
3. Снова зайти в Add-on Store, выбрать **Repositories** и добавить адрес репозитория: <https://github.com/ThomDietrich/home-assistant-addons>
4. Установить аддон **SSH Tunnel & Forwarding** из Add-on Store. Зайти в настройки аддона, на вкладке **Log** найти такой фрагмент и скопировать из него ключ:
```
[13:19:53] INFO: The public key is:
ssh-ed25519 XXXXXXXXXXXXXXXXXXXX hassio-setup-via-autossh
[13:19:53] WARNING: Add this key to '~/.ssh/authorized_keys' on your remote server now!
[13:19:53] WARNING: Please restart add-on when done. Exiting…
```
5. Подключиться к удалённой виртуальной машине с внешним IP-адресом (внешний хост, VPS) по SSH: ввести адрес, логин и пароль, выданные хостом. Найти или создать файл **.ssh/authorized\_keys** и добавить в него ключ, скопированный на прошлом шаге.
* [Как выбрать и за сколько купить VPS/VDS](https://habr.com/ru/post/510000/) (цены актуальны на 2020 год)
6. В **конфигурации** аддона SSH Tunnel & Forwarding ввести адрес и имя пользователя удалённой машины, к которой только что привязали ключ. Сохраниться и перезапустить аддон.
7. В зависимости от операционной системы, используя менеджер пакетов, установить на удалённой машине [**nginx**](https://habr.com/ru/post/311212/). Добавить в конфигурацию такую секцию:
```
map $http_upgrade $connection_upgrade {
default upgrade;
'' close;
}
server {
listen 80;
server_name ha.yourhost.ru;
root /data/www/ha;
location / {
try_files $uri $uri/index.html $uri.html @backend;
}
location @backend {
proxy_pass http://127.0.0.1:8123;
proxy_set_header Host $host;
# proxy_set_header X-Forwarded-For $remote_addr;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
}
}
```
Вместо **ha.yourhost.ru** здесь и далее вписывать адрес своего домена, если он есть; а если нет, то IP-адрес удалённой машины.
8. Проверить доступность <http://ha.yourhost.ru> на компьютере в локальной сети. Если там отображается интерфейс Home Assistant, значит, всё настроено правильно.
### 2. Настройка Yandex-плагина для Home Assistant
Пока мы используем наработки IoT-энтузиастов для интеграции Home Assistant с умным домом от Яндекса, чтобы аналогичным образом подключить Home Assistant к Марусе.
1. Открыть **терминал** в Home Assistant, запустить скрипт установки HACS: **wget -O - https://get.hacs.xyz | bash -**
Дождаться его установки и перезапустить Home Assistant.
2. Открыть **HACS → Integrations**, нажать кнопку **Explore & Download Repositories**, найти и выбрать **Yandex Smart Home**, установить.
3. Зайти в **Settings → Devices & Services**, нажать кнопку **Add Integration**, найти и выбрать **Yandex Smart Home.**
4. Открыть настройки интеграции, выбрать доступные устройства и тип подключения — **«напрямую».**
5. Проверить доступность внешнего адреса: <http://ha.yourhost.ru/api/yandex_smart_home/v1.0/ping>
Если всё ок, по ссылке должен отразиться список доступных устройств.
### 3. Подключение своего умного дома к Марусе/
Подключение Home Assistant к Марусе
Для этого вам нужно будет завести свой умный дом на базе Home Assistant на платформе VK для внешних разработчиков. Тогда он появится в приложении Маруси.
1. Зайти на [платформу](https://platform.vk.com/), авторизоваться с VK ID, создать проект и приложение.
2. В настройках приложения указать такие параметры:
* Адрес API — <http://ha.yourhost.ru/api/yandex_smart_home/v1.0>
* Адрес страницы авторизации — <http://ha.yourhost.ru/auth/authorize>
* Адрес для получения и обновления токена — <http://ha.yourhost.ru/auth/token>
* Авторизационные client\_id — <https://vc.go.mail.ru>
* Авторизационный secret — любой пароль
3. Через минуту открыть **приложение Маруси**, зайти в раздел **«Умный дом»**, найти свой проект среди провайдеров и авторизоваться с логином и паролем, установленными при настройке Home Assistant. После этого ваши устройства и сценарии добавятся к Марусе, и вы сможете управлять ими голосом.
### 4. Результат
Смотрите, как может работать ваш умный дом на базе Home Assistant с Марусей:
Если в процессе настройки что-то пойдёт не так, напишите в комментарии — мы постараемся ответить на вопросы и помочь. Удачных интеграций!
|
https://habr.com/ru/post/702986/
| null |
ru
| null |
# Основа для большого модульного SPA на Laravel + Vue + ElementUI с CRUD генератором

Последние годы удалось поработать над несколькими большими и не очень проектами с использованием разных back-end и front-end фреймворков. Сталкивался с разными проблемами, возникавшими по мере роста приложения.
Сейчас могу сделать вывод из того, какие решения были удачными, а какие — не очень.
Используя накопленный опыт, задался целью собрать все лучшие решения, на мой взгляд, и создать свою основу для SPA.
Как создавать сайт на Laravel или что такое SPA, я рассказывать не буду. Такой информации хватает в интернете. Эта статья рассчитана на более-менее опытных разработчиков, поэтому некоторые детали я упущу.
Кому не терпится, в конце статьи ссылка на мой репозиторий на гитхабе.
Основными технологиями были выбраны [Laravel](https://laravel.com) и [Vue.js](https://laravel.com) + [Vuex](https://vuex.vuejs.org) так как это мой основной стек.
Для быстрой разработки взял UI Kit — [ElementUI](https://element.eleme.io/).
#### Главная цель
Создать основание для среднего и большого проекта которое:
* поможет избежать жёсткой сцепленности модулей
* будет понятное для программиста c небольшим опытом
* поможет избежать дублирования кода
* будет легко расширяться
* уменьшит время старта проекта
* уменьшит время поддержки проекта и навигации по коду
* заложит основу для написания качественного кода
Чтобы максимально облегчить себе жизнь, не путаться в проекте, нужно правильно эго структурировать. Изначально приложение должно быть поделено на уровни ответственности, такие как пользовательский интерфейс, база данных, бизнес логика.
Дальше каждый слой следует разделить сначала по функциональности, а потом уже каждый функциональный модуль — соответственно выбранному паттерну.
Вдохновляясь философией DDD, решил и фронт-енд и бэк-енд разделить на смысловые модули. Но это не те классические домены, что описывает Эванс. Его модель тоже не идеальна. В любом приложении со временем всегда появляются связи между компонентами — те же отношения между моделями.
Модели оставил отдельным слоем, потому, что они как бы дублируют базу данных, со всеми ее связями.
На фронте создал каталог *resources/js/modules*, в котором и будут находиться разные модули. В каждом будет *api* — методы для работы с бэк-ендом, *components* — все компоненты и страницы, *store* — хранилище, и *routes*.
```
{moduleName}/
│
├── routes.js
│
├── api/
│ └── index.js
│
├── components/
│ ├── {ModuleName}List.vue
│ ├── {ModuleName}View.vue
│ └── {ModuleName}Form.vue
│
└── store/
├── store.js
├── types.js
└── actions.js
```
В *resources/js* создана папка *core*, где помещены основные компоненты системы.
Также есть папки bootstrap и *includes* для настройки дополнительных библиотек и утилит соответственно.
В проекте используется динамическая погрузка моделей. А именно в *core/routes* и в *core/states* мы подгружаем соответствующие файлы роутов и хранилищ автоматом (ничего прописывать не надо).
Вот пример как были подгружены *store.js* с разных модулей автоматически.
```
// Load store modules dynamically.
const requireContext = require.context('../../modules', true, /store\.js$/)
let modules = requireContext.keys()
.map(file =>
[file.replace(/(^.\/)|(\.js$)/g, ''), requireContext(file)]
)
.reduce((modules, [path, module]) => {
let name = path.split('/')[0]
return { ...modules, [name]: module.store }
}, {})
modules = {...modules, core}
export default new Vuex.Store({
modules
})
```
На бэк-енде в каталоге app будут аналогичные модули. Каждый модуль будет содержать папки *Controllers, Requests, Resources*. Файл с роутами тоже вынесен сюда — *routes\_api.php*.
```
{ModuleName}/
│
├── routes_api.php
│
├── Controllers/
│ └──{ModuleName}Controller.php
│
├── Requests/
│ └──{ModuleName}Request.php
│
└── Resources/
└── {ModuleName}Resource.php
```
Другие шаблоны проектирования типа events, jobs, polices и т.п. не будут включены в модули, так как они используются реже и логичнее их держать отдельным слоем.
Все манипуляции с динамической загрузкой модулей сделаны для того, чтобы между ними било минимальное зацепление. Это позволяет без последствий добавлять и удалять модули. Теперь можно сделать artisan make команду для создания такого модуля. С ее помощью мы сможем быстро наполнить проект нужными сущностями вместе с CRUD функциональностью.
Выполнив команду `php artisan make:module {ModuleName}`, у нас появятся все нужные файлы включая модель и миграции для работы полноценного CRUD. Вам останется только выполнить миграции `php artisan migrate` и все будет работать. Скорее всего вам понадобиться добавить дополнительные поля, поэтому перед миграцией не забудьте добавить их в модель, миграцию, а также, вывести во vue.
В данном шаблоне для аутентификации использовалась технология [JWT-Auth](https://jwt-auth.readthedocs.io/en/develop/), но возможно она избыточная и стоит переделать на Laravel Sanctum. В свою очередь На фронт-енде используется [vue-auth](https://websanova.com/docs/vue-auth/home), она позволяет легко управлять авторизацией пользователей и ролями.
В дальнейшем хотелось бы улучшить систему. Добавить глобальную шину событий, подключить websockets. Добавить тесты. Возможно в отдельных ветках сделать вариант с управлением ролями или создать ветки с другими UI Kit. Было бы хорошо, услышать рекомендации, замечания.
Изначально данный шаблон разрабатывался для своих нужд, но теперь надеюсь он станет полезным и для других пользователей.
Весь код можно посмотреть в [моем репозиторие на гитхабе](https://github.com/Yurich84/laravel-vue-spa-skeleton).
|
https://habr.com/ru/post/504674/
| null |
ru
| null |
# В тему I love Symbian
Небольшое предисловие:
`Прошлая попытка была воспринята неоднозначно - некоторые думали что я кого-то рекламирую, некоторые минусовали... Мы очень мирно пообщались с автором критикуемой мной статьи и вроде достигли консенсуса, но вот незадача - я не могу написать в блог I love Symbian, карма моя =0, поэтому хотелось бы попросить кого-нибудь подкинуть 5. Для дальнейшего, так сказать творчества.
Впрочем может и не надо мне ничего писать, а смело покидать сообщетво - если что, то вы так и напишите, я честно "развоплощусь" и больше никогда не вернусь.`
И сама статья:
В своей статье мне не хотелось бы долго и нудно описывать самые разнообразные программы, делать сравнительный обзор и т.д. Занимаясь 7 лет сетями мобильной связи я привык относться к телефонам не как к возлюбленным тамагочи, а как к инструментам помогающим мне решать различные задачи. Именно о задачах я и хотел бы написать, итак:
Задача: гоглосовое общение с друзьями по Skype и Google Talk когда под рукой нет компьютера.
Решение: Ставим fring (http://www.fring.com/), настраиваем его на работу со скайпом и гуглтолком (просто вводим текущие логины и пароли соответствующих мессенджеров), после чего ищем ближайший халявный WiFi (довольно часто есть в ресторанах, на вокзалах, аэропортах), подсоединяемся и говорим сколько нужно. Fring поддерживает не только Skype и GT, но и ICQ, и Yahoo Messenger, и MSN, и SIP и т.д. Подробности на их сайте.
Задача: бывает нужен перевод слова с иностранного языка, а компьютера с собой нет
Решение: ставим ABBYY Lingvo (http://www.lingvo.ru/) — этот самый лучший словарь для компьютера работает и на телефоне. Поддерживает 8 языков и знает какое-то невообразимое количество слов. В зависимости от потребностей можно добавлять, или убирать словари, т.е. если интересует только английский, то можно оставить только его, сэкономив таким образом место на флешке мобилы.
Задача: удобно читать новости с небольшого экрана телефона
Решение: Ставим OperaMini (http://www.opera.com/mini/) и пользуемся встроенным в него RSS-reader. Т.к. далеко не все сайты имеют версию контента, заточенного под маленький экран телефона, то лучшим способом подачи информации является именно RSS. Как правило RSS ленты состоят из заголовка новости, небольшой картинки и краткого описания с сылкой на полную версию статьи. Это как нельзя кстати подходит для экранов телефона — новости бывают разные, их можно быстро пролисать, а если что-то заинтересовало, то октрыть сайт и посмотреть подробности. Opera Mini прекрасно справляется с форматированием контента обычных сайтов под небольшое разрешение, так что лучше всего пользоваться ей, а не какой-либо отдельной RSS-читалкой
Задача: не попадать в пробки на дорогах
Решение: ставим Яндекс пробки (http://mobile.yandex.ru/maps/probki2.xml). Идея Яндекс-пробок проста — когда запущено это приложение, оно просто передает текущие координаты пользователя на сервер Яндекс-пробок. Сервер определяет на какой улице вы находитесь и если вы двигаетесь медленно, да еще есть много таких как вы, то это место отмечается на карте как затор. Т.е. этим приложением можно пользоваться и без GPS, а работает оно практически взде. Если в телефоне есть GPS, то это приложение ко всему еще и бесплатный навигатор с картами городов и возможностью проложить маршрут.
Задача: показать друзьям смешной видеоролик с YouTube когда под рукой нет компьютера.
Решение: ставим MobiTubia (http://www.mobitubia.com/dp/?q=node/2). Это мобильный проигрыватель видео в формате flv с возможностью поиска по YouTube. Ставим приложение, подключаемся к ближайшей WiFi сети (или через GPRS/3G), вводим фразу для поиска и смотрим клип. За счет того что количество точек на дюйм у экрана смартфона больше чем у компьюетра качество видео просто обалденное. MobiTubia позволяет так же сохранять видео на самом телефоне.
Задача: поиграться в игрушки не отрываясь осбо от окружающей реальности.
Решение: игр под телефоны много, но в основном все требуют быстрого жать кнопки ни на минуту не отрываясь от экрана телефона. Как раз такие мне не нравятся, т.к. требуют постоянного внимания, что несовместимо с мобильностью — в очереди, в ожидании блюда в кафе, в метро/маршрутке играть в них просто невозможно — все внимание на экран телефона, что может привести к плачевным последствиям. К тому же вам в любое время могут позвонить и придется начать игру заново. Я люлю игры в которых не требуется быстрая реакция + всегда есть возможность запустить игру с того уровня где ты прервался. Мой топ выглядит так:
1. TowerWars:Time Guardians (http://www.in-fusio.com/start.php) — стратегия в которой есть дорога, по ней идут монстры и нужно расставить башни таким образом чтоб потратить наименьшее количество денег, при этом уничтожитв всех монстров. Реально затягивает, т.к. денег переодически не хватает, а монстры с каждой волной все более выносливые. Игра сама по себе неспешная, вдумчивая, дает возможность подумать, посмотреть по сторонам, после чего поставить башню, потом позвонить, потом прочитать СМС, а потом вернуться в игру и продолжить с того места где прервался — при нажатии на клавишу «дом», а так же при звонке, или любом другом событии телефона, не имеющему отношения к игре, в ней включается пауза.
2. Модные куклы (http://modnye-kukly.ru) — не знаю как правильно описать эту игру. Это как в фильмах про «невзрачных подруг» которые приодевшись становятся красавицами. Обычно в таких фильмах есть сцены где «золушки» приходят в магазин одежды и «крутой специалист» оценивает как на них сидят разные шмотки, переодически заставляя их повернуться, подойти, отойти, пройтись, и т.д. Вот тут то же самое — видео полуодетых моделей, снующих туда-сюда. Разработчики уверяют что это «мобильный видеожурнал мод». Я не особый любитель каких-либо мод, особо в них ничего не понимаю, и т.д. Мне просто нравится возможность погонять полуодетую модель по экрану телефона :)
3. Танчики (http://tanchiki.ru/) — аналог «Battle city» для древней приставки «Денди». Отличная стратегия с элементами аркады в которой управляя своим танком нужно уничтожить противников. Танк можно апгрейдить — покупать оружие, броню, боеприпасы и т.д. Замечательна тем что в ней есть автосохранение, т.е. не надо начинать заново если кто-то внезапно позвонил — достаточно загрузить прерванный уровень. Игра моего поколения, поколения заставшего рекламу «в Денди играют все!». И ведь действительно играли! :)
4. Worms World Party (http://wwp.team17.com/). Задаем силу выстраела, угол наклона и стреляем из разных пушек через холм, пытаясь вынести червяков противника. Поддерживается до четырех игроков (как один против троих компьюетеров, так и все четыре — люди). Смешные червяки, разнообразное оружие — от банальной базуки до уморительной «старой бабушки» которая может достать хуже любой бомбы :) Поначалу раздражжает то, что все выстрелы производятся почти наугад — нельзя задать угол в градусах а силу в каких-либо еденицах. Компьютер ведет виртуозный прицельный огонь, а тебе нечем на это ответить. Впрочем потреннировавшись понимаешь, что особая точность и не нужна — у человека есть то, чего нет у компьютера — хитрость, позволяющая выигрывать даже у самого сильного компьютерного ai.
Задача: почитать книгу с телефона.
Решение: Если вы счастливый обладатель смартфона с большим экраном и хорошим запасом заряда батареи, то ставим QReader (http://www.qreader.com/) и наслаждаемся, пожалуй, самой полезной функцией телефона. Проще всего описать это приложение сказав что QReader — это HaaliReader под Symbian. Для тех кто не знает что такое легендарный HaaliReader, я ограничусь лишь основными функциями:
1. Поддержа .txt и TCR, Palm DOC (.prc и .pdb), FB2
2. Поддержка архивированных файлов (zip)
3. Поворот экрана — на 90 и 270%.
4. 5 размеров шрифтов
5. Поддержка каталогов
6. Поиск в тексте
7. Автопрокрутка текста
8. Авторасстановка переносов
9. Форматирование текста (align, margin)
10. Быстрый просмотр часов и объема прочитанного
11. Возможность изменения цвета текста
12. Быстрый переход внутри документа (по %)
13. Отправка текста по E-Mail, Bluetooth, IrDA или MMS.
14. Возможность включения и отключения подсветки.
|
https://habr.com/ru/post/48612/
| null |
ru
| null |
# Нейробугу́рт. Как мы научили нейросеть придумывать мемы на год раньше Стэнфорда
К написанию статьи меня подтолкнула вот эта [новость](https://motherboard.vice.com/en_us/article/gyk3dq/stanford-researchers-trained-a-neural-network-to-make-these-memes) (+[исследование](https://arxiv.org/abs/1806.04510)) про изобретение генератора мемов учеными из Стэнфордского университета. В своей статье я попытаюсь показать, что вам не нужно быть ученым из Стэнфорда, чтобы делать с нейросетями интересные вещи. В статье я описываю, как в 2017 году мы обучили нейронную сеть на корпусе из примерно 30 000 текстов и заставили ее генерировать новые интернет-мемы и мемы (коммуникационные знаки) в социологическом смысле слова. Описан использованный нами алгоритм машинного обучения, технические и административные трудности, с которыми мы столкнулись.
Небольшая предыстория о том, как мы пришли к идее нейрописателя и в чем именно она заключалась. В 2017 году мы сделали проект для одного паблика “Вконтакте”, название и скрины из которого модераторы Хабрахабра запретили публиковать, посчитав его упоминание «само»пиаром. Паблик существует с 2013 года и объединяет посты общей идеей разложения юмора через строчку и разделения строк символом “@”:
`СЕТАП
@
РАЗВИТИЕ СЕТАПА
@
ПАНЧЛАЙН`
Количество строк может меняться, сюжет может быть любой. Чаще всего это юмор или острые социальные заметки о бесящих фактах реальности. В целом такая конструкция называется «бугуртом».
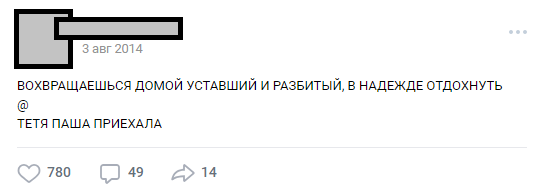
*Один из типичных бугуртов*
За годы существования паблик оброс внутренним лором (персонажи, сюжеты, локации), а количество постов перевалило за 30 000. На момент их парсинга для нужд проекта количество исходных строк текста превышало полмиллиона.
### Часть 0. Появление идеи и команды
На волне массовой популярности нейронных сетей идея обучить ИНС на наших текстах витала в воздухе где-то на протяжении полугода, но была окончательно сформулирована с помощью E7su в декабре 2016. Тогда же было придумано название (“Нейробугурт”). На тот момент команда заинтересованных в проекте состояла всего из трех человек. Все мы были студентами без практического опыта в алгоритмах и нейронных сетях. Хуже того — у нас даже не было ни одной подходящей GPU для обучения. Всё что у нас было — это энтузиазм и уверенность, что эта история может быть интересной.
### Часть 1. Формулировка гипотезы и задачи
Нашей гипотезой оказалось предположение, что если смешать все опубликованные за три с половиной года тексты и обучить на этом корпусе нейронную сеть, то может получится:
а) креативнее, чем у людей
б) смешно
Даже если в бугурте слова или буквы окажутся машинно перепутаны и расположены хаотично — мы верили, что это может сработать как фансервис и всё равно будет радовать читателей.
Задачу сильно упрощало то, что формат бугуртов, по сути, текстовый. А значит, нам не нужно было погружаться в машинное зрение и другие сложные вещи. Ещё одна хорошая новость состояла в том, что весь корпус текстов очень однотипный. Это давало возможность не использовать обучение с подкреплением — по крайней мере, на первых этапах. В тоже время мы четко понимали, что создать нейросеть-писателя с читаемым выводом больше чем на один раз не так то легко. Риск родить монстра, который будет хаотично швырять буквами, был очень велик.
### Часть 2. Подготовка корпуса текстов
Считается, что этап подготовки может занять очень много времени, так как связан со сбором и очисткой данных. В нашем случае он оказался достаточно коротким: был написан небольшой [парсер](https://github.com/Nejel/torch-rnn/blob/master/vk-wallparser/wallparser.py), который выкачал около 30к постов со стены сообщества и сложил их в [txt-файл](https://github.com/Nejel/torch-rnn/tree/master/data/parsed_bugurts).
Очистку данных перед первым обучением мы не проводили. В дальнейшем это сыграло с нами злую шутку, потому что из-за ошибки, закравшейся на данном этапе, мы долго не могли привести результаты в читаемый вид. Но об этом чуть дальше.

*Скрин файлика с бургерами*
### Часть 3. Анонсирование, уточнение гипотезы, выбор алгоритма
Мы использовали доступный ресурс — огромное количество подписчиков паблика. Предположение состояло в том, что среди 300 000 читателей найдутся несколько энтузиастов, которые владеют нейросетями на достаточном уровне, чтобы заполнить пробелы в знаниях нашей команды. Мы отталкивались от идеи широко анонсировать конкурс и привлечь энтузиастов машинного обучения к обсуждению сформулированной задачи. Написав тексты, мы рассказали людям о нашей идее и надеялись на отклик.
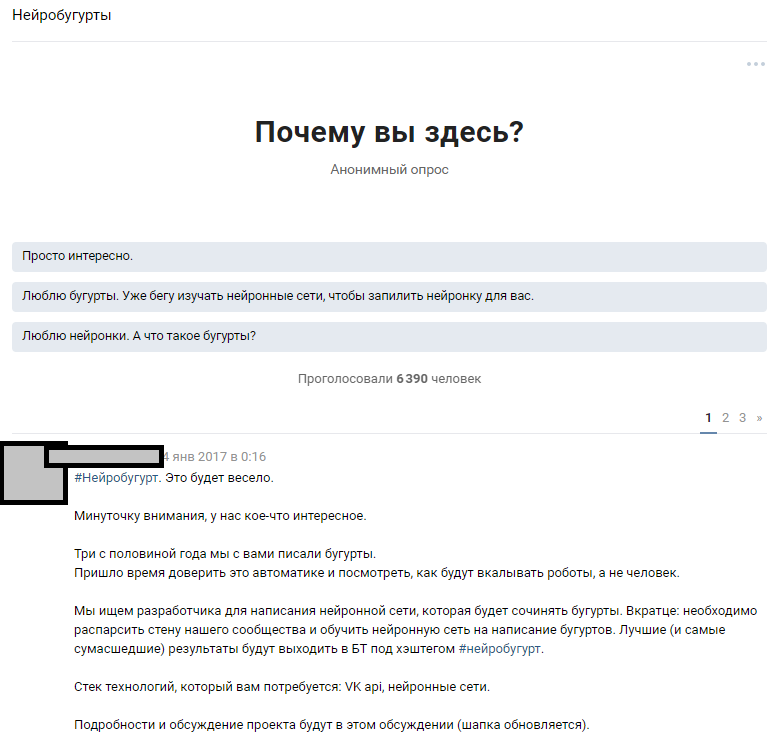
*Анонс в тематическом обсуждении*
Реакция людей превзошла наши самые смелые ожидания. Обсуждение самого факта, что мы собираемся обучить нейронную сеть, развело холивар почти на 1000 комментариев. Бóльшая часть читателей просто угарали и пытались представить, как будет выглядеть результат. В тематическое обсуждение заглянуло порядка 6000 человек, а комментарии оставили больше 50 заинтересованных любителей, которым мы выдали тестовый сет из [814 строчек бугуртов](https://github.com/Nejel/torch-rnn/blob/master/data/test-sample/814_lines_of_bugurts.txt) для проведения первичных тестов и обучения. Каждый заинтересованный мог взять датасет и обучить тот алгоритм, который ему наиболее интересен, а потом обсудить с нами и с другими энтузиастами. Мы заранее объявили, что продолжим работу с теми участниками, чьи результаты будут наиболее читаемы.
Работа завертелась: кто-то молча собирал генератор на цепях Маркова, кто-то пробовал различные реализации с гитхаб, а большинство просто угарало в обсуждении и с пеной у рта убеждало нас, что из этой затеи ничего не получится. С этого началась техническая часть реализации проекта.
Некоторые предложения энтузиастов
Люди предлагали десятки вариантов по реализации:
* Цепи Маркова.
* Найти готовую реализацию чего-то похожего на GitHub и обучить её.
* Генератор рандомных фраз, написанный на Паскале.
* Завести литературного негра, который будет писать рандомный бред, а мы будем выдавать это за вывод нейросети.
*Оценка сложности проекта от одного из подписчиков*
Бóльшая часть комментаторов сходились во мнении, что наш проект обречен на провал и мы не дойдем даже до стадии прототипа. Как мы поняли позднее — люди до сих пор склонны воспринимать нейронные сети как какую-то черную магию, которая происходит в “голове у Цукерберга” и секретных подразделениях Google.
### Часть 4. Выбор алгоритма, обучение и расширение команды
Через какое-то время запущенная нами кампания по краудсорсингу идей для алгоритма начала давать первые плоды. Мы получили около 30 работающих прототипов, бóльшая часть из которых выдавала абсолютно нечитаемый бред.
На этом этапе мы впервые столкнулись с демотивацией команды. Все результаты были очень слабо похожи на бугурты и чаще всего представляли собой абракадабру из букв и символов. Труды десятков энтузиастов шли прахом и это демотивировало как их, так и нас.
Лучше других себя показал алгоритм на базе pyTorch. Было принято решение взять за основу эту реализацию и алгоритм LSTM. Мы признали подписчика, который его предложил, победителем и начали работать над улучшением алгоритма совместно с ним. Наша распределенная команда увеличилась до четырех человек. Забавным фактом здесь является то, что [победителю конкурса](https://vk.com/alexajax), как оказалось, было всего 16 лет. Победа стала его первым реальным призом в области Data Science.
Для первого обучения был арендован кластер из 8 графических карточек GXT1080

*Консоль управления кластером карточек*
Оригинальный репозиторий и все мануалы проекта Torch-rnn находится здесь:
[github.com/jcjohnson/torch-rnn](https://github.com/jcjohnson/torch-rnn). Позже на её основе мы опубликовали [свой репозиторий](https://github.com/Nejel/torch-rnn), в котором есть наши исходники, ReadMe по установке, а также сами готовые нейробугурты.
Первые несколько раз мы обучались при помощи преднастроенной конфигурации на платном кластере GPU. Настроить его оказалось не так сложно — достаточно инструкции от разработчика Torch и помощи администрации хостинга, которая входит в оплату.
Однако очень быстро мы столкнулись с трудностью: каждое обучение стоило времени аренды GPU — а значит, денег, которых в проекте попросту не было. Из-за этого в январе-феврале 2017 обучение мы проводили на купленных мощностях, а генерацию пытались запустить на своих локальных машинах.
Для обучения модели подходит любой текст. Перед обучением его необходимо препроцессить, для чего в Torch есть специальный алгоритм preprocess.py, который преобразует ваш my\_data.txt в два файла: HDF5 и JSON:
Скрипт препроцессинга запускается так:
```
python scripts/preprocess.py \
--input_txt my_data.txt \
--output_h5 my_data.h5 \
--output_json my_data.json
```
*После препроцессинга появляются два файла, на которых в дальнейшем будет обучаться нейронная сеть*
Различные флаги, которые можно менять на стадии препроцессинга, описаны [здесь](https://github.com/jcjohnson/torch-rnn/blob/master/doc/flags.md#preprocessing). Также есть возможность запускать [Torch из Docker](https://github.com/crisbal/docker-torch-rnn), но автор статьи её не проверял.
#### Обучение нейронной сети
После препроцессинга можно переходить к обучению модели. В папке с HDF5 и JSON нужно запустить утилиту th, которая появилась у вас, если вы правильно установили Torch:
```
th train.lua -input_h5 my_data.h5 -input_json my_data.json
```
Обучение занимает огромное количество времени и генерирует файлы вида cv/checkpoint\_1000.t7, которые и являются “весами” нашей нейронной сети. Эти файлы весят впечатляющее количество мегабайт и содержат значения силы связей между конкретными буквами в вашем исходном датасете.
*Нейронную сеть часто сравнивают с человеческим мозгом, но мне кажется гораздо более понятной аналогия с математической функцией, которая принимает параметры на входе (ваш датасет) и выдает результат (новые данные) на выходе.*
В нашем случае каждое обучение на кластере из 8 GTX 1080 в дата-сете из 500 000 строк занимало около часа-двух, а аналогичное обучение на видавшем виды CPU i3-2120 занимало порядка 80-100 часов. В случае более долгих обучений нейросеть начинала жестко переобучаться — символы слишком часто повторяли друг друга, впадая в длиннющие циклы из предлогов, союзов и вводных слов.
Удобно, что можно выбрать частоту расстановки чекпоинтов и в ходе одного обучения сразу получить много моделей: от наименее обученных (checkpoint\_1000) до переобученных (checkpoint\_1000000). Хватило бы только места.
#### Генерация новых текстов
Получив хотя бы один готовый файлик с весами (checkpoint\_\*\*\*\*\*\*\*) можно переходить к следующему и самому интересному этапу: начать генерировать тексты. Для нас это был настоящий момент истины, потому что впервые мы получили какой-то ощутимый результат — бугурт, написанный машиной.
К этому моменту мы окончательно перестали пользоваться кластером и все генерации проводили на своих маломощных машинах. Однако при попытке запуститься локально, просто пройти по инструкции и установить Torch у нас не получилось. Первым барьером стало использование виртуальных машин. На виртуальной Ubuntu 16 торч просто не взлетает — забудьте. На помощь часто приходил StackOverflow, но некоторые ошибки были настолько нетривиальны, что ответ удавалось найти только с огромным трудом.
Установка Torch на локальную машину застопорила проект на добрые пару недель: мы сталкивались со всевозможными ошибками установки многочисленных необходимых пакетов, а также боролись с виртуализацией (virtualenv .env) и в конечном итоге не стали её использовать. Несколько раз стенд сносился до уровня sudo rm -rf и просто устанавливался заново.
Использовав получившийся файл с весами мы смогли начать генерацию текстов на своей локальной машине:

*Один из первых выводов*
### Часть 5. Очистка текстов
Еще одной очевидной трудностью стало то, что тематика постов очень сильно отличается, а наш алгоритм не предполагает никакого деления и рассматривает все 500 000 строк как единый текст. Мы рассматривали разные варианты по кластеризации датасета и даже были готовы вручную разбить корпус текстов по тематике или расставить теги в нескольких тысячах бугуртов (необходимый человеческий ресурс для этого был), но постоянно сталкивались с техническими трудностями подачи кластеров при обучении LSTM. Менять алгоритм и проводить конкурс заново показалось не самой здравой идеей с точки зрения тайминга проекта и мотивации участников.
Казалось, что мы в тупике — кластеризовать бугурты мы не можем, а обучения на едином огромном датасете давали сомнительный результат. Делать шаг назад и менять почти взлетевший алгоритм и реализацию тоже не хотелось — проект мог просто впасть в кому. В команде отчаянно не хватало знаний, чтобы решить ситуацию нормально, но на помощь пришла старая добрая СМЕ-КАЛ-ОЧК-А. Итоговое решение ~~костыль~~ оказалось до гениальности простым: в исходном датасете отделить имеющиеся бугурты друг от друга пустыми строками и обучить LSTM заново.
Мы расставили отбивки в 10 вертикальных пробелов после каждого бугурта, повторно провели обучение, а при генерации выставили ограничение на объем вывода в 500 символов (средняя длина одного “сюжетного” бугурта в исходном датасете).
*Как было. Интервалы между текстами минимальны.*
*Как стало. Интервалы в 10 строк дают LSTM “понять”, что один бугурт закончился и начался другой.*
Таким образом, удалось добиться того, что около 60% всех сгенерированных бугуртов стали обладать читаемым (хотя зачастую очень бредовым) сюжетом на всей длине бугурта от начала до конца. Длина одного сюжета составляла, в среднем, от 9 до 13 строк.
### Часть 6. Повторное обучение
Прикинув экономику проекта, мы решили больше не тратить деньги на аренду кластера, а вложиться в покупку собственных карточек. Время на обучение бы выросло, но купив карточку один раз, мы могли бы генерировать новые бугурты постоянно. В тоже время часто проводить обучения постоянно уже не было необходимости.

*Борьба с настройками на локальной машине*
### Часть 7. Балансировка результатов
На рубеже март-апрель 2017 мы повторно обучили нейронную сеть, уточнив параметры температуры и количество эпох обучения. В результате качество выходных текстов незначительно выросло.
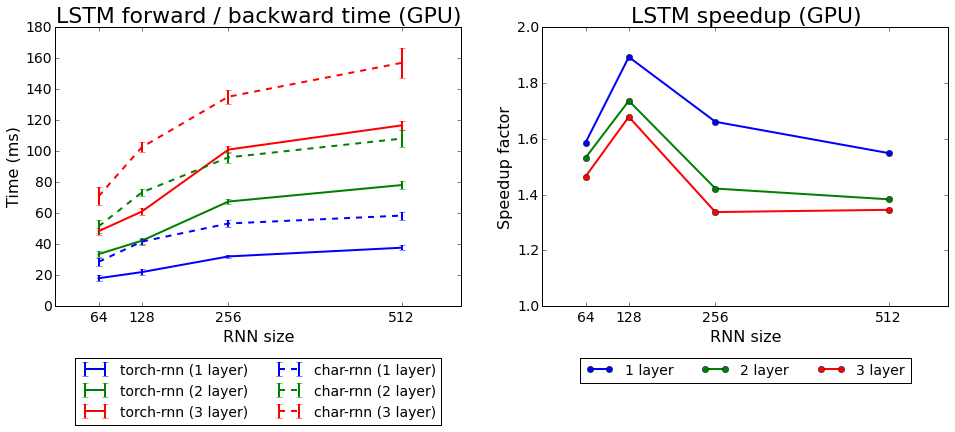
*Скорость обучения torch-rnn в сравнении с char-rnn*
Мы протестировали оба алгоритма, которые идут в комплекте с Torch: rnn и LSTM. Второй показал себя лучше.
### Часть 8. Чего мы добились?
Первый нейробугурт был опубликован 17 января 2017 года — сразу после обучения на кластере — и в первый же день собрали больше 1000 комментариев.

*Один из первых нейробугуртов*
Нейробугурты так хорошо зашли аудитории, что стали отдельной рубрикой, которая на протяжении года выходила под хэштегом #нейробугурт и веселила подписчиков. В общей сложности в 2017 и начале 2018 года мы сгенерировали больше [18 000 нейробугуртов](https://github.com/Nejel/torch-rnn/tree/master/results), в среднем по 500 символов в каждом. Кроме этого, появилось целое движение пабликов-пародий, участники которых изображали нейробугурты, рандомно переставляя фразы местами.

### Часть 9. Вместо заключения
Этой статьей я хотел показать, что даже если у вас нет опыта в нейронных сетях, это горе не беда. Вам не нужно работать в Стэнфорде, чтобы делать простые, но интересные вещи с нейронными сетями. Все участники нашего проекта были обычными студентами со своими текущими задачами, дипломами, работами, но общее дело позволило нам довести проект до финала. Благодаря продуманной идее, планированию и энергии участников нам удалось получить первые вменяемые результаты меньше чем через месяц после окончательного формулирования идеи (большая часть технических и организационных работ пришлась на зимние каникулы 2017).
*Более 18 000 бугуртов, сгенерированных машиной*
Надеюсь, эта статья поможет кому-то спланировать свой собственный амбициозный проект с нейросетями. Прошу не судить строго, так как это моя первая статья на Хабре. Если вы, как и я, энтузиаст ML — давайте [дружить](https://www.facebook.com/alexander.nejel).
|
https://habr.com/ru/post/416379/
| null |
ru
| null |
# Немного о клеточных автоматах

На хабре уже [много](http://habrahabr.ru/post/154753/)-[много](http://habrahabr.ru/post/136100/)-[много](http://habrahabr.ru/post/154015/) раз писали про игру «Жизнь». Совсем недавно была удивительная статья [Жизнь на плоскости Лобачевского](http://habrahabr.ru/post/168421/). Но игра «Жизнь» является частным случаем т. н. *клеточных автоматов*. Существует много других клеточных автоматов совсем не похожих на игру «Жизнь», но тем не менее очень интересных. Про некоторые из них и хочется рассказать здесь.
Начнём с того, что рассмотрим ряд клеток, в которых, кроме одной, находятся нули:
```
... 0 1 0 0 0 0 0 0 ...
```
Рассмотри следующее правило, заменяем число в клетке на сумму этого числа и соседа слева. Получим следующую серию состояний:
```
... 0 1 0 0 0 0 0 0 ...
... 0 1 1 0 0 0 0 0 ...
... 0 1 2 1 0 0 0 0 ...
... 0 1 3 3 1 0 0 0 ...
... 0 1 4 6 4 1 0 0 ...
... 0 1 5 10 10 5 1 0 ...
... 0 1 6 15 20 15 6 1 ...
```
Не сложно увидеть, что это — треугольник Паскаля. А теперь вместо обычного сложения будем использовать сложение по модулю два. Известно (и даже недавно рассказывалось в хабрастатье [Треугольник Серпинского и треугольник Паскаля](http://habrahabr.ru/post/167817/)), что получится дискретный аналог треугольника Серпинского:

```
... 0 1 0 0 0 0 0 0 ...
... 0 1 1 0 0 0 0 0 ...
... 0 1 0 1 0 0 0 0 ...
... 0 1 1 1 1 0 0 0 ...
... 0 1 0 0 0 1 0 0 ...
... 0 1 1 0 0 1 1 0 ...
... 0 1 0 1 0 1 0 1 ...
```
Интересно? Читаем дальше!
Давать точное определение клеточного автомата здесь не имеет смысла, но полезно отметить следующие свойства клеточных автоматов: *параллельность*, *локальность*, *однородность*. Параллельность означает то, что обновления всех клеток происходят независимо друг от друга. Под локальностью подразумевается то, что новое состояние клетки зависит только от старого состояния клетки и её окрестности. И, наконец, однородность означает, что все клетки обновляются по одним и те же правилам.
Чтобы не связываться с бесконечными сетками, будем рассматривать клеточные автоматы на конечной четырёхугольной сетке, а чтобы не было проблем с границами, завернём сетку в тор. Две окрестности клетки имеют именные названия: это *окрестность Мура* — соседями являются все восемь окружающих клеток, и *окрестность фон Неймана* — соседями являются только ближайшие клетки слева, справа, сверху и снизу. Чтобы избежать двусмысленностей, кроме словесного описания правила преобразования состояния клетки, будет также приведена реализация функции
```
int transformCell(
int northWestCell, int northCell, int northEastCell,
int westCell, int centerCell, int eastCell,
int southWestCell, int southCell, int southEastCell);
```
##### Ограниченный и неограниченный рост
Итак, пусть клетки могут находиться в двух состояниях 0 — мёртвая, и 1 — живая.
Рассмотрим следующее правило: клетка становится живой, если хотя бы один из её соседей живой; клетка, однажды став живой, остаётся живой всегда. В случае окрестности Мура тело функции `transformCell()` будет таким:
```
int sum = northWestCell + northCell + northEastCell +
westCell + eastCell +
southWestCell + southCell + southEastCell;
if (sum > 0) {
return 1;
} else {
return centerCell;
}
```
Если поле изначально будет заполнено нулями, то живых клеток не появится, но если одну из клеток сделать живой, то из этого «зародыша» возникнет растущий квадрат из живых клеток, который в итоге заполнит поле. При этом область из живых клеток увеличивается с максимально возможной скоростью — скоростью света.

Немного изменим правило выше: вместо условия «хотя бы один из соседей живой», рассмотрим условие «в точности один из соседей живой».
```
int sum = northWestCell + northCell + northEastCell +
westCell + eastCell +
southWestCell + southCell + southEastCell;
if (sum == 1) {
return 1;
} else {
return centerCell;
}
```
Получаемая из одной клетки структура будет, во-первых, гораздо разреженней, а, во-вторых, будет иметь явный фрактальных характер.
Можно вместо окрестности Мура рассмотреть окрестность фон Неймана:
```
int sum = northCell + westCell + eastCell + southCell;
if (sum == 1) {
return 1;
} else {
return centerCell;
}
```
##### Циклические клеточные автоматы
Циклические клеточные автоматы были придуманы Дэвидом Гриффитом. Клетка может находиться в *n* состояниях, которые будем нумеровать числами 0, 1, ..., *n* – 1. Будем говорить, что состояние *m* является *следующим* за состоянием *k*, если *m* + 1 = *k* (mod *n*). Клетка из состояния *m* переходит в следующее состояние *k*, только если одна из соседних клеток имеет состояние *k*. Например, в случае окрестности фон Неймана преобразование запишется следующим образом:
```
int nextState = (centerCell + 1) % statesNumber;
if (northCell == nextState ||
westCell == nextState ||
eastCell == nextState ||
southCell == nextState) {
return nextState;
} else {
return centerCell;
}
```
При этом, если начать со случайно заполненного поля, могут наблюдаться три различных стадии. Первая стадия — случайное поле. Затем начинают появляться цветные области, которые будут поглощать области, заполненные случайно. Эти блоки будут «волнообразно» менять свой цвет. Далее возникают спирали, которые также называют *демонами*. И наконец, на третьей стадии, поле будет поглощено демонами.
 
 
Можно также рассмотреть одномерный циклический клеточный автомат:
```
int transformCell(int leftCell, int centerCell, int rightCell) {
int nextState = (centerCell + 1) % statesNumber;
if (nextState == leftCell || nextState == rightCell) {
return nextState;
} else {
return centerCell;
}
}
```
Если интересно узнать больше подробностей, то рекомендую начать с википедии [Cyclic cellular automaton](http://en.wikipedia.org/wiki/Cyclic_cellular_automaton).
##### Мешанина
Пусть снова клетка может находиться в состояниях 0, 1, ..., *n* – 1.
Рассмотрим правило состоящее из трёх частей.
*Здоровье*. Если клетка находится в состоянии 0 (т. е. здорова), то она заболевает, если несколько из её соседей больны (т. е. находятся в ненулевом состоянии).
*Выздоровление*. Если клетка находится в состоянии *n* – 1, то она самовылечивается и переходит в состояние 0.
*Болезнь*. Иначе же состояние клетки рассчитывается как среднее состояний соседних клеток плюс некоторая константа. (Если полученное число больше чем *n* – 1, то новым состоянием будет *n* – 1.)
```
int sum = northWestCell + northCell + northEastCell +
westCell + eastCell +
southWestCell + southCell + southEastCell;
if (centerCell == 0) {
if (sum < 5) {
return 0;
} else if (sum < 100) {
return 2;
} else {
return 3;
}
} else if (centerCell == statesNumber - 1) {
return 0;
} else {
return Math.min(sum / 8 + 5, statesNumber - 1);
}
```
 
Отмечается, что получаемые таким образом волнообразные процессы, напоминают реакцию [Белоусова – Жаботинского](http://en.wikipedia.org/wiki/Belousov–Zhabotinsky_reaction).
##### Поверхность Венеры
Это правило (как впрочем и предыдущее) я нашёл в [Cellab Manual](http://www.cs.sjsu.edu/faculty/rucker/celdoc/rules.html#Hodge). Каждая клетка находится в состоянии 0, 1, 2 или 4. Правило имеет вид:
```
if (centerCell == 0) {
return 2 * ((northWestCell % 2) ^ (northEastCell % 2)) + northCell % 2;
} else if (centerCell == 1) {
return 2 * ((northWestCell % 2) ^ (southWestCell % 2)) + westCell % 2;
} else if (centerCell == 2) {
return 2 * ((southWestCell % 2) ^ (southEastCell % 2)) + southCell % 2;
} else {
return 2 * ((southEastCell % 2) ^ (northEastCell % 2)) + eastCell % 2;
}
```
Если начинать со случайно заполненного поля, то образуется два врезающихся друг в друга «потока»: вертикальный и горизонтальный. Через некоторое время один из «потоков» начинает преобладать. И в итоге остаётся только один.
 
 
Это небольшая часть клеточных автоматов, про которые я хотел рассказать, но я вынужден остановиться, чтобы статья не стала слишком большой. Для заинтересовавшихся дам несколько ссылок:
(1) Т. Тоффоли, Н. Марголус, *Машины клеточных автоматов*, М., Мир, 1991.
(2) М. Шредер, *Фракталы, хаос, степенные законы. Миниатюры из бесконечного рая*, Ижевск, РХД, 2001, стр. 469--490.
(3) R. Rucker, J. Walker *[Cellab Manual](http://www.cs.sjsu.edu/faculty/rucker/celdoc/cellab.html)*.
|
https://habr.com/ru/post/168291/
| null |
ru
| null |
# Использование Tomoyo Linux

Заблокировать подозрительное поведение программы? Смягчить последствия от эксплуатации уязвимостей? Исключить выполнение несанкционированного кода?
TOMOYO Linux — реализация мандатного управления доступом для операционной системы Linux. Встроена в ядро по умолчанию. Позволяет взять под контроль поведение системы и жестко ограничить в рамках заданной политики.
Ниже будет описано создание политик, как на отдельные приложения, так и на всю систему в целом.
Примеры будут построены на базе Debian Wheezy и Tomoyo 2.5 имеющейся в ядре.
##### Основы
**1. Домены.**
Tomoyo в своей работе руководствуется таким понятием, как **Домены**. Домены это процессы и взаимосвязь между процессами domain transition.
Базовый домен это всегда ````
О него разрастаются все остальные.
- домен
/sbin/init - домен
/sbin/init /etc/rc.d/rc - еще домен
/etc/init.d/gdm3 /sbin/start-stop-daemon /usr/sbin/gdm3 - еще
```
При этом учитывается, как был запущен процесс и кто его родитель.
Возьмем к примеру процесс /bin/bash, он может быть запущен локально, а может и от sshd в процессе удаленного логина.
Эти два состояния так-же сажаются в отдельные домены.
/sbin/init ..... /bin/bash
/sbin/init ..... /usr/sbin/sshd /bin/bash
К каждому домену можно применить свою политику безопасности.
Например, если bash запущен локально - одну. А если bash запущен удаленно - другую, более жесткую. Это сильная особенность Tomoyo.
Основным инструментом работы с доменами и политиками является редактор tomoyo-editpolicy.
Вот так выглядят домены в редакторе tomoyo-editpolicy

Редактор полностью управляется с клавиатуры. Вот так выглядит главное меню.

Для вывода главного меню нужно нажать **W**, для переключения к списку доменов **D** (w & d).
**2. Политики**
Политики содержат различные контроли поведения доменов. Операции записи, чтения, выхода в сеть, создания дочерних процессов. В общем стандартные вещи.
```
file execute /bin/ls - разрешение запуска ls
```
Помимо этого, каждый контроль можно обвешивать *условиями* его срабатывания.
```
file execute /bin/ls task.uid=0 - разрешение запуска ls только суперпользователю.
```
**3. Профили.**
Поведение каждого домена, помимо политик, определяется наложенным на него профилем.
Существует 4 базовых профиля.
0 - политики отключены, домен свободен от ограничений.
1 - режим обучения, все действия разрешаются и дописываются в политику конкретного домена.
2 - режим разрешения, по сути тоже что и 0
3 - режим запрета, запрещено все, что не определено политикой конкретного домена.
Вот так выглядят профили в редакторе tomoyo-editpolicy (w & p)

Стандартная цель для усиления безопасности - составить политику для домена и наложить профиль 3
**4. Исключения.**
Поведение доменов, так-же определяется с помощью Исключений. Исключения действуют глобально. Могут применяться ко всем доменам сразу. В политику исключений так-же прописывают различные, часто вызываемые переменные. Исключения используют для упрощения создания политик и улучшения читаемости конфигов.
Вот так выглядят исключения в редакторе tomoyo-editpolicy (w & e)

**5. Конфиги**
Конфигурационные файлы вышеописанных составляющих находятся тут:
/etc/tomoyo/domain_policy.conf - политики для каждого домена
/etc/tomoyo/profile.conf - профили
/etc/tomoyo/exception_policy.conf - исключения
Важно понимать, что когда вы запускаете tomoyo-editpolicy и начинаете править домены, накладывать ограничения. Вы правите оперативные правила загруженные в ядро. Не кофигурационные файлы!
Для сохранения проделанных изменений служат отдельные утилиты.
**6. Утилиты**
tomoyo-editpolicy - основной инструмент для работы. Позволяет работать с текущими загруженными в ядро оперативными политиками.
tomoyo-loadpolicy - загружает в ядро ранее сохраненные или свежесозданные в сторонних редакторах политики.
tomoyo-savepolicy - сохраняет политику, работающую в ядре на диск. Это важно! Если вы что-то правили в оперативных политиках с помощью tomoyo-editpolicy. А потом забыли дать эту команду сохранения, все будет потеряно.
tomoyo-checkpolicy - проверяет сохраненные политики на ошибки.
Это не все утилиты, далее будет еще несколько примеров.
*Подробнее о внутреннем устройстве Tomoyo: [tomoyo.sourceforge.jp/2.5/chapter-4.html.en](http://tomoyo.sourceforge.jp/2.5/chapter-4.html.en)*
*Подробнее об утилитах: [tomoyo.sourceforge.jp/2.5/man-pages/index.html.en](http://tomoyo.sourceforge.jp/2.5/man-pages/index.html.en)*
##### Включение Tomoyo.
1. Правим GRUB /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="quiet security=tomoyo"
Даем команду
update-grub
2. Ставим пакеты:
aptitude install tomoyo-tools
3. Выполняем команду:
/usr/lib/tomoyo/init_policy
для первичной инициализации системы.
4. Важно!
Если вы так закрутили гайки с помощью Tomoyo, что даже система не грузится. Ничего страшного, при загрузке нажмите e в меню grub и поменяйте:
security=tomoyo
на
security=none
##### Пишем политику для приложения
Попробуем наложить ограничения на браузер midori.
Выше было описано, что в зависимости от того, как процесс был запущен, создается каждый раз отдельный домен.
Сейчас нам нужно создать одну общую политику, в независимости от метода запуска midori.
Для этого в Исключениях используем команду initialize_domain.
Запускаем tomoyo-editpolicy.
Заходим в раздел Exeption Policy Editor (w & e) и нажав на клавиатуре **A** добавляем строчку:
```
initialize_domain /usr/bin/midori from any
```

*Подробнее об управлениями доменами в Исключениях.
[tomoyo.sourceforge.jp/2.5/chapter-5.html.en](http://tomoyo.sourceforge.jp/2.5/chapter-5.html.en)*
После этого возвращаемся в окно Domain Transition Editor (w & d)
И находим наш домен /usr/bin/midori с пометкой *
Нажав **S** переводим домен в режим обучения, выставив ему 1.

Запускаем midori и работаем в нем пару минут, совершая штатные операции. Посетим пару сайтов, сохраним страничку, покопаемся в настройках и тд.
Закроем midori.
В окне Domain Transition Editor нажимаем Enter на домене и попадаем в редактор политик Domain Policy Editor, видим все операции которые совершал midori в своей работе.

Основная работа будет проходить в этом окне.
Нажимая клавишу @ можно сортировать данные на экране в различных сочетаниях. По пути файлов или по выполняемой операции.
По сути это уже готовый конфиг. Теперь надо упростить его используя регулярные выражения.
В качестве примера используем типичные операции работы программы со своими настройками.

Разрешим некоторые операции для файлов по пути /home/home/.config/midori/
Нажимаем кнопку **А** (append) и пишем.
```
file read/write/unlink/truncate/rename /home/home/.config/midori/\*
```
Теперь удалим строчки попавшие под регулярку.
Нажимаем **О** и редактор выделяет все совпадения, затем нажимаем **D** и редактор удаляет теперь уже ненужные строчки, конфиг сокращается.
А вот, например, такой конструкцией можно разрешить определенные операции и для файлов любых подкаталогов /home/home/.config/midori/
```
file read/write/append/unlink/truncate /home/home/.config/midori/\{\*\}/\*
```
*Синтаксис регулярных выражений описан здесь
[tomoyo.sourceforge.jp/2.5/policy-specification/expression-rules.html.en#wildcard](http://tomoyo.sourceforge.jp/2.5/policy-specification/expression-rules.html.en#wildcard)
Возможные файловые операции здесь
[tomoyo.sourceforge.jp/2.5/policy-specification/domain-policy-syntax.html.en](http://tomoyo.sourceforge.jp/2.5/policy-specification/domain-policy-syntax.html.en)*
Давайте теперь посмотрим на операции с сетью.

Создадим правило разрешающее посещение любого сайта в интернете, с использованием определенных портов.
```
network inet stream connect 0.0.0.0-255.255.255.255 80-443
```
//упростил указав диапазон портов
И по аналогии выше применяем его, с сокращением конфига (O & D).
*Операции с сетью описаны тут
[tomoyo.sourceforge.jp/2.5/policy-specification/domain-policy-syntax.html.en#network\_inet](http://tomoyo.sourceforge.jp/2.5/policy-specification/domain-policy-syntax.html.en#network_inet)*
Постепенно сокращая конфиг, переходим наконец к запрету подозрительных операций.
Например, мне не нравится, что midori читает /etc/passwd

Попробуем удалить это разрешение и протестировать результат.
Нажимаем D, удалив таким образом разрешение.
Затем возвращаемся в Domain Transition Editor (w & d), нажимаем **S** и меняем профиль обучения 1 на профиль запрета 3.
Пробуем запустить.
Приложение работает? Значит так тому и быть. Приложение не работает? Значит стоит задуматься о доверии к такому приложению.
После всех манипуляций по причесыванию конфига сохраним его.
```
tomoyo-savepolicy -d | tomoyo-selectpolicy -r ' /usr/bin/midori' >> /etc/tomoyo/domain\_policy.conf
```
Пояснение:
```
tomoyo-savepolicy -d
```
выводит всю кучу доменов.
```
tomoyo-selectpolicy -r ' /usr/bin/midori'
```
выбирает только нужный домен, с нужной политикой.
```
>> /etc/tomoyo/domain_policy.conf
```
сохраняем политику домена.
Что в итоге получилось в политике для midori
**/etc/tomoyo/domain\_policy.conf**
```
/usr/bin/midori
use\_profile 3
use\_group 0
misc env GNOME\_KEYRING\_PID
misc env USER
misc env SSH\_AGENT\_PID
misc env HOME
misc env DESKTOP\_SESSION
misc env XDG\_SESSION\_COOKIE
misc env DBUS\_SESSION\_BUS\_ADDRESS
misc env GNOME\_KEYRING\_CONTROL
misc env LOGNAME
misc env USERNAME
misc env WINDOWPATH
misc env PATH
misc env DISPLAY
misc env LANG
misc env XAUTHORITY
misc env SSH\_AUTH\_SOCK
misc env SHELL
misc env GDMSESSION
misc env PWD
misc env XDG\_DATA\_DIRS
misc env GNOME\_DESKTOP\_SESSION\_ID
misc env SESSION\_MANAGER
misc env GPG\_AGENT\_INFO
misc env GIO\_LAUNCHED\_DESKTOP\_FILE
misc env GIO\_LAUNCHED\_DESKTOP\_FILE\_PID
misc env DESKTOP\_STARTUP\_ID
file read proc:/filesystems
file read /usr/lib/locale/locale-archive
file read /usr/lib/x86\_64-linux-gnu/gconv/gconv-modules.cache
network unix stream connect /var/run/nscd/socket
file read /etc/nsswitch.conf
network unix stream connect \000/tmp/.X11-unix/X0
file read /run/gdm3/auth-for-home-WxYaIE/database
file read /usr/lib/x86\_64-linux-gnu/gtk-2.0/2.10.0/engines/libclearlooks.so
file read /usr/lib/x86\_64-linux-gnu/gtk-2.0/modules/libcanberra-gtk-module.so
network unix stream connect \000/tmp/dbus-BKDp9V4Rww
file read /usr/lib/x86\_64-linux-gnu/gio/modules/giomodule.cache
file read /usr/lib/x86\_64-linux-gnu/gio/modules/libgiognomeproxy.so
file read /usr/lib/x86\_64-linux-gnu/gio/modules/libgiolibproxy.so
file read /usr/lib/x86\_64-linux-gnu/gio/modules/libdconfsettings.so
file read /etc/xdg/midori/search
file read /usr/lib/x86\_64-linux-gnu/gio/modules/libgiognutls.so
file read proc:/sys/crypto/fips\_enabled
file read /dev/urandom
file read /etc/pkcs11/modules/gnome-keyring-module
file read /usr/lib/x86\_64-linux-gnu/pkcs11/gnome-keyring-pkcs11.so
network unix stream connect /home/home/.cache/keyring-XULOQY/pkcs11
file read /etc/ssl/certs/ca-certificates.crt
file read /usr/lib/x86\_64-linux-gnu/gio/modules/libgvfsdbus.so
file read /usr/lib/x86\_64-linux-gnu/gvfs/libgvfscommon.so
file read /usr/lib/midori/libaddons.so
file read /usr/lib/midori/libtoolbar-editor.so
file read /usr/lib/midori/libtab-panel.so
file read /usr/lib/midori/libadblock.so
file read /usr/lib/midori/libcookie-manager.so
file read /usr/lib/midori/libstatusbar-features.so
file read /usr/lib/midori/libweb-cache.so
file read /usr/lib/midori/libshortcuts.so
file read /usr/lib/midori/libformhistory.so
file read /usr/lib/midori/libstatus-clock.so
file read /usr/lib/midori/libcolorful-tabs.so
file read /usr/lib/midori/libfeed-panel.so
file read /usr/lib/midori/libhistory-list.so
file read /usr/lib/midori/libmouse-gestures.so
file read /usr/lib/midori/libcopy-tabs.so
file read /usr/lib/midori/libtabs-minimized.so
file read /usr/lib/x86\_64-linux-gnu/gdk-pixbuf-2.0/2.10.0/loaders.cache
file read /usr/lib/x86\_64-linux-gnu/pango/1.6.0/module-files.d/libpango1.0-0.modules
file read /etc/fonts/fonts.conf
file read /usr/lib/x86\_64-linux-gnu/pango/1.6.0/modules/pango-basic-fc.so
file read /usr/lib/x86\_64-linux-gnu/gdk-pixbuf-2.0/2.10.0/loaders/libpixbufloader-svg.so
file read /usr/lib/x86\_64-linux-gnu/gtk-2.0/2.10.0/gtk.immodules
file read /usr/lib/enchant/libenchant\_hspell.so
file read /usr/lib/enchant/libenchant\_aspell.so
file read /usr/lib/enchant/libenchant\_myspell.so
file read /usr/lib/enchant/libenchant\_ispell.so
file read /usr/lib/x86\_64-linux-gnu/gconv/KOI8-R.so
file read /usr/lib/x86\_64-linux-gnu/gdk-pixbuf-2.0/2.10.0/loaders/libpixbufloader-png.so
file read /usr/lib/x86\_64-linux-gnu/gdk-pixbuf-2.0/2.10.0/loaders/libpixbufloader-ico.so
file read /etc/host.conf
file read /etc/resolv.conf
file read /etc/hosts
file ioctl socket:[family=2:type=2:protocol=17] 0x541B
file read /etc/gai.conf
file read /usr/lib/x86\_64-linux-gnu/gio/modules/libgioremote-volume-monitor.so
file ioctl anon\_inode:inotify 0x541B
file read /etc/gnome/defaults.list
file read /usr/lib/libreoffice/share/\{\\*\}/\\*
file read/write/append/unlink/truncate /home/home/\{\\*\}/\\*
file read/write/append/unlink/truncate /home/home/\\*
file create/chmod /home/home/\\* 0-0666
file create/chmod /home/home/\{\\*\}/\\* 0-0666
file rename /home/home/\\* /home/home/\\*
file rename /home/home/\{\\*\}/\\* /home/home/\{\\*\}/\\*
file rename /home/\{\\*\}/\\* /home/home/\{\\*\}/\\*
file read /etc/fonts/\{\\*\}/\\*
file read /usr/share/\{\\*\}/\\*
file read /var/cache/\{\\*\}/\\*
network inet stream connect 0.0.0.0-255.255.255.255 80-443
network inet dgram send 192.168.1.1 53
```
Затем сохраним политику исключений.
```
tomoyo-savepolicy -e > /etc/tomoyo/exception_policy.conf
```
После этого, по желанию, можно провести доводку в любом файловом редакторе.
Например добавить глобальную файловую группу с распространенными путями в exception_policy.conf
```
path_group Midoi_Allow /home/\*/midory/\{\*\}/\*
path_group Midoi_Allow /home/\*/.config/midori/\{\*\}/\*
path_group Midoi_Allow /home/home/.config/midori/\*
```
И прописать ее в domain_policy.conf, еще больше упростив конфиг.
```
file read/write/append/unlink/truncate @Midoi_Allow
```
В случае такой ручной правки, обязательно проверяем конфиги на ошибки, ведь обычный редактор не учитывает синтаксис Tomoyo.
```
tomoyo-checkpolicy d < /etc/tomoyo/domain_policy.conf
tomoyo-checkpolicy e < /etc/tomoyo/exception_policy.conf
```
Может случиться так, что приложение будет периодически падать или глючить из-за редких вызовов каких-то разрешений, которых не было в режиме обучения.
Тогда запускаем программу логирования запретов *tomoyo-auditd* и как только приложение глюкнуло, идем в /var/log/tomoyo и смотрим на что сработал запрет.
*Примеры политик для некоторых программ
[wiki.archlinux.org/index.php/skype#TOMOYO](https://wiki.archlinux.org/index.php/skype#TOMOYO)
[wiki.archlinux.org/index.php/Adobe\_Reader](https://wiki.archlinux.org/index.php/Adobe_Reader)*
##### Пишем глобальные правила
В Tomoyo можно реализовывать глобальные правила, применяющиеся для всех доменов.
Давайте сделаем глобальную политику запрета запуска программ из /home и /tmp для всех пользователей кроме учетной записи root.
Для отдельных программ установим более жесткие политики.
Создаем новый профиль с контролем только выполнения файлов.
**/etc/tomoyo/profile.conf**4-COMMENT=-----Enforcing file::execute only-----
4-PREFERENCE={ max\_audit\_log=1024 max\_learning\_entry=2048 }
4-CONFIG={ mode=disabled grant\_log=yes reject\_log=yes }
4-CONFIG::file::execute={ mode=enforcing grant\_log=no reject\_log=yes }
Добавляем в исключения следующие строчки.
**/etc/tomoyo/exception\_policy.conf**
```
path_group ALLOW_EXEC /\*
path_group ALLOW_EXEC /bin/\{\*\}/\*
path_group ALLOW_EXEC /etc/\{\*\}/\*
path_group ALLOW_EXEC /sbin/\{\*\}/\*
path_group ALLOW_EXEC /sys/\{\*\}/\*
path_group ALLOW_EXEC /boot/\{\*\}/\*
path_group ALLOW_EXEC /usr/\{\*\}/\*\-medit\-midori
path_group ALLOW_EXEC /run/\{\*\}/\*
path_group ALLOW_EXEC /bin/\*
path_group ALLOW_EXEC /etc/\*
path_group ALLOW_EXEC /sbin/\*
path_group ALLOW_EXEC /sys/\*
path_group ALLOW_EXEC /boot/\*
path_group ALLOW_EXEC /usr/\*
path_group ALLOW_EXEC /run/\*
path_group ALLOW_EXEC_ROOT /lib/\{\*\}/\*
path_group ALLOW_EXEC_ROOT /lib64/\{\*\}/\*
path_group ALLOW_EXEC_ROOT /home/\{\*\}/\*
path_group ALLOW_EXEC_ROOT /opt/\{\*\}/\*
path_group ALLOW_EXEC_ROOT /tmp/\{\*\}/\*
path_group ALLOW_EXEC_ROOT /var/\{\*\}/\*
path_group ALLOW_EXEC_ROOT /mnt/\{\*\}/\*
path_group ALLOW_EXEC_ROOT /media/\{\*\}/\*
path_group ALLOW_EXEC_ROOT /lib/\*
path_group ALLOW_EXEC_ROOT /lib64/\*
path_group ALLOW_EXEC_ROOT /home/\*
path_group ALLOW_EXEC_ROOT /opt/\*
path_group ALLOW_EXEC_ROOT /tmp/\*
path_group ALLOW_EXEC_ROOT /var/\*
path_group ALLOW_EXEC_ROOT /mnt/\*
path_group ALLOW_EXEC_ROOT /media/\*
keep_domain any from
initialize\_domain /usr/bin/midori from any
```
Правим политику домена:
**/etc/tomoyo/domain\_policy.conf**
```
use\_profile 4
use\_group 0
file execute @ALLOW\_EXEC
file execute @ALLOW\_EXEC\_ROOT task.uid=0
file execute /usr/bin/medit
file execute /usr/bin/midori
/usr/bin/midori
use\_profile 3
use\_group 0
```
Разбор полетов.
1.
Для чего сначала пришлось удалять midori из регулярки *\-midori*, а потом явно указывать снова через *file execute /usr/bin/medit*?
Все дело в логике Tomoyo. Когда система разбирает заданные правила, она учитывает как помечается каждый домен в конфиге и требует его указания в явном виде. Это свойство работает только для команд связанных с переходами между доменами, но не с запрещающими правилами.
Поэтому команда *initialize\_domain /usr/bin/midori from any* при переходе в домен medit, отработает только если она указана в явном виде в родительском домене ````
.
2.
file execute @ALLOW_EXEC_ROOT task.uid=0
```
Тут мы ставим *условие* на контроль, которое определяет, что только суперпользователь имеет право выполнять программы из заданных директорий.
*Подробнее об условиях.
[tomoyo.sourceforge.jp/2.5/chapter-10.html.en](http://tomoyo.sourceforge.jp/2.5/chapter-10.html.en)*
3.
```
keep_domain any from
```
Опция управления доменами в Исключениях. Принудительно оставляет все созданные дочерние процессы в рамках одного домена.
```
initialize_domain /usr/bin/midori from any
```
Помимо включения опции независимого запуска, принудительно выводит процесс в отдельные домен. То есть выходит процесс из под ограничения keep_domain.
4.
```
4-CONFIG::file::execute={ mode=enforcing grant_log=no reject_log=yes }
```
Настраиваем профиль только на контроль выполнения файлов. Командой use_profile 4, применяем данный профиль к политике.
*Подробнее о возможных состояния профиля.
[tomoyo.sourceforge.jp/2.5/chapter-9.html.en](http://tomoyo.sourceforge.jp/2.5/chapter-9.html.en)*
##### Итог
Tomoyo позволяет несколькими простыми шагами, поднять безопасность системы в целом.
Можно распространить конфигурацию по сети и защитить таким образом целые сегменты.
ps. Для интересующихся темой mac. Один из разработчиков Tomoyo, продемонстрировал еще один инструмент принудительного контроля - [caitsith.sourceforge.jp](http://caitsith.sourceforge.jp)
Update!
Выявлена возможность простого обхода правил Tomoyo из под прав простого пользователя.
Обход возможен с помощью ld-linux.so.2 библиотеки динамической линковки программ.
Поэтому во все конфиги обязательно включайте запрет на прямой вызов данной библиотеки.
Например:
```
/lib/x86\_64-linux-gnu/ld-2.13.so
use\_profile 3
use\_group 0
initialize\_domain /lib/x86\_64-linux-gnu/ld-2.13.so from any
```
Учтите, что может быть несколько копий данной библиотеки в системе.``
|
https://habr.com/ru/post/224335/
| null |
ru
| null |
# Что представляет собой веб-приложение в продакшне?
На заре карьеры я работал в компании, которая выпускала систему управления контентом. Эта CMS помогала отделам маркетинга самостоятельно управлять сайтами, а не полагаться на разработчиков при каждом изменении. Система помогла клиентам сократить операционные расходы, а мне — научиться создавать веб-приложения.
Хотя сам продукт имел очень общее назначение, клиенты обычно использовали его для конкретных задач. Эти задачи выжимали максимум из CMS, а разработчикам приходилось искать решение проблем. После десяти лет работы в таком окружении я узнал огромное число способов, как может сломаться веб-приложение в продакшне. Некоторые из них обсудим в этой статье.
Один из уроков, усвоенных за эти годы — отдельные инженеры обычно очень глубоко погружаются в интересующую их область, а всё остальное изучают до опасного поверхностно. Схема нормально работает в команде инженеров с хорошей коммуникацией, где знания перекрываются и заполняют отдельные пробелы у каждого из них. Но в командах с небольшим опытом или у отдельных инженеров происходит сбой.
Если вы начали работу в таком окружении, а затем приступили к созданию и развёртыванию веб-приложения с нуля, то очень быстро узнаете, что такое «до опасного поверхностные знания».
В отрасли существует ряд решений для решения этой проблемы: управляемые веб-приложения (Beanstalk, AppEngine и т. д.), управление контейнерами (Kubernetes, ECS и т. д.) и многие другие. Они хорошо работают из коробки и могут отлично решить проблему. Но это излишняя сложность при запуске веб-приложения, и обычно такие решения «просто работают».
К сожалению, не всегда они «просто работают». Если возникает какой-то нюанс, то хочется чуть больше знать об этом зловещем чёрном ящике.
В статье мы возьмём ненадёжную систему и доработаем её до разумного уровня надёжности. На каждом шагу используется реальная проблема, решение которой переносит нас на следующий этап. Я считаю, что эффективнее не анализировать все части окончательного дизайна, а использовать именно такой поэтапный подход. Он лучше демонстрирует, когда и в каком порядке принимать определённые решения. В конце концов, мы построим с нуля базовую структуру сервиса хостинга управляемых веб-приложений, и, надеюсь, подробно объясним причины существования каждой его части.
Начало
======
Представьте, что ваш бюджет на хостинг $500 в год, поэтому вы решили арендовать один сервер t2.medium на Amazon AWS. На момент написания статьи это около $400 в год.
Вы заранее знаете, что у вас будет система авторизации и что понадобится хранить информацию о пользователях, поэтому нужна база данных. Из-за ограниченного бюджета разместим её на нашем единственном сервере. В конечном итоге получаем такую инфраструктуру:

*Рис. 1*
Пока этого достаточно. На самом деле такая система может проработать довольно долго. Сервис маленький, менее 10 посещений в день. Возможно, и маленького инстанса было достаточно, но мы с оптимизмом смотрим на рост компании, поэтому предусмотрительно взяли t2.medium.
Ценность бизнеса — в базе данных, поэтому она очень важна. Нужно убедиться, что если сервер выходит из строя, вы не потеряете данные. Вероятно, следует убедиться, что содержимое базы не хранится на временном диске. Ведь если инстанс удалят, вы потеряете свои данные. Это очень страшная мысль.
Также следует убедиться, что у вас есть резервные копии на внешнем хранилище. S3 кажется хорошим местом для них, и относительно недорогим, поэтому давайте также настроим и это. И нужно обязательно проверить, что бэкап работает, периодически восстанавливая резервную копию.
Теперь система выглядит примерно так:

*Рис. 2*
Вы повысили надёжность базы данных, и пришло время подготовиться к «хабраэффекту», прогнав на сервере нагрузочный тест. Всё идет вроде нормально, пока не появляются ошибки 500, а затем поток ошибок 404, поэтому вы изучаете, что произошло.
Оказывается, вы понятия не имеете, что произошло, потому что писали логи в консоль и не направляли выдачу в файл. Вы также видите, что процесс не работает, так что можно с большой вероятностью предположить, что именно поэтому появляются ошибки 404. Накатывает волна облегчения, что вы грамотно запустили локальный нагрузочный тест, а не вызвали реальный хабраэффект в качестве тестовой нагрузки.
Вы исправляете проблему с автоматическим перезапуском, создав службу `systemd`, запускаете веб-сервер, который одновременно решает проблему с записью логов. Затем запускаете ещё один нагрузочный тест для проверки.
И опять видим ошибки 500 (к счастью, без 404). Вы проверяете логи. Обнаруживается, что пул подключений к базе данных заполнен, потому что было установлено маленькое ограничение в 10 подключений. Обновляете ограничение, перезапускаете БД и снова запускаете нагрузочный тест. Всё идёт хорошо, поэтому вы решаете рассказать о своём сайте на Хабре.
День запуска
============
Матерь божья! Ваш сервис мгновенно становится хитом. Вы попали на главную страницу и получаете 5000 просмотров за первые 30 минут — и видите комментарии. Что там пишут?
> У меня ошибка 404, поэтому пришлось открыть кэшированную версию страницы. Вот ссылка, если кому надо: …
…
> Ничего не открывается. Кроме того, у меня отключен Javascript. Почему люди считают, что я хочу грузить их Javascript на 2 МБ…
…
> Загрузка домашней страницы занимает 4 секунды. Traceroute из Австралии показывает, что сервер размещен где-то в Техасе. Кроме того, почему первая страница загружает 2 мегабайта Javascript?
В безумной спешке вы настраиваете Nginx в качестве обратного прокси-сервера для своего приложения и настраиваете там статическую страницу 404. Вы также изменяете процедуру деплоя, чтобы отправлять статические файлы в S3: это необходимо для работы CloudFront CDN, чтобы сократить время загрузки в Австралии.
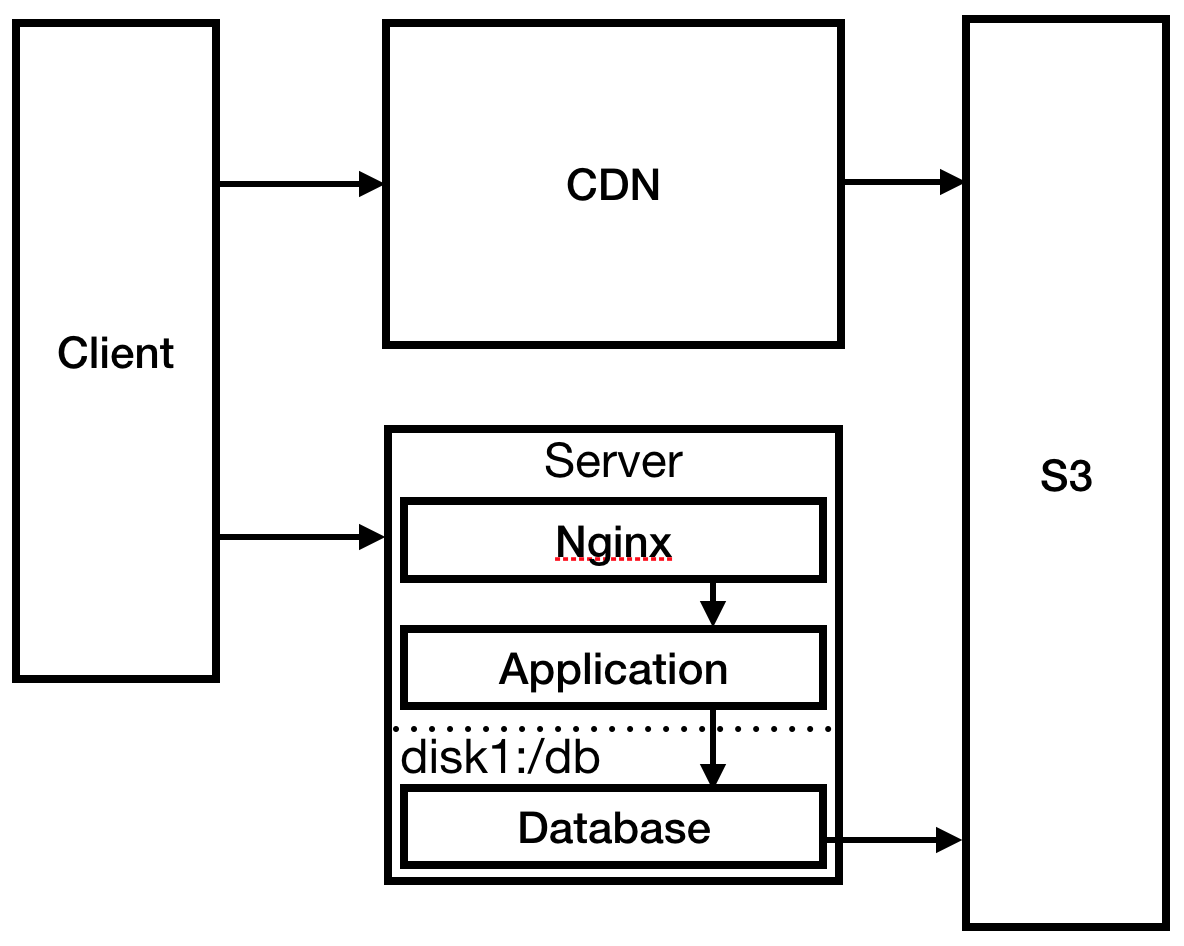
*Рис. 3*
Вы решили самую насущную проблему, идёте на сервер и проверяете логи. Ваше соединение SSH необычно лагает. После некоторого изучения вы видите, что файлы логов полностью израсходовали дисковое пространство, что привело к сбою процесса и предотвращению его повторного запуска. Создаёте диск гораздо большего размера и монтируете туда логи. Настраиваете `logrotate`, чтобы файлы логов больше не разрастались до таких размеров.
Проблемы с производительностью
==============================
Проходят месяцы. Аудитория растёт. Сайт начинает тормозить. Вы заметили в мониторинге CloudWatch, что это происходит только между 00:00 и 12:00 UTC. Из-за одинакового времени начала и окончания лагов вы догадываетесь, что это связано с запланированной задачей на сервере. Проверяете crontab и понимаете, что одно задание запланировано на полночь: резервное копирование. Конечно, резервное копирование занимает двенадцать часов и приводит к перегрузке базы данных, вызывая значительное замедление работы сайта.
Вы читали об этом раньше — и решаете запускать резервные копии в подчинённой БД (slave). Затем вспоминаете: у вас же нет подчинённой базы данных, поэтому её нужно создать. Не имеет большого смысла запускать базу данных slave на том же сервере, поэтому вы решаете расширяться. Создаёте два новых сервера: один для базы данных master и один для базы данных slave. Изменяете резервное копирование для работы с подчинённой БД.
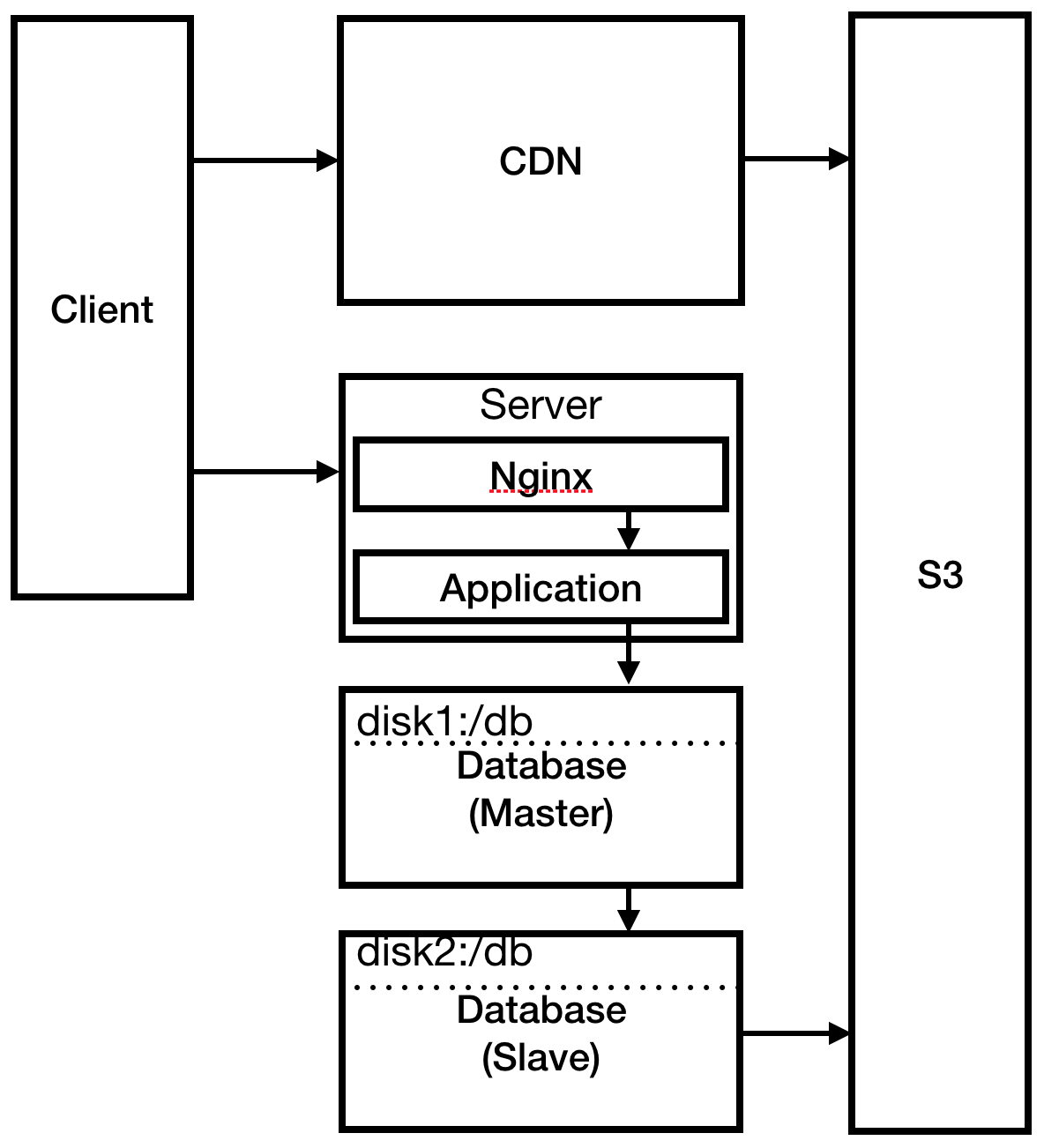
*Рис. 4*
Рост команды
============
Некоторое время всё идёт гладко. Проходят месяцы. Вы нанимаете разработчиков. Один из новичков вносит баг, который валит производственный сервер. Разработчик обвиняет среду разработки, которая отличается от продакшна. В его словах есть доля правды. Поскольку вы разумный человек с хорошим характером, то воспринимаете это событие как урок.
Пришло время создать дополнительные окружения: промежуточное (staging), QA и продакшн. К счастью, вы с первого дня автоматизировали создание инфраструктуры, так что всё проходит гладко и просто. У вас также с первого дня налажены хорошие практики непрерывной доставки, поэтому вы легко собираете конвейер из новых веток.
Отдел маркетинга настаивает на выпуске версии 2.0. Вы не совсем понимаете, что значит 2.0, но соглашаетесь. Пора готовиться к очередному всплеску трафика. Вы уже близки к пику на текущем сервере, так что пришло время для балансировки нагрузки. Amazon ELB легко делает это. Примерно в это время вы замечаете, что многоуровневые диаграммы в этой статье должны показывать слои сверху вниз, а не слева направо.
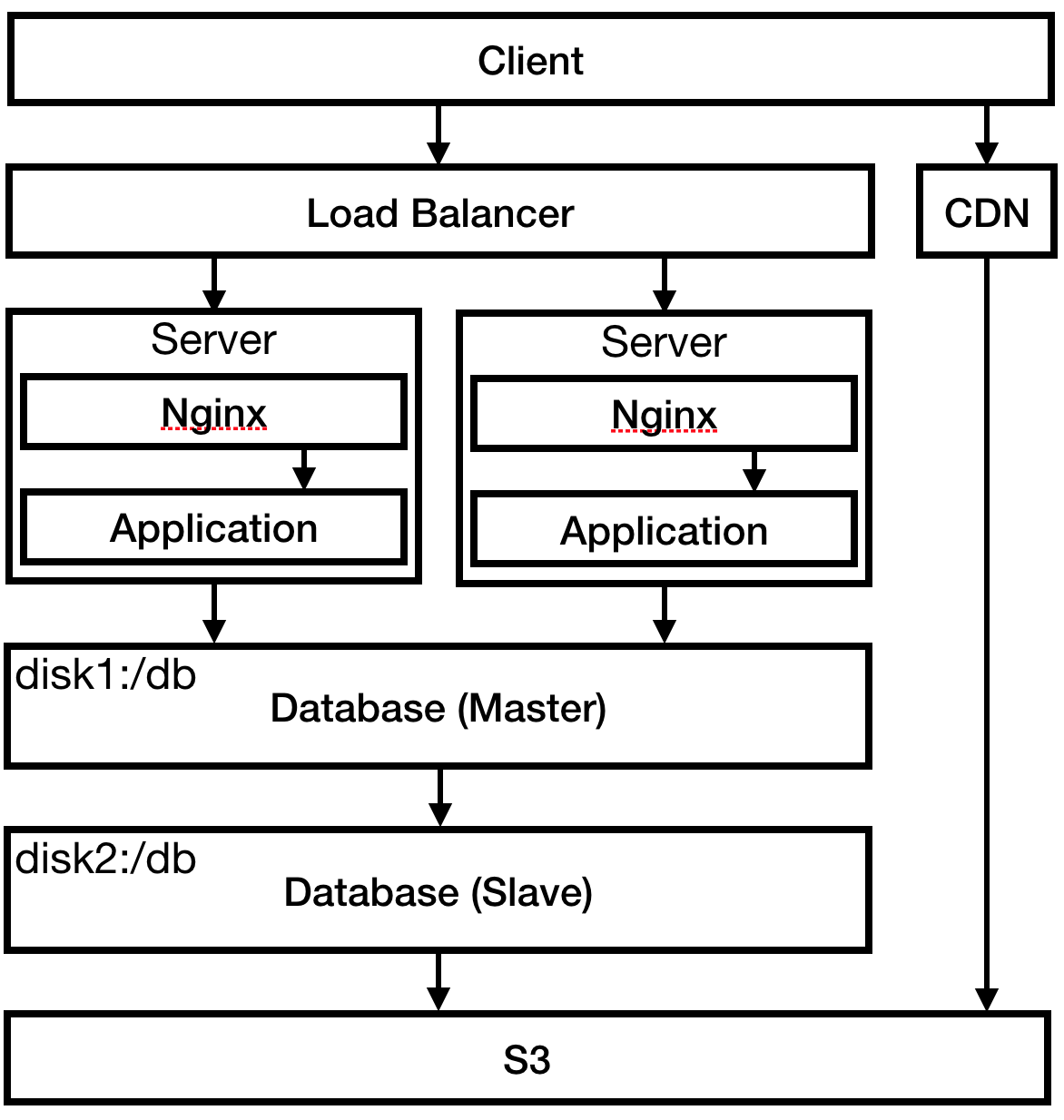
*Рис. 5*
Уверенный в том, что вы справитесь с нагрузкой, вы снова упоминаете свой сайт на Хабре. О чудо, он выдерживает трафик. Большой успех!
Всё вроде шло хорошо, пока вы не пошли проверять логи. На проверку 12 серверов ушёл час (по четыре сервера в каждом окружении). Настоящая нервотрёпка. К счастью, денег хватает на покупку стека ELK (ElasticSearch, LogStash, Kibana). Вы развёртываете его и направляете туда серверы со всех окружений.

*Рис. 6*
Теперь, можно снова обратиться к логам, вы смотрите их — и замечаете что-то странное. Они полны таких записей:
```
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
```
Вы не используете PHP или WordPress, так что это довольно странно. Вы замечаете похожие подозрительные записи в логах серверов БД и удивляетесь, как они вообще подключились к интернету. Пришло время внедрять публичные и частные подсети.

*Рис. 7*
Ещё раз проверьте логи. Попытки взлома остались, но теперь они ограничены портом 80 на балансировщике нагрузки, что немного утешает, потому что серверы приложений, серверы БД и стек ELK больше не в открытом доступе.
Несмотря на централизованные логи, вам надоело искать даунтаймы, проверяя логи вручную. Через Amazon CloudWatch вы настраиваете оповещения по электронной почте, когда диск, CPU и сеть достигают 80% утилизации. Отлично!
Бесперебойная работа
====================
Просто шучу! В программном обеспечении нет такого понятия, как бесперебойная работа. Что-то обязательно сломается. К счастью, теперь у вас много инструментов, чтобы справиться с ситуацией.
Мы создали масштабируемое веб-приложение с бэкапами, откатами (с использованием синих/зелёных деплоев между продакшном и промежуточным этапом), централизованные логи, мониторинг и оповещение. Дальнейшее масштабирование, как правило, зависит от конкретных потребностей приложения.
На рынке много вариантов хостинга, которые берут на себя бóльшую часть упомянутых задач. Вместо самостоятельной разработки вы можете положиться на Beanstalk, AppEngine, GKE, ECS и т. д. Большинство этих сервисов автоматически настраивают разумные разрешения, подсистемы балансировки нагрузки, подсети и т. д. Это устраняет существенную часть нервотрёпки при запуске веб-приложения на быстром и надёжном бэкенде, который работает в течение длительного времени.
Несмотря на это, я считаю полезным понять, какую функциональность предоставляет каждая из этих платформ и почему они её предоставляют. Это облегчает выбор платформы на основе ваших собственных потребностей. Размещая приложение на такой платформе, вы уже будете знать, как работают эти модули. Когда что-то пойдёт не так, полезно знать инструментарий для решения проблемы.
Заключение
==========
В этой статье опущено много деталей. В ней не описывается, как автоматизировать создание инфраструктуры, как подготовить и настроить серверы. Не рассматривается создание сред разработки, настройка конвейеров непрерывной доставки, а также выполнение развёртываний и откатов. Мы не затронули сетевую безопасность, разделение ключей и принцип минимальных привилегий. Не рассказали о важности неизменной (immutable) инфраструктуры, stateless-серверов и миграций. Каждая из тем требует отдельной статьи.
Цель этого поста — общий обзор, как должно выглядеть разумное веб-приложение в продакшне. Будущие статьи могут ссылаться сюда и расширять тему.
На данный момент это всё.
Спасибо за чтение и удачного кодирования!
Примечание: не принимайте буквально последовательность из этой иллюстративной статьи. По отдельности все эти события действительно происходили со мной, но в разное время, в совершенно разных окружениях и на разных задачах.
|
https://habr.com/ru/post/421765/
| null |
ru
| null |
# Задача о ранце и код Грея
Не так давно на Хабре была статья «[Коды Грея и задачи перебора](http://habrahabr.ru/post/200806/)». Статья эта скорее, математическая, нежели программистская, и мне, как простому программисту, читать её было невыносимо тяжело. Но сама тема мне знакома, поэтому я решил описать её своим взглядом, а так же рассказать о том, как использовал её в решении задачи о ранце.

*КДПВ: задача о ранце на живом примере*
#### Предыстория
Всё началось 10 лет назад, когда я учился в девятом классе. Я случайно подслушал разговор учителя по информатике, рассказывающего задачку кому-то из старших: дан набор чисел, и ещё одно число — контрольное. Надо найти максимальную сумму чисел из набора, которая не превышала бы контрольное число.
Задача почему-то запала мне в душу. Вернувшись домой, я быстро накатал решение: наивный перебор всех возможных сумм с выбором наилучшего. Сочетания я получал, перебирая все N-разрядные двоичные числа и беря суммы тех исходных чисел, которым соответствуют единицы. Но я с огорчением обнаружил, что при количестве элементов начиная где-то с 30, программа работает очень долго. Оно и не удивительно, ведь время работы такого алгоритма — n\*2n (количество сочетаний, умноженное на длину суммы).
Прошло 5 лет. Я успел закончить школу и поступить в университет, но эта задача по-прежнему была со мной. Один раз, листая книгу «Алгоритмические трюки для программистов» (Hacker's Delight / Henry S. Warren Jr.), я наткнулся на описание кода Грея: это последовательность двоичных чисел, каждое из которых отличается от предыдущего только одним битом. «Стоп!» — подумал я — «Это означает… Да! Это означает, что в той самой задаче на каждом шаге перебора можно не считать сумму целиком, а лишь добавлять или вычитать одно число». И я тут же углубился в изучение темы.
#### Построение кода Грея
Код Грея можно построить для числа любой разрядности. Для одного разряда он очевиден:
0
1
Чтобы добавить второй разряд, можно к этой последовательности дописать такую же задом наперёд
0
1
1
0
и ко второй половине дописать единицы:
00
01
11
10
Аналогично для трёх разрядов:
000
001
011
010
110
111
101
100
Такой код, полученный отражением кода меньшей разрядности, называется рефлексным (отражённым) кодом Грея. Бывают и другие последовательности, но на практике обычно используется именно эта.
Этот код назван в честь [Фрэнка Грея](https://en.wikipedia.org/wiki/Frank_Gray_(researcher)), который изобрёл ламповый АЦП, выдававший цифровой сигнал именно в этом коде. При небольших изменениях уровня входного сигнала цифровой выход мог измениться только в одном бите, и этим исключались резкие скачки из-за неодновременного переключения битов.
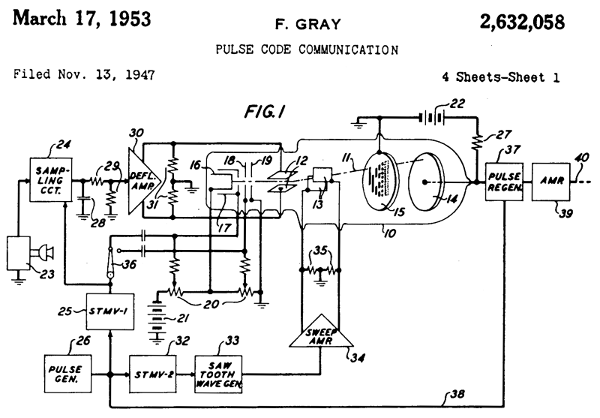
*Иллюстрация патента Фрэнка Грея*
Самое наглядное применение кода Грея — в датчиках угла поворота. Датчик, аналогичный тем, что был в старых механических мышах, но определяющий не относительное смещение, а абсолютное значение угла. Для этого на каждый датчик нужно несколько оптопар и несколько щелевых решёток. Причём каждое следующее положение датчика должно отличаться от предыдущего только состоянием одного бита, иначе на границах возможно несинхронное переключение битов, и следственно — резкие скачки в показаниях прибора. Здесь видна любопытная особенность кода Грея: последнее число также отличается от первого одним битом, поэтому его можно «закольцевать».

*Датчик абсолютного угла поворота. Оптические щели расположены в соответствии с кодом Грея*
#### Применение в задаче о ранце
Но вернёмся к задаче о ранце. Стандартная формула даёт нам код Грея по номеру:
```
G = i ^ (i >> 1)
```
По ней мы можем только посчитать сумму все нужных элементов. А мы собирались на каждой итерации добавлять или вычитать одно значение, верно? Значит, нам нужно получить номера изменяемых битов. Для многоразрядных чисел эти номера будут такими:
0
1
0
2
0
1
0
3
0
1
0
2
0
1
0
4
…
Ничего не напоминает? Это номер бита, который мы устанавливаем в единицу, когда просто перечисляем обычные двоичные числа. Или иначе — номер младшей единицы в двоичном числе. Эта операция называется [find first set](https://en.wikipedia.org/wiki/Find_first_set) и в большинстве процессоров существует в виде отдельной инструкции. Visual C++ предоставляет эту инструкцию в виде функции \_BitScanForward.
Итак, теперь мы готовы написать программу, решающую задачу о ранце через код Грея. Сформулируем задачу так:
> В файле input.txt в первой строке указана вместимость рюкзака, а в остальных строках — размеры вещей. В консоль нужно вывести максимальную загрузку рюкзака и размеры выбранных вещей. Проверку корректности ввода и пр. — нафиг.
Мы будем хранить битовую маску использованных вещей, и по мере необходимости добавлять или убирать одну из них. Чтобы обойтись int-ами, ограничим количество вещей (и используемых бит) тридцатью одной.
```
#include
#include
#include
#include
using namespace std;
void main()
{
int target; // размер ранца
int nItems = 0; // количество предметов
int weight[31]; // веса предметов
ifstream inFile("input.txt");
inFile >> target;
while(inFile >> weight[nItems])
nItems++;
inFile.close();
const unsigned int nIterations = 1 << nItems; // количество комбинаций, 2^n
int sum = 0; // текущий вес вещей
int bestSum = 0; // лучший вес (максимальный без перегрузки)
bitset<31> mask; // текущая комбинация выбранных вещей
bitset<31> bestMask; // лучшая комбинация выбранных вещей
for (unsigned int i = 1; i < nIterations; i++)
{
unsigned long position; // какой по счёту бит инвертируем
\_BitScanForward(&position, i);
mask[position] = !mask[position];
if (mask[position]) // кладём в рюкзак или убираем эту вещь
sum += weight[position];
else
sum -= weight[position];
if (sum > target) // перегруз
continue;
if (sum > bestSum) // Отличный вариант! Надо запомнить...
{
bestSum = sum;
bestMask = mask;
}
}
cout << "Best approximation: " << bestSum << endl;
cout << "Used weights:" << endl;
for (int i = 0; i < 31; i++)
if (bestMask[i])
cout << weight[i] << endl;
cin.get();
}
```
Прощу прощения за возможные шероховатости; к сожалению, C++ уже давно не мой профильный язык.
Работает действительно быстрее, чем сборка с нуля всех сумм, разница заметна уже при 20 числах, а при 30-и я так и не дождался выполнения наивного алгоритма, в то время как новый вариант выполняется за 7 секунд. Впрочем, учитывая экспоненциальную сложность, это совсем не мало: для 50 чисел использовать этот алгоритм уже нет смысла. К сожалению, любой точный алгоритм будет работать не быстрее, чем за 2n; быстрее возможно только приблизительное решение. *(Апдейт: в некоторых случаях динамическое программирование и meet-in-the-middle решают задачу быстрее; подробности см. в комментариях.)*
Наверное, именно поэтому я обречён до конца жизни нести свой ранец, пытаясь ускорить эту программу. Я уже однажды переписывал цикл на ассемблере, получив небольшой прирост в скорости, а сейчас даже подумываю сделать многопоточную версию программы. Вам же остаётся лишь мне посочувствовать. :)
|
https://habr.com/ru/post/203362/
| null |
ru
| null |
# AllcountJS: Делаем простую CRM с веб-интерфейсом и REST API за 15 минут
Допустим моя компания кому-то звонит и что-то продаёт и мне нужна простая CRM, которая позволит вести справочник контактов и наглядно отслеживать их состояние в плане продажи.
Сейчас мы с вами сделаем такую систему с нуля за считанные минуты. Для этого мы будем использовать фрэймворк Allcountjs.
Самые нетерпеливые могут сразу же посмотреть на [результат](https://allcountjs.com/entity/DemoGallery/55aa5f4990442bb21c4ecf58).

Что за AllcountJS?
==================
Так как это первая статья на русском про AllcountJS, то скажу пару слов о самом фреймворке.
AllcountJS — это фреймворк c открытым исходным кодом для быстрой разработки веб и мобильных приложений на Node.js. AllcountJS построен на MEAN стеке (MongoDB, Express, AngularJS, NodeJS). Развивается поддержка не только MongoDB, но и других БД, в первую очередь SQL.
Центральная часть AllcountJS приложения это конфигурационный .js файл с декларативным описанием структуры приложения: сущности, отношения между ними, права доступа и т.д.
CRUD операции к сущностям, управление пользователями, настройки прав доступа, и REST API до всех функций приложения — всё это доступно сразу, без необходимости написания дополнительного кода.
Базовый веб-интерфейс приложения генерируется автоматически. Естественно его можно дорабатывать и изменять как угодно — только необходимы знания AngularJS и и языка шаблонов jade. Если возможностей фреймворка окажется недостаточно, возможно расширение функциональности через использование механизма внедрения зависимостей.
Установка и запуск
==================
Начать работу с AllcountJS можно несколькими способами: в качестве самостоятельного приложения, как модуль другого NodeJS приложения или запустить приложение на AllcountJS.com.
Самый простой способ увидеть AllcountJS в деле — это просто запустить одно из демо-приложений в [галерее](https://allcountjs.com/entity/DemoGallery/).
Рассмотрим и вариант с отдельным приложением. Для этого должны быть установлены MongoDB, NodeJS и Git. (если у вас Ubuntu то вы можете посмотреть [скринкаст по установке](https://www.youtube.com/watch?v=GOcMq5CCneI) ). Для установки AllcountJS выполним:
```
npm install -g allcountjs-cli
allcountjs init cusdevcrm-allcount
cd cusdevcrm-allcount
npm install
```
Далее откройте app-config/main.js в директории с приложением и замените его содержимое следующим кодом:
```
A.app({
appName: "CusDev CRM",
appIcon: "phone",
onlyAuthenticated: true,
menuItems: [
{
name: "Contact",
entityTypeId: "Contact",
icon: "user"
}, {
name: "Board",
entityTypeId: "FlowBoard",
icon: "bars"
}, {
name: "Statuses",
entityTypeId: "Status",
icon: "sort"
}
],
entities: function(Fields) {
return {
Contact: {
fields: {
name: Fields.text("Name").required(),
company: Fields.text("Company").required(),
site: Fields.text("Site"),
email: Fields.text("Email"),
skype: Fields.text("Skype"),
phone: Fields.text("Phone"),
lastContactDate: Fields.date('Last contact date'),
status: Fields.fixedReference("Status", "Status")
},
views: {
FlowBoard: {
customView: "board"
}
}
},
Status: {
fields: {
name: Fields.text("Name").required(),
order: Fields.integer("Order").required()
},
sorting: [['order', 1]],
referenceName: "name"
}
}
},
});
```
Теперь давайте подробнее разберёмся с тем что же этот код делает.
Общие настройки приложения
==========================
Вся конфигурация приложения располагается внутри единственного метода. Название и иконка приложения задаются с помощью свойств appName и appIcon. AllcountJS использует иконки Font Awesome. Вы можете выбрать любую [иконку](http://fortawesome.github.io/Font-Awesome/icons/) и использовать её в приложении просто сославшись на неё по имени. При ссылке на иконку необходимо отбросить префикс fa-. Мы возьмем обычный телефонный значок для нашей «CusDev CRM».
```
appName: "CusDev CRM",
appIcon: "phone",
```
За настройку аутентификации отвечает свойство onlyAuthenticated. Оно определяет возможность использования приложения незарегистрированными пользователями. Мы же не хотим что бы доступ до CRM был у всех, поэтому:
```
onlyAuthenticated: true
```
Далее в конфигурации идёт пункт menuItems, но мы к нему вернёмся после того как опишем сущности и их представления.
Контакты и статусы
==================
Теперь мы готовы к тому что бы описать наши бизнес-сущности.
Опишем сущность Contact. Пусть у контакта будут два обязательных текстовых поля — Name и Company. Несколько текстовых полей с информацией о способах связи, дата последнего контакта и текущий статус контакта.
Поле status — это ссылка на сущность статус в которых может находиться контакт (например “Написали”, “Ответил”, “Готов на встречу”).
```
entities: function(Fields) {
return {
Contact: {
fields: {
name: Fields.text("Name").required(),
company: Fields.text("Company").required(),
site: Fields.text("Site"),
email: Fields.text("Email"),
skype: Fields.text("Skype"),
phone: Fields.text("Phone"),
lastContactDate: Fields.date('Last contact date'),
status: Fields.fixedReference("Status", "Status")
}
},
Status: {
fields: {
name: Fields.text("Name").required(),
order: Fields.integer("Order").required()
},
sorting: [['order', 1]],
referenceName: "name"
}
}
}
```
Отображение на доске
====================
Каждая сущность может иметь представления (вью). Они задаются в свойстве view. Представления в AllcountJS похожи на представления в SQL. Они не занимают дополнительного места в БД, но вы можете работать с ними как с обычными сущностями. Представления можно использовать для того что бы обеспечить специальное поведение, интерфейс и права доступа.
В нашем случае мы будем использовать представления для того что бы сделать специальный UI в виде интерактивной доски для отображения контактов. Зададим для контакта представление FlowBoard а внутри него, в свойстве customView, UI шаблон board.
```
views: {
FlowBoard: {
customView: "board"
}
}
```
Он ссылается на .jade файл, содержащий код шаблона. AllcountJS использует шаблонизатор jade для генерации конечного HTML для веб интерфейсов. Подробнее о jade можно прочитать на [jade-lang.com](http://jade-lang.com/)
В комплекте AllcountJS есть шаблон канбан доски с драг-анд-дропом. Наше представление board является его расширением. Создадим файл board.jade со следующим кодом внутри:
```
extends project/card-board
block panelBody
.panel-body
h4 {{item.name}}
p {{item.company}}
p {{item.lastContactDate | date}}
```
Меню
====
Теперь мы дошли и до меню нашего приложения. Оно задаётся в свойстве menuItems и состоит из ссылок на сущности и представления.
```
menuItems: [
{
name: "Contact",
entityTypeId: "Contact",
icon: "user"
}, {
name: "Board",
entityTypeId: "FlowBoard",
icon: "bars"
}, {
name: "Statuses",
entityTypeId: "Status",
icon: "sort"
}
]
```
REST API
========
Если у нас есть какое-нибудь другое приложение, которое нужно интегрировать с нашей CRM, то это не будет проблемой, т.к. все функции приложения доступны через REST API.
Для начала нужно получить токен для доступа. Допустим наша CRM располагается на <https://localhost:9080>, в таком случае необходимо отправить HTTP POST запрос на
<https://localhost:9080/api/sign-in>
С таким JSON содержимым в теле:
```
{"username": "admin", "password": "admin"}
```
В ответ вернётся примерно такой ответ:
```
{"token":"56026b8ad7939dcb552a1668:PSDhU6x_VeIzqPYtIATXzEdMTLE"}
```
Теперь можно, например, получить список всех контактов. Для этого отправим HTTP GET запрос, но уже с заголовком
X-Access-Token в который передадим полученный токен из предыдущего запроса.
На <https://localhost:9080/api/entity/FlowBoard>
или напрямую на <https://localhost:9080/api/entity/Contact>
В ответ вы получите список всех контактов в формате JSON. Естественно что вы можете также удалять, создавать и обновлять ваши контакты через API.
AllcountJS может больше
=======================
В статье, на примере простой CRM показана лишь малая часть возможностей AllcountJS. В демо-приложении кроме выше рассмотренного есть ещё и русская локализация, которую можно отключить вписав forcelocale: «en» в раздел с общими настройками. А завершает конфигурацию скрипт по добавлению тестовых данных.
В следующих статьях мы продолжим знакомить вас с устройством и возможностями фреймворка. В следующей [статье](http://habrahabr.ru/company/allcountjs/blog/271111/) мы покажем как можно сделать и мобильное приложение к нашей CRM. Тоже достаточно быстро. Кому не терпится узнать больше и кого не пугает английский — добро пожаловать на официальный сайт [allcountjs.com](http://allcountjs.com).
|
https://habr.com/ru/post/270119/
| null |
ru
| null |
# Метапрограммирование в C++ и русская литература: через страдания к просветлению
«Библиотеки для C++ нередко похожи на русскую классику: страдает либо их автор, либо пользователь, либо архитектура». Автор этой цитаты, Сергей Садовников из «Лаборатории Касперского», прошел свой путь от страданий к просветлению и узнал о метапрограммировании в С++ нечто важное и нужное. Сочувствующих приглашаем в волшебный мир макросов, шаблонов, boost и прочих loki или сразу [по ссылке в «Лабораторию Касперского»](https://u.tmtm.ru/Kaspersky_Sadovnikov_04_2019).
---
1. Всё есть страдание
Для начала возьмём довольно простую задачку: написать класс, реализующий вариантный тип. Чтобы пользователь этого класса мог тем или иным образом задать варианты хранимых типов и дальше пользоваться. Например, так:
```
my_variant val("Hello World!");
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
Встроенный в язык union для этого не годится — не обеспечивает нужного контроля. Да и более-менее вменяемым (с точки зрения C++) его сделали только начиная с C++11. Другой подход к реализации — с помощью шаблонов. Хороший подход, грамотный, но при его использовании очень быстро начинаются боль и страдания. К счастью, чаще у разработчика библиотеки, а не у пользователя.
 Типы конфликтов и страданий в литературе
1.1 Макросы
Если одной бессонной ночью в поисках реализаций вариантных типов в C++ зайти на гитхаб, например [сюда](https://github.com/martinmoene/variant-lite), то в коде реализации можно увидеть три, четыре, а то и пять — нет, не звёздочек, а фрагментов наподобие такого:
```
#define variant_TL1( T1 ) detail::typelist< T1, detail::nulltype >
#define variant_TL2( T1, T2) detail::typelist< T1, variant_TL1( T2) >
#define variant_TL3( T1, T2, T3) detail::typelist< T1, variant_TL2( T2, T3) >
#define variant_TL4( T1, T2, T3, T4) detail::typelist< T1, variant_TL3( T2, T3, T4) >
#define variant_TL5( T1, T2, T3, T4, T5) detail::typelist< T1, variant_TL4( T2, T3, T4, T5) >
#define variant_TL6( T1, T2, T3, T4, T5, T6) detail::typelist< T1, variant_TL5( T2, T3, T4, T5, T6) >
#define variant_TL7( T1, T2, T3, T4, T5, T6, T7) detail::typelist< T1, variant_TL6( T2, T3, T4, T5, T6, T7) >
#define variant_TL8( T1, T2, T3, T4, T5, T6, T7, T8) detail::typelist< T1, variant_TL7( T2, T3, T4, T5, T6, T7, T8) >
#define variant_TL9( T1, T2, T3, T4, T5, T6, T7, T8, T9) detail::typelist< T1, variant_TL8( T2, T3, T4, T5, T6, T7, T8, T9) >
#define variant_TL10( T1, T2, T3, T4, T5, T6, T7, T8, T9, T10) detail::typelist< T1, variant_TL9( T2, T3, T4, T5, T6, T7, T8, T9, T10) >
#define variant_TL11( T1, T2, T3, T4, T5, T6, T7, T8, T9, T10, T11) detail::typelist< T1, variant_TL10( T2, T3, T4, T5, T6, T7, T8, T9, T10, T11) >
#define variant_TL12( T1, T2, T3, T4, T5, T6, T7, T8, T9, T10, T11, T12) detail::typelist< T1, variant_TL11( T2, T3, T4, T5, T6, T7, T8, T9, T10, T11, T12) >
#define variant_TL13( T1, T2, T3, T4, T5, T6, T7, T8, T9, T10, T11, T12, T13) detail::typelist< T1, variant_TL12( T2, T3, T4, T5, T6, T7, T8, T9, T10, T11, T12, T13) >
#define variant_TL14( T1, T2, T3, T4, T5, T6, T7, T8, T9, T10, T11, T12, T13, T14) detail::typelist< T1, variant_TL13( T2, T3, T4, T5, T6, T7, T8, T9, T10, T11, T12, T13, T14) >
#define variant_TL15( T1, T2, T3, T4, T5, T6, T7, T8, T9, T10, T11, T12, T13, T14, T15) detail::typelist< T1, variant_TL14( T2, T3, T4, T5, T6, T7, T8, T9, T10, T11, T12, T13, T14, T15) >
#define variant_TL16( T1, T2, T3, T4, T5, T6, T7, T8, T9, T10, T11, T12, T13, T14, T15, T16) detail::typelist< T1, variant_TL15( T2, T3, T4, T5, T6, T7, T8, T9, T10, T11, T12, T13, T14, T15, T16) >
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
См. [GitHub](https://github.com/martinmoene/variant-lite/blob/c6be3a21ad31c00891992cdbec0471fcf0b0f776/include/nonstd/variant.hpp#L541).
Звезд у таких библиотек обычно гораздо больше. Тот, кто читал Александреску, без труда узнает здесь описание генераторов списка типов. Для чего нужны такие списки в реализации вариантных типов — догадаться несложно. Разработчик упрощает себе жизнь, обобщая реализацию различных функций, манипулирующих с вариантом. А для этого хранимые в варианте типы может оказаться проще передавать в виде одного типа-параметра (списка-кортежа), чем в виде явного перечня.
**Да, да, конечно, новые стандарты (начиная с C++11) допускают создание шаблонов с переменным списком параметров. Это упрощает жизнь, иногда сильно, но манипулировать такими списками может оказаться не всегда удобно.**
Впрочем, сейчас речь о макросах, которые использовались для реализации задач метапрограммирования ещё тогда, когда Бьерн Страуструп только придумывал C++. Макросы — это инструмент препроцессора, который позволяет сгенерировать часть исходного текста программы непосредственно во время компиляции. Сгенерировать по определённым правилам, как в примере выше. Упоминание макроса в исходном тексте заменяется на его тело, при этом может быть выполнена конкатенация токенов, некоторые другие их простые преобразования. И программисту на C++ становится чуть проще, так как чуть меньше кода приходится писать непосредственно руками. В некоторых случаях макросы действительно упрощают жизнь и уменьшают уровень страдания. Но, если увлечься, можно начать придумывать конструкции типа таких:
```
# /* Property-holder class property presence checker */
#
# define HAS_PROPERTY_PROPERTY_IMPL_GENERIC(ClassName, PI) \
else if (name == BOOST_PP_STRINGIZE(PROP_NAME(PI))) {return true;}
# define HAS_PROPERTY_PROPERTY(_, ClassName, PI)\
BOOST_PP_CAT(HAS_PROPERTY_PROPERTY_IMPL_, PROP_KIND(PI))(ClassName, PI)
# define PROPERTIES__DO_HAS_PROPERTY(ClassName, S) \
BOOST_PP_SEQ_FOR_EACH(HAS_PROPERTY_PROPERTY, ClassName, S)
# define MAKE_BASE_HAS_PROPERTY_CALL(ClassName, BaseClassName) \
return static_cast(m\_Host)->properties\_\_.has\_property(name);
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
Полный набор можно посмотреть [здесь](https://github.com/flexferrum/flex_lib/blob/master/include/flex_lib/properties/property_pp.hpp).
После чего сказать, как оно работает и во что будет раскрываться, становится довольно сложной задачей. И, главное, чтобы писать такие конструкции, надо довольно хорошо представлять себе, как именно работает препроцессор, при этом всегда держа в голове простой факт: препроцессор работает до компилятора. Он работает с исходным текстом как с набором токенов, а не как с программой на C или C++. В сущности препроцессор можно использовать для обработки любых текстовых файлов. Эта его особенность, его сила (и одновременно слабость) не позволяет использовать конструкции препроцессора в задачах, где требуется вмешательство в структуру исходного текста на уровне семантики.
1.2 Шаблоны
В этом случае на помощь приходят шаблоны. Долгое время (до известной книжки Александреску) шаблоны использовались в основном утилитарно. Но пришёл 2001 год и стало понятно, что в спецификации C++, сугубо императивного языка, присутствует тьюринг-полный декларативный язык, имеющий много атрибутов функционального. И понеслась...
**Диалог на собеседовании:
— Александреску читали?
— Да.
— В продакшн-коде его подходы используете?
И долгий испытующий взгляд на кандидата в ожидании ответа.**
В метапрограммировании на шаблонах, пока сложность решаемых задач ограничивается несложными функциями или классами, где реализация и используемые подходы очевидны, — всё хорошо. Но вот вернёмся к нашему my\_variant и попробуем написать для него оператор вывода в поток, инициализирующий конструктор или, скажем, метод apply\_visitor (с нуля). Сложность кода возрастает сразу и по экспоненте, даже если выражаться всё будет в десятке строчек. Например, так:
```
template< size_t NumVars, typename Visitor, typename ... V >
struct VisitorImpl
{
typedef decltype(std::declval()(get<0>(static\_cast(std::declval()))...)) result\_type;
typedef VisitorApplicator applicator\_type;
};
} // detail
// No perfect forwarding here in order to simplify code
template< typename Visitor, typename ... V >
inline auto visit(Visitor const& v, V const& ... vars) -> typename detail::VisitorImpl ::result\_type
{
typedef detail::VisitorImpl impl\_type;
return impl\_type::applicator\_type::apply(v, vars...);
}
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
В рамках C++14 этот код будет выглядеть несколько проще. Но если все же требуется совместимость с одиннадцатым или, о ужас, ноль-третьим, то разнообразные удовольствия и приключения разработчику обеспечены. В любом случае, независимо от минимального стандарта, в его арсенале должны быть такие техники, как SFINAE (для шаблонных функций и классов), работа с пакетами параметров (их индексация, модификация), знание элементов функционального подхода (каррирование, фолдинг, pattern matching, функции второго порядка и т. п.). Он должен хорошо представлять себе, что можно и чего нельзя сделать с помощью шаблонов ну и, конечно, уметь разбираться с такими ошибками:

Или [такими](https://asciinema.org/a/235994).
И, что важно, у всех этих техник есть один нюанс: в продакшене кто-то должен их поддерживать. Порог входа в эту область разработки очень высок, а потому программистов на C++, способных без гугла и stackoverflow написать что-нибудь этакое на шаблонах с использованием SFINAE и прочего, не то чтобы много. И тут главное, чтобы те, к кому такой вот код попадёт на поддержку, не оказались теми самыми маньяками, которые знают, где искать автора, и которых вопрос: «тварь я дрожащая или право имею» не остановит. Мне вот, скажем, коллеги до сих пор вспоминают несколько довольно заковыристых фрагментов кода, что я когда-то писал в сильной запарке. Очень надеюсь, эти куски уже выпилили.
1.3 boost и прочие loki
Странно было бы думать, что разработчики никак не пытаются облегчить страдания себе и другим. Хотя бы пользователям библиотек. И да, есть энтузиасты (и не очень), которым это действительно удаётся. Они тратят много времени и сил на разработку инструментария, который помогает сгладить эффект от отсутствия в языке вменяемой поддержки метапрограммирования, рефлексии и прочих подобных штук. Одним из первых был Андрей Александреску со своей [Loki](https://github.com/dutor/loki). Библиотека прекрасно иллюстрировала концепции, изложенные в его книге, и была прорывом для своего времени. Сейчас поддерживается энтузиастами, а автор (работая в Facebook) пишет [folly](https://github.com/facebook/folly) и активно трудится над языком D.
Примерно в то же время в boost появилась библиотека [MPL](https://www.boost.org/doc/libs/1_69_0/libs/mpl/doc/index.html), которую написали Алексей Гуртовой (Aleksey Gurtovoy) и Дэвид Абрахамс (David Abrahams). Она же легла в основу многих более дружественных к пользователю решений. Основная идея MPL — позволить разработчику оперировать с коллекциями типов так же, как с обычными. В библиотеке реализованы, собственно, коллекции разного вида (списки, массивы, наборы и т. п.), операции над ними и различные метафункции. Если серьёзно забираться в метапрограммирование — boost.mpl сильно упрощает жизнь, поскольку в ней уже реализован весь тот инструментарий, который так или иначе пришлось бы писать вручную. Но, с другой стороны, дизайн библиотеки таков, что с привычными обычному C++-разработчику императивными и объектно-ориентированными взглядами, разобраться в boost.mpl будет непросто.
Потом появился [boost.fusion](https://www.boost.org/doc/libs/1_69_0/libs/fusion/doc/html/), или «кортежи на стероидах» за авторством Джоэля де Гузмана (Joel de Guzman), Дэна Марсдена (Dan Marsden) и Тобиаса Швингера (Tobias Schwinger). Библиотека, по дизайну напоминающая одновременно MPL и STL, является этаким мостиком между миром компайл-тайма и рантайма. Позволяя создавать (или описывать) сложные кортежи типов (или пар «тип-значение») с одной стороны, она предоставляет алгоритмы манипуляции с этими кортежами в рантайме с другой. Например:
```
vector stuff(1, 'x', "howdy");
struct print\_xml
{
template
void operator()(T const& x) const
{
std::cout
<< '<' << typeid(x).name() << '>'
<< x
<< "'
;
}
};
for\_each(stuff, print\_xml());
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
А последние пару лет набирает популярность [boost.hana](https://www.boost.org/doc/libs/1_69_0/libs/hana/doc/html/index.html). Это boost.fusion, но с constexpr'ом и лямбдами. Автор hana, Луис Дионе (Louis Dionne), используя на полную мощь все возможности новых стандартов, в некотором смысле очеловечил метапрограммирование. С помощью hana всяческие манипуляции с типами, их кортежами, отображениями, а также компайл- и рантайм-работа с ними обрели практически человеческое лицо и читаемый вид. Ну, с поправкой на синтаксис C++, разумеется. Вот, например, как выглядит универсальный сериализатор структур, написанный с помощью hana:
```
// 1. Give introspection capabilities to 'Person'
struct Person {
BOOST_HANA_DEFINE_STRUCT(Person,
(std::string, name),
(int, age)
);
};
// 2. Write a generic serializer (bear with std::ostream for the example)
auto serialize = [](std::ostream& os, auto const& object) {
hana::for_each(hana::members(object), [&](auto member) {
os << member << std::endl;
});
};
// 3. Use it
Person john{"John", 30};
serialize(std::cout, john);
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
Ну да, структуры приходится описывать особым образом. А кому сейчас легко? И тут хочется также отметить библиотеку [tinyrefl](https://github.com/Manu343726/tinyrefl) за авторством Manu Sánchez (Мануэля Санчеса). Довольно неплохая попытка принести в мир C++-разработки статическую рефлексию без расширения компилятора. Для своей работы библиотека требует стороннюю утилиту ([cppast](https://github.com/foonathan/cppast)), но зато предоставляет довольно удобный доступ к информации о структурах, которую можно использовать в процессе разработки программы. Преимущество этой библиотеки (по сравнению с другими) в том, что для работы с ней не надо использовать «птичий язык», а элементы структур (как и сами структуры) можно произвольным образом атрибутировать прямо в исходном коде:
```
struct [[serializable]] Person {
std::string name;
int age;
};
template
auto serialize(std::ostream& os, Class&& object) -> std::enable\_if\_t<
tinyrefl::has\_metadata>() &&
tinyrefl::has\_attribute>("interesting"),
std::ostream&>
{
tinyrefl::visit\_member\_variables(object, [&os](const auto& /\* name \*/, const auto& var) {
os << var << std::endl;
});
return equal;
}
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
Таких примеров можно привести ещё много (или найти на гитхабе или гитлабе). Объединяет все эти библиотеки и инструменты одна особенность: значительно облегчая жизнь своим пользователям, они имеют такую реализацию, что остаётся лишь предполагать, какое количество страданий испытали их разработчики. Достаточно заглянуть в реализацию, увидеть забор из ifdef'ов и угловых скобок — и всё понятно. Нередко эти реализации делаются на грани возможностей компиляторов. workaround'ы банальных ошибок (или особенностей реализации языка конкретной версии конкретного компилятора с конкретными флагами) здорово раздувают их код. Желание поддерживать несколько стандартов сразу заставляет придумывать зубодробильные конструкции. Безусловно, простая попытка реализовать что-нибудь подобное здорово поднимает уровень владения языком (иногда — и самооценку). Но в какой-то момент, после многочасовой возни с очередной ошибкой, или непроходящим тестом, или крэшем компилятора руки опускаются, хочется плюнуть и бросить, ибо силы бороться иссякают.
1.4 Генерация кода
Но это, как говаривал Барон, ещё не все. Однажды в мир разработки C++ пришёл clang со своим фронтендом (а чуть позже — с libtooling), и мир изменился, заиграл новыми красками. Появилась надежда. Ибо появился инструмент, позволяющий относительно просто (относительно!) анализировать исходные тексты на C++ и что-нибудь с результатами этого анализа делать. Появились (и стали набирать популярность) утилиты типа clang tidy, clang format, clang static analyser и прочие. А некоторые разработчики приспособили clang frontend для решения задач рефлексии. Так, скажем, работают упомянутые выше cppast (за авторством Jonathan Müller) и tinyrefl на её базе. Так работает автопрограммист, используемый в нашей компании для кодогенерации (или его [open-source-аналог](https://github.com/flexferrum/autoprogrammer)).
**Разумеется, и до появления clang писались генераторы на основе исходного кода C++. Кто-то использовал для этого Python с самописными парсерами, кто-то разбирал C++ с помощью regexp'ов. Кто-то, как автор этой статьи, писал самопальный парсер на C++. Но, полагаю, с развитием инструментария это будет уходить в прошлое.**
Идея проста. Берётся исходный текст на C++ (например, объявления структур), пропускается через clang frontend, и на основе полученного AST генерируется новый исходный текст. Например вот так:
```
out::BracedStreamScope flNs("\nnamespace flex_lib", "\n\n", 0);
hdrOs << out::new_line(1) << flNs;
for (reflection::EnumInfoPtr enumInfo : enums)
{
auto scopedParams = MakeScopedParams(hdrOs, enumInfo);
{
hdrOs << out::new_line(1) << "template<>";
out::BracedStreamScope body("inline const char* Enum2String($enumFullQualifiedName$ e)", "\n");
hdrOs << out::new_line(1) << body;
hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);";
}
{
hdrOs << out::new_line(1) << "template<>";
out::BracedStreamScope body("inline $enumFullQualifiedName$ String2Enum<$enumFullQualifiedName$>(const char* itemName)", "\n");
hdrOs << out::new_line(1) << body;
hdrOs << out::new_line(1) << "return $namespaceQual$::StringTo$enumName$(itemName);";
}
}
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
См. [GitHub](https://github.com/AndreyBronin/autoprogrammer/blob/39e0ece1e91e81def0e9c157fdab386439d352f1/src/generators/enum2string_generator.cpp#L106).
Можно отобразить отрефлексированный AST внутрь какого-нибудь движка текстовых шаблонов, например на базе Jinja2, и получить возможность писать генерируемые c++/h-файлы в виде относительно простых текстовых шаблонов:
```
inline const char* {{enumName}}ToString({{scopedName}} e)
{
switch (e)
{
{% for itemName in enum.items | map(attribute="itemName") | sort%}
case {{prefix}}{{itemName}}:
return "{{itemName}}";
{% endfor %}
}
return "Unknown Item";
}
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
См. [GitHub](https://github.com/flexferrum/autoprogrammer/blob/db902121dd492a2df2b7287e0dafd7173062bcc7/src/generators/enum2string_generator.cpp#L38).
Подход с текстовым шаблонизатором особенно хорош тем, что позволяет отделить собственно шаблоны, по которым генерируются файлы, от средства генерации. Кроме того, он позволяет работать со структурой отрефлексированного текста в императивном стиле, привычном большинству разработчиков на C++. Таким образом, например, в последнем проекте, над которым я работаю, из нескольких заголовочных файлов с объявлениями конфигурационных структур генерируются (в процессе сборки) сериализаторы, валидаторы, отображения структур на RPC-сущности. Разработчику достаточно лишь написать с помощью Jinja2-нотации шаблон нужного файла и добавить пару инструкций в cmake-файл.
Знание всех этих приёмов и техник хорошо и полезно. И чем опытнее C++-разработчик, чем лучше он знает, как облегчить себе жизнь, и тем более сложные вещи он может создавать. Но всё это не отменяет как высокую сложность, так и высокий порог входа в эту сферу разработки на C++. И страданий (иногда вполне реальных), которые можно испытывать при написании такого вот кода.
2. Существует причина: сложные абстракции
У этих страданий существует причина. Это желание. Желание манипулировать в процессе разработки сложными абстракциями и делать это удобно и эффективно. Простое и логичное, в общем, желание. В разработке и проектировании существует принцип DRY: Don't Repeat Yourself. Парадигмы C++ позволяют многое обобщать. Но (как можно увидеть выше) с определённого уровня всё становится очень сложно, и возникает вопрос цены такого обобщения для конкретной команды или разработчика. Всё хорошо, пока задача укладывается в классическое ООП, но вот когда требуется более сложное обобщение — на уровне классов, групп типов и прочее... В более молодых языках (Java, C#, Python и т. п.) есть встроенная рефлексия и она помогает. В C++ же, увы, рефлексия пока только на уровне пропозала и технической спецификации.
 Типы конфликтов и страданий в литературе
2.1 Тривиальные задачи
Вот, скажем, один из самых популярных примеров. Можно сказать, классических. Сериализуются данные в, скажем, json. В структуре есть enum-поле, которое хочется сохранять в текстовом виде (а не числом). Всё. Стоп. Простого способа решить эту элементарную задачу на C++ не существует. Предлагаемые варианты решения — от описания enum'ов с помощью макросов, как в примере выше про boost.hana, до perl-скриптов для парсинга C++-исходников и генерации нужных функций. Магия на define'ах, магия на шаблонах, магия на скриптах, кодогенераторы — для решения задачи, которая (по всякому разумению) должна решаться средствами «из коробки». Вместо этого, как Лев Николаевич, строчка за строчкой, том за томом выводишь что-то на смеси C++ и препроцессора и страдаешь:
```
#define FL_MAKE_STRING_ENUM_NAME(Entry) Entry
#define FL_MAKE_WSTRING_ENUM_NAME(Entry) L ## Entry
#define FL_DECLARE_ENUM2STRING_ENTRY_IMPL(STRING_EXPANDER, EntryId, EntryName) \
case EntryId: \
result = STRING_EXPANDER(EntryName); \
break;
#define FL_DECLARE_STRING2ENUM_ENTRY_IMPL(STRING_EXPANDER, EntryId, EntryName) result[STRING_EXPANDER(EntryName)] = EntryId;
#define FL_DECLARE_ENUM2STRING_ENTRY(_, STRING_EXPANDER, Entry) FL_DECLARE_ENUM2STRING_ENTRY_IMPL(STRING_EXPANDER, BOOST_PP_TUPLE_ELEM(3, 0, Entry), BOOST_PP_TUPLE_ELEM(3, 2, Entry))
#define FL_DECLARE_STRING2ENUM_ENTRY(_, STRING_EXPANDER, Entry) FL_DECLARE_STRING2ENUM_ENTRY_IMPL(STRING_EXPANDER, BOOST_PP_TUPLE_ELEM(3, 0, Entry), BOOST_PP_TUPLE_ELEM(3, 2, Entry))
#define FL_DECLARE_ENUM_STRINGS(EnumName, MACRO_NAME, S) \
inline EnumName ## _StringMap_CharType const* EnumName##ToString(EnumName e) \
{ \
EnumName ## _StringMap_CharType const* result = NULL; \
switch (e) \
{ \
BOOST_PP_SEQ_FOR_EACH(FL_DECLARE_ENUM2STRING_ENTRY, MACRO_NAME, S) \
} \
\
return result; \
}
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
См. [GitHub](https://github.com/flexferrum/flex_lib/blob/ad361703e19c5ab84182f91040da4845bcd349bd/include/flex_lib/stringized_enum.h#L63).
**На StackOverflow я как-то находил примерно шестнадцать вопросов на эту тему. Полагаю, сейчас их больше.**
Да и собственно любая попытка в общем виде реализовать ту же сериализацию (ну так, чтобы универсально и без лишней магии) — хоть в json, хоть в бинарный поток, хоть в базу данных — очень быстро закончится танцами с макросами, шаблонами, специальными компиляторами (как у protobuf, скажем) и всё это с массой условностей и под аккомпанемент шаманского бубна. Ну нельзя в C++ (по крайней мере пока) взять произвольный тип и забраться к нему в потроха.
2.2 Паттерны
Знаменитая книжка GoF про паттерны сопровождается множеством примеров на C++. Примеры простые, аккуратные, иллюстративные. Для каждого паттерна. И только читавшие Александреску понимают, как на самом деле реализуются относительно несложные архитектурные концепции на C++. Вот тот же паттерн Visitor («Посетитель»). Иначе как: «Господа, я пришёл сообщить вам пренеприятнейшее известие: нам надо реализовать обобщённый Visitor» про него и не скажешь. И если с динамическими визиторами для закрытых иерархий типов всё ещё более-менее ничего ([здесь](https://github.com/dutor/loki/blob/master/Reference/Visitor.h) можно посмотреть классическую реализацию), то вот со статическими...
Разработчики вариантных типов обычно заморачиваются, делая интерфейс максимально удобным для пользователя. Чаще всего достаточно объявить класс с перечнем методов для нужных типов, как-то так:
```
struct ObjectInjector : boost::static_visitor<>
{
public:
ObjectInjector(ClassInfoPtr targetClass, reflection::AccessType accessType)
: m_target(targetClass)
, m_accessType(accessType)
{
}
void operator()(MethodInfoPtr method) const
{
auto m = std::make_shared(\*method);
if (m\_accessType != reflection::AccessType::Undefined)
{
m->accessType = m\_accessType;
}
m\_target->methods.push\_back(m);
}
template
void operator()(U) const
{
}
private:
ClassInfoPtr m\_target;
reflection::AccessType m\_accessType;
};
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
Cм. [GitHub](https://github.com/flexferrum/autoprogrammer/blob/db902121dd492a2df2b7287e0dafd7173062bcc7/src/generators/metaclasses/cpp_interpreter_impl.cpp#L516).
И вызвать метод, применяющий такой визитор к конкретному экземпляру варианта:
```
boost::apply_visitor(ObjectInjector(targetClass, ConvertVisibility(visibility)), obj.GetValue());
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
Но вот если заглянуть [под капот](https://github.com/mpark/variant/blob/99ef8fb19f5ea5f229587da3dd425a7d24c4fd80/include/mpark/variant.hpp#L498) реализации, всё становится значительно интереснее и мрачнее. Рука сама тянется к топору, а глаза ищут ту процентщицу, что ссудила несколько книжек по C++ в счёт будущей зарплаты, говоря, что это — именно то, что надо для старта! Фарш из макросов и шаблонов на несколько сот строчек при желании написать обобщённую реализацию с поддержкой n-арной диспетчеризации — это именно то, что нужно для простого в сущности типа. Ну да, нет статической рефлексии. Нет возможности легко покопаться в свойствах типов и функций, размножить нужный кусок кода. Вот и приходится — либо как по ссылке выше, либо с использованием той же Jinja:
```
template
static R apply(const Visitor& v, const V1& arg)
{
switch( arg.index() )
{
{% for n in range(NumParams) -%}
case {{n}}: return apply\_visitor<{{n}}>(v, arg);
{% endfor %}
default: return R();
}
}
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
См. [GitHub](https://github.com/martinmoene/variant-lite/blob/cfb931ed83a51151be282b1398e5e112a94e28ba/template/variant.hpp#L1732).
Тут надо отметить, что паттерн «мультиметод» — это отдельная головная боль. [Референсная реализация](https://github.com/dutor/loki/blob/master/Reference/MultiMethods.h) от Александреску занимает 416 строк. Реализация «[в полный рост](https://github.com/qraizer/Multimethods/blob/master/Visitor/mmethod.h)» с поддержкой нескольких стандартов, n-aрной диспетчеризации — уже 719 при сопоставимом объёме комментариев. И, что важно, сходу, имея лишь общие представления о возможностях метапрограммирования в C++, такое не напишешь. Локальные классы, шаблоны шаблонов, шаблоны-члены классов и прочий весьма специфичный инструментарий — это то, с чем придётся познакомиться довольно быстро.
И так — с любой более-менее сложной обобщённой концепцией или паттерном. Стоит ступить чуть дальше простого наследования (или простых шаблонов), попытаться обобщить чуть больше — наступают боль и страдания. К счастью, финал этой истории не так мрачен, как у большинства произведений русских классиков, и луч света в этом царстве чёрной магии и шаманства хорошо различим. И луч этот — метаклассы.
3. Выход есть: метаклассы
Недавно на выставке GPU Technology Conference 2019 nVidia показала интересный инструмент для «начинающих художников». Человек рисует нечто разноцветно-абстрактное на виртуальном холсте, а программа делает (в реальном времени) из этого рисунка пейзаж. Теперь даже не надо смотреть видео-уроки Боба Росса: мазок коричневым тут, линия синим там, и вот на экране — реки, поля, горы, водопады... Полагаю, с таким инструментом Остап не спрашивал бы у Кисы: «Вы рисовать умеете?» Впрочем, нет. Сеятеля ему бы пришлось всё равно рисовать самому. Слышал, что нечто подобное сделали для верстальщиков. Инструмент, который по дизайн-макету делает готовую вёрстку в html. К счастью, для программистов ничего подобного, на специально и глубоко обученных нейросетях, не придумали. Пока. Зато придумали кое-что другое.
 Типы конфликтов и страданий в литературе
3.1 Основы концепции
Макросы (C++), шаблоны (C++98), свойства типов и constexpr'ы (C++11), концепты (C++20) — с каждым новым стандартом и витком развития язык предоставляет разработчику всё больше информации о том, что творится в недрах компилятора: начиная от манипуляции на уровне лексем и заканчивая compile-time-вычислениями и декларативным описанием свойств пользовательских типов. Логичное завершение (или продолжение?) этой цепочки — предоставление разработчику возможности напрямую манипулировать процессом компиляции кода на уровне AST. И такое предложение уже есть.
**Это может выглядеть забавно, но сейчас уже заходит речь об интеграции в компилятор оптимизирующих JIT-движков. Потому как constexpr'ы как-то [медленно вычисляются](https://twitter.com/hankadusikova/status/1115351646178029568)...**
Метаклассы. Новая для C++ сущность. Новые возможности. И, разумеется, новые способы отстрелить себе ноги аж по шею, если переборщить. Тем не менее, презентация Саттера, посвящённая этой концепции, сделанная два года назад на ACCU 2017, произвела фурор. Из головы не выходила мысль: «Shut up and take my money!» Ибо слишком много проблем разом снимает этот подход, суть которого проста: пишется специального вида функция (называемая «метаклассом»), которая в compile-time позволяет управлять процессом компиляции кода для конкретного пользовательского типа. Например:
```
constexpr void interface(meta::type target, const meta::type source) { // 1
compiler.require(source.variables().empty(), "interfaces may not contain data"); // 2
for (auto f : source.functions()) { // 3
compiler.require(!f.is_copy() && !f.is_move(), "interfaces may not copy or move; consider a virtual clone() instead"); // 3.1
if (!f.has_access()) // 3.2
f.make_public();
compiler.require(f.is_public(), "interface functions must be public"); // 3.3
f.make_pure_virtual(); // 3.4
->(target) f; // 3.5
}
->(target) { virtual ~(source.name()$)() noexcept {} } // 4
}
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
См. [pdf](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/p0707r3.pdf).
Что делает эта функция-метакласс:
1. Берёт декларацию типа, к которому этот метакласс применили (параметр source).
2. Проверяет, что декларация не содержит переменных и, если содержит, генерирует ошибку.
3. Для каждой функции, объявленной в декларации source выполняет следующее:
1. Проверяет, что это не copy/move-конструктор (иначе — ошибка).
2. Для функций без явного заданного спецификатора видимости задаёт его как 'public'.
3. Проверяет, что функция — не private или protected.
4. Делает функцию pure virtual.
5. Добавляет её в генерируему декларацию (target).
4. Добавляет виртуальный деструктор.
И теперь, будучи применённой, скажем, таким вот образом к реальной декларации в коде:
```
interface Shape {
int area() const;
void scale_by(double factor);
};
или, альтернативный вариант:
class(interface) Shape {
int area() const;
void scale_by(double factor);
};
('interface' здесь - это название метакласса) внутри компилятора создаст декларацию:
class Shape {
public:
virtual ~Shape() {}
virtual int area() const = 0;
virtual void scale_by(double factor) = 0;
};
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
Что, собственно, произошло? Не ошибусь, если скажу, что в каждой компании, в которой есть CSG, и в которой в архитектуре ПО используются интерфейсы, в этом самом coding style guide есть раздел примерно следующего содержания:
1. Все функции интерфейсного класса должны быть pure virtual и public.
2. В интерфейсном классе не должно быть членов данных.
3. Деструктор интерфейсного класса должен быть явно объявлен и должен быть виртуальным.
Кроме того, в этом же CSG наверняка будут пункты в стиле «Явное лучше неявного» и «То, что может быть проверено на этапе компиляции, должно быть проверено» (если таких пунктов в вашем CSG нет, то их определённо стоит туда добавить). Так вот. Если посмотреть на пример метакласса **interface** — то легко заметить, что какой-то десяток строк немножко странного кода выбивает пять из пяти этих пунктов. Кроме того, архитектурная концепция (в данном случае «интерфейс») явным образом фиксируется, а её свойства — энфорсятся на уровне компилятора. Теперь разработчик совершенно точно не «забудет» добавить виртуальный деструктор (ну кто хотя бы раз не наступал на эти грабли?), все интерфейсы обладают общими свойствами, для модификации/дополнения этих свойств достаточно изменить всего лишь одно объявление. Объявление метакласса. Ну не чудеса ли? Итак, метаклассы:
* Позволяют фиксировать умолчания («должен быть виртуальный деструктор» и «все методы должны быть public pure virtual);
* Позволяют изменять структуру исходной декларации, добавляя/модифицируя/удаляя её элементы («добавить виртуальный деструктор», "сделать метод pure virtual);
* Позволяют не просто проверять, но накладывать и фиксировать ограничения на пользовательские типы (проверка на отсутствие переменных, проверка на отсутствие непубличных методов и т. п.).
До сих пор ни один элемент языка C++ (или их комбинация) не позволял всего этого в комплексе. Ровно как до сих пор ни один элемент языка не позволял напрямую вмешиваться в процесс интерпретации компилятором деклараций, а также в процесс их «дописывания». Но возможным это станет при соблюдении двух условий: а) появления в языке статической рефлексии и б) реализации механизмов code injection/code generation. И то, и другое — дело пусть и не отдалённого, но будущего. Как и сам пропозал по метаклассам за авторством Герба Саттера.
3.2 Статическая рефлексия
То, что давно есть в других мейнстримовых языках (рефлексия) в C++ до сих пор приходится тем или иным образом эмулировать (см. примеры в первом разделе). Добавленные в одиннадцатый стандарт свойства типов — штука полезная, но с точки зрения рефлексии не более, чем паллиатив. Обойти поля структуры? Элементы перечисления? Параметры функции? Декларации в namespace'е? Всё это недоступно. И вот, каждый пилит себе эрзац этой самой рефлексии под ехидные замечания в стиле: «Пилите, Шура, пилите...» И пилят. А в комитете тем временем пилят техническую спецификацию под названием «C++ Extensions for Reflection» Последняя редакция носит номер [N4766](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/n4766.pdf). Хороший документ, интересный. Его автор (David Sankel) предлагает ввести новый оператор '**reflexpr**(...)', результатом применения которого будет нечто шаблонное, зависящее от аргумента, но обязательно содержащее отрефлексированную информацию об этом аргументе. Например:
```
template std::string get\_type\_name() {
namespace reflect = std::experimental::reflect;
// Для шаблонного параметра reflexpr вернёт типа reflect::Alias с информацией об алиасе некоего типа:
using T\_t = reflexpr(T);
// Теперь мы получаем информацию об оригинальном типе, с которым инстанцировали get\_type\_name:
using aliased\_T\_t = reflect::get\_aliased\_t;
// Ну и получаем имя этого типа
return reflect::get\_name\_v;
}
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
Пример (взятый из N4766) несколько искусственный (то же самое в две строчки делается через typeid), но хорошо демонстрирует идею, саму возможность на этапе компиляции получать и анализировать всю доступную информацию о типах, их структуре и свойствах. А дальше — наворачивать поверх собственную логику (как в примере с интерфейсом): обойти все функции, члены данных, проверить спецификатор доступа, обойти базовые классы, и так далее. Собственно, именно то, что так давно хотелось. Появится ли это в двадцать третьем стандарте, или позже — вопрос пока открытый. Но работа идёт, и эта работа над тем, чего так давно хотелось иметь в языке (ну, после концептов и модулей, разумеется).
**К сожалению, пропозал Саттера по метаклассам (я в качестве референсного использую [p0707 rev. 3](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/p0707r3.pdf)) базируется немного на другом подходе к статической рефлексии. Одном из альтернативных, описанном в [p0712](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2017/p0712r0.pdf). Разумеется, когда дело дойдёт до серьёзного обсуждения уже на уровне технической спецификации, одно придёт в соответствие с другим.**
В отличие от **reflexpr** из N4766, Саттер использует следующие операторы:
**$...** — для получения информации (точнее, метаинформации) о той или иной сущности периода компиляции. Например, $std вернёт коллекцию с информацией о всех декларациях в неймспейсе std.
**...$** — для обратного преобразования. Например, f.name()$, встреченное в коде, компилятор должен заменить на результат вызова (в compile-time) f.name(), то есть на некий идентификатор.
Приведённый выше пример в нотации Саттера выглядел бы так:
```
template std::string get\_type\_name() {
auto T\_t = $T;
return T\_t.name();
}
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
Насколько я смог понять, у комитета к этой нотации возникли вопросы (относительно использования символа '$'), и Саттеру предложили рассмотреть какие-то другие варианты.
3.3 Code injection
Зачастую недостаточно просто понять, как устроен тот или иной пользовательский тип. Необходимо иметь возможность его модифицировать, иначе метаклассы потеряют добрую половину своей прелести. Традиционно этот механизм называется code injection, и в C++ пока только один пропозал по реализации этого механизма: [p0712](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2017/p0712r0.pdf). Суть подхода довольно проста. У оператора «->» появляется новый контекст использования, который позволяет в compile-time внедрять в код (на самом деле, в дерево разбора) новые элементы. Например, так:
```
->(target) {virtual ~(source.name()$)() noexcept {} }
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
Здесь в сущность target (которая отображена на создаваемый экземпляр метакласса) внедряется виртуальный деструктор, имя которого совпадает с именем этой самой сущности. Более сложный вариант:
```
template // constrained to enum types
std::string to\_string(E e) {
switch (value) {
constexpr {
for (const auto o : $E.variables())
if (!o.default\_value.empty())
-> { case o.default\_value()$: return std::string(o.name()$); }
}
}
}
```
$(document).ready(function(){
hljs.initHighlightingOnLoad();
});
.t264 .hljs {
background-color: ;
}
См. [pdf](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/p0707r3.pdf).
Именно так может выглядеть метод, преобразующий значение некоего enum'а в строку. Конструкция constexpr в четвёртой строчке обозначает, что блок должен выполниться в compile-time. И этот блок, на самом деле, генерирует тело оператора switch (весь нужный набор case'ов) с помощью выполняемого на этапе компиляции цикла for. Пусть и выглядит довольно необычно, но это всяко гораздо лучше привлечения сторонних утилит или игр с макросами.
Основная сложность всего этого механизма (для реализации в компиляторе) — это смесь конструкций и их контекстов. В примере с to\_string для enum'а компилятор «должен понимать», что ключевое слово case имеет право появляется внутри такого вот блока. А в примере с генерацией деструктора — что этот самый деструктор (или что-то на него похожее) может быть объявлен вне контекста класса. Грамматика C++ окончательно становится контекстно-зависимой — к чему, впрочем, все потихоньку привыкают. В конце концов, нам, разработчикам на C++ шашечки или ехать? Ну а страдания разработчиков компиляторов — кому они интересны?
Сергей Садовников @[FlexFerrum](https://habr.com/users/FlexFerrum/) / «Лаборатория Касперского» Автор – архитектор и разработчик ПО с опытом работы более 25 лет. Сейчас занимается IoT Security [в «Лаборатории Касперского»](https://u.tmtm.ru/Kaspersky_Sadovnikov_04_2019_final). Активно интересуется вопросами разработки библиотек общего назначения, ведет самостоятельные проекты в области автогенерации кода (на базе C++). О своих страданиях рассказал накануне конференции C++ Russia, на которой как раз собирается поделиться тем, как можно избавиться от этих страданий и достичь просветления. Все решения, которые Сергей озвучит на C++ Russia, будут опубликованы в блоге его родной компании.
var t531\_doResize;
$(window).resize(function(){
if (t531\_doResize) clearTimeout(t531\_doResize);
t531\_doResize = setTimeout(function() {
t531\_setHeight('100236854');
}, 200);
});
$(document).ready(function() {
t531\_setHeight('100236854');
});
|
https://habr.com/ru/post/448466/
| null |
ru
| null |
# Что нового в Apache Spark 3.2.0 — RocksDB state store
Это важное событие для всех пользователей Apache Spark Structured Streaming. RocksDB теперь доступен как state store бэкенд, поддерживаемый ванильным Spark!
### Инициализация
Чтобы начать использовать хранилище состояний (state store) RocksDB, вы должны явно определить класс провайдера в конфигурации Apache Spark: `.config("spark.sql.streaming.stateStore.providerClass", "org.apache.spark.sql.execution.streaming.state.RocksDBStateStoreProvider")`. Позже метод createAndInit объекта-компаньона StateStore инициализирует инстанс провайдера и вызовет метод `init` в RocksDBStateStoreProvider, где провайдер:
* запоминает схемы ключа и значения состояния
* создает соответствующий **RocksDBStateEncoder** - в настоящее время есть два энкодера: **PrefixKeyScanStateEncoder** и **NoPrefixKeyStateEncoder.**Почему два? Потому что Apache Spark 3.2.0 принес нам еще одну интересную фичу, называемую *сканированием префиксов* (*prefix scan*)*,* которая оптимизирует сканирование определенного диапазона ключей (подробнее об этом я напишу через пару недель). Эта функция не является обязательной, и только один из энкодеров поддерживает ее. Присутствует поддержка этой фичи или отсутствует - зависит от формата хранения ключа. NoPrefixKeyStateEncoder хранит ключ целиком, в то время как PrefixKeyScanStateEncoder разделяет ключ на две части: префикс и остальную часть. Этот формат также хранит длину префикса ключа, а длину остальной части - нет, поскольку она динамически генерируется при десериализации из результата `keyBytes.length - 4 - prefixKeyEncodedLen`.
* возвращает лениво создаваемый инстанс базы данных RocksDB; фактически он будет создан после первого вызова.
Что касается инициализации - на этом пока все. Но гораздо больше всего интересного произойдет позже, когда Apache Spark наконец задействует хранилище состояний в операции, фиксирующей состояние.
### Операции CRUD (Create, Read, Update, Delete)
Хранилище состояний RocksDB использует тот же API чтения-записи, что и версия с поддержкой HDFS. Вначале с помощью метода `load(version: Long)` загружается соответствующая версия хранилища. Версия соответствует порядковому номеру последнего микробатча, и функция начинается со сравнения версии для загрузки актуальной версии приложения. Если они разные, это означает, что контекст выполнения, вероятно, затрагивает репроцессинг, и локальной информации нет. Следовательно, хранилище состояний восстановит базу данных из контрольной точки с помощью **RocksDBFileManager**. Поскольку я раскрою тему восстановления в последнем разделе, давайте перейдем непосредственно к чтению/записи.
По вполне понятным причинам, для их выполнения Apache Spark задействует RocksDB API. В описании хранилища состояний вы можете найти такие классы RocksDB как:
**ReadOptions** - использует все параметры по умолчанию для чтения данных из инстанса RocksDB. Это может стать для вас сюрпризом, но Apache Spark использует его не только при возврате состояний вызывающей стороне, но и при их записи в методах put и remove. Зачем? Для отслеживания количества ключей в данной версии. Таким образом, операция put увеличивает счетчик, а операция remove его уменьшает:
```
def put(key: Array[Byte], value: Array[Byte]): Array[Byte] = {
val oldValue = writeBatch.getFromBatchAndDB(db, readOptions, key)
writeBatch.put(key, value)
if (oldValue == null) {
numKeysOnWritingVersion += 1
}
oldValue
}
def remove(key: Array[Byte]): Array[Byte] = {
val value = writeBatch.getFromBatchAndDB(db, readOptions, key)
if (value != null) {
writeBatch.remove(key)
numKeysOnWritingVersion -= 1
}
value
}
```
* **WriteOptions** - устанавливает значение флага *sync* в true, что означает, что должна быть произведена запись на диск (flush) из буферного кэша ОС перед тем, как операция записи будет считаться завершенной. Это замедляет процесс записи, но гарантирует отсутствие потери данных в случае отказа машины. Apache Spark использует его в коммите в хранилище состояний.
* **FlushOptions** - позволяет *waitForFlush* блокировать операцию flush, пока он не будет уничтожен. Также используется в коммите в хранилище состояний.
* **WriteBatchWithIndex** - сконфигурирован с включенным *overwriteKey* для замены любых существующих ключей в базе данных. Это интерфейс записи для RocksDB, но, поскольку он допускает возможность поиска (searchable), он также участвует в операциях получения данных, включая упомянутые выше в контексте записи.
* **BloomFilter** - используется как *политика фильтрации* (*filter policy*) для уменьшения количества операций чтения с диска при поиске ключей.
Если сравнивать с хранилищем состояний по умолчанию, реализация с RocksDB очень похожа в плане CRUD операций. За исключением одной важной разницы. Напомним, что операция удаления в дефолтном хранилище состояний реализуется через контрольные точки (checkpoints) и *delta*-файл. В RocksDB это работает не так - состояние просто удаляется из базы данных. Разница также есть в элементах, для которых создаются контрольные точки, представленных чуть ниже.
### Хранилище
На следующей схеме вы можете увидеть файлы, которыми оперирует хранилище состояний RocksDB:
В ней есть два “пространства”. В самой левой части хранятся все файлы, используемые действующим инстансом базы данных RocksDB. В рабочем каталоге (working directory) находятся файлы данных инстанса, SSTables и журналы. Пространство контрольных точек (checkpoint) - это каталог, созданный Apache Spark при коммите версии актуального микробатча (см. ниже). В нем хранятся все файлы, для которых будут создаваться контрольные точки. Наконец, пространство файлового менеджера (file manager) - это каталог, зарезервированный для активности **RocksDBFileManage**. Менеджер использует его в основном на этапе клинапа для хранения несжатого содержимого файлов, для которых создаются контрольные точки.
Что касается пространства контрольных точек, то вы найдете там файлы RocksDB (журналы, SST, каталог архивных журналов), некоторые метаданные со схемой хранилища состояний и zip-файлы, в которых хранятся другие файлы, необходимые для процесса восстановления, такие как параметры RocksDB или сопоставление между файлами, для которых создаются контрольные точки, и их локальными именами.
### Отказоустойчивость
Коммит из state store API запускается после обработки всех входных строк для нужной партиции, чтобы материализовать хранилище состояний до версии актуального микробатча. В RocksDB эта операция включает следующие этапы:
* создание пустого и временного каталогов контрольных точек в пространстве RocksDB
* запись всех обновлений версии в базу данных RocksDB - этот шаг вызывает метод write из RocksDB API. Но погодите-ка минутку, CRUD-часть использует функции вставки и удаления из API. В чем тогда разница? Хранилище состояний использует режим *Write Batch With Index, в* котором операции записи сериализуются в WriteBatch вместо того, чтобы воздействовать непосредственно на базу данных. Вызов операции записи гарантирует их атомарность записи в базу данных.
* запись на диск (flushing) всех данных из памяти - записи сначала попадают в структуру памяти, называемую *memtable*. Когда memtable заполняется, RocksDB записывает ее содержимое в *sstfile*’ы, хранящиеся на диске. Благодаря этому процесс создания контрольной точки покроет весь датасет.
* сжатие хранилища состояний, если оно включено - этот процесс состоит из очищения от удаленных или перезаписанных привязок “ключ-значение” в целях организации данных для повышения эффективности запросов. Он также объединяет небольшие файлы с записанными данными в более крупные.
* остановка всех текущих фоновых операций, чтобы избежать несогласованности файлов во время фиксации из-за одновременных действий с одними и теми же файлами,
* создание контрольной точки (*checkpoint*) RocksDB - это встроенная возможность RocksDB для создания моментального снапшота запущенного инстанса в отдельном каталоге. Если контрольная точка и база данных используют одну и ту же файловую систему, как в нашем случае с Apache Spark, контрольная точка будет создавать только жесткие ссылки на SSTable-файлы базы данных.
* инстанс **RocksDBFileManager** принимает все файлы контрольных точек и копирует их в пространство контрольных точек. В этом копировании есть несколько хитрых моментов. Для начала, есть два типа файлов: не архивируемые и архивируемые. Первая категория касается архивных *log* и актуальных *sst*-файлов. Процесс создания контрольных точек копирует только их в пространство контрольных точек. Отсюда следует еще один интересный факт. RocksDB может повторно использовать файлы sst из предыдущего микробатча. Когда это происходит и эти файлы совпадают с уже скопированными, процесс создания контрольной точки не копирует их. Вместо этого она только будет ссылаться на них в файле метаданных, в котором перечислены все sst-файлы, относящиеся к данному микробатчу. Вы можете найти содержимое этого файла ниже:
```
v1
{"sstFiles":[{"localFileName":"000009.sst","dfsSstFileName":"000009-1295c3cd-c504-4c1b-8405-61e15cdd3841.sst","sizeBytes":1080}],"numKeys":2}
```
В дополнение к этим sst-файлам и журналам процесс создания контрольной точки принимает метаданные (MANIFEST, CURRENT, OPTIONS), файл журнала и вышеупомянутый файл метаданных, которым оперирует Spark, и сжимает их в один zip-архив. Краткую схему этого процесса можно посмотреть на схеме ниже:
Когда дело доходит до восстановления хранилища состояний в методе load, хранилище состояний RocksDB делегирует это действие **RocksDBFileManager**. Во время восстановления менеджер загружает заархивированный файл и распаковывает его в локальный рабочий каталог RocksDB. Позже он проходит по всем *sstFiles* из метаданных и возвращает их из пространства контрольной точки в каталог RocksDB. Стоит отметить, что все скопированные файлы хранятся локально с правильными именами, т.е. UUID-имя заменяется атрибутом *localFileName*.
После завершения этой операции копирования у Apache Spark будут все необходимые файлы для перезапуска предыдущего инстанса RocksDB. Это делается через ссылку на рабочий каталог в вызове инициализации: *NativeRocksDB.open(dbOptions, workingDir.toString)*.
RocksDB - интересная альтернатива дефолтной реализации хранилища состояний на основе кучи, оптимизированная для оперирования большим количеством состояний. Однако разобраться в ней немного сложнее, поскольку требуется понимание новых технологий. К счастью, как конечному пользователю, возможно, вам и не нужно знать все эти подробности, но если все-таки нужно, я надеюсь, что эта статья вам поможет!
---
Перевод подготовлен в преддверии старта курса [Spark Developer](https://otus.pw/wGLq/).
* [Узнать о курсе подробнее](https://otus.pw/wGLq/)
|
https://habr.com/ru/post/596765/
| null |
ru
| null |
# Tun2Socks: прокси-сервер в качестве шлюза, или VPN через прокси
1. [Что такое Tun2Socks](#about)
2. [Инструкция для Windows](#windows)
3. [Инструкция для Linux](#linux)
В бытовом случае в сетевых настройках вашего компьютера указан шлюз по умолчанию. Чаще всего устройство, являющееся шлюзом, называют "роутер" или "маршрутизатор" — через него идут все запросы на IP-адреса, которые не входят в вашу локальную сеть. Прокси-сервер (от англ. "уполномоченный" или "доверенный") также выступает посредником между вами и целевым сетевым ресурсом, но не является шлюзом по умолчанию, то есть для его использования в приложении нужно явно указать соответствующие параметры. Самый простой пример — доступ в сети I2P или Tor. Всю внутреннюю логику этих сетей обеспечивает отдельное приложение, которое предоставляет пользователю прокси-интерфейс для подключения. Указав нужный прокси в настройках веб-браузера, мы можем посещать сайты с доменными именами ".i2p" и ".onion", о которых обычный маршрутизатор даже не догадывается. Также прокси-сервисы набирают популярность для обхода блокировок: прописал в настройках браузера какой-нибудь прокси из либеральной страны и открываешь любые сайты, не зная духоскрепного маразма.
Современные прокси-серверы имеют исчерпывающий функционал для контроля и мониторинга трафика — хорошее решение для офисов и государственных учреждений, в которых нужно огородить работников от нежелательных ресурсов, а также предоставлять доступ в интернет с дополнительной авторизацией и различной пропускной способностью канала для разных пользователей.
Какой бы сценарий использования прокси у вас ни был, использовать шлюз по умолчанию в большинстве случаев удобнее. Хотя бы потому, что некоторые приложения не умеют работать через прокси.
Tun2Socks
---------
[Tun2Socks](https://github.com/xjasonlyu/tun2socks/) — свободный кроссплатформенный проект ([GPL-3.0](https://ru.wikipedia.org/wiki/GNU_General_Public_License)), написанный на Golang. Костяк команды разработчиков составляют китайцы. Приложение не имеет графической оболочки и конфигурируется незамысловатыми параметрами при запуске. Название Tun2Socks (Tunnel to SOCKS) трактуется как "туннель через SOCKS-прокси". Почему именно SOCKS, когда есть HTTP-прокси? Ответ прост: работать через HTTP-прокси Tun2Socks тоже умеет, но протокол HTTP не поддерживает передачу UDP-трафика. Через UDP идет большинство информации, доставка которой требует максимальной скорости (аудио- и видеозвонки, онлайн игры, а также DNS-запросы, разрешающие человекочитаемые имена сетевых ресурсов в IP-адреса). Поэтому поддержку UDP нельзя недооценивать.
Суть работы Tun2Socks сводится к созданию виртуального сетевого адаптера, который операционная система будет воспринимать как обычный сетевой интерфейс. Вся информация, пришедшая на такой виртуальный адаптер, фактически будет передана внутрь Tun2Socks, который обеспечит необходимую логику дальнейшей передачи информации на прокси-сервер.
Информация об использовании утилиты при запуске с параметром `--help`:
```
Usage of tun2socks:
-device string
Use this device [driver://]name
-fwmark int
Set firewall MARK (Linux only)
-interface string
Use network INTERFACE (Linux/MacOS only)
-loglevel string
Log level [debug|info|warn|error|silent] (default "info")
-mtu int
Set device maximum transmission unit (MTU)
-proxy string
Use this proxy [protocol://]host[:port]
-stats string
HTTP statistic server listen address
-token string
HTTP statistic server auth token
-udp-timeout int
Set timeout for each UDP session
-version
Show version information and quit
```
Всё может показаться ясным с первого взгляда только бывалому админу, либо тому, кто ничего на самом деле не понял. При практическом знакомстве с Tun2Socks встает вопрос: если в системе создастся виртуальный сетевой адаптер, то как он станет шлюзом по умолчанию и нужно ли вручную задавать ему адрес. На помощь приходит [документация](https://github.com/xjasonlyu/tun2socks/wiki).
Дублировать здесь официальное описание проекта и всю документацию не имеет смысла, поэтому перейдем к сути — к практической конфигурации шлюза с пояснением каждого шага.
Windows
-------
Для начала необходимо скачать свежую версию Tun2Socks. Бинарники распространяются на [странице релизов](https://github.com/xjasonlyu/tun2socks/releases) в официальном гит-репозитории проекта. Выберите один из пакетов, название которого начинается на `tun2socks-windows`. Если у вас 64-разрядная Windows на стареньком железе, вам наверняка подойдет `tun2socks-windows-amd64.zip` (так как архитектура ARM на старых машинах с Windows мне еще не встречалась).
После загрузки распакуйте архив в любое удобное место.
Tun2Socks создает виртуальный сетевой адаптер, но драйвер для этого (Wintun) нужно скачать отдельно. [Вот прямая ссылка](https://www.wintun.net/builds/wintun-0.11.zip) для загрузки версии Wintun 0.11. Рекомендую именно эту версию, так как с более новыми версиями в моем случае Tun2Socks v2.3.1 работать отказался. При желании, свежий релиз драйвера можно найти на официальной [странице](https://www.wintun.net/). Из всего архива вам понадобится только один файл `wintun.dll`, который надо взять из нужной директории в зависимости от вашей операционной системы. В случае архитектуры amd64, путь до нужной библиотеки выглядит так: `wintun/bin/amd64/wintun.dll`. Положите подходящий файл `wintun.dll` в директорию, где находится исполняемый файл Tun2Socks.
Tun2Socks запускается с передаваемыми значениями через командную строку (команды, приведенные ниже, должны быть выполнены с правами администратора). Команда для простого запуска имеет следующий вид:
```
tun2socks-windows-amd64.exe -device tun://gatewaytun -proxy socks5://10.10.100.1:1080
```
* `tun2socks-windows-amd64.exe` является именем исполняемого файла Tun2Socks;
* `-device tun://gatewaytun` определяет название нового виртуального сетевого интерфейса (gatewaytun);
* `-proxy socks5://10.10.100.1:1080` сообщает протокол (в моем случае это SOCKS5) и адрес прокси-сервера.
Этого достаточно, чтобы создать в системе новый сетевой интерфейс, но работать, как нам хочется, он пока что не будет. Для этого необходимо вручную присвоить новому сетевому интерфейсу IP-адрес и объяснить операционной системе, что он является шлюзом.
Присвоить интерфейсу IP-адрес и указать маску подсети можно через стандартный графический интерфейс Windows, но воспользуемся благами командной строки:
```
netsh interface ip set address name="gatewaytun" static 127.254.254.1 255.255.255.255
```
В примере виртуальному интерфейсу присваивается адрес `127.254.254.1`, но фактически это может быть любой [частный](https://ru.wikipedia.org/wiki/%D0%A7%D0%B0%D1%81%D1%82%D0%BD%D1%8B%D0%B9_IP-%D0%B0%D0%B4%D1%80%D0%B5%D1%81) адрес из подсети, которая, во-первых, не используется другими сетевыми адаптерами вашей операционной системы, во-вторых, не используется в локальной сети вашего предприятия или дома (иначе будет нарушена локальная маршрутизация). В большинстве случаев адрес из примера будет корректным значением (так как используется диапазон 127.0.0.1/8). В некоторых тестах Windows 10 отказывалась применять подобный адрес к интерфейсу. Если отказалась и у вас — воспользуйтесь чем-нибудь вроде `10.254.254.1.`Итак, будем считать, что адрес виртуальному сетевому интерфейсу присвоен.
Теперь нужно сообщить операционной системе новый интерфейс в качестве шлюза:
```
route add 0.0.0.0 mask 0.0.0.0 127.254.254.1
```
Внимание! Если прокси-сервер находится не в локальной сети с той же подсетью, что и один из сетевых интерфейсов вашего компьютера, т.е. обращение к прокси-серверу осуществляется через уже существующий шлюз, необходимо оставить доступ к прокси-серверу в прежнем виде, иначе приведенная конфигурация работать не будет — согласитесь, что попытка подключения к прокси-серверу через сам же прокси-сервер является абсурдом. На практике это означает, что для подключения к прокси-серверу нужно добавить еще один маршрут:
```
route add 10.10.100.0 mask 255.255.255.0 10.10.5.25
```
В примере указано правило маршрутизации в подсеть `10.10.100.0/24`, которая должна идти не через общий шлюз (gatewaytun), а через сетевой интерфейс, имеющий доступ к устройству с адресом `10.10.5.25` (которое является шлюзом в нужную подсеть). Это правило справедливо, во-первых, если нужно сохранить доступ в подсеть локальной сети, которая недоступна непосредственно и, во-вторых, что более важно — если в заданной подсети находится сам прокси-сервер, через который в дальнейшем пойдет весь наш трафик.
При домашнем использовании, когда нет никаких локальных подсетей, и всё, что требуется, это подключение к прокси-серверу через интернет-провайдера, приведенная выше команда заменяется этой:
```
route add 11.11.11.11 mask 255.255.255.255 10.10.5.25
```
* `11.11.11.11` — адрес прокси-сервера в интернете;
* `255.255.255.255` — маска, означающая, что в правило входит только адрес прокси-сервера;
* `10.10.5.25` — адрес шлюза в локальной сети, который вам предоставляет интернет-провайдер.
Если вы используете не HTTP-, а SOCKS-прокси (который поддерживает UDP), в настройках виртуального сетевого интерфейса можно указать адрес DNS-сервера, через который мы хотим резолвить доменные имена. Это возможно сделать как через графический интерфейс Windows, так и через командную строку:
```
netsh interface ip set dns "gatewaytun" static 1.1.1.1
```
В примере адрес `1.1.1.1` является адресом DNS-сервера.
В итоге получается следующий набор команд:
```
tun2socks-windows-amd64.exe -device tun://gatewaytun -proxy ПРОТОКОЛ_ПРОКСИ://АДРЕС_ПРОКСИ_СЕРВЕРА:ПОРТ
netsh interface ip set address name="gatewaytun" static 127.254.254.1 255.255.255.255
route add 0.0.0.0 mask 0.0.0.0 127.254.254.1
# Опционально. Для локальной сети предприятия.
route add СЕГМЕНТ_ЛОКАЛЬНОЙ_СЕТИ mask МАСКА_СЕГМЕНТА АДРЕСА_ШЛЮЗА_В_СЕГМЕНТ
# Опционально. При использовании прокси-сервера в интернете.
route add АДРЕС_ПРОКСИ_СЕРВЕРА mask 255.255.255.255 АДРЕС_ШЛЮЗА_ПРОВАЙДЕРА
# Опционально. DNS-сервер, если прокси-сервер умеет работать с UDP.
netsh interface ip set dns "gatewaytun" static АДРЕС_СЕРВЕРА_DNS
```
Большинству пользователей ручное выполнение всех команд может показать неудобным. Такие люди могут поэкспериментировать с автоматизированными сценариями (батниками). Например, вписать все нужные команды в какой-нибудь `start.bat` и добавить его в автозагрузку. В батниках и правах доступа Windows я не силён. В напутствие лишь замечу, что все команды должны быть исполнены с правами администратора. Возможно, кто-то поделится красивым скриптом в комментариях.
Linux
-----
Пользователи GNU/Linux (и других \*nix-систем) в своем большинстве являются более компетентными в вопросах командной строки и системных настроек, поэтому местами пояснения будут более скудные (тем более, что суть происходящего уже подробно описана чуть выше). Практическая инструкция дана на примере Debian.
Бинарники для Linux есть среди прочих на [странице релизов](https://github.com/xjasonlyu/tun2socks/releases). Например, для Debian amd64 подойдет вариант `tun2socks-linux-amd64.zip`. Внутри архива находится один файл. После извлечения присвойте ему флаг исполняемости (`chmod +x tun2socks-linux-amd64`) и положите в удобное место, например, `/usr/sbin/`. Дополнительные драйвера для создания туннеля WireGuard в Linux не требуются — современные дистрибутивы поддерживают технологию на уровне ядра.
Все приведенные ниже команды нужно выполнять с правами суперпользователя.
Команда запуска выглядит следующим образом:
```
/usr/sbin/tun2socks-linux-amd64 -device tun://gatewaytun -proxy socks5://10.10.100.1:1080
```
* `-device tun://gatewaytun` определяет название нового виртуального сетевого интерфейса (gatewaytun);
* `-proxy socks5://10.10.100.1:1080` сообщает протокол (в моем случае это SOCKS5) и адрес прокси-сервера.
После запуска Tun2Socks в системе создается новый сетевой интерфейс с заданным именем. Теперь необходимо откорректировать правила маршрутизации:
```
# Присваиваем адрес новому интерфейсу
ip addr add 127.254.254.1/32 dev gatewaytun
# Включаем интерфейс
ip link set gatewaytun up
# Добавляем маршрут по умолчанию через новый интерфейс (спасибо @Aytuar)
ip route add default dev gatewaytun metric 50
# Опционально. Добавляем маршрут до прокси-сервера в локальной сети
ip route add АДРЕС_СЕТИ/ПРЕФИКС dev ИМЯ_ИНТЕРФЕЙСА_В_ЛОКАЛЬНОЙ_СЕТИ
# Опционально. Маршрут до прокси-сервера в интернете (наиболее вероятный вариант для дома)
ip route add АДРЕС_ПРОКСИ/32 dev ИМЯ_ИНТЕРФЕЙСА_В_СЕТИ_ПРОВАЙДЕРА
```
Настройки DNS в \*nix-системах, как правило, являются глобальными, поэтому нет нужды указывать их явно для каждого интерфейса. Однако, кому нужно, тот знает не только про `/etc/resolv.conf`, но и про возможность явного указания DNS-сервера в конфиге сетевых подключений. На этом останавливаться не будем.
Автоматизация — второе имя любого админа. Для Debian я напишу сервис systemd, который будет запускать Tun2Socks и поднимать интерфейс `gatewaytun`, а в конфигурации данного сетевого интерфейса укажу команды, которые нужно выполнять при его включении. При необходимости вы можете адаптировать данный подход под другие операционные системы с учетом их специфики.
Файл сервиса, который ляжет в `/etc/systemd/system/tun2socks.service`:
```
[Unit]
Description=Tun2Socks gateway
After=network.target
[Service]
User=root
Type=idle
ExecStart=/usr/sbin/tun2socks-linux-amd64 -device tun://gatewaytun -proxy socks5://10.10.100.1:1080 & sleep 3; ip link set gatewaytun up
Restart=on-failure
[Install]
WantedBy=multi-user.target
```
Обратите внимание на путь до Tun2Socks и адрес прокси-сервера в строке `ExecStart`. Измените эти параметры под себя. После амперсанда указана пауза в три секунды, следом за которой осуществляется включение нового сетевого интерфейса. Пауза задается на случай высокой загрузки системы, чтобы дать время на создание интерфейса перед попыткой его включения.
Указываем в `/etc/network/interfaces` параметры интерфейса и дополнительные инструкции для исполнения после его включения. Строки добавляются в конец файла:
```
allow-hotplug gatewaytun
iface gatewaytun inet static
address 127.254.254.0
netmask 255.255.255.255
post-up ip route add default dev gatewaytun metric 50
# Опционально. Добавляем маршрут до прокси-сервера в локальной сети
# post-up ip route add АДРЕС_СЕТИ/ПРЕФИКС dev ИМЯ_ИНТЕРФЕЙСА_В_ЛОКАЛЬНОЙ_СЕТИ
# Опционально. Маршрут до прокси-сервера в интернете (наиболее вероятный вариант для дома)
# post-up ip route add АДРЕС_ПРОКСИ/32 dev ИМЯ_ИНТЕРФЕЙСА_В_СЕТИ_ПРОВАЙДЕРА
# post-up <прочие правила, исполняемые после включения интерфейса (при надобности)>
```
Теперь, когда всё готово, запускать и отключать шлюз можно двумя простыми командами:
```
systemctl start tun2socks # ЗАПУСК
systemctl stop tun2socks # ОСТАНОВКА
```
Если Tun2Socks нужен на постоянной основе, созданную службу можно добавить в автозагрузку:
```
systemctl enable tun2socks
```
Послесловие
-----------
Мотивом для статьи послужило отсутствие адекватной поисковой выдачи по запросам вроде "шлюз через прокси", "как пустить весь трафик через прокси" и тому подобные. Полагаю, материал будет полезен самой широкой аудитории.
С автоматизацией на Windows долго, честно говоря, не разбирался. Из коробки не завелось и — пусть отдыхает. Не люблю я винду, простите. Да и как любить ее, если для исполнения команды из bat-файла с правами администратора нужно создать ярлык этого батника и поставить в нем галочку "Запускать с правами администратора". Ярлык и галочка, Карл! Да и более того, команда добавления маршрута все равно не хотела отрабатывать.
Спасибо за внимание.
|
https://habr.com/ru/post/584162/
| null |
ru
| null |
# «Offline first» подход к созданию веб-приложений
В этом году на конференции [Full Frontal](http://2012.full-frontal.org/), оффлайн-приложения были популярной темой. [Пол Кинлан](https://twitter.com/Paul_Kinlan) сделал отличный доклад «Строим веб-приложения будущего. Завтра, сегодня и вчера» ([вот](https://speakerdeck.com/paulkinlan/building-web-apps-of-the-future-tomorrow-today-and-yesterday) его слайды), в котором он сравнивал ощущения пользователей от работы с 50 популярными мобильными приложениями для iOS и Android с ощущениями от веб-сайтов и приложений.
Стоит ли говорить, что нативные приложения зарекомендовали себя с гораздо лучшей стороны, когда соединение с интернетом было недоступно. Оффлайн-режим — очень важная вещь, и стоит думать о нем с самого начала работы над приложением, а не рассчитывать добавить его потом, когда будет время. Работая над сайтом [Rareloop](http://rareloop.com/), мы с первого дня помнили об оффлайн-режиме. Мобильные клиенты [FormAgent](http://formagenthq.com/) тоже были изначально спроектированы для работы в оффлайне, чтобы пользователь мог продолжать работу в отсутствие интернета и прозрачно синхронизироваться, когда связь появляется. В этой статье я описываю принципы и практики, которые, на мой взгляд, очень помогают разрабатывать такие приложения.
Обратите внимание! Я не рассматриваю вопросы кэширования ресурсов приложения — вы можете использовать App Cache или гибридное решение (вроде [PhoneGap](http://phonegap.com/)), это не принципиально [*От переводчика: на Хабре есть [подробная статья](http://habrahabr.ru/post/151815/) про особенности работы с Application Cache API*]. Это руководство посвящено скорее тому, как спроектировать архитектуру веб-приложения для работы в оффлайн-режиме, а не тому, какие механизмы использовать для его реализации.
#### Базовые принципы
##### Максимально отвяжите приложение от сервера
Исторически большую часть работы над веб-страницей брал на себя сервер. Данные хранились в БД, доступ к ним осуществлялся через толстый слой кода на серверном языке врде PHP или Ruby, данные обрабатывались и рендерились в HTML с помощью шаблонов. Большинство современных фреймворков используют архитектуру MVC для разделения этих задач, но вся тяжёлая работа по-прежнему делается на сервере. Хранение, обработка и отображение информации требуют постоянной связи с сервером.
Подход offline first предполагает перемещение всего стека MVC на сторону клиента. На стороне сервера остаётся только лёгкий JSON API для доступа к БД. Благодаря этому серверный код становится намного меньше, проще, и его легче тестировать.
[Джеймс Пирс](https://twitter.com/jamespearce) тоже говорил об этом на Full Frontal ([слайды](https://speakerdeck.com/jamesgpearce/23181)), в несколько шутливой форме:
> Никаких угловых скобок на линии — только фигурные!
###### Резюме:
1. Убедитесь, что клиентское приложение способно обойтись без сервера, предоставляя минимальный функционал. В крайнем случае — хотя бы сообщение о том, что данные не доступны.
2. Используйте JSON.
##### Создайте объект-обёртку для серверного API на стороне клиента
Не загрязняйте код приложения вызовами AJAX с вложенными колбэками. Создайте объект, который будет представлять функциональность сервера внутри приложения. Это способствует разделению кода и облегчает тестирование и отладку, позволяет использовать удобные заглушки на месте ещё не реализованных серверных функций. Внутри этот объект может использовать AJAX, но с точки зрения остального приложения не должно быть видно, как именно он связывается с сервером.
###### Резюме:
1. Абстрагируйте JSON API в отдельном объекте.
2. Не засоряйте код приложения вызовами AJAX.
##### Отвяжите обновление данных от хранилища данных
Не стоит поддаваться искушению просто запрашивать данные напрямую у объекта, абстрагирующего API сервера, и сразу использовать их для рендеринга шаблонов. Лучше создайте объект данных, который будет служить прокси между объектом API и остальным приложением. Этот объект данных будет отвечать за запросы обновлений данных и обрабатывать ситуации, когда связь обрывается — синхронизировать данные, изменённые во время работы в оффлайне.
Объект данных может опрашивать сервер на предмет наличия обновлений, когда пользователь нажмёт кнопку «обновить», или по таймеру, или по событию браузера "`online`" — как угодно, а отсутствие прямых обращений к серверу позволяет легче управлять кэшированием данных.
Объект данных также должен отвечать за сериализацию и сохранение своего состояния в постоянном хранилище, в Local Storage или WebSQL/IndexedDB, и уметь восстанавливать эти данные.
###### Резюме:
1. Используйте отдельный объект данных для хранения и синхронизации состояния.
2. Вся работа с данными должна идти через это прокси-объект.
#### Пример
В качестве простого пример возьмём приложение для управления контактами. Сначала сделаем серверный API, который позволит нам получать сырые данные контактов. Предположим, что мы создали RESTful API, где URI `/contacts` возвращает список всех записей контактов. В каждой записи есть поля `id`, `firstName`, `lastName` и `email`.
Затем напишем объект-обёртку над этим API:
```
var API = function() { };
API.prototype.getContacts = function(success, failure) {
var win = function(data) {
if(success)
success(data);
};
var fail = function() {
if(failure)
failure()
};
$.ajax('http://myserver.com/contacts', {
success: win,
failure: fail
});
};
```
Теперь нам нужен объект данных, который станет интерфейсом между нашим приложением и хранилищем данных. Он может выглядеть так:
```
var Data = function() {
this.api = new API();
this.contacts = this.readFromStorage();
this.indexData();
};
Data.prototype.indexData = function() {
// Выполняем индексирование (например, по email)
};
/* -- API апдейтов-- */
Data.prototype.updateFromServer = function(callback) {
var _this = this;
var win = function(data) {
_this.contacts = data;
_this.indexData();
if(callback)
callback();
};
var fail = function() {
if(callback)
callback();
};
this.api.getContacts(win, fail);
};
/* -- Сериализация данных -- */
Data.prototype.readFromStorage = function() {
var c = JSON.parse(window.localStorage.getItem('appData'));
// позаботимся о результате по умолчанию
return c || [];
};
Data.prototype.writeToStorage = function() {
window.localStorage.setItem('appData', JSON.stringify(this.contacts));
};
/* -- Стандартные геттеры/сеттеры -- */
Data.prototype.getContacts = function() {
return this.contacts;
};
// Запрос данных, специфичный для приложения
Data.prototype.getContactWithEmail = function(email) {
// Поиск контактов с помощью механизмов индексирования...
return contact;
};
```
Теперь у нас есть объект данных, через который мы можем запросить обновление у серверного API, но по умолчанию он будет возвращать данные, сохранённые локально. В остальном приложении можно использовать вот такой код:
```
var App = function() {
this.data = new Data();
this.template = '...';
this.render();
this.setupListeners();
};
App.prototype.render = function() {
// Используем this.template и this.data.getContacts() для рендеринга HTML
return html;
}
App.prototype.setupListeners = function() {
var _this = this;
// Обновляем данные с сервера
$('button.refresh').on('click', function(event) {
_this.refresh();
});
};
App.prototype.refresh = function () {
_this.showLoadingSpinner();
_this.data.updateFromServer(function() {
// Данные пришли с сервера
_this.render();
_this.hideLoadingSpinner();
});
};
App.prototype.showLoadingSpinner = function() {
// показываем крутилку
};
App.prototype.hideLoadingSpinner = function() {
// прячем крутилку
};
```
Это очень простой пример, в реальном приложении, вы, вероятно, захотите реализовать объект данных, как singleton, но для илююстрации того, как надо структурировать код для работы в режиме оффлайн этого достаточно.
|
https://habr.com/ru/post/160477/
| null |
ru
| null |
# Всё, что нужно знать о выравнивании во Flexbox
**Об авторе**: Рэйчел Эндрю — не только главный редактор журнала Smashing Magazine, но и веб-разработчик, писатель и спикер. Она автор ряда книг, в том числе *[The New CSS Layout](https://abookapart.com/products/the-new-css-layout)*, один из разработчиков системы управления контентом [Perch](https://grabaperch.com/). Пишет о бизнесе и технологиях на своём сайте [rachelandrew.co.uk](https://rachelandrew.co.uk/).
***Краткое содержание:** в этой статье мы рассмотрим свойства выравнивания во Flexbox и некоторые основные правила, как работает выравнивание по основной и поперечной осям.*
В [первой статье](https://www.smashingmagazine.com/2018/08/flexbox-display-flex-container/) этого цикла я рассказала, что происходит при объявлении свойства `display: flex` для элемента. Сейчас рассмотрим свойства выравнивания и как они работают с Flexbox. Если вы когда-либо приходили в замешательство, применить `align` или `justify`, надеюсь, эта статья многое прояснит!
История выравнивания во Flexbox
-------------------------------
За всю историю CSS правильное выравнивание по обеим осям казалось самой сложной проблемой. Появление этой функции во Flexbox для многих стало главным преимуществом этой технологии. Выравнивание свелось к [двум строчкам CSS](https://codepen.io/rachelandrew/pen/WKLYEX).
Свойства выравнивания теперь полностью определены в [спецификации Box Alignment](https://www.w3.org/TR/css-align-3/). Она детализирует, как работает выравнивание в различных макетах. Это означает, что в CSS Grid можно использовать те же свойства, что и в Flexbox — а в будущем в других макетах тоже. Поэтому любая новая функция выравнивания Flexbox будет подробно описана в спецификации Box Alignment, а не в следующей версии Flexbox.
Свойства
--------
Многим трудно запомнить, следует ли использовать свойства, которые начинаются с `align-` или с `justify-`. Важно помнить следующее:
* `justify-` выполняет выравнивание по главной оси в том же направлении, что и `flex-direction`;
* `align-` выполняет выравнивание по оси поперёк направлению `flex-direction`.
Здесь действительно помогает мышление с точки зрения главной и поперечной осей, а не горизонтальной и вертикальной. Не имеет значения, как физически направлена ось.
### Выравнивание главной оси с помощью `justify-content`
Начнём с выравнивания по главной оси. Оно осуществляется с помощью свойства `justify-content`. Данное свойство обрабатывает все элементы как группу и управляет распределением пространства между ними.
Изначальное значение `justify-content` равняется `flex-start`. Вот почему при объявлении `display: flex` все элементы flex выстраиваются в начале строки. В письменности слева направо элементы группируются слева.

Обратите внимание, что свойство `justify-content` производит видимый эффект только **при наличии свободного места**. Поэтому если у вас набор элементов занимает всё пространство на главной оси, `justify-content` ничего не даст.

Если указать для `justify-content` значение `flex-end`, то все элементы переместятся в конец строки. Свободное место теперь находится в начале.
С этим пространством можно делать и другие вещи. Например, распределить его между нашими элементами, используя `justify-content: space-between`. В этом случае первый и последний элемент разместятся на концах контейнера, а всё пространство поровну поделится между элементами.

Мы можем распределить пространство с помощью `justify-content: space-around`. В этом случае доступное пространство делится на равные части и помещается с каждой стороны элемента.
Новое значение `justify-content` можно найти в спецификации Box Alignment; оно не указано в спецификации Flexbox. Это значение `space-evenly`. В этом случае элементы равномерно распределяются в контейнере, а дополнительное пространство поровну распределяется между элементами и с обеих сторон.

Вы можете поиграться со всеми значениями в [демо](https://codepen.io/rachelandrew/pen/Owraaj).
Значения точно так же работают по вертикали, то есть если `flex-direction` применяется для `column`. Правда, у вас в столбце может не оказаться свободного места для распределения, если не добавить высоту или block-size контейнера, как в [этом демо](https://codepen.io/rachelandrew/pen/zLyMyV).
### Выравнивание по осям с помощью `align-content`
Если в контейнере несколько осей и указано `flex-wrap: wrap`, то можно использовать `align-content` для выравнивания строк на поперечной оси. Но требуется дополнительное пространство. В [этой демонстрации](https://codepen.io/rachelandrew/pen/pZqqMJ) поперечная ось работает в направлении колонки, и я указала высоту контейнера `60vh`. Поскольку это больше, чем необходимо для отображения всех элементов, то появляется свободное пространство по вертикали.
Затем я могу применить `align-content` [с любым из значений](https://codepen.io/rachelandrew/pen/pZqqMJ).
Если в качестве `flex-direction` указано `column`, то `align-content` работает как в [следующем примере](https://codepen.io/rachelandrew/pen/MBZZNy).
Как и в случае с `justify-content`, мы работаем с группой строк и распределяем свободное пространство.
### Свойство по `place-content`
В спецификации Box Alignment можно найти свойство `place-content`. Использование этого свойства означает, что вы одновременно устанавливаете `justify-content` и `align-content`. Первое значение — для `align-content`, второе для `justify-content`. Если задано только одно значение, то оно применяется к обоим свойствам:
```
.container {
place-content: space-between stretch;
}
```
Соответствует этому:
```
.container {
align-content: space-between;
justify-content: stretch;
}
```
А такой код:
```
.container {
place-content: space-between;
}
```
Равноценен следующему:
```
.container {
align-content: space-between;
justify-content: space-between;
}
```
### Выравнивание по осям с помощью `align-items`
Теперь мы знаем, что можно выровнять набор элементов или строки как группу. Тем не менее, есть ещё один способ выровнять элементы по отношению друг к другу на поперечной оси. У контейнера есть высота, которая определяется высотой самого высокого элемента.

Как вариант, её можно определить свойством `height` в контейнере:

Почему элементы растягиваются до размера самого высокого элемента — это потому что начальным значением параметра `align-items` является `stretch`. Элементы растягиваются по поперечной оси до размера контейнера в этом направлении.
Обратите внимание, что в многострочном контейнере каждая строка действует как новый контейнер. Самый высокий элемент в этой строке будет определять размер всех элементов в этой строке.
Кроме начального значения `stretch`, можно присвоить элементам `align-items` значение `flex-start`, в этом случае они выравниваются по началу контейнера и больше не растягиваются по высоте.

Значение `flex-end` перемещает их в конец контейнера по поперечной оси.

Если вы используете значение `center`, то элементы центрируются относительно друг друга:

Мы также можем выровнять их по базовой линии. Это гарантирует выравнивание текста по одному основанию, в отличие от выравнивания полей вокруг текста.

Все эти варианты можно попробовать в [демо](https://codepen.io/rachelandrew/pen/WKLBpv).
### Индивидуальное выравнивание с помощью `align-self`
Свойство `align-items` задаёт выравнивание всех элементов одновременно. В действительности оно устанавливает значения `align-self` для всех элементов группы. Можно также использовать свойство `align-self` для любого отдельного элемента, чтобы выровнять его внутри строки и относительно других элементов.
В [следующем примере](https://codepen.io/rachelandrew/pen/KBbLmz) в контейнере используется `align-items` для выравнивания всей группы по центру, но также `align-self` для первого и последнего элементов.

Почему нет `justify-self`?
--------------------------
Часто возникает вопрос, почему невозможно выровнять один элемент или группу элементов по главной оси. Почему во Flexbox нет свойства `-self` для выравнивания по главной оси? Если вы представите `justify-content` и `align-content` как способ распределения пространства, то ответ становится более очевидным. Мы имеем дело с элементами как с группой и размещаем свободное пространство определённым образом: либо в начале, либо в конце группы, либо между элементами.
Также может быть полезно подумать, как `justify-content` и `align-content` работают в CSS Grid Layout. В Grid эти свойства используются для распределения свободного пространства в grid-контейнере *между grid-дорожками*. Здесь тоже мы берём группу дорожек — и с помощью этих свойств распределяем между ними свободное пространство. Поскольку мы оперируем в группе и в Grid, и во Flexbox, то не можем взять отдельный элемент и сделать с ним что-то другое. Тем не менее, есть способ получить оформление макета, которое хотят верстальщики, когда говорят о свойстве `self` на главной оси. Это использование автоматических полей.
### Использование автоматических полей на основной оси
Если вы когда-нибудь центрировали блок в CSS (например, враппер для контента главной страницы, установив поля слева и справа в `auto`), то у вас уже есть некоторый опыт работы с автоматическими полями. Значение `auto` для полей заполняет максимальное пространство в установленном направлении. Для центрирования блока мы устанавливаем и левое, и правое поля в `auto`: каждое из них пытается занять как можно больше места, и поэтому помещает наш блок в центр.
Автоматические поля очень хорошо работают во Flexbox для выравнивания отдельных элементов или групп элементов на главной оси. В [следующем примере](https://codepen.io/rachelandrew/pen/oMJROm) показан типичный случай. Есть панель навигации, элементы отображаются в виде строки и используют начальное значение `justify-content: start`. Я хочу, чтобы последний пункт отображался отдельно от других в конце строки — при условии, что в строке достаточно места для этого.
Берём этот элемент и указываем для свойства `margin-left` значение `auto`. Это значит, что поле пытается получить как можно больше места слева от элемента, то есть элемент выталкивается к правой границе.

Если вы используете автоматические поля на главной оси, то `justify-content` перестанет действовать, так как автоматические поля займут всё пространство, которое в противном случае распределялось бы с помощью `justify-content`.
Запасное выравнивание
---------------------
Для каждого метода выравнивания описан запасной вариант — что произойдёт, если заданное выравнивание невозможно. Например, если у вас есть только один элемент в контейнере, а вы указали `justify-content: space-between`, что должно произойти? В этом случае применяется запасное выравнивание `flex-start` — один элемент будет выровнен по началу контейнера. В случае `justify-content: space-around` используется запасное выравнивание `center`.
В текущей спецификации вы не можете изменить запасное выравнивание. Есть [примечание к спецификациям](https://www.w3.org/TR/css-align-3/#distribution-values), которое допускает возможность указания произвольного запасного варианта в будущих версиях.
Безопасное и небезопасное выравнивание
--------------------------------------
Недавним дополнением к спецификации Box Alignment стала концепция безопасного и небезопасного выравнивания с использованием ключевых слов *safe* и *unsafe*.
В следующем коде последний элемент слишком широк для контейнера, а при небезопасном выравнивании и гибком контейнере в левой части страницы элемент обрезается, поскольку переполнение выходит за границы страницы.
```
.container {
display: flex;
flex-direction: column;
width: 100px;
align-items: unsafe center;
}
.item:last-child {
width: 200px;
}
```

Безопасное выравнивание предотвращает потерю данных, перемещая переполнение на другую сторону.
```
.container {
display: flex;
flex-direction: column;
width: 100px;
align-items: safe center;
}
.item:last-child {
width: 200px;
}
```
Эти ключевые слова пока поддерживаются не всеми браузерами, однако демонстрируют, как спецификации Box Alignment добавляют контроля во Flexbox.
Заключение
----------
Свойства выравнивания начинались со списка в Flexbox, но теперь обзавелись собственной спецификацией и применяются к другим контекстам макетирования. Вот несколько ключевых фактов, которые помогут запомнить их использование во Flexbox:
* `justify-` для основных осей, а `align-` для поперечных;
* для `align-content` и `justify-content` требуется свободное пространство;
* свойства `align-content` и `justify-content` применяются к элементам в группе, распределяя пространство между ними. Нельзя указывать выравнивание отдельного элемента, потому что свойство `-self` отсутствует;
* если хотите выровнять один элемент или разбить группу по основной оси, используйте автоматические поля;
* `align-items` устанавливает одинаковые свойства `align-self` для всей группы. Используйте `align-self` для дочернего элемента группы, чтобы установить ему значение индивидуально.
|
https://habr.com/ru/post/420935/
| null |
ru
| null |
# UCS2 или UCS4? — pyodbc и работа с utf16 данными в MSSQL
Проблема
--------
Для работы с базой данных MSSQL Server 2005 в кодировке UTF-16(UCS2) я использую скрипт, написанный на python. Этот скрипт использует для работы с базой данных следующий набор инструментов:
* unixODBC
* FreeTDS
* pyodbc
* sqlachemy
И тут появилась трудность: при получении строковых данных из базы (поля nvarchar, ntext) неправильно обрабатывается юникод.
Как выяснилось, установленный у меня питон был собран с UCS4 юникодом. Методы получения типа юникода в сборке python хорошо описаны в данном [вопросе на stackoverflow](http://stackoverflow.com/questions/1446347/how-to-find-out-if-python-is-compiled-with-ucs-2-or-ucs-4). Т.е, если выполнить следующую строчку в терминале:
```
python -c "import sys;print 'UCS4' if sys.maxunicode > 65536 else 'UCS2'"
```
то мы получаем версию сборки юникода для python.В моем случае это было **UCS4**. Что это за собой тянет:
1. unixODBC вызывая соответствующие функции работы с базой данных с аппендиксом W (например, *SQLExecDirectW()*), получает результаты. в которых один символ текста занимает 2 байта(UCS2)
2. pyodbc получает результаты от ODBC-драйвера, и в свою очередь сохраняет результаты в переменную с типом **unicode**
3. Таким образом 1 символ результата, по мнению pyodbc, составляет 4 байта(UCS4). Именно так и сохраняется результат. полученный из ODBC-драйвера.
Драйвер возвращает данные, в которых символ занимает 2 байта, а pyodbc переделывает эти данные так, что символ занимает 4 байта. Все бы хорошо, если бы было какое-либо преобразование, но данные просто сохраняются как массив байтов в переменную с типом **unicode**, что несет неприятные последствия: символ результата по-сути содержит 2 символа того результата, который вернул ODBC-драйвер.
Не страшные последствия, решил я и самостоятельно преобразовал результат, разделив его по-символам:
```
def odbcUCS4toUCS2(ustr):
u = u""
for i in range(0, len(ustr)):
u32 = ord(ustr[i])
u16 = [(u32 & 0xFFFF0000) >> 16, (u32 & 0x0000FFFF)]
u += unichr(u16[1])
u += unichr(u16[0])
return u
```
Этого оказалось недостаточным. Появилось еще одно неприятное последствие: **если длина в символах результата нечетная, то последний символ результата обрезается**. Т.е. строка *'это слово'* будет получена в моем скрипте как *'это слов'*. Эту проблему я так и не смог решить преобразованиями: последних два байта результата фактически отсутствуют из-за неправильного сохранения юникода. Тогда я пришел к решению пересобрать python с UCS2 поддержкой юникода.
Решение
-------
Собираем, не забыв указать в опциях *--enable-unicode=ucs2*. При сборке нового питона надо не забыть поставить пакетик zlib1g-dev, иначе потом могут быть трудности с установкой пакетов с помощью pip.
Установка и настройка virtualenv:
```
$ sudo apt-get install virtualenv
$ virtualenv ~/ucs2env -p [путь к бинарнику ucs2 питона]
```
ну и добавим в в алиасы:
```
echo "alias ucs2env='source ~/ucs2env/bin/activate'">>~/.bashrc
```
Ну вот и все. теперь данные получаются таким же образом как и хранятся в базе данных:
```
$ ucs2env
(ucs2env)$ python -c "import sys;print 'UCS4' if sys.maxunicode > 65536 else 'UCS2'"
UCS2
```
|
https://habr.com/ru/post/148137/
| null |
ru
| null |
# Резервное копирование виртуальной машины и скрипты заморозки/оттаивания InterSystems Caché
В этой статье я рассмотрю стратегии резервного копирования Caché с использованием систем внешнего резервного копирования и приведу примеры интеграции с решениями на основе снимков состояния виртуальной машины (VM snapshot, снапшот). Большинство решений, с которыми я сталкиваюсь сегодня, развернуты на базе Linux и VMware, поэтому я приведу примеры решений именно с использованием снапшотов VMware.
Список моих статей из серии 'Платформы данных InterSystems и производительность' находится [здесь](https://community.intersystems.com/post/capacity-planning-and-performance-series-index) (англ.).
Для лучшего понимания данной статьи вам следует также ознакомиться с [руководством по резервному копированию и восстановлению](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI_backup) в онлайн-документации Caché.
Caché backup: батарейки в комплекте?
------------------------------------
Встроенное горячее резервное копирование (Caché online backup) поставляется вместе с Caché «из коробки» и предназначено для резервного копирования баз данных Caché без остановки системы. Однако существуют и более эффективные решения для резервного копирования, о которых стоит знать в те моменты, когда вы планируете масштабирование крупной системы. Внешнее резервное копирование (External Backup) с использованием технологий создания снимков — рекомендуемое мною решение для резервного копирования систем, в том числе, использующих базы данных Caché.
Что необходимо учитывать при внешнем резервном копировании?
-----------------------------------------------------------
В онлайн документации InterSystems, посвященной [внешнему резервному копированию](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI_backup#GCDI_backup_methods_ext), можно найти все интересующие детали. Отметим лишь ключевой момент:
> «Для обеспечения целостности снимка файловой системы Caché предоставляет возможности для заморозки (freeze) записи в базы данных в момент создания снимка. Заморозке подвергаются только попытки физической записи в файлы базы данных, что позволяет пользовательским процессам продолжать бесперебойно выполнять обновления базы данных в памяти».
Важно также отметить, что часть процесса создания снимка в виртуализированных системах вызывает небольшую паузу в работе виртуальной машины, которую принято называть замиранием (stun). Обычно замирание длится меньше секунды, поэтому его не замечают пользователи и оно не оказывает воздействия на работу системы, однако в некоторых случаях замирание может длиться и дольше. Если замирание длится дольше, чем таймаут QoS (Quality of service, показатель качества обслуживания) зеркалирования базы данных Caché, то резервный узел зеркала решит, что произошел сбой в основной системе, и произведет переключение зеркала. Позже в этой статье я расскажу как можно замерить время замирания на тот случай, если вам нужно будет внести изменения в настройку таймаута QoS для зеркалирования.
Варианты резервного копирования
-------------------------------
### Минималистичное решение для резервного копирования – встроенное резервное копирование (Caché Online Backup)
Если у вас нет возможности использовать другие средства, остается этот старый добрый способ, который входит в комплект поставки с платформами InterSystems. Учтите, что Caché online backup создает резервные копии только для файлов баз данных Caché, сохраняя все непустые блоки в базах данных, записывая их последовательно в файл. Caché Online Backup поддерживает накопительное (cumulative) и инкрементное (incremental) резервное копирование.
В контексте VMware, Caché Online Backup выполняется на гостевой машине. Подобно другим аналогичным решениям, операции, выполняемые Caché Online Backup, одинаковы независимо от того, виртуализировано ли приложение или выполняется непосредственно на физическом сервере. Соответственно, копии, полученные Caché Online Backup должны быть перемещены на резервный носитель вместе со всеми другими файлами, которыми пользуется ваше приложение. При резервном копировании системы необходимо помнить о каталоге приложения, основном и альтернативном каталогах журнала БД, и любых других каталогах, содержащих файлы, используемые приложением.
Caché Online Backup следует рассматривать либо как подход начального уровня для небольших проектов, желающих реализовать недорогое решение для «горячего» резервного копирования баз данных, либо для создания разовых резервных копий. Например, создание подобных копий очень полезно при первоначальной настройке зеркалирования. Однако, поскольку базы данных увеличиваются в размерах и поскольку базы данных Caché обычно являются лишь частью клиентского набора данных, внешние резервные копии в сочетании с технологией создания моментальных снимков при использовании сторонних утилит рекомендуются как наилучшее решение с такими преимуществами, как возможность включать в резервную копию файлы, отличных от файлов базы данных, уменьшенное время восстановления, возможность контроля данных в масштабах всей организации и доступность улучшенных инструментов для каталогизации и управления.
### Рекомендуемое решение для резервного копирования: внешнее резервное копирование
Рассмотрим его на примере VMware. Использование VMware для виртуализации добавляет новые функции и возможности для защиты виртуальных машин в целом. Виртуализация решения приводит систему (включая операционную систему) к эффективной инкапсуляции вашего приложения со всеми данными внутри одного файла vmdk (и нескольких других файлов). При необходимости этими файлами можно очень легко манипулировать, и они могут использоваться для быстрого восстановления целой системы. Это сильно отличается от восстановления работоспособности вашего приложения на голом железе, где вы должны восстановить и настроить каждый компонент по отдельности — операционную систему, драйверы, сторонние приложения, СУБД и файлы баз данных и т.д.
Снимок состояния VMware
-----------------------
VMware vSphere Data Protection (VDP) и другие сторонние решения для резервного копирования виртуальных машин, такие как Veeam или Commvault, используют функции снимков состояния (snapshot) виртуальных машин VMware для создания резервных копий. Ниже приведено краткое объяснение механизма работы снимков VMware. Для получения более подробной информации обратитесь к документации.
Важно помнить, что снимки делаются со всей виртуальной машины и что гостевая операционная система и любые приложения или СУБД не знают о том, что сейчас с них делают снимок. Запомните также следующее:
> Сами по себе снимки VMware не являются резервными копиями!
Снимки позволяют использовать ПО для резервного копирования и сделать резервные копии, но они не являются резервными копиями сами по себе.
VDP и другие сторонние решения используют процесс создания снимков состояния VMware в сочетании с каким-либо приложением для управления созданием и, что очень важно, удалением снимков. Вкратце последовательность событий для создания внешней резервной копии с помощью снимков VMware выглядит следующим образом:
* Стороннее программное обеспечение для резервного копирования запрашивает у хоста ESXi выполнение снимка состояния VMware.
* Файлы .vmdk виртуальной машины переводятся в режим «только для чтения» и для каждого файла .vmdk каждой виртуальной машины создаётся дочерний .vmdk дельта-файл.
* Любая запись на диск происходит в дельта файл виртуальной машины. Любые операции чтения выполняются сначала из дельта-файла.
* Программное обеспечение резервного копирования выполняет резервное копирование родительских .vmdk-файлов, находящихся в режиме «только для чтения»
* Когда резервное копирование завершено, снимок сливается с исходным файлом (диски виртуальной машины становятся доступными для записи и обновлённые блоки из дельта-файлов дописываются к родительским файлам).
* Снимки VMware удаляются.
Решения для резервного копирования также содержат специальные возможности, как например отслеживание измененных блоков (Changed Block Tracking, CBT), чтобы выполнять инкрементное или накопительное резервное копирование максимально быстро и эффективно (что особо важно для экономии места). Подобные решения обычно также добавляют другие полезные и важные функции, такие как сжатие данных, организация работы по расписанию, восстановление виртуальных машин с другим IP-адресом для проверки целостности, восстановление как всей виртуальной машины, так и отдельных файлов с нее, управление каталогом резервных копий и т.д.
> Снимки состояния VMware, которые должным образом не управляются или оставляются висеть длительное время, могут сильно уменьшить свободное место в хранилище (по мере накопления изменений дельта-файлы становятся всё больше и больше), а также замедлить работу виртуальной машины.
Следует очень хорошо подумать, прежде чем делать снимки состояния вручную на основном сервере баз данных. Зачем вы это делаете? Что произойдет, если вы вернетесь в прошлое к тому моменту, когда создавали снимок? Что происходит со всеми транзакциями между созданием снимка и откатом изменений?
Если ваше программное обеспечение резервного копирования создает и удаляет снимки состояния — это абсолютно нормально. Снимок и должен создаваться только на непродолжительное время, а ключевой частью вашей стратегии резервного копирования будет выбор времени копирования когда система минимально загружена, что еще больше снизит влияние на пользователей и общую производительность.
Особенности Caché для снимков состояния системы
-----------------------------------------------
Перед выполнением снимка база данных должна быть стабилизирована (quiesced): все записи в файлы должны быть завершены и файлы баз данных должны быть в корректном состоянии. Caché предоставляет методы и API для завершения, а затем замораживания (freeze) записи в базы данных на короткий период создания снимка. Заморозке во время создания снимка подвергаются только попытки физической записи в файлы базы данных, что позволяет пользовательским процессам продолжать выполнять обновления в памяти бесперебойно. После того как снимок был сделан, возможность записи в базу данных восстанавливается, база данных «оттаивает» (thaw), и резервная копия продолжает копироваться на резервный носитель. Время между замораживанием и оттаиванием должно быть небольшим (не более нескольких секунд).
В дополнение к приостановке записи, заморозка Caché также приводит к смене файлов журнала и помещению маркера создания резервной копии в журнал. Запись в файл журнала при этом продолжается нормально, пока запись в физическую базу данных заморожена. Если система рухнет в то время, пока записи в физической базе данных будут заморожены, данные будут восстановлены из журнала как обычно при запуске.
Следующая диаграмма показывает замораживание и оттаивание с выполнением снимков для создания резервной копии с корректным файлом базы данных.
Обратите внимание на короткое время между замораживанием и оттаиванием — это время только на создание снимка, а не время, которое требуется на копирование всего родительского объекта в резервную копию.
Заморозка и оттаивание Caché
----------------------------
vSphere позволяет автоматически вызывать скрипты до и после создания снимка: это и есть те самые моменты, которые называются заморозкой и оттаиванием Caché. Примечание: для правильной работы этого функционала ESXi хост запрашивает у гостевой операционной системы заморозку дисков через VMware Tools.
В гостевой операционной системе должны быть установлены Инструменты VMware. Скрипты должны соблюдать строгие требования к имени и местоположению. Необходимо также назначить корректные права на файлы. Имена скриптов для VMware на Linux:
```
# /usr/sbin/pre-freeze-script
# /usr/sbin/post-thaw-script
```
Ниже приведены примеры скриптов замораживания и оттаивания, которые наша команда использует для резервного копирования с помощью Veeam в наших внутренних тестовых лабораториях. Эти скрипты также должны подойти для работы и с использованием других продуктов. Примеры были протестированы и использовались на vSphere 6 и Red Hat 7.
Хотя эти сценарии могут использоваться в качестве примеров и являются иллюстрацией к описываемому методу, вы должны убедиться в их корректности для вашей собственной среды!
Пример скрипта заморозки:
```
#!/bin/sh
#
# Script called by VMWare immediately prior to snapshot for backup.
# Tested on Red Hat 7.2
#
LOGDIR=/var/log
SNAPLOG=$LOGDIR/snapshot.log
echo >> $SNAPLOG
echo "`date`: Pre freeze script started" >> $SNAPLOG
exit_code=0
# Только для запущенных экземпляров
for INST in `ccontrol qall 2>/dev/null | tail -n +3 | grep '^up' | cut -c5- | awk '{print $1}'`; do
echo "`date`: Attempting to freeze $INST" >> $SNAPLOG
# Detailed instances specific log
LOGFILE=$LOGDIR/$INST-pre_post.log
# Freeze
csession $INST -U '%SYS' "##Class(Backup.General).ExternalFreeze(\"$LOGFILE\",,,,,,1800)" >> $SNAPLOG $
status=$?
case $status in
5) echo "`date`: $INST IS FROZEN" >> $SNAPLOG
;;
3) echo "`date`: $INST FREEZE FAILED" >> $SNAPLOG
logger -p user.err "freeze of $INST failed"
exit_code=1
;;
*) echo "`date`: ERROR: Unknown status code: $status" >> $SNAPLOG
logger -p user.err "ERROR when freezing $INST"
exit_code=1
;;
esac
echo "`date`: Completed freeze of $INST" >> $SNAPLOG
done
echo "`date`: Pre freeze script finished" >> $SNAPLOG
exit $exit_code
```
Пример скрипта оттаивания:
```
#!/bin/sh
#
# Script called by VMWare immediately after backup snapshot has been created
# Tested on Red Hat 7.2
#
LOGDIR=/var/log
SNAPLOG=$LOGDIR/snapshot.log
echo >> $SNAPLOG
echo "`date`: Post thaw script started" >> $SNAPLOG
exit_code=0
if [ -d "$LOGDIR" ]; then
# Только для запущенных экземпляров
for INST in `ccontrol qall 2>/dev/null | tail -n +3 | grep '^up' | cut -c5- | awk '{print $1}'`; do
echo "`date`: Attempting to thaw $INST" >> $SNAPLOG
# Detailed instances specific log
LOGFILE=$LOGDIR/$INST-pre_post.log
# Оттаивание
csession $INST -U%SYS "##Class(Backup.General).ExternalThaw(\"$LOGFILE\")" >> $SNAPLOG 2>&1
status=$?
case $status in
5) echo "`date`: $INST IS THAWED" >> $SNAPLOG
csession $INST -U%SYS "##Class(Backup.General).ExternalSetHistory(\"$LOGFILE\")" >> $SNAPLOG$
;;
3) echo "`date`: $INST THAW FAILED" >> $SNAPLOG
logger -p user.err "thaw of $INST failed"
exit_code=1
;;
*) echo "`date`: ERROR: Unknown status code: $status" >> $SNAPLOG
logger -p user.err "ERROR when thawing $INST"
exit_code=1
;;
esac
echo "`date`: Completed thaw of $INST" >> $SNAPLOG
done
fi
echo "`date`: Post thaw script finished" >> $SNAPLOG
exit $exit_code
```
Не забудьте установить права на файлы:
```
# sudo chown root.root /usr/sbin/pre-freeze-script /usr/sbin/post-thaw-script
# sudo chmod 0700 /usr/sbin/pre-freeze-script /usr/sbin/post-thaw-script
```
Тестирование заморозки и оттаивания
-----------------------------------
Чтобы проверить работу приведенных сценариев, вы можете вручную запустить выполнение снимка на виртуальной машине и проверить что выведет сценарий. На следующем скриншоте показан диалог «Take VM Snapshot» и его опции.
**Сбросьте флажок** "Snapshot the virtual machine's memory" (Сохранить оперативную память виртуальной машины)
**Отметьте флажок** "Quiesce guest file system (Needs VMware Tools installed)" (Стабилизировать гостевую файловую систему). Это приведет к приостановке запущенных процессов в гостевой операционной системе и сбросу буферов, чтобы содержимое файловой системы находилось в известном непротиворечивом состоянии при выполнении снимка.
> **Важно!** После теста не забудьте удалить сделанный снимок!
Если флажок стабилизации (quiescing) отмечен и виртуальная машина работает в тот момент, когда делается снимок, для стабилизации файловой системы виртуальной машины будет использоваться VMware Tools. Стабилизация файловой системы представляет собой процесс приведения данных на диске в состояние "готов к резервному копированию". Этот процесс может включать в себя такие операции, как очистка заполненных буферов между кэшем операционной системы в памяти и диском.
Следующий вывод показывает содержимое файла журнала `$SNAPLOG`, указанного в приведенных выше примерах сценариев замораживания/оттаивания после запуска процедуры резервного копирования, которая в том числе делает выполнение снимка.
```
Wed Jan 4 16:30:35 EST 2017: Pre freeze script started
Wed Jan 4 16:30:35 EST 2017: Attempting to freeze H20152
Wed Jan 4 16:30:36 EST 2017: H20152 IS FROZEN
Wed Jan 4 16:30:36 EST 2017: Completed freeze of H20152
Wed Jan 4 16:30:36 EST 2017: Pre freeze script finished
Wed Jan 4 16:30:41 EST 2017: Post thaw script started
Wed Jan 4 16:30:41 EST 2017: Attempting to thaw H20152
Wed Jan 4 16:30:42 EST 2017: H20152 IS THAWED
Wed Jan 4 16:30:42 EST 2017: Completed thaw of H20152
Wed Jan 4 16:30:42 EST 2017: Post thaw script finished
```
На этом примере видно, что время между замораживанием и оттаиванием составляет 6 секунд (16:30:36 — 16:30:42). В течение этого периода работа пользователей НЕ прерывается. Вам нужно будет собрать статистику с ваших собственных систем, но для информации отметим, что данный пример был запущен во время тестирования производительности приложения на системе без «узких мест» в системе ввода/вывода, в среднем выполнявшей более 2 миллионов операций чтения БД в секунду (Glorefs/sec), 170 000 операций записи БД в секунду (Gloupds/sec) и в среднем 1100 физических операций чтения диска в секунду и 3000 записей за цикл демона записи БД (write daemon cycle).
Помните, что оперативная память не является частью снимка, поэтому при восстановлении резервной копии виртуальная машина будет перезагружена и выполнит процедуры восстановления. Файлы базы данных будут согласованными. Вы не ставите целью «продолжить работу» из резервной копии и просто хотите, чтобы у вас были корректные резервные копии файлов на конкретный момент времени. Вы можете затем выполнить прогон журналов БД и выполнить другие процедуры восстановления, необходимые для восстановления целостности приложения и согласованности транзакций после восстановления файлов.
Для дополнительной защиты данных, [смена журнала](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI_journal#GCDI_journal_util_JRNSWTCH) может также выполняться сама по себе, сопровождаемая резервным копированием или репликацией журнала, например, ежечасно.
Ниже приведено содержимое `$LOGFILE` из примера заморозки/оттаивания, приведенного выше, в котором показаны подробности журнала для снимка.
```
01/04/2017 16:30:35: Backup.General.ExternalFreeze: Suspending system
Journal file switched to:
/trak/jnl/jrnpri/h20152/H20152_20170104.011
01/04/2017 16:30:35: Backup.General.ExternalFreeze: Start a journal restore for this backup with journal file: /trak/jnl/jrnpri/h20152/H20152_20170104.011
Journal marker set at
offset 197192 of /trak/jnl/jrnpri/h20152/H20152_20170104.011
01/04/2017 16:30:36: Backup.General.ExternalFreeze: System suspended
01/04/2017 16:30:41: Backup.General.ExternalThaw: Resuming system
01/04/2017 16:30:42: Backup.General.ExternalThaw: System resumed
```
Замирание виртуальной машины
----------------------------
Во время создания снимка виртуальной машины, а также после завершения резервного копирования и удаления снимка виртуальную машину необходимо заморозить на короткий период времени. Это кратковременное замораживание часто называют замиранием (stun). Хорошая статья о замирании виртуальных машин есть [здесь](http://cormachogan.com/2015/04/28/when-and-why-do-we-stun-a-virtual-machine/). Я изложу некоторые подробности ниже, применительно базам данных Caché.
> Выдержка из статьи: «Чтобы создать снимок виртуальной машины, виртуальная машина «замирает», чтобы (i) сериализовать состояние устройства на диск и (ii) закрыть текущий работающий диск и создать точку начала снимка… При слиянии дельта-файлов виртуальная машина «замирает», чтобы закрыть диски для записи и перевести их в состояние, подходящее для слияния.»
Время замирания обычно составляет около 100 миллисекунд, однако, при очень высокой активности записи на диск, во время фазы слияния дельта-файлов замирание может длиться до нескольких секунд.
> Если виртуальная машина является основным или резервным участником зеркалирования Caché, и время замирания больше, чем таймаут QoS для зеркалирования, зеркало может ошибочно сообщить о сбое основной виртуальной машины и инициировать перехват зеркала резервной системой.
Для получения дополнительной информации о параметре QoS при зеркалировании обратитесь к [документации](https://community.intersystems.com/post/documentation%5D(http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror#GHA_mirror_set_tunable_params_qos)). Стратегии, сводящие к минимуму время замирания, включают выбор момента резервного копирования, когда активность базы данных является максимально низкой, а также наличие хорошо настроенной системы хранения.
Как отмечалось выше, при создании снимка есть несколько опций, которые можно указать. Одна из опций позволяет включать сохранение оперативной памяти в снимке. Помните, что сохранение оперативной памяти не требуется для резервного копирования базы данных Caché. Если установлен флаг сохранения памяти, дамп внутреннего состояния виртуальной машины будет входить в снимок. Выполнение снимка с памятью занимает гораздо больше времени. Снимки памяти используются для возврата к такому состоянию виртуальной машины, которое было на момент выполнения снимка. Этого НЕ требуется для резервного копирования файлов базы данных.
> Когда выполняется снимок оперативной памяти, состояние всей виртуальной машины будет **заморожено на неопределенное время**.
Как уже отмечалось ранее, для резервных копий флажок «согласованность» (quiesce) должен быть отмечен, чтобы гарантировать целостное и успешное резервное копирование.
Узнаем время замирания из журналов VMware
-----------------------------------------
Начиная с ESXi 5.0 время замирания регистрируется в файле журнала каждой виртуальной машины (vmware.log) сообщениями, похожими на следующие:
```
2017-01-04T22:15:58.846Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 38123 us
```
Время замирания указывается в микросекундах, поэтому в примере выше 38123 us это 38123/1,000,000 секунд или 0.038 секунды.
Чтобы быть уверенным в том, что продолжительность замирания машины находится в допустимых пределах, или если есть подозрение, что длительное время замирания машины вызывает проблемы, вы можете скачать и просмотреть файлы `vmware.log` из папки этой виртуальной машины. После загрузки вы можете открыть и упорядочить журнал с помощью стандартных команд Linux, которые мы рассмотрим в следующей главе.
### Пример загрузки файлов vmware.log
Существует несколько способов скачать журналы, в том числе путём создания пакета поддержки *(support bundle)* VMware через консоль управления vSphere или из командной строки хоста ESXi. Обратитесь к документации VMware за всеми подробностями, а ниже приведен простой способ создания и сбора минимального пакета журналов поддержки, который включает в себя файл vmware.log, позволяющий узнать продолжительность замирания.
Вам понадобится длинное имя каталога, где расположены файлы виртуальной машины. Зайдите по ssh на тот хост ESXi, где запущена виртуальная машина с базой данных и выполните команду `vim-cmd vmsvc/getallvms` для получения списка vmx файлов и связанных с ними уникальных длинных имён.
Пример длинного имени для базы данных виртуальной машины, упоминающейся в этой статье, будет выглядеть так:
```
26 vsan-tc2016-db1 [vsanDatastore] e2fe4e58-dbd1-5e79-e3e2-246e9613a6f0/vsan-tc2016-db1.vmx rhel7_64Guest vmx-11
```
Далее выполните команду для сбора файлов журнала:
```
vm-support -a VirtualMachines:logs
```
Команда отобразит местоположение созданного пакета поддержки, например:
```
To see the files collected, check '/vmfs/volumes/datastore1 (3)/esx-esxvsan4.iscinternal.com-2016-12-30--07.19-9235879.tgz'
```
Теперь вы можете забрать файлы с хоста для дальнейшей обработки и анализа по протоколу sftp.
В этом примере после распаковки пакета поддержки вы можете проследовать по путям, соответствующим длинным именам баз данных виртуальных машин. Например, в данном случае:
```
/vmfs/volumes//e2fe4e58-dbd1-5e79-e3e2-246e9613a6f0.
```
Там вы увидите несколько пронумерованных лог-файлов. Самый последний файл номера не имеет, это vmware.log. Журнал может быть не более 100 КБ, но при этом будет содержать очень много информации. Поскольку мы просто ищем моменты начала и конца замирания, их достаточно легко найти с помощью утилиты grep, например:
```
$ grep Unstun vmware.log
2017-01-04T21:30:19.662Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 1091706 us
---
2017-01-04T22:15:58.846Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 38123 us
2017-01-04T22:15:59.573Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 298346 us
2017-01-04T22:16:03.672Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 301099 us
2017-01-04T22:16:06.471Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 341616 us
2017-01-04T22:16:24.813Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 264392 us
2017-01-04T22:16:30.921Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 221633 us
```
В примере мы видим две группы замираний. Первая состоит из момента создания снимков, а вторая — через 45 минут для каждого диска при завершении объединения снимка (например, после того, как программное обеспечение для резервного копирования завершило копирование основного vmx файла). В приведенном выше примере мы можем видеть, что большинство замираний не превосходят секунды, хотя начальное замирание составляет чуть более одной секунды.
Короткое замирание незаметно для конечного пользователя. Тем не менее, системные процессы, такие как, например, зеркалирование Caché, постоянно контролируют, является ли база «живой». Если время замирания превышает таймаут QoS для зеркалирования, то узел может быть признан неконтактным и «мертвым», и произойдет обработка аварийной ситуации.
*Совет:* для обзора всех журналов или поиска неисправностей удобно использовать команду grep чтобы найти все времена замираний и затем отформатировать их с помощью утилиты awk и отсортировать, как в следующем примере:
```
grep Unstun vmware* | awk '{ printf ("%'"'"'d", $8)} {print " ---" $0}' | sort -nr
```
Итог
----
Вы должны регулярно контролировать свою систему во время нормальной работы, чтобы знать и понимать величину времени замирания и то, как она может повлиять на средства обеспечения высокой доступности, например, зеркалирование. Как уже отмечалось ранее, стратегии, направленные на то, чтобы свести к минимуму время замирания, включают запуск резервных копий, когда активность базы данных и хранилища низкая и когда производительность хранилища максимальная. Для постоянного мониторинга журналы могут обрабатываться с помощью VMware Log insight или других инструментов.
Я ещё вернусь к операциям резервного копирования для платформ данных InterSystems в будущих статьях. А теперь если у вас есть комментарии или предложения, основанные на процессах, происходящих в ваших системах, поделитесь ими в комментариях.
*Примечание переводчика:* поскольку мы работаем с автором в одном офисе, я могу передать ему ваши вопросы и переслать сюда его ответы. Также обсуждение на английском есть в [оригинале статьи](https://community.intersystems.com/post/intersystems-data-platforms-and-performance-%E2%80%93-vm-backups-and-cach%C3%A9-freezethaw-scripts) на InterSystems Developer Community.
|
https://habr.com/ru/post/334144/
| null |
ru
| null |
# Архитектура Playstation 2

*Оригинальная Playstation 2, выпущенная 04.03.2000 в Японии, 26.10.2000 в Америке и 24.11.2000 в Европе*
Краткое введение
----------------
Playstation 2 не была одной из самых мощных консолей своего поколения, однако смогла достичь уровня популярности, немыслимого для других компаний.
Эта машина даже близко не сравнится по простоте с первой Playstation, но вскоре мы узнаем, почему она не разделила судьбу рассмотренных нами ранее сложных консолей.


*Материнская плата версии «GH-001» модели SCPH-10000, выпускавшейся только в Японии. Благодаря полученным донатам мне удалось купить эту модель и сделать качественное фото, чтобы идентифицировать большинство чипов. Предполагаю, что чип в нижнем правом углу — это BIOS ROM на 4 МБ*

*Оригинальный дизайн (реализованный в версии SCPH-10000). На каждой шине данных указаны ширина и скорость. Эта архитектура подвергалась множеству ревизий, о чём я расскажу ниже.*
CPU
---
Сердцем этой консоли является спроектированный Sony мощный чипсет под названием **Emotion Engine** (EE), работающий с частотой примерно 294,91 МГц. Этот чипсет содержит множество компонентов, одним из которых является CPU, а остальные находятся в распоряжении CPU и предназначены для ускорения выполнения определённых задач.
#### Лидер
Основное ядро — это совместимый с MIPS R5900 ЦП, имеющий множество усовершенствований. Это первый чип, начинающий исполнять команды после включения консоли. Этот процесс обладает следующими особенностями:
* ISA **MIPS III**: 64-битный набор команд RISC. *Постойте, я что-то путаю, или та же ISA использовалась в [конкурирующей консоли](https://www.copetti.org/writings/consoles/nintendo-64/#cpu)?*. Да, это так, но Sony усовершенствовала этот CPU, добавив часть команд из **MIPS IV** (выборку из памяти с упреждением и условную пересылку) вместе с собственным расширением команд SIMD под названием **multimedia instructions** («мультимедийные команды»).
* **32 дополнительных 128-битных регистра**: ещё одно усовершенствование. Ими удобнее было управлять с помощью мультимедийных команд и они очень полезны для обработки векторов.
+ Доступ к этим регистрам выполняется через 128-битную шину, а остальная часть CPU использует внутреннюю 64-битную шину.
* **Двусторонняя суперскалярность**: параллельно выполняется до двух команд.
* **Кэш L1 на 24 КБ**: разделён на 16 КБ для команд и 8 КБ для данных.
+ Также он имеет функцию **prefetch** (выборки из памяти с упреждением) для кэширования команд и данных до того, как они будут запрошены. Это реализовано дополнительной схемой, определяющей, к каким областям памяти доступ выполняется чаще всего.
* **Scratchpad RAM на 16 КБ**: также называемая Fast RAM.
* **Блок управления памятью**: управляет доступом к памяти с остальной частью системы.
Ядро дополнено **выделенным модулем обработки чисел с плавающей запятой** (COP1), ускоряющим операции с 32-битными числами с плавающей запятой (в языке C называемыми `float`).
#### Уже знакомая память
Рядом с Emotion Engine расположены два блока по 16 МБ RAM, в сумме дающие **32 МБ** основной памяти. Используется тип памяти **RDRAM** ([*дежавю!*](https://www.copetti.org/writings/consoles/nintendo-64/#ram-available)), доступ к памяти осуществляется через 16-битную шину.
*Структура памяти Emotion Engine. Можно догадаться, где будут возникать заторы.*
Поначалу это может разочаровать, ведь внутренняя шина Emotion engine имеет ширину целых 128 бит. Однако оба чипа RAM продуманно расположены в соответствии с **двухканальной архитектурой**, заключающейся в подключении обоих чипов двумя независимыми 16-битными шинами (по одной шине на каждый чип) для повышения пропускной способности. В результате такая схема теоретически способна обеспечить скорость 3,2 ГБ/с, поэтому будьте уверены в том, что задержки памяти для этой консоли не проблема!
В сердце Emotion engine находится мощный **контроллер DMA** (DMAC), передающий данные между основной памятью и Scratchpad или между основной памятью и любым компонентом внутри EE. Передача данных выполняется пакетами по 128 бит и здесь есть интересный момент: Через каждые восемь пакетов основная шина временно разблокируется. Это создаёт небольшое окно для параллельного выполнения других передач DMA (до десяти) или для использования основной шины центральным процессором. Такой способ работы называется **slice mode**, он является одним из множества режимов, доступных для этого устройства DMA. Не надо забывать, что хотя этот slice mode снижает простои основной шины, ценой этого является общее замедление передач DMA.
#### Исправление ошибок прошлого
При таком объёме трафика, проходящего внутри Emotion Engine, эта архитектура начнёт страдать от последствий **Unified memory architecture** (UMA): несколько независимых компонентов пытаются одновременно получить доступ к основной памяти, создавая заторы. Чтобы устранить эти проблемы, Sony снизила потребность постоянного использования памяти следующими способами:
* Обернув процессоры **большим объёмом кэша**, благодаря чему доступ к памяти выполняется только в самом крайнем случае.
+ 99% упоминаний кэша/scratchpad в статье будет связано с этим.
* Добавив 128-байтный **буфер обратной записи**: он очень похож на [Write Gather Pipe](https://www.copetti.org/writings/consoles/gamecube/#ibms-enhancements), но вместо того, чтобы ждать своего заполнения на 25%, он выполняет запись в память, наблюдая за состоянием шины.
Это кажется очень удобным для приложений, способных пользоваться преимуществами кэша, но что насчёт тех задач, которые вообще не используют кэш, например, манипуляции с таблицами отображения (Display Lists)? К счастью, у ЦП есть другой режим доступа под названием **UnCached**, который использует только буфер обратной записи, не тратя такты на исправление кэша (которое происходит при *промахах кэша*). Более того, существует **ускоренный режим UnCached**, добавляющий буфер для ускорения считывания соседних адресов в памяти.
#### Другие интересные элементы
Внутри того же корпуса Emotion Engine есть ещё один процессор под названием **Image Processing Unit** (IPU), спроектированный для распаковки изображений. Он может быть полезным, когда игре нужно декодировать фильм в MPEG2, не загружая основной ЦП. Игра отправляет потоки сжатых изображений в IPU (по возможности с использованием DMA), а они потом декодируются в формат, который может отображать GPU. Операционная система PS2 также использует IPU для воспроизведения DVD.
Кроме того, IPU также позволяет манипулировать сжатыми **текстурами высокого разрешения**, что экономит ресурсы ЦП и позволяет избежать больших объёмов передаваемых данных.
Сопроцессоры
------------
Прошло уже два года с тех пор, как конкуренты представили свой [последний продукт](https://www.copetti.org/writings/consoles/dreamcast/). Если вы читали статью про Dreamcast, то, предполагаю, до сих пор ждёте упоминания того, что сделало PS2 такой мощной, какой она казалась в момент выпуска. Теперь я расскажу об *очень* важном наборе компонентов, которые Sony поместила в Emotion Engine — блоках **Vector Processing Unit** (VPU).
Vector Processing Unit — это небольшой независимый процессор, предназначенный для работы с векторами, в частности, с векторами, состоящими из четырёх значений `float`. Эти процессоры настолько быстры, что тратят на операцию всего один такт, что может быть чрезвычайно полезно для обработки геометрии.
VPU состоят из следующих компонентов:
* **Vector Unit**: ядро процессора. Содержит немного памяти (называемой **Micro Memory**) для хранения программы (называемой **Microprogram**), которая сообщает блоку, как оперировать данными, находящимися во VU Mem.
+ В нём используется 64-битная ISA, а блок исполнения разделён на два параллельных подблока. Первый умножает или складывает числа с плавающей запятой (float), а другой делит float или оперирует с целочисленными значениями (integer). Это позволяет параллельно оперировать и float, и integer.
* Немного **Vector Unit Memory** (VU Mem). Используется как рабочее пространство для Vector unit. Эта память хранит значения, с которыми нужно производить операции и/или результаты предыдущих операций.
* **Vector Interface**: автоматически распаковывает данные вершин, поступающие из основной памяти в формате, с которым может работать Vector unit. Также этот блок может передавать микропрограммы в Micro Memory.
Векторный блок нужно «завести», чтобы он начал работать; для этого основной ЦП передаёт нужный микрокод. В Emotion engine есть **два VPU**, но они имеют разную схему, что позволяет использовать их по-разному и оптимизировать работу.
#### Vector Processing Unit 0
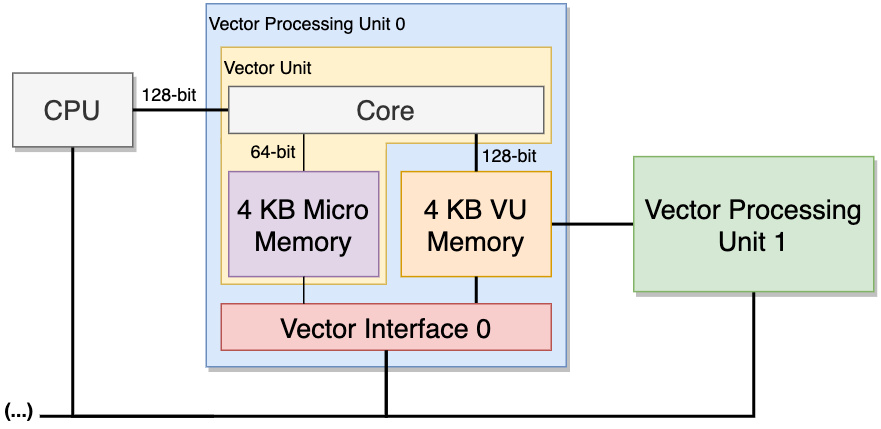
*Архитектура VPU0*
Первый VPU, имеющий обозначение **VPU0**, расположен между ЦП и другим векторным блоком (VPU1). Он является «вспомогательным» для основного ЦП.
VPU0 имеет два режима работы:
* **Micromode**: традиционный режим, исполняющий «микрокоманды» (microinstructions) из микропрограммы (microprogram), хранящейся в Micro memory. При этом он работает независимо.
* **Macromode**: VPU0 превращается в COP2 основного ЦП и исполняет «макрокоманды» (macro-instructions), получаемые от основного ЦП через выделенную 128-битную шину.
+ Макрокоманда имеет ту же функциональность, что и микрокоманды, но использует другие опкоды. Однако теперь блок исполнения VPU больше не разделён (то есть может исполнять за раз только одну команду).
+ Хотя этот режим и не использует полностью все компоненты VPU0, он ускоряет векторные операции ЦП, к тому же сопроцессор программировать проще, чем отдельное устройство (это будет полезным для программистов на PC).
Схема распределения памяти VPU0 также имеет доступ к некоторым другим регистрам и флагам VPU, предположительно для того, чтобы проверять их состояние или быстро считывать результаты операций, выполненных другим VPU.
#### Vector Processing Unit 1
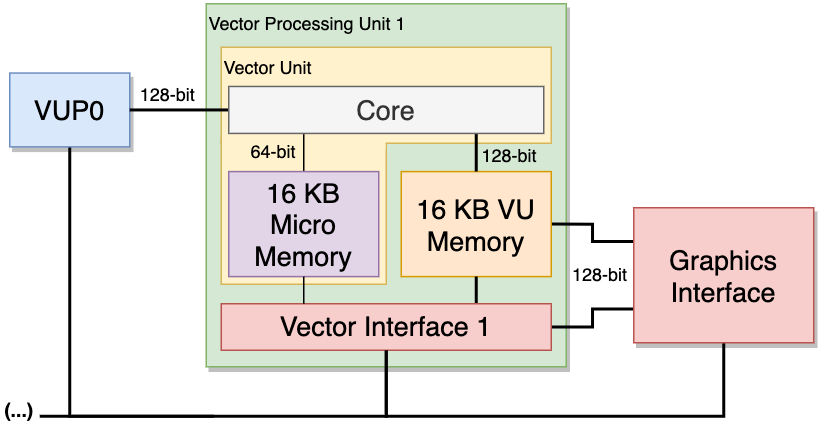
*Архитектура VPU1*
Второй VPU, называющийся **VPU1** — это расширенная версия VPU0 с удвоенным объёмом микропамяти и памяти VU. Кроме того, в этом блоке есть дополнительный компонент под названием **Elementary function unit** (EFU), ускоряющий исполнение степенных и тригонометрических функций.
VPU1 расположен между VPU0 и Graphics Interface («шлюзом» к GPU), поэтому он содержит дополнительные шины для максимально быстрой передачи геометрии в GPU без использования основной шины.
VPU1, в том числе и из-за своего расположения, **работает только в micromode**.
Очевидно, что этот VPU оптимизирован под тригонометрические операции и может использоваться в качестве препроцессора GPU, обеспечивая передачу знаменитых таблиц отображения (Display Lists).
#### Бесконечные миры
Полезная техника, которую можно реализовать с помощью этих блоков — это **процедурная генерация**. Другими словами, вместо построения сцены из жёстко прописанной геометрии можно позволить блокам VPU генерировать её алгоритмически. В таком случае VPU вычисляет **математические функции для создания геометрии**, которая может интерпретироваться GPU (например, треугольников, линий, четырёхугольников и т.д.) и в конечном итоге использоваться для отрисовки сцены.
В отличие от заданных явным образом данных, процедурный контент идеально подходит для распараллеленных задач, он разгружает канал, требует очень мало места и является динамическим (использует параметры для достижения разных результатов). Некоторые элементы значительно выигрывают от использования этой техники:
* **Сложные поверхности** (например, сферы и колёса).
* **Рендеринг мира** (например, рельефы, частицы, деревья).
* **Кривые Безье** (очень популярное в компьютерной графике уравнение, используемое для отрисовки кривых), которые превращаются в **поверхность Безье** (явно заданную геометрию) и поддерживает разные степени точности в зависимости от требуемой детализации.
С другой стороны, процедурный контент может сталкиваться с трудностями при анимировании и если алгоритм слишком сложный, VPU может и не сгенерировать геометрию за требуемое время.
Подведём итог: процедурный рендеринг — не новая технология, но благодаря VPU он открывает возможности дальнейших оптимизаций и более качественной графики. Тем не менее, это непростая в реализации техника и научно-исследовательский отдел Sony опубликовал несколько статей о различных подходах, которые можно использовать на консоли компании.
#### Рабочий процесс выбираете вы
Благодаря этим новым возможностям программисты могут с большой гибкостью проектировать графические движки. Опубликовано множество статей, анализирующих бенчмарки архитектур популярных конвейеров.
Вот несколько примеров графических конвейеров с различными оптимизациями:
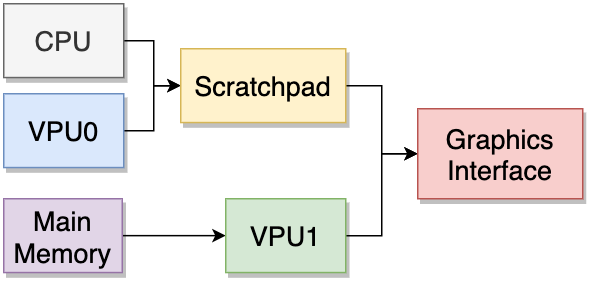
*Архитектура параллельного конвейера*
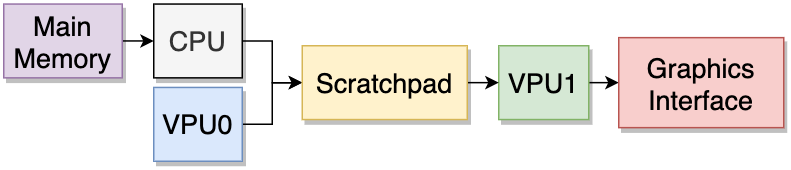
*Архитектура последовательного конвейера*
В первом примере (**параллельная** архитектура) ЦП (CPU) комбинируется с VPU0 в макрорежиме для создания геометрии параллельно с VPU1. Группа CPU/VPU0 полностью использует scratchpad и кэш, чтобы избежать использования основной шины, которую VPU1 использует для получения данных из основной памяти. В конце обе группы рендеринга паралелльно отправляют свои таблицы отображения в GPU.
Во втором примере (**последовательная** архитектура) используется другой подход, при котором группа CPU/VPU0 выполняет задачи препроцессора для VPU1. Первый этап получает и обрабатывает всю геометрию, которую VPU1 в дальнейшем превратит в таблицу отображения.
Существует и множество других примеров, поэтому программист сам может выбирать оптимальную схему, и это хорошо.

*Частицы, составляющие пламя свечей и свет, падающий из окна. Crash Bandicoot: The Wrath of Cortex (2001 год)*
Джон Бартон (бывший директор Travellers Tales) объяснил, как его команда реализовала систему частиц, полностью поместившуюся в VPU1. VPU1 получал из памяти предварительно заполненную базу данных, которая затем использовалась для вычисления координат частиц в текущий момент времени, результат можно было преобразовать в таблицы отображения и сразу же передать дальше.
Благодаря такой методике значительно снижена нагрузка на ЦП, что позволяет ему выполнять другие задачи, например, расчёт ИИ и физики.
Графика
-------
Учитывая, что вся работа выполняется процессором Emotion Engine, остаются ли ещё какие-то задачи? На самом деле остаётся последний шаг: отображение на экране!
*Final Fantasy X (2001 год)*
В консоли есть простой, но скоростной чип, специализирующийся на этой функции: **Graphics Synthesizer** (GS), работающий с частотой примерно 147,46 МГц. Он содержит 4 МБ встроенной внутрь памяти DDRAM, чтобы выполнять всю обработку самостоятельно, избавляясь таким образом от необходимости доступа к основной памяти. Доступ к встроенной RAM выполняется при помощи различных шин, в зависимости от типа необходимых данных.
GS имеет меньше функций, чем [ранее рассмотренные](https://www.copetti.org/writings/consoles/gamecube/#graphics) на этом сайте другие графические системы. Тем не менее, со своими задачами он справляется очень быстро.
### Архитектура и конструкция
Этот GPU занимается только **растеризацией**, то есть генерацией пикселей, наложением текстур, применением освещения и некоторыми другими эффектами. Это означает, что в нём нет преобразований вершин (их выполняют VPU). Кроме того, он является конвейером с фиксированными функциями, поэтому в нём невозможны [хитрые настройки](https://www.copetti.org/writings/consoles/gamecube/#creativity) или [шейдеры](https://www.copetti.org/writings/consoles/xbox/#graphics), можно использовать только постоянную модель затенения (например, по Гуро).
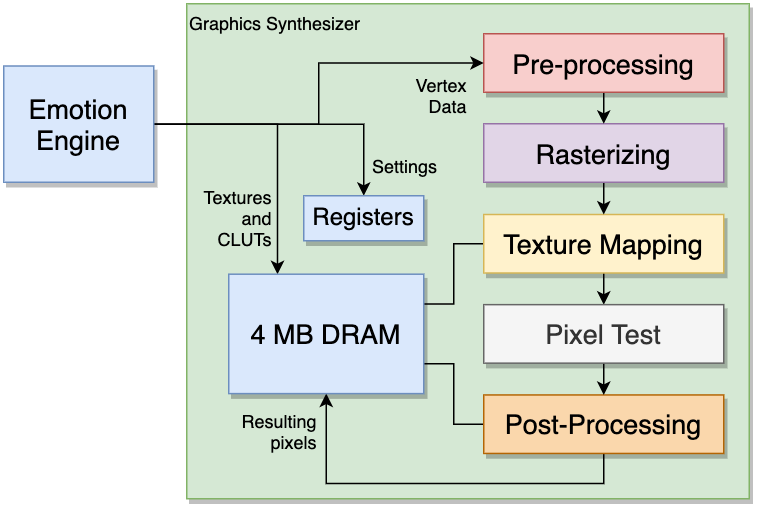
*Структура конвейера Graphics Synthesizer*
Выглядит довольно просто, верно? Давайте подробнее рассмотрим, что происходит на каждом из этапов.
#### Препроцессинг
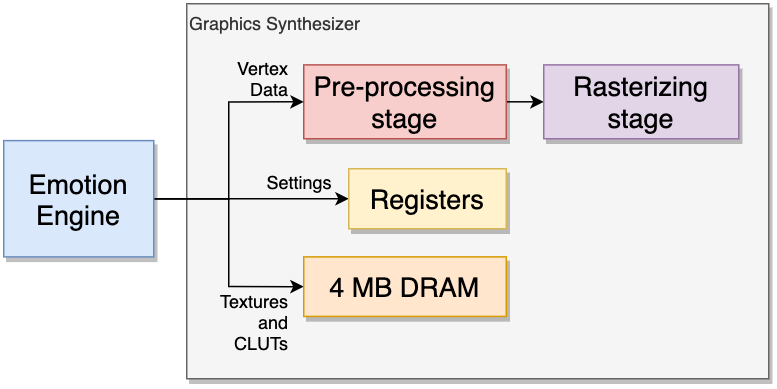
*Этап препроцессинга*
Emotion Engine запускает Graphics Synthesizer, заполняя встроенную DDRAM требуемыми материалами (**битовыми картами текстур** и **таблицами поиска цветов**, также известными под названием CLUT), назначает значения регистров GS, чтобы сконфигурировать его, а в конце отдаёт команды отрисовки (таблицы отображения), которые приказывают GS отрисовывать примитивы (точки, отрезки, треугольники, спрайты и т.п.) в нужных местах экрана.
Затем GS выполняет препроцессинг некоторых значений, которые потребуются для дальнейших вычислений. Самым важным из них является изначальное значение для **Digital Differential Algorithm**, который будет использоваться для интерполяций при отрисовке.
#### Растеризация
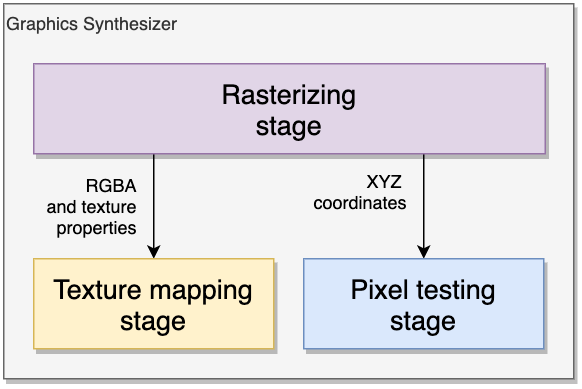
*Этап растеризации*
Используя предыдущие вычисленные значения, рендерер генерирует пиксели примитивов. Этот блок может параллельно генерировать 8 пикселей (с текстурами) или 16 пикселей (без текстур), и каждая запись пикселя содержит следующие вычисленные значения:
* **RGBA**: соответствует градиенту Red, Green, Blue и Alpha (прозрачности).
* **Z-value**: используется для проверки глубин на последующих этапах.
* **Туман**: для включения эффектов тумана.
* **Свойства текстур**: указывают адрес текстуры в DRAM и другие свойтва (координаты, уровень детализации, фильтрацию и т.п.), которые будут использоваться на следующем этапе.
Также на этом этапе выполняются **Scissoring Tests** для отбрасывания полигонов, находящихся вне области кадра (на основании из значений X/Y); некоторые свойства пикселей передаются на этап тестирования пикселей для дальнейших проверок.
Затем пакет передаётся в движок наложения текстур, но каждое свойство передаётся специализированному «субдвижку», что позволяет обрабатывать различные свойства параллельно.
**Освещение** также обеспечивается выбором одного из двух возможных вариантов, затенения **по Гуро (Gouraud)** и **плоского (Flat)**.
#### Текстуры
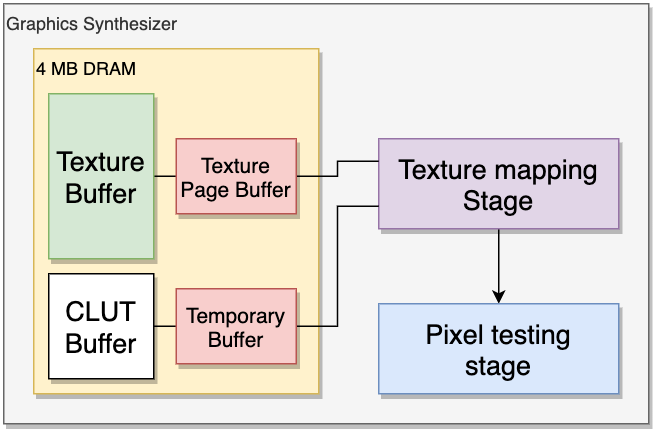
*Этап наложения текстур*
Этот этап выполняется большим «пиксельным блоком» (Pixel Unit), способным одновременно вычислять до 16 пикселей. На этом этапе текстуры накладываются на полигоны. Кроме того, могут быть наложены эффекты тумана и сглаживания.
Карты текстур запрашиваются из DRAM в области, называемой **буфером текстур** (Texture Buffer), однако взаимодействие с ней обеспечивается отдельной областью, называемой **буфером страниц текстур** (Texture Page Buffer); похоже, она используется как механизм кэширования текстур. CLUT также накладываются с помощью этой системы страниц. Оба элемента передаются по **512-битной шине**.
Pixel Unit выполняет **коррекцию перспективы** для наложения текстур на примитивы (это стало значительным усовершенствованием по сравнению с [аффинным наложением](https://www.copetti.org/writings/consoles/playstation/#tab-1-3-textures) PS1). Более того, он также обеспечивает **билинейную и трилинейную фильтрацию**, в дальнейшем она используется вместе с текстурами с mip-уровнями.
#### Тестирование
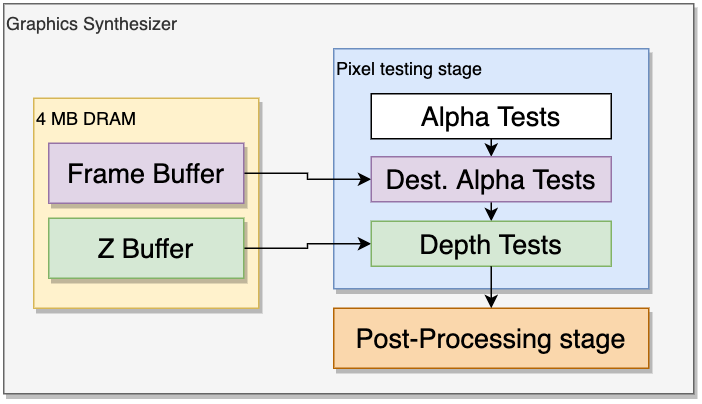
*Этап тестирования пикселей*
На этом этапе отбрасываются некоторые пиксели, не отвечающие определённым условиям. Выполняются следующие тесты:
* **Альфа-тест**: альфа-значение (прозрачность) пикселя сравнивается со «стандартным» значением. Это нужно, потому что в определённых случаях альфа-значение должно находиться в определённом диапазоне или быть больше/меньше произвольного значения.
* **Тест альфа-значения результата**: альфа-значение пикселя снова проверяется перед отрисовкой в буфер кадров.
* **Тест глубин**: Z-value пикселя сравнивается с соответствующим Z-value в Z-буфере. Это позволяет не обрабатывать пиксели, которые окажутся скрытыми за другими пикселями.
#### Постобработка
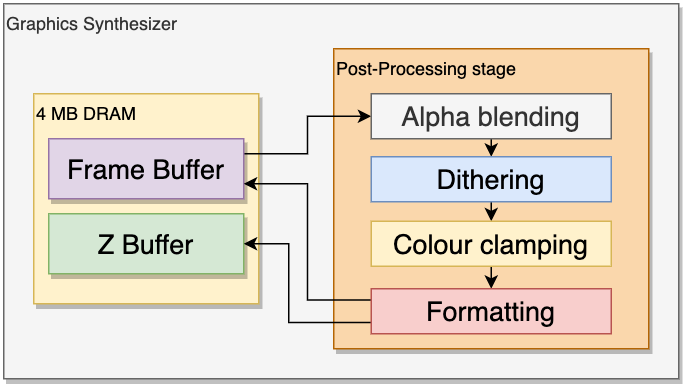
*Этап постобработки*
На последнем этапе могут применяться некоторые эффекты при помощи находящегося в DDRAM буфера кадров:
* **Альфа-смешение**: сливает цвета текущего буфера с предыдущим буфером в памяти.
* **Дизеринг**: большие значения RGBA необходимо урезать, поэтому для снижения потери точности можно применять дизеринг.
* **Ограничение цветов**: после применения таких операций, как альфа-смешение, новое значение RGB может превосходить допустимый интервал (0-255), поэтому ограничение (clamping) переносит значение в нужный интервал.
* **Форматирование**: этот эффект преобразует сгенерированный в конвейере готовый буфер кадров в формат, который можно хранить в памяти.
Затем новый буфер кадров с обновлённым Z-буфером записываются в памяти через **1024-битную шину**.
#### Дополнительная постобработка
Внутри GS есть специализированный компонент под названием **Programmable CRT Controller** (PCRTC), передающий находящийся в памяти буфер кадров на видеовыход, чтобы кадр отобразился на экране телевизора. Но это ещё не всё: также он содержит в себе специальный блок под названием **Merge Circuit**, позволяющий выполнять альфа-смешение двух отдельных буферов кадров (это полезно, когда играм нужно повторно использовать предыдущий кадр для создания нового). Получившийся кадр можно вывести через видеосигнал и/или записать обратно в память.
#### Улучшенные модели
Благодаря описанным выше системам разработчики игр могли улучшить дизайн уже известных персонажей. Взгляните на эти сравнения:

*Crash Bandicoot (1996 год) для PS1, 732 треугольника*

*Crash Bandicoot: The Wrath of Cortex (2001 год), 2226 треугольников*
А вот персонажи из новых серий игр, изначально моделировавшиеся с высоким уровнем детализации:

*Kingdom Hearts (2002 год), 2744 треугольника*

*Dragon Quest VIII (2004 год), 2700 треугольников*
Стоит упомянуть, что в играх наподобие *Dragon Quest* реализована собственная модель освещения под названием **Cel Shading** (этот термин я уже упоминал [ранее](https://www.copetti.org/writings/consoles/gamecube/#creativity)), однако в предыдущих статьях говорилось, что за это в основном отвечает GPU. В случае PS2 для реализации такой модели освещения требовались вычисления цветов, предположительно выполняемые Emotion Engine, поскольку GS не так гибок, как другие GPU.
#### Вывод видео
Как говорилось выше, PCRTC отправляет буфер кадров через видеосигнал; для совместимости с телевизорами из любых географических регионов он может транслировать видео в следующих форматах:
* **PAL**: передаёт до 640x512 пикселей с частотой 50 Гц, как в прогрессивном (576p) режиме, так и с чересстрочной развёрткой (576i).
+ Ни одна из продаваемых игр не использует 576p. Хотя некоторые игры поддерживают прогрессивный режим, они обеспечивают разрешение всего 480p.
* **NTSC**: до 640x448 пикселей с частотой 60 Гц, или в прогрессивном (480p), или в чересстрочном (480i) режиме.
* **VESA**: до 1280x1024 пикселей.
* **DTV**: до *огромного разрешения* в 720x480 пикселей в прогрессивном режиме или 1920x1080 в чересстрочном режиме.
+ Означает ли это, что PS2 может отображать HD-изображение? Теоретически это правда, но я не думаю, что большинство игровых студий рискнуло бы повышением требований ради формата, который ещё не был популярен.

*Правая задняя часть консоли, на которой видны разъёмы питания, цифровой аудиоразъём и AV Multi Out*
Консоль имела довольно много режимов, но основной вопрос заключался в популярности разных форматов в начале 2000-х, что сводило выбор только к PAL и NTSC. Кроме того, хотя PAL обеспечивал большее разрешение, чем NTSC, в некоторых европейских играх NTSC-игр использовалась обрезка кадра (letterboxing) для сокрытия неиспользуемых горизонтальных линий и замедление частоты обновления, чтобы уместиться в ограничение 50 Гц. Я называю такие игры «плохими портами»!
Разъём видеовыхода (**Multi A/V**) очень удобен. Он выводит сигнал RGB, компонентный, S-Video и композитный. То есть можно было использовать все важные сигналы без необходимости покупки проприетарных адаптеров и внутренних модификаций консоли.
Звук
----
Новый аудиочип стал усовершенствованной версией старого [SPU](https://www.copetti.org/writings/consoles/playstation/#audio) и получил название **SPU2**. В список улучшений вошло появление **2 МБ внутренней памяти** и **наличие 48 каналов** (в два раза больше, чем у PS1).
SPU2 состоит из двух процессоров обработки звука (называемых **CORE0** и **CORE1**), работающих на частоте примерно 36,86 МГц и обрабатывающих по 24 канала.
Любопытно, что они по-прежнему являются двумя независимыми процессорами, конфигурируемыми изменением регистров, однако Sony предупредила разработчиков, что оба набора регистров должны задаваться с интервалом в 1/48000 секунды. Если слишком поторопиться, то поведение SPU2 становится непредсказуемым!
Он содержит те же эффекты, что и первый SPU. Память устройства используется в качестве «рабочей области»: в ней можно хранить сырые данные о сигнале и резервировать место для их обработки, а также применения к ним эффектов. Кроме того, чип может микшировать все каналы, обеспечивая стереовывод. А теперь об интересном: SPU2 может подавать на себя в качестве новых входящих данных микшированный стереосэмпл, что позволяет EE получать к нему доступ (например, чтобы микшировать его с дополнительным звуком) или продолжать добавлять новые эффекты.
Такие цифровые эффекты, как реверберация, эхо и задержка, можно реализовать циклическим обходом выходных данных CORE0, памяти и сэмплов, обрабатываемых в CORE1. Для этого требуется резервирование большой части памяти.
*Без реверберации, Kingdom Hearts II (2005 год)*
*С реверберацией, Kingdom Hearts II (2005 год)*
Сигнал выводится через **Digital audio** (называемый Sony/Philips Digital Interface, или S/PDIF) или через **Analog Audio** (проходящий через ЦАП и оканчивающийся разъёмом Multi A/V).
Ввод-вывод
----------
Ввод-вывод PS2 несложен, однако многочисленные версии консоли полностью изменили различные внутренние и внешние интерфейсы.
Начнём с того, что в консоли есть специализированный процессор, управляющий коммуникациями между различными компонентами. Этот ЦП — не что иное, как **оригинальное ядро на основе MIPS R3000**, которое использовалось в [Playstation 1](https://www.copetti.org/writings/consoles/playstation/#cpu). На этот раз он называется **IOP**, работает с частотой 37,5 МГц и использует 32-битную шину.
IOP обменивается данными с Emotion Engine при помощи специализированного интерфейса ввода-вывода под названием **System Interface** (SIF). Обе конечные точки для обмена данными друг с другом используют свои блоки DMA. Также IOP имеет собственную память, применяемую в качестве буфера. IOP предоставляет доступ к разъёмам на передней части устройства, к DVD-контроллеру, SPU2, BIOS ROM и разъёму PC card.
#### Унаследованная совместимость
Можно заподозрить, что благодаря использованию ЦП PS1 будет каким-то образом реализована совместимость с этой консолью. Очень удобно, что в IOP содержится остальная часть компонентов, образующая подсистему ЦП консоли PS1, а у ядра можно опустить частоту, чтобы оно работало со скоростью PS1. К сожалению, SPU2 слишком изменился по сравнению с версией из PS1, но для решения этой задачи используется Emotion Engine, эмулирующий старый SPU.
В последующих версиях консоли IOP был заменён на **PowerPC 401 ‘Deckard’** и **4 МБ SDRAM** (на 2 МБ больше, чем ранее). Обратная совместимость сохранилась, но уже была реализована программно.
#### Доступные интерфейсы
В этой консоли сохранились передние разъёмы, существовавшие в первой Playstation, однако появилась и пара «экспериментальных» интерфейсов, поначалу выглядевших очень многообещающе.

*Передняя панель PS2, на которой видны стандартные разъёмы, в том числе для контроллеров и карт памяти, плюс новые USB и i.Link*
Наиболее популярные нововведения: **два порта USB 1.1**, активно использовавшихся различными аксессуарами и сохранившиеся во всех последующих версиях.
А как насчёт «пропавших» разъёмов? Начнём с того, что существовал передний **разъём i.Link** (также известный под именем IEEE 1394, или Fireware в мире Apple). Этот разъём использовался для подключения двух PS2 и реализации локального мультиплеера и был удалён после третьей версии (предположительно, его заменили на Network card; см. подробности ниже).
На задней панели консоли есть разъём для **PC card**. Можно было купить Network Adaptor card производства Sony, обеспечивающую два дополнительных разъёма: один для подключения кабеля Ethernet, другой для подключения проприетарного и внешнего Hard Disk Drive Unit, также продававшегося Sony. Наличие жёсткого диска позволяло хранить временные данные игр (или даже устанавливать их туда) для ускорения загрузки. Однако эту функцию использовали очень немногие игры.

*Отсек жёсткого диска на задней части PS2 (со снятой крышкой)*

*Передняя часть сетевого адаптера. Конкретно в этой модели есть разъёмы модема и ethernet*

*Сетевой адаптер, вид сзади, с установленным жёстким диском*

*Задняя панель slim-модели с несъёмным портом ethernet*
В последующих версиях разъём PCMCIA заменили на отсек **Expansion Bay**, через который внутрь консоли можно было установить 3,5-дюймовый жёсткий диск. Для начала надо было купить **сетевой адаптер**, в котором присутствовали не только разъёмы модема и/или ethernet (в зависимости от модели), но и разъёмы, необходимые для подключения жёсткого диска ATA-66. В «Slim»-версиях эта особенность пропала, зато появился несъёмный разъём ethernet, находящийся на задней панели. Кроме того, в новой версии появился новый передний порт — **инфракрасный датчик**.
#### Интерактивные аксессуары
Новая версия контроллера, **DualShock 2**, является слегка усовершенствованной версией DualShock. Во времена первой Playstation было выпущено множество версий оригинального контроллера с различными функциями, а значит, возникла и разрозненность. Теперь ради удобства разработчиков, использовался единственный контроллер, в котором были стандартизированы все появившиеся ранее функции.

*DualShock 2*

*Карта памяти*
По сравнению с DualShock, новая версия имеет незначительный редизайн, два аналоговых стика и два вибромотора для удобства ввода.
Рядом с разъёмом контроллера расположен разъём карты памяти **Memory Card**, совместимый с картами PS1 и PS2. В новых картах встроены дополнительные схемы для повышения защиты, называемые **MagicGate**; они позволяют играм блокировать передачу данных между разными картами памяти.
Операционная система
--------------------
На материнской плате установлен чип **ROM на 4 МБ**, хранящий большой объём кода, используемого для загрузки меню оболочки, с которой могут взаимодействовать пользователи; также он выполняет системные вызовы для упрощения доступа ввода-вывода, которые используются играми.
При загрузке ЦП исполняет команды в ROM, которые, в свою очередь:
1. Инициализируют оборудование.
2. Загружают **ядро** в ОЗУ, оно будет обрабатывать системные вызовы, а также обеспечит поддержку многопоточности (кооперативную и основанную на приоритетах).
3. Запускают процессор IOP и отправляют ему **модули**, позволяющие IOP управлять оборудованием консоли. В конце IOP переключается в состояние ожидания команды.
* Использование модулей позволило Sony выпускать новые версии оборудования без изменения IOP, что снизило затраты на производство.
4. Загружают модуль `OSDSYS`, отображающий анимацию заставки меню оболочки.

*Анимация заставки после включения консоли*

*Логотип PS2, отображающийся после вставки диска с официальной игрой PS2*
#### Интерактивная оболочка
Функциональность оболочки этой консоли очень походит на другие консоли того же поколения.
*Первоначальное меню, когда не вставлен диск*

*Браузер карты памяти*

*Браузер сохранений после выбора карты памяти*
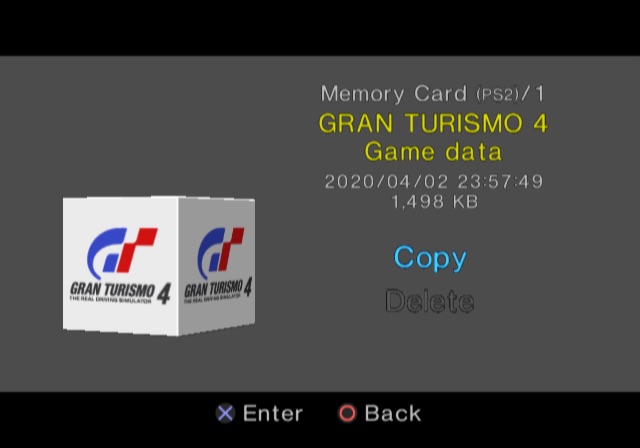
*Редактор сохранения после выбора сохранения*
*Системные конфигурации*
В оболочке есть удобные разделы, позволяющие выполнять повседневные операции, например, управление сохранениями на карте памяти. Также в ней есть дополнительные опции, например изменение текущего видеорежима.
Игры
----
В нулевые эта консоль достигла беспрецедентного уровня популярности, поэтому к концу её срока жизни (в 2013 году, спустя 13 лет!) библиотека игр состояла из 1850 названий.

*Когда кто-нибудь заявляет об изобилии игр для PS2, я вспоминаю вот эту, Mr Moskeeto (2001 год)*
Такая популярность весьма впечатляет. PS2 не обладает особо «дружественной для разработчиков» архитектурой (с точки зрения программиста для PC), однако учитывая количество созданных игр, можно задаться вопросом, повлияли ли на это какие-то другие факторы (например, более мягкая лицензия, низкие затраты на распространение, стоимость разрабтки, маленький размер корпуса и т.д.).
#### Экосистема разработки
Для помощи в разработке игр Sony предоставляла оборудование и ПО.
ПО называлось **Playstation 2 SDK** и состояло из следующих элементов:
* Тулчейн Emotion Engine: набор компиляторов C и C++, ассемблеров, компоновщиков и отладчиков, используемых для управления каждой частью EE. Основной ЦП обычно программировали на C/C++, однако, код критичных для производительности компонентов, например, векторных блоков, писался на ассемблере (микрокод/макрокод).
+ В пакет также входил «симулятор Emotion Engine», позволявший приблизительно тестировать код без передачи его на оборудование консоли, однако симулятор не был таким же точным, как физический чип EE.
+ Все эти инструменты работали в Linux, Solaris и Windows. Выпущенный позже работал через среду Cygnus.
* Низкоуровневые библиотеки: обеспечивали интерфейс для многих системных функций (при помощи вызовов BIOS).
* Инструменты анализа для профилирования производительности.
* Дополнительные инструменты для соединения с официальным оборудованием для разработки.
Sony предоставляла студиям-разработчикам специализированное оборудование для запуска и отладки игр. Изначально комплекты разработки (devkit) представляли собой собранные вместе голые платы, напоминавшие невыпущенное оборудование PS2. Позже эти комплекты, называемые **Development Tool**, получили более презентабельный внешний вид, улучшенный ввод-вывод и соединили в одном устройстве оборудование рабочей станции (под управлением RedHat 5.2) и оборудование PS2 для сборки и выпуска игры.
Комбинация из Devkit, официального SDK и Codewarrior (знаменитого IDE) была очень популярной схемой.
#### Носитель
Дисковый привод мог считывать и DVD, и CD, поэтому игры можно было распространять в любом из этих форматов, но по очевидным причинам большинство продавалось на DVD.

*Типичная розничная коробка и диск с игрой, Kingdom Hearts II (2005 год)*
На DVD можно записать до **4,7 ГБ** данных (в наиболее распространённой версии формата DVD-5) или 8,5 ГБ в случае DVD-9 (двуслойная версия, менее популярная). На самом деле, есть и третий формат, DVD-10, тоже двусторонний, но он не использовался ни для одной из игр.
Благодаря типу выбранного носителя можно было не только запускать игры, но и смотреть фильмы. Для этого требуется декодер, способный считывать формат фильмов DVD, и для этого необходимые части программы устанавливались на карту памяти PS2 (в конце концов, карта — это просто носитель для хранения данных), однако в более поздних версиях ПО DVD сразу устанавливалось в BIOS ROM.
Диски CD-ROM считывались со скоростью 24x (то есть 3,6 МБ/с), а DVD-ROM — со скоростью 4x (5,28 МБ/с).
#### Сетевой сервис
Как мы уже знаем, сетевые функции этой консоли были стандартизированы только в последующих версиях, появившихся спустя четыре года после первой версии. Поэтому если игровые студии решали предоставлять онлайн-услуги (например, мультиплеер), то они должны были самостоятельно обеспечивать всю необходимую инфраструктуру. В последующие годы Sony выпустила **Dynamic Network Authentication System** (DNAS). Это был не онлайн-сервер, а система авторизации, предотвращающая подключение пиратских игр к онлайну.
#### Необычный тип игры
Кроме всех этих игр с *крутой графикой* Sony выпустила дистрибутив Linux на основе Kondara (который, в свою очередь, был основан на Red Hat 6), поставлявшийся на двух DVD (первый диск назывался Runtime Environment, а второй — Software Packages), а также VGA-адаптер, USB-клавиатуру и мышь, плюс руководства разработчика. Этот комплект назывался **Linux Kit**, с его помощью можно было запустить ОС, сначала загрузившись с первого DVD, а затем выполнив все шаги, привычные для *олдскульной* среды Linux. Очевидно, что для этого требовалось подключение к консоли жёсткого диска; после установки на жёсткий диск для запуска ОС всегда требовался DVD.
Linux Kit содержал в себе компиляторы для EE (gcc 2.95.2 с glibc 2.2.2) и ассемблеры для векторных блоков, а также оконную систему (XFree86 3.3.6), «ускоряемую» устройством Graphics Synthesizer. В целом это кажется интересной средой. На самом деле, одна из статей, которые я читал при подготовке этого поста, была написана на такой конфигурации.
Защита от пиратства и Homebrew
------------------------------
Здесь нам многое предстоит обсудить, так что давайте начнём с привода DVD.
#### Защита от копирования
Этот аспект беспокоил игровые студии особенно сильно, потому что в консоли для хранения игр использовался очень доступный формат дисков с крайне высокой вероятностью пиратского копирования.

*Этот экран с сообщением об ошибке мог появиться при неисправности привода… или если был вставлен пиратский диск*
Когда ОС загружает игру, этот процесс выполняется передачей определённых команд приводу DVD. Команды, конкретно предназначенные для считывания контента игры, ведут себя сильно иначе, чем остальные команды (которые могут использоваться, например, для считывания фильма на DVD). Оказывается, официальные игры содержат во внутреннем разделе диска недоступный пользователю файл распределения памяти (map file), индексирующий файловую систему по имени, позиции и размеру. Когда привод DVD получает команду считать игровой диск, он всегда перемещается по диску с помощью map file, то есть спираченную копию игры, не содержащую этот файл, считать будет невозможно. Эта защита дополнена системой региональной блокировки, не позволяющей запускать импортированные игры на консоли из другого региона.
#### Обнаруженные возможности эксплойтов
Рассказывая о самой критически важной части консоли, давайте рассмотрим обнаруженные на протяжении срока её жизни способы, позволяющие обойти различные механизмы защиты.
#### Модчипы
Как и в случае с другими консолями того поколения (а также предыдущего) с дисковыми носителями, реверс-инжиниринг DVD-подсистемы с целью поиска эксплойта, заставляющего драйвер считывать файловую систему без необходимости map file, был всего лишь вопросом времени.
В конечном итоге эксплойты приняли облик **модчипов**, также устранявших региональную блокировку.
#### Читы
Наряду с модчипами, для установки которых требовались навыки пайки, на рынке появились неавторизованные, но «подлинные» диски, позволяющие обойти региональную защиту и использовать внутриигровые читы при помощи патчинга ОС. Они были удобны тем, что не требовали взлома консоли. Думаю, лучшим примером таких читов является *CodeBreaker*.
#### Подмена дисков
В процессе разработок появился ещё один трюк. На этот раз он эксплуатировал особенности работы со сбойными секторами считывающего устройства. **Swap Magic** выглядел как ещё один «подлинный» диск, но его «игра» приказывала DVD считывать несуществующий исполняемый файл, находящийся в произвольном сбойном секторе, что вызывало останов драйвера. Это окно возможностей позволяло пользователям заменить диск на пиратский. Затем Swap Magic, по-прежнему загруженный в память, запускал основной исполняемый файл нового диска, загружая в конце настоящую игру. При этом драйвер продолжал считать, что вставлен подлинный диск.
Такая методика не всегда требовала внесения изменений в консоль. Однако в некоторых моделях необходимо было вскрыть внешний корпус PS2, чтобы заблокировать датчики извлечения привода (в некоторых случаях достаточно было подложить в определённые точки вату).
#### Переполнение PS1
PS2 хранит на карте памяти файл базы данных под названием `TITLE.DB`, содержащий параметры для оптимизации эмуляции игр PS1. При вставке диска с игрой PS1 ОС запрашивает файл базы данных и загружает весь файл в фиксированный адрес памяти (*первая ошибка*). Парсер параметров реализован при помощи **`strncpy()`** — функции языка `C`, копирующей строки (последовательность символов) из одного места в другое.
Люди, знакомые с языком `C`, вероятно, догадались, к чему я веду. Дело в том, что `strncpy()` не знает длину строки, поэтому она не завершена (символом `\0` в конце строки), копия продолжается «бесконечно» (с непредсказуемыми результатами!). К счастью, эта функция имеет дополнительный параметр, указывающий максимальное количество копируемых байтов, что защищает копирование от переполнения буфера. Как бы ни абсурдно это не звучало, **Sony не использовала этот параметр**, хотя каждой записи параметра задан размер 256 байт (*вторая ошибка*).
При внимательном изучении ОЗУ становится ясно, что TITLE.DB копируется **рядом с сохранённым регистром** `$ra`, указывающим адрес возврата после завершения выполнения текущей функции (*третья ошибка*), что позволяет использовать **эксплойт независимости**: создать Title.db с длинной строкой, встроить в неё исполняемый файл и задать эту строку так, чтобы `$ra` указывал на исполняемый файл. Если удастся загрузить этот файл на карту памяти (с помощью ещё одного эксплойта или USB-адаптера для PC), то можно получить простое средство запуска самодельных программ (Homebrew).
После выпуска slim-версии эксплойт пропатчили (*интересно, как?*). Забавно, что это была не последняя [халатность](https://www.copetti.org/writings/consoles/wii/#the-fall-of-encryption), позволившая выявить топорный код.
#### Полупостоянная разблокировка ПО
Какое-то время назад выяснилось, что BIOS консоли можно обновлять при помощи карты памяти. Эта функция никогда не использовалась на практике, но так и не была удалена (по крайней мере, в течение большей части срока жизни консоли). Благодаря этому хакеры обнаружили, что если удастся установить ПО на карту памяти, то BIOS всегда будет загружать его при запуске. Это открытие привело к созданию **Free MCBoot** — программы, выдающей себя за «данные обновления», заменяющая исходную оболочку на другую, способную исполнять **Homebrew**. Стоит помнить, что эти изменения не постоянны и применяются только если во время запуска консоли вставлена карта памяти с установленной Free MCBoot.
Кроме того, это ПО каким-то образом нужно установить, поэтому для запуска установщика требуется другой эксплойт (например, подмена диска).
#### Другие трюки с дисками
В год выпуска Free MCBoot был обнаружен ещё один трюк: маскировка игр под DVD-фильмы, что позволяет считывать пиратские копии игр без модчипа. Для этого достаточно пропатчить образ игры, добавив пустые метаданные и разделы, используемые только DVD-фильмами. Когда записанную на болванку копию игры вставляют в консоль, привод её не отвергает, но и не запускает игру. Однако при помощи Homebrew-программы под названием **ESR** игру можно запустить.
Источники/дополнительное чтение
-------------------------------
#### Общая информация
* [**PS2 Dev Wiki**](https://playstationdev.wiki/)
* [**Все номера моделей Playstation (не только для консолей)**](https://maru-chang.com/hard/scph/index.php/all/english/)
#### CPU
* **Официальный документ EE Overview Version 6.0**
* **Официальный документ EE User’s Manual Version 6.0**
* **Sony Playstation-2 VPU: A Study on the Feasibility of Utilizing Gaming Vector Hardware for Scientific Computing by Pavan Tumati**
* [**Sound and Vision: A Technical Overview of the Emotion Engine by Jon “Hannibal” Stokes (архивированная статья с ArsTechnica)**](https://web.archive.org/web/20131114210122/https://archive.arstechnica.com/reviews/1q00/playstation2/m-ee-3.html)
* [**Джон Бартон рассказывает системе частиц в Crash и других играх**](https://www.youtube.com/watch?v=JK1aV_mzH3A)
* **Procedural generation: Procedural Rendering on Playstation 2, Робин Грин**
#### Графика
* **Официальный документ GS User’s Manual Version 6.0**
* [**The Models Resource** (архивировано)](https://web.archive.org/web/20200216025504/https://www.models-resource.com/)
#### Ввод-вывод
* [**Шины ввода-вывода** (архивировано)](https://web.archive.org/web/20191109145054/https://assemblergames.com/threads/the-playstation-2-busses-dev9.67961/)
* **Официальный документ EE Overview Version 6.0**
#### Звук
* **Официальный документ SPU2 Overview Version 6.0**
#### Операционная система
* [**Системные вызовы/вызовы BIOS**](https://psi-rockin.github.io/ps2tek/#bioseesyscalls)
#### Игры
* [**Объявление о выпуске Linux Kit**](https://arstechnica.com/civis/viewtopic.php?f=16&t=877557)
* [**Антология игр Gameradar**](https://www.gamesradar.com/wanna-see-every-playstation-2-game-ever-released-in-the-us/)
* [**Различные форматы DVD**](https://support.discmakers.com/hc/en-us/articles/209541847-What-s-the-difference-between-a-DVD-5-DVD-9-and-DVD-10-)
* [**Обсуждение скоростей передачи на PsxPlace**](https://www.psx-place.com/threads/max-theoretically-and-practical-ps2-transfer-speed-with-opl.21975/)
* [**Анализ официального SDK**](https://www.retroreversing.com/ps2-official-sdk/)
* [**Анализ разных Devkit**](https://www.retroreversing.com/playstation-2-development-hardware)
#### Защита от пиратства
* [**Список найденных хаков**](http://wololo.net/2014/01/16/10-days-of-hacking-day-3-the-ps2/)
* **Game Console Hacking: Xbox, PlayStation, Nintendo, Game Boy, Atari and Sega, автор Джо Гранд.**
#### Фотографии
* Консоль: [**Evan Amos Gallery**](https://commons.wikimedia.org/wiki/User:Evan-Amos) (я убрал фон)
* Схемы, материнская плата, фотографии slim-модели и скриншоты игр: **я**
|
https://habr.com/ru/post/544488/
| null |
ru
| null |
# Objective-C: как работают блоки
В этой статье я расскажу о расположении блоков (\_\_NSStackBlock\_\_/\_\_NSGlobalBlock\_\_/\_\_NSMallocBlock\_\_), о том, как происходит захват переменных и как это связано с тем, во что компилируется блок.
В данный момент, применение блоков в Objective-C начинается практически с первых дней изучения этого языка. Но в большинстве случаев разработчики не задумываются, как блоки работают внутри. Здесь не будет магии, я просто расскажу об этом подробнее.
Начнем с самого начала, как выглядит блок в Objective-C
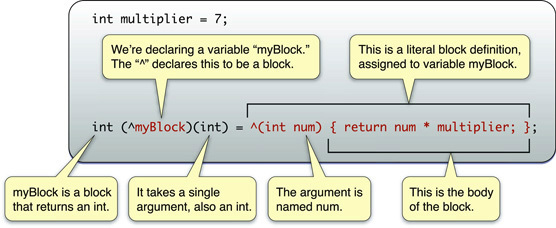
Для чего применяются блоки, я расписывать не буду, речь идет не об этом, поэтому давайте сразу рассмотрим интересные моменты на практике.
Что такое блок? В первую очередь, блок — это объект.
```
id thisIsBlock = ^{
};
```
Для понимания рассмотрим, что такое объект
```
struct objc_object {
Class isa OBJC_ISA_AVAILABILITY;
};
/// A pointer to an instance of a class.
typedef struct objc_object *id;
```
А у блока есть метод
```
- (Class)class
```
который возвращает isa
Воспользуемся тем, что знаем теперь, и посмотрим, какие классы имеет блок в какой ситуации
**\_\_NSStackBlock\_\_**
```
int foo = 3;
Class class = [^{
int foo1 = foo + 1;
} class];
NSLog(@"%@", NSStringFromClass(class));
```
2015-11-29 22:30:21.054 block\_testing[99727:13189641] \_\_NSStackBlock\_\_
**\_\_NSMallocBlock\_\_**
```
int foo = 3;
Class class = [[^{
int foo1 = foo + 1;
} copy] class];
NSLog(@"%@", NSStringFromClass(class));
```
2015-11-29 22:33:45.026 block\_testing[99735:13190778] \_\_NSMallocBlock\_\_
**\_\_NSGlobalBlock\_\_**
```
Class class = [^{
} class];
NSLog(@"%@", NSStringFromClass(class));
```
2015-11-29 22:34:49.645 block\_testing[99743:13191389] \_\_NSGlobalBlock\_\_
Но рассмотрим еще один вариант \_\_NSMallocBlock\_\_
**ARC**
```
int foo = 3;
id thisIsBlock = ^{
int foo1 = foo + 1;
};
Class class = [thisIsBlock class];
NSLog(@"%@", NSStringFromClass(class));
```
2015-11-29 22:37:27.638 block\_testing[99751:13192462] \_\_NSMallocBlock\_\_
Как видно, если блок не захватывает внешние переменные, то мы получаем \_\_NSGlobalBlock\_\_
**Эксперементы**
```
Class class = [[^{
} copy] class];
NSLog(@"%@", NSStringFromClass(class));
```
```
id thisIsBlock = ^{
};
Class class = [thisIsBlock class];
NSLog(@"%@", NSStringFromClass(class));
```
\_\_NSGlobalBlock\_\_
Если же блок захватывает внешние переменные, то блок \_\_NSStackBlock\_\_ (на стеке). Однако если же послать блоку 'copy', то блок будет скопирован в кучу (\_\_NSMallocBlock\_\_).
ARC нам в этом помогает, и при присваивание блока в переменную (\_\_strong) произойдет копирование блока в кучу, что можно заметить на примере выше. В общем, еще раз скажем ARC спасибо, ведь в MRC мы могли получить крайне неприятные баги
**object.h**
```
/*!
* @typedef dispatch_block_t
*
* @abstract
* The type of blocks submitted to dispatch queues, which take no arguments
* and have no return value.
*
* @discussion
* When not building with Objective-C ARC, a block object allocated on or
* copied to the heap must be released with a -[release] message or the
* Block_release() function.
*
* The declaration of a block literal allocates storage on the stack.
* Therefore, this is an invalid construct:
* `* dispatch_block_t block;
* if (x) {
* block = ^{ printf("true\n"); };
* } else {
* block = ^{ printf("false\n"); };
* }
* block(); // unsafe!!!
*`
*
* What is happening behind the scenes:
* `* if (x) {
* struct Block __tmp_1 = ...; // setup details
* block = &__tmp_1;
* } else {
* struct Block __tmp_2 = ...; // setup details
* block = &__tmp_2;
* }
*`
*
* As the example demonstrates, the address of a stack variable is escaping the
* scope in which it is allocated. That is a classic C bug.
*
* Instead, the block literal must be copied to the heap with the Block_copy()
* function or by sending it a -[copy] message.
*/
typedef void (^dispatch_block_t)(void);
```
Для чего тогда проперти обозначаются как 'copy'?
> Note: You should specify copy as the property attribute, because a block needs to be copied to keep track of its captured state outside of the original scope. This isn’t something you need to worry about when using Automatic Reference Counting, as it will happen automatically, but it’s best practice for the property attribute to show the resultant behavior. For more information, see Blocks Programming Topics.
>
>
[ссылка](https://developer.apple.com/library/ios/documentation/Cocoa/Conceptual/ProgrammingWithObjectiveC/WorkingwithBlocks/WorkingwithBlocks.html#//apple_ref/doc/uid/TP40011210-CH8-SW1)
Поэтому продолжайте и дальше писать property copy для блоков.
Также рассмотрим еще один небольшой пример о \_\_NSStackBlock\_\_
**Что будет, если передать \_\_NSStackBlock\_\_ в функцию?**
```
typedef void(^EmptyBlock)();
void fooFunc(EmptyBlock block) {
Class class = [block class];
NSLog(@"%@", NSStringFromClass(class));
}
int main(int argc, const char * argv[]) {
@autoreleasepool {
int foo = 1;
fooFunc(^{
int foo1 = foo + 1;
});
}
return 0;
}
```
2015-11-29 22:52:16.905 block\_testing[99800:13197825] \_\_NSStackBlock\_\_
**Зачем нужен \_\_NSGlobalBlock\_\_**О \_\_NSStackBlock\_\_ и \_\_NSMallocBlock\_\_ было достаточно много информации, какой толк от \_\_NSGlobalBlock\_\_? Внутри такого блока нет захвата внешний переменных, а значит не может произойти нарушений из-за видимости памяти, как при использовании \_\_NSStackBlock\_\_. И не нужно сперва создавать блок на стеке, потом при необходимости переносить в кучу, а значит, можно разрешить эту ситуацию намного проще.
В статье столько раз было сказано о захвате внешних переменных, однако мы все еще не сказали, как это происходит. В этом нам поможет [документация clang](http://clang.llvm.org/docs/Block-ABI-Apple.html). Не будем ее расписывать полностью, выделим лишь нужные идеи.
Блок превращается в структуру, а захваты превращаются в поля.
Это несложно проверить практически
**сноска для ценителей**
> clang -rewrite-objc -ObjC main.m -o out.cpp
и можно посмотреть весь процесс в C++ коде
```
MyObject *myObject = [[MyObject alloc] init];
NSLog(@"object %p, ptr myObject %p", myObject, &myObject);
^{
NSLog(@"object %p, ptr myObject %p", myObject, &myObject);
}();
```
2015-11-29 23:12:37.297 block\_testing[99850:13203592] object 0x100111e10, ptr myObject 0x7fff5fbff798
2015-11-29 23:12:37.298 block\_testing[99850:13203592] object 0x100111e10, ptr myObject 0x7fff5fbff790
Как видно, указатель myObject снаружи и внутри блока указывает на одну и ту же область памяти, однако сам указатель отличается.
Блок создает внутри себя константные локальные переменные и указатели того, что захватывает. Что при использовании объектов увеличит счетчик ссылок, по обычной для ARC логике (при копировании блока в кучу).
Однако при использовании \_\_block произойдет inout, поэтому счетчик ссылок не увеличится (однако не нужно использовать всегда и везде, const — это хорошее слово).
Для закрепления рассмотрим небольшой пример
**код**
```
#import
typedef NSInteger (^IncrementBlock)();
IncrementBlock createIncrementBlock(const NSInteger start, const NSInteger incrementValue) {
\_\_block NSInteger acc = start;
return ^NSInteger{
acc += incrementValue;
return acc;
};
}
int main(int argc, const char \* argv[]) {
@autoreleasepool {
IncrementBlock incrementBlock = createIncrementBlock(0, 2);
NSLog(@"%ld", incrementBlock());
NSLog(@"%ld", incrementBlock());
NSLog(@"%ld", incrementBlock());
IncrementBlock incrementBlock1 = createIncrementBlock(0, 2);
NSLog(@"%ld", incrementBlock1());
NSLog(@"%ld", incrementBlock1());
NSLog(@"%ld", incrementBlock1());
}
return 0;
}
```
2015-11-29 23:31:24.027 block\_testing[99910:13209611] 2
2015-11-29 23:31:24.028 block\_testing[99910:13209611] 4
2015-11-29 23:31:24.028 block\_testing[99910:13209611] 6
2015-11-29 23:31:24.028 block\_testing[99910:13209611] 2
2015-11-29 23:31:24.028 block\_testing[99910:13209611] 4
2015-11-29 23:31:24.029 block\_testing[99910:13209611] 6
Блок IncrementBlock был превращен компилятором в структуру, при возврате блока из функции произошло копирование текущего области, и тем самым мы получили структуру, у которой есть поле, в которой хранится аккумулятор. А на каждый вызов функции createIncrementBlock мы получаем новый экземпляр.
Остановлю так же внимание на случай использования self внутри блока ([что такое self](http://habrahabr.ru/post/270913/)). После прочтения статьи должно стать понятно, что использование self внутри \_\_NSMallocBlock\_\_ приведет к увеличению счетчика ссылок, однако вовсе не означает retain cycle. retain cycle это когда объект держит блок, а блок держит объект, который держит блок…
Параноя везде использовать \_\_weak \_\_strong не нужна, для нас блок — это объект. Просто объект, который можно сохранить, передать, использовать, с которым действуют обычные правила управления памятью.
|
https://habr.com/ru/post/271255/
| null |
ru
| null |
# Использование возможностей git-а в системе сборки модульного проекта
В нашем блоге мы уже рассказывали [о принципах организации репозитория большого проекта](http://habrahabr.ru/company/relex/blog/258505/) как совокупности независимых модулей, что позволяет организовать извлечение исходных кодов в произвольную файловую структуру рабочей копии. Разумеется, такой подход не мог не отразиться на системе сборки проекта, поскольку потребовал создание механизма отслеживания зависимостей между модулями с учетом их фактического размещения. Эта статья посвящена тому, как можно использовать возможности git-а для решения не только этой задачи, но и для извлечения фрагмента проекта с автоматическим учетом внутренних межмодульных зависимостей.

Несколько слов о примерах
=========================
Изначально предполагалось снабдить эту публикацию фрагментами системы сборки в том виде, как она реализована в [ЛИНТЕРе](https://linter.ru/ru/), однако мы не используем в этом проекте нативные модули git и применяем make утилиту собственной разработки. Поэтому, чтобы практическая ценность материала для читателей не пострадала, [все примеры](https://github.com/pechenkin/make) адаптированы для использования в связке git submodules и gnu make, что привело к определенным сложностям, которые будут указаны ниже.
Описание демонстрационного примера
==================================
В целях упрощения будем рассматривать интеграцию системы сборки с git-ом на примере условного продукта с названием project, который состоит из следующих функциональных модулей:
applications — непосредственно приложение;
demo — демонстрационные примеры;
libfoo и libbar — библиотеки, от которых зависит applications.
Граф зависимостей project будет следующим:
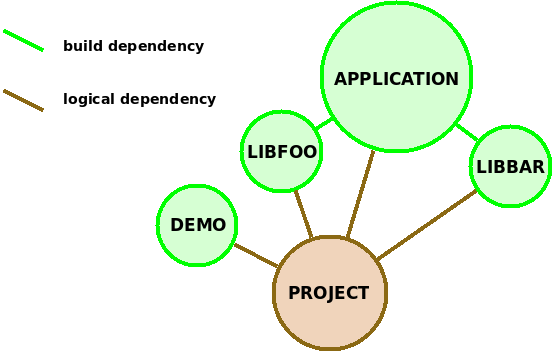
*Иллюстрация 1: Граф зависимостей проекта*
Организация хранения
====================
С точки зрения системы хранения версий проект разбит на пять отдельных репозиториев — четыре для модулей и пятый — project.git, выполняющий роль контейнера и содержащий систему сборки. Такой способ организации имеет несколько преимуществ в сравнении с монорепозиторием:
* каждый подмодуль имеет отдельную историю правок;
* возможность клонирования только части проекта;
* каждый репозиторий может иметь индивидуальные правила и политики доступа;
* возможность извлечения проекта в произвольную структуру рабочей копии.
Подмодули и зависимости
=======================
Несмотря на то, что рекурсивный подход к организации системы сборки [оправданно критикуется](http://habrahabr.ru/post/144127/), все-таки он позволяет существенно снизить затраты на сопровождение проекта, поэтому в нашем примере будем применять именно его. При этом, корневой makefile проекта должен не только «знать» положение модулей внутри проекта, но и обеспечивать вызов дочерних make-процессов в целях в нужной последовательности: от ветвей дерева зависимости к корням. Для этого следует явно описать эти межмодульные зависимости, в нашем примере это сделано [следующим образом](https://github.com/pechenkin/make/blob/master/make/examples/tree/Makefile):
```
MODS = project application libfoo libbar demo
submodule.project.deps = application demo
submodule.demo.deps = application
submodule.application.deps = libfoo libbar
submodule.libfoo.deps =
submodule.libbar.deps =
```
Корректный обход этого дерева можно обеспечить средствами make, создав динамические цели с явным указанием зависимостей, для чего объявим функцию gen-dep следующего вида:
```
define gen-dep
$(1):$(foreach dep,$(submodule.$(1).deps),$(dep)) ;
endef
```
Теперь, если в теле корневого Makefile вызвать gen-dep для всех модулей
```
$(foreach mod,$(MODS),$(eval $(call gen-dep,$(mod))))
```
то это сформирует следующие динамические цели во время исполнения (это можно проверить запустив make с ключом -p)
```
project: application demo
demo: application
application: libfoo libbar
libbar:
libfoo:
```
что позволяет при обращении к ним обеспечить вызов зависимостей в нужном порядке. При этом, если имя цели совпадет с существующим файлом или директорией, то это может нарушить выполнение, поскольку make «не знает» что эти наши цели — это действия, а не файлы, чтобы этого избежать явно укажем:
```
$(eval .PHONY: $(foreach mod,$(MODS), $(mod)))
```
Допустим, что перед разработчиком стоит задача внесения изменений в application, для чего ему нужно получить только подмодули application, libbar, libfoo. Для этого система сборки должна на основе объявленных выше зависимостей сформировать описание модулей и их размещения для последующего использования git-ом, который, [как известно](http://git-scm.com/docs/gitmodules), описывает зарегистрированные подмодули в файле с именем .gitmodules, расположенном в корне клонированного репозитория.
Внесем [следующие изменения](https://github.com/pechenkin/make/blob/master/make/examples/register/Makefile) в наш пример, чтобы обеспечить генерацию .gitmodules минимального необходимого состава:
```
…
MODURLPREFIX ?= [email protected]/
MODFILE ?= .gitmodules
…
define tmpl.module
"[submodule \"$(1)\"]"
endef
define tmpl.path
"\tpath = $(1)"
endef
define tmpl.url
"\turl = $(1)"
endef
…
define submodule-set
submodule.$(1).name := $(2)
submodule.$(1).path := $(3)
submodule.$(1).url := $(4)
endef
define set-default
$(call submodule-set,$(1),$(1),$(1),$(MODURLPREFIX)$(1).git)
endef
define gen-dep
$(1):$(foreach dep,$(submodule.$(1).deps),$(dep))
@echo "Register module $(1)"
@echo $(call tmpl.module,$(submodule.$(1).name)) >> $(MODFILE)
@echo $(call tmpl.path,$(submodule.$(1).path)) >> $(MODFILE)
@echo $(call tmpl.url,$(submodule.$(1).url)) >> $(MODFILE)
endef
…
$(foreach mod,$(MODS),$(eval $(call set-default,$(mod))))
```
Теперь наш условный разработчик, вызвав make application сможет создать файл следующего содержания:
```
[submodule "libfoo"]
path = libfoo
url = [email protected]/libfoo.git
[submodule "libbar"]
path = libbar
url = [email protected]/libbar.git
[submodule "application"]
path = application
url = [email protected]/application.git
```
который уже может быть изменен и разобран [средствами git-a](http://git-scm.com/docs/git-config), например таким образом:
```
git config -f .gitmodules --get submodule.application.path
application
```
Само по себе наличие файла .gitmodules в корне репозитория не регистрирует модули в индексе, поэтому до момента инициализации и клонирования подмодулей в файл можно внести все необходимые корректировки.
Что же касается непосредственно инициализации подмодулей — то тут проявляется первое серьезное неудобство в реализации нативных модулей в git-е: метаданные о модулях эта система управления версиями хранит и в индексе, и в файле .gitmodules. Заглянув в [исходные коды](https://github.com/git/git/blob/master/git-submodule.sh) становится понятным, что у нас есть две не самые лучшие альтернативы.
Первая — это внести информацию о модулях в индекс [следующим образом](http://stackoverflow.com/questions/11258737/restore-git-submodules-from-gitmodules):
```
#!/bin/sh
git config -f .gitmodules --get-regexp '^submodule\..*\.path$' |
while read path_key path
do
url_key=$(echo $path_key | sed 's/\.path/.url/')
url=$(git config -f .gitmodules --get "$url_key")
git submodule add --force $url $path
done
```
в этом случае появляется возможность работать с подмодулями используя штатный git-submodule (итераторы, групповые операции и пр.), однако перемещение/удаление модулей, а также их ветвление будет требовать дополнительных вспомогательных операций. Описанная ситуация стала одной из причин, по которой мы отказались от использования git-submodules в репозитории [ЛИНТЕРа](https://linter.ru). Альтернативой submodule add может служить клонирование модулей без регистрации в индексе, что можно сделать так:
```
#!/bin/sh
git config -f .gitmodules --get-regexp '^submodule\..*\.path$' |
while read path_key path
do
url_key=$(echo $path_key | sed 's/\.path/.url/')
url=$(git config -f .gitmodules --get "$url_key")
git clone $url $path
done
```
в этом случае обязательно требуется явное указание всех $path в .gitignore, иначе git будет воспринимать клонированные подмодули как обычные директории и обрабатывать их и содержимое как неотслеживаемые файлы.
Так или иначе, после клонирования любым из указанных способов рабочая копия будет соответствовать ситуации извлечения выделенного фрагмента дерева
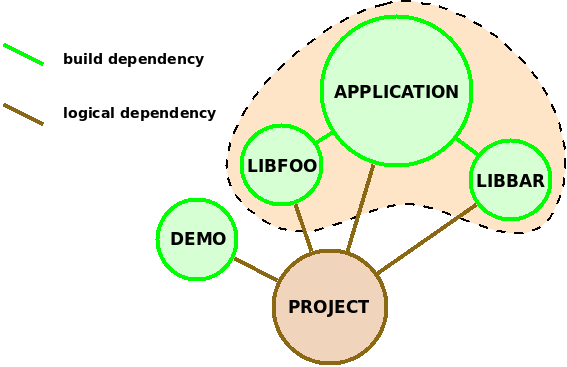
*Иллюстрация 2: Граф зависимостей проекта. Заливкой выделено извлекаемое дерево модулей.*
и, при условии правильного объявления межмодульных зависимостей, содержит все необходимое для компиляции application.
Определение положения модулей
=============================
Еще одну задачу, которую решает система сборки — это определение текущего положения модулей. Для этого будем использовать сформированный нами ранее файл-описатель. Как и в случае с инициализацией — здесь есть несколько вариантов. Самое простое — это воспользоваться возможностями git config:
```
define get-path
$(shell git config -f .gitmodules --get "submodule.$(1).path")
endef
define get-url
$(shell git config -f .gitmodules --get "submodule.$(1).url")
endef
```
Такое решение не является идеальным с точки зрения переносимости, но другой вариант доступен только если использовать GNU make версии 4 и выше — в этом случае парсинг файла .gitmodules можно реализовать с использованием расширений [GNU make](https://www.gnu.org/software/make/manual/html_node/Extending-make.html#Extending-make).
Заключение
==========
Позволим себе еще раз напомнить, что пример доступный на [github](https://github.com/pechenkin/make) является адаптацией наших решений на базе связки linmodules+linflow для gitmodules+GNU make, поэтому некоторые недостатки сопряжения этих инструментов решены не самым изящным способом, а вызовы дочерних make файлов в модулях заменены на «пустышки».
Тем не менее, механизм зарекомендовал себя достаточно хорошо при работе с большим проектом и успешно «справляется» с репозиторием в 102 подмодуля git, между которыми существует 308 межмодульных связей (как логических, так и по сборке) с диаметром графа связей в 5 единиц (см. иллюстрацию выше).
|
https://habr.com/ru/post/260311/
| null |
ru
| null |
# Подмена XMLHttpRequest или как не трогая тонны готового js-кода изменить поведение всех ajax-запросов
Здравствуйте, в этой маленькой заметке расскажу немного про ООП в JS, объект XMLHttpRequest, паттерн прокси, и дружелюбие джаваскрипта в этом плане.
Была у меня сегодня такая задача — есть проект, который довольно активно использует ajax-запросы, но вот проблема — бекенд у нас так устроен, что разаутентифицирует пользователя, если тот не активен в течение, скажем, получаса. В итоге случалось такое, что пользователь, пытаясь совершить какое-то действие, которое использует аякс, не мог его совершить (уж извините за тавтологию), нужно было решить эту проблему.
##### ТЗ, которое я для себя поставил
Если совершается аякс-запрос и в ответ приходит \*что-то, говорящее о том, что у пользователя завершилась сессия\*, нужно отобразить пользователю форму входа (обычным оверлейем, без всяких айфреймов), и дать ему возможность аутентифицироваться через нее (опять же по аяксу, т.к. нельзя потерять состояние страницы). Более того, если он пройдет аутентификацию, аякс-запросы, которые не прошли тогда, нужно отправить заново. Но вот первая проблема — нужно это сделать так, чтобы js-код, который опирается на этот запрос ничего не почувствовал, то есть нужно чтобы все callback-и сработали как надо и когда надо (они не должны сработать тогда, когда окажется, что нужна аутентификация, но должны тогда, когда она будет пройдена). И вторая проблема идет от асинхронности запросов — их может быть много, может получиться так, что сразу несколько запросов столкнутся с этой проблемой, надо наблюдать за всеми и, если нужно, перезапускать их после аутентификации. И, да, \*что-то, говорящее о том, что у пользователя завершилась сессия\* — в нашем случае это код ответа «403» и тело ответа «401» (401, потому что близко по духу, но нельзя из-за потребности в WWW-Authenticate, а просто 403 нельзя т.к. вообще по-хорошему с аутентификацией это никак не связано, но, хотя бы, близко).
##### Как же я люблю Javascript
Не долго думая я пришел к решению — воспользовавшись паттерном «прокси», создать, собственно, объект-проксю, и подменить им XMLHttpRequest (XHR), а в самом этом проксе уже общаться напрямую с XHR-ом. И да, представьте себе, в Javascript-е возможно подменить класс другим классом, фактически тут класс — это тот же объект (или прототип, в терминологии я не силен :( ).
Итак для начала, как же вообще создавать класс, инстанс которого можно будет получить с помощью new ClassName() и как вообще туда добавлять методы и свойства? Тут есть несколько способов, чтобы увидить все можете [погуглить](https://www.google.com/search?q=javascript+class+definition), я воспользовался наверное самым простым, вот как выглядит определение класса у нас:
```
(function () {
"use strict";
window.SomeClass = function () {
var randNumber = Math.random();
this.someMethod = function () {
console.log(randNumber);
};
this.randomized = randNumber;
};
})();
```
Если вы заметили, я сразу упаковал весь код в функцию, которую тут же вызвал, это обычная практика в JS, она используется во-первых для чистоты кода (не засоряем глобальный скоуп), и во-вторых из-за производительности (это вытекает из первого, дело в том, что когда вы создаете очень много переменных в одной области видимости (в данном случае в глобальной), то при обращении к ним, интерпретатор будет искать их дольше, т.к. ему придется перебрать больше вариантов, ведь поиск переменной начинается с самого близкого скоупа и идет вверх до глобального). Так же я использую use strict, можете почитать о нем [здесь](https://developer.mozilla.org/en/JavaScript/Strict_mode), он поможет избежать вам непредвиденных ситуаций, особенно если вы используете IDE (и особенно если используете JsLint/JsHint). И о коде – как видите мы создали «класс» SomeClass в глобальной области видимости, фактически конструктором этого класса является весь код внутри функции. В итоге мы имеем переменную randNumber, которая видная только изнутри класса (точнее его экземпляра), метод someMethod(), который шлет в консоль всегда одно и то же число для одного и того же экземпляра класса, и свойство randomized, которое равно этому же числу.
Делаем подмену:
```
(function () {
"use strict";
// сохраним оригинальный объект, т.к. без него не сможем слат запросы
var XHR = window.XMLHttpRequest;
window.XMLHttpRequest = function () {
// создаем экземпляр оригинала
var o = new XHR(),
t = this,
reassignAllProperties = function reassign() {
t.readyState = o.readyState;
t.responseText = o.responseText;
t.responseXML = o.responseXML;
t.status = o.status;
t.statusText = o.statusText;
};
t.readyState = 0;
t.responseText = "";
t.responseXML = null;
t.status = null;
t.statusText = "";
// просто подменим все методы, не меняя никак поведение
// но добавим вызов reassignAllProperties() т.к. после
// вызова любого из методов может быть изменено какое-то св-во
t.open = function open() {
o.open.apply(o, arguments);
reassignAllProperties();
};
t.send = function send() {
o.send.apply(o, arguments);
reassignAllProperties();
};
t.abort = function abort() {
o.abort();
reassignAllProperties();
};
t.setRequestHeader = o.setRequestHeader;
t.overrideMimeType = o.overrideMimeType;
t.getResponseHeader = o.getResponseHeader;
t.getAllResponseHeaders = o.getAllResponseHeaders;
t.onreadystatechange = function () {};
o.onreadystatechange = function onReady() {
reassignAllProperties();
t.onreadystatechange();
};
};
})();
```
Как видно из кода, он полностью повторяет оригинальный XMLHttpRequest (сводку по методам/св-вам можете посмотреть на русской [страничке википедии](http://ru.wikipedia.org/wiki/XMLHttpRequest)). Нам же нужно намного больше – надо следить за ответом сервера, и если заметим 403-й ответ и 401 в теле, то в срочном порядке открываем форму логина. Но пользовательский callback при этом не должен быть вызван. И более того, после «аборта» должна быть возможность перезапустить запрос и получить ответ. Следовательно мы должны хранить в объекте-прокси все данные, которые передавались каким-либо методам-сеттерам (в т.ч. open и send) и при перезапуске запроса нужно заново вызвать все эти методы. Но вот проблема остается – представим ситуацию, когда был совершен запрос, который окончился неудачей из-за разаутентификации, тогда, только после того как юзер залогинится, мы должны перезапустить запрос и запустить событие onreadystatechange, но это событие не должно быть запущено до того как запрос будет запущен повторно. Решение простое – дело в том, что событие onreadystatechange запускается по крайней мере четыре раза, при этом свойство readyState инкрементируется (тут все его [значения](http://msdn.microsoft.com/en-us/library/ie/ms534361(v=vs.85).aspx)), так что нам нужно вызвать пользовательский callback только тогда, когда мы будем уверены, что ответ легитимный. Но, если где-то используются состояния отличные от «complete», нужно это учесть, проще всего тогда будет запустить событие три раза с тремя последними readyState (от 2 до 4), просто в цикле. Также нужно хранить все запросы, завершившиеся неудачей, которые нужно будет перезапустить после этого.
##### Последние штрихи
```
(function () {
"use strict";
// сохраним оригинальный объект, т.к. без него не сможем слать запросы
var XHR = window.XMLHttpRequest,
// здесь будет хранить все завершившиеся неудачей запросы, которые ожидают ретрая
failedRequestsPool = [],
authenticationWindow = function () {
$("#auth-overlay").show();
};
$("#auth-overlay form").submit(function () {
$.ajax({
type: "post",
url: "/login",
data: {
login: $("#auth-login").val(),
password: $("#auth-password").val()
},
dataType: "json",
success: function (data) {
if (data.state === "OK") {
$("#auth-overlay").hide();
// если прошли логин, нужно перезапустить все ожидающие запросы
for (var i in failedRequestsPool) {
if (failedRequestsPool.hasOwnProperty(i)) {
failedRequestsPool[i].retry();
}
}
failedRequestsPool = [];
}
}
});
return false;
});
window.XMLHttpRequest = function () {
// создаем экземпляр оригинала
var o = new XHR(),
t = this,
// этот флаг понадобится, чтобы не пропустить плохой ответ до callback-а
aborted = false,
reassignAllProperties = function reassign() {
t.readyState = o.readyState;
t.responseText = o.responseText;
t.responseXML = o.responseXML;
t.status = o.status;
t.statusText = o.statusText;
},
// будем хранить все переданные данные здесь, чтобы при ретрае снова передать их
data = {
open: null,
send: null,
setRequestHeader: [],
overrideMimeType: null
};
t.readyState = 0;
t.responseText = "";
t.responseXML = null;
t.status = null;
t.statusText = "";
t.retry = function retry() {
aborted = false;
// снова передаем все данные
o.open.apply(o, data.open);
reassignAllProperties();
for (var i in data.setRequestHeader) {
if (data.setRequestHeader.hasOwnProperty(i)) {
o.setRequestHeader.apply(o, data.setRequestHeader[i]);
}
}
if ("overrideMimeType" in o && data.overrideMimeType !== null) {
o.overrideMimeType(data.overrideMimeType);
}
o.send(data.send);
reassignAllProperties();
};
// просто подменим все методы, не меняя никак поведение
// но добавим вызов reassignAllProperties() т.к. после
// вызова любого из методов может быть изменено какое-то св-во
t.open = function open() {
data.open = arguments; // запомним, для случая ретрая
o.open.apply(o, arguments);
reassignAllProperties();
};
t.send = function send(body) {
data.send = body;
o.send(body);
reassignAllProperties();
};
t.abort = function abort() {
o.abort();
reassignAllProperties();
};
t.setRequestHeader = function setRequestHeader() {
data.setRequestHeader.push(arguments);
o.setRequestHeader.apply(o, arguments);
};
// зметьте что в IE может не быть этого метода, поэтому проверим
if ("overrideMimeType" in o) {
t.overrideMimeType = function (mime) {
data.overrideMimeType = mime;
o.overrideMimeType(mime);
};
}
t.getResponseHeader = o.getResponseHeader;
t.getAllResponseHeaders = o.getAllResponseHeaders;
t.onreadystatechange = function () {};
o.onreadystatechange = function onReady() {
reassignAllProperties();
// если еще не остановили запрос и если видим при этом, что нужно, то останавливаем
if (!aborted && o.state === 403 && o.responseText.indexOf("401") !== -1) {
aborted = true;
o.abort();
failedRequestsPool.push(t);
authenticationWindow();
}
// если не был остановлен и уже готов ответ, то даем знать
if (!aborted && o.readyState === 4) {
for (var i = 1; i < 5; ++i) {
t.readyState = i;
t.onreadystatechange();
}
}
};
};
})();
```
Вот так, довольно просто, мы подменили XHR на прокси, который не даст упустить запросы, отправленные после «разаутентификации» пользователя.
ПС я заметил одну ошибку, метод getAllResponseHeaders() в опере выкидывает WRONG\_THIS\_ERR, только совершенно непонятно откуда это.
ППС давайте не будем обсуждать как лучше было решить исходную задачу. дело в том, что данное решение может пригодиться не только в случае разаутентификации
**UPD** Если вам действительно нужно будет сделать такую подмену (а я советую подумать перед этим, т.к., как многие заметили в комментариях, подменять корневые библиотеки — очень не хорошо), то пользуйтесь этим решением [github.com/ilinsky/xmlhttprequest](https://github.com/ilinsky/xmlhttprequest)
|
https://habr.com/ru/post/148140/
| null |
ru
| null |
# Как создать инфраструктуру в разных окружениях с помощью Terraform
Terraform — это опенсорс-инструмент IaC (инфраструктура как код), который предоставляет согласованный рабочий процесс в CLI для управления сотнями облачных сервисов. Terraform преобразует облачные API в декларативные файлы конфигурации.
Обычно мы деплоим инфраструктуру в нескольких окружениях, которые используем для разработки, стейджинга, тестирования и продакшена. Очень важно написать конфигурацию Terraform, которую будет легко поддерживать и масштабировать, чтобы подготавливать инфраструктуру в указанных окружениях.
В статье рассмотрим несколько способов подготовки инфраструктуры в разных окружениях. У каждого из них есть свои преимущества и недостатки.
### Введение
Каждое приложение проходит через несколько окружений до деплоймента в продакшен. Эти окружения должны быть максимально похожи друг на друга. Воспроизводить баги и быстро исправлять их будет несложно — чего не скажешь о воспроизведении аналогичной инфраструктуры в каждом окружении вручную. Terraform упрощает создание инфраструктуры в мультиоблачном окружении.
Раз Terraform — это инструмент IaC, мы прописываем инфраструктуру в коде, поэтому ее можно приспособить для разных окружений с помощью модульного подхода.
Рассмотрим способы создания инфраструктуры в нескольких окружениях.
#### Предварительные требования
Если у вас еще нет опыта работы с Terraform, сначала лучше почитать [эту статью](https://medium.com/bb-tutorials-and-thoughts/how-to-get-started-with-terraform-c9a693853598).
### Используем папки — метод 1
Здесь мы дублируем одну и ту же инфраструктуру в каждой папке с разными значениями в файле **terraform.tfvars**. Это не идеальный вариант, если у вас одинаковая инфраструктура во всех окружениях.
Папка представляет отдельное окружение. У вас может быть бэкэнд в каждой папке, а может не быть ничего общего между папками. В каждой папке могут находиться файлы outputs.tf, providers.tf, variables.tf и т. д. При выполнении команд terraform приходится переходить в соответствующую папку и выполнять три команды: `init, plan, apply`.

*Использование папок (метод 1)*
Преимущества:
* для каждого окружения можно легко добавлять или удалять ресурсы,
* изменения в одном окружении не влияют на другие окружения.
Недостатки:
* дублирование кода;
* если нужно изменить ресурс, приходится делать это во всех окружениях.
### Используем папки — метод 2
Здесь у нас одна и та же инфраструктура в общих файлах, но для каждого окружения есть отдельный файл terraform.tfvars. Это не идеальный вариант, если у вас разные инфраструктуры во всех окружениях.
Раз файлы main.tf и variables.tf у нас одинаковые, при выполнении команд terraform мы передаем разные переменные в зависимости от окружения. Например, если у нас три окружения, для создания инфраструктуры мы должны выполнить следующие три команды:
```
// Dev Environment
terraform plan --var-file="tfvars/environment/dev.tfvars"
// QA Environment
terraform plan --var-file="tfvars/environment/qa.tfvars"
// Prod Environment
terraform plan --var-file="tfvars/environment/prod.tfvars"
```
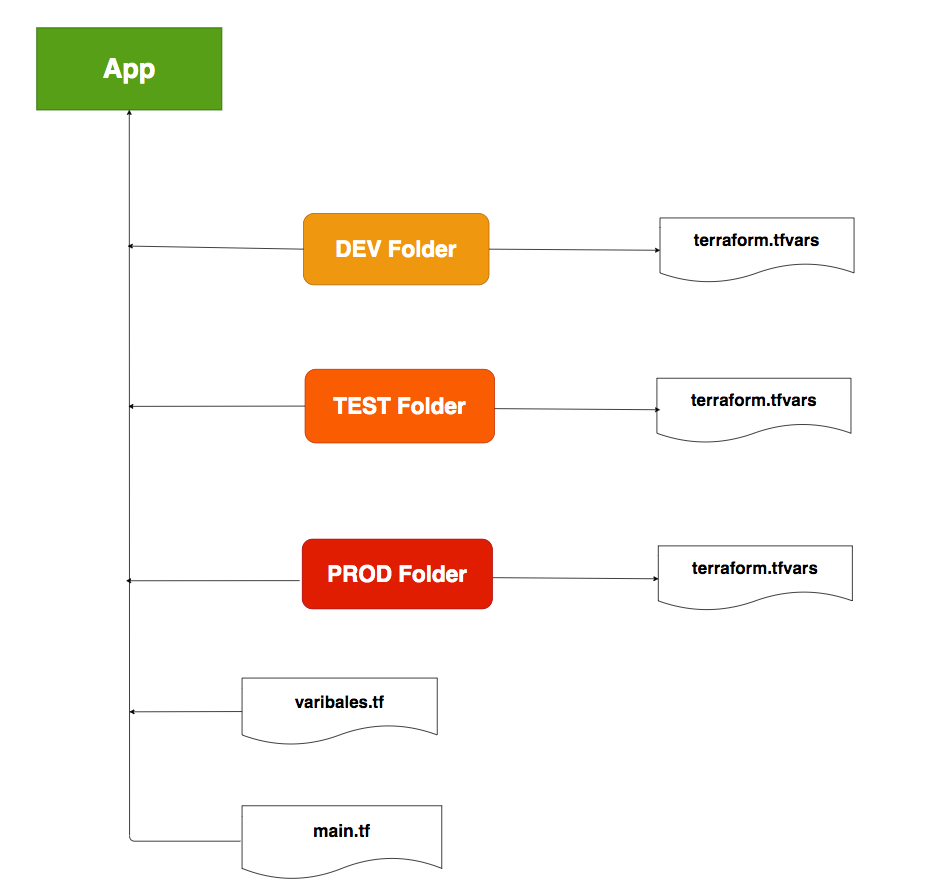
*Использование папок (метод 2)*
Преимущества:
* код не дублируется;
* если нужно изменить ресурс, не приходится делать это во всех окружениях.
Недостатки:
* для каждого окружения нельзя легко добавлять или удалять ресурсы;
* изменения в одном окружении влияют на другие окружения, ведь мы используем одни и те же файлы с разными файлами переменных.
### Воркспейсы
Terraform начинается с одного воркспейса с именем **default**. Это дефолтный воркспейс, который, в отличие от остальных, невозможно удалить. Если вы никогда явно не использовали воркспейсы, значит, вы работали только в воркспейсе **default**.
Воркспейсы управляются командами `terraform workspace`. Существует целый набор таких команд. Например, `terraform workspace new` создает воркспейс.
### Модули
Модуль — это контейнер для нескольких ресурсов, которые используются вместе. В каждой конфигурации Terraform есть хотя бы один модуль — root-модуль. Root-модуль обычно состоит из ресурсов, определенных в файлах с расширением .tf в главном рабочем каталоге.
Модуль может вызывать другие модули, которые становятся дочерними модулями для вызывающего. В модуле можно разместить множество ресурсов, а затем использовать их через главный модуль. Использование модулей можно настроить таким образом, чтобы один и тот же модуль подходил для разных окружений без изменения кода.
Ниже описываем использование комбинации папок и модулей. Мы импортируем модуль в главный файл и можем передавать соответствующие входные переменные в зависимости от окружения, как показано на схеме.

*Несколько окружений*
### Terragrunt
Terragrunt — это тонкая обертка, которая предоставляет дополнительные инструменты для соблюдения принципа DRY в конфигурациях, работы с несколькими модулями Terraform и управления удаленным стейтом.
Подробнее об этом на их [официальном сайте](https://terragrunt.gruntwork.io/).
### Итоги
* Terraform — это опенсорс-инструмент IaC, который предоставляет согласованный рабочий процесс в CLI для управления сотнями облачных сервисов.
* Обычно мы деплоим инфраструктуру в нескольких окружениях, которые мы используем для разработки, стейджинга, тестирования и продакшена.
* Есть пять способов написать многоразовый код для разных окружений в Terraform.
* Самый популярный из них — папки. Работать с папками можно двумя методами.
* Terraform начинается с одного воркспейса с именем **default**. Это дефолтный воркспейс, который, в отличие от остальных, невозможно удалить.
* Модуль — это контейнер для нескольких ресурсов, которые используются вместе. Использование модулей можно настроить таким образом, чтобы один и тот же модуль подходил для разных окружений без изменения кода.
* Terragrunt — это тонкая обертка, которая предоставляет дополнительные инструменты для соблюдения принципа DRY в конфигурациях, работы с несколькими модулями Terraform и управления удаленным стейтом.
Итак, мы рассмотрели несколько способов создать инфраструктуру для разных окружений с помощью Terraform. У каждого из них свои преимущества и недостатки. Эти способы можно сочетать друг с другом.
|
https://habr.com/ru/post/551554/
| null |
ru
| null |
# Балансировщик соотношения входящего/исходящего трафика linux-сервера на PHP
Как я некоторое время назад выяснил на собственном опыте, ещё остались провайдеры, для получения безлимитного тарифа от которых требуется выдерживать определённое соотношение входящего и исходящего трафиков.
В моём случае, при размещении сервера на colocation в одном московском датацентре, исходящего должно было быть не менее чем в 4 раза больше чем входящего (уж извините за такой оборот). Соотношение рассчитывается как за сутки, так и общее за месяц. Нарушение любого из них — штраф.
Само по себе соотношение не выдерживалось из-за переодических объёмных заливок бэкапов на сервер. Вручную (гиг заслал, 4 гига скачал) — надоело.
Тут я вспомнил, что когда-то давно на каком-то сайте видел примитивный скрипт в пару строк на sh-скрипте, который делал такую балансировку сам. Тогда не сохранил, сейчас найти не смог. Пришлось писать самому. Результат и выставляю на всеобщее обозрение — авось кому пригодится.
Скрипт тестировался только под Ubuntu, но и под другими линуксами работать должен.
В отличие от того примитивного на sh, мой скрипт умеет выдерживать как дневное, так и месячное соотношение, ведёт логи, и тщательно шифруется от своего обнаружения (фальшивый трафик делается путём передачи файлов случайного размера через SSH, между вбросами делается интервал случайной длины). Ещё одно отличие (но уже со знаком минус) — требуется ответная нода с безлимитным трафиком, до которой можно поднять ssh соединение по ключу. Я использую свой домашний канал и роутер на нём.
Поставьте свои значения в переменные $interface, $logfile и $server.
В переменной $server фактически указаны параметры для команды ssh.
То есть, в моём случае, выполнив в консоли «ssh my-host.no-ip.org -p 1022 -i /home/user/.ssh/my-key» я подключаюсь без ввода пароля к своей ответной ноде (данные условные, конечно).
Вызов этого скрипта надо сделать при запуске системы (например из /etc/rc.local) или настроить в виде сервиса.
```
php
$interface="eth0"; // какой интерфейс отслеживать
$server="my-host.no-ip.org -p 1022 -i /home/user/.ssh/my-key"; // куда валить мусор
$logfile="/usr/local/logs/trafic-balancer.log"; // для всего скрипта перенаправление вывода делать нельзя, так как logrotate прибивает файл
$curdate=0;
function echolog($str)
{
global $logfile;
file_put_contents($logfile, $str, FILE_APPEND);
echo($str);
}
echolog("\n".date('r')." \tЗапуск\n");
while(true)
{
$f=@fopen("/proc/net/dev", "r");
$stat=null;
while($str=fgets($f))
{
if(strpos($str, $interface)!==false)
{
$stat=$str;
break;
}
}
fclose($f);
if($stat)
{
$stat=preg_replace("/\s+/", " ", $stat);
$nums=explode(" ", $stat);
// трафик глобальный с пересчётом в мегабайты
$rx_g=round($nums[2]/1024/1024);
$tx_g=round($nums[10]/1024/1024);
$delta_g=$rx_g*4-$tx_g;
// трафик дневной
if($curdate!=date('j')) // начинается новый день
{
if($curdate)
echolog("\n".date('r')." \tРезультаты за $curdate число: RX:$rx_d Mb, TX:$tx_d Mb, дельта: $delta_d Mb\n");
$curdate=date('j');
$rx_d=0;
$tx_d=0;
$rx_s=$rx_g;
$tx_s=$tx_g;
}
$rx_d=$rx_g-$rx_s;
$tx_d=$tx_g-$tx_s;
$delta_d=$rx_d*4-$tx_d;
$delta=max($delta_g, $delta_d);
if(($delta0)&&(date('G')>8))
{
if($delta>1000) // если больше 1Г, то бьём на части
$size=round(rand(1000, min($delta/2, 5000))); // за один раз посылаем блок произвольного размера, но не слишком здоровый
else
$size=round(rand($delta*2, $delta*3)); // добиваем остаток с запасом чтоб кусками мелкими не качать
echolog("\n".date('r')." \tПревышение: общая дельта: $delta_g Mb, дневная дельта: $delta_d Mb, качаем $size Mb\n");
passthru("dd if=/dev/zero bs=1M count=$size | ssh $server 'cat > /dev/null'");
}
else echolog('.');
}
else
echolog("\n".date('r')." \tСтатистика не читается!\n");
sleep(round(rand(10, 600)));
}
?>
```
|
https://habr.com/ru/post/140697/
| null |
ru
| null |
# Такие неповторимые SSL-сертификаты на Azure
Немного предыстории: почти каждый инженер при разворачивании web проекта сталкивается с вопросом использования и реализации SSL-сертификатов. Я так точно с ним столкнулся)
Обычно в стартапах используются бесплатные сертификаты, например, от тех же Lets Encrypt. Но, как и любое бесплатное решение, оно имеет ряд неудобств и ограничений. Все ограничения подробно прописаны на [странице](https://letsencrypt.org/docs/rate-limits/) поставщика сертификатов, где вы и можете с ними ознакомиться.
А я бы хотел чуть подробнее остановиться именно на неудобствах, с которыми столкнулся сам:
* Сертификаты необходимо постоянно перевыпускать, а их максимальный срок действия составляет 3 месяца;
* В случае использования Kubernetes сертификаты приходится хранить в самом кубере и постоянно перегенерировать;
* Есть целый ряд нюансов с использованием Wildcard сертификатов и их перевыпуском;
* Некоторые особенности использования протоколов и алгоритмов шифрований.
Регулярно сталкиваясь с этими проблемами, я пришел к своей собственной настройке решения с Let’s Encrypt сертификатами, которой и хотел бы с вами поделиться.
Последнее время я работаю с определенным стеком технологий, поэтому речь пойдёт об инфраструктурном решении на базе Kubernetes кластеров в контексте облачного провайдера Azure. Есть такое известное решение как cert-manager. Установку лично мне удобнее делать через Helm, поэтому выполняем:
```
helm repo add jetstack https://charts.jetstack.io
helm repo update
kubectl apply -f https://github.com/jetstack/cert-manager/releases/download/v1.6.1/cert-manager.crds.yaml
helm install cert-manager jetstack/cert-manager --namespace cert-manager --create-namespace --version v1.6.1
```
После чего создаем ClusterIssuer на основе следующего yaml файла:
```
apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: letsencrypt-cluster-issuer
spec:
acme:
server: https://acme-v02.api.letsencrypt.org/directory
email: p…[email protected] #ваш e-mail
privateKeySecretRef:
name: letsencrypt-cluster-issuer
solvers:
- http01:
ingress:
class: nginx
```
Далее следует 2 варианта развития событий касательно реализации выпуска самих сертификатов:
* Делать сертификаты через добавление kind: Certificate
* Делать сертификаты через управление через ваш ingress
Предлагаю рассмотреть оба варианта.
В первом случае yaml файлы у меня выглядели следующим образом:
```
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: myservice2
namespace: test
Spec:
duration: 2160h
renewBefore: 72h
dnsNames:
- myservice2.mydomain.org #ваш ресурс
secretName: myservice2-tls
issuerRef:
name: letsencrypt-cluster-issuer
kind: ClusterIssuer
```
И при этом в ингрессе указывался только secretName: myservice2-tls в секции tls для конкретного сервиса.
Кстати, в вышеприведенном yaml файле есть очень удобные параметры:
* ***duration: 48h*** - срок действия сертификата в часах;
* ***renewBefore: 24h*** - за сколько часов до истечении срока действия сертификата можно попробовать обновить уже имеющийся сертификат.
А для любителей консоли приведу пример детального просмотра сертификата:
```
kubectl describe certificates <имя сертификата> -n <название namespace>
```
### Что же у нас остается по итогу?
* ***Not After*** *-* срок годности сертификата;
* ***Not Before***- как правило, дата создания сертификата, если вы явно не заполнили это поле в своем Certificate Ресурсе YAML;
* ***Renewal Time*** - временная отметка до истечения срока сертификата.
Схема работы по управлению Let’s Encrypt сертификатами через Ingress показалась мне удобнее и надежнее, так что в последнее время я использую именно её. Помимо добавления *secretName* и имени хоста в секцию tls необходимо указать/добавить в Ingress yaml файле только аннотации:
```
annotations:
cert-manager.io/cluster-issuer: "letsencrypt-cluster-issuer"
cert-manager.io/renew-before: 72h
```
Вот и вся магия! Сертификаты автоматически перевыпускаются (в данном примере за 3 суток) до истечении срока действия (в случае с Let’s Encrypt этот срок по умолчанию составляет 90 дней).
Учитывая ограничения бесплатных сертификатов от Let’s Encrypt, на определенном этапе разработки наша команда задумалась над единым полноценным сертификатом, который смог бы защитить не только наш домен, но и поддомены. Разрабатывая проект на Azure, удобным местом для хранения является Azure Key Vault. Для проброса в Kubernetes кластер используется утилита akv2k8s, с которой можно ознакомиться более подробнее по [ссылке](https://akv2k8s.io/quick-start/).
### А теперь немного о том, что это и с чем едят
После приобретения сертификата в Azure появляются советы по добавлению его в Azure Key Vault (или сокращенно AKV). В данном этапе нет ничего сложно, необходимо разве что подтвердить права на домен. После прохождения всех этапов подтверждения с “зелеными галочками” ваш сертификат появляется в хранилище ключей (AKV) в “Сикретах”.
В этой схеме есть свое преимущество, а именно автообновления сертификата. В случае необходимости сертификат перевыпускается через год и обновляется автоматически в AKV, т.е. сам синхронизируется с Secret в кубер.
Чтобы кластер Кубернейтс мог использовать этот сертификат нужно выдать права и установить разрешение.
Для этого получаем identityProfile.kubeletidentity.objectId кластера командой:
```
az aks show -g -n
```
Где RG - группа ресурсов, в которой находится кластер, а AKS\_name - имя вашего кластера.
Следующим шагом необходимо скопировать identityProfile.kubeletidentity.objectId. Затем подставляем полученные значения в команду разрешения доступа к секретам:
```
az keyvault set-policy --name <имя AKV> --object-id <полученное на предыдущем шаге значение> --secret-permissions get
```
После этого можно приступить к установке akv2k8s (через helm или другие удобные для вас способы). Установку смотрел [тут](https://github.com/SparebankenVest/public-helm-charts/tree/akv2k8s-2.0.10/stable/akv2k8s).
По официальной [документации](https://akv2k8s.io/quick-start/) делаем синхронизацию нашего сертификата из Azure Key Vault в Secret в конкретном namespace в Kubernetes. Вот мой пример yaml файла:
```
apiVersion: spv.no/v1
kind: AzureKeyVaultSecret
metadata:
name: wildcard-cert #любое имя - то как будет называться
namespace: default
spec:
vault:
name: SandboxKeyVault #имя хранилище вашего сертификата в Azure
object:
name: name_object_id #имя object id из Azure AKV конкретного серификата
type: secret
output:
secret:
name: wildcard-cert # любое имя как будет называться secret в вашем namespace
type: kubernetes.io/tls
chainOrder: ensureserverfirst # очень важная строка!!!
```
Хотелось бы отметить, что последняя строка была крайне важной, я не сразу нашел это решение. Поэтому сертификат прокидывался в кубер корректно, но не работал. И мне потребовалось какое-то время, чтобы разобраться в этой проблеме.
Оказалось, при экспорте сертификата PFX из Key Vault сертификат сервера иногда оказывается в конце цепочки, а не в начале, как и должно быть. Если эти параметры используются вместе, например, с ingress-nginx, сертификат не будет загружен и вернется к значению по умолчанию. Установив chainOrder на ensureserverfirst сертификат сервера будет перемещен первым в цепочке. При детальном рассмотрении сертификата мне удалось выявить, что цепочка выстраивается в следующем порядке:
1. Intermediate
2. Root
3. Server
**Поговорив про техническую составляющую и настройку, вернёмся к тонкостям именно ажуровских сертификатов.**
В Azure есть возможность заказа сертификата. Сертификаты поставляются от GoDaddy. Тут доступно два варианта:
* Сертификат отдельно для конкретного домена (поддомена);
* Wildcard сертификат.
Первый вариант нас не устраивал, так что мы выбрали второй, надеясь, что он сможет защитить все наши приложения и сервисы. Но даже тут имел место быть ряд нюансов.
Wildcard сертификат, который поставляется на Azure, защищает только поддомены первого уровня. Т.е. если у нас есть домен с именем [mydomail.com](http://mydomail.com), то Wildcard сертификат Azure подходит только для поддоменов первого уровня вида *.mydomain.com! Например, для ресурсов* [*service1.mydomain.com*](http://service1.mydomain.com)*,* [*service2.mydomain.com*](http://service2.mydomain.com)*,* [*service3.mydomain.com*](http://service3.mydomain.com) *сертификат подойдёт. Но, если нам необходим* [*service1.test.mydomain.com*](http://service1.test.mydomain.com) *или* [*mail.service1.mydomain.com*](http://mail.service1.mydomain.com)*, то тут сертификат идет мимо. Какие в целом могут быть тут варианты?*
* *Покупать отдельные сертификаты wildcard для всех необходимых поддоменов;*
* *Добавлять SAN (****Subject Alternative Name****) записи в сертификат.*
*Первый вариант, думаю, вряд ли кого устроит. Разработки, как и поддоменов второго уровня, может быть огромное количество и платить за wildcard сертификат для каждого поддомена (*.service1.mydomain.com, \*.dev.mydomain.com…) не самый разумный выход.
А вот по второму варианту я довольно долго общался со службой поддержки Azure. Прошел все стадии отрицания, разочарования и гнева, поняв в самом конце, что поддержка возможности SAN для сертификатов у них до сих пор не реализована.
До последнего хотелось верить, что такого не может быть на Azure… У их конкурентов (AWS Amazon) сертификаты, предоставляемые AWS Certificate Manager (ACM), поддерживают до 10 альтернативных имен субъектов, включая подстановочные знаки. Таким образом можно было придумать 10 поддоменов с подстановочным знаком \*, а также запросить увеличение квоты на AWS до 100 к.
На финал я оставил небольшой рассказ о том, как можно использовать сертификаты с сервисом FrontDoor на Azure.
### Что же такое Azure Front Door (AFD)?
В моем представлении, это глобальная масштабируемая точка входа, которая использует глобальную пограничную сеть Microsoft для распределения входного трафика и перенаправления его к соответствующим конечным точкам (веб приложениям и сервисам). Front Door работает на уровне 7 (уровень HTTP/HTTPS). Front Door будет направлять ваши клиентские запросы на доступный сервер приложения из пула. Серверная часть приложения — это любая служба с выходом в Интернет, размещенная внутри или за пределами Azure.
Пример с сайта документации https://docs.microsoft.com/Сервис достаточно удобный и позволяет быть балансером/проксёй для вашего входящего трафика, который обращается к распределенным приложениям и сервисам по всему миру. Тут же есть возможность привязки различных правил через конфигурацию обработчика правил, встроенного в этот сервис, присоединение политик и настройки фаервола. Сильно углублять по самому сервису AFD не буду, но готов поделиться этим в комментариях. А в рамках этого материала расскажу немного об особенностях работы сервиса именно с сертификатами.
Как вы уже догадались, входной трафик на Azure Front Door может поступать как по *Http*, так и по *https.* В случае выбора *https* есть возможность генерации сертификата на самом сервисе Azure Front Door, подгрузки собственного сертификата или синхронизации имеющегося у вас сертификата в Azure Key Vault (чтобы служба Frontdoor получила доступ к Key Vault, необходимо настроить нужные разрешения).
Рекомендую использовать последний вариант и выбрать последнюю версию сикрета, тогда при автопродлении и перегенерации сертификата вам ничего делать не придётся: всё само подтянется. Подключив сертификат из AKV получится такая картина:
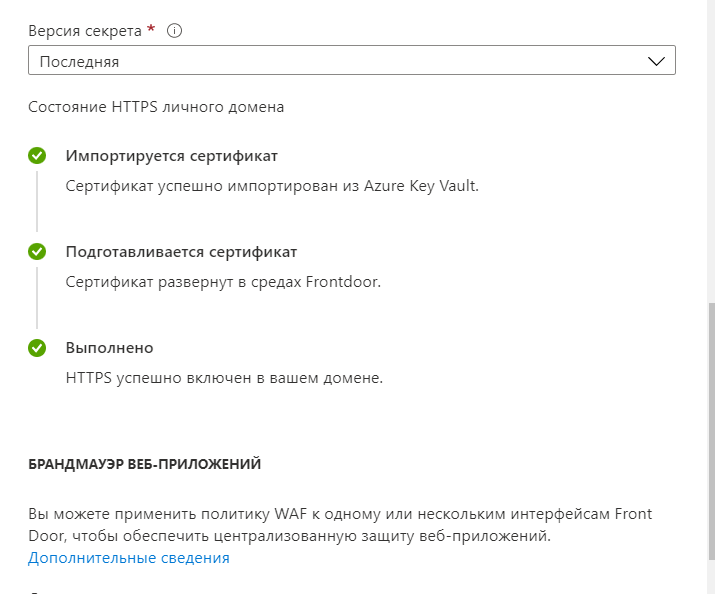Еще одна фишка: особенности перенаправлении трафика с Azure Front Door на AKS.
В случае с *http* никаких проблем не возникает. Но есть один нюанс: при создании пула ресурсов и указании вашего внешнего IP адреса AKS кластера, поле “заголовок узла серверного компонента” оставляйте пустым! Оно заполнится автоматически теми показателями, которые вы оставили в поле “ip или имя узла”.
Например, у вас есть доменный wildcard сертификат присоединенный через AKV как к сервису FrontDoor, так и прокинутый в AKS кластер через akv2k8s. Для всех ваших приложений и сервисов, доступных через FrontDoor, имя интерфейсного узла (и содержание CNAME записи в DNS) будет следующим:
* \*.mydomain.com – с пустым полем “заголовок узла серверного компонента”
* Ваш внешний IP адрес AKS будет иметь правило перенаправления *http* по умолчанию на */*
В таком случае все ваши сервисы формата \**.mydomain.com* будут работать)
На этом можно закончить настройку.
Но в некоторых случаях куда как интереснее настроить перенаправления трафика именно по *https* с AFD на AKS. Для корректной работы Azure Front Door в настройках серверного пула нужно обязательно указывать **именно DNS имя соответствующее вашему AKS кластеру** (это связано с SNI и hc), иначе ничего не сработает.
В моем кейсе никакого имени у AKS кластеров не было, имелись только сервисы, которые раньше работали напрямую, а сейчас должны были работать через Azure Front Door. Столкнувшись с такой ситуацией мне пришлось придумывать отдельное DNS имя для AKS кластера, настраивать DNS и заводить отдельный сервис с присоединением сертификата к ингрессу. Только после этого перенаправление по *https* на AKS кастеры заработало корректно для всех имеющихся сервисов.
Тут же отмечу, что из соображений безопасности стоит обратить внимание на возможности настройки (ограничения) разрешения подключения к AKS только с IP адресов Azure Front Door в вашей Network Security Group для AKS (*рис. ниже*).
Дополнительно в ингрессе AKS возможно указать разрешение принимать соединения только с заголовком именно вашего Azure Front Door по ID ([подробнее](https://docs.microsoft.com/en-us/azure/frontdoor/front-door-faq#how-do-i-lock-down-the-access-to-my-backend-to-only-azure-front-door) о параметре X-Azure-FDID).
### Чем всё это дело закончилось и что я могу посоветовать?
1. Azure не пишут подробно о возможностях и проблемах своих сертификатов. Но стоит отдать должное, они довольно оперативно вернули деньги за купленный нами сертификат.
2. Мы продолжаем использовать Lets Encrypt в разработке. Да, у него есть свои минусы, но это не самый худший вариант.
3. Если планируете создавать много различных поддоменов и вам необходимы разные уровни для ваших ресурсов на проектах, то присмотритесь к “Wildcard (иногда его называют Multidomain) with SAN” сертификатам от сторонних поставщиков. Вы вполне сможете импортировать его в Azure и полноценно использовать в своей работе.
4. Azure Front Door - достаточно неплохой сервис при грамотной его настройке, рекомендую к использованию!
|
https://habr.com/ru/post/648193/
| null |
ru
| null |
# Пакетный менеджер для Kubernetes — Helm: прошлое, настоящее, будущее
***Прим. перев.**: Этой статьёй мы открываем цикл публикаций про пакетный менеджер для Kubernetes, который активно используем в повседневной работе, — Helm. Оригинальным автором материала является Matt Butcher — один из основателей проекта Helm, работающий над Open Source-проектами в Microsoft и написавший 8 технических книг (в частности, «Go in Practice»). Однако статья дополнена нашими (местами — обширными) комментариями, а в скором времени будет ещё больше расширена новыми заметками по Helm более практической направленности. **ОБНОВЛЕНИЕ** (03.09.2018): вышло продолжение — «[Практическое знакомство с пакетным менеджером для Kubernetes — Helm](https://habr.com/company/flant/blog/420437/)».*

В июне Helm [перешёл](https://www.cncf.io/blog/2018/06/01/cncf-to-host-helm/) из статуса ведущего проекта Kubernetes в фонд Cloud Native Computing Foundation (CNCF). CNCF становится родительской организацией для лучших в своём роде cloud native-инструментов с открытым исходным кодом. Поэтому большая честь для Helm стать частью такого фонда. И наш первый значимый проект под покровительством CNCF по-настоящему масштабный: мы создаём Helm 3.
Краткая история Helm
--------------------
Helm изначально появился как Open Source-проект компании Deis. Его моделировали по подобию [Homebrew](https://brew.sh/) *(менеджер пакетов для macOS — **прим. перев.**)*, а стоящей перед Helm 1 задачей была облегчённая возможность для пользователей быстро установить свои первые рабочие нагрузки на Kubernetes. Официальный анонс Helm состоялся на первой конференции KubeCon San Francisco в 2015 году.
***Прим. перев.:** С первой версии, которая называлась dm (Deployment Manager), для описания ресурсов Kubernetes был выбран синтаксис YAML, а при написании конфигураций поддерживались [шаблоны Jinja](http://jinja.pocoo.org) и Python-скрипты.*
*Шаблон простого веб-приложения мог выглядеть следующим образом:*
**YAML**
```
resources:
- name: frontend
type: github.com/kubernetes/application-dm-templates/common/replicatedservice:v1
properties:
service_port: 80
container_port: 80
external_service: true
replicas: 3
image: gcr.io/google_containers/example-guestbook-php-redis:v3
- name: redis
type: github.com/kubernetes/application-dm-templates/storage/redis:v1
properties: null
```
*При описании компонентов выкатываемого приложения указывается имя, используемый шаблон, а также необходимые параметры этого шаблона. В примере выше ресурсы `frontend` и `redis` используют шаблоны из официального репозитория.*
*Уже в этой версии можно использовать ресурсы из общей базы знаний, создавать собственные репозитории шаблонов и компоновать комплексные приложения за счёт параметров и вложенности шаблонов.*
*Архитектура Helm 1 состоит из трёх компонентов. Следующая диаграмма иллюстрирует отношения между ними:*
1. *`Manager` выполняет функцию веб-сервера (общение с клиентами происходит по REST API), управляет развёртываниями в кластере Kubernetes и используется как хранилище данных.*
2. *Компонент `expandybird` приводит пользовательские конфигурации к плоской форме, т.е. применяет Jinja-шаблоны и выполняет Python-скрипты.*
3. *Получив плоскую конфигурацию, `resourcifier` выполняет необходимые вызовы kubectl и возвращает в `manager` статус и сообщения об ошибках, если таковые имеются.*
*Для понимания возможностей первой версии Helm приведу справку по команде `dm`*:
**Вывод help от dm**
```
Usage: ./dm [] [( | | ( [...]))]
Commands:
expand Expands the supplied configuration(s)
deploy Deploys the named template or the supplied configuration(s)
list Lists the deployments in the cluster
get Retrieves the supplied deployment
manifest Lists manifests for deployment or retrieves the supplied manifest in the form (deployment[/manifest])
delete Deletes the supplied deployment
update Updates a deployment using the supplied configuration(s)
deployed-types Lists the types deployed in the cluster
deployed-instances Lists the instances of the named type deployed in the cluster
templates Lists the templates in a given template registry (specified with --registry)
registries Lists the registries available
describe Describes the named template in a given template registry
getcredential Gets the named credential used by a registry
setcredential Sets a credential used by a registry
createregistry Creates a registry that holds charts
Flags:
-apitoken string
Github api token that overrides GITHUB\_API\_TOKEN environment variable
-binary string
Path to template expansion binary (default "../expandybird/expansion/expansion.py")
-httptest.serve string
if non-empty, httptest.NewServer serves on this address and blocks
-name string
Name of deployment, used for deploy and update commands (defaults to template name)
-password string
Github password that overrides GITHUB\_PASSWORD environment variable
-properties string
Properties to use when deploying a template (e.g., --properties k1=v1,k2=v2)
-regex string
Regular expression to filter the templates listed in a template registry
-registry string
Registry name (default "application-dm-templates")
-registryfile string
File containing registry specification
-service string
URL for deployment manager (default "http://localhost:8001/api/v1/proxy/namespaces/dm/services/manager-service:manager")
-serviceaccount string
Service account file containing JWT token
-stdin
Reads a configuration from the standard input
-timeout int
Time in seconds to wait for response (default 20)
-username string
Github user name that overrides GITHUB\_USERNAME environment variable
--stdin requires a file name and either the file contents or a tar archive containing the named file.
a tar archive may include any additional files referenced directly or indirectly by the named file.
```
*А теперь вернёмся к оригинальному тексту об истории Helm…*
Несколькими месяцами позже мы объединили усилия с командой Kubernetes Deployment Manager из Google и начали работу над Helm 2. Целью было сохранить простоту использования Helm, добавив в него следующее:
1. шаблоны чартов *(«чарт» — аналог пакета в экосистеме Helm — **прим. перев.**)* для кастомизации;
2. управление внутри кластера для команд;
3. полноценный репозиторий чартов;
4. стабильный и подписываемый формат пакетов;
5. твёрдая приверженность семантическому версионированию и сохранению обратной совместимости от версии к версии.
Чтобы достичь этих целей, в экосистему Helm был добавлен второй компонент. Им стал находящийся внутри кластера Tiller, который обеспечивал установку Helm-чартов и управление ими.
***Прим. перев.:** Таким образом, во второй версии Helm в кластере остаётся единственный компонент, который отвечает за жизненный цикл инсталяций ([release](https://docs.helm.sh/glossary/#release)), а подготовка конфигураций выносится в Helm-клиент.*
*Если перезагрузка кластера при использовании первой версии Helm приводила к полной потере служебных данных (т.к. они хранились в оперативной памяти), то в Helm 2 все данные хранятся в `ConfigMaps`, т.е. ресурсах внутри Kubernetes. Ещё одним важным шагом стал переход от синхронного API (где каждый запрос был блокирующим) к использованию асинхронного gRPC.*
Со времени выпуска Helm 2 в 2016 году проект Kubernetes пережил взрывной рост и появление новых значительных возможностей. Было добавлено управление доступом на основе ролей (RBAC). Представлено множество новых типов ресурсов. Изобретены сторонние ресурсы (Custom Resource Definitions, CRD). А что самое важное — появились лучшие практики. Проходя через все эти изменения, Helm продолжал служить потребностям пользователей Kubernetes. Но нам стало очевидно, что настало время внести в него крупные изменения для того, чтобы потребности этой развивающейся экосистемы продолжали удовлетворяться.
Так мы пришли к Helm 3. Далее я расскажу о некоторых из новшеств, фигурирующих на дорожной карте проекта.
Поприветствуем Lua
------------------
В Helm 2 мы представили шаблоны. На раннем этапе разработки Helm 2 мы поддерживали шаблоны Go, Jinja, чистый код на Python и у нас даже был прототип поддержки ksonnet. Но наличие множества движков для шаблонов породило больше проблем, чем решило. Поэтому мы пришли к тому, чтобы выбрать один.
У шаблонов Go было четыре преимущества:
1. библиотека [встроена в Go](https://godoc.org/text/template);
2. шаблоны исполняются в жёстко ограниченном песочницей окружении;
3. мы могли вставлять в движок [произвольные функции и объекты](https://docs.helm.sh/chart_template_guide/#built-in-objects);
4. они хорошо работали с YAML.
Хотя мы и сохранили в Helm интерфейс для поддержки других движков шаблонов, шаблоны Go стали нашим стандартом по умолчанию. И последующие несколько лет опыта показали, как инженеры из многих компаний создавали тысячи чартов, используя шаблоны Go.
И мы узнали об их разочарованиях:
1. Синтаксис сложен в чтении и плохо документирован.
2. Проблемы языка, такие как неизменные переменные, запутанные типы данных и ограничительные правила в области видимости, превратили простые вещи в сложные.
3. Отсутствие возможности определять функции внутри шаблонов ещё больше усложнили создание повторно используемых библиотек.
Самое важное — используя язык шаблонов, мы существенно «обрезали» объекты Kubernetes до их строчного представления. (Другими словами, разработчикам шаблонов приходилось управлять ресурсами Kubernetes как текстовыми документами в формате YAML.)
Работа над объектами, а не кусками YAML
---------------------------------------
Снова и снова мы слышали от пользователей запрос на возможность инспекции и модификации ресурсов Kubernetes как объектов, а не строк. В то же время они были непреклонны в том, что, какой бы путь реализации мы для этого ни выбрали, он должен быть простым в изучении и хорошо поддерживаться в экосистеме.
После месяцев исследований мы решили предоставить встроенный скриптовый язык, который можно упаковать в песочницу и кастомизировать. Среди 20 ведущих языков оказался лишь один кандидат, удовлетворяющий требованиям: [Lua](https://www.lua.org/home.html).
В 1993 году группа бразильских ИТ-инженеров создала легковесный скриптовый язык для встраивания в свои инструменты. У Lua простой синтаксис, он широко поддерживается и уже долгое время фигурирует в списке [топ-20 языков](https://redmonk.com/sogrady/2018/03/07/language-rankings-1-18/). Его поддерживают IDE и текстовые редакторы, есть множество руководств и обучающих книг. Вот на такой уже существующей экосистеме мы бы и хотели развивать своё решение.
Наша работа над Helm Lua всё ещё находится на этапе доказательства концепции, и мы ожидаем синтаксиса, который был бы одновременно знакомым и гибким. Сравнивая старый и новый подходы, можно увидеть, куда мы движемся.
Вот как выглядит [пример](https://github.com/kubernetes/helm/blob/master/docs/examples/alpine/templates/alpine-pod.yaml) шаблона пода с Alpine в Helm 2:
```
apiVersion: v1
kind: Pod
metadata:
name: {{ template "alpine.fullname" . }}
labels:
heritage: {{ .Release.Service }}
release: {{ .Release.Name }}
chart: {{ .Chart.Name }}-{{ .Chart.Version }}
app: {{ template "alpine.name" . }}
spec:
restartPolicy: {{ .Values.restartPolicy }}
containers:
- name: waiter
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
imagePullPolicy: {{ .Values.image.pullPolicy }}
command: ["/bin/sleep", "9000"]
```
В этом незамысловатом шаблоне можно сразу увидеть все встроенные директивы шаблонов, такие как `{{ .Chart.Name }}`.
А вот как выглядит определение того же пода в предварительной версии кода на Lua:
```
function create_alpine_pod(_)
local pod = {
apiVersion = "v1",
kind = "Pod",
metadata = {
name = alpine_fullname(_),
labels = {
heritage = _.Release.Service or "helm",
release = _.Release.Name,
chart = _.Chart.Name .. "-" .. _.Chart.Version,
app = alpine_name(_)
}
},
spec = {
restartPolicy = _.Values.restartPolicy,
containers = {
{
name = waiter,
image = _.Values.image.repository .. ":" .. _.Values.image.tag,
imagePullPolicy = _.Values.image.pullPolicy,
command = {
"/bin/sleep",
"9000"
}
}
}
}
}
_.resources.add(pod)
end
```
Нет необходимости рассматривать каждую строчку этого примера, чтобы понять, что происходит. Сразу видно, что в коде определяется под. Но вместо использования YAML-строк со встроенными директивами шаблонов мы определяем под как объект в Lua.
Давайте сократим этот код
-------------------------
Поскольку мы напрямую работаем с объектами (вместо манипуляции с большим glob'ом текста), можем воспользоваться всеми преимуществами скриптования. Появляющиеся здесь возможности создания разделяемых библиотек выглядят по-настоящему привлекательно. И мы надеемся, что, представив специализированные библиотеки (или позволив сообществу их создать), сможем сократить приведённый выше код примерно до такого:
```
local pods = require("mylib.pods");
function create_alpine_pod(_)
myPod = pods.new("alpine:3.7", _)
myPod.spec.restartPolicy = "Always"
-- set any other properties
_.Manifests.add(myPod)
end
```
В данном примере используется возможность работы с определением ресурса как с объектом, которому легко устанавливать свойства, сохраняя при этом лаконичность и читаемость кода.
Шаблоны… Lua… Почему бы не всё вместе?
--------------------------------------
Пусть шаблоны и не так замечательны для всех задач, у них всё же есть определённые преимущества. Шаблоны в Go — стабильная технология со сложившейся пользовательской базой и множеством существующих чартов. Многие разработчики чартов утверждают, что им нравится писать шаблоны. Поэтому поддержку шаблонов мы убирать не собираемся.
Вместо этого мы хотим разрешить использовать одновременно и шаблоны, и Lua. У скриптов Lua будет доступ к шаблонам Helm и до, и после того, как они отрендерены, что позволит разработчикам продвинутых чартов выполнять сложные преобразования для существующих чартов, сохраняя простую возможность создания Helm-чартов с шаблонами.
Мы очень воодушевлены поддержкой скриптов на Lua, но в то же время избавляемся от значимой части архитектуры Helm…
Прощаясь с Tiller
-----------------
Во время разработки Helm 2 мы представили Tiller в качестве компонента интеграции с Deployment Manager. Tiller играл важную роль для команд, работающих на одном кластере: он делал возможным взаимодействие с одним и тем же набором релизов для множества различных администраторов.
Однако Tiller работал как гигантский sudo-сервер, выдающий широкий диапазон прав каждому, у кого есть доступ к Tiller. И нашей схемой по умолчанию при инсталляции была разрешительная конфигурация. Поэтому DevOps- и SRE-инженерам приходилось обучаться дополнительным шагам для установки Tiller в кластерах категории multi-tenant.
Более того, при появлении CRD мы больше не могли надёжно полагаться на Tiller для поддержания состояния или функционирования в качестве центрального хаба для информации о релизе Helm. Мы могли только хранить эту информацию в виде отдельных записей в Kubernetes.
Главная цель Tiller может быть достигнута и без самого Tiller. Поэтому одним из первых решений, принятых на этапе планирования Helm 3, был полный отказ от Tiller.
Улучшение безопасности
----------------------
Без Tiller модель безопасности Helm радикально упрощается. Пользовательская аутентификация делегируется Kubernetes. И авторизация тоже. Права Helm определяются как права Kubernetes (через систему RBAC), и администраторы кластера могут ограничить права Helm на любом необходимом уровне детализации.
Releases, ReleaseVersions и State Storage
-----------------------------------------
В условиях отсутствия Tiller, для поддержания состояния различных релизов внутри кластера нам требуется новый способ взаимодействия всех клиентов (по управлению релизами).
Для этого мы представили две новые записи:
1. `Release` — для конкретной инсталляции конкретного чарта. Если мы выполним `helm install my-wordpress stable/wordpress`, будет создан релиз с названием `my-wordpress` и поддерживаться на протяжении всей жизни этой инсталляции WordPress.
2. `ReleaseVersion` — при каждом обновлении чарта Helm необходимо учитывать, что изменилось и было ли изменение успешным. `ReleaseVersion` привязан к релизу и хранит только записи с информацией об обновлении, откате и удалении. Когда мы выполним `helm upgrade my-wordpress stable/wordpress`, оригинальный объект `Release` останется прежним, но появится дочерний объект `ReleaseVersion` с информацией об операции обновления.
`Releases` и `ReleaseVersions` будут храниться в тех же пространствах имён, что и объекты чарта.
С этими возможностями команды пользователей Helm смогут отслеживать записи об инсталляциях Helm в кластере без потребности в Tiller.
Но подождите, это ещё не всё!
-----------------------------
В этой статье я постарался рассказать о некоторых крупнейших изменениях в Helm 3. Однако этот список вовсе не является полным. [План по Helm 3](https://github.com/kubernetes-helm/community/blob/master/helm-v3/000-helm-v3.md) включает в себя и другие изменения, такие как улучшения в формате чартов, улучшения в производительности для репозиториев чартов и новая событийная система, которой могут пользоваться разработчики чартов. Мы также предпринимаем усилия по тому, что Eric Raymond называется [археологией кода](http://www.itprotoday.com/open-source/eric-s-raymond-keeping-bazaar-secure-and-functional), вычищая кодовую базу и обновляя компоненты, утратившие актуальность за последние три года.
***Прим. перев.**: Парадокс, но пакетный менеджер Helm 2 при успешном выполнении `install` или `upgrade`, т.е. имея release в состоянии `success`, не гарантирует, что ресурсы приложения успешно выкатились (к примеру, нет ошибок типа `ImagePullError`). Возможно, новая событийная модель позволит добавлять дополнительные хуки для ресурсов и лучше контролировать процесс выката — скоро мы об этом узнаем.*
С присоединением Helm к CNCF нас вдохновляет не только Helm 3, но и [Chart Museum](https://github.com/kubernetes-helm/chartmuseum), замечательная утилита [Chart Testing](https://github.com/kubernetes-helm/chart-testing), [официальный репозиторий чартов](https://github.com/kubernetes/charts) и другие проекты под эгидой Helm в CNCF. Мы уверены, что хорошее управление пакетами для Kubernetes настолько же важно для облачной (cloud native) экосистемы, насколько важны хорошие пакетные менеджеры для Linux.
P.S. от переводчика
-------------------
Читайте также в нашем блоге:
* «[Практическое знакомство с пакетным менеджером для Kubernetes — Helm](https://habr.com/company/flant/blog/420437/)»;
* «[Практика с dapp. Часть 2. Деплой Docker-образов в Kubernetes с помощью Helm](https://habr.com/company/flant/blog/336170/)»;
* «[Сборка и дeплой приложений в Kubernetes с помощью dapp и GitLab CI](https://habr.com/company/flant/blog/345580/)»;
* «[Лучшие практики CI/CD с Kubernetes и GitLab](https://habr.com/company/flant/blog/345116/)» *(обзор и видео доклада)*;
* «[Наш опыт с Kubernetes в небольших проектах](https://habr.com/company/flant/blog/331188/)» *(видео доклада, включающего в себя знакомство с техническим устройством Kubernetes).*
|
https://habr.com/ru/post/417079/
| null |
ru
| null |
# Установка базы данных SAP HANA в Яндекс Облаке. Пошаговое руководство
Продолжаем эксперименты по установке различных SAP систем в Яндекс Облаке.
В [первой части](https://cloud.yandex.ru/blog/posts/2020/01/sap) (статья была опубликована в блоге Яндекс Облака) был рассмотрена установка платформы SAP Netweaver ABAP AS, которая является основой для большинства SAP систем. В этой публикации мы перейдем от сервера приложений к уровню базы данных.
Изначально SAP Netweaver работал на широком спектре баз данных, среди которых были как принадлежащие компании SAP (SAP MaxDB, SAP ASE) так и базы данных от сторонних производителей (DB2, Oracle и MS SQL Server). Ситуация кардинально начала меняться в 2015 году с выходом SAP HANA (High-performance Analytic Appliance). Эта база данных позиционировалась компанией SAP как революционный для рынка продукт:
* обработка всех запросов осуществляется исключительно в оперативной памяти
* совмещение построчного и поколоночного хранение данных
* встроенные библиотеки PAL (Predictive Analytics Library), BFL (Business Function Library), Text Analysis, SAP HANA SQLScript и другие инструменты для подготовки данных на стороне базы данных и таким образом уменьшения обмена данными с сервером приложений.
Чтобы максимально использовать потенциал новой БД в SAP перерабатывают свою флагманскую ERP-система, которая выходит в 2015 году под названием S/4HANA и уже работает исключительно на базе SAP HANA. В последствии глубоко переработанные HANA — версии появляются у других популярных продуктов хранилища данных BW (Business Warehouse) — решение выходит на рынок под названием SAP BW/4HANA и у CRM-системы — решение выходит на рынок под названием SAP C/4HANA.
Остальные SAP ABAP и JAVA системы, например, шина данных SAP Process Orсhestration теперь могут использовать SAP HANA, как одну из доступных для установки баз данных, наряду с Oracle, DB2 и другими.
Поскольку SAP HANA является мультиконтейнерной базой данных, типичный корпоративный SAP — ландшафт выглядит следующим образом:

в этом скриношоте каждый тенант – это изолированная база данных какой-либо SAP системы (SAP Process Orсhestration, SAP EWM, SAP ATTP, SAP S/4HANA и т.д) внутри одной инсталляции SAP HANA.
Со временем у SAP появились также и коммерческие продукты которые представляют собой связку веб-приложение + база данных SAP HANA.
Например, SAP Medical Research Insights. Данная система должна помочь врачам выработать правильный план лечения, опирающийся на огромный массив данных, в том числе и о генетических исследованиях.

Еще один важный момент это наличие в архитектуре SAP HANA встроенного веб сервера (SAP HANA Extended Application Service). Данный сервер имеет привилегированный доступ к базе данных и позволяет выполнять приложения на Java, Python, Node.js и множестве других языков программирования. В версии сервиса Advanced Model (XSA) в ландшафте SAP HANA появляется такой функционал, как интегрированная среда разработки с веб-интерфейсом (SAP WEB IDE), Codereview (Gerrit) планировщик зданий (SAP XS JOB SCHEDULER) и многое другое.
Архитектура SAP HANA XSA:

Появление и постоянное развитие SAP HANA требует новых знаний у администраторов и разработчиков приложений. Возможность установить и экспериментировать со своей собственной базой и средой разработки в облаке представляется в этом случае далеко не лишней.
Однако SAP HANA будет интересна не только в Enterprise-среде, и не только среди разработчиков SAP. Благодаря гибкой лицензионной политики этот продукт можно бесплатно установить и использовать, в том числе и в коммерческих целях (размер в этом случае ограничен 32 GB) Возможно приведённый ниже пример установки и использования даст идею о том какое место может занять база данных SAP HANA и SAP HANA Extended Application Service в Вашем проекте.
Шаг 1. Скачиваем установочные файлы SAP HANA
--------------------------------------------
Заходим на страницу загрузки [SAP HANA, express edition](https://www.sap.com/cmp/td/sap-hana-express-edition.html) и если у Вас нет учетной записи в SAP необходимо пройти простую регистрацию

Скачиваем и запускаем SAP HANA Express Edition Download Manager

В Download Manager укажем следующие варианты загрузки
Платформа – Linux/x86 – 64
Image – Binary Installer
Package – Applications\*

\* — Под Applications подразумевается база данных SAP HANA, сервер приложений и среда разработки SAP HANA Extended Application Services, Advanced Model (XSA)
Шаг 2. Создаём виртуальную машину в Яндекс Облаке
-------------------------------------------------
На этом шаге нам понадобится следующий бесплатный софт:
* PuTTY – SSH-клиент.
* PuTTYgen – Генератор Public/Private ключей.
* WinSCP – SFTP-клиент.
Как альтернативу для данных приложений можно также рассмотреть приложение MobaXTerm
Создадим связку Public-Private ключ с помощью PuTTYgen.
Регистрируемся / заходим в Яндекс Облако (https://cloud.yandex.ru/). Переходим в раздел Compute Cloud и приступаем к созданию виртуальной машины.
Имя виртуальной машины: saphana2
Зададим подходящие характеристики ВМ. В руководстве по установке для SAP HANA Express Edition (Server + Application) видим следующие рекомендуемые параметры:

Зададим их при создании нашей виртуальной машины.
vCPU — 2,
RAM – 32GB,
15 GB + 150 GB, где
15 GB (загрузочный диск — SSD)
150 GB (данные — \* HDD)
\* — т.к. SAP HANA все операции проводит в оперативной памяти в качестве носителя для снепшота данных мы можем выбрать более медленный HDD
В качестве операционной системы выберем последнюю стабильную ОС OpenSUSE, на момент написания статьи – это версия ОС OpenSUSE 42.3
Укажем Логин и Public SSH-ключ, сгенерированный с помощью PuTTYgen
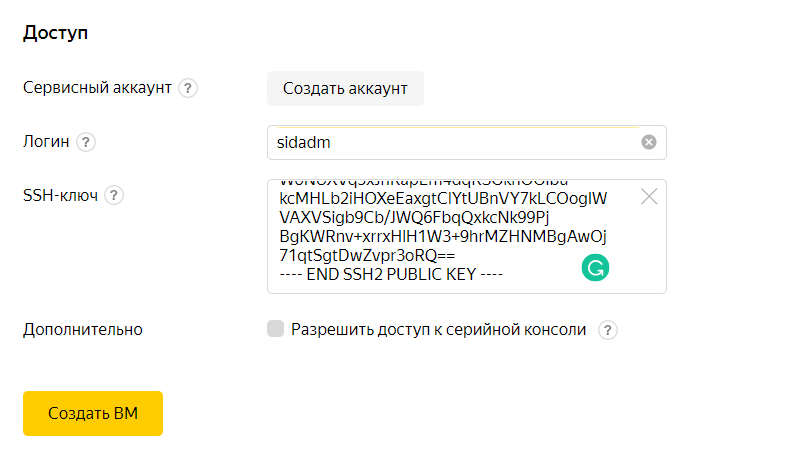
Шаг 3. Подготавливаем виртуальную машину к установке SAP HANA XSA
-----------------------------------------------------------------
Находим в настройках Публичный IPv4 адрес:

Подключаемся к созданной ВМ с помощью Putty-клиента, указав в подключении публичный IPv4, заданный логин и путь к Private – ключу

Подготовим файловую структуру к установке.
lsblk
vda – boot диск, vdb –диск, созданный под данные.
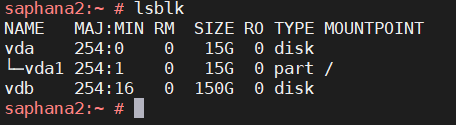
SAP рекомендует следующую файловую структуру:
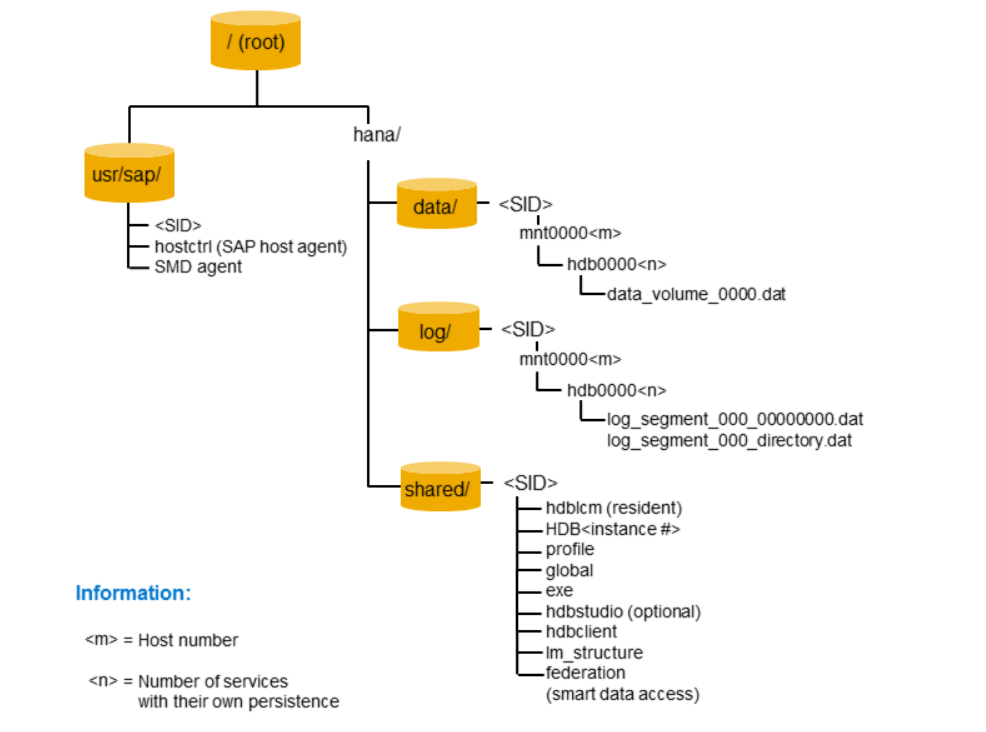
/usr/sap + /usr/sap/distr – 35 GB
/hana/shared/data — 60 GB
/hana/shared/log — 10 GB
/hana/shared –40 GB
Реализуем такую структуру с помощью утилиты fdisk:
```
fdisk /dev/vdb`
```
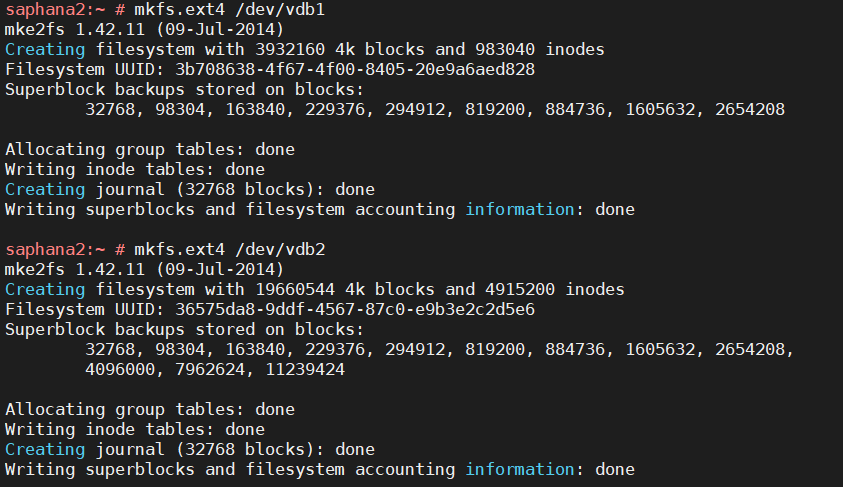
Проверим ещё раз структуру и создадим файловую систему *ext4* на всех созданных разделах:
```
lsblk
```

```
mkfs.ext4 /dev/vdb1
mkfs.ext4 /dev/vdb2
mkfs.ext4 /dev/vdb3
mkfs.ext4 /dev/vdb4
```

Создадим директории под дистрибутивы и базу данных SAP HANA, а также примонтируем к ним созданные на предыдущем шаге разделы. Также обновим файл */etc/fstab*, чтобы монтирование восстанавливалось при перезагрузке:
```
mkdir /usr/sap
mkdir /hana
mkdir /hana/shared
mkdir /hana/shared/data
mkdir /hana/shared/log
mount /dev/vdb1 /usr/sap
mount /dev/vdb2 /hana/shared/data
mount /dev/vdb3 /hana/shared/log
mount /dev/vdb4 /hana/shared
mkdir /usr/sap/distr
vi /etc/fstab
```


Установим разрешение на папку с установочными файлами SAP:
```
chmod -R 777 /usr/sap/distr
```
Импортируем в WinSCP настройки из Putty. Подключимся к ВМ и загрузим в */usr/sap/distr* архивы SAP HANA Server (hxe.tgz), SAP HANA Extended Application Services –XSA (hxeesa.tgz) и shine.tgz (Учебный контент)

Распакуем архивы:
```
cd /usr/sap/distr
tar -xvzf hxe.tgz
tar -xvzf hxexsa.tgz
tar -xvzf shine.tgz
```
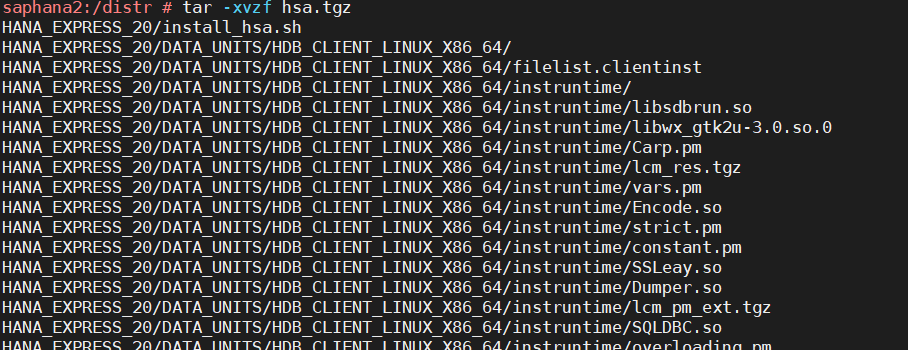
Добавим репозиторий:
```
sudo zypper ar -c https://download.opensuse.org/tumbleweed/repo/oss/ openSUSE-Tumbleweed-Oss-HTTPS
```
Установим требуемые для работы библиотеки libstdc++, libnuma1, libatomic и libgcc\_s1:
```
zypper install libstdc++6
zypper install libatomic1
zypper install libgcc_s1
zypper install libnuma1
```
Шаг 4. Устанавливаем SAP HANA XS
--------------------------------
Первое с чего стоит начать установку – это определением понятия **SID**
**SID (SAP System Identificator)** — представляет собой комбинацию трех символов и должен быть уникальным в рамках ландшафта. В рамках установки SAP HANA Express Edition значение SID по-умолчанию HXE. Предполагается, что мы не будем выбирать в качестве SID что-то другое.
Запускаем скрипт инсталляции с правами root – пользователя:
```
cd /usr/sap/distr
./setup_hxe.sh
```
В меню установки требуется несколько раз нажать Enter.
Таким образом мы установим предложенные значения по умолчанию:
Дистрибутивы лежат в */distr/HANA\_EXPRESS\_20*
SID – HXE
Номер инстанции – 90
Установка всех компонентов – all\*
\* — В данном случае это значит, что мы установим набор библиотек Application Function Library (AFL), куда входят Predictive Analysis Library (PAL), Business Function Library (BFL), Optimization Function Library (OFL).
Плагин SAP HANA EPM–MDS предназначен для получения данных из различных OLAP источников, а подсистема расширенных сервисов (Extended Services, XS) — это встроенный веб-сервер и набор различных компонентов, имеющих привилегированный доступ к базе данных.
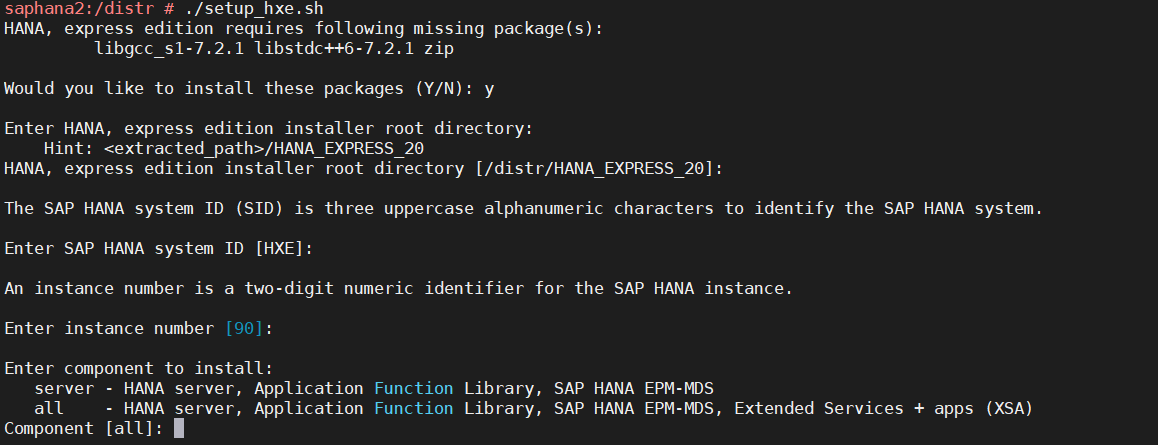
Указываем мастер-пароль для пользователей, которые создаются во время инсталляции SAP HANA.
Поскольку мы выбрали SID – HXE, adm – пользователь на уровне операционной системы будет hxeadm. Указанный мастер-пароль также применится и к пользователю SYSTEM на уровне базы данных.
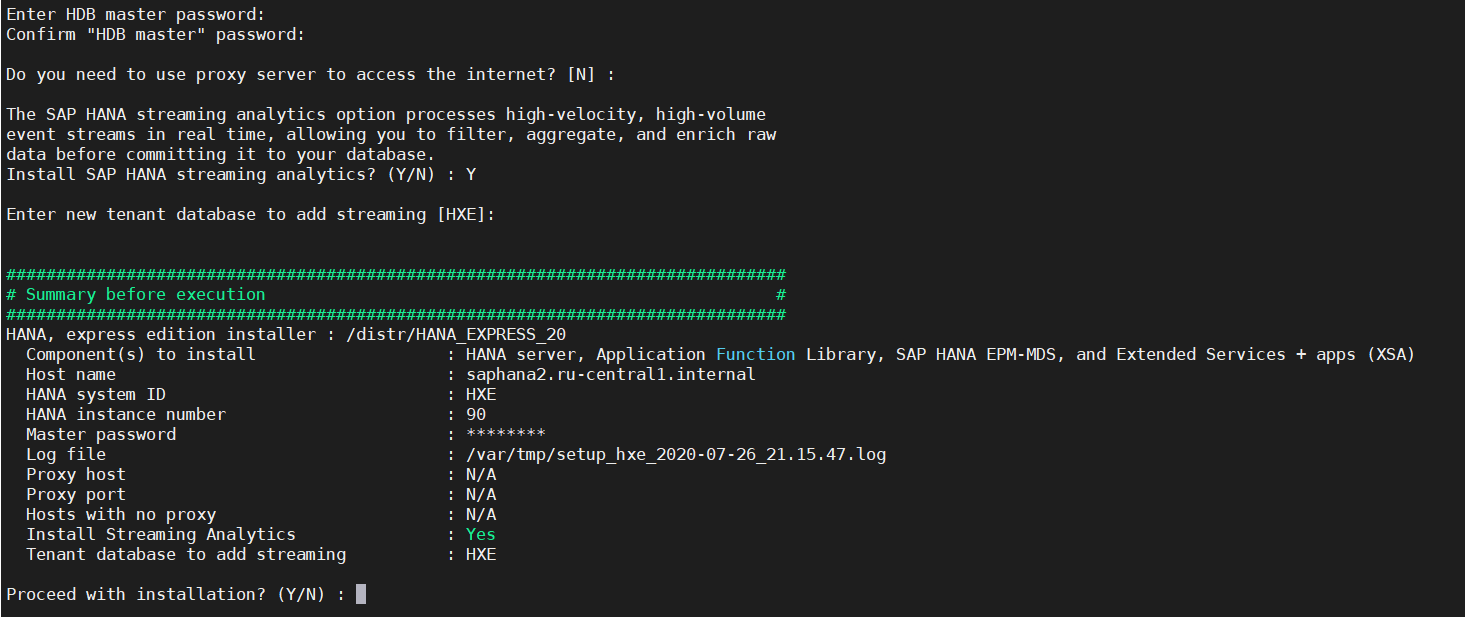
В процессе установки XSA потребуется также задать мастер-пароль от пользователей XSA\_ADMIN, XSA\_DEV, TEL\_ADMIN
Процесс инсталляции.

База SAP HANA Express Edition установлена.

Шаг 5. Проверка работы SAP HANA XSA
-----------------------------------
Проверим что база данных SAP HANA установлена и работает:
```
su – hxeadm
HDB info
```
Пример сервисов, которые будут запущены:

Пройдём авторизацию в SAP HANA Extended Application Services, Advanced Model:
```
xs-admin-login
```
Пользователь: XSA\_ADMIN
Пароль: Мастер-пароль, который мы задали при установке
Проверим версию SAP HANA Extended Application Services, Advanced Model:
```
xs -v
```
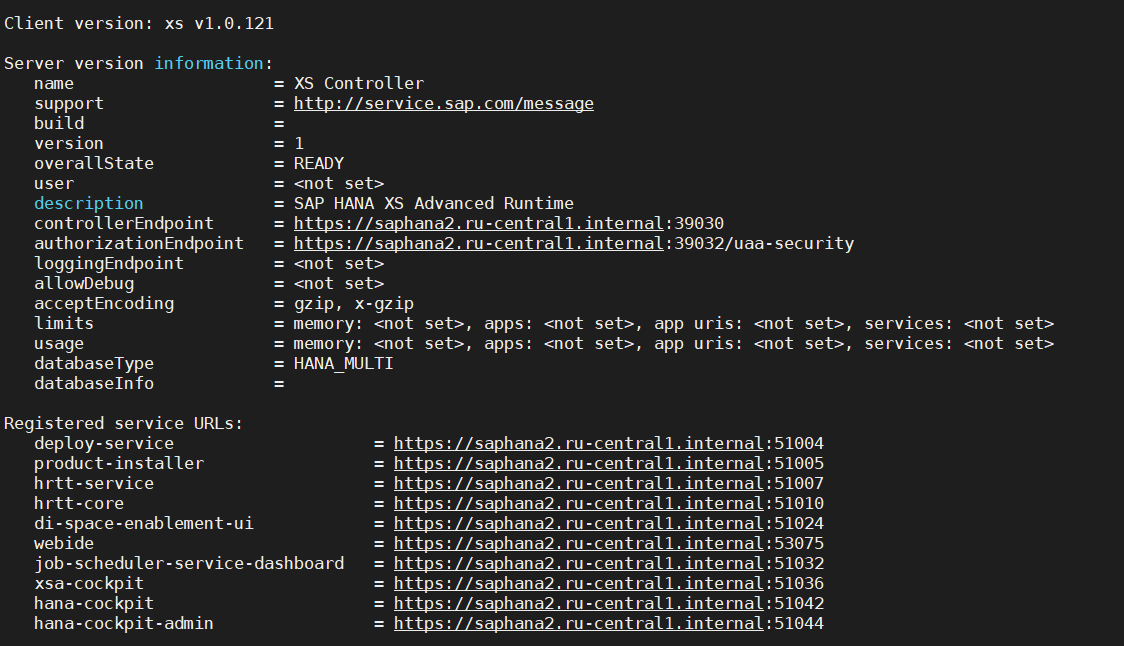
Шаг 6. Пост-инсталляционные действия
------------------------------------
Для того чтобы использовать веб-инструменты разработки и администрирования SAP HANA XSA необходимо отредактировать файл hosts на локальной Windows-мшине.
1. Открываем блокнот от имени Администратора
2. Открываем в блокноте файл C:\Windows\System32\drivers\etc\hosts
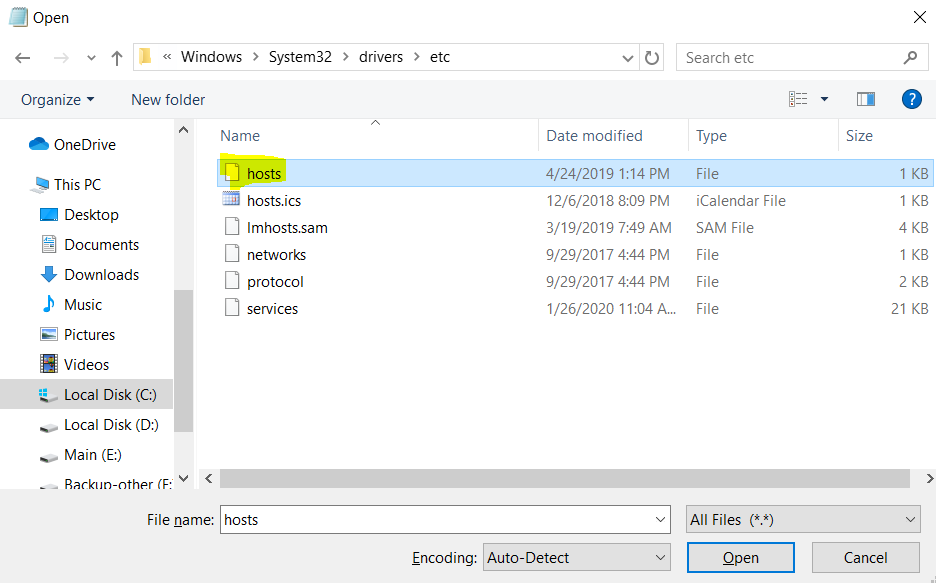
3. Вносим строку вида:
<внешний ip-адрес>

Шаг 7. Начало работы
--------------------
Существует несколько способов администрирования и разработки для SAP HANA XSA
Администрирование: SAP HANA Cockpit. В настоящее время SAP позиционирует его, как основной инструмент управления базой данных. Также возможно управление базой данных из Eclipse (Перспектива – SAP HANA Administration Console)

Разработка: Через веб-интерфейс, через инструмент SAP Web IDE или через Eclipse (Перспектива – SAP HANA Development)
Поскольку HANA Cockpit и WebIDE были установлены во время процесса инсталляции именно их как средства управления и администрирования мы и будем рассматривать.
Получим url для интересующих нас приложений xsa-cockpit, webide и cockpit-web-app:

```
xs app xsa-cockpit --urls
xs app webide --urls
xs app cockpit-web-app --urls
```
Скопируем https – адрес и откроем его в браузере для каждого из этих приложений.
### XSA Cockpit
XSA Cockpit — это браузерная система управления сервером приложений SAP HANA Extended Application Services, Advanced Model.
XSA Cockpit позволяет управлять пользователями и ролями, организациями и пространствами.
В разделе User Management можно проверить, и при необходимости назначить, для пользователя XSA\_DEV роли DEVX\_ADMINISTRATOR, DEVX\_DEVELOPER.
В разделе Tenant Databases можно расширить возможности XSA на новый тенант, в нашем случае – HXE и связать с ним пространство разработки development

### HANA Cockpit
HANA Cockpit — это система управления базой данных SAP HANA.
Cockpit можно использовать для управления пользователями и ролями на уровне базы данных, для создания бекапов, мониторинга работы, диагностирования проблем с производительностью на уровне базы и множества других административных задач.
Скрипт регистрации ресурсов базы данных в HANA Cockpit выполняется при установке, если скрипт по каким-либо причинам не выполнился – его необходимо запустить вручную до первого использования Cockpit-ом.
```
su – hxeadm
/usr/sap/distr/HANA_EXPRESS_20/register_cockpit.sh
```

### WebIDE
WebIDE –это интегрированная с GitHub-ом браузерная среда разработки.
В разделе Development можно разрабатывать, тестировать и публиковать модули на NodeJS, Java, HTML5.
В разделе Database Explorer можно создавать и управлять объектами на уровне базы данных (таблицы, представления, хранимые процедуры и т.д).
Подключение к тенанту и обзор объектов в нём:


Шаг 8. Первое Node.js приложение
--------------------------------
Откроем WebIDE и создадим простое UI5/Node.js приложение “Hello World!”
Для этого выберем
Workspace – Git – Clone Repository
В качестве репозитория укажем — Repository – [github.com/basisteam-io/SAPHANAXS\_helloworld.git](https://github.com/basisteam-io/SAPHANAXS_helloworld.git)
Таким образом мы получим копию простого приложения Hello world!, разобраться или модифицировать которое не составит никакого труда.
Установим пространство где будет развернуто данное приложение.
В нашем случае это пространство – development.

Последовательно сделаем Вuild приложения и проекта.
Результатом билдинга будет .mtar файл в папке mta\_archives, которая расположена в верхней части меню с иерархией проекта.
Необходимо выбрать содержащийся в папке .mtar файл и сделать для него операцию «Deploy to XS Advanced».

Вернёмся к командной строке и переключимся на пространство development:
```
xs target -o HANAExpress -s development
```
Выведем список всех запущенных приложений в этом пространстве:
```
xs apps
```
Отроем наше приложение в браузере:
Заключение
----------
Установить базу данных SAP HANA с сервером приложений HANA Extended Application Services, Advanced Model и написать своё первое приложение оказалось не сложно. В следующей статье рассмотрим более сложный пример, включающий в себя взаимодействие с базой данных SAP HANA.
Роман Горбенко, консультант SAP EWM / SAP BASIS
|
https://habr.com/ru/post/519460/
| null |
ru
| null |
# Особенности Swift
В рамках Mobile Camp Яндекса наш коллега [Денис Лебедев](http://tech.yandex.ru/people/452916/) представил доклад о новом языке программирования Swift. В своем докладе он затронул особенности взаимодействия с Objective-C, рассказал про фичи языка, которые показались ему наиболее интересными. А также про то куда сходить на Github, и какие репозитории посмотреть, чтобы понять, что со Swift можно делать в реальном мире.
Разработка Swift началась в 2010 году. Занимался ей Крис Латтнер. До 2013 процесс шел не очень активно. Постепенно вовлекалось все больше людей. В 2013 году Apple сфокусировалась на разработке этого языка. Перед презентацией на WWDC о Swift знало порядка 200 человек. Информация о нем хранилась в строжайшем секрете.
http://video.yandex.ru/users/ya-events/view/2941/
Swift – мультипарадигменный язык. В нем есть ООП, можно пробовать некоторые функциональные вещи, хотя адепты функционального программирования считают, что Swift немного не дотягивает. Но, мне кажется, что такая цель и не ставилась, все-таки это язык для людей, а не для математиков. Можно писать и в процедурном стиле, но я не уверен, что это применимо для целых проектов. Очень интересно в Swift все устроено с типизацией. В отличие от динамического Objective-C, она статическая. Также есть вывод типов. Т.е. большинство деклараций типов переменных можно просто опустить. Ну и киллер-фичей Swift можно считать очень глубокое взаимодействие с Objective-C. Позже я расскажу про runtime, а пока ограничимся тем, что код из Swift можно использовать в Objective C и наоборот. Указатели привычные всем разработчикам на Objective-С и С++ в Swift отсутствуют.
Перейдем к фичам. Их достаточно много. Я для себя выделил несколько основных.
* **Namespacing.** Все понимают, проблему Objective-C – из-за двухбуквенных и трехбуквенных классов часто возникают коллизии имен. Swift решает эту проблему, вводя очевидные и понятные всем нэймспейсы. Пока они не работают, но к релизу все должны починить.
* **Generic classes & functions.** Для людей, которые писали на С++, это достаточно очевидная вещь, но для тех, кто сталкивался в основном с Objective-C, это достаточно новая фича, с которой будет интересно поработать.
* **Named/default parameters.** Именованными параметрами никого не удивишь, в Objective-C они уже были. А вот параметры по умолчанию – очень полезная штука. Когда у нас метод принимает пять аргументов, три из которых заданы по умолчанию, вызов функции становится гораздо короче.
* **Functions are first class citizens.** Функции в Swift являются объектами первого порядка. Это означает, что их можно передавать в другие методы как параметры, а также возвращать их из других методов.
* **Optional types.** Необязательные типы – интересная концепция, которая пришла к нам в слегка видоизмененном виде из функционального программирования.
Рассмотрим последнюю фичу немного подробнее. Все мы привыкли, что в Objective-C, когда мы не знаем, что вернуть, мы возвращаем nil для объектов и -1 или NSNotFound для скаляров. Необязательные типы решают эту проблему достаточно радикально. Optional type можно представить как коробку, которая либо содержит в себе значение, либо не содержит ничего. И работает это с любыми типами. Предположим, что у нас есть вот такая сигнатура:
```
(NSInteger) indexOfObjec: (id)object;
```
В Objective-C неясно, что возвращает метод. Если объекта нет, то это может быть -1, NSNotFound или еще какая-нибудь константа известная только разработчику. Если мы рассмотрим такой же метод в Swift, мы увидим Int со знаком вопроса:
```
func indexOF(object: AnyObject) -> Int?
```
Эта конструкция говорит нам, что вернется либо число, либо пустота. Соответственно, когда мы получили запакованный Int, нам нужно его распаковать. Распаковка бывает двух видов: безопасная (все оборачивается в if/else) и принудительная. Последнюю мы можем использовать только если мы точно знаем, что в нашей воображаемой коробке будет значения. Если его там не окажется, будет крэш в рантайме.
Теперь коротко поговорим про основные фичи классов, структур и перечислений.Главное отличие классов от структур заключается в том, что они передаются по ссылке. Структуры же передаются по значению. Как говорит нам документация, использование структур затрачивает гораздо меньше ресурсов. И все скалярные типы и булевы переменные реализованы через структуры.
Перечисления хотелось бы выделить отдельно. Они абсолютно отличаются от аналогов в C, Objective-C и других языках. Это комбинация класса, структуры и даже немного больше. Чтобы показать, что я имею в виду, рассмотрим пример. Предположим, что я хочу реализовать дерево с помощью `enum`. Начнем с небольшого перечисления с тремя элементами (пустой, узел и лист):
```
enum Tree {
case Empty
case Leaf
case Node
}
```
Что с этим делать пока неясно. Но в Swift каждый элемент `enum` может нести какое-то значение. Для этого мы у листа добавим `Int`, а у узла будет еще два дерева:
```
enum Tree {
case Empty
case Leaf(Int)
case Node(Tree, Tree)
}
```
Но так как Swift поддерживает генерики, мы добавим в наше дерево поддержку любых типов:
```
enum Tree {
case Empty
case Leaf(T)
case Node(Tree, Tree)
}
```
Объявление дерева будет выглядеть примерно так:
```
let tree: Tree = .Node(.Leaf(1), .Leaf(1))
```
Здесь мы видим еще одну крутую фичу: мы можем не писать названия перечислений, потому что Swift выводит эти типы на этапе компиляции.
У `enum` в Swift есть еще одна интересная особенность: они могут содержать в себе функции, точно так же, как в структурах и классах. Предположим, что я хочу написать функцию, которая вернет глубину нашего дерева.
```
enum Tree {
case Empty
case Leaf(Int)
case Node(Tree, Tree)
func depth(t: Tree) -> Int {
return 0
}
}
```
Что мне в этой функции не нравится, так это то, что она принимает параметр дерева. Я хочу сделать так, чтобы функция просто возвращала мне значения, а мне ничего передавать бы не требовалось. Здесь мы воспользуемся еще одной интересной фичей Swift: вложенными функциями. Т.к. модификаторов доступа пока нет – это один из способов сделать функцию приватной. Соответственно, у нас есть `_depth`, которая сейчас будет считать глубину нашего дерева.
```
enum Tree {
case …
func depth() -> Int {
func \_depth(t: Tree) -> Int {
return 0
}
return \_depth(self)
}
}
```
Мы видим стандартный свитч, тут нет ничего свифтового, просто обрабатываем вариант, когда дерево пустое. Дальше начинаются интересные вещи. Мы распаковываем значение, которое хранится у нас в листе. Но так как оно нам не нужно, и мы хотим просто вернуть единицу, мы используем подчеркивание, которое означает, что переменная в листе нам не нужна. Дальше мы мы распаковываем узел, из которого мы достаем левую и правую части. Затем вызываем рекурсивно функцию глубины и возвращаем результат. По итогу у нас получается такое вот реализованное на `enum` дерево c какой-то базовой операцией.
```
enum Tree {
case Empty
case Leaf(T)
case Node(Tree, Tree)
func depth() -> Int {
func \_depth(t: Tree) -> Int {
switch t {
case .Empty:
return 0
case .Leaf(let\_):
return 1
case .Node(let lhs, let rhs):
return max(\_depth(lhs), \_depth(rhs))
}
}
return \_depth(self)
}
}
```
Интересная штука с этим `enum` заключается в том, что этот написанный им код, должен работать, но не работает. В текущей версии из-за бага `enum` не поддерживает рекурсивные типы. В будущем это все заработает. Пока для обхода этого бага используются разные хаки. Про один из них я расскажу чуть позже.
Следующий пункт моего моего рассказа – это коллекции, представленные в стандартной библиотеке массивом, словарями и строкой (коллекция чаров). Коллекции, как и скаляры, являются структурами, они также взаимозаменяемы со стандартными foundation-типами, такими как NSDictionary и NSArray. Кроме того, мы видим, что по какой-то странной причине нет типа NSSet. Вероятно, им слишком редко пользуются. В некоторых операциях (например, `filter` и `reverse`) есть ленивые вычисления:
```
func filter~~(…) -> Bool) ->
FilterSequenceView~~func reverce~~(source: C) ->
ReverseView~~~~~~
```
Т.е. типы `FilterSequenceView` и `ReverseView` – это не обработанная коллекция, а ее представление. Это говорит нам о том, что у этих методов высокая производительность. В том же Objective-C таких хитрых конструкций не встретишь, так как во времена создания этого языка о таких концепциях никто еще не думал. Сейчас lazy-вычисления проникают в языки программирования. Мне нравится эта тенденция, иногда это бывает очень эффективно.
Следующую фичу заметили уже, наверное, все, кто как-то интересовался новым языком. Но я все равно про нее расскажу. В Swift есть встроенная неизменяемость переменных. Мы можем объявить переменную двумя способами: через `var` и `let`. В первом случае переменные могут быть изменены, во втором – нет.
```
var и = 3
b += 1
let a = 3
a += 1 // error
```
Тут начинается интересная вещь. Например, если мы посмотрим на словарь, который объявлен с помощью директивы `let`, то при попытке изменения ключа или добавления нового, мы получим ошибку.
```
let d = ["key": 0]
d = ["key"] = 3 //error
d.updateValue(1, forKey: "key1") //error
```
С массивами все обстоит несколько иначе. Мы не можем увеличивать размер массива, но при этом мы можем изменять любой из его элементов.
```
let c = [1, 2, 3]
c[0] = 3 // success
c.append(5) // fail
```
На самом деле это очень странно, при попытке разобраться, в чем дело, выяснилось, что это подтвержденный разработчиком языка баг. В ближайшем будущем он будет исправлен, т.к. это действительно очень странное поведение.
Расширения в Swift очень похожи на категории из Objective-C, но больше проникают в язык. В Swift не нужно писать импорты: мы можем в любом месте в коде написать расширение, и оно подхватится абсолютно всем кодом. Соответственно, тем же образом можно расширять структуры и енамы, что тоже иногда бывает удобно. При помощи расширений можно очень хорошо структурировать код, это реализовано в стандартной библиотеке.
```
struct: Foo {
let value : Int
}
extension Foo : Printable {
var description : String {
get {return "Foo"}
}
}
extension Foo : Equatable {
}
func ==(lhs: Foo, rhs: Foo) -> Bool {
return lhs.value == rhs.value
}
```
Далее поговорим о том, чего в Swift нет. Я не могу сказать, что чего-то конкретного мне не хватает, т.к. в продакшене я его пока не использовал. Но есть вещи, на которые многие жалуются.
* **Preprocessor.** Понятно, что если нет препроцессора, то нет и тех крутых макросов, которые генерят за нас очень много кода. Также затрудняется кроссплатформенная разработка.
* **Exceptions.** Механизм эксепшенов полностью отсутстсует, но можно создаст NSException, и рантайм Objective-C все это обработает.
* **Access control.** После прочтения книги о Swift многие пришли в замешательство из-за отсутствия модификаторов доступа. В Objective-C этого не было, все понимали, что это необходимо, и ждали в новом языке. На самом деле, разработчики просто не успели имплементировать модификаторы доступа к бета-версии. В окончательном релизе они уже будут.
* **KVO, KVC.** По понятным причинам нет Key Value Observing и Key Value Coding. Swift – статический язык, а это фичи динамичесих языков.
* **Compiler attributes.** Отсутствуют директивы компилятора, которые сообщают о deprecated-методах или о том, есть ли метод на конкретной платформе.
* **`performSelector.`** Этот метод из Swift полностью выкосили. Это достаточно небезопасная штука и даже в Objective-C ее нужно использовать с оглядкой.
Теперь поговорим о том, как можно мешать Objective-C и Swift. Все уже знают, что из Swift можно вызвать код на Objective-C. В обратную сторону все работает точно так же, но с некоторыми ограничениями. Не работают перечисления, кортежи, обобщенные типы. Несмотря на то, что указателей нет, CoreFoundation-типы можно вызывать напрямую. Для многих стала расстройством невозможность вызывать код на С++ напрямую из Swift. Однако можно писать обертки на Objective-C и вызывать уже их. Ну и вполне естественно, что нельзя сабклассить в Objective-C нереализованные в нем классы из Swift.
Как я уже говорил выше, некоторые типы взаимозаменяемы:
* `NSArray < - > Array;`
* `NSDictionary < - > Dictionary`;
* `NSNumber - > Int, Double, Float`.
Приведу пример класса, который написан на Swift, но может использоваться в Objective-C, нужно лишь добавить одну директиву:
```
@objc class Foo {
int (bar: String) { /*...*/}
}
```
Если мы хотим, чтобы класс в Objective-C имел другое название (например, не `Foo`, а `objc_Foo`), а также поменять сигнатуру метода, все становится чуточку сложнее:
```
@objc(objc_Foo)
class Foo{
@objc(initWithBar:)
init (bar: String) { /*...*/}
}
```
Соответственно, в Objective-C все выглядит абсолютно ожидаемо:
```
Foo *foo = [[Foo alloc] initWithBar:@"Bar"];
```
Естественно, можно использовать все стандартные фреймворки. Для всех хедеров автоматически генерируется их репрезентация на Swift. Допустим, у нас есть функция `convertPoint`:
```
- (CGPoint)convertPoint:(CGPoint)point toWindow:(UIWindow *)window
```
Она полностью конвертируется в Swift с единственным отличием: около `UIWindow` есть восклицательный знак. Это указывает на тот самый необязательный тип, про который я говорил выше. Т.е. если там будет nil, и мы это не проверим, будет крэш в рантайме. Это происходит из-за того, что когда генератор создает эти хедеры, он не знает, может быть там nil или нет, поэтому и ставит везде эти восклицательные знаки. Возможно, скоро это как-нибудь поправят.
```
finc convertPoint(point: CGPoint, toWindow window: UIWindow!) -> GCPoint
```
Подробно, говорить о внутренностях и перформансе Swift пока рано, так как неизвестно, что из текущего рантайма доживет до первой версии. Поэтому пока что коснемся этой темы лишь поверхностно. Начнем с того, что все Swift-объекты – это объекты Objective-C. Появляется новый рутовый класс SwiftObject. Методы теперь хранятся не с классами, а в виртуальных таблицах. Еще одна интересная особенность – типы переменных хранятся отдельно. Поэтому декодировать классы налету становится чуть сложнее. Для кодирования метаданных методов используется подход называемый name mangling. Для примера посмотрим на класс `Foo` с методом `bar`, возвращающим `Bool`:
```
class Foo {
func bar() -> Bool {
return false
}
}
```
Если мы посмотрим в бинарник, для метода `bar`мы увидим сигнатуру следующего вида: `_TFC9test3Foo3barfS0_FT_Sb`. Тут у нас есть `Foo` с длиной 3 символа, длина метода также 3 символа, а `Sb` в конце означает, что метод возвращает `Bool`. C этим связана не очень приятная штука: дебаг-логи в XCode все попадает именно в таком, виде, поэтому читать их не очень удобно.
Наверное все уже читали про то, что Swift очень медленный. По большому счету это так и есть, но давайте попробуем разобраться. Если мы будем компилировать с флагом `-O0`, т.е. без каких-либо оптимизаций, то Swift будет медленнее С++ от 10 до 100 раз. Если компилировать с флагом `-O3`, мы получим нечно в 10 раз медленнее С++. Флаг `-Ofast` не очень безопасен, так как отключает в рантайме проверки переполнения интов и т.п. В продакшене его лучше не использовать. Однако он позволяет повысить производительность до уровня С++.
Нужно понимать, что язык очень молодой, он все еще в бете. В будущем основные проблемы с быстродействием будут фикститься. Кроме того, за Swift тянется наследие Objective-C, например, в циклах есть огромное количество ретэйнов и релизов, которые в Swift по сути не нужны, но очень тормозят быстродействие.
Дальше я буду рассказывать про не очень связанные друг с другом вещи, с которыми я сталкивался в процессе разработки. Как я уже говорил выше, макросы не поддерживаются, поэтому единственный способ сделать кроссплатформенную вьюшку выглядит следующим образом:
```
#if os(iOS)
typealias View = UView
#else
typealias View = NSView
#endif
class MyControl : View {
}
```
Этот `if` – это не совсем препроцессор, а просто конструкция языка, которая позволяет проверить платформу. Соответственно, у на есть метод, который нам возвращает, на какой мы платформе. В зависимости от этого мы делаем алиас на `View`. Таким образом мы создаем `MyControl`, который будет работать и на iOS и на OS X.
Следующая фича – сопоставление с образцом – мне очень нравится. Я немного увлекаюсь функциональными языками, там она используется очень широко. Возьмем для примера задачу: у нас есть точка на плоскости, и мы хотим понять, в каком из четырех квадрантов она находится. Все мы представляем, что это будет за код в Objective-C. Для каждого квадранта у нас будут вот такие абсолютно дикие условия, где мы должны проверять попадают ли x и y в эти рамки:
```
let point = (0, 1)
if point.0 >= 0 && point.0 <= 1 &&
point.1 >= 0 && point.1 <= 1 {
println("I")
}
...
```
Swift нам в этом случае нам дает несколько удобных штук. Во-первых, у нас появляется хитрый range-оператор с тремя точками. Соответственно, `case` может проверить, попадает ли точка в первый квадрант. И весь код будет выглядеть примерно таким образом:
```
let point = (0, 1)
switch point {
case (0, 0)
println("Point is at the origin")
case (0...1, 0...1):
println("I")
case (-1...0, 0...1):
println("II")
case (-1...0, -1...0):
println("III")
case (0...1, -1...0):
println("IV")
default:
println("I don't know")
}
```
На мой взгляд это в десятки раз более читаемо, чем то, что может нам предоставить Objective-C.
В Swift есть еще одна абсолютно нишевая штука, которая также пришла из функциональных языков программирования – function currying:
```
func add(a: Int)(b: Int) -> Int {
return a + b
}
let foo = add(5)(b: 3) // 8
let add5 = add(5) // (Int) -> Int
let bar = add(b: 3) // 8
```
Мы видим, что у нас есть функция `add` с таким хитрым объявлением: две пары скобок с параметрами вместо одной. Это дает нам возможность либо вызвать эту функцию почти что как обычную и получить результат 8, либо вызвать ее с одним параметром. Во втором случае происходит магия: на выходе мы получаем функцию, которая принимает `Int` и возвращает тоже `Int`, т.е. мы частично применили нашу функцию `add` к пятерке. Соответственно, мы можем потом применить функцию `add5` с тройкой и получить восьмерку.
Как я уже говорил, препроцессор отсутствует, поэтому даже реализовать `assert` – нетривиальная штука. Предположим, что у нас есть задача написать какой-нибудь свой `assert`. На дебаг мы его можем проверить, но чтобы код, который в ассерте не выполнится, мы должны передать его как замыкание. Т.е. мы видим, что у нас `5 % 2` в фигурных скобках. В терминологии Objective-C – это блок.
```
func assert(condition:() -> Bool, message: String) {
#if DEBUG
if !condition() { println(message) }
#endif
}
assert({5 % 2 == 0}, "5 isn't an even number.")
```
Понятно, что ассерты так использовать никто не будет. Поэтому в Swift есть автоматические замыкания. В декларации метода мы видим `@autoclosure`, соответственно, первый аргумент оборачивается в замыкание, и фигурные скобки можно не писать.
```
func assert(condition: @auto_closure () -> Bool, message: String) {
#if DEBUG
if !condition() { println(message) }
#endif
}
assert(5 % 2 == 0, "5 isn't an even number.")
```
Еще одна незадокументированная, но очень полезная вещь – явное преобразование типов. Swift – типизированный язык, поэтому как в Objective-C совать объекты с id-типом мы не можем. Поэтому рассмотрим следующий пример. Допустим у меня есть структура `Box`, которая в получает при инициализации какое-то значение, изменять которо нельзя. И у нас есть запакованный `Int` – единица.
```
struct Box {
let \_value : T
init (\_ value: T) {
\_value = value
}
}
let boxedInt = Box(1) //Box
```
Также у нас есть функция, которая принимает на вход `Int`. Соответственно, `boxedInt` мы туда передать не можем, т.к. компилятор нам скажет, что `Box` не конвертируется в `Int`. Умельцы немного распотрошили внутренности свифта и нашли функцию, позволяющую конвертировать тип `Box` в значение, которое он в себе скрывает:
```
extension Box {
@conversion Func __conversion() -> T {
return _value
}
}
foo(boxedInt) //success
```
Статическая типизация языка также не позволяет нам бегать по классу и подменять методы, как это можно было делать в Objective-C. Из того, что есть сейчас, мы можем только получить список свойств объекта и вывести их значения на данный момент. Т.е. информации о методах мы получить не можем.
```
struct Foo {
var str = "Apple"
let int = 13
func foo() { }
}
reflect(Foo()).count // 2
reflect(Foo())[0].0 // "str"
reflect(Foo())[0].1summary // "Apple"
```
Из свифта можно напрямую вызывать С-код. Эта фича не отражена в документации, но может быть полезна.
```
@asmname("my_c_func")
func my_c_func(UInt64, CMutablePointer) -> CInt;
```
Swift, конечно, компилируемый язык, но это не мешает ему поддерживать скрипты. Во-первых, есть интерактивная среда выполнения, запускаемая при помощи команды `xcrun swift`. Кроме того, можно писать скрипты не на привычных скриптовых языках, а непосредственно на Swift. Запускаются они при помощи команды `xcrun -i 'file.swift'`.
Напоследок я расскажу о репозиториях, на которые стоит посмотреть:
* BDD Testing framework: **[Quick](https://github.com/modocache/Quick)**. Это первое, чего всем не хватало. Фреймворк активно развивается, постоянно добавляются новые матчеры.
* Reactive programming: **[RXSwift](https://github.com/jspahrsummers/RxSwift)**. Это переосмысление ReactiveCocoa при помощи конструкций, предоставляемых свифтом.
* Model mapping: **[Crust](https://github.com/jspahrsummers/Crust)**. Аналог Mantle для Swift. Позволяет мапить JSON-объекты в объекты свифта. Используется многие интересные хаки, которые могут быть полезны в разработке.
* Handy JSON processing: **[SwiftyJSON](https://github.com/lingoer/SwiftyJSON)**. Это очень небольшая библиотека, буквально 200 строк. Но она демонстрирует всю мощь перечислений.
|
https://habr.com/ru/post/228709/
| null |
ru
| null |
# Как увеличить скорость работы 1С в 100 раз прямым обращением к MSSQL
Возникла задача пометить на удаление документы за 1 год. Эта операция выполняется перед бесследным удалением и включает выставление отметки и удаление движения по регистрам. Пробное удаление штатными средствами одного месяца заняло 4 часа. Это означало, что 12 месяцев удалялись бы 48 часов (2 суток). Забегая вперед, скажу, что прямым доступом к 1С документы удаляются за 30-40 минут. Обращение к MSSQL выполнялось через .Net framework и компонент .Net Bridge.
Определение имен таблиц MSSQL
-----------------------------
Структура базы данных 1С весьма запутана и состоит из малозначимых для человека названий. 1С содержит функцию определения структуры хранения по имени объекта. В основу разработки положена эта функция ПолучитьСтруктуруХраненияБазыДанных, которая согласно русскому названию возвращает описание структуры. В этой структуре важны 2 поля Назначение, которое должно быть равно «Основная», и название таблицы ИмяТаблицыХранения.
Определение смещения дат
------------------------
Таблица \_YearOffset содержит число, обозначающее смещение года дат. Оно принимает значение 0 или 2000. Так со смещением 2000 дата 01.01.2014 будет храниться в базе данных как 01.01.4014. Соответственно при отборе по датам (удаление происходит за период времени) нужно учитывать смещение. Смещение можно получить следующим кодом 1С:
```
командаСмещение = sqlConnection.CreateCommand();
командаСмещение.CommandText = "select top 1 Offset from _YearOffset";
командаСмещение.CommandTimeout = timeout;
чтениеСмещение = командаСмещение.ExecuteReader();
Если чтениеСмещение.Read() Тогда
Смещение = чтениеСмещение.GetInt32(0);
КонецЕсли;
чтениеСмещение.Dispose();
```
Установка пометки на удаление документов
----------------------------------------
Имея названия таблиц документов и зная, что поля \_Date\_Time, \_Marked и \_Posted отвечают за дату, отметку об удалении и отметку о проведении соответственно, можно одним SQL-запросом пометить их все на удаление. Делается это так:
```
командаДокумента = sqlConnection.CreateCommand();
командаДокумента.CommandText = "UPDATE " + строкаТаблицы.ИмяТаблицыХранения + " SET _Marked = 0x01, _Posted = 0x00 WHERE _Date_Time BETWEEN @StartDate AND @EndDate";
командаДокумента.Parameters.AddWithValue("@StartDate", StartDate);
командаДокумента.Parameters.AddWithValue("@EndDate", EndDate);
командаДокумента.ExecuteNonQuery();
командаДокумента.Dispose();
```
Установка пометки на удаление в журналах документов
---------------------------------------------------
Не смотря на установку отметки на удаление у документов, в журналах документов хранятся дубли отметок об удалении на каждый документ. Список журналов, где участвует документ можно получить из метаданных документа так: Метаданные.ЖурналыДокументов
Отметка на удаление через поля \_Marked и \_Posted происходит аналогично через команду:
```
командаЖурналов.CommandText = командаЖурналов.CommandText + "UPDATE " + ОсновнаяТаблицаЖурнала + " SET _Marked = 0x01, _Posted = 0x00 WHERE _DocumentRRef IN (SELECT _IDRRef FROM " + строкаТаблицы.ИмяТаблицыХранения + " WHERE _Date_Time BETWEEN @StartDate AND @EndDate);"
```
Удаление движений регистров
---------------------------
При удалении документов 1С удаляет движения документа по регистрам. В случае прямого доступа эти движения нужно удалить самостоятельно. Список регистров можно получить через метаданные ДокументМетаданные.Движения.
Команда, которой выполняется удаление движений следующая:
```
командаРегистров.CommandText = командаРегистров.CommandText + "DELETE FROM " + ОсновнаяТаблицаРегистра + " WHERE _RecorderRRef IN (SELECT _IDRRef FROM " + строкаТаблицы.ИмяТаблицыХранения + " WHERE _Date_Time BETWEEN @StartDate AND @EndDate);";
```
Заключение
----------
Как оказалось, добиться убыстрения работы 1С примерно на 2 порядка не так сложно, достаточно выполнить 3 вида команд. В конечной обработке логика расширена за счет выбора документов по видам, добавлением таймаута, добавлением транзакции, пакетным выполнением команд.
PS. Список возникающих проблем и пути устранения:
1. Обработка игнорирует документы, где запрещено проведение, например, корректировка записей регистров. В корректировке записей регистров удаление документа связано со снятием активности записей регистров.
2. Результат удаления не отражается в планах обмена. Решается одновременным запуском обработки в связанных базах.
3. Не затрагивает таблицы итогов. Решается пересчетом итогов через Конфигуратор-Тестирование и Исправление-Пересчет итогов.
Саму обработку можно скачать здесь:
[ПометкаУдаленияПрямымЗапросом.epf (13,77 kb)](http://www.richmedia.us/file.axd?file=2015%2f8%2f%d0%9f%d0%be%d0%bc%d0%b5%d1%82%d0%ba%d0%b0%d0%a3%d0%b4%d0%b0%d0%bb%d0%b5%d0%bd%d0%b8%d1%8f%d0%9f%d1%80%d1%8f%d0%bc%d1%8b%d0%bc%d0%97%d0%b0%d0%bf%d1%80%d0%be%d1%81%d0%be%d0%bc.epf)
|
https://habr.com/ru/post/264687/
| null |
ru
| null |
# Определяем выигрышную покерную руку с помощью map/reduce на JavaScript
[](https://habr.com/ru/company/edison/blog/507250/)
[](https://habr.com/ru/company/edison/blog/507250/)
Вы, как и я, может, иногда участвуете в мини-соревнованиях по олимпиадному программированию. Обычно на то, чтобы придумать решение, в котором более одной-двух строк с использованием какой-то нестандартной функции, у меня нет времени, но в этот раз задача была в том, чтобы определять старшие (выигрышные) покерные руки, и мне показалось что это из тех задач, которая «должна» быть лёгкой!
Получившийся у меня результат корректен, лаконичен и читабелен (по крайней мере, гораздо короче, чем решения, предложенные другими участниками).
Конечно же, в данном случае можно воспользоваться **map** и **reduce**, чтобы получить необходимую информацию. Вышел действительно удачный пример того, как использовать эти инструменты для решения в несколько шагов практических задач.
> [](https://www.edsd.ru/ru/princypy/investiruem-v-produkty "EDISON Software - web-development")
>
> Компания EDISON всегда рада помочь в исследовательских бизнес-проектах.
>
>
>
> [](https://www.edsd.ru/ru/princypy/investiruem-v-produkty)
>
> На протяжении многих лет мы делаем [инвестиции в стартапы](https://www.edsd.ru/ru/princypy/investiruem-v-produkty), помогая средствами и технической поддержкой в реализации свежих нестандартных идей.
>
>
>
> Речь не только о том, чтобы «дать взаймы». Мы готовы разделить риски и активно содействовать в создании чего-то нового.
Задача
------
Она состоит в том, чтобы сравнить две покерные руки и определить выигрышную.
Покерные руки представлены строками, содержащими подстроки (обозначающие отдельные карты) по 2 символа, разделённых пробелами. **2H** — это двойка червей, **TC** — крестовая десятка и т.д.
Первый символ означает ранжир.
Все возможные варианты, упорядоченные по старшинству: **2 3 4 5 6 7 8 9 T J Q K A**.
С циферными обозначениями всё понятно, что касается букв: **T** — это 10 (**T**en), **J** — валет (**J**ack), **Q** — дама (**Q**ueen), **K** — король (**K**ing), **A** — туз (**A**ce).
Второй символ определяет масть.
Возможные варианты: **H** — черви (**H**earts), **C** — кресты (**C**lubs), **S** — пики (**S**pades), **D** — бубны (**D**iamonds).
Например, такая полная строка для руки «2C 5C 3C 4C 6C» — в данном случае, это крестовый стрит-флеш от двойки до шестёрки.
Ранжирование рук взято как в [Техасском холдеме](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D1%85%D0%B0%D1%81%D1%81%D0%BA%D0%B8%D0%B9_%D1%85%D0%BE%D0%BB%D0%B4%D0%B5%D0%BC).
Нужно понимать, что здесь присутствуют скрытые сложности — использование дополнительных карт для разрешения ничейных ситуаций, использование номинальной стоимости пар и т.д.
Решение
-------
Итак, как же решить эту задачу? Сначала нужно определить способ сравнения, который решает вопрос ранжирования рук, а затем, если ранжирование совпадает, победитель определяется, если это возможно, путём сравнения дополнительных карт.
Поскольку постановка задачи предполагает, что масти равнозначны, используем простой объект для представления ранжирования рук:
```
{
rank: 1, // Значение в диапазоне от 1 до 9, для ранжирования руки, чем меньше тем выше
value: 'ABCDE' // Пример строки, для сравнения номиналов всех пяти карт в руке, буквы с меньшим ASCII-кодом обозначают более старшие карты
}
```
Теперь мы можем написать простую функцию для сравнения двух рук, представленных в виде этой структуры:
```
function compareHands(h1, h2) {
let d1 = getHandDetails(h1)
let d2 = getHandDetails(h2)
if (d1.rank === d2.rank) {
if (d1.value < d2.value) {
return "ВЫИГРЫШ"
} else if (d1.value > d2.value) {
return "ПРОИГРЫШ"
} else {
return "НИЧЬЯ"
}
}
return d1.rank < d2.rank ? "ВЫИГРЫШ" : "ПРОИГРЫШ"
}
```
Так что теперь всё, что нам нужно сделать, это создать объект из руки — и вот тут начинается самое интересное!
Разбираем покерную руку на составные части
------------------------------------------
В подобных случаях необходимо определить основные данные, необходимые для решения задачи. Здесь наша первая проблема — расставить руки по старшинству.
Покерные руки могут быть стритом, флешом или комбинацией нескольких карт с одинаковым номиналом. Наша задача — сначала собрать эту информацию из нашей входной строки. Первый шаг — решить, как распарсить эти данные.
### Распарсиваем входящие данные
```
const input = "AH KS TC 9D 3S" // Какая-то комбинация карт
```
Нам нужны как масть, так и номинал каждой карты. Однако, учитывая, что единственная причина, по которой мы интересуемся мастью, заключается в том, что если масть у всех карт в руке одинакова, то нет надобности сохранять связку номинал/масть. Это делает процесс парсинга довольно-таки простым:
1. **Конвертация входящей строки в последовательность карт.**
2. **Определение масти/номинала в каждой подстроке, обозначающей одну карту.**
Однако, если мы намерены сортировать наши карты, нам нужно, чтобы их было легко сравнивать друг с другом. То есть, A> K (туз больше короля), но при этом Q > J (дама выше валета), то есть видим, что классические буквенные обозначения номинала изначально не отвечают старшинству в алфавитном порядке. Поэтому, добавим третий шаг:
3. **Преобразование номинала в легко сравнимое представление.**
У нас в руке 5 карт, нам в итоге нужно, чтобы значения рук для разрешения ничейных коллизий можно было сравнить в одной операции — поэтому это должна быть именно строка. Поэтому будем переводить номинал наших карт в символы, чтобы потом их можно было вернуть в строку. В общем, нам нужно сделать так, чтобы туз был A, король — B, дама — С, валет — D, десятка — E, девятка — G и т.д.
```
const order = "23456789TJQKA" //Порядок ранжирования по номиналу во входящей строке
const cards = hand.split(" ") //Разделяем входящую строку на отдельные карты
const faces = cards.map(a => String.fromCharCode([77 - order.indexOf(a[0])])).sort()
const suits = cards.map(a => a[1]).sort()
```
Итак, здесь мы разделили на отдельные карты и выделили в каждой из них её номинал и масть. При этом мы преобразовали номинал в однобуквенное строковое представление, начиная с A (являющееся обозначением для туза, остальные следующие литеры по порядку соответствовали меньшим по номиналу картам). Для этого подсмотрели номер позиции номинала в строковой константе **order**, отняли это число от 77 и преобразовали обратно в строку. 65 — это код для A, поэтому получаем сопоставимую строку, начинающуюся с A, которая является оптимальным вариантом.
Мы также отсортировали по номиналу и по масти, чтобы позволяет сделать следующий шаг!
Создаём сравнимые данные
------------------------
Отлично, но теперь нужно сгенерировать ещё немного данных, чтобы можно было написать код для ранжирования рук.
1. Проверяем флеш.
2. Проверяем стрит.
3. Определяем дубликаты по номиналу — они нужны для всех остальных типов рук.
### Проверяем флеш
Это достаточно просто, поскольку мы распарсили входящую строку и отсортировали по мастям. Если масть последней карты совпадает с мастью первой — у нас флеш.
```
const flush = suits[0] === suits[4]
```
### Проверяем стрит
Стрит ненамного сложнее — если все карты (независимо от масти) имеют последовательный номинал, то это он и есть.
Мы начинаем с первой карты в руке и для каждой следующей проверяем, является ли значение её номинала последовательным по отношению к предыдущей карте. Используя при этом индекс, переданный через обратный вызов, следующим образом:
```
const first = faces[0].charCodeAt(0)
const straight = faces.every((f, index) => f.charCodeAt(0) - first === index)
```
### Определяем дубликаты
Этот шаг несколько сложнее. Надо посчитать количество для каждого номинала в нашей руке. А также нужен какой-то способ определения пар, троек и т.д., чтобы упростить ранжирование руки таким вот образом:
* Подсчёт количества для каждого номинала
* Преобразование подсчёта в такое предсавление, в котором можно искать.
Нужно добиться того, чтобы можно было определять наличие «четвёрки» (каре) или тройки в руке, количество пар (ни одной, одна или две) и т.д.
Итак, сначала подсчитываем, сколько раз встречаются карты каждого достоинства:
```
const counts = faces.reduce(count, {})
function count(c, a) {
c[a] = (c[a] || 0) + 1
return c
}
```
И затем производим поиск по этим подсчётам, в прямом смысле «подсчитывая подсчёты».
```
const duplicates = Object.values(counts).reduce(count, {})
```
### Ранжирование рук
Теперь у нас есть вся информация, необходимая для ранжирования рук, пока что без учёта возможных ничейных ситуаций.
```
let rank =
(flush && straight && 1) || /* Стрит-флеш, в том числе и флеш-рояль - пять последовательных по номиналу карт одной масти */
(duplicates[4] && 2) || /* Каре - четыре карты одного номинала */
(duplicates[3] && duplicates[2] && 3) || /* Фулл-хаус - тройка + пара */
(flush && 4) || /* Флеш - пять непоследовательных карт одной масти */
(straight && 5) || /* Стрит - пять разномастных последовательных по номиналу карт */
(duplicates[3] && 6) || /* Тройка - три карты одного номинала */
(duplicates[2] > 1 && 7) || /* Две пары */
(duplicates[2] && 8) || /*Пара - две карты одного номинала */
9 /* Ни одна из комбинаций выше, просто старшая карта в руке */
```
Таким образом, стрит-флеш является самой сильной комбинацией с рангом 1 (чтобы не усложнять, считаем что возможна ничья, если у кого-то флеш-рояль), затем каре, фулл-хаус и т.д.
При этом причудливо используется оператор **&&**, который просматривает до последнего значения, если значения в предыдущих скобках верны. Таким образом, `(flush && direct && 1)` возвращает 1, если flush и direct равны true, иначе возвращает false.
Ничейная ситуация
-----------------
Если две руки имеют одинаковый ранг, победитель определяется дополнительно по номиналу карт, если это возможно. С этим связаны некоторые правила.
* **Пара против пары.** Выигрывает пара с более высоким номиналом. Если номиналы совпадают, выигрывает самая высокая следующая карта. (Для двух пар решается аналогично).
Например, если сравниваем руку «2H 2D AH KC 3D» с рукой «4H 4C JC TC 3H», то выигрывают четвёрки из второй руки, хотя в первой руке самая старшая карта имеет наивысший номинал — туз.
* **Фул-хаус против фул-хауса**. Побеждает тройка с бо́льшим номиналом. Если номиналы троек в обеих руках равны, то смотрим на номиналы двоек.
* Аналогично действуем при сравнении любых рук с одинаковым рангом — решает номинал старшей карты в комбинации.
Поэтому нам нужно сначала отсортировать по количеству, а затем по номиналу в нашей исходящей строке. Помните, используется вся строка из пяти символов для того, чтобы решать случаи с совпадениями рангов рук.
```
let value = faces.sort(byCountFirst).join("")
function byCountFirst(a, b) {
//Подсчёт в обратном порядке - чем больше, тем лучше
const countDiff = counts[b] - counts[a]
if(countDiff) return countDiff //Если количество не совпадает, возвращаем разницу
return b > a ? -1 : b === a ? 0 : 1
}
```
И это все!
Весь шебанг
-----------
```
const order = "23456789TJQKA"
function getHandDetails(hand) {
const cards = hand.split(" ")
const faces = cards.map(a => String.fromCharCode([77 - order.indexOf(a[0])])).sort()
const suits = cards.map(a => a[1]).sort()
const counts = faces.reduce(count, {})
const duplicates = Object.values(counts).reduce(count, {})
const flush = suits[0] === suits[4]
const first = faces[0].charCodeAt(0)
const straight = faces.every((f, index) => f.charCodeAt(0) - first === index)
let rank =
(flush && straight && 1) || /* Стрит-флеш, в том числе и флеш-рояль - пять последовательных по номиналу карт одной масти */
(duplicates[4] && 2) || /* Каре - четыре карты одного номинала */
(duplicates[3] && duplicates[2] && 3) || /* Фулл-хаус - тройка + пара */
(flush && 4) || /* Флеш - пять непоследовательных карт одной масти */
(straight && 5) || /* Стрит - пять разномастных последовательных по номиналу карт */
(duplicates[3] && 6) || /* Тройка - три карты одного номинала */
(duplicates[2] > 1 && 7) || /* Две пары */
(duplicates[2] && 8) || /*Пара - две карты одного номинала */
9 /* Ни одна из комбинаций выше, просто старшая карта в руке */
return { rank, value: faces.sort(byCountFirst).join("") }
function byCountFirst(a, b) {
//Подсчёт в обратном порядке - чем больше, тем лучше
const countDiff = counts[b] - counts[a]
if(countDiff) return countDiff //Если количество не совпадает, возвращаем разницу
return b > a ? -1 : b === a ? 0 : 1
}
function count(c, a) {
c[a] = (c[a] || 0) + 1
return c
}
}
function compareHands(h1, h2) {
let d1 = getHandDetails(h1)
let d2 = getHandDetails(h2)
if (d1.rank === d2.rank) {
if (d1.value < d2.value) {
return "ВЫИГРЫШ"
} else if (d1.value > d2.value) {
return "ПРОИГРЫШ"
} else {
return "НИЧЬЯ"
}
}
return d1.rank < d2.rank ? "ВЫИГРЫШ" : "ПРОИГРЫШ"
}
```
Итог
----
Как видите, если мы аккуратно разберём всё по полочкам, можно, применив **map** и **reduce**, легко подготовить всю информацию, которая нам нужна для решения этой задачи.
|
https://habr.com/ru/post/507250/
| null |
ru
| null |
# Яндекс выложил YaLM 100B — сейчас это крупнейшая GPT-подобная нейросеть в свободном доступе. Вот как удалось её обучить

Больше примеров — [в конце](https://habr.com/ru/company/yandex/blog/672396/#examples) поста
В последние годы большие языковые модели на архитектуре трансформеров стали вершиной развития нейросетей в задачах NLP. С каждым месяцем они становятся всё больше и сложнее. Чтобы обучить подобные модели, уже сейчас требуются миллионы долларов, лучшие специалисты и годы разработки. В результате доступ к современным технологиям остался лишь у крупнейших IT-компаний. При этом у исследователей и разработчиков со всего мира есть потребность в доступе к таким решениям. Без новых исследований развитие технологий неизбежно снизит темпы. Единственный способ избежать этого — делиться с сообществом своими наработками.
Год назад мы впервые [рассказали](https://habr.com/ru/company/yandex/blog/561924/) Хабру о семействе языковых моделей YaLM и их применении в Алисе и Поиске. Сегодня мы выложили в свободный доступ нашу самую большую модель YaLM на 100 млрд параметров. Она обучалась 65 дней на 1,7 ТБ текстов из интернета, книг и множества других источников с помощью 800 видеокарт A100. Модель и дополнительные материалы [опубликованы на Гитхабе](https://github.com/yandex/YaLM-100B) под лицензией Apache 2.0, которая допускает применение как в исследовательских, так и в коммерческих проектах. Сейчас это самая большая в мире GPT-подобная нейросеть в свободном доступе как для английского, так и для русского языков.
В этой статье мы поделимся не только моделью, но и нашим опытом её обучения. Может показаться, что если у вас уже есть суперкомпьютер, то с обучением больших моделей никаких проблем не возникнет. К сожалению, это заблуждение. Под катом мы расскажем о том, как смогли обучить языковую модель такого размера. Вы узнаете, как удалось добиться стабильности обучения и при этом ускорить его в два раза. Кстати, многое из того, что будет описано ниже, может быть полезно при обучении нейросетей любого размера.
Как ускорить обучение модели?
-----------------------------
В масштабах обучения больших нейронных сетей ускорение на 10% может сэкономить неделю работы дорогостоящего кластера. Здесь мы поговорим об итоговом ускорении более чем в два раза.
Обычно одна итерация обучения состоит из следующих шагов:

На этапе forward мы вычисляем активации и loss, на этапе backward — вычисляем градиенты, затем — обновляем веса модели. Давайте обсудим, как эти шаги можно ускорить.
#### Ищем узкие места
Чтобы понять, куда уходит время вашего обучения, стоит профилировать. В PyTorch это можно сделать при помощи модуля torch.autograd.profiler ([статья](https://pytorch.org/tutorials/beginner/profiler.html)). Вот пример трейса, который мы получили, используя профайлер:

Это трейс небольшой 12-слойной нейронной сети. Сверху вы можете увидеть шаги forward, снизу — backward. Какую проблему можно увидеть в этом трейсе? Одна из операций занимает слишком много времени, около 50% работы всего обучения. Оказалось, что мы забыли изменить размер эмбеддинга токенов, когда копировали конфигурацию обучения большой модели. Это привело к слишком большому матричному умножению в конце сети. Уменьшение размера эмбеддинга помогло сильно ускорить обучение.
При помощи профайлера мы находили и более серьёзные проблемы, так что рекомендуем почаще им пользоваться.
#### Используем быстрые типы данных
В первую очередь на скорость вашего обучения и инференса влияет тип данных, в котором вы храните модель и производите вычисления. Мы используем четыре типа данных:
1. single-precision или fp32 — обычный float, очень точный, но занимает четыре байта и вычисления на нём очень долгие. Именно этот тип будет у вашей модели в PyTorch по умолчанию.
2. half-precision или fp16 — 16-битный тип данных, работает гораздо быстрее fp32 и занимает вдвое меньше памяти.
3. bfloat16 — ещё один 16-битный тип. По сравнению с fp16 мантисса на 3 бита меньше, а экспонента на 3 бита больше. Как итог — число может принимать больший диапазон значений, но страдает от потери точности при числовых операциях.
4. TensorFloat или tf32 — 19-битный тип данных, обладающий экспонентой от bf16 и мантиссой от fp16. Занимает те же четыре байта, что и fp32, но работает гораздо быстрее.
На видеокартах a100 и новее 16-битные типы в пять раз быстрее fp32, а tf32 — в 2,5 раза. Если вы используете a100, то tf32 всегда будет применяться вместо fp32, если вы явно не укажете другое поведение.
На более старых видеокартах bf16 и tf32 не поддерживаются, а fp16 всего вдвое быстрее fp32. Но это большой прирост в скорости. Имеет смысл всегда производить вычисления в half или bf16, хотя и у такого подхода есть свои недостатки. Мы их ещё обсудим.
#### Ускоряем операции на GPU
Что собой представляют операции на GPU, и как их ускорить, хорошо написано в [этой статье](https://horace.io/brrr_intro.html). Мы здесь приведем пару основных идей оттуда.
**Загружаем GPU полностью**
Для начала давайте поймём, как выглядит вычисление одного CUDA-kernel на GPU. Можно привести удобную аналогию с заводиком:
У GPU есть память — склад, и вычислитель — заводик. При выполнении одного ядра вычислитель заказывает из памяти нужные данные, вычисляет результат и записывает его обратно в память.
Что происходит, если заводик не загружен наполовину?
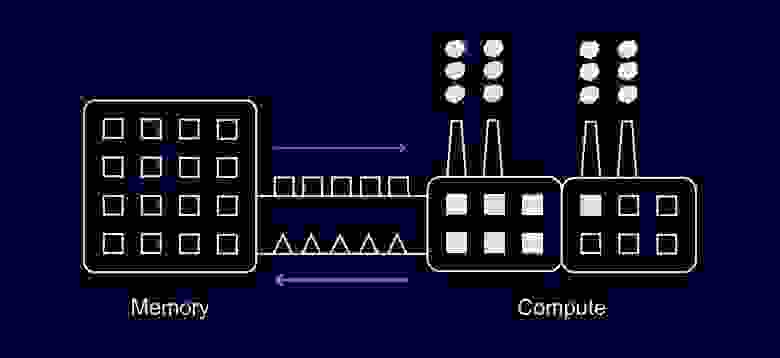
Тогда, как и в случае с реальным заводом, половина мощностей GPU будет простаивать. Как это поправить в обучении? Самая простая идея: **увеличить батч**.
Для небольших моделей увеличение батча в n раз может приводить к кратному ускорению обучения, хотя время итерации замедлится. Для больших моделей с миллиардами параметров увеличение размера батча также даст прирост, хотя и небольшой.
**Уменьшаем взаимодействие с памятью**
Вторая идея из статьи заключается в следующем. Пусть у нас есть три ядра, которые последовательно обрабатывают одни и те же данные:
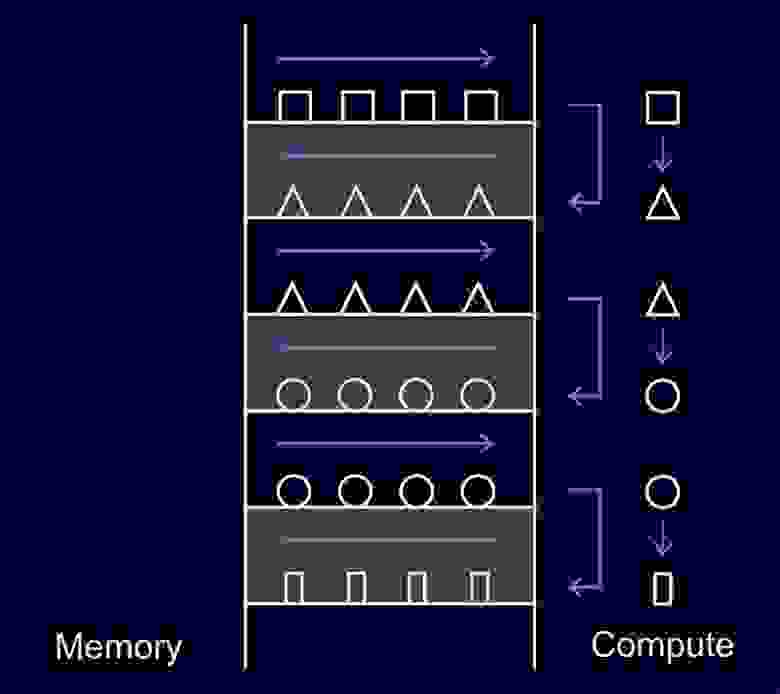
В этом случае всё время будет тратиться не только на вычисления, но и на работу с памятью: такие операции не бесплатны. Чтобы уменьшить количество таких операций, ядра можно объединить — «зафьюзить»:
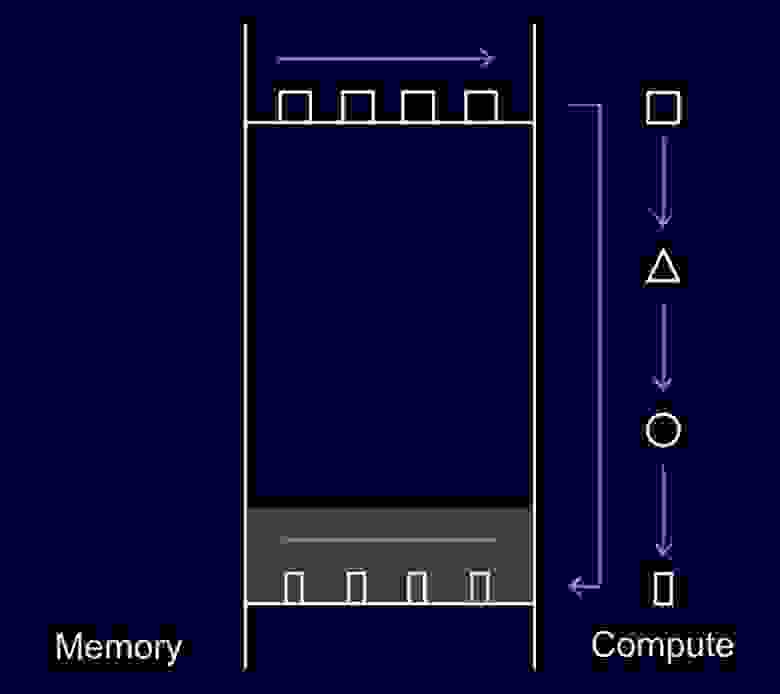
Как это сделать? Есть несколько способов:
1. Использовать torch.jit.script. Такой простой атрибут приведёт к компиляции кода функции в одно ядро. В коде ниже как раз происходит фьюзинг трёх операций: сложения тензоров, dropout и ещё одного сложения тензоров.
```
def bias_dropout_add(x, bias, residual, prob, training):
# type: (Tensor, Tensor, Tensor, float, bool) -> Tensor
out = torch.nn. functional.dropout (x + bias, p=prob, training=training)
out = residual + out
return out
def get_bias_dropout_add (training):
def _bias_dropout_add(x, bias, residual, prob):
return bias_dropout_add(x, bias, residual, prob, training)
return _bias_dropout_add
@torch.jit.script
def bias_dropout_add_fused_train(x, bias, residual, prob):
# type: (Tensor, Tensor, Tensor, float) -> Tensor
return bias dropout add(x, bias, residual, prob, True)
```
Такой подход обеспечил нам 5-процентный прирост скорости обучения.
2. Можно писать CUDA-ядра. Это позволит не просто зафьюзить операции, но и оптимизировать использование памяти, избежать лишних операций. Но написание такого кода требует очень специфичных знаний, и разработка такого ядра может оказаться слишком дорогой.
3. Можно использовать уже готовые CUDA-ядра. Коротко расскажу о ядрах в библиотеках [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) и [DeepSpeed](https://www.deepspeed.ai/), с ними мы много работаем:
* Attention softmax с треугольной маской даёт ускорение 20-100%. Ускорение особенно велико на маленьких сетях и в случае вычисления в fp32.
* Attention softmax с произвольной маской даёт ускорение до 90%.
* Fused LayerNorm — зафьюженный вариант LayerNorm в fp32. Мы такое ядро не использовали, но оно тоже должен дать прирост в скорости.
* [DeepSpeed Transformers](https://www.deepspeed.ai/tutorials/transformer_kernel/) — целиком зафьюженный блок трансформера. Даёт прирост в скорости, но его крайне сложно расширять и поддерживать, поэтому мы его не используем.
Использование зафьюженных тем или иным образом ядер позволило нам ускорить обучение больше чем в полтора раза.
#### Дропауты
Если у вас много данных и нет переобучения с dropout == 0, отключайте их! Наши вычисления это ускорило на 15%.
#### Случай с несколькими картами
Что меняется в случае с несколькими картами? Теперь схема выглядит так:
На этапе Reduce grads мы усредняем градиенты по видеокартам, чтобы объединить работу всех видеокарт, затем обновляем веса модели.
Усреднение всех градиентов — не быстрый шаг. Каждая видеокарта должна отправить и получить минимум столько же градиентов, сколько параметров есть в сети. Давайте посмотрим, как существенно ускорить этот шаг и шаг step.
#### Коммуникации
Как вообще устроены оптимальные коммуникации? Библиотека NVIDIA NCCL, которую мы используем, просчитывает их во время инициализации и позволяет GPU общаться друг с другом по сети без посредников в виде CPU. Тем самым обеспечивается максимальную скорость коммуникаций. Вот [статья](https://developer.nvidia.com/blog/fast-multi-gpu-collectives-nccl/) NVIDIA про эту библиотеку, а вот [наша хабрастатья](https://habr.com/ru/company/yandex/blog/661989/) про борьбу с ложной загрузкой GPU, в том числе про NCCL.
С точки зрения кода это выглядит примерно так:
```
from torch.distributed import all_reduce, all_gather
tensor_to_sum = torch.randn(100, 100, device='cuda')
all_reduce(tensor_to_sum) # Когда этот метод будет вызван на всех процессах, значение tensor_to_sum обновится на сумму входных тензоров
tensor_to_gather = torch.randn(100, 100, device='cuda')
gathered_tensors = [torch.zeros(100, 100, device='cuda') for i in range(proc_count)]
all_gather(gathered_tensors, tensor_to_gather) # Тензоры из различных tensor_to_gather будут собраны в gathered_tensors
```
NCCL-коммуникации очень быстрые, но даже с ними скорость шага all\_reduce будет отнимать много времени. В ускорении нам помогает ZeRO.
#### ZeRO
ZeRO (Zero Redundancy Optimizer) — это оптимизатор с нулевой избыточностью.
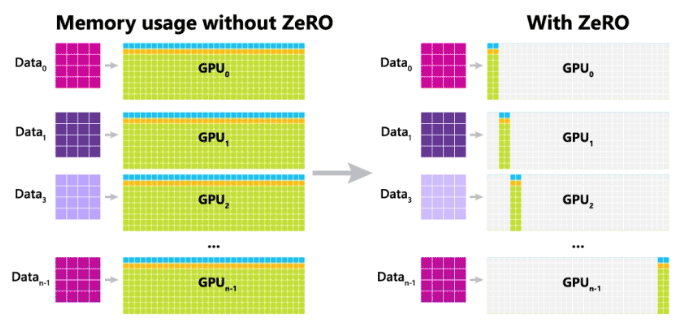
Слева на картинке — обычное обучение на нескольких GPU. В стандартной схеме мы распределяем между процессами все параметры и состояния оптимизатора, а также градиенты после усреднения. Как следствие, довольно много памяти тратится зря.
Справа изображён примерный принцип работы ZeRO. Мы назначаем каждый процесс ответственным за некоторую группу параметров. Процесс всегда хранит эти параметры, их состояния оптимизатора, и только он может их обновлять. За счёт этого достигается коллосальная экономия памяти, которую мы можем использовать под большие батчи. Но взамен добавляется новый шаг: all\_gather весов — нам надо собрать все параметры сети на каждом процессе, чтобы сделать forward и backward. Теперь сложности операций после подсчёта градиентов будут такими:
all\_reduce gradients: O(N), где N — количество параметров.
step: O(N/P), где P — количество процессов. Это уже хорошее ускорение.
all\_gather parameters: O(N).
Видно, что один шаг ускорился, но ценой добавления новых, тяжёлых операций. Как можно ускорить их? Оказалось, здесь нет ничего сложного: их можно делать асинхронно!
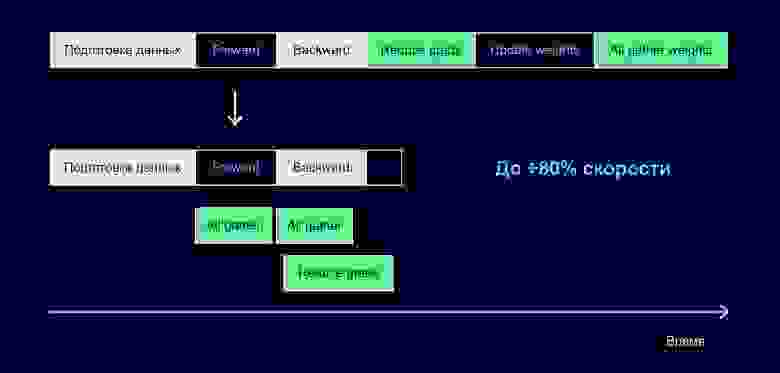
Можем асинхронно собирать слои друг за другом во время выполнения forward:
1. Собираем первый слой по всем процессам.
2. Пока собираем второй слой — делаем forward по первому.
3. Пока собираем третий слой — делаем forward по второму.
И так далее, до полного завершения forward. Почти таким же способом можно ускорить и backward.
На наших запусках это дало прирост скорости 80%! Даже на маленьких моделях (размера 100M на 16 GPU) мы видели ускорение в 40-50%. Такой подход требует достаточно быстрой сети, но если она у вас есть, вы можете существенно ускорить обучение на нескольких GPU.
#### Ускорение. Итоги
Мы в своём обучении применили четыре подхода:
* Зафьюзили часть операций: +5% скорости
* Использовали softmax attention kernel с треугольной маской: +20-80%
* Отключили dropout: +15%
* Применили ZeRO: +80%
Получилось неплохо. Двигаемся дальше.
Борьба с расхождениями
----------------------
Казалось бы, если есть достаточно вычислительных мощностей, можно просто запустить обучение, уйти на два месяца в отпуск, и в итоге вас будет ждать готовая модель. Но долгая итерация — не единственное, что может помешать обучению действительно больших моделей. При таких масштабах они довольно хрупкие и склонны к расхождениям. Что такое расхождения и как с ними бороться?
#### Расхождения
Допустим, вы поставили обучение. Смотрите на графики — видите, что loss падает, и так три дня подряд. А утром четвёртого дня график loss'а оказывается таким:
Loss поднялся выше, чем был через несколько часов после начала обучения. Более того: модель буквально забыла всё, что знала. Её уже не восстановить, несколько дней обучения ушло впустую. Это и есть расхождение. В чём же причина?
#### Первые наблюдения
Мы заметили три вещи:
* Оптимизатор LAMB куда менее склонен к расхождению, чем Adam.
* Уменьшая значения learning rate, можно побороть проблему расхождения. Но не всё так просто:
1. Подбор lr требует множества перезапусков обучений.
2. Уменьшение lr часто приводит к замедлению обучения. Например, здесь уменьшение lr в два раза привело к замедлению на 30%:
* Проблемы расхождения в fp16 проявлялись чаще, чем в fp32. В основном это было связано с переполнением значений fp16 в активациях и градиентах. Максимум fp16 по модулю — 65535. Итогом переполнения становился NaN в loss'е.
#### Градусники
Одно из решений, которые помогли нам поддерживать обучение достаточно долго, — это градусники. Мы замеряли максимумы/минимумы активаций на разных участках сети, замеряли глобальную норму градиентов. Вот пример градусников обучения с расхождением:
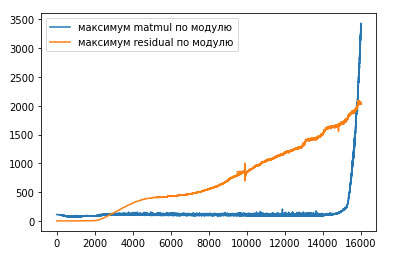
Хорошо видно: начиная примерно с 14 тысяч итераций максимумы matmul в attention резко стали расти. Этот рост — и есть причина расхождения. Если откатить обучение до 13 тысяч итераций и пропустить злополучные батчи, на которых расхождение началось, либо уменьшить learning rate, то можно существенно снизить вероятность повторного расхождения.
Проблемы такого подхода:
1. Он не решает проблему расхождений на 100%.
2. Мы теряем драгоценное время на откатывание обучения. Это, конечно лучше, чем проводить его впустую, но тем не менее.
Позднее мы внедрили несколько трюков, которые позволили снизить вероятность расхождения настолько, что мы спокойно и без проблем обучили множество моделей самых разных размеров, включая 100B.
#### Стабилизации. BFloat 16
BFloat 16 не переполняется даже при достаточно больших значениях градиентов и активаций. Поэтому оказалось хорошей идеей хранить веса и производить вычисления именно в нём. Но этот тип недостаточно точный, поэтому при произвольных арифметических операциях могла накапливаться ошибка, приводящая к замедлению обучения или расхождениям другой природы.
Чтобы компенсировать расхождения, мы стали вычислять следующие слои и операции в tf32 (или fp32 на старых карточках):
* Softmax в attention (вот и пригодились наши ядра), softmax по токенам перед лоссом.
* Все слои LayerNorm.
* Все операции с Residual — это позволило не накапливать ошибку и градиенты по глубине сети.
* all\_reduce градиентов, о котором было написано раньше.
Все эти стабилизации замедлили обучение всего на 2%.
#### Стабилизации. LayerNorm
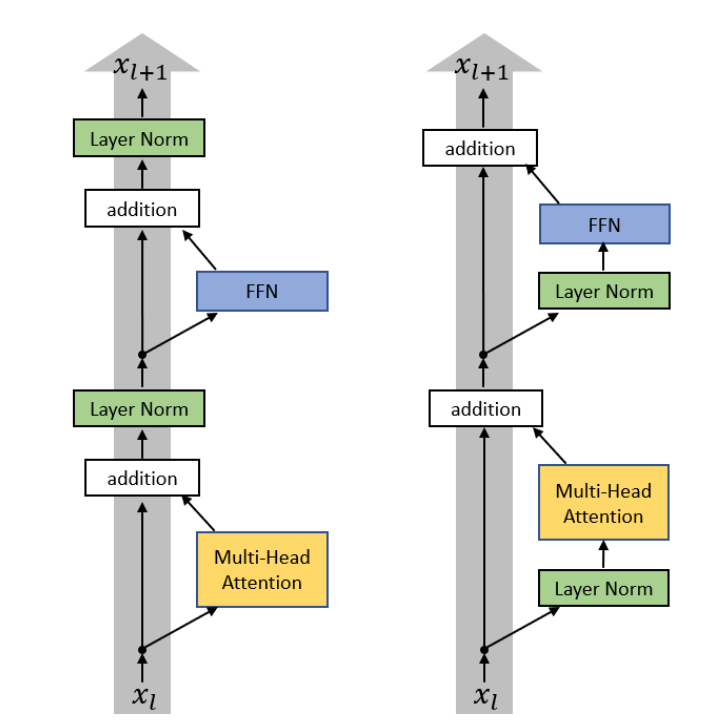
Если в статьях про BERT и GPT использовался подход, который сейчас называется post-layernorm (слева на картинке), то с точки зрения стабильности и скорости сходимости больших моделей хорошо себя показал pre-layernorm (справа). В реальных моделях мы используем именно его.
Неожиданный метод стабилизации открыли участники воркшопа BigScience: layernorm в самом начале сети, после эмбеддингов, также заметно снижает вероятность расхождения.
#### Стабилизации. Curriculum learning
Также мы внедрили к себе подход из статьи [Curriculum learning](https://arxiv.org/abs/2010.13166). Мы хотим обучаться с большим батчем и большой длиной строк, но начинаем с маленького батча и коротких строк, а в ходе обучения постепенно их увеличиваем.
У этого подхода два плюса:
1. Loss в самом начале падает достаточно быстро, вне зависимости от числа токенов, которые модель видит на каждой итерации. Поскольку мы уменьшаем количество вычислений в начале обучения, то быстрее проходим этот этап выхода лосса на плато.
2. Авторы статьи пишут, что такой подход приводит к стабильному обучению.
#### Стабилизации. Итоги
Мы внедрили пять подходов:
bf16 как основной тип для весов.
Вычисления, требующие точности, делаем в tf32.
Pre-layernorm.
LayerNorm сразу после эмбеддингов.
Curriculum learning.
Как итог, мы уже больше полугода обучаем модели без расхождений. Они бывают разных размеров. В том числе эти стабилизации помогли обучить модель со 100 млрд параметров, которой мы сейчас и делимся со всем сообществом.
И напоследок:
####
**Ещё немного примеров общения с YaLM 100B**
|
https://habr.com/ru/post/672396/
| null |
ru
| null |
# Макетная плата SPI NOR Flash
 Большинство современных CPU позволяют производить начальную загрузку с разных источников (media booting), одним из которых может быть **SPI NOR Flash**. Микросхемы энергонезависимой памяти **NOR Flash** с последовательным интерфейсом **SPI** используются на материнских платах для хранения образов BIOS, BMC, а так же данных различного назначения. Если же речь идет о популярных платах, постороенных на различных **SoCs**, таких как **Raspberry Pi**, **Orange Pi** и так далее, то на них **SPI**-интерфейс может быть выведен на контактные площадки для того, чтобы пользователь мог самостоятельно подключить ту или иную микросхему в качестве внешнего носителя.
Для разработки и отладки, как самих устройств, так и програмного обеспечения, возникает необходимость макетирования, то есть создания макетной платы, на которой распаяна микросхема **SPI NOR Flash**, служащая для подключения к основной плате устройства.
Требования к качеству такой макетной платы не велики и ее можно создать используя, так называемые, слепыши и платы для непосредственной распайки микросхемы, например, такой как **Winbond W25Q256JV**. На следующем рисунке показан пример подобной макетной платы.

Здесь распаяно два разъема: один для подключения программатора, например, [**CH341A**](https://www.onetransistor.eu/2017/08/ch341a-mini-programmer-schematic.html), другой для подключения к основному устройству.
Разумеется такая плата весьма неудобна и ненадежна, особенно, если речь идет о многократных подключениях и перепрошивке памяти. Кроме того, если работа ведется коллективом разработчиков, то ручное макетирование может отнимать много времени.
Наилучшим решением в таких случаях является создание макетной платы, на которой уже распаяны все пассивные элементы и имеется контактная площадка для напайки **NOR Flash** в различных исполнениях (SOP-16, SOP-8, 8-pad WSON 8x6-mm, 16-pin SOIC 300-mil).
Если распаять все пассивные элементы и разъемы, то пользователю останется только монтажная площадка для выбранной им микросхемы, монтаж которой будет удобен даже без использования дорогостоящей паяльной станции.

Электрическая принципиальная схема макетной платы показана на следующем рисунке.

Плата расчитана на **NOR Flash** c питающим напряжением **3.3V** и пригодна для работы с таким микросхемами, как Winbond [W25Q256JV](https://www.winbond.com/hq/product/code-storage-flash-memory/serial-nor-flash/?__locale=en&partNo=W25Q256JV), Infineon [S25FL512S](https://www.infineon.com/dgdl/Infineon-S25FL512S_512_Mb_(64_MB)_3.0_V_SPI_Flash_Memory-DataSheet-v20_00-EN.pdf?fileId=8ac78c8c7d0d8da4017d0ed046ae4b53) и т. д.
Разъем **J1** предназначен для подключения программатора. В случае использования программатора [CH341A](https://www.wch.cn/products/CH341.html), достаточно использовать обычный шлейф (Flat Ribbon Cable) 1.27mm и два разъема IDC (2X4 8 Pins 2.54mm Dual Row Socket), как показано на следующем рисунке.

Разъем **J2** предназначен для подключения к устройству, в качестве которого может выступать одноплатный компьютер.
Для примера, рассмотрим подключение микросхемы **Winbond W25Q256JVFIQ** к одноплатной машине [**Lenovo Leez P710**](https://github.com/leezsbc/resources/wiki/Leez-P710%EF%BC%88EN%EF%BC%89). На плате имеется 40-контактный блок, где SPI-интерфейс выведен на контакты 19, 21, 23, 24.

Следующая таблица показывает схему подключения контактов разъема **J2** макетной платы к контактам **Leez P710**.

Для того, чтобы ядро **Linux** могло определить подключеную таким образом микросхему, необходимо добавить в описание **dts** (arch/arm64/boot/dts/rockchip/rk3399-leez-p710.dts) следующие строки.
```
&spi1 {
status = "okay";
spiflash: flash@0 {
compatible = "winbond,w25q256", "jedec,spi-nor";
reg = <0>;
spi-max-frequency = <1000000>; // 1MHz
partitions {
compatible = "fixed-partitions";
#address-cells = <1>;
#size-cells = <1>;
spi-flash@0 {
reg = <0x0 0x2000000>; // 32MiB (Full flash)
label = "spi-flash";
};
};
};
};
```
Здесь определен только один раздел, занимающий весь объем памяти, которому будет соответствовать устройство **/dev/mtd0**. Разумеется, в разделе **partitions** можно определить и другие разделы. Следует только помнить, что выравнивания и размеры разделов **NOR Flash** должны быть кратны размеру **Erase Block**.
---
Оригинал статьи можно найти в блоге [**Radix cross Linux**](https://radix.pro/blog/?date=2022-08-26&post=00).
|
https://habr.com/ru/post/687616/
| null |
ru
| null |
# Пять способов показать выпадающий список в Asp.Net MVC, с достоинствами и недостатками
В большинстве интродукций к Asp.Net MVC рассказывается о том, как красиво и просто организовать привязку модели к простым полям ввода, таким, как текстовое или чекбокс. Если ты, бесстрашный кодер, осилил этот этап, и хочешь разобраться, как показывать выпадающие списки, списки чекбоксов или радиобаттонов, этот пост для тебя.
### **Постановка задачи**
У нас есть база фильмов, про которых мы знаем название и жанр. Хочется показать редактор информации о кино, у которого жанры выбираются из списка. Проблема в том, что наш View должен иметь данные как относящиеся к собственно фильму, так и к списку жанров. Причем, данные о фильме относятся к тому, **что** мы показываем, а список жанров — к тому, **как** мы **редактируем** нашу информацию.
### **Способ первый. The Ugly.**
Мы можем передавать данные о фильме через контроллер, а список жанров наш вью будет извлекать сам. Понятно, что это нарушение всех мыслимых принципов, но чисто теоретически такая возможность имеется.
Имеем такие классы моделей:
```
public class MovieModel {
public string Title { get; set; }
public int GenreId { get; set; }
}
public class GenreModel {
public int Id { get; set; }
public string Name { get; set; }
}
```
Метод контроллера, как в руководствах для начинающих:
```
public ActionResult TheUgly(){
var model = Data.GetMovie();
return View(model);
}
```
Здесь Data — это просто статический класс, который нам выдает данные. Он придуман исключительно для простоты обсуждения, и я бы не советовал использовать что-либо подобное в реальной жизни:
```
public static class Data {
public static MovieModel GetMovie() {
return new MovieModel {Title = "Santa Barbara", GenreId = 1};
}
}
```
Приведем теперь наш ужасный View, точнее, ту его часть, которая касается списка жанров. По сути, наш код должен вытащить все жанры и преобразовать их в элементы типа SelectListItem.
```
<%
var selectList = from genre in Data.GetGenres()
select new SelectListItem {Text = genre.Name, Value = genre.Id.ToString()};
%>
<%:Html.DropDownListFor(model => model.GenreId, selectList, "choose") %>
```
Что же здесь ужасного? Дело в том, что главное достоинство Asp.Net MVC, на мой взгляд, состоит в том, что у нас есть четкое разделение обязанностей (separation of concerns, или SoC). В частности, именно контроллер отвечает за передачу данных во вью. Разумеется, это не догма, а просто хорошее правило. Нарушая его, Вы рискуете наворотить кучу ненужного кода в Ваших представлениях, и разобраться через год, что к чему, будет очень непросто.
**Плюс**: простой контроллер.
**Минус**: в представление попадает код, свойственный контроллеру; грубое нарушение принципов модели MVC.
**Когда использовать**: если надо быстро набросать демку.
### **Способ второй. The Bad.**
Как и прежде, модель передаем стандартным образом через контроллер. Все дополнительные данные передаем через ViewData. Метод контроллера у нас вот:
```
public ActionResult TheBad() {
var model = Data.GetMovie();
ViewData["AllGenres"] = from genre in Data.GetGenres()
select new SelectListItem {Text = genre.Name, Value = genre.Id.ToString()};
return View(model);
}
```
Понятно, что в общем случае мы можем нагромоздить во ViewData все, что угодно. Дальше все это дело мы используем во View:
```
<%:Html.DropDownListFor(model => model.GenreId,
(IEnumerable) ViewData["AllGenres"],
"choose")%>
```
**Плюс**: данные для «что» и «как» четко разделены: первые хранятся в модели, вторые — во ViewData.
**Минусы**: данные-то разделены, а вот метод контроллера «перегружен»: он занимается двумя (а в перспективе — многими) вещами сразу; кроме того, у меня почему-то инстинктивное отношение к ViewData как к «хакерскому» средству решения проблем. Хотя, сторонники динамических языков, возможно, с удовольствием пользуются ViewData.
**Когда использовать**: в небольших формах с одним-двумя списками.
### **Способ третий. The Good.**
Мы используем модель, которая содержит все необходимые данные. Прямо как в книжке.
```
public class ViewModel {
public MovieModel Movie { get; set; }
public IEnumerable Genres { get; set; }
}
```
Теперь задача контроллера — изготовить эту модель из имеющихся данных:
```
public ActionResult TheGood() {
var model = new ViewModel();
model.Movie = Data.GetMovie();
model.Genres = from genre in Data.GetGenres()
select new SelectListItem {Text = genre.Name, Value = genre.Id.ToString()};
return View(model);
}
```
**Плюс**: каноническая реализация паттерна MVC (это хорошо не потому, что хорошо, а потому, что другим разработчикам будет проще врубиться в тему).
**Минусы**: как и в прошлом примере, метод контроллера перегружен: он озабочен «что» и «как»; кроме того, эти же «что» и «как» соединены в одном классе ViewModel.
**Когда использовать**: в небольших и средних формах с одним-тремя списками и другими нестандартными элементами ввода.
### **Способ четвертый. The Tricky.**
Есть еще одна «задняя дверь», через которую можно доставить данные во View — это метод RenderAction. Многие брезгливо морщатся при упоминании об этом методе, поскольку, по классике, View не должен знать о контроллере. Лично для меня это (да простят меня боги) хороший аналог UserControl-ов из WebForms. А именно, возможность создать некий элемент, практически (если не считать параметров вызова этого метода) независимый от всей остальной страницы.
Итак, в качестве модели мы используем MovieModel, и метод контроллера такой же, как и TheUgly. Но у нас теперь появится новый контроллер, и метод для отрисовки дропдауна в нем, а также partial с этим дропдауном. Этот partial мы сделаем макимально гибким, чтобы им пользоваться и в других случаях, назовем Dropdown.ascx, и поместим его в папку Views\Shared:
```
<%@ Control Language="C#" Inherits="System.Web.Mvc.ViewUserControl>" %>
<% =Html.DropDownList(ViewData.ModelMetadata.PropertyName, Model, ViewData.ModelMetadata.NullDisplayText)%>
```
Что касается метода, который рендерит этот вью, то тут есть пара хитростей:
```
public class GenreController : Controller{
public ActionResult GetGenresDropdown(int selectedId) {
ViewData.Model = from genre in Data.GetGenres()
select new SelectListItem
{ Text = genre.Name,
Value = genre.Id.ToString(),
Selected = (genre.Id == selectedId) };
ViewData.ModelMetadata =
new ModelMetadata(
ModelMetadataProviders.Current,
null,
null,
typeof (int),
"GenreId")
{NullDisplayText = "choose"};
return View("Dropdown");
}
}
```
Во-первых, мы теряем тут автоматический выбор нужного значения, поэтому нам нужно вручную устанавливать свойство Selected у SelectListItem. Во-вторых, если мы передаем какие-то нетривиальные метаданные в наш View, то мы должны сначала установить модель, а потом уже метаданные. В противном случае метаданные автоматически создадутся на основе модели. По той же причине мы не должны писать return View(model). Ну и собственно метаданные нужны для того, чтобы определить название свойства и текст по умолчанию (NullDisplayText). Без последнего, кстати, можно обойтись.
Наконец, метод контроллера вызывается из главного View:
```
<% Html.RenderAction("GetGenresDropdown", "Genre", new {selectedId = Model.GenreId}); %>
```
**Плюсы**: разделение ответственности на уровне контроллера: MovieController отвечает за данные о фильме, GenreController — за жанры. На уровне View у нас тоже полная победа: главный вью существенно упростился, а детали реализации выбора жанра отправились во вспомогательный. Здесь, кстати, есть некая аналогия с упрощением длинного метода и выносом части кода во вспомогательный метод.
**Минусы**: больше кода, сложнее структура.
**Когда использовать**: когда главный View становится достаточно большим, и дропдауны появляются у нескольких полей, либо когда выбор жанра необходимо использовать на нескольких страницах.
### **Способ пятый. The Smart.**
Когда вся нетривиальная часть по организации ввода (или выбора) нужного значения отделена от главного View, возникает желание как-то резко это главный View упростить. И очевидное тут решение — использовать Html.EditorForModel(). Теперь за выбор способа отображения того или иного поля отвечают метаданные класса модели. Единственная проблема — встроенными средствами мы можем лишь заставить движок вызвать в нужном месте RenderPartial(), но не RenderAction(). Поэтому придется создать Partial View, который не несет никакой нагрузки, кроме как вызвать соответствующий RenderAction. (Правда, если нам нужно будет кастомизировать редактор поля, то мы будем изменять именно этот вью, а DropDown.ascx оставим нейтральным.)
Итак, в папке \Views\Movie\EditorTemplates создаем Partial View под названием GenreEditor.ascx. Модель у него будет того же типа, что и свойство GenreId, которое мы редактируем, т.е., int. Сам вью будет содержать только вызов RenderAction:
```
<% Html.RenderAction("GetGenresDropdown", "Genre", new {selectedId = Model}); %>
```
Чтобы наш вью использовать, надо в модель добавить нужный атрибут к свойству GenreId:
```
[UIHint("GenreEditor")]
```
**Плюсы**: те же, что и в предыдущем примере, но при этом мы существенно упростили наш главный View.
**Минусы**: нам пришлось изготовить лишний View, который (пока) не несет никакой осмысленной нагрузки (но, возможно, позволит кастомизировать редактирование поля, например, добавить подсказку). Еще один, более важный, минус — труднее кастомизировать общую структуру формы (например, одно поле показать в левой части, а остальные — в правой). Если требуется глобальная кастомизация (например, везде использовать таблицы вместо дивов), можно изготовить свой шаблон для Object.
**Когда использовать**: когда полей много, показываются они более-менее страндартным образом, и часто вносятся изменения в список полей.
Теперь, если у нас появляются дропдауны с категориями, рейтингом и т.д., мы сможем по-прежнему использовать Dropdown.aspx (как и для других дропдаунов), но нам придется писать аналогичные методы контроллеров и partials, аналогичные нашему GenreEditor. Можно ли это как-то оптимизировать? Во-первых, можно изготовить базовый Generic Controller, и отправить наш метод туда. Во-вторых, можно каким-нибудь образом передать в наш partial название связанного класса («Genre») (например, через атрибут DataType), и сконструировать вызов RenderAction соответственным образом. Теперь вместо GenreEditor мы будем иметь универсальный редактор для выбора из выпадающего списка. В итоге мы получим, что добавление новых справочников никак не увеличит количество необходимого кода — надо лишь соответствующим образом проставить атрибуты у модели. В примерах этого нет, но читатель лекго это реализует сам.
### **А как еще можно?**
Единственный по-настоящему отличающийся от приведенных здесь способ, который пришел мне в голову — сделать наполнение дропдауна через AJAX. Плюс здесь очевиден: данные передаются независимо от html и могут быть использованы в других местах другим способом. Я слышал, что такая штука очень просто реализуется в Spark, но у меня руки еще не дошли попробовать.
### **А зачем, вообще, с этим париться?**
С примерами всегда одна беда: они должны быть достаточно простыми, чтобы было понятно, о чем речь, но тогда непонятно, зачем такое сложное решение. Если Вас по-прежнему волнует этот вопрос, перечитайте пункты «когда использовать».
Разумеется, прежде, чем пользоваться одним из этих решений, лучше прикинуть отношение сигнал/шум: небольшие проекты поддерживать проще, когда там меньше кода, классов, файлов и т.д., в то время, как в больших проще иметь дело с б**о**льшим количеством элементов, каждый из которых четко сфокусирован на решении своей маленькой задачи. К счастью, все это довольно неплохо рефакторится: мы можем начать с одного из первых решений, и, по мере усложнения нашей формы, переходить к более продвинутым вариантам.
Что еще? Ах да, исходники можно взять [здесь](http://sm-art.biz/%D1%81%D0%BA%D0%B0%D1%87%D0%B0%D1%82%D1%8C-%D0%BF%D1%80%D0%B8%D0%BC%D0%B5%D1%80%D1%8B.aspx). Наслаждайтесь!
|
https://habr.com/ru/post/106370/
| null |
ru
| null |
# BoxView — удобный autolayout для iOS
Хочу поделиться библиотекой для эффективного построения пользовательского интерфейса iOS приложений на основе autolayout.
Хотя с появлением SwiftUI актуальность autolayout быстро уменьшается, пока этот механизм все еще активно используется, и библиотека может быть полезна для тех, кто создает (или меняет) UI непосредственно в коде.
У такого способа построения интерфейса есть ряд недостатков, которые ограничивают его применение:
* Очень неудобно организовано создание NSLayoutConstraint элементов.
* Плохая наглядность — посмотрев на код трудно понять как будет выглядеть UI.
* Большое количество рутинного кода. Для размещения каждой view требуется создание в среднем около 3 constraints, т.е. три строки однотипного кода.
* Трудоемкость создания динамически изменяемых интерфейсов: требуется сохранять constraints в отдельных переменных, чтобы затем можно было их менять, а также часто создавать избыточные constraints и «выключать» ненужные.
Первая проблема достаточно легко решается обертыванием стандартных методов создания constraints во что-нибудь более гуманное. И это уже отлично реализовано, например, в [SnapKit](https://github.com/SnapKit/SnapKit), [TinyConstraints](https://github.com/roberthein/TinyConstraints) и других подобных библиотеках.
Но все равно приходится писать достаточно много однотипного кода, и остаются проблемы с наглядностью и динамическим изменениями лейаута. Эти проблемы изящно решает UIStackView, но к сожалению, в UIStackView очень ограничена настройка расположения отдельных элементов. Поэтому возникла идея контейнерной UIView, управляющей лейаутом стека своих subview, но с возможностью индивидуальной настройки расположения каждой subview.
Именно этот подход лежит в основе BoxView, и он оказался очень эффективным. BoxView позволяет почти полностью исключить ручное создание constraints, практически весь пользовательский интерфейс формируется в виде системы вложенных BoxView. В итоге код стал намного короче и нагляднее, выигрыш особенно ощутим для динамических UI.
BoxView во многом похожий на стандартный UIStackView, но для размещения subview он использует другие правила: в нем можно устанавливать отступы и размеры для каждой subview индивидуально. Для создания лейаута BoxView использует массив элементов типа BoxItem, который содержит все view которые надо отобразить, и информацию о том как их расположить. И для этого совсем не требуется много кода — большая часть параметров лейаута берется по умолчанию, а явно указываются только нужные значения.
Существенное свойство BoxView в том, что он **создает только указанные constraints** для добавленных subview, и ничего более. Поэтому его можно использовать без каких либо ограничений совместно с любыми другими библиотеками и методами лейаута.
В качестве примера рассмотрим создание простой логин формы с помощью BoxView (Полный код примера с пошаговым описанием доступен в проекте [BoxViewExample на github](https://github.com/vladimir-d/BoxView)).

Для создания такого лейаута на BoxView достаточно нескольких строк кода:
```
nameBoxView.items = [nameImageView.boxed.centerY(), nameField.boxed]
passwordBoxView.items = [passwordImageView.boxed.centerY(), passwordField.boxed]
boxView.insets = .all(16.0)
boxView.spacing = 20.0
boxView.items = [
titleLabel.boxed.centerX(padding: 30.0).bottom(20.0),
nameBoxView.boxed,
passwordBoxView.boxed,
forgotButton.boxed.left(>=0.0),
loginButton.boxed.top(30.0).left(50.0).right(50.0),
]
```
Элемент BoxItem создается из любой UIView с помощью переменной boxed, после этого ему можно задать отступы с 4 сторон, выравнивание, а также абсолютные или относительные размеры.
Любые элементы лейаута можно свободно добавлять и удалять (в том числе с анимацией), не затрагивая размещения остальных. В качестве примера добавим проверку на пустые поля ввода и в случае ошибки будем показывать сообщение непосредственно под пустым полем:
И хотя сообщение должно «встроиться» в существующий лейаут, для этого даже не потребуется менять имеющийся код!
```
func showErrorForField(_ field: UITextField) {
errorLabel.frame = field.convert(field.bounds, to: boxView)
let item = errorLabel.boxed.top(-boxView.spacing).left(errorLabel.frame.minX - boxView.insets.left)
boxView.insertItem(item, after: field.superview, z: .back)
boxView.animateChangesWithDurations(0.3)
}
@objc func onClickButton(sender: UIButton) {
for field in [nameField, passwordField] {
if field.text?.isEmpty ?? true {
showErrorForField(field)
return
}
}
// ok, can proceed with login
}
@objc func onChangeTextField(sender: UITextField) {
errorLabel.removeFromSuperview()
boxView.animateChangesWithDurations(0.3)
}
```
BoxView поддерживает весь инструментарий autolayout: расcтояния между элементами, абсолютные и относительные размеры, приоритеты, поддержку RTL языков. Помимо UIView в качестве элементов лейаута можно также использовать невидимые объекты — UILayoutGuides. Можно использовать также flex layout. Разумеется сама схема лейаута, в виде системы вложенных стеков UIView, не покрывает на 100% все мыслимые варианты относительного расположения элементов, но этого и не требуется. Она как раз хорошо походит для подавляющего большинство типичных пользовательских интерфейсов, а для более экзотических случаев, всегда можно добавить соответствующие дополнительные constraints любым другим способом. Несколько утилитных методов, например, для создания aspect ratio constraints также включены в библиотеку.
Еще один небольшой пример [доступный на github](https://github.com/vladimir-d/BoxView) (~100 строк кода!) иллюстрирует использование системы вложенных BoxView совместно с другими методами задания constraints, а также анимированное изменение параметров BoxView.

[BoxView project on github](https://github.com/vladimir-d/BoxView)
|
https://habr.com/ru/post/509044/
| null |
ru
| null |
# Система частиц в Core Animation. Рождественская история

Всем привет!
Рождество давно прошло, но после него у нас осталась занимательная история о том, как при помощи нечасто используемой возможности Core Animation можно создать пользователям праздничное настроение. Делюсь переводом статьи моего лондонского коллеги Алексиса.
Рождество всегда было для меня одним из самых любимых дней в году. Оно приносит в наши жизни много любви, смеха, счастья и волшебства.
Я родился и вырос в Испании, на Тенерифе — солнечном острове посреди Атлантического океана недалеко от побережья Африки. И, поверьте мне, Рождество на Тенерифе сильно отличается от Рождества в Лондоне, где я встречал его последние два года (с тех пор как начал работать в Badoo).
Одним из преимуществ жизни в Лондоне для меня стало созерцание снежинок. Здесь я увидел их впервые в жизни, это было просто невероятно!
Вспомнив об этом, я решил поделиться с вами одной интереснейшей историей, случившейся со мной в офисе незадолго до Рождества, перед тем как я отправился на Тенерифе, чтобы встретить праздник со своей семьёй.
Так уж случилось, что мне поручили одну необычную задачу со следующим описанием:

Хм, довольно занятно. Мы хотели добавить рождественскую анимацию со снежинками в наше iOS-приложение, и я стал тем счастливчиком, который должен был её создать. Но я не знал, с чего начать.
Как обычно, к задаче был прилинкован Sketch-файл c необходимым дизайном, который выглядел примерно так:

Как минимум я видел, что нам требуется, но не был до конца уверен, как эти снежинки должны себя вести. Чтобы прояснить все детали, я отправился общаться с дизайнерами.
Как я и подозревал, у них уже была готова великолепная анимация, нарисованная в [After Effects](https://www.adobe.com/uk/products/aftereffects.html).
Дизайнеры объяснили мне, что хотят добавить падающие сверху снежинки в уже существующую анимацию запуска приложения (а также шапку Санты на наш логотип, но это была простая подмена картинки, недостойная упоминания в этой статье).
Я знал, что анимация запуска приложения на iOS сделана с помощью [Lottie](https://github.com/airbnb/lottie-ios), так как её добавили уже после того, как я присоединился к компании (подробности можно найти в статье [Radek Cieciwa](https://badoo.com/techblog/blog/2017/07/12/behind-the-scenes-with-importing-adobe-after-effects-animation-into-badoo-ios-app/)). Однако я сказал дизайнерам, что попробую найти более простые решения для показа снежинок (без необходимости использовать Lottie) — и начал исследовать различные подходы.
Вот такую анимацию мой коллега Radek сделал для Badoo. Безупречно!

А вот так я добавил падающие снежинки. Хотите знать, как у меня это получилось? Ответ вы найдёте ниже.

Системы частиц (Particle Systems)
=================================
Во время чтения различной документации про анимации я вспомнил о том, что в играх и фильмах для решения подобных задач довольно часто используют системы частиц.
«[Википедия](https://en.wikipedia.org/wiki/Particle_system)» описывает это понятие довольно точно:
> «Систе́ма части́ц — используемый в компьютерной графике способ представления объектов, не имеющих чётких геометрических границ (различные облака, туманности, взрывы, струи пара, шлейфы от ракет, дым, снег, дождь и т. п.). Системы частиц могут быть реализованы как в двумерной, так и в трёхмерной графике».
**Эта техника впервые была использована в 1982 году в фильме «Звёздный путь 2: Гнев Хана» для создания «эффекта зарождения (genesis effect)».**
Система частиц состоит из одного или нескольких графических примитивов, таких как точки, линии или изображения, именуемых частицами. Эти частицы создаются и испускаются эмиттером, являющимся частью системы частиц.
Каждая частица обладает набором параметров, которые прямо или косвенно влияют на её поведение и определяют то, как она будет отрисована. Частицы могут двигаться одновременно в большом количестве и в различных направлениях, например для создания эффекта жидкости.
Анимация начинает действовать, когда частицы испускаются системой. Система испускает частицы в случайных местах в рамках заданной системой частиц области. Она может принимать различные формы: круг, прямоугольник, сфера, параллелепипед, линия, точка и т. д.
Система также определяет свойства частиц, влияющие на их геометрию, скорость и другие параметры. Разные API для работы с эмиттером имеют разные названия схожих свойств.
Когда частицы испускаются системой одновременно, они создают ошеломляющие анимации, которые могут выглядеть как дождь, огонь или снег.
От теории к практике
====================
Я подумал, что Apple, скорее всего, имеет встроенную поддержку системы частиц в одном из своих фреймворков. И результаты моих поисков показали, что я прав.
Система частиц является частью фреймворка Core Animation и хорошо описана в классах [CAEmitterLayer](https://developer.apple.com/documentation/quartzcore/caemitterlayer) и [CAEmitterCell](https://developer.apple.com/documentation/quartzcore/caemittercell).
После изучения всей необходимой информации о системе частиц и поддерживаемых API на iOS я приступил к моей любимой части — реализации нашей задумки.
К несчастью, Рождество не вечно, поэтому нам нужна была возможность отключить снежинки удалённо после 25 декабря.
Как я упомянул выше, анимация запуска приложения была реализована с помощью Lottie. То есть мне нужно было найти способ добавить снежинки таким образом, чтобы это не затрагивало существующую анимацию и её код, потому что моё решение должно было быть удалено сразу после релиза.
Я нашёл очень простой способ это сделать — добавил новый прозрачный UIView для показа снежинок перед существующей анимацией и фоном и затем контролировал его появление удалённо с помощью флага.
Изображение выше показывает UIView, которые были использованы в финальном решении:
1. **UIView** с системой частиц, которая испускала снежинки.
2. **UIViews**, используемые в анимации запуска приложения, управляемые Lottie.
После того как эта проблема была решена, мне оставалось создать компонент, содержащий логику испускания частиц для генерации анимированных снежинок.
Для начала мне были необходимы изображения снежинок, которые я мог бы использовал в качестве контента для эмиттера. Они должны быть довольно простыми, не так ли?
Каждая снежинка представляла собой либо обычный, либо размытый белый круг. Я создал их самостоятельно в программе Sketch.

Некоторые детали реализации
===========================
CAEmitterLayer — это специальный CALayer, который создаёт, анимирует и отрисовывает систему частиц. Он позволяет контролировать свою геометрию, позицию, режим отрисовки и многое другое.
Я начал разработку анимации с создания слоя:
```
snowEmitterLayer.emitterShape = CAEmitterLayerEmitterShape.line
snowEmitterLayer.beginTime = CACurrentMediaTime()
snowEmitterLayer.timeOffset = 10.0
```
Мне нужно было изменить только три свойства:
* **emitterShape**: определяет форму слоя. я использовал линию, что позволило снежинкам появляться вдоль всего экрана;
* **beginTime**: является частью CAMediaTiming-протокола и представляет собой время начала анимации слоя относительно анимаций родительского слоя;
* **timeOffset**: также является частью CAMediaTiming-протокола и, по сути, представляет собой перемотку анимации вперёд на заданное время относительно её начала. Я указал значение в 10 секунд, что привело к тому, что в момент начала анимации снежинки уже покрывали экран целиком, и это именно то, чего мы хотели (если бы я указал значение в 0 секунд, то снежинки начали бы появляться сверху и покрыли экран целиком только спустя какое-то время).
Имея готовый слой, я создал два разных эмиттера: для снежинок потяжелее и для снежинок полегче.
Для тяжёлых снежинок я настроил эмиттер следующим образом:
```
let flakeEmitterCell = CAEmitterCell()
flakeEmitterCell.contents = UIImage(named: "snowflake_dot")!.cgImage
flakeEmitterCell.emissionRange = .pi
flakeEmitterCell.lifetime = 20.0
flakeEmitterCell.birthRate = 30
flakeEmitterCell.scale = 0.15
flakeEmitterCell.scaleRange = 0.6
flakeEmitterCell.velocity = 30.0
flakeEmitterCell.velocityRange = 20
flakeEmitterCell.spin = -0.5
flakeEmitterCell.spinRange = 1.0
flakeEmitterCell.yAcceleration = 30.0
flakeEmitterCell.xAcceleration = 5.0
```
Как видите, мне пришлось изменить значительное количество свойств, каждое из которых очень важно для достижения желаемого эффекта:
* **contents**: CGImage, используемый для показа одной снежинки (как вы помните, это одно из тех изображений, которые я создал самостоятельно);
* **emissionRange**: угол в радианах, определяющий конус, внутри которого будут появляться частицы (я выбрал угол PI, чтобы частицы были видны на всём экране);
* **lifetime**: определяет время жизни одной частицы;
* **birthRate**: определяет количество частиц, испускаемых каждую секунду;
* **scale** и **scaleRange**: влияет на размер частиц, где значение 1.0 — максимальный размер; интервал определяет отклонения в размерах между созданными частицами, что позволяет излучать частицы случайных размеров;
* **velocity** и **velocityRange**: влияет на скорость появления частиц; отклоняется случайно в рамках значения, указанного в velocityRange;
* **spin** и **spinRange**: влияют на скорость вращения, измеряемого в радианах в секунду, и случайное отклонение в рамках значения, указанного в spinRange;
* **yAcceleration** и **xAcceleration**: это два компонента вектора ускорения, применённого к эмиттеру.
Мне также понадобился второй эмиттер для создания лёгких снежинок. Все свойства остались без изменений, за исключением двух:
* **contents**: тут я использовал изображения с размытым кругом;
* **velocity**: а здесь мне пришлось уменьшить скорость падения для придания снежинкам лёгкости.
```
let blurryFlakeEmitterCell = CAEmitterCell()
blurryFlakeEmitterCell.contents = UIImage(named: "snowflake_blurry_dot")?.cgImage
blurryFlakeEmitterCell.velocity = 40
// Остальные свойства остались без изменений
```
Мне оставалось только соединить слой и эмиттеры, что оказалось очень легко:
```
snowEmitterLayer.emitterCells = [flakeEmitterCell, blurryFlakeEmitterCell]
self.layer.addSublayer(snowEmitterLayer)
```
Заключение
==========
Я довольно быстро создал рабочий вариант с падающими снежинками, который выглядел очень неплохо. Он был довольно прост в реализации и не менял существующего кода. Я показал его дизайнерам, и он им очень понравился.
Анимации, созданные с помощью системы частиц, могут быть довольно впечатляющими и относительно простыми в реализации, если вы владеете правильными инструментами.
Больше информации о системах частиц вы найдёте в следующих источниках:
* [Wikipedia](https://en.wikipedia.org/wiki/Particle_system)
* [Ray Wenderlich](https://www.raywenderlich.com/1255-scene-kit-tutorial-with-swift-part-5-particle-systems)
* [Unity](https://docs.unity3d.com/Manual/PartSysWhatIs.html)
* [Allen Martin on particle systems](https://web.cs.wpi.edu/~matt/courses/cs563/talks/psys.html)
|
https://habr.com/ru/post/446938/
| null |
ru
| null |
# Раздача интернета с 3G модема в локальную сеть в Linux
Эта статья — продолжение статьи [Беспроводная точка доступа, используя Linux](http://habrahabr.ru/post/188274/). Тут я опишу, что же необходимо сделать для того, чтобы раздавать интернет с 3G-модема по уже созданной по инструкции из предыдущего топика вайфай-сети.
1) Прежде всего, научить Linux работать с модемом
2) Создать NAT для раздачи интернета
3) Запихнуть всё это дело в автозагрузку
Итак, bash, wvdial и iptables под мышку — и поехали!
#### Подключение USB 3G-модема
Бывает и так, что в некоторых странах есть свои провайдеры 3G-интернета, которые не предоставляют настроек для подключения, используя Linux, что, в общем-то, и понятно — 'популярность' как провайдера, так и Linux даёт о себе знать. Не все конфиги есть ещё на сайтах, тем более — для отдельных программ. Итак, в Латвии, где я и проживаю. есть два провайдера — LMT и Bite. Оба они предоставляют беспроводной интернет через модемы Huawei, залоченные, естественно, на них, ну да не в этом дело. Ну так вот — необходимо обеспечить интернет всюду, где есть 3G, используя модем и сервер. Что же делать?
Прежде всего, воткнуть модем в ноут. USB-модемы определяются в Linux как устройства под адресом /dev/ttyUSB\*, где \* — порядковый номер устройства, обычно адрес выглядит как /dev/ttyUSB0.
```
root@localhost:/# ls /dev/ttyUSB*
ls: cannot access /dev/ttyUSB*: No such file or directory
```
Ой. Что-то он не определяется. А проблема вот такая (обмусоленная уже тысячу раз): модем — это устройство типа “два в одном”. Почему? Он совмещает в одной флешке как собственно модем, так и встроенный накопитель с драйверами модема под Windows (я уже молчу про кардридер). В Linux по умолчанию включается режим диска, а не модема Для того, чтобы включить ещё и режим модема, нужно установить пакет usb-modeswitch. После этого нужно перезагрузить udev (service udev restart) и опять подключить модем, подождать секунд 10 и опять выполнить команду на вывод списка устройств модема:
```
root@localhost:/# ls /dev/ttyUSB*
/dev/ttyUSB0 /dev/ttyUSB1 /dev/ttyUSB2
```
Когда вывод походит на этот, всё отлично и можно двигаться дальше. У нас есть три устройства. Нам необходимо лишь одно — под номером 0, остальные 2 мы не используем — они не для наших целей. Насколько мне известно, одно из них, скорее всего, используется для отсылки СМС, а второе — для просмотра уровня сигнала сети и прочего.
Теперь — дело за программой, которая подключит нас. Я буду использовать программу wvdial, дополнительно к ней нужно установить пакет ppp, если он ещё не установлен.
```
apt-get install ppp wvdial
```
Многие советуют использовать программу wvdialconf для настройки подключения, но в данном случае она нам не поможет. После установки нам нужно отредактировать файл /etc/wvdial.conf. Стираем из него всё содержание, затем разбираемся в формате файла. Я предоставлю рабочие конфиги для провайдера LMT с тарифом OKarte Internets datorā и модемом Huawei E173 и Bite с неизвестным тарифом и модемом Huawei E1550.
```
[Dialer lmt]
Init1 = AT
Init2 = AT&FE0V1X1&D2&C1S0=0
#Init3 = AT+CPIN="1219"
Init4 = AT+CGDCONT=1,"IP","internet.lmt.lv"
Phone = *99#
ISDN = 0
Username = { }
Password = { }
Ask Password = 0
Modem = /dev/ttyUSB0
PPPD Options = noauth crtcts multilink usepeerdns lock defaultroute nobsdcomp nodeflate refuse-pap refuse-eap refuse-chap refuse-mschap +chap
Idle Seconds = 3000
Modem Type = USB Modem
Compuserve = 0
Auto DNS = 1
Dial Command = ATD
Stupid Mode = 1
FlowControl = NOFLOW
[Dialer bite]
Init1 = AT
Init2 = AT&FE0V1X1&D2&C1S0=0
#Init3 = AT+CPIN="1219"
Init4 = AT+CGDCONT=1,"IP","internet"
Phone = *99#
ISDN = 0
Username = { }
Password = { }
Ask Password = 0
Modem = /dev/ttyUSB0
PPPD Options = noauth crtcts multilink usepeerdns lock defaultroute nobsdcomp nodeflate refuse-pap refuse-eap refuse-chap refuse-mschap +chap
Idle Seconds = 3000
Modem Type = USB Modem
Compuserve = 0
Auto DNS = 1
Dial Command = ATD
Stupid Mode = 1
FlowControl = NOFLOW
```
Вкратце — файл разделён на секции. Каждая из секций отвечает за одну комбинацию модем-провайдер. Начало секции обозначается меткой [Dialer xxx], где ххх — это название метки, по которой мы будем указывать, какие именно настройки нужны для подключения. Если нам потребуются настройки LMT, мы наберём команду wvdial lmt, и будут использоваться настройки из секции [Dialer lmt] — суть понятна. Из этих настроек нам нужно обратить внимание на следующие:
```
InitX = AT-BLABLABLA
```
— AT-команды после InitX — те команды, которые wvdial отсылает модему перед тем, как поднять подключение.
```
#Init3 = AT+CPIN="1219"
```
— Эта настройка, если убрать # в начале, будет посылать модему команду ввода пин-кода. Если честно, желательно её отключить — у меня эта команда по непонятным причинам не работала корректно. Легче просто подключить модем один раз к компьютеру с Windows и отключить ввод пин-кода при подключении, используя программу, поставляемую с модемом.
```
Init4 = AT+CGDCONT=1,"IP","internet"
```
— Здесь прописывается адрес APN, который предоставляет провайдер. Нужно обратить внимание на две последних отделённых кавычками части. Первая — IP — указывает IP-адрес для подключения, если настройки провайдера подразумевают то, что используется IP-адрес APN. Если же используется буквенный адрес вида “internet” или “internet.lmt.lv”, в первой части нужно оставить “IP”, а во второй — прописать буквенный адрес, как это сделано в примере.
```
Phone = *99#
```
— Ну тут всё стандартно — этот номер телефона используют практически все провайдеры, и менять его в большинстве случаев не понадобится.
```
Username = { }
Password = { }
```
Имя пользователя и пароль для подключения к интернету. Если их нужно оставить пустыми, оставьте там скобочки вида { }. Если нет — просто поставьте там имя и пароль, без скобочек.
```
Modem = /dev/ttyUSB0
```
Имя устройства, которое нам нужно использовать. В 99% случаев оно будет именно таким.
Остальные параметры могут быть другими в случае других модемов, но для вышеперечисленных двух комбинаций модем-провайдер всё работает без проблем.
Ещё раз расскажу о том, как правильно запускать подключение вручную. Достаточно одной команды — wvdial xxx, где ххх — это название провайдера из конфигурационного файла (для меня это либо lmt, либо bite.) Однако — при запуске wvdial ”занимает собой” всю консоль, не давая возможности запустить что-либо ещё. Кроме того — если вы запустите wvdial в окне SSH и тут же разорвёте сессию, то и wvdial завершится. Нужно либо постоянно держать сессию открытой, либо использовать screen, который в данном случае решает сразу две проблемы довольно эффективно — что и советую.
Что в идеале нужно? Также научиться просто и легко запускать эти программы. В использовании мной описанной схемы есть свои нюансы:
1) Соединение нужно каждый раз запускать вручную.
— Достаточно немного изменить конфигурационные файлы системы, а именно — тот же /etc/network/interfaces:
```
auto ppp0
iface ppp0 inet wvdial
provider lmt
#Поднимать интерфейс ppp0 автоматически
#Для подключения вызывать команду wvdial с аргументом lmt. Естественно, аргумент будет меняться.
```
Для меня этот способ не подходит — он рассчитан на то, что провайдер не меняется, но большая вероятность, что это понадобится кому-то ещё. Да и не особо-то надёжно это работает, по моему опыту, лучше настроить udev. Для себя же я не нашёл подходящих решений — для этого надо было бы определять принадлежность вставленной сим-карты тому или иному провайдеру, а решение с использованием этого становится очень сложным.
Ну а если всё же надо быть постоянно подключённым, даже если что-то глючит и модем отключается от сети? Ну тогда поможет следующий скрипт. Он смотрит, есть ли wvdial в списке процессов, а если нет, то делает ifup ppp0, что в совокупности с вышеупомянутыми настройками в interfaces должно вызывать wvdial заново:
**Засунуть себе в cron**
```
#!/bin/bash
# (c)2009 John de Graaff, rewritten by CRImier
# This script checks if wvdial is running.
# If it's not, it brings ppp0 up and down.
# It is assumed that ifup ppp0 starts wvdial
if test "$(pidof wvdial)" != "" ;
then
exit 0
else
logger "wvdial not running. Better restart ppp0."
/sbin/ifdown ppp0
sleep 2
/sbin/ifup ppp0
logger "ppp0 restarted."
exit 0
```
2) При включении ноутбука, если модем был подключен во время загрузки системы, иной раз случаются зависания, которые выражаются в следующем — при попытке подключения, используя wvdial, выходят строчки вида
```
--> Cannot open /dev/ttyUSB0: Device or resource busy
```
, и подключиться не удаётся. Лечится на один раз просто — нужно лишь вынуть и воткнуть модем, а затем запустить соединение вручную, но вы же понимаете, что при отсутствии физического доступа к компьютеру эта задача усложняется до невозможности.
— Пока что я не могу предоставить нормального решения, поскольку сам ещё не занялся этим. Предполагают, что это из-за того, что программа usb-modeswitch не отрабатывает корректно, если модем вставлен в компьютер при запуске системы. Видимо, нужно покопаться с udev или указать какие-либо особые параметры для usb-modeswitch.
3) В условиях плохого приёма соединение часто обрубается
— Всё довольно просто. Дело в том, что у портов ЮСБ есть ограничение на отдаваемый ток, при превышении которого, насколько я помню, порт отрубается. Видимо, в условиях плохого приёма сигнала сети модем пытается повысить мощность приёмника и передатчика, и случается так, что модем начинает потреблять больший ток, чем выдерживает порт — порт отключается, модем выключается, соединение отрубается насовсем. Посоветовать могу лишь, к примеру, просто-напросто взять USB-хаб с внешним питанием ну или же купить отдельный адаптер питания для модема и впаять его в кабель.
4) Возможность смены порта, по которому нужно обращаться к устройству.
Как я уже упомянул, обычно при настройке используется одно устройство — /dev/ttyUSB0. Но, как заметил [freuser](https://habrahabr.ru/users/freuser/), есть ситуации, когда порт меняется. К примеру:* Использование двух модемов
* Зависание одного порта, которое выражается в том, что порт остаётся в /dev, даже если модем уже отключен...
* И тому подобные казусы, при которых внезапно назначается другой порт.
При дебаге неработающего подключения нельзя забыть про такую возможность. Если, к примеру. при запуске wvdial не стартует pppd, то это повод задуматься — а работает ли сам порт и тот ли это порт? Тогда придётся поэкспериментировать с номерами в конфиге, пока модем наконец не подключится.
После того, как интернет появился на нашем сервере, остаётся лишь настроить раздачу интернета с модема по Wi-Fi сети.
#### NAT
Если у компьютера есть два сетевых интерфейса, это ещё не означает, что из коробки можно спокойно раздавать интернет с одного на другой. Однако — не всё так сложно, чаще всего требуется всего пара настроек. Конечно, эти настройки сложно запомнить, не вникая в суть каждой строчки, но ведь для этого есть эта статья! Я нашёл наиболее подходящий для этой ситуации и безглючный [скрипт](http://www.debian-administration.org/articles/23), не могу не дать ссылку на него, поскольку найденный на нём скрипт самый короткий и ясный из тех, что я встречал — остальные умудряются растянуть пару правил iptables на несколько страниц… Прежде всего, посмотрю, что в нём надо бы изменить под мои нужды:
##### Найденный скрипт
**Спойлер:**
```
#!/bin/sh
PATH=/usr/sbin:/sbin:/bin:/usr/bin
#
# delete all existing rules.
#
iptables -F
iptables -t nat -F
iptables -t mangle -F
iptables -X
# Always accept loopback traffic
iptables -A INPUT -i lo -j ACCEPT
# Allow established connections, and those not coming from the outside
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -A INPUT -m state --state NEW -i ! eth1 -j ACCEPT
iptables -A FORWARD -i eth1 -o eth0 -m state --state ESTABLISHED,RELATED -j ACCEPT
# Allow outgoing connections from the LAN side.
iptables -A FORWARD -i eth0 -o eth1 -j ACCEPT
# Masquerade.
iptables -t nat -A POSTROUTING -o eth1 -j MASQUERADE
# Don't forward from the outside to the inside.
iptables -A FORWARD -i eth1 -o eth1 -j REJECT
# Enable routing.
echo 1 > /proc/sys/net/ipv4/ip_forward
```
Хм-хм. Этот скрипт уже староват — iptables ругается на одну из команд и не хочет выполнять, да и тот путь, которым в статье скрипт пытаются поместить в автозагрузку, тоже работает не всегда на моей практике. Более того, есть проблема — этот скрипт отлично подходит для ситуации, когда ничего не собирается меняться. Если бы так и было, я бы поставил iptables-persistent и на этом закончил бы статью. А вот я собираюсь иногда получать интернет по интерфейсу ppp0, иногда — по eth0, а иногда — вообще по wlan1, причём менять интерфейс хочу одной консольной командой. Так, eth1 в примере — внешний интерфейс, а eth0 — внутренний. Заменим их переменными, чтобы при необходимости можно было поменять одну строчку, а не редактировать весь текст. Также я хочу, чтобы при перезапуске компьютера последний выбранный внешний интерфейс сохранялся. Что тогда? Нужно всё поменять!
##### Задачи:
1. Принимать первый аргумент командной строки в качестве названия внешнего интерфейса, проверяя подлинность имени, используя команду ifconfig;
2. Добавить сохранение выбранного интерфейса в какой-нибудь файл в /etc и сделать ключ выбора последнего интерфейса, а лучше — при отсутствии имени интерфейса как аргумента.
3. Запихнуть это всё красиво в автозагрузку и в $PATH.
##### Что же вышло в итоге?
```
#!/bin/bash
#NAT script from www.debian-administration.org, modified by CRImier
# Exit status 0 if operation is correct
# Exit status 1 if trying to use last interface used when running for the first time
# Exit status 2 if interface doesn't exist
EIF=''
IIF='wlan0'
PATH=/usr/sbin:/sbin:/bin:/usr/bin
LOGFILE=/etc/nat-if.conf
touch $LOGFILE
#
#Checking command-line arguments and setting $EIF variable according to them
#
if [[ $1 == "" ]] #If there's no arguments, just use previous settings.
then
EIF=`cat $LOGFILE`
if [[ $EIF == "" ]] #Just check for an empty file!
then
echo "Please, specify interface name for first usage using 'firewall interface', e.g. 'firewall eth0'"
exit 1
fi
elif [ $1 == "help" ] #Output help message
then
echo "NAT script"
echo "(c) www.debian-administration.org, modified by CRImier"
echo "Usage: 'firewall interface', 'firewall info' or simply 'firewall' to use last interface firewall was set on."
echo "Argument is external interface name, internal interface name is hard-coded in the script"
exit 0
elif [ $1 == "info" ] #Print interface firewall is set on
then
cat $LOGFILE
exit 0
else
ifconfig $1 &>/dev/null
if [ $? == 0 ]
then #Interface name must be correct as ifconfig gives 0 exit code
EIF=$1
echo $EIF > $LOGFILE
else
echo "Incorrect interface name"
exit 2
fi
fi
#
#$EIF is set correctly, let's apply the rules:
#
iptables -F
iptables -t nat -F
iptables -t mangle -F
iptables -X
iptables -A INPUT -i lo -j ACCEPT
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -A FORWARD -i $EIF -o $IIF -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -A FORWARD -i $IIF -o $EIF -j ACCEPT
iptables -t nat -A POSTROUTING -o $EIF -j MASQUERADE
iptables -A FORWARD -i $EIF -o $IIF -j REJECT
echo 1 > /proc/sys/net/ipv4/ip_forward
echo "Firewall started."
```
###### *Комментарии писал на английском — так привычнее. Если будут просьбы — могу и перевести.*
Ну и не забываем обязательную часть:
```
chmod +x /etc/init.d/user-autorun
```
Окей, скрипт у нас готов. Как можно понять, вариантов вызова четыре — firewall (используется последний интерфейс), firewall наш\_интерфейс, firewall info (выводит текущий интерфейс, на котором настроен NAT) или firewall help. Осталась лишь автозагрузка и $PATH.
```
echo $PATH
>/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
```
Для того, чтобы вызывать скрипт командой firewall, не указывая местоположение, нужно запихнуть его в одну из папок, указанных в PATH. Я предпочитаю /usr/local/bin по религиозным соображениям. Полный путь к скрипту будет /usr/local/bin/firewall, а вот вызвать из консоли его всегда можно будет просто командой firewall.
#### Автозагрузка
А теперь — автозагрузка, с ней посложнее. Я сразу опишу создание скрипта автозагрузки, в который можно будет запихнуть всё, что угодно. Он будет стартовать вместе с системой, нооо…
Нельзя просто так взять и создать файл автозагрузки. Есть одна проблема — Debian с какого-то времени пересмотрел свои требования к файлам автозагрузки. Файл мало просто создать, его нужно ещё по-особому отформатировать:
1. Первая проблема — это LSB headers. Это заголовок файла автозагрузки. Нужен он потому, что компоненты автозагрузки должны выполняться в определённом порядке, поскольку часть из них зависят друг от друга. Предположим, у вас есть два скрипта в автозагрузке — один из них должен будет монтировать сетевую папку, а второй — делать в неё резервную копию файлов. Естественно, что сначала нужно выполнить первый, а потом — второй, поскольку второй зависит от первого. Для указания таких зависимостей и используются заголовки загрузочного файла. Впрочем, будет достаточно того заголовка, который я выложу в образце файла автозагрузки.
2. Вторая проблема — любой скрипт в автозагрузке при запуске системы вызывается командой /etc/init.d/script start, а при выключении компьютера — командой /etc/init.d/script stop. Нужно добавить условия для обработки этих случаев.
Я сделал просто — взял за основу скрипт из имеющихся в /etc/init.d/ — уж они-то должны быть созданы по правилам, потом изучил этот скрипт и вырезал из него всё ненужное. Осталось два места, которые нужно изменить — место для команд, которые выполняются при запуске системы, и место для команд, которые выполняются при выключении компьютера. Впрочем, сейчас всё увидите:
```
#!/bin/sh
### BEGIN INIT INFO
# Provides: firewall
# Required-Start: $network $local_fs $remote_fs
# Required-Stop: $network $local_fs $remote_fs
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# X-Interactive: false
# Short-Description: Start user autorun events
### END INIT INFO
case "$1" in
start)
echo "Starting user autorun events"
/usr/local/bin/firewall
#Место для команд, которые должны выполниться при запуске системы
;;
stop)
echo "Stopping user autorun events"
#Место для команд, которые должны выполниться при завершении работы системы
#Останавливать NAT нет необходимости
;;
*)
echo "Usage: /etc/init.d/user-autorun {start|stop}"
exit 1
;;
esac
exit 0
```
Опять же, дать права на исполнение:
```
chmod +x /etc/init.d/user-autorun
```
В файле автозагрузки лучше указывать полный путь к исполняемому файлу, поскольку иначе при загрузке иногда возникают проблемы вида “firewall: command not found”.
Этот файл кладём в папку /etc/init.d/. Полный путь к нашему файлу автозагрузки — /etc/init.d/user-autorun. Осталось лишь указать системе, что нужно выполнять этот файл при загрузке:
```
update-rc.d user-autorun defaults
```
Эта команда заодно и проверяет, соответствует ли заголовок скрипта нужному, поэтому — если с этим будут проблемы, ничего в автозагрузку не поставится и придётся разбираться с ошибками. Всё, скрипт автозагрузки готов к работе и будет выполняться каждый раз при запуске системы, запуская скрипт маршрутизации. Конечно, в данном решении есть свои недостатки, вроде невозможности как-либо контролировать доступ пользователей к Интернету, кроме отключения-включения самого скрипта, но для случая переносного сервера плюс один и огромный — это просто работает, без вмешательства и стабильно, а альтернативные системы при надобности я ещё успею рассмотреть.
Удачной настройки!
---
Следующая статья, скорее всего, будет про написание простого веб-интерфейса на Python, используя web.py. Через этот интерфейс можно будет управлять NAT (правда, не превышая возможностей написанного скрипта), включать/выключать wvdial, отсылать смс и просматривать состояние модема… А также делать всё, до чего дойдут руки. Пока что пишу скрипт для взаимодействия с модемом и продумываю интерфейс таким образом, чтобы его было легко использовать даже на мобильных устройствах. Также в запасе есть почти готовая статья по настройке параметров энергосбережения ноутбука, используя cpufreqd. Стоит ли выкладывать её, будет ли актуально?
##### **Аргументированная** критика и дополнения к статье категорически приветствуются.
|
https://habr.com/ru/post/188886/
| null |
ru
| null |
# История одного бага или почему следует знать не только РНР
Все началось с того, что стал падать мемкеш, вернее мемкешДб. И падал он как-то хитро. Переустановка мемкеш+мемкешДб+BerkeleyDb ничего не дала. После некоторых эмперических вычислений стало понятно, что падает на методе MultiGet, при том очень интересен тот факт, что падение зависит от порядка задания ключей и кол-во ключей должно быть более 3х.
Ошибка падения: #16 — неполный прием данных. Ага, значить барахлит мемкеш. Лезем в логи, анализируем логи на лету и видим заветное END — значить контент по логам отдается весь. Здесь следует раскрыть некоторые детали протокола обмена.
Существует два типа протокола обмена: бинарный и текстовый. В соответствии с текстовым протоколом сообщение состоит и
заголовка и собственно тела. Рассмотрим две основные команды, которые могут всем понадобиться при отладке: set и get.
``set <имя ключа> [noreply]\r\n
.... тело сообщения длинной length байт
если не установлен параметр noreply, то вернется STORED\r\n или ERROR\r\n
flags - флаги управления
expiraton - время, до которого кеш актуален
length - длинна
далее идет сообщения длинной length байт
get <имяключа>`
должны получить строку:``VALUE <имя ключа> .... тело сообщения длинной length байт
END
в случае мультигет:
gets <имяключа1> <имяключа2> <имяключа3> ...`
должны получить строки:``VALUE \r\n
.... тело сообщения длинной length байт
VALUE \r\n
.... тело сообщения длинной length байт
VALUE \r\n
.... тело сообщения длинной length байт
END
Более подробно в файле protokol.txt папки doc дистрибутива memcached
пробуем отладку из консоли:
telnet localhost 11211`
через раз выдает то полный контент (заветный END), то останавливается почти у конца. Вопрос со времен Чернышеского: "Что делать?". Однако мой глаз падает на результаты вывода. Лезут сплошные кроказаблы - и не удивительно, ведь в мемкеши данные хранятся в зазиповонном формате. Очевидно, один из символов просто воспринимался терминалом как служебный и терминал подивсал. По логам - всё Ok!
**Попытка #**2. Итак повторю, наша цель определить что багует. А баговать может:
* memcached
* BerkeleyDb ( как составная часть memcachedb )
* libmemcache (c-клиент)
* memcached pecl расширение PHP.
Пишем PHP программу из 10 строчек, которая реализует упрощенный нативный memcached протокол:
- установить соединение
- записать в сокет строку: "gets <имяключа1> <имяключа2> <имяключа3>"
- прочитать строку (до символов \r\n)
- ответ вывести на экран, распарсить, получить длинну сообщения
- пропустить n-байт
- перейти к пункту 3.
Результат вывода программы приблизительно следующий:
`VALUE key_1 67 678 178468
VALUE key_2 67 526 178468
VALUE key_3 67 349 178468
END`
Проверяем на 1000 случайных ключей (уже сгенерированных данных и записанных в кеш)
Ага, все в порядке, значит из списка уже выпадает два пункта.
**Попытка** #3.
Пересобираем memcached экстеншен. Безрезультатно. Следует заметить, что она была пропатчена и поэтому можно было грешить на патч. Остается последовательно копать. Попробуем поискать в libmemcached.
**Попытка #4**.
Переустанавливаем libmemcached. Берем из каталога test тестовый пример и переписываем его на мультигет. Компилим с опцией включенной отладки и запускаем. Наблюдаем Sigmentation fault. Падает в методе формирования хешей. Заходим на офф. сайт, читаем багреппорты, качаем новую версию libmemcached, переустанавливаем, пересобираем РНР и счастливы...
Оказывается, сообщение об ошибке может содержать совсем иные мотивы и чтоб устранить простой баг мало быть просто РНР программистом... А в прочем, может Хабражители найдут еще и пару иных полезных мыслей.```
|
https://habr.com/ru/post/74643/
| null |
ru
| null |
# Как я делал на Drupal каталог фриланс бирж
Более 10 лет работаю удаленно. Захотелось поделиться опытом поиска удаленных заказов и собрать список платформ для поиска фриланс-проектов. Сразу встал вопрос, на чем реализовывать проект. Я немного разбираюсь в PHP, JS и даже Python, но себя программистом не считаю и, в общем-то, не сильно люблю писать код. По этой причине было решено не использовать фреймворки, а сделать всё на готовой CMS. Выбор пал на Drupal — не самый популярный вариант сейчас, но, считаю, абсолютно незаслуженно.
В этой статье хочу показать, насколько быстро и легко можно сделать сайт-каталог на Drupal. Его можно адаптировать под любую тематику, например парихмахерские или автомастерские.
### Тип материала и поля
Основа сайта — контент. Главная фича, из-за которой выбран Drupal, — настраиваемые типы контента и модуль *Field*. В любой момент можно добавить поля разного вида. Если не хватает стандартных, есть множество модулей на drupal.org и всегда можно написать свой / заказать на фрилансе. Все настройки доступны в админке, а модули загружаются одной командой в Composer. Ну, покажите, где еще так можно?
В моем случае, чтобы понимать, какой сервис лучше, хочется иметь объективную метрику. Alexa и SimilarWeb — признанные источники данных о посещаемости, Ahrefs — сервис для специалистов по продвижению, анализирующий ссылки на сайт. Все три сервиса имеют API, к сожалению, довольно ограниченные в бесплатной версии. Для получения данных сделан простой модуль. Данные счетчика — это обычные числовые поля. При сохранении материала (ноды) запускается hook\_node\_presave, получающий информацию через API и сохраняющий в поле.
```
php
function freelanceabout_node_presave(Drupal\Core\Entity\EntityInterface $entity) {
if ($entity-getType() == 'site') {
$domain = $entity->field_link->uri; //Получаем значение поля адреса сайта
$domain = parse_url($domain);
$domain = $domain['host']; // Получаем доменное имя сайта
$entity->field_alexa_rank->value = alexa_rank_get($domain); // Получаем Alexa Rank
}
}
function alexa_rank_get($domain) {
$rank = 0; // На случай, если нет информации о сайте
// Ниже код из докуметации Amazon API
$url = 'https://awis.api.alexa.com/api?Action=UrlInfo&Output=json&Count=10&ResponseGroup=Rank,LinksInCount&Start=1&Url='.$domain;
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_TIMEOUT, 4);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
'Accept: application/xml',
'Content-Type: application/xml',
'x-api-key: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
));
$response = curl_exec($ch);
curl_close($ch);
$response = json_decode($response, true);
$rank = $response['Awis']['Results']['Result']['Alexa']['TrafficData']['Rank']; // Получаем нужное значение
return $rank;
}
```
### Темизация
В своем проекте хочется попробовать какие-то необычные дизайнерские решения. Шаблонизатор Twig позволяет проводить такие эксперименты. Для примера — страница фриланс-биржи. Это один Twig-шаблон, где расставлены все поля. Layout было решено не использовать, чтобы иметь полный контроль над версткой страницы.
### Каталог и поиск
Еще одно важное преимущество Drupal — модуль Views, позволяющий создавать динамические страницы без написания кода. Главная страница — Views c контекстными фильтрами по URL и сортировкой. Чаще всего в таких случаях используют Exposed Filters, но мне хотелось получить красивые адреса страниц вида «язык/страна/специализация». При использовании Contextual filters нет автоматической формы выбора, как в случае раскрытых фильтров. Поэтому все же пришлось написать простой модуль, добавляющий форму, с переходом на страницу с нужными параметрами.
### Отзывы
Технически отзыв — это комментарий. CMS дает возможность по аналогии с типами контента добавлять разные типы комментариев и подключать к ним любые поля. Для выставления оценки используется модуль *Fivestar*. Я работаю с ним еще с 6-й версии Drupal и не имею нареканий на работу. 9-я версия нестабильна, но работает отлично, а все возможные проблемы и сценарии использования описаны в трекере проекта.
Работает рейтинг так: в форме комментария есть поле оценки (Fivestar), где пользователи при написании отзыва выставляют оценку. В настройках типа материала добавлено еще одно поле Fivestar, но уже без возможности редактирования — оно агрегирует данные всех комментариев.
Вот так выглядит отзыв и настройки типа комментария в админке.### Регистрация
По умолчанию Drupal представляет функцию регистрации с адресом электронной почты. Одной почты в 2021 году недостаточно, поэтому подключен вход из Facebook и Google. Для этого есть готовые модули, где нужно только заполнить форму настроек. Самое сложное в этом процессе — разобраться в запутанном интерфейсе Facebook и получить свой API-ключ.
### Оптимизация и производительность
Сайт сейчас крутится на самом дешевом тарифе Vultr за 5$ в месяц. На Apache и MySQL с дефолтными настройками. При этом в PageSpeed Insights удалось достичь оценки 97 из 100. В этом помогли два модуля, мне не пришлось ничего писать самому.
*AdvAgg* сжимает CSS и JS, что значительно увеличивает скорость загрузки сайта.
Другой полезный модуль, *Webp*, преобразует все загруженные изображения в формат WebP, который очень любит «Гугл».
### Обновление с Drupal 8 на Drupal 9
Первую версию [FreelanceAbout](https://freelanceabout.com/) я сделал в 2020 году, когда Drupal 9 еще был в статусе беты. Сейчас захотелось перейти на новую версию. При обновлении обнаружилось, что некоторые модули не имеют версии под «девятку», но это не проблема: в большинстве случаев достаточно добавить одну строку в .info-файл модуля.
Надеюсь, я сумел показать, насколько просто можно делать нешаблонные проекты на Drupal. В отличие от фреймворков Laravel, CodeIgniter и других здесь вам не нужно писать много кода (почти всё можно сделать в админке). Без фронтэнд-библиотек React, Vue, не нужно знать и использовать два разных языка программирования. Это дает возможность запуска проекта в одиночку или командой из нескольких человек. При этом сайт сразу имеет базовую поисковую оптимизацию, возможность регистрации пользователей и быстро работает.
|
https://habr.com/ru/post/598243/
| null |
ru
| null |
# Структуры данных: двоичная куча (binary heap)
Двоичная куча (binary heap) – просто реализуемая структура данных, позволяющая быстро (за логарифмическое время) добавлять элементы и извлекать элемент с максимальным приоритетом (например, максимальный по значению).
Для дальнейшего чтения необходимо иметь представление о [деревьях](http://ru.wikipedia.org/wiki/%D0%94%D0%B5%D1%80%D0%B5%D0%B2%D0%BE_(%D1%81%D1%82%D1%80%D1%83%D0%BA%D1%82%D1%83%D1%80%D0%B0_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85)), а также желательно знать об [оценке сложности алгоритмов](http://habrahabr.ru/blogs/algorithm/78728/). Алгоритмы в этой статье будут сопровождаться кодом на C#.
Введение
--------
Двоичная куча представляет собой полное бинарное дерево, для которого выполняется *основное свойство кучи*: приоритет каждой вершины больше приоритетов её потомков. В простейшем случае приоритет каждой вершины можно считать равным её значению. В таком случае структура называется *max-heap*, поскольку корень поддерева является максимумом из значений элементов поддерева. В этой статье для простоты используется именно такое представление. Напомню также, что дерево называется *полным бинарным*, если у каждой вершины есть не более двух потомков, а заполнение уровней вершин идет сверху вниз (в пределах одного уровня – слева направо).
Двоичную кучу удобно хранить в виде одномерного массива, причем левый потомок вершины с индексом **`i`** имеет индекс **`2*i+1`**, а правый **`2*i+2`**. Корень дерева – элемент с индексом 0. Высота двоичной кучи равна высоте дерева, то есть log2 N, где **`N`** – количество элементов массива.
Приведу заготовку класса на C#:
```
public class BinaryHeap
{
private List list;
public int heapSize
{
get
{
return this.list.Count();
}
}
}
```
Добавление элемента
-------------------
Новый элемент добавляется на последнее место в массиве, то есть позицию с индексом **`heapSize`**:
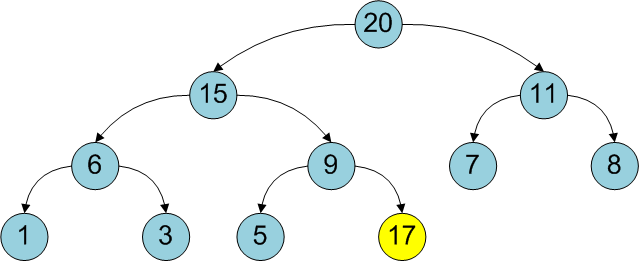
Возможно, что при этом будет нарушено основное свойство кучи, так как новый элемент может быть больше родителя. В таком случае следует «поднимать» новый элемент на один уровень (менять с вершиной-родителем) до тех пор, пока не будет соблюдено основное свойство кучи:

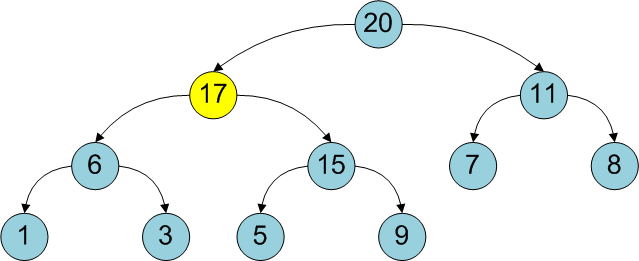
Иначе говоря, новый элемент «всплывает», «проталкивается» вверх, пока не займет свое место. Сложность алгоритма не превышает высоты двоичной кучи (так как количество «подъемов» не больше высоты дерева), то есть равна O(log2 N).
```
public void add(int value)
{
list.Add(value);
int i = heapSize - 1;
int parent = (i - 1) / 2;
while (i > 0 && list[parent] < list[i])
{
int temp = list[i];
list[i] = list[parent];
list[parent] = temp;
i = parent;
parent = (i - 1) / 2;
}
}
```
Упорядочение двоичной кучи
--------------------------
В ходе других операций с уже построенной двоичной кучей также может нарушиться основное свойство кучи: вершина может стать меньше своего потомка.

Метод **`heapify`** восстанавливает основное свойство кучи для дерева с корнем в i-ой вершине при условии, что оба поддерева ему удовлетворяют. Для этого необходимо «опускать» i-ую вершину (менять местами с наибольшим из потомков), пока основное свойство не будет восстановлено (процесс завершится, когда не найдется потомка, большего своего родителя). Нетрудно понять, что сложность этого алгоритма также равна O(log2 N).


```
public void heapify(int i)
{
int leftChild;
int rightChild;
int largestChild;
for (; ; )
{
leftChild = 2 * i + 1;
rightChild = 2 * i + 2;
largestChild = i;
if (leftChild < heapSize && list[leftChild] > list[largestChild])
{
largestChild = leftChild;
}
if (rightChild < heapSize && list[rightChild] > list[largestChild])
{
largestChild = rightChild;
}
if (largestChild == i)
{
break;
}
int temp = list[i];
list[i] = list[largestChild];
list[largestChild] = temp;
i = largestChild;
}
}
```
Построение двоичной кучи
------------------------
Наиболее очевидный способ построить кучу из неупорядоченного массива – это по очереди добавить все его элементы. Временная оценка такого алгоритма O(N log2 N). Однако можно построить кучу еще быстрее — за О(N). Сначала следует построить дерево из всех элементов массива, не заботясь о соблюдении основного свойства кучи, а потом вызвать метод **`heapify`** для всех вершин, у которых есть хотя бы один потомок (так как поддеревья, состоящие из одной вершины без потомков, уже упорядочены). Потомки гарантированно есть у первых **`heapSize/2`** вершин.
```
public void buildHeap(int[] sourceArray)
{
list = sourceArray.ToList();
for (int i = heapSize / 2; i >= 0; i--)
{
heapify(i);
}
}
```
Извлечение (удаление) максимального элемента
--------------------------------------------
В упорядоченном **`max-heap`** максимальный элемент всегда хранится в корне. Восстановить упорядоченность двоичной кучи после удаления максимального элемента можно, поставив на его место последний элемент и вызвав **`heapify`** для корня, то есть упорядочив все дерево.
```
public int getMax()
{
int result = list[0];
list[0] = list[heapSize - 1];
list.RemoveAt(heapSize - 1);
return result;
}
```
Сортировка с применением двоичной кучи
--------------------------------------
Заметим, что можно отсортировать массив, сначала построив из него двоичную кучу, а потом последовательно извлекая максимальные элементы. Оценим временную сложность такого элемента: построение кучи – O(N), извлечение **`N`** элементов – O(N log2 N). Следовательно, итоговая оценка O(N log2 N). При этом дополнительная память для массива не используется.
```
public void heapSort(int[] array)
{
buildHeap(array);
for (int i = array.Length - 1; i >= 0; i--)
{
array[i] = getMax();
heapify(0);
}
}
```
Заключение
----------
Таким образом, двоичная куча имеет структуру дерева логарифмической высоты (относительно количества вершин), позволяет за логарифмическое же время добавлять элементы и извлекать элемент с максимальным приоритетом за константное время. В то же время двоичная куча проста в реализации и не требует дополнительной памяти.
|
https://habr.com/ru/post/112222/
| null |
ru
| null |
# Букмарклет в помощь.
Итак, господа, перед вами часто встает вопрос сохранения данных с всяких ютубов, Вконтакте, файлообменников и прочая.
Коллега [mekal](https://geektimes.ru/users/mekal/) раскопал категорически полезный сервис [SaveFrom.net](http://SaveFrom.net), который как раз и помогает нам выкачивать из большого Интернета файлики на наши грешные харды. Принцип действия прост — перед урлом нужного ресурса надо добавить приставочку «savefrom.net**/**» или «sfrom.net**/**» и ресурс покажет страничку с прямыми ссылками. Полный список поддерживаемых ресурсов представлен на главной странице сайта.
НО! Это ведь требует определенных лишних движений по копипастингу этой самой приставки, не так ли? Вот что я предлагаю сделать для упрощения жизни.
Создаем в браузере закладку-[букмарклет](http://ru.wikipedia.org/wiki/%D0%91%D1%83%D0%BA%D0%BC%D0%B0%D1%80%D0%BA%D0%BB%D0%B5%D1%82). Я использую [Mozilla Firefox](http://www.mozilla-europe.org/ru/products/firefox/) с [тулбаром](http://del.icio.us/help/firefox/extensionnew) от [del.icio.us](http://del.icio.us/), но работать будет в любых браузерах с любыми менеджерами закладок, понимающих JavaScript.
[](http://flickr.com/photos/10481963@N00/2530748468/)
Текст букмарклета совсем простой:
`javascript:void(location.href='http://sfrom.net/'+location.href)`
Помещаем букмарклет на панель закладок, дабы он был всегда под рукой, и вуаля — теперь, чтобы скачать какой-либо хитроустроенный контент, нам достаточно, находясь на страничке с этим контентом, нажать кнопочку на панели закладок.
Пользуйтесь на здоровье :)
|
https://habr.com/ru/post/26323/
| null |
ru
| null |
# GitLab 12.3 с брандмауэром для веб-приложений и анализом продуктивности

Релиз GitLab 12.3 этого месяца особенно интересен после содержательной недели, на которой мы провели первую конференцию пользователей GitLab в Бруклине, штат Нью-Йорк, и объявили о завершении [этапа финансирования серии E: собрали 268 млн долларов](https://about.gitlab.com/2019/09/17/gitlab-series-e-funding/). На эти деньги мы сможем значительно улучшить все наши предложения для DevOps, включая мониторинг, безопасность и планирование.
### Брандмауэр для веб-приложений
Современные веб-приложения подвергаются новым рискам отовсюду, включая каждого подключенного клиента, который отправляет трафик. Брандмауэр для веб-приложений (Web Application Firewall, WAF) обеспечивает мониторинг и правила для защиты приложений в рабочей среде. В GitLab 12.3 мы представляем первую версию [брандмауэра для веб-приложений](https://about.gitlab.com/2019/09/22/gitlab-12-3-released/#web-application-firewall-for-kubernetes-ingress), встроенного в платформу GitLab SDLC. Он будет заниматься мониторингом и отчетностью по вопросам безопасности для кластеров Kubernetes. В дальнейших релизах мы расширим возможности WAF, чтобы можно было блокировать вредоносный трафик, создавать правила бандмауэра и управлять ими и получать информацию на ранних этапах разработки, чтобы принять меры и сократить риски.
### Productivity Analytics — первый выпуск
Командам, которые отвечают за поставку ПО, всегда нужна правильная информация и аналитика, чтобы повышать продуктивность и эффективность. Слишком часто незаметные узкие места и помехи заставляют их ждать и тратить время вместо того, чтобы заниматься новыми функциями. Начиная с релиза 12.3 мы предлагаем новые функции аналитики, чтобы команды и руководители лучше разбирались в продуктивности и эффективности групп и проектов. [Productivity Analytics](https://about.gitlab.com/2019/09/22/gitlab-12-3-released/#productivity-analytics) поможет командам и их руководителям найти лучшие методы повышения продуктивности. Изначально фокусируясь на времени, которое нужно для слияния мердж-реквестов, GitLab позволит подробно изучить данные и узнать, что и как можно улучшить. Во многих организациях руководители занимаются несколькими проектами, и [рабочее пространство аналитики на уровне группы](https://about.gitlab.com/2019/09/22/gitlab-12-3-released/#analytics-workspace) предоставляет сведения о продуктивности и производительности в нескольких проектах. Эти две фичи — первые в целом ряду обновлений, направленных на предоставление информации и аналитики, чтобы повысить эффективность.
### Улучшенное соблюдение требований
Соблюдение политик и процедур доставляет разработчикам немало проблем. Многим пользователям GitLab проще обеспечить соблюдение, когда разработчики вместе работают в одном приложении. В релизе GitLab 12.3 представлено несколько функций, которые упрощают действия по снижению рисков, связанных с соблюдением требований. [Правила утверждения мердж-реквестов](https://about.gitlab.com/2019/09/22/gitlab-12-3-released/#leverage-merge-request-approvals-to-prevent-merging-prohibited-licenses-mvc) позволяют предотвратить слияние кода, который вводит неподдерживаемые лицензии. [Требование утверждения от владельца кода для каждой ветки помогает защитить ветки](https://about.gitlab.com/2019/09/22/gitlab-12-3-released/#api-to-require-merge-request-approval-by-code-owners-per-branch), ведь владелец кода должен одобрить все изменения.
### И это еще не все!
В GitLab 12.3 столько классных фич, что обо всех рассказать просто невозможно (хотя очень хочется). Более удобный просмотр сведений о ресурсах с [глобальным представлением для сред и развертываний кластера на уровне группы](https://about.gitlab.com/2019/09/22/gitlab-12-3-released/#global-view-for-group-level-cluster-deploymentsenvironments), более эффективные получения в Git со [сжатыми объявлениями ссылок Git по HTTP](https://about.gitlab.com/2019/09/22/gitlab-12-3-released/#compress-git-ref-advertisements-over-http), более эффективные проверки с [сочетаниями клавиш для следующего и предыдущего неразрешенного обсуждения](https://about.gitlab.com/2019/09/22/gitlab-12-3-released/#keyboard-shortcut-for-next-and-previous-unresolved-discussion).
> **Самый ценный сотрудник этого месяца ([MVP](https://about.gitlab.com/community/mvp/)) — Седрик Табин ([Cédric Tabin](https://gitlab.com/ctabin))**
>
> Стараниями Седрика в GitLab 12.3 появилось новое [ключевое слово для задания CI, которое разрешает прерываемые сборки](https://about.gitlab.com/2019/09/22/gitlab-12-3-released/#interruptible-keyword-to-indicate-if-a-job-can-be-safely-canceled). Он больше 9 месяцев работал над этой фичей и сотрудничал с нашими командами проверки, чтобы включить ее в выпуск.
>
>
>
> Больше спасибо, Седрик, за твой неоценимый труд!
Главные фичи GitLab 12.3
------------------------
### Брандмауэр для веб-приложений для Kubernetes Ingress
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
GitLab теперь добавляет плагин modsecurity брандмауэра для веб-приложений (WAF) в кластер, когда вы устанавливаете приложение Ingress в кластере Kubernetes.
WAF определяет, содержит ли входящий трафик HTTP или HTTPS вредоносный код, например внедрение SQL, межсайтовый скриптинг или трояны. В WAF уже есть эффективные правила, OWASP ModSecurity Core Rules (CRS), которые определяют разные типы атак без дополнительной настройки.
В [документации](https://docs.gitlab.com/ee/user/clusters/applications.html#modsecurity-application-firewall) описывается, как просмотреть журналы WAF и узнать, какому вредоносному трафику подвержено ваше приложение в рабочей среде.
### Productivity Analytics
*PREMIUM, ULTIMATE, SILVER, GOLD*
Сейчас источников данных и аналитики относительно мало, а эти сведения нужны руководителям, чтобы понимать продуктивность команды, проекта и группы. Как однажды сказал Питер Друкер: «Что можно измерить, можно улучшить». Руководствуясь этим принципом, мы выпускаем первую версию Productivity Analytics, чтобы помочь руководителям разобраться в типовых схемах и найти лучшие методы повысить общую производительность. Этот релиз сосредоточен на том, сколько времени занимает слияние мердж-реквеста в зависимости от размера. Пользователи могут использовать существующие фильтры и изучать подробные ведения вплоть до конкретного автора или ярлыка в группе в указанный диапазон дат. В следующих версиях Productivity Analytics мы будем добавлять дополнительные данные, чтобы можно было находить зависимости, увеличивающие время активной разработки или ожидания.
В этом первом релизе Productivity Analytics мы не стали собирать данные за прошлые периоды для новых метрик, чтобы этот фоновый процесс не помешал переходу с 12.2 на 12.3. Вы можете следить за задачей, где мы [работаем над этим](https://gitlab.com/gitlab-org/gitlab/issues/32229).
[](https://habrastorage.org/webt/vo/wr/6e/vowr6eusxeb4ki7n-jonye6sjxq.png)
### Глобальное представление для сред и развертываний кластера на уровне группы
*PREMIUM, ULTIMATE, SILVER, GOLD*
Операторам удобно настраивать кластер на уровне группы, чтобы предоставить разработчикам платформу разработки приложения. Масштабировать ресурсы кластера бывает непросто. Для этого требуется глобальный взгляд на использование ресурсов. Новый раздел Environments (Среды) на странице кластера содержит обзор всех проектов, которые используют кластер Kubernetes, включая подготовленные среды и развертывания и число Pod’ов в каждой среде.
[](https://habrastorage.org/webt/q_/mj/8w/q_mj8wtcebwt2p3k5slydp1r9f4.png)
### Утверждение мердж-реквестов, чтобы предотвратить слияние запрещенных лицензий
*ULTIMATE, GOLD*
Если у вас строгие ограничения по лицензиям, можно настроить License Compliance, чтобы запретить слияние, когда в мердж-реквесте присутствует запрещенная лицензия. Так вы предотвратите появление лицензий, которые явным образом запрещены. Сейчас можно настроить утверждающих для группы License-Check в параметрах проекта и требовать проверку в соответствии с инструкциями, описанными в [документации](https://docs.gitlab.com/ee/user/application_security/license_compliance/#security-approvals-in-merge-requests-ultimate).
[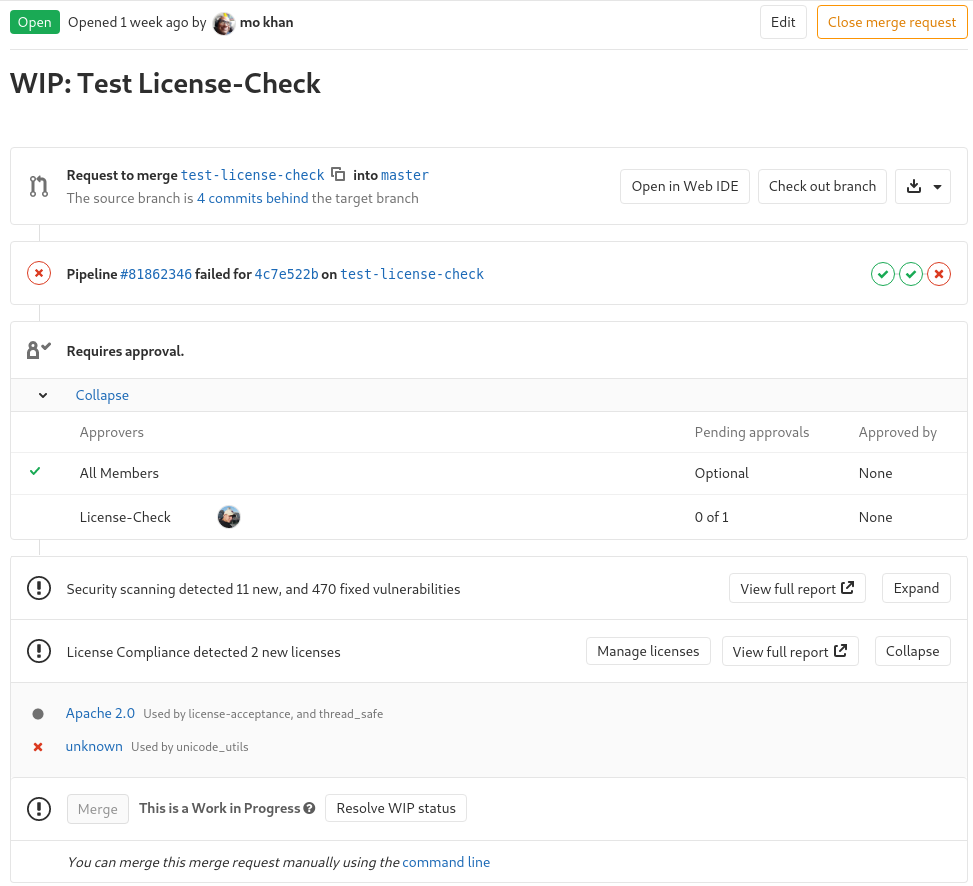](https://habrastorage.org/webt/_b/o_/xo/_bo_xo_y1fgxcvv21cy42ixtpuq.png)
Другие улучшения в GitLab 12.3
------------------------------
### Рабочее пространство аналитики
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
Инженеры и специалисты по продуктам могут входить в разные группы и проекты GitLab, но аналитика обычно разрабатывается на уровне проекта. Поэтому мы создали рабочее пространство, где пользователи могут собирать сведения из разных групп, подгрупп и проектов. Рабочее пространство аналитики упрощает анализ и управление метриками команды для участников и руководителей. Рабочее пространство будет доступно на уровне Core. Но в некоторых случаях определенные фичи будут доступны для Enterprise Edition. По мере развития рабочего пространства аналитики мы гарантируем, что существующий функционал аналитики на уровне проекта будет доступен пользователям Community Edition при переходе в новое рабочее пространство. В GitLab 12.3 мы выпускаем первую версию Productivity Analytics на уровне группы и проекта и Cycle Analytics на уровне группы. В следующих релизах можно будет выбирать разные группы и подгруппы и перенос всех функций аналитики для экземпляра. Мы будем рады услышать ваше мнение о стратегии для [аналитики и управления потоком создания ценности](https://about.gitlab.com/direction/manage/value_stream_management/).
[](https://habrastorage.org/webt/gb/ro/w0/gbrow0rphjhltrg15ah-0ef4wpa.png)
### Уведомления для Design Management
*PREMIUM, ULTIMATE, SILVER, GOLD*
В GitLab 12.2 мы выпустили первую версию Design Management. Для непрерывного развития необходимо, чтобы пользователи получали уведомления об этих действиях. Беседы в дизайнах теперь будут создавать задачи для упомянутых пользователей и отправлять уведомления в соответствии с их настройками. Это гарантирует, что они не пропустят важные отзывы и смогут принять меры. В следующем релизе мы добавим эти [беседы на главную вкладку обсуждений](https://gitlab.com/gitlab-org/gitlab/issues/11851) для удобства.
[](https://habrastorage.org/webt/nw/mu/jj/nwmujjo9wuvs8sy4kkzlo_caz7u.png)
### API для правил утверждения мердж-реквестов
*STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD*
Правила одобрения для мердж-реквестов позволяют указывать, кто должен участвовать в ревью кода, — вы назначаете утверждающих и минимальное число утверждений. Правила утверждения отображаются в виджете мердж-реквестов, так что следующего проверяющего легко увидеть.
В GitLab 12.3 поддержка правил утверждения добавлена в API для проектов и мердж-реквестов.
### Сочетания клавиш для следующего и предыдущего неразрешенного обсуждения
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
Проверка, обсуждение и разрешение фидбэка лежит в основе ревью кода на GitLab. С кнопкой **Jump to next unresolved discussion** (Перейти к следующему неразрешенному обсуждению) можно легко переходить от обсуждения к обсуждению.
В GitLab 12.3 новые сочетания клавиш “n” и “p” позволяют переходить к **n**ext (следующему) и **p**revious (предыдущему) неразрешенному обсуждению в мердж-реквестах, чтобы просматривать изменения было еще удобнее.
### API, требующее утверждение мердж-реквеста от владельца кода по ветке
*PREMIUM, ULTIMATE, SILVER, GOLD*
Утверждение мердж-реквестов ограничивает отправку кода в защищенные ветки, и это позволяет повысить качество кода и реализовать меры контроля за соблюдением требований. Но не все мердж-реквесты предназначены для стабильных веток и не все стабильные ветки требуют одинакового контроля.
В GitLab 12.3 можно требовать утверждения от владельца кода для некоторых веток (через API), чтобы предотвратить отправку изменений в файлы напрямую или слияние изменений без утверждения владельца кода.
Примечание. Эта фича доступна только через API в GitLab 12.3. В GitLab 12.4 она будет доступна в параметрах защищенной ветки. Следите за новостями в задаче [13251](https://gitlab.com/gitlab-org/gitlab/issues/13251).
### Гибкое ключевое слово “rules” для контроля поведения пайплайнов
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
Правила `only/except` в пайплайнах могут подразумевать разные неявные действия, и чем больше вы их добавляете, тем сложнее понять, будет ли определенное задание выполняться в разных ситуациях. Мы вводим новый синтаксис `rules:`, который серьезно упростит реализацию и понимание сложных правил. Этот синтаксис необязательный и может существовать в одном пайплайне, но не в одних заданиях, как текущий подход `only/except`.
### only/except: external\_pull\_requests для внешних репозиториев
*CORE, STARTER, PREMIUM, ULTIMATE, SILVER, GOLD*
В GitLab CI можно работать с внешними репозиториями, чтобы использовать их для контроля версий, а GitLab — для CI/CD. До этого момента `CI_PIPELINE_SOURCE` всегда показывал push, потому что был основан на зеркале `pull`, а не на внешнем репозитории или вебхуке. Поэтому GitLab некорректно поддерживал `only/except: merge_requests`. В релизе 12.3 мы устранили это ограничение.
### Удаление образов контейнеров из CI/CD
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
GitLab Container Registry позволяет пользователям собирать и отправлять образы и теги в проект с помощью GitLab CI/CD. Изменения в Container Registry вносит служебный аккаунт CI Registry User, который вызывается из `.gitlab-ci.yml` предопределенной переменной среды `CI_REGISTRY_USER`. Раньше служебный аккаунт мог отправлять новые теги в реестр, но ему не хватало разрешений, чтобы удалять эти теги. Это мешало удалению образов, относящихся к веткам, что приводило к дополнительным расходам на хранение и сложной навигации по интерфейсу реестра, ведь там было очень много лишних тегов.
В версии 12.3 мы расширили разрешения `CI_REGISTRY_USER` и позволили ему снимать теги образов, чтобы можно было удалять теги, относящиеся к ветке, в рамках обычного рабочего процесса CI/CD и использовать GitLab CI/CD для автоматизации скриптов очистки. Эта задача входит в большой эпик для [снижения затрат на Container Registry](https://gitlab.com/groups/gitlab-org/-/epics/434) благодаря улучшенному управлению хранением
[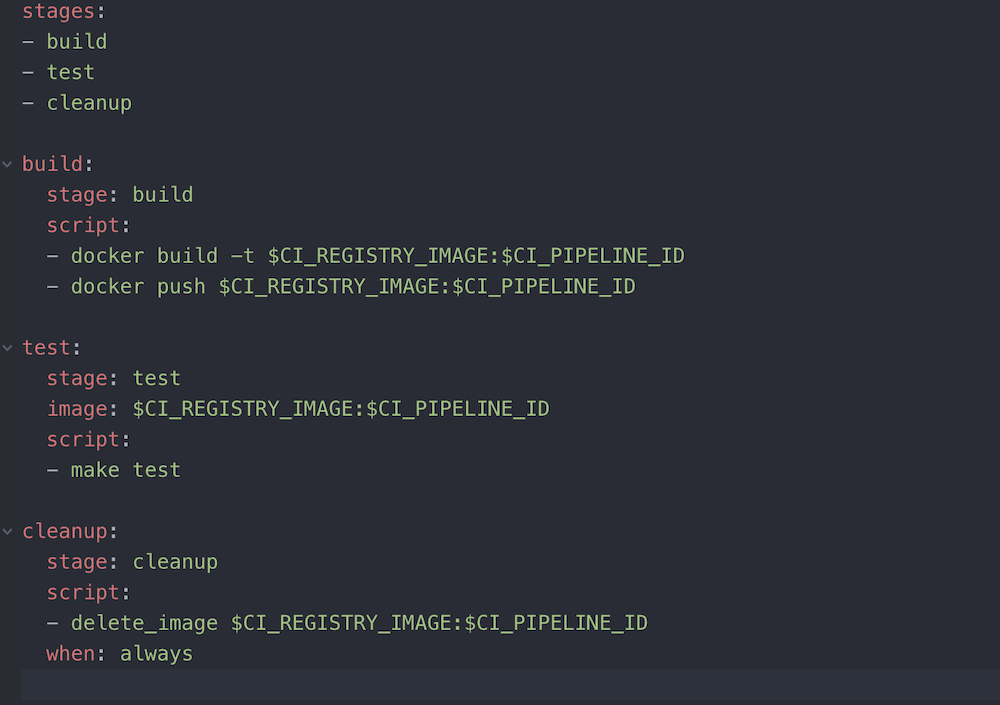](https://habrastorage.org/webt/9f/hf/gk/9fhfgkrdw0grsqcdyinxvj6mjrg.png)
### Проверка доменов при выполнении полных активных сканов DAST
*ULTIMATE, GOLD*
Теперь вы можете гарантировать, что DAST выполняет только активные сканы доменов, специально настроенных для сканирования DAST.
Так вы будете уверены, что активные сканы DAST случайно не выполняются в доменах, которые предоставляют контент или используются как рабочие.
В пассивных сканах DAST ничего не изменилось. Они и так никому не мешали.
### Анализатор SAST Spotbugs обновлен для Java 11
*ULTIMATE, GOLD*
Анализатор SAST SpotBugs обновлен и теперь может сканировать код на Java 11, если настроить переменную среды `SAST_JAVA_VERSION` в проекте.
### Кнопка Run Pipeline в пайплайнах для мердж-реквестов
*PREMIUM, ULTIMATE, SILVER, GOLD*
[Пайплайны для мердж-реквестов](https://docs.gitlab.com/ee/ci/merge_request_pipelines/) недавно получили новый способ запускать пайплайн в контексте мердж-реквеста, но для этого можно было использовать только push. В этом релизе мы добавили кнопку, которая запускает новый пайплайн, и перезапускать неудавшиеся пайплайны теперь гораздо проще.
### Определяемые пользователем переменные CI для docker build с Auto DevOps
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
Переменные CI позволяют настраивать выполнение процессов для сборки приложения в пайплайне CI. Начиная с GitLab 12.3 определяемые пользователем переменные могут быть доступны на этапе `docker build` в Auto DevOps. Данные предоставляются в виде нового значения `build secret`.
Выведите одну или несколько переменных с помощью переменной `AUTO_DEVOPS_BUILD_IMAGE_FORWARDED_CI_VARIABLES`, и она будет доступна для использования в `docker build`.
### Knative для кластеров на уровне групп и экземпляров
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
Кластеры на уровне групп и экземпляров теперь поддерживают установку [Knative](https://knative.dev/) — платформы на базе Kubernetes для развертывания бессерверных нагрузок и управления ими. Благодаря этому несколько проектов смогут использовать функции [GitLab Serverless](https://docs.gitlab.com/ee/user/project/clusters/serverless/) на одном кластере.
### Линейные диаграммы для панелей с метриками
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
Часто пользователи хотят выбирать тип диаграммы в зависимости от метрики (например, линейная диаграмма для ЦП, диаграмма с областями для пространства на диске). Для этого мы добавили линейные диаграммы, чтобы усовершенствовать панель мониторинга.
[](https://habrastorage.org/webt/rj/lp/rb/rjlprb8qmcaugfqy-l2vjoakiig.png)
### Быстрые действия для добавления и удаления встреч Zoom в задачах
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
В экстренных ситуациях очень важна синхронная совместная работа. Мы оптимизируем процесс начала конференции и привлечения всех нужных специалистов, встроив эту функцию прямо в задачу с помощью Zoom.
Когда пользователь начинает встречу Zoom, он может прикрепить ее к задаче с помощью быстрого действия, введя URL-адрес встречи (например, `/zoom https://gitlab.zoom.us/s/123456`). В верхней части задачи появится кнопка с прямым доступом к конференц-вызову. Когда инцидент будет решен, встречу Zoom можно будет удалить командой `/remove_zoom`.
Эта общедоступная фича на GitLab.com, а в самоуправляемых экземплярах нужно использовать переключатель. Если вы хотите использовать эту фичу в самоуправляемом экземпляре GitLab, операторы могут включить переключатель функции `issue_zoom_integration`. В релизе GitLab 12.4 в следующем месяце мы планируем [удалить переключатель функции](https://gitlab.com/gitlab-org/gitlab/issues/32133) и сделать интеграцию задач с Zoom общедоступной для всех пользователей самоуправляемых экземпляров.
### Geo показывает задержку для вторичных узлов при операции push через Git HTTP
*PREMIUM, ULTIMATE*
Получение больших объемов данных может занимать много времени, если пользователь находится далеко. Репликация репозиториев с Geo ускоряет процесс клонирования и получения больших репозиториев, поскольку создает вторичные узлы только для чтения рядом с удаленным пользователем. Вторичные узлы отстают от первичного, поэтому GitLab теперь показывает примерную задержку репликации при использовании `git push` по HTTP. Пользователи получают больше сведений при использовании узла Geo, могут заметить увеличение задержки и сообщить о нем системным администраторам.
Из-за ограничений протокола это сообщение недоступно при использовании `git pull`.
### Отключение двухфакторной аутентификации для некоторых провайдеров OAuth
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
Если организация использует обязательную [двухфакторную аутентификацию](https://docs.gitlab.com/ee/user/profile/account/two_factor_authentication.html) и [поставщика удостоверений, который тоже использует 2FA](https://docs.gitlab.com/ee/integration/omniauth.html#supported-providers), пользователи могут быть недовольны двойной аутентификацией. Благодаря вкладу сообщества теперь можно отключить 2FA для некоторых провайдеров OAuth в GitLab. Так организациям, которые используют поставщиков с 2FA, будет гораздо удобнее входить на GitLab.
Спасибо за вклад, [dodocat](https://gitlab.com/dodocat)!
### Ограничение IP-адреса поддерживает несколько подсетей
*ULTIMATE, GOLD*
В рамках развития функции [ограничения действий группы по IP-адресу](https://gitlab.com/gitlab-org/gitlab/issues/1985) GitLab 12.3 представляет возможность указывать несколько подсетей IP. Это очень удобно для географически распределенных организаций: вместо того, чтобы указывать один диапазон, которому предоставляется слишком много разрешений, большие организации теперь могут ограничивать входящий трафик в зависимости от конкретных потребностей.
### GitLab Runner 12.3
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
Сегодня мы выпустили GitLab Runner 12.3! GitLab Runner — это проект с открытым исходным кодом,
который используется для запуска заданий CI/CD и отправки результатов обратно в GitLab.
**Изменения:**
* [Добавлена документация с лучшими методами для начала работы](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1509).
* [Обновлена документация по PowerShell ErrorActionPreference](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1535).
* [Ошибки недопустимых сервисов теперь указывают конкретный сервис](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1531).
* [Команды, совместимые с PowerShell Core, теперь можно использовать для создания каталога](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1563).
* [Исправлен выход с нулевым кодом выхода при сбое командлетов](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1558).
* [Включена поддержка длинных путей](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1524).
* [Предоставляется переменная со значением короткого токена](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1571).
* [Устанавливается PATH по умолчанию для вспомогательного образа](https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/1573).
Полный список изменений можно найти в журнале изменений GitLab Runner: [CHANGELOG](https://gitlab.com/gitlab-org/gitlab-runner/blob/v12.3.0/CHANGELOG.md).
### Улучшения производительности
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
Мы продолжаем улучшать производительность GitLab с каждым выпуском для экземпляров GitLab любого размера.
### Некоторые улучшения в GitLab 12.3:
* [Ускорен вывод задач и мердж-реквестов через API благодаря удалению запроса N+1](https://gitlab.com/gitlab-org/gitlab-foss/merge_requests/31938).
* [Быстрое удаление связанных событий при удалении родительского объекта](https://gitlab.com/gitlab-org/gitlab-foss/merge_requests/32751).
* [GetCommitSignatures RPC перенесен из Ruby в Go](https://gitlab.com/gitlab-org/gitaly/issues/1604).
* [Проверки авторизации GitLab Shell перенесены из Ruby в Go](https://gitlab.com/gitlab-org/gitlab-shell/issues/181).
### Статус и число обсуждений в Design Management
*PREMIUM, ULTIMATE, SILVER, GOLD*
В GitLab 12.2 мы представили первую версию Design Management, которая позволяет загружать дизайны прямо в задачи. Они загружались на отдельную вкладку в задачах, и действия в каждой версии дизайна были непонятны пользователям. Теперь при загрузке дизайнов в каждую версию добавляются значки статуса, которые отличают новые дизайны от измененных старых. Еще мы добавили в дизайны число обсуждений, чтобы дать больше информации пользователям. Мы рады, что эти добавления в Design Management улучшат совместную работу и обсуждения на GitLab для дизайнеров и инженеров.
### Сжатие объявлений ссылок Git по HTTP
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
При получении изменений в репозитории Git сервер Git выдает список всех веток и тегов в репозитории. Это так называемое объявление ссылок, которое может весить много мегабайт, если проект большой.
В GitLab 12.3 при получении по HTTP объявление ссылок будет сжато для поддерживаемых клиентов, чтобы сократить объем передаваемых данных и ускорить операции получения.
В обычный будний день GitLab.com обрабатывает около 850 ГБ объявлений ссылок по HTTP. После включения сжатия ссылок этот объем сократился примерно на 70%.
[](https://habrastorage.org/webt/2e/ya/tk/2eyatkpiqrhkvipa_imlhmc5y88.png)
### Логи аудита для событий Git Push (бета)
*STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD*
Историю Git можно переписать, чтобы изменить коммиты, авторов и временные метки и оставить будущим разработчикам чистую и понятую историю. А вот для аудита это проблема.
В GitLab 12.3 события Git push, которые отправляют коммиты, переписывают историю или еще как-нибудь меняют репозиторий, можно добавить в лог аудита. Логи аудита для событий push отключены по умолчанию, чтобы не вредить производительности в экземплярах GitLab из-за высокого трафика записи Git.
В следующем релизе логи аудита для событий Git push будут включены по умолчанию. Следите за новостями в задаче [7865](https://gitlab.com/gitlab-org/gitlab/issues/7865).
### Более умные варианты коммитов в Web IDE по умолчанию
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
Раньше в Web IDE по умолчанию был выбран **коммит в текущую ветку**. Но в этом случае пользователи с разрешениями могли случайно отправить изменения в мастер или другие защищенные ветки. Теперь при внесении изменений в Web IDE варианты коммита по умолчанию не позволяют отправить изменения не в ту ветку. Более умные варианты коммита предотвращают случайную отправку в мастер и защищенные ветки для пользователей с правами на запись. Если у пользователя нет права на запись, предоставляется информация о том, почему варианты недоступны. Кроме того, новые варианты коммитов поддерживают коммиты в ветки не по умолчанию с существующим мердж-реквестом или без.
[](https://habrastorage.org/webt/td/cb/vk/tdcbvkl8mc9vuxjreyrwsumndp4.png)
### Разное время ожиданий для заданий в пайплайнах CI/CD
*CORE, STARTER, PREMIUM, ULTIMATE*
У разных заданий разные характеристики выполнения, поэтому время ожидания тоже может отличаться. Время ожидания можно настроить, указав ключевое слово `timeout:` в задании в `.gitlab-ci.yml` и число, которое будет означать, сколько минут нужно ждать, прежде чем произойдет сбой задания.
Спасибо за вклад, Михал Сивек ([Michal Siwek](https://gitlab.com/skycocker))!
### Ключевое слово interruptible указывает, можно ли безопасно отменить задание
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
С помощью нового ключевого слова `interruptible` можно указать, следует ли отменить задание, если после нового запуска того же задания в нем отпала необходимость. По умолчанию ключевое слово имеет значение `false`, и его можно использовать для заданий, которые можно безопасно остановить. Это значение можно указать, только если включена [автоматическая отмена лишних пайплайнов](https://docs.gitlab.com/ee/user/project/pipelines/settings.html#auto-cancel-pending-pipelines).
Это позволяет избежать дублирования ненужных заданий в пайплайнах, сократить расходы и повысить эффективность пайплайнов.
> Из-за [бага в Runner](https://gitlab.com/gitlab-org/gitlab-runner/issues/3376) некоторые исполняющие программы не останавливают запущенные задания после отмены. Мы планируем исправить это в 12.4.
### Проверка статуса для триггеров пайплайнов
*PREMIUM, ULTIMATE, SILVER, GOLD*
Недавно мы улучшили способ, которым пайплайны в разных проектах запускают друг друга, но одного не хватало — запускающий пайплайн должен ждать или подтвердить успешное завершение следующего пайплайна. Можно было сделать это через опрос API, но в этом релизе мы представили стратегии `depend` и `wait`, которые решают эту задачу автоматически. Если выбрать `depend`, предыдущий пайплайн будет ждать, чтобы этот пайплайн завершился, и проверит его успех, прежде чем закончить задание запуска. Если выбрать `wait`, пайплайн будет ждать завершения, но продолжит заниматься своими делами даже в случае сбоя.
### Конечная точка API для вывода тегов/образов Docker группы
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
С помощью GitLab Container Registry можно собирать и отправлять теги/образы Docker в проекты из командной строки, CI/CD или API. Но до выпуска GitLab 12.3 мы не предоставляли сведения о тегах и образах на уровне группы, хотя пользователи часто просят об этом.
Мы добавили две конечные точки API, которые будут показывать, какие образы и теги существуют на уровне группы. Это первый этап улучшения видимости и поиска в Container Registry. Затем мы используем API, чтобы создать [браузер на уровне группы](https://gitlab.com/gitlab-org/gitlab-ce/issues/49336) в пользовательском интерфейсе Container Registry.
### Сканирование SAST без Docker-in-Docker
*ULTIMATE, GOLD*
Сканы SAST можно по желанию выполнять без Docker-in-Docker.
То есть можно настроить сканирование SAST, чтобы ему не требовались повышенные привилегии.
### Редактирование причин игнорирования уязвимости
*ULTIMATE, GOLD*
Причины игнорирования уязвимости теперь можно редактировать и удалять.
Так вы сможете добавлять и изменять контекст для уязвимости, если у вас появилось больше сведений.
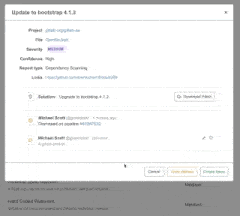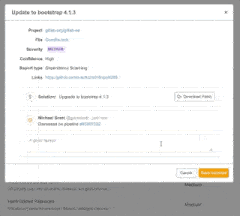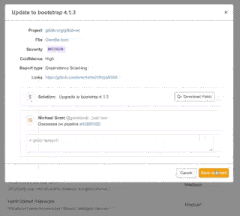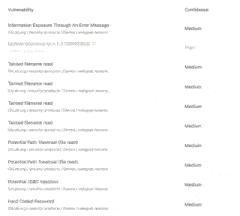
### Более удобная начальная настройка Pages
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
Чтобы работать с Pages было удобнее, мы добавили баннер, который уведомляет пользователей о приблизительном времени начальной настройки. Мы понимаем, как это раздражает, когда поздравительное сообщение появляется, а страница недоступна. Баннер помогает понять, чего ожидать.
### Отображение кластера Kubernetes, используемого для развертывания
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
На странице сведений о задании теперь отображается имя кластера Kubernetes, который использовался для конкретного развертывания. Владельцы и мейнтейнеры проекта видят ссылку с именем кластера, которая ведет на страницу сведений о кластере.
### JupyterHub для кластеров Kubernetes на уровне группы
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
Кластеры на уровне группы теперь поддерживают установку [JupyterHub](https://jupyterhub.readthedocs.io/en/stable/) — многопользовательского сервиса для легкого запуска записных книжек и создания [инструкций](https://docs.gitlab.com/ee/user/project/clusters/runbooks/) для операторов. Это расширяет доступность JupyterHub для кластеров на уровне проекта и группы.
### Слэш-команда закрывает задачу в Slack
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
Решение современных ИТ-инцидентов не обходится без чатов. Этот инструмент должен быть тесно интегрирован с системами, которыми вы управляете, и инструментами, где вы исправляете ситуацию. Контекст и переключение между инструментами желательно свести к минимуму, когда вы работаете над восстановлением служб и оповещением сторонних заинтересованных лиц.
В выпуске 12.3 мы добавили дополнительную слэш-команду в набор команд в нашем продукте ChatOps на основе Slack. Теперь задачи можно закрывать в Slack, не открывая другие инструменты, — просто найдите задачу и закройте ее вручную. Задачу можно закрыть прямо там, где вы работаете.

### Geo нативно поддерживает репликацию Docker Registry
*PREMIUM, ULTIMATE*
Geo нативно поддерживает репликацию [Docker Registry](https://docs.docker.com/registry/) между первичным и вторичным узлами Geo. Теперь пользователи Geo могут использовать Docker Registry на ближайшем вторичном узле. Этот подход не учитывает хранилище и может использоваться для хранилища объектов, например S3, или локального хранилища.
При использовании распределенного хранилища объектов (например S3) для Docker Registry первичный и вторичный узлы Geo могут использовать одинаковый тип хранилища. Этот подход не использует нативную репликацию Geo.
### Действия через API включены в ограничение IP-адресов для группы
*ULTIMATE, GOLD*
В GitLab 12.0 представлено [ограничение действий группы по IP-адресу](https://gitlab.com/gitlab-org/gitlab/issues/1985). Мы развили эту фичу и включили в нее действия через API. Теперь входящие запросы будут отклонены, если не соответствуют ограничению группы. Это решает важную проблему для предприятий со строгими требованиями и расширенным подходом к контролю доступа, так как здесь учитываются действия в пользовательском интерфейсе и через API.
### Системные хуки для обновления участников проекта и группы
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
Системные хуки дают широкие возможности для автоматизации, запуская запросы в результате разных событий на GitLab. Благодаря вкладу сообщества изменения участников проекта и группы теперь поддерживаются в системных хуках. Это отличное дополнение для тех, кому нужен новый уровень надзора и автоматизации для изменения участников.
Спасибо за вклад, Брэндон Уильямс ([Brandon Williams](https://gitlab.com/rocketeerbkw))!
### Подписание электронной почты с S/MIME
*CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD*
Уведомления по электронной почте от GitLab теперь можно подписывать с S/MIME для дополнительной безопасности на уровне экземпляра.
Спасибо за вклад, Siemens, [@bufferoverflow](https://gitlab.com/bufferoverflow) и [@dlouzan](https://gitlab.com/dlouzan)!
### Улучшения Omnibus
*CORE, STARTER, PREMIUM, ULTIMATE*
* Аутентификация SSL для внешних серверов Postgres теперь поддерживается с помощью [указания сертификата в gitlab.rb](https://gitlab.com/gitlab-org/omnibus-gitlab/issues/4296).
* GitLab 12.3 включает [Mattermost 5.14](https://mattermost.com/blog/mattermost-5-14-accessibility-improvements-enhanced-jira-integration-ldap-group-sync-upgrade-and-more/) — [альтернативу Slack с открытым кодом](https://mattermost.com/), в новый выпуск которого входят улучшения доступности клавиатуры, улучшенная интеграция с Jira и многое другое. Эта версия включает [обновления безопасности](https://mattermost.com/security-updates/), и мы советуем выполнить обновление.
Устаревшие фичи
---------------
### Пользователи с настроенным вручную `.gitlab-ci.yml`, использующие функции безопасности, должны ознакомиться с устаревшими фичами в GitLab 12.3
Если вы вручную настроили файл конфигурации .gitlab-ci.yml, чтобы использовать переменные параметров `DEP_SCAN_DISABLE_REMOTE_CHECKS или DS_DISABLE_REMOTE_CHECKS`, удалите их — они больше не поддерживаются.
Если вы используете [готовые шаблоны](https://docs.gitlab.com/ee/user/application_security/dependency_scanning/#including-the-provided-template), мы будем поддерживать актуальность вашей конфигурации с учетом изменений переменных и аргументов.
Об этом было объявлено в посте о [релизе GitLab 12.0](https://about.gitlab.com/2019/06/22/gitlab-12-0-released/#deprecated-variables-and-argument-for-manual-configurations-of-%2560.gitlab-ci.yml%2560-when-using-secure-features).
Дата удаления: **GitLab 12.3**
### gitlab-monitor переименован в gitlab-exporter.
Чтобы избежать путаницы с набором фич GitLab Monitor, gitlab-monitor переименован в gitlab-exporter. [gitlab-exporter](https://docs.gitlab.com/ee/administration/monitoring/prometheus/gitlab_exporter.html) — это веб-экспортер Prometheus, который предоставляет администраторам сведения об экземпляре GitLab, а фичи GitLab [Monitor](https://about.gitlab.com/stages-devops-lifecycle/monitor/) позволяют мониторить приложения, созданные с помощью GitLab. Если вы используете Omnibus, [обновите файл gitlab.rb](https://docs.gitlab.com/omnibus/update/gitlab_12_changes.html#123).
Дата удаления: **22 сентября 2019 г.**
### Общедоступные проекты и подгруппы в закрытых группах тоже считаются закрытыми.
В [GitLab 10.0](https://gitlab.com/gitlab-org/gitlab-foss/issues/31273/) появилось изменение, проясняющее параметр видимости общедоступных проектов и подгрупп в закрытых группах. Поскольку применялся самый строгий параметр видимости, попытка сделать проект или подгруппу общедоступными в рамках закрытой группы приводила к тому, что изменение видимости отклонялось.
Чтобы предотвратить ошибки в существующих общедоступных проектах и подгруппах, все общедоступные проекты и подгруппы в закрытых группах [будут изменены](https://gitlab.com/gitlab-org/gitlab/issues/22406) с общедоступных на закрытые в GitLab 12.5.
Если вам нужен менее строгий параметр видимости для определенного проекта или подгруппы, просто переместите их из закрытой группы.
Дата удаления: **22 ноября 2019 г.**
|
https://habr.com/ru/post/469623/
| null |
ru
| null |
# Перенос истории из CVS/PCVS/VSS/ClearCase/StarTeam/MKS в SVN
Доброго времени суток!
Данная статья посвящена одной небольшой задачке – переносу репозитория вместе со всей историей с одной системы управления версиями в другую, а точнее – в SVN. Речь пойдёт об использовании бесплатной утилиты [Importer for SVN](http://www.polarion.com/products/svn/svn_importer.php) от [Palarion](http://www.polarion.com/), с помощью которой можно мигрировать с CVS / PCVS / VSS / ClearCase / StarTeam / MKS на SVN, не потеряв при этом журнала изменений кода. В моём случае потребовалось перенести проекты из Borland StarTeam.
Почему было сказано «нет» StarTeam и «да» SVN? Сначала думал пропустить данный абзац во избежание холиваров. Но, пожалуй, без этого статья была бы лишена, скажем так, области определения. В моём случае отказаться от StarTeam вынудил уход человека, его внедрившего и администрировавшего. Пара дней безуспешных попыток заставить работать сервис под другой учётной записью породили мысль о том, что задача восстановления репозиториев из бэкапов станет ещё б*о*льшим вызовом. Конечно, радиус кривизны рук можно было значительно увеличить спустя какое-то время. Но оно нам надо, спрашивается, когда есть бесплатный, до безобразия лёгкий в установке и поддержке SVN? Тем более что у меня было предостаточно опыта его использования на предыдущих местах работы, а все два с половиной разработчика находятся в одной комнате.
Одно препятствие – жаль было терять историю изменений. Сначала думали залить в SVN текущие версии, а историю смотреть в StarTeam, переведя его предварительно в read-only. Но, как говорится, это не наш метод. И непродолжительный гуглопоиск навёл на выше в суе помянутый Palarion Importer for SVN.
Теперь непосредственно к сути. Имеем репозиторий в CVS / PCVS / VSS / ClearCase / StarTeam / MKS (с паролями и всеми доступами). Требуется его перенести в новый репозиторий в SVN.
**Замечание 1:** Судя по опциям в конфиге, существует возможность залития данных в уже существующий репозиторий, но я её не проверял.
#### Общий план действий:
0. Проверка системных требований.
1. Скачиваем утилиту.
2. Настраиваем общие параметры.
3. Настраиваем секцию SVN.
4. Настраиваем секцию VCS-источника.
5. Запуск утилиты.
#### 0. Проверка системных требований
Из всех системных требований – установленная и настроенная JRE (т.к. утилита написана на Java) на той машине, где будет работать утилита. С этой машины должны быть доступны и источник, и приёмник.
*В моём случае серверы и StarTeam, и SVN крутятся на одной машине, т.ч. для меня выбор был очевиден.*
#### 1. Скачиваем утилиту
[Здесь](http://www.polarion.com/products/svn/svn_importer.php) по ссылке «Download» слева от основного текста. Сразу после указания имени/компании/e-mail начнется закачка. Никакого запроса на подтверждение на мыло не приходит, но есть проверка существования адреса. Затем просто распаковываем zip-архив на целевую машину.
#### 2. Настраиваем общие параметры
В файле config.properties:
srcprovider=st
Это самое главное – источник данных. Здесь – StarTeam.
import\_dump\_into\_svn=yes
Можно создать только дамп-файл(ы) – для этого ставим здесь no. Например, если возникают какие-то ошибки именно на стадии импорта в SVN (см. раздел «Выявленные проблемы»).
existing\_svnrepos=yes
clear\_svn\_parent\_dir=yes
По идее с помощью этих параметров можно залить в уже существующий репозиторий. Не пробовал. Я создавал локально новый репозиторий, а потом импортировал его на сервер с помощью удобного интерфейса.
#### 3. Настраиваем секцию SVN
В файле же config.properties:
svnimporter\_user\_name=login
Я задействовал свой доменный (AD) логин. Но, сдается мне, можно любой указать.
svnadmin.executable=c:/Program Files/VisualSVN Server/bin/svnadmin.exe
Да. Я использую VisualSVN. Кому не нравится, прописывает путь к другому серверу.
svnadmin.repository\_path=D:/SvnRepositories/Repository1
Как ни парадоксально, но это место расположения репозитория SVN.
svnadmin.parent\_dir=.
Папка внутри SVN-репозитория. В данном случае – корневая.
svnadmin.tempdir=c:/temp/svnlocal
Временная помойка.
svnclient.executable=c:/Program Files/VisualSVN Server/bin/svn.exe
Вы не поверите…
svnadmin.verbose\_exec=yes
В лог будет писаться подробная информация о ходе процесса.
Ещё есть файл config.autoprops. Там указаны MIME- типы и свойства для отдельных расширений файлов. Мне «заводских» настроек хватило за уши. Кому мало – может подсмотреть, например, [здесь](http://rhubbarb.wordpress.com/2009/05/07/svn-props-mime-types/).
#### 4. Настраиваем секцию VCS-источника
Для каждой из поддерживаемых VCS всё в том же config.properties есть отдельная секция. Камменты помогают понять что зачем.
*В случае StarTeam указываем строку соединения (внутри вида можно также указывать отдельные папки):
st.url=LOGIN:PWD@SRV-NAME:49201/Project/View
st.tempdir=c:/temp/starteamtemp*
***Замечание 2:** Пробовал задействовать параметры st.includes.regex/ st.excludes.regex, но так и не постиг тайны их формата (что такое RegEx я знаю, но к какой части URL он применяется, серия экспериментов ясности не дала). Пытался писать на их [форум](http://forums.polarion.com/viewtopic.php?f=4&t=19314&e=0), но ответа не получил.*
#### 5. Запуск утилиты
Ну, вот – можно жать потными ручками красную кнопку. Для этого запускаем svnimporter.jar (для виндовз-пользователя уже заботливо приготовлен файл run.bat, где он передается JVM) и передаем ему 2 параметра:
%1 – команда. В нашем случае это full. Возможные варианты: list, incr.
%2 – наш поправленный выше конфиг: config.properties.
Т.е. как-то так:
```
SET JAVA_OPTS=-Xmx192m
java %JAVA_OPTS% -jar svnimporter.jar full config.properties
```
**Замечание 3.** Из известных мне команд есть ещё list для проверки корректности настроек экспорта/импорта.
**Замечание 4.** Есть ещё инкрементальный дамп, но в данной статье эта тема не раскрывается, хотя она может быть полезна тем, кто захочет синхронизировать две VCS на регулярной основе (по расписанию).
##### Критерий успешности
После завершения работы утилиты смотрим в журнал history.log и ищем сакраментальную строчку «successfully finished». Если её нет, то смотрим в svnimporter.log на предмет ошибки и устраняем оную.
*#### Выявленные проблемы:
1. У меня утилита ругалась, что не может найти каких-то борландо-стартимовских классов. Я кинул в папку lib библиотеку starteam80.jar, которую я взял из места установки моего StarTeam Server 2005. Возможно, нужно было просто настроить переменные среды для Java.
2. На 3-м заходе возникли проблемы при импорте в SVN. Утилита ругалась на недопустимый символ UTF-8. Не знаю, кривизна ли это утилиты или у меня в хранилище битая версия была. В общем варианты решения:
* задействовать st.includes.regex/ st.excludes.regex, чтобы пропустить проблемный файл, но, как я писал выше, мне удалось понять, как они работают (см. шаг 4).
* убить проблемный файл в репозитории-источнике.
* Создать только dump-файлы без импорта в SVN (см. шаг 2), hex-редактором поправить в дампе битый код и ручками залить dump-файлы в SVN — с помощью svnadmin.exe.*
|
https://habr.com/ru/post/140023/
| null |
ru
| null |
# Настраиваем SSH ключи на Node-ах Jenkins без ssh-доступа к ним

Всем привет! Думаю у каждого, кто когда-либо настраивал Jenkins для работы с Git-ом возникала проблема генерации ключей на Node-ах.
В очередной раз когда мне этим пришлось заняться я оказался в нелёгкой ситуации — ssh доступа к серверу с Jenkins-ом и к его слейвам у меня не было и, соответственно, ключи я сгенерировать не мог. Но всё оказалось не так плохо.
##### Добираемся до shell-а
Порывшись в недрах Jenkins-а была найдена **Script Console**, которая позволяет выполнять Groovy-код на нодах. Что нам это даёт? Возможность выполнять команды shell-а благодаря .execute() на строках. Только есть одно «но» — нельзя использовать перенаправление потоков и другие прелести bash, поэтому для начала надо придумать как исполнять код в интерпретаторе bash. Для этого были придуманы эти незамысловатые строки (буду благодарен советам по улучшению кода ибо на Groovy пишу впервые):
```
def file = new File(System.getenv("HOME") + "/testGroovyShell.sh")
file << "#!/bin/bash\n\
echo hello, world!"
def builder = new AntBuilder()
builder.chmod(file:file.getAbsolutePath(), perm:'+x')
println file.getAbsolutePath().execute().text
file.delete()
```
Теперь мы можем исполнять любой bash-код от имени пользователя, под которым запущен Jenkins!
##### Генерация SSH-ключей
Но тут меня ждал облом — для генерации ssh-ключей требуется жать Enter каждый раз когда он нас спросит о чем-нибудь. Это нас, мягко говоря, не устраивает, поэтому погуглив было найдено тупое, но зато работающее решение:
```
#!/bin/bash
echo -e "\n\n\n" | ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub
```
Тем самым мы говорим, что надо послать 3 раза перенос строки в поток ввода ssh-keygen. После выполнения этих команд скрипт выведет публичный ключ сервера. Осталось только добавить его в свой аккаунт (например, на GitHub), запустить Job и… опять обломаться.
##### Добавляем наш сервер в known\_hosts на примере GitHub
Казалось бы, ключ у нас есть, что ещё для счастья надо? Не тут то было! SSH устроен так, что при первом обращении к неизвестному ему хосту он запросит потверждение, мол, запомнить ли его? На этот раз обойдёмся без хаков, просто выполнив команду:
```
ssh-keyscan -H github.com >> ~/.ssh/known_hosts
```
, где github.com — хост, который вы хотите добавить.
После добавления хоста вы можете попробовать запустить вашу задачу и обрадоваться рабочему Git-у.
##### Заключение
Прошу тех, для кого полезность статьи стремится к нулю, не пинать сильно, т.к. задокументированного процесса как это сделать я в интернете не нашёл, а вопрос крайне актуальный.
О найденных ошибках и недочётах предпочитаю читать в ЛС, а не среди заминусованных комментов;)
Да прибудет с Вами дух Continuous Integration!
|
https://habr.com/ru/post/173625/
| null |
ru
| null |
# Установка Mikrotik Cloud Hosted Router на VPS хостинг Digital Ocean
###### … или другой Linux-хостинг.
*Сразу оговорюсь, что поскольку мне в процессе всех экспериментов уже поднадоело сносить и заново настраивать дроплет в DO, пример я буду выполнять в VMware ESXi, но на конечный результат это влиять не будет, команды все будут те же самые, в принципе, это применимо к любому облачному VPS хостингу, где у нас есть доступ по SSH.*
За основу взят доклад Дмитрия Пичулина [deemru](https://habrahabr.ru/users/deemru/) на прошедшем 30 сентября MUM в Москве. В отличии от доклада Дмитрия, в данной статье не будет рассматриваться вопросы выбора хостинга и цен на него (в стремлении намутить облачный роутер подешевле), настройки полученного устройства. Рассмотрена будет лишь техническая сторона вопроса и решены пара проблем.
Вернувшись с MUM, я был в предвкушении, руки чесались запилить Mikrotik на Digital Ocean (в тот момент, там была Ubuntu Server, которая выполняла функции VPN-сервера). Полез смотреть архив выступлений, но его ещё не было и я написал письмо Дмитрию с просьбой поделиться слайдами. Получив презентацию, с холодной головой ринулся в бой — ломать свой дроплет полностью. Сделал всё, как в презентации, всё завелось. Легче и придумать нельзя. Скачиваем на хостинг образ, распаковываем, переводим файловую систему в read-only, заливаем образ на диск через dd. Но тут то меня и подстерегала первая нестыковочка — у Дмитрия при первой загрузке CHR автоматически произошло расширение файловой системы и она заняла весь диск, у меня же этого не произошло и пришлось довольствоваться 128 МБ.
Кто-то скажет 128 МБ на роутере хватит всем. Но меня эта ситуация в корне не устраивала, поэтому я принялся её устранять. Всем известно, что RouterOS основана на Linux, но от Linux'а там мало что осталось, поэтому после установки системы, её штатными средствами переразметить диск уже нельзя. Нельзя и загрузиться с какого-нибудь LiveCD и переразметить в нём (ну по крайней мере у DO нельзя). Попытки тыкаться fdisk'ом и parted'ом после заливки образа на диск, но до перезагрузки так же не привели к какому-либо положительному результату (эффекта либо не было вообще, либо я получал не загружающуюся систему).
Нормальные герои всегда идут в обход.
Итак для того чтобы получить RouterOS, установленную на Digital Ocean, в которой доступно 20 ГБ дискового пространства (ну или сколько там у Вас по тарифу) нам потребуется:
* Собственно, сам droplet с установленным Linux дистрибутивом (в данном случае дистрибутив будет Ubuntu Server 16.04 x64, а вместо droplet'а будет виртуальная машина в ESXi, но ещё раз повторюсь, что роли это не сыграет), к которому у нас есть доступ по SSH.
* Установленный на компьютере или сервере гипервизор (изначально я делал в VirtualBox, сейчас буду делать опять же в ESXi, на конечный результат это не влияет).
* LiveCD вашего любимого Linux-дистрибутива (желательно, чтобы там был GUI, так будет удобнее).
Как вы видете, список не очень большой, каких-то особых требований к его пунктам нет, решение я старался сделать максимально универсальным и простым, чтобы можно было всё соорудить буквально на коленке из того, что есть.
Начнём с дроплета.
------------------
Нам нужно выяснить, какого объёма нам нужен диск в виртуальной машине, поэтому:
```
fdisk -l /dev/sda
Диск /dev/sda: 16 GiB, 17179869184 байтов, 33554432 секторов
Единицы измерения: секторов из 1 * 512 = 512 байтов
Размер сектора (логический/физический): 512 байт / 512 байт
I/O size (minimum/optimal): 512 bytes / 512 bytes
Тип метки диска: dos
Идентификатор диска: 0x7b5dbf9c
Устр-во Загрузочный Start Конец Секторы Size Id Тип
/dev/sda1 * 2048 31457279 31455232 15G 83 Linux
/dev/sda2 31459326 33552383 2093058 1022M 5 Расширенный
/dev/sda5 31459328 33552383 2093056 1022M 82 Linux своп / Solaris
```
Как мы видим, у нас диск 17179869184 байт, запомним это значение.
Подготовка промежуточной машины
-------------------------------
В гипервизоре создаём новую виртуальную машину. Её параметры особого значения не имеют, но можно, к примеру сделать их близкими к характеристикам дроплета. Размер диска лучше сделать с небольшим запасом, на всякий случай (почему-то 20ГБ в DO оказались меньше 20ГБ в VirtualBox). Настраиваем загрузку виртуальной машины с LiveCD.

Включаем её и после загрузки скачиваем любым удобным способом последнюю версию CHR, которую можно найти [по ссылке](http://www.mikrotik.com/download#chr):
Нам нужен образ Raw disk image (к примеру [chr-6.37.1.img.zip](http://download2.mikrotik.com/routeros/6.37.1/chr-6.37.1.img.zip)). Распаковываем архив:
```
unzip chr-6.37.1.img.zip
Archive: chr-6.37.1.img.zip
inflating: chr-6.37.1.img
```
И заливаем образ на жёсткий диск с помощью dd (Дмитрий тут использовал утилиту pv, но я, если честно не вижу в этом смысла, т.к. образ маленький и разворачивается довольно быстро):
```
dd if=chr-6.37.1.img.zip of=/dev/sda
262144+0 records in
262144+0 records out
134217728 bytes (134 MB, 128 MiB) copied, 5.64304 s, 23.8 MB/s
```
вместо sda нужно указать ваш диск, его имя может отличаться.
Расширяем файловую систему RouterOS
-----------------------------------
Любители всё делать в консоли могут делать там, мне показалось быстрее и проще сделать всё в GParted.
Запускаем GParted, выбираем диск, на который установили RouterOS и с помощью функции Resize/Move увеличиваем размер второго раздела. Обратите внимание, что размер раздела за вычетом размера первого раздела не должен превышать размер диска Вашего дроплета, который мы посмотрели в самом начале (т.е. первый раздел у нас 32 МиБ, значит второй должен быть не более 17179869184 байт / 1048576 = 16384 МиБ и — 32, т.е. 16352 МиБ)
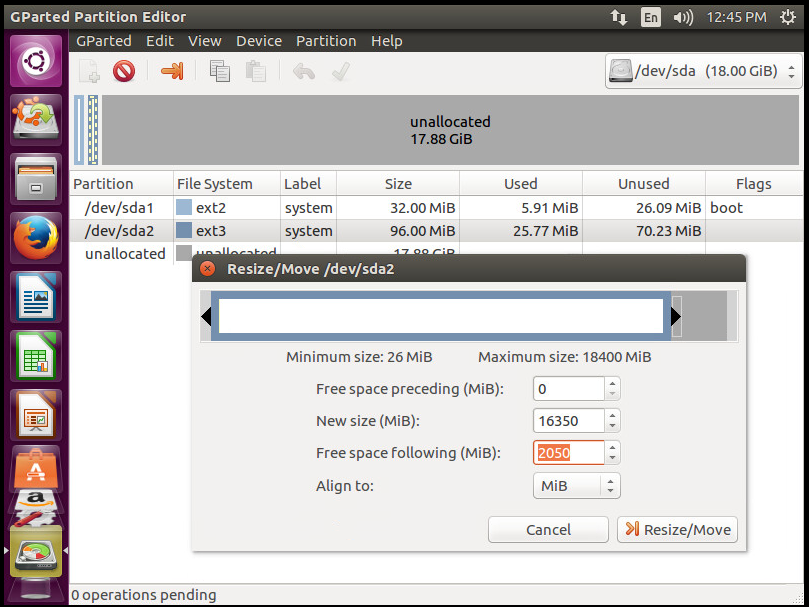
Не забываем применить изменения разметки диска.
Создаём новый образ и жмём его с помощью gzip:
----------------------------------------------
```
dd if=/dev/sda bs=8196 count 17000 | gzip -9cf > chr.img.gz
17000+0 records in
17000+0 records out
139332000 bytes (139 MB, 133 MiB) copied, 3.30824 s, 42.1 MB/s
```
Значение 17000 мы получаем путём приведения размера образа при его развёртывании на диск. Там было 128 МиБ, т.е. 128 \* 1024 = 131072 КиБ разделим размер на размер блока и округлим 131072 / 8 = 16384 ≈ 17000 блоков.
Заливаем полученный образ на дроплет и устанавливаем его
--------------------------------------------------------
```
scp chr.img.gz user@host:~/
```
Где user — имя пользователя на вашем дроплете, а host — его адрес. Копирование будет выполняться в домашний каталог пользователя.
Принимаем сертификат ssh сервера, и вводим пароль, когда нас об этом попросят. После окончания копирования, эта виртуальная машина нам больше не понадобится.
Переходим на наш дроплет. Можно подключиться к нему по ssh или зайти через консоль. Убедимся, что наш образ скопировался, желающие могут проверить контрольные суммы. Переведём файловую систему в режим read-only и развернём образ на диск через gzip и dd:
```
echo u > /proc/sysrq-trigger && gunzip -c chr.img.gz | dd of=/dev/vda
```
Всё! CHR установлен на наш дроплет. Перезагрузимся:
```
reboot
```
Вас приветствует Mikrotik Cloud Hosted Router
---------------------------------------------
**@gexogen - обманщик!!!**На самом деле, хоть я и обещал, что нет никакой разницы, в Digital Ocean мы это делаем или в ESXi, разница всё-таки есть. В DO всё работает, а вот ESXi после перезагрузки упал в Kernel Panic. Но, в ESXi файловая система растягивается и так при первой загрузке и данные манипуляции не потребуются.
После перезагрузки входим под пользователем admin без пароля, после чего задаём пароль, прописываем ip адрес и дефолтный маршрут:
> /system user set admin password=YOURPASSWORD
>
> /ip address add address=YOUR.IP.ADD.RESS/MASK
>
> /ip route add gateway=YOUR.GATE.WAY.IP
После чего можно подключаться к нему и настраивать через Winbox.
Заключение
----------

На доступном месте можно установить внутри RouterOS виртуальную машину с Linux или использовать его как-нибудь иначе — на Ваше усмотрение (поднять FTP сервер или ещё что-нибудь).
Ссылки:
-------
[Презентация Дмитрия в фомате PDF](http://mum.mikrotik.com/presentations/RU16/presentation_3932_1475483184.pdf)
[Запись его выступления](https://www.youtube.com/watch?v=YiDtUYBH9Ao)
[На всякий случай, ссылка на готовый образ под файловую систему на 20 ГБ (т.е. минимальный тариф DO за 5$)](https://www.dropbox.com/s/datfkkikvetvvby/chr.img.gz?dl=0)
|
https://habr.com/ru/post/312292/
| null |
ru
| null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.